
php禁止网页抓取
php禁止网页抓取(php禁止访问方法:在php文件头部写上“if($_SERVER)后面的两种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-12 17:17
今天PHP爱好者给大家带来一个禁止PHP访问的方法:1、在PHP文件的头部写上“if( $_SERVER['HTTP_REFERER'] == "" ){...}”;2、在程序中定义一个标识变量;3、 获取 config.php 中的变量。我希望能有所帮助。
本文运行环境:Windows7系统,PHP7.版本1,DELL G3电脑
php如何禁止访问方法?
PHP禁止从浏览器直接输入地址访问.php文件的方法:
具体实现方法如下:
一般来说,我们不希望用户直接输入地址来访问一些重要的文件,我们需要为此做一些设置。下面总结了一些禁止通过浏览器输入地址直接访问.PHP文件的PHP方法,非常实用。
比如我不想让别人直接从浏览器输入地址来访问这个文件。
但是如果从任何网站连接都无法访问,则即使建立连接并跳转到另一个地址也无法访问该机器。
1. 在 xx.php 文件的头部写入如下代码。
代码显示如下:
<p style="line-height: 2em; text-indent: 2em; text-align: left;">$fromurl="https://www.jb51.net/"; //跳转往这个地址。<br style="text-indent: 2em; text-align: left;"/>if( $_SERVER['HTTP_REFERER'] == "" )<br style="text-indent: 2em; text-align: left;"/>{<br style="text-indent: 2em; text-align: left;"/>header("Location:".$fromurl); exit;<br style="text-indent: 2em; text-align: left;"/>}<br style="text-indent: 2em; text-align: left;"/></p>
这样,我们只需要简单地伪造源头即可。为此,我们还可以执行以下操作:
2. 在程序中定义一个标识变量
代码显示如下:
<p style="line-height: 2em; text-indent: 2em; text-align: left;">define('IN_SYS', TRUE);<br style="text-indent: 2em; text-align: left;"/></p>
3. 在 config.php 中获取这个变量
代码显示如下:
<p style="line-height: 2em; text-indent: 2em; text-align: left;">if(!defined('IN_SYS')) { <br style="text-indent: 2em; text-align: left;"/>exit('禁止访问'); <br style="text-indent: 2em; text-align: left;"/>}<br style="text-indent: 2em; text-align: left;"/></p>
后两种方法是我们在很多cms中遇到的。
以上就是如何禁止php访问的详细内容,请其他相关php爱好者关注文章! 查看全部
php禁止网页抓取(php禁止访问方法:在php文件头部写上“if($_SERVER)后面的两种方法)
今天PHP爱好者给大家带来一个禁止PHP访问的方法:1、在PHP文件的头部写上“if( $_SERVER['HTTP_REFERER'] == "" ){...}”;2、在程序中定义一个标识变量;3、 获取 config.php 中的变量。我希望能有所帮助。

本文运行环境:Windows7系统,PHP7.版本1,DELL G3电脑
php如何禁止访问方法?
PHP禁止从浏览器直接输入地址访问.php文件的方法:
具体实现方法如下:
一般来说,我们不希望用户直接输入地址来访问一些重要的文件,我们需要为此做一些设置。下面总结了一些禁止通过浏览器输入地址直接访问.PHP文件的PHP方法,非常实用。
比如我不想让别人直接从浏览器输入地址来访问这个文件。
但是如果从任何网站连接都无法访问,则即使建立连接并跳转到另一个地址也无法访问该机器。
1. 在 xx.php 文件的头部写入如下代码。
代码显示如下:
<p style="line-height: 2em; text-indent: 2em; text-align: left;">$fromurl="https://www.jb51.net/"; //跳转往这个地址。<br style="text-indent: 2em; text-align: left;"/>if( $_SERVER['HTTP_REFERER'] == "" )<br style="text-indent: 2em; text-align: left;"/>{<br style="text-indent: 2em; text-align: left;"/>header("Location:".$fromurl); exit;<br style="text-indent: 2em; text-align: left;"/>}<br style="text-indent: 2em; text-align: left;"/></p>
这样,我们只需要简单地伪造源头即可。为此,我们还可以执行以下操作:
2. 在程序中定义一个标识变量
代码显示如下:
<p style="line-height: 2em; text-indent: 2em; text-align: left;">define('IN_SYS', TRUE);<br style="text-indent: 2em; text-align: left;"/></p>
3. 在 config.php 中获取这个变量
代码显示如下:
<p style="line-height: 2em; text-indent: 2em; text-align: left;">if(!defined('IN_SYS')) { <br style="text-indent: 2em; text-align: left;"/>exit('禁止访问'); <br style="text-indent: 2em; text-align: left;"/>}<br style="text-indent: 2em; text-align: left;"/></p>
后两种方法是我们在很多cms中遇到的。
以上就是如何禁止php访问的详细内容,请其他相关php爱好者关注文章!
php禁止网页抓取(先来了解一下什么是跨域?笙学术平台的认可)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-10 14:25
我们先来了解什么是跨域:
1.什么是跨域?跨域:即浏览器不能执行其他网站脚本。它是由浏览器的同源策略引起的,是浏览器对 javascript 施加的安全限制。例如:页面a想要获取页面b的资源。如果a和b页面的协议、域名、端口、子域不同,则执行的访问动作都是跨域的,浏览器一般出于安全原因限制跨域访问,即跨域请求资源不允许。注意:跨域访问限制实际上是浏览器限制。了解这一点很重要!!!同源策略:即协议、域名、端口必须相同,其中之一会导致跨域;
如果使用jsonp,则没有跨域限制
限制域名
1、允许单域名访问
header('Access-Control-Allow-Origin:https://www.baidu.com');
2、允许多个域访问
$origin = isset($_SERVER['HTTP_ORIGIN'])? $_SERVER['HTTP_ORIGIN'] : '';
$allow_origin = array('https://blog.oioweb.cn','https://my.oioweb.cn');
if(in_array($origin, $allow_origin)){
header('Access-Control-Allow-Origin:'.$origin);
}
3、允许所有域名访问
header('Access-Control-Allow-Origin:*');
转载:感谢您对良生学术平台的认可,感谢您对我们原创作品和文章的青睐。欢迎各位朋友分享到您的个人站长或朋友圈,但转载请注明文章出处“梁生学术”。
这很棒!(1) 查看全部
php禁止网页抓取(先来了解一下什么是跨域?笙学术平台的认可)
我们先来了解什么是跨域:
1.什么是跨域?跨域:即浏览器不能执行其他网站脚本。它是由浏览器的同源策略引起的,是浏览器对 javascript 施加的安全限制。例如:页面a想要获取页面b的资源。如果a和b页面的协议、域名、端口、子域不同,则执行的访问动作都是跨域的,浏览器一般出于安全原因限制跨域访问,即跨域请求资源不允许。注意:跨域访问限制实际上是浏览器限制。了解这一点很重要!!!同源策略:即协议、域名、端口必须相同,其中之一会导致跨域;
如果使用jsonp,则没有跨域限制
限制域名
1、允许单域名访问
header('Access-Control-Allow-Origin:https://www.baidu.com');
2、允许多个域访问
$origin = isset($_SERVER['HTTP_ORIGIN'])? $_SERVER['HTTP_ORIGIN'] : '';
$allow_origin = array('https://blog.oioweb.cn','https://my.oioweb.cn');
if(in_array($origin, $allow_origin)){
header('Access-Control-Allow-Origin:'.$origin);
}
3、允许所有域名访问
header('Access-Control-Allow-Origin:*');
转载:感谢您对良生学术平台的认可,感谢您对我们原创作品和文章的青睐。欢迎各位朋友分享到您的个人站长或朋友圈,但转载请注明文章出处“梁生学术”。
这很棒!(1)
php禁止网页抓取(PHP完整Curl数据函数:伪造客户端IP地址,伪造访问referer )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-08 12:19
)
