
php禁止网页抓取
php禁止网页抓取(百度不收录内容页面的原因及解决方法原因分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-10 10:32
相信很多网站都会遇到百度没有收录内容页面的现象,而通过站长统计工具查看流量来源,你会发现大部分流量来自网站的编辑尾部关键词,即网站的内容页,一旦百度不收录内容页,将对获取 网站 流量。如果你的网站也有百度没有收录内容页面的现象,那就跟我一起仔细分析一下原因吧。
百度没有收录内容页面的原因:
1、 网站内容质量太低
网站内容质量低是百度不收录的主要原因。8月22日,百度正式公布新算法“百度算法升级,将影响作弊网站收录和低质量内容”。在“站点排序”中,百度关注的是内容质量低的站点,尤其是采集内容的站点。所以,网站看来百度没有收录内容页面,先看看你的网站内容是否优质?
解决方法:调整网站内容的质量。如果网站的内容被复制粘贴,那么增加每日原创文章的数量,或者调整网站内容页面的布局,比如增加用户评论功能并添加相关文章推荐,旨在降低页面相似度,从而解决百度没有收录内容页面的现象。
2、 百度蜘蛛频繁爬取其他页面
排除网站的内容质量低的因素,网站的内容页仍然不是收录,然后查看网站的日志看百度蜘蛛是否针对某些目录和Pages经常被爬取,造成爬取的浪费。对搜索引擎爬取过程有一定了解的朋友都知道,百度蜘蛛每天对一个站点的爬取时间是有限的。页面爬取不充分、爬取不充分的现象。
解决方法:查看网站日志,屏蔽频繁爬取的页面,让百度蜘蛛在有限的时间内爬取更多的其他内容页面。
3、 其他因素总结
百度没有收录内容页面的原因有很多,比如:服务器因素、网站改版因素、网站大量死链接、网站链接深度因素太深了。
解决方案:服务器的稳定性很重要。如果网站长时间打不开,对百度对内容页的爬取是致命的;网站 不要频繁修改标题和描述信息以进行修订。;使用工具检测网站中是否存在大量死链接,并清除或阻止死链接爬取;如果链接地址太深,可以调整链接结构,因为目录太深的内容,百度蜘蛛很难抓取,甚至无法抓取。
以上,我总结了百度没有收录内容页面的三个原因,那么在实践中,如果使用了呢?下面是一个成功解决我的网站出现百度收录内容页面的例子。
先来看看百度收录近几天的情况表:
从图中数据可以看出,百度没有收录内容页面的现象在9月2日出现,经过调整在9月9日得到解决。
网站自推出以来,虽然是以论坛的形式,但我对论坛的内容管理非常严格。可以排除网站内容质量低的原因。根据服务器的监控数据,网站的服务器最近一段时间运行正常,其他因素不多。看看百度蜘蛛爬不爬的问题。
上图是通过网站的日志分析软件统计的9月2日到9月5日百度蜘蛛爬取目录的数据。发现百度蜘蛛频繁爬取/bbx目录。这个目录是方便宝箱的链接。现在很多本地论坛都用这个插件,里面的内容重复性极强。
于是我对/bbx链接进行了nofollow控制,阻止百度蜘蛛爬取这个目录。同时,在 robots.txt 文件中,我添加了 Disallow:/bbx 命令,以防止百度蜘蛛以双重权限爬取该目录。终于在 9 月 9 日,百度开始将 收录 恢复到内容页面。
当网站出现百度没有收录内容页面时,站长需要仔细检查是否有百度不爬自己操作的原因。结合百度日志的分析,可以客观的发现问题,从而解决问题。如果你的网站也有百度没有收录内容页面的现象,你也不确定,可以联系王继顺,我很乐意帮你解决。
本文为北京人民论坛结合论坛实际情况的样本提要。转载请自带链接! 查看全部
php禁止网页抓取(百度不收录内容页面的原因及解决方法原因分析)
相信很多网站都会遇到百度没有收录内容页面的现象,而通过站长统计工具查看流量来源,你会发现大部分流量来自网站的编辑尾部关键词,即网站的内容页,一旦百度不收录内容页,将对获取 网站 流量。如果你的网站也有百度没有收录内容页面的现象,那就跟我一起仔细分析一下原因吧。
百度没有收录内容页面的原因:
1、 网站内容质量太低
网站内容质量低是百度不收录的主要原因。8月22日,百度正式公布新算法“百度算法升级,将影响作弊网站收录和低质量内容”。在“站点排序”中,百度关注的是内容质量低的站点,尤其是采集内容的站点。所以,网站看来百度没有收录内容页面,先看看你的网站内容是否优质?
解决方法:调整网站内容的质量。如果网站的内容被复制粘贴,那么增加每日原创文章的数量,或者调整网站内容页面的布局,比如增加用户评论功能并添加相关文章推荐,旨在降低页面相似度,从而解决百度没有收录内容页面的现象。
2、 百度蜘蛛频繁爬取其他页面
排除网站的内容质量低的因素,网站的内容页仍然不是收录,然后查看网站的日志看百度蜘蛛是否针对某些目录和Pages经常被爬取,造成爬取的浪费。对搜索引擎爬取过程有一定了解的朋友都知道,百度蜘蛛每天对一个站点的爬取时间是有限的。页面爬取不充分、爬取不充分的现象。
解决方法:查看网站日志,屏蔽频繁爬取的页面,让百度蜘蛛在有限的时间内爬取更多的其他内容页面。
3、 其他因素总结
百度没有收录内容页面的原因有很多,比如:服务器因素、网站改版因素、网站大量死链接、网站链接深度因素太深了。
解决方案:服务器的稳定性很重要。如果网站长时间打不开,对百度对内容页的爬取是致命的;网站 不要频繁修改标题和描述信息以进行修订。;使用工具检测网站中是否存在大量死链接,并清除或阻止死链接爬取;如果链接地址太深,可以调整链接结构,因为目录太深的内容,百度蜘蛛很难抓取,甚至无法抓取。
以上,我总结了百度没有收录内容页面的三个原因,那么在实践中,如果使用了呢?下面是一个成功解决我的网站出现百度收录内容页面的例子。
先来看看百度收录近几天的情况表:

从图中数据可以看出,百度没有收录内容页面的现象在9月2日出现,经过调整在9月9日得到解决。
网站自推出以来,虽然是以论坛的形式,但我对论坛的内容管理非常严格。可以排除网站内容质量低的原因。根据服务器的监控数据,网站的服务器最近一段时间运行正常,其他因素不多。看看百度蜘蛛爬不爬的问题。



上图是通过网站的日志分析软件统计的9月2日到9月5日百度蜘蛛爬取目录的数据。发现百度蜘蛛频繁爬取/bbx目录。这个目录是方便宝箱的链接。现在很多本地论坛都用这个插件,里面的内容重复性极强。
于是我对/bbx链接进行了nofollow控制,阻止百度蜘蛛爬取这个目录。同时,在 robots.txt 文件中,我添加了 Disallow:/bbx 命令,以防止百度蜘蛛以双重权限爬取该目录。终于在 9 月 9 日,百度开始将 收录 恢复到内容页面。
当网站出现百度没有收录内容页面时,站长需要仔细检查是否有百度不爬自己操作的原因。结合百度日志的分析,可以客观的发现问题,从而解决问题。如果你的网站也有百度没有收录内容页面的现象,你也不确定,可以联系王继顺,我很乐意帮你解决。
本文为北京人民论坛结合论坛实际情况的样本提要。转载请自带链接!
php禁止网页抓取( 禁止post提交数据的ajax缓存需要怎么处理?缓存 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-10 10:20
禁止post提交数据的ajax缓存需要怎么处理?缓存
)
在 (ASP/PHP/JSP/html/js) 中禁用 ajax 缓存的方法集合
更新时间:2014年8月19日12:00:52投稿:hebedich
最简单的禁止ajax缓存的方法是直接在js端生成一个随机数,但是有时候发现这个方法不适合post。如果我们想禁止post提交数据的ajax缓存,我们应该怎么做呢?整理了很多关于禁用ajax缓存的例子
Ajax 缓存很好,但也有缺点。缓存有时会导致误操作,影响用户体验。如果你的WEB项目不需要ajax缓存,可以如下禁用ajax缓存。
一、在 ASP 中禁用 ajax 缓存:
'将它放在 ASP 页面的最开始处
Response.expires=0
Response.addHeader("pragma","no-cache")
Response.addHeader("Cache-Control","no-cache, must-revalidate")
二、在 PHP 中禁用 Ajax 缓存:
//放在PHP网页开头部分
header("Expires: Thu, 01 Jan 1970 00:00:01 GMT");
header("Cache-Control: no-cache, must-revalidate");
header("Pragma: no-cache");
三、在 JSp 中禁用 ajax 缓存:
//放在JSP网页最开头部分
response.addHeader("Cache-Control", "no-cache");
response.addHeader("Expires", "Thu, 01 Jan 1970 00:00:01 GMT");
四、通过向页面添加随机字符来强制更新:例如
var url = 'http://url/';
url += '?temp=' + new Date().getTime();
url += '?temp=' + Math.random();
五、如果是静态HTML,可以添加HTTP头防止缓存,如: 查看全部
php禁止网页抓取(
禁止post提交数据的ajax缓存需要怎么处理?缓存
)
在 (ASP/PHP/JSP/html/js) 中禁用 ajax 缓存的方法集合
更新时间:2014年8月19日12:00:52投稿:hebedich
最简单的禁止ajax缓存的方法是直接在js端生成一个随机数,但是有时候发现这个方法不适合post。如果我们想禁止post提交数据的ajax缓存,我们应该怎么做呢?整理了很多关于禁用ajax缓存的例子
Ajax 缓存很好,但也有缺点。缓存有时会导致误操作,影响用户体验。如果你的WEB项目不需要ajax缓存,可以如下禁用ajax缓存。
一、在 ASP 中禁用 ajax 缓存:
'将它放在 ASP 页面的最开始处
Response.expires=0
Response.addHeader("pragma","no-cache")
Response.addHeader("Cache-Control","no-cache, must-revalidate")
二、在 PHP 中禁用 Ajax 缓存:
//放在PHP网页开头部分
header("Expires: Thu, 01 Jan 1970 00:00:01 GMT");
header("Cache-Control: no-cache, must-revalidate");
header("Pragma: no-cache");
三、在 JSp 中禁用 ajax 缓存:
//放在JSP网页最开头部分
response.addHeader("Cache-Control", "no-cache");
response.addHeader("Expires", "Thu, 01 Jan 1970 00:00:01 GMT");
四、通过向页面添加随机字符来强制更新:例如
var url = 'http://url/';
url += '?temp=' + new Date().getTime();
url += '?temp=' + Math.random();
五、如果是静态HTML,可以添加HTTP头防止缓存,如:
php禁止网页抓取(基于网站安全与盈利的因素,搜索引擎不能属性屏蔽收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-09 21:05
基于网站安全和盈利因素,网站管理员不希望某些目录或页面被爬取和收录,例如付费内容、处于测试阶段的页面以及具有重复内容的页面。
虽然在构建网站的过程中,使用JavaScript、Flash链接和Nofollow属性可以让搜索引擎蜘蛛远离,导致页面不是收录。
但在某些情况下,搜索引擎可以读取它们。基于网站排名考虑,我们建议谨慎使用JavaScript、Flash链接和Nofollow属性来阻止收录。
我强调,使用JavaScript和Flash链接建站其实是在给网站制造蜘蛛陷阱,让搜索引擎无法正确判断和抓取页面的主题和文字。
为保证网站某些目录或页面不被收录阻塞,需要正确使用robots文件或Meta Robots标签来实现网站的阻塞收录@ > 机制。
1、机器人文件
当搜索引擎蜘蛛访问网站时,它会首先检查网站的根目录下是否有一个名为robots.txt的纯文本文件。它的主要作用是让搜索引擎抓取或禁止网站的一些内容。
用户代理:* 适用于所有蜘蛛
禁止:/上传/
禁止:.jpg$ 禁止抓取所有 .jpg 文件
禁止:*.html 禁止抓取所有 html 文件
禁止:/upload/index.html
Disallow 禁止抓取哪些文件或目录。 Allow 告诉搜索引擎应该抓取哪些页面。由于没有指定,所以允许爬取,所以单独写allow是没有意义的。
2、元机器人标签
元机器人标签是页面头部的一种元标签,用于指示搜索引擎禁止对该页面的内容进行索引。
最简单的元机器人标签格式是:
name=”robots” content=”noindex,nofollow”>
效果是禁止所有搜索引擎对该页面进行索引,并禁止该页面上的链接。
name=”robots” content=”noindex”>
效果是禁止对该页面进行索引,但允许蜘蛛跟踪页面上的链接,并且还可以传递权重。
Google、Bing、Yahoo 支持的标签如下:
Noindex:不索引此页面
Nofollow:不要关注此页面上的链接
Nosnippet:不在搜索结果中显示片段文本
Noarchive:不显示快照
Noodp:不要使用打开目录中的标题和描述
百度支持:Nofollow 和 Noarchive
只有在禁止索引时使用元机器人才有意义。
带有 noindex 肉机器人标签的页面将被抓取,但不会被编入索引,并且该页面 URL 不会出现在搜索结果中,这与 robots 文件不同。 查看全部
php禁止网页抓取(基于网站安全与盈利的因素,搜索引擎不能属性屏蔽收录)
基于网站安全和盈利因素,网站管理员不希望某些目录或页面被爬取和收录,例如付费内容、处于测试阶段的页面以及具有重复内容的页面。

虽然在构建网站的过程中,使用JavaScript、Flash链接和Nofollow属性可以让搜索引擎蜘蛛远离,导致页面不是收录。
但在某些情况下,搜索引擎可以读取它们。基于网站排名考虑,我们建议谨慎使用JavaScript、Flash链接和Nofollow属性来阻止收录。
我强调,使用JavaScript和Flash链接建站其实是在给网站制造蜘蛛陷阱,让搜索引擎无法正确判断和抓取页面的主题和文字。
为保证网站某些目录或页面不被收录阻塞,需要正确使用robots文件或Meta Robots标签来实现网站的阻塞收录@ > 机制。
1、机器人文件
当搜索引擎蜘蛛访问网站时,它会首先检查网站的根目录下是否有一个名为robots.txt的纯文本文件。它的主要作用是让搜索引擎抓取或禁止网站的一些内容。
用户代理:* 适用于所有蜘蛛
禁止:/上传/
禁止:.jpg$ 禁止抓取所有 .jpg 文件
禁止:*.html 禁止抓取所有 html 文件
禁止:/upload/index.html
Disallow 禁止抓取哪些文件或目录。 Allow 告诉搜索引擎应该抓取哪些页面。由于没有指定,所以允许爬取,所以单独写allow是没有意义的。
2、元机器人标签
元机器人标签是页面头部的一种元标签,用于指示搜索引擎禁止对该页面的内容进行索引。
最简单的元机器人标签格式是:
name=”robots” content=”noindex,nofollow”>
效果是禁止所有搜索引擎对该页面进行索引,并禁止该页面上的链接。
name=”robots” content=”noindex”>
效果是禁止对该页面进行索引,但允许蜘蛛跟踪页面上的链接,并且还可以传递权重。
Google、Bing、Yahoo 支持的标签如下:
Noindex:不索引此页面
Nofollow:不要关注此页面上的链接
Nosnippet:不在搜索结果中显示片段文本
Noarchive:不显示快照
Noodp:不要使用打开目录中的标题和描述
百度支持:Nofollow 和 Noarchive
只有在禁止索引时使用元机器人才有意义。
带有 noindex 肉机器人标签的页面将被抓取,但不会被编入索引,并且该页面 URL 不会出现在搜索结果中,这与 robots 文件不同。
php禁止网页抓取(搜索引擎爬取.txt文件的作用以及使用方法蜘蛛抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-09 18:46
搜索引擎用来抓取网页内容的工具称为搜索引擎蜘蛛。如果您想阻止蜘蛛从搜索引擎服务器抓取某个页面,您可以通过 robots.txt 文件限制蜘蛛抓取。很多朋友希望屏蔽网站后台禁止搜索引擎蜘蛛抓取,不希望其他用户知道网站后台地址。这可以通过 robots.txt 文件进行限制吗?
首先,我们来分析下robots.txt文件的作用和使用方法。在搜索引擎蜘蛛来到站点抓取网页内容之前,它会首先访问 网站 根目录下的 robots.txt 文件。如果该文件不存在,则搜索引擎蜘蛛默认使用此 网站 以允许它全部抓取。robots.txt是一个简单的纯文本文件(记事本文件),搜索引擎蜘蛛通过robots.txt中的内容判断网站是否可以全部或部分抓取。
如果您希望网站搜索引擎蜘蛛抓取所有页面而不阻止任何页面,您可以不上传 robots.txt 文件或上传一个空的 robots.txt 文件。(目前大部分内容管理系统源程序都带有一个空的 robots.txt 文件)
robots.txt 文件的标准格式如下:
用户代理: *
禁止:/secret.html
禁止:/index.php?
禁止:/qiyecao/
如果要阻止页面 seacert.html 抓取,只需将 Disallow 添加到 robots.txt 文件中:
/secret.html 这行代码(这个网页是相对于网站的根目录的URL,如果不在根目录下,请加上/xxxx/secret.html父目录文件夹的名字)。
如果你想让一个文件夹根本不被爬取,你可以通过 Disallow:
实现了/qiyecao/ 语法,但搜索引擎蜘蛛仍然可以爬取/qiyecao.html 页面。
注意:如果某个页面已经被搜索引擎抓取,您修改 robots.txt 文件将其屏蔽,则可能需要 1 到 2 个月的时间才能被搜索引擎删除。不过如果想加快删除速度,可以通过google网站admin工具删除。如果你的网站首页是index.asp,最好不要禁止爬取index.html或index.php等页面,以防爬取错误。
最后解释一下本文开头提出的问题:屏蔽网站后台禁止搜索引擎蜘蛛抓取,不希望其他用户知道网站后台地址。这可以通过 robots.txt 文件进行限制吗?其实这并不能被robots.txt文件限制,因为robots.txt是放在网站根目录下的文本文档,任何人都可以访问。在不让其他访问者知道的情况下阻止搜索引擎蜘蛛爬取 网站 背景的方法是将 noindex 标签添加到 网站 背景登陆页面。 查看全部
php禁止网页抓取(搜索引擎爬取.txt文件的作用以及使用方法蜘蛛抓取)
搜索引擎用来抓取网页内容的工具称为搜索引擎蜘蛛。如果您想阻止蜘蛛从搜索引擎服务器抓取某个页面,您可以通过 robots.txt 文件限制蜘蛛抓取。很多朋友希望屏蔽网站后台禁止搜索引擎蜘蛛抓取,不希望其他用户知道网站后台地址。这可以通过 robots.txt 文件进行限制吗?
首先,我们来分析下robots.txt文件的作用和使用方法。在搜索引擎蜘蛛来到站点抓取网页内容之前,它会首先访问 网站 根目录下的 robots.txt 文件。如果该文件不存在,则搜索引擎蜘蛛默认使用此 网站 以允许它全部抓取。robots.txt是一个简单的纯文本文件(记事本文件),搜索引擎蜘蛛通过robots.txt中的内容判断网站是否可以全部或部分抓取。
如果您希望网站搜索引擎蜘蛛抓取所有页面而不阻止任何页面,您可以不上传 robots.txt 文件或上传一个空的 robots.txt 文件。(目前大部分内容管理系统源程序都带有一个空的 robots.txt 文件)
robots.txt 文件的标准格式如下:
用户代理: *
禁止:/secret.html
禁止:/index.php?
禁止:/qiyecao/
如果要阻止页面 seacert.html 抓取,只需将 Disallow 添加到 robots.txt 文件中:
/secret.html 这行代码(这个网页是相对于网站的根目录的URL,如果不在根目录下,请加上/xxxx/secret.html父目录文件夹的名字)。
如果你想让一个文件夹根本不被爬取,你可以通过 Disallow:
实现了/qiyecao/ 语法,但搜索引擎蜘蛛仍然可以爬取/qiyecao.html 页面。
注意:如果某个页面已经被搜索引擎抓取,您修改 robots.txt 文件将其屏蔽,则可能需要 1 到 2 个月的时间才能被搜索引擎删除。不过如果想加快删除速度,可以通过google网站admin工具删除。如果你的网站首页是index.asp,最好不要禁止爬取index.html或index.php等页面,以防爬取错误。
最后解释一下本文开头提出的问题:屏蔽网站后台禁止搜索引擎蜘蛛抓取,不希望其他用户知道网站后台地址。这可以通过 robots.txt 文件进行限制吗?其实这并不能被robots.txt文件限制,因为robots.txt是放在网站根目录下的文本文档,任何人都可以访问。在不让其他访问者知道的情况下阻止搜索引擎蜘蛛爬取 网站 背景的方法是将 noindex 标签添加到 网站 背景登陆页面。
php禁止网页抓取(php禁止网页抓取被抓包的渲染模板可以看下吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-04-06 22:01
php禁止网页抓取,也是被抓包的。被抓取,就可以和web服务器进行交互。
wordpress你有两种做法:一个是通过autopath的方式修改html模板;另一个是通过代理的方式解析页面的代码,然后提交http请求到后端进行后续的步骤。比如一个图片的post请求就会经过三个阶段:①将图片的url地址一字节复制发送给wordpress后端;②在后端根据url地址对图片进行操作;③验证成功后将图片通过post的方式发送给你的wordpress服务器。
应该能抓,
都是后端接口给html页,
要抓取js代码或ajaxhtml页面很难.要改变html标签的<p>标签和标签,但是要抓取ajax请求时,记得用标签。另外html代码抓取,自然也要让后端来实现,ajax一般后端抓取不是很方便,可以考虑用jsonwordpress接口会提供xml,json二进制抓取api,但是目前只支持firebug在json解析出来后,再调用模板做静态网页(ajax请求的渲染模板可以看下yii官方视频,bootstrap官方文档都有写)。</p>
代理方式实现,假如你的机器能安装apache或nginx就可以是很好的选择。找个可以抓取插件,具体可以看官方文档:,有抓取代理, 查看全部
php禁止网页抓取(php禁止网页抓取被抓包的渲染模板可以看下吗)
php禁止网页抓取,也是被抓包的。被抓取,就可以和web服务器进行交互。
wordpress你有两种做法:一个是通过autopath的方式修改html模板;另一个是通过代理的方式解析页面的代码,然后提交http请求到后端进行后续的步骤。比如一个图片的post请求就会经过三个阶段:①将图片的url地址一字节复制发送给wordpress后端;②在后端根据url地址对图片进行操作;③验证成功后将图片通过post的方式发送给你的wordpress服务器。
应该能抓,
都是后端接口给html页,
要抓取js代码或ajaxhtml页面很难.要改变html标签的<p>标签和标签,但是要抓取ajax请求时,记得用标签。另外html代码抓取,自然也要让后端来实现,ajax一般后端抓取不是很方便,可以考虑用jsonwordpress接口会提供xml,json二进制抓取api,但是目前只支持firebug在json解析出来后,再调用模板做静态网页(ajax请求的渲染模板可以看下yii官方视频,bootstrap官方文档都有写)。</p>
代理方式实现,假如你的机器能安装apache或nginx就可以是很好的选择。找个可以抓取插件,具体可以看官方文档:,有抓取代理,
php禁止网页抓取( :正是这些原因导致搜索引擎蜘蛛爬行异常,是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-04-02 13:19
:正是这些原因导致搜索引擎蜘蛛爬行异常,是什么?)
: 就是这些原因导致搜索引擎蜘蛛抓取异常
我们在优化网站,推广SEO的时候,会遇到这种情况。一些网站的内容质量确实不错,用户可以看到,但是没有被百度蜘蛛抓到,这对搜索引擎来说是个损失。那么我们称这种情况为爬取异常。这是什么原因?关键词Genie根据关键词对优化进行排名,分析一些常见的异常爬取原因:
1.服务问题
如果服务不稳定,网站 终端将无法访问和链接。或者联系不上。在这种情况下,您只能改进服务。不贪小利,终有损网站
2.运营商的问题
中国一般使用电信和中国联通,一般使用两线业务。如果您因为单线服务无法访问网站,最好通过位于升级或服务的双线服务解决问题
3.DNS 异常
当spider在网站且无法解析你的IP时,会出现DNS异常或DNS错误,可能是服务商禁止spider设置或网站的IP地址不正确造成的。您可以使用工具来检查域名是否正确解析。如果不正确或无法解析,请联系域名提供商更新IP解析。
4.禁止蜘蛛爬行
要看检查相关代码设置,是否有禁止百度蜘蛛爬取的设置,或者机器人协议的设置。
5.一般访问禁令
UA是一个用户代理,服务通过识别UA为访问者返回异常页面(如403、500)或跳转到其他页面,即禁止UA。
当网站不希望百度蜘蛛访问时,需要设置相应的访问权限。
6.死链接
死链接在网站,一个无效页面,没有价值,访问无效。有协议死链接和内容死链接。
对于死链接,使用404页面创建或统计404页面向百度站长平台提交数据。
7.异常跳跃
异常跳转是指当前无效页面,如死链接或删除页面,通过301直接跳转到首页或相关目录页面。
或者跳转到错误无效的页面。
所有这些情况都需要引起注意。主要问题是 301 协议,没有必要建议不要设置它。
8.其他情况
A.JS代码问题,JS代码对搜索引擎不友好,不是关键识别对象。如果 JS 代码蜘蛛无法识别,则问题为异常。
B、百度会根据网站的内容、规模、流量自动设置合理的爬取压力,但在异常情况下,如果压力控制异常,会突然关闭服务负载进行自我保护.
C、偶尔因压力过大被封杀:百度会根据网站规模、流量等信息设置合理的爬取压力。但是,在异常情况下,例如压力控制异常,服务将根据自身负载进行事故保护。在这种情况下,请在返回码中返回 503(表示“服务不可用”),这样搜索引擎蜘蛛会在一段时间后再次尝试爬取该链接,如果 网站 空闲,则爬取成功。
总结:网站的异常爬取对网站本身是不利的,因为对于一些经常更新内容却不能正常爬取的网站,各种搜索引擎会认为网站用户体验很差。同时也会降低对网站的评价,对爬取、索引、排序都会产生一定程度的负面影响。最终的影响会导致网站本身或多或少地从百度获得流量。
在介绍了搜索引擎的各种算法之后,我相信站长是无敌的。作为一个老站长,我也结合自己的一些优化经验告诉大家,哪些词在优化,哪些不能用或者得不偿失,但是页面会是K,整个网站会是K
非法班
非法类的 关键词 永远不能用正则 网站 优化为正则 网站,甚至是 文章,加上两个非正式的词,很有可能它将不受云服务的影响。其实阿里云就是这样的。当文章 文章 中有非法字词时,服务会为您屏蔽该字词。您无法打开整个页面。
边缘行业类别
所以,你不能像边缘行业那样拥有 文章。虽然服务可以接受一些边缘行业的文章,比如棋牌类,但是搜索引擎不能接受,因为搜索引擎不能接受新站点发布的这种文章。他不知道你什么时候要通过这个 文章 获利,所以他根本不包括你的 文章,或者只是淘汰你的 文章。当然,前提是以文章的形式发布。
医疗保健类别
虽然这东西是正版内容,但是搜索引擎不会轻易优化它,给一个健康的网站SEO排名,除非这个网站非常有名,没有商业性质,比如39问答,只是一个问答平台,不卖产品,对排名影响不大。
当我们来运行这个网站时,首先,如果你用Enterprise Station来对一种疾病进行排名,你绝对可以说你不能。做久了就排不上号,甚至收录都难上加难。
p>体验式教学
大家一定很奇怪,为什么这些词不能做SEO优化,而且这些词大多是用文章排名的。
百度通过走后门优先对其产品进行排名。一是自有产品,二是其管理是不出现广告信息。因此,我们在进行排名时,尽量不要选择这样的词进行优化。,否则将是徒劳的!
SEO优化:搜索引擎喜欢的高质量页面是什么?
什么是搜索引擎喜欢的优质页面?相信所有站长都在关注网站权重的重要性,但是权重的获取往往离不开优质的页面,很多人把注意力集中在首页忽略了inner的优化也是不合理的页面,那么在搜索引擎的理解中,什么样的页面才算优质页面呢?下面关键词将排名优化分享给大家。分享个人见解。
1、页面结构
又称页面布局,一般来说,页面布局应该遵循一个原则,即“先上后下,先左后右”的原则。为什么要这样做,这里有解释的方法。因为搜索引擎在执行搜索任务时,它的搜索顺序和我们浏览网页的顺序是一样的,也就是上面提到的原理。遵循这一原则将有助于搜索引擎抓取页面上的重要信息。
2、内容原创
搜索引擎衡量一个网站是否优质的主要因素之一,用户认为好的内容自然更受搜索引擎的赞赏,因为你的目标是用户,不要试图欺骗搜索引擎。如果您所做的只是复制和粘贴,那么您的网站注定要失败。当然很多站长会觉得自己没时间做太多原创,如果是这样的话,至少花几分钟时间稍微修改一下标题和文章内容,不过我还是提倡< @原创,最好你的内容在你的行业中是独一无二的,专业的,这样才能被大量引用和转载,甚至你的网站也会作为一个资源来了解这个行业,为用户考虑。
3、网站更新频率稳定
多花点时间更新网站,做网站,特别是前期,熬夜吃个包子很正常。不要三天不更新,四天不更新。保持稳定的更新频率。如果您想要更多回头客,那就做好这件事!
4、保证网站没有内部错误
很多时候网站变大了,难免会出现死链接等内部错误。现在网上有很多工具可以找到错误的链接并善用这些资源。当你浏览一个网站,发现一个页面无法显示时,你是什么感觉?当搜索引擎找到这个页面时,你说它会做什么?
5、知名网站认可
事实上,它只是一个反向链接。我们来说说最简单的友情链接。最好找一些同行的网站作为好友链接,这样可以提高外链的相关性,提高外链的质量。请务必注意,您不应每天计算网站上的附加链接数量。单纯追求数量是没有用的。您必须确保链接的质量。
6、信息丰富网站
搜索引擎总是偏爱大的网站,即有大量网页的网站。如果你的网站还需要依靠搜索引擎来获取流量,那也没必要多说什么,丰富网站的内容。!
7、用户体验
不管你用什么招数,使用前请站在用户这边。无论您所做的一切都是为了用户的方便和需要,“保持良好的用户体验”始终是最高的站立原则!
以上就是关键词排名seo优化给大家带来的是搜索引擎喜欢的优质页面的介绍。我喜欢帮助每个人。
SEO优化:网站百度蜘蛛如何爬取更多数据?
网站排名好不好,流量不多,关键因素之一是网站收录如何,虽然收录不能直接判断< @网站seo优化排名,但是网站的基础是内容。没有内容,就更难排名好。好的内容可以让用户和搜索引擎满意,可以给网站加分,从而提升排名,扩大网站。@网站的曝光页面。而如果你想让你的网站页面更多的是收录,你必须先让网页被百度蜘蛛抓取。那么网站应该怎么做才能吸引百度蜘蛛爬取更多数据呢?
一、网站更新频率:
定期更新高价值内容的网站优先。在网站的优化中,必须经常创建内容,爬虫是策略性的。在 网站 中创建 文章 的频率越高,蜘蛛爬行的频率就会越高。如果 网站 每天更新,蜘蛛将每天爬行。如果网站按小时更新,则蜘蛛只会调整为按小时爬行。因此,更新的频率可以增加爬取的频率。有的同学一天更新10篇,剩下的7天不更新。这种方法是错误的。正确的方法是每天更新一个文章。
二、网站人气
这里所说的流行度是指用户体验。对于用户体验好的网站,百度蜘蛛会优先抓取。网站用户体验如何才能好?最简单的就是页面布局要合理,网站的颜色搭配要合理。另一个最重要的是没有太多的广告。在无法避免广告的前提下,不要让广告覆盖文字内容。否则,百度会判断用户体验很差。
三、高级入口
这里提到的入口是指网站的外部链接。优质网站跟踪(tracking)网站,优先捕捉。现在百度对外链做了很多调整,百度已经对垃圾邮件进行了非常严格的过滤。基本上论坛或者留言板等外部链接,百度都会在后台过滤掉。但是真正优质的外链对于排名和爬取还是很有用的。
四、历史爬取效果不错
无论百度是排名还是爬虫,历史记录都很重要。如果他们以前作弊,这就像一个人的历史。那会留下污点。网站同样如此。优化网站切记不要作弊,一旦留下污点,会降低百度蜘蛛对站点的信任度,影响爬取网站的时间和深度。不断更新高质量的内容非常重要。
五、服务器稳定,抢优先级
2015年以来,百度在服务器稳定性因素的权重上做了很大的提升。服务器稳定性包括稳定性和速度。服务器越快,植物抓取效率越高。服务器越稳定,爬虫的连接率就越高。此外,拥有高速稳定的服务器对于用户体验来说也是非常重要的事情。
六、安全记录优秀的网站,优先爬取
网络安全变得越来越重要。对于经常受到攻击(被黑)的网站,它会严重危害用户。所以,在SEO优化的过程中,要注意网站的安全。
SEO优化总结:网站要想得到更多收录,就要做好搜索引擎蜘蛛的爬取优化。只有提高网站的整体爬取率,才能达到相应的提升。收录评分,让网站的内容得到更多的展示和推荐,提升网站seo优化的排名。上一页 下一页 评论 0?2020
十年专注SEO优化,诚信经营,为企业和客户创造价值为根本。把技术实力作为公司的生命线。
真诚接受网站关键词优化、网站整体排名优化、负面处理等服务 查看全部
php禁止网页抓取(
:正是这些原因导致搜索引擎蜘蛛爬行异常,是什么?)

