
抓取jsp网页源代码
抓取jsp网页源代码(spring的实现机制和对比a的区别和方法设计)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-03-13 18:04
(2)比较支柱
一种。核心控制器:spring mvc核心控制器为Servlet,Struts2为Filter。
湾。控制器实例:Spring Mvc 会比 Struts 快。Spring Mvc 是基于方法设计的,而 Sturts 是基于对象的。每次发出请求时,都会实例化一个动作,并为每个动作注入属性。Spring更像Servlet,只有一个实例,每个请求都执行对应的方法。能。
C。管理方式:大部分公司的核心架构都使用spring,而spring mvc是spring中的一个模块,所以spring对spring mvc控制器的管理更加简单方便,并且提供了完整的注解方式进行管理,各种功能的注解比较全面好用,而struts需要使用很多XML配置参数来管理。
d。参数传递:Struts2本身提供了多种参数来接受,其实是通过(ValueStack)传递和赋值的,SpringMvc是通过方法的参数来接收的。
e. 拦截器实现机制:struts有自己的拦截器机制,spring mvc使用独立的AOP方式。这样一来,struts的配置文件量还是比spring mvc大,虽然struts的配置可以继承,所以我觉得在使用方面,spring mvc更加简洁,spring的开发效率mvc高于struts2。
F。spring mvc处理ajax请求,直接通过返回数据,使用方法中的注解@ResponseBody,spring mvc自动将我们的对象转换为JSON数据。
2. 自由标记
(1)FreeMarker 是一个模板引擎:即基于模板和要更改的数据生成输出文本(HTML 页面、电子邮件、配置文件、源代码等)的通用工具。它是不适用于最终用户,它是一个 Java 类库,程序员可以嵌入到他们开发的产品中的组件。
(2)比较jsp
一种。内置了很多常用功能,例如:html过滤、日期和金额格式化等,使用起来非常方便。
湾。宏定义比jsp方便。
C。支持jsp标签
d。可以实现严格的MAC分离
e. 在复杂的页面上,freemarker 表现最好
2.5 系统实现功能的具体说明
1.“新浪微博”:
(1)经过多次搜索,发现wap版新浪微博存在权限bug。利用这个bug,无需登录即可搜索微博内容,获取微博上的相应评论,从而避免了PC端的访问限制和API应用困难等问题。
(2)方法:本系统使用Apache HttpClient模拟http请求,爬取微博时直接向官方存在bug的请求地址发送请求,获取所需数据并解析数据格式构造所需内容由系统获取(默认获取微博前10页,每条微博评论前10页)。
(3)具体解析规则:
1、默认获取的第一页内容为html+data。html内容毫无意义。我们需要做的是从html中获取需要的数据字符串。在这里,我们使用正则表达式来匹配捕获的数据;
2.从第二页开始,请求直接返回需要的json字符串格式数据
3.使用alibaba fastjson将数据转成json格式,获取需要的字段值
4.同理,获取评论请求地址数据并解析
5.然后将解析后的数据存入数据库,微博内容存入article表,回复信息存入article_reply表
2、“天涯论坛”:
因为天涯论坛不限制登录权限,所以爬取天涯论坛的数据比较简单。下面对天涯论坛的抓取做一个简单的说明: 查看全部
抓取jsp网页源代码(spring的实现机制和对比a的区别和方法设计)
(2)比较支柱
一种。核心控制器:spring mvc核心控制器为Servlet,Struts2为Filter。
湾。控制器实例:Spring Mvc 会比 Struts 快。Spring Mvc 是基于方法设计的,而 Sturts 是基于对象的。每次发出请求时,都会实例化一个动作,并为每个动作注入属性。Spring更像Servlet,只有一个实例,每个请求都执行对应的方法。能。
C。管理方式:大部分公司的核心架构都使用spring,而spring mvc是spring中的一个模块,所以spring对spring mvc控制器的管理更加简单方便,并且提供了完整的注解方式进行管理,各种功能的注解比较全面好用,而struts需要使用很多XML配置参数来管理。
d。参数传递:Struts2本身提供了多种参数来接受,其实是通过(ValueStack)传递和赋值的,SpringMvc是通过方法的参数来接收的。
e. 拦截器实现机制:struts有自己的拦截器机制,spring mvc使用独立的AOP方式。这样一来,struts的配置文件量还是比spring mvc大,虽然struts的配置可以继承,所以我觉得在使用方面,spring mvc更加简洁,spring的开发效率mvc高于struts2。
F。spring mvc处理ajax请求,直接通过返回数据,使用方法中的注解@ResponseBody,spring mvc自动将我们的对象转换为JSON数据。
2. 自由标记
(1)FreeMarker 是一个模板引擎:即基于模板和要更改的数据生成输出文本(HTML 页面、电子邮件、配置文件、源代码等)的通用工具。它是不适用于最终用户,它是一个 Java 类库,程序员可以嵌入到他们开发的产品中的组件。
(2)比较jsp
一种。内置了很多常用功能,例如:html过滤、日期和金额格式化等,使用起来非常方便。
湾。宏定义比jsp方便。
C。支持jsp标签
d。可以实现严格的MAC分离
e. 在复杂的页面上,freemarker 表现最好
2.5 系统实现功能的具体说明
1.“新浪微博”:
(1)经过多次搜索,发现wap版新浪微博存在权限bug。利用这个bug,无需登录即可搜索微博内容,获取微博上的相应评论,从而避免了PC端的访问限制和API应用困难等问题。
(2)方法:本系统使用Apache HttpClient模拟http请求,爬取微博时直接向官方存在bug的请求地址发送请求,获取所需数据并解析数据格式构造所需内容由系统获取(默认获取微博前10页,每条微博评论前10页)。
(3)具体解析规则:
1、默认获取的第一页内容为html+data。html内容毫无意义。我们需要做的是从html中获取需要的数据字符串。在这里,我们使用正则表达式来匹配捕获的数据;
2.从第二页开始,请求直接返回需要的json字符串格式数据
3.使用alibaba fastjson将数据转成json格式,获取需要的字段值
4.同理,获取评论请求地址数据并解析
5.然后将解析后的数据存入数据库,微博内容存入article表,回复信息存入article_reply表
2、“天涯论坛”:
因为天涯论坛不限制登录权限,所以爬取天涯论坛的数据比较简单。下面对天涯论坛的抓取做一个简单的说明:
抓取jsp网页源代码(抓取jsp网页源代码中的应用方法-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-03-08 19:00
抓取jsp网页源代码中,把jsp页面中所有image对象的请求和响应的url写成一个字典,做成一个字典的key和value列表,判断出网页中所有的图片是不是存在这个字典中。imageitem=imageitem.getitem('key');responseitem=responseitem.getresponseitem('value');。
你解析jsp是写在jsp文件中的image=jsoup。reader(jsoup。read('jsp:btn。btn'))。
get_url('jsp:btn。btn')image=jsoup。reader(jsoup。read('jsp:btn。btn'))。get_url('jsp:btn。btn')但是要加上append方法%>如果不想再使用org。gson。python。tojson等工具来调用,可以使用pythonbeautifulsoup或lxml来读取和解析jsp页面。 查看全部
抓取jsp网页源代码(抓取jsp网页源代码中的应用方法-上海怡健医学)
抓取jsp网页源代码中,把jsp页面中所有image对象的请求和响应的url写成一个字典,做成一个字典的key和value列表,判断出网页中所有的图片是不是存在这个字典中。imageitem=imageitem.getitem('key');responseitem=responseitem.getresponseitem('value');。
你解析jsp是写在jsp文件中的image=jsoup。reader(jsoup。read('jsp:btn。btn'))。
get_url('jsp:btn。btn')image=jsoup。reader(jsoup。read('jsp:btn。btn'))。get_url('jsp:btn。btn')但是要加上append方法%>如果不想再使用org。gson。python。tojson等工具来调用,可以使用pythonbeautifulsoup或lxml来读取和解析jsp页面。
抓取jsp网页源代码(JSP页面间传递参数的方式及解决办法(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-03-01 03:05
在项目中经常需要在JSP页面之间传递参数,这应该算是web的基本功。
尝试总结各种方式,在需要权衡利弊时选择最合适的方式。
1. 在 URL 链接后附加参数
URL 后面追加参数
response.sendRedirect("next.jsp?paramA=A¶mB=B...")
window.location = "next.jsp?paramA=A¶mB=B..."
以上代码执行完毕后,会跳转到带参数的next.jsp页面。
在next.jsp页面中获取对应参数的方式如下:
//内嵌的 java 代码
//如果引入了 EL
{param.paramA}
优点:简单性和多浏览器支持(没有浏览器不支持 URL)。
缺点:
1)传输的数据只能是字符串,对数据类型和大小有一定的限制;
2)在浏览器地址栏中会看到传输数据的值,安全级别低。
2. 表格
在 next.jsp 页面中获取相应参数的方式类似于 (1).
优势:
1) 简单性和多浏览器支持(再次没有浏览器不支持表单);
2) 可以提交的数据量远大于URL方式;
3)传输的值会显示在浏览器的地址栏,但是有一点hack,也可以从页面源码中构造参数列表;
缺点:
1)传输的数据只能是字符串,对数据类型有一定的限制;
3. 设置 Cookie
使用客户端的认证凭证,一个小cookie,当然也可以实现JSP页面的值传递。
要读取 next.jsp 页面上的 cookie,请调用 request.getCookies() 方法以获取 javax.servlet.http.Cookie 对象数组。
然后遍历数组并使用 getName() 和 getValue() 方法来获取每个 cookie 的名称和值。
//内嵌的 java 代码
//EL 获取方式
${cookie.paramA.value}
优势:
1)cookie的值可以持久化,即使客户端机器关闭,下次打开时仍然可以获取到里面的值;
2) Cookies可以帮助服务器保存多个状态信息,但不需要在服务器上分配存储资源,减轻了服务器的负担。
缺点:
1)虽然相比URL和Form,安全性提升了很多,但是也有一些黑方法获取客户端cookie,暴露客户端信息。
4. 设置会话
个人认为session和cookie是服务器端一个,客户端一个。
在给它们添加键值对之后,它不仅提供了页面之间的传输,还提供了数据共享的解决方案。
在 next.jsp 中读取 session 的方式:
//内嵌java 片段
//EL 获取方式
{session.paramA}
Session的优缺点可以参考Cookies。 查看全部
抓取jsp网页源代码(JSP页面间传递参数的方式及解决办法(二))
在项目中经常需要在JSP页面之间传递参数,这应该算是web的基本功。
尝试总结各种方式,在需要权衡利弊时选择最合适的方式。
1. 在 URL 链接后附加参数
URL 后面追加参数
response.sendRedirect("next.jsp?paramA=A¶mB=B...")
window.location = "next.jsp?paramA=A¶mB=B..."
以上代码执行完毕后,会跳转到带参数的next.jsp页面。
在next.jsp页面中获取对应参数的方式如下:
//内嵌的 java 代码
//如果引入了 EL
{param.paramA}
优点:简单性和多浏览器支持(没有浏览器不支持 URL)。
缺点:
1)传输的数据只能是字符串,对数据类型和大小有一定的限制;
2)在浏览器地址栏中会看到传输数据的值,安全级别低。
2. 表格
在 next.jsp 页面中获取相应参数的方式类似于 (1).
优势:
1) 简单性和多浏览器支持(再次没有浏览器不支持表单);
2) 可以提交的数据量远大于URL方式;
3)传输的值会显示在浏览器的地址栏,但是有一点hack,也可以从页面源码中构造参数列表;
缺点:
1)传输的数据只能是字符串,对数据类型有一定的限制;
3. 设置 Cookie
使用客户端的认证凭证,一个小cookie,当然也可以实现JSP页面的值传递。
要读取 next.jsp 页面上的 cookie,请调用 request.getCookies() 方法以获取 javax.servlet.http.Cookie 对象数组。
然后遍历数组并使用 getName() 和 getValue() 方法来获取每个 cookie 的名称和值。
//内嵌的 java 代码
//EL 获取方式
${cookie.paramA.value}
优势:
1)cookie的值可以持久化,即使客户端机器关闭,下次打开时仍然可以获取到里面的值;
2) Cookies可以帮助服务器保存多个状态信息,但不需要在服务器上分配存储资源,减轻了服务器的负担。
缺点:
1)虽然相比URL和Form,安全性提升了很多,但是也有一些黑方法获取客户端cookie,暴露客户端信息。
4. 设置会话
个人认为session和cookie是服务器端一个,客户端一个。
在给它们添加键值对之后,它不仅提供了页面之间的传输,还提供了数据共享的解决方案。
在 next.jsp 中读取 session 的方式:
//内嵌java 片段
//EL 获取方式
{session.paramA}
Session的优缺点可以参考Cookies。
抓取jsp网页源代码(本文将略微详细的介绍SEO怎么优化代码与标签?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-02-28 18:05
通常,在网站上线之前,需要对网站的代码和标签进行必要的处理,以提高优化后的网站的打开速度,并强调想要的关键词达到排名。一个好的网站,在代码方面干净简洁。我们之前的文章中也提到了一些相关的标签页代码优化技术。本文将稍微详细介绍如何为 SEO 优化代码和标签。在合适的位置使用权重标签可以向搜索引擎传达友好,这是SEO的基本要求。
爬虫利用网站的代码简洁性来判断一个网页是否对人友好,浏览器能否获得良好的用户体验。简洁的网站通常不那么花哨,没有那么多广告,各种模块弹窗等。
1.减小网页大小,加快网页下载速度。减少页面噪音并突出显示页面主题。
2.提高蜘蛛抓取信息的速度和准确性。有利于减少错误码,提高页面对蜘蛛的友好度。
3.易于维护,提高工作效率。使用 div+css 布局。代码更加精简。
4.div+css可以简化很多样式,而且这些样式都放在一个专门的CSS文件中,维护和更改都很方便。
5.因为使用了css文件,蜘蛛爬取head里的内容更加快速准确。
6.浏览器下载div的速度比下载表格快很多倍,所以使用div+css排版可以有效稳定客户的等待情绪,增加客户访问的友好度。
7.使用 w3c 检查网页的错误代码。
8.减少网页上的jsp和JavaScript代码量,可以的话不要用。不要过分追求网页特效。
9.减少网页上图像的大小或数量。但不是没有图片。
10. 使用强调标签;使用高键标签,重音标签是粗体标签。
11.超链接需要标准化:链接对于网页来说非常重要,但是超链接需要标准化,而且超链接必须统一,一时不使用绝对路径,一时使用相对路径。
12.除了网页中必要的导航,尽量突出网站的重要内容,非关键的辅助内容可以通过框架、js等搜索引擎无法识别的技术调用.
13.网页的重要内容应该放在网页的最前面,这样搜索引擎就可以轻松抓取到关键信息。
注:本文版权归星宿云原创所有,禁止转载,一经发现追究版权责任! 查看全部
抓取jsp网页源代码(本文将略微详细的介绍SEO怎么优化代码与标签?)
通常,在网站上线之前,需要对网站的代码和标签进行必要的处理,以提高优化后的网站的打开速度,并强调想要的关键词达到排名。一个好的网站,在代码方面干净简洁。我们之前的文章中也提到了一些相关的标签页代码优化技术。本文将稍微详细介绍如何为 SEO 优化代码和标签。在合适的位置使用权重标签可以向搜索引擎传达友好,这是SEO的基本要求。

爬虫利用网站的代码简洁性来判断一个网页是否对人友好,浏览器能否获得良好的用户体验。简洁的网站通常不那么花哨,没有那么多广告,各种模块弹窗等。
1.减小网页大小,加快网页下载速度。减少页面噪音并突出显示页面主题。
2.提高蜘蛛抓取信息的速度和准确性。有利于减少错误码,提高页面对蜘蛛的友好度。
3.易于维护,提高工作效率。使用 div+css 布局。代码更加精简。
4.div+css可以简化很多样式,而且这些样式都放在一个专门的CSS文件中,维护和更改都很方便。
5.因为使用了css文件,蜘蛛爬取head里的内容更加快速准确。
6.浏览器下载div的速度比下载表格快很多倍,所以使用div+css排版可以有效稳定客户的等待情绪,增加客户访问的友好度。
7.使用 w3c 检查网页的错误代码。
8.减少网页上的jsp和JavaScript代码量,可以的话不要用。不要过分追求网页特效。
9.减少网页上图像的大小或数量。但不是没有图片。
10. 使用强调标签;使用高键标签,重音标签是粗体标签。
11.超链接需要标准化:链接对于网页来说非常重要,但是超链接需要标准化,而且超链接必须统一,一时不使用绝对路径,一时使用相对路径。
12.除了网页中必要的导航,尽量突出网站的重要内容,非关键的辅助内容可以通过框架、js等搜索引擎无法识别的技术调用.
13.网页的重要内容应该放在网页的最前面,这样搜索引擎就可以轻松抓取到关键信息。
注:本文版权归星宿云原创所有,禁止转载,一经发现追究版权责任!
抓取jsp网页源代码( 另外一个超棒的Java的HTML解析器-jsoup-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-02-25 14:03
另外一个超棒的Java的HTML解析器-jsoup-)
在线演示 本地下载
如果您曾经开发过内容聚合类网站,那么使用程序动态集成来自不同页面或网站 程序的内容的能力对您来说肯定非常熟悉。通常,如果我们使用java,我们会使用一些HTML解析,例如httpparser。最早的集成搜索是利用httpparser抓取谷歌和百度的搜索结果,并集成呈现给搜索用户,这就是GBin1域名的由来。
所以今天,我们介绍另一个很棒的Java HTML解析器——jsoup,这个类库可以帮助你实时处理HTML。提供非常方便的 API 来提取和处理数据。最重要的是它使用类似jQuery的语法来处理DOM、CSS等。如果你使用过jQuery,你就会知道它处理DOM的强大和方便。
主要特点
jsoup 实现了 WHATWG HTML5 标准,与现代浏览器解析 DOM 的方式相同。主要功能:
基本上jsoup可以帮你处理各种HTML问题,帮你验证非法标签,创建干净的DOM树。
实现抓取功能
这里我们将实现一个简单的抓取功能,你只需要指定url,并指定你需要抓取的具体元素,例如ID或者class。在后台我们将使用jsoup进行抓取,在前台我们将使用jQuery来美化结果。
您需要注意以下几点:
相对路径问题:你爬取的页面中的链接可能使用相对路径,需要处理成绝对路径,否则在本地服务器无法正常打开链接
的相对路径问题:同上,还需要处理转换
问题大小:如果你抓取的图片很大,需要用代码转换成本地样式,也可以选择在前台使用jQuery处理
下载jsoup jar包后,请添加你的classpath路径,如果使用jsp,请添加到web应用WEB-INF的lib目录下。
相关Java代码如下:
Document doc = Jsoup.connect("http://www.gbin1.com/portfolio/lastest.html").timeout(0).get();
Elements items = doc.select(".includeitem");
在上面的代码中,我们定义了jsoup使用一个url来获取HTML,这里就用到了。本页列出了 gbin1 最近发布的 文章。如果看这个页面的源码,可以看到每个文章都在.includeitem类中,所以我们这里使用doc.select方法来选择对应的类。
注意这里我们调用了timeout(0),意思是连续请求url,默认2000,即2秒后超时。可以看到这里使用了类似jQuery的链式调用,非常方便.
for (Element item : items) {
Elements links = item.select("a");
for(Element link: links){
link.attr("href",link.attr("abs:href"));
}
Elements imgs = item.select("img");
for(Element img: imgs){
img.attr("src",img.attr("abs:src"));
}
String html = item.html();
out.println("" + html + "");
}
在上面的代码中,我们处理了每个被查询的 includeitem 元素。找到“a”和“img”,将其中的href元素值修改为绝对路径。
link.attr("abs:href")
上面的代码会得到对应链接的绝对路径,其中属性为abs:href。同理可以得到图片abs:src的绝对路径。
代码运行后,我们可以看到修改后的代码,把它们放在li中。
接下来我们开发控制爬取的页面:
在这个页面的实现中,我们使用setInterval方法,以指定的时间间隔,调用上面使用ajax开发的java代码。基本代码如下:
//Run for first time
$(\'#msg\').html(\'请耐心等待, 页面抓取中 ...\').fadeIn(400);
//$(\'#content\').html(\'\');
$(\'#content\').load(\'siteproxy.jsp #result\', {url:url, elem:element}, function(){
$(\'#msg\').html(\'抓取已完成\').delay(1500).fadeOut(400);
})
上面的代码非常简单。我们使用jQuery的load方法调用siteproxy.jsp,然后在siteproxy.jsp的生成页面中获取#result元素,即抓取内容。如果不熟悉jQuery的ajax方法,请参考本系列文章:
jQuery 类库初学者指南的 AJAX 方法 - 第 1 部分
jQuery 类库初学者指南之 AJAX 方法 - 第二部分
jQuery 类库初学者指南之 AJAX 方法 - 第三部分
jQuery 类库初学者指南的 AJAX 方法 - 第 4 部分
为了让代码以指定的时间间隔运行爬取,我们将方法放在 setinterval 中如下:
runid = setInterval(
function getInfo(){
$(\'#msg\').html(\'请耐心等待, 页面抓取中 ...\').fadeIn(400);
//$(\'#content\').html(\'\');
$(\'#content\').load(\'siteproxy.jsp #result\', {url:url, elem:element}, function(){
$(\'#msg\').html(\'抓取已完成\').delay(1500).fadeOut(400);
})
}, interval*1000);
通过上述方法,我们可以在用户触发抓取后每隔指定时间触发抓取动作。
完整的js代码如下:
$(document).ready(function(){
var url, element, interval, runid;
$(\'#start\').click(function(){
url = $(\'#url\').val();
element = $(\'#element\').val();
interval = $(\'#interval\').val();
//Run for first time
$(\'#msg\').html(\'请耐心等待, 页面抓取中 ...\').fadeIn(400);
//$(\'#content\').html(\'\');
$(\'#content\').load(\'siteproxy.jsp #result\', {url:url, elem:element}, function(){
$(\'#msg\').html(\'抓取已完成\').delay(1500).fadeOut(400);
})
runid = setInterval(
function getInfo(){
$(\'#msg\').html(\'请耐心等待, 页面抓取中 ...\').fadeIn(400);
//$(\'#content\').html(\'\');
$(\'#content\').load(\'siteproxy.jsp #result\', {url:url, elem:element}, function(){
$(\'#msg\').html(\'抓取已完成\').delay(1500).fadeOut(400);
})
}, interval*1000);
});
$(\'#stop\').click(function(){
$(\'#msg\').html(\'抓取已暂停\').fadeIn(400).delay(1500);
clearInterval(runid);
});
});
部署上面的jsp和html文件后,会看到如下界面:
8、 查看全部
抓取jsp网页源代码(
另外一个超棒的Java的HTML解析器-jsoup-)
在线演示 本地下载
如果您曾经开发过内容聚合类网站,那么使用程序动态集成来自不同页面或网站 程序的内容的能力对您来说肯定非常熟悉。通常,如果我们使用java,我们会使用一些HTML解析,例如httpparser。最早的集成搜索是利用httpparser抓取谷歌和百度的搜索结果,并集成呈现给搜索用户,这就是GBin1域名的由来。
所以今天,我们介绍另一个很棒的Java HTML解析器——jsoup,这个类库可以帮助你实时处理HTML。提供非常方便的 API 来提取和处理数据。最重要的是它使用类似jQuery的语法来处理DOM、CSS等。如果你使用过jQuery,你就会知道它处理DOM的强大和方便。
主要特点
jsoup 实现了 WHATWG HTML5 标准,与现代浏览器解析 DOM 的方式相同。主要功能:
基本上jsoup可以帮你处理各种HTML问题,帮你验证非法标签,创建干净的DOM树。
实现抓取功能
这里我们将实现一个简单的抓取功能,你只需要指定url,并指定你需要抓取的具体元素,例如ID或者class。在后台我们将使用jsoup进行抓取,在前台我们将使用jQuery来美化结果。
您需要注意以下几点:
相对路径问题:你爬取的页面中的链接可能使用相对路径,需要处理成绝对路径,否则在本地服务器无法正常打开链接
的相对路径问题:同上,还需要处理转换
问题大小:如果你抓取的图片很大,需要用代码转换成本地样式,也可以选择在前台使用jQuery处理
下载jsoup jar包后,请添加你的classpath路径,如果使用jsp,请添加到web应用WEB-INF的lib目录下。
相关Java代码如下:
Document doc = Jsoup.connect("http://www.gbin1.com/portfolio/lastest.html";).timeout(0).get();
Elements items = doc.select(".includeitem");
在上面的代码中,我们定义了jsoup使用一个url来获取HTML,这里就用到了。本页列出了 gbin1 最近发布的 文章。如果看这个页面的源码,可以看到每个文章都在.includeitem类中,所以我们这里使用doc.select方法来选择对应的类。
注意这里我们调用了timeout(0),意思是连续请求url,默认2000,即2秒后超时。可以看到这里使用了类似jQuery的链式调用,非常方便.
for (Element item : items) {
Elements links = item.select("a");
for(Element link: links){
link.attr("href",link.attr("abs:href"));
}
Elements imgs = item.select("img");
for(Element img: imgs){
img.attr("src",img.attr("abs:src"));
}
String html = item.html();
out.println("" + html + "");
}
在上面的代码中,我们处理了每个被查询的 includeitem 元素。找到“a”和“img”,将其中的href元素值修改为绝对路径。
link.attr("abs:href")
上面的代码会得到对应链接的绝对路径,其中属性为abs:href。同理可以得到图片abs:src的绝对路径。
代码运行后,我们可以看到修改后的代码,把它们放在li中。
接下来我们开发控制爬取的页面:
在这个页面的实现中,我们使用setInterval方法,以指定的时间间隔,调用上面使用ajax开发的java代码。基本代码如下:
//Run for first time
$(\'#msg\').html(\'请耐心等待, 页面抓取中 ...\').fadeIn(400);
//$(\'#content\').html(\'\');
$(\'#content\').load(\'siteproxy.jsp #result\', {url:url, elem:element}, function(){
$(\'#msg\').html(\'抓取已完成\').delay(1500).fadeOut(400);
})
上面的代码非常简单。我们使用jQuery的load方法调用siteproxy.jsp,然后在siteproxy.jsp的生成页面中获取#result元素,即抓取内容。如果不熟悉jQuery的ajax方法,请参考本系列文章:
jQuery 类库初学者指南的 AJAX 方法 - 第 1 部分
jQuery 类库初学者指南之 AJAX 方法 - 第二部分
jQuery 类库初学者指南之 AJAX 方法 - 第三部分
jQuery 类库初学者指南的 AJAX 方法 - 第 4 部分
为了让代码以指定的时间间隔运行爬取,我们将方法放在 setinterval 中如下:
runid = setInterval(
function getInfo(){
$(\'#msg\').html(\'请耐心等待, 页面抓取中 ...\').fadeIn(400);
//$(\'#content\').html(\'\');
$(\'#content\').load(\'siteproxy.jsp #result\', {url:url, elem:element}, function(){
$(\'#msg\').html(\'抓取已完成\').delay(1500).fadeOut(400);
})
}, interval*1000);
通过上述方法,我们可以在用户触发抓取后每隔指定时间触发抓取动作。
完整的js代码如下:
$(document).ready(function(){
var url, element, interval, runid;
$(\'#start\').click(function(){
url = $(\'#url\').val();
element = $(\'#element\').val();
interval = $(\'#interval\').val();
//Run for first time
$(\'#msg\').html(\'请耐心等待, 页面抓取中 ...\').fadeIn(400);
//$(\'#content\').html(\'\');
$(\'#content\').load(\'siteproxy.jsp #result\', {url:url, elem:element}, function(){
$(\'#msg\').html(\'抓取已完成\').delay(1500).fadeOut(400);
})
runid = setInterval(
function getInfo(){
$(\'#msg\').html(\'请耐心等待, 页面抓取中 ...\').fadeIn(400);
//$(\'#content\').html(\'\');
$(\'#content\').load(\'siteproxy.jsp #result\', {url:url, elem:element}, function(){
$(\'#msg\').html(\'抓取已完成\').delay(1500).fadeOut(400);
})
}, interval*1000);
});
$(\'#stop\').click(function(){
$(\'#msg\').html(\'抓取已暂停\').fadeIn(400).delay(1500);
clearInterval(runid);
});
});
部署上面的jsp和html文件后,会看到如下界面:
8、
抓取jsp网页源代码(jsp页面的源代码有什么特殊的属性?页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-02-24 20:03
抓取jsp网页源代码能抓到jsp页面的源代码,那么看看jsp页面的源代码有什么特殊的属性。我通过浏览器的源代码分析,得到结论如下。
1、字段名:view-name字段名对应的view-id。
2、字段值:url(参数的意思就是里面的参数传过来是什么。
3、密码或者浏览器是否是activex控件这个比较容易理解,如果是activex控件的话,
4、jsp页面中是否包含cookie我通过代码抓取一些springmvc的cookie进来,可以清楚的看到springmvc生成的cookie,字段“authentication_key”是:jwt_file,那么问题来了,如果我有个cookie传给redis/mongodb,那么我可以获取到这个cookie中间的字段“authentication_key”,但是可惜这些cookie是通过json类型的springmvc来传递,那么我用redis或者mongodb可以读取这个springmvc生成的cookie,但是这些只能获取到header里面的值。
一些兼容性的问题可能影响读取。最后再说说https:请求/,有一个requestheader,里面包含着authentication_key,这个authentication_key我们只能得到header里面的值,这个值应该传递给springmvc,那么在springmvc中,可以使用beanmethod来判断authentication_key是否会指向web.xml,或者在web.xml中查找。 查看全部
抓取jsp网页源代码(jsp页面的源代码有什么特殊的属性?页面)
抓取jsp网页源代码能抓到jsp页面的源代码,那么看看jsp页面的源代码有什么特殊的属性。我通过浏览器的源代码分析,得到结论如下。
1、字段名:view-name字段名对应的view-id。
2、字段值:url(参数的意思就是里面的参数传过来是什么。
3、密码或者浏览器是否是activex控件这个比较容易理解,如果是activex控件的话,
4、jsp页面中是否包含cookie我通过代码抓取一些springmvc的cookie进来,可以清楚的看到springmvc生成的cookie,字段“authentication_key”是:jwt_file,那么问题来了,如果我有个cookie传给redis/mongodb,那么我可以获取到这个cookie中间的字段“authentication_key”,但是可惜这些cookie是通过json类型的springmvc来传递,那么我用redis或者mongodb可以读取这个springmvc生成的cookie,但是这些只能获取到header里面的值。
一些兼容性的问题可能影响读取。最后再说说https:请求/,有一个requestheader,里面包含着authentication_key,这个authentication_key我们只能得到header里面的值,这个值应该传递给springmvc,那么在springmvc中,可以使用beanmethod来判断authentication_key是否会指向web.xml,或者在web.xml中查找。
抓取jsp网页源代码(科技小能手1394人浏览评论数:04年前(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-02-21 21:20
阿里云>云栖社区>主题图>J>jsp信息网站源码
推荐活动:
更多优惠>
当前话题:jsp信息网站源码加入采集
相关话题:
jsp资料网站源码相关博客看更多博文
JSP漏洞视图
作者:科技甜1304人查看评论:04年前
总结:服务器漏洞是安全问题的根源,黑客对网站的攻击也大多是从发现对方漏洞开始的。因此,网站管理者只有了解自己的漏洞,才能采取相应的对策来防范外部攻击。下面介绍一些服务器(包括Web服务器和JSP服务器)的常见漏洞。Apache泄漏重写任意文件泄漏
阅读全文
JSP安全性初探
作者:科技甜1653 浏览评论:04年前
总结:暴露JSP代码的方式有多种,但经过大量测试,这绝对与WEB SERVER的配置有关。就拿IBM Websphere Commerce Suite来说,还有其他方法可以查看JSP源码,但相信是IBM HTTP SERVER的配置造成的。如果你想发现
阅读全文
邮箱网站jsp+python源码
作者:小技术专家 1394 浏览评论:04年前
源码针对以下系列邮箱: [url]
阅读全文
CVE-2017-12615/CVE-2017-12616:Tomcat信息泄露和远程代码执行漏洞分析报告
作者:郑和4130 浏览评论:04年前
<p>一. 漏洞概述 2017 年 9 月 19 日,Apache Tomcat 正式确认并修复了两个高危漏洞。漏洞 CVE 编号为:CVE-2017-12615 和 CVE-2017-12616。该漏洞的受影响版本为 查看全部
抓取jsp网页源代码(科技小能手1394人浏览评论数:04年前(组图))
阿里云>云栖社区>主题图>J>jsp信息网站源码

推荐活动:
更多优惠>
当前话题:jsp信息网站源码加入采集
相关话题:
jsp资料网站源码相关博客看更多博文
JSP漏洞视图

作者:科技甜1304人查看评论:04年前
总结:服务器漏洞是安全问题的根源,黑客对网站的攻击也大多是从发现对方漏洞开始的。因此,网站管理者只有了解自己的漏洞,才能采取相应的对策来防范外部攻击。下面介绍一些服务器(包括Web服务器和JSP服务器)的常见漏洞。Apache泄漏重写任意文件泄漏
阅读全文
JSP安全性初探

作者:科技甜1653 浏览评论:04年前
总结:暴露JSP代码的方式有多种,但经过大量测试,这绝对与WEB SERVER的配置有关。就拿IBM Websphere Commerce Suite来说,还有其他方法可以查看JSP源码,但相信是IBM HTTP SERVER的配置造成的。如果你想发现
阅读全文
邮箱网站jsp+python源码

作者:小技术专家 1394 浏览评论:04年前
源码针对以下系列邮箱: [url]
阅读全文
CVE-2017-12615/CVE-2017-12616:Tomcat信息泄露和远程代码执行漏洞分析报告


