
抓取jsp网页源代码
抓取jsp网页源代码( 三门峡网站建设中有各种各样云分析云分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-01 11:21
三门峡网站建设中有各种各样云分析云分析)
三门峡网站三门峡的建设存在着各种各样的问题。关于网站制作中遇到的一些问题,愿意相信的小伙伴,三门峡天云网愿为大家分析如下。请阅读。
针对网站生产中遇到的常见问题,全网云分析如下:
1.网站 文件格式,无论是静态页面还是动态页面,一般来说搜索引擎对动态页面的抓取效果不是很好。常用的有ASP、PHP和JSP。现在很多程序都支持伪静态,最好选择支持伪静态的网站程序。
2.程序路径,即目录层级,网站目录层级不要太多,提高搜索引擎友好度,文件名中收录关键词,有一组关键词 如果需要,可以用连字符“—”代替下划线“__”来分隔,因为搜索引擎蜘蛛程序会把“—”当成空格,可以很好的分隔关键词组
3.网站结构,这部分是最重要的,最重要的部分是网站是否做了。
1)导航栏:导航栏中最好不要使用特效代码、图片或flash进行导航,因为搜索引擎无法捕捉到此类信息。对网站收录有一定影响是正常的。
2)使用图片时,给图片添加注释(ALT属性),保证搜索引擎可以读取到图片中收录的信息。
3)Flash:Flash动画是一种很好的美化网页的方式,很多网站都是用Flash制作的,所以蜘蛛程序无法读取它的信息。建议不要使用。
4) 跳转和弹窗:网页代码中有跳转代码或弹窗代码,所以搜索引擎给你的网站评价会很差时间长了,很可能会惩罚你的网站。
5) 特殊字符:搜索引擎蜘蛛目前无法识别和读取特殊字符。
4.网站 代码是济南实施网站建设网站计划的重要渠道。对于网站的后期优化,代码要简洁冗余,或者直接删除无用代码。这提高了搜索引擎对网站的友好度。一些网页代码减肥软件执行网站减肥。建议不要使用它,因为它会导致代码损坏。
对于网站制作中的问题,希望三门峡网站建设的分享可以帮助到各家公司。所以。 网站 做哪个更好?很多客户可能会向三门峡天云网推荐大家。但是,我们希望您能找到答案。如果合适,我们会再次合作,不会给您带来任何损失。 查看全部
抓取jsp网页源代码(
三门峡网站建设中有各种各样云分析云分析)
三门峡网站三门峡的建设存在着各种各样的问题。关于网站制作中遇到的一些问题,愿意相信的小伙伴,三门峡天云网愿为大家分析如下。请阅读。
针对网站生产中遇到的常见问题,全网云分析如下:
1.网站 文件格式,无论是静态页面还是动态页面,一般来说搜索引擎对动态页面的抓取效果不是很好。常用的有ASP、PHP和JSP。现在很多程序都支持伪静态,最好选择支持伪静态的网站程序。
2.程序路径,即目录层级,网站目录层级不要太多,提高搜索引擎友好度,文件名中收录关键词,有一组关键词 如果需要,可以用连字符“—”代替下划线“__”来分隔,因为搜索引擎蜘蛛程序会把“—”当成空格,可以很好的分隔关键词组
3.网站结构,这部分是最重要的,最重要的部分是网站是否做了。
1)导航栏:导航栏中最好不要使用特效代码、图片或flash进行导航,因为搜索引擎无法捕捉到此类信息。对网站收录有一定影响是正常的。
2)使用图片时,给图片添加注释(ALT属性),保证搜索引擎可以读取到图片中收录的信息。
3)Flash:Flash动画是一种很好的美化网页的方式,很多网站都是用Flash制作的,所以蜘蛛程序无法读取它的信息。建议不要使用。
4) 跳转和弹窗:网页代码中有跳转代码或弹窗代码,所以搜索引擎给你的网站评价会很差时间长了,很可能会惩罚你的网站。
5) 特殊字符:搜索引擎蜘蛛目前无法识别和读取特殊字符。
4.网站 代码是济南实施网站建设网站计划的重要渠道。对于网站的后期优化,代码要简洁冗余,或者直接删除无用代码。这提高了搜索引擎对网站的友好度。一些网页代码减肥软件执行网站减肥。建议不要使用它,因为它会导致代码损坏。
对于网站制作中的问题,希望三门峡网站建设的分享可以帮助到各家公司。所以。 网站 做哪个更好?很多客户可能会向三门峡天云网推荐大家。但是,我们希望您能找到答案。如果合适,我们会再次合作,不会给您带来任何损失。
抓取jsp网页源代码(有人将robots.txt文件视为一组建议.py文件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-12-31 07:11
)
关于合法性,获得大量有价值的信息可能令人兴奋,但仅仅因为它是可能的并不意味着应该这样做。
幸运的是,有一些公共信息可以指导我们的道德和网络抓取工具。大多数网站都有一个与网站相关联的robots.txt文件,指明哪些爬行活动是允许的,哪些是不允许的。它主要用于与搜索引擎交互(网页抓取工具的终极形式)。但是,网站 上的大部分信息都被视为公开信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及道德采集和数据使用等主题。
在开始抓取项目之前,先问自己以下问题:
当我抓取 网站 时,请确保您可以对所有这些问题回答“否”。
要详细了解这些法律问题,请参阅 Krotov 和 Silva 于 2018 年撰写的“Legal and Ethical Web Scraping”和 Sellars 的“Web Scraping and Computer Fraud and Abuse Act 20 Years of Web Scraping and Computer Fraud and Abuse Act”。
现在开始爬取网站
经过上面的评估,我想出了一个项目。我的目标是爬取爱达荷州所有 Family Dollar 商店的地址。这些店在农村很大,所以我想知道有多少这样的店。
起点是Family Dollar的位置页面
爱达荷州家庭美元位置页面
首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 的单元格中运行。
import requests # for making standard html requestsfrom bs4 import BeautifulSoup # magical tool for parsing html dataimport json # for parsing datafrom pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get("https://locations.familydollar.com/id/")soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。这些是我们将使用的几种常见对象类型。
当我们查看 requests.get() 的输出时,还有更多问题需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。requests中的默认编码设置可以很好的解决这个问题。不过,除了纯英文网站,就是更大的互联网世界。为确保请求正确解析内容,您可以设置文本的编码:
page = requests.get(URL)page.encoding = 'ISO-885901'soup = BeautifulSoup(page.text, 'html.parser')
仔细看一下 BeautifulSoup 标签,我们会看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站 爬取过程中的提取可能是一个充满误解的艰巨过程。我认为解决这个问题最好的方法是从一个有代表性的例子开始,然后再扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 查看页面的整个源代码(不推荐)。运行此代码风险自负:
print(soup.prettify())
虽然打印页面的整个源代码可能适合一些教程中展示的玩具示例,但大多数现代 网站 页面都有很多内容。甚至 404 页面也可能充满了页眉、页脚和其他代码。
通常,在您喜欢的浏览器中通过“查看页面源代码”(右键单击并选择“查看页面源代码”)来浏览源代码是最容易的。这是找到目标内容最可靠的方式(我稍后会解释原因)。
家庭美元页面源代码
在这种情况下,我需要在这个巨大的 HTML 海洋中找到我的目标内容地址、城市、州和邮政编码。通常,在页面源上进行简单的搜索(ctrl+F)就会得到目标位置的位置。一旦我真正看到目标内容的一个例子(至少是一个商店的地址),我就会找到一个属性或标签来区分该内容与其他内容。
首先,我需要在爱达荷州的Family Dollar商店采集不同城市的URL,并访问这些网站以获取地址信息。这些 URL 似乎收录在 href 标签中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')dollar_tree_list
搜索 href 不会产生任何结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于下一次尝试,搜索 item_list。由于 class 是 Python 中的保留字,因此使用 class_ 代替。soup.find_all() 竟然是 bs4 函数的瑞士军刀。
dollar_tree_list = soup.find_all(class_ = 'itemlist')for i in dollar_tree_list[:2]: print(i)
有趣的是,我发现搜索特定类的方法通常是一种成功的方法。通过找出对象的类型和长度,我们可以了解更多关于对象的信息。
type(dollar_tree_list)len(dollar_tree_list)
您可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建单个代表性示例的好时机。
example = dollar_tree_list[2] # a representative exampleexample_content = example.contentsprint(example_content)
使用 .attr 查找对象内容中存在的属性。注意: .contents 通常返回一个精确的项目列表,所以第一步是使用方括号表示法来索引项目。
example_content = example.contents[0]example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取它:
example_href = example_content['href']print(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,以澄清上述逻辑。
city_hrefs = [] # initialise empty list for i in dollar_tree_list: cont = i.contents[0] href = cont['href'] city_hrefs.append(href) # check to be sure all went wellfor i in city_hrefs[:2]: print(i)
输出是用于抓取爱达荷州 Family Dollar 商店的 URL 列表。
也就是说,我还没有得到地址信息!现在,您需要抓取每个城市的 URL 以获取此信息。因此,我们使用一个具有代表性的示例来重新启动该过程。
page2 = requests.get(city_hrefs[2]) # again establish a representative examplesoup2 = BeautifulSoup(page2.text, 'html.parser')
家庭美元地图和代码
地址信息嵌套在 type="application/ld+json" 中。经过大量的地理位置爬取,我开始意识到这是一个存储地址信息的通用结构。幸运的是,soup.find_all() 支持类型搜索。
arco = soup2.find_all(type="application/ld+json")print(arco[1])
地址信息在第二个列表成员中!我明白!
使用 .contents 提取内容(从第二个列表项中)(这是过滤后合适的默认操作)。同样,由于输出是一个列表,我为列表项建立了索引:
arco_contents = arco[1].contents[0]arco_contents
哦,看起来不错。这里提供的格式与JSON格式一致(而且类型名称确实收录“json”)。JSON 对象的行为类似于带有嵌套字典的字典。一旦你熟悉了它,它实际上是一种很好的格式(当然,它比一长串正则表达式命令更容易编程)。虽然在结构上看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要通过编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
type(arco_json)print(arco_json)
在内容中,有一个被调用的地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']arco_address
嗯,请注意。现在我可以遍历存储的爱达荷州 URL 列表:
locs_dict = [] # initialise empty list for link in city_hrefs: locpage = requests.get(link) # request page info locsoup = BeautifulSoup(locpage.text, 'html.parser') # parse the page's content locinfo = locsoup.find_all(type="application/ld+json") # extract specific element loccont = locinfo[1].contents[0] # get contents from the bs4 element set locjson = json.loads(loccont) # convert to json locaddr = locjson['address'] # get address locs_dict.append(locaddr) # add address to list
使用 Pandas 来组织我们的 网站 爬取结果
我们在字典中加载了大量数据,但是还有一些额外的无用项使得重用数据变得比必要的复杂。为了进行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不需要的@type 和 country 列,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)locs_df.head(n = 5)
一定要保存结果!!
df.to_csv(locs_df, "family_dollar_ID_locations.csv", sep = ",", index = False)
我们做到了!爱达荷州的所有 Family Dollar 商店都有一个以逗号分隔的列表。多么激动人心。
Selenium 和数据抓取的一点解释
Selenium 是一种常用的工具,用于自动与网页交互。为了解释为什么有时需要使用它,让我们看一个使用 Walgreens 网站 的例子。“检查元素”提供浏览器显示内容的代码:
沃尔格林位置页面和代码
尽管“查看页面源代码”提供了有关请求将获得什么的代码:
沃尔格林源代码
如果这两个不一致,有插件可以修改源代码——因此,你应该将它加载到浏览器中后访问页面。请求无法做到这一点,但 Selenium 可以。
Selenium 需要一个 Web 驱动程序来检索内容。事实上,它会打开一个网络浏览器并采集这个页面的内容。Selenium 功能强大——它可以通过多种方式与加载的内容进行交互(请阅读文档)。使用Selenium获取数据后,继续像之前一样使用BeautifulSoup:
url = "https://www.walgreens.com/stor ... river = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')driver.get(url)soup_ID = BeautifulSoup(driver.page_source, 'html.parser')store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
在 Family Dollar 的情况下,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用网站爬行完成有意义的任务时:
如果您对答案感到好奇:
家庭美元位置图
在美国有很多 Family Dollar 商店。
完整的源代码是:
import requestsfrom bs4 import BeautifulSoupimport jsonfrom pandas import DataFrame as df page = requests.get("https://www.familydollar.com/locations/")soup = BeautifulSoup(page.text, 'html.parser') # find all state linksstate_list = soup.find_all(class_ = 'itemlist') state_links = [] for i in state_list: cont = i.contents[0] attr = cont.attrs hrefs = attr['href'] state_links.append(hrefs) # find all city linkscity_links = [] for link in state_links: page = requests.get(link) soup = BeautifulSoup(page.text, 'html.parser') familydollar_list = soup.find_all(class_ = 'itemlist') for store in familydollar_list: cont = store.contents[0] attr = cont.attrs city_hrefs = attr['href'] city_links.append(city_hrefs)# to get inpidual store linksstore_links = [] for link in city_links: locpage = requests.get(link) locsoup = BeautifulSoup(locpage.text, 'html.parser') locinfo = locsoup.find_all(type="application/ld+json") for i in locinfo: loccont = i.contents[0] locjson = json.loads(loccont) try: store_url = locjson['url'] store_links.append(store_url) except: pass # get address and geolocation informationstores = [] for store in store_links: storepage = requests.get(store) storesoup = BeautifulSoup(storepage.text, 'html.parser') storeinfo = storesoup.find_all(type="application/ld+json") for i in storeinfo: storecont = i.contents[0] storejson = json.loads(storecont) try: store_addr = storejson['address'] store_addr.update(storejson['geo']) stores.append(store_addr) except: pass # final data parsingstores_df = df.from_records(stores)stores_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)stores_df['Store'] = "Family Dollar" df.to_csv(stores_df, "family_dollar_locations.csv", sep = ",", index = False) 查看全部
抓取jsp网页源代码(有人将robots.txt文件视为一组建议.py文件
)
关于合法性,获得大量有价值的信息可能令人兴奋,但仅仅因为它是可能的并不意味着应该这样做。
幸运的是,有一些公共信息可以指导我们的道德和网络抓取工具。大多数网站都有一个与网站相关联的robots.txt文件,指明哪些爬行活动是允许的,哪些是不允许的。它主要用于与搜索引擎交互(网页抓取工具的终极形式)。但是,网站 上的大部分信息都被视为公开信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及道德采集和数据使用等主题。
在开始抓取项目之前,先问自己以下问题:
当我抓取 网站 时,请确保您可以对所有这些问题回答“否”。
要详细了解这些法律问题,请参阅 Krotov 和 Silva 于 2018 年撰写的“Legal and Ethical Web Scraping”和 Sellars 的“Web Scraping and Computer Fraud and Abuse Act 20 Years of Web Scraping and Computer Fraud and Abuse Act”。
现在开始爬取网站
经过上面的评估,我想出了一个项目。我的目标是爬取爱达荷州所有 Family Dollar 商店的地址。这些店在农村很大,所以我想知道有多少这样的店。
起点是Family Dollar的位置页面

爱达荷州家庭美元位置页面
首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 的单元格中运行。
import requests # for making standard html requestsfrom bs4 import BeautifulSoup # magical tool for parsing html dataimport json # for parsing datafrom pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get("https://locations.familydollar.com/id/";)soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。这些是我们将使用的几种常见对象类型。
当我们查看 requests.get() 的输出时,还有更多问题需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。requests中的默认编码设置可以很好的解决这个问题。不过,除了纯英文网站,就是更大的互联网世界。为确保请求正确解析内容,您可以设置文本的编码:
page = requests.get(URL)page.encoding = 'ISO-885901'soup = BeautifulSoup(page.text, 'html.parser')
仔细看一下 BeautifulSoup 标签,我们会看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站 爬取过程中的提取可能是一个充满误解的艰巨过程。我认为解决这个问题最好的方法是从一个有代表性的例子开始,然后再扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 查看页面的整个源代码(不推荐)。运行此代码风险自负:
print(soup.prettify())
虽然打印页面的整个源代码可能适合一些教程中展示的玩具示例,但大多数现代 网站 页面都有很多内容。甚至 404 页面也可能充满了页眉、页脚和其他代码。
通常,在您喜欢的浏览器中通过“查看页面源代码”(右键单击并选择“查看页面源代码”)来浏览源代码是最容易的。这是找到目标内容最可靠的方式(我稍后会解释原因)。

家庭美元页面源代码
在这种情况下,我需要在这个巨大的 HTML 海洋中找到我的目标内容地址、城市、州和邮政编码。通常,在页面源上进行简单的搜索(ctrl+F)就会得到目标位置的位置。一旦我真正看到目标内容的一个例子(至少是一个商店的地址),我就会找到一个属性或标签来区分该内容与其他内容。
首先,我需要在爱达荷州的Family Dollar商店采集不同城市的URL,并访问这些网站以获取地址信息。这些 URL 似乎收录在 href 标签中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')dollar_tree_list
搜索 href 不会产生任何结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于下一次尝试,搜索 item_list。由于 class 是 Python 中的保留字,因此使用 class_ 代替。soup.find_all() 竟然是 bs4 函数的瑞士军刀。
dollar_tree_list = soup.find_all(class_ = 'itemlist')for i in dollar_tree_list[:2]: print(i)
有趣的是,我发现搜索特定类的方法通常是一种成功的方法。通过找出对象的类型和长度,我们可以了解更多关于对象的信息。
type(dollar_tree_list)len(dollar_tree_list)
您可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建单个代表性示例的好时机。
example = dollar_tree_list[2] # a representative exampleexample_content = example.contentsprint(example_content)
使用 .attr 查找对象内容中存在的属性。注意: .contents 通常返回一个精确的项目列表,所以第一步是使用方括号表示法来索引项目。
example_content = example.contents[0]example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取它:
example_href = example_content['href']print(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,以澄清上述逻辑。
city_hrefs = [] # initialise empty list for i in dollar_tree_list: cont = i.contents[0] href = cont['href'] city_hrefs.append(href) # check to be sure all went wellfor i in city_hrefs[:2]: print(i)
输出是用于抓取爱达荷州 Family Dollar 商店的 URL 列表。
也就是说,我还没有得到地址信息!现在,您需要抓取每个城市的 URL 以获取此信息。因此,我们使用一个具有代表性的示例来重新启动该过程。
page2 = requests.get(city_hrefs[2]) # again establish a representative examplesoup2 = BeautifulSoup(page2.text, 'html.parser')

家庭美元地图和代码
地址信息嵌套在 type="application/ld+json" 中。经过大量的地理位置爬取,我开始意识到这是一个存储地址信息的通用结构。幸运的是,soup.find_all() 支持类型搜索。
arco = soup2.find_all(type="application/ld+json")print(arco[1])
地址信息在第二个列表成员中!我明白!
使用 .contents 提取内容(从第二个列表项中)(这是过滤后合适的默认操作)。同样,由于输出是一个列表,我为列表项建立了索引:
arco_contents = arco[1].contents[0]arco_contents
哦,看起来不错。这里提供的格式与JSON格式一致(而且类型名称确实收录“json”)。JSON 对象的行为类似于带有嵌套字典的字典。一旦你熟悉了它,它实际上是一种很好的格式(当然,它比一长串正则表达式命令更容易编程)。虽然在结构上看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要通过编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
type(arco_json)print(arco_json)
在内容中,有一个被调用的地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']arco_address
嗯,请注意。现在我可以遍历存储的爱达荷州 URL 列表:
locs_dict = [] # initialise empty list for link in city_hrefs: locpage = requests.get(link) # request page info locsoup = BeautifulSoup(locpage.text, 'html.parser') # parse the page's content locinfo = locsoup.find_all(type="application/ld+json") # extract specific element loccont = locinfo[1].contents[0] # get contents from the bs4 element set locjson = json.loads(loccont) # convert to json locaddr = locjson['address'] # get address locs_dict.append(locaddr) # add address to list
使用 Pandas 来组织我们的 网站 爬取结果
我们在字典中加载了大量数据,但是还有一些额外的无用项使得重用数据变得比必要的复杂。为了进行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不需要的@type 和 country 列,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)locs_df.head(n = 5)
一定要保存结果!!
df.to_csv(locs_df, "family_dollar_ID_locations.csv", sep = ",", index = False)
我们做到了!爱达荷州的所有 Family Dollar 商店都有一个以逗号分隔的列表。多么激动人心。
Selenium 和数据抓取的一点解释
Selenium 是一种常用的工具,用于自动与网页交互。为了解释为什么有时需要使用它,让我们看一个使用 Walgreens 网站 的例子。“检查元素”提供浏览器显示内容的代码:

沃尔格林位置页面和代码
尽管“查看页面源代码”提供了有关请求将获得什么的代码:

沃尔格林源代码
如果这两个不一致,有插件可以修改源代码——因此,你应该将它加载到浏览器中后访问页面。请求无法做到这一点,但 Selenium 可以。
Selenium 需要一个 Web 驱动程序来检索内容。事实上,它会打开一个网络浏览器并采集这个页面的内容。Selenium 功能强大——它可以通过多种方式与加载的内容进行交互(请阅读文档)。使用Selenium获取数据后,继续像之前一样使用BeautifulSoup:
url = "https://www.walgreens.com/stor ... river = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')driver.get(url)soup_ID = BeautifulSoup(driver.page_source, 'html.parser')store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
在 Family Dollar 的情况下,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用网站爬行完成有意义的任务时:
如果您对答案感到好奇:

家庭美元位置图
在美国有很多 Family Dollar 商店。
完整的源代码是:
import requestsfrom bs4 import BeautifulSoupimport jsonfrom pandas import DataFrame as df page = requests.get("https://www.familydollar.com/locations/";)soup = BeautifulSoup(page.text, 'html.parser') # find all state linksstate_list = soup.find_all(class_ = 'itemlist') state_links = [] for i in state_list: cont = i.contents[0] attr = cont.attrs hrefs = attr['href'] state_links.append(hrefs) # find all city linkscity_links = [] for link in state_links: page = requests.get(link) soup = BeautifulSoup(page.text, 'html.parser') familydollar_list = soup.find_all(class_ = 'itemlist') for store in familydollar_list: cont = store.contents[0] attr = cont.attrs city_hrefs = attr['href'] city_links.append(city_hrefs)# to get inpidual store linksstore_links = [] for link in city_links: locpage = requests.get(link) locsoup = BeautifulSoup(locpage.text, 'html.parser') locinfo = locsoup.find_all(type="application/ld+json") for i in locinfo: loccont = i.contents[0] locjson = json.loads(loccont) try: store_url = locjson['url'] store_links.append(store_url) except: pass # get address and geolocation informationstores = [] for store in store_links: storepage = requests.get(store) storesoup = BeautifulSoup(storepage.text, 'html.parser') storeinfo = storesoup.find_all(type="application/ld+json") for i in storeinfo: storecont = i.contents[0] storejson = json.loads(storecont) try: store_addr = storejson['address'] store_addr.update(storejson['geo']) stores.append(store_addr) except: pass # final data parsingstores_df = df.from_records(stores)stores_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)stores_df['Store'] = "Family Dollar" df.to_csv(stores_df, "family_dollar_locations.csv", sep = ",", index = False)
抓取jsp网页源代码(静态网页的工作原理(一)_光明网(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-12-31 07:10
)
静态网页的工作原理
静态网页也称为普通网页,是相对于网页而言的。静态网页并不是指网页中的元素是静态的,而是网页文件中没有程序代码,只有HTML(超文本标记语言)标记,一般后缀是.htm、.html、.shtml或 .xml 等。在静态网页中,可以收录GIF动画,鼠标经过Flash按钮时,按钮可能会发生变化。
静态网页一旦创建,内容将不再变化,无论谁访问,何时访问,显示的内容都是一样的。
如果要修改网页的内容,则必须修改其源代码,然后重新上传到服务器。
对于静态网页,用户可以直接双击打开,看到的效果和访问服务器是一样的,即服务器是否参与对页面内容没有影响。这是因为网页的内容是在用户访问网页之前确定的。无论用户何时以何种方式访问该网页,该网页的内容都不会发生变化。
静态网页的工作流程可以分为以下4个步骤。
写一个静态文件并发布到Web服务器上;用户在浏览器地址栏中输入静态网页的URL(统一资源定位符)并按回车键,浏览器向Web服务器发送请求;Web服务器找到这个静态文件的位置,并转换成HTML流发送给用户的浏览器;浏览器接收 HTML 流并显示该网页的内容;
在步骤2-4中,静态网页的内容不会改变。其工作原理图如下所示。
动态网页的工作原理
动态网页是指网页文件中除了收录 HTML 标签之外,还收录一些实现特定功能的程序代码。这些程序代码使浏览器和服务器进行交互,即服务器可以根据客户端的不同请求动态生成网页内容。. 动态网页的后缀通常根据使用的编程语言而不同,一般有.asp、.aspx、cgi、.php、.perl、.jsp等。动态网页可以根据不同的时间和不同的浏览者显示不同的信息. 常见的留言板、论坛和聊天室都是通过动态网页实现的。
动态网页比较复杂,不能直接双击打开。动态网页的工作流程分为以下4个步骤。
编写动态网页文件,包括程序代码,并发布到网页服务器上;
用户在浏览器地址栏中输入动态网页的URL并按回车键(Enter),浏览器向Web服务器发送访问请求;
web服务器找到这个动态网页的位置,并根据其中的程序代码动态构建一个HTML流传输到用户浏览器;
浏览器接收HTML流并显示该网页的内容;
从整个工作流程可以看出,当用户浏览动态网页时,需要在服务器上动态执行网页文件,将收录程序代码的动态网页转换为标准的静态网页,最终静态网页发送给用户。其工作原理图如下所示。
查看全部
抓取jsp网页源代码(静态网页的工作原理(一)_光明网(图)
)
静态网页的工作原理
静态网页也称为普通网页,是相对于网页而言的。静态网页并不是指网页中的元素是静态的,而是网页文件中没有程序代码,只有HTML(超文本标记语言)标记,一般后缀是.htm、.html、.shtml或 .xml 等。在静态网页中,可以收录GIF动画,鼠标经过Flash按钮时,按钮可能会发生变化。
静态网页一旦创建,内容将不再变化,无论谁访问,何时访问,显示的内容都是一样的。
如果要修改网页的内容,则必须修改其源代码,然后重新上传到服务器。
对于静态网页,用户可以直接双击打开,看到的效果和访问服务器是一样的,即服务器是否参与对页面内容没有影响。这是因为网页的内容是在用户访问网页之前确定的。无论用户何时以何种方式访问该网页,该网页的内容都不会发生变化。
静态网页的工作流程可以分为以下4个步骤。
写一个静态文件并发布到Web服务器上;用户在浏览器地址栏中输入静态网页的URL(统一资源定位符)并按回车键,浏览器向Web服务器发送请求;Web服务器找到这个静态文件的位置,并转换成HTML流发送给用户的浏览器;浏览器接收 HTML 流并显示该网页的内容;
在步骤2-4中,静态网页的内容不会改变。其工作原理图如下所示。
动态网页的工作原理
动态网页是指网页文件中除了收录 HTML 标签之外,还收录一些实现特定功能的程序代码。这些程序代码使浏览器和服务器进行交互,即服务器可以根据客户端的不同请求动态生成网页内容。. 动态网页的后缀通常根据使用的编程语言而不同,一般有.asp、.aspx、cgi、.php、.perl、.jsp等。动态网页可以根据不同的时间和不同的浏览者显示不同的信息. 常见的留言板、论坛和聊天室都是通过动态网页实现的。
动态网页比较复杂,不能直接双击打开。动态网页的工作流程分为以下4个步骤。
编写动态网页文件,包括程序代码,并发布到网页服务器上;
用户在浏览器地址栏中输入动态网页的URL并按回车键(Enter),浏览器向Web服务器发送访问请求;
web服务器找到这个动态网页的位置,并根据其中的程序代码动态构建一个HTML流传输到用户浏览器;
浏览器接收HTML流并显示该网页的内容;
从整个工作流程可以看出,当用户浏览动态网页时,需要在服务器上动态执行网页文件,将收录程序代码的动态网页转换为标准的静态网页,最终静态网页发送给用户。其工作原理图如下所示。
抓取jsp网页源代码(动态页面技术(JSP/EL)(/JSTL))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-28 22:16
动态页面技术(JSP/EL/JSTL)JSP技术jsp脚本和注释
jsp 脚本:
1) ----- 内部java代码翻译成service方法。
2) ----- 会被翻译成服务方法内部的out.print()局部变量
3) ---- 将翻译成servlet成员变量的内容
jsp 注释:不同注释的可见范围不同
1)Html 注释:---可见范围jsp源代码,翻译后的servlet,页面显示html源代码
2)java comment://single-line comment /*multi-line comment*/ --可见范围jsp源码翻译servlet
3)jsp 注释:----- 可见范围 jsp 源码可见
jsp运行原理----jsp本质就是servlet(面试)
jsp在第一次被访问时会被web容器翻译成servlet,并被执行
过程:
第一次访问---->helloServlet.jsp---->helloServlet_jsp.java---->编译运行
PS:翻译后的servlet可以在Tomcat的工作目录中找到
jsp使用说明(三)
JSP 的指令是指导 JSP 翻译和运行的命令。 JSP包括三大指令:
1)page指令---属性最多的指令(实际开发中默认page指令)
属性最多的命令根据不同的属性引导整个页面的特征
格式:
常用属性如下:
language:可以嵌入jsp脚本的语言类型
pageEncoding:里面可以收录
当前jsp文件的编码-contentType
contentType: response.setContentType(text/html;charset=UTF-8)
session:翻译时jsp是否自动创建session,默认为true
import:导入java包
errorPage:当前页面有错误时,错误500错误后跳转到哪个页面
↓
isErrorPage:当前页面为错误处理页面500错误
404 错误:更改 WEB.xml 中的设置
404
/error.jsp
2)include 指令
页面收录
(静态收录
)指令,可以将一个jsp页面收录
到另一个jsp页面中
格式:
3)taglib 指令
在jsp页面中引入标签库(jstl标签库、struts2标签库)
格式:
jsp内置/隐式对象(9)-----笔试
jsp翻译成servlet后,service方法中定义并初始化了9个对象。我们可以在jsp脚本中直接使用这9个对象。
输出对象
输出类型:JspWriter
out的作用是想让客户端输出内容----out.write()
out buffer的默认8kb可以设置为0(buffer="0kb"),即out buffer关闭,内容直接写入响应buffer
pageContext 对象
有四个jsp域对象
jsp页面的上下文对象有如下功能:
page 对象和 pageContext 对象不是一回事
1)pageContext 是一个域对象
setAttribute(String name,Object obj)
getAttribute(String name)
removeAttrbute(字符串名称)
pageContext 可以访问其他指定域的数据
setAttribute(String name,Object obj,int scope)
getAttribute(String name,int scope)
removeAttrbute(String name,int scope)
例如:
pageContext.setAttribute("name", "文昭",PageContext.REQUEST_SCOPE);
findAttribute(String name)
---依次从pageContext域、请求域、会话域、应用域中获取属性。拿到某个域后,就不会往后看了。
四个范围的总结:
pageContext domain:当前jsp页面范围
请求域:一个请求
会话域:一个会话
应用域:整个网络应用
2)你可以得到另外8个隐式对象
例如:pageContext.getRequest()
pageContext.getSession()
jsp 标签(动作)
1)页面收录
(动态收录
):
2)请求转发:
静态收录
和动态收录
的区别?
静态收录
:一个Servlet(结合成一)静态页面的引入(代码)
动态收录
:两个Servlet(导入地址) 查看全部
抓取jsp网页源代码(动态页面技术(JSP/EL)(/JSTL))
动态页面技术(JSP/EL/JSTL)JSP技术jsp脚本和注释
jsp 脚本:
1) ----- 内部java代码翻译成service方法。
2) ----- 会被翻译成服务方法内部的out.print()局部变量
3) ---- 将翻译成servlet成员变量的内容
jsp 注释:不同注释的可见范围不同
1)Html 注释:---可见范围jsp源代码,翻译后的servlet,页面显示html源代码
2)java comment://single-line comment /*multi-line comment*/ --可见范围jsp源码翻译servlet
3)jsp 注释:----- 可见范围 jsp 源码可见
jsp运行原理----jsp本质就是servlet(面试)
jsp在第一次被访问时会被web容器翻译成servlet,并被执行
过程:
第一次访问---->helloServlet.jsp---->helloServlet_jsp.java---->编译运行
PS:翻译后的servlet可以在Tomcat的工作目录中找到
jsp使用说明(三)
JSP 的指令是指导 JSP 翻译和运行的命令。 JSP包括三大指令:
1)page指令---属性最多的指令(实际开发中默认page指令)
属性最多的命令根据不同的属性引导整个页面的特征
格式:
常用属性如下:
language:可以嵌入jsp脚本的语言类型
pageEncoding:里面可以收录
当前jsp文件的编码-contentType
contentType: response.setContentType(text/html;charset=UTF-8)
session:翻译时jsp是否自动创建session,默认为true
import:导入java包
errorPage:当前页面有错误时,错误500错误后跳转到哪个页面
↓
isErrorPage:当前页面为错误处理页面500错误
404 错误:更改 WEB.xml 中的设置
404
/error.jsp
2)include 指令
页面收录
(静态收录
)指令,可以将一个jsp页面收录
到另一个jsp页面中
格式:
3)taglib 指令
在jsp页面中引入标签库(jstl标签库、struts2标签库)
格式:
jsp内置/隐式对象(9)-----笔试
jsp翻译成servlet后,service方法中定义并初始化了9个对象。我们可以在jsp脚本中直接使用这9个对象。
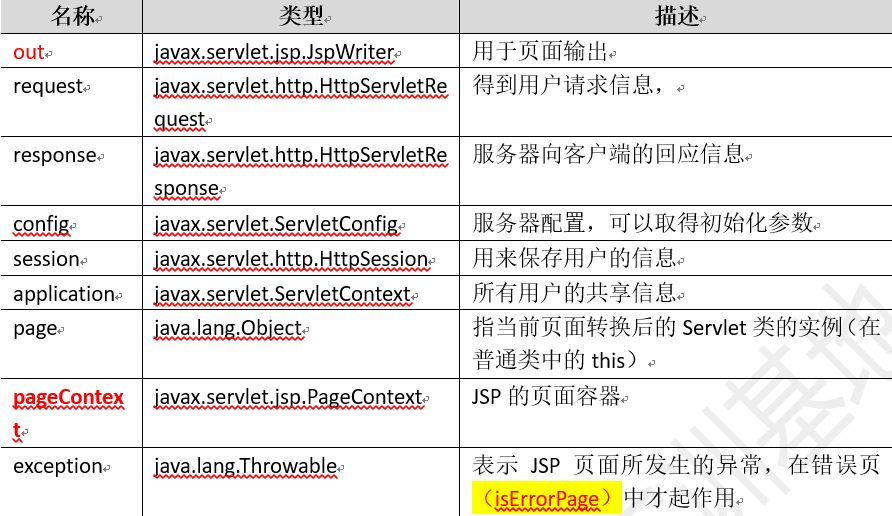
输出对象
输出类型:JspWriter
out的作用是想让客户端输出内容----out.write()
out buffer的默认8kb可以设置为0(buffer="0kb"),即out buffer关闭,内容直接写入响应buffer
pageContext 对象
有四个jsp域对象
jsp页面的上下文对象有如下功能:
page 对象和 pageContext 对象不是一回事
1)pageContext 是一个域对象
setAttribute(String name,Object obj)
getAttribute(String name)
removeAttrbute(字符串名称)
pageContext 可以访问其他指定域的数据
setAttribute(String name,Object obj,int scope)
getAttribute(String name,int scope)
removeAttrbute(String name,int scope)
例如:
pageContext.setAttribute("name", "文昭",PageContext.REQUEST_SCOPE);
findAttribute(String name)
---依次从pageContext域、请求域、会话域、应用域中获取属性。拿到某个域后,就不会往后看了。
四个范围的总结:
pageContext domain:当前jsp页面范围
请求域:一个请求
会话域:一个会话
应用域:整个网络应用
2)你可以得到另外8个隐式对象
例如:pageContext.getRequest()
pageContext.getSession()
jsp 标签(动作)
1)页面收录
(动态收录
):
2)请求转发:
静态收录
和动态收录
的区别?
静态收录
:一个Servlet(结合成一)静态页面的引入(代码)
动态收录
:两个Servlet(导入地址)
抓取jsp网页源代码(读取表单数据使用的POST方法(组图)()
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-28 20:16
我们在浏览网页时,经常需要向服务器提交信息,让后台程序处理。浏览器使用 GET 和 POST 方法向服务器提交数据。
GET 方法
GET 方法将请求的编码信息添加到 URL 中,URL 和编码信息之间用“?”分隔。符号。如下图:
http://www.runoob.com/hello%3F ... alue2
GET 方法是浏览器传递参数的默认方法。一些敏感信息,比如密码,不建议使用GET方式。
使用get时,传输数据大小有限制(注意参数个数不限制),最大为1024字节。
POST 方法
一些敏感信息,如密码等,可以通过POST方式传递,POST提交的数据是隐式的。
POST提交数据不可见,在url中传入GET(可以查看浏览器地址栏)。
JSP 使用 getParameter() 获取传入的参数,使用 getInputStream() 方法处理客户端的二进制数据流请求。
JSP 使用 URL GET 方法读取表单数据示例
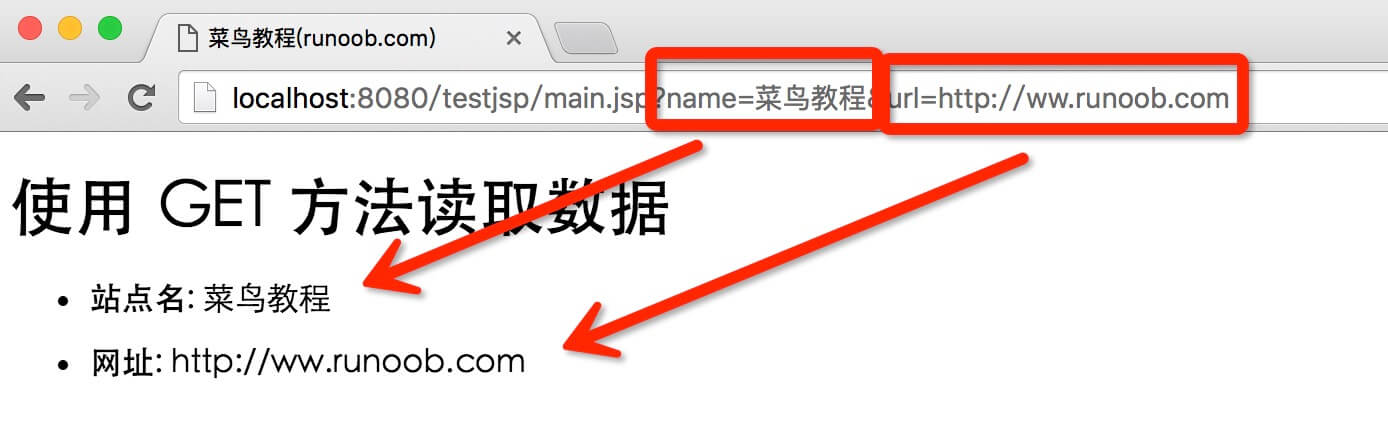
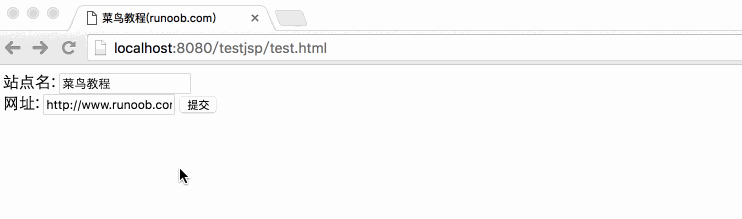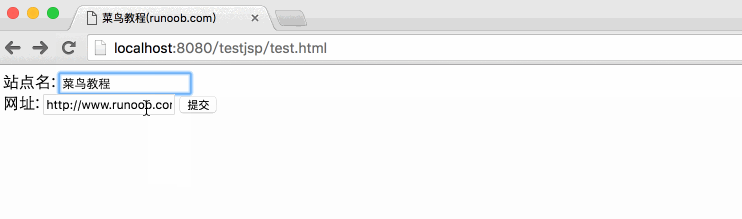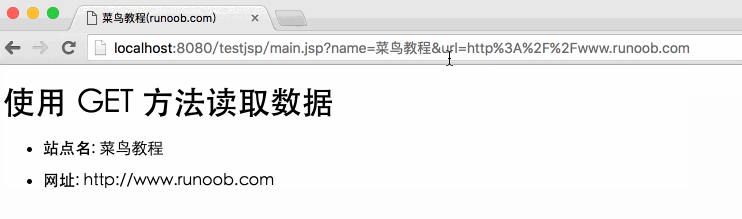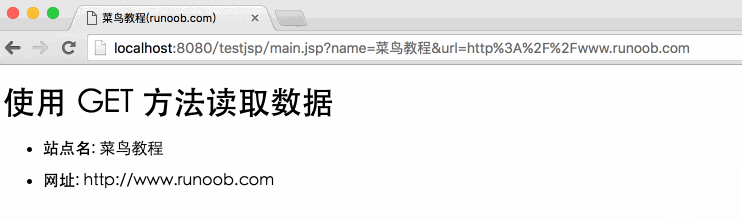
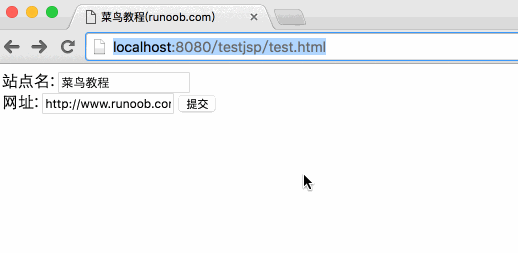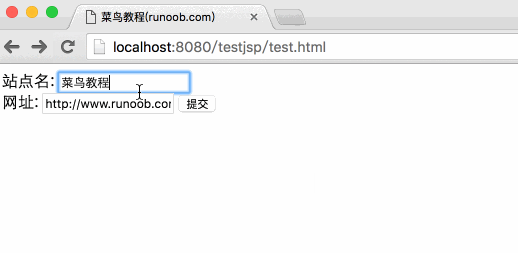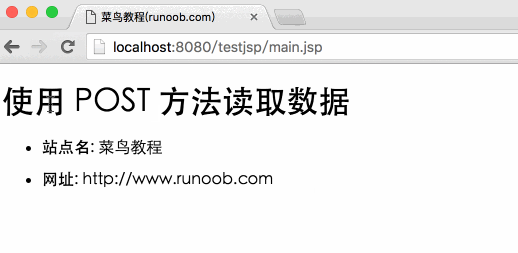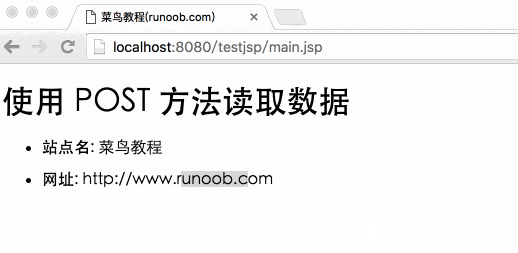
下面是一个简单的网址,在网址中使用GET方法传递参数:
http://localhost:8080/testjsp/main.jsp?name=菜鸟教程&url=http://ww.runoob.com
testjsp 是项目地址。
以下是用于处理客户端提交的表单数据的main.jsp文件的JSP程序。我们使用getParameter()方法获取提交的数据:
菜鸟教程(runoob.com)
使用 GET 方法读取数据
<p>站点名:
网址:
</p>
接下来我们通过浏览器访问:8080/testjsp/main.jsp?name=Novice Tutorial&url=输出结果如下:
使用表单GET方法的例子
下面是一个简单的 HTML 表单,它通过 GET 方法将客户端数据提交到 main.jsp 文件中:
菜鸟教程(runoob.com)
站点名:
网址:
将上述 HTML 代码保存到 test.htm 文件中。将该文件放在当前jsp项目的WebContent目录下(与main.jsp相同的目录)。
通过访问:8080/testjsp/test.html将表单数据提交到main.jsp文件中,演示Gif图片如下:
在“站点名称”和“URL”表单中填写信息,点击“提交”按钮,输出结果。
使用表单POST方法的例子
接下来,让我们使用POST方法传递表单数据,修改main.jsp和Hello.htm文件代码,如下图:
Main.jsp 文件代码:
菜鸟教程(runoob.com)
使用 POST 方法读取数据
<p><b>站点名:
网址:
</p>
在代码中,我们使用new String((request.getParameter("name")).getBytes("ISO-8859-1"),"UTF-8")进行编码转换,防止出现中文乱码。
以下是修改后的test.htm代码:
通过访问:8080/testjsp/test.html将表单数据提交到main.jsp文件中,演示Gif图片如下:
将复选框数据传递给 JSP 程序
复选框复选框可以传递一个或多个数据。
下面是一段简单的HTML代码,并将代码保存在test.htm文件中:
菜鸟教程(runoob.com)
菜鸟教程
淘宝
以上代码在浏览器中访问时如下:
以下是main.jsp文件代码,用于处理复选框数据:
菜鸟教程(runoob.com)
从复选框中读取数据
<p>Google 是否选中:
菜鸟教程是否选中:
淘宝是否选中:
</p>
通过访问:8080/testjsp/test.html将表单数据提交到main.jsp文件中,演示Gif图片如下:
读取所有表单参数 查看全部
抓取jsp网页源代码(读取表单数据使用的POST方法(组图)()
我们在浏览网页时,经常需要向服务器提交信息,让后台程序处理。浏览器使用 GET 和 POST 方法向服务器提交数据。
GET 方法
GET 方法将请求的编码信息添加到 URL 中,URL 和编码信息之间用“?”分隔。符号。如下图:
http://www.runoob.com/hello%3F ... alue2
GET 方法是浏览器传递参数的默认方法。一些敏感信息,比如密码,不建议使用GET方式。
使用get时,传输数据大小有限制(注意参数个数不限制),最大为1024字节。
POST 方法
一些敏感信息,如密码等,可以通过POST方式传递,POST提交的数据是隐式的。
POST提交数据不可见,在url中传入GET(可以查看浏览器地址栏)。
JSP 使用 getParameter() 获取传入的参数,使用 getInputStream() 方法处理客户端的二进制数据流请求。
JSP 使用 URL GET 方法读取表单数据示例
下面是一个简单的网址,在网址中使用GET方法传递参数:
http://localhost:8080/testjsp/main.jsp?name=菜鸟教程&url=http://ww.runoob.com
testjsp 是项目地址。
以下是用于处理客户端提交的表单数据的main.jsp文件的JSP程序。我们使用getParameter()方法获取提交的数据:
菜鸟教程(runoob.com)
使用 GET 方法读取数据
<p>站点名:
网址:
</p>
接下来我们通过浏览器访问:8080/testjsp/main.jsp?name=Novice Tutorial&url=输出结果如下:
使用表单GET方法的例子
下面是一个简单的 HTML 表单,它通过 GET 方法将客户端数据提交到 main.jsp 文件中:
菜鸟教程(runoob.com)
站点名:
网址:
将上述 HTML 代码保存到 test.htm 文件中。将该文件放在当前jsp项目的WebContent目录下(与main.jsp相同的目录)。
通过访问:8080/testjsp/test.html将表单数据提交到main.jsp文件中,演示Gif图片如下:
在“站点名称”和“URL”表单中填写信息,点击“提交”按钮,输出结果。
使用表单POST方法的例子
接下来,让我们使用POST方法传递表单数据,修改main.jsp和Hello.htm文件代码,如下图:
Main.jsp 文件代码:
菜鸟教程(runoob.com)
使用 POST 方法读取数据
<p><b>站点名:
网址:
</p>
在代码中,我们使用new String((request.getParameter("name")).getBytes("ISO-8859-1"),"UTF-8")进行编码转换,防止出现中文乱码。
以下是修改后的test.htm代码:
通过访问:8080/testjsp/test.html将表单数据提交到main.jsp文件中,演示Gif图片如下:
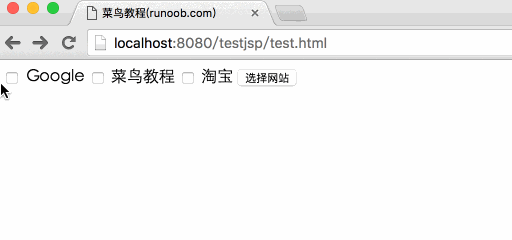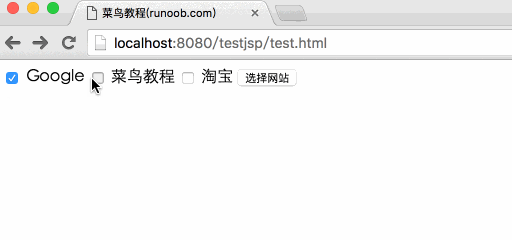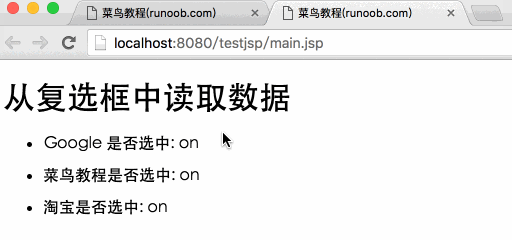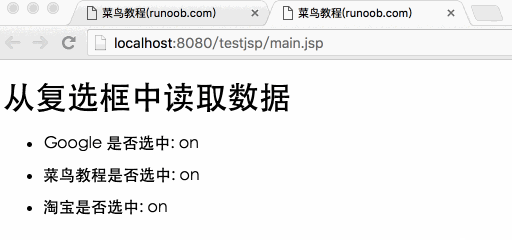
将复选框数据传递给 JSP 程序
复选框复选框可以传递一个或多个数据。
下面是一段简单的HTML代码,并将代码保存在test.htm文件中:
菜鸟教程(runoob.com)
菜鸟教程
淘宝
以上代码在浏览器中访问时如下:
以下是main.jsp文件代码,用于处理复选框数据:
菜鸟教程(runoob.com)
从复选框中读取数据
<p>Google 是否选中:
菜鸟教程是否选中:
淘宝是否选中:
</p>
通过访问:8080/testjsp/test.html将表单数据提交到main.jsp文件中,演示Gif图片如下:
读取所有表单参数
抓取jsp网页源代码(脚本表达式脚本的作用及方法脚本格式介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-12-26 08:06
)
功能:可以为jsp翻译的java类,甚至静态代码块,内部类等定义属性和方法。
Insert title here
3.2 表达式脚本
表达式脚本的格式为:
表达式脚本的作用是:表达式可以在jsp页面上输出数据。
Insert title here
需要注意的是,表达式脚本中的表达式不能以分号结尾。
3.3 代码脚本
代码脚本格式:
代码脚本函数:可以在jsp页面中编写我们需要的函数(编写java语句)
需要写什么声明?那么就需要配合要转换成servlet的源代码的jsp文件进行操作。
4. html、java、jsp三种注释
5. jsp 的九个内置对象
jsp中的内建对象是指Tomcat将jsp页面翻译成Servlet源码后内部提供的九个对象,称为内建对象。
6. jsp 四大领域对象
域对象是可以访问数据的对象,如地图。
这些领域对象的功能相似,但作用域不同!!!
(请求域对象的范围是请求及其捕获。)
scope.jsp 页面:
Insert title here
scope.jsp页面
pageContext域值是否有值:
request域值是否有值:
session域值是否有值:
application域值是否有值:
scope2.jsp 页面:
Insert title here
scope2.jsp页面
pageContext域值是否有值:
request域值是否有值:
session域值是否有值:
application域值是否有值:
7. jsp的out和response输出的区别
当out和response输出时,没有区别,但是有一定的顺序!!
如上图,在定义out.write("xxx")的输出数据时,会先进入out buffer。同样,当 response.getWriter().write() 写入数据时,也会进入响应缓冲区。之后,输出缓冲区的内容将附加到响应缓冲区以具有此顺序。
当 out.flush() 方法被执行时,当前缓冲区将被清空。如果缓冲区中有数据,则输出缓冲区中的数据,将当前输出缓冲区的内容直接添加到响应缓冲区中。所以,调用这个方法的时候,会注意out输出和响应的顺序!!
Insert title here
测试
因为我们使用out.write()方法来运行底层信息,所以我们在jsp页面中定义java代码并使用out进行输出,否则会遇到乱码的问题。
jsp中out变量有两种输出方式:
在out.print()方法中,不管它接受的参数类型是什么,都将其底层转换为字符串类型,然后调用write()方法。
Insert title here
因为可能会出现和上面类似的情况,我们在jsp页面中使用out.print()方法进行输出。
8. 收录
的jsp函数
收录
的功能如下:
8.1 个 jsp 静态收录
静态收录
的格式:
请注意,此处的“/”斜线还表示: :port/project 路径映射到代码的 web 目录。
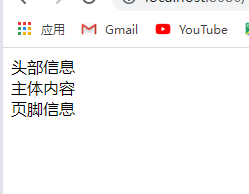
main.jsp 收录
了footer.jsp 的介绍:
Insert title here
头部信息
主体内容
页脚.jsp:
Insert title here
页脚信息
静态收录
的特点:
8.2 jsp动态收录
动态收录
的特点:
main.jsp 代码如下:
Insert title here
头部信息
主体内容
footer.jsp 代码如下:
Insert title here
页脚信息,动态包含
8.3 jsp请求转发
请求转发有两种方式:
a.jsp代码如下:
Insert title here
b.jsp 代码如下:
Insert title here
我是页面b,请求转发过来的,第二种方式。
9. jsp页面代码和html页面混合使用案例
九九乘法表的情况:
<p>
Insert title here
table{
width: 600px
}
九九乘法表居中 查看全部
抓取jsp网页源代码(脚本表达式脚本的作用及方法脚本格式介绍
)
功能:可以为jsp翻译的java类,甚至静态代码块,内部类等定义属性和方法。
Insert title here
3.2 表达式脚本
表达式脚本的格式为:
表达式脚本的作用是:表达式可以在jsp页面上输出数据。
Insert title here
需要注意的是,表达式脚本中的表达式不能以分号结尾。

