
动态网页抓取
动态网页抓取( 如何把网站的排名提上去又能使网站排名变得稳定)
网站优化 • 优采云 发表了文章 • 0 个评论 • 379 次浏览 • 2022-03-04 10:18
如何把网站的排名提上去又能使网站排名变得稳定)
在网站建设前期,很多公司只想着如何提升网站的排名,到了后期却绞尽脑汁想着如何稳定网站的排名. 很多SEOER在排名网站的过程中遇到了一个很尴尬的情况:努力把关键词优化到首页,几天后排名又下降了……那怎么提升网站的排名,稳定网站的排名?随着搜索引擎算法的不断更新,SEO也跟随搜索引擎的不断发展。本期智讯网黄升将与大家分享提升网站排名和稳定网站排名的小技巧:
一、内容更新
首先,一定要保持网站的活跃度,每天都要更新新内容,增加相关新闻或者热点内容,不仅要保持网站的活跃度,还要让< @网站感觉新鲜,意思是说原创有价值的内容;其次是网站内容更新的规律性,应该与蜘蛛定期定量地形成,方便搜索引擎蜘蛛的索引。
二、内链构建
内部链接优化是网站优化中的常用技术。做好内链可以提高关键词的排名,增加内页的权重,引导蜘蛛爬取更多的页面,提升用户体验。因此,内部链接的建设,现场优化起着至关重要的作用。
三、优质外链
为了稳定关键词的排名,外链的作用不可小觑。外链可以引导蜘蛛抓取网站,给网站传递权重,增加网站的曝光度,吸引用户点击,前提必须是优质的外链,垃圾邮件外部链接将被搜索引擎阻止。
四、检查死链接
定期检查 网站 的死链接。如果网站中有大量死链接,会影响蜘蛛索引网站的效果,从而影响搜索引擎对网站的判断,所以做好404页面,或使用 301 重定向到新的目标 URL。
五、服务器稳定性
服务器的稳定性是网站排名的保证。如果服务器不稳定,网站往往无法正常访问,这将严重影响用户体验并使搜索引擎降低收录、权重和关键词的排名,不仅提高服务器的稳定性,还要注意安全。
六、搜索引擎动态
既然做搜索引擎优化,一定要时刻关注搜索引擎算法的调整,增加了哪些新规则。根据搜索引擎算法,调整网站的SEO优化,关键词的排名会越来越高哦,不注意不懂算法, 网站 优化无法调整。
只有网站的排名提高并稳定下来,才能为公司带来更多的流量,更广泛地宣传企业形象,挖掘潜在客户,实现网站的最大价值。
新闻标题:网站优化:稳定网站排名的技巧
新闻链接:
本FAQ文章由网站Construction_Guangzhou网站Construction__智讯网络原创撰写,转载请保留此地址!
转载请注明,转载来自广州智讯网。感谢您的浏览和支持。祝您生活愉快!
标签: 查看全部
动态网页抓取(
如何把网站的排名提上去又能使网站排名变得稳定)

在网站建设前期,很多公司只想着如何提升网站的排名,到了后期却绞尽脑汁想着如何稳定网站的排名. 很多SEOER在排名网站的过程中遇到了一个很尴尬的情况:努力把关键词优化到首页,几天后排名又下降了……那怎么提升网站的排名,稳定网站的排名?随着搜索引擎算法的不断更新,SEO也跟随搜索引擎的不断发展。本期智讯网黄升将与大家分享提升网站排名和稳定网站排名的小技巧:
一、内容更新
首先,一定要保持网站的活跃度,每天都要更新新内容,增加相关新闻或者热点内容,不仅要保持网站的活跃度,还要让< @网站感觉新鲜,意思是说原创有价值的内容;其次是网站内容更新的规律性,应该与蜘蛛定期定量地形成,方便搜索引擎蜘蛛的索引。
二、内链构建
内部链接优化是网站优化中的常用技术。做好内链可以提高关键词的排名,增加内页的权重,引导蜘蛛爬取更多的页面,提升用户体验。因此,内部链接的建设,现场优化起着至关重要的作用。
三、优质外链
为了稳定关键词的排名,外链的作用不可小觑。外链可以引导蜘蛛抓取网站,给网站传递权重,增加网站的曝光度,吸引用户点击,前提必须是优质的外链,垃圾邮件外部链接将被搜索引擎阻止。
四、检查死链接
定期检查 网站 的死链接。如果网站中有大量死链接,会影响蜘蛛索引网站的效果,从而影响搜索引擎对网站的判断,所以做好404页面,或使用 301 重定向到新的目标 URL。
五、服务器稳定性
服务器的稳定性是网站排名的保证。如果服务器不稳定,网站往往无法正常访问,这将严重影响用户体验并使搜索引擎降低收录、权重和关键词的排名,不仅提高服务器的稳定性,还要注意安全。
六、搜索引擎动态
既然做搜索引擎优化,一定要时刻关注搜索引擎算法的调整,增加了哪些新规则。根据搜索引擎算法,调整网站的SEO优化,关键词的排名会越来越高哦,不注意不懂算法, 网站 优化无法调整。
只有网站的排名提高并稳定下来,才能为公司带来更多的流量,更广泛地宣传企业形象,挖掘潜在客户,实现网站的最大价值。
新闻标题:网站优化:稳定网站排名的技巧
新闻链接:
本FAQ文章由网站Construction_Guangzhou网站Construction__智讯网络原创撰写,转载请保留此地址!
转载请注明,转载来自广州智讯网。感谢您的浏览和支持。祝您生活愉快!
标签:
动态网页抓取(做网站优化增加索引是增加关键词排名和提升流量的基础 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-03-04 10:16
)
众所周知,做网站优化,增加索引,是提升关键词排名,增加流量的基础。为了增加蜘蛛对页面的抓取量,百度蜘蛛只有广大站长知道。蜘蛛一般爬得更深,没有给蜘蛛收录的页面会更多。对于新站点来说,权重达到1比较容易,但是进一步增加权重就比较困难了,那么如何吸引蜘蛛爬取页面呢?
1、创建站点地图
大多数网站管理员都熟悉 网站 地图的使用。站点地图可以方便搜索引擎蜘蛛抓取网站页面,引导搜索引擎蜘蛛,增加网站重要内容页面收录。指向动态页面或以其他方式难以访问的页面。因此,为了增加百度蜘蛛抓取网站的频率,网站站长需要定期将公司网站链接放入站点地图,直接提交给百度。
2、文章更新频率
<p>从SEO的角度来看,站长每天更新文章有助于增加收录的量,收录是获取流量的基础,百度蜘蛛爬虫会来 查看全部
动态网页抓取(做网站优化增加索引是增加关键词排名和提升流量的基础
)
众所周知,做网站优化,增加索引,是提升关键词排名,增加流量的基础。为了增加蜘蛛对页面的抓取量,百度蜘蛛只有广大站长知道。蜘蛛一般爬得更深,没有给蜘蛛收录的页面会更多。对于新站点来说,权重达到1比较容易,但是进一步增加权重就比较困难了,那么如何吸引蜘蛛爬取页面呢?
1、创建站点地图
大多数网站管理员都熟悉 网站 地图的使用。站点地图可以方便搜索引擎蜘蛛抓取网站页面,引导搜索引擎蜘蛛,增加网站重要内容页面收录。指向动态页面或以其他方式难以访问的页面。因此,为了增加百度蜘蛛抓取网站的频率,网站站长需要定期将公司网站链接放入站点地图,直接提交给百度。
2、文章更新频率
<p>从SEO的角度来看,站长每天更新文章有助于增加收录的量,收录是获取流量的基础,百度蜘蛛爬虫会来
动态网页抓取( 借助Chrome浏览器的开发者项目,从分析网站架构开始)
网站优化 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2022-03-03 01:13
借助Chrome浏览器的开发者项目,从分析网站架构开始)
Python爬虫——Scrapy框架(项目实战)——爬取动态页面
写在前面
经过前面的学习,对Scrapy框架有了一定的了解,也写了很多基础爬虫,不过这些都是基于自己掌握的知识,也就是会爬。今天尝试一个新的挑战,借助这个机会,我转战股票基金领域,通过分析网站的结构,开始了一个不知名的爬虫项目。
免责声明:本次爬取的网站为东方财富网,所有获取的数据仅用于学术分析,不得用于商业用途。
爬虫目标
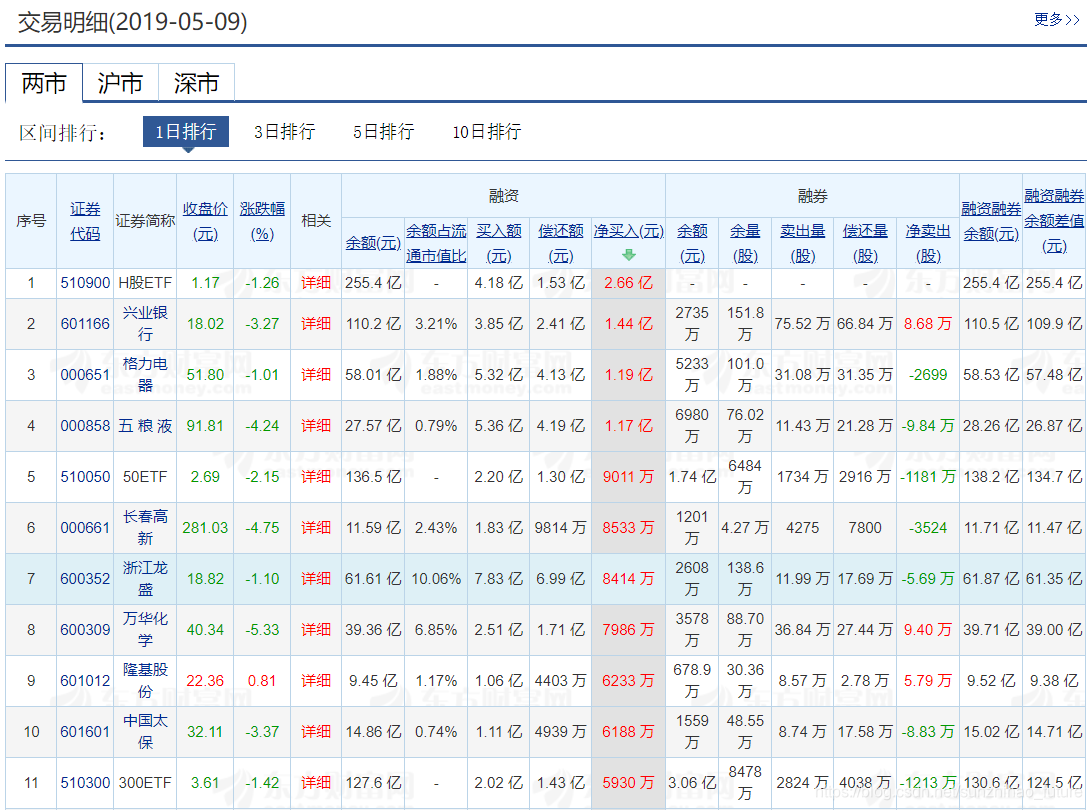
整个项目的主要目的是爬取东方财富网提供的各类证券融资融券的相关数据。我们要抓取过去六个月所有证券的每日收盘价、保证金余额和保证金差额。
当您来到东方财富网-融资融券,您会发现我们可以在下图所示部分获取所有证券信息。点击每只证券后,您可以进一步获取该证券每日的详细融资融券信息。
抓取动态加载的页面 动态加载的页面
如果你在浏览网站的时候注意网页的加载方式,你可能会发现两种常见的情况:一种是网页会加载一段时间,然后网页的所有内容一起显示;另一个是网页会加载一段时间。打开速度很快,但是网页中的内容是部分加载的。这种情况就是所谓的动态加载页面。
动态加载是通过ajax请求接口获取数据,并在网页上进行染色。当然,对于像我这样的新手,我不知道ajax是什么。让我们用 Chrome 浏览器的开发者工具来观察一些神奇的东西。
这是这个爬虫项目要爬取的网站。我暂时不关心我要爬取的数据在哪里。到开发者工具的网络选项,会发现这里暂时没有内容。
接下来,刷新页面,也就是通常意义上的重新加载页面。你会发现这里有很多内容。这些是加载页面时动态加载的内容。
我可以以原创方式抓取这个 网站 吗?
这里我们简单的使用命令行程序通过shell命令来演示,如果我们用原来的方法爬取这个网站,会不会爬到想要的数据。
以上是shell得到的响应。很明显,和我们预想的有很大出入,我们想要获取的数据并没有被爬取。这也表明包括该部分在内的许多元素是动态加载的。
另一种方式
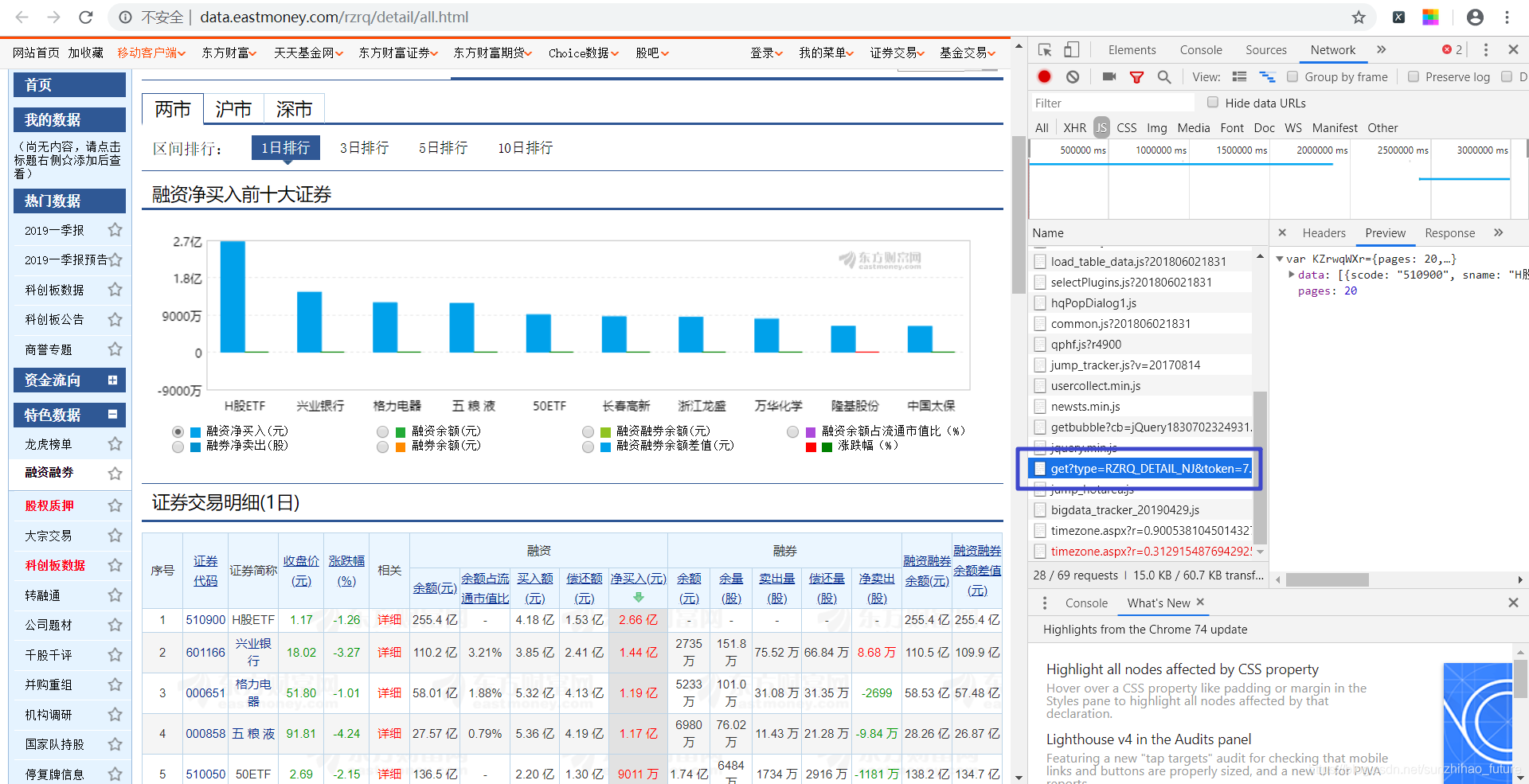
首先点击查看更多数据进入证券交易详情页面。接下来,从所有刚刚动态加载的内容中寻找我们想要的数据。虽然我们不知道它会是什么类型的数据,但如果不出意外,它肯定会出现在这里。经过不懈的搜索,我找到了以下文件。
通过预览,我们可以预览内容,发现data里面存储的数据正是我们想要的数据。
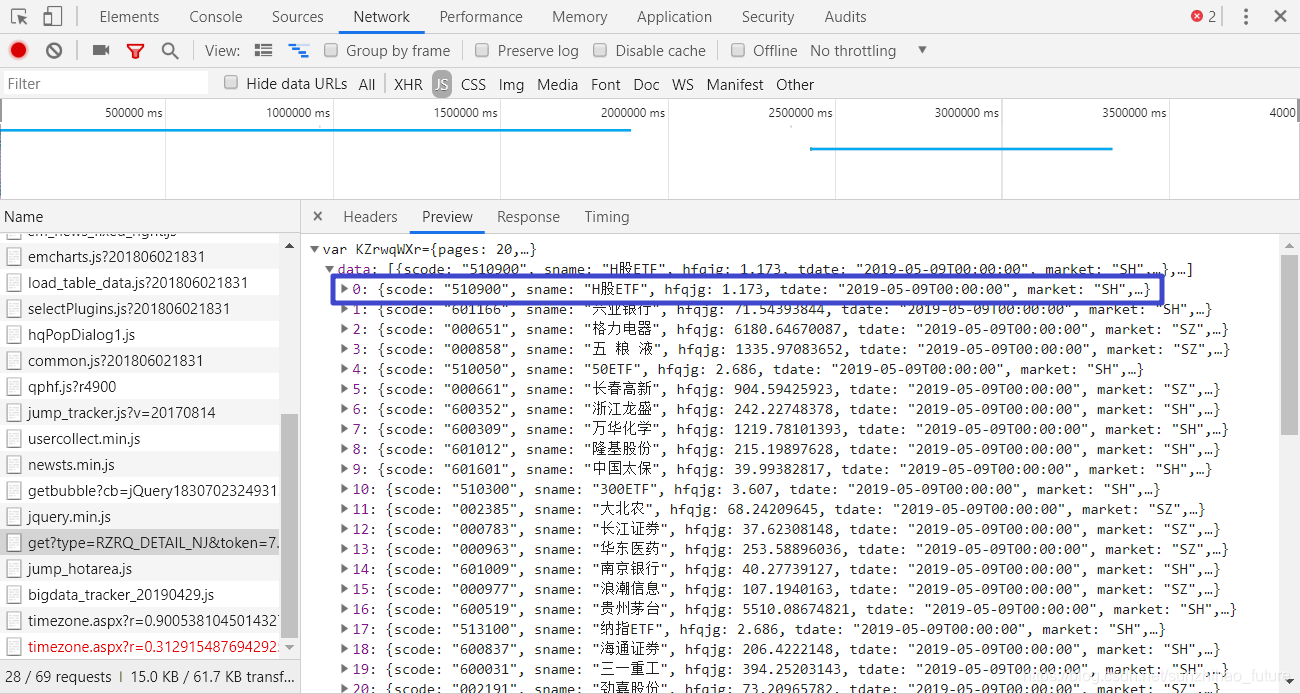
右键单击文件并选择在新选项卡中打开。突然,我意识到这实际上是一个 Json 格式的文件。这很简单。我们只需要抓取这个页面。
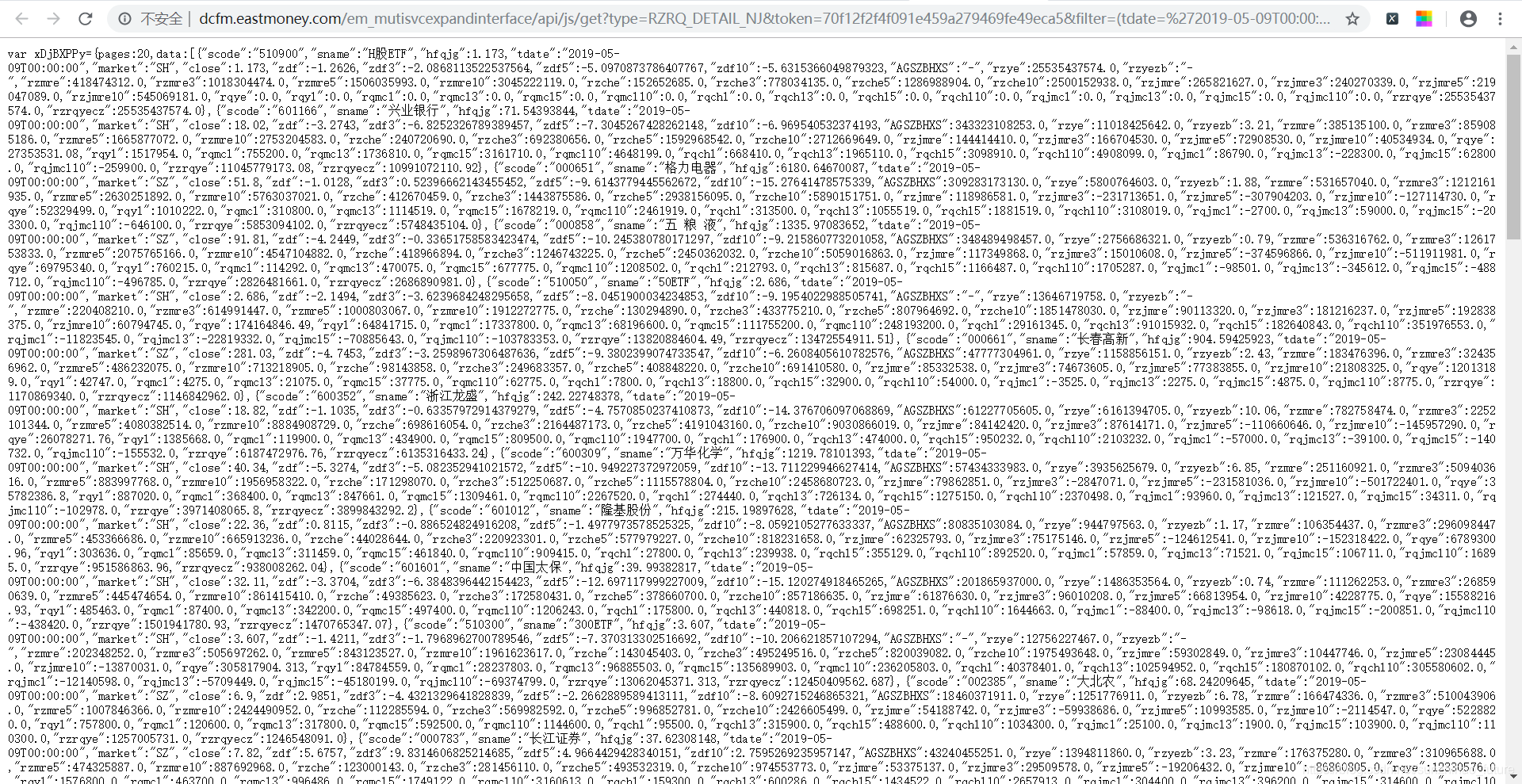
接下来按照原来的思路,分析一下这个比较长的url地址。
(tdate='2019-05-09T00:00:00')&st=rzjmre&sr=-1&p=1&ps=50&js=var xDjBXPPy={pages:(tp),data:(x)}&type=RZRQ_DETAIL_NJ&time=1&rt=51916124
尝试改变url地址中不同部分的值,你会发现p代表页数,ps代表每页显示的数据个数,那么这里我们把ps的值改成997,让它变成一页所有的数据都显示在里面,方便我们爬取。
Json数据的处理
通过爬虫直接爬取这个页面,得到Json类型的数据。显然,不能直接用python语言处理。这里使用json包中的decode函数对Json数据进行解码。
datas = response.body.decode('UTF-8')
接下来,我们可以利用字典和列表的知识继续对数据进行进一步的处理,然后得到我们需要的所有信息。
综上所述
事实上,整个项目在这里并没有达到最初的目标,但最困难的问题已经解决了。接下来的操作可以利用我们之前的思路,从当前页面获取每一个证券的scode,然后拼接得到一个新的。url,进一步获取每天的详细数据,最终达到目的。
由于种种原因,我这次没有提供很多源码,只是更详细的解释了原理。如果您遇到这方面的问题并阅读此文章 仍然无法解决,请通过电子邮件与我联系。愿意尽我所能提供帮助,希望共同进步。 查看全部
动态网页抓取(
借助Chrome浏览器的开发者项目,从分析网站架构开始)
Python爬虫——Scrapy框架(项目实战)——爬取动态页面
写在前面
经过前面的学习,对Scrapy框架有了一定的了解,也写了很多基础爬虫,不过这些都是基于自己掌握的知识,也就是会爬。今天尝试一个新的挑战,借助这个机会,我转战股票基金领域,通过分析网站的结构,开始了一个不知名的爬虫项目。
免责声明:本次爬取的网站为东方财富网,所有获取的数据仅用于学术分析,不得用于商业用途。
爬虫目标
整个项目的主要目的是爬取东方财富网提供的各类证券融资融券的相关数据。我们要抓取过去六个月所有证券的每日收盘价、保证金余额和保证金差额。
当您来到东方财富网-融资融券,您会发现我们可以在下图所示部分获取所有证券信息。点击每只证券后,您可以进一步获取该证券每日的详细融资融券信息。
抓取动态加载的页面 动态加载的页面
如果你在浏览网站的时候注意网页的加载方式,你可能会发现两种常见的情况:一种是网页会加载一段时间,然后网页的所有内容一起显示;另一个是网页会加载一段时间。打开速度很快,但是网页中的内容是部分加载的。这种情况就是所谓的动态加载页面。
动态加载是通过ajax请求接口获取数据,并在网页上进行染色。当然,对于像我这样的新手,我不知道ajax是什么。让我们用 Chrome 浏览器的开发者工具来观察一些神奇的东西。
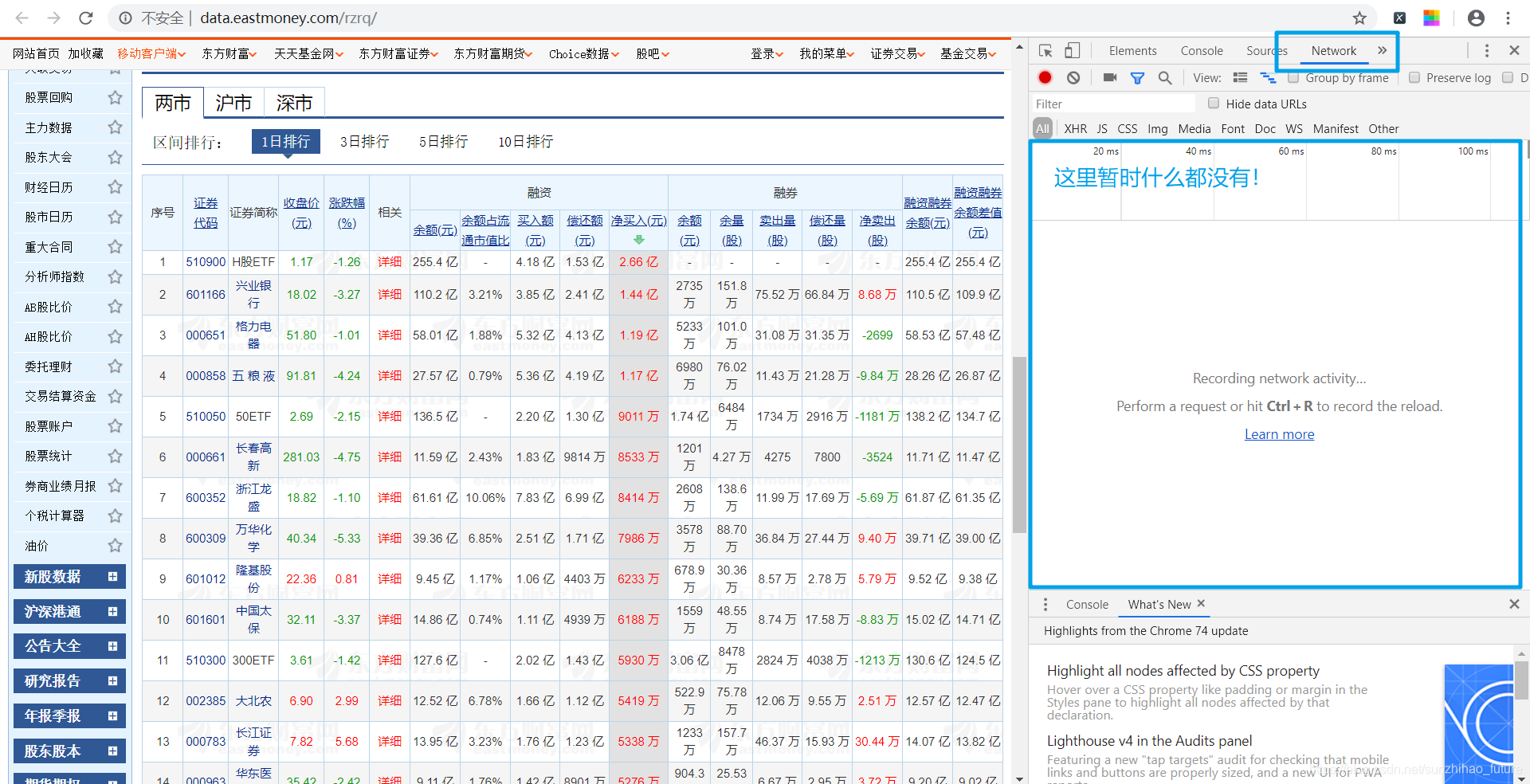
这是这个爬虫项目要爬取的网站。我暂时不关心我要爬取的数据在哪里。到开发者工具的网络选项,会发现这里暂时没有内容。
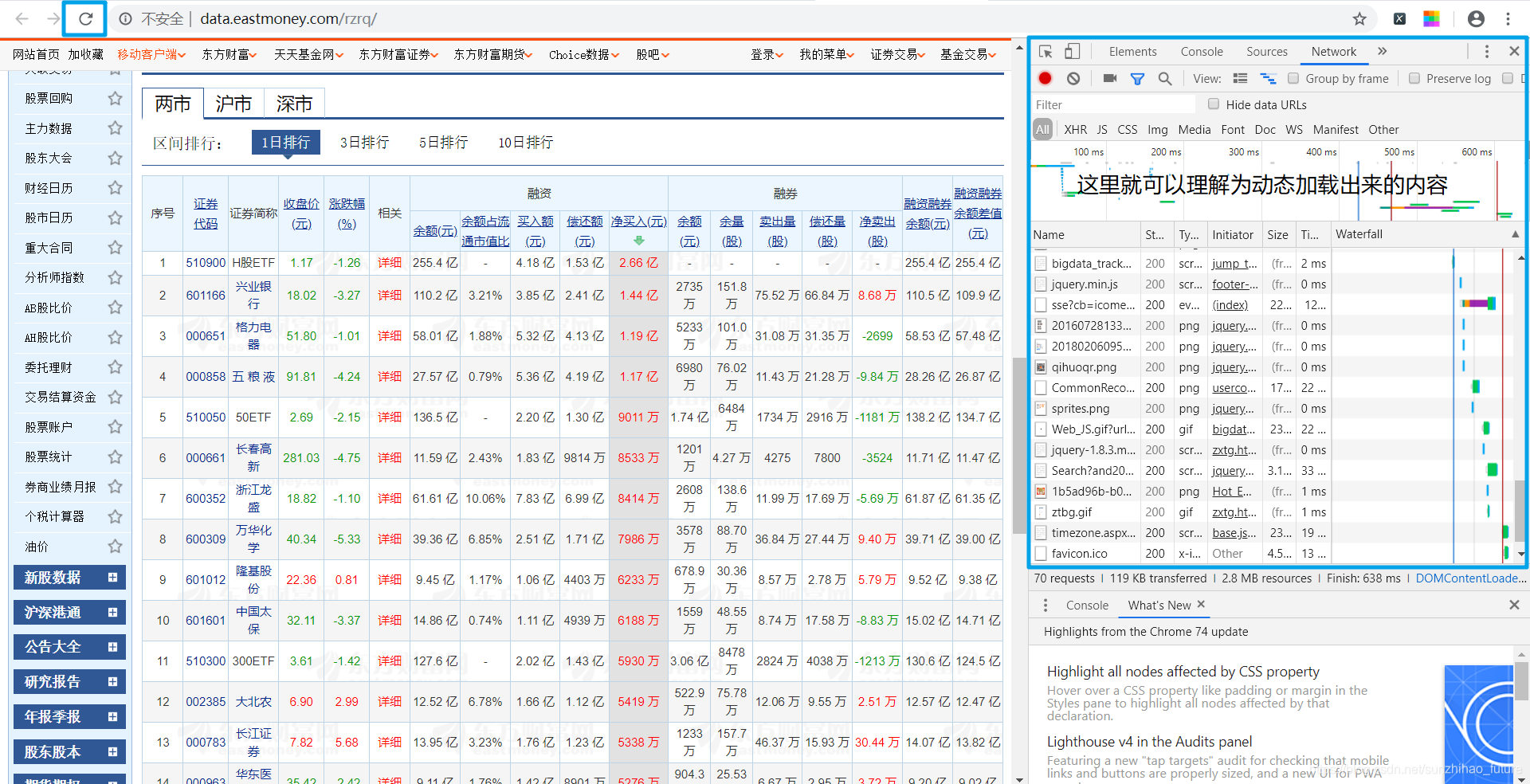
接下来,刷新页面,也就是通常意义上的重新加载页面。你会发现这里有很多内容。这些是加载页面时动态加载的内容。
我可以以原创方式抓取这个 网站 吗?
这里我们简单的使用命令行程序通过shell命令来演示,如果我们用原来的方法爬取这个网站,会不会爬到想要的数据。

以上是shell得到的响应。很明显,和我们预想的有很大出入,我们想要获取的数据并没有被爬取。这也表明包括该部分在内的许多元素是动态加载的。
另一种方式
首先点击查看更多数据进入证券交易详情页面。接下来,从所有刚刚动态加载的内容中寻找我们想要的数据。虽然我们不知道它会是什么类型的数据,但如果不出意外,它肯定会出现在这里。经过不懈的搜索,我找到了以下文件。
通过预览,我们可以预览内容,发现data里面存储的数据正是我们想要的数据。
右键单击文件并选择在新选项卡中打开。突然,我意识到这实际上是一个 Json 格式的文件。这很简单。我们只需要抓取这个页面。
接下来按照原来的思路,分析一下这个比较长的url地址。
(tdate='2019-05-09T00:00:00')&st=rzjmre&sr=-1&p=1&ps=50&js=var xDjBXPPy={pages:(tp),data:(x)}&type=RZRQ_DETAIL_NJ&time=1&rt=51916124
尝试改变url地址中不同部分的值,你会发现p代表页数,ps代表每页显示的数据个数,那么这里我们把ps的值改成997,让它变成一页所有的数据都显示在里面,方便我们爬取。
Json数据的处理
通过爬虫直接爬取这个页面,得到Json类型的数据。显然,不能直接用python语言处理。这里使用json包中的decode函数对Json数据进行解码。
datas = response.body.decode('UTF-8')
接下来,我们可以利用字典和列表的知识继续对数据进行进一步的处理,然后得到我们需要的所有信息。
综上所述
事实上,整个项目在这里并没有达到最初的目标,但最困难的问题已经解决了。接下来的操作可以利用我们之前的思路,从当前页面获取每一个证券的scode,然后拼接得到一个新的。url,进一步获取每天的详细数据,最终达到目的。
由于种种原因,我这次没有提供很多源码,只是更详细的解释了原理。如果您遇到这方面的问题并阅读此文章 仍然无法解决,请通过电子邮件与我联系。愿意尽我所能提供帮助,希望共同进步。
动态网页抓取(静态网站的优缺点分析:非常利于搜索引擎的收录和抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-03-03 01:05
静态网站优缺点分析:对搜索引擎收录和爬取非常有利;动态网站优缺点分析:网站交互性很强;动态网站转换静态网站需要注意的问题
图 27962-1:
网站的发展已经从静态到动态,现在又从动态回归到新静态。随着搜索引擎对网站的影响越来越大,越来越多的站长开始选择动态的网站静态的,因为静态网页很容易被搜索引擎和收录抓取,这对提高网站的权重和排名有很大的帮助,但是作者却发现很多站长在将动态的网站转换成静态的网站后,发现自己的网站实际上是K。这是什么原因?可见动态网站静态化并不是一件容易的事,很多问题需要注意!
1:静态网站优缺点分析
static 网站 的优势非常明显。用户的浏览器打开静态 网站 比动态 网站 更快,因为动态 网站 网页需要结合用户参数。,然后就可以形成对应的页面了。服务器速度和网速会严重影响动态网站的访问速度,而静态网站网页已经在服务器上可用,用户只需提交申请后,静态网页会被下载到浏览器中,也可以被浏览器缓存,这样用户第二次打开时基本不需要再次从服务器下载。可以看出,这个访问速度比动态网站要快。
静态网站的另一个好处是对搜索引擎收录和爬取非常有利。只要能在服务器上的各个静态网页之间形成内链网络,搜索引擎蜘蛛就可以通过收录@网站的首页,遍历整个网站@中的静态网页>,从而实现网站的完整收录,当然为了提高蜘蛛爬网站的速度,很多站长可能会设置ROBOTS.TXT文件来屏蔽一些不必要的收录页面,比如很多公司的联系我们页面网站、支付方式页面等。通过内部链接和ROBOTS.TXT文件的设置,网站@的爬取速度> 可以大大提高。
当然,静态网站的缺点也很明显。如果是很大的网站,尤其是信息网站,如果每个页面都变成静态页面,工作量就会减少。肯定很大,而且对网站的维护也很不利,因为静态的网站没有数据库,每个页面都需要手动检查。如果网站的链接有错误,想要更正,往往需要很长时间才能一一检查!
二:动态网站优缺点分析
动态的优势也非常突出。首先,网站的交互性非常好。现在很多网页游戏都是典型的动态网页。通过交互,可以提高网站的粘性。另外,动态网站对网站的管理非常简单,因为网站几乎都是通过数据库来管理的。其实网站的维护只有操作数据库就可以实现,现在很多免费建站程序都使用这种数据库。该架构非常适合个人站长使用。
不过动态网站的缺点也很明显。首先,随着访问者数量的增加,服务器负载会不断增加,最终访问速度会极慢甚至崩溃。另外,因为是交互设计,那么很容易给黑客留下后门。前段时间很多论坛和社区账号信息被盗,可见动态网站的安全隐患很大。另外,对搜索引擎的亲和力不强,因为动态的网站网页大多是动态形成的,蜘蛛不能很好的抓取,导致网站收录的数量为不高。
三:动态网站转静态网站需要注意的问题
相对来说静态网站的优势比较明显,尤其是对于搜索引擎来说,而现在网站在没有搜索引擎的支持下越来越难成功,所以现在很多站长原本经营动态网站,开始把他们的网站转成静态网站,这样我们就可以同时得到动态网站和静态网站的优势。
然而,在转换的过程中,很多站长都渴望获得成功。通过一些号称可以转换成静态网站的程序,瞬间实现了动态网站的伪静态化。这样的结果就是如前文所述,网站已经完全K了,正确的做法应该是网站的动静结合,换句话说,就是很多网站页面上丰富的关键词@,用户信息页面,网站地图页面,应该使用静态网页,对于网站的大量更新版块,应该是通过静态和动态转换程序完成!
目前,将动态页面转换为静态页面的方法有很多。其中,使用现成的插件最为常见,如Apache HTTP服务器的ISAPI_REWIRITE、IISRewrite、MOD_Rewrite等。这些都是基于正则表达式解析器开发的重写引擎,使用方法也是很简单。简单的。掌握了正确的动静变换方法后,要避免那种瞬间整站的变换,要遵循循序渐进的原则!只有这样,才能避免百度的处罚。 查看全部
动态网页抓取(静态网站的优缺点分析:非常利于搜索引擎的收录和抓取)
静态网站优缺点分析:对搜索引擎收录和爬取非常有利;动态网站优缺点分析:网站交互性很强;动态网站转换静态网站需要注意的问题

图 27962-1:
网站的发展已经从静态到动态,现在又从动态回归到新静态。随着搜索引擎对网站的影响越来越大,越来越多的站长开始选择动态的网站静态的,因为静态网页很容易被搜索引擎和收录抓取,这对提高网站的权重和排名有很大的帮助,但是作者却发现很多站长在将动态的网站转换成静态的网站后,发现自己的网站实际上是K。这是什么原因?可见动态网站静态化并不是一件容易的事,很多问题需要注意!
1:静态网站优缺点分析
static 网站 的优势非常明显。用户的浏览器打开静态 网站 比动态 网站 更快,因为动态 网站 网页需要结合用户参数。,然后就可以形成对应的页面了。服务器速度和网速会严重影响动态网站的访问速度,而静态网站网页已经在服务器上可用,用户只需提交申请后,静态网页会被下载到浏览器中,也可以被浏览器缓存,这样用户第二次打开时基本不需要再次从服务器下载。可以看出,这个访问速度比动态网站要快。
静态网站的另一个好处是对搜索引擎收录和爬取非常有利。只要能在服务器上的各个静态网页之间形成内链网络,搜索引擎蜘蛛就可以通过收录@网站的首页,遍历整个网站@中的静态网页>,从而实现网站的完整收录,当然为了提高蜘蛛爬网站的速度,很多站长可能会设置ROBOTS.TXT文件来屏蔽一些不必要的收录页面,比如很多公司的联系我们页面网站、支付方式页面等。通过内部链接和ROBOTS.TXT文件的设置,网站@的爬取速度> 可以大大提高。
当然,静态网站的缺点也很明显。如果是很大的网站,尤其是信息网站,如果每个页面都变成静态页面,工作量就会减少。肯定很大,而且对网站的维护也很不利,因为静态的网站没有数据库,每个页面都需要手动检查。如果网站的链接有错误,想要更正,往往需要很长时间才能一一检查!
