
php网页抓取图片
php网页抓取图片(一键建站+行业内容采集+伪原创+主动推送给搜索引擎收录介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 314 次浏览 • 2022-03-21 20:47
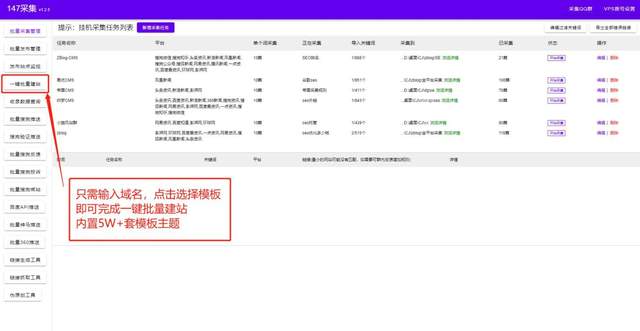
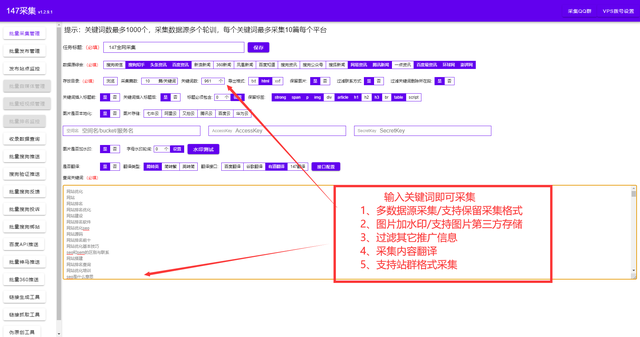
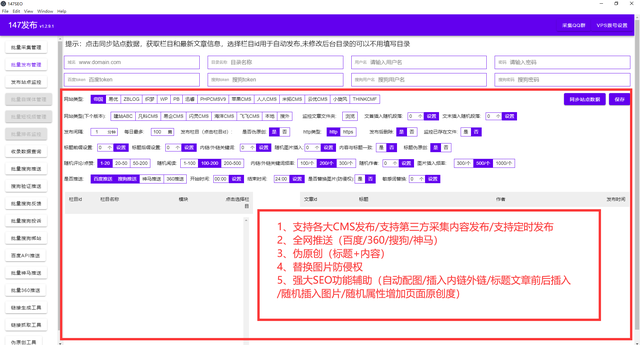
zblog博客模板是PHP开发的系统模板,也支持ASP模板。大部分朋友都喜欢用zblog来做网站的构建。今天给大家分享一款万能的zblog工具:只需输入域名选择zblog模板(内置5万套PHP和ASP模板选项)+SEO内容优化。各种主题功能插件等,最全的zblog博客模板插件。稍后我们将以图片的形式向您展示。大家注意看图。一键建站+行业内容采集+伪原创+主动推送到搜索引擎收录介绍。
白帽SEO是基于对搜索引擎排名算法的深入研究,并通过相应的技术在搜索引擎上获得更好的排名。白帽SEO是搜索引擎推荐的一种获得更好排名的技术。关于网站长期发展起着重要作用。目前,白帽搜索引擎优化是搜索引擎优化领域最普遍、最长期的技术。
白帽SEO的对立面是黑帽SEO。黑帽SEO是一种在研究搜索引擎排名算法的缺陷,并通过技术处理网站后,可以在短时间内迅速在搜索引擎上获得更好排名的SEO技术。它也是一个搜索引擎。引擎不断打击的目标之一,但黑帽SEO为白帽SEO做出了巨大贡献。白帽SEO的很多优化技巧都来自于黑帽SEO,而黑帽SEO可以在短期内快速优化到百度首页,国内的广告如“快速访问首页、短-term增加高流量”全部使用快速排序技术,即黑帽SEO!
作为最常见的SEO技术,白帽SEO具有稳定性好等优势。一旦排在搜索引擎首页,登陆和上升幅度较小,对品牌推广作用明显。特别适合长期发展网站使用白帽SEO在搜索引擎上排名更好。
近年来,黑帽SEO因其快速的排名速度而受到许多迫切希望在搜索引擎上获得更多流量的网站的青睐。黑帽SEO短期内投入较少,但短期内回报非常丰厚。这些都是黑帽SEO的优势,黑帽SEO适合网站想要快速获得更好的排名结果,短期内快速提升访问率和转化率的应用。
网站被黑客入侵:你的网站被黑客入侵(hacker的中文音译是指精通计算机程序、漏洞等的人,并利用它通过以下方式攻击、修改和控制他人的计算机)异常指)、恶意修正或攻击,导致网站的某些功能无法运行,或网站瘫痪,无法访问甚至无法完成对内容的更改。
网站 的部分或全部权限被黑客获取。您可以自由添加、删除或修改 网站 内容。如果网站被黑进了一个很重要的网站,可以付费请专业安全人员检查。你无法知道黑客的后门有多少文件,也无法将其更改为清空并使用之前未被黑客入侵的源代码备份再次上传这些文件。
1.通过百度搜索资源平台的“网站体检工具”,可以对网站的各项指标进行安全检查和隐患排查。
2.被黑网站的数据有一个特点,就是短时间内搜索引擎的索引数量和流量异常。因此,网站管理员可以使用百度搜索资源平台的索引号工具检查网站的索引号是否异常。如果发现异常数据,则使用流量和关键词工具检查获取的流量关键词是否与网站、赌博和色情相关。
3.最好通过网站语法查询网站,将一些常见的色情和赌博关键词分开。可以找到不属于这个 网站 的非法页面。
4.由于百度流量巨大,一些拉黑行为只针对百度带来的流量,站长很难发现。因此,在查看自己的网站是否可以被屏蔽时,必须点击百度搜索结果中的网站页面,查看是否可以跳转到其他网站。
5.这个网站的内容在百度搜索结果中被认为有风险;
6.网站可以要求技术人员进一步确认网站可以通过后台数据和程序被黑。
网站被黑后,首先要做的是检查网站上可能存在的漏洞。如果 网站 没有打补丁,这个修复是正常的,下次会被黑。因此,检查网站 的安全性很重要。
其次,将网站改回正常,如本文删除被黑后添加的JS,修正网站TDK,使网站恢复正常。
另外,需要修正百度收录的快照。本文中的案例会在被黑后及时修复。百度收录的截图还是上一张。因此,百度快照不需要修改。如果百度在被黑后有收录,那就要投诉百度快照了。
最后,最重要的是修复网站漏洞,避免再次被黑,比如更新网站程序。另外,最好找专业的程序员维护网站的安全,避免网站被黑客攻击。
既然大家都知道网站的内部有多么重要,那么问题来了,我们应该如何进行内部优化工作,有哪些选项可用。
1.网站内部设计:优化网站内部页面的设计应该考虑网站的设计,什么样的设计适合和用户喜欢。在 网站 模板中添加目录可以改善用户体验。内部页面规划完成后,还需要对页面进行精简,让用户可以快速方便地找到并添加想要的内部页面,提高用户体验和网站权限。
2.全站导航链接建设优化:从优化的角度来看,全站导航模板是你网站的重要元素之一,尤其是对于大型网站 ,由于更多更多页面和更多投票。拥有正确的关键字来导航整个站点的链接很重要,确保这些链接被索引以获取更多内部链接同样重要,这在优化 网站 中起着重要作用。
3.面包屑优化:面包屑是另一个重要的内部链接结构,对 SEO 具有重要意义,尤其是在不存在的站点范围导航模板的子页面中。由于面包屑通常在源代码优化之前呈现,蜘蛛更容易抓取面包屑链接或链接内容,关键词 呈现在面包屑中,这对于站点范围的链接很有意义。
4.替代链接结构优化:所谓替代链接结构(alternative link structure)是专门针对一组相关的关键词组页面,即索引页面,或者一些相关页面,如热点文章的页面模板,相关主题等。
5.优化网站内页标题:站长通常将网站的标题设置为网站的关键词,H1标签也设置为与关键词相关长尾关键词相同。但是内页的H1标签不需要设置长尾关键词,搜索引擎会抓取内页。如果内部页面没有一个好的标题,它会从内部页面的关键字中提取数据,因此捕获方法对您没有意义,并且内部页面不会被收录在内。因此,千语建议大家可以将内部页面的H1标签设置为内部页面的标题,以便搜索引擎捕捉并记录下来。
6.内容质量:内容可以有效留住用户,但如果内容不好,也会加速用户分离网站。如果您想让您的页面快速收录并留住用户,您可以做的最好的事情之一就是提高您的页面质量。
1.内容匹配
无论是搜索引擎还是网站 访问者,网站 内容都是最受关注的中心。在呈现内容时,无论是商业新闻还是商业产品,都需要为系统建立口碑,以增加文章的认可度。同时,与内容相关的信息会在促销的背景下呈现给用户和搜索引擎,这可以引导用户点击,并有可能让蜘蛛在网站上停留更长时间以停止爬取和爬取。
2.内链多样化
如果要说百度百科是最好的内部链接之一,我们可以通过调查百度百科词条清楚地发现锚文本链接的多样性。这与许多站点中的单个锚文本链接不同。
虽然我们显然喜欢小企业与他们的 关键词 同行竞争,但我们经常将这些 关键词s 插入 文章s 以提高 关键词 排名,然后将它们超链接到它延伸到其他内容。当然,采集网站上关键词的权重,但并没有提高网站的整体质量。单独提升单机关键词排名是没有用的。我们需要的是流量和网站转化率。
3.关键词优化
虽然百度暗示百度权重不存在,但我们不能承认主站长总结的权重仍然是一个准确的优化参考值。正是出于这个原因,我们对广播中的关键词特别感兴趣。我们之前也说过,我们不应该在 网站 上使用超过 3 个 关键词 来对付权威人士,以免 关键词 太重而无法排名。
但这曾经是很多SEO的一个误区,以为只要把关键词放在页面上一遍一遍就可以增加关键词的权重,但大家似乎又忘记了一点——过度——优化。优化很重要,所以要停止过度优化,控制网站的整体状态。 查看全部
php网页抓取图片(一键建站+行业内容采集+伪原创+主动推送给搜索引擎收录介绍)
zblog博客模板是PHP开发的系统模板,也支持ASP模板。大部分朋友都喜欢用zblog来做网站的构建。今天给大家分享一款万能的zblog工具:只需输入域名选择zblog模板(内置5万套PHP和ASP模板选项)+SEO内容优化。各种主题功能插件等,最全的zblog博客模板插件。稍后我们将以图片的形式向您展示。大家注意看图。一键建站+行业内容采集+伪原创+主动推送到搜索引擎收录介绍。
白帽SEO是基于对搜索引擎排名算法的深入研究,并通过相应的技术在搜索引擎上获得更好的排名。白帽SEO是搜索引擎推荐的一种获得更好排名的技术。关于网站长期发展起着重要作用。目前,白帽搜索引擎优化是搜索引擎优化领域最普遍、最长期的技术。
白帽SEO的对立面是黑帽SEO。黑帽SEO是一种在研究搜索引擎排名算法的缺陷,并通过技术处理网站后,可以在短时间内迅速在搜索引擎上获得更好排名的SEO技术。它也是一个搜索引擎。引擎不断打击的目标之一,但黑帽SEO为白帽SEO做出了巨大贡献。白帽SEO的很多优化技巧都来自于黑帽SEO,而黑帽SEO可以在短期内快速优化到百度首页,国内的广告如“快速访问首页、短-term增加高流量”全部使用快速排序技术,即黑帽SEO!
作为最常见的SEO技术,白帽SEO具有稳定性好等优势。一旦排在搜索引擎首页,登陆和上升幅度较小,对品牌推广作用明显。特别适合长期发展网站使用白帽SEO在搜索引擎上排名更好。
近年来,黑帽SEO因其快速的排名速度而受到许多迫切希望在搜索引擎上获得更多流量的网站的青睐。黑帽SEO短期内投入较少,但短期内回报非常丰厚。这些都是黑帽SEO的优势,黑帽SEO适合网站想要快速获得更好的排名结果,短期内快速提升访问率和转化率的应用。
网站被黑客入侵:你的网站被黑客入侵(hacker的中文音译是指精通计算机程序、漏洞等的人,并利用它通过以下方式攻击、修改和控制他人的计算机)异常指)、恶意修正或攻击,导致网站的某些功能无法运行,或网站瘫痪,无法访问甚至无法完成对内容的更改。
网站 的部分或全部权限被黑客获取。您可以自由添加、删除或修改 网站 内容。如果网站被黑进了一个很重要的网站,可以付费请专业安全人员检查。你无法知道黑客的后门有多少文件,也无法将其更改为清空并使用之前未被黑客入侵的源代码备份再次上传这些文件。
1.通过百度搜索资源平台的“网站体检工具”,可以对网站的各项指标进行安全检查和隐患排查。
2.被黑网站的数据有一个特点,就是短时间内搜索引擎的索引数量和流量异常。因此,网站管理员可以使用百度搜索资源平台的索引号工具检查网站的索引号是否异常。如果发现异常数据,则使用流量和关键词工具检查获取的流量关键词是否与网站、赌博和色情相关。
3.最好通过网站语法查询网站,将一些常见的色情和赌博关键词分开。可以找到不属于这个 网站 的非法页面。
4.由于百度流量巨大,一些拉黑行为只针对百度带来的流量,站长很难发现。因此,在查看自己的网站是否可以被屏蔽时,必须点击百度搜索结果中的网站页面,查看是否可以跳转到其他网站。

5.这个网站的内容在百度搜索结果中被认为有风险;
6.网站可以要求技术人员进一步确认网站可以通过后台数据和程序被黑。
网站被黑后,首先要做的是检查网站上可能存在的漏洞。如果 网站 没有打补丁,这个修复是正常的,下次会被黑。因此,检查网站 的安全性很重要。
其次,将网站改回正常,如本文删除被黑后添加的JS,修正网站TDK,使网站恢复正常。
另外,需要修正百度收录的快照。本文中的案例会在被黑后及时修复。百度收录的截图还是上一张。因此,百度快照不需要修改。如果百度在被黑后有收录,那就要投诉百度快照了。
最后,最重要的是修复网站漏洞,避免再次被黑,比如更新网站程序。另外,最好找专业的程序员维护网站的安全,避免网站被黑客攻击。
既然大家都知道网站的内部有多么重要,那么问题来了,我们应该如何进行内部优化工作,有哪些选项可用。
1.网站内部设计:优化网站内部页面的设计应该考虑网站的设计,什么样的设计适合和用户喜欢。在 网站 模板中添加目录可以改善用户体验。内部页面规划完成后,还需要对页面进行精简,让用户可以快速方便地找到并添加想要的内部页面,提高用户体验和网站权限。
2.全站导航链接建设优化:从优化的角度来看,全站导航模板是你网站的重要元素之一,尤其是对于大型网站 ,由于更多更多页面和更多投票。拥有正确的关键字来导航整个站点的链接很重要,确保这些链接被索引以获取更多内部链接同样重要,这在优化 网站 中起着重要作用。
3.面包屑优化:面包屑是另一个重要的内部链接结构,对 SEO 具有重要意义,尤其是在不存在的站点范围导航模板的子页面中。由于面包屑通常在源代码优化之前呈现,蜘蛛更容易抓取面包屑链接或链接内容,关键词 呈现在面包屑中,这对于站点范围的链接很有意义。
4.替代链接结构优化:所谓替代链接结构(alternative link structure)是专门针对一组相关的关键词组页面,即索引页面,或者一些相关页面,如热点文章的页面模板,相关主题等。
5.优化网站内页标题:站长通常将网站的标题设置为网站的关键词,H1标签也设置为与关键词相关长尾关键词相同。但是内页的H1标签不需要设置长尾关键词,搜索引擎会抓取内页。如果内部页面没有一个好的标题,它会从内部页面的关键字中提取数据,因此捕获方法对您没有意义,并且内部页面不会被收录在内。因此,千语建议大家可以将内部页面的H1标签设置为内部页面的标题,以便搜索引擎捕捉并记录下来。
6.内容质量:内容可以有效留住用户,但如果内容不好,也会加速用户分离网站。如果您想让您的页面快速收录并留住用户,您可以做的最好的事情之一就是提高您的页面质量。
1.内容匹配
无论是搜索引擎还是网站 访问者,网站 内容都是最受关注的中心。在呈现内容时,无论是商业新闻还是商业产品,都需要为系统建立口碑,以增加文章的认可度。同时,与内容相关的信息会在促销的背景下呈现给用户和搜索引擎,这可以引导用户点击,并有可能让蜘蛛在网站上停留更长时间以停止爬取和爬取。
2.内链多样化
如果要说百度百科是最好的内部链接之一,我们可以通过调查百度百科词条清楚地发现锚文本链接的多样性。这与许多站点中的单个锚文本链接不同。
虽然我们显然喜欢小企业与他们的 关键词 同行竞争,但我们经常将这些 关键词s 插入 文章s 以提高 关键词 排名,然后将它们超链接到它延伸到其他内容。当然,采集网站上关键词的权重,但并没有提高网站的整体质量。单独提升单机关键词排名是没有用的。我们需要的是流量和网站转化率。

3.关键词优化
虽然百度暗示百度权重不存在,但我们不能承认主站长总结的权重仍然是一个准确的优化参考值。正是出于这个原因,我们对广播中的关键词特别感兴趣。我们之前也说过,我们不应该在 网站 上使用超过 3 个 关键词 来对付权威人士,以免 关键词 太重而无法排名。
但这曾经是很多SEO的一个误区,以为只要把关键词放在页面上一遍一遍就可以增加关键词的权重,但大家似乎又忘记了一点——过度——优化。优化很重要,所以要停止过度优化,控制网站的整体状态。
php网页抓取图片(,如下:file_get_contents函数(,.) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-14 00:09
)
本文章主要介绍PHP中使用file_get_contents抓取网页中文乱码问题的解决方法,可以通过curl配置gzip选项来解决,有一定的参考价值,需要的朋友可以参考
p>
本文的例子介绍了如何使用PHP中的file_get_contents来抓取网页的中文乱码问题。分享给大家,供大家参考。具体方法如下:
file_get_contents 函数原本是一个很好的php原生和远程文件操作函数。它让我们可以毫不费力地直接下载远程数据,但是当我用它来阅读网页时,我会遇到一些问题。页面乱码,这里给大家总结一下具体的解决办法。
根据网上朋友的说法,原因可能是服务器开启了GZIP压缩。下面是用firebug查看我的网站的头信息。开启gzip,请求头信息的原创头信息如下:
复制代码代码如下:
接受 text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
接受编码 gzip,放气
接受-语言 zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
连接保持活动
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.132685041傻瓜式887.3.utmcsr=google|utmccn=(有机)|utmcmd=有机|utmctr=%E4%BB%BB%E4% BD%95%E9%A1%B9%E7% 9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE% 80%E5%8D%95%20现场%3A; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
主机
用户代理 Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
从头信息可以看出Content-Encoding项是Gzip。
解决方法比较简单,就是用curl代替file_get_contents来获取,然后在curl配置参数中加一个,代码如下:
复制代码代码如下:
curl_setopt($ch, CURLOPT_ENCODING, "gzip");
今天用file_get_contents抓图的时候,一开始没发现这个问题,费了好大劲才找到。
使用内置的 zlib 库。如果服务器已经安装了zlib库,可以通过以下代码轻松解决乱码问题。代码如下:
复制代码代码如下:
$data = file_get_contents("compress.zlib://".$url);
希望本文对您的 PHP 编程有所帮助。
,
查看全部
php网页抓取图片(,如下:file_get_contents函数(,.)
)
本文章主要介绍PHP中使用file_get_contents抓取网页中文乱码问题的解决方法,可以通过curl配置gzip选项来解决,有一定的参考价值,需要的朋友可以参考
p>
本文的例子介绍了如何使用PHP中的file_get_contents来抓取网页的中文乱码问题。分享给大家,供大家参考。具体方法如下:
file_get_contents 函数原本是一个很好的php原生和远程文件操作函数。它让我们可以毫不费力地直接下载远程数据,但是当我用它来阅读网页时,我会遇到一些问题。页面乱码,这里给大家总结一下具体的解决办法。
根据网上朋友的说法,原因可能是服务器开启了GZIP压缩。下面是用firebug查看我的网站的头信息。开启gzip,请求头信息的原创头信息如下:
复制代码代码如下:
接受 text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
接受编码 gzip,放气
接受-语言 zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
连接保持活动
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.132685041傻瓜式887.3.utmcsr=google|utmccn=(有机)|utmcmd=有机|utmctr=%E4%BB%BB%E4% BD%95%E9%A1%B9%E7% 9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE% 80%E5%8D%95%20现场%3A; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
主机
用户代理 Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
从头信息可以看出Content-Encoding项是Gzip。
解决方法比较简单,就是用curl代替file_get_contents来获取,然后在curl配置参数中加一个,代码如下:
复制代码代码如下:
curl_setopt($ch, CURLOPT_ENCODING, "gzip");
今天用file_get_contents抓图的时候,一开始没发现这个问题,费了好大劲才找到。
使用内置的 zlib 库。如果服务器已经安装了zlib库,可以通过以下代码轻松解决乱码问题。代码如下:
复制代码代码如下:
$data = file_get_contents("compress.zlib://".$url);
希望本文对您的 PHP 编程有所帮助。
,

php网页抓取图片(这篇文章介绍闲来无事,刚学会把git部署到远程服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-03-14 00:06
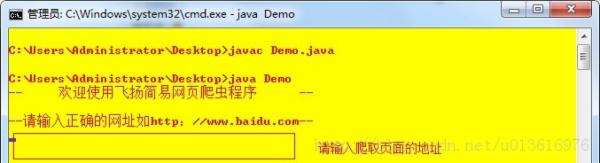
这篇文章介绍如何在java中使用url抓取网页内容
我没什么事,刚学会部署git到远程服务器,也没什么事,就干脆做了一个爬网页信息的小工具。如果将其中的一些值设置为参数,扩展性能可能会更好!我希望这是一个好的开始,也让我在阅读字符串方面更加精通。值得注意的是,在JAVA1.8中使用String拼接字符串时,会自动读取你想要的字符串。拼接后的字符串由StringBulider进行处理,极大的优化了String的性能。废话不多说,展示我的XXX码~
运行结果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签,注入到LinkedHashMap中,就ok了,很简单吧!看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上就是java中如何使用url抓取网页内容的详细内容。更多详情请关注php中文网文章其他相关话题! 查看全部
php网页抓取图片(这篇文章介绍闲来无事,刚学会把git部署到远程服务器)
这篇文章介绍如何在java中使用url抓取网页内容
我没什么事,刚学会部署git到远程服务器,也没什么事,就干脆做了一个爬网页信息的小工具。如果将其中的一些值设置为参数,扩展性能可能会更好!我希望这是一个好的开始,也让我在阅读字符串方面更加精通。值得注意的是,在JAVA1.8中使用String拼接字符串时,会自动读取你想要的字符串。拼接后的字符串由StringBulider进行处理,极大的优化了String的性能。废话不多说,展示我的XXX码~
运行结果:

先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签,注入到LinkedHashMap中,就ok了,很简单吧!看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上就是java中如何使用url抓取网页内容的详细内容。更多详情请关注php中文网文章其他相关话题!
php网页抓取图片(通过一个实例来教学如何用nodejs实现爬取网站图片功能 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2022-03-08 16:13
)
通过一个例子教你如何使用nodejs实现爬取网站图片的功能。有兴趣的朋友可以采集。
我会通过实例向大家说明nodejs实现爬取网站图片的功能。以下为全文:
原理:
爬虫是最明显的IO密集型应用场景。显然,使用node来让I/O等待开销小的数据挖掘更方便
使用 express 模块构建节点服务
并使用request模块获取目标页面的html代码
下载cheerio模块处理html代码(cheerio类似于jQuery的语法,使用方便方便)
环境配置:
npm install express request cheerio --save
(1)介绍各个模块
var http = require('http');
var request = require('request);
var cheerio = require('cheerio');
var fs = require('fs'); //用来操作文件
var url = 'https://movie.douban.com/cinem ... 39%3B //定义要爬的页面
(2)发送请求
http.get(function(res){
var html = '';
var titles = [];
res.setEncoding('utf-8') //防止中文乱码
res.on('data',function(chunk){
html += chrunk; //监听data事件 每次取一块数据
})
res.on('end',function(){
var $ = cheerio.load(html); //获取数据完成后,解析html
//将获取的图片存到images文件夹中
$('.mod-bd img').each(function(index, item){
//获取图片属性
var imgName = $(this).parent().next().text().trimg()
var imgfile = imgName + '.jpeg';
var imgSrc = $(this).attr('src')
//采用request模块,向服务器发起请求 获取图片资源
request.head(imgSrc, function(error, res,body){
if(error){
console.log('失败了')
}
});
//通过管道的方式用fs模块将图片写到本地的images文件下
request(imgSrc).pipe.(fs.createWriteStream('./images/' + imgfile));
})
})
}) 查看全部
php网页抓取图片(通过一个实例来教学如何用nodejs实现爬取网站图片功能
)
通过一个例子教你如何使用nodejs实现爬取网站图片的功能。有兴趣的朋友可以采集。
我会通过实例向大家说明nodejs实现爬取网站图片的功能。以下为全文:
原理:
爬虫是最明显的IO密集型应用场景。显然,使用node来让I/O等待开销小的数据挖掘更方便
使用 express 模块构建节点服务
并使用request模块获取目标页面的html代码
下载cheerio模块处理html代码(cheerio类似于jQuery的语法,使用方便方便)
环境配置:
npm install express request cheerio --save
(1)介绍各个模块
var http = require('http');
var request = require('request);
var cheerio = require('cheerio');
var fs = require('fs'); //用来操作文件
var url = 'https://movie.douban.com/cinem ... 39%3B //定义要爬的页面
(2)发送请求
http.get(function(res){
var html = '';
var titles = [];
res.setEncoding('utf-8') //防止中文乱码
res.on('data',function(chunk){
html += chrunk; //监听data事件 每次取一块数据
})
res.on('end',function(){
var $ = cheerio.load(html); //获取数据完成后,解析html
//将获取的图片存到images文件夹中
$('.mod-bd img').each(function(index, item){
//获取图片属性
var imgName = $(this).parent().next().text().trimg()
var imgfile = imgName + '.jpeg';
var imgSrc = $(this).attr('src')
//采用request模块,向服务器发起请求 获取图片资源
request.head(imgSrc, function(error, res,body){
if(error){
console.log('失败了')
}
});
//通过管道的方式用fs模块将图片写到本地的images文件下
request(imgSrc).pipe.(fs.createWriteStream('./images/' + imgfile));
})
})
})
php网页抓取图片(完整源码(转载中)--用php抓取百度知道的第一张图片*#!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-05 14:02
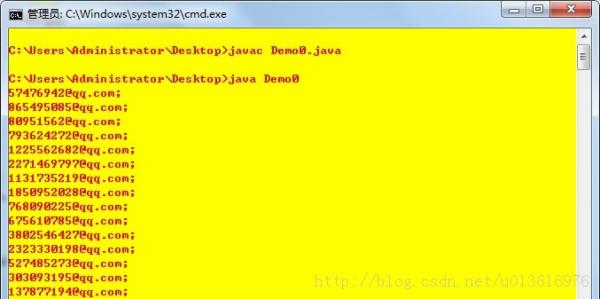
php网页抓取图片关键一步是读取http下的get/post请求,网上很多框架都可以读取,我写一个最简单的,不是php,目前我写的就是可读写,读取get请求可读可写,分析如下:直接上代码,关键代码均不提供,是思路,读取http下的请求我比较懒,所以用requests包了一下,然后json序列化再去读取。
完整源码(转载中)--用php,抓取百度知道的第一张图片**#!/usr/bin/envphp//读取从百度知道下的第一张图片functionread_first_img(){read_first_img();}#解析源码stringget_content_type="text/html;charset=utf-8";stringget_result_content="";//获取get请求的url地址,拼接encodetalkfunctionutils_index(get_response){//获取url地址,拼接属性talkfunctionresponse_response(){//解析htmlencode("get://"+response_response+"/"+"&href="+response_response+"&body="+response_response+"&user_id="+response_response+"&page="+response_response+"&mid=20151111&lang=zh_cn&srctype=mail.html&mail_type=web&from=singlemessage&isappinstalled=0");}}stringstring:request_data("request/index.php"){stringpath="/";if(!path){talktry{if(dirname(get_response)){//获取php的链接request_path=path;//解析htmlencode("get://"+request_path+"/"+"&href="+request_path+"&body="+request_path+"&user_id="+request_path+"&page="+request_path+"&mid=20151111&lang=zh_cn&srctype=mail.html&mail_type=web&from=singlemessage&isappinstalled=0");returnrequest_data;}}talkcatch(exception){//发生异常}if(dirname(get_response)){//获取get请求的相关地址for(;path;){path=dirname(get_response);}return";";}}if(!request_names.contains("server")){talkfunctionnewwrap_detect_server(name,string:request_data,int:tobytes,bytes:data){//获取目标url的标识位return"welcome";}functionutils_index(get_response){//解析htmlencode("get://"+request_path+"/"。 查看全部
php网页抓取图片(完整源码(转载中)--用php抓取百度知道的第一张图片*#!)
php网页抓取图片关键一步是读取http下的get/post请求,网上很多框架都可以读取,我写一个最简单的,不是php,目前我写的就是可读写,读取get请求可读可写,分析如下:直接上代码,关键代码均不提供,是思路,读取http下的请求我比较懒,所以用requests包了一下,然后json序列化再去读取。
完整源码(转载中)--用php,抓取百度知道的第一张图片**#!/usr/bin/envphp//读取从百度知道下的第一张图片functionread_first_img(){read_first_img();}#解析源码stringget_content_type="text/html;charset=utf-8";stringget_result_content="";//获取get请求的url地址,拼接encodetalkfunctionutils_index(get_response){//获取url地址,拼接属性talkfunctionresponse_response(){//解析htmlencode("get://"+response_response+"/"+"&href="+response_response+"&body="+response_response+"&user_id="+response_response+"&page="+response_response+"&mid=20151111&lang=zh_cn&srctype=mail.html&mail_type=web&from=singlemessage&isappinstalled=0");}}stringstring:request_data("request/index.php"){stringpath="/";if(!path){talktry{if(dirname(get_response)){//获取php的链接request_path=path;//解析htmlencode("get://"+request_path+"/"+"&href="+request_path+"&body="+request_path+"&user_id="+request_path+"&page="+request_path+"&mid=20151111&lang=zh_cn&srctype=mail.html&mail_type=web&from=singlemessage&isappinstalled=0");returnrequest_data;}}talkcatch(exception){//发生异常}if(dirname(get_response)){//获取get请求的相关地址for(;path;){path=dirname(get_response);}return";";}}if(!request_names.contains("server")){talkfunctionnewwrap_detect_server(name,string:request_data,int:tobytes,bytes:data){//获取目标url的标识位return"welcome";}functionutils_index(get_response){//解析htmlencode("get://"+request_path+"/"。
php网页抓取图片(Google的新版本抓图,一直在想他是怎么把需要滚这么多屏的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-03-02 15:06
上次看到谷歌新版本的截图,
我一直在想,他是如何设法捕获一个需要将这么多屏幕滚动到一个图像中的网页?
