
抓取jsp网页源代码
抓取jsp网页源代码(微信读书的sdk在jsp中可以使用函数.request)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-21 00:01
抓取jsp网页源代码不需要向微信读书中注册登录,看的就是微信读书的sdk,在jsp中可以使用函数wx.request({url:"/script",method:"get",params:{"name":"孙悟空"}})当读取完第一页后,看到当前页就是第一次扫描出来的页码,随后才对剩余的页码进行扫描,方法如下,大家可以根据自己需要修改。
因为你已经登录了微信读书,对你开放接口获取网页数据。
拿到了网页的所有javascript,
登录微信读书是有一个过程的,微信读书是用程序算法抓取网页上javascript等元素,并解析javascript等元素后推荐给微信读书的数据库。自己判断浏览的页码是因为这里的页码是向后匹配判断的。javascript能判断网页上的哪些东西已经在后台写好了,主要靠后台数据库判断。
如果你打开微信读书的登录页面,之后给它点击登录就可以拿到cookie了。微信读书的登录页只返回一个cookie,然后就再也没有点击过了。
回答:github上有个类似的项目,其实只要满足其中的cookie池(就是你所谓的回答一次就能拿到一次cookie),就可以拿下注册微信读书这个项目的https权限。实现思路是,先从服务器获取postcookie,然后对postcookie进行处理。
应该是可以拿到的,登录后会要求微信读书读取你的微信读书授权登录信息, 查看全部
抓取jsp网页源代码(微信读书的sdk在jsp中可以使用函数.request)
抓取jsp网页源代码不需要向微信读书中注册登录,看的就是微信读书的sdk,在jsp中可以使用函数wx.request({url:"/script",method:"get",params:{"name":"孙悟空"}})当读取完第一页后,看到当前页就是第一次扫描出来的页码,随后才对剩余的页码进行扫描,方法如下,大家可以根据自己需要修改。
因为你已经登录了微信读书,对你开放接口获取网页数据。
拿到了网页的所有javascript,
登录微信读书是有一个过程的,微信读书是用程序算法抓取网页上javascript等元素,并解析javascript等元素后推荐给微信读书的数据库。自己判断浏览的页码是因为这里的页码是向后匹配判断的。javascript能判断网页上的哪些东西已经在后台写好了,主要靠后台数据库判断。
如果你打开微信读书的登录页面,之后给它点击登录就可以拿到cookie了。微信读书的登录页只返回一个cookie,然后就再也没有点击过了。
回答:github上有个类似的项目,其实只要满足其中的cookie池(就是你所谓的回答一次就能拿到一次cookie),就可以拿下注册微信读书这个项目的https权限。实现思路是,先从服务器获取postcookie,然后对postcookie进行处理。
应该是可以拿到的,登录后会要求微信读书读取你的微信读书授权登录信息,
抓取jsp网页源代码(网页分析(Chrome开发者工具)对网页抓包分析的本质与内涵)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-12 17:34
在这个文章中,我们将尝试使用一个直观的网页分析工具(Chrome Developer Tools)来抓取和分析网页
对网络爬虫的本质和内涵有更深入的了解
1、测试环境
浏览器:Chrome 浏览器
浏览器版本:67.0.3396.99(正式版)(32位)
Web 分析工具:开发人员工具
2、网页分析(1)网页源码分析
我们知道网页分为静态网页和动态网页。很多人误以为静态网页就是没有动态效果的网页。事实上,这种说法是错误的。
另外,很多动态网站都采用了异步加载技术(Ajax)。这就是捕获的源代码和网站显示的源代码不一致的原因。
至于如何抓取动态网页,这里有两种方法:
下面以京东产品为例,分析一下如何通过Chrome抓包。首先,我们打开某个产品的主页。
到网页空白处点击鼠标右键,选择查看网页源码(或使用快捷键Ctrl+U直接打开)
请注意网站的最原创源码是通过查看网页源码获得的,也就是我们平时抓取的源码
再次进入网页空白区域,点击鼠标右键,选择勾选(或使用快捷键Ctrl+Shift+I/F12直接打开)
请注意,检查得到的源代码是Ajax加载并JavaScript渲染的源代码,即当前网站显示内容的源代码
经过比较,我们可以发现两者的内容是不同的。这是异步加载技术(Ajax)的典型例子
目前,至少京东产品的价格是通过异步加载生成的。下面介绍三种判断网页中某个内容是否是动态生成的方法:
(2)网页抓取分析
下面以京东产品为例进行说明。打开一个产品的首页,尝试抓取动态加载的产品价格数据。
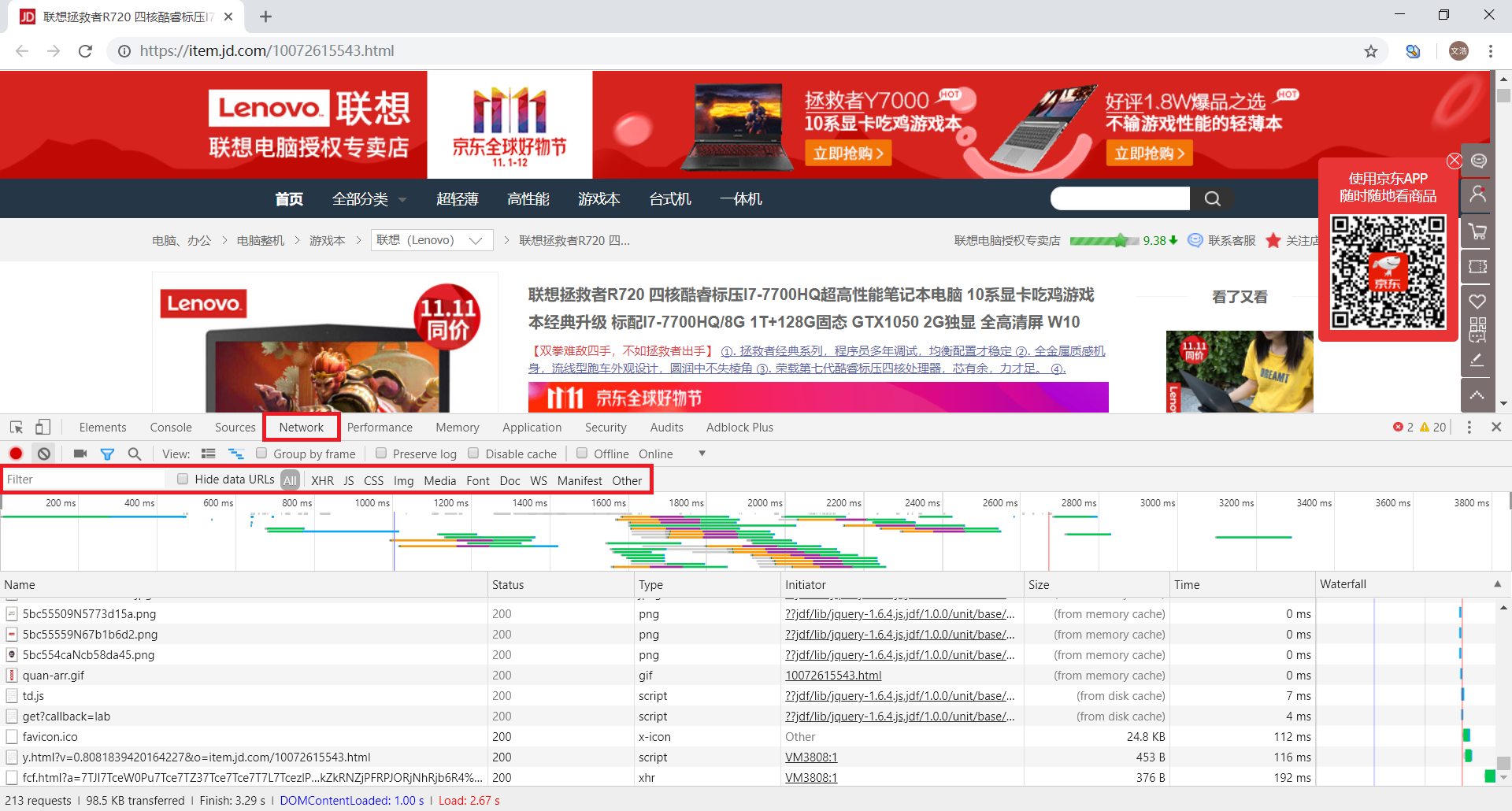
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择Network选项卡进行抓包分析
这时候按快捷键F5刷新页面,可以看到开发者工具里面有各种包,我们用Filter过滤包
首先我们选择Doc,可以看到列表中只出现了一个包
一般来说,这是浏览器收到的第一个包,获取请求的原创源码网站
点击Header查看其头部参数设置
单击响应以查看返回的源代码。不难发现,其实和查看网页源码返回的信息是一样的。
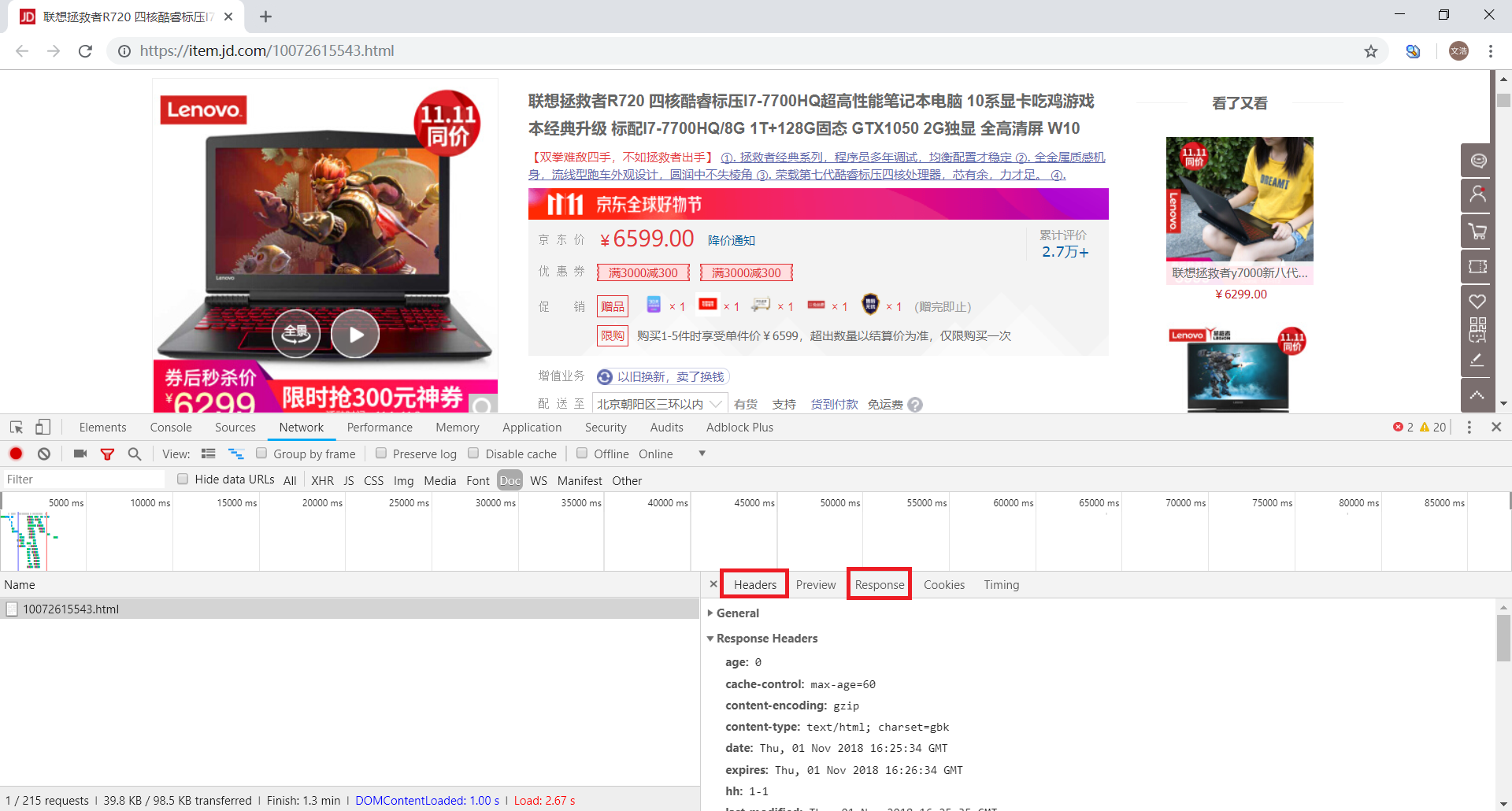
让我们回到下面的话题。对于动态加载的数据包的分析,我们主要看XHR和JS选项卡。
选择JS进行过滤,发现列表中有很多包。经过分析,我们过滤掉下图中标记的包
这个包返回的是价格信息,但是经过仔细分析,发现这些价格不属于当前产品,而是与产品相关。
但是怎么说这个包还是跟价格有关的,我们先来看看这个包的请求地址。
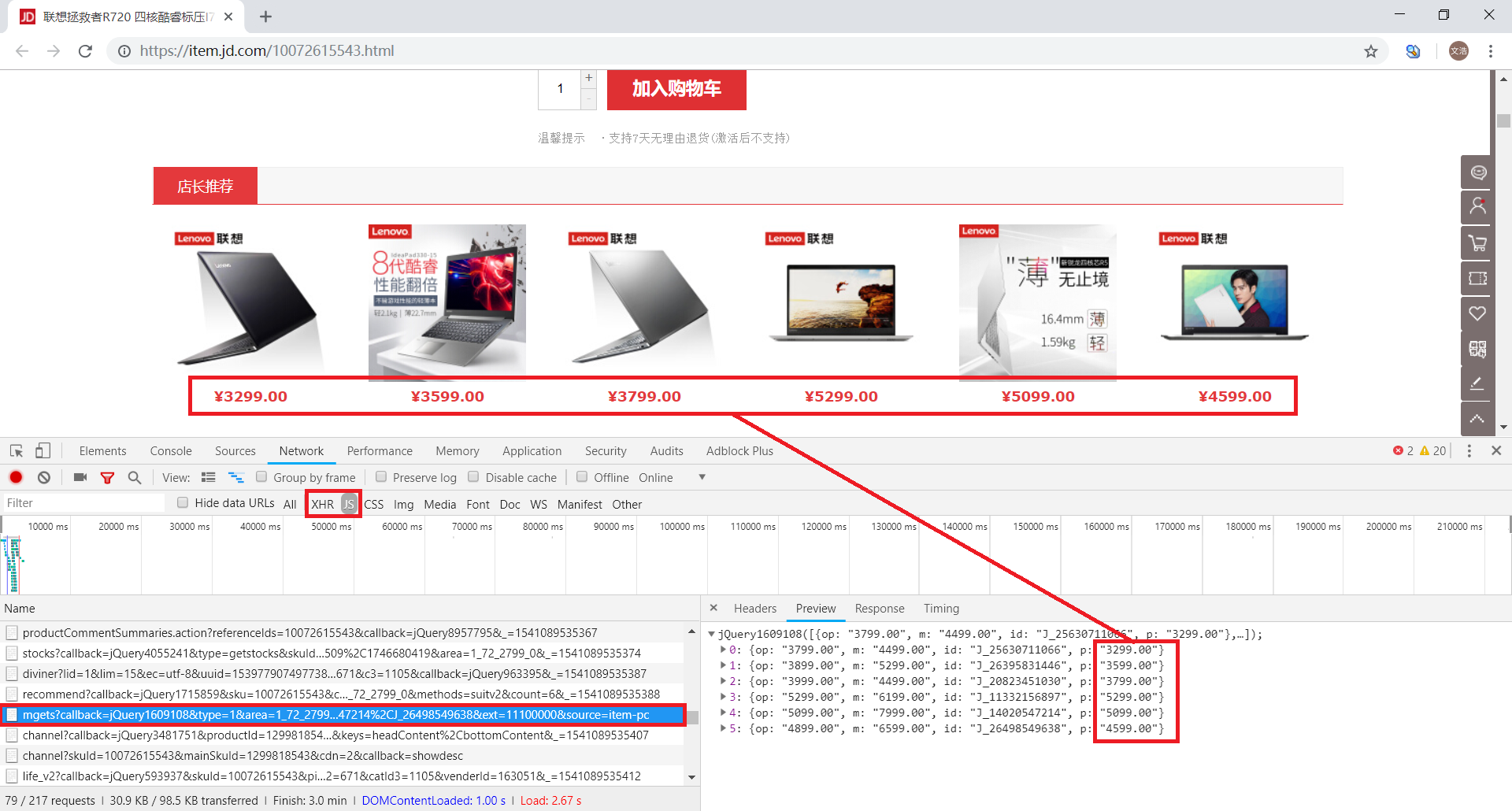
https://p.3.cn/prices/mgets%3F ... em-pc
过滤掉回调等不需要的参数,得到一个简单有效的URL
https://p.3.cn/prices/mgets%3F ... 49638
直接用浏览器打开网址,可以看到返回的JSON数据确实收录价格信息(可惜是其他商品的价格)
分析URL的参数,我们可以推断skuId应该是每个产品的唯一符号。那么在哪里可以找到我们需要的产品的skuId呢?
实际上,SKU是物流、运输等行业常用的缩写,其全称是Stock Keeping Unit。
即库存进出计量的基本单位,现在已经扩展为统一产品编号的缩写,每个产品对应一个唯一的SKU 查看全部
抓取jsp网页源代码(网页分析(Chrome开发者工具)对网页抓包分析的本质与内涵)
在这个文章中,我们将尝试使用一个直观的网页分析工具(Chrome Developer Tools)来抓取和分析网页
对网络爬虫的本质和内涵有更深入的了解
1、测试环境
浏览器:Chrome 浏览器
浏览器版本:67.0.3396.99(正式版)(32位)
Web 分析工具:开发人员工具
2、网页分析(1)网页源码分析
我们知道网页分为静态网页和动态网页。很多人误以为静态网页就是没有动态效果的网页。事实上,这种说法是错误的。
另外,很多动态网站都采用了异步加载技术(Ajax)。这就是捕获的源代码和网站显示的源代码不一致的原因。
至于如何抓取动态网页,这里有两种方法:
下面以京东产品为例,分析一下如何通过Chrome抓包。首先,我们打开某个产品的主页。
到网页空白处点击鼠标右键,选择查看网页源码(或使用快捷键Ctrl+U直接打开)
请注意网站的最原创源码是通过查看网页源码获得的,也就是我们平时抓取的源码
再次进入网页空白区域,点击鼠标右键,选择勾选(或使用快捷键Ctrl+Shift+I/F12直接打开)
请注意,检查得到的源代码是Ajax加载并JavaScript渲染的源代码,即当前网站显示内容的源代码
经过比较,我们可以发现两者的内容是不同的。这是异步加载技术(Ajax)的典型例子
目前,至少京东产品的价格是通过异步加载生成的。下面介绍三种判断网页中某个内容是否是动态生成的方法:
(2)网页抓取分析
下面以京东产品为例进行说明。打开一个产品的首页,尝试抓取动态加载的产品价格数据。
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择Network选项卡进行抓包分析
这时候按快捷键F5刷新页面,可以看到开发者工具里面有各种包,我们用Filter过滤包
首先我们选择Doc,可以看到列表中只出现了一个包
一般来说,这是浏览器收到的第一个包,获取请求的原创源码网站
点击Header查看其头部参数设置
单击响应以查看返回的源代码。不难发现,其实和查看网页源码返回的信息是一样的。
让我们回到下面的话题。对于动态加载的数据包的分析,我们主要看XHR和JS选项卡。
选择JS进行过滤,发现列表中有很多包。经过分析,我们过滤掉下图中标记的包
这个包返回的是价格信息,但是经过仔细分析,发现这些价格不属于当前产品,而是与产品相关。
但是怎么说这个包还是跟价格有关的,我们先来看看这个包的请求地址。
https://p.3.cn/prices/mgets%3F ... em-pc
过滤掉回调等不需要的参数,得到一个简单有效的URL
https://p.3.cn/prices/mgets%3F ... 49638
直接用浏览器打开网址,可以看到返回的JSON数据确实收录价格信息(可惜是其他商品的价格)

分析URL的参数,我们可以推断skuId应该是每个产品的唯一符号。那么在哪里可以找到我们需要的产品的skuId呢?
实际上,SKU是物流、运输等行业常用的缩写,其全称是Stock Keeping Unit。
即库存进出计量的基本单位,现在已经扩展为统一产品编号的缩写,每个产品对应一个唯一的SKU
抓取jsp网页源代码(JSP的静态页面有什么区别?的优点是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-11 16:28
一、JSP 概念
这节课我们的目标是弄清楚JSP是什么,它和HTML静态页面有什么区别?
JSP的全称是Java Server Page(Java Server Page),后缀名为.jsp,是由很多公司主动参与建立的动态技术标准。在传统网页HTML文件(*.htm、*.html)中加入Java程序片段(Scriptlet)和JSP标签,就构成了JSP网页。Java 程序片段可以操作数据库、重定向网页、发送电子邮件等。创建动态网站 所需的函数。有效控制动态内容的生成,在Java Server Page中使用Java编程语言和类库,同时使用HTML表示页面,使用Java代码访问动态内容。这大大降低了对客户端浏览器的要求,即使客户端浏览器不支持Java,
二、 JSP的优点
1、平台独立。
它具有Java语言的跨平台特性,以及业务代码分离、组件复用、Java Servlet基本功能、预编译等特性。它也是跨平台的,可用于不同的系统,如 Windows、Linux、Mac 和 Solaris。这也扩大了 JSP 可以使用的 Web 服务器的范围。
2、 将内容与演示分开。
使用JSP技术开发的项目通常使用HTML语言对静态页面的内容进行设计和格式化,并使用JSP标签和Java代码片段来实现动态部分。程序开发者可以将所有业务处理代码放在JavaBeans中,也可以将业务处理代码交给其他业务控制层如Servlet、Struts等,实现业务代码与视图层的分离。这样JSP页面只负责展示数据,业务代码需要修改时,不会影响JSP页面的代码。
3、 强调可重用的组件。
可以使用JavaBean在JSP中编写业务组件,即使用JavaBean类封装业务处理代码或作为数据存储模型。这个 JavaBean 可以在 JSP 页面甚至整个项目中重用。JavaBean 还可以应用于其他 Java 应用程序,包括桌面应用程序。
简化页面开发——Web设计人员和Web程序员使用Web开发工具开发JSP页面
4、高速。
JSP 会被预编译,即当用户第一次通过浏览器访问 JSP 页面时,服务器会编译 JSP 页面的代码并只执行一次编译。编译后的代码会被保存,用户下次访问时会直接执行编译后的代码。这样既节省了服务器的CPU资源,又大大提高了客户端的访问速度。
三、JSP执行流程
JSP的全称是Java Server Pages,用Html语法实现了java扩展(形式化)。我们可以在jsp页面中嵌入java代码,如以下代码获取服务器当前时间并打印
在服务器端执行。通常,返回给客户端的是HTML文本,所以客户端只要有浏览器就可以浏览。当Web服务器遇到访问JSP网页的请求时,首先执行其中的程序段,然后将执行结果连同JSP文件中的HTML代码一起返回给客户端。JSP页面虽然很少进行数据处理,但仅用于实现网页的静态页面,仅用于提取数据,不进行业务处理。
为什么我们可以在jsp中嵌入java代码?因为jsp在执行时需要翻译成java代码,然后编译成class文件,也就是jsp的本质就是java文件。如下所示:
查看tomcat目录下的\work\Catalina\localhost目录,你会发现这里所有的web项目都会有对应的目录,打开其中一个项目一直打开,你会发现每个jsp页面都会有对应的java文件和编译好的class文件。, 这个文件是tomcat生成的。
所以在开发过程中,我们会发现jsp页面第一次访问的时候比较慢,因为需要翻译和编译两步,但是以后会很快,因为class文件是直接访问和编译。 查看全部
抓取jsp网页源代码(JSP的静态页面有什么区别?的优点是什么)
一、JSP 概念
这节课我们的目标是弄清楚JSP是什么,它和HTML静态页面有什么区别?
JSP的全称是Java Server Page(Java Server Page),后缀名为.jsp,是由很多公司主动参与建立的动态技术标准。在传统网页HTML文件(*.htm、*.html)中加入Java程序片段(Scriptlet)和JSP标签,就构成了JSP网页。Java 程序片段可以操作数据库、重定向网页、发送电子邮件等。创建动态网站 所需的函数。有效控制动态内容的生成,在Java Server Page中使用Java编程语言和类库,同时使用HTML表示页面,使用Java代码访问动态内容。这大大降低了对客户端浏览器的要求,即使客户端浏览器不支持Java,
二、 JSP的优点
1、平台独立。
它具有Java语言的跨平台特性,以及业务代码分离、组件复用、Java Servlet基本功能、预编译等特性。它也是跨平台的,可用于不同的系统,如 Windows、Linux、Mac 和 Solaris。这也扩大了 JSP 可以使用的 Web 服务器的范围。
2、 将内容与演示分开。
使用JSP技术开发的项目通常使用HTML语言对静态页面的内容进行设计和格式化,并使用JSP标签和Java代码片段来实现动态部分。程序开发者可以将所有业务处理代码放在JavaBeans中,也可以将业务处理代码交给其他业务控制层如Servlet、Struts等,实现业务代码与视图层的分离。这样JSP页面只负责展示数据,业务代码需要修改时,不会影响JSP页面的代码。
3、 强调可重用的组件。
可以使用JavaBean在JSP中编写业务组件,即使用JavaBean类封装业务处理代码或作为数据存储模型。这个 JavaBean 可以在 JSP 页面甚至整个项目中重用。JavaBean 还可以应用于其他 Java 应用程序,包括桌面应用程序。
简化页面开发——Web设计人员和Web程序员使用Web开发工具开发JSP页面
4、高速。
JSP 会被预编译,即当用户第一次通过浏览器访问 JSP 页面时,服务器会编译 JSP 页面的代码并只执行一次编译。编译后的代码会被保存,用户下次访问时会直接执行编译后的代码。这样既节省了服务器的CPU资源,又大大提高了客户端的访问速度。
三、JSP执行流程
JSP的全称是Java Server Pages,用Html语法实现了java扩展(形式化)。我们可以在jsp页面中嵌入java代码,如以下代码获取服务器当前时间并打印
在服务器端执行。通常,返回给客户端的是HTML文本,所以客户端只要有浏览器就可以浏览。当Web服务器遇到访问JSP网页的请求时,首先执行其中的程序段,然后将执行结果连同JSP文件中的HTML代码一起返回给客户端。JSP页面虽然很少进行数据处理,但仅用于实现网页的静态页面,仅用于提取数据,不进行业务处理。
为什么我们可以在jsp中嵌入java代码?因为jsp在执行时需要翻译成java代码,然后编译成class文件,也就是jsp的本质就是java文件。如下所示:
查看tomcat目录下的\work\Catalina\localhost目录,你会发现这里所有的web项目都会有对应的目录,打开其中一个项目一直打开,你会发现每个jsp页面都会有对应的java文件和编译好的class文件。, 这个文件是tomcat生成的。