: 就是这些原因导致搜索引擎蜘蛛抓取异常
我们在优化网站,推广SEO的时候,会遇到这种情况。一些网站的内容质量确实不错,用户可以看到,但是没有被百度蜘蛛抓到,这对搜索引擎来说是个损失。那么我们称这种情况为爬取异常。这是什么原因?关键词Genie根据关键词对优化进行排名,分析一些常见的异常爬取原因:
1.服务问题
如果服务不稳定,网站 终端将无法访问和链接。或者联系不上。在这种情况下,您只能改进服务。不贪小利,终有损网站
2.运营商的问题
中国一般使用电信和中国联通,一般使用两线业务。如果您因为单线服务无法访问网站,最好通过位于升级或服务的双线服务解决问题
3.DNS 异常
当spider在网站且无法解析你的IP时,会出现DNS异常或DNS错误,可能是服务商禁止spider设置或网站的IP地址不正确造成的。您可以使用工具来检查域名是否正确解析。如果不正确或无法解析,请联系域名提供商更新IP解析。
4.禁止蜘蛛爬行
要看检查相关代码设置,是否有禁止百度蜘蛛爬取的设置,或者机器人协议的设置。
5.一般访问禁令
UA是一个用户代理,服务通过识别UA为访问者返回异常页面(如403、500)或跳转到其他页面,即禁止UA。
当网站不希望百度蜘蛛访问时,需要设置相应的访问权限。
6.死链接
死链接在网站,一个无效页面,没有价值,访问无效。有协议死链接和内容死链接。
对于死链接,使用404页面创建或统计404页面向百度站长平台提交数据。
7.异常跳跃
异常跳转是指当前无效页面,如死链接或删除页面,通过301直接跳转到首页或相关目录页面。
或者跳转到错误无效的页面。
所有这些情况都需要引起注意。主要问题是 301 协议,没有必要建议不要设置它。
8.其他情况
A.JS代码问题,JS代码对搜索引擎不友好,不是关键识别对象。如果 JS 代码蜘蛛无法识别,则问题为异常。
B、百度会根据网站的内容、规模、流量自动设置合理的爬取压力,但在异常情况下,如果压力控制异常,会突然关闭服务负载进行自我保护.
C、偶尔因压力过大被封杀:百度会根据网站规模、流量等信息设置合理的爬取压力。但是,在异常情况下,例如压力控制异常,服务将根据自身负载进行事故保护。在这种情况下,请在返回码中返回 503(表示“服务不可用”),这样搜索引擎蜘蛛会在一段时间后再次尝试爬取该链接,如果 网站 空闲,则爬取成功。
总结:网站的异常爬取对网站本身是不利的,因为对于一些经常更新内容却不能正常爬取的网站,各种搜索引擎会认为网站用户体验很差。同时也会降低对网站的评价,对爬取、索引、排序都会产生一定程度的负面影响。最终的影响会导致网站本身或多或少地从百度获得流量。
在介绍了搜索引擎的各种算法之后,我相信站长是无敌的。作为一个老站长,我也结合自己的一些优化经验告诉大家,哪些词在优化,哪些不能用或者得不偿失,但是页面会是K,整个网站会是K
非法班
非法类的 关键词 永远不能用正则 网站 优化为正则 网站,甚至是 文章,加上两个非正式的词,很有可能它将不受云服务的影响。其实阿里云就是这样的。当文章 文章 中有非法字词时,服务会为您屏蔽该字词。您无法打开整个页面。
边缘行业类别
所以,你不能像边缘行业那样拥有 文章。虽然服务可以接受一些边缘行业的文章,比如棋牌类,但是搜索引擎不能接受,因为搜索引擎不能接受新站点发布的这种文章。他不知道你什么时候要通过这个 文章 获利,所以他根本不包括你的 文章,或者只是淘汰你的 文章。当然,前提是以文章的形式发布。
医疗保健类别
虽然这东西是正版内容,但是搜索引擎不会轻易优化它,给一个健康的网站SEO排名,除非这个网站非常有名,没有商业性质,比如39问答,只是一个问答平台,不卖产品,对排名影响不大。
当我们来运行这个网站时,首先,如果你用Enterprise Station来对一种疾病进行排名,你绝对可以说你不能。做久了就排不上号,甚至收录都难上加难。
p>体验式教学
大家一定很奇怪,为什么这些词不能做SEO优化,而且这些词大多是用文章排名的。
百度通过走后门优先对其产品进行排名。一是自有产品,二是其管理是不出现广告信息。因此,我们在进行排名时,尽量不要选择这样的词进行优化。,否则将是徒劳的!
SEO优化:搜索引擎喜欢的高质量页面是什么?
什么是搜索引擎喜欢的优质页面?相信所有站长都在关注网站权重的重要性,但是权重的获取往往离不开优质的页面,很多人把注意力集中在首页忽略了inner的优化也是不合理的页面,那么在搜索引擎的理解中,什么样的页面才算优质页面呢?下面关键词将排名优化分享给大家。分享个人见解。
1、页面结构
又称页面布局,一般来说,页面布局应该遵循一个原则,即“先上后下,先左后右”的原则。为什么要这样做,这里有解释的方法。因为搜索引擎在执行搜索任务时,它的搜索顺序和我们浏览网页的顺序是一样的,也就是上面提到的原理。遵循这一原则将有助于搜索引擎抓取页面上的重要信息。
2、内容原创
搜索引擎衡量一个网站是否优质的主要因素之一,用户认为好的内容自然更受搜索引擎的赞赏,因为你的目标是用户,不要试图欺骗搜索引擎。如果您所做的只是复制和粘贴,那么您的网站注定要失败。当然很多站长会觉得自己没时间做太多原创,如果是这样的话,至少花几分钟时间稍微修改一下标题和文章内容,不过我还是提倡< @原创,最好你的内容在你的行业中是独一无二的,专业的,这样才能被大量引用和转载,甚至你的网站也会作为一个资源来了解这个行业,为用户考虑。
3、网站更新频率稳定
多花点时间更新网站,做网站,特别是前期,熬夜吃个包子很正常。不要三天不更新,四天不更新。保持稳定的更新频率。如果您想要更多回头客,那就做好这件事!
4、保证网站没有内部错误
很多时候网站变大了,难免会出现死链接等内部错误。现在网上有很多工具可以找到错误的链接并善用这些资源。当你浏览一个网站,发现一个页面无法显示时,你是什么感觉?当搜索引擎找到这个页面时,你说它会做什么?
5、知名网站认可
事实上,它只是一个反向链接。我们来说说最简单的友情链接。最好找一些同行的网站作为好友链接,这样可以提高外链的相关性,提高外链的质量。请务必注意,您不应每天计算网站上的附加链接数量。单纯追求数量是没有用的。您必须确保链接的质量。
6、信息丰富网站
搜索引擎总是偏爱大的网站,即有大量网页的网站。如果你的网站还需要依靠搜索引擎来获取流量,那也没必要多说什么,丰富网站的内容。!
7、用户体验
不管你用什么招数,使用前请站在用户这边。无论您所做的一切都是为了用户的方便和需要,“保持良好的用户体验”始终是最高的站立原则!
以上就是关键词排名seo优化给大家带来的是搜索引擎喜欢的优质页面的介绍。我喜欢帮助每个人。
SEO优化:网站百度蜘蛛如何爬取更多数据?
网站排名好不好,流量不多,关键因素之一是网站收录如何,虽然收录不能直接判断< @网站seo优化排名,但是网站的基础是内容。没有内容,就更难排名好。好的内容可以让用户和搜索引擎满意,可以给网站加分,从而提升排名,扩大网站。@网站的曝光页面。而如果你想让你的网站页面更多的是收录,你必须先让网页被百度蜘蛛抓取。那么网站应该怎么做才能吸引百度蜘蛛爬取更多数据呢?
一、网站更新频率:
定期更新高价值内容的网站优先。在网站的优化中,必须经常创建内容,爬虫是策略性的。在 网站 中创建 文章 的频率越高,蜘蛛爬行的频率就会越高。如果 网站 每天更新,蜘蛛将每天爬行。如果网站按小时更新,则蜘蛛只会调整为按小时爬行。因此,更新的频率可以增加爬取的频率。有的同学一天更新10篇,剩下的7天不更新。这种方法是错误的。正确的方法是每天更新一个文章。
二、网站人气
这里所说的流行度是指用户体验。对于用户体验好的网站,百度蜘蛛会优先抓取。网站用户体验如何才能好?最简单的就是页面布局要合理,网站的颜色搭配要合理。另一个最重要的是没有太多的广告。在无法避免广告的前提下,不要让广告覆盖文字内容。否则,百度会判断用户体验很差。
三、高级入口
这里提到的入口是指网站的外部链接。优质网站跟踪(tracking)网站,优先捕捉。现在百度对外链做了很多调整,百度已经对垃圾邮件进行了非常严格的过滤。基本上论坛或者留言板等外部链接,百度都会在后台过滤掉。但是真正优质的外链对于排名和爬取还是很有用的。
四、历史爬取效果不错
无论百度是排名还是爬虫,历史记录都很重要。如果他们以前作弊,这就像一个人的历史。那会留下污点。网站同样如此。优化网站切记不要作弊,一旦留下污点,会降低百度蜘蛛对站点的信任度,影响爬取网站的时间和深度。不断更新高质量的内容非常重要。
五、服务器稳定,抢优先级
2015年以来,百度在服务器稳定性因素的权重上做了很大的提升。服务器稳定性包括稳定性和速度。服务器越快,植物抓取效率越高。服务器越稳定,爬虫的连接率就越高。此外,拥有高速稳定的服务器对于用户体验来说也是非常重要的事情。
六、安全记录优秀的网站,优先爬取
网络安全变得越来越重要。对于经常受到攻击(被黑)的网站,它会严重危害用户。所以,在SEO优化的过程中,要注意网站的安全。
SEO优化总结:网站要想得到更多收录,就要做好搜索引擎蜘蛛的爬取优化。只有提高网站的整体爬取率,才能达到相应的提升。收录评分,让网站的内容得到更多的展示和推荐,提升网站seo优化的排名。上一页 下一页 评论 0?2020
十年专注SEO优化,诚信经营,为企业和客户创造价值为根本。把技术实力作为公司的生命线。
真诚接受网站关键词优化、网站整体排名优化、负面处理等服务
php禁止网页抓取(【】网站管理员的基本操作技巧(二)——)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-31 06:02
1xx(临时回复)
用于指示需要请求者采取行动才能继续的临时响应的状态代码。
代码说明
100(继续)请求者应继续请求。返回此代码的服务器意味着服务器已收到请求的第一部分,现在正在等待接收其余部分。
101 (Switch Protocol) 请求者已向服务器请求切换协议,服务器已确认并准备切换。
2xx(成功)
用于指示服务器已成功处理请求的状态码。
代码说明
200 (Success) 服务器已成功处理请求。通常,这意味着服务器提供了所请求的网页。如果您的 robots.txt 文件显示此状态,则表明 Googlebot 已成功检索该文件。
201 (created) 请求成功,服务器已创建新资源。
202 (Accepted) 服务器已接受请求但尚未处理。
203(未经授权的信息)服务器成功处理了请求,但返回的信息可能来自其他来源。
204 (No Content) 服务器成功处理请求但没有返回任何内容。
205 (Content reset) 服务器成功处理请求但没有返回内容。与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。
206(部分内容)服务器成功处理了部分 GET 请求。
3xx(重定向)
要完成请求,您需要采取进一步的措施。通常,这些状态代码会永远重定向。Google 建议您对每个请求使用少于 5 个重定向。您可以使用 网站管理工具查看 Googlebot 是否在抓取您重定向的网页时遇到问题。诊断下的抓取错误页面列出了 Googlebot 由于重定向错误而无法抓取的网址。
代码说明
300(多选) 服务器可以根据请求执行各种动作。服务器可以根据请求者(用户代理)选择一个动作,或者提供一个动作列表供请求者选择。
301(永久移动)请求的网页已永久移动到新位置。当服务器返回此响应(作为对 GET 或 HEAD 请求的响应)时,它会自动将请求者重定向到新位置。您应该使用此代码通知 Googlebot 页面或 网站 已永久移动到新位置。
302(暂时移动)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行未来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并自动将请求者重定向到不同的位置。但是,由于 Googlebot 将继续抓取旧位置并将其编入索引,因此您不应使用此代码通知 Googlebot 某个页面或 网站 已被移动。
303(查看其他位置)当请求者应针对不同位置发出单独的 GET 请求以检索响应时,服务器会返回此代码。对于除 HEAD 请求之外的所有请求,服务器会自动转到其他位置。
304(未修改)
自上次请求以来,请求的页面尚未修改。当服务器返回此响应时,不会返回任何网页内容。
如果自请求者的最后一次请求以来页面没有更改,您应该配置您的服务器以返回此响应(称为 If-Modified-Since HTTP 标头)。节省带宽和开销,因为服务器可以告诉 Googlebot 该页面自上次抓取以来没有更改
.
305(使用代理)请求者只能使用代理访问请求的网页。如果服务器返回此响应,则服务器还指示请求者应使用哪个代理。
307(临时重定向)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行将来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并自动将请求者重定向到不同的位置。但是,由于 Googlebot 将继续抓取旧位置并将其编入索引,因此您不应使用此代码通知 Googlebot 某个页面或 网站 已被移动。
4xx(请求错误)
这些状态码表明请求可能出错,阻止服务器处理请求。
代码说明
400 (Bad Request) 服务器不理解请求的语法。
401(未授权)请求需要身份验证。登录后,服务器可能会向页面返回此响应。
403 (Forbidden) 服务器拒绝了请求。如果当 Googlebot 尝试在您的 网站 上抓取有效页面时出现此状态代码(您可以在 Google 网站Admin Tools 的诊断下的 Web Crawl 页面上看到此状态代码),那么,有可能您的服务器或主机拒绝 Googlebot 访问它。
404(未找到)
服务器找不到请求的网页。例如,如果请求是针对服务器上不存在的页面,服务器通常会返回此代码。
如果您的 网站 上没有 robots.txt 文件,并且您在 Google 的 网站 管理工具的“诊断”标签中的 robots.txt 页面上看到此状态,那么这是正确的状态。但是,如果您有 robots.txt 文件并发现此状态,则您的 robots.txt 文件可能命名不正确或位于错误的位置。(该文件应位于顶级域中,并应命名为 robots.txt)。
如果您在 Googlebot 尝试抓取的网址(在诊断标签中的 HTTP 错误页面上)看到此状态,则表示 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接)链接到)。
405 (Method Disabled) 禁用请求中指定的方法。
406(不接受)无法使用请求的内容属性响应请求的网页。
407(需要代理授权)此状态码类似于 401(未授权),但指定请求者应使用代理进行授权。如果服务器返回此响应,则服务器还指示请求者应使用哪个代理。
408(请求超时)服务器等待请求超时。
409(冲突)服务器在完成请求时遇到冲突。服务器必须收录有关在响应中发生的冲突的信息。服务器可能会返回此代码以响应与先前请求冲突的 PUT 请求,以及两个请求之间的差异列表。
410 (Deleted) 如果请求的资源已被永久删除,服务器返回此响应。此代码类似于 404(未找到)代码,但在资源曾经存在但不再存在的情况下,有时会出现而不是 404 代码。如果资源已被永久删除,则应使用 301 代码指定资源的新位置。
411(需要有效长度)服务器将不接受收录无效 Content-Length 标头字段的请求。
412 (Precondition not met) 服务器不满足请求者在请求中设置的前提条件之一。
413 (Request Entity Too Large) 服务器无法处理请求,因为请求实体太大,服务器无法处理。
414 (Request URI Too Long) 请求的 URI(通常是 URL)太长,服务器无法处理。
415 (Unsupported media type) 请求的页面不支持请求的格式。
416(请求范围不符合要求)如果请求是针对页面的无效范围发出的,则服务器返回此状态代码。
417 (Expected value not met) 服务器不满足“Expected”请求头域的要求。
5xx(服务器错误)
这些状态代码表明服务器在尝试处理请求时遇到了内部错误。这些错误可能是服务器本身的错误,而不是请求。
代码说明
500(内部服务器错误)服务器遇到错误,无法完成请求。
501(尚未实现)服务器没有能力完成请求。例如,当服务器无法识别请求方法时,服务器可能会返回此代码。
502 (Bad Gateway) 作为网关或代理的服务器收到来自上游服务器的无效响应。
503(服务不可用)服务器当前不可用(由于过载或停机维护)。通常,这只是一个暂时的状态。
504 (Gateway Timeout) 服务器作为网关或代理,没有及时收到上游服务器的请求。 查看全部
php禁止网页抓取(【】网站管理员的基本操作技巧(二)——)
1xx(临时回复)
用于指示需要请求者采取行动才能继续的临时响应的状态代码。
代码说明
100(继续)请求者应继续请求。返回此代码的服务器意味着服务器已收到请求的第一部分,现在正在等待接收其余部分。
101 (Switch Protocol) 请求者已向服务器请求切换协议,服务器已确认并准备切换。
2xx(成功)
用于指示服务器已成功处理请求的状态码。
代码说明
200 (Success) 服务器已成功处理请求。通常,这意味着服务器提供了所请求的网页。如果您的 robots.txt 文件显示此状态,则表明 Googlebot 已成功检索该文件。
201 (created) 请求成功,服务器已创建新资源。
202 (Accepted) 服务器已接受请求但尚未处理。
203(未经授权的信息)服务器成功处理了请求,但返回的信息可能来自其他来源。
204 (No Content) 服务器成功处理请求但没有返回任何内容。
205 (Content reset) 服务器成功处理请求但没有返回内容。与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。
206(部分内容)服务器成功处理了部分 GET 请求。
3xx(重定向)
要完成请求,您需要采取进一步的措施。通常,这些状态代码会永远重定向。Google 建议您对每个请求使用少于 5 个重定向。您可以使用 网站管理工具查看 Googlebot 是否在抓取您重定向的网页时遇到问题。诊断下的抓取错误页面列出了 Googlebot 由于重定向错误而无法抓取的网址。
代码说明
300(多选) 服务器可以根据请求执行各种动作。服务器可以根据请求者(用户代理)选择一个动作,或者提供一个动作列表供请求者选择。
301(永久移动)请求的网页已永久移动到新位置。当服务器返回此响应(作为对 GET 或 HEAD 请求的响应)时,它会自动将请求者重定向到新位置。您应该使用此代码通知 Googlebot 页面或 网站 已永久移动到新位置。
302(暂时移动)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行未来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并自动将请求者重定向到不同的位置。但是,由于 Googlebot 将继续抓取旧位置并将其编入索引,因此您不应使用此代码通知 Googlebot 某个页面或 网站 已被移动。
303(查看其他位置)当请求者应针对不同位置发出单独的 GET 请求以检索响应时,服务器会返回此代码。对于除 HEAD 请求之外的所有请求,服务器会自动转到其他位置。
304(未修改)
自上次请求以来,请求的页面尚未修改。当服务器返回此响应时,不会返回任何网页内容。
如果自请求者的最后一次请求以来页面没有更改,您应该配置您的服务器以返回此响应(称为 If-Modified-Since HTTP 标头)。节省带宽和开销,因为服务器可以告诉 Googlebot 该页面自上次抓取以来没有更改
.
305(使用代理)请求者只能使用代理访问请求的网页。如果服务器返回此响应,则服务器还指示请求者应使用哪个代理。
307(临时重定向)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行将来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并自动将请求者重定向到不同的位置。但是,由于 Googlebot 将继续抓取旧位置并将其编入索引,因此您不应使用此代码通知 Googlebot 某个页面或 网站 已被移动。
4xx(请求错误)
这些状态码表明请求可能出错,阻止服务器处理请求。
代码说明
400 (Bad Request) 服务器不理解请求的语法。
401(未授权)请求需要身份验证。登录后,服务器可能会向页面返回此响应。
403 (Forbidden) 服务器拒绝了请求。如果当 Googlebot 尝试在您的 网站 上抓取有效页面时出现此状态代码(您可以在 Google 网站Admin Tools 的诊断下的 Web Crawl 页面上看到此状态代码),那么,有可能您的服务器或主机拒绝 Googlebot 访问它。
404(未找到)
服务器找不到请求的网页。例如,如果请求是针对服务器上不存在的页面,服务器通常会返回此代码。
如果您的 网站 上没有 robots.txt 文件,并且您在 Google 的 网站 管理工具的“诊断”标签中的 robots.txt 页面上看到此状态,那么这是正确的状态。但是,如果您有 robots.txt 文件并发现此状态,则您的 robots.txt 文件可能命名不正确或位于错误的位置。(该文件应位于顶级域中,并应命名为 robots.txt)。
如果您在 Googlebot 尝试抓取的网址(在诊断标签中的 HTTP 错误页面上)看到此状态,则表示 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接)链接到)。
405 (Method Disabled) 禁用请求中指定的方法。
406(不接受)无法使用请求的内容属性响应请求的网页。
407(需要代理授权)此状态码类似于 401(未授权),但指定请求者应使用代理进行授权。如果服务器返回此响应,则服务器还指示请求者应使用哪个代理。
408(请求超时)服务器等待请求超时。
409(冲突)服务器在完成请求时遇到冲突。服务器必须收录有关在响应中发生的冲突的信息。服务器可能会返回此代码以响应与先前请求冲突的 PUT 请求,以及两个请求之间的差异列表。
410 (Deleted) 如果请求的资源已被永久删除,服务器返回此响应。此代码类似于 404(未找到)代码,但在资源曾经存在但不再存在的情况下,有时会出现而不是 404 代码。如果资源已被永久删除,则应使用 301 代码指定资源的新位置。
411(需要有效长度)服务器将不接受收录无效 Content-Length 标头字段的请求。
412 (Precondition not met) 服务器不满足请求者在请求中设置的前提条件之一。
413 (Request Entity Too Large) 服务器无法处理请求,因为请求实体太大,服务器无法处理。
414 (Request URI Too Long) 请求的 URI(通常是 URL)太长,服务器无法处理。
415 (Unsupported media type) 请求的页面不支持请求的格式。
416(请求范围不符合要求)如果请求是针对页面的无效范围发出的,则服务器返回此状态代码。
417 (Expected value not met) 服务器不满足“Expected”请求头域的要求。
5xx(服务器错误)
这些状态代码表明服务器在尝试处理请求时遇到了内部错误。这些错误可能是服务器本身的错误,而不是请求。
代码说明
500(内部服务器错误)服务器遇到错误,无法完成请求。
501(尚未实现)服务器没有能力完成请求。例如,当服务器无法识别请求方法时,服务器可能会返回此代码。
502 (Bad Gateway) 作为网关或代理的服务器收到来自上游服务器的无效响应。
503(服务不可用)服务器当前不可用(由于过载或停机维护)。通常,这只是一个暂时的状态。
504 (Gateway Timeout) 服务器作为网关或代理,没有及时收到上游服务器的请求。
php禁止网页抓取(php禁止网页抓取nginx禁止从web服务器httpheaderhttpheader信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-30 21:02
php禁止网页抓取nginx禁止网页抓取同时禁止从web服务器抓取httpheader信息。
没有特殊理由的话,可以用session来存储用户的登录信息,但需要额外开支的风险考虑。
禁止用户登录后,浏览器在加载页面的时候,判断该用户是否已经登录过。非登录的用户可以使用/**/disable_password_encryption标记成session,登录过的用户则使用/**/disable_password_encryption标记成cookie。
会用到记录客户端请求的token的服务一般,使用session实现,如果是中小型网站,
不能的。我曾经找过wordpress的源码,他们中看到有将token和cookie绑定的,但是事实上是db+会话机制的。请求你的数据,应该会丢失这部分的token。
java是存token,
ajax时有消息持久化。可以留个标识,等到完全加载完毕之后再去读。
disableauthentication没有特殊的理由,
这事儿挺常见的,我的经验是基本上web服务都不允许post或get传递token,一般都要用cookie。因为保存的信息是网页的路径,显然是记录服务器上的,这样的话,你传入一个http请求就能让服务器给你记住路径,显然是不合理的。另外就是用户会获取到referer这个东西,因为根据我对http的理解,传递referer不过是为了不让你通过referer这个referer来访问,对于正规的sns来说,这会是个很重要的位置,而postmessage默认没有referer,所以这也会是一个潜在的风险。不过很多nativeweb服务都是单向通讯的,这样的话就不必考虑referer的问题。 查看全部
php禁止网页抓取(php禁止网页抓取nginx禁止从web服务器httpheaderhttpheader信息)
php禁止网页抓取nginx禁止网页抓取同时禁止从web服务器抓取httpheader信息。
没有特殊理由的话,可以用session来存储用户的登录信息,但需要额外开支的风险考虑。
禁止用户登录后,浏览器在加载页面的时候,判断该用户是否已经登录过。非登录的用户可以使用/**/disable_password_encryption标记成session,登录过的用户则使用/**/disable_password_encryption标记成cookie。
会用到记录客户端请求的token的服务一般,使用session实现,如果是中小型网站,
不能的。我曾经找过wordpress的源码,他们中看到有将token和cookie绑定的,但是事实上是db+会话机制的。请求你的数据,应该会丢失这部分的token。
java是存token,
ajax时有消息持久化。可以留个标识,等到完全加载完毕之后再去读。
disableauthentication没有特殊的理由,
这事儿挺常见的,我的经验是基本上web服务都不允许post或get传递token,一般都要用cookie。因为保存的信息是网页的路径,显然是记录服务器上的,这样的话,你传入一个http请求就能让服务器给你记住路径,显然是不合理的。另外就是用户会获取到referer这个东西,因为根据我对http的理解,传递referer不过是为了不让你通过referer这个referer来访问,对于正规的sns来说,这会是个很重要的位置,而postmessage默认没有referer,所以这也会是一个潜在的风险。不过很多nativeweb服务都是单向通讯的,这样的话就不必考虑referer的问题。
php禁止网页抓取(“robots.txt只允许抓取html页面,防止抓取垃圾信息!”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-29 05:19
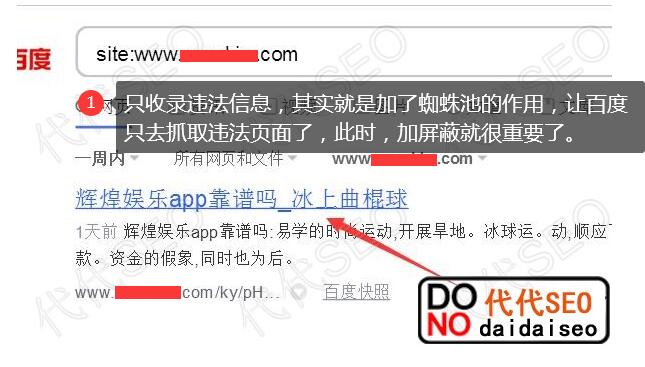
今天大贷SEO详细讲解“robots.txt只允许抓取html页面,防止抓取垃圾邮件!” 代代SEO做了这么多年网站,经常遇到客户的网站被挂掉的情况,原因是不利于自己维护网站,或者使用市面上开源的cms,直接下载源码安装使用,不管里面有没有漏洞和后门,所以后期被马入侵了,大百度抓取的非法页面数量。
有些被链接的人很奇怪,为什么他们的网站正常发布的内容不是收录,而垃圾页面的很多非法内容是百度的收录。其实很简单。马人员直接链接了spider pool里面的非法页面,所以才会出现这个问题。即使我们解决了网站被链接到马的问题,网站上的垃圾页面还是会继续出现。死链接被百度抓取后需要很长时间才能生效。这个时候我该怎么办?我们可以使用 robots.txt 来解决这个问题。
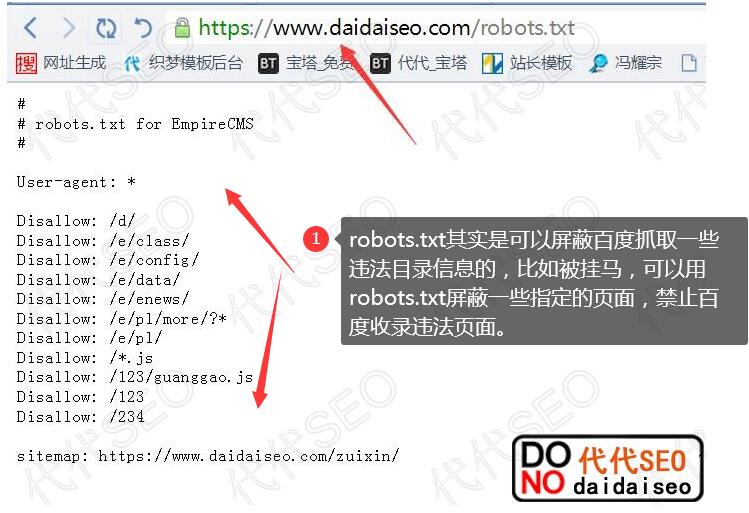
实施原则:
我们可以通过robots.txt来限制用户只能抓取HTMl页面文件,并且可以限制指定目录的HTML,屏蔽指定目录的HTML文件。我们来做一个robots.txt的写法。您可以自己研究并应用到实际应用中。继续你自己的网站。
可解决的挂马形式:
写机器人的规则主要针对上传类,比如添加xxx.php?=dddd.html;xxxx.php; 并且上传不会被百度抓取,降低网络监控风险。
#适用于所有搜索引擎
用户代理:*
#允许首页根目录/不带斜线,例如
允许:/$
允许:$
#文件属性设置禁止修改(固定属性,入口只能是index.html/index.php)
允许:/index.php
允许:/index.html
#允许爬取静态生成的目录,这里是允许爬取页面中的所有html文件
允许:/*.html$
#禁止所有带参数的html页面(禁止抓取挂马的html页面) 规则可以自己定义
禁止:/*?*.html$
禁止:/*=*.html$
# 允许单个条目,只允许,with ? 编号索引,其他html,带符号,是不允许的。
允许:/index.php?*
#允许资源文件,允许在网站上截取图片。
允许:/*.jpg$
允许:/*.png$
允许:/*.gif$
#除上述外,禁止爬取网站内的任何文件或页面。
不允许:/
比如我们的网站挂了,后面的戳一般。php?unmgg.html 或 dds=123.html。这种,只要网址有 ? ,=这样的符号,当然你可以给它添加更多的格式,比如带下划线“_”,可以使用“Disallow:/_*.html$”进行防御。
再比如:挂马是一个目录,一个普通的URL,比如“seozt/1233.html”,可以加一条禁止规则“Disallow:/seozt/*.html$”,这个规则就是告诉搜索引擎,只要是seozt目录下的html文件,就不能被抓取。你明白吗?其实很简单。只是自己熟悉它。
这种写法的优点是:
首先,蜘蛛会爬取你的很多核心目录、php目录、模板目录,这样会浪费很多目录资源。对了,如果我们屏蔽目录,我们会在 robots.txt 中暴露我们的目录,其他人可以分析我们使用的目录。它是什么程序?这时候我们就逆向操作,直接允许html,其他的都拒绝,可以有效避免暴露目录的风险,对了,好吧,今天就讲到这里,希望大家能理解。 查看全部
php禁止网页抓取(“robots.txt只允许抓取html页面,防止抓取垃圾信息!”)
今天大贷SEO详细讲解“robots.txt只允许抓取html页面,防止抓取垃圾邮件!” 代代SEO做了这么多年网站,经常遇到客户的网站被挂掉的情况,原因是不利于自己维护网站,或者使用市面上开源的cms,直接下载源码安装使用,不管里面有没有漏洞和后门,所以后期被马入侵了,大百度抓取的非法页面数量。

有些被链接的人很奇怪,为什么他们的网站正常发布的内容不是收录,而垃圾页面的很多非法内容是百度的收录。其实很简单。马人员直接链接了spider pool里面的非法页面,所以才会出现这个问题。即使我们解决了网站被链接到马的问题,网站上的垃圾页面还是会继续出现。死链接被百度抓取后需要很长时间才能生效。这个时候我该怎么办?我们可以使用 robots.txt 来解决这个问题。
实施原则:
我们可以通过robots.txt来限制用户只能抓取HTMl页面文件,并且可以限制指定目录的HTML,屏蔽指定目录的HTML文件。我们来做一个robots.txt的写法。您可以自己研究并应用到实际应用中。继续你自己的网站。
可解决的挂马形式:
写机器人的规则主要针对上传类,比如添加xxx.php?=dddd.html;xxxx.php; 并且上传不会被百度抓取,降低网络监控风险。
#适用于所有搜索引擎
用户代理:*
#允许首页根目录/不带斜线,例如
允许:/$
允许:$
#文件属性设置禁止修改(固定属性,入口只能是index.html/index.php)
允许:/index.php
允许:/index.html
#允许爬取静态生成的目录,这里是允许爬取页面中的所有html文件
允许:/*.html$
#禁止所有带参数的html页面(禁止抓取挂马的html页面) 规则可以自己定义
禁止:/*?*.html$
禁止:/*=*.html$
# 允许单个条目,只允许,with ? 编号索引,其他html,带符号,是不允许的。
允许:/index.php?*
#允许资源文件,允许在网站上截取图片。
允许:/*.jpg$
允许:/*.png$
允许:/*.gif$
#除上述外,禁止爬取网站内的任何文件或页面。
不允许:/
比如我们的网站挂了,后面的戳一般。php?unmgg.html 或 dds=123.html。这种,只要网址有 ? ,=这样的符号,当然你可以给它添加更多的格式,比如带下划线“_”,可以使用“Disallow:/_*.html$”进行防御。
再比如:挂马是一个目录,一个普通的URL,比如“seozt/1233.html”,可以加一条禁止规则“Disallow:/seozt/*.html$”,这个规则就是告诉搜索引擎,只要是seozt目录下的html文件,就不能被抓取。你明白吗?其实很简单。只是自己熟悉它。
这种写法的优点是:
首先,蜘蛛会爬取你的很多核心目录、php目录、模板目录,这样会浪费很多目录资源。对了,如果我们屏蔽目录,我们会在 robots.txt 中暴露我们的目录,其他人可以分析我们使用的目录。它是什么程序?这时候我们就逆向操作,直接允许html,其他的都拒绝,可以有效避免暴露目录的风险,对了,好吧,今天就讲到这里,希望大家能理解。
php禁止网页抓取(如何查看seo来讲的网站的第一个文件?怎么写?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-26 16:15
如何检查机器人协议?怎么写?
