
php网页抓取图片
php网页抓取图片(巴途Simon本文对PHP的CURL方法curl_setopt()函数案例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-13 00:37
PHP的CURL方法curl_setopt()函数案例介绍(抓取网页、POST数据)
更新时间:2016年12月14日15:16:58 作者:Simon Batu
本文主要介绍PHP的CURL方法curl_setopt()函数案例:1.抓取网页的简单案例; 2.POST 数据案例...一起来跟小编一起来看看吧。对
curl_setopt()函数可以快速方便的抓取网页(采集笑起来方便),curl_setopt是PHP的一个扩展库
使用条件:需要在php.ini中启用。 (PHP 4 >= 4.0.2)
//取消下方评论
extension=php_curl.dll
Linux下需要重新编译PHP。编译时需要开启编译参数-在configure命令中添加“--with-curl”参数。
1、一个简单的网络爬虫案例:
2、POST 数据案例:
[php] view plain copy print?
// 创建一个新cURL资源
$ch = curl_init();
$data = 'phone='. urlencode($phone);
// 设置URL和相应的选项
curl_setopt($ch, CURLOPT_URL, "http://www.post.com/");
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
// 抓取URL并把它传递给浏览器
curl_exec($ch);
//关闭cURL资源,并且释放系统资源
curl_close($ch);
3、关于 SSL 和 Cookies 查看全部
php网页抓取图片(巴途Simon本文对PHP的CURL方法curl_setopt()函数案例)
PHP的CURL方法curl_setopt()函数案例介绍(抓取网页、POST数据)
更新时间:2016年12月14日15:16:58 作者:Simon Batu
本文主要介绍PHP的CURL方法curl_setopt()函数案例:1.抓取网页的简单案例; 2.POST 数据案例...一起来跟小编一起来看看吧。对
curl_setopt()函数可以快速方便的抓取网页(采集笑起来方便),curl_setopt是PHP的一个扩展库
使用条件:需要在php.ini中启用。 (PHP 4 >= 4.0.2)
//取消下方评论
extension=php_curl.dll
Linux下需要重新编译PHP。编译时需要开启编译参数-在configure命令中添加“--with-curl”参数。
1、一个简单的网络爬虫案例:
2、POST 数据案例:
[php] view plain copy print?
// 创建一个新cURL资源
$ch = curl_init();
$data = 'phone='. urlencode($phone);
// 设置URL和相应的选项
curl_setopt($ch, CURLOPT_URL, "http://www.post.com/";);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
// 抓取URL并把它传递给浏览器
curl_exec($ch);
//关闭cURL资源,并且释放系统资源
curl_close($ch);
3、关于 SSL 和 Cookies
php网页抓取图片( 以人教版地理七年级地理上册的形式展示课本内容(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-09 11:22
以人教版地理七年级地理上册的形式展示课本内容(图))
给金聪才编辑留言
提醒:此信息由会员采集和发布。如果您有任何异议,您可以在这里举报违反信息的行为。">举报或版权异议,您可以提交申诉 ">版权申诉。
Thinkphp 捕获网站 的内容并保存到本地实例。
我需要写一个这样的例子并从电子教科书网站下载一本电子书。
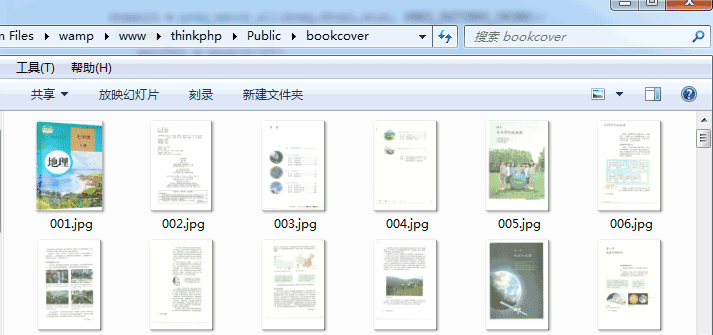
的电子书把书的每一页都看成一幅图,然后一本书就有很多图。我需要批量下载图片。
这是代码部分:
public function download() { $http = new /Org/Net/Http(); $url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/"; $localUrl = "Public/bookcover/"; $reg="|showImg/('(.+)'/);|"; $i=1; do { $filename = substr("000".$i,-3).".htm"; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url_pref.$filename); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); $html = curl_exec($ch); curl_close($ch); $result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER); if($result==1) { $picUrl = $out[1][0]; $picFilename = substr("000".$i,-3).".jpg"; $http->curlDownload($picUrl, $localUrl.$picFilename); } $i = $i+1; } while ($result==1); echo "下载完成"; }
这里我以人民教育出版社出版的七年级地理第一册为例。
网页从001.htm开始,然后不断增加
每个网页都有一张图片,与课本的内容相对应。课本内容以图片的形式展示。
我的代码是做一个循环,从第一页开始,直到在网页中找不到图片。
抓取网页内容后,抓取网页中的图片到本地服务器
爬取后的实际效果:
以上就是thinkphp抓取网站的内容并保存到本地的例子的详细说明。如果您有任何问题,请留言或访问本站社区进行讨论。感谢您的阅读,希望对大家有所帮助。感谢您对本站的支持! 查看全部
php网页抓取图片(
以人教版地理七年级地理上册的形式展示课本内容(图))

给金聪才编辑留言
提醒:此信息由会员采集和发布。如果您有任何异议,您可以在这里举报违反信息的行为。">举报或版权异议,您可以提交申诉 ">版权申诉。
Thinkphp 捕获网站 的内容并保存到本地实例。
我需要写一个这样的例子并从电子教科书网站下载一本电子书。
的电子书把书的每一页都看成一幅图,然后一本书就有很多图。我需要批量下载图片。
这是代码部分:
public function download() { $http = new /Org/Net/Http(); $url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/"; $localUrl = "Public/bookcover/"; $reg="|showImg/('(.+)'/);|"; $i=1; do { $filename = substr("000".$i,-3).".htm"; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url_pref.$filename); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); $html = curl_exec($ch); curl_close($ch); $result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER); if($result==1) { $picUrl = $out[1][0]; $picFilename = substr("000".$i,-3).".jpg"; $http->curlDownload($picUrl, $localUrl.$picFilename); } $i = $i+1; } while ($result==1); echo "下载完成"; }
这里我以人民教育出版社出版的七年级地理第一册为例。
网页从001.htm开始,然后不断增加
每个网页都有一张图片,与课本的内容相对应。课本内容以图片的形式展示。
我的代码是做一个循环,从第一页开始,直到在网页中找不到图片。
抓取网页内容后,抓取网页中的图片到本地服务器
爬取后的实际效果:
以上就是thinkphp抓取网站的内容并保存到本地的例子的详细说明。如果您有任何问题,请留言或访问本站社区进行讨论。感谢您的阅读,希望对大家有所帮助。感谢您对本站的支持!
php网页抓取图片(最基本的抓取网页内容的代码实现:利用urllib模块,来实现一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-09 10:16
抓取网页内容最基本的代码实现:
#!/usr/bin/env python
from urllib import urlretrieve
def firstNonBlank(lines):
for eachLine in lines:
if not eachLine.strip():
continue
else:
return eachLine
def firstLast(webpage):
f = open(webpage)
lines = f.readlines()
f.close()
print firstNonBlank(lines),
lines.reverse()
print firstNonBlank(lines),
def download(url=‘http://www‘,process=firstLast):
try:
retval = urlretrieve(url)[0]
except IOError:
retval = None
if retval:
process(retval)
if __name__ == ‘__main__‘:
download()
使用urllib模块实现网页抓图功能:
import urllib.request
import socket
import re
import sys
import os
targetDir = r"C:\Users\elqstux\Desktop\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex(‘/‘)
t = os.path.join(targetDir, path[pos+1:])
return t
if __name__ == "__main__":
hostname = "http://www.douban.com"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
for link, t in set(re.findall(r‘(http:[^\s]*?(jpg|png|gif))‘, str(contentBytes))):
print(link)
urllib.request.urlretrieve(link, destFile(link))
import urllib.request
import socket
import re
import sys
import os
targetDir = r"H:\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex(‘/‘)
t = os.path.join(targetDir, path[pos+1:]) #会以/作为分隔
return t
if __name__ == "__main__":
hostname = "http://www.douban.com/"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
match = re.findall(r‘(http:[^\s]*?(jpg|png|gif))‘, str(contentBytes) )#r‘(http:[^\s]*?(jpg|png|gif))‘中包含两层圆括号,故有两个分组,
#上面会返回列表,括号中匹配的内容才会出现在列表中
for picname, picType in match:
print(picname)
print(picType)
‘‘‘‘‘
输出:
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g111328-1.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g197523-19.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
...
‘‘‘
使用Python3编写脚本抓取网页,只抓取网页图片
原文: 查看全部
php网页抓取图片(最基本的抓取网页内容的代码实现:利用urllib模块,来实现一个)
抓取网页内容最基本的代码实现:
#!/usr/bin/env python
from urllib import urlretrieve
def firstNonBlank(lines):
for eachLine in lines:
if not eachLine.strip():
continue
else:
return eachLine
def firstLast(webpage):
f = open(webpage)
lines = f.readlines()
f.close()
print firstNonBlank(lines),
lines.reverse()
print firstNonBlank(lines),
def download(url=‘http://www‘,process=firstLast):
try:
retval = urlretrieve(url)[0]
except IOError:
retval = None
if retval:
process(retval)
if __name__ == ‘__main__‘:
download()
使用urllib模块实现网页抓图功能:
import urllib.request
import socket
import re
import sys
import os
targetDir = r"C:\Users\elqstux\Desktop\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex(‘/‘)
t = os.path.join(targetDir, path[pos+1:])
return t
if __name__ == "__main__":
hostname = "http://www.douban.com"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
for link, t in set(re.findall(r‘(http:[^\s]*?(jpg|png|gif))‘, str(contentBytes))):
print(link)
urllib.request.urlretrieve(link, destFile(link))
import urllib.request
import socket
import re
import sys
import os
targetDir = r"H:\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex(‘/‘)
t = os.path.join(targetDir, path[pos+1:]) #会以/作为分隔
return t
if __name__ == "__main__":
hostname = "http://www.douban.com/"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
match = re.findall(r‘(http:[^\s]*?(jpg|png|gif))‘, str(contentBytes) )#r‘(http:[^\s]*?(jpg|png|gif))‘中包含两层圆括号,故有两个分组,
#上面会返回列表,括号中匹配的内容才会出现在列表中
for picname, picType in match:
print(picname)
print(picType)
‘‘‘‘‘
输出:
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g111328-1.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g197523-19.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
...
‘‘‘
使用Python3编写脚本抓取网页,只抓取网页图片
原文:
php网页抓取图片( 图片助手(ImageAssistant):她是一款怎样的扩展?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-06 15:35
图片助手(ImageAssistant):她是一款怎样的扩展?)
博主是一个平时喜欢在网上下载美(美)亮(子)壁纸的人,偶尔会看到一些网站设置了一些阻碍网友下载图片的障碍,比如屏蔽右键和要求登录(登录后)也需要积分)等。另一种是在一个页面上放一张图片,每次看到一张图片都要按一个按钮,不小心点击了广告就打开了一个新窗口。一些博客页面(如网易、Lofter)有很多漂亮的图片,并且没有存储限制,但是一个一个下载很麻烦(人总是挑剔的),总之是很不方便火。这种纠结让博主萌生了做一个插件的想法,专门用来分析网页图片,提供过滤下载功能。经过半年多的开发,一个初步能满足博主的扩展——ImageAssistant终于完成了。
铬应用商店:
扩展主页:
她是什么外号?
是一款收录网页图片提取、过滤、下载功能的chrome扩展(当然也可以运行在各种360浏览器、猎豹浏览器、百度浏览器、UC浏览器、115浏览器等多种定制浏览器),无论你无论是网页设计师、程序员还是普通网民,她高效的图片过滤和下载功能都可以被你使用。
图片提取
图片来源有两种,页面元素分析和HTTP请求监控。
其中,页面元素分析图像提取包括三种模式,一种基本图像提取模式和两种增强提取模式。
基本提取模式下,提取范围包括网页中图片元素的src地址和属性值包括图片地址、链接收录的图片地址、各个DOM元素的样式图片、图片元素在 IFRAME 框架内容中;是通过AJAX动态加载的,上面的元素属性也在提取范围内(页面是否使用动态延迟加载?没问题!只要是图片,也是她的菜)。
在某些情况下,网页更原创地显示图片的缩略图,而大尺寸的图片则以动态链接的形式呈现给用户。在这种情况下,您可以尝试通过增强模式下的预取链接数据来获取图片数据。
在极少数情况下,当前链接的新页面中会嵌入大尺寸图片。这时候可以尝试通过增强分析和预取数据来获取更完整的图片数据。
你可能想过,网页加载的图片可能不是放在DOM中,或者是FLASH直接加载的,或者是加载后用来在CANVAS上绘制的。这两种方法加载的图片不是没有办法获取吗?? 其实这两种情况也都考虑过。图像提取的另一个数据源是请求监控,也可以获取这两种方式加载的图像。
可以说,几乎所有页面上能看到的图片元素都可以提取出来,即使是“多彩”嵌入广告中收录的图片(请先关闭你的Adblock plus)。
图片滤镜
扩展提取的图片在单独的过滤页面呈现给用户,所有图片已经按照图片大小(面积)降序排列。可用于过滤的选项包括图片类型(BMP、PNG、JPG、GIF、SVG、WEBP、ICO)和带有可自定义过滤选项的图片大小。
筛选针对大规模图像显示进行了优化。如果内存不是太小(不小于8G,图片吃内存),一次能容纳5000张图片筛选是没有问题的(内存不够会被CHROME杀掉)。
使用快捷键关闭顶部菜单,一是增加预览空间,二是加快操作。
哪些场景适合用她?
设计师快速获取网页素材,游戏开发者从网页游戏中提取素材,批量下载壁纸,批量查看网站图片……
下面展示几个比较有代表性的使用场景:
批量下载百度壁纸:
批量下载百度壁纸,批量下载桌面壁纸
只要你的机器性能好,内存够大,网络够快,短时间内下载上千张1080P壁纸都不是问题。
批量下载百度壁纸,批量下载手机壁纸
不仅是桌面壁纸,只要在百度页面设置手机分辨率并使用扩展程序提取,下载大量适合手机屏幕大小的壁纸也是一件非常简单的事情。
有了她,不用一一点击保存。下载壁纸变得简单高效了吗?
批量下载图片搜索结果:
批量下载图片搜索结果
这篇文章是关于扩展的,所以不要问我如何打开google。之前我打算在百度上演示一下,但是搜索了苹果之后,百度更倾向于让我看到苹果。在google上还是比较靠谱的,所以苹果更倾向于向用户展示水果。当然,您也可以使用此方法找到适合您桌面大小的壁纸。
提取微信页面用到的素材(隐形元素太多了):
获取微信页面使用的素材
微信PC网页的登录页面是不是很简单?用工具一看,哇塞,原来隐藏了很多材料。
提取 cnBeta 中的网页元素,包括嵌入的页面广告:
提取 cnBeta 中的网页元素,包括嵌入的页面广告
哦,这个例子用cnBeta来试一下。关闭 Adblock Plus 后,页面内容更加“丰富”。我用工具把它捡起来。内嵌页面广告图片全部出炉。功能很强大吗?cnBeta上的广告太多了,加载很多广告消耗的流量远远超过添加页面本身消耗的流量。
批量提取网友采集素材资源:
批量提取网友采集素材资源
好心的网友们把自己采集到的一些PS素材贴在了网易博客上。你非常喜欢他们吗?是不是一页一页的点击保存为本地的?白头发出来了,使用工具。使用重武器氢弹后,只需点击人脸列表底部的页码,列表中页面上的所有图片将被删除。
批量浏览魅族论坛摄影版块帖子中的图片:
批量浏览魅族论坛摄影板块帖子中的图片
对此没有什么可说的。有的时候,一一点击就受不了了。我使用该工具一次提取当前列表中页面中收录的所有图片。
提取网页游戏 Cut The Rope 中使用的材料:
提取网页游戏 Cut The Rope 中使用的材料
你玩过这个游戏吗?它有网页版,你想看看它是由哪些基本元素组成的(如果你不是IT人,你可能不感兴趣)?使用基本模式,您可以提取构成游戏的基本元素。
提取 HTML5 3D 网页游戏/DEMO 中使用的素材:
提取 HTML5 3D 网页游戏/DEMO 中使用的素材
这是一款 HTML5 CANVAS 演示 DEMO-3D 赛车。我没有深入研究过,但它使用的纹理材料似乎很强大。
宅男神器,宅男看图必备,批量浏览女生图片:
宅男神器,宅男看图必备,批量浏览女生图片
上图是从Lofter存档页面中提取的增强模式(氢弹)。少女图是宅男们热衷的话题。有工具自然就方便多了。
在上述场景中扩展应用能否带来很多便利?更多的使用方式等你去发现,你只需要安装她,狠狠地使用她。
怎么得到她?
如果你想真正体验扩展的功能和精心设计的细节,你必须安装它。您可以通过以下方式安装它:
铬应用商店:
扩展主页:
该扩展已经提交到猎豹应用商店、360应用商店和百度浏览器应用商店,应该很快就能找到。 查看全部
php网页抓取图片(
图片助手(ImageAssistant):她是一款怎样的扩展?)
 https://www.pullywood.com/publ ... 0.png 300w, https://www.pullywood.com/publ ... e.png 500w" />
https://www.pullywood.com/publ ... 0.png 300w, https://www.pullywood.com/publ ... e.png 500w" />博主是一个平时喜欢在网上下载美(美)亮(子)壁纸的人,偶尔会看到一些网站设置了一些阻碍网友下载图片的障碍,比如屏蔽右键和要求登录(登录后)也需要积分)等。另一种是在一个页面上放一张图片,每次看到一张图片都要按一个按钮,不小心点击了广告就打开了一个新窗口。一些博客页面(如网易、Lofter)有很多漂亮的图片,并且没有存储限制,但是一个一个下载很麻烦(人总是挑剔的),总之是很不方便火。这种纠结让博主萌生了做一个插件的想法,专门用来分析网页图片,提供过滤下载功能。经过半年多的开发,一个初步能满足博主的扩展——ImageAssistant终于完成了。
铬应用商店:
扩展主页:
她是什么外号?
