
php禁止网页抓取
php禁止网页抓取(【】访问日志如下图解决解决思路(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-31 08:04
)
问题
过去客户可以正常访问的网站现在很慢,有时甚至拒绝访问。通过查看Nginx访问日志,发现大量请求指向同一个页面,并且访问的客户端IP地址不断变化,没有太多规则。很难通过限制IP来拒绝访问。但是请求的用户代理被标记为 Bytespider,这是一种流氓爬虫。访问日志如下:
解决
解决方法:因为user-agent被标记了Bytespider爬虫,这样可以通过Nginx规则限制流氓爬虫的访问,直接返回403错误。
1、在/etc/nginx/conf.d目录下新建文件deny_agent.config配置文件(由于安装了Nginx,站点配置文件的路径可能不同):
#forbidden Scrapy
if ($http_user_agent ~* (Scrapy|Curl|HttpClient))
{
return 403;
}
#forbidden UA
if ($http_user_agent ~ "Bytespider|FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" )
{
return 403;
}
#forbidden not GET|HEAD|POST method access
if ($request_method !~ ^(GET|HEAD|POST)$)
{
return 403;
}
2、在对应的站点配置文件中收录deny_agent.config配置文件(注意是在服务器中):
3、重启Nginx,建议通过nginx -s reload平滑重启。重启前请先使用 nginx -t 命令检查配置文件是否正确。
4、使用curl命令模拟访问,看看配置是否生效(如果返回403 Forbidden,则配置OK):
附录:UA 集合
FeedDemon 内容采集
BOT/0.1 (BOT for JCE) sql注入
CrawlDaddy sql注入
Java 内容采集
Jullo 内容采集
Feedly 内容采集
UniversalFeedParser 内容采集
ApacheBench cc攻击器
Swiftbot 无用爬虫
YandexBot 无用爬虫
AhrefsBot 无用爬虫
YisouSpider 无用爬虫(已被UC神马搜索收购,此蜘蛛可以放开!)
jikeSpider 无用爬虫
MJ12bot 无用爬虫
ZmEu phpmyadmin 漏洞扫描
WinHttp 采集cc攻击
EasouSpider 无用爬虫
HttpClient tcp攻击
Microsoft URL Control 扫描
YYSpider 无用爬虫
jaunty wordpress**扫描器
oBot 无用爬虫
Python-urllib 内容采集
Indy Library 扫描
FlightDeckReports Bot 无用爬虫
Linguee Bot 无用爬虫<br /> 查看全部
php禁止网页抓取(【】访问日志如下图解决解决思路(一)
)
问题
过去客户可以正常访问的网站现在很慢,有时甚至拒绝访问。通过查看Nginx访问日志,发现大量请求指向同一个页面,并且访问的客户端IP地址不断变化,没有太多规则。很难通过限制IP来拒绝访问。但是请求的用户代理被标记为 Bytespider,这是一种流氓爬虫。访问日志如下:

解决
解决方法:因为user-agent被标记了Bytespider爬虫,这样可以通过Nginx规则限制流氓爬虫的访问,直接返回403错误。
1、在/etc/nginx/conf.d目录下新建文件deny_agent.config配置文件(由于安装了Nginx,站点配置文件的路径可能不同):
#forbidden Scrapy
if ($http_user_agent ~* (Scrapy|Curl|HttpClient))
{
return 403;
}
#forbidden UA
if ($http_user_agent ~ "Bytespider|FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" )
{
return 403;
}
#forbidden not GET|HEAD|POST method access
if ($request_method !~ ^(GET|HEAD|POST)$)
{
return 403;
}
2、在对应的站点配置文件中收录deny_agent.config配置文件(注意是在服务器中):

3、重启Nginx,建议通过nginx -s reload平滑重启。重启前请先使用 nginx -t 命令检查配置文件是否正确。
4、使用curl命令模拟访问,看看配置是否生效(如果返回403 Forbidden,则配置OK):

附录:UA 集合
FeedDemon 内容采集
BOT/0.1 (BOT for JCE) sql注入
CrawlDaddy sql注入
Java 内容采集
Jullo 内容采集
Feedly 内容采集
UniversalFeedParser 内容采集
ApacheBench cc攻击器
Swiftbot 无用爬虫
YandexBot 无用爬虫
AhrefsBot 无用爬虫
YisouSpider 无用爬虫(已被UC神马搜索收购,此蜘蛛可以放开!)
jikeSpider 无用爬虫
MJ12bot 无用爬虫
ZmEu phpmyadmin 漏洞扫描
WinHttp 采集cc攻击
EasouSpider 无用爬虫
HttpClient tcp攻击
Microsoft URL Control 扫描
YYSpider 无用爬虫
jaunty wordpress**扫描器
oBot 无用爬虫
Python-urllib 内容采集
Indy Library 扫描
FlightDeckReports Bot 无用爬虫
Linguee Bot 无用爬虫<br />
php禁止网页抓取(php禁止网页抓取的方法(一)__)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-29 19:01
php禁止网页抓取的方法
一、我们先来说说php在http请求下可以获取的数据项;1.php自带的全局命名空间http3.5.4;网页代码post/posthttp/1.1host:xxxx/path://refer:phphttp/1.1timeout:404解决方案:1post中的请求方法使用get;2http/1.1协议下,只有get请求可以使用:get('request-uri',uri)。
二、php获取网页的url地址解析问题
1、php网页中存在的无效url:使用http/1.1协议代理上去,被屏蔽的。
2、查看url地址是否存在连接字符串。在http服务器中存在的字符串必须使用ascii字符:*/ahttp/1.1connection:keep-alivecontent-length:1content-type:text/plainserver:example.io/publicform-datamethod:get或者查看http服务器的源码。
三、解析php脚本执行后带来的问题?
1、解析php脚本耗时
2、解析bat脚本框架耗时
3、解析php小程序框架框架耗时
四、保护php解析的请求,
五、php执行过程中的一些特殊情况处理
一)数据请求发送,常见的有三种发送形式:1.post,2.get3.ajax发送请求时可以在里面发送属性,返回属性,
二)post发送数据1.post发送get请求的形式:返回一个数据2.post发送的数据只能是json
三)get发送数据1.get请求形式:在客户端和服务端中发送两个请求2.get请求也可以是json,java的get和post形式请求地址都可以。post请求方式需要根据模板写这个语句,$xxx是本服务器的路径,可以不使用$action_name和$type_name。
?>和?>?>两个都是php内置的函数,
六、php解析的两种方式1.(i)general-phphtml||php可以采用整个php包中的函数,也可以定义inpractice,用户不必每次都能看到网页,建议采用这种方式,可以添加数组,以便下次查找。2.(ii)php文件->org.php.cache->php文件设置inpractice是先写到php文件中inpractice可以是任何你想要inpractice的文件,inpractice。 查看全部
php禁止网页抓取(php禁止网页抓取的方法(一)__)
php禁止网页抓取的方法
一、我们先来说说php在http请求下可以获取的数据项;1.php自带的全局命名空间http3.5.4;网页代码post/posthttp/1.1host:xxxx/path://refer:phphttp/1.1timeout:404解决方案:1post中的请求方法使用get;2http/1.1协议下,只有get请求可以使用:get('request-uri',uri)。
二、php获取网页的url地址解析问题
1、php网页中存在的无效url:使用http/1.1协议代理上去,被屏蔽的。
2、查看url地址是否存在连接字符串。在http服务器中存在的字符串必须使用ascii字符:*/ahttp/1.1connection:keep-alivecontent-length:1content-type:text/plainserver:example.io/publicform-datamethod:get或者查看http服务器的源码。
三、解析php脚本执行后带来的问题?
1、解析php脚本耗时
2、解析bat脚本框架耗时
3、解析php小程序框架框架耗时
四、保护php解析的请求,
五、php执行过程中的一些特殊情况处理
一)数据请求发送,常见的有三种发送形式:1.post,2.get3.ajax发送请求时可以在里面发送属性,返回属性,
二)post发送数据1.post发送get请求的形式:返回一个数据2.post发送的数据只能是json
三)get发送数据1.get请求形式:在客户端和服务端中发送两个请求2.get请求也可以是json,java的get和post形式请求地址都可以。post请求方式需要根据模板写这个语句,$xxx是本服务器的路径,可以不使用$action_name和$type_name。
?>和?>?>两个都是php内置的函数,
六、php解析的两种方式1.(i)general-phphtml||php可以采用整个php包中的函数,也可以定义inpractice,用户不必每次都能看到网页,建议采用这种方式,可以添加数组,以便下次查找。2.(ii)php文件->org.php.cache->php文件设置inpractice是先写到php文件中inpractice可以是任何你想要inpractice的文件,inpractice。
php禁止网页抓取(“robots.txt只允许抓取html页面,防止抓取垃圾信息!”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-29 16:03
今天大贷SEO详细讲解“robots.txt只允许抓取html页面,防止抓取垃圾邮件!” 代代SEO做了这么多年网站,经常遇到客户的网站被挂掉的情况,原因是不利于自己维护网站,或者使用市面上开源的cms,直接下载源码安装使用,不管里面有没有漏洞和后门,所以后期被马入侵了,大百度抓取的非法页面数量。
有些被链接的人很奇怪,为什么他们的网站正常发布的内容不是收录,而垃圾页面的很多非法内容是百度的收录。其实很简单。马人员直接链接了spider pool里面的非法页面,所以才会出现这个问题。即使我们解决了网站被链接到马的问题,网站上的垃圾页面还是会继续出现。死链接被百度抓取后需要很长时间才能生效。这个时候我该怎么办?我们可以使用 robots.txt 来解决这个问题。
实施原则:
我们可以通过robots.txt来限制用户只能抓取HTMl页面文件,并且可以限制指定目录的HTML,屏蔽指定目录的HTML文件。我们来做一个robots.txt的写法。您可以自己研究并应用到实际应用中。继续你自己的网站。
可解决的挂马形式:
写机器人的规则主要针对上传类,比如添加xxx.php?=dddd.html;xxxx.php; 并且上传不会被百度抓取,降低网络监控风险。
#适用于所有搜索引擎
用户代理:*
#允许首页根目录/不带斜线,例如
允许:/$
允许:$
#文件属性设置禁止修改(固定属性,入口只能是index.html/index.php)
允许:/index.php
允许:/index.html
#允许爬取静态生成的目录,这里是允许爬取页面中的所有html文件
允许:/*.html$
#禁止所有带参数的html页面(禁止抓取挂马的html页面) 规则可以自己定义
禁止:/*?*.html$
禁止:/*=*.html$
# 允许单个条目,只允许,with ? 编号索引,其他html,带符号,是不允许的。
允许:/index.php?*
#允许资源文件,允许在网站上截取图片。
允许:/*.jpg$
允许:/*.png$
允许:/*.gif$
#除上述外,禁止爬取网站内的任何文件或页面。
不允许:/
比如我们的网站挂了,后面的戳一般。php?unmgg.html 或 dds=123.html。这种,只要网址有 ? ,=这样的符号,当然你可以给它加更多的格式,比如下划线“_”,可以用“Disallow:/_*.html$”来防御。
再比如:挂马是一个目录,一个普通的URL,比如“seozt/1233.html”,可以加一条禁止规则“Disallow:/seozt/*.html$”,这个规则就是告诉搜索引擎,只要是seozt目录下的html文件,就不能被抓取。你明白吗?其实很简单。只是自己熟悉它。
这种写法的优点是:
首先,蜘蛛会爬取你的很多核心目录、php目录、模板目录,这样会浪费很多目录资源。对了,如果我们屏蔽目录,我们会在 robots.txt 中暴露我们的目录,其他人可以分析我们使用的目录。它是什么程序?这时候我们就逆向操作,直接允许html,其他的都拒绝,可以有效避免暴露目录的风险,对了,好吧,今天就讲到这里,希望大家能理解。 查看全部
php禁止网页抓取(“robots.txt只允许抓取html页面,防止抓取垃圾信息!”)
今天大贷SEO详细讲解“robots.txt只允许抓取html页面,防止抓取垃圾邮件!” 代代SEO做了这么多年网站,经常遇到客户的网站被挂掉的情况,原因是不利于自己维护网站,或者使用市面上开源的cms,直接下载源码安装使用,不管里面有没有漏洞和后门,所以后期被马入侵了,大百度抓取的非法页面数量。

有些被链接的人很奇怪,为什么他们的网站正常发布的内容不是收录,而垃圾页面的很多非法内容是百度的收录。其实很简单。马人员直接链接了spider pool里面的非法页面,所以才会出现这个问题。即使我们解决了网站被链接到马的问题,网站上的垃圾页面还是会继续出现。死链接被百度抓取后需要很长时间才能生效。这个时候我该怎么办?我们可以使用 robots.txt 来解决这个问题。
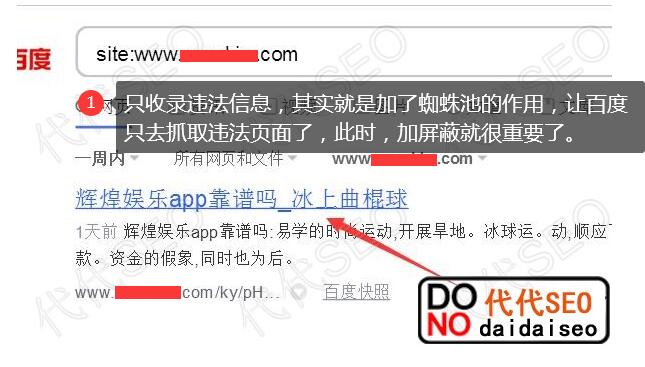
实施原则:
我们可以通过robots.txt来限制用户只能抓取HTMl页面文件,并且可以限制指定目录的HTML,屏蔽指定目录的HTML文件。我们来做一个robots.txt的写法。您可以自己研究并应用到实际应用中。继续你自己的网站。
可解决的挂马形式:
写机器人的规则主要针对上传类,比如添加xxx.php?=dddd.html;xxxx.php; 并且上传不会被百度抓取,降低网络监控风险。
#适用于所有搜索引擎
用户代理:*
#允许首页根目录/不带斜线,例如
允许:/$
允许:$
#文件属性设置禁止修改(固定属性,入口只能是index.html/index.php)
允许:/index.php
允许:/index.html
#允许爬取静态生成的目录,这里是允许爬取页面中的所有html文件
允许:/*.html$
#禁止所有带参数的html页面(禁止抓取挂马的html页面) 规则可以自己定义
禁止:/*?*.html$
禁止:/*=*.html$
# 允许单个条目,只允许,with ? 编号索引,其他html,带符号,是不允许的。
允许:/index.php?*
#允许资源文件,允许在网站上截取图片。
允许:/*.jpg$
允许:/*.png$
允许:/*.gif$
#除上述外,禁止爬取网站内的任何文件或页面。
不允许:/
比如我们的网站挂了,后面的戳一般。php?unmgg.html 或 dds=123.html。这种,只要网址有 ? ,=这样的符号,当然你可以给它加更多的格式,比如下划线“_”,可以用“Disallow:/_*.html$”来防御。
再比如:挂马是一个目录,一个普通的URL,比如“seozt/1233.html”,可以加一条禁止规则“Disallow:/seozt/*.html$”,这个规则就是告诉搜索引擎,只要是seozt目录下的html文件,就不能被抓取。你明白吗?其实很简单。只是自己熟悉它。
这种写法的优点是:
首先,蜘蛛会爬取你的很多核心目录、php目录、模板目录,这样会浪费很多目录资源。对了,如果我们屏蔽目录,我们会在 robots.txt 中暴露我们的目录,其他人可以分析我们使用的目录。它是什么程序?这时候我们就逆向操作,直接允许html,其他的都拒绝,可以有效避免暴露目录的风险,对了,好吧,今天就讲到这里,希望大家能理解。
php禁止网页抓取( 百度对robots.txt反应很到位,部分禁止目录收录下降)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-01-27 23:23
百度对robots.txt反应很到位,部分禁止目录收录下降)
<p>
最近在做一个网站,因为域名要备案所以就没有直接放上去,而是放到一个二级域名上,test.XXXX.com,因为是测试的域名所以不希望百度收录
robots.txt的文件内容为
User-agent:*
Disallow:/
Disallow:/go/*</p>
原来百度收录有这个二级域名,然后查了一下网站,发现只有首页。百度不是很按照机器人和百度百科的描述吗?
百度对robots.txt有响应,但是比较慢。它减少了对正常目录的爬取,同时减少了对禁止目录的爬取。
原因应该是条目数减少了,正常目录收录后面需要慢慢增加。
谷歌对robots.txt的反应非常好,被禁目录立即消失,一些正常目录收录立即上升。/comment/ 目录收录 也宕机了,仍然受到一些旧目标减少的影响。
搜狗的爬取平衡性普遍上升,部分被禁目录收录下降。
总结一下:谷歌似乎最懂站长的意思,其他搜索引擎比如百度只是被动受词条数量的影响
我只知道360搜索忽略了robots协议。之前,部分服务器被360搜索引擎瘫痪。机器人被用来禁止360蜘蛛爬行。
只能感叹国内搜索引擎离google有多远
QQ交流群:136351212 查看全部
php禁止网页抓取(
百度对robots.txt反应很到位,部分禁止目录收录下降)
<p>

