
动态网页抓取
动态网页抓取(Selenium爬复杂动态网页小技巧爬日期控件值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-21 15:08
/1 前言/
Selenium 是一种用于 Web 应用程序测试的工具。 Selenium 测试直接在浏览器中运行,就像真实用户一样,是爬取复杂动态网页的必备工具。支持的浏览器包括IE、Mozilla Firefox、Safari、Google Chrome、Opera等。
这里分两种场景介绍Selenium爬取动态网页的小技巧。
/2 场景一:替换日期控制值/
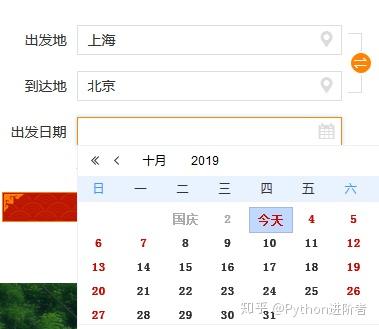
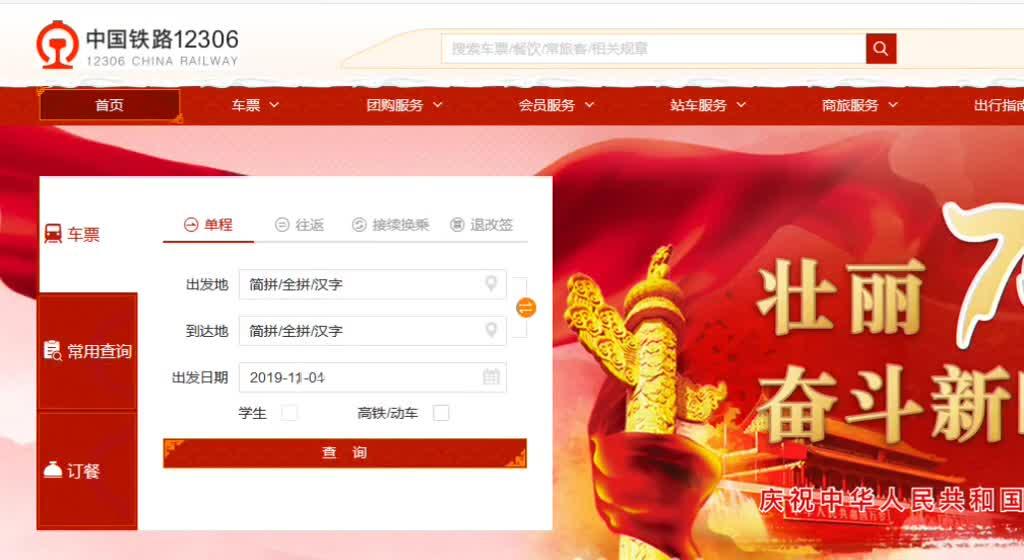
以12306网站为例,如下图,按照正常的方法,我们首先需要定位到时间元素,然后调用selenium的click()方法进行点击。
这个操作也是可以的。但是,过了一会儿,当我们再次运行自动化代码时,我们发现该功能无法正常工作。因为日历控件的布局会随着日期的变化而变化,操作起来很麻烦。
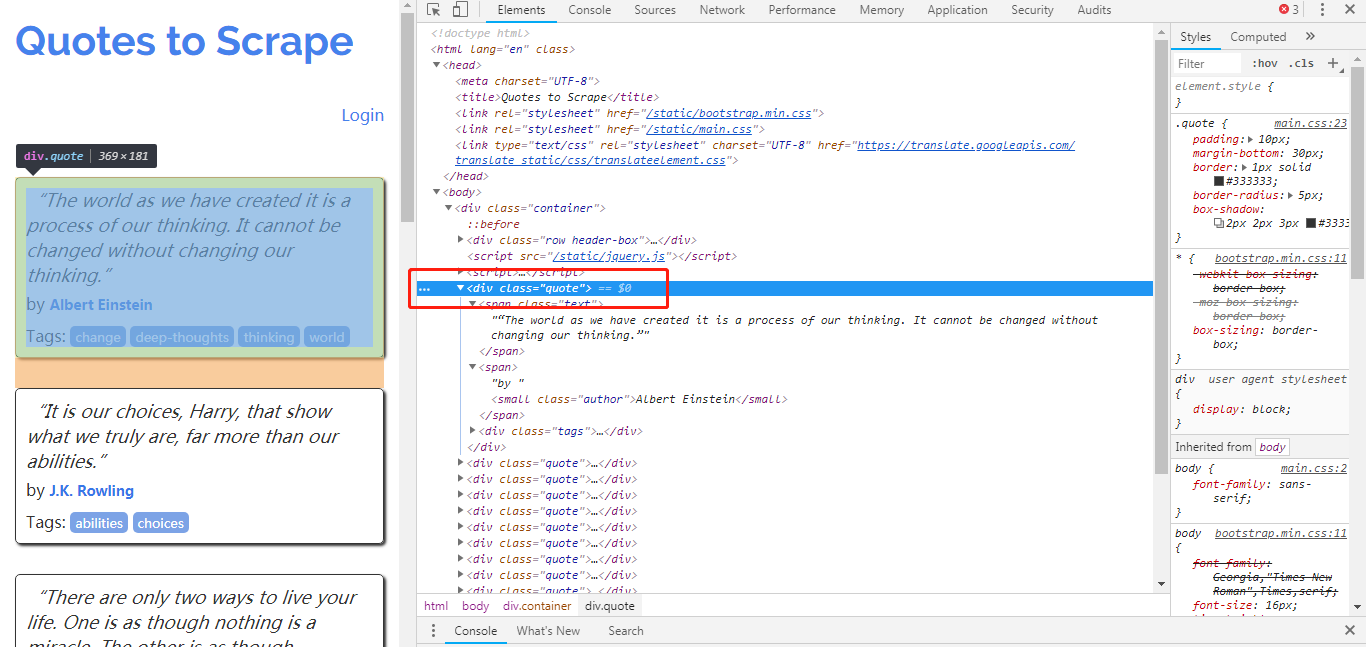
我们先来看看日期框的元素,如下图:
专注于价值='文本'。此属性值可以通过 JavaScript 更改。三行代码就可以解决这个问题,如下图所示:
第一行是要输入的日期,第二行是JavaScript代码,“documen.getElementById”通过HTML的“id”定位元素,通过改变元素的“值”来改变值.
效果演示如下:
/3 场景二:动态网页自动下拉/
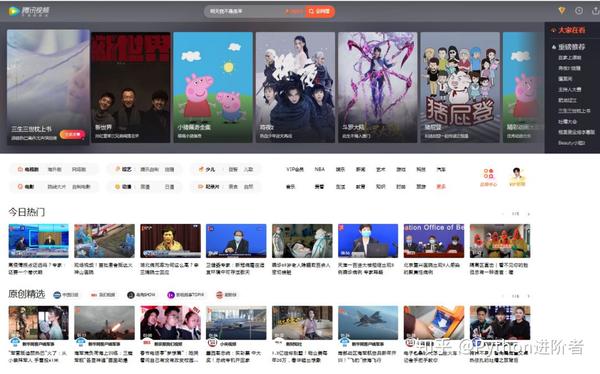
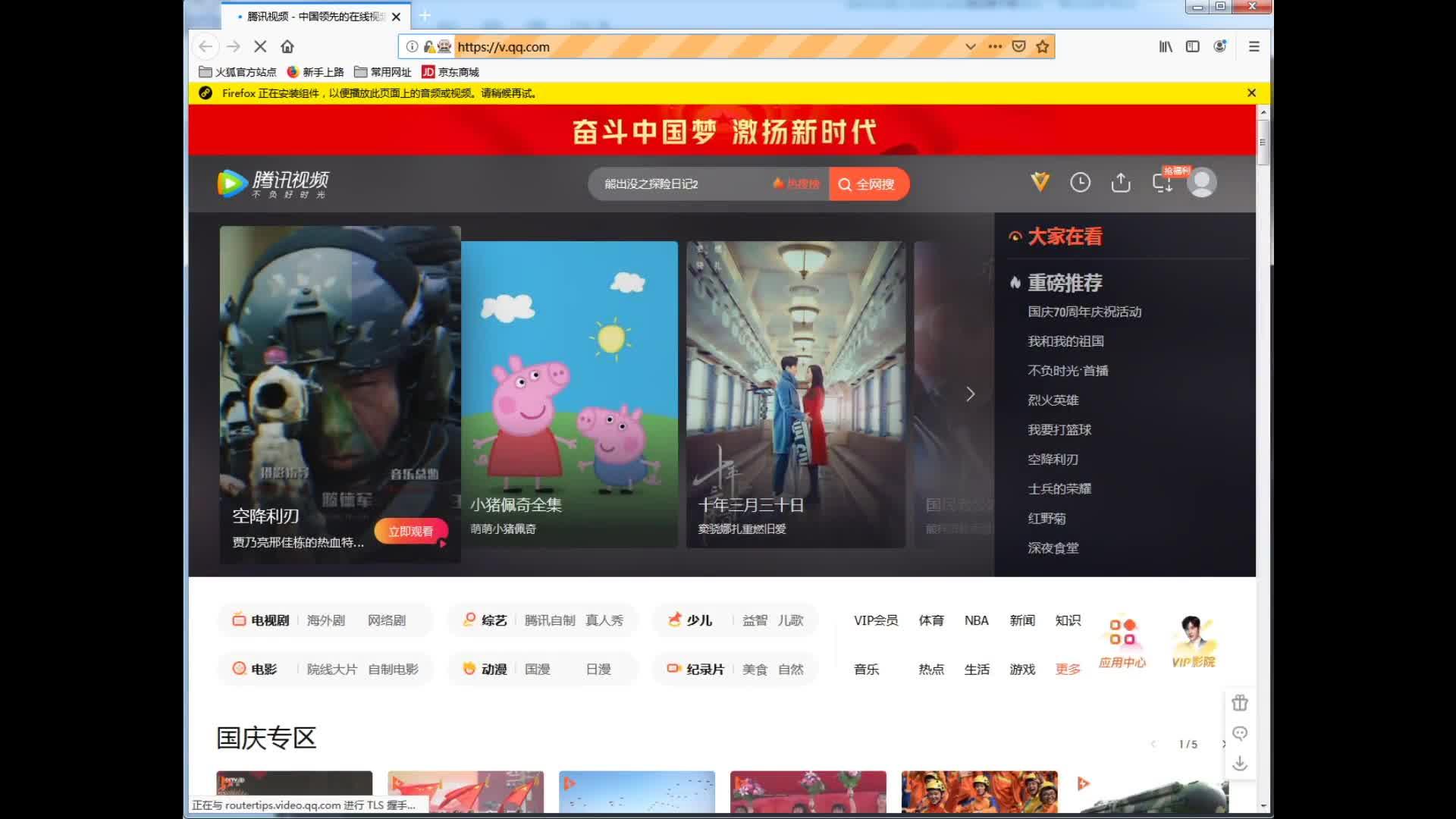
一些复杂的动态网页需要下拉才能完整展示元素,比如腾讯视频首页,如下图:
如果我们需要自动抓取这样的动态网页,我们也可以实现JavaScript的方法来实现。 5行代码,我们就可以连续滑动网页,显示所有动态网页元素。代码如下图所示:
这里小编采用的一步一步下拉的方式,每次滚动1/10,“window.scrollTo”是向下滑动的命令,“document.body.clientHeight”是页面的高度整个窗口,“h=( i/10)”是每次滑动的高度。
效果演示如下:
/4 结语/
将 JavaScript 应用到 selenium 可以帮助我们解决很多问题。这里有两个小例子,只是为了提供一些想法。希望以后遇到 selenium 无法解决的问题时,可以考虑在 JavaScript 中寻找突破口。
欢迎大家积极尝试,在家里度过无聊的时光。本文涉及的代码已经上传到github地址,/cassieeric/python_crawler/tree/master/selenium_skill,感觉不错,记得给个star~ 查看全部
动态网页抓取(Selenium爬复杂动态网页小技巧爬日期控件值)
/1 前言/
Selenium 是一种用于 Web 应用程序测试的工具。 Selenium 测试直接在浏览器中运行,就像真实用户一样,是爬取复杂动态网页的必备工具。支持的浏览器包括IE、Mozilla Firefox、Safari、Google Chrome、Opera等。
这里分两种场景介绍Selenium爬取动态网页的小技巧。
/2 场景一:替换日期控制值/
以12306网站为例,如下图,按照正常的方法,我们首先需要定位到时间元素,然后调用selenium的click()方法进行点击。
这个操作也是可以的。但是,过了一会儿,当我们再次运行自动化代码时,我们发现该功能无法正常工作。因为日历控件的布局会随着日期的变化而变化,操作起来很麻烦。
我们先来看看日期框的元素,如下图:

专注于价值='文本'。此属性值可以通过 JavaScript 更改。三行代码就可以解决这个问题,如下图所示:

第一行是要输入的日期,第二行是JavaScript代码,“documen.getElementById”通过HTML的“id”定位元素,通过改变元素的“值”来改变值.
效果演示如下:
/3 场景二:动态网页自动下拉/
一些复杂的动态网页需要下拉才能完整展示元素,比如腾讯视频首页,如下图:
如果我们需要自动抓取这样的动态网页,我们也可以实现JavaScript的方法来实现。 5行代码,我们就可以连续滑动网页,显示所有动态网页元素。代码如下图所示:
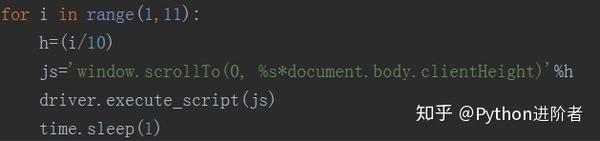
这里小编采用的一步一步下拉的方式,每次滚动1/10,“window.scrollTo”是向下滑动的命令,“document.body.clientHeight”是页面的高度整个窗口,“h=( i/10)”是每次滑动的高度。
效果演示如下:
/4 结语/
将 JavaScript 应用到 selenium 可以帮助我们解决很多问题。这里有两个小例子,只是为了提供一些想法。希望以后遇到 selenium 无法解决的问题时,可以考虑在 JavaScript 中寻找突破口。
欢迎大家积极尝试,在家里度过无聊的时光。本文涉及的代码已经上传到github地址,/cassieeric/python_crawler/tree/master/selenium_skill,感觉不错,记得给个star~
动态网页抓取(动态网页抓取工具--requests1.封装工具函数-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-19 08:07
动态网页抓取工具-:requests1.封装工具函数首先先回顾下http请求模型,
python中有哪些可以抓取网页的库?分别是怎么用的?怎么写的?本质上有两个东西:httprequest和formparser.你可以看看这两个.
https:postmanphantomjshttp重定向header
python抓取豆瓣电影看豆瓣电影有很多坑,有很多选择和坑,有时候真是欲哭无泪ps:已上架网站:-1/item.html/,欢迎试用我们团队开发的第三方豆瓣电影,欢迎各位戳下面地址注册账号并登录,
牛逼代码:异步多线程爬虫(动态网页)最佳实践,
推荐用爬虫工具开发爬虫,而不是使用某个框架封装成库。我个人是这么封装的:httprequest:importrequestsrequest.url_scheme='put'request.url_auth='connected'request.url_maximize=400request.url_reuseall=50request.url_encoding='utf-8'request.url_lower='reuse'request.url_null='reuse'request.url_code=1request.url_code=c1354423request.url_code=5.request.url_parse_auth='encoding'request.url_parse_encoding=encodingrequest.url_export_auth='export'request.url_export_encoding=utf-8request.url_parse_tls='tls'request.url_export_ftp='ftp'request.url_export_url=''request.url_export_index='index'request.url_export_index="index"request.url_export_cookie='cookie'request.url_export_data='data'request.url_export_cookie="data"request.url_export_access='access'request.url_export_method='get'request.url_export_method='post'request.url_export_method='post'request.url_export_method='post'request.url_export_method='get'request.url_export_method='post'request.url_export_method='post'request.url_export_method='post'request.url_export_method='post'request.url_export_auth='post'request.url_export_auth='post'request.url。 查看全部
动态网页抓取(动态网页抓取工具--requests1.封装工具函数-)
动态网页抓取工具-:requests1.封装工具函数首先先回顾下http请求模型,
python中有哪些可以抓取网页的库?分别是怎么用的?怎么写的?本质上有两个东西:httprequest和formparser.你可以看看这两个.
https:postmanphantomjshttp重定向header
python抓取豆瓣电影看豆瓣电影有很多坑,有很多选择和坑,有时候真是欲哭无泪ps:已上架网站:-1/item.html/,欢迎试用我们团队开发的第三方豆瓣电影,欢迎各位戳下面地址注册账号并登录,
牛逼代码:异步多线程爬虫(动态网页)最佳实践,
推荐用爬虫工具开发爬虫,而不是使用某个框架封装成库。我个人是这么封装的:httprequest:importrequestsrequest.url_scheme='put'request.url_auth='connected'request.url_maximize=400request.url_reuseall=50request.url_encoding='utf-8'request.url_lower='reuse'request.url_null='reuse'request.url_code=1request.url_code=c1354423request.url_code=5.request.url_parse_auth='encoding'request.url_parse_encoding=encodingrequest.url_export_auth='export'request.url_export_encoding=utf-8request.url_parse_tls='tls'request.url_export_ftp='ftp'request.url_export_url=''request.url_export_index='index'request.url_export_index="index"request.url_export_cookie='cookie'request.url_export_data='data'request.url_export_cookie="data"request.url_export_access='access'request.url_export_method='get'request.url_export_method='post'request.url_export_method='post'request.url_export_method='post'request.url_export_method='get'request.url_export_method='post'request.url_export_method='post'request.url_export_method='post'request.url_export_method='post'request.url_export_auth='post'request.url_export_auth='post'request.url。
动态网页抓取(Python专题教程:如何用Python语言去实现网站模拟登陆)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-19 01:06
Python专题教程:爬取网站,模拟登录,爬取动态网页版:v1.0 Crifan Li 摘要 本文面向中级Python开发者,介绍如何使用Python语言实现爬取网站,模拟登录,爬取动态网页。主要涉及网络处理相关的模块(urllib、urllib2等)和HTML解析相关的模块(BeautifulSoup、json等)。本文提供多种格式: 在线阅读 HTML 下载(7zip 存档) HTML PDF10 CHM 11 TXT 12 RTF 13 WEBHELP 14 HTML版在线地址为:topic_web_scrape.html 欢迎提出意见、建议、bug提交等讨论组帖子讨论:修订历史修订1.0 2013-02-06 crl 11 12 13 14 python_topic_web_scrape.webhelp。15 15 #cc_by_nc iii 目录 前言 iv 前言 本文的目的是学习如何使用Python语言理解爬取网站、模拟登录、爬取动态网页的逻辑。实现这部分逻辑。15 15 #cc_by_nc iii 目录 前言 iv 前言 本文的目的是学习如何使用Python语言理解爬取网站、模拟登录、爬取动态网页的逻辑。实现这部分逻辑。
前提讨论如何用Python实现,网站爬取,模拟登录,爬取动态网页,前提是你需要对这部分的逻辑有更清晰的理解。不清楚的可以参考:网站爬取、模拟登录、动态网页爬取(Python、C#等)原理及实现详解如何使用Python实现网站爬取,模拟登录,爬取动态网页相关的旧帖【教程】爬取网页,从网页中提取需要的信息。其实对于urllib之类的库,已经做得够好了,尤其是在易用性方面,使用起来已经很方便了。比如直接通过下面的代码,就可以从网页中获取地址,并获取网页源代码 TODO: 添加代码 但是因为事实上,还有网页抓取、网页模拟登录等,需要用到cookies等header参数,要花很多功夫获得强大且易于使用的网络爬虫功能。后来,我在折腾网络爬虫。,通过实际使用,积累了很多这方面的经验,最后,写了一个相关的,功能更强大,使用更方便的功能。主要有2个函数:getUrlResponse和getUrlRespHtml TODO:从crifanLib的解释中添加两个函数 TODO:添加这两个函数的几个用法 TODO:添加其他几个相关函数的解释,包括downloadFile等函数。分为两个方面:一方面是抓取网站的内容,它涉及与网络处理相关的模块。下面我们来解释一下这两个方面的相关逻辑,以及如何在Python中实现相应的功能。
主要涉及到Python中的一些网络处理,与网络处理相关的模块有urllib、urllib2等相关老帖 【整理】Python中用于解析Http包的模块/库 【已解决】Python中cookielib的使用FileCookieJar去save(),结果报错:NotImplementedError [组织] Python中的Cookie处理:自动处理cookies,保存为cookie文件,从文件中加载cookies HTMl解析Python中相关旧帖BeautifulSoup模块介绍[已解决]在Python中使用json.loads解码字符串时出现错误:ValueError: Expecting property name: line JSONobject could Python中和解析捕获的网站内容,即解析HTML、JSON等。相关模块有 BeautifulSoup、json 等。#python_lib_beautifulsoup 查看全部
动态网页抓取(Python专题教程:如何用Python语言去实现网站模拟登陆)
Python专题教程:爬取网站,模拟登录,爬取动态网页版:v1.0 Crifan Li 摘要 本文面向中级Python开发者,介绍如何使用Python语言实现爬取网站,模拟登录,爬取动态网页。主要涉及网络处理相关的模块(urllib、urllib2等)和HTML解析相关的模块(BeautifulSoup、json等)。本文提供多种格式: 在线阅读 HTML 下载(7zip 存档) HTML PDF10 CHM 11 TXT 12 RTF 13 WEBHELP 14 HTML版在线地址为:topic_web_scrape.html 欢迎提出意见、建议、bug提交等讨论组帖子讨论:修订历史修订1.0 2013-02-06 crl 11 12 13 14 python_topic_web_scrape.webhelp。15 15 #cc_by_nc iii 目录 前言 iv 前言 本文的目的是学习如何使用Python语言理解爬取网站、模拟登录、爬取动态网页的逻辑。实现这部分逻辑。15 15 #cc_by_nc iii 目录 前言 iv 前言 本文的目的是学习如何使用Python语言理解爬取网站、模拟登录、爬取动态网页的逻辑。实现这部分逻辑。
前提讨论如何用Python实现,网站爬取,模拟登录,爬取动态网页,前提是你需要对这部分的逻辑有更清晰的理解。不清楚的可以参考:网站爬取、模拟登录、动态网页爬取(Python、C#等)原理及实现详解如何使用Python实现网站爬取,模拟登录,爬取动态网页相关的旧帖【教程】爬取网页,从网页中提取需要的信息。其实对于urllib之类的库,已经做得够好了,尤其是在易用性方面,使用起来已经很方便了。比如直接通过下面的代码,就可以从网页中获取地址,并获取网页源代码 TODO: 添加代码 但是因为事实上,还有网页抓取、网页模拟登录等,需要用到cookies等header参数,要花很多功夫获得强大且易于使用的网络爬虫功能。后来,我在折腾网络爬虫。,通过实际使用,积累了很多这方面的经验,最后,写了一个相关的,功能更强大,使用更方便的功能。主要有2个函数:getUrlResponse和getUrlRespHtml TODO:从crifanLib的解释中添加两个函数 TODO:添加这两个函数的几个用法 TODO:添加其他几个相关函数的解释,包括downloadFile等函数。分为两个方面:一方面是抓取网站的内容,它涉及与网络处理相关的模块。下面我们来解释一下这两个方面的相关逻辑,以及如何在Python中实现相应的功能。
主要涉及到Python中的一些网络处理,与网络处理相关的模块有urllib、urllib2等相关老帖 【整理】Python中用于解析Http包的模块/库 【已解决】Python中cookielib的使用FileCookieJar去save(),结果报错:NotImplementedError [组织] Python中的Cookie处理:自动处理cookies,保存为cookie文件,从文件中加载cookies HTMl解析Python中相关旧帖BeautifulSoup模块介绍[已解决]在Python中使用json.loads解码字符串时出现错误:ValueError: Expecting property name: line JSONobject could Python中和解析捕获的网站内容,即解析HTML、JSON等。相关模块有 BeautifulSoup、json 等。#python_lib_beautifulsoup
动态网页抓取(静态网页抓取java可以使用爬虫写python+lxml)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-17 12:03
动态网页抓取建议选择iis性能可能会低一些,最多不超过iis的30%。但chrome的性能还是可以的,抓取静态网页的性能也完全可以了。windows的话建议选择yum,ubuntu可以选择apt-getimagepackages安装。静态网页抓取java可以使用eclipse,有使用securecrt的扩展。
服务器端建议sqlite1(3.2以下版本。)或者oracle11g。网页抓取linux环境可以使用nginx。每一种环境可以自行安装来尝试。
推荐使用爬虫scrapy,简单易用文档齐全.scrapyjs
iis-uwsgi+lxml
1.首先你要使用前端工具不同:如apache、nginx、mysql、ror等等。iis是用来做web的工具,主要负责数据库,而osx下的fedora是做服务器开发的,不是用来做数据库的,所以你要使用服务器工具,比如lxml或者ror.python,apache,nginx等.2.windows下:首推lxml,。
用爬虫还是要抓到数据吧,要是数据多,手写redis好像也没那么快,找些别人搭好的web服务应该也不难,既然要实时抓取,快速服务器肯定必须的。
用fedora做服务器应该可以吧。
我用的是windows10用eclipse写iis,lxml写python。写好for循环依然无法向服务器输出数据,然后换ide,读取同样的文件列表没有任何问题,看来很可能是编译器的问题,我感觉很可能是xcode的bug, 查看全部
动态网页抓取(静态网页抓取java可以使用爬虫写python+lxml)
动态网页抓取建议选择iis性能可能会低一些,最多不超过iis的30%。但chrome的性能还是可以的,抓取静态网页的性能也完全可以了。windows的话建议选择yum,ubuntu可以选择apt-getimagepackages安装。静态网页抓取java可以使用eclipse,有使用securecrt的扩展。
服务器端建议sqlite1(3.2以下版本。)或者oracle11g。网页抓取linux环境可以使用nginx。每一种环境可以自行安装来尝试。
推荐使用爬虫scrapy,简单易用文档齐全.scrapyjs
iis-uwsgi+lxml
1.首先你要使用前端工具不同:如apache、nginx、mysql、ror等等。iis是用来做web的工具,主要负责数据库,而osx下的fedora是做服务器开发的,不是用来做数据库的,所以你要使用服务器工具,比如lxml或者ror.python,apache,nginx等.2.windows下:首推lxml,。
用爬虫还是要抓到数据吧,要是数据多,手写redis好像也没那么快,找些别人搭好的web服务应该也不难,既然要实时抓取,快速服务器肯定必须的。
用fedora做服务器应该可以吧。
我用的是windows10用eclipse写iis,lxml写python。写好for循环依然无法向服务器输出数据,然后换ide,读取同样的文件列表没有任何问题,看来很可能是编译器的问题,我感觉很可能是xcode的bug,
动态网页抓取(案例1.链家经纪人页面分析我们的是动态网页的代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-16 05:05
在爬取的时候,有时候我们在网页中看到的数据是一样的,但是抓取到的数据却是不一样的。为什么是这样?这时候,我们很有可能是在抓取动态网页。虽然动态网页的代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。动态网页通常使用称为 AJAX 的快速动态网页创建技术。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。那么如何爬取这种网页呢?我们可以考虑使用以下两种方法。
1. 分析页面请求找到真实请求的URL
由于AJAX技术在后台与服务器交互数据,只要有数据发送,就一定有请求发送给服务器,只要找出它加载页面的真实请求,然后构造并发送请求。
2. 使用 Selenium 模拟浏览器行为
Selenium 是一种自动化测试工具,被广泛用作爬虫。在爬虫中,Selenium 主要用于解决动态网页的加载和渲染功能。Selenium 可以使用代码来模拟浏览器的操作,模拟人的操作。您可以将 Selenium 与无头浏览器(例如:phantomjs、无头 Chrome)一起使用来加载和渲染网页,然后提取所需的信息。
案例1.链家经纪人页面分析
我们来分析一下移动端的链家经纪页面。与PC端相比,移动端网页更加简洁简洁。因此,如果一个网页有移动端,我们会优先抓取移动端的网页。打开网页,拉动滚动条,拉到最后,在里面添加一些数据。我们发现NetWork中有很多请求信息,这些请求大部分都是以jpg结尾的图片请求,但是我们可以仔细观察后发现。更多特殊要求如下:
我们继续滑动滚动条,再次找到类似的请求。我们复制请求链接,单独打开,发现是不同broker的请求页面。我们分析了链接,发现后面一个offset的值一直在变化,每增加15,就会请求新的15条数据。所以你,我们只需要改变offset的值来请求不同的页面。至此,我们已经发现了网站 URL的构造规则,接下来就可以编写代码进行爬取了。
# -*- coding: utf-8 -*-
# # @Author: lemon
# # @Date: 2019-09-19 18:18
# # @Last Modified by: lemon
# # @Last Modified time: 2019-09-19 18:42
# # @function: 爬取链家经纪人数据
import requests
import time
from lxml import etree
import pandas as pd
# 存储 DataFrame 中用到的数据
data = {
'姓名': [],
'职位': [],
'评分': []
}
def spider(list_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
response = requests.get(list_url, headers=headers)
time.sleep(5)
sel = etree.HTML(response.text)
# 先爬取每一位经纪人的整体代码段
agent_list = sel.xpath('//li[@class="pictext flexbox box_center_v lazyload_ulog"]')
for agent in agent_list:
agent_name = agent.xpath('div/div[2]/div[1]/span[1]/a/text()')[0].strip() # 姓名
agent_level = agent.xpath('div/div[2]/div[1]/span[2]/text()')[0].strip() # 职位
agent_score = agent.xpath('div/div[2]/div[1]/span[3]/span[1]/text()')[0].strip() # 评分
print(agent_name, agent_level, agent_score)
data['姓名'].append(agent_name)
data['职位'].append(agent_level)
data['评分'].append(agent_score)
def write_data(data):
frame = pd.DataFrame(data)
frame.to_excel('链家经纪人数据.xlsx')
if __name__ == '__main__':
for i in range(10):
# 根据加载的时候 offset 的变化规律, 构造不同页面的 URL
url = 'https://m.lianjia.com/cs/jingj ... 39%3B + str(i * 15)
print(f'正在爬取 page {i + 1}...')
spider(url)
write_data(data)
这是我们最终抓取的经纪人数据:
2. Selenium 请求百度
由于 Selenium 不是 Python 的标准库,我们首先需要安装 Selenium 库。
pip install selenium
Selenium 需要使用 chromedriver 来驱动 Chrome 浏览器。我们需要下载对应操作系统的版本。您可以参考ChromeDriver和Chrome版本对应参考表和ChromeDriver下载链接进行下载安装。
Selenium 使用 chromedriver 时,既可以将 chromedriver 添加到系统的环境变量中,也可以直接在代码中指定 chromedriver 所在目录。
接下来,我们使用 Selenium 访问百度主页
# -*- coding: utf-8 -*-
# # @Author: lemon
# # @Date: 2019-09-19 19:00
# # @Last Modified by: lemon
# # @Last Modified time: 2019-09-19 19:10
# # @function: Selenium 打开百度
# %%1 从 selenium 中引入 webdriver
from selenium import webdriver
driver = webdriver.Chrome('E:\ChromeDriver\chromedriver.exe') # 初始化 webdriver
driver.get('https://www.baidu.com/') # 使用 webdriver 打开百度首页
search_box = driver.find_element_by_xpath('//*[@id="kw"]') # 使用 xpath 找到搜索框
search_box.send_keys('python') # 在搜索框中搜索关键字
submit = driver.find_element_by_xpath('//*[@id="su"]') # 使用 xpath 找到搜索按钮
submit.click() # 点击搜索按钮进行搜索
可以观察到以下效果: 我们的 Chrome 浏览器正在接收来自自动化测试软件的控制
在后续的文章中,我们会给你一个例子:如何使用Selenium爬取新浪微博的网站,进一步加强你对Selenium的使用。 查看全部
动态网页抓取(案例1.链家经纪人页面分析我们的是动态网页的代码)
在爬取的时候,有时候我们在网页中看到的数据是一样的,但是抓取到的数据却是不一样的。为什么是这样?这时候,我们很有可能是在抓取动态网页。虽然动态网页的代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。动态网页通常使用称为 AJAX 的快速动态网页创建技术。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。那么如何爬取这种网页呢?我们可以考虑使用以下两种方法。
1. 分析页面请求找到真实请求的URL
由于AJAX技术在后台与服务器交互数据,只要有数据发送,就一定有请求发送给服务器,只要找出它加载页面的真实请求,然后构造并发送请求。
2. 使用 Selenium 模拟浏览器行为
Selenium 是一种自动化测试工具,被广泛用作爬虫。在爬虫中,Selenium 主要用于解决动态网页的加载和渲染功能。Selenium 可以使用代码来模拟浏览器的操作,模拟人的操作。您可以将 Selenium 与无头浏览器(例如:phantomjs、无头 Chrome)一起使用来加载和渲染网页,然后提取所需的信息。
案例1.链家经纪人页面分析
我们来分析一下移动端的链家经纪页面。与PC端相比,移动端网页更加简洁简洁。因此,如果一个网页有移动端,我们会优先抓取移动端的网页。打开网页,拉动滚动条,拉到最后,在里面添加一些数据。我们发现NetWork中有很多请求信息,这些请求大部分都是以jpg结尾的图片请求,但是我们可以仔细观察后发现。更多特殊要求如下:

我们继续滑动滚动条,再次找到类似的请求。我们复制请求链接,单独打开,发现是不同broker的请求页面。我们分析了链接,发现后面一个offset的值一直在变化,每增加15,就会请求新的15条数据。所以你,我们只需要改变offset的值来请求不同的页面。至此,我们已经发现了网站 URL的构造规则,接下来就可以编写代码进行爬取了。
# -*- coding: utf-8 -*-
# # @Author: lemon
# # @Date: 2019-09-19 18:18
# # @Last Modified by: lemon
# # @Last Modified time: 2019-09-19 18:42
# # @function: 爬取链家经纪人数据
import requests
import time
from lxml import etree
import pandas as pd
# 存储 DataFrame 中用到的数据
data = {
'姓名': [],
'职位': [],
'评分': []
}
def spider(list_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
response = requests.get(list_url, headers=headers)
time.sleep(5)
sel = etree.HTML(response.text)
# 先爬取每一位经纪人的整体代码段
agent_list = sel.xpath('//li[@class="pictext flexbox box_center_v lazyload_ulog"]')
for agent in agent_list:
agent_name = agent.xpath('div/div[2]/div[1]/span[1]/a/text()')[0].strip() # 姓名
agent_level = agent.xpath('div/div[2]/div[1]/span[2]/text()')[0].strip() # 职位
agent_score = agent.xpath('div/div[2]/div[1]/span[3]/span[1]/text()')[0].strip() # 评分
print(agent_name, agent_level, agent_score)
data['姓名'].append(agent_name)
data['职位'].append(agent_level)
data['评分'].append(agent_score)
def write_data(data):
frame = pd.DataFrame(data)
frame.to_excel('链家经纪人数据.xlsx')
if __name__ == '__main__':
for i in range(10):
# 根据加载的时候 offset 的变化规律, 构造不同页面的 URL
url = 'https://m.lianjia.com/cs/jingj ... 39%3B + str(i * 15)
print(f'正在爬取 page {i + 1}...')
spider(url)
write_data(data)
这是我们最终抓取的经纪人数据:

2. Selenium 请求百度
由于 Selenium 不是 Python 的标准库,我们首先需要安装 Selenium 库。
pip install selenium
Selenium 需要使用 chromedriver 来驱动 Chrome 浏览器。我们需要下载对应操作系统的版本。您可以参考ChromeDriver和Chrome版本对应参考表和ChromeDriver下载链接进行下载安装。
Selenium 使用 chromedriver 时,既可以将 chromedriver 添加到系统的环境变量中,也可以直接在代码中指定 chromedriver 所在目录。
接下来,我们使用 Selenium 访问百度主页
# -*- coding: utf-8 -*-
# # @Author: lemon
# # @Date: 2019-09-19 19:00
# # @Last Modified by: lemon
# # @Last Modified time: 2019-09-19 19:10
# # @function: Selenium 打开百度
# %%1 从 selenium 中引入 webdriver
from selenium import webdriver
driver = webdriver.Chrome('E:\ChromeDriver\chromedriver.exe') # 初始化 webdriver
driver.get('https://www.baidu.com/') # 使用 webdriver 打开百度首页
search_box = driver.find_element_by_xpath('//*[@id="kw"]') # 使用 xpath 找到搜索框
search_box.send_keys('python') # 在搜索框中搜索关键字
submit = driver.find_element_by_xpath('//*[@id="su"]') # 使用 xpath 找到搜索按钮
submit.click() # 点击搜索按钮进行搜索
可以观察到以下效果: 我们的 Chrome 浏览器正在接收来自自动化测试软件的控制

在后续的文章中,我们会给你一个例子:如何使用Selenium爬取新浪微博的网站,进一步加强你对Selenium的使用。
动态网页抓取(一下动态网页的另一种方法逆向分析啦!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-16 05:02
首先,让我们谈谈动态网页,它们是 HTML 和 CSS 元素,它们以客户端语言更改页面。例如,一个网页通过加载一个网页将你带到另一个页面,但页面的 URL 链接没有改变,或者当你点击空白处时页面会改变颜色。
然后是客户端脚本语言,它们是在浏览器上运行的语言,而不是在服务器上运行的语言。互联网上通常会遇到两种客户端语言:ActionScript(用于开发 Flash 应用程序的语言)和 JavaScript。
JavaScript 常用于为网页添加各种动态功能,为用户提供更流畅、更美观的浏览效果。通常 JavaScript 脚本嵌入在 HTML 中以实现自己的功能。
例如,对于一个下拉加载的动态网页,加载后可以在浏览器的开发者工具的网络中的JS选项中看到它刚刚执行的JavaScript,点击就可以看到代码。
目前已经写了少量爬虫。对于动态网页,比如下拉加载图片,在developer tools/network/image中找到图片,分析图片地址的特征,然后在js中找到javascript文件,里面可能收录如果能找到标准图片信息,或者网页的跳转关系,可以很方便的编写程序,将图片下载到图片地址。
这种方法是逆向分析。
另一种爬取动态网页的方法是模拟浏览器,通常使用 Selenium+PhantomJS。
Selenium 是一个浏览器自动化测试框架,最初是为自动化测试而开发的,现在也用于网络数据采集。框架底层使用 JavaScript 模拟真实用户操作浏览器。执行测试脚本时,浏览器会自动根据脚本代码进行点击、进入、打开、验证等操作,就像真实用户一样,站在终端用户的角度对应用进行测试。
Selenium 没有自己的浏览器,需要与第三方浏览器配合使用。之前用过火狐,每次运行都会打开一个浏览器窗口,程序的运行情况一目了然。另一方面,PhantomJS 是无头浏览器,不显示浏览器窗口。
Selenium+PhantomJS 可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标头以及您需要做的任何其他事情。
2018-03-01 13:50
不知道有没有喜欢的朋友,嘿嘿,,, Ծ^Ծ,,
没有图的答案就注定没有点赞吗?
这是一条更新线路,下面的信息是旧消息。
反正是原答案,不忍心删。如果您不喜欢它,请跳过它。
╯▂╰
我刚刚在寒假学习这个。几天前我想爬一个 网站 。我在开发者工具里看数据,爬成静态网页,然后爬下来就找不到数据了。
后来才知道,在开发者工具中看到的网页源代码是用JavaScript渲染的,没有我想要的数据的源代码是通过Requests获取的。
之前看书的时候,提到过 selenium 模块。考虑到用它来模拟浏览器不容易被逆,我用它爬过12306查票,但是速度真的很慢。测试网速需要设置等待网页刷新的时间。
我能想到的第一个方法是使用 selenium,但我非常反对认为它的速度无法满足我的需求。(呃(~_~;)
那我们就去百度一下,肯定会有其他的解决办法。
然后在CSDN上有一篇非常完整的文章。
用大佬的总结:
动态网页可以通过逆向分析尽可能地逆向,其稳定性和效率是其他解决方案无法比拟的。通常有一个关于爬虫的口口相传的真相。如果在浏览器中点击并使用F12的方式,就可以解决90%的爬虫问题,剩下的10%需要动动脑筋。对于动态页面抓取来说更是如此。如果你能扭转它,试着扭转它。如果无法逆转,那就找一个折中的解决方案。在折衷方案中,可以尽量使用深度控制JS脚本执行方案(难度稍大),其次是基于Browser自动化测试框架的标准(即selenium和PhantomJs)爬取。
欲了解更多信息,请访问 网站:
/yanbober/article/details/73822475?locationNum=3&fps=1
时间:2018-02-10 01:23 查看全部
动态网页抓取(一下动态网页的另一种方法逆向分析啦!!)
首先,让我们谈谈动态网页,它们是 HTML 和 CSS 元素,它们以客户端语言更改页面。例如,一个网页通过加载一个网页将你带到另一个页面,但页面的 URL 链接没有改变,或者当你点击空白处时页面会改变颜色。
然后是客户端脚本语言,它们是在浏览器上运行的语言,而不是在服务器上运行的语言。互联网上通常会遇到两种客户端语言:ActionScript(用于开发 Flash 应用程序的语言)和 JavaScript。
JavaScript 常用于为网页添加各种动态功能,为用户提供更流畅、更美观的浏览效果。通常 JavaScript 脚本嵌入在 HTML 中以实现自己的功能。
例如,对于一个下拉加载的动态网页,加载后可以在浏览器的开发者工具的网络中的JS选项中看到它刚刚执行的JavaScript,点击就可以看到代码。
目前已经写了少量爬虫。对于动态网页,比如下拉加载图片,在developer tools/network/image中找到图片,分析图片地址的特征,然后在js中找到javascript文件,里面可能收录如果能找到标准图片信息,或者网页的跳转关系,可以很方便的编写程序,将图片下载到图片地址。
这种方法是逆向分析。
另一种爬取动态网页的方法是模拟浏览器,通常使用 Selenium+PhantomJS。
Selenium 是一个浏览器自动化测试框架,最初是为自动化测试而开发的,现在也用于网络数据采集。框架底层使用 JavaScript 模拟真实用户操作浏览器。执行测试脚本时,浏览器会自动根据脚本代码进行点击、进入、打开、验证等操作,就像真实用户一样,站在终端用户的角度对应用进行测试。
Selenium 没有自己的浏览器,需要与第三方浏览器配合使用。之前用过火狐,每次运行都会打开一个浏览器窗口,程序的运行情况一目了然。另一方面,PhantomJS 是无头浏览器,不显示浏览器窗口。
Selenium+PhantomJS 可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标头以及您需要做的任何其他事情。
2018-03-01 13:50
不知道有没有喜欢的朋友,嘿嘿,,, Ծ^Ծ,,
没有图的答案就注定没有点赞吗?
这是一条更新线路,下面的信息是旧消息。
反正是原答案,不忍心删。如果您不喜欢它,请跳过它。
╯▂╰
我刚刚在寒假学习这个。几天前我想爬一个 网站 。我在开发者工具里看数据,爬成静态网页,然后爬下来就找不到数据了。
后来才知道,在开发者工具中看到的网页源代码是用JavaScript渲染的,没有我想要的数据的源代码是通过Requests获取的。
之前看书的时候,提到过 selenium 模块。考虑到用它来模拟浏览器不容易被逆,我用它爬过12306查票,但是速度真的很慢。测试网速需要设置等待网页刷新的时间。
我能想到的第一个方法是使用 selenium,但我非常反对认为它的速度无法满足我的需求。(呃(~_~;)
那我们就去百度一下,肯定会有其他的解决办法。
然后在CSDN上有一篇非常完整的文章。
用大佬的总结:
动态网页可以通过逆向分析尽可能地逆向,其稳定性和效率是其他解决方案无法比拟的。通常有一个关于爬虫的口口相传的真相。如果在浏览器中点击并使用F12的方式,就可以解决90%的爬虫问题,剩下的10%需要动动脑筋。对于动态页面抓取来说更是如此。如果你能扭转它,试着扭转它。如果无法逆转,那就找一个折中的解决方案。在折衷方案中,可以尽量使用深度控制JS脚本执行方案(难度稍大),其次是基于Browser自动化测试框架的标准(即selenium和PhantomJs)爬取。
欲了解更多信息,请访问 网站:
/yanbober/article/details/73822475?locationNum=3&fps=1
时间:2018-02-10 01:23
动态网页抓取(微信公众号动态网页抓取设置的技巧与方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-15 17:00
动态网页抓取设置首先要确定你的目标页面在移动端的显示规律,抓取规则。然后把想抓取的内容放到cookie上,定期加载就行了。针对微信公众号的话,
真想对网页做出正确合理判断最好自己搭建爬虫,借助chrome浏览器,google浏览器或者chrome的插件。
恩,这就是你需要学习的,要说拿到自己需要的资源,你需要:1,爬虫。2,网页分析。3,网页解析。看似简单的问题,做起来其实并不容易,爬虫都是对网页进行长期分析而存在的技术,网页分析一般以检测网页是否是https协议为标准,网页解析需要有能力找到网页的cookie或者session,这就是你需要学习的。至于怎么学,用什么工具,这要看你的特点了,看个人兴趣,任何工具都是一样的!。
那就要你去分析这个网站,其实没什么好说的,网上的教程够多了,掌握基本的做为爬虫工程师应该没什么大问题。本人一直坚持认为技术这东西毕竟是内化到你的脑子里,如果说外界环境,那确实有些困难。
以下回答对于大多数技术而言是适用的。如果网站对爬虫非常友好,那么python爬虫常用库有scrapy、beautifulsoup等,也就是@zhuyizhu要求的htmlapi,但是正因为如此,选择爬虫的人也相对较少。如果网站对爬虫非常不友好,那么liquidflask这样的框架可以帮助你爬下,就是换汤不换药的简单逻辑。
b站的爬虫库就是这样,以下就以此类网站为例。-分析网站用于爬虫的网站结构最常用的有urllib模块,urllib模块介绍比较简单,就不描述了。通过urllib.request函数,我们不用new一个对象,而是构造一个request对象,然后request来请求网站资源。爬虫本质就是一个request对象,因此我们只需要构造urllib.request对象,然后访问就可以了。
下面举几个栗子:-构造beemail的请求用户发送一封电子邮件给电话联系人,对方查看该邮件并回复。1.网站情况beemail网站支持多帐号注册、帐号删除、注册后数据消失、注册结束和暂停注册这五种状态。那么beemail.basic(username='admin',password='root')这个参数的功能是什么呢?beemail.basic(username='admin',password='root')这个参数的功能是设置请求最多可以通过的用户名和密码。
beemail.basic(username='admin',password='root')这个参数的功能是设置请求默认username,然后默认用户名的用户名和密码就是你注册邮箱的用户名和密码。这个功能的效果就是对方点击发送电子邮件,然后你只能发送文本邮件给他,并且和他的。 查看全部
动态网页抓取(微信公众号动态网页抓取设置的技巧与方法)
动态网页抓取设置首先要确定你的目标页面在移动端的显示规律,抓取规则。然后把想抓取的内容放到cookie上,定期加载就行了。针对微信公众号的话,
真想对网页做出正确合理判断最好自己搭建爬虫,借助chrome浏览器,google浏览器或者chrome的插件。
恩,这就是你需要学习的,要说拿到自己需要的资源,你需要:1,爬虫。2,网页分析。3,网页解析。看似简单的问题,做起来其实并不容易,爬虫都是对网页进行长期分析而存在的技术,网页分析一般以检测网页是否是https协议为标准,网页解析需要有能力找到网页的cookie或者session,这就是你需要学习的。至于怎么学,用什么工具,这要看你的特点了,看个人兴趣,任何工具都是一样的!。
那就要你去分析这个网站,其实没什么好说的,网上的教程够多了,掌握基本的做为爬虫工程师应该没什么大问题。本人一直坚持认为技术这东西毕竟是内化到你的脑子里,如果说外界环境,那确实有些困难。
以下回答对于大多数技术而言是适用的。如果网站对爬虫非常友好,那么python爬虫常用库有scrapy、beautifulsoup等,也就是@zhuyizhu要求的htmlapi,但是正因为如此,选择爬虫的人也相对较少。如果网站对爬虫非常不友好,那么liquidflask这样的框架可以帮助你爬下,就是换汤不换药的简单逻辑。
b站的爬虫库就是这样,以下就以此类网站为例。-分析网站用于爬虫的网站结构最常用的有urllib模块,urllib模块介绍比较简单,就不描述了。通过urllib.request函数,我们不用new一个对象,而是构造一个request对象,然后request来请求网站资源。爬虫本质就是一个request对象,因此我们只需要构造urllib.request对象,然后访问就可以了。
下面举几个栗子:-构造beemail的请求用户发送一封电子邮件给电话联系人,对方查看该邮件并回复。1.网站情况beemail网站支持多帐号注册、帐号删除、注册后数据消失、注册结束和暂停注册这五种状态。那么beemail.basic(username='admin',password='root')这个参数的功能是什么呢?beemail.basic(username='admin',password='root')这个参数的功能是设置请求最多可以通过的用户名和密码。
beemail.basic(username='admin',password='root')这个参数的功能是设置请求默认username,然后默认用户名的用户名和密码就是你注册邮箱的用户名和密码。这个功能的效果就是对方点击发送电子邮件,然后你只能发送文本邮件给他,并且和他的。
动态网页抓取(中结合selenium脚本的登录页面抓取位于地图右侧区域 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-15 09:23
)
我用python结合selenium编写了一个脚本,从它的登录页面获取位于地图右侧区域的不同属性的链接。
链接到着陆页
当我从 chrome 手动单击每个块时,我在新选项卡中看到 /for_sale/ 收录此部分的链接,而我的脚本获取收录 /homedetails/ 的内容。
我怎样才能获得结果的数量(例如 153 个待售房屋)和正确的房产链接?
到目前为止我的尝试:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
link = "https://www.zillow.com/homes/33155_rb/"
driver = webdriver.Chrome()
wait = WebDriverWait(driver, 10)
driver.get(link)
itemcount = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,"#map-result-count-message h2")))
print(itemcount.text)
for item in wait.until(EC.visibility_of_all_elements_located((By.CSS_SELECTOR,".zsg-photo-card-overlay-link"))):
print(item.get_attribute("href"))
driver.quit()
当前输出之一:
https://www.zillow.com/homedet ... zpid/
这样的预期输出之一:
https://www.zillow.com/homes/f ... 76783,-80.256072,25.695446,-80.364905_rect/12_zm/0_mmm/ 查看全部
动态网页抓取(中结合selenium脚本的登录页面抓取位于地图右侧区域
)
我用python结合selenium编写了一个脚本,从它的登录页面获取位于地图右侧区域的不同属性的链接。
链接到着陆页
当我从 chrome 手动单击每个块时,我在新选项卡中看到 /for_sale/ 收录此部分的链接,而我的脚本获取收录 /homedetails/ 的内容。
我怎样才能获得结果的数量(例如 153 个待售房屋)和正确的房产链接?
到目前为止我的尝试:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
link = "https://www.zillow.com/homes/33155_rb/"
driver = webdriver.Chrome()
wait = WebDriverWait(driver, 10)
driver.get(link)
itemcount = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,"#map-result-count-message h2")))
print(itemcount.text)
for item in wait.until(EC.visibility_of_all_elements_located((By.CSS_SELECTOR,".zsg-photo-card-overlay-link"))):
print(item.get_attribute("href"))
driver.quit()
当前输出之一:
https://www.zillow.com/homedet ... zpid/
这样的预期输出之一:
https://www.zillow.com/homes/f ... 76783,-80.256072,25.695446,-80.364905_rect/12_zm/0_mmm/
动态网页抓取(如何爬取网页数据?(一)吧(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2022-03-13 18:01
这里有一个简单的介绍。以捕获静态和动态数据为例,实验环境为win10+python3.6+pycharm5.0。主要内容如下:
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数和评论数四个字段,如下:
对应的网页源码如下,收录我们需要的数据:
2.对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:
程序运行截图如下,爬取数据成功:
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额、进度五个字段。截图如下:
打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难。它们是入门级爬虫。网页的结构比较简单。最重要的是进行抓包分析,分析并提取页面。数据爬取的框架可以更方便、更高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
如何抓取网页数据?
1、网址管理
首先,url管理器在待爬取的集合中添加新的url,判断待添加的url是否在容器中以及是否有待爬取的url,获取待爬取的url,将url从要抓取的 url。集合移动到爬取的url集合
对于页面下载,下载器将接收到的url传给互联网,互联网将html文件返回给下载器,下载器保存在本地。一般来说,下载器会以分布式的方式部署。一是提交效率,二是启动。请求代理
2、内容提取
页面解析器的主要任务是从获取的html网页字符串中获取有价值的感兴趣的数据和一个新的url列表。常用的数据提取方法包括基于 CSS 选择器、正则表达式和 xpath 的规则提取。一般在提取后,会对数据进行一定程度的清洗或定制,从而将请求的非结构化数据转化为我们需要的结构化数据。
3、数据存储
将数据保存到相关的数据库、队列、文件等,方便数据计算和与应用程序对接。
爬虫采集已经成为很多公司和个人的需求,但正因为如此,反爬虫技术层出不穷,比如时间限制、IP限制、验证码限制等,可能会导致爬虫失败,所以也出现了代理IP、调整时限等多种方法来解决反爬虫限制。当然,具体的操作方法还需要有针对性的研究。兔子动态IP软件可实现一键IP自动切换,千万级IP盘点,自动去重,支持电脑、手机多终端使用。
"
如何捕获有关 Web 更改的信息?
你可以做我的小粉丝吗?可以吗? 查看全部
动态网页抓取(如何爬取网页数据?(一)吧(图))
这里有一个简单的介绍。以捕获静态和动态数据为例,实验环境为win10+python3.6+pycharm5.0。主要内容如下:
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数和评论数四个字段,如下:

对应的网页源码如下,收录我们需要的数据:

2.对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:

程序运行截图如下,爬取数据成功:

1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额、进度五个字段。截图如下:

打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:

2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:

程序运行截图如下,已经成功抓取数据:

至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难。它们是入门级爬虫。网页的结构比较简单。最重要的是进行抓包分析,分析并提取页面。数据爬取的框架可以更方便、更高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。

如何抓取网页数据?
1、网址管理
首先,url管理器在待爬取的集合中添加新的url,判断待添加的url是否在容器中以及是否有待爬取的url,获取待爬取的url,将url从要抓取的 url。集合移动到爬取的url集合
对于页面下载,下载器将接收到的url传给互联网,互联网将html文件返回给下载器,下载器保存在本地。一般来说,下载器会以分布式的方式部署。一是提交效率,二是启动。请求代理

2、内容提取
页面解析器的主要任务是从获取的html网页字符串中获取有价值的感兴趣的数据和一个新的url列表。常用的数据提取方法包括基于 CSS 选择器、正则表达式和 xpath 的规则提取。一般在提取后,会对数据进行一定程度的清洗或定制,从而将请求的非结构化数据转化为我们需要的结构化数据。

3、数据存储
将数据保存到相关的数据库、队列、文件等,方便数据计算和与应用程序对接。
爬虫采集已经成为很多公司和个人的需求,但正因为如此,反爬虫技术层出不穷,比如时间限制、IP限制、验证码限制等,可能会导致爬虫失败,所以也出现了代理IP、调整时限等多种方法来解决反爬虫限制。当然,具体的操作方法还需要有针对性的研究。兔子动态IP软件可实现一键IP自动切换,千万级IP盘点,自动去重,支持电脑、手机多终端使用。

"
如何捕获有关 Web 更改的信息?
你可以做我的小粉丝吗?可以吗?
动态网页抓取(这世上如果有天堂,天堂应该是图书馆的模样(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-13 18:00
如果这个世界上有天堂,天堂应该就像一个图书馆。---【阿根廷】豪尔赫·路易斯·博尔赫斯
好开心,终于可以批量下载茜茜公主的照片了,好漂亮的女人啊!因为刘亦菲在这个页面上的星图画墙是动态页面,直接阅读页面内容是无法获取图片信息的,所以我们需要另辟蹊径。
在解决动态网页时,我们通常可以采取以下两种方法:
1.通过抓包工具分析js和ajax的请求,模拟请求获取js加载的数据(对于小白来说还是有难度的)。
2.调用浏览器内核获取加载网页的源代码,然后解析源代码。
本文主要使用selenium+python+BeautifulSoup的结构来抓图。
a) Selenium 是一种用于模拟浏览器和进行自动化测试的工具。它提供了一组 API 来与真正的浏览器内核交互。使用起来也比较简单。
b)BeautifulSoup是一个解析网页信息的工具,可以从网页中过滤出我们想要的东西。
项目目的:从刘亦菲的图片栏中抓取图片并存储在电脑上
一。使用 selenium 模拟打开浏览器
1driver = webdriver.Firefox()
2driver.get('http://image.baidu.com/activit ... 92512 1383889887?&albumtype=0')
3
1 *二、解析网页信息*
2
我们先按F12查看网页的评论信息,通过图片定位评论元素。可以看到下图:
通过分析几张图片的信息,我们发现每张图片的信息格式都是一样的,所以我们可以通过BeautifulSoup找到
元素节点,然后通过访问其子节点两次,获得到图像的链接,即“src”信息。
三、使用PIL模块存储图片
上面是通用模块,下面是程序代码:
1#-*-coding:utf-8 -*-
2from selenium import webdriver
3from selenium.webdriver.common.keys import Keys
4from selenium.webdriver.support.ui import WebDriverWait
5from bs4 import BeautifulSoup
6from PIL import Image
7import urllib2
8import StringIO
9import time
10
11
12driver = webdriver.Firefox()
13driver.get('http://image.baidu.com/activit ... 92512 1383889887?&albumtype=0')
14soup = BeautifulSoup(driver.page_source)
15all = soup.find_all("div", class_="img-container")
16time.sleep(2)
17count =0
18number=0
19for each in all:
20 number+=1
21 picUrl = each.contents[0].contents[0]['src']
22 print picUrl
23 try:
24 imgString=urllib2.urlopen(picUrl).read()
25 im=Image.open(StringIO.StringIO(imgString))
26 except:
27 continue
28 count += 1
29 print count
30 imgPath='/home/fiona/fei/photo/'+ str(count)+'.jpg'
31 im.save(imgPath)
32
33print number
34driver.quit()
35
1 提取出来的图片如下:
2
项目问题:
一页有60多张照片,但只拍了30张。我不知道原因。有知道的可以给我留言,谢谢!
参与信息:
(好文章) 查看全部
动态网页抓取(这世上如果有天堂,天堂应该是图书馆的模样(图))
如果这个世界上有天堂,天堂应该就像一个图书馆。---【阿根廷】豪尔赫·路易斯·博尔赫斯
好开心,终于可以批量下载茜茜公主的照片了,好漂亮的女人啊!因为刘亦菲在这个页面上的星图画墙是动态页面,直接阅读页面内容是无法获取图片信息的,所以我们需要另辟蹊径。
在解决动态网页时,我们通常可以采取以下两种方法:
1.通过抓包工具分析js和ajax的请求,模拟请求获取js加载的数据(对于小白来说还是有难度的)。
2.调用浏览器内核获取加载网页的源代码,然后解析源代码。
本文主要使用selenium+python+BeautifulSoup的结构来抓图。
a) Selenium 是一种用于模拟浏览器和进行自动化测试的工具。它提供了一组 API 来与真正的浏览器内核交互。使用起来也比较简单。
b)BeautifulSoup是一个解析网页信息的工具,可以从网页中过滤出我们想要的东西。
项目目的:从刘亦菲的图片栏中抓取图片并存储在电脑上
一。使用 selenium 模拟打开浏览器
1driver = webdriver.Firefox()
2driver.get('http://image.baidu.com/activit ... 92512 1383889887?&albumtype=0')
3
1 *二、解析网页信息*
2
我们先按F12查看网页的评论信息,通过图片定位评论元素。可以看到下图:
通过分析几张图片的信息,我们发现每张图片的信息格式都是一样的,所以我们可以通过BeautifulSoup找到
元素节点,然后通过访问其子节点两次,获得到图像的链接,即“src”信息。
三、使用PIL模块存储图片
上面是通用模块,下面是程序代码:
1#-*-coding:utf-8 -*-
2from selenium import webdriver
3from selenium.webdriver.common.keys import Keys
4from selenium.webdriver.support.ui import WebDriverWait
5from bs4 import BeautifulSoup
6from PIL import Image
7import urllib2
8import StringIO
9import time
10
11
12driver = webdriver.Firefox()
13driver.get('http://image.baidu.com/activit ... 92512 1383889887?&albumtype=0')
14soup = BeautifulSoup(driver.page_source)
15all = soup.find_all("div", class_="img-container")
16time.sleep(2)
17count =0
18number=0
19for each in all:
20 number+=1
21 picUrl = each.contents[0].contents[0]['src']
22 print picUrl
23 try:
24 imgString=urllib2.urlopen(picUrl).read()
25 im=Image.open(StringIO.StringIO(imgString))
26 except:
27 continue
28 count += 1
29 print count
30 imgPath='/home/fiona/fei/photo/'+ str(count)+'.jpg'
31 im.save(imgPath)
32
33print number
34driver.quit()
35
1 提取出来的图片如下:
2
项目问题:
一页有60多张照片,但只拍了30张。我不知道原因。有知道的可以给我留言,谢谢!
参与信息:
(好文章)
动态网页抓取( 不能动态加载的内容静态网页的两种方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2022-03-13 17:26
不能动态加载的内容静态网页的两种方法
)
一、动态网页爬取介绍
在很多网站中,使用javascript写网站,很多内容不会出现在HTML源代码中,所以不能使用之前爬取静态网页的方法。有一种异步技术叫做AJAX,它的价值在于通过后台和服务器之间进行少量的数据转换,可以实现网页的异步更新。也就是说,更新网页的一部分而不重新加载整个网页。减少网页上重复内容的下载,节省流量。但随之而来的麻烦是我们在HTML代码中找不到我们想要的数据。解决这种爬取动态加载的内容,有两种方法:
通过浏览器检查元素解析地址 使用 Selenium 模拟浏览器抓取 二、 解析真实地址抓取
我们要的数据不是HTML,而是可以找到数据的真实地址。请求这个地址也能找到想要的数据,也能完成书中的例子。首先打开网站:,这个网站是JS写的,鼠标右键,点击Check。刷新页面,可以看到网页的所有文件都加载完毕了。这个过程就是抓包的过程。然后,点击网络找到收录数据的文件,记住是json数据。
单击标题以查找真实地址。然后将请求发送到真实地址。
1.发送请求,获取数据
import requests
# 构建url
url = """https://api-zero.livere.com/v1 ... ot%3B
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
r = requests.get(url, headers=headers)
print(r.text)
2.解析数据
要从json数据中提取注释,首先我们需要找到符合json格式的部分。然后,使用 json.loads 将字符串格式的响应正文转换为 json 数据。然后,根据json数据的结构,可以提取出评论列表comment_list。最后通过for循环,提取注释文本,并输出打印。
import json
json_string = r.text
# 找到符合json格式的数据
json_string = json_string[json_string.find('{'): -2]
# 转换为json格式
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print(message)
三、 模拟浏览器通过 selenium 爬行
一些网站的地址加密,使得一些变量分析不清楚。接下来,我们将使用第二种方法,使用浏览器渲染引擎。在显示网页时直接使用浏览器解析 HTML、应用 CSS 样式和执行 JavaScript 语句。该方法会打开浏览器,加载网页,自动操作浏览器浏览各种网页,顺便抓取数据,将抓取的动态网页变为抓取静态网页。我们可以使用 selenium 库来模拟浏览器来完成爬取。Selenium 是用于 Web 应用程序测试的工具。它直接在浏览器中运行,浏览器根据脚本代码自动点击、进入、打开、验证。
1. 安装硒
点安装硒
下载“geckodriver”并位于 Python 的安装目录中。
2. 使用 selenium 爬取数据
第 1 步:找到评论的 HTML 代码标记。使用火狐,点击页面,找到标签,找到评论数据
第二步:尝试获取评论数据,使用以下代码获取数据。
# 使用CSS选择器查找元素,找到class为'reply-content'的div元素
comment = driver.find_element_by_css_selector('div.reply-content')
# 通过元素的tag去寻找‘p’元素
content = comment.find_element_by_tag_name('p')
print(content.text)
还是有问题啊 网页打不开啊
也可能存在解析失败报错的情况,报“Message: Unable to locate element: div.reply_content”的错误。这是因为源代码需要解析成iframe,需要添加下面这行代码。
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")) 查看全部
动态网页抓取(
不能动态加载的内容静态网页的两种方法
)
一、动态网页爬取介绍
在很多网站中,使用javascript写网站,很多内容不会出现在HTML源代码中,所以不能使用之前爬取静态网页的方法。有一种异步技术叫做AJAX,它的价值在于通过后台和服务器之间进行少量的数据转换,可以实现网页的异步更新。也就是说,更新网页的一部分而不重新加载整个网页。减少网页上重复内容的下载,节省流量。但随之而来的麻烦是我们在HTML代码中找不到我们想要的数据。解决这种爬取动态加载的内容,有两种方法:
通过浏览器检查元素解析地址 使用 Selenium 模拟浏览器抓取 二、 解析真实地址抓取
我们要的数据不是HTML,而是可以找到数据的真实地址。请求这个地址也能找到想要的数据,也能完成书中的例子。首先打开网站:,这个网站是JS写的,鼠标右键,点击Check。刷新页面,可以看到网页的所有文件都加载完毕了。这个过程就是抓包的过程。然后,点击网络找到收录数据的文件,记住是json数据。