作者:郑和4130 浏览评论:04年前
<p>一. 漏洞概述 2017 年 9 月 19 日,Apache Tomcat 正式确认并修复了两个高危漏洞。漏洞 CVE 编号为:CVE-2017-12615 和 CVE-2017-12616。该漏洞的受影响版本为
抓取jsp网页源代码(怎么看别人的代码-如何自动提取他人网页上的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-02-19 10:24
if(substr($url, 0, 4) == 'http')
回声 $url。
';
}
获取网页源代码中文件的具体步骤如下:
1、首先,我们在浏览器中随意打开一个网页,查看其源代码。
2、然后我们在浏览器上点击查看。
3、在选项中的以下位置选择查看源代码。
4、然后我们可以在那个网页中看到源代码。
5、源代码也是可以点击的。
6、点击下图显示的访问源代码,可以看到源代码显示的数据。
我要提取别人网页的代码怎么办-:网页界面右键,==》“查看源代码”,就可以看到了
如何提取别人的网页代码:在网页上右击会看到一个“查看源文件”的选项,可以点击,但是不完整,这个方法不是很好
如何提取网站代码-:直接打开你想要的页面,然后 CTRL+S ,然后在文件类型中选择【网页,全部】,即可保存对应的文件代码 CSS 和 JS 代码以及所有相关文件将被保存下来
敢问各位程序高手,如何自动提取别人网页的数据:如果你用php,可以用file、stream_get_contents等方法获取别人网页的内容。但我不知道你在说什么形式的数据。
怎么看别人的代码 - 如何获取网站的源码?看别人的网站做的很好,我也想入,怎么直接入?: 基本上是不可能的,但是很难用 有些方法可能是可行的。复制网站首页内页及各个角落的链接,去掉=、数值等。比如get.asp?***,把问候语去掉后,用迅雷把所有的类都去掉,然后再包括系统后台。一般admin.asp打开记事本查看。你可以从一个案例中得出推论。建议下载一些开源代码进行研究,了解最基本的结构。
如何从别人的网页中窃取一段代码——:这很简单,但是如果你想修改一段理想的代码,你需要精通代码。方法如下:1、用360浏览器打开修改后的网站,然后右键查看源码。2,然后复制代码保存修改。
如何获取别人的网站的代码?:如果是静态的网站,直接查看源文件即可。如果是动态的网站,比如ASP、JSP、PHP、ASP.NET,一般是没有办法获取源文件的。
我想用软件把网页某部分的代码提取出来,把提取出来的代码放到另一个页面上,和提取的时候一样——:Macromedia Dreamweaver
如何在其他网页上得到你想要的源代码,复制出来直接使用?:点击查看-源文件
如何获取别人的网站源码-:如果是静态页面,可以直接使用全站下载器获取。如果它是用动态语言编写的,例如:ASP、ASP.NET、JSP、PHP。然后破解它网站服务器后台。否则是不可能得到的! 查看全部
抓取jsp网页源代码(怎么看别人的代码-如何自动提取他人网页上的数据)
if(substr($url, 0, 4) == 'http')
回声 $url。
';
}
获取网页源代码中文件的具体步骤如下:
1、首先,我们在浏览器中随意打开一个网页,查看其源代码。
2、然后我们在浏览器上点击查看。
3、在选项中的以下位置选择查看源代码。
4、然后我们可以在那个网页中看到源代码。
5、源代码也是可以点击的。
6、点击下图显示的访问源代码,可以看到源代码显示的数据。
我要提取别人网页的代码怎么办-:网页界面右键,==》“查看源代码”,就可以看到了
如何提取别人的网页代码:在网页上右击会看到一个“查看源文件”的选项,可以点击,但是不完整,这个方法不是很好
如何提取网站代码-:直接打开你想要的页面,然后 CTRL+S ,然后在文件类型中选择【网页,全部】,即可保存对应的文件代码 CSS 和 JS 代码以及所有相关文件将被保存下来
敢问各位程序高手,如何自动提取别人网页的数据:如果你用php,可以用file、stream_get_contents等方法获取别人网页的内容。但我不知道你在说什么形式的数据。
怎么看别人的代码 - 如何获取网站的源码?看别人的网站做的很好,我也想入,怎么直接入?: 基本上是不可能的,但是很难用 有些方法可能是可行的。复制网站首页内页及各个角落的链接,去掉=、数值等。比如get.asp?***,把问候语去掉后,用迅雷把所有的类都去掉,然后再包括系统后台。一般admin.asp打开记事本查看。你可以从一个案例中得出推论。建议下载一些开源代码进行研究,了解最基本的结构。
如何从别人的网页中窃取一段代码——:这很简单,但是如果你想修改一段理想的代码,你需要精通代码。方法如下:1、用360浏览器打开修改后的网站,然后右键查看源码。2,然后复制代码保存修改。
如何获取别人的网站的代码?:如果是静态的网站,直接查看源文件即可。如果是动态的网站,比如ASP、JSP、PHP、ASP.NET,一般是没有办法获取源文件的。
我想用软件把网页某部分的代码提取出来,把提取出来的代码放到另一个页面上,和提取的时候一样——:Macromedia Dreamweaver
如何在其他网页上得到你想要的源代码,复制出来直接使用?:点击查看-源文件
如何获取别人的网站源码-:如果是静态页面,可以直接使用全站下载器获取。如果它是用动态语言编写的,例如:ASP、ASP.NET、JSP、PHP。然后破解它网站服务器后台。否则是不可能得到的!
抓取jsp网页源代码(在jsp页面上生成word文档很是简单,只需把contentType=)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-18 22:22
在jsp页面上生成word文档很简单,把contentType="text/html"改成contentType="application/msword;charset=gb2312",代码如下:html
应用程序
设置后,原页面内容可以word显示。框架
++++++++++++++++++++++++++++++++++++++++++++++++++ + ++++++++jsp
从 JSP ui 生成 WORD 文档的另一种方法
此方法无需使用第三方类库,只需将WORD模板文档保存为网页,提取源代码,将源代码保存为JSP文件,然后添加xml即可
,htm
这样访问JSP时,会弹出“打开”和“保存”对话框。如果客户端有WORD程序,生成的WORD文档可以直接在网页中打开。文档
++++++++++++++++++++++++++++++++++++++++++++++++++ + ++++++++获取
导入JSP页面实现Word保存要方便很多,但也有不足之处。首先,如果需要导入的话
如果需要下载,请导入
其实如果你用一个框架,比如Struts2,会方便很多。直接在Action中写如下代码:
如果(out!=null){
字符串文件名="";
fileName+="评估报告.doc";
试试{
HttpServletResponse 响应 = ServletActionContext.getResponse();
response.setHeader("Content-disposition","attachment; filename="+new String(fileName.getBytes("GB2312"), "8859_1"));
} 捕捉 (UnsupportedEncodingException e) {
e.printStackTrace();
}
out是一个jsp页面表单元素,一个按钮用来提交表单到对应的Action for Word下载。动作设置jsp页面头文件。这样每次点击按钮,对应的jsp页面的内容都可以保存到Word中,并且支持下载,Word中的内容是可编辑的。
缺点是因为表格的内容是动态生成的,有些需要先查看下载Word,需要新建一个JSP页面进行Word下载。当然,页面重定向必须先在struts.xml中配置。
新创建的页面的值应该与视图页面保持一致。 查看全部
抓取jsp网页源代码(在jsp页面上生成word文档很是简单,只需把contentType=)
在jsp页面上生成word文档很简单,把contentType="text/html"改成contentType="application/msword;charset=gb2312",代码如下:html
应用程序
设置后,原页面内容可以word显示。框架
++++++++++++++++++++++++++++++++++++++++++++++++++ + ++++++++jsp
从 JSP ui 生成 WORD 文档的另一种方法
此方法无需使用第三方类库,只需将WORD模板文档保存为网页,提取源代码,将源代码保存为JSP文件,然后添加xml即可
,htm
这样访问JSP时,会弹出“打开”和“保存”对话框。如果客户端有WORD程序,生成的WORD文档可以直接在网页中打开。文档
++++++++++++++++++++++++++++++++++++++++++++++++++ + ++++++++获取
导入JSP页面实现Word保存要方便很多,但也有不足之处。首先,如果需要导入的话
如果需要下载,请导入
其实如果你用一个框架,比如Struts2,会方便很多。直接在Action中写如下代码:
如果(out!=null){
字符串文件名="";
fileName+="评估报告.doc";
试试{
HttpServletResponse 响应 = ServletActionContext.getResponse();
response.setHeader("Content-disposition","attachment; filename="+new String(fileName.getBytes("GB2312"), "8859_1"));
} 捕捉 (UnsupportedEncodingException e) {
e.printStackTrace();
}
out是一个jsp页面表单元素,一个按钮用来提交表单到对应的Action for Word下载。动作设置jsp页面头文件。这样每次点击按钮,对应的jsp页面的内容都可以保存到Word中,并且支持下载,Word中的内容是可编辑的。
缺点是因为表格的内容是动态生成的,有些需要先查看下载Word,需要新建一个JSP页面进行Word下载。当然,页面重定向必须先在struts.xml中配置。
新创建的页面的值应该与视图页面保持一致。
抓取jsp网页源代码(为Development学习,这个软件包提供了大量可供修改的示例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-02-15 22:13
在 Sun 正式发布 JSP(JavaServer Pages)之后,这种新的 Web 应用程序开发技术非常流行
很快就引起了人们的注意。JSP 为创建高度动态的 Web 应用程序提供了独特的开发环境。
据Sun介绍,JSP可以适配市面上的8个包括Apache WebServer、IIS4.0
5%的服务器产品。即使你对 ASP “深爱”,我们认为仍然值得关注 JSP 的演变
必要的。
JSP和ASP的简单比较
JSP 与微软的 ASP 技术非常相似。两者都提供在 HTML 代码中混合某种程序
程序代码,由语言引擎解释和执行程序代码的能力。在 ASP 或 JSP 环境中,HTML 代码主要是
它负责描述信息的显示风格,程序代码用于描述处理逻辑。普通的HTML页面只依赖
根据 Web 服务器,ASP 和 JSP 页面需要额外的语言引擎来解析和执行程序代码。程序
代码执行的结果被重新嵌入到 HTML 代码中,并一起发送到浏览器。ASP 和 JSP
它是一种面向 Web 服务器的技术,客户端浏览器不需要任何额外的软件支持。
ASP的编程语言是VBScript等脚本语言,JSP用的是Java,是两者
最明显的区别。另外,ASP和JSP还有一个更本质的区别:两种语言引擎使用完全不同
嵌入在页面中的程序代码以同样的方式处理。在 ASP 下,VBScript 代码由 ASP 引擎解释和执行。
线; JSP下,代码被编译成servlet,由Java虚拟机执行,这个编译操作只是
发生在 JSP 页面的第一个请求上。
二次运行环境
Sun 的 JSP 主页位于,
您还可以从这里下载 JSP 规范,该规范定义了供应商在创建 JSP 引擎时必须遵循的内容
一些规则。
执行 JSP 代码需要在服务器上安装 JSP 引擎。这里我们使用 Sun 的 JavaS
erver Web 开发工具包 (JSWDK)。为了便于学习,此软件包提供了许多
修改示例。安装 JSWDK 后,只需执行 startserver 命令即可启动服务器。在默认配置中
设置服务器监听 8080 端口,使用 :8080 打开默认页面。
在运行 JSP 示例页面之前,请注意 JSWDK 的安装目录,尤其是“work”子目录
目录的内容。执行示例页面时,您可以在此处看到 JSP 页面如何转换为 Java 源文件
,然后编译成一个类文件(即Servlet)。JSWDK包中的示例页面分为两类
,它们可以是 JSP 文件,也可以是收录由 JSP 代码编写的表单的 HTML 文件
处理。与 ASP 一样,JSP 中的 Java 代码在服务器端执行。因此,在浏览器中使用
“查看源代码”菜单看不到 JSP 源代码,只能看到生成的 HTML 代码。所有的例子
源代码通过单独的“示例”页面提供。
三个 JSP 页面示例
下面我们分析一个简单的JSP页面。您可以在 JSWDK 的示例目录中创建另一个文件
这个文件存放在外面的一个目录下,文件名可以是任意的,但扩展名必须是.jsp。从下面的代码中清除
从列表中可以看出,除了比普通 HTML 页面多一些 Java 代码外,JSP 页面具有基本的相似之处。
相同的结构。Java 代码通过 <% 和 %> 符号添加到 HTML 代码中,它的主要功能
就是生成并显示一个从0到9的字符串。这个字符串的前后都是一些通过HTM
L 码输出的文本。
<HTML>
<HEAD><TITLE>JSP 页面</TITLE></HEAD>
<身体>
< %@ 页面语言="java" %>
<%! 字符串 str="0"; %>
< % for (int i=1; i < 10; i++) {
str = str + i;
} %>
在 JSP 输出之前。
<P>
< %= 字符串 %>
<P>
JSP 输出后。
</正文>
</HTML>
这个JSP页面可以分成几个部分进行分析。
第一个是JSP 指令。它描述了页面的基本信息,例如使用的语言,是否保持会话状态,
是否使用缓冲等。JSP 指令以 < %@ 开头,以 %> 结尾。在本例中,指令“< %@ page
language=”java” %> ” 简单定义了这个例子使用Java语言(目前在JSP规范中
Java 是唯一受支持的语言)。
接下来是 JSP 声明。JSP 声明可以被认为是在类级别定义变量和方法的地方。Ĵ
SP 声明以 <%! 并以 %> 结尾。如本例中“ < %! String str="0"; %> ” 定义
一个字符串变量。每个声明后面必须跟一个分号,就像在普通的 Java 类声明中一样
成员变量。
<%和%>之间的代码块是描述JSP页面处理逻辑的Java代码,例如本例中的f
或如图所示循环。
最后,< %= 和 %> 之间的代码称为 JSP 表达式,如本例中的“< %= str %>”
显示。JSP 表达式提供了一种将 JSP 生成的值嵌入到 HTML 页面中的简单方法。
二、会话状态管理
作者:仙人掌工作室
会话状态维护是Web 应用程序开发人员必须面对的问题。有多种方法可以解决这个问题
诸如使用 cookie、隐藏表单输入字段或将状态信息直接附加到 URL 等问题。熟
servlet 提供了一个会话对象,该对象在多个请求中持续存在,允许用户存储和
获取会话状态信息。JSP 在 servlet 中也支持这个概念。
请参阅 Sun 的 JSP 指南以了解有关隐式对象的更多信息(隐式地,这些
可以直接引用对象,不需要显式声明,也不需要专门的代码来创建它们的实例)。例如请求
uest 对象,它是 HttpServletRequest 的子类。此对象收录有关当前浏览器的所有信息
请求的信息,包括 cookie、HTML 表单变量等。session 对象也是这样一个隐含的
目的。该对象在第一个 JSP 页面加载时自动创建,并与请求对象相关联。
与 ASP 中的会话对象类似,JSP 中的会话对象对于那些希望完成一个
事务的应用非常有用。
为了说明session对象的具体应用,接下来我们用三个页面来模拟一个多页面的Web
应用。第一个页面( q1.html )只收录一个 HTML 表单,它询问用户的姓名,代码如下
向下:
<HTML>
<身体>
<FORM METHOD=POST ACTION="q2.jsp">
请输入你的名字:
<输入类型=文本>
<输入类型=提交值=“提交”>
</表格>
</正文>
</HTML>
第二个页面是一个 JSP 页面( q2.jsp ),它通过请求对象提取 q1.html
表单中的name值,将其存储为name变量,然后将name值保存到会话中
在对象中。会话对象是名称/值对的集合,其中名称/值对中的名称为 "
thename",其值为name变量的值。由于会话对象在会话期间始终有效,
因此,此处保存的变量对后续页面也有效。q2.jsp的附加任务是问第二个问题
. 这是它的代码:
<HTML>
<身体>
< %@ 页面语言="java" %>
<%! 细绳; %>
< %
name = request.getParameter("thename");
session.putValue("名称", name);
%>
你的名字是:< %= name %>
<p>
<FORM METHOD=POST ACTION="q3.jsp">
你喜欢吃什么?
<输入类型=文本>
<P>
<输入类型=提交值=“提交”>
</表格>
</正文>
</HTML>
第三个页面也是一个 JSP 页面( q3.jsp ),其主要任务是显示问答的结果。它来自 s
session对象提取了name的值并显示出来,证明虽然在第一页输入了值,
会话对象被保留。q3.jsp的另一个任务是在第二页提取用户输入
并显示它:
<HTML>
<身体>
< %@ 页面语言="java" %>
<%! 字符串食物=""; %>
< %
food = request.getParameter("food");
String name = (String) session.getValue("thename");
%>
你的名字是:< %= name %>
<P>
你喜欢吃:< %= food %>
</正文>
</HTML>
三、对 JavaBean 组件的引用
作者:仙人掌工作室
JavaBean 是基于 Java 的软件组件。用于在 Web 应用程序中集成 JavaBea 的 JSP
n 组件提供完整的支持。这种支持不仅减少了开发时间(可以直接利用经过测试和信任的
任何现有的组件,避免重复开发),也为 JSP 应用程序带来了更多的可扩展性。JavaBeans
组件可以用来执行复杂的计算任务,或者负责与数据库交互、数据提取等,如果我们
共有三个JavaBean,分别具有显示新闻、股票价格和天气状况的功能。
具有全部三个功能的网页只需要实例化这三个bean,并使用HTML表格依次指定它们。
点它。
为了说明 JavaBeans 在 JSP 环境中的应用,我们创建了一个名为 TaxRate 的 Bean
. 它有两个属性,Product 和 Rate。两种set方法用于设置
设置这两个属性,使用两个get方法提取这两个属性。在实际应用中,这个Bean一般是
应从数据库中提取税率值,这里我们简化了过程以允许任意税率。下面是这个
豆代码清单:
包裹税;
公共课税率 {
字符串产品;
双倍率;
公共税率(){
this.Product = "A001";
this.Rate = 5;
}
公共无效集产品(字符串产品名称){
this.Product = 产品名称;
}
公共字符串 getProduct() {
返回(this.Product);
}
公共无效setRate(双倍率值){
this.Rate = rateValue;
}
公共双getRate(){
返回(this.Rate);
}
}
<jsp:useBean> 标记用于在 JSP 页面中应用上述 bean。取决于具体用途
根据 JSP 引擎,配置 bean 的位置和方式的方法可能略有不同。本文将
Bean的.class文件放在c:/jswdk-1.0/examples/WEB-INF/jsp/beans/tax目录下,
这里的 tax 是一个专门用来存放 Bean 的目录。这是应用上述 bean 的示例页面:
<HTML>
<身体>
< %@ 页面语言="java" %>
<jsp:useBean scope="application" />
< % taxbean.setProduct("A002");
taxbean.setRate(17);
%>
方法一:<p>
产品:< %= taxbean.getProduct() %> < br>
税率:< %= taxbean.getRate() %>
<p>
< % taxbean.setProduct("A003");
taxbean.setRate(3);
%>
<b>使用方法二:</b> <p>
产品:< jsp:getProperty property="Product" />
<br>
速率:< jsp:getProperty property="Rate" />
</正文>
</HTML>
<jsp:useBean> 标记中定义了几个属性,其中 id 是整个 JSP 页面中的 Bea
n的标识,scope属性定义了bean的生命周期,class属性描述了bean的类
文件(以包名开头)。
这个 JSP 页面不仅使用 Bean 的 set 和 get 方法来设置和提取属性值,还使用
使用 <jsp:getProperty> 标记提供了提取 bean 属性值的第二种方法。< jsp:getPr
operty> 中的 name 属性是 <jsp:useBean> 中定义的 bean 的 id,及其属性
y 属性指定目标属性的名称。
事实证明,Java servlet 是开发 Web 应用程序的理想框架。JSP 到 Servlet
在技术的基础上,它在许多方面都得到了改进。JSP 页面看起来像普通的 HTML 页面,但它允许嵌入
在这方面,它与 ASP 技术非常相似。利用跨平台运行的 JavaBean 组件
, JSP 为分离处理逻辑和显示样式提供了出色的解决方案。JSP必将成为ASP技术的核心
强大的竞争对手。
嘿嘿……
上一篇:解决Can not find the tag library descriptor for "core"的问题 查看全部
抓取jsp网页源代码(为Development学习,这个软件包提供了大量可供修改的示例)
在 Sun 正式发布 JSP(JavaServer Pages)之后,这种新的 Web 应用程序开发技术非常流行
很快就引起了人们的注意。JSP 为创建高度动态的 Web 应用程序提供了独特的开发环境。
据Sun介绍,JSP可以适配市面上的8个包括Apache WebServer、IIS4.0
5%的服务器产品。即使你对 ASP “深爱”,我们认为仍然值得关注 JSP 的演变
必要的。
JSP和ASP的简单比较
JSP 与微软的 ASP 技术非常相似。两者都提供在 HTML 代码中混合某种程序
程序代码,由语言引擎解释和执行程序代码的能力。在 ASP 或 JSP 环境中,HTML 代码主要是
它负责描述信息的显示风格,程序代码用于描述处理逻辑。普通的HTML页面只依赖
根据 Web 服务器,ASP 和 JSP 页面需要额外的语言引擎来解析和执行程序代码。程序
代码执行的结果被重新嵌入到 HTML 代码中,并一起发送到浏览器。ASP 和 JSP
它是一种面向 Web 服务器的技术,客户端浏览器不需要任何额外的软件支持。
ASP的编程语言是VBScript等脚本语言,JSP用的是Java,是两者
最明显的区别。另外,ASP和JSP还有一个更本质的区别:两种语言引擎使用完全不同
嵌入在页面中的程序代码以同样的方式处理。在 ASP 下,VBScript 代码由 ASP 引擎解释和执行。
线; JSP下,代码被编译成servlet,由Java虚拟机执行,这个编译操作只是
发生在 JSP 页面的第一个请求上。
二次运行环境
Sun 的 JSP 主页位于,
您还可以从这里下载 JSP 规范,该规范定义了供应商在创建 JSP 引擎时必须遵循的内容
一些规则。
执行 JSP 代码需要在服务器上安装 JSP 引擎。这里我们使用 Sun 的 JavaS
erver Web 开发工具包 (JSWDK)。为了便于学习,此软件包提供了许多
修改示例。安装 JSWDK 后,只需执行 startserver 命令即可启动服务器。在默认配置中
设置服务器监听 8080 端口,使用 :8080 打开默认页面。
在运行 JSP 示例页面之前,请注意 JSWDK 的安装目录,尤其是“work”子目录
目录的内容。执行示例页面时,您可以在此处看到 JSP 页面如何转换为 Java 源文件
,然后编译成一个类文件(即Servlet)。JSWDK包中的示例页面分为两类
,它们可以是 JSP 文件,也可以是收录由 JSP 代码编写的表单的 HTML 文件
处理。与 ASP 一样,JSP 中的 Java 代码在服务器端执行。因此,在浏览器中使用
“查看源代码”菜单看不到 JSP 源代码,只能看到生成的 HTML 代码。所有的例子
源代码通过单独的“示例”页面提供。
三个 JSP 页面示例
下面我们分析一个简单的JSP页面。您可以在 JSWDK 的示例目录中创建另一个文件
这个文件存放在外面的一个目录下,文件名可以是任意的,但扩展名必须是.jsp。从下面的代码中清除
从列表中可以看出,除了比普通 HTML 页面多一些 Java 代码外,JSP 页面具有基本的相似之处。
相同的结构。Java 代码通过 <% 和 %> 符号添加到 HTML 代码中,它的主要功能
就是生成并显示一个从0到9的字符串。这个字符串的前后都是一些通过HTM
L 码输出的文本。
<HTML>
<HEAD><TITLE>JSP 页面</TITLE></HEAD>
<身体>
< %@ 页面语言="java" %>
<%! 字符串 str="0"; %>
< % for (int i=1; i < 10; i++) {
str = str + i;
} %>
在 JSP 输出之前。
<P>
< %= 字符串 %>
<P>
JSP 输出后。
</正文>
</HTML>
这个JSP页面可以分成几个部分进行分析。
第一个是JSP 指令。它描述了页面的基本信息,例如使用的语言,是否保持会话状态,
是否使用缓冲等。JSP 指令以 < %@ 开头,以 %> 结尾。在本例中,指令“< %@ page
language=”java” %> ” 简单定义了这个例子使用Java语言(目前在JSP规范中
Java 是唯一受支持的语言)。
接下来是 JSP 声明。JSP 声明可以被认为是在类级别定义变量和方法的地方。Ĵ
SP 声明以 <%! 并以 %> 结尾。如本例中“ < %! String str="0"; %> ” 定义
一个字符串变量。每个声明后面必须跟一个分号,就像在普通的 Java 类声明中一样
成员变量。
<%和%>之间的代码块是描述JSP页面处理逻辑的Java代码,例如本例中的f
或如图所示循环。
最后,< %= 和 %> 之间的代码称为 JSP 表达式,如本例中的“< %= str %>”
显示。JSP 表达式提供了一种将 JSP 生成的值嵌入到 HTML 页面中的简单方法。
二、会话状态管理
作者:仙人掌工作室
会话状态维护是Web 应用程序开发人员必须面对的问题。有多种方法可以解决这个问题
诸如使用 cookie、隐藏表单输入字段或将状态信息直接附加到 URL 等问题。熟
servlet 提供了一个会话对象,该对象在多个请求中持续存在,允许用户存储和
获取会话状态信息。JSP 在 servlet 中也支持这个概念。
请参阅 Sun 的 JSP 指南以了解有关隐式对象的更多信息(隐式地,这些
可以直接引用对象,不需要显式声明,也不需要专门的代码来创建它们的实例)。例如请求
uest 对象,它是 HttpServletRequest 的子类。此对象收录有关当前浏览器的所有信息
请求的信息,包括 cookie、HTML 表单变量等。session 对象也是这样一个隐含的
目的。该对象在第一个 JSP 页面加载时自动创建,并与请求对象相关联。
与 ASP 中的会话对象类似,JSP 中的会话对象对于那些希望完成一个
事务的应用非常有用。
为了说明session对象的具体应用,接下来我们用三个页面来模拟一个多页面的Web
应用。第一个页面( q1.html )只收录一个 HTML 表单,它询问用户的姓名,代码如下
向下:
<HTML>
<身体>
<FORM METHOD=POST ACTION="q2.jsp">
请输入你的名字:
<输入类型=文本>
<输入类型=提交值=“提交”>
</表格>
</正文>
</HTML>
第二个页面是一个 JSP 页面( q2.jsp ),它通过请求对象提取 q1.html
表单中的name值,将其存储为name变量,然后将name值保存到会话中
在对象中。会话对象是名称/值对的集合,其中名称/值对中的名称为 "
thename",其值为name变量的值。由于会话对象在会话期间始终有效,
因此,此处保存的变量对后续页面也有效。q2.jsp的附加任务是问第二个问题
. 这是它的代码:
<HTML>
<身体>
< %@ 页面语言="java" %>
<%! 细绳; %>
< %
name = request.getParameter("thename");
session.putValue("名称", name);
%>
你的名字是:< %= name %>
<p>
<FORM METHOD=POST ACTION="q3.jsp">
你喜欢吃什么?
<输入类型=文本>
<P>
<输入类型=提交值=“提交”>
</表格>
</正文>
</HTML>
第三个页面也是一个 JSP 页面( q3.jsp ),其主要任务是显示问答的结果。它来自 s
session对象提取了name的值并显示出来,证明虽然在第一页输入了值,
会话对象被保留。q3.jsp的另一个任务是在第二页提取用户输入
并显示它:
<HTML>
<身体>
< %@ 页面语言="java" %>
<%! 字符串食物=""; %>
< %
food = request.getParameter("food");
String name = (String) session.getValue("thename");
%>
你的名字是:< %= name %>
<P>
你喜欢吃:< %= food %>
</正文>
</HTML>
三、对 JavaBean 组件的引用
作者:仙人掌工作室
JavaBean 是基于 Java 的软件组件。用于在 Web 应用程序中集成 JavaBea 的 JSP
n 组件提供完整的支持。这种支持不仅减少了开发时间(可以直接利用经过测试和信任的
任何现有的组件,避免重复开发),也为 JSP 应用程序带来了更多的可扩展性。JavaBeans
组件可以用来执行复杂的计算任务,或者负责与数据库交互、数据提取等,如果我们
共有三个JavaBean,分别具有显示新闻、股票价格和天气状况的功能。
具有全部三个功能的网页只需要实例化这三个bean,并使用HTML表格依次指定它们。
点它。
为了说明 JavaBeans 在 JSP 环境中的应用,我们创建了一个名为 TaxRate 的 Bean
. 它有两个属性,Product 和 Rate。两种set方法用于设置
设置这两个属性,使用两个get方法提取这两个属性。在实际应用中,这个Bean一般是
应从数据库中提取税率值,这里我们简化了过程以允许任意税率。下面是这个
豆代码清单:
包裹税;
公共课税率 {
字符串产品;
双倍率;
公共税率(){
this.Product = "A001";
this.Rate = 5;
}
公共无效集产品(字符串产品名称){
this.Product = 产品名称;
}
公共字符串 getProduct() {
返回(this.Product);
}
公共无效setRate(双倍率值){
this.Rate = rateValue;
}
公共双getRate(){
返回(this.Rate);
}
}
<jsp:useBean> 标记用于在 JSP 页面中应用上述 bean。取决于具体用途
根据 JSP 引擎,配置 bean 的位置和方式的方法可能略有不同。本文将
Bean的.class文件放在c:/jswdk-1.0/examples/WEB-INF/jsp/beans/tax目录下,
这里的 tax 是一个专门用来存放 Bean 的目录。这是应用上述 bean 的示例页面:
<HTML>
<身体>
< %@ 页面语言="java" %>
<jsp:useBean scope="application" />
< % taxbean.setProduct("A002");
taxbean.setRate(17);
%>
方法一:<p>
产品:< %= taxbean.getProduct() %> < br>
税率:< %= taxbean.getRate() %>
<p>
< % taxbean.setProduct("A003");
taxbean.setRate(3);
%>
<b>使用方法二:</b> <p>
产品:< jsp:getProperty property="Product" />
<br>
速率:< jsp:getProperty property="Rate" />
</正文>
</HTML>
<jsp:useBean> 标记中定义了几个属性,其中 id 是整个 JSP 页面中的 Bea
n的标识,scope属性定义了bean的生命周期,class属性描述了bean的类
文件(以包名开头)。
这个 JSP 页面不仅使用 Bean 的 set 和 get 方法来设置和提取属性值,还使用
使用 <jsp:getProperty> 标记提供了提取 bean 属性值的第二种方法。< jsp:getPr
operty> 中的 name 属性是 <jsp:useBean> 中定义的 bean 的 id,及其属性
y 属性指定目标属性的名称。
事实证明,Java servlet 是开发 Web 应用程序的理想框架。JSP 到 Servlet
在技术的基础上,它在许多方面都得到了改进。JSP 页面看起来像普通的 HTML 页面,但它允许嵌入
在这方面,它与 ASP 技术非常相似。利用跨平台运行的 JavaBean 组件
, JSP 为分离处理逻辑和显示样式提供了出色的解决方案。JSP必将成为ASP技术的核心
强大的竞争对手。
嘿嘿……
上一篇:解决Can not find the tag library descriptor for "core"的问题
抓取jsp网页源代码(㈠JSP与ASP引擎的区别及发展趋势分析-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-02-15 22:09
一、 JSP 技术概述
在 Sun 正式发布 JSP(JavaServer Pages)之后,这种新的 Web 应用程序开发技术迅速引起了人们的关注。JSP 为创建高度动态的 Web 应用程序提供了独特的开发环境。据Sun介绍,JSP可以适配市场上85%的服务器产品,包括Apache WebServer、IIS4.0。即使您“深深地爱上了” ASP,我们认为仍然值得关注 JSP 的演变。
(1) JSP与ASP的简单对比
JSP 与微软的 ASP 技术非常相似。两者都提供了在 HTML 代码中混合某种程序代码的能力,并让程序代码由语言引擎解释和执行。在ASP或JSP环境中,HTML代码主要负责描述信息的显示风格,而程序代码则用于描述处理逻辑。普通的 HTML 页面只依赖于 Web 服务器,而 ASP 和 JSP 页面需要额外的语言引擎来解析和执行程序代码。程序代码的执行结果被重新嵌入到 HTML 代码中,并一起发送给浏览器。ASP 和 JSP 都是面向 Web 服务器的技术,客户端浏览器不需要任何额外的软件支持。
ASP的编程语言是VBScript等脚本语言,而JSP使用Java,这是两者最明显的区别。此外,ASP 和 JSP 之间还有一个更根本的区别:两种语言引擎以完全不同的方式处理嵌入在页面中的程序代码。在 ASP 下,VBScript 代码由 ASP 引擎解释和执行;在 JSP 下,代码被编译成 servlet 并由 Java 虚拟机执行,这种编译只发生在对 JSP 页面的第一次请求时。
(二)经营环境
从 Sun 的 JSP 主页上,您还可以下载 JSP 规范,这些规范定义了供应商在创建 JSP 引擎时必须遵循的一些规则。
执行 JSP 代码需要在服务器上安装 JSP 引擎。这里我们使用 Sun 的 JavaServer Web 开发工具包 (JSWDK)。为了便于学习,此软件包提供了许多可修改的示例。安装 JSWDK 后,只需执行 startserver 命令即可启动服务器。在默认配置中,服务器监听 8080 端口。使用 :8080 打开默认页面。
在运行 JSP 示例页面之前,请注意 JSWDK 的安装目录,尤其是“work”子目录的内容。执行示例页面时,您可以在此处看到 JSP 页面如何转换为 Java 源文件,然后将其编译为类文件(即 servlet)。JSWDK 包中的示例页面分为两类,它们是 JSP 文件或收录由 JSP 代码处理的表单的 HTML 文件。与 ASP 一样,JSP 中的 Java 代码在服务器端执行。因此,在浏览器中使用“查看源代码”菜单无法看到 JSP 源代码,只能看到生成的 HTML 代码。所有示例的源代码均通过单独的“示例”页面提供。
(iii) JSP 页面示例
下面我们分析一个简单的JSP页面。您可以在 JSWDK 的示例目录下创建另一个目录来存储此文件。文件名可以是任意的,但扩展名必须是.jsp。从下面的代码清单可以看出,JSP 页面的结构基本相同,只是它们比普通的 HTML 页面多一些 Java 代码。Java代码是通过<%和%>符号添加到HTML代码中间的,它的主要作用是生成并显示一个从0到9的字符串。该字符串的前后是一些通过HTML代码输出的文本。
<HTML>
<HEAD><TITLE>JSP 页面</TITLE></HEAD>
<身体>
< %@ 页面语言="java" %>
<%! 字符串 str="0"; %>
< % for (int i=1; i < 10; i++) {
str = str + i;
} %>
在 JSP 输出之前。
<P>
< %= 字符串 %>
<P>
JSP 输出后。
</正文>
</HTML>
这个JSP页面可以分成几个部分进行分析。
第一个是JSP 指令。它描述了页面的基本信息,例如使用的语言、是否保持会话状态、是否使用缓冲等。JSP 指令以<%@ 开头,以%> 结尾。在这个例子中,指令“< %@ page language="java" %> ”简单地定义了这个例子使用Java 语言(目前,Java 是JSP 规范中唯一支持的语言)。
接下来是 JSP 声明。JSP 声明可以被认为是在类级别定义变量和方法的地方。JSP 声明以 <%! 并以 %> 结尾。如本例中的“<%!String str="0"; %>”定义了一个字符串变量。每个声明后面必须跟一个分号,就像在普通 Java 类中声明成员变量一样。
<% 和 %> 之间的代码块是描述 JSP 页面处理逻辑的 Java 代码,如本例中的 for 循环所示。
最后,< %= 和 %> 之间的代码称为 JSP 表达式,如本例中的“< %= str %>”。JSP 表达式提供了一种将 JSP 生成的值嵌入到 HTML 页面中的简单方法。
会话状态维护是Web 应用程序开发人员必须面对的问题。有多种方法可以解决此问题,例如使用 cookie、隐藏表单输入字段或将状态信息直接附加到 URL。Java servlet 提供了一个跨多个请求持续存在的会话对象,它允许用户存储和检索会话状态信息。JSP 在 servlet 中也支持这个概念。
在 Sun 的 JSP 指南中,您可以看到很多关于隐式对象的内容(隐式意味着这些对象可以直接引用而无需显式声明或特殊代码来创建它们的实例)。例如请求对象,它是 HttpServletRequest 的子类。此对象收录有关当前浏览器请求的所有信息,包括 cookie、HTML 表单变量等。会话对象也是这样一个隐含对象。该对象在第一个 JSP 页面加载时自动创建,并与请求对象相关联。与 ASP 中的会话对象类似,JSP 中的会话对象对于想要通过多个页面完成一个事务的应用程序非常有用。
为了说明session对象的具体应用,接下来我们用三个页面来模拟一个多页面的Web应用。第一个页面( q1.html )只收录一个询问用户名的 HTML 表单,代码如下:
<HTML>
<身体>
<FORM METHOD=POST ACTION="q2.jsp">
请输入你的名字:
<输入类型=文本>
<输入类型=提交值=“提交”>
</表格>
</正文>
</HTML>
第二个页面是一个JSP页面(q2.jsp),通过request对象从q1.html表单中提取name值,存储为name变量,然后将这个name值保存到会话对象。会话对象是名称/值对的集合,其中名称/值对中的名称是“thename”,值是名称变量的值。由于会话对象在会话期间始终有效,因此此处保存的变量对后续页面也有效。q2.jsp 的另一个任务是问第二个问题。这是它的代码:
<HTML>
<身体>
< %@ 页面语言="java" %>
<%! 细绳; %>
< %
name = request.getParameter("thename");
session.putValue("名称", name);
%>
你的名字是:< %= name %>
<p>
<FORM METHOD=POST ACTION="q3.jsp">
你喜欢吃什么?
<输入类型=文本>
<P>
<输入类型=提交值=“提交”>
</表格>
</正文>
</HTML>
第三个页面也是一个 JSP 页面( q3.jsp ),其主要任务是显示问答的结果。它从会话对象中提取 name 的值并显示它,证明虽然该值是在第一页输入的,但它是通过会话对象保留的。q3.jsp 的另一个任务是提取第二页中的用户输入并显示出来:
<HTML>
<身体>
< %@ 页面语言="java" %>
<%! 字符串食物=""; %>
< %
food = request.getParameter("food");
String name = (String) session.getValue("thename");
%>
你的名字是:< %= name %>
<P>
你喜欢吃:< %= food %>
</正文>
</HTML>
JavaBean 是基于 Java 的软件组件。JSP 为在 Web 应用程序中集成 JavaBean 组件提供了完整的支持。这种支持不仅缩短了开发时间(通过直接利用经过测试和信任的现有组件,避免重复开发),而且还为 JSP 应用程序带来了更多的可扩展性。JavaBean 组件可用于执行复杂的计算任务,或负责与数据库交互和数据提取。如果我们有三个具有显示新闻、股票价格和天气状况的功能的 JavaBean,那么创建一个收录所有三个功能的 Web 页面只需要实例化这三个 bean 并使用 HTML 表按顺序定位它们。.
为了说明 JavaBeans 在 JSP 环境中的应用,我们创建了一个名为 TaxRate 的 Bean。它有两个属性,Product 和 Rate。两个 set 方法用于设置这两个属性,两个 get 方法用于提取这两个属性。在实际应用中,这种bean一般应该从数据库中提取税率值。这里我们简化了流程,允许任意设定税率。下面是这个 bean 的代码清单:
包裹税;
公共课税率 {
字符串产品;
双倍率;
公共税率(){
this.Product = "A001";
this.Rate = 5;
}
公共无效集产品(字符串产品名称){
this.Product = 产品名称;
}
公共字符串 getProduct() {
返回(this.Product);
}
公共无效setRate(双倍率值){
this.Rate = rateValue;
}
公共双getRate(){
返回(this.Rate);
}
}
<jsp:useBean> 标记用于在 JSP 页面中应用上述 bean。根据所使用的特定 JSP 引擎,bean 的配置位置和方式可能略有不同。本文将这个bean的.class文件放在c:jswdk-1.0examplesWEB-INFjspeans ax目录下,其中tax是专门存放bean的目录。这是应用上述 bean 的示例页面:
<HTML>
<身体>
< %@ 页面语言="java" %>
<jsp:useBean scope="application" />
< % taxbean.setProduct("A002");
taxbean.setRate(17);
%>
方法一:<p>
产品:< %= taxbean.getProduct() %> < br>
税率:< %= taxbean.getRate() %>
<p>
< % taxbean.setProduct("A003");
taxbean.setRate(3);
%>
<b>使用方法二:</b> <p>
产品:< jsp:getProperty property="Product" />
<br>
速率:< jsp:getProperty property="Rate" />
</正文>
</HTML>
<jsp:useBean> 标签中定义了几个属性,其中 id 是 bean 在整个 JSP 页面中的标识,scope 属性定义了 bean 的生命周期,class 属性描述了 bean 的类文件(开始来自包名))。
这个 JSP 页面不仅使用 bean 的 set 和 get 方法来设置和检索属性值,而且还使用了第二种检索 bean 属性值的方法,即使用 <jsp:getProperty> 标记。<jsp:getProperty> 中的name 属性是<jsp:useBean> 中定义的bean 的id,其property 属性指定了目标属性的名称。
事实证明,Java servlet 是开发 Web 应用程序的理想框架。JSP 基于 Servlet 技术,并在很多方面进行了改进。JSP 页面看起来像一个普通的 HTML 页面,但它允许嵌入执行代码,在这方面它与 ASP 技术非常相似。使用跨平台运行的 JavaBean 组件,JSP 为分离处理逻辑和表示样式提供了出色的解决方案。JSP必将成为ASP技术的有力竞争者。 查看全部
抓取jsp网页源代码(㈠JSP与ASP引擎的区别及发展趋势分析-乐题库)
一、 JSP 技术概述
在 Sun 正式发布 JSP(JavaServer Pages)之后,这种新的 Web 应用程序开发技术迅速引起了人们的关注。JSP 为创建高度动态的 Web 应用程序提供了独特的开发环境。据Sun介绍,JSP可以适配市场上85%的服务器产品,包括Apache WebServer、IIS4.0。即使您“深深地爱上了” ASP,我们认为仍然值得关注 JSP 的演变。
(1) JSP与ASP的简单对比
JSP 与微软的 ASP 技术非常相似。两者都提供了在 HTML 代码中混合某种程序代码的能力,并让程序代码由语言引擎解释和执行。在ASP或JSP环境中,HTML代码主要负责描述信息的显示风格,而程序代码则用于描述处理逻辑。普通的 HTML 页面只依赖于 Web 服务器,而 ASP 和 JSP 页面需要额外的语言引擎来解析和执行程序代码。程序代码的执行结果被重新嵌入到 HTML 代码中,并一起发送给浏览器。ASP 和 JSP 都是面向 Web 服务器的技术,客户端浏览器不需要任何额外的软件支持。
ASP的编程语言是VBScript等脚本语言,而JSP使用Java,这是两者最明显的区别。此外,ASP 和 JSP 之间还有一个更根本的区别:两种语言引擎以完全不同的方式处理嵌入在页面中的程序代码。在 ASP 下,VBScript 代码由 ASP 引擎解释和执行;在 JSP 下,代码被编译成 servlet 并由 Java 虚拟机执行,这种编译只发生在对 JSP 页面的第一次请求时。
(二)经营环境
从 Sun 的 JSP 主页上,您还可以下载 JSP 规范,这些规范定义了供应商在创建 JSP 引擎时必须遵循的一些规则。
执行 JSP 代码需要在服务器上安装 JSP 引擎。这里我们使用 Sun 的 JavaServer Web 开发工具包 (JSWDK)。为了便于学习,此软件包提供了许多可修改的示例。安装 JSWDK 后,只需执行 startserver 命令即可启动服务器。在默认配置中,服务器监听 8080 端口。使用 :8080 打开默认页面。
在运行 JSP 示例页面之前,请注意 JSWDK 的安装目录,尤其是“work”子目录的内容。执行示例页面时,您可以在此处看到 JSP 页面如何转换为 Java 源文件,然后将其编译为类文件(即 servlet)。JSWDK 包中的示例页面分为两类,它们是 JSP 文件或收录由 JSP 代码处理的表单的 HTML 文件。与 ASP 一样,JSP 中的 Java 代码在服务器端执行。因此,在浏览器中使用“查看源代码”菜单无法看到 JSP 源代码,只能看到生成的 HTML 代码。所有示例的源代码均通过单独的“示例”页面提供。
(iii) JSP 页面示例
下面我们分析一个简单的JSP页面。您可以在 JSWDK 的示例目录下创建另一个目录来存储此文件。文件名可以是任意的,但扩展名必须是.jsp。从下面的代码清单可以看出,JSP 页面的结构基本相同,只是它们比普通的 HTML 页面多一些 Java 代码。Java代码是通过<%和%>符号添加到HTML代码中间的,它的主要作用是生成并显示一个从0到9的字符串。该字符串的前后是一些通过HTML代码输出的文本。
<HTML>
<HEAD><TITLE>JSP 页面</TITLE></HEAD>
<身体>
< %@ 页面语言="java" %>
<%! 字符串 str="0"; %>
< % for (int i=1; i < 10; i++) {
str = str + i;
} %>
在 JSP 输出之前。
<P>
< %= 字符串 %>
<P>
JSP 输出后。
</正文>
</HTML>
这个JSP页面可以分成几个部分进行分析。
第一个是JSP 指令。它描述了页面的基本信息,例如使用的语言、是否保持会话状态、是否使用缓冲等。JSP 指令以<%@ 开头,以%> 结尾。在这个例子中,指令“< %@ page language="java" %> ”简单地定义了这个例子使用Java 语言(目前,Java 是JSP 规范中唯一支持的语言)。
接下来是 JSP 声明。JSP 声明可以被认为是在类级别定义变量和方法的地方。JSP 声明以 <%! 并以 %> 结尾。如本例中的“<%!String str="0"; %>”定义了一个字符串变量。每个声明后面必须跟一个分号,就像在普通 Java 类中声明成员变量一样。
<% 和 %> 之间的代码块是描述 JSP 页面处理逻辑的 Java 代码,如本例中的 for 循环所示。
最后,< %= 和 %> 之间的代码称为 JSP 表达式,如本例中的“< %= str %>”。JSP 表达式提供了一种将 JSP 生成的值嵌入到 HTML 页面中的简单方法。
会话状态维护是Web 应用程序开发人员必须面对的问题。有多种方法可以解决此问题,例如使用 cookie、隐藏表单输入字段或将状态信息直接附加到 URL。Java servlet 提供了一个跨多个请求持续存在的会话对象,它允许用户存储和检索会话状态信息。JSP 在 servlet 中也支持这个概念。
在 Sun 的 JSP 指南中,您可以看到很多关于隐式对象的内容(隐式意味着这些对象可以直接引用而无需显式声明或特殊代码来创建它们的实例)。例如请求对象,它是 HttpServletRequest 的子类。此对象收录有关当前浏览器请求的所有信息,包括 cookie、HTML 表单变量等。会话对象也是这样一个隐含对象。该对象在第一个 JSP 页面加载时自动创建,并与请求对象相关联。与 ASP 中的会话对象类似,JSP 中的会话对象对于想要通过多个页面完成一个事务的应用程序非常有用。
为了说明session对象的具体应用,接下来我们用三个页面来模拟一个多页面的Web应用。第一个页面( q1.html )只收录一个询问用户名的 HTML 表单,代码如下:
<HTML>
<身体>
<FORM METHOD=POST ACTION="q2.jsp">
请输入你的名字:
<输入类型=文本>
<输入类型=提交值=“提交”>
</表格>
</正文>
</HTML>
第二个页面是一个JSP页面(q2.jsp),通过request对象从q1.html表单中提取name值,存储为name变量,然后将这个name值保存到会话对象。会话对象是名称/值对的集合,其中名称/值对中的名称是“thename”,值是名称变量的值。由于会话对象在会话期间始终有效,因此此处保存的变量对后续页面也有效。q2.jsp 的另一个任务是问第二个问题。这是它的代码:
<HTML>
<身体>
< %@ 页面语言="java" %>
<%! 细绳; %>
< %
name = request.getParameter("thename");
session.putValue("名称", name);
%>
你的名字是:< %= name %>
<p>
<FORM METHOD=POST ACTION="q3.jsp">
你喜欢吃什么?
<输入类型=文本>
<P>
<输入类型=提交值=“提交”>
</表格>
</正文>
</HTML>
第三个页面也是一个 JSP 页面( q3.jsp ),其主要任务是显示问答的结果。它从会话对象中提取 name 的值并显示它,证明虽然该值是在第一页输入的,但它是通过会话对象保留的。q3.jsp 的另一个任务是提取第二页中的用户输入并显示出来:
<HTML>
<身体>
< %@ 页面语言="java" %>
<%! 字符串食物=""; %>
< %
food = request.getParameter("food");
String name = (String) session.getValue("thename");
%>
你的名字是:< %= name %>
<P>
你喜欢吃:< %= food %>
</正文>
</HTML>
JavaBean 是基于 Java 的软件组件。JSP 为在 Web 应用程序中集成 JavaBean 组件提供了完整的支持。这种支持不仅缩短了开发时间(通过直接利用经过测试和信任的现有组件,避免重复开发),而且还为 JSP 应用程序带来了更多的可扩展性。JavaBean 组件可用于执行复杂的计算任务,或负责与数据库交互和数据提取。如果我们有三个具有显示新闻、股票价格和天气状况的功能的 JavaBean,那么创建一个收录所有三个功能的 Web 页面只需要实例化这三个 bean 并使用 HTML 表按顺序定位它们。.
为了说明 JavaBeans 在 JSP 环境中的应用,我们创建了一个名为 TaxRate 的 Bean。它有两个属性,Product 和 Rate。两个 set 方法用于设置这两个属性,两个 get 方法用于提取这两个属性。在实际应用中,这种bean一般应该从数据库中提取税率值。这里我们简化了流程,允许任意设定税率。下面是这个 bean 的代码清单:
包裹税;
公共课税率 {
字符串产品;
双倍率;
公共税率(){
this.Product = "A001";
this.Rate = 5;
}
公共无效集产品(字符串产品名称){
this.Product = 产品名称;
}
公共字符串 getProduct() {
返回(this.Product);
}
公共无效setRate(双倍率值){
this.Rate = rateValue;
}
公共双getRate(){
返回(this.Rate);
}
}
<jsp:useBean> 标记用于在 JSP 页面中应用上述 bean。根据所使用的特定 JSP 引擎,bean 的配置位置和方式可能略有不同。本文将这个bean的.class文件放在c:jswdk-1.0examplesWEB-INFjspeans ax目录下,其中tax是专门存放bean的目录。这是应用上述 bean 的示例页面:
<HTML>
<身体>
< %@ 页面语言="java" %>
<jsp:useBean scope="application" />
< % taxbean.setProduct("A002");
taxbean.setRate(17);
%>
方法一:<p>
产品:< %= taxbean.getProduct() %> < br>
税率:< %= taxbean.getRate() %>
<p>
< % taxbean.setProduct("A003");
taxbean.setRate(3);
%>
<b>使用方法二:</b> <p>
产品:< jsp:getProperty property="Product" />
<br>
速率:< jsp:getProperty property="Rate" />
</正文>
</HTML>
<jsp:useBean> 标签中定义了几个属性,其中 id 是 bean 在整个 JSP 页面中的标识,scope 属性定义了 bean 的生命周期,class 属性描述了 bean 的类文件(开始来自包名))。
这个 JSP 页面不仅使用 bean 的 set 和 get 方法来设置和检索属性值,而且还使用了第二种检索 bean 属性值的方法,即使用 <jsp:getProperty> 标记。<jsp:getProperty> 中的name 属性是<jsp:useBean> 中定义的bean 的id,其property 属性指定了目标属性的名称。
事实证明,Java servlet 是开发 Web 应用程序的理想框架。JSP 基于 Servlet 技术,并在很多方面进行了改进。JSP 页面看起来像一个普通的 HTML 页面,但它允许嵌入执行代码,在这方面它与 ASP 技术非常相似。使用跨平台运行的 JavaBean 组件,JSP 为分离处理逻辑和表示样式提供了出色的解决方案。JSP必将成为ASP技术的有力竞争者。
抓取jsp网页源代码(你可以用Java的URL类来读获得这个HTTP的输入流)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-02-15 16:30
您可以使用 Java 的 URL 类,然后使用 openConnection 来获取这个 HTTP 输入流。但是,此信息已被静态转换。
因此,如果要获取源代码,这种方法是不可接受的。
但是如果是你的本地文件,可以直接使用File方法读取。(不是吗?)
如果服务器将这些网页视为文件供您访问(即通过设置 MIME 允许您下载),您可以使用 Java URL 类读取源代码。事实上,你可以直接下载它。(不会有服务器这样做吗?)
从客户端得到的已经是html代码
如果要获取jsp源码,可以通过访问url获取。以这种方式获得的结果由服务器解析。
除非你知道这个文件的绝对地址而且这个目录是对外共享的~
不然可以知道这个项目所在的代码库,svn等~
补充:框架dwr以JavaScript的形式公开了java源码
好像不行,除非JAVA和ASP、PHP、JSP放在服务器端,并且知道它们的文件地址
.
不,开源框架 dwr 做得不好(被批准)是它暴露了 java 对象及其方法。其他技术没有这样的问题,可见无法获取php、asp、jsp、Python、ruby等的源码。
只需将jsp页面作为普通文件读取,
要读取的 FileInputStream
本文相关:使用Mybatis执行sql时如何统一校验输入参数?js中这个表达式是什么意思?返回(y1 - y2 > 0 ?“上”:“下”);基于云架构的J2EE架构应该做什么?spring 和 hibernate 都使用 asm 字节码技术。他们使用 ASM 来实现哪些功能?或者如何判断操作系统是32位还是64位在哪个函数中使用?DBA_OBJECTS + ROWNUM 和 DUAL + ROWNUM 结果比较的可疑 ajax 缺点?判断字符串是否以数字开头,使用java程序监控mysql的变化。如何加密或保护 URL 地址栏中传递的信息 查看全部
抓取jsp网页源代码(你可以用Java的URL类来读获得这个HTTP的输入流)
您可以使用 Java 的 URL 类,然后使用 openConnection 来获取这个 HTTP 输入流。但是,此信息已被静态转换。
因此,如果要获取源代码,这种方法是不可接受的。
但是如果是你的本地文件,可以直接使用File方法读取。(不是吗?)
如果服务器将这些网页视为文件供您访问(即通过设置 MIME 允许您下载),您可以使用 Java URL 类读取源代码。事实上,你可以直接下载它。(不会有服务器这样做吗?)
从客户端得到的已经是html代码
如果要获取jsp源码,可以通过访问url获取。以这种方式获得的结果由服务器解析。
除非你知道这个文件的绝对地址而且这个目录是对外共享的~
不然可以知道这个项目所在的代码库,svn等~
补充:框架dwr以JavaScript的形式公开了java源码
好像不行,除非JAVA和ASP、PHP、JSP放在服务器端,并且知道它们的文件地址
.
不,开源框架 dwr 做得不好(被批准)是它暴露了 java 对象及其方法。其他技术没有这样的问题,可见无法获取php、asp、jsp、Python、ruby等的源码。
只需将jsp页面作为普通文件读取,
要读取的 FileInputStream
本文相关:使用Mybatis执行sql时如何统一校验输入参数?js中这个表达式是什么意思?返回(y1 - y2 > 0 ?“上”:“下”);基于云架构的J2EE架构应该做什么?spring 和 hibernate 都使用 asm 字节码技术。他们使用 ASM 来实现哪些功能?或者如何判断操作系统是32位还是64位在哪个函数中使用?DBA_OBJECTS + ROWNUM 和 DUAL + ROWNUM 结果比较的可疑 ajax 缺点?判断字符串是否以数字开头,使用java程序监控mysql的变化。如何加密或保护 URL 地址栏中传递的信息
抓取jsp网页源代码(2.java注释/*多行注释:可见范围jsp源码可见运行原理 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-14 14:07
)
JSP 概念
JSP的全称是Java Server Pages,中文名称是java server page。它基本上是一个简化的 Servlet 设计。它将Java程序段和JSP标签插入到网页的传统HTML文件中,形成JSP文件。后缀是(*.jsp)。使用 JSP 开发的 Web 应用程序是跨平台的,可以在 Linux 和其他操作系统上运行。
与 Servlet 一样,JSP 在服务器端执行。通常返回给客户端的是HTML文本,所以客户端只要有浏览器就可以浏览。
JSP 脚本
1.
内部java代码被翻译成服务方法的内部
2.
会在service方法里面翻译成out.print()
3.
会被翻译成servlet成员的内容
JSP 注释
不同注解可见范围不同
1. html 评论:
可见范围jsp源码,翻译后的servlet,页面展示html源码
2. java 注释://单行注释/*多行注释*/
可见范围jsp源码,翻译后的servlet
3. jsp 注释:
可见范围jsp源码可见
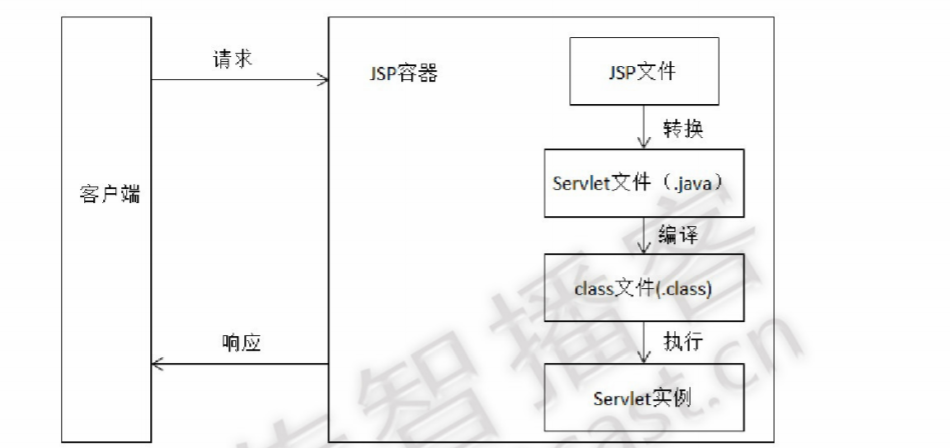
JSP运行原理-----jsp本质上是一个servlet
JSP 的工作模式是请求/响应模式。客户端首先发送一个HTTP请求,JSP程序接收请求并返回处理结果。当第一次请求一个 JSP 文件时,JSP 引擎(容器)将 JSP 文件转换成一个 Servlet,它本身也是一个 Servlet
JSP操作流程如下:
1)客户端发送访问JSP文件的请求
2)JSP 容器首先将JSP 文件转换为java 源文件(Java Servlet 源程序)。在转换过程中,如果发现JSP文件中有语法错误,转换过程将被中断,服务器和客户端返回错误信息。
3)如果转换成功,JSP会生成Java源文件,编译成相关字节码文件*.class。类文件是一个 servlet,servlet 容器像处理任何其他 servlet 一样处理它。
JSP编译后的两个文件:
PS:翻译后的servlet可以在Tomcat的工作目录中找到
JSP 指令
jsp的指令是指导jsp的翻译和操作的命令。jsp包括三个主要指令:
1. 页面指令(实际开发中默认的页面指令)
属性最多的一条指令,根据不同的属性,引导整个页面的特点
格式:
常见属性如下:
language:jsp脚本中可以嵌入的语言种类
pageEncoding:当前jsp文件的编码---可以收录contentType
contentType: response.setContentType(text/html;charset=UTF-8)
session:jsp在翻译过程中是否自动创建会话
import:导入java的包
errorPage:当前页面出错时跳转到哪个页面
isErrorPage:当前页面是错误处理页面
PS:page指令对整个页面都有效,不管它的书写位置如何,但是习惯上把Page指令写在JSP页面的顶部
2. 收录指令
页面收录(静态收录)指令,可以将一个jsp页面/HTML文件/文本文件收录到另一个jsp页面中
格式:
收录include指令的jsp页面的编译过程:
导入文件中除指令元素外,其他元素都转换成对应的java源代码,然后插入到当前jsp页面翻译的Servlet源文件中。插入位置与当前jsp页面中include的位置一致。
3. 标签库指令
在jsp页面中引入标签库(jstl标签库、struts2标签库)
格式:
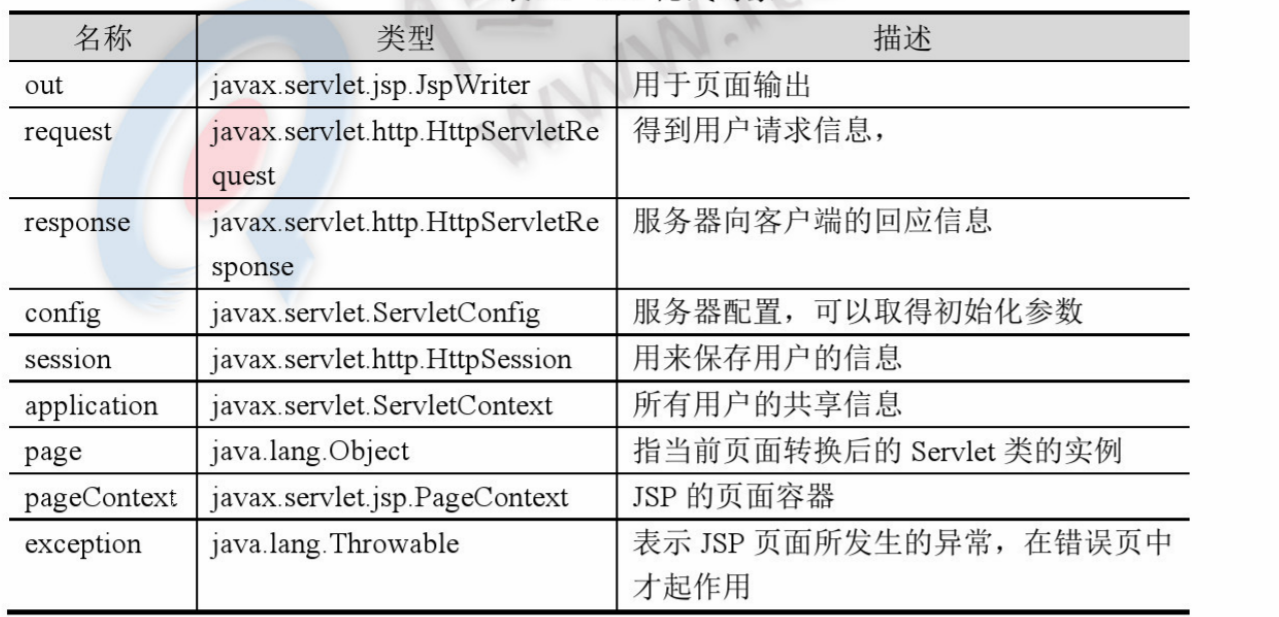
jsp 内置/隐式对象
jsp翻译成servlet后,service方法中有9个对象被定义和初始化,我们可以在jsp脚本中直接使用这9个对象
既然已经了解了对象,这里就重点学习out和pageContext
1. 输出对象
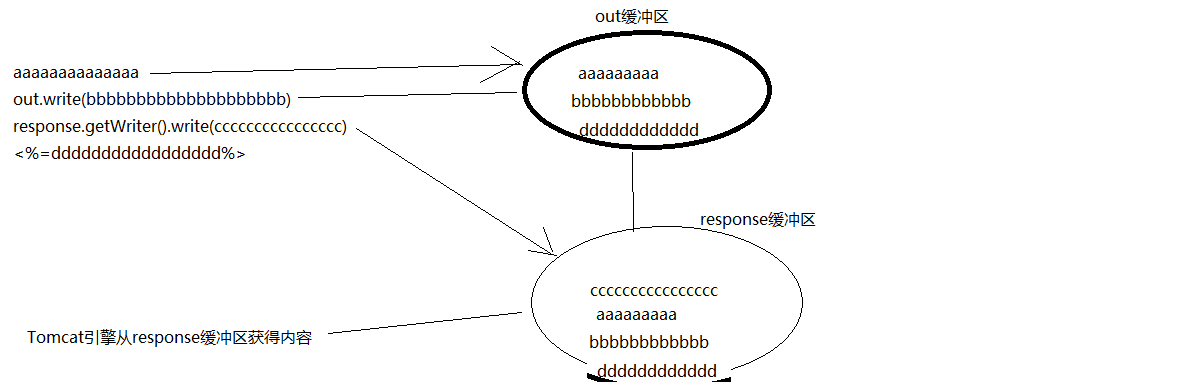
输出类型:JspWriter
它的功能和response.getWriter返回的PrintWriter很相似,输出内容到客户端out.write()
也相当于一个带有缓存功能的PrintWriter,如图:
在 JSP 页面中,通过 out 隐式对象写入数据,相当于将数据插入到 JspWriter 对象的缓冲区中。只有调用 ServletResponse.getWriter 方法,才能真正将缓冲区中的数据写入 servlet 引擎提供的缓冲区。在那个地区。
默认输出缓冲区为 8kb。可以设置为 0 关闭 out 缓冲区,将内容直接写入响应缓冲区。
2. pageContext 对象
jsp页面的context对象,page对象和pageContext对象不是一回事
效果如下:
1) pageContext 是一个域对象
setAttribute(字符串名称,对象 obj)
获取属性(字符串名称)
删除属性(字符串名称)
pageContext 可以访问其他指定域的数据
setAttribute(字符串名称,对象 obj,int 范围)
getAttribute(字符串名称,整数范围)
removeAttrbute(字符串名称,int 范围)
findAttribute(字符串名称)
PS:使用findAttribute()方法查找名为name的属性时,该属性依次从pageContext域、请求域、会话域、应用域中获取。在某个域中获取后,不会向后搜索。
四个范围的总结:
page domain:当前jsp页面的范围
请求字段:请求
会话字段:会话
应用领域:整个网络应用
2)可以获取其他8个隐式对象(不常用)
例如:pageContext.getRequest()
pageContext.getSession()
jsp标签(动作)
页面收录(动态收录):
收录的原则是对收录的页面进行编译处理后,将结果收录在页面中。当浏览器第一次请求使用其他页面的页面时,web容器首先编译被收录的页面,然后将编译过程的结果收录在页面中,再编译被收录的页面,最后编译这两个页面。合并的结果返回给浏览器。
请求转发:
动态收录和静态收录的区别
查看全部
抓取jsp网页源代码(2.java注释/*多行注释:可见范围jsp源码可见运行原理
)
JSP 概念
JSP的全称是Java Server Pages,中文名称是java server page。它基本上是一个简化的 Servlet 设计。它将Java程序段和JSP标签插入到网页的传统HTML文件中,形成JSP文件。后缀是(*.jsp)。使用 JSP 开发的 Web 应用程序是跨平台的,可以在 Linux 和其他操作系统上运行。
与 Servlet 一样,JSP 在服务器端执行。通常返回给客户端的是HTML文本,所以客户端只要有浏览器就可以浏览。
JSP 脚本
1.
内部java代码被翻译成服务方法的内部
2.
会在service方法里面翻译成out.print()
3.
会被翻译成servlet成员的内容
JSP 注释
不同注解可见范围不同
1. html 评论:
可见范围jsp源码,翻译后的servlet,页面展示html源码
2. java 注释://单行注释/*多行注释*/
可见范围jsp源码,翻译后的servlet
3. jsp 注释:
可见范围jsp源码可见
JSP运行原理-----jsp本质上是一个servlet
JSP 的工作模式是请求/响应模式。客户端首先发送一个HTTP请求,JSP程序接收请求并返回处理结果。当第一次请求一个 JSP 文件时,JSP 引擎(容器)将 JSP 文件转换成一个 Servlet,它本身也是一个 Servlet
JSP操作流程如下:
1)客户端发送访问JSP文件的请求
2)JSP 容器首先将JSP 文件转换为java 源文件(Java Servlet 源程序)。在转换过程中,如果发现JSP文件中有语法错误,转换过程将被中断,服务器和客户端返回错误信息。
3)如果转换成功,JSP会生成Java源文件,编译成相关字节码文件*.class。类文件是一个 servlet,servlet 容器像处理任何其他 servlet 一样处理它。
JSP编译后的两个文件:

PS:翻译后的servlet可以在Tomcat的工作目录中找到
JSP 指令
jsp的指令是指导jsp的翻译和操作的命令。jsp包括三个主要指令:
1. 页面指令(实际开发中默认的页面指令)
属性最多的一条指令,根据不同的属性,引导整个页面的特点
格式:
常见属性如下:
language:jsp脚本中可以嵌入的语言种类
pageEncoding:当前jsp文件的编码---可以收录contentType
contentType: response.setContentType(text/html;charset=UTF-8)
session:jsp在翻译过程中是否自动创建会话
import:导入java的包
errorPage:当前页面出错时跳转到哪个页面
isErrorPage:当前页面是错误处理页面
PS:page指令对整个页面都有效,不管它的书写位置如何,但是习惯上把Page指令写在JSP页面的顶部
2. 收录指令
页面收录(静态收录)指令,可以将一个jsp页面/HTML文件/文本文件收录到另一个jsp页面中
格式:
收录include指令的jsp页面的编译过程:
导入文件中除指令元素外,其他元素都转换成对应的java源代码,然后插入到当前jsp页面翻译的Servlet源文件中。插入位置与当前jsp页面中include的位置一致。
3. 标签库指令
在jsp页面中引入标签库(jstl标签库、struts2标签库)
格式:
jsp 内置/隐式对象
jsp翻译成servlet后,service方法中有9个对象被定义和初始化,我们可以在jsp脚本中直接使用这9个对象
既然已经了解了对象,这里就重点学习out和pageContext
1. 输出对象
输出类型:JspWriter
它的功能和response.getWriter返回的PrintWriter很相似,输出内容到客户端out.write()
也相当于一个带有缓存功能的PrintWriter,如图:
在 JSP 页面中,通过 out 隐式对象写入数据,相当于将数据插入到 JspWriter 对象的缓冲区中。只有调用 ServletResponse.getWriter 方法,才能真正将缓冲区中的数据写入 servlet 引擎提供的缓冲区。在那个地区。
默认输出缓冲区为 8kb。可以设置为 0 关闭 out 缓冲区,将内容直接写入响应缓冲区。
2. pageContext 对象
jsp页面的context对象,page对象和pageContext对象不是一回事
效果如下:
1) pageContext 是一个域对象
setAttribute(字符串名称,对象 obj)
获取属性(字符串名称)
删除属性(字符串名称)
pageContext 可以访问其他指定域的数据
setAttribute(字符串名称,对象 obj,int 范围)
getAttribute(字符串名称,整数范围)
removeAttrbute(字符串名称,int 范围)
findAttribute(字符串名称)
PS:使用findAttribute()方法查找名为name的属性时,该属性依次从pageContext域、请求域、会话域、应用域中获取。在某个域中获取后,不会向后搜索。
四个范围的总结:
page domain:当前jsp页面的范围
请求字段:请求
会话字段:会话
应用领域:整个网络应用
2)可以获取其他8个隐式对象(不常用)
例如:pageContext.getRequest()
pageContext.getSession()
jsp标签(动作)
页面收录(动态收录):
收录的原则是对收录的页面进行编译处理后,将结果收录在页面中。当浏览器第一次请求使用其他页面的页面时,web容器首先编译被收录的页面,然后将编译过程的结果收录在页面中,再编译被收录的页面,最后编译这两个页面。合并的结果返回给浏览器。
请求转发:
动态收录和静态收录的区别