二:动态网站优缺点分析
动态的优势也非常突出。首先,网站的交互性非常好。现在很多网页游戏都是典型的动态网页。通过交互,可以提高网站的粘性。另外,动态网站对网站的管理非常简单,因为网站几乎都是通过数据库来管理的。其实网站的维护只有操作数据库就可以实现,现在很多免费建站程序都使用这种数据库。该架构非常适合个人站长使用。
不过动态网站的缺点也很明显。首先,随着访问者数量的增加,服务器负载会不断增加,最终访问速度会极慢甚至崩溃。另外,因为是交互设计,那么很容易给黑客留下后门。前段时间很多论坛和社区账号信息被盗,可见动态网站的安全隐患很大。另外,对搜索引擎的亲和力不强,因为动态的网站网页大多是动态形成的,蜘蛛不能很好的抓取,导致网站收录的数量为不高。
三:动态网站转静态网站需要注意的问题
相对来说静态网站的优势比较明显,尤其是对于搜索引擎来说,而现在网站在没有搜索引擎的支持下越来越难成功,所以现在很多站长原本经营动态网站,开始把他们的网站转成静态网站,这样我们就可以同时得到动态网站和静态网站的优势。
然而,在转换的过程中,很多站长都渴望获得成功。通过一些号称可以转换成静态网站的程序,瞬间实现了动态网站的伪静态化。这样的结果就是如前文所述,网站已经完全K了,正确的做法应该是网站的动静结合,换句话说,就是很多网站页面上丰富的关键词@,用户信息页面,网站地图页面,应该使用静态网页,对于网站的大量更新版块,应该是通过静态和动态转换程序完成!
目前,将动态页面转换为静态页面的方法有很多。其中,使用现成的插件最为常见,如Apache HTTP服务器的ISAPI_REWIRITE、IISRewrite、MOD_Rewrite等。这些都是基于正则表达式解析器开发的重写引擎,使用方法也是很简单。简单的。掌握了正确的动静变换方法后,要避免那种瞬间整站的变换,要遵循循序渐进的原则!只有这样,才能避免百度的处罚。
动态网页抓取(ajax横行的年代,我们的网页是残缺的吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-01 23:22
)
在ajax时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中包括
跳过js加载部分,表示爬虫抓取的网页不完整,不完整。您可以在下面看到博客园的主页
从首页的加载中可以看出,页面渲染完成后,会有5个异步ajax请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候,如果你想得到它,你必须调用浏览器的内核引擎来下载这些动态页面。目前内核引擎是三足的。
Trident:也就是IE内核,WebBrowser就是基于这个内核,但是加载性能比较差。
Gecko:FF的内核比Trident的性能更好。
WebKit:Safari和Chrome的核心,性能你懂的,在真实场景中还是主要的。
好的,为了简单方便,这里我们使用WebBrowser来玩,使用WebBrowser的时候要注意以下几点:
首先:因为WebBrowser是System.Windows.Forms中的winform控件,所以我们需要设置STAThread标签。
第二:winform是事件驱动的,Console不响应事件,所有事件都在windows的消息队列中等待执行,以防止程序假死,
我们需要调用DoEvents方法来传递控制权,让操作系统执行其他事件。
第三:WebBrowser内容,我们需要使用DomDocument来查看,而不是DocumentText。
判断动态网页是否加载一般有两种方式:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们这里需要这样做
记录计数值
.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们还可以通过设置一个Timer来判断,比如3s、4s、5s,稍后再查看
WEB浏览器是否加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果还是一样的,就不截图了。从以上两种写法来看,我们的WebBrowser放在主线程中。让我们看看如何把它放在工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 } 查看全部
动态网页抓取(ajax横行的年代,我们的网页是残缺的吗?
)
在ajax时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中包括
跳过js加载部分,表示爬虫抓取的网页不完整,不完整。您可以在下面看到博客园的主页

从首页的加载中可以看出,页面渲染完成后,会有5个异步ajax请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候,如果你想得到它,你必须调用浏览器的内核引擎来下载这些动态页面。目前内核引擎是三足的。
Trident:也就是IE内核,WebBrowser就是基于这个内核,但是加载性能比较差。
Gecko:FF的内核比Trident的性能更好。
WebKit:Safari和Chrome的核心,性能你懂的,在真实场景中还是主要的。
好的,为了简单方便,这里我们使用WebBrowser来玩,使用WebBrowser的时候要注意以下几点:
首先:因为WebBrowser是System.Windows.Forms中的winform控件,所以我们需要设置STAThread标签。
第二:winform是事件驱动的,Console不响应事件,所有事件都在windows的消息队列中等待执行,以防止程序假死,
我们需要调用DoEvents方法来传递控制权,让操作系统执行其他事件。
第三:WebBrowser内容,我们需要使用DomDocument来查看,而不是DocumentText。
判断动态网页是否加载一般有两种方式:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们这里需要这样做
记录计数值
.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。

②:当然,除了通过判断最大值来判断加载是否完成,我们还可以通过设置一个Timer来判断,比如3s、4s、5s,稍后再查看
WEB浏览器是否加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果还是一样的,就不截图了。从以上两种写法来看,我们的WebBrowser放在主线程中。让我们看看如何把它放在工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
动态网页抓取(如何抓取网页中的动态网页源码中特定的特定内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-01 23:14
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
【教程】Python版爬网并从网页中提取需要的信息
和
【教程】C#版爬网并从网页中提取需要的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
不熟悉的可以参考:
【组织】爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站
2.学会使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的可以参考:
【教程】教你如何使用工具(IE9的F12)解析模拟登录内部逻辑流程网站(百度首页))
3.对于一个普通的静态网页,如何提取想要的内容
对此不熟悉的可以参考:
(1)Python 版本:
【教程】Python版爬网并从网页中提取需要的信息
(2)C# 版本:
【教程】C#版爬网并从网页中提取需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据你通过工具分析的结果,找到对应的数据并提取出来;
不过这个数据有时候可以在分析结果的过程中直接提取出来,有时候可能是通过js计算出来的。
想抓取数据,是js脚本生成的
虽然最终的动态内容是由js脚本执行生成的,但是对于你要抓取的数据:
想爬取数据是通过访问另一个url获取的
如果你要抓取的对应内容是访问另一个url地址和返回的数据,那么很简单,你也需要访问这个url,然后获取对应的返回内容,从中提取你想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。 查看全部
动态网页抓取(如何抓取网页中的动态网页源码中特定的特定内容)
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
【教程】Python版爬网并从网页中提取需要的信息
和
【教程】C#版爬网并从网页中提取需要的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
不熟悉的可以参考:
【组织】爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站
2.学会使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的可以参考:
【教程】教你如何使用工具(IE9的F12)解析模拟登录内部逻辑流程网站(百度首页))
3.对于一个普通的静态网页,如何提取想要的内容
对此不熟悉的可以参考:
(1)Python 版本:
【教程】Python版爬网并从网页中提取需要的信息
(2)C# 版本:
【教程】C#版爬网并从网页中提取需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据你通过工具分析的结果,找到对应的数据并提取出来;
不过这个数据有时候可以在分析结果的过程中直接提取出来,有时候可能是通过js计算出来的。
想抓取数据,是js脚本生成的
虽然最终的动态内容是由js脚本执行生成的,但是对于你要抓取的数据:
想爬取数据是通过访问另一个url获取的
如果你要抓取的对应内容是访问另一个url地址和返回的数据,那么很简单,你也需要访问这个url,然后获取对应的返回内容,从中提取你想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。
动态网页抓取(3.安装selenium库,可直接用#39;pipinstallselenium#pip )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-01 21:11
)
这个过程比较麻烦,需要分几个步骤来完成。下面将一一介绍:
1. 要安装 selenium 库,您可以直接使用 'pip install selenium' 命令安装它。
2. 下载chromeDriver并将其添加到环境变量中,或者直接将.exe文件放在python安装目录的scripts文件夹中。下载时请务必选择与您的浏览器对应的版本。查看浏览器版本的方法是:右上角->帮助->关于google chrome查看,驱动下载地址为chromedriver下载地址,与chrome版本对应关系为对应关系。验证下载安装是否成功,只需执行下面这段代码,如果没有错误,则安装成功。
import selenium.webdriver as driver
index = driver.Chrome()
index.get('https://www.wdzj.com/dangan')
print(index)
3. Selenium 实现爬虫,定位方法很多,简单介绍一下:
官网地址为:
查找单个元素的方法是:
查找多个元素(返回一个列表)的方法是:
4. 基本功能有了之后,就可以愉快的爬取了(由于还没写,先放一些代码,以后再更新)!
import selenium.webdriver as driver
import xlwt
import types
URL = 'https://www.wdzj.com/dangan/'
# KEYWORD = '银行存管'
def key_word():
# index = driver.Chrome()
# index.get(URL)
# select_data = index.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
# print(index.current_url)
# keyword_index = index.find_element_by_link_text()
# keyword_index.click()
names = []
banks = []
tel_nums = []
urls = []
for i in range(0, 76):
page_url = URL + 'search?filter=e1¤tPage=' + str(i + 1)
index_page = driver.Chrome()
index_page.get(page_url)
select_data = index_page.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
print(index_page.current_url)
for data in select_data:
names.append(data.text)
print(names) #名字
sec_url = data.get_attribute("href")
index_sec = driver.Chrome()
index_sec.get(sec_url)
# print(index_sec.current_url) #链接
yhcg = index_sec.find_element_by_xpath('/html/body/div[10]/div/div[1]/div[1]/dl[1]/dd[2]/div[2]')
banks.append(yhcg.text)
# print(banks) #银行存管
tel_num = index_sec.find_element_by_link_text('联系方式')
tel_num.click()
number = index_sec.find_element_by_xpath('//*[@class="da-lxfs zzfwbox"]/dl[1]/dd[1]/div[2]')
tel_nums.append(number.text)
# print(tel_nums) #客服电话
yuming = index_sec.find_element_by_link_text('工商/备案')
yuming.click()
yu_beian = index_sec.find_element_by_xpath('//*[@class="lcen"]/table/tbody/tr[7]/td[2]')
urls.append(yu_beian.text)
print(urls) #域名
index_sec.close()
# print(page_url)
# next_page = index.find_element_by_link_text('下一页')
# next_page.click()
return names, banks, tel_nums, urls
def xls():
wb = xlwt.Workbook()
ws = wb.add_sheet('numbers')
ws.write(0, 0, '序号')
ws.write(0, 1, '公司名称')
ws.write(0, 2, '银行存管')
ws.write(0, 3, '客服电话')
ws.write(0, 4, '公司域名')
names, banks, tel_nums, urls = key_word()
print(len(names))
for i in range (0, len(names)):
ws.write(i + 1, 0, i+1)
ws.write(i + 1, 1, names[i])
ws.write(i + 1, 2, banks[i])
ws.write(i + 1, 3, tel_nums[i])
ws.write(i + 1, 4, urls[i])
wb.save('D:\\number.xls')
def run():
xls()
run()
改变:
import selenium.webdriver as driver
import xlwt
from xlutils.copy import copy
import xlrd
URL = 'https://www.wdzj.com/dangan/'
# KEYWORD = '银行存管'
def key_word():
names = []
banks = []
tel_nums = []
urls = []
count= 0
wb = xlwt.Workbook()
ws = wb.add_sheet('numbers')
ws.write(0, 0, '序号')
ws.write(0, 1, '公司名称')
ws.write(0, 2, '银行存管')
ws.write(0, 3, '客服电话')
ws.write(0, 4, '公司域名')
wb.save('D:\\number.xls')
for i in range(0, 76):
page_url = URL + 'search?filter=e1¤tPage=' + str(i + 1)
index_page = driver.Chrome()
index_page.get(page_url)
select_data = index_page.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
print(index_page.current_url)
for data in select_data:
names.append(data.text)
print(names) #名字
sec_url = data.get_attribute("href")
index_sec = driver.Chrome()
index_sec.get(sec_url)
# print(index_sec.current_url) #链接
yhcg = index_sec.find_element_by_xpath('//*[@class="bgbox-bt zzfwbox"]/dl/dd/div[@class="r" and contains(text(),"存管")]')
banks.append(yhcg.text)
print(banks) #银行存管
tel_num = index_sec.find_element_by_link_text('联系方式')
tel_num.click()
number = index_sec.find_element_by_xpath('//*[@class="da-lxfs zzfwbox"]/dl[1]/dd[1]/div[2]')
tel_nums.append(number.text)
# print(tel_nums) #客服电话
yuming = index_sec.find_element_by_link_text('工商/备案')
yuming.click()
yu_beian = index_sec.find_element_by_xpath('//*[@class="lcen"]/table/tbody/tr[7]/td[2]')
urls.append(yu_beian.text)
print(urls) #域名
oldWb =xlrd.open_workbook('D:\\number.xls', formatting_info=True)
newWb = copy(oldWb)
news = newWb.get_sheet(0)
news.write(count + 1, 0, count + 1)
news.write(count + 1, 1, names[count])
news.write(count + 1, 2, banks[count])
news.write(count + 1, 3, tel_nums[count])
news.write(count + 1, 4, urls[count])
newWb.save('D:\\number.xls')
print(count)
count+=1
index_sec.close()
index_page.close()
return names, banks, tel_nums, urls
def run():
key_word()
run() 查看全部
动态网页抓取(3.安装selenium库,可直接用#39;pipinstallselenium#pip
)
这个过程比较麻烦,需要分几个步骤来完成。下面将一一介绍:
1. 要安装 selenium 库,您可以直接使用 'pip install selenium' 命令安装它。
2. 下载chromeDriver并将其添加到环境变量中,或者直接将.exe文件放在python安装目录的scripts文件夹中。下载时请务必选择与您的浏览器对应的版本。查看浏览器版本的方法是:右上角->帮助->关于google chrome查看,驱动下载地址为chromedriver下载地址,与chrome版本对应关系为对应关系。验证下载安装是否成功,只需执行下面这段代码,如果没有错误,则安装成功。
import selenium.webdriver as driver
index = driver.Chrome()
index.get('https://www.wdzj.com/dangan')
print(index)
3. Selenium 实现爬虫,定位方法很多,简单介绍一下:
官网地址为:
查找单个元素的方法是:
查找多个元素(返回一个列表)的方法是:
4. 基本功能有了之后,就可以愉快的爬取了(由于还没写,先放一些代码,以后再更新)!
import selenium.webdriver as driver
import xlwt
import types
URL = 'https://www.wdzj.com/dangan/'
# KEYWORD = '银行存管'
def key_word():
# index = driver.Chrome()
# index.get(URL)
# select_data = index.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
# print(index.current_url)
# keyword_index = index.find_element_by_link_text()
# keyword_index.click()
names = []
banks = []
tel_nums = []
urls = []
for i in range(0, 76):
page_url = URL + 'search?filter=e1¤tPage=' + str(i + 1)
index_page = driver.Chrome()
index_page.get(page_url)
select_data = index_page.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
print(index_page.current_url)
for data in select_data:
names.append(data.text)
print(names) #名字
sec_url = data.get_attribute("href")
index_sec = driver.Chrome()
index_sec.get(sec_url)
# print(index_sec.current_url) #链接
yhcg = index_sec.find_element_by_xpath('/html/body/div[10]/div/div[1]/div[1]/dl[1]/dd[2]/div[2]')
banks.append(yhcg.text)
# print(banks) #银行存管
tel_num = index_sec.find_element_by_link_text('联系方式')
tel_num.click()
number = index_sec.find_element_by_xpath('//*[@class="da-lxfs zzfwbox"]/dl[1]/dd[1]/div[2]')
tel_nums.append(number.text)
# print(tel_nums) #客服电话
yuming = index_sec.find_element_by_link_text('工商/备案')
yuming.click()
yu_beian = index_sec.find_element_by_xpath('//*[@class="lcen"]/table/tbody/tr[7]/td[2]')
urls.append(yu_beian.text)
print(urls) #域名
index_sec.close()
# print(page_url)
# next_page = index.find_element_by_link_text('下一页')
# next_page.click()
return names, banks, tel_nums, urls
def xls():
wb = xlwt.Workbook()
ws = wb.add_sheet('numbers')
ws.write(0, 0, '序号')
ws.write(0, 1, '公司名称')
ws.write(0, 2, '银行存管')
ws.write(0, 3, '客服电话')
ws.write(0, 4, '公司域名')
names, banks, tel_nums, urls = key_word()
print(len(names))
for i in range (0, len(names)):
ws.write(i + 1, 0, i+1)
ws.write(i + 1, 1, names[i])
ws.write(i + 1, 2, banks[i])
ws.write(i + 1, 3, tel_nums[i])
ws.write(i + 1, 4, urls[i])
wb.save('D:\\number.xls')
def run():
xls()
run()
改变:
import selenium.webdriver as driver
import xlwt
from xlutils.copy import copy
import xlrd
URL = 'https://www.wdzj.com/dangan/'
# KEYWORD = '银行存管'
def key_word():
names = []
banks = []
tel_nums = []
urls = []
count= 0
wb = xlwt.Workbook()
ws = wb.add_sheet('numbers')
ws.write(0, 0, '序号')
ws.write(0, 1, '公司名称')
ws.write(0, 2, '银行存管')
ws.write(0, 3, '客服电话')
ws.write(0, 4, '公司域名')
wb.save('D:\\number.xls')
for i in range(0, 76):
page_url = URL + 'search?filter=e1¤tPage=' + str(i + 1)
index_page = driver.Chrome()
index_page.get(page_url)
select_data = index_page.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
print(index_page.current_url)
for data in select_data:
names.append(data.text)
print(names) #名字
sec_url = data.get_attribute("href")
index_sec = driver.Chrome()
index_sec.get(sec_url)
# print(index_sec.current_url) #链接
yhcg = index_sec.find_element_by_xpath('//*[@class="bgbox-bt zzfwbox"]/dl/dd/div[@class="r" and contains(text(),"存管")]')
banks.append(yhcg.text)
print(banks) #银行存管
tel_num = index_sec.find_element_by_link_text('联系方式')
tel_num.click()
number = index_sec.find_element_by_xpath('//*[@class="da-lxfs zzfwbox"]/dl[1]/dd[1]/div[2]')
tel_nums.append(number.text)
# print(tel_nums) #客服电话
yuming = index_sec.find_element_by_link_text('工商/备案')
yuming.click()
yu_beian = index_sec.find_element_by_xpath('//*[@class="lcen"]/table/tbody/tr[7]/td[2]')
urls.append(yu_beian.text)
print(urls) #域名
oldWb =xlrd.open_workbook('D:\\number.xls', formatting_info=True)
newWb = copy(oldWb)
news = newWb.get_sheet(0)
news.write(count + 1, 0, count + 1)
news.write(count + 1, 1, names[count])
news.write(count + 1, 2, banks[count])
news.write(count + 1, 3, tel_nums[count])
news.write(count + 1, 4, urls[count])
newWb.save('D:\\number.xls')
print(count)
count+=1
index_sec.close()
index_page.close()
return names, banks, tel_nums, urls
def run():
key_word()
run()
动态网页抓取(怎样行使python中BeautifulSoup举办WEB中Soup抓取中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-01 07:15
爬虫实时更新
互联网是一个绝对大胆的数据来源。不幸的是,如果没有可供下载和说明的易于构建的 CSV 文档,那么绝大多数都是。如果要从大量 网站 中获取数据,则有必要尝试进行网络抓取。
如果你还是初学者,别着急——在数据说明如何使用Beautiful Soup在python中进行网页抓取,我们将介绍如何使用Python从头开始进行网页抓取,并首先回答一些相关的网页抓取常见问题看过的话题。
一旦你掌握了这个概念的窍门,请随意滚动浏览这些元素并直接跳到有关如何在 python 中使用 Beautiful Soup 进行网页抓取的数据说明!
网站 提供的一些数据集可以以 CSV 格式下载或通过应用程序编程接口 (API) 访问。然而,许多具有有效数据的 网站 并没有提供这些简单的选择。
例如,咨询国家统计局的网站。它收录每个位置的最新天气预报,但无法通过 CSV 或 API 访问此天气数据。
如果我们想解释这些数据,或者下载它以用于其他操作,我们将无法复制粘贴完整的内容。网页抓取是一种使我们能够使用编程来完成困难任务的技术。我们将编写一些在 NWS 站点上查找的代码,只获取我们想要使用的数据,并以所需的方式输出它。
在 Data Explains How to Use Beautiful Soup in Python for Web Scraping 中,我们将向您展示如何使用 Python 3 和 Beautiful Soup 库来实现 Web 抓取。我们将从国家统计局获取天气预报,然后使用 pandas 库来托管描述。
在抓取网络时,我们编写代码将请求发送到托管我们指定页面的服务器。通常,我们的代码会像浏览器一样下载页面的源代码。但是,它不是直观地显示页面,而是过滤页面以查找我们指定的 HTML 元素,并提取我们指示它提取的任何内容。
例如,如果我们想从网站中获取H2标签中的所有问题,我们可以编写一些代码来完成它。我们的代码将从其服务器请求 网站 的内容并下载它。然后,它将通过页面的 HTML 查找 H2 标签。一旦找到 H2 标签,它将复制标签内的全文并以我们指定的任何方式输出。
需要注意的一件事:从服务器的角度来看,通过网络抓取请求页面类似于在网络浏览器中加载页面。当我们使用代码提交这些请求时,我们可能会比普通用户更快地“加载”页面,从而迅速耗尽网站所有服务器资源。
可以使用许多其他编程语言执行 Web 抓取。例如,我们还有一个关于使用 R 进行网页抓取的教程。
然而,使用 Python 和 Beautiful Soup 库是最流行的网络抓取技术之一。这意味着一旦你掌握了 Beautiful Soup 的基础知识,就会有大量的教程、操作视频和一些示例代码来帮助你加深知识。
我们将解释如何在 python 中使用 Beautiful Soup 来托管网页抓取端,并介绍一些其他常见的网页抓取问题和答案,但现在是开始了解我们的网页抓取项目的时候了!每个网络抓取项目都应该从回答以下问题开始:
不幸的是,这里没有一个粗略的答案。一些网站知道愿意进行网络抓取。其他人明确禁止这样做。许多 网站 没有以一种或另一种形式提供任何明确的命令。
在抓取任何网站之前,我们应该查看一个条件和条件页面,看看是否有明确的抓取指南。如果有,我们应该跟随他们。如果不是,那么它更像是一个推论。
但是,请记住,网络抓取会消耗主机 网站 上的服务器资源。如果我们只刮一页,就不会造成问题。但是,如果我们的代码每时钟抓取 1,000 页,那么对于 网站all-timers 来说,这很快就会变得昂贵。
因此,除了遵循 网站 上发布的关于全面和一体式采集抓取的明确指南之外,遵循以下最佳实践也是一个很好的目标:
2)学会缓存你抓取的内容,这样在处理用于过滤和描述它的代码时只下载一次,而不是每次运行代码时都重新下载
3)学习使用效果 time.sleep() 在代码中创建暂停,例如避免在太短的时间内发出过多的请求以使不堪重负的服务器瘫痪。
在数据显示如何在python中使用Beautiful Soup进行网页抓取的情况下,NWS数据是海量的,它的术语不禁止网页抓取,所以我们可以继续做。
当我们访问一个网页时,我们的网络浏览器会向网络服务器发出一个请求。此请求称为 GET 请求,因为我们正在从服务器获取文档。然后服务器发回文档,告诉我们的浏览器如何为我们呈现页面。文学分为几种严肃的类型:
浏览器收到完整的文档后,会渲染页面并展示给我们。为了让页面看起来漂亮,幕后发生了很多事情,但是当我们进行网页抓取时,我们不需要担心很多这些问题。在做网页抓取的时候,我们对网页的严肃性很感兴趣,所以我们来看看HTML。
超文本标记语言 (HTML) 是一种用于创建网页的语言。HTML 不是像 Python 那样的编程演讲,而是告诉浏览器如何组织内容的横幅演讲。HTML 使您能够执行与 Microsoft Word 等文字处理器类似的操作 - 粗体文本、创建段落等。由于 HTML 不是一种编程语言,因此它不像 Python 那样复杂。
让我们快速浏览一下 HTML,这样我们就可以有效地进行爬网。HTML 由称为标签的元素组成。最基本的标签是标签。此标志告诉 Web 浏览器其中的所有内容都是 HTML。我们可以使用以下标志来创建一个简单的 HTML 文档:
我们没有在页面中添加任何内容,因此如果我们要在 Web 浏览器中查看 HTML 文档,我们将看不到任何内容:
在 html 标签内,我们放置了另外两个标签,head 标签和 body 标签。网页的主要内容进入body标签。head 标签收录相关的网页标题,以及在网页抓取中通常无效的其他信息:
我们还没有向页面添加任何内容(在 body 标签内),所以我们不再看到任何内容:
正如您在上面可能已经注意到的,我们将 head 和 body 标签放在 html 标签中。在 HTML 中,标签是嵌套的,可以放在其他标签内。
后一个参数是毫秒时间戳。测量的目的是改造缓存。如果你的爬虫没有缓存数据,这个参数可以省略,加起来很简单~
爬虫实时更新 查看全部
动态网页抓取(怎样行使python中BeautifulSoup举办WEB中Soup抓取中)
爬虫实时更新
互联网是一个绝对大胆的数据来源。不幸的是,如果没有可供下载和说明的易于构建的 CSV 文档,那么绝大多数都是。如果要从大量 网站 中获取数据,则有必要尝试进行网络抓取。
如果你还是初学者,别着急——在数据说明如何使用Beautiful Soup在python中进行网页抓取,我们将介绍如何使用Python从头开始进行网页抓取,并首先回答一些相关的网页抓取常见问题看过的话题。
一旦你掌握了这个概念的窍门,请随意滚动浏览这些元素并直接跳到有关如何在 python 中使用 Beautiful Soup 进行网页抓取的数据说明!
网站 提供的一些数据集可以以 CSV 格式下载或通过应用程序编程接口 (API) 访问。然而,许多具有有效数据的 网站 并没有提供这些简单的选择。
例如,咨询国家统计局的网站。它收录每个位置的最新天气预报,但无法通过 CSV 或 API 访问此天气数据。
如果我们想解释这些数据,或者下载它以用于其他操作,我们将无法复制粘贴完整的内容。网页抓取是一种使我们能够使用编程来完成困难任务的技术。我们将编写一些在 NWS 站点上查找的代码,只获取我们想要使用的数据,并以所需的方式输出它。
在 Data Explains How to Use Beautiful Soup in Python for Web Scraping 中,我们将向您展示如何使用 Python 3 和 Beautiful Soup 库来实现 Web 抓取。我们将从国家统计局获取天气预报,然后使用 pandas 库来托管描述。
在抓取网络时,我们编写代码将请求发送到托管我们指定页面的服务器。通常,我们的代码会像浏览器一样下载页面的源代码。但是,它不是直观地显示页面,而是过滤页面以查找我们指定的 HTML 元素,并提取我们指示它提取的任何内容。
例如,如果我们想从网站中获取H2标签中的所有问题,我们可以编写一些代码来完成它。我们的代码将从其服务器请求 网站 的内容并下载它。然后,它将通过页面的 HTML 查找 H2 标签。一旦找到 H2 标签,它将复制标签内的全文并以我们指定的任何方式输出。
需要注意的一件事:从服务器的角度来看,通过网络抓取请求页面类似于在网络浏览器中加载页面。当我们使用代码提交这些请求时,我们可能会比普通用户更快地“加载”页面,从而迅速耗尽网站所有服务器资源。
可以使用许多其他编程语言执行 Web 抓取。例如,我们还有一个关于使用 R 进行网页抓取的教程。
然而,使用 Python 和 Beautiful Soup 库是最流行的网络抓取技术之一。这意味着一旦你掌握了 Beautiful Soup 的基础知识,就会有大量的教程、操作视频和一些示例代码来帮助你加深知识。
我们将解释如何在 python 中使用 Beautiful Soup 来托管网页抓取端,并介绍一些其他常见的网页抓取问题和答案,但现在是开始了解我们的网页抓取项目的时候了!每个网络抓取项目都应该从回答以下问题开始:
不幸的是,这里没有一个粗略的答案。一些网站知道愿意进行网络抓取。其他人明确禁止这样做。许多 网站 没有以一种或另一种形式提供任何明确的命令。
在抓取任何网站之前,我们应该查看一个条件和条件页面,看看是否有明确的抓取指南。如果有,我们应该跟随他们。如果不是,那么它更像是一个推论。
但是,请记住,网络抓取会消耗主机 网站 上的服务器资源。如果我们只刮一页,就不会造成问题。但是,如果我们的代码每时钟抓取 1,000 页,那么对于 网站all-timers 来说,这很快就会变得昂贵。
因此,除了遵循 网站 上发布的关于全面和一体式采集抓取的明确指南之外,遵循以下最佳实践也是一个很好的目标:
2)学会缓存你抓取的内容,这样在处理用于过滤和描述它的代码时只下载一次,而不是每次运行代码时都重新下载
3)学习使用效果 time.sleep() 在代码中创建暂停,例如避免在太短的时间内发出过多的请求以使不堪重负的服务器瘫痪。
在数据显示如何在python中使用Beautiful Soup进行网页抓取的情况下,NWS数据是海量的,它的术语不禁止网页抓取,所以我们可以继续做。
当我们访问一个网页时,我们的网络浏览器会向网络服务器发出一个请求。此请求称为 GET 请求,因为我们正在从服务器获取文档。然后服务器发回文档,告诉我们的浏览器如何为我们呈现页面。文学分为几种严肃的类型:
浏览器收到完整的文档后,会渲染页面并展示给我们。为了让页面看起来漂亮,幕后发生了很多事情,但是当我们进行网页抓取时,我们不需要担心很多这些问题。在做网页抓取的时候,我们对网页的严肃性很感兴趣,所以我们来看看HTML。
超文本标记语言 (HTML) 是一种用于创建网页的语言。HTML 不是像 Python 那样的编程演讲,而是告诉浏览器如何组织内容的横幅演讲。HTML 使您能够执行与 Microsoft Word 等文字处理器类似的操作 - 粗体文本、创建段落等。由于 HTML 不是一种编程语言,因此它不像 Python 那样复杂。
让我们快速浏览一下 HTML,这样我们就可以有效地进行爬网。HTML 由称为标签的元素组成。最基本的标签是标签。此标志告诉 Web 浏览器其中的所有内容都是 HTML。我们可以使用以下标志来创建一个简单的 HTML 文档:
我们没有在页面中添加任何内容,因此如果我们要在 Web 浏览器中查看 HTML 文档,我们将看不到任何内容:
在 html 标签内,我们放置了另外两个标签,head 标签和 body 标签。网页的主要内容进入body标签。head 标签收录相关的网页标题,以及在网页抓取中通常无效的其他信息:
我们还没有向页面添加任何内容(在 body 标签内),所以我们不再看到任何内容:
正如您在上面可能已经注意到的,我们将 head 和 body 标签放在 html 标签中。在 HTML 中,标签是嵌套的,可以放在其他标签内。
后一个参数是毫秒时间戳。测量的目的是改造缓存。如果你的爬虫没有缓存数据,这个参数可以省略,加起来很简单~
爬虫实时更新
动态网页抓取(如何抓取网页中的动态网页源码中特定的特定内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-02-26 02:15
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
【教程】Python版爬网并从网页中提取需要的信息
和
【教程】C#版爬网并从网页中提取需要的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
不熟悉的可以参考:
【组织】爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站
2.学会使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的可以参考:
【教程】教你如何使用工具(IE9的F12)解析模拟登录内部逻辑流程网站(百度首页))
3.对于一个普通的静态网页,如何提取想要的内容
对此不熟悉的可以参考:
(1)Python 版本:
【教程】Python版爬网并从网页中提取需要的信息
(2)C# 版本:
【教程】C#版爬网并从网页中提取需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据你通过工具分析的结果,找到对应的数据并提取出来;
不过这个数据有时候可以在分析结果的过程中直接提取出来,有时候可能是通过js计算出来的。
想抓取数据,是js脚本生成的
虽然最终的动态内容是由js脚本执行生成的,但是对于你要抓取的数据:
想爬取数据是通过访问另一个url获取的
如果你要抓取的对应内容是访问另一个url地址和返回的数据,那么很简单,你也需要访问这个url,然后获取对应的返回内容,从中提取你想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。 查看全部
动态网页抓取(如何抓取网页中的动态网页源码中特定的特定内容)
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
【教程】Python版爬网并从网页中提取需要的信息
和
【教程】C#版爬网并从网页中提取需要的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
不熟悉的可以参考:
【组织】爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站
2.学会使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的可以参考:
【教程】教你如何使用工具(IE9的F12)解析模拟登录内部逻辑流程网站(百度首页))
3.对于一个普通的静态网页,如何提取想要的内容
对此不熟悉的可以参考:
(1)Python 版本:
【教程】Python版爬网并从网页中提取需要的信息
(2)C# 版本:
【教程】C#版爬网并从网页中提取需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据你通过工具分析的结果,找到对应的数据并提取出来;
不过这个数据有时候可以在分析结果的过程中直接提取出来,有时候可能是通过js计算出来的。
想抓取数据,是js脚本生成的
虽然最终的动态内容是由js脚本执行生成的,但是对于你要抓取的数据:
想爬取数据是通过访问另一个url获取的
如果你要抓取的对应内容是访问另一个url地址和返回的数据,那么很简单,你也需要访问这个url,然后获取对应的返回内容,从中提取你想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。
动态网页抓取(ajax横行的年代,我们的网页是残缺的吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-26 02:14
)
在ajax时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中包括
跳过js加载部分,表示爬虫抓取的网页不完整,不完整。您可以在下面看到博客园的主页
从首页的加载中可以看出,页面渲染完成后,会有5个异步ajax请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候,如果你想得到它,你必须调用浏览器的内核引擎来下载这些动态页面。目前内核引擎是三足的。
Trident:也就是IE内核,WebBrowser就是基于这个内核,但是加载性能比较差。
Gecko:FF的内核比Trident的性能更好。
WebKit:Safari和Chrome的核心,性能你懂的,在真实场景中还是主要的。
好的,为了简单方便,这里我们使用WebBrowser来玩,使用WebBrowser的时候要注意以下几点:
首先:因为WebBrowser是System.Windows.Forms中的winform控件,所以我们需要设置STAThread标签。
第二:winform是事件驱动的,Console不响应事件。所有事件都在窗口的消息队列中等待执行。为了防止程序假死,
我们需要调用DoEvents方法来传递控制权,让操作系统执行其他事件。
第三:WebBrowser内容,我们需要使用DomDocument来查看,而不是DocumentText。
判断动态网页是否加载一般有两种方式:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们这里需要这样做
记录计数值
.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们还可以通过设置一个Timer来判断,比如3s、4s、5s,稍后查看
WEB浏览器是否加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果还是一样的,就不截图了。从以上两种写法来看,我们的WebBrowser放在主线程中。让我们看看如何把它放在工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 } 查看全部
动态网页抓取(ajax横行的年代,我们的网页是残缺的吗?
)
在ajax时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中包括
跳过js加载部分,表示爬虫抓取的网页不完整,不完整。您可以在下面看到博客园的主页
从首页的加载中可以看出,页面渲染完成后,会有5个异步ajax请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候,如果你想得到它,你必须调用浏览器的内核引擎来下载这些动态页面。目前内核引擎是三足的。
Trident:也就是IE内核,WebBrowser就是基于这个内核,但是加载性能比较差。
Gecko:FF的内核比Trident的性能更好。
WebKit:Safari和Chrome的核心,性能你懂的,在真实场景中还是主要的。
好的,为了简单方便,这里我们使用WebBrowser来玩,使用WebBrowser的时候要注意以下几点:
首先:因为WebBrowser是System.Windows.Forms中的winform控件,所以我们需要设置STAThread标签。
第二:winform是事件驱动的,Console不响应事件。所有事件都在窗口的消息队列中等待执行。为了防止程序假死,
我们需要调用DoEvents方法来传递控制权,让操作系统执行其他事件。
第三:WebBrowser内容,我们需要使用DomDocument来查看,而不是DocumentText。
判断动态网页是否加载一般有两种方式:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们这里需要这样做
记录计数值
.

1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们还可以通过设置一个Timer来判断,比如3s、4s、5s,稍后查看
WEB浏览器是否加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果还是一样的,就不截图了。从以上两种写法来看,我们的WebBrowser放在主线程中。让我们看看如何把它放在工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
动态网页抓取(什么是爬虫?反爬的出发点是什么?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-02-25 23:23
?作者|leo
01 什么是爬行动物?
爬虫,顾名思义,就像一个探索、模拟人类行为的小型机器人,传播到网络的各个角落,按照一定的规则采集和组织数据,并反馈回来。这是一个非常形象的描述爬行原理的方式。
从技术角度看,爬虫主要是根据一定的程序规则或技术指标,通过网络请求获取资源,然后通过一定的分析方法提取所需的信息,并将获取的资源存储起来。
02 为什么会出现反爬虫?
你见过的最奇怪的验证码是什么?不管是考小学数学的验证码,还是考人文知识的验证码,现在越来越多的奇葩验证码出现,这在一定程度上给我们参观者带来了很多不便,但他们真正的目的不是为了给用户增加难度,而是为了防止大多数不受控制的访问机器人。
爬虫的访问速度和目的很容易发现与普通用户不同。大多数爬虫都有无节制地大量爬取访问目标的行为。这些访问请求会给访问目标带来巨大的服务器压力。以及不必要的资源投入,因此经常被运营商定义为“垃圾流量”。
因此,运营商为了更好地维护自身利益,会根据爬虫的特点采取不同的手段来阻止大量爬虫的访问。
根据反爬的起点,反爬的限制方法可分为:
? 主动限制:开发者会通过技术手段主动限制爬虫的访问请求,如:验证请求头信息、限制重复访问同一个ip、验证码技术等。
? 被动限制:为了在不降低用户体验的情况下节省访问资源,开发者采用了间接的技术手段限制爬虫访问,如:动态网页加载、数据分段加载、鼠标悬停预览数据等。
? 根据具体的反爬虫实现方式,大致可分为:信息验证反爬虫、动态渲染反爬虫、文本混淆反爬虫、特征识别反爬虫。爬虫和反爬虫无异于一场攻防的博弈,既有竞争又有相互促进的可能。
常见的反爬策略及对策:
信息验证爬虫:
一种。User-Agent 发送爬虫:
基本原理:可以向服务器发送请求的客户端有多种形式,可以是不同类型的个人电脑、手机、平板电脑、编程程序,也可以是网络请求软件。服务器应该如何识别这些不同的客户端?结尾?
User-Agent 就是用户发送请求时附加的请求信息的记录。其主要格式包括以下部分:
**浏览器 ID(操作系统 ID、加密级别 ID;浏览器语言)渲染引擎 ID 版本信息**
例如:
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, 像 Gecko)
User-Agent的反爬主要是通过对User-Agent头域的值进行校验。如果黑名单中有值,则会被服务器屏蔽。
例如Python常用的Requests库,如果发送请求时没有设置header参数,服务器读取User-Agent的值为python-requests/2.21.0
湾。Cookies 反爬虫
Cookies不仅可以用来存储网络用户的身份信息或保持登录状态,还可以作为反爬虫的识别信息。
主要原理是客户端访问服务端时,服务端会返回Set-Cookie头域,客户端存储信息,再次访问服务端时携带相应的cookie信息。此时,服务器只需要验证cookie是否符合要求即可。规则没问题,如果不匹配,就会重定向到另一个页面,并在响应中添加 Set-Cookie 头字段和 Cookie 值。
上述验证cookies的方法只是一种比较简单的反爬机制。爬虫工程师只需要复制浏览器请求头中的cookie即可轻松规避。这时候cookie验证往往结合javascript文件生成随机cookie值进行验证。:
**Cookie名称+3个小于9的随机正整数+5个随机大写字母+6个小于9的正整数+3个随机大写字母**
这种机制仍有被重复使用的可能。即使加上cookie过期时间也不能完全保证cookie的重用。在这种情况下,需要结合上述方法引入时间戳进行进一步判断。取出cookie值的时间戳和当前时间。对邮票进行差值计算,如果超过一定时间,就会被认定为伪造。
C。签名验证反爬虫:
主要原理是在发送请求时,将客户端生成的一些随机数和不可逆的MD5加密字符串发送给服务器。服务器使用相同的方法进行随机值计算和MD5加密。如果MD5值相等,则表示请求正常,否则返回403.
目前这种反爬虫方法广泛应用于各种大型网站,绕过它不仅需要从XHR信息中查找相关请求信息,还需要在Javascript代码中查找加密方法.