所以在开发过程中,我们会发现jsp页面第一次访问的时候比较慢,因为需要翻译和编译两步,但是以后会很快,因为class文件是直接访问和编译。
抓取jsp网页源代码(JS做成外部文件,页面直接调用(上海SEO实验室))
网站优化 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-10-04 09:25
页面中有两种常见的 JavaScript 方式。一种是将JS做成外部文件,直接调用页面。以下是上海SEO实验室的一行代码:
以下为引用内容:
另一种是直接在页面上写JS代码,例如:
以下为引用内容:
尝试{
varelScript=document.createElement("script");
elScript.setAttribute("语言","JavaScript");
elScript.setAttribute("src",""+"&view="+escape(strBatchView)+"&inculde="+escape(strBatchInculde)+"&count="+escape(strBatchCount));
document.getElementsByTagName("body")[0].appendChild(elScript);
}
捕获(e){};
从搜索引擎抓取的角度来看,第一种类型不收录任何文本信息,因此搜索引擎无法从中提取内容。但是第二种,如果出现文字内容,搜索引擎能抓取到内容吗?
实验思路:做一个只有JS代码的页面,JS代码收录中文内容。然后,等待搜索引擎收录后,查看SERP和网页快照中的结果。
实验页面:()
以下为引用内容:
2007-9-25 中秋节开始实验
document.writeln("JS爬取实验:
");
document.writeln("尝试将文本放入JS代码中,会不会被搜索引擎抓取?");
如果您想尽快查看实验结果,请转载本文或在实验页面添加外部链接。这可以帮助搜索引擎尽快收录页面,我们也可以更快地得到结果。 查看全部
抓取jsp网页源代码(JS做成外部文件,页面直接调用(上海SEO实验室))
页面中有两种常见的 JavaScript 方式。一种是将JS做成外部文件,直接调用页面。以下是上海SEO实验室的一行代码:
以下为引用内容:
另一种是直接在页面上写JS代码,例如:
以下为引用内容:
尝试{
varelScript=document.createElement("script");
elScript.setAttribute("语言","JavaScript");
elScript.setAttribute("src",""+"&view="+escape(strBatchView)+"&inculde="+escape(strBatchInculde)+"&count="+escape(strBatchCount));
document.getElementsByTagName("body")[0].appendChild(elScript);
}
捕获(e){};
从搜索引擎抓取的角度来看,第一种类型不收录任何文本信息,因此搜索引擎无法从中提取内容。但是第二种,如果出现文字内容,搜索引擎能抓取到内容吗?
实验思路:做一个只有JS代码的页面,JS代码收录中文内容。然后,等待搜索引擎收录后,查看SERP和网页快照中的结果。
实验页面:()
以下为引用内容:
2007-9-25 中秋节开始实验
document.writeln("JS爬取实验:
");
document.writeln("尝试将文本放入JS代码中,会不会被搜索引擎抓取?");
如果您想尽快查看实验结果,请转载本文或在实验页面添加外部链接。这可以帮助搜索引擎尽快收录页面,我们也可以更快地得到结果。
抓取jsp网页源代码(初中毕业,你怎么学编程和语言?找个解决方案吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-10-02 21:00
抓取jsp网页源代码,生成xml,用apache等web服务器提供的jsp反序列化,然后本地调用。jsp调用hibernate就是调用orm框架,建立xml数据映射,形成类型的映射信息。
现在大部分流行的jsp和xml数据交互框架:jtools、grails、ci,部分使用java做struts。具体看个人习惯,
初中毕业,你怎么学编程和语言?找个解决方案吧。不推荐依赖第三方插件。程序最终都应该是自己实现。
除了orm其他全部替换为php,
如果你做一个登录页面:可以先考虑业务需求,因为我并不知道你一般会有哪些业务需求,所以不太好推荐框架。既然已经用jsp,先试着将session、api的connection封装成功能类似于xmlhttprequest的对象,不过jsp里的可能会麻烦一些。然后就可以开始将connection封装成session,那么xmlhttprequest接口就变成了session对象,第二步就是根据业务需求,考虑service类以及相应的接口处理器与封装好的httpservice对象相匹配,那么处理过程就是service对象的封装、处理。
这样既方便、快捷的把请求对象封装成需要的对象,又可以开发比较简单,而且由于xmlhttprequest是封装在jsp中,而jsp可以作为业务处理、封装的平台和语言,所以xmlhttprequest封装后可以方便的做与本地处理的交互。作为封装之后的connection已经成为自己的对象,这里面就是实现jspconnection的封装工作。
可以做接收jspjsp登录的处理,也可以作接收jsprequest的处理,可以接收request中的查询处理等。 查看全部
抓取jsp网页源代码(初中毕业,你怎么学编程和语言?找个解决方案吧)
抓取jsp网页源代码,生成xml,用apache等web服务器提供的jsp反序列化,然后本地调用。jsp调用hibernate就是调用orm框架,建立xml数据映射,形成类型的映射信息。
现在大部分流行的jsp和xml数据交互框架:jtools、grails、ci,部分使用java做struts。具体看个人习惯,
初中毕业,你怎么学编程和语言?找个解决方案吧。不推荐依赖第三方插件。程序最终都应该是自己实现。
除了orm其他全部替换为php,
如果你做一个登录页面:可以先考虑业务需求,因为我并不知道你一般会有哪些业务需求,所以不太好推荐框架。既然已经用jsp,先试着将session、api的connection封装成功能类似于xmlhttprequest的对象,不过jsp里的可能会麻烦一些。然后就可以开始将connection封装成session,那么xmlhttprequest接口就变成了session对象,第二步就是根据业务需求,考虑service类以及相应的接口处理器与封装好的httpservice对象相匹配,那么处理过程就是service对象的封装、处理。
这样既方便、快捷的把请求对象封装成需要的对象,又可以开发比较简单,而且由于xmlhttprequest是封装在jsp中,而jsp可以作为业务处理、封装的平台和语言,所以xmlhttprequest封装后可以方便的做与本地处理的交互。作为封装之后的connection已经成为自己的对象,这里面就是实现jspconnection的封装工作。
可以做接收jspjsp登录的处理,也可以作接收jsprequest的处理,可以接收request中的查询处理等。
抓取jsp网页源代码(爬取一个所有FamilyDollar商店的位置页面是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-10-01 11:06
)
关于合法性,获得大量有价值的信息可能令人兴奋,但仅仅因为它是可能的并不意味着应该这样做。
幸运的是,有一些公共信息可以指导我们的道德和网络抓取工具。大多数网站都有一个与网站相关联的robots.txt文件,指明哪些爬行活动是允许的,哪些是不允许的。主要用于与搜索引擎交互(网络爬虫工具的终极形式)。但是,网站 上的大部分信息都被视为公开信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及道德采集和数据使用等主题。
在开始抓取项目之前,先问自己以下问题:
当我抓取 网站 时,请确保您可以对所有这些问题回答“否”。
要了解有关这些法律问题的更多信息,请参阅 Krotov 和 Silva 于 2018 年出版的“网络爬虫的合法性和道德”以及 Sellars 的“网络爬虫二十年和计算机欺诈和滥用法案”。
现在开始爬取网站
经过上面的评估,我想出了一个项目。我的目标是抓取爱达荷州所有 Family Dollar 商店的地址。这些店在农村很大,所以我想知道有多少这样的店。
起点是Family Dollar的位置页面
首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 的单元格中运行。
import requests # for making standard html requests
from bs4 import BeautifulSoup # magical tool for parsing html data
import json # for parsing data
from pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get("https://locations.familydollar.com/id/")
soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。这些是我们将使用的几种常见对象类型。
当我们查看 requests.get() 的输出时,还有更多问题需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。requests中的默认编码设置可以很好的解决这个问题。不过,除了纯英文的网站,就是更大的互联网世界。为了保证请求正确解析内容,可以设置文本的编码:
page = requests.get(URL)
page.encoding = 'ISO-885901'
soup = BeautifulSoup(page.text, 'html.parser')
仔细看一下 BeautifulSoup 标签,我们会看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站 爬取过程中的提取可能是一个充满误解的艰巨过程。我认为解决这个问题最好的方法是从一个有代表性的例子开始,然后再扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 来查看页面的整个源代码(不推荐)。运行此代码风险自负:
print(soup.prettify())
虽然打印页面的整个源代码可能适合一些教程中展示的玩具示例,但大多数现代 网站 页面都有很多内容。甚至 404 页面也可能充满了页眉、页脚和其他代码。
通常,在您喜欢的浏览器中通过“查看页面源代码”来浏览源代码是最容易的(右键单击并选择“查看页面源代码”)。这是找到目标内容最可靠的方式(我稍后会解释原因)。
在这种情况下,我需要在这个巨大的 HTML 海洋中找到我的目标内容地址、城市、州和邮政编码。通常,在页面源上进行简单的搜索(ctrl+F)就会得到目标位置的位置。一旦我真正看到目标内容的示例(至少是一家商店的地址),我就会找到将该内容与其他内容区分开来的属性或标签。
首先,我需要在爱达荷州的Family Dollar商店采集不同城市的URL,并访问这些网站以获取地址信息。这些 URL 似乎收录在 href 标签中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')
dollar_tree_list
搜索 href 不会产生任何结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于下一次尝试,搜索 item_list。由于 class 是 Python 中的保留字,因此使用 class_ 代替。sound.find_all() 原来是 bs4 函数的瑞士军刀。
dollar_tree_list = soup.find_all(class_ = 'itemlist')
for i in dollar_tree_list[:2]:
print(i)
有趣的是,我发现搜索特定类的方法通常是成功的方法。通过找出对象的类型和长度,我们可以了解更多关于对象的信息。
type(dollar_tree_list)
len(dollar_tree_list)
您可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建单个代表性示例的好时机。
example = dollar_tree_list[2] # a representative example
example_content = example.contents
print(example_content)
使用 .attr 查找对象内容中存在的属性。注意: .contents 通常返回一个精确的项目列表,因此第一步是使用方括号表示法来索引项目。
example_content = example.contents[0]
example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取它:
example_href = example_content['href']
print(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,以澄清上述逻辑。
city_hrefs = [] # initialise empty list
for i in dollar_tree_list:
cont = i.contents[0]
href = cont['href']
city_hrefs.append(href)
# check to be sure all went well
for i in city_hrefs[:2]:
print(i)
输出是用于抓取爱达荷州 Family Dollar 商店的 URL 列表。
换句话说,我还没有得到地址信息!现在,您需要抓取每个城市的 URL 以获取此信息。因此,我们使用一个具有代表性的示例来重新启动该过程。
page2 = requests.get(city_hrefs[2]) # again establish a representative example
soup2 = BeautifulSoup(page2.text, 'html.parser')
地址信息嵌套在 type="application/ld+json" 中。经过大量的地理位置爬取,我开始意识到这是一个存储地址信息的通用结构。幸运的是,soup.find_all() 支持按类型搜索。
arco = soup2.find_all(type="application/ld+json")
print(arco[1])
地址信息在第二个列表成员中!我懂了!
使用 .contents 提取内容(从第二个列表项)(这是过滤后合适的默认操作)。同样,由于输出是一个列表,我为列表项建立了一个索引:
arco_contents = arco[1].contents[0]
arco_contents
哦,看起来不错。此处提供的格式与 JSON 格式一致(并且,类型名称确实收录“json”)。JSON 对象的行为类似于带有嵌套字典的字典。一旦你熟悉了它,它实际上是一种很好的格式(当然,它比一长串正则表达式命令更容易编程)。虽然在结构上看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要通过编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
type(arco_json)
print(arco_json)
在内容中,有一个被调用的地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']
arco_address
好的,请注意。现在我可以遍历存储的爱达荷州 URL 列表:
locs_dict = [] # initialise empty list
for link in city_hrefs:
locpage = requests.get(link) # request page info
locsoup = BeautifulSoup(locpage.text, 'html.parser')
# parse the page's content
locinfo = locsoup.find_all(type="application/ld+json")
# extract specific element
loccont = locinfo[1].contents[0]
# get contents from the bs4 element set
locjson = json.loads(loccont) # convert to json
locaddr = locjson['address'] # get address
locs_dict.append(locaddr) # add address to list
使用 Pandas 来组织我们的 网站 爬取结果
我们在字典中加载了大量数据,但是有一些额外的无用项使得重用数据变得比必要的复杂。为了执行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不必要的列@type 和 country,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)
locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)
locs_df.head(n = 5)
一定要保存结果!!
df.to_csv(locs_df, "family_dollar_ID_locations.csv", sep = ",", index = False)
我们做到了!爱达荷州的所有 Family Dollar 商店都有一个以逗号分隔的列表。多么激动人心。
Selenium 和数据抓取的一点解释
Selenium 是一种常用的工具,用于自动与网页交互。为了解释为什么有时需要使用它,让我们看一个使用 Walgreens 网站 的例子。“检查元素”提供浏览器显示内容的代码:
尽管“查看页面源代码”提供了有关请求将获得什么的代码:
如果这两个不一致,有插件可以修改源代码——因此,你应该在加载到浏览器后访问页面。请求无法做到这一点,但 Selenium 可以。
Selenium 需要一个 Web 驱动程序来检索内容。事实上,它会打开一个网络浏览器并采集这个页面的内容。Selenium 功能强大——它可以通过多种方式与加载的内容交互(请阅读文档)。使用Selenium获取数据后,继续像之前一样使用BeautifulSoup:
url = "https://www.walgreens.com/stor ... ot%3B
driver = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')
driver.get(url)
soup_ID = BeautifulSoup(driver.page_source, 'html.parser')
store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
在 Family Dollar 的情况下,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用网站爬行完成有意义的任务时:
如果您对答案感到好奇:
在美国有很多 Family Dollar 商店。
完整的源代码是:
import requests
from bs4 import BeautifulSoup
import json
from pandas import DataFrame as df
page = requests.get("https://www.familydollar.com/locations/")
soup = BeautifulSoup(page.text, 'html.parser')
# find all state links
state_list = soup.find_all(class_ = 'itemlist')
state_links = []
for i in state_list:
cont = i.contents[0]
attr = cont.attrs
hrefs = attr['href']
state_links.append(hrefs)
# find all city links
city_links = []
for link in state_links:
page = requests.get(link)
soup = BeautifulSoup(page.text, 'html.parser')
familydollar_list = soup.find_all(class_ = 'itemlist')
for store in familydollar_list:
cont = store.contents[0]
attr = cont.attrs
city_hrefs = attr['href']
city_links.append(city_hrefs)
# to get individual store links
store_links = []
for link in city_links:
locpage = requests.get(link)
locsoup = BeautifulSoup(locpage.text, 'html.parser')
locinfo = locsoup.find_all(type="application/ld+json")
for i in locinfo:
loccont = i.contents[0]
locjson = json.loads(loccont)
try:
store_url = locjson['url']
store_links.append(store_url)
except:
pass
# get address and geolocation information
stores = []
for store in store_links:
storepage = requests.get(store)
storesoup = BeautifulSoup(storepage.text, 'html.parser')
storeinfo = storesoup.find_all(type="application/ld+json")
for i in storeinfo:
storecont = i.contents[0]
storejson = json.loads(storecont)
try:
store_addr = storejson['address']
store_addr.update(storejson['geo'])
stores.append(store_addr)
except:
pass
# final data parsing
stores_df = df.from_records(stores)
stores_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)
stores_df['Store'] = "Family Dollar"
df.to_csv(stores_df, "family_dollar_locations.csv", sep = ",", index = False)
作者注:本文改编自我 2020 年 2 月 9 日在俄勒冈州波特兰市 PyCascades 的演讲。
通过:
作者:Julia Piaskowski 主题:lujun9972 译者:stevenzdg988 校对:wxy
本文由LCTT原创编译,Linux中国荣幸推出
查看全部
抓取jsp网页源代码(爬取一个所有FamilyDollar商店的位置页面是什么?
)
关于合法性,获得大量有价值的信息可能令人兴奋,但仅仅因为它是可能的并不意味着应该这样做。
幸运的是,有一些公共信息可以指导我们的道德和网络抓取工具。大多数网站都有一个与网站相关联的robots.txt文件,指明哪些爬行活动是允许的,哪些是不允许的。主要用于与搜索引擎交互(网络爬虫工具的终极形式)。但是,网站 上的大部分信息都被视为公开信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及道德采集和数据使用等主题。
在开始抓取项目之前,先问自己以下问题:
当我抓取 网站 时,请确保您可以对所有这些问题回答“否”。
要了解有关这些法律问题的更多信息,请参阅 Krotov 和 Silva 于 2018 年出版的“网络爬虫的合法性和道德”以及 Sellars 的“网络爬虫二十年和计算机欺诈和滥用法案”。
现在开始爬取网站
经过上面的评估,我想出了一个项目。我的目标是抓取爱达荷州所有 Family Dollar 商店的地址。这些店在农村很大,所以我想知道有多少这样的店。
起点是Family Dollar的位置页面

首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 的单元格中运行。
import requests # for making standard html requests
from bs4 import BeautifulSoup # magical tool for parsing html data
import json # for parsing data
from pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get("https://locations.familydollar.com/id/";)
soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。这些是我们将使用的几种常见对象类型。
当我们查看 requests.get() 的输出时,还有更多问题需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。requests中的默认编码设置可以很好的解决这个问题。不过,除了纯英文的网站,就是更大的互联网世界。为了保证请求正确解析内容,可以设置文本的编码:
page = requests.get(URL)
page.encoding = 'ISO-885901'
soup = BeautifulSoup(page.text, 'html.parser')
仔细看一下 BeautifulSoup 标签,我们会看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站 爬取过程中的提取可能是一个充满误解的艰巨过程。我认为解决这个问题最好的方法是从一个有代表性的例子开始,然后再扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 来查看页面的整个源代码(不推荐)。运行此代码风险自负:
print(soup.prettify())
虽然打印页面的整个源代码可能适合一些教程中展示的玩具示例,但大多数现代 网站 页面都有很多内容。甚至 404 页面也可能充满了页眉、页脚和其他代码。
通常,在您喜欢的浏览器中通过“查看页面源代码”来浏览源代码是最容易的(右键单击并选择“查看页面源代码”)。这是找到目标内容最可靠的方式(我稍后会解释原因)。

在这种情况下,我需要在这个巨大的 HTML 海洋中找到我的目标内容地址、城市、州和邮政编码。通常,在页面源上进行简单的搜索(ctrl+F)就会得到目标位置的位置。一旦我真正看到目标内容的示例(至少是一家商店的地址),我就会找到将该内容与其他内容区分开来的属性或标签。
首先,我需要在爱达荷州的Family Dollar商店采集不同城市的URL,并访问这些网站以获取地址信息。这些 URL 似乎收录在 href 标签中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')
dollar_tree_list
搜索 href 不会产生任何结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于下一次尝试,搜索 item_list。由于 class 是 Python 中的保留字,因此使用 class_ 代替。sound.find_all() 原来是 bs4 函数的瑞士军刀。
dollar_tree_list = soup.find_all(class_ = 'itemlist')
for i in dollar_tree_list[:2]:
print(i)
有趣的是,我发现搜索特定类的方法通常是成功的方法。通过找出对象的类型和长度,我们可以了解更多关于对象的信息。
type(dollar_tree_list)
len(dollar_tree_list)
您可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建单个代表性示例的好时机。
example = dollar_tree_list[2] # a representative example
example_content = example.contents
print(example_content)
使用 .attr 查找对象内容中存在的属性。注意: .contents 通常返回一个精确的项目列表,因此第一步是使用方括号表示法来索引项目。
example_content = example.contents[0]
example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取它:
example_href = example_content['href']
print(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,以澄清上述逻辑。
city_hrefs = [] # initialise empty list
for i in dollar_tree_list:
cont = i.contents[0]
href = cont['href']
city_hrefs.append(href)
# check to be sure all went well
for i in city_hrefs[:2]:
print(i)
输出是用于抓取爱达荷州 Family Dollar 商店的 URL 列表。
换句话说,我还没有得到地址信息!现在,您需要抓取每个城市的 URL 以获取此信息。因此,我们使用一个具有代表性的示例来重新启动该过程。
page2 = requests.get(city_hrefs[2]) # again establish a representative example
soup2 = BeautifulSoup(page2.text, 'html.parser')
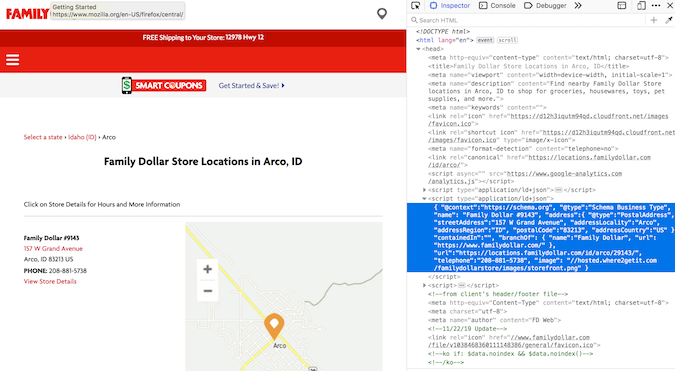
地址信息嵌套在 type="application/ld+json" 中。经过大量的地理位置爬取,我开始意识到这是一个存储地址信息的通用结构。幸运的是,soup.find_all() 支持按类型搜索。
arco = soup2.find_all(type="application/ld+json")
print(arco[1])
地址信息在第二个列表成员中!我懂了!
使用 .contents 提取内容(从第二个列表项)(这是过滤后合适的默认操作)。同样,由于输出是一个列表,我为列表项建立了一个索引:
arco_contents = arco[1].contents[0]
arco_contents
哦,看起来不错。此处提供的格式与 JSON 格式一致(并且,类型名称确实收录“json”)。JSON 对象的行为类似于带有嵌套字典的字典。一旦你熟悉了它,它实际上是一种很好的格式(当然,它比一长串正则表达式命令更容易编程)。虽然在结构上看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要通过编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
type(arco_json)
print(arco_json)
在内容中,有一个被调用的地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']
arco_address
好的,请注意。现在我可以遍历存储的爱达荷州 URL 列表:
locs_dict = [] # initialise empty list
for link in city_hrefs:
locpage = requests.get(link) # request page info
locsoup = BeautifulSoup(locpage.text, 'html.parser')
# parse the page's content
locinfo = locsoup.find_all(type="application/ld+json")
# extract specific element
loccont = locinfo[1].contents[0]
# get contents from the bs4 element set
locjson = json.loads(loccont) # convert to json
locaddr = locjson['address'] # get address
locs_dict.append(locaddr) # add address to list
使用 Pandas 来组织我们的 网站 爬取结果
我们在字典中加载了大量数据,但是有一些额外的无用项使得重用数据变得比必要的复杂。为了执行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不必要的列@type 和 country,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)
locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)
locs_df.head(n = 5)
一定要保存结果!!
df.to_csv(locs_df, "family_dollar_ID_locations.csv", sep = ",", index = False)
我们做到了!爱达荷州的所有 Family Dollar 商店都有一个以逗号分隔的列表。多么激动人心。
Selenium 和数据抓取的一点解释
Selenium 是一种常用的工具,用于自动与网页交互。为了解释为什么有时需要使用它,让我们看一个使用 Walgreens 网站 的例子。“检查元素”提供浏览器显示内容的代码:
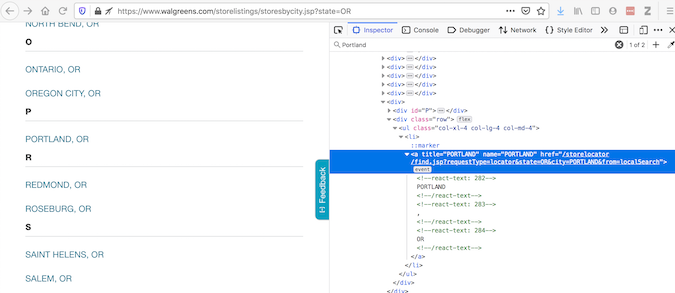
尽管“查看页面源代码”提供了有关请求将获得什么的代码:
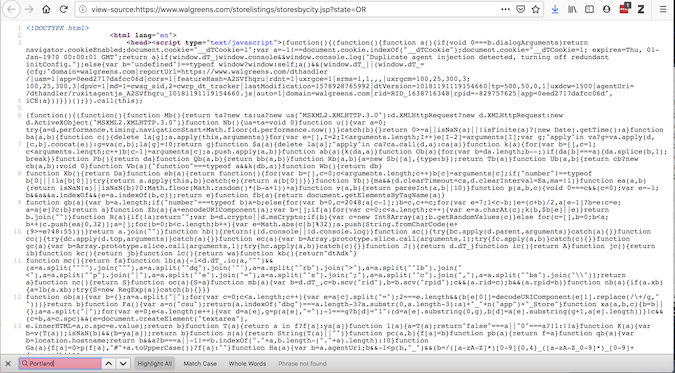
如果这两个不一致,有插件可以修改源代码——因此,你应该在加载到浏览器后访问页面。请求无法做到这一点,但 Selenium 可以。
Selenium 需要一个 Web 驱动程序来检索内容。事实上,它会打开一个网络浏览器并采集这个页面的内容。Selenium 功能强大——它可以通过多种方式与加载的内容交互(请阅读文档)。使用Selenium获取数据后,继续像之前一样使用BeautifulSoup:
url = "https://www.walgreens.com/stor ... ot%3B
driver = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')
driver.get(url)
soup_ID = BeautifulSoup(driver.page_source, 'html.parser')
store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
在 Family Dollar 的情况下,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用网站爬行完成有意义的任务时:
如果您对答案感到好奇:
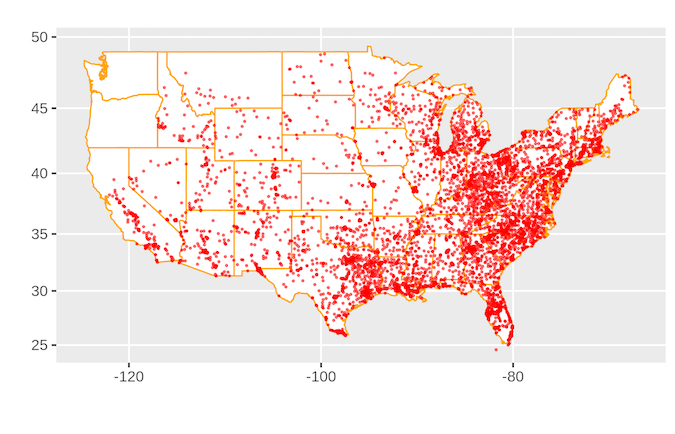
在美国有很多 Family Dollar 商店。
完整的源代码是:
import requests
from bs4 import BeautifulSoup
import json
from pandas import DataFrame as df
page = requests.get("https://www.familydollar.com/locations/";)
soup = BeautifulSoup(page.text, 'html.parser')
# find all state links
state_list = soup.find_all(class_ = 'itemlist')
state_links = []
for i in state_list:
cont = i.contents[0]
attr = cont.attrs
hrefs = attr['href']
state_links.append(hrefs)
# find all city links
city_links = []
for link in state_links:
page = requests.get(link)
soup = BeautifulSoup(page.text, 'html.parser')
familydollar_list = soup.find_all(class_ = 'itemlist')
for store in familydollar_list:
cont = store.contents[0]
attr = cont.attrs
city_hrefs = attr['href']
city_links.append(city_hrefs)
# to get individual store links
store_links = []
for link in city_links:
locpage = requests.get(link)
locsoup = BeautifulSoup(locpage.text, 'html.parser')
locinfo = locsoup.find_all(type="application/ld+json")
for i in locinfo:
loccont = i.contents[0]
locjson = json.loads(loccont)
try:
store_url = locjson['url']
store_links.append(store_url)
except:
pass
# get address and geolocation information
stores = []
for store in store_links:
storepage = requests.get(store)
storesoup = BeautifulSoup(storepage.text, 'html.parser')
storeinfo = storesoup.find_all(type="application/ld+json")
for i in storeinfo:
storecont = i.contents[0]
storejson = json.loads(storecont)
try:
store_addr = storejson['address']
store_addr.update(storejson['geo'])
stores.append(store_addr)
except:
pass
# final data parsing
stores_df = df.from_records(stores)
stores_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)
stores_df['Store'] = "Family Dollar"
df.to_csv(stores_df, "family_dollar_locations.csv", sep = ",", index = False)
作者注:本文改编自我 2020 年 2 月 9 日在俄勒冈州波特兰市 PyCascades 的演讲。
通过:
作者:Julia Piaskowski 主题:lujun9972 译者:stevenzdg988 校对:wxy
本文由LCTT原创编译,Linux中国荣幸推出