3.3 代码脚本
代码脚本格式:
代码脚本函数:可以在jsp页面中编写我们需要的函数(编写java语句)
需要写什么声明?那么就需要配合要转换成servlet的源代码的jsp文件进行操作。
4. html、java、jsp三种注释



5. jsp 的九个内置对象
jsp中的内建对象是指Tomcat将jsp页面翻译成Servlet源码后内部提供的九个对象,称为内建对象。

6. jsp 四大领域对象
域对象是可以访问数据的对象,如地图。
这些领域对象的功能相似,但作用域不同!!!

(请求域对象的范围是请求及其捕获。)

scope.jsp 页面:
Insert title here
scope.jsp页面
pageContext域值是否有值:
request域值是否有值:
session域值是否有值:
application域值是否有值:
scope2.jsp 页面:
Insert title here
scope2.jsp页面
pageContext域值是否有值:
request域值是否有值:
session域值是否有值:
application域值是否有值:
7. jsp的out和response输出的区别
当out和response输出时,没有区别,但是有一定的顺序!!

如上图,在定义out.write("xxx")的输出数据时,会先进入out buffer。同样,当 response.getWriter().write() 写入数据时,也会进入响应缓冲区。之后,输出缓冲区的内容将附加到响应缓冲区以具有此顺序。
当 out.flush() 方法被执行时,当前缓冲区将被清空。如果缓冲区中有数据,则输出缓冲区中的数据,将当前输出缓冲区的内容直接添加到响应缓冲区中。所以,调用这个方法的时候,会注意out输出和响应的顺序!!
Insert title here
测试
因为我们使用out.write()方法来运行底层信息,所以我们在jsp页面中定义java代码并使用out进行输出,否则会遇到乱码的问题。
jsp中out变量有两种输出方式:
在out.print()方法中,不管它接受的参数类型是什么,都将其底层转换为字符串类型,然后调用write()方法。
Insert title here
因为可能会出现和上面类似的情况,我们在jsp页面中使用out.print()方法进行输出。
8. 收录
的jsp函数
收录
的功能如下:

8.1 个 jsp 静态收录
静态收录
的格式:
请注意,此处的“/”斜线还表示: :port/project 路径映射到代码的 web 目录。
main.jsp 收录
了footer.jsp 的介绍:
Insert title here
头部信息
主体内容
页脚.jsp:
Insert title here
页脚信息
静态收录
的特点:
8.2 jsp动态收录
动态收录
的特点:
main.jsp 代码如下:
Insert title here
头部信息
主体内容
footer.jsp 代码如下:
Insert title here
页脚信息,动态包含
8.3 jsp请求转发
请求转发有两种方式:
a.jsp代码如下:
Insert title here
b.jsp 代码如下:
Insert title here
我是页面b,请求转发过来的,第二种方式。
9. jsp页面代码和html页面混合使用案例
九九乘法表的情况:
<p>
Insert title here
table{
width: 600px
}
九九乘法表居中
抓取jsp网页源代码( 斯巴达,常用爬虫制作模块的基本用法极度推荐!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-12-26 08:05
斯巴达,常用爬虫制作模块的基本用法极度推荐!)
使用Python的urllib和urllib2模块制作爬虫示例教程
更新时间:2016-01-20 10:25:51 作者:小璐D
本文主要介绍了使用Python的urllib和urllib2模块制作爬虫的示例教程,并展示了这两个常用的爬虫制作模块的基本用法。强烈推荐!有需要的朋友可以参考
网址库
在学习了python的基础知识后,我有点困惑。当我闭上眼睛时,一种空白的窒息感不断袭来。我还缺乏练习,所以我拿着履带练习我的手。学习了Spartan python爬虫课程后,我将自己的经验整理如下,供后续的翻阅。整个笔记主要分为以下几个部分:
1.做一个简单的爬虫
第一个环境描述
这个没什么好说的,直接上代码吧!
'''
@ urllib为python自带的一个网络库
@ urlopen为urllib的一个方法,用于打开一个连接并抓取网页,
然后通过read()方法把值赋给read()
'''
import urllib
url = "http://www.lifevc.com"#多嘴两句,为什么要选lifevc呢,主要是最近它很惹我.
html = urllib.urlopen(url)
content = html.read()
html.close()
#可以通过print打印出网页内容
print content
很简单,基本没什么好说的,这就是python的魅力,几行代码就可以完成。
当然,我们只是爬网,并没有真正的价值。然后我们将开始做一些有意义的事情。
2.一个小测试
抢百度贴吧图片
其实很简单,因为要抓取图片,首先要分析网页的源代码。
(这里是了解基本的html知识,浏览器以chrome为例)
如图,这里是对后续步骤的简要说明,请参考。
打开网页,右键单击并选择“检查元素”(底部项目)
点击下方弹出框最左边的问号,问号会变成蓝色
移动鼠标点击我们要捕捉的图片(一个可爱的女孩)
如图,我们可以在源码中获取图片的位置
复制下面的源代码
经过分析对比(这里略略),基本上可以看到要抓拍的图像的特征:
以后我会更新正则表达式,请大家注意
根据上面的判断,直接上传代码
'''
@本程序用来下载百度贴吧图片
@re 为正则说明库
'''
import urllib
import re
# 获取网页html信息
url = "http://tieba.baidu.com/p/2336739808"
html = urllib.urlopen(url)
content = html.read()
html.close()
# 通过正则匹配图片特征,并获取图片链接
img_tag = re.compile(r'class="BDE_Image" src="(.+?\.jpg)"')
img_links = re.findall(img_tag, content)
# 下载图片 img_counter为图片计数器(文件名)
img_counter = 0
for img_link in img_links:
img_name = '%s.jpg' % img_counter
urllib.urlretrieve(img_link, "//Users//Sean//Downloads//tieba//%s" %img_name)
img_counter += 1
如图所示,我们将抓取您理解的图片
3.总结
与前两节一样,我们可以轻松访问网页或图片。
补充一点小技巧,如果遇到不是很了解的库或者方法,可以使用下面的方法来初步了解一下。
或输入相关搜索。
当然,百度也可以,只是效率太低。建议使用相关搜索(你懂的,绝对满意)。
这里我们讲解如何抓取网页和下载图片,下面我们将讲解如何抓取限制抓取的网站。
urllib2
上面我们解释了如何抓取网页和下载图片,下一节我们将解释如何抓取限制抓取的网站
首先我们还是用上节课的方法爬取一个大家都用的网站作为例子。本文主要分为以下几个部分:
1. 抓取受限网页
首先使用我们在上一节中学到的知识进行测试:
'''
@本程序用来抓取blog.csdn.net网页
'''
import urllib
url = "http://blog.csdn.net/FansUnion"
html = urllib.urlopen(url)
#getcode()方法为返回Http状态码
print html.getcode()
html.close()
#输出
403
这里我们的输出是 403,这意味着访问被拒绝;同样,200 表示请求成功完成;404 表示未找到该 URL。
可以看到csdn被屏蔽了,无法通过第一节的方法获取到网页。这里我们需要启动一个新的库:urllib2
但我们也看到浏览器可以发布该文本。我们可以模拟浏览器操作来获取网页信息吗?
老办法,我们来看看浏览器是如何向csdn服务器提交请求的。首先简单介绍一下方法:
以下是整理后的头部信息
Request Method:GET
Host:blog.csdn.net
Referer:http://blog.csdn.net/?ref=toolbar_logo
User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.104 Safari/537.36
然后根据提取的Header信息,使用urllib2的Request方法模拟浏览器向服务器提交请求。代码如下:
# coding=utf-8
'''
@本程序用来抓取受限网页(blog.csdn.net)
@User-Agent:客户端浏览器版本
@Host:服务器地址
@Referer:跳转地址
@GET:请求方法为GET
'''
import urllib2
url = "http://blog.csdn.net/FansUnion"
#定制自定义Header,模拟浏览器向服务器提交请求
req = urllib2.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36')
req.add_header('Host', 'blog.csdn.net')
req.add_header('Referer', 'http://blog.csdn.net')
req.add_header('GET', url)
#下载网页html并打印
html = urllib2.urlopen(req)
content = html.read()
print content
html.close()
哈哈,如果你限制我,我就跳过你的限制。据说只要浏览器可以访问,就可以被爬虫抓取。
2. 对代码的一些优化
简化提交头方法
发现每次写这么多req.add_header对自己来说都是一种折磨。有什么办法可以复制并使用它吗?答案是肯定的。
#input:
help(urllib2.Request)
#output(因篇幅关系,只取__init__方法)
__init__(self, url, data=None, headers={}, origin_req_host=None, unverifiable=False)
通过观察,我们发现headers={},就是说可以以字典的方式提交header信息.那就动手试试咯!!
#只取自定义Header部分代码
csdn_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Host": "blog.csdn.net",
'Referer': 'http://blog.csdn.net',
"GET": url
}
req = urllib2.Request(url,headers=csdn_headers)
很容易找到,我要感谢斯巴达的无私教导。
提供动态头信息
如果按照上面的方法进行爬取,很多时候提交的信息会过于单一,会被服务器当作机器爬虫来拒绝。
那么我们是否有一些更聪明的方式来提交一些动态数据,答案肯定是肯定的。而且很简单,直接上代码!
'''
@本程序是用来动态提交Header信息
@random 动态库,详情请参考
'''
# coding=utf-8
import urllib2
import random
url = 'http://www.lifevc.com/'
my_headers = [
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.04506.648)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; InfoPath.1',
'Mozilla/4.0 (compatible; GoogleToolbar 5.0.2124.2070; Windows 6.0; MSIE 8.0.6001.18241)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; Sleipnir/2.9.8)',
#因篇幅关系,此处省略N条
]
random_header = random.choice(headers)
# 可以通过print random_header查看提交的header信息
req = urllib2.Request(url)
req.add_header("User-Agent", random_header)
req.add_header('Host', 'blog.csdn.net')
req.add_header('Referer', 'http://blog.csdn.net')
req.add_header('GET', url)
content = urllib2.urlopen(req).read()
print content
其实很简单,所以我们就完成了代码的一些优化。 查看全部
抓取jsp网页源代码(
斯巴达,常用爬虫制作模块的基本用法极度推荐!)
使用Python的urllib和urllib2模块制作爬虫示例教程
更新时间:2016-01-20 10:25:51 作者:小璐D
本文主要介绍了使用Python的urllib和urllib2模块制作爬虫的示例教程,并展示了这两个常用的爬虫制作模块的基本用法。强烈推荐!有需要的朋友可以参考
网址库
在学习了python的基础知识后,我有点困惑。当我闭上眼睛时,一种空白的窒息感不断袭来。我还缺乏练习,所以我拿着履带练习我的手。学习了Spartan python爬虫课程后,我将自己的经验整理如下,供后续的翻阅。整个笔记主要分为以下几个部分:
1.做一个简单的爬虫
第一个环境描述
这个没什么好说的,直接上代码吧!
'''
@ urllib为python自带的一个网络库
@ urlopen为urllib的一个方法,用于打开一个连接并抓取网页,
然后通过read()方法把值赋给read()
'''
import urllib
url = "http://www.lifevc.com"#多嘴两句,为什么要选lifevc呢,主要是最近它很惹我.
html = urllib.urlopen(url)
content = html.read()
html.close()
#可以通过print打印出网页内容
print content
很简单,基本没什么好说的,这就是python的魅力,几行代码就可以完成。
当然,我们只是爬网,并没有真正的价值。然后我们将开始做一些有意义的事情。
2.一个小测试
抢百度贴吧图片
其实很简单,因为要抓取图片,首先要分析网页的源代码。
(这里是了解基本的html知识,浏览器以chrome为例)
如图,这里是对后续步骤的简要说明,请参考。
打开网页,右键单击并选择“检查元素”(底部项目)
点击下方弹出框最左边的问号,问号会变成蓝色
移动鼠标点击我们要捕捉的图片(一个可爱的女孩)
如图,我们可以在源码中获取图片的位置

复制下面的源代码
经过分析对比(这里略略),基本上可以看到要抓拍的图像的特征:
以后我会更新正则表达式,请大家注意
根据上面的判断,直接上传代码
'''
@本程序用来下载百度贴吧图片
@re 为正则说明库
'''
import urllib
import re
# 获取网页html信息
url = "http://tieba.baidu.com/p/2336739808"
html = urllib.urlopen(url)
content = html.read()
html.close()
# 通过正则匹配图片特征,并获取图片链接
img_tag = re.compile(r'class="BDE_Image" src="(.+?\.jpg)"')
img_links = re.findall(img_tag, content)
# 下载图片 img_counter为图片计数器(文件名)
img_counter = 0
for img_link in img_links:
img_name = '%s.jpg' % img_counter
urllib.urlretrieve(img_link, "//Users//Sean//Downloads//tieba//%s" %img_name)
img_counter += 1
如图所示,我们将抓取您理解的图片

3.总结
与前两节一样,我们可以轻松访问网页或图片。
补充一点小技巧,如果遇到不是很了解的库或者方法,可以使用下面的方法来初步了解一下。
或输入相关搜索。
当然,百度也可以,只是效率太低。建议使用相关搜索(你懂的,绝对满意)。
这里我们讲解如何抓取网页和下载图片,下面我们将讲解如何抓取限制抓取的网站。
urllib2
上面我们解释了如何抓取网页和下载图片,下一节我们将解释如何抓取限制抓取的网站
首先我们还是用上节课的方法爬取一个大家都用的网站作为例子。本文主要分为以下几个部分:
1. 抓取受限网页
首先使用我们在上一节中学到的知识进行测试:
'''
@本程序用来抓取blog.csdn.net网页
'''
import urllib
url = "http://blog.csdn.net/FansUnion"
html = urllib.urlopen(url)
#getcode()方法为返回Http状态码
print html.getcode()
html.close()
#输出
403
这里我们的输出是 403,这意味着访问被拒绝;同样,200 表示请求成功完成;404 表示未找到该 URL。
可以看到csdn被屏蔽了,无法通过第一节的方法获取到网页。这里我们需要启动一个新的库:urllib2
但我们也看到浏览器可以发布该文本。我们可以模拟浏览器操作来获取网页信息吗?
老办法,我们来看看浏览器是如何向csdn服务器提交请求的。首先简单介绍一下方法:

以下是整理后的头部信息
Request Method:GET
Host:blog.csdn.net
Referer:http://blog.csdn.net/?ref=toolbar_logo
User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.104 Safari/537.36
然后根据提取的Header信息,使用urllib2的Request方法模拟浏览器向服务器提交请求。代码如下:
# coding=utf-8
'''
@本程序用来抓取受限网页(blog.csdn.net)
@User-Agent:客户端浏览器版本
@Host:服务器地址
@Referer:跳转地址
@GET:请求方法为GET
'''
import urllib2
url = "http://blog.csdn.net/FansUnion"
#定制自定义Header,模拟浏览器向服务器提交请求
req = urllib2.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36')
req.add_header('Host', 'blog.csdn.net')
req.add_header('Referer', 'http://blog.csdn.net')
req.add_header('GET', url)
#下载网页html并打印
html = urllib2.urlopen(req)
content = html.read()
print content
html.close()
哈哈,如果你限制我,我就跳过你的限制。据说只要浏览器可以访问,就可以被爬虫抓取。
2. 对代码的一些优化
简化提交头方法
发现每次写这么多req.add_header对自己来说都是一种折磨。有什么办法可以复制并使用它吗?答案是肯定的。
#input:
help(urllib2.Request)
#output(因篇幅关系,只取__init__方法)
__init__(self, url, data=None, headers={}, origin_req_host=None, unverifiable=False)
通过观察,我们发现headers={},就是说可以以字典的方式提交header信息.那就动手试试咯!!
#只取自定义Header部分代码
csdn_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Host": "blog.csdn.net",
'Referer': 'http://blog.csdn.net',
"GET": url
}
req = urllib2.Request(url,headers=csdn_headers)
很容易找到,我要感谢斯巴达的无私教导。
提供动态头信息
如果按照上面的方法进行爬取,很多时候提交的信息会过于单一,会被服务器当作机器爬虫来拒绝。
那么我们是否有一些更聪明的方式来提交一些动态数据,答案肯定是肯定的。而且很简单,直接上代码!
'''
@本程序是用来动态提交Header信息
@random 动态库,详情请参考
'''
# coding=utf-8
import urllib2
import random
url = 'http://www.lifevc.com/'
my_headers = [
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.04506.648)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; InfoPath.1',
'Mozilla/4.0 (compatible; GoogleToolbar 5.0.2124.2070; Windows 6.0; MSIE 8.0.6001.18241)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; Sleipnir/2.9.8)',
#因篇幅关系,此处省略N条
]
random_header = random.choice(headers)
# 可以通过print random_header查看提交的header信息
req = urllib2.Request(url)
req.add_header("User-Agent", random_header)
req.add_header('Host', 'blog.csdn.net')
req.add_header('Referer', 'http://blog.csdn.net')
req.add_header('GET', url)
content = urllib2.urlopen(req).read()
print content
其实很简单,所以我们就完成了代码的一些优化。
抓取jsp网页源代码(如何应对数据匮乏的问题?最简单的方法在这里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-12-25 22:20
作者 | 拉克夏阿罗拉
编译|弗林
来源|analyticsvidhya
概述介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络爬行。我个人发现网络抓取是一种非常有用的技术,可以从多个网站采集
数据。如今,一些网站还为您可能想要使用的许多不同类型的数据提供 API,例如推文或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的网站采集
数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库进行网页抓取。
我们还为本文创建了一个免费课程:
请注意,网络抓取受许多准则和规则的约束。并非每个网站都允许用户抓取内容,因此存在一定的法律限制。在尝试执行此操作之前,请确保您已阅读该网站的网站条款和条件。
内容
3 个流行的 Python 网络爬虫工具和库
网络爬虫组件
CrawlParse 和 TransformStore
从网页中抓取 URL 和电子邮件 ID
抓取图片
页面加载时抓取数据
3 个流行的 Python 网络爬虫工具和库
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
刮痧
硒
网络爬虫组件
这是构成网络爬行的三个主要组件的极好说明:
让我们详细了解这些组件。我们将使用 goibibo 网站获取酒店详细信息,例如酒店名称和每间客房的价格,以实现此目的:
注意:请始终遵循目标网站的robots.txt文件,也称为机器人排除协议。这可以告诉网络机器人不抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。开始吧!
第 1 步:爬网
网页抓取的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
\'User-Agent\': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, \'html.parser\')
print(data)
第 2 步:解析和转换
网络抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,就像大多数页面一样,特定酒店的详细信息位于不同的卡片上。
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下信息:
所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
# find all the sections with specifiedd class name
cards_data = data.find_all(\'div\', attrs={\'class\', \'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block\'})
# total number of cards
print(\'Total Number of Cards Found : \', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录
有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find(\'p\')
# get the room price
room_price = card.find(\'li\', attrs={\'class\': \'htl-tile-discount-prc\'})
print(hotel_name.text, room_price.text)
第 3 步:Store(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find(\'p\')
# get the room price
room_price = card.find(\'li\', attrs={\'class\': \'htl-tile-discount-prc\'})
# add data to the dictionary
card_details[\'hotel_name\'] = hotel_name.text
card_details[\'room_price\'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv(\'hotels_data.csv\', index=False)
恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网络抓取来抓取的两个最常见的功能是网站 URL 和电子邮件 ID。我相信你参与过一个需要大量电子邮件 ID 提取的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台 查看全部
抓取jsp网页源代码(如何应对数据匮乏的问题?最简单的方法在这里)
作者 | 拉克夏阿罗拉
编译|弗林
来源|analyticsvidhya
概述介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络爬行。我个人发现网络抓取是一种非常有用的技术,可以从多个网站采集
数据。如今,一些网站还为您可能想要使用的许多不同类型的数据提供 API,例如推文或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的网站采集
数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库进行网页抓取。
我们还为本文创建了一个免费课程:
请注意,网络抓取受许多准则和规则的约束。并非每个网站都允许用户抓取内容,因此存在一定的法律限制。在尝试执行此操作之前,请确保您已阅读该网站的网站条款和条件。
内容
3 个流行的 Python 网络爬虫工具和库
网络爬虫组件
CrawlParse 和 TransformStore
从网页中抓取 URL 和电子邮件 ID
抓取图片
页面加载时抓取数据
3 个流行的 Python 网络爬虫工具和库
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
刮痧
硒
网络爬虫组件
这是构成网络爬行的三个主要组件的极好说明:
让我们详细了解这些组件。我们将使用 goibibo 网站获取酒店详细信息,例如酒店名称和每间客房的价格,以实现此目的:
注意:请始终遵循目标网站的robots.txt文件,也称为机器人排除协议。这可以告诉网络机器人不抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。开始吧!
第 1 步:爬网
网页抓取的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
\'User-Agent\': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, \'html.parser\')
print(data)
第 2 步:解析和转换
网络抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,就像大多数页面一样,特定酒店的详细信息位于不同的卡片上。
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下信息:
所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
# find all the sections with specifiedd class name
cards_data = data.find_all(\'div\', attrs={\'class\', \'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block\'})
# total number of cards
print(\'Total Number of Cards Found : \', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录
有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find(\'p\')
# get the room price
room_price = card.find(\'li\', attrs={\'class\': \'htl-tile-discount-prc\'})
print(hotel_name.text, room_price.text)
第 3 步:Store(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find(\'p\')
# get the room price
room_price = card.find(\'li\', attrs={\'class\': \'htl-tile-discount-prc\'})
# add data to the dictionary
card_details[\'hotel_name\'] = hotel_name.text
card_details[\'room_price\'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv(\'hotels_data.csv\', index=False)
恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网络抓取来抓取的两个最常见的功能是网站 URL 和电子邮件 ID。我相信你参与过一个需要大量电子邮件 ID 提取的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台
抓取jsp网页源代码(部分系统截图如下:基于javaweb的众筹网源码分享(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-18 13:04
这是一个类似于CSDN网站的博客,用户可以发布博客,智能检索博客,还具有文件上传下载、在线预览等功能,方便大家实现资源共享;部分系统截图如下:
基于javaweb的众筹网络源码分享
这个网站是为同学们做的毕业设计。指目前主流的众筹网站,包括发起众筹项目、赞助项目、资金管理、智能检索等功能,部分截图如下:
操作说明
类似这个网站我写过很多,这两个网站的风格差别很大,所以非常适合大家训练。我之前买的服务器已经过期了,不然可以直接在网上浏览这两个网站,我用的是MySQL数据库,eclipse作为开发软件,里面有代码需要用到的jar。
hibernate连接的数据库有自己的建表功能。只要程序运行,它就会根据你的代码逻辑在数据库中自动构建系统所需的表。运行代码时,只需要修改WebContent/WEB-INF/applicationContext.xml文件中的MySQL用户名和密码即可。如下所示:
另外,还需要在MySQL中创建一个与applicationContext.xml配置文件中的数据库名同名的数据库。这时候代码就可以顺利运行了,还得自己消化代码。
干货: 查看全部
抓取jsp网页源代码(部分系统截图如下:基于javaweb的众筹网源码分享(组图))
这是一个类似于CSDN网站的博客,用户可以发布博客,智能检索博客,还具有文件上传下载、在线预览等功能,方便大家实现资源共享;部分系统截图如下:


基于javaweb的众筹网络源码分享
这个网站是为同学们做的毕业设计。指目前主流的众筹网站,包括发起众筹项目、赞助项目、资金管理、智能检索等功能,部分截图如下:


操作说明
类似这个网站我写过很多,这两个网站的风格差别很大,所以非常适合大家训练。我之前买的服务器已经过期了,不然可以直接在网上浏览这两个网站,我用的是MySQL数据库,eclipse作为开发软件,里面有代码需要用到的jar。
hibernate连接的数据库有自己的建表功能。只要程序运行,它就会根据你的代码逻辑在数据库中自动构建系统所需的表。运行代码时,只需要修改WebContent/WEB-INF/applicationContext.xml文件中的MySQL用户名和密码即可。如下所示:

另外,还需要在MySQL中创建一个与applicationContext.xml配置文件中的数据库名同名的数据库。这时候代码就可以顺利运行了,还得自己消化代码。
干货:
抓取jsp网页源代码(抓取jsp网页源代码,首先要懂得基本语法(htmlapi))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-12-16 18:43
抓取jsp网页源代码,首先要懂得基本语法(htmlapi),例如:pagelogin:返回cookie登录状态。setloginonlogin:返回cookie登录状态。setloginaccount:返回session的会话权限。setloginpassword:返回密码。..有了这些基本语法,再看一遍《jsp源码剖析》,这时,需要抓取的网页就被看懂了。
抓取页面还可以同时做分析,包括分析某个控件使用的parameter参数(设置之类的)、servlet的请求方式(post方式还是get方式)等等。
网站分析还是要花大量的时间的...主要是要做的东西比较多,有些你可能没遇到过的。可以主攻web服务器,
感觉其实主要用熟了就好了,
框架工具一个都不能少
分析分析源码
web服务器内部有这么几个主要部分:1.accesstoken,是访问的dom,dom中包含所有的name,attribute等等。2.domainapi,对domain进行的操作,必须经过这个api。
框架的话,不仅仅是要分析框架,最重要的是需要学习的是开发思路和一套完整的工具(或者说是工具组件)。可以采用基于源码的分析工具来分析。现在比较成熟的可以用一点金蜂源码分析工具。基于百度百科的,很容易上手的。 查看全部
抓取jsp网页源代码(抓取jsp网页源代码,首先要懂得基本语法(htmlapi))
抓取jsp网页源代码,首先要懂得基本语法(htmlapi),例如:pagelogin:返回cookie登录状态。setloginonlogin:返回cookie登录状态。setloginaccount:返回session的会话权限。setloginpassword:返回密码。..有了这些基本语法,再看一遍《jsp源码剖析》,这时,需要抓取的网页就被看懂了。
抓取页面还可以同时做分析,包括分析某个控件使用的parameter参数(设置之类的)、servlet的请求方式(post方式还是get方式)等等。
网站分析还是要花大量的时间的...主要是要做的东西比较多,有些你可能没遇到过的。可以主攻web服务器,
感觉其实主要用熟了就好了,
框架工具一个都不能少
分析分析源码
web服务器内部有这么几个主要部分:1.accesstoken,是访问的dom,dom中包含所有的name,attribute等等。2.domainapi,对domain进行的操作,必须经过这个api。
框架的话,不仅仅是要分析框架,最重要的是需要学习的是开发思路和一套完整的工具(或者说是工具组件)。可以采用基于源码的分析工具来分析。现在比较成熟的可以用一点金蜂源码分析工具。基于百度百科的,很容易上手的。
抓取jsp网页源代码(㈠JSP与ASP还有一个更为的本质的区别??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-12-15 19:15
一、 JSP 技术概述
Sun正式发布JSP(JavaServer Pages)后,这种全新的Web应用开发技术迅速引起了人们的关注。JSP 为创建高度动态的 Web 应用程序提供了独特的开发环境。Sun表示,JSP可以适应市场上85%的服务器产品,包括Apache WebServer和IIS4.0。即使你对 ASP 有很深的热爱,我们认为关注 JSP 的开发还是很有必要的。
(一)JSP和ASP的简单比较
JSP 与微软的 ASP 技术非常相似。两者都提供了在 HTML 代码中混合某种程序代码的能力,并且语言引擎解释并执行程序代码。在 ASP 或 JSP 环境中,HTML 代码主要负责描述信息的显示风格,而程序代码则用于描述处理逻辑。普通的 HTML 页面只依赖 Web 服务器,而 ASP 和 JSP 页面则需要额外的语言引擎来分析和执行程序代码。程序代码的执行结果被重新嵌入到HTML代码中,然后一起发送给浏览器。ASP 和 JSP 都是针对 Web 服务器的技术,客户端浏览器不需要任何额外的软件支持。
ASP编程语言是VBScript等脚本语言,JSP使用Java。这是两者最明显的区别。另外,ASP和JSP还有一个更本质的区别:两种语言引擎对嵌入页面的程序代码的处理方式完全不同。在ASP下,VBScript代码由ASP引擎解释和执行;在JSP下,代码被编译成一个Servlet,由Java虚拟机执行。该编译操作仅在第一次请求 JSP 页面时发生。
(2) 运行环境
Sun 的 JSP 主页在这里。您还可以从这里下载 JSP 规范。这些规范定义了供应商在创建 JSP 引擎时必须遵循的一些规则。
JSP 代码的执行需要在服务器上安装 JSP 引擎。这里我们使用 Sun 的 JavaServer Web Development Kit (JSWDK)。为方便学习,本软件包提供了大量可修改的示例。安装 JSWDK 后,只需执行 startserver 命令即可启动服务器。默认配置下,服务器监听8080端口。使用:8080打开默认页面。
在运行 JSP 示例页面之前,请注意 JSWDK 的安装目录,尤其是“work”子目录下的内容。在执行示例页面时,您可以在此处看到 JSP 页面如何转换为 Java 源文件,然后编译为类文件(即 Servlet)。JSWDK 软件包中的示例页面分为两类。它们是收录表单的 JSP 文件或 HTML 文件。这些表单由 JSP 代码处理。与ASP 一样,JSP 中的Java 代码在服务器端执行。因此,您无法通过浏览器中的“查看源文件”菜单看到 JSP 源代码,只能看到生成的 HTML 代码。所有示例的源代码都在单独的“示例”页面上提供。
(3) JSP页面示例
我们来分析一个简单的JSP页面。您可以在JSWDK 的examples 目录中创建另一个目录来存储此文件。文件名可以是任何名称,但扩展名必须是 .jsp。从下面的代码清单中可以看出,JSP 页面的结构基本相同,只是 Java 代码比普通 HTML 页面多。Java 代码通过<% 和%> 符号添加到HTML 代码中。它的主要功能是生成并显示一个从0到9的字符串。这个字符串前后是一些通过HTML代码输出的文本。
<HTML>
<HEAD><TITLE>JSP 页面< /TITLE>< /HEAD>
<身体>
<%@ 页面语言="java" %>
<%! 字符串 str="0"; %>
<% for (int i=1; i <10; i++) {
str = str + i;
}%>
在 JSP 输出之前。
<P>
<%= 字符串 %>
<P>
JSP输出后。
</BODY>
</HTML>
这个JSP页面可以分成几个部分进行分析。
首先是JSP指令。它描述了页面的基本信息,如使用的语言、是否保持会话状态、是否使用缓冲等。JSP指令以<%@开头,以%>结尾。在这个例子中,指令“<%@ page language="java" %>”简单地定义了这个例子使用Java语言(目前,Java是JSP规范中唯一支持的语言)。
接下来是 JSP 声明。JSP 声明可以看作是在类级别定义变量和方法的地方。JSP 声明以 <%! 并以 %> 结尾。例如,本例中的“<%!String str="0"; %>”定义了一个字符串变量。每个声明后必须有一个分号,就像在普通Java类中声明成员变量一样。
<% 和 %> 之间的代码块是 Java 代码,描述了 JSP 页面的处理逻辑,如本例中的 for 循环所示。
最后,<%= 和 %> 之间的代码称为 JSP 表达式,如本示例中的“<%= str %>”所示。JSP 表达式提供了一种将 JSP 生成的值嵌入 HTML 页面的简单方法。
二、会话状态管理
作者:仙人掌工作室
会话状态维护是 Web 应用程序开发人员必须面临的问题。解决这个问题的方法有很多,比如使用Cookies、隐藏表单输入字段,或者直接在URL中附加状态信息。Java Servlet 提供了一个在多个请求之间持久化的会话对象,它允许用户存储和检索会话状态信息。JSP 在 Servlet 中也支持这个概念。
在 Sun 的 JSP 指南中,可以看到很多关于隐式对象的解释(隐式的意思是这些对象可以直接引用,无需显式声明,也不需要特殊的代码来创建它们的实例)。比如请求对象,它是HttpServletRequest的子类。该对象收录当前浏览器请求的所有信息,包括 Cookies、HTML 表单变量等。session对象也是这样一个隐式对象。该对象在加载第一个 JSP 页面时自动创建,并与请求对象相关联。与ASP 中的会话对象类似,JSP 中的会话对象对于希望通过多个页面完成一个事务的应用程序非常有用。
为了说明session对象的具体应用,接下来我们用三个页面来模拟一个多页面的Web应用。第一个页面(q1.html)只收录一个要求用户名的HTML表单,代码如下:
<HTML>
<身体>
<FORM METHOD=POST ACTION="q2.jsp">
请输入你的名字:
<输入类型=文本>
<输入类型=提交值="提交">
</FORM>
</BODY>
</HTML>
第二个页面是一个JSP页面(q2.jsp),通过request对象提取q1.html表单中的name值,存储为name变量,然后保存name值到会话对象。会话对象是一个名称/值对的集合,其中名称/值对中的名称是“thename”,值是名称变量的值。由于会话对象在会话期间始终有效,因此这里保存的变量对于后续页面也有效。q2.jsp 的另一个任务是问第二个问题。这是它的代码:
<HTML>
<身体>
<%@ 页面语言="java" %>
<%! 细绳; %>
<%
name = request.getParameter("thename");
session.putValue("thename", name);
%>
你的名字是:<%=名字%>
<p>
<FORM METHOD=POST ACTION="q3.jsp">
你喜欢吃什么?
<输入类型=文本>
<P>
<输入类型=提交值="提交">
</FORM>
</BODY>
</HTML>
第三个页面也是一个JSP页面(q3.jsp),主要任务是展示问答的结果。它从 session 对象中提取出 thename 的值并显示出来,这就证明了虽然这个值是在第一页输入的,但是它被 session 对象保留了。q3.jsp 的另一个任务是提取第二页中的用户输入并显示出来:
<HTML>
<身体>
<%@ 页面语言="java" %>
<%! 字符串食物=""; %>
<%
食物 = request.getParameter("食物");
String name = (String) session.getValue("thename");
%>
你的名字是:<%=名字%>
<P>
你喜欢吃吗:<%=食物%>
</BODY>
</HTML>
三、参考JavaBean组件
作者:Cactus Studio 编译
JavaBean 是一个基于 Java 的软件组件。JSP 为在 Web 应用程序中集成 JavaBean 组件提供了完整的支持。这种支持不仅缩短了开发时间(您可以直接使用经过测试和信任的现有组件,避免重复开发),还为 JSP 应用程序带来了更多的可扩展性。JavaBean 组件可用于执行复杂的计算任务,或负责与数据库交互和数据提取。如果我们有三个JavaBean,分别具有显示新闻、股票价格和天气状况的功能,那么创建一个收录所有这三个功能的网页只需要实例化这三个Bean,并使用HTML表格依次定位它们。.
为了说明JavaBean 在JSP 环境中的应用,我们创建了一个名为TaxRate 的Bean。它有两个属性,即产品和费率。两个set方法用于设置这两个属性,两个get方法用于提取这两个属性。在实际应用中,这种Bean一般应该是从数据库中提取税率值。在这里,我们简化了这个过程,并允许设置任意税率。下面是这个Bean的代码清单:
包裹税;
公共课税率{
字符串产品;
双倍率;
公共税率(){
this.Product = "A001";
this.Rate = 5;
}
public void setProduct (String ProductName) {
this.Product = 产品名称;
}
公共字符串 getProduct() {
返回 (this.Product);
}
public void setRate (double rateValue) {
this.Rate = rateValue;
}
公共双getRate(){
返回 (this.Rate);
}
}
<jsp:useBean> 标签用于在JSP 页面中应用上述Bean。根据所使用的具体 JSP 引擎,在何处配置 Bean 以及如何配置 Bean 的方法也可能略有不同。本文将Bean的.class文件放在c:jswdk-1.0examplesWEB-INFjspbeanstax目录下,其中tax是专用于存放Bean的目录。这是使用上述 Bean 的示例页面:
<HTML>
<身体>
<%@ 页面语言="java" %>
<jsp:useBean scope="应用程序" />
<% taxbean.setProduct("A002");
taxbean.setRate(17);
%>
使用方法一:<p>
产品:<%= taxbean.getProduct() %> <br>
税率:<%= taxbean.getRate() %>
<p>
<% taxbean.setProduct("A003");
taxbean.setRate(3);
%>
<b>如何使用2:</b> <p>
产品:<jsp:getProperty property="Product" />
<br>
税率:<jsp:getProperty property="Rate" />
</BODY>
</HTML>
<jsp:useBean>标签定义了几个属性,其中id是整个JSP页面中Bean的ID,scope属性定义了Bean的生命周期,class属性描述了Bean的类文件(从包裹名字) )。
这个JSP页面不仅使用Bean的set和get方法设置和提取属性值,还使用了第二种提取Bean属性值的方法,即使用<jsp:getProperty>标签。<jsp:getProperty>中的name属性是<jsp:useBean>中定义的Bean的id,其property属性指定了目标属性的名称。
事实证明,Java Servlet 是开发Web 应用程序的理想框架。JSP 基于 Servlet 技术,并在很多方面进行了改进。JSP 页面看起来像一个普通的 HTML 页面,但它允许嵌入执行代码。在这方面,它与 ASP 技术非常相似。JSP利用跨平台运行的JavaBean组件,为分离处理逻辑和显示样式提供了一个很好的解决方案。JSP势必成为ASP技术的有力竞争者。 查看全部
抓取jsp网页源代码(㈠JSP与ASP还有一个更为的本质的区别??)
一、 JSP 技术概述
Sun正式发布JSP(JavaServer Pages)后,这种全新的Web应用开发技术迅速引起了人们的关注。JSP 为创建高度动态的 Web 应用程序提供了独特的开发环境。Sun表示,JSP可以适应市场上85%的服务器产品,包括Apache WebServer和IIS4.0。即使你对 ASP 有很深的热爱,我们认为关注 JSP 的开发还是很有必要的。
(一)JSP和ASP的简单比较
JSP 与微软的 ASP 技术非常相似。两者都提供了在 HTML 代码中混合某种程序代码的能力,并且语言引擎解释并执行程序代码。在 ASP 或 JSP 环境中,HTML 代码主要负责描述信息的显示风格,而程序代码则用于描述处理逻辑。普通的 HTML 页面只依赖 Web 服务器,而 ASP 和 JSP 页面则需要额外的语言引擎来分析和执行程序代码。程序代码的执行结果被重新嵌入到HTML代码中,然后一起发送给浏览器。ASP 和 JSP 都是针对 Web 服务器的技术,客户端浏览器不需要任何额外的软件支持。
ASP编程语言是VBScript等脚本语言,JSP使用Java。这是两者最明显的区别。另外,ASP和JSP还有一个更本质的区别:两种语言引擎对嵌入页面的程序代码的处理方式完全不同。在ASP下,VBScript代码由ASP引擎解释和执行;在JSP下,代码被编译成一个Servlet,由Java虚拟机执行。该编译操作仅在第一次请求 JSP 页面时发生。
(2) 运行环境
Sun 的 JSP 主页在这里。您还可以从这里下载 JSP 规范。这些规范定义了供应商在创建 JSP 引擎时必须遵循的一些规则。
JSP 代码的执行需要在服务器上安装 JSP 引擎。这里我们使用 Sun 的 JavaServer Web Development Kit (JSWDK)。为方便学习,本软件包提供了大量可修改的示例。安装 JSWDK 后,只需执行 startserver 命令即可启动服务器。默认配置下,服务器监听8080端口。使用:8080打开默认页面。
在运行 JSP 示例页面之前,请注意 JSWDK 的安装目录,尤其是“work”子目录下的内容。在执行示例页面时,您可以在此处看到 JSP 页面如何转换为 Java 源文件,然后编译为类文件(即 Servlet)。JSWDK 软件包中的示例页面分为两类。它们是收录表单的 JSP 文件或 HTML 文件。这些表单由 JSP 代码处理。与ASP 一样,JSP 中的Java 代码在服务器端执行。因此,您无法通过浏览器中的“查看源文件”菜单看到 JSP 源代码,只能看到生成的 HTML 代码。所有示例的源代码都在单独的“示例”页面上提供。
(3) JSP页面示例
我们来分析一个简单的JSP页面。您可以在JSWDK 的examples 目录中创建另一个目录来存储此文件。文件名可以是任何名称,但扩展名必须是 .jsp。从下面的代码清单中可以看出,JSP 页面的结构基本相同,只是 Java 代码比普通 HTML 页面多。Java 代码通过<% 和%> 符号添加到HTML 代码中。它的主要功能是生成并显示一个从0到9的字符串。这个字符串前后是一些通过HTML代码输出的文本。
<HTML>
<HEAD><TITLE>JSP 页面< /TITLE>< /HEAD>
<身体>
<%@ 页面语言="java" %>
<%! 字符串 str="0"; %>
<% for (int i=1; i <10; i++) {
str = str + i;
}%>
在 JSP 输出之前。
<P>
<%= 字符串 %>
<P>
JSP输出后。
</BODY>
</HTML>
这个JSP页面可以分成几个部分进行分析。
首先是JSP指令。它描述了页面的基本信息,如使用的语言、是否保持会话状态、是否使用缓冲等。JSP指令以<%@开头,以%>结尾。在这个例子中,指令“<%@ page language="java" %>”简单地定义了这个例子使用Java语言(目前,Java是JSP规范中唯一支持的语言)。
接下来是 JSP 声明。JSP 声明可以看作是在类级别定义变量和方法的地方。JSP 声明以 <%! 并以 %> 结尾。例如,本例中的“<%!String str="0"; %>”定义了一个字符串变量。每个声明后必须有一个分号,就像在普通Java类中声明成员变量一样。
<% 和 %> 之间的代码块是 Java 代码,描述了 JSP 页面的处理逻辑,如本例中的 for 循环所示。
最后,<%= 和 %> 之间的代码称为 JSP 表达式,如本示例中的“<%= str %>”所示。JSP 表达式提供了一种将 JSP 生成的值嵌入 HTML 页面的简单方法。
二、会话状态管理
作者:仙人掌工作室
会话状态维护是 Web 应用程序开发人员必须面临的问题。解决这个问题的方法有很多,比如使用Cookies、隐藏表单输入字段,或者直接在URL中附加状态信息。Java Servlet 提供了一个在多个请求之间持久化的会话对象,它允许用户存储和检索会话状态信息。JSP 在 Servlet 中也支持这个概念。
在 Sun 的 JSP 指南中,可以看到很多关于隐式对象的解释(隐式的意思是这些对象可以直接引用,无需显式声明,也不需要特殊的代码来创建它们的实例)。比如请求对象,它是HttpServletRequest的子类。该对象收录当前浏览器请求的所有信息,包括 Cookies、HTML 表单变量等。session对象也是这样一个隐式对象。该对象在加载第一个 JSP 页面时自动创建,并与请求对象相关联。与ASP 中的会话对象类似,JSP 中的会话对象对于希望通过多个页面完成一个事务的应用程序非常有用。
为了说明session对象的具体应用,接下来我们用三个页面来模拟一个多页面的Web应用。第一个页面(q1.html)只收录一个要求用户名的HTML表单,代码如下:
<HTML>
<身体>
<FORM METHOD=POST ACTION="q2.jsp">
请输入你的名字:
<输入类型=文本>
<输入类型=提交值="提交">
</FORM>
</BODY>
</HTML>
第二个页面是一个JSP页面(q2.jsp),通过request对象提取q1.html表单中的name值,存储为name变量,然后保存name值到会话对象。会话对象是一个名称/值对的集合,其中名称/值对中的名称是“thename”,值是名称变量的值。由于会话对象在会话期间始终有效,因此这里保存的变量对于后续页面也有效。q2.jsp 的另一个任务是问第二个问题。这是它的代码:
<HTML>
<身体>
<%@ 页面语言="java" %>
<%! 细绳; %>
<%
name = request.getParameter("thename");
session.putValue("thename", name);
%>
你的名字是:<%=名字%>
<p>
<FORM METHOD=POST ACTION="q3.jsp">
你喜欢吃什么?
<输入类型=文本>
<P>
<输入类型=提交值="提交">
</FORM>
</BODY>
</HTML>
第三个页面也是一个JSP页面(q3.jsp),主要任务是展示问答的结果。它从 session 对象中提取出 thename 的值并显示出来,这就证明了虽然这个值是在第一页输入的,但是它被 session 对象保留了。q3.jsp 的另一个任务是提取第二页中的用户输入并显示出来:
<HTML>
<身体>
<%@ 页面语言="java" %>
<%! 字符串食物=""; %>
<%
食物 = request.getParameter("食物");
String name = (String) session.getValue("thename");
%>
你的名字是:<%=名字%>
<P>
你喜欢吃吗:<%=食物%>
</BODY>
</HTML>
三、参考JavaBean组件
作者:Cactus Studio 编译
JavaBean 是一个基于 Java 的软件组件。JSP 为在 Web 应用程序中集成 JavaBean 组件提供了完整的支持。这种支持不仅缩短了开发时间(您可以直接使用经过测试和信任的现有组件,避免重复开发),还为 JSP 应用程序带来了更多的可扩展性。JavaBean 组件可用于执行复杂的计算任务,或负责与数据库交互和数据提取。如果我们有三个JavaBean,分别具有显示新闻、股票价格和天气状况的功能,那么创建一个收录所有这三个功能的网页只需要实例化这三个Bean,并使用HTML表格依次定位它们。.
为了说明JavaBean 在JSP 环境中的应用,我们创建了一个名为TaxRate 的Bean。它有两个属性,即产品和费率。两个set方法用于设置这两个属性,两个get方法用于提取这两个属性。在实际应用中,这种Bean一般应该是从数据库中提取税率值。在这里,我们简化了这个过程,并允许设置任意税率。下面是这个Bean的代码清单:
包裹税;
公共课税率{
字符串产品;
双倍率;
公共税率(){
this.Product = "A001";
this.Rate = 5;
}
public void setProduct (String ProductName) {
this.Product = 产品名称;
}
公共字符串 getProduct() {
返回 (this.Product);
}
public void setRate (double rateValue) {
this.Rate = rateValue;
}
公共双getRate(){
返回 (this.Rate);
}
}
<jsp:useBean> 标签用于在JSP 页面中应用上述Bean。根据所使用的具体 JSP 引擎,在何处配置 Bean 以及如何配置 Bean 的方法也可能略有不同。本文将Bean的.class文件放在c:jswdk-1.0examplesWEB-INFjspbeanstax目录下,其中tax是专用于存放Bean的目录。这是使用上述 Bean 的示例页面:
<HTML>
<身体>
<%@ 页面语言="java" %>
<jsp:useBean scope="应用程序" />
<% taxbean.setProduct("A002");
taxbean.setRate(17);
%>
使用方法一:<p>
产品:<%= taxbean.getProduct() %> <br>
税率:<%= taxbean.getRate() %>
<p>
<% taxbean.setProduct("A003");
taxbean.setRate(3);
%>
<b>如何使用2:</b> <p>
产品:<jsp:getProperty property="Product" />
<br>
税率:<jsp:getProperty property="Rate" />
</BODY>
</HTML>
<jsp:useBean>标签定义了几个属性,其中id是整个JSP页面中Bean的ID,scope属性定义了Bean的生命周期,class属性描述了Bean的类文件(从包裹名字) )。
这个JSP页面不仅使用Bean的set和get方法设置和提取属性值,还使用了第二种提取Bean属性值的方法,即使用<jsp:getProperty>标签。<jsp:getProperty>中的name属性是<jsp:useBean>中定义的Bean的id,其property属性指定了目标属性的名称。
事实证明,Java Servlet 是开发Web 应用程序的理想框架。JSP 基于 Servlet 技术,并在很多方面进行了改进。JSP 页面看起来像一个普通的 HTML 页面,但它允许嵌入执行代码。在这方面,它与 ASP 技术非常相似。JSP利用跨平台运行的JavaBean组件,为分离处理逻辑和显示样式提供了一个很好的解决方案。JSP势必成为ASP技术的有力竞争者。
抓取jsp网页源代码(Java开发:JSP页面的基本属性的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-12-15 09:36
--用于声明当前JSP页面基本属性的页面指令可以写在JSP页面的任何位置,但为了可读性,通常最好将其放在JSP页面的前面
格式:
(1)——用于通知JSP解析引擎使用指定的代码翻译JSP。如果要防止JSP代码乱码,则应确保保存JSP文件时的代码与pageencoding指定的代码一致
(2)——为JSP翻译的servlet指定依赖jar包。例如:
--您可以实现页面收录的效果,即页面的合并效果
格式:
使用JSTL标记库中的标记时,应将JSTL标记库引入当前jsp:
前缀值可以是任意值,但在使用JSTL标记库时应将其用作标记名
注意:在导入之前,还需要导入与JSTL相关的jar包
JSP标记技术
在JSP页面中编写大量Java代码将导致JSP页面中HTML代码和Java代码的混合,这将导致页面非常混乱,难以维护
因此,在JSP的2.0版本中,sun提出了JSP标记技术,建议使用标记替换JSP页面中的java代码,并建议JSP2.0之后JSP页面中不应出现任何java代码行
El表达式
格式:${constant,expression,variable}变量必须事先存储在字段中
功能:主要功能是从域中获取数据并输出
(1)获取常量、表达式或变量的值(变量必须位于现有字段中)
<p>${ "Hello EL" } Hello EL
${ 100+123 } ${ (23*54) > 1250 ? 23*54 : 1250 }
${ name1 }
在EL中书写变量, 会通过变量名(name1)到四个域中去
寻找指定名称(name1)属性值, 如果找到就返回属性值,
如果找不到, 就什么也不输出。
寻找时按照域的范围大小, 按照从小到大的顺序去寻找,
找到就输出,找不到就接着往后查找,最终还找不到,就
什么也不输出!
pageContext 查看全部
抓取jsp网页源代码(Java开发:JSP页面的基本属性的)
--用于声明当前JSP页面基本属性的页面指令可以写在JSP页面的任何位置,但为了可读性,通常最好将其放在JSP页面的前面
格式:
(1)——用于通知JSP解析引擎使用指定的代码翻译JSP。如果要防止JSP代码乱码,则应确保保存JSP文件时的代码与pageencoding指定的代码一致
(2)——为JSP翻译的servlet指定依赖jar包。例如:
--您可以实现页面收录的效果,即页面的合并效果
格式:
使用JSTL标记库中的标记时,应将JSTL标记库引入当前jsp:
前缀值可以是任意值,但在使用JSTL标记库时应将其用作标记名
注意:在导入之前,还需要导入与JSTL相关的jar包

JSP标记技术
在JSP页面中编写大量Java代码将导致JSP页面中HTML代码和Java代码的混合,这将导致页面非常混乱,难以维护
因此,在JSP的2.0版本中,sun提出了JSP标记技术,建议使用标记替换JSP页面中的java代码,并建议JSP2.0之后JSP页面中不应出现任何java代码行
El表达式
格式:${constant,expression,variable}变量必须事先存储在字段中
功能:主要功能是从域中获取数据并输出
(1)获取常量、表达式或变量的值(变量必须位于现有字段中)
<p>${ "Hello EL" } Hello EL
${ 100+123 } ${ (23*54) > 1250 ? 23*54 : 1250 }
${ name1 }
在EL中书写变量, 会通过变量名(name1)到四个域中去
寻找指定名称(name1)属性值, 如果找到就返回属性值,
如果找不到, 就什么也不输出。
寻找时按照域的范围大小, 按照从小到大的顺序去寻找,
找到就输出,找不到就接着往后查找,最终还找不到,就
什么也不输出!
pageContext
抓取jsp网页源代码(参加学校软件杯大赛,弄一个简单的页面搜索也出错)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-12-15 08:03
我最近参加了学校软件杯比赛。我真的属于菜鸟,什么都不懂。所以简单的页面搜索也是很多错误的。
今天实现了一个通过jsp的模糊搜索,访问数据库并显示出来
表单的action属性中的jsp页面是传递数据,提交jsp页面的onclick属性是跳转到需要到达的页面
search.jsp页面的接收数据,第一句是通过jsp从首页接收到的数据,第二句是建立模糊查询语句,第三局是通过自己的连接查询数据库的方式进行查询
以上就是通过表单实现传输数据和跳转页面的功能
接下来是跳过 a 标签并传递值
">
HomePage.jsp 中的href 是跳转到的第三页,?下面的 CORP_NAME=555 是传递的常量值
是jsp查询的数据,我做的项目就是我搜索的公司名称,是一个变量
HomePage.jsp页面中的接收代码,第一句是通过jsp从首页接收数据,第二句是建立谨慎查询语句,第三局是通过自己的连接查询数据库的方式进行查询
如果运行时报错,建议传入out.print();检查自己的查询语句和查询数据
如果出现乱码,建议修改浏览器的编码设置自动检测,在tomcat conf子目录下的server.xml
后面添加URIEncoding="utf-8",小峰设置为utf-8
最后写到第三页的时候,发现jsp代码的复用性太差了。一个新的jdbc对象需要新建一个,多表关联时,需要列出所有条件。 查看全部
抓取jsp网页源代码(参加学校软件杯大赛,弄一个简单的页面搜索也出错)
我最近参加了学校软件杯比赛。我真的属于菜鸟,什么都不懂。所以简单的页面搜索也是很多错误的。
今天实现了一个通过jsp的模糊搜索,访问数据库并显示出来
表单的action属性中的jsp页面是传递数据,提交jsp页面的onclick属性是跳转到需要到达的页面
search.jsp页面的接收数据,第一句是通过jsp从首页接收到的数据,第二句是建立模糊查询语句,第三局是通过自己的连接查询数据库的方式进行查询
以上就是通过表单实现传输数据和跳转页面的功能
接下来是跳过 a 标签并传递值
">
HomePage.jsp 中的href 是跳转到的第三页,?下面的 CORP_NAME=555 是传递的常量值
是jsp查询的数据,我做的项目就是我搜索的公司名称,是一个变量
HomePage.jsp页面中的接收代码,第一句是通过jsp从首页接收数据,第二句是建立谨慎查询语句,第三局是通过自己的连接查询数据库的方式进行查询
如果运行时报错,建议传入out.print();检查自己的查询语句和查询数据
如果出现乱码,建议修改浏览器的编码设置自动检测,在tomcat conf子目录下的server.xml
后面添加URIEncoding="utf-8",小峰设置为utf-8