最近在做一个网站,因为域名要备案所以就没有直接放上去,而是放到一个二级域名上,test.XXXX.com,因为是测试的域名所以不希望百度收录
robots.txt的文件内容为
User-agent:*
Disallow:/
Disallow:/go/*</p>
原来百度收录有这个二级域名,然后查了一下网站,发现只有首页。百度不是很按照机器人和百度百科的描述吗?
百度对robots.txt有响应,但是比较慢。它减少了对正常目录的爬取,同时减少了对禁止目录的爬取。
原因应该是条目数减少了,正常目录收录后面需要慢慢增加。
谷歌对robots.txt的反应非常好,被禁目录立即消失,一些正常目录收录立即上升。/comment/ 目录收录 也宕机了,仍然受到一些旧目标减少的影响。
搜狗的爬取平衡性普遍上升,部分被禁目录收录下降。
总结一下:谷歌似乎最懂站长的意思,其他搜索引擎比如百度只是被动受词条数量的影响
我只知道360搜索忽略了robots协议。之前,部分服务器被360搜索引擎瘫痪。机器人被用来禁止360蜘蛛爬行。
只能感叹国内搜索引擎离google有多远
QQ交流群:136351212
php禁止网页抓取( 两种对MySQL注入攻击的常见误解--MySQL注入)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-27 18:07
两种对MySQL注入攻击的常见误解--MySQL注入)
使用 PHP 编程防止 MySQL 注入或 HTML 表单滥用
MySQL 注入的目的是接管 网站 数据库并窃取信息。许多网站开发人员已经使用常见的开源数据库,例如MySQL,来存储密码、个人信息和管理信息等重要信息。
MySQL 很受欢迎,因为它与最流行的服务器端脚本语言 PHP 一起使用。此外,PHP 是主导 Internet 的 Linux-Apache 服务器的主要语言。所以这意味着黑客可以很容易地利用 PHP,就像 Windows 的间谍软件一样。
黑客将大量恶意代码(通过下拉菜单、搜索框、联系表单、查询表单和复选框)输入到不安全的 Web 表单中。
恶意代码将被发送到 MySQL 数据库,然后“注入”。要查看此过程,首先考虑以下基本 MySQL SELECT 查询:
SELECT * FROM xmen WHERE 用户名 = 'wolverine'
该查询将请求具有“xmen”表的数据库返回MySQL中用户名为“wolverine”的某条数据。
在 web 表单中,用户将输入 wolverine,此数据将传递给 MySQL 查询。
如果输入无效,黑客还有其他方式控制数据库,比如设置用户名:
' 或 ''=''
您可能认为使用普通的 PHP 和 MySQL 语法来执行输入是安全的,因为每当有人输入恶意代码时,他们都会收到“无效查询”消息,但事实并非如此。黑客很聪明,因为它涉及数据库清理和重置管理权限,任何安全漏洞都不容易纠正。
关于 MySQL 注入攻击的两个常见误解如下:
1.网管认为恶意注入可以用杀毒软件或反间谍软件清理。事实上,这种类型的感染利用了 MySQL 数据库的弱点。它不能简单地被任何反间谍软件或防病毒程序删除。
2. MySQL 注入是由于从另一台服务器或外部源复制受感染的文件。但事实上,并非如此。这种类型的感染是由于有人将恶意代码输入到 网站 未受保护的表单中,然后访问数据库造成的。MySQL 注入可以通过删除恶意脚本来清理,而不是使用防病毒程序。
用户输入验证过程
备份一个干净的数据库并将其放置在服务器之外。导出一组 MySQL 表并将它们保存在桌面上。
然后去服务器,先暂时关闭表单输入。这意味着表单无法处理数据并且 网站 已关闭。
然后开始清理过程。首先,在您的服务器上,清理剩余的混乱 MySQL 注入。更改所有数据库、FTP 和 网站 密码。
在最坏的情况下,如果您清理晚了,您可以仔细检查服务器上运行的隐藏程序。这些隐藏的程序是黑客安装的木马。完全删除它并更改所有 FTP 权限。扫描服务器以查找所有特洛伊木马和恶意软件。
修改 PHP 脚本时会处理表单数据。防止 MySQL 注入的一个好方法是甚至不信任用户数据。用户输入验证对于防止 MySQL 注入非常重要。
要设计一个过滤器来过滤掉用户输入,这里有一些提示:
1.数字被输入到表格中。您可以通过测试它是否等于或大于 0.001 来验证它是否是一个数字(假设您不接受零)。
2.如果是电子邮件地址。验证它是否收录允许的字符组合,例如“@”、AZ、az 或一些数字。
3.如果是人名或用户名。可以通过是否收录and、*等非法字符来验证,这些非法字符是可以用于SQL注入的恶意字符。
验证数字输入
下面的脚本验证输入了从 0.001 到无穷大的有效数字。值得一提的是,在 PHP 程序中,甚至可以允许一定范围的数字。使用此验证脚本可确保仅在表单中输入数字。
假设您的程序中有三个数值变量;您需要验证它们,让我们将它们命名为 num1、num2 和 num3:
//验证数字输入
if($_POST['num1'] >= 0.001 && $_POST['num2'] >= 0.001 && $_POST['num3'] >= 0.00< @1)
{
}
别的
{
}
并且可以扩展条件以容纳三个以上的数字。所以如果你有 10 个,你只需要扩展 AND 语句。
这可用于验证仅接受数字的表单,例如合同数量、许可证号码、电话号码等。
验证文本和电子邮件地址条目
以下内容可用于验证表单输入,例如用户名、名字和电子邮件地址:
//验证文本输入
if (!preg_match('/^[-az.-@,'s]*$/i',$_POST['name']))
{
}
别的
if ($empty==0)
{
}
别的
{
}
此验证脚本的一个优点是它不接受空白输入。一些恶意用户还通过空白输入操作数据库。使用上面的脚本,只验证了一个文字变量“$name”。这意味着如果你有三个字面变量,你可以为每个变量设置一个验证脚本,以确保每个变量在进入数据库之前通过审查。 查看全部
php禁止网页抓取(
两种对MySQL注入攻击的常见误解--MySQL注入)
使用 PHP 编程防止 MySQL 注入或 HTML 表单滥用
MySQL 注入的目的是接管 网站 数据库并窃取信息。许多网站开发人员已经使用常见的开源数据库,例如MySQL,来存储密码、个人信息和管理信息等重要信息。
MySQL 很受欢迎,因为它与最流行的服务器端脚本语言 PHP 一起使用。此外,PHP 是主导 Internet 的 Linux-Apache 服务器的主要语言。所以这意味着黑客可以很容易地利用 PHP,就像 Windows 的间谍软件一样。
黑客将大量恶意代码(通过下拉菜单、搜索框、联系表单、查询表单和复选框)输入到不安全的 Web 表单中。
恶意代码将被发送到 MySQL 数据库,然后“注入”。要查看此过程,首先考虑以下基本 MySQL SELECT 查询:
SELECT * FROM xmen WHERE 用户名 = 'wolverine'
该查询将请求具有“xmen”表的数据库返回MySQL中用户名为“wolverine”的某条数据。
在 web 表单中,用户将输入 wolverine,此数据将传递给 MySQL 查询。
如果输入无效,黑客还有其他方式控制数据库,比如设置用户名:
' 或 ''=''
您可能认为使用普通的 PHP 和 MySQL 语法来执行输入是安全的,因为每当有人输入恶意代码时,他们都会收到“无效查询”消息,但事实并非如此。黑客很聪明,因为它涉及数据库清理和重置管理权限,任何安全漏洞都不容易纠正。
关于 MySQL 注入攻击的两个常见误解如下:
1.网管认为恶意注入可以用杀毒软件或反间谍软件清理。事实上,这种类型的感染利用了 MySQL 数据库的弱点。它不能简单地被任何反间谍软件或防病毒程序删除。
2. MySQL 注入是由于从另一台服务器或外部源复制受感染的文件。但事实上,并非如此。这种类型的感染是由于有人将恶意代码输入到 网站 未受保护的表单中,然后访问数据库造成的。MySQL 注入可以通过删除恶意脚本来清理,而不是使用防病毒程序。
用户输入验证过程
备份一个干净的数据库并将其放置在服务器之外。导出一组 MySQL 表并将它们保存在桌面上。
然后去服务器,先暂时关闭表单输入。这意味着表单无法处理数据并且 网站 已关闭。
然后开始清理过程。首先,在您的服务器上,清理剩余的混乱 MySQL 注入。更改所有数据库、FTP 和 网站 密码。
在最坏的情况下,如果您清理晚了,您可以仔细检查服务器上运行的隐藏程序。这些隐藏的程序是黑客安装的木马。完全删除它并更改所有 FTP 权限。扫描服务器以查找所有特洛伊木马和恶意软件。
修改 PHP 脚本时会处理表单数据。防止 MySQL 注入的一个好方法是甚至不信任用户数据。用户输入验证对于防止 MySQL 注入非常重要。
要设计一个过滤器来过滤掉用户输入,这里有一些提示:
1.数字被输入到表格中。您可以通过测试它是否等于或大于 0.001 来验证它是否是一个数字(假设您不接受零)。
2.如果是电子邮件地址。验证它是否收录允许的字符组合,例如“@”、AZ、az 或一些数字。
3.如果是人名或用户名。可以通过是否收录and、*等非法字符来验证,这些非法字符是可以用于SQL注入的恶意字符。
验证数字输入
下面的脚本验证输入了从 0.001 到无穷大的有效数字。值得一提的是,在 PHP 程序中,甚至可以允许一定范围的数字。使用此验证脚本可确保仅在表单中输入数字。
假设您的程序中有三个数值变量;您需要验证它们,让我们将它们命名为 num1、num2 和 num3:
//验证数字输入
if($_POST['num1'] >= 0.001 && $_POST['num2'] >= 0.001 && $_POST['num3'] >= 0.00< @1)
{
}
别的
{
}
并且可以扩展条件以容纳三个以上的数字。所以如果你有 10 个,你只需要扩展 AND 语句。
这可用于验证仅接受数字的表单,例如合同数量、许可证号码、电话号码等。
验证文本和电子邮件地址条目
以下内容可用于验证表单输入,例如用户名、名字和电子邮件地址:
//验证文本输入
if (!preg_match('/^[-az.-@,'s]*$/i',$_POST['name']))
{
}
别的
if ($empty==0)
{
}
别的
{
}
此验证脚本的一个优点是它不接受空白输入。一些恶意用户还通过空白输入操作数据库。使用上面的脚本,只验证了一个文字变量“$name”。这意味着如果你有三个字面变量,你可以为每个变量设置一个验证脚本,以确保每个变量在进入数据库之前通过审查。
php禁止网页抓取(在seo优化的全过程之中,有时是必须对搜索引擎蜘蛛开展)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-27 18:07
要了解,在整个seo优化过程中,有时需要屏蔽搜索引擎蜘蛛,也就是严格禁止爬取网站的某个区域,那么人们应该如何屏蔽搜索引擎蜘蛛呢?下面我们来看看实际的操作步骤。
百度蜘蛛爬取人们的网址,期望他们的网页被收录在其搜索引擎中。未来,当客户搜索时,它可以让我们产生一定量的搜索引擎提升总流量。自然,人们不愿意让搜索引擎抓取所有内容。
因此,此时人们只期望抓取搜索引擎检索到的内容。例如,客户隐私保护和背景图片信息内容预计不会被搜索引擎捕获和收录。有两种最好的方法来处理这种困境,如下所示:
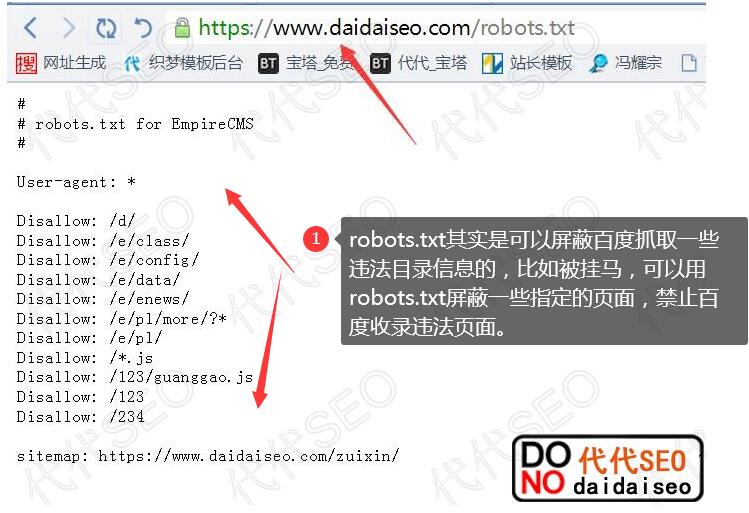
robots协议文档阻止百度蜘蛛爬行
robots协议是放置在网站根目录下的协议文件,可以根据网站地址(网站地址:)浏览,百度蜘蛛抓取人的网站时,会浏览这个第一份文件。因为它告诉蜘蛛抓取什么,不抓取什么。
robots协议文档的设置非常简单,可以根据User-Agent、Disallow、Allow三个主要参数进行设置。
下面大家看一个例子,情况是我不会指望百度搜索会爬到我网站的所有css文件,数据文件目录,seo-tag.html页面
User-Agent:BaidusppiderDisallow:/*.cssDisallow:/data/Disallow:/seo/seo-tag.html
如前所述,user-agent 声明了蜘蛛的名字,也就是说它是给百度蜘蛛的。以下几点无法获取“/*.css”,首先/指的是网站根目录,也就是你的网站域名。* 是一个通配符,表示一切。这意味着无法抓取所有以 .css 结尾的文档。这是你自己的2个人经历。逻辑是一样的。
根据403状态码,限制内容输出,阻止蜘蛛爬取。
403状态码是http协议中网页的返回状态码。当搜索引擎遇到 403 状态代码时,它会理解这样的页面受到管理权限的限制。我无法打开它。例如,如果你必须登录才能搜索内容,搜索引擎本身将无法登录。如果你回到403,他也明白这是一个权限管理页面,无法加载内容。自然,它不能轻易收录在内。
回到403状态码,应该有一个类似404页面的页面。提醒客户端或蜘蛛实现他们想要浏览的内容。两者都是必不可少的。只能提醒页面状态码回到200,对于百度蜘蛛来说是很多重复页面。有 403 个状态码,但返回不同的内容。它也不是很友好。
最后,对于智能机器人协议,我想填一点:“现在搜索引擎会根据网页的布局合理性和布局合理性来区分网页的客户友好度。如果屏蔽css文件和js文件是涉及到合理的布局,那么我不知道你的网页界面设计对搜索引擎来说是好是坏,所以不建议屏蔽这类内容。
热搜词 查看全部
php禁止网页抓取(在seo优化的全过程之中,有时是必须对搜索引擎蜘蛛开展)
要了解,在整个seo优化过程中,有时需要屏蔽搜索引擎蜘蛛,也就是严格禁止爬取网站的某个区域,那么人们应该如何屏蔽搜索引擎蜘蛛呢?下面我们来看看实际的操作步骤。
百度蜘蛛爬取人们的网址,期望他们的网页被收录在其搜索引擎中。未来,当客户搜索时,它可以让我们产生一定量的搜索引擎提升总流量。自然,人们不愿意让搜索引擎抓取所有内容。
因此,此时人们只期望抓取搜索引擎检索到的内容。例如,客户隐私保护和背景图片信息内容预计不会被搜索引擎捕获和收录。有两种最好的方法来处理这种困境,如下所示:
robots协议文档阻止百度蜘蛛爬行
robots协议是放置在网站根目录下的协议文件,可以根据网站地址(网站地址:)浏览,百度蜘蛛抓取人的网站时,会浏览这个第一份文件。因为它告诉蜘蛛抓取什么,不抓取什么。
robots协议文档的设置非常简单,可以根据User-Agent、Disallow、Allow三个主要参数进行设置。
下面大家看一个例子,情况是我不会指望百度搜索会爬到我网站的所有css文件,数据文件目录,seo-tag.html页面
User-Agent:BaidusppiderDisallow:/*.cssDisallow:/data/Disallow:/seo/seo-tag.html
如前所述,user-agent 声明了蜘蛛的名字,也就是说它是给百度蜘蛛的。以下几点无法获取“/*.css”,首先/指的是网站根目录,也就是你的网站域名。* 是一个通配符,表示一切。这意味着无法抓取所有以 .css 结尾的文档。这是你自己的2个人经历。逻辑是一样的。
根据403状态码,限制内容输出,阻止蜘蛛爬取。
403状态码是http协议中网页的返回状态码。当搜索引擎遇到 403 状态代码时,它会理解这样的页面受到管理权限的限制。我无法打开它。例如,如果你必须登录才能搜索内容,搜索引擎本身将无法登录。如果你回到403,他也明白这是一个权限管理页面,无法加载内容。自然,它不能轻易收录在内。
回到403状态码,应该有一个类似404页面的页面。提醒客户端或蜘蛛实现他们想要浏览的内容。两者都是必不可少的。只能提醒页面状态码回到200,对于百度蜘蛛来说是很多重复页面。有 403 个状态码,但返回不同的内容。它也不是很友好。
最后,对于智能机器人协议,我想填一点:“现在搜索引擎会根据网页的布局合理性和布局合理性来区分网页的客户友好度。如果屏蔽css文件和js文件是涉及到合理的布局,那么我不知道你的网页界面设计对搜索引擎来说是好是坏,所以不建议屏蔽这类内容。
热搜词
php禁止网页抓取( CDN域名下的robots.txt重定向到robots2.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-27 08:09
CDN域名下的robots.txt重定向到robots2.)
百度收录CDN域名是SEO的大忌。因为相同的内容出现在两个或多个域名中,会受到搜索引擎的惩罚。基本上所有的搜索引擎都会将多个域名指向同一页面的结果判断为镜像,判断为镜像的域名会降级。
很多WordPress网站用户会使用CDN,CDN域名的回源IP地址与主站相同。如果启用了静态缓存,即使使用WordPress后台未设置的站点地址(域名)访问,仍然可以访问。的缓存页面。因为经过静态缓存后,前端并没有执行PHP,而是直接输出HTML。只有没有启用静态缓存的站点才会跳转到设置的站点地址。
如上图,可以看到静态资源的CDN域名是百度收录。
防止CDN域名中的非静态资源被搜索引擎抓取创建robots2.txt文件
用记事本创建一个robots2.txt,添加如下内容,上传到网站根目录。
User-agent: *
Allow: /robots.txt
Allow: /*.png*
Allow: /*.jpg*
Allow: /*.jpeg*
Allow: /*.gif*
Allow: /*.bmp*
Allow: /*.ico*
Allow: /*.js*
Allow: /*.css*
Allow: /wp-content/
Disallow: /
通过 robots 协议,禁止搜索引擎抓取除 .js、.css 或图片之外的所有内容。因为是静态资源的CDN域名,静态资源还是需要公开爬取,否则会影响正常收录。
Nginx 重定向 robots.txt
当然,也不可能把主域名的robots.txt改成上面那样,那么所有的页面都不会被搜索引擎抓取。可以使用 Nginx 的条件判断来指定将 robots.txt 重定向到 robots2.txt 的域名。
if ($http_host !~ "^www.zhanzhangb.com$") {
rewrite /robots.txt /robots2.txt last;
}
以上是将非域名下的robots.txt重定向到robots2.txt。
if ($http_host ~ "^cdn.zhanzhangb.com$") {
rewrite /robots.txt /robots2.txt last;
}
以上就是将域名下的robots.txt重定向到robots2.txt。
Apache 重定向 robots.txt
RewriteEngine On
RewriteCond %{HTTP_HOST} !^www.zhanzhangb.com [NC]
RewriteRule robots.txt robots2.txt [L]
设置完成后,使用CDN域名访问robots.txt,看看是否成功。域名对应的robots.txt不要弄错了,否则会造成很大的SEO损失。 查看全部
php禁止网页抓取(
CDN域名下的robots.txt重定向到robots2.)
 https://ima.tkcdk.cn/wp-conten ... 0.png 300w" />
https://ima.tkcdk.cn/wp-conten ... 0.png 300w" />百度收录CDN域名是SEO的大忌。因为相同的内容出现在两个或多个域名中,会受到搜索引擎的惩罚。基本上所有的搜索引擎都会将多个域名指向同一页面的结果判断为镜像,判断为镜像的域名会降级。
很多WordPress网站用户会使用CDN,CDN域名的回源IP地址与主站相同。如果启用了静态缓存,即使使用WordPress后台未设置的站点地址(域名)访问,仍然可以访问。的缓存页面。因为经过静态缓存后,前端并没有执行PHP,而是直接输出HTML。只有没有启用静态缓存的站点才会跳转到设置的站点地址。
如上图,可以看到静态资源的CDN域名是百度收录。
防止CDN域名中的非静态资源被搜索引擎抓取创建robots2.txt文件
用记事本创建一个robots2.txt,添加如下内容,上传到网站根目录。
User-agent: *
Allow: /robots.txt
Allow: /*.png*
Allow: /*.jpg*
Allow: /*.jpeg*
Allow: /*.gif*
Allow: /*.bmp*
Allow: /*.ico*
Allow: /*.js*
Allow: /*.css*
Allow: /wp-content/
Disallow: /
通过 robots 协议,禁止搜索引擎抓取除 .js、.css 或图片之外的所有内容。因为是静态资源的CDN域名,静态资源还是需要公开爬取,否则会影响正常收录。
Nginx 重定向 robots.txt
当然,也不可能把主域名的robots.txt改成上面那样,那么所有的页面都不会被搜索引擎抓取。可以使用 Nginx 的条件判断来指定将 robots.txt 重定向到 robots2.txt 的域名。
if ($http_host !~ "^www.zhanzhangb.com$") {
rewrite /robots.txt /robots2.txt last;
}
以上是将非域名下的robots.txt重定向到robots2.txt。
if ($http_host ~ "^cdn.zhanzhangb.com$") {
rewrite /robots.txt /robots2.txt last;
}
以上就是将域名下的robots.txt重定向到robots2.txt。
Apache 重定向 robots.txt
RewriteEngine On
RewriteCond %{HTTP_HOST} !^www.zhanzhangb.com [NC]
RewriteRule robots.txt robots2.txt [L]
设置完成后,使用CDN域名访问robots.txt,看看是否成功。域名对应的robots.txt不要弄错了,否则会造成很大的SEO损失。
php禁止网页抓取( 如果我们有些文件夹或者文件不想让百度收录的时候应该怎么办呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-27 04:17
如果我们有些文件夹或者文件不想让百度收录的时候应该怎么办呢?)
如何设置机器人拒绝百度和谷歌收录
不想让百度收录一些文件夹或文件怎么办?
我们可以使用机器人来解决这个问题。机器人可以和搜索引擎达成一定的协议,让搜索引擎不收录指定文件和文件夹。
robots.txt 是最简单的 .txt 文件,它告诉搜索引擎哪些页面允许收录,哪些页面不允许收录。
关于robots.txt 一般站长需要注意以下几点:
如果您的网站对所有搜索引擎开放,则无需将此文件设为空,否则 robots.txt 为空。
必须命名为:robots.txt,全小写,robots后加“s”。
robots.txt 必须放在站点的根目录中。如:可以通过 成功访问,说明站点放置正确。
robots.txt中一般只写两个函数:User-agent和Disallow。
观察此页面并将其修改为您自己的:
如果有多个禁止,则必须有多个 Disallow 函数并在单独的行中进行描述。
必须至少有一个 Disallow 函数,如果所有 收录 都允许,则写: Disallow: ,如果 收录 都不允许,则写: Disallow: / (注意:只有一个斜杠不见了)。
附加说明:
User-agent: * 星号表示允许所有搜索引擎收录
Disallow: /search.html 该页面被搜索引擎禁止抓取。
不允许:/index.php?表示此类页面禁止被搜索引擎抓取。
以上是拒绝搜索引擎收录的设置方法,根据以上设置即可满足拒绝搜索引擎收录的要求。 查看全部
php禁止网页抓取(
如果我们有些文件夹或者文件不想让百度收录的时候应该怎么办呢?)
如何设置机器人拒绝百度和谷歌收录
不想让百度收录一些文件夹或文件怎么办?
我们可以使用机器人来解决这个问题。机器人可以和搜索引擎达成一定的协议,让搜索引擎不收录指定文件和文件夹。
robots.txt 是最简单的 .txt 文件,它告诉搜索引擎哪些页面允许收录,哪些页面不允许收录。
关于robots.txt 一般站长需要注意以下几点:
如果您的网站对所有搜索引擎开放,则无需将此文件设为空,否则 robots.txt 为空。
必须命名为:robots.txt,全小写,robots后加“s”。
robots.txt 必须放在站点的根目录中。如:可以通过 成功访问,说明站点放置正确。
robots.txt中一般只写两个函数:User-agent和Disallow。
观察此页面并将其修改为您自己的:
如果有多个禁止,则必须有多个 Disallow 函数并在单独的行中进行描述。
必须至少有一个 Disallow 函数,如果所有 收录 都允许,则写: Disallow: ,如果 收录 都不允许,则写: Disallow: / (注意:只有一个斜杠不见了)。
附加说明:
User-agent: * 星号表示允许所有搜索引擎收录
Disallow: /search.html 该页面被搜索引擎禁止抓取。
不允许:/index.php?表示此类页面禁止被搜索引擎抓取。
以上是拒绝搜索引擎收录的设置方法,根据以上设置即可满足拒绝搜索引擎收录的要求。
php禁止网页抓取(综艺影视类长禁止搜索引擎抓取和收录的创建抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-27 04:15
大家做seo都是千方百计让搜索引擎抓取和收录,但其实很多时候我们还需要禁止搜索引擎抓取和收录
比如公司内测的网站,或者内网,或者后台登录页面,肯定不想被外人搜索到,所以应该禁止搜索引擎抓取。禁止搜索引擎爬取方法:在WEB根目录下创建robots.txt文件,其内容为:
User-agent: Baiduspider
Disallow: /
User-agent: Sosospider
Disallow: /
User-agent: sogou spider
Disallow:
User-agent: YodaoBot
Disallow:
User-agent: Googlebot
Disallow: /
User-agent: Bingbot
Disallow: /
User-agent: Slurp
Disallow: /
User-agent: Teoma
Disallow: /
User-agent: ia_archiver
Disallow: /
User-agent: twiceler
Disallow: /
User-agent: MSNBot
Disallow: /
User-agent: Scrubby
Disallow: /
User-agent: Robozilla
Disallow: /
User-agent: googlebot-image
Disallow: /
User-agent: googlebot-mobile
Disallow: /
User-agent: yahoo-mmcrawler
Disallow: /
User-agent: yahoo-blogs/v3.9
Disallow: /
User-agent: psbot
Disallow: /
给你发一张禁止搜索引擎爬取网站的搜索结果截图:
百度官方对robots.txt的解释如下: 机器人是网站与蜘蛛沟通的重要渠道。本站通过robots文件声明,本网站的部分不希望被搜索引擎收录或指定搜索引擎仅搜索到收录特定部分。
9月11日,百度搜索机器人全新升级。升级后机器人会优化网站视频网址收录的抓取。只有当您的 网站 收录您不希望被视频搜索引擎 收录 看到的内容时,才需要 robots.txt 文件。如果您想要搜索引擎 收录网站 上的所有内容,请不要创建 robots.txt 文件。
如果你的网站没有设置robots协议,百度搜索会在网站的视频URL中收录视频播放页面的URL、视频文件、视频的周边文字等信息。已收录的短视频资源将作为视频速度体验页面呈现给用户。另外,对于综艺、电影等长视频,搜索引擎只使用收录页面URL。 查看全部
php禁止网页抓取(综艺影视类长禁止搜索引擎抓取和收录的创建抓取方法)
大家做seo都是千方百计让搜索引擎抓取和收录,但其实很多时候我们还需要禁止搜索引擎抓取和收录
比如公司内测的网站,或者内网,或者后台登录页面,肯定不想被外人搜索到,所以应该禁止搜索引擎抓取。禁止搜索引擎爬取方法:在WEB根目录下创建robots.txt文件,其内容为:
User-agent: Baiduspider
Disallow: /
User-agent: Sosospider
Disallow: /
User-agent: sogou spider
Disallow:
User-agent: YodaoBot
Disallow:
User-agent: Googlebot
Disallow: /
User-agent: Bingbot
Disallow: /
User-agent: Slurp
Disallow: /
User-agent: Teoma
Disallow: /
User-agent: ia_archiver
Disallow: /
User-agent: twiceler
Disallow: /
User-agent: MSNBot
Disallow: /
User-agent: Scrubby
Disallow: /
User-agent: Robozilla
Disallow: /
User-agent: googlebot-image
Disallow: /
User-agent: googlebot-mobile
Disallow: /
User-agent: yahoo-mmcrawler
Disallow: /
User-agent: yahoo-blogs/v3.9
Disallow: /
User-agent: psbot
Disallow: /
给你发一张禁止搜索引擎爬取网站的搜索结果截图:
百度官方对robots.txt的解释如下: 机器人是网站与蜘蛛沟通的重要渠道。本站通过robots文件声明,本网站的部分不希望被搜索引擎收录或指定搜索引擎仅搜索到收录特定部分。
9月11日,百度搜索机器人全新升级。升级后机器人会优化网站视频网址收录的抓取。只有当您的 网站 收录您不希望被视频搜索引擎 收录 看到的内容时,才需要 robots.txt 文件。如果您想要搜索引擎 收录网站 上的所有内容,请不要创建 robots.txt 文件。
如果你的网站没有设置robots协议,百度搜索会在网站的视频URL中收录视频播放页面的URL、视频文件、视频的周边文字等信息。已收录的短视频资源将作为视频速度体验页面呈现给用户。另外,对于综艺、电影等长视频,搜索引擎只使用收录页面URL。
php禁止网页抓取(关于“别人怎么访问PHP虚拟主机”的介绍(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-27 04:13
其他人如何访问 PHP 虚拟主机?访问PHP虚拟主机,主要通过控制面板、域名、FTP。其中,控制面板、FTP等方式主要用于管理PHP虚拟主机;PHP虚拟主机设置好网站后,我们就可以通过域名访问来访问网站的数据了。接下来简单介绍一下这些接入方式,以及其他接入方式。
1、控制面板
这是虚拟主机最重要的管理方式,也是虚拟主机的特点之一。虚拟主机的各项管理功能一一快速入门,站长只需点击即可完成功能操作。这使得许多不懂技术的网站管理员可以使用虚拟主机来构建 网站 和管理服务器。
如果需要允许他人访问虚拟主机,可以将控制面板地址、用户名、密码提供给对方,从而实现访问。但是,会存在严重的安全隐患。切记不要随意将您的用户名和密码提供给他人。
2、FTP方式
FTP是虚拟主机管理文件最重要的方式。虚拟主机在管理文件和批量操作时,都是通过FTP软件来完成的。