抓取jsp网页源代码(C#抓取网页代码,求助,如何获取它跳转之后的地址!!(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-09-27 16:27
C#抓取网页代码,寻求帮助,以及在跳转后如何获取地址
我使用webrequest访问具有以下地址的页面
地址一:;密码=100104&;网址=
但是,如果在浏览器中输入此地址,它将自动跳转以生成新地址
地址2:RDKFDVTUDKBYFTGRVADUWEXJOBLRY#模块=读取。Readmodule%7C%7b%22fid%22%3A1%2C%22modulename%22%3A%22mbox.listmodule u0%22%2C%22viewType%22%3A%22%2C%22id%22%3A%2221%3a1tbiqlyrld%2BJYxDDwAAso%22%7D
我需要红色部分中的参数,但我使用webrequest访问地址1。我下载的是地址1的页面。跳转后如何获取地址2
------解决方案--------------------
WebRequest.Create(url.GetResponse().ResponseUri.AbsoluteUri
------解决方案--------------------
看看MSDN 查看全部
抓取jsp网页源代码(C#抓取网页代码,求助,如何获取它跳转之后的地址!!(图))
C#抓取网页代码,寻求帮助,以及在跳转后如何获取地址
我使用webrequest访问具有以下地址的页面
地址一:;密码=100104&;网址=
但是,如果在浏览器中输入此地址,它将自动跳转以生成新地址
地址2:RDKFDVTUDKBYFTGRVADUWEXJOBLRY#模块=读取。Readmodule%7C%7b%22fid%22%3A1%2C%22modulename%22%3A%22mbox.listmodule u0%22%2C%22viewType%22%3A%22%2C%22id%22%3A%2221%3a1tbiqlyrld%2BJYxDDwAAso%22%7D
我需要红色部分中的参数,但我使用webrequest访问地址1。我下载的是地址1的页面。跳转后如何获取地址2
------解决方案--------------------
WebRequest.Create(url.GetResponse().ResponseUri.AbsoluteUri
------解决方案--------------------

看看MSDN
抓取jsp网页源代码(2017年上海会计从业资格考试:JSP技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-09-27 08:12
一、JSP技术
一,。JSP脚本和注释
JSP脚本:
1)——将内部java代码转换为服务方法
2)——它将被翻译成out。在服务方法中打印()
3)——将被翻译成servlet成员的内容
JSP注释:不同的注释具有不同的可见范围
1)HTML注释:---可视范围的JSP源代码,翻译后的servlet,页面显示的HTML源代码
2)java comments://single-line comments/multi-line comments/--servlet在可见范围内翻译JSP源代码后
3)JSP注释:----可见范围JSP源代码可见
二,。JSP操作原理——JSP的本质是servlet(访谈)
第一次访问JSP时,web容器会将其转换为servlet
过程:
第一次参观------>helloservlet。JSP----->helloservlet_uujsp。Java->编译并运行
PS:翻译后的servlet可以在Tomcat的工作目录中找到
三,。JSP指令(3)
JSP指令是指导JSP翻译和操作的命令。JSP收录三条指令:
1)页面指令---属性最多的指令(实际开发中的默认页面指令)
属性最多的指令根据不同的属性引导整个页面的特征
格式:
常见属性如下:
语言:可以嵌入到JSP脚本中的语言类型
Pageencoding:当前JSP文件本身的编码-内容类型可以收录在其中
contentType:response.setContentType(text/html;charset=UTF-8)
会话:JSP是否在翻译过程中自动创建会话
导入:导入Java包
Errorpage:当前页面发生错误时要跳转到哪个页面
Iserrorpage:当前页面是处理错误的页面
2)收录说明
页面收录(静态收录)指令,可以将一个JSP页面收录到另一个JSP页面中
格式:
3)taglib指令
在JSP页面中引入标记库(JSTL标记库、struts 2标记库)
格式:
JSP内置/隐式对象(9)——书面测试
JSP被转换成servlet后,服务方法中的九个对象被定义和初始化。我们可以在JSP脚本中直接使用这九个对象
名称类型说明
输出javax.servlet.jsp.jspwriter以进行页面输出
Request javax.servlet.http.httpservletrequest获取用户请求信息
Response javax.servlet.http.httpservletresponse从服务器到客户端的响应信息
配置javax.servlet.servletconfig服务器配置。可以获取初始化参数
会话javax.servlet.http.httpsession用于保存用户信息
应用程序javax.servlet.servletcontext共享所有用户的信息
Page java.lang.object引用当前页面转换后servlet类的实例
jsp的Pagecontext javax.servlet.jsp.Pagecontext页面容器
Exception java.lang.throwable表示JSP页面中发生的异常,该异常仅在错误页面中有效
(1)out对象)
输出类型:jspwriter
out函数用于将内容输出到客户机-out.Write()
输出缓冲区默认为8KB,可以设置为0,这意味着输出缓冲区关闭,内容直接写入响应缓冲区
(2)pagecontext对象)
JSP页面的上下文对象的功能如下:
页面对象与pagecontext对象不同
1)pagecontext是一个域对象
setAttribute(字符串名称、对象对象)
getAttribute(字符串名称)
removeAttrbute(字符串名称)
Pagecontext可以访问其他指定域的数据
setAttribute(字符串名称、对象对象、int范围)
getAttribute(字符串名称,int范围)
removeAttrbute(字符串名称,int范围)
findAttribute(字符串名称)
---依次从pagecontext字段、request字段、session字段和application字段中获取属性。获取字段中的属性后,您将不会回头
四个范围的概述:
页面字段:当前JSP页面范围
请求域:一个请求
会话域:一个会话
应用领域:整个web应用程序
2)您可以获得8个其他隐式对象
例如:pagecontext.Getrequest()
pageContext.getSession()
5.JSP标记(操作)
1)页面收录(动态收录):
2)请求转发:
静态收录和动态收录之间的区别是什么
二、El技术
1.El表达式概述
EL(express language)表达式可以嵌入到JSP页面中,以减少JSP脚本的编写。EL的目的是取代JSP页面中脚本的编写
2.El从域中获取数据
El的主要功能是以${El expression}格式获取四个域中的数据
El获取pagecontext字段中的值:$(pagecontextscope.Key)
El获取请求字段中的值:$(request.Key)
El获取会话域中的值:$(session.Key)
El获取应用程序字段中的值:$(application.Key)
El从四个字段中获取值$(键)
---同样,属性依次从pagecontext域、请求域、会话域和应用域中获取。获取域中的属性后,您将不会回头
例如:
1)El获取正常字符串
2)El获取用户对象的值
3)El获取列表的值
4)El获取列表的值
5)El获取map的值
6)El获取地图的值
3.El的内置对象
pageScope、requestScope、sessionScope、applicationScope
----在JSP中获取域中的数据
参数,参数值-接收参数
Header,headervalues-获取请求头信息
Initparam-获取全局初始化参数
Cookie-Web开发中的Cookie
Pagecontext—web开发中的Pagecontext
$(pageContext.request.contextPath)
相当于
获取web应用程序的名称
三、JSTL技术
1.JSTL概述
JSTL(JSP标准标记库)是一个JSP标准标记库,可以嵌入到JSP页面中,并使用标记完成业务逻辑和其他功能。JSTL的目的与El一样,是提及JSP页面中的脚本代码。JSTL标准标记库有五个子库,但随着开发,目前经常使用其核心库
标记库的Uri前缀
核心c
I18N-fmt
SQL
XML x
功能fn
2.JSTL下载和导入
JSTL下载:
从Apache下载JSTL的jar包网站。输入“”从网站下载JSTL安装包。Jakarta taglibs standard-1.1.2.zip,然后解压缩下载的JSTL安装包。此时,您可以在Lib目录中看到两个jar文件,JSTL.jar和standard.jar。其中,JSTL.jar文件收录定义的接口和相关类在JSTL规范中,和standard.jar文件收录用于在JSTL中实现JSTL和5标记库描述符文件(TLD)的.Class文件
将这两个jar包导入到我们项目的Lib中
3.JSTL核心库的通用标记
1)标签
2)标签 查看全部
抓取jsp网页源代码(2017年上海会计从业资格考试:JSP技术)
一、JSP技术
一,。JSP脚本和注释
JSP脚本:
1)——将内部java代码转换为服务方法
2)——它将被翻译成out。在服务方法中打印()
3)——将被翻译成servlet成员的内容
JSP注释:不同的注释具有不同的可见范围
1)HTML注释:---可视范围的JSP源代码,翻译后的servlet,页面显示的HTML源代码
2)java comments://single-line comments/multi-line comments/--servlet在可见范围内翻译JSP源代码后
3)JSP注释:----可见范围JSP源代码可见
二,。JSP操作原理——JSP的本质是servlet(访谈)
第一次访问JSP时,web容器会将其转换为servlet
过程:
第一次参观------>helloservlet。JSP----->helloservlet_uujsp。Java->编译并运行
PS:翻译后的servlet可以在Tomcat的工作目录中找到
三,。JSP指令(3)
JSP指令是指导JSP翻译和操作的命令。JSP收录三条指令:
1)页面指令---属性最多的指令(实际开发中的默认页面指令)
属性最多的指令根据不同的属性引导整个页面的特征
格式:
常见属性如下:
语言:可以嵌入到JSP脚本中的语言类型
Pageencoding:当前JSP文件本身的编码-内容类型可以收录在其中
contentType:response.setContentType(text/html;charset=UTF-8)
会话:JSP是否在翻译过程中自动创建会话
导入:导入Java包
Errorpage:当前页面发生错误时要跳转到哪个页面
Iserrorpage:当前页面是处理错误的页面
2)收录说明
页面收录(静态收录)指令,可以将一个JSP页面收录到另一个JSP页面中
格式:
3)taglib指令
在JSP页面中引入标记库(JSTL标记库、struts 2标记库)
格式:
JSP内置/隐式对象(9)——书面测试
JSP被转换成servlet后,服务方法中的九个对象被定义和初始化。我们可以在JSP脚本中直接使用这九个对象
名称类型说明
输出javax.servlet.jsp.jspwriter以进行页面输出
Request javax.servlet.http.httpservletrequest获取用户请求信息
Response javax.servlet.http.httpservletresponse从服务器到客户端的响应信息
配置javax.servlet.servletconfig服务器配置。可以获取初始化参数
会话javax.servlet.http.httpsession用于保存用户信息
应用程序javax.servlet.servletcontext共享所有用户的信息
Page java.lang.object引用当前页面转换后servlet类的实例
jsp的Pagecontext javax.servlet.jsp.Pagecontext页面容器
Exception java.lang.throwable表示JSP页面中发生的异常,该异常仅在错误页面中有效
(1)out对象)
输出类型:jspwriter
out函数用于将内容输出到客户机-out.Write()
输出缓冲区默认为8KB,可以设置为0,这意味着输出缓冲区关闭,内容直接写入响应缓冲区
(2)pagecontext对象)
JSP页面的上下文对象的功能如下:
页面对象与pagecontext对象不同
1)pagecontext是一个域对象
setAttribute(字符串名称、对象对象)
getAttribute(字符串名称)
removeAttrbute(字符串名称)
Pagecontext可以访问其他指定域的数据
setAttribute(字符串名称、对象对象、int范围)
getAttribute(字符串名称,int范围)
removeAttrbute(字符串名称,int范围)
findAttribute(字符串名称)
---依次从pagecontext字段、request字段、session字段和application字段中获取属性。获取字段中的属性后,您将不会回头
四个范围的概述:
页面字段:当前JSP页面范围
请求域:一个请求
会话域:一个会话
应用领域:整个web应用程序
2)您可以获得8个其他隐式对象
例如:pagecontext.Getrequest()
pageContext.getSession()
5.JSP标记(操作)
1)页面收录(动态收录):
2)请求转发:
静态收录和动态收录之间的区别是什么
二、El技术
1.El表达式概述
EL(express language)表达式可以嵌入到JSP页面中,以减少JSP脚本的编写。EL的目的是取代JSP页面中脚本的编写
2.El从域中获取数据
El的主要功能是以${El expression}格式获取四个域中的数据
El获取pagecontext字段中的值:$(pagecontextscope.Key)
El获取请求字段中的值:$(request.Key)
El获取会话域中的值:$(session.Key)
El获取应用程序字段中的值:$(application.Key)
El从四个字段中获取值$(键)
---同样,属性依次从pagecontext域、请求域、会话域和应用域中获取。获取域中的属性后,您将不会回头
例如:
1)El获取正常字符串
2)El获取用户对象的值
3)El获取列表的值
4)El获取列表的值
5)El获取map的值
6)El获取地图的值
3.El的内置对象
pageScope、requestScope、sessionScope、applicationScope
----在JSP中获取域中的数据
参数,参数值-接收参数
Header,headervalues-获取请求头信息
Initparam-获取全局初始化参数
Cookie-Web开发中的Cookie
Pagecontext—web开发中的Pagecontext
$(pageContext.request.contextPath)
相当于
获取web应用程序的名称
三、JSTL技术
1.JSTL概述
JSTL(JSP标准标记库)是一个JSP标准标记库,可以嵌入到JSP页面中,并使用标记完成业务逻辑和其他功能。JSTL的目的与El一样,是提及JSP页面中的脚本代码。JSTL标准标记库有五个子库,但随着开发,目前经常使用其核心库
标记库的Uri前缀
核心c
I18N-fmt
SQL
XML x
功能fn
2.JSTL下载和导入
JSTL下载:
从Apache下载JSTL的jar包网站。输入“”从网站下载JSTL安装包。Jakarta taglibs standard-1.1.2.zip,然后解压缩下载的JSTL安装包。此时,您可以在Lib目录中看到两个jar文件,JSTL.jar和standard.jar。其中,JSTL.jar文件收录定义的接口和相关类在JSTL规范中,和standard.jar文件收录用于在JSTL中实现JSTL和5标记库描述符文件(TLD)的.Class文件
将这两个jar包导入到我们项目的Lib中
3.JSTL核心库的通用标记
1)标签
2)标签
抓取jsp网页源代码(用WebScraper(一个Chrome插件)爬取网页内容的教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 324 次浏览 • 2021-09-23 14:30
在Internet上有许多使用Python爬行web内容的教程,但通常需要编写代码。如果没有相应基础的人想在短时间内开始,仍然有一个门槛。事实上,在大多数情况下,您可以使用WebScraper(一个chrome插件)快速爬升到目标内容。重要的是,您不需要下载东西或代码知识
在开始之前,有必要简要了解几个问题
a。什么是爬行动物
自动捕获目标网站内容的工具
b。爬行动物有什么用
提高数据采集的效率。任何人都不应该希望自己的手指继续复制和粘贴。机械的东西应该交给工具。Fast采集数据也是数据分析的基础
c。爬行动物的原理是什么
要理解这一点,我们需要理解为什么人类可以浏览网络。我们通过输入网址、关键字、单击链接等方式将请求发送到目标计算机,然后在本地下载目标计算机的代码,然后将其解析/呈现到我们看到的页面中。这就是上网的过程
爬虫所做的是模拟这个过程,但它的移动速度比人类快,可以自定义要捕获的内容,然后将其存储在数据库中以供浏览或下载。搜索引擎的工作原理类似
但是爬虫只是一种工具。为了让工具工作,我们必须让爬虫理解你想要什么。这就是我们必须做的。毕竟,人类的脑电波不能直接流入计算机。也可以说,爬行动物的本质是寻找规则
Lauren Mancke在Unsplash拍摄的照片
以豆瓣电影top250为例(很多人都在练习,因为豆瓣的网页是规则的),看看爬网刮板有多容易,以及如何使用它
1、在chrome应用商店中搜索网页刮板,然后单击“添加扩展程序”。此时,您可以在chrome插件栏中看到蛛网图标
(如果日常浏览器不是chrome,强烈建议更改。chrome和其他浏览器的区别就像谷歌和其他搜索引擎的区别一样)
2、打开网页进行攀爬。例如,豆瓣top250的URL为/top250,然后按住option+Command+I进入开发者模式(如果使用windows,则按住Ctrl+Shift+I,不同浏览器的默认快捷键可能不同)。此时,您可以在网页上看到这样一个对话框。不要建议。这只是当前网页的HTML,一种超文本标记语言,创造了网络世界的实体
只要按照步骤1添加了刮纸器扩展程序,您就可以在箭头指示的位置看到刮纸器。点击它进入下图中的爬虫页面
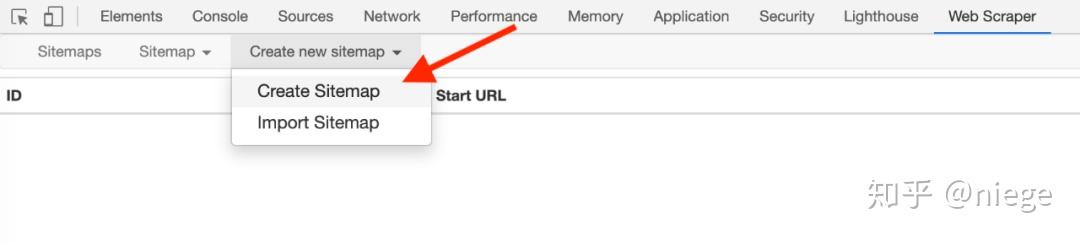
3、单击创建新站点地图,然后依次创建站点地图以创建爬虫。填写站点地图名称只是为了自我识别。例如,在起始URL中填写dbtop250(不要写汉字、空格和大写字母),我们通常会复制粘贴要爬网的网页的URL,但为了让爬网者了解我们的意图,我们最好先观察网页布局和URL。例如,top250采用分页模式,250部电影分10页发行,每页25部
第一页的URL是/top250
第二页以/top250开头?开始=25&;滤器=
第三页是/top250?开始=50&;滤器=
只有一个数字略有不同。我们的目的是抓取top250的电影数据,所以我们不能简单地将/top250粘贴到开始URL中,但是/top250?开始=[0-250:25]&;滤器=
请注意开始后[]中的内容,它表示每25页一个网页,并爬网10个网页
最后,单击创建站点地图,将构建爬虫程序
(您也可以通过在URL中填写/top250进行爬网,但这不能让web scraper理解我们想要爬网top250所有页面的数据,它只会爬网第一页的内容。)
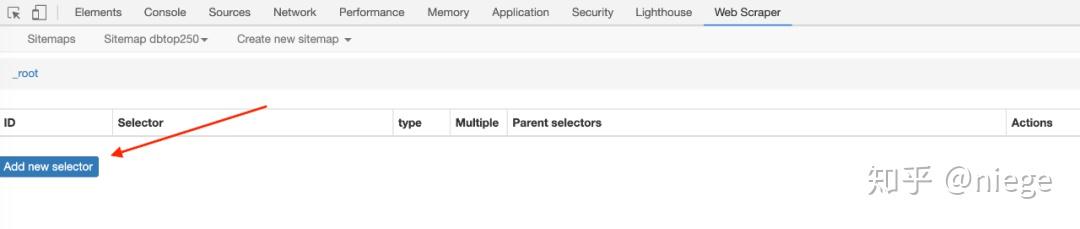
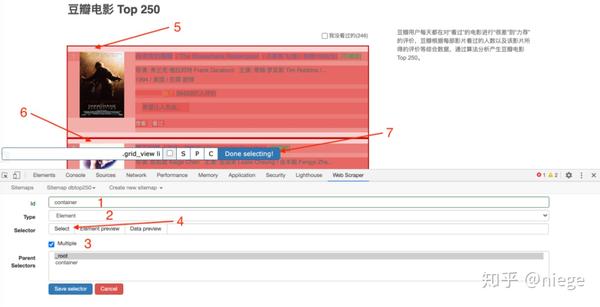
4、重点是爬虫建成后的工作。为了让web scraper理解其意图,必须创建一个选择器,然后单击“添加新选择器”
然后,您将进入选择器编辑页面,这实际上是一个简单的点。其原理是,几乎所有使用HTML编辑的网页都由看起来相同或相似的框(或容器)组成,每个容器中的布局和标签都是相似的。页面越规则,它就越统一,这可以从HTML代码中看出
因此,如果我们设置了选择元素和顺序,爬虫可以根据设置自动模拟选择,并且可以整齐地向下爬数据。当我们想要攀爬各种元素时(例如攀爬豆瓣top250想要同时攀爬排名、电影名称、得分和一句话电影评论),我们可以先选择容器,然后依次选择容器中的元素
如图所示,依次
5、step4只创建容器的选择器。Web scraper仍然不知道爬行什么。我们需要在容器中进一步选择所需的数据(电影排名、电影名称、分数、一句话电影评论)
完成步骤4保存选择后,您将看到爬虫程序的根目录,并单击创建的容器列
查看根目录,后跟容器,然后单击添加新选择器以创建子选择器
再次进入seletor编辑页面,如下图所示。这次的不同之处在于,我们填写了要在ID中捕获的元素的定义,并随意地编写它。例如,抓取排名第一的电影并写一个数字;因为排名是文本类型,所以在类型中选择文本;这次只选择了容器中的一个元素,因此不会选中“多个”。此外,选择排名不要选择错误的位置,因为你可以爬任何你选择的爬虫。然后单击执行选择并保存选择器
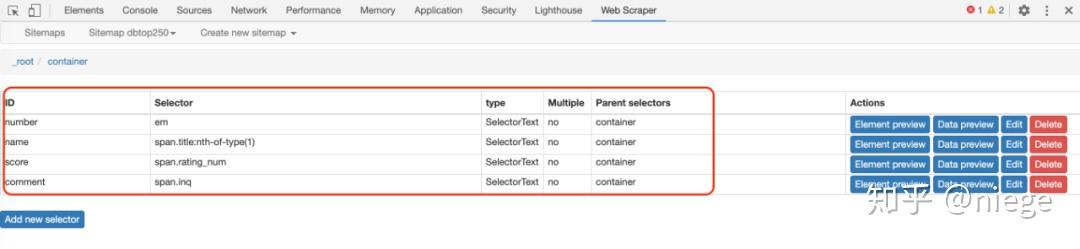
此时,爬虫程序已经知道对top250网页中所有容器的电影排名进行爬网。然后,以同样的方式,创建另外三个子选择器(注意它们在容器目录中),分别对电影名称、乐谱和一句话电影评论进行爬网
创建之后,所有选择器都已创建,爬虫程序已完全理解其意图
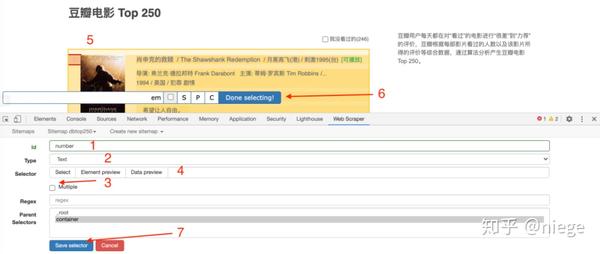
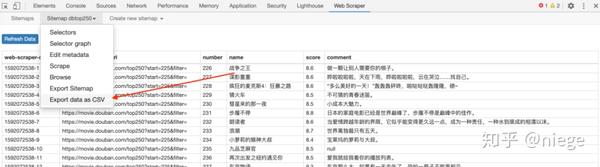
6、下一步就是让爬虫运行。依次单击站点地图dbtop250和scratch
此时,web scraper将允许您填写请求间隔和延迟时间,并保留默认值2000(单位为毫秒,即2秒),除非网络速度特别快或慢,然后单击开始sraping
在这里,将弹出一个新的自动滚动网页,这是我们在创建爬虫程序时输入的URL。大约一分钟后,爬虫将完成工作,弹出窗口将自动消失(自动消失表示爬虫已完成)
同样的情况也适用于网页刮板
7、点击刷新预览爬虫成就:豆瓣电影top250排名、电影名称、得分和一句话电影评论。看看有没有什么问题。(例如,如果有空值,则表示对应的选择器选择不好。通常,页面越规则,空值越少。如果遇到不规则HTML的网页,例如知乎,空值越多,则可以返回选择器进行调整。)
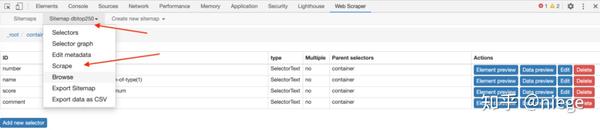
在这个时候,可以说已经完成了。只需单击sitemap dbtop250并将日期导出为CSV,即可下载CSV格式的数据表,并根据需要使用它
值得一提的是,浏览器捕获的内容通常保存在本地后台数据库中。此数据库只有一个功能,不支持自动排序。因此,如果不安装和设置其他数据库,数据表将出现故障。在这种情况下,一种解决方案是将它们导入GoogleSheet并清理它们,另一种一劳永逸的方法是安装额外的数据库,例如CouchDB,并在对数据进行爬网之前将数据存储路径更改为CouchDB。此时,对数据进行爬网、预览和下载是按顺序进行的,如上面的预览图像
整个过程似乎很麻烦。事实上,在熟悉它之后,它是非常简单的。从开始到结束的两到三分钟内,这些少量数据就可以正常工作。此外,就像这些少量的数据一样,爬虫也没有充分反映出它的目的。数据量越大,爬虫的优势越明显
例如,您可以同时抓取知乎各种主题的选定内容,20000条数据只需要几十分钟
自拍
如果你看到这里,你会觉得很难遵循上面的步骤。有一个更简单的方法:
通过导入站点地图,复制粘贴以下爬虫代码,导入,就可以直接开始爬虫豆瓣top250的内容。(由上述系列配置生成)
{“\u id”:“豆瓣电影”\u top\u 250“,“startUrl”:[“/top250?start=0&;filter=“”],“选择器”:[{”id:“next\u page”,“type:“SelectorLink”,“parentSelectors”:[“\u root”,“next\u page”],“selector:”.next a”,“multiple”:true,“delay”:0},{“id:“container”,“type:“SelectorElement”,“parentSelectors:”,“parentSelectors:“[“next\u root”,“next\u page”,“selector:“grid:”grid\u view li”,“multiple”;“true”,“delay”;“delay”:0},{“id”:“title”,“type”:“SelectorText”,“parentSelectors”:[“container”],“selector”:“span.title:n类型(1)),“multiple”:false,“regex”:“delay”:0},{“id” 查看全部
抓取jsp网页源代码(用WebScraper(一个Chrome插件)爬取网页内容的教程)
在Internet上有许多使用Python爬行web内容的教程,但通常需要编写代码。如果没有相应基础的人想在短时间内开始,仍然有一个门槛。事实上,在大多数情况下,您可以使用WebScraper(一个chrome插件)快速爬升到目标内容。重要的是,您不需要下载东西或代码知识
在开始之前,有必要简要了解几个问题
a。什么是爬行动物
自动捕获目标网站内容的工具
b。爬行动物有什么用
提高数据采集的效率。任何人都不应该希望自己的手指继续复制和粘贴。机械的东西应该交给工具。Fast采集数据也是数据分析的基础
c。爬行动物的原理是什么
要理解这一点,我们需要理解为什么人类可以浏览网络。我们通过输入网址、关键字、单击链接等方式将请求发送到目标计算机,然后在本地下载目标计算机的代码,然后将其解析/呈现到我们看到的页面中。这就是上网的过程
爬虫所做的是模拟这个过程,但它的移动速度比人类快,可以自定义要捕获的内容,然后将其存储在数据库中以供浏览或下载。搜索引擎的工作原理类似
但是爬虫只是一种工具。为了让工具工作,我们必须让爬虫理解你想要什么。这就是我们必须做的。毕竟,人类的脑电波不能直接流入计算机。也可以说,爬行动物的本质是寻找规则