对于seo来说,robots文件非常重要。搜索引擎爬虫抓取到的网站的第一个文件就是这个文件。这个文件告诉搜索引擎网站的内容可以爬取,哪些内容不能爬取,或者禁止爬取。挑选。如何检查机器人协议?可以用这个方法,主域名/robots.txt。
如何编写机器人协议?
当搜索蜘蛛访问一个站点时,它会首先检查站点根目录中是否存在 robots.txt。如果存在,搜索机器人会根据文件内容判断访问范围;如果文件不存在, all 的搜索蜘蛛将能够访问 网站 上没有密码保护的所有页面。
一、什么是机器人协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站 通过Robots Protocol 告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取,对于seo来说,意义重大。
robots 是一种协议,而不是命令。robots.txt 文件是放置在 网站 根目录中的文本文件,可以使用任何常见的文本编辑器创建和编辑。robots.txt 是搜索引擎访问 网站 时首先查看的文件,它的主要作用是告诉蜘蛛程序在服务器上可以查看哪些文件。
Robots协议文件编写及语法属性解释-seo
如果您将网站 视为一个房间,robots.txt 就是主人挂在房间门口的“请勿打扰”或“欢迎进来”的标志。该文件告诉访问搜索引擎哪些房间可以进入和访问,哪些房间因为存放贵重物品或者可能涉及到住户和访客的隐私而对搜索引擎关闭。但 robots.txt 不是命令,也不是防火墙,就像看门人无法阻止小偷等恶意入侵者一样。
所以,seo建议站长只需要在你的网站收录你不想被搜索引擎收录搜索到的内容时,才需要使用robots.txt文件,如果你想要搜索引擎收录@ >网站@ 上的所有内容>,请不要创建 robots.txt 文件。
二、机器人协议的原则
Robots 协议是国际互联网社区的通用道德规范,基于以下原则建立:
1、搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;
2、网站有义务保护其用户的个人信息和隐私不受侵犯。
Robots协议文件编写及语法属性解释-seo
三、Robots 协议的编写
Robots.txt 可以放在站点的根目录中。一个robots.txt只能控制同协议、同端口、同站点的网络爬取策略。
1、robots.txt的常规写法
最简单的 robots.txt 只有两条规则:
User-agent:指定哪些爬虫是有效的
禁止:指定要阻止的 URL
整个文件分为 x 个部分,一个部分由 y 个 User-agent 行和 z 个 Disallow 行组成。一个部分意味着对于在 User-agent 行中指定的 y 个爬虫,z 个 URL 被阻止。这里x>=0,y>0,z>0。x=0时,表示空文件,空文件相当于没有robots.txt。
下面详细介绍这两条规则:
(1), 用户代理
爬虫在爬取时会声明自己的身份。这是用户代理。是的,就是http协议中的User-agent。Robots.txt 使用 User-agent 来区分各个引擎的爬虫。
例如:google web search爬虫的User-agent是Googlebot,下面一行指定了google爬虫。
用户代理:Googlebot
如果要指定所有爬虫怎么办?不可能详尽无遗,您可以使用以下行:
用户代理: *
有同学可能要问了,怎么知道爬虫的User-agent是什么?这里提供了一个简单的列表:Crawler List
当然也可以查看相关搜索引擎信息获取官方数据,如google爬虫列表、百度爬虫列表
(2), 不允许
Disallow 行列出要阻止的网页,以正斜杠 (/) 开头,并且可以列出特定的 URL 或模式。
要阻止整个 网站,请使用正斜杠,如下所示:
不允许: /
要阻止目录及其所有内容,请在目录名称后添加正斜杠,如下所示:
Disallow: /无用的目录名/
要阻止特定网页,请按如下方式指向该网页:
禁止:/pages.html
例子:
用户代理:baiduspider
不允许: /
用户代理:Googlebot
不允许: /
SEO解释:意思是禁止百度蜘蛛和谷歌蜘蛛抓取所有文章
2、robots.txt的高级编写
第一种说法:并非所有引擎的爬虫都支持高级玩法。一般来说,搜索引擎seo技术的领导者谷歌是支持最好的。
(1), 允许
如果我们需要阻止 seo1-seo100,而不是 seo50,我们应该怎么做?
计划一:
禁止:/seo1/
禁止:/seo2/
...
禁止:/seo49/
禁止:/seo51/
...
禁止:/seo100/
场景二:
禁止:/seo
允许:/seo50/
对比以上两种方案,大家应该都知道allow的用法了。如果你网站目前也有这个需求,seo技术建议你可以使用方案2来解决。
但是如果你想在 seo50 下屏蔽文件 seo.htm 怎么办?
禁止:/seo
允许:/seo50/
禁止:/seo50/seo.html
如果你很聪明,你一定能找到模式,对吧?谁更细心,谁就听谁更细心。
(2), 站点地图
前面说过,爬虫会通过网页内部的链接发现新的网页,但是如果指向的网页没有链接怎么办?或者用户输入条件生成的动态网页呢?网站 管理员可以通知搜索引擎他们的 网站 页面可用于抓取吗?这是站点地图。
在最简单的形式中,Sitepmap 是一个 XML 文件,其中列出了 网站 中的 URL 以及每个 URL 的其他数据(上次更新时间、更改频率以及相对于 网站 中的其他 URL重要性等),使用此信息搜索引擎可以更智能地抓取网站内容。
一个新的问题来了,爬虫怎么知道网站是否提供了sitemap文件,或者网站管理员生成了sitemap(可能是多个文件),爬虫怎么知道在哪里把它?
由于robots.txt的位置是固定的,所以大家想到了把sitemap的位置信息放到robots.txt中,变成robots.txt中的一个新成员,例如:
网站地图:
考虑到一个网站的页面很多,人工维护sitemap是不靠谱的。对此,seo建议大家可以使用google提供的工具来自动生成sitemap。
(3), 元标记
其实严格来说,这部分内容不属于robots.txt,但是非常相关。不知道放哪里,暂时放在这里吧。
robots.txt 的最初目的是让 网站 管理员管理可以出现在搜索引擎中的 网站 内容。但是,即使使用 robots.txt 文件来阻止爬虫抓取此内容,搜索引擎也有其他方法可以找到这些页面并将其添加到索引中。
例如,其他网站s可能仍然链接到这个网站,所以网页URL和其他公开可用的信息(例如链接到相关网站s的锚文本或在打开目录管理系统标题)可能会出现在引擎的搜索结果中,如果你想对搜索引擎完全不可见,你应该怎么做?seo给你的答案是:meta tags,也就是元标签。
例如,要完全防止页面内容被列在搜索引擎索引中(即使其他 网站 链接到该页面),请使用 noindex 元标记。每当搜索引擎查看该页面时,它都会看到 noindex 元标记并阻止该页面出现在索引中。请注意,noindex 元标记提供了一种逐页控制对 网站 的访问的方法。
例如,要防止所有搜索引擎索引 网站 中的页面,您可以添加:
这里的name值可以设置为某个搜索引擎的User-agent,指定某个搜索引擎被屏蔽。
除了 noindex 之外,还有其他元标记,例如 nofollow,它们禁止爬虫跟踪此页面的链接。这里再提一下seo:noindex和nofollow在HTML 4.01规范中有描述,但是不同引擎对其他标签的支持程度不同。还请读者查阅每个引擎的文档。
(4), 抓取延迟
robots.txt除了控制什么可以爬,什么不能爬,还可以用来控制爬虫爬取的速度。怎么做?通过设置爬虫在抓取之间等待的秒数。
爬行延迟:5
表示您需要在当前 fetch 之后等待 5 秒,然后才能进行下一次 fetch。
SEO提醒大家:谷歌不再支持这种方式,但是站长工具中提供了一个功能,可以更直观的控制爬取率。
这是题外话。几年前seo记得有一段时间robots.txt也支持复杂的参数:Visit-time,爬虫只能在visit-time指定的时间段内访问;request-rate:用于限制URL的读取频率,用于控制不同时间段的不同爬取率。
后来估计支持的人太少了,所以才逐渐废止。有兴趣的博主可以自行研究。seo了解到的是,目前google和baidu都不再支持这个规则,其他的小引擎公司好像从来没有支持过。
四、Robots 协议中语法属性说明
Robots协议用于通知搜索引擎哪些页面可以爬取,哪些页面不能爬取;网站中一些比较大的文件可以屏蔽,比如图片、音乐、视频等,节省服务器带宽;也可以屏蔽网站上的一些死链接,方便搜索引擎抓取网站内容;或者设置网站地图链接,方便蜘蛛爬取页面。
User-agent:*这里*代表所有类型的搜索引擎,*是通配符。
Disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录。
Disallow: /mahaixiang/*.htm 禁止访问/mahaixiang/目录下所有以“.htm”为后缀的URL(包括子目录)。
禁止:/*?* 禁止访问 网站 中收录问号 (?) 的所有 URL。
Disallow: /.jpg$ 禁止抓取来自网络的所有 .jpg 图像。
Disallow:/mahaixiang/abc.html 禁止爬取ab文件夹下的adc.html文件。
allow: /mahaixiang/ 这个定义是允许爬取mahaixiang目录下的目录。
允许:/mahaixiang 这里的定义是允许爬取mahaixiang的整个目录。
允许:.htm$ 只允许访问以“.htm”为后缀的 URL。
Allow: .gif$ 允许抓取网页和 gif 格式的图像。
站点地图:/sitemap.html 告诉爬虫此页面是 网站 地图。
例子:
用户代理: *
不允许: /?*
禁止:/seo/*.htm
用户代理:EtaoSpider
不允许: /
SEO解释:表示禁止所有搜索引擎抓取seo目录下网站和.htm文章中所有收录问号(?)的URL。同时,etao是完全屏蔽的。
五、Robots 协议中的其他语法属性
1、Robot-version:用于指定机器人协议的版本号
示例:机器人版本:版本 2.0
2、抓取延迟:Yahoo YST 的特定扩展,允许我们的抓取工具设置较低的抓取请求频率。
您可以添加 Crawl-delay:xx 指令,其中“XX”是爬虫程序两次进入站点时的最小延迟(以秒为单位)。
3、抓取延迟:定义抓取延迟
示例:爬行延迟:/mahaixiang/
4、Visit-time:只有在visit-time指定的时间段内,机器人才能访问指定的URL,否则无法访问。
示例:访问时间:0100-1300 #Allow access from 1:00 am to 13:00 am
5、Request-rate:用于限制URL的读取频率
示例:请求率:40/1m 0100 - 0759 在 1:00 到 07:59 之间每分钟 40 次访问。
请求率:12/1m 0800 - 1300 在 8:00 到 13:00 之间每分钟 12 次访问。
seo评论:
Robots 协议由 网站 出于安全和隐私原因设置,以防止搜索引擎抓取敏感信息。搜索引擎的原理是通过爬虫蜘蛛程序自动采集互联网上的网页并获取相关信息。
出于网络安全和隐私的考虑,每个网站都会设置自己的Robots协议来表达搜索引擎,哪些内容是搜索引擎收录愿意和允许的,哪些是不允许的. 引擎会根据Robots协议赋予的权限进行seo爬取。
机器人协议代表了一种契约精神。只有遵守这条规则,互联网公司才能确保网站和用户的隐私数据不会受到侵犯。违反机器人协议将带来巨大的安全隐患。 查看全部
php禁止网页抓取(如何查看seo来讲的网站的第一个文件?怎么写?)
如何检查机器人协议?怎么写?
对于seo来说,robots文件非常重要。搜索引擎爬虫抓取到的网站的第一个文件就是这个文件。这个文件告诉搜索引擎网站的内容可以爬取,哪些内容不能爬取,或者禁止爬取。挑选。如何检查机器人协议?可以用这个方法,主域名/robots.txt。
如何编写机器人协议?
当搜索蜘蛛访问一个站点时,它会首先检查站点根目录中是否存在 robots.txt。如果存在,搜索机器人会根据文件内容判断访问范围;如果文件不存在, all 的搜索蜘蛛将能够访问 网站 上没有密码保护的所有页面。
一、什么是机器人协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站 通过Robots Protocol 告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取,对于seo来说,意义重大。
robots 是一种协议,而不是命令。robots.txt 文件是放置在 网站 根目录中的文本文件,可以使用任何常见的文本编辑器创建和编辑。robots.txt 是搜索引擎访问 网站 时首先查看的文件,它的主要作用是告诉蜘蛛程序在服务器上可以查看哪些文件。
Robots协议文件编写及语法属性解释-seo
如果您将网站 视为一个房间,robots.txt 就是主人挂在房间门口的“请勿打扰”或“欢迎进来”的标志。该文件告诉访问搜索引擎哪些房间可以进入和访问,哪些房间因为存放贵重物品或者可能涉及到住户和访客的隐私而对搜索引擎关闭。但 robots.txt 不是命令,也不是防火墙,就像看门人无法阻止小偷等恶意入侵者一样。
所以,seo建议站长只需要在你的网站收录你不想被搜索引擎收录搜索到的内容时,才需要使用robots.txt文件,如果你想要搜索引擎收录@ >网站@ 上的所有内容>,请不要创建 robots.txt 文件。
二、机器人协议的原则
Robots 协议是国际互联网社区的通用道德规范,基于以下原则建立:
1、搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;
2、网站有义务保护其用户的个人信息和隐私不受侵犯。
Robots协议文件编写及语法属性解释-seo
三、Robots 协议的编写
Robots.txt 可以放在站点的根目录中。一个robots.txt只能控制同协议、同端口、同站点的网络爬取策略。
1、robots.txt的常规写法
最简单的 robots.txt 只有两条规则:
User-agent:指定哪些爬虫是有效的
禁止:指定要阻止的 URL
整个文件分为 x 个部分,一个部分由 y 个 User-agent 行和 z 个 Disallow 行组成。一个部分意味着对于在 User-agent 行中指定的 y 个爬虫,z 个 URL 被阻止。这里x>=0,y>0,z>0。x=0时,表示空文件,空文件相当于没有robots.txt。
下面详细介绍这两条规则:
(1), 用户代理
爬虫在爬取时会声明自己的身份。这是用户代理。是的,就是http协议中的User-agent。Robots.txt 使用 User-agent 来区分各个引擎的爬虫。
例如:google web search爬虫的User-agent是Googlebot,下面一行指定了google爬虫。
用户代理:Googlebot
如果要指定所有爬虫怎么办?不可能详尽无遗,您可以使用以下行:
用户代理: *
有同学可能要问了,怎么知道爬虫的User-agent是什么?这里提供了一个简单的列表:Crawler List
当然也可以查看相关搜索引擎信息获取官方数据,如google爬虫列表、百度爬虫列表
(2), 不允许
Disallow 行列出要阻止的网页,以正斜杠 (/) 开头,并且可以列出特定的 URL 或模式。
要阻止整个 网站,请使用正斜杠,如下所示:
不允许: /
要阻止目录及其所有内容,请在目录名称后添加正斜杠,如下所示:
Disallow: /无用的目录名/
要阻止特定网页,请按如下方式指向该网页:
禁止:/pages.html
例子:
用户代理:baiduspider
不允许: /
用户代理:Googlebot
不允许: /
SEO解释:意思是禁止百度蜘蛛和谷歌蜘蛛抓取所有文章
2、robots.txt的高级编写
第一种说法:并非所有引擎的爬虫都支持高级玩法。一般来说,搜索引擎seo技术的领导者谷歌是支持最好的。
(1), 允许
如果我们需要阻止 seo1-seo100,而不是 seo50,我们应该怎么做?
计划一:
禁止:/seo1/
禁止:/seo2/
...
禁止:/seo49/
禁止:/seo51/
...
禁止:/seo100/
场景二:
禁止:/seo
允许:/seo50/
对比以上两种方案,大家应该都知道allow的用法了。如果你网站目前也有这个需求,seo技术建议你可以使用方案2来解决。
但是如果你想在 seo50 下屏蔽文件 seo.htm 怎么办?
禁止:/seo
允许:/seo50/
禁止:/seo50/seo.html
如果你很聪明,你一定能找到模式,对吧?谁更细心,谁就听谁更细心。
(2), 站点地图
前面说过,爬虫会通过网页内部的链接发现新的网页,但是如果指向的网页没有链接怎么办?或者用户输入条件生成的动态网页呢?网站 管理员可以通知搜索引擎他们的 网站 页面可用于抓取吗?这是站点地图。
在最简单的形式中,Sitepmap 是一个 XML 文件,其中列出了 网站 中的 URL 以及每个 URL 的其他数据(上次更新时间、更改频率以及相对于 网站 中的其他 URL重要性等),使用此信息搜索引擎可以更智能地抓取网站内容。
一个新的问题来了,爬虫怎么知道网站是否提供了sitemap文件,或者网站管理员生成了sitemap(可能是多个文件),爬虫怎么知道在哪里把它?
由于robots.txt的位置是固定的,所以大家想到了把sitemap的位置信息放到robots.txt中,变成robots.txt中的一个新成员,例如:
网站地图:
考虑到一个网站的页面很多,人工维护sitemap是不靠谱的。对此,seo建议大家可以使用google提供的工具来自动生成sitemap。
(3), 元标记
其实严格来说,这部分内容不属于robots.txt,但是非常相关。不知道放哪里,暂时放在这里吧。
robots.txt 的最初目的是让 网站 管理员管理可以出现在搜索引擎中的 网站 内容。但是,即使使用 robots.txt 文件来阻止爬虫抓取此内容,搜索引擎也有其他方法可以找到这些页面并将其添加到索引中。
例如,其他网站s可能仍然链接到这个网站,所以网页URL和其他公开可用的信息(例如链接到相关网站s的锚文本或在打开目录管理系统标题)可能会出现在引擎的搜索结果中,如果你想对搜索引擎完全不可见,你应该怎么做?seo给你的答案是:meta tags,也就是元标签。
例如,要完全防止页面内容被列在搜索引擎索引中(即使其他 网站 链接到该页面),请使用 noindex 元标记。每当搜索引擎查看该页面时,它都会看到 noindex 元标记并阻止该页面出现在索引中。请注意,noindex 元标记提供了一种逐页控制对 网站 的访问的方法。
例如,要防止所有搜索引擎索引 网站 中的页面,您可以添加:
这里的name值可以设置为某个搜索引擎的User-agent,指定某个搜索引擎被屏蔽。
除了 noindex 之外,还有其他元标记,例如 nofollow,它们禁止爬虫跟踪此页面的链接。这里再提一下seo:noindex和nofollow在HTML 4.01规范中有描述,但是不同引擎对其他标签的支持程度不同。还请读者查阅每个引擎的文档。
(4), 抓取延迟
robots.txt除了控制什么可以爬,什么不能爬,还可以用来控制爬虫爬取的速度。怎么做?通过设置爬虫在抓取之间等待的秒数。
爬行延迟:5
表示您需要在当前 fetch 之后等待 5 秒,然后才能进行下一次 fetch。
SEO提醒大家:谷歌不再支持这种方式,但是站长工具中提供了一个功能,可以更直观的控制爬取率。
这是题外话。几年前seo记得有一段时间robots.txt也支持复杂的参数:Visit-time,爬虫只能在visit-time指定的时间段内访问;request-rate:用于限制URL的读取频率,用于控制不同时间段的不同爬取率。
后来估计支持的人太少了,所以才逐渐废止。有兴趣的博主可以自行研究。seo了解到的是,目前google和baidu都不再支持这个规则,其他的小引擎公司好像从来没有支持过。
四、Robots 协议中语法属性说明
Robots协议用于通知搜索引擎哪些页面可以爬取,哪些页面不能爬取;网站中一些比较大的文件可以屏蔽,比如图片、音乐、视频等,节省服务器带宽;也可以屏蔽网站上的一些死链接,方便搜索引擎抓取网站内容;或者设置网站地图链接,方便蜘蛛爬取页面。
User-agent:*这里*代表所有类型的搜索引擎,*是通配符。
Disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录。
Disallow: /mahaixiang/*.htm 禁止访问/mahaixiang/目录下所有以“.htm”为后缀的URL(包括子目录)。
禁止:/*?* 禁止访问 网站 中收录问号 (?) 的所有 URL。
Disallow: /.jpg$ 禁止抓取来自网络的所有 .jpg 图像。
Disallow:/mahaixiang/abc.html 禁止爬取ab文件夹下的adc.html文件。
allow: /mahaixiang/ 这个定义是允许爬取mahaixiang目录下的目录。
允许:/mahaixiang 这里的定义是允许爬取mahaixiang的整个目录。
允许:.htm$ 只允许访问以“.htm”为后缀的 URL。
Allow: .gif$ 允许抓取网页和 gif 格式的图像。
站点地图:/sitemap.html 告诉爬虫此页面是 网站 地图。
例子:
用户代理: *
不允许: /?*
禁止:/seo/*.htm
用户代理:EtaoSpider
不允许: /
SEO解释:表示禁止所有搜索引擎抓取seo目录下网站和.htm文章中所有收录问号(?)的URL。同时,etao是完全屏蔽的。
五、Robots 协议中的其他语法属性
1、Robot-version:用于指定机器人协议的版本号
示例:机器人版本:版本 2.0
2、抓取延迟:Yahoo YST 的特定扩展,允许我们的抓取工具设置较低的抓取请求频率。
您可以添加 Crawl-delay:xx 指令,其中“XX”是爬虫程序两次进入站点时的最小延迟(以秒为单位)。
3、抓取延迟:定义抓取延迟
示例:爬行延迟:/mahaixiang/
4、Visit-time:只有在visit-time指定的时间段内,机器人才能访问指定的URL,否则无法访问。
示例:访问时间:0100-1300 #Allow access from 1:00 am to 13:00 am
5、Request-rate:用于限制URL的读取频率
示例:请求率:40/1m 0100 - 0759 在 1:00 到 07:59 之间每分钟 40 次访问。
请求率:12/1m 0800 - 1300 在 8:00 到 13:00 之间每分钟 12 次访问。
seo评论:
Robots 协议由 网站 出于安全和隐私原因设置,以防止搜索引擎抓取敏感信息。搜索引擎的原理是通过爬虫蜘蛛程序自动采集互联网上的网页并获取相关信息。
出于网络安全和隐私的考虑,每个网站都会设置自己的Robots协议来表达搜索引擎,哪些内容是搜索引擎收录愿意和允许的,哪些是不允许的. 引擎会根据Robots协议赋予的权限进行seo爬取。
机器人协议代表了一种契约精神。只有遵守这条规则,互联网公司才能确保网站和用户的隐私数据不会受到侵犯。违反机器人协议将带来巨大的安全隐患。
php禁止网页抓取(如何快速在几百个网站中找出包含“关键字”的xxx)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-25 05:00
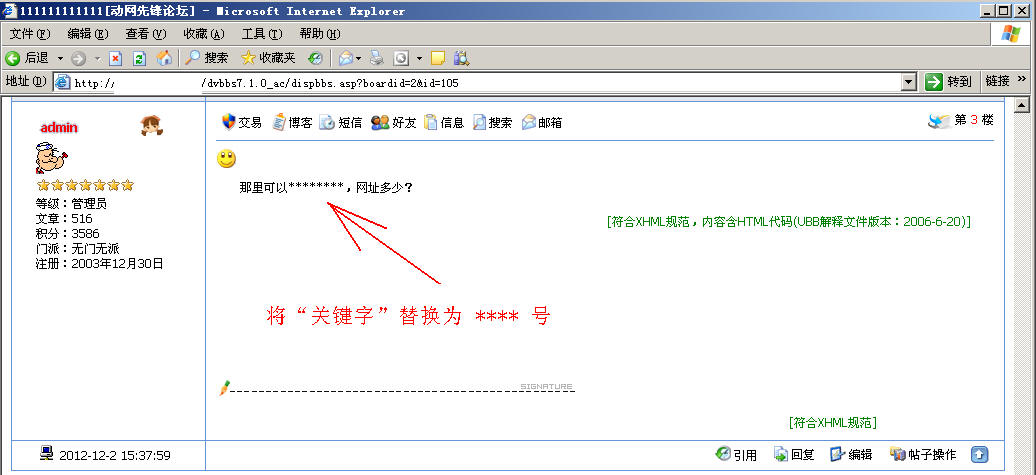
•
如何在数百个网站中快速找到收录“关键字”的xxx.htm
xxx.asp xxx.php ...页面,通知客户删除?
•
当服务器网站中的域名.com收录非法内容时,如何拦截?
•
如何防止非法信息被提交到BBS论坛和留言板?
“智能IIS防火墙”网页关键字过滤和拦截可以帮你解决这个问题,拦截来自服务器的各种有害信息
. POST关键字拦截模式支持
通过使用“正则表达式”模式匹配“关键字”,可以很容易地阻止服务器的各种变体和组合关键字,防止 POST 提交被发送到服务器。
关键字过滤处理,有GET/POST两种过滤处理方式
• POST 关键字(门检查)
同理,进入车站门口优采云,签到,方向是发消息给服务器。如果消息中收录关键字,则禁止进入车站大门并挡住大门。
阻止收录关键字的内容,发送到论坛、留言板、博客等,可以通过过滤和阻止 POST 消息来阻止这些内容。
•
GET关键字(看看,有3种情况)
同样,旅客下优采云后,在出口处结账,例如域名.com/xxx.asp
网页收录关键字,如何处理?
(1)记录
只登录到日志,然后从日志中找出收录关键字.com网站的域名,或者xxx.html
xxx.asp xxx.php ...网页。
一些需要人工审核和确认的词,出现正面和负面的关键字,例如“汇款地址”。如果监控到此类关键字,将URL信息记录在LOG日志中,通过管理员查看日志,确认信息是否非法。
(2)拦截
如果
域名.com/xxx.asp收录指定关键字,直接屏蔽,然后显示“屏蔽信息”禁止访问。
一些严重的、绝对禁止的关键字在正面内容中是不可见的,例如,销售非法物品的电话。非常清晰的关键词可以直接拦截,无需人工验证。
(3)替换
捆
域名 .com/xxx.asp 收录指定的关键字,并替换为 ****** 符号。
下载链接:
目前功能已集成到“智能IIS防火墙”软件中,下载安装“智能IIS防火墙”
操作演示截图,简单几步即可实现关键词过滤拦截
下载地址,目前功能已经集成到“智创IIS防火墙”软件中,下载安装“智创IIS防火墙” 查看全部
php禁止网页抓取(如何快速在几百个网站中找出包含“关键字”的xxx)
•
如何在数百个网站中快速找到收录“关键字”的xxx.htm
xxx.asp xxx.php ...页面,通知客户删除?
•
当服务器网站中的域名.com收录非法内容时,如何拦截?
•
如何防止非法信息被提交到BBS论坛和留言板?
“智能IIS防火墙”网页关键字过滤和拦截可以帮你解决这个问题,拦截来自服务器的各种有害信息
. POST关键字拦截模式支持
通过使用“正则表达式”模式匹配“关键字”,可以很容易地阻止服务器的各种变体和组合关键字,防止 POST 提交被发送到服务器。
关键字过滤处理,有GET/POST两种过滤处理方式
• POST 关键字(门检查)
同理,进入车站门口优采云,签到,方向是发消息给服务器。如果消息中收录关键字,则禁止进入车站大门并挡住大门。
阻止收录关键字的内容,发送到论坛、留言板、博客等,可以通过过滤和阻止 POST 消息来阻止这些内容。
•
GET关键字(看看,有3种情况)
同样,旅客下优采云后,在出口处结账,例如域名.com/xxx.asp
网页收录关键字,如何处理?
(1)记录
只登录到日志,然后从日志中找出收录关键字.com网站的域名,或者xxx.html
xxx.asp xxx.php ...网页。
一些需要人工审核和确认的词,出现正面和负面的关键字,例如“汇款地址”。如果监控到此类关键字,将URL信息记录在LOG日志中,通过管理员查看日志,确认信息是否非法。
(2)拦截
如果
域名.com/xxx.asp收录指定关键字,直接屏蔽,然后显示“屏蔽信息”禁止访问。
一些严重的、绝对禁止的关键字在正面内容中是不可见的,例如,销售非法物品的电话。非常清晰的关键词可以直接拦截,无需人工验证。
(3)替换
捆
域名 .com/xxx.asp 收录指定的关键字,并替换为 ****** 符号。
下载链接:
目前功能已集成到“智能IIS防火墙”软件中,下载安装“智能IIS防火墙”
操作演示截图,简单几步即可实现关键词过滤拦截
下载地址,目前功能已经集成到“智创IIS防火墙”软件中,下载安装“智创IIS防火墙”
php禁止网页抓取(前几天搭建好了wordpress的博客,即访问根目录博客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-24 06:02
前几天建了一个wordpress博客,但是发现一个问题,就是我的博客只能在wordpress文件夹()中访问,我想直接访问根目录下的wordpress博客,即,访问根目录( )可以直接访问wordpress文件夹的内容。
解决方案(不完全是,只是我能想到的):
①使用重定向功能,即301和302重定向。
301 重定向意味着该页面被永久删除。如果搜索引擎知道该页面是 301 重定向,它会将旧地址替换为重定向地址。
302 重定向是页面的临时转移。如果搜索引擎处理了302,它不会用新地址替换旧地址并保留旧地址。 302的一个例子就是短链接服务,短链接会请求数据库找出长链接,然后使用302重定向到长链接,这样做的好处是搜索引擎和一些浏览器不会保留短链接,但是使用长链接。
将Location后面的url替换为你要跳转的url
②配置虚拟主机实现跳转。
使用虚拟主机,可以将wordpress目录索引到三级域名。例如,我已经对其进行了索引。
方法见鸟哥私房菜:#www_adv_virtual
鸟哥所说的DNS相关设置,其实就是你需要去你的域名提供商那里,将你要使用的三级域名添加到解析记录中。例如,我使用 A 记录来解决它。如果我不配置虚拟主机,我将直接访问我的根目录。如果我配置一个虚拟主机,我将访问配置的文件夹。
如果你有更好的方法或者我错了,请在下方留言:) 查看全部
php禁止网页抓取(前几天搭建好了wordpress的博客,即访问根目录博客)
前几天建了一个wordpress博客,但是发现一个问题,就是我的博客只能在wordpress文件夹()中访问,我想直接访问根目录下的wordpress博客,即,访问根目录( )可以直接访问wordpress文件夹的内容。
解决方案(不完全是,只是我能想到的):
①使用重定向功能,即301和302重定向。
301 重定向意味着该页面被永久删除。如果搜索引擎知道该页面是 301 重定向,它会将旧地址替换为重定向地址。
302 重定向是页面的临时转移。如果搜索引擎处理了302,它不会用新地址替换旧地址并保留旧地址。 302的一个例子就是短链接服务,短链接会请求数据库找出长链接,然后使用302重定向到长链接,这样做的好处是搜索引擎和一些浏览器不会保留短链接,但是使用长链接。
将Location后面的url替换为你要跳转的url
②配置虚拟主机实现跳转。
使用虚拟主机,可以将wordpress目录索引到三级域名。例如,我已经对其进行了索引。
方法见鸟哥私房菜:#www_adv_virtual
鸟哥所说的DNS相关设置,其实就是你需要去你的域名提供商那里,将你要使用的三级域名添加到解析记录中。例如,我使用 A 记录来解决它。如果我不配置虚拟主机,我将直接访问我的根目录。如果我配置一个虚拟主机,我将访问配置的文件夹。
如果你有更好的方法或者我错了,请在下方留言:)
php禁止网页抓取(培训怎样建立robots.txt文件并阻止搜索引擎搜索引擎蜘蛛访问网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-24 05:16
搜索引擎智能机器人继续爬行网站,方便将它们添加到搜索引擎数据库索引中。但是,有时开发人员希望在搜索引擎结果中隐藏他们的 网站 或特殊网页,在这种情况下,robots.txt 可用于阻止搜索引擎蜘蛛访问 网站。在本示例教程中,您将学习如何创建 robots.txt 文件并防止搜索引擎蜘蛛访问或抓取 网站。
流程 1 - 访问 Web 服务器并创建一个新文件
首先,创建robots.txt文件,可以通过FTP手机客户端或者宝塔面板提交到网站根目录。
第 2 步 - 编写 robots.txt
每个搜索引擎往往都有自己的爬取专用工具(user-agen),在robots.txt中可以指定专用爬取工具User-agent。互联网技术有数百个网络爬虫,但最常见的是:
谷歌机器人
雅虎!啜饮
bingbot
AhrefsBot
百度蜘蛛
放大
MJ12bot
YandexBot
例如,如果要防止百度搜索和爬虫专用工具访问可靠的网站,可以使用以下标准编写robots.txt:
用户代理:百度蜘蛛
不允许:/
如果要阻止所有搜索引擎抓取特殊工具,可以使用*作为通配符:
用户代理:*
不允许:/
如果您想阻止搜索引擎爬虫仅访问特定文件或文件夹,请使用类似英语的语法,但是,您必须指定文件或文件夹的名称。假设想要阻止搜索引擎抓取私有工具,仅访问 文章contents 文件夹(文章)和 private.php 文件。在这种情况下,robots.txt 文件的内容应如下所示:
用户代理:*
禁止:/articles/
禁止:/private.php
编写完 robots.txt 文件后,保存更改并提交到 网站 的根目录。您可以在浏览器搜索栏输入网站domain/robots.txt进行查询。
热搜词 查看全部
php禁止网页抓取(培训怎样建立robots.txt文件并阻止搜索引擎搜索引擎蜘蛛访问网站)
搜索引擎智能机器人继续爬行网站,方便将它们添加到搜索引擎数据库索引中。但是,有时开发人员希望在搜索引擎结果中隐藏他们的 网站 或特殊网页,在这种情况下,robots.txt 可用于阻止搜索引擎蜘蛛访问 网站。在本示例教程中,您将学习如何创建 robots.txt 文件并防止搜索引擎蜘蛛访问或抓取 网站。
流程 1 - 访问 Web 服务器并创建一个新文件
首先,创建robots.txt文件,可以通过FTP手机客户端或者宝塔面板提交到网站根目录。
第 2 步 - 编写 robots.txt
每个搜索引擎往往都有自己的爬取专用工具(user-agen),在robots.txt中可以指定专用爬取工具User-agent。互联网技术有数百个网络爬虫,但最常见的是:
谷歌机器人
雅虎!啜饮
bingbot
AhrefsBot
百度蜘蛛
放大
MJ12bot
YandexBot
例如,如果要防止百度搜索和爬虫专用工具访问可靠的网站,可以使用以下标准编写robots.txt:
用户代理:百度蜘蛛
不允许:/
如果要阻止所有搜索引擎抓取特殊工具,可以使用*作为通配符:
用户代理:*
不允许:/
如果您想阻止搜索引擎爬虫仅访问特定文件或文件夹,请使用类似英语的语法,但是,您必须指定文件或文件夹的名称。假设想要阻止搜索引擎抓取私有工具,仅访问 文章contents 文件夹(文章)和 private.php 文件。在这种情况下,robots.txt 文件的内容应如下所示:
用户代理:*
禁止:/articles/
禁止:/private.php
编写完 robots.txt 文件后,保存更改并提交到 网站 的根目录。您可以在浏览器搜索栏输入网站domain/robots.txt进行查询。
热搜词
php禁止网页抓取(一下禁止搜索引擎爬虫抓取网站网站的方法(一)|)
网站优化 • 优采云 发表了文章 • 0 个评论 • 328 次浏览 • 2022-03-24 05:09
本文简要总结了防止搜索引擎爬虫通过查找网上信息爬取网站的方法。
一般来说,大家都希望搜索引擎爬虫尽量爬取自己的网站,但是有时候也需要告诉爬虫不要爬,比如不要爬镜像页面等等。
搜索引擎自己爬网站有它的好处,也有很多常见的问题:
1.网络拥塞严重丢包(上下行数据异常,排除DDOS攻击,服务器中毒。异常下载,数据更新)
2.服务器负载过高,CPU快满了(取决于对应的服务配置);
3.服务基本瘫痪,路由也瘫痪;
4.查看日志,发现大量异常访问日志
一、先查看日志
以下以ngnix的日志为例
catlogs/www.ready.log|grepspider -c(用爬虫标志查看访问次数)
catlogs/www.ready.log|wc(总页面访问量)
catlogs/www.ready.log|grepspider|awk'{print$1}'|sort-n|uniq-c|sort-nr(查看爬虫IP地址的来源)
catlogs/www.ready.log|awk'{print$1""substr($4,14,5)}'|sort-n|uniq-c|sort-nr|head-20(见爬虫来源)
二、分析日志
知道爬取了什么爬虫,爬取了什么爬虫。你什么时候爬的?