动态渲染反爬虫:
动态网页常用于改善用户体验,节省资源消耗,提高响应速度。不是直接针对爬虫程序的反爬措施,而是无意中产生反爬效果,爬虫程序没有页面渲染。功能,但是一旦遇到动态渲染的页面,就无法完全返回所需的信息。
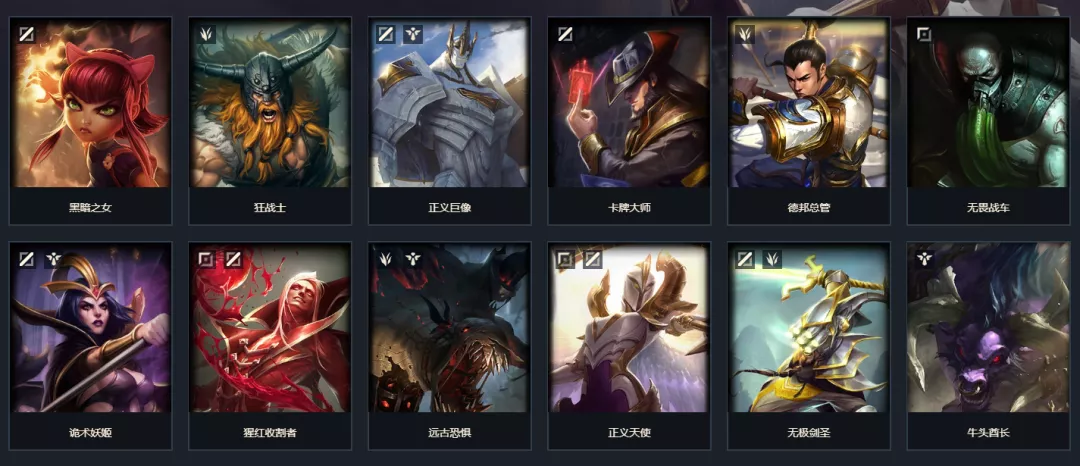
比如我们要爬取英雄联盟中的英雄名字并下载对应的图片时,使用requests库按照原来的爬取方式进行爬取,会发现获取到的字段都是空值。主要原因是网站使用了javacript动态加载技术,只有找到核心js传输代码才能找到对应的信息。
通过网页检查工具,我们可以清楚的看到 hero_list.js 文件中存放了所有的英雄信息,以及对应的英雄图片链接和详情页信息。
那么我们在分析信息的时候,需要针对js文件来做。
动态渲染的主要解决方案:
动态渲染技术组合非常灵活。如果每次遇到这样的网站都要分析接口、参数和javascript代码逻辑,时间和成本会高很多。那么直接提取渲染结果页面的能力对于爬虫分析来说会简单很多。目前主要的渲染提取工具有:Puppeter、Selenium、Splash。
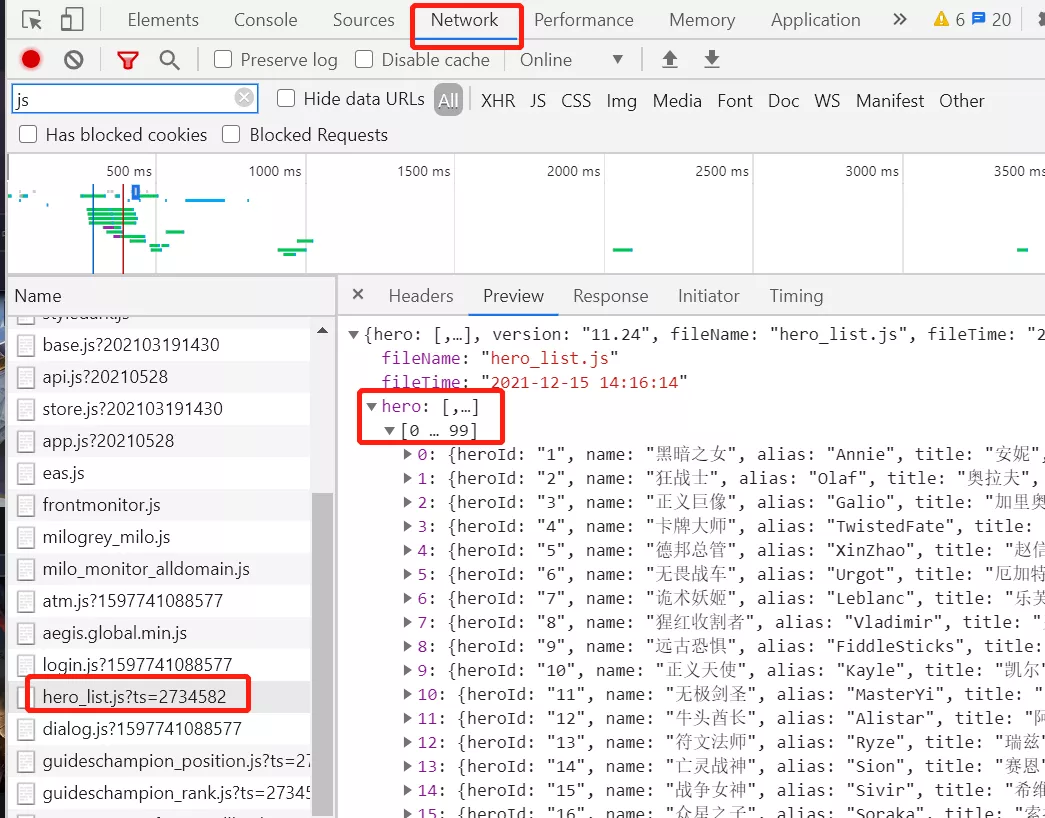
2.1 硒
Selenium 是解决动态渲染最常用的技术之一。
浏览器驱动程序是 Selenium 向浏览器发送指令或传递渲染结果的主要工具。
目前驱动一般从以下网址下载:
[]()
我们可以通过简单的代码提取相应的信息。
from selenium import webdriver
url = 'https://www.udemy.com/course/network-security-course/'
driver = webdriver.Chrome()
res = driver.get(url)
course = driver.find_element_by_css_selector('.clp-lead__title').text.replace('\n','')
print(course)
driver.quit()
2.2 傀儡师
在使用 Selenium 进行数据爬取时,执行大批量的任务显然需要很长时间。这时候我们要介绍一种异步加载和提取数据的方法,就是Puppeter方法,它是谷歌开源的Node库。除了拥有一组高级 API 来控制浏览器之外,它还提供了许多手动操作的替代方案,最重要的是,它支持异步。
import asyncio
from pyppeter import launch
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://www.udemy.com/course/network-security-course/')
res = await page.xpath("//*[@class='clp-lead__title']")
text = await(await res[0].getProperty('textContent')).jsonValue()
print(text)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
2.3 分布式渲染服务Splash
Splash 应用于分布式爬取需求。假设我们想在更多的机器上运行爬虫程序,是否可以通过安装 Puppeter 和 Selenium 组件来完成?显然没有。
Splash 是一个带有轻量级 Web 浏览器的异步 Js 渲染服务。当我们将它部署在云端时,多个爬虫可以通过同一个 API 访问渲染的页面。
动态网页的广泛应用,不仅提升了用户体验,也在一定程度上限制了爬虫程序的使用。页面解析结合动态渲染技术解决了80%以上复杂页面的爬取,但效率远不如直接解析javascript。文件速度很快,往往要花很多时间才能找到网站入口和js文件的位置。因此,具体技术需要根据实际情况灵活运用。
03 文本混淆和反爬虫
文本混淆可以有效防止爬虫获取Web应用中的文本数据。通过混淆文本信息来限制爬虫获取数据的技术手段称为文本混淆反爬虫。
文字混淆和反爬虫的前提是不影响普通用户的体验,所以文字混淆不能直接显示,所以开发者通常使用CSS特性来实现混淆。
常见的文本混淆方法包括:图像伪装、文本映射、自定义字体
3.1 图片伪装
该方法使用图片替换原创文本信息,使得直接提取文本的方法无效。例如:电话
电话
这段代码是某个网站的截取代码,通过图片的方式伪装了原文电话号码。因此,如果要获取这些信息,简单的爬虫方法是不可能实现的,那么主要应对措施是什么?
这里主要需要的是光学字符识别技术,对于纯文本信息,可以很容易的实现,没有像素干扰。在 python 中,我们主要使用 PyTesseract 库来提取图像文本。
3.2 SVG 映射反爬虫
SVG是一种基于XML描述图形的二维矢量图形格式,图形质量不受图形放大或缩小的影响。这个特性在 Web网站 中被广泛使用。
使用SVG映射反爬虫的主要原理是映射不同的字符串和不同的数字。当服务器进行数据解析时,进行相关处理,然后浏览器进行渲染,最终达到隐藏信息的目的。
绕过SVG映射可以通过提取数据对应的相关信息来解决。如下图所示,我们最终通过在html代码中找到class-to-numbers的映射关系得到电话号码信息。
mappings = {
'vhk08k':0, 'vhk6zl':1,'vhk9or':2,'vhkfln':3,'vhkbvu':4,'vhk84t':5,'vhkvxd':6,
'vhkqsc':7,'vhkkj4':8,'vhk0f1':9,
}
html_class = ['vhkbvu','vhk08k','vhkfln','vhk0f1']
phone_num = [mappings.get(i) for i in html_class]
print(phone_num)
目前主流的反爬虫技术表明:
除上述爬虫技术外,还包括常见的验证码识别反爬虫。它的主要实现机制是通过各种动态生成的验证码来防止爬虫访问网页信息,所以绕过验证码也是目前的技术。难点,传统的文字和图形验证码可以通过光学识别来解决,而动态滑块验证码和逻辑操作验证码只能通过多种技术的结合来实现。
另一种常见的反爬虫是特征识别反爬虫。如果你尝试过爬取Boss直接招聘网页上的信息,你会发现无论是使用常规爬取方式还是使用Selenium动态渲染工具,还是分析Javascript文件,基本上都无法有效提取相关数据,并且返回值都是空值。主要原因是目标站采用WebDriver特征识别。主要原理是反爬虫程序可以识别发送请求的客户端的webdriver属性是否由webdriver驱动。要访问的话,绕过方法也是基于这个属性。webdriver 检测的主要结果有三个:true、false 和 undefined。当我们使用渲染工具拥有webdriver属性时,返回值为真,那么我正在触发验证。可以通过在此属性之前将其更改为 false 或 undefined 来规避此识别。
以上就是对目前主流的反爬技术和绕行策略的简单介绍。在这场攻防博弈中,核心思想是如何分析对手的执行机制,以便更好地提出解决方案。当然,涉及的也很多。深入的理论知识,也有大量的人为逻辑陷阱在其中,所以掌握爬虫技术,实践和理论学习同等重要。
目前主流的反爬虫技术表明:
除上述爬虫技术外,还包括常见的验证码识别反爬虫。它的主要实现机制是防止爬虫通过各种状态下生成的验证码访问网页信息,所以绕过验证码也是目前的技术。难点,传统的文字和图形验证码可以通过光学识别来解决,而动态滑块验证码和逻辑操作验证码只能通过多种技术的结合来实现。
另一种常见的反爬虫是特征识别反爬虫。如果你尝试过爬取Boss直接招聘网页上的信息,你会发现无论是使用常规爬取方式还是使用Selenium动态渲染工具,还是分析Javascript文件,基本上都无法有效提取相关数据,并且返回values 都是空值。
主要原因是目标站采用了WebDriver特征识别。主要原理是反爬虫程序可以识别发送请求的客户端的webdriver属性是否通过webdriver驱动的浏览器访问。
那么绕过的方法也是围绕着这个属性来的。webdriver 检测的主要结果有三个:true、false 和 undefined。当我们使用渲染工具有webdriver属性时,返回值为true,那么我会在触发之前验证这个属性。将其修改为 false 或 undefined 可以绕过这种识别。
以上就是对目前主流的反爬技术和绕行策略的简单介绍。在这场攻防博弈中,核心思想是如何分析对手的执行机制,以便更好地提出解决方案。当然,涉及的也很多。深入的理论知识,也有大量的人为逻辑陷阱在其中,所以掌握爬虫技术,实践和理论学习同等重要。 查看全部
动态网页抓取(什么是爬虫?反爬的出发点是什么?(上))
?作者|leo
01 什么是爬行动物?
爬虫,顾名思义,就像一个探索、模拟人类行为的小型机器人,传播到网络的各个角落,按照一定的规则采集和组织数据,并反馈回来。这是一个非常形象的描述爬行原理的方式。
从技术角度看,爬虫主要是根据一定的程序规则或技术指标,通过网络请求获取资源,然后通过一定的分析方法提取所需的信息,并将获取的资源存储起来。
02 为什么会出现反爬虫?
你见过的最奇怪的验证码是什么?不管是考小学数学的验证码,还是考人文知识的验证码,现在越来越多的奇葩验证码出现,这在一定程度上给我们参观者带来了很多不便,但他们真正的目的不是为了给用户增加难度,而是为了防止大多数不受控制的访问机器人。
爬虫的访问速度和目的很容易发现与普通用户不同。大多数爬虫都有无节制地大量爬取访问目标的行为。这些访问请求会给访问目标带来巨大的服务器压力。以及不必要的资源投入,因此经常被运营商定义为“垃圾流量”。
因此,运营商为了更好地维护自身利益,会根据爬虫的特点采取不同的手段来阻止大量爬虫的访问。
根据反爬的起点,反爬的限制方法可分为:
? 主动限制:开发者会通过技术手段主动限制爬虫的访问请求,如:验证请求头信息、限制重复访问同一个ip、验证码技术等。
? 被动限制:为了在不降低用户体验的情况下节省访问资源,开发者采用了间接的技术手段限制爬虫访问,如:动态网页加载、数据分段加载、鼠标悬停预览数据等。
? 根据具体的反爬虫实现方式,大致可分为:信息验证反爬虫、动态渲染反爬虫、文本混淆反爬虫、特征识别反爬虫。爬虫和反爬虫无异于一场攻防的博弈,既有竞争又有相互促进的可能。
常见的反爬策略及对策:
信息验证爬虫:
一种。User-Agent 发送爬虫:
基本原理:可以向服务器发送请求的客户端有多种形式,可以是不同类型的个人电脑、手机、平板电脑、编程程序,也可以是网络请求软件。服务器应该如何识别这些不同的客户端?结尾?
User-Agent 就是用户发送请求时附加的请求信息的记录。其主要格式包括以下部分:
**浏览器 ID(操作系统 ID、加密级别 ID;浏览器语言)渲染引擎 ID 版本信息**
例如:
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, 像 Gecko)
User-Agent的反爬主要是通过对User-Agent头域的值进行校验。如果黑名单中有值,则会被服务器屏蔽。
例如Python常用的Requests库,如果发送请求时没有设置header参数,服务器读取User-Agent的值为python-requests/2.21.0
湾。Cookies 反爬虫
Cookies不仅可以用来存储网络用户的身份信息或保持登录状态,还可以作为反爬虫的识别信息。
主要原理是客户端访问服务端时,服务端会返回Set-Cookie头域,客户端存储信息,再次访问服务端时携带相应的cookie信息。此时,服务器只需要验证cookie是否符合要求即可。规则没问题,如果不匹配,就会重定向到另一个页面,并在响应中添加 Set-Cookie 头字段和 Cookie 值。
上述验证cookies的方法只是一种比较简单的反爬机制。爬虫工程师只需要复制浏览器请求头中的cookie即可轻松规避。这时候cookie验证往往结合javascript文件生成随机cookie值进行验证。:
**Cookie名称+3个小于9的随机正整数+5个随机大写字母+6个小于9的正整数+3个随机大写字母**
这种机制仍有被重复使用的可能。即使加上cookie过期时间也不能完全保证cookie的重用。在这种情况下,需要结合上述方法引入时间戳进行进一步判断。取出cookie值的时间戳和当前时间。对邮票进行差值计算,如果超过一定时间,就会被认定为伪造。
C。签名验证反爬虫:
主要原理是在发送请求时,将客户端生成的一些随机数和不可逆的MD5加密字符串发送给服务器。服务器使用相同的方法进行随机值计算和MD5加密。如果MD5值相等,则表示请求正常,否则返回403.
目前这种反爬虫方法广泛应用于各种大型网站,绕过它不仅需要从XHR信息中查找相关请求信息,还需要在Javascript代码中查找加密方法.
动态渲染反爬虫:
动态网页常用于改善用户体验,节省资源消耗,提高响应速度。不是直接针对爬虫程序的反爬措施,而是无意中产生反爬效果,爬虫程序没有页面渲染。功能,但是一旦遇到动态渲染的页面,就无法完全返回所需的信息。
比如我们要爬取英雄联盟中的英雄名字并下载对应的图片时,使用requests库按照原来的爬取方式进行爬取,会发现获取到的字段都是空值。主要原因是网站使用了javacript动态加载技术,只有找到核心js传输代码才能找到对应的信息。
通过网页检查工具,我们可以清楚的看到 hero_list.js 文件中存放了所有的英雄信息,以及对应的英雄图片链接和详情页信息。
那么我们在分析信息的时候,需要针对js文件来做。
动态渲染的主要解决方案:
动态渲染技术组合非常灵活。如果每次遇到这样的网站都要分析接口、参数和javascript代码逻辑,时间和成本会高很多。那么直接提取渲染结果页面的能力对于爬虫分析来说会简单很多。目前主要的渲染提取工具有:Puppeter、Selenium、Splash。
2.1 硒
Selenium 是解决动态渲染最常用的技术之一。
浏览器驱动程序是 Selenium 向浏览器发送指令或传递渲染结果的主要工具。
目前驱动一般从以下网址下载:
[]()
我们可以通过简单的代码提取相应的信息。
from selenium import webdriver
url = 'https://www.udemy.com/course/network-security-course/'
driver = webdriver.Chrome()
res = driver.get(url)
course = driver.find_element_by_css_selector('.clp-lead__title').text.replace('\n','')
print(course)
driver.quit()
2.2 傀儡师
在使用 Selenium 进行数据爬取时,执行大批量的任务显然需要很长时间。这时候我们要介绍一种异步加载和提取数据的方法,就是Puppeter方法,它是谷歌开源的Node库。除了拥有一组高级 API 来控制浏览器之外,它还提供了许多手动操作的替代方案,最重要的是,它支持异步。
import asyncio
from pyppeter import launch
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://www.udemy.com/course/network-security-course/')
res = await page.xpath("//*[@class='clp-lead__title']")
text = await(await res[0].getProperty('textContent')).jsonValue()
print(text)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
2.3 分布式渲染服务Splash
Splash 应用于分布式爬取需求。假设我们想在更多的机器上运行爬虫程序,是否可以通过安装 Puppeter 和 Selenium 组件来完成?显然没有。
Splash 是一个带有轻量级 Web 浏览器的异步 Js 渲染服务。当我们将它部署在云端时,多个爬虫可以通过同一个 API 访问渲染的页面。
动态网页的广泛应用,不仅提升了用户体验,也在一定程度上限制了爬虫程序的使用。页面解析结合动态渲染技术解决了80%以上复杂页面的爬取,但效率远不如直接解析javascript。文件速度很快,往往要花很多时间才能找到网站入口和js文件的位置。因此,具体技术需要根据实际情况灵活运用。
03 文本混淆和反爬虫
文本混淆可以有效防止爬虫获取Web应用中的文本数据。通过混淆文本信息来限制爬虫获取数据的技术手段称为文本混淆反爬虫。
文字混淆和反爬虫的前提是不影响普通用户的体验,所以文字混淆不能直接显示,所以开发者通常使用CSS特性来实现混淆。
常见的文本混淆方法包括:图像伪装、文本映射、自定义字体
3.1 图片伪装
该方法使用图片替换原创文本信息,使得直接提取文本的方法无效。例如:电话
电话
这段代码是某个网站的截取代码,通过图片的方式伪装了原文电话号码。因此,如果要获取这些信息,简单的爬虫方法是不可能实现的,那么主要应对措施是什么?
这里主要需要的是光学字符识别技术,对于纯文本信息,可以很容易的实现,没有像素干扰。在 python 中,我们主要使用 PyTesseract 库来提取图像文本。
3.2 SVG 映射反爬虫
SVG是一种基于XML描述图形的二维矢量图形格式,图形质量不受图形放大或缩小的影响。这个特性在 Web网站 中被广泛使用。
使用SVG映射反爬虫的主要原理是映射不同的字符串和不同的数字。当服务器进行数据解析时,进行相关处理,然后浏览器进行渲染,最终达到隐藏信息的目的。
绕过SVG映射可以通过提取数据对应的相关信息来解决。如下图所示,我们最终通过在html代码中找到class-to-numbers的映射关系得到电话号码信息。
mappings = {
'vhk08k':0, 'vhk6zl':1,'vhk9or':2,'vhkfln':3,'vhkbvu':4,'vhk84t':5,'vhkvxd':6,
'vhkqsc':7,'vhkkj4':8,'vhk0f1':9,
}
html_class = ['vhkbvu','vhk08k','vhkfln','vhk0f1']
phone_num = [mappings.get(i) for i in html_class]
print(phone_num)
目前主流的反爬虫技术表明:
除上述爬虫技术外,还包括常见的验证码识别反爬虫。它的主要实现机制是通过各种动态生成的验证码来防止爬虫访问网页信息,所以绕过验证码也是目前的技术。难点,传统的文字和图形验证码可以通过光学识别来解决,而动态滑块验证码和逻辑操作验证码只能通过多种技术的结合来实现。
另一种常见的反爬虫是特征识别反爬虫。如果你尝试过爬取Boss直接招聘网页上的信息,你会发现无论是使用常规爬取方式还是使用Selenium动态渲染工具,还是分析Javascript文件,基本上都无法有效提取相关数据,并且返回值都是空值。主要原因是目标站采用WebDriver特征识别。主要原理是反爬虫程序可以识别发送请求的客户端的webdriver属性是否由webdriver驱动。要访问的话,绕过方法也是基于这个属性。webdriver 检测的主要结果有三个:true、false 和 undefined。当我们使用渲染工具拥有webdriver属性时,返回值为真,那么我正在触发验证。可以通过在此属性之前将其更改为 false 或 undefined 来规避此识别。
以上就是对目前主流的反爬技术和绕行策略的简单介绍。在这场攻防博弈中,核心思想是如何分析对手的执行机制,以便更好地提出解决方案。当然,涉及的也很多。深入的理论知识,也有大量的人为逻辑陷阱在其中,所以掌握爬虫技术,实践和理论学习同等重要。
目前主流的反爬虫技术表明:
除上述爬虫技术外,还包括常见的验证码识别反爬虫。它的主要实现机制是防止爬虫通过各种状态下生成的验证码访问网页信息,所以绕过验证码也是目前的技术。难点,传统的文字和图形验证码可以通过光学识别来解决,而动态滑块验证码和逻辑操作验证码只能通过多种技术的结合来实现。
另一种常见的反爬虫是特征识别反爬虫。如果你尝试过爬取Boss直接招聘网页上的信息,你会发现无论是使用常规爬取方式还是使用Selenium动态渲染工具,还是分析Javascript文件,基本上都无法有效提取相关数据,并且返回values 都是空值。
主要原因是目标站采用了WebDriver特征识别。主要原理是反爬虫程序可以识别发送请求的客户端的webdriver属性是否通过webdriver驱动的浏览器访问。
那么绕过的方法也是围绕着这个属性来的。webdriver 检测的主要结果有三个:true、false 和 undefined。当我们使用渲染工具有webdriver属性时,返回值为true,那么我会在触发之前验证这个属性。将其修改为 false 或 undefined 可以绕过这种识别。
以上就是对目前主流的反爬技术和绕行策略的简单介绍。在这场攻防博弈中,核心思想是如何分析对手的执行机制,以便更好地提出解决方案。当然,涉及的也很多。深入的理论知识,也有大量的人为逻辑陷阱在其中,所以掌握爬虫技术,实践和理论学习同等重要。
动态网页抓取( 网站到底是动态路径好还是伪静态好?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-25 13:22
网站到底是动态路径好还是伪静态好?(图))
所谓路径其实是指“URL”,通常我们称之为“链接”,所以我想知道网站是动态路径还是伪静态路径?首先,我们需要知道什么是动态的,什么是静态的,什么是伪静态的。其实这三个只是网站链接的形式。对于这三种链接形式,90%以上的SEO站长都会优先考虑静态的,因为这样更有利于搜索引擎蜘蛛的抓取和识别,那么阿南就给大家介绍一下这三种链接。
静态路径
在网站中,每个静态路径在空间服务器中都会有一个静态文件,这个文件不会随着不同浏览器的访问而改变。用户在访问时根本不需要调用数据库,这也是静态网页打开速度惊人的原因,同时也减少了服务器对数据响应的负载,使搜索引擎更容易检索。在安全方面,静态页面几乎不受Asp相关漏洞的影响,无需担心SQL注入攻击。但是我们之前提到过,每个路径都有一个静态页面,所以如果网站的内容太大,会产生大量的文件,严重占用网站的空间,如果如果没有自动化工具,维护这些大量的静态文件几乎是不切实际的。
动态路径
动态路径其实是指网站路径中带有动态参数的路径。它与静态路径正好相反。静态路径会生成大量静态文件,而动态路径不会。当你的网站路径是动态的,那么当用户访问一个页面时,服务器会收到浏览器的请求,然后根据当前时间、环境参数、数据库操作等动态生成一个HTML页面,发送到浏览器,用户可以访问。因为访问动态路径的网站,动态网页会调用数据库中的数据,所以这也是动态路径网页加载速度比较慢的原因。但是,还是有一些行业专家可以对数据库进行几乎零调用,并且网页的加载速度极快。这个操作非常非常6,但是相对来说,服务成本会比较高。动态路径的另一个缺点是不利于搜索引擎蜘蛛的爬取。即使路径中的动态参数过多,也可能导致搜索引擎蜘蛛无法识别的情况。至于网站的安全性,因为动态网页需要调用数据库中的数据,所以对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。动态路径的另一个缺点是不利于搜索引擎蜘蛛的爬取。即使路径中的动态参数过多,也可能导致搜索引擎蜘蛛无法识别的情况。至于网站的安全性,因为动态网页需要调用数据库中的数据,所以对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。动态路径的另一个缺点是不利于搜索引擎蜘蛛的爬取。即使路径中的动态参数过多,也可能导致搜索引擎蜘蛛无法识别的情况。至于网站的安全性,因为动态网页需要调用数据库中的数据,所以对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。
伪静态
前面我们提到静态路径便于搜索引擎蜘蛛识别和爬取,而动态路径不利于搜索引擎蜘蛛识别和爬取。那么有没有办法两全其美呢?是的,伪静态。其实伪静态并不是真正意义上的静态路径,而是一种通过重写URL来去除动态网页中的参数的方法,从而达到其他更有利于搜索引擎抓取的效果。它同时具有动态路径和静态路径的一些优点,这也是为什么大部分wordpress网站会选择首选路径,这样网站的路径就可以达到静态形式而不生成很多静态文件。
一般像我们看到的论坛 网站 ,如果他们的路径是动态的或者伪静态的,所以这就是为什么使用 织梦 的程序通常不用来建论坛网站 ,因为静态的太多了生成文件,维护起来比较麻烦。小网站推荐使用带静态路径的网站程序。大的 网站 是不够的。以上是阿南对路径格式的理解。如果您有任何问题,请留言。 查看全部
动态网页抓取(
网站到底是动态路径好还是伪静态好?(图))

所谓路径其实是指“URL”,通常我们称之为“链接”,所以我想知道网站是动态路径还是伪静态路径?首先,我们需要知道什么是动态的,什么是静态的,什么是伪静态的。其实这三个只是网站链接的形式。对于这三种链接形式,90%以上的SEO站长都会优先考虑静态的,因为这样更有利于搜索引擎蜘蛛的抓取和识别,那么阿南就给大家介绍一下这三种链接。
静态路径
在网站中,每个静态路径在空间服务器中都会有一个静态文件,这个文件不会随着不同浏览器的访问而改变。用户在访问时根本不需要调用数据库,这也是静态网页打开速度惊人的原因,同时也减少了服务器对数据响应的负载,使搜索引擎更容易检索。在安全方面,静态页面几乎不受Asp相关漏洞的影响,无需担心SQL注入攻击。但是我们之前提到过,每个路径都有一个静态页面,所以如果网站的内容太大,会产生大量的文件,严重占用网站的空间,如果如果没有自动化工具,维护这些大量的静态文件几乎是不切实际的。
动态路径
动态路径其实是指网站路径中带有动态参数的路径。它与静态路径正好相反。静态路径会生成大量静态文件,而动态路径不会。当你的网站路径是动态的,那么当用户访问一个页面时,服务器会收到浏览器的请求,然后根据当前时间、环境参数、数据库操作等动态生成一个HTML页面,发送到浏览器,用户可以访问。因为访问动态路径的网站,动态网页会调用数据库中的数据,所以这也是动态路径网页加载速度比较慢的原因。但是,还是有一些行业专家可以对数据库进行几乎零调用,并且网页的加载速度极快。这个操作非常非常6,但是相对来说,服务成本会比较高。动态路径的另一个缺点是不利于搜索引擎蜘蛛的爬取。即使路径中的动态参数过多,也可能导致搜索引擎蜘蛛无法识别的情况。至于网站的安全性,因为动态网页需要调用数据库中的数据,所以对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。动态路径的另一个缺点是不利于搜索引擎蜘蛛的爬取。即使路径中的动态参数过多,也可能导致搜索引擎蜘蛛无法识别的情况。至于网站的安全性,因为动态网页需要调用数据库中的数据,所以对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。动态路径的另一个缺点是不利于搜索引擎蜘蛛的爬取。即使路径中的动态参数过多,也可能导致搜索引擎蜘蛛无法识别的情况。至于网站的安全性,因为动态网页需要调用数据库中的数据,所以对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。
伪静态
前面我们提到静态路径便于搜索引擎蜘蛛识别和爬取,而动态路径不利于搜索引擎蜘蛛识别和爬取。那么有没有办法两全其美呢?是的,伪静态。其实伪静态并不是真正意义上的静态路径,而是一种通过重写URL来去除动态网页中的参数的方法,从而达到其他更有利于搜索引擎抓取的效果。它同时具有动态路径和静态路径的一些优点,这也是为什么大部分wordpress网站会选择首选路径,这样网站的路径就可以达到静态形式而不生成很多静态文件。
一般像我们看到的论坛 网站 ,如果他们的路径是动态的或者伪静态的,所以这就是为什么使用 织梦 的程序通常不用来建论坛网站 ,因为静态的太多了生成文件,维护起来比较麻烦。小网站推荐使用带静态路径的网站程序。大的 网站 是不够的。以上是阿南对路径格式的理解。如果您有任何问题,请留言。
动态网页抓取(浙江很多刚做seo的人,不知道网站的页面有静态和动态之分,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-25 13:21
很多刚做seo的浙江人不知道网站的页面分静态和动态。与动态网页相比,静态网页是指没有后台数据库、不收录程序、不具有交互性的网页。你就是它所显示的,什么都不会改变。
静态网页更新比较麻烦,适合一般更新较少的显示类型网站。另外,如果扩展名是.jsp但没有数据库连接,那是一个完全静态的页面,也是静态的网站。
只是 .jsp 扩展名。静态和动态都可以做seo,不会有太大影响。只要网站可以打开,路径不变,不出现404就可以了。了解更多。
一.网站静态好还是动态好?
静态网页的特点
1)。静态网页的每个网页都有一个固定的网址,网页网址以.htm、.html、.shtml等常用方法后缀,不收录“?”;
2)。一旦网页内容发布到网站服务器上,每个静态网页的内容都会保存在网站服务器上,不管是否有用户访问,即静态网页它是实际保存在服务器上的一个文件,每个网页都是一个独立的文件;
3)。静态网页内容比较稳定,容易被搜索引擎检索;
4)。静态网页没有数据库支持,网站制作和维护的工作量比较大,所以当网站有大量的静态网页制作方式时,很难完全依赖静态网页制作方式。信息;
5)。静态网页的交互性较低,并且对功能的限制更大。
动态网页的特点
1)。动态网页基于数据库技术,可以大大减少网站保护的工作量;网站 使用动态网页技术可以实现更多功能,如用户注册、用户登录、在线查询、用户处理、订单处理等;
2).动态网页实际上并不是一个独立存在于服务器上的网页文件,只有当用户请求服务器返回一个完整的网页时;
3)。这 ”?” 在动态网页中对于搜索引擎检索有一定的问题。一般搜索引擎无法从网站的数据库中访问所有网页,或者出于技术考虑,搜索蜘蛛不会抓取“?”后面的内容。在网址中,
因此,选择动态网页的网站在实现搜索引擎时需要进行一定的技巧处理,以适应搜索引擎的要求。
二.两者的区别
静态网页和动态网页各有特点。网站选择动态网页还是静态网页,主要看网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页的方法会比较简单,否则就应该使用动态网页技术来完成。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了网站适应搜索引擎检索的需要,即使使用动态网站技能,将网页内容转换为静态网页发布。
动态网站也可以利用动静结合的原则,适合动态网页使用动态网页。如果需要使用静态网页,可以考虑使用静态网页。动态网页内容与静态网页内容共存也很常见。
动态url的优缺点:
使用动态 url 有缺点也有优点。最大的优点之一是 网站 的内容可以实时更新。后台更新文章很方便。我们判断url为动态的标志是url内部收录动态参数如?、=、&等参数。
另一种判断方式是网页以jsp、PHP等为后缀的网页结束。伪静态和静态网页的后缀都是html。
动态url有很多缺陷。比如大型网站流量很大的时候,使用动态url会给服务器带来很大的压力。另外,动态urls无法从url中看到网站的目录状态。,无法从url判断当时的目录状态。再者,不利于用户对url的回忆。
伪静态的优缺点:
伪静态的优点是可以继承动态url的优点。后台发布文章时,也会实时更新内容。而且从用户的角度来看,伪静态url和静态url没有什么区别。当然,缺陷也是众所周知的。它还会在服务器上产生压力负载。
对某些人来说,伪静态可能对搜索引擎爬行有益。事实上,这是完全错误的。对于搜索引擎来说,伪静态url和动态url在爬取时仍然是动态的。这个怎么判断??如果你的网站是伪静态类型,可以用百度抢诊断工具来抢。
可以清楚的看到百度蜘蛛还在抓取动态网址。
伪静态中,百度蜘蛛抓取的其实是动态URL
静态网页的优缺点:
静态网页的优点是响应速度快,可以直接加载到客户端的浏览器中,无需服务器编译,而且无论你如何访问,服务器只是将数据传输给请求者,并且不进行脚本计算和读取。后台数据库。访问速度快,可以跨平台、跨服务器。
这大大提高了访问速度,降低了一些安全隐患,让搜索引擎可以轻松简单地访问页面内容。
当然,它的缺点也很明显,就是占用空间。每次生成一个静态网页,都会存储在你的网页空间中,这对于大型网站来说是非常不利的!另外,后台更新文章也很麻烦。每次发布 文章 时,都必须手动生成它。如果要生成数百万页,那将是浪费时间!
三.哪个网址更适合网站优化?
从优化的角度来看,当然纯静态的url最有利于网站的优化,不过要看网站的大小。如果是中小型企业网站,一般都会更新文章,如果量不大,完全可以使用静态url。
对于动态 url,搜索引擎不会区别对待它们。这也是李百度在回答网友提问时提到的。他主要强调动态url不要放太多动态参数。对于搜索引擎爬取,毫无疑问!
综合以上总结,是动态网站好还是静态网站好?主要看网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页会更简单,反之,一般使用动态网页技术来实现。
不过现在一般使用动态的网站。如果有内容更新,可以随时在后台更新,方便后期维护和管理,但最好使用静态页面或伪静态进行优化。
温州小编认为,无论是动态还是静态,都可以稳定打开,不会对用户阅读产生404等影响,有利于seo优化! 查看全部
动态网页抓取(浙江很多刚做seo的人,不知道网站的页面有静态和动态之分,)
很多刚做seo的浙江人不知道网站的页面分静态和动态。与动态网页相比,静态网页是指没有后台数据库、不收录程序、不具有交互性的网页。你就是它所显示的,什么都不会改变。
静态网页更新比较麻烦,适合一般更新较少的显示类型网站。另外,如果扩展名是.jsp但没有数据库连接,那是一个完全静态的页面,也是静态的网站。
只是 .jsp 扩展名。静态和动态都可以做seo,不会有太大影响。只要网站可以打开,路径不变,不出现404就可以了。了解更多。

一.网站静态好还是动态好?
静态网页的特点
1)。静态网页的每个网页都有一个固定的网址,网页网址以.htm、.html、.shtml等常用方法后缀,不收录“?”;
2)。一旦网页内容发布到网站服务器上,每个静态网页的内容都会保存在网站服务器上,不管是否有用户访问,即静态网页它是实际保存在服务器上的一个文件,每个网页都是一个独立的文件;
3)。静态网页内容比较稳定,容易被搜索引擎检索;
4)。静态网页没有数据库支持,网站制作和维护的工作量比较大,所以当网站有大量的静态网页制作方式时,很难完全依赖静态网页制作方式。信息;
5)。静态网页的交互性较低,并且对功能的限制更大。
动态网页的特点
1)。动态网页基于数据库技术,可以大大减少网站保护的工作量;网站 使用动态网页技术可以实现更多功能,如用户注册、用户登录、在线查询、用户处理、订单处理等;
2).动态网页实际上并不是一个独立存在于服务器上的网页文件,只有当用户请求服务器返回一个完整的网页时;
3)。这 ”?” 在动态网页中对于搜索引擎检索有一定的问题。一般搜索引擎无法从网站的数据库中访问所有网页,或者出于技术考虑,搜索蜘蛛不会抓取“?”后面的内容。在网址中,
因此,选择动态网页的网站在实现搜索引擎时需要进行一定的技巧处理,以适应搜索引擎的要求。
二.两者的区别
静态网页和动态网页各有特点。网站选择动态网页还是静态网页,主要看网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页的方法会比较简单,否则就应该使用动态网页技术来完成。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了网站适应搜索引擎检索的需要,即使使用动态网站技能,将网页内容转换为静态网页发布。
动态网站也可以利用动静结合的原则,适合动态网页使用动态网页。如果需要使用静态网页,可以考虑使用静态网页。动态网页内容与静态网页内容共存也很常见。
动态url的优缺点:
使用动态 url 有缺点也有优点。最大的优点之一是 网站 的内容可以实时更新。后台更新文章很方便。我们判断url为动态的标志是url内部收录动态参数如?、=、&等参数。
另一种判断方式是网页以jsp、PHP等为后缀的网页结束。伪静态和静态网页的后缀都是html。
动态url有很多缺陷。比如大型网站流量很大的时候,使用动态url会给服务器带来很大的压力。另外,动态urls无法从url中看到网站的目录状态。,无法从url判断当时的目录状态。再者,不利于用户对url的回忆。
伪静态的优缺点:
伪静态的优点是可以继承动态url的优点。后台发布文章时,也会实时更新内容。而且从用户的角度来看,伪静态url和静态url没有什么区别。当然,缺陷也是众所周知的。它还会在服务器上产生压力负载。
对某些人来说,伪静态可能对搜索引擎爬行有益。事实上,这是完全错误的。对于搜索引擎来说,伪静态url和动态url在爬取时仍然是动态的。这个怎么判断??如果你的网站是伪静态类型,可以用百度抢诊断工具来抢。
可以清楚的看到百度蜘蛛还在抓取动态网址。
伪静态中,百度蜘蛛抓取的其实是动态URL
静态网页的优缺点:
静态网页的优点是响应速度快,可以直接加载到客户端的浏览器中,无需服务器编译,而且无论你如何访问,服务器只是将数据传输给请求者,并且不进行脚本计算和读取。后台数据库。访问速度快,可以跨平台、跨服务器。
这大大提高了访问速度,降低了一些安全隐患,让搜索引擎可以轻松简单地访问页面内容。
当然,它的缺点也很明显,就是占用空间。每次生成一个静态网页,都会存储在你的网页空间中,这对于大型网站来说是非常不利的!另外,后台更新文章也很麻烦。每次发布 文章 时,都必须手动生成它。如果要生成数百万页,那将是浪费时间!
三.哪个网址更适合网站优化?
从优化的角度来看,当然纯静态的url最有利于网站的优化,不过要看网站的大小。如果是中小型企业网站,一般都会更新文章,如果量不大,完全可以使用静态url。
对于动态 url,搜索引擎不会区别对待它们。这也是李百度在回答网友提问时提到的。他主要强调动态url不要放太多动态参数。对于搜索引擎爬取,毫无疑问!
综合以上总结,是动态网站好还是静态网站好?主要看网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页会更简单,反之,一般使用动态网页技术来实现。
不过现在一般使用动态的网站。如果有内容更新,可以随时在后台更新,方便后期维护和管理,但最好使用静态页面或伪静态进行优化。
温州小编认为,无论是动态还是静态,都可以稳定打开,不会对用户阅读产生404等影响,有利于seo优化!
动态网页抓取(如下京东商城网站源代码:对应的网页源码如下(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 356 次浏览 • 2022-02-25 13:19
这里简单介绍一下京东商城网站的源码,以抓取网站静态和动态数据为例,实验环境win10+python3.6+pycharm< @5.0,主要内容如下:
抓取网站静态数据(数据在网页源码中)京东商城网站源码:以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数和评论数四个字段。京东商城网站源码如下:
对应的网页源码如下,包括我们需要的数据京东商城网站源码:
2.对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面京东商城网站 源代码:
程序运行截图如下,爬取数据成功:
抓取网站动态数据(网页源码、json等文件中没有数据):以人人贷网站数据为例
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额和进度五个字段。截图如下:
打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难,都是入门级爬虫,网页结构也比较简单。最重要的是进行抓包分析,分析提取页面,等你熟悉了之后,可以使用scrapy框架进行数据爬取,可以更加方便高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
PHP开发的商城网站源码好用吗?
近日了解到,随着电子商务行业的快速发展,网上商城系统成本低、速度快等优势为众多企业带来了商机,营销功能丰富、商品体系完善、用户良好经验。那么开源的php mall系统主要有哪些特点呢?
1、PHP开源商城系统更方便
PHP程序开发快,运行快,技术本身也能很快学会。嵌入 HTML:因为 PHP 可以嵌入 HTML 语言,所以它与其他语言相关。编辑简单实用,再满足企业发展需要的功能,或增加企业新需求;
2、php开源商城系统适应性强
通过选择开源商城系统,企业可以根据自己的意愿访问源代码并修改开源商城系统,以降低此类风险,因为开源社区中会有源源不断的维护和更新。因此受到各行各业中小企业的欢迎和广泛使用,使得开源商城软件的适应性更强;
3.强大的跨平台php开源商城系统
由于 PHP 是服务器端脚本,它可以在 UNIX、LINUX、WINDOWS、iOS 和 Android 等平台上运行;
4.php开源商城系统更高效
效率是每个用户在选择商城系统时都会考虑的问题。PHP商城系统消耗的系统资源相对较少。
5、PHP开源商城系统更安全
安全是每个用户在选择电商系统时首先会考虑的问题,因为开源商城系统的源代码是开放的,没有得到很好的保护,用户会认为开源商城系统的安全性不可靠。然而,随着电子商务系统开发技术的成熟,开源商城系统的研究也取得了长足的进步。有专人解决电商系统的BUG等问题。因此,开源商城系统的安全性能不断提升。 查看全部
动态网页抓取(如下京东商城网站源代码:对应的网页源码如下(组图))
这里简单介绍一下京东商城网站的源码,以抓取网站静态和动态数据为例,实验环境win10+python3.6+pycharm< @5.0,主要内容如下:
抓取网站静态数据(数据在网页源码中)京东商城网站源码:以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数和评论数四个字段。京东商城网站源码如下:
对应的网页源码如下,包括我们需要的数据京东商城网站源码:
2.对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面京东商城网站 源代码:
程序运行截图如下,爬取数据成功:
抓取网站动态数据(网页源码、json等文件中没有数据):以人人贷网站数据为例
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额和进度五个字段。截图如下:
打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难,都是入门级爬虫,网页结构也比较简单。最重要的是进行抓包分析,分析提取页面,等你熟悉了之后,可以使用scrapy框架进行数据爬取,可以更加方便高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
PHP开发的商城网站源码好用吗?
近日了解到,随着电子商务行业的快速发展,网上商城系统成本低、速度快等优势为众多企业带来了商机,营销功能丰富、商品体系完善、用户良好经验。那么开源的php mall系统主要有哪些特点呢?