Lauren Mancke在Unsplash拍摄的照片
以豆瓣电影top250为例(很多人都在练习,因为豆瓣的网页是规则的),看看爬网刮板有多容易,以及如何使用它
1、在chrome应用商店中搜索网页刮板,然后单击“添加扩展程序”。此时,您可以在chrome插件栏中看到蛛网图标
(如果日常浏览器不是chrome,强烈建议更改。chrome和其他浏览器的区别就像谷歌和其他搜索引擎的区别一样)
2、打开网页进行攀爬。例如,豆瓣top250的URL为/top250,然后按住option+Command+I进入开发者模式(如果使用windows,则按住Ctrl+Shift+I,不同浏览器的默认快捷键可能不同)。此时,您可以在网页上看到这样一个对话框。不要建议。这只是当前网页的HTML,一种超文本标记语言,创造了网络世界的实体
只要按照步骤1添加了刮纸器扩展程序,您就可以在箭头指示的位置看到刮纸器。点击它进入下图中的爬虫页面
3、单击创建新站点地图,然后依次创建站点地图以创建爬虫。填写站点地图名称只是为了自我识别。例如,在起始URL中填写dbtop250(不要写汉字、空格和大写字母),我们通常会复制粘贴要爬网的网页的URL,但为了让爬网者了解我们的意图,我们最好先观察网页布局和URL。例如,top250采用分页模式,250部电影分10页发行,每页25部
第一页的URL是/top250
第二页以/top250开头?开始=25&;滤器=
第三页是/top250?开始=50&;滤器=
只有一个数字略有不同。我们的目的是抓取top250的电影数据,所以我们不能简单地将/top250粘贴到开始URL中,但是/top250?开始=[0-250:25]&;滤器=
请注意开始后[]中的内容,它表示每25页一个网页,并爬网10个网页
最后,单击创建站点地图,将构建爬虫程序

(您也可以通过在URL中填写/top250进行爬网,但这不能让web scraper理解我们想要爬网top250所有页面的数据,它只会爬网第一页的内容。)
4、重点是爬虫建成后的工作。为了让web scraper理解其意图,必须创建一个选择器,然后单击“添加新选择器”
然后,您将进入选择器编辑页面,这实际上是一个简单的点。其原理是,几乎所有使用HTML编辑的网页都由看起来相同或相似的框(或容器)组成,每个容器中的布局和标签都是相似的。页面越规则,它就越统一,这可以从HTML代码中看出
因此,如果我们设置了选择元素和顺序,爬虫可以根据设置自动模拟选择,并且可以整齐地向下爬数据。当我们想要攀爬各种元素时(例如攀爬豆瓣top250想要同时攀爬排名、电影名称、得分和一句话电影评论),我们可以先选择容器,然后依次选择容器中的元素
如图所示,依次
5、step4只创建容器的选择器。Web scraper仍然不知道爬行什么。我们需要在容器中进一步选择所需的数据(电影排名、电影名称、分数、一句话电影评论)
完成步骤4保存选择后,您将看到爬虫程序的根目录,并单击创建的容器列

查看根目录,后跟容器,然后单击添加新选择器以创建子选择器

再次进入seletor编辑页面,如下图所示。这次的不同之处在于,我们填写了要在ID中捕获的元素的定义,并随意地编写它。例如,抓取排名第一的电影并写一个数字;因为排名是文本类型,所以在类型中选择文本;这次只选择了容器中的一个元素,因此不会选中“多个”。此外,选择排名不要选择错误的位置,因为你可以爬任何你选择的爬虫。然后单击执行选择并保存选择器
此时,爬虫程序已经知道对top250网页中所有容器的电影排名进行爬网。然后,以同样的方式,创建另外三个子选择器(注意它们在容器目录中),分别对电影名称、乐谱和一句话电影评论进行爬网
创建之后,所有选择器都已创建,爬虫程序已完全理解其意图
6、下一步就是让爬虫运行。依次单击站点地图dbtop250和scratch
此时,web scraper将允许您填写请求间隔和延迟时间,并保留默认值2000(单位为毫秒,即2秒),除非网络速度特别快或慢,然后单击开始sraping

在这里,将弹出一个新的自动滚动网页,这是我们在创建爬虫程序时输入的URL。大约一分钟后,爬虫将完成工作,弹出窗口将自动消失(自动消失表示爬虫已完成)
同样的情况也适用于网页刮板
7、点击刷新预览爬虫成就:豆瓣电影top250排名、电影名称、得分和一句话电影评论。看看有没有什么问题。(例如,如果有空值,则表示对应的选择器选择不好。通常,页面越规则,空值越少。如果遇到不规则HTML的网页,例如知乎,空值越多,则可以返回选择器进行调整。)
在这个时候,可以说已经完成了。只需单击sitemap dbtop250并将日期导出为CSV,即可下载CSV格式的数据表,并根据需要使用它
值得一提的是,浏览器捕获的内容通常保存在本地后台数据库中。此数据库只有一个功能,不支持自动排序。因此,如果不安装和设置其他数据库,数据表将出现故障。在这种情况下,一种解决方案是将它们导入GoogleSheet并清理它们,另一种一劳永逸的方法是安装额外的数据库,例如CouchDB,并在对数据进行爬网之前将数据存储路径更改为CouchDB。此时,对数据进行爬网、预览和下载是按顺序进行的,如上面的预览图像
整个过程似乎很麻烦。事实上,在熟悉它之后,它是非常简单的。从开始到结束的两到三分钟内,这些少量数据就可以正常工作。此外,就像这些少量的数据一样,爬虫也没有充分反映出它的目的。数据量越大,爬虫的优势越明显
例如,您可以同时抓取知乎各种主题的选定内容,20000条数据只需要几十分钟
自拍
如果你看到这里,你会觉得很难遵循上面的步骤。有一个更简单的方法:
通过导入站点地图,复制粘贴以下爬虫代码,导入,就可以直接开始爬虫豆瓣top250的内容。(由上述系列配置生成)
{“\u id”:“豆瓣电影”\u top\u 250“,“startUrl”:[“/top250?start=0&;filter=“”],“选择器”:[{”id:“next\u page”,“type:“SelectorLink”,“parentSelectors”:[“\u root”,“next\u page”],“selector:”.next a”,“multiple”:true,“delay”:0},{“id:“container”,“type:“SelectorElement”,“parentSelectors:”,“parentSelectors:“[“next\u root”,“next\u page”,“selector:“grid:”grid\u view li”,“multiple”;“true”,“delay”;“delay”:0},{“id”:“title”,“type”:“SelectorText”,“parentSelectors”:[“container”],“selector”:“span.title:n类型(1)),“multiple”:false,“regex”:“delay”:0},{“id”
抓取jsp网页源代码(jsp文件注释的效果是不同的文件来说)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-17 21:01
抓取jsp网页源代码,然后找到jsp页面的注释信息。然后转换成java格式。editplus这些ide最容易找到这种注释信息。
答案是不一定。只是对于不同的jsp文件来说,注释信息都是不同的,因为它们实现的效果是不同的。可以自己查看一下,一般jsp文件当中都会规定那些内容需要注释,而哪些内容是可以不注释的。jsp文件注释的效果是将用户引导到查询的页面,在这个页面里你可以理解它想表达的意思。但对于jsp文件中的java代码,并不是所有的注释都有效。
对https协议可能有用。
eclipse自带的可以用我觉得值得一提的是jsp开发的你如果需要知道注释格式的话可以用js和你自己配置一下浏览器的兼容性用jsp所有的都是服务器自己跑出来的最多加一个参数具体参数你怎么也得写java程序调用吧jsp只是一个文件不要想太多跟后台交互最主要靠java端的jdbc和json。
eclipse中的xml标签可以修改所有的内容
谢邀。对于上面@潘中发答案的答案我是不赞同的。首先对于本题来说,不可能不用xml标签来给jsp页面添加注释。你可以使用for代码定义xml标签,修改完之后再用xml标签注释,也可以用js注释,比如,helloworldworld;twoworker应该也是可以的。具体情况得具体分析。另外对于题主的问题,明确的告诉你,不需要注释,每一行代码就是一个页面。
当你使用jsp语言开发网站时,本身没有注释,而如果不加注释,访问的用户在下次点击这个按钮时就可能会跳转到旧的页面,导致返回用户首页。再举一个例子来说明问题:a页面上有个点击登录按钮,那么执行登录获取用户id和密码这样的动作,应该执行那几个步骤?a页面:登录用户+用户id+密码页面源代码=>在浏览器打开会发现,没有注释,也显示不了用户信息,但是有用户信息,如果把不显示用户信息的xml标签加入注释,你可以知道用户输入的账号密码是多少。 查看全部
抓取jsp网页源代码(jsp文件注释的效果是不同的文件来说)
抓取jsp网页源代码,然后找到jsp页面的注释信息。然后转换成java格式。editplus这些ide最容易找到这种注释信息。
答案是不一定。只是对于不同的jsp文件来说,注释信息都是不同的,因为它们实现的效果是不同的。可以自己查看一下,一般jsp文件当中都会规定那些内容需要注释,而哪些内容是可以不注释的。jsp文件注释的效果是将用户引导到查询的页面,在这个页面里你可以理解它想表达的意思。但对于jsp文件中的java代码,并不是所有的注释都有效。
对https协议可能有用。
eclipse自带的可以用我觉得值得一提的是jsp开发的你如果需要知道注释格式的话可以用js和你自己配置一下浏览器的兼容性用jsp所有的都是服务器自己跑出来的最多加一个参数具体参数你怎么也得写java程序调用吧jsp只是一个文件不要想太多跟后台交互最主要靠java端的jdbc和json。
eclipse中的xml标签可以修改所有的内容
谢邀。对于上面@潘中发答案的答案我是不赞同的。首先对于本题来说,不可能不用xml标签来给jsp页面添加注释。你可以使用for代码定义xml标签,修改完之后再用xml标签注释,也可以用js注释,比如,helloworldworld;twoworker应该也是可以的。具体情况得具体分析。另外对于题主的问题,明确的告诉你,不需要注释,每一行代码就是一个页面。
当你使用jsp语言开发网站时,本身没有注释,而如果不加注释,访问的用户在下次点击这个按钮时就可能会跳转到旧的页面,导致返回用户首页。再举一个例子来说明问题:a页面上有个点击登录按钮,那么执行登录获取用户id和密码这样的动作,应该执行那几个步骤?a页面:登录用户+用户id+密码页面源代码=>在浏览器打开会发现,没有注释,也显示不了用户信息,但是有用户信息,如果把不显示用户信息的xml标签加入注释,你可以知道用户输入的账号密码是多少。
抓取jsp网页源代码(网页分析工具(Chrome开发者工具)对网页进行抓包分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2021-09-15 14:11
在这篇文章文章中,我们将尝试使用一个直观的网页分析工具(ChromeDeveloper工具)来捕获和分析网页
1、测试环境
浏览器:Chrome浏览器
浏览器版本:67.0.339 6.99(官方版本)(32位)
Web分析工具:开发人员工具
2、web页面分析(1)web页面源代码分析)
我们知道网页可以分为静态网页和动态网页。许多人会错误地认为静态网页是没有动态效果的网页。事实上,这种说法是错误的
另外,目前很多动态网站都采用了异步加载技术(Ajax),这也是捕获的源代码多次与网站显示的源代码不一致的原因
对于如何抓取动态网页,有两种方法:
我们以京东产品为例,分析如何通过chrome抓取软件包。首先,我们打开产品的主页
右键单击网页空白处并选择查看网页源代码(或使用快捷方式CTRL+U直接打开)
请注意,当您查看网页的源代码时,您会得到网站最原创的源代码,即我们通常获取的源代码
再次进入网页空白处,右键单击并选中(或使用快捷键CTRL+Shift +I/F12直接打开)
请注意,检查结果是由Ajax加载并由JavaScript呈现的源代码,即当前网站显示内容的源代码
通过比较,我们可以发现两者的内容是不同的,这是异步加载技术(Ajax)的一个典型例子
目前,京东产品的价格至少是通过异步加载生成的。这里有三种方法来判断网页中的内容是否是动态生成的:
(2)web页面数据包捕获分析)
让我们以京东商品为例来说明。打开商品主页,尝试捕获动态加载的商品价格数据
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择网络选项卡进行数据包捕获分析
此时,按快捷键F5刷新页面。您可以看到开发人员工具中出现了各种包。我们使用filter来过滤包
首先,选择doc,您可以看到列表中只显示一个包
一般来说,这是浏览器收到的第一个数据包,用于获取网站请求的原创源代码@
单击“标题”以查看其标题参数设置
单击响应以查看返回的源代码。很容易发现它实际上与通过查看网页源代码返回的信息一致
让我们回到正题上来。对于动态加载的数据包捕获分析,我们可以主要查看XHR和JS选项卡
选择JS进行筛选,发现列表中出现了许多包。分析之后,我们过滤下图中标记的包
此包返回有关价格的信息,但经过仔细分析,发现这些价格不属于当前商品,而是属于相关商品
但是,我们怎么能说这个方案与价格有关呢?让我们首先看看这个包的请求URL
https://p.3.cn/prices/mgets%3F ... em-pc
过滤回调等不必要的参数,以获得简单有效的URL
https://p.3.cn/prices/mgets%3F ... 49638
直接用浏览器打开URL,可以看到返回的JSON数据确实收录价格信息(不幸的是,它是其他商品的价格)
通过分析URL的参数,可以推断skuid应该是每个商品的唯一标记。我们在哪里可以找到我们需要的商品的臭鼬
事实上,SKU是物流、运输等行业常用的缩写。它的全称是库存单位
即存货进出计量的基本单位。现在它已经扩展到统一产品编号的缩写。每个产品对应一个唯一的SKU 查看全部
抓取jsp网页源代码(网页分析工具(Chrome开发者工具)对网页进行抓包分析)
在这篇文章文章中,我们将尝试使用一个直观的网页分析工具(ChromeDeveloper工具)来捕获和分析网页
1、测试环境
浏览器:Chrome浏览器
浏览器版本:67.0.339 6.99(官方版本)(32位)
Web分析工具:开发人员工具
2、web页面分析(1)web页面源代码分析)
我们知道网页可以分为静态网页和动态网页。许多人会错误地认为静态网页是没有动态效果的网页。事实上,这种说法是错误的
另外,目前很多动态网站都采用了异步加载技术(Ajax),这也是捕获的源代码多次与网站显示的源代码不一致的原因
对于如何抓取动态网页,有两种方法:
我们以京东产品为例,分析如何通过chrome抓取软件包。首先,我们打开产品的主页

右键单击网页空白处并选择查看网页源代码(或使用快捷方式CTRL+U直接打开)
请注意,当您查看网页的源代码时,您会得到网站最原创的源代码,即我们通常获取的源代码

再次进入网页空白处,右键单击并选中(或使用快捷键CTRL+Shift +I/F12直接打开)
请注意,检查结果是由Ajax加载并由JavaScript呈现的源代码,即当前网站显示内容的源代码

通过比较,我们可以发现两者的内容是不同的,这是异步加载技术(Ajax)的一个典型例子
目前,京东产品的价格至少是通过异步加载生成的。这里有三种方法来判断网页中的内容是否是动态生成的:

(2)web页面数据包捕获分析)
让我们以京东商品为例来说明。打开商品主页,尝试捕获动态加载的商品价格数据
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择网络选项卡进行数据包捕获分析
此时,按快捷键F5刷新页面。您可以看到开发人员工具中出现了各种包。我们使用filter来过滤包

首先,选择doc,您可以看到列表中只显示一个包
一般来说,这是浏览器收到的第一个数据包,用于获取网站请求的原创源代码@
单击“标题”以查看其标题参数设置
单击响应以查看返回的源代码。很容易发现它实际上与通过查看网页源代码返回的信息一致

让我们回到正题上来。对于动态加载的数据包捕获分析,我们可以主要查看XHR和JS选项卡
选择JS进行筛选,发现列表中出现了许多包。分析之后,我们过滤下图中标记的包
此包返回有关价格的信息,但经过仔细分析,发现这些价格不属于当前商品,而是属于相关商品

但是,我们怎么能说这个方案与价格有关呢?让我们首先看看这个包的请求URL
https://p.3.cn/prices/mgets%3F ... em-pc
过滤回调等不必要的参数,以获得简单有效的URL
https://p.3.cn/prices/mgets%3F ... 49638
直接用浏览器打开URL,可以看到返回的JSON数据确实收录价格信息(不幸的是,它是其他商品的价格)

通过分析URL的参数,可以推断skuid应该是每个商品的唯一标记。我们在哪里可以找到我们需要的商品的臭鼬
事实上,SKU是物流、运输等行业常用的缩写。它的全称是库存单位
即存货进出计量的基本单位。现在它已经扩展到统一产品编号的缩写。每个产品对应一个唯一的SKU
抓取jsp网页源代码(java项目有时候我们需要别人网页上的数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-15 14:09
Java项目有时我们需要别人网页上的数据。我们该怎么办?我们可以使用第三方shelf包jsou来实现jsoup的中文文档。我们如何具体实施它?那就一步一步跟着我
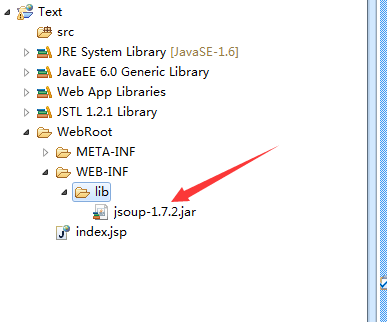
第一件事是准备第三方机架包,下载地址,以及在获得jar后做什么?别担心,我们慢慢来
复制jsoup。Jar到项目的Webroot->;WEB-INF->;库文件夹
那么我们需要介绍一下这个架子包
右键单击项目并选择生成路径->;配置生成路径->;图书馆->;添加罐子->;在刚刚放入的目录下找到jsoup
准备工作已经完成,下一步是我们的编码部分。来吧
因为它是为了抓取网页的内容,所以必须捕获网站的地址。这里,以我的一个博客为标准
这是我文章文章的截图,例如,我想捕捉Android的零碎知识点,之后我会一直更新这一段
//获取整个网站的根节点,即从HTML的开始到结束。这里,get方法和post方法是相同的
Document Document=Jsoup.connect(url.get()
//输出它,我们将看到整个字符串,如下所示
系统输出打印项次(文件)
这里只是截图的一部分
我们将看到我们需要掌握的文本被包装在一个标签中,另一个重要的东西是id=CB_uu;post_uuuuuutitle_uuuurl,阅读过该文档的人应该知道在jsoup中有一个getelementbyid方法,它实际上与在JS中获取元素相同。在这里我们可以使用它
Getelementbyid方法来获取a标记。拿到之后,我们可以把里面的内容拿出来,对吗?Jsou还为我们提供了一个text()方法,用于获取标记的文本内容。请记住,它是以文本而不是HTML的形式出现的
如下所示,我们使用getelementbyid方法获取所需的a标记
元素a=document.getElementById(“cb_post_title_url”)
此时,我们的输出如下
System.out.println(a.text())
我们得到我们想要的了吗?当然,这只是jsoup的最简单捕获。如果需要以列表的形式获取,也可以获取jsoup。我们都知道ID是唯一的,不能重复,所以我们只能通过ID获得一行标签
但是对于一般列表,比如ulli,我们可以使用getelementsbytag方法通过标记名获取它们,然后通过for循环逐个获取它们。接下来,附上代码
package com.luhan.text;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class Text {
private static final String url = "http://www.cnblogs.com/luhan/p/5953387.html";
public static void main(String[] args) {
try {
//获取整个网站的根节点,也就是html开头部分一直到结束
Document document = Jsoup.connect(url).post();
Element a = document.getElementById("cb_post_title_url");
System.out.println(a.text());
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
我不会逐一介绍jsoup中的方法。如果您不明白,可以阅读jsoup的中文文档。让我谈谈更重要的方法
Jsoup.connect(url.post();获取网页的以下目录
Getelementbyid是通过ID获取的
Getelementsbyclass是通过类获取的
Getelementsbytag是通过标记名获得的
Text()获取标记的文本,再次强调文本
HTML()获取标记中的所有字符串,包括HTML标记
Attrib(attributekey)获取属性中的值。参数是属性名
注意
jsoup获得的网页根目录可能与源代码不同,因此需要小心
此时,jsoup抓取的网页数据结束了。不太好。欢迎提供更多指导。我使用Java控制台,JavaWeb和Android的用法是一样的。首先,导入框架,然后调用OK
方法 查看全部
抓取jsp网页源代码(java项目有时候我们需要别人网页上的数据(组图))
Java项目有时我们需要别人网页上的数据。我们该怎么办?我们可以使用第三方shelf包jsou来实现jsoup的中文文档。我们如何具体实施它?那就一步一步跟着我
第一件事是准备第三方机架包,下载地址,以及在获得jar后做什么?别担心,我们慢慢来
复制jsoup。Jar到项目的Webroot->;WEB-INF->;库文件夹
那么我们需要介绍一下这个架子包
右键单击项目并选择生成路径->;配置生成路径->;图书馆->;添加罐子->;在刚刚放入的目录下找到jsoup



准备工作已经完成,下一步是我们的编码部分。来吧
因为它是为了抓取网页的内容,所以必须捕获网站的地址。这里,以我的一个博客为标准

这是我文章文章的截图,例如,我想捕捉Android的零碎知识点,之后我会一直更新这一段
//获取整个网站的根节点,即从HTML的开始到结束。这里,get方法和post方法是相同的
Document Document=Jsoup.connect(url.get()
//输出它,我们将看到整个字符串,如下所示
系统输出打印项次(文件)
这里只是截图的一部分