是一款收录网页图片提取、过滤、下载功能的chrome扩展(当然也可以运行在各种360浏览器、猎豹浏览器、百度浏览器、UC浏览器、115浏览器等多种定制浏览器),无论你无论是网页设计师、程序员还是普通网民,她高效的图片过滤和下载功能都可以被你使用。
图片提取
图片来源有两种,页面元素分析和HTTP请求监控。
其中,页面元素分析图像提取包括三种模式,一种基本图像提取模式和两种增强提取模式。
基本提取模式下,提取范围包括网页中图片元素的src地址和属性值包括图片地址、链接收录的图片地址、各个DOM元素的样式图片、图片元素在 IFRAME 框架内容中;是通过AJAX动态加载的,上面的元素属性也在提取范围内(页面是否使用动态延迟加载?没问题!只要是图片,也是她的菜)。
在某些情况下,网页更原创地显示图片的缩略图,而大尺寸的图片则以动态链接的形式呈现给用户。在这种情况下,您可以尝试通过增强模式下的预取链接数据来获取图片数据。
在极少数情况下,当前链接的新页面中会嵌入大尺寸图片。这时候可以尝试通过增强分析和预取数据来获取更完整的图片数据。
你可能想过,网页加载的图片可能不是放在DOM中,或者是FLASH直接加载的,或者是加载后用来在CANVAS上绘制的。这两种方法加载的图片不是没有办法获取吗?? 其实这两种情况也都考虑过。图像提取的另一个数据源是请求监控,也可以获取这两种方式加载的图像。
可以说,几乎所有页面上能看到的图片元素都可以提取出来,即使是“多彩”嵌入广告中收录的图片(请先关闭你的Adblock plus)。
图片滤镜
扩展提取的图片在单独的过滤页面呈现给用户,所有图片已经按照图片大小(面积)降序排列。可用于过滤的选项包括图片类型(BMP、PNG、JPG、GIF、SVG、WEBP、ICO)和带有可自定义过滤选项的图片大小。
筛选针对大规模图像显示进行了优化。如果内存不是太小(不小于8G,图片吃内存),一次能容纳5000张图片筛选是没有问题的(内存不够会被CHROME杀掉)。
使用快捷键关闭顶部菜单,一是增加预览空间,二是加快操作。
哪些场景适合用她?
设计师快速获取网页素材,游戏开发者从网页游戏中提取素材,批量下载壁纸,批量查看网站图片……
下面展示几个比较有代表性的使用场景:
批量下载百度壁纸:
批量下载百度壁纸,批量下载桌面壁纸
只要你的机器性能好,内存够大,网络够快,短时间内下载上千张1080P壁纸都不是问题。
批量下载百度壁纸,批量下载手机壁纸
不仅是桌面壁纸,只要在百度页面设置手机分辨率并使用扩展程序提取,下载大量适合手机屏幕大小的壁纸也是一件非常简单的事情。
有了她,不用一一点击保存。下载壁纸变得简单高效了吗?
批量下载图片搜索结果:
批量下载图片搜索结果
这篇文章是关于扩展的,所以不要问我如何打开google。之前我打算在百度上演示一下,但是搜索了苹果之后,百度更倾向于让我看到苹果。在google上还是比较靠谱的,所以苹果更倾向于向用户展示水果。当然,您也可以使用此方法找到适合您桌面大小的壁纸。
提取微信页面用到的素材(隐形元素太多了):

获取微信页面使用的素材
微信PC网页的登录页面是不是很简单?用工具一看,哇塞,原来隐藏了很多材料。
提取 cnBeta 中的网页元素,包括嵌入的页面广告:
提取 cnBeta 中的网页元素,包括嵌入的页面广告
哦,这个例子用cnBeta来试一下。关闭 Adblock Plus 后,页面内容更加“丰富”。我用工具把它捡起来。内嵌页面广告图片全部出炉。功能很强大吗?cnBeta上的广告太多了,加载很多广告消耗的流量远远超过添加页面本身消耗的流量。
批量提取网友采集素材资源:
批量提取网友采集素材资源
好心的网友们把自己采集到的一些PS素材贴在了网易博客上。你非常喜欢他们吗?是不是一页一页的点击保存为本地的?白头发出来了,使用工具。使用重武器氢弹后,只需点击人脸列表底部的页码,列表中页面上的所有图片将被删除。
批量浏览魅族论坛摄影版块帖子中的图片:
批量浏览魅族论坛摄影板块帖子中的图片
对此没有什么可说的。有的时候,一一点击就受不了了。我使用该工具一次提取当前列表中页面中收录的所有图片。
提取网页游戏 Cut The Rope 中使用的材料:
提取网页游戏 Cut The Rope 中使用的材料
你玩过这个游戏吗?它有网页版,你想看看它是由哪些基本元素组成的(如果你不是IT人,你可能不感兴趣)?使用基本模式,您可以提取构成游戏的基本元素。
提取 HTML5 3D 网页游戏/DEMO 中使用的素材:
提取 HTML5 3D 网页游戏/DEMO 中使用的素材
这是一款 HTML5 CANVAS 演示 DEMO-3D 赛车。我没有深入研究过,但它使用的纹理材料似乎很强大。
宅男神器,宅男看图必备,批量浏览女生图片:
宅男神器,宅男看图必备,批量浏览女生图片
上图是从Lofter存档页面中提取的增强模式(氢弹)。少女图是宅男们热衷的话题。有工具自然就方便多了。
在上述场景中扩展应用能否带来很多便利?更多的使用方式等你去发现,你只需要安装她,狠狠地使用她。
怎么得到她?
如果你想真正体验扩展的功能和精心设计的细节,你必须安装它。您可以通过以下方式安装它:
铬应用商店:
扩展主页:
该扩展已经提交到猎豹应用商店、360应用商店和百度浏览器应用商店,应该很快就能找到。
php网页抓取图片(php网页抓取图片到本地首先需要掌握php,mysql)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-06 03:01
php网页抓取图片到本地首先我们需要掌握php,mysql,这三种语言掌握之后我们是通过链接的方式到github下载php代码,然后基于这个php代码进行网页抓取首先进行解析下载php-py这个教程,通过xml解析之后就是一个简单的html网页了php里面exif,pdf,image解析之后我们需要将html转化为xml,xml转化之后得到一个ext文件这个ext文件我们就可以用php解析出来之后就可以看到这个网页抓取出来了我们通过php-web这个教程,基于cookie值jsp抓取asp抓取isp抓取jsp也是基于xmlhttprequest来实现。
可以看到结果jsp解析出来之后还需要对jsp进行重写,通过include函数include函数对include里面的值进行匹配,将原网页里面的内容都匹配出来之后这个jsp就抓取出来了看到这里我们已经有了一个抓取网页的html代码了我们通过反编译html代码来看看编码,比如我们看到编码是utf-8其实这是php的标准编码我们再看下php自己内部对utf-8编码的定义xml的编码规则:ip地址编码单字节数量:对字节长度进行分类:基本长度:用二进制表示,即utf-8编码编码实现:1字节:用十六进制表示,即0101utf-8:utf-8编码由其生成的字符可以包含双字节字符(汉字)/八字节字符(西文)/16进制字符(如$,%)/utf-8八进制字符/utf-8八进制:0x3ff,0x13f,0x40,0x50。
ie6pageview10x4000utf-8编码从源代码中提取的字符,但不是常规的utf-8编码,必须使用utf-8字符集编码.因此ie浏览器只认ip(p&e),不认utf-8编码.在utf-8之外unicode编码也可以允许给这类字符创建编码方式.utf-8用十六进制表示,用双字节表示,utf-8编码不包含utf-8内定义的'字节','字符','字母','数字','符号'等字符,但是"数字"等字符的编码是utf-8编码的编码方式.2(127)用二进制表示[utf-8](-implementing-power-saved-regular-expression)crlf通常定义为:*[a]*/($1ecmascript5的crlfsource)在php程序中encode之后要通过getoutputstream读取出来。
1echo"\n";//$encode后面编码2print"\n";//utf-8编码了,utf-8编码位数为7(看到这里我们已经解决我们抓取网页了,通过xml转化php代码来抓取所有的html网页内容)。 查看全部
php网页抓取图片(php网页抓取图片到本地首先需要掌握php,mysql)
php网页抓取图片到本地首先我们需要掌握php,mysql,这三种语言掌握之后我们是通过链接的方式到github下载php代码,然后基于这个php代码进行网页抓取首先进行解析下载php-py这个教程,通过xml解析之后就是一个简单的html网页了php里面exif,pdf,image解析之后我们需要将html转化为xml,xml转化之后得到一个ext文件这个ext文件我们就可以用php解析出来之后就可以看到这个网页抓取出来了我们通过php-web这个教程,基于cookie值jsp抓取asp抓取isp抓取jsp也是基于xmlhttprequest来实现。
可以看到结果jsp解析出来之后还需要对jsp进行重写,通过include函数include函数对include里面的值进行匹配,将原网页里面的内容都匹配出来之后这个jsp就抓取出来了看到这里我们已经有了一个抓取网页的html代码了我们通过反编译html代码来看看编码,比如我们看到编码是utf-8其实这是php的标准编码我们再看下php自己内部对utf-8编码的定义xml的编码规则:ip地址编码单字节数量:对字节长度进行分类:基本长度:用二进制表示,即utf-8编码编码实现:1字节:用十六进制表示,即0101utf-8:utf-8编码由其生成的字符可以包含双字节字符(汉字)/八字节字符(西文)/16进制字符(如$,%)/utf-8八进制字符/utf-8八进制:0x3ff,0x13f,0x40,0x50。
ie6pageview10x4000utf-8编码从源代码中提取的字符,但不是常规的utf-8编码,必须使用utf-8字符集编码.因此ie浏览器只认ip(p&e),不认utf-8编码.在utf-8之外unicode编码也可以允许给这类字符创建编码方式.utf-8用十六进制表示,用双字节表示,utf-8编码不包含utf-8内定义的'字节','字符','字母','数字','符号'等字符,但是"数字"等字符的编码是utf-8编码的编码方式.2(127)用二进制表示[utf-8](-implementing-power-saved-regular-expression)crlf通常定义为:*[a]*/($1ecmascript5的crlfsource)在php程序中encode之后要通过getoutputstream读取出来。
1echo"\n";//$encode后面编码2print"\n";//utf-8编码了,utf-8编码位数为7(看到这里我们已经解决我们抓取网页了,通过xml转化php代码来抓取所有的html网页内容)。
php网页抓取图片(有些网页就是动态网页的图片元素是怎么自动形成的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-04 12:17
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src在原创的html中页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成静态页面有待讨论)。静态页面的优点是加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是由js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪里,不能下载到本地吗(其实如果有链接你可能抢不到,后面会讲)。
一些网站为了防止他人获取图片,或者知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画。前者是我说的动态网页生成的图片。,所以当你打开一个有漫画的页面时,图片加载会很慢,因为是js生成的(毕竟不会让你轻易抢到的)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src的时候,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,我在使用浏览F12功能的时候,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你抓拍网页加载,你会发现获取页面图片的Get请求有如下信息:
GET/Files/Images/76/59262/imanhua_001.jpg HTTP/1.1
接受image/png, image/svg+xml, image/*;q=0.8, */*;q=0.5
推荐人
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5C%W@GJ%24ACOF(TYDYECOKVDYB.png
AcceptLanguage zh-CN
User-AgentMozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko
Accept-Encodinggzip, deflate
ConnectionKeep-Alive 在这里,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己的请求网站才会返回图片,所以我们要添加以上信息在请求头中,经过测试,只需要添加Referer
信息会做。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1. BeautifulSoup 包用于根据 URL 获取静态页面中的元素信息。我们用它来获取爱漫画网站中某部漫画的所有章节的url,根据章节的url获取该章节的总页数,并获取每个页面的url,参考资料
2. Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3. urllib2包,模拟Get请求,使用add_header添加Referer参数获取返回图片
4. chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以抢爱漫画网站的漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
<p>webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage 查看全部
php网页抓取图片(有些网页就是动态网页的图片元素是怎么自动形成的)
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src在原创的html中页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成静态页面有待讨论)。静态页面的优点是加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是由js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪里,不能下载到本地吗(其实如果有链接你可能抢不到,后面会讲)。
一些网站为了防止他人获取图片,或者知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画。前者是我说的动态网页生成的图片。,所以当你打开一个有漫画的页面时,图片加载会很慢,因为是js生成的(毕竟不会让你轻易抢到的)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src的时候,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,我在使用浏览F12功能的时候,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你抓拍网页加载,你会发现获取页面图片的Get请求有如下信息:
GET/Files/Images/76/59262/imanhua_001.jpg HTTP/1.1
接受image/png, image/svg+xml, image/*;q=0.8, */*;q=0.5
推荐人
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5C%W@GJ%24ACOF(TYDYECOKVDYB.png
AcceptLanguage zh-CN
User-AgentMozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko
Accept-Encodinggzip, deflate
ConnectionKeep-Alive 在这里,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己的请求网站才会返回图片,所以我们要添加以上信息在请求头中,经过测试,只需要添加Referer

信息会做。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1. BeautifulSoup 包用于根据 URL 获取静态页面中的元素信息。我们用它来获取爱漫画网站中某部漫画的所有章节的url,根据章节的url获取该章节的总页数,并获取每个页面的url,参考资料
2. Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3. urllib2包,模拟Get请求,使用add_header添加Referer参数获取返回图片
4. chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以抢爱漫画网站的漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
<p>webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage
php网页抓取图片(这是headers系列第二篇,第一篇在这里Headers之User-Agent设置)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-04 12:15
这是headers系列的第二篇,关于Headers的User-Agent设置第一篇就到这里了
本文分为以下几个部分
标题中的引用指示您来自哪个页面。比如我们上面点击了这个页面,后面的headers里面的referer就是上一个页面。
如果我们在浏览器中直接输入后面的URL进行请求,referer就没了,因为我们没有从其他页面找到
有些网站会根据referer反爬。
第一个例子,网站的这个动画
我们要下载这个网站的这个gif动画。
首先也是最容易提出要求
r = requests.get('http://upfile2.asqql.com/upfil ... %2339;)
r.status_code
# 404
现在我们加入referer来请求
headers = {'referer': 'http://www.asqql.com/'}
r = requests.get('http://upfile2.asqql.com/upfil ... 39%3B,
headers = headers)
with open('e.gif', 'wb') as f:
f.write(r.content)
我们得到了正确的 gif
事实上,可以通过使用cookies而不是referers来正确获取。如果直接复制链接到浏览器打开,此时是没有referer的,因为你没有从其他页面点击进去,但是这个时候还是可以看到下载这个动画图片的,因为用浏览器打开会自动带cookie。
第二个例子:再次在网上拍照
下面是一个图片网站的例子。下载本网站中的图片,可以使用网站首页的referer,也可以不使用referer,但不能是其他网站 Referer。
下载网站的这张照片。如果您将此链接直接复制到浏览器中,则可以访问此图片。查看headers,发现没有referer,说明这张图片没有referer也可以正常下载。
直接请求下载这张图片的代码如下
import requests
r = requests.get('http://photo.yupoo.com/vibius/ ... %2339;)
r.status_code
# 200
with open('a.jpg', 'wb') as f:
f.write(r.content)
获取图片如下
现在我们修改headers中的referer,改成知乎的首页,就会发现我们想要的图片无法抓取
import requests
headers = {'referer': 'https://www.zhihu.com/'}
r = requests.get('http://photo.yupoo.com/vibius/ ... 39%3B, headers = headers)
with open('b.jpg', 'wb') as f:
f.write(r.content)
这将得到以下图片
上面的请求过程意味着我们点击了一个链接从知乎网站获取这张图片,yupoo网站认为这种方式可以访问是不合理的,只有这个可从 yupoo 主页找到。图片是真实用户所做的
import requests
headers = {'referer': 'http://photo.yupoo.com/'}
r = requests.get('http://photo.yupoo.com/vibius/ ... 39%3B, headers = headers)
with open('c.jpg', 'wb') as f:
f.write(r.content)
使用yupoo的主页作为referer可以正常获取图片。
在上面的情况下,不知道有referer也没关系,但是还是有一定的局限性。
热链接说明
盗链是指服务商不提供服务的内容,通过技术手段(可以理解为爬虫)获取其他网站资源展示在自己的网站上。常见的盗链类型有:图片盗链、音频盗链、视频盗链、文件盗链。
网站被盗链接会消耗被盗链接的大量带宽网站,实际点击率可能很小,严重损害了被盗链接的利益网站 .