如果需要允许其他人访问虚拟主机,可以使用 FTP。将FTP地址、用户名和密码给对方,对方可以通过FTP软件等方式连接到虚拟主机。我们可以提前设置虚拟主机文件管理权限,比如只允许“只读”,不允许“可写”,这样设置后,当对方通过FTP访问时,可以在一定程度上降低安全隐患。
这样,当PHP虚拟主机一般作为存储服务器使用时,可以与他人共享文件,可以查看和下载。您还可以打开一些具有“可读可写”权限的目录和文件,以达到在线编辑、修改等目的。
3、域名访问
如果 PHP 虚拟主机已经设置了 网站,我们会发布域名。大家可以通过域名访问PHP虚拟主机,浏览我们在网站上发布的信息、图片等。
以上就是“别人如何访问php虚拟主机”的介绍。如果您需要购买虚拟主机,我们推荐无忧主机。虚拟主机产品种类繁多,从共享虚拟主机到独占虚拟主机;Linux系统和Windows系统主机配置齐全,PHP虚拟主机、ASP虚拟主机、Java虚拟主机等。另外价格便宜,支持试用,技术客服7*24小时协助维护。同时,它提供快速的电子归档,无需窗帘摄影。
购买入口:
专属入口: 查看全部
php禁止网页抓取(关于“别人怎么访问PHP虚拟主机”的介绍(图))
其他人如何访问 PHP 虚拟主机?访问PHP虚拟主机,主要通过控制面板、域名、FTP。其中,控制面板、FTP等方式主要用于管理PHP虚拟主机;PHP虚拟主机设置好网站后,我们就可以通过域名访问来访问网站的数据了。接下来简单介绍一下这些接入方式,以及其他接入方式。
1、控制面板
这是虚拟主机最重要的管理方式,也是虚拟主机的特点之一。虚拟主机的各项管理功能一一快速入门,站长只需点击即可完成功能操作。这使得许多不懂技术的网站管理员可以使用虚拟主机来构建 网站 和管理服务器。
如果需要允许他人访问虚拟主机,可以将控制面板地址、用户名、密码提供给对方,从而实现访问。但是,会存在严重的安全隐患。切记不要随意将您的用户名和密码提供给他人。
2、FTP方式
FTP是虚拟主机管理文件最重要的方式。虚拟主机在管理文件和批量操作时,都是通过FTP软件来完成的。
如果需要允许其他人访问虚拟主机,可以使用 FTP。将FTP地址、用户名和密码给对方,对方可以通过FTP软件等方式连接到虚拟主机。我们可以提前设置虚拟主机文件管理权限,比如只允许“只读”,不允许“可写”,这样设置后,当对方通过FTP访问时,可以在一定程度上降低安全隐患。
这样,当PHP虚拟主机一般作为存储服务器使用时,可以与他人共享文件,可以查看和下载。您还可以打开一些具有“可读可写”权限的目录和文件,以达到在线编辑、修改等目的。
3、域名访问
如果 PHP 虚拟主机已经设置了 网站,我们会发布域名。大家可以通过域名访问PHP虚拟主机,浏览我们在网站上发布的信息、图片等。
以上就是“别人如何访问php虚拟主机”的介绍。如果您需要购买虚拟主机,我们推荐无忧主机。虚拟主机产品种类繁多,从共享虚拟主机到独占虚拟主机;Linux系统和Windows系统主机配置齐全,PHP虚拟主机、ASP虚拟主机、Java虚拟主机等。另外价格便宜,支持试用,技术客服7*24小时协助维护。同时,它提供快速的电子归档,无需窗帘摄影。
购买入口:
专属入口:
php禁止网页抓取(我负责的一个网站流量突然下降至5分之一的流量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-24 00:15
一月中旬,我负责的一个网站,网站的流量突然下降到五分之一。于是查了一下百度收录的卷。发现 网站网站收录 页数超过 9,000,而之前为超过 130,000。难怪流量下降如此明显。这个网站是7月份静态处理的论坛。当时发射后不久,网站收录正常,并没有大面积缩减的迹象。由于网站的工作量大,每天观察数据,没有明显的流量下降迹象。
它仅在 1 月中旬显着下降。通过观察收录的页面发现百度只有收录网站的8080端口页面,而且几乎只有收录动态地址,几乎没有静态地址< @收录。谷歌查询量 收录 原来是 0.
这令人费解。我从来没有遇到过这样的问题。那个时候ZAC正好在PHPWIND面试,所以问了他这个问题。他当时的回答也没有解决我的问题。可能这个问题在其他地方很少出现。对问题一一排查,终于找到问题所在。事实证明,在 8 月,Tech 修改了 robots.txt 文件。当时的语法是这样的:
#
#robots.txtforDiscuz!Board
#版本6.0.0
#
用户代理:*
不允许:/
禁止:/admin/
禁止:/api/
禁止:/附件/
禁止:/customavatars/
禁止:/图像/
禁止:/forumdata/
禁止:/包括/
禁止:/ipdata/
禁止:/模板/
禁止:/plugins/
禁止:/mspace/
禁止:/wap/
禁止:/admincp.php
禁止:/ajax.php
禁止:/digest.php
禁止:/logging.php
禁止:/member.php
禁止:/memcp.php
禁止:/misc.php
禁止:/my.php
禁止:/pm.php
禁止:/post.php
禁止:/register.php
禁止:/rss.php
禁止:/search.php
禁止:/seccode.php
禁止:/topicadmin.php
禁止:/space.php
不知道大家有没有注意到上面的语法错误,但是错误已经很明显了。第一句话是错的。不应该被禁止:/
取而代之的是,Allow:/或者干脆不写这句话,直接删掉这句话。不要小看多写的3封信,而是让搜索引擎的蜘蛛不再抓取你的网页。网站收录音量变化开始缓慢下降,直到从搜索引擎数据库中删除。例如,谷歌几乎等于删除了这个 网站 页面。让百度蜘蛛误以为只允许抓取8080端口页面。事实上,8080 端口是不可访问的。为了尽量减少损失,我要求技术立即恢复对8080端口的访问。几天后,流量又增加了,网站收录的量已经恢复到2万多,但距离13万还差得很远。谷歌收录也有两万多,收录很正常。但是百度还是只有收录8080端口,偶尔收录默认端口下,动态占多数,静态占少数。来自论坛管理员的后台数据显示,网站整体流量下降了近三分之一2.
问题还在处理中,希望尽快恢复流量。总结:作为一名SEO,一定要定期查看网站的robots.txt,建议每月一次,同时对技术人员进行SEO相关培训。让技术人员了解基本的SEO知识。最好为技术部门制定SEO规范。让大家有参考。 查看全部
php禁止网页抓取(我负责的一个网站流量突然下降至5分之一的流量)
一月中旬,我负责的一个网站,网站的流量突然下降到五分之一。于是查了一下百度收录的卷。发现 网站网站收录 页数超过 9,000,而之前为超过 130,000。难怪流量下降如此明显。这个网站是7月份静态处理的论坛。当时发射后不久,网站收录正常,并没有大面积缩减的迹象。由于网站的工作量大,每天观察数据,没有明显的流量下降迹象。
它仅在 1 月中旬显着下降。通过观察收录的页面发现百度只有收录网站的8080端口页面,而且几乎只有收录动态地址,几乎没有静态地址< @收录。谷歌查询量 收录 原来是 0.
这令人费解。我从来没有遇到过这样的问题。那个时候ZAC正好在PHPWIND面试,所以问了他这个问题。他当时的回答也没有解决我的问题。可能这个问题在其他地方很少出现。对问题一一排查,终于找到问题所在。事实证明,在 8 月,Tech 修改了 robots.txt 文件。当时的语法是这样的:
#
#robots.txtforDiscuz!Board
#版本6.0.0
#
用户代理:*
不允许:/
禁止:/admin/
禁止:/api/
禁止:/附件/
禁止:/customavatars/
禁止:/图像/
禁止:/forumdata/
禁止:/包括/
禁止:/ipdata/
禁止:/模板/
禁止:/plugins/
禁止:/mspace/
禁止:/wap/
禁止:/admincp.php
禁止:/ajax.php
禁止:/digest.php
禁止:/logging.php
禁止:/member.php
禁止:/memcp.php
禁止:/misc.php
禁止:/my.php
禁止:/pm.php
禁止:/post.php
禁止:/register.php
禁止:/rss.php
禁止:/search.php
禁止:/seccode.php
禁止:/topicadmin.php
禁止:/space.php
不知道大家有没有注意到上面的语法错误,但是错误已经很明显了。第一句话是错的。不应该被禁止:/
取而代之的是,Allow:/或者干脆不写这句话,直接删掉这句话。不要小看多写的3封信,而是让搜索引擎的蜘蛛不再抓取你的网页。网站收录音量变化开始缓慢下降,直到从搜索引擎数据库中删除。例如,谷歌几乎等于删除了这个 网站 页面。让百度蜘蛛误以为只允许抓取8080端口页面。事实上,8080 端口是不可访问的。为了尽量减少损失,我要求技术立即恢复对8080端口的访问。几天后,流量又增加了,网站收录的量已经恢复到2万多,但距离13万还差得很远。谷歌收录也有两万多,收录很正常。但是百度还是只有收录8080端口,偶尔收录默认端口下,动态占多数,静态占少数。来自论坛管理员的后台数据显示,网站整体流量下降了近三分之一2.
问题还在处理中,希望尽快恢复流量。总结:作为一名SEO,一定要定期查看网站的robots.txt,建议每月一次,同时对技术人员进行SEO相关培训。让技术人员了解基本的SEO知识。最好为技术部门制定SEO规范。让大家有参考。
php禁止网页抓取(4.禁止百度图片搜索收录某些图片,该如何设置?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-23 18:01
3.我在robots.txt中设置了禁止百度的内容收录my网站,为什么百度搜索结果里还出现?
如果其他网站s链接到你robots.txt文件中禁止收录的页面,这些页面可能仍然会出现在百度搜索结果中,但是你页面上的内容不会被抓取、索引和显示,百度搜索结果只显示您相关页面的其他网站描述。
4.禁止搜索引擎跟踪网页链接,但只索引网页
如果您不希望搜索引擎跟踪此页面上的链接,并且不传递链接的权重,请将此元标记放置在页面的部分中:
如果不希望百度跟踪特定链接,百度也支持更精准的控制,请直接在链接上写下这个标记:登录
要允许其他搜索引擎关注,但只阻止百度关注您页面的链接,请将此元标记放置在您页面的部分中:
5.禁止搜索引擎在搜索结果中显示网页快照,但只索引网页
要阻止所有搜索引擎显示您的 网站 快照,请将此元标记放置在您网页的某个部分:要允许其他搜索引擎显示快照,但仅阻止百度显示它们,请使用以下标记:注意:这个标签只是禁止百度显示页面的快照,百度会继续索引页面并在搜索结果中显示页面摘要。
6.我要禁止百度图片搜索收录一些图片,怎么设置?
禁止百度蜘蛛抓取网站上的所有图片,或者允许百度蜘蛛抓取网站上某种格式的图片文件可以通过设置robots来实现,请参考“robots.txt文件使用示例”示例1 0、11、12。
7. robots.txt 文件格式
“robots.txt”文件收录一个或多个由空行分隔的记录(以 CR、CR/NL 或 NL 结尾),每个记录格式如下:
:
在这个文件中可以使用#作为注解,具体用法同UNIX中的约定。此文件中的记录通常以一行或多行 User-agent 开头,然后是几行 Disallow 和 Allow 行。详情如下:
用户代理:
该项目的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,则表示多个机器人会受到“robots.txt”的限制。对于此文件,必须至少有一个 User-agent 记录。如果此项的值设置为 *,则对任何机器人都有效。在“robots.txt”文件中,“User-agent:*”只能有一条记录。如果在“robots.txt”文件中,添加“User-agent: SomeBot”和几行Disallow和Allow行,“SomeBot”的名称只受“User-agent: SomeBot”后面的Disallow和Allow行的限制。
不允许:
该项目的值用于描述一组不想被访问的 URL。该值可以是完整路径,也可以是路径的非空前缀。机器人不会访问以 Disallow 项的值开头的 URL。例如,“Disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,而“Disallow:/help/”则允许机器人访问/help.html、/helpabc。 html,并且无法访问/help/index.html。“Disallow:”表示允许机器人访问网站的所有URL,且“/robots.txt”文件中必须至少有一条Disallow记录。如果“/robots.txt”不存在或为空文件,则 网站 对所有搜索引擎机器人开放。
允许:
该项目的值用于描述您希望访问的一组 URL。与 Disallow 项类似,该值可以是完整路径,也可以是路径前缀。以 Allow 项的值开头的 URL 允许机器人访问。例如“允许:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。网站 的所有 URL 默认为 Allow,因此 Allow 通常与 Disallow 结合使用,以允许访问某些网页,同时禁止访问所有其他 URL。
需要注意的是,Disallow 和 Allow 行的顺序是有意义的,机器人会根据第一个匹配的 Allow 或 Disallow 行来判断是否访问 URL。
使用“*”和“$”:
百度蜘蛛支持使用通配符“*”和“$”来模糊匹配url。
"$" 匹配行终止符。
"*" 匹配零个或多个任意字符。
注意:我们会严格遵守robots的相关协议,请注意区分您不想被爬取的目录或收录的大小写,我们会处理robots里写的文件和你做的文件不想被爬取和收录@>的目录必须完全匹配,否则robots协议不会生效。
8. URL 匹配示例 Allow or Disallow URL 匹配结果的值
/tmp/tmpye
/tmp/tmp.html是的
/tmp/tmp/a.html是的
/tmp/tmphohono
/你好*/Hello.html是的
/He*lo/你好,loloyes
/Heap*lo/你好,lolono
html$/tmpa.html是的
/a.html$/a.html是的
htm$/a.htmlno 查看全部
php禁止网页抓取(4.禁止百度图片搜索收录某些图片,该如何设置?)
3.我在robots.txt中设置了禁止百度的内容收录my网站,为什么百度搜索结果里还出现?
如果其他网站s链接到你robots.txt文件中禁止收录的页面,这些页面可能仍然会出现在百度搜索结果中,但是你页面上的内容不会被抓取、索引和显示,百度搜索结果只显示您相关页面的其他网站描述。
4.禁止搜索引擎跟踪网页链接,但只索引网页
如果您不希望搜索引擎跟踪此页面上的链接,并且不传递链接的权重,请将此元标记放置在页面的部分中:
如果不希望百度跟踪特定链接,百度也支持更精准的控制,请直接在链接上写下这个标记:登录
要允许其他搜索引擎关注,但只阻止百度关注您页面的链接,请将此元标记放置在您页面的部分中:
5.禁止搜索引擎在搜索结果中显示网页快照,但只索引网页
要阻止所有搜索引擎显示您的 网站 快照,请将此元标记放置在您网页的某个部分:要允许其他搜索引擎显示快照,但仅阻止百度显示它们,请使用以下标记:注意:这个标签只是禁止百度显示页面的快照,百度会继续索引页面并在搜索结果中显示页面摘要。
6.我要禁止百度图片搜索收录一些图片,怎么设置?
禁止百度蜘蛛抓取网站上的所有图片,或者允许百度蜘蛛抓取网站上某种格式的图片文件可以通过设置robots来实现,请参考“robots.txt文件使用示例”示例1 0、11、12。
7. robots.txt 文件格式
“robots.txt”文件收录一个或多个由空行分隔的记录(以 CR、CR/NL 或 NL 结尾),每个记录格式如下:
:
在这个文件中可以使用#作为注解,具体用法同UNIX中的约定。此文件中的记录通常以一行或多行 User-agent 开头,然后是几行 Disallow 和 Allow 行。详情如下:
用户代理:
该项目的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,则表示多个机器人会受到“robots.txt”的限制。对于此文件,必须至少有一个 User-agent 记录。如果此项的值设置为 *,则对任何机器人都有效。在“robots.txt”文件中,“User-agent:*”只能有一条记录。如果在“robots.txt”文件中,添加“User-agent: SomeBot”和几行Disallow和Allow行,“SomeBot”的名称只受“User-agent: SomeBot”后面的Disallow和Allow行的限制。
不允许:
该项目的值用于描述一组不想被访问的 URL。该值可以是完整路径,也可以是路径的非空前缀。机器人不会访问以 Disallow 项的值开头的 URL。例如,“Disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,而“Disallow:/help/”则允许机器人访问/help.html、/helpabc。 html,并且无法访问/help/index.html。“Disallow:”表示允许机器人访问网站的所有URL,且“/robots.txt”文件中必须至少有一条Disallow记录。如果“/robots.txt”不存在或为空文件,则 网站 对所有搜索引擎机器人开放。
允许:
该项目的值用于描述您希望访问的一组 URL。与 Disallow 项类似,该值可以是完整路径,也可以是路径前缀。以 Allow 项的值开头的 URL 允许机器人访问。例如“允许:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。网站 的所有 URL 默认为 Allow,因此 Allow 通常与 Disallow 结合使用,以允许访问某些网页,同时禁止访问所有其他 URL。
需要注意的是,Disallow 和 Allow 行的顺序是有意义的,机器人会根据第一个匹配的 Allow 或 Disallow 行来判断是否访问 URL。
使用“*”和“$”:
百度蜘蛛支持使用通配符“*”和“$”来模糊匹配url。
"$" 匹配行终止符。
"*" 匹配零个或多个任意字符。
注意:我们会严格遵守robots的相关协议,请注意区分您不想被爬取的目录或收录的大小写,我们会处理robots里写的文件和你做的文件不想被爬取和收录@>的目录必须完全匹配,否则robots协议不会生效。
8. URL 匹配示例 Allow or Disallow URL 匹配结果的值
/tmp/tmpye
/tmp/tmp.html是的
/tmp/tmp/a.html是的
/tmp/tmphohono
/你好*/Hello.html是的
/He*lo/你好,loloyes
/Heap*lo/你好,lolono
html$/tmpa.html是的
/a.html$/a.html是的
htm$/a.htmlno
php禁止网页抓取(吃完虾爬什么,怎么爬才是导致锒铛入狱的罪魁祸首? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-23 17:23
)
导读
偶尔大数据公司被抓,不法流量自媒体就是为了博眼球,夸大事实,说爬虫玩的好,监狱早点吃,想学爬虫就瑟瑟发抖,怕自己写爬虫被抄进去了,我很害怕,我:说实话,我对大部分新技术能力想的太多了。这种贸然下结论的方式,类似于先吃虾再吃维生素C的砒霜中毒理论。同理,无剂量谈毒——都是流氓行为。
从技术中立的角度来看,爬虫技术本身不存在违法违规行为。爬什么、怎么爬是导致二当入狱的罪魁祸首。Github上有一个库,记录了国内爬虫开发者诉讼和违规相关的新闻、资料、法律法规:
为了节省读者的时间,我们可以直接总结:
1、 忽略robots协议,爬取不给爬取数据
robots.txt,纯文本文件,网站管理者可以在这个文件中声明不希望被搜索引擎访问的部分,或者指定搜索引擎只指定收录的内容,语法很简单:
通配符 (*) → 匹配零个或多个任意字符;
匹配字符 ($) → 匹配 URL 末尾的字符;
User-agent → 搜索引擎爬虫的名字,各大搜索引擎都有固定的名字,比如百度百度百科,如果该项为*(通配符),表示该协议对任何搜索引擎爬虫都有效;
Disallow → 禁止路径;
Allow → 允许访问的路径;
但是,这个协议可以说是君子协议。谨防君子,不防小人,无视机器人协议随意抢网站内容,将涉嫌构成违反《反不正当竞争法》第二条,即违反《反不正当竞争法》第二条。诚实。信用原则和商业道德的不公平竞争。
2、强行突破网站设定的技术措施
网站一般会做反爬,以减轻爬虫批量访问给网站带来的巨大压力和负担。爬虫开发者通过技术手段绕过反爬虫,客观上影响网站正常运行(甚至挂机),适用反不正当竞争法第十二条(四)其他障碍、行为)扰乱其他运营商合法提供的网络产品或者服务的正常运行的。
强行突破已经爬取和发布的一些具体技术措施,也可能构成犯罪行为。
这里稍微提防一下:为非法组织提供爬虫相关服务,也可能间接承担刑事责任。在这种情况下,抓捕极端黑客就是模板。尽管技术本身是无辜的,但您已经开发了它并被定罪。使用它的分子同样负责。
3、爬取特定类型的信息
1)用户个人隐私
2)用户个人信息
3)受版权法保护的产品
4)商业机密
5)保护数据免受不公平竞争
如果担心自己写的爬虫违法,可以看一看,总结一下爬山的基本伦理:
先确定要爬什么网站:国事、国防建设、前沿科技等领域的不要碰;
确定哪些内容:不触碰个人隐私、个人信息、商业秘密;受著作权法和不正当竞争保护的数据,最好是偷偷享用,不要传播和营利(比如数据分析,见下文~)。
爬取方法:轻柔一点,尽量不要影响正常用户的使用,水会继续流,其他人网站会被挂掉,不做就奇怪了。
机器人协议:嗯...我是一个恶棍
天网已满,稀稀拉拉但不容错过~
相信对爬虫非法类别的解读可以打消一些想学Python爬虫的小白梦心的顾虑。爬虫学习
相信进来看看的朋友都对爬虫很感兴趣,我也是。当我第一次接触爬行动物的时候,就被深深吸引了,因为我觉得SO COOL!每当我打完代码,看着屏幕上飘浮的一串数据,都有一种成就感,有没有?而且爬虫技术可以应用到很多生活场景,比如自动投票,批量下载有趣的文章,小说,视频,微信机器人,爬取重要数据进行数据分析啊,我真的感觉这些代码都是为自己写的,可以为自己和他人服务,所以人生太短,我选择爬虫。
1、要学习爬虫,首先要了解什么是爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
其实说白了,爬虫可以模拟浏览器的行为为所欲为,自定义自己的搜索和下载内容,实现操作自动化。比如浏览器可以下载小说,但有时不能批量下载,所以爬虫的功能就派上用场了。
2、爬虫学习路线
学习Python爬虫的一般步骤如下:
1)。首先学习基本的Python语法知识
2).学习Python爬虫常用的几个重要的内置库,urllib,http等,用于下载网页
3)。学习正则表达式re、BeautifulSoup(bs4)、Xpath(lxml)等网页解析工具
4)。开始一些简单的网站爬取(博主从百度开始,哈哈)了解爬取数据的过程
5)。了解爬虫、header、robot、时间间隔、代理ip、隐藏字段等的一些反爬机制。
6)。学习一些特殊的网站爬取,解决登录、cookies、动态网页等问题。
7)。了解爬虫和数据库的结合,如何存储爬取的数据
8)。学习应用Python的多线程多进程爬取提高爬虫效率
9)。学习爬虫框架、Scrapy、PySpider等。
10).学习分布式爬虫(海量数据需求)
3、Python爬虫Selenium库的使用
1)基础知识
首先,要使用python语言作为爬虫,需要学习python的基础知识,以及HTML、CSS、JS、Ajax等相关知识。这里列举一些python中爬虫相关的库和框架:
1.1、urllib和urllib2
1.2、Requests
1.3、Beautiful Soup
1.4、Xpath语法与lxml库
1.5、PhantomJS
1.6、Selenium
1.7、PyQuery
1.8、Scrapy
......
由于时间有限,本文只介绍Selenium库的爬虫技术,如自动化测试,以及其他库和框架的资料。有兴趣的小伙伴可以自行学习。
2)硒基础知识
2.1、Selenium是一款用于测试网站的自动化测试工具,支持包括Chrome、Firefox、Safari等多种主流界面浏览器在内的多种浏览器,也支持phantomJS无界面浏览器。
2.2、安装
pip install Selenium
关于Python技术储备
学好 Python 是赚钱的好方法,不管是工作还是副业,但要学好 Python,还是要有学习计划的。最后,我们将分享一套完整的Python学习资料,以帮助那些想学习Python的朋友!
一、Python全方位学习路线
Python的各个方向都是将Python中常用的技术点进行整理,形成各个领域知识点的汇总。它的用处是你可以根据以上知识点找到对应的学习资源,保证你能学得更全面。
二、学习软件
工人要做好工作,首先要磨利他的工具。学习Python常用的开发软件就到这里,为大家节省不少时间。
三、入门视频
当我们看视频学习时,没有手我们就无法移动眼睛和大脑。更科学的学习方式是理解后再使用。这时候动手项目就很合适了。
四、实际案例
光学理论是无用的。你必须学会跟随,你必须先进行实际练习,然后才能将所学应用于实践。这时候可以借鉴实战案例。
五、采访信息
我们必须学习 Python 才能找到一份高薪工作。以下面试题是来自阿里、腾讯、字节跳动等一线互联网公司的最新面试资料,部分阿里大佬给出了权威答案。看完这套面试材料相信大家都能找到一份满意的工作。
本完整版Python全套学习资料已上传至CSDN。需要的可以微信扫描下方CSDN官方认证二维码免费获取【保证100%免费】
查看全部
php禁止网页抓取(吃完虾爬什么,怎么爬才是导致锒铛入狱的罪魁祸首?
)
导读
偶尔大数据公司被抓,不法流量自媒体就是为了博眼球,夸大事实,说爬虫玩的好,监狱早点吃,想学爬虫就瑟瑟发抖,怕自己写爬虫被抄进去了,我很害怕,我:说实话,我对大部分新技术能力想的太多了。这种贸然下结论的方式,类似于先吃虾再吃维生素C的砒霜中毒理论。同理,无剂量谈毒——都是流氓行为。
从技术中立的角度来看,爬虫技术本身不存在违法违规行为。爬什么、怎么爬是导致二当入狱的罪魁祸首。Github上有一个库,记录了国内爬虫开发者诉讼和违规相关的新闻、资料、法律法规:
为了节省读者的时间,我们可以直接总结:
1、 忽略robots协议,爬取不给爬取数据
robots.txt,纯文本文件,网站管理者可以在这个文件中声明不希望被搜索引擎访问的部分,或者指定搜索引擎只指定收录的内容,语法很简单:
通配符 (*) → 匹配零个或多个任意字符;
匹配字符 ($) → 匹配 URL 末尾的字符;
User-agent → 搜索引擎爬虫的名字,各大搜索引擎都有固定的名字,比如百度百度百科,如果该项为*(通配符),表示该协议对任何搜索引擎爬虫都有效;
Disallow → 禁止路径;
Allow → 允许访问的路径;
但是,这个协议可以说是君子协议。谨防君子,不防小人,无视机器人协议随意抢网站内容,将涉嫌构成违反《反不正当竞争法》第二条,即违反《反不正当竞争法》第二条。诚实。信用原则和商业道德的不公平竞争。
2、强行突破网站设定的技术措施
网站一般会做反爬,以减轻爬虫批量访问给网站带来的巨大压力和负担。爬虫开发者通过技术手段绕过反爬虫,客观上影响网站正常运行(甚至挂机),适用反不正当竞争法第十二条(四)其他障碍、行为)扰乱其他运营商合法提供的网络产品或者服务的正常运行的。
强行突破已经爬取和发布的一些具体技术措施,也可能构成犯罪行为。
这里稍微提防一下:为非法组织提供爬虫相关服务,也可能间接承担刑事责任。在这种情况下,抓捕极端黑客就是模板。尽管技术本身是无辜的,但您已经开发了它并被定罪。使用它的分子同样负责。
3、爬取特定类型的信息
1)用户个人隐私
2)用户个人信息
3)受版权法保护的产品
4)商业机密
5)保护数据免受不公平竞争
如果担心自己写的爬虫违法,可以看一看,总结一下爬山的基本伦理:
先确定要爬什么网站:国事、国防建设、前沿科技等领域的不要碰;
确定哪些内容:不触碰个人隐私、个人信息、商业秘密;受著作权法和不正当竞争保护的数据,最好是偷偷享用,不要传播和营利(比如数据分析,见下文~)。
爬取方法:轻柔一点,尽量不要影响正常用户的使用,水会继续流,其他人网站会被挂掉,不做就奇怪了。
机器人协议:嗯...我是一个恶棍
天网已满,稀稀拉拉但不容错过~
相信对爬虫非法类别的解读可以打消一些想学Python爬虫的小白梦心的顾虑。爬虫学习
相信进来看看的朋友都对爬虫很感兴趣,我也是。当我第一次接触爬行动物的时候,就被深深吸引了,因为我觉得SO COOL!每当我打完代码,看着屏幕上飘浮的一串数据,都有一种成就感,有没有?而且爬虫技术可以应用到很多生活场景,比如自动投票,批量下载有趣的文章,小说,视频,微信机器人,爬取重要数据进行数据分析啊,我真的感觉这些代码都是为自己写的,可以为自己和他人服务,所以人生太短,我选择爬虫。
1、要学习爬虫,首先要了解什么是爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
其实说白了,爬虫可以模拟浏览器的行为为所欲为,自定义自己的搜索和下载内容,实现操作自动化。比如浏览器可以下载小说,但有时不能批量下载,所以爬虫的功能就派上用场了。
2、爬虫学习路线
学习Python爬虫的一般步骤如下:
1)。首先学习基本的Python语法知识
2).学习Python爬虫常用的几个重要的内置库,urllib,http等,用于下载网页
3)。学习正则表达式re、BeautifulSoup(bs4)、Xpath(lxml)等网页解析工具
4)。开始一些简单的网站爬取(博主从百度开始,哈哈)了解爬取数据的过程
5)。了解爬虫、header、robot、时间间隔、代理ip、隐藏字段等的一些反爬机制。
6)。学习一些特殊的网站爬取,解决登录、cookies、动态网页等问题。
7)。了解爬虫和数据库的结合,如何存储爬取的数据
8)。学习应用Python的多线程多进程爬取提高爬虫效率
9)。学习爬虫框架、Scrapy、PySpider等。
10).学习分布式爬虫(海量数据需求)
3、Python爬虫Selenium库的使用
1)基础知识
首先,要使用python语言作为爬虫,需要学习python的基础知识,以及HTML、CSS、JS、Ajax等相关知识。这里列举一些python中爬虫相关的库和框架:
1.1、urllib和urllib2
1.2、Requests
1.3、Beautiful Soup
1.4、Xpath语法与lxml库
1.5、PhantomJS
1.6、Selenium
1.7、PyQuery
1.8、Scrapy
......
由于时间有限,本文只介绍Selenium库的爬虫技术,如自动化测试,以及其他库和框架的资料。有兴趣的小伙伴可以自行学习。
2)硒基础知识
2.1、Selenium是一款用于测试网站的自动化测试工具,支持包括Chrome、Firefox、Safari等多种主流界面浏览器在内的多种浏览器,也支持phantomJS无界面浏览器。
2.2、安装
pip install Selenium
关于Python技术储备
学好 Python 是赚钱的好方法,不管是工作还是副业,但要学好 Python,还是要有学习计划的。最后,我们将分享一套完整的Python学习资料,以帮助那些想学习Python的朋友!
一、Python全方位学习路线
Python的各个方向都是将Python中常用的技术点进行整理,形成各个领域知识点的汇总。它的用处是你可以根据以上知识点找到对应的学习资源,保证你能学得更全面。