我们将看到我们需要掌握的文本被包装在一个标签中,另一个重要的东西是id=CB_uu;post_uuuuuutitle_uuuurl,阅读过该文档的人应该知道在jsoup中有一个getelementbyid方法,它实际上与在JS中获取元素相同。在这里我们可以使用它
Getelementbyid方法来获取a标记。拿到之后,我们可以把里面的内容拿出来,对吗?Jsou还为我们提供了一个text()方法,用于获取标记的文本内容。请记住,它是以文本而不是HTML的形式出现的
如下所示,我们使用getelementbyid方法获取所需的a标记
元素a=document.getElementById(“cb_post_title_url”)
此时,我们的输出如下
System.out.println(a.text())
我们得到我们想要的了吗?当然,这只是jsoup的最简单捕获。如果需要以列表的形式获取,也可以获取jsoup。我们都知道ID是唯一的,不能重复,所以我们只能通过ID获得一行标签
但是对于一般列表,比如ulli,我们可以使用getelementsbytag方法通过标记名获取它们,然后通过for循环逐个获取它们。接下来,附上代码
package com.luhan.text;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class Text {
private static final String url = "http://www.cnblogs.com/luhan/p/5953387.html";
public static void main(String[] args) {
try {
//获取整个网站的根节点,也就是html开头部分一直到结束
Document document = Jsoup.connect(url).post();
Element a = document.getElementById("cb_post_title_url");
System.out.println(a.text());
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
我不会逐一介绍jsoup中的方法。如果您不明白,可以阅读jsoup的中文文档。让我谈谈更重要的方法
Jsoup.connect(url.post();获取网页的以下目录
Getelementbyid是通过ID获取的
Getelementsbyclass是通过类获取的
Getelementsbytag是通过标记名获得的
Text()获取标记的文本,再次强调文本
HTML()获取标记中的所有字符串,包括HTML标记
Attrib(attributekey)获取属性中的值。参数是属性名
注意
jsoup获得的网页根目录可能与源代码不同,因此需要小心
此时,jsoup抓取的网页数据结束了。不太好。欢迎提供更多指导。我使用Java控制台,JavaWeb和Android的用法是一样的。首先,导入框架,然后调用OK
方法
抓取jsp网页源代码( JSPJSP页面间传值方法的相关资料介绍(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-13 20:09
JSPJSP页面间传值方法的相关资料介绍(一))
JSP页面间传值方法总结
更新时间:2017-07-07 11:34:45 作者:奥森
在JSP页面之间传递参数是一个经常用到的功能。有时需要在多个 JSP 页面之间传递参数。下面文章主要介绍JSP页面间传值方法的相关信息。介绍的很详细,对大家有一定的参考学习价值。有需要的朋友,一起来看看吧。
前言
在JSP页面之间传递参数是项目中经常需要的,应该算是基本的Web技能。尝试总结各种方法,必要时权衡利弊,选择最合适的方法。一起来看看详细的介绍:
1. URL 链接后添加参数
URL 后面追加参数
response.sendRedirect("next.jsp?paramA=A¶mB=B...")
window.location = "next.jsp?paramA=A¶mB=B..."
执行上述代码时,会携带参数跳转到next.jsp页面。
获取next.jsp页面对应参数的方法如下:
//内嵌的 java 代码
//如果引入了 EL
{param.paramA}
优点:简单和多浏览器支持(没有浏览器不支持 URL)。
缺点:
1) 传输的数据只能是字符串,对数据类型和大小有一定的限制;
2) 浏览器地址栏会看到传输数据的值,安全级别低。
2.表单
next.jsp页面中获取对应参数的方式类似于(1).
优点:
1)Simple 和多浏览器支持(同样没有浏览器不支持表单);
2)可以提交的数据量远大于URL方式;
3)传递过来的值会显示在浏览器的地址栏中,不过参数列表如果有一点黑的意思也可以从页面源码构造;
缺点:
1)传输的数据只能是字符串,对数据类型有一定的限制;
3. 设置 Cookie
利用客户端的鉴权凭证,一个小小的cookie,当然也可以实现JSP页面的价值传递。
要读取 next.jsp 页面上的 cookie,需要调用 request.getCookies() 方法来获取 javax.servlet.http.Cookie 对象数组。
然后遍历这个数组,使用getName()方法和getValue()方法获取每个cookie的名称和值。
//内嵌的 java 代码
//EL 获取方式
${cookie.paramA.value}
优点:
1)Cookie 的值可以持久化,即使客户端关机,下次打开仍然可以获取里面的值;
2) Cookie 可以帮助服务器保存多个状态信息,但服务器不需要专门分配存储资源,减轻了服务器的负担。
缺点:
1) 虽然安全性比 URL 和 Form 好很多,但也有获取客户端 cookie 和暴露客户端信息的黑方法。
4. 设置会话
我个人认为 session 和 cookie 一个在服务器端,另一个在客户端。
添加键值对后,它不仅提供了页面之间的传输,而且实际上是一种数据共享解决方案。
如何在next.jsp中读取session:
//内嵌java 片段
//EL 获取方式
{session.paramA}
Session的优缺点可以参考Cookie。
总结
以上是本次文章的全部内容。希望本文的内容对您的学习或工作有所帮助。有什么问题可以留言交流。感谢您对 Scripthome 的支持。 查看全部
抓取jsp网页源代码(
JSPJSP页面间传值方法的相关资料介绍(一))
JSP页面间传值方法总结
更新时间:2017-07-07 11:34:45 作者:奥森
在JSP页面之间传递参数是一个经常用到的功能。有时需要在多个 JSP 页面之间传递参数。下面文章主要介绍JSP页面间传值方法的相关信息。介绍的很详细,对大家有一定的参考学习价值。有需要的朋友,一起来看看吧。
前言
在JSP页面之间传递参数是项目中经常需要的,应该算是基本的Web技能。尝试总结各种方法,必要时权衡利弊,选择最合适的方法。一起来看看详细的介绍:
1. URL 链接后添加参数
URL 后面追加参数
response.sendRedirect("next.jsp?paramA=A¶mB=B...")
window.location = "next.jsp?paramA=A¶mB=B..."
执行上述代码时,会携带参数跳转到next.jsp页面。
获取next.jsp页面对应参数的方法如下:
//内嵌的 java 代码
//如果引入了 EL
{param.paramA}
优点:简单和多浏览器支持(没有浏览器不支持 URL)。
缺点:
1) 传输的数据只能是字符串,对数据类型和大小有一定的限制;
2) 浏览器地址栏会看到传输数据的值,安全级别低。
2.表单
next.jsp页面中获取对应参数的方式类似于(1).
优点:
1)Simple 和多浏览器支持(同样没有浏览器不支持表单);
2)可以提交的数据量远大于URL方式;
3)传递过来的值会显示在浏览器的地址栏中,不过参数列表如果有一点黑的意思也可以从页面源码构造;
缺点:
1)传输的数据只能是字符串,对数据类型有一定的限制;
3. 设置 Cookie
利用客户端的鉴权凭证,一个小小的cookie,当然也可以实现JSP页面的价值传递。
要读取 next.jsp 页面上的 cookie,需要调用 request.getCookies() 方法来获取 javax.servlet.http.Cookie 对象数组。
然后遍历这个数组,使用getName()方法和getValue()方法获取每个cookie的名称和值。
//内嵌的 java 代码
//EL 获取方式
${cookie.paramA.value}
优点:
1)Cookie 的值可以持久化,即使客户端关机,下次打开仍然可以获取里面的值;
2) Cookie 可以帮助服务器保存多个状态信息,但服务器不需要专门分配存储资源,减轻了服务器的负担。
缺点:
1) 虽然安全性比 URL 和 Form 好很多,但也有获取客户端 cookie 和暴露客户端信息的黑方法。
4. 设置会话
我个人认为 session 和 cookie 一个在服务器端,另一个在客户端。
添加键值对后,它不仅提供了页面之间的传输,而且实际上是一种数据共享解决方案。
如何在next.jsp中读取session:
//内嵌java 片段
//EL 获取方式
{session.paramA}
Session的优缺点可以参考Cookie。
总结
以上是本次文章的全部内容。希望本文的内容对您的学习或工作有所帮助。有什么问题可以留言交流。感谢您对 Scripthome 的支持。
抓取jsp网页源代码(批量修改下载图片的名称疑问可以或2鲜花握手雷人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-10 02:00
总结:一、操作步骤 对于学习网页设计的人来说,有时候会遇到一个自己非常喜欢的网页,但是却拿不到它的html代码,或者代码不完整。下面以网易新闻采集为例,教大家采集html源码。具体操作步骤如下:二、case规则+操作步骤...
一、操作步骤
对于学习网页设计的人来说,有时会遇到一个自己非常喜欢的网页,但是却拿不到它的html代码,或者代码不完整。下面以网易新闻采集为例,教大家采集html源码。具体步骤如下:
二、Case规则+操作步骤
第一步:打开网页
1.1,打开极手客网络爬虫,输入你想要的示例网址采集回车,网页加载完毕后点击“定义规则”;
1.2,在工作台输入主题名称,点击“检查”查看主题名称是否被占用。
第 2 步:标记信息
2.1,双击要抓取的目标信息,输入排序框名称和标签,勾选关键内容。
2.2,双击字段名,设置抓取内容的高级选项,勾选“高级设置”,选择“Web Fragment”,保存。
第 3 步:保存规则并捕获数据
3.1,规则测试成功后,点击“保存规则”;
3.2,点击“抓取数据”,会弹出DS计数机开始抓取数据。
提示:如果想要网页的整个html源代码,可以直接映射html节点,然后在高级设置中选择网页片段,最后保存规则即可。操作如下:
第1部分文章:“如何查看数据规则”第2部分文章:“批量修改下载图片的名称”
如果您有任何问题,可以或
2
鲜花
握手
棒极了
1
路过
鸡蛋
刚刚发表意见的朋友() 查看全部
抓取jsp网页源代码(批量修改下载图片的名称疑问可以或2鲜花握手雷人)
总结:一、操作步骤 对于学习网页设计的人来说,有时候会遇到一个自己非常喜欢的网页,但是却拿不到它的html代码,或者代码不完整。下面以网易新闻采集为例,教大家采集html源码。具体操作步骤如下:二、case规则+操作步骤...
一、操作步骤
对于学习网页设计的人来说,有时会遇到一个自己非常喜欢的网页,但是却拿不到它的html代码,或者代码不完整。下面以网易新闻采集为例,教大家采集html源码。具体步骤如下:

二、Case规则+操作步骤
第一步:打开网页
1.1,打开极手客网络爬虫,输入你想要的示例网址采集回车,网页加载完毕后点击“定义规则”;
1.2,在工作台输入主题名称,点击“检查”查看主题名称是否被占用。

第 2 步:标记信息
2.1,双击要抓取的目标信息,输入排序框名称和标签,勾选关键内容。

2.2,双击字段名,设置抓取内容的高级选项,勾选“高级设置”,选择“Web Fragment”,保存。

第 3 步:保存规则并捕获数据
3.1,规则测试成功后,点击“保存规则”;
3.2,点击“抓取数据”,会弹出DS计数机开始抓取数据。

提示:如果想要网页的整个html源代码,可以直接映射html节点,然后在高级设置中选择网页片段,最后保存规则即可。操作如下:
第1部分文章:“如何查看数据规则”第2部分文章:“批量修改下载图片的名称”
如果您有任何问题,可以或