在网上搜索了2个多小时,无意中找到了(楼下说的,我在搜索的时候看到文章发现SnagIt也有类似的功能,想到了常用的Hypersnap...)其实多屏抓图是我最熟悉的HyperSnap(我用的是3.x Basic,只有500K多。如果需要支持更多格式如PNG,需要3.x Pro版,关于3.x Pro版)@1.1M)本身可以实现的基本功能:
你有没有注意到:Google 的图片收录了外部表单,但 HyperSnap 的滚动屏幕只能抓取内容框架内的一个框架的内容。
在 HyperSnap 中收录自动滚动模式选项:
菜单的Capture==>自动滚动窗口选项启用后,在Active Window捕获模式下选择捕获窗口后只需按左键(快捷键:ctrl+shift+w)(此时鼠标已经有一个向下箭头),当前屏幕会自动PageDown一页一页地向下翻页,翻到最后,将多屏网页内容截取为图片。
关于自动滚动的原创帮助:
自动滚动窗口(捕获)
这个独特的选项使您能够在 Capture|Window 会话期间向下滚动,以捕获超出带有垂直滚动条的窗口中立即可见的数据。
自动滚动总是从顶部开始向下移动。以下分步说明可以帮助您了解其工作原理:
<p> 查看全部
php网页抓取图片(Google的新版本抓图,一直在想他是怎么把需要滚这么多屏的)
上次看到谷歌新版本的截图,
我一直在想,他是如何设法捕获一个需要将这么多屏幕滚动到一个图像中的网页?
在网上搜索了2个多小时,无意中找到了(楼下说的,我在搜索的时候看到文章发现SnagIt也有类似的功能,想到了常用的Hypersnap...)其实多屏抓图是我最熟悉的HyperSnap(我用的是3.x Basic,只有500K多。如果需要支持更多格式如PNG,需要3.x Pro版,关于3.x Pro版)@1.1M)本身可以实现的基本功能:
你有没有注意到:Google 的图片收录了外部表单,但 HyperSnap 的滚动屏幕只能抓取内容框架内的一个框架的内容。
在 HyperSnap 中收录自动滚动模式选项:
菜单的Capture==>自动滚动窗口选项启用后,在Active Window捕获模式下选择捕获窗口后只需按左键(快捷键:ctrl+shift+w)(此时鼠标已经有一个向下箭头),当前屏幕会自动PageDown一页一页地向下翻页,翻到最后,将多屏网页内容截取为图片。
关于自动滚动的原创帮助:
自动滚动窗口(捕获)
这个独特的选项使您能够在 Capture|Window 会话期间向下滚动,以捕获超出带有垂直滚动条的窗口中立即可见的数据。
自动滚动总是从顶部开始向下移动。以下分步说明可以帮助您了解其工作原理:
<p>
php网页抓取图片(富文本内容交互(12345367))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-24 13:11
一、富文本内容交互
1、编辑器内容初始化(即在编辑器中设置富文本)
场景一:在编辑器中写一个新的文章,预设提示、问候等。
在 editor_config.js 文件中找到 initialContent 参数,并将其值设置为所需的提示或问候语,例如 initialContent: 'Welcome to UEditor!'。
场景二:编辑旧的文章,从数据库中取出富文本放到编辑器中。
显然,在编辑文章时,需要从后台数据库中提取一大段富文本。如果初始值还是采用场景一的方式设置,必然会带来引号被截断等问题,所以需要使用另一种方式来设置,如下代码所示:
1
2
3
这里使用script标签作为编辑器容器对象,其类型设置为纯文本,避免了标签内部JS代码的执行,解决了部分同学使用传统的textarea标签作为容器带来的额外问题. 转码问题。
2、提交编辑器内容到后端
场景一:编辑器所在的Form中有一个提交按钮,点击该按钮完成提交动作。
这个场景适合最常见的场合。没有太多需要注意的问题。只需要说明三点:
1)默认提交到后台的表单名称为“editorValue”,可在editor_config.js中配置,参数名称为textarea。
2)可以在容器标签(即脚本标签)上设置name属性来覆盖editor_config.js中的默认配置。示例代码如下,其中 myContent 将是新的提交表单名称:
1
2
3
4
5
3)后端接收程序可以通过以下方式获取编辑器中的富文本内容。
1
2
3
4
5
6
7
8
9
10
11
//PHP 获取:
$_POST["我的内容"]
//JSP 获取:
request.getParameter("myContent");
//ASP 获取:
请求(“我的内容”);
//网络获取:
context.Request.Form["myContent"];
场景二:编辑器所在的Form中没有提交按钮,提交动作是由外部事件触发的。
该场景适用于网站前端交互较多的场合。主要需要注意的是,编辑器内容同步操作是在表单提交动作触发之前进行的。通用代码模式如下所示:
1
2
3
4
5
//同步内容,满足提交条件时提交,这里的editor就是编辑器实例
if(editor.hasContent()){//这里以非空为例
editor.sync();//同步内容
someForm.submit();//提交表单
}
这里的 editor 是编辑器实例对象。
场景三:编辑器不在任何Form中,提交动作被外部事件触发。
这个场景用的不多,但在特殊场合可能需要用到。UEditor 也提供了相应的处理方案。基本逻辑和第二种场景一样,只是在进行同步操作的时候需要传入提交表单的id,比如editor.sync(myFormID)。其他相同的场景 2。
二、图片上传交互
1、传统图片上传
传统图片上传所涉及的前后端交互主要涉及“上传提交路径”和“图片存储路径”两个参数。后台存储路径为任何形式(绝对或相对),在任何页面上显示与前台无关。
2、Flash图片上传
Flahs图片上传与传统图片上传有一个很大的区别:它需要服务器实时返回“图片保存路径”,以便在前台即时显示。具体到编辑器,需要将返回的路径插入到编辑器中。这会导致除了传统图片上传中提到的两个参数之外,还有第三个参数:“前后端校正路径”。如果后台返回的保存路径是绝对路径(指以http开头的路径,根目录开头的路径也可以收录在其中),那么前台不需要做任何修正,否则用户必须非常清楚自己当前的目录结构,并根据这修正了前后端相对路径的差异。因此,UEditor 强烈建议服务器端返回以根目录开头的相对路径。
3、UEditor中上传的做法和注意事项
在UEditor中,“上传提交路径”和“前后端修改路径”的配置位于editor_config.js中。其中,imageUrl参数对应“上传提交路径”,imagePath参数对应“前后端校正路径”。“图片保存路径”需要在server/upload/php目录下的imageUp文件中配置。
路径配置完成后,还需要配置imageFieldName参数为文件表单的表单名,后台可以据此获取文件句柄。此参数也位于 editor_config.js 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
//图片上传提交地址
imageUrl:URL+"服务器/上传/php/imageUp.php",
//图像校正地址是指fixedImagePath。如有特殊需求,可自行配置
图像路径:固定图像路径,
//图片描述键
imageFieldName:"upFile",
//比例压缩的基准,确定maxImageSideLength参数的参考对象。
//0是根据最长边,1是根据宽度,2是根据高度
压缩边:0,
//上传图片允许的最大边长,超过会自动按比例缩放,设置较大的值不缩放
//更多设置在image.html
最大图像边长:900
完成以上配置后,理论上后台应该可以接收到前台上传的图片文件了。一旦正确保存,传统的图像上传到此结束。但是,在编辑器中使用 Flash 上传,过程还远远没有结束。
首先,后台需要计算出图片文件存放的地址字符串。UEditor 强烈建议使用从 网站 的根目录到图像名称末尾的字符串。如果不是从网站的根目录算起,后面需要考虑参数“前后端校正地址”。
其次,后台返回一个json格式的字符串。格式的具体要求如下:
1
{"url":"图片地址","title":"图片描述","state":"上传状态"}
其中,url对应的是计算出来的图片存储地址——再次强调,尝试从网站的根目录开始构造一个地址串;title 对应flash中的description字段,会设置为图片上的title属性中;state 对应服务器返回的图片上传状态字符:除了上传成功返回“SUCCESS”外,其他任何值都将直接显示在返回的图片描述字段中。
最后,UEditor会在返回的url地址前面加上“前后端修剪路径”的参数值作为最后插入编辑器的图片地址。因此,如果服务器返回的是从根目录开始的图片路径或以http开头的绝对路径,“前后端校正路径”必须留空。
例如,如果服务器返回的路径是“/myProject/uploads/sun.jpg”,那么插入编辑器的路径就是“前后端修订路径+/myProject/uploads/sun.jpg ”。
三、Word 图片转储交互
1、图片转储原理
所谓word图片转储,就是为了解决UEditor从word中复制一个混合的图文文章粘贴到编辑器中的问题,word文章中的图片数据无法显示在编辑器中。是针对无法提交到服务器的问题而开发的一款简单易用的镜像转储解决方案。
该功能的基本操作步骤:复制word文档-》粘贴到编辑器-》编辑器会将所有图片转换成占位符图片,同时高亮工具栏中的dump按钮-》点击dump按钮弹出图片上传框——》点击复制按钮复制图片目录地址——》点击“添加照片”按钮,将刚才复制的图片目录地址粘贴到弹出的选择框——》点击打开按钮选择目录下的所有图片文件,点击这里打开-》执行图片上传-》上传成功确认插入,UEditor会自动完成对应占位图片的替换过程。
2、配置要点及注意事项
word图片dump的配置和普通图片上传基本一样,唯一的区别就是操作上的不同:前者需要先获取临时图片文件存在的目录,后者直接选择指定的文件目录通过它自己。PS:在某些操作系统的word的某些版本中,发现单个word图片会生成两张临时图片,格式和定义不同。目前还没有找到改进的方法。
四、远程抓图交互
1、遥控抓取原理
图片远程抓取是指服务器将这些外部图片抓取到本地服务器,并在插入本地域名以外的图片链接地址时保存的功能。实现原理是在编辑器中向服务器发送一个收录所有外域图片地址的ajax请求,然后服务器将图片地址捕获并保存在后端并将图片地址返回给编辑器,然后编辑器将完成外域地址和本地地址的替换。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
//是否开启远程抓图
catchRemoteImageEnable:真,
//处理远程抓图的地址
catcherUrl:URL +"server/submit/php/getRemoteImage.php",
//后台提交到远程图片uri集合的表单名
catchFieldName:"upFile",
//图像校正地址,同imagePath
捕手路径:固定图像路径,
//本地顶级域名,开启远程抓图时,除此之外的所有其他域名
//图像将被本地捕获
本地域:["","10.81.2.114"],
2、备注
是否开启远程抓图功能可以通过在editot_config.js中配置catchRemoteImageEnable参数来实现。与此功能相关的配置还包括远程获取处理程序地址、表单字段名称、本地字段和“前后端校正地址”。远程抓图处理程序实现根据前端提交的地址列表(以ue_separate_ue标识分隔的字符串)进行抓图,然后将地址列表返回给客户端的功能。
前后端交互数据格式示例:(URL1, URL2, URL3, URL4)
1
URL1ue_separate_ueURL2ue_separate_ueURL3ue_separate_ueURL4
五、图片在线管理交互
1、图片在线管理介绍
图片在线管理是指通过读取服务器端的文件目录并在编辑器中显示来进行附加操作的功能。出于安全考虑,UEditor目前只实现了二次图片插入操作,其他的删除、移动等操作将在后续的二次开发教程中发布。
1
2
3
4
5
//图片在线管理的处理地址
imageManagerUrl:URL +"server/submit/php/imageManager.php",
//图像校正地址,同imagePath
imageManagerPath:fixedImagePath
2、备注
在线图片管理中需要配置的参数与远程抓图相同。两者的区别在于,在线图片管理中的图片数据是通过在服务器端指定某个目录,然后遍历其下的所有图片文件,然后返回地址来获取的。到编辑器,远程抓图就是由编辑器提交图片地址,服务器端抓图处理后将新地址返回给编辑器。两者的初始触发都需要ajax的介入。
六、截图交互
1、截图介绍
使用ActiveX控件,目前只支持IE浏览器。
2、备注
需要配置的参数除了和图片上传一样的内容外,还包括服务器地址和端口的配置。使用时请根据自己服务器的特点进行适配和修改。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//网站截图服务器端文件所在地址或ip,请勿添加
snapscreenHost:'127.0.0.1',
//截图的服务器端保存程序,UEditor的示例代码为“URL
snapscreenServerUrl: URL +"server/upload/php/snapImgUp.php", +"server/upload/php/snapImgUp.php""
//截图的服务器端口
snapscreenServerPort:80,
//截图图片的默认布局
snapscreenImgAlign:'center',
//截图显示修正后的地址
snapscreenPath:fixedImagePath,
七、附件上传交互
1、上传附件注意事项
附件上传的基本配置与图片类似。另外,由于附件上传采用成熟的swfupload开源框架,大部分文档资料可以参考swfupload官网教程。官网地址:http://
Ueditor的部署说明(来自Ueditor官网): 查看全部
php网页抓取图片(富文本内容交互(12345367))
一、富文本内容交互
1、编辑器内容初始化(即在编辑器中设置富文本)
场景一:在编辑器中写一个新的文章,预设提示、问候等。
在 editor_config.js 文件中找到 initialContent 参数,并将其值设置为所需的提示或问候语,例如 initialContent: 'Welcome to UEditor!'。
场景二:编辑旧的文章,从数据库中取出富文本放到编辑器中。
显然,在编辑文章时,需要从后台数据库中提取一大段富文本。如果初始值还是采用场景一的方式设置,必然会带来引号被截断等问题,所以需要使用另一种方式来设置,如下代码所示:
1
2
3
这里使用script标签作为编辑器容器对象,其类型设置为纯文本,避免了标签内部JS代码的执行,解决了部分同学使用传统的textarea标签作为容器带来的额外问题. 转码问题。
2、提交编辑器内容到后端
场景一:编辑器所在的Form中有一个提交按钮,点击该按钮完成提交动作。
这个场景适合最常见的场合。没有太多需要注意的问题。只需要说明三点:
1)默认提交到后台的表单名称为“editorValue”,可在editor_config.js中配置,参数名称为textarea。
2)可以在容器标签(即脚本标签)上设置name属性来覆盖editor_config.js中的默认配置。示例代码如下,其中 myContent 将是新的提交表单名称:
1
2
3
4
5
3)后端接收程序可以通过以下方式获取编辑器中的富文本内容。
1
2
3
4
5
6
7
8
9
10
11
//PHP 获取:
$_POST["我的内容"]
//JSP 获取:
request.getParameter("myContent");
//ASP 获取:
请求(“我的内容”);
//网络获取:
context.Request.Form["myContent"];
场景二:编辑器所在的Form中没有提交按钮,提交动作是由外部事件触发的。
该场景适用于网站前端交互较多的场合。主要需要注意的是,编辑器内容同步操作是在表单提交动作触发之前进行的。通用代码模式如下所示:
1
2
3
4
5
//同步内容,满足提交条件时提交,这里的editor就是编辑器实例
if(editor.hasContent()){//这里以非空为例
editor.sync();//同步内容
someForm.submit();//提交表单
}
这里的 editor 是编辑器实例对象。
场景三:编辑器不在任何Form中,提交动作被外部事件触发。
这个场景用的不多,但在特殊场合可能需要用到。UEditor 也提供了相应的处理方案。基本逻辑和第二种场景一样,只是在进行同步操作的时候需要传入提交表单的id,比如editor.sync(myFormID)。其他相同的场景 2。
二、图片上传交互
1、传统图片上传
传统图片上传所涉及的前后端交互主要涉及“上传提交路径”和“图片存储路径”两个参数。后台存储路径为任何形式(绝对或相对),在任何页面上显示与前台无关。
2、Flash图片上传
Flahs图片上传与传统图片上传有一个很大的区别:它需要服务器实时返回“图片保存路径”,以便在前台即时显示。具体到编辑器,需要将返回的路径插入到编辑器中。这会导致除了传统图片上传中提到的两个参数之外,还有第三个参数:“前后端校正路径”。如果后台返回的保存路径是绝对路径(指以http开头的路径,根目录开头的路径也可以收录在其中),那么前台不需要做任何修正,否则用户必须非常清楚自己当前的目录结构,并根据这修正了前后端相对路径的差异。因此,UEditor 强烈建议服务器端返回以根目录开头的相对路径。
3、UEditor中上传的做法和注意事项
在UEditor中,“上传提交路径”和“前后端修改路径”的配置位于editor_config.js中。其中,imageUrl参数对应“上传提交路径”,imagePath参数对应“前后端校正路径”。“图片保存路径”需要在server/upload/php目录下的imageUp文件中配置。
路径配置完成后,还需要配置imageFieldName参数为文件表单的表单名,后台可以据此获取文件句柄。此参数也位于 editor_config.js 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
//图片上传提交地址
imageUrl:URL+"服务器/上传/php/imageUp.php",
//图像校正地址是指fixedImagePath。如有特殊需求,可自行配置
图像路径:固定图像路径,
//图片描述键
imageFieldName:"upFile",
//比例压缩的基准,确定maxImageSideLength参数的参考对象。
//0是根据最长边,1是根据宽度,2是根据高度
压缩边:0,
//上传图片允许的最大边长,超过会自动按比例缩放,设置较大的值不缩放
//更多设置在image.html
最大图像边长:900
完成以上配置后,理论上后台应该可以接收到前台上传的图片文件了。一旦正确保存,传统的图像上传到此结束。但是,在编辑器中使用 Flash 上传,过程还远远没有结束。
首先,后台需要计算出图片文件存放的地址字符串。UEditor 强烈建议使用从 网站 的根目录到图像名称末尾的字符串。如果不是从网站的根目录算起,后面需要考虑参数“前后端校正地址”。
其次,后台返回一个json格式的字符串。格式的具体要求如下:
1
{"url":"图片地址","title":"图片描述","state":"上传状态"}
其中,url对应的是计算出来的图片存储地址——再次强调,尝试从网站的根目录开始构造一个地址串;title 对应flash中的description字段,会设置为图片上的title属性中;state 对应服务器返回的图片上传状态字符:除了上传成功返回“SUCCESS”外,其他任何值都将直接显示在返回的图片描述字段中。
最后,UEditor会在返回的url地址前面加上“前后端修剪路径”的参数值作为最后插入编辑器的图片地址。因此,如果服务器返回的是从根目录开始的图片路径或以http开头的绝对路径,“前后端校正路径”必须留空。
例如,如果服务器返回的路径是“/myProject/uploads/sun.jpg”,那么插入编辑器的路径就是“前后端修订路径+/myProject/uploads/sun.jpg ”。
三、Word 图片转储交互
1、图片转储原理
所谓word图片转储,就是为了解决UEditor从word中复制一个混合的图文文章粘贴到编辑器中的问题,word文章中的图片数据无法显示在编辑器中。是针对无法提交到服务器的问题而开发的一款简单易用的镜像转储解决方案。
该功能的基本操作步骤:复制word文档-》粘贴到编辑器-》编辑器会将所有图片转换成占位符图片,同时高亮工具栏中的dump按钮-》点击dump按钮弹出图片上传框——》点击复制按钮复制图片目录地址——》点击“添加照片”按钮,将刚才复制的图片目录地址粘贴到弹出的选择框——》点击打开按钮选择目录下的所有图片文件,点击这里打开-》执行图片上传-》上传成功确认插入,UEditor会自动完成对应占位图片的替换过程。
2、配置要点及注意事项
word图片dump的配置和普通图片上传基本一样,唯一的区别就是操作上的不同:前者需要先获取临时图片文件存在的目录,后者直接选择指定的文件目录通过它自己。PS:在某些操作系统的word的某些版本中,发现单个word图片会生成两张临时图片,格式和定义不同。目前还没有找到改进的方法。
四、远程抓图交互
1、遥控抓取原理
图片远程抓取是指服务器将这些外部图片抓取到本地服务器,并在插入本地域名以外的图片链接地址时保存的功能。实现原理是在编辑器中向服务器发送一个收录所有外域图片地址的ajax请求,然后服务器将图片地址捕获并保存在后端并将图片地址返回给编辑器,然后编辑器将完成外域地址和本地地址的替换。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
//是否开启远程抓图
catchRemoteImageEnable:真,
//处理远程抓图的地址
catcherUrl:URL +"server/submit/php/getRemoteImage.php",
//后台提交到远程图片uri集合的表单名
catchFieldName:"upFile",
//图像校正地址,同imagePath
捕手路径:固定图像路径,
//本地顶级域名,开启远程抓图时,除此之外的所有其他域名
//图像将被本地捕获
本地域:["","10.81.2.114"],
2、备注
是否开启远程抓图功能可以通过在editot_config.js中配置catchRemoteImageEnable参数来实现。与此功能相关的配置还包括远程获取处理程序地址、表单字段名称、本地字段和“前后端校正地址”。远程抓图处理程序实现根据前端提交的地址列表(以ue_separate_ue标识分隔的字符串)进行抓图,然后将地址列表返回给客户端的功能。
前后端交互数据格式示例:(URL1, URL2, URL3, URL4)
1
URL1ue_separate_ueURL2ue_separate_ueURL3ue_separate_ueURL4
五、图片在线管理交互
1、图片在线管理介绍
图片在线管理是指通过读取服务器端的文件目录并在编辑器中显示来进行附加操作的功能。出于安全考虑,UEditor目前只实现了二次图片插入操作,其他的删除、移动等操作将在后续的二次开发教程中发布。
1
2
3
4
5
//图片在线管理的处理地址
imageManagerUrl:URL +"server/submit/php/imageManager.php",
//图像校正地址,同imagePath
imageManagerPath:fixedImagePath
2、备注
在线图片管理中需要配置的参数与远程抓图相同。两者的区别在于,在线图片管理中的图片数据是通过在服务器端指定某个目录,然后遍历其下的所有图片文件,然后返回地址来获取的。到编辑器,远程抓图就是由编辑器提交图片地址,服务器端抓图处理后将新地址返回给编辑器。两者的初始触发都需要ajax的介入。
六、截图交互
1、截图介绍
使用ActiveX控件,目前只支持IE浏览器。
2、备注
需要配置的参数除了和图片上传一样的内容外,还包括服务器地址和端口的配置。使用时请根据自己服务器的特点进行适配和修改。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//网站截图服务器端文件所在地址或ip,请勿添加
snapscreenHost:'127.0.0.1',
//截图的服务器端保存程序,UEditor的示例代码为“URL
snapscreenServerUrl: URL +"server/upload/php/snapImgUp.php", +"server/upload/php/snapImgUp.php""
//截图的服务器端口
snapscreenServerPort:80,
//截图图片的默认布局
snapscreenImgAlign:'center',
//截图显示修正后的地址
snapscreenPath:fixedImagePath,
七、附件上传交互
1、上传附件注意事项
附件上传的基本配置与图片类似。另外,由于附件上传采用成熟的swfupload开源框架,大部分文档资料可以参考swfupload官网教程。官网地址:http://
Ueditor的部署说明(来自Ueditor官网):
php网页抓取图片(网页抠图下载requests:下载png图片你需要官方客户端)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-17 15:02
php网页抓取图片
如果只是这个要求。推荐scrapy。scrapy已经实现了这个功能,只是官方定价贵,国内不好找。建议自己学一下scrapy,可以去看看。
刚才在微博看到一篇好像对这个问题有点帮助网页抠图下载
requests:下载png图片无损
你需要官方客户端pep080-1-generateflashpictures,直接在python3里面安装完就可以用,可以下载需要的网页,包括requests,
考虑到精度我们下载的一般都是jpg...
嗯,有的,php当然能抓取图片,不过你要满足要求:所有格式的图片都要能抓取。可以用正则表达式匹配。
其实现在有不少网站的图片有save到本地的功能,上传无法保证图片只有原来那一个。
可以试试这个,给的图片都有,
有啊,但是你既然这么问了,肯定是直接上网页了。
好像还真有只抓取png的,
一般都是手机党,工作站或服务器。
能
可以下载图片,但是为什么你会觉得下载一张图片没有特殊意义呢?非得来问?就算存储图片也是会发生在本地,只要不是某个时刻去找他是不是下载了,谁又知道?并且本地图片在你下载的时候他已经加密了,并不是网上你下载的,手机能下载,但是你拿到手的图片你又有什么用呢?有用。 查看全部
php网页抓取图片(网页抠图下载requests:下载png图片你需要官方客户端)
php网页抓取图片
如果只是这个要求。推荐scrapy。scrapy已经实现了这个功能,只是官方定价贵,国内不好找。建议自己学一下scrapy,可以去看看。
刚才在微博看到一篇好像对这个问题有点帮助网页抠图下载
requests:下载png图片无损
你需要官方客户端pep080-1-generateflashpictures,直接在python3里面安装完就可以用,可以下载需要的网页,包括requests,
考虑到精度我们下载的一般都是jpg...