1、伪造客户端IP地址,伪造访问referer:(一般这样可以访问数据)
curl_setopt($curl, CURLOPT_HTTPHEADER, ['X-FORWARDED-FOR:110.85.108.185', 'CLIENT-IP:110.85.108.185']);
curl_setopt($curl, CURLOPT_REFERER, 'http://www.demo.com/test.php');
2、如果以上还是不行,可能是别人抓到了真实IP。这个时候我们会使用代理访问。
# 详细方式
curl_setopt($curl, CURLOPT_PROXY, '112.85.209.72'); //代理服务器地址
curl_setopt($curl, CURLOPT_PROXYPORT, 80); //代理服务器端口
//curl_setopt($curl, CURLOPT_PROXYUSERPWD, ':''); //http代理认证帐号,username:password的格式
curl_setopt($curl, CURLOPT_PROXYTYPE, CURLPROXY_HTTP); //使用http代理模式
# 简写方式
curl_setopt($curl, CURLOPT_PROXY, 'http://112.85.209.72:80');
3、 还有另一种类型可以用浏览器访问,但不能用 curl。 (对方检查了useragent,如果没有,则认为是非法来源等)
$useragent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 ';
$useragent.= '(KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36';
curl_setopt($curl, CURLOPT_USERAGENT, $useragent);
PHP完整的Curl抓取数据功能:
/**
* 请求接口
* @access public
* @param string $url 请求地址
* @param array $data 提交参数 没有get 有post
* @return bean|array
*/
public function send($url='')
{
set_time_limit(0);
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($curl, CURLOPT_HTTPHEADER, ['X-FORWARDED-FOR:127.0.1.1', 'CLIENT-IP:127.0.1.1']);
curl_setopt($curl, CURLOPT_REFERER, 'http://www.demo.com/demo.php');
curl_setopt($curl, CURLOPT_PROXY, 'http://127.0.0.1:80');
$useragent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 ';
$useragent.= '(KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36';
curl_setopt($curl, CURLOPT_USERAGENT, $useragent);
if(!empty($data) && is_array($data)){
curl_setopt($curl, CURLOPT_POST, true);
curl_setopt($curl, CURLOPT_POSTFIELDS, $data);
}
$html = curl_exec($curl);
if($error=curl_errno($curl)){
return false;
}
curl_close($curl);
return $html;
} 查看全部
php禁止网页抓取(PHP完整Curl数据函数:伪造客户端IP地址,伪造访问referer
)
1、伪造客户端IP地址,伪造访问referer:(一般这样可以访问数据)
curl_setopt($curl, CURLOPT_HTTPHEADER, ['X-FORWARDED-FOR:110.85.108.185', 'CLIENT-IP:110.85.108.185']);
curl_setopt($curl, CURLOPT_REFERER, 'http://www.demo.com/test.php');
2、如果以上还是不行,可能是别人抓到了真实IP。这个时候我们会使用代理访问。
# 详细方式
curl_setopt($curl, CURLOPT_PROXY, '112.85.209.72'); //代理服务器地址
curl_setopt($curl, CURLOPT_PROXYPORT, 80); //代理服务器端口
//curl_setopt($curl, CURLOPT_PROXYUSERPWD, ':''); //http代理认证帐号,username:password的格式
curl_setopt($curl, CURLOPT_PROXYTYPE, CURLPROXY_HTTP); //使用http代理模式
# 简写方式
curl_setopt($curl, CURLOPT_PROXY, 'http://112.85.209.72:80');
3、 还有另一种类型可以用浏览器访问,但不能用 curl。 (对方检查了useragent,如果没有,则认为是非法来源等)
$useragent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 ';
$useragent.= '(KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36';
curl_setopt($curl, CURLOPT_USERAGENT, $useragent);
PHP完整的Curl抓取数据功能:
/**
* 请求接口
* @access public
* @param string $url 请求地址
* @param array $data 提交参数 没有get 有post
* @return bean|array
*/
public function send($url='')
{
set_time_limit(0);
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($curl, CURLOPT_HTTPHEADER, ['X-FORWARDED-FOR:127.0.1.1', 'CLIENT-IP:127.0.1.1']);
curl_setopt($curl, CURLOPT_REFERER, 'http://www.demo.com/demo.php');
curl_setopt($curl, CURLOPT_PROXY, 'http://127.0.0.1:80');
$useragent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 ';
$useragent.= '(KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36';
curl_setopt($curl, CURLOPT_USERAGENT, $useragent);
if(!empty($data) && is_array($data)){
curl_setopt($curl, CURLOPT_POST, true);
curl_setopt($curl, CURLOPT_POSTFIELDS, $data);
}
$html = curl_exec($curl);
if($error=curl_errno($curl)){
return false;
}
curl_close($curl);
return $html;
}
php禁止网页抓取(浙江四HB源码SEO与您分享SEO优化如何禁止捕捉和记录机制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-05 23:14
在网站,搜索引擎优化的过程中,并不是所有的页面和内容都被搜索引擎抓取和索引。例如,如果复制的内容被捕获,则会对网站产生负面影响。例如,一些电商平台为了用户更好地搜索和过滤产品而屏蔽了大量页面,以及布局格式的页面。如果抓取了大量这样的页面,就会浪费搜索和引擎分配给网站的总爬取时间,进而影响搜索和引擎真正想要抓取的页面,记录。网站管理员可以通过查询网站来访问日志。如果出现类似情况,大量无用页面被抓取,重要内容从未抓取,网站
今天浙江四HB源码SEO与大家分享SEO优化如何禁止抓拍和记录机制,希望对大家有所帮助。
在前面的章节中,熟悉的JavaScript、flash links、nofollow等方法并不能保证页面不会被收录。在其他情况下,由于未知原因,可能存在导入的外部链接导致页面被收录。浙江SEO将在本文中讨论机器人文档和非索引元机器人标签。前者确保不捕获页面,而后者确保不收录页面。
文本文件
机器人。网站的根目录中存在.txt文件。它的指令用于禁止引擎、搜索、蜘蛛抓取某些页面内容或允许抓取某些内容。蜘蛛在搜索、引擎或爬取网站上爬取时,会先检查这个文件的权限。
机器人文件不存在或文件中没有内容。默认情况下,搜索引擎和引擎可以抓取网站的所有页面。如果需要禁止捕获某些信息,则必须专门编写机器人文件。另外,浙江SEO建议,如果允许爬取网站的所有内容,还应该在根目录下放置一个空的robots.txt文件。因为如果由于设置问题导致robot文件不存在,有些服务器会返回200状态码和其他一些错误信息,而不是404状态码,所以搜索引擎误解了robot的信息。下面简单介绍一下如何写robot文件:
用户代理:*
不允许:/
以上是机器人文件的简要说明。根据一些英文单词,大家会更容易理解和记忆。例如,允许和禁止。以上描述可以分为: User Agent:指定以下规则适用于哪个搜索引擎蜘蛛。*通配符表示所有蜘蛛。如果仅适用于百度蜘蛛,请将通配符替换为百度蜘蛛*
用户代理:百度蜘蛛
以下规则仅适用于百度蜘蛛
禁止:提醒人们不允许蜘蛛抓取内容。后缀文件或者目录名就够了,可以在以后的学习实践中详细学习,浙江seo这里有个提示,禁止文件和目录写在同一行。文件或目录需要占一行,每行必须先写Disallow:指令。
没有indexmeta机器人标签