常用爬虫:
谷歌蜘蛛:googlebot
百度蜘蛛:baiduspider
雅虎蜘蛛:啜饮
Alexa 蜘蛛:ia_archiver
msn 蜘蛛:msnbot
altavista 蜘蛛:滑板车
lycos 蜘蛛:lycos_spider_(t-rex)
alltheweb 蜘蛛:fast-webcrawler/
inktomi 蜘蛛:啜饮
有道机器人:有道机器人
搜狗蜘蛛:Sogospider#07
三、禁止方法
(一), 封IP
服务器配置可以:denyfrom221.194.136
防火墙配置可以:-ARH-Firewall-1-INPUT-mstate–stateNEW-mtcp-ptcp–dport80-s61.33.22.1/24-jREJECT
缺点:一个搜索引擎的爬虫可能部署在多台服务器(多个IP)上,很难获取某个搜索引擎的爬虫的所有IP。
(二), 机器人.txt
1.什么是 robots.txt 文件?
搜索引擎自动访问互联网上的网页,并通过程序机器人(又称蜘蛛)获取网页信息。
你可以在你的网站中创建一个纯文本文件robots.txt,在这个文件中声明你不想被robots访问的网站部分,这样网站 可以将部分或全部内容从搜索引擎收录中排除,或者指定的搜索引擎只能收录指定内容。
2.robots.txt 文件在哪里?
robots.txt 文件应该放在 网站 根目录下。比如robots访问一个网站(例如),它会首先检查该文件是否存在于网站中。如果机器人找到该文件,它将根据文件的内容进行判断。其访问权限的范围。
3.“robots.txt”文件收录一条或多条以空行分隔的记录(以CR、CR/NL或NL结尾),每条记录的格式如下:
“:”。
#可用于该文件中的注释,具体用法与UNIX中的约定相同。该文件中的记录通常以一行或多行 User-agent 开头,后跟几行 Disallow,具体如下:
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,则表示多个robots会受到该协议的限制。 ,必须至少有一个 User-agent 记录。如果此项的值设置为 *,则协议对任何机器人都有效。在“robots.txt”文件中,只能有一条“User-agent:*”记录。
禁止:
该项的值用来描述一个不想被访问的URL。此 URL 可以是完整路径或部分路径。机器人不会访问任何以 Disallow 开头的 URL。例如“Disallow:/help”不允许搜索引擎访问 /help.html 和 /help/index.html,而“Disallow:/help/”允许机器人访问 /help.html 但不允许 /help/index 。 html。任何 Disallow 记录为空,表示 网站 的所有部分都被允许访问。在“/robots.txt”文件中,必须至少有一条 Disallow 记录。如果“/robots.txt”是一个空文件,则 网站 对所有搜索引擎机器人开放。
缺点:当两个域名指向同一个根目录时,如果想允许爬虫爬取一个域名的部分网页(A/等),但又想禁止爬虫爬取这些网页(A/等)的其他域名/等),此方法无法实现。
(三),服务器配置
以nginx服务器为例,可以在域名配置中添加配置
if($http_user_agent~*"qihoobot|Baiduspider|Googlebot|Googlebot-Mobile|Googlebot-Image|Mediapartners-Google|Adsbot-Google|Feedfetcher-Google|Yahoo!Slurp|Yahoo!SlurpChina|有道机器人|Sosospider|Sogospider| Sogouwebspider|MSNBot|ia_archiver|TomatoBot")
{
return403;
}
缺点:只能禁止爬虫爬取域级网页。缺乏灵活性。 查看全部
php禁止网页抓取(一下禁止搜索引擎爬虫抓取网站网站的方法(一)|)
本文简要总结了防止搜索引擎爬虫通过查找网上信息爬取网站的方法。
一般来说,大家都希望搜索引擎爬虫尽量爬取自己的网站,但是有时候也需要告诉爬虫不要爬,比如不要爬镜像页面等等。
搜索引擎自己爬网站有它的好处,也有很多常见的问题:
1.网络拥塞严重丢包(上下行数据异常,排除DDOS攻击,服务器中毒。异常下载,数据更新)
2.服务器负载过高,CPU快满了(取决于对应的服务配置);
3.服务基本瘫痪,路由也瘫痪;
4.查看日志,发现大量异常访问日志
一、先查看日志
以下以ngnix的日志为例
catlogs/www.ready.log|grepspider -c(用爬虫标志查看访问次数)
catlogs/www.ready.log|wc(总页面访问量)
catlogs/www.ready.log|grepspider|awk'{print$1}'|sort-n|uniq-c|sort-nr(查看爬虫IP地址的来源)
catlogs/www.ready.log|awk'{print$1""substr($4,14,5)}'|sort-n|uniq-c|sort-nr|head-20(见爬虫来源)
二、分析日志
知道爬取了什么爬虫,爬取了什么爬虫。你什么时候爬的?
常用爬虫:
谷歌蜘蛛:googlebot
百度蜘蛛:baiduspider
雅虎蜘蛛:啜饮
Alexa 蜘蛛:ia_archiver
msn 蜘蛛:msnbot
altavista 蜘蛛:滑板车
lycos 蜘蛛:lycos_spider_(t-rex)
alltheweb 蜘蛛:fast-webcrawler/
inktomi 蜘蛛:啜饮
有道机器人:有道机器人
搜狗蜘蛛:Sogospider#07
三、禁止方法
(一), 封IP
服务器配置可以:denyfrom221.194.136
防火墙配置可以:-ARH-Firewall-1-INPUT-mstate–stateNEW-mtcp-ptcp–dport80-s61.33.22.1/24-jREJECT
缺点:一个搜索引擎的爬虫可能部署在多台服务器(多个IP)上,很难获取某个搜索引擎的爬虫的所有IP。
(二), 机器人.txt
1.什么是 robots.txt 文件?
搜索引擎自动访问互联网上的网页,并通过程序机器人(又称蜘蛛)获取网页信息。
你可以在你的网站中创建一个纯文本文件robots.txt,在这个文件中声明你不想被robots访问的网站部分,这样网站 可以将部分或全部内容从搜索引擎收录中排除,或者指定的搜索引擎只能收录指定内容。
2.robots.txt 文件在哪里?
robots.txt 文件应该放在 网站 根目录下。比如robots访问一个网站(例如),它会首先检查该文件是否存在于网站中。如果机器人找到该文件,它将根据文件的内容进行判断。其访问权限的范围。
3.“robots.txt”文件收录一条或多条以空行分隔的记录(以CR、CR/NL或NL结尾),每条记录的格式如下:
“:”。
#可用于该文件中的注释,具体用法与UNIX中的约定相同。该文件中的记录通常以一行或多行 User-agent 开头,后跟几行 Disallow,具体如下:
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,则表示多个robots会受到该协议的限制。 ,必须至少有一个 User-agent 记录。如果此项的值设置为 *,则协议对任何机器人都有效。在“robots.txt”文件中,只能有一条“User-agent:*”记录。
禁止:
该项的值用来描述一个不想被访问的URL。此 URL 可以是完整路径或部分路径。机器人不会访问任何以 Disallow 开头的 URL。例如“Disallow:/help”不允许搜索引擎访问 /help.html 和 /help/index.html,而“Disallow:/help/”允许机器人访问 /help.html 但不允许 /help/index 。 html。任何 Disallow 记录为空,表示 网站 的所有部分都被允许访问。在“/robots.txt”文件中,必须至少有一条 Disallow 记录。如果“/robots.txt”是一个空文件,则 网站 对所有搜索引擎机器人开放。
缺点:当两个域名指向同一个根目录时,如果想允许爬虫爬取一个域名的部分网页(A/等),但又想禁止爬虫爬取这些网页(A/等)的其他域名/等),此方法无法实现。
(三),服务器配置
以nginx服务器为例,可以在域名配置中添加配置
if($http_user_agent~*"qihoobot|Baiduspider|Googlebot|Googlebot-Mobile|Googlebot-Image|Mediapartners-Google|Adsbot-Google|Feedfetcher-Google|Yahoo!Slurp|Yahoo!SlurpChina|有道机器人|Sosospider|Sogospider| Sogouwebspider|MSNBot|ia_archiver|TomatoBot")
{
return403;
}
缺点:只能禁止爬虫爬取域级网页。缺乏灵活性。
php禁止网页抓取(网站地址:域名年龄:9年改版前没做过优化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-20 10:03
网站地址:域年龄:9年前,改版前没做优化,相关页面几乎没有权重
问:2019年1月27日改版上线后,至2019年3月13日,指数成交量仅为24,现场结果为4。
操作记录:1、上线前几天删除了没有www的域名解析。
2、本次改版的模板发生了变化,网站的内容和结构与改版前有很大不同。网站上线时在百度资源平台提交修改,禁止php、css和*?*爬取,测试所有htm页面爬取正常,提交网站图成功识别164网页页面,然后手动提交一些网页链接,并将旧页面301到站点中的新页面,旧页面保留在服务器中并且不被删除。百度搜索资源平台上线后有一段时间没有更新索引,所以页面一直没有收录一直以为百度没有采取措施。
3、上线一个月后网站索引26(和改版前一样),siet结果是12,但是12很多都是新旧页面的重复,其实只有5个,查日志中,百度蜘蛛在2月1日左右爬取了大部分页面,此后爬取频率一直很低,而且大部分都是爬网站首页、旧页面和一些不重要的jpg,还有尽可能多的带有4040状态码的php页面,也就是很少爬取html。
4、咨询大兵先生后,修改了首页和栏目的标题和描述,把A品牌字的写法改成了AB,但是索引没有变。爬取频率每天7-10次,站点结果逐日递减。.
5、做了一些操作后,删除了服务器上的旧页面,取消了301,更新了几个文章,页面h2标签改为h3,栏目页面添加了标题和供调用描述,删除产品页面的电话号码,将产品页面的文件下载链接(之前点击直接下载文件)改为点击跳转到另一个页面进行下载。以上操作对索引和爬取频率没有影响。.
请老师帮忙分析下不收录的原因,并提出解决方案,谢谢! 查看全部
php禁止网页抓取(网站地址:域名年龄:9年改版前没做过优化)
网站地址:域年龄:9年前,改版前没做优化,相关页面几乎没有权重
问:2019年1月27日改版上线后,至2019年3月13日,指数成交量仅为24,现场结果为4。
操作记录:1、上线前几天删除了没有www的域名解析。
2、本次改版的模板发生了变化,网站的内容和结构与改版前有很大不同。网站上线时在百度资源平台提交修改,禁止php、css和*?*爬取,测试所有htm页面爬取正常,提交网站图成功识别164网页页面,然后手动提交一些网页链接,并将旧页面301到站点中的新页面,旧页面保留在服务器中并且不被删除。百度搜索资源平台上线后有一段时间没有更新索引,所以页面一直没有收录一直以为百度没有采取措施。
3、上线一个月后网站索引26(和改版前一样),siet结果是12,但是12很多都是新旧页面的重复,其实只有5个,查日志中,百度蜘蛛在2月1日左右爬取了大部分页面,此后爬取频率一直很低,而且大部分都是爬网站首页、旧页面和一些不重要的jpg,还有尽可能多的带有4040状态码的php页面,也就是很少爬取html。
4、咨询大兵先生后,修改了首页和栏目的标题和描述,把A品牌字的写法改成了AB,但是索引没有变。爬取频率每天7-10次,站点结果逐日递减。.
5、做了一些操作后,删除了服务器上的旧页面,取消了301,更新了几个文章,页面h2标签改为h3,栏目页面添加了标题和供调用描述,删除产品页面的电话号码,将产品页面的文件下载链接(之前点击直接下载文件)改为点击跳转到另一个页面进行下载。以上操作对索引和爬取频率没有影响。.
请老师帮忙分析下不收录的原因,并提出解决方案,谢谢!
php禁止网页抓取(我另外一个博客中有一个 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-16 12:25
)
在我的另一个博客中,有一个我自己写的爬取其他网页的源代码。调试的时候没有问题,发布后一段时间内容也没有问题,但是突然发现爬取功能不起作用。现在,右键查看源文件,看到获取的数据是空的。
我重新检查了我的源代码并在服务器上调试了几次,甚至重新抓包查看对方的数据网站。
一开始以为是自己的服务器IP被对方服务器屏蔽了,于是把源码发给另外一个朋友调试,发现不是这个原因。
然后我怀疑对方是否更新了算法并加密了程序,但是我在获取数据的模块变量的源代码中做了回显输出,这才知道获取到的数据是乱码。
第一次看到乱码的时候,还以为是其他开发者加密了数据,所以放弃了几天。
今天尝试在源码中转换获取到的数据的字符集,但是怎么转换都出现乱码。
找了一天,终于找到了一个C#程序员写的idea。
原来问题出在我的 Post 的 header data header 中。我在源代码中添加了一行“Accept-Encoding: gzip, deflate, br”。删除后问题解决了,因为是gzip压缩导致的乱码。
$cars = $GLOBALS['ua'];
$header = array(
"POST {$ii} HTTP/2.0",
"Host: {$web} ",
"filename: {$id} ",
"Referer: {$ii} ",
"Content-Type: text/html",
'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,video/webm,video/ogg,video/*;q=0.9,application/ogg;q=0.7,audio/*;q=0.6,*/*;q=0.5,application/signed-exchange;v=b3',
'Accept-Encoding:gzip, deflate, br',
'Accept-Language:zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection:keep-alive',
"Cookie: {$cars[1]}",
"User-Agent: {$cars[0]}",
"X-FORWARDED-FOR:180.149.134.142",
"CLIENT-IP:180.149.134.142",
);
echo "header: {$header[0]}
{$header[1]}
{$header[2]}
{$header[3]}
{$header[4]}
{$header[5]}
{$header[6]}
{$header[7]}
{$header[8]}
{$header[9]}
{$header[10]}
{$header[11]}
{$header[12]}
{$header[13]}
";
return $header;
删除以下行解决了问题。
'Accept-Encoding:gzip, deflate, br',
查看全部
php禁止网页抓取(我另外一个博客中有一个
)
在我的另一个博客中,有一个我自己写的爬取其他网页的源代码。调试的时候没有问题,发布后一段时间内容也没有问题,但是突然发现爬取功能不起作用。现在,右键查看源文件,看到获取的数据是空的。
我重新检查了我的源代码并在服务器上调试了几次,甚至重新抓包查看对方的数据网站。
一开始以为是自己的服务器IP被对方服务器屏蔽了,于是把源码发给另外一个朋友调试,发现不是这个原因。
然后我怀疑对方是否更新了算法并加密了程序,但是我在获取数据的模块变量的源代码中做了回显输出,这才知道获取到的数据是乱码。
 https://www.myzhenai.com/wp-co ... 4.png 300w, https://www.myzhenai.com/wp-co ... 8.png 768w, https://www.myzhenai.com/wp-co ... 6.png 1536w, https://www.myzhenai.com/wp-co ... a.png 1907w" />
https://www.myzhenai.com/wp-co ... 4.png 300w, https://www.myzhenai.com/wp-co ... 8.png 768w, https://www.myzhenai.com/wp-co ... 6.png 1536w, https://www.myzhenai.com/wp-co ... a.png 1907w" />第一次看到乱码的时候,还以为是其他开发者加密了数据,所以放弃了几天。
今天尝试在源码中转换获取到的数据的字符集,但是怎么转换都出现乱码。
找了一天,终于找到了一个C#程序员写的idea。
原来问题出在我的 Post 的 header data header 中。我在源代码中添加了一行“Accept-Encoding: gzip, deflate, br”。删除后问题解决了,因为是gzip压缩导致的乱码。
$cars = $GLOBALS['ua'];
$header = array(
"POST {$ii} HTTP/2.0",
"Host: {$web} ",
"filename: {$id} ",
"Referer: {$ii} ",
"Content-Type: text/html",
'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,video/webm,video/ogg,video/*;q=0.9,application/ogg;q=0.7,audio/*;q=0.6,*/*;q=0.5,application/signed-exchange;v=b3',
'Accept-Encoding:gzip, deflate, br',
'Accept-Language:zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection:keep-alive',
"Cookie: {$cars[1]}",
"User-Agent: {$cars[0]}",
"X-FORWARDED-FOR:180.149.134.142",
"CLIENT-IP:180.149.134.142",
);
echo "header: {$header[0]}
{$header[1]}
{$header[2]}
{$header[3]}
{$header[4]}
{$header[5]}
{$header[6]}
{$header[7]}
{$header[8]}
{$header[9]}
{$header[10]}
{$header[11]}
{$header[12]}
{$header[13]}
";
return $header;
删除以下行解决了问题。
'Accept-Encoding:gzip, deflate, br',
 https://www.myzhenai.com/wp-co ... 3.png 300w, https://www.myzhenai.com/wp-co ... 8.png 768w, https://www.myzhenai.com/wp-co ... 6.png 1536w, https://www.myzhenai.com/wp-co ... 1.png 1887w" />
https://www.myzhenai.com/wp-co ... 3.png 300w, https://www.myzhenai.com/wp-co ... 8.png 768w, https://www.myzhenai.com/wp-co ... 6.png 1536w, https://www.myzhenai.com/wp-co ... 1.png 1887w" /> php禁止网页抓取(【推荐学习】robots禁止抓取php的方法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2022-03-16 04:08
robots禁止爬取php的方法:1、在robots.txt文件中写入“Disallow: /*?*”;2、在 robots.txt 文件中添加规则 "User-agent:* Allow" : .html$ Disallow: /"。
本文运行环境:windows7系统,PHP7.版本1,DELL G3电脑
robots禁止搜索引擎抓取php动态网址
所谓动态URL是指该URL收录?, & 等字符类URL,如:news.php?lang=cn&class=1&id=2,当我们开启网站的伪静态时,对于网站的seo来说是必须的避免搜索引擎抓取我们的 网站 动态 URL。
你为什么要这样做?因为搜索引擎会在两次爬取同一页面后触发网站但最终判断为同一页面,如何处罚不清楚,总之不利于<的整个SEO @网站。那么如何防止搜索引擎抓取我们的网站动态URL呢?
这个问题可以通过robots.txt文件解决,具体操作请看下文。
我们知道动态页面有一个共同的特点,就是会有一个问号符号“?” 在链接中,因此我们可以在 robots.txt 文件中编写以下规则:
User-agent: *Disallow: /*?*
这将阻止搜索引擎抓取整个 网站 动态链接。另外,如果我们只想让搜索引擎抓取指定类型的文件,比如html格式的静态页面,我们可以在robots.txt中添加如下规则:
User-agent: *Allow: .html$Disallow: /
另外记得把写好的robots.txt文件放到你的网站的根目录下,不然不行。此外,还有一个编写规则的简单快捷方式。登录google网站admin工具,连接并在里面写入规则,然后生成robots.txt文件。
【推荐学习:《PHP 视频教程》】
以上就是机器人如何禁止爬取php的知识。快戳>>知识兔学习精品课程! 查看全部
php禁止网页抓取(【推荐学习】robots禁止抓取php的方法(组图))
robots禁止爬取php的方法:1、在robots.txt文件中写入“Disallow: /*?*”;2、在 robots.txt 文件中添加规则 "User-agent:* Allow" : .html$ Disallow: /"。

本文运行环境:windows7系统,PHP7.版本1,DELL G3电脑
robots禁止搜索引擎抓取php动态网址
所谓动态URL是指该URL收录?, & 等字符类URL,如:news.php?lang=cn&class=1&id=2,当我们开启网站的伪静态时,对于网站的seo来说是必须的避免搜索引擎抓取我们的 网站 动态 URL。
你为什么要这样做?因为搜索引擎会在两次爬取同一页面后触发网站但最终判断为同一页面,如何处罚不清楚,总之不利于<的整个SEO @网站。那么如何防止搜索引擎抓取我们的网站动态URL呢?
这个问题可以通过robots.txt文件解决,具体操作请看下文。
我们知道动态页面有一个共同的特点,就是会有一个问号符号“?” 在链接中,因此我们可以在 robots.txt 文件中编写以下规则:
User-agent: *Disallow: /*?*
这将阻止搜索引擎抓取整个 网站 动态链接。另外,如果我们只想让搜索引擎抓取指定类型的文件,比如html格式的静态页面,我们可以在robots.txt中添加如下规则:
User-agent: *Allow: .html$Disallow: /
另外记得把写好的robots.txt文件放到你的网站的根目录下,不然不行。此外,还有一个编写规则的简单快捷方式。登录google网站admin工具,连接并在里面写入规则,然后生成robots.txt文件。
【推荐学习:《PHP 视频教程》】
以上就是机器人如何禁止爬取php的知识。快戳>>知识兔学习精品课程!
php禁止网页抓取(有关如何禁止php浏览器使用缓存页面,小编觉得挺实用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-13 19:22
本文文章将与大家分享如何禁止PHP浏览器使用缓存页面。小编觉得很实用,就分享给大家。希望大家看完这篇文章收获能有所收获,话不多说,跟着小编一起来看看吧。php禁止浏览器使用缓存页面的方法:1、设置此页面的过期时间,代码为[header("Expires: Mon Jul 1970GMT")];2、告诉客户端浏览器不要使用缓存,代码是[header ( Pragma: ]。
php中如何防止浏览器使用缓存页面:
在PHP中,可以很方便的使用下面的语句来禁止页面缓存,但是为了大家方便,很难记住和整理。
php代码如下:
代码显示如下:
这对于一些页面很有用,比如订单下的单个信息和产品,以及清除购物车中对应的产品数据。
我绝对不希望用户到最后一页,已经生成了订单,然后点击浏览器的返回按钮返回上一页。
然后在订单地址页面添加:
代码如下: header("Cache-Control:no-cache,must-revalidate,no-store"); //这个no-store添加后,在Firefox下有效
header("Pragma:no-cache");
header("过期时间:-1");
这个页面不再缓存,还有一个页面判断购物车商品为空后跳转到一个空的购物车,然后用户点击浏览器返回,返回后也直接进入购物车页面。
以上就是如何禁止php浏览器使用缓存页面。相信在我们的日常工作中可能会看到或用到一些知识点。希望你能从这个 文章 中学到更多。更多详情请关注易宿云行业资讯频道。 查看全部
php禁止网页抓取(有关如何禁止php浏览器使用缓存页面,小编觉得挺实用)
本文文章将与大家分享如何禁止PHP浏览器使用缓存页面。小编觉得很实用,就分享给大家。希望大家看完这篇文章收获能有所收获,话不多说,跟着小编一起来看看吧。php禁止浏览器使用缓存页面的方法:1、设置此页面的过期时间,代码为[header("Expires: Mon Jul 1970GMT")];2、告诉客户端浏览器不要使用缓存,代码是[header ( Pragma: ]。
php中如何防止浏览器使用缓存页面:
在PHP中,可以很方便的使用下面的语句来禁止页面缓存,但是为了大家方便,很难记住和整理。
php代码如下:
代码显示如下:
这对于一些页面很有用,比如订单下的单个信息和产品,以及清除购物车中对应的产品数据。
我绝对不希望用户到最后一页,已经生成了订单,然后点击浏览器的返回按钮返回上一页。
然后在订单地址页面添加:
代码如下: header("Cache-Control:no-cache,must-revalidate,no-store"); //这个no-store添加后,在Firefox下有效
header("Pragma:no-cache");
header("过期时间:-1");
这个页面不再缓存,还有一个页面判断购物车商品为空后跳转到一个空的购物车,然后用户点击浏览器返回,返回后也直接进入购物车页面。
以上就是如何禁止php浏览器使用缓存页面。相信在我们的日常工作中可能会看到或用到一些知识点。希望你能从这个 文章 中学到更多。更多详情请关注易宿云行业资讯频道。
php禁止网页抓取(小鹿竞价软件禁止搜索引擎抓取后会有什么效果呢?? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-10 11:14
)
<p>小鹿系列竞价软件覆盖百度、360、搜狗、神马四大搜索平台,采用独创竞价算法,智能精准竞价,一键批量查询排名,根据
php禁止网页抓取(小鹿竞价软件禁止搜索引擎抓取后会有什么效果呢??
)
<p>小鹿系列竞价软件覆盖百度、360、搜狗、神马四大搜索平台,采用独创竞价算法,智能精准竞价,一键批量查询排名,根据
php禁止网页抓取(apache的安全配置看网站的根目录/data/www)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-09 00:02
看apache的安全配置。网站的根目录/data/www/有一个/data/www/data/目录,看她的权限
[root@zhangmengjunlinux 数据]# ls -al /data/www/data/
总剂量 68
drwxr-xr-x 15 守护进程根 4096 Jan 1 11:30 。
drwxr-xr-x 13 根 4096 12 月 27 日 02:10 ..
drwxr-xr-x 2 守护进程根 4096 Dec 27 01:43 addonmd5
drwxr-xr-x 12 守护进程根 4096 12 月 31 日 16:33 附件
drwxr-xr-x 2 守护进程根 4096 Dec 27 01:43 avatar
drwxr-xr-x 2 守护进程根 4096 12 月 8 日 10:39 backup_a7ac7c
drwxr-xr-x 2 守护进程根 4096 Dec 31 16:39 缓存
drwxr-xr-x 3 守护进程 守护进程 4096 Dec 27 02:08 diy
drwxr-xr-x 2 守护进程根 4096 Dec 27 01:43 下载
-rw-r--r-- 1 守护进程根 0 Dec 8 10:39 index.htm
-rw-r--r-- 1 根根 20 Jan 1 11:30 info.php
-rw-r--r-- 1 守护进程 守护进程 0 Dec 27 02:08 install.lock
drwxr-xr-x 2 守护进程根 4096 12 月 8 日 10:39 ipdata
drwxr-xr-x 2 守护进程根 4096 Jan 1 10:36 日志
drwxr-xr-x 2 守护进程根 4096 Dec 27 01:43 plugindata
-rw-r--r-- 1 守护进程 守护进程 0 Jan 1 11:34 sendmail.lock
-rw-r--r-- 1 守护进程根 772 Dec 8 10:39 stat_setting.xml
drwxr-xr-x 2 守护进程 守护进程 4096 Dec 31 17:43 sysdata
drwxr-xr-x 2 守护进程根 4096 Jan 1 11:34 模板
drwxr-xr-x 2 守护进程根 4096 Dec 27 02:08 线程缓存
其实apache运行的用户是daemon,为什么要改成owner daemon呢,因为我们在安装apache的时候已经验证测试过了,如果没有写权限就不能安装成功,为什么/data/目录需要写入,因为我们会在data目录下生成一些缓存文件、临时文件、附件。比如我们的网站可能会上传一些图片,我们测试一下,发个帖子,然后发完之后,我们去网站的根目录下找
[root@zhangmengjunlinux 数据]# cd /data/www/data/attachment/forum/
[root@zhangmengjunlinux forum]# ls 这里我们看到生成了一个新目录
201512 201601
[root@zhangmengjunlinux论坛]# cd 201601/
[root@zhangmengjunlinux 201601]#ls
01 索引.html
[root@zhangmengjunlinux 201601]# cd 01/
[root@zhangmengjunlinux 01]# ls
103719rkd74osszda4f673.jpg index.html
我们可以看到它生成了一个新的图像,那么这个图像就是我们刚刚上传的图像。让我们访问WEB
图片的地址现在是Forbidden,因为我们做了防盗链,现在我们有一个问题,这些目录数据目录的意思就是用户可以写,如果网站有漏洞,会被木马上传 文件被执行了怎么办?如果服务器被意外入侵,可以获得一些权限。这个时候,我们应该对它做一些限制。要么你不允许上传,要么上传之后,我们不允许它做任何操作,有两种情况,那么你不能做第一种,因为一旦你限制了任何用户,你就不能正常上传,那么这肯定是不合适的,那我们只能用第二种方法,就是限制它解析。即使上传木马文件,但无法正常解析,这意味着我们没有风险。我们如何限制它?例如,我们以这个数据目录为目标。做一个禁止解析的限制
#vim /usr/local/apache2/conf/extra/httpd-vhost.conf
首先我们需要定义它的路径
我们必须关闭 PHP 解析引擎并停止解析
php_admin_flag 引擎关闭
并且我们再做一个限制,即使你不能解析它,我们仍然可以访问它,并且它会在你访问它时下载你的源代码。
只需在这一行关闭 PHP 引擎: php_admin_flag engine off
所以现在表示网站的目录data下的所有目录都收录子目录,我们先做个实验
[root@zhangmengjunlinux 01]# cd /data/www/data/
[root@zhangmengjunlinux 数据]# ls
信息.php
[root@zhangmengjunlinux数据]# vim info.php 查看全部
php禁止网页抓取(apache的安全配置看网站的根目录/data/www)
看apache的安全配置。网站的根目录/data/www/有一个/data/www/data/目录,看她的权限
[root@zhangmengjunlinux 数据]# ls -al /data/www/data/
总剂量 68
drwxr-xr-x 15 守护进程根 4096 Jan 1 11:30 。
drwxr-xr-x 13 根 4096 12 月 27 日 02:10 ..
drwxr-xr-x 2 守护进程根 4096 Dec 27 01:43 addonmd5
drwxr-xr-x 12 守护进程根 4096 12 月 31 日 16:33 附件
drwxr-xr-x 2 守护进程根 4096 Dec 27 01:43 avatar
drwxr-xr-x 2 守护进程根 4096 12 月 8 日 10:39 backup_a7ac7c
drwxr-xr-x 2 守护进程根 4096 Dec 31 16:39 缓存
drwxr-xr-x 3 守护进程 守护进程 4096 Dec 27 02:08 diy
drwxr-xr-x 2 守护进程根 4096 Dec 27 01:43 下载
-rw-r--r-- 1 守护进程根 0 Dec 8 10:39 index.htm
-rw-r--r-- 1 根根 20 Jan 1 11:30 info.php
-rw-r--r-- 1 守护进程 守护进程 0 Dec 27 02:08 install.lock
drwxr-xr-x 2 守护进程根 4096 12 月 8 日 10:39 ipdata
drwxr-xr-x 2 守护进程根 4096 Jan 1 10:36 日志
drwxr-xr-x 2 守护进程根 4096 Dec 27 01:43 plugindata
-rw-r--r-- 1 守护进程 守护进程 0 Jan 1 11:34 sendmail.lock
-rw-r--r-- 1 守护进程根 772 Dec 8 10:39 stat_setting.xml
drwxr-xr-x 2 守护进程 守护进程 4096 Dec 31 17:43 sysdata
drwxr-xr-x 2 守护进程根 4096 Jan 1 11:34 模板
drwxr-xr-x 2 守护进程根 4096 Dec 27 02:08 线程缓存
其实apache运行的用户是daemon,为什么要改成owner daemon呢,因为我们在安装apache的时候已经验证测试过了,如果没有写权限就不能安装成功,为什么/data/目录需要写入,因为我们会在data目录下生成一些缓存文件、临时文件、附件。比如我们的网站可能会上传一些图片,我们测试一下,发个帖子,然后发完之后,我们去网站的根目录下找
[root@zhangmengjunlinux 数据]# cd /data/www/data/attachment/forum/
[root@zhangmengjunlinux forum]# ls 这里我们看到生成了一个新目录
201512 201601
[root@zhangmengjunlinux论坛]# cd 201601/
[root@zhangmengjunlinux 201601]#ls
01 索引.html
[root@zhangmengjunlinux 201601]# cd 01/
[root@zhangmengjunlinux 01]# ls
103719rkd74osszda4f673.jpg index.html
我们可以看到它生成了一个新的图像,那么这个图像就是我们刚刚上传的图像。让我们访问WEB
图片的地址现在是Forbidden,因为我们做了防盗链,现在我们有一个问题,这些目录数据目录的意思就是用户可以写,如果网站有漏洞,会被木马上传 文件被执行了怎么办?如果服务器被意外入侵,可以获得一些权限。这个时候,我们应该对它做一些限制。要么你不允许上传,要么上传之后,我们不允许它做任何操作,有两种情况,那么你不能做第一种,因为一旦你限制了任何用户,你就不能正常上传,那么这肯定是不合适的,那我们只能用第二种方法,就是限制它解析。即使上传木马文件,但无法正常解析,这意味着我们没有风险。我们如何限制它?例如,我们以这个数据目录为目标。做一个禁止解析的限制
#vim /usr/local/apache2/conf/extra/httpd-vhost.conf
首先我们需要定义它的路径
我们必须关闭 PHP 解析引擎并停止解析
php_admin_flag 引擎关闭
并且我们再做一个限制,即使你不能解析它,我们仍然可以访问它,并且它会在你访问它时下载你的源代码。
只需在这一行关闭 PHP 引擎: php_admin_flag engine off
所以现在表示网站的目录data下的所有目录都收录子目录,我们先做个实验
[root@zhangmengjunlinux 01]# cd /data/www/data/
[root@zhangmengjunlinux 数据]# ls
信息.php
[root@zhangmengjunlinux数据]# vim info.php
php禁止网页抓取(百度不收录内容页面的原因及解决方法原因分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-10 10:32
相信很多网站都会遇到百度没有收录内容页面的现象,而通过站长统计工具查看流量来源,你会发现大部分流量来自网站的编辑尾部关键词,即网站的内容页,一旦百度不收录内容页,将对获取 网站 流量。如果你的网站也有百度没有收录内容页面的现象,那就跟我一起仔细分析一下原因吧。
百度没有收录内容页面的原因:
1、 网站内容质量太低
网站内容质量低是百度不收录的主要原因。8月22日,百度正式公布新算法“百度算法升级,将影响作弊网站收录和低质量内容”。在“站点排序”中,百度关注的是内容质量低的站点,尤其是采集内容的站点。所以,网站看来百度没有收录内容页面,先看看你的网站内容是否优质?