1、PHP开源商城系统更方便
PHP程序开发快,运行快,技术本身也能很快学会。嵌入 HTML:因为 PHP 可以嵌入 HTML 语言,所以它与其他语言相关。编辑简单实用,再满足企业发展需要的功能,或增加企业新需求;
2、php开源商城系统适应性强
通过选择开源商城系统,企业可以根据自己的意愿访问源代码并修改开源商城系统,以降低此类风险,因为开源社区中会有源源不断的维护和更新。因此受到各行各业中小企业的欢迎和广泛使用,使得开源商城软件的适应性更强;
3.强大的跨平台php开源商城系统
由于 PHP 是服务器端脚本,它可以在 UNIX、LINUX、WINDOWS、iOS 和 Android 等平台上运行;
4.php开源商城系统更高效
效率是每个用户在选择商城系统时都会考虑的问题。PHP商城系统消耗的系统资源相对较少。
5、PHP开源商城系统更安全
安全是每个用户在选择电商系统时首先会考虑的问题,因为开源商城系统的源代码是开放的,没有得到很好的保护,用户会认为开源商城系统的安全性不可靠。然而,随着电子商务系统开发技术的成熟,开源商城系统的研究也取得了长足的进步。有专人解决电商系统的BUG等问题。因此,开源商城系统的安全性能不断提升。
动态网页抓取(Selenium驱动GeckoDriver安装方法(组图)实践案例(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-25 12:24
上面得到的结果令人困惑。要从这些json数据中提取出我们想要的数据,我们需要使用json库来解析数据。
# coding: UTF-8
import requests
from bs4 import BeautifulSoup
import json
url = "https://www.zhihu.com/api/v4/a ... %255B*%5D.author%2Ccollapsed%2Creply_to_author%2Cdisliked%2Ccontent%2Cvoting%2Cvote_count%2Cis_parent_author%2Cis_author%2Calgorithm_right&order=normal&limit=20&offset=0&status=open"
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
r = requests.get(url, headers = headers)
json_data = json.loads(r.text)
comments_list = json_data['data']
for eachone in comments_list:
message = eachone['content']
print message
以上代码只能爬取单个页面,要想爬取更多的内容需要了解URL的规律
首页的真实网址:%5B*%5D.author%2Ccollapsed%2Creply_to_author%2Cdisliked%2Ccontent%2Cvoting%2Cvote_count%2Cis_parent_author%2Cis_author%2Calgorithm_right&order=normal&limit=20&offset=0&status=open
第二页的真实网址:%5B*%5D.author%2Ccollapsed%2Creply_to_author%2Cdisliked%2Ccontent%2Cvoting%2Cvote_count%2Cis_parent_author%2Cis_author%2Calgorithm_right&order=normal&limit=20&offset=20&status=open
对比上面两个网址,我们会发现两个特别重要的变量,offset和limit
# coding : utf-8
import requests
import json
def single_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
r = requests.get(url, headers = headers)
json_data = json.loads(r.text)
comments_list = json_data['data']
for eachone in comments_list:
message = eachone['content']
print(message)
for page in (0,2):
link1 = "https://www.zhihu.com/api/v4/a ... %255B*%5D.author%2Ccollapsed%2Creply_to_author%2Cdisliked%2Ccontent%2Cvoting%2Cvote_count%2Cis_parent_author%2Cis_author%2Calgorithm_right&order=normal&limit=20&offset="
link2 = "&status=open"
page_str = str(page * 20)
link = link1 + page_str + link2
single_page(link)
3.Selenium 模拟浏览器捕获
对于一些复杂的网站,上述方法将不再适用。另外,有些数据的真实地址的URL很长很复杂,有的网站为了避免这些会加密地址,使得一些变量难以破解。
因此,我们将使用 selenium 浏览器渲染引擎,直接用浏览器显示网页,解析 HTML、JS 和 CSS
(1)Selenium安装及基本介绍
参考博文:火狐浏览器驱动GeckoDriver安装方法
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
import sys
#reload(sys)
#sys.setdefaultencoding("utf-8")
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
# windows版,需要安装 greckodriver
binary = FirefoxBinary(r'D:\Program Files (x86)\Mozilla Firefox\firefox.exe')
driver = webdriver.Firefox(firefox_binary = binary, capabilities = caps)
driver.get("https://www.baidu.com")
以下操作以Chrome浏览器为例;
# coding:utf-8
from selenium import webdriver
#windows版
driver = webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
driver.get("https://www.baidu.com")
(2)硒实践案例
现在我们使用浏览器渲染来抓取之前的评论数据
先在“Inspect”页面找到HTML代码标签,尝试获取第一条评论
代码如下:
# coding:utf-8
from selenium import webdriver
driver = webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
driver.get("https://www.zhihu.com/question/22913650")
comment = driver.find_element_by_css_selector('')
print(comment.text)
(3)Selenium 获取文章的所有评论
要获取所有评论,脚本需要能够自动点击“加载更多”、“所有评论”、“下一页”等。
代码如下:
# coding: utf-8
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
import time
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
binary = FirefoxBinary(r'D:\Program Files\Mozilla Firefox\firefox.exe')
#把上述地址改成你电脑中Firefox程序的地址
driver = webdriver.Firefox(firefox_binary=binary, capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments = driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content = eachcomment.find_element_by_tag_name('p')
print (content.text)
Selenium 选择元素的方法:
# text
find_element_by_css_selector('div.body_inner')
#
find_element_by_xpath("//form[@id='loginForm']"
# text
find_element_by_id
# text
find_element_by_name('myname')
# text
find_element_by_link_text('text')
# text
find_element_by_partial_link_text('te')
# text
find_element_by_tag_name('div')
# text
find_element_by_class_name('body_inner')
要查找多个元素,可以在上面的'element'后面加s成为元素。前两个比较常用
(4)Selenium的高级操作
为了加快selenium的爬取速度,常通过以下方法实现:
(1)控制 CSS 加载
fp = webdriver.FirefoxProfile()
fp.set_preference("permissions.default.stylesheet",2)
(2)控制图片的显示
fp = webdriver.FirefoxProfile()
fp.set_preference("permissions.default.image",2)
(3)控制 JavaScript 的执行
fp = webdriver.FirefoxProfile()
fp.set_preference("javascript.enabled", False)
对于 Chrome 浏览器:
options=webdriver.ChromeOptions()
prefs={
'profile.default_content_setting_values': {
'images': 2,
'javascript':2
}
}
options.add_experimental_option('prefs',prefs)
browser = webdriver.Chrome(chrome_options=options)
4.Selenium爬虫实战:深圳短租数据
(1)网站分析
(2)项目实战 查看全部
动态网页抓取(Selenium驱动GeckoDriver安装方法(组图)实践案例(图))
上面得到的结果令人困惑。要从这些json数据中提取出我们想要的数据,我们需要使用json库来解析数据。
# coding: UTF-8
import requests
from bs4 import BeautifulSoup
import json
url = "https://www.zhihu.com/api/v4/a ... %255B*%5D.author%2Ccollapsed%2Creply_to_author%2Cdisliked%2Ccontent%2Cvoting%2Cvote_count%2Cis_parent_author%2Cis_author%2Calgorithm_right&order=normal&limit=20&offset=0&status=open"
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
r = requests.get(url, headers = headers)
json_data = json.loads(r.text)
comments_list = json_data['data']
for eachone in comments_list:
message = eachone['content']
print message
以上代码只能爬取单个页面,要想爬取更多的内容需要了解URL的规律
首页的真实网址:%5B*%5D.author%2Ccollapsed%2Creply_to_author%2Cdisliked%2Ccontent%2Cvoting%2Cvote_count%2Cis_parent_author%2Cis_author%2Calgorithm_right&order=normal&limit=20&offset=0&status=open
第二页的真实网址:%5B*%5D.author%2Ccollapsed%2Creply_to_author%2Cdisliked%2Ccontent%2Cvoting%2Cvote_count%2Cis_parent_author%2Cis_author%2Calgorithm_right&order=normal&limit=20&offset=20&status=open
对比上面两个网址,我们会发现两个特别重要的变量,offset和limit
# coding : utf-8
import requests
import json
def single_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
r = requests.get(url, headers = headers)
json_data = json.loads(r.text)
comments_list = json_data['data']
for eachone in comments_list:
message = eachone['content']
print(message)
for page in (0,2):
link1 = "https://www.zhihu.com/api/v4/a ... %255B*%5D.author%2Ccollapsed%2Creply_to_author%2Cdisliked%2Ccontent%2Cvoting%2Cvote_count%2Cis_parent_author%2Cis_author%2Calgorithm_right&order=normal&limit=20&offset="
link2 = "&status=open"
page_str = str(page * 20)
link = link1 + page_str + link2
single_page(link)
3.Selenium 模拟浏览器捕获
对于一些复杂的网站,上述方法将不再适用。另外,有些数据的真实地址的URL很长很复杂,有的网站为了避免这些会加密地址,使得一些变量难以破解。
因此,我们将使用 selenium 浏览器渲染引擎,直接用浏览器显示网页,解析 HTML、JS 和 CSS
(1)Selenium安装及基本介绍
参考博文:火狐浏览器驱动GeckoDriver安装方法
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
import sys
#reload(sys)
#sys.setdefaultencoding("utf-8")
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
# windows版,需要安装 greckodriver
binary = FirefoxBinary(r'D:\Program Files (x86)\Mozilla Firefox\firefox.exe')
driver = webdriver.Firefox(firefox_binary = binary, capabilities = caps)
driver.get("https://www.baidu.com";)
以下操作以Chrome浏览器为例;
# coding:utf-8
from selenium import webdriver
#windows版
driver = webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
driver.get("https://www.baidu.com";)
(2)硒实践案例
现在我们使用浏览器渲染来抓取之前的评论数据
先在“Inspect”页面找到HTML代码标签,尝试获取第一条评论
代码如下:
# coding:utf-8
from selenium import webdriver
driver = webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
driver.get("https://www.zhihu.com/question/22913650";)
comment = driver.find_element_by_css_selector('')
print(comment.text)
(3)Selenium 获取文章的所有评论
要获取所有评论,脚本需要能够自动点击“加载更多”、“所有评论”、“下一页”等。
代码如下:
# coding: utf-8
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
import time
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
binary = FirefoxBinary(r'D:\Program Files\Mozilla Firefox\firefox.exe')
#把上述地址改成你电脑中Firefox程序的地址
driver = webdriver.Firefox(firefox_binary=binary, capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments = driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content = eachcomment.find_element_by_tag_name('p')
print (content.text)
Selenium 选择元素的方法:
# text
find_element_by_css_selector('div.body_inner')
#
find_element_by_xpath("//form[@id='loginForm']"
# text
find_element_by_id
# text
find_element_by_name('myname')
# text
find_element_by_link_text('text')
# text
find_element_by_partial_link_text('te')
# text
find_element_by_tag_name('div')
# text
find_element_by_class_name('body_inner')
要查找多个元素,可以在上面的'element'后面加s成为元素。前两个比较常用
(4)Selenium的高级操作
为了加快selenium的爬取速度,常通过以下方法实现:
(1)控制 CSS 加载
fp = webdriver.FirefoxProfile()
fp.set_preference("permissions.default.stylesheet",2)
(2)控制图片的显示
fp = webdriver.FirefoxProfile()
fp.set_preference("permissions.default.image",2)
(3)控制 JavaScript 的执行
fp = webdriver.FirefoxProfile()
fp.set_preference("javascript.enabled", False)
对于 Chrome 浏览器:
options=webdriver.ChromeOptions()
prefs={
'profile.default_content_setting_values': {
'images': 2,
'javascript':2
}
}
options.add_experimental_option('prefs',prefs)
browser = webdriver.Chrome(chrome_options=options)
4.Selenium爬虫实战:深圳短租数据
(1)网站分析
(2)项目实战
动态网页抓取(如何利用动态片段吸引精准流量呢?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-25 12:06
我们知道,提高拍卖中的点击率一直是我们的优化目标。为了提高点击率,我们用了很多方法,比如我们经常做的优化思路。当然,最直接的一种就是提高出价来提高点击率。当然,如果你只是一味的加价,并没有优化的意义,而百度还有更多的工具可以让你提高点击率,比如西京子链、品牌推广位等。灯塔要讲另一种推广方式:动态片段。启用动态剪辑后,如果使用它们,可以大大提高点击率。我们来看看什么是动态剪辑。
在详细说动态片段之前,我们先来了解一下动态片段的样式是什么样的?
位置方面,动态剪辑类似于路径子链的位置,都显示在广告素材下,不同的是路径的广告字数限制太小,而要表达的信息不能很好地解释。但是动态剪辑没有明确的字数限制,可以更好地诠释要表达的信息。
那么我们如何使用动态片段来吸引精准流量呢?
在设置动态片段时,我们有两种设置方法:
一、系统可以自动抓取描述和链接
这种方法百度凤凰巢系统会自动抓取描述和链接,这种方法没有针对性,一般不推荐。
二、自己手动添加(强烈推荐)
虽然系统爬取的相关性也不错,但有些描述还是不够理想,还有爬取的链接,没有推广标识,不能用来识别推广的效果。影响。
如何添加精准吸引力的动态描述?
1、对焦点选择:根据单位的分类,选择合适的对焦点;一般来说,一个广告素材只能有4个焦点,适当的选择可以更好地提高相关性。
2、动态描述:这也是本文的重点部分文章;要想精准吸引人,首先要了解用户的需求,然后才能写出正确的动态描述,满足有针对性的用户需求。
以上是对动态片段的一些使用优化的介绍。最后提出增加动态片段的样式展示,可以在单元层面的创意上进行展示,让招标维护人员可以根据样式的效果更好的修改和调整动态片段的描述,更有效地提升点击效果。. 查看全部
动态网页抓取(如何利用动态片段吸引精准流量呢?-八维教育)
我们知道,提高拍卖中的点击率一直是我们的优化目标。为了提高点击率,我们用了很多方法,比如我们经常做的优化思路。当然,最直接的一种就是提高出价来提高点击率。当然,如果你只是一味的加价,并没有优化的意义,而百度还有更多的工具可以让你提高点击率,比如西京子链、品牌推广位等。灯塔要讲另一种推广方式:动态片段。启用动态剪辑后,如果使用它们,可以大大提高点击率。我们来看看什么是动态剪辑。
在详细说动态片段之前,我们先来了解一下动态片段的样式是什么样的?
位置方面,动态剪辑类似于路径子链的位置,都显示在广告素材下,不同的是路径的广告字数限制太小,而要表达的信息不能很好地解释。但是动态剪辑没有明确的字数限制,可以更好地诠释要表达的信息。
那么我们如何使用动态片段来吸引精准流量呢?
在设置动态片段时,我们有两种设置方法:
一、系统可以自动抓取描述和链接
这种方法百度凤凰巢系统会自动抓取描述和链接,这种方法没有针对性,一般不推荐。
二、自己手动添加(强烈推荐)
虽然系统爬取的相关性也不错,但有些描述还是不够理想,还有爬取的链接,没有推广标识,不能用来识别推广的效果。影响。
如何添加精准吸引力的动态描述?
1、对焦点选择:根据单位的分类,选择合适的对焦点;一般来说,一个广告素材只能有4个焦点,适当的选择可以更好地提高相关性。
2、动态描述:这也是本文的重点部分文章;要想精准吸引人,首先要了解用户的需求,然后才能写出正确的动态描述,满足有针对性的用户需求。
以上是对动态片段的一些使用优化的介绍。最后提出增加动态片段的样式展示,可以在单元层面的创意上进行展示,让招标维护人员可以根据样式的效果更好的修改和调整动态片段的描述,更有效地提升点击效果。.
动态网页抓取(企业想做好网站SEO优化就要了解查找引擎的抓取规矩 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-02-21 20:08
)
企业要想做好网站SEO优化,就要了解搜索引擎的爬取规律,做好百度动态页面SEO。我们都知道,搜索引擎爬取动态页面是非常困难的。是的,我们来谈谈如何为SEO优化动态页面:
一、创建静态导入
在“动静结合,静制动”的原则指导下,我们可以对网站进行一些修正,尽可能增加动态网页的搜索引擎可见度。SEO优化方法是将动态网页编译成静态主页或网站图的链接,动态页面会以静态目录的形式出现。也许为动态页面创建一个专用的静态导入页面,链接到动态页面,并将静态导入页面提交给搜索引擎。
二、付费登录搜索引擎
关于整个网站使用连接数据库的内容管理系统发布的动态网站,优化SEO最直接的方式是付费登录,建议直接提交动态网页页面到搜索引擎目录或做关键字广告,确保 网站 是由搜索引擎输入的。
三、搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些搜索引擎在抓取动态页面时,为了防止搜索机器人被困,搜索引擎只抓取过去从静态页面链接的动态页面,从动态页面链接出去。所有的动态页面都不再被爬取,也就是说,动态页面中的链接将不再被访问。
相信大家对超人科技小编为我们整理的SEO优化动态页面的内容已经有了一定的了解。其实小编给我们整理的还不是很全面,SEO优化的内容也比较多。我们可以在本站阅读其他的SEO优化技术和经验,相信一定能取得很好的效果。
查看全部
动态网页抓取(企业想做好网站SEO优化就要了解查找引擎的抓取规矩
)
企业要想做好网站SEO优化,就要了解搜索引擎的爬取规律,做好百度动态页面SEO。我们都知道,搜索引擎爬取动态页面是非常困难的。是的,我们来谈谈如何为SEO优化动态页面:
一、创建静态导入
在“动静结合,静制动”的原则指导下,我们可以对网站进行一些修正,尽可能增加动态网页的搜索引擎可见度。SEO优化方法是将动态网页编译成静态主页或网站图的链接,动态页面会以静态目录的形式出现。也许为动态页面创建一个专用的静态导入页面,链接到动态页面,并将静态导入页面提交给搜索引擎。
二、付费登录搜索引擎
关于整个网站使用连接数据库的内容管理系统发布的动态网站,优化SEO最直接的方式是付费登录,建议直接提交动态网页页面到搜索引擎目录或做关键字广告,确保 网站 是由搜索引擎输入的。
三、搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些搜索引擎在抓取动态页面时,为了防止搜索机器人被困,搜索引擎只抓取过去从静态页面链接的动态页面,从动态页面链接出去。所有的动态页面都不再被爬取,也就是说,动态页面中的链接将不再被访问。
相信大家对超人科技小编为我们整理的SEO优化动态页面的内容已经有了一定的了解。其实小编给我们整理的还不是很全面,SEO优化的内容也比较多。我们可以在本站阅读其他的SEO优化技术和经验,相信一定能取得很好的效果。

动态网页抓取((43页珍藏版)搜索引擎基本原理及实现技术搜索引擎的工作原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-02-21 20:03
《搜索引擎基本原理与实现技术.ppt》为会员共享,可在线阅读。更多相关《搜索引擎基本原理与实现技术.ppt(43页珍藏版)》,请在usdt平台_usdt官网搜索。
1、搜索引擎基本原理及实现技术搜索引擎工作原理通用搜索引擎框架示意图通用网络爬虫爬虫技术概述网络爬虫是自动提取网页进行搜索的程序来自 Internet 的引擎 下载网页是搜索引擎的重要组成部分。网络爬虫使用多线程技术使爬虫更加强大。网络爬虫还需要完成信息抽取任务。提取新闻、电子书、行业信息等,针对MP3图片、Flash等。对各类内容进行自动识别、分类和相关属性测试,如MP3文件的文件大小、下载速度等。爬网时
2、继续从当前页面中提取新的URL,放入队列中,直到满足系统的某个停止条件。2 动态网页分析 动态网页参数按照一定的规则拼出所有要爬取的URL,并且只爬取这些特定的范围。动态网页 3 RSS XML 数据等特殊内容需要特殊处理 如新闻滚动新闻页面需要爬虫不断监控扫描发现新内容,立即抓取 4 文件对象图片 MP3 Flash 视频等文件需要特殊抓取例如,图像捕获后,需要知道图像文件类型的大小,图像文件的大小,图像的像素大小,图像的像素大小需要进行转换。
3、抓取会定期更新捕获的网页。垂直爬虫只关注特定主题或属于特定行业的网页。难点在于如何识别网页是否属于指定的类别。优秀爬虫的特点 高性能URL队列的存储方式会影响性能 可扩展性 多服务器 多线程爬取 不同地域 部署数据中心 将爬虫分散到不同的数据中心 禁止爬虫的几种情况 User agent GoogleBotDisallow tmp Disallow cgi bin Disallow users paranoid Robot txt 禁止索引网页内容 禁止抓取网页链接 Content 标签对应的具体含义 爬虫质量的评价标准
4、1 覆盖范围 2 爬取网页的新颖性 3 爬取网页的重要性 大型商业搜索引擎一般至少收录两套不同用途的爬虫系统。针对更新频率较低的网页的网页抓取策略 1 广度优先遍历策略 2 深度优先遍历策略 3 不完整的页面排名策略 4 OPIC 策略 OnlinePageImportanceComputation 5 大站点优先策略 广度优先策略 将新下载页面中的链接直接插入等待中URL队列的末尾,表示网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页继续爬取该网页链接的所有网页。爬行顺序 1 2
5、 3 4 5 6 7 8 9 深度优先策略从起始页开始,一个链接,一个链接,然后向下。处理完这一行,进入下一个起始页面,继续按照链接爬取顺序 1 2 5 6 3 7 4 8 9 PageRank简介 1 初始阶段,网页通过链接关系构建Web图。每个页面设置相同的 PageRank 值。经过几轮计算,将得到每个页面最终得到的PageRank值。随着每一轮计算,网页当前的PageRank值会不断更新。2 一轮更新页面PageRank得分的计算方法在一轮更新页面的PageRank得分计算中,每个页面都会将其当前的 PageRank 值平均分配给该页面中收录的传出链接。转到每个链接,以便您可以获取
6、对应的权重和每个页面将所有指向该页面的传入链接中传递的权重相加得到一个新的PageRank分数。当每个页面得到更新后的PageRank值时,就完成了一轮PageRank计算。不完整的PageRank策略 将下载的网页和URL队列中的URL一起爬取,形成一组网页。该集合中pagerank计算完成后,根据PageRank计算URL队列中待爬取的网页。分数从高到低排列形成的序列就是爬虫接下来应该爬的URL列表。每当下载K个页面时,重新计算所有下载的页面及其不完整的PageRank值OPIC策略OnlinePageImportanceComputation这个算法
7、其实也是一个页面的重要性分数。在算法开始之前,所有页面都被赋予相同的初始现金现金。当一个页面P被下载时,P的cash被分配给从P分析的所有链接。并清除P的cash。根据cash的数量对URL队列中所有待爬取的页面进行排序。大站点优先策略以 网站 为单位衡量网页的重要性。对于URL队列中所有待爬取的网页,根据其网站的网站对待下载的页面进行分类网站
在8、中,关于不断变化的主题内容的用户体验策略假设用户经常只查看前3页的搜索内容。Principle 保存网页的多个历史版本,并根据过去每次内容变化对搜索质量的影响取平均值。作为判断抓取网页时机的参考依据,对质量影响较严重的网页将优先安排重新抓取聚类抽样策略。前两种更新策略是有前提的,需要网页的历史信息。存在两个问题: 1、每个系统保存多个版本的历史信息,增加了很多系统负担。2 新网页完全没有历史信息,无法确定更新策略。聚类抽样策略 聚类抽样策略考虑到网页有很多属性。同理,计算某一类页面的更新频率,只需按更新周对该类页面进行采样即可。
9、周期是整个类的更新周期。分布式爬虫系统结构 一般来说,爬虫系统需要面对整个互联网上亿万的网页。单个爬虫程序不可能完成这样的任务。往往需要多个爬取程序一起处理。一般来说,爬虫系统往往是分布式的三层结构。底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器上可以部署多套爬虫程序,构成一个基本的分布式爬虫系统。主从基本结构有一个专门的主服务器来维护要爬取的URL队列,它负责每次分发 URL。转到不同的 Slave 服务器,Slave 服务器负责实际的网页下载。主服务器还负责维护要爬取的 URL 队列和分发 URL。
10、负责调整各个从服务器的负载,防止部分从服务器过于空闲或过度工作。在这种模式下,master容易成为系统的瓶颈。对等的工作结构。所有抓取服务器之间的分工没有区别。每一个爬取服务器都可以从待爬取的URL队列中获取该URL,然后计算该URL主域名的哈希值H,进而计算出Hmodm,其中m为服务器数量。比如上图中m为3,计算出来的个数是为了处理URL的主机号的缺点是扩展性差。一致性哈希对 URL 的主域名进行哈希运算,并将其映射到 0 232 范围内的一个数字,并根据 URL 的主域名将该范围平均分配给 m 个服务器。哈希运算的取值范围决定了要爬取的服务器。如果某个服务器有问题,那么
11、 那么应该负责这个服务器的网页会被下一个服务器按顺时针顺序爬取。暗网爬取查询组合题文本框填入题目的网络爬虫实现环节的存储队列的数据结构。待爬取队列已爬取队列无效 链接错误链接 网页抓取 Jsoup jar 官方网站http jsoup org 相关学习资料 getElementById Stringid 获取id为getElementsByTag Stringtag 获取标签为getElementsByClass StringclassName 获取class为getElementsByAttribute的元素Stringkey 使用 Attribute 获取元素 获取元素的数据 attr 方法如下
12、 Stringkey 获取元素数据 attr Stringkey Stringvalue t 设置元素数据属性 获取所有属性 id className classNames 获取 idclass 值 text 获取文本值 text Stringvalue 设置文本值 html 获取 html 字符串值设置 htmlouterHtml 获取内部 html try doc Jsoup connect urlStr userAgent Mozilla 5 0 Windows U WindowsNT5 1 zh CN rv 1 9 2 15 设置用户代理超时
13、t 5000 设置连接超时时间 get catch MalformedURLExceptione log error e return catch IOExceptione if einstanceofSocketTimeoutException log error e return if einstanceofUnknownHostException log error e return log error e return system out println doc title Elementhead doc head Elementsmetas head select meta为了
14、 Elementmeta metas Stringcontent meta attr content Elementbody doc body Elementses body select a for Iteratorit es iterator it hasNext Elemente Element it next href e attr href 链接 提取 机构部门 招生就业 合作交流 提高爬虫效率 多线程爬取优化存储结构根据不同类型的链接制定爬取策略。示例说明 主要步骤 1 输入种子页面的URL,爬取爬取线程的深度。2 根据初始url获取种子页面的内容。注 1。
15、 合法的两种方法 a 判断url是否符合协议规则 b 判断url是否可以打开 while counts 3 try URLurl newURL urlStr HttpURLConnectioncon HttpURLConnection url openConnection intstate con getResponseCode if state 200 retu ok break catch Exceptionex counts continue 2种子 页面要获取的内容收录标题正文文本超链接开源jar包jsoup Documentdoc Jsoup connect sUrl get El
16、ementslinks doc select a href for Elementlink links StringlinkHref link attr href 获取href属性中的值,也就是你的地址 StringlinkTitle budge link text 获取anchor上的文字描述 3 多线程爬取根据爬行深度其实就是把第2步重复很多次。注意判断url是否重复。推荐使用hashset存储 HashSetallurlSet newHashSet 定义 hashsetallurlSet contains url 判断url是否已经存在 allurlSet add url 将url添加到allurlSet 4 存储爬取过程中页面的信息 信息包括网页地址页面、标题、链接数、正文、正文、超链接、锚文本等 5.存储方式 1.文档推荐。易于更改的信息存储在文件中。2.数据库存储在数据库中。网站所有地址均采用深度优先或广度优先的爬取策略。合理高效的存储结构,禁止爬行循环。课后学习PageRank算法的原理和实现方法。Java网络编程不需要jsoup。深入研究自己感兴趣的话题,比如在暗网上爬取分布式爬虫等。 查看全部
动态网页抓取((43页珍藏版)搜索引擎基本原理及实现技术搜索引擎的工作原理)
《搜索引擎基本原理与实现技术.ppt》为会员共享,可在线阅读。更多相关《搜索引擎基本原理与实现技术.ppt(43页珍藏版)》,请在usdt平台_usdt官网搜索。
1、搜索引擎基本原理及实现技术搜索引擎工作原理通用搜索引擎框架示意图通用网络爬虫爬虫技术概述网络爬虫是自动提取网页进行搜索的程序来自 Internet 的引擎 下载网页是搜索引擎的重要组成部分。网络爬虫使用多线程技术使爬虫更加强大。网络爬虫还需要完成信息抽取任务。提取新闻、电子书、行业信息等,针对MP3图片、Flash等。对各类内容进行自动识别、分类和相关属性测试,如MP3文件的文件大小、下载速度等。爬网时
2、继续从当前页面中提取新的URL,放入队列中,直到满足系统的某个停止条件。2 动态网页分析 动态网页参数按照一定的规则拼出所有要爬取的URL,并且只爬取这些特定的范围。动态网页 3 RSS XML 数据等特殊内容需要特殊处理 如新闻滚动新闻页面需要爬虫不断监控扫描发现新内容,立即抓取 4 文件对象图片 MP3 Flash 视频等文件需要特殊抓取例如,图像捕获后,需要知道图像文件类型的大小,图像文件的大小,图像的像素大小,图像的像素大小需要进行转换。
3、抓取会定期更新捕获的网页。垂直爬虫只关注特定主题或属于特定行业的网页。难点在于如何识别网页是否属于指定的类别。优秀爬虫的特点 高性能URL队列的存储方式会影响性能 可扩展性 多服务器 多线程爬取 不同地域 部署数据中心 将爬虫分散到不同的数据中心 禁止爬虫的几种情况 User agent GoogleBotDisallow tmp Disallow cgi bin Disallow users paranoid Robot txt 禁止索引网页内容 禁止抓取网页链接 Content 标签对应的具体含义 爬虫质量的评价标准
4、1 覆盖范围 2 爬取网页的新颖性 3 爬取网页的重要性 大型商业搜索引擎一般至少收录两套不同用途的爬虫系统。针对更新频率较低的网页的网页抓取策略 1 广度优先遍历策略 2 深度优先遍历策略 3 不完整的页面排名策略 4 OPIC 策略 OnlinePageImportanceComputation 5 大站点优先策略 广度优先策略 将新下载页面中的链接直接插入等待中URL队列的末尾,表示网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页继续爬取该网页链接的所有网页。爬行顺序 1 2
5、 3 4 5 6 7 8 9 深度优先策略从起始页开始,一个链接,一个链接,然后向下。处理完这一行,进入下一个起始页面,继续按照链接爬取顺序 1 2 5 6 3 7 4 8 9 PageRank简介 1 初始阶段,网页通过链接关系构建Web图。每个页面设置相同的 PageRank 值。经过几轮计算,将得到每个页面最终得到的PageRank值。随着每一轮计算,网页当前的PageRank值会不断更新。2 一轮更新页面PageRank得分的计算方法在一轮更新页面的PageRank得分计算中,每个页面都会将其当前的 PageRank 值平均分配给该页面中收录的传出链接。转到每个链接,以便您可以获取
6、对应的权重和每个页面将所有指向该页面的传入链接中传递的权重相加得到一个新的PageRank分数。当每个页面得到更新后的PageRank值时,就完成了一轮PageRank计算。不完整的PageRank策略 将下载的网页和URL队列中的URL一起爬取,形成一组网页。该集合中pagerank计算完成后,根据PageRank计算URL队列中待爬取的网页。分数从高到低排列形成的序列就是爬虫接下来应该爬的URL列表。每当下载K个页面时,重新计算所有下载的页面及其不完整的PageRank值OPIC策略OnlinePageImportanceComputation这个算法
7、其实也是一个页面的重要性分数。在算法开始之前,所有页面都被赋予相同的初始现金现金。当一个页面P被下载时,P的cash被分配给从P分析的所有链接。并清除P的cash。根据cash的数量对URL队列中所有待爬取的页面进行排序。大站点优先策略以 网站 为单位衡量网页的重要性。对于URL队列中所有待爬取的网页,根据其网站的网站对待下载的页面进行分类网站
在8、中,关于不断变化的主题内容的用户体验策略假设用户经常只查看前3页的搜索内容。Principle 保存网页的多个历史版本,并根据过去每次内容变化对搜索质量的影响取平均值。作为判断抓取网页时机的参考依据,对质量影响较严重的网页将优先安排重新抓取聚类抽样策略。前两种更新策略是有前提的,需要网页的历史信息。存在两个问题: 1、每个系统保存多个版本的历史信息,增加了很多系统负担。2 新网页完全没有历史信息,无法确定更新策略。聚类抽样策略 聚类抽样策略考虑到网页有很多属性。同理,计算某一类页面的更新频率,只需按更新周对该类页面进行采样即可。
9、周期是整个类的更新周期。分布式爬虫系统结构 一般来说,爬虫系统需要面对整个互联网上亿万的网页。单个爬虫程序不可能完成这样的任务。往往需要多个爬取程序一起处理。一般来说,爬虫系统往往是分布式的三层结构。底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器上可以部署多套爬虫程序,构成一个基本的分布式爬虫系统。主从基本结构有一个专门的主服务器来维护要爬取的URL队列,它负责每次分发 URL。转到不同的 Slave 服务器,Slave 服务器负责实际的网页下载。主服务器还负责维护要爬取的 URL 队列和分发 URL。
10、负责调整各个从服务器的负载,防止部分从服务器过于空闲或过度工作。在这种模式下,master容易成为系统的瓶颈。对等的工作结构。所有抓取服务器之间的分工没有区别。每一个爬取服务器都可以从待爬取的URL队列中获取该URL,然后计算该URL主域名的哈希值H,进而计算出Hmodm,其中m为服务器数量。比如上图中m为3,计算出来的个数是为了处理URL的主机号的缺点是扩展性差。一致性哈希对 URL 的主域名进行哈希运算,并将其映射到 0 232 范围内的一个数字,并根据 URL 的主域名将该范围平均分配给 m 个服务器。哈希运算的取值范围决定了要爬取的服务器。如果某个服务器有问题,那么
11、 那么应该负责这个服务器的网页会被下一个服务器按顺时针顺序爬取。暗网爬取查询组合题文本框填入题目的网络爬虫实现环节的存储队列的数据结构。待爬取队列已爬取队列无效 链接错误链接 网页抓取 Jsoup jar 官方网站http jsoup org 相关学习资料 getElementById Stringid 获取id为getElementsByTag Stringtag 获取标签为getElementsByClass StringclassName 获取class为getElementsByAttribute的元素Stringkey 使用 Attribute 获取元素 获取元素的数据 attr 方法如下
12、 Stringkey 获取元素数据 attr Stringkey Stringvalue t 设置元素数据属性 获取所有属性 id className classNames 获取 idclass 值 text 获取文本值 text Stringvalue 设置文本值 html 获取 html 字符串值设置 htmlouterHtml 获取内部 html try doc Jsoup connect urlStr userAgent Mozilla 5 0 Windows U WindowsNT5 1 zh CN rv 1 9 2 15 设置用户代理超时
13、t 5000 设置连接超时时间 get catch MalformedURLExceptione log error e return catch IOExceptione if einstanceofSocketTimeoutException log error e return if einstanceofUnknownHostException log error e return log error e return system out println doc title Elementhead doc head Elementsmetas head select meta为了
14、 Elementmeta metas Stringcontent meta attr content Elementbody doc body Elementses body select a for Iteratorit es iterator it hasNext Elemente Element it next href e attr href 链接 提取 机构部门 招生就业 合作交流 提高爬虫效率 多线程爬取优化存储结构根据不同类型的链接制定爬取策略。示例说明 主要步骤 1 输入种子页面的URL,爬取爬取线程的深度。2 根据初始url获取种子页面的内容。注 1。
15、 合法的两种方法 a 判断url是否符合协议规则 b 判断url是否可以打开 while counts 3 try URLurl newURL urlStr HttpURLConnectioncon HttpURLConnection url openConnection intstate con getResponseCode if state 200 retu ok break catch Exceptionex counts continue 2种子 页面要获取的内容收录标题正文文本超链接开源jar包jsoup Documentdoc Jsoup connect sUrl get El
16、ementslinks doc select a href for Elementlink links StringlinkHref link attr href 获取href属性中的值,也就是你的地址 StringlinkTitle budge link text 获取anchor上的文字描述 3 多线程爬取根据爬行深度其实就是把第2步重复很多次。注意判断url是否重复。推荐使用hashset存储 HashSetallurlSet newHashSet 定义 hashsetallurlSet contains url 判断url是否已经存在 allurlSet add url 将url添加到allurlSet 4 存储爬取过程中页面的信息 信息包括网页地址页面、标题、链接数、正文、正文、超链接、锚文本等 5.存储方式 1.文档推荐。易于更改的信息存储在文件中。2.数据库存储在数据库中。网站所有地址均采用深度优先或广度优先的爬取策略。合理高效的存储结构,禁止爬行循环。课后学习PageRank算法的原理和实现方法。Java网络编程不需要jsoup。深入研究自己感兴趣的话题,比如在暗网上爬取分布式爬虫等。
动态网页抓取(动态网页抓取文章目录(1)(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-21 09:08
)
动态网页抓取
文章目录
前言
静态网页在浏览器中显示的内容在 HTML 源代码中。
但是由于主流的网站都使用JavaScript来展示网页内容,不像静态网页,在使用JavaScript的时候,很多内容不会出现在HTML源代码中,所以爬取静态网页的技术可能不会工作正常使用。
因此,我们需要使用两种动态网页抓取技术:通过浏览器检查元素解析真实网址和使用 selenium 模拟浏览器。
1 动态爬取示例
通过在后台与服务器交换少量数据,可以异步更新网页。
这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
一方面减少了网页重复内容的下载,另一方面节省了流量,
与使用 AJAX 网页相比,如果传统网页需要更新内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更友好。但是AJAX网页的爬取过程比较麻烦。
动态网页示例:
网页下方的评论是用 JavaScript 加载的,这些评论数据不会出现在网页的源代码中。
2 解析真实地址抓取
虽然数据并没有出现在网页的源代码中,但是我们仍然可以找到数据的真实地址,并且请求这个真实地址也可以得到想要的数据。此处使用浏览器的“检查”功能。
点击“Network”,刷新,点击左侧list?callback开头的链接,真实链接如下:
%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=&_=59
点击 JS - preview 可以找到这些评论的内容。
import requests
link = '''https://api-zero.livere.com/v1/comments/list?callback=jQuery112409913001985965064_1613139610757&limit=10
&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=&_=1613139610759'''
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36 Edg/88.0.705.63'}
r = requests.get(link, headers=headers)
print('页响应状态码:', r.status_code)
print(r.text)
3 通过 Selenium 模拟浏览器抓取
使用浏览器渲染引擎:直接使用浏览器加载和卸载HTML,应用CSS样式,显示网页时执行Javascript语句
自动打开浏览器加载网页,独立浏览每个网页,顺便抓取数据。
Selenium 测试直接在浏览器中运行,浏览器根据脚本代码自动点击、进入、打开、验证,就像真正的用户在操作一样。
3.1 Selenium安装及基本介绍
点安装硒
3.2个Selenium的实际案例
from selenium import webdriver
import time
# 下载的geckodriver的存储位置
driver = webdriver.Firefox(executable_path=r'F:\Programming\python_bag\geckodriver.exe')
# 隐性等待,最长等20秒
driver.implicitly_wait(20)
# 自动访问的网站
driver.get('http://www.santostang.com/2018/07/04/hello-world')
time.sleep(5)
# 先把所有的评论加载出来
for i in range(0, 5):
# 下滑到页面底部
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
# 解析iframe框架里面的评论, 注意外边是双引号,里边是单引号
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere-comment']"))
# 找到更多/下一页所在的点击位置
# load_more = driver.find_element_by_css_selector('button.more-btn')
page_next = driver.find_element_by_css_selector('button.page-btn')
# page_next = driver.find_element_by_css_selector('span.z-next')
# 点击“更多”
# load_more.click()
page_next.click()
# 把frame转回去:因为解析frame后,下滑的代码就用不了了,所以又要用下面的代码转回本来未解析的iframe
driver.switch_to.default_content()
time.sleep(2) # 等待2秒,加载评论
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere-comment']"))
# driver.find_elements_by_css_selector是用CSS选择器查找元素,找到class为’ reply-content '的div元素,注意为elements
comments = driver.find_elements_by_css_selector('div.reply-content')
for each_comment in comments:
# find_element_by_tag_name则是通过元素的tag去寻找,找到comment中的p元素
content = each_comment.find_element_by_tag_name('p')
# 输出p元素中的text文本
print(content.text)
3.3 Selenium 获取 文章 的所有评论
# 自动登录程序
from selenium import webdriver
import time
driver = webdriver.Firefox(executable_path=r'F:\Programming\python_bag\geckodriver.exe')
user = driver.find_element_by_name('username') # 找到用户名输入框
user.clear() # 清除用户名输入框
user.send_keys('1234567') # 在框中输入用户名
pwd = driver.find_element_by_name('password') # 找到密码输入框
pwd.clear() # 清除密码输入框的内容
pwd.send_keys('*******') # 在框中输入密码
driver.find_element_by_id('loginBtn').click() # 单击登录
Selenium 还可以实现简单的鼠标操作,复杂的双击、拖放,获取网页中每个元素的大小,模拟键盘的操作。欲了解更多信息,请参阅
Selenium 官方 网站
3.4 Selenium 的高级操作
from selenium import webdriver
fp = webdriver.FirefoxProfile()
fp.set_preference('permission.default.stylesheet', 2) # stylesheet | 设定不加载css,则参数为2
# firefox_profile=fp控制不加载CSS
driver = webdriver.Firefox(firefox_profile=fp, executable_path=r'F:\Programming\python_bag\geckodriver.exe')
driver.get('http://www.santostang.com/2018/07/04/hello-world/')
from selenium import webdriver
fp = webdriver.FirefoxProfile()
fp.set_preference('permission.default.image', 2) # image | 设定不加载css,则参数为2
# firefox_profile=fp控制不加载CSS
driver = webdriver.Firefox(firefox_profile=fp, executable_path=r'F:\Programming\python_bag\geckodriver.exe')
driver.get('http://www.santostang.com/2018/07/04/hello-world/')
from selenium import webdriver
fp = webdriver.FirefoxProfile()
fp.set_preference('javascript.enabled', False) # image | 设定不加载css,则参数为2
# firefox_profile=fp控制不加载CSS
driver = webdriver.Firefox(firefox_profile=fp, executable_path=r'F:\Programming\python_bag\geckodriver.exe')
driver.get('http://www.santostang.com/2018/07/04/hello-world/')
4 Selenium爬虫实践:深圳短租数据
获取Airbnb深圳前5名的短租房源:名称、价格、评论数、房型、床位数、房客数
网站:爱彼迎深圳
4.1 网站分析
一个房子所有数据的地址是:div._gigle7
价格数据:div._lyarz4r
评论数:span._lcy09umr
房屋名称数据:div._l90019zr
房间类型:小._f7heglr
房间/床位数:span._l4ksqu3j
4.2 项目实践
from selenium import webdriver
import time
driver = webdriver.Firefox(executable_path=r'F:\Programming\python_bag\geckodriver.exe')
for i in range(0, 5):
link = 'http://zh.airbnb.com/s/Shenzhen--China/homes?itmes_offset=' + str(i*18)
# 在虚拟浏览器中打开Airbnb页面
driver.get(link)
# 找到页面中所有的出租房
rent_list = driver.find_elements_by_css_selector('div._gigle7')
# 对于每个出租房
for each_house in rent_list:
# 找到评论数量
try:
comment = each_house.find_element_by_css_selector('span._lcy09umr').text
# except:
finally:
comment = 0
# 找到价格 | 替换掉所有无用字符,只保留价格符号和数字
price = each_house.find_element_by_css_selector('div._lyarz4r').text.replace('每晚', '').replace('价格', '').replace('\n', '')
# 找到名称
name = each_house.find_element_by_css_selector('div._l90019zr').text
# 找到房屋类型、大小
details = each_house.find_element_by_css_selector('small._f7heglr').text
house_type = details.split(' . ')[0] # split将字符串变成列表
bed_number = details.split(' . ')[1]
print('price\t', 'name\t', 'house_type\t', 'bed_number\t', 'comment')
print(price, name, house_type, bed_number, comment)
time.sleep(5) 查看全部
动态网页抓取(动态网页抓取文章目录(1)(图)
)
动态网页抓取
文章目录
前言
静态网页在浏览器中显示的内容在 HTML 源代码中。
但是由于主流的网站都使用JavaScript来展示网页内容,不像静态网页,在使用JavaScript的时候,很多内容不会出现在HTML源代码中,所以爬取静态网页的技术可能不会工作正常使用。
因此,我们需要使用两种动态网页抓取技术:通过浏览器检查元素解析真实网址和使用 selenium 模拟浏览器。
1 动态爬取示例
通过在后台与服务器交换少量数据,可以异步更新网页。
这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
一方面减少了网页重复内容的下载,另一方面节省了流量,
与使用 AJAX 网页相比,如果传统网页需要更新内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更友好。但是AJAX网页的爬取过程比较麻烦。
动态网页示例:
网页下方的评论是用 JavaScript 加载的,这些评论数据不会出现在网页的源代码中。
2 解析真实地址抓取
虽然数据并没有出现在网页的源代码中,但是我们仍然可以找到数据的真实地址,并且请求这个真实地址也可以得到想要的数据。此处使用浏览器的“检查”功能。
点击“Network”,刷新,点击左侧list?callback开头的链接,真实链接如下:
%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=&_=59
点击 JS - preview 可以找到这些评论的内容。
import requests
link = '''https://api-zero.livere.com/v1/comments/list?callback=jQuery112409913001985965064_1613139610757&limit=10
&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=&_=1613139610759'''
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36 Edg/88.0.705.63'}
r = requests.get(link, headers=headers)
print('页响应状态码:', r.status_code)
print(r.text)
3 通过 Selenium 模拟浏览器抓取
使用浏览器渲染引擎:直接使用浏览器加载和卸载HTML,应用CSS样式,显示网页时执行Javascript语句
自动打开浏览器加载网页,独立浏览每个网页,顺便抓取数据。
Selenium 测试直接在浏览器中运行,浏览器根据脚本代码自动点击、进入、打开、验证,就像真正的用户在操作一样。
3.1 Selenium安装及基本介绍
点安装硒
3.2个Selenium的实际案例
from selenium import webdriver
import time
# 下载的geckodriver的存储位置
driver = webdriver.Firefox(executable_path=r'F:\Programming\python_bag\geckodriver.exe')
# 隐性等待,最长等20秒
driver.implicitly_wait(20)
# 自动访问的网站
driver.get('http://www.santostang.com/2018/07/04/hello-world')
time.sleep(5)
# 先把所有的评论加载出来
for i in range(0, 5):
# 下滑到页面底部
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
# 解析iframe框架里面的评论, 注意外边是双引号,里边是单引号
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere-comment']"))
# 找到更多/下一页所在的点击位置
# load_more = driver.find_element_by_css_selector('button.more-btn')
page_next = driver.find_element_by_css_selector('button.page-btn')
# page_next = driver.find_element_by_css_selector('span.z-next')
# 点击“更多”
# load_more.click()
page_next.click()
# 把frame转回去:因为解析frame后,下滑的代码就用不了了,所以又要用下面的代码转回本来未解析的iframe
driver.switch_to.default_content()
time.sleep(2) # 等待2秒,加载评论
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere-comment']"))
# driver.find_elements_by_css_selector是用CSS选择器查找元素,找到class为’ reply-content '的div元素,注意为elements
comments = driver.find_elements_by_css_selector('div.reply-content')
for each_comment in comments:
# find_element_by_tag_name则是通过元素的tag去寻找,找到comment中的p元素
content = each_comment.find_element_by_tag_name('p')
# 输出p元素中的text文本
print(content.text)
3.3 Selenium 获取 文章 的所有评论
# 自动登录程序
from selenium import webdriver
import time
driver = webdriver.Firefox(executable_path=r'F:\Programming\python_bag\geckodriver.exe')
user = driver.find_element_by_name('username') # 找到用户名输入框
user.clear() # 清除用户名输入框
user.send_keys('1234567') # 在框中输入用户名
pwd = driver.find_element_by_name('password') # 找到密码输入框
pwd.clear() # 清除密码输入框的内容
pwd.send_keys('*******') # 在框中输入密码
driver.find_element_by_id('loginBtn').click() # 单击登录
Selenium 还可以实现简单的鼠标操作,复杂的双击、拖放,获取网页中每个元素的大小,模拟键盘的操作。欲了解更多信息,请参阅
Selenium 官方 网站
3.4 Selenium 的高级操作
from selenium import webdriver
fp = webdriver.FirefoxProfile()
fp.set_preference('permission.default.stylesheet', 2) # stylesheet | 设定不加载css,则参数为2
# firefox_profile=fp控制不加载CSS
driver = webdriver.Firefox(firefox_profile=fp, executable_path=r'F:\Programming\python_bag\geckodriver.exe')
driver.get('http://www.santostang.com/2018/07/04/hello-world/')
from selenium import webdriver
fp = webdriver.FirefoxProfile()
fp.set_preference('permission.default.image', 2) # image | 设定不加载css,则参数为2
# firefox_profile=fp控制不加载CSS
driver = webdriver.Firefox(firefox_profile=fp, executable_path=r'F:\Programming\python_bag\geckodriver.exe')
driver.get('http://www.santostang.com/2018/07/04/hello-world/')
from selenium import webdriver
fp = webdriver.FirefoxProfile()
fp.set_preference('javascript.enabled', False) # image | 设定不加载css,则参数为2
# firefox_profile=fp控制不加载CSS
driver = webdriver.Firefox(firefox_profile=fp, executable_path=r'F:\Programming\python_bag\geckodriver.exe')
driver.get('http://www.santostang.com/2018/07/04/hello-world/')
4 Selenium爬虫实践:深圳短租数据
获取Airbnb深圳前5名的短租房源:名称、价格、评论数、房型、床位数、房客数
网站:爱彼迎深圳
4.1 网站分析
一个房子所有数据的地址是:div._gigle7
价格数据:div._lyarz4r
评论数:span._lcy09umr
房屋名称数据:div._l90019zr
房间类型:小._f7heglr
房间/床位数:span._l4ksqu3j
4.2 项目实践
from selenium import webdriver
import time
driver = webdriver.Firefox(executable_path=r'F:\Programming\python_bag\geckodriver.exe')
for i in range(0, 5):
link = 'http://zh.airbnb.com/s/Shenzhen--China/homes?itmes_offset=' + str(i*18)
# 在虚拟浏览器中打开Airbnb页面
driver.get(link)
# 找到页面中所有的出租房
rent_list = driver.find_elements_by_css_selector('div._gigle7')
# 对于每个出租房
for each_house in rent_list:
# 找到评论数量
try:
comment = each_house.find_element_by_css_selector('span._lcy09umr').text
# except:
finally:
comment = 0
# 找到价格 | 替换掉所有无用字符,只保留价格符号和数字
price = each_house.find_element_by_css_selector('div._lyarz4r').text.replace('每晚', '').replace('价格', '').replace('\n', '')
# 找到名称
name = each_house.find_element_by_css_selector('div._l90019zr').text
# 找到房屋类型、大小
details = each_house.find_element_by_css_selector('small._f7heglr').text
house_type = details.split(' . ')[0] # split将字符串变成列表
bed_number = details.split(' . ')[1]
print('price\t', 'name\t', 'house_type\t', 'bed_number\t', 'comment')
print(price, name, house_type, bed_number, comment)
time.sleep(5)
动态网页抓取(做SEO优化时,挑选动态页面、静态页面哪个好)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-02-18 05:04
网站的动态页面和静态页面是什么,以及它们的区别,本文将介绍,在做SEO优化时,动态页面、静态页面和伪静态页面哪个更好?