抓取jsp网页源代码(GoogleAds广告系列之如何使用URL参数和动态替换内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-13 20:14
或)和页面。
使用 innerHTML 属性的动态内容演示了三种在网页上动态添加或替换 HTML 内容的方法,我将演示所有这三种方法,您可以选择最适合您的情况的方法。第 1 步:选择 HTML 动态内容 在一个测试项目中,我决定为我的 Google Ads 广告系列中的每个关键字显示一些独特的内容:标题、标题、说明和按钮文本。如果你选择了 100+ 个关键词和 4 个元素,那么你需要拿出 400 条文字,所以我的建议是:不要选择太多。. 动态页面/替换内容,通过使用所有现代浏览器都支持的这个属性,我们可以将新的 HTML 或文本分配给任何收录元素(例如。
或 ),以及页面中描述的三种动态替换 HTML 内容的方法(响应用户操作);我会示范。
动态页面/替代内容,第 1 步:选择 HTML 动态内容 在一个测试项目中,我决定为我的 Google Ads 广告系列中的每个关键字显示一些独特的内容:标题、标题、描述和按钮文本。如果你选择了 100+ 个关键词和 4 个元素,那么你需要拿出 400 条文字,所以我的建议是:不要选择太多。通过使用所有现代浏览器都支持的这个属性,我们可以将新的 HTML 或文本分配给任何收录元素(例如
或)和页面。如何使用 URL 参数在页面上显示动态内容,本文介绍的三种动态替换 HTML 内容(响应用户操作)的方法都可以正常工作;我将演示动态网页是在每次查看时显示不同内容的网页。例如,页面可能会随着时间、访问网页的用户或用户交互的类型而改变。有两种类型的动态网页。客户端脚本。
如何使用 URL 参数在页面上显示动态内容,通过使用所有现代浏览器都支持的这个属性,我们可以将新的 HTML 或文本分配给任何收录元素(例如
或 ),本文中描述的三种动态替换 HTML 内容(响应用户操作)的方法可以正常工作;我会示范。如何在html页面上显示动态内容,
在不重新加载页面的情况下更改内容
如何在不刷新页面的情况下更改 div 的内容 如何在不刷新页面的情况下使用 jQuery 更改 div 的内容
·
· 查看全部
抓取jsp网页源代码(GoogleAds广告系列之如何使用URL参数和动态替换内容)
或)和页面。
使用 innerHTML 属性的动态内容演示了三种在网页上动态添加或替换 HTML 内容的方法,我将演示所有这三种方法,您可以选择最适合您的情况的方法。第 1 步:选择 HTML 动态内容 在一个测试项目中,我决定为我的 Google Ads 广告系列中的每个关键字显示一些独特的内容:标题、标题、说明和按钮文本。如果你选择了 100+ 个关键词和 4 个元素,那么你需要拿出 400 条文字,所以我的建议是:不要选择太多。. 动态页面/替换内容,通过使用所有现代浏览器都支持的这个属性,我们可以将新的 HTML 或文本分配给任何收录元素(例如。
或 ),以及页面中描述的三种动态替换 HTML 内容的方法(响应用户操作);我会示范。
动态页面/替代内容,第 1 步:选择 HTML 动态内容 在一个测试项目中,我决定为我的 Google Ads 广告系列中的每个关键字显示一些独特的内容:标题、标题、描述和按钮文本。如果你选择了 100+ 个关键词和 4 个元素,那么你需要拿出 400 条文字,所以我的建议是:不要选择太多。通过使用所有现代浏览器都支持的这个属性,我们可以将新的 HTML 或文本分配给任何收录元素(例如
或)和页面。如何使用 URL 参数在页面上显示动态内容,本文介绍的三种动态替换 HTML 内容(响应用户操作)的方法都可以正常工作;我将演示动态网页是在每次查看时显示不同内容的网页。例如,页面可能会随着时间、访问网页的用户或用户交互的类型而改变。有两种类型的动态网页。客户端脚本。
如何使用 URL 参数在页面上显示动态内容,通过使用所有现代浏览器都支持的这个属性,我们可以将新的 HTML 或文本分配给任何收录元素(例如
或 ),本文中描述的三种动态替换 HTML 内容(响应用户操作)的方法可以正常工作;我会示范。如何在html页面上显示动态内容,
在不重新加载页面的情况下更改内容
如何在不刷新页面的情况下更改 div 的内容 如何在不刷新页面的情况下使用 jQuery 更改 div 的内容
·
·
抓取jsp网页源代码(网络爬虫的制作方法和使用方法,你值得拥有!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-02-07 22:21
一、什么是爬虫
大东:小白,你平时都是自己做作业吗?
小白:大大大大的,怎么了?
大东:看你,吓得结巴。
小白:我这么好的学生,怎么会抄作业这种事!
大东:好的,我知道你不抄作业,所以有同学抄作业?
小白:哇!尤其是作业检查的前一天,我的同学们快速跑了一遍,一起抄了一遍,非常壮观。
大东:在网络世界里,也有人喜欢抄“作业”。
小白:诶!是谁!
大东:叫做网络爬虫。
小白:这个名字我早就羡慕了!
大东:网络爬虫也可以称为网络蜘蛛、网络机器人,还有一个文学名称——网页追赶者。网络爬虫是根据预定规则自动从万维网上爬取所需信息的程序或脚本。
小白:如果我学得好,我可以自动为我抓取作业答案。不,课外资料,听起来很不错~
网络爬虫(图片来自网络)
二、爬虫能做什么
小白:这个网络爬虫能抓到什么吗?
大东:只要在写的时候定义好,就可以根据自己的要求去抓取。从这个角度来看,它就是你想要抓住的东西。常见,可用于网页文字、图片、视频。
小白:哇~
大东:根据网络爬虫的爬取对象、程序结构和使用技术,通常可以分为以下四类:通用爬虫、聚焦爬虫、增量爬虫和深度爬虫。
小白:要注意的东西太多了!
大东:通用爬虫已经变成了全网爬虫,主要用在搜索引擎上。通用爬虫从初始URL开始,可以获取整个网页。工作量巨大,要求存储容量大、处理速度快、工作性能强大。
小白:你要不要,先拿下来!
大东:专注爬虫专注于抓取特定网页和特定信息,只搜索和抓取预先定义好的关键信息。焦点类型通常用于数据分析工作的数据采集阶段,具有很强的焦点。
小白:不求数量,只求准确!
大东:增量爬虫在固定的时间段内自动重新抓取网页,可以获取网页的更新内容并存入数据库。
小白:有点自动化的意思!
大东:深度爬虫可以快速抓取并保存网页上的文字、图片等信息,无需人工操作,通常用于需要提交登录数据才能进入的页面。深度爬虫可以自动处理图像存储的复杂操作,同时获取大量感知知识难以获取的数据,为后续决策提供支持。
小白:哇,这个最厉害了!节省大量人力
蜘蛛侠(图片来自网络)
三、简单爬虫的养成
小白:爬虫好用,我也想写一个试试看,请告诉我怎么做~
大东:爬虫一般有两种工作方式:一种是模拟真实用户,在页面上操作;另一种是向网站发起HTTP请求,直接获取整个页面的内容。
小白:哦~第一个我知道。您可以使用软件测试工具来模拟用户的浏览和点击操作。比如在python语言中,Selenium就是一个可以用来模拟用户操作的包,加上lxml包。定位网页的相框简直完美~
大东:没想到小白也有经验。
小白:嘻嘻嘻,你不像人啊~
大东:另外一种方式,同样以python语言为例,就是程序先使用HTTP库向目标网站发起请求,等待服务器响应。如果服务器能正常响应,程序就可以收到一个Response。这个Response中的内容就是要获取的页面的内容。它可能有 HTML、Json 字符串、二进制和其他类型的数据。程序需要不断地对内容进行解析和提取,最终得到需要的信息。
小白:也好听~
大东:一般来说,第二种方法比第一种更有效。
小白:好!今晚可以回去写爬虫了~
大东:爬虫程序一般分为几个模块,分别负责不同的功能。简单来说,爬虫调度端就是用来控制和监控爬虫的运行;URL管理器管理要爬取的目标网站URL和已经爬取过的URL;网页下载器从 URL 管理从浏览器中的 URL 下载网页并生成字符串;网页解析器需要解析网页下载器完成的内容。一方面解析出有用的价值数据,另一方面取出网页中的链接发送给URL管理器。.
小白:哇,小爬虫分工有条不紊~
爬虫程序的基本流程(图片来自网络)
四、防爬技术
小白:大冬冬,我有一个问题。总有一些同学不愿意轻易分享他的劳动成果,所以就不要让别人看到他的功课。但是在这个网络上,网站 是公开的,任何人都可以看到它。如果我不想让别人复制它怎么办?
大东:有爬虫技术,当然还有反爬虫技术。
小白:听前排讲课~
大东:据我所知,目前的防爬技术大致分为四种。最经典的反爬策略是“验证码”。
小白:我知道~是永远不会失败的反人类验证码吗!
大东:是的,因为验证码是图片,所以用户只需要输入一次就可以登录成功。程序在抓取数据的过程中,需要不断的登录,抓取1000个用户的个人信息,需要填写1000个验证码,可以减缓甚至停止程序的爬取过程。
小白:哇,好麻烦。
大东:另一个更狠的反爬策略是封IP和封号。网站一旦某个IP或网站账号被怀疑为爬虫,该账号和IP将立即被封杀,将无法再通过该IP访问网站或占短时间甚至永久。
小白:太残忍了!
大东:比较常见的是通过cookies来限制信息的抓取。比如程序模拟登录后,如果想获取登录后某个页面的信息,需要请求一些中间页面获取特定的cookie,然后就可以抓取我们需要的页面了。
小白:操作比较复杂。
大东:另一种常见的反爬模式是使用JS渲染页面。这是什么意思?返回的页面不是直接请求的,而是JS操作数据文件得到的一部分,而那部分数据我们也拿不到。
小白:看来大家都在尽力防止自己的“作业”被抄袭了!
大东:所以小白,从现在开始,不管是你还是你的同学,好好做好功课。想要通过抄袭取得好成绩,迟早会有“报应”!
小白:那一定要做好~
对峙(图片来自网络) 查看全部
抓取jsp网页源代码(网络爬虫的制作方法和使用方法,你值得拥有!)
一、什么是爬虫
大东:小白,你平时都是自己做作业吗?
小白:大大大大的,怎么了?
大东:看你,吓得结巴。
小白:我这么好的学生,怎么会抄作业这种事!
大东:好的,我知道你不抄作业,所以有同学抄作业?
小白:哇!尤其是作业检查的前一天,我的同学们快速跑了一遍,一起抄了一遍,非常壮观。
大东:在网络世界里,也有人喜欢抄“作业”。
小白:诶!是谁!
大东:叫做网络爬虫。
小白:这个名字我早就羡慕了!
大东:网络爬虫也可以称为网络蜘蛛、网络机器人,还有一个文学名称——网页追赶者。网络爬虫是根据预定规则自动从万维网上爬取所需信息的程序或脚本。
小白:如果我学得好,我可以自动为我抓取作业答案。不,课外资料,听起来很不错~
网络爬虫(图片来自网络)
二、爬虫能做什么
小白:这个网络爬虫能抓到什么吗?
大东:只要在写的时候定义好,就可以根据自己的要求去抓取。从这个角度来看,它就是你想要抓住的东西。常见,可用于网页文字、图片、视频。
小白:哇~
大东:根据网络爬虫的爬取对象、程序结构和使用技术,通常可以分为以下四类:通用爬虫、聚焦爬虫、增量爬虫和深度爬虫。
小白:要注意的东西太多了!
大东:通用爬虫已经变成了全网爬虫,主要用在搜索引擎上。通用爬虫从初始URL开始,可以获取整个网页。工作量巨大,要求存储容量大、处理速度快、工作性能强大。
小白:你要不要,先拿下来!
大东:专注爬虫专注于抓取特定网页和特定信息,只搜索和抓取预先定义好的关键信息。焦点类型通常用于数据分析工作的数据采集阶段,具有很强的焦点。
小白:不求数量,只求准确!
大东:增量爬虫在固定的时间段内自动重新抓取网页,可以获取网页的更新内容并存入数据库。
小白:有点自动化的意思!
大东:深度爬虫可以快速抓取并保存网页上的文字、图片等信息,无需人工操作,通常用于需要提交登录数据才能进入的页面。深度爬虫可以自动处理图像存储的复杂操作,同时获取大量感知知识难以获取的数据,为后续决策提供支持。
小白:哇,这个最厉害了!节省大量人力
蜘蛛侠(图片来自网络)
三、简单爬虫的养成
小白:爬虫好用,我也想写一个试试看,请告诉我怎么做~
大东:爬虫一般有两种工作方式:一种是模拟真实用户,在页面上操作;另一种是向网站发起HTTP请求,直接获取整个页面的内容。
小白:哦~第一个我知道。您可以使用软件测试工具来模拟用户的浏览和点击操作。比如在python语言中,Selenium就是一个可以用来模拟用户操作的包,加上lxml包。定位网页的相框简直完美~
大东:没想到小白也有经验。
小白:嘻嘻嘻,你不像人啊~
大东:另外一种方式,同样以python语言为例,就是程序先使用HTTP库向目标网站发起请求,等待服务器响应。如果服务器能正常响应,程序就可以收到一个Response。这个Response中的内容就是要获取的页面的内容。它可能有 HTML、Json 字符串、二进制和其他类型的数据。程序需要不断地对内容进行解析和提取,最终得到需要的信息。
小白:也好听~
大东:一般来说,第二种方法比第一种更有效。
小白:好!今晚可以回去写爬虫了~
大东:爬虫程序一般分为几个模块,分别负责不同的功能。简单来说,爬虫调度端就是用来控制和监控爬虫的运行;URL管理器管理要爬取的目标网站URL和已经爬取过的URL;网页下载器从 URL 管理从浏览器中的 URL 下载网页并生成字符串;网页解析器需要解析网页下载器完成的内容。一方面解析出有用的价值数据,另一方面取出网页中的链接发送给URL管理器。.
小白:哇,小爬虫分工有条不紊~
爬虫程序的基本流程(图片来自网络)
四、防爬技术
小白:大冬冬,我有一个问题。总有一些同学不愿意轻易分享他的劳动成果,所以就不要让别人看到他的功课。但是在这个网络上,网站 是公开的,任何人都可以看到它。如果我不想让别人复制它怎么办?
大东:有爬虫技术,当然还有反爬虫技术。
小白:听前排讲课~
大东:据我所知,目前的防爬技术大致分为四种。最经典的反爬策略是“验证码”。
小白:我知道~是永远不会失败的反人类验证码吗!
大东:是的,因为验证码是图片,所以用户只需要输入一次就可以登录成功。程序在抓取数据的过程中,需要不断的登录,抓取1000个用户的个人信息,需要填写1000个验证码,可以减缓甚至停止程序的爬取过程。
小白:哇,好麻烦。
大东:另一个更狠的反爬策略是封IP和封号。网站一旦某个IP或网站账号被怀疑为爬虫,该账号和IP将立即被封杀,将无法再通过该IP访问网站或占短时间甚至永久。
小白:太残忍了!
大东:比较常见的是通过cookies来限制信息的抓取。比如程序模拟登录后,如果想获取登录后某个页面的信息,需要请求一些中间页面获取特定的cookie,然后就可以抓取我们需要的页面了。
小白:操作比较复杂。
大东:另一种常见的反爬模式是使用JS渲染页面。这是什么意思?返回的页面不是直接请求的,而是JS操作数据文件得到的一部分,而那部分数据我们也拿不到。
小白:看来大家都在尽力防止自己的“作业”被抄袭了!
大东:所以小白,从现在开始,不管是你还是你的同学,好好做好功课。想要通过抄袭取得好成绩,迟早会有“报应”!
小白:那一定要做好~
对峙(图片来自网络)
抓取jsp网页源代码(如何提高网站百度蜘蛛量量?(组图)期)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-02-06 15:13
阿里云 > 云栖社区 > 主题图 > W>网站 js css 代码抓取
推荐活动:
更多优惠>
当前话题:网站js css代码爬取加入采集
相关话题:
网站js css代码抓取相关博文看更多博文
编写现代 CSS 代码的 20 个技巧
作者:迟到991人查看评论:04年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.sq
阅读全文
编写现代 CSS 代码的 20 个技巧
作者:熊哥 club903 浏览评论:05年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.
阅读全文
CSS黑魔法,让你少写不必要的JS,代码更优雅
作者:沃克·武松 1735观众评论:04年前
前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术,伪装指南,高级代码,让你惊叹不已。没想到会受到大家的欢迎。有人希望做博主我也可以整理出一些CSS的黑魔法,可惜我的CSS一直是渣渣,我也无计可施。我最近写了一篇Ch
阅读全文
百度网站优化:如何增加蜘蛛爬取量?
作者:蝙蝠侠it1205 浏览评论:03年前
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛的数量之前,我们必须考虑:增加网站的开启速度。百度网站优化:如何增加爬虫
阅读全文
前端面试题总结(HTML和CSS)
作者:赖1681人查看评论:03年前
回顾旧的并保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前是 presto,现在改为 G
阅读全文
加快网站访问的9种方法
作者:迟来凶猛1068人查看评论:04年前
一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
阅读全文
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序
作者:我是小助手2146人查看评论:03年前
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
阅读全文
HTML5 和 CSS3 新特性一览
作者:云栖大讲堂 4140观众评论:03年前
HTML5 和 CSS3 新功能一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
阅读全文
网站js css代码爬取相关问题
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
抓取jsp网页源代码(如何提高网站百度蜘蛛量量?(组图)期)
阿里云 > 云栖社区 > 主题图 > W>网站 js css 代码抓取
推荐活动:
更多优惠>
当前话题:网站js css代码爬取加入采集
相关话题:
网站js css代码抓取相关博文看更多博文
编写现代 CSS 代码的 20 个技巧


作者:迟到991人查看评论:04年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.sq
阅读全文
编写现代 CSS 代码的 20 个技巧


作者:熊哥 club903 浏览评论:05年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.
阅读全文
CSS黑魔法,让你少写不必要的JS,代码更优雅


作者:沃克·武松 1735观众评论:04年前
前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术,伪装指南,高级代码,让你惊叹不已。没想到会受到大家的欢迎。有人希望做博主我也可以整理出一些CSS的黑魔法,可惜我的CSS一直是渣渣,我也无计可施。我最近写了一篇Ch
阅读全文
百度网站优化:如何增加蜘蛛爬取量?

作者:蝙蝠侠it1205 浏览评论:03年前
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛的数量之前,我们必须考虑:增加网站的开启速度。百度网站优化:如何增加爬虫
阅读全文
前端面试题总结(HTML和CSS)


作者:赖1681人查看评论:03年前
回顾旧的并保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前是 presto,现在改为 G
阅读全文
加快网站访问的9种方法

作者:迟来凶猛1068人查看评论:04年前
一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
阅读全文
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序

作者:我是小助手2146人查看评论:03年前
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
阅读全文
HTML5 和 CSS3 新特性一览


作者:云栖大讲堂 4140观众评论:03年前
HTML5 和 CSS3 新功能一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
阅读全文
网站js css代码爬取相关问题
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑


作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
抓取jsp网页源代码( 自动化检测函数供检测Url连接连接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-02-04 00:16
自动化检测函数供检测Url连接连接)
python获取网页编码的实现代码
更新时间:2017年3月11日16:26:00投稿时间:lqh
本文文章主要介绍python获取网页编码的代码的相关资料。有需要的朋友可以参考以下
python获取网页编码的实现代码
python开发,自动化获取网页编码方式用到了chardet库,字符集检测,这个类在python2.7中没有,需要在官网上下载。
这里我下载好了chardet-2.3.0.tar.gz压缩包文件,只需要将压缩包文件解压后的chardet文件放到python安装包下的
python27/lib/site-packages/下,就可以了。
然后导入chardet
下面写了一个自动检测函数,检测Url连接,然后返回网页URL的编码方式。
import chardet #字符集检测
import urllib
url="http://www.jd.com"
def automatic_detect(url):
content=urllib.urlopen(url).read()
result=chardet.detect(content)
encoding=result['encoding']
return encoding
urls=['http://www.baidu.com','http://www.163.com','http://dangdang.com']
for url in urls:
print url,automatic_detect(url)
上面使用了chardet类的detect方法,返回一个字典,然后取出编码方法
感谢您的阅读,希望对您有所帮助,感谢您对本站的支持! 查看全部
抓取jsp网页源代码(
自动化检测函数供检测Url连接连接)
python获取网页编码的实现代码
更新时间:2017年3月11日16:26:00投稿时间:lqh
本文文章主要介绍python获取网页编码的代码的相关资料。有需要的朋友可以参考以下
python获取网页编码的实现代码
python开发,自动化获取网页编码方式用到了chardet库,字符集检测,这个类在python2.7中没有,需要在官网上下载。
这里我下载好了chardet-2.3.0.tar.gz压缩包文件,只需要将压缩包文件解压后的chardet文件放到python安装包下的
python27/lib/site-packages/下,就可以了。
然后导入chardet
下面写了一个自动检测函数,检测Url连接,然后返回网页URL的编码方式。
import chardet #字符集检测
import urllib
url="http://www.jd.com"
def automatic_detect(url):
content=urllib.urlopen(url).read()
result=chardet.detect(content)
encoding=result['encoding']
return encoding
urls=['http://www.baidu.com','http://www.163.com','http://dangdang.com']
for url in urls:
print url,automatic_detect(url)
上面使用了chardet类的detect方法,返回一个字典,然后取出编码方法
感谢您的阅读,希望对您有所帮助,感谢您对本站的支持!
抓取jsp网页源代码(#这里需要正则匹配jsp页面源代码的内容#进行解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-03 22:02
抓取jsp网页源代码来进行数据抓取,不过网上有很多css库提供jsp中的css引用,有些我也在自己写,最后还是放弃了,因为jsp本身的可读性并不好,我改进了下smarty+iocp抓取jsp代码,或许你也可以用它来完成爬取jsp的目的。frombs4importbeautifulsoupurl=''#这里需要正则匹配jsp页面源代码的内容req=requests.get(url)resp=req.text#进行解析这里我们没有需要转换过的jsp页面,只需要浏览器的cookie之类的对我们在大部分的情况下都是没有用的,因为在爬取某些不那么正规的jsp页面时还会涉及到兼容性的问题。
再上面最开始我提到了需要正则匹配,相信很多同学都会去了解,也尝试去实践过去实现过,比如有道词典等等有词典匹配可以对英文进行匹配,它的兼容性也可以保证,但是就没有抓取其他语言的页面了,有时间再学其他语言吧。在chrome下进行抓取不太方便,而浏览器内置的beautifulsoup也未采用正则匹配,我特意去下载了支持正则匹配的代码提取工具来使用。
本次我用到的工具如下,下载链接如下#contenttype是html(大部分支持正则匹配)url='/'resp=req.text在beautifulsoup的官方文档文档中我就是用了如上代码来抓取网页,但是chrome下不知道为什么不能正则匹配,导致抓取返回的html是空字符串。尝试了其他文本处理工具后都不行,直到我发现了iocp,不仅支持正则匹配而且也可以实现beautifulsoup的正则匹配,于是我就开始尝试用iocp抓取jsp,顺便看看有没有能够解决该问题的工具。
之前通过代码提取抓取后,我是先把jsp文件所在目录上传github,在starteraction中加入对url=''的修改,可以修改为'',这里我只修改了其中两个地方,其中第一个修改为‘’,意为‘根’不能接受request,而第二个修改为‘’意为‘多维的url’。上传starteraction我用的是这个starteraction.jsp在description中加入starteraction.url='',其实这个是可以理解为多级嵌套的starteraction.而文档中有一段关于iocp的介绍,其中iocp允许你嵌套更多的starteraction.这是从html代码下手是无法达到题主要求的效果的,因为我们是使用html代码下手爬取jsp网页,在html代码里如果我们爬取starteraction并且配合beautifulsoup的正则,需要先匹配jsp页面源代码,然后再匹配对应的页面文件.我写了这篇文章本来是想跟大家分享下通过查看jsp源代码来爬取jsp网页的,但是还是未达到我们要求的效果,所以只得放弃,可是代码真的已经写好了,就让其交付他人使。 查看全部
抓取jsp网页源代码(#这里需要正则匹配jsp页面源代码的内容#进行解析)
抓取jsp网页源代码来进行数据抓取,不过网上有很多css库提供jsp中的css引用,有些我也在自己写,最后还是放弃了,因为jsp本身的可读性并不好,我改进了下smarty+iocp抓取jsp代码,或许你也可以用它来完成爬取jsp的目的。frombs4importbeautifulsoupurl=''#这里需要正则匹配jsp页面源代码的内容req=requests.get(url)resp=req.text#进行解析这里我们没有需要转换过的jsp页面,只需要浏览器的cookie之类的对我们在大部分的情况下都是没有用的,因为在爬取某些不那么正规的jsp页面时还会涉及到兼容性的问题。
再上面最开始我提到了需要正则匹配,相信很多同学都会去了解,也尝试去实践过去实现过,比如有道词典等等有词典匹配可以对英文进行匹配,它的兼容性也可以保证,但是就没有抓取其他语言的页面了,有时间再学其他语言吧。在chrome下进行抓取不太方便,而浏览器内置的beautifulsoup也未采用正则匹配,我特意去下载了支持正则匹配的代码提取工具来使用。
本次我用到的工具如下,下载链接如下#contenttype是html(大部分支持正则匹配)url='/'resp=req.text在beautifulsoup的官方文档文档中我就是用了如上代码来抓取网页,但是chrome下不知道为什么不能正则匹配,导致抓取返回的html是空字符串。尝试了其他文本处理工具后都不行,直到我发现了iocp,不仅支持正则匹配而且也可以实现beautifulsoup的正则匹配,于是我就开始尝试用iocp抓取jsp,顺便看看有没有能够解决该问题的工具。
之前通过代码提取抓取后,我是先把jsp文件所在目录上传github,在starteraction中加入对url=''的修改,可以修改为'',这里我只修改了其中两个地方,其中第一个修改为‘’,意为‘根’不能接受request,而第二个修改为‘’意为‘多维的url’。上传starteraction我用的是这个starteraction.jsp在description中加入starteraction.url='',其实这个是可以理解为多级嵌套的starteraction.而文档中有一段关于iocp的介绍,其中iocp允许你嵌套更多的starteraction.这是从html代码下手是无法达到题主要求的效果的,因为我们是使用html代码下手爬取jsp网页,在html代码里如果我们爬取starteraction并且配合beautifulsoup的正则,需要先匹配jsp页面源代码,然后再匹配对应的页面文件.我写了这篇文章本来是想跟大家分享下通过查看jsp源代码来爬取jsp网页的,但是还是未达到我们要求的效果,所以只得放弃,可是代码真的已经写好了,就让其交付他人使。
抓取jsp网页源代码(一下动态网页的一些特点:1.动态Web的最大特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-02-01 22:00
2021-04-23静态网页
关于静态网页,我想很多人都按字面理解,按字面意思理解。如果是这样,那就错了。
所谓“静态”,是指一旦网页准备好并上传到服务器,无论谁访问该网页,都会呈现相同的效果。而这个静态网页可以收录动态元素,比如gif动画、滚动字幕等。
如果要修改网页,则需要修改源代码并再次上传到服务器。
当我们使用 Hexo+GitPages 构建个人博客时,我们使用的是静态网页。
比如你有一个这样的个人博客,无论谁访问你的博客,显示的内容都是一样的。
那么我们来看看静态网页的一些特点:
1. 主要包括一些HTML页面。网页中没有程序代码,只有HTML标签,后缀为.htm或.html。
2.无法实现人机交互;如果要修改网页,必须修改源代码并重新上传,需要大量维护。
动态网页
也不要从字面上理解,动态网页也可以是纯文本。
但是,动态网页可以根据不同的时间和不同的浏览者显示不同的信息。例如,博客下方的评论,或留言板等。
虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合。
那么我们来看看动态网页的一些特点:
1.网页收录程序代码和脚本,利用ASP、PHP、JSP等技术动态生成网页,以扩展名.asp、.php、.jsp存储在服务器端,收录需要执行的程序。
2.Dynamic Web 最大的特点是它的交互性。
分类:
技术要点:
相关文章: 查看全部
抓取jsp网页源代码(一下动态网页的一些特点:1.动态Web的最大特点)
2021-04-23静态网页
关于静态网页,我想很多人都按字面理解,按字面意思理解。如果是这样,那就错了。
所谓“静态”,是指一旦网页准备好并上传到服务器,无论谁访问该网页,都会呈现相同的效果。而这个静态网页可以收录动态元素,比如gif动画、滚动字幕等。
如果要修改网页,则需要修改源代码并再次上传到服务器。
当我们使用 Hexo+GitPages 构建个人博客时,我们使用的是静态网页。
比如你有一个这样的个人博客,无论谁访问你的博客,显示的内容都是一样的。
那么我们来看看静态网页的一些特点:
1. 主要包括一些HTML页面。网页中没有程序代码,只有HTML标签,后缀为.htm或.html。
2.无法实现人机交互;如果要修改网页,必须修改源代码并重新上传,需要大量维护。
动态网页
也不要从字面上理解,动态网页也可以是纯文本。
但是,动态网页可以根据不同的时间和不同的浏览者显示不同的信息。例如,博客下方的评论,或留言板等。
虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合。
那么我们来看看动态网页的一些特点:
1.网页收录程序代码和脚本,利用ASP、PHP、JSP等技术动态生成网页,以扩展名.asp、.php、.jsp存储在服务器端,收录需要执行的程序。
2.Dynamic Web 最大的特点是它的交互性。
分类:
技术要点:
相关文章:
抓取jsp网页源代码(抓取jsp网页源代码要么进行反编译(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-01-29 09:01
抓取jsp网页源代码要么进行反编译(如果你没反编译过jsp建议你换台电脑查看,或者用一个代码生成器如phpexcel,通过phpexcel可以生成jsp可以调用的代码),要么用封装jsp的jstl模板引擎。
有第三方包jsplayer.jsp可以生成jsphtml。如果你想往网页里面嵌入html,其实可以实现的。
可以在html模板里加css,
源码是xml格式,
boostjs里对jsp的写法有提示,然后nodejs也可以转
要把源码转换成java可以调用的代码,关键要看原来的jsp是什么类型,如果是基于jsp的java开发库这种形式的话,如jstl,jsppack等,那么你可以从这些库里寻找你需要的,如果你是java的话,那只能jsp转换为java开发库里的html文件形式的源码,或者对原来的jsp改为struts,action,spring等这些基于jsp的应用。
boost库,
正好刚下了jspviewer(angularjs网页代码代码生成工具)。看起来和网页生成器类似,你这么做可以先把源码转换,看看原来的jsp内容生成代码,
代码生成jsp要用到:boostjs,ng-boost,web.service等
你可以把网页打包成jsp转换成java的代码 查看全部
抓取jsp网页源代码(抓取jsp网页源代码要么进行反编译(图))
抓取jsp网页源代码要么进行反编译(如果你没反编译过jsp建议你换台电脑查看,或者用一个代码生成器如phpexcel,通过phpexcel可以生成jsp可以调用的代码),要么用封装jsp的jstl模板引擎。
有第三方包jsplayer.jsp可以生成jsphtml。如果你想往网页里面嵌入html,其实可以实现的。
可以在html模板里加css,
源码是xml格式,
boostjs里对jsp的写法有提示,然后nodejs也可以转
要把源码转换成java可以调用的代码,关键要看原来的jsp是什么类型,如果是基于jsp的java开发库这种形式的话,如jstl,jsppack等,那么你可以从这些库里寻找你需要的,如果你是java的话,那只能jsp转换为java开发库里的html文件形式的源码,或者对原来的jsp改为struts,action,spring等这些基于jsp的应用。
boost库,
正好刚下了jspviewer(angularjs网页代码代码生成工具)。看起来和网页生成器类似,你这么做可以先把源码转换,看看原来的jsp内容生成代码,
代码生成jsp要用到:boostjs,ng-boost,web.service等
你可以把网页打包成jsp转换成java的代码
抓取jsp网页源代码(spring的实现机制和对比a的区别和方法设计)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-03-13 18:04
(2)比较支柱
一种。核心控制器:spring mvc核心控制器为Servlet,Struts2为Filter。
湾。控制器实例:Spring Mvc 会比 Struts 快。Spring Mvc 是基于方法设计的,而 Sturts 是基于对象的。每次发出请求时,都会实例化一个动作,并为每个动作注入属性。Spring更像Servlet,只有一个实例,每个请求都执行对应的方法。能。
C。管理方式:大部分公司的核心架构都使用spring,而spring mvc是spring中的一个模块,所以spring对spring mvc控制器的管理更加简单方便,并且提供了完整的注解方式进行管理,各种功能的注解比较全面好用,而struts需要使用很多XML配置参数来管理。
d。参数传递:Struts2本身提供了多种参数来接受,其实是通过(ValueStack)传递和赋值的,SpringMvc是通过方法的参数来接收的。
e. 拦截器实现机制:struts有自己的拦截器机制,spring mvc使用独立的AOP方式。这样一来,struts的配置文件量还是比spring mvc大,虽然struts的配置可以继承,所以我觉得在使用方面,spring mvc更加简洁,spring的开发效率mvc高于struts2。
F。spring mvc处理ajax请求,直接通过返回数据,使用方法中的注解@ResponseBody,spring mvc自动将我们的对象转换为JSON数据。
2. 自由标记
(1)FreeMarker 是一个模板引擎:即基于模板和要更改的数据生成输出文本(HTML 页面、电子邮件、配置文件、源代码等)的通用工具。它是不适用于最终用户,它是一个 Java 类库,程序员可以嵌入到他们开发的产品中的组件。
(2)比较jsp
一种。内置了很多常用功能,例如:html过滤、日期和金额格式化等,使用起来非常方便。
湾。宏定义比jsp方便。
C。支持jsp标签
d。可以实现严格的MAC分离
e. 在复杂的页面上,freemarker 表现最好
2.5 系统实现功能的具体说明
1.“新浪微博”:
(1)经过多次搜索,发现wap版新浪微博存在权限bug。利用这个bug,无需登录即可搜索微博内容,获取微博上的相应评论,从而避免了PC端的访问限制和API应用困难等问题。
(2)方法:本系统使用Apache HttpClient模拟http请求,爬取微博时直接向官方存在bug的请求地址发送请求,获取所需数据并解析数据格式构造所需内容由系统获取(默认获取微博前10页,每条微博评论前10页)。
(3)具体解析规则:
1、默认获取的第一页内容为html+data。html内容毫无意义。我们需要做的是从html中获取需要的数据字符串。在这里,我们使用正则表达式来匹配捕获的数据;
2.从第二页开始,请求直接返回需要的json字符串格式数据
3.使用alibaba fastjson将数据转成json格式,获取需要的字段值
4.同理,获取评论请求地址数据并解析
5.然后将解析后的数据存入数据库,微博内容存入article表,回复信息存入article_reply表
2、“天涯论坛”:
因为天涯论坛不限制登录权限,所以爬取天涯论坛的数据比较简单。下面对天涯论坛的抓取做一个简单的说明: 查看全部
抓取jsp网页源代码(spring的实现机制和对比a的区别和方法设计)
(2)比较支柱
一种。核心控制器:spring mvc核心控制器为Servlet,Struts2为Filter。
湾。控制器实例:Spring Mvc 会比 Struts 快。Spring Mvc 是基于方法设计的,而 Sturts 是基于对象的。每次发出请求时,都会实例化一个动作,并为每个动作注入属性。Spring更像Servlet,只有一个实例,每个请求都执行对应的方法。能。
C。管理方式:大部分公司的核心架构都使用spring,而spring mvc是spring中的一个模块,所以spring对spring mvc控制器的管理更加简单方便,并且提供了完整的注解方式进行管理,各种功能的注解比较全面好用,而struts需要使用很多XML配置参数来管理。
d。参数传递:Struts2本身提供了多种参数来接受,其实是通过(ValueStack)传递和赋值的,SpringMvc是通过方法的参数来接收的。
e. 拦截器实现机制:struts有自己的拦截器机制,spring mvc使用独立的AOP方式。这样一来,struts的配置文件量还是比spring mvc大,虽然struts的配置可以继承,所以我觉得在使用方面,spring mvc更加简洁,spring的开发效率mvc高于struts2。
F。spring mvc处理ajax请求,直接通过返回数据,使用方法中的注解@ResponseBody,spring mvc自动将我们的对象转换为JSON数据。
2. 自由标记
(1)FreeMarker 是一个模板引擎:即基于模板和要更改的数据生成输出文本(HTML 页面、电子邮件、配置文件、源代码等)的通用工具。它是不适用于最终用户,它是一个 Java 类库,程序员可以嵌入到他们开发的产品中的组件。
(2)比较jsp
一种。内置了很多常用功能,例如:html过滤、日期和金额格式化等,使用起来非常方便。
湾。宏定义比jsp方便。
C。支持jsp标签
d。可以实现严格的MAC分离
e. 在复杂的页面上,freemarker 表现最好
2.5 系统实现功能的具体说明
1.“新浪微博”:
(1)经过多次搜索,发现wap版新浪微博存在权限bug。利用这个bug,无需登录即可搜索微博内容,获取微博上的相应评论,从而避免了PC端的访问限制和API应用困难等问题。
(2)方法:本系统使用Apache HttpClient模拟http请求,爬取微博时直接向官方存在bug的请求地址发送请求,获取所需数据并解析数据格式构造所需内容由系统获取(默认获取微博前10页,每条微博评论前10页)。
(3)具体解析规则:
1、默认获取的第一页内容为html+data。html内容毫无意义。我们需要做的是从html中获取需要的数据字符串。在这里,我们使用正则表达式来匹配捕获的数据;
2.从第二页开始,请求直接返回需要的json字符串格式数据
3.使用alibaba fastjson将数据转成json格式,获取需要的字段值
4.同理,获取评论请求地址数据并解析
5.然后将解析后的数据存入数据库,微博内容存入article表,回复信息存入article_reply表
2、“天涯论坛”:
因为天涯论坛不限制登录权限,所以爬取天涯论坛的数据比较简单。下面对天涯论坛的抓取做一个简单的说明:
抓取jsp网页源代码(抓取jsp网页源代码中的应用方法-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-03-08 19:00
抓取jsp网页源代码中,把jsp页面中所有image对象的请求和响应的url写成一个字典,做成一个字典的key和value列表,判断出网页中所有的图片是不是存在这个字典中。imageitem=imageitem.getitem('key');responseitem=responseitem.getresponseitem('value');。
你解析jsp是写在jsp文件中的image=jsoup。reader(jsoup。read('jsp:btn。btn'))。
get_url('jsp:btn。btn')image=jsoup。reader(jsoup。read('jsp:btn。btn'))。get_url('jsp:btn。btn')但是要加上append方法%>如果不想再使用org。gson。python。tojson等工具来调用,可以使用pythonbeautifulsoup或lxml来读取和解析jsp页面。 查看全部
抓取jsp网页源代码(抓取jsp网页源代码中的应用方法-上海怡健医学)
抓取jsp网页源代码中,把jsp页面中所有image对象的请求和响应的url写成一个字典,做成一个字典的key和value列表,判断出网页中所有的图片是不是存在这个字典中。imageitem=imageitem.getitem('key');responseitem=responseitem.getresponseitem('value');。
你解析jsp是写在jsp文件中的image=jsoup。reader(jsoup。read('jsp:btn。btn'))。
get_url('jsp:btn。btn')image=jsoup。reader(jsoup。read('jsp:btn。btn'))。get_url('jsp:btn。btn')但是要加上append方法%>如果不想再使用org。gson。python。tojson等工具来调用,可以使用pythonbeautifulsoup或lxml来读取和解析jsp页面。
抓取jsp网页源代码(JSP页面间传递参数的方式及解决办法(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-03-01 03:05
在项目中经常需要在JSP页面之间传递参数,这应该算是web的基本功。
尝试总结各种方式,在需要权衡利弊时选择最合适的方式。
1. 在 URL 链接后附加参数
URL 后面追加参数
response.sendRedirect("next.jsp?paramA=A¶mB=B...")
window.location = "next.jsp?paramA=A¶mB=B..."
以上代码执行完毕后,会跳转到带参数的next.jsp页面。
在next.jsp页面中获取对应参数的方式如下:
//内嵌的 java 代码
//如果引入了 EL
{param.paramA}
优点:简单性和多浏览器支持(没有浏览器不支持 URL)。
缺点:
1)传输的数据只能是字符串,对数据类型和大小有一定的限制;
2)在浏览器地址栏中会看到传输数据的值,安全级别低。
2. 表格
在 next.jsp 页面中获取相应参数的方式类似于 (1).
优势:
1) 简单性和多浏览器支持(再次没有浏览器不支持表单);
2) 可以提交的数据量远大于URL方式;
3)传输的值会显示在浏览器的地址栏,但是有一点hack,也可以从页面源码中构造参数列表;
缺点:
1)传输的数据只能是字符串,对数据类型有一定的限制;
3. 设置 Cookie
使用客户端的认证凭证,一个小cookie,当然也可以实现JSP页面的值传递。
要读取 next.jsp 页面上的 cookie,请调用 request.getCookies() 方法以获取 javax.servlet.http.Cookie 对象数组。
然后遍历数组并使用 getName() 和 getValue() 方法来获取每个 cookie 的名称和值。
//内嵌的 java 代码
//EL 获取方式
${cookie.paramA.value}
优势:
1)cookie的值可以持久化,即使客户端机器关闭,下次打开时仍然可以获取到里面的值;
2) Cookies可以帮助服务器保存多个状态信息,但不需要在服务器上分配存储资源,减轻了服务器的负担。
缺点:
1)虽然相比URL和Form,安全性提升了很多,但是也有一些黑方法获取客户端cookie,暴露客户端信息。
4. 设置会话
个人认为session和cookie是服务器端一个,客户端一个。
在给它们添加键值对之后,它不仅提供了页面之间的传输,还提供了数据共享的解决方案。
在 next.jsp 中读取 session 的方式:
//内嵌java 片段
//EL 获取方式
{session.paramA}
Session的优缺点可以参考Cookies。 查看全部
抓取jsp网页源代码(JSP页面间传递参数的方式及解决办法(二))
在项目中经常需要在JSP页面之间传递参数,这应该算是web的基本功。
尝试总结各种方式,在需要权衡利弊时选择最合适的方式。
1. 在 URL 链接后附加参数
URL 后面追加参数
response.sendRedirect("next.jsp?paramA=A¶mB=B...")
window.location = "next.jsp?paramA=A¶mB=B..."
以上代码执行完毕后,会跳转到带参数的next.jsp页面。
在next.jsp页面中获取对应参数的方式如下:
//内嵌的 java 代码
//如果引入了 EL
{param.paramA}
优点:简单性和多浏览器支持(没有浏览器不支持 URL)。
缺点:
1)传输的数据只能是字符串,对数据类型和大小有一定的限制;
2)在浏览器地址栏中会看到传输数据的值,安全级别低。
2. 表格
在 next.jsp 页面中获取相应参数的方式类似于 (1).
优势:
1) 简单性和多浏览器支持(再次没有浏览器不支持表单);
2) 可以提交的数据量远大于URL方式;
3)传输的值会显示在浏览器的地址栏,但是有一点hack,也可以从页面源码中构造参数列表;
缺点:
1)传输的数据只能是字符串,对数据类型有一定的限制;
3. 设置 Cookie
使用客户端的认证凭证,一个小cookie,当然也可以实现JSP页面的值传递。
要读取 next.jsp 页面上的 cookie,请调用 request.getCookies() 方法以获取 javax.servlet.http.Cookie 对象数组。
然后遍历数组并使用 getName() 和 getValue() 方法来获取每个 cookie 的名称和值。
//内嵌的 java 代码
//EL 获取方式
${cookie.paramA.value}
优势:
1)cookie的值可以持久化,即使客户端机器关闭,下次打开时仍然可以获取到里面的值;
2) Cookies可以帮助服务器保存多个状态信息,但不需要在服务器上分配存储资源,减轻了服务器的负担。
缺点:
1)虽然相比URL和Form,安全性提升了很多,但是也有一些黑方法获取客户端cookie,暴露客户端信息。
4. 设置会话
个人认为session和cookie是服务器端一个,客户端一个。
在给它们添加键值对之后,它不仅提供了页面之间的传输,还提供了数据共享的解决方案。
在 next.jsp 中读取 session 的方式:
//内嵌java 片段
//EL 获取方式
{session.paramA}
Session的优缺点可以参考Cookies。
抓取jsp网页源代码(本文将略微详细的介绍SEO怎么优化代码与标签?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-02-28 18:05
通常,在网站上线之前,需要对网站的代码和标签进行必要的处理,以提高优化后的网站的打开速度,并强调想要的关键词达到排名。一个好的网站,在代码方面干净简洁。我们之前的文章中也提到了一些相关的标签页代码优化技术。本文将稍微详细介绍如何为 SEO 优化代码和标签。在合适的位置使用权重标签可以向搜索引擎传达友好,这是SEO的基本要求。
爬虫利用网站的代码简洁性来判断一个网页是否对人友好,浏览器能否获得良好的用户体验。简洁的网站通常不那么花哨,没有那么多广告,各种模块弹窗等。
1.减小网页大小,加快网页下载速度。减少页面噪音并突出显示页面主题。
2.提高蜘蛛抓取信息的速度和准确性。有利于减少错误码,提高页面对蜘蛛的友好度。
3.易于维护,提高工作效率。使用 div+css 布局。代码更加精简。
4.div+css可以简化很多样式,而且这些样式都放在一个专门的CSS文件中,维护和更改都很方便。
5.因为使用了css文件,蜘蛛爬取head里的内容更加快速准确。
6.浏览器下载div的速度比下载表格快很多倍,所以使用div+css排版可以有效稳定客户的等待情绪,增加客户访问的友好度。
7.使用 w3c 检查网页的错误代码。
8.减少网页上的jsp和JavaScript代码量,可以的话不要用。不要过分追求网页特效。
9.减少网页上图像的大小或数量。但不是没有图片。
10. 使用强调标签;使用高键标签,重音标签是粗体标签。
11.超链接需要标准化:链接对于网页来说非常重要,但是超链接需要标准化,而且超链接必须统一,一时不使用绝对路径,一时使用相对路径。
12.除了网页中必要的导航,尽量突出网站的重要内容,非关键的辅助内容可以通过框架、js等搜索引擎无法识别的技术调用.
13.网页的重要内容应该放在网页的最前面,这样搜索引擎就可以轻松抓取到关键信息。
注:本文版权归星宿云原创所有,禁止转载,一经发现追究版权责任! 查看全部
抓取jsp网页源代码(本文将略微详细的介绍SEO怎么优化代码与标签?)
通常,在网站上线之前,需要对网站的代码和标签进行必要的处理,以提高优化后的网站的打开速度,并强调想要的关键词达到排名。一个好的网站,在代码方面干净简洁。我们之前的文章中也提到了一些相关的标签页代码优化技术。本文将稍微详细介绍如何为 SEO 优化代码和标签。在合适的位置使用权重标签可以向搜索引擎传达友好,这是SEO的基本要求。
爬虫利用网站的代码简洁性来判断一个网页是否对人友好,浏览器能否获得良好的用户体验。简洁的网站通常不那么花哨,没有那么多广告,各种模块弹窗等。
1.减小网页大小,加快网页下载速度。减少页面噪音并突出显示页面主题。
2.提高蜘蛛抓取信息的速度和准确性。有利于减少错误码,提高页面对蜘蛛的友好度。
3.易于维护,提高工作效率。使用 div+css 布局。代码更加精简。
4.div+css可以简化很多样式,而且这些样式都放在一个专门的CSS文件中,维护和更改都很方便。
5.因为使用了css文件,蜘蛛爬取head里的内容更加快速准确。
6.浏览器下载div的速度比下载表格快很多倍,所以使用div+css排版可以有效稳定客户的等待情绪,增加客户访问的友好度。
7.使用 w3c 检查网页的错误代码。
8.减少网页上的jsp和JavaScript代码量,可以的话不要用。不要过分追求网页特效。
9.减少网页上图像的大小或数量。但不是没有图片。
10. 使用强调标签;使用高键标签,重音标签是粗体标签。
11.超链接需要标准化:链接对于网页来说非常重要,但是超链接需要标准化,而且超链接必须统一,一时不使用绝对路径,一时使用相对路径。
12.除了网页中必要的导航,尽量突出网站的重要内容,非关键的辅助内容可以通过框架、js等搜索引擎无法识别的技术调用.
13.网页的重要内容应该放在网页的最前面,这样搜索引擎就可以轻松抓取到关键信息。
注:本文版权归星宿云原创所有,禁止转载,一经发现追究版权责任!
抓取jsp网页源代码( 另外一个超棒的Java的HTML解析器-jsoup-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-02-25 14:03
另外一个超棒的Java的HTML解析器-jsoup-)
在线演示 本地下载
如果您曾经开发过内容聚合类网站,那么使用程序动态集成来自不同页面或网站 程序的内容的能力对您来说肯定非常熟悉。通常,如果我们使用java,我们会使用一些HTML解析,例如httpparser。最早的集成搜索是利用httpparser抓取谷歌和百度的搜索结果,并集成呈现给搜索用户,这就是GBin1域名的由来。
所以今天,我们介绍另一个很棒的Java HTML解析器——jsoup,这个类库可以帮助你实时处理HTML。提供非常方便的 API 来提取和处理数据。最重要的是它使用类似jQuery的语法来处理DOM、CSS等。如果你使用过jQuery,你就会知道它处理DOM的强大和方便。
主要特点
jsoup 实现了 WHATWG HTML5 标准,与现代浏览器解析 DOM 的方式相同。主要功能:
基本上jsoup可以帮你处理各种HTML问题,帮你验证非法标签,创建干净的DOM树。
实现抓取功能
这里我们将实现一个简单的抓取功能,你只需要指定url,并指定你需要抓取的具体元素,例如ID或者class。在后台我们将使用jsoup进行抓取,在前台我们将使用jQuery来美化结果。
您需要注意以下几点:
相对路径问题:你爬取的页面中的链接可能使用相对路径,需要处理成绝对路径,否则在本地服务器无法正常打开链接
的相对路径问题:同上,还需要处理转换
问题大小:如果你抓取的图片很大,需要用代码转换成本地样式,也可以选择在前台使用jQuery处理
下载jsoup jar包后,请添加你的classpath路径,如果使用jsp,请添加到web应用WEB-INF的lib目录下。
相关Java代码如下:
Document doc = Jsoup.connect("http://www.gbin1.com/portfolio/lastest.html").timeout(0).get();
Elements items = doc.select(".includeitem");
在上面的代码中,我们定义了jsoup使用一个url来获取HTML,这里就用到了。本页列出了 gbin1 最近发布的 文章。如果看这个页面的源码,可以看到每个文章都在.includeitem类中,所以我们这里使用doc.select方法来选择对应的类。
注意这里我们调用了timeout(0),意思是连续请求url,默认2000,即2秒后超时。可以看到这里使用了类似jQuery的链式调用,非常方便.
for (Element item : items) {
Elements links = item.select("a");
for(Element link: links){
link.attr("href",link.attr("abs:href"));
}
Elements imgs = item.select("img");
for(Element img: imgs){
img.attr("src",img.attr("abs:src"));
}
String html = item.html();
out.println("" + html + "");
}
在上面的代码中,我们处理了每个被查询的 includeitem 元素。找到“a”和“img”,将其中的href元素值修改为绝对路径。
link.attr("abs:href")
上面的代码会得到对应链接的绝对路径,其中属性为abs:href。同理可以得到图片abs:src的绝对路径。
代码运行后,我们可以看到修改后的代码,把它们放在li中。
接下来我们开发控制爬取的页面:
在这个页面的实现中,我们使用setInterval方法,以指定的时间间隔,调用上面使用ajax开发的java代码。基本代码如下:
//Run for first time
$(\'#msg\').html(\'请耐心等待, 页面抓取中 ...\').fadeIn(400);
//$(\'#content\').html(\'\');
$(\'#content\').load(\'siteproxy.jsp #result\', {url:url, elem:element}, function(){
$(\'#msg\').html(\'抓取已完成\').delay(1500).fadeOut(400);
})
上面的代码非常简单。我们使用jQuery的load方法调用siteproxy.jsp,然后在siteproxy.jsp的生成页面中获取#result元素,即抓取内容。如果不熟悉jQuery的ajax方法,请参考本系列文章:
jQuery 类库初学者指南的 AJAX 方法 - 第 1 部分
jQuery 类库初学者指南之 AJAX 方法 - 第二部分
jQuery 类库初学者指南之 AJAX 方法 - 第三部分
jQuery 类库初学者指南的 AJAX 方法 - 第 4 部分
为了让代码以指定的时间间隔运行爬取,我们将方法放在 setinterval 中如下:
runid = setInterval(
function getInfo(){
$(\'#msg\').html(\'请耐心等待, 页面抓取中 ...\').fadeIn(400);
//$(\'#content\').html(\'\');
$(\'#content\').load(\'siteproxy.jsp #result\', {url:url, elem:element}, function(){
$(\'#msg\').html(\'抓取已完成\').delay(1500).fadeOut(400);
})
}, interval*1000);
通过上述方法,我们可以在用户触发抓取后每隔指定时间触发抓取动作。
完整的js代码如下:
$(document).ready(function(){
var url, element, interval, runid;
$(\'#start\').click(function(){
url = $(\'#url\').val();
element = $(\'#element\').val();
interval = $(\'#interval\').val();
//Run for first time
$(\'#msg\').html(\'请耐心等待, 页面抓取中 ...\').fadeIn(400);
//$(\'#content\').html(\'\');
$(\'#content\').load(\'siteproxy.jsp #result\', {url:url, elem:element}, function(){
$(\'#msg\').html(\'抓取已完成\').delay(1500).fadeOut(400);
})
runid = setInterval(
function getInfo(){
$(\'#msg\').html(\'请耐心等待, 页面抓取中 ...\').fadeIn(400);
//$(\'#content\').html(\'\');
$(\'#content\').load(\'siteproxy.jsp #result\', {url:url, elem:element}, function(){
$(\'#msg\').html(\'抓取已完成\').delay(1500).fadeOut(400);
})
}, interval*1000);
});
$(\'#stop\').click(function(){
$(\'#msg\').html(\'抓取已暂停\').fadeIn(400).delay(1500);