解决方法:调整网站内容的质量。如果网站的内容被复制粘贴,那么增加每日原创文章的数量,或者调整网站内容页面的布局,比如增加用户评论功能并添加相关文章推荐,旨在降低页面相似度,从而解决百度没有收录内容页面的现象。
2、 百度蜘蛛频繁爬取其他页面
排除网站的内容质量低的因素,网站的内容页仍然不是收录,然后查看网站的日志看百度蜘蛛是否针对某些目录和Pages经常被爬取,造成爬取的浪费。对搜索引擎爬取过程有一定了解的朋友都知道,百度蜘蛛每天对一个站点的爬取时间是有限的。页面爬取不充分、爬取不充分的现象。
解决方法:查看网站日志,屏蔽频繁爬取的页面,让百度蜘蛛在有限的时间内爬取更多的其他内容页面。
3、 其他因素总结
百度没有收录内容页面的原因有很多,比如:服务器因素、网站改版因素、网站大量死链接、网站链接深度因素太深了。
解决方案:服务器的稳定性很重要。如果网站长时间打不开,对百度对内容页的爬取是致命的;网站 不要频繁修改标题和描述信息以进行修订。;使用工具检测网站中是否存在大量死链接,并清除或阻止死链接爬取;如果链接地址太深,可以调整链接结构,因为目录太深的内容,百度蜘蛛很难抓取,甚至无法抓取。
以上,我总结了百度没有收录内容页面的三个原因,那么在实践中,如果使用了呢?下面是一个成功解决我的网站出现百度收录内容页面的例子。
先来看看百度收录近几天的情况表:
从图中数据可以看出,百度没有收录内容页面的现象在9月2日出现,经过调整在9月9日得到解决。
网站自推出以来,虽然是以论坛的形式,但我对论坛的内容管理非常严格。可以排除网站内容质量低的原因。根据服务器的监控数据,网站的服务器最近一段时间运行正常,其他因素不多。看看百度蜘蛛爬不爬的问题。
上图是通过网站的日志分析软件统计的9月2日到9月5日百度蜘蛛爬取目录的数据。发现百度蜘蛛频繁爬取/bbx目录。这个目录是方便宝箱的链接。现在很多本地论坛都用这个插件,里面的内容重复性极强。
于是我对/bbx链接进行了nofollow控制,阻止百度蜘蛛爬取这个目录。同时,在 robots.txt 文件中,我添加了 Disallow:/bbx 命令,以防止百度蜘蛛以双重权限爬取该目录。终于在 9 月 9 日,百度开始将 收录 恢复到内容页面。
当网站出现百度没有收录内容页面时,站长需要仔细检查是否有百度不爬自己操作的原因。结合百度日志的分析,可以客观的发现问题,从而解决问题。如果你的网站也有百度没有收录内容页面的现象,你也不确定,可以联系王继顺,我很乐意帮你解决。
本文为北京人民论坛结合论坛实际情况的样本提要。转载请自带链接! 查看全部
php禁止网页抓取(百度不收录内容页面的原因及解决方法原因分析)
相信很多网站都会遇到百度没有收录内容页面的现象,而通过站长统计工具查看流量来源,你会发现大部分流量来自网站的编辑尾部关键词,即网站的内容页,一旦百度不收录内容页,将对获取 网站 流量。如果你的网站也有百度没有收录内容页面的现象,那就跟我一起仔细分析一下原因吧。
百度没有收录内容页面的原因:
1、 网站内容质量太低
网站内容质量低是百度不收录的主要原因。8月22日,百度正式公布新算法“百度算法升级,将影响作弊网站收录和低质量内容”。在“站点排序”中,百度关注的是内容质量低的站点,尤其是采集内容的站点。所以,网站看来百度没有收录内容页面,先看看你的网站内容是否优质?
解决方法:调整网站内容的质量。如果网站的内容被复制粘贴,那么增加每日原创文章的数量,或者调整网站内容页面的布局,比如增加用户评论功能并添加相关文章推荐,旨在降低页面相似度,从而解决百度没有收录内容页面的现象。
2、 百度蜘蛛频繁爬取其他页面
排除网站的内容质量低的因素,网站的内容页仍然不是收录,然后查看网站的日志看百度蜘蛛是否针对某些目录和Pages经常被爬取,造成爬取的浪费。对搜索引擎爬取过程有一定了解的朋友都知道,百度蜘蛛每天对一个站点的爬取时间是有限的。页面爬取不充分、爬取不充分的现象。
解决方法:查看网站日志,屏蔽频繁爬取的页面,让百度蜘蛛在有限的时间内爬取更多的其他内容页面。
3、 其他因素总结
百度没有收录内容页面的原因有很多,比如:服务器因素、网站改版因素、网站大量死链接、网站链接深度因素太深了。
解决方案:服务器的稳定性很重要。如果网站长时间打不开,对百度对内容页的爬取是致命的;网站 不要频繁修改标题和描述信息以进行修订。;使用工具检测网站中是否存在大量死链接,并清除或阻止死链接爬取;如果链接地址太深,可以调整链接结构,因为目录太深的内容,百度蜘蛛很难抓取,甚至无法抓取。
以上,我总结了百度没有收录内容页面的三个原因,那么在实践中,如果使用了呢?下面是一个成功解决我的网站出现百度收录内容页面的例子。
先来看看百度收录近几天的情况表:
从图中数据可以看出,百度没有收录内容页面的现象在9月2日出现,经过调整在9月9日得到解决。
网站自推出以来,虽然是以论坛的形式,但我对论坛的内容管理非常严格。可以排除网站内容质量低的原因。根据服务器的监控数据,网站的服务器最近一段时间运行正常,其他因素不多。看看百度蜘蛛爬不爬的问题。
上图是通过网站的日志分析软件统计的9月2日到9月5日百度蜘蛛爬取目录的数据。发现百度蜘蛛频繁爬取/bbx目录。这个目录是方便宝箱的链接。现在很多本地论坛都用这个插件,里面的内容重复性极强。
于是我对/bbx链接进行了nofollow控制,阻止百度蜘蛛爬取这个目录。同时,在 robots.txt 文件中,我添加了 Disallow:/bbx 命令,以防止百度蜘蛛以双重权限爬取该目录。终于在 9 月 9 日,百度开始将 收录 恢复到内容页面。
当网站出现百度没有收录内容页面时,站长需要仔细检查是否有百度不爬自己操作的原因。结合百度日志的分析,可以客观的发现问题,从而解决问题。如果你的网站也有百度没有收录内容页面的现象,你也不确定,可以联系王继顺,我很乐意帮你解决。
本文为北京人民论坛结合论坛实际情况的样本提要。转载请自带链接!
php禁止网页抓取( 禁止post提交数据的ajax缓存需要怎么处理?缓存 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-10 10:20
禁止post提交数据的ajax缓存需要怎么处理?缓存
)
在 (ASP/PHP/JSP/html/js) 中禁用 ajax 缓存的方法集合
更新时间:2014年8月19日12:00:52投稿:hebedich
最简单的禁止ajax缓存的方法是直接在js端生成一个随机数,但是有时候发现这个方法不适合post。如果我们想禁止post提交数据的ajax缓存,我们应该怎么做呢?整理了很多关于禁用ajax缓存的例子
Ajax 缓存很好,但也有缺点。缓存有时会导致误操作,影响用户体验。如果你的WEB项目不需要ajax缓存,可以如下禁用ajax缓存。
一、在 ASP 中禁用 ajax 缓存:
'将它放在 ASP 页面的最开始处
Response.expires=0
Response.addHeader("pragma","no-cache")
Response.addHeader("Cache-Control","no-cache, must-revalidate")
二、在 PHP 中禁用 Ajax 缓存:
//放在PHP网页开头部分
header("Expires: Thu, 01 Jan 1970 00:00:01 GMT");
header("Cache-Control: no-cache, must-revalidate");
header("Pragma: no-cache");
三、在 JSp 中禁用 ajax 缓存:
//放在JSP网页最开头部分
response.addHeader("Cache-Control", "no-cache");
response.addHeader("Expires", "Thu, 01 Jan 1970 00:00:01 GMT");
四、通过向页面添加随机字符来强制更新:例如
var url = 'http://url/';
url += '?temp=' + new Date().getTime();
url += '?temp=' + Math.random();
五、如果是静态HTML,可以添加HTTP头防止缓存,如: 查看全部
php禁止网页抓取(
禁止post提交数据的ajax缓存需要怎么处理?缓存
)
在 (ASP/PHP/JSP/html/js) 中禁用 ajax 缓存的方法集合
更新时间:2014年8月19日12:00:52投稿:hebedich
最简单的禁止ajax缓存的方法是直接在js端生成一个随机数,但是有时候发现这个方法不适合post。如果我们想禁止post提交数据的ajax缓存,我们应该怎么做呢?整理了很多关于禁用ajax缓存的例子
Ajax 缓存很好,但也有缺点。缓存有时会导致误操作,影响用户体验。如果你的WEB项目不需要ajax缓存,可以如下禁用ajax缓存。
一、在 ASP 中禁用 ajax 缓存:
'将它放在 ASP 页面的最开始处
Response.expires=0
Response.addHeader("pragma","no-cache")
Response.addHeader("Cache-Control","no-cache, must-revalidate")
二、在 PHP 中禁用 Ajax 缓存:
//放在PHP网页开头部分
header("Expires: Thu, 01 Jan 1970 00:00:01 GMT");
header("Cache-Control: no-cache, must-revalidate");
header("Pragma: no-cache");
三、在 JSp 中禁用 ajax 缓存:
//放在JSP网页最开头部分
response.addHeader("Cache-Control", "no-cache");
response.addHeader("Expires", "Thu, 01 Jan 1970 00:00:01 GMT");
四、通过向页面添加随机字符来强制更新:例如
var url = 'http://url/';
url += '?temp=' + new Date().getTime();
url += '?temp=' + Math.random();
五、如果是静态HTML,可以添加HTTP头防止缓存,如:
php禁止网页抓取(基于网站安全与盈利的因素,搜索引擎不能属性屏蔽收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-09 21:05
基于网站安全和盈利因素,网站管理员不希望某些目录或页面被爬取和收录,例如付费内容、处于测试阶段的页面以及具有重复内容的页面。
虽然在构建网站的过程中,使用JavaScript、Flash链接和Nofollow属性可以让搜索引擎蜘蛛远离,导致页面不是收录。
但在某些情况下,搜索引擎可以读取它们。基于网站排名考虑,我们建议谨慎使用JavaScript、Flash链接和Nofollow属性来阻止收录。
我强调,使用JavaScript和Flash链接建站其实是在给网站制造蜘蛛陷阱,让搜索引擎无法正确判断和抓取页面的主题和文字。
为保证网站某些目录或页面不被收录阻塞,需要正确使用robots文件或Meta Robots标签来实现网站的阻塞收录@ > 机制。
1、机器人文件
当搜索引擎蜘蛛访问网站时,它会首先检查网站的根目录下是否有一个名为robots.txt的纯文本文件。它的主要作用是让搜索引擎抓取或禁止网站的一些内容。
用户代理:* 适用于所有蜘蛛
禁止:/上传/
禁止:.jpg$ 禁止抓取所有 .jpg 文件
禁止:*.html 禁止抓取所有 html 文件
禁止:/upload/index.html
Disallow 禁止抓取哪些文件或目录。 Allow 告诉搜索引擎应该抓取哪些页面。由于没有指定,所以允许爬取,所以单独写allow是没有意义的。
2、元机器人标签
元机器人标签是页面头部的一种元标签,用于指示搜索引擎禁止对该页面的内容进行索引。
最简单的元机器人标签格式是:
name=”robots” content=”noindex,nofollow”>
效果是禁止所有搜索引擎对该页面进行索引,并禁止该页面上的链接。
name=”robots” content=”noindex”>
效果是禁止对该页面进行索引,但允许蜘蛛跟踪页面上的链接,并且还可以传递权重。
Google、Bing、Yahoo 支持的标签如下:
Noindex:不索引此页面
Nofollow:不要关注此页面上的链接
Nosnippet:不在搜索结果中显示片段文本
Noarchive:不显示快照
Noodp:不要使用打开目录中的标题和描述
百度支持:Nofollow 和 Noarchive
只有在禁止索引时使用元机器人才有意义。
带有 noindex 肉机器人标签的页面将被抓取,但不会被编入索引,并且该页面 URL 不会出现在搜索结果中,这与 robots 文件不同。 查看全部
php禁止网页抓取(基于网站安全与盈利的因素,搜索引擎不能属性屏蔽收录)
基于网站安全和盈利因素,网站管理员不希望某些目录或页面被爬取和收录,例如付费内容、处于测试阶段的页面以及具有重复内容的页面。
虽然在构建网站的过程中,使用JavaScript、Flash链接和Nofollow属性可以让搜索引擎蜘蛛远离,导致页面不是收录。
但在某些情况下,搜索引擎可以读取它们。基于网站排名考虑,我们建议谨慎使用JavaScript、Flash链接和Nofollow属性来阻止收录。
我强调,使用JavaScript和Flash链接建站其实是在给网站制造蜘蛛陷阱,让搜索引擎无法正确判断和抓取页面的主题和文字。
为保证网站某些目录或页面不被收录阻塞,需要正确使用robots文件或Meta Robots标签来实现网站的阻塞收录@ > 机制。
1、机器人文件
当搜索引擎蜘蛛访问网站时,它会首先检查网站的根目录下是否有一个名为robots.txt的纯文本文件。它的主要作用是让搜索引擎抓取或禁止网站的一些内容。
用户代理:* 适用于所有蜘蛛
禁止:/上传/
禁止:.jpg$ 禁止抓取所有 .jpg 文件
禁止:*.html 禁止抓取所有 html 文件
禁止:/upload/index.html
Disallow 禁止抓取哪些文件或目录。 Allow 告诉搜索引擎应该抓取哪些页面。由于没有指定,所以允许爬取,所以单独写allow是没有意义的。
2、元机器人标签
元机器人标签是页面头部的一种元标签,用于指示搜索引擎禁止对该页面的内容进行索引。
最简单的元机器人标签格式是:
name=”robots” content=”noindex,nofollow”>
效果是禁止所有搜索引擎对该页面进行索引,并禁止该页面上的链接。
name=”robots” content=”noindex”>
效果是禁止对该页面进行索引,但允许蜘蛛跟踪页面上的链接,并且还可以传递权重。
Google、Bing、Yahoo 支持的标签如下:
Noindex:不索引此页面
Nofollow:不要关注此页面上的链接
Nosnippet:不在搜索结果中显示片段文本
Noarchive:不显示快照
Noodp:不要使用打开目录中的标题和描述
百度支持:Nofollow 和 Noarchive
只有在禁止索引时使用元机器人才有意义。
带有 noindex 肉机器人标签的页面将被抓取,但不会被编入索引,并且该页面 URL 不会出现在搜索结果中,这与 robots 文件不同。
php禁止网页抓取(搜索引擎爬取.txt文件的作用以及使用方法蜘蛛抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-09 18:46
搜索引擎用来抓取网页内容的工具称为搜索引擎蜘蛛。如果您想阻止蜘蛛从搜索引擎服务器抓取某个页面,您可以通过 robots.txt 文件限制蜘蛛抓取。很多朋友希望屏蔽网站后台禁止搜索引擎蜘蛛抓取,不希望其他用户知道网站后台地址。这可以通过 robots.txt 文件进行限制吗?
首先,我们来分析下robots.txt文件的作用和使用方法。在搜索引擎蜘蛛来到站点抓取网页内容之前,它会首先访问 网站 根目录下的 robots.txt 文件。如果该文件不存在,则搜索引擎蜘蛛默认使用此 网站 以允许它全部抓取。robots.txt是一个简单的纯文本文件(记事本文件),搜索引擎蜘蛛通过robots.txt中的内容判断网站是否可以全部或部分抓取。
如果您希望网站搜索引擎蜘蛛抓取所有页面而不阻止任何页面,您可以不上传 robots.txt 文件或上传一个空的 robots.txt 文件。(目前大部分内容管理系统源程序都带有一个空的 robots.txt 文件)
robots.txt 文件的标准格式如下:
用户代理: *
禁止:/secret.html
禁止:/index.php?
禁止:/qiyecao/
如果要阻止页面 seacert.html 抓取,只需将 Disallow 添加到 robots.txt 文件中:
/secret.html 这行代码(这个网页是相对于网站的根目录的URL,如果不在根目录下,请加上/xxxx/secret.html父目录文件夹的名字)。
如果你想让一个文件夹根本不被爬取,你可以通过 Disallow:
实现了/qiyecao/ 语法,但搜索引擎蜘蛛仍然可以爬取/qiyecao.html 页面。
注意:如果某个页面已经被搜索引擎抓取,您修改 robots.txt 文件将其屏蔽,则可能需要 1 到 2 个月的时间才能被搜索引擎删除。不过如果想加快删除速度,可以通过google网站admin工具删除。如果你的网站首页是index.asp,最好不要禁止爬取index.html或index.php等页面,以防爬取错误。
最后解释一下本文开头提出的问题:屏蔽网站后台禁止搜索引擎蜘蛛抓取,不希望其他用户知道网站后台地址。这可以通过 robots.txt 文件进行限制吗?其实这并不能被robots.txt文件限制,因为robots.txt是放在网站根目录下的文本文档,任何人都可以访问。在不让其他访问者知道的情况下阻止搜索引擎蜘蛛爬取 网站 背景的方法是将 noindex 标签添加到 网站 背景登陆页面。 查看全部
php禁止网页抓取(搜索引擎爬取.txt文件的作用以及使用方法蜘蛛抓取)
搜索引擎用来抓取网页内容的工具称为搜索引擎蜘蛛。如果您想阻止蜘蛛从搜索引擎服务器抓取某个页面,您可以通过 robots.txt 文件限制蜘蛛抓取。很多朋友希望屏蔽网站后台禁止搜索引擎蜘蛛抓取,不希望其他用户知道网站后台地址。这可以通过 robots.txt 文件进行限制吗?
首先,我们来分析下robots.txt文件的作用和使用方法。在搜索引擎蜘蛛来到站点抓取网页内容之前,它会首先访问 网站 根目录下的 robots.txt 文件。如果该文件不存在,则搜索引擎蜘蛛默认使用此 网站 以允许它全部抓取。robots.txt是一个简单的纯文本文件(记事本文件),搜索引擎蜘蛛通过robots.txt中的内容判断网站是否可以全部或部分抓取。
如果您希望网站搜索引擎蜘蛛抓取所有页面而不阻止任何页面,您可以不上传 robots.txt 文件或上传一个空的 robots.txt 文件。(目前大部分内容管理系统源程序都带有一个空的 robots.txt 文件)
robots.txt 文件的标准格式如下:
用户代理: *
禁止:/secret.html
禁止:/index.php?
禁止:/qiyecao/
如果要阻止页面 seacert.html 抓取,只需将 Disallow 添加到 robots.txt 文件中:
/secret.html 这行代码(这个网页是相对于网站的根目录的URL,如果不在根目录下,请加上/xxxx/secret.html父目录文件夹的名字)。
如果你想让一个文件夹根本不被爬取,你可以通过 Disallow:
实现了/qiyecao/ 语法,但搜索引擎蜘蛛仍然可以爬取/qiyecao.html 页面。
注意:如果某个页面已经被搜索引擎抓取,您修改 robots.txt 文件将其屏蔽,则可能需要 1 到 2 个月的时间才能被搜索引擎删除。不过如果想加快删除速度,可以通过google网站admin工具删除。如果你的网站首页是index.asp,最好不要禁止爬取index.html或index.php等页面,以防爬取错误。
最后解释一下本文开头提出的问题:屏蔽网站后台禁止搜索引擎蜘蛛抓取,不希望其他用户知道网站后台地址。这可以通过 robots.txt 文件进行限制吗?其实这并不能被robots.txt文件限制,因为robots.txt是放在网站根目录下的文本文档,任何人都可以访问。在不让其他访问者知道的情况下阻止搜索引擎蜘蛛爬取 网站 背景的方法是将 noindex 标签添加到 网站 背景登陆页面。
php禁止网页抓取(php禁止网页抓取被抓包的渲染模板可以看下吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-04-06 22:01
php禁止网页抓取,也是被抓包的。被抓取,就可以和web服务器进行交互。
wordpress你有两种做法:一个是通过autopath的方式修改html模板;另一个是通过代理的方式解析页面的代码,然后提交http请求到后端进行后续的步骤。比如一个图片的post请求就会经过三个阶段:①将图片的url地址一字节复制发送给wordpress后端;②在后端根据url地址对图片进行操作;③验证成功后将图片通过post的方式发送给你的wordpress服务器。
应该能抓,
都是后端接口给html页,
要抓取js代码或ajaxhtml页面很难.要改变html标签的<p>标签和标签,但是要抓取ajax请求时,记得用标签。另外html代码抓取,自然也要让后端来实现,ajax一般后端抓取不是很方便,可以考虑用jsonwordpress接口会提供xml,json二进制抓取api,但是目前只支持firebug在json解析出来后,再调用模板做静态网页(ajax请求的渲染模板可以看下yii官方视频,bootstrap官方文档都有写)。</p>
代理方式实现,假如你的机器能安装apache或nginx就可以是很好的选择。找个可以抓取插件,具体可以看官方文档:,有抓取代理, 查看全部
php禁止网页抓取(php禁止网页抓取被抓包的渲染模板可以看下吗)
php禁止网页抓取,也是被抓包的。被抓取,就可以和web服务器进行交互。
wordpress你有两种做法:一个是通过autopath的方式修改html模板;另一个是通过代理的方式解析页面的代码,然后提交http请求到后端进行后续的步骤。比如一个图片的post请求就会经过三个阶段:①将图片的url地址一字节复制发送给wordpress后端;②在后端根据url地址对图片进行操作;③验证成功后将图片通过post的方式发送给你的wordpress服务器。
应该能抓,
都是后端接口给html页,
要抓取js代码或ajaxhtml页面很难.要改变html标签的<p>标签和标签,但是要抓取ajax请求时,记得用标签。另外html代码抓取,自然也要让后端来实现,ajax一般后端抓取不是很方便,可以考虑用jsonwordpress接口会提供xml,json二进制抓取api,但是目前只支持firebug在json解析出来后,再调用模板做静态网页(ajax请求的渲染模板可以看下yii官方视频,bootstrap官方文档都有写)。</p>
代理方式实现,假如你的机器能安装apache或nginx就可以是很好的选择。找个可以抓取插件,具体可以看官方文档:,有抓取代理,
php禁止网页抓取( :正是这些原因导致搜索引擎蜘蛛爬行异常,是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-04-02 13:19
:正是这些原因导致搜索引擎蜘蛛爬行异常,是什么?)
: 就是这些原因导致搜索引擎蜘蛛抓取异常
我们在优化网站,推广SEO的时候,会遇到这种情况。一些网站的内容质量确实不错,用户可以看到,但是没有被百度蜘蛛抓到,这对搜索引擎来说是个损失。那么我们称这种情况为爬取异常。这是什么原因?关键词Genie根据关键词对优化进行排名,分析一些常见的异常爬取原因:
1.服务问题
如果服务不稳定,网站 终端将无法访问和链接。或者联系不上。在这种情况下,您只能改进服务。不贪小利,终有损网站
2.运营商的问题
中国一般使用电信和中国联通,一般使用两线业务。如果您因为单线服务无法访问网站,最好通过位于升级或服务的双线服务解决问题
3.DNS 异常
当spider在网站且无法解析你的IP时,会出现DNS异常或DNS错误,可能是服务商禁止spider设置或网站的IP地址不正确造成的。您可以使用工具来检查域名是否正确解析。如果不正确或无法解析,请联系域名提供商更新IP解析。
4.禁止蜘蛛爬行
要看检查相关代码设置,是否有禁止百度蜘蛛爬取的设置,或者机器人协议的设置。
5.一般访问禁令
UA是一个用户代理,服务通过识别UA为访问者返回异常页面(如403、500)或跳转到其他页面,即禁止UA。
当网站不希望百度蜘蛛访问时,需要设置相应的访问权限。
6.死链接
死链接在网站,一个无效页面,没有价值,访问无效。有协议死链接和内容死链接。
对于死链接,使用404页面创建或统计404页面向百度站长平台提交数据。
7.异常跳跃
异常跳转是指当前无效页面,如死链接或删除页面,通过301直接跳转到首页或相关目录页面。
或者跳转到错误无效的页面。
所有这些情况都需要引起注意。主要问题是 301 协议,没有必要建议不要设置它。
8.其他情况
A.JS代码问题,JS代码对搜索引擎不友好,不是关键识别对象。如果 JS 代码蜘蛛无法识别,则问题为异常。
B、百度会根据网站的内容、规模、流量自动设置合理的爬取压力,但在异常情况下,如果压力控制异常,会突然关闭服务负载进行自我保护.
C、偶尔因压力过大被封杀:百度会根据网站规模、流量等信息设置合理的爬取压力。但是,在异常情况下,例如压力控制异常,服务将根据自身负载进行事故保护。在这种情况下,请在返回码中返回 503(表示“服务不可用”),这样搜索引擎蜘蛛会在一段时间后再次尝试爬取该链接,如果 网站 空闲,则爬取成功。
总结:网站的异常爬取对网站本身是不利的,因为对于一些经常更新内容却不能正常爬取的网站,各种搜索引擎会认为网站用户体验很差。同时也会降低对网站的评价,对爬取、索引、排序都会产生一定程度的负面影响。最终的影响会导致网站本身或多或少地从百度获得流量。
在介绍了搜索引擎的各种算法之后,我相信站长是无敌的。作为一个老站长,我也结合自己的一些优化经验告诉大家,哪些词在优化,哪些不能用或者得不偿失,但是页面会是K,整个网站会是K
非法班
非法类的 关键词 永远不能用正则 网站 优化为正则 网站,甚至是 文章,加上两个非正式的词,很有可能它将不受云服务的影响。其实阿里云就是这样的。当文章 文章 中有非法字词时,服务会为您屏蔽该字词。您无法打开整个页面。
边缘行业类别
所以,你不能像边缘行业那样拥有 文章。虽然服务可以接受一些边缘行业的文章,比如棋牌类,但是搜索引擎不能接受,因为搜索引擎不能接受新站点发布的这种文章。他不知道你什么时候要通过这个 文章 获利,所以他根本不包括你的 文章,或者只是淘汰你的 文章。当然,前提是以文章的形式发布。
医疗保健类别
虽然这东西是正版内容,但是搜索引擎不会轻易优化它,给一个健康的网站SEO排名,除非这个网站非常有名,没有商业性质,比如39问答,只是一个问答平台,不卖产品,对排名影响不大。
当我们来运行这个网站时,首先,如果你用Enterprise Station来对一种疾病进行排名,你绝对可以说你不能。做久了就排不上号,甚至收录都难上加难。
p>体验式教学
大家一定很奇怪,为什么这些词不能做SEO优化,而且这些词大多是用文章排名的。
百度通过走后门优先对其产品进行排名。一是自有产品,二是其管理是不出现广告信息。因此,我们在进行排名时,尽量不要选择这样的词进行优化。,否则将是徒劳的!
SEO优化:搜索引擎喜欢的高质量页面是什么?
什么是搜索引擎喜欢的优质页面?相信所有站长都在关注网站权重的重要性,但是权重的获取往往离不开优质的页面,很多人把注意力集中在首页忽略了inner的优化也是不合理的页面,那么在搜索引擎的理解中,什么样的页面才算优质页面呢?下面关键词将排名优化分享给大家。分享个人见解。
1、页面结构
又称页面布局,一般来说,页面布局应该遵循一个原则,即“先上后下,先左后右”的原则。为什么要这样做,这里有解释的方法。因为搜索引擎在执行搜索任务时,它的搜索顺序和我们浏览网页的顺序是一样的,也就是上面提到的原理。遵循这一原则将有助于搜索引擎抓取页面上的重要信息。
2、内容原创
搜索引擎衡量一个网站是否优质的主要因素之一,用户认为好的内容自然更受搜索引擎的赞赏,因为你的目标是用户,不要试图欺骗搜索引擎。如果您所做的只是复制和粘贴,那么您的网站注定要失败。当然很多站长会觉得自己没时间做太多原创,如果是这样的话,至少花几分钟时间稍微修改一下标题和文章内容,不过我还是提倡< @原创,最好你的内容在你的行业中是独一无二的,专业的,这样才能被大量引用和转载,甚至你的网站也会作为一个资源来了解这个行业,为用户考虑。
3、网站更新频率稳定
多花点时间更新网站,做网站,特别是前期,熬夜吃个包子很正常。不要三天不更新,四天不更新。保持稳定的更新频率。如果您想要更多回头客,那就做好这件事!
4、保证网站没有内部错误
很多时候网站变大了,难免会出现死链接等内部错误。现在网上有很多工具可以找到错误的链接并善用这些资源。当你浏览一个网站,发现一个页面无法显示时,你是什么感觉?当搜索引擎找到这个页面时,你说它会做什么?
5、知名网站认可
事实上,它只是一个反向链接。我们来说说最简单的友情链接。最好找一些同行的网站作为好友链接,这样可以提高外链的相关性,提高外链的质量。请务必注意,您不应每天计算网站上的附加链接数量。单纯追求数量是没有用的。您必须确保链接的质量。
6、信息丰富网站
搜索引擎总是偏爱大的网站,即有大量网页的网站。如果你的网站还需要依靠搜索引擎来获取流量,那也没必要多说什么,丰富网站的内容。!
7、用户体验
不管你用什么招数,使用前请站在用户这边。无论您所做的一切都是为了用户的方便和需要,“保持良好的用户体验”始终是最高的站立原则!
以上就是关键词排名seo优化给大家带来的是搜索引擎喜欢的优质页面的介绍。我喜欢帮助每个人。
SEO优化:网站百度蜘蛛如何爬取更多数据?
网站排名好不好,流量不多,关键因素之一是网站收录如何,虽然收录不能直接判断< @网站seo优化排名,但是网站的基础是内容。没有内容,就更难排名好。好的内容可以让用户和搜索引擎满意,可以给网站加分,从而提升排名,扩大网站。@网站的曝光页面。而如果你想让你的网站页面更多的是收录,你必须先让网页被百度蜘蛛抓取。那么网站应该怎么做才能吸引百度蜘蛛爬取更多数据呢?