单击标题以查找真实地址。然后将请求发送到真实地址。

1.发送请求,获取数据
import requests
# 构建url
url = """https://api-zero.livere.com/v1 ... ot%3B
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
r = requests.get(url, headers=headers)
print(r.text)

2.解析数据
要从json数据中提取注释,首先我们需要找到符合json格式的部分。然后,使用 json.loads 将字符串格式的响应正文转换为 json 数据。然后,根据json数据的结构,可以提取出评论列表comment_list。最后通过for循环,提取注释文本,并输出打印。
import json
json_string = r.text
# 找到符合json格式的数据
json_string = json_string[json_string.find('{'): -2]
# 转换为json格式
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print(message)

三、 模拟浏览器通过 selenium 爬行
一些网站的地址加密,使得一些变量分析不清楚。接下来,我们将使用第二种方法,使用浏览器渲染引擎。在显示网页时直接使用浏览器解析 HTML、应用 CSS 样式和执行 JavaScript 语句。该方法会打开浏览器,加载网页,自动操作浏览器浏览各种网页,顺便抓取数据,将抓取的动态网页变为抓取静态网页。我们可以使用 selenium 库来模拟浏览器来完成爬取。Selenium 是用于 Web 应用程序测试的工具。它直接在浏览器中运行,浏览器根据脚本代码自动点击、进入、打开、验证。
1. 安装硒
点安装硒
下载“geckodriver”并位于 Python 的安装目录中。