clearInterval(runid);
});
});
部署上面的jsp和html文件后,会看到如下界面:
8、 查看全部
抓取jsp网页源代码(
另外一个超棒的Java的HTML解析器-jsoup-)
在线演示 本地下载
如果您曾经开发过内容聚合类网站,那么使用程序动态集成来自不同页面或网站 程序的内容的能力对您来说肯定非常熟悉。通常,如果我们使用java,我们会使用一些HTML解析,例如httpparser。最早的集成搜索是利用httpparser抓取谷歌和百度的搜索结果,并集成呈现给搜索用户,这就是GBin1域名的由来。
所以今天,我们介绍另一个很棒的Java HTML解析器——jsoup,这个类库可以帮助你实时处理HTML。提供非常方便的 API 来提取和处理数据。最重要的是它使用类似jQuery的语法来处理DOM、CSS等。如果你使用过jQuery,你就会知道它处理DOM的强大和方便。
主要特点
jsoup 实现了 WHATWG HTML5 标准,与现代浏览器解析 DOM 的方式相同。主要功能:
基本上jsoup可以帮你处理各种HTML问题,帮你验证非法标签,创建干净的DOM树。
实现抓取功能
这里我们将实现一个简单的抓取功能,你只需要指定url,并指定你需要抓取的具体元素,例如ID或者class。在后台我们将使用jsoup进行抓取,在前台我们将使用jQuery来美化结果。
您需要注意以下几点:
相对路径问题:你爬取的页面中的链接可能使用相对路径,需要处理成绝对路径,否则在本地服务器无法正常打开链接
的相对路径问题:同上,还需要处理转换
问题大小:如果你抓取的图片很大,需要用代码转换成本地样式,也可以选择在前台使用jQuery处理
下载jsoup jar包后,请添加你的classpath路径,如果使用jsp,请添加到web应用WEB-INF的lib目录下。
相关Java代码如下:
Document doc = Jsoup.connect("http://www.gbin1.com/portfolio/lastest.html";).timeout(0).get();
Elements items = doc.select(".includeitem");
在上面的代码中,我们定义了jsoup使用一个url来获取HTML,这里就用到了。本页列出了 gbin1 最近发布的 文章。如果看这个页面的源码,可以看到每个文章都在.includeitem类中,所以我们这里使用doc.select方法来选择对应的类。
注意这里我们调用了timeout(0),意思是连续请求url,默认2000,即2秒后超时。可以看到这里使用了类似jQuery的链式调用,非常方便.
for (Element item : items) {
Elements links = item.select("a");
for(Element link: links){
link.attr("href",link.attr("abs:href"));
}
Elements imgs = item.select("img");
for(Element img: imgs){
img.attr("src",img.attr("abs:src"));
}
String html = item.html();
out.println("" + html + "");
}
在上面的代码中,我们处理了每个被查询的 includeitem 元素。找到“a”和“img”,将其中的href元素值修改为绝对路径。
link.attr("abs:href")
上面的代码会得到对应链接的绝对路径,其中属性为abs:href。同理可以得到图片abs:src的绝对路径。
代码运行后,我们可以看到修改后的代码,把它们放在li中。
接下来我们开发控制爬取的页面:
在这个页面的实现中,我们使用setInterval方法,以指定的时间间隔,调用上面使用ajax开发的java代码。基本代码如下:
//Run for first time
$(\'#msg\').html(\'请耐心等待, 页面抓取中 ...\').fadeIn(400);
//$(\'#content\').html(\'\');
$(\'#content\').load(\'siteproxy.jsp #result\', {url:url, elem:element}, function(){
$(\'#msg\').html(\'抓取已完成\').delay(1500).fadeOut(400);
})
上面的代码非常简单。我们使用jQuery的load方法调用siteproxy.jsp,然后在siteproxy.jsp的生成页面中获取#result元素,即抓取内容。如果不熟悉jQuery的ajax方法,请参考本系列文章:
jQuery 类库初学者指南的 AJAX 方法 - 第 1 部分
jQuery 类库初学者指南之 AJAX 方法 - 第二部分
jQuery 类库初学者指南之 AJAX 方法 - 第三部分
jQuery 类库初学者指南的 AJAX 方法 - 第 4 部分
为了让代码以指定的时间间隔运行爬取,我们将方法放在 setinterval 中如下:
runid = setInterval(
function getInfo(){
$(\'#msg\').html(\'请耐心等待, 页面抓取中 ...\').fadeIn(400);
//$(\'#content\').html(\'\');
$(\'#content\').load(\'siteproxy.jsp #result\', {url:url, elem:element}, function(){
$(\'#msg\').html(\'抓取已完成\').delay(1500).fadeOut(400);
})
}, interval*1000);
通过上述方法,我们可以在用户触发抓取后每隔指定时间触发抓取动作。
完整的js代码如下:
$(document).ready(function(){
var url, element, interval, runid;
$(\'#start\').click(function(){
url = $(\'#url\').val();
element = $(\'#element\').val();
interval = $(\'#interval\').val();
//Run for first time
$(\'#msg\').html(\'请耐心等待, 页面抓取中 ...\').fadeIn(400);
//$(\'#content\').html(\'\');
$(\'#content\').load(\'siteproxy.jsp #result\', {url:url, elem:element}, function(){
$(\'#msg\').html(\'抓取已完成\').delay(1500).fadeOut(400);
})
runid = setInterval(
function getInfo(){
$(\'#msg\').html(\'请耐心等待, 页面抓取中 ...\').fadeIn(400);
//$(\'#content\').html(\'\');
$(\'#content\').load(\'siteproxy.jsp #result\', {url:url, elem:element}, function(){
$(\'#msg\').html(\'抓取已完成\').delay(1500).fadeOut(400);
})
}, interval*1000);
});
$(\'#stop\').click(function(){
$(\'#msg\').html(\'抓取已暂停\').fadeIn(400).delay(1500);
clearInterval(runid);
});
});
部署上面的jsp和html文件后,会看到如下界面:
8、
抓取jsp网页源代码(jsp页面的源代码有什么特殊的属性?页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-02-24 20:03
抓取jsp网页源代码能抓到jsp页面的源代码,那么看看jsp页面的源代码有什么特殊的属性。我通过浏览器的源代码分析,得到结论如下。
1、字段名:view-name字段名对应的view-id。
2、字段值:url(参数的意思就是里面的参数传过来是什么。
3、密码或者浏览器是否是activex控件这个比较容易理解,如果是activex控件的话,
4、jsp页面中是否包含cookie我通过代码抓取一些springmvc的cookie进来,可以清楚的看到springmvc生成的cookie,字段“authentication_key”是:jwt_file,那么问题来了,如果我有个cookie传给redis/mongodb,那么我可以获取到这个cookie中间的字段“authentication_key”,但是可惜这些cookie是通过json类型的springmvc来传递,那么我用redis或者mongodb可以读取这个springmvc生成的cookie,但是这些只能获取到header里面的值。
一些兼容性的问题可能影响读取。最后再说说https:请求/,有一个requestheader,里面包含着authentication_key,这个authentication_key我们只能得到header里面的值,这个值应该传递给springmvc,那么在springmvc中,可以使用beanmethod来判断authentication_key是否会指向web.xml,或者在web.xml中查找。 查看全部
抓取jsp网页源代码(jsp页面的源代码有什么特殊的属性?页面)
抓取jsp网页源代码能抓到jsp页面的源代码,那么看看jsp页面的源代码有什么特殊的属性。我通过浏览器的源代码分析,得到结论如下。
1、字段名:view-name字段名对应的view-id。
2、字段值:url(参数的意思就是里面的参数传过来是什么。
3、密码或者浏览器是否是activex控件这个比较容易理解,如果是activex控件的话,
4、jsp页面中是否包含cookie我通过代码抓取一些springmvc的cookie进来,可以清楚的看到springmvc生成的cookie,字段“authentication_key”是:jwt_file,那么问题来了,如果我有个cookie传给redis/mongodb,那么我可以获取到这个cookie中间的字段“authentication_key”,但是可惜这些cookie是通过json类型的springmvc来传递,那么我用redis或者mongodb可以读取这个springmvc生成的cookie,但是这些只能获取到header里面的值。
一些兼容性的问题可能影响读取。最后再说说https:请求/,有一个requestheader,里面包含着authentication_key,这个authentication_key我们只能得到header里面的值,这个值应该传递给springmvc,那么在springmvc中,可以使用beanmethod来判断authentication_key是否会指向web.xml,或者在web.xml中查找。
抓取jsp网页源代码(科技小能手1394人浏览评论数:04年前(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-02-21 21:20
阿里云>云栖社区>主题图>J>jsp信息网站源码
推荐活动:
更多优惠>
当前话题:jsp信息网站源码加入采集
相关话题:
jsp资料网站源码相关博客看更多博文
JSP漏洞视图
作者:科技甜1304人查看评论:04年前
总结:服务器漏洞是安全问题的根源,黑客对网站的攻击也大多是从发现对方漏洞开始的。因此,网站管理者只有了解自己的漏洞,才能采取相应的对策来防范外部攻击。下面介绍一些服务器(包括Web服务器和JSP服务器)的常见漏洞。Apache泄漏重写任意文件泄漏
阅读全文
JSP安全性初探
作者:科技甜1653 浏览评论:04年前
总结:暴露JSP代码的方式有多种,但经过大量测试,这绝对与WEB SERVER的配置有关。就拿IBM Websphere Commerce Suite来说,还有其他方法可以查看JSP源码,但相信是IBM HTTP SERVER的配置造成的。如果你想发现
阅读全文
邮箱网站jsp+python源码
作者:小技术专家 1394 浏览评论:04年前
源码针对以下系列邮箱: [url]
阅读全文
CVE-2017-12615/CVE-2017-12616:Tomcat信息泄露和远程代码执行漏洞分析报告
作者:郑和4130 浏览评论:04年前
<p>一. 漏洞概述 2017 年 9 月 19 日,Apache Tomcat 正式确认并修复了两个高危漏洞。漏洞 CVE 编号为:CVE-2017-12615 和 CVE-2017-12616。该漏洞的受影响版本为 查看全部
抓取jsp网页源代码(科技小能手1394人浏览评论数:04年前(组图))
阿里云>云栖社区>主题图>J>jsp信息网站源码
推荐活动:
更多优惠>
当前话题:jsp信息网站源码加入采集
相关话题:
jsp资料网站源码相关博客看更多博文
JSP漏洞视图
作者:科技甜1304人查看评论:04年前
总结:服务器漏洞是安全问题的根源,黑客对网站的攻击也大多是从发现对方漏洞开始的。因此,网站管理者只有了解自己的漏洞,才能采取相应的对策来防范外部攻击。下面介绍一些服务器(包括Web服务器和JSP服务器)的常见漏洞。Apache泄漏重写任意文件泄漏
阅读全文
JSP安全性初探
作者:科技甜1653 浏览评论:04年前
总结:暴露JSP代码的方式有多种,但经过大量测试,这绝对与WEB SERVER的配置有关。就拿IBM Websphere Commerce Suite来说,还有其他方法可以查看JSP源码,但相信是IBM HTTP SERVER的配置造成的。如果你想发现
阅读全文
邮箱网站jsp+python源码
作者:小技术专家 1394 浏览评论:04年前
源码针对以下系列邮箱: [url]
阅读全文
CVE-2017-12615/CVE-2017-12616:Tomcat信息泄露和远程代码执行漏洞分析报告
作者:郑和4130 浏览评论:04年前
<p>一. 漏洞概述 2017 年 9 月 19 日,Apache Tomcat 正式确认并修复了两个高危漏洞。漏洞 CVE 编号为:CVE-2017-12615 和 CVE-2017-12616。该漏洞的受影响版本为
抓取jsp网页源代码(怎么看别人的代码-如何自动提取他人网页上的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-02-19 10:24
if(substr($url, 0, 4) == 'http')
回声 $url。
';
}
获取网页源代码中文件的具体步骤如下:
1、首先,我们在浏览器中随意打开一个网页,查看其源代码。
2、然后我们在浏览器上点击查看。
3、在选项中的以下位置选择查看源代码。
4、然后我们可以在那个网页中看到源代码。
5、源代码也是可以点击的。
6、点击下图显示的访问源代码,可以看到源代码显示的数据。
我要提取别人网页的代码怎么办-:网页界面右键,==》“查看源代码”,就可以看到了
如何提取别人的网页代码:在网页上右击会看到一个“查看源文件”的选项,可以点击,但是不完整,这个方法不是很好
如何提取网站代码-:直接打开你想要的页面,然后 CTRL+S ,然后在文件类型中选择【网页,全部】,即可保存对应的文件代码 CSS 和 JS 代码以及所有相关文件将被保存下来
敢问各位程序高手,如何自动提取别人网页的数据:如果你用php,可以用file、stream_get_contents等方法获取别人网页的内容。但我不知道你在说什么形式的数据。
怎么看别人的代码 - 如何获取网站的源码?看别人的网站做的很好,我也想入,怎么直接入?: 基本上是不可能的,但是很难用 有些方法可能是可行的。复制网站首页内页及各个角落的链接,去掉=、数值等。比如get.asp?***,把问候语去掉后,用迅雷把所有的类都去掉,然后再包括系统后台。一般admin.asp打开记事本查看。你可以从一个案例中得出推论。建议下载一些开源代码进行研究,了解最基本的结构。
如何从别人的网页中窃取一段代码——:这很简单,但是如果你想修改一段理想的代码,你需要精通代码。方法如下:1、用360浏览器打开修改后的网站,然后右键查看源码。2,然后复制代码保存修改。
如何获取别人的网站的代码?:如果是静态的网站,直接查看源文件即可。如果是动态的网站,比如ASP、JSP、PHP、ASP.NET,一般是没有办法获取源文件的。
我想用软件把网页某部分的代码提取出来,把提取出来的代码放到另一个页面上,和提取的时候一样——:Macromedia Dreamweaver
如何在其他网页上得到你想要的源代码,复制出来直接使用?:点击查看-源文件
如何获取别人的网站源码-:如果是静态页面,可以直接使用全站下载器获取。如果它是用动态语言编写的,例如:ASP、ASP.NET、JSP、PHP。然后破解它网站服务器后台。否则是不可能得到的! 查看全部
抓取jsp网页源代码(怎么看别人的代码-如何自动提取他人网页上的数据)
if(substr($url, 0, 4) == 'http')
回声 $url。
';
}
获取网页源代码中文件的具体步骤如下:
1、首先,我们在浏览器中随意打开一个网页,查看其源代码。
2、然后我们在浏览器上点击查看。
3、在选项中的以下位置选择查看源代码。
4、然后我们可以在那个网页中看到源代码。
5、源代码也是可以点击的。
6、点击下图显示的访问源代码,可以看到源代码显示的数据。
我要提取别人网页的代码怎么办-:网页界面右键,==》“查看源代码”,就可以看到了
如何提取别人的网页代码:在网页上右击会看到一个“查看源文件”的选项,可以点击,但是不完整,这个方法不是很好
如何提取网站代码-:直接打开你想要的页面,然后 CTRL+S ,然后在文件类型中选择【网页,全部】,即可保存对应的文件代码 CSS 和 JS 代码以及所有相关文件将被保存下来
敢问各位程序高手,如何自动提取别人网页的数据:如果你用php,可以用file、stream_get_contents等方法获取别人网页的内容。但我不知道你在说什么形式的数据。
怎么看别人的代码 - 如何获取网站的源码?看别人的网站做的很好,我也想入,怎么直接入?: 基本上是不可能的,但是很难用 有些方法可能是可行的。复制网站首页内页及各个角落的链接,去掉=、数值等。比如get.asp?***,把问候语去掉后,用迅雷把所有的类都去掉,然后再包括系统后台。一般admin.asp打开记事本查看。你可以从一个案例中得出推论。建议下载一些开源代码进行研究,了解最基本的结构。
如何从别人的网页中窃取一段代码——:这很简单,但是如果你想修改一段理想的代码,你需要精通代码。方法如下:1、用360浏览器打开修改后的网站,然后右键查看源码。2,然后复制代码保存修改。
如何获取别人的网站的代码?:如果是静态的网站,直接查看源文件即可。如果是动态的网站,比如ASP、JSP、PHP、ASP.NET,一般是没有办法获取源文件的。
我想用软件把网页某部分的代码提取出来,把提取出来的代码放到另一个页面上,和提取的时候一样——:Macromedia Dreamweaver
如何在其他网页上得到你想要的源代码,复制出来直接使用?:点击查看-源文件
如何获取别人的网站源码-:如果是静态页面,可以直接使用全站下载器获取。如果它是用动态语言编写的,例如:ASP、ASP.NET、JSP、PHP。然后破解它网站服务器后台。否则是不可能得到的!
抓取jsp网页源代码(在jsp页面上生成word文档很是简单,只需把contentType=)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-18 22:22
在jsp页面上生成word文档很简单,把contentType="text/html"改成contentType="application/msword;charset=gb2312",代码如下:html
应用程序
设置后,原页面内容可以word显示。框架
++++++++++++++++++++++++++++++++++++++++++++++++++ + ++++++++jsp
从 JSP ui 生成 WORD 文档的另一种方法
此方法无需使用第三方类库,只需将WORD模板文档保存为网页,提取源代码,将源代码保存为JSP文件,然后添加xml即可
,htm
这样访问JSP时,会弹出“打开”和“保存”对话框。如果客户端有WORD程序,生成的WORD文档可以直接在网页中打开。文档
++++++++++++++++++++++++++++++++++++++++++++++++++ + ++++++++获取
导入JSP页面实现Word保存要方便很多,但也有不足之处。首先,如果需要导入的话
如果需要下载,请导入
其实如果你用一个框架,比如Struts2,会方便很多。直接在Action中写如下代码:
如果(out!=null){
字符串文件名="";
fileName+="评估报告.doc";
试试{
HttpServletResponse 响应 = ServletActionContext.getResponse();
response.setHeader("Content-disposition","attachment; filename="+new String(fileName.getBytes("GB2312"), "8859_1"));
} 捕捉 (UnsupportedEncodingException e) {
e.printStackTrace();
}
out是一个jsp页面表单元素,一个按钮用来提交表单到对应的Action for Word下载。动作设置jsp页面头文件。这样每次点击按钮,对应的jsp页面的内容都可以保存到Word中,并且支持下载,Word中的内容是可编辑的。
缺点是因为表格的内容是动态生成的,有些需要先查看下载Word,需要新建一个JSP页面进行Word下载。当然,页面重定向必须先在struts.xml中配置。
新创建的页面的值应该与视图页面保持一致。 查看全部
抓取jsp网页源代码(在jsp页面上生成word文档很是简单,只需把contentType=)
在jsp页面上生成word文档很简单,把contentType="text/html"改成contentType="application/msword;charset=gb2312",代码如下:html
应用程序
设置后,原页面内容可以word显示。框架
++++++++++++++++++++++++++++++++++++++++++++++++++ + ++++++++jsp
从 JSP ui 生成 WORD 文档的另一种方法
此方法无需使用第三方类库,只需将WORD模板文档保存为网页,提取源代码,将源代码保存为JSP文件,然后添加xml即可
,htm
这样访问JSP时,会弹出“打开”和“保存”对话框。如果客户端有WORD程序,生成的WORD文档可以直接在网页中打开。文档
++++++++++++++++++++++++++++++++++++++++++++++++++ + ++++++++获取
导入JSP页面实现Word保存要方便很多,但也有不足之处。首先,如果需要导入的话
如果需要下载,请导入
其实如果你用一个框架,比如Struts2,会方便很多。直接在Action中写如下代码:
如果(out!=null){
字符串文件名="";
fileName+="评估报告.doc";
试试{
HttpServletResponse 响应 = ServletActionContext.getResponse();
response.setHeader("Content-disposition","attachment; filename="+new String(fileName.getBytes("GB2312"), "8859_1"));
} 捕捉 (UnsupportedEncodingException e) {
e.printStackTrace();
}
out是一个jsp页面表单元素,一个按钮用来提交表单到对应的Action for Word下载。动作设置jsp页面头文件。这样每次点击按钮,对应的jsp页面的内容都可以保存到Word中,并且支持下载,Word中的内容是可编辑的。
缺点是因为表格的内容是动态生成的,有些需要先查看下载Word,需要新建一个JSP页面进行Word下载。当然,页面重定向必须先在struts.xml中配置。
新创建的页面的值应该与视图页面保持一致。
抓取jsp网页源代码(为Development学习,这个软件包提供了大量可供修改的示例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-02-15 22:13
在 Sun 正式发布 JSP(JavaServer Pages)之后,这种新的 Web 应用程序开发技术非常流行
很快就引起了人们的注意。JSP 为创建高度动态的 Web 应用程序提供了独特的开发环境。
据Sun介绍,JSP可以适配市面上的8个包括Apache WebServer、IIS4.0
5%的服务器产品。即使你对 ASP “深爱”,我们认为仍然值得关注 JSP 的演变
必要的。
JSP和ASP的简单比较
JSP 与微软的 ASP 技术非常相似。两者都提供在 HTML 代码中混合某种程序
程序代码,由语言引擎解释和执行程序代码的能力。在 ASP 或 JSP 环境中,HTML 代码主要是
它负责描述信息的显示风格,程序代码用于描述处理逻辑。普通的HTML页面只依赖
根据 Web 服务器,ASP 和 JSP 页面需要额外的语言引擎来解析和执行程序代码。程序
代码执行的结果被重新嵌入到 HTML 代码中,并一起发送到浏览器。ASP 和 JSP
它是一种面向 Web 服务器的技术,客户端浏览器不需要任何额外的软件支持。
ASP的编程语言是VBScript等脚本语言,JSP用的是Java,是两者
最明显的区别。另外,ASP和JSP还有一个更本质的区别:两种语言引擎使用完全不同
嵌入在页面中的程序代码以同样的方式处理。在 ASP 下,VBScript 代码由 ASP 引擎解释和执行。
线; JSP下,代码被编译成servlet,由Java虚拟机执行,这个编译操作只是
发生在 JSP 页面的第一个请求上。
二次运行环境
Sun 的 JSP 主页位于,
您还可以从这里下载 JSP 规范,该规范定义了供应商在创建 JSP 引擎时必须遵循的内容
一些规则。
执行 JSP 代码需要在服务器上安装 JSP 引擎。这里我们使用 Sun 的 JavaS
erver Web 开发工具包 (JSWDK)。为了便于学习,此软件包提供了许多
修改示例。安装 JSWDK 后,只需执行 startserver 命令即可启动服务器。在默认配置中
设置服务器监听 8080 端口,使用 :8080 打开默认页面。
在运行 JSP 示例页面之前,请注意 JSWDK 的安装目录,尤其是“work”子目录
目录的内容。执行示例页面时,您可以在此处看到 JSP 页面如何转换为 Java 源文件
,然后编译成一个类文件(即Servlet)。JSWDK包中的示例页面分为两类
,它们可以是 JSP 文件,也可以是收录由 JSP 代码编写的表单的 HTML 文件
处理。与 ASP 一样,JSP 中的 Java 代码在服务器端执行。因此,在浏览器中使用
“查看源代码”菜单看不到 JSP 源代码,只能看到生成的 HTML 代码。所有的例子
源代码通过单独的“示例”页面提供。
三个 JSP 页面示例
下面我们分析一个简单的JSP页面。您可以在 JSWDK 的示例目录中创建另一个文件
这个文件存放在外面的一个目录下,文件名可以是任意的,但扩展名必须是.jsp。从下面的代码中清除
从列表中可以看出,除了比普通 HTML 页面多一些 Java 代码外,JSP 页面具有基本的相似之处。
相同的结构。Java 代码通过 <% 和 %> 符号添加到 HTML 代码中,它的主要功能
就是生成并显示一个从0到9的字符串。这个字符串的前后都是一些通过HTM
L 码输出的文本。
<HTML>
<HEAD><TITLE>JSP 页面</TITLE></HEAD>
<身体>
< %@ 页面语言="java" %>
<%! 字符串 str="0"; %>
< % for (int i=1; i < 10; i++) {
str = str + i;
} %>
在 JSP 输出之前。
<P>
< %= 字符串 %>
<P>
JSP 输出后。
</正文>
</HTML>
这个JSP页面可以分成几个部分进行分析。
第一个是JSP 指令。它描述了页面的基本信息,例如使用的语言,是否保持会话状态,
是否使用缓冲等。JSP 指令以 < %@ 开头,以 %> 结尾。在本例中,指令“< %@ page
language=”java” %> ” 简单定义了这个例子使用Java语言(目前在JSP规范中
Java 是唯一受支持的语言)。
接下来是 JSP 声明。JSP 声明可以被认为是在类级别定义变量和方法的地方。Ĵ
SP 声明以 <%! 并以 %> 结尾。如本例中“ < %! String str="0"; %> ” 定义
一个字符串变量。每个声明后面必须跟一个分号,就像在普通的 Java 类声明中一样
成员变量。
<%和%>之间的代码块是描述JSP页面处理逻辑的Java代码,例如本例中的f
或如图所示循环。
最后,< %= 和 %> 之间的代码称为 JSP 表达式,如本例中的“< %= str %>”
显示。JSP 表达式提供了一种将 JSP 生成的值嵌入到 HTML 页面中的简单方法。
二、会话状态管理
作者:仙人掌工作室
会话状态维护是Web 应用程序开发人员必须面对的问题。有多种方法可以解决这个问题
诸如使用 cookie、隐藏表单输入字段或将状态信息直接附加到 URL 等问题。熟
servlet 提供了一个会话对象,该对象在多个请求中持续存在,允许用户存储和
获取会话状态信息。JSP 在 servlet 中也支持这个概念。
请参阅 Sun 的 JSP 指南以了解有关隐式对象的更多信息(隐式地,这些
可以直接引用对象,不需要显式声明,也不需要专门的代码来创建它们的实例)。例如请求
uest 对象,它是 HttpServletRequest 的子类。此对象收录有关当前浏览器的所有信息
请求的信息,包括 cookie、HTML 表单变量等。session 对象也是这样一个隐含的
目的。该对象在第一个 JSP 页面加载时自动创建,并与请求对象相关联。
与 ASP 中的会话对象类似,JSP 中的会话对象对于那些希望完成一个
事务的应用非常有用。
为了说明session对象的具体应用,接下来我们用三个页面来模拟一个多页面的Web
应用。第一个页面( q1.html )只收录一个 HTML 表单,它询问用户的姓名,代码如下
向下:
<HTML>
<身体>
<FORM METHOD=POST ACTION="q2.jsp">
请输入你的名字:
<输入类型=文本>
<输入类型=提交值=“提交”>
</表格>
</正文>
</HTML>
第二个页面是一个 JSP 页面( q2.jsp ),它通过请求对象提取 q1.html
表单中的name值,将其存储为name变量,然后将name值保存到会话中
在对象中。会话对象是名称/值对的集合,其中名称/值对中的名称为 "
thename",其值为name变量的值。由于会话对象在会话期间始终有效,
因此,此处保存的变量对后续页面也有效。q2.jsp的附加任务是问第二个问题
. 这是它的代码:
<HTML>
<身体>
< %@ 页面语言="java" %>
<%! 细绳; %>
< %
name = request.getParameter("thename");
session.putValue("名称", name);
%>
你的名字是:< %= name %>
<p>
<FORM METHOD=POST ACTION="q3.jsp">
你喜欢吃什么?
<输入类型=文本>
<P>
<输入类型=提交值=“提交”>
</表格>
</正文>
</HTML>
第三个页面也是一个 JSP 页面( q3.jsp ),其主要任务是显示问答的结果。它来自 s
session对象提取了name的值并显示出来,证明虽然在第一页输入了值,
会话对象被保留。q3.jsp的另一个任务是在第二页提取用户输入
并显示它:
<HTML>
<身体>
< %@ 页面语言="java" %>
<%! 字符串食物=""; %>
< %
food = request.getParameter("food");
String name = (String) session.getValue("thename");
%>
你的名字是:< %= name %>
<P>
你喜欢吃:< %= food %>
</正文>
</HTML>
三、对 JavaBean 组件的引用
作者:仙人掌工作室
JavaBean 是基于 Java 的软件组件。用于在 Web 应用程序中集成 JavaBea 的 JSP
n 组件提供完整的支持。这种支持不仅减少了开发时间(可以直接利用经过测试和信任的
任何现有的组件,避免重复开发),也为 JSP 应用程序带来了更多的可扩展性。JavaBeans
组件可以用来执行复杂的计算任务,或者负责与数据库交互、数据提取等,如果我们
共有三个JavaBean,分别具有显示新闻、股票价格和天气状况的功能。
具有全部三个功能的网页只需要实例化这三个bean,并使用HTML表格依次指定它们。
点它。
为了说明 JavaBeans 在 JSP 环境中的应用,我们创建了一个名为 TaxRate 的 Bean
. 它有两个属性,Product 和 Rate。两种set方法用于设置
设置这两个属性,使用两个get方法提取这两个属性。在实际应用中,这个Bean一般是
应从数据库中提取税率值,这里我们简化了过程以允许任意税率。下面是这个
豆代码清单:
包裹税;
公共课税率 {
字符串产品;
双倍率;
公共税率(){
this.Product = "A001";
this.Rate = 5;
}
公共无效集产品(字符串产品名称){
this.Product = 产品名称;
}
公共字符串 getProduct() {
返回(this.Product);
}
公共无效setRate(双倍率值){
this.Rate = rateValue;
}
公共双getRate(){
返回(this.Rate);
}
}
<jsp:useBean> 标记用于在 JSP 页面中应用上述 bean。取决于具体用途
根据 JSP 引擎,配置 bean 的位置和方式的方法可能略有不同。本文将
Bean的.class文件放在c:/jswdk-1.0/examples/WEB-INF/jsp/beans/tax目录下,
这里的 tax 是一个专门用来存放 Bean 的目录。这是应用上述 bean 的示例页面:
<HTML>
<身体>
< %@ 页面语言="java" %>
<jsp:useBean scope="application" />
< % taxbean.setProduct("A002");
taxbean.setRate(17);
%>
方法一:<p>
产品:< %= taxbean.getProduct() %> < br>
税率:< %= taxbean.getRate() %>
<p>
< % taxbean.setProduct("A003");
taxbean.setRate(3);
%>
<b>使用方法二:</b> <p>
产品:< jsp:getProperty property="Product" />
<br>
速率:< jsp:getProperty property="Rate" />
</正文>
</HTML>
<jsp:useBean> 标记中定义了几个属性,其中 id 是整个 JSP 页面中的 Bea
n的标识,scope属性定义了bean的生命周期,class属性描述了bean的类
文件(以包名开头)。
这个 JSP 页面不仅使用 Bean 的 set 和 get 方法来设置和提取属性值,还使用
使用 <jsp:getProperty> 标记提供了提取 bean 属性值的第二种方法。< jsp:getPr
operty> 中的 name 属性是 <jsp:useBean> 中定义的 bean 的 id,及其属性
y 属性指定目标属性的名称。
事实证明,Java servlet 是开发 Web 应用程序的理想框架。JSP 到 Servlet
在技术的基础上,它在许多方面都得到了改进。JSP 页面看起来像普通的 HTML 页面,但它允许嵌入
在这方面,它与 ASP 技术非常相似。利用跨平台运行的 JavaBean 组件
, JSP 为分离处理逻辑和显示样式提供了出色的解决方案。JSP必将成为ASP技术的核心
强大的竞争对手。
嘿嘿……
上一篇:解决Can not find the tag library descriptor for "core"的问题 查看全部
抓取jsp网页源代码(为Development学习,这个软件包提供了大量可供修改的示例)
在 Sun 正式发布 JSP(JavaServer Pages)之后,这种新的 Web 应用程序开发技术非常流行
很快就引起了人们的注意。JSP 为创建高度动态的 Web 应用程序提供了独特的开发环境。
据Sun介绍,JSP可以适配市面上的8个包括Apache WebServer、IIS4.0
5%的服务器产品。即使你对 ASP “深爱”,我们认为仍然值得关注 JSP 的演变
必要的。
JSP和ASP的简单比较
JSP 与微软的 ASP 技术非常相似。两者都提供在 HTML 代码中混合某种程序
程序代码,由语言引擎解释和执行程序代码的能力。在 ASP 或 JSP 环境中,HTML 代码主要是
它负责描述信息的显示风格,程序代码用于描述处理逻辑。普通的HTML页面只依赖
根据 Web 服务器,ASP 和 JSP 页面需要额外的语言引擎来解析和执行程序代码。程序
代码执行的结果被重新嵌入到 HTML 代码中,并一起发送到浏览器。ASP 和 JSP
它是一种面向 Web 服务器的技术,客户端浏览器不需要任何额外的软件支持。
ASP的编程语言是VBScript等脚本语言,JSP用的是Java,是两者
最明显的区别。另外,ASP和JSP还有一个更本质的区别:两种语言引擎使用完全不同
嵌入在页面中的程序代码以同样的方式处理。在 ASP 下,VBScript 代码由 ASP 引擎解释和执行。
线; JSP下,代码被编译成servlet,由Java虚拟机执行,这个编译操作只是
发生在 JSP 页面的第一个请求上。
二次运行环境
Sun 的 JSP 主页位于,
您还可以从这里下载 JSP 规范,该规范定义了供应商在创建 JSP 引擎时必须遵循的内容
一些规则。
执行 JSP 代码需要在服务器上安装 JSP 引擎。这里我们使用 Sun 的 JavaS
erver Web 开发工具包 (JSWDK)。为了便于学习,此软件包提供了许多
修改示例。安装 JSWDK 后,只需执行 startserver 命令即可启动服务器。在默认配置中
设置服务器监听 8080 端口,使用 :8080 打开默认页面。
在运行 JSP 示例页面之前,请注意 JSWDK 的安装目录,尤其是“work”子目录
目录的内容。执行示例页面时,您可以在此处看到 JSP 页面如何转换为 Java 源文件
,然后编译成一个类文件(即Servlet)。JSWDK包中的示例页面分为两类
,它们可以是 JSP 文件,也可以是收录由 JSP 代码编写的表单的 HTML 文件
处理。与 ASP 一样,JSP 中的 Java 代码在服务器端执行。因此,在浏览器中使用
“查看源代码”菜单看不到 JSP 源代码,只能看到生成的 HTML 代码。所有的例子
源代码通过单独的“示例”页面提供。
三个 JSP 页面示例
下面我们分析一个简单的JSP页面。您可以在 JSWDK 的示例目录中创建另一个文件
这个文件存放在外面的一个目录下,文件名可以是任意的,但扩展名必须是.jsp。从下面的代码中清除
从列表中可以看出,除了比普通 HTML 页面多一些 Java 代码外,JSP 页面具有基本的相似之处。
相同的结构。Java 代码通过 <% 和 %> 符号添加到 HTML 代码中,它的主要功能
就是生成并显示一个从0到9的字符串。这个字符串的前后都是一些通过HTM
L 码输出的文本。
<HTML>
<HEAD><TITLE>JSP 页面</TITLE></HEAD>
<身体>
< %@ 页面语言="java" %>
<%! 字符串 str="0"; %>
< % for (int i=1; i < 10; i++) {
str = str + i;
} %>
在 JSP 输出之前。
<P>
< %= 字符串 %>
<P>
JSP 输出后。
</正文>
</HTML>
这个JSP页面可以分成几个部分进行分析。
第一个是JSP 指令。它描述了页面的基本信息,例如使用的语言,是否保持会话状态,
是否使用缓冲等。JSP 指令以 < %@ 开头,以 %> 结尾。在本例中,指令“< %@ page
language=”java” %> ” 简单定义了这个例子使用Java语言(目前在JSP规范中
Java 是唯一受支持的语言)。
接下来是 JSP 声明。JSP 声明可以被认为是在类级别定义变量和方法的地方。Ĵ
SP 声明以 <%! 并以 %> 结尾。如本例中“ < %! String str="0"; %> ” 定义
一个字符串变量。每个声明后面必须跟一个分号,就像在普通的 Java 类声明中一样
成员变量。