虽然robot文件可以禁止搜索引擎抓取特定的URL,搜索引擎也会做同样的事情,但是在一些导入链接的作用下,虽然搜索引擎没有抓取到该URL,但是该URL还是会出现在一些相关的链接。在查询的结果页面,标题和描述会显示您获得的相关信息。如果你想完全禁止 URL 出现在搜索结果中,你需要使用现在提到的没有索引的元机器人标签。
元机器人标签是页面头部的元标签之一。它的作用是告诉搜索引擎和引擎禁止索引这个页面的内容。
简单的元机器人标签格式如下
这意味着禁止所有搜索蜘蛛索引该页面,并且禁止跟踪该页面上的所有链接。
有时使用上述标签。指令是禁止蜘蛛索引,但它可以跟踪页面上的链接。
浙江seo提醒,学习这个文章需要注意的内容是爬取和索引或者采集是两个不同的概念。使用robot文件可以禁止爬取,但不会影响索引;index用于禁止Index,但可以检索。另外,为了让Meta NOindex标签起作用,必须允许蜘蛛抓取页面,否则禁止索引的标签根本看不到。
以上就是浙江四HB源码seo关于SEO禁止爬取、索引、采集机制的知识。感谢您的阅读。 查看全部
php禁止网页抓取(浙江四HB源码SEO与您分享SEO优化如何禁止捕捉和记录机制)
在网站,搜索引擎优化的过程中,并不是所有的页面和内容都被搜索引擎抓取和索引。例如,如果复制的内容被捕获,则会对网站产生负面影响。例如,一些电商平台为了用户更好地搜索和过滤产品而屏蔽了大量页面,以及布局格式的页面。如果抓取了大量这样的页面,就会浪费搜索和引擎分配给网站的总爬取时间,进而影响搜索和引擎真正想要抓取的页面,记录。网站管理员可以通过查询网站来访问日志。如果出现类似情况,大量无用页面被抓取,重要内容从未抓取,网站
今天浙江四HB源码SEO与大家分享SEO优化如何禁止抓拍和记录机制,希望对大家有所帮助。
在前面的章节中,熟悉的JavaScript、flash links、nofollow等方法并不能保证页面不会被收录。在其他情况下,由于未知原因,可能存在导入的外部链接导致页面被收录。浙江SEO将在本文中讨论机器人文档和非索引元机器人标签。前者确保不捕获页面,而后者确保不收录页面。
文本文件
机器人。网站的根目录中存在.txt文件。它的指令用于禁止引擎、搜索、蜘蛛抓取某些页面内容或允许抓取某些内容。蜘蛛在搜索、引擎或爬取网站上爬取时,会先检查这个文件的权限。
机器人文件不存在或文件中没有内容。默认情况下,搜索引擎和引擎可以抓取网站的所有页面。如果需要禁止捕获某些信息,则必须专门编写机器人文件。另外,浙江SEO建议,如果允许爬取网站的所有内容,还应该在根目录下放置一个空的robots.txt文件。因为如果由于设置问题导致robot文件不存在,有些服务器会返回200状态码和其他一些错误信息,而不是404状态码,所以搜索引擎误解了robot的信息。下面简单介绍一下如何写robot文件:
用户代理:*
不允许:/
以上是机器人文件的简要说明。根据一些英文单词,大家会更容易理解和记忆。例如,允许和禁止。以上描述可以分为: User Agent:指定以下规则适用于哪个搜索引擎蜘蛛。*通配符表示所有蜘蛛。如果仅适用于百度蜘蛛,请将通配符替换为百度蜘蛛*
用户代理:百度蜘蛛
以下规则仅适用于百度蜘蛛
禁止:提醒人们不允许蜘蛛抓取内容。后缀文件或者目录名就够了,可以在以后的学习实践中详细学习,浙江seo这里有个提示,禁止文件和目录写在同一行。文件或目录需要占一行,每行必须先写Disallow:指令。
没有indexmeta机器人标签
虽然robot文件可以禁止搜索引擎抓取特定的URL,搜索引擎也会做同样的事情,但是在一些导入链接的作用下,虽然搜索引擎没有抓取到该URL,但是该URL还是会出现在一些相关的链接。在查询的结果页面,标题和描述会显示您获得的相关信息。如果你想完全禁止 URL 出现在搜索结果中,你需要使用现在提到的没有索引的元机器人标签。
元机器人标签是页面头部的元标签之一。它的作用是告诉搜索引擎和引擎禁止索引这个页面的内容。
简单的元机器人标签格式如下
这意味着禁止所有搜索蜘蛛索引该页面,并且禁止跟踪该页面上的所有链接。
有时使用上述标签。指令是禁止蜘蛛索引,但它可以跟踪页面上的链接。
 https://wwwhhhhbbbbcom.oss-cn- ... ality,q_50%2Fresize,m_fill,w_300,h_200 300w" />
https://wwwhhhhbbbbcom.oss-cn- ... ality,q_50%2Fresize,m_fill,w_300,h_200 300w" />浙江seo提醒,学习这个文章需要注意的内容是爬取和索引或者采集是两个不同的概念。使用robot文件可以禁止爬取,但不会影响索引;index用于禁止Index,但可以检索。另外,为了让Meta NOindex标签起作用,必须允许蜘蛛抓取页面,否则禁止索引的标签根本看不到。
以上就是浙江四HB源码seo关于SEO禁止爬取、索引、采集机制的知识。感谢您的阅读。
php禁止网页抓取(浏览器端负责解析php禁止网页抓取任何内容是个坑)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-05 01:03
php禁止网页抓取任何内容是个坑。
意思是禁止蜘蛛访问该网页。
最后打个补丁的关系。
curl就是一个http客户端请求就是发出去一次。浏览器端负责解析跳转就是跳转到用户设定好的页面客户端发送请求,服务器端获取响应,返回内容,接着发送过来一样就是请求和响应过程中,
出现过getlib,就是类似websocket的东西。就像http2的getpost。
出现过opener,
只有必要时使用,
curl
iis的话叫做httpoverhttps
chrome的话叫做filebasedpagetransferprotocol
以php为例,用request建立tcp连接,控制其过程使用new的一对参数,以init()方法初始化为每一次的用户请求httpframe但是每一次http请求并不是首次发出的请求,还有requestscope的问题while(true){assertrequest。http。createsession();//只有在请求有了sessionpost(request,assertrequest。
http。createsession())//并不能把session状态写到结果}try{try。assertrequest。http。createsession();}catch(exceptione){}request。close();//关闭连接。 查看全部
php禁止网页抓取(浏览器端负责解析php禁止网页抓取任何内容是个坑)
php禁止网页抓取任何内容是个坑。
意思是禁止蜘蛛访问该网页。
最后打个补丁的关系。
curl就是一个http客户端请求就是发出去一次。浏览器端负责解析跳转就是跳转到用户设定好的页面客户端发送请求,服务器端获取响应,返回内容,接着发送过来一样就是请求和响应过程中,
出现过getlib,就是类似websocket的东西。就像http2的getpost。
出现过opener,
只有必要时使用,
curl
iis的话叫做httpoverhttps
chrome的话叫做filebasedpagetransferprotocol
以php为例,用request建立tcp连接,控制其过程使用new的一对参数,以init()方法初始化为每一次的用户请求httpframe但是每一次http请求并不是首次发出的请求,还有requestscope的问题while(true){assertrequest。http。createsession();//只有在请求有了sessionpost(request,assertrequest。
http。createsession())//并不能把session状态写到结果}try{try。assertrequest。http。createsession();}catch(exceptione){}request。close();//关闭连接。
php禁止网页抓取( 什么是robots.txt文件?搜索引擎使用spider程序自动访问互联网上的网页并获取网页信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-02 15:11
什么是robots.txt文件?搜索引擎使用spider程序自动访问互联网上的网页并获取网页信息)
禁止搜索引擎的方法收录
禁止搜索引擎的方法收录
什么是 robots.txt 文件?
搜索引擎使用蜘蛛程序自动访问互联网上的网页并获取网页信息。当蜘蛛访问一个网站时,它首先会检查网站的根域下是否有一个名为robots.txt的纯文本文件。这个文件是用来指定蜘蛛在你的网站 爬取范围上的。您可以在您的网站中创建一个robots.txt,并在文件中声明网站中不想被搜索引擎收录搜索到的部分或指定搜索引擎仅是 收录 特定部分。
请注意,只有当您的网站收录您不想被收录搜索的内容时,您才需要使用robots.txt文件。如果您想要搜索引擎收录网站 上的所有内容,请不要创建robots.txt 文件。
robots.txt 文件在哪里?
robots.txt文件应该放在网站的根目录下。例如,当蜘蛛访问一个网站(例如)时,它会首先检查网站中是否存在该文件。如果蜘蛛找到该文件,它会根据文件的内容确定其访问权限的范围。
网站 robots.txt:///robots.txt:80/:80/robots.txt:1234/:1234/robots.txt:///robots.txt的URL对应的URL
我在robots.txt中设置了禁止百度收录me网站,为什么还是出现在百度搜索结果中?
如果您的robots.txt文件中设置了禁止收录的其他网站链接,这些网页可能仍会出现在百度的搜索结果中,但您网页上的内容将不会被抓取,索引和显示,百度搜索结果中显示的只是您相关网页的其他网站描述。
禁止搜索引擎关注网页链接,仅索引网页
如果您不希望搜索引擎跟踪此页面上的链接并且不传递链接的权重,请将此元标记放在页面的一部分中:
如果您不想让百度跟踪特定链接,百度也支持更精确的控制,请直接在链接上写下这个标记:
登入
要允许其他搜索引擎跟踪,但仅阻止百度跟踪指向您页面的链接,请将此元标记放置在页面的一部分中:
防止搜索引擎在搜索结果中显示网页快照,只索引网页
为了防止所有搜索引擎显示您的 网站 快照,请将此元标记放在页面的一部分中:
要允许其他搜索引擎显示快照,但只阻止百度显示,请使用以下标签:
注意:此标签仅禁止百度显示网页快照。百度将继续对网页进行索引,并在搜索结果中显示网页摘要。
我想禁止百度图片搜索收录中的一些图片,我该如何设置?