最后写到第三页的时候,发现jsp代码的复用性太差了。一个新的jdbc对象需要新建一个,多表关联时,需要列出所有条件。
抓取jsp网页源代码(我的Python技能很烂示例代码(-ib图片))
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-12-12 21:31
我的任务是为用户制作一个应用程序来搜索他们查询的三张图片。可以用任何语言编写,推荐使用Python。不过我的Python技术很烂,我最熟悉Java,我已经下载了我打算使用的Eclipse SWT包。
好的,到目前为止你做了什么
我介绍了他们的示例代码,这使得一个简单的网络浏览器成为可能。我将 Google 图片显示为主页,并计划使用 JavaScript/jQuery 自动填充他们的查询并返回前三张图片。 (我还计划使用 JavaScript/jQuery 以某种方式返回三个图像。)
根据Eclipse SWT文档evaluate(),execute()用于评估和执行JavaScript: api/org/eclipse/swt/browser/Browser.html
这是我使用的代码:
import org.eclipse.swt.*;
import org.eclipse.swt.browser.Browser;
import org.eclipse.swt.browser.LocationEvent;
import org.eclipse.swt.browser.LocationListener;
import org.eclipse.swt.browser.ProgressEvent;
import org.eclipse.swt.browser.ProgressListener;
import org.eclipse.swt.browser.StatusTextEvent;
import org.eclipse.swt.layout.GridData;
import org.eclipse.swt.layout.GridLayout;
import org.eclipse.swt.widgets.Display;
import org.eclipse.swt.widgets.Event;
import org.eclipse.swt.widgets.Label;
import org.eclipse.swt.widgets.Listener;
import org.eclipse.swt.widgets.ProgressBar;
import org.eclipse.swt.widgets.Shell;
import org.eclipse.swt.widgets.Text;
import org.eclipse.swt.widgets.ToolBar;
import org.eclipse.swt.widgets.ToolItem;
public class BrowserCodeDemo {
public static void main(String[] args) {
Display display = new Display();
final Shell shell = new Shell(display);
GridLayout gridLayout = new GridLayout();
gridLayout.numColumns = 3;
shell.setLayout(gridLayout);
ToolBar toolbar = new ToolBar(shell, SWT.NONE);
ToolItem itemBack = new ToolItem(toolbar, SWT.PUSH);
itemBack.setText("Back");
ToolItem itemForward = new ToolItem(toolbar, SWT.PUSH);
itemForward.setText("Forward");
ToolItem itemStop = new ToolItem(toolbar, SWT.PUSH);
itemStop.setText("Stop");
ToolItem itemRefresh = new ToolItem(toolbar, SWT.PUSH);
itemRefresh.setText("Refresh");
ToolItem itemGo = new ToolItem(toolbar, SWT.PUSH);
itemGo.setText("Go");
GridData data = new GridData();
data.horizontalSpan = 3;
toolbar.setLayoutData(data);
Label labelAddress = new Label(shell, SWT.NONE);
labelAddress.setText("Address");
final Text location = new Text(shell, SWT.BORDER);
data = new GridData();
data.horizontalAlignment = GridData.FILL;
data.horizontalSpan = 2;
data.grabExcessHorizontalSpace = true;
location.setLayoutData(data);
final Browser browser;
try {
browser = new Browser(shell, SWT.NONE);
} catch (SWTError e) {
System.out.println("Could not instantiate Browser: " + e.getMessage());
display.dispose();
return;
}
data = new GridData();
data.horizontalAlignment = GridData.FILL;
data.verticalAlignment = GridData.FILL;
data.horizontalSpan = 3;
data.grabExcessHorizontalSpace = true;
data.grabExcessVerticalSpace = true;
browser.setLayoutData(data);
final Label status = new Label(shell, SWT.NONE);
data = new GridData(GridData.FILL_HORIZONTAL);
data.horizontalSpan = 2;
status.setLayoutData(data);
final ProgressBar progressBar = new ProgressBar(shell, SWT.NONE);
data = new GridData();
data.horizontalAlignment = GridData.END;
progressBar.setLayoutData(data);
/* event handling */
Listener listener = new Listener() {
@Override
public void handleEvent(Event event) {
ToolItem item = (ToolItem)event.widget;
String string = item.getText();
if (string.equals("Back")) browser.back();
else if (string.equals("Forward")) browser.forward();
else if (string.equals("Stop")) browser.stop();
else if (string.equals("Refresh")) browser.refresh();
else if (string.equals("Go")) browser.setUrl(location.getText());
}
};
browser.addProgressListener(new ProgressListener() {
@Override
public void changed(ProgressEvent event) {
if (event.total == 0) return;
int ratio = event.current * 100 / event.total;
progressBar.setSelection(ratio);
}
@Override
public void completed(ProgressEvent event) {
progressBar.setSelection(0);
}
});
browser.addLocationListener(new LocationListener() {
@Override
public void changed(LocationEvent event) {
if (event.top) location.setText(event.location);
}
@Override
public void changing(LocationEvent event)
{
//System.out.println("Something is happening.");
}
});
itemBack.addListener(SWT.Selection, listener);
itemForward.addListener(SWT.Selection, listener);
itemStop.addListener(SWT.Selection, listener);
itemRefresh.addListener(SWT.Selection, listener);
itemGo.addListener(SWT.Selection, listener);
location.addListener(SWT.DefaultSelection, new Listener() {
@Override
public void handleEvent(Event e)
{
browser.setUrl(location.getText());
System.out.println("New URL loaded");
}
});
shell.open();
browser.setUrl(
"https://www.google.com/imghp%3 ... 6quot;);
//browser.setVisible(false);
boolean jQueryExecuted = browser.execute("$(\'#lst-ib\').val(\'snopes\')");
if (!jQueryExecuted)
{
System.out.println("Your jQuery didn't execute.");
}
jQueryExecuted = browser.execute("$(\'[name=btnG]\').click()");
if (!jQueryExecuted)
{
System.out.println("Your jQuery didn't execute.");
}
while (!shell.isDisposed()) {
if (!display.readAndDispatch())
display.sleep();
}
display.dispose();
}
}
我认为问题不是代码本身,因为我尝试自动设置文本字段,但是在Java和浏览器中都失败了。 /* 文本字段的名称是“lst-ib” * /
你想抓取什么?
我正在尝试从网络获取 Google 图片: tab = wi & ei = m8g4VLndMaz4igKlvoDADg & ved =0CAMQqi4oAQ。
文本字段是名为“lst-ib”的输入。该按钮是名为“btnG”的输入。文本字段位于 ID 为“gs_lc0”的 div 内。 (我还在那里看到了多个其他输入元素,它们的大小完全相同)。 查看全部
抓取jsp网页源代码(我的Python技能很烂示例代码(-ib图片))
我的任务是为用户制作一个应用程序来搜索他们查询的三张图片。可以用任何语言编写,推荐使用Python。不过我的Python技术很烂,我最熟悉Java,我已经下载了我打算使用的Eclipse SWT包。
好的,到目前为止你做了什么
我介绍了他们的示例代码,这使得一个简单的网络浏览器成为可能。我将 Google 图片显示为主页,并计划使用 JavaScript/jQuery 自动填充他们的查询并返回前三张图片。 (我还计划使用 JavaScript/jQuery 以某种方式返回三个图像。)
根据Eclipse SWT文档evaluate(),execute()用于评估和执行JavaScript: api/org/eclipse/swt/browser/Browser.html
这是我使用的代码:
import org.eclipse.swt.*;
import org.eclipse.swt.browser.Browser;
import org.eclipse.swt.browser.LocationEvent;
import org.eclipse.swt.browser.LocationListener;
import org.eclipse.swt.browser.ProgressEvent;
import org.eclipse.swt.browser.ProgressListener;
import org.eclipse.swt.browser.StatusTextEvent;
import org.eclipse.swt.layout.GridData;
import org.eclipse.swt.layout.GridLayout;
import org.eclipse.swt.widgets.Display;
import org.eclipse.swt.widgets.Event;
import org.eclipse.swt.widgets.Label;
import org.eclipse.swt.widgets.Listener;
import org.eclipse.swt.widgets.ProgressBar;
import org.eclipse.swt.widgets.Shell;
import org.eclipse.swt.widgets.Text;
import org.eclipse.swt.widgets.ToolBar;
import org.eclipse.swt.widgets.ToolItem;
public class BrowserCodeDemo {
public static void main(String[] args) {
Display display = new Display();
final Shell shell = new Shell(display);
GridLayout gridLayout = new GridLayout();
gridLayout.numColumns = 3;
shell.setLayout(gridLayout);
ToolBar toolbar = new ToolBar(shell, SWT.NONE);
ToolItem itemBack = new ToolItem(toolbar, SWT.PUSH);
itemBack.setText("Back");
ToolItem itemForward = new ToolItem(toolbar, SWT.PUSH);
itemForward.setText("Forward");
ToolItem itemStop = new ToolItem(toolbar, SWT.PUSH);
itemStop.setText("Stop");
ToolItem itemRefresh = new ToolItem(toolbar, SWT.PUSH);
itemRefresh.setText("Refresh");
ToolItem itemGo = new ToolItem(toolbar, SWT.PUSH);
itemGo.setText("Go");
GridData data = new GridData();
data.horizontalSpan = 3;
toolbar.setLayoutData(data);
Label labelAddress = new Label(shell, SWT.NONE);
labelAddress.setText("Address");
final Text location = new Text(shell, SWT.BORDER);
data = new GridData();
data.horizontalAlignment = GridData.FILL;
data.horizontalSpan = 2;
data.grabExcessHorizontalSpace = true;
location.setLayoutData(data);
final Browser browser;
try {
browser = new Browser(shell, SWT.NONE);
} catch (SWTError e) {
System.out.println("Could not instantiate Browser: " + e.getMessage());
display.dispose();
return;
}
data = new GridData();
data.horizontalAlignment = GridData.FILL;
data.verticalAlignment = GridData.FILL;
data.horizontalSpan = 3;
data.grabExcessHorizontalSpace = true;
data.grabExcessVerticalSpace = true;
browser.setLayoutData(data);
final Label status = new Label(shell, SWT.NONE);
data = new GridData(GridData.FILL_HORIZONTAL);
data.horizontalSpan = 2;
status.setLayoutData(data);
final ProgressBar progressBar = new ProgressBar(shell, SWT.NONE);
data = new GridData();
data.horizontalAlignment = GridData.END;
progressBar.setLayoutData(data);
/* event handling */
Listener listener = new Listener() {
@Override
public void handleEvent(Event event) {
ToolItem item = (ToolItem)event.widget;
String string = item.getText();
if (string.equals("Back")) browser.back();
else if (string.equals("Forward")) browser.forward();
else if (string.equals("Stop")) browser.stop();
else if (string.equals("Refresh")) browser.refresh();
else if (string.equals("Go")) browser.setUrl(location.getText());
}
};
browser.addProgressListener(new ProgressListener() {
@Override
public void changed(ProgressEvent event) {
if (event.total == 0) return;
int ratio = event.current * 100 / event.total;
progressBar.setSelection(ratio);
}
@Override
public void completed(ProgressEvent event) {
progressBar.setSelection(0);
}
});
browser.addLocationListener(new LocationListener() {
@Override
public void changed(LocationEvent event) {
if (event.top) location.setText(event.location);
}
@Override
public void changing(LocationEvent event)
{
//System.out.println("Something is happening.");
}
});
itemBack.addListener(SWT.Selection, listener);
itemForward.addListener(SWT.Selection, listener);
itemStop.addListener(SWT.Selection, listener);
itemRefresh.addListener(SWT.Selection, listener);
itemGo.addListener(SWT.Selection, listener);
location.addListener(SWT.DefaultSelection, new Listener() {
@Override
public void handleEvent(Event e)
{
browser.setUrl(location.getText());
System.out.println("New URL loaded");
}
});
shell.open();
browser.setUrl(
"https://www.google.com/imghp%3 ... 6quot;);
//browser.setVisible(false);
boolean jQueryExecuted = browser.execute("$(\'#lst-ib\').val(\'snopes\')");
if (!jQueryExecuted)
{
System.out.println("Your jQuery didn't execute.");
}
jQueryExecuted = browser.execute("$(\'[name=btnG]\').click()");
if (!jQueryExecuted)
{
System.out.println("Your jQuery didn't execute.");
}
while (!shell.isDisposed()) {
if (!display.readAndDispatch())
display.sleep();
}
display.dispose();
}
}
我认为问题不是代码本身,因为我尝试自动设置文本字段,但是在Java和浏览器中都失败了。 /* 文本字段的名称是“lst-ib” * /
你想抓取什么?
我正在尝试从网络获取 Google 图片: tab = wi & ei = m8g4VLndMaz4igKlvoDADg & ved =0CAMQqi4oAQ。
文本字段是名为“lst-ib”的输入。该按钮是名为“btnG”的输入。文本字段位于 ID 为“gs_lc0”的 div 内。 (我还在那里看到了多个其他输入元素,它们的大小完全相同)。
抓取jsp网页源代码(第一章选择题1.1.早期的动态网站答:1.一次编写,随处运行2.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-12-10 09:21
第一章选择题1.早期动态网站 开发技术主要采用()技术。该技术的基本原理是将浏览器提交给Web服务器的数据通过环境变量传递给其他外部程序。由外部程序处理后,将处理结果传送到Web服务器,最后由Web服务器将处理结果返回给浏览器。A.JSPB.ASPC.PHPD.CGI2.JSP页面的代码由()和()两部分组成。A.javascript 代码 B.vbscript 代码 C.HTML 代码 D.JSP 代码 都是 4. JSP 页面代码中不能收录的部分是 () A.javascript 代码 B.JSP 指令 C.JSP动作 D.HTML 代码问答 简述 JSP 的基本运行原理。列出 JSP 的一些特性。参考答案选择题1.D2.CD3.C4.A Q&A问题1.答:首先,浏览器向网页发起请求服务器访问JSP页面(Request),然后JSP容器负责将JSP转换成Servlet,生成的Servlet被编译生成class文件,然后将class文件加载到内存中执行。最后,Web 服务器向客户端浏览器发送执行结果响应(Response)。然后JSP容器负责将JSP转换成Servlet,生成的Servlet被编译生成class文件,然后将class文件加载到内存中执行。最后,Web 服务器向客户端浏览器发送执行结果响应(Response)。然后JSP容器负责将JSP转换成Servlet,生成的Servlet被编译生成class文件,然后将class文件加载到内存中执行。最后,Web 服务器向客户端浏览器发送执行结果响应(Response)。
2.答:1.一次编写,随处运行2.可复用组件技术3.令牌化页面开发4.对大型复杂Web应用的良好支持第2章** **多选题1.以下不是JSP开发工具()A.JBuilderB.IBMWebSphereC.MyEclipseD.Firework2.搭建JSP开发环境,除了安装以上JSP开发工具另外还必须安装()和()A.JDKB.DreamweaverMXC.FlashMXD.Tomcat3.JSP属于Java家族,以下不属于JAVA家族的是()A。 servletB.javabeanC.javaD.javascript4.web应用体系结构最多可以分为三层。不属于这三层的为()A.表示层B. 业务层 C. 数据访问层 D. 网络链路层 问答简单描述了Tomcat的作用。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。网络链路层问答简单描述了Tomcat的作用。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。网络链路层问答简单描述了Tomcat的作用。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。@2.AD3.D4.D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务,并允许用户进行配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。@2.AD3.D4.D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务,并允许用户进行配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。
A.pageB.forwardC.includeD.taglib2. 在J2EE中,test.jsp文件如下,当试图运行时,() stris A.翻译周期错误 B.编译周期错误 C.运行后,浏览器显示:strisnullD. 运行后浏览器显示: strisstr3. 给定的JSP程序源码如下: __________ 下划线处可插入以下()语句,运行后输出为: 1. ABCD< @4.Page 指令用于定义 JSP 文件中的全局属性。以下对该指令使用的描述是不正确的:()A.作用于整个 JSP 页面。B. 一个页面可以使用多个指令。C.为了增强程序的可读性,建议将指令放在JSP文件的开头,但不是必须的 D. 指令中的属性只能出现一次5. JSP语句中的语句是错误的:() A.一次可以声明多个变量和方法,只要以“;”结尾即可 B. 一个声明只在一页内有效 C. 声明的变量将用作局部变量 D. 声明中声明的变量将是 Initializing JSP 页面初始化时的填空题 JSP 有三个指令,它们是___、_____、_____。JSP 有七个标准的“动作元素”。本章学习的四个“动作要素”分别是_________、___________、____________、________ 只要它们以“;”结尾 B. 一个声明只在一页内有效 C. 声明的变量将用作局部变量 D. 声明中声明的变量将是 Initializing JSP 页面初始化时的填空题 JSP 有三个指令,它们是___、_____、_____。JSP 有七个标准的“动作元素”。本章学习的四个“动作要素”分别是_________、___________、____________、________ 只要它们以“;”结尾 B. 一个声明只在一页内有效 C. 声明的变量将用作局部变量 D. 声明中声明的变量将是 Initializing JSP 页面初始化时的填空题 JSP 有三个指令,它们是___、_____、_____。JSP 有七个标准的“动作元素”。本章学习的四个“动作要素”分别是_________、___________、____________、________ 查看全部
抓取jsp网页源代码(第一章选择题1.1.早期的动态网站答:1.一次编写,随处运行2.)
第一章选择题1.早期动态网站 开发技术主要采用()技术。该技术的基本原理是将浏览器提交给Web服务器的数据通过环境变量传递给其他外部程序。由外部程序处理后,将处理结果传送到Web服务器,最后由Web服务器将处理结果返回给浏览器。A.JSPB.ASPC.PHPD.CGI2.JSP页面的代码由()和()两部分组成。A.javascript 代码 B.vbscript 代码 C.HTML 代码 D.JSP 代码 都是 4. JSP 页面代码中不能收录的部分是 () A.javascript 代码 B.JSP 指令 C.JSP动作 D.HTML 代码问答 简述 JSP 的基本运行原理。列出 JSP 的一些特性。参考答案选择题1.D2.CD3.C4.A Q&A问题1.答:首先,浏览器向网页发起请求服务器访问JSP页面(Request),然后JSP容器负责将JSP转换成Servlet,生成的Servlet被编译生成class文件,然后将class文件加载到内存中执行。最后,Web 服务器向客户端浏览器发送执行结果响应(Response)。然后JSP容器负责将JSP转换成Servlet,生成的Servlet被编译生成class文件,然后将class文件加载到内存中执行。最后,Web 服务器向客户端浏览器发送执行结果响应(Response)。然后JSP容器负责将JSP转换成Servlet,生成的Servlet被编译生成class文件,然后将class文件加载到内存中执行。最后,Web 服务器向客户端浏览器发送执行结果响应(Response)。
2.答:1.一次编写,随处运行2.可复用组件技术3.令牌化页面开发4.对大型复杂Web应用的良好支持第2章** **多选题1.以下不是JSP开发工具()A.JBuilderB.IBMWebSphereC.MyEclipseD.Firework2.搭建JSP开发环境,除了安装以上JSP开发工具另外还必须安装()和()A.JDKB.DreamweaverMXC.FlashMXD.Tomcat3.JSP属于Java家族,以下不属于JAVA家族的是()A。 servletB.javabeanC.javaD.javascript4.web应用体系结构最多可以分为三层。不属于这三层的为()A.表示层B. 业务层 C. 数据访问层 D. 网络链路层 问答简单描述了Tomcat的作用。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。网络链路层问答简单描述了Tomcat的作用。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。网络链路层问答简单描述了Tomcat的作用。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。@2.AD3.D4.D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务,并允许用户进行配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。@2.AD3.D4.D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务,并允许用户进行配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。
A.pageB.forwardC.includeD.taglib2. 在J2EE中,test.jsp文件如下,当试图运行时,() stris A.翻译周期错误 B.编译周期错误 C.运行后,浏览器显示:strisnullD. 运行后浏览器显示: strisstr3. 给定的JSP程序源码如下: __________ 下划线处可插入以下()语句,运行后输出为: 1. ABCD< @4.Page 指令用于定义 JSP 文件中的全局属性。以下对该指令使用的描述是不正确的:()A.作用于整个 JSP 页面。B. 一个页面可以使用多个指令。C.为了增强程序的可读性,建议将指令放在JSP文件的开头,但不是必须的 D. 指令中的属性只能出现一次5. JSP语句中的语句是错误的:() A.一次可以声明多个变量和方法,只要以“;”结尾即可 B. 一个声明只在一页内有效 C. 声明的变量将用作局部变量 D. 声明中声明的变量将是 Initializing JSP 页面初始化时的填空题 JSP 有三个指令,它们是___、_____、_____。JSP 有七个标准的“动作元素”。本章学习的四个“动作要素”分别是_________、___________、____________、________ 只要它们以“;”结尾 B. 一个声明只在一页内有效 C. 声明的变量将用作局部变量 D. 声明中声明的变量将是 Initializing JSP 页面初始化时的填空题 JSP 有三个指令,它们是___、_____、_____。JSP 有七个标准的“动作元素”。本章学习的四个“动作要素”分别是_________、___________、____________、________ 只要它们以“;”结尾 B. 一个声明只在一页内有效 C. 声明的变量将用作局部变量 D. 声明中声明的变量将是 Initializing JSP 页面初始化时的填空题 JSP 有三个指令,它们是___、_____、_____。JSP 有七个标准的“动作元素”。本章学习的四个“动作要素”分别是_________、___________、____________、________
抓取jsp网页源代码(怎么从网站提取网站模板源代码?和CSS源代码。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-12-10 09:20
如何从网站中提取网站模板源代码?
获取 HTML 源代码和 CSS 源代码。1 在您的计算机上找到此路径并删除此目录中的内容。2 用ie.3打开你要下载的网页。回到这个路径刷新 C:\document and settings\administrator\local settings\temporary Internet 此时,这个路径下会显示需要页面的HTML源代码和CSS代码;4. 将本页的HTML、CSS、图片等复制到一个新的文件夹中。删除复制的文件名后的“[1]”,改相关链接直接使用。
如何获取网页源代码中的文件?
网页的源代码是父网页的代码。网页中有一种叫做iframe的节点,相当于网页的子页面。其结构与外部网页完全相同。框架源代码是子页面的源代码。另外,网易云爬网推荐使用selenium,因为我们在进行网易云爬网热审操作时,此时请求的代码是父网页的源码。此时,我们无法请求子页面的源代码,也无法获取需要提取的信息。这是因为打开selenium的页面后,默认操作是在父框架中。这时候如果页面在中间,也有子帧,子帧无法获取子帧中的节点。您需要使用 switch to frame() 方法来切换帧。至此,请求的代码从网页源代码切换到框架源代码,然后我们就可以提取出需要的信息了。
提取图片的网页源代码 查看全部
抓取jsp网页源代码(怎么从网站提取网站模板源代码?和CSS源代码。)
如何从网站中提取网站模板源代码?
获取 HTML 源代码和 CSS 源代码。1 在您的计算机上找到此路径并删除此目录中的内容。2 用ie.3打开你要下载的网页。回到这个路径刷新 C:\document and settings\administrator\local settings\temporary Internet 此时,这个路径下会显示需要页面的HTML源代码和CSS代码;4. 将本页的HTML、CSS、图片等复制到一个新的文件夹中。删除复制的文件名后的“[1]”,改相关链接直接使用。
如何获取网页源代码中的文件?
网页的源代码是父网页的代码。网页中有一种叫做iframe的节点,相当于网页的子页面。其结构与外部网页完全相同。框架源代码是子页面的源代码。另外,网易云爬网推荐使用selenium,因为我们在进行网易云爬网热审操作时,此时请求的代码是父网页的源码。此时,我们无法请求子页面的源代码,也无法获取需要提取的信息。这是因为打开selenium的页面后,默认操作是在父框架中。这时候如果页面在中间,也有子帧,子帧无法获取子帧中的节点。您需要使用 switch to frame() 方法来切换帧。至此,请求的代码从网页源代码切换到框架源代码,然后我们就可以提取出需要的信息了。
提取图片的网页源代码
抓取jsp网页源代码(Java后端服务器的静态网页动态网页设计)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-12-08 18:13
后端服务器一般是指一个servlet容器,用于执行java源程序
常见的网页有html、htm、shtml、asp、aspx、php、jsp等格式
前两者常用于静态网页,后者常用于动态网页。
这里的前端网页使用比较常见的xx.html和xx.jsp网页作为介绍,其他类似
一、静态页面xx.html如何与后台交互:
先看一个最简单的登录界面源码
用户:密码:
这是一个表格。我们看到它充满了纯 html 内容。这是一个静态页面。当我们点击提交按钮时,浏览器会将表单中的数据提交到服务器的loginServlet的相对地址。让我们来看看。什么变成了浏览器的地址:
这不是我们后端servlet的地址吗?然后这个地址指向loginServlet servlet,然后在web.xml文件中找到这个servlet关联的java类来执行服务端程序(先执行,然后会被实例化,然后执行init()函数里面,然后执行service()函数,如果是第二次调用,那么就不用实例化了,直接执行service()函数),我们来看一下服务端的源码程序:
包com.atguigu.javaweb;
导入 java.io.IOException;
导入 java.io.PrintWriter;
导入 javax.servlet.Servlet;
导入 javax.servlet.ServletConfig;
导入 javax.servlet.ServletContext;
导入 javax.servlet.ServletException;
导入 javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
导入 javax.servlet.http.HttpServletRequest;
公共类 loginServlet 扩展了 MyGeneriServlet {
public void init(javax.servlet.ServletConfig config) 抛出 ServletException{
super.init(config);
}
public void service(ServletRequest request, ServletResponse response)
抛出 ServletException, IOException {
//如何获取请求是GET、POST?
HttpServletRequest httpServletRequest=(HttpServletRequest) 请求;
String method=httpServletRequest.getMethod();
System.out.println(方法);
//1.获取请求参数:用户名、密码
String username=request.getParameter("username");
String password=request.getParameter("password");
//获取请求参数
String initUser=getServletContext().getInitParameter("user");
String initpassword=getServletContext().getInitParameter("password");
PrintWriter out=response.getWriter();
//3.对比
if(initUser.equals(username)&&initpassword.equals(password)){
out.print("Hello"+username); // 生成html内容
}else{
out.print("Sorry"+username); // 生成html内容
}
}
}
上面没有判断此时对servlet的请求是post方法还是get方法,不过没关系。请求中传递的参数和信息都收录在内。您可以自行判断并进行相应的操作。
既然页面路径已经跳转到servlet了,但是servlet不是.html文件,浏览器是不是就没有内容可以显示了?不是,我们看到返回的参数response中输出的对象PrintWriter用于html内容的字符串“Hello”是动态生成的,所以此时相当于servlet的路径也有html内容,浏览器页面将显示上面的字符串
二、jsp页面如何与后端服务器交互:
jsp 网页文件是插入到 html 内容中的 java 代码。当我们访问.jsp网页文件时,服务器已经预先知道该页面收录java代码,所以服务器必须先执行这些代码(跟java源代码一样),同时嵌入当前.jsp页面中的执行结果,我们看一下源码:
//如果在这个.jsp页面中使用了一些java函数,则需要导入库,与java源文件相同
第一个 JSP 程序
<p>上面红色的代码是java代码。刚才说了,对象PrintWriter out是用来动态生成一串html内容的,所以服务端执行嵌入的java代码后,动态生成一串html代码,然后一起传输给客户端浏览器显示 查看全部
抓取jsp网页源代码(Java后端服务器的静态网页动态网页设计)
后端服务器一般是指一个servlet容器,用于执行java源程序
常见的网页有html、htm、shtml、asp、aspx、php、jsp等格式
前两者常用于静态网页,后者常用于动态网页。
这里的前端网页使用比较常见的xx.html和xx.jsp网页作为介绍,其他类似
一、静态页面xx.html如何与后台交互:
先看一个最简单的登录界面源码
用户:密码:
这是一个表格。我们看到它充满了纯 html 内容。这是一个静态页面。当我们点击提交按钮时,浏览器会将表单中的数据提交到服务器的loginServlet的相对地址。让我们来看看。什么变成了浏览器的地址:
这不是我们后端servlet的地址吗?然后这个地址指向loginServlet servlet,然后在web.xml文件中找到这个servlet关联的java类来执行服务端程序(先执行,然后会被实例化,然后执行init()函数里面,然后执行service()函数,如果是第二次调用,那么就不用实例化了,直接执行service()函数),我们来看一下服务端的源码程序:
包com.atguigu.javaweb;
导入 java.io.IOException;
导入 java.io.PrintWriter;
导入 javax.servlet.Servlet;
导入 javax.servlet.ServletConfig;
导入 javax.servlet.ServletContext;
导入 javax.servlet.ServletException;
导入 javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
导入 javax.servlet.http.HttpServletRequest;
公共类 loginServlet 扩展了 MyGeneriServlet {
public void init(javax.servlet.ServletConfig config) 抛出 ServletException{
super.init(config);
}
public void service(ServletRequest request, ServletResponse response)
抛出 ServletException, IOException {
//如何获取请求是GET、POST?
HttpServletRequest httpServletRequest=(HttpServletRequest) 请求;
String method=httpServletRequest.getMethod();
System.out.println(方法);
//1.获取请求参数:用户名、密码
String username=request.getParameter("username");
String password=request.getParameter("password");
//获取请求参数
String initUser=getServletContext().getInitParameter("user");
String initpassword=getServletContext().getInitParameter("password");
PrintWriter out=response.getWriter();
//3.对比
if(initUser.equals(username)&&initpassword.equals(password)){
out.print("Hello"+username); // 生成html内容
}else{
out.print("Sorry"+username); // 生成html内容
}
}
}
上面没有判断此时对servlet的请求是post方法还是get方法,不过没关系。请求中传递的参数和信息都收录在内。您可以自行判断并进行相应的操作。
既然页面路径已经跳转到servlet了,但是servlet不是.html文件,浏览器是不是就没有内容可以显示了?不是,我们看到返回的参数response中输出的对象PrintWriter用于html内容的字符串“Hello”是动态生成的,所以此时相当于servlet的路径也有html内容,浏览器页面将显示上面的字符串
二、jsp页面如何与后端服务器交互:
jsp 网页文件是插入到 html 内容中的 java 代码。当我们访问.jsp网页文件时,服务器已经预先知道该页面收录java代码,所以服务器必须先执行这些代码(跟java源代码一样),同时嵌入当前.jsp页面中的执行结果,我们看一下源码:
//如果在这个.jsp页面中使用了一些java函数,则需要导入库,与java源文件相同
第一个 JSP 程序
<p>上面红色的代码是java代码。刚才说了,对象PrintWriter out是用来动态生成一串html内容的,所以服务端执行嵌入的java代码后,动态生成一串html代码,然后一起传输给客户端浏览器显示
抓取jsp网页源代码(从功能方面来说动态网站与静态网站的区别和区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-12-08 18:01
一、动态网站和静态网站在功能上的区别
1、动态网站可以实现静态网站无法实现的功能,例如:聊天室、论坛、音乐播放器、浏览器、搜索等;而静态 网站 不能。
2.静态网站,比如Frontpage或者Dreamweaver开发的网站,它的源代码是完全公开的,任何浏览者都可以很容易地得到它的源代码,也就是说,自己设计的东西可以很容易的被别人偷走。动态网站,如:ASP开发的网站,虽然浏览器也能看到源码,但已经是转换代码了。窃取源代码是不可能的。因为它的源代码已经在服务器上,客户端看不到它。
二、 动态网站和静态网站的区别从数据的使用
1.动态网站可以直接使用数据库,通过数据源直接操作数据库;而静态网站不能用,静态网站只能用表格硬性实现动态网站数据库表中少部分数据的显示不能操作。
2、动态网站放在服务器上。要查看源程序或直接修改它,必须在服务器上进行,因此保密性能优越。静态网站无法实现信息的保密功能。
3、动态网站可以用来调用远程数据,而静态网站甚至不能使用本地数据,更不用说远程数据了。
三、本质上是动态网站和静态网站的区别
1、动态网站的开发语言是一种编程语言,例如ASP是用Vbscript或Javascript开发的。静态 网站 只能用 HTML 开发标记语言开发。它只是一种标记语言,并不能实现程序的功能。
2、动态网站本身就是一个系统,一个可以实现程序几乎所有功能的系统,而静态网站不是,只能实现文字和图片的平面显示。
3、动态网站可以实现程序的高效、快速的执行,而普通的静态网站根本没有效率和快速。
以上是动态网站和静态网站的基本分析。在实际应用中,每个人都会有不同的体验,其中细微和本质的区别远不止上面列举的那样。这只能通过个人经验来区分。
四、动态网站和静态网站从外观上的区别
网站的静态网页以.htmlhtm结尾,客户不能随意修改,需要特殊软件。而且大部分动态网站都是带数据库的,可以随时在线修改,网页往往以php、asp等结尾。我们公司的网站大部分都是动态网站。
静态网页:指不使用应用程序直接或间接制作成html的网页。这类网页的内容是固定的,修改和更新必须通过专用的网页制作工具,如Dreamweaver。动态网页:指使用网页脚本语言,如php、asp等,通过脚本将网站的内容动态存储到数据库中。用户访问网站是一种通过读取数据库动态生成网页的方法。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。
静态网页和动态网页的最大区别在于网页是否有固定内容或可以在线更新
网站的构建如何决定是使用动态网页还是静态网页?
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,采用纯静态网页比较简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了满足搜索引擎对网站的需求,即使使用动态的网站技术,也将网页内容转化为静态网页并发布。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现。在同一个网站上面,动态网页内容和静态网页内容同时存在也是很常见的。
静态网页是指无需应用程序直接或间接制作成html的网页。这种网页的内容是固定的。修改和更新必须通过专用的网页制作工具,如Dreamweaver、Frontpage等,而且只要修改了网页,就必须重新上传一个字符或图片来覆盖原来的页面。
动态网页是指运行在服务器端的程序或网页,会在不同的时间、不同的客户返回不同的网页。
动态网页是指利用网页脚本语言,如php、asp、jsp等,通过脚本将网站的内容动态存储到数据库中,用户访问网站是一种方法通过读取数据库动态生成网页。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。当然,可以使用某些技术将动态网页内容生成静态网页,有利于网站的优化,方便搜索引擎搜索。
动态网页的特点:交互性、自动更新、随机性 查看全部
抓取jsp网页源代码(从功能方面来说动态网站与静态网站的区别和区别)
一、动态网站和静态网站在功能上的区别
1、动态网站可以实现静态网站无法实现的功能,例如:聊天室、论坛、音乐播放器、浏览器、搜索等;而静态 网站 不能。
2.静态网站,比如Frontpage或者Dreamweaver开发的网站,它的源代码是完全公开的,任何浏览者都可以很容易地得到它的源代码,也就是说,自己设计的东西可以很容易的被别人偷走。动态网站,如:ASP开发的网站,虽然浏览器也能看到源码,但已经是转换代码了。窃取源代码是不可能的。因为它的源代码已经在服务器上,客户端看不到它。
二、 动态网站和静态网站的区别从数据的使用
1.动态网站可以直接使用数据库,通过数据源直接操作数据库;而静态网站不能用,静态网站只能用表格硬性实现动态网站数据库表中少部分数据的显示不能操作。
2、动态网站放在服务器上。要查看源程序或直接修改它,必须在服务器上进行,因此保密性能优越。静态网站无法实现信息的保密功能。