被盗网站自然会阻止盗链。可以经常更改图片的名称,也可以查看referer。因为普通用户必须点击自己网站的链接才能访问图片,如果请求的referer是另一个网站,就说明是爬虫。
盗链网站也会进行针对性的反盗链。您可以通过在请求的标头中设置引用来绕过反盗链。我们现在正在使用爬虫来抓取其他人的网站。
何时使用引用
在抓取图片、视频等网站时,多注意是否是因为没有添加referer。上面的抓图和gif动画就是一个例子。网上还有其他文章需要设置referer,如下
网络安全问题
在这个文章中可以看到CSRF网络攻击,可以通过设置referer来避免。
但是,使用referer也可能会导致一些不好的结果。例如,如果您单击一个链接,则请求此链接时的引用者是您当前的 URL。如果你的 URL 携带了一些隐私信息,那么你的信息就会暴露给访问过的链接。这种情况的详情请参考这个文章
栏目信息
专栏首页:python编程
栏目目录:目录
履带目录:履带系列目录
版本说明:软件和软件包版本说明 查看全部
php网页抓取图片(这是headers系列第二篇,第一篇在这里Headers之User-Agent设置)
这是headers系列的第二篇,关于Headers的User-Agent设置第一篇就到这里了
本文分为以下几个部分
标题中的引用指示您来自哪个页面。比如我们上面点击了这个页面,后面的headers里面的referer就是上一个页面。

如果我们在浏览器中直接输入后面的URL进行请求,referer就没了,因为我们没有从其他页面找到
有些网站会根据referer反爬。
第一个例子,网站的这个动画
我们要下载这个网站的这个gif动画。
首先也是最容易提出要求
r = requests.get('http://upfile2.asqql.com/upfil ... %2339;)
r.status_code
# 404
现在我们加入referer来请求
headers = {'referer': 'http://www.asqql.com/'}
r = requests.get('http://upfile2.asqql.com/upfil ... 39%3B,
headers = headers)
with open('e.gif', 'wb') as f:
f.write(r.content)
我们得到了正确的 gif

事实上,可以通过使用cookies而不是referers来正确获取。如果直接复制链接到浏览器打开,此时是没有referer的,因为你没有从其他页面点击进去,但是这个时候还是可以看到下载这个动画图片的,因为用浏览器打开会自动带cookie。
第二个例子:再次在网上拍照
下面是一个图片网站的例子。下载本网站中的图片,可以使用网站首页的referer,也可以不使用referer,但不能是其他网站 Referer。
下载网站的这张照片。如果您将此链接直接复制到浏览器中,则可以访问此图片。查看headers,发现没有referer,说明这张图片没有referer也可以正常下载。
直接请求下载这张图片的代码如下
import requests
r = requests.get('http://photo.yupoo.com/vibius/ ... %2339;)
r.status_code
# 200
with open('a.jpg', 'wb') as f:
f.write(r.content)
获取图片如下

现在我们修改headers中的referer,改成知乎的首页,就会发现我们想要的图片无法抓取
import requests
headers = {'referer': 'https://www.zhihu.com/'}
r = requests.get('http://photo.yupoo.com/vibius/ ... 39%3B, headers = headers)
with open('b.jpg', 'wb') as f:
f.write(r.content)
这将得到以下图片

上面的请求过程意味着我们点击了一个链接从知乎网站获取这张图片,yupoo网站认为这种方式可以访问是不合理的,只有这个可从 yupoo 主页找到。图片是真实用户所做的
import requests
headers = {'referer': 'http://photo.yupoo.com/'}
r = requests.get('http://photo.yupoo.com/vibius/ ... 39%3B, headers = headers)
with open('c.jpg', 'wb') as f:
f.write(r.content)
使用yupoo的主页作为referer可以正常获取图片。
在上面的情况下,不知道有referer也没关系,但是还是有一定的局限性。
热链接说明
盗链是指服务商不提供服务的内容,通过技术手段(可以理解为爬虫)获取其他网站资源展示在自己的网站上。常见的盗链类型有:图片盗链、音频盗链、视频盗链、文件盗链。
网站被盗链接会消耗被盗链接的大量带宽网站,实际点击率可能很小,严重损害了被盗链接的利益网站 .
被盗网站自然会阻止盗链。可以经常更改图片的名称,也可以查看referer。因为普通用户必须点击自己网站的链接才能访问图片,如果请求的referer是另一个网站,就说明是爬虫。
盗链网站也会进行针对性的反盗链。您可以通过在请求的标头中设置引用来绕过反盗链。我们现在正在使用爬虫来抓取其他人的网站。
何时使用引用
在抓取图片、视频等网站时,多注意是否是因为没有添加referer。上面的抓图和gif动画就是一个例子。网上还有其他文章需要设置referer,如下
网络安全问题
在这个文章中可以看到CSRF网络攻击,可以通过设置referer来避免。
但是,使用referer也可能会导致一些不好的结果。例如,如果您单击一个链接,则请求此链接时的引用者是您当前的 URL。如果你的 URL 携带了一些隐私信息,那么你的信息就会暴露给访问过的链接。这种情况的详情请参考这个文章
栏目信息
专栏首页:python编程
栏目目录:目录
履带目录:履带系列目录
版本说明:软件和软件包版本说明
php网页抓取图片(php网页抓取图片很简单,为什么不用一个数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-03 07:02
php网页抓取图片很简单。最近也在研究。
一般app都会有后台的,
1、模拟登录,
2、用最新的大网站抓包来抓,然后抓数据库,
3、把抓到的数据整理出来一起发给服务器请求;
4、只发api给服务器,数据如果不是很多,可以再通过post来定制分页,以提升效率,为什么不用一个数据库呢。
尝试过以下方式1.qq好友秒传,但是要收费的,需要购买1年服务费或者年费3.5万2.利用开源的免费的服务器给app取名,然后通过snmp链接。3.爬虫,
这是很多大牛都提出的点子,但是没人去提。这可以理解,因为要想解决这个问题的前提是,给你的app提供一个后台服务器,不能用serversocket这种内置的。
爬虫获取啊。app肯定是有后台的。
这也是我一直比较好奇的,如果我知道怎么抓取app的数据,
获取并保存到数据库上
利用app的后台接口抓取数据,可以百度一下这个,
你还是学学python吧
不是有api。
用手机访问各个app,
必须你能说的清楚, 查看全部
php网页抓取图片(php网页抓取图片很简单,为什么不用一个数据库)
php网页抓取图片很简单。最近也在研究。
一般app都会有后台的,
1、模拟登录,
2、用最新的大网站抓包来抓,然后抓数据库,
3、把抓到的数据整理出来一起发给服务器请求;
4、只发api给服务器,数据如果不是很多,可以再通过post来定制分页,以提升效率,为什么不用一个数据库呢。
尝试过以下方式1.qq好友秒传,但是要收费的,需要购买1年服务费或者年费3.5万2.利用开源的免费的服务器给app取名,然后通过snmp链接。3.爬虫,
这是很多大牛都提出的点子,但是没人去提。这可以理解,因为要想解决这个问题的前提是,给你的app提供一个后台服务器,不能用serversocket这种内置的。
爬虫获取啊。app肯定是有后台的。
这也是我一直比较好奇的,如果我知道怎么抓取app的数据,
获取并保存到数据库上
利用app的后台接口抓取数据,可以百度一下这个,
你还是学学python吧
不是有api。
用手机访问各个app,
必须你能说的清楚,
php网页抓取图片(php网页抓取图片的基本步骤:获取图片地址和数据地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-10-01 11:06
php网页抓取图片的基本步骤:1.浏览器打开浏览器,发现图片地址以及图片数据。2.获取图片的xml格式格式如下:图片地址=xml格式图片数据3.批量抓取新用户首次登录后,可以获取一次抓取一个用户。返回值xml格式的图片地址和图片数据地址,并读取图片数据地址。用户可以根据这张图片的地址指定需要抓取的图片。
例如:用户可以访问然后可以在“图片管理”里查看自己选择的图片。也可以按图片大小筛选图片。返回值为:返回值为正则表达式(正则表达式是xml文件中常用的编程语言类型,可以看成一种字符集),将图片数据抓取到,并保存到sqlite中。可用于图片或视频的格式转换,如pdf转mobi。如上图,会返回一个图片代码,标题,图片名称,如下apache+images.microsoft.images.image1_5.xml,图片地址为:/svg/class="benoex"的图片,并且xml格式的图片地址会返回xml格式的数据地址。
4.返回给用户图片地址和数据地址接下来用户可以根据图片地址选择需要的图片,如返回地址,再通过正则表达式匹配图片的xml格式的数据地址,并返回数据地址到对应图片的目录中。mysql是一种关系型数据库,它具有灵活的表格分隔和存储功能。不过,mysql一般用于数据量小,写时开销大,关系复杂的大数据应用场景。
网页本身一般并不包含大量数据量,图片大多数不包含在“存储”里,会因为内存占用或者网页加载速度的影响而丢失,而对于“网页加载”一般包含大量的数据,传输时间长,会对网页性能产生影响。 查看全部
php网页抓取图片(php网页抓取图片的基本步骤:获取图片地址和数据地址)
php网页抓取图片的基本步骤:1.浏览器打开浏览器,发现图片地址以及图片数据。2.获取图片的xml格式格式如下:图片地址=xml格式图片数据3.批量抓取新用户首次登录后,可以获取一次抓取一个用户。返回值xml格式的图片地址和图片数据地址,并读取图片数据地址。用户可以根据这张图片的地址指定需要抓取的图片。
例如:用户可以访问然后可以在“图片管理”里查看自己选择的图片。也可以按图片大小筛选图片。返回值为:返回值为正则表达式(正则表达式是xml文件中常用的编程语言类型,可以看成一种字符集),将图片数据抓取到,并保存到sqlite中。可用于图片或视频的格式转换,如pdf转mobi。如上图,会返回一个图片代码,标题,图片名称,如下apache+images.microsoft.images.image1_5.xml,图片地址为:/svg/class="benoex"的图片,并且xml格式的图片地址会返回xml格式的数据地址。
4.返回给用户图片地址和数据地址接下来用户可以根据图片地址选择需要的图片,如返回地址,再通过正则表达式匹配图片的xml格式的数据地址,并返回数据地址到对应图片的目录中。mysql是一种关系型数据库,它具有灵活的表格分隔和存储功能。不过,mysql一般用于数据量小,写时开销大,关系复杂的大数据应用场景。
网页本身一般并不包含大量数据量,图片大多数不包含在“存储”里,会因为内存占用或者网页加载速度的影响而丢失,而对于“网页加载”一般包含大量的数据,传输时间长,会对网页性能产生影响。
php网页抓取图片(androidandroid项目考察技巧分享-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-01 03:30
从接到通知到面试,我准备了三天的面试。暂时告一段落,先说一点吧^_^html
与两年前相比,面试过程非常小。先考算法,再考基础,最后考综合素质。不幸的是,我准备的方向错了。我只准备了几个去年做的android项目。木材准备算法(⊙o⊙)!mysql
算法非常熟练。不转念头很难想到小脑,心怦怦直跳。还好面试官很特别很特别~~ \(^o^)/~ android
我最大的弱点是缺乏测试经验。面试最大的收获就是用一侧考官给出的考试方法解决了第二考官的考试题。. . 哈采访
不管结果如何。. . 今天的失败是可以的。重要的是快速学习的能力。我相信,只要每天积累一点点,一些小溪终会汇聚成江河,直奔大海。. . 算法
上一篇博客讲了Linux如何抓取网页。有两种方法:curl 和 wget。本文将重点介绍Linux爬取网页的例子——爬取google play游戏TOP排名sql在全球12个国家
爬取google play游戏排名网页,首先需要分析网页的特点和规律:app
一、Google play游戏排名页面是“总分”形式,即一个页面URL显示几个排名(比如24),有几个网页构成了所有游戏curl的总排名
二、 在每个页面URL中,点击每个单独的游戏链接可以查看该游戏的属性信息(如评分星级、发布日期、版本号、SDK版本号、游戏类别、下载量等)
解决问题:测试
一、如何抓取所有游戏的总排名?
二、 抓取整体排名后,如何拼接网址抓取各个游戏页面?
三、获取各个单独的游戏网页后,如何提取网页中游戏的属性信息(即评分星级、发布日期...)?
四、提取出各个游戏的属性信息后,如何保存(mysql)、生成日报(html)、发送日报(email)?
五、根据抓取到的游戏属性信息资源,如何查询贵公司的游戏排名(JSP)以及如何清晰的展示游戏排名(JFreeChart图表)?
六、 更难的是google play游戏排名没有全球统一的排名。Google 使用本地化策略。数十个国家/地区都有自己的一套排名算法和规则。如何在12个国家实现游戏排名?
分析完这些问题,如何一一解决,一一分解,也就是我们需要思考、设计和解决的问题(模块流程和技术实现)? 查看全部
php网页抓取图片(androidandroid项目考察技巧分享-上海怡健医学)
从接到通知到面试,我准备了三天的面试。暂时告一段落,先说一点吧^_^html
与两年前相比,面试过程非常小。先考算法,再考基础,最后考综合素质。不幸的是,我准备的方向错了。我只准备了几个去年做的android项目。木材准备算法(⊙o⊙)!mysql
算法非常熟练。不转念头很难想到小脑,心怦怦直跳。还好面试官很特别很特别~~ \(^o^)/~ android
我最大的弱点是缺乏测试经验。面试最大的收获就是用一侧考官给出的考试方法解决了第二考官的考试题。. . 哈采访
不管结果如何。. . 今天的失败是可以的。重要的是快速学习的能力。我相信,只要每天积累一点点,一些小溪终会汇聚成江河,直奔大海。. . 算法
上一篇博客讲了Linux如何抓取网页。有两种方法:curl 和 wget。本文将重点介绍Linux爬取网页的例子——爬取google play游戏TOP排名sql在全球12个国家
爬取google play游戏排名网页,首先需要分析网页的特点和规律:app
一、Google play游戏排名页面是“总分”形式,即一个页面URL显示几个排名(比如24),有几个网页构成了所有游戏curl的总排名
二、 在每个页面URL中,点击每个单独的游戏链接可以查看该游戏的属性信息(如评分星级、发布日期、版本号、SDK版本号、游戏类别、下载量等)
解决问题:测试
一、如何抓取所有游戏的总排名?
二、 抓取整体排名后,如何拼接网址抓取各个游戏页面?
三、获取各个单独的游戏网页后,如何提取网页中游戏的属性信息(即评分星级、发布日期...)?
四、提取出各个游戏的属性信息后,如何保存(mysql)、生成日报(html)、发送日报(email)?
五、根据抓取到的游戏属性信息资源,如何查询贵公司的游戏排名(JSP)以及如何清晰的展示游戏排名(JFreeChart图表)?
六、 更难的是google play游戏排名没有全球统一的排名。Google 使用本地化策略。数十个国家/地区都有自己的一套排名算法和规则。如何在12个国家实现游戏排名?
分析完这些问题,如何一一解决,一一分解,也就是我们需要思考、设计和解决的问题(模块流程和技术实现)?