一、网站更新频率:
定期更新高价值内容的网站优先。在网站的优化中,必须经常创建内容,爬虫是策略性的。在 网站 中创建 文章 的频率越高,蜘蛛爬行的频率就会越高。如果 网站 每天更新,蜘蛛将每天爬行。如果网站按小时更新,则蜘蛛只会调整为按小时爬行。因此,更新的频率可以增加爬取的频率。有的同学一天更新10篇,剩下的7天不更新。这种方法是错误的。正确的方法是每天更新一个文章。
二、网站人气
这里所说的流行度是指用户体验。对于用户体验好的网站,百度蜘蛛会优先抓取。网站用户体验如何才能好?最简单的就是页面布局要合理,网站的颜色搭配要合理。另一个最重要的是没有太多的广告。在无法避免广告的前提下,不要让广告覆盖文字内容。否则,百度会判断用户体验很差。
三、高级入口
这里提到的入口是指网站的外部链接。优质网站跟踪(tracking)网站,优先捕捉。现在百度对外链做了很多调整,百度已经对垃圾邮件进行了非常严格的过滤。基本上论坛或者留言板等外部链接,百度都会在后台过滤掉。但是真正优质的外链对于排名和爬取还是很有用的。
四、历史爬取效果不错
无论百度是排名还是爬虫,历史记录都很重要。如果他们以前作弊,这就像一个人的历史。那会留下污点。网站同样如此。优化网站切记不要作弊,一旦留下污点,会降低百度蜘蛛对站点的信任度,影响爬取网站的时间和深度。不断更新高质量的内容非常重要。
五、服务器稳定,抢优先级
2015年以来,百度在服务器稳定性因素的权重上做了很大的提升。服务器稳定性包括稳定性和速度。服务器越快,植物抓取效率越高。服务器越稳定,爬虫的连接率就越高。此外,拥有高速稳定的服务器对于用户体验来说也是非常重要的事情。
六、安全记录优秀的网站,优先爬取
网络安全变得越来越重要。对于经常受到攻击(被黑)的网站,它会严重危害用户。所以,在SEO优化的过程中,要注意网站的安全。
SEO优化总结:网站要想得到更多收录,就要做好搜索引擎蜘蛛的爬取优化。只有提高网站的整体爬取率,才能达到相应的提升。收录评分,让网站的内容得到更多的展示和推荐,提升网站seo优化的排名。上一页 下一页 评论 0?2020
十年专注SEO优化,诚信经营,为企业和客户创造价值为根本。把技术实力作为公司的生命线。
真诚接受网站关键词优化、网站整体排名优化、负面处理等服务 查看全部
php禁止网页抓取(
:正是这些原因导致搜索引擎蜘蛛爬行异常,是什么?)
: 就是这些原因导致搜索引擎蜘蛛抓取异常
我们在优化网站,推广SEO的时候,会遇到这种情况。一些网站的内容质量确实不错,用户可以看到,但是没有被百度蜘蛛抓到,这对搜索引擎来说是个损失。那么我们称这种情况为爬取异常。这是什么原因?关键词Genie根据关键词对优化进行排名,分析一些常见的异常爬取原因:
1.服务问题
如果服务不稳定,网站 终端将无法访问和链接。或者联系不上。在这种情况下,您只能改进服务。不贪小利,终有损网站
2.运营商的问题
中国一般使用电信和中国联通,一般使用两线业务。如果您因为单线服务无法访问网站,最好通过位于升级或服务的双线服务解决问题
3.DNS 异常
当spider在网站且无法解析你的IP时,会出现DNS异常或DNS错误,可能是服务商禁止spider设置或网站的IP地址不正确造成的。您可以使用工具来检查域名是否正确解析。如果不正确或无法解析,请联系域名提供商更新IP解析。
4.禁止蜘蛛爬行
要看检查相关代码设置,是否有禁止百度蜘蛛爬取的设置,或者机器人协议的设置。
5.一般访问禁令
UA是一个用户代理,服务通过识别UA为访问者返回异常页面(如403、500)或跳转到其他页面,即禁止UA。
当网站不希望百度蜘蛛访问时,需要设置相应的访问权限。
6.死链接
死链接在网站,一个无效页面,没有价值,访问无效。有协议死链接和内容死链接。
对于死链接,使用404页面创建或统计404页面向百度站长平台提交数据。
7.异常跳跃
异常跳转是指当前无效页面,如死链接或删除页面,通过301直接跳转到首页或相关目录页面。
或者跳转到错误无效的页面。
所有这些情况都需要引起注意。主要问题是 301 协议,没有必要建议不要设置它。
8.其他情况
A.JS代码问题,JS代码对搜索引擎不友好,不是关键识别对象。如果 JS 代码蜘蛛无法识别,则问题为异常。
B、百度会根据网站的内容、规模、流量自动设置合理的爬取压力,但在异常情况下,如果压力控制异常,会突然关闭服务负载进行自我保护.
C、偶尔因压力过大被封杀:百度会根据网站规模、流量等信息设置合理的爬取压力。但是,在异常情况下,例如压力控制异常,服务将根据自身负载进行事故保护。在这种情况下,请在返回码中返回 503(表示“服务不可用”),这样搜索引擎蜘蛛会在一段时间后再次尝试爬取该链接,如果 网站 空闲,则爬取成功。
总结:网站的异常爬取对网站本身是不利的,因为对于一些经常更新内容却不能正常爬取的网站,各种搜索引擎会认为网站用户体验很差。同时也会降低对网站的评价,对爬取、索引、排序都会产生一定程度的负面影响。最终的影响会导致网站本身或多或少地从百度获得流量。
在介绍了搜索引擎的各种算法之后,我相信站长是无敌的。作为一个老站长,我也结合自己的一些优化经验告诉大家,哪些词在优化,哪些不能用或者得不偿失,但是页面会是K,整个网站会是K
非法班
非法类的 关键词 永远不能用正则 网站 优化为正则 网站,甚至是 文章,加上两个非正式的词,很有可能它将不受云服务的影响。其实阿里云就是这样的。当文章 文章 中有非法字词时,服务会为您屏蔽该字词。您无法打开整个页面。
边缘行业类别
所以,你不能像边缘行业那样拥有 文章。虽然服务可以接受一些边缘行业的文章,比如棋牌类,但是搜索引擎不能接受,因为搜索引擎不能接受新站点发布的这种文章。他不知道你什么时候要通过这个 文章 获利,所以他根本不包括你的 文章,或者只是淘汰你的 文章。当然,前提是以文章的形式发布。
医疗保健类别
虽然这东西是正版内容,但是搜索引擎不会轻易优化它,给一个健康的网站SEO排名,除非这个网站非常有名,没有商业性质,比如39问答,只是一个问答平台,不卖产品,对排名影响不大。
当我们来运行这个网站时,首先,如果你用Enterprise Station来对一种疾病进行排名,你绝对可以说你不能。做久了就排不上号,甚至收录都难上加难。
p>体验式教学
大家一定很奇怪,为什么这些词不能做SEO优化,而且这些词大多是用文章排名的。
百度通过走后门优先对其产品进行排名。一是自有产品,二是其管理是不出现广告信息。因此,我们在进行排名时,尽量不要选择这样的词进行优化。,否则将是徒劳的!
SEO优化:搜索引擎喜欢的高质量页面是什么?
什么是搜索引擎喜欢的优质页面?相信所有站长都在关注网站权重的重要性,但是权重的获取往往离不开优质的页面,很多人把注意力集中在首页忽略了inner的优化也是不合理的页面,那么在搜索引擎的理解中,什么样的页面才算优质页面呢?下面关键词将排名优化分享给大家。分享个人见解。
1、页面结构
又称页面布局,一般来说,页面布局应该遵循一个原则,即“先上后下,先左后右”的原则。为什么要这样做,这里有解释的方法。因为搜索引擎在执行搜索任务时,它的搜索顺序和我们浏览网页的顺序是一样的,也就是上面提到的原理。遵循这一原则将有助于搜索引擎抓取页面上的重要信息。
2、内容原创
搜索引擎衡量一个网站是否优质的主要因素之一,用户认为好的内容自然更受搜索引擎的赞赏,因为你的目标是用户,不要试图欺骗搜索引擎。如果您所做的只是复制和粘贴,那么您的网站注定要失败。当然很多站长会觉得自己没时间做太多原创,如果是这样的话,至少花几分钟时间稍微修改一下标题和文章内容,不过我还是提倡< @原创,最好你的内容在你的行业中是独一无二的,专业的,这样才能被大量引用和转载,甚至你的网站也会作为一个资源来了解这个行业,为用户考虑。
3、网站更新频率稳定
多花点时间更新网站,做网站,特别是前期,熬夜吃个包子很正常。不要三天不更新,四天不更新。保持稳定的更新频率。如果您想要更多回头客,那就做好这件事!
4、保证网站没有内部错误
很多时候网站变大了,难免会出现死链接等内部错误。现在网上有很多工具可以找到错误的链接并善用这些资源。当你浏览一个网站,发现一个页面无法显示时,你是什么感觉?当搜索引擎找到这个页面时,你说它会做什么?
5、知名网站认可
事实上,它只是一个反向链接。我们来说说最简单的友情链接。最好找一些同行的网站作为好友链接,这样可以提高外链的相关性,提高外链的质量。请务必注意,您不应每天计算网站上的附加链接数量。单纯追求数量是没有用的。您必须确保链接的质量。
6、信息丰富网站
搜索引擎总是偏爱大的网站,即有大量网页的网站。如果你的网站还需要依靠搜索引擎来获取流量,那也没必要多说什么,丰富网站的内容。!
7、用户体验
不管你用什么招数,使用前请站在用户这边。无论您所做的一切都是为了用户的方便和需要,“保持良好的用户体验”始终是最高的站立原则!
以上就是关键词排名seo优化给大家带来的是搜索引擎喜欢的优质页面的介绍。我喜欢帮助每个人。
SEO优化:网站百度蜘蛛如何爬取更多数据?
网站排名好不好,流量不多,关键因素之一是网站收录如何,虽然收录不能直接判断< @网站seo优化排名,但是网站的基础是内容。没有内容,就更难排名好。好的内容可以让用户和搜索引擎满意,可以给网站加分,从而提升排名,扩大网站。@网站的曝光页面。而如果你想让你的网站页面更多的是收录,你必须先让网页被百度蜘蛛抓取。那么网站应该怎么做才能吸引百度蜘蛛爬取更多数据呢?
一、网站更新频率:
定期更新高价值内容的网站优先。在网站的优化中,必须经常创建内容,爬虫是策略性的。在 网站 中创建 文章 的频率越高,蜘蛛爬行的频率就会越高。如果 网站 每天更新,蜘蛛将每天爬行。如果网站按小时更新,则蜘蛛只会调整为按小时爬行。因此,更新的频率可以增加爬取的频率。有的同学一天更新10篇,剩下的7天不更新。这种方法是错误的。正确的方法是每天更新一个文章。
二、网站人气
这里所说的流行度是指用户体验。对于用户体验好的网站,百度蜘蛛会优先抓取。网站用户体验如何才能好?最简单的就是页面布局要合理,网站的颜色搭配要合理。另一个最重要的是没有太多的广告。在无法避免广告的前提下,不要让广告覆盖文字内容。否则,百度会判断用户体验很差。
三、高级入口
这里提到的入口是指网站的外部链接。优质网站跟踪(tracking)网站,优先捕捉。现在百度对外链做了很多调整,百度已经对垃圾邮件进行了非常严格的过滤。基本上论坛或者留言板等外部链接,百度都会在后台过滤掉。但是真正优质的外链对于排名和爬取还是很有用的。
四、历史爬取效果不错
无论百度是排名还是爬虫,历史记录都很重要。如果他们以前作弊,这就像一个人的历史。那会留下污点。网站同样如此。优化网站切记不要作弊,一旦留下污点,会降低百度蜘蛛对站点的信任度,影响爬取网站的时间和深度。不断更新高质量的内容非常重要。
五、服务器稳定,抢优先级
2015年以来,百度在服务器稳定性因素的权重上做了很大的提升。服务器稳定性包括稳定性和速度。服务器越快,植物抓取效率越高。服务器越稳定,爬虫的连接率就越高。此外,拥有高速稳定的服务器对于用户体验来说也是非常重要的事情。
六、安全记录优秀的网站,优先爬取
网络安全变得越来越重要。对于经常受到攻击(被黑)的网站,它会严重危害用户。所以,在SEO优化的过程中,要注意网站的安全。
SEO优化总结:网站要想得到更多收录,就要做好搜索引擎蜘蛛的爬取优化。只有提高网站的整体爬取率,才能达到相应的提升。收录评分,让网站的内容得到更多的展示和推荐,提升网站seo优化的排名。上一页 下一页 评论 0?2020
十年专注SEO优化,诚信经营,为企业和客户创造价值为根本。把技术实力作为公司的生命线。
真诚接受网站关键词优化、网站整体排名优化、负面处理等服务
php禁止网页抓取(【】网站管理员的基本操作技巧(二)——)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-31 06:02
1xx(临时回复)
用于指示需要请求者采取行动才能继续的临时响应的状态代码。
代码说明
100(继续)请求者应继续请求。返回此代码的服务器意味着服务器已收到请求的第一部分,现在正在等待接收其余部分。
101 (Switch Protocol) 请求者已向服务器请求切换协议,服务器已确认并准备切换。
2xx(成功)
用于指示服务器已成功处理请求的状态码。
代码说明
200 (Success) 服务器已成功处理请求。通常,这意味着服务器提供了所请求的网页。如果您的 robots.txt 文件显示此状态,则表明 Googlebot 已成功检索该文件。
201 (created) 请求成功,服务器已创建新资源。
202 (Accepted) 服务器已接受请求但尚未处理。
203(未经授权的信息)服务器成功处理了请求,但返回的信息可能来自其他来源。
204 (No Content) 服务器成功处理请求但没有返回任何内容。
205 (Content reset) 服务器成功处理请求但没有返回内容。与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。
206(部分内容)服务器成功处理了部分 GET 请求。
3xx(重定向)
要完成请求,您需要采取进一步的措施。通常,这些状态代码会永远重定向。Google 建议您对每个请求使用少于 5 个重定向。您可以使用 网站管理工具查看 Googlebot 是否在抓取您重定向的网页时遇到问题。诊断下的抓取错误页面列出了 Googlebot 由于重定向错误而无法抓取的网址。
代码说明
300(多选) 服务器可以根据请求执行各种动作。服务器可以根据请求者(用户代理)选择一个动作,或者提供一个动作列表供请求者选择。
301(永久移动)请求的网页已永久移动到新位置。当服务器返回此响应(作为对 GET 或 HEAD 请求的响应)时,它会自动将请求者重定向到新位置。您应该使用此代码通知 Googlebot 页面或 网站 已永久移动到新位置。
302(暂时移动)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行未来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并自动将请求者重定向到不同的位置。但是,由于 Googlebot 将继续抓取旧位置并将其编入索引,因此您不应使用此代码通知 Googlebot 某个页面或 网站 已被移动。
303(查看其他位置)当请求者应针对不同位置发出单独的 GET 请求以检索响应时,服务器会返回此代码。对于除 HEAD 请求之外的所有请求,服务器会自动转到其他位置。
304(未修改)
自上次请求以来,请求的页面尚未修改。当服务器返回此响应时,不会返回任何网页内容。
如果自请求者的最后一次请求以来页面没有更改,您应该配置您的服务器以返回此响应(称为 If-Modified-Since HTTP 标头)。节省带宽和开销,因为服务器可以告诉 Googlebot 该页面自上次抓取以来没有更改
.
305(使用代理)请求者只能使用代理访问请求的网页。如果服务器返回此响应,则服务器还指示请求者应使用哪个代理。
307(临时重定向)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行将来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并自动将请求者重定向到不同的位置。但是,由于 Googlebot 将继续抓取旧位置并将其编入索引,因此您不应使用此代码通知 Googlebot 某个页面或 网站 已被移动。
4xx(请求错误)
这些状态码表明请求可能出错,阻止服务器处理请求。
代码说明
400 (Bad Request) 服务器不理解请求的语法。
401(未授权)请求需要身份验证。登录后,服务器可能会向页面返回此响应。
403 (Forbidden) 服务器拒绝了请求。如果当 Googlebot 尝试在您的 网站 上抓取有效页面时出现此状态代码(您可以在 Google 网站Admin Tools 的诊断下的 Web Crawl 页面上看到此状态代码),那么,有可能您的服务器或主机拒绝 Googlebot 访问它。
404(未找到)
服务器找不到请求的网页。例如,如果请求是针对服务器上不存在的页面,服务器通常会返回此代码。
如果您的 网站 上没有 robots.txt 文件,并且您在 Google 的 网站 管理工具的“诊断”标签中的 robots.txt 页面上看到此状态,那么这是正确的状态。但是,如果您有 robots.txt 文件并发现此状态,则您的 robots.txt 文件可能命名不正确或位于错误的位置。(该文件应位于顶级域中,并应命名为 robots.txt)。
如果您在 Googlebot 尝试抓取的网址(在诊断标签中的 HTTP 错误页面上)看到此状态,则表示 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接)链接到)。
405 (Method Disabled) 禁用请求中指定的方法。
406(不接受)无法使用请求的内容属性响应请求的网页。
407(需要代理授权)此状态码类似于 401(未授权),但指定请求者应使用代理进行授权。如果服务器返回此响应,则服务器还指示请求者应使用哪个代理。
408(请求超时)服务器等待请求超时。
409(冲突)服务器在完成请求时遇到冲突。服务器必须收录有关在响应中发生的冲突的信息。服务器可能会返回此代码以响应与先前请求冲突的 PUT 请求,以及两个请求之间的差异列表。
410 (Deleted) 如果请求的资源已被永久删除,服务器返回此响应。此代码类似于 404(未找到)代码,但在资源曾经存在但不再存在的情况下,有时会出现而不是 404 代码。如果资源已被永久删除,则应使用 301 代码指定资源的新位置。
411(需要有效长度)服务器将不接受收录无效 Content-Length 标头字段的请求。
412 (Precondition not met) 服务器不满足请求者在请求中设置的前提条件之一。
413 (Request Entity Too Large) 服务器无法处理请求,因为请求实体太大,服务器无法处理。
414 (Request URI Too Long) 请求的 URI(通常是 URL)太长,服务器无法处理。
415 (Unsupported media type) 请求的页面不支持请求的格式。
416(请求范围不符合要求)如果请求是针对页面的无效范围发出的,则服务器返回此状态代码。
417 (Expected value not met) 服务器不满足“Expected”请求头域的要求。
5xx(服务器错误)
这些状态代码表明服务器在尝试处理请求时遇到了内部错误。这些错误可能是服务器本身的错误,而不是请求。
代码说明
500(内部服务器错误)服务器遇到错误,无法完成请求。
501(尚未实现)服务器没有能力完成请求。例如,当服务器无法识别请求方法时,服务器可能会返回此代码。
502 (Bad Gateway) 作为网关或代理的服务器收到来自上游服务器的无效响应。
503(服务不可用)服务器当前不可用(由于过载或停机维护)。通常,这只是一个暂时的状态。
504 (Gateway Timeout) 服务器作为网关或代理,没有及时收到上游服务器的请求。 查看全部
php禁止网页抓取(【】网站管理员的基本操作技巧(二)——)
1xx(临时回复)
用于指示需要请求者采取行动才能继续的临时响应的状态代码。
代码说明
100(继续)请求者应继续请求。返回此代码的服务器意味着服务器已收到请求的第一部分,现在正在等待接收其余部分。
101 (Switch Protocol) 请求者已向服务器请求切换协议,服务器已确认并准备切换。
2xx(成功)
用于指示服务器已成功处理请求的状态码。
代码说明
200 (Success) 服务器已成功处理请求。通常,这意味着服务器提供了所请求的网页。如果您的 robots.txt 文件显示此状态,则表明 Googlebot 已成功检索该文件。
201 (created) 请求成功,服务器已创建新资源。
202 (Accepted) 服务器已接受请求但尚未处理。
203(未经授权的信息)服务器成功处理了请求,但返回的信息可能来自其他来源。
204 (No Content) 服务器成功处理请求但没有返回任何内容。
205 (Content reset) 服务器成功处理请求但没有返回内容。与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。
206(部分内容)服务器成功处理了部分 GET 请求。
3xx(重定向)
要完成请求,您需要采取进一步的措施。通常,这些状态代码会永远重定向。Google 建议您对每个请求使用少于 5 个重定向。您可以使用 网站管理工具查看 Googlebot 是否在抓取您重定向的网页时遇到问题。诊断下的抓取错误页面列出了 Googlebot 由于重定向错误而无法抓取的网址。
代码说明
300(多选) 服务器可以根据请求执行各种动作。服务器可以根据请求者(用户代理)选择一个动作,或者提供一个动作列表供请求者选择。
301(永久移动)请求的网页已永久移动到新位置。当服务器返回此响应(作为对 GET 或 HEAD 请求的响应)时,它会自动将请求者重定向到新位置。您应该使用此代码通知 Googlebot 页面或 网站 已永久移动到新位置。
302(暂时移动)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行未来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并自动将请求者重定向到不同的位置。但是,由于 Googlebot 将继续抓取旧位置并将其编入索引,因此您不应使用此代码通知 Googlebot 某个页面或 网站 已被移动。
303(查看其他位置)当请求者应针对不同位置发出单独的 GET 请求以检索响应时,服务器会返回此代码。对于除 HEAD 请求之外的所有请求,服务器会自动转到其他位置。
304(未修改)
自上次请求以来,请求的页面尚未修改。当服务器返回此响应时,不会返回任何网页内容。
如果自请求者的最后一次请求以来页面没有更改,您应该配置您的服务器以返回此响应(称为 If-Modified-Since HTTP 标头)。节省带宽和开销,因为服务器可以告诉 Googlebot 该页面自上次抓取以来没有更改
.
305(使用代理)请求者只能使用代理访问请求的网页。如果服务器返回此响应,则服务器还指示请求者应使用哪个代理。
307(临时重定向)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行将来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并自动将请求者重定向到不同的位置。但是,由于 Googlebot 将继续抓取旧位置并将其编入索引,因此您不应使用此代码通知 Googlebot 某个页面或 网站 已被移动。
4xx(请求错误)
这些状态码表明请求可能出错,阻止服务器处理请求。
代码说明
400 (Bad Request) 服务器不理解请求的语法。
401(未授权)请求需要身份验证。登录后,服务器可能会向页面返回此响应。
403 (Forbidden) 服务器拒绝了请求。如果当 Googlebot 尝试在您的 网站 上抓取有效页面时出现此状态代码(您可以在 Google 网站Admin Tools 的诊断下的 Web Crawl 页面上看到此状态代码),那么,有可能您的服务器或主机拒绝 Googlebot 访问它。
404(未找到)
服务器找不到请求的网页。例如,如果请求是针对服务器上不存在的页面,服务器通常会返回此代码。
如果您的 网站 上没有 robots.txt 文件,并且您在 Google 的 网站 管理工具的“诊断”标签中的 robots.txt 页面上看到此状态,那么这是正确的状态。但是,如果您有 robots.txt 文件并发现此状态,则您的 robots.txt 文件可能命名不正确或位于错误的位置。(该文件应位于顶级域中,并应命名为 robots.txt)。
如果您在 Googlebot 尝试抓取的网址(在诊断标签中的 HTTP 错误页面上)看到此状态,则表示 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接)链接到)。
405 (Method Disabled) 禁用请求中指定的方法。
406(不接受)无法使用请求的内容属性响应请求的网页。
407(需要代理授权)此状态码类似于 401(未授权),但指定请求者应使用代理进行授权。如果服务器返回此响应,则服务器还指示请求者应使用哪个代理。
408(请求超时)服务器等待请求超时。
409(冲突)服务器在完成请求时遇到冲突。服务器必须收录有关在响应中发生的冲突的信息。服务器可能会返回此代码以响应与先前请求冲突的 PUT 请求,以及两个请求之间的差异列表。
410 (Deleted) 如果请求的资源已被永久删除,服务器返回此响应。此代码类似于 404(未找到)代码,但在资源曾经存在但不再存在的情况下,有时会出现而不是 404 代码。如果资源已被永久删除,则应使用 301 代码指定资源的新位置。
411(需要有效长度)服务器将不接受收录无效 Content-Length 标头字段的请求。
412 (Precondition not met) 服务器不满足请求者在请求中设置的前提条件之一。
413 (Request Entity Too Large) 服务器无法处理请求,因为请求实体太大,服务器无法处理。
414 (Request URI Too Long) 请求的 URI(通常是 URL)太长,服务器无法处理。
415 (Unsupported media type) 请求的页面不支持请求的格式。
416(请求范围不符合要求)如果请求是针对页面的无效范围发出的,则服务器返回此状态代码。
417 (Expected value not met) 服务器不满足“Expected”请求头域的要求。
5xx(服务器错误)
这些状态代码表明服务器在尝试处理请求时遇到了内部错误。这些错误可能是服务器本身的错误,而不是请求。
代码说明
500(内部服务器错误)服务器遇到错误,无法完成请求。
501(尚未实现)服务器没有能力完成请求。例如,当服务器无法识别请求方法时,服务器可能会返回此代码。
502 (Bad Gateway) 作为网关或代理的服务器收到来自上游服务器的无效响应。
503(服务不可用)服务器当前不可用(由于过载或停机维护)。通常,这只是一个暂时的状态。
504 (Gateway Timeout) 服务器作为网关或代理,没有及时收到上游服务器的请求。
php禁止网页抓取(php禁止网页抓取nginx禁止从web服务器httpheaderhttpheader信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-30 21:02
php禁止网页抓取nginx禁止网页抓取同时禁止从web服务器抓取httpheader信息。
没有特殊理由的话,可以用session来存储用户的登录信息,但需要额外开支的风险考虑。
禁止用户登录后,浏览器在加载页面的时候,判断该用户是否已经登录过。非登录的用户可以使用/**/disable_password_encryption标记成session,登录过的用户则使用/**/disable_password_encryption标记成cookie。
会用到记录客户端请求的token的服务一般,使用session实现,如果是中小型网站,
不能的。我曾经找过wordpress的源码,他们中看到有将token和cookie绑定的,但是事实上是db+会话机制的。请求你的数据,应该会丢失这部分的token。
java是存token,
ajax时有消息持久化。可以留个标识,等到完全加载完毕之后再去读。
disableauthentication没有特殊的理由,
这事儿挺常见的,我的经验是基本上web服务都不允许post或get传递token,一般都要用cookie。因为保存的信息是网页的路径,显然是记录服务器上的,这样的话,你传入一个http请求就能让服务器给你记住路径,显然是不合理的。另外就是用户会获取到referer这个东西,因为根据我对http的理解,传递referer不过是为了不让你通过referer这个referer来访问,对于正规的sns来说,这会是个很重要的位置,而postmessage默认没有referer,所以这也会是一个潜在的风险。不过很多nativeweb服务都是单向通讯的,这样的话就不必考虑referer的问题。 查看全部
php禁止网页抓取(php禁止网页抓取nginx禁止从web服务器httpheaderhttpheader信息)
php禁止网页抓取nginx禁止网页抓取同时禁止从web服务器抓取httpheader信息。
没有特殊理由的话,可以用session来存储用户的登录信息,但需要额外开支的风险考虑。
禁止用户登录后,浏览器在加载页面的时候,判断该用户是否已经登录过。非登录的用户可以使用/**/disable_password_encryption标记成session,登录过的用户则使用/**/disable_password_encryption标记成cookie。
会用到记录客户端请求的token的服务一般,使用session实现,如果是中小型网站,
不能的。我曾经找过wordpress的源码,他们中看到有将token和cookie绑定的,但是事实上是db+会话机制的。请求你的数据,应该会丢失这部分的token。
java是存token,
ajax时有消息持久化。可以留个标识,等到完全加载完毕之后再去读。
disableauthentication没有特殊的理由,
这事儿挺常见的,我的经验是基本上web服务都不允许post或get传递token,一般都要用cookie。因为保存的信息是网页的路径,显然是记录服务器上的,这样的话,你传入一个http请求就能让服务器给你记住路径,显然是不合理的。另外就是用户会获取到referer这个东西,因为根据我对http的理解,传递referer不过是为了不让你通过referer这个referer来访问,对于正规的sns来说,这会是个很重要的位置,而postmessage默认没有referer,所以这也会是一个潜在的风险。不过很多nativeweb服务都是单向通讯的,这样的话就不必考虑referer的问题。
php禁止网页抓取(“robots.txt只允许抓取html页面,防止抓取垃圾信息!”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-29 05:19
今天大贷SEO详细讲解“robots.txt只允许抓取html页面,防止抓取垃圾邮件!” 代代SEO做了这么多年网站,经常遇到客户的网站被挂掉的情况,原因是不利于自己维护网站,或者使用市面上开源的cms,直接下载源码安装使用,不管里面有没有漏洞和后门,所以后期被马入侵了,大百度抓取的非法页面数量。
有些被链接的人很奇怪,为什么他们的网站正常发布的内容不是收录,而垃圾页面的很多非法内容是百度的收录。其实很简单。马人员直接链接了spider pool里面的非法页面,所以才会出现这个问题。即使我们解决了网站被链接到马的问题,网站上的垃圾页面还是会继续出现。死链接被百度抓取后需要很长时间才能生效。这个时候我该怎么办?我们可以使用 robots.txt 来解决这个问题。
实施原则:
我们可以通过robots.txt来限制用户只能抓取HTMl页面文件,并且可以限制指定目录的HTML,屏蔽指定目录的HTML文件。我们来做一个robots.txt的写法。您可以自己研究并应用到实际应用中。继续你自己的网站。
可解决的挂马形式:
写机器人的规则主要针对上传类,比如添加xxx.php?=dddd.html;xxxx.php; 并且上传不会被百度抓取,降低网络监控风险。
#适用于所有搜索引擎
用户代理:*
#允许首页根目录/不带斜线,例如
允许:/$
允许:$
#文件属性设置禁止修改(固定属性,入口只能是index.html/index.php)
允许:/index.php
允许:/index.html
#允许爬取静态生成的目录,这里是允许爬取页面中的所有html文件
允许:/*.html$
#禁止所有带参数的html页面(禁止抓取挂马的html页面) 规则可以自己定义
禁止:/*?*.html$
禁止:/*=*.html$
# 允许单个条目,只允许,with ? 编号索引,其他html,带符号,是不允许的。
允许:/index.php?*
#允许资源文件,允许在网站上截取图片。
允许:/*.jpg$
允许:/*.png$
允许:/*.gif$
#除上述外,禁止爬取网站内的任何文件或页面。
不允许:/
比如我们的网站挂了,后面的戳一般。php?unmgg.html 或 dds=123.html。这种,只要网址有 ? ,=这样的符号,当然你可以给它添加更多的格式,比如带下划线“_”,可以使用“Disallow:/_*.html$”进行防御。
再比如:挂马是一个目录,一个普通的URL,比如“seozt/1233.html”,可以加一条禁止规则“Disallow:/seozt/*.html$”,这个规则就是告诉搜索引擎,只要是seozt目录下的html文件,就不能被抓取。你明白吗?其实很简单。只是自己熟悉它。
这种写法的优点是:
首先,蜘蛛会爬取你的很多核心目录、php目录、模板目录,这样会浪费很多目录资源。对了,如果我们屏蔽目录,我们会在 robots.txt 中暴露我们的目录,其他人可以分析我们使用的目录。它是什么程序?这时候我们就逆向操作,直接允许html,其他的都拒绝,可以有效避免暴露目录的风险,对了,好吧,今天就讲到这里,希望大家能理解。 查看全部
php禁止网页抓取(“robots.txt只允许抓取html页面,防止抓取垃圾信息!”)
今天大贷SEO详细讲解“robots.txt只允许抓取html页面,防止抓取垃圾邮件!” 代代SEO做了这么多年网站,经常遇到客户的网站被挂掉的情况,原因是不利于自己维护网站,或者使用市面上开源的cms,直接下载源码安装使用,不管里面有没有漏洞和后门,所以后期被马入侵了,大百度抓取的非法页面数量。
有些被链接的人很奇怪,为什么他们的网站正常发布的内容不是收录,而垃圾页面的很多非法内容是百度的收录。其实很简单。马人员直接链接了spider pool里面的非法页面,所以才会出现这个问题。即使我们解决了网站被链接到马的问题,网站上的垃圾页面还是会继续出现。死链接被百度抓取后需要很长时间才能生效。这个时候我该怎么办?我们可以使用 robots.txt 来解决这个问题。
实施原则:
我们可以通过robots.txt来限制用户只能抓取HTMl页面文件,并且可以限制指定目录的HTML,屏蔽指定目录的HTML文件。我们来做一个robots.txt的写法。您可以自己研究并应用到实际应用中。继续你自己的网站。
可解决的挂马形式:
写机器人的规则主要针对上传类,比如添加xxx.php?=dddd.html;xxxx.php; 并且上传不会被百度抓取,降低网络监控风险。
#适用于所有搜索引擎
用户代理:*
#允许首页根目录/不带斜线,例如
允许:/$
允许:$
#文件属性设置禁止修改(固定属性,入口只能是index.html/index.php)
允许:/index.php
允许:/index.html
#允许爬取静态生成的目录,这里是允许爬取页面中的所有html文件
允许:/*.html$
#禁止所有带参数的html页面(禁止抓取挂马的html页面) 规则可以自己定义
禁止:/*?*.html$
禁止:/*=*.html$
# 允许单个条目,只允许,with ? 编号索引,其他html,带符号,是不允许的。
允许:/index.php?*
#允许资源文件,允许在网站上截取图片。
允许:/*.jpg$
允许:/*.png$
允许:/*.gif$
#除上述外,禁止爬取网站内的任何文件或页面。
不允许:/
比如我们的网站挂了,后面的戳一般。php?unmgg.html 或 dds=123.html。这种,只要网址有 ? ,=这样的符号,当然你可以给它添加更多的格式,比如带下划线“_”,可以使用“Disallow:/_*.html$”进行防御。
再比如:挂马是一个目录,一个普通的URL,比如“seozt/1233.html”,可以加一条禁止规则“Disallow:/seozt/*.html$”,这个规则就是告诉搜索引擎,只要是seozt目录下的html文件,就不能被抓取。你明白吗?其实很简单。只是自己熟悉它。
这种写法的优点是:
首先,蜘蛛会爬取你的很多核心目录、php目录、模板目录,这样会浪费很多目录资源。对了,如果我们屏蔽目录,我们会在 robots.txt 中暴露我们的目录,其他人可以分析我们使用的目录。它是什么程序?这时候我们就逆向操作,直接允许html,其他的都拒绝,可以有效避免暴露目录的风险,对了,好吧,今天就讲到这里,希望大家能理解。
php禁止网页抓取(如何查看seo来讲的网站的第一个文件?怎么写?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-26 16:15
如何检查机器人协议?怎么写?