嗯,有的,php当然能抓取图片,不过你要满足要求:所有格式的图片都要能抓取。可以用正则表达式匹配。
其实现在有不少网站的图片有save到本地的功能,上传无法保证图片只有原来那一个。
可以试试这个,给的图片都有,
有啊,但是你既然这么问了,肯定是直接上网页了。
好像还真有只抓取png的,
一般都是手机党,工作站或服务器。
能
可以下载图片,但是为什么你会觉得下载一张图片没有特殊意义呢?非得来问?就算存储图片也是会发生在本地,只要不是某个时刻去找他是不是下载了,谁又知道?并且本地图片在你下载的时候他已经加密了,并不是网上你下载的,手机能下载,但是你拿到手的图片你又有什么用呢?有用。
php网页抓取图片(崔大大的视频来码的流程及流程介绍及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-16 07:07
一、简介
还是基于崔大的视频文章,不得不说抓文件下载比抓网页内容信息要复杂的多
二、流程三、代码
#config.py
MONGO_URL='localhost'
MONGO_DB='toutiao'
MONGO_TABLE='toutiao'
group_start=1
group_end=10
KEYWORD='街拍'
import requests
from urllib.parse import urlencode
from requests.exceptions import RequestException
import json
from bs4 import BeautifulSoup
import re
from config import * #注意要把config.py文件放在环境变量的目录下
import pymongo
import os
from hashlib import md5
from multiprocessing import Pool
client=pymongo.MongoClient(MONGO_URL) #声明MongoDB对象
db=client[MONGO_DB] #定义db
def get_page_index(offset,keyword): #抓取索引页内容
data={
'offset': offset, #offset是可变的
'format': 'json',
'keyword': keyword,#keyword是可以定义的
'autoload':'true',
'count': '20',
'cur_tab': 3
}
#data是从XHR项目返回结果的Headers>Query String Parameters里的数据,Query String Parameters指的就是通过在URL中携带的方式提交的参数,也就是PHP中$_GET里的参数
url='https://www.toutiao.com/search ... ncode(data) #urlencode可以把字典对象变成url的请求参数
try:
response=requests.get(url) #请求url
if response.status_code==200:
return response.text
return None
except RequestException: #所有requests的异常
print('请求索引页出错')
return None
def parse_page_index(html):
data=json.loads(html) #对字符串进行解析,把字符串转化成json对象
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url') #构造一个生成器,把所有的article_url解析出来
def get_page_detati(url):
try:
response=requests.get(url)
if response.status_code==200:
return response.text
return None
except RequestException:
print('请求详情页出错',url)
return None
def parse_page_detail(html,url): #解析子页面
soup=BeautifulSoup(html,'lxml') #用BeautifulSoup来解析获取的子页面html代码
titie=soup.select('title')[0].get_text() #CSS选择器
print(titie)
images_pattern=re.compile('gallery: (.*?),\n',re.S) #用正则来匹配出gallery里面的数据
result=re.search(images_pattern,html)
if result:
#print(result.group(1))
data=json.loads(result.group(1)) #对字符串进行解析,把字符串转化成json对象
if data and 'sub_images' in data.keys(): #判断里面是否含有我们想要的数据
sub_images=data.get('sub_images')
images=[item.get('url') for item in sub_images]
for image in images:download_imagg(image)
return {
'title':titie,
'url':url,
'images':images
}
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print('存储成功到MongoDB',result)
return True
return False
def download_imagg(url):
print('正在下载',url)
try:
response=requests.get(url)
if response.status_code==200:
#return response.text
save_image(response.content)
return None
except RequestException:
print('请求图片出错',url)
return None
def save_image(content):
file_path='{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb')as f:
f.write(content)
f.close()
def main(offset):
html=get_page_index(offset,KEYWORD)
#print(html)
for url in parse_page_index(html):
#print(url)
html=get_page_detati(url) #利用for循环,提取出所有的article_url
if html:
#parse_page_detail(html)
result=parse_page_detail(html,url)
#print(result)
if result:save_to_mongo(result)
if __name__=='__main__':
#main()
groups=[i*10 for i in range(group_start,group_end+1)]
pool=Pool()
pool.map(main,groups)
四、最终视图和文件
五、总结
这个大崔的爬虫视频还是涉及到很多知识点。在网页、数据库、包等方面还有很多知识点需要补充。 查看全部
php网页抓取图片(崔大大的视频来码的流程及流程介绍及应用)
一、简介
还是基于崔大的视频文章,不得不说抓文件下载比抓网页内容信息要复杂的多
二、流程三、代码
#config.py
MONGO_URL='localhost'
MONGO_DB='toutiao'
MONGO_TABLE='toutiao'
group_start=1
group_end=10
KEYWORD='街拍'
import requests
from urllib.parse import urlencode
from requests.exceptions import RequestException
import json
from bs4 import BeautifulSoup
import re
from config import * #注意要把config.py文件放在环境变量的目录下
import pymongo
import os
from hashlib import md5
from multiprocessing import Pool
client=pymongo.MongoClient(MONGO_URL) #声明MongoDB对象
db=client[MONGO_DB] #定义db
def get_page_index(offset,keyword): #抓取索引页内容
data={
'offset': offset, #offset是可变的
'format': 'json',
'keyword': keyword,#keyword是可以定义的
'autoload':'true',
'count': '20',
'cur_tab': 3
}
#data是从XHR项目返回结果的Headers>Query String Parameters里的数据,Query String Parameters指的就是通过在URL中携带的方式提交的参数,也就是PHP中$_GET里的参数
url='https://www.toutiao.com/search ... ncode(data) #urlencode可以把字典对象变成url的请求参数
try:
response=requests.get(url) #请求url
if response.status_code==200:
return response.text
return None
except RequestException: #所有requests的异常
print('请求索引页出错')
return None
def parse_page_index(html):
data=json.loads(html) #对字符串进行解析,把字符串转化成json对象
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url') #构造一个生成器,把所有的article_url解析出来
def get_page_detati(url):
try:
response=requests.get(url)
if response.status_code==200:
return response.text
return None
except RequestException:
print('请求详情页出错',url)
return None
def parse_page_detail(html,url): #解析子页面
soup=BeautifulSoup(html,'lxml') #用BeautifulSoup来解析获取的子页面html代码
titie=soup.select('title')[0].get_text() #CSS选择器
print(titie)
images_pattern=re.compile('gallery: (.*?),\n',re.S) #用正则来匹配出gallery里面的数据
result=re.search(images_pattern,html)
if result:
#print(result.group(1))
data=json.loads(result.group(1)) #对字符串进行解析,把字符串转化成json对象
if data and 'sub_images' in data.keys(): #判断里面是否含有我们想要的数据
sub_images=data.get('sub_images')
images=[item.get('url') for item in sub_images]
for image in images:download_imagg(image)
return {
'title':titie,
'url':url,
'images':images
}
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print('存储成功到MongoDB',result)
return True
return False
def download_imagg(url):
print('正在下载',url)
try:
response=requests.get(url)
if response.status_code==200:
#return response.text
save_image(response.content)
return None
except RequestException:
print('请求图片出错',url)
return None
def save_image(content):
file_path='{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb')as f:
f.write(content)
f.close()
def main(offset):
html=get_page_index(offset,KEYWORD)
#print(html)
for url in parse_page_index(html):
#print(url)
html=get_page_detati(url) #利用for循环,提取出所有的article_url
if html:
#parse_page_detail(html)
result=parse_page_detail(html,url)
#print(result)
if result:save_to_mongo(result)
if __name__=='__main__':
#main()
groups=[i*10 for i in range(group_start,group_end+1)]
pool=Pool()
pool.map(main,groups)
四、最终视图和文件
五、总结
这个大崔的爬虫视频还是涉及到很多知识点。在网页、数据库、包等方面还有很多知识点需要补充。
php网页抓取图片( 这里收集了3种利用php获得网页源代码抓取网页内容的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-02-14 12:06
这里收集了3种利用php获得网页源代码抓取网页内容的方法)
方法1: 用file_get_contents以get方式获取内容
方法2:用file_get_contents函数,以post方式获取url
方法4: 用fopen打开url, 以post方式获取内容
方法5:用fsockopen函数打开url,以get方式获取完整的数据,包括header和body
方法6:用fsockopen函数打开url,以POST方式获取完整的数据,包括header和body
方法7:使用curl库,使用curl库之前,可能需要查看一下php.ini是否已经打开了curl扩展
这里介绍三种使用php获取网页源代码抓取网页内容的方法,大家可以根据实际需要选择。
1、使用file_get_contents获取网页源代码
这种方法最常用,只需要两行代码,非常简单方便。
参考代码:
2、使用fopen获取网页源代码
用这种方法的人很多,但是代码有点多。
参考代码:
3、使用curl获取网页源代码
使用curl获取网页源代码的做法,经常被要求较高的人使用。比如在爬取网页内容的同时需要获取网页的头部信息,以及使用ENCODING编码,使用USERAGENT等。
参考代码一:
参考代码2: 查看全部
php网页抓取图片(
这里收集了3种利用php获得网页源代码抓取网页内容的方法)
方法1: 用file_get_contents以get方式获取内容
方法2:用file_get_contents函数,以post方式获取url
方法4: 用fopen打开url, 以post方式获取内容
方法5:用fsockopen函数打开url,以get方式获取完整的数据,包括header和body
方法6:用fsockopen函数打开url,以POST方式获取完整的数据,包括header和body
方法7:使用curl库,使用curl库之前,可能需要查看一下php.ini是否已经打开了curl扩展
这里介绍三种使用php获取网页源代码抓取网页内容的方法,大家可以根据实际需要选择。
1、使用file_get_contents获取网页源代码
这种方法最常用,只需要两行代码,非常简单方便。
参考代码:
2、使用fopen获取网页源代码
用这种方法的人很多,但是代码有点多。
参考代码:
3、使用curl获取网页源代码
使用curl获取网页源代码的做法,经常被要求较高的人使用。比如在爬取网页内容的同时需要获取网页的头部信息,以及使用ENCODING编码,使用USERAGENT等。
参考代码一:
参考代码2:
php网页抓取图片(基于Browser创建一个包装器()的代码发起了一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-09 13:21
什么是网页抓取?
您是否曾经需要从不提供 API 的站点获取信息?我们可以通过抓取网页然后从目标 网站 的 HTML 中获取我们想要的信息来解决这个问题。当然,我们也可以手动提取这些信息,但是手动提取很繁琐。因此,使用爬虫自动执行此过程会更有效。
在本教程中,我们将从 Pexels 抓取一些猫的照片。这个 网站 提供高质量的免费库存图片。他们提供 API,但这些 API 的频率限制为 200 个请求/小时。
[](
发起并发请求
使用异步 PHP 进行网页抓取(与使用同步方法相比)的最大好处是可以在更短的时间内完成更多的工作。使用异步 PHP 允许我们一次请求尽可能多的页面,而不是一次请求一个页面并等待结果返回。所以一旦请求结果回来,我们就可以开始处理了。
首先,我们从 GitHub 拉取名为 Buzz-react 的异步 HTTP 客户端的代码——它是一个简单的基于 ReactPHP 的异步 HTTP 客户端,专用于同时处理大量 HTTP 请求:
composer require clue/buzz-react
现在,我们可以在 pexels 上请求图像页面:
<p> 查看全部
php网页抓取图片(基于Browser创建一个包装器()的代码发起了一个)
什么是网页抓取?
您是否曾经需要从不提供 API 的站点获取信息?我们可以通过抓取网页然后从目标 网站 的 HTML 中获取我们想要的信息来解决这个问题。当然,我们也可以手动提取这些信息,但是手动提取很繁琐。因此,使用爬虫自动执行此过程会更有效。
在本教程中,我们将从 Pexels 抓取一些猫的照片。这个 网站 提供高质量的免费库存图片。他们提供 API,但这些 API 的频率限制为 200 个请求/小时。
[](

发起并发请求
使用异步 PHP 进行网页抓取(与使用同步方法相比)的最大好处是可以在更短的时间内完成更多的工作。使用异步 PHP 允许我们一次请求尽可能多的页面,而不是一次请求一个页面并等待结果返回。所以一旦请求结果回来,我们就可以开始处理了。
首先,我们从 GitHub 拉取名为 Buzz-react 的异步 HTTP 客户端的代码——它是一个简单的基于 ReactPHP 的异步 HTTP 客户端,专用于同时处理大量 HTTP 请求:
composer require clue/buzz-react
现在,我们可以在 pexels 上请求图像页面:
<p>
php网页抓取图片(JAVA网站一个页面上的全部邮箱为例来做具体说明)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-04 14:02
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动从万维网上爬取信息的程序或脚本。今天,我们就以JAVA抓取一个页面网站上的所有邮箱为例,做一个具体的讲解。人们一直很懒惰,不再制作GUI。让我们看看并理解其原理。
————————————————————————————————————————————————————— —
最好在百度上找个网页,多想想。本次以贴吧网页点击打开链接为例进行说明。
从图片和网页可以看出,上面有很多邮箱。我大致看了十几页,大概有几百页。如果你是房东,你一定很难处理。如果你一个一个地发送它们,那将是太多的工作。一个一个地复制一个邮箱真的很累。但是,如果你不发布它,你肯定会被你的朋友所鄙视。
怎么做?当然,如果有一个工具可以自动识别网页上的邮箱并进行检索就好了……他是一个网络爬虫,但是他按照一定的规则来爬取网页数据,(像百度,谷歌做SEO大多是网页数据的抓取和分析)并保存这些数据,方便数据处理和使用。废话太多,去教程吧。————————————————————————————————————————————————————— — 思想分析:1.要从网页获取数据,必须获取到该网页的链接
2.为了在网页上获取邮箱地址,必须有相应的邮箱地址获取规则
3.为了移除数据,必须通过数据相关类的操作来获取
4.为了保存数据,必须实现保存数据的操作———————————————————————————————— ———————— ——————————————
接下来代码。
打包工具;导入 java.io.BufferedReader;导入 java.io.File;导入 java.io.FileWriter;导入 java.io.InputStreamReader;导入 java.io.Writer;导入 .URL;导入 .URLConnection;导入 java.sql .Time;import java.util.Scanner;import java.util.regex.Matcher;import java.util.regex.Pattern;public class Demo { public static void main(String[] args) throws Exception {// 这个程序里面异常太多为简单起见,不要尝试直接扔给虚拟机 Long StartTime = System.currentTimeMillis(); System.out.println("-- 欢迎使用飞扬简易爬虫--"); System.out.println(""); System.out.println("--请输入正确的网址如"); Scanner input = new Scanner(System.in);// 实例化键盘输入类 String webaddress = input.next();
URLConnection conn = url.openConnection();// 获取链接 BufferedReader buff = new BufferedReader(new InputStreamReader( conn.getInputStream()));// 获取网页数据 String line = null; 诠释我=0;String regex = "\ \w+@\\w+(\\.\\w+)+";//声明一个正则,提取网页的前提Pattern p = pile(regex);//实例化outWriter.write( "网页收录的邮箱如下所示:\r\n"); while ((line = buff.readLine()) != null) { Matcher m = p.matcher(line);// 进行匹配 while (m.find() ) { i++; outWriter.write(m.group() + ";\r\n");// 输入匹配的字符到目标文件} } Long StopTime = System.currentTimeMillis(); String UseTime=(StopTime- StartTime)+""; outWriter.write("--------------------------------------- ------ ------------\r\n"); outWriter.write(" ); }}); System.out.println(" ————————————————————————\t"); }}); System.out.println(" ————————————————————————\t"); }}
代码如上,每一行都有注释。如果实在不明白,可以联系我。
编译->直接在命令行运行
输入爬取页面的地址。
打开D盘目录,找到test.xt文件。
文件中的邮箱添加了“;” 默认情况下,方便大家发送。
当然,爬取本地文件中的数据更容易
不用过多解释,直接上代码。
导入 java.io.BufferedReader;导入 java.io.File;导入 java.io.FileReader;导入 java.util.regex.Matcher;导入 java.util.regex.Pattern;公共类 Demo0 { public static void main(String[ ] args)throws Exception { BufferedReader buff=new BufferedReader(new FileReader("D:"+File.separator+"test.txt")); 字符串行=空;字符串正则表达式="\\w+@\\w+(\\ .\\w+)+"; 模式 p=pile(正则表达式); while ((line=buff.readLine())!= null) { Matcher m=p.matcher(line); while (m.find()) { System.out.println(m.group()+";"); } } }} 查看全部
php网页抓取图片(JAVA网站一个页面上的全部邮箱为例来做具体说明)
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动从万维网上爬取信息的程序或脚本。今天,我们就以JAVA抓取一个页面网站上的所有邮箱为例,做一个具体的讲解。人们一直很懒惰,不再制作GUI。让我们看看并理解其原理。
————————————————————————————————————————————————————— —
最好在百度上找个网页,多想想。本次以贴吧网页点击打开链接为例进行说明。
从图片和网页可以看出,上面有很多邮箱。我大致看了十几页,大概有几百页。如果你是房东,你一定很难处理。如果你一个一个地发送它们,那将是太多的工作。一个一个地复制一个邮箱真的很累。但是,如果你不发布它,你肯定会被你的朋友所鄙视。
怎么做?当然,如果有一个工具可以自动识别网页上的邮箱并进行检索就好了……他是一个网络爬虫,但是他按照一定的规则来爬取网页数据,(像百度,谷歌做SEO大多是网页数据的抓取和分析)并保存这些数据,方便数据处理和使用。废话太多,去教程吧。————————————————————————————————————————————————————— — 思想分析:1.要从网页获取数据,必须获取到该网页的链接
2.为了在网页上获取邮箱地址,必须有相应的邮箱地址获取规则
3.为了移除数据,必须通过数据相关类的操作来获取
4.为了保存数据,必须实现保存数据的操作———————————————————————————————— ———————— ——————————————
接下来代码。
打包工具;导入 java.io.BufferedReader;导入 java.io.File;导入 java.io.FileWriter;导入 java.io.InputStreamReader;导入 java.io.Writer;导入 .URL;导入 .URLConnection;导入 java.sql .Time;import java.util.Scanner;import java.util.regex.Matcher;import java.util.regex.Pattern;public class Demo { public static void main(String[] args) throws Exception {// 这个程序里面异常太多为简单起见,不要尝试直接扔给虚拟机 Long StartTime = System.currentTimeMillis(); System.out.println("-- 欢迎使用飞扬简易爬虫--"); System.out.println(""); System.out.println("--请输入正确的网址如"); Scanner input = new Scanner(System.in);// 实例化键盘输入类 String webaddress = input.next();
URLConnection conn = url.openConnection();// 获取链接 BufferedReader buff = new BufferedReader(new InputStreamReader( conn.getInputStream()));// 获取网页数据 String line = null; 诠释我=0;String regex = "\ \w+@\\w+(\\.\\w+)+";//声明一个正则,提取网页的前提Pattern p = pile(regex);//实例化outWriter.write( "网页收录的邮箱如下所示:\r\n"); while ((line = buff.readLine()) != null) { Matcher m = p.matcher(line);// 进行匹配 while (m.find() ) { i++; outWriter.write(m.group() + ";\r\n");// 输入匹配的字符到目标文件} } Long StopTime = System.currentTimeMillis(); String UseTime=(StopTime- StartTime)+""; outWriter.write("--------------------------------------- ------ ------------\r\n"); outWriter.write(" ); }}); System.out.println(" ————————————————————————\t"); }}); System.out.println(" ————————————————————————\t"); }}
代码如上,每一行都有注释。如果实在不明白,可以联系我。
编译->直接在命令行运行
输入爬取页面的地址。

打开D盘目录,找到test.xt文件。
文件中的邮箱添加了“;” 默认情况下,方便大家发送。

当然,爬取本地文件中的数据更容易
不用过多解释,直接上代码。
导入 java.io.BufferedReader;导入 java.io.File;导入 java.io.FileReader;导入 java.util.regex.Matcher;导入 java.util.regex.Pattern;公共类 Demo0 { public static void main(String[ ] args)throws Exception { BufferedReader buff=new BufferedReader(new FileReader("D:"+File.separator+"test.txt")); 字符串行=空;字符串正则表达式="\\w+@\\w+(\\ .\\w+)+"; 模式 p=pile(正则表达式); while ((line=buff.readLine())!= null) { Matcher m=p.matcher(line); while (m.find()) { System.out.println(m.group()+";"); } } }}
php网页抓取图片(php网页抓取图片已有多种方法:javascriptjquerypythonphp都能实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-25 04:06
php网页抓取图片已有多种方法:javascriptjquerypythonphp都能实现。这里介绍使用php的。流程:1.抓取分析图片2.解析获取地址、图片资源以及restfulapi3.爬取持久化图片解析的方法主要有:1.图片imagetoken2.selenium3.浏览器请求请求获取网页源码网页传输消息etc注意事项1.被请求的http协议方向可能不一样2.图片格式需求(jpg,bmp,png,mp4,gif,jpg,png等)以上仅仅根据实际需求作的一个总结和整理,详细的实现和php原理还有一点就是web的多媒体协议,欢迎补充和探讨。
这种问题问度娘绝对有结果,没必要问这种话题。
我用这里给出的答案做了个爬虫图片
php,图片的话看你是要和谁互相传递的
图片是用http,和图片分类完全是2个东西,
网页上有一种图片爬虫工具,比你这种写法简单很多,
1.php可以直接解析返回数据,图片分类的数据,最重要的是可以发布到站外。
目前moocs学习网站还是有比较有价值的图片资源,如清华大学图书馆,都是免费给学生进行图片处理使用的。下面分享下我们最近针对这类资源处理工作所总结的处理思路和用法。 查看全部
php网页抓取图片(php网页抓取图片已有多种方法:javascriptjquerypythonphp都能实现)
php网页抓取图片已有多种方法:javascriptjquerypythonphp都能实现。这里介绍使用php的。流程:1.抓取分析图片2.解析获取地址、图片资源以及restfulapi3.爬取持久化图片解析的方法主要有:1.图片imagetoken2.selenium3.浏览器请求请求获取网页源码网页传输消息etc注意事项1.被请求的http协议方向可能不一样2.图片格式需求(jpg,bmp,png,mp4,gif,jpg,png等)以上仅仅根据实际需求作的一个总结和整理,详细的实现和php原理还有一点就是web的多媒体协议,欢迎补充和探讨。
这种问题问度娘绝对有结果,没必要问这种话题。
我用这里给出的答案做了个爬虫图片
php,图片的话看你是要和谁互相传递的
图片是用http,和图片分类完全是2个东西,
网页上有一种图片爬虫工具,比你这种写法简单很多,
1.php可以直接解析返回数据,图片分类的数据,最重要的是可以发布到站外。
目前moocs学习网站还是有比较有价值的图片资源,如清华大学图书馆,都是免费给学生进行图片处理使用的。下面分享下我们最近针对这类资源处理工作所总结的处理思路和用法。
php网页抓取图片(php网页抓取图片功能需要考虑几个因素?不需要解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-24 00:04
php网页抓取图片功能,可以说是一个单一的网站的标配了,你会需要用到很多功能,因为你会同时需要做数据存储,数据抓取,网页解析,网页分析,并不是说我们想不到这些功能,而是需要分步骤去实现。当我们爬取别人网站的数据时,可能需要考虑几个因素1,从哪里开始2,去哪里获取3,怎么样保证数据准确性4,重复率会不会很高不重复率肯定不是php网页抓取图片功能的关键因素,重复率一般情况是比较低的,但是对于每个网站来说就不一定了,对于某些网站(例如新浪微博),是会有特殊要求的。
另外:网页要不要加密实时性也会影响,如果网页都是经过加密处理过的,抓取的文件肯定会增加很多东西。总的来说php网页抓取图片功能用到的库还是很多的,你不可能会给你一个刚入门的新手所能接触到的各种封装好的库,只能靠自己去扩展了。
php就是python的简化版,
php有模板引擎,js插件,能做一些简单的轮播动画,css3选择器。再加上原始图片不会加密处理。所以可以做轮播类的静态图,也就是上述三项大概占两项以内的重复问题。不需要解析网页数据。
单做出一个xxx.php测试完别人所有的网站,确定哪些我的代码没写对,哪些别人的代码没有做出来,哪些是错误代码,剩下的的按照实际情况再动手吧,php转java的话, 查看全部
php网页抓取图片(php网页抓取图片功能需要考虑几个因素?不需要解析)
php网页抓取图片功能,可以说是一个单一的网站的标配了,你会需要用到很多功能,因为你会同时需要做数据存储,数据抓取,网页解析,网页分析,并不是说我们想不到这些功能,而是需要分步骤去实现。当我们爬取别人网站的数据时,可能需要考虑几个因素1,从哪里开始2,去哪里获取3,怎么样保证数据准确性4,重复率会不会很高不重复率肯定不是php网页抓取图片功能的关键因素,重复率一般情况是比较低的,但是对于每个网站来说就不一定了,对于某些网站(例如新浪微博),是会有特殊要求的。
另外:网页要不要加密实时性也会影响,如果网页都是经过加密处理过的,抓取的文件肯定会增加很多东西。总的来说php网页抓取图片功能用到的库还是很多的,你不可能会给你一个刚入门的新手所能接触到的各种封装好的库,只能靠自己去扩展了。
php就是python的简化版,
php有模板引擎,js插件,能做一些简单的轮播动画,css3选择器。再加上原始图片不会加密处理。所以可以做轮播类的静态图,也就是上述三项大概占两项以内的重复问题。不需要解析网页数据。
单做出一个xxx.php测试完别人所有的网站,确定哪些我的代码没写对,哪些别人的代码没有做出来,哪些是错误代码,剩下的的按照实际情况再动手吧,php转java的话,
php网页抓取图片(Python爬虫()实战之爬取())
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-23 21:13
之前的传送门:
小白学Python爬虫(1):开
小白学Python爬虫(2):前期准备(一)基础类库安装)
小白学Python爬虫(3):前期准备(二)Linux基础介绍)
小白学习Python爬虫(4):前期准备(三)Docker基础介绍)
小白学Python爬虫(5):前期准备(四)数据库基础)
小白学习Python爬虫(6):前期准备(五)爬虫框架的安装)
小白学习Python爬虫(7):HTTP基础
小白学Python爬虫(8):网页基础
小白学习Python爬虫(9):爬虫基础
小白学习Python爬虫(一0):Session和Cookies
小白学Python爬虫(一1):urllib的基本使用(一)
小白学习Python爬虫(一2):urllib的基本使用(二)
小白学Python爬虫(一3):urllib的基本使用(三)
小白学习Python爬虫(14):urllib(四))的基本使用
小白学习Python爬虫(一5):urllib的基本使用(五)
小白学Python爬虫(一6):urllib实战爬虫图)
小白学习Python爬虫(一7):Requests的基本使用)
小白学Python爬虫(18):请求高级操作
小白学Python爬虫(一9):Xpath基础操作
小白学Python爬虫(20):Xpath进阶
小白学Python爬虫(二1):分析库美汤(上))
小白学Python爬虫(二2):分析库美汤(下))
小白学Python爬虫(二3):解析库pyquery简介
小白学Python爬虫(24):2019豆瓣电影排行榜
介绍
上一篇实战最后没有使用页面元素分析,感觉有点遗憾,不过最后的片单还是挺香的,真心推荐。
本次选题是先写代码再写文章,肯定可以用于页面元素分析,还需要对网站的数据加载有一定的分析,才能得到最终数据,和小编找到的两个数据源没有IP访问限制,质量有保障。绝对是小白修炼的绝佳选择。
郑重声明:本文仅供学习及其他用途。
分析
首先,要爬取股票数据,首先要知道有哪些股票。在这里,小编发现了一个网站,而这个网站有一个股票代码列表:.
打开Chrome的开发者模式,一一选择代码。具体过程这里就不贴了,同学们可以自己实现。
我们可以将所有股票代码存储在一个列表中,剩下的就是找到一个网站,然后循环获取每只股票的数据。
这个网站编辑器已经找到了,是同花顺,链接:。
聪明的同学一定都发现,这个链接里的000001就是股票代码。
接下来,我们只需要拼接这个链接,就可以不断得到我们想要的数据。
实战
首先介绍一下本次实战用到的请求库和解析库:Requests和pyquery。数据存储终于落地Mysql。
获取股票代码列表
第一步当然是建立一个股票代码列表。我们先定义一个方法:
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
把上面的链接作为参数传入,大家可以自己运行看看结果,小编这里就不贴结果了,有点长。. .
获取详细数据
详细信息的数据似乎在页面上,但实际上并不存在。最终获取数据的实际地方不是页面,而是数据接口。
http://qd.10jqka.com.cn/quote. ... 00001
至于怎么找,小编这次就不多说了。还是希望所有想学爬虫的同学都能自己动手,去找找吧。多找几遍,自然会找到路。
既然有了数据接口,我们再来看看返回的数据:
showStockDate({"info":{"000001":{"name":"\u5e73\u5b89\u94f6\u884c"}},"data":{"000001":{"10":"16.13","8":"16.14","9":"15.87","13":"78795234.00","19":"1262802470.00","7":"16.12","15":"40225508.00","14":"37528826.00","69":"17.73","70":"14.51","12":"5","17":"945400.00","264648":"0.010","199112":"0.062","1968584":"0.406","2034120":"9.939","1378761":"16.026","526792":"1.675","395720":"-948073.000","461256":"-39.763","3475914":"313014790000.000","1771976":"1.100","6":"16.12","11":""}}})
显然,这个结果并不是标准的json数据,而是JSONP返回的标准格式数据。这里我们先对head和tail进行处理,变成标准的json数据,然后针对本页的数据进行解析,最后将解析后的值写入数据库。
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
这里我们添加异常处理,因为这次爬取的数据很多,很可能会因为某种原因抛出异常。当然,我们不想在出现异常的时候中断数据采集,所以在这里添加异常处理,继续采集数据。
完整代码
我们将代码稍微封装一下来完成这个实战。
import requests
import re
import json
from pyquery import PyQuery
import pymysql
# 数据库连接
def connect():
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
password='password',
database='test',
charset='utf8mb4')
# 获取操作游标
cursor = conn.cursor()
return {"conn": conn, "cursor": cursor}
connection = connect()
conn, cursor = connection['conn'], connection['cursor']
sql_insert = "insert into stock(code, name, jinkai, chengjiaoliang, zhenfu, zuigao, chengjiaoe, huanshou, zuidi, zuoshou, liutongshizhi, create_date) values (%(code)s, %(name)s, %(jinkai)s, %(chengjiaoliang)s, %(zhenfu)s, %(zuigao)s, %(chengjiaoe)s, %(huanshou)s, %(zuidi)s, %(zuoshou)s, %(liutongshizhi)s, now())"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
def main():
stock_list_url = 'https://hq.gucheng.com/gpdmylb.html'
stock_info_url = 'http://qd.10jqka.com.cn/quote. ... 39%3B
list = get_stock_list(stock_list_url)
# list = ['601766']
getStockInfo(list, stock_info_url)
if __name__ == '__main__':
main()
成就
最终,编辑器用了15分钟左右,成功捕获了4600+条数据,结果就不显示了。
示例代码
为了您的方便,本系列中的所有代码编辑器都将放在代码管理存储库 Github 和 Gitee 上。
示例代码 - Github
示例代码 - Gitee 查看全部
php网页抓取图片(Python爬虫()实战之爬取())
之前的传送门:
小白学Python爬虫(1):开
小白学Python爬虫(2):前期准备(一)基础类库安装)
小白学Python爬虫(3):前期准备(二)Linux基础介绍)
小白学习Python爬虫(4):前期准备(三)Docker基础介绍)
小白学Python爬虫(5):前期准备(四)数据库基础)
小白学习Python爬虫(6):前期准备(五)爬虫框架的安装)
小白学习Python爬虫(7):HTTP基础
小白学Python爬虫(8):网页基础
小白学习Python爬虫(9):爬虫基础
小白学习Python爬虫(一0):Session和Cookies
小白学Python爬虫(一1):urllib的基本使用(一)
小白学习Python爬虫(一2):urllib的基本使用(二)
小白学Python爬虫(一3):urllib的基本使用(三)
小白学习Python爬虫(14):urllib(四))的基本使用
小白学习Python爬虫(一5):urllib的基本使用(五)
小白学Python爬虫(一6):urllib实战爬虫图)
小白学习Python爬虫(一7):Requests的基本使用)
小白学Python爬虫(18):请求高级操作
小白学Python爬虫(一9):Xpath基础操作
小白学Python爬虫(20):Xpath进阶
小白学Python爬虫(二1):分析库美汤(上))
小白学Python爬虫(二2):分析库美汤(下))
小白学Python爬虫(二3):解析库pyquery简介
小白学Python爬虫(24):2019豆瓣电影排行榜
介绍
上一篇实战最后没有使用页面元素分析,感觉有点遗憾,不过最后的片单还是挺香的,真心推荐。
本次选题是先写代码再写文章,肯定可以用于页面元素分析,还需要对网站的数据加载有一定的分析,才能得到最终数据,和小编找到的两个数据源没有IP访问限制,质量有保障。绝对是小白修炼的绝佳选择。
郑重声明:本文仅供学习及其他用途。
分析
首先,要爬取股票数据,首先要知道有哪些股票。在这里,小编发现了一个网站,而这个网站有一个股票代码列表:.