禁止百度蜘蛛抓取网站上的所有图片,禁止或允许百度蜘蛛抓取网站上特定格式的图片文件可以通过设置robots实现,请参考“robots.txt文件使用示例”示例10、11、12。
robots.txt 文件的格式
“robots.txt”文件收录一个或多个记录,由空行分隔(以CR、CR/NL或NL作为终止符)。每条记录的格式如下:
“:”。
可以在这个文件中使用#做注释,具体用法同UNIX中的约定。此文件中的记录通常以一行或多行 User-agent 开头,后跟几行 Disallow 和 Allow 行。详细情况如下:
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被“robots.txt”限制。对于此文件,必须至少有一个用户代理记录。如果此项的值设置为*,则对任何机器人都有效。在“robots.txt”文件中,只能有“User-agent:*”这样的一条记录。如果您在“robots.txt”文件中添加“User-agent:SomeBot”和几行禁止和允许行,则名称“SomeBot”仅受“User-agent: SomeBot”后的禁止和允许行的限制。
不允许:
该项的值用于描述一组不想被访问的 URL。该值可以是完整路径或路径的非空前缀。机器人不会访问以 Disallow 项的值开头的 URL。例如,“Disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,“Disallow:/help/”允许机器人访问/help.html、/helpabc。 html,而不是访问 /help/index.html。“禁止:”表示允许机器人访问网站的所有URL。“/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”不存在或为空文件,则此网站 对所有搜索引擎机器人开放。
允许:
此项的值用于描述您要访问的一组 URL。与 Disallow 项类似,该值可以是完整路径或路径前缀。允许机器人访问以 Allow 项的值开头的 URL。例如,“Allow:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。网站 的所有 URL 默认都是 Allow 的,所以 Allow 通常与 Disallow 结合使用,允许访问某些网页,同时禁止访问所有其他 URL。
需要注意的是,Disallow 和 Allow 行的顺序是有意义的,机器人会根据第一个匹配成功的 Allow 或 Disallow 行来决定是否访问 URL。
使用“*”和“$”:
百度蜘蛛支持使用通配符“*”和“$”来模糊匹配URL。
"$" 匹配行尾。
“*”匹配 0 个或多个任意字符。
URL匹配示例
Allow 或 Disallow 值的 URL 匹配结果 /tmp/tmpyes/tmp/tmp.htmlyes/tmp/tmp/a.htmlyes/tmp//tmpno/tmp//tmphohono/tmp//tmp/a.htmlyes/Hello*/Hello .htmlyes/He*lo/Hello,loloyes/Heap*lo/Hello,lolonohtml$/tmpa.htmlyes/a.html$/a.htmlyeshtm$/a.htmlno
需要注意的是,每个目录必须单独声明,不能写成“Disallow: /cgi-bin/ /tmp/”。User-agent: *Disallow: /cgi-bin/Disallow: /tmp/Disallow: /~joe/Example6. 允许访问特定目录中的部分 url User-agent: *Allow: /cgi- bin/seeAllow: /tmp/hiAllow: /~joe/lookDisallow: /cgi-bin/Disallow: /tmp/Disallow: /~joe/Example 7. 使用“*”来限制访问url,禁止访问/cgi-bin/ 后缀为“.htm”的所有 URL(包括子目录)。
User-agent: *Disallow: /cgi-bin/*.htm 示例 8. 使用“$”限制对 URL 的访问,只允许访问带有“.htm”后缀的 URL。User-agent: *Allow: .htm$Disallow: /example9. 禁止访问网站 中的所有动态页面 User-agent: *Disallow: /*?*Example 10. 禁止百度蜘蛛抓取了网站上的所有图片。只允许抓取网页,不允许抓取图片。用户代理:BaiduspiderDisallow: /*.jpg$Disallow: /*.jpeg$Disallow: /*.gif$Disallow: /*.png$Disallow: /*.bmp$Example 11. 只允许Baiduspider抓取网页和.gif格式的图片允许抓取gif格式的网页和图片,但不允许抓取其他格式的图片。用户代理:BaiduspiderAllow: /*.gif$Disallow: /*.jpg$Disallow: /*.
robots.txt 文件参考
关于robots.txt文件更具体的设置,请参考以下链接:
· 机器人排除协议的 Web 服务器管理员指南
· 机器人排除协议的 HTML 作者指南
· 1994 年的原创协议描述,如当前部署
· 修订后的 Internet-Draft 规范,尚未完成或实施 查看全部
php禁止网页抓取(
什么是robots.txt文件?搜索引擎使用spider程序自动访问互联网上的网页并获取网页信息)
禁止搜索引擎的方法收录
禁止搜索引擎的方法收录
什么是 robots.txt 文件?
搜索引擎使用蜘蛛程序自动访问互联网上的网页并获取网页信息。当蜘蛛访问一个网站时,它首先会检查网站的根域下是否有一个名为robots.txt的纯文本文件。这个文件是用来指定蜘蛛在你的网站 爬取范围上的。您可以在您的网站中创建一个robots.txt,并在文件中声明网站中不想被搜索引擎收录搜索到的部分或指定搜索引擎仅是 收录 特定部分。
请注意,只有当您的网站收录您不想被收录搜索的内容时,您才需要使用robots.txt文件。如果您想要搜索引擎收录网站 上的所有内容,请不要创建robots.txt 文件。
robots.txt 文件在哪里?
robots.txt文件应该放在网站的根目录下。例如,当蜘蛛访问一个网站(例如)时,它会首先检查网站中是否存在该文件。如果蜘蛛找到该文件,它会根据文件的内容确定其访问权限的范围。
网站 robots.txt:///robots.txt:80/:80/robots.txt:1234/:1234/robots.txt:///robots.txt的URL对应的URL
我在robots.txt中设置了禁止百度收录me网站,为什么还是出现在百度搜索结果中?
如果您的robots.txt文件中设置了禁止收录的其他网站链接,这些网页可能仍会出现在百度的搜索结果中,但您网页上的内容将不会被抓取,索引和显示,百度搜索结果中显示的只是您相关网页的其他网站描述。
禁止搜索引擎关注网页链接,仅索引网页
如果您不希望搜索引擎跟踪此页面上的链接并且不传递链接的权重,请将此元标记放在页面的一部分中:
如果您不想让百度跟踪特定链接,百度也支持更精确的控制,请直接在链接上写下这个标记:
登入
要允许其他搜索引擎跟踪,但仅阻止百度跟踪指向您页面的链接,请将此元标记放置在页面的一部分中:
防止搜索引擎在搜索结果中显示网页快照,只索引网页
为了防止所有搜索引擎显示您的 网站 快照,请将此元标记放在页面的一部分中:
要允许其他搜索引擎显示快照,但只阻止百度显示,请使用以下标签:
注意:此标签仅禁止百度显示网页快照。百度将继续对网页进行索引,并在搜索结果中显示网页摘要。
我想禁止百度图片搜索收录中的一些图片,我该如何设置?
