动态网页抓取( 借助Chrome浏览器的开发者项目,从分析网站架构开始)
优采云 发布时间: 2022-03-03 01:13动态网页抓取(
借助Chrome浏览器的开发者项目,从分析网站架构开始)
Python爬虫——Scrapy框架(项目实战)——爬取动态页面
写在前面
经过前面的学习,对Scrapy框架有了一定的了解,也写了很多基础爬虫,不过这些都是基于自己掌握的知识,也就是会爬。今天尝试一个新的挑战,借助这个机会,我转战股票基金领域,通过分析网站的结构,开始了一个不知名的爬虫项目。
免责声明:本次爬取的网站为东方财富网,所有获取的数据仅用于学术分析,不得用于商业用途。
爬虫目标
整个项目的主要目的是爬取东方财富网提供的各类证券融资融券的相关数据。我们要抓取过去六个月所有证券的每日收盘价、保证金余额和保证金差额。
当您来到东方财富网-融资融券,您会发现我们可以在下图所示部分获取所有证券信息。点击每只证券后,您可以进一步获取该证券每日的详细融资融券信息。
抓取动态加载的页面 动态加载的页面
如果你在浏览网站的时候注意网页的加载方式,你可能会发现两种常见的情况:一种是网页会加载一段时间,然后网页的所有内容一起显示;另一个是网页会加载一段时间。打开速度很快,但是网页中的内容是部分加载的。这种情况就是所谓的动态加载页面。
动态加载是通过ajax请求接口获取数据,并在网页上进行染色。当然,对于像我这样的新手,我不知道ajax是什么。让我们用 Chrome 浏览器的开发者工具来观察一些神奇的东西。