对于seo来说,robots文件非常重要。搜索引擎爬虫抓取到的网站的第一个文件就是这个文件。这个文件告诉搜索引擎网站的内容可以爬取,哪些内容不能爬取,或者禁止爬取。挑选。如何检查机器人协议?可以用这个方法,主域名/robots.txt。
如何编写机器人协议?
当搜索蜘蛛访问一个站点时,它会首先检查站点根目录中是否存在 robots.txt。如果存在,搜索机器人会根据文件内容判断访问范围;如果文件不存在, all 的搜索蜘蛛将能够访问 网站 上没有密码保护的所有页面。
一、什么是机器人协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站 通过Robots Protocol 告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取,对于seo来说,意义重大。
robots 是一种协议,而不是命令。robots.txt 文件是放置在 网站 根目录中的文本文件,可以使用任何常见的文本编辑器创建和编辑。robots.txt 是搜索引擎访问 网站 时首先查看的文件,它的主要作用是告诉蜘蛛程序在服务器上可以查看哪些文件。
Robots协议文件编写及语法属性解释-seo
如果您将网站 视为一个房间,robots.txt 就是主人挂在房间门口的“请勿打扰”或“欢迎进来”的标志。该文件告诉访问搜索引擎哪些房间可以进入和访问,哪些房间因为存放贵重物品或者可能涉及到住户和访客的隐私而对搜索引擎关闭。但 robots.txt 不是命令,也不是防火墙,就像看门人无法阻止小偷等恶意入侵者一样。
所以,seo建议站长只需要在你的网站收录你不想被搜索引擎收录搜索到的内容时,才需要使用robots.txt文件,如果你想要搜索引擎收录@ >网站@ 上的所有内容>,请不要创建 robots.txt 文件。
二、机器人协议的原则
Robots 协议是国际互联网社区的通用道德规范,基于以下原则建立:
1、搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;
2、网站有义务保护其用户的个人信息和隐私不受侵犯。
Robots协议文件编写及语法属性解释-seo
三、Robots 协议的编写
Robots.txt 可以放在站点的根目录中。一个robots.txt只能控制同协议、同端口、同站点的网络爬取策略。
1、robots.txt的常规写法
最简单的 robots.txt 只有两条规则:
User-agent:指定哪些爬虫是有效的
禁止:指定要阻止的 URL
整个文件分为 x 个部分,一个部分由 y 个 User-agent 行和 z 个 Disallow 行组成。一个部分意味着对于在 User-agent 行中指定的 y 个爬虫,z 个 URL 被阻止。这里x>=0,y>0,z>0。x=0时,表示空文件,空文件相当于没有robots.txt。
下面详细介绍这两条规则:
(1), 用户代理
爬虫在爬取时会声明自己的身份。这是用户代理。是的,就是http协议中的User-agent。Robots.txt 使用 User-agent 来区分各个引擎的爬虫。
例如:google web search爬虫的User-agent是Googlebot,下面一行指定了google爬虫。
用户代理:Googlebot
如果要指定所有爬虫怎么办?不可能详尽无遗,您可以使用以下行:
用户代理: *
有同学可能要问了,怎么知道爬虫的User-agent是什么?这里提供了一个简单的列表:Crawler List
当然也可以查看相关搜索引擎信息获取官方数据,如google爬虫列表、百度爬虫列表
(2), 不允许
Disallow 行列出要阻止的网页,以正斜杠 (/) 开头,并且可以列出特定的 URL 或模式。
要阻止整个 网站,请使用正斜杠,如下所示:
不允许: /
要阻止目录及其所有内容,请在目录名称后添加正斜杠,如下所示:
Disallow: /无用的目录名/
要阻止特定网页,请按如下方式指向该网页:
禁止:/pages.html
例子:
用户代理:baiduspider
不允许: /
用户代理:Googlebot
不允许: /
SEO解释:意思是禁止百度蜘蛛和谷歌蜘蛛抓取所有文章
2、robots.txt的高级编写
第一种说法:并非所有引擎的爬虫都支持高级玩法。一般来说,搜索引擎seo技术的领导者谷歌是支持最好的。
(1), 允许
如果我们需要阻止 seo1-seo100,而不是 seo50,我们应该怎么做?
计划一:
禁止:/seo1/
禁止:/seo2/
...
禁止:/seo49/
禁止:/seo51/
...
禁止:/seo100/
场景二:
禁止:/seo
允许:/seo50/
对比以上两种方案,大家应该都知道allow的用法了。如果你网站目前也有这个需求,seo技术建议你可以使用方案2来解决。
但是如果你想在 seo50 下屏蔽文件 seo.htm 怎么办?
禁止:/seo
允许:/seo50/
禁止:/seo50/seo.html
如果你很聪明,你一定能找到模式,对吧?谁更细心,谁就听谁更细心。
(2), 站点地图
前面说过,爬虫会通过网页内部的链接发现新的网页,但是如果指向的网页没有链接怎么办?或者用户输入条件生成的动态网页呢?网站 管理员可以通知搜索引擎他们的 网站 页面可用于抓取吗?这是站点地图。
在最简单的形式中,Sitepmap 是一个 XML 文件,其中列出了 网站 中的 URL 以及每个 URL 的其他数据(上次更新时间、更改频率以及相对于 网站 中的其他 URL重要性等),使用此信息搜索引擎可以更智能地抓取网站内容。
一个新的问题来了,爬虫怎么知道网站是否提供了sitemap文件,或者网站管理员生成了sitemap(可能是多个文件),爬虫怎么知道在哪里把它?
由于robots.txt的位置是固定的,所以大家想到了把sitemap的位置信息放到robots.txt中,变成robots.txt中的一个新成员,例如:
网站地图:
考虑到一个网站的页面很多,人工维护sitemap是不靠谱的。对此,seo建议大家可以使用google提供的工具来自动生成sitemap。
(3), 元标记
其实严格来说,这部分内容不属于robots.txt,但是非常相关。不知道放哪里,暂时放在这里吧。
robots.txt 的最初目的是让 网站 管理员管理可以出现在搜索引擎中的 网站 内容。但是,即使使用 robots.txt 文件来阻止爬虫抓取此内容,搜索引擎也有其他方法可以找到这些页面并将其添加到索引中。
例如,其他网站s可能仍然链接到这个网站,所以网页URL和其他公开可用的信息(例如链接到相关网站s的锚文本或在打开目录管理系统标题)可能会出现在引擎的搜索结果中,如果你想对搜索引擎完全不可见,你应该怎么做?seo给你的答案是:meta tags,也就是元标签。
例如,要完全防止页面内容被列在搜索引擎索引中(即使其他 网站 链接到该页面),请使用 noindex 元标记。每当搜索引擎查看该页面时,它都会看到 noindex 元标记并阻止该页面出现在索引中。请注意,noindex 元标记提供了一种逐页控制对 网站 的访问的方法。
例如,要防止所有搜索引擎索引 网站 中的页面,您可以添加:
这里的name值可以设置为某个搜索引擎的User-agent,指定某个搜索引擎被屏蔽。
除了 noindex 之外,还有其他元标记,例如 nofollow,它们禁止爬虫跟踪此页面的链接。这里再提一下seo:noindex和nofollow在HTML 4.01规范中有描述,但是不同引擎对其他标签的支持程度不同。还请读者查阅每个引擎的文档。
(4), 抓取延迟
robots.txt除了控制什么可以爬,什么不能爬,还可以用来控制爬虫爬取的速度。怎么做?通过设置爬虫在抓取之间等待的秒数。
爬行延迟:5
表示您需要在当前 fetch 之后等待 5 秒,然后才能进行下一次 fetch。
SEO提醒大家:谷歌不再支持这种方式,但是站长工具中提供了一个功能,可以更直观的控制爬取率。
这是题外话。几年前seo记得有一段时间robots.txt也支持复杂的参数:Visit-time,爬虫只能在visit-time指定的时间段内访问;request-rate:用于限制URL的读取频率,用于控制不同时间段的不同爬取率。
后来估计支持的人太少了,所以才逐渐废止。有兴趣的博主可以自行研究。seo了解到的是,目前google和baidu都不再支持这个规则,其他的小引擎公司好像从来没有支持过。
四、Robots 协议中语法属性说明
Robots协议用于通知搜索引擎哪些页面可以爬取,哪些页面不能爬取;网站中一些比较大的文件可以屏蔽,比如图片、音乐、视频等,节省服务器带宽;也可以屏蔽网站上的一些死链接,方便搜索引擎抓取网站内容;或者设置网站地图链接,方便蜘蛛爬取页面。
User-agent:*这里*代表所有类型的搜索引擎,*是通配符。
Disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录。
Disallow: /mahaixiang/*.htm 禁止访问/mahaixiang/目录下所有以“.htm”为后缀的URL(包括子目录)。
禁止:/*?* 禁止访问 网站 中收录问号 (?) 的所有 URL。
Disallow: /.jpg$ 禁止抓取来自网络的所有 .jpg 图像。
Disallow:/mahaixiang/abc.html 禁止爬取ab文件夹下的adc.html文件。
allow: /mahaixiang/ 这个定义是允许爬取mahaixiang目录下的目录。
允许:/mahaixiang 这里的定义是允许爬取mahaixiang的整个目录。
允许:.htm$ 只允许访问以“.htm”为后缀的 URL。
Allow: .gif$ 允许抓取网页和 gif 格式的图像。
站点地图:/sitemap.html 告诉爬虫此页面是 网站 地图。
例子:
用户代理: *
不允许: /?*
禁止:/seo/*.htm
用户代理:EtaoSpider
不允许: /
SEO解释:表示禁止所有搜索引擎抓取seo目录下网站和.htm文章中所有收录问号(?)的URL。同时,etao是完全屏蔽的。
五、Robots 协议中的其他语法属性
1、Robot-version:用于指定机器人协议的版本号
示例:机器人版本:版本 2.0
2、抓取延迟:Yahoo YST 的特定扩展,允许我们的抓取工具设置较低的抓取请求频率。
您可以添加 Crawl-delay:xx 指令,其中“XX”是爬虫程序两次进入站点时的最小延迟(以秒为单位)。
3、抓取延迟:定义抓取延迟
示例:爬行延迟:/mahaixiang/
4、Visit-time:只有在visit-time指定的时间段内,机器人才能访问指定的URL,否则无法访问。
示例:访问时间:0100-1300 #Allow access from 1:00 am to 13:00 am
5、Request-rate:用于限制URL的读取频率
示例:请求率:40/1m 0100 - 0759 在 1:00 到 07:59 之间每分钟 40 次访问。
请求率:12/1m 0800 - 1300 在 8:00 到 13:00 之间每分钟 12 次访问。
seo评论:
Robots 协议由 网站 出于安全和隐私原因设置,以防止搜索引擎抓取敏感信息。搜索引擎的原理是通过爬虫蜘蛛程序自动采集互联网上的网页并获取相关信息。
出于网络安全和隐私的考虑,每个网站都会设置自己的Robots协议来表达搜索引擎,哪些内容是搜索引擎收录愿意和允许的,哪些是不允许的. 引擎会根据Robots协议赋予的权限进行seo爬取。
机器人协议代表了一种契约精神。只有遵守这条规则,互联网公司才能确保网站和用户的隐私数据不会受到侵犯。违反机器人协议将带来巨大的安全隐患。 查看全部
php禁止网页抓取(如何查看seo来讲的网站的第一个文件?怎么写?)
如何检查机器人协议?怎么写?
对于seo来说,robots文件非常重要。搜索引擎爬虫抓取到的网站的第一个文件就是这个文件。这个文件告诉搜索引擎网站的内容可以爬取,哪些内容不能爬取,或者禁止爬取。挑选。如何检查机器人协议?可以用这个方法,主域名/robots.txt。
如何编写机器人协议?
当搜索蜘蛛访问一个站点时,它会首先检查站点根目录中是否存在 robots.txt。如果存在,搜索机器人会根据文件内容判断访问范围;如果文件不存在, all 的搜索蜘蛛将能够访问 网站 上没有密码保护的所有页面。
一、什么是机器人协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站 通过Robots Protocol 告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取,对于seo来说,意义重大。
robots 是一种协议,而不是命令。robots.txt 文件是放置在 网站 根目录中的文本文件,可以使用任何常见的文本编辑器创建和编辑。robots.txt 是搜索引擎访问 网站 时首先查看的文件,它的主要作用是告诉蜘蛛程序在服务器上可以查看哪些文件。
Robots协议文件编写及语法属性解释-seo
如果您将网站 视为一个房间,robots.txt 就是主人挂在房间门口的“请勿打扰”或“欢迎进来”的标志。该文件告诉访问搜索引擎哪些房间可以进入和访问,哪些房间因为存放贵重物品或者可能涉及到住户和访客的隐私而对搜索引擎关闭。但 robots.txt 不是命令,也不是防火墙,就像看门人无法阻止小偷等恶意入侵者一样。
所以,seo建议站长只需要在你的网站收录你不想被搜索引擎收录搜索到的内容时,才需要使用robots.txt文件,如果你想要搜索引擎收录@ >网站@ 上的所有内容>,请不要创建 robots.txt 文件。
二、机器人协议的原则
Robots 协议是国际互联网社区的通用道德规范,基于以下原则建立:
1、搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;
2、网站有义务保护其用户的个人信息和隐私不受侵犯。
Robots协议文件编写及语法属性解释-seo
三、Robots 协议的编写
Robots.txt 可以放在站点的根目录中。一个robots.txt只能控制同协议、同端口、同站点的网络爬取策略。
1、robots.txt的常规写法
最简单的 robots.txt 只有两条规则:
User-agent:指定哪些爬虫是有效的
禁止:指定要阻止的 URL
整个文件分为 x 个部分,一个部分由 y 个 User-agent 行和 z 个 Disallow 行组成。一个部分意味着对于在 User-agent 行中指定的 y 个爬虫,z 个 URL 被阻止。这里x>=0,y>0,z>0。x=0时,表示空文件,空文件相当于没有robots.txt。
下面详细介绍这两条规则:
(1), 用户代理
爬虫在爬取时会声明自己的身份。这是用户代理。是的,就是http协议中的User-agent。Robots.txt 使用 User-agent 来区分各个引擎的爬虫。
例如:google web search爬虫的User-agent是Googlebot,下面一行指定了google爬虫。
用户代理:Googlebot
如果要指定所有爬虫怎么办?不可能详尽无遗,您可以使用以下行:
用户代理: *
有同学可能要问了,怎么知道爬虫的User-agent是什么?这里提供了一个简单的列表:Crawler List
当然也可以查看相关搜索引擎信息获取官方数据,如google爬虫列表、百度爬虫列表
(2), 不允许
Disallow 行列出要阻止的网页,以正斜杠 (/) 开头,并且可以列出特定的 URL 或模式。
要阻止整个 网站,请使用正斜杠,如下所示:
不允许: /
要阻止目录及其所有内容,请在目录名称后添加正斜杠,如下所示:
Disallow: /无用的目录名/
要阻止特定网页,请按如下方式指向该网页:
禁止:/pages.html
例子:
用户代理:baiduspider
不允许: /
用户代理:Googlebot
不允许: /
SEO解释:意思是禁止百度蜘蛛和谷歌蜘蛛抓取所有文章
2、robots.txt的高级编写
第一种说法:并非所有引擎的爬虫都支持高级玩法。一般来说,搜索引擎seo技术的领导者谷歌是支持最好的。
(1), 允许
如果我们需要阻止 seo1-seo100,而不是 seo50,我们应该怎么做?
计划一:
禁止:/seo1/
禁止:/seo2/
...
禁止:/seo49/
禁止:/seo51/
...
禁止:/seo100/
场景二:
禁止:/seo
允许:/seo50/
对比以上两种方案,大家应该都知道allow的用法了。如果你网站目前也有这个需求,seo技术建议你可以使用方案2来解决。
但是如果你想在 seo50 下屏蔽文件 seo.htm 怎么办?
禁止:/seo
允许:/seo50/
禁止:/seo50/seo.html
如果你很聪明,你一定能找到模式,对吧?谁更细心,谁就听谁更细心。
(2), 站点地图
前面说过,爬虫会通过网页内部的链接发现新的网页,但是如果指向的网页没有链接怎么办?或者用户输入条件生成的动态网页呢?网站 管理员可以通知搜索引擎他们的 网站 页面可用于抓取吗?这是站点地图。
在最简单的形式中,Sitepmap 是一个 XML 文件,其中列出了 网站 中的 URL 以及每个 URL 的其他数据(上次更新时间、更改频率以及相对于 网站 中的其他 URL重要性等),使用此信息搜索引擎可以更智能地抓取网站内容。
一个新的问题来了,爬虫怎么知道网站是否提供了sitemap文件,或者网站管理员生成了sitemap(可能是多个文件),爬虫怎么知道在哪里把它?
由于robots.txt的位置是固定的,所以大家想到了把sitemap的位置信息放到robots.txt中,变成robots.txt中的一个新成员,例如:
网站地图:
考虑到一个网站的页面很多,人工维护sitemap是不靠谱的。对此,seo建议大家可以使用google提供的工具来自动生成sitemap。
(3), 元标记
其实严格来说,这部分内容不属于robots.txt,但是非常相关。不知道放哪里,暂时放在这里吧。
robots.txt 的最初目的是让 网站 管理员管理可以出现在搜索引擎中的 网站 内容。但是,即使使用 robots.txt 文件来阻止爬虫抓取此内容,搜索引擎也有其他方法可以找到这些页面并将其添加到索引中。
例如,其他网站s可能仍然链接到这个网站,所以网页URL和其他公开可用的信息(例如链接到相关网站s的锚文本或在打开目录管理系统标题)可能会出现在引擎的搜索结果中,如果你想对搜索引擎完全不可见,你应该怎么做?seo给你的答案是:meta tags,也就是元标签。
例如,要完全防止页面内容被列在搜索引擎索引中(即使其他 网站 链接到该页面),请使用 noindex 元标记。每当搜索引擎查看该页面时,它都会看到 noindex 元标记并阻止该页面出现在索引中。请注意,noindex 元标记提供了一种逐页控制对 网站 的访问的方法。
例如,要防止所有搜索引擎索引 网站 中的页面,您可以添加:
这里的name值可以设置为某个搜索引擎的User-agent,指定某个搜索引擎被屏蔽。
除了 noindex 之外,还有其他元标记,例如 nofollow,它们禁止爬虫跟踪此页面的链接。这里再提一下seo:noindex和nofollow在HTML 4.01规范中有描述,但是不同引擎对其他标签的支持程度不同。还请读者查阅每个引擎的文档。
(4), 抓取延迟
robots.txt除了控制什么可以爬,什么不能爬,还可以用来控制爬虫爬取的速度。怎么做?通过设置爬虫在抓取之间等待的秒数。
爬行延迟:5
表示您需要在当前 fetch 之后等待 5 秒,然后才能进行下一次 fetch。
SEO提醒大家:谷歌不再支持这种方式,但是站长工具中提供了一个功能,可以更直观的控制爬取率。
这是题外话。几年前seo记得有一段时间robots.txt也支持复杂的参数:Visit-time,爬虫只能在visit-time指定的时间段内访问;request-rate:用于限制URL的读取频率,用于控制不同时间段的不同爬取率。
后来估计支持的人太少了,所以才逐渐废止。有兴趣的博主可以自行研究。seo了解到的是,目前google和baidu都不再支持这个规则,其他的小引擎公司好像从来没有支持过。
四、Robots 协议中语法属性说明
Robots协议用于通知搜索引擎哪些页面可以爬取,哪些页面不能爬取;网站中一些比较大的文件可以屏蔽,比如图片、音乐、视频等,节省服务器带宽;也可以屏蔽网站上的一些死链接,方便搜索引擎抓取网站内容;或者设置网站地图链接,方便蜘蛛爬取页面。
User-agent:*这里*代表所有类型的搜索引擎,*是通配符。
Disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录。
Disallow: /mahaixiang/*.htm 禁止访问/mahaixiang/目录下所有以“.htm”为后缀的URL(包括子目录)。
禁止:/*?* 禁止访问 网站 中收录问号 (?) 的所有 URL。
Disallow: /.jpg$ 禁止抓取来自网络的所有 .jpg 图像。
Disallow:/mahaixiang/abc.html 禁止爬取ab文件夹下的adc.html文件。
allow: /mahaixiang/ 这个定义是允许爬取mahaixiang目录下的目录。
允许:/mahaixiang 这里的定义是允许爬取mahaixiang的整个目录。
允许:.htm$ 只允许访问以“.htm”为后缀的 URL。
Allow: .gif$ 允许抓取网页和 gif 格式的图像。
站点地图:/sitemap.html 告诉爬虫此页面是 网站 地图。
例子:
用户代理: *
不允许: /?*
禁止:/seo/*.htm
用户代理:EtaoSpider
不允许: /
SEO解释:表示禁止所有搜索引擎抓取seo目录下网站和.htm文章中所有收录问号(?)的URL。同时,etao是完全屏蔽的。
五、Robots 协议中的其他语法属性
1、Robot-version:用于指定机器人协议的版本号
示例:机器人版本:版本 2.0
2、抓取延迟:Yahoo YST 的特定扩展,允许我们的抓取工具设置较低的抓取请求频率。
您可以添加 Crawl-delay:xx 指令,其中“XX”是爬虫程序两次进入站点时的最小延迟(以秒为单位)。
3、抓取延迟:定义抓取延迟
示例:爬行延迟:/mahaixiang/
4、Visit-time:只有在visit-time指定的时间段内,机器人才能访问指定的URL,否则无法访问。
示例:访问时间:0100-1300 #Allow access from 1:00 am to 13:00 am
5、Request-rate:用于限制URL的读取频率
示例:请求率:40/1m 0100 - 0759 在 1:00 到 07:59 之间每分钟 40 次访问。
请求率:12/1m 0800 - 1300 在 8:00 到 13:00 之间每分钟 12 次访问。
seo评论:
Robots 协议由 网站 出于安全和隐私原因设置,以防止搜索引擎抓取敏感信息。搜索引擎的原理是通过爬虫蜘蛛程序自动采集互联网上的网页并获取相关信息。
出于网络安全和隐私的考虑,每个网站都会设置自己的Robots协议来表达搜索引擎,哪些内容是搜索引擎收录愿意和允许的,哪些是不允许的. 引擎会根据Robots协议赋予的权限进行seo爬取。
机器人协议代表了一种契约精神。只有遵守这条规则,互联网公司才能确保网站和用户的隐私数据不会受到侵犯。违反机器人协议将带来巨大的安全隐患。
php禁止网页抓取(如何快速在几百个网站中找出包含“关键字”的xxx)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-25 05:00
•
如何在数百个网站中快速找到收录“关键字”的xxx.htm
xxx.asp xxx.php ...页面,通知客户删除?
•
当服务器网站中的域名.com收录非法内容时,如何拦截?
•
如何防止非法信息被提交到BBS论坛和留言板?
“智能IIS防火墙”网页关键字过滤和拦截可以帮你解决这个问题,拦截来自服务器的各种有害信息
. POST关键字拦截模式支持
通过使用“正则表达式”模式匹配“关键字”,可以很容易地阻止服务器的各种变体和组合关键字,防止 POST 提交被发送到服务器。
关键字过滤处理,有GET/POST两种过滤处理方式
• POST 关键字(门检查)
同理,进入车站门口优采云,签到,方向是发消息给服务器。如果消息中收录关键字,则禁止进入车站大门并挡住大门。
阻止收录关键字的内容,发送到论坛、留言板、博客等,可以通过过滤和阻止 POST 消息来阻止这些内容。
•
GET关键字(看看,有3种情况)
同样,旅客下优采云后,在出口处结账,例如域名.com/xxx.asp
网页收录关键字,如何处理?
(1)记录
只登录到日志,然后从日志中找出收录关键字.com网站的域名,或者xxx.html
xxx.asp xxx.php ...网页。
一些需要人工审核和确认的词,出现正面和负面的关键字,例如“汇款地址”。如果监控到此类关键字,将URL信息记录在LOG日志中,通过管理员查看日志,确认信息是否非法。
(2)拦截
如果
域名.com/xxx.asp收录指定关键字,直接屏蔽,然后显示“屏蔽信息”禁止访问。
一些严重的、绝对禁止的关键字在正面内容中是不可见的,例如,销售非法物品的电话。非常清晰的关键词可以直接拦截,无需人工验证。
(3)替换
捆
域名 .com/xxx.asp 收录指定的关键字,并替换为 ****** 符号。
下载链接:
目前功能已集成到“智能IIS防火墙”软件中,下载安装“智能IIS防火墙”
操作演示截图,简单几步即可实现关键词过滤拦截
下载地址,目前功能已经集成到“智创IIS防火墙”软件中,下载安装“智创IIS防火墙” 查看全部
php禁止网页抓取(如何快速在几百个网站中找出包含“关键字”的xxx)
•
如何在数百个网站中快速找到收录“关键字”的xxx.htm
xxx.asp xxx.php ...页面,通知客户删除?
•
当服务器网站中的域名.com收录非法内容时,如何拦截?
•
如何防止非法信息被提交到BBS论坛和留言板?
“智能IIS防火墙”网页关键字过滤和拦截可以帮你解决这个问题,拦截来自服务器的各种有害信息
. POST关键字拦截模式支持
通过使用“正则表达式”模式匹配“关键字”,可以很容易地阻止服务器的各种变体和组合关键字,防止 POST 提交被发送到服务器。
关键字过滤处理,有GET/POST两种过滤处理方式
• POST 关键字(门检查)
同理,进入车站门口优采云,签到,方向是发消息给服务器。如果消息中收录关键字,则禁止进入车站大门并挡住大门。
阻止收录关键字的内容,发送到论坛、留言板、博客等,可以通过过滤和阻止 POST 消息来阻止这些内容。
•
GET关键字(看看,有3种情况)
同样,旅客下优采云后,在出口处结账,例如域名.com/xxx.asp
网页收录关键字,如何处理?
(1)记录
只登录到日志,然后从日志中找出收录关键字.com网站的域名,或者xxx.html
xxx.asp xxx.php ...网页。
一些需要人工审核和确认的词,出现正面和负面的关键字,例如“汇款地址”。如果监控到此类关键字,将URL信息记录在LOG日志中,通过管理员查看日志,确认信息是否非法。
(2)拦截
如果
域名.com/xxx.asp收录指定关键字,直接屏蔽,然后显示“屏蔽信息”禁止访问。
一些严重的、绝对禁止的关键字在正面内容中是不可见的,例如,销售非法物品的电话。非常清晰的关键词可以直接拦截,无需人工验证。
(3)替换
捆
域名 .com/xxx.asp 收录指定的关键字,并替换为 ****** 符号。
下载链接:
目前功能已集成到“智能IIS防火墙”软件中,下载安装“智能IIS防火墙”
操作演示截图,简单几步即可实现关键词过滤拦截
下载地址,目前功能已经集成到“智创IIS防火墙”软件中,下载安装“智创IIS防火墙”
php禁止网页抓取(前几天搭建好了wordpress的博客,即访问根目录博客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-24 06:02
前几天建了一个wordpress博客,但是发现一个问题,就是我的博客只能在wordpress文件夹()中访问,我想直接访问根目录下的wordpress博客,即,访问根目录( )可以直接访问wordpress文件夹的内容。
解决方案(不完全是,只是我能想到的):
①使用重定向功能,即301和302重定向。
301 重定向意味着该页面被永久删除。如果搜索引擎知道该页面是 301 重定向,它会将旧地址替换为重定向地址。
302 重定向是页面的临时转移。如果搜索引擎处理了302,它不会用新地址替换旧地址并保留旧地址。 302的一个例子就是短链接服务,短链接会请求数据库找出长链接,然后使用302重定向到长链接,这样做的好处是搜索引擎和一些浏览器不会保留短链接,但是使用长链接。
将Location后面的url替换为你要跳转的url
②配置虚拟主机实现跳转。
使用虚拟主机,可以将wordpress目录索引到三级域名。例如,我已经对其进行了索引。
方法见鸟哥私房菜:#www_adv_virtual
鸟哥所说的DNS相关设置,其实就是你需要去你的域名提供商那里,将你要使用的三级域名添加到解析记录中。例如,我使用 A 记录来解决它。如果我不配置虚拟主机,我将直接访问我的根目录。如果我配置一个虚拟主机,我将访问配置的文件夹。
如果你有更好的方法或者我错了,请在下方留言:) 查看全部
php禁止网页抓取(前几天搭建好了wordpress的博客,即访问根目录博客)
前几天建了一个wordpress博客,但是发现一个问题,就是我的博客只能在wordpress文件夹()中访问,我想直接访问根目录下的wordpress博客,即,访问根目录( )可以直接访问wordpress文件夹的内容。
解决方案(不完全是,只是我能想到的):
①使用重定向功能,即301和302重定向。
301 重定向意味着该页面被永久删除。如果搜索引擎知道该页面是 301 重定向,它会将旧地址替换为重定向地址。
302 重定向是页面的临时转移。如果搜索引擎处理了302,它不会用新地址替换旧地址并保留旧地址。 302的一个例子就是短链接服务,短链接会请求数据库找出长链接,然后使用302重定向到长链接,这样做的好处是搜索引擎和一些浏览器不会保留短链接,但是使用长链接。
将Location后面的url替换为你要跳转的url
②配置虚拟主机实现跳转。
使用虚拟主机,可以将wordpress目录索引到三级域名。例如,我已经对其进行了索引。
方法见鸟哥私房菜:#www_adv_virtual
鸟哥所说的DNS相关设置,其实就是你需要去你的域名提供商那里,将你要使用的三级域名添加到解析记录中。例如,我使用 A 记录来解决它。如果我不配置虚拟主机,我将直接访问我的根目录。如果我配置一个虚拟主机,我将访问配置的文件夹。
如果你有更好的方法或者我错了,请在下方留言:)
php禁止网页抓取(培训怎样建立robots.txt文件并阻止搜索引擎搜索引擎蜘蛛访问网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-24 05:16
搜索引擎智能机器人继续爬行网站,方便将它们添加到搜索引擎数据库索引中。但是,有时开发人员希望在搜索引擎结果中隐藏他们的 网站 或特殊网页,在这种情况下,robots.txt 可用于阻止搜索引擎蜘蛛访问 网站。在本示例教程中,您将学习如何创建 robots.txt 文件并防止搜索引擎蜘蛛访问或抓取 网站。
流程 1 - 访问 Web 服务器并创建一个新文件
首先,创建robots.txt文件,可以通过FTP手机客户端或者宝塔面板提交到网站根目录。
第 2 步 - 编写 robots.txt
每个搜索引擎往往都有自己的爬取专用工具(user-agen),在robots.txt中可以指定专用爬取工具User-agent。互联网技术有数百个网络爬虫,但最常见的是:
谷歌机器人
雅虎!啜饮
bingbot
AhrefsBot
百度蜘蛛
放大
MJ12bot
YandexBot
例如,如果要防止百度搜索和爬虫专用工具访问可靠的网站,可以使用以下标准编写robots.txt:
用户代理:百度蜘蛛
不允许:/
如果要阻止所有搜索引擎抓取特殊工具,可以使用*作为通配符:
用户代理:*
不允许:/
如果您想阻止搜索引擎爬虫仅访问特定文件或文件夹,请使用类似英语的语法,但是,您必须指定文件或文件夹的名称。假设想要阻止搜索引擎抓取私有工具,仅访问 文章contents 文件夹(文章)和 private.php 文件。在这种情况下,robots.txt 文件的内容应如下所示:
用户代理:*
禁止:/articles/
禁止:/private.php
编写完 robots.txt 文件后,保存更改并提交到 网站 的根目录。您可以在浏览器搜索栏输入网站domain/robots.txt进行查询。
热搜词 查看全部
php禁止网页抓取(培训怎样建立robots.txt文件并阻止搜索引擎搜索引擎蜘蛛访问网站)
搜索引擎智能机器人继续爬行网站,方便将它们添加到搜索引擎数据库索引中。但是,有时开发人员希望在搜索引擎结果中隐藏他们的 网站 或特殊网页,在这种情况下,robots.txt 可用于阻止搜索引擎蜘蛛访问 网站。在本示例教程中,您将学习如何创建 robots.txt 文件并防止搜索引擎蜘蛛访问或抓取 网站。
流程 1 - 访问 Web 服务器并创建一个新文件
首先,创建robots.txt文件,可以通过FTP手机客户端或者宝塔面板提交到网站根目录。
第 2 步 - 编写 robots.txt
每个搜索引擎往往都有自己的爬取专用工具(user-agen),在robots.txt中可以指定专用爬取工具User-agent。互联网技术有数百个网络爬虫,但最常见的是:
谷歌机器人
雅虎!啜饮
bingbot
AhrefsBot
百度蜘蛛
放大
MJ12bot
YandexBot
例如,如果要防止百度搜索和爬虫专用工具访问可靠的网站,可以使用以下标准编写robots.txt:
用户代理:百度蜘蛛
不允许:/
如果要阻止所有搜索引擎抓取特殊工具,可以使用*作为通配符:
用户代理:*
不允许:/
如果您想阻止搜索引擎爬虫仅访问特定文件或文件夹,请使用类似英语的语法,但是,您必须指定文件或文件夹的名称。假设想要阻止搜索引擎抓取私有工具,仅访问 文章contents 文件夹(文章)和 private.php 文件。在这种情况下,robots.txt 文件的内容应如下所示:
用户代理:*
禁止:/articles/
禁止:/private.php
编写完 robots.txt 文件后,保存更改并提交到 网站 的根目录。您可以在浏览器搜索栏输入网站domain/robots.txt进行查询。
热搜词
php禁止网页抓取(一下禁止搜索引擎爬虫抓取网站网站的方法(一)|)
网站优化 • 优采云 发表了文章 • 0 个评论 • 328 次浏览 • 2022-03-24 05:09
本文简要总结了防止搜索引擎爬虫通过查找网上信息爬取网站的方法。
一般来说,大家都希望搜索引擎爬虫尽量爬取自己的网站,但是有时候也需要告诉爬虫不要爬,比如不要爬镜像页面等等。
搜索引擎自己爬网站有它的好处,也有很多常见的问题:
1.网络拥塞严重丢包(上下行数据异常,排除DDOS攻击,服务器中毒。异常下载,数据更新)
2.服务器负载过高,CPU快满了(取决于对应的服务配置);
3.服务基本瘫痪,路由也瘫痪;
4.查看日志,发现大量异常访问日志
一、先查看日志
以下以ngnix的日志为例
catlogs/www.ready.log|grepspider -c(用爬虫标志查看访问次数)
catlogs/www.ready.log|wc(总页面访问量)
catlogs/www.ready.log|grepspider|awk'{print$1}'|sort-n|uniq-c|sort-nr(查看爬虫IP地址的来源)
catlogs/www.ready.log|awk'{print$1""substr($4,14,5)}'|sort-n|uniq-c|sort-nr|head-20(见爬虫来源)
二、分析日志
知道爬取了什么爬虫,爬取了什么爬虫。你什么时候爬的?