3、动态网站可以用来调用远程数据,而静态网站甚至不能使用本地数据,更不用说远程数据了。
三、本质上是动态网站和静态网站的区别
1、动态网站的开发语言是一种编程语言,例如ASP是用Vbscript或Javascript开发的。静态 网站 只能用 HTML 开发标记语言开发。它只是一种标记语言,并不能实现程序的功能。
2、动态网站本身就是一个系统,一个可以实现程序几乎所有功能的系统,而静态网站不是,只能实现文字和图片的平面显示。
3、动态网站可以实现程序的高效、快速的执行,而普通的静态网站根本没有效率和快速。
以上是动态网站和静态网站的基本分析。在实际应用中,每个人都会有不同的体验,其中细微和本质的区别远不止上面列举的那样。这只能通过个人经验来区分。
四、动态网站和静态网站从外观上的区别
网站的静态网页以.htmlhtm结尾,客户不能随意修改,需要特殊软件。而且大部分动态网站都是带数据库的,可以随时在线修改,网页往往以php、asp等结尾。我们公司的网站大部分都是动态网站。
静态网页:指不使用应用程序直接或间接制作成html的网页。这类网页的内容是固定的,修改和更新必须通过专用的网页制作工具,如Dreamweaver。动态网页:指使用网页脚本语言,如php、asp等,通过脚本将网站的内容动态存储到数据库中。用户访问网站是一种通过读取数据库动态生成网页的方法。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。
静态网页和动态网页的最大区别在于网页是否有固定内容或可以在线更新
网站的构建如何决定是使用动态网页还是静态网页?
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,采用纯静态网页比较简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了满足搜索引擎对网站的需求,即使使用动态的网站技术,也将网页内容转化为静态网页并发布。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现。在同一个网站上面,动态网页内容和静态网页内容同时存在也是很常见的。
静态网页是指无需应用程序直接或间接制作成html的网页。这种网页的内容是固定的。修改和更新必须通过专用的网页制作工具,如Dreamweaver、Frontpage等,而且只要修改了网页,就必须重新上传一个字符或图片来覆盖原来的页面。
动态网页是指运行在服务器端的程序或网页,会在不同的时间、不同的客户返回不同的网页。
动态网页是指利用网页脚本语言,如php、asp、jsp等,通过脚本将网站的内容动态存储到数据库中,用户访问网站是一种方法通过读取数据库动态生成网页。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。当然,可以使用某些技术将动态网页内容生成静态网页,有利于网站的优化,方便搜索引擎搜索。
动态网页的特点:交互性、自动更新、随机性
抓取jsp网页源代码(从功能方面来说动态网站与静态网站的区别和区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-12-08 17:23
一、动态网站和静态网站在功能上的区别
1、动态网站可以实现静态网站无法实现的功能,例如:聊天室、论坛、音乐播放器、浏览器、搜索等;而静态 网站 不能。
2.静态网站,比如Frontpage或者Dreamweaver开发的网站,它的源代码是完全公开的,任何浏览者都可以很容易地得到它的源代码,也就是说,自己设计的东西可以很容易的被别人偷走。动态网站,如:ASP开发的网站,虽然浏览器也能看到源码,但已经是转换代码了。窃取源代码是不可能的。因为它的源代码已经在服务器上,客户端看不到它。
二、 动态网站和静态网站的区别从数据的使用
1.动态网站可以直接使用数据库,通过数据源直接操作数据库;而静态网站不能用,静态网站只能用表格硬性实现动态网站数据库表中少部分数据的显示不能操作。
2、动态网站放在服务器上。要查看源程序或直接修改它,必须在服务器上进行,因此保密性能优越。静态网站无法实现信息的保密功能。
3、动态网站可以用来调用远程数据,而静态网站甚至不能使用本地数据,更不用说远程数据了。
三、本质上是动态网站和静态网站的区别
1、动态网站的开发语言是一种编程语言,例如ASP是用Vbscript或Javascript开发的。静态 网站 只能用 HTML 开发标记语言开发。它只是一种标记语言,并不能实现程序的功能。
2、动态网站本身就是一个系统,一个可以实现程序几乎所有功能的系统,而静态网站不是,只能实现文字和图片的平面显示。
3、动态网站可以实现程序的高效、快速的执行,而普通的静态网站根本没有效率和快速。
以上是动态网站和静态网站的基本分析。在实际应用中,每个人都会有不同的体验,其中细微和本质的区别远不止上面列举的那样。这只能通过个人经验来区分。
四、动态网站和静态网站从外观上的区别
网站的静态网页以.htmlhtm结尾,客户不能随意修改,需要特殊软件。而且大部分动态网站都是带数据库的,可以随时在线修改,网页往往以php、asp等结尾。我们公司的网站大部分都是动态网站。
静态网页:指不使用应用程序直接或间接制作成html的网页。这类网页的内容是固定的,修改和更新必须通过专用的网页制作工具,如Dreamweaver。动态网页:指使用网页脚本语言,如php、asp等,通过脚本将网站的内容动态存储到数据库中。用户访问网站是一种通过读取数据库动态生成网页的方法。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。
静态网页和动态网页的最大区别在于网页是否有固定内容或可以在线更新
网站的构建如何决定是使用动态网页还是静态网页?
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,采用纯静态网页比较简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了满足搜索引擎对网站的需求,即使使用动态的网站技术,也将网页内容转化为静态网页并发布。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现。在同一个网站上面,动态网页内容和静态网页内容同时存在也是很常见的。
静态网页是指无需应用程序直接或间接制作成html的网页。这种网页的内容是固定的。修改和更新必须通过专用的网页制作工具,如Dreamweaver、Frontpage等,而且只要修改了网页,就必须重新上传一个字符或图片来覆盖原来的页面。
动态网页是指运行在服务器端的程序或网页,会在不同的时间、不同的客户返回不同的网页。
动态网页是指利用网页脚本语言,如php、asp、jsp等,通过脚本将网站的内容动态存储到数据库中,用户访问网站是一种方法通过读取数据库动态生成网页。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。当然,可以使用某些技术将动态网页内容生成静态网页,有利于网站的优化,方便搜索引擎搜索。
动态网页的特点:交互性、自动更新、随机性 查看全部
抓取jsp网页源代码(从功能方面来说动态网站与静态网站的区别和区别)
一、动态网站和静态网站在功能上的区别
1、动态网站可以实现静态网站无法实现的功能,例如:聊天室、论坛、音乐播放器、浏览器、搜索等;而静态 网站 不能。
2.静态网站,比如Frontpage或者Dreamweaver开发的网站,它的源代码是完全公开的,任何浏览者都可以很容易地得到它的源代码,也就是说,自己设计的东西可以很容易的被别人偷走。动态网站,如:ASP开发的网站,虽然浏览器也能看到源码,但已经是转换代码了。窃取源代码是不可能的。因为它的源代码已经在服务器上,客户端看不到它。
二、 动态网站和静态网站的区别从数据的使用
1.动态网站可以直接使用数据库,通过数据源直接操作数据库;而静态网站不能用,静态网站只能用表格硬性实现动态网站数据库表中少部分数据的显示不能操作。
2、动态网站放在服务器上。要查看源程序或直接修改它,必须在服务器上进行,因此保密性能优越。静态网站无法实现信息的保密功能。
3、动态网站可以用来调用远程数据,而静态网站甚至不能使用本地数据,更不用说远程数据了。
三、本质上是动态网站和静态网站的区别
1、动态网站的开发语言是一种编程语言,例如ASP是用Vbscript或Javascript开发的。静态 网站 只能用 HTML 开发标记语言开发。它只是一种标记语言,并不能实现程序的功能。
2、动态网站本身就是一个系统,一个可以实现程序几乎所有功能的系统,而静态网站不是,只能实现文字和图片的平面显示。
3、动态网站可以实现程序的高效、快速的执行,而普通的静态网站根本没有效率和快速。
以上是动态网站和静态网站的基本分析。在实际应用中,每个人都会有不同的体验,其中细微和本质的区别远不止上面列举的那样。这只能通过个人经验来区分。
四、动态网站和静态网站从外观上的区别
网站的静态网页以.htmlhtm结尾,客户不能随意修改,需要特殊软件。而且大部分动态网站都是带数据库的,可以随时在线修改,网页往往以php、asp等结尾。我们公司的网站大部分都是动态网站。
静态网页:指不使用应用程序直接或间接制作成html的网页。这类网页的内容是固定的,修改和更新必须通过专用的网页制作工具,如Dreamweaver。动态网页:指使用网页脚本语言,如php、asp等,通过脚本将网站的内容动态存储到数据库中。用户访问网站是一种通过读取数据库动态生成网页的方法。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。
静态网页和动态网页的最大区别在于网页是否有固定内容或可以在线更新
网站的构建如何决定是使用动态网页还是静态网页?
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,采用纯静态网页比较简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了满足搜索引擎对网站的需求,即使使用动态的网站技术,也将网页内容转化为静态网页并发布。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现。在同一个网站上面,动态网页内容和静态网页内容同时存在也是很常见的。
静态网页是指无需应用程序直接或间接制作成html的网页。这种网页的内容是固定的。修改和更新必须通过专用的网页制作工具,如Dreamweaver、Frontpage等,而且只要修改了网页,就必须重新上传一个字符或图片来覆盖原来的页面。
动态网页是指运行在服务器端的程序或网页,会在不同的时间、不同的客户返回不同的网页。
动态网页是指利用网页脚本语言,如php、asp、jsp等,通过脚本将网站的内容动态存储到数据库中,用户访问网站是一种方法通过读取数据库动态生成网页。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。当然,可以使用某些技术将动态网页内容生成静态网页,有利于网站的优化,方便搜索引擎搜索。
动态网页的特点:交互性、自动更新、随机性
抓取jsp网页源代码(抓取jsp网页源代码网上有很多教程可以去看一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-12-01 04:03
抓取jsp网页源代码网上有很多教程可以去看一下jsp是asp的阉割版,在pagecontroller下有一个directory表,里面记录了jsp站点目录结构,
抓取jsp的源代码,然后把网址拷贝到application文件夹下,通过api接口等方式获取数据。
你可以先自己写个jsp然后连接api调用api用request写上url发送ajax请求就可以获取到数据
下载jsp,并写jspjs代码写成ajax,然后以http的方式向后端发送get/post请求,即可。jsp直接调用api的方式太危险,可以使用定时器以及正则匹配。ajax的跨域不用担心,通过反向代理就可以做到跨域。
就这个需求,写成ajax的方式更合适,直接写在后端就可以直接调用了。
forwardpost请求,完成。
要是新手我给一个网址你去看看,jsp只不过是可以简单的修改url,
这样吧,你把jsp的所有逻辑写到一个pojo类里,那就完成了。forwardpost请求,完成。
forwardpost请求
我刚好也碰到这个问题,遇到这种问题,先弄懂jsp,然后如果碰到那种来回post或get的就用jdk的get/post方法,最后测试跨域,你发现服务器打死不让跨,这个时候就借助你的爬虫。当然,ajax最简单的方法, 查看全部
抓取jsp网页源代码(抓取jsp网页源代码网上有很多教程可以去看一下)
抓取jsp网页源代码网上有很多教程可以去看一下jsp是asp的阉割版,在pagecontroller下有一个directory表,里面记录了jsp站点目录结构,
抓取jsp的源代码,然后把网址拷贝到application文件夹下,通过api接口等方式获取数据。
你可以先自己写个jsp然后连接api调用api用request写上url发送ajax请求就可以获取到数据
下载jsp,并写jspjs代码写成ajax,然后以http的方式向后端发送get/post请求,即可。jsp直接调用api的方式太危险,可以使用定时器以及正则匹配。ajax的跨域不用担心,通过反向代理就可以做到跨域。
就这个需求,写成ajax的方式更合适,直接写在后端就可以直接调用了。
forwardpost请求,完成。
要是新手我给一个网址你去看看,jsp只不过是可以简单的修改url,
这样吧,你把jsp的所有逻辑写到一个pojo类里,那就完成了。forwardpost请求,完成。
forwardpost请求
我刚好也碰到这个问题,遇到这种问题,先弄懂jsp,然后如果碰到那种来回post或get的就用jdk的get/post方法,最后测试跨域,你发现服务器打死不让跨,这个时候就借助你的爬虫。当然,ajax最简单的方法,
抓取jsp网页源代码( 三门峡网站建设中有各种各样云分析云分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-01 11:21
三门峡网站建设中有各种各样云分析云分析)
三门峡网站三门峡的建设存在着各种各样的问题。关于网站制作中遇到的一些问题,愿意相信的小伙伴,三门峡天云网愿为大家分析如下。请阅读。
针对网站生产中遇到的常见问题,全网云分析如下:
1.网站 文件格式,无论是静态页面还是动态页面,一般来说搜索引擎对动态页面的抓取效果不是很好。常用的有ASP、PHP和JSP。现在很多程序都支持伪静态,最好选择支持伪静态的网站程序。
2.程序路径,即目录层级,网站目录层级不要太多,提高搜索引擎友好度,文件名中收录关键词,有一组关键词 如果需要,可以用连字符“—”代替下划线“__”来分隔,因为搜索引擎蜘蛛程序会把“—”当成空格,可以很好的分隔关键词组
3.网站结构,这部分是最重要的,最重要的部分是网站是否做了。
1)导航栏:导航栏中最好不要使用特效代码、图片或flash进行导航,因为搜索引擎无法捕捉到此类信息。对网站收录有一定影响是正常的。
2)使用图片时,给图片添加注释(ALT属性),保证搜索引擎可以读取到图片中收录的信息。
3)Flash:Flash动画是一种很好的美化网页的方式,很多网站都是用Flash制作的,所以蜘蛛程序无法读取它的信息。建议不要使用。
4) 跳转和弹窗:网页代码中有跳转代码或弹窗代码,所以搜索引擎给你的网站评价会很差时间长了,很可能会惩罚你的网站。
5) 特殊字符:搜索引擎蜘蛛目前无法识别和读取特殊字符。
4.网站 代码是济南实施网站建设网站计划的重要渠道。对于网站的后期优化,代码要简洁冗余,或者直接删除无用代码。这提高了搜索引擎对网站的友好度。一些网页代码减肥软件执行网站减肥。建议不要使用它,因为它会导致代码损坏。
对于网站制作中的问题,希望三门峡网站建设的分享可以帮助到各家公司。所以。 网站 做哪个更好?很多客户可能会向三门峡天云网推荐大家。但是,我们希望您能找到答案。如果合适,我们会再次合作,不会给您带来任何损失。 查看全部
抓取jsp网页源代码(
三门峡网站建设中有各种各样云分析云分析)
三门峡网站三门峡的建设存在着各种各样的问题。关于网站制作中遇到的一些问题,愿意相信的小伙伴,三门峡天云网愿为大家分析如下。请阅读。
针对网站生产中遇到的常见问题,全网云分析如下:
1.网站 文件格式,无论是静态页面还是动态页面,一般来说搜索引擎对动态页面的抓取效果不是很好。常用的有ASP、PHP和JSP。现在很多程序都支持伪静态,最好选择支持伪静态的网站程序。
2.程序路径,即目录层级,网站目录层级不要太多,提高搜索引擎友好度,文件名中收录关键词,有一组关键词 如果需要,可以用连字符“—”代替下划线“__”来分隔,因为搜索引擎蜘蛛程序会把“—”当成空格,可以很好的分隔关键词组
3.网站结构,这部分是最重要的,最重要的部分是网站是否做了。
1)导航栏:导航栏中最好不要使用特效代码、图片或flash进行导航,因为搜索引擎无法捕捉到此类信息。对网站收录有一定影响是正常的。
2)使用图片时,给图片添加注释(ALT属性),保证搜索引擎可以读取到图片中收录的信息。
3)Flash:Flash动画是一种很好的美化网页的方式,很多网站都是用Flash制作的,所以蜘蛛程序无法读取它的信息。建议不要使用。
4) 跳转和弹窗:网页代码中有跳转代码或弹窗代码,所以搜索引擎给你的网站评价会很差时间长了,很可能会惩罚你的网站。
5) 特殊字符:搜索引擎蜘蛛目前无法识别和读取特殊字符。
4.网站 代码是济南实施网站建设网站计划的重要渠道。对于网站的后期优化,代码要简洁冗余,或者直接删除无用代码。这提高了搜索引擎对网站的友好度。一些网页代码减肥软件执行网站减肥。建议不要使用它,因为它会导致代码损坏。
对于网站制作中的问题,希望三门峡网站建设的分享可以帮助到各家公司。所以。 网站 做哪个更好?很多客户可能会向三门峡天云网推荐大家。但是,我们希望您能找到答案。如果合适,我们会再次合作,不会给您带来任何损失。
抓取jsp网页源代码(有人将robots.txt文件视为一组建议.py文件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-12-31 07:11
)
关于合法性,获得大量有价值的信息可能令人兴奋,但仅仅因为它是可能的并不意味着应该这样做。
幸运的是,有一些公共信息可以指导我们的道德和网络抓取工具。大多数网站都有一个与网站相关联的robots.txt文件,指明哪些爬行活动是允许的,哪些是不允许的。它主要用于与搜索引擎交互(网页抓取工具的终极形式)。但是,网站 上的大部分信息都被视为公开信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及道德采集和数据使用等主题。
在开始抓取项目之前,先问自己以下问题:
当我抓取 网站 时,请确保您可以对所有这些问题回答“否”。
要详细了解这些法律问题,请参阅 Krotov 和 Silva 于 2018 年撰写的“Legal and Ethical Web Scraping”和 Sellars 的“Web Scraping and Computer Fraud and Abuse Act 20 Years of Web Scraping and Computer Fraud and Abuse Act”。
现在开始爬取网站
经过上面的评估,我想出了一个项目。我的目标是爬取爱达荷州所有 Family Dollar 商店的地址。这些店在农村很大,所以我想知道有多少这样的店。
起点是Family Dollar的位置页面
爱达荷州家庭美元位置页面
首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 的单元格中运行。
import requests # for making standard html requestsfrom bs4 import BeautifulSoup # magical tool for parsing html dataimport json # for parsing datafrom pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get("https://locations.familydollar.com/id/")soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。这些是我们将使用的几种常见对象类型。
当我们查看 requests.get() 的输出时,还有更多问题需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。requests中的默认编码设置可以很好的解决这个问题。不过,除了纯英文网站,就是更大的互联网世界。为确保请求正确解析内容,您可以设置文本的编码:
page = requests.get(URL)page.encoding = 'ISO-885901'soup = BeautifulSoup(page.text, 'html.parser')
仔细看一下 BeautifulSoup 标签,我们会看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站 爬取过程中的提取可能是一个充满误解的艰巨过程。我认为解决这个问题最好的方法是从一个有代表性的例子开始,然后再扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 查看页面的整个源代码(不推荐)。运行此代码风险自负:
print(soup.prettify())
虽然打印页面的整个源代码可能适合一些教程中展示的玩具示例,但大多数现代 网站 页面都有很多内容。甚至 404 页面也可能充满了页眉、页脚和其他代码。
通常,在您喜欢的浏览器中通过“查看页面源代码”(右键单击并选择“查看页面源代码”)来浏览源代码是最容易的。这是找到目标内容最可靠的方式(我稍后会解释原因)。
家庭美元页面源代码
在这种情况下,我需要在这个巨大的 HTML 海洋中找到我的目标内容地址、城市、州和邮政编码。通常,在页面源上进行简单的搜索(ctrl+F)就会得到目标位置的位置。一旦我真正看到目标内容的一个例子(至少是一个商店的地址),我就会找到一个属性或标签来区分该内容与其他内容。
首先,我需要在爱达荷州的Family Dollar商店采集不同城市的URL,并访问这些网站以获取地址信息。这些 URL 似乎收录在 href 标签中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')dollar_tree_list
搜索 href 不会产生任何结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于下一次尝试,搜索 item_list。由于 class 是 Python 中的保留字,因此使用 class_ 代替。soup.find_all() 竟然是 bs4 函数的瑞士军刀。
dollar_tree_list = soup.find_all(class_ = 'itemlist')for i in dollar_tree_list[:2]: print(i)
有趣的是,我发现搜索特定类的方法通常是一种成功的方法。通过找出对象的类型和长度,我们可以了解更多关于对象的信息。
type(dollar_tree_list)len(dollar_tree_list)
您可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建单个代表性示例的好时机。
example = dollar_tree_list[2] # a representative exampleexample_content = example.contentsprint(example_content)
使用 .attr 查找对象内容中存在的属性。注意: .contents 通常返回一个精确的项目列表,所以第一步是使用方括号表示法来索引项目。
example_content = example.contents[0]example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取它:
example_href = example_content['href']print(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,以澄清上述逻辑。
city_hrefs = [] # initialise empty list for i in dollar_tree_list: cont = i.contents[0] href = cont['href'] city_hrefs.append(href) # check to be sure all went wellfor i in city_hrefs[:2]: print(i)
输出是用于抓取爱达荷州 Family Dollar 商店的 URL 列表。
也就是说,我还没有得到地址信息!现在,您需要抓取每个城市的 URL 以获取此信息。因此,我们使用一个具有代表性的示例来重新启动该过程。
page2 = requests.get(city_hrefs[2]) # again establish a representative examplesoup2 = BeautifulSoup(page2.text, 'html.parser')
家庭美元地图和代码
地址信息嵌套在 type="application/ld+json" 中。经过大量的地理位置爬取,我开始意识到这是一个存储地址信息的通用结构。幸运的是,soup.find_all() 支持类型搜索。
arco = soup2.find_all(type="application/ld+json")print(arco[1])
地址信息在第二个列表成员中!我明白!
使用 .contents 提取内容(从第二个列表项中)(这是过滤后合适的默认操作)。同样,由于输出是一个列表,我为列表项建立了索引:
arco_contents = arco[1].contents[0]arco_contents
哦,看起来不错。这里提供的格式与JSON格式一致(而且类型名称确实收录“json”)。JSON 对象的行为类似于带有嵌套字典的字典。一旦你熟悉了它,它实际上是一种很好的格式(当然,它比一长串正则表达式命令更容易编程)。虽然在结构上看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要通过编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
type(arco_json)print(arco_json)
在内容中,有一个被调用的地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']arco_address
嗯,请注意。现在我可以遍历存储的爱达荷州 URL 列表:
locs_dict = [] # initialise empty list for link in city_hrefs: locpage = requests.get(link) # request page info locsoup = BeautifulSoup(locpage.text, 'html.parser') # parse the page's content locinfo = locsoup.find_all(type="application/ld+json") # extract specific element loccont = locinfo[1].contents[0] # get contents from the bs4 element set locjson = json.loads(loccont) # convert to json locaddr = locjson['address'] # get address locs_dict.append(locaddr) # add address to list
使用 Pandas 来组织我们的 网站 爬取结果
我们在字典中加载了大量数据,但是还有一些额外的无用项使得重用数据变得比必要的复杂。为了进行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不需要的@type 和 country 列,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)locs_df.head(n = 5)
一定要保存结果!!
df.to_csv(locs_df, "family_dollar_ID_locations.csv", sep = ",", index = False)
我们做到了!爱达荷州的所有 Family Dollar 商店都有一个以逗号分隔的列表。多么激动人心。
Selenium 和数据抓取的一点解释
Selenium 是一种常用的工具,用于自动与网页交互。为了解释为什么有时需要使用它,让我们看一个使用 Walgreens 网站 的例子。“检查元素”提供浏览器显示内容的代码:
沃尔格林位置页面和代码
尽管“查看页面源代码”提供了有关请求将获得什么的代码:
沃尔格林源代码
如果这两个不一致,有插件可以修改源代码——因此,你应该将它加载到浏览器中后访问页面。请求无法做到这一点,但 Selenium 可以。
Selenium 需要一个 Web 驱动程序来检索内容。事实上,它会打开一个网络浏览器并采集这个页面的内容。Selenium 功能强大——它可以通过多种方式与加载的内容进行交互(请阅读文档)。使用Selenium获取数据后,继续像之前一样使用BeautifulSoup:
url = "https://www.walgreens.com/stor ... river = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')driver.get(url)soup_ID = BeautifulSoup(driver.page_source, 'html.parser')store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
在 Family Dollar 的情况下,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用网站爬行完成有意义的任务时:
如果您对答案感到好奇:
家庭美元位置图
在美国有很多 Family Dollar 商店。
完整的源代码是:
import requestsfrom bs4 import BeautifulSoupimport jsonfrom pandas import DataFrame as df page = requests.get("https://www.familydollar.com/locations/")soup = BeautifulSoup(page.text, 'html.parser') # find all state linksstate_list = soup.find_all(class_ = 'itemlist') state_links = [] for i in state_list: cont = i.contents[0] attr = cont.attrs hrefs = attr['href'] state_links.append(hrefs) # find all city linkscity_links = [] for link in state_links: page = requests.get(link) soup = BeautifulSoup(page.text, 'html.parser') familydollar_list = soup.find_all(class_ = 'itemlist') for store in familydollar_list: cont = store.contents[0] attr = cont.attrs city_hrefs = attr['href'] city_links.append(city_hrefs)# to get inpidual store linksstore_links = [] for link in city_links: locpage = requests.get(link) locsoup = BeautifulSoup(locpage.text, 'html.parser') locinfo = locsoup.find_all(type="application/ld+json") for i in locinfo: loccont = i.contents[0] locjson = json.loads(loccont) try: store_url = locjson['url'] store_links.append(store_url) except: pass # get address and geolocation informationstores = [] for store in store_links: storepage = requests.get(store) storesoup = BeautifulSoup(storepage.text, 'html.parser') storeinfo = storesoup.find_all(type="application/ld+json") for i in storeinfo: storecont = i.contents[0] storejson = json.loads(storecont) try: store_addr = storejson['address'] store_addr.update(storejson['geo']) stores.append(store_addr) except: pass # final data parsingstores_df = df.from_records(stores)stores_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)stores_df['Store'] = "Family Dollar" df.to_csv(stores_df, "family_dollar_locations.csv", sep = ",", index = False) 查看全部
抓取jsp网页源代码(有人将robots.txt文件视为一组建议.py文件
)
关于合法性,获得大量有价值的信息可能令人兴奋,但仅仅因为它是可能的并不意味着应该这样做。
幸运的是,有一些公共信息可以指导我们的道德和网络抓取工具。大多数网站都有一个与网站相关联的robots.txt文件,指明哪些爬行活动是允许的,哪些是不允许的。它主要用于与搜索引擎交互(网页抓取工具的终极形式)。但是,网站 上的大部分信息都被视为公开信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及道德采集和数据使用等主题。
在开始抓取项目之前,先问自己以下问题:
当我抓取 网站 时,请确保您可以对所有这些问题回答“否”。
要详细了解这些法律问题,请参阅 Krotov 和 Silva 于 2018 年撰写的“Legal and Ethical Web Scraping”和 Sellars 的“Web Scraping and Computer Fraud and Abuse Act 20 Years of Web Scraping and Computer Fraud and Abuse Act”。
现在开始爬取网站
经过上面的评估,我想出了一个项目。我的目标是爬取爱达荷州所有 Family Dollar 商店的地址。这些店在农村很大,所以我想知道有多少这样的店。
起点是Family Dollar的位置页面
爱达荷州家庭美元位置页面
首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 的单元格中运行。
import requests # for making standard html requestsfrom bs4 import BeautifulSoup # magical tool for parsing html dataimport json # for parsing datafrom pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get("https://locations.familydollar.com/id/";)soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。这些是我们将使用的几种常见对象类型。
当我们查看 requests.get() 的输出时,还有更多问题需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。requests中的默认编码设置可以很好的解决这个问题。不过,除了纯英文网站,就是更大的互联网世界。为确保请求正确解析内容,您可以设置文本的编码:
page = requests.get(URL)page.encoding = 'ISO-885901'soup = BeautifulSoup(page.text, 'html.parser')
仔细看一下 BeautifulSoup 标签,我们会看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站 爬取过程中的提取可能是一个充满误解的艰巨过程。我认为解决这个问题最好的方法是从一个有代表性的例子开始,然后再扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 查看页面的整个源代码(不推荐)。运行此代码风险自负:
print(soup.prettify())
虽然打印页面的整个源代码可能适合一些教程中展示的玩具示例,但大多数现代 网站 页面都有很多内容。甚至 404 页面也可能充满了页眉、页脚和其他代码。
通常,在您喜欢的浏览器中通过“查看页面源代码”(右键单击并选择“查看页面源代码”)来浏览源代码是最容易的。这是找到目标内容最可靠的方式(我稍后会解释原因)。
家庭美元页面源代码
在这种情况下,我需要在这个巨大的 HTML 海洋中找到我的目标内容地址、城市、州和邮政编码。通常,在页面源上进行简单的搜索(ctrl+F)就会得到目标位置的位置。一旦我真正看到目标内容的一个例子(至少是一个商店的地址),我就会找到一个属性或标签来区分该内容与其他内容。
首先,我需要在爱达荷州的Family Dollar商店采集不同城市的URL,并访问这些网站以获取地址信息。这些 URL 似乎收录在 href 标签中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')dollar_tree_list
搜索 href 不会产生任何结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于下一次尝试,搜索 item_list。由于 class 是 Python 中的保留字,因此使用 class_ 代替。soup.find_all() 竟然是 bs4 函数的瑞士军刀。
dollar_tree_list = soup.find_all(class_ = 'itemlist')for i in dollar_tree_list[:2]: print(i)
有趣的是,我发现搜索特定类的方法通常是一种成功的方法。通过找出对象的类型和长度,我们可以了解更多关于对象的信息。
type(dollar_tree_list)len(dollar_tree_list)
您可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建单个代表性示例的好时机。
example = dollar_tree_list[2] # a representative exampleexample_content = example.contentsprint(example_content)
使用 .attr 查找对象内容中存在的属性。注意: .contents 通常返回一个精确的项目列表,所以第一步是使用方括号表示法来索引项目。
example_content = example.contents[0]example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取它:
example_href = example_content['href']print(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,以澄清上述逻辑。
city_hrefs = [] # initialise empty list for i in dollar_tree_list: cont = i.contents[0] href = cont['href'] city_hrefs.append(href) # check to be sure all went wellfor i in city_hrefs[:2]: print(i)
输出是用于抓取爱达荷州 Family Dollar 商店的 URL 列表。
也就是说,我还没有得到地址信息!现在,您需要抓取每个城市的 URL 以获取此信息。因此,我们使用一个具有代表性的示例来重新启动该过程。
page2 = requests.get(city_hrefs[2]) # again establish a representative examplesoup2 = BeautifulSoup(page2.text, 'html.parser')
家庭美元地图和代码
地址信息嵌套在 type="application/ld+json" 中。经过大量的地理位置爬取,我开始意识到这是一个存储地址信息的通用结构。幸运的是,soup.find_all() 支持类型搜索。
arco = soup2.find_all(type="application/ld+json")print(arco[1])
地址信息在第二个列表成员中!我明白!
使用 .contents 提取内容(从第二个列表项中)(这是过滤后合适的默认操作)。同样,由于输出是一个列表,我为列表项建立了索引:
arco_contents = arco[1].contents[0]arco_contents
哦,看起来不错。这里提供的格式与JSON格式一致(而且类型名称确实收录“json”)。JSON 对象的行为类似于带有嵌套字典的字典。一旦你熟悉了它,它实际上是一种很好的格式(当然,它比一长串正则表达式命令更容易编程)。虽然在结构上看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要通过编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
type(arco_json)print(arco_json)
在内容中,有一个被调用的地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']arco_address
嗯,请注意。现在我可以遍历存储的爱达荷州 URL 列表:
locs_dict = [] # initialise empty list for link in city_hrefs: locpage = requests.get(link) # request page info locsoup = BeautifulSoup(locpage.text, 'html.parser') # parse the page's content locinfo = locsoup.find_all(type="application/ld+json") # extract specific element loccont = locinfo[1].contents[0] # get contents from the bs4 element set locjson = json.loads(loccont) # convert to json locaddr = locjson['address'] # get address locs_dict.append(locaddr) # add address to list
使用 Pandas 来组织我们的 网站 爬取结果
我们在字典中加载了大量数据,但是还有一些额外的无用项使得重用数据变得比必要的复杂。为了进行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不需要的@type 和 country 列,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)locs_df.head(n = 5)
一定要保存结果!!
df.to_csv(locs_df, "family_dollar_ID_locations.csv", sep = ",", index = False)
我们做到了!爱达荷州的所有 Family Dollar 商店都有一个以逗号分隔的列表。多么激动人心。
Selenium 和数据抓取的一点解释
Selenium 是一种常用的工具,用于自动与网页交互。为了解释为什么有时需要使用它,让我们看一个使用 Walgreens 网站 的例子。“检查元素”提供浏览器显示内容的代码:
沃尔格林位置页面和代码
尽管“查看页面源代码”提供了有关请求将获得什么的代码:
沃尔格林源代码
如果这两个不一致,有插件可以修改源代码——因此,你应该将它加载到浏览器中后访问页面。请求无法做到这一点,但 Selenium 可以。
Selenium 需要一个 Web 驱动程序来检索内容。事实上,它会打开一个网络浏览器并采集这个页面的内容。Selenium 功能强大——它可以通过多种方式与加载的内容进行交互(请阅读文档)。使用Selenium获取数据后,继续像之前一样使用BeautifulSoup:
url = "https://www.walgreens.com/stor ... river = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')driver.get(url)soup_ID = BeautifulSoup(driver.page_source, 'html.parser')store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
在 Family Dollar 的情况下,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用网站爬行完成有意义的任务时:
如果您对答案感到好奇:
家庭美元位置图
在美国有很多 Family Dollar 商店。
完整的源代码是:
import requestsfrom bs4 import BeautifulSoupimport jsonfrom pandas import DataFrame as df page = requests.get("https://www.familydollar.com/locations/";)soup = BeautifulSoup(page.text, 'html.parser') # find all state linksstate_list = soup.find_all(class_ = 'itemlist') state_links = [] for i in state_list: cont = i.contents[0] attr = cont.attrs hrefs = attr['href'] state_links.append(hrefs) # find all city linkscity_links = [] for link in state_links: page = requests.get(link) soup = BeautifulSoup(page.text, 'html.parser') familydollar_list = soup.find_all(class_ = 'itemlist') for store in familydollar_list: cont = store.contents[0] attr = cont.attrs city_hrefs = attr['href'] city_links.append(city_hrefs)# to get inpidual store linksstore_links = [] for link in city_links: locpage = requests.get(link) locsoup = BeautifulSoup(locpage.text, 'html.parser') locinfo = locsoup.find_all(type="application/ld+json") for i in locinfo: loccont = i.contents[0] locjson = json.loads(loccont) try: store_url = locjson['url'] store_links.append(store_url) except: pass # get address and geolocation informationstores = [] for store in store_links: storepage = requests.get(store) storesoup = BeautifulSoup(storepage.text, 'html.parser') storeinfo = storesoup.find_all(type="application/ld+json") for i in storeinfo: storecont = i.contents[0] storejson = json.loads(storecont) try: store_addr = storejson['address'] store_addr.update(storejson['geo']) stores.append(store_addr) except: pass # final data parsingstores_df = df.from_records(stores)stores_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)stores_df['Store'] = "Family Dollar" df.to_csv(stores_df, "family_dollar_locations.csv", sep = ",", index = False)
抓取jsp网页源代码(静态网页的工作原理(一)_光明网(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-12-31 07:10
)
静态网页的工作原理
静态网页也称为普通网页,是相对于网页而言的。静态网页并不是指网页中的元素是静态的,而是网页文件中没有程序代码,只有HTML(超文本标记语言)标记,一般后缀是.htm、.html、.shtml或 .xml 等。在静态网页中,可以收录GIF动画,鼠标经过Flash按钮时,按钮可能会发生变化。
静态网页一旦创建,内容将不再变化,无论谁访问,何时访问,显示的内容都是一样的。
如果要修改网页的内容,则必须修改其源代码,然后重新上传到服务器。
对于静态网页,用户可以直接双击打开,看到的效果和访问服务器是一样的,即服务器是否参与对页面内容没有影响。这是因为网页的内容是在用户访问网页之前确定的。无论用户何时以何种方式访问该网页,该网页的内容都不会发生变化。
静态网页的工作流程可以分为以下4个步骤。
写一个静态文件并发布到Web服务器上;用户在浏览器地址栏中输入静态网页的URL(统一资源定位符)并按回车键,浏览器向Web服务器发送请求;Web服务器找到这个静态文件的位置,并转换成HTML流发送给用户的浏览器;浏览器接收 HTML 流并显示该网页的内容;
在步骤2-4中,静态网页的内容不会改变。其工作原理图如下所示。
动态网页的工作原理
动态网页是指网页文件中除了收录 HTML 标签之外,还收录一些实现特定功能的程序代码。这些程序代码使浏览器和服务器进行交互,即服务器可以根据客户端的不同请求动态生成网页内容。. 动态网页的后缀通常根据使用的编程语言而不同,一般有.asp、.aspx、cgi、.php、.perl、.jsp等。动态网页可以根据不同的时间和不同的浏览者显示不同的信息. 常见的留言板、论坛和聊天室都是通过动态网页实现的。
动态网页比较复杂,不能直接双击打开。动态网页的工作流程分为以下4个步骤。
编写动态网页文件,包括程序代码,并发布到网页服务器上;
用户在浏览器地址栏中输入动态网页的URL并按回车键(Enter),浏览器向Web服务器发送访问请求;
web服务器找到这个动态网页的位置,并根据其中的程序代码动态构建一个HTML流传输到用户浏览器;