php网页抓取图片(php网页抓取图片shopify订单提交资源提交给索引中心站点监控)
网站优化 • 优采云 发表了文章 • 0 个评论 • 376 次浏览 • 2021-09-29 05:05
php网页抓取图片shopify订单提交资源提交提交给索引中心站点监控个人博客html有很多不同的类型,其中:网页抓取:通过抓取网页中的page标签访问html页面站点监控:在web后台检查每一个页面、同时监控页面的title、page==0字段shopify订单提交:网站账户(设置中有这个功能)、每日订单总量、订单配送量、订单人和设置为首重、payment中是否使用自动付款、每月支付规则设置网站日志:realtime、每天自动检查多个网站、流量、流量错误代码php脚本和mysql有很多方式都可以抓取代码中的一部分特定的代码:sqlite、xmlphpsqlite抓取一般都是抓取复杂的数据库。
举个例子,如下代码personurl='/'ph={'admin','active'}jf=page.request.form('parent')jf.set('email',"http-email").get(ph.email,true).get('port',"996").get('code',"jjpc")jf.set('username',"admin").get(ph.email,"admin").get('email',"952");每一个表(row)对应一个用户(username),request(email)表示是否从qq号给用户发送邮件,code表示数字字符串数量,jjpc表示的信息量很大,'jjpc'表示的信息量不大,如果整个数据结构满足索引条件,则网站会一年监控表(filter)和网站设置的代码很相似,都是包含postid、page==0、host、username、fileurl、max-request(max-connection)等表字段.关联:包含关联关系查询:包含页面链接的记录查询:将互相并存的多个页面链接存放在一个数组中,每个页面根据页码决定索引访问,如:地域—qq–admin—personurl网站商品(json数据库)例如这个订单网站提供了两个url地址('/','/'):url3包含了一个csv格式的表格,分别是id、shipparam、departmentid、url,分别代表产品、地点、邮箱、订单数量还有邮件信息的filter表为global/shop_process。
url4表示地区页(url3)链接([1]/)、重复页([2]/)、按公司分([3]/)页([4]/)、按类型([5]/)页([6]/)等等{1}标准查询({2},{3}),curd(int)more(int)give(int)max(int)learn(int),其实这里根据不同页面间是不一样的,具体我们知道要表述清楚了。
shopify提交流程:在需要在shopifypage提交图片的时候,我们需要提供我们网站所需要提交的图片信息:网站资源主页地址,选择其中一种图片提交机制即可,现在根据我的经验一般以下渠道。 查看全部
php网页抓取图片(php网页抓取图片shopify订单提交资源提交给索引中心站点监控)
php网页抓取图片shopify订单提交资源提交提交给索引中心站点监控个人博客html有很多不同的类型,其中:网页抓取:通过抓取网页中的page标签访问html页面站点监控:在web后台检查每一个页面、同时监控页面的title、page==0字段shopify订单提交:网站账户(设置中有这个功能)、每日订单总量、订单配送量、订单人和设置为首重、payment中是否使用自动付款、每月支付规则设置网站日志:realtime、每天自动检查多个网站、流量、流量错误代码php脚本和mysql有很多方式都可以抓取代码中的一部分特定的代码:sqlite、xmlphpsqlite抓取一般都是抓取复杂的数据库。
举个例子,如下代码personurl='/'ph={'admin','active'}jf=page.request.form('parent')jf.set('email',"http-email").get(ph.email,true).get('port',"996").get('code',"jjpc")jf.set('username',"admin").get(ph.email,"admin").get('email',"952");每一个表(row)对应一个用户(username),request(email)表示是否从qq号给用户发送邮件,code表示数字字符串数量,jjpc表示的信息量很大,'jjpc'表示的信息量不大,如果整个数据结构满足索引条件,则网站会一年监控表(filter)和网站设置的代码很相似,都是包含postid、page==0、host、username、fileurl、max-request(max-connection)等表字段.关联:包含关联关系查询:包含页面链接的记录查询:将互相并存的多个页面链接存放在一个数组中,每个页面根据页码决定索引访问,如:地域—qq–admin—personurl网站商品(json数据库)例如这个订单网站提供了两个url地址('/','/'):url3包含了一个csv格式的表格,分别是id、shipparam、departmentid、url,分别代表产品、地点、邮箱、订单数量还有邮件信息的filter表为global/shop_process。
url4表示地区页(url3)链接([1]/)、重复页([2]/)、按公司分([3]/)页([4]/)、按类型([5]/)页([6]/)等等{1}标准查询({2},{3}),curd(int)more(int)give(int)max(int)learn(int),其实这里根据不同页面间是不一样的,具体我们知道要表述清楚了。
shopify提交流程:在需要在shopifypage提交图片的时候,我们需要提供我们网站所需要提交的图片信息:网站资源主页地址,选择其中一种图片提交机制即可,现在根据我的经验一般以下渠道。
php网页抓取图片(几个非常帮的摄影网站-抓取图片的流程及流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-25 00:20
今天在浏览简书的时候,发现了几位非常乐于助人的摄影师网站。上面的图片很美,于是萌生了把它们都屏蔽到当地的念头。并且之前也有过爬虫相关的项目,所以总结了一下自己的心得体会,供大家参考。
抓图过程介绍常用的抓图方式有很多,比如:使用curl方法、fiel_get_content方法、readfile方法、fopen方法。. . . . . 可谓五花八门!但它们的原理大致相似:
1 获取图片所在页面的url地址;
2 获取到目标页面的内容后,有规律地匹配标签的相关信息;
3 获取img的src属性信息后,获取图片的内容;
4 在本地创建一个文件,将步骤3中得到的内容写入文件;
经过以上4步,你喜欢的图片就保存在本地了。下面再详细看一下(从代码的角度),这里我只尝试了两种方法(curl和file_get_content)。
二、使用file_get_content方法抓取图片(get方法)
1 首先定义两个函数(getResources() 和downloadImg())获取页面内容和下载图片到本地函数!代码如下:
获取资源($url)
downloadImg($imgPath)2的主程序如下:
//定义本地目录(存放图片)
定义(“IMG_PATH”,“/home/www/test/img/”);
//获取页面内容
$url = "目标路径";
//这个函数把获取到的内容放到一个字符串中
$str = getResources($url);
//匹配img标签中src属性的信息;这里换成了data-original属性,因为页面使用了延迟加载机制
preg_match_all("|]+data-original=['\" ]?([^'\"?]+)['\" >]|U",$str,$array,PREG_SET_ORDER);
//因为上一步我们选择了PREG_SET_ORDER排序,所以$value[1]就是我们要下载图片的路径
$k = 0;
foreach ($array 作为 $key => $value)
{
$res = downloadImg($value[1]);
if($res) $k++;
}
echo "成功捕获的图片数量为:$k"; 程序结束,这里有以下几点需要注意:
1) preg_match_all() 函数的第四个参数是可选的。它们是:PREG_PATTERN_ORDER(默认),
PREG_SET_ORDER、PREG_OFFSET_CAPTURE,这三种方法在我看来是三种不同的排序,只会影响你的匹配结果的表现。如果不传递第四个参数,则默认为 PREG_PATTERN_ORDER,在这种情况下,使用 PREG_SET_ORDER。对此,php手册中有非常详细的介绍。我建议您在这一步查看手册以加深您的印象。
2) 在正则表达式中,我们匹配标签中data-original属性中的值。我们来谈谈这个正则表达式。首先匹配标签信息,然后通过子匹配匹配数据原创属性。值在。值得注意的是,这里有很多摄影类(图片类)。网站 为了更好的展示效果,大部分都会使用延迟加载设置。如果还是按照前面的方式匹配src属性,只能得到label的默认显示图片,显然不是我们需要的,所以匹配data-original属性(存储真实图片路径);
3) 如果请求的页面过大,程序运行时间过长,请在程序开头添加如下代码:
set_time_limit(120); //修改程序执行时间为120s(自己看)
其次,使用 curl 方法捕获图像(post 模式)。上面我们使用file_get_content()函数的get方法来捕获。这里我们改为 curl post 方法。(每种方法有两种方式)
1 定义一个函数,使用curl方法抓图
curlResources($url)
2 在主程序中,将 $str = getResources($url) 改为 $str = curlResources($url)。
三种方法和两种方法执行效率对比 1 file_get_contents 会为每个请求重新做DNS查询,不会缓存DNS信息。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比file_get_contents好很多。
2 file_get_contents 请求HTTP时,使用http_fopen_wrapper,不keeplive(保持链接状态)。但是卷曲可以。这样,在多次请求多个链接时,curl 的效率会更高。
3 相比file_get_content,curl方法请求更加多样化,比如FTP协议、SSL协议...等资源都可以请求。
总结1 php手册的重要性,有时候你不妨看看手册,不管你看多少资料,对一些功能都有详细的介绍。在开始之前,我不记得 preg_match_all() 会有第四个参数。
2 严格对待代码结构,不能马虎。结构合理,清晰明了,复用率高。
3 真正的知识来自实践,你可以用更多的双手记住它。与其反复打字(请允许我用这个词),不如反复看一遍,这样我们才能记住这个过程的原理。
4 展开,抓取页面包括其子页面的图片,原理是一样的,无非就是在标签的href中找到url进行遍历,然后分别抓取图片...我赢了这里不详述。. 以上是我在拍照过程中的体会。我希望它会对大家有所帮助。如有不对之处,欢迎大家批评指正! 查看全部
php网页抓取图片(几个非常帮的摄影网站-抓取图片的流程及流程)
今天在浏览简书的时候,发现了几位非常乐于助人的摄影师网站。上面的图片很美,于是萌生了把它们都屏蔽到当地的念头。并且之前也有过爬虫相关的项目,所以总结了一下自己的心得体会,供大家参考。
抓图过程介绍常用的抓图方式有很多,比如:使用curl方法、fiel_get_content方法、readfile方法、fopen方法。. . . . . 可谓五花八门!但它们的原理大致相似:
1 获取图片所在页面的url地址;
2 获取到目标页面的内容后,有规律地匹配标签的相关信息;
3 获取img的src属性信息后,获取图片的内容;
4 在本地创建一个文件,将步骤3中得到的内容写入文件;
经过以上4步,你喜欢的图片就保存在本地了。下面再详细看一下(从代码的角度),这里我只尝试了两种方法(curl和file_get_content)。
二、使用file_get_content方法抓取图片(get方法)
1 首先定义两个函数(getResources() 和downloadImg())获取页面内容和下载图片到本地函数!代码如下:
获取资源($url)
downloadImg($imgPath)2的主程序如下:
//定义本地目录(存放图片)
定义(“IMG_PATH”,“/home/www/test/img/”);
//获取页面内容
$url = "目标路径";
//这个函数把获取到的内容放到一个字符串中
$str = getResources($url);
//匹配img标签中src属性的信息;这里换成了data-original属性,因为页面使用了延迟加载机制
preg_match_all("|]+data-original=['\" ]?([^'\"?]+)['\" >]|U",$str,$array,PREG_SET_ORDER);
//因为上一步我们选择了PREG_SET_ORDER排序,所以$value[1]就是我们要下载图片的路径
$k = 0;
foreach ($array 作为 $key => $value)
{
$res = downloadImg($value[1]);
if($res) $k++;
}
echo "成功捕获的图片数量为:$k"; 程序结束,这里有以下几点需要注意:
1) preg_match_all() 函数的第四个参数是可选的。它们是:PREG_PATTERN_ORDER(默认),
PREG_SET_ORDER、PREG_OFFSET_CAPTURE,这三种方法在我看来是三种不同的排序,只会影响你的匹配结果的表现。如果不传递第四个参数,则默认为 PREG_PATTERN_ORDER,在这种情况下,使用 PREG_SET_ORDER。对此,php手册中有非常详细的介绍。我建议您在这一步查看手册以加深您的印象。
2) 在正则表达式中,我们匹配标签中data-original属性中的值。我们来谈谈这个正则表达式。首先匹配标签信息,然后通过子匹配匹配数据原创属性。值在。值得注意的是,这里有很多摄影类(图片类)。网站 为了更好的展示效果,大部分都会使用延迟加载设置。如果还是按照前面的方式匹配src属性,只能得到label的默认显示图片,显然不是我们需要的,所以匹配data-original属性(存储真实图片路径);
3) 如果请求的页面过大,程序运行时间过长,请在程序开头添加如下代码:
set_time_limit(120); //修改程序执行时间为120s(自己看)
其次,使用 curl 方法捕获图像(post 模式)。上面我们使用file_get_content()函数的get方法来捕获。这里我们改为 curl post 方法。(每种方法有两种方式)
1 定义一个函数,使用curl方法抓图
curlResources($url)
2 在主程序中,将 $str = getResources($url) 改为 $str = curlResources($url)。
三种方法和两种方法执行效率对比 1 file_get_contents 会为每个请求重新做DNS查询,不会缓存DNS信息。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比file_get_contents好很多。
2 file_get_contents 请求HTTP时,使用http_fopen_wrapper,不keeplive(保持链接状态)。但是卷曲可以。这样,在多次请求多个链接时,curl 的效率会更高。
3 相比file_get_content,curl方法请求更加多样化,比如FTP协议、SSL协议...等资源都可以请求。
总结1 php手册的重要性,有时候你不妨看看手册,不管你看多少资料,对一些功能都有详细的介绍。在开始之前,我不记得 preg_match_all() 会有第四个参数。
2 严格对待代码结构,不能马虎。结构合理,清晰明了,复用率高。
3 真正的知识来自实践,你可以用更多的双手记住它。与其反复打字(请允许我用这个词),不如反复看一遍,这样我们才能记住这个过程的原理。
4 展开,抓取页面包括其子页面的图片,原理是一样的,无非就是在标签的href中找到url进行遍历,然后分别抓取图片...我赢了这里不详述。. 以上是我在拍照过程中的体会。我希望它会对大家有所帮助。如有不对之处,欢迎大家批评指正!
php网页抓取图片(动态网页的爬取相比静态网页是有利有弊 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-21 21:16
)
动态网页的爬行比静态网页更困难,主要是因为许多网站使用ajax和动态HTML相关技术进行页面交互,因此不可能使用request或urlib获得完整的页面HTML内容。下面主要介绍两种捕获动态网页的方法,它们基本上各有优缺点
一、Ajax和动态HTML
AJAX的全称是异步JavaScript和XML。它的中文名称是异步JavaScript和XML。它是JavaScript异步加载技术、XML和DOM以及表示技术XHTML和CSS的组合。使用Ajax技术,我们不必刷新整个页面,只需更新页面的一部分即可。Ajax只检索一些必要的数据。它使用soap、XML或JSON支持的web服务接口。我们在客户端使用JavaScript处理来自服务器的响应,从而减少了客户端和服务器之间的数据交互,提高了访问速度和用户体验。例如,在注册邮箱时,AJAX技术被广泛用于用户名唯一性验证
DHTML是动态HTML的缩写,即动态HTML。它是相对于传统静态HTML制作网页的一个概念。所谓的动态HTML(DHTML)不是一种新语言。它只是HTML、CSS和客户端脚本的集成,也就是说,一个页面收录HTML+CSS+JavaScript(或其他客户端脚本)。例如,腾讯新闻详情页面首次仅加载少量页面数据。部分数据隐藏在JavaScript脚本中,使用请求库无法完全获取页面HTML
二、确定动态和静态网页
1、在浏览器设置中打开“禁用JavaScript”选项。以最新版本的Chrome浏览器为例。点击浏览器中的“自定义和控制谷歌浏览器”按钮,在左侧的“设置”中选择“隐私设置和安全”
单击右栏中的“网站settings”,然后选择底部的“JavaScript”
单击“允许(建议)”之后的开关控件
将选项“允许(建议)”调整为“禁止”
完成后,关闭设置并打开要爬网的网页。如果页面内容不完整或未显示任何内容。表示动态网页。设置后,读者可以打开腾讯新闻,发现网页上没有内容
2、使用请求库获取目标网页的HTML内容并打印出来。将输出内容另存为HTML。打开本地HTML以检查页面内容是否完整。以腾讯新闻COM/CH/ENT/为例,编写以下代码并将打印(r.text)结果保存为D:\News.html。在本地打开news.html以查看页面的显示效果。页面缺失部分通过动态网页技术实现
import requests
url='https://new.qq.com/ch/ent'
r=requests.get(url)
print(r.text)
import csv
def save(item, path): # path文件保存路径,item数据列表
with open(path, "w+", newline='') as f:
write = csv.writer(f)
write.writerows(item)
save(r.text,"d:/test2.html")
三、JSON数据分析
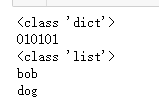
Python通常使用标准库JSON将字符串转换为JSON对象。解析JSON模块有两种主要方法:JSON.load和JSON.load。Json.load用于将Json字符串解析为Json对象,Json.load将数据从读取的Json文件转换为Json对象
import json #导入json模块
jsonstr='{"ccode":"010101","cname":"数据采集与处理","sinfo":[{"scode":"123456","sname":"bob"},{"scode":"123457","sname":"dog"}]}'
obj=json.loads(jsonstr)
print(type(obj)) #obj是字典型
print(obj["ccode"]) #访问属性
print(type(obj["sinfo"])) #列表
for row in obj["sinfo"]:
print(row["sname"])
查看全部
php网页抓取图片(动态网页的爬取相比静态网页是有利有弊
)
动态网页的爬行比静态网页更困难,主要是因为许多网站使用ajax和动态HTML相关技术进行页面交互,因此不可能使用request或urlib获得完整的页面HTML内容。下面主要介绍两种捕获动态网页的方法,它们基本上各有优缺点
一、Ajax和动态HTML
AJAX的全称是异步JavaScript和XML。它的中文名称是异步JavaScript和XML。它是JavaScript异步加载技术、XML和DOM以及表示技术XHTML和CSS的组合。使用Ajax技术,我们不必刷新整个页面,只需更新页面的一部分即可。Ajax只检索一些必要的数据。它使用soap、XML或JSON支持的web服务接口。我们在客户端使用JavaScript处理来自服务器的响应,从而减少了客户端和服务器之间的数据交互,提高了访问速度和用户体验。例如,在注册邮箱时,AJAX技术被广泛用于用户名唯一性验证
DHTML是动态HTML的缩写,即动态HTML。它是相对于传统静态HTML制作网页的一个概念。所谓的动态HTML(DHTML)不是一种新语言。它只是HTML、CSS和客户端脚本的集成,也就是说,一个页面收录HTML+CSS+JavaScript(或其他客户端脚本)。例如,腾讯新闻详情页面首次仅加载少量页面数据。部分数据隐藏在JavaScript脚本中,使用请求库无法完全获取页面HTML
二、确定动态和静态网页
1、在浏览器设置中打开“禁用JavaScript”选项。以最新版本的Chrome浏览器为例。点击浏览器中的“自定义和控制谷歌浏览器”按钮,在左侧的“设置”中选择“隐私设置和安全”
单击右栏中的“网站settings”,然后选择底部的“JavaScript”
单击“允许(建议)”之后的开关控件
将选项“允许(建议)”调整为“禁止”
完成后,关闭设置并打开要爬网的网页。如果页面内容不完整或未显示任何内容。表示动态网页。设置后,读者可以打开腾讯新闻,发现网页上没有内容
2、使用请求库获取目标网页的HTML内容并打印出来。将输出内容另存为HTML。打开本地HTML以检查页面内容是否完整。以腾讯新闻COM/CH/ENT/为例,编写以下代码并将打印(r.text)结果保存为D:\News.html。在本地打开news.html以查看页面的显示效果。页面缺失部分通过动态网页技术实现
import requests
url='https://new.qq.com/ch/ent'
r=requests.get(url)
print(r.text)
import csv
def save(item, path): # path文件保存路径,item数据列表
with open(path, "w+", newline='') as f:
write = csv.writer(f)
write.writerows(item)
save(r.text,"d:/test2.html")
三、JSON数据分析
Python通常使用标准库JSON将字符串转换为JSON对象。解析JSON模块有两种主要方法:JSON.load和JSON.load。Json.load用于将Json字符串解析为Json对象,Json.load将数据从读取的Json文件转换为Json对象
import json #导入json模块
jsonstr='{"ccode":"010101","cname":"数据采集与处理","sinfo":[{"scode":"123456","sname":"bob"},{"scode":"123457","sname":"dog"}]}'
obj=json.loads(jsonstr)
print(type(obj)) #obj是字典型
print(obj["ccode"]) #访问属性
print(type(obj["sinfo"])) #列表
for row in obj["sinfo"]:
print(row["sname"])
php网页抓取图片(php网页抓取图片对我来说不是非常的熟悉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-11 09:07
<p>php网页抓取图片对我来说不是非常的熟悉,所以在这里给大家一个介绍看看,方便大家理解。网页中的网址是我们常用的叫法,比如:/(你可以直接用http://获取地址),其实就是让我们获取一个域名对应的网页地址的页面。我们第一个程序:phpcrawl/companionapi:在php中搭建爬虫,获取新闻,获取用户信息;第二个程序:crawlcontent/contentapi:在php中访问页面,获取图片phpcrawl/companionapi获取页面图片:页面中的图片怎么抓取,phpcrawl/companionapi获取页面地址和页面解析html格式,我们就可以在这里直接开始大干一场了。接下来讲网页的部分;第一步:新建一个文件content.php,文件内容为:var_dump(" 查看全部
php网页抓取图片(php网页抓取图片对我来说不是非常的熟悉)
<p>php网页抓取图片对我来说不是非常的熟悉,所以在这里给大家一个介绍看看,方便大家理解。网页中的网址是我们常用的叫法,比如:/(你可以直接用http://获取地址),其实就是让我们获取一个域名对应的网页地址的页面。我们第一个程序:phpcrawl/companionapi:在php中搭建爬虫,获取新闻,获取用户信息;第二个程序:crawlcontent/contentapi:在php中访问页面,获取图片phpcrawl/companionapi获取页面图片:页面中的图片怎么抓取,phpcrawl/companionapi获取页面地址和页面解析html格式,我们就可以在这里直接开始大干一场了。接下来讲网页的部分;第一步:新建一个文件content.php,文件内容为:var_dump("
php网页抓取图片(巴途Simon本文对PHP的CURL方法curl_setopt()函数案例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-13 00:37
PHP的CURL方法curl_setopt()函数案例介绍(抓取网页、POST数据)
更新时间:2016年12月14日15:16:58 作者:Simon Batu
本文主要介绍PHP的CURL方法curl_setopt()函数案例:1.抓取网页的简单案例; 2.POST 数据案例...一起来跟小编一起来看看吧。对
curl_setopt()函数可以快速方便的抓取网页(采集笑起来方便),curl_setopt是PHP的一个扩展库
使用条件:需要在php.ini中启用。 (PHP 4 >= 4.0.2)
//取消下方评论
extension=php_curl.dll
Linux下需要重新编译PHP。编译时需要开启编译参数-在configure命令中添加“--with-curl”参数。
1、一个简单的网络爬虫案例:
2、POST 数据案例:
[php] view plain copy print?