禁止百度蜘蛛抓取网站上的所有图片,禁止或允许百度蜘蛛抓取网站上特定格式的图片文件可以通过设置robots实现,请参考“robots.txt文件使用示例”示例10、11、12。
robots.txt 文件的格式
“robots.txt”文件收录一个或多个记录,由空行分隔(以CR、CR/NL或NL作为终止符)。每条记录的格式如下:
“:”。
可以在这个文件中使用#做注释,具体用法同UNIX中的约定。此文件中的记录通常以一行或多行 User-agent 开头,后跟几行 Disallow 和 Allow 行。详细情况如下:
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被“robots.txt”限制。对于此文件,必须至少有一个用户代理记录。如果此项的值设置为*,则对任何机器人都有效。在“robots.txt”文件中,只能有“User-agent:*”这样的一条记录。如果您在“robots.txt”文件中添加“User-agent:SomeBot”和几行禁止和允许行,则名称“SomeBot”仅受“User-agent: SomeBot”后的禁止和允许行的限制。
不允许:
该项的值用于描述一组不想被访问的 URL。该值可以是完整路径或路径的非空前缀。机器人不会访问以 Disallow 项的值开头的 URL。例如,“Disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,“Disallow:/help/”允许机器人访问/help.html、/helpabc。 html,而不是访问 /help/index.html。“禁止:”表示允许机器人访问网站的所有URL。“/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”不存在或为空文件,则此网站 对所有搜索引擎机器人开放。
允许:
此项的值用于描述您要访问的一组 URL。与 Disallow 项类似,该值可以是完整路径或路径前缀。允许机器人访问以 Allow 项的值开头的 URL。例如,“Allow:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。网站 的所有 URL 默认都是 Allow 的,所以 Allow 通常与 Disallow 结合使用,允许访问某些网页,同时禁止访问所有其他 URL。
需要注意的是,Disallow 和 Allow 行的顺序是有意义的,机器人会根据第一个匹配成功的 Allow 或 Disallow 行来决定是否访问 URL。
使用“*”和“$”:
百度蜘蛛支持使用通配符“*”和“$”来模糊匹配URL。
"$" 匹配行尾。
“*”匹配 0 个或多个任意字符。
URL匹配示例
Allow 或 Disallow 值的 URL 匹配结果 /tmp/tmpyes/tmp/tmp.htmlyes/tmp/tmp/a.htmlyes/tmp//tmpno/tmp//tmphohono/tmp//tmp/a.htmlyes/Hello*/Hello .htmlyes/He*lo/Hello,loloyes/Heap*lo/Hello,lolonohtml$/tmpa.htmlyes/a.html$/a.htmlyeshtm$/a.htmlno
需要注意的是,每个目录必须单独声明,不能写成“Disallow: /cgi-bin/ /tmp/”。User-agent: *Disallow: /cgi-bin/Disallow: /tmp/Disallow: /~joe/Example6. 允许访问特定目录中的部分 url User-agent: *Allow: /cgi- bin/seeAllow: /tmp/hiAllow: /~joe/lookDisallow: /cgi-bin/Disallow: /tmp/Disallow: /~joe/Example 7. 使用“*”来限制访问url,禁止访问/cgi-bin/ 后缀为“.htm”的所有 URL(包括子目录)。
User-agent: *Disallow: /cgi-bin/*.htm 示例 8. 使用“$”限制对 URL 的访问,只允许访问带有“.htm”后缀的 URL。User-agent: *Allow: .htm$Disallow: /example9. 禁止访问网站 中的所有动态页面 User-agent: *Disallow: /*?*Example 10. 禁止百度蜘蛛抓取了网站上的所有图片。只允许抓取网页,不允许抓取图片。用户代理:BaiduspiderDisallow: /*.jpg$Disallow: /*.jpeg$Disallow: /*.gif$Disallow: /*.png$Disallow: /*.bmp$Example 11. 只允许Baiduspider抓取网页和.gif格式的图片允许抓取gif格式的网页和图片,但不允许抓取其他格式的图片。用户代理:BaiduspiderAllow: /*.gif$Disallow: /*.jpg$Disallow: /*.
robots.txt 文件参考
关于robots.txt文件更具体的设置,请参考以下链接:
· 机器人排除协议的 Web 服务器管理员指南
· 机器人排除协议的 HTML 作者指南
· 1994 年的原创协议描述,如当前部署
· 修订后的 Internet-Draft 规范,尚未完成或实施
php禁止网页抓取(代码添加一个屏蔽功能更为方便方便!!! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-02 05:05
)
由于 WordPress 是一个开源博客程序,因此受到世界各地许多用户的喜爱。也会有很多个性化的需求。
比如有些文章我们可能不想让搜索引擎抓取,这个可以通过robots实现,但是很麻烦。代码中加入阻塞函数更方便
一、设置方法
方法还是很简单的,就几段代码。我们在主题文件中找到了“functions.php”文件。我们不保证每个主题文件的名称完全相同,但大部分都是一样的。
然后将以下代码添加到“functions.php”文件中。提示:如果您的 WordPress 站点启用了页面缓存,则此功能将不起作用!!
// 站点开启了页面缓存,此功能无效
function ludouse_add_custom_box() {
if (function_exists('add_meta_box')) {
add_meta_box('ludou_allow_se', '搜索引擎', 'ludou_allow_se', 'post', 'side', 'low');
add_meta_box('ludou_allow_se', '搜索引擎', 'ludou_allow_se', 'page', 'side', 'low');
}
}
add_action('add_meta_boxes', 'ludouse_add_custom_box');
function ludou_allow_se() {
global $post;
//添加验证字段
wp_nonce_field('ludou_allow_se', 'ludou_allow_se_nonce');
$meta_value = get_post_meta($post->ID, 'ludou_allow_se', true);
if($meta_value)
echo ' 屏蔽搜索引擎';
else
echo ' 屏蔽搜索引擎';
}
// 保存选项设置
function ludouse_save_postdata($post_id) {
// 验证
if ( !isset( $_POST['ludou_allow_se_nonce']))
return $post_id;
$nonce = $_POST['ludou_allow_se_nonce'];
// 验证字段是否合法
if (!wp_verify_nonce( $nonce, 'ludou_allow_se'))
return $post_id;
// 判断是否自动保存
if (defined('DOING_AUTOSAVE') && DOING_AUTOSAVE)
return $post_id;
// 验证用户权限
if ('page' == $_POST['post_type']) {
if ( !current_user_can('edit_page', $post_id))
return $post_id;
}
else {
if (!current_user_can('edit_post', $post_id))
return $post_id;
}
// 更新设置
if(!empty($_POST['ludou-allow-se']))
update_post_meta($post_id, 'ludou_allow_se', '1');
else
update_post_meta($post_id, 'ludou_allow_se', '0');
}
add_action('save_post', 'ludouse_save_postdata');
// 对于设置不允许抓取文章和页面
// 禁止搜索引擎抓取,返回404
function do_ludou_allow_se() {
// 本功能只对文章和页面有效
if(is_singular()) {
global $post;
$is_robots = 0;
$ludou_allow_se = get_post_meta($post->ID, 'ludou_allow_se', true);
if(!empty($ludou_allow_se)) {
// 下面是爬虫Agent判断关键字数组
// 有点简单,自己优化一下吧
$bots = array(
'spider',
'bot',
'crawl',
'Slurp',
'yahoo-blogs',
'Yandex',
'Yeti',
'blogsearch',
'ia_archive',
'Google',
'baidu'
);
$useragent = $_SERVER['HTTP_USER_AGENT'];
if(!empty($useragent)) {
foreach ($bots as $lookfor) {
if (stristr($useragent, $lookfor) !== false) {
$is_robots = 1;
break;
}
}
}
// 如果当前文章/页面禁止搜索引擎抓取,返回404
// 当然你可以改成403
if($is_robots) {
status_header(404);
exit;
}
}
}
}
add_action('wp', 'do_ludou_allow_se');
二、优化方法
当我们将上述代码添加到主题“functions.php”中时,WordPress后台的文章编辑页面会出现一个文件拦截搜索引擎按钮。如果你想要某篇文章文章不要检查它是否被搜索引擎抓取。
但是上面的代码是勾选时,被勾选的文章在被搜索引擎访问时会返回404状态。如果您担心返回404死链接会影响SEO,那么我们可以使用以下代码。
但前提是你先在主题文件的“header.php”中添加一个meta语句告诉搜索引擎不要收录这个页面。
并且以下代码必须在您的主题 header.php 文件中:
wp_head();
然后在主题“functions.php”文件中添加如下优化代码。当然,如果有问题,我们可以选择不使用优化后的代码,因为你设置不为收录的页面肯定很少,所以不会对搜索引擎造成太大影响。
// 站点开启了页面缓存,此功能无效
function ludouse_add_custom_box() {
if (function_exists('add_meta_box')) {
add_meta_box('ludou_allow_se', '搜索引擎', 'ludou_allow_se', 'post', 'side', 'low');
add_meta_box('ludou_allow_se', '搜索引擎', 'ludou_allow_se', 'page', 'side', 'low');
}
}
add_action('add_meta_boxes', 'ludouse_add_custom_box');
function ludou_allow_se() {
global $post;
//添加验证字段
wp_nonce_field('ludou_allow_se', 'ludou_allow_se_nonce');
$meta_value = get_post_meta($post->ID, 'ludou_allow_se', true);
if($meta_value)
echo ' 屏蔽搜索引擎';
else
echo ' 屏蔽搜索引擎';
}
// 保存选项设置
function ludouse_save_postdata($post_id) {
// 验证
if ( !isset( $_POST['ludou_allow_se_nonce']))
return $post_id;
$nonce = $_POST['ludou_allow_se_nonce'];
// 验证字段是否合法
if (!wp_verify_nonce( $nonce, 'ludou_allow_se'))
return $post_id;
// 判断是否自动保存
if (defined('DOING_AUTOSAVE') && DOING_AUTOSAVE)
return $post_id;
// 验证用户权限
if ('page' == $_POST['post_type']) {
if ( !current_user_can('edit_page', $post_id))
return $post_id;
}
else {
if (!current_user_can('edit_post', $post_id))
return $post_id;
}
// 更新设置
if(!empty($_POST['ludou-allow-se']))
update_post_meta($post_id, 'ludou_allow_se', '1');
else
update_post_meta($post_id, 'ludou_allow_se', '0');
}
add_action('save_post', 'ludouse_save_postdata');
// 对于设置不允许抓取文章和页面
// 禁止搜索引擎抓取,返回404
function do_ludou_allow_se() {
// 本功能只对文章和页面有效
if(is_singular()) {
global $post;
$is_robots = 0;
$ludou_allow_se = get_post_meta($post->ID, 'ludou_allow_se', true);
if(!empty($ludou_allow_se)) {
// 下面是爬虫Agent判断关键字数组
// 有点简单,自己优化一下吧
$bots = array(
'spider',
'bot',
'crawl',
'Slurp',
'yahoo-blogs',
'Yandex',
'Yeti',
'blogsearch',
'ia_archive',
'Google',
'baidu'
);
$useragent = $_SERVER['HTTP_USER_AGENT'];
if(!empty($useragent)) {
foreach ($bots as $lookfor) {
if (stristr($useragent, $lookfor) !== false) {
$is_robots = 1;
break;
}
}
}
// 如果当前文章/页面禁止搜索引擎抓取,返回404
// 当然你可以改成403
if($is_robots) {
echo "\n";
}
}
}
}
add_action('wp_head', 'do_ludou_allow_se'); 查看全部
php禁止网页抓取(代码添加一个屏蔽功能更为方便方便!!!