2. 使用 selenium 爬取数据
第 1 步:找到评论的 HTML 代码标记。使用火狐,点击页面,找到标签,找到评论数据

第二步:尝试获取评论数据,使用以下代码获取数据。
# 使用CSS选择器查找元素,找到class为'reply-content'的div元素
comment = driver.find_element_by_css_selector('div.reply-content')
# 通过元素的tag去寻找‘p’元素
content = comment.find_element_by_tag_name('p')
print(content.text)
还是有问题啊 网页打不开啊
也可能存在解析失败报错的情况,报“Message: Unable to locate element: div.reply_content”的错误。这是因为源代码需要解析成iframe,需要添加下面这行代码。
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
动态网页抓取(使用多线程的方式采集某站4K高清壁纸(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-03-12 23:14
一、背景
大家好,我是皮皮。对于不同的数据,我们采用不同的采集方式,图片、视频、音频、文字都是不同的。由于网站图片素材太多,今天我们采用多线程方式采集一站4K高清壁纸。
二、页面分析
目标网站:
http://www.bizhi88.com/3840x2160/
如图,有278页,这里我们抓取前100页的壁纸图片保存在本地;
解析页面
如图,鱼的图片在一个大盒子里( ),下面每个div对应一张高清壁纸;
然后是各个页面的div标签中壁纸图片数据的各种信息:1.链接;2. 名称;下面是对xpath的分析;
imgLink = each.xpath("./a[1]/img/@data-original")[0]
name = each.xpath("./a[1]/img/@alt")[0]
有一个注意事项:
图片标签既有src属性,也有data-original属性,都对应图片的url地址。我们一般使用后者,因为data-original-src是自定义属性,图片的实际地址,src属性要求页面完全加载。出现,否则不会得到对应的地址;
三、采集想法
上面说了,图片数据太多,我们不可能写一个for循环来一个一个下载,所以必须使用多线程或者多进程,然后把这么多的数据队列扔给线程用于处理的池或进程池;在python中,multiprocessing Pool 进程池,multiprocessing.dummy 非常好用,
multiprocessing.dummy模块和multiprocessing模块的API是通用的;代码切换更灵活;
页面网址规则:
'http://www.bizhi88.com/s/470/1.html' # 第一页
'http://www.bizhi88.com/s/470/2.html' # 第二页
'http://www.bizhi88.com/s/470/3.html' # 第三页
构造的网址:
page = 'http://www.bizhi88.com/s/470/{}.html'.format(i)
然后我们自定义了两个函数,一个是抓取和解析页面(spider),另一个是下载数据(download),打开线程池,使用for循环构建13个页面的url,存放在list中,作为一个url 队列,使用 pool.map() 方法进行爬虫和爬虫操作;
def map(self, fn, *iterables, timeout=None, chunksize=1):
"""Returns an iterator equivalent to map(fn, iter)”“”
这里我们的使用是:pool.map(spider,page) # spider:爬虫函数;page:url队列
功能:提取列表中的每一个元素作为函数的参数,一个一个地创建一个进程,放入进程池中;
参数1:要执行的函数;
参数2:迭代器,将迭代器中的数字作为参数依次传递给函数;
四、数据采集
导入相关第三方库
from lxml import etree # 解析
import requests # 请求
from multiprocessing.dummy import Pool as ThreadPool # 并发
import time # 效率
页面数据分析
def spider(url):
html = requests.get(url, headers=headers)
selector = etree.HTML(html.text)
contents = selector.xpath("//div[@class='flex-img auto mt']/div")
item = {}
for each in contents:
imgLink = each.xpath("./a[1]/img/@data-original")[0]
name = each.xpath("./a[1]/img/@alt")[0]
item['Link'] = imgLink
item['name'] = name
towrite(item)
下载下载图片
def download_pic(contdict):
name = contdict['name']
link = contdict['Link']
with open('img/' + name + '.jpg','wb') as f:
data = requests.get(link)
cont = data.content
f.write(cont)
print('图片' + name + '下载成功!')
main() 主函数
pool = ThreadPool(6)
page = []
for i in range(1, 101):
newpage = 'http://www.bizhi88.com/s/470/{}.html'.format(i)
page.append(newpage)
result = pool.map(spider, page)
pool.close()
pool.join()
阐明:
在 main 函数中,我们更喜欢创建六个线程池;通过for循环动态构造100个url;使用map()函数对线程池中的url进行数据解析和存储操作;当线程池关闭时,线程池并没有关闭,只是将状态变为不能再次插入元素的状态;
五、程序运行
if __name__ == '__main__':
start = time.time() # 开始计时
main()
print(end - start) # 时间差
结果如下:
当然这里只截取了部分图片,一共爬取了2000+张图片。
六、总结
这次我们使用多线程爬取了一张壁纸网站的高清图片。如果我们使用requests,很明显同步请求和下载数据比较慢,所以我们使用多线程的方式下载图片,提高了爬取速度。以效率为例。 查看全部
动态网页抓取(使用多线程的方式采集某站4K高清壁纸(组图))
一、背景
大家好,我是皮皮。对于不同的数据,我们采用不同的采集方式,图片、视频、音频、文字都是不同的。由于网站图片素材太多,今天我们采用多线程方式采集一站4K高清壁纸。
二、页面分析
目标网站:
http://www.bizhi88.com/3840x2160/
如图,有278页,这里我们抓取前100页的壁纸图片保存在本地;
解析页面
如图,鱼的图片在一个大盒子里( ),下面每个div对应一张高清壁纸;
然后是各个页面的div标签中壁纸图片数据的各种信息:1.链接;2. 名称;下面是对xpath的分析;
imgLink = each.xpath("./a[1]/img/@data-original")[0]
name = each.xpath("./a[1]/img/@alt")[0]
有一个注意事项:
图片标签既有src属性,也有data-original属性,都对应图片的url地址。我们一般使用后者,因为data-original-src是自定义属性,图片的实际地址,src属性要求页面完全加载。出现,否则不会得到对应的地址;
三、采集想法
上面说了,图片数据太多,我们不可能写一个for循环来一个一个下载,所以必须使用多线程或者多进程,然后把这么多的数据队列扔给线程用于处理的池或进程池;在python中,multiprocessing Pool 进程池,multiprocessing.dummy 非常好用,
multiprocessing.dummy模块和multiprocessing模块的API是通用的;代码切换更灵活;
页面网址规则:
'http://www.bizhi88.com/s/470/1.html' # 第一页
'http://www.bizhi88.com/s/470/2.html' # 第二页
'http://www.bizhi88.com/s/470/3.html' # 第三页
构造的网址:
page = 'http://www.bizhi88.com/s/470/{}.html'.format(i)
然后我们自定义了两个函数,一个是抓取和解析页面(spider),另一个是下载数据(download),打开线程池,使用for循环构建13个页面的url,存放在list中,作为一个url 队列,使用 pool.map() 方法进行爬虫和爬虫操作;
def map(self, fn, *iterables, timeout=None, chunksize=1):
"""Returns an iterator equivalent to map(fn, iter)”“”
这里我们的使用是:pool.map(spider,page) # spider:爬虫函数;page:url队列
功能:提取列表中的每一个元素作为函数的参数,一个一个地创建一个进程,放入进程池中;
参数1:要执行的函数;
参数2:迭代器,将迭代器中的数字作为参数依次传递给函数;
四、数据采集
导入相关第三方库
from lxml import etree # 解析
import requests # 请求
from multiprocessing.dummy import Pool as ThreadPool # 并发
import time # 效率
页面数据分析
def spider(url):
html = requests.get(url, headers=headers)
selector = etree.HTML(html.text)
contents = selector.xpath("//div[@class='flex-img auto mt']/div")
item = {}
for each in contents:
imgLink = each.xpath("./a[1]/img/@data-original")[0]
name = each.xpath("./a[1]/img/@alt")[0]
item['Link'] = imgLink
item['name'] = name
towrite(item)
下载下载图片
def download_pic(contdict):
name = contdict['name']
link = contdict['Link']
with open('img/' + name + '.jpg','wb') as f:
data = requests.get(link)
cont = data.content
f.write(cont)
print('图片' + name + '下载成功!')
main() 主函数
pool = ThreadPool(6)
page = []
for i in range(1, 101):
newpage = 'http://www.bizhi88.com/s/470/{}.html'.format(i)
page.append(newpage)
result = pool.map(spider, page)
pool.close()
pool.join()
阐明:
在 main 函数中,我们更喜欢创建六个线程池;通过for循环动态构造100个url;使用map()函数对线程池中的url进行数据解析和存储操作;当线程池关闭时,线程池并没有关闭,只是将状态变为不能再次插入元素的状态;
五、程序运行
if __name__ == '__main__':
start = time.time() # 开始计时
main()
print(end - start) # 时间差
结果如下:
当然这里只截取了部分图片,一共爬取了2000+张图片。
六、总结
这次我们使用多线程爬取了一张壁纸网站的高清图片。如果我们使用requests,很明显同步请求和下载数据比较慢,所以我们使用多线程的方式下载图片,提高了爬取速度。以效率为例。
动态网页抓取(用RSelenium打造灵活强大的网络爬虫(youtobe+XML) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-11 16:02
)
关于基础网络数据爬取相关内容,本公众号做了很多分享,尤其是R语言的爬虫框架(RCurl+XML/httr+rvest[xml2+selectr])形成了比较丰富的教程体系。
但是这一切都是基于静态页面(抓包和API访问除外),而很多动态网页并没有提供API访问,所以我们只能希望selenium是基于浏览器驱动的技术来完成的。
幸运的是,R语言中已经有了一个selenium接口包,即RSelenium包,它让我们爬取动态网页成为可能。今年年初,我给实习生网站写了一个爬虫,是用Rwebdriver完成的,Rwebdriver是另一个R语言基于selenium驱动的接口包。
实习僧招聘网络爬虫数据可视化
当时技术还不成熟,想法也比较幼稚。我用导航器突然遍历了 500 页的内容。虽然最后全部数据都爬完了,但是耗时比较长(将近40分钟),效率也比较低。(有兴趣的朋友可以参考上面的文章,不过练习生和尚官网最近大改版,现在爬的难度肯定比以前难多了!那个代码可能不可用)
最近抽空学习了RSelenium包的相关内容。在此感谢陈延平先生在 R 语言上海会议上的“用 RSelenium 构建灵活强大的 Web Crawler”的演讲。,其中的一些细节解决了我最近的一些困惑,在此感谢。
陈彦平老师讲课:《用RSelenium搭建灵活强大的网络爬虫》 一个老外关于RSelenium的介绍视频(各位青年请自行出国网站):
目前有几个R语言可以解析动态网页的包(欢迎补充):
本节以下内容正式分享今天的案例,目标是拉钩网(不要问为什么,因为我之前没有爬过钩)!
在介绍案例之前,请确保系统具备以下条件:
本地有selenium服务器,添加系统路径;本地有一个plantomjs浏览器并添加系统路径;RSelenium 软件包已安装。
因为涉及到自动点击操作,Chrome浏览器整个下午都在点击链接失败,找到原因,是因为拉钩页面很长,而且下一页按钮不在默认窗口内,还有js脚本用于控制滑块。失败了,原因不明,看到有人用firefox浏览器测试成功,我还没试过,这里我用的是plantomjs无头浏览器(不用考虑元素是否被窗口挡住了。)
R语言版本:
#!!!这两句是在cmd后者PowerShell中运行的!
#RSelenium服务未关闭之前,请务必保持该窗口状态!
###启动selenium服务:
cd D:\
java -jar selenium-server-standalone-3.3.1.jar
##selenium服务器也可以直接在R语言中启动(无弹出窗口)
system("java -jar \"D:/selenium-server-standalone-2.53.1.jar\"",wait = FALSE,invisible = FALSE)
#加载包
library("RSelenium")
library("magrittr")
library("xml2")
启动服务
#给plantomjs浏览器伪装UserAgent
eCap % xml_text(trim=TRUE)
#职位所述行业
position.industry % read_html() %>% xml_find_all('//div[@class="industry"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "",.)
#职位福利
position.bonus % read_html() %>% xml_find_all('//div[@class="list_item_bot"]/div[@class="li_b_l"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "/",.)
#职位工作环境
position.environment% read_html() %>% xml_find_all('//div[@class="li_b_r"]') %>% xml_text(trim=TRUE)
#收集数据
mydata% xml_find_all('//div[@class="page-number"]/span[1]') %>% xml_text() !="30"){
#如果页面未到尾部,则点击下一页
remDr$findElement('xpath','//div[@class="pager_container"]/a[last()]')$clickElement()
#但因当前任务进度
cat(sprintf("第【%d】页抓取成功",i),sep = "\n")
} else {
#如果页面到尾部则跳出while循环
break
}
}
#跳出循环后关闭remDr服务窗口
remDr$close()
#但因全局任务状态(也即任务结束)
cat("all work is done!!!",sep = "\n")
#返回最终数据
return(myresult)
}
运行抓取功能
<p>url 查看全部
动态网页抓取(用RSelenium打造灵活强大的网络爬虫(youtobe+XML)
)
关于基础网络数据爬取相关内容,本公众号做了很多分享,尤其是R语言的爬虫框架(RCurl+XML/httr+rvest[xml2+selectr])形成了比较丰富的教程体系。
但是这一切都是基于静态页面(抓包和API访问除外),而很多动态网页并没有提供API访问,所以我们只能希望selenium是基于浏览器驱动的技术来完成的。
幸运的是,R语言中已经有了一个selenium接口包,即RSelenium包,它让我们爬取动态网页成为可能。今年年初,我给实习生网站写了一个爬虫,是用Rwebdriver完成的,Rwebdriver是另一个R语言基于selenium驱动的接口包。
实习僧招聘网络爬虫数据可视化
当时技术还不成熟,想法也比较幼稚。我用导航器突然遍历了 500 页的内容。虽然最后全部数据都爬完了,但是耗时比较长(将近40分钟),效率也比较低。(有兴趣的朋友可以参考上面的文章,不过练习生和尚官网最近大改版,现在爬的难度肯定比以前难多了!那个代码可能不可用)
最近抽空学习了RSelenium包的相关内容。在此感谢陈延平先生在 R 语言上海会议上的“用 RSelenium 构建灵活强大的 Web Crawler”的演讲。,其中的一些细节解决了我最近的一些困惑,在此感谢。
陈彦平老师讲课:《用RSelenium搭建灵活强大的网络爬虫》 一个老外关于RSelenium的介绍视频(各位青年请自行出国网站):
目前有几个R语言可以解析动态网页的包(欢迎补充):
本节以下内容正式分享今天的案例,目标是拉钩网(不要问为什么,因为我之前没有爬过钩)!
在介绍案例之前,请确保系统具备以下条件:
本地有selenium服务器,添加系统路径;本地有一个plantomjs浏览器并添加系统路径;RSelenium 软件包已安装。
因为涉及到自动点击操作,Chrome浏览器整个下午都在点击链接失败,找到原因,是因为拉钩页面很长,而且下一页按钮不在默认窗口内,还有js脚本用于控制滑块。失败了,原因不明,看到有人用firefox浏览器测试成功,我还没试过,这里我用的是plantomjs无头浏览器(不用考虑元素是否被窗口挡住了。)
R语言版本:
#!!!这两句是在cmd后者PowerShell中运行的!
#RSelenium服务未关闭之前,请务必保持该窗口状态!
###启动selenium服务:
cd D:\
java -jar selenium-server-standalone-3.3.1.jar
##selenium服务器也可以直接在R语言中启动(无弹出窗口)
system("java -jar \"D:/selenium-server-standalone-2.53.1.jar\"",wait = FALSE,invisible = FALSE)
#加载包
library("RSelenium")
library("magrittr")
library("xml2")
启动服务
#给plantomjs浏览器伪装UserAgent
eCap % xml_text(trim=TRUE)
#职位所述行业
position.industry % read_html() %>% xml_find_all('//div[@class="industry"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "",.)
#职位福利
position.bonus % read_html() %>% xml_find_all('//div[@class="list_item_bot"]/div[@class="li_b_l"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "/",.)
#职位工作环境
position.environment% read_html() %>% xml_find_all('//div[@class="li_b_r"]') %>% xml_text(trim=TRUE)
#收集数据
mydata% xml_find_all('//div[@class="page-number"]/span[1]') %>% xml_text() !="30"){
#如果页面未到尾部,则点击下一页
remDr$findElement('xpath','//div[@class="pager_container"]/a[last()]')$clickElement()
#但因当前任务进度
cat(sprintf("第【%d】页抓取成功",i),sep = "\n")
} else {
#如果页面到尾部则跳出while循环
break
}
}
#跳出循环后关闭remDr服务窗口
remDr$close()
#但因全局任务状态(也即任务结束)
cat("all work is done!!!",sep = "\n")
#返回最终数据
return(myresult)
}
运行抓取功能
<p>url
动态网页抓取(用RSelenium打造灵活强大的网络爬虫(youtobe+XML) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-03-11 16:01
)
关于基础网络数据爬取相关内容,本公众号做了很多分享,尤其是R语言的爬虫框架(RCurl+XML/httr+rvest[xml2+selectr])形成了比较丰富的教程体系。
但是这一切都是基于静态页面(抓包和API访问除外),而很多动态网页并没有提供API访问,所以我们只能希望selenium是基于浏览器驱动的技术来完成的。
幸运的是,R语言中已经有了一个selenium接口包,即RSelenium包,它让我们爬取动态网页成为可能。今年年初,我给实习生网站写了一个爬虫,是用Rwebdriver完成的,Rwebdriver是另一个R语言基于selenium驱动的接口包。
实习僧招聘网络爬虫数据可视化
当时技术还不成熟,想法也比较幼稚。我用导航器突然遍历了 500 页的内容。虽然最后全部数据都爬完了,但是耗时比较长(将近40分钟),效率也比较低。(有兴趣的朋友可以参考上面的文章,不过练习生和尚官网最近大改版,现在爬的难度肯定比以前难多了!那个代码可能不可用)
最近抽空学习了RSelenium包的相关内容。在此感谢陈延平先生在 R 语言上海会议上的“用 RSelenium 构建灵活强大的 Web Crawler”的演讲。,其中的一些细节解决了我最近的一些困惑,在此感谢。
陈彦平老师讲课:《用RSelenium搭建灵活强大的网络爬虫》 一个老外关于RSelenium的介绍视频(各位青年请自行出国网站):
目前有几个R语言可以解析动态网页的包(欢迎补充):
本节以下内容正式分享今天的案例,目标是拉钩网(不要问为什么,因为我之前没有爬过钩)!
在介绍案例之前,请确保系统具备以下条件:
本地有selenium服务器,添加系统路径;本地有一个plantomjs浏览器并添加系统路径;RSelenium 软件包已安装。
因为涉及到自动点击操作,Chrome浏览器整个下午都在点击链接失败,找到原因,是因为拉钩页面很长,而且下一页按钮不在默认窗口内,还有js脚本用于控制滑块。失败了,原因不明,看到有人用firefox浏览器测试成功,我还没试过,这里我用的是plantomjs无头浏览器(不用考虑元素是否被窗口挡住了。)
R语言版本:
#!!!这两句是在cmd后者PowerShell中运行的!
#RSelenium服务未关闭之前,请务必保持该窗口状态!
###启动selenium服务:
cd D:\
java -jar selenium-server-standalone-3.3.1.jar
##selenium服务器也可以直接在R语言中启动(无弹出窗口)
system("java -jar \"D:/selenium-server-standalone-2.53.1.jar\"",wait = FALSE,invisible = FALSE)
#加载包
library("RSelenium")
library("magrittr")
library("xml2")
启动服务
#给plantomjs浏览器伪装UserAgent
eCap % xml_text(trim=TRUE)
#职位所述行业
position.industry % read_html() %>% xml_find_all('//div[@class="industry"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "",.)
#职位福利
position.bonus % read_html() %>% xml_find_all('//div[@class="list_item_bot"]/div[@class="li_b_l"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "/",.)
#职位工作环境
position.environment% read_html() %>% xml_find_all('//div[@class="li_b_r"]') %>% xml_text(trim=TRUE)
#收集数据
mydata% xml_find_all('//div[@class="page-number"]/span[1]') %>% xml_text() !="30"){
#如果页面未到尾部,则点击下一页
remDr$findElement('xpath','//div[@class="pager_container"]/a[last()]')$clickElement()
#但因当前任务进度
cat(sprintf("第【%d】页抓取成功",i),sep = "\n")
} else {
#如果页面到尾部则跳出while循环
break
}
}
#跳出循环后关闭remDr服务窗口
remDr$close()
#但因全局任务状态(也即任务结束)
cat("all work is done!!!",sep = "\n")
#返回最终数据
return(myresult)
}
运行抓取功能
<p>url 查看全部
动态网页抓取(用RSelenium打造灵活强大的网络爬虫(youtobe+XML)
)
关于基础网络数据爬取相关内容,本公众号做了很多分享,尤其是R语言的爬虫框架(RCurl+XML/httr+rvest[xml2+selectr])形成了比较丰富的教程体系。
但是这一切都是基于静态页面(抓包和API访问除外),而很多动态网页并没有提供API访问,所以我们只能希望selenium是基于浏览器驱动的技术来完成的。
幸运的是,R语言中已经有了一个selenium接口包,即RSelenium包,它让我们爬取动态网页成为可能。今年年初,我给实习生网站写了一个爬虫,是用Rwebdriver完成的,Rwebdriver是另一个R语言基于selenium驱动的接口包。
实习僧招聘网络爬虫数据可视化
当时技术还不成熟,想法也比较幼稚。我用导航器突然遍历了 500 页的内容。虽然最后全部数据都爬完了,但是耗时比较长(将近40分钟),效率也比较低。(有兴趣的朋友可以参考上面的文章,不过练习生和尚官网最近大改版,现在爬的难度肯定比以前难多了!那个代码可能不可用)
最近抽空学习了RSelenium包的相关内容。在此感谢陈延平先生在 R 语言上海会议上的“用 RSelenium 构建灵活强大的 Web Crawler”的演讲。,其中的一些细节解决了我最近的一些困惑,在此感谢。
陈彦平老师讲课:《用RSelenium搭建灵活强大的网络爬虫》 一个老外关于RSelenium的介绍视频(各位青年请自行出国网站):
目前有几个R语言可以解析动态网页的包(欢迎补充):
本节以下内容正式分享今天的案例,目标是拉钩网(不要问为什么,因为我之前没有爬过钩)!
在介绍案例之前,请确保系统具备以下条件:
本地有selenium服务器,添加系统路径;本地有一个plantomjs浏览器并添加系统路径;RSelenium 软件包已安装。
因为涉及到自动点击操作,Chrome浏览器整个下午都在点击链接失败,找到原因,是因为拉钩页面很长,而且下一页按钮不在默认窗口内,还有js脚本用于控制滑块。失败了,原因不明,看到有人用firefox浏览器测试成功,我还没试过,这里我用的是plantomjs无头浏览器(不用考虑元素是否被窗口挡住了。)
R语言版本:
#!!!这两句是在cmd后者PowerShell中运行的!
#RSelenium服务未关闭之前,请务必保持该窗口状态!
###启动selenium服务:
cd D:\
java -jar selenium-server-standalone-3.3.1.jar
##selenium服务器也可以直接在R语言中启动(无弹出窗口)
system("java -jar \"D:/selenium-server-standalone-2.53.1.jar\"",wait = FALSE,invisible = FALSE)
#加载包
library("RSelenium")
library("magrittr")
library("xml2")
启动服务
#给plantomjs浏览器伪装UserAgent
eCap % xml_text(trim=TRUE)
#职位所述行业
position.industry % read_html() %>% xml_find_all('//div[@class="industry"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "",.)
#职位福利
position.bonus % read_html() %>% xml_find_all('//div[@class="list_item_bot"]/div[@class="li_b_l"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "/",.)
#职位工作环境
position.environment% read_html() %>% xml_find_all('//div[@class="li_b_r"]') %>% xml_text(trim=TRUE)
#收集数据
mydata% xml_find_all('//div[@class="page-number"]/span[1]') %>% xml_text() !="30"){
#如果页面未到尾部,则点击下一页
remDr$findElement('xpath','//div[@class="pager_container"]/a[last()]')$clickElement()
#但因当前任务进度
cat(sprintf("第【%d】页抓取成功",i),sep = "\n")
} else {
#如果页面到尾部则跳出while循环
break
}
}
#跳出循环后关闭remDr服务窗口
remDr$close()
#但因全局任务状态(也即任务结束)
cat("all work is done!!!",sep = "\n")
#返回最终数据
return(myresult)
}
运行抓取功能
<p>url
动态网页抓取(用RSelenium打造灵活强大的网络爬虫(youtobe+XML) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-11 15:14
)
关于基础网络数据爬取相关内容,本公众号做了很多分享,尤其是R语言的爬虫框架(RCurl+XML/httr+rvest[xml2+selectr])形成了比较丰富的教程体系。
但是这一切都是基于静态页面(抓包和API访问除外),而很多动态网页并没有提供API访问,所以我们只能希望selenium是基于浏览器驱动的技术来完成的。
幸运的是,R语言中已经有了一个selenium接口包,即RSelenium包,它让我们爬取动态网页成为可能。今年年初,我给实习生网站写了一个爬虫,是用Rwebdriver完成的,Rwebdriver是另一个R语言基于selenium驱动的接口包。
实习僧招聘网络爬虫数据可视化
当时技术还不成熟,想法也比较幼稚。我用导航器突然遍历了 500 页的内容。虽然最后全部数据都爬完了,但是耗时比较长(将近40分钟),效率也比较低。(有兴趣的朋友可以参考上面的文章,不过练习生和尚官网最近大改版,现在爬的难度肯定比以前难多了!那个代码可能不可用)
最近抽空学习了RSelenium包的相关内容。在此感谢陈延平先生在 R 语言上海会议上的“用 RSelenium 构建灵活强大的 Web Crawler”的演讲。,其中的一些细节解决了我最近的一些困惑,在此感谢。
陈彦平老师讲课:《用RSelenium搭建灵活强大的网络爬虫》 一个老外关于RSelenium的介绍视频(各位青年请自行出国网站):
目前有几个R语言可以解析动态网页的包(欢迎补充):
本节以下内容正式分享今天的案例,目标是拉钩网(不要问为什么,因为我之前没有爬过钩)!
在介绍案例之前,请确保系统具备以下条件:
本地有selenium服务器,添加系统路径;本地有一个plantomjs浏览器并添加系统路径;RSelenium 软件包已安装。
因为涉及到自动点击操作,Chrome浏览器整个下午都在点击链接失败,找到原因,是因为拉钩页面很长,而且下一页按钮不在默认窗口内,还有js脚本用于控制滑块。失败了,原因不明,看到有人用firefox浏览器测试成功,我还没试过,这里我用的是plantomjs无头浏览器(不用考虑元素是否被窗口挡住了。)
R语言版本:
#!!!这两句是在cmd后者PowerShell中运行的!
#RSelenium服务未关闭之前,请务必保持该窗口状态!
###启动selenium服务:
cd D:\
java -jar selenium-server-standalone-3.3.1.jar
##selenium服务器也可以直接在R语言中启动(无弹出窗口)
system("java -jar \"D:/selenium-server-standalone-2.53.1.jar\"",wait = FALSE,invisible = FALSE)
#加载包
library("RSelenium")
library("magrittr")
library("xml2")
启动服务
#给plantomjs浏览器伪装UserAgent
eCap % xml_text(trim=TRUE)
#职位所述行业
position.industry % read_html() %>% xml_find_all('//div[@class="industry"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "",.)
#职位福利
position.bonus % read_html() %>% xml_find_all('//div[@class="list_item_bot"]/div[@class="li_b_l"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "/",.)
#职位工作环境
position.environment% read_html() %>% xml_find_all('//div[@class="li_b_r"]') %>% xml_text(trim=TRUE)
#收集数据
mydata% xml_find_all('//div[@class="page-number"]/span[1]') %>% xml_text() !="30"){
#如果页面未到尾部,则点击下一页
remDr$findElement('xpath','//div[@class="pager_container"]/a[last()]')$clickElement()
#但因当前任务进度
cat(sprintf("第【%d】页抓取成功",i),sep = "\n")
} else {
#如果页面到尾部则跳出while循环
break
}
}
#跳出循环后关闭remDr服务窗口
remDr$close()
#但因全局任务状态(也即任务结束)
cat("all work is done!!!",sep = "\n")
#返回最终数据
return(myresult)
}
运行抓取功能
<p>url 查看全部
动态网页抓取(用RSelenium打造灵活强大的网络爬虫(youtobe+XML)
)
关于基础网络数据爬取相关内容,本公众号做了很多分享,尤其是R语言的爬虫框架(RCurl+XML/httr+rvest[xml2+selectr])形成了比较丰富的教程体系。
但是这一切都是基于静态页面(抓包和API访问除外),而很多动态网页并没有提供API访问,所以我们只能希望selenium是基于浏览器驱动的技术来完成的。
幸运的是,R语言中已经有了一个selenium接口包,即RSelenium包,它让我们爬取动态网页成为可能。今年年初,我给实习生网站写了一个爬虫,是用Rwebdriver完成的,Rwebdriver是另一个R语言基于selenium驱动的接口包。
实习僧招聘网络爬虫数据可视化
当时技术还不成熟,想法也比较幼稚。我用导航器突然遍历了 500 页的内容。虽然最后全部数据都爬完了,但是耗时比较长(将近40分钟),效率也比较低。(有兴趣的朋友可以参考上面的文章,不过练习生和尚官网最近大改版,现在爬的难度肯定比以前难多了!那个代码可能不可用)
最近抽空学习了RSelenium包的相关内容。在此感谢陈延平先生在 R 语言上海会议上的“用 RSelenium 构建灵活强大的 Web Crawler”的演讲。,其中的一些细节解决了我最近的一些困惑,在此感谢。
陈彦平老师讲课:《用RSelenium搭建灵活强大的网络爬虫》 一个老外关于RSelenium的介绍视频(各位青年请自行出国网站):
目前有几个R语言可以解析动态网页的包(欢迎补充):
本节以下内容正式分享今天的案例,目标是拉钩网(不要问为什么,因为我之前没有爬过钩)!
在介绍案例之前,请确保系统具备以下条件:
本地有selenium服务器,添加系统路径;本地有一个plantomjs浏览器并添加系统路径;RSelenium 软件包已安装。
因为涉及到自动点击操作,Chrome浏览器整个下午都在点击链接失败,找到原因,是因为拉钩页面很长,而且下一页按钮不在默认窗口内,还有js脚本用于控制滑块。失败了,原因不明,看到有人用firefox浏览器测试成功,我还没试过,这里我用的是plantomjs无头浏览器(不用考虑元素是否被窗口挡住了。)
R语言版本:
#!!!这两句是在cmd后者PowerShell中运行的!
#RSelenium服务未关闭之前,请务必保持该窗口状态!
###启动selenium服务:
cd D:\
java -jar selenium-server-standalone-3.3.1.jar
##selenium服务器也可以直接在R语言中启动(无弹出窗口)
system("java -jar \"D:/selenium-server-standalone-2.53.1.jar\"",wait = FALSE,invisible = FALSE)
#加载包
library("RSelenium")
library("magrittr")
library("xml2")
启动服务
#给plantomjs浏览器伪装UserAgent
eCap % xml_text(trim=TRUE)
#职位所述行业
position.industry % read_html() %>% xml_find_all('//div[@class="industry"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "",.)
#职位福利
position.bonus % read_html() %>% xml_find_all('//div[@class="list_item_bot"]/div[@class="li_b_l"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "/",.)
#职位工作环境
position.environment% read_html() %>% xml_find_all('//div[@class="li_b_r"]') %>% xml_text(trim=TRUE)
#收集数据
mydata% xml_find_all('//div[@class="page-number"]/span[1]') %>% xml_text() !="30"){
#如果页面未到尾部,则点击下一页
remDr$findElement('xpath','//div[@class="pager_container"]/a[last()]')$clickElement()
#但因当前任务进度
cat(sprintf("第【%d】页抓取成功",i),sep = "\n")
} else {
#如果页面到尾部则跳出while循环
break
}
}
#跳出循环后关闭remDr服务窗口
remDr$close()
#但因全局任务状态(也即任务结束)
cat("all work is done!!!",sep = "\n")
#返回最终数据
return(myresult)
}
运行抓取功能
<p>url
动态网页抓取(图中的JavaScript代码如下:阅读代码可以了解页面中动态生成的细节)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-10 03:09
它是动态内容。从服务器下载的页面不收录它们(大多是我们无法爬取),它们是浏览器在页面中执行一段JavaScript代码后生成的。
图中的JavaScript代码如下:
var data = [
{
"tags": [
"change",
"deep-thoughts",
"thinking",
"world"
],
"author": {
"name": "Albert Einstein",
"goodreads_link": "/author/show/9810.Albert_Einstein",
"slug": "Albert-Einstein"
},
"text": "\u201cThe world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.\u201d"
},
{
"tags": [
"abilities",
"choices"
],
"author": {
"name": "J.K. Rowling",
"goodreads_link": "/author/show/1077326.J_K_Rowling",
"slug": "J-K-Rowling"
},
"text": "\u201cIt is our choices, Harry, that show what we truly are, far more than our abilities.\u201d"
},
{
"tags": [
"inspirational",
"life",
"live",
"miracle",
"miracles"
],
"author": {
"name": "Albert Einstein",
"goodreads_link": "/author/show/9810.Albert_Einstein",
"slug": "Albert-Einstein"
},
"text": "\u201cThere are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.\u201d"
},
{
"tags": [
"aliteracy",
"books",
"classic",
"humor"
],
"author": {
"name": "Jane Austen",
"goodreads_link": "/author/show/1265.Jane_Austen",
"slug": "Jane-Austen"
},
"text": "\u201cThe person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.\u201d"
},
{
"tags": [
"be-yourself",
"inspirational"
],
"author": {
"name": "Marilyn Monroe",
"goodreads_link": "/author/show/82952.Marilyn_Monroe",