常用爬虫:
谷歌蜘蛛:googlebot
百度蜘蛛:baiduspider
雅虎蜘蛛:啜饮
Alexa 蜘蛛:ia_archiver
msn 蜘蛛:msnbot
altavista 蜘蛛:滑板车
lycos 蜘蛛:lycos_spider_(t-rex)
alltheweb 蜘蛛:fast-webcrawler/
inktomi 蜘蛛:啜饮
有道机器人:有道机器人
搜狗蜘蛛:Sogospider#07
三、禁止方法
(一), 封IP
服务器配置可以:denyfrom221.194.136
防火墙配置可以:-ARH-Firewall-1-INPUT-mstate–stateNEW-mtcp-ptcp–dport80-s61.33.22.1/24-jREJECT
缺点:一个搜索引擎的爬虫可能部署在多台服务器(多个IP)上,很难获取某个搜索引擎的爬虫的所有IP。
(二), 机器人.txt
1.什么是 robots.txt 文件?
搜索引擎自动访问互联网上的网页,并通过程序机器人(又称蜘蛛)获取网页信息。
你可以在你的网站中创建一个纯文本文件robots.txt,在这个文件中声明你不想被robots访问的网站部分,这样网站 可以将部分或全部内容从搜索引擎收录中排除,或者指定的搜索引擎只能收录指定内容。
2.robots.txt 文件在哪里?
robots.txt 文件应该放在 网站 根目录下。比如robots访问一个网站(例如),它会首先检查该文件是否存在于网站中。如果机器人找到该文件,它将根据文件的内容进行判断。其访问权限的范围。
3.“robots.txt”文件收录一条或多条以空行分隔的记录(以CR、CR/NL或NL结尾),每条记录的格式如下:
“:”。
#可用于该文件中的注释,具体用法与UNIX中的约定相同。该文件中的记录通常以一行或多行 User-agent 开头,后跟几行 Disallow,具体如下:
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,则表示多个robots会受到该协议的限制。 ,必须至少有一个 User-agent 记录。如果此项的值设置为 *,则协议对任何机器人都有效。在“robots.txt”文件中,只能有一条“User-agent:*”记录。
禁止:
该项的值用来描述一个不想被访问的URL。此 URL 可以是完整路径或部分路径。机器人不会访问任何以 Disallow 开头的 URL。例如“Disallow:/help”不允许搜索引擎访问 /help.html 和 /help/index.html,而“Disallow:/help/”允许机器人访问 /help.html 但不允许 /help/index 。 html。任何 Disallow 记录为空,表示 网站 的所有部分都被允许访问。在“/robots.txt”文件中,必须至少有一条 Disallow 记录。如果“/robots.txt”是一个空文件,则 网站 对所有搜索引擎机器人开放。
缺点:当两个域名指向同一个根目录时,如果想允许爬虫爬取一个域名的部分网页(A/等),但又想禁止爬虫爬取这些网页(A/等)的其他域名/等),此方法无法实现。
(三),服务器配置
以nginx服务器为例,可以在域名配置中添加配置
if($http_user_agent~*"qihoobot|Baiduspider|Googlebot|Googlebot-Mobile|Googlebot-Image|Mediapartners-Google|Adsbot-Google|Feedfetcher-Google|Yahoo!Slurp|Yahoo!SlurpChina|有道机器人|Sosospider|Sogospider| Sogouwebspider|MSNBot|ia_archiver|TomatoBot")
{
return403;
}
缺点:只能禁止爬虫爬取域级网页。缺乏灵活性。 查看全部
php禁止网页抓取(一下禁止搜索引擎爬虫抓取网站网站的方法(一)|)
本文简要总结了防止搜索引擎爬虫通过查找网上信息爬取网站的方法。
一般来说,大家都希望搜索引擎爬虫尽量爬取自己的网站,但是有时候也需要告诉爬虫不要爬,比如不要爬镜像页面等等。
搜索引擎自己爬网站有它的好处,也有很多常见的问题:
1.网络拥塞严重丢包(上下行数据异常,排除DDOS攻击,服务器中毒。异常下载,数据更新)
2.服务器负载过高,CPU快满了(取决于对应的服务配置);
3.服务基本瘫痪,路由也瘫痪;
4.查看日志,发现大量异常访问日志
一、先查看日志
以下以ngnix的日志为例
catlogs/www.ready.log|grepspider -c(用爬虫标志查看访问次数)
catlogs/www.ready.log|wc(总页面访问量)
catlogs/www.ready.log|grepspider|awk'{print$1}'|sort-n|uniq-c|sort-nr(查看爬虫IP地址的来源)
catlogs/www.ready.log|awk'{print$1""substr($4,14,5)}'|sort-n|uniq-c|sort-nr|head-20(见爬虫来源)
二、分析日志
知道爬取了什么爬虫,爬取了什么爬虫。你什么时候爬的?
常用爬虫:
谷歌蜘蛛:googlebot
百度蜘蛛:baiduspider
雅虎蜘蛛:啜饮
Alexa 蜘蛛:ia_archiver
msn 蜘蛛:msnbot
altavista 蜘蛛:滑板车
lycos 蜘蛛:lycos_spider_(t-rex)
alltheweb 蜘蛛:fast-webcrawler/
inktomi 蜘蛛:啜饮
有道机器人:有道机器人
搜狗蜘蛛:Sogospider#07
三、禁止方法
(一), 封IP
服务器配置可以:denyfrom221.194.136
防火墙配置可以:-ARH-Firewall-1-INPUT-mstate–stateNEW-mtcp-ptcp–dport80-s61.33.22.1/24-jREJECT
缺点:一个搜索引擎的爬虫可能部署在多台服务器(多个IP)上,很难获取某个搜索引擎的爬虫的所有IP。
(二), 机器人.txt
1.什么是 robots.txt 文件?
搜索引擎自动访问互联网上的网页,并通过程序机器人(又称蜘蛛)获取网页信息。
你可以在你的网站中创建一个纯文本文件robots.txt,在这个文件中声明你不想被robots访问的网站部分,这样网站 可以将部分或全部内容从搜索引擎收录中排除,或者指定的搜索引擎只能收录指定内容。
2.robots.txt 文件在哪里?
robots.txt 文件应该放在 网站 根目录下。比如robots访问一个网站(例如),它会首先检查该文件是否存在于网站中。如果机器人找到该文件,它将根据文件的内容进行判断。其访问权限的范围。
3.“robots.txt”文件收录一条或多条以空行分隔的记录(以CR、CR/NL或NL结尾),每条记录的格式如下:
“:”。
#可用于该文件中的注释,具体用法与UNIX中的约定相同。该文件中的记录通常以一行或多行 User-agent 开头,后跟几行 Disallow,具体如下:
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,则表示多个robots会受到该协议的限制。 ,必须至少有一个 User-agent 记录。如果此项的值设置为 *,则协议对任何机器人都有效。在“robots.txt”文件中,只能有一条“User-agent:*”记录。
禁止:
该项的值用来描述一个不想被访问的URL。此 URL 可以是完整路径或部分路径。机器人不会访问任何以 Disallow 开头的 URL。例如“Disallow:/help”不允许搜索引擎访问 /help.html 和 /help/index.html,而“Disallow:/help/”允许机器人访问 /help.html 但不允许 /help/index 。 html。任何 Disallow 记录为空,表示 网站 的所有部分都被允许访问。在“/robots.txt”文件中,必须至少有一条 Disallow 记录。如果“/robots.txt”是一个空文件,则 网站 对所有搜索引擎机器人开放。
缺点:当两个域名指向同一个根目录时,如果想允许爬虫爬取一个域名的部分网页(A/等),但又想禁止爬虫爬取这些网页(A/等)的其他域名/等),此方法无法实现。
(三),服务器配置
以nginx服务器为例,可以在域名配置中添加配置
if($http_user_agent~*"qihoobot|Baiduspider|Googlebot|Googlebot-Mobile|Googlebot-Image|Mediapartners-Google|Adsbot-Google|Feedfetcher-Google|Yahoo!Slurp|Yahoo!SlurpChina|有道机器人|Sosospider|Sogospider| Sogouwebspider|MSNBot|ia_archiver|TomatoBot")
{
return403;
}
缺点:只能禁止爬虫爬取域级网页。缺乏灵活性。
php禁止网页抓取(网站地址:域名年龄:9年改版前没做过优化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-20 10:03
网站地址:域年龄:9年前,改版前没做优化,相关页面几乎没有权重
问:2019年1月27日改版上线后,至2019年3月13日,指数成交量仅为24,现场结果为4。
操作记录:1、上线前几天删除了没有www的域名解析。
2、本次改版的模板发生了变化,网站的内容和结构与改版前有很大不同。网站上线时在百度资源平台提交修改,禁止php、css和*?*爬取,测试所有htm页面爬取正常,提交网站图成功识别164网页页面,然后手动提交一些网页链接,并将旧页面301到站点中的新页面,旧页面保留在服务器中并且不被删除。百度搜索资源平台上线后有一段时间没有更新索引,所以页面一直没有收录一直以为百度没有采取措施。
3、上线一个月后网站索引26(和改版前一样),siet结果是12,但是12很多都是新旧页面的重复,其实只有5个,查日志中,百度蜘蛛在2月1日左右爬取了大部分页面,此后爬取频率一直很低,而且大部分都是爬网站首页、旧页面和一些不重要的jpg,还有尽可能多的带有4040状态码的php页面,也就是很少爬取html。
4、咨询大兵先生后,修改了首页和栏目的标题和描述,把A品牌字的写法改成了AB,但是索引没有变。爬取频率每天7-10次,站点结果逐日递减。.
5、做了一些操作后,删除了服务器上的旧页面,取消了301,更新了几个文章,页面h2标签改为h3,栏目页面添加了标题和供调用描述,删除产品页面的电话号码,将产品页面的文件下载链接(之前点击直接下载文件)改为点击跳转到另一个页面进行下载。以上操作对索引和爬取频率没有影响。.
请老师帮忙分析下不收录的原因,并提出解决方案,谢谢! 查看全部
php禁止网页抓取(网站地址:域名年龄:9年改版前没做过优化)
网站地址:域年龄:9年前,改版前没做优化,相关页面几乎没有权重
问:2019年1月27日改版上线后,至2019年3月13日,指数成交量仅为24,现场结果为4。
操作记录:1、上线前几天删除了没有www的域名解析。
2、本次改版的模板发生了变化,网站的内容和结构与改版前有很大不同。网站上线时在百度资源平台提交修改,禁止php、css和*?*爬取,测试所有htm页面爬取正常,提交网站图成功识别164网页页面,然后手动提交一些网页链接,并将旧页面301到站点中的新页面,旧页面保留在服务器中并且不被删除。百度搜索资源平台上线后有一段时间没有更新索引,所以页面一直没有收录一直以为百度没有采取措施。
3、上线一个月后网站索引26(和改版前一样),siet结果是12,但是12很多都是新旧页面的重复,其实只有5个,查日志中,百度蜘蛛在2月1日左右爬取了大部分页面,此后爬取频率一直很低,而且大部分都是爬网站首页、旧页面和一些不重要的jpg,还有尽可能多的带有4040状态码的php页面,也就是很少爬取html。
4、咨询大兵先生后,修改了首页和栏目的标题和描述,把A品牌字的写法改成了AB,但是索引没有变。爬取频率每天7-10次,站点结果逐日递减。.
5、做了一些操作后,删除了服务器上的旧页面,取消了301,更新了几个文章,页面h2标签改为h3,栏目页面添加了标题和供调用描述,删除产品页面的电话号码,将产品页面的文件下载链接(之前点击直接下载文件)改为点击跳转到另一个页面进行下载。以上操作对索引和爬取频率没有影响。.
请老师帮忙分析下不收录的原因,并提出解决方案,谢谢!
php禁止网页抓取(我另外一个博客中有一个 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-16 12:25
)
在我的另一个博客中,有一个我自己写的爬取其他网页的源代码。调试的时候没有问题,发布后一段时间内容也没有问题,但是突然发现爬取功能不起作用。现在,右键查看源文件,看到获取的数据是空的。
我重新检查了我的源代码并在服务器上调试了几次,甚至重新抓包查看对方的数据网站。
一开始以为是自己的服务器IP被对方服务器屏蔽了,于是把源码发给另外一个朋友调试,发现不是这个原因。
然后我怀疑对方是否更新了算法并加密了程序,但是我在获取数据的模块变量的源代码中做了回显输出,这才知道获取到的数据是乱码。
第一次看到乱码的时候,还以为是其他开发者加密了数据,所以放弃了几天。
今天尝试在源码中转换获取到的数据的字符集,但是怎么转换都出现乱码。
找了一天,终于找到了一个C#程序员写的idea。
原来问题出在我的 Post 的 header data header 中。我在源代码中添加了一行“Accept-Encoding: gzip, deflate, br”。删除后问题解决了,因为是gzip压缩导致的乱码。
$cars = $GLOBALS['ua'];
$header = array(
"POST {$ii} HTTP/2.0",
"Host: {$web} ",
"filename: {$id} ",
"Referer: {$ii} ",
"Content-Type: text/html",
'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,video/webm,video/ogg,video/*;q=0.9,application/ogg;q=0.7,audio/*;q=0.6,*/*;q=0.5,application/signed-exchange;v=b3',
'Accept-Encoding:gzip, deflate, br',
'Accept-Language:zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection:keep-alive',
"Cookie: {$cars[1]}",
"User-Agent: {$cars[0]}",
"X-FORWARDED-FOR:180.149.134.142",
"CLIENT-IP:180.149.134.142",
);
echo "header: {$header[0]}
{$header[1]}
{$header[2]}
{$header[3]}
{$header[4]}
{$header[5]}
{$header[6]}
{$header[7]}
{$header[8]}
{$header[9]}
{$header[10]}
{$header[11]}
{$header[12]}
{$header[13]}
";
return $header;
删除以下行解决了问题。
'Accept-Encoding:gzip, deflate, br',
查看全部
php禁止网页抓取(我另外一个博客中有一个
)
在我的另一个博客中,有一个我自己写的爬取其他网页的源代码。调试的时候没有问题,发布后一段时间内容也没有问题,但是突然发现爬取功能不起作用。现在,右键查看源文件,看到获取的数据是空的。
我重新检查了我的源代码并在服务器上调试了几次,甚至重新抓包查看对方的数据网站。
一开始以为是自己的服务器IP被对方服务器屏蔽了,于是把源码发给另外一个朋友调试,发现不是这个原因。
然后我怀疑对方是否更新了算法并加密了程序,但是我在获取数据的模块变量的源代码中做了回显输出,这才知道获取到的数据是乱码。
https://www.myzhenai.com/wp-co ... 4.png 300w, https://www.myzhenai.com/wp-co ... 8.png 768w, https://www.myzhenai.com/wp-co ... 6.png 1536w, https://www.myzhenai.com/wp-co ... a.png 1907w" />第一次看到乱码的时候,还以为是其他开发者加密了数据,所以放弃了几天。
今天尝试在源码中转换获取到的数据的字符集,但是怎么转换都出现乱码。
找了一天,终于找到了一个C#程序员写的idea。
原来问题出在我的 Post 的 header data header 中。我在源代码中添加了一行“Accept-Encoding: gzip, deflate, br”。删除后问题解决了,因为是gzip压缩导致的乱码。
$cars = $GLOBALS['ua'];
$header = array(
"POST {$ii} HTTP/2.0",
"Host: {$web} ",
"filename: {$id} ",
"Referer: {$ii} ",
"Content-Type: text/html",
'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,video/webm,video/ogg,video/*;q=0.9,application/ogg;q=0.7,audio/*;q=0.6,*/*;q=0.5,application/signed-exchange;v=b3',
'Accept-Encoding:gzip, deflate, br',
'Accept-Language:zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection:keep-alive',
"Cookie: {$cars[1]}",
"User-Agent: {$cars[0]}",
"X-FORWARDED-FOR:180.149.134.142",
"CLIENT-IP:180.149.134.142",
);
echo "header: {$header[0]}
{$header[1]}
{$header[2]}
{$header[3]}
{$header[4]}
{$header[5]}
{$header[6]}
{$header[7]}
{$header[8]}
{$header[9]}
{$header[10]}
{$header[11]}
{$header[12]}
{$header[13]}
";
return $header;
删除以下行解决了问题。
'Accept-Encoding:gzip, deflate, br',
https://www.myzhenai.com/wp-co ... 3.png 300w, https://www.myzhenai.com/wp-co ... 8.png 768w, https://www.myzhenai.com/wp-co ... 6.png 1536w, https://www.myzhenai.com/wp-co ... 1.png 1887w" /> php禁止网页抓取(【推荐学习】robots禁止抓取php的方法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2022-03-16 04:08
robots禁止爬取php的方法:1、在robots.txt文件中写入“Disallow: /*?*”;2、在 robots.txt 文件中添加规则 "User-agent:* Allow" : .html$ Disallow: /"。
本文运行环境:windows7系统,PHP7.版本1,DELL G3电脑
robots禁止搜索引擎抓取php动态网址
所谓动态URL是指该URL收录?, & 等字符类URL,如:news.php?lang=cn&class=1&id=2,当我们开启网站的伪静态时,对于网站的seo来说是必须的避免搜索引擎抓取我们的 网站 动态 URL。
你为什么要这样做?因为搜索引擎会在两次爬取同一页面后触发网站但最终判断为同一页面,如何处罚不清楚,总之不利于<的整个SEO @网站。那么如何防止搜索引擎抓取我们的网站动态URL呢?
这个问题可以通过robots.txt文件解决,具体操作请看下文。
我们知道动态页面有一个共同的特点,就是会有一个问号符号“?” 在链接中,因此我们可以在 robots.txt 文件中编写以下规则:
User-agent: *Disallow: /*?*
这将阻止搜索引擎抓取整个 网站 动态链接。另外,如果我们只想让搜索引擎抓取指定类型的文件,比如html格式的静态页面,我们可以在robots.txt中添加如下规则:
User-agent: *Allow: .html$Disallow: /
另外记得把写好的robots.txt文件放到你的网站的根目录下,不然不行。此外,还有一个编写规则的简单快捷方式。登录google网站admin工具,连接并在里面写入规则,然后生成robots.txt文件。
【推荐学习:《PHP 视频教程》】
以上就是机器人如何禁止爬取php的知识。快戳>>知识兔学习精品课程! 查看全部
php禁止网页抓取(【推荐学习】robots禁止抓取php的方法(组图))
robots禁止爬取php的方法:1、在robots.txt文件中写入“Disallow: /*?*”;2、在 robots.txt 文件中添加规则 "User-agent:* Allow" : .html$ Disallow: /"。
本文运行环境:windows7系统,PHP7.版本1,DELL G3电脑
robots禁止搜索引擎抓取php动态网址
所谓动态URL是指该URL收录?, & 等字符类URL,如:news.php?lang=cn&class=1&id=2,当我们开启网站的伪静态时,对于网站的seo来说是必须的避免搜索引擎抓取我们的 网站 动态 URL。
你为什么要这样做?因为搜索引擎会在两次爬取同一页面后触发网站但最终判断为同一页面,如何处罚不清楚,总之不利于<的整个SEO @网站。那么如何防止搜索引擎抓取我们的网站动态URL呢?
这个问题可以通过robots.txt文件解决,具体操作请看下文。
我们知道动态页面有一个共同的特点,就是会有一个问号符号“?” 在链接中,因此我们可以在 robots.txt 文件中编写以下规则:
User-agent: *Disallow: /*?*
这将阻止搜索引擎抓取整个 网站 动态链接。另外,如果我们只想让搜索引擎抓取指定类型的文件,比如html格式的静态页面,我们可以在robots.txt中添加如下规则:
User-agent: *Allow: .html$Disallow: /
另外记得把写好的robots.txt文件放到你的网站的根目录下,不然不行。此外,还有一个编写规则的简单快捷方式。登录google网站admin工具,连接并在里面写入规则,然后生成robots.txt文件。
【推荐学习:《PHP 视频教程》】
以上就是机器人如何禁止爬取php的知识。快戳>>知识兔学习精品课程!
php禁止网页抓取(有关如何禁止php浏览器使用缓存页面,小编觉得挺实用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-13 19:22
本文文章将与大家分享如何禁止PHP浏览器使用缓存页面。小编觉得很实用,就分享给大家。希望大家看完这篇文章收获能有所收获,话不多说,跟着小编一起来看看吧。php禁止浏览器使用缓存页面的方法:1、设置此页面的过期时间,代码为[header("Expires: Mon Jul 1970GMT")];2、告诉客户端浏览器不要使用缓存,代码是[header ( Pragma: ]。
php中如何防止浏览器使用缓存页面:
在PHP中,可以很方便的使用下面的语句来禁止页面缓存,但是为了大家方便,很难记住和整理。
php代码如下:
代码显示如下:
这对于一些页面很有用,比如订单下的单个信息和产品,以及清除购物车中对应的产品数据。
我绝对不希望用户到最后一页,已经生成了订单,然后点击浏览器的返回按钮返回上一页。
然后在订单地址页面添加:
代码如下: header("Cache-Control:no-cache,must-revalidate,no-store"); //这个no-store添加后,在Firefox下有效
header("Pragma:no-cache");
header("过期时间:-1");
这个页面不再缓存,还有一个页面判断购物车商品为空后跳转到一个空的购物车,然后用户点击浏览器返回,返回后也直接进入购物车页面。
以上就是如何禁止php浏览器使用缓存页面。相信在我们的日常工作中可能会看到或用到一些知识点。希望你能从这个 文章 中学到更多。更多详情请关注易宿云行业资讯频道。 查看全部
php禁止网页抓取(有关如何禁止php浏览器使用缓存页面,小编觉得挺实用)
本文文章将与大家分享如何禁止PHP浏览器使用缓存页面。小编觉得很实用,就分享给大家。希望大家看完这篇文章收获能有所收获,话不多说,跟着小编一起来看看吧。php禁止浏览器使用缓存页面的方法:1、设置此页面的过期时间,代码为[header("Expires: Mon Jul 1970GMT")];2、告诉客户端浏览器不要使用缓存,代码是[header ( Pragma: ]。
php中如何防止浏览器使用缓存页面:
在PHP中,可以很方便的使用下面的语句来禁止页面缓存,但是为了大家方便,很难记住和整理。
php代码如下:
代码显示如下:
这对于一些页面很有用,比如订单下的单个信息和产品,以及清除购物车中对应的产品数据。
我绝对不希望用户到最后一页,已经生成了订单,然后点击浏览器的返回按钮返回上一页。
然后在订单地址页面添加:
代码如下: header("Cache-Control:no-cache,must-revalidate,no-store"); //这个no-store添加后,在Firefox下有效
header("Pragma:no-cache");
header("过期时间:-1");
这个页面不再缓存,还有一个页面判断购物车商品为空后跳转到一个空的购物车,然后用户点击浏览器返回,返回后也直接进入购物车页面。
以上就是如何禁止php浏览器使用缓存页面。相信在我们的日常工作中可能会看到或用到一些知识点。希望你能从这个 文章 中学到更多。更多详情请关注易宿云行业资讯频道。
php禁止网页抓取(小鹿竞价软件禁止搜索引擎抓取后会有什么效果呢?? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-10 11:14
)
<p>小鹿系列竞价软件覆盖百度、360、搜狗、神马四大搜索平台,采用独创竞价算法,智能精准竞价,一键批量查询排名,根据
php禁止网页抓取(小鹿竞价软件禁止搜索引擎抓取后会有什么效果呢??
)
<p>小鹿系列竞价软件覆盖百度、360、搜狗、神马四大搜索平台,采用独创竞价算法,智能精准竞价,一键批量查询排名,根据
php禁止网页抓取(apache的安全配置看网站的根目录/data/www)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-09 00:02
看apache的安全配置。网站的根目录/data/www/有一个/data/www/data/目录,看她的权限
[root@zhangmengjunlinux 数据]# ls -al /data/www/data/
总剂量 68
drwxr-xr-x 15 守护进程根 4096 Jan 1 11:30 。
drwxr-xr-x 13 根 4096 12 月 27 日 02:10 ..
drwxr-xr-x 2 守护进程根 4096 Dec 27 01:43 addonmd5
drwxr-xr-x 12 守护进程根 4096 12 月 31 日 16:33 附件
drwxr-xr-x 2 守护进程根 4096 Dec 27 01:43 avatar
drwxr-xr-x 2 守护进程根 4096 12 月 8 日 10:39 backup_a7ac7c
drwxr-xr-x 2 守护进程根 4096 Dec 31 16:39 缓存
drwxr-xr-x 3 守护进程 守护进程 4096 Dec 27 02:08 diy
drwxr-xr-x 2 守护进程根 4096 Dec 27 01:43 下载
-rw-r--r-- 1 守护进程根 0 Dec 8 10:39 index.htm
-rw-r--r-- 1 根根 20 Jan 1 11:30 info.php
-rw-r--r-- 1 守护进程 守护进程 0 Dec 27 02:08 install.lock
drwxr-xr-x 2 守护进程根 4096 12 月 8 日 10:39 ipdata
drwxr-xr-x 2 守护进程根 4096 Jan 1 10:36 日志
drwxr-xr-x 2 守护进程根 4096 Dec 27 01:43 plugindata
-rw-r--r-- 1 守护进程 守护进程 0 Jan 1 11:34 sendmail.lock
-rw-r--r-- 1 守护进程根 772 Dec 8 10:39 stat_setting.xml
drwxr-xr-x 2 守护进程 守护进程 4096 Dec 31 17:43 sysdata
drwxr-xr-x 2 守护进程根 4096 Jan 1 11:34 模板
drwxr-xr-x 2 守护进程根 4096 Dec 27 02:08 线程缓存
其实apache运行的用户是daemon,为什么要改成owner daemon呢,因为我们在安装apache的时候已经验证测试过了,如果没有写权限就不能安装成功,为什么/data/目录需要写入,因为我们会在data目录下生成一些缓存文件、临时文件、附件。比如我们的网站可能会上传一些图片,我们测试一下,发个帖子,然后发完之后,我们去网站的根目录下找
[root@zhangmengjunlinux 数据]# cd /data/www/data/attachment/forum/
[root@zhangmengjunlinux forum]# ls 这里我们看到生成了一个新目录
201512 201601
[root@zhangmengjunlinux论坛]# cd 201601/
[root@zhangmengjunlinux 201601]#ls
01 索引.html
[root@zhangmengjunlinux 201601]# cd 01/
[root@zhangmengjunlinux 01]# ls
103719rkd74osszda4f673.jpg index.html
我们可以看到它生成了一个新的图像,那么这个图像就是我们刚刚上传的图像。让我们访问WEB
图片的地址现在是Forbidden,因为我们做了防盗链,现在我们有一个问题,这些目录数据目录的意思就是用户可以写,如果网站有漏洞,会被木马上传 文件被执行了怎么办?如果服务器被意外入侵,可以获得一些权限。这个时候,我们应该对它做一些限制。要么你不允许上传,要么上传之后,我们不允许它做任何操作,有两种情况,那么你不能做第一种,因为一旦你限制了任何用户,你就不能正常上传,那么这肯定是不合适的,那我们只能用第二种方法,就是限制它解析。即使上传木马文件,但无法正常解析,这意味着我们没有风险。我们如何限制它?例如,我们以这个数据目录为目标。做一个禁止解析的限制
#vim /usr/local/apache2/conf/extra/httpd-vhost.conf
首先我们需要定义它的路径
我们必须关闭 PHP 解析引擎并停止解析
php_admin_flag 引擎关闭
并且我们再做一个限制,即使你不能解析它,我们仍然可以访问它,并且它会在你访问它时下载你的源代码。
只需在这一行关闭 PHP 引擎: php_admin_flag engine off
所以现在表示网站的目录data下的所有目录都收录子目录,我们先做个实验
[root@zhangmengjunlinux 01]# cd /data/www/data/
[root@zhangmengjunlinux 数据]# ls
信息.php
[root@zhangmengjunlinux数据]# vim info.php 查看全部
php禁止网页抓取(apache的安全配置看网站的根目录/data/www)
看apache的安全配置。网站的根目录/data/www/有一个/data/www/data/目录,看她的权限
[root@zhangmengjunlinux 数据]# ls -al /data/www/data/
总剂量 68
drwxr-xr-x 15 守护进程根 4096 Jan 1 11:30 。
drwxr-xr-x 13 根 4096 12 月 27 日 02:10 ..
drwxr-xr-x 2 守护进程根 4096 Dec 27 01:43 addonmd5
drwxr-xr-x 12 守护进程根 4096 12 月 31 日 16:33 附件
drwxr-xr-x 2 守护进程根 4096 Dec 27 01:43 avatar
drwxr-xr-x 2 守护进程根 4096 12 月 8 日 10:39 backup_a7ac7c
drwxr-xr-x 2 守护进程根 4096 Dec 31 16:39 缓存
drwxr-xr-x 3 守护进程 守护进程 4096 Dec 27 02:08 diy
drwxr-xr-x 2 守护进程根 4096 Dec 27 01:43 下载
-rw-r--r-- 1 守护进程根 0 Dec 8 10:39 index.htm
-rw-r--r-- 1 根根 20 Jan 1 11:30 info.php
-rw-r--r-- 1 守护进程 守护进程 0 Dec 27 02:08 install.lock
drwxr-xr-x 2 守护进程根 4096 12 月 8 日 10:39 ipdata
drwxr-xr-x 2 守护进程根 4096 Jan 1 10:36 日志
drwxr-xr-x 2 守护进程根 4096 Dec 27 01:43 plugindata
-rw-r--r-- 1 守护进程 守护进程 0 Jan 1 11:34 sendmail.lock
-rw-r--r-- 1 守护进程根 772 Dec 8 10:39 stat_setting.xml
drwxr-xr-x 2 守护进程 守护进程 4096 Dec 31 17:43 sysdata
drwxr-xr-x 2 守护进程根 4096 Jan 1 11:34 模板
drwxr-xr-x 2 守护进程根 4096 Dec 27 02:08 线程缓存
其实apache运行的用户是daemon,为什么要改成owner daemon呢,因为我们在安装apache的时候已经验证测试过了,如果没有写权限就不能安装成功,为什么/data/目录需要写入,因为我们会在data目录下生成一些缓存文件、临时文件、附件。比如我们的网站可能会上传一些图片,我们测试一下,发个帖子,然后发完之后,我们去网站的根目录下找
[root@zhangmengjunlinux 数据]# cd /data/www/data/attachment/forum/
[root@zhangmengjunlinux forum]# ls 这里我们看到生成了一个新目录
201512 201601
[root@zhangmengjunlinux论坛]# cd 201601/
[root@zhangmengjunlinux 201601]#ls
01 索引.html
[root@zhangmengjunlinux 201601]# cd 01/
[root@zhangmengjunlinux 01]# ls
103719rkd74osszda4f673.jpg index.html
我们可以看到它生成了一个新的图像,那么这个图像就是我们刚刚上传的图像。让我们访问WEB
图片的地址现在是Forbidden,因为我们做了防盗链,现在我们有一个问题,这些目录数据目录的意思就是用户可以写,如果网站有漏洞,会被木马上传 文件被执行了怎么办?如果服务器被意外入侵,可以获得一些权限。这个时候,我们应该对它做一些限制。要么你不允许上传,要么上传之后,我们不允许它做任何操作,有两种情况,那么你不能做第一种,因为一旦你限制了任何用户,你就不能正常上传,那么这肯定是不合适的,那我们只能用第二种方法,就是限制它解析。即使上传木马文件,但无法正常解析,这意味着我们没有风险。我们如何限制它?例如,我们以这个数据目录为目标。做一个禁止解析的限制
#vim /usr/local/apache2/conf/extra/httpd-vhost.conf
首先我们需要定义它的路径
我们必须关闭 PHP 解析引擎并停止解析
php_admin_flag 引擎关闭
并且我们再做一个限制,即使你不能解析它,我们仍然可以访问它,并且它会在你访问它时下载你的源代码。
只需在这一行关闭 PHP 引擎: php_admin_flag engine off
所以现在表示网站的目录data下的所有目录都收录子目录,我们先做个实验
[root@zhangmengjunlinux 01]# cd /data/www/data/
[root@zhangmengjunlinux 数据]# ls
信息.php
[root@zhangmengjunlinux数据]# vim info.php