浏览器接收HTML流并显示该网页的内容;
从整个工作流程可以看出,当用户浏览动态网页时,需要在服务器上动态执行网页文件,将收录程序代码的动态网页转换为标准的静态网页,最终静态网页发送给用户。其工作原理图如下所示。
查看全部
抓取jsp网页源代码(静态网页的工作原理(一)_光明网(图)
)
静态网页的工作原理
静态网页也称为普通网页,是相对于网页而言的。静态网页并不是指网页中的元素是静态的,而是网页文件中没有程序代码,只有HTML(超文本标记语言)标记,一般后缀是.htm、.html、.shtml或 .xml 等。在静态网页中,可以收录GIF动画,鼠标经过Flash按钮时,按钮可能会发生变化。
静态网页一旦创建,内容将不再变化,无论谁访问,何时访问,显示的内容都是一样的。
如果要修改网页的内容,则必须修改其源代码,然后重新上传到服务器。
对于静态网页,用户可以直接双击打开,看到的效果和访问服务器是一样的,即服务器是否参与对页面内容没有影响。这是因为网页的内容是在用户访问网页之前确定的。无论用户何时以何种方式访问该网页,该网页的内容都不会发生变化。
静态网页的工作流程可以分为以下4个步骤。
写一个静态文件并发布到Web服务器上;用户在浏览器地址栏中输入静态网页的URL(统一资源定位符)并按回车键,浏览器向Web服务器发送请求;Web服务器找到这个静态文件的位置,并转换成HTML流发送给用户的浏览器;浏览器接收 HTML 流并显示该网页的内容;
在步骤2-4中,静态网页的内容不会改变。其工作原理图如下所示。
动态网页的工作原理
动态网页是指网页文件中除了收录 HTML 标签之外,还收录一些实现特定功能的程序代码。这些程序代码使浏览器和服务器进行交互,即服务器可以根据客户端的不同请求动态生成网页内容。. 动态网页的后缀通常根据使用的编程语言而不同,一般有.asp、.aspx、cgi、.php、.perl、.jsp等。动态网页可以根据不同的时间和不同的浏览者显示不同的信息. 常见的留言板、论坛和聊天室都是通过动态网页实现的。
动态网页比较复杂,不能直接双击打开。动态网页的工作流程分为以下4个步骤。
编写动态网页文件,包括程序代码,并发布到网页服务器上;
用户在浏览器地址栏中输入动态网页的URL并按回车键(Enter),浏览器向Web服务器发送访问请求;
web服务器找到这个动态网页的位置,并根据其中的程序代码动态构建一个HTML流传输到用户浏览器;
浏览器接收HTML流并显示该网页的内容;
从整个工作流程可以看出,当用户浏览动态网页时,需要在服务器上动态执行网页文件,将收录程序代码的动态网页转换为标准的静态网页,最终静态网页发送给用户。其工作原理图如下所示。
抓取jsp网页源代码(动态页面技术(JSP/EL)(/JSTL))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-28 22:16
动态页面技术(JSP/EL/JSTL)JSP技术jsp脚本和注释
jsp 脚本:
1) ----- 内部java代码翻译成service方法。
2) ----- 会被翻译成服务方法内部的out.print()局部变量
3) ---- 将翻译成servlet成员变量的内容
jsp 注释:不同注释的可见范围不同
1)Html 注释:---可见范围jsp源代码,翻译后的servlet,页面显示html源代码
2)java comment://single-line comment /*multi-line comment*/ --可见范围jsp源码翻译servlet
3)jsp 注释:----- 可见范围 jsp 源码可见
jsp运行原理----jsp本质就是servlet(面试)
jsp在第一次被访问时会被web容器翻译成servlet,并被执行
过程:
第一次访问---->helloServlet.jsp---->helloServlet_jsp.java---->编译运行
PS:翻译后的servlet可以在Tomcat的工作目录中找到
jsp使用说明(三)
JSP 的指令是指导 JSP 翻译和运行的命令。 JSP包括三大指令:
1)page指令---属性最多的指令(实际开发中默认page指令)
属性最多的命令根据不同的属性引导整个页面的特征
格式:
常用属性如下:
language:可以嵌入jsp脚本的语言类型
pageEncoding:里面可以收录
当前jsp文件的编码-contentType
contentType: response.setContentType(text/html;charset=UTF-8)
session:翻译时jsp是否自动创建session,默认为true
import:导入java包
errorPage:当前页面有错误时,错误500错误后跳转到哪个页面
↓
isErrorPage:当前页面为错误处理页面500错误
404 错误:更改 WEB.xml 中的设置
404
/error.jsp
2)include 指令
页面收录
(静态收录
)指令,可以将一个jsp页面收录
到另一个jsp页面中
格式:
3)taglib 指令
在jsp页面中引入标签库(jstl标签库、struts2标签库)
格式:
jsp内置/隐式对象(9)-----笔试
jsp翻译成servlet后,service方法中定义并初始化了9个对象。我们可以在jsp脚本中直接使用这9个对象。
输出对象
输出类型:JspWriter
out的作用是想让客户端输出内容----out.write()
out buffer的默认8kb可以设置为0(buffer="0kb"),即out buffer关闭,内容直接写入响应buffer
pageContext 对象
有四个jsp域对象
jsp页面的上下文对象有如下功能:
page 对象和 pageContext 对象不是一回事
1)pageContext 是一个域对象
setAttribute(String name,Object obj)
getAttribute(String name)
removeAttrbute(字符串名称)
pageContext 可以访问其他指定域的数据
setAttribute(String name,Object obj,int scope)
getAttribute(String name,int scope)
removeAttrbute(String name,int scope)
例如:
pageContext.setAttribute("name", "文昭",PageContext.REQUEST_SCOPE);
findAttribute(String name)
---依次从pageContext域、请求域、会话域、应用域中获取属性。拿到某个域后,就不会往后看了。
四个范围的总结:
pageContext domain:当前jsp页面范围
请求域:一个请求
会话域:一个会话
应用域:整个网络应用
2)你可以得到另外8个隐式对象
例如:pageContext.getRequest()
pageContext.getSession()
jsp 标签(动作)
1)页面收录
(动态收录
):
2)请求转发:
静态收录
和动态收录
的区别?
静态收录
:一个Servlet(结合成一)静态页面的引入(代码)
动态收录
:两个Servlet(导入地址) 查看全部
抓取jsp网页源代码(动态页面技术(JSP/EL)(/JSTL))
动态页面技术(JSP/EL/JSTL)JSP技术jsp脚本和注释
jsp 脚本:
1) ----- 内部java代码翻译成service方法。
2) ----- 会被翻译成服务方法内部的out.print()局部变量
3) ---- 将翻译成servlet成员变量的内容
jsp 注释:不同注释的可见范围不同
1)Html 注释:---可见范围jsp源代码,翻译后的servlet,页面显示html源代码
2)java comment://single-line comment /*multi-line comment*/ --可见范围jsp源码翻译servlet
3)jsp 注释:----- 可见范围 jsp 源码可见
jsp运行原理----jsp本质就是servlet(面试)
jsp在第一次被访问时会被web容器翻译成servlet,并被执行
过程:
第一次访问---->helloServlet.jsp---->helloServlet_jsp.java---->编译运行
PS:翻译后的servlet可以在Tomcat的工作目录中找到
jsp使用说明(三)
JSP 的指令是指导 JSP 翻译和运行的命令。 JSP包括三大指令:
1)page指令---属性最多的指令(实际开发中默认page指令)
属性最多的命令根据不同的属性引导整个页面的特征
格式:
常用属性如下:
language:可以嵌入jsp脚本的语言类型
pageEncoding:里面可以收录
当前jsp文件的编码-contentType
contentType: response.setContentType(text/html;charset=UTF-8)
session:翻译时jsp是否自动创建session,默认为true
import:导入java包
errorPage:当前页面有错误时,错误500错误后跳转到哪个页面
↓
isErrorPage:当前页面为错误处理页面500错误
404 错误:更改 WEB.xml 中的设置
404
/error.jsp
2)include 指令
页面收录
(静态收录
)指令,可以将一个jsp页面收录
到另一个jsp页面中
格式:
3)taglib 指令
在jsp页面中引入标签库(jstl标签库、struts2标签库)
格式:
jsp内置/隐式对象(9)-----笔试
jsp翻译成servlet后,service方法中定义并初始化了9个对象。我们可以在jsp脚本中直接使用这9个对象。
输出对象
输出类型:JspWriter
out的作用是想让客户端输出内容----out.write()
out buffer的默认8kb可以设置为0(buffer="0kb"),即out buffer关闭,内容直接写入响应buffer
pageContext 对象
有四个jsp域对象
jsp页面的上下文对象有如下功能:
page 对象和 pageContext 对象不是一回事
1)pageContext 是一个域对象
setAttribute(String name,Object obj)
getAttribute(String name)
removeAttrbute(字符串名称)
pageContext 可以访问其他指定域的数据
setAttribute(String name,Object obj,int scope)
getAttribute(String name,int scope)
removeAttrbute(String name,int scope)
例如:
pageContext.setAttribute("name", "文昭",PageContext.REQUEST_SCOPE);
findAttribute(String name)
---依次从pageContext域、请求域、会话域、应用域中获取属性。拿到某个域后,就不会往后看了。
四个范围的总结:
pageContext domain:当前jsp页面范围
请求域:一个请求
会话域:一个会话
应用域:整个网络应用
2)你可以得到另外8个隐式对象
例如:pageContext.getRequest()
pageContext.getSession()
jsp 标签(动作)
1)页面收录
(动态收录
):
2)请求转发:
静态收录
和动态收录
的区别?
静态收录
:一个Servlet(结合成一)静态页面的引入(代码)
动态收录
:两个Servlet(导入地址)
抓取jsp网页源代码(读取表单数据使用的POST方法(组图)()
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-28 20:16
我们在浏览网页时,经常需要向服务器提交信息,让后台程序处理。浏览器使用 GET 和 POST 方法向服务器提交数据。
GET 方法
GET 方法将请求的编码信息添加到 URL 中,URL 和编码信息之间用“?”分隔。符号。如下图:
http://www.runoob.com/hello%3F ... alue2
GET 方法是浏览器传递参数的默认方法。一些敏感信息,比如密码,不建议使用GET方式。
使用get时,传输数据大小有限制(注意参数个数不限制),最大为1024字节。
POST 方法
一些敏感信息,如密码等,可以通过POST方式传递,POST提交的数据是隐式的。
POST提交数据不可见,在url中传入GET(可以查看浏览器地址栏)。
JSP 使用 getParameter() 获取传入的参数,使用 getInputStream() 方法处理客户端的二进制数据流请求。
JSP 使用 URL GET 方法读取表单数据示例
下面是一个简单的网址,在网址中使用GET方法传递参数:
http://localhost:8080/testjsp/main.jsp?name=菜鸟教程&url=http://ww.runoob.com
testjsp 是项目地址。
以下是用于处理客户端提交的表单数据的main.jsp文件的JSP程序。我们使用getParameter()方法获取提交的数据:
菜鸟教程(runoob.com)
使用 GET 方法读取数据
<p>站点名:
网址:
</p>
接下来我们通过浏览器访问:8080/testjsp/main.jsp?name=Novice Tutorial&url=输出结果如下:
使用表单GET方法的例子
下面是一个简单的 HTML 表单,它通过 GET 方法将客户端数据提交到 main.jsp 文件中:
菜鸟教程(runoob.com)
站点名:
网址:
将上述 HTML 代码保存到 test.htm 文件中。将该文件放在当前jsp项目的WebContent目录下(与main.jsp相同的目录)。
通过访问:8080/testjsp/test.html将表单数据提交到main.jsp文件中,演示Gif图片如下:
在“站点名称”和“URL”表单中填写信息,点击“提交”按钮,输出结果。
使用表单POST方法的例子
接下来,让我们使用POST方法传递表单数据,修改main.jsp和Hello.htm文件代码,如下图:
Main.jsp 文件代码:
菜鸟教程(runoob.com)
使用 POST 方法读取数据
<p><b>站点名:
网址:
</p>
在代码中,我们使用new String((request.getParameter("name")).getBytes("ISO-8859-1"),"UTF-8")进行编码转换,防止出现中文乱码。
以下是修改后的test.htm代码:
通过访问:8080/testjsp/test.html将表单数据提交到main.jsp文件中,演示Gif图片如下:
将复选框数据传递给 JSP 程序
复选框复选框可以传递一个或多个数据。
下面是一段简单的HTML代码,并将代码保存在test.htm文件中:
菜鸟教程(runoob.com)
菜鸟教程
淘宝
以上代码在浏览器中访问时如下:
以下是main.jsp文件代码,用于处理复选框数据:
菜鸟教程(runoob.com)
从复选框中读取数据
<p>Google 是否选中:
菜鸟教程是否选中:
淘宝是否选中:
</p>
通过访问:8080/testjsp/test.html将表单数据提交到main.jsp文件中,演示Gif图片如下:
读取所有表单参数 查看全部
抓取jsp网页源代码(读取表单数据使用的POST方法(组图)()
我们在浏览网页时,经常需要向服务器提交信息,让后台程序处理。浏览器使用 GET 和 POST 方法向服务器提交数据。
GET 方法
GET 方法将请求的编码信息添加到 URL 中,URL 和编码信息之间用“?”分隔。符号。如下图:
http://www.runoob.com/hello%3F ... alue2
GET 方法是浏览器传递参数的默认方法。一些敏感信息,比如密码,不建议使用GET方式。
使用get时,传输数据大小有限制(注意参数个数不限制),最大为1024字节。
POST 方法
一些敏感信息,如密码等,可以通过POST方式传递,POST提交的数据是隐式的。
POST提交数据不可见,在url中传入GET(可以查看浏览器地址栏)。
JSP 使用 getParameter() 获取传入的参数,使用 getInputStream() 方法处理客户端的二进制数据流请求。
JSP 使用 URL GET 方法读取表单数据示例
下面是一个简单的网址,在网址中使用GET方法传递参数:
http://localhost:8080/testjsp/main.jsp?name=菜鸟教程&url=http://ww.runoob.com
testjsp 是项目地址。
以下是用于处理客户端提交的表单数据的main.jsp文件的JSP程序。我们使用getParameter()方法获取提交的数据:
菜鸟教程(runoob.com)
使用 GET 方法读取数据
<p>站点名:
网址:
</p>
接下来我们通过浏览器访问:8080/testjsp/main.jsp?name=Novice Tutorial&url=输出结果如下:
使用表单GET方法的例子
下面是一个简单的 HTML 表单,它通过 GET 方法将客户端数据提交到 main.jsp 文件中:
菜鸟教程(runoob.com)
站点名:
网址:
将上述 HTML 代码保存到 test.htm 文件中。将该文件放在当前jsp项目的WebContent目录下(与main.jsp相同的目录)。
通过访问:8080/testjsp/test.html将表单数据提交到main.jsp文件中,演示Gif图片如下:
在“站点名称”和“URL”表单中填写信息,点击“提交”按钮,输出结果。
使用表单POST方法的例子
接下来,让我们使用POST方法传递表单数据,修改main.jsp和Hello.htm文件代码,如下图:
Main.jsp 文件代码:
菜鸟教程(runoob.com)
使用 POST 方法读取数据
<p><b>站点名:
网址:
</p>
在代码中,我们使用new String((request.getParameter("name")).getBytes("ISO-8859-1"),"UTF-8")进行编码转换,防止出现中文乱码。
以下是修改后的test.htm代码:
通过访问:8080/testjsp/test.html将表单数据提交到main.jsp文件中,演示Gif图片如下:
将复选框数据传递给 JSP 程序
复选框复选框可以传递一个或多个数据。
下面是一段简单的HTML代码,并将代码保存在test.htm文件中:
菜鸟教程(runoob.com)
菜鸟教程
淘宝
以上代码在浏览器中访问时如下:
以下是main.jsp文件代码,用于处理复选框数据:
菜鸟教程(runoob.com)
从复选框中读取数据
<p>Google 是否选中:
菜鸟教程是否选中:
淘宝是否选中:
</p>
通过访问:8080/testjsp/test.html将表单数据提交到main.jsp文件中,演示Gif图片如下:
读取所有表单参数
抓取jsp网页源代码(脚本表达式脚本的作用及方法脚本格式介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-12-26 08:06
)
功能:可以为jsp翻译的java类,甚至静态代码块,内部类等定义属性和方法。
Insert title here
3.2 表达式脚本
表达式脚本的格式为:
表达式脚本的作用是:表达式可以在jsp页面上输出数据。
Insert title here
需要注意的是,表达式脚本中的表达式不能以分号结尾。
3.3 代码脚本
代码脚本格式:
代码脚本函数:可以在jsp页面中编写我们需要的函数(编写java语句)
需要写什么声明?那么就需要配合要转换成servlet的源代码的jsp文件进行操作。
4. html、java、jsp三种注释
5. jsp 的九个内置对象
jsp中的内建对象是指Tomcat将jsp页面翻译成Servlet源码后内部提供的九个对象,称为内建对象。
6. jsp 四大领域对象
域对象是可以访问数据的对象,如地图。
这些领域对象的功能相似,但作用域不同!!!
(请求域对象的范围是请求及其捕获。)
scope.jsp 页面:
Insert title here
scope.jsp页面
pageContext域值是否有值:
request域值是否有值:
session域值是否有值:
application域值是否有值:
scope2.jsp 页面:
Insert title here
scope2.jsp页面
pageContext域值是否有值:
request域值是否有值:
session域值是否有值:
application域值是否有值:
7. jsp的out和response输出的区别
当out和response输出时,没有区别,但是有一定的顺序!!
如上图,在定义out.write("xxx")的输出数据时,会先进入out buffer。同样,当 response.getWriter().write() 写入数据时,也会进入响应缓冲区。之后,输出缓冲区的内容将附加到响应缓冲区以具有此顺序。
当 out.flush() 方法被执行时,当前缓冲区将被清空。如果缓冲区中有数据,则输出缓冲区中的数据,将当前输出缓冲区的内容直接添加到响应缓冲区中。所以,调用这个方法的时候,会注意out输出和响应的顺序!!
Insert title here
测试
因为我们使用out.write()方法来运行底层信息,所以我们在jsp页面中定义java代码并使用out进行输出,否则会遇到乱码的问题。
jsp中out变量有两种输出方式:
在out.print()方法中,不管它接受的参数类型是什么,都将其底层转换为字符串类型,然后调用write()方法。
Insert title here
因为可能会出现和上面类似的情况,我们在jsp页面中使用out.print()方法进行输出。
8. 收录
的jsp函数
收录
的功能如下:
8.1 个 jsp 静态收录
静态收录
的格式:
请注意,此处的“/”斜线还表示: :port/project 路径映射到代码的 web 目录。
main.jsp 收录
了footer.jsp 的介绍:
Insert title here
头部信息
主体内容
页脚.jsp:
Insert title here
页脚信息
静态收录
的特点:
8.2 jsp动态收录
动态收录
的特点:
main.jsp 代码如下:
Insert title here
头部信息
主体内容
footer.jsp 代码如下:
Insert title here
页脚信息,动态包含
8.3 jsp请求转发
请求转发有两种方式:
a.jsp代码如下:
Insert title here
b.jsp 代码如下:
Insert title here
我是页面b,请求转发过来的,第二种方式。
9. jsp页面代码和html页面混合使用案例
九九乘法表的情况:
<p>
Insert title here
table{
width: 600px
}
九九乘法表居中 查看全部
抓取jsp网页源代码(脚本表达式脚本的作用及方法脚本格式介绍
)
功能:可以为jsp翻译的java类,甚至静态代码块,内部类等定义属性和方法。
Insert title here
3.2 表达式脚本
表达式脚本的格式为:
表达式脚本的作用是:表达式可以在jsp页面上输出数据。
Insert title here
需要注意的是,表达式脚本中的表达式不能以分号结尾。
3.3 代码脚本
代码脚本格式:
代码脚本函数:可以在jsp页面中编写我们需要的函数(编写java语句)
需要写什么声明?那么就需要配合要转换成servlet的源代码的jsp文件进行操作。
4. html、java、jsp三种注释
5. jsp 的九个内置对象
jsp中的内建对象是指Tomcat将jsp页面翻译成Servlet源码后内部提供的九个对象,称为内建对象。
6. jsp 四大领域对象
域对象是可以访问数据的对象,如地图。
这些领域对象的功能相似,但作用域不同!!!
(请求域对象的范围是请求及其捕获。)
scope.jsp 页面:
Insert title here
scope.jsp页面
pageContext域值是否有值:
request域值是否有值:
session域值是否有值:
application域值是否有值:
scope2.jsp 页面:
Insert title here
scope2.jsp页面
pageContext域值是否有值:
request域值是否有值:
session域值是否有值:
application域值是否有值:
7. jsp的out和response输出的区别
当out和response输出时,没有区别,但是有一定的顺序!!
如上图,在定义out.write("xxx")的输出数据时,会先进入out buffer。同样,当 response.getWriter().write() 写入数据时,也会进入响应缓冲区。之后,输出缓冲区的内容将附加到响应缓冲区以具有此顺序。
当 out.flush() 方法被执行时,当前缓冲区将被清空。如果缓冲区中有数据,则输出缓冲区中的数据,将当前输出缓冲区的内容直接添加到响应缓冲区中。所以,调用这个方法的时候,会注意out输出和响应的顺序!!
Insert title here
测试
因为我们使用out.write()方法来运行底层信息,所以我们在jsp页面中定义java代码并使用out进行输出,否则会遇到乱码的问题。
jsp中out变量有两种输出方式:
在out.print()方法中,不管它接受的参数类型是什么,都将其底层转换为字符串类型,然后调用write()方法。
Insert title here
因为可能会出现和上面类似的情况,我们在jsp页面中使用out.print()方法进行输出。
8. 收录
的jsp函数
收录
的功能如下:
8.1 个 jsp 静态收录
静态收录
的格式:
请注意,此处的“/”斜线还表示: :port/project 路径映射到代码的 web 目录。
main.jsp 收录
了footer.jsp 的介绍:
Insert title here
头部信息
主体内容
页脚.jsp:
Insert title here
页脚信息
静态收录
的特点:
8.2 jsp动态收录
动态收录
的特点:
main.jsp 代码如下:
Insert title here
头部信息
主体内容
footer.jsp 代码如下:
Insert title here
页脚信息,动态包含
8.3 jsp请求转发
请求转发有两种方式:
a.jsp代码如下:
Insert title here
b.jsp 代码如下:
Insert title here
我是页面b,请求转发过来的,第二种方式。
9. jsp页面代码和html页面混合使用案例
九九乘法表的情况:
<p>
Insert title here
table{
width: 600px
}
九九乘法表居中
抓取jsp网页源代码( 斯巴达,常用爬虫制作模块的基本用法极度推荐!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-12-26 08:05
斯巴达,常用爬虫制作模块的基本用法极度推荐!)
使用Python的urllib和urllib2模块制作爬虫示例教程
更新时间:2016-01-20 10:25:51 作者:小璐D
本文主要介绍了使用Python的urllib和urllib2模块制作爬虫的示例教程,并展示了这两个常用的爬虫制作模块的基本用法。强烈推荐!有需要的朋友可以参考
网址库
在学习了python的基础知识后,我有点困惑。当我闭上眼睛时,一种空白的窒息感不断袭来。我还缺乏练习,所以我拿着履带练习我的手。学习了Spartan python爬虫课程后,我将自己的经验整理如下,供后续的翻阅。整个笔记主要分为以下几个部分:
1.做一个简单的爬虫
第一个环境描述
这个没什么好说的,直接上代码吧!
'''
@ urllib为python自带的一个网络库
@ urlopen为urllib的一个方法,用于打开一个连接并抓取网页,
然后通过read()方法把值赋给read()
'''
import urllib
url = "http://www.lifevc.com"#多嘴两句,为什么要选lifevc呢,主要是最近它很惹我.
html = urllib.urlopen(url)
content = html.read()
html.close()
#可以通过print打印出网页内容
print content
很简单,基本没什么好说的,这就是python的魅力,几行代码就可以完成。
当然,我们只是爬网,并没有真正的价值。然后我们将开始做一些有意义的事情。
2.一个小测试
抢百度贴吧图片
其实很简单,因为要抓取图片,首先要分析网页的源代码。
(这里是了解基本的html知识,浏览器以chrome为例)
如图,这里是对后续步骤的简要说明,请参考。
打开网页,右键单击并选择“检查元素”(底部项目)
点击下方弹出框最左边的问号,问号会变成蓝色
移动鼠标点击我们要捕捉的图片(一个可爱的女孩)
如图,我们可以在源码中获取图片的位置
复制下面的源代码
经过分析对比(这里略略),基本上可以看到要抓拍的图像的特征:
以后我会更新正则表达式,请大家注意
根据上面的判断,直接上传代码
'''
@本程序用来下载百度贴吧图片
@re 为正则说明库
'''
import urllib
import re
# 获取网页html信息
url = "http://tieba.baidu.com/p/2336739808"
html = urllib.urlopen(url)
content = html.read()
html.close()
# 通过正则匹配图片特征,并获取图片链接
img_tag = re.compile(r'class="BDE_Image" src="(.+?\.jpg)"')
img_links = re.findall(img_tag, content)
# 下载图片 img_counter为图片计数器(文件名)
img_counter = 0
for img_link in img_links:
img_name = '%s.jpg' % img_counter
urllib.urlretrieve(img_link, "//Users//Sean//Downloads//tieba//%s" %img_name)
img_counter += 1
如图所示,我们将抓取您理解的图片
3.总结
与前两节一样,我们可以轻松访问网页或图片。
补充一点小技巧,如果遇到不是很了解的库或者方法,可以使用下面的方法来初步了解一下。
或输入相关搜索。
当然,百度也可以,只是效率太低。建议使用相关搜索(你懂的,绝对满意)。
这里我们讲解如何抓取网页和下载图片,下面我们将讲解如何抓取限制抓取的网站。
urllib2
上面我们解释了如何抓取网页和下载图片,下一节我们将解释如何抓取限制抓取的网站
首先我们还是用上节课的方法爬取一个大家都用的网站作为例子。本文主要分为以下几个部分:
1. 抓取受限网页
首先使用我们在上一节中学到的知识进行测试:
'''
@本程序用来抓取blog.csdn.net网页
'''
import urllib
url = "http://blog.csdn.net/FansUnion"
html = urllib.urlopen(url)
#getcode()方法为返回Http状态码
print html.getcode()
html.close()
#输出
403
这里我们的输出是 403,这意味着访问被拒绝;同样,200 表示请求成功完成;404 表示未找到该 URL。
可以看到csdn被屏蔽了,无法通过第一节的方法获取到网页。这里我们需要启动一个新的库:urllib2
但我们也看到浏览器可以发布该文本。我们可以模拟浏览器操作来获取网页信息吗?
老办法,我们来看看浏览器是如何向csdn服务器提交请求的。首先简单介绍一下方法:
以下是整理后的头部信息
Request Method:GET
Host:blog.csdn.net
Referer:http://blog.csdn.net/?ref=toolbar_logo
User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.104 Safari/537.36
然后根据提取的Header信息,使用urllib2的Request方法模拟浏览器向服务器提交请求。代码如下:
# coding=utf-8
'''
@本程序用来抓取受限网页(blog.csdn.net)
@User-Agent:客户端浏览器版本
@Host:服务器地址
@Referer:跳转地址
@GET:请求方法为GET
'''
import urllib2
url = "http://blog.csdn.net/FansUnion"
#定制自定义Header,模拟浏览器向服务器提交请求
req = urllib2.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36')
req.add_header('Host', 'blog.csdn.net')
req.add_header('Referer', 'http://blog.csdn.net')
req.add_header('GET', url)
#下载网页html并打印
html = urllib2.urlopen(req)
content = html.read()
print content
html.close()
哈哈,如果你限制我,我就跳过你的限制。据说只要浏览器可以访问,就可以被爬虫抓取。
2. 对代码的一些优化
简化提交头方法
发现每次写这么多req.add_header对自己来说都是一种折磨。有什么办法可以复制并使用它吗?答案是肯定的。
#input:
help(urllib2.Request)
#output(因篇幅关系,只取__init__方法)
__init__(self, url, data=None, headers={}, origin_req_host=None, unverifiable=False)
通过观察,我们发现headers={},就是说可以以字典的方式提交header信息.那就动手试试咯!!
#只取自定义Header部分代码
csdn_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Host": "blog.csdn.net",
'Referer': 'http://blog.csdn.net',
"GET": url
}
req = urllib2.Request(url,headers=csdn_headers)
很容易找到,我要感谢斯巴达的无私教导。
提供动态头信息
如果按照上面的方法进行爬取,很多时候提交的信息会过于单一,会被服务器当作机器爬虫来拒绝。
那么我们是否有一些更聪明的方式来提交一些动态数据,答案肯定是肯定的。而且很简单,直接上代码!
'''
@本程序是用来动态提交Header信息
@random 动态库,详情请参考
'''
# coding=utf-8
import urllib2
import random
url = 'http://www.lifevc.com/'
my_headers = [
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.04506.648)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; InfoPath.1',
'Mozilla/4.0 (compatible; GoogleToolbar 5.0.2124.2070; Windows 6.0; MSIE 8.0.6001.18241)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; Sleipnir/2.9.8)',
#因篇幅关系,此处省略N条
]
random_header = random.choice(headers)
# 可以通过print random_header查看提交的header信息
req = urllib2.Request(url)
req.add_header("User-Agent", random_header)
req.add_header('Host', 'blog.csdn.net')
req.add_header('Referer', 'http://blog.csdn.net')
req.add_header('GET', url)
content = urllib2.urlopen(req).read()
print content
其实很简单,所以我们就完成了代码的一些优化。 查看全部
抓取jsp网页源代码(
斯巴达,常用爬虫制作模块的基本用法极度推荐!)
使用Python的urllib和urllib2模块制作爬虫示例教程
更新时间:2016-01-20 10:25:51 作者:小璐D
本文主要介绍了使用Python的urllib和urllib2模块制作爬虫的示例教程,并展示了这两个常用的爬虫制作模块的基本用法。强烈推荐!有需要的朋友可以参考
网址库
在学习了python的基础知识后,我有点困惑。当我闭上眼睛时,一种空白的窒息感不断袭来。我还缺乏练习,所以我拿着履带练习我的手。学习了Spartan python爬虫课程后,我将自己的经验整理如下,供后续的翻阅。整个笔记主要分为以下几个部分:
1.做一个简单的爬虫
第一个环境描述
这个没什么好说的,直接上代码吧!
'''
@ urllib为python自带的一个网络库
@ urlopen为urllib的一个方法,用于打开一个连接并抓取网页,
然后通过read()方法把值赋给read()
'''
import urllib
url = "http://www.lifevc.com"#多嘴两句,为什么要选lifevc呢,主要是最近它很惹我.
html = urllib.urlopen(url)
content = html.read()
html.close()
#可以通过print打印出网页内容
print content
很简单,基本没什么好说的,这就是python的魅力,几行代码就可以完成。
当然,我们只是爬网,并没有真正的价值。然后我们将开始做一些有意义的事情。
2.一个小测试
抢百度贴吧图片
其实很简单,因为要抓取图片,首先要分析网页的源代码。
(这里是了解基本的html知识,浏览器以chrome为例)
如图,这里是对后续步骤的简要说明,请参考。
打开网页,右键单击并选择“检查元素”(底部项目)
点击下方弹出框最左边的问号,问号会变成蓝色
移动鼠标点击我们要捕捉的图片(一个可爱的女孩)
如图,我们可以在源码中获取图片的位置
复制下面的源代码
经过分析对比(这里略略),基本上可以看到要抓拍的图像的特征:
以后我会更新正则表达式,请大家注意
根据上面的判断,直接上传代码
'''
@本程序用来下载百度贴吧图片
@re 为正则说明库
'''
import urllib
import re
# 获取网页html信息
url = "http://tieba.baidu.com/p/2336739808"
html = urllib.urlopen(url)
content = html.read()
html.close()
# 通过正则匹配图片特征,并获取图片链接
img_tag = re.compile(r'class="BDE_Image" src="(.+?\.jpg)"')
img_links = re.findall(img_tag, content)
# 下载图片 img_counter为图片计数器(文件名)
img_counter = 0
for img_link in img_links:
img_name = '%s.jpg' % img_counter
urllib.urlretrieve(img_link, "//Users//Sean//Downloads//tieba//%s" %img_name)
img_counter += 1
如图所示,我们将抓取您理解的图片
3.总结
与前两节一样,我们可以轻松访问网页或图片。
补充一点小技巧,如果遇到不是很了解的库或者方法,可以使用下面的方法来初步了解一下。
或输入相关搜索。
当然,百度也可以,只是效率太低。建议使用相关搜索(你懂的,绝对满意)。
这里我们讲解如何抓取网页和下载图片,下面我们将讲解如何抓取限制抓取的网站。
urllib2
上面我们解释了如何抓取网页和下载图片,下一节我们将解释如何抓取限制抓取的网站
首先我们还是用上节课的方法爬取一个大家都用的网站作为例子。本文主要分为以下几个部分:
1. 抓取受限网页
首先使用我们在上一节中学到的知识进行测试:
'''
@本程序用来抓取blog.csdn.net网页
'''
import urllib
url = "http://blog.csdn.net/FansUnion"
html = urllib.urlopen(url)
#getcode()方法为返回Http状态码
print html.getcode()
html.close()
#输出
403
这里我们的输出是 403,这意味着访问被拒绝;同样,200 表示请求成功完成;404 表示未找到该 URL。
可以看到csdn被屏蔽了,无法通过第一节的方法获取到网页。这里我们需要启动一个新的库:urllib2
但我们也看到浏览器可以发布该文本。我们可以模拟浏览器操作来获取网页信息吗?
老办法,我们来看看浏览器是如何向csdn服务器提交请求的。首先简单介绍一下方法:
以下是整理后的头部信息
Request Method:GET
Host:blog.csdn.net
Referer:http://blog.csdn.net/?ref=toolbar_logo
User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.104 Safari/537.36
然后根据提取的Header信息,使用urllib2的Request方法模拟浏览器向服务器提交请求。代码如下:
# coding=utf-8
'''
@本程序用来抓取受限网页(blog.csdn.net)
@User-Agent:客户端浏览器版本
@Host:服务器地址
@Referer:跳转地址
@GET:请求方法为GET
'''
import urllib2
url = "http://blog.csdn.net/FansUnion"
#定制自定义Header,模拟浏览器向服务器提交请求
req = urllib2.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36')
req.add_header('Host', 'blog.csdn.net')
req.add_header('Referer', 'http://blog.csdn.net')
req.add_header('GET', url)
#下载网页html并打印
html = urllib2.urlopen(req)
content = html.read()
print content
html.close()
哈哈,如果你限制我,我就跳过你的限制。据说只要浏览器可以访问,就可以被爬虫抓取。
2. 对代码的一些优化
简化提交头方法
发现每次写这么多req.add_header对自己来说都是一种折磨。有什么办法可以复制并使用它吗?答案是肯定的。
#input:
help(urllib2.Request)
#output(因篇幅关系,只取__init__方法)
__init__(self, url, data=None, headers={}, origin_req_host=None, unverifiable=False)
通过观察,我们发现headers={},就是说可以以字典的方式提交header信息.那就动手试试咯!!
#只取自定义Header部分代码
csdn_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Host": "blog.csdn.net",
'Referer': 'http://blog.csdn.net',
"GET": url
}
req = urllib2.Request(url,headers=csdn_headers)
很容易找到,我要感谢斯巴达的无私教导。
提供动态头信息
如果按照上面的方法进行爬取,很多时候提交的信息会过于单一,会被服务器当作机器爬虫来拒绝。
那么我们是否有一些更聪明的方式来提交一些动态数据,答案肯定是肯定的。而且很简单,直接上代码!
'''
@本程序是用来动态提交Header信息
@random 动态库,详情请参考
'''
# coding=utf-8
import urllib2
import random
url = 'http://www.lifevc.com/'
my_headers = [
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.04506.648)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; InfoPath.1',
'Mozilla/4.0 (compatible; GoogleToolbar 5.0.2124.2070; Windows 6.0; MSIE 8.0.6001.18241)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; Sleipnir/2.9.8)',
#因篇幅关系,此处省略N条
]
random_header = random.choice(headers)
# 可以通过print random_header查看提交的header信息
req = urllib2.Request(url)
req.add_header("User-Agent", random_header)
req.add_header('Host', 'blog.csdn.net')
req.add_header('Referer', 'http://blog.csdn.net')
req.add_header('GET', url)
content = urllib2.urlopen(req).read()
print content
其实很简单,所以我们就完成了代码的一些优化。
抓取jsp网页源代码(如何应对数据匮乏的问题?最简单的方法在这里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-12-25 22:20
作者 | 拉克夏阿罗拉
编译|弗林
来源|analyticsvidhya
概述介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络爬行。我个人发现网络抓取是一种非常有用的技术,可以从多个网站采集
数据。如今,一些网站还为您可能想要使用的许多不同类型的数据提供 API,例如推文或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的网站采集
数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库进行网页抓取。
我们还为本文创建了一个免费课程:
请注意,网络抓取受许多准则和规则的约束。并非每个网站都允许用户抓取内容,因此存在一定的法律限制。在尝试执行此操作之前,请确保您已阅读该网站的网站条款和条件。
内容
3 个流行的 Python 网络爬虫工具和库
网络爬虫组件
CrawlParse 和 TransformStore
从网页中抓取 URL 和电子邮件 ID
抓取图片
页面加载时抓取数据
3 个流行的 Python 网络爬虫工具和库
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
刮痧
硒
网络爬虫组件
这是构成网络爬行的三个主要组件的极好说明:
让我们详细了解这些组件。我们将使用 goibibo 网站获取酒店详细信息,例如酒店名称和每间客房的价格,以实现此目的:
注意:请始终遵循目标网站的robots.txt文件,也称为机器人排除协议。这可以告诉网络机器人不抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。开始吧!
第 1 步:爬网
网页抓取的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
\'User-Agent\': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, \'html.parser\')
print(data)
第 2 步:解析和转换
网络抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,就像大多数页面一样,特定酒店的详细信息位于不同的卡片上。
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下信息:
所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
# find all the sections with specifiedd class name
cards_data = data.find_all(\'div\', attrs={\'class\', \'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block\'})
# total number of cards
print(\'Total Number of Cards Found : \', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录
有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find(\'p\')
# get the room price
room_price = card.find(\'li\', attrs={\'class\': \'htl-tile-discount-prc\'})
print(hotel_name.text, room_price.text)
第 3 步:Store(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find(\'p\')
# get the room price
room_price = card.find(\'li\', attrs={\'class\': \'htl-tile-discount-prc\'})
# add data to the dictionary
card_details[\'hotel_name\'] = hotel_name.text
card_details[\'room_price\'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv(\'hotels_data.csv\', index=False)
恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网络抓取来抓取的两个最常见的功能是网站 URL 和电子邮件 ID。我相信你参与过一个需要大量电子邮件 ID 提取的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台 查看全部
抓取jsp网页源代码(如何应对数据匮乏的问题?最简单的方法在这里)
作者 | 拉克夏阿罗拉
编译|弗林
来源|analyticsvidhya
概述介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络爬行。我个人发现网络抓取是一种非常有用的技术,可以从多个网站采集
数据。如今,一些网站还为您可能想要使用的许多不同类型的数据提供 API,例如推文或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的网站采集
数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库进行网页抓取。
我们还为本文创建了一个免费课程:
请注意,网络抓取受许多准则和规则的约束。并非每个网站都允许用户抓取内容,因此存在一定的法律限制。在尝试执行此操作之前,请确保您已阅读该网站的网站条款和条件。
内容
3 个流行的 Python 网络爬虫工具和库
网络爬虫组件
CrawlParse 和 TransformStore
从网页中抓取 URL 和电子邮件 ID
抓取图片
页面加载时抓取数据
3 个流行的 Python 网络爬虫工具和库
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
刮痧
硒
网络爬虫组件
这是构成网络爬行的三个主要组件的极好说明:
让我们详细了解这些组件。我们将使用 goibibo 网站获取酒店详细信息,例如酒店名称和每间客房的价格,以实现此目的:
注意:请始终遵循目标网站的robots.txt文件,也称为机器人排除协议。这可以告诉网络机器人不抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。开始吧!
第 1 步:爬网