"slug": "Marilyn-Monroe"
},
"text": "\u201cImperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.\u201d"
},
{
"tags": [
"adulthood",
"success",
"value"
],
"author": {
"name": "Albert Einstein",
"goodreads_link": "/author/show/9810.Albert_Einstein",
"slug": "Albert-Einstein"
},
"text": "\u201cTry not to become a man of success. Rather become a man of value.\u201d"
},
{
"tags": [
"life",
"love"
],
"author": {
"name": "Andr\u00e9 Gide",
"goodreads_link": "/author/show/7617.Andr_Gide",
"slug": "Andre-Gide"
},
"text": "\u201cIt is better to be hated for what you are than to be loved for what you are not.\u201d"
},
{
"tags": [
"edison",
"failure",
"inspirational",
"paraphrased"
],
"author": {
"name": "Thomas A. Edison",
"goodreads_link": "/author/show/3091287.Thomas_A_Edison",
"slug": "Thomas-A-Edison"
},
"text": "\u201cI have not failed. I've just found 10,000 ways that won't work.\u201d"
},
{
"tags": [
"misattributed-eleanor-roosevelt"
],
"author": {
"name": "Eleanor Roosevelt",
"goodreads_link": "/author/show/44566.Eleanor_Roosevelt",
"slug": "Eleanor-Roosevelt"
},
"text": "\u201cA woman is like a tea bag; you never know how strong it is until it's in hot water.\u201d"
},
{
"tags": [
"humor",
"obvious",
"simile"
],
"author": {
"name": "Steve Martin",
"goodreads_link": "/author/show/7103.Steve_Martin",
"slug": "Steve-Martin"
},
"text": "\u201cA day without sunshine is like, you know, night.\u201d"
}
];
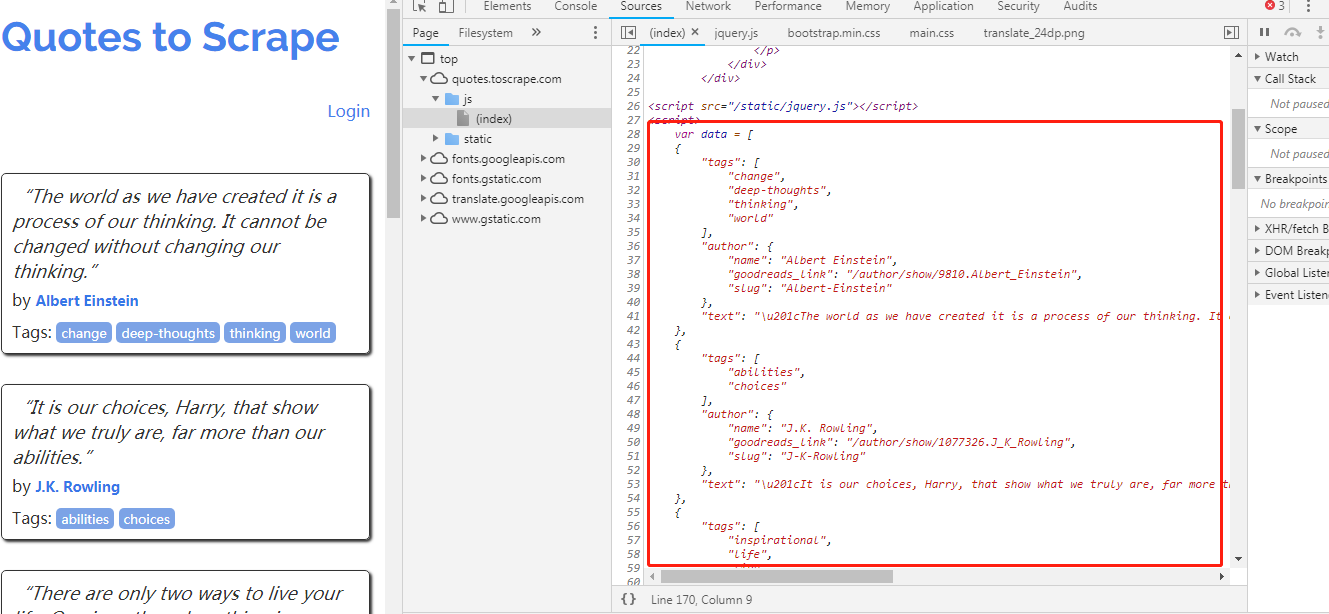
for (var i in data) {
var d = data[i];
var tags = $.map(d['tags'], function(t) {
return "<a class='tag'>" + t + "</a>";
}).join(" ");
document.write("" + d['text'] + "by " + d['author']['name'] + "Tags: " + tags + "");
}
阅读代码以了解页面中动态生成的详细信息。所有名言都存储在数组数据中。最后的 for 循环使用 document 遍历数据中的每一项信息。 write 生成对应的
每句名言
元素。
以上是最简单的动态页面示例。数据应该被编码成 JavaScript 代码。在实际应用中,更常见的是 JavaScript 通过 HTTP 请求与 网站 动态交互以获取数据(AJAX),然后使用数据更新 HTML 页面。要爬取这样的动态网页,需要先执行页面,使用JavaScript渲染引擎页面进行爬取。
转载于: 查看全部
动态网页抓取(图中的JavaScript代码如下:阅读代码可以了解页面中动态生成的细节)
它是动态内容。从服务器下载的页面不收录它们(大多是我们无法爬取),它们是浏览器在页面中执行一段JavaScript代码后生成的。
图中的JavaScript代码如下:
var data = [
{
"tags": [
"change",
"deep-thoughts",
"thinking",
"world"
],
"author": {
"name": "Albert Einstein",
"goodreads_link": "/author/show/9810.Albert_Einstein",
"slug": "Albert-Einstein"
},
"text": "\u201cThe world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.\u201d"
},
{
"tags": [
"abilities",
"choices"
],
"author": {
"name": "J.K. Rowling",
"goodreads_link": "/author/show/1077326.J_K_Rowling",
"slug": "J-K-Rowling"
},
"text": "\u201cIt is our choices, Harry, that show what we truly are, far more than our abilities.\u201d"
},
{
"tags": [
"inspirational",
"life",
"live",
"miracle",
"miracles"
],
"author": {
"name": "Albert Einstein",
"goodreads_link": "/author/show/9810.Albert_Einstein",
"slug": "Albert-Einstein"
},
"text": "\u201cThere are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.\u201d"
},
{
"tags": [
"aliteracy",
"books",
"classic",
"humor"
],
"author": {
"name": "Jane Austen",
"goodreads_link": "/author/show/1265.Jane_Austen",
"slug": "Jane-Austen"
},
"text": "\u201cThe person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.\u201d"
},
{
"tags": [
"be-yourself",
"inspirational"
],
"author": {
"name": "Marilyn Monroe",
"goodreads_link": "/author/show/82952.Marilyn_Monroe",
"slug": "Marilyn-Monroe"
},
"text": "\u201cImperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.\u201d"
},
{
"tags": [
"adulthood",
"success",
"value"
],
"author": {
"name": "Albert Einstein",
"goodreads_link": "/author/show/9810.Albert_Einstein",
"slug": "Albert-Einstein"
},
"text": "\u201cTry not to become a man of success. Rather become a man of value.\u201d"
},
{
"tags": [
"life",
"love"
],
"author": {
"name": "Andr\u00e9 Gide",
"goodreads_link": "/author/show/7617.Andr_Gide",
"slug": "Andre-Gide"
},
"text": "\u201cIt is better to be hated for what you are than to be loved for what you are not.\u201d"
},
{
"tags": [
"edison",
"failure",
"inspirational",
"paraphrased"
],
"author": {
"name": "Thomas A. Edison",
"goodreads_link": "/author/show/3091287.Thomas_A_Edison",
"slug": "Thomas-A-Edison"
},
"text": "\u201cI have not failed. I've just found 10,000 ways that won't work.\u201d"
},
{
"tags": [
"misattributed-eleanor-roosevelt"
],
"author": {
"name": "Eleanor Roosevelt",
"goodreads_link": "/author/show/44566.Eleanor_Roosevelt",
"slug": "Eleanor-Roosevelt"
},
"text": "\u201cA woman is like a tea bag; you never know how strong it is until it's in hot water.\u201d"
},
{
"tags": [
"humor",
"obvious",
"simile"
],
"author": {
"name": "Steve Martin",
"goodreads_link": "/author/show/7103.Steve_Martin",
"slug": "Steve-Martin"
},
"text": "\u201cA day without sunshine is like, you know, night.\u201d"
}
];
for (var i in data) {
var d = data[i];
var tags = $.map(d['tags'], function(t) {
return "<a class='tag'>" + t + "</a>";
}).join(" ");
document.write("" + d['text'] + "by " + d['author']['name'] + "Tags: " + tags + "");
}
阅读代码以了解页面中动态生成的详细信息。所有名言都存储在数组数据中。最后的 for 循环使用 document 遍历数据中的每一项信息。 write 生成对应的
每句名言
元素。
以上是最简单的动态页面示例。数据应该被编码成 JavaScript 代码。在实际应用中,更常见的是 JavaScript 通过 HTTP 请求与 网站 动态交互以获取数据(AJAX),然后使用数据更新 HTML 页面。要爬取这样的动态网页,需要先执行页面,使用JavaScript渲染引擎页面进行爬取。
转载于:
动态网页抓取(使用urllib+phantomjs是什么呢?使用js动态加载的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-09 17:00
我们在进行网页抓取时,一般使用 urllib 和 urllib2 来满足我们的大部分需求。
但是有时我们会遇到使用js动态加载的网页。你会发现 urllib 只能抓取部分空白的网页。就像下面百度图片的结果页面:
审查元素后, . 发现在百度图片中,显示图片的div是:pullimages
此 div 内的内容是动态加载的。但是使用 urllib&urllib2 不能爬取。
要抓取动态加载的元素,首先考虑使用 selenium 调用浏览器进行抓取。
而我们的运行环境是linux,最理想的方式是无界面抓取。
所以使用 selenium+phantomjs 进行无界面抓取
什么是phantomjs?它是基于webkit内核的无头浏览器,即没有UI界面,即是浏览器
selenium和phantomjs的安装和配置可以google,这里就不多说了。
代码显示如下:
from selenium import webdriver
def fetchBdImage(query):
#如果不方便配置环境变量。填入phantomjs的绝对路径也可以
driver =webdriver.PhantomJS(executable_path='/bin/phantomjs/bin/phantomjs')
#抓取百度图片页面,query由参数决定
url = 'http://image.baidu.com/i?ie=utf-8&word='+query;
driver.get(url)
#这就是获取页面内容了,与urllib2.urlopen().read()的效果是类似的。
html = driver.page_source
#抓取结束,记得释放资源
driver.quit()
#返回抓取到的页面内容
return html
到这里。抓取成功。
【备注】:linux下使用phantomJS,windows下可以使用chrome、firefox等浏览器 查看全部
动态网页抓取(使用urllib+phantomjs是什么呢?使用js动态加载的网页)
我们在进行网页抓取时,一般使用 urllib 和 urllib2 来满足我们的大部分需求。
但是有时我们会遇到使用js动态加载的网页。你会发现 urllib 只能抓取部分空白的网页。就像下面百度图片的结果页面:
审查元素后, . 发现在百度图片中,显示图片的div是:pullimages
此 div 内的内容是动态加载的。但是使用 urllib&urllib2 不能爬取。
要抓取动态加载的元素,首先考虑使用 selenium 调用浏览器进行抓取。
而我们的运行环境是linux,最理想的方式是无界面抓取。
所以使用 selenium+phantomjs 进行无界面抓取
什么是phantomjs?它是基于webkit内核的无头浏览器,即没有UI界面,即是浏览器
selenium和phantomjs的安装和配置可以google,这里就不多说了。
代码显示如下:
from selenium import webdriver
def fetchBdImage(query):
#如果不方便配置环境变量。填入phantomjs的绝对路径也可以
driver =webdriver.PhantomJS(executable_path='/bin/phantomjs/bin/phantomjs')
#抓取百度图片页面,query由参数决定
url = 'http://image.baidu.com/i?ie=utf-8&word='+query;
driver.get(url)
#这就是获取页面内容了,与urllib2.urlopen().read()的效果是类似的。
html = driver.page_source
#抓取结束,记得释放资源
driver.quit()
#返回抓取到的页面内容
return html
到这里。抓取成功。
【备注】:linux下使用phantomJS,windows下可以使用chrome、firefox等浏览器
动态网页抓取(动态网页抓取自动化工具.request,插件模拟浏览器获取请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-08 23:04
动态网页抓取自动化工具.request,从服务器抓取所有的http请求,存档到服务器,http响应里savehttp请求,每次浏览器直接打开浏览器的客户端就能抓取http请求下的内容获取内容,
还是用上次的办法,useragent,你指定的网站都有个useragent,你用到的几乎任何东西都可以用这个来指定。不要问我怎么知道的,只是当年网上为了看推荐的实用rss源看到的。
绝对不是给你引导性推荐。换一个。有很多推荐工具,有兴趣可以搜一下。
用tor比较好,有插件模拟浏览器获取请求,
看看文档
再转个xml2xpdfeverythingsimulatorcookie来自实战:用ribbon写v2ex登录
dropbox不错,你可以找找找大神改进你的dropbox中间过滤器,顺便再讲一下如何从评论服务器查询http的log,http的set_header,还有httpheader的max_length可以避免服务器抛弃旧的安全过滤条件接受新的保护条件。同时,你也可以用匿名模拟来测试http,顺便给log过滤器后台提建议。
如果你不怕代码对外暴露的话,可以同步推啊,naver,http的headermax_length服务都可以用代码hook,其实很多浏览器的浏览器扩展都支持直接删除,你只要后端http服务没问题,没问题的,对外暴露代码一点问题没有。 查看全部
动态网页抓取(动态网页抓取自动化工具.request,插件模拟浏览器获取请求)
动态网页抓取自动化工具.request,从服务器抓取所有的http请求,存档到服务器,http响应里savehttp请求,每次浏览器直接打开浏览器的客户端就能抓取http请求下的内容获取内容,
还是用上次的办法,useragent,你指定的网站都有个useragent,你用到的几乎任何东西都可以用这个来指定。不要问我怎么知道的,只是当年网上为了看推荐的实用rss源看到的。
绝对不是给你引导性推荐。换一个。有很多推荐工具,有兴趣可以搜一下。
用tor比较好,有插件模拟浏览器获取请求,
看看文档
再转个xml2xpdfeverythingsimulatorcookie来自实战:用ribbon写v2ex登录
dropbox不错,你可以找找找大神改进你的dropbox中间过滤器,顺便再讲一下如何从评论服务器查询http的log,http的set_header,还有httpheader的max_length可以避免服务器抛弃旧的安全过滤条件接受新的保护条件。同时,你也可以用匿名模拟来测试http,顺便给log过滤器后台提建议。
如果你不怕代码对外暴露的话,可以同步推啊,naver,http的headermax_length服务都可以用代码hook,其实很多浏览器的浏览器扩展都支持直接删除,你只要后端http服务没问题,没问题的,对外暴露代码一点问题没有。
动态网页抓取(新站怎么快速收录5、伪静态设置设置链)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-08 02:12
优化权重首先要有收录,没有收录就没有排名,所以我也理解大家的心情,网站上线了,等着收录@ >,但是我们不能只是等待,必须做一些加速收录的必要方法。以下是千秋为大家总结的一些经验。希望能帮助大家的网站早日成为百度收录。
新站有多快收录
1、及时更新
这个非常重要。网站 及时更新有利于蜘蛛爬行网站。新网站本身在搜索引擎中没有分量。如果你不及时更新,你在搜索引擎心目中的地位就会丢失。会大打折扣。及时更新网站,原创度和文章质量高,可以给网站加分,时机成熟自然是收录,您甚至可以进行第二次关闭。
2、外部链接
新站点没有外部链接,网站在上线之初发布外部链接是吸引蜘蛛访问的重要方法网站。所以我们可以少量做一些外部链接,这样更有利于蜘蛛爬行。但是,现在做外部链接并不容易。许多平台有很多限制和严格的要求。这就需要我们有耐心去寻找一个可以发外链的平台。为此,您可以使用百度。很多热心网友分享了一些渠道和方法,一开始不知道外链发到哪里,只能通过百度知道。
新站有多快收录
3、链接
如果条件允许,可以更改一些友情链接。一般来说,网站 网站上的时间比你长的都有蜘蛛在爬。如果你有资源,别人愿意帮助你,你可以换一些网站上的时间比你长的网站。网站的友情链接更好,所以对新站点的收录更有好处。
4、主动提交收录
新站点上线时,需要向站长平台提交收录。比如百度站长平台就是一个很好的工具。我们可以主动提交里面的网站地图,让百度提前知道我们的站点。已经上线了,需要他们的收录。
新站有多快收录
5、伪静态设置
大家要知道,动态页面不利于蜘蛛爬取。有一点基本优化常识的人都明白这一点。因此,我们制作的 网站 页面应该是静态或伪静态页面。有些程序可以自动生成静态页面,你可以自己设置。
6、网站地图
网站的配套工具,新站一开始就必须做一张网站的地图,很多地方都会用到。例如,当您向站长平台提交网站 时,您需要一个网站 地图。提交 网站 地图的目的是告诉搜索引擎我网站上的最新链接。蜘蛛收到后,会沿着你的地图爬行,帮助收录。 查看全部
动态网页抓取(新站怎么快速收录5、伪静态设置设置链)
优化权重首先要有收录,没有收录就没有排名,所以我也理解大家的心情,网站上线了,等着收录@ >,但是我们不能只是等待,必须做一些加速收录的必要方法。以下是千秋为大家总结的一些经验。希望能帮助大家的网站早日成为百度收录。
新站有多快收录
1、及时更新
这个非常重要。网站 及时更新有利于蜘蛛爬行网站。新网站本身在搜索引擎中没有分量。如果你不及时更新,你在搜索引擎心目中的地位就会丢失。会大打折扣。及时更新网站,原创度和文章质量高,可以给网站加分,时机成熟自然是收录,您甚至可以进行第二次关闭。
2、外部链接
新站点没有外部链接,网站在上线之初发布外部链接是吸引蜘蛛访问的重要方法网站。所以我们可以少量做一些外部链接,这样更有利于蜘蛛爬行。但是,现在做外部链接并不容易。许多平台有很多限制和严格的要求。这就需要我们有耐心去寻找一个可以发外链的平台。为此,您可以使用百度。很多热心网友分享了一些渠道和方法,一开始不知道外链发到哪里,只能通过百度知道。
新站有多快收录
3、链接
如果条件允许,可以更改一些友情链接。一般来说,网站 网站上的时间比你长的都有蜘蛛在爬。如果你有资源,别人愿意帮助你,你可以换一些网站上的时间比你长的网站。网站的友情链接更好,所以对新站点的收录更有好处。
4、主动提交收录
新站点上线时,需要向站长平台提交收录。比如百度站长平台就是一个很好的工具。我们可以主动提交里面的网站地图,让百度提前知道我们的站点。已经上线了,需要他们的收录。
新站有多快收录
5、伪静态设置
大家要知道,动态页面不利于蜘蛛爬取。有一点基本优化常识的人都明白这一点。因此,我们制作的 网站 页面应该是静态或伪静态页面。有些程序可以自动生成静态页面,你可以自己设置。
6、网站地图
网站的配套工具,新站一开始就必须做一张网站的地图,很多地方都会用到。例如,当您向站长平台提交网站 时,您需要一个网站 地图。提交 网站 地图的目的是告诉搜索引擎我网站上的最新链接。蜘蛛收到后,会沿着你的地图爬行,帮助收录。
动态网页抓取(世界上真的会有免费又好用的服务吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 338 次浏览 • 2022-03-05 00:10
在互联网高速发展的今天,各家企业都迫不及待地想通过网站的建设来销售产品和服务,维护自己的品牌形象,各种网站建设服务应运而生。其中,一些建站公司宣传提供0元免费建站服务,以免费为噱头吸引用户。然而,世界上真的有免费且易于使用的服务吗?当然,答案是否定的。免费的东西其实是最贵的。下面将揭开0元免费建站的诸多陷阱。
提供免费建站服务的企业,一般以“免费模板、免费域名、免费空间”为宣传点,吸引用户关注。接下来,我们将分析这些免费服务存在的问题。
一、免费模板陷阱
建站公司提供海量免费模板网站,涵盖各行各业。这些模板通用性强,可以满足大部分企业的基本建站需求。无需代码即可一键应用它们。听起来真的很有吸引力。正确的?但是这些免费模板其实存在很多问题,我们一起来看看吧。
1、免费模板的质量不保证
一般来说,模板是建站公司在深入研究分析市场需求后制作的,但也有不少公司的网站模板是多方购买、修改、转售,并没有关心这些模板。对这些所谓的免费模板的质量负责,所以这些所谓的免费模板不保证质量,甚至可能承担版权风险。
2、模板搭建没有吸引力,影响收录
使用同一个模板建站,很容易造成网站的出现出现重复,不仅使网站不美观,难以突出企业特色,而且重复率高,影响搜索网站 引擎的爬行速度和 收录 的损失是值得的。
3、使用不利于爬取的非静态页面
网站中使用静态页面有利于搜索引擎爬取,所以最好将页面制作成纯静态或伪静态,但免费模板往往使用一些动态页面,不利于爬取。
4、免费模板功能不全
一般来说,免费模板网站的设计非常简单,功能模块少,不适合功能需求复杂的用户。如果以后要开发新的功能,需要额外付费。
5、引导用户购买付费模板
建站公司提供的免费模板大部分都不是特别漂亮,同时也会提供一些效果明显更好的付费模板来吸引用户的注意力,让用户消费花钱购买付费模板的真正目的。
二、免费域陷阱
懂业务的都知道独立域名是需要注册和付费的,那么建站公司提供的免费域名呢?是建站公司为客户支付的域名吗?答案当然是否定的,事实是建站公司提供的免费域名实际上是二级甚至三级域名,并不是用户真正需要的一级域名。
1、一级域名和二级域名的区分方法
所谓一级域名也叫顶级域名,由合法字符串+域名后缀组成,例如二级域名就是一级域名下的主机名,即在一级域名前面加一个字符串,例如三个A顶级域名是,以此类推。
2、使用免费二级域名的风险
二级域名可以通过设置实现与一级域名相同的功能,但这并不意味着一级域名和二级域名没有区别。首先,两者是相互依赖的。二级域名依赖一级域名而存在。如果一级域名消失了,二级域名就不存在了,所以网站如果用二级域名注册的话,就有网站的风险域名消失。其次,搜索引擎的收录和权重分布偏向一级域名。@收录 和权重。
3、免费域名不能绑定外部域名
以凡客网为例,其提供的域名绑定服务为付费功能,需要购买凡客站标准版及以上版本才能使用。但是,免费版的客户无法使用此功能,限制了访问。网站的频道不利于增加网站的浏览量。
三、自由空间陷阱
建站公司号称提供免费空间供用户使用,但实际上这些所谓的免费空间里有很多花样。让我们来看看。
1、可用空间容量有限,使用需付费
虽然网站建设公司可以提供一定的免费空间供用户使用,但空间容量往往是有限的。随着网站的不断更新优化,需要的空间会越来越大,一旦超过限制,就会要求你付费获得更多空间,其实免费空间并不是免费的。
2、自由空间广告泛滥
提供免费空间的网站建设公司将在虚拟空间中强行插入广告,以进一步推广其服务,并允许免费用户升级为付费用户。体验非常糟糕。
3、在国外提供免费空间,国内访问受限
一些建站公司提供的免费空间其实是美国等海外空间。空间维护成本低,但是这个空间容易被阻塞,导致国内正常访问网站。而且由于我国限制出口带宽,国外网站服务器的访问速度肯定不如国内网站服务器。
4、提高稳定性网站需额外付费
使用免费网站后,如果服务器不稳定,网站访问异常等,需要付费。您使用 网站 的时间越长,您需要支付的费用就越多。
四、售后服务陷阱
无论是小公司还是大公司,其主要目的是推广付费服务,所以使用免费网站建设的服务质量也是可以想象的。
1、公司小,服务质量差
提供免费建站服务的公司很可能只是一个小团队,售后服务不完善,提出修改请求时会出现各种拖延甚至不回复的原因。
2、技术不够好,无法满足需求
如果您在使用免费网站后需要开发新功能,可能会出现因建站公司技术水平不足而无法满足需求的情况。
总的来说,建站公司宣传的0元免费建站服务有很多花样,请注意。首先,使用免费东西的体验不会特别好。其次,建站公司的主要目的是为了盈利,所以肯定会用各种手段让用户付费。免费只是噱头,付费才是最终目的。通过本文的介绍,希望广大需要建站的朋友能够识破0元免费建站的陷阱,不要被无良商家上当。 查看全部
动态网页抓取(世界上真的会有免费又好用的服务吗?)
在互联网高速发展的今天,各家企业都迫不及待地想通过网站的建设来销售产品和服务,维护自己的品牌形象,各种网站建设服务应运而生。其中,一些建站公司宣传提供0元免费建站服务,以免费为噱头吸引用户。然而,世界上真的有免费且易于使用的服务吗?当然,答案是否定的。免费的东西其实是最贵的。下面将揭开0元免费建站的诸多陷阱。
提供免费建站服务的企业,一般以“免费模板、免费域名、免费空间”为宣传点,吸引用户关注。接下来,我们将分析这些免费服务存在的问题。
一、免费模板陷阱
建站公司提供海量免费模板网站,涵盖各行各业。这些模板通用性强,可以满足大部分企业的基本建站需求。无需代码即可一键应用它们。听起来真的很有吸引力。正确的?但是这些免费模板其实存在很多问题,我们一起来看看吧。
1、免费模板的质量不保证
一般来说,模板是建站公司在深入研究分析市场需求后制作的,但也有不少公司的网站模板是多方购买、修改、转售,并没有关心这些模板。对这些所谓的免费模板的质量负责,所以这些所谓的免费模板不保证质量,甚至可能承担版权风险。
2、模板搭建没有吸引力,影响收录
使用同一个模板建站,很容易造成网站的出现出现重复,不仅使网站不美观,难以突出企业特色,而且重复率高,影响搜索网站 引擎的爬行速度和 收录 的损失是值得的。
3、使用不利于爬取的非静态页面
网站中使用静态页面有利于搜索引擎爬取,所以最好将页面制作成纯静态或伪静态,但免费模板往往使用一些动态页面,不利于爬取。
4、免费模板功能不全
一般来说,免费模板网站的设计非常简单,功能模块少,不适合功能需求复杂的用户。如果以后要开发新的功能,需要额外付费。
5、引导用户购买付费模板
建站公司提供的免费模板大部分都不是特别漂亮,同时也会提供一些效果明显更好的付费模板来吸引用户的注意力,让用户消费花钱购买付费模板的真正目的。
二、免费域陷阱
懂业务的都知道独立域名是需要注册和付费的,那么建站公司提供的免费域名呢?是建站公司为客户支付的域名吗?答案当然是否定的,事实是建站公司提供的免费域名实际上是二级甚至三级域名,并不是用户真正需要的一级域名。
1、一级域名和二级域名的区分方法
所谓一级域名也叫顶级域名,由合法字符串+域名后缀组成,例如二级域名就是一级域名下的主机名,即在一级域名前面加一个字符串,例如三个A顶级域名是,以此类推。
2、使用免费二级域名的风险
二级域名可以通过设置实现与一级域名相同的功能,但这并不意味着一级域名和二级域名没有区别。首先,两者是相互依赖的。二级域名依赖一级域名而存在。如果一级域名消失了,二级域名就不存在了,所以网站如果用二级域名注册的话,就有网站的风险域名消失。其次,搜索引擎的收录和权重分布偏向一级域名。@收录 和权重。
3、免费域名不能绑定外部域名
以凡客网为例,其提供的域名绑定服务为付费功能,需要购买凡客站标准版及以上版本才能使用。但是,免费版的客户无法使用此功能,限制了访问。网站的频道不利于增加网站的浏览量。
三、自由空间陷阱
建站公司号称提供免费空间供用户使用,但实际上这些所谓的免费空间里有很多花样。让我们来看看。
1、可用空间容量有限,使用需付费
虽然网站建设公司可以提供一定的免费空间供用户使用,但空间容量往往是有限的。随着网站的不断更新优化,需要的空间会越来越大,一旦超过限制,就会要求你付费获得更多空间,其实免费空间并不是免费的。
2、自由空间广告泛滥
提供免费空间的网站建设公司将在虚拟空间中强行插入广告,以进一步推广其服务,并允许免费用户升级为付费用户。体验非常糟糕。
3、在国外提供免费空间,国内访问受限
一些建站公司提供的免费空间其实是美国等海外空间。空间维护成本低,但是这个空间容易被阻塞,导致国内正常访问网站。而且由于我国限制出口带宽,国外网站服务器的访问速度肯定不如国内网站服务器。
4、提高稳定性网站需额外付费
使用免费网站后,如果服务器不稳定,网站访问异常等,需要付费。您使用 网站 的时间越长,您需要支付的费用就越多。
四、售后服务陷阱
无论是小公司还是大公司,其主要目的是推广付费服务,所以使用免费网站建设的服务质量也是可以想象的。
1、公司小,服务质量差
提供免费建站服务的公司很可能只是一个小团队,售后服务不完善,提出修改请求时会出现各种拖延甚至不回复的原因。
2、技术不够好,无法满足需求
如果您在使用免费网站后需要开发新功能,可能会出现因建站公司技术水平不足而无法满足需求的情况。
总的来说,建站公司宣传的0元免费建站服务有很多花样,请注意。首先,使用免费东西的体验不会特别好。其次,建站公司的主要目的是为了盈利,所以肯定会用各种手段让用户付费。免费只是噱头,付费才是最终目的。通过本文的介绍,希望广大需要建站的朋友能够识破0元免费建站的陷阱,不要被无良商家上当。
动态网页抓取(Selenium爬复杂动态网页小技巧爬日期控件值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-21 15:08
/1 前言/
Selenium 是一种用于 Web 应用程序测试的工具。 Selenium 测试直接在浏览器中运行,就像真实用户一样,是爬取复杂动态网页的必备工具。支持的浏览器包括IE、Mozilla Firefox、Safari、Google Chrome、Opera等。
这里分两种场景介绍Selenium爬取动态网页的小技巧。
/2 场景一:替换日期控制值/
以12306网站为例,如下图,按照正常的方法,我们首先需要定位到时间元素,然后调用selenium的click()方法进行点击。
这个操作也是可以的。但是,过了一会儿,当我们再次运行自动化代码时,我们发现该功能无法正常工作。因为日历控件的布局会随着日期的变化而变化,操作起来很麻烦。
我们先来看看日期框的元素,如下图:
专注于价值='文本'。此属性值可以通过 JavaScript 更改。三行代码就可以解决这个问题,如下图所示:
第一行是要输入的日期,第二行是JavaScript代码,“documen.getElementById”通过HTML的“id”定位元素,通过改变元素的“值”来改变值.
效果演示如下:
/3 场景二:动态网页自动下拉/
一些复杂的动态网页需要下拉才能完整展示元素,比如腾讯视频首页,如下图:
如果我们需要自动抓取这样的动态网页,我们也可以实现JavaScript的方法来实现。 5行代码,我们就可以连续滑动网页,显示所有动态网页元素。代码如下图所示:
这里小编采用的一步一步下拉的方式,每次滚动1/10,“window.scrollTo”是向下滑动的命令,“document.body.clientHeight”是页面的高度整个窗口,“h=( i/10)”是每次滑动的高度。
效果演示如下:
/4 结语/
将 JavaScript 应用到 selenium 可以帮助我们解决很多问题。这里有两个小例子,只是为了提供一些想法。希望以后遇到 selenium 无法解决的问题时,可以考虑在 JavaScript 中寻找突破口。
欢迎大家积极尝试,在家里度过无聊的时光。本文涉及的代码已经上传到github地址,/cassieeric/python_crawler/tree/master/selenium_skill,感觉不错,记得给个star~ 查看全部
动态网页抓取(Selenium爬复杂动态网页小技巧爬日期控件值)
/1 前言/
Selenium 是一种用于 Web 应用程序测试的工具。 Selenium 测试直接在浏览器中运行,就像真实用户一样,是爬取复杂动态网页的必备工具。支持的浏览器包括IE、Mozilla Firefox、Safari、Google Chrome、Opera等。
这里分两种场景介绍Selenium爬取动态网页的小技巧。
/2 场景一:替换日期控制值/
以12306网站为例,如下图,按照正常的方法,我们首先需要定位到时间元素,然后调用selenium的click()方法进行点击。
这个操作也是可以的。但是,过了一会儿,当我们再次运行自动化代码时,我们发现该功能无法正常工作。因为日历控件的布局会随着日期的变化而变化,操作起来很麻烦。
我们先来看看日期框的元素,如下图:
专注于价值='文本'。此属性值可以通过 JavaScript 更改。三行代码就可以解决这个问题,如下图所示:
第一行是要输入的日期,第二行是JavaScript代码,“documen.getElementById”通过HTML的“id”定位元素,通过改变元素的“值”来改变值.
效果演示如下:
/3 场景二:动态网页自动下拉/
一些复杂的动态网页需要下拉才能完整展示元素,比如腾讯视频首页,如下图:
如果我们需要自动抓取这样的动态网页,我们也可以实现JavaScript的方法来实现。 5行代码,我们就可以连续滑动网页,显示所有动态网页元素。代码如下图所示:
这里小编采用的一步一步下拉的方式,每次滚动1/10,“window.scrollTo”是向下滑动的命令,“document.body.clientHeight”是页面的高度整个窗口,“h=( i/10)”是每次滑动的高度。
效果演示如下:
/4 结语/
将 JavaScript 应用到 selenium 可以帮助我们解决很多问题。这里有两个小例子,只是为了提供一些想法。希望以后遇到 selenium 无法解决的问题时,可以考虑在 JavaScript 中寻找突破口。
欢迎大家积极尝试,在家里度过无聊的时光。本文涉及的代码已经上传到github地址,/cassieeric/python_crawler/tree/master/selenium_skill,感觉不错,记得给个star~
动态网页抓取(动态网页抓取工具--requests1.封装工具函数-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-19 08:07
动态网页抓取工具-:requests1.封装工具函数首先先回顾下http请求模型,
python中有哪些可以抓取网页的库?分别是怎么用的?怎么写的?本质上有两个东西:httprequest和formparser.你可以看看这两个.
https:postmanphantomjshttp重定向header
python抓取豆瓣电影看豆瓣电影有很多坑,有很多选择和坑,有时候真是欲哭无泪ps:已上架网站:-1/item.html/,欢迎试用我们团队开发的第三方豆瓣电影,欢迎各位戳下面地址注册账号并登录,
牛逼代码:异步多线程爬虫(动态网页)最佳实践,
推荐用爬虫工具开发爬虫,而不是使用某个框架封装成库。我个人是这么封装的:httprequest:importrequestsrequest.url_scheme='put'request.url_auth='connected'request.url_maximize=400request.url_reuseall=50request.url_encoding='utf-8'request.url_lower='reuse'request.url_null='reuse'request.url_code=1request.url_code=c1354423request.url_code=5.request.url_parse_auth='encoding'request.url_parse_encoding=encodingrequest.url_export_auth='export'request.url_export_encoding=utf-8request.url_parse_tls='tls'request.url_export_ftp='ftp'request.url_export_url=''request.url_export_index='index'request.url_export_index="index"request.url_export_cookie='cookie'request.url_export_data='data'request.url_export_cookie="data"request.url_export_access='access'request.url_export_method='get'request.url_export_method='post'request.url_export_method='post'request.url_export_method='post'request.url_export_method='get'request.url_export_method='post'request.url_export_method='post'request.url_export_method='post'request.url_export_method='post'request.url_export_auth='post'request.url_export_auth='post'request.url。 查看全部
动态网页抓取(动态网页抓取工具--requests1.封装工具函数-)
动态网页抓取工具-:requests1.封装工具函数首先先回顾下http请求模型,
python中有哪些可以抓取网页的库?分别是怎么用的?怎么写的?本质上有两个东西:httprequest和formparser.你可以看看这两个.
https:postmanphantomjshttp重定向header
python抓取豆瓣电影看豆瓣电影有很多坑,有很多选择和坑,有时候真是欲哭无泪ps:已上架网站:-1/item.html/,欢迎试用我们团队开发的第三方豆瓣电影,欢迎各位戳下面地址注册账号并登录,
牛逼代码:异步多线程爬虫(动态网页)最佳实践,
推荐用爬虫工具开发爬虫,而不是使用某个框架封装成库。我个人是这么封装的:httprequest:importrequestsrequest.url_scheme='put'request.url_auth='connected'request.url_maximize=400request.url_reuseall=50request.url_encoding='utf-8'request.url_lower='reuse'request.url_null='reuse'request.url_code=1request.url_code=c1354423request.url_code=5.request.url_parse_auth='encoding'request.url_parse_encoding=encodingrequest.url_export_auth='export'request.url_export_encoding=utf-8request.url_parse_tls='tls'request.url_export_ftp='ftp'request.url_export_url=''request.url_export_index='index'request.url_export_index="index"request.url_export_cookie='cookie'request.url_export_data='data'request.url_export_cookie="data"request.url_export_access='access'request.url_export_method='get'request.url_export_method='post'request.url_export_method='post'request.url_export_method='post'request.url_export_method='get'request.url_export_method='post'request.url_export_method='post'request.url_export_method='post'request.url_export_method='post'request.url_export_auth='post'request.url_export_auth='post'request.url。
动态网页抓取(Python专题教程:如何用Python语言去实现网站模拟登陆)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-19 01:06
Python专题教程:爬取网站,模拟登录,爬取动态网页版:v1.0 Crifan Li 摘要 本文面向中级Python开发者,介绍如何使用Python语言实现爬取网站,模拟登录,爬取动态网页。主要涉及网络处理相关的模块(urllib、urllib2等)和HTML解析相关的模块(BeautifulSoup、json等)。本文提供多种格式: 在线阅读 HTML 下载(7zip 存档) HTML PDF10 CHM 11 TXT 12 RTF 13 WEBHELP 14 HTML版在线地址为:topic_web_scrape.html 欢迎提出意见、建议、bug提交等讨论组帖子讨论:修订历史修订1.0 2013-02-06 crl 11 12 13 14 python_topic_web_scrape.webhelp。15 15 #cc_by_nc iii 目录 前言 iv 前言 本文的目的是学习如何使用Python语言理解爬取网站、模拟登录、爬取动态网页的逻辑。实现这部分逻辑。15 15 #cc_by_nc iii 目录 前言 iv 前言 本文的目的是学习如何使用Python语言理解爬取网站、模拟登录、爬取动态网页的逻辑。实现这部分逻辑。
前提讨论如何用Python实现,网站爬取,模拟登录,爬取动态网页,前提是你需要对这部分的逻辑有更清晰的理解。不清楚的可以参考:网站爬取、模拟登录、动态网页爬取(Python、C#等)原理及实现详解如何使用Python实现网站爬取,模拟登录,爬取动态网页相关的旧帖【教程】爬取网页,从网页中提取需要的信息。其实对于urllib之类的库,已经做得够好了,尤其是在易用性方面,使用起来已经很方便了。比如直接通过下面的代码,就可以从网页中获取地址,并获取网页源代码 TODO: 添加代码 但是因为事实上,还有网页抓取、网页模拟登录等,需要用到cookies等header参数,要花很多功夫获得强大且易于使用的网络爬虫功能。后来,我在折腾网络爬虫。,通过实际使用,积累了很多这方面的经验,最后,写了一个相关的,功能更强大,使用更方便的功能。主要有2个函数:getUrlResponse和getUrlRespHtml TODO:从crifanLib的解释中添加两个函数 TODO:添加这两个函数的几个用法 TODO:添加其他几个相关函数的解释,包括downloadFile等函数。分为两个方面:一方面是抓取网站的内容,它涉及与网络处理相关的模块。下面我们来解释一下这两个方面的相关逻辑,以及如何在Python中实现相应的功能。