<%和%>之间的代码块是描述JSP页面处理逻辑的Java代码,例如本例中的f
或如图所示循环。
最后,< %= 和 %> 之间的代码称为 JSP 表达式,如本例中的“< %= str %>”
显示。JSP 表达式提供了一种将 JSP 生成的值嵌入到 HTML 页面中的简单方法。
二、会话状态管理
作者:仙人掌工作室
会话状态维护是Web 应用程序开发人员必须面对的问题。有多种方法可以解决这个问题
诸如使用 cookie、隐藏表单输入字段或将状态信息直接附加到 URL 等问题。熟
servlet 提供了一个会话对象,该对象在多个请求中持续存在,允许用户存储和
获取会话状态信息。JSP 在 servlet 中也支持这个概念。
请参阅 Sun 的 JSP 指南以了解有关隐式对象的更多信息(隐式地,这些
可以直接引用对象,不需要显式声明,也不需要专门的代码来创建它们的实例)。例如请求
uest 对象,它是 HttpServletRequest 的子类。此对象收录有关当前浏览器的所有信息
请求的信息,包括 cookie、HTML 表单变量等。session 对象也是这样一个隐含的
目的。该对象在第一个 JSP 页面加载时自动创建,并与请求对象相关联。
与 ASP 中的会话对象类似,JSP 中的会话对象对于那些希望完成一个
事务的应用非常有用。
为了说明session对象的具体应用,接下来我们用三个页面来模拟一个多页面的Web
应用。第一个页面( q1.html )只收录一个 HTML 表单,它询问用户的姓名,代码如下
向下:
<HTML>
<身体>
<FORM METHOD=POST ACTION="q2.jsp">
请输入你的名字:
<输入类型=文本>
<输入类型=提交值=“提交”>
</表格>
</正文>
</HTML>
第二个页面是一个 JSP 页面( q2.jsp ),它通过请求对象提取 q1.html
表单中的name值,将其存储为name变量,然后将name值保存到会话中
在对象中。会话对象是名称/值对的集合,其中名称/值对中的名称为 "
thename",其值为name变量的值。由于会话对象在会话期间始终有效,
因此,此处保存的变量对后续页面也有效。q2.jsp的附加任务是问第二个问题
. 这是它的代码:
<HTML>
<身体>
< %@ 页面语言="java" %>
<%! 细绳; %>
< %
name = request.getParameter("thename");
session.putValue("名称", name);
%>
你的名字是:< %= name %>
<p>
<FORM METHOD=POST ACTION="q3.jsp">
你喜欢吃什么?
<输入类型=文本>
<P>
<输入类型=提交值=“提交”>
</表格>
</正文>
</HTML>
第三个页面也是一个 JSP 页面( q3.jsp ),其主要任务是显示问答的结果。它来自 s
session对象提取了name的值并显示出来,证明虽然在第一页输入了值,
会话对象被保留。q3.jsp的另一个任务是在第二页提取用户输入
并显示它:
<HTML>
<身体>
< %@ 页面语言="java" %>
<%! 字符串食物=""; %>
< %
food = request.getParameter("food");
String name = (String) session.getValue("thename");
%>
你的名字是:< %= name %>
<P>
你喜欢吃:< %= food %>
</正文>
</HTML>
三、对 JavaBean 组件的引用
作者:仙人掌工作室
JavaBean 是基于 Java 的软件组件。用于在 Web 应用程序中集成 JavaBea 的 JSP
n 组件提供完整的支持。这种支持不仅减少了开发时间(可以直接利用经过测试和信任的
任何现有的组件,避免重复开发),也为 JSP 应用程序带来了更多的可扩展性。JavaBeans
组件可以用来执行复杂的计算任务,或者负责与数据库交互、数据提取等,如果我们
共有三个JavaBean,分别具有显示新闻、股票价格和天气状况的功能。
具有全部三个功能的网页只需要实例化这三个bean,并使用HTML表格依次指定它们。
点它。
为了说明 JavaBeans 在 JSP 环境中的应用,我们创建了一个名为 TaxRate 的 Bean
. 它有两个属性,Product 和 Rate。两种set方法用于设置
设置这两个属性,使用两个get方法提取这两个属性。在实际应用中,这个Bean一般是
应从数据库中提取税率值,这里我们简化了过程以允许任意税率。下面是这个
豆代码清单:
包裹税;
公共课税率 {
字符串产品;
双倍率;
公共税率(){
this.Product = "A001";
this.Rate = 5;
}
公共无效集产品(字符串产品名称){
this.Product = 产品名称;
}
公共字符串 getProduct() {
返回(this.Product);
}
公共无效setRate(双倍率值){
this.Rate = rateValue;
}
公共双getRate(){
返回(this.Rate);
}
}
<jsp:useBean> 标记用于在 JSP 页面中应用上述 bean。取决于具体用途
根据 JSP 引擎,配置 bean 的位置和方式的方法可能略有不同。本文将
Bean的.class文件放在c:/jswdk-1.0/examples/WEB-INF/jsp/beans/tax目录下,
这里的 tax 是一个专门用来存放 Bean 的目录。这是应用上述 bean 的示例页面:
<HTML>
<身体>
< %@ 页面语言="java" %>
<jsp:useBean scope="application" />
< % taxbean.setProduct("A002");
taxbean.setRate(17);
%>
方法一:<p>
产品:< %= taxbean.getProduct() %> < br>
税率:< %= taxbean.getRate() %>
<p>
< % taxbean.setProduct("A003");
taxbean.setRate(3);
%>
<b>使用方法二:</b> <p>
产品:< jsp:getProperty property="Product" />
<br>
速率:< jsp:getProperty property="Rate" />
</正文>
</HTML>
<jsp:useBean> 标记中定义了几个属性,其中 id 是整个 JSP 页面中的 Bea
n的标识,scope属性定义了bean的生命周期,class属性描述了bean的类
文件(以包名开头)。
这个 JSP 页面不仅使用 Bean 的 set 和 get 方法来设置和提取属性值,还使用
使用 <jsp:getProperty> 标记提供了提取 bean 属性值的第二种方法。< jsp:getPr
operty> 中的 name 属性是 <jsp:useBean> 中定义的 bean 的 id,及其属性
y 属性指定目标属性的名称。
事实证明,Java servlet 是开发 Web 应用程序的理想框架。JSP 到 Servlet
在技术的基础上,它在许多方面都得到了改进。JSP 页面看起来像普通的 HTML 页面,但它允许嵌入
在这方面,它与 ASP 技术非常相似。利用跨平台运行的 JavaBean 组件
, JSP 为分离处理逻辑和显示样式提供了出色的解决方案。JSP必将成为ASP技术的核心
强大的竞争对手。
嘿嘿……
上一篇:解决Can not find the tag library descriptor for "core"的问题
抓取jsp网页源代码(㈠JSP与ASP引擎的区别及发展趋势分析-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-02-15 22:09
一、 JSP 技术概述
在 Sun 正式发布 JSP(JavaServer Pages)之后,这种新的 Web 应用程序开发技术迅速引起了人们的关注。JSP 为创建高度动态的 Web 应用程序提供了独特的开发环境。据Sun介绍,JSP可以适配市场上85%的服务器产品,包括Apache WebServer、IIS4.0。即使您“深深地爱上了” ASP,我们认为仍然值得关注 JSP 的演变。
(1) JSP与ASP的简单对比
JSP 与微软的 ASP 技术非常相似。两者都提供了在 HTML 代码中混合某种程序代码的能力,并让程序代码由语言引擎解释和执行。在ASP或JSP环境中,HTML代码主要负责描述信息的显示风格,而程序代码则用于描述处理逻辑。普通的 HTML 页面只依赖于 Web 服务器,而 ASP 和 JSP 页面需要额外的语言引擎来解析和执行程序代码。程序代码的执行结果被重新嵌入到 HTML 代码中,并一起发送给浏览器。ASP 和 JSP 都是面向 Web 服务器的技术,客户端浏览器不需要任何额外的软件支持。
ASP的编程语言是VBScript等脚本语言,而JSP使用Java,这是两者最明显的区别。此外,ASP 和 JSP 之间还有一个更根本的区别:两种语言引擎以完全不同的方式处理嵌入在页面中的程序代码。在 ASP 下,VBScript 代码由 ASP 引擎解释和执行;在 JSP 下,代码被编译成 servlet 并由 Java 虚拟机执行,这种编译只发生在对 JSP 页面的第一次请求时。
(二)经营环境
从 Sun 的 JSP 主页上,您还可以下载 JSP 规范,这些规范定义了供应商在创建 JSP 引擎时必须遵循的一些规则。
执行 JSP 代码需要在服务器上安装 JSP 引擎。这里我们使用 Sun 的 JavaServer Web 开发工具包 (JSWDK)。为了便于学习,此软件包提供了许多可修改的示例。安装 JSWDK 后,只需执行 startserver 命令即可启动服务器。在默认配置中,服务器监听 8080 端口。使用 :8080 打开默认页面。
在运行 JSP 示例页面之前,请注意 JSWDK 的安装目录,尤其是“work”子目录的内容。执行示例页面时,您可以在此处看到 JSP 页面如何转换为 Java 源文件,然后将其编译为类文件(即 servlet)。JSWDK 包中的示例页面分为两类,它们是 JSP 文件或收录由 JSP 代码处理的表单的 HTML 文件。与 ASP 一样,JSP 中的 Java 代码在服务器端执行。因此,在浏览器中使用“查看源代码”菜单无法看到 JSP 源代码,只能看到生成的 HTML 代码。所有示例的源代码均通过单独的“示例”页面提供。
(iii) JSP 页面示例
下面我们分析一个简单的JSP页面。您可以在 JSWDK 的示例目录下创建另一个目录来存储此文件。文件名可以是任意的,但扩展名必须是.jsp。从下面的代码清单可以看出,JSP 页面的结构基本相同,只是它们比普通的 HTML 页面多一些 Java 代码。Java代码是通过<%和%>符号添加到HTML代码中间的,它的主要作用是生成并显示一个从0到9的字符串。该字符串的前后是一些通过HTML代码输出的文本。
<HTML>
<HEAD><TITLE>JSP 页面</TITLE></HEAD>
<身体>
< %@ 页面语言="java" %>
<%! 字符串 str="0"; %>
< % for (int i=1; i < 10; i++) {
str = str + i;
} %>
在 JSP 输出之前。
<P>
< %= 字符串 %>
<P>
JSP 输出后。
</正文>
</HTML>
这个JSP页面可以分成几个部分进行分析。
第一个是JSP 指令。它描述了页面的基本信息,例如使用的语言、是否保持会话状态、是否使用缓冲等。JSP 指令以<%@ 开头,以%> 结尾。在这个例子中,指令“< %@ page language="java" %> ”简单地定义了这个例子使用Java 语言(目前,Java 是JSP 规范中唯一支持的语言)。
接下来是 JSP 声明。JSP 声明可以被认为是在类级别定义变量和方法的地方。JSP 声明以 <%! 并以 %> 结尾。如本例中的“<%!String str="0"; %>”定义了一个字符串变量。每个声明后面必须跟一个分号,就像在普通 Java 类中声明成员变量一样。
<% 和 %> 之间的代码块是描述 JSP 页面处理逻辑的 Java 代码,如本例中的 for 循环所示。
最后,< %= 和 %> 之间的代码称为 JSP 表达式,如本例中的“< %= str %>”。JSP 表达式提供了一种将 JSP 生成的值嵌入到 HTML 页面中的简单方法。
会话状态维护是Web 应用程序开发人员必须面对的问题。有多种方法可以解决此问题,例如使用 cookie、隐藏表单输入字段或将状态信息直接附加到 URL。Java servlet 提供了一个跨多个请求持续存在的会话对象,它允许用户存储和检索会话状态信息。JSP 在 servlet 中也支持这个概念。
在 Sun 的 JSP 指南中,您可以看到很多关于隐式对象的内容(隐式意味着这些对象可以直接引用而无需显式声明或特殊代码来创建它们的实例)。例如请求对象,它是 HttpServletRequest 的子类。此对象收录有关当前浏览器请求的所有信息,包括 cookie、HTML 表单变量等。会话对象也是这样一个隐含对象。该对象在第一个 JSP 页面加载时自动创建,并与请求对象相关联。与 ASP 中的会话对象类似,JSP 中的会话对象对于想要通过多个页面完成一个事务的应用程序非常有用。
为了说明session对象的具体应用,接下来我们用三个页面来模拟一个多页面的Web应用。第一个页面( q1.html )只收录一个询问用户名的 HTML 表单,代码如下:
<HTML>
<身体>
<FORM METHOD=POST ACTION="q2.jsp">
请输入你的名字:
<输入类型=文本>
<输入类型=提交值=“提交”>
</表格>
</正文>
</HTML>
第二个页面是一个JSP页面(q2.jsp),通过request对象从q1.html表单中提取name值,存储为name变量,然后将这个name值保存到会话对象。会话对象是名称/值对的集合,其中名称/值对中的名称是“thename”,值是名称变量的值。由于会话对象在会话期间始终有效,因此此处保存的变量对后续页面也有效。q2.jsp 的另一个任务是问第二个问题。这是它的代码:
<HTML>
<身体>
< %@ 页面语言="java" %>
<%! 细绳; %>
< %
name = request.getParameter("thename");
session.putValue("名称", name);
%>
你的名字是:< %= name %>
<p>
<FORM METHOD=POST ACTION="q3.jsp">
你喜欢吃什么?
<输入类型=文本>
<P>
<输入类型=提交值=“提交”>
</表格>
</正文>
</HTML>
第三个页面也是一个 JSP 页面( q3.jsp ),其主要任务是显示问答的结果。它从会话对象中提取 name 的值并显示它,证明虽然该值是在第一页输入的,但它是通过会话对象保留的。q3.jsp 的另一个任务是提取第二页中的用户输入并显示出来:
<HTML>
<身体>
< %@ 页面语言="java" %>
<%! 字符串食物=""; %>
< %
food = request.getParameter("food");
String name = (String) session.getValue("thename");
%>
你的名字是:< %= name %>
<P>
你喜欢吃:< %= food %>
</正文>
</HTML>
JavaBean 是基于 Java 的软件组件。JSP 为在 Web 应用程序中集成 JavaBean 组件提供了完整的支持。这种支持不仅缩短了开发时间(通过直接利用经过测试和信任的现有组件,避免重复开发),而且还为 JSP 应用程序带来了更多的可扩展性。JavaBean 组件可用于执行复杂的计算任务,或负责与数据库交互和数据提取。如果我们有三个具有显示新闻、股票价格和天气状况的功能的 JavaBean,那么创建一个收录所有三个功能的 Web 页面只需要实例化这三个 bean 并使用 HTML 表按顺序定位它们。.
为了说明 JavaBeans 在 JSP 环境中的应用,我们创建了一个名为 TaxRate 的 Bean。它有两个属性,Product 和 Rate。两个 set 方法用于设置这两个属性,两个 get 方法用于提取这两个属性。在实际应用中,这种bean一般应该从数据库中提取税率值。这里我们简化了流程,允许任意设定税率。下面是这个 bean 的代码清单:
包裹税;
公共课税率 {
字符串产品;
双倍率;
公共税率(){
this.Product = "A001";
this.Rate = 5;
}
公共无效集产品(字符串产品名称){
this.Product = 产品名称;
}
公共字符串 getProduct() {
返回(this.Product);
}
公共无效setRate(双倍率值){
this.Rate = rateValue;
}
公共双getRate(){
返回(this.Rate);
}
}
<jsp:useBean> 标记用于在 JSP 页面中应用上述 bean。根据所使用的特定 JSP 引擎,bean 的配置位置和方式可能略有不同。本文将这个bean的.class文件放在c:jswdk-1.0examplesWEB-INFjspeans ax目录下,其中tax是专门存放bean的目录。这是应用上述 bean 的示例页面:
<HTML>
<身体>
< %@ 页面语言="java" %>
<jsp:useBean scope="application" />
< % taxbean.setProduct("A002");
taxbean.setRate(17);
%>
方法一:<p>
产品:< %= taxbean.getProduct() %> < br>
税率:< %= taxbean.getRate() %>
<p>
< % taxbean.setProduct("A003");
taxbean.setRate(3);
%>
<b>使用方法二:</b> <p>
产品:< jsp:getProperty property="Product" />
<br>
速率:< jsp:getProperty property="Rate" />
</正文>
</HTML>
<jsp:useBean> 标签中定义了几个属性,其中 id 是 bean 在整个 JSP 页面中的标识,scope 属性定义了 bean 的生命周期,class 属性描述了 bean 的类文件(开始来自包名))。
这个 JSP 页面不仅使用 bean 的 set 和 get 方法来设置和检索属性值,而且还使用了第二种检索 bean 属性值的方法,即使用 <jsp:getProperty> 标记。<jsp:getProperty> 中的name 属性是<jsp:useBean> 中定义的bean 的id,其property 属性指定了目标属性的名称。
事实证明,Java servlet 是开发 Web 应用程序的理想框架。JSP 基于 Servlet 技术,并在很多方面进行了改进。JSP 页面看起来像一个普通的 HTML 页面,但它允许嵌入执行代码,在这方面它与 ASP 技术非常相似。使用跨平台运行的 JavaBean 组件,JSP 为分离处理逻辑和表示样式提供了出色的解决方案。JSP必将成为ASP技术的有力竞争者。 查看全部
抓取jsp网页源代码(㈠JSP与ASP引擎的区别及发展趋势分析-乐题库)
一、 JSP 技术概述
在 Sun 正式发布 JSP(JavaServer Pages)之后,这种新的 Web 应用程序开发技术迅速引起了人们的关注。JSP 为创建高度动态的 Web 应用程序提供了独特的开发环境。据Sun介绍,JSP可以适配市场上85%的服务器产品,包括Apache WebServer、IIS4.0。即使您“深深地爱上了” ASP,我们认为仍然值得关注 JSP 的演变。
(1) JSP与ASP的简单对比
JSP 与微软的 ASP 技术非常相似。两者都提供了在 HTML 代码中混合某种程序代码的能力,并让程序代码由语言引擎解释和执行。在ASP或JSP环境中,HTML代码主要负责描述信息的显示风格,而程序代码则用于描述处理逻辑。普通的 HTML 页面只依赖于 Web 服务器,而 ASP 和 JSP 页面需要额外的语言引擎来解析和执行程序代码。程序代码的执行结果被重新嵌入到 HTML 代码中,并一起发送给浏览器。ASP 和 JSP 都是面向 Web 服务器的技术,客户端浏览器不需要任何额外的软件支持。
ASP的编程语言是VBScript等脚本语言,而JSP使用Java,这是两者最明显的区别。此外,ASP 和 JSP 之间还有一个更根本的区别:两种语言引擎以完全不同的方式处理嵌入在页面中的程序代码。在 ASP 下,VBScript 代码由 ASP 引擎解释和执行;在 JSP 下,代码被编译成 servlet 并由 Java 虚拟机执行,这种编译只发生在对 JSP 页面的第一次请求时。
(二)经营环境
从 Sun 的 JSP 主页上,您还可以下载 JSP 规范,这些规范定义了供应商在创建 JSP 引擎时必须遵循的一些规则。
执行 JSP 代码需要在服务器上安装 JSP 引擎。这里我们使用 Sun 的 JavaServer Web 开发工具包 (JSWDK)。为了便于学习,此软件包提供了许多可修改的示例。安装 JSWDK 后,只需执行 startserver 命令即可启动服务器。在默认配置中,服务器监听 8080 端口。使用 :8080 打开默认页面。
在运行 JSP 示例页面之前,请注意 JSWDK 的安装目录,尤其是“work”子目录的内容。执行示例页面时,您可以在此处看到 JSP 页面如何转换为 Java 源文件,然后将其编译为类文件(即 servlet)。JSWDK 包中的示例页面分为两类,它们是 JSP 文件或收录由 JSP 代码处理的表单的 HTML 文件。与 ASP 一样,JSP 中的 Java 代码在服务器端执行。因此,在浏览器中使用“查看源代码”菜单无法看到 JSP 源代码,只能看到生成的 HTML 代码。所有示例的源代码均通过单独的“示例”页面提供。
(iii) JSP 页面示例
下面我们分析一个简单的JSP页面。您可以在 JSWDK 的示例目录下创建另一个目录来存储此文件。文件名可以是任意的,但扩展名必须是.jsp。从下面的代码清单可以看出,JSP 页面的结构基本相同,只是它们比普通的 HTML 页面多一些 Java 代码。Java代码是通过<%和%>符号添加到HTML代码中间的,它的主要作用是生成并显示一个从0到9的字符串。该字符串的前后是一些通过HTML代码输出的文本。
<HTML>
<HEAD><TITLE>JSP 页面</TITLE></HEAD>
<身体>
< %@ 页面语言="java" %>
<%! 字符串 str="0"; %>
< % for (int i=1; i < 10; i++) {
str = str + i;
} %>
在 JSP 输出之前。
<P>
< %= 字符串 %>
<P>
JSP 输出后。
</正文>
</HTML>
这个JSP页面可以分成几个部分进行分析。
第一个是JSP 指令。它描述了页面的基本信息,例如使用的语言、是否保持会话状态、是否使用缓冲等。JSP 指令以<%@ 开头,以%> 结尾。在这个例子中,指令“< %@ page language="java" %> ”简单地定义了这个例子使用Java 语言(目前,Java 是JSP 规范中唯一支持的语言)。
接下来是 JSP 声明。JSP 声明可以被认为是在类级别定义变量和方法的地方。JSP 声明以 <%! 并以 %> 结尾。如本例中的“<%!String str="0"; %>”定义了一个字符串变量。每个声明后面必须跟一个分号,就像在普通 Java 类中声明成员变量一样。
<% 和 %> 之间的代码块是描述 JSP 页面处理逻辑的 Java 代码,如本例中的 for 循环所示。
最后,< %= 和 %> 之间的代码称为 JSP 表达式,如本例中的“< %= str %>”。JSP 表达式提供了一种将 JSP 生成的值嵌入到 HTML 页面中的简单方法。
会话状态维护是Web 应用程序开发人员必须面对的问题。有多种方法可以解决此问题,例如使用 cookie、隐藏表单输入字段或将状态信息直接附加到 URL。Java servlet 提供了一个跨多个请求持续存在的会话对象,它允许用户存储和检索会话状态信息。JSP 在 servlet 中也支持这个概念。
在 Sun 的 JSP 指南中,您可以看到很多关于隐式对象的内容(隐式意味着这些对象可以直接引用而无需显式声明或特殊代码来创建它们的实例)。例如请求对象,它是 HttpServletRequest 的子类。此对象收录有关当前浏览器请求的所有信息,包括 cookie、HTML 表单变量等。会话对象也是这样一个隐含对象。该对象在第一个 JSP 页面加载时自动创建,并与请求对象相关联。与 ASP 中的会话对象类似,JSP 中的会话对象对于想要通过多个页面完成一个事务的应用程序非常有用。
为了说明session对象的具体应用,接下来我们用三个页面来模拟一个多页面的Web应用。第一个页面( q1.html )只收录一个询问用户名的 HTML 表单,代码如下:
<HTML>
<身体>
<FORM METHOD=POST ACTION="q2.jsp">
请输入你的名字:
<输入类型=文本>
<输入类型=提交值=“提交”>
</表格>
</正文>
</HTML>
第二个页面是一个JSP页面(q2.jsp),通过request对象从q1.html表单中提取name值,存储为name变量,然后将这个name值保存到会话对象。会话对象是名称/值对的集合,其中名称/值对中的名称是“thename”,值是名称变量的值。由于会话对象在会话期间始终有效,因此此处保存的变量对后续页面也有效。q2.jsp 的另一个任务是问第二个问题。这是它的代码:
<HTML>
<身体>
< %@ 页面语言="java" %>
<%! 细绳; %>
< %
name = request.getParameter("thename");
session.putValue("名称", name);
%>
你的名字是:< %= name %>
<p>
<FORM METHOD=POST ACTION="q3.jsp">
你喜欢吃什么?
<输入类型=文本>
<P>
<输入类型=提交值=“提交”>
</表格>
</正文>
</HTML>
第三个页面也是一个 JSP 页面( q3.jsp ),其主要任务是显示问答的结果。它从会话对象中提取 name 的值并显示它,证明虽然该值是在第一页输入的,但它是通过会话对象保留的。q3.jsp 的另一个任务是提取第二页中的用户输入并显示出来:
<HTML>
<身体>
< %@ 页面语言="java" %>
<%! 字符串食物=""; %>
< %
food = request.getParameter("food");
String name = (String) session.getValue("thename");
%>
你的名字是:< %= name %>
<P>
你喜欢吃:< %= food %>
</正文>
</HTML>
JavaBean 是基于 Java 的软件组件。JSP 为在 Web 应用程序中集成 JavaBean 组件提供了完整的支持。这种支持不仅缩短了开发时间(通过直接利用经过测试和信任的现有组件,避免重复开发),而且还为 JSP 应用程序带来了更多的可扩展性。JavaBean 组件可用于执行复杂的计算任务,或负责与数据库交互和数据提取。如果我们有三个具有显示新闻、股票价格和天气状况的功能的 JavaBean,那么创建一个收录所有三个功能的 Web 页面只需要实例化这三个 bean 并使用 HTML 表按顺序定位它们。.
为了说明 JavaBeans 在 JSP 环境中的应用,我们创建了一个名为 TaxRate 的 Bean。它有两个属性,Product 和 Rate。两个 set 方法用于设置这两个属性,两个 get 方法用于提取这两个属性。在实际应用中,这种bean一般应该从数据库中提取税率值。这里我们简化了流程,允许任意设定税率。下面是这个 bean 的代码清单:
包裹税;
公共课税率 {
字符串产品;
双倍率;
公共税率(){
this.Product = "A001";
this.Rate = 5;
}
公共无效集产品(字符串产品名称){
this.Product = 产品名称;
}
公共字符串 getProduct() {
返回(this.Product);
}
公共无效setRate(双倍率值){
this.Rate = rateValue;
}
公共双getRate(){
返回(this.Rate);
}
}
<jsp:useBean> 标记用于在 JSP 页面中应用上述 bean。根据所使用的特定 JSP 引擎,bean 的配置位置和方式可能略有不同。本文将这个bean的.class文件放在c:jswdk-1.0examplesWEB-INFjspeans ax目录下,其中tax是专门存放bean的目录。这是应用上述 bean 的示例页面:
<HTML>
<身体>
< %@ 页面语言="java" %>
<jsp:useBean scope="application" />
< % taxbean.setProduct("A002");
taxbean.setRate(17);
%>
方法一:<p>
产品:< %= taxbean.getProduct() %> < br>
税率:< %= taxbean.getRate() %>
<p>
< % taxbean.setProduct("A003");
taxbean.setRate(3);
%>
<b>使用方法二:</b> <p>
产品:< jsp:getProperty property="Product" />
<br>
速率:< jsp:getProperty property="Rate" />
</正文>
</HTML>
<jsp:useBean> 标签中定义了几个属性,其中 id 是 bean 在整个 JSP 页面中的标识,scope 属性定义了 bean 的生命周期,class 属性描述了 bean 的类文件(开始来自包名))。
这个 JSP 页面不仅使用 bean 的 set 和 get 方法来设置和检索属性值,而且还使用了第二种检索 bean 属性值的方法,即使用 <jsp:getProperty> 标记。<jsp:getProperty> 中的name 属性是<jsp:useBean> 中定义的bean 的id,其property 属性指定了目标属性的名称。
事实证明,Java servlet 是开发 Web 应用程序的理想框架。JSP 基于 Servlet 技术,并在很多方面进行了改进。JSP 页面看起来像一个普通的 HTML 页面,但它允许嵌入执行代码,在这方面它与 ASP 技术非常相似。使用跨平台运行的 JavaBean 组件,JSP 为分离处理逻辑和表示样式提供了出色的解决方案。JSP必将成为ASP技术的有力竞争者。
抓取jsp网页源代码(你可以用Java的URL类来读获得这个HTTP的输入流)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-02-15 16:30
您可以使用 Java 的 URL 类,然后使用 openConnection 来获取这个 HTTP 输入流。但是,此信息已被静态转换。
因此,如果要获取源代码,这种方法是不可接受的。
但是如果是你的本地文件,可以直接使用File方法读取。(不是吗?)
如果服务器将这些网页视为文件供您访问(即通过设置 MIME 允许您下载),您可以使用 Java URL 类读取源代码。事实上,你可以直接下载它。(不会有服务器这样做吗?)
从客户端得到的已经是html代码
如果要获取jsp源码,可以通过访问url获取。以这种方式获得的结果由服务器解析。
除非你知道这个文件的绝对地址而且这个目录是对外共享的~
不然可以知道这个项目所在的代码库,svn等~
补充:框架dwr以JavaScript的形式公开了java源码
好像不行,除非JAVA和ASP、PHP、JSP放在服务器端,并且知道它们的文件地址
.
不,开源框架 dwr 做得不好(被批准)是它暴露了 java 对象及其方法。其他技术没有这样的问题,可见无法获取php、asp、jsp、Python、ruby等的源码。
只需将jsp页面作为普通文件读取,
要读取的 FileInputStream
本文相关:使用Mybatis执行sql时如何统一校验输入参数?js中这个表达式是什么意思?返回(y1 - y2 > 0 ?“上”:“下”);基于云架构的J2EE架构应该做什么?spring 和 hibernate 都使用 asm 字节码技术。他们使用 ASM 来实现哪些功能?或者如何判断操作系统是32位还是64位在哪个函数中使用?DBA_OBJECTS + ROWNUM 和 DUAL + ROWNUM 结果比较的可疑 ajax 缺点?判断字符串是否以数字开头,使用java程序监控mysql的变化。如何加密或保护 URL 地址栏中传递的信息 查看全部
抓取jsp网页源代码(你可以用Java的URL类来读获得这个HTTP的输入流)
您可以使用 Java 的 URL 类,然后使用 openConnection 来获取这个 HTTP 输入流。但是,此信息已被静态转换。
因此,如果要获取源代码,这种方法是不可接受的。
但是如果是你的本地文件,可以直接使用File方法读取。(不是吗?)
如果服务器将这些网页视为文件供您访问(即通过设置 MIME 允许您下载),您可以使用 Java URL 类读取源代码。事实上,你可以直接下载它。(不会有服务器这样做吗?)
从客户端得到的已经是html代码
如果要获取jsp源码,可以通过访问url获取。以这种方式获得的结果由服务器解析。
除非你知道这个文件的绝对地址而且这个目录是对外共享的~
不然可以知道这个项目所在的代码库,svn等~
补充:框架dwr以JavaScript的形式公开了java源码
好像不行,除非JAVA和ASP、PHP、JSP放在服务器端,并且知道它们的文件地址
.
不,开源框架 dwr 做得不好(被批准)是它暴露了 java 对象及其方法。其他技术没有这样的问题,可见无法获取php、asp、jsp、Python、ruby等的源码。
只需将jsp页面作为普通文件读取,
要读取的 FileInputStream
本文相关:使用Mybatis执行sql时如何统一校验输入参数?js中这个表达式是什么意思?返回(y1 - y2 > 0 ?“上”:“下”);基于云架构的J2EE架构应该做什么?spring 和 hibernate 都使用 asm 字节码技术。他们使用 ASM 来实现哪些功能?或者如何判断操作系统是32位还是64位在哪个函数中使用?DBA_OBJECTS + ROWNUM 和 DUAL + ROWNUM 结果比较的可疑 ajax 缺点?判断字符串是否以数字开头,使用java程序监控mysql的变化。如何加密或保护 URL 地址栏中传递的信息
抓取jsp网页源代码(2.java注释/*多行注释:可见范围jsp源码可见运行原理 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-14 14:07
)
JSP 概念
JSP的全称是Java Server Pages,中文名称是java server page。它基本上是一个简化的 Servlet 设计。它将Java程序段和JSP标签插入到网页的传统HTML文件中,形成JSP文件。后缀是(*.jsp)。使用 JSP 开发的 Web 应用程序是跨平台的,可以在 Linux 和其他操作系统上运行。
与 Servlet 一样,JSP 在服务器端执行。通常返回给客户端的是HTML文本,所以客户端只要有浏览器就可以浏览。
JSP 脚本
1.
内部java代码被翻译成服务方法的内部
2.
会在service方法里面翻译成out.print()
3.
会被翻译成servlet成员的内容
JSP 注释
不同注解可见范围不同
1. html 评论:
可见范围jsp源码,翻译后的servlet,页面展示html源码
2. java 注释://单行注释/*多行注释*/
可见范围jsp源码,翻译后的servlet
3. jsp 注释:
可见范围jsp源码可见
JSP运行原理-----jsp本质上是一个servlet
JSP 的工作模式是请求/响应模式。客户端首先发送一个HTTP请求,JSP程序接收请求并返回处理结果。当第一次请求一个 JSP 文件时,JSP 引擎(容器)将 JSP 文件转换成一个 Servlet,它本身也是一个 Servlet
JSP操作流程如下:
1)客户端发送访问JSP文件的请求
2)JSP 容器首先将JSP 文件转换为java 源文件(Java Servlet 源程序)。在转换过程中,如果发现JSP文件中有语法错误,转换过程将被中断,服务器和客户端返回错误信息。
3)如果转换成功,JSP会生成Java源文件,编译成相关字节码文件*.class。类文件是一个 servlet,servlet 容器像处理任何其他 servlet 一样处理它。
JSP编译后的两个文件:
PS:翻译后的servlet可以在Tomcat的工作目录中找到
JSP 指令
jsp的指令是指导jsp的翻译和操作的命令。jsp包括三个主要指令:
1. 页面指令(实际开发中默认的页面指令)
属性最多的一条指令,根据不同的属性,引导整个页面的特点
格式:
常见属性如下:
language:jsp脚本中可以嵌入的语言种类
pageEncoding:当前jsp文件的编码---可以收录contentType
contentType: response.setContentType(text/html;charset=UTF-8)
session:jsp在翻译过程中是否自动创建会话
import:导入java的包
errorPage:当前页面出错时跳转到哪个页面
isErrorPage:当前页面是错误处理页面
PS:page指令对整个页面都有效,不管它的书写位置如何,但是习惯上把Page指令写在JSP页面的顶部
2. 收录指令
页面收录(静态收录)指令,可以将一个jsp页面/HTML文件/文本文件收录到另一个jsp页面中
格式:
收录include指令的jsp页面的编译过程:
导入文件中除指令元素外,其他元素都转换成对应的java源代码,然后插入到当前jsp页面翻译的Servlet源文件中。插入位置与当前jsp页面中include的位置一致。
3. 标签库指令
在jsp页面中引入标签库(jstl标签库、struts2标签库)
格式:
jsp 内置/隐式对象
jsp翻译成servlet后,service方法中有9个对象被定义和初始化,我们可以在jsp脚本中直接使用这9个对象
既然已经了解了对象,这里就重点学习out和pageContext
1. 输出对象
输出类型:JspWriter
它的功能和response.getWriter返回的PrintWriter很相似,输出内容到客户端out.write()
也相当于一个带有缓存功能的PrintWriter,如图:
在 JSP 页面中,通过 out 隐式对象写入数据,相当于将数据插入到 JspWriter 对象的缓冲区中。只有调用 ServletResponse.getWriter 方法,才能真正将缓冲区中的数据写入 servlet 引擎提供的缓冲区。在那个地区。
默认输出缓冲区为 8kb。可以设置为 0 关闭 out 缓冲区,将内容直接写入响应缓冲区。
2. pageContext 对象
jsp页面的context对象,page对象和pageContext对象不是一回事
效果如下:
1) pageContext 是一个域对象
setAttribute(字符串名称,对象 obj)
获取属性(字符串名称)
删除属性(字符串名称)
pageContext 可以访问其他指定域的数据
setAttribute(字符串名称,对象 obj,int 范围)
getAttribute(字符串名称,整数范围)
removeAttrbute(字符串名称,int 范围)
findAttribute(字符串名称)
PS:使用findAttribute()方法查找名为name的属性时,该属性依次从pageContext域、请求域、会话域、应用域中获取。在某个域中获取后,不会向后搜索。
四个范围的总结:
page domain:当前jsp页面的范围
请求字段:请求
会话字段:会话
应用领域:整个网络应用
2)可以获取其他8个隐式对象(不常用)
例如:pageContext.getRequest()
pageContext.getSession()
jsp标签(动作)
页面收录(动态收录):
收录的原则是对收录的页面进行编译处理后,将结果收录在页面中。当浏览器第一次请求使用其他页面的页面时,web容器首先编译被收录的页面,然后将编译过程的结果收录在页面中,再编译被收录的页面,最后编译这两个页面。合并的结果返回给浏览器。
请求转发:
动态收录和静态收录的区别
查看全部
抓取jsp网页源代码(2.java注释/*多行注释:可见范围jsp源码可见运行原理
)
JSP 概念
JSP的全称是Java Server Pages,中文名称是java server page。它基本上是一个简化的 Servlet 设计。它将Java程序段和JSP标签插入到网页的传统HTML文件中,形成JSP文件。后缀是(*.jsp)。使用 JSP 开发的 Web 应用程序是跨平台的,可以在 Linux 和其他操作系统上运行。
与 Servlet 一样,JSP 在服务器端执行。通常返回给客户端的是HTML文本,所以客户端只要有浏览器就可以浏览。