二、学习软件
工人要做好工作,首先要磨利他的工具。学习Python常用的开发软件就到这里,为大家节省不少时间。

三、入门视频
当我们看视频学习时,没有手我们就无法移动眼睛和大脑。更科学的学习方式是理解后再使用。这时候动手项目就很合适了。

四、实际案例
光学理论是无用的。你必须学会跟随,你必须先进行实际练习,然后才能将所学应用于实践。这时候可以借鉴实战案例。

五、采访信息
我们必须学习 Python 才能找到一份高薪工作。以下面试题是来自阿里、腾讯、字节跳动等一线互联网公司的最新面试资料,部分阿里大佬给出了权威答案。看完这套面试材料相信大家都能找到一份满意的工作。


本完整版Python全套学习资料已上传至CSDN。需要的可以微信扫描下方CSDN官方认证二维码免费获取【保证100%免费】

php禁止网页抓取(小鹿竞价软件禁止搜索引擎抓取后会有什么效果呢?? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-22 20:13
)
<p>小鹿系列竞价软件覆盖百度、360、搜狗、神马四大搜索平台,采用独创竞价算法,智能精准竞价,一键批量查询排名,根据
php禁止网页抓取(小鹿竞价软件禁止搜索引擎抓取后会有什么效果呢??
)
<p>小鹿系列竞价软件覆盖百度、360、搜狗、神马四大搜索平台,采用独创竞价算法,智能精准竞价,一键批量查询排名,根据
php禁止网页抓取(【】使用robots.txt文件拦截或删除网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-01-22 20:13
用户代理: *
不允许: /
允许所有机器人访问您的页面
用户代理: *
不允许:
(替代方案:创建一个空的“/robots.txt”文件,或者不使用 robots.txt。)
使用 robots.txt 文件阻止或删除网页
您可以使用 robots.txt 文件来阻止 Googlebot 抓取您 网站 上的网页。例如,如果您手动创建 robots.txt 文件以防止 Googlebot 抓取特定目录(例如私有目录)中的所有网页,请使用以下 robots.txt 条目:
用户代理:Googlebot
禁止:/private
要防止 Googlebot 抓取特定文件类型(例如 .gif)的所有文件,请使用以下 robots.txt 条目:
用户代理:Googlebot
禁止:/*.gif$
想要阻止 Googlebot 抓取所有内容?(具体来说,一个以您的域名开头的 URL,后跟任意字符串,后跟问号,后跟任意字符串),您可以使用以下条目:
用户代理:Googlebot
不允许: /*?
尽管我们不会抓取 robots.txt 阻止的网页的内容或将其编入索引,但如果我们在网络上的其他网页上找到它们的网址,我们仍会抓取它们并将其编入索引。因此,网页 URL 和其他公开可用的信息,例如指向此 网站 的链接中的锚文本,可能会出现在 Google 搜索结果中。但是,您页面上的内容不会被抓取、索引和显示。
作为 网站Admin Tools 的一部分,Google 提供了 robots.txt 分析工具。它可以像 Googlebot 读取文件一样读取 robots.txt 文件,并且可以为 Google 用户代理(例如 Googlebot)提供结果。我们强烈建议您使用它。在创建 robots.txt 文件之前,有必要考虑用户应该搜索哪些内容以及不应该搜索哪些内容。这样,通过对robots.txt的合理使用,搜索引擎可以将用户带到你的网站,同时保证隐私信息不是收录。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机! 查看全部
php禁止网页抓取(【】使用robots.txt文件拦截或删除网页)
用户代理: *
不允许: /
允许所有机器人访问您的页面
用户代理: *
不允许:
(替代方案:创建一个空的“/robots.txt”文件,或者不使用 robots.txt。)
使用 robots.txt 文件阻止或删除网页
您可以使用 robots.txt 文件来阻止 Googlebot 抓取您 网站 上的网页。例如,如果您手动创建 robots.txt 文件以防止 Googlebot 抓取特定目录(例如私有目录)中的所有网页,请使用以下 robots.txt 条目:
用户代理:Googlebot
禁止:/private
要防止 Googlebot 抓取特定文件类型(例如 .gif)的所有文件,请使用以下 robots.txt 条目:
用户代理:Googlebot
禁止:/*.gif$
想要阻止 Googlebot 抓取所有内容?(具体来说,一个以您的域名开头的 URL,后跟任意字符串,后跟问号,后跟任意字符串),您可以使用以下条目:
用户代理:Googlebot
不允许: /*?
尽管我们不会抓取 robots.txt 阻止的网页的内容或将其编入索引,但如果我们在网络上的其他网页上找到它们的网址,我们仍会抓取它们并将其编入索引。因此,网页 URL 和其他公开可用的信息,例如指向此 网站 的链接中的锚文本,可能会出现在 Google 搜索结果中。但是,您页面上的内容不会被抓取、索引和显示。
作为 网站Admin Tools 的一部分,Google 提供了 robots.txt 分析工具。它可以像 Googlebot 读取文件一样读取 robots.txt 文件,并且可以为 Google 用户代理(例如 Googlebot)提供结果。我们强烈建议您使用它。在创建 robots.txt 文件之前,有必要考虑用户应该搜索哪些内容以及不应该搜索哪些内容。这样,通过对robots.txt的合理使用,搜索引擎可以将用户带到你的网站,同时保证隐私信息不是收录。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机!
php禁止网页抓取(之一就是通过robots.txt文件来实现收录/抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-21 18:20
平时比如后台管理登录页面、会员登录注册页面等,不想被搜索引擎抓取收录/,怎么办?一种方法是通过 robots.txt 文件。
机器人也称为爬虫协议。写成robots.txt(不需要写成Robots.txt),必须放在网站的根目录下。其他目录无效。搜索引擎爬虫首先访问/爬取网站 robots.txt文件,然后是index.html/index.php、网站目录等网站告诉搜索引擎哪些页面可以爬取以及哪些页面不能通过robots协议爬取。很多人知道其中一个,不知道另一个,并且知道一些简单的拼写和用法。但是有些人仍然忽略它,那就是安全和隐私问题。
以下为个人写作,仅供参考:
User-agent:*搜索引擎的标识,*代表任何引擎,包括百度、谷歌等,如果要具体指定,这里不再详述。
Disallow: /a*/ 禁止访问以“a”开头的目录改编,例如:admin/index.html 是不可访问的。
Disallow: /C*/ 同上,这个大写的 C 应该区分大小写。
Disallow: /js/ 禁止对 js 目录的任何访问
不允许: /*?不允许收录 ? 的 URL,例如 : 或 this。
Disallow: /*.jpg$ 禁止访问所有以 .jpg 结尾的图像
站点地图:允许访问此 网站 地图文件。
这里需要注意的一点是使用网站 map 命令,将网站 map 的URL 地址用"" 包裹起来。有人说不用加。
使用 * 适配符号来防止黑客或恶意攻击。觉得不重要的不要用*,写全名就好,比如“/js/”。
一些像谷歌这样的搜索引擎也支持在网页上书写来实现它们的功能。
注意:robots.txt 命令只是给爬虫访问你的 网站 的指令,robots.txt 文件中的命令不会强制爬虫爬取你的 网站 进行相应的操作。 查看全部
php禁止网页抓取(之一就是通过robots.txt文件来实现收录/抓取)
平时比如后台管理登录页面、会员登录注册页面等,不想被搜索引擎抓取收录/,怎么办?一种方法是通过 robots.txt 文件。
机器人也称为爬虫协议。写成robots.txt(不需要写成Robots.txt),必须放在网站的根目录下。其他目录无效。搜索引擎爬虫首先访问/爬取网站 robots.txt文件,然后是index.html/index.php、网站目录等网站告诉搜索引擎哪些页面可以爬取以及哪些页面不能通过robots协议爬取。很多人知道其中一个,不知道另一个,并且知道一些简单的拼写和用法。但是有些人仍然忽略它,那就是安全和隐私问题。
以下为个人写作,仅供参考:
User-agent:*搜索引擎的标识,*代表任何引擎,包括百度、谷歌等,如果要具体指定,这里不再详述。
Disallow: /a*/ 禁止访问以“a”开头的目录改编,例如:admin/index.html 是不可访问的。
Disallow: /C*/ 同上,这个大写的 C 应该区分大小写。
Disallow: /js/ 禁止对 js 目录的任何访问
不允许: /*?不允许收录 ? 的 URL,例如 : 或 this。
Disallow: /*.jpg$ 禁止访问所有以 .jpg 结尾的图像
站点地图:允许访问此 网站 地图文件。
这里需要注意的一点是使用网站 map 命令,将网站 map 的URL 地址用"" 包裹起来。有人说不用加。
使用 * 适配符号来防止黑客或恶意攻击。觉得不重要的不要用*,写全名就好,比如“/js/”。
一些像谷歌这样的搜索引擎也支持在网页上书写来实现它们的功能。
注意:robots.txt 命令只是给爬虫访问你的 网站 的指令,robots.txt 文件中的命令不会强制爬虫爬取你的 网站 进行相应的操作。
php禁止网页抓取(【推荐学习】有关robots怎么禁止php抓取(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-18 21:14
下面我给大家讲解一下如何禁止robots爬取php。相信各位朋友也应该非常关注这个话题。下面我来告诉大家如何禁止机器人爬取php。拿php的相关资料,希望大家看到后会喜欢。
robots禁止爬取php的方法:1、在robots.txt文件中写入“Disallow: /*?*”;2、在 robots.txt 文件中添加规则 "User-agent:* Allow" : .html$ Disallow: /"。
本文运行环境:Windows7系统,PHP7.1版DELL G3电脑
robots禁止搜索引擎抓取php动态网址
所谓动态URL是指URL中收录&等字符的URL,如:news.php?lang=cn&class=1&id=2 当我们打开网站的伪静态为网站 SEO 是防止搜索引擎抓取我们的 网站 动态 URL 所必需的。
为什么要这样做,因为搜索引擎会做一些事情来触发 网站 两次爬取同一页面但最终判断为同一页面。具体处罚是什么?这个不清楚,总之不利于整个网站的SEO。那么如何防止搜索引擎抓取我们的网站动态URL呢?
这个问题可以通过使用 robots.txt 文件来解决。请看下面的详细操作。
我们知道动态页面的一个共同特点就是会有一个“?” 链接中的问号符号,所以我们可以在 robots.txt 文件中编写如下规则:
User-agent: *
Disallow: /*?*
这将阻止搜索引擎抓取整个 网站 动态链接。另外,如果我们只想让搜索引擎抓取html格式等指定类型文件的静态页面,可以在robots.txt中添加如下规则:
User-agent: *
Allow: .html$
Disallow: /
另外,记得把写好的robots.txt文件放到你的网站根目录下,不然不行。另外,还有一个方便的写规则快捷方式登录google网站admin工具,连接规则生成robots.txt文件即可。
【推荐学习:《PHP 视频教程》】 查看全部
php禁止网页抓取(【推荐学习】有关robots怎么禁止php抓取(图))
下面我给大家讲解一下如何禁止robots爬取php。相信各位朋友也应该非常关注这个话题。下面我来告诉大家如何禁止机器人爬取php。拿php的相关资料,希望大家看到后会喜欢。
robots禁止爬取php的方法:1、在robots.txt文件中写入“Disallow: /*?*”;2、在 robots.txt 文件中添加规则 "User-agent:* Allow" : .html$ Disallow: /"。