打开Chrome的开发者模式,一一选择代码。具体过程这里就不贴了,同学们可以自己实现。
我们可以将所有股票代码存储在一个列表中,剩下的就是找到一个网站,然后循环获取每只股票的数据。
这个网站编辑器已经找到了,是同花顺,链接:。
聪明的同学一定都发现,这个链接里的000001就是股票代码。
接下来,我们只需要拼接这个链接,就可以不断得到我们想要的数据。
实战
首先介绍一下本次实战用到的请求库和解析库:Requests和pyquery。数据存储终于落地Mysql。
获取股票代码列表
第一步当然是建立一个股票代码列表。我们先定义一个方法:
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
把上面的链接作为参数传入,大家可以自己运行看看结果,小编这里就不贴结果了,有点长。. .
获取详细数据
详细信息的数据似乎在页面上,但实际上并不存在。最终获取数据的实际地方不是页面,而是数据接口。
http://qd.10jqka.com.cn/quote. ... 00001
至于怎么找,小编这次就不多说了。还是希望所有想学爬虫的同学都能自己动手,去找找吧。多找几遍,自然会找到路。
既然有了数据接口,我们再来看看返回的数据:
showStockDate({"info":{"000001":{"name":"\u5e73\u5b89\u94f6\u884c"}},"data":{"000001":{"10":"16.13","8":"16.14","9":"15.87","13":"78795234.00","19":"1262802470.00","7":"16.12","15":"40225508.00","14":"37528826.00","69":"17.73","70":"14.51","12":"5","17":"945400.00","264648":"0.010","199112":"0.062","1968584":"0.406","2034120":"9.939","1378761":"16.026","526792":"1.675","395720":"-948073.000","461256":"-39.763","3475914":"313014790000.000","1771976":"1.100","6":"16.12","11":""}}})
显然,这个结果并不是标准的json数据,而是JSONP返回的标准格式数据。这里我们先对head和tail进行处理,变成标准的json数据,然后针对本页的数据进行解析,最后将解析后的值写入数据库。
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
这里我们添加异常处理,因为这次爬取的数据很多,很可能会因为某种原因抛出异常。当然,我们不想在出现异常的时候中断数据采集,所以在这里添加异常处理,继续采集数据。
完整代码
我们将代码稍微封装一下来完成这个实战。
import requests
import re
import json
from pyquery import PyQuery
import pymysql
# 数据库连接
def connect():
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
password='password',
database='test',
charset='utf8mb4')
# 获取操作游标
cursor = conn.cursor()
return {"conn": conn, "cursor": cursor}
connection = connect()
conn, cursor = connection['conn'], connection['cursor']
sql_insert = "insert into stock(code, name, jinkai, chengjiaoliang, zhenfu, zuigao, chengjiaoe, huanshou, zuidi, zuoshou, liutongshizhi, create_date) values (%(code)s, %(name)s, %(jinkai)s, %(chengjiaoliang)s, %(zhenfu)s, %(zuigao)s, %(chengjiaoe)s, %(huanshou)s, %(zuidi)s, %(zuoshou)s, %(liutongshizhi)s, now())"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
def main():
stock_list_url = 'https://hq.gucheng.com/gpdmylb.html'
stock_info_url = 'http://qd.10jqka.com.cn/quote. ... 39%3B
list = get_stock_list(stock_list_url)
# list = ['601766']
getStockInfo(list, stock_info_url)
if __name__ == '__main__':
main()
成就
最终,编辑器用了15分钟左右,成功捕获了4600+条数据,结果就不显示了。
示例代码
为了您的方便,本系列中的所有代码编辑器都将放在代码管理存储库 Github 和 Gitee 上。
示例代码 - Github
示例代码 - Gitee
php网页抓取图片(php网页抓取图片数据接口来源于官方javascript网页调用apijs数据爬取图片的网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-22 19:07
<p>php网页抓取图片数据图片数据接口来源于官方javascript网页调用api抓取js数据爬取图片的网站:imgurlhttpcache只需抓取api数据,仅需了解javascriptapi规则即可完成抓取(默认抓取格式为图片数据)imgurl 查看全部
php网页抓取图片(php网页抓取图片数据接口来源于官方javascript网页调用apijs数据爬取图片的网站)
<p>php网页抓取图片数据图片数据接口来源于官方javascript网页调用api抓取js数据爬取图片的网站:imgurlhttpcache只需抓取api数据,仅需了解javascriptapi规则即可完成抓取(默认抓取格式为图片数据)imgurl
php网页抓取图片(经典PHP加密解密函数Authcode()修复版代码讲述)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-13 02:31
本文的例子描述了php获取网页中所有图片并存储到数组中的方法。分享给大家,供大家参考。详情如下:
$images = array();preg_match_all("/(img|src)=("|")[^"">]+/i", $data, $media);unset($data);$data=preg_replace("/(img|src)("|"|="|=")(.*)/i","$3",$media[0]);foreach($data as $url){ $info = pathinfo($url); if (isset($info["extension"])) { if (($info["extension"] == "jpg") || ($info["extension"] == "jpeg") || ($info["extension"] == "gif") || ($info["extension"] == "png")) array_push($images, $url); }}
我希望这篇文章对你的 php 编程有所帮助。
TAG标签:php方法获取网页中的所有图片并存储在数组中
一白互联网是国内知名的网站建设品牌服务商。我们在网站 建设、网站 制作、网页设计、php 开发、域名注册和虚拟主机服务方面拥有九年的经验。所提供的自助建站服务更是享誉全国。近年来,还整合团队优势,自主研发可视化多用户《点云站建站系统》3.0平台版,拖放排版网站制作设计,轻松实现PC站、手机微网站、小程序、APP一体化网络营销网站建设,已成功为全国数百家网络公司提供自助平台搭建服务。
上一篇:如何在 CodeIgniter 中删除和设置 cookie | 下一篇:经典PHP加解密函数Authcode()修复版代码 查看全部
php网页抓取图片(经典PHP加密解密函数Authcode()修复版代码讲述)
本文的例子描述了php获取网页中所有图片并存储到数组中的方法。分享给大家,供大家参考。详情如下:
$images = array();preg_match_all("/(img|src)=("|")[^"">]+/i", $data, $media);unset($data);$data=preg_replace("/(img|src)("|"|="|=")(.*)/i","$3",$media[0]);foreach($data as $url){ $info = pathinfo($url); if (isset($info["extension"])) { if (($info["extension"] == "jpg") || ($info["extension"] == "jpeg") || ($info["extension"] == "gif") || ($info["extension"] == "png")) array_push($images, $url); }}
我希望这篇文章对你的 php 编程有所帮助。
TAG标签:php方法获取网页中的所有图片并存储在数组中
一白互联网是国内知名的网站建设品牌服务商。我们在网站 建设、网站 制作、网页设计、php 开发、域名注册和虚拟主机服务方面拥有九年的经验。所提供的自助建站服务更是享誉全国。近年来,还整合团队优势,自主研发可视化多用户《点云站建站系统》3.0平台版,拖放排版网站制作设计,轻松实现PC站、手机微网站、小程序、APP一体化网络营销网站建设,已成功为全国数百家网络公司提供自助平台搭建服务。
上一篇:如何在 CodeIgniter 中删除和设置 cookie | 下一篇:经典PHP加解密函数Authcode()修复版代码
php网页抓取图片(php网页抓取图片的话我推荐我的电脑软件“赛优采云科技”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-04 12:02
php网页抓取图片的话我推荐我的电脑软件“赛优采云科技”~主要是获取http服务器返回的数据,速度比python和ruby、selenium都要快很多,网页抓取和网页分析、网络爬虫分离,操作非常简单,
python入门的话推荐/
requests或者beautifulsoup。
推荐python3-pil-webdriver-7.4.1-windows-x64-py3-gcc.exe
没有,你去看书自己看吧,推荐几本书吧:python编程:从入门到实践(这本书非常棒,可以作为python入门的教材)python编程——从入门到实践2(写的比较好,适合python入门教材)pythonfordataanalysis:amodernapproachandguide(这本也很好,比第一本好)pythonessentials(这个不错,看过,可以作为linux下python开发的教材)如果是初学者,那么最好看网上的教程,这个比较适合入门。
python的相关资料太多了,任何一本入门书上的示例代码在网上都可以找到,我当时第一本看的书就是array和map总是搞混,看过第二本后好一些,你要看书,要找经典的书看,能让你有信心看下去。
我当时看了
1、
2、
3、4,综合来说,推荐看python2.x的书籍,很多框架都是2.x的,看官方文档就好了。个人觉得1.x的书籍内容还是比较多的,基本覆盖python的所有知识。2.x的书籍侧重点也不同,像3.x的书籍,注重的是编程语言,像python3.x的书籍,更侧重python的算法等,内容也更专业。看你的学习方式是先过一遍python语言本身,学一些python的框架,如numpy、pandas等,如果要深入,可以去看一些python基础的教程,python入门很简单的。 查看全部
php网页抓取图片(php网页抓取图片的话我推荐我的电脑软件“赛优采云科技”)
php网页抓取图片的话我推荐我的电脑软件“赛优采云科技”~主要是获取http服务器返回的数据,速度比python和ruby、selenium都要快很多,网页抓取和网页分析、网络爬虫分离,操作非常简单,
python入门的话推荐/
requests或者beautifulsoup。
推荐python3-pil-webdriver-7.4.1-windows-x64-py3-gcc.exe
没有,你去看书自己看吧,推荐几本书吧:python编程:从入门到实践(这本书非常棒,可以作为python入门的教材)python编程——从入门到实践2(写的比较好,适合python入门教材)pythonfordataanalysis:amodernapproachandguide(这本也很好,比第一本好)pythonessentials(这个不错,看过,可以作为linux下python开发的教材)如果是初学者,那么最好看网上的教程,这个比较适合入门。
python的相关资料太多了,任何一本入门书上的示例代码在网上都可以找到,我当时第一本看的书就是array和map总是搞混,看过第二本后好一些,你要看书,要找经典的书看,能让你有信心看下去。
我当时看了
1、
2、
3、4,综合来说,推荐看python2.x的书籍,很多框架都是2.x的,看官方文档就好了。个人觉得1.x的书籍内容还是比较多的,基本覆盖python的所有知识。2.x的书籍侧重点也不同,像3.x的书籍,注重的是编程语言,像python3.x的书籍,更侧重python的算法等,内容也更专业。看你的学习方式是先过一遍python语言本身,学一些python的框架,如numpy、pandas等,如果要深入,可以去看一些python基础的教程,python入门很简单的。
php网页抓取图片(Python中有多个多个类型的页面对象用子类属性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-12-29 09:03
此类元素用于标识产品页面,即使爬虫对相关产品的内容不感兴趣。
为了跟踪多种页面类型,您需要在 Python 中拥有多种类型的页面对象。这是通过两种方式实现的。
如果页面相似(它们的内容类型基本相同),则可能需要在现有页面对象中添加 pageType 属性:
class Website: """所有文章/网页的共同基类""" def __init__(self, type, name, url, searchUrl, resultListing, resultUrl, absoluteUrl, titleTag, bodyTag): self.name = name self.url = url self.titleTag = titleTag self.bodyTag = bodyTag self.pageType = pageType
如果在类 SQL 的数据库中对这些页面进行排序,则此模式类型意味着这些页面应存储在同一个表中,并添加了一个额外的 pageType 列。
如果抓取不同的页面或内容(它们收录
不同类型的字段),则需要为每种页面类型创建一个新对象。当然,有些东西是所有网页共有的——它们都有一个 URL,它们也可能有一个名称或页面标题。这种情况非常适合子类:
class Website: """所有文章/网页的共同基类""" def __init__(self, name, url, titleTag): self.name = name self.url = url self.titleTag = titleTag
这不是您的爬虫直接使用的对象,而是您的页面类型将引用的对象:
class Product(Website): """产品页面要抓取的信息""" def __init__(self, name, url, titleTag, productNumber, price): Website.__init__(self, name, url, TitleTag) self.productNumberTag = productNumberTag self.priceTag = priceTag class Article(Website): """文章页面要抓取的信息""" def __init__(self, name, url, titleTag, bodyTag, dateTag): Website.__init__(self, name, url, titleTag) self.bodyTag = bodyTag self.dateTag = dateTag
该产品页面扩展了Website 基类,增加了仅适用于产品的productNumber 和price 属性,而Article 类增加了不适用于产品的body 和date 属性。
您可以使用这两个类别来抓取商店网站,其中除了产品之外还可能收录
博客文章或新闻稿。
希望以上知识点可以帮助到大家,也感谢各位攻城狮对我的支持。 查看全部
php网页抓取图片(Python中有多个多个类型的页面对象用子类属性)
此类元素用于标识产品页面,即使爬虫对相关产品的内容不感兴趣。
为了跟踪多种页面类型,您需要在 Python 中拥有多种类型的页面对象。这是通过两种方式实现的。
如果页面相似(它们的内容类型基本相同),则可能需要在现有页面对象中添加 pageType 属性:
class Website: """所有文章/网页的共同基类""" def __init__(self, type, name, url, searchUrl, resultListing, resultUrl, absoluteUrl, titleTag, bodyTag): self.name = name self.url = url self.titleTag = titleTag self.bodyTag = bodyTag self.pageType = pageType
如果在类 SQL 的数据库中对这些页面进行排序,则此模式类型意味着这些页面应存储在同一个表中,并添加了一个额外的 pageType 列。
如果抓取不同的页面或内容(它们收录
不同类型的字段),则需要为每种页面类型创建一个新对象。当然,有些东西是所有网页共有的——它们都有一个 URL,它们也可能有一个名称或页面标题。这种情况非常适合子类:
class Website: """所有文章/网页的共同基类""" def __init__(self, name, url, titleTag): self.name = name self.url = url self.titleTag = titleTag
这不是您的爬虫直接使用的对象,而是您的页面类型将引用的对象:
class Product(Website): """产品页面要抓取的信息""" def __init__(self, name, url, titleTag, productNumber, price): Website.__init__(self, name, url, TitleTag) self.productNumberTag = productNumberTag self.priceTag = priceTag class Article(Website): """文章页面要抓取的信息""" def __init__(self, name, url, titleTag, bodyTag, dateTag): Website.__init__(self, name, url, titleTag) self.bodyTag = bodyTag self.dateTag = dateTag
该产品页面扩展了Website 基类,增加了仅适用于产品的productNumber 和price 属性,而Article 类增加了不适用于产品的body 和date 属性。
您可以使用这两个类别来抓取商店网站,其中除了产品之外还可能收录
博客文章或新闻稿。
希望以上知识点可以帮助到大家,也感谢各位攻城狮对我的支持。
php网页抓取图片(桌面壁纸电脑桌面壁纸高清壁纸大全下载(二):将图片下载到本地有了图片链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-12-28 04:22
)
一:目标站点信息
卞桌面网站为:桌面壁纸,电脑桌面壁纸,高清壁纸,下载,桌面背景图片,卞桌面
2:目标站点分析
(1): 构建页面的 URL 列表
我们需要做的是抓取网站上给定数量页面的图片,所以我们首先需要观察每个页面的链接之间的关系,然后构建一个需要抓取的URL列表。
第一页的链接:http://www.netbian.com/
第二页的链接:http://www.netbian.com/index_2.htm
可以看到第二页后面的页面链接只是和后面的数字不同,我们可以写一个简单的代码来获取页面的url列表
# 页面链接的初始化列表
page_links_list=['http://www.netbian.com/']
#获取爬取的页数和页面链接
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
print(page_links_list)
请输入你想爬取的页数:5
['http://www.netbian.com/', 'http://www.netbian.com/index_2.htm', 'http://www.netbian.com/index_3.htm', 'http://www.netbian.com/index_4.htm', 'http://www.netbian.com/index_5.htm']
(2): 获取一个页面上所有图片的链接
我们已经获取了所有页面的链接,但是还没有获取到每张图片的链接,那么接下来我们要做的就是获取一个页面中所有图片的链接。这里以第一页为例,获取每张图片的链接,其他页面类似。
首先右击页面->查看元素,然后点击查看器左侧的小光标,然后将鼠标放在随机一张图片上,这样就可以定位到图片的代码位置;我们可以知道每个页面有18张图片。接下来,我们需要使用标签来定位图片在页面上的具体位置。如下图所示,我们使用 div.list li a img 来精确定位 18 个 img 标签。img 标签收录
我们需要的图片链接。
接下来我们以第一页为例,获取每张图片的链接。
#python3 -m pip install bs4
#python3 -m pip install lxml
import requests
from bs4 import BeautifulSoup
# 页面链接的初始化列表
url='http://www.netbian.com/'
# 图片链接列表
img_links_list = []
#获取img标签,在获取图片链接
html = requests.get(url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
for img in imgs:
img_link = img['src']
img_links_list.append(img_link)
print(img_links_list)
print(len(img_links_list))
['http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B]
18
(3): 下载图片到本地
有了图片链接后,我们需要将图片下载到本地,这里以第一张图片为例进行下载
import urllib.request
url='http://img.netbian.com/file/20 ... 39%3B
urllib.request.urlretrieve(url, filename='test.jpg')
(4): 一个简单的获取图片的爬虫
结合以上三部分,构建页面的url列表,获取一个页面中的所有图片链接,将图片下载到本地。构建一个完整但效率低下的爬虫。
import requests
from bs4 import BeautifulSoup
import lxml
import urllib
import os
import time
#获取图片并下载到本地
def GetImages(url):
html=requests.get(url, timeout = 2).content.decode('gbk')
soup=BeautifulSoup(html,'lxml')
imgs=soup.select("div.list li a img")
for img in imgs:
link=img['src']
display=link.split('/')[-1]
print('正在下载:',display)
filename='./images/'+display
urllib.request.urlretrieve(link,filename)
#获取爬取的页数,返回链接数
def GetUrls(page_links_list):
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
if __name__ == '__main__':
page_links_list=['http://www.netbian.com/']
GetUrls(page_links_list)
os.mkdir('./images')
print("开始下载图片!!!")
start = time.time()
for url in page_links_list:
GetImages(url)
print('图片下载成功!!!')
end = time.time() - start
print('消耗时间为:', end)
请输入你想爬取的页数:5
开始下载图片!!!
正在下载: smalle213d95e54c5b4fb355b710a473292ea1566035585.jpg
正在下载: small15ca224d7c4c119affe2cfd2d811862e1566035332.jpg
正在下载: 604a688cd6f79161236e6250189bc25b.jpg
正在下载: smallab7249d18e67c9336109e3bedc094f381566034907.jpg
正在下载: small5816e940e6957f7db5e499de9978bda41566031298.jpg
正在下载: smalladda3febb072e9103f8f06f27dcb19c21566031139.jpg
正在下载: small0e9f43492debe6dc2ce7a3e6cc48c1ad1566030965.jpg
正在下载: smallcfd5b4c6fa10ffcbcdcc8b1b9e6db91a1566030209.jpg
。。。。。。
图片下载成功!!!
消耗时间为: 21.575999975204468
上面这部分代码完全可以运行,但是效率不高,因为是下载图片,需要排队一一下载。因此,为了解决这个问题,下面的代码使用多线程来实现图片的抓取和下载。
(5)使用Python多线程抓取图片并下载到本地
对于多线程,我们使用 Python 自带的线程模块。我们使用称为生产者和消费者的模型。生产者专门用于从每个页面中获取图片的下载链接并将其存储在全局列表中。消费者专门从这个全局列表中提取图像链接以供下载。
需要注意的是,在多线程中使用全局变量需要使用锁来保证数据的一致性。
import urllib
import threading
from bs4 import BeautifulSoup
import requests
import os
import time
import lxml
# 页面链接的初始化列表
page_links_list=['http://www.netbian.com/']
# 图片链接列表
img_links_list = []
#获取爬取的页数和页面链接
def GetUrls(page_links_list):
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
#初始化锁,创建一把锁
gLock=threading.Lock()
#生产者,负责从每个页面中获取图片的链接
class Producer(threading.Thread):
def run(self):
while len(page_links_list)>0:
#上锁
gLock.acquire()
#默认取出列表中的最后一个元素
page_url=page_links_list.pop()
#释放锁
gLock.release()
#获取img标签
html = requests.get(page_url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
#加锁3
gLock.acquire()
for img in imgs:
img_link = img['src']
img_links_list.append(img_link)
#释放锁
gLock.release()
#print(len(img_links_list))
#消费者,负责从获取的图片链接中下载图片
class Consumer(threading.Thread,):
def run(self):
print("%s is running"%threading.current_thread())
while True:
#print(len(img_links_list))
#上锁
gLock.acquire()
if len(img_links_list)==0:
#不管什么情况,都要释放锁
gLock.release()
continue
else:
img_url=img_links_list.pop()
#print(img_links_list)
gLock.release()
filename=img_url.split('/')[-1]
print('正在下载:', filename)
path = './images/'+filename
urllib.request.urlretrieve(img_url, filename=path)
if len(img_links_list)==0:
end=time.time()
print("消耗的时间为:", (end - start))
exit()
if __name__ == '__main__':
GetUrls(page_links_list)
os.mkdir('./images')
start=time.time()
# 5个生产者线程,去从页面中爬取图片链接
for x in range(5):
Producer().start()
# 10个消费者线程,去从中提取下载链接,然后下载
for x in range(10):
Consumer().start()
请输入你想爬取的页数:5
is running
is running
is running
is running
is running
is running
is running
is running
is running
is running
正在下载: small9e75d6ac9506efe1d87e96062791fb261564149099.jpg
正在下载: small02961cac5e02a901b77779eaed43c6f91564156941.jpg
正在下载: small117c84b2f427c981bf33184c1c5c4bb91564193581.jpg
正在下载: smallfedb420af6f753512c169021587982621564455847.jpg
正在下载: small14d3739bf11dd92055abb56e3f792d3f1564456102.jpg
正在下载: smallaf755644af7d114d4cbf36fbe0e84d0c1564456347.jpg
正在下载: small9f7af6d0e2372a4d9e536d8ea9fc40341564456537.jpg
。。。。。。
消耗的时间为: 1.635000228881836 #分别是10个进程结束的时间
消耗的时间为: 1.6419999599456787
消耗的时间为: 1.6560001373291016
消耗的时间为: 1.684000015258789
消耗的时间为: 1.7009999752044678
消耗的时间为: 1.7030000686645508
消耗的时间为: 1.7060000896453857
消耗的时间为: 1.7139999866485596
消耗的时间为: 1.7350001335144043
消耗的时间为: 1.748000144958496 查看全部
php网页抓取图片(桌面壁纸电脑桌面壁纸高清壁纸大全下载(二):将图片下载到本地有了图片链接
)
一:目标站点信息
卞桌面网站为:桌面壁纸,电脑桌面壁纸,高清壁纸,下载,桌面背景图片,卞桌面
2:目标站点分析
(1): 构建页面的 URL 列表
我们需要做的是抓取网站上给定数量页面的图片,所以我们首先需要观察每个页面的链接之间的关系,然后构建一个需要抓取的URL列表。
第一页的链接:http://www.netbian.com/
第二页的链接:http://www.netbian.com/index_2.htm
可以看到第二页后面的页面链接只是和后面的数字不同,我们可以写一个简单的代码来获取页面的url列表
# 页面链接的初始化列表
page_links_list=['http://www.netbian.com/']
#获取爬取的页数和页面链接
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
print(page_links_list)
请输入你想爬取的页数:5
['http://www.netbian.com/', 'http://www.netbian.com/index_2.htm', 'http://www.netbian.com/index_3.htm', 'http://www.netbian.com/index_4.htm', 'http://www.netbian.com/index_5.htm']
(2): 获取一个页面上所有图片的链接
我们已经获取了所有页面的链接,但是还没有获取到每张图片的链接,那么接下来我们要做的就是获取一个页面中所有图片的链接。这里以第一页为例,获取每张图片的链接,其他页面类似。
首先右击页面->查看元素,然后点击查看器左侧的小光标,然后将鼠标放在随机一张图片上,这样就可以定位到图片的代码位置;我们可以知道每个页面有18张图片。接下来,我们需要使用标签来定位图片在页面上的具体位置。如下图所示,我们使用 div.list li a img 来精确定位 18 个 img 标签。img 标签收录
我们需要的图片链接。
接下来我们以第一页为例,获取每张图片的链接。
#python3 -m pip install bs4
#python3 -m pip install lxml
import requests
from bs4 import BeautifulSoup
# 页面链接的初始化列表
url='http://www.netbian.com/'
# 图片链接列表
img_links_list = []
#获取img标签,在获取图片链接
html = requests.get(url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
for img in imgs:
img_link = img['src']
img_links_list.append(img_link)
print(img_links_list)
print(len(img_links_list))
['http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B]
18
(3): 下载图片到本地
有了图片链接后,我们需要将图片下载到本地,这里以第一张图片为例进行下载
import urllib.request
url='http://img.netbian.com/file/20 ... 39%3B
urllib.request.urlretrieve(url, filename='test.jpg')
(4): 一个简单的获取图片的爬虫
结合以上三部分,构建页面的url列表,获取一个页面中的所有图片链接,将图片下载到本地。构建一个完整但效率低下的爬虫。
import requests
from bs4 import BeautifulSoup
import lxml
import urllib
import os
import time
#获取图片并下载到本地
def GetImages(url):
html=requests.get(url, timeout = 2).content.decode('gbk')
soup=BeautifulSoup(html,'lxml')
imgs=soup.select("div.list li a img")
for img in imgs:
link=img['src']
display=link.split('/')[-1]
print('正在下载:',display)
filename='./images/'+display
urllib.request.urlretrieve(link,filename)
#获取爬取的页数,返回链接数
def GetUrls(page_links_list):
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
if __name__ == '__main__':
page_links_list=['http://www.netbian.com/']
GetUrls(page_links_list)
os.mkdir('./images')
print("开始下载图片!!!")
start = time.time()
for url in page_links_list:
GetImages(url)
print('图片下载成功!!!')
end = time.time() - start
print('消耗时间为:', end)
请输入你想爬取的页数:5
开始下载图片!!!
正在下载: smalle213d95e54c5b4fb355b710a473292ea1566035585.jpg
正在下载: small15ca224d7c4c119affe2cfd2d811862e1566035332.jpg
正在下载: 604a688cd6f79161236e6250189bc25b.jpg
正在下载: smallab7249d18e67c9336109e3bedc094f381566034907.jpg
正在下载: small5816e940e6957f7db5e499de9978bda41566031298.jpg
正在下载: smalladda3febb072e9103f8f06f27dcb19c21566031139.jpg
正在下载: small0e9f43492debe6dc2ce7a3e6cc48c1ad1566030965.jpg
正在下载: smallcfd5b4c6fa10ffcbcdcc8b1b9e6db91a1566030209.jpg
。。。。。。
图片下载成功!!!