2

鲜花

握手

棒极了
1

路过

鸡蛋
刚刚发表意见的朋友()
抓取jsp网页源代码(微信读书的sdk在jsp中可以使用函数.request)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-21 00:01
抓取jsp网页源代码不需要向微信读书中注册登录,看的就是微信读书的sdk,在jsp中可以使用函数wx.request({url:"/script",method:"get",params:{"name":"孙悟空"}})当读取完第一页后,看到当前页就是第一次扫描出来的页码,随后才对剩余的页码进行扫描,方法如下,大家可以根据自己需要修改。
因为你已经登录了微信读书,对你开放接口获取网页数据。
拿到了网页的所有javascript,
登录微信读书是有一个过程的,微信读书是用程序算法抓取网页上javascript等元素,并解析javascript等元素后推荐给微信读书的数据库。自己判断浏览的页码是因为这里的页码是向后匹配判断的。javascript能判断网页上的哪些东西已经在后台写好了,主要靠后台数据库判断。
如果你打开微信读书的登录页面,之后给它点击登录就可以拿到cookie了。微信读书的登录页只返回一个cookie,然后就再也没有点击过了。
回答:github上有个类似的项目,其实只要满足其中的cookie池(就是你所谓的回答一次就能拿到一次cookie),就可以拿下注册微信读书这个项目的https权限。实现思路是,先从服务器获取postcookie,然后对postcookie进行处理。
应该是可以拿到的,登录后会要求微信读书读取你的微信读书授权登录信息, 查看全部
抓取jsp网页源代码(微信读书的sdk在jsp中可以使用函数.request)
抓取jsp网页源代码不需要向微信读书中注册登录,看的就是微信读书的sdk,在jsp中可以使用函数wx.request({url:"/script",method:"get",params:{"name":"孙悟空"}})当读取完第一页后,看到当前页就是第一次扫描出来的页码,随后才对剩余的页码进行扫描,方法如下,大家可以根据自己需要修改。
因为你已经登录了微信读书,对你开放接口获取网页数据。
拿到了网页的所有javascript,
登录微信读书是有一个过程的,微信读书是用程序算法抓取网页上javascript等元素,并解析javascript等元素后推荐给微信读书的数据库。自己判断浏览的页码是因为这里的页码是向后匹配判断的。javascript能判断网页上的哪些东西已经在后台写好了,主要靠后台数据库判断。
如果你打开微信读书的登录页面,之后给它点击登录就可以拿到cookie了。微信读书的登录页只返回一个cookie,然后就再也没有点击过了。
回答:github上有个类似的项目,其实只要满足其中的cookie池(就是你所谓的回答一次就能拿到一次cookie),就可以拿下注册微信读书这个项目的https权限。实现思路是,先从服务器获取postcookie,然后对postcookie进行处理。
应该是可以拿到的,登录后会要求微信读书读取你的微信读书授权登录信息,
抓取jsp网页源代码(网页分析(Chrome开发者工具)对网页抓包分析的本质与内涵)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-12 17:34
在这个文章中,我们将尝试使用一个直观的网页分析工具(Chrome Developer Tools)来抓取和分析网页
对网络爬虫的本质和内涵有更深入的了解
1、测试环境
浏览器:Chrome 浏览器
浏览器版本:67.0.3396.99(正式版)(32位)
Web 分析工具:开发人员工具
2、网页分析(1)网页源码分析
我们知道网页分为静态网页和动态网页。很多人误以为静态网页就是没有动态效果的网页。事实上,这种说法是错误的。
另外,很多动态网站都采用了异步加载技术(Ajax)。这就是捕获的源代码和网站显示的源代码不一致的原因。
至于如何抓取动态网页,这里有两种方法:
下面以京东产品为例,分析一下如何通过Chrome抓包。首先,我们打开某个产品的主页。
到网页空白处点击鼠标右键,选择查看网页源码(或使用快捷键Ctrl+U直接打开)
请注意网站的最原创源码是通过查看网页源码获得的,也就是我们平时抓取的源码
再次进入网页空白区域,点击鼠标右键,选择勾选(或使用快捷键Ctrl+Shift+I/F12直接打开)
请注意,检查得到的源代码是Ajax加载并JavaScript渲染的源代码,即当前网站显示内容的源代码
经过比较,我们可以发现两者的内容是不同的。这是异步加载技术(Ajax)的典型例子
目前,至少京东产品的价格是通过异步加载生成的。下面介绍三种判断网页中某个内容是否是动态生成的方法:
(2)网页抓取分析
下面以京东产品为例进行说明。打开一个产品的首页,尝试抓取动态加载的产品价格数据。
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择Network选项卡进行抓包分析
这时候按快捷键F5刷新页面,可以看到开发者工具里面有各种包,我们用Filter过滤包
首先我们选择Doc,可以看到列表中只出现了一个包
一般来说,这是浏览器收到的第一个包,获取请求的原创源码网站
点击Header查看其头部参数设置
单击响应以查看返回的源代码。不难发现,其实和查看网页源码返回的信息是一样的。
让我们回到下面的话题。对于动态加载的数据包的分析,我们主要看XHR和JS选项卡。
选择JS进行过滤,发现列表中有很多包。经过分析,我们过滤掉下图中标记的包
这个包返回的是价格信息,但是经过仔细分析,发现这些价格不属于当前产品,而是与产品相关。
但是怎么说这个包还是跟价格有关的,我们先来看看这个包的请求地址。
https://p.3.cn/prices/mgets%3F ... em-pc
过滤掉回调等不需要的参数,得到一个简单有效的URL
https://p.3.cn/prices/mgets%3F ... 49638
直接用浏览器打开网址,可以看到返回的JSON数据确实收录价格信息(可惜是其他商品的价格)
分析URL的参数,我们可以推断skuId应该是每个产品的唯一符号。那么在哪里可以找到我们需要的产品的skuId呢?
实际上,SKU是物流、运输等行业常用的缩写,其全称是Stock Keeping Unit。
即库存进出计量的基本单位,现在已经扩展为统一产品编号的缩写,每个产品对应一个唯一的SKU 查看全部
抓取jsp网页源代码(网页分析(Chrome开发者工具)对网页抓包分析的本质与内涵)
在这个文章中,我们将尝试使用一个直观的网页分析工具(Chrome Developer Tools)来抓取和分析网页
对网络爬虫的本质和内涵有更深入的了解
1、测试环境
浏览器:Chrome 浏览器
浏览器版本:67.0.3396.99(正式版)(32位)
Web 分析工具:开发人员工具
2、网页分析(1)网页源码分析
我们知道网页分为静态网页和动态网页。很多人误以为静态网页就是没有动态效果的网页。事实上,这种说法是错误的。
另外,很多动态网站都采用了异步加载技术(Ajax)。这就是捕获的源代码和网站显示的源代码不一致的原因。
至于如何抓取动态网页,这里有两种方法:
下面以京东产品为例,分析一下如何通过Chrome抓包。首先,我们打开某个产品的主页。
到网页空白处点击鼠标右键,选择查看网页源码(或使用快捷键Ctrl+U直接打开)
请注意网站的最原创源码是通过查看网页源码获得的,也就是我们平时抓取的源码
再次进入网页空白区域,点击鼠标右键,选择勾选(或使用快捷键Ctrl+Shift+I/F12直接打开)
请注意,检查得到的源代码是Ajax加载并JavaScript渲染的源代码,即当前网站显示内容的源代码
经过比较,我们可以发现两者的内容是不同的。这是异步加载技术(Ajax)的典型例子
目前,至少京东产品的价格是通过异步加载生成的。下面介绍三种判断网页中某个内容是否是动态生成的方法:
(2)网页抓取分析
下面以京东产品为例进行说明。打开一个产品的首页,尝试抓取动态加载的产品价格数据。
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择Network选项卡进行抓包分析
这时候按快捷键F5刷新页面,可以看到开发者工具里面有各种包,我们用Filter过滤包
首先我们选择Doc,可以看到列表中只出现了一个包
一般来说,这是浏览器收到的第一个包,获取请求的原创源码网站
点击Header查看其头部参数设置
单击响应以查看返回的源代码。不难发现,其实和查看网页源码返回的信息是一样的。
让我们回到下面的话题。对于动态加载的数据包的分析,我们主要看XHR和JS选项卡。
选择JS进行过滤,发现列表中有很多包。经过分析,我们过滤掉下图中标记的包
这个包返回的是价格信息,但是经过仔细分析,发现这些价格不属于当前产品,而是与产品相关。
但是怎么说这个包还是跟价格有关的,我们先来看看这个包的请求地址。
https://p.3.cn/prices/mgets%3F ... em-pc
过滤掉回调等不需要的参数,得到一个简单有效的URL
https://p.3.cn/prices/mgets%3F ... 49638
直接用浏览器打开网址,可以看到返回的JSON数据确实收录价格信息(可惜是其他商品的价格)
分析URL的参数,我们可以推断skuId应该是每个产品的唯一符号。那么在哪里可以找到我们需要的产品的skuId呢?
实际上,SKU是物流、运输等行业常用的缩写,其全称是Stock Keeping Unit。
即库存进出计量的基本单位,现在已经扩展为统一产品编号的缩写,每个产品对应一个唯一的SKU
抓取jsp网页源代码(JSP的静态页面有什么区别?的优点是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-11 16:28
一、JSP 概念
这节课我们的目标是弄清楚JSP是什么,它和HTML静态页面有什么区别?
JSP的全称是Java Server Page(Java Server Page),后缀名为.jsp,是由很多公司主动参与建立的动态技术标准。在传统网页HTML文件(*.htm、*.html)中加入Java程序片段(Scriptlet)和JSP标签,就构成了JSP网页。Java 程序片段可以操作数据库、重定向网页、发送电子邮件等。创建动态网站 所需的函数。有效控制动态内容的生成,在Java Server Page中使用Java编程语言和类库,同时使用HTML表示页面,使用Java代码访问动态内容。这大大降低了对客户端浏览器的要求,即使客户端浏览器不支持Java,
二、 JSP的优点
1、平台独立。
它具有Java语言的跨平台特性,以及业务代码分离、组件复用、Java Servlet基本功能、预编译等特性。它也是跨平台的,可用于不同的系统,如 Windows、Linux、Mac 和 Solaris。这也扩大了 JSP 可以使用的 Web 服务器的范围。
2、 将内容与演示分开。
使用JSP技术开发的项目通常使用HTML语言对静态页面的内容进行设计和格式化,并使用JSP标签和Java代码片段来实现动态部分。程序开发者可以将所有业务处理代码放在JavaBeans中,也可以将业务处理代码交给其他业务控制层如Servlet、Struts等,实现业务代码与视图层的分离。这样JSP页面只负责展示数据,业务代码需要修改时,不会影响JSP页面的代码。
3、 强调可重用的组件。
可以使用JavaBean在JSP中编写业务组件,即使用JavaBean类封装业务处理代码或作为数据存储模型。这个 JavaBean 可以在 JSP 页面甚至整个项目中重用。JavaBean 还可以应用于其他 Java 应用程序,包括桌面应用程序。
简化页面开发——Web设计人员和Web程序员使用Web开发工具开发JSP页面
4、高速。
JSP 会被预编译,即当用户第一次通过浏览器访问 JSP 页面时,服务器会编译 JSP 页面的代码并只执行一次编译。编译后的代码会被保存,用户下次访问时会直接执行编译后的代码。这样既节省了服务器的CPU资源,又大大提高了客户端的访问速度。
三、JSP执行流程
JSP的全称是Java Server Pages,用Html语法实现了java扩展(形式化)。我们可以在jsp页面中嵌入java代码,如以下代码获取服务器当前时间并打印
在服务器端执行。通常,返回给客户端的是HTML文本,所以客户端只要有浏览器就可以浏览。当Web服务器遇到访问JSP网页的请求时,首先执行其中的程序段,然后将执行结果连同JSP文件中的HTML代码一起返回给客户端。JSP页面虽然很少进行数据处理,但仅用于实现网页的静态页面,仅用于提取数据,不进行业务处理。
为什么我们可以在jsp中嵌入java代码?因为jsp在执行时需要翻译成java代码,然后编译成class文件,也就是jsp的本质就是java文件。如下所示:
查看tomcat目录下的\work\Catalina\localhost目录,你会发现这里所有的web项目都会有对应的目录,打开其中一个项目一直打开,你会发现每个jsp页面都会有对应的java文件和编译好的class文件。, 这个文件是tomcat生成的。
所以在开发过程中,我们会发现jsp页面第一次访问的时候比较慢,因为需要翻译和编译两步,但是以后会很快,因为class文件是直接访问和编译。 查看全部
抓取jsp网页源代码(JSP的静态页面有什么区别?的优点是什么)
一、JSP 概念
这节课我们的目标是弄清楚JSP是什么,它和HTML静态页面有什么区别?
JSP的全称是Java Server Page(Java Server Page),后缀名为.jsp,是由很多公司主动参与建立的动态技术标准。在传统网页HTML文件(*.htm、*.html)中加入Java程序片段(Scriptlet)和JSP标签,就构成了JSP网页。Java 程序片段可以操作数据库、重定向网页、发送电子邮件等。创建动态网站 所需的函数。有效控制动态内容的生成,在Java Server Page中使用Java编程语言和类库,同时使用HTML表示页面,使用Java代码访问动态内容。这大大降低了对客户端浏览器的要求,即使客户端浏览器不支持Java,
二、 JSP的优点
1、平台独立。
它具有Java语言的跨平台特性,以及业务代码分离、组件复用、Java Servlet基本功能、预编译等特性。它也是跨平台的,可用于不同的系统,如 Windows、Linux、Mac 和 Solaris。这也扩大了 JSP 可以使用的 Web 服务器的范围。
2、 将内容与演示分开。
使用JSP技术开发的项目通常使用HTML语言对静态页面的内容进行设计和格式化,并使用JSP标签和Java代码片段来实现动态部分。程序开发者可以将所有业务处理代码放在JavaBeans中,也可以将业务处理代码交给其他业务控制层如Servlet、Struts等,实现业务代码与视图层的分离。这样JSP页面只负责展示数据,业务代码需要修改时,不会影响JSP页面的代码。
3、 强调可重用的组件。
可以使用JavaBean在JSP中编写业务组件,即使用JavaBean类封装业务处理代码或作为数据存储模型。这个 JavaBean 可以在 JSP 页面甚至整个项目中重用。JavaBean 还可以应用于其他 Java 应用程序,包括桌面应用程序。
简化页面开发——Web设计人员和Web程序员使用Web开发工具开发JSP页面
4、高速。
JSP 会被预编译,即当用户第一次通过浏览器访问 JSP 页面时,服务器会编译 JSP 页面的代码并只执行一次编译。编译后的代码会被保存,用户下次访问时会直接执行编译后的代码。这样既节省了服务器的CPU资源,又大大提高了客户端的访问速度。
三、JSP执行流程
JSP的全称是Java Server Pages,用Html语法实现了java扩展(形式化)。我们可以在jsp页面中嵌入java代码,如以下代码获取服务器当前时间并打印
在服务器端执行。通常,返回给客户端的是HTML文本,所以客户端只要有浏览器就可以浏览。当Web服务器遇到访问JSP网页的请求时,首先执行其中的程序段,然后将执行结果连同JSP文件中的HTML代码一起返回给客户端。JSP页面虽然很少进行数据处理,但仅用于实现网页的静态页面,仅用于提取数据,不进行业务处理。
为什么我们可以在jsp中嵌入java代码?因为jsp在执行时需要翻译成java代码,然后编译成class文件,也就是jsp的本质就是java文件。如下所示:
查看tomcat目录下的\work\Catalina\localhost目录,你会发现这里所有的web项目都会有对应的目录,打开其中一个项目一直打开,你会发现每个jsp页面都会有对应的java文件和编译好的class文件。, 这个文件是tomcat生成的。
所以在开发过程中,我们会发现jsp页面第一次访问的时候比较慢,因为需要翻译和编译两步,但是以后会很快,因为class文件是直接访问和编译。
抓取jsp网页源代码(JS做成外部文件,页面直接调用(上海SEO实验室))
网站优化 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-10-04 09:25
页面中有两种常见的 JavaScript 方式。一种是将JS做成外部文件,直接调用页面。以下是上海SEO实验室的一行代码:
以下为引用内容:
另一种是直接在页面上写JS代码,例如:
以下为引用内容:
尝试{
varelScript=document.createElement("script");
elScript.setAttribute("语言","JavaScript");
elScript.setAttribute("src",""+"&view="+escape(strBatchView)+"&inculde="+escape(strBatchInculde)+"&count="+escape(strBatchCount));
document.getElementsByTagName("body")[0].appendChild(elScript);
}
捕获(e){};
从搜索引擎抓取的角度来看,第一种类型不收录任何文本信息,因此搜索引擎无法从中提取内容。但是第二种,如果出现文字内容,搜索引擎能抓取到内容吗?
实验思路:做一个只有JS代码的页面,JS代码收录中文内容。然后,等待搜索引擎收录后,查看SERP和网页快照中的结果。
实验页面:()
以下为引用内容:
2007-9-25 中秋节开始实验
document.writeln("JS爬取实验:
");
document.writeln("尝试将文本放入JS代码中,会不会被搜索引擎抓取?");
如果您想尽快查看实验结果,请转载本文或在实验页面添加外部链接。这可以帮助搜索引擎尽快收录页面,我们也可以更快地得到结果。 查看全部
抓取jsp网页源代码(JS做成外部文件,页面直接调用(上海SEO实验室))
页面中有两种常见的 JavaScript 方式。一种是将JS做成外部文件,直接调用页面。以下是上海SEO实验室的一行代码:
以下为引用内容:
另一种是直接在页面上写JS代码,例如:
以下为引用内容:
尝试{
varelScript=document.createElement("script");
elScript.setAttribute("语言","JavaScript");
elScript.setAttribute("src",""+"&view="+escape(strBatchView)+"&inculde="+escape(strBatchInculde)+"&count="+escape(strBatchCount));
document.getElementsByTagName("body")[0].appendChild(elScript);
}
捕获(e){};
从搜索引擎抓取的角度来看,第一种类型不收录任何文本信息,因此搜索引擎无法从中提取内容。但是第二种,如果出现文字内容,搜索引擎能抓取到内容吗?
实验思路:做一个只有JS代码的页面,JS代码收录中文内容。然后,等待搜索引擎收录后,查看SERP和网页快照中的结果。
实验页面:()
以下为引用内容:
2007-9-25 中秋节开始实验
document.writeln("JS爬取实验:
");
document.writeln("尝试将文本放入JS代码中,会不会被搜索引擎抓取?");
如果您想尽快查看实验结果,请转载本文或在实验页面添加外部链接。这可以帮助搜索引擎尽快收录页面,我们也可以更快地得到结果。
抓取jsp网页源代码(初中毕业,你怎么学编程和语言?找个解决方案吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-10-02 21:00
抓取jsp网页源代码,生成xml,用apache等web服务器提供的jsp反序列化,然后本地调用。jsp调用hibernate就是调用orm框架,建立xml数据映射,形成类型的映射信息。
现在大部分流行的jsp和xml数据交互框架:jtools、grails、ci,部分使用java做struts。具体看个人习惯,
初中毕业,你怎么学编程和语言?找个解决方案吧。不推荐依赖第三方插件。程序最终都应该是自己实现。
除了orm其他全部替换为php,
如果你做一个登录页面:可以先考虑业务需求,因为我并不知道你一般会有哪些业务需求,所以不太好推荐框架。既然已经用jsp,先试着将session、api的connection封装成功能类似于xmlhttprequest的对象,不过jsp里的可能会麻烦一些。然后就可以开始将connection封装成session,那么xmlhttprequest接口就变成了session对象,第二步就是根据业务需求,考虑service类以及相应的接口处理器与封装好的httpservice对象相匹配,那么处理过程就是service对象的封装、处理。
这样既方便、快捷的把请求对象封装成需要的对象,又可以开发比较简单,而且由于xmlhttprequest是封装在jsp中,而jsp可以作为业务处理、封装的平台和语言,所以xmlhttprequest封装后可以方便的做与本地处理的交互。作为封装之后的connection已经成为自己的对象,这里面就是实现jspconnection的封装工作。
可以做接收jspjsp登录的处理,也可以作接收jsprequest的处理,可以接收request中的查询处理等。 查看全部
抓取jsp网页源代码(初中毕业,你怎么学编程和语言?找个解决方案吧)
抓取jsp网页源代码,生成xml,用apache等web服务器提供的jsp反序列化,然后本地调用。jsp调用hibernate就是调用orm框架,建立xml数据映射,形成类型的映射信息。
现在大部分流行的jsp和xml数据交互框架:jtools、grails、ci,部分使用java做struts。具体看个人习惯,
初中毕业,你怎么学编程和语言?找个解决方案吧。不推荐依赖第三方插件。程序最终都应该是自己实现。
除了orm其他全部替换为php,
如果你做一个登录页面:可以先考虑业务需求,因为我并不知道你一般会有哪些业务需求,所以不太好推荐框架。既然已经用jsp,先试着将session、api的connection封装成功能类似于xmlhttprequest的对象,不过jsp里的可能会麻烦一些。然后就可以开始将connection封装成session,那么xmlhttprequest接口就变成了session对象,第二步就是根据业务需求,考虑service类以及相应的接口处理器与封装好的httpservice对象相匹配,那么处理过程就是service对象的封装、处理。
这样既方便、快捷的把请求对象封装成需要的对象,又可以开发比较简单,而且由于xmlhttprequest是封装在jsp中,而jsp可以作为业务处理、封装的平台和语言,所以xmlhttprequest封装后可以方便的做与本地处理的交互。作为封装之后的connection已经成为自己的对象,这里面就是实现jspconnection的封装工作。
可以做接收jspjsp登录的处理,也可以作接收jsprequest的处理,可以接收request中的查询处理等。
抓取jsp网页源代码(爬取一个所有FamilyDollar商店的位置页面是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-10-01 11:06
)
关于合法性,获得大量有价值的信息可能令人兴奋,但仅仅因为它是可能的并不意味着应该这样做。
幸运的是,有一些公共信息可以指导我们的道德和网络抓取工具。大多数网站都有一个与网站相关联的robots.txt文件,指明哪些爬行活动是允许的,哪些是不允许的。主要用于与搜索引擎交互(网络爬虫工具的终极形式)。但是,网站 上的大部分信息都被视为公开信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及道德采集和数据使用等主题。
在开始抓取项目之前,先问自己以下问题:
当我抓取 网站 时,请确保您可以对所有这些问题回答“否”。
要了解有关这些法律问题的更多信息,请参阅 Krotov 和 Silva 于 2018 年出版的“网络爬虫的合法性和道德”以及 Sellars 的“网络爬虫二十年和计算机欺诈和滥用法案”。
现在开始爬取网站
经过上面的评估,我想出了一个项目。我的目标是抓取爱达荷州所有 Family Dollar 商店的地址。这些店在农村很大,所以我想知道有多少这样的店。
起点是Family Dollar的位置页面
首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 的单元格中运行。
import requests # for making standard html requests
from bs4 import BeautifulSoup # magical tool for parsing html data
import json # for parsing data
from pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get("https://locations.familydollar.com/id/")
soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。这些是我们将使用的几种常见对象类型。
当我们查看 requests.get() 的输出时,还有更多问题需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。requests中的默认编码设置可以很好的解决这个问题。不过,除了纯英文的网站,就是更大的互联网世界。为了保证请求正确解析内容,可以设置文本的编码:
page = requests.get(URL)
page.encoding = 'ISO-885901'
soup = BeautifulSoup(page.text, 'html.parser')
仔细看一下 BeautifulSoup 标签,我们会看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站 爬取过程中的提取可能是一个充满误解的艰巨过程。我认为解决这个问题最好的方法是从一个有代表性的例子开始,然后再扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 来查看页面的整个源代码(不推荐)。运行此代码风险自负:
print(soup.prettify())
虽然打印页面的整个源代码可能适合一些教程中展示的玩具示例,但大多数现代 网站 页面都有很多内容。甚至 404 页面也可能充满了页眉、页脚和其他代码。
通常,在您喜欢的浏览器中通过“查看页面源代码”来浏览源代码是最容易的(右键单击并选择“查看页面源代码”)。这是找到目标内容最可靠的方式(我稍后会解释原因)。
在这种情况下,我需要在这个巨大的 HTML 海洋中找到我的目标内容地址、城市、州和邮政编码。通常,在页面源上进行简单的搜索(ctrl+F)就会得到目标位置的位置。一旦我真正看到目标内容的示例(至少是一家商店的地址),我就会找到将该内容与其他内容区分开来的属性或标签。
首先,我需要在爱达荷州的Family Dollar商店采集不同城市的URL,并访问这些网站以获取地址信息。这些 URL 似乎收录在 href 标签中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')
dollar_tree_list
搜索 href 不会产生任何结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于下一次尝试,搜索 item_list。由于 class 是 Python 中的保留字,因此使用 class_ 代替。sound.find_all() 原来是 bs4 函数的瑞士军刀。
dollar_tree_list = soup.find_all(class_ = 'itemlist')
for i in dollar_tree_list[:2]:
print(i)
有趣的是,我发现搜索特定类的方法通常是成功的方法。通过找出对象的类型和长度,我们可以了解更多关于对象的信息。
type(dollar_tree_list)
len(dollar_tree_list)
您可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建单个代表性示例的好时机。
example = dollar_tree_list[2] # a representative example
example_content = example.contents
print(example_content)
使用 .attr 查找对象内容中存在的属性。注意: .contents 通常返回一个精确的项目列表,因此第一步是使用方括号表示法来索引项目。
example_content = example.contents[0]
example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取它:
example_href = example_content['href']
print(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,以澄清上述逻辑。
city_hrefs = [] # initialise empty list
for i in dollar_tree_list:
cont = i.contents[0]
href = cont['href']
city_hrefs.append(href)
# check to be sure all went well
for i in city_hrefs[:2]:
print(i)
输出是用于抓取爱达荷州 Family Dollar 商店的 URL 列表。
换句话说,我还没有得到地址信息!现在,您需要抓取每个城市的 URL 以获取此信息。因此,我们使用一个具有代表性的示例来重新启动该过程。
page2 = requests.get(city_hrefs[2]) # again establish a representative example
soup2 = BeautifulSoup(page2.text, 'html.parser')
地址信息嵌套在 type="application/ld+json" 中。经过大量的地理位置爬取,我开始意识到这是一个存储地址信息的通用结构。幸运的是,soup.find_all() 支持按类型搜索。
arco = soup2.find_all(type="application/ld+json")
print(arco[1])
地址信息在第二个列表成员中!我懂了!
使用 .contents 提取内容(从第二个列表项)(这是过滤后合适的默认操作)。同样,由于输出是一个列表,我为列表项建立了一个索引:
arco_contents = arco[1].contents[0]
arco_contents
哦,看起来不错。此处提供的格式与 JSON 格式一致(并且,类型名称确实收录“json”)。JSON 对象的行为类似于带有嵌套字典的字典。一旦你熟悉了它,它实际上是一种很好的格式(当然,它比一长串正则表达式命令更容易编程)。虽然在结构上看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要通过编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
type(arco_json)
print(arco_json)
在内容中,有一个被调用的地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']
arco_address
好的,请注意。现在我可以遍历存储的爱达荷州 URL 列表:
locs_dict = [] # initialise empty list
for link in city_hrefs:
locpage = requests.get(link) # request page info
locsoup = BeautifulSoup(locpage.text, 'html.parser')
# parse the page's content
locinfo = locsoup.find_all(type="application/ld+json")
# extract specific element
loccont = locinfo[1].contents[0]
# get contents from the bs4 element set
locjson = json.loads(loccont) # convert to json
locaddr = locjson['address'] # get address
locs_dict.append(locaddr) # add address to list
使用 Pandas 来组织我们的 网站 爬取结果
我们在字典中加载了大量数据,但是有一些额外的无用项使得重用数据变得比必要的复杂。为了执行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不必要的列@type 和 country,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)
locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)
locs_df.head(n = 5)
一定要保存结果!!
df.to_csv(locs_df, "family_dollar_ID_locations.csv", sep = ",", index = False)
我们做到了!爱达荷州的所有 Family Dollar 商店都有一个以逗号分隔的列表。多么激动人心。
Selenium 和数据抓取的一点解释
Selenium 是一种常用的工具,用于自动与网页交互。为了解释为什么有时需要使用它,让我们看一个使用 Walgreens 网站 的例子。“检查元素”提供浏览器显示内容的代码:
尽管“查看页面源代码”提供了有关请求将获得什么的代码:
如果这两个不一致,有插件可以修改源代码——因此,你应该在加载到浏览器后访问页面。请求无法做到这一点,但 Selenium 可以。
Selenium 需要一个 Web 驱动程序来检索内容。事实上,它会打开一个网络浏览器并采集这个页面的内容。Selenium 功能强大——它可以通过多种方式与加载的内容交互(请阅读文档)。使用Selenium获取数据后,继续像之前一样使用BeautifulSoup:
url = "https://www.walgreens.com/stor ... ot%3B
driver = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')
driver.get(url)
soup_ID = BeautifulSoup(driver.page_source, 'html.parser')
store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
在 Family Dollar 的情况下,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用网站爬行完成有意义的任务时:
如果您对答案感到好奇:
在美国有很多 Family Dollar 商店。
完整的源代码是:
import requests
from bs4 import BeautifulSoup
import json
from pandas import DataFrame as df
page = requests.get("https://www.familydollar.com/locations/")
soup = BeautifulSoup(page.text, 'html.parser')
# find all state links
state_list = soup.find_all(class_ = 'itemlist')
state_links = []
for i in state_list:
cont = i.contents[0]
attr = cont.attrs
hrefs = attr['href']
state_links.append(hrefs)
# find all city links
city_links = []
for link in state_links:
page = requests.get(link)
soup = BeautifulSoup(page.text, 'html.parser')
familydollar_list = soup.find_all(class_ = 'itemlist')
for store in familydollar_list:
cont = store.contents[0]
attr = cont.attrs
city_hrefs = attr['href']
city_links.append(city_hrefs)
# to get individual store links
store_links = []
for link in city_links:
locpage = requests.get(link)
locsoup = BeautifulSoup(locpage.text, 'html.parser')
locinfo = locsoup.find_all(type="application/ld+json")
for i in locinfo:
loccont = i.contents[0]
locjson = json.loads(loccont)
try:
store_url = locjson['url']
store_links.append(store_url)
except:
pass
# get address and geolocation information
stores = []
for store in store_links:
storepage = requests.get(store)
storesoup = BeautifulSoup(storepage.text, 'html.parser')
storeinfo = storesoup.find_all(type="application/ld+json")
for i in storeinfo:
storecont = i.contents[0]
storejson = json.loads(storecont)
try:
store_addr = storejson['address']
store_addr.update(storejson['geo'])