让我们简要总结一下各自的优缺点:
1. 静态页面访问速度最快;但是,由于数据存储在 HTML 中,源代码必须全部更改,而不是一处。全站静态页面自动更换,维护起来比较麻烦。
2. 动态页面占用空间小,易于维护;访问速度慢,访问者多,会对数据库造成压力。
3. 使用伪静态页面和静态页面进行SEO(搜索引擎优化:Search Engine Optimization)没有本质区别。
基于以上几点,从用户体验的角度来看,对于SEO优化者来说,必须选择静态页面,但是如果动态页面和静态页面结合起来,似乎还是选择伪静态页面比较好。
我们都知道静态页面对SEO优化有很大的好处。它们不仅加载速度快,而且不会对服务器造成压力。它们对搜索引擎非常友好,但静态页面的缺点是不能随时更新,不易维护。与静态页面相比,伪静态页面并没有明显的速度提升,但由于是“假”静态页面,所以仍然是动态页面,还需要翻译成静态页面。将其视为静态页面以提高搜索引擎的友好性。
搜索引擎,如简单和常规的网页,以及动态页面,都有各种参数。搜索引擎如果想读到里面的内容,就需要通过一系列的动作来解码,就像对搜索引擎说:加油,想看懂我的内容,就先解开这些谜题吧!如果是参数较少的动态页面,也许搜索引擎会抓取它,但是如果参数很多呢?也许搜索引擎只是转身离开了。因此,那些参数堆积如山、数据长的链接,搜索引擎对这类页面的印象并不好。
我们做SEO优化。为了迎合搜索引擎的喜好,动态页面、静态页面和伪静态页面哪个更好?小编建议还是伪静态比较好。因为静态页面维护起来太麻烦,而且伪静态页面对搜索引擎的意义与静态页面相同,所以我们选择伪静态页面。
以上内容并不代表伪静态页面的选择就一定是最好的,但目前无数公司网站数据都比较少,可以采用生成伪静态页面的方法。现在可以生成基本的网站建设程序。伪静态页面。 查看全部
动态网页抓取(做SEO优化时,挑选动态页面、静态页面哪个好)
网站的动态页面和静态页面是什么,以及它们的区别,本文将介绍,在做SEO优化时,动态页面、静态页面和伪静态页面哪个更好?
让我们简要总结一下各自的优缺点:
1. 静态页面访问速度最快;但是,由于数据存储在 HTML 中,源代码必须全部更改,而不是一处。全站静态页面自动更换,维护起来比较麻烦。
2. 动态页面占用空间小,易于维护;访问速度慢,访问者多,会对数据库造成压力。
3. 使用伪静态页面和静态页面进行SEO(搜索引擎优化:Search Engine Optimization)没有本质区别。
基于以上几点,从用户体验的角度来看,对于SEO优化者来说,必须选择静态页面,但是如果动态页面和静态页面结合起来,似乎还是选择伪静态页面比较好。
我们都知道静态页面对SEO优化有很大的好处。它们不仅加载速度快,而且不会对服务器造成压力。它们对搜索引擎非常友好,但静态页面的缺点是不能随时更新,不易维护。与静态页面相比,伪静态页面并没有明显的速度提升,但由于是“假”静态页面,所以仍然是动态页面,还需要翻译成静态页面。将其视为静态页面以提高搜索引擎的友好性。
搜索引擎,如简单和常规的网页,以及动态页面,都有各种参数。搜索引擎如果想读到里面的内容,就需要通过一系列的动作来解码,就像对搜索引擎说:加油,想看懂我的内容,就先解开这些谜题吧!如果是参数较少的动态页面,也许搜索引擎会抓取它,但是如果参数很多呢?也许搜索引擎只是转身离开了。因此,那些参数堆积如山、数据长的链接,搜索引擎对这类页面的印象并不好。
我们做SEO优化。为了迎合搜索引擎的喜好,动态页面、静态页面和伪静态页面哪个更好?小编建议还是伪静态比较好。因为静态页面维护起来太麻烦,而且伪静态页面对搜索引擎的意义与静态页面相同,所以我们选择伪静态页面。
以上内容并不代表伪静态页面的选择就一定是最好的,但目前无数公司网站数据都比较少,可以采用生成伪静态页面的方法。现在可以生成基本的网站建设程序。伪静态页面。
动态网页抓取( 如何把网站的排名提上去又能使网站排名变得稳定)
网站优化 • 优采云 发表了文章 • 0 个评论 • 379 次浏览 • 2022-03-04 10:18
如何把网站的排名提上去又能使网站排名变得稳定)
在网站建设前期,很多公司只想着如何提升网站的排名,到了后期却绞尽脑汁想着如何稳定网站的排名. 很多SEOER在排名网站的过程中遇到了一个很尴尬的情况:努力把关键词优化到首页,几天后排名又下降了……那怎么提升网站的排名,稳定网站的排名?随着搜索引擎算法的不断更新,SEO也跟随搜索引擎的不断发展。本期智讯网黄升将与大家分享提升网站排名和稳定网站排名的小技巧:
一、内容更新
首先,一定要保持网站的活跃度,每天都要更新新内容,增加相关新闻或者热点内容,不仅要保持网站的活跃度,还要让< @网站感觉新鲜,意思是说原创有价值的内容;其次是网站内容更新的规律性,应该与蜘蛛定期定量地形成,方便搜索引擎蜘蛛的索引。
二、内链构建
内部链接优化是网站优化中的常用技术。做好内链可以提高关键词的排名,增加内页的权重,引导蜘蛛爬取更多的页面,提升用户体验。因此,内部链接的建设,现场优化起着至关重要的作用。
三、优质外链
为了稳定关键词的排名,外链的作用不可小觑。外链可以引导蜘蛛抓取网站,给网站传递权重,增加网站的曝光度,吸引用户点击,前提必须是优质的外链,垃圾邮件外部链接将被搜索引擎阻止。
四、检查死链接
定期检查 网站 的死链接。如果网站中有大量死链接,会影响蜘蛛索引网站的效果,从而影响搜索引擎对网站的判断,所以做好404页面,或使用 301 重定向到新的目标 URL。
五、服务器稳定性
服务器的稳定性是网站排名的保证。如果服务器不稳定,网站往往无法正常访问,这将严重影响用户体验并使搜索引擎降低收录、权重和关键词的排名,不仅提高服务器的稳定性,还要注意安全。
六、搜索引擎动态
既然做搜索引擎优化,一定要时刻关注搜索引擎算法的调整,增加了哪些新规则。根据搜索引擎算法,调整网站的SEO优化,关键词的排名会越来越高哦,不注意不懂算法, 网站 优化无法调整。
只有网站的排名提高并稳定下来,才能为公司带来更多的流量,更广泛地宣传企业形象,挖掘潜在客户,实现网站的最大价值。
新闻标题:网站优化:稳定网站排名的技巧
新闻链接:
本FAQ文章由网站Construction_Guangzhou网站Construction__智讯网络原创撰写,转载请保留此地址!
转载请注明,转载来自广州智讯网。感谢您的浏览和支持。祝您生活愉快!
标签: 查看全部
动态网页抓取(
如何把网站的排名提上去又能使网站排名变得稳定)
在网站建设前期,很多公司只想着如何提升网站的排名,到了后期却绞尽脑汁想着如何稳定网站的排名. 很多SEOER在排名网站的过程中遇到了一个很尴尬的情况:努力把关键词优化到首页,几天后排名又下降了……那怎么提升网站的排名,稳定网站的排名?随着搜索引擎算法的不断更新,SEO也跟随搜索引擎的不断发展。本期智讯网黄升将与大家分享提升网站排名和稳定网站排名的小技巧:
一、内容更新
首先,一定要保持网站的活跃度,每天都要更新新内容,增加相关新闻或者热点内容,不仅要保持网站的活跃度,还要让< @网站感觉新鲜,意思是说原创有价值的内容;其次是网站内容更新的规律性,应该与蜘蛛定期定量地形成,方便搜索引擎蜘蛛的索引。
二、内链构建
内部链接优化是网站优化中的常用技术。做好内链可以提高关键词的排名,增加内页的权重,引导蜘蛛爬取更多的页面,提升用户体验。因此,内部链接的建设,现场优化起着至关重要的作用。
三、优质外链
为了稳定关键词的排名,外链的作用不可小觑。外链可以引导蜘蛛抓取网站,给网站传递权重,增加网站的曝光度,吸引用户点击,前提必须是优质的外链,垃圾邮件外部链接将被搜索引擎阻止。
四、检查死链接
定期检查 网站 的死链接。如果网站中有大量死链接,会影响蜘蛛索引网站的效果,从而影响搜索引擎对网站的判断,所以做好404页面,或使用 301 重定向到新的目标 URL。
五、服务器稳定性
服务器的稳定性是网站排名的保证。如果服务器不稳定,网站往往无法正常访问,这将严重影响用户体验并使搜索引擎降低收录、权重和关键词的排名,不仅提高服务器的稳定性,还要注意安全。
六、搜索引擎动态
既然做搜索引擎优化,一定要时刻关注搜索引擎算法的调整,增加了哪些新规则。根据搜索引擎算法,调整网站的SEO优化,关键词的排名会越来越高哦,不注意不懂算法, 网站 优化无法调整。
只有网站的排名提高并稳定下来,才能为公司带来更多的流量,更广泛地宣传企业形象,挖掘潜在客户,实现网站的最大价值。
新闻标题:网站优化:稳定网站排名的技巧
新闻链接:
本FAQ文章由网站Construction_Guangzhou网站Construction__智讯网络原创撰写,转载请保留此地址!
转载请注明,转载来自广州智讯网。感谢您的浏览和支持。祝您生活愉快!
标签:
动态网页抓取(做网站优化增加索引是增加关键词排名和提升流量的基础 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-03-04 10:16
)
众所周知,做网站优化,增加索引,是提升关键词排名,增加流量的基础。为了增加蜘蛛对页面的抓取量,百度蜘蛛只有广大站长知道。蜘蛛一般爬得更深,没有给蜘蛛收录的页面会更多。对于新站点来说,权重达到1比较容易,但是进一步增加权重就比较困难了,那么如何吸引蜘蛛爬取页面呢?
1、创建站点地图
大多数网站管理员都熟悉 网站 地图的使用。站点地图可以方便搜索引擎蜘蛛抓取网站页面,引导搜索引擎蜘蛛,增加网站重要内容页面收录。指向动态页面或以其他方式难以访问的页面。因此,为了增加百度蜘蛛抓取网站的频率,网站站长需要定期将公司网站链接放入站点地图,直接提交给百度。
2、文章更新频率
<p>从SEO的角度来看,站长每天更新文章有助于增加收录的量,收录是获取流量的基础,百度蜘蛛爬虫会来 查看全部
动态网页抓取(做网站优化增加索引是增加关键词排名和提升流量的基础
)
众所周知,做网站优化,增加索引,是提升关键词排名,增加流量的基础。为了增加蜘蛛对页面的抓取量,百度蜘蛛只有广大站长知道。蜘蛛一般爬得更深,没有给蜘蛛收录的页面会更多。对于新站点来说,权重达到1比较容易,但是进一步增加权重就比较困难了,那么如何吸引蜘蛛爬取页面呢?
1、创建站点地图
大多数网站管理员都熟悉 网站 地图的使用。站点地图可以方便搜索引擎蜘蛛抓取网站页面,引导搜索引擎蜘蛛,增加网站重要内容页面收录。指向动态页面或以其他方式难以访问的页面。因此,为了增加百度蜘蛛抓取网站的频率,网站站长需要定期将公司网站链接放入站点地图,直接提交给百度。
2、文章更新频率
<p>从SEO的角度来看,站长每天更新文章有助于增加收录的量,收录是获取流量的基础,百度蜘蛛爬虫会来
动态网页抓取( 借助Chrome浏览器的开发者项目,从分析网站架构开始)
网站优化 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2022-03-03 01:13
借助Chrome浏览器的开发者项目,从分析网站架构开始)
Python爬虫——Scrapy框架(项目实战)——爬取动态页面
写在前面
经过前面的学习,对Scrapy框架有了一定的了解,也写了很多基础爬虫,不过这些都是基于自己掌握的知识,也就是会爬。今天尝试一个新的挑战,借助这个机会,我转战股票基金领域,通过分析网站的结构,开始了一个不知名的爬虫项目。
免责声明:本次爬取的网站为东方财富网,所有获取的数据仅用于学术分析,不得用于商业用途。
爬虫目标
整个项目的主要目的是爬取东方财富网提供的各类证券融资融券的相关数据。我们要抓取过去六个月所有证券的每日收盘价、保证金余额和保证金差额。
当您来到东方财富网-融资融券,您会发现我们可以在下图所示部分获取所有证券信息。点击每只证券后,您可以进一步获取该证券每日的详细融资融券信息。
抓取动态加载的页面 动态加载的页面
如果你在浏览网站的时候注意网页的加载方式,你可能会发现两种常见的情况:一种是网页会加载一段时间,然后网页的所有内容一起显示;另一个是网页会加载一段时间。打开速度很快,但是网页中的内容是部分加载的。这种情况就是所谓的动态加载页面。
动态加载是通过ajax请求接口获取数据,并在网页上进行染色。当然,对于像我这样的新手,我不知道ajax是什么。让我们用 Chrome 浏览器的开发者工具来观察一些神奇的东西。
这是这个爬虫项目要爬取的网站。我暂时不关心我要爬取的数据在哪里。到开发者工具的网络选项,会发现这里暂时没有内容。
接下来,刷新页面,也就是通常意义上的重新加载页面。你会发现这里有很多内容。这些是加载页面时动态加载的内容。
我可以以原创方式抓取这个 网站 吗?
这里我们简单的使用命令行程序通过shell命令来演示,如果我们用原来的方法爬取这个网站,会不会爬到想要的数据。
以上是shell得到的响应。很明显,和我们预想的有很大出入,我们想要获取的数据并没有被爬取。这也表明包括该部分在内的许多元素是动态加载的。
另一种方式
首先点击查看更多数据进入证券交易详情页面。接下来,从所有刚刚动态加载的内容中寻找我们想要的数据。虽然我们不知道它会是什么类型的数据,但如果不出意外,它肯定会出现在这里。经过不懈的搜索,我找到了以下文件。
通过预览,我们可以预览内容,发现data里面存储的数据正是我们想要的数据。
右键单击文件并选择在新选项卡中打开。突然,我意识到这实际上是一个 Json 格式的文件。这很简单。我们只需要抓取这个页面。
接下来按照原来的思路,分析一下这个比较长的url地址。
(tdate='2019-05-09T00:00:00')&st=rzjmre&sr=-1&p=1&ps=50&js=var xDjBXPPy={pages:(tp),data:(x)}&type=RZRQ_DETAIL_NJ&time=1&rt=51916124
尝试改变url地址中不同部分的值,你会发现p代表页数,ps代表每页显示的数据个数,那么这里我们把ps的值改成997,让它变成一页所有的数据都显示在里面,方便我们爬取。
Json数据的处理
通过爬虫直接爬取这个页面,得到Json类型的数据。显然,不能直接用python语言处理。这里使用json包中的decode函数对Json数据进行解码。
datas = response.body.decode('UTF-8')
接下来,我们可以利用字典和列表的知识继续对数据进行进一步的处理,然后得到我们需要的所有信息。
综上所述
事实上,整个项目在这里并没有达到最初的目标,但最困难的问题已经解决了。接下来的操作可以利用我们之前的思路,从当前页面获取每一个证券的scode,然后拼接得到一个新的。url,进一步获取每天的详细数据,最终达到目的。
由于种种原因,我这次没有提供很多源码,只是更详细的解释了原理。如果您遇到这方面的问题并阅读此文章 仍然无法解决,请通过电子邮件与我联系。愿意尽我所能提供帮助,希望共同进步。 查看全部
动态网页抓取(
借助Chrome浏览器的开发者项目,从分析网站架构开始)
Python爬虫——Scrapy框架(项目实战)——爬取动态页面
写在前面
经过前面的学习,对Scrapy框架有了一定的了解,也写了很多基础爬虫,不过这些都是基于自己掌握的知识,也就是会爬。今天尝试一个新的挑战,借助这个机会,我转战股票基金领域,通过分析网站的结构,开始了一个不知名的爬虫项目。
免责声明:本次爬取的网站为东方财富网,所有获取的数据仅用于学术分析,不得用于商业用途。
爬虫目标
整个项目的主要目的是爬取东方财富网提供的各类证券融资融券的相关数据。我们要抓取过去六个月所有证券的每日收盘价、保证金余额和保证金差额。
当您来到东方财富网-融资融券,您会发现我们可以在下图所示部分获取所有证券信息。点击每只证券后,您可以进一步获取该证券每日的详细融资融券信息。
抓取动态加载的页面 动态加载的页面
如果你在浏览网站的时候注意网页的加载方式,你可能会发现两种常见的情况:一种是网页会加载一段时间,然后网页的所有内容一起显示;另一个是网页会加载一段时间。打开速度很快,但是网页中的内容是部分加载的。这种情况就是所谓的动态加载页面。
动态加载是通过ajax请求接口获取数据,并在网页上进行染色。当然,对于像我这样的新手,我不知道ajax是什么。让我们用 Chrome 浏览器的开发者工具来观察一些神奇的东西。
这是这个爬虫项目要爬取的网站。我暂时不关心我要爬取的数据在哪里。到开发者工具的网络选项,会发现这里暂时没有内容。
接下来,刷新页面,也就是通常意义上的重新加载页面。你会发现这里有很多内容。这些是加载页面时动态加载的内容。
我可以以原创方式抓取这个 网站 吗?
这里我们简单的使用命令行程序通过shell命令来演示,如果我们用原来的方法爬取这个网站,会不会爬到想要的数据。
以上是shell得到的响应。很明显,和我们预想的有很大出入,我们想要获取的数据并没有被爬取。这也表明包括该部分在内的许多元素是动态加载的。
另一种方式
首先点击查看更多数据进入证券交易详情页面。接下来,从所有刚刚动态加载的内容中寻找我们想要的数据。虽然我们不知道它会是什么类型的数据,但如果不出意外,它肯定会出现在这里。经过不懈的搜索,我找到了以下文件。
通过预览,我们可以预览内容,发现data里面存储的数据正是我们想要的数据。
右键单击文件并选择在新选项卡中打开。突然,我意识到这实际上是一个 Json 格式的文件。这很简单。我们只需要抓取这个页面。
接下来按照原来的思路,分析一下这个比较长的url地址。
(tdate='2019-05-09T00:00:00')&st=rzjmre&sr=-1&p=1&ps=50&js=var xDjBXPPy={pages:(tp),data:(x)}&type=RZRQ_DETAIL_NJ&time=1&rt=51916124
尝试改变url地址中不同部分的值,你会发现p代表页数,ps代表每页显示的数据个数,那么这里我们把ps的值改成997,让它变成一页所有的数据都显示在里面,方便我们爬取。
Json数据的处理
通过爬虫直接爬取这个页面,得到Json类型的数据。显然,不能直接用python语言处理。这里使用json包中的decode函数对Json数据进行解码。
datas = response.body.decode('UTF-8')
接下来,我们可以利用字典和列表的知识继续对数据进行进一步的处理,然后得到我们需要的所有信息。
综上所述
事实上,整个项目在这里并没有达到最初的目标,但最困难的问题已经解决了。接下来的操作可以利用我们之前的思路,从当前页面获取每一个证券的scode,然后拼接得到一个新的。url,进一步获取每天的详细数据,最终达到目的。
由于种种原因,我这次没有提供很多源码,只是更详细的解释了原理。如果您遇到这方面的问题并阅读此文章 仍然无法解决,请通过电子邮件与我联系。愿意尽我所能提供帮助,希望共同进步。
动态网页抓取(静态网站的优缺点分析:非常利于搜索引擎的收录和抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-03-03 01:05
静态网站优缺点分析:对搜索引擎收录和爬取非常有利;动态网站优缺点分析:网站交互性很强;动态网站转换静态网站需要注意的问题
图 27962-1:
网站的发展已经从静态到动态,现在又从动态回归到新静态。随着搜索引擎对网站的影响越来越大,越来越多的站长开始选择动态的网站静态的,因为静态网页很容易被搜索引擎和收录抓取,这对提高网站的权重和排名有很大的帮助,但是作者却发现很多站长在将动态的网站转换成静态的网站后,发现自己的网站实际上是K。这是什么原因?可见动态网站静态化并不是一件容易的事,很多问题需要注意!
1:静态网站优缺点分析
static 网站 的优势非常明显。用户的浏览器打开静态 网站 比动态 网站 更快,因为动态 网站 网页需要结合用户参数。,然后就可以形成对应的页面了。服务器速度和网速会严重影响动态网站的访问速度,而静态网站网页已经在服务器上可用,用户只需提交申请后,静态网页会被下载到浏览器中,也可以被浏览器缓存,这样用户第二次打开时基本不需要再次从服务器下载。可以看出,这个访问速度比动态网站要快。
静态网站的另一个好处是对搜索引擎收录和爬取非常有利。只要能在服务器上的各个静态网页之间形成内链网络,搜索引擎蜘蛛就可以通过收录@网站的首页,遍历整个网站@中的静态网页>,从而实现网站的完整收录,当然为了提高蜘蛛爬网站的速度,很多站长可能会设置ROBOTS.TXT文件来屏蔽一些不必要的收录页面,比如很多公司的联系我们页面网站、支付方式页面等。通过内部链接和ROBOTS.TXT文件的设置,网站@的爬取速度> 可以大大提高。
当然,静态网站的缺点也很明显。如果是很大的网站,尤其是信息网站,如果每个页面都变成静态页面,工作量就会减少。肯定很大,而且对网站的维护也很不利,因为静态的网站没有数据库,每个页面都需要手动检查。如果网站的链接有错误,想要更正,往往需要很长时间才能一一检查!
二:动态网站优缺点分析
动态的优势也非常突出。首先,网站的交互性非常好。现在很多网页游戏都是典型的动态网页。通过交互,可以提高网站的粘性。另外,动态网站对网站的管理非常简单,因为网站几乎都是通过数据库来管理的。其实网站的维护只有操作数据库就可以实现,现在很多免费建站程序都使用这种数据库。该架构非常适合个人站长使用。
不过动态网站的缺点也很明显。首先,随着访问者数量的增加,服务器负载会不断增加,最终访问速度会极慢甚至崩溃。另外,因为是交互设计,那么很容易给黑客留下后门。前段时间很多论坛和社区账号信息被盗,可见动态网站的安全隐患很大。另外,对搜索引擎的亲和力不强,因为动态的网站网页大多是动态形成的,蜘蛛不能很好的抓取,导致网站收录的数量为不高。
三:动态网站转静态网站需要注意的问题
相对来说静态网站的优势比较明显,尤其是对于搜索引擎来说,而现在网站在没有搜索引擎的支持下越来越难成功,所以现在很多站长原本经营动态网站,开始把他们的网站转成静态网站,这样我们就可以同时得到动态网站和静态网站的优势。
然而,在转换的过程中,很多站长都渴望获得成功。通过一些号称可以转换成静态网站的程序,瞬间实现了动态网站的伪静态化。这样的结果就是如前文所述,网站已经完全K了,正确的做法应该是网站的动静结合,换句话说,就是很多网站页面上丰富的关键词@,用户信息页面,网站地图页面,应该使用静态网页,对于网站的大量更新版块,应该是通过静态和动态转换程序完成!
目前,将动态页面转换为静态页面的方法有很多。其中,使用现成的插件最为常见,如Apache HTTP服务器的ISAPI_REWIRITE、IISRewrite、MOD_Rewrite等。这些都是基于正则表达式解析器开发的重写引擎,使用方法也是很简单。简单的。掌握了正确的动静变换方法后,要避免那种瞬间整站的变换,要遵循循序渐进的原则!只有这样,才能避免百度的处罚。 查看全部
动态网页抓取(静态网站的优缺点分析:非常利于搜索引擎的收录和抓取)
静态网站优缺点分析:对搜索引擎收录和爬取非常有利;动态网站优缺点分析:网站交互性很强;动态网站转换静态网站需要注意的问题
图 27962-1:
网站的发展已经从静态到动态,现在又从动态回归到新静态。随着搜索引擎对网站的影响越来越大,越来越多的站长开始选择动态的网站静态的,因为静态网页很容易被搜索引擎和收录抓取,这对提高网站的权重和排名有很大的帮助,但是作者却发现很多站长在将动态的网站转换成静态的网站后,发现自己的网站实际上是K。这是什么原因?可见动态网站静态化并不是一件容易的事,很多问题需要注意!
1:静态网站优缺点分析
static 网站 的优势非常明显。用户的浏览器打开静态 网站 比动态 网站 更快,因为动态 网站 网页需要结合用户参数。,然后就可以形成对应的页面了。服务器速度和网速会严重影响动态网站的访问速度,而静态网站网页已经在服务器上可用,用户只需提交申请后,静态网页会被下载到浏览器中,也可以被浏览器缓存,这样用户第二次打开时基本不需要再次从服务器下载。可以看出,这个访问速度比动态网站要快。
静态网站的另一个好处是对搜索引擎收录和爬取非常有利。只要能在服务器上的各个静态网页之间形成内链网络,搜索引擎蜘蛛就可以通过收录@网站的首页,遍历整个网站@中的静态网页>,从而实现网站的完整收录,当然为了提高蜘蛛爬网站的速度,很多站长可能会设置ROBOTS.TXT文件来屏蔽一些不必要的收录页面,比如很多公司的联系我们页面网站、支付方式页面等。通过内部链接和ROBOTS.TXT文件的设置,网站@的爬取速度> 可以大大提高。
当然,静态网站的缺点也很明显。如果是很大的网站,尤其是信息网站,如果每个页面都变成静态页面,工作量就会减少。肯定很大,而且对网站的维护也很不利,因为静态的网站没有数据库,每个页面都需要手动检查。如果网站的链接有错误,想要更正,往往需要很长时间才能一一检查!
二:动态网站优缺点分析
动态的优势也非常突出。首先,网站的交互性非常好。现在很多网页游戏都是典型的动态网页。通过交互,可以提高网站的粘性。另外,动态网站对网站的管理非常简单,因为网站几乎都是通过数据库来管理的。其实网站的维护只有操作数据库就可以实现,现在很多免费建站程序都使用这种数据库。该架构非常适合个人站长使用。
不过动态网站的缺点也很明显。首先,随着访问者数量的增加,服务器负载会不断增加,最终访问速度会极慢甚至崩溃。另外,因为是交互设计,那么很容易给黑客留下后门。前段时间很多论坛和社区账号信息被盗,可见动态网站的安全隐患很大。另外,对搜索引擎的亲和力不强,因为动态的网站网页大多是动态形成的,蜘蛛不能很好的抓取,导致网站收录的数量为不高。
三:动态网站转静态网站需要注意的问题
相对来说静态网站的优势比较明显,尤其是对于搜索引擎来说,而现在网站在没有搜索引擎的支持下越来越难成功,所以现在很多站长原本经营动态网站,开始把他们的网站转成静态网站,这样我们就可以同时得到动态网站和静态网站的优势。
然而,在转换的过程中,很多站长都渴望获得成功。通过一些号称可以转换成静态网站的程序,瞬间实现了动态网站的伪静态化。这样的结果就是如前文所述,网站已经完全K了,正确的做法应该是网站的动静结合,换句话说,就是很多网站页面上丰富的关键词@,用户信息页面,网站地图页面,应该使用静态网页,对于网站的大量更新版块,应该是通过静态和动态转换程序完成!
目前,将动态页面转换为静态页面的方法有很多。其中,使用现成的插件最为常见,如Apache HTTP服务器的ISAPI_REWIRITE、IISRewrite、MOD_Rewrite等。这些都是基于正则表达式解析器开发的重写引擎,使用方法也是很简单。简单的。掌握了正确的动静变换方法后,要避免那种瞬间整站的变换,要遵循循序渐进的原则!只有这样,才能避免百度的处罚。
动态网页抓取(ajax横行的年代,我们的网页是残缺的吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-01 23:22
)
在ajax时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中包括
跳过js加载部分,表示爬虫抓取的网页不完整,不完整。您可以在下面看到博客园的主页
从首页的加载中可以看出,页面渲染完成后,会有5个异步ajax请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候,如果你想得到它,你必须调用浏览器的内核引擎来下载这些动态页面。目前内核引擎是三足的。
Trident:也就是IE内核,WebBrowser就是基于这个内核,但是加载性能比较差。
Gecko:FF的内核比Trident的性能更好。
WebKit:Safari和Chrome的核心,性能你懂的,在真实场景中还是主要的。
好的,为了简单方便,这里我们使用WebBrowser来玩,使用WebBrowser的时候要注意以下几点:
首先:因为WebBrowser是System.Windows.Forms中的winform控件,所以我们需要设置STAThread标签。
第二:winform是事件驱动的,Console不响应事件,所有事件都在windows的消息队列中等待执行,以防止程序假死,
我们需要调用DoEvents方法来传递控制权,让操作系统执行其他事件。
第三:WebBrowser内容,我们需要使用DomDocument来查看,而不是DocumentText。
判断动态网页是否加载一般有两种方式:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们这里需要这样做
记录计数值
.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们还可以通过设置一个Timer来判断,比如3s、4s、5s,稍后再查看
WEB浏览器是否加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果还是一样的,就不截图了。从以上两种写法来看,我们的WebBrowser放在主线程中。让我们看看如何把它放在工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 } 查看全部
动态网页抓取(ajax横行的年代,我们的网页是残缺的吗?