消耗时间为: 21.575999975204468
上面这部分代码完全可以运行,但是效率不高,因为是下载图片,需要排队一一下载。因此,为了解决这个问题,下面的代码使用多线程来实现图片的抓取和下载。
(5)使用Python多线程抓取图片并下载到本地
对于多线程,我们使用 Python 自带的线程模块。我们使用称为生产者和消费者的模型。生产者专门用于从每个页面中获取图片的下载链接并将其存储在全局列表中。消费者专门从这个全局列表中提取图像链接以供下载。
需要注意的是,在多线程中使用全局变量需要使用锁来保证数据的一致性。
import urllib
import threading
from bs4 import BeautifulSoup
import requests
import os
import time
import lxml
# 页面链接的初始化列表
page_links_list=['http://www.netbian.com/']
# 图片链接列表
img_links_list = []
#获取爬取的页数和页面链接
def GetUrls(page_links_list):
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
#初始化锁,创建一把锁
gLock=threading.Lock()
#生产者,负责从每个页面中获取图片的链接
class Producer(threading.Thread):
def run(self):
while len(page_links_list)>0:
#上锁
gLock.acquire()
#默认取出列表中的最后一个元素
page_url=page_links_list.pop()
#释放锁
gLock.release()
#获取img标签
html = requests.get(page_url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
#加锁3
gLock.acquire()
for img in imgs:
img_link = img['src']
img_links_list.append(img_link)
#释放锁
gLock.release()
#print(len(img_links_list))
#消费者,负责从获取的图片链接中下载图片
class Consumer(threading.Thread,):
def run(self):
print("%s is running"%threading.current_thread())
while True:
#print(len(img_links_list))
#上锁
gLock.acquire()
if len(img_links_list)==0:
#不管什么情况,都要释放锁
gLock.release()
continue
else:
img_url=img_links_list.pop()
#print(img_links_list)
gLock.release()
filename=img_url.split('/')[-1]
print('正在下载:', filename)
path = './images/'+filename
urllib.request.urlretrieve(img_url, filename=path)
if len(img_links_list)==0:
end=time.time()
print("消耗的时间为:", (end - start))
exit()
if __name__ == '__main__':
GetUrls(page_links_list)
os.mkdir('./images')
start=time.time()
# 5个生产者线程,去从页面中爬取图片链接
for x in range(5):
Producer().start()
# 10个消费者线程,去从中提取下载链接,然后下载
for x in range(10):
Consumer().start()
请输入你想爬取的页数:5
is running
is running
is running
is running
is running
is running
is running
is running
is running
is running
正在下载: small9e75d6ac9506efe1d87e96062791fb261564149099.jpg
正在下载: small02961cac5e02a901b77779eaed43c6f91564156941.jpg
正在下载: small117c84b2f427c981bf33184c1c5c4bb91564193581.jpg
正在下载: smallfedb420af6f753512c169021587982621564455847.jpg
正在下载: small14d3739bf11dd92055abb56e3f792d3f1564456102.jpg
正在下载: smallaf755644af7d114d4cbf36fbe0e84d0c1564456347.jpg
正在下载: small9f7af6d0e2372a4d9e536d8ea9fc40341564456537.jpg
。。。。。。
消耗的时间为: 1.635000228881836 #分别是10个进程结束的时间
消耗的时间为: 1.6419999599456787
消耗的时间为: 1.6560001373291016
消耗的时间为: 1.684000015258789
消耗的时间为: 1.7009999752044678
消耗的时间为: 1.7030000686645508
消耗的时间为: 1.7060000896453857
消耗的时间为: 1.7139999866485596
消耗的时间为: 1.7350001335144043
消耗的时间为: 1.748000144958496
php网页抓取图片(一键建站+行业内容采集+伪原创+主动推送给搜索引擎收录介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 314 次浏览 • 2022-03-21 20:47
zblog博客模板是PHP开发的系统模板,也支持ASP模板。大部分朋友都喜欢用zblog来做网站的构建。今天给大家分享一款万能的zblog工具:只需输入域名选择zblog模板(内置5万套PHP和ASP模板选项)+SEO内容优化。各种主题功能插件等,最全的zblog博客模板插件。稍后我们将以图片的形式向您展示。大家注意看图。一键建站+行业内容采集+伪原创+主动推送到搜索引擎收录介绍。
白帽SEO是基于对搜索引擎排名算法的深入研究,并通过相应的技术在搜索引擎上获得更好的排名。白帽SEO是搜索引擎推荐的一种获得更好排名的技术。关于网站长期发展起着重要作用。目前,白帽搜索引擎优化是搜索引擎优化领域最普遍、最长期的技术。
白帽SEO的对立面是黑帽SEO。黑帽SEO是一种在研究搜索引擎排名算法的缺陷,并通过技术处理网站后,可以在短时间内迅速在搜索引擎上获得更好排名的SEO技术。它也是一个搜索引擎。引擎不断打击的目标之一,但黑帽SEO为白帽SEO做出了巨大贡献。白帽SEO的很多优化技巧都来自于黑帽SEO,而黑帽SEO可以在短期内快速优化到百度首页,国内的广告如“快速访问首页、短-term增加高流量”全部使用快速排序技术,即黑帽SEO!
作为最常见的SEO技术,白帽SEO具有稳定性好等优势。一旦排在搜索引擎首页,登陆和上升幅度较小,对品牌推广作用明显。特别适合长期发展网站使用白帽SEO在搜索引擎上排名更好。
近年来,黑帽SEO因其快速的排名速度而受到许多迫切希望在搜索引擎上获得更多流量的网站的青睐。黑帽SEO短期内投入较少,但短期内回报非常丰厚。这些都是黑帽SEO的优势,黑帽SEO适合网站想要快速获得更好的排名结果,短期内快速提升访问率和转化率的应用。
网站被黑客入侵:你的网站被黑客入侵(hacker的中文音译是指精通计算机程序、漏洞等的人,并利用它通过以下方式攻击、修改和控制他人的计算机)异常指)、恶意修正或攻击,导致网站的某些功能无法运行,或网站瘫痪,无法访问甚至无法完成对内容的更改。
网站 的部分或全部权限被黑客获取。您可以自由添加、删除或修改 网站 内容。如果网站被黑进了一个很重要的网站,可以付费请专业安全人员检查。你无法知道黑客的后门有多少文件,也无法将其更改为清空并使用之前未被黑客入侵的源代码备份再次上传这些文件。
1.通过百度搜索资源平台的“网站体检工具”,可以对网站的各项指标进行安全检查和隐患排查。
2.被黑网站的数据有一个特点,就是短时间内搜索引擎的索引数量和流量异常。因此,网站管理员可以使用百度搜索资源平台的索引号工具检查网站的索引号是否异常。如果发现异常数据,则使用流量和关键词工具检查获取的流量关键词是否与网站、赌博和色情相关。
3.最好通过网站语法查询网站,将一些常见的色情和赌博关键词分开。可以找到不属于这个 网站 的非法页面。
4.由于百度流量巨大,一些拉黑行为只针对百度带来的流量,站长很难发现。因此,在查看自己的网站是否可以被屏蔽时,必须点击百度搜索结果中的网站页面,查看是否可以跳转到其他网站。
5.这个网站的内容在百度搜索结果中被认为有风险;
6.网站可以要求技术人员进一步确认网站可以通过后台数据和程序被黑。
网站被黑后,首先要做的是检查网站上可能存在的漏洞。如果 网站 没有打补丁,这个修复是正常的,下次会被黑。因此,检查网站 的安全性很重要。
其次,将网站改回正常,如本文删除被黑后添加的JS,修正网站TDK,使网站恢复正常。
另外,需要修正百度收录的快照。本文中的案例会在被黑后及时修复。百度收录的截图还是上一张。因此,百度快照不需要修改。如果百度在被黑后有收录,那就要投诉百度快照了。
最后,最重要的是修复网站漏洞,避免再次被黑,比如更新网站程序。另外,最好找专业的程序员维护网站的安全,避免网站被黑客攻击。
既然大家都知道网站的内部有多么重要,那么问题来了,我们应该如何进行内部优化工作,有哪些选项可用。
1.网站内部设计:优化网站内部页面的设计应该考虑网站的设计,什么样的设计适合和用户喜欢。在 网站 模板中添加目录可以改善用户体验。内部页面规划完成后,还需要对页面进行精简,让用户可以快速方便地找到并添加想要的内部页面,提高用户体验和网站权限。
2.全站导航链接建设优化:从优化的角度来看,全站导航模板是你网站的重要元素之一,尤其是对于大型网站 ,由于更多更多页面和更多投票。拥有正确的关键字来导航整个站点的链接很重要,确保这些链接被索引以获取更多内部链接同样重要,这在优化 网站 中起着重要作用。
3.面包屑优化:面包屑是另一个重要的内部链接结构,对 SEO 具有重要意义,尤其是在不存在的站点范围导航模板的子页面中。由于面包屑通常在源代码优化之前呈现,蜘蛛更容易抓取面包屑链接或链接内容,关键词 呈现在面包屑中,这对于站点范围的链接很有意义。
4.替代链接结构优化:所谓替代链接结构(alternative link structure)是专门针对一组相关的关键词组页面,即索引页面,或者一些相关页面,如热点文章的页面模板,相关主题等。
5.优化网站内页标题:站长通常将网站的标题设置为网站的关键词,H1标签也设置为与关键词相关长尾关键词相同。但是内页的H1标签不需要设置长尾关键词,搜索引擎会抓取内页。如果内部页面没有一个好的标题,它会从内部页面的关键字中提取数据,因此捕获方法对您没有意义,并且内部页面不会被收录在内。因此,千语建议大家可以将内部页面的H1标签设置为内部页面的标题,以便搜索引擎捕捉并记录下来。
6.内容质量:内容可以有效留住用户,但如果内容不好,也会加速用户分离网站。如果您想让您的页面快速收录并留住用户,您可以做的最好的事情之一就是提高您的页面质量。
1.内容匹配
无论是搜索引擎还是网站 访问者,网站 内容都是最受关注的中心。在呈现内容时,无论是商业新闻还是商业产品,都需要为系统建立口碑,以增加文章的认可度。同时,与内容相关的信息会在促销的背景下呈现给用户和搜索引擎,这可以引导用户点击,并有可能让蜘蛛在网站上停留更长时间以停止爬取和爬取。
2.内链多样化
如果要说百度百科是最好的内部链接之一,我们可以通过调查百度百科词条清楚地发现锚文本链接的多样性。这与许多站点中的单个锚文本链接不同。
虽然我们显然喜欢小企业与他们的 关键词 同行竞争,但我们经常将这些 关键词s 插入 文章s 以提高 关键词 排名,然后将它们超链接到它延伸到其他内容。当然,采集网站上关键词的权重,但并没有提高网站的整体质量。单独提升单机关键词排名是没有用的。我们需要的是流量和网站转化率。
3.关键词优化
虽然百度暗示百度权重不存在,但我们不能承认主站长总结的权重仍然是一个准确的优化参考值。正是出于这个原因,我们对广播中的关键词特别感兴趣。我们之前也说过,我们不应该在 网站 上使用超过 3 个 关键词 来对付权威人士,以免 关键词 太重而无法排名。
但这曾经是很多SEO的一个误区,以为只要把关键词放在页面上一遍一遍就可以增加关键词的权重,但大家似乎又忘记了一点——过度——优化。优化很重要,所以要停止过度优化,控制网站的整体状态。 查看全部
php网页抓取图片(一键建站+行业内容采集+伪原创+主动推送给搜索引擎收录介绍)
zblog博客模板是PHP开发的系统模板,也支持ASP模板。大部分朋友都喜欢用zblog来做网站的构建。今天给大家分享一款万能的zblog工具:只需输入域名选择zblog模板(内置5万套PHP和ASP模板选项)+SEO内容优化。各种主题功能插件等,最全的zblog博客模板插件。稍后我们将以图片的形式向您展示。大家注意看图。一键建站+行业内容采集+伪原创+主动推送到搜索引擎收录介绍。
白帽SEO是基于对搜索引擎排名算法的深入研究,并通过相应的技术在搜索引擎上获得更好的排名。白帽SEO是搜索引擎推荐的一种获得更好排名的技术。关于网站长期发展起着重要作用。目前,白帽搜索引擎优化是搜索引擎优化领域最普遍、最长期的技术。
白帽SEO的对立面是黑帽SEO。黑帽SEO是一种在研究搜索引擎排名算法的缺陷,并通过技术处理网站后,可以在短时间内迅速在搜索引擎上获得更好排名的SEO技术。它也是一个搜索引擎。引擎不断打击的目标之一,但黑帽SEO为白帽SEO做出了巨大贡献。白帽SEO的很多优化技巧都来自于黑帽SEO,而黑帽SEO可以在短期内快速优化到百度首页,国内的广告如“快速访问首页、短-term增加高流量”全部使用快速排序技术,即黑帽SEO!
作为最常见的SEO技术,白帽SEO具有稳定性好等优势。一旦排在搜索引擎首页,登陆和上升幅度较小,对品牌推广作用明显。特别适合长期发展网站使用白帽SEO在搜索引擎上排名更好。
近年来,黑帽SEO因其快速的排名速度而受到许多迫切希望在搜索引擎上获得更多流量的网站的青睐。黑帽SEO短期内投入较少,但短期内回报非常丰厚。这些都是黑帽SEO的优势,黑帽SEO适合网站想要快速获得更好的排名结果,短期内快速提升访问率和转化率的应用。
网站被黑客入侵:你的网站被黑客入侵(hacker的中文音译是指精通计算机程序、漏洞等的人,并利用它通过以下方式攻击、修改和控制他人的计算机)异常指)、恶意修正或攻击,导致网站的某些功能无法运行,或网站瘫痪,无法访问甚至无法完成对内容的更改。
网站 的部分或全部权限被黑客获取。您可以自由添加、删除或修改 网站 内容。如果网站被黑进了一个很重要的网站,可以付费请专业安全人员检查。你无法知道黑客的后门有多少文件,也无法将其更改为清空并使用之前未被黑客入侵的源代码备份再次上传这些文件。
1.通过百度搜索资源平台的“网站体检工具”,可以对网站的各项指标进行安全检查和隐患排查。
2.被黑网站的数据有一个特点,就是短时间内搜索引擎的索引数量和流量异常。因此,网站管理员可以使用百度搜索资源平台的索引号工具检查网站的索引号是否异常。如果发现异常数据,则使用流量和关键词工具检查获取的流量关键词是否与网站、赌博和色情相关。
3.最好通过网站语法查询网站,将一些常见的色情和赌博关键词分开。可以找到不属于这个 网站 的非法页面。
4.由于百度流量巨大,一些拉黑行为只针对百度带来的流量,站长很难发现。因此,在查看自己的网站是否可以被屏蔽时,必须点击百度搜索结果中的网站页面,查看是否可以跳转到其他网站。
5.这个网站的内容在百度搜索结果中被认为有风险;
6.网站可以要求技术人员进一步确认网站可以通过后台数据和程序被黑。
网站被黑后,首先要做的是检查网站上可能存在的漏洞。如果 网站 没有打补丁,这个修复是正常的,下次会被黑。因此,检查网站 的安全性很重要。
其次,将网站改回正常,如本文删除被黑后添加的JS,修正网站TDK,使网站恢复正常。
另外,需要修正百度收录的快照。本文中的案例会在被黑后及时修复。百度收录的截图还是上一张。因此,百度快照不需要修改。如果百度在被黑后有收录,那就要投诉百度快照了。
最后,最重要的是修复网站漏洞,避免再次被黑,比如更新网站程序。另外,最好找专业的程序员维护网站的安全,避免网站被黑客攻击。
既然大家都知道网站的内部有多么重要,那么问题来了,我们应该如何进行内部优化工作,有哪些选项可用。
1.网站内部设计:优化网站内部页面的设计应该考虑网站的设计,什么样的设计适合和用户喜欢。在 网站 模板中添加目录可以改善用户体验。内部页面规划完成后,还需要对页面进行精简,让用户可以快速方便地找到并添加想要的内部页面,提高用户体验和网站权限。
2.全站导航链接建设优化:从优化的角度来看,全站导航模板是你网站的重要元素之一,尤其是对于大型网站 ,由于更多更多页面和更多投票。拥有正确的关键字来导航整个站点的链接很重要,确保这些链接被索引以获取更多内部链接同样重要,这在优化 网站 中起着重要作用。
3.面包屑优化:面包屑是另一个重要的内部链接结构,对 SEO 具有重要意义,尤其是在不存在的站点范围导航模板的子页面中。由于面包屑通常在源代码优化之前呈现,蜘蛛更容易抓取面包屑链接或链接内容,关键词 呈现在面包屑中,这对于站点范围的链接很有意义。
4.替代链接结构优化:所谓替代链接结构(alternative link structure)是专门针对一组相关的关键词组页面,即索引页面,或者一些相关页面,如热点文章的页面模板,相关主题等。
5.优化网站内页标题:站长通常将网站的标题设置为网站的关键词,H1标签也设置为与关键词相关长尾关键词相同。但是内页的H1标签不需要设置长尾关键词,搜索引擎会抓取内页。如果内部页面没有一个好的标题,它会从内部页面的关键字中提取数据,因此捕获方法对您没有意义,并且内部页面不会被收录在内。因此,千语建议大家可以将内部页面的H1标签设置为内部页面的标题,以便搜索引擎捕捉并记录下来。
6.内容质量:内容可以有效留住用户,但如果内容不好,也会加速用户分离网站。如果您想让您的页面快速收录并留住用户,您可以做的最好的事情之一就是提高您的页面质量。
1.内容匹配
无论是搜索引擎还是网站 访问者,网站 内容都是最受关注的中心。在呈现内容时,无论是商业新闻还是商业产品,都需要为系统建立口碑,以增加文章的认可度。同时,与内容相关的信息会在促销的背景下呈现给用户和搜索引擎,这可以引导用户点击,并有可能让蜘蛛在网站上停留更长时间以停止爬取和爬取。
2.内链多样化
如果要说百度百科是最好的内部链接之一,我们可以通过调查百度百科词条清楚地发现锚文本链接的多样性。这与许多站点中的单个锚文本链接不同。
虽然我们显然喜欢小企业与他们的 关键词 同行竞争,但我们经常将这些 关键词s 插入 文章s 以提高 关键词 排名,然后将它们超链接到它延伸到其他内容。当然,采集网站上关键词的权重,但并没有提高网站的整体质量。单独提升单机关键词排名是没有用的。我们需要的是流量和网站转化率。
3.关键词优化
虽然百度暗示百度权重不存在,但我们不能承认主站长总结的权重仍然是一个准确的优化参考值。正是出于这个原因,我们对广播中的关键词特别感兴趣。我们之前也说过,我们不应该在 网站 上使用超过 3 个 关键词 来对付权威人士,以免 关键词 太重而无法排名。
但这曾经是很多SEO的一个误区,以为只要把关键词放在页面上一遍一遍就可以增加关键词的权重,但大家似乎又忘记了一点——过度——优化。优化很重要,所以要停止过度优化,控制网站的整体状态。
php网页抓取图片(,如下:file_get_contents函数(,.) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-14 00:09
)
本文章主要介绍PHP中使用file_get_contents抓取网页中文乱码问题的解决方法,可以通过curl配置gzip选项来解决,有一定的参考价值,需要的朋友可以参考
p>
本文的例子介绍了如何使用PHP中的file_get_contents来抓取网页的中文乱码问题。分享给大家,供大家参考。具体方法如下:
file_get_contents 函数原本是一个很好的php原生和远程文件操作函数。它让我们可以毫不费力地直接下载远程数据,但是当我用它来阅读网页时,我会遇到一些问题。页面乱码,这里给大家总结一下具体的解决办法。
根据网上朋友的说法,原因可能是服务器开启了GZIP压缩。下面是用firebug查看我的网站的头信息。开启gzip,请求头信息的原创头信息如下:
复制代码代码如下:
接受 text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
接受编码 gzip,放气
接受-语言 zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
连接保持活动
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.132685041傻瓜式887.3.utmcsr=google|utmccn=(有机)|utmcmd=有机|utmctr=%E4%BB%BB%E4% BD%95%E9%A1%B9%E7% 9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE% 80%E5%8D%95%20现场%3A; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
主机
用户代理 Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
从头信息可以看出Content-Encoding项是Gzip。
解决方法比较简单,就是用curl代替file_get_contents来获取,然后在curl配置参数中加一个,代码如下:
复制代码代码如下:
curl_setopt($ch, CURLOPT_ENCODING, "gzip");
今天用file_get_contents抓图的时候,一开始没发现这个问题,费了好大劲才找到。
使用内置的 zlib 库。如果服务器已经安装了zlib库,可以通过以下代码轻松解决乱码问题。代码如下:
复制代码代码如下:
$data = file_get_contents("compress.zlib://".$url);
希望本文对您的 PHP 编程有所帮助。
,
查看全部
php网页抓取图片(,如下:file_get_contents函数(,.)
)
本文章主要介绍PHP中使用file_get_contents抓取网页中文乱码问题的解决方法,可以通过curl配置gzip选项来解决,有一定的参考价值,需要的朋友可以参考
p>
本文的例子介绍了如何使用PHP中的file_get_contents来抓取网页的中文乱码问题。分享给大家,供大家参考。具体方法如下:
file_get_contents 函数原本是一个很好的php原生和远程文件操作函数。它让我们可以毫不费力地直接下载远程数据,但是当我用它来阅读网页时,我会遇到一些问题。页面乱码,这里给大家总结一下具体的解决办法。
根据网上朋友的说法,原因可能是服务器开启了GZIP压缩。下面是用firebug查看我的网站的头信息。开启gzip,请求头信息的原创头信息如下:
复制代码代码如下:
接受 text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
接受编码 gzip,放气
接受-语言 zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
连接保持活动
Cookie __utma=225240837.787252530.1317310581.1335406161.1335411401.1537; __utmz=225240837.132685041傻瓜式887.3.utmcsr=google|utmccn=(有机)|utmcmd=有机|utmctr=%E4%BB%BB%E4% BD%95%E9%A1%B9%E7% 9B%AE%E9%83%BD%E4%B8%8D%E4%BC%9A%E9%82%A3%E4%B9%88%E7%AE% 80%E5%8D%95%20现场%3A; PHPSESSID=888mj4425p8s0m7s0frre3ovc7; __utmc=225240837; __utmb=225240837.1.10.1335411401
主机
用户代理 Mozilla/5.0 (Windows NT 5.1; rv:12.0) Gecko/20100101 Firefox/12.0
从头信息可以看出Content-Encoding项是Gzip。
解决方法比较简单,就是用curl代替file_get_contents来获取,然后在curl配置参数中加一个,代码如下:
复制代码代码如下:
curl_setopt($ch, CURLOPT_ENCODING, "gzip");
今天用file_get_contents抓图的时候,一开始没发现这个问题,费了好大劲才找到。
使用内置的 zlib 库。如果服务器已经安装了zlib库,可以通过以下代码轻松解决乱码问题。代码如下:
复制代码代码如下:
$data = file_get_contents("compress.zlib://".$url);
希望本文对您的 PHP 编程有所帮助。
,
php网页抓取图片(这篇文章介绍闲来无事,刚学会把git部署到远程服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-03-14 00:06
这篇文章介绍如何在java中使用url抓取网页内容
我没什么事,刚学会部署git到远程服务器,也没什么事,就干脆做了一个爬网页信息的小工具。如果将其中的一些值设置为参数,扩展性能可能会更好!我希望这是一个好的开始,也让我在阅读字符串方面更加精通。值得注意的是,在JAVA1.8中使用String拼接字符串时,会自动读取你想要的字符串。拼接后的字符串由StringBulider进行处理,极大的优化了String的性能。废话不多说,展示我的XXX码~
运行结果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签,注入到LinkedHashMap中,就ok了,很简单吧!看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上就是java中如何使用url抓取网页内容的详细内容。更多详情请关注php中文网文章其他相关话题! 查看全部
php网页抓取图片(这篇文章介绍闲来无事,刚学会把git部署到远程服务器)
这篇文章介绍如何在java中使用url抓取网页内容
我没什么事,刚学会部署git到远程服务器,也没什么事,就干脆做了一个爬网页信息的小工具。如果将其中的一些值设置为参数,扩展性能可能会更好!我希望这是一个好的开始,也让我在阅读字符串方面更加精通。值得注意的是,在JAVA1.8中使用String拼接字符串时,会自动读取你想要的字符串。拼接后的字符串由StringBulider进行处理,极大的优化了String的性能。废话不多说,展示我的XXX码~
运行结果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签,注入到LinkedHashMap中,就ok了,很简单吧!看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上就是java中如何使用url抓取网页内容的详细内容。更多详情请关注php中文网文章其他相关话题!
php网页抓取图片(通过一个实例来教学如何用nodejs实现爬取网站图片功能 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2022-03-08 16:13
)
通过一个例子教你如何使用nodejs实现爬取网站图片的功能。有兴趣的朋友可以采集。
我会通过实例向大家说明nodejs实现爬取网站图片的功能。以下为全文:
原理:
爬虫是最明显的IO密集型应用场景。显然,使用node来让I/O等待开销小的数据挖掘更方便
使用 express 模块构建节点服务
并使用request模块获取目标页面的html代码
下载cheerio模块处理html代码(cheerio类似于jQuery的语法,使用方便方便)
环境配置:
npm install express request cheerio --save
(1)介绍各个模块
var http = require('http');
var request = require('request);
var cheerio = require('cheerio');
var fs = require('fs'); //用来操作文件
var url = 'https://movie.douban.com/cinem ... 39%3B //定义要爬的页面
(2)发送请求
http.get(function(res){
var html = '';
var titles = [];
res.setEncoding('utf-8') //防止中文乱码
res.on('data',function(chunk){
html += chrunk; //监听data事件 每次取一块数据
})
res.on('end',function(){
var $ = cheerio.load(html); //获取数据完成后,解析html
//将获取的图片存到images文件夹中
$('.mod-bd img').each(function(index, item){
//获取图片属性
var imgName = $(this).parent().next().text().trimg()
var imgfile = imgName + '.jpeg';
var imgSrc = $(this).attr('src')
//采用request模块,向服务器发起请求 获取图片资源
request.head(imgSrc, function(error, res,body){
if(error){
console.log('失败了')
}
});
//通过管道的方式用fs模块将图片写到本地的images文件下
request(imgSrc).pipe.(fs.createWriteStream('./images/' + imgfile));
})
})
}) 查看全部
php网页抓取图片(通过一个实例来教学如何用nodejs实现爬取网站图片功能
)
通过一个例子教你如何使用nodejs实现爬取网站图片的功能。有兴趣的朋友可以采集。
我会通过实例向大家说明nodejs实现爬取网站图片的功能。以下为全文:
原理:
爬虫是最明显的IO密集型应用场景。显然,使用node来让I/O等待开销小的数据挖掘更方便
使用 express 模块构建节点服务
并使用request模块获取目标页面的html代码
下载cheerio模块处理html代码(cheerio类似于jQuery的语法,使用方便方便)
环境配置:
npm install express request cheerio --save
(1)介绍各个模块
var http = require('http');
var request = require('request);
var cheerio = require('cheerio');
var fs = require('fs'); //用来操作文件
var url = 'https://movie.douban.com/cinem ... 39%3B //定义要爬的页面
(2)发送请求
http.get(function(res){
var html = '';
var titles = [];
res.setEncoding('utf-8') //防止中文乱码
res.on('data',function(chunk){
html += chrunk; //监听data事件 每次取一块数据
})
res.on('end',function(){
var $ = cheerio.load(html); //获取数据完成后,解析html
//将获取的图片存到images文件夹中
$('.mod-bd img').each(function(index, item){
//获取图片属性
var imgName = $(this).parent().next().text().trimg()
var imgfile = imgName + '.jpeg';
var imgSrc = $(this).attr('src')
//采用request模块,向服务器发起请求 获取图片资源
request.head(imgSrc, function(error, res,body){
if(error){
console.log('失败了')
}
});
//通过管道的方式用fs模块将图片写到本地的images文件下
request(imgSrc).pipe.(fs.createWriteStream('./images/' + imgfile));
})
})
})
php网页抓取图片(完整源码(转载中)--用php抓取百度知道的第一张图片*#!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-05 14:02
php网页抓取图片关键一步是读取http下的get/post请求,网上很多框架都可以读取,我写一个最简单的,不是php,目前我写的就是可读写,读取get请求可读可写,分析如下:直接上代码,关键代码均不提供,是思路,读取http下的请求我比较懒,所以用requests包了一下,然后json序列化再去读取。
完整源码(转载中)--用php,抓取百度知道的第一张图片**#!/usr/bin/envphp//读取从百度知道下的第一张图片functionread_first_img(){read_first_img();}#解析源码stringget_content_type="text/html;charset=utf-8";stringget_result_content="";//获取get请求的url地址,拼接encodetalkfunctionutils_index(get_response){//获取url地址,拼接属性talkfunctionresponse_response(){//解析htmlencode("get://"+response_response+"/"+"&href="+response_response+"&body="+response_response+"&user_id="+response_response+"&page="+response_response+"&mid=20151111&lang=zh_cn&srctype=mail.html&mail_type=web&from=singlemessage&isappinstalled=0");}}stringstring:request_data("request/index.php"){stringpath="/";if(!path){talktry{if(dirname(get_response)){//获取php的链接request_path=path;//解析htmlencode("get://"+request_path+"/"+"&href="+request_path+"&body="+request_path+"&user_id="+request_path+"&page="+request_path+"&mid=20151111&lang=zh_cn&srctype=mail.html&mail_type=web&from=singlemessage&isappinstalled=0");returnrequest_data;}}talkcatch(exception){//发生异常}if(dirname(get_response)){//获取get请求的相关地址for(;path;){path=dirname(get_response);}return";";}}if(!request_names.contains("server")){talkfunctionnewwrap_detect_server(name,string:request_data,int:tobytes,bytes:data){//获取目标url的标识位return"welcome";}functionutils_index(get_response){//解析htmlencode("get://"+request_path+"/"。 查看全部
php网页抓取图片(完整源码(转载中)--用php抓取百度知道的第一张图片*#!)
php网页抓取图片关键一步是读取http下的get/post请求,网上很多框架都可以读取,我写一个最简单的,不是php,目前我写的就是可读写,读取get请求可读可写,分析如下:直接上代码,关键代码均不提供,是思路,读取http下的请求我比较懒,所以用requests包了一下,然后json序列化再去读取。
完整源码(转载中)--用php,抓取百度知道的第一张图片**#!/usr/bin/envphp//读取从百度知道下的第一张图片functionread_first_img(){read_first_img();}#解析源码stringget_content_type="text/html;charset=utf-8";stringget_result_content="";//获取get请求的url地址,拼接encodetalkfunctionutils_index(get_response){//获取url地址,拼接属性talkfunctionresponse_response(){//解析htmlencode("get://"+response_response+"/"+"&href="+response_response+"&body="+response_response+"&user_id="+response_response+"&page="+response_response+"&mid=20151111&lang=zh_cn&srctype=mail.html&mail_type=web&from=singlemessage&isappinstalled=0");}}stringstring:request_data("request/index.php"){stringpath="/";if(!path){talktry{if(dirname(get_response)){//获取php的链接request_path=path;//解析htmlencode("get://"+request_path+"/"+"&href="+request_path+"&body="+request_path+"&user_id="+request_path+"&page="+request_path+"&mid=20151111&lang=zh_cn&srctype=mail.html&mail_type=web&from=singlemessage&isappinstalled=0");returnrequest_data;}}talkcatch(exception){//发生异常}if(dirname(get_response)){//获取get请求的相关地址for(;path;){path=dirname(get_response);}return";";}}if(!request_names.contains("server")){talkfunctionnewwrap_detect_server(name,string:request_data,int:tobytes,bytes:data){//获取目标url的标识位return"welcome";}functionutils_index(get_response){//解析htmlencode("get://"+request_path+"/"。
php网页抓取图片(Google的新版本抓图,一直在想他是怎么把需要滚这么多屏的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-03-02 15:06
上次看到谷歌新版本的截图,
我一直在想,他是如何设法捕获一个需要将这么多屏幕滚动到一个图像中的网页?