这是这个爬虫项目要爬取的网站。我暂时不关心我要爬取的数据在哪里。到开发者工具的网络选项,会发现这里暂时没有内容。
接下来,刷新页面,也就是通常意义上的重新加载页面。你会发现这里有很多内容。这些是加载页面时动态加载的内容。
我可以以原创方式抓取这个 网站 吗?
这里我们简单的使用命令行程序通过shell命令来演示,如果我们用原来的方法爬取这个网站,会不会爬到想要的数据。
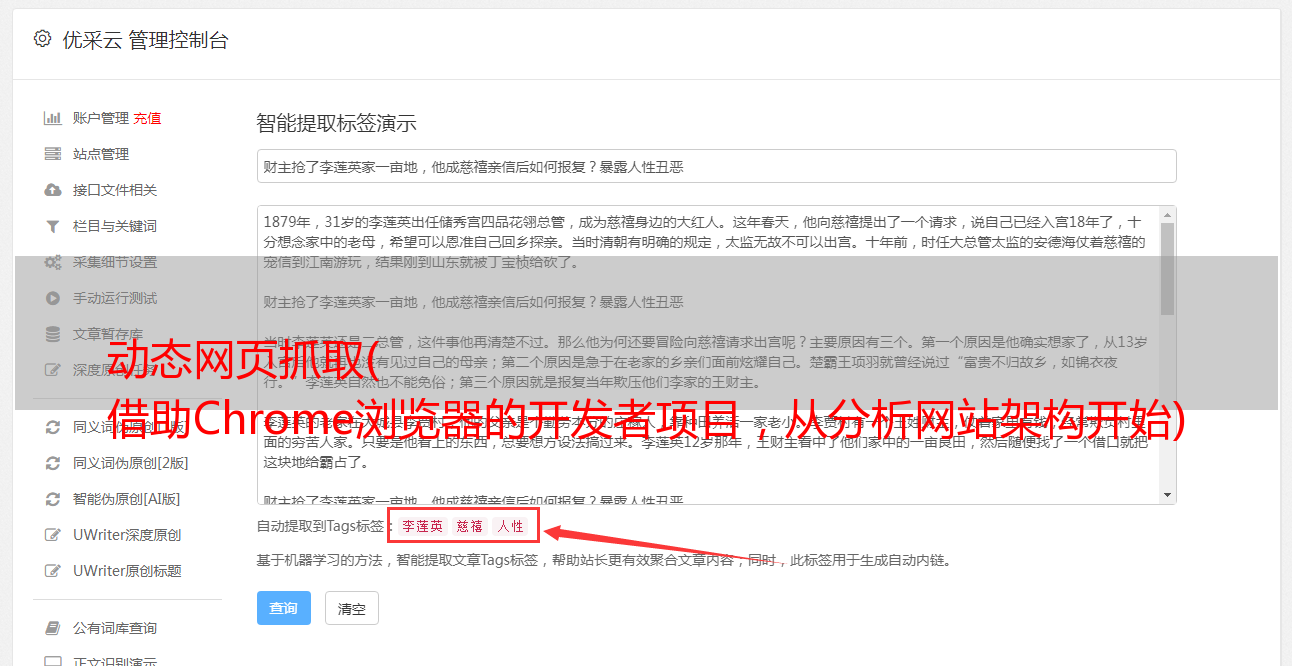
以上是shell得到的响应。很明显,和我们预想的有很大出入,我们想要获取的数据并没有被爬取。这也表明包括该部分在内的许多元素是动态加载的。
另一种方式
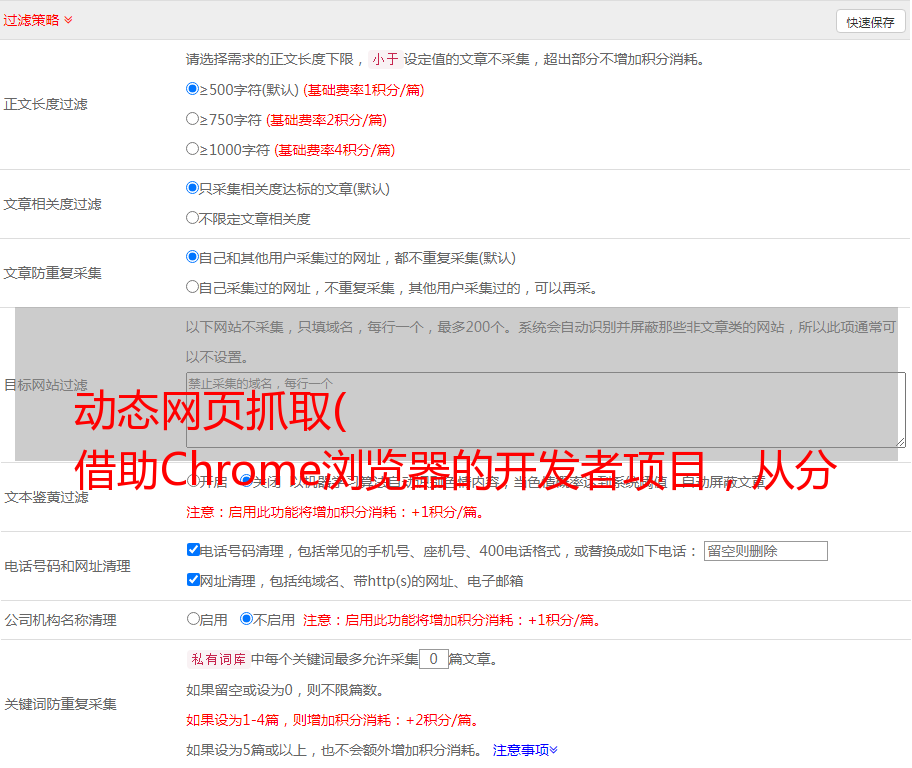
首先点击查看更多数据进入证券交易详情页面。接下来,从所有刚刚动态加载的内容中寻找我们想要的数据。虽然我们不知道它会是什么类型的数据,但如果不出意外,它肯定会出现在这里。经过不懈的搜索,我找到了以下文件。
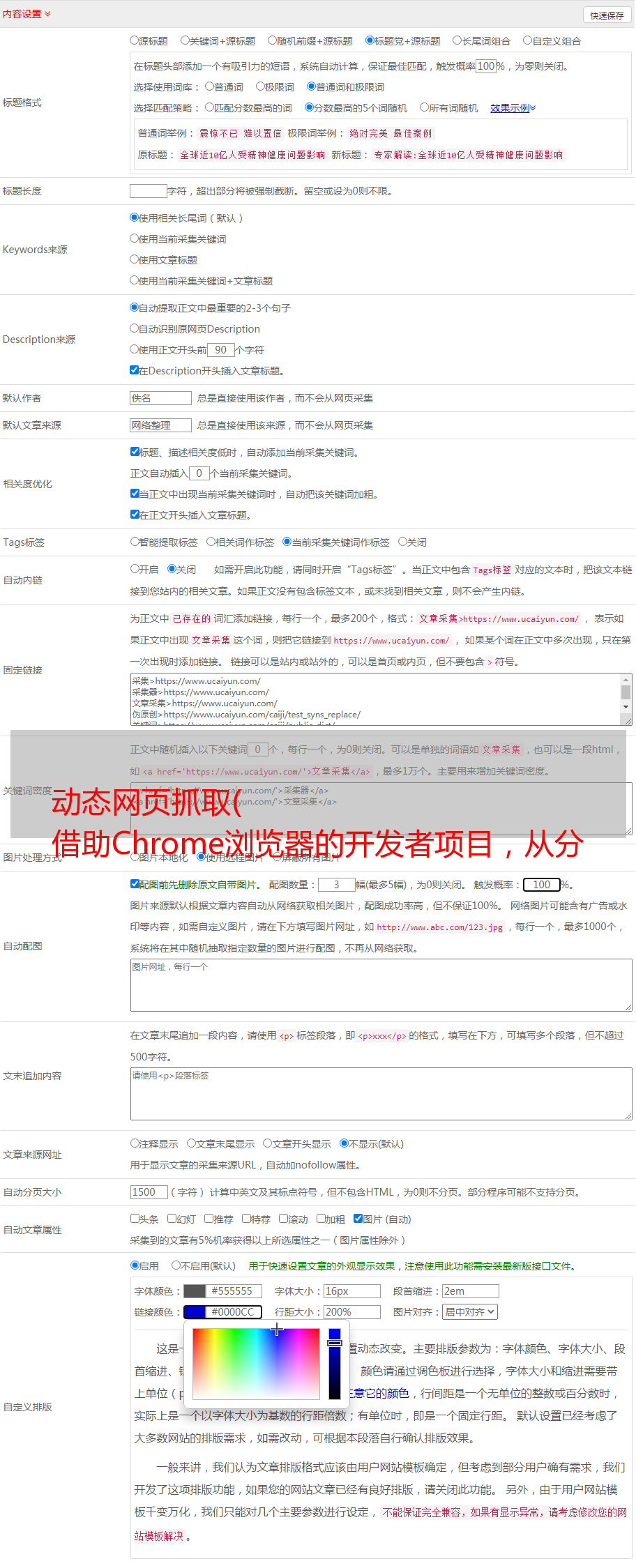
通过预览,我们可以预览内容,发现data里面存储的数据正是我们想要的数据。
右键单击文件并选择在新选项卡中打开。突然,我意识到这实际上是一个 Json 格式的文件。这很简单。我们只需要抓取这个页面。