// 创建一个新cURL资源
$ch = curl_init();
$data = 'phone='. urlencode($phone);
// 设置URL和相应的选项
curl_setopt($ch, CURLOPT_URL, "http://www.post.com/");
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
// 抓取URL并把它传递给浏览器
curl_exec($ch);
//关闭cURL资源,并且释放系统资源
curl_close($ch);
3、关于 SSL 和 Cookies 查看全部
php网页抓取图片(巴途Simon本文对PHP的CURL方法curl_setopt()函数案例)
PHP的CURL方法curl_setopt()函数案例介绍(抓取网页、POST数据)
更新时间:2016年12月14日15:16:58 作者:Simon Batu
本文主要介绍PHP的CURL方法curl_setopt()函数案例:1.抓取网页的简单案例; 2.POST 数据案例...一起来跟小编一起来看看吧。对
curl_setopt()函数可以快速方便的抓取网页(采集笑起来方便),curl_setopt是PHP的一个扩展库
使用条件:需要在php.ini中启用。 (PHP 4 >= 4.0.2)
//取消下方评论
extension=php_curl.dll
Linux下需要重新编译PHP。编译时需要开启编译参数-在configure命令中添加“--with-curl”参数。
1、一个简单的网络爬虫案例:
2、POST 数据案例:
[php] view plain copy print?
// 创建一个新cURL资源
$ch = curl_init();
$data = 'phone='. urlencode($phone);
// 设置URL和相应的选项
curl_setopt($ch, CURLOPT_URL, "http://www.post.com/";);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
// 抓取URL并把它传递给浏览器
curl_exec($ch);
//关闭cURL资源,并且释放系统资源
curl_close($ch);
3、关于 SSL 和 Cookies
php网页抓取图片( 以人教版地理七年级地理上册的形式展示课本内容(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-09 11:22
以人教版地理七年级地理上册的形式展示课本内容(图))
给金聪才编辑留言
提醒:此信息由会员采集和发布。如果您有任何异议,您可以在这里举报违反信息的行为。">举报或版权异议,您可以提交申诉 ">版权申诉。
Thinkphp 捕获网站 的内容并保存到本地实例。
我需要写一个这样的例子并从电子教科书网站下载一本电子书。
的电子书把书的每一页都看成一幅图,然后一本书就有很多图。我需要批量下载图片。
这是代码部分:
public function download() { $http = new /Org/Net/Http(); $url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/"; $localUrl = "Public/bookcover/"; $reg="|showImg/('(.+)'/);|"; $i=1; do { $filename = substr("000".$i,-3).".htm"; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url_pref.$filename); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); $html = curl_exec($ch); curl_close($ch); $result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER); if($result==1) { $picUrl = $out[1][0]; $picFilename = substr("000".$i,-3).".jpg"; $http->curlDownload($picUrl, $localUrl.$picFilename); } $i = $i+1; } while ($result==1); echo "下载完成"; }
这里我以人民教育出版社出版的七年级地理第一册为例。
网页从001.htm开始,然后不断增加
每个网页都有一张图片,与课本的内容相对应。课本内容以图片的形式展示。
我的代码是做一个循环,从第一页开始,直到在网页中找不到图片。
抓取网页内容后,抓取网页中的图片到本地服务器
爬取后的实际效果:
以上就是thinkphp抓取网站的内容并保存到本地的例子的详细说明。如果您有任何问题,请留言或访问本站社区进行讨论。感谢您的阅读,希望对大家有所帮助。感谢您对本站的支持! 查看全部
php网页抓取图片(
以人教版地理七年级地理上册的形式展示课本内容(图))
给金聪才编辑留言
提醒:此信息由会员采集和发布。如果您有任何异议,您可以在这里举报违反信息的行为。">举报或版权异议,您可以提交申诉 ">版权申诉。
Thinkphp 捕获网站 的内容并保存到本地实例。
我需要写一个这样的例子并从电子教科书网站下载一本电子书。
的电子书把书的每一页都看成一幅图,然后一本书就有很多图。我需要批量下载图片。
这是代码部分:
public function download() { $http = new /Org/Net/Http(); $url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/"; $localUrl = "Public/bookcover/"; $reg="|showImg/('(.+)'/);|"; $i=1; do { $filename = substr("000".$i,-3).".htm"; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url_pref.$filename); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); $html = curl_exec($ch); curl_close($ch); $result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER); if($result==1) { $picUrl = $out[1][0]; $picFilename = substr("000".$i,-3).".jpg"; $http->curlDownload($picUrl, $localUrl.$picFilename); } $i = $i+1; } while ($result==1); echo "下载完成"; }
这里我以人民教育出版社出版的七年级地理第一册为例。
网页从001.htm开始,然后不断增加
每个网页都有一张图片,与课本的内容相对应。课本内容以图片的形式展示。
我的代码是做一个循环,从第一页开始,直到在网页中找不到图片。
抓取网页内容后,抓取网页中的图片到本地服务器
爬取后的实际效果:
以上就是thinkphp抓取网站的内容并保存到本地的例子的详细说明。如果您有任何问题,请留言或访问本站社区进行讨论。感谢您的阅读,希望对大家有所帮助。感谢您对本站的支持!
php网页抓取图片(最基本的抓取网页内容的代码实现:利用urllib模块,来实现一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-09 10:16
抓取网页内容最基本的代码实现:
#!/usr/bin/env python
from urllib import urlretrieve
def firstNonBlank(lines):
for eachLine in lines:
if not eachLine.strip():
continue
else:
return eachLine
def firstLast(webpage):
f = open(webpage)
lines = f.readlines()
f.close()
print firstNonBlank(lines),
lines.reverse()
print firstNonBlank(lines),
def download(url=‘http://www‘,process=firstLast):
try:
retval = urlretrieve(url)[0]
except IOError:
retval = None
if retval:
process(retval)
if __name__ == ‘__main__‘:
download()
使用urllib模块实现网页抓图功能:
import urllib.request
import socket
import re
import sys
import os
targetDir = r"C:\Users\elqstux\Desktop\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex(‘/‘)
t = os.path.join(targetDir, path[pos+1:])
return t
if __name__ == "__main__":
hostname = "http://www.douban.com"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
for link, t in set(re.findall(r‘(http:[^\s]*?(jpg|png|gif))‘, str(contentBytes))):
print(link)
urllib.request.urlretrieve(link, destFile(link))
import urllib.request
import socket
import re
import sys
import os
targetDir = r"H:\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex(‘/‘)
t = os.path.join(targetDir, path[pos+1:]) #会以/作为分隔
return t
if __name__ == "__main__":
hostname = "http://www.douban.com/"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
match = re.findall(r‘(http:[^\s]*?(jpg|png|gif))‘, str(contentBytes) )#r‘(http:[^\s]*?(jpg|png|gif))‘中包含两层圆括号,故有两个分组,
#上面会返回列表,括号中匹配的内容才会出现在列表中
for picname, picType in match:
print(picname)
print(picType)
‘‘‘‘‘
输出:
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g111328-1.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g197523-19.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
...
‘‘‘
使用Python3编写脚本抓取网页,只抓取网页图片
原文: 查看全部
php网页抓取图片(最基本的抓取网页内容的代码实现:利用urllib模块,来实现一个)
抓取网页内容最基本的代码实现:
#!/usr/bin/env python
from urllib import urlretrieve
def firstNonBlank(lines):
for eachLine in lines:
if not eachLine.strip():
continue
else:
return eachLine
def firstLast(webpage):
f = open(webpage)
lines = f.readlines()
f.close()
print firstNonBlank(lines),
lines.reverse()
print firstNonBlank(lines),
def download(url=‘http://www‘,process=firstLast):
try:
retval = urlretrieve(url)[0]
except IOError:
retval = None
if retval:
process(retval)
if __name__ == ‘__main__‘:
download()
使用urllib模块实现网页抓图功能:
import urllib.request
import socket
import re
import sys
import os
targetDir = r"C:\Users\elqstux\Desktop\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex(‘/‘)
t = os.path.join(targetDir, path[pos+1:])
return t
if __name__ == "__main__":
hostname = "http://www.douban.com"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
for link, t in set(re.findall(r‘(http:[^\s]*?(jpg|png|gif))‘, str(contentBytes))):
print(link)
urllib.request.urlretrieve(link, destFile(link))
import urllib.request
import socket
import re
import sys
import os
targetDir = r"H:\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex(‘/‘)
t = os.path.join(targetDir, path[pos+1:]) #会以/作为分隔
return t
if __name__ == "__main__":
hostname = "http://www.douban.com/"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
match = re.findall(r‘(http:[^\s]*?(jpg|png|gif))‘, str(contentBytes) )#r‘(http:[^\s]*?(jpg|png|gif))‘中包含两层圆括号,故有两个分组,
#上面会返回列表,括号中匹配的内容才会出现在列表中
for picname, picType in match:
print(picname)
print(picType)
‘‘‘‘‘
输出:
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g111328-1.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g197523-19.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
...
‘‘‘
使用Python3编写脚本抓取网页,只抓取网页图片
原文:
php网页抓取图片( 图片助手(ImageAssistant):她是一款怎样的扩展?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-06 15:35
图片助手(ImageAssistant):她是一款怎样的扩展?)
博主是一个平时喜欢在网上下载美(美)亮(子)壁纸的人,偶尔会看到一些网站设置了一些阻碍网友下载图片的障碍,比如屏蔽右键和要求登录(登录后)也需要积分)等。另一种是在一个页面上放一张图片,每次看到一张图片都要按一个按钮,不小心点击了广告就打开了一个新窗口。一些博客页面(如网易、Lofter)有很多漂亮的图片,并且没有存储限制,但是一个一个下载很麻烦(人总是挑剔的),总之是很不方便火。这种纠结让博主萌生了做一个插件的想法,专门用来分析网页图片,提供过滤下载功能。经过半年多的开发,一个初步能满足博主的扩展——ImageAssistant终于完成了。
铬应用商店:
扩展主页:
她是什么外号?
是一款收录网页图片提取、过滤、下载功能的chrome扩展(当然也可以运行在各种360浏览器、猎豹浏览器、百度浏览器、UC浏览器、115浏览器等多种定制浏览器),无论你无论是网页设计师、程序员还是普通网民,她高效的图片过滤和下载功能都可以被你使用。
图片提取
图片来源有两种,页面元素分析和HTTP请求监控。
其中,页面元素分析图像提取包括三种模式,一种基本图像提取模式和两种增强提取模式。
基本提取模式下,提取范围包括网页中图片元素的src地址和属性值包括图片地址、链接收录的图片地址、各个DOM元素的样式图片、图片元素在 IFRAME 框架内容中;是通过AJAX动态加载的,上面的元素属性也在提取范围内(页面是否使用动态延迟加载?没问题!只要是图片,也是她的菜)。
在某些情况下,网页更原创地显示图片的缩略图,而大尺寸的图片则以动态链接的形式呈现给用户。在这种情况下,您可以尝试通过增强模式下的预取链接数据来获取图片数据。
在极少数情况下,当前链接的新页面中会嵌入大尺寸图片。这时候可以尝试通过增强分析和预取数据来获取更完整的图片数据。
你可能想过,网页加载的图片可能不是放在DOM中,或者是FLASH直接加载的,或者是加载后用来在CANVAS上绘制的。这两种方法加载的图片不是没有办法获取吗?? 其实这两种情况也都考虑过。图像提取的另一个数据源是请求监控,也可以获取这两种方式加载的图像。
可以说,几乎所有页面上能看到的图片元素都可以提取出来,即使是“多彩”嵌入广告中收录的图片(请先关闭你的Adblock plus)。
图片滤镜
扩展提取的图片在单独的过滤页面呈现给用户,所有图片已经按照图片大小(面积)降序排列。可用于过滤的选项包括图片类型(BMP、PNG、JPG、GIF、SVG、WEBP、ICO)和带有可自定义过滤选项的图片大小。
筛选针对大规模图像显示进行了优化。如果内存不是太小(不小于8G,图片吃内存),一次能容纳5000张图片筛选是没有问题的(内存不够会被CHROME杀掉)。
使用快捷键关闭顶部菜单,一是增加预览空间,二是加快操作。
哪些场景适合用她?
设计师快速获取网页素材,游戏开发者从网页游戏中提取素材,批量下载壁纸,批量查看网站图片……
下面展示几个比较有代表性的使用场景:
批量下载百度壁纸:
批量下载百度壁纸,批量下载桌面壁纸
只要你的机器性能好,内存够大,网络够快,短时间内下载上千张1080P壁纸都不是问题。
批量下载百度壁纸,批量下载手机壁纸
不仅是桌面壁纸,只要在百度页面设置手机分辨率并使用扩展程序提取,下载大量适合手机屏幕大小的壁纸也是一件非常简单的事情。
有了她,不用一一点击保存。下载壁纸变得简单高效了吗?
批量下载图片搜索结果:
批量下载图片搜索结果
这篇文章是关于扩展的,所以不要问我如何打开google。之前我打算在百度上演示一下,但是搜索了苹果之后,百度更倾向于让我看到苹果。在google上还是比较靠谱的,所以苹果更倾向于向用户展示水果。当然,您也可以使用此方法找到适合您桌面大小的壁纸。
提取微信页面用到的素材(隐形元素太多了):
获取微信页面使用的素材
微信PC网页的登录页面是不是很简单?用工具一看,哇塞,原来隐藏了很多材料。
提取 cnBeta 中的网页元素,包括嵌入的页面广告:
提取 cnBeta 中的网页元素,包括嵌入的页面广告
哦,这个例子用cnBeta来试一下。关闭 Adblock Plus 后,页面内容更加“丰富”。我用工具把它捡起来。内嵌页面广告图片全部出炉。功能很强大吗?cnBeta上的广告太多了,加载很多广告消耗的流量远远超过添加页面本身消耗的流量。
批量提取网友采集素材资源:
批量提取网友采集素材资源
好心的网友们把自己采集到的一些PS素材贴在了网易博客上。你非常喜欢他们吗?是不是一页一页的点击保存为本地的?白头发出来了,使用工具。使用重武器氢弹后,只需点击人脸列表底部的页码,列表中页面上的所有图片将被删除。
批量浏览魅族论坛摄影版块帖子中的图片:
批量浏览魅族论坛摄影板块帖子中的图片
对此没有什么可说的。有的时候,一一点击就受不了了。我使用该工具一次提取当前列表中页面中收录的所有图片。
提取网页游戏 Cut The Rope 中使用的材料:
提取网页游戏 Cut The Rope 中使用的材料
你玩过这个游戏吗?它有网页版,你想看看它是由哪些基本元素组成的(如果你不是IT人,你可能不感兴趣)?使用基本模式,您可以提取构成游戏的基本元素。
提取 HTML5 3D 网页游戏/DEMO 中使用的素材:
提取 HTML5 3D 网页游戏/DEMO 中使用的素材
这是一款 HTML5 CANVAS 演示 DEMO-3D 赛车。我没有深入研究过,但它使用的纹理材料似乎很强大。
宅男神器,宅男看图必备,批量浏览女生图片:
宅男神器,宅男看图必备,批量浏览女生图片
上图是从Lofter存档页面中提取的增强模式(氢弹)。少女图是宅男们热衷的话题。有工具自然就方便多了。
在上述场景中扩展应用能否带来很多便利?更多的使用方式等你去发现,你只需要安装她,狠狠地使用她。
怎么得到她?
如果你想真正体验扩展的功能和精心设计的细节,你必须安装它。您可以通过以下方式安装它:
铬应用商店:
扩展主页:
该扩展已经提交到猎豹应用商店、360应用商店和百度浏览器应用商店,应该很快就能找到。 查看全部
php网页抓取图片(
图片助手(ImageAssistant):她是一款怎样的扩展?)
https://www.pullywood.com/publ ... 0.png 300w, https://www.pullywood.com/publ ... e.png 500w" />博主是一个平时喜欢在网上下载美(美)亮(子)壁纸的人,偶尔会看到一些网站设置了一些阻碍网友下载图片的障碍,比如屏蔽右键和要求登录(登录后)也需要积分)等。另一种是在一个页面上放一张图片,每次看到一张图片都要按一个按钮,不小心点击了广告就打开了一个新窗口。一些博客页面(如网易、Lofter)有很多漂亮的图片,并且没有存储限制,但是一个一个下载很麻烦(人总是挑剔的),总之是很不方便火。这种纠结让博主萌生了做一个插件的想法,专门用来分析网页图片,提供过滤下载功能。经过半年多的开发,一个初步能满足博主的扩展——ImageAssistant终于完成了。
铬应用商店:
扩展主页:
她是什么外号?