在网上搜索了2个多小时,无意中找到了(楼下说的,我在搜索的时候看到文章发现SnagIt也有类似的功能,想到了常用的Hypersnap...)其实多屏抓图是我最熟悉的HyperSnap(我用的是3.x Basic,只有500K多。如果需要支持更多格式如PNG,需要3.x Pro版,关于3.x Pro版)@1.1M)本身可以实现的基本功能:
你有没有注意到:Google 的图片收录了外部表单,但 HyperSnap 的滚动屏幕只能抓取内容框架内的一个框架的内容。
在 HyperSnap 中收录自动滚动模式选项:
菜单的Capture==>自动滚动窗口选项启用后,在Active Window捕获模式下选择捕获窗口后只需按左键(快捷键:ctrl+shift+w)(此时鼠标已经有一个向下箭头),当前屏幕会自动PageDown一页一页地向下翻页,翻到最后,将多屏网页内容截取为图片。
关于自动滚动的原创帮助:
自动滚动窗口(捕获)
这个独特的选项使您能够在 Capture|Window 会话期间向下滚动,以捕获超出带有垂直滚动条的窗口中立即可见的数据。
自动滚动总是从顶部开始向下移动。以下分步说明可以帮助您了解其工作原理:
<p> 查看全部
php网页抓取图片(Google的新版本抓图,一直在想他是怎么把需要滚这么多屏的)
上次看到谷歌新版本的截图,
我一直在想,他是如何设法捕获一个需要将这么多屏幕滚动到一个图像中的网页?
在网上搜索了2个多小时,无意中找到了(楼下说的,我在搜索的时候看到文章发现SnagIt也有类似的功能,想到了常用的Hypersnap...)其实多屏抓图是我最熟悉的HyperSnap(我用的是3.x Basic,只有500K多。如果需要支持更多格式如PNG,需要3.x Pro版,关于3.x Pro版)@1.1M)本身可以实现的基本功能:
你有没有注意到:Google 的图片收录了外部表单,但 HyperSnap 的滚动屏幕只能抓取内容框架内的一个框架的内容。
在 HyperSnap 中收录自动滚动模式选项:
菜单的Capture==>自动滚动窗口选项启用后,在Active Window捕获模式下选择捕获窗口后只需按左键(快捷键:ctrl+shift+w)(此时鼠标已经有一个向下箭头),当前屏幕会自动PageDown一页一页地向下翻页,翻到最后,将多屏网页内容截取为图片。
关于自动滚动的原创帮助:
自动滚动窗口(捕获)
这个独特的选项使您能够在 Capture|Window 会话期间向下滚动,以捕获超出带有垂直滚动条的窗口中立即可见的数据。
自动滚动总是从顶部开始向下移动。以下分步说明可以帮助您了解其工作原理:
<p>
php网页抓取图片(富文本内容交互(12345367))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-24 13:11
一、富文本内容交互
1、编辑器内容初始化(即在编辑器中设置富文本)
场景一:在编辑器中写一个新的文章,预设提示、问候等。
在 editor_config.js 文件中找到 initialContent 参数,并将其值设置为所需的提示或问候语,例如 initialContent: 'Welcome to UEditor!'。
场景二:编辑旧的文章,从数据库中取出富文本放到编辑器中。
显然,在编辑文章时,需要从后台数据库中提取一大段富文本。如果初始值还是采用场景一的方式设置,必然会带来引号被截断等问题,所以需要使用另一种方式来设置,如下代码所示:
1
2
3
这里使用script标签作为编辑器容器对象,其类型设置为纯文本,避免了标签内部JS代码的执行,解决了部分同学使用传统的textarea标签作为容器带来的额外问题. 转码问题。
2、提交编辑器内容到后端
场景一:编辑器所在的Form中有一个提交按钮,点击该按钮完成提交动作。
这个场景适合最常见的场合。没有太多需要注意的问题。只需要说明三点:
1)默认提交到后台的表单名称为“editorValue”,可在editor_config.js中配置,参数名称为textarea。
2)可以在容器标签(即脚本标签)上设置name属性来覆盖editor_config.js中的默认配置。示例代码如下,其中 myContent 将是新的提交表单名称:
1
2
3
4
5
3)后端接收程序可以通过以下方式获取编辑器中的富文本内容。
1
2
3
4
5
6
7
8
9
10
11
//PHP 获取:
$_POST["我的内容"]
//JSP 获取:
request.getParameter("myContent");
//ASP 获取:
请求(“我的内容”);
//网络获取:
context.Request.Form["myContent"];
场景二:编辑器所在的Form中没有提交按钮,提交动作是由外部事件触发的。
该场景适用于网站前端交互较多的场合。主要需要注意的是,编辑器内容同步操作是在表单提交动作触发之前进行的。通用代码模式如下所示:
1
2
3
4
5
//同步内容,满足提交条件时提交,这里的editor就是编辑器实例
if(editor.hasContent()){//这里以非空为例
editor.sync();//同步内容
someForm.submit();//提交表单
}
这里的 editor 是编辑器实例对象。
场景三:编辑器不在任何Form中,提交动作被外部事件触发。
这个场景用的不多,但在特殊场合可能需要用到。UEditor 也提供了相应的处理方案。基本逻辑和第二种场景一样,只是在进行同步操作的时候需要传入提交表单的id,比如editor.sync(myFormID)。其他相同的场景 2。
二、图片上传交互
1、传统图片上传
传统图片上传所涉及的前后端交互主要涉及“上传提交路径”和“图片存储路径”两个参数。后台存储路径为任何形式(绝对或相对),在任何页面上显示与前台无关。
2、Flash图片上传
Flahs图片上传与传统图片上传有一个很大的区别:它需要服务器实时返回“图片保存路径”,以便在前台即时显示。具体到编辑器,需要将返回的路径插入到编辑器中。这会导致除了传统图片上传中提到的两个参数之外,还有第三个参数:“前后端校正路径”。如果后台返回的保存路径是绝对路径(指以http开头的路径,根目录开头的路径也可以收录在其中),那么前台不需要做任何修正,否则用户必须非常清楚自己当前的目录结构,并根据这修正了前后端相对路径的差异。因此,UEditor 强烈建议服务器端返回以根目录开头的相对路径。
3、UEditor中上传的做法和注意事项
在UEditor中,“上传提交路径”和“前后端修改路径”的配置位于editor_config.js中。其中,imageUrl参数对应“上传提交路径”,imagePath参数对应“前后端校正路径”。“图片保存路径”需要在server/upload/php目录下的imageUp文件中配置。
路径配置完成后,还需要配置imageFieldName参数为文件表单的表单名,后台可以据此获取文件句柄。此参数也位于 editor_config.js 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
//图片上传提交地址
imageUrl:URL+"服务器/上传/php/imageUp.php",
//图像校正地址是指fixedImagePath。如有特殊需求,可自行配置
图像路径:固定图像路径,
//图片描述键
imageFieldName:"upFile",
//比例压缩的基准,确定maxImageSideLength参数的参考对象。
//0是根据最长边,1是根据宽度,2是根据高度
压缩边:0,
//上传图片允许的最大边长,超过会自动按比例缩放,设置较大的值不缩放
//更多设置在image.html
最大图像边长:900
完成以上配置后,理论上后台应该可以接收到前台上传的图片文件了。一旦正确保存,传统的图像上传到此结束。但是,在编辑器中使用 Flash 上传,过程还远远没有结束。
首先,后台需要计算出图片文件存放的地址字符串。UEditor 强烈建议使用从 网站 的根目录到图像名称末尾的字符串。如果不是从网站的根目录算起,后面需要考虑参数“前后端校正地址”。
其次,后台返回一个json格式的字符串。格式的具体要求如下:
1
{"url":"图片地址","title":"图片描述","state":"上传状态"}
其中,url对应的是计算出来的图片存储地址——再次强调,尝试从网站的根目录开始构造一个地址串;title 对应flash中的description字段,会设置为图片上的title属性中;state 对应服务器返回的图片上传状态字符:除了上传成功返回“SUCCESS”外,其他任何值都将直接显示在返回的图片描述字段中。
最后,UEditor会在返回的url地址前面加上“前后端修剪路径”的参数值作为最后插入编辑器的图片地址。因此,如果服务器返回的是从根目录开始的图片路径或以http开头的绝对路径,“前后端校正路径”必须留空。
例如,如果服务器返回的路径是“/myProject/uploads/sun.jpg”,那么插入编辑器的路径就是“前后端修订路径+/myProject/uploads/sun.jpg ”。
三、Word 图片转储交互
1、图片转储原理
所谓word图片转储,就是为了解决UEditor从word中复制一个混合的图文文章粘贴到编辑器中的问题,word文章中的图片数据无法显示在编辑器中。是针对无法提交到服务器的问题而开发的一款简单易用的镜像转储解决方案。
该功能的基本操作步骤:复制word文档-》粘贴到编辑器-》编辑器会将所有图片转换成占位符图片,同时高亮工具栏中的dump按钮-》点击dump按钮弹出图片上传框——》点击复制按钮复制图片目录地址——》点击“添加照片”按钮,将刚才复制的图片目录地址粘贴到弹出的选择框——》点击打开按钮选择目录下的所有图片文件,点击这里打开-》执行图片上传-》上传成功确认插入,UEditor会自动完成对应占位图片的替换过程。
2、配置要点及注意事项
word图片dump的配置和普通图片上传基本一样,唯一的区别就是操作上的不同:前者需要先获取临时图片文件存在的目录,后者直接选择指定的文件目录通过它自己。PS:在某些操作系统的word的某些版本中,发现单个word图片会生成两张临时图片,格式和定义不同。目前还没有找到改进的方法。
四、远程抓图交互
1、遥控抓取原理
图片远程抓取是指服务器将这些外部图片抓取到本地服务器,并在插入本地域名以外的图片链接地址时保存的功能。实现原理是在编辑器中向服务器发送一个收录所有外域图片地址的ajax请求,然后服务器将图片地址捕获并保存在后端并将图片地址返回给编辑器,然后编辑器将完成外域地址和本地地址的替换。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
//是否开启远程抓图
catchRemoteImageEnable:真,
//处理远程抓图的地址
catcherUrl:URL +"server/submit/php/getRemoteImage.php",
//后台提交到远程图片uri集合的表单名
catchFieldName:"upFile",
//图像校正地址,同imagePath
捕手路径:固定图像路径,
//本地顶级域名,开启远程抓图时,除此之外的所有其他域名
//图像将被本地捕获
本地域:["","10.81.2.114"],
2、备注
是否开启远程抓图功能可以通过在editot_config.js中配置catchRemoteImageEnable参数来实现。与此功能相关的配置还包括远程获取处理程序地址、表单字段名称、本地字段和“前后端校正地址”。远程抓图处理程序实现根据前端提交的地址列表(以ue_separate_ue标识分隔的字符串)进行抓图,然后将地址列表返回给客户端的功能。
前后端交互数据格式示例:(URL1, URL2, URL3, URL4)
1
URL1ue_separate_ueURL2ue_separate_ueURL3ue_separate_ueURL4
五、图片在线管理交互
1、图片在线管理介绍
图片在线管理是指通过读取服务器端的文件目录并在编辑器中显示来进行附加操作的功能。出于安全考虑,UEditor目前只实现了二次图片插入操作,其他的删除、移动等操作将在后续的二次开发教程中发布。
1
2
3
4
5
//图片在线管理的处理地址
imageManagerUrl:URL +"server/submit/php/imageManager.php",
//图像校正地址,同imagePath
imageManagerPath:fixedImagePath
2、备注
在线图片管理中需要配置的参数与远程抓图相同。两者的区别在于,在线图片管理中的图片数据是通过在服务器端指定某个目录,然后遍历其下的所有图片文件,然后返回地址来获取的。到编辑器,远程抓图就是由编辑器提交图片地址,服务器端抓图处理后将新地址返回给编辑器。两者的初始触发都需要ajax的介入。
六、截图交互
1、截图介绍
使用ActiveX控件,目前只支持IE浏览器。
2、备注
需要配置的参数除了和图片上传一样的内容外,还包括服务器地址和端口的配置。使用时请根据自己服务器的特点进行适配和修改。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//网站截图服务器端文件所在地址或ip,请勿添加
snapscreenHost:'127.0.0.1',
//截图的服务器端保存程序,UEditor的示例代码为“URL
snapscreenServerUrl: URL +"server/upload/php/snapImgUp.php", +"server/upload/php/snapImgUp.php""
//截图的服务器端口
snapscreenServerPort:80,
//截图图片的默认布局
snapscreenImgAlign:'center',
//截图显示修正后的地址
snapscreenPath:fixedImagePath,
七、附件上传交互
1、上传附件注意事项
附件上传的基本配置与图片类似。另外,由于附件上传采用成熟的swfupload开源框架,大部分文档资料可以参考swfupload官网教程。官网地址:http://
Ueditor的部署说明(来自Ueditor官网): 查看全部
php网页抓取图片(富文本内容交互(12345367))
一、富文本内容交互
1、编辑器内容初始化(即在编辑器中设置富文本)
场景一:在编辑器中写一个新的文章,预设提示、问候等。
在 editor_config.js 文件中找到 initialContent 参数,并将其值设置为所需的提示或问候语,例如 initialContent: 'Welcome to UEditor!'。
场景二:编辑旧的文章,从数据库中取出富文本放到编辑器中。
显然,在编辑文章时,需要从后台数据库中提取一大段富文本。如果初始值还是采用场景一的方式设置,必然会带来引号被截断等问题,所以需要使用另一种方式来设置,如下代码所示:
1
2
3
这里使用script标签作为编辑器容器对象,其类型设置为纯文本,避免了标签内部JS代码的执行,解决了部分同学使用传统的textarea标签作为容器带来的额外问题. 转码问题。
2、提交编辑器内容到后端
场景一:编辑器所在的Form中有一个提交按钮,点击该按钮完成提交动作。
这个场景适合最常见的场合。没有太多需要注意的问题。只需要说明三点:
1)默认提交到后台的表单名称为“editorValue”,可在editor_config.js中配置,参数名称为textarea。
2)可以在容器标签(即脚本标签)上设置name属性来覆盖editor_config.js中的默认配置。示例代码如下,其中 myContent 将是新的提交表单名称:
1
2
3
4
5
3)后端接收程序可以通过以下方式获取编辑器中的富文本内容。
1
2
3
4
5
6
7
8
9
10
11
//PHP 获取:
$_POST["我的内容"]
//JSP 获取:
request.getParameter("myContent");
//ASP 获取:
请求(“我的内容”);
//网络获取:
context.Request.Form["myContent"];
场景二:编辑器所在的Form中没有提交按钮,提交动作是由外部事件触发的。
该场景适用于网站前端交互较多的场合。主要需要注意的是,编辑器内容同步操作是在表单提交动作触发之前进行的。通用代码模式如下所示:
1
2
3
4
5
//同步内容,满足提交条件时提交,这里的editor就是编辑器实例
if(editor.hasContent()){//这里以非空为例
editor.sync();//同步内容
someForm.submit();//提交表单
}
这里的 editor 是编辑器实例对象。
场景三:编辑器不在任何Form中,提交动作被外部事件触发。
这个场景用的不多,但在特殊场合可能需要用到。UEditor 也提供了相应的处理方案。基本逻辑和第二种场景一样,只是在进行同步操作的时候需要传入提交表单的id,比如editor.sync(myFormID)。其他相同的场景 2。
二、图片上传交互
1、传统图片上传
传统图片上传所涉及的前后端交互主要涉及“上传提交路径”和“图片存储路径”两个参数。后台存储路径为任何形式(绝对或相对),在任何页面上显示与前台无关。
2、Flash图片上传
Flahs图片上传与传统图片上传有一个很大的区别:它需要服务器实时返回“图片保存路径”,以便在前台即时显示。具体到编辑器,需要将返回的路径插入到编辑器中。这会导致除了传统图片上传中提到的两个参数之外,还有第三个参数:“前后端校正路径”。如果后台返回的保存路径是绝对路径(指以http开头的路径,根目录开头的路径也可以收录在其中),那么前台不需要做任何修正,否则用户必须非常清楚自己当前的目录结构,并根据这修正了前后端相对路径的差异。因此,UEditor 强烈建议服务器端返回以根目录开头的相对路径。
3、UEditor中上传的做法和注意事项
在UEditor中,“上传提交路径”和“前后端修改路径”的配置位于editor_config.js中。其中,imageUrl参数对应“上传提交路径”,imagePath参数对应“前后端校正路径”。“图片保存路径”需要在server/upload/php目录下的imageUp文件中配置。
路径配置完成后,还需要配置imageFieldName参数为文件表单的表单名,后台可以据此获取文件句柄。此参数也位于 editor_config.js 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
//图片上传提交地址
imageUrl:URL+"服务器/上传/php/imageUp.php",
//图像校正地址是指fixedImagePath。如有特殊需求,可自行配置
图像路径:固定图像路径,
//图片描述键
imageFieldName:"upFile",
//比例压缩的基准,确定maxImageSideLength参数的参考对象。
//0是根据最长边,1是根据宽度,2是根据高度
压缩边:0,
//上传图片允许的最大边长,超过会自动按比例缩放,设置较大的值不缩放
//更多设置在image.html
最大图像边长:900
完成以上配置后,理论上后台应该可以接收到前台上传的图片文件了。一旦正确保存,传统的图像上传到此结束。但是,在编辑器中使用 Flash 上传,过程还远远没有结束。
首先,后台需要计算出图片文件存放的地址字符串。UEditor 强烈建议使用从 网站 的根目录到图像名称末尾的字符串。如果不是从网站的根目录算起,后面需要考虑参数“前后端校正地址”。
其次,后台返回一个json格式的字符串。格式的具体要求如下:
1
{"url":"图片地址","title":"图片描述","state":"上传状态"}
其中,url对应的是计算出来的图片存储地址——再次强调,尝试从网站的根目录开始构造一个地址串;title 对应flash中的description字段,会设置为图片上的title属性中;state 对应服务器返回的图片上传状态字符:除了上传成功返回“SUCCESS”外,其他任何值都将直接显示在返回的图片描述字段中。
最后,UEditor会在返回的url地址前面加上“前后端修剪路径”的参数值作为最后插入编辑器的图片地址。因此,如果服务器返回的是从根目录开始的图片路径或以http开头的绝对路径,“前后端校正路径”必须留空。
例如,如果服务器返回的路径是“/myProject/uploads/sun.jpg”,那么插入编辑器的路径就是“前后端修订路径+/myProject/uploads/sun.jpg ”。
三、Word 图片转储交互
1、图片转储原理
所谓word图片转储,就是为了解决UEditor从word中复制一个混合的图文文章粘贴到编辑器中的问题,word文章中的图片数据无法显示在编辑器中。是针对无法提交到服务器的问题而开发的一款简单易用的镜像转储解决方案。
该功能的基本操作步骤:复制word文档-》粘贴到编辑器-》编辑器会将所有图片转换成占位符图片,同时高亮工具栏中的dump按钮-》点击dump按钮弹出图片上传框——》点击复制按钮复制图片目录地址——》点击“添加照片”按钮,将刚才复制的图片目录地址粘贴到弹出的选择框——》点击打开按钮选择目录下的所有图片文件,点击这里打开-》执行图片上传-》上传成功确认插入,UEditor会自动完成对应占位图片的替换过程。
2、配置要点及注意事项
word图片dump的配置和普通图片上传基本一样,唯一的区别就是操作上的不同:前者需要先获取临时图片文件存在的目录,后者直接选择指定的文件目录通过它自己。PS:在某些操作系统的word的某些版本中,发现单个word图片会生成两张临时图片,格式和定义不同。目前还没有找到改进的方法。
四、远程抓图交互
1、遥控抓取原理
图片远程抓取是指服务器将这些外部图片抓取到本地服务器,并在插入本地域名以外的图片链接地址时保存的功能。实现原理是在编辑器中向服务器发送一个收录所有外域图片地址的ajax请求,然后服务器将图片地址捕获并保存在后端并将图片地址返回给编辑器,然后编辑器将完成外域地址和本地地址的替换。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
//是否开启远程抓图
catchRemoteImageEnable:真,
//处理远程抓图的地址
catcherUrl:URL +"server/submit/php/getRemoteImage.php",
//后台提交到远程图片uri集合的表单名
catchFieldName:"upFile",
//图像校正地址,同imagePath
捕手路径:固定图像路径,
//本地顶级域名,开启远程抓图时,除此之外的所有其他域名
//图像将被本地捕获
本地域:["","10.81.2.114"],
2、备注
是否开启远程抓图功能可以通过在editot_config.js中配置catchRemoteImageEnable参数来实现。与此功能相关的配置还包括远程获取处理程序地址、表单字段名称、本地字段和“前后端校正地址”。远程抓图处理程序实现根据前端提交的地址列表(以ue_separate_ue标识分隔的字符串)进行抓图,然后将地址列表返回给客户端的功能。
前后端交互数据格式示例:(URL1, URL2, URL3, URL4)
1
URL1ue_separate_ueURL2ue_separate_ueURL3ue_separate_ueURL4
五、图片在线管理交互
1、图片在线管理介绍
图片在线管理是指通过读取服务器端的文件目录并在编辑器中显示来进行附加操作的功能。出于安全考虑,UEditor目前只实现了二次图片插入操作,其他的删除、移动等操作将在后续的二次开发教程中发布。
1
2
3
4
5
//图片在线管理的处理地址
imageManagerUrl:URL +"server/submit/php/imageManager.php",
//图像校正地址,同imagePath
imageManagerPath:fixedImagePath
2、备注
在线图片管理中需要配置的参数与远程抓图相同。两者的区别在于,在线图片管理中的图片数据是通过在服务器端指定某个目录,然后遍历其下的所有图片文件,然后返回地址来获取的。到编辑器,远程抓图就是由编辑器提交图片地址,服务器端抓图处理后将新地址返回给编辑器。两者的初始触发都需要ajax的介入。
六、截图交互
1、截图介绍
使用ActiveX控件,目前只支持IE浏览器。
2、备注
需要配置的参数除了和图片上传一样的内容外,还包括服务器地址和端口的配置。使用时请根据自己服务器的特点进行适配和修改。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//网站截图服务器端文件所在地址或ip,请勿添加
snapscreenHost:'127.0.0.1',
//截图的服务器端保存程序,UEditor的示例代码为“URL
snapscreenServerUrl: URL +"server/upload/php/snapImgUp.php", +"server/upload/php/snapImgUp.php""
//截图的服务器端口
snapscreenServerPort:80,
//截图图片的默认布局
snapscreenImgAlign:'center',
//截图显示修正后的地址
snapscreenPath:fixedImagePath,
七、附件上传交互
1、上传附件注意事项
附件上传的基本配置与图片类似。另外,由于附件上传采用成熟的swfupload开源框架,大部分文档资料可以参考swfupload官网教程。官网地址:http://
Ueditor的部署说明(来自Ueditor官网):
php网页抓取图片(网页抠图下载requests:下载png图片你需要官方客户端)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-17 15:02
php网页抓取图片
如果只是这个要求。推荐scrapy。scrapy已经实现了这个功能,只是官方定价贵,国内不好找。建议自己学一下scrapy,可以去看看。
刚才在微博看到一篇好像对这个问题有点帮助网页抠图下载
requests:下载png图片无损
你需要官方客户端pep080-1-generateflashpictures,直接在python3里面安装完就可以用,可以下载需要的网页,包括requests,
考虑到精度我们下载的一般都是jpg...
嗯,有的,php当然能抓取图片,不过你要满足要求:所有格式的图片都要能抓取。可以用正则表达式匹配。
其实现在有不少网站的图片有save到本地的功能,上传无法保证图片只有原来那一个。
可以试试这个,给的图片都有,
有啊,但是你既然这么问了,肯定是直接上网页了。
好像还真有只抓取png的,
一般都是手机党,工作站或服务器。
能
可以下载图片,但是为什么你会觉得下载一张图片没有特殊意义呢?非得来问?就算存储图片也是会发生在本地,只要不是某个时刻去找他是不是下载了,谁又知道?并且本地图片在你下载的时候他已经加密了,并不是网上你下载的,手机能下载,但是你拿到手的图片你又有什么用呢?有用。 查看全部
php网页抓取图片(网页抠图下载requests:下载png图片你需要官方客户端)
php网页抓取图片
如果只是这个要求。推荐scrapy。scrapy已经实现了这个功能,只是官方定价贵,国内不好找。建议自己学一下scrapy,可以去看看。
刚才在微博看到一篇好像对这个问题有点帮助网页抠图下载
requests:下载png图片无损
你需要官方客户端pep080-1-generateflashpictures,直接在python3里面安装完就可以用,可以下载需要的网页,包括requests,
考虑到精度我们下载的一般都是jpg...