)
由于 WordPress 是一个开源博客程序,因此受到世界各地许多用户的喜爱。也会有很多个性化的需求。
比如有些文章我们可能不想让搜索引擎抓取,这个可以通过robots实现,但是很麻烦。代码中加入阻塞函数更方便

一、设置方法
方法还是很简单的,就几段代码。我们在主题文件中找到了“functions.php”文件。我们不保证每个主题文件的名称完全相同,但大部分都是一样的。
然后将以下代码添加到“functions.php”文件中。提示:如果您的 WordPress 站点启用了页面缓存,则此功能将不起作用!!
// 站点开启了页面缓存,此功能无效
function ludouse_add_custom_box() {
if (function_exists('add_meta_box')) {
add_meta_box('ludou_allow_se', '搜索引擎', 'ludou_allow_se', 'post', 'side', 'low');
add_meta_box('ludou_allow_se', '搜索引擎', 'ludou_allow_se', 'page', 'side', 'low');
}
}
add_action('add_meta_boxes', 'ludouse_add_custom_box');
function ludou_allow_se() {
global $post;
//添加验证字段
wp_nonce_field('ludou_allow_se', 'ludou_allow_se_nonce');
$meta_value = get_post_meta($post->ID, 'ludou_allow_se', true);
if($meta_value)
echo ' 屏蔽搜索引擎';
else
echo ' 屏蔽搜索引擎';
}
// 保存选项设置
function ludouse_save_postdata($post_id) {
// 验证
if ( !isset( $_POST['ludou_allow_se_nonce']))
return $post_id;
$nonce = $_POST['ludou_allow_se_nonce'];
// 验证字段是否合法
if (!wp_verify_nonce( $nonce, 'ludou_allow_se'))
return $post_id;
// 判断是否自动保存
if (defined('DOING_AUTOSAVE') && DOING_AUTOSAVE)
return $post_id;
// 验证用户权限
if ('page' == $_POST['post_type']) {
if ( !current_user_can('edit_page', $post_id))
return $post_id;
}
else {
if (!current_user_can('edit_post', $post_id))
return $post_id;
}
// 更新设置
if(!empty($_POST['ludou-allow-se']))
update_post_meta($post_id, 'ludou_allow_se', '1');
else
update_post_meta($post_id, 'ludou_allow_se', '0');
}
add_action('save_post', 'ludouse_save_postdata');
// 对于设置不允许抓取文章和页面
// 禁止搜索引擎抓取,返回404
function do_ludou_allow_se() {
// 本功能只对文章和页面有效
if(is_singular()) {
global $post;
$is_robots = 0;
$ludou_allow_se = get_post_meta($post->ID, 'ludou_allow_se', true);
if(!empty($ludou_allow_se)) {
// 下面是爬虫Agent判断关键字数组
// 有点简单,自己优化一下吧
$bots = array(
'spider',
'bot',
'crawl',
'Slurp',
'yahoo-blogs',
'Yandex',
'Yeti',
'blogsearch',
'ia_archive',
'Google',
'baidu'
);
$useragent = $_SERVER['HTTP_USER_AGENT'];
if(!empty($useragent)) {
foreach ($bots as $lookfor) {
if (stristr($useragent, $lookfor) !== false) {
$is_robots = 1;
break;
}
}
}
// 如果当前文章/页面禁止搜索引擎抓取,返回404
// 当然你可以改成403
if($is_robots) {
status_header(404);
exit;
}
}
}
}
add_action('wp', 'do_ludou_allow_se');
二、优化方法
当我们将上述代码添加到主题“functions.php”中时,WordPress后台的文章编辑页面会出现一个文件拦截搜索引擎按钮。如果你想要某篇文章文章不要检查它是否被搜索引擎抓取。
但是上面的代码是勾选时,被勾选的文章在被搜索引擎访问时会返回404状态。如果您担心返回404死链接会影响SEO,那么我们可以使用以下代码。
但前提是你先在主题文件的“header.php”中添加一个meta语句告诉搜索引擎不要收录这个页面。
并且以下代码必须在您的主题 header.php 文件中:
wp_head();
然后在主题“functions.php”文件中添加如下优化代码。当然,如果有问题,我们可以选择不使用优化后的代码,因为你设置不为收录的页面肯定很少,所以不会对搜索引擎造成太大影响。
// 站点开启了页面缓存,此功能无效
function ludouse_add_custom_box() {
if (function_exists('add_meta_box')) {
add_meta_box('ludou_allow_se', '搜索引擎', 'ludou_allow_se', 'post', 'side', 'low');
add_meta_box('ludou_allow_se', '搜索引擎', 'ludou_allow_se', 'page', 'side', 'low');
}
}
add_action('add_meta_boxes', 'ludouse_add_custom_box');
function ludou_allow_se() {
global $post;
//添加验证字段
wp_nonce_field('ludou_allow_se', 'ludou_allow_se_nonce');
$meta_value = get_post_meta($post->ID, 'ludou_allow_se', true);
if($meta_value)
echo ' 屏蔽搜索引擎';
else
echo ' 屏蔽搜索引擎';
}
// 保存选项设置
function ludouse_save_postdata($post_id) {
// 验证
if ( !isset( $_POST['ludou_allow_se_nonce']))
return $post_id;
$nonce = $_POST['ludou_allow_se_nonce'];
// 验证字段是否合法
if (!wp_verify_nonce( $nonce, 'ludou_allow_se'))
return $post_id;
// 判断是否自动保存
if (defined('DOING_AUTOSAVE') && DOING_AUTOSAVE)
return $post_id;
// 验证用户权限
if ('page' == $_POST['post_type']) {
if ( !current_user_can('edit_page', $post_id))
return $post_id;
}
else {
if (!current_user_can('edit_post', $post_id))
return $post_id;
}
// 更新设置
if(!empty($_POST['ludou-allow-se']))
update_post_meta($post_id, 'ludou_allow_se', '1');
else
update_post_meta($post_id, 'ludou_allow_se', '0');
}
add_action('save_post', 'ludouse_save_postdata');
// 对于设置不允许抓取文章和页面
// 禁止搜索引擎抓取,返回404
function do_ludou_allow_se() {
// 本功能只对文章和页面有效
if(is_singular()) {
global $post;
$is_robots = 0;
$ludou_allow_se = get_post_meta($post->ID, 'ludou_allow_se', true);
if(!empty($ludou_allow_se)) {
// 下面是爬虫Agent判断关键字数组
// 有点简单,自己优化一下吧
$bots = array(
'spider',
'bot',
'crawl',
'Slurp',
'yahoo-blogs',
'Yandex',
'Yeti',
'blogsearch',
'ia_archive',
'Google',
'baidu'
);
$useragent = $_SERVER['HTTP_USER_AGENT'];
if(!empty($useragent)) {
foreach ($bots as $lookfor) {
if (stristr($useragent, $lookfor) !== false) {
$is_robots = 1;
break;
}
}
}
// 如果当前文章/页面禁止搜索引擎抓取,返回404
// 当然你可以改成403
if($is_robots) {
echo "\n";
}
}
}
}
add_action('wp_head', 'do_ludou_allow_se');
php禁止网页抓取(如何禁止搜索引擎抓取我们网站的动态网址呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-02 05:02
所谓动态网址是指收录?、&等字符的网址,如news.php?lang=cn&class=1&id=2。当我们开启网站的伪静态时,对于@网站 SEO,要避免搜索引擎爬取我们的动态网址网站。
你为什么要这样做?因为搜索引擎在对同一个页面爬了两次但最终确定是同一个页面后会触发网站。具体处罚不明确。,总之,不利于整个网站的SEO。那么如何禁止搜索引擎抓取我们的动态网址网站呢?