)
在ajax时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中包括
跳过js加载部分,表示爬虫抓取的网页不完整,不完整。您可以在下面看到博客园的主页
从首页的加载中可以看出,页面渲染完成后,会有5个异步ajax请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候,如果你想得到它,你必须调用浏览器的内核引擎来下载这些动态页面。目前内核引擎是三足的。
Trident:也就是IE内核,WebBrowser就是基于这个内核,但是加载性能比较差。
Gecko:FF的内核比Trident的性能更好。
WebKit:Safari和Chrome的核心,性能你懂的,在真实场景中还是主要的。
好的,为了简单方便,这里我们使用WebBrowser来玩,使用WebBrowser的时候要注意以下几点:
首先:因为WebBrowser是System.Windows.Forms中的winform控件,所以我们需要设置STAThread标签。
第二:winform是事件驱动的,Console不响应事件,所有事件都在windows的消息队列中等待执行,以防止程序假死,
我们需要调用DoEvents方法来传递控制权,让操作系统执行其他事件。
第三:WebBrowser内容,我们需要使用DomDocument来查看,而不是DocumentText。
判断动态网页是否加载一般有两种方式:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们这里需要这样做
记录计数值
.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们还可以通过设置一个Timer来判断,比如3s、4s、5s,稍后再查看
WEB浏览器是否加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果还是一样的,就不截图了。从以上两种写法来看,我们的WebBrowser放在主线程中。让我们看看如何把它放在工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
动态网页抓取(如何抓取网页中的动态网页源码中特定的特定内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-01 23:14
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
【教程】Python版爬网并从网页中提取需要的信息
和
【教程】C#版爬网并从网页中提取需要的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
不熟悉的可以参考:
【组织】爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站
2.学会使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的可以参考:
【教程】教你如何使用工具(IE9的F12)解析模拟登录内部逻辑流程网站(百度首页))
3.对于一个普通的静态网页,如何提取想要的内容
对此不熟悉的可以参考:
(1)Python 版本:
【教程】Python版爬网并从网页中提取需要的信息
(2)C# 版本:
【教程】C#版爬网并从网页中提取需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据你通过工具分析的结果,找到对应的数据并提取出来;
不过这个数据有时候可以在分析结果的过程中直接提取出来,有时候可能是通过js计算出来的。
想抓取数据,是js脚本生成的
虽然最终的动态内容是由js脚本执行生成的,但是对于你要抓取的数据:
想爬取数据是通过访问另一个url获取的
如果你要抓取的对应内容是访问另一个url地址和返回的数据,那么很简单,你也需要访问这个url,然后获取对应的返回内容,从中提取你想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。 查看全部
动态网页抓取(如何抓取网页中的动态网页源码中特定的特定内容)
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
【教程】Python版爬网并从网页中提取需要的信息
和
【教程】C#版爬网并从网页中提取需要的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
不熟悉的可以参考:
【组织】爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站
2.学会使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的可以参考:
【教程】教你如何使用工具(IE9的F12)解析模拟登录内部逻辑流程网站(百度首页))
3.对于一个普通的静态网页,如何提取想要的内容
对此不熟悉的可以参考:
(1)Python 版本:
【教程】Python版爬网并从网页中提取需要的信息
(2)C# 版本:
【教程】C#版爬网并从网页中提取需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据你通过工具分析的结果,找到对应的数据并提取出来;
不过这个数据有时候可以在分析结果的过程中直接提取出来,有时候可能是通过js计算出来的。
想抓取数据,是js脚本生成的
虽然最终的动态内容是由js脚本执行生成的,但是对于你要抓取的数据:
想爬取数据是通过访问另一个url获取的
如果你要抓取的对应内容是访问另一个url地址和返回的数据,那么很简单,你也需要访问这个url,然后获取对应的返回内容,从中提取你想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。
动态网页抓取(3.安装selenium库,可直接用#39;pipinstallselenium#pip )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-01 21:11
)
这个过程比较麻烦,需要分几个步骤来完成。下面将一一介绍:
1. 要安装 selenium 库,您可以直接使用 'pip install selenium' 命令安装它。
2. 下载chromeDriver并将其添加到环境变量中,或者直接将.exe文件放在python安装目录的scripts文件夹中。下载时请务必选择与您的浏览器对应的版本。查看浏览器版本的方法是:右上角->帮助->关于google chrome查看,驱动下载地址为chromedriver下载地址,与chrome版本对应关系为对应关系。验证下载安装是否成功,只需执行下面这段代码,如果没有错误,则安装成功。
import selenium.webdriver as driver
index = driver.Chrome()
index.get('https://www.wdzj.com/dangan')
print(index)
3. Selenium 实现爬虫,定位方法很多,简单介绍一下:
官网地址为:
查找单个元素的方法是:
查找多个元素(返回一个列表)的方法是:
4. 基本功能有了之后,就可以愉快的爬取了(由于还没写,先放一些代码,以后再更新)!
import selenium.webdriver as driver
import xlwt
import types
URL = 'https://www.wdzj.com/dangan/'
# KEYWORD = '银行存管'
def key_word():
# index = driver.Chrome()
# index.get(URL)
# select_data = index.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
# print(index.current_url)
# keyword_index = index.find_element_by_link_text()
# keyword_index.click()
names = []
banks = []
tel_nums = []
urls = []
for i in range(0, 76):
page_url = URL + 'search?filter=e1¤tPage=' + str(i + 1)
index_page = driver.Chrome()
index_page.get(page_url)
select_data = index_page.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
print(index_page.current_url)
for data in select_data:
names.append(data.text)
print(names) #名字
sec_url = data.get_attribute("href")
index_sec = driver.Chrome()
index_sec.get(sec_url)
# print(index_sec.current_url) #链接
yhcg = index_sec.find_element_by_xpath('/html/body/div[10]/div/div[1]/div[1]/dl[1]/dd[2]/div[2]')
banks.append(yhcg.text)
# print(banks) #银行存管
tel_num = index_sec.find_element_by_link_text('联系方式')
tel_num.click()
number = index_sec.find_element_by_xpath('//*[@class="da-lxfs zzfwbox"]/dl[1]/dd[1]/div[2]')
tel_nums.append(number.text)
# print(tel_nums) #客服电话
yuming = index_sec.find_element_by_link_text('工商/备案')
yuming.click()
yu_beian = index_sec.find_element_by_xpath('//*[@class="lcen"]/table/tbody/tr[7]/td[2]')
urls.append(yu_beian.text)
print(urls) #域名
index_sec.close()
# print(page_url)
# next_page = index.find_element_by_link_text('下一页')
# next_page.click()
return names, banks, tel_nums, urls
def xls():
wb = xlwt.Workbook()
ws = wb.add_sheet('numbers')
ws.write(0, 0, '序号')
ws.write(0, 1, '公司名称')
ws.write(0, 2, '银行存管')
ws.write(0, 3, '客服电话')
ws.write(0, 4, '公司域名')
names, banks, tel_nums, urls = key_word()
print(len(names))
for i in range (0, len(names)):
ws.write(i + 1, 0, i+1)
ws.write(i + 1, 1, names[i])
ws.write(i + 1, 2, banks[i])
ws.write(i + 1, 3, tel_nums[i])
ws.write(i + 1, 4, urls[i])
wb.save('D:\\number.xls')
def run():
xls()
run()
改变:
import selenium.webdriver as driver
import xlwt
from xlutils.copy import copy
import xlrd
URL = 'https://www.wdzj.com/dangan/'
# KEYWORD = '银行存管'
def key_word():
names = []
banks = []
tel_nums = []
urls = []
count= 0
wb = xlwt.Workbook()
ws = wb.add_sheet('numbers')
ws.write(0, 0, '序号')
ws.write(0, 1, '公司名称')
ws.write(0, 2, '银行存管')
ws.write(0, 3, '客服电话')
ws.write(0, 4, '公司域名')
wb.save('D:\\number.xls')
for i in range(0, 76):
page_url = URL + 'search?filter=e1¤tPage=' + str(i + 1)
index_page = driver.Chrome()
index_page.get(page_url)
select_data = index_page.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
print(index_page.current_url)
for data in select_data:
names.append(data.text)
print(names) #名字
sec_url = data.get_attribute("href")
index_sec = driver.Chrome()
index_sec.get(sec_url)
# print(index_sec.current_url) #链接
yhcg = index_sec.find_element_by_xpath('//*[@class="bgbox-bt zzfwbox"]/dl/dd/div[@class="r" and contains(text(),"存管")]')
banks.append(yhcg.text)
print(banks) #银行存管
tel_num = index_sec.find_element_by_link_text('联系方式')
tel_num.click()
number = index_sec.find_element_by_xpath('//*[@class="da-lxfs zzfwbox"]/dl[1]/dd[1]/div[2]')
tel_nums.append(number.text)
# print(tel_nums) #客服电话
yuming = index_sec.find_element_by_link_text('工商/备案')
yuming.click()
yu_beian = index_sec.find_element_by_xpath('//*[@class="lcen"]/table/tbody/tr[7]/td[2]')
urls.append(yu_beian.text)
print(urls) #域名
oldWb =xlrd.open_workbook('D:\\number.xls', formatting_info=True)
newWb = copy(oldWb)
news = newWb.get_sheet(0)
news.write(count + 1, 0, count + 1)
news.write(count + 1, 1, names[count])
news.write(count + 1, 2, banks[count])
news.write(count + 1, 3, tel_nums[count])
news.write(count + 1, 4, urls[count])
newWb.save('D:\\number.xls')
print(count)
count+=1
index_sec.close()
index_page.close()
return names, banks, tel_nums, urls
def run():
key_word()
run() 查看全部
动态网页抓取(3.安装selenium库,可直接用#39;pipinstallselenium#pip
)
这个过程比较麻烦,需要分几个步骤来完成。下面将一一介绍:
1. 要安装 selenium 库,您可以直接使用 'pip install selenium' 命令安装它。
2. 下载chromeDriver并将其添加到环境变量中,或者直接将.exe文件放在python安装目录的scripts文件夹中。下载时请务必选择与您的浏览器对应的版本。查看浏览器版本的方法是:右上角->帮助->关于google chrome查看,驱动下载地址为chromedriver下载地址,与chrome版本对应关系为对应关系。验证下载安装是否成功,只需执行下面这段代码,如果没有错误,则安装成功。
import selenium.webdriver as driver
index = driver.Chrome()
index.get('https://www.wdzj.com/dangan')
print(index)
3. Selenium 实现爬虫,定位方法很多,简单介绍一下:
官网地址为:
查找单个元素的方法是:
查找多个元素(返回一个列表)的方法是:
4. 基本功能有了之后,就可以愉快的爬取了(由于还没写,先放一些代码,以后再更新)!
import selenium.webdriver as driver
import xlwt
import types
URL = 'https://www.wdzj.com/dangan/'
# KEYWORD = '银行存管'
def key_word():
# index = driver.Chrome()
# index.get(URL)
# select_data = index.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
# print(index.current_url)
# keyword_index = index.find_element_by_link_text()
# keyword_index.click()
names = []
banks = []
tel_nums = []
urls = []
for i in range(0, 76):
page_url = URL + 'search?filter=e1¤tPage=' + str(i + 1)
index_page = driver.Chrome()
index_page.get(page_url)
select_data = index_page.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
print(index_page.current_url)
for data in select_data:
names.append(data.text)
print(names) #名字
sec_url = data.get_attribute("href")
index_sec = driver.Chrome()
index_sec.get(sec_url)
# print(index_sec.current_url) #链接
yhcg = index_sec.find_element_by_xpath('/html/body/div[10]/div/div[1]/div[1]/dl[1]/dd[2]/div[2]')
banks.append(yhcg.text)
# print(banks) #银行存管
tel_num = index_sec.find_element_by_link_text('联系方式')
tel_num.click()
number = index_sec.find_element_by_xpath('//*[@class="da-lxfs zzfwbox"]/dl[1]/dd[1]/div[2]')
tel_nums.append(number.text)
# print(tel_nums) #客服电话
yuming = index_sec.find_element_by_link_text('工商/备案')
yuming.click()
yu_beian = index_sec.find_element_by_xpath('//*[@class="lcen"]/table/tbody/tr[7]/td[2]')
urls.append(yu_beian.text)
print(urls) #域名
index_sec.close()
# print(page_url)
# next_page = index.find_element_by_link_text('下一页')
# next_page.click()
return names, banks, tel_nums, urls
def xls():
wb = xlwt.Workbook()
ws = wb.add_sheet('numbers')
ws.write(0, 0, '序号')
ws.write(0, 1, '公司名称')
ws.write(0, 2, '银行存管')
ws.write(0, 3, '客服电话')
ws.write(0, 4, '公司域名')
names, banks, tel_nums, urls = key_word()
print(len(names))
for i in range (0, len(names)):
ws.write(i + 1, 0, i+1)
ws.write(i + 1, 1, names[i])
ws.write(i + 1, 2, banks[i])
ws.write(i + 1, 3, tel_nums[i])
ws.write(i + 1, 4, urls[i])
wb.save('D:\\number.xls')
def run():
xls()
run()
改变:
import selenium.webdriver as driver
import xlwt
from xlutils.copy import copy
import xlrd
URL = 'https://www.wdzj.com/dangan/'
# KEYWORD = '银行存管'
def key_word():
names = []
banks = []
tel_nums = []
urls = []
count= 0
wb = xlwt.Workbook()
ws = wb.add_sheet('numbers')
ws.write(0, 0, '序号')
ws.write(0, 1, '公司名称')
ws.write(0, 2, '银行存管')
ws.write(0, 3, '客服电话')
ws.write(0, 4, '公司域名')
wb.save('D:\\number.xls')
for i in range(0, 76):
page_url = URL + 'search?filter=e1¤tPage=' + str(i + 1)
index_page = driver.Chrome()
index_page.get(page_url)
select_data = index_page.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
print(index_page.current_url)
for data in select_data:
names.append(data.text)
print(names) #名字
sec_url = data.get_attribute("href")
index_sec = driver.Chrome()
index_sec.get(sec_url)
# print(index_sec.current_url) #链接
yhcg = index_sec.find_element_by_xpath('//*[@class="bgbox-bt zzfwbox"]/dl/dd/div[@class="r" and contains(text(),"存管")]')
banks.append(yhcg.text)
print(banks) #银行存管
tel_num = index_sec.find_element_by_link_text('联系方式')
tel_num.click()
number = index_sec.find_element_by_xpath('//*[@class="da-lxfs zzfwbox"]/dl[1]/dd[1]/div[2]')
tel_nums.append(number.text)
# print(tel_nums) #客服电话
yuming = index_sec.find_element_by_link_text('工商/备案')
yuming.click()
yu_beian = index_sec.find_element_by_xpath('//*[@class="lcen"]/table/tbody/tr[7]/td[2]')
urls.append(yu_beian.text)
print(urls) #域名
oldWb =xlrd.open_workbook('D:\\number.xls', formatting_info=True)
newWb = copy(oldWb)
news = newWb.get_sheet(0)
news.write(count + 1, 0, count + 1)
news.write(count + 1, 1, names[count])
news.write(count + 1, 2, banks[count])
news.write(count + 1, 3, tel_nums[count])
news.write(count + 1, 4, urls[count])
newWb.save('D:\\number.xls')
print(count)
count+=1
index_sec.close()
index_page.close()
return names, banks, tel_nums, urls
def run():
key_word()
run()
动态网页抓取(怎样行使python中BeautifulSoup举办WEB中Soup抓取中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-01 07:15
爬虫实时更新
互联网是一个绝对大胆的数据来源。不幸的是,如果没有可供下载和说明的易于构建的 CSV 文档,那么绝大多数都是。如果要从大量 网站 中获取数据,则有必要尝试进行网络抓取。
如果你还是初学者,别着急——在数据说明如何使用Beautiful Soup在python中进行网页抓取,我们将介绍如何使用Python从头开始进行网页抓取,并首先回答一些相关的网页抓取常见问题看过的话题。
一旦你掌握了这个概念的窍门,请随意滚动浏览这些元素并直接跳到有关如何在 python 中使用 Beautiful Soup 进行网页抓取的数据说明!
网站 提供的一些数据集可以以 CSV 格式下载或通过应用程序编程接口 (API) 访问。然而,许多具有有效数据的 网站 并没有提供这些简单的选择。
例如,咨询国家统计局的网站。它收录每个位置的最新天气预报,但无法通过 CSV 或 API 访问此天气数据。
如果我们想解释这些数据,或者下载它以用于其他操作,我们将无法复制粘贴完整的内容。网页抓取是一种使我们能够使用编程来完成困难任务的技术。我们将编写一些在 NWS 站点上查找的代码,只获取我们想要使用的数据,并以所需的方式输出它。
在 Data Explains How to Use Beautiful Soup in Python for Web Scraping 中,我们将向您展示如何使用 Python 3 和 Beautiful Soup 库来实现 Web 抓取。我们将从国家统计局获取天气预报,然后使用 pandas 库来托管描述。
在抓取网络时,我们编写代码将请求发送到托管我们指定页面的服务器。通常,我们的代码会像浏览器一样下载页面的源代码。但是,它不是直观地显示页面,而是过滤页面以查找我们指定的 HTML 元素,并提取我们指示它提取的任何内容。
例如,如果我们想从网站中获取H2标签中的所有问题,我们可以编写一些代码来完成它。我们的代码将从其服务器请求 网站 的内容并下载它。然后,它将通过页面的 HTML 查找 H2 标签。一旦找到 H2 标签,它将复制标签内的全文并以我们指定的任何方式输出。
需要注意的一件事:从服务器的角度来看,通过网络抓取请求页面类似于在网络浏览器中加载页面。当我们使用代码提交这些请求时,我们可能会比普通用户更快地“加载”页面,从而迅速耗尽网站所有服务器资源。
可以使用许多其他编程语言执行 Web 抓取。例如,我们还有一个关于使用 R 进行网页抓取的教程。
然而,使用 Python 和 Beautiful Soup 库是最流行的网络抓取技术之一。这意味着一旦你掌握了 Beautiful Soup 的基础知识,就会有大量的教程、操作视频和一些示例代码来帮助你加深知识。
我们将解释如何在 python 中使用 Beautiful Soup 来托管网页抓取端,并介绍一些其他常见的网页抓取问题和答案,但现在是开始了解我们的网页抓取项目的时候了!每个网络抓取项目都应该从回答以下问题开始:
不幸的是,这里没有一个粗略的答案。一些网站知道愿意进行网络抓取。其他人明确禁止这样做。许多 网站 没有以一种或另一种形式提供任何明确的命令。
在抓取任何网站之前,我们应该查看一个条件和条件页面,看看是否有明确的抓取指南。如果有,我们应该跟随他们。如果不是,那么它更像是一个推论。
但是,请记住,网络抓取会消耗主机 网站 上的服务器资源。如果我们只刮一页,就不会造成问题。但是,如果我们的代码每时钟抓取 1,000 页,那么对于 网站all-timers 来说,这很快就会变得昂贵。
因此,除了遵循 网站 上发布的关于全面和一体式采集抓取的明确指南之外,遵循以下最佳实践也是一个很好的目标:
2)学会缓存你抓取的内容,这样在处理用于过滤和描述它的代码时只下载一次,而不是每次运行代码时都重新下载
3)学习使用效果 time.sleep() 在代码中创建暂停,例如避免在太短的时间内发出过多的请求以使不堪重负的服务器瘫痪。
在数据显示如何在python中使用Beautiful Soup进行网页抓取的情况下,NWS数据是海量的,它的术语不禁止网页抓取,所以我们可以继续做。
当我们访问一个网页时,我们的网络浏览器会向网络服务器发出一个请求。此请求称为 GET 请求,因为我们正在从服务器获取文档。然后服务器发回文档,告诉我们的浏览器如何为我们呈现页面。文学分为几种严肃的类型:
浏览器收到完整的文档后,会渲染页面并展示给我们。为了让页面看起来漂亮,幕后发生了很多事情,但是当我们进行网页抓取时,我们不需要担心很多这些问题。在做网页抓取的时候,我们对网页的严肃性很感兴趣,所以我们来看看HTML。
超文本标记语言 (HTML) 是一种用于创建网页的语言。HTML 不是像 Python 那样的编程演讲,而是告诉浏览器如何组织内容的横幅演讲。HTML 使您能够执行与 Microsoft Word 等文字处理器类似的操作 - 粗体文本、创建段落等。由于 HTML 不是一种编程语言,因此它不像 Python 那样复杂。
让我们快速浏览一下 HTML,这样我们就可以有效地进行爬网。HTML 由称为标签的元素组成。最基本的标签是标签。此标志告诉 Web 浏览器其中的所有内容都是 HTML。我们可以使用以下标志来创建一个简单的 HTML 文档:
我们没有在页面中添加任何内容,因此如果我们要在 Web 浏览器中查看 HTML 文档,我们将看不到任何内容:
在 html 标签内,我们放置了另外两个标签,head 标签和 body 标签。网页的主要内容进入body标签。head 标签收录相关的网页标题,以及在网页抓取中通常无效的其他信息:
我们还没有向页面添加任何内容(在 body 标签内),所以我们不再看到任何内容:
正如您在上面可能已经注意到的,我们将 head 和 body 标签放在 html 标签中。在 HTML 中,标签是嵌套的,可以放在其他标签内。
后一个参数是毫秒时间戳。测量的目的是改造缓存。如果你的爬虫没有缓存数据,这个参数可以省略,加起来很简单~
爬虫实时更新 查看全部
动态网页抓取(怎样行使python中BeautifulSoup举办WEB中Soup抓取中)
爬虫实时更新
互联网是一个绝对大胆的数据来源。不幸的是,如果没有可供下载和说明的易于构建的 CSV 文档,那么绝大多数都是。如果要从大量 网站 中获取数据,则有必要尝试进行网络抓取。
如果你还是初学者,别着急——在数据说明如何使用Beautiful Soup在python中进行网页抓取,我们将介绍如何使用Python从头开始进行网页抓取,并首先回答一些相关的网页抓取常见问题看过的话题。
一旦你掌握了这个概念的窍门,请随意滚动浏览这些元素并直接跳到有关如何在 python 中使用 Beautiful Soup 进行网页抓取的数据说明!
网站 提供的一些数据集可以以 CSV 格式下载或通过应用程序编程接口 (API) 访问。然而,许多具有有效数据的 网站 并没有提供这些简单的选择。
例如,咨询国家统计局的网站。它收录每个位置的最新天气预报,但无法通过 CSV 或 API 访问此天气数据。
如果我们想解释这些数据,或者下载它以用于其他操作,我们将无法复制粘贴完整的内容。网页抓取是一种使我们能够使用编程来完成困难任务的技术。我们将编写一些在 NWS 站点上查找的代码,只获取我们想要使用的数据,并以所需的方式输出它。
在 Data Explains How to Use Beautiful Soup in Python for Web Scraping 中,我们将向您展示如何使用 Python 3 和 Beautiful Soup 库来实现 Web 抓取。我们将从国家统计局获取天气预报,然后使用 pandas 库来托管描述。
在抓取网络时,我们编写代码将请求发送到托管我们指定页面的服务器。通常,我们的代码会像浏览器一样下载页面的源代码。但是,它不是直观地显示页面,而是过滤页面以查找我们指定的 HTML 元素,并提取我们指示它提取的任何内容。
例如,如果我们想从网站中获取H2标签中的所有问题,我们可以编写一些代码来完成它。我们的代码将从其服务器请求 网站 的内容并下载它。然后,它将通过页面的 HTML 查找 H2 标签。一旦找到 H2 标签,它将复制标签内的全文并以我们指定的任何方式输出。
需要注意的一件事:从服务器的角度来看,通过网络抓取请求页面类似于在网络浏览器中加载页面。当我们使用代码提交这些请求时,我们可能会比普通用户更快地“加载”页面,从而迅速耗尽网站所有服务器资源。
可以使用许多其他编程语言执行 Web 抓取。例如,我们还有一个关于使用 R 进行网页抓取的教程。
然而,使用 Python 和 Beautiful Soup 库是最流行的网络抓取技术之一。这意味着一旦你掌握了 Beautiful Soup 的基础知识,就会有大量的教程、操作视频和一些示例代码来帮助你加深知识。
我们将解释如何在 python 中使用 Beautiful Soup 来托管网页抓取端,并介绍一些其他常见的网页抓取问题和答案,但现在是开始了解我们的网页抓取项目的时候了!每个网络抓取项目都应该从回答以下问题开始:
不幸的是,这里没有一个粗略的答案。一些网站知道愿意进行网络抓取。其他人明确禁止这样做。许多 网站 没有以一种或另一种形式提供任何明确的命令。
在抓取任何网站之前,我们应该查看一个条件和条件页面,看看是否有明确的抓取指南。如果有,我们应该跟随他们。如果不是,那么它更像是一个推论。
但是,请记住,网络抓取会消耗主机 网站 上的服务器资源。如果我们只刮一页,就不会造成问题。但是,如果我们的代码每时钟抓取 1,000 页,那么对于 网站all-timers 来说,这很快就会变得昂贵。
因此,除了遵循 网站 上发布的关于全面和一体式采集抓取的明确指南之外,遵循以下最佳实践也是一个很好的目标:
2)学会缓存你抓取的内容,这样在处理用于过滤和描述它的代码时只下载一次,而不是每次运行代码时都重新下载
3)学习使用效果 time.sleep() 在代码中创建暂停,例如避免在太短的时间内发出过多的请求以使不堪重负的服务器瘫痪。
在数据显示如何在python中使用Beautiful Soup进行网页抓取的情况下,NWS数据是海量的,它的术语不禁止网页抓取,所以我们可以继续做。
当我们访问一个网页时,我们的网络浏览器会向网络服务器发出一个请求。此请求称为 GET 请求,因为我们正在从服务器获取文档。然后服务器发回文档,告诉我们的浏览器如何为我们呈现页面。文学分为几种严肃的类型:
浏览器收到完整的文档后,会渲染页面并展示给我们。为了让页面看起来漂亮,幕后发生了很多事情,但是当我们进行网页抓取时,我们不需要担心很多这些问题。在做网页抓取的时候,我们对网页的严肃性很感兴趣,所以我们来看看HTML。
超文本标记语言 (HTML) 是一种用于创建网页的语言。HTML 不是像 Python 那样的编程演讲,而是告诉浏览器如何组织内容的横幅演讲。HTML 使您能够执行与 Microsoft Word 等文字处理器类似的操作 - 粗体文本、创建段落等。由于 HTML 不是一种编程语言,因此它不像 Python 那样复杂。
让我们快速浏览一下 HTML,这样我们就可以有效地进行爬网。HTML 由称为标签的元素组成。最基本的标签是标签。此标志告诉 Web 浏览器其中的所有内容都是 HTML。我们可以使用以下标志来创建一个简单的 HTML 文档:
我们没有在页面中添加任何内容,因此如果我们要在 Web 浏览器中查看 HTML 文档,我们将看不到任何内容:
在 html 标签内,我们放置了另外两个标签,head 标签和 body 标签。网页的主要内容进入body标签。head 标签收录相关的网页标题,以及在网页抓取中通常无效的其他信息:
我们还没有向页面添加任何内容(在 body 标签内),所以我们不再看到任何内容:
正如您在上面可能已经注意到的,我们将 head 和 body 标签放在 html 标签中。在 HTML 中,标签是嵌套的,可以放在其他标签内。
后一个参数是毫秒时间戳。测量的目的是改造缓存。如果你的爬虫没有缓存数据,这个参数可以省略,加起来很简单~
爬虫实时更新
动态网页抓取(如何抓取网页中的动态网页源码中特定的特定内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-02-26 02:15
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
【教程】Python版爬网并从网页中提取需要的信息
和
【教程】C#版爬网并从网页中提取需要的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
不熟悉的可以参考:
【组织】爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站
2.学会使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的可以参考:
【教程】教你如何使用工具(IE9的F12)解析模拟登录内部逻辑流程网站(百度首页))
3.对于一个普通的静态网页,如何提取想要的内容
对此不熟悉的可以参考:
(1)Python 版本:
【教程】Python版爬网并从网页中提取需要的信息
(2)C# 版本:
【教程】C#版爬网并从网页中提取需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据你通过工具分析的结果,找到对应的数据并提取出来;
不过这个数据有时候可以在分析结果的过程中直接提取出来,有时候可能是通过js计算出来的。
想抓取数据,是js脚本生成的
虽然最终的动态内容是由js脚本执行生成的,但是对于你要抓取的数据:
想爬取数据是通过访问另一个url获取的
如果你要抓取的对应内容是访问另一个url地址和返回的数据,那么很简单,你也需要访问这个url,然后获取对应的返回内容,从中提取你想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。 查看全部
动态网页抓取(如何抓取网页中的动态网页源码中特定的特定内容)
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
【教程】Python版爬网并从网页中提取需要的信息
和
【教程】C#版爬网并从网页中提取需要的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
不熟悉的可以参考:
【组织】爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站
2.学会使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的可以参考:
【教程】教你如何使用工具(IE9的F12)解析模拟登录内部逻辑流程网站(百度首页))
3.对于一个普通的静态网页,如何提取想要的内容
对此不熟悉的可以参考:
(1)Python 版本:
【教程】Python版爬网并从网页中提取需要的信息
(2)C# 版本:
【教程】C#版爬网并从网页中提取需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据你通过工具分析的结果,找到对应的数据并提取出来;
不过这个数据有时候可以在分析结果的过程中直接提取出来,有时候可能是通过js计算出来的。
想抓取数据,是js脚本生成的
虽然最终的动态内容是由js脚本执行生成的,但是对于你要抓取的数据:
想爬取数据是通过访问另一个url获取的
如果你要抓取的对应内容是访问另一个url地址和返回的数据,那么很简单,你也需要访问这个url,然后获取对应的返回内容,从中提取你想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。
动态网页抓取(ajax横行的年代,我们的网页是残缺的吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-26 02:14
)
在ajax时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中包括
跳过js加载部分,表示爬虫抓取的网页不完整,不完整。您可以在下面看到博客园的主页
从首页的加载中可以看出,页面渲染完成后,会有5个异步ajax请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候,如果你想得到它,你必须调用浏览器的内核引擎来下载这些动态页面。目前内核引擎是三足的。
Trident:也就是IE内核,WebBrowser就是基于这个内核,但是加载性能比较差。
Gecko:FF的内核比Trident的性能更好。
WebKit:Safari和Chrome的核心,性能你懂的,在真实场景中还是主要的。
好的,为了简单方便,这里我们使用WebBrowser来玩,使用WebBrowser的时候要注意以下几点:
首先:因为WebBrowser是System.Windows.Forms中的winform控件,所以我们需要设置STAThread标签。
第二:winform是事件驱动的,Console不响应事件。所有事件都在窗口的消息队列中等待执行。为了防止程序假死,
我们需要调用DoEvents方法来传递控制权,让操作系统执行其他事件。
第三:WebBrowser内容,我们需要使用DomDocument来查看,而不是DocumentText。
判断动态网页是否加载一般有两种方式:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们这里需要这样做
记录计数值
.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们还可以通过设置一个Timer来判断,比如3s、4s、5s,稍后查看
WEB浏览器是否加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果还是一样的,就不截图了。从以上两种写法来看,我们的WebBrowser放在主线程中。让我们看看如何把它放在工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 } 查看全部
动态网页抓取(ajax横行的年代,我们的网页是残缺的吗?
)
在ajax时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中包括
跳过js加载部分,表示爬虫抓取的网页不完整,不完整。您可以在下面看到博客园的主页
从首页的加载中可以看出,页面渲染完成后,会有5个异步ajax请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候,如果你想得到它,你必须调用浏览器的内核引擎来下载这些动态页面。目前内核引擎是三足的。
Trident:也就是IE内核,WebBrowser就是基于这个内核,但是加载性能比较差。
Gecko:FF的内核比Trident的性能更好。
WebKit:Safari和Chrome的核心,性能你懂的,在真实场景中还是主要的。
好的,为了简单方便,这里我们使用WebBrowser来玩,使用WebBrowser的时候要注意以下几点:
首先:因为WebBrowser是System.Windows.Forms中的winform控件,所以我们需要设置STAThread标签。
第二:winform是事件驱动的,Console不响应事件。所有事件都在窗口的消息队列中等待执行。为了防止程序假死,
我们需要调用DoEvents方法来传递控制权,让操作系统执行其他事件。
第三:WebBrowser内容,我们需要使用DomDocument来查看,而不是DocumentText。
判断动态网页是否加载一般有两种方式:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们这里需要这样做
记录计数值
.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们还可以通过设置一个Timer来判断,比如3s、4s、5s,稍后查看
WEB浏览器是否加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果还是一样的,就不截图了。从以上两种写法来看,我们的WebBrowser放在主线程中。让我们看看如何把它放在工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
动态网页抓取(什么是爬虫?反爬的出发点是什么?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-02-25 23:23
?作者|leo
01 什么是爬行动物?
爬虫,顾名思义,就像一个探索、模拟人类行为的小型机器人,传播到网络的各个角落,按照一定的规则采集和组织数据,并反馈回来。这是一个非常形象的描述爬行原理的方式。
从技术角度看,爬虫主要是根据一定的程序规则或技术指标,通过网络请求获取资源,然后通过一定的分析方法提取所需的信息,并将获取的资源存储起来。
02 为什么会出现反爬虫?
你见过的最奇怪的验证码是什么?不管是考小学数学的验证码,还是考人文知识的验证码,现在越来越多的奇葩验证码出现,这在一定程度上给我们参观者带来了很多不便,但他们真正的目的不是为了给用户增加难度,而是为了防止大多数不受控制的访问机器人。
爬虫的访问速度和目的很容易发现与普通用户不同。大多数爬虫都有无节制地大量爬取访问目标的行为。这些访问请求会给访问目标带来巨大的服务器压力。以及不必要的资源投入,因此经常被运营商定义为“垃圾流量”。
因此,运营商为了更好地维护自身利益,会根据爬虫的特点采取不同的手段来阻止大量爬虫的访问。
根据反爬的起点,反爬的限制方法可分为:
? 主动限制:开发者会通过技术手段主动限制爬虫的访问请求,如:验证请求头信息、限制重复访问同一个ip、验证码技术等。
? 被动限制:为了在不降低用户体验的情况下节省访问资源,开发者采用了间接的技术手段限制爬虫访问,如:动态网页加载、数据分段加载、鼠标悬停预览数据等。
? 根据具体的反爬虫实现方式,大致可分为:信息验证反爬虫、动态渲染反爬虫、文本混淆反爬虫、特征识别反爬虫。爬虫和反爬虫无异于一场攻防的博弈,既有竞争又有相互促进的可能。
常见的反爬策略及对策:
信息验证爬虫:
一种。User-Agent 发送爬虫:
基本原理:可以向服务器发送请求的客户端有多种形式,可以是不同类型的个人电脑、手机、平板电脑、编程程序,也可以是网络请求软件。服务器应该如何识别这些不同的客户端?结尾?
User-Agent 就是用户发送请求时附加的请求信息的记录。其主要格式包括以下部分:
**浏览器 ID(操作系统 ID、加密级别 ID;浏览器语言)渲染引擎 ID 版本信息**
例如:
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, 像 Gecko)
User-Agent的反爬主要是通过对User-Agent头域的值进行校验。如果黑名单中有值,则会被服务器屏蔽。
例如Python常用的Requests库,如果发送请求时没有设置header参数,服务器读取User-Agent的值为python-requests/2.21.0
湾。Cookies 反爬虫
Cookies不仅可以用来存储网络用户的身份信息或保持登录状态,还可以作为反爬虫的识别信息。
主要原理是客户端访问服务端时,服务端会返回Set-Cookie头域,客户端存储信息,再次访问服务端时携带相应的cookie信息。此时,服务器只需要验证cookie是否符合要求即可。规则没问题,如果不匹配,就会重定向到另一个页面,并在响应中添加 Set-Cookie 头字段和 Cookie 值。
上述验证cookies的方法只是一种比较简单的反爬机制。爬虫工程师只需要复制浏览器请求头中的cookie即可轻松规避。这时候cookie验证往往结合javascript文件生成随机cookie值进行验证。:
**Cookie名称+3个小于9的随机正整数+5个随机大写字母+6个小于9的正整数+3个随机大写字母**
这种机制仍有被重复使用的可能。即使加上cookie过期时间也不能完全保证cookie的重用。在这种情况下,需要结合上述方法引入时间戳进行进一步判断。取出cookie值的时间戳和当前时间。对邮票进行差值计算,如果超过一定时间,就会被认定为伪造。
C。签名验证反爬虫:
主要原理是在发送请求时,将客户端生成的一些随机数和不可逆的MD5加密字符串发送给服务器。服务器使用相同的方法进行随机值计算和MD5加密。如果MD5值相等,则表示请求正常,否则返回403.
目前这种反爬虫方法广泛应用于各种大型网站,绕过它不仅需要从XHR信息中查找相关请求信息,还需要在Javascript代码中查找加密方法.
动态渲染反爬虫:
动态网页常用于改善用户体验,节省资源消耗,提高响应速度。不是直接针对爬虫程序的反爬措施,而是无意中产生反爬效果,爬虫程序没有页面渲染。功能,但是一旦遇到动态渲染的页面,就无法完全返回所需的信息。
比如我们要爬取英雄联盟中的英雄名字并下载对应的图片时,使用requests库按照原来的爬取方式进行爬取,会发现获取到的字段都是空值。主要原因是网站使用了javacript动态加载技术,只有找到核心js传输代码才能找到对应的信息。
通过网页检查工具,我们可以清楚的看到 hero_list.js 文件中存放了所有的英雄信息,以及对应的英雄图片链接和详情页信息。
那么我们在分析信息的时候,需要针对js文件来做。
动态渲染的主要解决方案:
动态渲染技术组合非常灵活。如果每次遇到这样的网站都要分析接口、参数和javascript代码逻辑,时间和成本会高很多。那么直接提取渲染结果页面的能力对于爬虫分析来说会简单很多。目前主要的渲染提取工具有:Puppeter、Selenium、Splash。
2.1 硒
Selenium 是解决动态渲染最常用的技术之一。
浏览器驱动程序是 Selenium 向浏览器发送指令或传递渲染结果的主要工具。
目前驱动一般从以下网址下载:
[]()
我们可以通过简单的代码提取相应的信息。
from selenium import webdriver
url = 'https://www.udemy.com/course/network-security-course/'
driver = webdriver.Chrome()
res = driver.get(url)
course = driver.find_element_by_css_selector('.clp-lead__title').text.replace('\n','')
print(course)
driver.quit()
2.2 傀儡师
在使用 Selenium 进行数据爬取时,执行大批量的任务显然需要很长时间。这时候我们要介绍一种异步加载和提取数据的方法,就是Puppeter方法,它是谷歌开源的Node库。除了拥有一组高级 API 来控制浏览器之外,它还提供了许多手动操作的替代方案,最重要的是,它支持异步。
import asyncio
from pyppeter import launch
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://www.udemy.com/course/network-security-course/')
res = await page.xpath("//*[@class='clp-lead__title']")
text = await(await res[0].getProperty('textContent')).jsonValue()
print(text)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
2.3 分布式渲染服务Splash
Splash 应用于分布式爬取需求。假设我们想在更多的机器上运行爬虫程序,是否可以通过安装 Puppeter 和 Selenium 组件来完成?显然没有。
Splash 是一个带有轻量级 Web 浏览器的异步 Js 渲染服务。当我们将它部署在云端时,多个爬虫可以通过同一个 API 访问渲染的页面。
动态网页的广泛应用,不仅提升了用户体验,也在一定程度上限制了爬虫程序的使用。页面解析结合动态渲染技术解决了80%以上复杂页面的爬取,但效率远不如直接解析javascript。文件速度很快,往往要花很多时间才能找到网站入口和js文件的位置。因此,具体技术需要根据实际情况灵活运用。
03 文本混淆和反爬虫
文本混淆可以有效防止爬虫获取Web应用中的文本数据。通过混淆文本信息来限制爬虫获取数据的技术手段称为文本混淆反爬虫。
文字混淆和反爬虫的前提是不影响普通用户的体验,所以文字混淆不能直接显示,所以开发者通常使用CSS特性来实现混淆。
常见的文本混淆方法包括:图像伪装、文本映射、自定义字体
3.1 图片伪装
该方法使用图片替换原创文本信息,使得直接提取文本的方法无效。例如:电话
电话
这段代码是某个网站的截取代码,通过图片的方式伪装了原文电话号码。因此,如果要获取这些信息,简单的爬虫方法是不可能实现的,那么主要应对措施是什么?
这里主要需要的是光学字符识别技术,对于纯文本信息,可以很容易的实现,没有像素干扰。在 python 中,我们主要使用 PyTesseract 库来提取图像文本。
3.2 SVG 映射反爬虫
SVG是一种基于XML描述图形的二维矢量图形格式,图形质量不受图形放大或缩小的影响。这个特性在 Web网站 中被广泛使用。
使用SVG映射反爬虫的主要原理是映射不同的字符串和不同的数字。当服务器进行数据解析时,进行相关处理,然后浏览器进行渲染,最终达到隐藏信息的目的。
绕过SVG映射可以通过提取数据对应的相关信息来解决。如下图所示,我们最终通过在html代码中找到class-to-numbers的映射关系得到电话号码信息。
mappings = {
'vhk08k':0, 'vhk6zl':1,'vhk9or':2,'vhkfln':3,'vhkbvu':4,'vhk84t':5,'vhkvxd':6,
'vhkqsc':7,'vhkkj4':8,'vhk0f1':9,
}
html_class = ['vhkbvu','vhk08k','vhkfln','vhk0f1']
phone_num = [mappings.get(i) for i in html_class]
print(phone_num)
目前主流的反爬虫技术表明:
除上述爬虫技术外,还包括常见的验证码识别反爬虫。它的主要实现机制是通过各种动态生成的验证码来防止爬虫访问网页信息,所以绕过验证码也是目前的技术。难点,传统的文字和图形验证码可以通过光学识别来解决,而动态滑块验证码和逻辑操作验证码只能通过多种技术的结合来实现。
另一种常见的反爬虫是特征识别反爬虫。如果你尝试过爬取Boss直接招聘网页上的信息,你会发现无论是使用常规爬取方式还是使用Selenium动态渲染工具,还是分析Javascript文件,基本上都无法有效提取相关数据,并且返回值都是空值。主要原因是目标站采用WebDriver特征识别。主要原理是反爬虫程序可以识别发送请求的客户端的webdriver属性是否由webdriver驱动。要访问的话,绕过方法也是基于这个属性。webdriver 检测的主要结果有三个:true、false 和 undefined。当我们使用渲染工具拥有webdriver属性时,返回值为真,那么我正在触发验证。可以通过在此属性之前将其更改为 false 或 undefined 来规避此识别。
以上就是对目前主流的反爬技术和绕行策略的简单介绍。在这场攻防博弈中,核心思想是如何分析对手的执行机制,以便更好地提出解决方案。当然,涉及的也很多。深入的理论知识,也有大量的人为逻辑陷阱在其中,所以掌握爬虫技术,实践和理论学习同等重要。
目前主流的反爬虫技术表明:
除上述爬虫技术外,还包括常见的验证码识别反爬虫。它的主要实现机制是防止爬虫通过各种状态下生成的验证码访问网页信息,所以绕过验证码也是目前的技术。难点,传统的文字和图形验证码可以通过光学识别来解决,而动态滑块验证码和逻辑操作验证码只能通过多种技术的结合来实现。
另一种常见的反爬虫是特征识别反爬虫。如果你尝试过爬取Boss直接招聘网页上的信息,你会发现无论是使用常规爬取方式还是使用Selenium动态渲染工具,还是分析Javascript文件,基本上都无法有效提取相关数据,并且返回values 都是空值。
主要原因是目标站采用了WebDriver特征识别。主要原理是反爬虫程序可以识别发送请求的客户端的webdriver属性是否通过webdriver驱动的浏览器访问。
那么绕过的方法也是围绕着这个属性来的。webdriver 检测的主要结果有三个:true、false 和 undefined。当我们使用渲染工具有webdriver属性时,返回值为true,那么我会在触发之前验证这个属性。将其修改为 false 或 undefined 可以绕过这种识别。
以上就是对目前主流的反爬技术和绕行策略的简单介绍。在这场攻防博弈中,核心思想是如何分析对手的执行机制,以便更好地提出解决方案。当然,涉及的也很多。深入的理论知识,也有大量的人为逻辑陷阱在其中,所以掌握爬虫技术,实践和理论学习同等重要。 查看全部
动态网页抓取(什么是爬虫?反爬的出发点是什么?(上))
?作者|leo
01 什么是爬行动物?
爬虫,顾名思义,就像一个探索、模拟人类行为的小型机器人,传播到网络的各个角落,按照一定的规则采集和组织数据,并反馈回来。这是一个非常形象的描述爬行原理的方式。
从技术角度看,爬虫主要是根据一定的程序规则或技术指标,通过网络请求获取资源,然后通过一定的分析方法提取所需的信息,并将获取的资源存储起来。
02 为什么会出现反爬虫?
你见过的最奇怪的验证码是什么?不管是考小学数学的验证码,还是考人文知识的验证码,现在越来越多的奇葩验证码出现,这在一定程度上给我们参观者带来了很多不便,但他们真正的目的不是为了给用户增加难度,而是为了防止大多数不受控制的访问机器人。
爬虫的访问速度和目的很容易发现与普通用户不同。大多数爬虫都有无节制地大量爬取访问目标的行为。这些访问请求会给访问目标带来巨大的服务器压力。以及不必要的资源投入,因此经常被运营商定义为“垃圾流量”。
因此,运营商为了更好地维护自身利益,会根据爬虫的特点采取不同的手段来阻止大量爬虫的访问。
根据反爬的起点,反爬的限制方法可分为:
? 主动限制:开发者会通过技术手段主动限制爬虫的访问请求,如:验证请求头信息、限制重复访问同一个ip、验证码技术等。
? 被动限制:为了在不降低用户体验的情况下节省访问资源,开发者采用了间接的技术手段限制爬虫访问,如:动态网页加载、数据分段加载、鼠标悬停预览数据等。
? 根据具体的反爬虫实现方式,大致可分为:信息验证反爬虫、动态渲染反爬虫、文本混淆反爬虫、特征识别反爬虫。爬虫和反爬虫无异于一场攻防的博弈,既有竞争又有相互促进的可能。
常见的反爬策略及对策:
信息验证爬虫:
一种。User-Agent 发送爬虫:
基本原理:可以向服务器发送请求的客户端有多种形式,可以是不同类型的个人电脑、手机、平板电脑、编程程序,也可以是网络请求软件。服务器应该如何识别这些不同的客户端?结尾?
User-Agent 就是用户发送请求时附加的请求信息的记录。其主要格式包括以下部分:
**浏览器 ID(操作系统 ID、加密级别 ID;浏览器语言)渲染引擎 ID 版本信息**
例如:
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, 像 Gecko)
User-Agent的反爬主要是通过对User-Agent头域的值进行校验。如果黑名单中有值,则会被服务器屏蔽。
例如Python常用的Requests库,如果发送请求时没有设置header参数,服务器读取User-Agent的值为python-requests/2.21.0
湾。Cookies 反爬虫
Cookies不仅可以用来存储网络用户的身份信息或保持登录状态,还可以作为反爬虫的识别信息。
主要原理是客户端访问服务端时,服务端会返回Set-Cookie头域,客户端存储信息,再次访问服务端时携带相应的cookie信息。此时,服务器只需要验证cookie是否符合要求即可。规则没问题,如果不匹配,就会重定向到另一个页面,并在响应中添加 Set-Cookie 头字段和 Cookie 值。
上述验证cookies的方法只是一种比较简单的反爬机制。爬虫工程师只需要复制浏览器请求头中的cookie即可轻松规避。这时候cookie验证往往结合javascript文件生成随机cookie值进行验证。:
**Cookie名称+3个小于9的随机正整数+5个随机大写字母+6个小于9的正整数+3个随机大写字母**
这种机制仍有被重复使用的可能。即使加上cookie过期时间也不能完全保证cookie的重用。在这种情况下,需要结合上述方法引入时间戳进行进一步判断。取出cookie值的时间戳和当前时间。对邮票进行差值计算,如果超过一定时间,就会被认定为伪造。
C。签名验证反爬虫:
主要原理是在发送请求时,将客户端生成的一些随机数和不可逆的MD5加密字符串发送给服务器。服务器使用相同的方法进行随机值计算和MD5加密。如果MD5值相等,则表示请求正常,否则返回403.