嗯,有的,php当然能抓取图片,不过你要满足要求:所有格式的图片都要能抓取。可以用正则表达式匹配。
其实现在有不少网站的图片有save到本地的功能,上传无法保证图片只有原来那一个。
可以试试这个,给的图片都有,
有啊,但是你既然这么问了,肯定是直接上网页了。
好像还真有只抓取png的,
一般都是手机党,工作站或服务器。
能
可以下载图片,但是为什么你会觉得下载一张图片没有特殊意义呢?非得来问?就算存储图片也是会发生在本地,只要不是某个时刻去找他是不是下载了,谁又知道?并且本地图片在你下载的时候他已经加密了,并不是网上你下载的,手机能下载,但是你拿到手的图片你又有什么用呢?有用。
php网页抓取图片(崔大大的视频来码的流程及流程介绍及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-16 07:07
一、简介
还是基于崔大的视频文章,不得不说抓文件下载比抓网页内容信息要复杂的多
二、流程三、代码
#config.py
MONGO_URL='localhost'
MONGO_DB='toutiao'
MONGO_TABLE='toutiao'
group_start=1
group_end=10
KEYWORD='街拍'
import requests
from urllib.parse import urlencode
from requests.exceptions import RequestException
import json
from bs4 import BeautifulSoup
import re
from config import * #注意要把config.py文件放在环境变量的目录下
import pymongo
import os
from hashlib import md5
from multiprocessing import Pool
client=pymongo.MongoClient(MONGO_URL) #声明MongoDB对象
db=client[MONGO_DB] #定义db
def get_page_index(offset,keyword): #抓取索引页内容
data={
'offset': offset, #offset是可变的
'format': 'json',
'keyword': keyword,#keyword是可以定义的
'autoload':'true',
'count': '20',
'cur_tab': 3
}
#data是从XHR项目返回结果的Headers>Query String Parameters里的数据,Query String Parameters指的就是通过在URL中携带的方式提交的参数,也就是PHP中$_GET里的参数
url='https://www.toutiao.com/search ... ncode(data) #urlencode可以把字典对象变成url的请求参数
try:
response=requests.get(url) #请求url
if response.status_code==200:
return response.text
return None
except RequestException: #所有requests的异常
print('请求索引页出错')
return None
def parse_page_index(html):
data=json.loads(html) #对字符串进行解析,把字符串转化成json对象
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url') #构造一个生成器,把所有的article_url解析出来
def get_page_detati(url):
try:
response=requests.get(url)
if response.status_code==200:
return response.text
return None
except RequestException:
print('请求详情页出错',url)
return None
def parse_page_detail(html,url): #解析子页面
soup=BeautifulSoup(html,'lxml') #用BeautifulSoup来解析获取的子页面html代码
titie=soup.select('title')[0].get_text() #CSS选择器
print(titie)
images_pattern=re.compile('gallery: (.*?),\n',re.S) #用正则来匹配出gallery里面的数据
result=re.search(images_pattern,html)
if result:
#print(result.group(1))
data=json.loads(result.group(1)) #对字符串进行解析,把字符串转化成json对象
if data and 'sub_images' in data.keys(): #判断里面是否含有我们想要的数据
sub_images=data.get('sub_images')
images=[item.get('url') for item in sub_images]
for image in images:download_imagg(image)
return {
'title':titie,
'url':url,
'images':images
}
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print('存储成功到MongoDB',result)
return True
return False
def download_imagg(url):
print('正在下载',url)
try:
response=requests.get(url)
if response.status_code==200:
#return response.text
save_image(response.content)
return None
except RequestException:
print('请求图片出错',url)
return None
def save_image(content):
file_path='{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb')as f:
f.write(content)
f.close()
def main(offset):
html=get_page_index(offset,KEYWORD)
#print(html)
for url in parse_page_index(html):
#print(url)
html=get_page_detati(url) #利用for循环,提取出所有的article_url
if html:
#parse_page_detail(html)
result=parse_page_detail(html,url)
#print(result)
if result:save_to_mongo(result)
if __name__=='__main__':
#main()
groups=[i*10 for i in range(group_start,group_end+1)]
pool=Pool()
pool.map(main,groups)
四、最终视图和文件
五、总结
这个大崔的爬虫视频还是涉及到很多知识点。在网页、数据库、包等方面还有很多知识点需要补充。 查看全部
php网页抓取图片(崔大大的视频来码的流程及流程介绍及应用)
一、简介
还是基于崔大的视频文章,不得不说抓文件下载比抓网页内容信息要复杂的多
二、流程三、代码
#config.py
MONGO_URL='localhost'
MONGO_DB='toutiao'
MONGO_TABLE='toutiao'
group_start=1
group_end=10
KEYWORD='街拍'
import requests
from urllib.parse import urlencode
from requests.exceptions import RequestException
import json
from bs4 import BeautifulSoup
import re
from config import * #注意要把config.py文件放在环境变量的目录下
import pymongo
import os
from hashlib import md5
from multiprocessing import Pool
client=pymongo.MongoClient(MONGO_URL) #声明MongoDB对象
db=client[MONGO_DB] #定义db
def get_page_index(offset,keyword): #抓取索引页内容
data={
'offset': offset, #offset是可变的
'format': 'json',
'keyword': keyword,#keyword是可以定义的
'autoload':'true',
'count': '20',
'cur_tab': 3
}
#data是从XHR项目返回结果的Headers>Query String Parameters里的数据,Query String Parameters指的就是通过在URL中携带的方式提交的参数,也就是PHP中$_GET里的参数
url='https://www.toutiao.com/search ... ncode(data) #urlencode可以把字典对象变成url的请求参数
try:
response=requests.get(url) #请求url
if response.status_code==200:
return response.text
return None
except RequestException: #所有requests的异常
print('请求索引页出错')
return None
def parse_page_index(html):
data=json.loads(html) #对字符串进行解析,把字符串转化成json对象
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url') #构造一个生成器,把所有的article_url解析出来
def get_page_detati(url):
try:
response=requests.get(url)
if response.status_code==200:
return response.text
return None
except RequestException:
print('请求详情页出错',url)
return None
def parse_page_detail(html,url): #解析子页面
soup=BeautifulSoup(html,'lxml') #用BeautifulSoup来解析获取的子页面html代码
titie=soup.select('title')[0].get_text() #CSS选择器
print(titie)
images_pattern=re.compile('gallery: (.*?),\n',re.S) #用正则来匹配出gallery里面的数据
result=re.search(images_pattern,html)
if result:
#print(result.group(1))
data=json.loads(result.group(1)) #对字符串进行解析,把字符串转化成json对象
if data and 'sub_images' in data.keys(): #判断里面是否含有我们想要的数据
sub_images=data.get('sub_images')
images=[item.get('url') for item in sub_images]
for image in images:download_imagg(image)
return {
'title':titie,
'url':url,
'images':images
}
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print('存储成功到MongoDB',result)
return True
return False
def download_imagg(url):
print('正在下载',url)
try:
response=requests.get(url)
if response.status_code==200:
#return response.text
save_image(response.content)
return None
except RequestException:
print('请求图片出错',url)
return None
def save_image(content):
file_path='{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb')as f:
f.write(content)
f.close()
def main(offset):
html=get_page_index(offset,KEYWORD)
#print(html)
for url in parse_page_index(html):
#print(url)
html=get_page_detati(url) #利用for循环,提取出所有的article_url
if html:
#parse_page_detail(html)
result=parse_page_detail(html,url)
#print(result)
if result:save_to_mongo(result)
if __name__=='__main__':
#main()
groups=[i*10 for i in range(group_start,group_end+1)]
pool=Pool()
pool.map(main,groups)
四、最终视图和文件
五、总结
这个大崔的爬虫视频还是涉及到很多知识点。在网页、数据库、包等方面还有很多知识点需要补充。
php网页抓取图片( 这里收集了3种利用php获得网页源代码抓取网页内容的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-02-14 12:06
这里收集了3种利用php获得网页源代码抓取网页内容的方法)
方法1: 用file_get_contents以get方式获取内容
方法2:用file_get_contents函数,以post方式获取url
方法4: 用fopen打开url, 以post方式获取内容
方法5:用fsockopen函数打开url,以get方式获取完整的数据,包括header和body
方法6:用fsockopen函数打开url,以POST方式获取完整的数据,包括header和body
方法7:使用curl库,使用curl库之前,可能需要查看一下php.ini是否已经打开了curl扩展
这里介绍三种使用php获取网页源代码抓取网页内容的方法,大家可以根据实际需要选择。
1、使用file_get_contents获取网页源代码
这种方法最常用,只需要两行代码,非常简单方便。
参考代码:
2、使用fopen获取网页源代码
用这种方法的人很多,但是代码有点多。
参考代码:
3、使用curl获取网页源代码
使用curl获取网页源代码的做法,经常被要求较高的人使用。比如在爬取网页内容的同时需要获取网页的头部信息,以及使用ENCODING编码,使用USERAGENT等。
参考代码一:
参考代码2: 查看全部
php网页抓取图片(
这里收集了3种利用php获得网页源代码抓取网页内容的方法)
方法1: 用file_get_contents以get方式获取内容
方法2:用file_get_contents函数,以post方式获取url
方法4: 用fopen打开url, 以post方式获取内容
方法5:用fsockopen函数打开url,以get方式获取完整的数据,包括header和body
方法6:用fsockopen函数打开url,以POST方式获取完整的数据,包括header和body
方法7:使用curl库,使用curl库之前,可能需要查看一下php.ini是否已经打开了curl扩展
这里介绍三种使用php获取网页源代码抓取网页内容的方法,大家可以根据实际需要选择。
1、使用file_get_contents获取网页源代码
这种方法最常用,只需要两行代码,非常简单方便。
参考代码:
2、使用fopen获取网页源代码
用这种方法的人很多,但是代码有点多。
参考代码:
3、使用curl获取网页源代码
使用curl获取网页源代码的做法,经常被要求较高的人使用。比如在爬取网页内容的同时需要获取网页的头部信息,以及使用ENCODING编码,使用USERAGENT等。
参考代码一:
参考代码2:
php网页抓取图片(基于Browser创建一个包装器()的代码发起了一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-09 13:21
什么是网页抓取?
您是否曾经需要从不提供 API 的站点获取信息?我们可以通过抓取网页然后从目标 网站 的 HTML 中获取我们想要的信息来解决这个问题。当然,我们也可以手动提取这些信息,但是手动提取很繁琐。因此,使用爬虫自动执行此过程会更有效。
在本教程中,我们将从 Pexels 抓取一些猫的照片。这个 网站 提供高质量的免费库存图片。他们提供 API,但这些 API 的频率限制为 200 个请求/小时。
[](
发起并发请求
使用异步 PHP 进行网页抓取(与使用同步方法相比)的最大好处是可以在更短的时间内完成更多的工作。使用异步 PHP 允许我们一次请求尽可能多的页面,而不是一次请求一个页面并等待结果返回。所以一旦请求结果回来,我们就可以开始处理了。
首先,我们从 GitHub 拉取名为 Buzz-react 的异步 HTTP 客户端的代码——它是一个简单的基于 ReactPHP 的异步 HTTP 客户端,专用于同时处理大量 HTTP 请求:
composer require clue/buzz-react
现在,我们可以在 pexels 上请求图像页面:
<p> 查看全部
php网页抓取图片(基于Browser创建一个包装器()的代码发起了一个)
什么是网页抓取?
您是否曾经需要从不提供 API 的站点获取信息?我们可以通过抓取网页然后从目标 网站 的 HTML 中获取我们想要的信息来解决这个问题。当然,我们也可以手动提取这些信息,但是手动提取很繁琐。因此,使用爬虫自动执行此过程会更有效。
在本教程中,我们将从 Pexels 抓取一些猫的照片。这个 网站 提供高质量的免费库存图片。他们提供 API,但这些 API 的频率限制为 200 个请求/小时。
[](
发起并发请求
使用异步 PHP 进行网页抓取(与使用同步方法相比)的最大好处是可以在更短的时间内完成更多的工作。使用异步 PHP 允许我们一次请求尽可能多的页面,而不是一次请求一个页面并等待结果返回。所以一旦请求结果回来,我们就可以开始处理了。
首先,我们从 GitHub 拉取名为 Buzz-react 的异步 HTTP 客户端的代码——它是一个简单的基于 ReactPHP 的异步 HTTP 客户端,专用于同时处理大量 HTTP 请求:
composer require clue/buzz-react
现在,我们可以在 pexels 上请求图像页面:
<p>
php网页抓取图片(JAVA网站一个页面上的全部邮箱为例来做具体说明)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-04 14:02
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动从万维网上爬取信息的程序或脚本。今天,我们就以JAVA抓取一个页面网站上的所有邮箱为例,做一个具体的讲解。人们一直很懒惰,不再制作GUI。让我们看看并理解其原理。
————————————————————————————————————————————————————— —
最好在百度上找个网页,多想想。本次以贴吧网页点击打开链接为例进行说明。
从图片和网页可以看出,上面有很多邮箱。我大致看了十几页,大概有几百页。如果你是房东,你一定很难处理。如果你一个一个地发送它们,那将是太多的工作。一个一个地复制一个邮箱真的很累。但是,如果你不发布它,你肯定会被你的朋友所鄙视。
怎么做?当然,如果有一个工具可以自动识别网页上的邮箱并进行检索就好了……他是一个网络爬虫,但是他按照一定的规则来爬取网页数据,(像百度,谷歌做SEO大多是网页数据的抓取和分析)并保存这些数据,方便数据处理和使用。废话太多,去教程吧。————————————————————————————————————————————————————— — 思想分析:1.要从网页获取数据,必须获取到该网页的链接
2.为了在网页上获取邮箱地址,必须有相应的邮箱地址获取规则
3.为了移除数据,必须通过数据相关类的操作来获取
4.为了保存数据,必须实现保存数据的操作———————————————————————————————— ———————— ——————————————
接下来代码。
打包工具;导入 java.io.BufferedReader;导入 java.io.File;导入 java.io.FileWriter;导入 java.io.InputStreamReader;导入 java.io.Writer;导入 .URL;导入 .URLConnection;导入 java.sql .Time;import java.util.Scanner;import java.util.regex.Matcher;import java.util.regex.Pattern;public class Demo { public static void main(String[] args) throws Exception {// 这个程序里面异常太多为简单起见,不要尝试直接扔给虚拟机 Long StartTime = System.currentTimeMillis(); System.out.println("-- 欢迎使用飞扬简易爬虫--"); System.out.println(""); System.out.println("--请输入正确的网址如"); Scanner input = new Scanner(System.in);// 实例化键盘输入类 String webaddress = input.next();
URLConnection conn = url.openConnection();// 获取链接 BufferedReader buff = new BufferedReader(new InputStreamReader( conn.getInputStream()));// 获取网页数据 String line = null; 诠释我=0;String regex = "\ \w+@\\w+(\\.\\w+)+";//声明一个正则,提取网页的前提Pattern p = pile(regex);//实例化outWriter.write( "网页收录的邮箱如下所示:\r\n"); while ((line = buff.readLine()) != null) { Matcher m = p.matcher(line);// 进行匹配 while (m.find() ) { i++; outWriter.write(m.group() + ";\r\n");// 输入匹配的字符到目标文件} } Long StopTime = System.currentTimeMillis(); String UseTime=(StopTime- StartTime)+""; outWriter.write("--------------------------------------- ------ ------------\r\n"); outWriter.write(" ); }}); System.out.println(" ————————————————————————\t"); }}); System.out.println(" ————————————————————————\t"); }}
代码如上,每一行都有注释。如果实在不明白,可以联系我。
编译->直接在命令行运行
输入爬取页面的地址。
打开D盘目录,找到test.xt文件。
文件中的邮箱添加了“;” 默认情况下,方便大家发送。
当然,爬取本地文件中的数据更容易
不用过多解释,直接上代码。
导入 java.io.BufferedReader;导入 java.io.File;导入 java.io.FileReader;导入 java.util.regex.Matcher;导入 java.util.regex.Pattern;公共类 Demo0 { public static void main(String[ ] args)throws Exception { BufferedReader buff=new BufferedReader(new FileReader("D:"+File.separator+"test.txt")); 字符串行=空;字符串正则表达式="\\w+@\\w+(\\ .\\w+)+"; 模式 p=pile(正则表达式); while ((line=buff.readLine())!= null) { Matcher m=p.matcher(line); while (m.find()) { System.out.println(m.group()+";"); } } }} 查看全部
php网页抓取图片(JAVA网站一个页面上的全部邮箱为例来做具体说明)
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动从万维网上爬取信息的程序或脚本。今天,我们就以JAVA抓取一个页面网站上的所有邮箱为例,做一个具体的讲解。人们一直很懒惰,不再制作GUI。让我们看看并理解其原理。
————————————————————————————————————————————————————— —
最好在百度上找个网页,多想想。本次以贴吧网页点击打开链接为例进行说明。
从图片和网页可以看出,上面有很多邮箱。我大致看了十几页,大概有几百页。如果你是房东,你一定很难处理。如果你一个一个地发送它们,那将是太多的工作。一个一个地复制一个邮箱真的很累。但是,如果你不发布它,你肯定会被你的朋友所鄙视。
怎么做?当然,如果有一个工具可以自动识别网页上的邮箱并进行检索就好了……他是一个网络爬虫,但是他按照一定的规则来爬取网页数据,(像百度,谷歌做SEO大多是网页数据的抓取和分析)并保存这些数据,方便数据处理和使用。废话太多,去教程吧。————————————————————————————————————————————————————— — 思想分析:1.要从网页获取数据,必须获取到该网页的链接
2.为了在网页上获取邮箱地址,必须有相应的邮箱地址获取规则
3.为了移除数据,必须通过数据相关类的操作来获取
4.为了保存数据,必须实现保存数据的操作———————————————————————————————— ———————— ——————————————
接下来代码。
打包工具;导入 java.io.BufferedReader;导入 java.io.File;导入 java.io.FileWriter;导入 java.io.InputStreamReader;导入 java.io.Writer;导入 .URL;导入 .URLConnection;导入 java.sql .Time;import java.util.Scanner;import java.util.regex.Matcher;import java.util.regex.Pattern;public class Demo { public static void main(String[] args) throws Exception {// 这个程序里面异常太多为简单起见,不要尝试直接扔给虚拟机 Long StartTime = System.currentTimeMillis(); System.out.println("-- 欢迎使用飞扬简易爬虫--"); System.out.println(""); System.out.println("--请输入正确的网址如"); Scanner input = new Scanner(System.in);// 实例化键盘输入类 String webaddress = input.next();
URLConnection conn = url.openConnection();// 获取链接 BufferedReader buff = new BufferedReader(new InputStreamReader( conn.getInputStream()));// 获取网页数据 String line = null; 诠释我=0;String regex = "\ \w+@\\w+(\\.\\w+)+";//声明一个正则,提取网页的前提Pattern p = pile(regex);//实例化outWriter.write( "网页收录的邮箱如下所示:\r\n"); while ((line = buff.readLine()) != null) { Matcher m = p.matcher(line);// 进行匹配 while (m.find() ) { i++; outWriter.write(m.group() + ";\r\n");// 输入匹配的字符到目标文件} } Long StopTime = System.currentTimeMillis(); String UseTime=(StopTime- StartTime)+""; outWriter.write("--------------------------------------- ------ ------------\r\n"); outWriter.write(" ); }}); System.out.println(" ————————————————————————\t"); }}); System.out.println(" ————————————————————————\t"); }}
代码如上,每一行都有注释。如果实在不明白,可以联系我。
编译->直接在命令行运行
输入爬取页面的地址。
打开D盘目录,找到test.xt文件。
文件中的邮箱添加了“;” 默认情况下,方便大家发送。
当然,爬取本地文件中的数据更容易
不用过多解释,直接上代码。
导入 java.io.BufferedReader;导入 java.io.File;导入 java.io.FileReader;导入 java.util.regex.Matcher;导入 java.util.regex.Pattern;公共类 Demo0 { public static void main(String[ ] args)throws Exception { BufferedReader buff=new BufferedReader(new FileReader("D:"+File.separator+"test.txt")); 字符串行=空;字符串正则表达式="\\w+@\\w+(\\ .\\w+)+"; 模式 p=pile(正则表达式); while ((line=buff.readLine())!= null) { Matcher m=p.matcher(line); while (m.find()) { System.out.println(m.group()+";"); } } }}
php网页抓取图片(php网页抓取图片已有多种方法:javascriptjquerypythonphp都能实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-25 04:06
php网页抓取图片已有多种方法:javascriptjquerypythonphp都能实现。这里介绍使用php的。流程:1.抓取分析图片2.解析获取地址、图片资源以及restfulapi3.爬取持久化图片解析的方法主要有:1.图片imagetoken2.selenium3.浏览器请求请求获取网页源码网页传输消息etc注意事项1.被请求的http协议方向可能不一样2.图片格式需求(jpg,bmp,png,mp4,gif,jpg,png等)以上仅仅根据实际需求作的一个总结和整理,详细的实现和php原理还有一点就是web的多媒体协议,欢迎补充和探讨。
这种问题问度娘绝对有结果,没必要问这种话题。
我用这里给出的答案做了个爬虫图片
php,图片的话看你是要和谁互相传递的
图片是用http,和图片分类完全是2个东西,
网页上有一种图片爬虫工具,比你这种写法简单很多,
1.php可以直接解析返回数据,图片分类的数据,最重要的是可以发布到站外。
目前moocs学习网站还是有比较有价值的图片资源,如清华大学图书馆,都是免费给学生进行图片处理使用的。下面分享下我们最近针对这类资源处理工作所总结的处理思路和用法。 查看全部
php网页抓取图片(php网页抓取图片已有多种方法:javascriptjquerypythonphp都能实现)
php网页抓取图片已有多种方法:javascriptjquerypythonphp都能实现。这里介绍使用php的。流程:1.抓取分析图片2.解析获取地址、图片资源以及restfulapi3.爬取持久化图片解析的方法主要有:1.图片imagetoken2.selenium3.浏览器请求请求获取网页源码网页传输消息etc注意事项1.被请求的http协议方向可能不一样2.图片格式需求(jpg,bmp,png,mp4,gif,jpg,png等)以上仅仅根据实际需求作的一个总结和整理,详细的实现和php原理还有一点就是web的多媒体协议,欢迎补充和探讨。
这种问题问度娘绝对有结果,没必要问这种话题。
我用这里给出的答案做了个爬虫图片
php,图片的话看你是要和谁互相传递的
图片是用http,和图片分类完全是2个东西,
网页上有一种图片爬虫工具,比你这种写法简单很多,
1.php可以直接解析返回数据,图片分类的数据,最重要的是可以发布到站外。
目前moocs学习网站还是有比较有价值的图片资源,如清华大学图书馆,都是免费给学生进行图片处理使用的。下面分享下我们最近针对这类资源处理工作所总结的处理思路和用法。
php网页抓取图片(php网页抓取图片功能需要考虑几个因素?不需要解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-24 00:04
php网页抓取图片功能,可以说是一个单一的网站的标配了,你会需要用到很多功能,因为你会同时需要做数据存储,数据抓取,网页解析,网页分析,并不是说我们想不到这些功能,而是需要分步骤去实现。当我们爬取别人网站的数据时,可能需要考虑几个因素1,从哪里开始2,去哪里获取3,怎么样保证数据准确性4,重复率会不会很高不重复率肯定不是php网页抓取图片功能的关键因素,重复率一般情况是比较低的,但是对于每个网站来说就不一定了,对于某些网站(例如新浪微博),是会有特殊要求的。
另外:网页要不要加密实时性也会影响,如果网页都是经过加密处理过的,抓取的文件肯定会增加很多东西。总的来说php网页抓取图片功能用到的库还是很多的,你不可能会给你一个刚入门的新手所能接触到的各种封装好的库,只能靠自己去扩展了。
php就是python的简化版,
php有模板引擎,js插件,能做一些简单的轮播动画,css3选择器。再加上原始图片不会加密处理。所以可以做轮播类的静态图,也就是上述三项大概占两项以内的重复问题。不需要解析网页数据。
单做出一个xxx.php测试完别人所有的网站,确定哪些我的代码没写对,哪些别人的代码没有做出来,哪些是错误代码,剩下的的按照实际情况再动手吧,php转java的话, 查看全部
php网页抓取图片(php网页抓取图片功能需要考虑几个因素?不需要解析)
php网页抓取图片功能,可以说是一个单一的网站的标配了,你会需要用到很多功能,因为你会同时需要做数据存储,数据抓取,网页解析,网页分析,并不是说我们想不到这些功能,而是需要分步骤去实现。当我们爬取别人网站的数据时,可能需要考虑几个因素1,从哪里开始2,去哪里获取3,怎么样保证数据准确性4,重复率会不会很高不重复率肯定不是php网页抓取图片功能的关键因素,重复率一般情况是比较低的,但是对于每个网站来说就不一定了,对于某些网站(例如新浪微博),是会有特殊要求的。
另外:网页要不要加密实时性也会影响,如果网页都是经过加密处理过的,抓取的文件肯定会增加很多东西。总的来说php网页抓取图片功能用到的库还是很多的,你不可能会给你一个刚入门的新手所能接触到的各种封装好的库,只能靠自己去扩展了。
php就是python的简化版,
php有模板引擎,js插件,能做一些简单的轮播动画,css3选择器。再加上原始图片不会加密处理。所以可以做轮播类的静态图,也就是上述三项大概占两项以内的重复问题。不需要解析网页数据。
单做出一个xxx.php测试完别人所有的网站,确定哪些我的代码没写对,哪些别人的代码没有做出来,哪些是错误代码,剩下的的按照实际情况再动手吧,php转java的话,
php网页抓取图片(Python爬虫()实战之爬取())
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-23 21:13
之前的传送门:
小白学Python爬虫(1):开
小白学Python爬虫(2):前期准备(一)基础类库安装)
小白学Python爬虫(3):前期准备(二)Linux基础介绍)
小白学习Python爬虫(4):前期准备(三)Docker基础介绍)
小白学Python爬虫(5):前期准备(四)数据库基础)
小白学习Python爬虫(6):前期准备(五)爬虫框架的安装)
小白学习Python爬虫(7):HTTP基础
小白学Python爬虫(8):网页基础
小白学习Python爬虫(9):爬虫基础
小白学习Python爬虫(一0):Session和Cookies
小白学Python爬虫(一1):urllib的基本使用(一)
小白学习Python爬虫(一2):urllib的基本使用(二)
小白学Python爬虫(一3):urllib的基本使用(三)
小白学习Python爬虫(14):urllib(四))的基本使用
小白学习Python爬虫(一5):urllib的基本使用(五)
小白学Python爬虫(一6):urllib实战爬虫图)
小白学习Python爬虫(一7):Requests的基本使用)
小白学Python爬虫(18):请求高级操作
小白学Python爬虫(一9):Xpath基础操作
小白学Python爬虫(20):Xpath进阶
小白学Python爬虫(二1):分析库美汤(上))
小白学Python爬虫(二2):分析库美汤(下))
小白学Python爬虫(二3):解析库pyquery简介
小白学Python爬虫(24):2019豆瓣电影排行榜
介绍
上一篇实战最后没有使用页面元素分析,感觉有点遗憾,不过最后的片单还是挺香的,真心推荐。
本次选题是先写代码再写文章,肯定可以用于页面元素分析,还需要对网站的数据加载有一定的分析,才能得到最终数据,和小编找到的两个数据源没有IP访问限制,质量有保障。绝对是小白修炼的绝佳选择。
郑重声明:本文仅供学习及其他用途。
分析
首先,要爬取股票数据,首先要知道有哪些股票。在这里,小编发现了一个网站,而这个网站有一个股票代码列表:.
打开Chrome的开发者模式,一一选择代码。具体过程这里就不贴了,同学们可以自己实现。
我们可以将所有股票代码存储在一个列表中,剩下的就是找到一个网站,然后循环获取每只股票的数据。
这个网站编辑器已经找到了,是同花顺,链接:。
聪明的同学一定都发现,这个链接里的000001就是股票代码。
接下来,我们只需要拼接这个链接,就可以不断得到我们想要的数据。
实战
首先介绍一下本次实战用到的请求库和解析库:Requests和pyquery。数据存储终于落地Mysql。
获取股票代码列表
第一步当然是建立一个股票代码列表。我们先定义一个方法:
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
把上面的链接作为参数传入,大家可以自己运行看看结果,小编这里就不贴结果了,有点长。. .
获取详细数据
详细信息的数据似乎在页面上,但实际上并不存在。最终获取数据的实际地方不是页面,而是数据接口。
http://qd.10jqka.com.cn/quote. ... 00001
至于怎么找,小编这次就不多说了。还是希望所有想学爬虫的同学都能自己动手,去找找吧。多找几遍,自然会找到路。
既然有了数据接口,我们再来看看返回的数据:
showStockDate({"info":{"000001":{"name":"\u5e73\u5b89\u94f6\u884c"}},"data":{"000001":{"10":"16.13","8":"16.14","9":"15.87","13":"78795234.00","19":"1262802470.00","7":"16.12","15":"40225508.00","14":"37528826.00","69":"17.73","70":"14.51","12":"5","17":"945400.00","264648":"0.010","199112":"0.062","1968584":"0.406","2034120":"9.939","1378761":"16.026","526792":"1.675","395720":"-948073.000","461256":"-39.763","3475914":"313014790000.000","1771976":"1.100","6":"16.12","11":""}}})
显然,这个结果并不是标准的json数据,而是JSONP返回的标准格式数据。这里我们先对head和tail进行处理,变成标准的json数据,然后针对本页的数据进行解析,最后将解析后的值写入数据库。
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
这里我们添加异常处理,因为这次爬取的数据很多,很可能会因为某种原因抛出异常。当然,我们不想在出现异常的时候中断数据采集,所以在这里添加异常处理,继续采集数据。
完整代码
我们将代码稍微封装一下来完成这个实战。
import requests
import re
import json
from pyquery import PyQuery
import pymysql
# 数据库连接
def connect():
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
password='password',
database='test',
charset='utf8mb4')
# 获取操作游标
cursor = conn.cursor()
return {"conn": conn, "cursor": cursor}
connection = connect()
conn, cursor = connection['conn'], connection['cursor']
sql_insert = "insert into stock(code, name, jinkai, chengjiaoliang, zhenfu, zuigao, chengjiaoe, huanshou, zuidi, zuoshou, liutongshizhi, create_date) values (%(code)s, %(name)s, %(jinkai)s, %(chengjiaoliang)s, %(zhenfu)s, %(zuigao)s, %(chengjiaoe)s, %(huanshou)s, %(zuidi)s, %(zuoshou)s, %(liutongshizhi)s, now())"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
def main():
stock_list_url = 'https://hq.gucheng.com/gpdmylb.html'
stock_info_url = 'http://qd.10jqka.com.cn/quote. ... 39%3B
list = get_stock_list(stock_list_url)
# list = ['601766']
getStockInfo(list, stock_info_url)
if __name__ == '__main__':
main()
成就
最终,编辑器用了15分钟左右,成功捕获了4600+条数据,结果就不显示了。
示例代码
为了您的方便,本系列中的所有代码编辑器都将放在代码管理存储库 Github 和 Gitee 上。
示例代码 - Github
示例代码 - Gitee 查看全部
php网页抓取图片(Python爬虫()实战之爬取())
之前的传送门:
小白学Python爬虫(1):开
小白学Python爬虫(2):前期准备(一)基础类库安装)
小白学Python爬虫(3):前期准备(二)Linux基础介绍)
小白学习Python爬虫(4):前期准备(三)Docker基础介绍)
小白学Python爬虫(5):前期准备(四)数据库基础)
小白学习Python爬虫(6):前期准备(五)爬虫框架的安装)
小白学习Python爬虫(7):HTTP基础
小白学Python爬虫(8):网页基础
小白学习Python爬虫(9):爬虫基础
小白学习Python爬虫(一0):Session和Cookies
小白学Python爬虫(一1):urllib的基本使用(一)
小白学习Python爬虫(一2):urllib的基本使用(二)
小白学Python爬虫(一3):urllib的基本使用(三)
小白学习Python爬虫(14):urllib(四))的基本使用
小白学习Python爬虫(一5):urllib的基本使用(五)
小白学Python爬虫(一6):urllib实战爬虫图)
小白学习Python爬虫(一7):Requests的基本使用)
小白学Python爬虫(18):请求高级操作
小白学Python爬虫(一9):Xpath基础操作
小白学Python爬虫(20):Xpath进阶
小白学Python爬虫(二1):分析库美汤(上))
小白学Python爬虫(二2):分析库美汤(下))
小白学Python爬虫(二3):解析库pyquery简介
小白学Python爬虫(24):2019豆瓣电影排行榜
介绍
上一篇实战最后没有使用页面元素分析,感觉有点遗憾,不过最后的片单还是挺香的,真心推荐。
本次选题是先写代码再写文章,肯定可以用于页面元素分析,还需要对网站的数据加载有一定的分析,才能得到最终数据,和小编找到的两个数据源没有IP访问限制,质量有保障。绝对是小白修炼的绝佳选择。
郑重声明:本文仅供学习及其他用途。
分析
首先,要爬取股票数据,首先要知道有哪些股票。在这里,小编发现了一个网站,而这个网站有一个股票代码列表:.
打开Chrome的开发者模式,一一选择代码。具体过程这里就不贴了,同学们可以自己实现。
我们可以将所有股票代码存储在一个列表中,剩下的就是找到一个网站,然后循环获取每只股票的数据。
这个网站编辑器已经找到了,是同花顺,链接:。
聪明的同学一定都发现,这个链接里的000001就是股票代码。
接下来,我们只需要拼接这个链接,就可以不断得到我们想要的数据。
实战
首先介绍一下本次实战用到的请求库和解析库:Requests和pyquery。数据存储终于落地Mysql。
获取股票代码列表
第一步当然是建立一个股票代码列表。我们先定义一个方法:
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
把上面的链接作为参数传入,大家可以自己运行看看结果,小编这里就不贴结果了,有点长。. .