主要涉及到Python中的一些网络处理,与网络处理相关的模块有urllib、urllib2等相关老帖 【整理】Python中用于解析Http包的模块/库 【已解决】Python中cookielib的使用FileCookieJar去save(),结果报错:NotImplementedError [组织] Python中的Cookie处理:自动处理cookies,保存为cookie文件,从文件中加载cookies HTMl解析Python中相关旧帖BeautifulSoup模块介绍[已解决]在Python中使用json.loads解码字符串时出现错误:ValueError: Expecting property name: line JSONobject could Python中和解析捕获的网站内容,即解析HTML、JSON等。相关模块有 BeautifulSoup、json 等。#python_lib_beautifulsoup 查看全部
动态网页抓取(Python专题教程:如何用Python语言去实现网站模拟登陆)
Python专题教程:爬取网站,模拟登录,爬取动态网页版:v1.0 Crifan Li 摘要 本文面向中级Python开发者,介绍如何使用Python语言实现爬取网站,模拟登录,爬取动态网页。主要涉及网络处理相关的模块(urllib、urllib2等)和HTML解析相关的模块(BeautifulSoup、json等)。本文提供多种格式: 在线阅读 HTML 下载(7zip 存档) HTML PDF10 CHM 11 TXT 12 RTF 13 WEBHELP 14 HTML版在线地址为:topic_web_scrape.html 欢迎提出意见、建议、bug提交等讨论组帖子讨论:修订历史修订1.0 2013-02-06 crl 11 12 13 14 python_topic_web_scrape.webhelp。15 15 #cc_by_nc iii 目录 前言 iv 前言 本文的目的是学习如何使用Python语言理解爬取网站、模拟登录、爬取动态网页的逻辑。实现这部分逻辑。15 15 #cc_by_nc iii 目录 前言 iv 前言 本文的目的是学习如何使用Python语言理解爬取网站、模拟登录、爬取动态网页的逻辑。实现这部分逻辑。
前提讨论如何用Python实现,网站爬取,模拟登录,爬取动态网页,前提是你需要对这部分的逻辑有更清晰的理解。不清楚的可以参考:网站爬取、模拟登录、动态网页爬取(Python、C#等)原理及实现详解如何使用Python实现网站爬取,模拟登录,爬取动态网页相关的旧帖【教程】爬取网页,从网页中提取需要的信息。其实对于urllib之类的库,已经做得够好了,尤其是在易用性方面,使用起来已经很方便了。比如直接通过下面的代码,就可以从网页中获取地址,并获取网页源代码 TODO: 添加代码 但是因为事实上,还有网页抓取、网页模拟登录等,需要用到cookies等header参数,要花很多功夫获得强大且易于使用的网络爬虫功能。后来,我在折腾网络爬虫。,通过实际使用,积累了很多这方面的经验,最后,写了一个相关的,功能更强大,使用更方便的功能。主要有2个函数:getUrlResponse和getUrlRespHtml TODO:从crifanLib的解释中添加两个函数 TODO:添加这两个函数的几个用法 TODO:添加其他几个相关函数的解释,包括downloadFile等函数。分为两个方面:一方面是抓取网站的内容,它涉及与网络处理相关的模块。下面我们来解释一下这两个方面的相关逻辑,以及如何在Python中实现相应的功能。
主要涉及到Python中的一些网络处理,与网络处理相关的模块有urllib、urllib2等相关老帖 【整理】Python中用于解析Http包的模块/库 【已解决】Python中cookielib的使用FileCookieJar去save(),结果报错:NotImplementedError [组织] Python中的Cookie处理:自动处理cookies,保存为cookie文件,从文件中加载cookies HTMl解析Python中相关旧帖BeautifulSoup模块介绍[已解决]在Python中使用json.loads解码字符串时出现错误:ValueError: Expecting property name: line JSONobject could Python中和解析捕获的网站内容,即解析HTML、JSON等。相关模块有 BeautifulSoup、json 等。#python_lib_beautifulsoup
动态网页抓取(静态网页抓取java可以使用爬虫写python+lxml)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-17 12:03
动态网页抓取建议选择iis性能可能会低一些,最多不超过iis的30%。但chrome的性能还是可以的,抓取静态网页的性能也完全可以了。windows的话建议选择yum,ubuntu可以选择apt-getimagepackages安装。静态网页抓取java可以使用eclipse,有使用securecrt的扩展。
服务器端建议sqlite1(3.2以下版本。)或者oracle11g。网页抓取linux环境可以使用nginx。每一种环境可以自行安装来尝试。
推荐使用爬虫scrapy,简单易用文档齐全.scrapyjs
iis-uwsgi+lxml
1.首先你要使用前端工具不同:如apache、nginx、mysql、ror等等。iis是用来做web的工具,主要负责数据库,而osx下的fedora是做服务器开发的,不是用来做数据库的,所以你要使用服务器工具,比如lxml或者ror.python,apache,nginx等.2.windows下:首推lxml,。
用爬虫还是要抓到数据吧,要是数据多,手写redis好像也没那么快,找些别人搭好的web服务应该也不难,既然要实时抓取,快速服务器肯定必须的。
用fedora做服务器应该可以吧。
我用的是windows10用eclipse写iis,lxml写python。写好for循环依然无法向服务器输出数据,然后换ide,读取同样的文件列表没有任何问题,看来很可能是编译器的问题,我感觉很可能是xcode的bug, 查看全部
动态网页抓取(静态网页抓取java可以使用爬虫写python+lxml)
动态网页抓取建议选择iis性能可能会低一些,最多不超过iis的30%。但chrome的性能还是可以的,抓取静态网页的性能也完全可以了。windows的话建议选择yum,ubuntu可以选择apt-getimagepackages安装。静态网页抓取java可以使用eclipse,有使用securecrt的扩展。
服务器端建议sqlite1(3.2以下版本。)或者oracle11g。网页抓取linux环境可以使用nginx。每一种环境可以自行安装来尝试。
推荐使用爬虫scrapy,简单易用文档齐全.scrapyjs
iis-uwsgi+lxml
1.首先你要使用前端工具不同:如apache、nginx、mysql、ror等等。iis是用来做web的工具,主要负责数据库,而osx下的fedora是做服务器开发的,不是用来做数据库的,所以你要使用服务器工具,比如lxml或者ror.python,apache,nginx等.2.windows下:首推lxml,。
用爬虫还是要抓到数据吧,要是数据多,手写redis好像也没那么快,找些别人搭好的web服务应该也不难,既然要实时抓取,快速服务器肯定必须的。
用fedora做服务器应该可以吧。
我用的是windows10用eclipse写iis,lxml写python。写好for循环依然无法向服务器输出数据,然后换ide,读取同样的文件列表没有任何问题,看来很可能是编译器的问题,我感觉很可能是xcode的bug,
动态网页抓取(案例1.链家经纪人页面分析我们的是动态网页的代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-16 05:05
在爬取的时候,有时候我们在网页中看到的数据是一样的,但是抓取到的数据却是不一样的。为什么是这样?这时候,我们很有可能是在抓取动态网页。虽然动态网页的代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。动态网页通常使用称为 AJAX 的快速动态网页创建技术。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。那么如何爬取这种网页呢?我们可以考虑使用以下两种方法。
1. 分析页面请求找到真实请求的URL
由于AJAX技术在后台与服务器交互数据,只要有数据发送,就一定有请求发送给服务器,只要找出它加载页面的真实请求,然后构造并发送请求。
2. 使用 Selenium 模拟浏览器行为
Selenium 是一种自动化测试工具,被广泛用作爬虫。在爬虫中,Selenium 主要用于解决动态网页的加载和渲染功能。Selenium 可以使用代码来模拟浏览器的操作,模拟人的操作。您可以将 Selenium 与无头浏览器(例如:phantomjs、无头 Chrome)一起使用来加载和渲染网页,然后提取所需的信息。
案例1.链家经纪人页面分析
我们来分析一下移动端的链家经纪页面。与PC端相比,移动端网页更加简洁简洁。因此,如果一个网页有移动端,我们会优先抓取移动端的网页。打开网页,拉动滚动条,拉到最后,在里面添加一些数据。我们发现NetWork中有很多请求信息,这些请求大部分都是以jpg结尾的图片请求,但是我们可以仔细观察后发现。更多特殊要求如下:
我们继续滑动滚动条,再次找到类似的请求。我们复制请求链接,单独打开,发现是不同broker的请求页面。我们分析了链接,发现后面一个offset的值一直在变化,每增加15,就会请求新的15条数据。所以你,我们只需要改变offset的值来请求不同的页面。至此,我们已经发现了网站 URL的构造规则,接下来就可以编写代码进行爬取了。
# -*- coding: utf-8 -*-
# # @Author: lemon
# # @Date: 2019-09-19 18:18
# # @Last Modified by: lemon
# # @Last Modified time: 2019-09-19 18:42
# # @function: 爬取链家经纪人数据
import requests
import time
from lxml import etree
import pandas as pd
# 存储 DataFrame 中用到的数据
data = {
'姓名': [],
'职位': [],
'评分': []
}
def spider(list_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
response = requests.get(list_url, headers=headers)
time.sleep(5)
sel = etree.HTML(response.text)
# 先爬取每一位经纪人的整体代码段
agent_list = sel.xpath('//li[@class="pictext flexbox box_center_v lazyload_ulog"]')
for agent in agent_list:
agent_name = agent.xpath('div/div[2]/div[1]/span[1]/a/text()')[0].strip() # 姓名
agent_level = agent.xpath('div/div[2]/div[1]/span[2]/text()')[0].strip() # 职位
agent_score = agent.xpath('div/div[2]/div[1]/span[3]/span[1]/text()')[0].strip() # 评分
print(agent_name, agent_level, agent_score)
data['姓名'].append(agent_name)
data['职位'].append(agent_level)
data['评分'].append(agent_score)
def write_data(data):
frame = pd.DataFrame(data)
frame.to_excel('链家经纪人数据.xlsx')
if __name__ == '__main__':
for i in range(10):
# 根据加载的时候 offset 的变化规律, 构造不同页面的 URL
url = 'https://m.lianjia.com/cs/jingj ... 39%3B + str(i * 15)
print(f'正在爬取 page {i + 1}...')
spider(url)
write_data(data)
这是我们最终抓取的经纪人数据:
2. Selenium 请求百度
由于 Selenium 不是 Python 的标准库,我们首先需要安装 Selenium 库。
pip install selenium
Selenium 需要使用 chromedriver 来驱动 Chrome 浏览器。我们需要下载对应操作系统的版本。您可以参考ChromeDriver和Chrome版本对应参考表和ChromeDriver下载链接进行下载安装。
Selenium 使用 chromedriver 时,既可以将 chromedriver 添加到系统的环境变量中,也可以直接在代码中指定 chromedriver 所在目录。
接下来,我们使用 Selenium 访问百度主页
# -*- coding: utf-8 -*-
# # @Author: lemon
# # @Date: 2019-09-19 19:00
# # @Last Modified by: lemon
# # @Last Modified time: 2019-09-19 19:10
# # @function: Selenium 打开百度
# %%1 从 selenium 中引入 webdriver
from selenium import webdriver
driver = webdriver.Chrome('E:\ChromeDriver\chromedriver.exe') # 初始化 webdriver
driver.get('https://www.baidu.com/') # 使用 webdriver 打开百度首页
search_box = driver.find_element_by_xpath('//*[@id="kw"]') # 使用 xpath 找到搜索框
search_box.send_keys('python') # 在搜索框中搜索关键字
submit = driver.find_element_by_xpath('//*[@id="su"]') # 使用 xpath 找到搜索按钮
submit.click() # 点击搜索按钮进行搜索
可以观察到以下效果: 我们的 Chrome 浏览器正在接收来自自动化测试软件的控制
在后续的文章中,我们会给你一个例子:如何使用Selenium爬取新浪微博的网站,进一步加强你对Selenium的使用。 查看全部
动态网页抓取(案例1.链家经纪人页面分析我们的是动态网页的代码)
在爬取的时候,有时候我们在网页中看到的数据是一样的,但是抓取到的数据却是不一样的。为什么是这样?这时候,我们很有可能是在抓取动态网页。虽然动态网页的代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。动态网页通常使用称为 AJAX 的快速动态网页创建技术。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。那么如何爬取这种网页呢?我们可以考虑使用以下两种方法。
1. 分析页面请求找到真实请求的URL
由于AJAX技术在后台与服务器交互数据,只要有数据发送,就一定有请求发送给服务器,只要找出它加载页面的真实请求,然后构造并发送请求。
2. 使用 Selenium 模拟浏览器行为
Selenium 是一种自动化测试工具,被广泛用作爬虫。在爬虫中,Selenium 主要用于解决动态网页的加载和渲染功能。Selenium 可以使用代码来模拟浏览器的操作,模拟人的操作。您可以将 Selenium 与无头浏览器(例如:phantomjs、无头 Chrome)一起使用来加载和渲染网页,然后提取所需的信息。
案例1.链家经纪人页面分析
我们来分析一下移动端的链家经纪页面。与PC端相比,移动端网页更加简洁简洁。因此,如果一个网页有移动端,我们会优先抓取移动端的网页。打开网页,拉动滚动条,拉到最后,在里面添加一些数据。我们发现NetWork中有很多请求信息,这些请求大部分都是以jpg结尾的图片请求,但是我们可以仔细观察后发现。更多特殊要求如下:
我们继续滑动滚动条,再次找到类似的请求。我们复制请求链接,单独打开,发现是不同broker的请求页面。我们分析了链接,发现后面一个offset的值一直在变化,每增加15,就会请求新的15条数据。所以你,我们只需要改变offset的值来请求不同的页面。至此,我们已经发现了网站 URL的构造规则,接下来就可以编写代码进行爬取了。
# -*- coding: utf-8 -*-
# # @Author: lemon
# # @Date: 2019-09-19 18:18
# # @Last Modified by: lemon
# # @Last Modified time: 2019-09-19 18:42
# # @function: 爬取链家经纪人数据
import requests
import time
from lxml import etree
import pandas as pd
# 存储 DataFrame 中用到的数据
data = {
'姓名': [],
'职位': [],
'评分': []
}
def spider(list_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
response = requests.get(list_url, headers=headers)
time.sleep(5)
sel = etree.HTML(response.text)
# 先爬取每一位经纪人的整体代码段
agent_list = sel.xpath('//li[@class="pictext flexbox box_center_v lazyload_ulog"]')
for agent in agent_list:
agent_name = agent.xpath('div/div[2]/div[1]/span[1]/a/text()')[0].strip() # 姓名
agent_level = agent.xpath('div/div[2]/div[1]/span[2]/text()')[0].strip() # 职位
agent_score = agent.xpath('div/div[2]/div[1]/span[3]/span[1]/text()')[0].strip() # 评分
print(agent_name, agent_level, agent_score)
data['姓名'].append(agent_name)
data['职位'].append(agent_level)
data['评分'].append(agent_score)
def write_data(data):
frame = pd.DataFrame(data)
frame.to_excel('链家经纪人数据.xlsx')
if __name__ == '__main__':
for i in range(10):
# 根据加载的时候 offset 的变化规律, 构造不同页面的 URL
url = 'https://m.lianjia.com/cs/jingj ... 39%3B + str(i * 15)
print(f'正在爬取 page {i + 1}...')
spider(url)
write_data(data)
这是我们最终抓取的经纪人数据:
2. Selenium 请求百度
由于 Selenium 不是 Python 的标准库,我们首先需要安装 Selenium 库。
pip install selenium
Selenium 需要使用 chromedriver 来驱动 Chrome 浏览器。我们需要下载对应操作系统的版本。您可以参考ChromeDriver和Chrome版本对应参考表和ChromeDriver下载链接进行下载安装。
Selenium 使用 chromedriver 时,既可以将 chromedriver 添加到系统的环境变量中,也可以直接在代码中指定 chromedriver 所在目录。
接下来,我们使用 Selenium 访问百度主页
# -*- coding: utf-8 -*-
# # @Author: lemon
# # @Date: 2019-09-19 19:00
# # @Last Modified by: lemon
# # @Last Modified time: 2019-09-19 19:10
# # @function: Selenium 打开百度
# %%1 从 selenium 中引入 webdriver
from selenium import webdriver
driver = webdriver.Chrome('E:\ChromeDriver\chromedriver.exe') # 初始化 webdriver
driver.get('https://www.baidu.com/') # 使用 webdriver 打开百度首页
search_box = driver.find_element_by_xpath('//*[@id="kw"]') # 使用 xpath 找到搜索框
search_box.send_keys('python') # 在搜索框中搜索关键字
submit = driver.find_element_by_xpath('//*[@id="su"]') # 使用 xpath 找到搜索按钮
submit.click() # 点击搜索按钮进行搜索
可以观察到以下效果: 我们的 Chrome 浏览器正在接收来自自动化测试软件的控制
在后续的文章中,我们会给你一个例子:如何使用Selenium爬取新浪微博的网站,进一步加强你对Selenium的使用。
动态网页抓取(一下动态网页的另一种方法逆向分析啦!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-16 05:02
首先,让我们谈谈动态网页,它们是 HTML 和 CSS 元素,它们以客户端语言更改页面。例如,一个网页通过加载一个网页将你带到另一个页面,但页面的 URL 链接没有改变,或者当你点击空白处时页面会改变颜色。
然后是客户端脚本语言,它们是在浏览器上运行的语言,而不是在服务器上运行的语言。互联网上通常会遇到两种客户端语言:ActionScript(用于开发 Flash 应用程序的语言)和 JavaScript。
JavaScript 常用于为网页添加各种动态功能,为用户提供更流畅、更美观的浏览效果。通常 JavaScript 脚本嵌入在 HTML 中以实现自己的功能。
例如,对于一个下拉加载的动态网页,加载后可以在浏览器的开发者工具的网络中的JS选项中看到它刚刚执行的JavaScript,点击就可以看到代码。
目前已经写了少量爬虫。对于动态网页,比如下拉加载图片,在developer tools/network/image中找到图片,分析图片地址的特征,然后在js中找到javascript文件,里面可能收录如果能找到标准图片信息,或者网页的跳转关系,可以很方便的编写程序,将图片下载到图片地址。
这种方法是逆向分析。
另一种爬取动态网页的方法是模拟浏览器,通常使用 Selenium+PhantomJS。
Selenium 是一个浏览器自动化测试框架,最初是为自动化测试而开发的,现在也用于网络数据采集。框架底层使用 JavaScript 模拟真实用户操作浏览器。执行测试脚本时,浏览器会自动根据脚本代码进行点击、进入、打开、验证等操作,就像真实用户一样,站在终端用户的角度对应用进行测试。
Selenium 没有自己的浏览器,需要与第三方浏览器配合使用。之前用过火狐,每次运行都会打开一个浏览器窗口,程序的运行情况一目了然。另一方面,PhantomJS 是无头浏览器,不显示浏览器窗口。
Selenium+PhantomJS 可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标头以及您需要做的任何其他事情。
2018-03-01 13:50
不知道有没有喜欢的朋友,嘿嘿,,, Ծ^Ծ,,
没有图的答案就注定没有点赞吗?
这是一条更新线路,下面的信息是旧消息。
反正是原答案,不忍心删。如果您不喜欢它,请跳过它。
╯▂╰
我刚刚在寒假学习这个。几天前我想爬一个 网站 。我在开发者工具里看数据,爬成静态网页,然后爬下来就找不到数据了。
后来才知道,在开发者工具中看到的网页源代码是用JavaScript渲染的,没有我想要的数据的源代码是通过Requests获取的。
之前看书的时候,提到过 selenium 模块。考虑到用它来模拟浏览器不容易被逆,我用它爬过12306查票,但是速度真的很慢。测试网速需要设置等待网页刷新的时间。
我能想到的第一个方法是使用 selenium,但我非常反对认为它的速度无法满足我的需求。(呃(~_~;)
那我们就去百度一下,肯定会有其他的解决办法。
然后在CSDN上有一篇非常完整的文章。
用大佬的总结:
动态网页可以通过逆向分析尽可能地逆向,其稳定性和效率是其他解决方案无法比拟的。通常有一个关于爬虫的口口相传的真相。如果在浏览器中点击并使用F12的方式,就可以解决90%的爬虫问题,剩下的10%需要动动脑筋。对于动态页面抓取来说更是如此。如果你能扭转它,试着扭转它。如果无法逆转,那就找一个折中的解决方案。在折衷方案中,可以尽量使用深度控制JS脚本执行方案(难度稍大),其次是基于Browser自动化测试框架的标准(即selenium和PhantomJs)爬取。
欲了解更多信息,请访问 网站:
/yanbober/article/details/73822475?locationNum=3&fps=1
时间:2018-02-10 01:23 查看全部
动态网页抓取(一下动态网页的另一种方法逆向分析啦!!)
首先,让我们谈谈动态网页,它们是 HTML 和 CSS 元素,它们以客户端语言更改页面。例如,一个网页通过加载一个网页将你带到另一个页面,但页面的 URL 链接没有改变,或者当你点击空白处时页面会改变颜色。
然后是客户端脚本语言,它们是在浏览器上运行的语言,而不是在服务器上运行的语言。互联网上通常会遇到两种客户端语言:ActionScript(用于开发 Flash 应用程序的语言)和 JavaScript。
JavaScript 常用于为网页添加各种动态功能,为用户提供更流畅、更美观的浏览效果。通常 JavaScript 脚本嵌入在 HTML 中以实现自己的功能。
例如,对于一个下拉加载的动态网页,加载后可以在浏览器的开发者工具的网络中的JS选项中看到它刚刚执行的JavaScript,点击就可以看到代码。
目前已经写了少量爬虫。对于动态网页,比如下拉加载图片,在developer tools/network/image中找到图片,分析图片地址的特征,然后在js中找到javascript文件,里面可能收录如果能找到标准图片信息,或者网页的跳转关系,可以很方便的编写程序,将图片下载到图片地址。
这种方法是逆向分析。
另一种爬取动态网页的方法是模拟浏览器,通常使用 Selenium+PhantomJS。
Selenium 是一个浏览器自动化测试框架,最初是为自动化测试而开发的,现在也用于网络数据采集。框架底层使用 JavaScript 模拟真实用户操作浏览器。执行测试脚本时,浏览器会自动根据脚本代码进行点击、进入、打开、验证等操作,就像真实用户一样,站在终端用户的角度对应用进行测试。
Selenium 没有自己的浏览器,需要与第三方浏览器配合使用。之前用过火狐,每次运行都会打开一个浏览器窗口,程序的运行情况一目了然。另一方面,PhantomJS 是无头浏览器,不显示浏览器窗口。
Selenium+PhantomJS 可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标头以及您需要做的任何其他事情。
2018-03-01 13:50
不知道有没有喜欢的朋友,嘿嘿,,, Ծ^Ծ,,
没有图的答案就注定没有点赞吗?
这是一条更新线路,下面的信息是旧消息。
反正是原答案,不忍心删。如果您不喜欢它,请跳过它。
╯▂╰
我刚刚在寒假学习这个。几天前我想爬一个 网站 。我在开发者工具里看数据,爬成静态网页,然后爬下来就找不到数据了。
后来才知道,在开发者工具中看到的网页源代码是用JavaScript渲染的,没有我想要的数据的源代码是通过Requests获取的。
之前看书的时候,提到过 selenium 模块。考虑到用它来模拟浏览器不容易被逆,我用它爬过12306查票,但是速度真的很慢。测试网速需要设置等待网页刷新的时间。
我能想到的第一个方法是使用 selenium,但我非常反对认为它的速度无法满足我的需求。(呃(~_~;)
那我们就去百度一下,肯定会有其他的解决办法。
然后在CSDN上有一篇非常完整的文章。
用大佬的总结:
动态网页可以通过逆向分析尽可能地逆向,其稳定性和效率是其他解决方案无法比拟的。通常有一个关于爬虫的口口相传的真相。如果在浏览器中点击并使用F12的方式,就可以解决90%的爬虫问题,剩下的10%需要动动脑筋。对于动态页面抓取来说更是如此。如果你能扭转它,试着扭转它。如果无法逆转,那就找一个折中的解决方案。在折衷方案中,可以尽量使用深度控制JS脚本执行方案(难度稍大),其次是基于Browser自动化测试框架的标准(即selenium和PhantomJs)爬取。
欲了解更多信息,请访问 网站:
/yanbober/article/details/73822475?locationNum=3&fps=1
时间:2018-02-10 01:23
动态网页抓取(微信公众号动态网页抓取设置的技巧与方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-15 17:00
动态网页抓取设置首先要确定你的目标页面在移动端的显示规律,抓取规则。然后把想抓取的内容放到cookie上,定期加载就行了。针对微信公众号的话,
真想对网页做出正确合理判断最好自己搭建爬虫,借助chrome浏览器,google浏览器或者chrome的插件。
恩,这就是你需要学习的,要说拿到自己需要的资源,你需要:1,爬虫。2,网页分析。3,网页解析。看似简单的问题,做起来其实并不容易,爬虫都是对网页进行长期分析而存在的技术,网页分析一般以检测网页是否是https协议为标准,网页解析需要有能力找到网页的cookie或者session,这就是你需要学习的。至于怎么学,用什么工具,这要看你的特点了,看个人兴趣,任何工具都是一样的!。
那就要你去分析这个网站,其实没什么好说的,网上的教程够多了,掌握基本的做为爬虫工程师应该没什么大问题。本人一直坚持认为技术这东西毕竟是内化到你的脑子里,如果说外界环境,那确实有些困难。
以下回答对于大多数技术而言是适用的。如果网站对爬虫非常友好,那么python爬虫常用库有scrapy、beautifulsoup等,也就是@zhuyizhu要求的htmlapi,但是正因为如此,选择爬虫的人也相对较少。如果网站对爬虫非常不友好,那么liquidflask这样的框架可以帮助你爬下,就是换汤不换药的简单逻辑。
b站的爬虫库就是这样,以下就以此类网站为例。-分析网站用于爬虫的网站结构最常用的有urllib模块,urllib模块介绍比较简单,就不描述了。通过urllib.request函数,我们不用new一个对象,而是构造一个request对象,然后request来请求网站资源。爬虫本质就是一个request对象,因此我们只需要构造urllib.request对象,然后访问就可以了。
下面举几个栗子:-构造beemail的请求用户发送一封电子邮件给电话联系人,对方查看该邮件并回复。1.网站情况beemail网站支持多帐号注册、帐号删除、注册后数据消失、注册结束和暂停注册这五种状态。那么beemail.basic(username='admin',password='root')这个参数的功能是什么呢?beemail.basic(username='admin',password='root')这个参数的功能是设置请求最多可以通过的用户名和密码。
beemail.basic(username='admin',password='root')这个参数的功能是设置请求默认username,然后默认用户名的用户名和密码就是你注册邮箱的用户名和密码。这个功能的效果就是对方点击发送电子邮件,然后你只能发送文本邮件给他,并且和他的。 查看全部
动态网页抓取(微信公众号动态网页抓取设置的技巧与方法)
动态网页抓取设置首先要确定你的目标页面在移动端的显示规律,抓取规则。然后把想抓取的内容放到cookie上,定期加载就行了。针对微信公众号的话,
真想对网页做出正确合理判断最好自己搭建爬虫,借助chrome浏览器,google浏览器或者chrome的插件。
恩,这就是你需要学习的,要说拿到自己需要的资源,你需要:1,爬虫。2,网页分析。3,网页解析。看似简单的问题,做起来其实并不容易,爬虫都是对网页进行长期分析而存在的技术,网页分析一般以检测网页是否是https协议为标准,网页解析需要有能力找到网页的cookie或者session,这就是你需要学习的。至于怎么学,用什么工具,这要看你的特点了,看个人兴趣,任何工具都是一样的!。
那就要你去分析这个网站,其实没什么好说的,网上的教程够多了,掌握基本的做为爬虫工程师应该没什么大问题。本人一直坚持认为技术这东西毕竟是内化到你的脑子里,如果说外界环境,那确实有些困难。
以下回答对于大多数技术而言是适用的。如果网站对爬虫非常友好,那么python爬虫常用库有scrapy、beautifulsoup等,也就是@zhuyizhu要求的htmlapi,但是正因为如此,选择爬虫的人也相对较少。如果网站对爬虫非常不友好,那么liquidflask这样的框架可以帮助你爬下,就是换汤不换药的简单逻辑。
b站的爬虫库就是这样,以下就以此类网站为例。-分析网站用于爬虫的网站结构最常用的有urllib模块,urllib模块介绍比较简单,就不描述了。通过urllib.request函数,我们不用new一个对象,而是构造一个request对象,然后request来请求网站资源。爬虫本质就是一个request对象,因此我们只需要构造urllib.request对象,然后访问就可以了。
下面举几个栗子:-构造beemail的请求用户发送一封电子邮件给电话联系人,对方查看该邮件并回复。1.网站情况beemail网站支持多帐号注册、帐号删除、注册后数据消失、注册结束和暂停注册这五种状态。那么beemail.basic(username='admin',password='root')这个参数的功能是什么呢?beemail.basic(username='admin',password='root')这个参数的功能是设置请求最多可以通过的用户名和密码。
beemail.basic(username='admin',password='root')这个参数的功能是设置请求默认username,然后默认用户名的用户名和密码就是你注册邮箱的用户名和密码。这个功能的效果就是对方点击发送电子邮件,然后你只能发送文本邮件给他,并且和他的。
动态网页抓取(中结合selenium脚本的登录页面抓取位于地图右侧区域 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-15 09:23
)
我用python结合selenium编写了一个脚本,从它的登录页面获取位于地图右侧区域的不同属性的链接。
链接到着陆页
当我从 chrome 手动单击每个块时,我在新选项卡中看到 /for_sale/ 收录此部分的链接,而我的脚本获取收录 /homedetails/ 的内容。
我怎样才能获得结果的数量(例如 153 个待售房屋)和正确的房产链接?
到目前为止我的尝试:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
link = "https://www.zillow.com/homes/33155_rb/"
driver = webdriver.Chrome()
wait = WebDriverWait(driver, 10)
driver.get(link)
itemcount = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,"#map-result-count-message h2")))
print(itemcount.text)
for item in wait.until(EC.visibility_of_all_elements_located((By.CSS_SELECTOR,".zsg-photo-card-overlay-link"))):
print(item.get_attribute("href"))
driver.quit()
当前输出之一:
https://www.zillow.com/homedet ... zpid/
这样的预期输出之一:
https://www.zillow.com/homes/f ... 76783,-80.256072,25.695446,-80.364905_rect/12_zm/0_mmm/ 查看全部
动态网页抓取(中结合selenium脚本的登录页面抓取位于地图右侧区域
)
我用python结合selenium编写了一个脚本,从它的登录页面获取位于地图右侧区域的不同属性的链接。
链接到着陆页
当我从 chrome 手动单击每个块时,我在新选项卡中看到 /for_sale/ 收录此部分的链接,而我的脚本获取收录 /homedetails/ 的内容。
我怎样才能获得结果的数量(例如 153 个待售房屋)和正确的房产链接?
到目前为止我的尝试:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
link = "https://www.zillow.com/homes/33155_rb/"
driver = webdriver.Chrome()
wait = WebDriverWait(driver, 10)
driver.get(link)
itemcount = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,"#map-result-count-message h2")))
print(itemcount.text)
for item in wait.until(EC.visibility_of_all_elements_located((By.CSS_SELECTOR,".zsg-photo-card-overlay-link"))):
print(item.get_attribute("href"))
driver.quit()
当前输出之一:
https://www.zillow.com/homedet ... zpid/
这样的预期输出之一:
https://www.zillow.com/homes/f ... 76783,-80.256072,25.695446,-80.364905_rect/12_zm/0_mmm/
动态网页抓取(如何爬取网页数据?(一)吧(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2022-03-13 18:01
这里有一个简单的介绍。以捕获静态和动态数据为例,实验环境为win10+python3.6+pycharm5.0。主要内容如下:
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数和评论数四个字段,如下:
对应的网页源码如下,收录我们需要的数据:
2.对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:
程序运行截图如下,爬取数据成功:
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额、进度五个字段。截图如下:
打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难。它们是入门级爬虫。网页的结构比较简单。最重要的是进行抓包分析,分析并提取页面。数据爬取的框架可以更方便、更高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
如何抓取网页数据?
1、网址管理
首先,url管理器在待爬取的集合中添加新的url,判断待添加的url是否在容器中以及是否有待爬取的url,获取待爬取的url,将url从要抓取的 url。集合移动到爬取的url集合
对于页面下载,下载器将接收到的url传给互联网,互联网将html文件返回给下载器,下载器保存在本地。一般来说,下载器会以分布式的方式部署。一是提交效率,二是启动。请求代理
2、内容提取
页面解析器的主要任务是从获取的html网页字符串中获取有价值的感兴趣的数据和一个新的url列表。常用的数据提取方法包括基于 CSS 选择器、正则表达式和 xpath 的规则提取。一般在提取后,会对数据进行一定程度的清洗或定制,从而将请求的非结构化数据转化为我们需要的结构化数据。
3、数据存储
将数据保存到相关的数据库、队列、文件等,方便数据计算和与应用程序对接。
爬虫采集已经成为很多公司和个人的需求,但正因为如此,反爬虫技术层出不穷,比如时间限制、IP限制、验证码限制等,可能会导致爬虫失败,所以也出现了代理IP、调整时限等多种方法来解决反爬虫限制。当然,具体的操作方法还需要有针对性的研究。兔子动态IP软件可实现一键IP自动切换,千万级IP盘点,自动去重,支持电脑、手机多终端使用。
"
如何捕获有关 Web 更改的信息?
你可以做我的小粉丝吗?可以吗? 查看全部
动态网页抓取(如何爬取网页数据?(一)吧(图))
这里有一个简单的介绍。以捕获静态和动态数据为例,实验环境为win10+python3.6+pycharm5.0。主要内容如下:
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数和评论数四个字段,如下:
对应的网页源码如下,收录我们需要的数据:
2.对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:
程序运行截图如下,爬取数据成功:
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额、进度五个字段。截图如下:
打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难。它们是入门级爬虫。网页的结构比较简单。最重要的是进行抓包分析,分析并提取页面。数据爬取的框架可以更方便、更高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
如何抓取网页数据?
1、网址管理
首先,url管理器在待爬取的集合中添加新的url,判断待添加的url是否在容器中以及是否有待爬取的url,获取待爬取的url,将url从要抓取的 url。集合移动到爬取的url集合
对于页面下载,下载器将接收到的url传给互联网,互联网将html文件返回给下载器,下载器保存在本地。一般来说,下载器会以分布式的方式部署。一是提交效率,二是启动。请求代理
2、内容提取
页面解析器的主要任务是从获取的html网页字符串中获取有价值的感兴趣的数据和一个新的url列表。常用的数据提取方法包括基于 CSS 选择器、正则表达式和 xpath 的规则提取。一般在提取后,会对数据进行一定程度的清洗或定制,从而将请求的非结构化数据转化为我们需要的结构化数据。
3、数据存储
将数据保存到相关的数据库、队列、文件等,方便数据计算和与应用程序对接。
爬虫采集已经成为很多公司和个人的需求,但正因为如此,反爬虫技术层出不穷,比如时间限制、IP限制、验证码限制等,可能会导致爬虫失败,所以也出现了代理IP、调整时限等多种方法来解决反爬虫限制。当然,具体的操作方法还需要有针对性的研究。兔子动态IP软件可实现一键IP自动切换,千万级IP盘点,自动去重,支持电脑、手机多终端使用。
"
如何捕获有关 Web 更改的信息?
你可以做我的小粉丝吗?可以吗?
动态网页抓取(这世上如果有天堂,天堂应该是图书馆的模样(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-13 18:00
如果这个世界上有天堂,天堂应该就像一个图书馆。---【阿根廷】豪尔赫·路易斯·博尔赫斯
好开心,终于可以批量下载茜茜公主的照片了,好漂亮的女人啊!因为刘亦菲在这个页面上的星图画墙是动态页面,直接阅读页面内容是无法获取图片信息的,所以我们需要另辟蹊径。
在解决动态网页时,我们通常可以采取以下两种方法:
1.通过抓包工具分析js和ajax的请求,模拟请求获取js加载的数据(对于小白来说还是有难度的)。
2.调用浏览器内核获取加载网页的源代码,然后解析源代码。
本文主要使用selenium+python+BeautifulSoup的结构来抓图。
a) Selenium 是一种用于模拟浏览器和进行自动化测试的工具。它提供了一组 API 来与真正的浏览器内核交互。使用起来也比较简单。
b)BeautifulSoup是一个解析网页信息的工具,可以从网页中过滤出我们想要的东西。
项目目的:从刘亦菲的图片栏中抓取图片并存储在电脑上
一。使用 selenium 模拟打开浏览器
1driver = webdriver.Firefox()
2driver.get('http://image.baidu.com/activit ... 92512 1383889887?&albumtype=0')