网页抓取的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
\'User-Agent\': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, \'html.parser\')
print(data)
第 2 步:解析和转换
网络抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,就像大多数页面一样,特定酒店的详细信息位于不同的卡片上。
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下信息:
所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
# find all the sections with specifiedd class name
cards_data = data.find_all(\'div\', attrs={\'class\', \'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block\'})
# total number of cards
print(\'Total Number of Cards Found : \', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录
有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find(\'p\')
# get the room price
room_price = card.find(\'li\', attrs={\'class\': \'htl-tile-discount-prc\'})
print(hotel_name.text, room_price.text)
第 3 步:Store(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find(\'p\')
# get the room price
room_price = card.find(\'li\', attrs={\'class\': \'htl-tile-discount-prc\'})
# add data to the dictionary
card_details[\'hotel_name\'] = hotel_name.text
card_details[\'room_price\'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv(\'hotels_data.csv\', index=False)
恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网络抓取来抓取的两个最常见的功能是网站 URL 和电子邮件 ID。我相信你参与过一个需要大量电子邮件 ID 提取的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台
抓取jsp网页源代码(部分系统截图如下:基于javaweb的众筹网源码分享(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-18 13:04
这是一个类似于CSDN网站的博客,用户可以发布博客,智能检索博客,还具有文件上传下载、在线预览等功能,方便大家实现资源共享;部分系统截图如下:
基于javaweb的众筹网络源码分享
这个网站是为同学们做的毕业设计。指目前主流的众筹网站,包括发起众筹项目、赞助项目、资金管理、智能检索等功能,部分截图如下:
操作说明
类似这个网站我写过很多,这两个网站的风格差别很大,所以非常适合大家训练。我之前买的服务器已经过期了,不然可以直接在网上浏览这两个网站,我用的是MySQL数据库,eclipse作为开发软件,里面有代码需要用到的jar。
hibernate连接的数据库有自己的建表功能。只要程序运行,它就会根据你的代码逻辑在数据库中自动构建系统所需的表。运行代码时,只需要修改WebContent/WEB-INF/applicationContext.xml文件中的MySQL用户名和密码即可。如下所示:
另外,还需要在MySQL中创建一个与applicationContext.xml配置文件中的数据库名同名的数据库。这时候代码就可以顺利运行了,还得自己消化代码。
干货: 查看全部
抓取jsp网页源代码(部分系统截图如下:基于javaweb的众筹网源码分享(组图))
这是一个类似于CSDN网站的博客,用户可以发布博客,智能检索博客,还具有文件上传下载、在线预览等功能,方便大家实现资源共享;部分系统截图如下:
基于javaweb的众筹网络源码分享
这个网站是为同学们做的毕业设计。指目前主流的众筹网站,包括发起众筹项目、赞助项目、资金管理、智能检索等功能,部分截图如下:
操作说明
类似这个网站我写过很多,这两个网站的风格差别很大,所以非常适合大家训练。我之前买的服务器已经过期了,不然可以直接在网上浏览这两个网站,我用的是MySQL数据库,eclipse作为开发软件,里面有代码需要用到的jar。
hibernate连接的数据库有自己的建表功能。只要程序运行,它就会根据你的代码逻辑在数据库中自动构建系统所需的表。运行代码时,只需要修改WebContent/WEB-INF/applicationContext.xml文件中的MySQL用户名和密码即可。如下所示:
另外,还需要在MySQL中创建一个与applicationContext.xml配置文件中的数据库名同名的数据库。这时候代码就可以顺利运行了,还得自己消化代码。
干货:
抓取jsp网页源代码(抓取jsp网页源代码,首先要懂得基本语法(htmlapi))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-12-16 18:43
抓取jsp网页源代码,首先要懂得基本语法(htmlapi),例如:pagelogin:返回cookie登录状态。setloginonlogin:返回cookie登录状态。setloginaccount:返回session的会话权限。setloginpassword:返回密码。..有了这些基本语法,再看一遍《jsp源码剖析》,这时,需要抓取的网页就被看懂了。
抓取页面还可以同时做分析,包括分析某个控件使用的parameter参数(设置之类的)、servlet的请求方式(post方式还是get方式)等等。
网站分析还是要花大量的时间的...主要是要做的东西比较多,有些你可能没遇到过的。可以主攻web服务器,
感觉其实主要用熟了就好了,
框架工具一个都不能少
分析分析源码
web服务器内部有这么几个主要部分:1.accesstoken,是访问的dom,dom中包含所有的name,attribute等等。2.domainapi,对domain进行的操作,必须经过这个api。
框架的话,不仅仅是要分析框架,最重要的是需要学习的是开发思路和一套完整的工具(或者说是工具组件)。可以采用基于源码的分析工具来分析。现在比较成熟的可以用一点金蜂源码分析工具。基于百度百科的,很容易上手的。 查看全部
抓取jsp网页源代码(抓取jsp网页源代码,首先要懂得基本语法(htmlapi))
抓取jsp网页源代码,首先要懂得基本语法(htmlapi),例如:pagelogin:返回cookie登录状态。setloginonlogin:返回cookie登录状态。setloginaccount:返回session的会话权限。setloginpassword:返回密码。..有了这些基本语法,再看一遍《jsp源码剖析》,这时,需要抓取的网页就被看懂了。
抓取页面还可以同时做分析,包括分析某个控件使用的parameter参数(设置之类的)、servlet的请求方式(post方式还是get方式)等等。
网站分析还是要花大量的时间的...主要是要做的东西比较多,有些你可能没遇到过的。可以主攻web服务器,
感觉其实主要用熟了就好了,
框架工具一个都不能少
分析分析源码
web服务器内部有这么几个主要部分:1.accesstoken,是访问的dom,dom中包含所有的name,attribute等等。2.domainapi,对domain进行的操作,必须经过这个api。
框架的话,不仅仅是要分析框架,最重要的是需要学习的是开发思路和一套完整的工具(或者说是工具组件)。可以采用基于源码的分析工具来分析。现在比较成熟的可以用一点金蜂源码分析工具。基于百度百科的,很容易上手的。
抓取jsp网页源代码(㈠JSP与ASP还有一个更为的本质的区别??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-12-15 19:15
一、 JSP 技术概述
Sun正式发布JSP(JavaServer Pages)后,这种全新的Web应用开发技术迅速引起了人们的关注。JSP 为创建高度动态的 Web 应用程序提供了独特的开发环境。Sun表示,JSP可以适应市场上85%的服务器产品,包括Apache WebServer和IIS4.0。即使你对 ASP 有很深的热爱,我们认为关注 JSP 的开发还是很有必要的。
(一)JSP和ASP的简单比较
JSP 与微软的 ASP 技术非常相似。两者都提供了在 HTML 代码中混合某种程序代码的能力,并且语言引擎解释并执行程序代码。在 ASP 或 JSP 环境中,HTML 代码主要负责描述信息的显示风格,而程序代码则用于描述处理逻辑。普通的 HTML 页面只依赖 Web 服务器,而 ASP 和 JSP 页面则需要额外的语言引擎来分析和执行程序代码。程序代码的执行结果被重新嵌入到HTML代码中,然后一起发送给浏览器。ASP 和 JSP 都是针对 Web 服务器的技术,客户端浏览器不需要任何额外的软件支持。
ASP编程语言是VBScript等脚本语言,JSP使用Java。这是两者最明显的区别。另外,ASP和JSP还有一个更本质的区别:两种语言引擎对嵌入页面的程序代码的处理方式完全不同。在ASP下,VBScript代码由ASP引擎解释和执行;在JSP下,代码被编译成一个Servlet,由Java虚拟机执行。该编译操作仅在第一次请求 JSP 页面时发生。
(2) 运行环境
Sun 的 JSP 主页在这里。您还可以从这里下载 JSP 规范。这些规范定义了供应商在创建 JSP 引擎时必须遵循的一些规则。
JSP 代码的执行需要在服务器上安装 JSP 引擎。这里我们使用 Sun 的 JavaServer Web Development Kit (JSWDK)。为方便学习,本软件包提供了大量可修改的示例。安装 JSWDK 后,只需执行 startserver 命令即可启动服务器。默认配置下,服务器监听8080端口。使用:8080打开默认页面。
在运行 JSP 示例页面之前,请注意 JSWDK 的安装目录,尤其是“work”子目录下的内容。在执行示例页面时,您可以在此处看到 JSP 页面如何转换为 Java 源文件,然后编译为类文件(即 Servlet)。JSWDK 软件包中的示例页面分为两类。它们是收录表单的 JSP 文件或 HTML 文件。这些表单由 JSP 代码处理。与ASP 一样,JSP 中的Java 代码在服务器端执行。因此,您无法通过浏览器中的“查看源文件”菜单看到 JSP 源代码,只能看到生成的 HTML 代码。所有示例的源代码都在单独的“示例”页面上提供。
(3) JSP页面示例
我们来分析一个简单的JSP页面。您可以在JSWDK 的examples 目录中创建另一个目录来存储此文件。文件名可以是任何名称,但扩展名必须是 .jsp。从下面的代码清单中可以看出,JSP 页面的结构基本相同,只是 Java 代码比普通 HTML 页面多。Java 代码通过<% 和%> 符号添加到HTML 代码中。它的主要功能是生成并显示一个从0到9的字符串。这个字符串前后是一些通过HTML代码输出的文本。
<HTML>
<HEAD><TITLE>JSP 页面< /TITLE>< /HEAD>
<身体>
<%@ 页面语言="java" %>
<%! 字符串 str="0"; %>
<% for (int i=1; i <10; i++) {
str = str + i;
}%>
在 JSP 输出之前。
<P>
<%= 字符串 %>
<P>
JSP输出后。
</BODY>
</HTML>
这个JSP页面可以分成几个部分进行分析。
首先是JSP指令。它描述了页面的基本信息,如使用的语言、是否保持会话状态、是否使用缓冲等。JSP指令以<%@开头,以%>结尾。在这个例子中,指令“<%@ page language="java" %>”简单地定义了这个例子使用Java语言(目前,Java是JSP规范中唯一支持的语言)。
接下来是 JSP 声明。JSP 声明可以看作是在类级别定义变量和方法的地方。JSP 声明以 <%! 并以 %> 结尾。例如,本例中的“<%!String str="0"; %>”定义了一个字符串变量。每个声明后必须有一个分号,就像在普通Java类中声明成员变量一样。
<% 和 %> 之间的代码块是 Java 代码,描述了 JSP 页面的处理逻辑,如本例中的 for 循环所示。
最后,<%= 和 %> 之间的代码称为 JSP 表达式,如本示例中的“<%= str %>”所示。JSP 表达式提供了一种将 JSP 生成的值嵌入 HTML 页面的简单方法。
二、会话状态管理
作者:仙人掌工作室
会话状态维护是 Web 应用程序开发人员必须面临的问题。解决这个问题的方法有很多,比如使用Cookies、隐藏表单输入字段,或者直接在URL中附加状态信息。Java Servlet 提供了一个在多个请求之间持久化的会话对象,它允许用户存储和检索会话状态信息。JSP 在 Servlet 中也支持这个概念。
在 Sun 的 JSP 指南中,可以看到很多关于隐式对象的解释(隐式的意思是这些对象可以直接引用,无需显式声明,也不需要特殊的代码来创建它们的实例)。比如请求对象,它是HttpServletRequest的子类。该对象收录当前浏览器请求的所有信息,包括 Cookies、HTML 表单变量等。session对象也是这样一个隐式对象。该对象在加载第一个 JSP 页面时自动创建,并与请求对象相关联。与ASP 中的会话对象类似,JSP 中的会话对象对于希望通过多个页面完成一个事务的应用程序非常有用。
为了说明session对象的具体应用,接下来我们用三个页面来模拟一个多页面的Web应用。第一个页面(q1.html)只收录一个要求用户名的HTML表单,代码如下:
<HTML>
<身体>
<FORM METHOD=POST ACTION="q2.jsp">
请输入你的名字:
<输入类型=文本>
<输入类型=提交值="提交">
</FORM>
</BODY>
</HTML>
第二个页面是一个JSP页面(q2.jsp),通过request对象提取q1.html表单中的name值,存储为name变量,然后保存name值到会话对象。会话对象是一个名称/值对的集合,其中名称/值对中的名称是“thename”,值是名称变量的值。由于会话对象在会话期间始终有效,因此这里保存的变量对于后续页面也有效。q2.jsp 的另一个任务是问第二个问题。这是它的代码:
<HTML>
<身体>
<%@ 页面语言="java" %>
<%! 细绳; %>
<%
name = request.getParameter("thename");
session.putValue("thename", name);
%>
你的名字是:<%=名字%>
<p>
<FORM METHOD=POST ACTION="q3.jsp">
你喜欢吃什么?
<输入类型=文本>
<P>
<输入类型=提交值="提交">
</FORM>
</BODY>
</HTML>
第三个页面也是一个JSP页面(q3.jsp),主要任务是展示问答的结果。它从 session 对象中提取出 thename 的值并显示出来,这就证明了虽然这个值是在第一页输入的,但是它被 session 对象保留了。q3.jsp 的另一个任务是提取第二页中的用户输入并显示出来:
<HTML>
<身体>
<%@ 页面语言="java" %>
<%! 字符串食物=""; %>
<%
食物 = request.getParameter("食物");
String name = (String) session.getValue("thename");
%>
你的名字是:<%=名字%>
<P>
你喜欢吃吗:<%=食物%>
</BODY>
</HTML>
三、参考JavaBean组件
作者:Cactus Studio 编译
JavaBean 是一个基于 Java 的软件组件。JSP 为在 Web 应用程序中集成 JavaBean 组件提供了完整的支持。这种支持不仅缩短了开发时间(您可以直接使用经过测试和信任的现有组件,避免重复开发),还为 JSP 应用程序带来了更多的可扩展性。JavaBean 组件可用于执行复杂的计算任务,或负责与数据库交互和数据提取。如果我们有三个JavaBean,分别具有显示新闻、股票价格和天气状况的功能,那么创建一个收录所有这三个功能的网页只需要实例化这三个Bean,并使用HTML表格依次定位它们。.
为了说明JavaBean 在JSP 环境中的应用,我们创建了一个名为TaxRate 的Bean。它有两个属性,即产品和费率。两个set方法用于设置这两个属性,两个get方法用于提取这两个属性。在实际应用中,这种Bean一般应该是从数据库中提取税率值。在这里,我们简化了这个过程,并允许设置任意税率。下面是这个Bean的代码清单:
包裹税;
公共课税率{
字符串产品;
双倍率;
公共税率(){
this.Product = "A001";
this.Rate = 5;
}
public void setProduct (String ProductName) {
this.Product = 产品名称;
}
公共字符串 getProduct() {
返回 (this.Product);
}
public void setRate (double rateValue) {
this.Rate = rateValue;
}
公共双getRate(){
返回 (this.Rate);
}
}
<jsp:useBean> 标签用于在JSP 页面中应用上述Bean。根据所使用的具体 JSP 引擎,在何处配置 Bean 以及如何配置 Bean 的方法也可能略有不同。本文将Bean的.class文件放在c:jswdk-1.0examplesWEB-INFjspbeanstax目录下,其中tax是专用于存放Bean的目录。这是使用上述 Bean 的示例页面:
<HTML>
<身体>
<%@ 页面语言="java" %>
<jsp:useBean scope="应用程序" />
<% taxbean.setProduct("A002");
taxbean.setRate(17);
%>
使用方法一:<p>
产品:<%= taxbean.getProduct() %> <br>
税率:<%= taxbean.getRate() %>
<p>
<% taxbean.setProduct("A003");
taxbean.setRate(3);
%>
<b>如何使用2:</b> <p>
产品:<jsp:getProperty property="Product" />
<br>
税率:<jsp:getProperty property="Rate" />
</BODY>
</HTML>
<jsp:useBean>标签定义了几个属性,其中id是整个JSP页面中Bean的ID,scope属性定义了Bean的生命周期,class属性描述了Bean的类文件(从包裹名字) )。
这个JSP页面不仅使用Bean的set和get方法设置和提取属性值,还使用了第二种提取Bean属性值的方法,即使用<jsp:getProperty>标签。<jsp:getProperty>中的name属性是<jsp:useBean>中定义的Bean的id,其property属性指定了目标属性的名称。
事实证明,Java Servlet 是开发Web 应用程序的理想框架。JSP 基于 Servlet 技术,并在很多方面进行了改进。JSP 页面看起来像一个普通的 HTML 页面,但它允许嵌入执行代码。在这方面,它与 ASP 技术非常相似。JSP利用跨平台运行的JavaBean组件,为分离处理逻辑和显示样式提供了一个很好的解决方案。JSP势必成为ASP技术的有力竞争者。 查看全部
抓取jsp网页源代码(㈠JSP与ASP还有一个更为的本质的区别??)
一、 JSP 技术概述
Sun正式发布JSP(JavaServer Pages)后,这种全新的Web应用开发技术迅速引起了人们的关注。JSP 为创建高度动态的 Web 应用程序提供了独特的开发环境。Sun表示,JSP可以适应市场上85%的服务器产品,包括Apache WebServer和IIS4.0。即使你对 ASP 有很深的热爱,我们认为关注 JSP 的开发还是很有必要的。
(一)JSP和ASP的简单比较
JSP 与微软的 ASP 技术非常相似。两者都提供了在 HTML 代码中混合某种程序代码的能力,并且语言引擎解释并执行程序代码。在 ASP 或 JSP 环境中,HTML 代码主要负责描述信息的显示风格,而程序代码则用于描述处理逻辑。普通的 HTML 页面只依赖 Web 服务器,而 ASP 和 JSP 页面则需要额外的语言引擎来分析和执行程序代码。程序代码的执行结果被重新嵌入到HTML代码中,然后一起发送给浏览器。ASP 和 JSP 都是针对 Web 服务器的技术,客户端浏览器不需要任何额外的软件支持。
ASP编程语言是VBScript等脚本语言,JSP使用Java。这是两者最明显的区别。另外,ASP和JSP还有一个更本质的区别:两种语言引擎对嵌入页面的程序代码的处理方式完全不同。在ASP下,VBScript代码由ASP引擎解释和执行;在JSP下,代码被编译成一个Servlet,由Java虚拟机执行。该编译操作仅在第一次请求 JSP 页面时发生。
(2) 运行环境
Sun 的 JSP 主页在这里。您还可以从这里下载 JSP 规范。这些规范定义了供应商在创建 JSP 引擎时必须遵循的一些规则。
JSP 代码的执行需要在服务器上安装 JSP 引擎。这里我们使用 Sun 的 JavaServer Web Development Kit (JSWDK)。为方便学习,本软件包提供了大量可修改的示例。安装 JSWDK 后,只需执行 startserver 命令即可启动服务器。默认配置下,服务器监听8080端口。使用:8080打开默认页面。
在运行 JSP 示例页面之前,请注意 JSWDK 的安装目录,尤其是“work”子目录下的内容。在执行示例页面时,您可以在此处看到 JSP 页面如何转换为 Java 源文件,然后编译为类文件(即 Servlet)。JSWDK 软件包中的示例页面分为两类。它们是收录表单的 JSP 文件或 HTML 文件。这些表单由 JSP 代码处理。与ASP 一样,JSP 中的Java 代码在服务器端执行。因此,您无法通过浏览器中的“查看源文件”菜单看到 JSP 源代码,只能看到生成的 HTML 代码。所有示例的源代码都在单独的“示例”页面上提供。
(3) JSP页面示例
我们来分析一个简单的JSP页面。您可以在JSWDK 的examples 目录中创建另一个目录来存储此文件。文件名可以是任何名称,但扩展名必须是 .jsp。从下面的代码清单中可以看出,JSP 页面的结构基本相同,只是 Java 代码比普通 HTML 页面多。Java 代码通过<% 和%> 符号添加到HTML 代码中。它的主要功能是生成并显示一个从0到9的字符串。这个字符串前后是一些通过HTML代码输出的文本。
<HTML>
<HEAD><TITLE>JSP 页面< /TITLE>< /HEAD>
<身体>
<%@ 页面语言="java" %>
<%! 字符串 str="0"; %>
<% for (int i=1; i <10; i++) {
str = str + i;
}%>
在 JSP 输出之前。
<P>
<%= 字符串 %>
<P>
JSP输出后。
</BODY>
</HTML>
这个JSP页面可以分成几个部分进行分析。
首先是JSP指令。它描述了页面的基本信息,如使用的语言、是否保持会话状态、是否使用缓冲等。JSP指令以<%@开头,以%>结尾。在这个例子中,指令“<%@ page language="java" %>”简单地定义了这个例子使用Java语言(目前,Java是JSP规范中唯一支持的语言)。
接下来是 JSP 声明。JSP 声明可以看作是在类级别定义变量和方法的地方。JSP 声明以 <%! 并以 %> 结尾。例如,本例中的“<%!String str="0"; %>”定义了一个字符串变量。每个声明后必须有一个分号,就像在普通Java类中声明成员变量一样。
<% 和 %> 之间的代码块是 Java 代码,描述了 JSP 页面的处理逻辑,如本例中的 for 循环所示。
最后,<%= 和 %> 之间的代码称为 JSP 表达式,如本示例中的“<%= str %>”所示。JSP 表达式提供了一种将 JSP 生成的值嵌入 HTML 页面的简单方法。
二、会话状态管理
作者:仙人掌工作室
会话状态维护是 Web 应用程序开发人员必须面临的问题。解决这个问题的方法有很多,比如使用Cookies、隐藏表单输入字段,或者直接在URL中附加状态信息。Java Servlet 提供了一个在多个请求之间持久化的会话对象,它允许用户存储和检索会话状态信息。JSP 在 Servlet 中也支持这个概念。
在 Sun 的 JSP 指南中,可以看到很多关于隐式对象的解释(隐式的意思是这些对象可以直接引用,无需显式声明,也不需要特殊的代码来创建它们的实例)。比如请求对象,它是HttpServletRequest的子类。该对象收录当前浏览器请求的所有信息,包括 Cookies、HTML 表单变量等。session对象也是这样一个隐式对象。该对象在加载第一个 JSP 页面时自动创建,并与请求对象相关联。与ASP 中的会话对象类似,JSP 中的会话对象对于希望通过多个页面完成一个事务的应用程序非常有用。
为了说明session对象的具体应用,接下来我们用三个页面来模拟一个多页面的Web应用。第一个页面(q1.html)只收录一个要求用户名的HTML表单,代码如下:
<HTML>
<身体>
<FORM METHOD=POST ACTION="q2.jsp">
请输入你的名字:
<输入类型=文本>
<输入类型=提交值="提交">
</FORM>
</BODY>
</HTML>
第二个页面是一个JSP页面(q2.jsp),通过request对象提取q1.html表单中的name值,存储为name变量,然后保存name值到会话对象。会话对象是一个名称/值对的集合,其中名称/值对中的名称是“thename”,值是名称变量的值。由于会话对象在会话期间始终有效,因此这里保存的变量对于后续页面也有效。q2.jsp 的另一个任务是问第二个问题。这是它的代码:
<HTML>
<身体>
<%@ 页面语言="java" %>
<%! 细绳; %>
<%
name = request.getParameter("thename");
session.putValue("thename", name);
%>
你的名字是:<%=名字%>
<p>
<FORM METHOD=POST ACTION="q3.jsp">
你喜欢吃什么?
<输入类型=文本>
<P>
<输入类型=提交值="提交">
</FORM>
</BODY>
</HTML>
第三个页面也是一个JSP页面(q3.jsp),主要任务是展示问答的结果。它从 session 对象中提取出 thename 的值并显示出来,这就证明了虽然这个值是在第一页输入的,但是它被 session 对象保留了。q3.jsp 的另一个任务是提取第二页中的用户输入并显示出来:
<HTML>
<身体>
<%@ 页面语言="java" %>
<%! 字符串食物=""; %>
<%
食物 = request.getParameter("食物");
String name = (String) session.getValue("thename");
%>
你的名字是:<%=名字%>
<P>
你喜欢吃吗:<%=食物%>
</BODY>
</HTML>
三、参考JavaBean组件
作者:Cactus Studio 编译
JavaBean 是一个基于 Java 的软件组件。JSP 为在 Web 应用程序中集成 JavaBean 组件提供了完整的支持。这种支持不仅缩短了开发时间(您可以直接使用经过测试和信任的现有组件,避免重复开发),还为 JSP 应用程序带来了更多的可扩展性。JavaBean 组件可用于执行复杂的计算任务,或负责与数据库交互和数据提取。如果我们有三个JavaBean,分别具有显示新闻、股票价格和天气状况的功能,那么创建一个收录所有这三个功能的网页只需要实例化这三个Bean,并使用HTML表格依次定位它们。.
为了说明JavaBean 在JSP 环境中的应用,我们创建了一个名为TaxRate 的Bean。它有两个属性,即产品和费率。两个set方法用于设置这两个属性,两个get方法用于提取这两个属性。在实际应用中,这种Bean一般应该是从数据库中提取税率值。在这里,我们简化了这个过程,并允许设置任意税率。下面是这个Bean的代码清单:
包裹税;
公共课税率{
字符串产品;
双倍率;
公共税率(){
this.Product = "A001";
this.Rate = 5;
}
public void setProduct (String ProductName) {
this.Product = 产品名称;
}
公共字符串 getProduct() {
返回 (this.Product);
}
public void setRate (double rateValue) {
this.Rate = rateValue;
}
公共双getRate(){
返回 (this.Rate);
}
}
<jsp:useBean> 标签用于在JSP 页面中应用上述Bean。根据所使用的具体 JSP 引擎,在何处配置 Bean 以及如何配置 Bean 的方法也可能略有不同。本文将Bean的.class文件放在c:jswdk-1.0examplesWEB-INFjspbeanstax目录下,其中tax是专用于存放Bean的目录。这是使用上述 Bean 的示例页面:
<HTML>
<身体>
<%@ 页面语言="java" %>
<jsp:useBean scope="应用程序" />
<% taxbean.setProduct("A002");
taxbean.setRate(17);
%>
使用方法一:<p>
产品:<%= taxbean.getProduct() %> <br>
税率:<%= taxbean.getRate() %>
<p>
<% taxbean.setProduct("A003");
taxbean.setRate(3);
%>
<b>如何使用2:</b> <p>
产品:<jsp:getProperty property="Product" />
<br>
税率:<jsp:getProperty property="Rate" />
</BODY>
</HTML>
<jsp:useBean>标签定义了几个属性,其中id是整个JSP页面中Bean的ID,scope属性定义了Bean的生命周期,class属性描述了Bean的类文件(从包裹名字) )。
这个JSP页面不仅使用Bean的set和get方法设置和提取属性值,还使用了第二种提取Bean属性值的方法,即使用<jsp:getProperty>标签。<jsp:getProperty>中的name属性是<jsp:useBean>中定义的Bean的id,其property属性指定了目标属性的名称。
事实证明,Java Servlet 是开发Web 应用程序的理想框架。JSP 基于 Servlet 技术,并在很多方面进行了改进。JSP 页面看起来像一个普通的 HTML 页面,但它允许嵌入执行代码。在这方面,它与 ASP 技术非常相似。JSP利用跨平台运行的JavaBean组件,为分离处理逻辑和显示样式提供了一个很好的解决方案。JSP势必成为ASP技术的有力竞争者。
抓取jsp网页源代码(Java开发:JSP页面的基本属性的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-12-15 09:36
--用于声明当前JSP页面基本属性的页面指令可以写在JSP页面的任何位置,但为了可读性,通常最好将其放在JSP页面的前面
格式:
(1)——用于通知JSP解析引擎使用指定的代码翻译JSP。如果要防止JSP代码乱码,则应确保保存JSP文件时的代码与pageencoding指定的代码一致
(2)——为JSP翻译的servlet指定依赖jar包。例如:
--您可以实现页面收录的效果,即页面的合并效果
格式:
使用JSTL标记库中的标记时,应将JSTL标记库引入当前jsp:
前缀值可以是任意值,但在使用JSTL标记库时应将其用作标记名
注意:在导入之前,还需要导入与JSTL相关的jar包
JSP标记技术
在JSP页面中编写大量Java代码将导致JSP页面中HTML代码和Java代码的混合,这将导致页面非常混乱,难以维护
因此,在JSP的2.0版本中,sun提出了JSP标记技术,建议使用标记替换JSP页面中的java代码,并建议JSP2.0之后JSP页面中不应出现任何java代码行
El表达式
格式:${constant,expression,variable}变量必须事先存储在字段中
功能:主要功能是从域中获取数据并输出
(1)获取常量、表达式或变量的值(变量必须位于现有字段中)
<p>${ "Hello EL" } Hello EL
${ 100+123 } ${ (23*54) > 1250 ? 23*54 : 1250 }
${ name1 }
在EL中书写变量, 会通过变量名(name1)到四个域中去
寻找指定名称(name1)属性值, 如果找到就返回属性值,
如果找不到, 就什么也不输出。
寻找时按照域的范围大小, 按照从小到大的顺序去寻找,
找到就输出,找不到就接着往后查找,最终还找不到,就
什么也不输出!
pageContext 查看全部
抓取jsp网页源代码(Java开发:JSP页面的基本属性的)
--用于声明当前JSP页面基本属性的页面指令可以写在JSP页面的任何位置,但为了可读性,通常最好将其放在JSP页面的前面
格式:
(1)——用于通知JSP解析引擎使用指定的代码翻译JSP。如果要防止JSP代码乱码,则应确保保存JSP文件时的代码与pageencoding指定的代码一致
(2)——为JSP翻译的servlet指定依赖jar包。例如:
--您可以实现页面收录的效果,即页面的合并效果
格式:
使用JSTL标记库中的标记时,应将JSTL标记库引入当前jsp:
前缀值可以是任意值,但在使用JSTL标记库时应将其用作标记名
注意:在导入之前,还需要导入与JSTL相关的jar包
JSP标记技术
在JSP页面中编写大量Java代码将导致JSP页面中HTML代码和Java代码的混合,这将导致页面非常混乱,难以维护
因此,在JSP的2.0版本中,sun提出了JSP标记技术,建议使用标记替换JSP页面中的java代码,并建议JSP2.0之后JSP页面中不应出现任何java代码行
El表达式
格式:${constant,expression,variable}变量必须事先存储在字段中
功能:主要功能是从域中获取数据并输出
(1)获取常量、表达式或变量的值(变量必须位于现有字段中)
<p>${ "Hello EL" } Hello EL
${ 100+123 } ${ (23*54) > 1250 ? 23*54 : 1250 }
${ name1 }
在EL中书写变量, 会通过变量名(name1)到四个域中去
寻找指定名称(name1)属性值, 如果找到就返回属性值,
如果找不到, 就什么也不输出。
寻找时按照域的范围大小, 按照从小到大的顺序去寻找,
找到就输出,找不到就接着往后查找,最终还找不到,就
什么也不输出!
pageContext
抓取jsp网页源代码(参加学校软件杯大赛,弄一个简单的页面搜索也出错)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-12-15 08:03
我最近参加了学校软件杯比赛。我真的属于菜鸟,什么都不懂。所以简单的页面搜索也是很多错误的。
今天实现了一个通过jsp的模糊搜索,访问数据库并显示出来
表单的action属性中的jsp页面是传递数据,提交jsp页面的onclick属性是跳转到需要到达的页面
search.jsp页面的接收数据,第一句是通过jsp从首页接收到的数据,第二句是建立模糊查询语句,第三局是通过自己的连接查询数据库的方式进行查询
以上就是通过表单实现传输数据和跳转页面的功能
接下来是跳过 a 标签并传递值
">
HomePage.jsp 中的href 是跳转到的第三页,?下面的 CORP_NAME=555 是传递的常量值
是jsp查询的数据,我做的项目就是我搜索的公司名称,是一个变量
HomePage.jsp页面中的接收代码,第一句是通过jsp从首页接收数据,第二句是建立谨慎查询语句,第三局是通过自己的连接查询数据库的方式进行查询
如果运行时报错,建议传入out.print();检查自己的查询语句和查询数据
如果出现乱码,建议修改浏览器的编码设置自动检测,在tomcat conf子目录下的server.xml
后面添加URIEncoding="utf-8",小峰设置为utf-8
最后写到第三页的时候,发现jsp代码的复用性太差了。一个新的jdbc对象需要新建一个,多表关联时,需要列出所有条件。 查看全部
抓取jsp网页源代码(参加学校软件杯大赛,弄一个简单的页面搜索也出错)
我最近参加了学校软件杯比赛。我真的属于菜鸟,什么都不懂。所以简单的页面搜索也是很多错误的。
今天实现了一个通过jsp的模糊搜索,访问数据库并显示出来
表单的action属性中的jsp页面是传递数据,提交jsp页面的onclick属性是跳转到需要到达的页面
search.jsp页面的接收数据,第一句是通过jsp从首页接收到的数据,第二句是建立模糊查询语句,第三局是通过自己的连接查询数据库的方式进行查询
以上就是通过表单实现传输数据和跳转页面的功能
接下来是跳过 a 标签并传递值
">
HomePage.jsp 中的href 是跳转到的第三页,?下面的 CORP_NAME=555 是传递的常量值
是jsp查询的数据,我做的项目就是我搜索的公司名称,是一个变量
HomePage.jsp页面中的接收代码,第一句是通过jsp从首页接收数据,第二句是建立谨慎查询语句,第三局是通过自己的连接查询数据库的方式进行查询
如果运行时报错,建议传入out.print();检查自己的查询语句和查询数据
如果出现乱码,建议修改浏览器的编码设置自动检测,在tomcat conf子目录下的server.xml
后面添加URIEncoding="utf-8",小峰设置为utf-8
最后写到第三页的时候,发现jsp代码的复用性太差了。一个新的jdbc对象需要新建一个,多表关联时,需要列出所有条件。
抓取jsp网页源代码(我的Python技能很烂示例代码(-ib图片))
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-12-12 21:31
我的任务是为用户制作一个应用程序来搜索他们查询的三张图片。可以用任何语言编写,推荐使用Python。不过我的Python技术很烂,我最熟悉Java,我已经下载了我打算使用的Eclipse SWT包。
好的,到目前为止你做了什么
我介绍了他们的示例代码,这使得一个简单的网络浏览器成为可能。我将 Google 图片显示为主页,并计划使用 JavaScript/jQuery 自动填充他们的查询并返回前三张图片。 (我还计划使用 JavaScript/jQuery 以某种方式返回三个图像。)
根据Eclipse SWT文档evaluate(),execute()用于评估和执行JavaScript: api/org/eclipse/swt/browser/Browser.html
这是我使用的代码:
import org.eclipse.swt.*;
import org.eclipse.swt.browser.Browser;
import org.eclipse.swt.browser.LocationEvent;
import org.eclipse.swt.browser.LocationListener;
import org.eclipse.swt.browser.ProgressEvent;
import org.eclipse.swt.browser.ProgressListener;
import org.eclipse.swt.browser.StatusTextEvent;
import org.eclipse.swt.layout.GridData;
import org.eclipse.swt.layout.GridLayout;
import org.eclipse.swt.widgets.Display;
import org.eclipse.swt.widgets.Event;
import org.eclipse.swt.widgets.Label;
import org.eclipse.swt.widgets.Listener;
import org.eclipse.swt.widgets.ProgressBar;
import org.eclipse.swt.widgets.Shell;
import org.eclipse.swt.widgets.Text;
import org.eclipse.swt.widgets.ToolBar;
import org.eclipse.swt.widgets.ToolItem;
public class BrowserCodeDemo {
public static void main(String[] args) {
Display display = new Display();
final Shell shell = new Shell(display);
GridLayout gridLayout = new GridLayout();
gridLayout.numColumns = 3;
shell.setLayout(gridLayout);
ToolBar toolbar = new ToolBar(shell, SWT.NONE);
ToolItem itemBack = new ToolItem(toolbar, SWT.PUSH);
itemBack.setText("Back");
ToolItem itemForward = new ToolItem(toolbar, SWT.PUSH);
itemForward.setText("Forward");
ToolItem itemStop = new ToolItem(toolbar, SWT.PUSH);
itemStop.setText("Stop");
ToolItem itemRefresh = new ToolItem(toolbar, SWT.PUSH);
itemRefresh.setText("Refresh");
ToolItem itemGo = new ToolItem(toolbar, SWT.PUSH);
itemGo.setText("Go");
GridData data = new GridData();
data.horizontalSpan = 3;
toolbar.setLayoutData(data);
Label labelAddress = new Label(shell, SWT.NONE);
labelAddress.setText("Address");
final Text location = new Text(shell, SWT.BORDER);
data = new GridData();
data.horizontalAlignment = GridData.FILL;
data.horizontalSpan = 2;
data.grabExcessHorizontalSpace = true;
location.setLayoutData(data);
final Browser browser;
try {
browser = new Browser(shell, SWT.NONE);
} catch (SWTError e) {
System.out.println("Could not instantiate Browser: " + e.getMessage());
display.dispose();
return;
}
data = new GridData();
data.horizontalAlignment = GridData.FILL;
data.verticalAlignment = GridData.FILL;
data.horizontalSpan = 3;
data.grabExcessHorizontalSpace = true;
data.grabExcessVerticalSpace = true;
browser.setLayoutData(data);
final Label status = new Label(shell, SWT.NONE);
data = new GridData(GridData.FILL_HORIZONTAL);
data.horizontalSpan = 2;
status.setLayoutData(data);
final ProgressBar progressBar = new ProgressBar(shell, SWT.NONE);
data = new GridData();
data.horizontalAlignment = GridData.END;
progressBar.setLayoutData(data);
/* event handling */
Listener listener = new Listener() {
@Override
public void handleEvent(Event event) {
ToolItem item = (ToolItem)event.widget;
String string = item.getText();
if (string.equals("Back")) browser.back();
else if (string.equals("Forward")) browser.forward();
else if (string.equals("Stop")) browser.stop();
else if (string.equals("Refresh")) browser.refresh();
else if (string.equals("Go")) browser.setUrl(location.getText());
}
};
browser.addProgressListener(new ProgressListener() {
@Override
public void changed(ProgressEvent event) {
if (event.total == 0) return;
int ratio = event.current * 100 / event.total;
progressBar.setSelection(ratio);
}
@Override
public void completed(ProgressEvent event) {
progressBar.setSelection(0);
}
});
browser.addLocationListener(new LocationListener() {
@Override
public void changed(LocationEvent event) {
if (event.top) location.setText(event.location);
}
@Override
public void changing(LocationEvent event)
{
//System.out.println("Something is happening.");
}
});
itemBack.addListener(SWT.Selection, listener);
itemForward.addListener(SWT.Selection, listener);
itemStop.addListener(SWT.Selection, listener);
itemRefresh.addListener(SWT.Selection, listener);
itemGo.addListener(SWT.Selection, listener);
location.addListener(SWT.DefaultSelection, new Listener() {
@Override
public void handleEvent(Event e)
{
browser.setUrl(location.getText());
System.out.println("New URL loaded");
}
});
shell.open();
browser.setUrl(
"https://www.google.com/imghp%3 ... 6quot;);
//browser.setVisible(false);
boolean jQueryExecuted = browser.execute("$(\'#lst-ib\').val(\'snopes\')");
if (!jQueryExecuted)
{
System.out.println("Your jQuery didn't execute.");
}
jQueryExecuted = browser.execute("$(\'[name=btnG]\').click()");
if (!jQueryExecuted)
{
System.out.println("Your jQuery didn't execute.");
}
while (!shell.isDisposed()) {
if (!display.readAndDispatch())
display.sleep();
}
display.dispose();
}
}
我认为问题不是代码本身,因为我尝试自动设置文本字段,但是在Java和浏览器中都失败了。 /* 文本字段的名称是“lst-ib” * /
你想抓取什么?
我正在尝试从网络获取 Google 图片: tab = wi & ei = m8g4VLndMaz4igKlvoDADg & ved =0CAMQqi4oAQ。
文本字段是名为“lst-ib”的输入。该按钮是名为“btnG”的输入。文本字段位于 ID 为“gs_lc0”的 div 内。 (我还在那里看到了多个其他输入元素,它们的大小完全相同)。 查看全部
抓取jsp网页源代码(我的Python技能很烂示例代码(-ib图片))
我的任务是为用户制作一个应用程序来搜索他们查询的三张图片。可以用任何语言编写,推荐使用Python。不过我的Python技术很烂,我最熟悉Java,我已经下载了我打算使用的Eclipse SWT包。
好的,到目前为止你做了什么
我介绍了他们的示例代码,这使得一个简单的网络浏览器成为可能。我将 Google 图片显示为主页,并计划使用 JavaScript/jQuery 自动填充他们的查询并返回前三张图片。 (我还计划使用 JavaScript/jQuery 以某种方式返回三个图像。)
根据Eclipse SWT文档evaluate(),execute()用于评估和执行JavaScript: api/org/eclipse/swt/browser/Browser.html
这是我使用的代码:
import org.eclipse.swt.*;
import org.eclipse.swt.browser.Browser;
import org.eclipse.swt.browser.LocationEvent;
import org.eclipse.swt.browser.LocationListener;
import org.eclipse.swt.browser.ProgressEvent;
import org.eclipse.swt.browser.ProgressListener;
import org.eclipse.swt.browser.StatusTextEvent;
import org.eclipse.swt.layout.GridData;
import org.eclipse.swt.layout.GridLayout;
import org.eclipse.swt.widgets.Display;
import org.eclipse.swt.widgets.Event;
import org.eclipse.swt.widgets.Label;
import org.eclipse.swt.widgets.Listener;
import org.eclipse.swt.widgets.ProgressBar;
import org.eclipse.swt.widgets.Shell;