可以使用robots.txt文件来解决这个问题,具体操作请看下面。
我们知道动态页面有一个共同的特点,就是会有一个“?” 链接中的问号符号,因此我们可以在robots.txt文件中写入以下规则:
用户代理: *
不允许: /*?*
这将禁止搜索引擎抓取网站的整个动态链接。另外,如果我们只想让搜索引擎抓取特定类型的文件,比如html格式的静态页面,我们可以在robots.txt中加入如下规则:
用户代理: *
允许:.html$
不允许: /
另外,记得把你写的robots.txt文件放在你的网站的根目录下,否则是不行的。此外,还有一个简单的快捷方式来编写规则。登录google网站管理员工具,在里面写规则,生成robots.txt文件即可。 查看全部
php禁止网页抓取(如何禁止搜索引擎抓取我们网站的动态网址呢?(图))
所谓动态网址是指收录?、&等字符的网址,如news.php?lang=cn&class=1&id=2。当我们开启网站的伪静态时,对于@网站 SEO,要避免搜索引擎爬取我们的动态网址网站。

你为什么要这样做?因为搜索引擎在对同一个页面爬了两次但最终确定是同一个页面后会触发网站。具体处罚不明确。,总之,不利于整个网站的SEO。那么如何禁止搜索引擎抓取我们的动态网址网站呢?
可以使用robots.txt文件来解决这个问题,具体操作请看下面。
我们知道动态页面有一个共同的特点,就是会有一个“?” 链接中的问号符号,因此我们可以在robots.txt文件中写入以下规则:
用户代理: *
不允许: /*?*
这将禁止搜索引擎抓取网站的整个动态链接。另外,如果我们只想让搜索引擎抓取特定类型的文件,比如html格式的静态页面,我们可以在robots.txt中加入如下规则:
用户代理: *
允许:.html$
不允许: /
另外,记得把你写的robots.txt文件放在你的网站的根目录下,否则是不行的。此外,还有一个简单的快捷方式来编写规则。登录google网站管理员工具,在里面写规则,生成robots.txt文件即可。
php禁止网页抓取(怎么禁止这些不遵循robots协议的搜索引擎我们不想的评判)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-02 05:00
相信大家还记得,360搜索引擎刚出来的时候,因为没有遵守robots协议,就被百度抓到了。我们不会判断谁对谁错。今天我们要讨论的是如何禁止这些不遵守机器人协议的搜索。引擎抓取我们不希望它们抓取的内容。
前不久,WordPress官方插件目录中新增了一个名为Blackhole for Bad Bots的插件。这个插件就是用来清理这些不守规矩的搜索引擎蜘蛛的。插件的原理很有意思。一个虚拟链接被添加到 robots.txt 文件中。一旦蜘蛛试图访问它,插件就会禁止蜘蛛访问网站中的其他页面。遵守规则的蜘蛛自然不会访问此链接,可以畅通无阻地抓取网站允许搜索引擎收录的页面。
这相当于设置了一个巧妙的陷阱。如果你遵守规则,我自然欢迎你。你已经踏入了我不守规矩布置的圈套。哈哈,对不起,这里不欢迎你。更棒的是普通用户看不到这个隐藏链接,遵循robots协议的搜索引擎不受影响。
特征
如果你的网站不是基于WordPress的,没关系,只要你使用的语言是PHP,通过Blackhole的独立PHP版本就可以实现同样的功能!
白名单
默认情况下,该插件不会屏蔽以下任何主流搜索引擎。以下搜索引擎默认添加到插件的白名单中。该插件还允许我们在设置中手动将其他搜索引擎添加到白名单中。
如果您的 网站 不是基于 WordPress 构建的,您也可以使用该插件的 PHP 版本。 查看全部
php禁止网页抓取(怎么禁止这些不遵循robots协议的搜索引擎我们不想的评判)
相信大家还记得,360搜索引擎刚出来的时候,因为没有遵守robots协议,就被百度抓到了。我们不会判断谁对谁错。今天我们要讨论的是如何禁止这些不遵守机器人协议的搜索。引擎抓取我们不希望它们抓取的内容。
前不久,WordPress官方插件目录中新增了一个名为Blackhole for Bad Bots的插件。这个插件就是用来清理这些不守规矩的搜索引擎蜘蛛的。插件的原理很有意思。一个虚拟链接被添加到 robots.txt 文件中。一旦蜘蛛试图访问它,插件就会禁止蜘蛛访问网站中的其他页面。遵守规则的蜘蛛自然不会访问此链接,可以畅通无阻地抓取网站允许搜索引擎收录的页面。
这相当于设置了一个巧妙的陷阱。如果你遵守规则,我自然欢迎你。你已经踏入了我不守规矩布置的圈套。哈哈,对不起,这里不欢迎你。更棒的是普通用户看不到这个隐藏链接,遵循robots协议的搜索引擎不受影响。
特征
如果你的网站不是基于WordPress的,没关系,只要你使用的语言是PHP,通过Blackhole的独立PHP版本就可以实现同样的功能!
白名单
默认情况下,该插件不会屏蔽以下任何主流搜索引擎。以下搜索引擎默认添加到插件的白名单中。该插件还允许我们在设置中手动将其他搜索引擎添加到白名单中。
如果您的 网站 不是基于 WordPress 构建的,您也可以使用该插件的 PHP 版本。
php禁止网页抓取(利于网站优化的robots.txt使用技巧及注意事项!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-01 19:22
这篇文章有更多资源!
需要登录才能下载或查看,还没有账号?立即注册
X
Robots.txt 是搜索引擎蜘蛛抓取您的网站时查看的第一个文件。这个文件告诉搜索引擎的蜘蛛程序你网站上哪些文件可以查看,哪些不可以查看。现在主流的搜索引擎还是遵守这个规则的。
robots.txt 是一个文本文件。它必须命名为“robots.txt”并上传到站点的根目录。上传到子目录是无效的,因为搜索引擎机器人只会在你的域名文档的根目录中找到这个。
一、使用针对网站优化的robots.txt的提示
1、在线建站提供了便捷的途径。当我们把域名解析到服务器后,就可以访问站点了,但是此时站点还没有布局,meta标签还是乱七八糟的。如果此时的站点被搜索引擎蜘蛛收录 抓取,则此时更改它不利于 SEO 优化。这时候可以使用robots.txt文件设置所有搜索引擎蜘蛛不查询网站的所有内容。语法格式为:
用户代理: *
不允许: /
复制代码
2、自定义搜索引擎蜘蛛抓取特定内容,让您根据网站情况选择如何处理搜索引擎。这里有两层意思。
(1)自定义搜索引擎。如果你不屑杜娘的做法,你可以让它只盯着你看。语法格式是:
用户代理:baiduspider
不允许: /
复制代码
注意:常见的搜索引擎机器人名称。
名称搜索引擎
百度蜘蛛
小型摩托车
ia_archiver
谷歌机器人
FAST-WebCrawler
啜饮
MSNBOT
(2)自定义站点内容。也就是说可以指定一个目录允许蜘蛛爬行,一个目录禁止爬行。比如所有的搜索引擎蜘蛛都允许爬取的内容目录abc,禁止目录def。如下内容,其语法格式为:
用户代理: *
允许:/abc/
禁止:/def/
复制代码
3、引导搜索引擎获取网站内容。这里最典型的做法是
(1)引导蜘蛛抓取你的网站地图,语法格式为:
用户代理: *
站点地图:站点地图-url
复制代码
(2)防止蜘蛛抓取您的网站重复内容。
4、404 错误页面问题。如果你的服务器响应404错误页面,没有在你站点的根目录配置robots.txt文件,搜索引擎蜘蛛会把它当成robots.txt文件,影响搜索引擎对你的处理<页面的@网站 收录。
二、用特定程序建网站的robots.txt的写法。这里只是提供一个大概的写法,具体情况自己考虑吧!