3
1 *二、解析网页信息*
2
我们先按F12查看网页的评论信息,通过图片定位评论元素。可以看到下图:
通过分析几张图片的信息,我们发现每张图片的信息格式都是一样的,所以我们可以通过BeautifulSoup找到
元素节点,然后通过访问其子节点两次,获得到图像的链接,即“src”信息。
三、使用PIL模块存储图片
上面是通用模块,下面是程序代码:
1#-*-coding:utf-8 -*-
2from selenium import webdriver
3from selenium.webdriver.common.keys import Keys
4from selenium.webdriver.support.ui import WebDriverWait
5from bs4 import BeautifulSoup
6from PIL import Image
7import urllib2
8import StringIO
9import time
10
11
12driver = webdriver.Firefox()
13driver.get('http://image.baidu.com/activit ... 92512 1383889887?&albumtype=0')
14soup = BeautifulSoup(driver.page_source)
15all = soup.find_all("div", class_="img-container")
16time.sleep(2)
17count =0
18number=0
19for each in all:
20 number+=1
21 picUrl = each.contents[0].contents[0]['src']
22 print picUrl
23 try:
24 imgString=urllib2.urlopen(picUrl).read()
25 im=Image.open(StringIO.StringIO(imgString))
26 except:
27 continue
28 count += 1
29 print count
30 imgPath='/home/fiona/fei/photo/'+ str(count)+'.jpg'
31 im.save(imgPath)
32
33print number
34driver.quit()
35
1 提取出来的图片如下:
2
项目问题:
一页有60多张照片,但只拍了30张。我不知道原因。有知道的可以给我留言,谢谢!
参与信息:
(好文章) 查看全部
动态网页抓取(这世上如果有天堂,天堂应该是图书馆的模样(图))
如果这个世界上有天堂,天堂应该就像一个图书馆。---【阿根廷】豪尔赫·路易斯·博尔赫斯
好开心,终于可以批量下载茜茜公主的照片了,好漂亮的女人啊!因为刘亦菲在这个页面上的星图画墙是动态页面,直接阅读页面内容是无法获取图片信息的,所以我们需要另辟蹊径。
在解决动态网页时,我们通常可以采取以下两种方法:
1.通过抓包工具分析js和ajax的请求,模拟请求获取js加载的数据(对于小白来说还是有难度的)。
2.调用浏览器内核获取加载网页的源代码,然后解析源代码。
本文主要使用selenium+python+BeautifulSoup的结构来抓图。
a) Selenium 是一种用于模拟浏览器和进行自动化测试的工具。它提供了一组 API 来与真正的浏览器内核交互。使用起来也比较简单。
b)BeautifulSoup是一个解析网页信息的工具,可以从网页中过滤出我们想要的东西。
项目目的:从刘亦菲的图片栏中抓取图片并存储在电脑上
一。使用 selenium 模拟打开浏览器
1driver = webdriver.Firefox()
2driver.get('http://image.baidu.com/activit ... 92512 1383889887?&albumtype=0')
3
1 *二、解析网页信息*
2
我们先按F12查看网页的评论信息,通过图片定位评论元素。可以看到下图:
通过分析几张图片的信息,我们发现每张图片的信息格式都是一样的,所以我们可以通过BeautifulSoup找到
元素节点,然后通过访问其子节点两次,获得到图像的链接,即“src”信息。
三、使用PIL模块存储图片
上面是通用模块,下面是程序代码:
1#-*-coding:utf-8 -*-
2from selenium import webdriver
3from selenium.webdriver.common.keys import Keys
4from selenium.webdriver.support.ui import WebDriverWait
5from bs4 import BeautifulSoup
6from PIL import Image
7import urllib2
8import StringIO
9import time
10
11
12driver = webdriver.Firefox()
13driver.get('http://image.baidu.com/activit ... 92512 1383889887?&albumtype=0')
14soup = BeautifulSoup(driver.page_source)
15all = soup.find_all("div", class_="img-container")
16time.sleep(2)
17count =0
18number=0
19for each in all:
20 number+=1
21 picUrl = each.contents[0].contents[0]['src']
22 print picUrl
23 try:
24 imgString=urllib2.urlopen(picUrl).read()
25 im=Image.open(StringIO.StringIO(imgString))
26 except:
27 continue
28 count += 1
29 print count
30 imgPath='/home/fiona/fei/photo/'+ str(count)+'.jpg'
31 im.save(imgPath)
32
33print number
34driver.quit()
35
1 提取出来的图片如下:
2
项目问题:
一页有60多张照片,但只拍了30张。我不知道原因。有知道的可以给我留言,谢谢!
参与信息:
(好文章)
动态网页抓取( 不能动态加载的内容静态网页的两种方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2022-03-13 17:26
不能动态加载的内容静态网页的两种方法
)
一、动态网页爬取介绍
在很多网站中,使用javascript写网站,很多内容不会出现在HTML源代码中,所以不能使用之前爬取静态网页的方法。有一种异步技术叫做AJAX,它的价值在于通过后台和服务器之间进行少量的数据转换,可以实现网页的异步更新。也就是说,更新网页的一部分而不重新加载整个网页。减少网页上重复内容的下载,节省流量。但随之而来的麻烦是我们在HTML代码中找不到我们想要的数据。解决这种爬取动态加载的内容,有两种方法:
通过浏览器检查元素解析地址 使用 Selenium 模拟浏览器抓取 二、 解析真实地址抓取
我们要的数据不是HTML,而是可以找到数据的真实地址。请求这个地址也能找到想要的数据,也能完成书中的例子。首先打开网站:,这个网站是JS写的,鼠标右键,点击Check。刷新页面,可以看到网页的所有文件都加载完毕了。这个过程就是抓包的过程。然后,点击网络找到收录数据的文件,记住是json数据。
单击标题以查找真实地址。然后将请求发送到真实地址。
1.发送请求,获取数据
import requests
# 构建url
url = """https://api-zero.livere.com/v1 ... ot%3B
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
r = requests.get(url, headers=headers)
print(r.text)
2.解析数据
要从json数据中提取注释,首先我们需要找到符合json格式的部分。然后,使用 json.loads 将字符串格式的响应正文转换为 json 数据。然后,根据json数据的结构,可以提取出评论列表comment_list。最后通过for循环,提取注释文本,并输出打印。
import json
json_string = r.text
# 找到符合json格式的数据
json_string = json_string[json_string.find('{'): -2]
# 转换为json格式
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print(message)
三、 模拟浏览器通过 selenium 爬行
一些网站的地址加密,使得一些变量分析不清楚。接下来,我们将使用第二种方法,使用浏览器渲染引擎。在显示网页时直接使用浏览器解析 HTML、应用 CSS 样式和执行 JavaScript 语句。该方法会打开浏览器,加载网页,自动操作浏览器浏览各种网页,顺便抓取数据,将抓取的动态网页变为抓取静态网页。我们可以使用 selenium 库来模拟浏览器来完成爬取。Selenium 是用于 Web 应用程序测试的工具。它直接在浏览器中运行,浏览器根据脚本代码自动点击、进入、打开、验证。
1. 安装硒
点安装硒
下载“geckodriver”并位于 Python 的安装目录中。
2. 使用 selenium 爬取数据
第 1 步:找到评论的 HTML 代码标记。使用火狐,点击页面,找到标签,找到评论数据
第二步:尝试获取评论数据,使用以下代码获取数据。
# 使用CSS选择器查找元素,找到class为'reply-content'的div元素
comment = driver.find_element_by_css_selector('div.reply-content')
# 通过元素的tag去寻找‘p’元素
content = comment.find_element_by_tag_name('p')
print(content.text)
还是有问题啊 网页打不开啊
也可能存在解析失败报错的情况,报“Message: Unable to locate element: div.reply_content”的错误。这是因为源代码需要解析成iframe,需要添加下面这行代码。
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")) 查看全部
动态网页抓取(
不能动态加载的内容静态网页的两种方法
)
一、动态网页爬取介绍
在很多网站中,使用javascript写网站,很多内容不会出现在HTML源代码中,所以不能使用之前爬取静态网页的方法。有一种异步技术叫做AJAX,它的价值在于通过后台和服务器之间进行少量的数据转换,可以实现网页的异步更新。也就是说,更新网页的一部分而不重新加载整个网页。减少网页上重复内容的下载,节省流量。但随之而来的麻烦是我们在HTML代码中找不到我们想要的数据。解决这种爬取动态加载的内容,有两种方法:
通过浏览器检查元素解析地址 使用 Selenium 模拟浏览器抓取 二、 解析真实地址抓取
我们要的数据不是HTML,而是可以找到数据的真实地址。请求这个地址也能找到想要的数据,也能完成书中的例子。首先打开网站:,这个网站是JS写的,鼠标右键,点击Check。刷新页面,可以看到网页的所有文件都加载完毕了。这个过程就是抓包的过程。然后,点击网络找到收录数据的文件,记住是json数据。
单击标题以查找真实地址。然后将请求发送到真实地址。
1.发送请求,获取数据
import requests
# 构建url
url = """https://api-zero.livere.com/v1 ... ot%3B
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
r = requests.get(url, headers=headers)
print(r.text)
2.解析数据
要从json数据中提取注释,首先我们需要找到符合json格式的部分。然后,使用 json.loads 将字符串格式的响应正文转换为 json 数据。然后,根据json数据的结构,可以提取出评论列表comment_list。最后通过for循环,提取注释文本,并输出打印。
import json
json_string = r.text
# 找到符合json格式的数据
json_string = json_string[json_string.find('{'): -2]
# 转换为json格式
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print(message)
三、 模拟浏览器通过 selenium 爬行
一些网站的地址加密,使得一些变量分析不清楚。接下来,我们将使用第二种方法,使用浏览器渲染引擎。在显示网页时直接使用浏览器解析 HTML、应用 CSS 样式和执行 JavaScript 语句。该方法会打开浏览器,加载网页,自动操作浏览器浏览各种网页,顺便抓取数据,将抓取的动态网页变为抓取静态网页。我们可以使用 selenium 库来模拟浏览器来完成爬取。Selenium 是用于 Web 应用程序测试的工具。它直接在浏览器中运行,浏览器根据脚本代码自动点击、进入、打开、验证。
1. 安装硒
点安装硒
下载“geckodriver”并位于 Python 的安装目录中。
2. 使用 selenium 爬取数据
第 1 步:找到评论的 HTML 代码标记。使用火狐,点击页面,找到标签,找到评论数据
第二步:尝试获取评论数据,使用以下代码获取数据。
# 使用CSS选择器查找元素,找到class为'reply-content'的div元素
comment = driver.find_element_by_css_selector('div.reply-content')
# 通过元素的tag去寻找‘p’元素
content = comment.find_element_by_tag_name('p')
print(content.text)
还是有问题啊 网页打不开啊
也可能存在解析失败报错的情况,报“Message: Unable to locate element: div.reply_content”的错误。这是因为源代码需要解析成iframe,需要添加下面这行代码。
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
动态网页抓取(使用多线程的方式采集某站4K高清壁纸(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-03-12 23:14
一、背景
大家好,我是皮皮。对于不同的数据,我们采用不同的采集方式,图片、视频、音频、文字都是不同的。由于网站图片素材太多,今天我们采用多线程方式采集一站4K高清壁纸。
二、页面分析
目标网站:
http://www.bizhi88.com/3840x2160/
如图,有278页,这里我们抓取前100页的壁纸图片保存在本地;
解析页面
如图,鱼的图片在一个大盒子里( ),下面每个div对应一张高清壁纸;
然后是各个页面的div标签中壁纸图片数据的各种信息:1.链接;2. 名称;下面是对xpath的分析;
imgLink = each.xpath("./a[1]/img/@data-original")[0]
name = each.xpath("./a[1]/img/@alt")[0]
有一个注意事项:
图片标签既有src属性,也有data-original属性,都对应图片的url地址。我们一般使用后者,因为data-original-src是自定义属性,图片的实际地址,src属性要求页面完全加载。出现,否则不会得到对应的地址;
三、采集想法
上面说了,图片数据太多,我们不可能写一个for循环来一个一个下载,所以必须使用多线程或者多进程,然后把这么多的数据队列扔给线程用于处理的池或进程池;在python中,multiprocessing Pool 进程池,multiprocessing.dummy 非常好用,
multiprocessing.dummy模块和multiprocessing模块的API是通用的;代码切换更灵活;
页面网址规则:
'http://www.bizhi88.com/s/470/1.html' # 第一页
'http://www.bizhi88.com/s/470/2.html' # 第二页
'http://www.bizhi88.com/s/470/3.html' # 第三页
构造的网址:
page = 'http://www.bizhi88.com/s/470/{}.html'.format(i)
然后我们自定义了两个函数,一个是抓取和解析页面(spider),另一个是下载数据(download),打开线程池,使用for循环构建13个页面的url,存放在list中,作为一个url 队列,使用 pool.map() 方法进行爬虫和爬虫操作;
def map(self, fn, *iterables, timeout=None, chunksize=1):
"""Returns an iterator equivalent to map(fn, iter)”“”
这里我们的使用是:pool.map(spider,page) # spider:爬虫函数;page:url队列
功能:提取列表中的每一个元素作为函数的参数,一个一个地创建一个进程,放入进程池中;
参数1:要执行的函数;
参数2:迭代器,将迭代器中的数字作为参数依次传递给函数;
四、数据采集
导入相关第三方库
from lxml import etree # 解析
import requests # 请求
from multiprocessing.dummy import Pool as ThreadPool # 并发
import time # 效率
页面数据分析
def spider(url):
html = requests.get(url, headers=headers)
selector = etree.HTML(html.text)
contents = selector.xpath("//div[@class='flex-img auto mt']/div")
item = {}
for each in contents:
imgLink = each.xpath("./a[1]/img/@data-original")[0]
name = each.xpath("./a[1]/img/@alt")[0]
item['Link'] = imgLink
item['name'] = name
towrite(item)
下载下载图片
def download_pic(contdict):
name = contdict['name']
link = contdict['Link']
with open('img/' + name + '.jpg','wb') as f:
data = requests.get(link)
cont = data.content
f.write(cont)
print('图片' + name + '下载成功!')
main() 主函数
pool = ThreadPool(6)
page = []
for i in range(1, 101):
newpage = 'http://www.bizhi88.com/s/470/{}.html'.format(i)
page.append(newpage)
result = pool.map(spider, page)
pool.close()
pool.join()
阐明:
在 main 函数中,我们更喜欢创建六个线程池;通过for循环动态构造100个url;使用map()函数对线程池中的url进行数据解析和存储操作;当线程池关闭时,线程池并没有关闭,只是将状态变为不能再次插入元素的状态;
五、程序运行
if __name__ == '__main__':
start = time.time() # 开始计时
main()
print(end - start) # 时间差
结果如下:
当然这里只截取了部分图片,一共爬取了2000+张图片。
六、总结
这次我们使用多线程爬取了一张壁纸网站的高清图片。如果我们使用requests,很明显同步请求和下载数据比较慢,所以我们使用多线程的方式下载图片,提高了爬取速度。以效率为例。 查看全部
动态网页抓取(使用多线程的方式采集某站4K高清壁纸(组图))
一、背景
大家好,我是皮皮。对于不同的数据,我们采用不同的采集方式,图片、视频、音频、文字都是不同的。由于网站图片素材太多,今天我们采用多线程方式采集一站4K高清壁纸。
二、页面分析
目标网站:
http://www.bizhi88.com/3840x2160/
如图,有278页,这里我们抓取前100页的壁纸图片保存在本地;
解析页面
如图,鱼的图片在一个大盒子里( ),下面每个div对应一张高清壁纸;
然后是各个页面的div标签中壁纸图片数据的各种信息:1.链接;2. 名称;下面是对xpath的分析;
imgLink = each.xpath("./a[1]/img/@data-original")[0]
name = each.xpath("./a[1]/img/@alt")[0]
有一个注意事项:
图片标签既有src属性,也有data-original属性,都对应图片的url地址。我们一般使用后者,因为data-original-src是自定义属性,图片的实际地址,src属性要求页面完全加载。出现,否则不会得到对应的地址;
三、采集想法
上面说了,图片数据太多,我们不可能写一个for循环来一个一个下载,所以必须使用多线程或者多进程,然后把这么多的数据队列扔给线程用于处理的池或进程池;在python中,multiprocessing Pool 进程池,multiprocessing.dummy 非常好用,
multiprocessing.dummy模块和multiprocessing模块的API是通用的;代码切换更灵活;
页面网址规则:
'http://www.bizhi88.com/s/470/1.html' # 第一页
'http://www.bizhi88.com/s/470/2.html' # 第二页
'http://www.bizhi88.com/s/470/3.html' # 第三页
构造的网址:
page = 'http://www.bizhi88.com/s/470/{}.html'.format(i)
然后我们自定义了两个函数,一个是抓取和解析页面(spider),另一个是下载数据(download),打开线程池,使用for循环构建13个页面的url,存放在list中,作为一个url 队列,使用 pool.map() 方法进行爬虫和爬虫操作;
def map(self, fn, *iterables, timeout=None, chunksize=1):
"""Returns an iterator equivalent to map(fn, iter)”“”
这里我们的使用是:pool.map(spider,page) # spider:爬虫函数;page:url队列
功能:提取列表中的每一个元素作为函数的参数,一个一个地创建一个进程,放入进程池中;
参数1:要执行的函数;
参数2:迭代器,将迭代器中的数字作为参数依次传递给函数;
四、数据采集
导入相关第三方库
from lxml import etree # 解析
import requests # 请求
from multiprocessing.dummy import Pool as ThreadPool # 并发
import time # 效率
页面数据分析
def spider(url):
html = requests.get(url, headers=headers)
selector = etree.HTML(html.text)
contents = selector.xpath("//div[@class='flex-img auto mt']/div")
item = {}
for each in contents:
imgLink = each.xpath("./a[1]/img/@data-original")[0]
name = each.xpath("./a[1]/img/@alt")[0]
item['Link'] = imgLink
item['name'] = name
towrite(item)
下载下载图片
def download_pic(contdict):
name = contdict['name']
link = contdict['Link']
with open('img/' + name + '.jpg','wb') as f:
data = requests.get(link)
cont = data.content
f.write(cont)
print('图片' + name + '下载成功!')
main() 主函数
pool = ThreadPool(6)
page = []
for i in range(1, 101):
newpage = 'http://www.bizhi88.com/s/470/{}.html'.format(i)
page.append(newpage)
result = pool.map(spider, page)
pool.close()
pool.join()
阐明:
在 main 函数中,我们更喜欢创建六个线程池;通过for循环动态构造100个url;使用map()函数对线程池中的url进行数据解析和存储操作;当线程池关闭时,线程池并没有关闭,只是将状态变为不能再次插入元素的状态;
五、程序运行
if __name__ == '__main__':
start = time.time() # 开始计时
main()
print(end - start) # 时间差
结果如下:
当然这里只截取了部分图片,一共爬取了2000+张图片。
六、总结
这次我们使用多线程爬取了一张壁纸网站的高清图片。如果我们使用requests,很明显同步请求和下载数据比较慢,所以我们使用多线程的方式下载图片,提高了爬取速度。以效率为例。
动态网页抓取(用RSelenium打造灵活强大的网络爬虫(youtobe+XML) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-11 16:02
)
关于基础网络数据爬取相关内容,本公众号做了很多分享,尤其是R语言的爬虫框架(RCurl+XML/httr+rvest[xml2+selectr])形成了比较丰富的教程体系。
但是这一切都是基于静态页面(抓包和API访问除外),而很多动态网页并没有提供API访问,所以我们只能希望selenium是基于浏览器驱动的技术来完成的。
幸运的是,R语言中已经有了一个selenium接口包,即RSelenium包,它让我们爬取动态网页成为可能。今年年初,我给实习生网站写了一个爬虫,是用Rwebdriver完成的,Rwebdriver是另一个R语言基于selenium驱动的接口包。
实习僧招聘网络爬虫数据可视化
当时技术还不成熟,想法也比较幼稚。我用导航器突然遍历了 500 页的内容。虽然最后全部数据都爬完了,但是耗时比较长(将近40分钟),效率也比较低。(有兴趣的朋友可以参考上面的文章,不过练习生和尚官网最近大改版,现在爬的难度肯定比以前难多了!那个代码可能不可用)
最近抽空学习了RSelenium包的相关内容。在此感谢陈延平先生在 R 语言上海会议上的“用 RSelenium 构建灵活强大的 Web Crawler”的演讲。,其中的一些细节解决了我最近的一些困惑,在此感谢。
陈彦平老师讲课:《用RSelenium搭建灵活强大的网络爬虫》 一个老外关于RSelenium的介绍视频(各位青年请自行出国网站):
目前有几个R语言可以解析动态网页的包(欢迎补充):
本节以下内容正式分享今天的案例,目标是拉钩网(不要问为什么,因为我之前没有爬过钩)!
在介绍案例之前,请确保系统具备以下条件:
本地有selenium服务器,添加系统路径;本地有一个plantomjs浏览器并添加系统路径;RSelenium 软件包已安装。
因为涉及到自动点击操作,Chrome浏览器整个下午都在点击链接失败,找到原因,是因为拉钩页面很长,而且下一页按钮不在默认窗口内,还有js脚本用于控制滑块。失败了,原因不明,看到有人用firefox浏览器测试成功,我还没试过,这里我用的是plantomjs无头浏览器(不用考虑元素是否被窗口挡住了。)
R语言版本:
#!!!这两句是在cmd后者PowerShell中运行的!
#RSelenium服务未关闭之前,请务必保持该窗口状态!
###启动selenium服务:
cd D:\
java -jar selenium-server-standalone-3.3.1.jar
##selenium服务器也可以直接在R语言中启动(无弹出窗口)
system("java -jar \"D:/selenium-server-standalone-2.53.1.jar\"",wait = FALSE,invisible = FALSE)
#加载包
library("RSelenium")
library("magrittr")
library("xml2")
启动服务
#给plantomjs浏览器伪装UserAgent
eCap % xml_text(trim=TRUE)
#职位所述行业
position.industry % read_html() %>% xml_find_all('//div[@class="industry"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "",.)
#职位福利
position.bonus % read_html() %>% xml_find_all('//div[@class="list_item_bot"]/div[@class="li_b_l"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "/",.)
#职位工作环境
position.environment% read_html() %>% xml_find_all('//div[@class="li_b_r"]') %>% xml_text(trim=TRUE)
#收集数据
mydata% xml_find_all('//div[@class="page-number"]/span[1]') %>% xml_text() !="30"){
#如果页面未到尾部,则点击下一页
remDr$findElement('xpath','//div[@class="pager_container"]/a[last()]')$clickElement()
#但因当前任务进度
cat(sprintf("第【%d】页抓取成功",i),sep = "\n")
} else {
#如果页面到尾部则跳出while循环
break
}
}
#跳出循环后关闭remDr服务窗口
remDr$close()
#但因全局任务状态(也即任务结束)
cat("all work is done!!!",sep = "\n")
#返回最终数据
return(myresult)
}
运行抓取功能
<p>url 查看全部
动态网页抓取(用RSelenium打造灵活强大的网络爬虫(youtobe+XML)
)
关于基础网络数据爬取相关内容,本公众号做了很多分享,尤其是R语言的爬虫框架(RCurl+XML/httr+rvest[xml2+selectr])形成了比较丰富的教程体系。
但是这一切都是基于静态页面(抓包和API访问除外),而很多动态网页并没有提供API访问,所以我们只能希望selenium是基于浏览器驱动的技术来完成的。
幸运的是,R语言中已经有了一个selenium接口包,即RSelenium包,它让我们爬取动态网页成为可能。今年年初,我给实习生网站写了一个爬虫,是用Rwebdriver完成的,Rwebdriver是另一个R语言基于selenium驱动的接口包。
实习僧招聘网络爬虫数据可视化
当时技术还不成熟,想法也比较幼稚。我用导航器突然遍历了 500 页的内容。虽然最后全部数据都爬完了,但是耗时比较长(将近40分钟),效率也比较低。(有兴趣的朋友可以参考上面的文章,不过练习生和尚官网最近大改版,现在爬的难度肯定比以前难多了!那个代码可能不可用)
最近抽空学习了RSelenium包的相关内容。在此感谢陈延平先生在 R 语言上海会议上的“用 RSelenium 构建灵活强大的 Web Crawler”的演讲。,其中的一些细节解决了我最近的一些困惑,在此感谢。
陈彦平老师讲课:《用RSelenium搭建灵活强大的网络爬虫》 一个老外关于RSelenium的介绍视频(各位青年请自行出国网站):
目前有几个R语言可以解析动态网页的包(欢迎补充):
本节以下内容正式分享今天的案例,目标是拉钩网(不要问为什么,因为我之前没有爬过钩)!
在介绍案例之前,请确保系统具备以下条件:
本地有selenium服务器,添加系统路径;本地有一个plantomjs浏览器并添加系统路径;RSelenium 软件包已安装。
因为涉及到自动点击操作,Chrome浏览器整个下午都在点击链接失败,找到原因,是因为拉钩页面很长,而且下一页按钮不在默认窗口内,还有js脚本用于控制滑块。失败了,原因不明,看到有人用firefox浏览器测试成功,我还没试过,这里我用的是plantomjs无头浏览器(不用考虑元素是否被窗口挡住了。)
R语言版本:
#!!!这两句是在cmd后者PowerShell中运行的!
#RSelenium服务未关闭之前,请务必保持该窗口状态!
###启动selenium服务:
cd D:\
java -jar selenium-server-standalone-3.3.1.jar
##selenium服务器也可以直接在R语言中启动(无弹出窗口)
system("java -jar \"D:/selenium-server-standalone-2.53.1.jar\"",wait = FALSE,invisible = FALSE)
#加载包
library("RSelenium")
library("magrittr")
library("xml2")
启动服务
#给plantomjs浏览器伪装UserAgent
eCap % xml_text(trim=TRUE)
#职位所述行业
position.industry % read_html() %>% xml_find_all('//div[@class="industry"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "",.)
#职位福利
position.bonus % read_html() %>% xml_find_all('//div[@class="list_item_bot"]/div[@class="li_b_l"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "/",.)
#职位工作环境
position.environment% read_html() %>% xml_find_all('//div[@class="li_b_r"]') %>% xml_text(trim=TRUE)
#收集数据
mydata% xml_find_all('//div[@class="page-number"]/span[1]') %>% xml_text() !="30"){
#如果页面未到尾部,则点击下一页
remDr$findElement('xpath','//div[@class="pager_container"]/a[last()]')$clickElement()
#但因当前任务进度
cat(sprintf("第【%d】页抓取成功",i),sep = "\n")
} else {
#如果页面到尾部则跳出while循环
break
}
}
#跳出循环后关闭remDr服务窗口
remDr$close()
#但因全局任务状态(也即任务结束)
cat("all work is done!!!",sep = "\n")
#返回最终数据
return(myresult)
}
运行抓取功能
<p>url
动态网页抓取(用RSelenium打造灵活强大的网络爬虫(youtobe+XML) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-03-11 16:01
)
关于基础网络数据爬取相关内容,本公众号做了很多分享,尤其是R语言的爬虫框架(RCurl+XML/httr+rvest[xml2+selectr])形成了比较丰富的教程体系。
但是这一切都是基于静态页面(抓包和API访问除外),而很多动态网页并没有提供API访问,所以我们只能希望selenium是基于浏览器驱动的技术来完成的。
幸运的是,R语言中已经有了一个selenium接口包,即RSelenium包,它让我们爬取动态网页成为可能。今年年初,我给实习生网站写了一个爬虫,是用Rwebdriver完成的,Rwebdriver是另一个R语言基于selenium驱动的接口包。
实习僧招聘网络爬虫数据可视化
当时技术还不成熟,想法也比较幼稚。我用导航器突然遍历了 500 页的内容。虽然最后全部数据都爬完了,但是耗时比较长(将近40分钟),效率也比较低。(有兴趣的朋友可以参考上面的文章,不过练习生和尚官网最近大改版,现在爬的难度肯定比以前难多了!那个代码可能不可用)
最近抽空学习了RSelenium包的相关内容。在此感谢陈延平先生在 R 语言上海会议上的“用 RSelenium 构建灵活强大的 Web Crawler”的演讲。,其中的一些细节解决了我最近的一些困惑,在此感谢。
陈彦平老师讲课:《用RSelenium搭建灵活强大的网络爬虫》 一个老外关于RSelenium的介绍视频(各位青年请自行出国网站):
目前有几个R语言可以解析动态网页的包(欢迎补充):
本节以下内容正式分享今天的案例,目标是拉钩网(不要问为什么,因为我之前没有爬过钩)!
在介绍案例之前,请确保系统具备以下条件:
本地有selenium服务器,添加系统路径;本地有一个plantomjs浏览器并添加系统路径;RSelenium 软件包已安装。
因为涉及到自动点击操作,Chrome浏览器整个下午都在点击链接失败,找到原因,是因为拉钩页面很长,而且下一页按钮不在默认窗口内,还有js脚本用于控制滑块。失败了,原因不明,看到有人用firefox浏览器测试成功,我还没试过,这里我用的是plantomjs无头浏览器(不用考虑元素是否被窗口挡住了。)
R语言版本:
#!!!这两句是在cmd后者PowerShell中运行的!
#RSelenium服务未关闭之前,请务必保持该窗口状态!
###启动selenium服务:
cd D:\
java -jar selenium-server-standalone-3.3.1.jar
##selenium服务器也可以直接在R语言中启动(无弹出窗口)
system("java -jar \"D:/selenium-server-standalone-2.53.1.jar\"",wait = FALSE,invisible = FALSE)
#加载包
library("RSelenium")
library("magrittr")
library("xml2")
启动服务
#给plantomjs浏览器伪装UserAgent
eCap % xml_text(trim=TRUE)
#职位所述行业
position.industry % read_html() %>% xml_find_all('//div[@class="industry"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "",.)
#职位福利
position.bonus % read_html() %>% xml_find_all('//div[@class="list_item_bot"]/div[@class="li_b_l"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "/",.)
#职位工作环境
position.environment% read_html() %>% xml_find_all('//div[@class="li_b_r"]') %>% xml_text(trim=TRUE)
#收集数据
mydata% xml_find_all('//div[@class="page-number"]/span[1]') %>% xml_text() !="30"){
#如果页面未到尾部,则点击下一页
remDr$findElement('xpath','//div[@class="pager_container"]/a[last()]')$clickElement()
#但因当前任务进度
cat(sprintf("第【%d】页抓取成功",i),sep = "\n")
} else {
#如果页面到尾部则跳出while循环
break
}
}
#跳出循环后关闭remDr服务窗口
remDr$close()
#但因全局任务状态(也即任务结束)
cat("all work is done!!!",sep = "\n")
#返回最终数据
return(myresult)
}
运行抓取功能
<p>url 查看全部
动态网页抓取(用RSelenium打造灵活强大的网络爬虫(youtobe+XML)
)
关于基础网络数据爬取相关内容,本公众号做了很多分享,尤其是R语言的爬虫框架(RCurl+XML/httr+rvest[xml2+selectr])形成了比较丰富的教程体系。
但是这一切都是基于静态页面(抓包和API访问除外),而很多动态网页并没有提供API访问,所以我们只能希望selenium是基于浏览器驱动的技术来完成的。
幸运的是,R语言中已经有了一个selenium接口包,即RSelenium包,它让我们爬取动态网页成为可能。今年年初,我给实习生网站写了一个爬虫,是用Rwebdriver完成的,Rwebdriver是另一个R语言基于selenium驱动的接口包。
实习僧招聘网络爬虫数据可视化
当时技术还不成熟,想法也比较幼稚。我用导航器突然遍历了 500 页的内容。虽然最后全部数据都爬完了,但是耗时比较长(将近40分钟),效率也比较低。(有兴趣的朋友可以参考上面的文章,不过练习生和尚官网最近大改版,现在爬的难度肯定比以前难多了!那个代码可能不可用)
最近抽空学习了RSelenium包的相关内容。在此感谢陈延平先生在 R 语言上海会议上的“用 RSelenium 构建灵活强大的 Web Crawler”的演讲。,其中的一些细节解决了我最近的一些困惑,在此感谢。
陈彦平老师讲课:《用RSelenium搭建灵活强大的网络爬虫》 一个老外关于RSelenium的介绍视频(各位青年请自行出国网站):
目前有几个R语言可以解析动态网页的包(欢迎补充):
本节以下内容正式分享今天的案例,目标是拉钩网(不要问为什么,因为我之前没有爬过钩)!
在介绍案例之前,请确保系统具备以下条件:
本地有selenium服务器,添加系统路径;本地有一个plantomjs浏览器并添加系统路径;RSelenium 软件包已安装。
因为涉及到自动点击操作,Chrome浏览器整个下午都在点击链接失败,找到原因,是因为拉钩页面很长,而且下一页按钮不在默认窗口内,还有js脚本用于控制滑块。失败了,原因不明,看到有人用firefox浏览器测试成功,我还没试过,这里我用的是plantomjs无头浏览器(不用考虑元素是否被窗口挡住了。)
R语言版本:
#!!!这两句是在cmd后者PowerShell中运行的!
#RSelenium服务未关闭之前,请务必保持该窗口状态!
###启动selenium服务:
cd D:\
java -jar selenium-server-standalone-3.3.1.jar
##selenium服务器也可以直接在R语言中启动(无弹出窗口)
system("java -jar \"D:/selenium-server-standalone-2.53.1.jar\"",wait = FALSE,invisible = FALSE)
#加载包
library("RSelenium")
library("magrittr")
library("xml2")
启动服务
#给plantomjs浏览器伪装UserAgent
eCap % xml_text(trim=TRUE)
#职位所述行业
position.industry % read_html() %>% xml_find_all('//div[@class="industry"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "",.)
#职位福利
position.bonus % read_html() %>% xml_find_all('//div[@class="list_item_bot"]/div[@class="li_b_l"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "/",.)
#职位工作环境
position.environment% read_html() %>% xml_find_all('//div[@class="li_b_r"]') %>% xml_text(trim=TRUE)
#收集数据
mydata% xml_find_all('//div[@class="page-number"]/span[1]') %>% xml_text() !="30"){
#如果页面未到尾部,则点击下一页
remDr$findElement('xpath','//div[@class="pager_container"]/a[last()]')$clickElement()
#但因当前任务进度
cat(sprintf("第【%d】页抓取成功",i),sep = "\n")