接下来按照原来的思路,分析一下这个比较长的url地址。
(tdate='2019-05-09T00:00:00')&st=rzjmre&sr=-1&p=1&ps=50&js=var xDjBXPPy={pages:(tp),data:(x)}&type=RZRQ_DETAIL_NJ&time=1&rt=51916124
尝试改变url地址中不同部分的值,你会发现p代表页数,ps代表每页显示的数据个数,那么这里我们把ps的值改成997,让它变成一页所有的数据都显示在里面,方便我们爬取。
Json数据的处理
通过爬虫直接爬取这个页面,得到Json类型的数据。显然,不能直接用python语言处理。这里使用json包中的decode函数对Json数据进行解码。
datas = response.body.decode('UTF-8')
接下来,我们可以利用字典和列表的知识继续对数据进行进一步的处理,然后得到我们需要的所有信息。
综上所述
事实上,整个项目在这里并没有达到最初的目标,但最困难的问题已经解决了。接下来的操作可以利用我们之前的思路,从当前页面获取每一个证券的scode,然后拼接得到一个新的。url,进一步获取每天的详细数据,最终达到目的。
由于种种原因,我这次没有提供很多源码,只是更详细的解释了原理。如果您遇到这方面的问题并阅读此文章 仍然无法解决,请通过电子邮件与我联系。愿意尽我所能提供帮助,希望共同进步。