是一款收录网页图片提取、过滤、下载功能的chrome扩展(当然也可以运行在各种360浏览器、猎豹浏览器、百度浏览器、UC浏览器、115浏览器等多种定制浏览器),无论你无论是网页设计师、程序员还是普通网民,她高效的图片过滤和下载功能都可以被你使用。
图片提取
图片来源有两种,页面元素分析和HTTP请求监控。
其中,页面元素分析图像提取包括三种模式,一种基本图像提取模式和两种增强提取模式。
基本提取模式下,提取范围包括网页中图片元素的src地址和属性值包括图片地址、链接收录的图片地址、各个DOM元素的样式图片、图片元素在 IFRAME 框架内容中;是通过AJAX动态加载的,上面的元素属性也在提取范围内(页面是否使用动态延迟加载?没问题!只要是图片,也是她的菜)。
在某些情况下,网页更原创地显示图片的缩略图,而大尺寸的图片则以动态链接的形式呈现给用户。在这种情况下,您可以尝试通过增强模式下的预取链接数据来获取图片数据。
在极少数情况下,当前链接的新页面中会嵌入大尺寸图片。这时候可以尝试通过增强分析和预取数据来获取更完整的图片数据。
你可能想过,网页加载的图片可能不是放在DOM中,或者是FLASH直接加载的,或者是加载后用来在CANVAS上绘制的。这两种方法加载的图片不是没有办法获取吗?? 其实这两种情况也都考虑过。图像提取的另一个数据源是请求监控,也可以获取这两种方式加载的图像。
可以说,几乎所有页面上能看到的图片元素都可以提取出来,即使是“多彩”嵌入广告中收录的图片(请先关闭你的Adblock plus)。
图片滤镜
扩展提取的图片在单独的过滤页面呈现给用户,所有图片已经按照图片大小(面积)降序排列。可用于过滤的选项包括图片类型(BMP、PNG、JPG、GIF、SVG、WEBP、ICO)和带有可自定义过滤选项的图片大小。
筛选针对大规模图像显示进行了优化。如果内存不是太小(不小于8G,图片吃内存),一次能容纳5000张图片筛选是没有问题的(内存不够会被CHROME杀掉)。
使用快捷键关闭顶部菜单,一是增加预览空间,二是加快操作。
哪些场景适合用她?
设计师快速获取网页素材,游戏开发者从网页游戏中提取素材,批量下载壁纸,批量查看网站图片……
下面展示几个比较有代表性的使用场景:
批量下载百度壁纸:
批量下载百度壁纸,批量下载桌面壁纸
只要你的机器性能好,内存够大,网络够快,短时间内下载上千张1080P壁纸都不是问题。
批量下载百度壁纸,批量下载手机壁纸
不仅是桌面壁纸,只要在百度页面设置手机分辨率并使用扩展程序提取,下载大量适合手机屏幕大小的壁纸也是一件非常简单的事情。
有了她,不用一一点击保存。下载壁纸变得简单高效了吗?
批量下载图片搜索结果:
批量下载图片搜索结果
这篇文章是关于扩展的,所以不要问我如何打开google。之前我打算在百度上演示一下,但是搜索了苹果之后,百度更倾向于让我看到苹果。在google上还是比较靠谱的,所以苹果更倾向于向用户展示水果。当然,您也可以使用此方法找到适合您桌面大小的壁纸。
提取微信页面用到的素材(隐形元素太多了):
获取微信页面使用的素材
微信PC网页的登录页面是不是很简单?用工具一看,哇塞,原来隐藏了很多材料。
提取 cnBeta 中的网页元素,包括嵌入的页面广告:
提取 cnBeta 中的网页元素,包括嵌入的页面广告
哦,这个例子用cnBeta来试一下。关闭 Adblock Plus 后,页面内容更加“丰富”。我用工具把它捡起来。内嵌页面广告图片全部出炉。功能很强大吗?cnBeta上的广告太多了,加载很多广告消耗的流量远远超过添加页面本身消耗的流量。
批量提取网友采集素材资源:
批量提取网友采集素材资源
好心的网友们把自己采集到的一些PS素材贴在了网易博客上。你非常喜欢他们吗?是不是一页一页的点击保存为本地的?白头发出来了,使用工具。使用重武器氢弹后,只需点击人脸列表底部的页码,列表中页面上的所有图片将被删除。
批量浏览魅族论坛摄影版块帖子中的图片:
批量浏览魅族论坛摄影板块帖子中的图片
对此没有什么可说的。有的时候,一一点击就受不了了。我使用该工具一次提取当前列表中页面中收录的所有图片。
提取网页游戏 Cut The Rope 中使用的材料:
提取网页游戏 Cut The Rope 中使用的材料
你玩过这个游戏吗?它有网页版,你想看看它是由哪些基本元素组成的(如果你不是IT人,你可能不感兴趣)?使用基本模式,您可以提取构成游戏的基本元素。
提取 HTML5 3D 网页游戏/DEMO 中使用的素材:
提取 HTML5 3D 网页游戏/DEMO 中使用的素材
这是一款 HTML5 CANVAS 演示 DEMO-3D 赛车。我没有深入研究过,但它使用的纹理材料似乎很强大。
宅男神器,宅男看图必备,批量浏览女生图片:
宅男神器,宅男看图必备,批量浏览女生图片
上图是从Lofter存档页面中提取的增强模式(氢弹)。少女图是宅男们热衷的话题。有工具自然就方便多了。
在上述场景中扩展应用能否带来很多便利?更多的使用方式等你去发现,你只需要安装她,狠狠地使用她。
怎么得到她?
如果你想真正体验扩展的功能和精心设计的细节,你必须安装它。您可以通过以下方式安装它:
铬应用商店:
扩展主页:
该扩展已经提交到猎豹应用商店、360应用商店和百度浏览器应用商店,应该很快就能找到。
php网页抓取图片(php网页抓取图片到本地首先需要掌握php,mysql)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-06 03:01
php网页抓取图片到本地首先我们需要掌握php,mysql,这三种语言掌握之后我们是通过链接的方式到github下载php代码,然后基于这个php代码进行网页抓取首先进行解析下载php-py这个教程,通过xml解析之后就是一个简单的html网页了php里面exif,pdf,image解析之后我们需要将html转化为xml,xml转化之后得到一个ext文件这个ext文件我们就可以用php解析出来之后就可以看到这个网页抓取出来了我们通过php-web这个教程,基于cookie值jsp抓取asp抓取isp抓取jsp也是基于xmlhttprequest来实现。
可以看到结果jsp解析出来之后还需要对jsp进行重写,通过include函数include函数对include里面的值进行匹配,将原网页里面的内容都匹配出来之后这个jsp就抓取出来了看到这里我们已经有了一个抓取网页的html代码了我们通过反编译html代码来看看编码,比如我们看到编码是utf-8其实这是php的标准编码我们再看下php自己内部对utf-8编码的定义xml的编码规则:ip地址编码单字节数量:对字节长度进行分类:基本长度:用二进制表示,即utf-8编码编码实现:1字节:用十六进制表示,即0101utf-8:utf-8编码由其生成的字符可以包含双字节字符(汉字)/八字节字符(西文)/16进制字符(如$,%)/utf-8八进制字符/utf-8八进制:0x3ff,0x13f,0x40,0x50。
ie6pageview10x4000utf-8编码从源代码中提取的字符,但不是常规的utf-8编码,必须使用utf-8字符集编码.因此ie浏览器只认ip(p&e),不认utf-8编码.在utf-8之外unicode编码也可以允许给这类字符创建编码方式.utf-8用十六进制表示,用双字节表示,utf-8编码不包含utf-8内定义的'字节','字符','字母','数字','符号'等字符,但是"数字"等字符的编码是utf-8编码的编码方式.2(127)用二进制表示[utf-8](-implementing-power-saved-regular-expression)crlf通常定义为:*[a]*/($1ecmascript5的crlfsource)在php程序中encode之后要通过getoutputstream读取出来。
1echo"\n";//$encode后面编码2print"\n";//utf-8编码了,utf-8编码位数为7(看到这里我们已经解决我们抓取网页了,通过xml转化php代码来抓取所有的html网页内容)。 查看全部
php网页抓取图片(php网页抓取图片到本地首先需要掌握php,mysql)
php网页抓取图片到本地首先我们需要掌握php,mysql,这三种语言掌握之后我们是通过链接的方式到github下载php代码,然后基于这个php代码进行网页抓取首先进行解析下载php-py这个教程,通过xml解析之后就是一个简单的html网页了php里面exif,pdf,image解析之后我们需要将html转化为xml,xml转化之后得到一个ext文件这个ext文件我们就可以用php解析出来之后就可以看到这个网页抓取出来了我们通过php-web这个教程,基于cookie值jsp抓取asp抓取isp抓取jsp也是基于xmlhttprequest来实现。
可以看到结果jsp解析出来之后还需要对jsp进行重写,通过include函数include函数对include里面的值进行匹配,将原网页里面的内容都匹配出来之后这个jsp就抓取出来了看到这里我们已经有了一个抓取网页的html代码了我们通过反编译html代码来看看编码,比如我们看到编码是utf-8其实这是php的标准编码我们再看下php自己内部对utf-8编码的定义xml的编码规则:ip地址编码单字节数量:对字节长度进行分类:基本长度:用二进制表示,即utf-8编码编码实现:1字节:用十六进制表示,即0101utf-8:utf-8编码由其生成的字符可以包含双字节字符(汉字)/八字节字符(西文)/16进制字符(如$,%)/utf-8八进制字符/utf-8八进制:0x3ff,0x13f,0x40,0x50。
ie6pageview10x4000utf-8编码从源代码中提取的字符,但不是常规的utf-8编码,必须使用utf-8字符集编码.因此ie浏览器只认ip(p&e),不认utf-8编码.在utf-8之外unicode编码也可以允许给这类字符创建编码方式.utf-8用十六进制表示,用双字节表示,utf-8编码不包含utf-8内定义的'字节','字符','字母','数字','符号'等字符,但是"数字"等字符的编码是utf-8编码的编码方式.2(127)用二进制表示[utf-8](-implementing-power-saved-regular-expression)crlf通常定义为:*[a]*/($1ecmascript5的crlfsource)在php程序中encode之后要通过getoutputstream读取出来。
1echo"\n";//$encode后面编码2print"\n";//utf-8编码了,utf-8编码位数为7(看到这里我们已经解决我们抓取网页了,通过xml转化php代码来抓取所有的html网页内容)。
php网页抓取图片(有些网页就是动态网页的图片元素是怎么自动形成的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-04 12:17
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src在原创的html中页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成静态页面有待讨论)。静态页面的优点是加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是由js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪里,不能下载到本地吗(其实如果有链接你可能抢不到,后面会讲)。
一些网站为了防止他人获取图片,或者知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画。前者是我说的动态网页生成的图片。,所以当你打开一个有漫画的页面时,图片加载会很慢,因为是js生成的(毕竟不会让你轻易抢到的)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src的时候,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,我在使用浏览F12功能的时候,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你抓拍网页加载,你会发现获取页面图片的Get请求有如下信息:
GET/Files/Images/76/59262/imanhua_001.jpg HTTP/1.1
接受image/png, image/svg+xml, image/*;q=0.8, */*;q=0.5
推荐人
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5C%W@GJ%24ACOF(TYDYECOKVDYB.png
AcceptLanguage zh-CN
User-AgentMozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko
Accept-Encodinggzip, deflate
ConnectionKeep-Alive 在这里,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己的请求网站才会返回图片,所以我们要添加以上信息在请求头中,经过测试,只需要添加Referer
信息会做。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1. BeautifulSoup 包用于根据 URL 获取静态页面中的元素信息。我们用它来获取爱漫画网站中某部漫画的所有章节的url,根据章节的url获取该章节的总页数,并获取每个页面的url,参考资料
2. Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3. urllib2包,模拟Get请求,使用add_header添加Referer参数获取返回图片
4. chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以抢爱漫画网站的漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
<p>webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage 查看全部
php网页抓取图片(有些网页就是动态网页的图片元素是怎么自动形成的)
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src在原创的html中页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成静态页面有待讨论)。静态页面的优点是加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是由js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪里,不能下载到本地吗(其实如果有链接你可能抢不到,后面会讲)。
一些网站为了防止他人获取图片,或者知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画。前者是我说的动态网页生成的图片。,所以当你打开一个有漫画的页面时,图片加载会很慢,因为是js生成的(毕竟不会让你轻易抢到的)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src的时候,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,我在使用浏览F12功能的时候,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你抓拍网页加载,你会发现获取页面图片的Get请求有如下信息:
GET/Files/Images/76/59262/imanhua_001.jpg HTTP/1.1
接受image/png, image/svg+xml, image/*;q=0.8, */*;q=0.5
推荐人
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5C%W@GJ%24ACOF(TYDYECOKVDYB.png
AcceptLanguage zh-CN
User-AgentMozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko
Accept-Encodinggzip, deflate
ConnectionKeep-Alive 在这里,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己的请求网站才会返回图片,所以我们要添加以上信息在请求头中,经过测试,只需要添加Referer
信息会做。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1. BeautifulSoup 包用于根据 URL 获取静态页面中的元素信息。我们用它来获取爱漫画网站中某部漫画的所有章节的url,根据章节的url获取该章节的总页数,并获取每个页面的url,参考资料
2. Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3. urllib2包,模拟Get请求,使用add_header添加Referer参数获取返回图片
4. chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以抢爱漫画网站的漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
<p>webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage
php网页抓取图片(这是headers系列第二篇,第一篇在这里Headers之User-Agent设置)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-04 12:15
这是headers系列的第二篇,关于Headers的User-Agent设置第一篇就到这里了
本文分为以下几个部分
标题中的引用指示您来自哪个页面。比如我们上面点击了这个页面,后面的headers里面的referer就是上一个页面。
如果我们在浏览器中直接输入后面的URL进行请求,referer就没了,因为我们没有从其他页面找到
有些网站会根据referer反爬。
第一个例子,网站的这个动画
我们要下载这个网站的这个gif动画。
首先也是最容易提出要求
r = requests.get('http://upfile2.asqql.com/upfil ... %2339;)
r.status_code
# 404
现在我们加入referer来请求
headers = {'referer': 'http://www.asqql.com/'}
r = requests.get('http://upfile2.asqql.com/upfil ... 39%3B,
headers = headers)
with open('e.gif', 'wb') as f:
f.write(r.content)
我们得到了正确的 gif
事实上,可以通过使用cookies而不是referers来正确获取。如果直接复制链接到浏览器打开,此时是没有referer的,因为你没有从其他页面点击进去,但是这个时候还是可以看到下载这个动画图片的,因为用浏览器打开会自动带cookie。
第二个例子:再次在网上拍照
下面是一个图片网站的例子。下载本网站中的图片,可以使用网站首页的referer,也可以不使用referer,但不能是其他网站 Referer。
下载网站的这张照片。如果您将此链接直接复制到浏览器中,则可以访问此图片。查看headers,发现没有referer,说明这张图片没有referer也可以正常下载。
直接请求下载这张图片的代码如下
import requests
r = requests.get('http://photo.yupoo.com/vibius/ ... %2339;)
r.status_code
# 200
with open('a.jpg', 'wb') as f:
f.write(r.content)
获取图片如下
现在我们修改headers中的referer,改成知乎的首页,就会发现我们想要的图片无法抓取
import requests
headers = {'referer': 'https://www.zhihu.com/'}
r = requests.get('http://photo.yupoo.com/vibius/ ... 39%3B, headers = headers)
with open('b.jpg', 'wb') as f:
f.write(r.content)
这将得到以下图片
上面的请求过程意味着我们点击了一个链接从知乎网站获取这张图片,yupoo网站认为这种方式可以访问是不合理的,只有这个可从 yupoo 主页找到。图片是真实用户所做的
import requests
headers = {'referer': 'http://photo.yupoo.com/'}
r = requests.get('http://photo.yupoo.com/vibius/ ... 39%3B, headers = headers)
with open('c.jpg', 'wb') as f:
f.write(r.content)
使用yupoo的主页作为referer可以正常获取图片。
在上面的情况下,不知道有referer也没关系,但是还是有一定的局限性。
热链接说明
盗链是指服务商不提供服务的内容,通过技术手段(可以理解为爬虫)获取其他网站资源展示在自己的网站上。常见的盗链类型有:图片盗链、音频盗链、视频盗链、文件盗链。
网站被盗链接会消耗被盗链接的大量带宽网站,实际点击率可能很小,严重损害了被盗链接的利益网站 .