stores.append(store_addr)
except:
pass
# final data parsing
stores_df = df.from_records(stores)
stores_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)
stores_df['Store'] = "Family Dollar"
df.to_csv(stores_df, "family_dollar_locations.csv", sep = ",", index = False)
作者注:本文改编自我 2020 年 2 月 9 日在俄勒冈州波特兰市 PyCascades 的演讲。
通过:
作者:Julia Piaskowski 主题:lujun9972 译者:stevenzdg988 校对:wxy
本文由LCTT原创编译,Linux中国荣幸推出
查看全部
抓取jsp网页源代码(爬取一个所有FamilyDollar商店的位置页面是什么?
)
关于合法性,获得大量有价值的信息可能令人兴奋,但仅仅因为它是可能的并不意味着应该这样做。
幸运的是,有一些公共信息可以指导我们的道德和网络抓取工具。大多数网站都有一个与网站相关联的robots.txt文件,指明哪些爬行活动是允许的,哪些是不允许的。主要用于与搜索引擎交互(网络爬虫工具的终极形式)。但是,网站 上的大部分信息都被视为公开信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及道德采集和数据使用等主题。
在开始抓取项目之前,先问自己以下问题:
当我抓取 网站 时,请确保您可以对所有这些问题回答“否”。
要了解有关这些法律问题的更多信息,请参阅 Krotov 和 Silva 于 2018 年出版的“网络爬虫的合法性和道德”以及 Sellars 的“网络爬虫二十年和计算机欺诈和滥用法案”。
现在开始爬取网站
经过上面的评估,我想出了一个项目。我的目标是抓取爱达荷州所有 Family Dollar 商店的地址。这些店在农村很大,所以我想知道有多少这样的店。
起点是Family Dollar的位置页面
首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 的单元格中运行。
import requests # for making standard html requests
from bs4 import BeautifulSoup # magical tool for parsing html data
import json # for parsing data
from pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get("https://locations.familydollar.com/id/";)
soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。这些是我们将使用的几种常见对象类型。
当我们查看 requests.get() 的输出时,还有更多问题需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。requests中的默认编码设置可以很好的解决这个问题。不过,除了纯英文的网站,就是更大的互联网世界。为了保证请求正确解析内容,可以设置文本的编码:
page = requests.get(URL)
page.encoding = 'ISO-885901'
soup = BeautifulSoup(page.text, 'html.parser')
仔细看一下 BeautifulSoup 标签,我们会看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站 爬取过程中的提取可能是一个充满误解的艰巨过程。我认为解决这个问题最好的方法是从一个有代表性的例子开始,然后再扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 来查看页面的整个源代码(不推荐)。运行此代码风险自负:
print(soup.prettify())
虽然打印页面的整个源代码可能适合一些教程中展示的玩具示例,但大多数现代 网站 页面都有很多内容。甚至 404 页面也可能充满了页眉、页脚和其他代码。
通常,在您喜欢的浏览器中通过“查看页面源代码”来浏览源代码是最容易的(右键单击并选择“查看页面源代码”)。这是找到目标内容最可靠的方式(我稍后会解释原因)。
在这种情况下,我需要在这个巨大的 HTML 海洋中找到我的目标内容地址、城市、州和邮政编码。通常,在页面源上进行简单的搜索(ctrl+F)就会得到目标位置的位置。一旦我真正看到目标内容的示例(至少是一家商店的地址),我就会找到将该内容与其他内容区分开来的属性或标签。
首先,我需要在爱达荷州的Family Dollar商店采集不同城市的URL,并访问这些网站以获取地址信息。这些 URL 似乎收录在 href 标签中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')
dollar_tree_list
搜索 href 不会产生任何结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于下一次尝试,搜索 item_list。由于 class 是 Python 中的保留字,因此使用 class_ 代替。sound.find_all() 原来是 bs4 函数的瑞士军刀。
dollar_tree_list = soup.find_all(class_ = 'itemlist')
for i in dollar_tree_list[:2]:
print(i)
有趣的是,我发现搜索特定类的方法通常是成功的方法。通过找出对象的类型和长度,我们可以了解更多关于对象的信息。
type(dollar_tree_list)
len(dollar_tree_list)
您可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建单个代表性示例的好时机。
example = dollar_tree_list[2] # a representative example
example_content = example.contents
print(example_content)
使用 .attr 查找对象内容中存在的属性。注意: .contents 通常返回一个精确的项目列表,因此第一步是使用方括号表示法来索引项目。
example_content = example.contents[0]
example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取它:
example_href = example_content['href']
print(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,以澄清上述逻辑。
city_hrefs = [] # initialise empty list
for i in dollar_tree_list:
cont = i.contents[0]
href = cont['href']
city_hrefs.append(href)
# check to be sure all went well
for i in city_hrefs[:2]:
print(i)
输出是用于抓取爱达荷州 Family Dollar 商店的 URL 列表。
换句话说,我还没有得到地址信息!现在,您需要抓取每个城市的 URL 以获取此信息。因此,我们使用一个具有代表性的示例来重新启动该过程。
page2 = requests.get(city_hrefs[2]) # again establish a representative example
soup2 = BeautifulSoup(page2.text, 'html.parser')
地址信息嵌套在 type="application/ld+json" 中。经过大量的地理位置爬取,我开始意识到这是一个存储地址信息的通用结构。幸运的是,soup.find_all() 支持按类型搜索。
arco = soup2.find_all(type="application/ld+json")
print(arco[1])
地址信息在第二个列表成员中!我懂了!
使用 .contents 提取内容(从第二个列表项)(这是过滤后合适的默认操作)。同样,由于输出是一个列表,我为列表项建立了一个索引:
arco_contents = arco[1].contents[0]
arco_contents
哦,看起来不错。此处提供的格式与 JSON 格式一致(并且,类型名称确实收录“json”)。JSON 对象的行为类似于带有嵌套字典的字典。一旦你熟悉了它,它实际上是一种很好的格式(当然,它比一长串正则表达式命令更容易编程)。虽然在结构上看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要通过编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
type(arco_json)
print(arco_json)
在内容中,有一个被调用的地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']
arco_address
好的,请注意。现在我可以遍历存储的爱达荷州 URL 列表:
locs_dict = [] # initialise empty list
for link in city_hrefs:
locpage = requests.get(link) # request page info
locsoup = BeautifulSoup(locpage.text, 'html.parser')
# parse the page's content
locinfo = locsoup.find_all(type="application/ld+json")
# extract specific element
loccont = locinfo[1].contents[0]
# get contents from the bs4 element set
locjson = json.loads(loccont) # convert to json
locaddr = locjson['address'] # get address
locs_dict.append(locaddr) # add address to list
使用 Pandas 来组织我们的 网站 爬取结果
我们在字典中加载了大量数据,但是有一些额外的无用项使得重用数据变得比必要的复杂。为了执行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不必要的列@type 和 country,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)
locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)
locs_df.head(n = 5)
一定要保存结果!!
df.to_csv(locs_df, "family_dollar_ID_locations.csv", sep = ",", index = False)
我们做到了!爱达荷州的所有 Family Dollar 商店都有一个以逗号分隔的列表。多么激动人心。
Selenium 和数据抓取的一点解释
Selenium 是一种常用的工具,用于自动与网页交互。为了解释为什么有时需要使用它,让我们看一个使用 Walgreens 网站 的例子。“检查元素”提供浏览器显示内容的代码:
尽管“查看页面源代码”提供了有关请求将获得什么的代码:
如果这两个不一致,有插件可以修改源代码——因此,你应该在加载到浏览器后访问页面。请求无法做到这一点,但 Selenium 可以。
Selenium 需要一个 Web 驱动程序来检索内容。事实上,它会打开一个网络浏览器并采集这个页面的内容。Selenium 功能强大——它可以通过多种方式与加载的内容交互(请阅读文档)。使用Selenium获取数据后,继续像之前一样使用BeautifulSoup:
url = "https://www.walgreens.com/stor ... ot%3B
driver = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')
driver.get(url)
soup_ID = BeautifulSoup(driver.page_source, 'html.parser')
store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
在 Family Dollar 的情况下,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用网站爬行完成有意义的任务时:
如果您对答案感到好奇:
在美国有很多 Family Dollar 商店。
完整的源代码是:
import requests
from bs4 import BeautifulSoup
import json
from pandas import DataFrame as df
page = requests.get("https://www.familydollar.com/locations/";)
soup = BeautifulSoup(page.text, 'html.parser')
# find all state links
state_list = soup.find_all(class_ = 'itemlist')
state_links = []
for i in state_list:
cont = i.contents[0]
attr = cont.attrs
hrefs = attr['href']
state_links.append(hrefs)
# find all city links
city_links = []
for link in state_links:
page = requests.get(link)
soup = BeautifulSoup(page.text, 'html.parser')
familydollar_list = soup.find_all(class_ = 'itemlist')
for store in familydollar_list:
cont = store.contents[0]
attr = cont.attrs
city_hrefs = attr['href']
city_links.append(city_hrefs)
# to get individual store links
store_links = []
for link in city_links:
locpage = requests.get(link)
locsoup = BeautifulSoup(locpage.text, 'html.parser')
locinfo = locsoup.find_all(type="application/ld+json")
for i in locinfo:
loccont = i.contents[0]
locjson = json.loads(loccont)
try:
store_url = locjson['url']
store_links.append(store_url)
except:
pass
# get address and geolocation information
stores = []
for store in store_links:
storepage = requests.get(store)
storesoup = BeautifulSoup(storepage.text, 'html.parser')
storeinfo = storesoup.find_all(type="application/ld+json")
for i in storeinfo:
storecont = i.contents[0]
storejson = json.loads(storecont)
try:
store_addr = storejson['address']
store_addr.update(storejson['geo'])
stores.append(store_addr)
except:
pass
# final data parsing
stores_df = df.from_records(stores)
stores_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)
stores_df['Store'] = "Family Dollar"
df.to_csv(stores_df, "family_dollar_locations.csv", sep = ",", index = False)
作者注:本文改编自我 2020 年 2 月 9 日在俄勒冈州波特兰市 PyCascades 的演讲。
通过:
作者:Julia Piaskowski 主题:lujun9972 译者:stevenzdg988 校对:wxy
本文由LCTT原创编译,Linux中国荣幸推出
抓取jsp网页源代码(C#抓取网页代码,求助,如何获取它跳转之后的地址!!(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-09-27 16:27
C#抓取网页代码,寻求帮助,以及在跳转后如何获取地址
我使用webrequest访问具有以下地址的页面
地址一:;密码=100104&;网址=
但是,如果在浏览器中输入此地址,它将自动跳转以生成新地址
地址2:RDKFDVTUDKBYFTGRVADUWEXJOBLRY#模块=读取。Readmodule%7C%7b%22fid%22%3A1%2C%22modulename%22%3A%22mbox.listmodule u0%22%2C%22viewType%22%3A%22%2C%22id%22%3A%2221%3a1tbiqlyrld%2BJYxDDwAAso%22%7D
我需要红色部分中的参数,但我使用webrequest访问地址1。我下载的是地址1的页面。跳转后如何获取地址2
------解决方案--------------------
WebRequest.Create(url.GetResponse().ResponseUri.AbsoluteUri
------解决方案--------------------
看看MSDN 查看全部
抓取jsp网页源代码(C#抓取网页代码,求助,如何获取它跳转之后的地址!!(图))
C#抓取网页代码,寻求帮助,以及在跳转后如何获取地址
我使用webrequest访问具有以下地址的页面
地址一:;密码=100104&;网址=
但是,如果在浏览器中输入此地址,它将自动跳转以生成新地址
地址2:RDKFDVTUDKBYFTGRVADUWEXJOBLRY#模块=读取。Readmodule%7C%7b%22fid%22%3A1%2C%22modulename%22%3A%22mbox.listmodule u0%22%2C%22viewType%22%3A%22%2C%22id%22%3A%2221%3a1tbiqlyrld%2BJYxDDwAAso%22%7D
我需要红色部分中的参数,但我使用webrequest访问地址1。我下载的是地址1的页面。跳转后如何获取地址2
------解决方案--------------------
WebRequest.Create(url.GetResponse().ResponseUri.AbsoluteUri
------解决方案--------------------
看看MSDN
抓取jsp网页源代码(2017年上海会计从业资格考试:JSP技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-09-27 08:12
一、JSP技术
一,。JSP脚本和注释
JSP脚本:
1)——将内部java代码转换为服务方法
2)——它将被翻译成out。在服务方法中打印()
3)——将被翻译成servlet成员的内容
JSP注释:不同的注释具有不同的可见范围
1)HTML注释:---可视范围的JSP源代码,翻译后的servlet,页面显示的HTML源代码
2)java comments://single-line comments/multi-line comments/--servlet在可见范围内翻译JSP源代码后
3)JSP注释:----可见范围JSP源代码可见
二,。JSP操作原理——JSP的本质是servlet(访谈)
第一次访问JSP时,web容器会将其转换为servlet
过程:
第一次参观------>helloservlet。JSP----->helloservlet_uujsp。Java->编译并运行
PS:翻译后的servlet可以在Tomcat的工作目录中找到
三,。JSP指令(3)
JSP指令是指导JSP翻译和操作的命令。JSP收录三条指令:
1)页面指令---属性最多的指令(实际开发中的默认页面指令)
属性最多的指令根据不同的属性引导整个页面的特征
格式:
常见属性如下:
语言:可以嵌入到JSP脚本中的语言类型
Pageencoding:当前JSP文件本身的编码-内容类型可以收录在其中
contentType:response.setContentType(text/html;charset=UTF-8)
会话:JSP是否在翻译过程中自动创建会话
导入:导入Java包
Errorpage:当前页面发生错误时要跳转到哪个页面
Iserrorpage:当前页面是处理错误的页面
2)收录说明
页面收录(静态收录)指令,可以将一个JSP页面收录到另一个JSP页面中
格式:
3)taglib指令
在JSP页面中引入标记库(JSTL标记库、struts 2标记库)
格式:
JSP内置/隐式对象(9)——书面测试
JSP被转换成servlet后,服务方法中的九个对象被定义和初始化。我们可以在JSP脚本中直接使用这九个对象
名称类型说明
输出javax.servlet.jsp.jspwriter以进行页面输出
Request javax.servlet.http.httpservletrequest获取用户请求信息
Response javax.servlet.http.httpservletresponse从服务器到客户端的响应信息
配置javax.servlet.servletconfig服务器配置。可以获取初始化参数
会话javax.servlet.http.httpsession用于保存用户信息
应用程序javax.servlet.servletcontext共享所有用户的信息
Page java.lang.object引用当前页面转换后servlet类的实例
jsp的Pagecontext javax.servlet.jsp.Pagecontext页面容器
Exception java.lang.throwable表示JSP页面中发生的异常,该异常仅在错误页面中有效
(1)out对象)
输出类型:jspwriter
out函数用于将内容输出到客户机-out.Write()
输出缓冲区默认为8KB,可以设置为0,这意味着输出缓冲区关闭,内容直接写入响应缓冲区
(2)pagecontext对象)
JSP页面的上下文对象的功能如下:
页面对象与pagecontext对象不同
1)pagecontext是一个域对象
setAttribute(字符串名称、对象对象)
getAttribute(字符串名称)
removeAttrbute(字符串名称)
Pagecontext可以访问其他指定域的数据
setAttribute(字符串名称、对象对象、int范围)
getAttribute(字符串名称,int范围)
removeAttrbute(字符串名称,int范围)
findAttribute(字符串名称)
---依次从pagecontext字段、request字段、session字段和application字段中获取属性。获取字段中的属性后,您将不会回头
四个范围的概述:
页面字段:当前JSP页面范围
请求域:一个请求
会话域:一个会话
应用领域:整个web应用程序
2)您可以获得8个其他隐式对象
例如:pagecontext.Getrequest()
pageContext.getSession()
5.JSP标记(操作)
1)页面收录(动态收录):
2)请求转发:
静态收录和动态收录之间的区别是什么
二、El技术
1.El表达式概述
EL(express language)表达式可以嵌入到JSP页面中,以减少JSP脚本的编写。EL的目的是取代JSP页面中脚本的编写
2.El从域中获取数据
El的主要功能是以${El expression}格式获取四个域中的数据
El获取pagecontext字段中的值:$(pagecontextscope.Key)
El获取请求字段中的值:$(request.Key)
El获取会话域中的值:$(session.Key)
El获取应用程序字段中的值:$(application.Key)
El从四个字段中获取值$(键)
---同样,属性依次从pagecontext域、请求域、会话域和应用域中获取。获取域中的属性后,您将不会回头
例如:
1)El获取正常字符串
2)El获取用户对象的值
3)El获取列表的值
4)El获取列表的值
5)El获取map的值
6)El获取地图的值
3.El的内置对象
pageScope、requestScope、sessionScope、applicationScope
----在JSP中获取域中的数据
参数,参数值-接收参数
Header,headervalues-获取请求头信息
Initparam-获取全局初始化参数
Cookie-Web开发中的Cookie
Pagecontext—web开发中的Pagecontext
$(pageContext.request.contextPath)
相当于
获取web应用程序的名称
三、JSTL技术
1.JSTL概述
JSTL(JSP标准标记库)是一个JSP标准标记库,可以嵌入到JSP页面中,并使用标记完成业务逻辑和其他功能。JSTL的目的与El一样,是提及JSP页面中的脚本代码。JSTL标准标记库有五个子库,但随着开发,目前经常使用其核心库
标记库的Uri前缀
核心c
I18N-fmt
SQL
XML x
功能fn
2.JSTL下载和导入
JSTL下载:
从Apache下载JSTL的jar包网站。输入“”从网站下载JSTL安装包。Jakarta taglibs standard-1.1.2.zip,然后解压缩下载的JSTL安装包。此时,您可以在Lib目录中看到两个jar文件,JSTL.jar和standard.jar。其中,JSTL.jar文件收录定义的接口和相关类在JSTL规范中,和standard.jar文件收录用于在JSTL中实现JSTL和5标记库描述符文件(TLD)的.Class文件
将这两个jar包导入到我们项目的Lib中
3.JSTL核心库的通用标记
1)标签
2)标签 查看全部
抓取jsp网页源代码(2017年上海会计从业资格考试:JSP技术)
一、JSP技术
一,。JSP脚本和注释
JSP脚本:
1)——将内部java代码转换为服务方法
2)——它将被翻译成out。在服务方法中打印()
3)——将被翻译成servlet成员的内容
JSP注释:不同的注释具有不同的可见范围
1)HTML注释:---可视范围的JSP源代码,翻译后的servlet,页面显示的HTML源代码
2)java comments://single-line comments/multi-line comments/--servlet在可见范围内翻译JSP源代码后
3)JSP注释:----可见范围JSP源代码可见
二,。JSP操作原理——JSP的本质是servlet(访谈)
第一次访问JSP时,web容器会将其转换为servlet
过程:
第一次参观------>helloservlet。JSP----->helloservlet_uujsp。Java->编译并运行
PS:翻译后的servlet可以在Tomcat的工作目录中找到
三,。JSP指令(3)
JSP指令是指导JSP翻译和操作的命令。JSP收录三条指令:
1)页面指令---属性最多的指令(实际开发中的默认页面指令)
属性最多的指令根据不同的属性引导整个页面的特征
格式:
常见属性如下:
语言:可以嵌入到JSP脚本中的语言类型
Pageencoding:当前JSP文件本身的编码-内容类型可以收录在其中
contentType:response.setContentType(text/html;charset=UTF-8)
会话:JSP是否在翻译过程中自动创建会话
导入:导入Java包
Errorpage:当前页面发生错误时要跳转到哪个页面
Iserrorpage:当前页面是处理错误的页面
2)收录说明
页面收录(静态收录)指令,可以将一个JSP页面收录到另一个JSP页面中
格式:
3)taglib指令
在JSP页面中引入标记库(JSTL标记库、struts 2标记库)
格式:
JSP内置/隐式对象(9)——书面测试
JSP被转换成servlet后,服务方法中的九个对象被定义和初始化。我们可以在JSP脚本中直接使用这九个对象
名称类型说明
输出javax.servlet.jsp.jspwriter以进行页面输出
Request javax.servlet.http.httpservletrequest获取用户请求信息
Response javax.servlet.http.httpservletresponse从服务器到客户端的响应信息
配置javax.servlet.servletconfig服务器配置。可以获取初始化参数
会话javax.servlet.http.httpsession用于保存用户信息
应用程序javax.servlet.servletcontext共享所有用户的信息
Page java.lang.object引用当前页面转换后servlet类的实例
jsp的Pagecontext javax.servlet.jsp.Pagecontext页面容器
Exception java.lang.throwable表示JSP页面中发生的异常,该异常仅在错误页面中有效
(1)out对象)
输出类型:jspwriter
out函数用于将内容输出到客户机-out.Write()
输出缓冲区默认为8KB,可以设置为0,这意味着输出缓冲区关闭,内容直接写入响应缓冲区
(2)pagecontext对象)
JSP页面的上下文对象的功能如下:
页面对象与pagecontext对象不同
1)pagecontext是一个域对象
setAttribute(字符串名称、对象对象)
getAttribute(字符串名称)
removeAttrbute(字符串名称)
Pagecontext可以访问其他指定域的数据
setAttribute(字符串名称、对象对象、int范围)
getAttribute(字符串名称,int范围)
removeAttrbute(字符串名称,int范围)
findAttribute(字符串名称)
---依次从pagecontext字段、request字段、session字段和application字段中获取属性。获取字段中的属性后,您将不会回头
四个范围的概述:
页面字段:当前JSP页面范围
请求域:一个请求
会话域:一个会话
应用领域:整个web应用程序
2)您可以获得8个其他隐式对象
例如:pagecontext.Getrequest()
pageContext.getSession()
5.JSP标记(操作)
1)页面收录(动态收录):
2)请求转发:
静态收录和动态收录之间的区别是什么
二、El技术
1.El表达式概述
EL(express language)表达式可以嵌入到JSP页面中,以减少JSP脚本的编写。EL的目的是取代JSP页面中脚本的编写
2.El从域中获取数据
El的主要功能是以${El expression}格式获取四个域中的数据
El获取pagecontext字段中的值:$(pagecontextscope.Key)
El获取请求字段中的值:$(request.Key)
El获取会话域中的值:$(session.Key)
El获取应用程序字段中的值:$(application.Key)
El从四个字段中获取值$(键)
---同样,属性依次从pagecontext域、请求域、会话域和应用域中获取。获取域中的属性后,您将不会回头
例如:
1)El获取正常字符串
2)El获取用户对象的值
3)El获取列表的值
4)El获取列表的值
5)El获取map的值
6)El获取地图的值
3.El的内置对象
pageScope、requestScope、sessionScope、applicationScope
----在JSP中获取域中的数据
参数,参数值-接收参数
Header,headervalues-获取请求头信息
Initparam-获取全局初始化参数
Cookie-Web开发中的Cookie
Pagecontext—web开发中的Pagecontext
$(pageContext.request.contextPath)
相当于
获取web应用程序的名称
三、JSTL技术
1.JSTL概述
JSTL(JSP标准标记库)是一个JSP标准标记库,可以嵌入到JSP页面中,并使用标记完成业务逻辑和其他功能。JSTL的目的与El一样,是提及JSP页面中的脚本代码。JSTL标准标记库有五个子库,但随着开发,目前经常使用其核心库
标记库的Uri前缀
核心c
I18N-fmt
SQL
XML x
功能fn
2.JSTL下载和导入
JSTL下载:
从Apache下载JSTL的jar包网站。输入“”从网站下载JSTL安装包。Jakarta taglibs standard-1.1.2.zip,然后解压缩下载的JSTL安装包。此时,您可以在Lib目录中看到两个jar文件,JSTL.jar和standard.jar。其中,JSTL.jar文件收录定义的接口和相关类在JSTL规范中,和standard.jar文件收录用于在JSTL中实现JSTL和5标记库描述符文件(TLD)的.Class文件
将这两个jar包导入到我们项目的Lib中
3.JSTL核心库的通用标记
1)标签
2)标签
抓取jsp网页源代码(用WebScraper(一个Chrome插件)爬取网页内容的教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 324 次浏览 • 2021-09-23 14:30
在Internet上有许多使用Python爬行web内容的教程,但通常需要编写代码。如果没有相应基础的人想在短时间内开始,仍然有一个门槛。事实上,在大多数情况下,您可以使用WebScraper(一个chrome插件)快速爬升到目标内容。重要的是,您不需要下载东西或代码知识
在开始之前,有必要简要了解几个问题
a。什么是爬行动物
自动捕获目标网站内容的工具
b。爬行动物有什么用
提高数据采集的效率。任何人都不应该希望自己的手指继续复制和粘贴。机械的东西应该交给工具。Fast采集数据也是数据分析的基础
c。爬行动物的原理是什么
要理解这一点,我们需要理解为什么人类可以浏览网络。我们通过输入网址、关键字、单击链接等方式将请求发送到目标计算机,然后在本地下载目标计算机的代码,然后将其解析/呈现到我们看到的页面中。这就是上网的过程
爬虫所做的是模拟这个过程,但它的移动速度比人类快,可以自定义要捕获的内容,然后将其存储在数据库中以供浏览或下载。搜索引擎的工作原理类似
但是爬虫只是一种工具。为了让工具工作,我们必须让爬虫理解你想要什么。这就是我们必须做的。毕竟,人类的脑电波不能直接流入计算机。也可以说,爬行动物的本质是寻找规则
Lauren Mancke在Unsplash拍摄的照片
以豆瓣电影top250为例(很多人都在练习,因为豆瓣的网页是规则的),看看爬网刮板有多容易,以及如何使用它
1、在chrome应用商店中搜索网页刮板,然后单击“添加扩展程序”。此时,您可以在chrome插件栏中看到蛛网图标
(如果日常浏览器不是chrome,强烈建议更改。chrome和其他浏览器的区别就像谷歌和其他搜索引擎的区别一样)
2、打开网页进行攀爬。例如,豆瓣top250的URL为/top250,然后按住option+Command+I进入开发者模式(如果使用windows,则按住Ctrl+Shift+I,不同浏览器的默认快捷键可能不同)。此时,您可以在网页上看到这样一个对话框。不要建议。这只是当前网页的HTML,一种超文本标记语言,创造了网络世界的实体
只要按照步骤1添加了刮纸器扩展程序,您就可以在箭头指示的位置看到刮纸器。点击它进入下图中的爬虫页面
3、单击创建新站点地图,然后依次创建站点地图以创建爬虫。填写站点地图名称只是为了自我识别。例如,在起始URL中填写dbtop250(不要写汉字、空格和大写字母),我们通常会复制粘贴要爬网的网页的URL,但为了让爬网者了解我们的意图,我们最好先观察网页布局和URL。例如,top250采用分页模式,250部电影分10页发行,每页25部
第一页的URL是/top250
第二页以/top250开头?开始=25&;滤器=
第三页是/top250?开始=50&;滤器=
只有一个数字略有不同。我们的目的是抓取top250的电影数据,所以我们不能简单地将/top250粘贴到开始URL中,但是/top250?开始=[0-250:25]&;滤器=
请注意开始后[]中的内容,它表示每25页一个网页,并爬网10个网页
最后,单击创建站点地图,将构建爬虫程序
(您也可以通过在URL中填写/top250进行爬网,但这不能让web scraper理解我们想要爬网top250所有页面的数据,它只会爬网第一页的内容。)
4、重点是爬虫建成后的工作。为了让web scraper理解其意图,必须创建一个选择器,然后单击“添加新选择器”
然后,您将进入选择器编辑页面,这实际上是一个简单的点。其原理是,几乎所有使用HTML编辑的网页都由看起来相同或相似的框(或容器)组成,每个容器中的布局和标签都是相似的。页面越规则,它就越统一,这可以从HTML代码中看出
因此,如果我们设置了选择元素和顺序,爬虫可以根据设置自动模拟选择,并且可以整齐地向下爬数据。当我们想要攀爬各种元素时(例如攀爬豆瓣top250想要同时攀爬排名、电影名称、得分和一句话电影评论),我们可以先选择容器,然后依次选择容器中的元素
如图所示,依次
5、step4只创建容器的选择器。Web scraper仍然不知道爬行什么。我们需要在容器中进一步选择所需的数据(电影排名、电影名称、分数、一句话电影评论)
完成步骤4保存选择后,您将看到爬虫程序的根目录,并单击创建的容器列
查看根目录,后跟容器,然后单击添加新选择器以创建子选择器
再次进入seletor编辑页面,如下图所示。这次的不同之处在于,我们填写了要在ID中捕获的元素的定义,并随意地编写它。例如,抓取排名第一的电影并写一个数字;因为排名是文本类型,所以在类型中选择文本;这次只选择了容器中的一个元素,因此不会选中“多个”。此外,选择排名不要选择错误的位置,因为你可以爬任何你选择的爬虫。然后单击执行选择并保存选择器
此时,爬虫程序已经知道对top250网页中所有容器的电影排名进行爬网。然后,以同样的方式,创建另外三个子选择器(注意它们在容器目录中),分别对电影名称、乐谱和一句话电影评论进行爬网