目前这种反爬虫方法广泛应用于各种大型网站,绕过它不仅需要从XHR信息中查找相关请求信息,还需要在Javascript代码中查找加密方法.
动态渲染反爬虫:
动态网页常用于改善用户体验,节省资源消耗,提高响应速度。不是直接针对爬虫程序的反爬措施,而是无意中产生反爬效果,爬虫程序没有页面渲染。功能,但是一旦遇到动态渲染的页面,就无法完全返回所需的信息。
比如我们要爬取英雄联盟中的英雄名字并下载对应的图片时,使用requests库按照原来的爬取方式进行爬取,会发现获取到的字段都是空值。主要原因是网站使用了javacript动态加载技术,只有找到核心js传输代码才能找到对应的信息。
通过网页检查工具,我们可以清楚的看到 hero_list.js 文件中存放了所有的英雄信息,以及对应的英雄图片链接和详情页信息。
那么我们在分析信息的时候,需要针对js文件来做。
动态渲染的主要解决方案:
动态渲染技术组合非常灵活。如果每次遇到这样的网站都要分析接口、参数和javascript代码逻辑,时间和成本会高很多。那么直接提取渲染结果页面的能力对于爬虫分析来说会简单很多。目前主要的渲染提取工具有:Puppeter、Selenium、Splash。
2.1 硒
Selenium 是解决动态渲染最常用的技术之一。
浏览器驱动程序是 Selenium 向浏览器发送指令或传递渲染结果的主要工具。
目前驱动一般从以下网址下载:
[]()
我们可以通过简单的代码提取相应的信息。
from selenium import webdriver
url = 'https://www.udemy.com/course/network-security-course/'
driver = webdriver.Chrome()
res = driver.get(url)
course = driver.find_element_by_css_selector('.clp-lead__title').text.replace('\n','')
print(course)
driver.quit()
2.2 傀儡师
在使用 Selenium 进行数据爬取时,执行大批量的任务显然需要很长时间。这时候我们要介绍一种异步加载和提取数据的方法,就是Puppeter方法,它是谷歌开源的Node库。除了拥有一组高级 API 来控制浏览器之外,它还提供了许多手动操作的替代方案,最重要的是,它支持异步。
import asyncio
from pyppeter import launch
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://www.udemy.com/course/network-security-course/')
res = await page.xpath("//*[@class='clp-lead__title']")
text = await(await res[0].getProperty('textContent')).jsonValue()
print(text)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
2.3 分布式渲染服务Splash
Splash 应用于分布式爬取需求。假设我们想在更多的机器上运行爬虫程序,是否可以通过安装 Puppeter 和 Selenium 组件来完成?显然没有。
Splash 是一个带有轻量级 Web 浏览器的异步 Js 渲染服务。当我们将它部署在云端时,多个爬虫可以通过同一个 API 访问渲染的页面。
动态网页的广泛应用,不仅提升了用户体验,也在一定程度上限制了爬虫程序的使用。页面解析结合动态渲染技术解决了80%以上复杂页面的爬取,但效率远不如直接解析javascript。文件速度很快,往往要花很多时间才能找到网站入口和js文件的位置。因此,具体技术需要根据实际情况灵活运用。
03 文本混淆和反爬虫
文本混淆可以有效防止爬虫获取Web应用中的文本数据。通过混淆文本信息来限制爬虫获取数据的技术手段称为文本混淆反爬虫。
文字混淆和反爬虫的前提是不影响普通用户的体验,所以文字混淆不能直接显示,所以开发者通常使用CSS特性来实现混淆。
常见的文本混淆方法包括:图像伪装、文本映射、自定义字体
3.1 图片伪装
该方法使用图片替换原创文本信息,使得直接提取文本的方法无效。例如:电话
电话
这段代码是某个网站的截取代码,通过图片的方式伪装了原文电话号码。因此,如果要获取这些信息,简单的爬虫方法是不可能实现的,那么主要应对措施是什么?
这里主要需要的是光学字符识别技术,对于纯文本信息,可以很容易的实现,没有像素干扰。在 python 中,我们主要使用 PyTesseract 库来提取图像文本。
3.2 SVG 映射反爬虫
SVG是一种基于XML描述图形的二维矢量图形格式,图形质量不受图形放大或缩小的影响。这个特性在 Web网站 中被广泛使用。
使用SVG映射反爬虫的主要原理是映射不同的字符串和不同的数字。当服务器进行数据解析时,进行相关处理,然后浏览器进行渲染,最终达到隐藏信息的目的。
绕过SVG映射可以通过提取数据对应的相关信息来解决。如下图所示,我们最终通过在html代码中找到class-to-numbers的映射关系得到电话号码信息。
mappings = {
'vhk08k':0, 'vhk6zl':1,'vhk9or':2,'vhkfln':3,'vhkbvu':4,'vhk84t':5,'vhkvxd':6,
'vhkqsc':7,'vhkkj4':8,'vhk0f1':9,
}
html_class = ['vhkbvu','vhk08k','vhkfln','vhk0f1']
phone_num = [mappings.get(i) for i in html_class]
print(phone_num)
目前主流的反爬虫技术表明:
除上述爬虫技术外,还包括常见的验证码识别反爬虫。它的主要实现机制是通过各种动态生成的验证码来防止爬虫访问网页信息,所以绕过验证码也是目前的技术。难点,传统的文字和图形验证码可以通过光学识别来解决,而动态滑块验证码和逻辑操作验证码只能通过多种技术的结合来实现。
另一种常见的反爬虫是特征识别反爬虫。如果你尝试过爬取Boss直接招聘网页上的信息,你会发现无论是使用常规爬取方式还是使用Selenium动态渲染工具,还是分析Javascript文件,基本上都无法有效提取相关数据,并且返回值都是空值。主要原因是目标站采用WebDriver特征识别。主要原理是反爬虫程序可以识别发送请求的客户端的webdriver属性是否由webdriver驱动。要访问的话,绕过方法也是基于这个属性。webdriver 检测的主要结果有三个:true、false 和 undefined。当我们使用渲染工具拥有webdriver属性时,返回值为真,那么我正在触发验证。可以通过在此属性之前将其更改为 false 或 undefined 来规避此识别。
以上就是对目前主流的反爬技术和绕行策略的简单介绍。在这场攻防博弈中,核心思想是如何分析对手的执行机制,以便更好地提出解决方案。当然,涉及的也很多。深入的理论知识,也有大量的人为逻辑陷阱在其中,所以掌握爬虫技术,实践和理论学习同等重要。
目前主流的反爬虫技术表明:
除上述爬虫技术外,还包括常见的验证码识别反爬虫。它的主要实现机制是防止爬虫通过各种状态下生成的验证码访问网页信息,所以绕过验证码也是目前的技术。难点,传统的文字和图形验证码可以通过光学识别来解决,而动态滑块验证码和逻辑操作验证码只能通过多种技术的结合来实现。
另一种常见的反爬虫是特征识别反爬虫。如果你尝试过爬取Boss直接招聘网页上的信息,你会发现无论是使用常规爬取方式还是使用Selenium动态渲染工具,还是分析Javascript文件,基本上都无法有效提取相关数据,并且返回values 都是空值。
主要原因是目标站采用了WebDriver特征识别。主要原理是反爬虫程序可以识别发送请求的客户端的webdriver属性是否通过webdriver驱动的浏览器访问。
那么绕过的方法也是围绕着这个属性来的。webdriver 检测的主要结果有三个:true、false 和 undefined。当我们使用渲染工具有webdriver属性时,返回值为true,那么我会在触发之前验证这个属性。将其修改为 false 或 undefined 可以绕过这种识别。
以上就是对目前主流的反爬技术和绕行策略的简单介绍。在这场攻防博弈中,核心思想是如何分析对手的执行机制,以便更好地提出解决方案。当然,涉及的也很多。深入的理论知识,也有大量的人为逻辑陷阱在其中,所以掌握爬虫技术,实践和理论学习同等重要。
动态网页抓取( 网站到底是动态路径好还是伪静态好?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-25 13:22
网站到底是动态路径好还是伪静态好?(图))
所谓路径其实是指“URL”,通常我们称之为“链接”,所以我想知道网站是动态路径还是伪静态路径?首先,我们需要知道什么是动态的,什么是静态的,什么是伪静态的。其实这三个只是网站链接的形式。对于这三种链接形式,90%以上的SEO站长都会优先考虑静态的,因为这样更有利于搜索引擎蜘蛛的抓取和识别,那么阿南就给大家介绍一下这三种链接。
静态路径
在网站中,每个静态路径在空间服务器中都会有一个静态文件,这个文件不会随着不同浏览器的访问而改变。用户在访问时根本不需要调用数据库,这也是静态网页打开速度惊人的原因,同时也减少了服务器对数据响应的负载,使搜索引擎更容易检索。在安全方面,静态页面几乎不受Asp相关漏洞的影响,无需担心SQL注入攻击。但是我们之前提到过,每个路径都有一个静态页面,所以如果网站的内容太大,会产生大量的文件,严重占用网站的空间,如果如果没有自动化工具,维护这些大量的静态文件几乎是不切实际的。
动态路径
动态路径其实是指网站路径中带有动态参数的路径。它与静态路径正好相反。静态路径会生成大量静态文件,而动态路径不会。当你的网站路径是动态的,那么当用户访问一个页面时,服务器会收到浏览器的请求,然后根据当前时间、环境参数、数据库操作等动态生成一个HTML页面,发送到浏览器,用户可以访问。因为访问动态路径的网站,动态网页会调用数据库中的数据,所以这也是动态路径网页加载速度比较慢的原因。但是,还是有一些行业专家可以对数据库进行几乎零调用,并且网页的加载速度极快。这个操作非常非常6,但是相对来说,服务成本会比较高。动态路径的另一个缺点是不利于搜索引擎蜘蛛的爬取。即使路径中的动态参数过多,也可能导致搜索引擎蜘蛛无法识别的情况。至于网站的安全性,因为动态网页需要调用数据库中的数据,所以对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。动态路径的另一个缺点是不利于搜索引擎蜘蛛的爬取。即使路径中的动态参数过多,也可能导致搜索引擎蜘蛛无法识别的情况。至于网站的安全性,因为动态网页需要调用数据库中的数据,所以对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。动态路径的另一个缺点是不利于搜索引擎蜘蛛的爬取。即使路径中的动态参数过多,也可能导致搜索引擎蜘蛛无法识别的情况。至于网站的安全性,因为动态网页需要调用数据库中的数据,所以对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。
伪静态
前面我们提到静态路径便于搜索引擎蜘蛛识别和爬取,而动态路径不利于搜索引擎蜘蛛识别和爬取。那么有没有办法两全其美呢?是的,伪静态。其实伪静态并不是真正意义上的静态路径,而是一种通过重写URL来去除动态网页中的参数的方法,从而达到其他更有利于搜索引擎抓取的效果。它同时具有动态路径和静态路径的一些优点,这也是为什么大部分wordpress网站会选择首选路径,这样网站的路径就可以达到静态形式而不生成很多静态文件。
一般像我们看到的论坛 网站 ,如果他们的路径是动态的或者伪静态的,所以这就是为什么使用 织梦 的程序通常不用来建论坛网站 ,因为静态的太多了生成文件,维护起来比较麻烦。小网站推荐使用带静态路径的网站程序。大的 网站 是不够的。以上是阿南对路径格式的理解。如果您有任何问题,请留言。 查看全部
动态网页抓取(
网站到底是动态路径好还是伪静态好?(图))
所谓路径其实是指“URL”,通常我们称之为“链接”,所以我想知道网站是动态路径还是伪静态路径?首先,我们需要知道什么是动态的,什么是静态的,什么是伪静态的。其实这三个只是网站链接的形式。对于这三种链接形式,90%以上的SEO站长都会优先考虑静态的,因为这样更有利于搜索引擎蜘蛛的抓取和识别,那么阿南就给大家介绍一下这三种链接。
静态路径
在网站中,每个静态路径在空间服务器中都会有一个静态文件,这个文件不会随着不同浏览器的访问而改变。用户在访问时根本不需要调用数据库,这也是静态网页打开速度惊人的原因,同时也减少了服务器对数据响应的负载,使搜索引擎更容易检索。在安全方面,静态页面几乎不受Asp相关漏洞的影响,无需担心SQL注入攻击。但是我们之前提到过,每个路径都有一个静态页面,所以如果网站的内容太大,会产生大量的文件,严重占用网站的空间,如果如果没有自动化工具,维护这些大量的静态文件几乎是不切实际的。
动态路径
动态路径其实是指网站路径中带有动态参数的路径。它与静态路径正好相反。静态路径会生成大量静态文件,而动态路径不会。当你的网站路径是动态的,那么当用户访问一个页面时,服务器会收到浏览器的请求,然后根据当前时间、环境参数、数据库操作等动态生成一个HTML页面,发送到浏览器,用户可以访问。因为访问动态路径的网站,动态网页会调用数据库中的数据,所以这也是动态路径网页加载速度比较慢的原因。但是,还是有一些行业专家可以对数据库进行几乎零调用,并且网页的加载速度极快。这个操作非常非常6,但是相对来说,服务成本会比较高。动态路径的另一个缺点是不利于搜索引擎蜘蛛的爬取。即使路径中的动态参数过多,也可能导致搜索引擎蜘蛛无法识别的情况。至于网站的安全性,因为动态网页需要调用数据库中的数据,所以对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。动态路径的另一个缺点是不利于搜索引擎蜘蛛的爬取。即使路径中的动态参数过多,也可能导致搜索引擎蜘蛛无法识别的情况。至于网站的安全性,因为动态网页需要调用数据库中的数据,所以对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。动态路径的另一个缺点是不利于搜索引擎蜘蛛的爬取。即使路径中的动态参数过多,也可能导致搜索引擎蜘蛛无法识别的情况。至于网站的安全性,因为动态网页需要调用数据库中的数据,所以对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。对数据库的安全性和保密性要求比较高,需要一些专业的技术人员进行维护,以保证网站。安全。
伪静态
前面我们提到静态路径便于搜索引擎蜘蛛识别和爬取,而动态路径不利于搜索引擎蜘蛛识别和爬取。那么有没有办法两全其美呢?是的,伪静态。其实伪静态并不是真正意义上的静态路径,而是一种通过重写URL来去除动态网页中的参数的方法,从而达到其他更有利于搜索引擎抓取的效果。它同时具有动态路径和静态路径的一些优点,这也是为什么大部分wordpress网站会选择首选路径,这样网站的路径就可以达到静态形式而不生成很多静态文件。
一般像我们看到的论坛 网站 ,如果他们的路径是动态的或者伪静态的,所以这就是为什么使用 织梦 的程序通常不用来建论坛网站 ,因为静态的太多了生成文件,维护起来比较麻烦。小网站推荐使用带静态路径的网站程序。大的 网站 是不够的。以上是阿南对路径格式的理解。如果您有任何问题,请留言。
动态网页抓取(浙江很多刚做seo的人,不知道网站的页面有静态和动态之分,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-25 13:21
很多刚做seo的浙江人不知道网站的页面分静态和动态。与动态网页相比,静态网页是指没有后台数据库、不收录程序、不具有交互性的网页。你就是它所显示的,什么都不会改变。
静态网页更新比较麻烦,适合一般更新较少的显示类型网站。另外,如果扩展名是.jsp但没有数据库连接,那是一个完全静态的页面,也是静态的网站。
只是 .jsp 扩展名。静态和动态都可以做seo,不会有太大影响。只要网站可以打开,路径不变,不出现404就可以了。了解更多。
一.网站静态好还是动态好?
静态网页的特点
1)。静态网页的每个网页都有一个固定的网址,网页网址以.htm、.html、.shtml等常用方法后缀,不收录“?”;
2)。一旦网页内容发布到网站服务器上,每个静态网页的内容都会保存在网站服务器上,不管是否有用户访问,即静态网页它是实际保存在服务器上的一个文件,每个网页都是一个独立的文件;
3)。静态网页内容比较稳定,容易被搜索引擎检索;
4)。静态网页没有数据库支持,网站制作和维护的工作量比较大,所以当网站有大量的静态网页制作方式时,很难完全依赖静态网页制作方式。信息;
5)。静态网页的交互性较低,并且对功能的限制更大。
动态网页的特点
1)。动态网页基于数据库技术,可以大大减少网站保护的工作量;网站 使用动态网页技术可以实现更多功能,如用户注册、用户登录、在线查询、用户处理、订单处理等;
2).动态网页实际上并不是一个独立存在于服务器上的网页文件,只有当用户请求服务器返回一个完整的网页时;
3)。这 ”?” 在动态网页中对于搜索引擎检索有一定的问题。一般搜索引擎无法从网站的数据库中访问所有网页,或者出于技术考虑,搜索蜘蛛不会抓取“?”后面的内容。在网址中,
因此,选择动态网页的网站在实现搜索引擎时需要进行一定的技巧处理,以适应搜索引擎的要求。
二.两者的区别
静态网页和动态网页各有特点。网站选择动态网页还是静态网页,主要看网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页的方法会比较简单,否则就应该使用动态网页技术来完成。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了网站适应搜索引擎检索的需要,即使使用动态网站技能,将网页内容转换为静态网页发布。
动态网站也可以利用动静结合的原则,适合动态网页使用动态网页。如果需要使用静态网页,可以考虑使用静态网页。动态网页内容与静态网页内容共存也很常见。
动态url的优缺点:
使用动态 url 有缺点也有优点。最大的优点之一是 网站 的内容可以实时更新。后台更新文章很方便。我们判断url为动态的标志是url内部收录动态参数如?、=、&等参数。
另一种判断方式是网页以jsp、PHP等为后缀的网页结束。伪静态和静态网页的后缀都是html。
动态url有很多缺陷。比如大型网站流量很大的时候,使用动态url会给服务器带来很大的压力。另外,动态urls无法从url中看到网站的目录状态。,无法从url判断当时的目录状态。再者,不利于用户对url的回忆。
伪静态的优缺点:
伪静态的优点是可以继承动态url的优点。后台发布文章时,也会实时更新内容。而且从用户的角度来看,伪静态url和静态url没有什么区别。当然,缺陷也是众所周知的。它还会在服务器上产生压力负载。
对某些人来说,伪静态可能对搜索引擎爬行有益。事实上,这是完全错误的。对于搜索引擎来说,伪静态url和动态url在爬取时仍然是动态的。这个怎么判断??如果你的网站是伪静态类型,可以用百度抢诊断工具来抢。
可以清楚的看到百度蜘蛛还在抓取动态网址。
伪静态中,百度蜘蛛抓取的其实是动态URL
静态网页的优缺点:
静态网页的优点是响应速度快,可以直接加载到客户端的浏览器中,无需服务器编译,而且无论你如何访问,服务器只是将数据传输给请求者,并且不进行脚本计算和读取。后台数据库。访问速度快,可以跨平台、跨服务器。
这大大提高了访问速度,降低了一些安全隐患,让搜索引擎可以轻松简单地访问页面内容。
当然,它的缺点也很明显,就是占用空间。每次生成一个静态网页,都会存储在你的网页空间中,这对于大型网站来说是非常不利的!另外,后台更新文章也很麻烦。每次发布 文章 时,都必须手动生成它。如果要生成数百万页,那将是浪费时间!
三.哪个网址更适合网站优化?
从优化的角度来看,当然纯静态的url最有利于网站的优化,不过要看网站的大小。如果是中小型企业网站,一般都会更新文章,如果量不大,完全可以使用静态url。
对于动态 url,搜索引擎不会区别对待它们。这也是李百度在回答网友提问时提到的。他主要强调动态url不要放太多动态参数。对于搜索引擎爬取,毫无疑问!
综合以上总结,是动态网站好还是静态网站好?主要看网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页会更简单,反之,一般使用动态网页技术来实现。
不过现在一般使用动态的网站。如果有内容更新,可以随时在后台更新,方便后期维护和管理,但最好使用静态页面或伪静态进行优化。
温州小编认为,无论是动态还是静态,都可以稳定打开,不会对用户阅读产生404等影响,有利于seo优化! 查看全部
动态网页抓取(浙江很多刚做seo的人,不知道网站的页面有静态和动态之分,)
很多刚做seo的浙江人不知道网站的页面分静态和动态。与动态网页相比,静态网页是指没有后台数据库、不收录程序、不具有交互性的网页。你就是它所显示的,什么都不会改变。
静态网页更新比较麻烦,适合一般更新较少的显示类型网站。另外,如果扩展名是.jsp但没有数据库连接,那是一个完全静态的页面,也是静态的网站。
只是 .jsp 扩展名。静态和动态都可以做seo,不会有太大影响。只要网站可以打开,路径不变,不出现404就可以了。了解更多。
一.网站静态好还是动态好?
静态网页的特点
1)。静态网页的每个网页都有一个固定的网址,网页网址以.htm、.html、.shtml等常用方法后缀,不收录“?”;
2)。一旦网页内容发布到网站服务器上,每个静态网页的内容都会保存在网站服务器上,不管是否有用户访问,即静态网页它是实际保存在服务器上的一个文件,每个网页都是一个独立的文件;
3)。静态网页内容比较稳定,容易被搜索引擎检索;
4)。静态网页没有数据库支持,网站制作和维护的工作量比较大,所以当网站有大量的静态网页制作方式时,很难完全依赖静态网页制作方式。信息;
5)。静态网页的交互性较低,并且对功能的限制更大。
动态网页的特点
1)。动态网页基于数据库技术,可以大大减少网站保护的工作量;网站 使用动态网页技术可以实现更多功能,如用户注册、用户登录、在线查询、用户处理、订单处理等;
2).动态网页实际上并不是一个独立存在于服务器上的网页文件,只有当用户请求服务器返回一个完整的网页时;
3)。这 ”?” 在动态网页中对于搜索引擎检索有一定的问题。一般搜索引擎无法从网站的数据库中访问所有网页,或者出于技术考虑,搜索蜘蛛不会抓取“?”后面的内容。在网址中,
因此,选择动态网页的网站在实现搜索引擎时需要进行一定的技巧处理,以适应搜索引擎的要求。
二.两者的区别
静态网页和动态网页各有特点。网站选择动态网页还是静态网页,主要看网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页的方法会比较简单,否则就应该使用动态网页技术来完成。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了网站适应搜索引擎检索的需要,即使使用动态网站技能,将网页内容转换为静态网页发布。
动态网站也可以利用动静结合的原则,适合动态网页使用动态网页。如果需要使用静态网页,可以考虑使用静态网页。动态网页内容与静态网页内容共存也很常见。
动态url的优缺点:
使用动态 url 有缺点也有优点。最大的优点之一是 网站 的内容可以实时更新。后台更新文章很方便。我们判断url为动态的标志是url内部收录动态参数如?、=、&等参数。
另一种判断方式是网页以jsp、PHP等为后缀的网页结束。伪静态和静态网页的后缀都是html。
动态url有很多缺陷。比如大型网站流量很大的时候,使用动态url会给服务器带来很大的压力。另外,动态urls无法从url中看到网站的目录状态。,无法从url判断当时的目录状态。再者,不利于用户对url的回忆。
伪静态的优缺点:
伪静态的优点是可以继承动态url的优点。后台发布文章时,也会实时更新内容。而且从用户的角度来看,伪静态url和静态url没有什么区别。当然,缺陷也是众所周知的。它还会在服务器上产生压力负载。
对某些人来说,伪静态可能对搜索引擎爬行有益。事实上,这是完全错误的。对于搜索引擎来说,伪静态url和动态url在爬取时仍然是动态的。这个怎么判断??如果你的网站是伪静态类型,可以用百度抢诊断工具来抢。
可以清楚的看到百度蜘蛛还在抓取动态网址。
伪静态中,百度蜘蛛抓取的其实是动态URL
静态网页的优缺点:
静态网页的优点是响应速度快,可以直接加载到客户端的浏览器中,无需服务器编译,而且无论你如何访问,服务器只是将数据传输给请求者,并且不进行脚本计算和读取。后台数据库。访问速度快,可以跨平台、跨服务器。
这大大提高了访问速度,降低了一些安全隐患,让搜索引擎可以轻松简单地访问页面内容。
当然,它的缺点也很明显,就是占用空间。每次生成一个静态网页,都会存储在你的网页空间中,这对于大型网站来说是非常不利的!另外,后台更新文章也很麻烦。每次发布 文章 时,都必须手动生成它。如果要生成数百万页,那将是浪费时间!
三.哪个网址更适合网站优化?
从优化的角度来看,当然纯静态的url最有利于网站的优化,不过要看网站的大小。如果是中小型企业网站,一般都会更新文章,如果量不大,完全可以使用静态url。
对于动态 url,搜索引擎不会区别对待它们。这也是李百度在回答网友提问时提到的。他主要强调动态url不要放太多动态参数。对于搜索引擎爬取,毫无疑问!
综合以上总结,是动态网站好还是静态网站好?主要看网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页会更简单,反之,一般使用动态网页技术来实现。
不过现在一般使用动态的网站。如果有内容更新,可以随时在后台更新,方便后期维护和管理,但最好使用静态页面或伪静态进行优化。
温州小编认为,无论是动态还是静态,都可以稳定打开,不会对用户阅读产生404等影响,有利于seo优化!
动态网页抓取(如下京东商城网站源代码:对应的网页源码如下(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 356 次浏览 • 2022-02-25 13:19
这里简单介绍一下京东商城网站的源码,以抓取网站静态和动态数据为例,实验环境win10+python3.6+pycharm< @5.0,主要内容如下:
抓取网站静态数据(数据在网页源码中)京东商城网站源码:以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数和评论数四个字段。京东商城网站源码如下:
对应的网页源码如下,包括我们需要的数据京东商城网站源码:
2.对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面京东商城网站 源代码:
程序运行截图如下,爬取数据成功:
抓取网站动态数据(网页源码、json等文件中没有数据):以人人贷网站数据为例
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额和进度五个字段。截图如下:
打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难,都是入门级爬虫,网页结构也比较简单。最重要的是进行抓包分析,分析提取页面,等你熟悉了之后,可以使用scrapy框架进行数据爬取,可以更加方便高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
PHP开发的商城网站源码好用吗?
近日了解到,随着电子商务行业的快速发展,网上商城系统成本低、速度快等优势为众多企业带来了商机,营销功能丰富、商品体系完善、用户良好经验。那么开源的php mall系统主要有哪些特点呢?
1、PHP开源商城系统更方便
PHP程序开发快,运行快,技术本身也能很快学会。嵌入 HTML:因为 PHP 可以嵌入 HTML 语言,所以它与其他语言相关。编辑简单实用,再满足企业发展需要的功能,或增加企业新需求;
2、php开源商城系统适应性强
通过选择开源商城系统,企业可以根据自己的意愿访问源代码并修改开源商城系统,以降低此类风险,因为开源社区中会有源源不断的维护和更新。因此受到各行各业中小企业的欢迎和广泛使用,使得开源商城软件的适应性更强;
3.强大的跨平台php开源商城系统
由于 PHP 是服务器端脚本,它可以在 UNIX、LINUX、WINDOWS、iOS 和 Android 等平台上运行;
4.php开源商城系统更高效
效率是每个用户在选择商城系统时都会考虑的问题。PHP商城系统消耗的系统资源相对较少。
5、PHP开源商城系统更安全
安全是每个用户在选择电商系统时首先会考虑的问题,因为开源商城系统的源代码是开放的,没有得到很好的保护,用户会认为开源商城系统的安全性不可靠。然而,随着电子商务系统开发技术的成熟,开源商城系统的研究也取得了长足的进步。有专人解决电商系统的BUG等问题。因此,开源商城系统的安全性能不断提升。 查看全部
动态网页抓取(如下京东商城网站源代码:对应的网页源码如下(组图))
这里简单介绍一下京东商城网站的源码,以抓取网站静态和动态数据为例,实验环境win10+python3.6+pycharm< @5.0,主要内容如下:
抓取网站静态数据(数据在网页源码中)京东商城网站源码:以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数和评论数四个字段。京东商城网站源码如下:
对应的网页源码如下,包括我们需要的数据京东商城网站源码:
2.对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面京东商城网站 源代码:
程序运行截图如下,爬取数据成功:
抓取网站动态数据(网页源码、json等文件中没有数据):以人人贷网站数据为例
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额和进度五个字段。截图如下:
打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难,都是入门级爬虫,网页结构也比较简单。最重要的是进行抓包分析,分析提取页面,等你熟悉了之后,可以使用scrapy框架进行数据爬取,可以更加方便高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
PHP开发的商城网站源码好用吗?
近日了解到,随着电子商务行业的快速发展,网上商城系统成本低、速度快等优势为众多企业带来了商机,营销功能丰富、商品体系完善、用户良好经验。那么开源的php mall系统主要有哪些特点呢?
1、PHP开源商城系统更方便
PHP程序开发快,运行快,技术本身也能很快学会。嵌入 HTML:因为 PHP 可以嵌入 HTML 语言,所以它与其他语言相关。编辑简单实用,再满足企业发展需要的功能,或增加企业新需求;
2、php开源商城系统适应性强
通过选择开源商城系统,企业可以根据自己的意愿访问源代码并修改开源商城系统,以降低此类风险,因为开源社区中会有源源不断的维护和更新。因此受到各行各业中小企业的欢迎和广泛使用,使得开源商城软件的适应性更强;
3.强大的跨平台php开源商城系统
由于 PHP 是服务器端脚本,它可以在 UNIX、LINUX、WINDOWS、iOS 和 Android 等平台上运行;
4.php开源商城系统更高效
效率是每个用户在选择商城系统时都会考虑的问题。PHP商城系统消耗的系统资源相对较少。
5、PHP开源商城系统更安全
安全是每个用户在选择电商系统时首先会考虑的问题,因为开源商城系统的源代码是开放的,没有得到很好的保护,用户会认为开源商城系统的安全性不可靠。然而,随着电子商务系统开发技术的成熟,开源商城系统的研究也取得了长足的进步。有专人解决电商系统的BUG等问题。因此,开源商城系统的安全性能不断提升。
动态网页抓取(Selenium驱动GeckoDriver安装方法(组图)实践案例(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-25 12:24
上面得到的结果令人困惑。要从这些json数据中提取出我们想要的数据,我们需要使用json库来解析数据。
# coding: UTF-8
import requests
from bs4 import BeautifulSoup
import json
url = "https://www.zhihu.com/api/v4/a ... %255B*%5D.author%2Ccollapsed%2Creply_to_author%2Cdisliked%2Ccontent%2Cvoting%2Cvote_count%2Cis_parent_author%2Cis_author%2Calgorithm_right&order=normal&limit=20&offset=0&status=open"
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
r = requests.get(url, headers = headers)
json_data = json.loads(r.text)
comments_list = json_data['data']
for eachone in comments_list:
message = eachone['content']
print message
以上代码只能爬取单个页面,要想爬取更多的内容需要了解URL的规律
首页的真实网址:%5B*%5D.author%2Ccollapsed%2Creply_to_author%2Cdisliked%2Ccontent%2Cvoting%2Cvote_count%2Cis_parent_author%2Cis_author%2Calgorithm_right&order=normal&limit=20&offset=0&status=open
第二页的真实网址:%5B*%5D.author%2Ccollapsed%2Creply_to_author%2Cdisliked%2Ccontent%2Cvoting%2Cvote_count%2Cis_parent_author%2Cis_author%2Calgorithm_right&order=normal&limit=20&offset=20&status=open
对比上面两个网址,我们会发现两个特别重要的变量,offset和limit
# coding : utf-8
import requests
import json
def single_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
r = requests.get(url, headers = headers)
json_data = json.loads(r.text)
comments_list = json_data['data']
for eachone in comments_list:
message = eachone['content']
print(message)
for page in (0,2):
link1 = "https://www.zhihu.com/api/v4/a ... %255B*%5D.author%2Ccollapsed%2Creply_to_author%2Cdisliked%2Ccontent%2Cvoting%2Cvote_count%2Cis_parent_author%2Cis_author%2Calgorithm_right&order=normal&limit=20&offset="
link2 = "&status=open"
page_str = str(page * 20)
link = link1 + page_str + link2
single_page(link)
3.Selenium 模拟浏览器捕获
对于一些复杂的网站,上述方法将不再适用。另外,有些数据的真实地址的URL很长很复杂,有的网站为了避免这些会加密地址,使得一些变量难以破解。
因此,我们将使用 selenium 浏览器渲染引擎,直接用浏览器显示网页,解析 HTML、JS 和 CSS
(1)Selenium安装及基本介绍
参考博文:火狐浏览器驱动GeckoDriver安装方法
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
import sys
#reload(sys)
#sys.setdefaultencoding("utf-8")
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
# windows版,需要安装 greckodriver
binary = FirefoxBinary(r'D:\Program Files (x86)\Mozilla Firefox\firefox.exe')
driver = webdriver.Firefox(firefox_binary = binary, capabilities = caps)
driver.get("https://www.baidu.com")
以下操作以Chrome浏览器为例;
# coding:utf-8
from selenium import webdriver
#windows版
driver = webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
driver.get("https://www.baidu.com")
(2)硒实践案例
现在我们使用浏览器渲染来抓取之前的评论数据
先在“Inspect”页面找到HTML代码标签,尝试获取第一条评论
代码如下:
# coding:utf-8
from selenium import webdriver
driver = webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
driver.get("https://www.zhihu.com/question/22913650")
comment = driver.find_element_by_css_selector('')
print(comment.text)
(3)Selenium 获取文章的所有评论
要获取所有评论,脚本需要能够自动点击“加载更多”、“所有评论”、“下一页”等。
代码如下:
# coding: utf-8
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
import time
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
binary = FirefoxBinary(r'D:\Program Files\Mozilla Firefox\firefox.exe')
#把上述地址改成你电脑中Firefox程序的地址
driver = webdriver.Firefox(firefox_binary=binary, capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments = driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content = eachcomment.find_element_by_tag_name('p')
print (content.text)
Selenium 选择元素的方法:
# text
find_element_by_css_selector('div.body_inner')
#
find_element_by_xpath("//form[@id='loginForm']"
# text
find_element_by_id
# text
find_element_by_name('myname')
# text
find_element_by_link_text('text')
# text
find_element_by_partial_link_text('te')
# text
find_element_by_tag_name('div')
# text
find_element_by_class_name('body_inner')
要查找多个元素,可以在上面的'element'后面加s成为元素。前两个比较常用
(4)Selenium的高级操作
为了加快selenium的爬取速度,常通过以下方法实现:
(1)控制 CSS 加载
fp = webdriver.FirefoxProfile()
fp.set_preference("permissions.default.stylesheet",2)
(2)控制图片的显示
fp = webdriver.FirefoxProfile()
fp.set_preference("permissions.default.image",2)
(3)控制 JavaScript 的执行
fp = webdriver.FirefoxProfile()
fp.set_preference("javascript.enabled", False)
对于 Chrome 浏览器:
options=webdriver.ChromeOptions()
prefs={
'profile.default_content_setting_values': {
'images': 2,
'javascript':2
}
}
options.add_experimental_option('prefs',prefs)
browser = webdriver.Chrome(chrome_options=options)
4.Selenium爬虫实战:深圳短租数据
(1)网站分析
(2)项目实战 查看全部
动态网页抓取(Selenium驱动GeckoDriver安装方法(组图)实践案例(图))
上面得到的结果令人困惑。要从这些json数据中提取出我们想要的数据,我们需要使用json库来解析数据。
# coding: UTF-8
import requests
from bs4 import BeautifulSoup
import json
url = "https://www.zhihu.com/api/v4/a ... %255B*%5D.author%2Ccollapsed%2Creply_to_author%2Cdisliked%2Ccontent%2Cvoting%2Cvote_count%2Cis_parent_author%2Cis_author%2Calgorithm_right&order=normal&limit=20&offset=0&status=open"
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
r = requests.get(url, headers = headers)
json_data = json.loads(r.text)
comments_list = json_data['data']
for eachone in comments_list:
message = eachone['content']
print message
以上代码只能爬取单个页面,要想爬取更多的内容需要了解URL的规律
首页的真实网址:%5B*%5D.author%2Ccollapsed%2Creply_to_author%2Cdisliked%2Ccontent%2Cvoting%2Cvote_count%2Cis_parent_author%2Cis_author%2Calgorithm_right&order=normal&limit=20&offset=0&status=open
第二页的真实网址:%5B*%5D.author%2Ccollapsed%2Creply_to_author%2Cdisliked%2Ccontent%2Cvoting%2Cvote_count%2Cis_parent_author%2Cis_author%2Calgorithm_right&order=normal&limit=20&offset=20&status=open
对比上面两个网址,我们会发现两个特别重要的变量,offset和limit
# coding : utf-8
import requests
import json
def single_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
r = requests.get(url, headers = headers)
json_data = json.loads(r.text)
comments_list = json_data['data']
for eachone in comments_list:
message = eachone['content']
print(message)
for page in (0,2):
link1 = "https://www.zhihu.com/api/v4/a ... %255B*%5D.author%2Ccollapsed%2Creply_to_author%2Cdisliked%2Ccontent%2Cvoting%2Cvote_count%2Cis_parent_author%2Cis_author%2Calgorithm_right&order=normal&limit=20&offset="
link2 = "&status=open"
page_str = str(page * 20)
link = link1 + page_str + link2
single_page(link)
3.Selenium 模拟浏览器捕获
对于一些复杂的网站,上述方法将不再适用。另外,有些数据的真实地址的URL很长很复杂,有的网站为了避免这些会加密地址,使得一些变量难以破解。
因此,我们将使用 selenium 浏览器渲染引擎,直接用浏览器显示网页,解析 HTML、JS 和 CSS
(1)Selenium安装及基本介绍
参考博文:火狐浏览器驱动GeckoDriver安装方法
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
import sys
#reload(sys)
#sys.setdefaultencoding("utf-8")
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
# windows版,需要安装 greckodriver
binary = FirefoxBinary(r'D:\Program Files (x86)\Mozilla Firefox\firefox.exe')
driver = webdriver.Firefox(firefox_binary = binary, capabilities = caps)
driver.get("https://www.baidu.com";)
以下操作以Chrome浏览器为例;
# coding:utf-8
from selenium import webdriver
#windows版
driver = webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
driver.get("https://www.baidu.com";)
(2)硒实践案例
现在我们使用浏览器渲染来抓取之前的评论数据
先在“Inspect”页面找到HTML代码标签,尝试获取第一条评论
代码如下:
# coding:utf-8
from selenium import webdriver
driver = webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
driver.get("https://www.zhihu.com/question/22913650";)
comment = driver.find_element_by_css_selector('')
print(comment.text)
(3)Selenium 获取文章的所有评论
要获取所有评论,脚本需要能够自动点击“加载更多”、“所有评论”、“下一页”等。
代码如下:
# coding: utf-8
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
import time
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
binary = FirefoxBinary(r'D:\Program Files\Mozilla Firefox\firefox.exe')
#把上述地址改成你电脑中Firefox程序的地址
driver = webdriver.Firefox(firefox_binary=binary, capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments = driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content = eachcomment.find_element_by_tag_name('p')
print (content.text)
Selenium 选择元素的方法:
# text
find_element_by_css_selector('div.body_inner')
#
find_element_by_xpath("//form[@id='loginForm']"
# text
find_element_by_id
# text
find_element_by_name('myname')
# text
find_element_by_link_text('text')
# text
find_element_by_partial_link_text('te')
# text
find_element_by_tag_name('div')
# text
find_element_by_class_name('body_inner')
要查找多个元素,可以在上面的'element'后面加s成为元素。前两个比较常用
(4)Selenium的高级操作
为了加快selenium的爬取速度,常通过以下方法实现:
(1)控制 CSS 加载
fp = webdriver.FirefoxProfile()
fp.set_preference("permissions.default.stylesheet",2)
(2)控制图片的显示
fp = webdriver.FirefoxProfile()
fp.set_preference("permissions.default.image",2)
(3)控制 JavaScript 的执行
fp = webdriver.FirefoxProfile()
fp.set_preference("javascript.enabled", False)
对于 Chrome 浏览器:
options=webdriver.ChromeOptions()
prefs={
'profile.default_content_setting_values': {
'images': 2,
'javascript':2
}
}
options.add_experimental_option('prefs',prefs)
browser = webdriver.Chrome(chrome_options=options)
4.Selenium爬虫实战:深圳短租数据
(1)网站分析
(2)项目实战
动态网页抓取(如何利用动态片段吸引精准流量呢?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-25 12:06
我们知道,提高拍卖中的点击率一直是我们的优化目标。为了提高点击率,我们用了很多方法,比如我们经常做的优化思路。当然,最直接的一种就是提高出价来提高点击率。当然,如果你只是一味的加价,并没有优化的意义,而百度还有更多的工具可以让你提高点击率,比如西京子链、品牌推广位等。灯塔要讲另一种推广方式:动态片段。启用动态剪辑后,如果使用它们,可以大大提高点击率。我们来看看什么是动态剪辑。
在详细说动态片段之前,我们先来了解一下动态片段的样式是什么样的?
位置方面,动态剪辑类似于路径子链的位置,都显示在广告素材下,不同的是路径的广告字数限制太小,而要表达的信息不能很好地解释。但是动态剪辑没有明确的字数限制,可以更好地诠释要表达的信息。
那么我们如何使用动态片段来吸引精准流量呢?
在设置动态片段时,我们有两种设置方法:
一、系统可以自动抓取描述和链接
这种方法百度凤凰巢系统会自动抓取描述和链接,这种方法没有针对性,一般不推荐。
二、自己手动添加(强烈推荐)
虽然系统爬取的相关性也不错,但有些描述还是不够理想,还有爬取的链接,没有推广标识,不能用来识别推广的效果。影响。
如何添加精准吸引力的动态描述?