import org.eclipse.swt.widgets.Text;
import org.eclipse.swt.widgets.ToolBar;
import org.eclipse.swt.widgets.ToolItem;
public class BrowserCodeDemo {
public static void main(String[] args) {
Display display = new Display();
final Shell shell = new Shell(display);
GridLayout gridLayout = new GridLayout();
gridLayout.numColumns = 3;
shell.setLayout(gridLayout);
ToolBar toolbar = new ToolBar(shell, SWT.NONE);
ToolItem itemBack = new ToolItem(toolbar, SWT.PUSH);
itemBack.setText("Back");
ToolItem itemForward = new ToolItem(toolbar, SWT.PUSH);
itemForward.setText("Forward");
ToolItem itemStop = new ToolItem(toolbar, SWT.PUSH);
itemStop.setText("Stop");
ToolItem itemRefresh = new ToolItem(toolbar, SWT.PUSH);
itemRefresh.setText("Refresh");
ToolItem itemGo = new ToolItem(toolbar, SWT.PUSH);
itemGo.setText("Go");
GridData data = new GridData();
data.horizontalSpan = 3;
toolbar.setLayoutData(data);
Label labelAddress = new Label(shell, SWT.NONE);
labelAddress.setText("Address");
final Text location = new Text(shell, SWT.BORDER);
data = new GridData();
data.horizontalAlignment = GridData.FILL;
data.horizontalSpan = 2;
data.grabExcessHorizontalSpace = true;
location.setLayoutData(data);
final Browser browser;
try {
browser = new Browser(shell, SWT.NONE);
} catch (SWTError e) {
System.out.println("Could not instantiate Browser: " + e.getMessage());
display.dispose();
return;
}
data = new GridData();
data.horizontalAlignment = GridData.FILL;
data.verticalAlignment = GridData.FILL;
data.horizontalSpan = 3;
data.grabExcessHorizontalSpace = true;
data.grabExcessVerticalSpace = true;
browser.setLayoutData(data);
final Label status = new Label(shell, SWT.NONE);
data = new GridData(GridData.FILL_HORIZONTAL);
data.horizontalSpan = 2;
status.setLayoutData(data);
final ProgressBar progressBar = new ProgressBar(shell, SWT.NONE);
data = new GridData();
data.horizontalAlignment = GridData.END;
progressBar.setLayoutData(data);
/* event handling */
Listener listener = new Listener() {
@Override
public void handleEvent(Event event) {
ToolItem item = (ToolItem)event.widget;
String string = item.getText();
if (string.equals("Back")) browser.back();
else if (string.equals("Forward")) browser.forward();
else if (string.equals("Stop")) browser.stop();
else if (string.equals("Refresh")) browser.refresh();
else if (string.equals("Go")) browser.setUrl(location.getText());
}
};
browser.addProgressListener(new ProgressListener() {
@Override
public void changed(ProgressEvent event) {
if (event.total == 0) return;
int ratio = event.current * 100 / event.total;
progressBar.setSelection(ratio);
}
@Override
public void completed(ProgressEvent event) {
progressBar.setSelection(0);
}
});
browser.addLocationListener(new LocationListener() {
@Override
public void changed(LocationEvent event) {
if (event.top) location.setText(event.location);
}
@Override
public void changing(LocationEvent event)
{
//System.out.println("Something is happening.");
}
});
itemBack.addListener(SWT.Selection, listener);
itemForward.addListener(SWT.Selection, listener);
itemStop.addListener(SWT.Selection, listener);
itemRefresh.addListener(SWT.Selection, listener);
itemGo.addListener(SWT.Selection, listener);
location.addListener(SWT.DefaultSelection, new Listener() {
@Override
public void handleEvent(Event e)
{
browser.setUrl(location.getText());
System.out.println("New URL loaded");
}
});
shell.open();
browser.setUrl(
"https://www.google.com/imghp%3 ... 6quot;);
//browser.setVisible(false);
boolean jQueryExecuted = browser.execute("$(\'#lst-ib\').val(\'snopes\')");
if (!jQueryExecuted)
{
System.out.println("Your jQuery didn't execute.");
}
jQueryExecuted = browser.execute("$(\'[name=btnG]\').click()");
if (!jQueryExecuted)
{
System.out.println("Your jQuery didn't execute.");
}
while (!shell.isDisposed()) {
if (!display.readAndDispatch())
display.sleep();
}
display.dispose();
}
}
我认为问题不是代码本身,因为我尝试自动设置文本字段,但是在Java和浏览器中都失败了。 /* 文本字段的名称是“lst-ib” * /
你想抓取什么?
我正在尝试从网络获取 Google 图片: tab = wi & ei = m8g4VLndMaz4igKlvoDADg & ved =0CAMQqi4oAQ。
文本字段是名为“lst-ib”的输入。该按钮是名为“btnG”的输入。文本字段位于 ID 为“gs_lc0”的 div 内。 (我还在那里看到了多个其他输入元素,它们的大小完全相同)。
抓取jsp网页源代码(第一章选择题1.1.早期的动态网站答:1.一次编写,随处运行2.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-12-10 09:21
第一章选择题1.早期动态网站 开发技术主要采用()技术。该技术的基本原理是将浏览器提交给Web服务器的数据通过环境变量传递给其他外部程序。由外部程序处理后,将处理结果传送到Web服务器,最后由Web服务器将处理结果返回给浏览器。A.JSPB.ASPC.PHPD.CGI2.JSP页面的代码由()和()两部分组成。A.javascript 代码 B.vbscript 代码 C.HTML 代码 D.JSP 代码 都是 4. JSP 页面代码中不能收录的部分是 () A.javascript 代码 B.JSP 指令 C.JSP动作 D.HTML 代码问答 简述 JSP 的基本运行原理。列出 JSP 的一些特性。参考答案选择题1.D2.CD3.C4.A Q&A问题1.答:首先,浏览器向网页发起请求服务器访问JSP页面(Request),然后JSP容器负责将JSP转换成Servlet,生成的Servlet被编译生成class文件,然后将class文件加载到内存中执行。最后,Web 服务器向客户端浏览器发送执行结果响应(Response)。然后JSP容器负责将JSP转换成Servlet,生成的Servlet被编译生成class文件,然后将class文件加载到内存中执行。最后,Web 服务器向客户端浏览器发送执行结果响应(Response)。然后JSP容器负责将JSP转换成Servlet,生成的Servlet被编译生成class文件,然后将class文件加载到内存中执行。最后,Web 服务器向客户端浏览器发送执行结果响应(Response)。
2.答:1.一次编写,随处运行2.可复用组件技术3.令牌化页面开发4.对大型复杂Web应用的良好支持第2章** **多选题1.以下不是JSP开发工具()A.JBuilderB.IBMWebSphereC.MyEclipseD.Firework2.搭建JSP开发环境,除了安装以上JSP开发工具另外还必须安装()和()A.JDKB.DreamweaverMXC.FlashMXD.Tomcat3.JSP属于Java家族,以下不属于JAVA家族的是()A。 servletB.javabeanC.javaD.javascript4.web应用体系结构最多可以分为三层。不属于这三层的为()A.表示层B. 业务层 C. 数据访问层 D. 网络链路层 问答简单描述了Tomcat的作用。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。网络链路层问答简单描述了Tomcat的作用。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。网络链路层问答简单描述了Tomcat的作用。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。@2.AD3.D4.D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务,并允许用户进行配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。@2.AD3.D4.D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务,并允许用户进行配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。
A.pageB.forwardC.includeD.taglib2. 在J2EE中,test.jsp文件如下,当试图运行时,() stris A.翻译周期错误 B.编译周期错误 C.运行后,浏览器显示:strisnullD. 运行后浏览器显示: strisstr3. 给定的JSP程序源码如下: __________ 下划线处可插入以下()语句,运行后输出为: 1. ABCD< @4.Page 指令用于定义 JSP 文件中的全局属性。以下对该指令使用的描述是不正确的:()A.作用于整个 JSP 页面。B. 一个页面可以使用多个指令。C.为了增强程序的可读性,建议将指令放在JSP文件的开头,但不是必须的 D. 指令中的属性只能出现一次5. JSP语句中的语句是错误的:() A.一次可以声明多个变量和方法,只要以“;”结尾即可 B. 一个声明只在一页内有效 C. 声明的变量将用作局部变量 D. 声明中声明的变量将是 Initializing JSP 页面初始化时的填空题 JSP 有三个指令,它们是___、_____、_____。JSP 有七个标准的“动作元素”。本章学习的四个“动作要素”分别是_________、___________、____________、________ 只要它们以“;”结尾 B. 一个声明只在一页内有效 C. 声明的变量将用作局部变量 D. 声明中声明的变量将是 Initializing JSP 页面初始化时的填空题 JSP 有三个指令,它们是___、_____、_____。JSP 有七个标准的“动作元素”。本章学习的四个“动作要素”分别是_________、___________、____________、________ 只要它们以“;”结尾 B. 一个声明只在一页内有效 C. 声明的变量将用作局部变量 D. 声明中声明的变量将是 Initializing JSP 页面初始化时的填空题 JSP 有三个指令,它们是___、_____、_____。JSP 有七个标准的“动作元素”。本章学习的四个“动作要素”分别是_________、___________、____________、________ 查看全部
抓取jsp网页源代码(第一章选择题1.1.早期的动态网站答:1.一次编写,随处运行2.)
第一章选择题1.早期动态网站 开发技术主要采用()技术。该技术的基本原理是将浏览器提交给Web服务器的数据通过环境变量传递给其他外部程序。由外部程序处理后,将处理结果传送到Web服务器,最后由Web服务器将处理结果返回给浏览器。A.JSPB.ASPC.PHPD.CGI2.JSP页面的代码由()和()两部分组成。A.javascript 代码 B.vbscript 代码 C.HTML 代码 D.JSP 代码 都是 4. JSP 页面代码中不能收录的部分是 () A.javascript 代码 B.JSP 指令 C.JSP动作 D.HTML 代码问答 简述 JSP 的基本运行原理。列出 JSP 的一些特性。参考答案选择题1.D2.CD3.C4.A Q&A问题1.答:首先,浏览器向网页发起请求服务器访问JSP页面(Request),然后JSP容器负责将JSP转换成Servlet,生成的Servlet被编译生成class文件,然后将class文件加载到内存中执行。最后,Web 服务器向客户端浏览器发送执行结果响应(Response)。然后JSP容器负责将JSP转换成Servlet,生成的Servlet被编译生成class文件,然后将class文件加载到内存中执行。最后,Web 服务器向客户端浏览器发送执行结果响应(Response)。然后JSP容器负责将JSP转换成Servlet,生成的Servlet被编译生成class文件,然后将class文件加载到内存中执行。最后,Web 服务器向客户端浏览器发送执行结果响应(Response)。
2.答:1.一次编写,随处运行2.可复用组件技术3.令牌化页面开发4.对大型复杂Web应用的良好支持第2章** **多选题1.以下不是JSP开发工具()A.JBuilderB.IBMWebSphereC.MyEclipseD.Firework2.搭建JSP开发环境,除了安装以上JSP开发工具另外还必须安装()和()A.JDKB.DreamweaverMXC.FlashMXD.Tomcat3.JSP属于Java家族,以下不属于JAVA家族的是()A。 servletB.javabeanC.javaD.javascript4.web应用体系结构最多可以分为三层。不属于这三层的为()A.表示层B. 业务层 C. 数据访问层 D. 网络链路层 问答简单描述了Tomcat的作用。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。网络链路层问答简单描述了Tomcat的作用。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。网络链路层问答简单描述了Tomcat的作用。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。配置JSP开发环境,测试如下程序: 第一个JSP实例早上好下午好参考答案选择题1.D2.AD3.D4. D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务并允许用户配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。@2.AD3.D4.D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务,并允许用户进行配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。@2.AD3.D4.D问答@1.答:Tomcat是一个强大的jspWeb服务器,可以处理静态和动态页面,处理大量的网络客户端请求,支持各种服务,并允许用户进行配置。高速、强大,具备分析JSP/Servlet的能力。2. 运行页面如下: 第三章选择题 1. 在JSP中,()动作用于将文件收录到JSP页面中。
A.pageB.forwardC.includeD.taglib2. 在J2EE中,test.jsp文件如下,当试图运行时,() stris A.翻译周期错误 B.编译周期错误 C.运行后,浏览器显示:strisnullD. 运行后浏览器显示: strisstr3. 给定的JSP程序源码如下: __________ 下划线处可插入以下()语句,运行后输出为: 1. ABCD< @4.Page 指令用于定义 JSP 文件中的全局属性。以下对该指令使用的描述是不正确的:()A.作用于整个 JSP 页面。B. 一个页面可以使用多个指令。C.为了增强程序的可读性,建议将指令放在JSP文件的开头,但不是必须的 D. 指令中的属性只能出现一次5. JSP语句中的语句是错误的:() A.一次可以声明多个变量和方法,只要以“;”结尾即可 B. 一个声明只在一页内有效 C. 声明的变量将用作局部变量 D. 声明中声明的变量将是 Initializing JSP 页面初始化时的填空题 JSP 有三个指令,它们是___、_____、_____。JSP 有七个标准的“动作元素”。本章学习的四个“动作要素”分别是_________、___________、____________、________ 只要它们以“;”结尾 B. 一个声明只在一页内有效 C. 声明的变量将用作局部变量 D. 声明中声明的变量将是 Initializing JSP 页面初始化时的填空题 JSP 有三个指令,它们是___、_____、_____。JSP 有七个标准的“动作元素”。本章学习的四个“动作要素”分别是_________、___________、____________、________ 只要它们以“;”结尾 B. 一个声明只在一页内有效 C. 声明的变量将用作局部变量 D. 声明中声明的变量将是 Initializing JSP 页面初始化时的填空题 JSP 有三个指令,它们是___、_____、_____。JSP 有七个标准的“动作元素”。本章学习的四个“动作要素”分别是_________、___________、____________、________
抓取jsp网页源代码(怎么从网站提取网站模板源代码?和CSS源代码。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-12-10 09:20
如何从网站中提取网站模板源代码?
获取 HTML 源代码和 CSS 源代码。1 在您的计算机上找到此路径并删除此目录中的内容。2 用ie.3打开你要下载的网页。回到这个路径刷新 C:\document and settings\administrator\local settings\temporary Internet 此时,这个路径下会显示需要页面的HTML源代码和CSS代码;4. 将本页的HTML、CSS、图片等复制到一个新的文件夹中。删除复制的文件名后的“[1]”,改相关链接直接使用。
如何获取网页源代码中的文件?
网页的源代码是父网页的代码。网页中有一种叫做iframe的节点,相当于网页的子页面。其结构与外部网页完全相同。框架源代码是子页面的源代码。另外,网易云爬网推荐使用selenium,因为我们在进行网易云爬网热审操作时,此时请求的代码是父网页的源码。此时,我们无法请求子页面的源代码,也无法获取需要提取的信息。这是因为打开selenium的页面后,默认操作是在父框架中。这时候如果页面在中间,也有子帧,子帧无法获取子帧中的节点。您需要使用 switch to frame() 方法来切换帧。至此,请求的代码从网页源代码切换到框架源代码,然后我们就可以提取出需要的信息了。
提取图片的网页源代码 查看全部
抓取jsp网页源代码(怎么从网站提取网站模板源代码?和CSS源代码。)
如何从网站中提取网站模板源代码?
获取 HTML 源代码和 CSS 源代码。1 在您的计算机上找到此路径并删除此目录中的内容。2 用ie.3打开你要下载的网页。回到这个路径刷新 C:\document and settings\administrator\local settings\temporary Internet 此时,这个路径下会显示需要页面的HTML源代码和CSS代码;4. 将本页的HTML、CSS、图片等复制到一个新的文件夹中。删除复制的文件名后的“[1]”,改相关链接直接使用。
如何获取网页源代码中的文件?
网页的源代码是父网页的代码。网页中有一种叫做iframe的节点,相当于网页的子页面。其结构与外部网页完全相同。框架源代码是子页面的源代码。另外,网易云爬网推荐使用selenium,因为我们在进行网易云爬网热审操作时,此时请求的代码是父网页的源码。此时,我们无法请求子页面的源代码,也无法获取需要提取的信息。这是因为打开selenium的页面后,默认操作是在父框架中。这时候如果页面在中间,也有子帧,子帧无法获取子帧中的节点。您需要使用 switch to frame() 方法来切换帧。至此,请求的代码从网页源代码切换到框架源代码,然后我们就可以提取出需要的信息了。
提取图片的网页源代码
抓取jsp网页源代码(Java后端服务器的静态网页动态网页设计)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-12-08 18:13
后端服务器一般是指一个servlet容器,用于执行java源程序
常见的网页有html、htm、shtml、asp、aspx、php、jsp等格式
前两者常用于静态网页,后者常用于动态网页。
这里的前端网页使用比较常见的xx.html和xx.jsp网页作为介绍,其他类似
一、静态页面xx.html如何与后台交互:
先看一个最简单的登录界面源码
用户:密码:
这是一个表格。我们看到它充满了纯 html 内容。这是一个静态页面。当我们点击提交按钮时,浏览器会将表单中的数据提交到服务器的loginServlet的相对地址。让我们来看看。什么变成了浏览器的地址:
这不是我们后端servlet的地址吗?然后这个地址指向loginServlet servlet,然后在web.xml文件中找到这个servlet关联的java类来执行服务端程序(先执行,然后会被实例化,然后执行init()函数里面,然后执行service()函数,如果是第二次调用,那么就不用实例化了,直接执行service()函数),我们来看一下服务端的源码程序:
包com.atguigu.javaweb;
导入 java.io.IOException;
导入 java.io.PrintWriter;
导入 javax.servlet.Servlet;
导入 javax.servlet.ServletConfig;
导入 javax.servlet.ServletContext;
导入 javax.servlet.ServletException;
导入 javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
导入 javax.servlet.http.HttpServletRequest;
公共类 loginServlet 扩展了 MyGeneriServlet {
public void init(javax.servlet.ServletConfig config) 抛出 ServletException{
super.init(config);
}
public void service(ServletRequest request, ServletResponse response)
抛出 ServletException, IOException {
//如何获取请求是GET、POST?
HttpServletRequest httpServletRequest=(HttpServletRequest) 请求;
String method=httpServletRequest.getMethod();
System.out.println(方法);
//1.获取请求参数:用户名、密码
String username=request.getParameter("username");
String password=request.getParameter("password");
//获取请求参数
String initUser=getServletContext().getInitParameter("user");
String initpassword=getServletContext().getInitParameter("password");
PrintWriter out=response.getWriter();
//3.对比
if(initUser.equals(username)&&initpassword.equals(password)){
out.print("Hello"+username); // 生成html内容
}else{
out.print("Sorry"+username); // 生成html内容
}
}
}
上面没有判断此时对servlet的请求是post方法还是get方法,不过没关系。请求中传递的参数和信息都收录在内。您可以自行判断并进行相应的操作。
既然页面路径已经跳转到servlet了,但是servlet不是.html文件,浏览器是不是就没有内容可以显示了?不是,我们看到返回的参数response中输出的对象PrintWriter用于html内容的字符串“Hello”是动态生成的,所以此时相当于servlet的路径也有html内容,浏览器页面将显示上面的字符串
二、jsp页面如何与后端服务器交互:
jsp 网页文件是插入到 html 内容中的 java 代码。当我们访问.jsp网页文件时,服务器已经预先知道该页面收录java代码,所以服务器必须先执行这些代码(跟java源代码一样),同时嵌入当前.jsp页面中的执行结果,我们看一下源码:
//如果在这个.jsp页面中使用了一些java函数,则需要导入库,与java源文件相同
第一个 JSP 程序
<p>上面红色的代码是java代码。刚才说了,对象PrintWriter out是用来动态生成一串html内容的,所以服务端执行嵌入的java代码后,动态生成一串html代码,然后一起传输给客户端浏览器显示 查看全部
抓取jsp网页源代码(Java后端服务器的静态网页动态网页设计)
后端服务器一般是指一个servlet容器,用于执行java源程序
常见的网页有html、htm、shtml、asp、aspx、php、jsp等格式
前两者常用于静态网页,后者常用于动态网页。
这里的前端网页使用比较常见的xx.html和xx.jsp网页作为介绍,其他类似
一、静态页面xx.html如何与后台交互:
先看一个最简单的登录界面源码
用户:密码:
这是一个表格。我们看到它充满了纯 html 内容。这是一个静态页面。当我们点击提交按钮时,浏览器会将表单中的数据提交到服务器的loginServlet的相对地址。让我们来看看。什么变成了浏览器的地址:
这不是我们后端servlet的地址吗?然后这个地址指向loginServlet servlet,然后在web.xml文件中找到这个servlet关联的java类来执行服务端程序(先执行,然后会被实例化,然后执行init()函数里面,然后执行service()函数,如果是第二次调用,那么就不用实例化了,直接执行service()函数),我们来看一下服务端的源码程序:
包com.atguigu.javaweb;
导入 java.io.IOException;
导入 java.io.PrintWriter;
导入 javax.servlet.Servlet;
导入 javax.servlet.ServletConfig;
导入 javax.servlet.ServletContext;
导入 javax.servlet.ServletException;
导入 javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
导入 javax.servlet.http.HttpServletRequest;
公共类 loginServlet 扩展了 MyGeneriServlet {
public void init(javax.servlet.ServletConfig config) 抛出 ServletException{
super.init(config);
}
public void service(ServletRequest request, ServletResponse response)
抛出 ServletException, IOException {
//如何获取请求是GET、POST?
HttpServletRequest httpServletRequest=(HttpServletRequest) 请求;
String method=httpServletRequest.getMethod();
System.out.println(方法);
//1.获取请求参数:用户名、密码
String username=request.getParameter("username");
String password=request.getParameter("password");
//获取请求参数
String initUser=getServletContext().getInitParameter("user");
String initpassword=getServletContext().getInitParameter("password");
PrintWriter out=response.getWriter();
//3.对比
if(initUser.equals(username)&&initpassword.equals(password)){
out.print("Hello"+username); // 生成html内容
}else{
out.print("Sorry"+username); // 生成html内容
}
}
}
上面没有判断此时对servlet的请求是post方法还是get方法,不过没关系。请求中传递的参数和信息都收录在内。您可以自行判断并进行相应的操作。
既然页面路径已经跳转到servlet了,但是servlet不是.html文件,浏览器是不是就没有内容可以显示了?不是,我们看到返回的参数response中输出的对象PrintWriter用于html内容的字符串“Hello”是动态生成的,所以此时相当于servlet的路径也有html内容,浏览器页面将显示上面的字符串
二、jsp页面如何与后端服务器交互:
jsp 网页文件是插入到 html 内容中的 java 代码。当我们访问.jsp网页文件时,服务器已经预先知道该页面收录java代码,所以服务器必须先执行这些代码(跟java源代码一样),同时嵌入当前.jsp页面中的执行结果,我们看一下源码:
//如果在这个.jsp页面中使用了一些java函数,则需要导入库,与java源文件相同
第一个 JSP 程序
<p>上面红色的代码是java代码。刚才说了,对象PrintWriter out是用来动态生成一串html内容的,所以服务端执行嵌入的java代码后,动态生成一串html代码,然后一起传输给客户端浏览器显示
抓取jsp网页源代码(从功能方面来说动态网站与静态网站的区别和区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-12-08 18:01
一、动态网站和静态网站在功能上的区别
1、动态网站可以实现静态网站无法实现的功能,例如:聊天室、论坛、音乐播放器、浏览器、搜索等;而静态 网站 不能。
2.静态网站,比如Frontpage或者Dreamweaver开发的网站,它的源代码是完全公开的,任何浏览者都可以很容易地得到它的源代码,也就是说,自己设计的东西可以很容易的被别人偷走。动态网站,如:ASP开发的网站,虽然浏览器也能看到源码,但已经是转换代码了。窃取源代码是不可能的。因为它的源代码已经在服务器上,客户端看不到它。
二、 动态网站和静态网站的区别从数据的使用
1.动态网站可以直接使用数据库,通过数据源直接操作数据库;而静态网站不能用,静态网站只能用表格硬性实现动态网站数据库表中少部分数据的显示不能操作。
2、动态网站放在服务器上。要查看源程序或直接修改它,必须在服务器上进行,因此保密性能优越。静态网站无法实现信息的保密功能。
3、动态网站可以用来调用远程数据,而静态网站甚至不能使用本地数据,更不用说远程数据了。
三、本质上是动态网站和静态网站的区别
1、动态网站的开发语言是一种编程语言,例如ASP是用Vbscript或Javascript开发的。静态 网站 只能用 HTML 开发标记语言开发。它只是一种标记语言,并不能实现程序的功能。
2、动态网站本身就是一个系统,一个可以实现程序几乎所有功能的系统,而静态网站不是,只能实现文字和图片的平面显示。
3、动态网站可以实现程序的高效、快速的执行,而普通的静态网站根本没有效率和快速。
以上是动态网站和静态网站的基本分析。在实际应用中,每个人都会有不同的体验,其中细微和本质的区别远不止上面列举的那样。这只能通过个人经验来区分。
四、动态网站和静态网站从外观上的区别
网站的静态网页以.htmlhtm结尾,客户不能随意修改,需要特殊软件。而且大部分动态网站都是带数据库的,可以随时在线修改,网页往往以php、asp等结尾。我们公司的网站大部分都是动态网站。
静态网页:指不使用应用程序直接或间接制作成html的网页。这类网页的内容是固定的,修改和更新必须通过专用的网页制作工具,如Dreamweaver。动态网页:指使用网页脚本语言,如php、asp等,通过脚本将网站的内容动态存储到数据库中。用户访问网站是一种通过读取数据库动态生成网页的方法。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。
静态网页和动态网页的最大区别在于网页是否有固定内容或可以在线更新
网站的构建如何决定是使用动态网页还是静态网页?
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,采用纯静态网页比较简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了满足搜索引擎对网站的需求,即使使用动态的网站技术,也将网页内容转化为静态网页并发布。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现。在同一个网站上面,动态网页内容和静态网页内容同时存在也是很常见的。
静态网页是指无需应用程序直接或间接制作成html的网页。这种网页的内容是固定的。修改和更新必须通过专用的网页制作工具,如Dreamweaver、Frontpage等,而且只要修改了网页,就必须重新上传一个字符或图片来覆盖原来的页面。
动态网页是指运行在服务器端的程序或网页,会在不同的时间、不同的客户返回不同的网页。
动态网页是指利用网页脚本语言,如php、asp、jsp等,通过脚本将网站的内容动态存储到数据库中,用户访问网站是一种方法通过读取数据库动态生成网页。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。当然,可以使用某些技术将动态网页内容生成静态网页,有利于网站的优化,方便搜索引擎搜索。
动态网页的特点:交互性、自动更新、随机性 查看全部
抓取jsp网页源代码(从功能方面来说动态网站与静态网站的区别和区别)
一、动态网站和静态网站在功能上的区别
1、动态网站可以实现静态网站无法实现的功能,例如:聊天室、论坛、音乐播放器、浏览器、搜索等;而静态 网站 不能。
2.静态网站,比如Frontpage或者Dreamweaver开发的网站,它的源代码是完全公开的,任何浏览者都可以很容易地得到它的源代码,也就是说,自己设计的东西可以很容易的被别人偷走。动态网站,如:ASP开发的网站,虽然浏览器也能看到源码,但已经是转换代码了。窃取源代码是不可能的。因为它的源代码已经在服务器上,客户端看不到它。
二、 动态网站和静态网站的区别从数据的使用
1.动态网站可以直接使用数据库,通过数据源直接操作数据库;而静态网站不能用,静态网站只能用表格硬性实现动态网站数据库表中少部分数据的显示不能操作。
2、动态网站放在服务器上。要查看源程序或直接修改它,必须在服务器上进行,因此保密性能优越。静态网站无法实现信息的保密功能。
3、动态网站可以用来调用远程数据,而静态网站甚至不能使用本地数据,更不用说远程数据了。
三、本质上是动态网站和静态网站的区别
1、动态网站的开发语言是一种编程语言,例如ASP是用Vbscript或Javascript开发的。静态 网站 只能用 HTML 开发标记语言开发。它只是一种标记语言,并不能实现程序的功能。
2、动态网站本身就是一个系统,一个可以实现程序几乎所有功能的系统,而静态网站不是,只能实现文字和图片的平面显示。
3、动态网站可以实现程序的高效、快速的执行,而普通的静态网站根本没有效率和快速。
以上是动态网站和静态网站的基本分析。在实际应用中,每个人都会有不同的体验,其中细微和本质的区别远不止上面列举的那样。这只能通过个人经验来区分。
四、动态网站和静态网站从外观上的区别
网站的静态网页以.htmlhtm结尾,客户不能随意修改,需要特殊软件。而且大部分动态网站都是带数据库的,可以随时在线修改,网页往往以php、asp等结尾。我们公司的网站大部分都是动态网站。
静态网页:指不使用应用程序直接或间接制作成html的网页。这类网页的内容是固定的,修改和更新必须通过专用的网页制作工具,如Dreamweaver。动态网页:指使用网页脚本语言,如php、asp等,通过脚本将网站的内容动态存储到数据库中。用户访问网站是一种通过读取数据库动态生成网页的方法。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。
静态网页和动态网页的最大区别在于网页是否有固定内容或可以在线更新
网站的构建如何决定是使用动态网页还是静态网页?
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,采用纯静态网页比较简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了满足搜索引擎对网站的需求,即使使用动态的网站技术,也将网页内容转化为静态网页并发布。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现。在同一个网站上面,动态网页内容和静态网页内容同时存在也是很常见的。
静态网页是指无需应用程序直接或间接制作成html的网页。这种网页的内容是固定的。修改和更新必须通过专用的网页制作工具,如Dreamweaver、Frontpage等,而且只要修改了网页,就必须重新上传一个字符或图片来覆盖原来的页面。
动态网页是指运行在服务器端的程序或网页,会在不同的时间、不同的客户返回不同的网页。
动态网页是指利用网页脚本语言,如php、asp、jsp等,通过脚本将网站的内容动态存储到数据库中,用户访问网站是一种方法通过读取数据库动态生成网页。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。当然,可以使用某些技术将动态网页内容生成静态网页,有利于网站的优化,方便搜索引擎搜索。
动态网页的特点:交互性、自动更新、随机性
抓取jsp网页源代码(从功能方面来说动态网站与静态网站的区别和区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-12-08 17:23
一、动态网站和静态网站在功能上的区别
1、动态网站可以实现静态网站无法实现的功能,例如:聊天室、论坛、音乐播放器、浏览器、搜索等;而静态 网站 不能。
2.静态网站,比如Frontpage或者Dreamweaver开发的网站,它的源代码是完全公开的,任何浏览者都可以很容易地得到它的源代码,也就是说,自己设计的东西可以很容易的被别人偷走。动态网站,如:ASP开发的网站,虽然浏览器也能看到源码,但已经是转换代码了。窃取源代码是不可能的。因为它的源代码已经在服务器上,客户端看不到它。
二、 动态网站和静态网站的区别从数据的使用
1.动态网站可以直接使用数据库,通过数据源直接操作数据库;而静态网站不能用,静态网站只能用表格硬性实现动态网站数据库表中少部分数据的显示不能操作。
2、动态网站放在服务器上。要查看源程序或直接修改它,必须在服务器上进行,因此保密性能优越。静态网站无法实现信息的保密功能。
3、动态网站可以用来调用远程数据,而静态网站甚至不能使用本地数据,更不用说远程数据了。
三、本质上是动态网站和静态网站的区别
1、动态网站的开发语言是一种编程语言,例如ASP是用Vbscript或Javascript开发的。静态 网站 只能用 HTML 开发标记语言开发。它只是一种标记语言,并不能实现程序的功能。
2、动态网站本身就是一个系统,一个可以实现程序几乎所有功能的系统,而静态网站不是,只能实现文字和图片的平面显示。
3、动态网站可以实现程序的高效、快速的执行,而普通的静态网站根本没有效率和快速。
以上是动态网站和静态网站的基本分析。在实际应用中,每个人都会有不同的体验,其中细微和本质的区别远不止上面列举的那样。这只能通过个人经验来区分。
四、动态网站和静态网站从外观上的区别
网站的静态网页以.htmlhtm结尾,客户不能随意修改,需要特殊软件。而且大部分动态网站都是带数据库的,可以随时在线修改,网页往往以php、asp等结尾。我们公司的网站大部分都是动态网站。
静态网页:指不使用应用程序直接或间接制作成html的网页。这类网页的内容是固定的,修改和更新必须通过专用的网页制作工具,如Dreamweaver。动态网页:指使用网页脚本语言,如php、asp等,通过脚本将网站的内容动态存储到数据库中。用户访问网站是一种通过读取数据库动态生成网页的方法。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。
静态网页和动态网页的最大区别在于网页是否有固定内容或可以在线更新
网站的构建如何决定是使用动态网页还是静态网页?
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,采用纯静态网页比较简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了满足搜索引擎对网站的需求,即使使用动态的网站技术,也将网页内容转化为静态网页并发布。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现。在同一个网站上面,动态网页内容和静态网页内容同时存在也是很常见的。
静态网页是指无需应用程序直接或间接制作成html的网页。这种网页的内容是固定的。修改和更新必须通过专用的网页制作工具,如Dreamweaver、Frontpage等,而且只要修改了网页,就必须重新上传一个字符或图片来覆盖原来的页面。
动态网页是指运行在服务器端的程序或网页,会在不同的时间、不同的客户返回不同的网页。
动态网页是指利用网页脚本语言,如php、asp、jsp等,通过脚本将网站的内容动态存储到数据库中,用户访问网站是一种方法通过读取数据库动态生成网页。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。当然,可以使用某些技术将动态网页内容生成静态网页,有利于网站的优化,方便搜索引擎搜索。
动态网页的特点:交互性、自动更新、随机性 查看全部
抓取jsp网页源代码(从功能方面来说动态网站与静态网站的区别和区别)
一、动态网站和静态网站在功能上的区别
1、动态网站可以实现静态网站无法实现的功能,例如:聊天室、论坛、音乐播放器、浏览器、搜索等;而静态 网站 不能。
2.静态网站,比如Frontpage或者Dreamweaver开发的网站,它的源代码是完全公开的,任何浏览者都可以很容易地得到它的源代码,也就是说,自己设计的东西可以很容易的被别人偷走。动态网站,如:ASP开发的网站,虽然浏览器也能看到源码,但已经是转换代码了。窃取源代码是不可能的。因为它的源代码已经在服务器上,客户端看不到它。
二、 动态网站和静态网站的区别从数据的使用
1.动态网站可以直接使用数据库,通过数据源直接操作数据库;而静态网站不能用,静态网站只能用表格硬性实现动态网站数据库表中少部分数据的显示不能操作。
2、动态网站放在服务器上。要查看源程序或直接修改它,必须在服务器上进行,因此保密性能优越。静态网站无法实现信息的保密功能。
3、动态网站可以用来调用远程数据,而静态网站甚至不能使用本地数据,更不用说远程数据了。
三、本质上是动态网站和静态网站的区别
1、动态网站的开发语言是一种编程语言,例如ASP是用Vbscript或Javascript开发的。静态 网站 只能用 HTML 开发标记语言开发。它只是一种标记语言,并不能实现程序的功能。
2、动态网站本身就是一个系统,一个可以实现程序几乎所有功能的系统,而静态网站不是,只能实现文字和图片的平面显示。
3、动态网站可以实现程序的高效、快速的执行,而普通的静态网站根本没有效率和快速。
以上是动态网站和静态网站的基本分析。在实际应用中,每个人都会有不同的体验,其中细微和本质的区别远不止上面列举的那样。这只能通过个人经验来区分。
四、动态网站和静态网站从外观上的区别
网站的静态网页以.htmlhtm结尾,客户不能随意修改,需要特殊软件。而且大部分动态网站都是带数据库的,可以随时在线修改,网页往往以php、asp等结尾。我们公司的网站大部分都是动态网站。
静态网页:指不使用应用程序直接或间接制作成html的网页。这类网页的内容是固定的,修改和更新必须通过专用的网页制作工具,如Dreamweaver。动态网页:指使用网页脚本语言,如php、asp等,通过脚本将网站的内容动态存储到数据库中。用户访问网站是一种通过读取数据库动态生成网页的方法。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。
静态网页和动态网页的最大区别在于网页是否有固定内容或可以在线更新
网站的构建如何决定是使用动态网页还是静态网页?
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,采用纯静态网页比较简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了满足搜索引擎对网站的需求,即使使用动态的网站技术,也将网页内容转化为静态网页并发布。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现。在同一个网站上面,动态网页内容和静态网页内容同时存在也是很常见的。
静态网页是指无需应用程序直接或间接制作成html的网页。这种网页的内容是固定的。修改和更新必须通过专用的网页制作工具,如Dreamweaver、Frontpage等,而且只要修改了网页,就必须重新上传一个字符或图片来覆盖原来的页面。
动态网页是指运行在服务器端的程序或网页,会在不同的时间、不同的客户返回不同的网页。
动态网页是指利用网页脚本语言,如php、asp、jsp等,通过脚本将网站的内容动态存储到数据库中,用户访问网站是一种方法通过读取数据库动态生成网页。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。当然,可以使用某些技术将动态网页内容生成静态网页,有利于网站的优化,方便搜索引擎搜索。
动态网页的特点:交互性、自动更新、随机性
抓取jsp网页源代码(抓取jsp网页源代码网上有很多教程可以去看一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-12-01 04:03
抓取jsp网页源代码网上有很多教程可以去看一下jsp是asp的阉割版,在pagecontroller下有一个directory表,里面记录了jsp站点目录结构,
抓取jsp的源代码,然后把网址拷贝到application文件夹下,通过api接口等方式获取数据。
你可以先自己写个jsp然后连接api调用api用request写上url发送ajax请求就可以获取到数据
下载jsp,并写jspjs代码写成ajax,然后以http的方式向后端发送get/post请求,即可。jsp直接调用api的方式太危险,可以使用定时器以及正则匹配。ajax的跨域不用担心,通过反向代理就可以做到跨域。
就这个需求,写成ajax的方式更合适,直接写在后端就可以直接调用了。
forwardpost请求,完成。
要是新手我给一个网址你去看看,jsp只不过是可以简单的修改url,
这样吧,你把jsp的所有逻辑写到一个pojo类里,那就完成了。forwardpost请求,完成。
forwardpost请求
我刚好也碰到这个问题,遇到这种问题,先弄懂jsp,然后如果碰到那种来回post或get的就用jdk的get/post方法,最后测试跨域,你发现服务器打死不让跨,这个时候就借助你的爬虫。当然,ajax最简单的方法, 查看全部
抓取jsp网页源代码(抓取jsp网页源代码网上有很多教程可以去看一下)
抓取jsp网页源代码网上有很多教程可以去看一下jsp是asp的阉割版,在pagecontroller下有一个directory表,里面记录了jsp站点目录结构,
抓取jsp的源代码,然后把网址拷贝到application文件夹下,通过api接口等方式获取数据。
你可以先自己写个jsp然后连接api调用api用request写上url发送ajax请求就可以获取到数据
下载jsp,并写jspjs代码写成ajax,然后以http的方式向后端发送get/post请求,即可。jsp直接调用api的方式太危险,可以使用定时器以及正则匹配。ajax的跨域不用担心,通过反向代理就可以做到跨域。
就这个需求,写成ajax的方式更合适,直接写在后端就可以直接调用了。
forwardpost请求,完成。
要是新手我给一个网址你去看看,jsp只不过是可以简单的修改url,
这样吧,你把jsp的所有逻辑写到一个pojo类里,那就完成了。forwardpost请求,完成。
forwardpost请求
我刚好也碰到这个问题,遇到这种问题,先弄懂jsp,然后如果碰到那种来回post或get的就用jdk的get/post方法,最后测试跨域,你发现服务器打死不让跨,这个时候就借助你的爬虫。当然,ajax最简单的方法,