本文运行环境:Windows7系统,PHP7.1版DELL G3电脑
robots禁止搜索引擎抓取php动态网址
所谓动态URL是指URL中收录&等字符的URL,如:news.php?lang=cn&class=1&id=2 当我们打开网站的伪静态为网站 SEO 是防止搜索引擎抓取我们的 网站 动态 URL 所必需的。
为什么要这样做,因为搜索引擎会做一些事情来触发 网站 两次爬取同一页面但最终判断为同一页面。具体处罚是什么?这个不清楚,总之不利于整个网站的SEO。那么如何防止搜索引擎抓取我们的网站动态URL呢?
这个问题可以通过使用 robots.txt 文件来解决。请看下面的详细操作。
我们知道动态页面的一个共同特点就是会有一个“?” 链接中的问号符号,所以我们可以在 robots.txt 文件中编写如下规则:
User-agent: *
Disallow: /*?*
这将阻止搜索引擎抓取整个 网站 动态链接。另外,如果我们只想让搜索引擎抓取html格式等指定类型文件的静态页面,可以在robots.txt中添加如下规则:
User-agent: *
Allow: .html$
Disallow: /
另外,记得把写好的robots.txt文件放到你的网站根目录下,不然不行。另外,还有一个方便的写规则快捷方式登录google网站admin工具,连接规则生成robots.txt文件即可。
【推荐学习:《PHP 视频教程》】
php禁止网页抓取(本文实例讲述非常实用的常见技巧--本文实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 34 次浏览 • 2022-01-17 12:17
本文介绍了一个PHP+iFrame实现不刷新页面的异步文件上传的例子,是一个非常实用的常用技巧。分享给大家,供大家参考。具体分析如下:
说起iframe,现在用的人越来越少了,很多人认为应该换成AJAX,确实是这样,因为AJAX太好用了。
不过有一种情况我还是选择了iframe,就是本文要提到的文件异步上传。如果你有兴趣,你可以试试。如果使用原生 AJAX 来实现,应该会复杂很多。
首先给初学者补充一下基础知识:
1. 在iframe标签中,一般指定name属性进行标识;
2.form表单中,提交的目的地由action(目标地址)和target(目标窗口,默认为_self)决定;
3. 如果表单中的target指向iframe的名字,则表单可以提交到隐藏框架iframe;
4. iframe中的内容其实就是一个页面,js中的parent对象指的是父页面,也就是嵌入iframe中的页面;
5. php中使用move_uploaded_file()函数实现文件上传,$_FILES数组存储上传文件的相关信息。
本文实现了一个用户选择头像文件并立即上传并显示在页面上的示例。废话不多说,思路如下:
1. 在表单中嵌入一个iframe,并设置name属性的值;
2. 当文件上传选择的控件值发生变化时触发一个js函数,将表单提交到iframe,使用iframe内嵌的页面来处理文件上传;
3.在iframe中完成文件上传后,通过js中的parent对父页面进行操作,将图片显示在特定的tag中,并将图片的保存地址分配给隐藏字段;
4. 回到原来的页面,此时文件上传完成,隐藏域中记录了文件的路径。整个过程不刷新页面;
5. 最后,用户只需要在提交原创页面时,重新设置表单的action和target属性的值即可。
下面是效果截图和实现的代码:
upload.php页面如下:
iFrame异步文件上传
iFrame异步文件上传
用户名: <br />
上传头像:
proceedupload.php 页面如下:
<p> 查看全部
php禁止网页抓取(本文实例讲述非常实用的常见技巧--本文实例)
本文介绍了一个PHP+iFrame实现不刷新页面的异步文件上传的例子,是一个非常实用的常用技巧。分享给大家,供大家参考。具体分析如下:
说起iframe,现在用的人越来越少了,很多人认为应该换成AJAX,确实是这样,因为AJAX太好用了。
不过有一种情况我还是选择了iframe,就是本文要提到的文件异步上传。如果你有兴趣,你可以试试。如果使用原生 AJAX 来实现,应该会复杂很多。
首先给初学者补充一下基础知识:
1. 在iframe标签中,一般指定name属性进行标识;
2.form表单中,提交的目的地由action(目标地址)和target(目标窗口,默认为_self)决定;
3. 如果表单中的target指向iframe的名字,则表单可以提交到隐藏框架iframe;
4. iframe中的内容其实就是一个页面,js中的parent对象指的是父页面,也就是嵌入iframe中的页面;
5. php中使用move_uploaded_file()函数实现文件上传,$_FILES数组存储上传文件的相关信息。
本文实现了一个用户选择头像文件并立即上传并显示在页面上的示例。废话不多说,思路如下:
1. 在表单中嵌入一个iframe,并设置name属性的值;
2. 当文件上传选择的控件值发生变化时触发一个js函数,将表单提交到iframe,使用iframe内嵌的页面来处理文件上传;
3.在iframe中完成文件上传后,通过js中的parent对父页面进行操作,将图片显示在特定的tag中,并将图片的保存地址分配给隐藏字段;
4. 回到原来的页面,此时文件上传完成,隐藏域中记录了文件的路径。整个过程不刷新页面;
5. 最后,用户只需要在提交原创页面时,重新设置表单的action和target属性的值即可。
下面是效果截图和实现的代码:

upload.php页面如下:
iFrame异步文件上传
iFrame异步文件上传
用户名: <br />
上传头像:
proceedupload.php 页面如下:
<p>
php禁止网页抓取(一种的使用技巧,不追踪你的隐私总结前 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-17 12:11
)
分享一个简单的搜索思路,帮助你快速找到你想要的资源。
例子
关键字+百度网盘/提取码/密码...
上面的搜索方法只是一种思路,不仅如此,如果一个关键字找不到我们可以尝试其他关键字,并且不限于百度作为搜索引擎。Bing 和 Google 也是不错的选择。
与搜索工具的合作
配合搜索引擎的搜索工具,通过内容的时间限制、格式限制、固定站点。它使我们能够更快地过滤掉我们需要的东西。.
如何使用搜索引擎,你使用什么搜索引擎,你有什么建议?
搜索引擎的质量显然取决于其搜索体验。目前,百度、360、搜狗等是国内最受欢迎的。国外的有Bing(区分国内版和国外版),google,但是作为程序员,通常需要在网上搜索各种资料,所以遇到问题时搜索体验非常重要。实际上搜索引擎只有几个,但我们可以采取一些措施来改善我们的搜索体验。下面的截图展示了所有它是通过一个插件来实现的。浏览器可以是谷歌内核或者谷歌Chrome,即将被废弃的微软Edge也可以:
必须
国内版:
外国版
搜狗没有广告
百度广告不见了
秘密搜索这是一个不跟踪您的隐私的利基搜索引擎
综上所述,前三个是通过油猴插件实现的搜索体验。最重要的是广告没了,通过插件可以获得更好的体验。由于谷歌搜索在中国无法访问,因此不会推出。最后一个也是我平时用的,比较简单,注意隐私。油猴的脚本是开源的,以下是开源地址:
/
该插件不仅去除了广告,还提供了其他功能,非常有用:
可以直接搜索tampermonkey,在网上各种方式下载安装,然后从github安装脚本就有以上搜索体验
我相信这会解决你的问题,因为我遇到过你的问题。
搜索引擎使用技巧,如何做一个搜索引擎友好的网站?
搜索引擎是网站大部分流量的来源,搜索流量占比很大。所以在做网站优化的时候,需要提高网站对搜索引擎的友好度,这样网站优化才能达到最好的效果。那么如何设计网站来提高搜索引擎的友好度呢?
从搜索引擎蜘蛛网站的角度来看,我们在爬取、索引和排名的时候会遇到哪些问题?只要解决了这些问题,就能提高搜索引擎的友好度。
1、蜘蛛爬虫能找到网站
为了让搜索引擎发现 网站,必须有一个指向 网站 的外部链接。蜘蛛爬虫找到网站后,会沿着内部链接进入网站内容页面。因此,网站的结构必须合理、合乎逻辑,网站内的所有页面都可以通过HTML链接到达。蜘蛛爬虫一般不会进入flash页面,自然不会收录这样的页面。
网站所有页面距离首页不要太远,最好在3次点击内到达想要的页面。网站要被搜索引擎搜索到收录,页面必须有一定的权重,一个好的网站结构可以很好的传递权重,让更多的页面到达收录 标准。
2、找到网站后可以成功抓取页面内容
蜘蛛爬虫找到网站首页后,seo人员必须保证网站的url可以被抓取。虽然这些网址可能不全是收录,但还是需要尽可能的扩展。页面被抓取的可能性。动态数据库生成、参数过多的URL、flash页面等,对搜索引擎友好,搜索引擎自然不会收录这样的页面。
如果网站有你不想被搜索引擎或收录抓取的目录或页面,除了不链接到那些目录或页面,更好的方法是使用robots协议或meta机器人标记以阻止蜘蛛。
3、爬取页面后能否提取有用信息
如果想让搜索引擎在爬取页面后快速识别页面信息,首先要保证网站代码的简化,尽量减少代码行数。比例越大越好,整个网页文件越小越好。另外,页面上关键词的布局要合理,有利于搜索引擎对有用信息的抓取和提取。
只有当搜索引擎能够成功找到所有页面,爬取这些页面并提取相关内容,这样的网站才能提高搜索引擎的友好度。
如何用好谷歌等搜索引擎?
了解更多谷歌搜索技巧,可以让你的网页搜索能力大幅提升10倍
1、双引号,即通过“”实现精准搜索
在要搜索的关键词后面加上双引号("")的指令,表示完全匹配搜索,即使是顺序也完全匹配。即搜索引擎只会返回与关键词完全匹配的搜索结果,从而达到精准搜索的效果。
如果没有双引号,如果两个单词之间加了空格,它会分别搜索这两个单词,返回的结果可能不是我们想要的结果。
2、减号,即用“-”排除关键词
如果不想在搜索结果中看到一些关键词,可以使用-减号排除指定内容。
减号 (-) 表示搜索不收录减号后面的单词的页面。使用减号 (-) 命令时,减号前必须有一个空格,减号后不能有空格,然后是要排除的单词。
注意:“-”之前应该有一个空格。
3、星号,即按*(通配符)搜索
当你想搜索一个成语或一个段落,只记得两个或三个单词或一个段落时,可以通过星号(*)的通配符进行搜索,将忘记的单词替换为*。
4、site 搜索指定网站中的内容
在输入框中输入 site: URL 关键字,将在输入的 URL 中进行站点关键字搜索。
当您想对 网站 执行 关键词 搜索时,例如 amazon网站,您可以使用“site: .
site:是最熟悉的SEO高级搜索命令,用于搜索一个域名下的所有文件。
5、related:查找相似的相关网站
根据网站查找相似站点,使用方法:Related::,返回结果是与某个网站关联的页面。
6、filetype 搜索指定的文件类型
修饰符 filetype:[file extension] 可用于搜索指定的文件类型。例如,搜索 filetype:pdfmedical mask 返回所有收录医用口罩 关键词 的 pdf 文件。
Google 支持所有可编入索引的文件格式,包括 HTML、PHP 等。
7、inurl,搜索 关键词 出现在 url 中的页面。
inurl 指令用于搜索 关键词 出现在 url 中的页面。例如,搜索:inurl:medicalmasks 会返回 URL 中收录“medicalmasks”的所有页面的结果。
8、allintitle 页面标题收录文件组关键词
allintitle:搜索返回页面标题中收录多组 关键词 的文件。例如: allintitle: 医用口罩等价于: intitle: 医用 intitle:mask 返回标题中同时收录“medical”和“masks”的页面
9、allinurl 喜欢
allinurl:医用口罩相当于:inurl:医用 inurl:口罩
10、inanchor 导入在链接的锚文本中收录搜索词的页面
inanchor:该命令返回的结果是导入链接的锚文本中收录搜索词的页面。比如搜索:inanchor:“medical mask”,返回的结果是这些页面的链接的锚文本中出现了“medical mask”四个字。
查看全部
php禁止网页抓取(一种的使用技巧,不追踪你的隐私总结前
)
分享一个简单的搜索思路,帮助你快速找到你想要的资源。
例子
关键字+百度网盘/提取码/密码...
上面的搜索方法只是一种思路,不仅如此,如果一个关键字找不到我们可以尝试其他关键字,并且不限于百度作为搜索引擎。Bing 和 Google 也是不错的选择。
与搜索工具的合作
配合搜索引擎的搜索工具,通过内容的时间限制、格式限制、固定站点。它使我们能够更快地过滤掉我们需要的东西。.
如何使用搜索引擎,你使用什么搜索引擎,你有什么建议?
搜索引擎的质量显然取决于其搜索体验。目前,百度、360、搜狗等是国内最受欢迎的。国外的有Bing(区分国内版和国外版),google,但是作为程序员,通常需要在网上搜索各种资料,所以遇到问题时搜索体验非常重要。实际上搜索引擎只有几个,但我们可以采取一些措施来改善我们的搜索体验。下面的截图展示了所有它是通过一个插件来实现的。浏览器可以是谷歌内核或者谷歌Chrome,即将被废弃的微软Edge也可以:
必须
国内版:

外国版

搜狗没有广告

百度广告不见了

秘密搜索这是一个不跟踪您的隐私的利基搜索引擎

综上所述,前三个是通过油猴插件实现的搜索体验。最重要的是广告没了,通过插件可以获得更好的体验。由于谷歌搜索在中国无法访问,因此不会推出。最后一个也是我平时用的,比较简单,注意隐私。油猴的脚本是开源的,以下是开源地址:
/
该插件不仅去除了广告,还提供了其他功能,非常有用:

可以直接搜索tampermonkey,在网上各种方式下载安装,然后从github安装脚本就有以上搜索体验
我相信这会解决你的问题,因为我遇到过你的问题。
搜索引擎使用技巧,如何做一个搜索引擎友好的网站?
搜索引擎是网站大部分流量的来源,搜索流量占比很大。所以在做网站优化的时候,需要提高网站对搜索引擎的友好度,这样网站优化才能达到最好的效果。那么如何设计网站来提高搜索引擎的友好度呢?
从搜索引擎蜘蛛网站的角度来看,我们在爬取、索引和排名的时候会遇到哪些问题?只要解决了这些问题,就能提高搜索引擎的友好度。

1、蜘蛛爬虫能找到网站
为了让搜索引擎发现 网站,必须有一个指向 网站 的外部链接。蜘蛛爬虫找到网站后,会沿着内部链接进入网站内容页面。因此,网站的结构必须合理、合乎逻辑,网站内的所有页面都可以通过HTML链接到达。蜘蛛爬虫一般不会进入flash页面,自然不会收录这样的页面。
网站所有页面距离首页不要太远,最好在3次点击内到达想要的页面。网站要被搜索引擎搜索到收录,页面必须有一定的权重,一个好的网站结构可以很好的传递权重,让更多的页面到达收录 标准。
2、找到网站后可以成功抓取页面内容
蜘蛛爬虫找到网站首页后,seo人员必须保证网站的url可以被抓取。虽然这些网址可能不全是收录,但还是需要尽可能的扩展。页面被抓取的可能性。动态数据库生成、参数过多的URL、flash页面等,对搜索引擎友好,搜索引擎自然不会收录这样的页面。
如果网站有你不想被搜索引擎或收录抓取的目录或页面,除了不链接到那些目录或页面,更好的方法是使用robots协议或meta机器人标记以阻止蜘蛛。
3、爬取页面后能否提取有用信息
如果想让搜索引擎在爬取页面后快速识别页面信息,首先要保证网站代码的简化,尽量减少代码行数。比例越大越好,整个网页文件越小越好。另外,页面上关键词的布局要合理,有利于搜索引擎对有用信息的抓取和提取。
只有当搜索引擎能够成功找到所有页面,爬取这些页面并提取相关内容,这样的网站才能提高搜索引擎的友好度。
如何用好谷歌等搜索引擎?
了解更多谷歌搜索技巧,可以让你的网页搜索能力大幅提升10倍
1、双引号,即通过“”实现精准搜索
在要搜索的关键词后面加上双引号("")的指令,表示完全匹配搜索,即使是顺序也完全匹配。即搜索引擎只会返回与关键词完全匹配的搜索结果,从而达到精准搜索的效果。
如果没有双引号,如果两个单词之间加了空格,它会分别搜索这两个单词,返回的结果可能不是我们想要的结果。
2、减号,即用“-”排除关键词
如果不想在搜索结果中看到一些关键词,可以使用-减号排除指定内容。
减号 (-) 表示搜索不收录减号后面的单词的页面。使用减号 (-) 命令时,减号前必须有一个空格,减号后不能有空格,然后是要排除的单词。
注意:“-”之前应该有一个空格。
3、星号,即按*(通配符)搜索
当你想搜索一个成语或一个段落,只记得两个或三个单词或一个段落时,可以通过星号(*)的通配符进行搜索,将忘记的单词替换为*。
4、site 搜索指定网站中的内容
在输入框中输入 site: URL 关键字,将在输入的 URL 中进行站点关键字搜索。
当您想对 网站 执行 关键词 搜索时,例如 amazon网站,您可以使用“site: .
site:是最熟悉的SEO高级搜索命令,用于搜索一个域名下的所有文件。
5、related:查找相似的相关网站
根据网站查找相似站点,使用方法:Related::,返回结果是与某个网站关联的页面。
6、filetype 搜索指定的文件类型
修饰符 filetype:[file extension] 可用于搜索指定的文件类型。例如,搜索 filetype:pdfmedical mask 返回所有收录医用口罩 关键词 的 pdf 文件。
Google 支持所有可编入索引的文件格式,包括 HTML、PHP 等。
7、inurl,搜索 关键词 出现在 url 中的页面。
inurl 指令用于搜索 关键词 出现在 url 中的页面。例如,搜索:inurl:medicalmasks 会返回 URL 中收录“medicalmasks”的所有页面的结果。
8、allintitle 页面标题收录文件组关键词
allintitle:搜索返回页面标题中收录多组 关键词 的文件。例如: allintitle: 医用口罩等价于: intitle: 医用 intitle:mask 返回标题中同时收录“medical”和“masks”的页面
9、allinurl 喜欢
allinurl:医用口罩相当于:inurl:医用 inurl:口罩
10、inanchor 导入在链接的锚文本中收录搜索词的页面
inanchor:该命令返回的结果是导入链接的锚文本中收录搜索词的页面。比如搜索:inanchor:“medical mask”,返回的结果是这些页面的链接的锚文本中出现了“medical mask”四个字。