} else {
#如果页面到尾部则跳出while循环
break
}
}
#跳出循环后关闭remDr服务窗口
remDr$close()
#但因全局任务状态(也即任务结束)
cat("all work is done!!!",sep = "\n")
#返回最终数据
return(myresult)
}
运行抓取功能
<p>url
动态网页抓取(用RSelenium打造灵活强大的网络爬虫(youtobe+XML) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-11 15:14
)
关于基础网络数据爬取相关内容,本公众号做了很多分享,尤其是R语言的爬虫框架(RCurl+XML/httr+rvest[xml2+selectr])形成了比较丰富的教程体系。
但是这一切都是基于静态页面(抓包和API访问除外),而很多动态网页并没有提供API访问,所以我们只能希望selenium是基于浏览器驱动的技术来完成的。
幸运的是,R语言中已经有了一个selenium接口包,即RSelenium包,它让我们爬取动态网页成为可能。今年年初,我给实习生网站写了一个爬虫,是用Rwebdriver完成的,Rwebdriver是另一个R语言基于selenium驱动的接口包。
实习僧招聘网络爬虫数据可视化
当时技术还不成熟,想法也比较幼稚。我用导航器突然遍历了 500 页的内容。虽然最后全部数据都爬完了,但是耗时比较长(将近40分钟),效率也比较低。(有兴趣的朋友可以参考上面的文章,不过练习生和尚官网最近大改版,现在爬的难度肯定比以前难多了!那个代码可能不可用)
最近抽空学习了RSelenium包的相关内容。在此感谢陈延平先生在 R 语言上海会议上的“用 RSelenium 构建灵活强大的 Web Crawler”的演讲。,其中的一些细节解决了我最近的一些困惑,在此感谢。
陈彦平老师讲课:《用RSelenium搭建灵活强大的网络爬虫》 一个老外关于RSelenium的介绍视频(各位青年请自行出国网站):
目前有几个R语言可以解析动态网页的包(欢迎补充):
本节以下内容正式分享今天的案例,目标是拉钩网(不要问为什么,因为我之前没有爬过钩)!
在介绍案例之前,请确保系统具备以下条件:
本地有selenium服务器,添加系统路径;本地有一个plantomjs浏览器并添加系统路径;RSelenium 软件包已安装。
因为涉及到自动点击操作,Chrome浏览器整个下午都在点击链接失败,找到原因,是因为拉钩页面很长,而且下一页按钮不在默认窗口内,还有js脚本用于控制滑块。失败了,原因不明,看到有人用firefox浏览器测试成功,我还没试过,这里我用的是plantomjs无头浏览器(不用考虑元素是否被窗口挡住了。)
R语言版本:
#!!!这两句是在cmd后者PowerShell中运行的!
#RSelenium服务未关闭之前,请务必保持该窗口状态!
###启动selenium服务:
cd D:\
java -jar selenium-server-standalone-3.3.1.jar
##selenium服务器也可以直接在R语言中启动(无弹出窗口)
system("java -jar \"D:/selenium-server-standalone-2.53.1.jar\"",wait = FALSE,invisible = FALSE)
#加载包
library("RSelenium")
library("magrittr")
library("xml2")
启动服务
#给plantomjs浏览器伪装UserAgent
eCap % xml_text(trim=TRUE)
#职位所述行业
position.industry % read_html() %>% xml_find_all('//div[@class="industry"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "",.)
#职位福利
position.bonus % read_html() %>% xml_find_all('//div[@class="list_item_bot"]/div[@class="li_b_l"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "/",.)
#职位工作环境
position.environment% read_html() %>% xml_find_all('//div[@class="li_b_r"]') %>% xml_text(trim=TRUE)
#收集数据
mydata% xml_find_all('//div[@class="page-number"]/span[1]') %>% xml_text() !="30"){
#如果页面未到尾部,则点击下一页
remDr$findElement('xpath','//div[@class="pager_container"]/a[last()]')$clickElement()
#但因当前任务进度
cat(sprintf("第【%d】页抓取成功",i),sep = "\n")
} else {
#如果页面到尾部则跳出while循环
break
}
}
#跳出循环后关闭remDr服务窗口
remDr$close()
#但因全局任务状态(也即任务结束)
cat("all work is done!!!",sep = "\n")
#返回最终数据
return(myresult)
}
运行抓取功能
<p>url 查看全部
动态网页抓取(用RSelenium打造灵活强大的网络爬虫(youtobe+XML)
)
关于基础网络数据爬取相关内容,本公众号做了很多分享,尤其是R语言的爬虫框架(RCurl+XML/httr+rvest[xml2+selectr])形成了比较丰富的教程体系。
但是这一切都是基于静态页面(抓包和API访问除外),而很多动态网页并没有提供API访问,所以我们只能希望selenium是基于浏览器驱动的技术来完成的。
幸运的是,R语言中已经有了一个selenium接口包,即RSelenium包,它让我们爬取动态网页成为可能。今年年初,我给实习生网站写了一个爬虫,是用Rwebdriver完成的,Rwebdriver是另一个R语言基于selenium驱动的接口包。
实习僧招聘网络爬虫数据可视化
当时技术还不成熟,想法也比较幼稚。我用导航器突然遍历了 500 页的内容。虽然最后全部数据都爬完了,但是耗时比较长(将近40分钟),效率也比较低。(有兴趣的朋友可以参考上面的文章,不过练习生和尚官网最近大改版,现在爬的难度肯定比以前难多了!那个代码可能不可用)
最近抽空学习了RSelenium包的相关内容。在此感谢陈延平先生在 R 语言上海会议上的“用 RSelenium 构建灵活强大的 Web Crawler”的演讲。,其中的一些细节解决了我最近的一些困惑,在此感谢。
陈彦平老师讲课:《用RSelenium搭建灵活强大的网络爬虫》 一个老外关于RSelenium的介绍视频(各位青年请自行出国网站):
目前有几个R语言可以解析动态网页的包(欢迎补充):
本节以下内容正式分享今天的案例,目标是拉钩网(不要问为什么,因为我之前没有爬过钩)!
在介绍案例之前,请确保系统具备以下条件:
本地有selenium服务器,添加系统路径;本地有一个plantomjs浏览器并添加系统路径;RSelenium 软件包已安装。
因为涉及到自动点击操作,Chrome浏览器整个下午都在点击链接失败,找到原因,是因为拉钩页面很长,而且下一页按钮不在默认窗口内,还有js脚本用于控制滑块。失败了,原因不明,看到有人用firefox浏览器测试成功,我还没试过,这里我用的是plantomjs无头浏览器(不用考虑元素是否被窗口挡住了。)
R语言版本:
#!!!这两句是在cmd后者PowerShell中运行的!
#RSelenium服务未关闭之前,请务必保持该窗口状态!
###启动selenium服务:
cd D:\
java -jar selenium-server-standalone-3.3.1.jar
##selenium服务器也可以直接在R语言中启动(无弹出窗口)
system("java -jar \"D:/selenium-server-standalone-2.53.1.jar\"",wait = FALSE,invisible = FALSE)
#加载包
library("RSelenium")
library("magrittr")
library("xml2")
启动服务
#给plantomjs浏览器伪装UserAgent
eCap % xml_text(trim=TRUE)
#职位所述行业
position.industry % read_html() %>% xml_find_all('//div[@class="industry"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "",.)
#职位福利
position.bonus % read_html() %>% xml_find_all('//div[@class="list_item_bot"]/div[@class="li_b_l"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "/",.)
#职位工作环境
position.environment% read_html() %>% xml_find_all('//div[@class="li_b_r"]') %>% xml_text(trim=TRUE)
#收集数据
mydata% xml_find_all('//div[@class="page-number"]/span[1]') %>% xml_text() !="30"){
#如果页面未到尾部,则点击下一页
remDr$findElement('xpath','//div[@class="pager_container"]/a[last()]')$clickElement()
#但因当前任务进度
cat(sprintf("第【%d】页抓取成功",i),sep = "\n")
} else {
#如果页面到尾部则跳出while循环
break
}
}
#跳出循环后关闭remDr服务窗口
remDr$close()
#但因全局任务状态(也即任务结束)
cat("all work is done!!!",sep = "\n")
#返回最终数据
return(myresult)
}
运行抓取功能
<p>url
动态网页抓取(图中的JavaScript代码如下:阅读代码可以了解页面中动态生成的细节)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-10 03:09
它是动态内容。从服务器下载的页面不收录它们(大多是我们无法爬取),它们是浏览器在页面中执行一段JavaScript代码后生成的。
图中的JavaScript代码如下:
var data = [
{
"tags": [
"change",
"deep-thoughts",
"thinking",
"world"
],
"author": {
"name": "Albert Einstein",
"goodreads_link": "/author/show/9810.Albert_Einstein",
"slug": "Albert-Einstein"
},
"text": "\u201cThe world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.\u201d"
},
{
"tags": [
"abilities",
"choices"
],
"author": {
"name": "J.K. Rowling",
"goodreads_link": "/author/show/1077326.J_K_Rowling",
"slug": "J-K-Rowling"
},
"text": "\u201cIt is our choices, Harry, that show what we truly are, far more than our abilities.\u201d"
},
{
"tags": [
"inspirational",
"life",
"live",
"miracle",
"miracles"
],
"author": {
"name": "Albert Einstein",
"goodreads_link": "/author/show/9810.Albert_Einstein",
"slug": "Albert-Einstein"
},
"text": "\u201cThere are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.\u201d"
},
{
"tags": [
"aliteracy",
"books",
"classic",
"humor"
],
"author": {
"name": "Jane Austen",
"goodreads_link": "/author/show/1265.Jane_Austen",
"slug": "Jane-Austen"
},
"text": "\u201cThe person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.\u201d"
},
{
"tags": [
"be-yourself",
"inspirational"
],
"author": {
"name": "Marilyn Monroe",
"goodreads_link": "/author/show/82952.Marilyn_Monroe",
"slug": "Marilyn-Monroe"
},
"text": "\u201cImperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.\u201d"
},
{
"tags": [
"adulthood",
"success",
"value"
],
"author": {
"name": "Albert Einstein",
"goodreads_link": "/author/show/9810.Albert_Einstein",
"slug": "Albert-Einstein"
},
"text": "\u201cTry not to become a man of success. Rather become a man of value.\u201d"
},
{
"tags": [
"life",
"love"
],
"author": {
"name": "Andr\u00e9 Gide",
"goodreads_link": "/author/show/7617.Andr_Gide",
"slug": "Andre-Gide"
},
"text": "\u201cIt is better to be hated for what you are than to be loved for what you are not.\u201d"
},
{
"tags": [
"edison",
"failure",
"inspirational",
"paraphrased"
],
"author": {
"name": "Thomas A. Edison",
"goodreads_link": "/author/show/3091287.Thomas_A_Edison",
"slug": "Thomas-A-Edison"
},
"text": "\u201cI have not failed. I've just found 10,000 ways that won't work.\u201d"
},
{
"tags": [
"misattributed-eleanor-roosevelt"
],
"author": {
"name": "Eleanor Roosevelt",
"goodreads_link": "/author/show/44566.Eleanor_Roosevelt",
"slug": "Eleanor-Roosevelt"
},
"text": "\u201cA woman is like a tea bag; you never know how strong it is until it's in hot water.\u201d"
},
{
"tags": [
"humor",
"obvious",
"simile"
],
"author": {
"name": "Steve Martin",
"goodreads_link": "/author/show/7103.Steve_Martin",
"slug": "Steve-Martin"
},
"text": "\u201cA day without sunshine is like, you know, night.\u201d"
}
];
for (var i in data) {
var d = data[i];
var tags = $.map(d['tags'], function(t) {
return "<a class='tag'>" + t + "</a>";
}).join(" ");
document.write("" + d['text'] + "by " + d['author']['name'] + "Tags: " + tags + "");
}
阅读代码以了解页面中动态生成的详细信息。所有名言都存储在数组数据中。最后的 for 循环使用 document 遍历数据中的每一项信息。 write 生成对应的
每句名言
元素。
以上是最简单的动态页面示例。数据应该被编码成 JavaScript 代码。在实际应用中,更常见的是 JavaScript 通过 HTTP 请求与 网站 动态交互以获取数据(AJAX),然后使用数据更新 HTML 页面。要爬取这样的动态网页,需要先执行页面,使用JavaScript渲染引擎页面进行爬取。
转载于: 查看全部
动态网页抓取(图中的JavaScript代码如下:阅读代码可以了解页面中动态生成的细节)
它是动态内容。从服务器下载的页面不收录它们(大多是我们无法爬取),它们是浏览器在页面中执行一段JavaScript代码后生成的。
图中的JavaScript代码如下:
var data = [
{
"tags": [
"change",
"deep-thoughts",
"thinking",
"world"
],
"author": {
"name": "Albert Einstein",
"goodreads_link": "/author/show/9810.Albert_Einstein",
"slug": "Albert-Einstein"
},
"text": "\u201cThe world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.\u201d"
},
{
"tags": [
"abilities",
"choices"
],
"author": {
"name": "J.K. Rowling",
"goodreads_link": "/author/show/1077326.J_K_Rowling",
"slug": "J-K-Rowling"
},
"text": "\u201cIt is our choices, Harry, that show what we truly are, far more than our abilities.\u201d"
},
{
"tags": [
"inspirational",
"life",
"live",
"miracle",
"miracles"
],
"author": {
"name": "Albert Einstein",
"goodreads_link": "/author/show/9810.Albert_Einstein",
"slug": "Albert-Einstein"
},
"text": "\u201cThere are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.\u201d"
},
{
"tags": [
"aliteracy",
"books",
"classic",
"humor"
],
"author": {
"name": "Jane Austen",
"goodreads_link": "/author/show/1265.Jane_Austen",
"slug": "Jane-Austen"
},
"text": "\u201cThe person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.\u201d"
},
{
"tags": [
"be-yourself",
"inspirational"
],
"author": {
"name": "Marilyn Monroe",
"goodreads_link": "/author/show/82952.Marilyn_Monroe",
"slug": "Marilyn-Monroe"
},
"text": "\u201cImperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.\u201d"
},
{
"tags": [
"adulthood",
"success",
"value"
],
"author": {
"name": "Albert Einstein",
"goodreads_link": "/author/show/9810.Albert_Einstein",
"slug": "Albert-Einstein"
},
"text": "\u201cTry not to become a man of success. Rather become a man of value.\u201d"
},
{
"tags": [
"life",
"love"
],
"author": {
"name": "Andr\u00e9 Gide",
"goodreads_link": "/author/show/7617.Andr_Gide",
"slug": "Andre-Gide"
},
"text": "\u201cIt is better to be hated for what you are than to be loved for what you are not.\u201d"
},
{
"tags": [
"edison",
"failure",
"inspirational",
"paraphrased"
],
"author": {
"name": "Thomas A. Edison",
"goodreads_link": "/author/show/3091287.Thomas_A_Edison",
"slug": "Thomas-A-Edison"
},
"text": "\u201cI have not failed. I've just found 10,000 ways that won't work.\u201d"
},
{
"tags": [
"misattributed-eleanor-roosevelt"
],
"author": {
"name": "Eleanor Roosevelt",
"goodreads_link": "/author/show/44566.Eleanor_Roosevelt",
"slug": "Eleanor-Roosevelt"
},
"text": "\u201cA woman is like a tea bag; you never know how strong it is until it's in hot water.\u201d"
},
{
"tags": [
"humor",
"obvious",
"simile"
],
"author": {
"name": "Steve Martin",
"goodreads_link": "/author/show/7103.Steve_Martin",
"slug": "Steve-Martin"
},
"text": "\u201cA day without sunshine is like, you know, night.\u201d"
}
];
for (var i in data) {
var d = data[i];
var tags = $.map(d['tags'], function(t) {
return "<a class='tag'>" + t + "</a>";
}).join(" ");
document.write("" + d['text'] + "by " + d['author']['name'] + "Tags: " + tags + "");
}
阅读代码以了解页面中动态生成的详细信息。所有名言都存储在数组数据中。最后的 for 循环使用 document 遍历数据中的每一项信息。 write 生成对应的
每句名言
元素。
以上是最简单的动态页面示例。数据应该被编码成 JavaScript 代码。在实际应用中,更常见的是 JavaScript 通过 HTTP 请求与 网站 动态交互以获取数据(AJAX),然后使用数据更新 HTML 页面。要爬取这样的动态网页,需要先执行页面,使用JavaScript渲染引擎页面进行爬取。
转载于:
动态网页抓取(使用urllib+phantomjs是什么呢?使用js动态加载的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-09 17:00
我们在进行网页抓取时,一般使用 urllib 和 urllib2 来满足我们的大部分需求。
但是有时我们会遇到使用js动态加载的网页。你会发现 urllib 只能抓取部分空白的网页。就像下面百度图片的结果页面:
审查元素后, . 发现在百度图片中,显示图片的div是:pullimages
此 div 内的内容是动态加载的。但是使用 urllib&urllib2 不能爬取。
要抓取动态加载的元素,首先考虑使用 selenium 调用浏览器进行抓取。
而我们的运行环境是linux,最理想的方式是无界面抓取。
所以使用 selenium+phantomjs 进行无界面抓取
什么是phantomjs?它是基于webkit内核的无头浏览器,即没有UI界面,即是浏览器
selenium和phantomjs的安装和配置可以google,这里就不多说了。
代码显示如下:
from selenium import webdriver
def fetchBdImage(query):
#如果不方便配置环境变量。填入phantomjs的绝对路径也可以
driver =webdriver.PhantomJS(executable_path='/bin/phantomjs/bin/phantomjs')
#抓取百度图片页面,query由参数决定
url = 'http://image.baidu.com/i?ie=utf-8&word='+query;
driver.get(url)
#这就是获取页面内容了,与urllib2.urlopen().read()的效果是类似的。
html = driver.page_source
#抓取结束,记得释放资源
driver.quit()
#返回抓取到的页面内容
return html
到这里。抓取成功。
【备注】:linux下使用phantomJS,windows下可以使用chrome、firefox等浏览器 查看全部
动态网页抓取(使用urllib+phantomjs是什么呢?使用js动态加载的网页)
我们在进行网页抓取时,一般使用 urllib 和 urllib2 来满足我们的大部分需求。
但是有时我们会遇到使用js动态加载的网页。你会发现 urllib 只能抓取部分空白的网页。就像下面百度图片的结果页面:
审查元素后, . 发现在百度图片中,显示图片的div是:pullimages
此 div 内的内容是动态加载的。但是使用 urllib&urllib2 不能爬取。
要抓取动态加载的元素,首先考虑使用 selenium 调用浏览器进行抓取。
而我们的运行环境是linux,最理想的方式是无界面抓取。
所以使用 selenium+phantomjs 进行无界面抓取
什么是phantomjs?它是基于webkit内核的无头浏览器,即没有UI界面,即是浏览器
selenium和phantomjs的安装和配置可以google,这里就不多说了。
代码显示如下:
from selenium import webdriver
def fetchBdImage(query):
#如果不方便配置环境变量。填入phantomjs的绝对路径也可以
driver =webdriver.PhantomJS(executable_path='/bin/phantomjs/bin/phantomjs')
#抓取百度图片页面,query由参数决定
url = 'http://image.baidu.com/i?ie=utf-8&word='+query;
driver.get(url)
#这就是获取页面内容了,与urllib2.urlopen().read()的效果是类似的。
html = driver.page_source
#抓取结束,记得释放资源
driver.quit()
#返回抓取到的页面内容
return html
到这里。抓取成功。
【备注】:linux下使用phantomJS,windows下可以使用chrome、firefox等浏览器
动态网页抓取(动态网页抓取自动化工具.request,插件模拟浏览器获取请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-08 23:04
动态网页抓取自动化工具.request,从服务器抓取所有的http请求,存档到服务器,http响应里savehttp请求,每次浏览器直接打开浏览器的客户端就能抓取http请求下的内容获取内容,
还是用上次的办法,useragent,你指定的网站都有个useragent,你用到的几乎任何东西都可以用这个来指定。不要问我怎么知道的,只是当年网上为了看推荐的实用rss源看到的。
绝对不是给你引导性推荐。换一个。有很多推荐工具,有兴趣可以搜一下。
用tor比较好,有插件模拟浏览器获取请求,
看看文档
再转个xml2xpdfeverythingsimulatorcookie来自实战:用ribbon写v2ex登录
dropbox不错,你可以找找找大神改进你的dropbox中间过滤器,顺便再讲一下如何从评论服务器查询http的log,http的set_header,还有httpheader的max_length可以避免服务器抛弃旧的安全过滤条件接受新的保护条件。同时,你也可以用匿名模拟来测试http,顺便给log过滤器后台提建议。
如果你不怕代码对外暴露的话,可以同步推啊,naver,http的headermax_length服务都可以用代码hook,其实很多浏览器的浏览器扩展都支持直接删除,你只要后端http服务没问题,没问题的,对外暴露代码一点问题没有。 查看全部
动态网页抓取(动态网页抓取自动化工具.request,插件模拟浏览器获取请求)
动态网页抓取自动化工具.request,从服务器抓取所有的http请求,存档到服务器,http响应里savehttp请求,每次浏览器直接打开浏览器的客户端就能抓取http请求下的内容获取内容,
还是用上次的办法,useragent,你指定的网站都有个useragent,你用到的几乎任何东西都可以用这个来指定。不要问我怎么知道的,只是当年网上为了看推荐的实用rss源看到的。
绝对不是给你引导性推荐。换一个。有很多推荐工具,有兴趣可以搜一下。
用tor比较好,有插件模拟浏览器获取请求,
看看文档
再转个xml2xpdfeverythingsimulatorcookie来自实战:用ribbon写v2ex登录
dropbox不错,你可以找找找大神改进你的dropbox中间过滤器,顺便再讲一下如何从评论服务器查询http的log,http的set_header,还有httpheader的max_length可以避免服务器抛弃旧的安全过滤条件接受新的保护条件。同时,你也可以用匿名模拟来测试http,顺便给log过滤器后台提建议。
如果你不怕代码对外暴露的话,可以同步推啊,naver,http的headermax_length服务都可以用代码hook,其实很多浏览器的浏览器扩展都支持直接删除,你只要后端http服务没问题,没问题的,对外暴露代码一点问题没有。
动态网页抓取(新站怎么快速收录5、伪静态设置设置链)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-08 02:12
优化权重首先要有收录,没有收录就没有排名,所以我也理解大家的心情,网站上线了,等着收录@ >,但是我们不能只是等待,必须做一些加速收录的必要方法。以下是千秋为大家总结的一些经验。希望能帮助大家的网站早日成为百度收录。
新站有多快收录
1、及时更新
这个非常重要。网站 及时更新有利于蜘蛛爬行网站。新网站本身在搜索引擎中没有分量。如果你不及时更新,你在搜索引擎心目中的地位就会丢失。会大打折扣。及时更新网站,原创度和文章质量高,可以给网站加分,时机成熟自然是收录,您甚至可以进行第二次关闭。
2、外部链接
新站点没有外部链接,网站在上线之初发布外部链接是吸引蜘蛛访问的重要方法网站。所以我们可以少量做一些外部链接,这样更有利于蜘蛛爬行。但是,现在做外部链接并不容易。许多平台有很多限制和严格的要求。这就需要我们有耐心去寻找一个可以发外链的平台。为此,您可以使用百度。很多热心网友分享了一些渠道和方法,一开始不知道外链发到哪里,只能通过百度知道。
新站有多快收录
3、链接
如果条件允许,可以更改一些友情链接。一般来说,网站 网站上的时间比你长的都有蜘蛛在爬。如果你有资源,别人愿意帮助你,你可以换一些网站上的时间比你长的网站。网站的友情链接更好,所以对新站点的收录更有好处。
4、主动提交收录
新站点上线时,需要向站长平台提交收录。比如百度站长平台就是一个很好的工具。我们可以主动提交里面的网站地图,让百度提前知道我们的站点。已经上线了,需要他们的收录。
新站有多快收录
5、伪静态设置
大家要知道,动态页面不利于蜘蛛爬取。有一点基本优化常识的人都明白这一点。因此,我们制作的 网站 页面应该是静态或伪静态页面。有些程序可以自动生成静态页面,你可以自己设置。
6、网站地图
网站的配套工具,新站一开始就必须做一张网站的地图,很多地方都会用到。例如,当您向站长平台提交网站 时,您需要一个网站 地图。提交 网站 地图的目的是告诉搜索引擎我网站上的最新链接。蜘蛛收到后,会沿着你的地图爬行,帮助收录。 查看全部
动态网页抓取(新站怎么快速收录5、伪静态设置设置链)
优化权重首先要有收录,没有收录就没有排名,所以我也理解大家的心情,网站上线了,等着收录@ >,但是我们不能只是等待,必须做一些加速收录的必要方法。以下是千秋为大家总结的一些经验。希望能帮助大家的网站早日成为百度收录。
新站有多快收录
1、及时更新
这个非常重要。网站 及时更新有利于蜘蛛爬行网站。新网站本身在搜索引擎中没有分量。如果你不及时更新,你在搜索引擎心目中的地位就会丢失。会大打折扣。及时更新网站,原创度和文章质量高,可以给网站加分,时机成熟自然是收录,您甚至可以进行第二次关闭。
2、外部链接
新站点没有外部链接,网站在上线之初发布外部链接是吸引蜘蛛访问的重要方法网站。所以我们可以少量做一些外部链接,这样更有利于蜘蛛爬行。但是,现在做外部链接并不容易。许多平台有很多限制和严格的要求。这就需要我们有耐心去寻找一个可以发外链的平台。为此,您可以使用百度。很多热心网友分享了一些渠道和方法,一开始不知道外链发到哪里,只能通过百度知道。
新站有多快收录
3、链接
如果条件允许,可以更改一些友情链接。一般来说,网站 网站上的时间比你长的都有蜘蛛在爬。如果你有资源,别人愿意帮助你,你可以换一些网站上的时间比你长的网站。网站的友情链接更好,所以对新站点的收录更有好处。
4、主动提交收录
新站点上线时,需要向站长平台提交收录。比如百度站长平台就是一个很好的工具。我们可以主动提交里面的网站地图,让百度提前知道我们的站点。已经上线了,需要他们的收录。
新站有多快收录
5、伪静态设置
大家要知道,动态页面不利于蜘蛛爬取。有一点基本优化常识的人都明白这一点。因此,我们制作的 网站 页面应该是静态或伪静态页面。有些程序可以自动生成静态页面,你可以自己设置。
6、网站地图
网站的配套工具,新站一开始就必须做一张网站的地图,很多地方都会用到。例如,当您向站长平台提交网站 时,您需要一个网站 地图。提交 网站 地图的目的是告诉搜索引擎我网站上的最新链接。蜘蛛收到后,会沿着你的地图爬行,帮助收录。
动态网页抓取(世界上真的会有免费又好用的服务吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 338 次浏览 • 2022-03-05 00:10
在互联网高速发展的今天,各家企业都迫不及待地想通过网站的建设来销售产品和服务,维护自己的品牌形象,各种网站建设服务应运而生。其中,一些建站公司宣传提供0元免费建站服务,以免费为噱头吸引用户。然而,世界上真的有免费且易于使用的服务吗?当然,答案是否定的。免费的东西其实是最贵的。下面将揭开0元免费建站的诸多陷阱。
提供免费建站服务的企业,一般以“免费模板、免费域名、免费空间”为宣传点,吸引用户关注。接下来,我们将分析这些免费服务存在的问题。
一、免费模板陷阱
建站公司提供海量免费模板网站,涵盖各行各业。这些模板通用性强,可以满足大部分企业的基本建站需求。无需代码即可一键应用它们。听起来真的很有吸引力。正确的?但是这些免费模板其实存在很多问题,我们一起来看看吧。
1、免费模板的质量不保证
一般来说,模板是建站公司在深入研究分析市场需求后制作的,但也有不少公司的网站模板是多方购买、修改、转售,并没有关心这些模板。对这些所谓的免费模板的质量负责,所以这些所谓的免费模板不保证质量,甚至可能承担版权风险。
2、模板搭建没有吸引力,影响收录
使用同一个模板建站,很容易造成网站的出现出现重复,不仅使网站不美观,难以突出企业特色,而且重复率高,影响搜索网站 引擎的爬行速度和 收录 的损失是值得的。
3、使用不利于爬取的非静态页面
网站中使用静态页面有利于搜索引擎爬取,所以最好将页面制作成纯静态或伪静态,但免费模板往往使用一些动态页面,不利于爬取。
4、免费模板功能不全
一般来说,免费模板网站的设计非常简单,功能模块少,不适合功能需求复杂的用户。如果以后要开发新的功能,需要额外付费。
5、引导用户购买付费模板
建站公司提供的免费模板大部分都不是特别漂亮,同时也会提供一些效果明显更好的付费模板来吸引用户的注意力,让用户消费花钱购买付费模板的真正目的。
二、免费域陷阱
懂业务的都知道独立域名是需要注册和付费的,那么建站公司提供的免费域名呢?是建站公司为客户支付的域名吗?答案当然是否定的,事实是建站公司提供的免费域名实际上是二级甚至三级域名,并不是用户真正需要的一级域名。
1、一级域名和二级域名的区分方法
所谓一级域名也叫顶级域名,由合法字符串+域名后缀组成,例如二级域名就是一级域名下的主机名,即在一级域名前面加一个字符串,例如三个A顶级域名是,以此类推。
2、使用免费二级域名的风险
二级域名可以通过设置实现与一级域名相同的功能,但这并不意味着一级域名和二级域名没有区别。首先,两者是相互依赖的。二级域名依赖一级域名而存在。如果一级域名消失了,二级域名就不存在了,所以网站如果用二级域名注册的话,就有网站的风险域名消失。其次,搜索引擎的收录和权重分布偏向一级域名。@收录 和权重。
3、免费域名不能绑定外部域名
以凡客网为例,其提供的域名绑定服务为付费功能,需要购买凡客站标准版及以上版本才能使用。但是,免费版的客户无法使用此功能,限制了访问。网站的频道不利于增加网站的浏览量。
三、自由空间陷阱
建站公司号称提供免费空间供用户使用,但实际上这些所谓的免费空间里有很多花样。让我们来看看。
1、可用空间容量有限,使用需付费
虽然网站建设公司可以提供一定的免费空间供用户使用,但空间容量往往是有限的。随着网站的不断更新优化,需要的空间会越来越大,一旦超过限制,就会要求你付费获得更多空间,其实免费空间并不是免费的。
2、自由空间广告泛滥
提供免费空间的网站建设公司将在虚拟空间中强行插入广告,以进一步推广其服务,并允许免费用户升级为付费用户。体验非常糟糕。
3、在国外提供免费空间,国内访问受限
一些建站公司提供的免费空间其实是美国等海外空间。空间维护成本低,但是这个空间容易被阻塞,导致国内正常访问网站。而且由于我国限制出口带宽,国外网站服务器的访问速度肯定不如国内网站服务器。
4、提高稳定性网站需额外付费
使用免费网站后,如果服务器不稳定,网站访问异常等,需要付费。您使用 网站 的时间越长,您需要支付的费用就越多。
四、售后服务陷阱
无论是小公司还是大公司,其主要目的是推广付费服务,所以使用免费网站建设的服务质量也是可以想象的。
1、公司小,服务质量差
提供免费建站服务的公司很可能只是一个小团队,售后服务不完善,提出修改请求时会出现各种拖延甚至不回复的原因。
2、技术不够好,无法满足需求
如果您在使用免费网站后需要开发新功能,可能会出现因建站公司技术水平不足而无法满足需求的情况。
总的来说,建站公司宣传的0元免费建站服务有很多花样,请注意。首先,使用免费东西的体验不会特别好。其次,建站公司的主要目的是为了盈利,所以肯定会用各种手段让用户付费。免费只是噱头,付费才是最终目的。通过本文的介绍,希望广大需要建站的朋友能够识破0元免费建站的陷阱,不要被无良商家上当。 查看全部
动态网页抓取(世界上真的会有免费又好用的服务吗?)
在互联网高速发展的今天,各家企业都迫不及待地想通过网站的建设来销售产品和服务,维护自己的品牌形象,各种网站建设服务应运而生。其中,一些建站公司宣传提供0元免费建站服务,以免费为噱头吸引用户。然而,世界上真的有免费且易于使用的服务吗?当然,答案是否定的。免费的东西其实是最贵的。下面将揭开0元免费建站的诸多陷阱。
提供免费建站服务的企业,一般以“免费模板、免费域名、免费空间”为宣传点,吸引用户关注。接下来,我们将分析这些免费服务存在的问题。
一、免费模板陷阱
建站公司提供海量免费模板网站,涵盖各行各业。这些模板通用性强,可以满足大部分企业的基本建站需求。无需代码即可一键应用它们。听起来真的很有吸引力。正确的?但是这些免费模板其实存在很多问题,我们一起来看看吧。
1、免费模板的质量不保证
一般来说,模板是建站公司在深入研究分析市场需求后制作的,但也有不少公司的网站模板是多方购买、修改、转售,并没有关心这些模板。对这些所谓的免费模板的质量负责,所以这些所谓的免费模板不保证质量,甚至可能承担版权风险。
2、模板搭建没有吸引力,影响收录
使用同一个模板建站,很容易造成网站的出现出现重复,不仅使网站不美观,难以突出企业特色,而且重复率高,影响搜索网站 引擎的爬行速度和 收录 的损失是值得的。
3、使用不利于爬取的非静态页面
网站中使用静态页面有利于搜索引擎爬取,所以最好将页面制作成纯静态或伪静态,但免费模板往往使用一些动态页面,不利于爬取。
4、免费模板功能不全
一般来说,免费模板网站的设计非常简单,功能模块少,不适合功能需求复杂的用户。如果以后要开发新的功能,需要额外付费。
5、引导用户购买付费模板
建站公司提供的免费模板大部分都不是特别漂亮,同时也会提供一些效果明显更好的付费模板来吸引用户的注意力,让用户消费花钱购买付费模板的真正目的。
二、免费域陷阱
懂业务的都知道独立域名是需要注册和付费的,那么建站公司提供的免费域名呢?是建站公司为客户支付的域名吗?答案当然是否定的,事实是建站公司提供的免费域名实际上是二级甚至三级域名,并不是用户真正需要的一级域名。
1、一级域名和二级域名的区分方法
所谓一级域名也叫顶级域名,由合法字符串+域名后缀组成,例如二级域名就是一级域名下的主机名,即在一级域名前面加一个字符串,例如三个A顶级域名是,以此类推。
2、使用免费二级域名的风险
二级域名可以通过设置实现与一级域名相同的功能,但这并不意味着一级域名和二级域名没有区别。首先,两者是相互依赖的。二级域名依赖一级域名而存在。如果一级域名消失了,二级域名就不存在了,所以网站如果用二级域名注册的话,就有网站的风险域名消失。其次,搜索引擎的收录和权重分布偏向一级域名。@收录 和权重。
3、免费域名不能绑定外部域名
以凡客网为例,其提供的域名绑定服务为付费功能,需要购买凡客站标准版及以上版本才能使用。但是,免费版的客户无法使用此功能,限制了访问。网站的频道不利于增加网站的浏览量。
三、自由空间陷阱
建站公司号称提供免费空间供用户使用,但实际上这些所谓的免费空间里有很多花样。让我们来看看。
1、可用空间容量有限,使用需付费
虽然网站建设公司可以提供一定的免费空间供用户使用,但空间容量往往是有限的。随着网站的不断更新优化,需要的空间会越来越大,一旦超过限制,就会要求你付费获得更多空间,其实免费空间并不是免费的。
2、自由空间广告泛滥
提供免费空间的网站建设公司将在虚拟空间中强行插入广告,以进一步推广其服务,并允许免费用户升级为付费用户。体验非常糟糕。
3、在国外提供免费空间,国内访问受限
一些建站公司提供的免费空间其实是美国等海外空间。空间维护成本低,但是这个空间容易被阻塞,导致国内正常访问网站。而且由于我国限制出口带宽,国外网站服务器的访问速度肯定不如国内网站服务器。
4、提高稳定性网站需额外付费
使用免费网站后,如果服务器不稳定,网站访问异常等,需要付费。您使用 网站 的时间越长,您需要支付的费用就越多。
四、售后服务陷阱
无论是小公司还是大公司,其主要目的是推广付费服务,所以使用免费网站建设的服务质量也是可以想象的。
1、公司小,服务质量差
提供免费建站服务的公司很可能只是一个小团队,售后服务不完善,提出修改请求时会出现各种拖延甚至不回复的原因。
2、技术不够好,无法满足需求
如果您在使用免费网站后需要开发新功能,可能会出现因建站公司技术水平不足而无法满足需求的情况。
总的来说,建站公司宣传的0元免费建站服务有很多花样,请注意。首先,使用免费东西的体验不会特别好。其次,建站公司的主要目的是为了盈利,所以肯定会用各种手段让用户付费。免费只是噱头,付费才是最终目的。通过本文的介绍,希望广大需要建站的朋友能够识破0元免费建站的陷阱,不要被无良商家上当。