创建之后,所有选择器都已创建,爬虫程序已完全理解其意图
6、下一步就是让爬虫运行。依次单击站点地图dbtop250和scratch
此时,web scraper将允许您填写请求间隔和延迟时间,并保留默认值2000(单位为毫秒,即2秒),除非网络速度特别快或慢,然后单击开始sraping
在这里,将弹出一个新的自动滚动网页,这是我们在创建爬虫程序时输入的URL。大约一分钟后,爬虫将完成工作,弹出窗口将自动消失(自动消失表示爬虫已完成)
同样的情况也适用于网页刮板
7、点击刷新预览爬虫成就:豆瓣电影top250排名、电影名称、得分和一句话电影评论。看看有没有什么问题。(例如,如果有空值,则表示对应的选择器选择不好。通常,页面越规则,空值越少。如果遇到不规则HTML的网页,例如知乎,空值越多,则可以返回选择器进行调整。)
在这个时候,可以说已经完成了。只需单击sitemap dbtop250并将日期导出为CSV,即可下载CSV格式的数据表,并根据需要使用它
值得一提的是,浏览器捕获的内容通常保存在本地后台数据库中。此数据库只有一个功能,不支持自动排序。因此,如果不安装和设置其他数据库,数据表将出现故障。在这种情况下,一种解决方案是将它们导入GoogleSheet并清理它们,另一种一劳永逸的方法是安装额外的数据库,例如CouchDB,并在对数据进行爬网之前将数据存储路径更改为CouchDB。此时,对数据进行爬网、预览和下载是按顺序进行的,如上面的预览图像
整个过程似乎很麻烦。事实上,在熟悉它之后,它是非常简单的。从开始到结束的两到三分钟内,这些少量数据就可以正常工作。此外,就像这些少量的数据一样,爬虫也没有充分反映出它的目的。数据量越大,爬虫的优势越明显
例如,您可以同时抓取知乎各种主题的选定内容,20000条数据只需要几十分钟
自拍
如果你看到这里,你会觉得很难遵循上面的步骤。有一个更简单的方法:
通过导入站点地图,复制粘贴以下爬虫代码,导入,就可以直接开始爬虫豆瓣top250的内容。(由上述系列配置生成)
{“\u id”:“豆瓣电影”\u top\u 250“,“startUrl”:[“/top250?start=0&;filter=“”],“选择器”:[{”id:“next\u page”,“type:“SelectorLink”,“parentSelectors”:[“\u root”,“next\u page”],“selector:”.next a”,“multiple”:true,“delay”:0},{“id:“container”,“type:“SelectorElement”,“parentSelectors:”,“parentSelectors:“[“next\u root”,“next\u page”,“selector:“grid:”grid\u view li”,“multiple”;“true”,“delay”;“delay”:0},{“id”:“title”,“type”:“SelectorText”,“parentSelectors”:[“container”],“selector”:“span.title:n类型(1)),“multiple”:false,“regex”:“delay”:0},{“id” 查看全部
抓取jsp网页源代码(用WebScraper(一个Chrome插件)爬取网页内容的教程)
在Internet上有许多使用Python爬行web内容的教程,但通常需要编写代码。如果没有相应基础的人想在短时间内开始,仍然有一个门槛。事实上,在大多数情况下,您可以使用WebScraper(一个chrome插件)快速爬升到目标内容。重要的是,您不需要下载东西或代码知识
在开始之前,有必要简要了解几个问题
a。什么是爬行动物
自动捕获目标网站内容的工具
b。爬行动物有什么用
提高数据采集的效率。任何人都不应该希望自己的手指继续复制和粘贴。机械的东西应该交给工具。Fast采集数据也是数据分析的基础
c。爬行动物的原理是什么
要理解这一点,我们需要理解为什么人类可以浏览网络。我们通过输入网址、关键字、单击链接等方式将请求发送到目标计算机,然后在本地下载目标计算机的代码,然后将其解析/呈现到我们看到的页面中。这就是上网的过程
爬虫所做的是模拟这个过程,但它的移动速度比人类快,可以自定义要捕获的内容,然后将其存储在数据库中以供浏览或下载。搜索引擎的工作原理类似
但是爬虫只是一种工具。为了让工具工作,我们必须让爬虫理解你想要什么。这就是我们必须做的。毕竟,人类的脑电波不能直接流入计算机。也可以说,爬行动物的本质是寻找规则
Lauren Mancke在Unsplash拍摄的照片
以豆瓣电影top250为例(很多人都在练习,因为豆瓣的网页是规则的),看看爬网刮板有多容易,以及如何使用它
1、在chrome应用商店中搜索网页刮板,然后单击“添加扩展程序”。此时,您可以在chrome插件栏中看到蛛网图标
(如果日常浏览器不是chrome,强烈建议更改。chrome和其他浏览器的区别就像谷歌和其他搜索引擎的区别一样)
2、打开网页进行攀爬。例如,豆瓣top250的URL为/top250,然后按住option+Command+I进入开发者模式(如果使用windows,则按住Ctrl+Shift+I,不同浏览器的默认快捷键可能不同)。此时,您可以在网页上看到这样一个对话框。不要建议。这只是当前网页的HTML,一种超文本标记语言,创造了网络世界的实体
只要按照步骤1添加了刮纸器扩展程序,您就可以在箭头指示的位置看到刮纸器。点击它进入下图中的爬虫页面
3、单击创建新站点地图,然后依次创建站点地图以创建爬虫。填写站点地图名称只是为了自我识别。例如,在起始URL中填写dbtop250(不要写汉字、空格和大写字母),我们通常会复制粘贴要爬网的网页的URL,但为了让爬网者了解我们的意图,我们最好先观察网页布局和URL。例如,top250采用分页模式,250部电影分10页发行,每页25部
第一页的URL是/top250
第二页以/top250开头?开始=25&;滤器=
第三页是/top250?开始=50&;滤器=
只有一个数字略有不同。我们的目的是抓取top250的电影数据,所以我们不能简单地将/top250粘贴到开始URL中,但是/top250?开始=[0-250:25]&;滤器=
请注意开始后[]中的内容,它表示每25页一个网页,并爬网10个网页
最后,单击创建站点地图,将构建爬虫程序
(您也可以通过在URL中填写/top250进行爬网,但这不能让web scraper理解我们想要爬网top250所有页面的数据,它只会爬网第一页的内容。)
4、重点是爬虫建成后的工作。为了让web scraper理解其意图,必须创建一个选择器,然后单击“添加新选择器”
然后,您将进入选择器编辑页面,这实际上是一个简单的点。其原理是,几乎所有使用HTML编辑的网页都由看起来相同或相似的框(或容器)组成,每个容器中的布局和标签都是相似的。页面越规则,它就越统一,这可以从HTML代码中看出
因此,如果我们设置了选择元素和顺序,爬虫可以根据设置自动模拟选择,并且可以整齐地向下爬数据。当我们想要攀爬各种元素时(例如攀爬豆瓣top250想要同时攀爬排名、电影名称、得分和一句话电影评论),我们可以先选择容器,然后依次选择容器中的元素
如图所示,依次
5、step4只创建容器的选择器。Web scraper仍然不知道爬行什么。我们需要在容器中进一步选择所需的数据(电影排名、电影名称、分数、一句话电影评论)
完成步骤4保存选择后,您将看到爬虫程序的根目录,并单击创建的容器列
查看根目录,后跟容器,然后单击添加新选择器以创建子选择器
再次进入seletor编辑页面,如下图所示。这次的不同之处在于,我们填写了要在ID中捕获的元素的定义,并随意地编写它。例如,抓取排名第一的电影并写一个数字;因为排名是文本类型,所以在类型中选择文本;这次只选择了容器中的一个元素,因此不会选中“多个”。此外,选择排名不要选择错误的位置,因为你可以爬任何你选择的爬虫。然后单击执行选择并保存选择器
此时,爬虫程序已经知道对top250网页中所有容器的电影排名进行爬网。然后,以同样的方式,创建另外三个子选择器(注意它们在容器目录中),分别对电影名称、乐谱和一句话电影评论进行爬网
创建之后,所有选择器都已创建,爬虫程序已完全理解其意图
6、下一步就是让爬虫运行。依次单击站点地图dbtop250和scratch
此时,web scraper将允许您填写请求间隔和延迟时间,并保留默认值2000(单位为毫秒,即2秒),除非网络速度特别快或慢,然后单击开始sraping
在这里,将弹出一个新的自动滚动网页,这是我们在创建爬虫程序时输入的URL。大约一分钟后,爬虫将完成工作,弹出窗口将自动消失(自动消失表示爬虫已完成)
同样的情况也适用于网页刮板
7、点击刷新预览爬虫成就:豆瓣电影top250排名、电影名称、得分和一句话电影评论。看看有没有什么问题。(例如,如果有空值,则表示对应的选择器选择不好。通常,页面越规则,空值越少。如果遇到不规则HTML的网页,例如知乎,空值越多,则可以返回选择器进行调整。)
在这个时候,可以说已经完成了。只需单击sitemap dbtop250并将日期导出为CSV,即可下载CSV格式的数据表,并根据需要使用它
值得一提的是,浏览器捕获的内容通常保存在本地后台数据库中。此数据库只有一个功能,不支持自动排序。因此,如果不安装和设置其他数据库,数据表将出现故障。在这种情况下,一种解决方案是将它们导入GoogleSheet并清理它们,另一种一劳永逸的方法是安装额外的数据库,例如CouchDB,并在对数据进行爬网之前将数据存储路径更改为CouchDB。此时,对数据进行爬网、预览和下载是按顺序进行的,如上面的预览图像
整个过程似乎很麻烦。事实上,在熟悉它之后,它是非常简单的。从开始到结束的两到三分钟内,这些少量数据就可以正常工作。此外,就像这些少量的数据一样,爬虫也没有充分反映出它的目的。数据量越大,爬虫的优势越明显
例如,您可以同时抓取知乎各种主题的选定内容,20000条数据只需要几十分钟
自拍
如果你看到这里,你会觉得很难遵循上面的步骤。有一个更简单的方法:
通过导入站点地图,复制粘贴以下爬虫代码,导入,就可以直接开始爬虫豆瓣top250的内容。(由上述系列配置生成)
{“\u id”:“豆瓣电影”\u top\u 250“,“startUrl”:[“/top250?start=0&;filter=“”],“选择器”:[{”id:“next\u page”,“type:“SelectorLink”,“parentSelectors”:[“\u root”,“next\u page”],“selector:”.next a”,“multiple”:true,“delay”:0},{“id:“container”,“type:“SelectorElement”,“parentSelectors:”,“parentSelectors:“[“next\u root”,“next\u page”,“selector:“grid:”grid\u view li”,“multiple”;“true”,“delay”;“delay”:0},{“id”:“title”,“type”:“SelectorText”,“parentSelectors”:[“container”],“selector”:“span.title:n类型(1)),“multiple”:false,“regex”:“delay”:0},{“id”
抓取jsp网页源代码(jsp文件注释的效果是不同的文件来说)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-17 21:01
抓取jsp网页源代码,然后找到jsp页面的注释信息。然后转换成java格式。editplus这些ide最容易找到这种注释信息。
答案是不一定。只是对于不同的jsp文件来说,注释信息都是不同的,因为它们实现的效果是不同的。可以自己查看一下,一般jsp文件当中都会规定那些内容需要注释,而哪些内容是可以不注释的。jsp文件注释的效果是将用户引导到查询的页面,在这个页面里你可以理解它想表达的意思。但对于jsp文件中的java代码,并不是所有的注释都有效。
对https协议可能有用。
eclipse自带的可以用我觉得值得一提的是jsp开发的你如果需要知道注释格式的话可以用js和你自己配置一下浏览器的兼容性用jsp所有的都是服务器自己跑出来的最多加一个参数具体参数你怎么也得写java程序调用吧jsp只是一个文件不要想太多跟后台交互最主要靠java端的jdbc和json。
eclipse中的xml标签可以修改所有的内容
谢邀。对于上面@潘中发答案的答案我是不赞同的。首先对于本题来说,不可能不用xml标签来给jsp页面添加注释。你可以使用for代码定义xml标签,修改完之后再用xml标签注释,也可以用js注释,比如,helloworldworld;twoworker应该也是可以的。具体情况得具体分析。另外对于题主的问题,明确的告诉你,不需要注释,每一行代码就是一个页面。
当你使用jsp语言开发网站时,本身没有注释,而如果不加注释,访问的用户在下次点击这个按钮时就可能会跳转到旧的页面,导致返回用户首页。再举一个例子来说明问题:a页面上有个点击登录按钮,那么执行登录获取用户id和密码这样的动作,应该执行那几个步骤?a页面:登录用户+用户id+密码页面源代码=>在浏览器打开会发现,没有注释,也显示不了用户信息,但是有用户信息,如果把不显示用户信息的xml标签加入注释,你可以知道用户输入的账号密码是多少。 查看全部
抓取jsp网页源代码(jsp文件注释的效果是不同的文件来说)
抓取jsp网页源代码,然后找到jsp页面的注释信息。然后转换成java格式。editplus这些ide最容易找到这种注释信息。
答案是不一定。只是对于不同的jsp文件来说,注释信息都是不同的,因为它们实现的效果是不同的。可以自己查看一下,一般jsp文件当中都会规定那些内容需要注释,而哪些内容是可以不注释的。jsp文件注释的效果是将用户引导到查询的页面,在这个页面里你可以理解它想表达的意思。但对于jsp文件中的java代码,并不是所有的注释都有效。
对https协议可能有用。
eclipse自带的可以用我觉得值得一提的是jsp开发的你如果需要知道注释格式的话可以用js和你自己配置一下浏览器的兼容性用jsp所有的都是服务器自己跑出来的最多加一个参数具体参数你怎么也得写java程序调用吧jsp只是一个文件不要想太多跟后台交互最主要靠java端的jdbc和json。
eclipse中的xml标签可以修改所有的内容
谢邀。对于上面@潘中发答案的答案我是不赞同的。首先对于本题来说,不可能不用xml标签来给jsp页面添加注释。你可以使用for代码定义xml标签,修改完之后再用xml标签注释,也可以用js注释,比如,helloworldworld;twoworker应该也是可以的。具体情况得具体分析。另外对于题主的问题,明确的告诉你,不需要注释,每一行代码就是一个页面。
当你使用jsp语言开发网站时,本身没有注释,而如果不加注释,访问的用户在下次点击这个按钮时就可能会跳转到旧的页面,导致返回用户首页。再举一个例子来说明问题:a页面上有个点击登录按钮,那么执行登录获取用户id和密码这样的动作,应该执行那几个步骤?a页面:登录用户+用户id+密码页面源代码=>在浏览器打开会发现,没有注释,也显示不了用户信息,但是有用户信息,如果把不显示用户信息的xml标签加入注释,你可以知道用户输入的账号密码是多少。
抓取jsp网页源代码(网页分析工具(Chrome开发者工具)对网页进行抓包分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2021-09-15 14:11
在这篇文章文章中,我们将尝试使用一个直观的网页分析工具(ChromeDeveloper工具)来捕获和分析网页
1、测试环境
浏览器:Chrome浏览器
浏览器版本:67.0.339 6.99(官方版本)(32位)
Web分析工具:开发人员工具
2、web页面分析(1)web页面源代码分析)
我们知道网页可以分为静态网页和动态网页。许多人会错误地认为静态网页是没有动态效果的网页。事实上,这种说法是错误的
另外,目前很多动态网站都采用了异步加载技术(Ajax),这也是捕获的源代码多次与网站显示的源代码不一致的原因
对于如何抓取动态网页,有两种方法:
我们以京东产品为例,分析如何通过chrome抓取软件包。首先,我们打开产品的主页
右键单击网页空白处并选择查看网页源代码(或使用快捷方式CTRL+U直接打开)
请注意,当您查看网页的源代码时,您会得到网站最原创的源代码,即我们通常获取的源代码
再次进入网页空白处,右键单击并选中(或使用快捷键CTRL+Shift +I/F12直接打开)
请注意,检查结果是由Ajax加载并由JavaScript呈现的源代码,即当前网站显示内容的源代码
通过比较,我们可以发现两者的内容是不同的,这是异步加载技术(Ajax)的一个典型例子
目前,京东产品的价格至少是通过异步加载生成的。这里有三种方法来判断网页中的内容是否是动态生成的:
(2)web页面数据包捕获分析)
让我们以京东商品为例来说明。打开商品主页,尝试捕获动态加载的商品价格数据
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择网络选项卡进行数据包捕获分析
此时,按快捷键F5刷新页面。您可以看到开发人员工具中出现了各种包。我们使用filter来过滤包
首先,选择doc,您可以看到列表中只显示一个包
一般来说,这是浏览器收到的第一个数据包,用于获取网站请求的原创源代码@
单击“标题”以查看其标题参数设置
单击响应以查看返回的源代码。很容易发现它实际上与通过查看网页源代码返回的信息一致
让我们回到正题上来。对于动态加载的数据包捕获分析,我们可以主要查看XHR和JS选项卡
选择JS进行筛选,发现列表中出现了许多包。分析之后,我们过滤下图中标记的包
此包返回有关价格的信息,但经过仔细分析,发现这些价格不属于当前商品,而是属于相关商品
但是,我们怎么能说这个方案与价格有关呢?让我们首先看看这个包的请求URL
https://p.3.cn/prices/mgets%3F ... em-pc
过滤回调等不必要的参数,以获得简单有效的URL
https://p.3.cn/prices/mgets%3F ... 49638
直接用浏览器打开URL,可以看到返回的JSON数据确实收录价格信息(不幸的是,它是其他商品的价格)
通过分析URL的参数,可以推断skuid应该是每个商品的唯一标记。我们在哪里可以找到我们需要的商品的臭鼬
事实上,SKU是物流、运输等行业常用的缩写。它的全称是库存单位
即存货进出计量的基本单位。现在它已经扩展到统一产品编号的缩写。每个产品对应一个唯一的SKU 查看全部
抓取jsp网页源代码(网页分析工具(Chrome开发者工具)对网页进行抓包分析)
在这篇文章文章中,我们将尝试使用一个直观的网页分析工具(ChromeDeveloper工具)来捕获和分析网页
1、测试环境
浏览器:Chrome浏览器
浏览器版本:67.0.339 6.99(官方版本)(32位)
Web分析工具:开发人员工具
2、web页面分析(1)web页面源代码分析)
我们知道网页可以分为静态网页和动态网页。许多人会错误地认为静态网页是没有动态效果的网页。事实上,这种说法是错误的
另外,目前很多动态网站都采用了异步加载技术(Ajax),这也是捕获的源代码多次与网站显示的源代码不一致的原因
对于如何抓取动态网页,有两种方法:
我们以京东产品为例,分析如何通过chrome抓取软件包。首先,我们打开产品的主页
右键单击网页空白处并选择查看网页源代码(或使用快捷方式CTRL+U直接打开)
请注意,当您查看网页的源代码时,您会得到网站最原创的源代码,即我们通常获取的源代码
再次进入网页空白处,右键单击并选中(或使用快捷键CTRL+Shift +I/F12直接打开)
请注意,检查结果是由Ajax加载并由JavaScript呈现的源代码,即当前网站显示内容的源代码
通过比较,我们可以发现两者的内容是不同的,这是异步加载技术(Ajax)的一个典型例子
目前,京东产品的价格至少是通过异步加载生成的。这里有三种方法来判断网页中的内容是否是动态生成的:
(2)web页面数据包捕获分析)
让我们以京东商品为例来说明。打开商品主页,尝试捕获动态加载的商品价格数据
使用快捷键Ctrl+Shift+I或F12打开开发者工具,然后选择网络选项卡进行数据包捕获分析
此时,按快捷键F5刷新页面。您可以看到开发人员工具中出现了各种包。我们使用filter来过滤包
首先,选择doc,您可以看到列表中只显示一个包
一般来说,这是浏览器收到的第一个数据包,用于获取网站请求的原创源代码@
单击“标题”以查看其标题参数设置
单击响应以查看返回的源代码。很容易发现它实际上与通过查看网页源代码返回的信息一致
让我们回到正题上来。对于动态加载的数据包捕获分析,我们可以主要查看XHR和JS选项卡
选择JS进行筛选,发现列表中出现了许多包。分析之后,我们过滤下图中标记的包
此包返回有关价格的信息,但经过仔细分析,发现这些价格不属于当前商品,而是属于相关商品
但是,我们怎么能说这个方案与价格有关呢?让我们首先看看这个包的请求URL
https://p.3.cn/prices/mgets%3F ... em-pc
过滤回调等不必要的参数,以获得简单有效的URL
https://p.3.cn/prices/mgets%3F ... 49638
直接用浏览器打开URL,可以看到返回的JSON数据确实收录价格信息(不幸的是,它是其他商品的价格)
通过分析URL的参数,可以推断skuid应该是每个商品的唯一标记。我们在哪里可以找到我们需要的商品的臭鼬
事实上,SKU是物流、运输等行业常用的缩写。它的全称是库存单位
即存货进出计量的基本单位。现在它已经扩展到统一产品编号的缩写。每个产品对应一个唯一的SKU
抓取jsp网页源代码(java项目有时候我们需要别人网页上的数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-15 14:09
Java项目有时我们需要别人网页上的数据。我们该怎么办?我们可以使用第三方shelf包jsou来实现jsoup的中文文档。我们如何具体实施它?那就一步一步跟着我
第一件事是准备第三方机架包,下载地址,以及在获得jar后做什么?别担心,我们慢慢来
复制jsoup。Jar到项目的Webroot->;WEB-INF->;库文件夹
那么我们需要介绍一下这个架子包
右键单击项目并选择生成路径->;配置生成路径->;图书馆->;添加罐子->;在刚刚放入的目录下找到jsoup
准备工作已经完成,下一步是我们的编码部分。来吧
因为它是为了抓取网页的内容,所以必须捕获网站的地址。这里,以我的一个博客为标准
这是我文章文章的截图,例如,我想捕捉Android的零碎知识点,之后我会一直更新这一段
//获取整个网站的根节点,即从HTML的开始到结束。这里,get方法和post方法是相同的
Document Document=Jsoup.connect(url.get()
//输出它,我们将看到整个字符串,如下所示
系统输出打印项次(文件)
这里只是截图的一部分
我们将看到我们需要掌握的文本被包装在一个标签中,另一个重要的东西是id=CB_uu;post_uuuuuutitle_uuuurl,阅读过该文档的人应该知道在jsoup中有一个getelementbyid方法,它实际上与在JS中获取元素相同。在这里我们可以使用它
Getelementbyid方法来获取a标记。拿到之后,我们可以把里面的内容拿出来,对吗?Jsou还为我们提供了一个text()方法,用于获取标记的文本内容。请记住,它是以文本而不是HTML的形式出现的
如下所示,我们使用getelementbyid方法获取所需的a标记
元素a=document.getElementById(“cb_post_title_url”)
此时,我们的输出如下
System.out.println(a.text())
我们得到我们想要的了吗?当然,这只是jsoup的最简单捕获。如果需要以列表的形式获取,也可以获取jsoup。我们都知道ID是唯一的,不能重复,所以我们只能通过ID获得一行标签
但是对于一般列表,比如ulli,我们可以使用getelementsbytag方法通过标记名获取它们,然后通过for循环逐个获取它们。接下来,附上代码
package com.luhan.text;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class Text {
private static final String url = "http://www.cnblogs.com/luhan/p/5953387.html";
public static void main(String[] args) {
try {
//获取整个网站的根节点,也就是html开头部分一直到结束
Document document = Jsoup.connect(url).post();
Element a = document.getElementById("cb_post_title_url");
System.out.println(a.text());
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
我不会逐一介绍jsoup中的方法。如果您不明白,可以阅读jsoup的中文文档。让我谈谈更重要的方法
Jsoup.connect(url.post();获取网页的以下目录
Getelementbyid是通过ID获取的
Getelementsbyclass是通过类获取的
Getelementsbytag是通过标记名获得的
Text()获取标记的文本,再次强调文本
HTML()获取标记中的所有字符串,包括HTML标记
Attrib(attributekey)获取属性中的值。参数是属性名
注意
jsoup获得的网页根目录可能与源代码不同,因此需要小心
此时,jsoup抓取的网页数据结束了。不太好。欢迎提供更多指导。我使用Java控制台,JavaWeb和Android的用法是一样的。首先,导入框架,然后调用OK
方法 查看全部
抓取jsp网页源代码(java项目有时候我们需要别人网页上的数据(组图))
Java项目有时我们需要别人网页上的数据。我们该怎么办?我们可以使用第三方shelf包jsou来实现jsoup的中文文档。我们如何具体实施它?那就一步一步跟着我
第一件事是准备第三方机架包,下载地址,以及在获得jar后做什么?别担心,我们慢慢来
复制jsoup。Jar到项目的Webroot->;WEB-INF->;库文件夹
那么我们需要介绍一下这个架子包
右键单击项目并选择生成路径->;配置生成路径->;图书馆->;添加罐子->;在刚刚放入的目录下找到jsoup
准备工作已经完成,下一步是我们的编码部分。来吧
因为它是为了抓取网页的内容,所以必须捕获网站的地址。这里,以我的一个博客为标准
这是我文章文章的截图,例如,我想捕捉Android的零碎知识点,之后我会一直更新这一段
//获取整个网站的根节点,即从HTML的开始到结束。这里,get方法和post方法是相同的
Document Document=Jsoup.connect(url.get()
//输出它,我们将看到整个字符串,如下所示
系统输出打印项次(文件)
这里只是截图的一部分
我们将看到我们需要掌握的文本被包装在一个标签中,另一个重要的东西是id=CB_uu;post_uuuuuutitle_uuuurl,阅读过该文档的人应该知道在jsoup中有一个getelementbyid方法,它实际上与在JS中获取元素相同。在这里我们可以使用它
Getelementbyid方法来获取a标记。拿到之后,我们可以把里面的内容拿出来,对吗?Jsou还为我们提供了一个text()方法,用于获取标记的文本内容。请记住,它是以文本而不是HTML的形式出现的
如下所示,我们使用getelementbyid方法获取所需的a标记
元素a=document.getElementById(“cb_post_title_url”)
此时,我们的输出如下
System.out.println(a.text())
我们得到我们想要的了吗?当然,这只是jsoup的最简单捕获。如果需要以列表的形式获取,也可以获取jsoup。我们都知道ID是唯一的,不能重复,所以我们只能通过ID获得一行标签
但是对于一般列表,比如ulli,我们可以使用getelementsbytag方法通过标记名获取它们,然后通过for循环逐个获取它们。接下来,附上代码
package com.luhan.text;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class Text {
private static final String url = "http://www.cnblogs.com/luhan/p/5953387.html";
public static void main(String[] args) {
try {
//获取整个网站的根节点,也就是html开头部分一直到结束
Document document = Jsoup.connect(url).post();
Element a = document.getElementById("cb_post_title_url");
System.out.println(a.text());
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
我不会逐一介绍jsoup中的方法。如果您不明白,可以阅读jsoup的中文文档。让我谈谈更重要的方法
Jsoup.connect(url.post();获取网页的以下目录
Getelementbyid是通过ID获取的
Getelementsbyclass是通过类获取的
Getelementsbytag是通过标记名获得的
Text()获取标记的文本,再次强调文本
HTML()获取标记中的所有字符串,包括HTML标记
Attrib(attributekey)获取属性中的值。参数是属性名
注意
jsoup获得的网页根目录可能与源代码不同,因此需要小心
此时,jsoup抓取的网页数据结束了。不太好。欢迎提供更多指导。我使用Java控制台,JavaWeb和Android的用法是一样的。首先,导入框架,然后调用OK
方法
抓取jsp网页源代码( JSPJSP页面间传值方法的相关资料介绍(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-13 20:09
JSPJSP页面间传值方法的相关资料介绍(一))
JSP页面间传值方法总结
更新时间:2017-07-07 11:34:45 作者:奥森
在JSP页面之间传递参数是一个经常用到的功能。有时需要在多个 JSP 页面之间传递参数。下面文章主要介绍JSP页面间传值方法的相关信息。介绍的很详细,对大家有一定的参考学习价值。有需要的朋友,一起来看看吧。
前言
在JSP页面之间传递参数是项目中经常需要的,应该算是基本的Web技能。尝试总结各种方法,必要时权衡利弊,选择最合适的方法。一起来看看详细的介绍:
1. URL 链接后添加参数
URL 后面追加参数
response.sendRedirect("next.jsp?paramA=A¶mB=B...")
window.location = "next.jsp?paramA=A¶mB=B..."
执行上述代码时,会携带参数跳转到next.jsp页面。
获取next.jsp页面对应参数的方法如下:
//内嵌的 java 代码
//如果引入了 EL
{param.paramA}
优点:简单和多浏览器支持(没有浏览器不支持 URL)。
缺点:
1) 传输的数据只能是字符串,对数据类型和大小有一定的限制;
2) 浏览器地址栏会看到传输数据的值,安全级别低。
2.表单
next.jsp页面中获取对应参数的方式类似于(1).
优点:
1)Simple 和多浏览器支持(同样没有浏览器不支持表单);
2)可以提交的数据量远大于URL方式;
3)传递过来的值会显示在浏览器的地址栏中,不过参数列表如果有一点黑的意思也可以从页面源码构造;
缺点:
1)传输的数据只能是字符串,对数据类型有一定的限制;
3. 设置 Cookie
利用客户端的鉴权凭证,一个小小的cookie,当然也可以实现JSP页面的价值传递。
要读取 next.jsp 页面上的 cookie,需要调用 request.getCookies() 方法来获取 javax.servlet.http.Cookie 对象数组。
然后遍历这个数组,使用getName()方法和getValue()方法获取每个cookie的名称和值。
//内嵌的 java 代码
//EL 获取方式
${cookie.paramA.value}
优点:
1)Cookie 的值可以持久化,即使客户端关机,下次打开仍然可以获取里面的值;
2) Cookie 可以帮助服务器保存多个状态信息,但服务器不需要专门分配存储资源,减轻了服务器的负担。
缺点:
1) 虽然安全性比 URL 和 Form 好很多,但也有获取客户端 cookie 和暴露客户端信息的黑方法。
4. 设置会话
我个人认为 session 和 cookie 一个在服务器端,另一个在客户端。
添加键值对后,它不仅提供了页面之间的传输,而且实际上是一种数据共享解决方案。
如何在next.jsp中读取session:
//内嵌java 片段
//EL 获取方式
{session.paramA}
Session的优缺点可以参考Cookie。
总结
以上是本次文章的全部内容。希望本文的内容对您的学习或工作有所帮助。有什么问题可以留言交流。感谢您对 Scripthome 的支持。 查看全部
抓取jsp网页源代码(
JSPJSP页面间传值方法的相关资料介绍(一))
JSP页面间传值方法总结
更新时间:2017-07-07 11:34:45 作者:奥森
在JSP页面之间传递参数是一个经常用到的功能。有时需要在多个 JSP 页面之间传递参数。下面文章主要介绍JSP页面间传值方法的相关信息。介绍的很详细,对大家有一定的参考学习价值。有需要的朋友,一起来看看吧。
前言
在JSP页面之间传递参数是项目中经常需要的,应该算是基本的Web技能。尝试总结各种方法,必要时权衡利弊,选择最合适的方法。一起来看看详细的介绍:
1. URL 链接后添加参数
URL 后面追加参数
response.sendRedirect("next.jsp?paramA=A¶mB=B...")
window.location = "next.jsp?paramA=A¶mB=B..."
执行上述代码时,会携带参数跳转到next.jsp页面。
获取next.jsp页面对应参数的方法如下:
//内嵌的 java 代码
//如果引入了 EL
{param.paramA}
优点:简单和多浏览器支持(没有浏览器不支持 URL)。
缺点:
1) 传输的数据只能是字符串,对数据类型和大小有一定的限制;
2) 浏览器地址栏会看到传输数据的值,安全级别低。
2.表单
next.jsp页面中获取对应参数的方式类似于(1).
优点:
1)Simple 和多浏览器支持(同样没有浏览器不支持表单);
2)可以提交的数据量远大于URL方式;
3)传递过来的值会显示在浏览器的地址栏中,不过参数列表如果有一点黑的意思也可以从页面源码构造;
缺点:
1)传输的数据只能是字符串,对数据类型有一定的限制;
3. 设置 Cookie
利用客户端的鉴权凭证,一个小小的cookie,当然也可以实现JSP页面的价值传递。
要读取 next.jsp 页面上的 cookie,需要调用 request.getCookies() 方法来获取 javax.servlet.http.Cookie 对象数组。
然后遍历这个数组,使用getName()方法和getValue()方法获取每个cookie的名称和值。
//内嵌的 java 代码
//EL 获取方式
${cookie.paramA.value}
优点:
1)Cookie 的值可以持久化,即使客户端关机,下次打开仍然可以获取里面的值;
2) Cookie 可以帮助服务器保存多个状态信息,但服务器不需要专门分配存储资源,减轻了服务器的负担。
缺点:
1) 虽然安全性比 URL 和 Form 好很多,但也有获取客户端 cookie 和暴露客户端信息的黑方法。
4. 设置会话
我个人认为 session 和 cookie 一个在服务器端,另一个在客户端。
添加键值对后,它不仅提供了页面之间的传输,而且实际上是一种数据共享解决方案。
如何在next.jsp中读取session:
//内嵌java 片段
//EL 获取方式
{session.paramA}
Session的优缺点可以参考Cookie。
总结
以上是本次文章的全部内容。希望本文的内容对您的学习或工作有所帮助。有什么问题可以留言交流。感谢您对 Scripthome 的支持。
抓取jsp网页源代码(批量修改下载图片的名称疑问可以或2鲜花握手雷人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-10 02:00
总结:一、操作步骤 对于学习网页设计的人来说,有时候会遇到一个自己非常喜欢的网页,但是却拿不到它的html代码,或者代码不完整。下面以网易新闻采集为例,教大家采集html源码。具体操作步骤如下:二、case规则+操作步骤...
一、操作步骤
对于学习网页设计的人来说,有时会遇到一个自己非常喜欢的网页,但是却拿不到它的html代码,或者代码不完整。下面以网易新闻采集为例,教大家采集html源码。具体步骤如下:
二、Case规则+操作步骤
第一步:打开网页
1.1,打开极手客网络爬虫,输入你想要的示例网址采集回车,网页加载完毕后点击“定义规则”;
1.2,在工作台输入主题名称,点击“检查”查看主题名称是否被占用。
第 2 步:标记信息
2.1,双击要抓取的目标信息,输入排序框名称和标签,勾选关键内容。
2.2,双击字段名,设置抓取内容的高级选项,勾选“高级设置”,选择“Web Fragment”,保存。
第 3 步:保存规则并捕获数据
3.1,规则测试成功后,点击“保存规则”;
3.2,点击“抓取数据”,会弹出DS计数机开始抓取数据。
提示:如果想要网页的整个html源代码,可以直接映射html节点,然后在高级设置中选择网页片段,最后保存规则即可。操作如下:
第1部分文章:“如何查看数据规则”第2部分文章:“批量修改下载图片的名称”
如果您有任何问题,可以或
2
鲜花
握手
棒极了
1
路过
鸡蛋
刚刚发表意见的朋友() 查看全部
抓取jsp网页源代码(批量修改下载图片的名称疑问可以或2鲜花握手雷人)
总结:一、操作步骤 对于学习网页设计的人来说,有时候会遇到一个自己非常喜欢的网页,但是却拿不到它的html代码,或者代码不完整。下面以网易新闻采集为例,教大家采集html源码。具体操作步骤如下:二、case规则+操作步骤...
一、操作步骤
对于学习网页设计的人来说,有时会遇到一个自己非常喜欢的网页,但是却拿不到它的html代码,或者代码不完整。下面以网易新闻采集为例,教大家采集html源码。具体步骤如下:
二、Case规则+操作步骤
第一步:打开网页
1.1,打开极手客网络爬虫,输入你想要的示例网址采集回车,网页加载完毕后点击“定义规则”;
1.2,在工作台输入主题名称,点击“检查”查看主题名称是否被占用。
第 2 步:标记信息
2.1,双击要抓取的目标信息,输入排序框名称和标签,勾选关键内容。
2.2,双击字段名,设置抓取内容的高级选项,勾选“高级设置”,选择“Web Fragment”,保存。
第 3 步:保存规则并捕获数据
3.1,规则测试成功后,点击“保存规则”;
3.2,点击“抓取数据”,会弹出DS计数机开始抓取数据。
提示:如果想要网页的整个html源代码,可以直接映射html节点,然后在高级设置中选择网页片段,最后保存规则即可。操作如下:
第1部分文章:“如何查看数据规则”第2部分文章:“批量修改下载图片的名称”
如果您有任何问题,可以或
2
鲜花
握手
棒极了
1
路过
鸡蛋
刚刚发表意见的朋友()