php禁止网页抓取(如下协议文件屏蔽百度蜘蛛抓取协议的设置协议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-17 12:10
百度蜘蛛爬我们的网站是希望把我们的网页收录放到它的搜索引擎中,以后用户搜索的时候,可以给我们带来一定的SEO流量。当然,我们不希望搜索引擎抓取所有内容。
所以,这个时候,我们只希望我们想被搜索引擎搜索到的内容被爬取。像用户隐私、背景信息等,不希望搜索引擎被爬取和收录。解决这个问题有两种最好的方法,如下:
robots协议文件阻止百度蜘蛛爬行
robots协议是放置在网站根目录下的协议文件,可以通过URL地址访问:你的域名/robots.txt。当百度蜘蛛爬取我们的网站时,会先访问这个文件。因为它告诉蜘蛛抓取什么,不抓取什么。
robots协议文件的设置比较简单,可以通过User-Agent、Disallow、Allow这三个参数来设置。
User-Agent:针对不同搜索引擎的语句;
Disallow:不允许爬取的目录或页面;
Allow:允许爬取的目录或页面,一般可以省略不写,因为不写不能爬取的东西是可以爬取的;
我们来看一个例子,场景是不想让百度抢我所有的网站css文件、数据目录、seo-tag.html页面
用户代理:百度蜘蛛
禁止:/*.css
禁止:/数据/
禁止:/seo/seo-tag.html
如上,user-agent 声明的蜘蛛名称表示它是给百度蜘蛛的。以下不能抓取“/*.css”。首先前面的/指的是根目录,也就是你的域名。* 是一个通配符,代表任何东西。这意味着无法抓取所有以 .css 结尾的文件。亲身体验以下两点。逻辑是一样的。
如果你想检查你上次设置的robots文件是否正确,可以访问这个文章《检查Robots是否正确的工具介绍》,里面有详细的工具可以检查你的设置。
通过403状态码限制内容输出,阻止蜘蛛爬行。
403状态码是网页在http协议中返回的状态码。当搜索引擎遇到 403 状态码时,它就知道这种类型的页面是受限的。我无法访问。比如你需要登录才能查看内容,搜索引擎本身是不会登录的,所以当你返回403的时候,他也知道这是一个权限设置页面,无法读取内容。自然不是收录。
在返回 403 状态码时,应该有一个类似于 404 页面的页面。提示用户或蜘蛛该页面想要做什么以访问它。两者缺一不可。你只有一个提示页面,状态码返回200,是百度蜘蛛的大量重复页面。有 403 状态码,但返回不同的东西。它也不是很友好。
最后,对于机器人协议,我想再补充一点:“现在搜索引擎会通过你网页的排版和布局来识别你网页的用户友好性。如果css文件的爬取和布局相关js文件被屏蔽了,那么搜索引擎就会不知道你的网页布局是好是坏,所以不建议屏蔽这些内容蜘蛛。”
好了,今天的分享就到这里,希望对大家有所帮助。当然,以上两个设置对除了百度蜘蛛之外的所有蜘蛛都有效。设置时要小心。 查看全部
php禁止网页抓取(如下协议文件屏蔽百度蜘蛛抓取协议的设置协议)
百度蜘蛛爬我们的网站是希望把我们的网页收录放到它的搜索引擎中,以后用户搜索的时候,可以给我们带来一定的SEO流量。当然,我们不希望搜索引擎抓取所有内容。
所以,这个时候,我们只希望我们想被搜索引擎搜索到的内容被爬取。像用户隐私、背景信息等,不希望搜索引擎被爬取和收录。解决这个问题有两种最好的方法,如下:
robots协议文件阻止百度蜘蛛爬行
robots协议是放置在网站根目录下的协议文件,可以通过URL地址访问:你的域名/robots.txt。当百度蜘蛛爬取我们的网站时,会先访问这个文件。因为它告诉蜘蛛抓取什么,不抓取什么。
robots协议文件的设置比较简单,可以通过User-Agent、Disallow、Allow这三个参数来设置。
User-Agent:针对不同搜索引擎的语句;
Disallow:不允许爬取的目录或页面;
Allow:允许爬取的目录或页面,一般可以省略不写,因为不写不能爬取的东西是可以爬取的;
我们来看一个例子,场景是不想让百度抢我所有的网站css文件、数据目录、seo-tag.html页面
用户代理:百度蜘蛛
禁止:/*.css
禁止:/数据/
禁止:/seo/seo-tag.html
如上,user-agent 声明的蜘蛛名称表示它是给百度蜘蛛的。以下不能抓取“/*.css”。首先前面的/指的是根目录,也就是你的域名。* 是一个通配符,代表任何东西。这意味着无法抓取所有以 .css 结尾的文件。亲身体验以下两点。逻辑是一样的。
如果你想检查你上次设置的robots文件是否正确,可以访问这个文章《检查Robots是否正确的工具介绍》,里面有详细的工具可以检查你的设置。
通过403状态码限制内容输出,阻止蜘蛛爬行。
403状态码是网页在http协议中返回的状态码。当搜索引擎遇到 403 状态码时,它就知道这种类型的页面是受限的。我无法访问。比如你需要登录才能查看内容,搜索引擎本身是不会登录的,所以当你返回403的时候,他也知道这是一个权限设置页面,无法读取内容。自然不是收录。
在返回 403 状态码时,应该有一个类似于 404 页面的页面。提示用户或蜘蛛该页面想要做什么以访问它。两者缺一不可。你只有一个提示页面,状态码返回200,是百度蜘蛛的大量重复页面。有 403 状态码,但返回不同的东西。它也不是很友好。
最后,对于机器人协议,我想再补充一点:“现在搜索引擎会通过你网页的排版和布局来识别你网页的用户友好性。如果css文件的爬取和布局相关js文件被屏蔽了,那么搜索引擎就会不知道你的网页布局是好是坏,所以不建议屏蔽这些内容蜘蛛。”
好了,今天的分享就到这里,希望对大家有所帮助。当然,以上两个设置对除了百度蜘蛛之外的所有蜘蛛都有效。设置时要小心。
php禁止网页抓取(【】访问日志如下图解决解决思路(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-31 08:04
)
问题
过去客户可以正常访问的网站现在很慢,有时甚至拒绝访问。通过查看Nginx访问日志,发现大量请求指向同一个页面,并且访问的客户端IP地址不断变化,没有太多规则。很难通过限制IP来拒绝访问。但是请求的用户代理被标记为 Bytespider,这是一种流氓爬虫。访问日志如下:
解决
解决方法:因为user-agent被标记了Bytespider爬虫,这样可以通过Nginx规则限制流氓爬虫的访问,直接返回403错误。
1、在/etc/nginx/conf.d目录下新建文件deny_agent.config配置文件(由于安装了Nginx,站点配置文件的路径可能不同):
#forbidden Scrapy
if ($http_user_agent ~* (Scrapy|Curl|HttpClient))
{
return 403;
}
#forbidden UA
if ($http_user_agent ~ "Bytespider|FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" )
{
return 403;
}
#forbidden not GET|HEAD|POST method access
if ($request_method !~ ^(GET|HEAD|POST)$)
{
return 403;
}
2、在对应的站点配置文件中收录deny_agent.config配置文件(注意是在服务器中):
3、重启Nginx,建议通过nginx -s reload平滑重启。重启前请先使用 nginx -t 命令检查配置文件是否正确。
4、使用curl命令模拟访问,看看配置是否生效(如果返回403 Forbidden,则配置OK):
附录:UA 集合
FeedDemon 内容采集
BOT/0.1 (BOT for JCE) sql注入
CrawlDaddy sql注入
Java 内容采集
Jullo 内容采集
Feedly 内容采集
UniversalFeedParser 内容采集
ApacheBench cc攻击器
Swiftbot 无用爬虫
YandexBot 无用爬虫
AhrefsBot 无用爬虫
YisouSpider 无用爬虫(已被UC神马搜索收购,此蜘蛛可以放开!)
jikeSpider 无用爬虫
MJ12bot 无用爬虫
ZmEu phpmyadmin 漏洞扫描
WinHttp 采集cc攻击
EasouSpider 无用爬虫
HttpClient tcp攻击
Microsoft URL Control 扫描
YYSpider 无用爬虫
jaunty wordpress**扫描器
oBot 无用爬虫
Python-urllib 内容采集
Indy Library 扫描
FlightDeckReports Bot 无用爬虫
Linguee Bot 无用爬虫<br /> 查看全部
php禁止网页抓取(【】访问日志如下图解决解决思路(一)
)
问题
过去客户可以正常访问的网站现在很慢,有时甚至拒绝访问。通过查看Nginx访问日志,发现大量请求指向同一个页面,并且访问的客户端IP地址不断变化,没有太多规则。很难通过限制IP来拒绝访问。但是请求的用户代理被标记为 Bytespider,这是一种流氓爬虫。访问日志如下:
解决
解决方法:因为user-agent被标记了Bytespider爬虫,这样可以通过Nginx规则限制流氓爬虫的访问,直接返回403错误。
1、在/etc/nginx/conf.d目录下新建文件deny_agent.config配置文件(由于安装了Nginx,站点配置文件的路径可能不同):
#forbidden Scrapy
if ($http_user_agent ~* (Scrapy|Curl|HttpClient))
{
return 403;
}
#forbidden UA
if ($http_user_agent ~ "Bytespider|FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" )
{
return 403;
}
#forbidden not GET|HEAD|POST method access
if ($request_method !~ ^(GET|HEAD|POST)$)
{
return 403;
}
2、在对应的站点配置文件中收录deny_agent.config配置文件(注意是在服务器中):
3、重启Nginx,建议通过nginx -s reload平滑重启。重启前请先使用 nginx -t 命令检查配置文件是否正确。
4、使用curl命令模拟访问,看看配置是否生效(如果返回403 Forbidden,则配置OK):
附录:UA 集合
FeedDemon 内容采集
BOT/0.1 (BOT for JCE) sql注入
CrawlDaddy sql注入
Java 内容采集
Jullo 内容采集
Feedly 内容采集
UniversalFeedParser 内容采集
ApacheBench cc攻击器
Swiftbot 无用爬虫
YandexBot 无用爬虫
AhrefsBot 无用爬虫
YisouSpider 无用爬虫(已被UC神马搜索收购,此蜘蛛可以放开!)
jikeSpider 无用爬虫
MJ12bot 无用爬虫
ZmEu phpmyadmin 漏洞扫描
WinHttp 采集cc攻击
EasouSpider 无用爬虫
HttpClient tcp攻击
Microsoft URL Control 扫描
YYSpider 无用爬虫
jaunty wordpress**扫描器
oBot 无用爬虫
Python-urllib 内容采集
Indy Library 扫描
FlightDeckReports Bot 无用爬虫
Linguee Bot 无用爬虫<br />
php禁止网页抓取(php禁止网页抓取的方法(一)__)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-29 19:01
php禁止网页抓取的方法
一、我们先来说说php在http请求下可以获取的数据项;1.php自带的全局命名空间http3.5.4;网页代码post/posthttp/1.1host:xxxx/path://refer:phphttp/1.1timeout:404解决方案:1post中的请求方法使用get;2http/1.1协议下,只有get请求可以使用:get('request-uri',uri)。
二、php获取网页的url地址解析问题
1、php网页中存在的无效url:使用http/1.1协议代理上去,被屏蔽的。
2、查看url地址是否存在连接字符串。在http服务器中存在的字符串必须使用ascii字符:*/ahttp/1.1connection:keep-alivecontent-length:1content-type:text/plainserver:example.io/publicform-datamethod:get或者查看http服务器的源码。
三、解析php脚本执行后带来的问题?
1、解析php脚本耗时
2、解析bat脚本框架耗时
3、解析php小程序框架框架耗时
四、保护php解析的请求,
五、php执行过程中的一些特殊情况处理
一)数据请求发送,常见的有三种发送形式:1.post,2.get3.ajax发送请求时可以在里面发送属性,返回属性,
二)post发送数据1.post发送get请求的形式:返回一个数据2.post发送的数据只能是json
三)get发送数据1.get请求形式:在客户端和服务端中发送两个请求2.get请求也可以是json,java的get和post形式请求地址都可以。post请求方式需要根据模板写这个语句,$xxx是本服务器的路径,可以不使用$action_name和$type_name。
?>和?>?>两个都是php内置的函数,
六、php解析的两种方式1.(i)general-phphtml||php可以采用整个php包中的函数,也可以定义inpractice,用户不必每次都能看到网页,建议采用这种方式,可以添加数组,以便下次查找。2.(ii)php文件->org.php.cache->php文件设置inpractice是先写到php文件中inpractice可以是任何你想要inpractice的文件,inpractice。 查看全部
php禁止网页抓取(php禁止网页抓取的方法(一)__)
php禁止网页抓取的方法
一、我们先来说说php在http请求下可以获取的数据项;1.php自带的全局命名空间http3.5.4;网页代码post/posthttp/1.1host:xxxx/path://refer:phphttp/1.1timeout:404解决方案:1post中的请求方法使用get;2http/1.1协议下,只有get请求可以使用:get('request-uri',uri)。
二、php获取网页的url地址解析问题
1、php网页中存在的无效url:使用http/1.1协议代理上去,被屏蔽的。
2、查看url地址是否存在连接字符串。在http服务器中存在的字符串必须使用ascii字符:*/ahttp/1.1connection:keep-alivecontent-length:1content-type:text/plainserver:example.io/publicform-datamethod:get或者查看http服务器的源码。
三、解析php脚本执行后带来的问题?
1、解析php脚本耗时
2、解析bat脚本框架耗时
3、解析php小程序框架框架耗时
四、保护php解析的请求,
五、php执行过程中的一些特殊情况处理
一)数据请求发送,常见的有三种发送形式:1.post,2.get3.ajax发送请求时可以在里面发送属性,返回属性,
二)post发送数据1.post发送get请求的形式:返回一个数据2.post发送的数据只能是json
三)get发送数据1.get请求形式:在客户端和服务端中发送两个请求2.get请求也可以是json,java的get和post形式请求地址都可以。post请求方式需要根据模板写这个语句,$xxx是本服务器的路径,可以不使用$action_name和$type_name。
?>和?>?>两个都是php内置的函数,
六、php解析的两种方式1.(i)general-phphtml||php可以采用整个php包中的函数,也可以定义inpractice,用户不必每次都能看到网页,建议采用这种方式,可以添加数组,以便下次查找。2.(ii)php文件->org.php.cache->php文件设置inpractice是先写到php文件中inpractice可以是任何你想要inpractice的文件,inpractice。
php禁止网页抓取(“robots.txt只允许抓取html页面,防止抓取垃圾信息!”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-29 16:03
今天大贷SEO详细讲解“robots.txt只允许抓取html页面,防止抓取垃圾邮件!” 代代SEO做了这么多年网站,经常遇到客户的网站被挂掉的情况,原因是不利于自己维护网站,或者使用市面上开源的cms,直接下载源码安装使用,不管里面有没有漏洞和后门,所以后期被马入侵了,大百度抓取的非法页面数量。
有些被链接的人很奇怪,为什么他们的网站正常发布的内容不是收录,而垃圾页面的很多非法内容是百度的收录。其实很简单。马人员直接链接了spider pool里面的非法页面,所以才会出现这个问题。即使我们解决了网站被链接到马的问题,网站上的垃圾页面还是会继续出现。死链接被百度抓取后需要很长时间才能生效。这个时候我该怎么办?我们可以使用 robots.txt 来解决这个问题。
实施原则:
我们可以通过robots.txt来限制用户只能抓取HTMl页面文件,并且可以限制指定目录的HTML,屏蔽指定目录的HTML文件。我们来做一个robots.txt的写法。您可以自己研究并应用到实际应用中。继续你自己的网站。
可解决的挂马形式:
写机器人的规则主要针对上传类,比如添加xxx.php?=dddd.html;xxxx.php; 并且上传不会被百度抓取,降低网络监控风险。
#适用于所有搜索引擎
用户代理:*
#允许首页根目录/不带斜线,例如
允许:/$
允许:$
#文件属性设置禁止修改(固定属性,入口只能是index.html/index.php)
允许:/index.php
允许:/index.html
#允许爬取静态生成的目录,这里是允许爬取页面中的所有html文件
允许:/*.html$
#禁止所有带参数的html页面(禁止抓取挂马的html页面) 规则可以自己定义
禁止:/*?*.html$
禁止:/*=*.html$
# 允许单个条目,只允许,with ? 编号索引,其他html,带符号,是不允许的。
允许:/index.php?*
#允许资源文件,允许在网站上截取图片。
允许:/*.jpg$
允许:/*.png$
允许:/*.gif$
#除上述外,禁止爬取网站内的任何文件或页面。
不允许:/
比如我们的网站挂了,后面的戳一般。php?unmgg.html 或 dds=123.html。这种,只要网址有 ? ,=这样的符号,当然你可以给它加更多的格式,比如下划线“_”,可以用“Disallow:/_*.html$”来防御。
再比如:挂马是一个目录,一个普通的URL,比如“seozt/1233.html”,可以加一条禁止规则“Disallow:/seozt/*.html$”,这个规则就是告诉搜索引擎,只要是seozt目录下的html文件,就不能被抓取。你明白吗?其实很简单。只是自己熟悉它。
这种写法的优点是:
首先,蜘蛛会爬取你的很多核心目录、php目录、模板目录,这样会浪费很多目录资源。对了,如果我们屏蔽目录,我们会在 robots.txt 中暴露我们的目录,其他人可以分析我们使用的目录。它是什么程序?这时候我们就逆向操作,直接允许html,其他的都拒绝,可以有效避免暴露目录的风险,对了,好吧,今天就讲到这里,希望大家能理解。 查看全部
php禁止网页抓取(“robots.txt只允许抓取html页面,防止抓取垃圾信息!”)
今天大贷SEO详细讲解“robots.txt只允许抓取html页面,防止抓取垃圾邮件!” 代代SEO做了这么多年网站,经常遇到客户的网站被挂掉的情况,原因是不利于自己维护网站,或者使用市面上开源的cms,直接下载源码安装使用,不管里面有没有漏洞和后门,所以后期被马入侵了,大百度抓取的非法页面数量。
有些被链接的人很奇怪,为什么他们的网站正常发布的内容不是收录,而垃圾页面的很多非法内容是百度的收录。其实很简单。马人员直接链接了spider pool里面的非法页面,所以才会出现这个问题。即使我们解决了网站被链接到马的问题,网站上的垃圾页面还是会继续出现。死链接被百度抓取后需要很长时间才能生效。这个时候我该怎么办?我们可以使用 robots.txt 来解决这个问题。
实施原则:
我们可以通过robots.txt来限制用户只能抓取HTMl页面文件,并且可以限制指定目录的HTML,屏蔽指定目录的HTML文件。我们来做一个robots.txt的写法。您可以自己研究并应用到实际应用中。继续你自己的网站。
可解决的挂马形式:
写机器人的规则主要针对上传类,比如添加xxx.php?=dddd.html;xxxx.php; 并且上传不会被百度抓取,降低网络监控风险。
#适用于所有搜索引擎
用户代理:*
#允许首页根目录/不带斜线,例如
允许:/$
允许:$
#文件属性设置禁止修改(固定属性,入口只能是index.html/index.php)
允许:/index.php
允许:/index.html
#允许爬取静态生成的目录,这里是允许爬取页面中的所有html文件
允许:/*.html$
#禁止所有带参数的html页面(禁止抓取挂马的html页面) 规则可以自己定义
禁止:/*?*.html$
禁止:/*=*.html$
# 允许单个条目,只允许,with ? 编号索引,其他html,带符号,是不允许的。
允许:/index.php?*
#允许资源文件,允许在网站上截取图片。
允许:/*.jpg$
允许:/*.png$
允许:/*.gif$
#除上述外,禁止爬取网站内的任何文件或页面。
不允许:/
比如我们的网站挂了,后面的戳一般。php?unmgg.html 或 dds=123.html。这种,只要网址有 ? ,=这样的符号,当然你可以给它加更多的格式,比如下划线“_”,可以用“Disallow:/_*.html$”来防御。
再比如:挂马是一个目录,一个普通的URL,比如“seozt/1233.html”,可以加一条禁止规则“Disallow:/seozt/*.html$”,这个规则就是告诉搜索引擎,只要是seozt目录下的html文件,就不能被抓取。你明白吗?其实很简单。只是自己熟悉它。
这种写法的优点是:
首先,蜘蛛会爬取你的很多核心目录、php目录、模板目录,这样会浪费很多目录资源。对了,如果我们屏蔽目录,我们会在 robots.txt 中暴露我们的目录,其他人可以分析我们使用的目录。它是什么程序?这时候我们就逆向操作,直接允许html,其他的都拒绝,可以有效避免暴露目录的风险,对了,好吧,今天就讲到这里,希望大家能理解。
php禁止网页抓取( 百度对robots.txt反应很到位,部分禁止目录收录下降)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-01-27 23:23
百度对robots.txt反应很到位,部分禁止目录收录下降)
<p>
最近在做一个网站,因为域名要备案所以就没有直接放上去,而是放到一个二级域名上,test.XXXX.com,因为是测试的域名所以不希望百度收录
robots.txt的文件内容为
User-agent:*
Disallow:/
Disallow:/go/*</p>
原来百度收录有这个二级域名,然后查了一下网站,发现只有首页。百度不是很按照机器人和百度百科的描述吗?
百度对robots.txt有响应,但是比较慢。它减少了对正常目录的爬取,同时减少了对禁止目录的爬取。
原因应该是条目数减少了,正常目录收录后面需要慢慢增加。
谷歌对robots.txt的反应非常好,被禁目录立即消失,一些正常目录收录立即上升。/comment/ 目录收录 也宕机了,仍然受到一些旧目标减少的影响。
搜狗的爬取平衡性普遍上升,部分被禁目录收录下降。
总结一下:谷歌似乎最懂站长的意思,其他搜索引擎比如百度只是被动受词条数量的影响
我只知道360搜索忽略了robots协议。之前,部分服务器被360搜索引擎瘫痪。机器人被用来禁止360蜘蛛爬行。
只能感叹国内搜索引擎离google有多远
QQ交流群:136351212 查看全部
php禁止网页抓取(
百度对robots.txt反应很到位,部分禁止目录收录下降)
<p>
最近在做一个网站,因为域名要备案所以就没有直接放上去,而是放到一个二级域名上,test.XXXX.com,因为是测试的域名所以不希望百度收录
robots.txt的文件内容为
User-agent:*
Disallow:/
Disallow:/go/*</p>
原来百度收录有这个二级域名,然后查了一下网站,发现只有首页。百度不是很按照机器人和百度百科的描述吗?
百度对robots.txt有响应,但是比较慢。它减少了对正常目录的爬取,同时减少了对禁止目录的爬取。
原因应该是条目数减少了,正常目录收录后面需要慢慢增加。
谷歌对robots.txt的反应非常好,被禁目录立即消失,一些正常目录收录立即上升。/comment/ 目录收录 也宕机了,仍然受到一些旧目标减少的影响。
搜狗的爬取平衡性普遍上升,部分被禁目录收录下降。
总结一下:谷歌似乎最懂站长的意思,其他搜索引擎比如百度只是被动受词条数量的影响
我只知道360搜索忽略了robots协议。之前,部分服务器被360搜索引擎瘫痪。机器人被用来禁止360蜘蛛爬行。
只能感叹国内搜索引擎离google有多远
QQ交流群:136351212
php禁止网页抓取( 两种对MySQL注入攻击的常见误解--MySQL注入)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-27 18:07
两种对MySQL注入攻击的常见误解--MySQL注入)
使用 PHP 编程防止 MySQL 注入或 HTML 表单滥用
MySQL 注入的目的是接管 网站 数据库并窃取信息。许多网站开发人员已经使用常见的开源数据库,例如MySQL,来存储密码、个人信息和管理信息等重要信息。
MySQL 很受欢迎,因为它与最流行的服务器端脚本语言 PHP 一起使用。此外,PHP 是主导 Internet 的 Linux-Apache 服务器的主要语言。所以这意味着黑客可以很容易地利用 PHP,就像 Windows 的间谍软件一样。
黑客将大量恶意代码(通过下拉菜单、搜索框、联系表单、查询表单和复选框)输入到不安全的 Web 表单中。
恶意代码将被发送到 MySQL 数据库,然后“注入”。要查看此过程,首先考虑以下基本 MySQL SELECT 查询:
SELECT * FROM xmen WHERE 用户名 = 'wolverine'
该查询将请求具有“xmen”表的数据库返回MySQL中用户名为“wolverine”的某条数据。
在 web 表单中,用户将输入 wolverine,此数据将传递给 MySQL 查询。
如果输入无效,黑客还有其他方式控制数据库,比如设置用户名:
' 或 ''=''
您可能认为使用普通的 PHP 和 MySQL 语法来执行输入是安全的,因为每当有人输入恶意代码时,他们都会收到“无效查询”消息,但事实并非如此。黑客很聪明,因为它涉及数据库清理和重置管理权限,任何安全漏洞都不容易纠正。
关于 MySQL 注入攻击的两个常见误解如下:
1.网管认为恶意注入可以用杀毒软件或反间谍软件清理。事实上,这种类型的感染利用了 MySQL 数据库的弱点。它不能简单地被任何反间谍软件或防病毒程序删除。
2. MySQL 注入是由于从另一台服务器或外部源复制受感染的文件。但事实上,并非如此。这种类型的感染是由于有人将恶意代码输入到 网站 未受保护的表单中,然后访问数据库造成的。MySQL 注入可以通过删除恶意脚本来清理,而不是使用防病毒程序。
用户输入验证过程
备份一个干净的数据库并将其放置在服务器之外。导出一组 MySQL 表并将它们保存在桌面上。
然后去服务器,先暂时关闭表单输入。这意味着表单无法处理数据并且 网站 已关闭。
然后开始清理过程。首先,在您的服务器上,清理剩余的混乱 MySQL 注入。更改所有数据库、FTP 和 网站 密码。
在最坏的情况下,如果您清理晚了,您可以仔细检查服务器上运行的隐藏程序。这些隐藏的程序是黑客安装的木马。完全删除它并更改所有 FTP 权限。扫描服务器以查找所有特洛伊木马和恶意软件。
修改 PHP 脚本时会处理表单数据。防止 MySQL 注入的一个好方法是甚至不信任用户数据。用户输入验证对于防止 MySQL 注入非常重要。
要设计一个过滤器来过滤掉用户输入,这里有一些提示:
1.数字被输入到表格中。您可以通过测试它是否等于或大于 0.001 来验证它是否是一个数字(假设您不接受零)。
2.如果是电子邮件地址。验证它是否收录允许的字符组合,例如“@”、AZ、az 或一些数字。
3.如果是人名或用户名。可以通过是否收录and、*等非法字符来验证,这些非法字符是可以用于SQL注入的恶意字符。
验证数字输入
下面的脚本验证输入了从 0.001 到无穷大的有效数字。值得一提的是,在 PHP 程序中,甚至可以允许一定范围的数字。使用此验证脚本可确保仅在表单中输入数字。
假设您的程序中有三个数值变量;您需要验证它们,让我们将它们命名为 num1、num2 和 num3:
//验证数字输入
if($_POST['num1'] >= 0.001 && $_POST['num2'] >= 0.001 && $_POST['num3'] >= 0.00< @1)
{
}
别的
{
}
并且可以扩展条件以容纳三个以上的数字。所以如果你有 10 个,你只需要扩展 AND 语句。
这可用于验证仅接受数字的表单,例如合同数量、许可证号码、电话号码等。
验证文本和电子邮件地址条目
以下内容可用于验证表单输入,例如用户名、名字和电子邮件地址:
//验证文本输入
if (!preg_match('/^[-az.-@,'s]*$/i',$_POST['name']))
{
}
别的
if ($empty==0)
{
}
别的
{
}
此验证脚本的一个优点是它不接受空白输入。一些恶意用户还通过空白输入操作数据库。使用上面的脚本,只验证了一个文字变量“$name”。这意味着如果你有三个字面变量,你可以为每个变量设置一个验证脚本,以确保每个变量在进入数据库之前通过审查。 查看全部
php禁止网页抓取(
两种对MySQL注入攻击的常见误解--MySQL注入)
使用 PHP 编程防止 MySQL 注入或 HTML 表单滥用
MySQL 注入的目的是接管 网站 数据库并窃取信息。许多网站开发人员已经使用常见的开源数据库,例如MySQL,来存储密码、个人信息和管理信息等重要信息。
MySQL 很受欢迎,因为它与最流行的服务器端脚本语言 PHP 一起使用。此外,PHP 是主导 Internet 的 Linux-Apache 服务器的主要语言。所以这意味着黑客可以很容易地利用 PHP,就像 Windows 的间谍软件一样。
黑客将大量恶意代码(通过下拉菜单、搜索框、联系表单、查询表单和复选框)输入到不安全的 Web 表单中。
恶意代码将被发送到 MySQL 数据库,然后“注入”。要查看此过程,首先考虑以下基本 MySQL SELECT 查询:
SELECT * FROM xmen WHERE 用户名 = 'wolverine'
该查询将请求具有“xmen”表的数据库返回MySQL中用户名为“wolverine”的某条数据。
在 web 表单中,用户将输入 wolverine,此数据将传递给 MySQL 查询。
如果输入无效,黑客还有其他方式控制数据库,比如设置用户名:
' 或 ''=''
您可能认为使用普通的 PHP 和 MySQL 语法来执行输入是安全的,因为每当有人输入恶意代码时,他们都会收到“无效查询”消息,但事实并非如此。黑客很聪明,因为它涉及数据库清理和重置管理权限,任何安全漏洞都不容易纠正。
关于 MySQL 注入攻击的两个常见误解如下:
1.网管认为恶意注入可以用杀毒软件或反间谍软件清理。事实上,这种类型的感染利用了 MySQL 数据库的弱点。它不能简单地被任何反间谍软件或防病毒程序删除。
2. MySQL 注入是由于从另一台服务器或外部源复制受感染的文件。但事实上,并非如此。这种类型的感染是由于有人将恶意代码输入到 网站 未受保护的表单中,然后访问数据库造成的。MySQL 注入可以通过删除恶意脚本来清理,而不是使用防病毒程序。
用户输入验证过程
备份一个干净的数据库并将其放置在服务器之外。导出一组 MySQL 表并将它们保存在桌面上。
然后去服务器,先暂时关闭表单输入。这意味着表单无法处理数据并且 网站 已关闭。
然后开始清理过程。首先,在您的服务器上,清理剩余的混乱 MySQL 注入。更改所有数据库、FTP 和 网站 密码。
在最坏的情况下,如果您清理晚了,您可以仔细检查服务器上运行的隐藏程序。这些隐藏的程序是黑客安装的木马。完全删除它并更改所有 FTP 权限。扫描服务器以查找所有特洛伊木马和恶意软件。
修改 PHP 脚本时会处理表单数据。防止 MySQL 注入的一个好方法是甚至不信任用户数据。用户输入验证对于防止 MySQL 注入非常重要。
要设计一个过滤器来过滤掉用户输入,这里有一些提示:
1.数字被输入到表格中。您可以通过测试它是否等于或大于 0.001 来验证它是否是一个数字(假设您不接受零)。
2.如果是电子邮件地址。验证它是否收录允许的字符组合,例如“@”、AZ、az 或一些数字。
3.如果是人名或用户名。可以通过是否收录and、*等非法字符来验证,这些非法字符是可以用于SQL注入的恶意字符。
验证数字输入
下面的脚本验证输入了从 0.001 到无穷大的有效数字。值得一提的是,在 PHP 程序中,甚至可以允许一定范围的数字。使用此验证脚本可确保仅在表单中输入数字。
假设您的程序中有三个数值变量;您需要验证它们,让我们将它们命名为 num1、num2 和 num3:
//验证数字输入
if($_POST['num1'] >= 0.001 && $_POST['num2'] >= 0.001 && $_POST['num3'] >= 0.00< @1)
{
}
别的
{
}
并且可以扩展条件以容纳三个以上的数字。所以如果你有 10 个,你只需要扩展 AND 语句。
这可用于验证仅接受数字的表单,例如合同数量、许可证号码、电话号码等。
验证文本和电子邮件地址条目
以下内容可用于验证表单输入,例如用户名、名字和电子邮件地址:
//验证文本输入
if (!preg_match('/^[-az.-@,'s]*$/i',$_POST['name']))
{
}
别的
if ($empty==0)
{
}
别的
{
}
此验证脚本的一个优点是它不接受空白输入。一些恶意用户还通过空白输入操作数据库。使用上面的脚本,只验证了一个文字变量“$name”。这意味着如果你有三个字面变量,你可以为每个变量设置一个验证脚本,以确保每个变量在进入数据库之前通过审查。
php禁止网页抓取(在seo优化的全过程之中,有时是必须对搜索引擎蜘蛛开展)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-27 18:07
要了解,在整个seo优化过程中,有时需要屏蔽搜索引擎蜘蛛,也就是严格禁止爬取网站的某个区域,那么人们应该如何屏蔽搜索引擎蜘蛛呢?下面我们来看看实际的操作步骤。
百度蜘蛛爬取人们的网址,期望他们的网页被收录在其搜索引擎中。未来,当客户搜索时,它可以让我们产生一定量的搜索引擎提升总流量。自然,人们不愿意让搜索引擎抓取所有内容。
因此,此时人们只期望抓取搜索引擎检索到的内容。例如,客户隐私保护和背景图片信息内容预计不会被搜索引擎捕获和收录。有两种最好的方法来处理这种困境,如下所示:
robots协议文档阻止百度蜘蛛爬行
robots协议是放置在网站根目录下的协议文件,可以根据网站地址(网站地址:)浏览,百度蜘蛛抓取人的网站时,会浏览这个第一份文件。因为它告诉蜘蛛抓取什么,不抓取什么。
robots协议文档的设置非常简单,可以根据User-Agent、Disallow、Allow三个主要参数进行设置。
下面大家看一个例子,情况是我不会指望百度搜索会爬到我网站的所有css文件,数据文件目录,seo-tag.html页面
User-Agent:BaidusppiderDisallow:/*.cssDisallow:/data/Disallow:/seo/seo-tag.html
如前所述,user-agent 声明了蜘蛛的名字,也就是说它是给百度蜘蛛的。以下几点无法获取“/*.css”,首先/指的是网站根目录,也就是你的网站域名。* 是一个通配符,表示一切。这意味着无法抓取所有以 .css 结尾的文档。这是你自己的2个人经历。逻辑是一样的。
根据403状态码,限制内容输出,阻止蜘蛛爬取。
403状态码是http协议中网页的返回状态码。当搜索引擎遇到 403 状态代码时,它会理解这样的页面受到管理权限的限制。我无法打开它。例如,如果你必须登录才能搜索内容,搜索引擎本身将无法登录。如果你回到403,他也明白这是一个权限管理页面,无法加载内容。自然,它不能轻易收录在内。
回到403状态码,应该有一个类似404页面的页面。提醒客户端或蜘蛛实现他们想要浏览的内容。两者都是必不可少的。只能提醒页面状态码回到200,对于百度蜘蛛来说是很多重复页面。有 403 个状态码,但返回不同的内容。它也不是很友好。
最后,对于智能机器人协议,我想填一点:“现在搜索引擎会根据网页的布局合理性和布局合理性来区分网页的客户友好度。如果屏蔽css文件和js文件是涉及到合理的布局,那么我不知道你的网页界面设计对搜索引擎来说是好是坏,所以不建议屏蔽这类内容。
热搜词 查看全部
php禁止网页抓取(在seo优化的全过程之中,有时是必须对搜索引擎蜘蛛开展)
要了解,在整个seo优化过程中,有时需要屏蔽搜索引擎蜘蛛,也就是严格禁止爬取网站的某个区域,那么人们应该如何屏蔽搜索引擎蜘蛛呢?下面我们来看看实际的操作步骤。
百度蜘蛛爬取人们的网址,期望他们的网页被收录在其搜索引擎中。未来,当客户搜索时,它可以让我们产生一定量的搜索引擎提升总流量。自然,人们不愿意让搜索引擎抓取所有内容。
因此,此时人们只期望抓取搜索引擎检索到的内容。例如,客户隐私保护和背景图片信息内容预计不会被搜索引擎捕获和收录。有两种最好的方法来处理这种困境,如下所示:
robots协议文档阻止百度蜘蛛爬行
robots协议是放置在网站根目录下的协议文件,可以根据网站地址(网站地址:)浏览,百度蜘蛛抓取人的网站时,会浏览这个第一份文件。因为它告诉蜘蛛抓取什么,不抓取什么。
robots协议文档的设置非常简单,可以根据User-Agent、Disallow、Allow三个主要参数进行设置。
下面大家看一个例子,情况是我不会指望百度搜索会爬到我网站的所有css文件,数据文件目录,seo-tag.html页面
User-Agent:BaidusppiderDisallow:/*.cssDisallow:/data/Disallow:/seo/seo-tag.html
如前所述,user-agent 声明了蜘蛛的名字,也就是说它是给百度蜘蛛的。以下几点无法获取“/*.css”,首先/指的是网站根目录,也就是你的网站域名。* 是一个通配符,表示一切。这意味着无法抓取所有以 .css 结尾的文档。这是你自己的2个人经历。逻辑是一样的。
根据403状态码,限制内容输出,阻止蜘蛛爬取。
403状态码是http协议中网页的返回状态码。当搜索引擎遇到 403 状态代码时,它会理解这样的页面受到管理权限的限制。我无法打开它。例如,如果你必须登录才能搜索内容,搜索引擎本身将无法登录。如果你回到403,他也明白这是一个权限管理页面,无法加载内容。自然,它不能轻易收录在内。
回到403状态码,应该有一个类似404页面的页面。提醒客户端或蜘蛛实现他们想要浏览的内容。两者都是必不可少的。只能提醒页面状态码回到200,对于百度蜘蛛来说是很多重复页面。有 403 个状态码,但返回不同的内容。它也不是很友好。
最后,对于智能机器人协议,我想填一点:“现在搜索引擎会根据网页的布局合理性和布局合理性来区分网页的客户友好度。如果屏蔽css文件和js文件是涉及到合理的布局,那么我不知道你的网页界面设计对搜索引擎来说是好是坏,所以不建议屏蔽这类内容。
热搜词
php禁止网页抓取( CDN域名下的robots.txt重定向到robots2.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-27 08:09
CDN域名下的robots.txt重定向到robots2.)
百度收录CDN域名是SEO的大忌。因为相同的内容出现在两个或多个域名中,会受到搜索引擎的惩罚。基本上所有的搜索引擎都会将多个域名指向同一页面的结果判断为镜像,判断为镜像的域名会降级。
很多WordPress网站用户会使用CDN,CDN域名的回源IP地址与主站相同。如果启用了静态缓存,即使使用WordPress后台未设置的站点地址(域名)访问,仍然可以访问。的缓存页面。因为经过静态缓存后,前端并没有执行PHP,而是直接输出HTML。只有没有启用静态缓存的站点才会跳转到设置的站点地址。
如上图,可以看到静态资源的CDN域名是百度收录。
防止CDN域名中的非静态资源被搜索引擎抓取创建robots2.txt文件