被盗网站自然会阻止盗链。可以经常更改图片的名称,也可以查看referer。因为普通用户必须点击自己网站的链接才能访问图片,如果请求的referer是另一个网站,就说明是爬虫。
盗链网站也会进行针对性的反盗链。您可以通过在请求的标头中设置引用来绕过反盗链。我们现在正在使用爬虫来抓取其他人的网站。
何时使用引用
在抓取图片、视频等网站时,多注意是否是因为没有添加referer。上面的抓图和gif动画就是一个例子。网上还有其他文章需要设置referer,如下
网络安全问题
在这个文章中可以看到CSRF网络攻击,可以通过设置referer来避免。
但是,使用referer也可能会导致一些不好的结果。例如,如果您单击一个链接,则请求此链接时的引用者是您当前的 URL。如果你的 URL 携带了一些隐私信息,那么你的信息就会暴露给访问过的链接。这种情况的详情请参考这个文章
栏目信息
专栏首页:python编程
栏目目录:目录
履带目录:履带系列目录
版本说明:软件和软件包版本说明 查看全部
php网页抓取图片(这是headers系列第二篇,第一篇在这里Headers之User-Agent设置)
这是headers系列的第二篇,关于Headers的User-Agent设置第一篇就到这里了
本文分为以下几个部分
标题中的引用指示您来自哪个页面。比如我们上面点击了这个页面,后面的headers里面的referer就是上一个页面。
如果我们在浏览器中直接输入后面的URL进行请求,referer就没了,因为我们没有从其他页面找到
有些网站会根据referer反爬。
第一个例子,网站的这个动画
我们要下载这个网站的这个gif动画。
首先也是最容易提出要求
r = requests.get('http://upfile2.asqql.com/upfil ... %2339;)
r.status_code
# 404
现在我们加入referer来请求
headers = {'referer': 'http://www.asqql.com/'}
r = requests.get('http://upfile2.asqql.com/upfil ... 39%3B,
headers = headers)
with open('e.gif', 'wb') as f:
f.write(r.content)
我们得到了正确的 gif
事实上,可以通过使用cookies而不是referers来正确获取。如果直接复制链接到浏览器打开,此时是没有referer的,因为你没有从其他页面点击进去,但是这个时候还是可以看到下载这个动画图片的,因为用浏览器打开会自动带cookie。
第二个例子:再次在网上拍照
下面是一个图片网站的例子。下载本网站中的图片,可以使用网站首页的referer,也可以不使用referer,但不能是其他网站 Referer。
下载网站的这张照片。如果您将此链接直接复制到浏览器中,则可以访问此图片。查看headers,发现没有referer,说明这张图片没有referer也可以正常下载。
直接请求下载这张图片的代码如下
import requests
r = requests.get('http://photo.yupoo.com/vibius/ ... %2339;)
r.status_code
# 200
with open('a.jpg', 'wb') as f:
f.write(r.content)
获取图片如下
现在我们修改headers中的referer,改成知乎的首页,就会发现我们想要的图片无法抓取
import requests
headers = {'referer': 'https://www.zhihu.com/'}
r = requests.get('http://photo.yupoo.com/vibius/ ... 39%3B, headers = headers)
with open('b.jpg', 'wb') as f:
f.write(r.content)
这将得到以下图片
上面的请求过程意味着我们点击了一个链接从知乎网站获取这张图片,yupoo网站认为这种方式可以访问是不合理的,只有这个可从 yupoo 主页找到。图片是真实用户所做的
import requests
headers = {'referer': 'http://photo.yupoo.com/'}
r = requests.get('http://photo.yupoo.com/vibius/ ... 39%3B, headers = headers)
with open('c.jpg', 'wb') as f:
f.write(r.content)
使用yupoo的主页作为referer可以正常获取图片。
在上面的情况下,不知道有referer也没关系,但是还是有一定的局限性。
热链接说明
盗链是指服务商不提供服务的内容,通过技术手段(可以理解为爬虫)获取其他网站资源展示在自己的网站上。常见的盗链类型有:图片盗链、音频盗链、视频盗链、文件盗链。
网站被盗链接会消耗被盗链接的大量带宽网站,实际点击率可能很小,严重损害了被盗链接的利益网站 .
被盗网站自然会阻止盗链。可以经常更改图片的名称,也可以查看referer。因为普通用户必须点击自己网站的链接才能访问图片,如果请求的referer是另一个网站,就说明是爬虫。
盗链网站也会进行针对性的反盗链。您可以通过在请求的标头中设置引用来绕过反盗链。我们现在正在使用爬虫来抓取其他人的网站。
何时使用引用
在抓取图片、视频等网站时,多注意是否是因为没有添加referer。上面的抓图和gif动画就是一个例子。网上还有其他文章需要设置referer,如下
网络安全问题
在这个文章中可以看到CSRF网络攻击,可以通过设置referer来避免。
但是,使用referer也可能会导致一些不好的结果。例如,如果您单击一个链接,则请求此链接时的引用者是您当前的 URL。如果你的 URL 携带了一些隐私信息,那么你的信息就会暴露给访问过的链接。这种情况的详情请参考这个文章
栏目信息
专栏首页:python编程
栏目目录:目录
履带目录:履带系列目录
版本说明:软件和软件包版本说明
php网页抓取图片(php网页抓取图片很简单,为什么不用一个数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-03 07:02
php网页抓取图片很简单。最近也在研究。
一般app都会有后台的,
1、模拟登录,
2、用最新的大网站抓包来抓,然后抓数据库,
3、把抓到的数据整理出来一起发给服务器请求;
4、只发api给服务器,数据如果不是很多,可以再通过post来定制分页,以提升效率,为什么不用一个数据库呢。
尝试过以下方式1.qq好友秒传,但是要收费的,需要购买1年服务费或者年费3.5万2.利用开源的免费的服务器给app取名,然后通过snmp链接。3.爬虫,
这是很多大牛都提出的点子,但是没人去提。这可以理解,因为要想解决这个问题的前提是,给你的app提供一个后台服务器,不能用serversocket这种内置的。
爬虫获取啊。app肯定是有后台的。
这也是我一直比较好奇的,如果我知道怎么抓取app的数据,
获取并保存到数据库上
利用app的后台接口抓取数据,可以百度一下这个,
你还是学学python吧
不是有api。
用手机访问各个app,
必须你能说的清楚, 查看全部
php网页抓取图片(php网页抓取图片很简单,为什么不用一个数据库)
php网页抓取图片很简单。最近也在研究。
一般app都会有后台的,
1、模拟登录,
2、用最新的大网站抓包来抓,然后抓数据库,
3、把抓到的数据整理出来一起发给服务器请求;
4、只发api给服务器,数据如果不是很多,可以再通过post来定制分页,以提升效率,为什么不用一个数据库呢。
尝试过以下方式1.qq好友秒传,但是要收费的,需要购买1年服务费或者年费3.5万2.利用开源的免费的服务器给app取名,然后通过snmp链接。3.爬虫,
这是很多大牛都提出的点子,但是没人去提。这可以理解,因为要想解决这个问题的前提是,给你的app提供一个后台服务器,不能用serversocket这种内置的。
爬虫获取啊。app肯定是有后台的。
这也是我一直比较好奇的,如果我知道怎么抓取app的数据,
获取并保存到数据库上
利用app的后台接口抓取数据,可以百度一下这个,
你还是学学python吧
不是有api。
用手机访问各个app,
必须你能说的清楚,
php网页抓取图片(php网页抓取图片的基本步骤:获取图片地址和数据地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-10-01 11:06
php网页抓取图片的基本步骤:1.浏览器打开浏览器,发现图片地址以及图片数据。2.获取图片的xml格式格式如下:图片地址=xml格式图片数据3.批量抓取新用户首次登录后,可以获取一次抓取一个用户。返回值xml格式的图片地址和图片数据地址,并读取图片数据地址。用户可以根据这张图片的地址指定需要抓取的图片。
例如:用户可以访问然后可以在“图片管理”里查看自己选择的图片。也可以按图片大小筛选图片。返回值为:返回值为正则表达式(正则表达式是xml文件中常用的编程语言类型,可以看成一种字符集),将图片数据抓取到,并保存到sqlite中。可用于图片或视频的格式转换,如pdf转mobi。如上图,会返回一个图片代码,标题,图片名称,如下apache+images.microsoft.images.image1_5.xml,图片地址为:/svg/class="benoex"的图片,并且xml格式的图片地址会返回xml格式的数据地址。
4.返回给用户图片地址和数据地址接下来用户可以根据图片地址选择需要的图片,如返回地址,再通过正则表达式匹配图片的xml格式的数据地址,并返回数据地址到对应图片的目录中。mysql是一种关系型数据库,它具有灵活的表格分隔和存储功能。不过,mysql一般用于数据量小,写时开销大,关系复杂的大数据应用场景。
网页本身一般并不包含大量数据量,图片大多数不包含在“存储”里,会因为内存占用或者网页加载速度的影响而丢失,而对于“网页加载”一般包含大量的数据,传输时间长,会对网页性能产生影响。 查看全部
php网页抓取图片(php网页抓取图片的基本步骤:获取图片地址和数据地址)
php网页抓取图片的基本步骤:1.浏览器打开浏览器,发现图片地址以及图片数据。2.获取图片的xml格式格式如下:图片地址=xml格式图片数据3.批量抓取新用户首次登录后,可以获取一次抓取一个用户。返回值xml格式的图片地址和图片数据地址,并读取图片数据地址。用户可以根据这张图片的地址指定需要抓取的图片。
例如:用户可以访问然后可以在“图片管理”里查看自己选择的图片。也可以按图片大小筛选图片。返回值为:返回值为正则表达式(正则表达式是xml文件中常用的编程语言类型,可以看成一种字符集),将图片数据抓取到,并保存到sqlite中。可用于图片或视频的格式转换,如pdf转mobi。如上图,会返回一个图片代码,标题,图片名称,如下apache+images.microsoft.images.image1_5.xml,图片地址为:/svg/class="benoex"的图片,并且xml格式的图片地址会返回xml格式的数据地址。
4.返回给用户图片地址和数据地址接下来用户可以根据图片地址选择需要的图片,如返回地址,再通过正则表达式匹配图片的xml格式的数据地址,并返回数据地址到对应图片的目录中。mysql是一种关系型数据库,它具有灵活的表格分隔和存储功能。不过,mysql一般用于数据量小,写时开销大,关系复杂的大数据应用场景。
网页本身一般并不包含大量数据量,图片大多数不包含在“存储”里,会因为内存占用或者网页加载速度的影响而丢失,而对于“网页加载”一般包含大量的数据,传输时间长,会对网页性能产生影响。
php网页抓取图片(androidandroid项目考察技巧分享-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-01 03:30
从接到通知到面试,我准备了三天的面试。暂时告一段落,先说一点吧^_^html
与两年前相比,面试过程非常小。先考算法,再考基础,最后考综合素质。不幸的是,我准备的方向错了。我只准备了几个去年做的android项目。木材准备算法(⊙o⊙)!mysql
算法非常熟练。不转念头很难想到小脑,心怦怦直跳。还好面试官很特别很特别~~ \(^o^)/~ android
我最大的弱点是缺乏测试经验。面试最大的收获就是用一侧考官给出的考试方法解决了第二考官的考试题。. . 哈采访
不管结果如何。. . 今天的失败是可以的。重要的是快速学习的能力。我相信,只要每天积累一点点,一些小溪终会汇聚成江河,直奔大海。. . 算法
上一篇博客讲了Linux如何抓取网页。有两种方法:curl 和 wget。本文将重点介绍Linux爬取网页的例子——爬取google play游戏TOP排名sql在全球12个国家
爬取google play游戏排名网页,首先需要分析网页的特点和规律:app
一、Google play游戏排名页面是“总分”形式,即一个页面URL显示几个排名(比如24),有几个网页构成了所有游戏curl的总排名
二、 在每个页面URL中,点击每个单独的游戏链接可以查看该游戏的属性信息(如评分星级、发布日期、版本号、SDK版本号、游戏类别、下载量等)
解决问题:测试
一、如何抓取所有游戏的总排名?
二、 抓取整体排名后,如何拼接网址抓取各个游戏页面?
三、获取各个单独的游戏网页后,如何提取网页中游戏的属性信息(即评分星级、发布日期...)?
四、提取出各个游戏的属性信息后,如何保存(mysql)、生成日报(html)、发送日报(email)?
五、根据抓取到的游戏属性信息资源,如何查询贵公司的游戏排名(JSP)以及如何清晰的展示游戏排名(JFreeChart图表)?
六、 更难的是google play游戏排名没有全球统一的排名。Google 使用本地化策略。数十个国家/地区都有自己的一套排名算法和规则。如何在12个国家实现游戏排名?
分析完这些问题,如何一一解决,一一分解,也就是我们需要思考、设计和解决的问题(模块流程和技术实现)? 查看全部
php网页抓取图片(androidandroid项目考察技巧分享-上海怡健医学)
从接到通知到面试,我准备了三天的面试。暂时告一段落,先说一点吧^_^html
与两年前相比,面试过程非常小。先考算法,再考基础,最后考综合素质。不幸的是,我准备的方向错了。我只准备了几个去年做的android项目。木材准备算法(⊙o⊙)!mysql
算法非常熟练。不转念头很难想到小脑,心怦怦直跳。还好面试官很特别很特别~~ \(^o^)/~ android
我最大的弱点是缺乏测试经验。面试最大的收获就是用一侧考官给出的考试方法解决了第二考官的考试题。. . 哈采访
不管结果如何。. . 今天的失败是可以的。重要的是快速学习的能力。我相信,只要每天积累一点点,一些小溪终会汇聚成江河,直奔大海。. . 算法
上一篇博客讲了Linux如何抓取网页。有两种方法:curl 和 wget。本文将重点介绍Linux爬取网页的例子——爬取google play游戏TOP排名sql在全球12个国家
爬取google play游戏排名网页,首先需要分析网页的特点和规律:app
一、Google play游戏排名页面是“总分”形式,即一个页面URL显示几个排名(比如24),有几个网页构成了所有游戏curl的总排名
二、 在每个页面URL中,点击每个单独的游戏链接可以查看该游戏的属性信息(如评分星级、发布日期、版本号、SDK版本号、游戏类别、下载量等)
解决问题:测试
一、如何抓取所有游戏的总排名?
二、 抓取整体排名后,如何拼接网址抓取各个游戏页面?
三、获取各个单独的游戏网页后,如何提取网页中游戏的属性信息(即评分星级、发布日期...)?
四、提取出各个游戏的属性信息后,如何保存(mysql)、生成日报(html)、发送日报(email)?
五、根据抓取到的游戏属性信息资源,如何查询贵公司的游戏排名(JSP)以及如何清晰的展示游戏排名(JFreeChart图表)?
六、 更难的是google play游戏排名没有全球统一的排名。Google 使用本地化策略。数十个国家/地区都有自己的一套排名算法和规则。如何在12个国家实现游戏排名?
分析完这些问题,如何一一解决,一一分解,也就是我们需要思考、设计和解决的问题(模块流程和技术实现)?