1、对焦点选择:根据单位的分类,选择合适的对焦点;一般来说,一个广告素材只能有4个焦点,适当的选择可以更好地提高相关性。
2、动态描述:这也是本文的重点部分文章;要想精准吸引人,首先要了解用户的需求,然后才能写出正确的动态描述,满足有针对性的用户需求。
以上是对动态片段的一些使用优化的介绍。最后提出增加动态片段的样式展示,可以在单元层面的创意上进行展示,让招标维护人员可以根据样式的效果更好的修改和调整动态片段的描述,更有效地提升点击效果。. 查看全部
动态网页抓取(如何利用动态片段吸引精准流量呢?-八维教育)
我们知道,提高拍卖中的点击率一直是我们的优化目标。为了提高点击率,我们用了很多方法,比如我们经常做的优化思路。当然,最直接的一种就是提高出价来提高点击率。当然,如果你只是一味的加价,并没有优化的意义,而百度还有更多的工具可以让你提高点击率,比如西京子链、品牌推广位等。灯塔要讲另一种推广方式:动态片段。启用动态剪辑后,如果使用它们,可以大大提高点击率。我们来看看什么是动态剪辑。
在详细说动态片段之前,我们先来了解一下动态片段的样式是什么样的?
位置方面,动态剪辑类似于路径子链的位置,都显示在广告素材下,不同的是路径的广告字数限制太小,而要表达的信息不能很好地解释。但是动态剪辑没有明确的字数限制,可以更好地诠释要表达的信息。
那么我们如何使用动态片段来吸引精准流量呢?
在设置动态片段时,我们有两种设置方法:
一、系统可以自动抓取描述和链接
这种方法百度凤凰巢系统会自动抓取描述和链接,这种方法没有针对性,一般不推荐。
二、自己手动添加(强烈推荐)
虽然系统爬取的相关性也不错,但有些描述还是不够理想,还有爬取的链接,没有推广标识,不能用来识别推广的效果。影响。
如何添加精准吸引力的动态描述?
1、对焦点选择:根据单位的分类,选择合适的对焦点;一般来说,一个广告素材只能有4个焦点,适当的选择可以更好地提高相关性。
2、动态描述:这也是本文的重点部分文章;要想精准吸引人,首先要了解用户的需求,然后才能写出正确的动态描述,满足有针对性的用户需求。
以上是对动态片段的一些使用优化的介绍。最后提出增加动态片段的样式展示,可以在单元层面的创意上进行展示,让招标维护人员可以根据样式的效果更好的修改和调整动态片段的描述,更有效地提升点击效果。.
动态网页抓取(企业想做好网站SEO优化就要了解查找引擎的抓取规矩 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-02-21 20:08
)
企业要想做好网站SEO优化,就要了解搜索引擎的爬取规律,做好百度动态页面SEO。我们都知道,搜索引擎爬取动态页面是非常困难的。是的,我们来谈谈如何为SEO优化动态页面:
一、创建静态导入
在“动静结合,静制动”的原则指导下,我们可以对网站进行一些修正,尽可能增加动态网页的搜索引擎可见度。SEO优化方法是将动态网页编译成静态主页或网站图的链接,动态页面会以静态目录的形式出现。也许为动态页面创建一个专用的静态导入页面,链接到动态页面,并将静态导入页面提交给搜索引擎。
二、付费登录搜索引擎
关于整个网站使用连接数据库的内容管理系统发布的动态网站,优化SEO最直接的方式是付费登录,建议直接提交动态网页页面到搜索引擎目录或做关键字广告,确保 网站 是由搜索引擎输入的。
三、搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些搜索引擎在抓取动态页面时,为了防止搜索机器人被困,搜索引擎只抓取过去从静态页面链接的动态页面,从动态页面链接出去。所有的动态页面都不再被爬取,也就是说,动态页面中的链接将不再被访问。
相信大家对超人科技小编为我们整理的SEO优化动态页面的内容已经有了一定的了解。其实小编给我们整理的还不是很全面,SEO优化的内容也比较多。我们可以在本站阅读其他的SEO优化技术和经验,相信一定能取得很好的效果。
查看全部
动态网页抓取(企业想做好网站SEO优化就要了解查找引擎的抓取规矩
)
企业要想做好网站SEO优化,就要了解搜索引擎的爬取规律,做好百度动态页面SEO。我们都知道,搜索引擎爬取动态页面是非常困难的。是的,我们来谈谈如何为SEO优化动态页面:
一、创建静态导入
在“动静结合,静制动”的原则指导下,我们可以对网站进行一些修正,尽可能增加动态网页的搜索引擎可见度。SEO优化方法是将动态网页编译成静态主页或网站图的链接,动态页面会以静态目录的形式出现。也许为动态页面创建一个专用的静态导入页面,链接到动态页面,并将静态导入页面提交给搜索引擎。
二、付费登录搜索引擎
关于整个网站使用连接数据库的内容管理系统发布的动态网站,优化SEO最直接的方式是付费登录,建议直接提交动态网页页面到搜索引擎目录或做关键字广告,确保 网站 是由搜索引擎输入的。
三、搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些搜索引擎在抓取动态页面时,为了防止搜索机器人被困,搜索引擎只抓取过去从静态页面链接的动态页面,从动态页面链接出去。所有的动态页面都不再被爬取,也就是说,动态页面中的链接将不再被访问。
相信大家对超人科技小编为我们整理的SEO优化动态页面的内容已经有了一定的了解。其实小编给我们整理的还不是很全面,SEO优化的内容也比较多。我们可以在本站阅读其他的SEO优化技术和经验,相信一定能取得很好的效果。
动态网页抓取((43页珍藏版)搜索引擎基本原理及实现技术搜索引擎的工作原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-02-21 20:03
《搜索引擎基本原理与实现技术.ppt》为会员共享,可在线阅读。更多相关《搜索引擎基本原理与实现技术.ppt(43页珍藏版)》,请在usdt平台_usdt官网搜索。
1、搜索引擎基本原理及实现技术搜索引擎工作原理通用搜索引擎框架示意图通用网络爬虫爬虫技术概述网络爬虫是自动提取网页进行搜索的程序来自 Internet 的引擎 下载网页是搜索引擎的重要组成部分。网络爬虫使用多线程技术使爬虫更加强大。网络爬虫还需要完成信息抽取任务。提取新闻、电子书、行业信息等,针对MP3图片、Flash等。对各类内容进行自动识别、分类和相关属性测试,如MP3文件的文件大小、下载速度等。爬网时
2、继续从当前页面中提取新的URL,放入队列中,直到满足系统的某个停止条件。2 动态网页分析 动态网页参数按照一定的规则拼出所有要爬取的URL,并且只爬取这些特定的范围。动态网页 3 RSS XML 数据等特殊内容需要特殊处理 如新闻滚动新闻页面需要爬虫不断监控扫描发现新内容,立即抓取 4 文件对象图片 MP3 Flash 视频等文件需要特殊抓取例如,图像捕获后,需要知道图像文件类型的大小,图像文件的大小,图像的像素大小,图像的像素大小需要进行转换。
3、抓取会定期更新捕获的网页。垂直爬虫只关注特定主题或属于特定行业的网页。难点在于如何识别网页是否属于指定的类别。优秀爬虫的特点 高性能URL队列的存储方式会影响性能 可扩展性 多服务器 多线程爬取 不同地域 部署数据中心 将爬虫分散到不同的数据中心 禁止爬虫的几种情况 User agent GoogleBotDisallow tmp Disallow cgi bin Disallow users paranoid Robot txt 禁止索引网页内容 禁止抓取网页链接 Content 标签对应的具体含义 爬虫质量的评价标准
4、1 覆盖范围 2 爬取网页的新颖性 3 爬取网页的重要性 大型商业搜索引擎一般至少收录两套不同用途的爬虫系统。针对更新频率较低的网页的网页抓取策略 1 广度优先遍历策略 2 深度优先遍历策略 3 不完整的页面排名策略 4 OPIC 策略 OnlinePageImportanceComputation 5 大站点优先策略 广度优先策略 将新下载页面中的链接直接插入等待中URL队列的末尾,表示网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页继续爬取该网页链接的所有网页。爬行顺序 1 2
5、 3 4 5 6 7 8 9 深度优先策略从起始页开始,一个链接,一个链接,然后向下。处理完这一行,进入下一个起始页面,继续按照链接爬取顺序 1 2 5 6 3 7 4 8 9 PageRank简介 1 初始阶段,网页通过链接关系构建Web图。每个页面设置相同的 PageRank 值。经过几轮计算,将得到每个页面最终得到的PageRank值。随着每一轮计算,网页当前的PageRank值会不断更新。2 一轮更新页面PageRank得分的计算方法在一轮更新页面的PageRank得分计算中,每个页面都会将其当前的 PageRank 值平均分配给该页面中收录的传出链接。转到每个链接,以便您可以获取
6、对应的权重和每个页面将所有指向该页面的传入链接中传递的权重相加得到一个新的PageRank分数。当每个页面得到更新后的PageRank值时,就完成了一轮PageRank计算。不完整的PageRank策略 将下载的网页和URL队列中的URL一起爬取,形成一组网页。该集合中pagerank计算完成后,根据PageRank计算URL队列中待爬取的网页。分数从高到低排列形成的序列就是爬虫接下来应该爬的URL列表。每当下载K个页面时,重新计算所有下载的页面及其不完整的PageRank值OPIC策略OnlinePageImportanceComputation这个算法
7、其实也是一个页面的重要性分数。在算法开始之前,所有页面都被赋予相同的初始现金现金。当一个页面P被下载时,P的cash被分配给从P分析的所有链接。并清除P的cash。根据cash的数量对URL队列中所有待爬取的页面进行排序。大站点优先策略以 网站 为单位衡量网页的重要性。对于URL队列中所有待爬取的网页,根据其网站的网站对待下载的页面进行分类网站
在8、中,关于不断变化的主题内容的用户体验策略假设用户经常只查看前3页的搜索内容。Principle 保存网页的多个历史版本,并根据过去每次内容变化对搜索质量的影响取平均值。作为判断抓取网页时机的参考依据,对质量影响较严重的网页将优先安排重新抓取聚类抽样策略。前两种更新策略是有前提的,需要网页的历史信息。存在两个问题: 1、每个系统保存多个版本的历史信息,增加了很多系统负担。2 新网页完全没有历史信息,无法确定更新策略。聚类抽样策略 聚类抽样策略考虑到网页有很多属性。同理,计算某一类页面的更新频率,只需按更新周对该类页面进行采样即可。
9、周期是整个类的更新周期。分布式爬虫系统结构 一般来说,爬虫系统需要面对整个互联网上亿万的网页。单个爬虫程序不可能完成这样的任务。往往需要多个爬取程序一起处理。一般来说,爬虫系统往往是分布式的三层结构。底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器上可以部署多套爬虫程序,构成一个基本的分布式爬虫系统。主从基本结构有一个专门的主服务器来维护要爬取的URL队列,它负责每次分发 URL。转到不同的 Slave 服务器,Slave 服务器负责实际的网页下载。主服务器还负责维护要爬取的 URL 队列和分发 URL。
10、负责调整各个从服务器的负载,防止部分从服务器过于空闲或过度工作。在这种模式下,master容易成为系统的瓶颈。对等的工作结构。所有抓取服务器之间的分工没有区别。每一个爬取服务器都可以从待爬取的URL队列中获取该URL,然后计算该URL主域名的哈希值H,进而计算出Hmodm,其中m为服务器数量。比如上图中m为3,计算出来的个数是为了处理URL的主机号的缺点是扩展性差。一致性哈希对 URL 的主域名进行哈希运算,并将其映射到 0 232 范围内的一个数字,并根据 URL 的主域名将该范围平均分配给 m 个服务器。哈希运算的取值范围决定了要爬取的服务器。如果某个服务器有问题,那么
11、 那么应该负责这个服务器的网页会被下一个服务器按顺时针顺序爬取。暗网爬取查询组合题文本框填入题目的网络爬虫实现环节的存储队列的数据结构。待爬取队列已爬取队列无效 链接错误链接 网页抓取 Jsoup jar 官方网站http jsoup org 相关学习资料 getElementById Stringid 获取id为getElementsByTag Stringtag 获取标签为getElementsByClass StringclassName 获取class为getElementsByAttribute的元素Stringkey 使用 Attribute 获取元素 获取元素的数据 attr 方法如下
12、 Stringkey 获取元素数据 attr Stringkey Stringvalue t 设置元素数据属性 获取所有属性 id className classNames 获取 idclass 值 text 获取文本值 text Stringvalue 设置文本值 html 获取 html 字符串值设置 htmlouterHtml 获取内部 html try doc Jsoup connect urlStr userAgent Mozilla 5 0 Windows U WindowsNT5 1 zh CN rv 1 9 2 15 设置用户代理超时
13、t 5000 设置连接超时时间 get catch MalformedURLExceptione log error e return catch IOExceptione if einstanceofSocketTimeoutException log error e return if einstanceofUnknownHostException log error e return log error e return system out println doc title Elementhead doc head Elementsmetas head select meta为了
14、 Elementmeta metas Stringcontent meta attr content Elementbody doc body Elementses body select a for Iteratorit es iterator it hasNext Elemente Element it next href e attr href 链接 提取 机构部门 招生就业 合作交流 提高爬虫效率 多线程爬取优化存储结构根据不同类型的链接制定爬取策略。示例说明 主要步骤 1 输入种子页面的URL,爬取爬取线程的深度。2 根据初始url获取种子页面的内容。注 1。
15、 合法的两种方法 a 判断url是否符合协议规则 b 判断url是否可以打开 while counts 3 try URLurl newURL urlStr HttpURLConnectioncon HttpURLConnection url openConnection intstate con getResponseCode if state 200 retu ok break catch Exceptionex counts continue 2种子 页面要获取的内容收录标题正文文本超链接开源jar包jsoup Documentdoc Jsoup connect sUrl get El
16、ementslinks doc select a href for Elementlink links StringlinkHref link attr href 获取href属性中的值,也就是你的地址 StringlinkTitle budge link text 获取anchor上的文字描述 3 多线程爬取根据爬行深度其实就是把第2步重复很多次。注意判断url是否重复。推荐使用hashset存储 HashSetallurlSet newHashSet 定义 hashsetallurlSet contains url 判断url是否已经存在 allurlSet add url 将url添加到allurlSet 4 存储爬取过程中页面的信息 信息包括网页地址页面、标题、链接数、正文、正文、超链接、锚文本等 5.存储方式 1.文档推荐。易于更改的信息存储在文件中。2.数据库存储在数据库中。网站所有地址均采用深度优先或广度优先的爬取策略。合理高效的存储结构,禁止爬行循环。课后学习PageRank算法的原理和实现方法。Java网络编程不需要jsoup。深入研究自己感兴趣的话题,比如在暗网上爬取分布式爬虫等。 查看全部
动态网页抓取((43页珍藏版)搜索引擎基本原理及实现技术搜索引擎的工作原理)
《搜索引擎基本原理与实现技术.ppt》为会员共享,可在线阅读。更多相关《搜索引擎基本原理与实现技术.ppt(43页珍藏版)》,请在usdt平台_usdt官网搜索。
1、搜索引擎基本原理及实现技术搜索引擎工作原理通用搜索引擎框架示意图通用网络爬虫爬虫技术概述网络爬虫是自动提取网页进行搜索的程序来自 Internet 的引擎 下载网页是搜索引擎的重要组成部分。网络爬虫使用多线程技术使爬虫更加强大。网络爬虫还需要完成信息抽取任务。提取新闻、电子书、行业信息等,针对MP3图片、Flash等。对各类内容进行自动识别、分类和相关属性测试,如MP3文件的文件大小、下载速度等。爬网时
2、继续从当前页面中提取新的URL,放入队列中,直到满足系统的某个停止条件。2 动态网页分析 动态网页参数按照一定的规则拼出所有要爬取的URL,并且只爬取这些特定的范围。动态网页 3 RSS XML 数据等特殊内容需要特殊处理 如新闻滚动新闻页面需要爬虫不断监控扫描发现新内容,立即抓取 4 文件对象图片 MP3 Flash 视频等文件需要特殊抓取例如,图像捕获后,需要知道图像文件类型的大小,图像文件的大小,图像的像素大小,图像的像素大小需要进行转换。
3、抓取会定期更新捕获的网页。垂直爬虫只关注特定主题或属于特定行业的网页。难点在于如何识别网页是否属于指定的类别。优秀爬虫的特点 高性能URL队列的存储方式会影响性能 可扩展性 多服务器 多线程爬取 不同地域 部署数据中心 将爬虫分散到不同的数据中心 禁止爬虫的几种情况 User agent GoogleBotDisallow tmp Disallow cgi bin Disallow users paranoid Robot txt 禁止索引网页内容 禁止抓取网页链接 Content 标签对应的具体含义 爬虫质量的评价标准
4、1 覆盖范围 2 爬取网页的新颖性 3 爬取网页的重要性 大型商业搜索引擎一般至少收录两套不同用途的爬虫系统。针对更新频率较低的网页的网页抓取策略 1 广度优先遍历策略 2 深度优先遍历策略 3 不完整的页面排名策略 4 OPIC 策略 OnlinePageImportanceComputation 5 大站点优先策略 广度优先策略 将新下载页面中的链接直接插入等待中URL队列的末尾,表示网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页继续爬取该网页链接的所有网页。爬行顺序 1 2
5、 3 4 5 6 7 8 9 深度优先策略从起始页开始,一个链接,一个链接,然后向下。处理完这一行,进入下一个起始页面,继续按照链接爬取顺序 1 2 5 6 3 7 4 8 9 PageRank简介 1 初始阶段,网页通过链接关系构建Web图。每个页面设置相同的 PageRank 值。经过几轮计算,将得到每个页面最终得到的PageRank值。随着每一轮计算,网页当前的PageRank值会不断更新。2 一轮更新页面PageRank得分的计算方法在一轮更新页面的PageRank得分计算中,每个页面都会将其当前的 PageRank 值平均分配给该页面中收录的传出链接。转到每个链接,以便您可以获取
6、对应的权重和每个页面将所有指向该页面的传入链接中传递的权重相加得到一个新的PageRank分数。当每个页面得到更新后的PageRank值时,就完成了一轮PageRank计算。不完整的PageRank策略 将下载的网页和URL队列中的URL一起爬取,形成一组网页。该集合中pagerank计算完成后,根据PageRank计算URL队列中待爬取的网页。分数从高到低排列形成的序列就是爬虫接下来应该爬的URL列表。每当下载K个页面时,重新计算所有下载的页面及其不完整的PageRank值OPIC策略OnlinePageImportanceComputation这个算法
7、其实也是一个页面的重要性分数。在算法开始之前,所有页面都被赋予相同的初始现金现金。当一个页面P被下载时,P的cash被分配给从P分析的所有链接。并清除P的cash。根据cash的数量对URL队列中所有待爬取的页面进行排序。大站点优先策略以 网站 为单位衡量网页的重要性。对于URL队列中所有待爬取的网页,根据其网站的网站对待下载的页面进行分类网站
在8、中,关于不断变化的主题内容的用户体验策略假设用户经常只查看前3页的搜索内容。Principle 保存网页的多个历史版本,并根据过去每次内容变化对搜索质量的影响取平均值。作为判断抓取网页时机的参考依据,对质量影响较严重的网页将优先安排重新抓取聚类抽样策略。前两种更新策略是有前提的,需要网页的历史信息。存在两个问题: 1、每个系统保存多个版本的历史信息,增加了很多系统负担。2 新网页完全没有历史信息,无法确定更新策略。聚类抽样策略 聚类抽样策略考虑到网页有很多属性。同理,计算某一类页面的更新频率,只需按更新周对该类页面进行采样即可。
9、周期是整个类的更新周期。分布式爬虫系统结构 一般来说,爬虫系统需要面对整个互联网上亿万的网页。单个爬虫程序不可能完成这样的任务。往往需要多个爬取程序一起处理。一般来说,爬虫系统往往是分布式的三层结构。底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器上可以部署多套爬虫程序,构成一个基本的分布式爬虫系统。主从基本结构有一个专门的主服务器来维护要爬取的URL队列,它负责每次分发 URL。转到不同的 Slave 服务器,Slave 服务器负责实际的网页下载。主服务器还负责维护要爬取的 URL 队列和分发 URL。
10、负责调整各个从服务器的负载,防止部分从服务器过于空闲或过度工作。在这种模式下,master容易成为系统的瓶颈。对等的工作结构。所有抓取服务器之间的分工没有区别。每一个爬取服务器都可以从待爬取的URL队列中获取该URL,然后计算该URL主域名的哈希值H,进而计算出Hmodm,其中m为服务器数量。比如上图中m为3,计算出来的个数是为了处理URL的主机号的缺点是扩展性差。一致性哈希对 URL 的主域名进行哈希运算,并将其映射到 0 232 范围内的一个数字,并根据 URL 的主域名将该范围平均分配给 m 个服务器。哈希运算的取值范围决定了要爬取的服务器。如果某个服务器有问题,那么
11、 那么应该负责这个服务器的网页会被下一个服务器按顺时针顺序爬取。暗网爬取查询组合题文本框填入题目的网络爬虫实现环节的存储队列的数据结构。待爬取队列已爬取队列无效 链接错误链接 网页抓取 Jsoup jar 官方网站http jsoup org 相关学习资料 getElementById Stringid 获取id为getElementsByTag Stringtag 获取标签为getElementsByClass StringclassName 获取class为getElementsByAttribute的元素Stringkey 使用 Attribute 获取元素 获取元素的数据 attr 方法如下
12、 Stringkey 获取元素数据 attr Stringkey Stringvalue t 设置元素数据属性 获取所有属性 id className classNames 获取 idclass 值 text 获取文本值 text Stringvalue 设置文本值 html 获取 html 字符串值设置 htmlouterHtml 获取内部 html try doc Jsoup connect urlStr userAgent Mozilla 5 0 Windows U WindowsNT5 1 zh CN rv 1 9 2 15 设置用户代理超时
13、t 5000 设置连接超时时间 get catch MalformedURLExceptione log error e return catch IOExceptione if einstanceofSocketTimeoutException log error e return if einstanceofUnknownHostException log error e return log error e return system out println doc title Elementhead doc head Elementsmetas head select meta为了
14、 Elementmeta metas Stringcontent meta attr content Elementbody doc body Elementses body select a for Iteratorit es iterator it hasNext Elemente Element it next href e attr href 链接 提取 机构部门 招生就业 合作交流 提高爬虫效率 多线程爬取优化存储结构根据不同类型的链接制定爬取策略。示例说明 主要步骤 1 输入种子页面的URL,爬取爬取线程的深度。2 根据初始url获取种子页面的内容。注 1。
15、 合法的两种方法 a 判断url是否符合协议规则 b 判断url是否可以打开 while counts 3 try URLurl newURL urlStr HttpURLConnectioncon HttpURLConnection url openConnection intstate con getResponseCode if state 200 retu ok break catch Exceptionex counts continue 2种子 页面要获取的内容收录标题正文文本超链接开源jar包jsoup Documentdoc Jsoup connect sUrl get El
16、ementslinks doc select a href for Elementlink links StringlinkHref link attr href 获取href属性中的值,也就是你的地址 StringlinkTitle budge link text 获取anchor上的文字描述 3 多线程爬取根据爬行深度其实就是把第2步重复很多次。注意判断url是否重复。推荐使用hashset存储 HashSetallurlSet newHashSet 定义 hashsetallurlSet contains url 判断url是否已经存在 allurlSet add url 将url添加到allurlSet 4 存储爬取过程中页面的信息 信息包括网页地址页面、标题、链接数、正文、正文、超链接、锚文本等 5.存储方式 1.文档推荐。易于更改的信息存储在文件中。2.数据库存储在数据库中。网站所有地址均采用深度优先或广度优先的爬取策略。合理高效的存储结构,禁止爬行循环。课后学习PageRank算法的原理和实现方法。Java网络编程不需要jsoup。深入研究自己感兴趣的话题,比如在暗网上爬取分布式爬虫等。
动态网页抓取(动态网页抓取文章目录(1)(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-21 09:08
)
动态网页抓取
文章目录
前言
静态网页在浏览器中显示的内容在 HTML 源代码中。
但是由于主流的网站都使用JavaScript来展示网页内容,不像静态网页,在使用JavaScript的时候,很多内容不会出现在HTML源代码中,所以爬取静态网页的技术可能不会工作正常使用。
因此,我们需要使用两种动态网页抓取技术:通过浏览器检查元素解析真实网址和使用 selenium 模拟浏览器。
1 动态爬取示例
通过在后台与服务器交换少量数据,可以异步更新网页。
这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
一方面减少了网页重复内容的下载,另一方面节省了流量,
与使用 AJAX 网页相比,如果传统网页需要更新内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更友好。但是AJAX网页的爬取过程比较麻烦。
动态网页示例:
网页下方的评论是用 JavaScript 加载的,这些评论数据不会出现在网页的源代码中。
2 解析真实地址抓取
虽然数据并没有出现在网页的源代码中,但是我们仍然可以找到数据的真实地址,并且请求这个真实地址也可以得到想要的数据。此处使用浏览器的“检查”功能。
点击“Network”,刷新,点击左侧list?callback开头的链接,真实链接如下:
%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=&_=59
点击 JS - preview 可以找到这些评论的内容。
import requests
link = '''https://api-zero.livere.com/v1/comments/list?callback=jQuery112409913001985965064_1613139610757&limit=10
&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=&_=1613139610759'''
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36 Edg/88.0.705.63'}
r = requests.get(link, headers=headers)
print('页响应状态码:', r.status_code)
print(r.text)
3 通过 Selenium 模拟浏览器抓取
使用浏览器渲染引擎:直接使用浏览器加载和卸载HTML,应用CSS样式,显示网页时执行Javascript语句
自动打开浏览器加载网页,独立浏览每个网页,顺便抓取数据。
Selenium 测试直接在浏览器中运行,浏览器根据脚本代码自动点击、进入、打开、验证,就像真正的用户在操作一样。
3.1 Selenium安装及基本介绍
点安装硒
3.2个Selenium的实际案例
from selenium import webdriver
import time
# 下载的geckodriver的存储位置
driver = webdriver.Firefox(executable_path=r'F:\Programming\python_bag\geckodriver.exe')
# 隐性等待,最长等20秒
driver.implicitly_wait(20)
# 自动访问的网站
driver.get('http://www.santostang.com/2018/07/04/hello-world')
time.sleep(5)
# 先把所有的评论加载出来
for i in range(0, 5):
# 下滑到页面底部
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
# 解析iframe框架里面的评论, 注意外边是双引号,里边是单引号
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere-comment']"))
# 找到更多/下一页所在的点击位置
# load_more = driver.find_element_by_css_selector('button.more-btn')
page_next = driver.find_element_by_css_selector('button.page-btn')
# page_next = driver.find_element_by_css_selector('span.z-next')
# 点击“更多”
# load_more.click()
page_next.click()
# 把frame转回去:因为解析frame后,下滑的代码就用不了了,所以又要用下面的代码转回本来未解析的iframe
driver.switch_to.default_content()
time.sleep(2) # 等待2秒,加载评论
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere-comment']"))
# driver.find_elements_by_css_selector是用CSS选择器查找元素,找到class为’ reply-content '的div元素,注意为elements
comments = driver.find_elements_by_css_selector('div.reply-content')
for each_comment in comments:
# find_element_by_tag_name则是通过元素的tag去寻找,找到comment中的p元素
content = each_comment.find_element_by_tag_name('p')
# 输出p元素中的text文本
print(content.text)
3.3 Selenium 获取 文章 的所有评论
# 自动登录程序
from selenium import webdriver
import time
driver = webdriver.Firefox(executable_path=r'F:\Programming\python_bag\geckodriver.exe')
user = driver.find_element_by_name('username') # 找到用户名输入框
user.clear() # 清除用户名输入框
user.send_keys('1234567') # 在框中输入用户名
pwd = driver.find_element_by_name('password') # 找到密码输入框
pwd.clear() # 清除密码输入框的内容
pwd.send_keys('*******') # 在框中输入密码
driver.find_element_by_id('loginBtn').click() # 单击登录
Selenium 还可以实现简单的鼠标操作,复杂的双击、拖放,获取网页中每个元素的大小,模拟键盘的操作。欲了解更多信息,请参阅
Selenium 官方 网站
3.4 Selenium 的高级操作
from selenium import webdriver
fp = webdriver.FirefoxProfile()
fp.set_preference('permission.default.stylesheet', 2) # stylesheet | 设定不加载css,则参数为2
# firefox_profile=fp控制不加载CSS
driver = webdriver.Firefox(firefox_profile=fp, executable_path=r'F:\Programming\python_bag\geckodriver.exe')
driver.get('http://www.santostang.com/2018/07/04/hello-world/')
from selenium import webdriver
fp = webdriver.FirefoxProfile()
fp.set_preference('permission.default.image', 2) # image | 设定不加载css,则参数为2
# firefox_profile=fp控制不加载CSS
driver = webdriver.Firefox(firefox_profile=fp, executable_path=r'F:\Programming\python_bag\geckodriver.exe')
driver.get('http://www.santostang.com/2018/07/04/hello-world/')
from selenium import webdriver
fp = webdriver.FirefoxProfile()
fp.set_preference('javascript.enabled', False) # image | 设定不加载css,则参数为2
# firefox_profile=fp控制不加载CSS
driver = webdriver.Firefox(firefox_profile=fp, executable_path=r'F:\Programming\python_bag\geckodriver.exe')
driver.get('http://www.santostang.com/2018/07/04/hello-world/')
4 Selenium爬虫实践:深圳短租数据
获取Airbnb深圳前5名的短租房源:名称、价格、评论数、房型、床位数、房客数
网站:爱彼迎深圳
4.1 网站分析
一个房子所有数据的地址是:div._gigle7
价格数据:div._lyarz4r
评论数:span._lcy09umr
房屋名称数据:div._l90019zr
房间类型:小._f7heglr
房间/床位数:span._l4ksqu3j
4.2 项目实践
from selenium import webdriver
import time
driver = webdriver.Firefox(executable_path=r'F:\Programming\python_bag\geckodriver.exe')
for i in range(0, 5):
link = 'http://zh.airbnb.com/s/Shenzhen--China/homes?itmes_offset=' + str(i*18)
# 在虚拟浏览器中打开Airbnb页面
driver.get(link)
# 找到页面中所有的出租房
rent_list = driver.find_elements_by_css_selector('div._gigle7')
# 对于每个出租房
for each_house in rent_list:
# 找到评论数量
try:
comment = each_house.find_element_by_css_selector('span._lcy09umr').text
# except:
finally:
comment = 0
# 找到价格 | 替换掉所有无用字符,只保留价格符号和数字
price = each_house.find_element_by_css_selector('div._lyarz4r').text.replace('每晚', '').replace('价格', '').replace('\n', '')
# 找到名称
name = each_house.find_element_by_css_selector('div._l90019zr').text
# 找到房屋类型、大小
details = each_house.find_element_by_css_selector('small._f7heglr').text
house_type = details.split(' . ')[0] # split将字符串变成列表
bed_number = details.split(' . ')[1]
print('price\t', 'name\t', 'house_type\t', 'bed_number\t', 'comment')
print(price, name, house_type, bed_number, comment)
time.sleep(5) 查看全部
动态网页抓取(动态网页抓取文章目录(1)(图)
)
动态网页抓取
文章目录
前言
静态网页在浏览器中显示的内容在 HTML 源代码中。
但是由于主流的网站都使用JavaScript来展示网页内容,不像静态网页,在使用JavaScript的时候,很多内容不会出现在HTML源代码中,所以爬取静态网页的技术可能不会工作正常使用。
因此,我们需要使用两种动态网页抓取技术:通过浏览器检查元素解析真实网址和使用 selenium 模拟浏览器。
1 动态爬取示例
通过在后台与服务器交换少量数据,可以异步更新网页。
这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
一方面减少了网页重复内容的下载,另一方面节省了流量,
与使用 AJAX 网页相比,如果传统网页需要更新内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更友好。但是AJAX网页的爬取过程比较麻烦。
动态网页示例:
网页下方的评论是用 JavaScript 加载的,这些评论数据不会出现在网页的源代码中。
2 解析真实地址抓取
虽然数据并没有出现在网页的源代码中,但是我们仍然可以找到数据的真实地址,并且请求这个真实地址也可以得到想要的数据。此处使用浏览器的“检查”功能。
点击“Network”,刷新,点击左侧list?callback开头的链接,真实链接如下:
%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=&_=59
点击 JS - preview 可以找到这些评论的内容。
import requests
link = '''https://api-zero.livere.com/v1/comments/list?callback=jQuery112409913001985965064_1613139610757&limit=10
&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=&_=1613139610759'''
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36 Edg/88.0.705.63'}
r = requests.get(link, headers=headers)
print('页响应状态码:', r.status_code)
print(r.text)
3 通过 Selenium 模拟浏览器抓取
使用浏览器渲染引擎:直接使用浏览器加载和卸载HTML,应用CSS样式,显示网页时执行Javascript语句
自动打开浏览器加载网页,独立浏览每个网页,顺便抓取数据。
Selenium 测试直接在浏览器中运行,浏览器根据脚本代码自动点击、进入、打开、验证,就像真正的用户在操作一样。
3.1 Selenium安装及基本介绍
点安装硒
3.2个Selenium的实际案例
from selenium import webdriver
import time
# 下载的geckodriver的存储位置
driver = webdriver.Firefox(executable_path=r'F:\Programming\python_bag\geckodriver.exe')
# 隐性等待,最长等20秒
driver.implicitly_wait(20)
# 自动访问的网站
driver.get('http://www.santostang.com/2018/07/04/hello-world')
time.sleep(5)
# 先把所有的评论加载出来
for i in range(0, 5):
# 下滑到页面底部
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
# 解析iframe框架里面的评论, 注意外边是双引号,里边是单引号
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere-comment']"))
# 找到更多/下一页所在的点击位置
# load_more = driver.find_element_by_css_selector('button.more-btn')
page_next = driver.find_element_by_css_selector('button.page-btn')
# page_next = driver.find_element_by_css_selector('span.z-next')
# 点击“更多”
# load_more.click()
page_next.click()
# 把frame转回去:因为解析frame后,下滑的代码就用不了了,所以又要用下面的代码转回本来未解析的iframe
driver.switch_to.default_content()
time.sleep(2) # 等待2秒,加载评论
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere-comment']"))
# driver.find_elements_by_css_selector是用CSS选择器查找元素,找到class为’ reply-content '的div元素,注意为elements
comments = driver.find_elements_by_css_selector('div.reply-content')
for each_comment in comments:
# find_element_by_tag_name则是通过元素的tag去寻找,找到comment中的p元素
content = each_comment.find_element_by_tag_name('p')
# 输出p元素中的text文本
print(content.text)
3.3 Selenium 获取 文章 的所有评论
# 自动登录程序
from selenium import webdriver
import time
driver = webdriver.Firefox(executable_path=r'F:\Programming\python_bag\geckodriver.exe')
user = driver.find_element_by_name('username') # 找到用户名输入框
user.clear() # 清除用户名输入框
user.send_keys('1234567') # 在框中输入用户名
pwd = driver.find_element_by_name('password') # 找到密码输入框
pwd.clear() # 清除密码输入框的内容
pwd.send_keys('*******') # 在框中输入密码
driver.find_element_by_id('loginBtn').click() # 单击登录
Selenium 还可以实现简单的鼠标操作,复杂的双击、拖放,获取网页中每个元素的大小,模拟键盘的操作。欲了解更多信息,请参阅
Selenium 官方 网站
3.4 Selenium 的高级操作
from selenium import webdriver
fp = webdriver.FirefoxProfile()
fp.set_preference('permission.default.stylesheet', 2) # stylesheet | 设定不加载css,则参数为2
# firefox_profile=fp控制不加载CSS
driver = webdriver.Firefox(firefox_profile=fp, executable_path=r'F:\Programming\python_bag\geckodriver.exe')
driver.get('http://www.santostang.com/2018/07/04/hello-world/')
from selenium import webdriver
fp = webdriver.FirefoxProfile()
fp.set_preference('permission.default.image', 2) # image | 设定不加载css,则参数为2
# firefox_profile=fp控制不加载CSS
driver = webdriver.Firefox(firefox_profile=fp, executable_path=r'F:\Programming\python_bag\geckodriver.exe')
driver.get('http://www.santostang.com/2018/07/04/hello-world/')
from selenium import webdriver
fp = webdriver.FirefoxProfile()
fp.set_preference('javascript.enabled', False) # image | 设定不加载css,则参数为2
# firefox_profile=fp控制不加载CSS
driver = webdriver.Firefox(firefox_profile=fp, executable_path=r'F:\Programming\python_bag\geckodriver.exe')
driver.get('http://www.santostang.com/2018/07/04/hello-world/')
4 Selenium爬虫实践:深圳短租数据
获取Airbnb深圳前5名的短租房源:名称、价格、评论数、房型、床位数、房客数
网站:爱彼迎深圳
4.1 网站分析
一个房子所有数据的地址是:div._gigle7
价格数据:div._lyarz4r
评论数:span._lcy09umr
房屋名称数据:div._l90019zr
房间类型:小._f7heglr
房间/床位数:span._l4ksqu3j
4.2 项目实践
from selenium import webdriver
import time
driver = webdriver.Firefox(executable_path=r'F:\Programming\python_bag\geckodriver.exe')
for i in range(0, 5):
link = 'http://zh.airbnb.com/s/Shenzhen--China/homes?itmes_offset=' + str(i*18)
# 在虚拟浏览器中打开Airbnb页面
driver.get(link)
# 找到页面中所有的出租房
rent_list = driver.find_elements_by_css_selector('div._gigle7')
# 对于每个出租房
for each_house in rent_list:
# 找到评论数量
try:
comment = each_house.find_element_by_css_selector('span._lcy09umr').text
# except:
finally:
comment = 0
# 找到价格 | 替换掉所有无用字符,只保留价格符号和数字
price = each_house.find_element_by_css_selector('div._lyarz4r').text.replace('每晚', '').replace('价格', '').replace('\n', '')
# 找到名称
name = each_house.find_element_by_css_selector('div._l90019zr').text
# 找到房屋类型、大小
details = each_house.find_element_by_css_selector('small._f7heglr').text
house_type = details.split(' . ')[0] # split将字符串变成列表
bed_number = details.split(' . ')[1]
print('price\t', 'name\t', 'house_type\t', 'bed_number\t', 'comment')
print(price, name, house_type, bed_number, comment)
time.sleep(5)
动态网页抓取(做SEO优化时,挑选动态页面、静态页面哪个好)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-02-18 05:04
网站的动态页面和静态页面是什么,以及它们的区别,本文将介绍,在做SEO优化时,动态页面、静态页面和伪静态页面哪个更好?
让我们简要总结一下各自的优缺点:
1. 静态页面访问速度最快;但是,由于数据存储在 HTML 中,源代码必须全部更改,而不是一处。全站静态页面自动更换,维护起来比较麻烦。
2. 动态页面占用空间小,易于维护;访问速度慢,访问者多,会对数据库造成压力。
3. 使用伪静态页面和静态页面进行SEO(搜索引擎优化:Search Engine Optimization)没有本质区别。
基于以上几点,从用户体验的角度来看,对于SEO优化者来说,必须选择静态页面,但是如果动态页面和静态页面结合起来,似乎还是选择伪静态页面比较好。
我们都知道静态页面对SEO优化有很大的好处。它们不仅加载速度快,而且不会对服务器造成压力。它们对搜索引擎非常友好,但静态页面的缺点是不能随时更新,不易维护。与静态页面相比,伪静态页面并没有明显的速度提升,但由于是“假”静态页面,所以仍然是动态页面,还需要翻译成静态页面。将其视为静态页面以提高搜索引擎的友好性。
搜索引擎,如简单和常规的网页,以及动态页面,都有各种参数。搜索引擎如果想读到里面的内容,就需要通过一系列的动作来解码,就像对搜索引擎说:加油,想看懂我的内容,就先解开这些谜题吧!如果是参数较少的动态页面,也许搜索引擎会抓取它,但是如果参数很多呢?也许搜索引擎只是转身离开了。因此,那些参数堆积如山、数据长的链接,搜索引擎对这类页面的印象并不好。
我们做SEO优化。为了迎合搜索引擎的喜好,动态页面、静态页面和伪静态页面哪个更好?小编建议还是伪静态比较好。因为静态页面维护起来太麻烦,而且伪静态页面对搜索引擎的意义与静态页面相同,所以我们选择伪静态页面。
以上内容并不代表伪静态页面的选择就一定是最好的,但目前无数公司网站数据都比较少,可以采用生成伪静态页面的方法。现在可以生成基本的网站建设程序。伪静态页面。 查看全部
动态网页抓取(做SEO优化时,挑选动态页面、静态页面哪个好)
网站的动态页面和静态页面是什么,以及它们的区别,本文将介绍,在做SEO优化时,动态页面、静态页面和伪静态页面哪个更好?
让我们简要总结一下各自的优缺点:
1. 静态页面访问速度最快;但是,由于数据存储在 HTML 中,源代码必须全部更改,而不是一处。全站静态页面自动更换,维护起来比较麻烦。
2. 动态页面占用空间小,易于维护;访问速度慢,访问者多,会对数据库造成压力。
3. 使用伪静态页面和静态页面进行SEO(搜索引擎优化:Search Engine Optimization)没有本质区别。
基于以上几点,从用户体验的角度来看,对于SEO优化者来说,必须选择静态页面,但是如果动态页面和静态页面结合起来,似乎还是选择伪静态页面比较好。
我们都知道静态页面对SEO优化有很大的好处。它们不仅加载速度快,而且不会对服务器造成压力。它们对搜索引擎非常友好,但静态页面的缺点是不能随时更新,不易维护。与静态页面相比,伪静态页面并没有明显的速度提升,但由于是“假”静态页面,所以仍然是动态页面,还需要翻译成静态页面。将其视为静态页面以提高搜索引擎的友好性。
搜索引擎,如简单和常规的网页,以及动态页面,都有各种参数。搜索引擎如果想读到里面的内容,就需要通过一系列的动作来解码,就像对搜索引擎说:加油,想看懂我的内容,就先解开这些谜题吧!如果是参数较少的动态页面,也许搜索引擎会抓取它,但是如果参数很多呢?也许搜索引擎只是转身离开了。因此,那些参数堆积如山、数据长的链接,搜索引擎对这类页面的印象并不好。
我们做SEO优化。为了迎合搜索引擎的喜好,动态页面、静态页面和伪静态页面哪个更好?小编建议还是伪静态比较好。因为静态页面维护起来太麻烦,而且伪静态页面对搜索引擎的意义与静态页面相同,所以我们选择伪静态页面。
以上内容并不代表伪静态页面的选择就一定是最好的,但目前无数公司网站数据都比较少,可以采用生成伪静态页面的方法。现在可以生成基本的网站建设程序。伪静态页面。