JSP 脚本
1.
内部java代码被翻译成服务方法的内部
2.
会在service方法里面翻译成out.print()
3.
会被翻译成servlet成员的内容
JSP 注释
不同注解可见范围不同
1. html 评论:
可见范围jsp源码,翻译后的servlet,页面展示html源码
2. java 注释://单行注释/*多行注释*/
可见范围jsp源码,翻译后的servlet
3. jsp 注释:
可见范围jsp源码可见
JSP运行原理-----jsp本质上是一个servlet
JSP 的工作模式是请求/响应模式。客户端首先发送一个HTTP请求,JSP程序接收请求并返回处理结果。当第一次请求一个 JSP 文件时,JSP 引擎(容器)将 JSP 文件转换成一个 Servlet,它本身也是一个 Servlet
JSP操作流程如下:
1)客户端发送访问JSP文件的请求
2)JSP 容器首先将JSP 文件转换为java 源文件(Java Servlet 源程序)。在转换过程中,如果发现JSP文件中有语法错误,转换过程将被中断,服务器和客户端返回错误信息。
3)如果转换成功,JSP会生成Java源文件,编译成相关字节码文件*.class。类文件是一个 servlet,servlet 容器像处理任何其他 servlet 一样处理它。
JSP编译后的两个文件:
PS:翻译后的servlet可以在Tomcat的工作目录中找到
JSP 指令
jsp的指令是指导jsp的翻译和操作的命令。jsp包括三个主要指令:
1. 页面指令(实际开发中默认的页面指令)
属性最多的一条指令,根据不同的属性,引导整个页面的特点
格式:
常见属性如下:
language:jsp脚本中可以嵌入的语言种类
pageEncoding:当前jsp文件的编码---可以收录contentType
contentType: response.setContentType(text/html;charset=UTF-8)
session:jsp在翻译过程中是否自动创建会话
import:导入java的包
errorPage:当前页面出错时跳转到哪个页面
isErrorPage:当前页面是错误处理页面
PS:page指令对整个页面都有效,不管它的书写位置如何,但是习惯上把Page指令写在JSP页面的顶部
2. 收录指令
页面收录(静态收录)指令,可以将一个jsp页面/HTML文件/文本文件收录到另一个jsp页面中
格式:
收录include指令的jsp页面的编译过程:
导入文件中除指令元素外,其他元素都转换成对应的java源代码,然后插入到当前jsp页面翻译的Servlet源文件中。插入位置与当前jsp页面中include的位置一致。
3. 标签库指令
在jsp页面中引入标签库(jstl标签库、struts2标签库)
格式:
jsp 内置/隐式对象
jsp翻译成servlet后,service方法中有9个对象被定义和初始化,我们可以在jsp脚本中直接使用这9个对象
既然已经了解了对象,这里就重点学习out和pageContext
1. 输出对象
输出类型:JspWriter
它的功能和response.getWriter返回的PrintWriter很相似,输出内容到客户端out.write()
也相当于一个带有缓存功能的PrintWriter,如图:
在 JSP 页面中,通过 out 隐式对象写入数据,相当于将数据插入到 JspWriter 对象的缓冲区中。只有调用 ServletResponse.getWriter 方法,才能真正将缓冲区中的数据写入 servlet 引擎提供的缓冲区。在那个地区。
默认输出缓冲区为 8kb。可以设置为 0 关闭 out 缓冲区,将内容直接写入响应缓冲区。
2. pageContext 对象
jsp页面的context对象,page对象和pageContext对象不是一回事
效果如下:
1) pageContext 是一个域对象
setAttribute(字符串名称,对象 obj)
获取属性(字符串名称)
删除属性(字符串名称)
pageContext 可以访问其他指定域的数据
setAttribute(字符串名称,对象 obj,int 范围)
getAttribute(字符串名称,整数范围)
removeAttrbute(字符串名称,int 范围)
findAttribute(字符串名称)
PS:使用findAttribute()方法查找名为name的属性时,该属性依次从pageContext域、请求域、会话域、应用域中获取。在某个域中获取后,不会向后搜索。
四个范围的总结:
page domain:当前jsp页面的范围
请求字段:请求
会话字段:会话
应用领域:整个网络应用
2)可以获取其他8个隐式对象(不常用)
例如:pageContext.getRequest()
pageContext.getSession()
jsp标签(动作)
页面收录(动态收录):
收录的原则是对收录的页面进行编译处理后,将结果收录在页面中。当浏览器第一次请求使用其他页面的页面时,web容器首先编译被收录的页面,然后将编译过程的结果收录在页面中,再编译被收录的页面,最后编译这两个页面。合并的结果返回给浏览器。
请求转发:
动态收录和静态收录的区别
抓取jsp网页源代码(GoogleAds广告系列之如何使用URL参数和动态替换内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-13 20:14
或)和页面。
使用 innerHTML 属性的动态内容演示了三种在网页上动态添加或替换 HTML 内容的方法,我将演示所有这三种方法,您可以选择最适合您的情况的方法。第 1 步:选择 HTML 动态内容 在一个测试项目中,我决定为我的 Google Ads 广告系列中的每个关键字显示一些独特的内容:标题、标题、说明和按钮文本。如果你选择了 100+ 个关键词和 4 个元素,那么你需要拿出 400 条文字,所以我的建议是:不要选择太多。. 动态页面/替换内容,通过使用所有现代浏览器都支持的这个属性,我们可以将新的 HTML 或文本分配给任何收录元素(例如。
或 ),以及页面中描述的三种动态替换 HTML 内容的方法(响应用户操作);我会示范。
动态页面/替代内容,第 1 步:选择 HTML 动态内容 在一个测试项目中,我决定为我的 Google Ads 广告系列中的每个关键字显示一些独特的内容:标题、标题、描述和按钮文本。如果你选择了 100+ 个关键词和 4 个元素,那么你需要拿出 400 条文字,所以我的建议是:不要选择太多。通过使用所有现代浏览器都支持的这个属性,我们可以将新的 HTML 或文本分配给任何收录元素(例如
或)和页面。如何使用 URL 参数在页面上显示动态内容,本文介绍的三种动态替换 HTML 内容(响应用户操作)的方法都可以正常工作;我将演示动态网页是在每次查看时显示不同内容的网页。例如,页面可能会随着时间、访问网页的用户或用户交互的类型而改变。有两种类型的动态网页。客户端脚本。
如何使用 URL 参数在页面上显示动态内容,通过使用所有现代浏览器都支持的这个属性,我们可以将新的 HTML 或文本分配给任何收录元素(例如
或 ),本文中描述的三种动态替换 HTML 内容(响应用户操作)的方法可以正常工作;我会示范。如何在html页面上显示动态内容,
在不重新加载页面的情况下更改内容
如何在不刷新页面的情况下更改 div 的内容 如何在不刷新页面的情况下使用 jQuery 更改 div 的内容
·
· 查看全部
抓取jsp网页源代码(GoogleAds广告系列之如何使用URL参数和动态替换内容)
或)和页面。
使用 innerHTML 属性的动态内容演示了三种在网页上动态添加或替换 HTML 内容的方法,我将演示所有这三种方法,您可以选择最适合您的情况的方法。第 1 步:选择 HTML 动态内容 在一个测试项目中,我决定为我的 Google Ads 广告系列中的每个关键字显示一些独特的内容:标题、标题、说明和按钮文本。如果你选择了 100+ 个关键词和 4 个元素,那么你需要拿出 400 条文字,所以我的建议是:不要选择太多。. 动态页面/替换内容,通过使用所有现代浏览器都支持的这个属性,我们可以将新的 HTML 或文本分配给任何收录元素(例如。
或 ),以及页面中描述的三种动态替换 HTML 内容的方法(响应用户操作);我会示范。
动态页面/替代内容,第 1 步:选择 HTML 动态内容 在一个测试项目中,我决定为我的 Google Ads 广告系列中的每个关键字显示一些独特的内容:标题、标题、描述和按钮文本。如果你选择了 100+ 个关键词和 4 个元素,那么你需要拿出 400 条文字,所以我的建议是:不要选择太多。通过使用所有现代浏览器都支持的这个属性,我们可以将新的 HTML 或文本分配给任何收录元素(例如
或)和页面。如何使用 URL 参数在页面上显示动态内容,本文介绍的三种动态替换 HTML 内容(响应用户操作)的方法都可以正常工作;我将演示动态网页是在每次查看时显示不同内容的网页。例如,页面可能会随着时间、访问网页的用户或用户交互的类型而改变。有两种类型的动态网页。客户端脚本。
如何使用 URL 参数在页面上显示动态内容,通过使用所有现代浏览器都支持的这个属性,我们可以将新的 HTML 或文本分配给任何收录元素(例如
或 ),本文中描述的三种动态替换 HTML 内容(响应用户操作)的方法可以正常工作;我会示范。如何在html页面上显示动态内容,
在不重新加载页面的情况下更改内容
如何在不刷新页面的情况下更改 div 的内容 如何在不刷新页面的情况下使用 jQuery 更改 div 的内容
·
·
抓取jsp网页源代码(网络爬虫的制作方法和使用方法,你值得拥有!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-02-07 22:21
一、什么是爬虫
大东:小白,你平时都是自己做作业吗?
小白:大大大大的,怎么了?
大东:看你,吓得结巴。
小白:我这么好的学生,怎么会抄作业这种事!
大东:好的,我知道你不抄作业,所以有同学抄作业?
小白:哇!尤其是作业检查的前一天,我的同学们快速跑了一遍,一起抄了一遍,非常壮观。
大东:在网络世界里,也有人喜欢抄“作业”。
小白:诶!是谁!
大东:叫做网络爬虫。
小白:这个名字我早就羡慕了!
大东:网络爬虫也可以称为网络蜘蛛、网络机器人,还有一个文学名称——网页追赶者。网络爬虫是根据预定规则自动从万维网上爬取所需信息的程序或脚本。
小白:如果我学得好,我可以自动为我抓取作业答案。不,课外资料,听起来很不错~
网络爬虫(图片来自网络)
二、爬虫能做什么
小白:这个网络爬虫能抓到什么吗?
大东:只要在写的时候定义好,就可以根据自己的要求去抓取。从这个角度来看,它就是你想要抓住的东西。常见,可用于网页文字、图片、视频。
小白:哇~
大东:根据网络爬虫的爬取对象、程序结构和使用技术,通常可以分为以下四类:通用爬虫、聚焦爬虫、增量爬虫和深度爬虫。
小白:要注意的东西太多了!
大东:通用爬虫已经变成了全网爬虫,主要用在搜索引擎上。通用爬虫从初始URL开始,可以获取整个网页。工作量巨大,要求存储容量大、处理速度快、工作性能强大。
小白:你要不要,先拿下来!
大东:专注爬虫专注于抓取特定网页和特定信息,只搜索和抓取预先定义好的关键信息。焦点类型通常用于数据分析工作的数据采集阶段,具有很强的焦点。
小白:不求数量,只求准确!
大东:增量爬虫在固定的时间段内自动重新抓取网页,可以获取网页的更新内容并存入数据库。
小白:有点自动化的意思!
大东:深度爬虫可以快速抓取并保存网页上的文字、图片等信息,无需人工操作,通常用于需要提交登录数据才能进入的页面。深度爬虫可以自动处理图像存储的复杂操作,同时获取大量感知知识难以获取的数据,为后续决策提供支持。
小白:哇,这个最厉害了!节省大量人力
蜘蛛侠(图片来自网络)
三、简单爬虫的养成
小白:爬虫好用,我也想写一个试试看,请告诉我怎么做~
大东:爬虫一般有两种工作方式:一种是模拟真实用户,在页面上操作;另一种是向网站发起HTTP请求,直接获取整个页面的内容。
小白:哦~第一个我知道。您可以使用软件测试工具来模拟用户的浏览和点击操作。比如在python语言中,Selenium就是一个可以用来模拟用户操作的包,加上lxml包。定位网页的相框简直完美~
大东:没想到小白也有经验。
小白:嘻嘻嘻,你不像人啊~
大东:另外一种方式,同样以python语言为例,就是程序先使用HTTP库向目标网站发起请求,等待服务器响应。如果服务器能正常响应,程序就可以收到一个Response。这个Response中的内容就是要获取的页面的内容。它可能有 HTML、Json 字符串、二进制和其他类型的数据。程序需要不断地对内容进行解析和提取,最终得到需要的信息。
小白:也好听~
大东:一般来说,第二种方法比第一种更有效。
小白:好!今晚可以回去写爬虫了~
大东:爬虫程序一般分为几个模块,分别负责不同的功能。简单来说,爬虫调度端就是用来控制和监控爬虫的运行;URL管理器管理要爬取的目标网站URL和已经爬取过的URL;网页下载器从 URL 管理从浏览器中的 URL 下载网页并生成字符串;网页解析器需要解析网页下载器完成的内容。一方面解析出有用的价值数据,另一方面取出网页中的链接发送给URL管理器。.
小白:哇,小爬虫分工有条不紊~
爬虫程序的基本流程(图片来自网络)
四、防爬技术
小白:大冬冬,我有一个问题。总有一些同学不愿意轻易分享他的劳动成果,所以就不要让别人看到他的功课。但是在这个网络上,网站 是公开的,任何人都可以看到它。如果我不想让别人复制它怎么办?
大东:有爬虫技术,当然还有反爬虫技术。
小白:听前排讲课~
大东:据我所知,目前的防爬技术大致分为四种。最经典的反爬策略是“验证码”。
小白:我知道~是永远不会失败的反人类验证码吗!
大东:是的,因为验证码是图片,所以用户只需要输入一次就可以登录成功。程序在抓取数据的过程中,需要不断的登录,抓取1000个用户的个人信息,需要填写1000个验证码,可以减缓甚至停止程序的爬取过程。
小白:哇,好麻烦。
大东:另一个更狠的反爬策略是封IP和封号。网站一旦某个IP或网站账号被怀疑为爬虫,该账号和IP将立即被封杀,将无法再通过该IP访问网站或占短时间甚至永久。
小白:太残忍了!
大东:比较常见的是通过cookies来限制信息的抓取。比如程序模拟登录后,如果想获取登录后某个页面的信息,需要请求一些中间页面获取特定的cookie,然后就可以抓取我们需要的页面了。
小白:操作比较复杂。
大东:另一种常见的反爬模式是使用JS渲染页面。这是什么意思?返回的页面不是直接请求的,而是JS操作数据文件得到的一部分,而那部分数据我们也拿不到。
小白:看来大家都在尽力防止自己的“作业”被抄袭了!
大东:所以小白,从现在开始,不管是你还是你的同学,好好做好功课。想要通过抄袭取得好成绩,迟早会有“报应”!
小白:那一定要做好~
对峙(图片来自网络) 查看全部
抓取jsp网页源代码(网络爬虫的制作方法和使用方法,你值得拥有!)
一、什么是爬虫
大东:小白,你平时都是自己做作业吗?
小白:大大大大的,怎么了?
大东:看你,吓得结巴。
小白:我这么好的学生,怎么会抄作业这种事!
大东:好的,我知道你不抄作业,所以有同学抄作业?
小白:哇!尤其是作业检查的前一天,我的同学们快速跑了一遍,一起抄了一遍,非常壮观。
大东:在网络世界里,也有人喜欢抄“作业”。
小白:诶!是谁!
大东:叫做网络爬虫。
小白:这个名字我早就羡慕了!
大东:网络爬虫也可以称为网络蜘蛛、网络机器人,还有一个文学名称——网页追赶者。网络爬虫是根据预定规则自动从万维网上爬取所需信息的程序或脚本。
小白:如果我学得好,我可以自动为我抓取作业答案。不,课外资料,听起来很不错~
网络爬虫(图片来自网络)
二、爬虫能做什么
小白:这个网络爬虫能抓到什么吗?
大东:只要在写的时候定义好,就可以根据自己的要求去抓取。从这个角度来看,它就是你想要抓住的东西。常见,可用于网页文字、图片、视频。
小白:哇~
大东:根据网络爬虫的爬取对象、程序结构和使用技术,通常可以分为以下四类:通用爬虫、聚焦爬虫、增量爬虫和深度爬虫。
小白:要注意的东西太多了!
大东:通用爬虫已经变成了全网爬虫,主要用在搜索引擎上。通用爬虫从初始URL开始,可以获取整个网页。工作量巨大,要求存储容量大、处理速度快、工作性能强大。
小白:你要不要,先拿下来!
大东:专注爬虫专注于抓取特定网页和特定信息,只搜索和抓取预先定义好的关键信息。焦点类型通常用于数据分析工作的数据采集阶段,具有很强的焦点。
小白:不求数量,只求准确!
大东:增量爬虫在固定的时间段内自动重新抓取网页,可以获取网页的更新内容并存入数据库。
小白:有点自动化的意思!
大东:深度爬虫可以快速抓取并保存网页上的文字、图片等信息,无需人工操作,通常用于需要提交登录数据才能进入的页面。深度爬虫可以自动处理图像存储的复杂操作,同时获取大量感知知识难以获取的数据,为后续决策提供支持。
小白:哇,这个最厉害了!节省大量人力
蜘蛛侠(图片来自网络)
三、简单爬虫的养成
小白:爬虫好用,我也想写一个试试看,请告诉我怎么做~
大东:爬虫一般有两种工作方式:一种是模拟真实用户,在页面上操作;另一种是向网站发起HTTP请求,直接获取整个页面的内容。
小白:哦~第一个我知道。您可以使用软件测试工具来模拟用户的浏览和点击操作。比如在python语言中,Selenium就是一个可以用来模拟用户操作的包,加上lxml包。定位网页的相框简直完美~
大东:没想到小白也有经验。
小白:嘻嘻嘻,你不像人啊~
大东:另外一种方式,同样以python语言为例,就是程序先使用HTTP库向目标网站发起请求,等待服务器响应。如果服务器能正常响应,程序就可以收到一个Response。这个Response中的内容就是要获取的页面的内容。它可能有 HTML、Json 字符串、二进制和其他类型的数据。程序需要不断地对内容进行解析和提取,最终得到需要的信息。
小白:也好听~
大东:一般来说,第二种方法比第一种更有效。
小白:好!今晚可以回去写爬虫了~
大东:爬虫程序一般分为几个模块,分别负责不同的功能。简单来说,爬虫调度端就是用来控制和监控爬虫的运行;URL管理器管理要爬取的目标网站URL和已经爬取过的URL;网页下载器从 URL 管理从浏览器中的 URL 下载网页并生成字符串;网页解析器需要解析网页下载器完成的内容。一方面解析出有用的价值数据,另一方面取出网页中的链接发送给URL管理器。.
小白:哇,小爬虫分工有条不紊~
爬虫程序的基本流程(图片来自网络)
四、防爬技术
小白:大冬冬,我有一个问题。总有一些同学不愿意轻易分享他的劳动成果,所以就不要让别人看到他的功课。但是在这个网络上,网站 是公开的,任何人都可以看到它。如果我不想让别人复制它怎么办?
大东:有爬虫技术,当然还有反爬虫技术。
小白:听前排讲课~
大东:据我所知,目前的防爬技术大致分为四种。最经典的反爬策略是“验证码”。
小白:我知道~是永远不会失败的反人类验证码吗!
大东:是的,因为验证码是图片,所以用户只需要输入一次就可以登录成功。程序在抓取数据的过程中,需要不断的登录,抓取1000个用户的个人信息,需要填写1000个验证码,可以减缓甚至停止程序的爬取过程。
小白:哇,好麻烦。
大东:另一个更狠的反爬策略是封IP和封号。网站一旦某个IP或网站账号被怀疑为爬虫,该账号和IP将立即被封杀,将无法再通过该IP访问网站或占短时间甚至永久。
小白:太残忍了!
大东:比较常见的是通过cookies来限制信息的抓取。比如程序模拟登录后,如果想获取登录后某个页面的信息,需要请求一些中间页面获取特定的cookie,然后就可以抓取我们需要的页面了。
小白:操作比较复杂。
大东:另一种常见的反爬模式是使用JS渲染页面。这是什么意思?返回的页面不是直接请求的,而是JS操作数据文件得到的一部分,而那部分数据我们也拿不到。
小白:看来大家都在尽力防止自己的“作业”被抄袭了!
大东:所以小白,从现在开始,不管是你还是你的同学,好好做好功课。想要通过抄袭取得好成绩,迟早会有“报应”!
小白:那一定要做好~
对峙(图片来自网络)
抓取jsp网页源代码(如何提高网站百度蜘蛛量量?(组图)期)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-02-06 15:13
阿里云 > 云栖社区 > 主题图 > W>网站 js css 代码抓取
推荐活动:
更多优惠>
当前话题:网站js css代码爬取加入采集
相关话题:
网站js css代码抓取相关博文看更多博文
编写现代 CSS 代码的 20 个技巧
作者:迟到991人查看评论:04年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.sq
阅读全文
编写现代 CSS 代码的 20 个技巧
作者:熊哥 club903 浏览评论:05年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.
阅读全文
CSS黑魔法,让你少写不必要的JS,代码更优雅
作者:沃克·武松 1735观众评论:04年前
前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术,伪装指南,高级代码,让你惊叹不已。没想到会受到大家的欢迎。有人希望做博主我也可以整理出一些CSS的黑魔法,可惜我的CSS一直是渣渣,我也无计可施。我最近写了一篇Ch
阅读全文
百度网站优化:如何增加蜘蛛爬取量?
作者:蝙蝠侠it1205 浏览评论:03年前
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛的数量之前,我们必须考虑:增加网站的开启速度。百度网站优化:如何增加爬虫
阅读全文
前端面试题总结(HTML和CSS)
作者:赖1681人查看评论:03年前
回顾旧的并保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前是 presto,现在改为 G
阅读全文
加快网站访问的9种方法
作者:迟来凶猛1068人查看评论:04年前
一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
阅读全文
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序
作者:我是小助手2146人查看评论:03年前
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
阅读全文
HTML5 和 CSS3 新特性一览
作者:云栖大讲堂 4140观众评论:03年前
HTML5 和 CSS3 新功能一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
阅读全文
网站js css代码爬取相关问题
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
抓取jsp网页源代码(如何提高网站百度蜘蛛量量?(组图)期)
阿里云 > 云栖社区 > 主题图 > W>网站 js css 代码抓取
推荐活动:
更多优惠>
当前话题:网站js css代码爬取加入采集
相关话题:
网站js css代码抓取相关博文看更多博文
编写现代 CSS 代码的 20 个技巧
作者:迟到991人查看评论:04年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.sq
阅读全文
编写现代 CSS 代码的 20 个技巧
作者:熊哥 club903 浏览评论:05年前
了解什么是 Margin Collapse 与很多其他属性不同的是,box模型中的vertical Margin在它们相遇时会collapse,即当一个元素的bottom Margin与另一个元素的top Margin相邻时,只有两个较大的值of 被保留,这可以从这个简单的例子中学到:.
阅读全文
CSS黑魔法,让你少写不必要的JS,代码更优雅
作者:沃克·武松 1735观众评论:04年前
前不久,因为平时涉猎面比较广,所以总结了一篇博客:这些JavaScript编程黑技术,伪装指南,高级代码,让你惊叹不已。没想到会受到大家的欢迎。有人希望做博主我也可以整理出一些CSS的黑魔法,可惜我的CSS一直是渣渣,我也无计可施。我最近写了一篇Ch
阅读全文
百度网站优化:如何增加蜘蛛爬取量?
作者:蝙蝠侠it1205 浏览评论:03年前
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。这是每一个网站运营经理都必须思考的问题,所以在增加网站百度蜘蛛的数量之前,我们必须考虑:增加网站的开启速度。百度网站优化:如何增加爬虫
阅读全文
前端面试题总结(HTML和CSS)
作者:赖1681人查看评论:03年前
回顾旧的并保持空杯心态 HTML 和 CSS 您在哪些浏览器上测试过您的页面?这些浏览器的内核是什么?浏览器名称 Kernel IE trident Firefox (Firefox) gecko Safari webkit Opera 以前是 presto,现在改为 G
阅读全文
加快网站访问的9种方法
作者:迟来凶猛1068人查看评论:04年前
一、 网站在没有Table的程序中使用DIV+CSS模式。目前,DIV+CSS是主流的编程语言,这与其体积小、加载速度快的优势密不可分。主流的网站和cms也采用这种模式。因此,建议您也使用这种模式进行编程,而不是使用原来的 Table 结构。表结构
阅读全文
使用 Nuxt.js 创建服务器端渲染的 Vue.js 应用程序
作者:我是小助手2146人查看评论:03年前
浏览 网站 时,Vue 等 JavaScript 框架/库可以提供出色的用户体验。大多数都提供了一种动态更改页面内容的方法,而无需每次都向服务器发送请求。但是,这种方法存在问题。当您的 网站 最初加载时,您的浏览器没有收到完整的页面显示。相反,它将一堆文件发送到
阅读全文
HTML5 和 CSS3 新特性一览
作者:云栖大讲堂 4140观众评论:03年前
HTML5 和 CSS3 新功能一览 HTML5 1.HTML5 新元素 HTML5 提供了新元素来创建更好的页面结构:标签描述定义页面上的单独内容区域。定义页面的侧边栏内容。允许您设置一段文本,使其脱离其父级
阅读全文
网站js css代码爬取相关问题
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
抓取jsp网页源代码( 自动化检测函数供检测Url连接连接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-02-04 00:16
自动化检测函数供检测Url连接连接)
python获取网页编码的实现代码
更新时间:2017年3月11日16:26:00投稿时间:lqh
本文文章主要介绍python获取网页编码的代码的相关资料。有需要的朋友可以参考以下
python获取网页编码的实现代码
python开发,自动化获取网页编码方式用到了chardet库,字符集检测,这个类在python2.7中没有,需要在官网上下载。
这里我下载好了chardet-2.3.0.tar.gz压缩包文件,只需要将压缩包文件解压后的chardet文件放到python安装包下的
python27/lib/site-packages/下,就可以了。
然后导入chardet
下面写了一个自动检测函数,检测Url连接,然后返回网页URL的编码方式。
import chardet #字符集检测
import urllib
url="http://www.jd.com"
def automatic_detect(url):
content=urllib.urlopen(url).read()
result=chardet.detect(content)
encoding=result['encoding']
return encoding
urls=['http://www.baidu.com','http://www.163.com','http://dangdang.com']
for url in urls:
print url,automatic_detect(url)
上面使用了chardet类的detect方法,返回一个字典,然后取出编码方法
感谢您的阅读,希望对您有所帮助,感谢您对本站的支持! 查看全部
抓取jsp网页源代码(
自动化检测函数供检测Url连接连接)
python获取网页编码的实现代码
更新时间:2017年3月11日16:26:00投稿时间:lqh
本文文章主要介绍python获取网页编码的代码的相关资料。有需要的朋友可以参考以下
python获取网页编码的实现代码
python开发,自动化获取网页编码方式用到了chardet库,字符集检测,这个类在python2.7中没有,需要在官网上下载。
这里我下载好了chardet-2.3.0.tar.gz压缩包文件,只需要将压缩包文件解压后的chardet文件放到python安装包下的
python27/lib/site-packages/下,就可以了。
然后导入chardet
下面写了一个自动检测函数,检测Url连接,然后返回网页URL的编码方式。
import chardet #字符集检测
import urllib
url="http://www.jd.com"
def automatic_detect(url):
content=urllib.urlopen(url).read()
result=chardet.detect(content)
encoding=result['encoding']
return encoding
urls=['http://www.baidu.com','http://www.163.com','http://dangdang.com']
for url in urls:
print url,automatic_detect(url)
上面使用了chardet类的detect方法,返回一个字典,然后取出编码方法
感谢您的阅读,希望对您有所帮助,感谢您对本站的支持!
抓取jsp网页源代码(#这里需要正则匹配jsp页面源代码的内容#进行解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-03 22:02
抓取jsp网页源代码来进行数据抓取,不过网上有很多css库提供jsp中的css引用,有些我也在自己写,最后还是放弃了,因为jsp本身的可读性并不好,我改进了下smarty+iocp抓取jsp代码,或许你也可以用它来完成爬取jsp的目的。frombs4importbeautifulsoupurl=''#这里需要正则匹配jsp页面源代码的内容req=requests.get(url)resp=req.text#进行解析这里我们没有需要转换过的jsp页面,只需要浏览器的cookie之类的对我们在大部分的情况下都是没有用的,因为在爬取某些不那么正规的jsp页面时还会涉及到兼容性的问题。
再上面最开始我提到了需要正则匹配,相信很多同学都会去了解,也尝试去实践过去实现过,比如有道词典等等有词典匹配可以对英文进行匹配,它的兼容性也可以保证,但是就没有抓取其他语言的页面了,有时间再学其他语言吧。在chrome下进行抓取不太方便,而浏览器内置的beautifulsoup也未采用正则匹配,我特意去下载了支持正则匹配的代码提取工具来使用。
本次我用到的工具如下,下载链接如下#contenttype是html(大部分支持正则匹配)url='/'resp=req.text在beautifulsoup的官方文档文档中我就是用了如上代码来抓取网页,但是chrome下不知道为什么不能正则匹配,导致抓取返回的html是空字符串。尝试了其他文本处理工具后都不行,直到我发现了iocp,不仅支持正则匹配而且也可以实现beautifulsoup的正则匹配,于是我就开始尝试用iocp抓取jsp,顺便看看有没有能够解决该问题的工具。
之前通过代码提取抓取后,我是先把jsp文件所在目录上传github,在starteraction中加入对url=''的修改,可以修改为'',这里我只修改了其中两个地方,其中第一个修改为‘’,意为‘根’不能接受request,而第二个修改为‘’意为‘多维的url’。上传starteraction我用的是这个starteraction.jsp在description中加入starteraction.url='',其实这个是可以理解为多级嵌套的starteraction.而文档中有一段关于iocp的介绍,其中iocp允许你嵌套更多的starteraction.这是从html代码下手是无法达到题主要求的效果的,因为我们是使用html代码下手爬取jsp网页,在html代码里如果我们爬取starteraction并且配合beautifulsoup的正则,需要先匹配jsp页面源代码,然后再匹配对应的页面文件.我写了这篇文章本来是想跟大家分享下通过查看jsp源代码来爬取jsp网页的,但是还是未达到我们要求的效果,所以只得放弃,可是代码真的已经写好了,就让其交付他人使。 查看全部
抓取jsp网页源代码(#这里需要正则匹配jsp页面源代码的内容#进行解析)
抓取jsp网页源代码来进行数据抓取,不过网上有很多css库提供jsp中的css引用,有些我也在自己写,最后还是放弃了,因为jsp本身的可读性并不好,我改进了下smarty+iocp抓取jsp代码,或许你也可以用它来完成爬取jsp的目的。frombs4importbeautifulsoupurl=''#这里需要正则匹配jsp页面源代码的内容req=requests.get(url)resp=req.text#进行解析这里我们没有需要转换过的jsp页面,只需要浏览器的cookie之类的对我们在大部分的情况下都是没有用的,因为在爬取某些不那么正规的jsp页面时还会涉及到兼容性的问题。
再上面最开始我提到了需要正则匹配,相信很多同学都会去了解,也尝试去实践过去实现过,比如有道词典等等有词典匹配可以对英文进行匹配,它的兼容性也可以保证,但是就没有抓取其他语言的页面了,有时间再学其他语言吧。在chrome下进行抓取不太方便,而浏览器内置的beautifulsoup也未采用正则匹配,我特意去下载了支持正则匹配的代码提取工具来使用。
本次我用到的工具如下,下载链接如下#contenttype是html(大部分支持正则匹配)url='/'resp=req.text在beautifulsoup的官方文档文档中我就是用了如上代码来抓取网页,但是chrome下不知道为什么不能正则匹配,导致抓取返回的html是空字符串。尝试了其他文本处理工具后都不行,直到我发现了iocp,不仅支持正则匹配而且也可以实现beautifulsoup的正则匹配,于是我就开始尝试用iocp抓取jsp,顺便看看有没有能够解决该问题的工具。
之前通过代码提取抓取后,我是先把jsp文件所在目录上传github,在starteraction中加入对url=''的修改,可以修改为'',这里我只修改了其中两个地方,其中第一个修改为‘’,意为‘根’不能接受request,而第二个修改为‘’意为‘多维的url’。上传starteraction我用的是这个starteraction.jsp在description中加入starteraction.url='',其实这个是可以理解为多级嵌套的starteraction.而文档中有一段关于iocp的介绍,其中iocp允许你嵌套更多的starteraction.这是从html代码下手是无法达到题主要求的效果的,因为我们是使用html代码下手爬取jsp网页,在html代码里如果我们爬取starteraction并且配合beautifulsoup的正则,需要先匹配jsp页面源代码,然后再匹配对应的页面文件.我写了这篇文章本来是想跟大家分享下通过查看jsp源代码来爬取jsp网页的,但是还是未达到我们要求的效果,所以只得放弃,可是代码真的已经写好了,就让其交付他人使。
抓取jsp网页源代码(一下动态网页的一些特点:1.动态Web的最大特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-02-01 22:00
2021-04-23静态网页
关于静态网页,我想很多人都按字面理解,按字面意思理解。如果是这样,那就错了。
所谓“静态”,是指一旦网页准备好并上传到服务器,无论谁访问该网页,都会呈现相同的效果。而这个静态网页可以收录动态元素,比如gif动画、滚动字幕等。
如果要修改网页,则需要修改源代码并再次上传到服务器。
当我们使用 Hexo+GitPages 构建个人博客时,我们使用的是静态网页。
比如你有一个这样的个人博客,无论谁访问你的博客,显示的内容都是一样的。
那么我们来看看静态网页的一些特点:
1. 主要包括一些HTML页面。网页中没有程序代码,只有HTML标签,后缀为.htm或.html。
2.无法实现人机交互;如果要修改网页,必须修改源代码并重新上传,需要大量维护。
动态网页
也不要从字面上理解,动态网页也可以是纯文本。
但是,动态网页可以根据不同的时间和不同的浏览者显示不同的信息。例如,博客下方的评论,或留言板等。
虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合。
那么我们来看看动态网页的一些特点:
1.网页收录程序代码和脚本,利用ASP、PHP、JSP等技术动态生成网页,以扩展名.asp、.php、.jsp存储在服务器端,收录需要执行的程序。
2.Dynamic Web 最大的特点是它的交互性。
分类:
技术要点:
相关文章: 查看全部
抓取jsp网页源代码(一下动态网页的一些特点:1.动态Web的最大特点)
2021-04-23静态网页
关于静态网页,我想很多人都按字面理解,按字面意思理解。如果是这样,那就错了。
所谓“静态”,是指一旦网页准备好并上传到服务器,无论谁访问该网页,都会呈现相同的效果。而这个静态网页可以收录动态元素,比如gif动画、滚动字幕等。
如果要修改网页,则需要修改源代码并再次上传到服务器。
当我们使用 Hexo+GitPages 构建个人博客时,我们使用的是静态网页。
比如你有一个这样的个人博客,无论谁访问你的博客,显示的内容都是一样的。
那么我们来看看静态网页的一些特点:
1. 主要包括一些HTML页面。网页中没有程序代码,只有HTML标签,后缀为.htm或.html。
2.无法实现人机交互;如果要修改网页,必须修改源代码并重新上传,需要大量维护。
动态网页
也不要从字面上理解,动态网页也可以是纯文本。
但是,动态网页可以根据不同的时间和不同的浏览者显示不同的信息。例如,博客下方的评论,或留言板等。
虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合。
那么我们来看看动态网页的一些特点:
1.网页收录程序代码和脚本,利用ASP、PHP、JSP等技术动态生成网页,以扩展名.asp、.php、.jsp存储在服务器端,收录需要执行的程序。
2.Dynamic Web 最大的特点是它的交互性。
分类:
技术要点:
相关文章:
抓取jsp网页源代码(抓取jsp网页源代码要么进行反编译(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-01-29 09:01
抓取jsp网页源代码要么进行反编译(如果你没反编译过jsp建议你换台电脑查看,或者用一个代码生成器如phpexcel,通过phpexcel可以生成jsp可以调用的代码),要么用封装jsp的jstl模板引擎。
有第三方包jsplayer.jsp可以生成jsphtml。如果你想往网页里面嵌入html,其实可以实现的。
可以在html模板里加css,
源码是xml格式,
boostjs里对jsp的写法有提示,然后nodejs也可以转
要把源码转换成java可以调用的代码,关键要看原来的jsp是什么类型,如果是基于jsp的java开发库这种形式的话,如jstl,jsppack等,那么你可以从这些库里寻找你需要的,如果你是java的话,那只能jsp转换为java开发库里的html文件形式的源码,或者对原来的jsp改为struts,action,spring等这些基于jsp的应用。
boost库,
正好刚下了jspviewer(angularjs网页代码代码生成工具)。看起来和网页生成器类似,你这么做可以先把源码转换,看看原来的jsp内容生成代码,
代码生成jsp要用到:boostjs,ng-boost,web.service等
你可以把网页打包成jsp转换成java的代码 查看全部
抓取jsp网页源代码(抓取jsp网页源代码要么进行反编译(图))
抓取jsp网页源代码要么进行反编译(如果你没反编译过jsp建议你换台电脑查看,或者用一个代码生成器如phpexcel,通过phpexcel可以生成jsp可以调用的代码),要么用封装jsp的jstl模板引擎。
有第三方包jsplayer.jsp可以生成jsphtml。如果你想往网页里面嵌入html,其实可以实现的。
可以在html模板里加css,
源码是xml格式,
boostjs里对jsp的写法有提示,然后nodejs也可以转
要把源码转换成java可以调用的代码,关键要看原来的jsp是什么类型,如果是基于jsp的java开发库这种形式的话,如jstl,jsppack等,那么你可以从这些库里寻找你需要的,如果你是java的话,那只能jsp转换为java开发库里的html文件形式的源码,或者对原来的jsp改为struts,action,spring等这些基于jsp的应用。
boost库,
正好刚下了jspviewer(angularjs网页代码代码生成工具)。看起来和网页生成器类似,你这么做可以先把源码转换,看看原来的jsp内容生成代码,
代码生成jsp要用到:boostjs,ng-boost,web.service等
你可以把网页打包成jsp转换成java的代码