php网页抓取图片(php网页抓取图片shopify订单提交资源提交给索引中心站点监控)
网站优化 • 优采云 发表了文章 • 0 个评论 • 376 次浏览 • 2021-09-29 05:05
php网页抓取图片shopify订单提交资源提交提交给索引中心站点监控个人博客html有很多不同的类型,其中:网页抓取:通过抓取网页中的page标签访问html页面站点监控:在web后台检查每一个页面、同时监控页面的title、page==0字段shopify订单提交:网站账户(设置中有这个功能)、每日订单总量、订单配送量、订单人和设置为首重、payment中是否使用自动付款、每月支付规则设置网站日志:realtime、每天自动检查多个网站、流量、流量错误代码php脚本和mysql有很多方式都可以抓取代码中的一部分特定的代码:sqlite、xmlphpsqlite抓取一般都是抓取复杂的数据库。
举个例子,如下代码personurl='/'ph={'admin','active'}jf=page.request.form('parent')jf.set('email',"http-email").get(ph.email,true).get('port',"996").get('code',"jjpc")jf.set('username',"admin").get(ph.email,"admin").get('email',"952");每一个表(row)对应一个用户(username),request(email)表示是否从qq号给用户发送邮件,code表示数字字符串数量,jjpc表示的信息量很大,'jjpc'表示的信息量不大,如果整个数据结构满足索引条件,则网站会一年监控表(filter)和网站设置的代码很相似,都是包含postid、page==0、host、username、fileurl、max-request(max-connection)等表字段.关联:包含关联关系查询:包含页面链接的记录查询:将互相并存的多个页面链接存放在一个数组中,每个页面根据页码决定索引访问,如:地域—qq–admin—personurl网站商品(json数据库)例如这个订单网站提供了两个url地址('/','/'):url3包含了一个csv格式的表格,分别是id、shipparam、departmentid、url,分别代表产品、地点、邮箱、订单数量还有邮件信息的filter表为global/shop_process。
url4表示地区页(url3)链接([1]/)、重复页([2]/)、按公司分([3]/)页([4]/)、按类型([5]/)页([6]/)等等{1}标准查询({2},{3}),curd(int)more(int)give(int)max(int)learn(int),其实这里根据不同页面间是不一样的,具体我们知道要表述清楚了。
shopify提交流程:在需要在shopifypage提交图片的时候,我们需要提供我们网站所需要提交的图片信息:网站资源主页地址,选择其中一种图片提交机制即可,现在根据我的经验一般以下渠道。 查看全部
php网页抓取图片(php网页抓取图片shopify订单提交资源提交给索引中心站点监控)
php网页抓取图片shopify订单提交资源提交提交给索引中心站点监控个人博客html有很多不同的类型,其中:网页抓取:通过抓取网页中的page标签访问html页面站点监控:在web后台检查每一个页面、同时监控页面的title、page==0字段shopify订单提交:网站账户(设置中有这个功能)、每日订单总量、订单配送量、订单人和设置为首重、payment中是否使用自动付款、每月支付规则设置网站日志:realtime、每天自动检查多个网站、流量、流量错误代码php脚本和mysql有很多方式都可以抓取代码中的一部分特定的代码:sqlite、xmlphpsqlite抓取一般都是抓取复杂的数据库。
举个例子,如下代码personurl='/'ph={'admin','active'}jf=page.request.form('parent')jf.set('email',"http-email").get(ph.email,true).get('port',"996").get('code',"jjpc")jf.set('username',"admin").get(ph.email,"admin").get('email',"952");每一个表(row)对应一个用户(username),request(email)表示是否从qq号给用户发送邮件,code表示数字字符串数量,jjpc表示的信息量很大,'jjpc'表示的信息量不大,如果整个数据结构满足索引条件,则网站会一年监控表(filter)和网站设置的代码很相似,都是包含postid、page==0、host、username、fileurl、max-request(max-connection)等表字段.关联:包含关联关系查询:包含页面链接的记录查询:将互相并存的多个页面链接存放在一个数组中,每个页面根据页码决定索引访问,如:地域—qq–admin—personurl网站商品(json数据库)例如这个订单网站提供了两个url地址('/','/'):url3包含了一个csv格式的表格,分别是id、shipparam、departmentid、url,分别代表产品、地点、邮箱、订单数量还有邮件信息的filter表为global/shop_process。
url4表示地区页(url3)链接([1]/)、重复页([2]/)、按公司分([3]/)页([4]/)、按类型([5]/)页([6]/)等等{1}标准查询({2},{3}),curd(int)more(int)give(int)max(int)learn(int),其实这里根据不同页面间是不一样的,具体我们知道要表述清楚了。
shopify提交流程:在需要在shopifypage提交图片的时候,我们需要提供我们网站所需要提交的图片信息:网站资源主页地址,选择其中一种图片提交机制即可,现在根据我的经验一般以下渠道。
php网页抓取图片(几个非常帮的摄影网站-抓取图片的流程及流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-25 00:20
今天在浏览简书的时候,发现了几位非常乐于助人的摄影师网站。上面的图片很美,于是萌生了把它们都屏蔽到当地的念头。并且之前也有过爬虫相关的项目,所以总结了一下自己的心得体会,供大家参考。
抓图过程介绍常用的抓图方式有很多,比如:使用curl方法、fiel_get_content方法、readfile方法、fopen方法。. . . . . 可谓五花八门!但它们的原理大致相似:
1 获取图片所在页面的url地址;
2 获取到目标页面的内容后,有规律地匹配标签的相关信息;
3 获取img的src属性信息后,获取图片的内容;
4 在本地创建一个文件,将步骤3中得到的内容写入文件;
经过以上4步,你喜欢的图片就保存在本地了。下面再详细看一下(从代码的角度),这里我只尝试了两种方法(curl和file_get_content)。
二、使用file_get_content方法抓取图片(get方法)
1 首先定义两个函数(getResources() 和downloadImg())获取页面内容和下载图片到本地函数!代码如下:
获取资源($url)
downloadImg($imgPath)2的主程序如下:
//定义本地目录(存放图片)
定义(“IMG_PATH”,“/home/www/test/img/”);
//获取页面内容
$url = "目标路径";
//这个函数把获取到的内容放到一个字符串中
$str = getResources($url);
//匹配img标签中src属性的信息;这里换成了data-original属性,因为页面使用了延迟加载机制
preg_match_all("|]+data-original=['\" ]?([^'\"?]+)['\" >]|U",$str,$array,PREG_SET_ORDER);
//因为上一步我们选择了PREG_SET_ORDER排序,所以$value[1]就是我们要下载图片的路径
$k = 0;
foreach ($array 作为 $key => $value)
{
$res = downloadImg($value[1]);
if($res) $k++;
}
echo "成功捕获的图片数量为:$k"; 程序结束,这里有以下几点需要注意:
1) preg_match_all() 函数的第四个参数是可选的。它们是:PREG_PATTERN_ORDER(默认),
PREG_SET_ORDER、PREG_OFFSET_CAPTURE,这三种方法在我看来是三种不同的排序,只会影响你的匹配结果的表现。如果不传递第四个参数,则默认为 PREG_PATTERN_ORDER,在这种情况下,使用 PREG_SET_ORDER。对此,php手册中有非常详细的介绍。我建议您在这一步查看手册以加深您的印象。
2) 在正则表达式中,我们匹配标签中data-original属性中的值。我们来谈谈这个正则表达式。首先匹配标签信息,然后通过子匹配匹配数据原创属性。值在。值得注意的是,这里有很多摄影类(图片类)。网站 为了更好的展示效果,大部分都会使用延迟加载设置。如果还是按照前面的方式匹配src属性,只能得到label的默认显示图片,显然不是我们需要的,所以匹配data-original属性(存储真实图片路径);
3) 如果请求的页面过大,程序运行时间过长,请在程序开头添加如下代码:
set_time_limit(120); //修改程序执行时间为120s(自己看)
其次,使用 curl 方法捕获图像(post 模式)。上面我们使用file_get_content()函数的get方法来捕获。这里我们改为 curl post 方法。(每种方法有两种方式)
1 定义一个函数,使用curl方法抓图
curlResources($url)
2 在主程序中,将 $str = getResources($url) 改为 $str = curlResources($url)。
三种方法和两种方法执行效率对比 1 file_get_contents 会为每个请求重新做DNS查询,不会缓存DNS信息。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比file_get_contents好很多。
2 file_get_contents 请求HTTP时,使用http_fopen_wrapper,不keeplive(保持链接状态)。但是卷曲可以。这样,在多次请求多个链接时,curl 的效率会更高。
3 相比file_get_content,curl方法请求更加多样化,比如FTP协议、SSL协议...等资源都可以请求。
总结1 php手册的重要性,有时候你不妨看看手册,不管你看多少资料,对一些功能都有详细的介绍。在开始之前,我不记得 preg_match_all() 会有第四个参数。
2 严格对待代码结构,不能马虎。结构合理,清晰明了,复用率高。
3 真正的知识来自实践,你可以用更多的双手记住它。与其反复打字(请允许我用这个词),不如反复看一遍,这样我们才能记住这个过程的原理。
4 展开,抓取页面包括其子页面的图片,原理是一样的,无非就是在标签的href中找到url进行遍历,然后分别抓取图片...我赢了这里不详述。. 以上是我在拍照过程中的体会。我希望它会对大家有所帮助。如有不对之处,欢迎大家批评指正! 查看全部
php网页抓取图片(几个非常帮的摄影网站-抓取图片的流程及流程)
今天在浏览简书的时候,发现了几位非常乐于助人的摄影师网站。上面的图片很美,于是萌生了把它们都屏蔽到当地的念头。并且之前也有过爬虫相关的项目,所以总结了一下自己的心得体会,供大家参考。
抓图过程介绍常用的抓图方式有很多,比如:使用curl方法、fiel_get_content方法、readfile方法、fopen方法。. . . . . 可谓五花八门!但它们的原理大致相似:
1 获取图片所在页面的url地址;
2 获取到目标页面的内容后,有规律地匹配标签的相关信息;
3 获取img的src属性信息后,获取图片的内容;
4 在本地创建一个文件,将步骤3中得到的内容写入文件;
经过以上4步,你喜欢的图片就保存在本地了。下面再详细看一下(从代码的角度),这里我只尝试了两种方法(curl和file_get_content)。
二、使用file_get_content方法抓取图片(get方法)
1 首先定义两个函数(getResources() 和downloadImg())获取页面内容和下载图片到本地函数!代码如下:
获取资源($url)
downloadImg($imgPath)2的主程序如下:
//定义本地目录(存放图片)
定义(“IMG_PATH”,“/home/www/test/img/”);
//获取页面内容
$url = "目标路径";
//这个函数把获取到的内容放到一个字符串中
$str = getResources($url);
//匹配img标签中src属性的信息;这里换成了data-original属性,因为页面使用了延迟加载机制
preg_match_all("|]+data-original=['\" ]?([^'\"?]+)['\" >]|U",$str,$array,PREG_SET_ORDER);
//因为上一步我们选择了PREG_SET_ORDER排序,所以$value[1]就是我们要下载图片的路径
$k = 0;
foreach ($array 作为 $key => $value)
{
$res = downloadImg($value[1]);
if($res) $k++;
}
echo "成功捕获的图片数量为:$k"; 程序结束,这里有以下几点需要注意:
1) preg_match_all() 函数的第四个参数是可选的。它们是:PREG_PATTERN_ORDER(默认),
PREG_SET_ORDER、PREG_OFFSET_CAPTURE,这三种方法在我看来是三种不同的排序,只会影响你的匹配结果的表现。如果不传递第四个参数,则默认为 PREG_PATTERN_ORDER,在这种情况下,使用 PREG_SET_ORDER。对此,php手册中有非常详细的介绍。我建议您在这一步查看手册以加深您的印象。
2) 在正则表达式中,我们匹配标签中data-original属性中的值。我们来谈谈这个正则表达式。首先匹配标签信息,然后通过子匹配匹配数据原创属性。值在。值得注意的是,这里有很多摄影类(图片类)。网站 为了更好的展示效果,大部分都会使用延迟加载设置。如果还是按照前面的方式匹配src属性,只能得到label的默认显示图片,显然不是我们需要的,所以匹配data-original属性(存储真实图片路径);
3) 如果请求的页面过大,程序运行时间过长,请在程序开头添加如下代码:
set_time_limit(120); //修改程序执行时间为120s(自己看)
其次,使用 curl 方法捕获图像(post 模式)。上面我们使用file_get_content()函数的get方法来捕获。这里我们改为 curl post 方法。(每种方法有两种方式)
1 定义一个函数,使用curl方法抓图
curlResources($url)
2 在主程序中,将 $str = getResources($url) 改为 $str = curlResources($url)。
三种方法和两种方法执行效率对比 1 file_get_contents 会为每个请求重新做DNS查询,不会缓存DNS信息。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比file_get_contents好很多。
2 file_get_contents 请求HTTP时,使用http_fopen_wrapper,不keeplive(保持链接状态)。但是卷曲可以。这样,在多次请求多个链接时,curl 的效率会更高。
3 相比file_get_content,curl方法请求更加多样化,比如FTP协议、SSL协议...等资源都可以请求。
总结1 php手册的重要性,有时候你不妨看看手册,不管你看多少资料,对一些功能都有详细的介绍。在开始之前,我不记得 preg_match_all() 会有第四个参数。
2 严格对待代码结构,不能马虎。结构合理,清晰明了,复用率高。
3 真正的知识来自实践,你可以用更多的双手记住它。与其反复打字(请允许我用这个词),不如反复看一遍,这样我们才能记住这个过程的原理。
4 展开,抓取页面包括其子页面的图片,原理是一样的,无非就是在标签的href中找到url进行遍历,然后分别抓取图片...我赢了这里不详述。. 以上是我在拍照过程中的体会。我希望它会对大家有所帮助。如有不对之处,欢迎大家批评指正!
php网页抓取图片(动态网页的爬取相比静态网页是有利有弊 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-21 21:16
)
动态网页的爬行比静态网页更困难,主要是因为许多网站使用ajax和动态HTML相关技术进行页面交互,因此不可能使用request或urlib获得完整的页面HTML内容。下面主要介绍两种捕获动态网页的方法,它们基本上各有优缺点
一、Ajax和动态HTML
AJAX的全称是异步JavaScript和XML。它的中文名称是异步JavaScript和XML。它是JavaScript异步加载技术、XML和DOM以及表示技术XHTML和CSS的组合。使用Ajax技术,我们不必刷新整个页面,只需更新页面的一部分即可。Ajax只检索一些必要的数据。它使用soap、XML或JSON支持的web服务接口。我们在客户端使用JavaScript处理来自服务器的响应,从而减少了客户端和服务器之间的数据交互,提高了访问速度和用户体验。例如,在注册邮箱时,AJAX技术被广泛用于用户名唯一性验证
DHTML是动态HTML的缩写,即动态HTML。它是相对于传统静态HTML制作网页的一个概念。所谓的动态HTML(DHTML)不是一种新语言。它只是HTML、CSS和客户端脚本的集成,也就是说,一个页面收录HTML+CSS+JavaScript(或其他客户端脚本)。例如,腾讯新闻详情页面首次仅加载少量页面数据。部分数据隐藏在JavaScript脚本中,使用请求库无法完全获取页面HTML
二、确定动态和静态网页
1、在浏览器设置中打开“禁用JavaScript”选项。以最新版本的Chrome浏览器为例。点击浏览器中的“自定义和控制谷歌浏览器”按钮,在左侧的“设置”中选择“隐私设置和安全”
单击右栏中的“网站settings”,然后选择底部的“JavaScript”
单击“允许(建议)”之后的开关控件
将选项“允许(建议)”调整为“禁止”
完成后,关闭设置并打开要爬网的网页。如果页面内容不完整或未显示任何内容。表示动态网页。设置后,读者可以打开腾讯新闻,发现网页上没有内容
2、使用请求库获取目标网页的HTML内容并打印出来。将输出内容另存为HTML。打开本地HTML以检查页面内容是否完整。以腾讯新闻COM/CH/ENT/为例,编写以下代码并将打印(r.text)结果保存为D:\News.html。在本地打开news.html以查看页面的显示效果。页面缺失部分通过动态网页技术实现
import requests
url='https://new.qq.com/ch/ent'
r=requests.get(url)
print(r.text)
import csv
def save(item, path): # path文件保存路径,item数据列表
with open(path, "w+", newline='') as f:
write = csv.writer(f)
write.writerows(item)
save(r.text,"d:/test2.html")
三、JSON数据分析
Python通常使用标准库JSON将字符串转换为JSON对象。解析JSON模块有两种主要方法:JSON.load和JSON.load。Json.load用于将Json字符串解析为Json对象,Json.load将数据从读取的Json文件转换为Json对象
import json #导入json模块
jsonstr='{"ccode":"010101","cname":"数据采集与处理","sinfo":[{"scode":"123456","sname":"bob"},{"scode":"123457","sname":"dog"}]}'
obj=json.loads(jsonstr)
print(type(obj)) #obj是字典型
print(obj["ccode"]) #访问属性
print(type(obj["sinfo"])) #列表
for row in obj["sinfo"]:
print(row["sname"])
查看全部
php网页抓取图片(动态网页的爬取相比静态网页是有利有弊
)
动态网页的爬行比静态网页更困难,主要是因为许多网站使用ajax和动态HTML相关技术进行页面交互,因此不可能使用request或urlib获得完整的页面HTML内容。下面主要介绍两种捕获动态网页的方法,它们基本上各有优缺点
一、Ajax和动态HTML
AJAX的全称是异步JavaScript和XML。它的中文名称是异步JavaScript和XML。它是JavaScript异步加载技术、XML和DOM以及表示技术XHTML和CSS的组合。使用Ajax技术,我们不必刷新整个页面,只需更新页面的一部分即可。Ajax只检索一些必要的数据。它使用soap、XML或JSON支持的web服务接口。我们在客户端使用JavaScript处理来自服务器的响应,从而减少了客户端和服务器之间的数据交互,提高了访问速度和用户体验。例如,在注册邮箱时,AJAX技术被广泛用于用户名唯一性验证
DHTML是动态HTML的缩写,即动态HTML。它是相对于传统静态HTML制作网页的一个概念。所谓的动态HTML(DHTML)不是一种新语言。它只是HTML、CSS和客户端脚本的集成,也就是说,一个页面收录HTML+CSS+JavaScript(或其他客户端脚本)。例如,腾讯新闻详情页面首次仅加载少量页面数据。部分数据隐藏在JavaScript脚本中,使用请求库无法完全获取页面HTML
二、确定动态和静态网页
1、在浏览器设置中打开“禁用JavaScript”选项。以最新版本的Chrome浏览器为例。点击浏览器中的“自定义和控制谷歌浏览器”按钮,在左侧的“设置”中选择“隐私设置和安全”
单击右栏中的“网站settings”,然后选择底部的“JavaScript”
单击“允许(建议)”之后的开关控件
将选项“允许(建议)”调整为“禁止”
完成后,关闭设置并打开要爬网的网页。如果页面内容不完整或未显示任何内容。表示动态网页。设置后,读者可以打开腾讯新闻,发现网页上没有内容
2、使用请求库获取目标网页的HTML内容并打印出来。将输出内容另存为HTML。打开本地HTML以检查页面内容是否完整。以腾讯新闻COM/CH/ENT/为例,编写以下代码并将打印(r.text)结果保存为D:\News.html。在本地打开news.html以查看页面的显示效果。页面缺失部分通过动态网页技术实现
import requests
url='https://new.qq.com/ch/ent'
r=requests.get(url)
print(r.text)
import csv
def save(item, path): # path文件保存路径,item数据列表
with open(path, "w+", newline='') as f:
write = csv.writer(f)
write.writerows(item)
save(r.text,"d:/test2.html")
三、JSON数据分析
Python通常使用标准库JSON将字符串转换为JSON对象。解析JSON模块有两种主要方法:JSON.load和JSON.load。Json.load用于将Json字符串解析为Json对象,Json.load将数据从读取的Json文件转换为Json对象
import json #导入json模块
jsonstr='{"ccode":"010101","cname":"数据采集与处理","sinfo":[{"scode":"123456","sname":"bob"},{"scode":"123457","sname":"dog"}]}'
obj=json.loads(jsonstr)
print(type(obj)) #obj是字典型
print(obj["ccode"]) #访问属性
print(type(obj["sinfo"])) #列表
for row in obj["sinfo"]:
print(row["sname"])
php网页抓取图片(php网页抓取图片对我来说不是非常的熟悉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-11 09:07
<p>php网页抓取图片对我来说不是非常的熟悉,所以在这里给大家一个介绍看看,方便大家理解。网页中的网址是我们常用的叫法,比如:/(你可以直接用http://获取地址),其实就是让我们获取一个域名对应的网页地址的页面。我们第一个程序:phpcrawl/companionapi:在php中搭建爬虫,获取新闻,获取用户信息;第二个程序:crawlcontent/contentapi:在php中访问页面,获取图片phpcrawl/companionapi获取页面图片:页面中的图片怎么抓取,phpcrawl/companionapi获取页面地址和页面解析html格式,我们就可以在这里直接开始大干一场了。接下来讲网页的部分;第一步:新建一个文件content.php,文件内容为:var_dump(" 查看全部
php网页抓取图片(php网页抓取图片对我来说不是非常的熟悉)
<p>php网页抓取图片对我来说不是非常的熟悉,所以在这里给大家一个介绍看看,方便大家理解。网页中的网址是我们常用的叫法,比如:/(你可以直接用http://获取地址),其实就是让我们获取一个域名对应的网页地址的页面。我们第一个程序:phpcrawl/companionapi:在php中搭建爬虫,获取新闻,获取用户信息;第二个程序:crawlcontent/contentapi:在php中访问页面,获取图片phpcrawl/companionapi获取页面图片:页面中的图片怎么抓取,phpcrawl/companionapi获取页面地址和页面解析html格式,我们就可以在这里直接开始大干一场了。接下来讲网页的部分;第一步:新建一个文件content.php,文件内容为:var_dump("