用记事本创建一个robots2.txt,添加如下内容,上传到网站根目录。
User-agent: *
Allow: /robots.txt
Allow: /*.png*
Allow: /*.jpg*
Allow: /*.jpeg*
Allow: /*.gif*
Allow: /*.bmp*
Allow: /*.ico*
Allow: /*.js*
Allow: /*.css*
Allow: /wp-content/
Disallow: /
通过 robots 协议,禁止搜索引擎抓取除 .js、.css 或图片之外的所有内容。因为是静态资源的CDN域名,静态资源还是需要公开爬取,否则会影响正常收录。
Nginx 重定向 robots.txt
当然,也不可能把主域名的robots.txt改成上面那样,那么所有的页面都不会被搜索引擎抓取。可以使用 Nginx 的条件判断来指定将 robots.txt 重定向到 robots2.txt 的域名。
if ($http_host !~ "^www.zhanzhangb.com$") {
rewrite /robots.txt /robots2.txt last;
}
以上是将非域名下的robots.txt重定向到robots2.txt。
if ($http_host ~ "^cdn.zhanzhangb.com$") {
rewrite /robots.txt /robots2.txt last;
}
以上就是将域名下的robots.txt重定向到robots2.txt。
Apache 重定向 robots.txt
RewriteEngine On
RewriteCond %{HTTP_HOST} !^www.zhanzhangb.com [NC]
RewriteRule robots.txt robots2.txt [L]
设置完成后,使用CDN域名访问robots.txt,看看是否成功。域名对应的robots.txt不要弄错了,否则会造成很大的SEO损失。 查看全部
php禁止网页抓取(
CDN域名下的robots.txt重定向到robots2.)
https://ima.tkcdk.cn/wp-conten ... 0.png 300w" />百度收录CDN域名是SEO的大忌。因为相同的内容出现在两个或多个域名中,会受到搜索引擎的惩罚。基本上所有的搜索引擎都会将多个域名指向同一页面的结果判断为镜像,判断为镜像的域名会降级。
很多WordPress网站用户会使用CDN,CDN域名的回源IP地址与主站相同。如果启用了静态缓存,即使使用WordPress后台未设置的站点地址(域名)访问,仍然可以访问。的缓存页面。因为经过静态缓存后,前端并没有执行PHP,而是直接输出HTML。只有没有启用静态缓存的站点才会跳转到设置的站点地址。
如上图,可以看到静态资源的CDN域名是百度收录。
防止CDN域名中的非静态资源被搜索引擎抓取创建robots2.txt文件
用记事本创建一个robots2.txt,添加如下内容,上传到网站根目录。
User-agent: *
Allow: /robots.txt
Allow: /*.png*
Allow: /*.jpg*
Allow: /*.jpeg*
Allow: /*.gif*
Allow: /*.bmp*
Allow: /*.ico*
Allow: /*.js*
Allow: /*.css*
Allow: /wp-content/
Disallow: /
通过 robots 协议,禁止搜索引擎抓取除 .js、.css 或图片之外的所有内容。因为是静态资源的CDN域名,静态资源还是需要公开爬取,否则会影响正常收录。
Nginx 重定向 robots.txt
当然,也不可能把主域名的robots.txt改成上面那样,那么所有的页面都不会被搜索引擎抓取。可以使用 Nginx 的条件判断来指定将 robots.txt 重定向到 robots2.txt 的域名。
if ($http_host !~ "^www.zhanzhangb.com$") {
rewrite /robots.txt /robots2.txt last;
}
以上是将非域名下的robots.txt重定向到robots2.txt。
if ($http_host ~ "^cdn.zhanzhangb.com$") {
rewrite /robots.txt /robots2.txt last;
}
以上就是将域名下的robots.txt重定向到robots2.txt。
Apache 重定向 robots.txt
RewriteEngine On
RewriteCond %{HTTP_HOST} !^www.zhanzhangb.com [NC]
RewriteRule robots.txt robots2.txt [L]
设置完成后,使用CDN域名访问robots.txt,看看是否成功。域名对应的robots.txt不要弄错了,否则会造成很大的SEO损失。
php禁止网页抓取( 如果我们有些文件夹或者文件不想让百度收录的时候应该怎么办呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-27 04:17
如果我们有些文件夹或者文件不想让百度收录的时候应该怎么办呢?)
如何设置机器人拒绝百度和谷歌收录
不想让百度收录一些文件夹或文件怎么办?
我们可以使用机器人来解决这个问题。机器人可以和搜索引擎达成一定的协议,让搜索引擎不收录指定文件和文件夹。
robots.txt 是最简单的 .txt 文件,它告诉搜索引擎哪些页面允许收录,哪些页面不允许收录。
关于robots.txt 一般站长需要注意以下几点:
如果您的网站对所有搜索引擎开放,则无需将此文件设为空,否则 robots.txt 为空。
必须命名为:robots.txt,全小写,robots后加“s”。
robots.txt 必须放在站点的根目录中。如:可以通过 成功访问,说明站点放置正确。
robots.txt中一般只写两个函数:User-agent和Disallow。
观察此页面并将其修改为您自己的:
如果有多个禁止,则必须有多个 Disallow 函数并在单独的行中进行描述。
必须至少有一个 Disallow 函数,如果所有 收录 都允许,则写: Disallow: ,如果 收录 都不允许,则写: Disallow: / (注意:只有一个斜杠不见了)。
附加说明:
User-agent: * 星号表示允许所有搜索引擎收录
Disallow: /search.html 该页面被搜索引擎禁止抓取。
不允许:/index.php?表示此类页面禁止被搜索引擎抓取。
以上是拒绝搜索引擎收录的设置方法,根据以上设置即可满足拒绝搜索引擎收录的要求。 查看全部
php禁止网页抓取(
如果我们有些文件夹或者文件不想让百度收录的时候应该怎么办呢?)
如何设置机器人拒绝百度和谷歌收录
不想让百度收录一些文件夹或文件怎么办?
我们可以使用机器人来解决这个问题。机器人可以和搜索引擎达成一定的协议,让搜索引擎不收录指定文件和文件夹。
robots.txt 是最简单的 .txt 文件,它告诉搜索引擎哪些页面允许收录,哪些页面不允许收录。
关于robots.txt 一般站长需要注意以下几点:
如果您的网站对所有搜索引擎开放,则无需将此文件设为空,否则 robots.txt 为空。
必须命名为:robots.txt,全小写,robots后加“s”。
robots.txt 必须放在站点的根目录中。如:可以通过 成功访问,说明站点放置正确。
robots.txt中一般只写两个函数:User-agent和Disallow。
观察此页面并将其修改为您自己的:
如果有多个禁止,则必须有多个 Disallow 函数并在单独的行中进行描述。
必须至少有一个 Disallow 函数,如果所有 收录 都允许,则写: Disallow: ,如果 收录 都不允许,则写: Disallow: / (注意:只有一个斜杠不见了)。
附加说明:
User-agent: * 星号表示允许所有搜索引擎收录
Disallow: /search.html 该页面被搜索引擎禁止抓取。
不允许:/index.php?表示此类页面禁止被搜索引擎抓取。
以上是拒绝搜索引擎收录的设置方法,根据以上设置即可满足拒绝搜索引擎收录的要求。
php禁止网页抓取(综艺影视类长禁止搜索引擎抓取和收录的创建抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-27 04:15
大家做seo都是千方百计让搜索引擎抓取和收录,但其实很多时候我们还需要禁止搜索引擎抓取和收录
比如公司内测的网站,或者内网,或者后台登录页面,肯定不想被外人搜索到,所以应该禁止搜索引擎抓取。禁止搜索引擎爬取方法:在WEB根目录下创建robots.txt文件,其内容为:
User-agent: Baiduspider
Disallow: /
User-agent: Sosospider
Disallow: /
User-agent: sogou spider
Disallow:
User-agent: YodaoBot
Disallow:
User-agent: Googlebot
Disallow: /
User-agent: Bingbot
Disallow: /
User-agent: Slurp
Disallow: /
User-agent: Teoma
Disallow: /
User-agent: ia_archiver
Disallow: /
User-agent: twiceler
Disallow: /
User-agent: MSNBot
Disallow: /
User-agent: Scrubby
Disallow: /
User-agent: Robozilla
Disallow: /
User-agent: googlebot-image
Disallow: /
User-agent: googlebot-mobile
Disallow: /
User-agent: yahoo-mmcrawler
Disallow: /
User-agent: yahoo-blogs/v3.9
Disallow: /
User-agent: psbot
Disallow: /
给你发一张禁止搜索引擎爬取网站的搜索结果截图:
百度官方对robots.txt的解释如下: 机器人是网站与蜘蛛沟通的重要渠道。本站通过robots文件声明,本网站的部分不希望被搜索引擎收录或指定搜索引擎仅搜索到收录特定部分。
9月11日,百度搜索机器人全新升级。升级后机器人会优化网站视频网址收录的抓取。只有当您的 网站 收录您不希望被视频搜索引擎 收录 看到的内容时,才需要 robots.txt 文件。如果您想要搜索引擎 收录网站 上的所有内容,请不要创建 robots.txt 文件。
如果你的网站没有设置robots协议,百度搜索会在网站的视频URL中收录视频播放页面的URL、视频文件、视频的周边文字等信息。已收录的短视频资源将作为视频速度体验页面呈现给用户。另外,对于综艺、电影等长视频,搜索引擎只使用收录页面URL。 查看全部
php禁止网页抓取(综艺影视类长禁止搜索引擎抓取和收录的创建抓取方法)
大家做seo都是千方百计让搜索引擎抓取和收录,但其实很多时候我们还需要禁止搜索引擎抓取和收录
比如公司内测的网站,或者内网,或者后台登录页面,肯定不想被外人搜索到,所以应该禁止搜索引擎抓取。禁止搜索引擎爬取方法:在WEB根目录下创建robots.txt文件,其内容为:
User-agent: Baiduspider
Disallow: /
User-agent: Sosospider
Disallow: /
User-agent: sogou spider
Disallow:
User-agent: YodaoBot
Disallow:
User-agent: Googlebot
Disallow: /
User-agent: Bingbot
Disallow: /
User-agent: Slurp
Disallow: /
User-agent: Teoma
Disallow: /
User-agent: ia_archiver
Disallow: /
User-agent: twiceler
Disallow: /
User-agent: MSNBot
Disallow: /
User-agent: Scrubby
Disallow: /
User-agent: Robozilla
Disallow: /
User-agent: googlebot-image
Disallow: /
User-agent: googlebot-mobile
Disallow: /
User-agent: yahoo-mmcrawler
Disallow: /
User-agent: yahoo-blogs/v3.9
Disallow: /
User-agent: psbot
Disallow: /
给你发一张禁止搜索引擎爬取网站的搜索结果截图:
百度官方对robots.txt的解释如下: 机器人是网站与蜘蛛沟通的重要渠道。本站通过robots文件声明,本网站的部分不希望被搜索引擎收录或指定搜索引擎仅搜索到收录特定部分。
9月11日,百度搜索机器人全新升级。升级后机器人会优化网站视频网址收录的抓取。只有当您的 网站 收录您不希望被视频搜索引擎 收录 看到的内容时,才需要 robots.txt 文件。如果您想要搜索引擎 收录网站 上的所有内容,请不要创建 robots.txt 文件。
如果你的网站没有设置robots协议,百度搜索会在网站的视频URL中收录视频播放页面的URL、视频文件、视频的周边文字等信息。已收录的短视频资源将作为视频速度体验页面呈现给用户。另外,对于综艺、电影等长视频,搜索引擎只使用收录页面URL。
php禁止网页抓取(关于“别人怎么访问PHP虚拟主机”的介绍(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-27 04:13
其他人如何访问 PHP 虚拟主机?访问PHP虚拟主机,主要通过控制面板、域名、FTP。其中,控制面板、FTP等方式主要用于管理PHP虚拟主机;PHP虚拟主机设置好网站后,我们就可以通过域名访问来访问网站的数据了。接下来简单介绍一下这些接入方式,以及其他接入方式。
1、控制面板
这是虚拟主机最重要的管理方式,也是虚拟主机的特点之一。虚拟主机的各项管理功能一一快速入门,站长只需点击即可完成功能操作。这使得许多不懂技术的网站管理员可以使用虚拟主机来构建 网站 和管理服务器。
如果需要允许他人访问虚拟主机,可以将控制面板地址、用户名、密码提供给对方,从而实现访问。但是,会存在严重的安全隐患。切记不要随意将您的用户名和密码提供给他人。
2、FTP方式
FTP是虚拟主机管理文件最重要的方式。虚拟主机在管理文件和批量操作时,都是通过FTP软件来完成的。
如果需要允许其他人访问虚拟主机,可以使用 FTP。将FTP地址、用户名和密码给对方,对方可以通过FTP软件等方式连接到虚拟主机。我们可以提前设置虚拟主机文件管理权限,比如只允许“只读”,不允许“可写”,这样设置后,当对方通过FTP访问时,可以在一定程度上降低安全隐患。
这样,当PHP虚拟主机一般作为存储服务器使用时,可以与他人共享文件,可以查看和下载。您还可以打开一些具有“可读可写”权限的目录和文件,以达到在线编辑、修改等目的。
3、域名访问
如果 PHP 虚拟主机已经设置了 网站,我们会发布域名。大家可以通过域名访问PHP虚拟主机,浏览我们在网站上发布的信息、图片等。
以上就是“别人如何访问php虚拟主机”的介绍。如果您需要购买虚拟主机,我们推荐无忧主机。虚拟主机产品种类繁多,从共享虚拟主机到独占虚拟主机;Linux系统和Windows系统主机配置齐全,PHP虚拟主机、ASP虚拟主机、Java虚拟主机等。另外价格便宜,支持试用,技术客服7*24小时协助维护。同时,它提供快速的电子归档,无需窗帘摄影。
购买入口:
专属入口: 查看全部
php禁止网页抓取(关于“别人怎么访问PHP虚拟主机”的介绍(图))
其他人如何访问 PHP 虚拟主机?访问PHP虚拟主机,主要通过控制面板、域名、FTP。其中,控制面板、FTP等方式主要用于管理PHP虚拟主机;PHP虚拟主机设置好网站后,我们就可以通过域名访问来访问网站的数据了。接下来简单介绍一下这些接入方式,以及其他接入方式。
1、控制面板
这是虚拟主机最重要的管理方式,也是虚拟主机的特点之一。虚拟主机的各项管理功能一一快速入门,站长只需点击即可完成功能操作。这使得许多不懂技术的网站管理员可以使用虚拟主机来构建 网站 和管理服务器。
如果需要允许他人访问虚拟主机,可以将控制面板地址、用户名、密码提供给对方,从而实现访问。但是,会存在严重的安全隐患。切记不要随意将您的用户名和密码提供给他人。
2、FTP方式
FTP是虚拟主机管理文件最重要的方式。虚拟主机在管理文件和批量操作时,都是通过FTP软件来完成的。
如果需要允许其他人访问虚拟主机,可以使用 FTP。将FTP地址、用户名和密码给对方,对方可以通过FTP软件等方式连接到虚拟主机。我们可以提前设置虚拟主机文件管理权限,比如只允许“只读”,不允许“可写”,这样设置后,当对方通过FTP访问时,可以在一定程度上降低安全隐患。
这样,当PHP虚拟主机一般作为存储服务器使用时,可以与他人共享文件,可以查看和下载。您还可以打开一些具有“可读可写”权限的目录和文件,以达到在线编辑、修改等目的。
3、域名访问
如果 PHP 虚拟主机已经设置了 网站,我们会发布域名。大家可以通过域名访问PHP虚拟主机,浏览我们在网站上发布的信息、图片等。
以上就是“别人如何访问php虚拟主机”的介绍。如果您需要购买虚拟主机,我们推荐无忧主机。虚拟主机产品种类繁多,从共享虚拟主机到独占虚拟主机;Linux系统和Windows系统主机配置齐全,PHP虚拟主机、ASP虚拟主机、Java虚拟主机等。另外价格便宜,支持试用,技术客服7*24小时协助维护。同时,它提供快速的电子归档,无需窗帘摄影。
购买入口:
专属入口:
php禁止网页抓取(我负责的一个网站流量突然下降至5分之一的流量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-24 00:15
一月中旬,我负责的一个网站,网站的流量突然下降到五分之一。于是查了一下百度收录的卷。发现 网站网站收录 页数超过 9,000,而之前为超过 130,000。难怪流量下降如此明显。这个网站是7月份静态处理的论坛。当时发射后不久,网站收录正常,并没有大面积缩减的迹象。由于网站的工作量大,每天观察数据,没有明显的流量下降迹象。
它仅在 1 月中旬显着下降。通过观察收录的页面发现百度只有收录网站的8080端口页面,而且几乎只有收录动态地址,几乎没有静态地址< @收录。谷歌查询量 收录 原来是 0.
这令人费解。我从来没有遇到过这样的问题。那个时候ZAC正好在PHPWIND面试,所以问了他这个问题。他当时的回答也没有解决我的问题。可能这个问题在其他地方很少出现。对问题一一排查,终于找到问题所在。事实证明,在 8 月,Tech 修改了 robots.txt 文件。当时的语法是这样的:
#
#robots.txtforDiscuz!Board
#版本6.0.0
#
用户代理:*
不允许:/
禁止:/admin/
禁止:/api/
禁止:/附件/
禁止:/customavatars/
禁止:/图像/
禁止:/forumdata/
禁止:/包括/
禁止:/ipdata/
禁止:/模板/
禁止:/plugins/
禁止:/mspace/
禁止:/wap/
禁止:/admincp.php
禁止:/ajax.php
禁止:/digest.php
禁止:/logging.php
禁止:/member.php
禁止:/memcp.php
禁止:/misc.php
禁止:/my.php
禁止:/pm.php
禁止:/post.php
禁止:/register.php
禁止:/rss.php
禁止:/search.php
禁止:/seccode.php
禁止:/topicadmin.php
禁止:/space.php
不知道大家有没有注意到上面的语法错误,但是错误已经很明显了。第一句话是错的。不应该被禁止:/
取而代之的是,Allow:/或者干脆不写这句话,直接删掉这句话。不要小看多写的3封信,而是让搜索引擎的蜘蛛不再抓取你的网页。网站收录音量变化开始缓慢下降,直到从搜索引擎数据库中删除。例如,谷歌几乎等于删除了这个 网站 页面。让百度蜘蛛误以为只允许抓取8080端口页面。事实上,8080 端口是不可访问的。为了尽量减少损失,我要求技术立即恢复对8080端口的访问。几天后,流量又增加了,网站收录的量已经恢复到2万多,但距离13万还差得很远。谷歌收录也有两万多,收录很正常。但是百度还是只有收录8080端口,偶尔收录默认端口下,动态占多数,静态占少数。来自论坛管理员的后台数据显示,网站整体流量下降了近三分之一2.
问题还在处理中,希望尽快恢复流量。总结:作为一名SEO,一定要定期查看网站的robots.txt,建议每月一次,同时对技术人员进行SEO相关培训。让技术人员了解基本的SEO知识。最好为技术部门制定SEO规范。让大家有参考。 查看全部
php禁止网页抓取(我负责的一个网站流量突然下降至5分之一的流量)
一月中旬,我负责的一个网站,网站的流量突然下降到五分之一。于是查了一下百度收录的卷。发现 网站网站收录 页数超过 9,000,而之前为超过 130,000。难怪流量下降如此明显。这个网站是7月份静态处理的论坛。当时发射后不久,网站收录正常,并没有大面积缩减的迹象。由于网站的工作量大,每天观察数据,没有明显的流量下降迹象。
它仅在 1 月中旬显着下降。通过观察收录的页面发现百度只有收录网站的8080端口页面,而且几乎只有收录动态地址,几乎没有静态地址< @收录。谷歌查询量 收录 原来是 0.
这令人费解。我从来没有遇到过这样的问题。那个时候ZAC正好在PHPWIND面试,所以问了他这个问题。他当时的回答也没有解决我的问题。可能这个问题在其他地方很少出现。对问题一一排查,终于找到问题所在。事实证明,在 8 月,Tech 修改了 robots.txt 文件。当时的语法是这样的:
#
#robots.txtforDiscuz!Board
#版本6.0.0
#
用户代理:*
不允许:/
禁止:/admin/
禁止:/api/
禁止:/附件/
禁止:/customavatars/
禁止:/图像/
禁止:/forumdata/
禁止:/包括/
禁止:/ipdata/
禁止:/模板/
禁止:/plugins/
禁止:/mspace/
禁止:/wap/
禁止:/admincp.php
禁止:/ajax.php
禁止:/digest.php
禁止:/logging.php
禁止:/member.php
禁止:/memcp.php
禁止:/misc.php
禁止:/my.php
禁止:/pm.php
禁止:/post.php
禁止:/register.php
禁止:/rss.php
禁止:/search.php
禁止:/seccode.php
禁止:/topicadmin.php
禁止:/space.php
不知道大家有没有注意到上面的语法错误,但是错误已经很明显了。第一句话是错的。不应该被禁止:/
取而代之的是,Allow:/或者干脆不写这句话,直接删掉这句话。不要小看多写的3封信,而是让搜索引擎的蜘蛛不再抓取你的网页。网站收录音量变化开始缓慢下降,直到从搜索引擎数据库中删除。例如,谷歌几乎等于删除了这个 网站 页面。让百度蜘蛛误以为只允许抓取8080端口页面。事实上,8080 端口是不可访问的。为了尽量减少损失,我要求技术立即恢复对8080端口的访问。几天后,流量又增加了,网站收录的量已经恢复到2万多,但距离13万还差得很远。谷歌收录也有两万多,收录很正常。但是百度还是只有收录8080端口,偶尔收录默认端口下,动态占多数,静态占少数。来自论坛管理员的后台数据显示,网站整体流量下降了近三分之一2.
问题还在处理中,希望尽快恢复流量。总结:作为一名SEO,一定要定期查看网站的robots.txt,建议每月一次,同时对技术人员进行SEO相关培训。让技术人员了解基本的SEO知识。最好为技术部门制定SEO规范。让大家有参考。
php禁止网页抓取(4.禁止百度图片搜索收录某些图片,该如何设置?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-23 18:01
3.我在robots.txt中设置了禁止百度的内容收录my网站,为什么百度搜索结果里还出现?
如果其他网站s链接到你robots.txt文件中禁止收录的页面,这些页面可能仍然会出现在百度搜索结果中,但是你页面上的内容不会被抓取、索引和显示,百度搜索结果只显示您相关页面的其他网站描述。
4.禁止搜索引擎跟踪网页链接,但只索引网页
如果您不希望搜索引擎跟踪此页面上的链接,并且不传递链接的权重,请将此元标记放置在页面的部分中:
如果不希望百度跟踪特定链接,百度也支持更精准的控制,请直接在链接上写下这个标记:登录
要允许其他搜索引擎关注,但只阻止百度关注您页面的链接,请将此元标记放置在您页面的部分中:
5.禁止搜索引擎在搜索结果中显示网页快照,但只索引网页
要阻止所有搜索引擎显示您的 网站 快照,请将此元标记放置在您网页的某个部分:要允许其他搜索引擎显示快照,但仅阻止百度显示它们,请使用以下标记:注意:这个标签只是禁止百度显示页面的快照,百度会继续索引页面并在搜索结果中显示页面摘要。
6.我要禁止百度图片搜索收录一些图片,怎么设置?
禁止百度蜘蛛抓取网站上的所有图片,或者允许百度蜘蛛抓取网站上某种格式的图片文件可以通过设置robots来实现,请参考“robots.txt文件使用示例”示例1 0、11、12。
7. robots.txt 文件格式
“robots.txt”文件收录一个或多个由空行分隔的记录(以 CR、CR/NL 或 NL 结尾),每个记录格式如下:
:
在这个文件中可以使用#作为注解,具体用法同UNIX中的约定。此文件中的记录通常以一行或多行 User-agent 开头,然后是几行 Disallow 和 Allow 行。详情如下:
用户代理:
该项目的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,则表示多个机器人会受到“robots.txt”的限制。对于此文件,必须至少有一个 User-agent 记录。如果此项的值设置为 *,则对任何机器人都有效。在“robots.txt”文件中,“User-agent:*”只能有一条记录。如果在“robots.txt”文件中,添加“User-agent: SomeBot”和几行Disallow和Allow行,“SomeBot”的名称只受“User-agent: SomeBot”后面的Disallow和Allow行的限制。
不允许:
该项目的值用于描述一组不想被访问的 URL。该值可以是完整路径,也可以是路径的非空前缀。机器人不会访问以 Disallow 项的值开头的 URL。例如,“Disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,而“Disallow:/help/”则允许机器人访问/help.html、/helpabc。 html,并且无法访问/help/index.html。“Disallow:”表示允许机器人访问网站的所有URL,且“/robots.txt”文件中必须至少有一条Disallow记录。如果“/robots.txt”不存在或为空文件,则 网站 对所有搜索引擎机器人开放。
允许:
该项目的值用于描述您希望访问的一组 URL。与 Disallow 项类似,该值可以是完整路径,也可以是路径前缀。以 Allow 项的值开头的 URL 允许机器人访问。例如“允许:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。网站 的所有 URL 默认为 Allow,因此 Allow 通常与 Disallow 结合使用,以允许访问某些网页,同时禁止访问所有其他 URL。
需要注意的是,Disallow 和 Allow 行的顺序是有意义的,机器人会根据第一个匹配的 Allow 或 Disallow 行来判断是否访问 URL。
使用“*”和“$”:
百度蜘蛛支持使用通配符“*”和“$”来模糊匹配url。
"$" 匹配行终止符。
"*" 匹配零个或多个任意字符。
注意:我们会严格遵守robots的相关协议,请注意区分您不想被爬取的目录或收录的大小写,我们会处理robots里写的文件和你做的文件不想被爬取和收录@>的目录必须完全匹配,否则robots协议不会生效。
8. URL 匹配示例 Allow or Disallow URL 匹配结果的值
/tmp/tmpye
/tmp/tmp.html是的
/tmp/tmp/a.html是的
/tmp/tmphohono
/你好*/Hello.html是的
/He*lo/你好,loloyes
/Heap*lo/你好,lolono
html$/tmpa.html是的
/a.html$/a.html是的
htm$/a.htmlno 查看全部
php禁止网页抓取(4.禁止百度图片搜索收录某些图片,该如何设置?)
3.我在robots.txt中设置了禁止百度的内容收录my网站,为什么百度搜索结果里还出现?
如果其他网站s链接到你robots.txt文件中禁止收录的页面,这些页面可能仍然会出现在百度搜索结果中,但是你页面上的内容不会被抓取、索引和显示,百度搜索结果只显示您相关页面的其他网站描述。
4.禁止搜索引擎跟踪网页链接,但只索引网页
如果您不希望搜索引擎跟踪此页面上的链接,并且不传递链接的权重,请将此元标记放置在页面的部分中:
如果不希望百度跟踪特定链接,百度也支持更精准的控制,请直接在链接上写下这个标记:登录
要允许其他搜索引擎关注,但只阻止百度关注您页面的链接,请将此元标记放置在您页面的部分中:
5.禁止搜索引擎在搜索结果中显示网页快照,但只索引网页
要阻止所有搜索引擎显示您的 网站 快照,请将此元标记放置在您网页的某个部分:要允许其他搜索引擎显示快照,但仅阻止百度显示它们,请使用以下标记:注意:这个标签只是禁止百度显示页面的快照,百度会继续索引页面并在搜索结果中显示页面摘要。
6.我要禁止百度图片搜索收录一些图片,怎么设置?
禁止百度蜘蛛抓取网站上的所有图片,或者允许百度蜘蛛抓取网站上某种格式的图片文件可以通过设置robots来实现,请参考“robots.txt文件使用示例”示例1 0、11、12。
7. robots.txt 文件格式
“robots.txt”文件收录一个或多个由空行分隔的记录(以 CR、CR/NL 或 NL 结尾),每个记录格式如下:
:
在这个文件中可以使用#作为注解,具体用法同UNIX中的约定。此文件中的记录通常以一行或多行 User-agent 开头,然后是几行 Disallow 和 Allow 行。详情如下:
用户代理:
该项目的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,则表示多个机器人会受到“robots.txt”的限制。对于此文件,必须至少有一个 User-agent 记录。如果此项的值设置为 *,则对任何机器人都有效。在“robots.txt”文件中,“User-agent:*”只能有一条记录。如果在“robots.txt”文件中,添加“User-agent: SomeBot”和几行Disallow和Allow行,“SomeBot”的名称只受“User-agent: SomeBot”后面的Disallow和Allow行的限制。
不允许:
该项目的值用于描述一组不想被访问的 URL。该值可以是完整路径,也可以是路径的非空前缀。机器人不会访问以 Disallow 项的值开头的 URL。例如,“Disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,而“Disallow:/help/”则允许机器人访问/help.html、/helpabc。 html,并且无法访问/help/index.html。“Disallow:”表示允许机器人访问网站的所有URL,且“/robots.txt”文件中必须至少有一条Disallow记录。如果“/robots.txt”不存在或为空文件,则 网站 对所有搜索引擎机器人开放。
允许:
该项目的值用于描述您希望访问的一组 URL。与 Disallow 项类似,该值可以是完整路径,也可以是路径前缀。以 Allow 项的值开头的 URL 允许机器人访问。例如“允许:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。网站 的所有 URL 默认为 Allow,因此 Allow 通常与 Disallow 结合使用,以允许访问某些网页,同时禁止访问所有其他 URL。
需要注意的是,Disallow 和 Allow 行的顺序是有意义的,机器人会根据第一个匹配的 Allow 或 Disallow 行来判断是否访问 URL。
使用“*”和“$”:
百度蜘蛛支持使用通配符“*”和“$”来模糊匹配url。
"$" 匹配行终止符。
"*" 匹配零个或多个任意字符。
注意:我们会严格遵守robots的相关协议,请注意区分您不想被爬取的目录或收录的大小写,我们会处理robots里写的文件和你做的文件不想被爬取和收录@>的目录必须完全匹配,否则robots协议不会生效。
8. URL 匹配示例 Allow or Disallow URL 匹配结果的值
/tmp/tmpye
/tmp/tmp.html是的
/tmp/tmp/a.html是的
/tmp/tmphohono
/你好*/Hello.html是的
/He*lo/你好,loloyes
/Heap*lo/你好,lolono
html$/tmpa.html是的
/a.html$/a.html是的
htm$/a.htmlno
php禁止网页抓取(吃完虾爬什么,怎么爬才是导致锒铛入狱的罪魁祸首? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-23 17:23
)
导读
偶尔大数据公司被抓,不法流量自媒体就是为了博眼球,夸大事实,说爬虫玩的好,监狱早点吃,想学爬虫就瑟瑟发抖,怕自己写爬虫被抄进去了,我很害怕,我:说实话,我对大部分新技术能力想的太多了。这种贸然下结论的方式,类似于先吃虾再吃维生素C的砒霜中毒理论。同理,无剂量谈毒——都是流氓行为。
从技术中立的角度来看,爬虫技术本身不存在违法违规行为。爬什么、怎么爬是导致二当入狱的罪魁祸首。Github上有一个库,记录了国内爬虫开发者诉讼和违规相关的新闻、资料、法律法规:
为了节省读者的时间,我们可以直接总结:
1、 忽略robots协议,爬取不给爬取数据
robots.txt,纯文本文件,网站管理者可以在这个文件中声明不希望被搜索引擎访问的部分,或者指定搜索引擎只指定收录的内容,语法很简单:
通配符 (*) → 匹配零个或多个任意字符;
匹配字符 ($) → 匹配 URL 末尾的字符;
User-agent → 搜索引擎爬虫的名字,各大搜索引擎都有固定的名字,比如百度百度百科,如果该项为*(通配符),表示该协议对任何搜索引擎爬虫都有效;
Disallow → 禁止路径;
Allow → 允许访问的路径;
但是,这个协议可以说是君子协议。谨防君子,不防小人,无视机器人协议随意抢网站内容,将涉嫌构成违反《反不正当竞争法》第二条,即违反《反不正当竞争法》第二条。诚实。信用原则和商业道德的不公平竞争。
2、强行突破网站设定的技术措施
网站一般会做反爬,以减轻爬虫批量访问给网站带来的巨大压力和负担。爬虫开发者通过技术手段绕过反爬虫,客观上影响网站正常运行(甚至挂机),适用反不正当竞争法第十二条(四)其他障碍、行为)扰乱其他运营商合法提供的网络产品或者服务的正常运行的。
强行突破已经爬取和发布的一些具体技术措施,也可能构成犯罪行为。
这里稍微提防一下:为非法组织提供爬虫相关服务,也可能间接承担刑事责任。在这种情况下,抓捕极端黑客就是模板。尽管技术本身是无辜的,但您已经开发了它并被定罪。使用它的分子同样负责。
3、爬取特定类型的信息
1)用户个人隐私
2)用户个人信息
3)受版权法保护的产品
4)商业机密
5)保护数据免受不公平竞争
如果担心自己写的爬虫违法,可以看一看,总结一下爬山的基本伦理:
先确定要爬什么网站:国事、国防建设、前沿科技等领域的不要碰;
确定哪些内容:不触碰个人隐私、个人信息、商业秘密;受著作权法和不正当竞争保护的数据,最好是偷偷享用,不要传播和营利(比如数据分析,见下文~)。
爬取方法:轻柔一点,尽量不要影响正常用户的使用,水会继续流,其他人网站会被挂掉,不做就奇怪了。
机器人协议:嗯...我是一个恶棍
天网已满,稀稀拉拉但不容错过~
相信对爬虫非法类别的解读可以打消一些想学Python爬虫的小白梦心的顾虑。爬虫学习
相信进来看看的朋友都对爬虫很感兴趣,我也是。当我第一次接触爬行动物的时候,就被深深吸引了,因为我觉得SO COOL!每当我打完代码,看着屏幕上飘浮的一串数据,都有一种成就感,有没有?而且爬虫技术可以应用到很多生活场景,比如自动投票,批量下载有趣的文章,小说,视频,微信机器人,爬取重要数据进行数据分析啊,我真的感觉这些代码都是为自己写的,可以为自己和他人服务,所以人生太短,我选择爬虫。
1、要学习爬虫,首先要了解什么是爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
其实说白了,爬虫可以模拟浏览器的行为为所欲为,自定义自己的搜索和下载内容,实现操作自动化。比如浏览器可以下载小说,但有时不能批量下载,所以爬虫的功能就派上用场了。
2、爬虫学习路线
学习Python爬虫的一般步骤如下:
1)。首先学习基本的Python语法知识
2).学习Python爬虫常用的几个重要的内置库,urllib,http等,用于下载网页
3)。学习正则表达式re、BeautifulSoup(bs4)、Xpath(lxml)等网页解析工具
4)。开始一些简单的网站爬取(博主从百度开始,哈哈)了解爬取数据的过程
5)。了解爬虫、header、robot、时间间隔、代理ip、隐藏字段等的一些反爬机制。
6)。学习一些特殊的网站爬取,解决登录、cookies、动态网页等问题。
7)。了解爬虫和数据库的结合,如何存储爬取的数据
8)。学习应用Python的多线程多进程爬取提高爬虫效率
9)。学习爬虫框架、Scrapy、PySpider等。
10).学习分布式爬虫(海量数据需求)
3、Python爬虫Selenium库的使用
1)基础知识
首先,要使用python语言作为爬虫,需要学习python的基础知识,以及HTML、CSS、JS、Ajax等相关知识。这里列举一些python中爬虫相关的库和框架:
1.1、urllib和urllib2
1.2、Requests
1.3、Beautiful Soup
1.4、Xpath语法与lxml库
1.5、PhantomJS
1.6、Selenium
1.7、PyQuery
1.8、Scrapy
......
由于时间有限,本文只介绍Selenium库的爬虫技术,如自动化测试,以及其他库和框架的资料。有兴趣的小伙伴可以自行学习。
2)硒基础知识
2.1、Selenium是一款用于测试网站的自动化测试工具,支持包括Chrome、Firefox、Safari等多种主流界面浏览器在内的多种浏览器,也支持phantomJS无界面浏览器。
2.2、安装
pip install Selenium
关于Python技术储备
学好 Python 是赚钱的好方法,不管是工作还是副业,但要学好 Python,还是要有学习计划的。最后,我们将分享一套完整的Python学习资料,以帮助那些想学习Python的朋友!
一、Python全方位学习路线
Python的各个方向都是将Python中常用的技术点进行整理,形成各个领域知识点的汇总。它的用处是你可以根据以上知识点找到对应的学习资源,保证你能学得更全面。
二、学习软件
工人要做好工作,首先要磨利他的工具。学习Python常用的开发软件就到这里,为大家节省不少时间。
三、入门视频
当我们看视频学习时,没有手我们就无法移动眼睛和大脑。更科学的学习方式是理解后再使用。这时候动手项目就很合适了。
四、实际案例
光学理论是无用的。你必须学会跟随,你必须先进行实际练习,然后才能将所学应用于实践。这时候可以借鉴实战案例。
五、采访信息
我们必须学习 Python 才能找到一份高薪工作。以下面试题是来自阿里、腾讯、字节跳动等一线互联网公司的最新面试资料,部分阿里大佬给出了权威答案。看完这套面试材料相信大家都能找到一份满意的工作。
本完整版Python全套学习资料已上传至CSDN。需要的可以微信扫描下方CSDN官方认证二维码免费获取【保证100%免费】
查看全部
php禁止网页抓取(吃完虾爬什么,怎么爬才是导致锒铛入狱的罪魁祸首?
)
导读
偶尔大数据公司被抓,不法流量自媒体就是为了博眼球,夸大事实,说爬虫玩的好,监狱早点吃,想学爬虫就瑟瑟发抖,怕自己写爬虫被抄进去了,我很害怕,我:说实话,我对大部分新技术能力想的太多了。这种贸然下结论的方式,类似于先吃虾再吃维生素C的砒霜中毒理论。同理,无剂量谈毒——都是流氓行为。
从技术中立的角度来看,爬虫技术本身不存在违法违规行为。爬什么、怎么爬是导致二当入狱的罪魁祸首。Github上有一个库,记录了国内爬虫开发者诉讼和违规相关的新闻、资料、法律法规:
为了节省读者的时间,我们可以直接总结:
1、 忽略robots协议,爬取不给爬取数据
robots.txt,纯文本文件,网站管理者可以在这个文件中声明不希望被搜索引擎访问的部分,或者指定搜索引擎只指定收录的内容,语法很简单:
通配符 (*) → 匹配零个或多个任意字符;
匹配字符 ($) → 匹配 URL 末尾的字符;
User-agent → 搜索引擎爬虫的名字,各大搜索引擎都有固定的名字,比如百度百度百科,如果该项为*(通配符),表示该协议对任何搜索引擎爬虫都有效;
Disallow → 禁止路径;
Allow → 允许访问的路径;
但是,这个协议可以说是君子协议。谨防君子,不防小人,无视机器人协议随意抢网站内容,将涉嫌构成违反《反不正当竞争法》第二条,即违反《反不正当竞争法》第二条。诚实。信用原则和商业道德的不公平竞争。
2、强行突破网站设定的技术措施
网站一般会做反爬,以减轻爬虫批量访问给网站带来的巨大压力和负担。爬虫开发者通过技术手段绕过反爬虫,客观上影响网站正常运行(甚至挂机),适用反不正当竞争法第十二条(四)其他障碍、行为)扰乱其他运营商合法提供的网络产品或者服务的正常运行的。
强行突破已经爬取和发布的一些具体技术措施,也可能构成犯罪行为。
这里稍微提防一下:为非法组织提供爬虫相关服务,也可能间接承担刑事责任。在这种情况下,抓捕极端黑客就是模板。尽管技术本身是无辜的,但您已经开发了它并被定罪。使用它的分子同样负责。
3、爬取特定类型的信息
1)用户个人隐私
2)用户个人信息
3)受版权法保护的产品
4)商业机密
5)保护数据免受不公平竞争
如果担心自己写的爬虫违法,可以看一看,总结一下爬山的基本伦理:
先确定要爬什么网站:国事、国防建设、前沿科技等领域的不要碰;
确定哪些内容:不触碰个人隐私、个人信息、商业秘密;受著作权法和不正当竞争保护的数据,最好是偷偷享用,不要传播和营利(比如数据分析,见下文~)。
爬取方法:轻柔一点,尽量不要影响正常用户的使用,水会继续流,其他人网站会被挂掉,不做就奇怪了。
机器人协议:嗯...我是一个恶棍
天网已满,稀稀拉拉但不容错过~
相信对爬虫非法类别的解读可以打消一些想学Python爬虫的小白梦心的顾虑。爬虫学习
相信进来看看的朋友都对爬虫很感兴趣,我也是。当我第一次接触爬行动物的时候,就被深深吸引了,因为我觉得SO COOL!每当我打完代码,看着屏幕上飘浮的一串数据,都有一种成就感,有没有?而且爬虫技术可以应用到很多生活场景,比如自动投票,批量下载有趣的文章,小说,视频,微信机器人,爬取重要数据进行数据分析啊,我真的感觉这些代码都是为自己写的,可以为自己和他人服务,所以人生太短,我选择爬虫。
1、要学习爬虫,首先要了解什么是爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
其实说白了,爬虫可以模拟浏览器的行为为所欲为,自定义自己的搜索和下载内容,实现操作自动化。比如浏览器可以下载小说,但有时不能批量下载,所以爬虫的功能就派上用场了。
2、爬虫学习路线
学习Python爬虫的一般步骤如下:
1)。首先学习基本的Python语法知识
2).学习Python爬虫常用的几个重要的内置库,urllib,http等,用于下载网页
3)。学习正则表达式re、BeautifulSoup(bs4)、Xpath(lxml)等网页解析工具
4)。开始一些简单的网站爬取(博主从百度开始,哈哈)了解爬取数据的过程
5)。了解爬虫、header、robot、时间间隔、代理ip、隐藏字段等的一些反爬机制。
6)。学习一些特殊的网站爬取,解决登录、cookies、动态网页等问题。
7)。了解爬虫和数据库的结合,如何存储爬取的数据
8)。学习应用Python的多线程多进程爬取提高爬虫效率
9)。学习爬虫框架、Scrapy、PySpider等。
10).学习分布式爬虫(海量数据需求)
3、Python爬虫Selenium库的使用
1)基础知识
首先,要使用python语言作为爬虫,需要学习python的基础知识,以及HTML、CSS、JS、Ajax等相关知识。这里列举一些python中爬虫相关的库和框架:
1.1、urllib和urllib2
1.2、Requests
1.3、Beautiful Soup
1.4、Xpath语法与lxml库
1.5、PhantomJS
1.6、Selenium
1.7、PyQuery
1.8、Scrapy
......
由于时间有限,本文只介绍Selenium库的爬虫技术,如自动化测试,以及其他库和框架的资料。有兴趣的小伙伴可以自行学习。
2)硒基础知识
2.1、Selenium是一款用于测试网站的自动化测试工具,支持包括Chrome、Firefox、Safari等多种主流界面浏览器在内的多种浏览器,也支持phantomJS无界面浏览器。
2.2、安装
pip install Selenium
关于Python技术储备
学好 Python 是赚钱的好方法,不管是工作还是副业,但要学好 Python,还是要有学习计划的。最后,我们将分享一套完整的Python学习资料,以帮助那些想学习Python的朋友!
一、Python全方位学习路线
Python的各个方向都是将Python中常用的技术点进行整理,形成各个领域知识点的汇总。它的用处是你可以根据以上知识点找到对应的学习资源,保证你能学得更全面。
二、学习软件
工人要做好工作,首先要磨利他的工具。学习Python常用的开发软件就到这里,为大家节省不少时间。
三、入门视频
当我们看视频学习时,没有手我们就无法移动眼睛和大脑。更科学的学习方式是理解后再使用。这时候动手项目就很合适了。
四、实际案例
光学理论是无用的。你必须学会跟随,你必须先进行实际练习,然后才能将所学应用于实践。这时候可以借鉴实战案例。
五、采访信息
我们必须学习 Python 才能找到一份高薪工作。以下面试题是来自阿里、腾讯、字节跳动等一线互联网公司的最新面试资料,部分阿里大佬给出了权威答案。看完这套面试材料相信大家都能找到一份满意的工作。
本完整版Python全套学习资料已上传至CSDN。需要的可以微信扫描下方CSDN官方认证二维码免费获取【保证100%免费】
php禁止网页抓取(小鹿竞价软件禁止搜索引擎抓取后会有什么效果呢?? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-22 20:13
)
<p>小鹿系列竞价软件覆盖百度、360、搜狗、神马四大搜索平台,采用独创竞价算法,智能精准竞价,一键批量查询排名,根据
php禁止网页抓取(小鹿竞价软件禁止搜索引擎抓取后会有什么效果呢??
)
<p>小鹿系列竞价软件覆盖百度、360、搜狗、神马四大搜索平台,采用独创竞价算法,智能精准竞价,一键批量查询排名,根据
php禁止网页抓取(【】使用robots.txt文件拦截或删除网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-01-22 20:13
用户代理: *
不允许: /
允许所有机器人访问您的页面
用户代理: *
不允许:
(替代方案:创建一个空的“/robots.txt”文件,或者不使用 robots.txt。)
使用 robots.txt 文件阻止或删除网页
您可以使用 robots.txt 文件来阻止 Googlebot 抓取您 网站 上的网页。例如,如果您手动创建 robots.txt 文件以防止 Googlebot 抓取特定目录(例如私有目录)中的所有网页,请使用以下 robots.txt 条目:
用户代理:Googlebot
禁止:/private
要防止 Googlebot 抓取特定文件类型(例如 .gif)的所有文件,请使用以下 robots.txt 条目:
用户代理:Googlebot
禁止:/*.gif$
想要阻止 Googlebot 抓取所有内容?(具体来说,一个以您的域名开头的 URL,后跟任意字符串,后跟问号,后跟任意字符串),您可以使用以下条目:
用户代理:Googlebot
不允许: /*?
尽管我们不会抓取 robots.txt 阻止的网页的内容或将其编入索引,但如果我们在网络上的其他网页上找到它们的网址,我们仍会抓取它们并将其编入索引。因此,网页 URL 和其他公开可用的信息,例如指向此 网站 的链接中的锚文本,可能会出现在 Google 搜索结果中。但是,您页面上的内容不会被抓取、索引和显示。
作为 网站Admin Tools 的一部分,Google 提供了 robots.txt 分析工具。它可以像 Googlebot 读取文件一样读取 robots.txt 文件,并且可以为 Google 用户代理(例如 Googlebot)提供结果。我们强烈建议您使用它。在创建 robots.txt 文件之前,有必要考虑用户应该搜索哪些内容以及不应该搜索哪些内容。这样,通过对robots.txt的合理使用,搜索引擎可以将用户带到你的网站,同时保证隐私信息不是收录。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机! 查看全部
php禁止网页抓取(【】使用robots.txt文件拦截或删除网页)
用户代理: *
不允许: /
允许所有机器人访问您的页面
用户代理: *
不允许:
(替代方案:创建一个空的“/robots.txt”文件,或者不使用 robots.txt。)
使用 robots.txt 文件阻止或删除网页
您可以使用 robots.txt 文件来阻止 Googlebot 抓取您 网站 上的网页。例如,如果您手动创建 robots.txt 文件以防止 Googlebot 抓取特定目录(例如私有目录)中的所有网页,请使用以下 robots.txt 条目:
用户代理:Googlebot
禁止:/private
要防止 Googlebot 抓取特定文件类型(例如 .gif)的所有文件,请使用以下 robots.txt 条目:
用户代理:Googlebot
禁止:/*.gif$
想要阻止 Googlebot 抓取所有内容?(具体来说,一个以您的域名开头的 URL,后跟任意字符串,后跟问号,后跟任意字符串),您可以使用以下条目:
用户代理:Googlebot
不允许: /*?
尽管我们不会抓取 robots.txt 阻止的网页的内容或将其编入索引,但如果我们在网络上的其他网页上找到它们的网址,我们仍会抓取它们并将其编入索引。因此,网页 URL 和其他公开可用的信息,例如指向此 网站 的链接中的锚文本,可能会出现在 Google 搜索结果中。但是,您页面上的内容不会被抓取、索引和显示。
作为 网站Admin Tools 的一部分,Google 提供了 robots.txt 分析工具。它可以像 Googlebot 读取文件一样读取 robots.txt 文件,并且可以为 Google 用户代理(例如 Googlebot)提供结果。我们强烈建议您使用它。在创建 robots.txt 文件之前,有必要考虑用户应该搜索哪些内容以及不应该搜索哪些内容。这样,通过对robots.txt的合理使用,搜索引擎可以将用户带到你的网站,同时保证隐私信息不是收录。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机!
php禁止网页抓取(之一就是通过robots.txt文件来实现收录/抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-21 18:20
平时比如后台管理登录页面、会员登录注册页面等,不想被搜索引擎抓取收录/,怎么办?一种方法是通过 robots.txt 文件。
机器人也称为爬虫协议。写成robots.txt(不需要写成Robots.txt),必须放在网站的根目录下。其他目录无效。搜索引擎爬虫首先访问/爬取网站 robots.txt文件,然后是index.html/index.php、网站目录等网站告诉搜索引擎哪些页面可以爬取以及哪些页面不能通过robots协议爬取。很多人知道其中一个,不知道另一个,并且知道一些简单的拼写和用法。但是有些人仍然忽略它,那就是安全和隐私问题。
以下为个人写作,仅供参考:
User-agent:*搜索引擎的标识,*代表任何引擎,包括百度、谷歌等,如果要具体指定,这里不再详述。
Disallow: /a*/ 禁止访问以“a”开头的目录改编,例如:admin/index.html 是不可访问的。
Disallow: /C*/ 同上,这个大写的 C 应该区分大小写。
Disallow: /js/ 禁止对 js 目录的任何访问
不允许: /*?不允许收录 ? 的 URL,例如 : 或 this。
Disallow: /*.jpg$ 禁止访问所有以 .jpg 结尾的图像
站点地图:允许访问此 网站 地图文件。
这里需要注意的一点是使用网站 map 命令,将网站 map 的URL 地址用"" 包裹起来。有人说不用加。
使用 * 适配符号来防止黑客或恶意攻击。觉得不重要的不要用*,写全名就好,比如“/js/”。
一些像谷歌这样的搜索引擎也支持在网页上书写来实现它们的功能。
注意:robots.txt 命令只是给爬虫访问你的 网站 的指令,robots.txt 文件中的命令不会强制爬虫爬取你的 网站 进行相应的操作。 查看全部
php禁止网页抓取(之一就是通过robots.txt文件来实现收录/抓取)
平时比如后台管理登录页面、会员登录注册页面等,不想被搜索引擎抓取收录/,怎么办?一种方法是通过 robots.txt 文件。
机器人也称为爬虫协议。写成robots.txt(不需要写成Robots.txt),必须放在网站的根目录下。其他目录无效。搜索引擎爬虫首先访问/爬取网站 robots.txt文件,然后是index.html/index.php、网站目录等网站告诉搜索引擎哪些页面可以爬取以及哪些页面不能通过robots协议爬取。很多人知道其中一个,不知道另一个,并且知道一些简单的拼写和用法。但是有些人仍然忽略它,那就是安全和隐私问题。
以下为个人写作,仅供参考:
User-agent:*搜索引擎的标识,*代表任何引擎,包括百度、谷歌等,如果要具体指定,这里不再详述。
Disallow: /a*/ 禁止访问以“a”开头的目录改编,例如:admin/index.html 是不可访问的。
Disallow: /C*/ 同上,这个大写的 C 应该区分大小写。
Disallow: /js/ 禁止对 js 目录的任何访问
不允许: /*?不允许收录 ? 的 URL,例如 : 或 this。
Disallow: /*.jpg$ 禁止访问所有以 .jpg 结尾的图像
站点地图:允许访问此 网站 地图文件。
这里需要注意的一点是使用网站 map 命令,将网站 map 的URL 地址用"" 包裹起来。有人说不用加。
使用 * 适配符号来防止黑客或恶意攻击。觉得不重要的不要用*,写全名就好,比如“/js/”。
一些像谷歌这样的搜索引擎也支持在网页上书写来实现它们的功能。
注意:robots.txt 命令只是给爬虫访问你的 网站 的指令,robots.txt 文件中的命令不会强制爬虫爬取你的 网站 进行相应的操作。
php禁止网页抓取(【推荐学习】有关robots怎么禁止php抓取(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-18 21:14
下面我给大家讲解一下如何禁止robots爬取php。相信各位朋友也应该非常关注这个话题。下面我来告诉大家如何禁止机器人爬取php。拿php的相关资料,希望大家看到后会喜欢。
robots禁止爬取php的方法:1、在robots.txt文件中写入“Disallow: /*?*”;2、在 robots.txt 文件中添加规则 "User-agent:* Allow" : .html$ Disallow: /"。
本文运行环境:Windows7系统,PHP7.1版DELL G3电脑
robots禁止搜索引擎抓取php动态网址
所谓动态URL是指URL中收录&等字符的URL,如:news.php?lang=cn&class=1&id=2 当我们打开网站的伪静态为网站 SEO 是防止搜索引擎抓取我们的 网站 动态 URL 所必需的。
为什么要这样做,因为搜索引擎会做一些事情来触发 网站 两次爬取同一页面但最终判断为同一页面。具体处罚是什么?这个不清楚,总之不利于整个网站的SEO。那么如何防止搜索引擎抓取我们的网站动态URL呢?
这个问题可以通过使用 robots.txt 文件来解决。请看下面的详细操作。
我们知道动态页面的一个共同特点就是会有一个“?” 链接中的问号符号,所以我们可以在 robots.txt 文件中编写如下规则:
User-agent: *
Disallow: /*?*
这将阻止搜索引擎抓取整个 网站 动态链接。另外,如果我们只想让搜索引擎抓取html格式等指定类型文件的静态页面,可以在robots.txt中添加如下规则:
User-agent: *
Allow: .html$
Disallow: /
另外,记得把写好的robots.txt文件放到你的网站根目录下,不然不行。另外,还有一个方便的写规则快捷方式登录google网站admin工具,连接规则生成robots.txt文件即可。
【推荐学习:《PHP 视频教程》】 查看全部
php禁止网页抓取(【推荐学习】有关robots怎么禁止php抓取(图))
下面我给大家讲解一下如何禁止robots爬取php。相信各位朋友也应该非常关注这个话题。下面我来告诉大家如何禁止机器人爬取php。拿php的相关资料,希望大家看到后会喜欢。
robots禁止爬取php的方法:1、在robots.txt文件中写入“Disallow: /*?*”;2、在 robots.txt 文件中添加规则 "User-agent:* Allow" : .html$ Disallow: /"。
本文运行环境:Windows7系统,PHP7.1版DELL G3电脑
robots禁止搜索引擎抓取php动态网址
所谓动态URL是指URL中收录&等字符的URL,如:news.php?lang=cn&class=1&id=2 当我们打开网站的伪静态为网站 SEO 是防止搜索引擎抓取我们的 网站 动态 URL 所必需的。
为什么要这样做,因为搜索引擎会做一些事情来触发 网站 两次爬取同一页面但最终判断为同一页面。具体处罚是什么?这个不清楚,总之不利于整个网站的SEO。那么如何防止搜索引擎抓取我们的网站动态URL呢?
这个问题可以通过使用 robots.txt 文件来解决。请看下面的详细操作。
我们知道动态页面的一个共同特点就是会有一个“?” 链接中的问号符号,所以我们可以在 robots.txt 文件中编写如下规则:
User-agent: *
Disallow: /*?*
这将阻止搜索引擎抓取整个 网站 动态链接。另外,如果我们只想让搜索引擎抓取html格式等指定类型文件的静态页面,可以在robots.txt中添加如下规则:
User-agent: *
Allow: .html$
Disallow: /
另外,记得把写好的robots.txt文件放到你的网站根目录下,不然不行。另外,还有一个方便的写规则快捷方式登录google网站admin工具,连接规则生成robots.txt文件即可。
【推荐学习:《PHP 视频教程》】
php禁止网页抓取(本文实例讲述非常实用的常见技巧--本文实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 34 次浏览 • 2022-01-17 12:17
本文介绍了一个PHP+iFrame实现不刷新页面的异步文件上传的例子,是一个非常实用的常用技巧。分享给大家,供大家参考。具体分析如下:
说起iframe,现在用的人越来越少了,很多人认为应该换成AJAX,确实是这样,因为AJAX太好用了。
不过有一种情况我还是选择了iframe,就是本文要提到的文件异步上传。如果你有兴趣,你可以试试。如果使用原生 AJAX 来实现,应该会复杂很多。
首先给初学者补充一下基础知识:
1. 在iframe标签中,一般指定name属性进行标识;
2.form表单中,提交的目的地由action(目标地址)和target(目标窗口,默认为_self)决定;
3. 如果表单中的target指向iframe的名字,则表单可以提交到隐藏框架iframe;
4. iframe中的内容其实就是一个页面,js中的parent对象指的是父页面,也就是嵌入iframe中的页面;
5. php中使用move_uploaded_file()函数实现文件上传,$_FILES数组存储上传文件的相关信息。
本文实现了一个用户选择头像文件并立即上传并显示在页面上的示例。废话不多说,思路如下:
1. 在表单中嵌入一个iframe,并设置name属性的值;
2. 当文件上传选择的控件值发生变化时触发一个js函数,将表单提交到iframe,使用iframe内嵌的页面来处理文件上传;
3.在iframe中完成文件上传后,通过js中的parent对父页面进行操作,将图片显示在特定的tag中,并将图片的保存地址分配给隐藏字段;
4. 回到原来的页面,此时文件上传完成,隐藏域中记录了文件的路径。整个过程不刷新页面;
5. 最后,用户只需要在提交原创页面时,重新设置表单的action和target属性的值即可。
下面是效果截图和实现的代码:
upload.php页面如下:
iFrame异步文件上传
iFrame异步文件上传
用户名: <br />
上传头像:
proceedupload.php 页面如下:
<p> 查看全部
php禁止网页抓取(本文实例讲述非常实用的常见技巧--本文实例)
本文介绍了一个PHP+iFrame实现不刷新页面的异步文件上传的例子,是一个非常实用的常用技巧。分享给大家,供大家参考。具体分析如下:
说起iframe,现在用的人越来越少了,很多人认为应该换成AJAX,确实是这样,因为AJAX太好用了。
不过有一种情况我还是选择了iframe,就是本文要提到的文件异步上传。如果你有兴趣,你可以试试。如果使用原生 AJAX 来实现,应该会复杂很多。
首先给初学者补充一下基础知识:
1. 在iframe标签中,一般指定name属性进行标识;
2.form表单中,提交的目的地由action(目标地址)和target(目标窗口,默认为_self)决定;
3. 如果表单中的target指向iframe的名字,则表单可以提交到隐藏框架iframe;
4. iframe中的内容其实就是一个页面,js中的parent对象指的是父页面,也就是嵌入iframe中的页面;
5. php中使用move_uploaded_file()函数实现文件上传,$_FILES数组存储上传文件的相关信息。
本文实现了一个用户选择头像文件并立即上传并显示在页面上的示例。废话不多说,思路如下:
1. 在表单中嵌入一个iframe,并设置name属性的值;
2. 当文件上传选择的控件值发生变化时触发一个js函数,将表单提交到iframe,使用iframe内嵌的页面来处理文件上传;
3.在iframe中完成文件上传后,通过js中的parent对父页面进行操作,将图片显示在特定的tag中,并将图片的保存地址分配给隐藏字段;
4. 回到原来的页面,此时文件上传完成,隐藏域中记录了文件的路径。整个过程不刷新页面;
5. 最后,用户只需要在提交原创页面时,重新设置表单的action和target属性的值即可。
下面是效果截图和实现的代码:
upload.php页面如下:
iFrame异步文件上传
iFrame异步文件上传
用户名: <br />
上传头像:
proceedupload.php 页面如下:
<p>
php禁止网页抓取(一种的使用技巧,不追踪你的隐私总结前 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-17 12:11
)
分享一个简单的搜索思路,帮助你快速找到你想要的资源。
例子
关键字+百度网盘/提取码/密码...
上面的搜索方法只是一种思路,不仅如此,如果一个关键字找不到我们可以尝试其他关键字,并且不限于百度作为搜索引擎。Bing 和 Google 也是不错的选择。
与搜索工具的合作
配合搜索引擎的搜索工具,通过内容的时间限制、格式限制、固定站点。它使我们能够更快地过滤掉我们需要的东西。.
如何使用搜索引擎,你使用什么搜索引擎,你有什么建议?
搜索引擎的质量显然取决于其搜索体验。目前,百度、360、搜狗等是国内最受欢迎的。国外的有Bing(区分国内版和国外版),google,但是作为程序员,通常需要在网上搜索各种资料,所以遇到问题时搜索体验非常重要。实际上搜索引擎只有几个,但我们可以采取一些措施来改善我们的搜索体验。下面的截图展示了所有它是通过一个插件来实现的。浏览器可以是谷歌内核或者谷歌Chrome,即将被废弃的微软Edge也可以:
必须
国内版:
外国版
搜狗没有广告
百度广告不见了
秘密搜索这是一个不跟踪您的隐私的利基搜索引擎
综上所述,前三个是通过油猴插件实现的搜索体验。最重要的是广告没了,通过插件可以获得更好的体验。由于谷歌搜索在中国无法访问,因此不会推出。最后一个也是我平时用的,比较简单,注意隐私。油猴的脚本是开源的,以下是开源地址:
/
该插件不仅去除了广告,还提供了其他功能,非常有用:
可以直接搜索tampermonkey,在网上各种方式下载安装,然后从github安装脚本就有以上搜索体验
我相信这会解决你的问题,因为我遇到过你的问题。
搜索引擎使用技巧,如何做一个搜索引擎友好的网站?
搜索引擎是网站大部分流量的来源,搜索流量占比很大。所以在做网站优化的时候,需要提高网站对搜索引擎的友好度,这样网站优化才能达到最好的效果。那么如何设计网站来提高搜索引擎的友好度呢?
从搜索引擎蜘蛛网站的角度来看,我们在爬取、索引和排名的时候会遇到哪些问题?只要解决了这些问题,就能提高搜索引擎的友好度。
1、蜘蛛爬虫能找到网站
为了让搜索引擎发现 网站,必须有一个指向 网站 的外部链接。蜘蛛爬虫找到网站后,会沿着内部链接进入网站内容页面。因此,网站的结构必须合理、合乎逻辑,网站内的所有页面都可以通过HTML链接到达。蜘蛛爬虫一般不会进入flash页面,自然不会收录这样的页面。
网站所有页面距离首页不要太远,最好在3次点击内到达想要的页面。网站要被搜索引擎搜索到收录,页面必须有一定的权重,一个好的网站结构可以很好的传递权重,让更多的页面到达收录 标准。
2、找到网站后可以成功抓取页面内容
蜘蛛爬虫找到网站首页后,seo人员必须保证网站的url可以被抓取。虽然这些网址可能不全是收录,但还是需要尽可能的扩展。页面被抓取的可能性。动态数据库生成、参数过多的URL、flash页面等,对搜索引擎友好,搜索引擎自然不会收录这样的页面。
如果网站有你不想被搜索引擎或收录抓取的目录或页面,除了不链接到那些目录或页面,更好的方法是使用robots协议或meta机器人标记以阻止蜘蛛。
3、爬取页面后能否提取有用信息
如果想让搜索引擎在爬取页面后快速识别页面信息,首先要保证网站代码的简化,尽量减少代码行数。比例越大越好,整个网页文件越小越好。另外,页面上关键词的布局要合理,有利于搜索引擎对有用信息的抓取和提取。
只有当搜索引擎能够成功找到所有页面,爬取这些页面并提取相关内容,这样的网站才能提高搜索引擎的友好度。
如何用好谷歌等搜索引擎?
了解更多谷歌搜索技巧,可以让你的网页搜索能力大幅提升10倍
1、双引号,即通过“”实现精准搜索
在要搜索的关键词后面加上双引号("")的指令,表示完全匹配搜索,即使是顺序也完全匹配。即搜索引擎只会返回与关键词完全匹配的搜索结果,从而达到精准搜索的效果。
如果没有双引号,如果两个单词之间加了空格,它会分别搜索这两个单词,返回的结果可能不是我们想要的结果。
2、减号,即用“-”排除关键词
如果不想在搜索结果中看到一些关键词,可以使用-减号排除指定内容。
减号 (-) 表示搜索不收录减号后面的单词的页面。使用减号 (-) 命令时,减号前必须有一个空格,减号后不能有空格,然后是要排除的单词。
注意:“-”之前应该有一个空格。
3、星号,即按*(通配符)搜索
当你想搜索一个成语或一个段落,只记得两个或三个单词或一个段落时,可以通过星号(*)的通配符进行搜索,将忘记的单词替换为*。
4、site 搜索指定网站中的内容
在输入框中输入 site: URL 关键字,将在输入的 URL 中进行站点关键字搜索。
当您想对 网站 执行 关键词 搜索时,例如 amazon网站,您可以使用“site: .
site:是最熟悉的SEO高级搜索命令,用于搜索一个域名下的所有文件。
5、related:查找相似的相关网站
根据网站查找相似站点,使用方法:Related::,返回结果是与某个网站关联的页面。
6、filetype 搜索指定的文件类型
修饰符 filetype:[file extension] 可用于搜索指定的文件类型。例如,搜索 filetype:pdfmedical mask 返回所有收录医用口罩 关键词 的 pdf 文件。
Google 支持所有可编入索引的文件格式,包括 HTML、PHP 等。
7、inurl,搜索 关键词 出现在 url 中的页面。
inurl 指令用于搜索 关键词 出现在 url 中的页面。例如,搜索:inurl:medicalmasks 会返回 URL 中收录“medicalmasks”的所有页面的结果。
8、allintitle 页面标题收录文件组关键词
allintitle:搜索返回页面标题中收录多组 关键词 的文件。例如: allintitle: 医用口罩等价于: intitle: 医用 intitle:mask 返回标题中同时收录“medical”和“masks”的页面
9、allinurl 喜欢
allinurl:医用口罩相当于:inurl:医用 inurl:口罩
10、inanchor 导入在链接的锚文本中收录搜索词的页面
inanchor:该命令返回的结果是导入链接的锚文本中收录搜索词的页面。比如搜索:inanchor:“medical mask”,返回的结果是这些页面的链接的锚文本中出现了“medical mask”四个字。
查看全部
php禁止网页抓取(一种的使用技巧,不追踪你的隐私总结前
)
分享一个简单的搜索思路,帮助你快速找到你想要的资源。
例子
关键字+百度网盘/提取码/密码...
上面的搜索方法只是一种思路,不仅如此,如果一个关键字找不到我们可以尝试其他关键字,并且不限于百度作为搜索引擎。Bing 和 Google 也是不错的选择。
与搜索工具的合作
配合搜索引擎的搜索工具,通过内容的时间限制、格式限制、固定站点。它使我们能够更快地过滤掉我们需要的东西。.
如何使用搜索引擎,你使用什么搜索引擎,你有什么建议?
搜索引擎的质量显然取决于其搜索体验。目前,百度、360、搜狗等是国内最受欢迎的。国外的有Bing(区分国内版和国外版),google,但是作为程序员,通常需要在网上搜索各种资料,所以遇到问题时搜索体验非常重要。实际上搜索引擎只有几个,但我们可以采取一些措施来改善我们的搜索体验。下面的截图展示了所有它是通过一个插件来实现的。浏览器可以是谷歌内核或者谷歌Chrome,即将被废弃的微软Edge也可以:
必须
国内版:
外国版
搜狗没有广告
百度广告不见了
秘密搜索这是一个不跟踪您的隐私的利基搜索引擎
综上所述,前三个是通过油猴插件实现的搜索体验。最重要的是广告没了,通过插件可以获得更好的体验。由于谷歌搜索在中国无法访问,因此不会推出。最后一个也是我平时用的,比较简单,注意隐私。油猴的脚本是开源的,以下是开源地址:
/
该插件不仅去除了广告,还提供了其他功能,非常有用:
可以直接搜索tampermonkey,在网上各种方式下载安装,然后从github安装脚本就有以上搜索体验
我相信这会解决你的问题,因为我遇到过你的问题。
搜索引擎使用技巧,如何做一个搜索引擎友好的网站?
搜索引擎是网站大部分流量的来源,搜索流量占比很大。所以在做网站优化的时候,需要提高网站对搜索引擎的友好度,这样网站优化才能达到最好的效果。那么如何设计网站来提高搜索引擎的友好度呢?
从搜索引擎蜘蛛网站的角度来看,我们在爬取、索引和排名的时候会遇到哪些问题?只要解决了这些问题,就能提高搜索引擎的友好度。
1、蜘蛛爬虫能找到网站
为了让搜索引擎发现 网站,必须有一个指向 网站 的外部链接。蜘蛛爬虫找到网站后,会沿着内部链接进入网站内容页面。因此,网站的结构必须合理、合乎逻辑,网站内的所有页面都可以通过HTML链接到达。蜘蛛爬虫一般不会进入flash页面,自然不会收录这样的页面。
网站所有页面距离首页不要太远,最好在3次点击内到达想要的页面。网站要被搜索引擎搜索到收录,页面必须有一定的权重,一个好的网站结构可以很好的传递权重,让更多的页面到达收录 标准。
2、找到网站后可以成功抓取页面内容
蜘蛛爬虫找到网站首页后,seo人员必须保证网站的url可以被抓取。虽然这些网址可能不全是收录,但还是需要尽可能的扩展。页面被抓取的可能性。动态数据库生成、参数过多的URL、flash页面等,对搜索引擎友好,搜索引擎自然不会收录这样的页面。
如果网站有你不想被搜索引擎或收录抓取的目录或页面,除了不链接到那些目录或页面,更好的方法是使用robots协议或meta机器人标记以阻止蜘蛛。
3、爬取页面后能否提取有用信息
如果想让搜索引擎在爬取页面后快速识别页面信息,首先要保证网站代码的简化,尽量减少代码行数。比例越大越好,整个网页文件越小越好。另外,页面上关键词的布局要合理,有利于搜索引擎对有用信息的抓取和提取。
只有当搜索引擎能够成功找到所有页面,爬取这些页面并提取相关内容,这样的网站才能提高搜索引擎的友好度。
如何用好谷歌等搜索引擎?
了解更多谷歌搜索技巧,可以让你的网页搜索能力大幅提升10倍
1、双引号,即通过“”实现精准搜索
在要搜索的关键词后面加上双引号("")的指令,表示完全匹配搜索,即使是顺序也完全匹配。即搜索引擎只会返回与关键词完全匹配的搜索结果,从而达到精准搜索的效果。
如果没有双引号,如果两个单词之间加了空格,它会分别搜索这两个单词,返回的结果可能不是我们想要的结果。
2、减号,即用“-”排除关键词
如果不想在搜索结果中看到一些关键词,可以使用-减号排除指定内容。
减号 (-) 表示搜索不收录减号后面的单词的页面。使用减号 (-) 命令时,减号前必须有一个空格,减号后不能有空格,然后是要排除的单词。
注意:“-”之前应该有一个空格。
3、星号,即按*(通配符)搜索
当你想搜索一个成语或一个段落,只记得两个或三个单词或一个段落时,可以通过星号(*)的通配符进行搜索,将忘记的单词替换为*。
4、site 搜索指定网站中的内容
在输入框中输入 site: URL 关键字,将在输入的 URL 中进行站点关键字搜索。
当您想对 网站 执行 关键词 搜索时,例如 amazon网站,您可以使用“site: .
site:是最熟悉的SEO高级搜索命令,用于搜索一个域名下的所有文件。
5、related:查找相似的相关网站
根据网站查找相似站点,使用方法:Related::,返回结果是与某个网站关联的页面。
6、filetype 搜索指定的文件类型
修饰符 filetype:[file extension] 可用于搜索指定的文件类型。例如,搜索 filetype:pdfmedical mask 返回所有收录医用口罩 关键词 的 pdf 文件。
Google 支持所有可编入索引的文件格式,包括 HTML、PHP 等。
7、inurl,搜索 关键词 出现在 url 中的页面。
inurl 指令用于搜索 关键词 出现在 url 中的页面。例如,搜索:inurl:medicalmasks 会返回 URL 中收录“medicalmasks”的所有页面的结果。
8、allintitle 页面标题收录文件组关键词
allintitle:搜索返回页面标题中收录多组 关键词 的文件。例如: allintitle: 医用口罩等价于: intitle: 医用 intitle:mask 返回标题中同时收录“medical”和“masks”的页面
9、allinurl 喜欢
allinurl:医用口罩相当于:inurl:医用 inurl:口罩
10、inanchor 导入在链接的锚文本中收录搜索词的页面
inanchor:该命令返回的结果是导入链接的锚文本中收录搜索词的页面。比如搜索:inanchor:“medical mask”,返回的结果是这些页面的链接的锚文本中出现了“medical mask”四个字。
php禁止网页抓取(如下协议文件屏蔽百度蜘蛛抓取协议的设置协议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-17 12:10
百度蜘蛛爬我们的网站是希望把我们的网页收录放到它的搜索引擎中,以后用户搜索的时候,可以给我们带来一定的SEO流量。当然,我们不希望搜索引擎抓取所有内容。
所以,这个时候,我们只希望我们想被搜索引擎搜索到的内容被爬取。像用户隐私、背景信息等,不希望搜索引擎被爬取和收录。解决这个问题有两种最好的方法,如下:
robots协议文件阻止百度蜘蛛爬行
robots协议是放置在网站根目录下的协议文件,可以通过URL地址访问:你的域名/robots.txt。当百度蜘蛛爬取我们的网站时,会先访问这个文件。因为它告诉蜘蛛抓取什么,不抓取什么。
robots协议文件的设置比较简单,可以通过User-Agent、Disallow、Allow这三个参数来设置。
User-Agent:针对不同搜索引擎的语句;
Disallow:不允许爬取的目录或页面;
Allow:允许爬取的目录或页面,一般可以省略不写,因为不写不能爬取的东西是可以爬取的;
我们来看一个例子,场景是不想让百度抢我所有的网站css文件、数据目录、seo-tag.html页面
用户代理:百度蜘蛛
禁止:/*.css
禁止:/数据/
禁止:/seo/seo-tag.html
如上,user-agent 声明的蜘蛛名称表示它是给百度蜘蛛的。以下不能抓取“/*.css”。首先前面的/指的是根目录,也就是你的域名。* 是一个通配符,代表任何东西。这意味着无法抓取所有以 .css 结尾的文件。亲身体验以下两点。逻辑是一样的。
如果你想检查你上次设置的robots文件是否正确,可以访问这个文章《检查Robots是否正确的工具介绍》,里面有详细的工具可以检查你的设置。
通过403状态码限制内容输出,阻止蜘蛛爬行。
403状态码是网页在http协议中返回的状态码。当搜索引擎遇到 403 状态码时,它就知道这种类型的页面是受限的。我无法访问。比如你需要登录才能查看内容,搜索引擎本身是不会登录的,所以当你返回403的时候,他也知道这是一个权限设置页面,无法读取内容。自然不是收录。
在返回 403 状态码时,应该有一个类似于 404 页面的页面。提示用户或蜘蛛该页面想要做什么以访问它。两者缺一不可。你只有一个提示页面,状态码返回200,是百度蜘蛛的大量重复页面。有 403 状态码,但返回不同的东西。它也不是很友好。
最后,对于机器人协议,我想再补充一点:“现在搜索引擎会通过你网页的排版和布局来识别你网页的用户友好性。如果css文件的爬取和布局相关js文件被屏蔽了,那么搜索引擎就会不知道你的网页布局是好是坏,所以不建议屏蔽这些内容蜘蛛。”
好了,今天的分享就到这里,希望对大家有所帮助。当然,以上两个设置对除了百度蜘蛛之外的所有蜘蛛都有效。设置时要小心。 查看全部
php禁止网页抓取(如下协议文件屏蔽百度蜘蛛抓取协议的设置协议)
百度蜘蛛爬我们的网站是希望把我们的网页收录放到它的搜索引擎中,以后用户搜索的时候,可以给我们带来一定的SEO流量。当然,我们不希望搜索引擎抓取所有内容。
所以,这个时候,我们只希望我们想被搜索引擎搜索到的内容被爬取。像用户隐私、背景信息等,不希望搜索引擎被爬取和收录。解决这个问题有两种最好的方法,如下:
robots协议文件阻止百度蜘蛛爬行
robots协议是放置在网站根目录下的协议文件,可以通过URL地址访问:你的域名/robots.txt。当百度蜘蛛爬取我们的网站时,会先访问这个文件。因为它告诉蜘蛛抓取什么,不抓取什么。
robots协议文件的设置比较简单,可以通过User-Agent、Disallow、Allow这三个参数来设置。
User-Agent:针对不同搜索引擎的语句;
Disallow:不允许爬取的目录或页面;
Allow:允许爬取的目录或页面,一般可以省略不写,因为不写不能爬取的东西是可以爬取的;
我们来看一个例子,场景是不想让百度抢我所有的网站css文件、数据目录、seo-tag.html页面
用户代理:百度蜘蛛
禁止:/*.css
禁止:/数据/
禁止:/seo/seo-tag.html
如上,user-agent 声明的蜘蛛名称表示它是给百度蜘蛛的。以下不能抓取“/*.css”。首先前面的/指的是根目录,也就是你的域名。* 是一个通配符,代表任何东西。这意味着无法抓取所有以 .css 结尾的文件。亲身体验以下两点。逻辑是一样的。
如果你想检查你上次设置的robots文件是否正确,可以访问这个文章《检查Robots是否正确的工具介绍》,里面有详细的工具可以检查你的设置。
通过403状态码限制内容输出,阻止蜘蛛爬行。
403状态码是网页在http协议中返回的状态码。当搜索引擎遇到 403 状态码时,它就知道这种类型的页面是受限的。我无法访问。比如你需要登录才能查看内容,搜索引擎本身是不会登录的,所以当你返回403的时候,他也知道这是一个权限设置页面,无法读取内容。自然不是收录。
在返回 403 状态码时,应该有一个类似于 404 页面的页面。提示用户或蜘蛛该页面想要做什么以访问它。两者缺一不可。你只有一个提示页面,状态码返回200,是百度蜘蛛的大量重复页面。有 403 状态码,但返回不同的东西。它也不是很友好。
最后,对于机器人协议,我想再补充一点:“现在搜索引擎会通过你网页的排版和布局来识别你网页的用户友好性。如果css文件的爬取和布局相关js文件被屏蔽了,那么搜索引擎就会不知道你的网页布局是好是坏,所以不建议屏蔽这些内容蜘蛛。”
好了,今天的分享就到这里,希望对大家有所帮助。当然,以上两个设置对除了百度蜘蛛之外的所有蜘蛛都有效。设置时要小心。