获取详细数据
详细信息的数据似乎在页面上,但实际上并不存在。最终获取数据的实际地方不是页面,而是数据接口。
http://qd.10jqka.com.cn/quote. ... 00001
至于怎么找,小编这次就不多说了。还是希望所有想学爬虫的同学都能自己动手,去找找吧。多找几遍,自然会找到路。
既然有了数据接口,我们再来看看返回的数据:
showStockDate({"info":{"000001":{"name":"\u5e73\u5b89\u94f6\u884c"}},"data":{"000001":{"10":"16.13","8":"16.14","9":"15.87","13":"78795234.00","19":"1262802470.00","7":"16.12","15":"40225508.00","14":"37528826.00","69":"17.73","70":"14.51","12":"5","17":"945400.00","264648":"0.010","199112":"0.062","1968584":"0.406","2034120":"9.939","1378761":"16.026","526792":"1.675","395720":"-948073.000","461256":"-39.763","3475914":"313014790000.000","1771976":"1.100","6":"16.12","11":""}}})
显然,这个结果并不是标准的json数据,而是JSONP返回的标准格式数据。这里我们先对head和tail进行处理,变成标准的json数据,然后针对本页的数据进行解析,最后将解析后的值写入数据库。
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
这里我们添加异常处理,因为这次爬取的数据很多,很可能会因为某种原因抛出异常。当然,我们不想在出现异常的时候中断数据采集,所以在这里添加异常处理,继续采集数据。
完整代码
我们将代码稍微封装一下来完成这个实战。
import requests
import re
import json
from pyquery import PyQuery
import pymysql
# 数据库连接
def connect():
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
password='password',
database='test',
charset='utf8mb4')
# 获取操作游标
cursor = conn.cursor()
return {"conn": conn, "cursor": cursor}
connection = connect()
conn, cursor = connection['conn'], connection['cursor']
sql_insert = "insert into stock(code, name, jinkai, chengjiaoliang, zhenfu, zuigao, chengjiaoe, huanshou, zuidi, zuoshou, liutongshizhi, create_date) values (%(code)s, %(name)s, %(jinkai)s, %(chengjiaoliang)s, %(zhenfu)s, %(zuigao)s, %(chengjiaoe)s, %(huanshou)s, %(zuidi)s, %(zuoshou)s, %(liutongshizhi)s, now())"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
def main():
stock_list_url = 'https://hq.gucheng.com/gpdmylb.html'
stock_info_url = 'http://qd.10jqka.com.cn/quote. ... 39%3B
list = get_stock_list(stock_list_url)
# list = ['601766']
getStockInfo(list, stock_info_url)
if __name__ == '__main__':
main()
成就
最终,编辑器用了15分钟左右,成功捕获了4600+条数据,结果就不显示了。
示例代码
为了您的方便,本系列中的所有代码编辑器都将放在代码管理存储库 Github 和 Gitee 上。
示例代码 - Github
示例代码 - Gitee
php网页抓取图片(php网页抓取图片数据接口来源于官方javascript网页调用apijs数据爬取图片的网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-22 19:07
<p>php网页抓取图片数据图片数据接口来源于官方javascript网页调用api抓取js数据爬取图片的网站:imgurlhttpcache只需抓取api数据,仅需了解javascriptapi规则即可完成抓取(默认抓取格式为图片数据)imgurl 查看全部
php网页抓取图片(php网页抓取图片数据接口来源于官方javascript网页调用apijs数据爬取图片的网站)
<p>php网页抓取图片数据图片数据接口来源于官方javascript网页调用api抓取js数据爬取图片的网站:imgurlhttpcache只需抓取api数据,仅需了解javascriptapi规则即可完成抓取(默认抓取格式为图片数据)imgurl
php网页抓取图片(经典PHP加密解密函数Authcode()修复版代码讲述)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-13 02:31
本文的例子描述了php获取网页中所有图片并存储到数组中的方法。分享给大家,供大家参考。详情如下:
$images = array();preg_match_all("/(img|src)=("|")[^"">]+/i", $data, $media);unset($data);$data=preg_replace("/(img|src)("|"|="|=")(.*)/i","$3",$media[0]);foreach($data as $url){ $info = pathinfo($url); if (isset($info["extension"])) { if (($info["extension"] == "jpg") || ($info["extension"] == "jpeg") || ($info["extension"] == "gif") || ($info["extension"] == "png")) array_push($images, $url); }}
我希望这篇文章对你的 php 编程有所帮助。
TAG标签:php方法获取网页中的所有图片并存储在数组中
一白互联网是国内知名的网站建设品牌服务商。我们在网站 建设、网站 制作、网页设计、php 开发、域名注册和虚拟主机服务方面拥有九年的经验。所提供的自助建站服务更是享誉全国。近年来,还整合团队优势,自主研发可视化多用户《点云站建站系统》3.0平台版,拖放排版网站制作设计,轻松实现PC站、手机微网站、小程序、APP一体化网络营销网站建设,已成功为全国数百家网络公司提供自助平台搭建服务。
上一篇:如何在 CodeIgniter 中删除和设置 cookie | 下一篇:经典PHP加解密函数Authcode()修复版代码 查看全部
php网页抓取图片(经典PHP加密解密函数Authcode()修复版代码讲述)
本文的例子描述了php获取网页中所有图片并存储到数组中的方法。分享给大家,供大家参考。详情如下:
$images = array();preg_match_all("/(img|src)=("|")[^"">]+/i", $data, $media);unset($data);$data=preg_replace("/(img|src)("|"|="|=")(.*)/i","$3",$media[0]);foreach($data as $url){ $info = pathinfo($url); if (isset($info["extension"])) { if (($info["extension"] == "jpg") || ($info["extension"] == "jpeg") || ($info["extension"] == "gif") || ($info["extension"] == "png")) array_push($images, $url); }}
我希望这篇文章对你的 php 编程有所帮助。
TAG标签:php方法获取网页中的所有图片并存储在数组中
一白互联网是国内知名的网站建设品牌服务商。我们在网站 建设、网站 制作、网页设计、php 开发、域名注册和虚拟主机服务方面拥有九年的经验。所提供的自助建站服务更是享誉全国。近年来,还整合团队优势,自主研发可视化多用户《点云站建站系统》3.0平台版,拖放排版网站制作设计,轻松实现PC站、手机微网站、小程序、APP一体化网络营销网站建设,已成功为全国数百家网络公司提供自助平台搭建服务。
上一篇:如何在 CodeIgniter 中删除和设置 cookie | 下一篇:经典PHP加解密函数Authcode()修复版代码
php网页抓取图片(php网页抓取图片的话我推荐我的电脑软件“赛优采云科技”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-04 12:02
php网页抓取图片的话我推荐我的电脑软件“赛优采云科技”~主要是获取http服务器返回的数据,速度比python和ruby、selenium都要快很多,网页抓取和网页分析、网络爬虫分离,操作非常简单,
python入门的话推荐/
requests或者beautifulsoup。
推荐python3-pil-webdriver-7.4.1-windows-x64-py3-gcc.exe
没有,你去看书自己看吧,推荐几本书吧:python编程:从入门到实践(这本书非常棒,可以作为python入门的教材)python编程——从入门到实践2(写的比较好,适合python入门教材)pythonfordataanalysis:amodernapproachandguide(这本也很好,比第一本好)pythonessentials(这个不错,看过,可以作为linux下python开发的教材)如果是初学者,那么最好看网上的教程,这个比较适合入门。
python的相关资料太多了,任何一本入门书上的示例代码在网上都可以找到,我当时第一本看的书就是array和map总是搞混,看过第二本后好一些,你要看书,要找经典的书看,能让你有信心看下去。
我当时看了
1、
2、
3、4,综合来说,推荐看python2.x的书籍,很多框架都是2.x的,看官方文档就好了。个人觉得1.x的书籍内容还是比较多的,基本覆盖python的所有知识。2.x的书籍侧重点也不同,像3.x的书籍,注重的是编程语言,像python3.x的书籍,更侧重python的算法等,内容也更专业。看你的学习方式是先过一遍python语言本身,学一些python的框架,如numpy、pandas等,如果要深入,可以去看一些python基础的教程,python入门很简单的。 查看全部
php网页抓取图片(php网页抓取图片的话我推荐我的电脑软件“赛优采云科技”)
php网页抓取图片的话我推荐我的电脑软件“赛优采云科技”~主要是获取http服务器返回的数据,速度比python和ruby、selenium都要快很多,网页抓取和网页分析、网络爬虫分离,操作非常简单,
python入门的话推荐/
requests或者beautifulsoup。
推荐python3-pil-webdriver-7.4.1-windows-x64-py3-gcc.exe
没有,你去看书自己看吧,推荐几本书吧:python编程:从入门到实践(这本书非常棒,可以作为python入门的教材)python编程——从入门到实践2(写的比较好,适合python入门教材)pythonfordataanalysis:amodernapproachandguide(这本也很好,比第一本好)pythonessentials(这个不错,看过,可以作为linux下python开发的教材)如果是初学者,那么最好看网上的教程,这个比较适合入门。
python的相关资料太多了,任何一本入门书上的示例代码在网上都可以找到,我当时第一本看的书就是array和map总是搞混,看过第二本后好一些,你要看书,要找经典的书看,能让你有信心看下去。
我当时看了
1、
2、
3、4,综合来说,推荐看python2.x的书籍,很多框架都是2.x的,看官方文档就好了。个人觉得1.x的书籍内容还是比较多的,基本覆盖python的所有知识。2.x的书籍侧重点也不同,像3.x的书籍,注重的是编程语言,像python3.x的书籍,更侧重python的算法等,内容也更专业。看你的学习方式是先过一遍python语言本身,学一些python的框架,如numpy、pandas等,如果要深入,可以去看一些python基础的教程,python入门很简单的。
php网页抓取图片(Python中有多个多个类型的页面对象用子类属性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-12-29 09:03
此类元素用于标识产品页面,即使爬虫对相关产品的内容不感兴趣。
为了跟踪多种页面类型,您需要在 Python 中拥有多种类型的页面对象。这是通过两种方式实现的。
如果页面相似(它们的内容类型基本相同),则可能需要在现有页面对象中添加 pageType 属性:
class Website: """所有文章/网页的共同基类""" def __init__(self, type, name, url, searchUrl, resultListing, resultUrl, absoluteUrl, titleTag, bodyTag): self.name = name self.url = url self.titleTag = titleTag self.bodyTag = bodyTag self.pageType = pageType
如果在类 SQL 的数据库中对这些页面进行排序,则此模式类型意味着这些页面应存储在同一个表中,并添加了一个额外的 pageType 列。
如果抓取不同的页面或内容(它们收录
不同类型的字段),则需要为每种页面类型创建一个新对象。当然,有些东西是所有网页共有的——它们都有一个 URL,它们也可能有一个名称或页面标题。这种情况非常适合子类:
class Website: """所有文章/网页的共同基类""" def __init__(self, name, url, titleTag): self.name = name self.url = url self.titleTag = titleTag
这不是您的爬虫直接使用的对象,而是您的页面类型将引用的对象:
class Product(Website): """产品页面要抓取的信息""" def __init__(self, name, url, titleTag, productNumber, price): Website.__init__(self, name, url, TitleTag) self.productNumberTag = productNumberTag self.priceTag = priceTag class Article(Website): """文章页面要抓取的信息""" def __init__(self, name, url, titleTag, bodyTag, dateTag): Website.__init__(self, name, url, titleTag) self.bodyTag = bodyTag self.dateTag = dateTag
该产品页面扩展了Website 基类,增加了仅适用于产品的productNumber 和price 属性,而Article 类增加了不适用于产品的body 和date 属性。
您可以使用这两个类别来抓取商店网站,其中除了产品之外还可能收录
博客文章或新闻稿。
希望以上知识点可以帮助到大家,也感谢各位攻城狮对我的支持。 查看全部
php网页抓取图片(Python中有多个多个类型的页面对象用子类属性)
此类元素用于标识产品页面,即使爬虫对相关产品的内容不感兴趣。
为了跟踪多种页面类型,您需要在 Python 中拥有多种类型的页面对象。这是通过两种方式实现的。
如果页面相似(它们的内容类型基本相同),则可能需要在现有页面对象中添加 pageType 属性:
class Website: """所有文章/网页的共同基类""" def __init__(self, type, name, url, searchUrl, resultListing, resultUrl, absoluteUrl, titleTag, bodyTag): self.name = name self.url = url self.titleTag = titleTag self.bodyTag = bodyTag self.pageType = pageType
如果在类 SQL 的数据库中对这些页面进行排序,则此模式类型意味着这些页面应存储在同一个表中,并添加了一个额外的 pageType 列。
如果抓取不同的页面或内容(它们收录
不同类型的字段),则需要为每种页面类型创建一个新对象。当然,有些东西是所有网页共有的——它们都有一个 URL,它们也可能有一个名称或页面标题。这种情况非常适合子类:
class Website: """所有文章/网页的共同基类""" def __init__(self, name, url, titleTag): self.name = name self.url = url self.titleTag = titleTag
这不是您的爬虫直接使用的对象,而是您的页面类型将引用的对象:
class Product(Website): """产品页面要抓取的信息""" def __init__(self, name, url, titleTag, productNumber, price): Website.__init__(self, name, url, TitleTag) self.productNumberTag = productNumberTag self.priceTag = priceTag class Article(Website): """文章页面要抓取的信息""" def __init__(self, name, url, titleTag, bodyTag, dateTag): Website.__init__(self, name, url, titleTag) self.bodyTag = bodyTag self.dateTag = dateTag
该产品页面扩展了Website 基类,增加了仅适用于产品的productNumber 和price 属性,而Article 类增加了不适用于产品的body 和date 属性。
您可以使用这两个类别来抓取商店网站,其中除了产品之外还可能收录
博客文章或新闻稿。
希望以上知识点可以帮助到大家,也感谢各位攻城狮对我的支持。
php网页抓取图片(桌面壁纸电脑桌面壁纸高清壁纸大全下载(二):将图片下载到本地有了图片链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-12-28 04:22
)
一:目标站点信息
卞桌面网站为:桌面壁纸,电脑桌面壁纸,高清壁纸,下载,桌面背景图片,卞桌面
2:目标站点分析
(1): 构建页面的 URL 列表
我们需要做的是抓取网站上给定数量页面的图片,所以我们首先需要观察每个页面的链接之间的关系,然后构建一个需要抓取的URL列表。
第一页的链接:http://www.netbian.com/
第二页的链接:http://www.netbian.com/index_2.htm
可以看到第二页后面的页面链接只是和后面的数字不同,我们可以写一个简单的代码来获取页面的url列表
# 页面链接的初始化列表
page_links_list=['http://www.netbian.com/']
#获取爬取的页数和页面链接
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
print(page_links_list)
请输入你想爬取的页数:5
['http://www.netbian.com/', 'http://www.netbian.com/index_2.htm', 'http://www.netbian.com/index_3.htm', 'http://www.netbian.com/index_4.htm', 'http://www.netbian.com/index_5.htm']
(2): 获取一个页面上所有图片的链接
我们已经获取了所有页面的链接,但是还没有获取到每张图片的链接,那么接下来我们要做的就是获取一个页面中所有图片的链接。这里以第一页为例,获取每张图片的链接,其他页面类似。
首先右击页面->查看元素,然后点击查看器左侧的小光标,然后将鼠标放在随机一张图片上,这样就可以定位到图片的代码位置;我们可以知道每个页面有18张图片。接下来,我们需要使用标签来定位图片在页面上的具体位置。如下图所示,我们使用 div.list li a img 来精确定位 18 个 img 标签。img 标签收录
我们需要的图片链接。
接下来我们以第一页为例,获取每张图片的链接。
#python3 -m pip install bs4
#python3 -m pip install lxml
import requests
from bs4 import BeautifulSoup
# 页面链接的初始化列表
url='http://www.netbian.com/'
# 图片链接列表
img_links_list = []
#获取img标签,在获取图片链接
html = requests.get(url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
for img in imgs:
img_link = img['src']
img_links_list.append(img_link)
print(img_links_list)
print(len(img_links_list))
['http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B]
18
(3): 下载图片到本地
有了图片链接后,我们需要将图片下载到本地,这里以第一张图片为例进行下载
import urllib.request
url='http://img.netbian.com/file/20 ... 39%3B
urllib.request.urlretrieve(url, filename='test.jpg')
(4): 一个简单的获取图片的爬虫
结合以上三部分,构建页面的url列表,获取一个页面中的所有图片链接,将图片下载到本地。构建一个完整但效率低下的爬虫。
import requests
from bs4 import BeautifulSoup
import lxml
import urllib
import os
import time
#获取图片并下载到本地
def GetImages(url):
html=requests.get(url, timeout = 2).content.decode('gbk')
soup=BeautifulSoup(html,'lxml')
imgs=soup.select("div.list li a img")
for img in imgs:
link=img['src']
display=link.split('/')[-1]
print('正在下载:',display)
filename='./images/'+display
urllib.request.urlretrieve(link,filename)
#获取爬取的页数,返回链接数
def GetUrls(page_links_list):
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
if __name__ == '__main__':
page_links_list=['http://www.netbian.com/']
GetUrls(page_links_list)
os.mkdir('./images')
print("开始下载图片!!!")
start = time.time()
for url in page_links_list:
GetImages(url)
print('图片下载成功!!!')
end = time.time() - start
print('消耗时间为:', end)
请输入你想爬取的页数:5
开始下载图片!!!
正在下载: smalle213d95e54c5b4fb355b710a473292ea1566035585.jpg
正在下载: small15ca224d7c4c119affe2cfd2d811862e1566035332.jpg
正在下载: 604a688cd6f79161236e6250189bc25b.jpg
正在下载: smallab7249d18e67c9336109e3bedc094f381566034907.jpg
正在下载: small5816e940e6957f7db5e499de9978bda41566031298.jpg
正在下载: smalladda3febb072e9103f8f06f27dcb19c21566031139.jpg
正在下载: small0e9f43492debe6dc2ce7a3e6cc48c1ad1566030965.jpg
正在下载: smallcfd5b4c6fa10ffcbcdcc8b1b9e6db91a1566030209.jpg
。。。。。。
图片下载成功!!!
消耗时间为: 21.575999975204468
上面这部分代码完全可以运行,但是效率不高,因为是下载图片,需要排队一一下载。因此,为了解决这个问题,下面的代码使用多线程来实现图片的抓取和下载。
(5)使用Python多线程抓取图片并下载到本地
对于多线程,我们使用 Python 自带的线程模块。我们使用称为生产者和消费者的模型。生产者专门用于从每个页面中获取图片的下载链接并将其存储在全局列表中。消费者专门从这个全局列表中提取图像链接以供下载。
需要注意的是,在多线程中使用全局变量需要使用锁来保证数据的一致性。
import urllib
import threading
from bs4 import BeautifulSoup
import requests
import os
import time
import lxml
# 页面链接的初始化列表
page_links_list=['http://www.netbian.com/']
# 图片链接列表
img_links_list = []
#获取爬取的页数和页面链接
def GetUrls(page_links_list):
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
#初始化锁,创建一把锁
gLock=threading.Lock()
#生产者,负责从每个页面中获取图片的链接
class Producer(threading.Thread):
def run(self):
while len(page_links_list)>0:
#上锁
gLock.acquire()
#默认取出列表中的最后一个元素
page_url=page_links_list.pop()
#释放锁
gLock.release()
#获取img标签
html = requests.get(page_url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
#加锁3
gLock.acquire()
for img in imgs:
img_link = img['src']
img_links_list.append(img_link)
#释放锁
gLock.release()
#print(len(img_links_list))
#消费者,负责从获取的图片链接中下载图片
class Consumer(threading.Thread,):
def run(self):
print("%s is running"%threading.current_thread())
while True:
#print(len(img_links_list))
#上锁
gLock.acquire()
if len(img_links_list)==0:
#不管什么情况,都要释放锁
gLock.release()
continue
else:
img_url=img_links_list.pop()
#print(img_links_list)
gLock.release()
filename=img_url.split('/')[-1]
print('正在下载:', filename)
path = './images/'+filename
urllib.request.urlretrieve(img_url, filename=path)
if len(img_links_list)==0:
end=time.time()
print("消耗的时间为:", (end - start))
exit()
if __name__ == '__main__':
GetUrls(page_links_list)
os.mkdir('./images')
start=time.time()
# 5个生产者线程,去从页面中爬取图片链接
for x in range(5):
Producer().start()
# 10个消费者线程,去从中提取下载链接,然后下载
for x in range(10):
Consumer().start()
请输入你想爬取的页数:5
is running
is running
is running
is running
is running
is running
is running
is running
is running
is running
正在下载: small9e75d6ac9506efe1d87e96062791fb261564149099.jpg
正在下载: small02961cac5e02a901b77779eaed43c6f91564156941.jpg
正在下载: small117c84b2f427c981bf33184c1c5c4bb91564193581.jpg
正在下载: smallfedb420af6f753512c169021587982621564455847.jpg
正在下载: small14d3739bf11dd92055abb56e3f792d3f1564456102.jpg
正在下载: smallaf755644af7d114d4cbf36fbe0e84d0c1564456347.jpg
正在下载: small9f7af6d0e2372a4d9e536d8ea9fc40341564456537.jpg
。。。。。。
消耗的时间为: 1.635000228881836 #分别是10个进程结束的时间
消耗的时间为: 1.6419999599456787
消耗的时间为: 1.6560001373291016
消耗的时间为: 1.684000015258789
消耗的时间为: 1.7009999752044678
消耗的时间为: 1.7030000686645508
消耗的时间为: 1.7060000896453857
消耗的时间为: 1.7139999866485596
消耗的时间为: 1.7350001335144043
消耗的时间为: 1.748000144958496 查看全部
php网页抓取图片(桌面壁纸电脑桌面壁纸高清壁纸大全下载(二):将图片下载到本地有了图片链接
)
一:目标站点信息
卞桌面网站为:桌面壁纸,电脑桌面壁纸,高清壁纸,下载,桌面背景图片,卞桌面
2:目标站点分析
(1): 构建页面的 URL 列表
我们需要做的是抓取网站上给定数量页面的图片,所以我们首先需要观察每个页面的链接之间的关系,然后构建一个需要抓取的URL列表。
第一页的链接:http://www.netbian.com/
第二页的链接:http://www.netbian.com/index_2.htm
可以看到第二页后面的页面链接只是和后面的数字不同,我们可以写一个简单的代码来获取页面的url列表
# 页面链接的初始化列表
page_links_list=['http://www.netbian.com/']
#获取爬取的页数和页面链接
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
print(page_links_list)
请输入你想爬取的页数:5
['http://www.netbian.com/', 'http://www.netbian.com/index_2.htm', 'http://www.netbian.com/index_3.htm', 'http://www.netbian.com/index_4.htm', 'http://www.netbian.com/index_5.htm']
(2): 获取一个页面上所有图片的链接
我们已经获取了所有页面的链接,但是还没有获取到每张图片的链接,那么接下来我们要做的就是获取一个页面中所有图片的链接。这里以第一页为例,获取每张图片的链接,其他页面类似。
首先右击页面->查看元素,然后点击查看器左侧的小光标,然后将鼠标放在随机一张图片上,这样就可以定位到图片的代码位置;我们可以知道每个页面有18张图片。接下来,我们需要使用标签来定位图片在页面上的具体位置。如下图所示,我们使用 div.list li a img 来精确定位 18 个 img 标签。img 标签收录
我们需要的图片链接。
接下来我们以第一页为例,获取每张图片的链接。
#python3 -m pip install bs4
#python3 -m pip install lxml
import requests
from bs4 import BeautifulSoup
# 页面链接的初始化列表
url='http://www.netbian.com/'
# 图片链接列表
img_links_list = []
#获取img标签,在获取图片链接
html = requests.get(url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
for img in imgs:
img_link = img['src']
img_links_list.append(img_link)
print(img_links_list)
print(len(img_links_list))
['http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B]
18
(3): 下载图片到本地
有了图片链接后,我们需要将图片下载到本地,这里以第一张图片为例进行下载
import urllib.request
url='http://img.netbian.com/file/20 ... 39%3B
urllib.request.urlretrieve(url, filename='test.jpg')
(4): 一个简单的获取图片的爬虫
结合以上三部分,构建页面的url列表,获取一个页面中的所有图片链接,将图片下载到本地。构建一个完整但效率低下的爬虫。
import requests
from bs4 import BeautifulSoup
import lxml
import urllib
import os
import time
#获取图片并下载到本地
def GetImages(url):
html=requests.get(url, timeout = 2).content.decode('gbk')
soup=BeautifulSoup(html,'lxml')
imgs=soup.select("div.list li a img")
for img in imgs:
link=img['src']
display=link.split('/')[-1]
print('正在下载:',display)
filename='./images/'+display
urllib.request.urlretrieve(link,filename)
#获取爬取的页数,返回链接数
def GetUrls(page_links_list):
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
if __name__ == '__main__':
page_links_list=['http://www.netbian.com/']
GetUrls(page_links_list)
os.mkdir('./images')
print("开始下载图片!!!")
start = time.time()
for url in page_links_list:
GetImages(url)
print('图片下载成功!!!')
end = time.time() - start
print('消耗时间为:', end)
请输入你想爬取的页数:5
开始下载图片!!!
正在下载: smalle213d95e54c5b4fb355b710a473292ea1566035585.jpg
正在下载: small15ca224d7c4c119affe2cfd2d811862e1566035332.jpg
正在下载: 604a688cd6f79161236e6250189bc25b.jpg
正在下载: smallab7249d18e67c9336109e3bedc094f381566034907.jpg
正在下载: small5816e940e6957f7db5e499de9978bda41566031298.jpg
正在下载: smalladda3febb072e9103f8f06f27dcb19c21566031139.jpg
正在下载: small0e9f43492debe6dc2ce7a3e6cc48c1ad1566030965.jpg
正在下载: smallcfd5b4c6fa10ffcbcdcc8b1b9e6db91a1566030209.jpg
。。。。。。
图片下载成功!!!
消耗时间为: 21.575999975204468
上面这部分代码完全可以运行,但是效率不高,因为是下载图片,需要排队一一下载。因此,为了解决这个问题,下面的代码使用多线程来实现图片的抓取和下载。
(5)使用Python多线程抓取图片并下载到本地
对于多线程,我们使用 Python 自带的线程模块。我们使用称为生产者和消费者的模型。生产者专门用于从每个页面中获取图片的下载链接并将其存储在全局列表中。消费者专门从这个全局列表中提取图像链接以供下载。
需要注意的是,在多线程中使用全局变量需要使用锁来保证数据的一致性。
import urllib
import threading
from bs4 import BeautifulSoup
import requests
import os
import time
import lxml
# 页面链接的初始化列表
page_links_list=['http://www.netbian.com/']
# 图片链接列表
img_links_list = []
#获取爬取的页数和页面链接
def GetUrls(page_links_list):
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
#初始化锁,创建一把锁
gLock=threading.Lock()
#生产者,负责从每个页面中获取图片的链接
class Producer(threading.Thread):
def run(self):
while len(page_links_list)>0:
#上锁
gLock.acquire()
#默认取出列表中的最后一个元素
page_url=page_links_list.pop()
#释放锁
gLock.release()
#获取img标签
html = requests.get(page_url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
#加锁3
gLock.acquire()
for img in imgs:
img_link = img['src']
img_links_list.append(img_link)
#释放锁
gLock.release()
#print(len(img_links_list))
#消费者,负责从获取的图片链接中下载图片
class Consumer(threading.Thread,):
def run(self):
print("%s is running"%threading.current_thread())
while True:
#print(len(img_links_list))
#上锁
gLock.acquire()
if len(img_links_list)==0:
#不管什么情况,都要释放锁
gLock.release()
continue
else:
img_url=img_links_list.pop()
#print(img_links_list)
gLock.release()
filename=img_url.split('/')[-1]
print('正在下载:', filename)
path = './images/'+filename
urllib.request.urlretrieve(img_url, filename=path)
if len(img_links_list)==0:
end=time.time()
print("消耗的时间为:", (end - start))
exit()
if __name__ == '__main__':
GetUrls(page_links_list)
os.mkdir('./images')
start=time.time()
# 5个生产者线程,去从页面中爬取图片链接
for x in range(5):
Producer().start()
# 10个消费者线程,去从中提取下载链接,然后下载
for x in range(10):
Consumer().start()
请输入你想爬取的页数:5
is running
is running
is running
is running
is running
is running
is running
is running
is running
is running
正在下载: small9e75d6ac9506efe1d87e96062791fb261564149099.jpg
正在下载: small02961cac5e02a901b77779eaed43c6f91564156941.jpg
正在下载: small117c84b2f427c981bf33184c1c5c4bb91564193581.jpg
正在下载: smallfedb420af6f753512c169021587982621564455847.jpg
正在下载: small14d3739bf11dd92055abb56e3f792d3f1564456102.jpg
正在下载: smallaf755644af7d114d4cbf36fbe0e84d0c1564456347.jpg
正在下载: small9f7af6d0e2372a4d9e536d8ea9fc40341564456537.jpg
。。。。。。
消耗的时间为: 1.635000228881836 #分别是10个进程结束的时间
消耗的时间为: 1.6419999599456787
消耗的时间为: 1.6560001373291016
消耗的时间为: 1.684000015258789
消耗的时间为: 1.7009999752044678
消耗的时间为: 1.7030000686645508
消耗的时间为: 1.7060000896453857
消耗的时间为: 1.7139999866485596
消耗的时间为: 1.7350001335144043
消耗的时间为: 1.748000144958496