1、如何为WordPress网站编写robots.txt文件
用户代理: *
禁止:/wp-admin
禁止:/wp-content/plugins
禁止:/wp-content/themes
禁止:/wp-includes
禁止:/?s=
站点地图:***.com/sitemap.xml
复制代码
2、Discuz论坛如何写robots.txt文件
用户代理: *
允许:/redirect.php
允许:/viewthread.php
允许:/forumdisplay.php
不允许: /?
禁止:/*.php
复制代码
有人说设置robots.txt文件会带来被“一厢情愿者”攻击的危险,但既然你是“一厢情愿的人”,那你就没有问题(这不仅仅是建站程序本身,还有服务器安全等)。 查看全部
php禁止网页抓取(利于网站优化的robots.txt使用技巧及注意事项!)
这篇文章有更多资源!
需要登录才能下载或查看,还没有账号?立即注册

X
Robots.txt 是搜索引擎蜘蛛抓取您的网站时查看的第一个文件。这个文件告诉搜索引擎的蜘蛛程序你网站上哪些文件可以查看,哪些不可以查看。现在主流的搜索引擎还是遵守这个规则的。
robots.txt 是一个文本文件。它必须命名为“robots.txt”并上传到站点的根目录。上传到子目录是无效的,因为搜索引擎机器人只会在你的域名文档的根目录中找到这个。
一、使用针对网站优化的robots.txt的提示
1、在线建站提供了便捷的途径。当我们把域名解析到服务器后,就可以访问站点了,但是此时站点还没有布局,meta标签还是乱七八糟的。如果此时的站点被搜索引擎蜘蛛收录 抓取,则此时更改它不利于 SEO 优化。这时候可以使用robots.txt文件设置所有搜索引擎蜘蛛不查询网站的所有内容。语法格式为:
用户代理: *
不允许: /
复制代码
2、自定义搜索引擎蜘蛛抓取特定内容,让您根据网站情况选择如何处理搜索引擎。这里有两层意思。
(1)自定义搜索引擎。如果你不屑杜娘的做法,你可以让它只盯着你看。语法格式是:
用户代理:baiduspider
不允许: /
复制代码
注意:常见的搜索引擎机器人名称。
名称搜索引擎
百度蜘蛛
小型摩托车
ia_archiver
谷歌机器人
FAST-WebCrawler
啜饮
MSNBOT
(2)自定义站点内容。也就是说可以指定一个目录允许蜘蛛爬行,一个目录禁止爬行。比如所有的搜索引擎蜘蛛都允许爬取的内容目录abc,禁止目录def。如下内容,其语法格式为:
用户代理: *
允许:/abc/
禁止:/def/
复制代码
3、引导搜索引擎获取网站内容。这里最典型的做法是
(1)引导蜘蛛抓取你的网站地图,语法格式为:
用户代理: *
站点地图:站点地图-url
复制代码
(2)防止蜘蛛抓取您的网站重复内容。
4、404 错误页面问题。如果你的服务器响应404错误页面,没有在你站点的根目录配置robots.txt文件,搜索引擎蜘蛛会把它当成robots.txt文件,影响搜索引擎对你的处理<页面的@网站 收录。
二、用特定程序建网站的robots.txt的写法。这里只是提供一个大概的写法,具体情况自己考虑吧!
1、如何为WordPress网站编写robots.txt文件
用户代理: *
禁止:/wp-admin
禁止:/wp-content/plugins
禁止:/wp-content/themes
禁止:/wp-includes
禁止:/?s=
站点地图:***.com/sitemap.xml
复制代码
2、Discuz论坛如何写robots.txt文件
用户代理: *
允许:/redirect.php
允许:/viewthread.php
允许:/forumdisplay.php
不允许: /?
禁止:/*.php
复制代码
有人说设置robots.txt文件会带来被“一厢情愿者”攻击的危险,但既然你是“一厢情愿的人”,那你就没有问题(这不仅仅是建站程序本身,还有服务器安全等)。
php禁止网页抓取(robots协议Robots协议(也称为爬虫协议、机器人协议等))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-01 19:20
机器人协议
Robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站通过Robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
机器人.txt
1. 什么是robots.txt?
搜索蜘蛛访问站点时,首先会检查站点根目录下是否存在robots.txt。如果存在,搜索机器人会根据文件内容确定访问范围;如果该文件不存在,所有 'S 搜索蜘蛛将能够访问 网站 上所有不受密码保护的页面。从表面上看,这个功能是有限的。从搜索引擎优化的角度来看,集中权重的效果可以通过拦截页面来实现,这也是优化者最重要的地方。
这个文件必须放在网站的根目录下,并且有字母大小限制,文件名必须是小写字母。所有命令的第一个字母必须大写,其余的必须小写。并且命令后必须有一个英文字符空格。
2.网站设置robots.txt的几个原因
1)设置访问权限以保护网站安全。
2) 禁止搜索引擎抓取无效页面,权重集中在主页面。
3.如何编写标准语法的robots.txt协议?
有几个概念需要掌握。
User-agent表示定义的是哪个搜索引擎,比如User-agent:Baiduspider,定义了百度蜘蛛。
Disallow 表示禁止访问。
允许意味着运行访问。
通过以上三个命令,你可以组合出多种写法,允许哪个搜索引擎访问或者禁止哪个页面。
1) 允许所有搜索引擎访问网站的所有部分
Robots.txt 的写法如下:
用户代理: *
不允许:
或者
用户代理: *
允许: /
注意:第一个英文必须大写。当冒号是英文时,冒号后面有一个空格。这几点不能错。
2)禁止所有搜索引擎访问网站的所有部分
Robots.txt 的写法如下:
用户代理: *
不允许: /
3)允许或禁止访问搜索引擎
禁止访问搜索引擎,例如禁止访问谷歌搜索引擎
用户代理:Googlebot
不允许: /
允许访问某个搜索引擎,例如允许访问百度搜索引擎
用户代理:百度蜘蛛
允许: /
4) 你只需要禁止蜘蛛访问某个目录,比如禁止admin、css、images等目录被索引
Robots.txt 的写法如下:
用户代理: *
禁止:/css/
禁止:/管理员/
禁止:/图像/
注意:路径后面有斜线和不带斜线的区别:比如Disallow:/images/带斜线是禁止抓取整个文件夹的图片,Disallow:/images不带斜线表示有/images路径@> 中的关键词将被阻止。
5) 阻止文件夹 /templets,但可以抓取其中一个文件:/templets/main
Robots.txt 的写法如下:
用户代理: *
禁止:/templets
允许:/main
6) 禁止访问/html/目录(包括子目录)中所有后缀为“.php”的URL
Robots.txt 的写法如下:
用户代理: *
禁止:/html/*.php
7) 只允许访问某个目录下有某个后缀的文件,使用“$”
Robots.txt 的写法如下:
用户代理: *
允许:.html$
不允许: /
8)禁止索引网站中的所有动态页面
例如,带有“?”的域名 这里被限制了,比如index.php?id=1
Robots.txt 的写法如下:
用户代理: *
不允许: /*?*
9)禁止搜索引擎抓取我们网站上的所有图片(如果您的网站使用了其他后缀的图片名称,您也可以在这里直接添加)
有时,为了节省服务器资源,我们需要禁止各种搜索引擎在网站上索引我们的图片。这里的方法除了使用“Disallow:/images/”直接屏蔽文件夹之外。也可以直接屏蔽图片后缀名。
Robots.txt 的写法如下:
用户代理: *
禁止:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
SEO(搜索引擎优化)
4. 写robots.txt要注意什么
1) 第一个英文要大写。当冒号是英文时,冒号后面有一个空格。这几点不能错。
2)斜线:/代表整个网站
3) 如果“/”后面有多余的空格,整个网站都会被阻塞
4)不要禁止正常内容
5) 生效时间是几天到两个月
5. 我什么时候需要使用这个协议?
1)无用页面,很多网站都有联系我们、用户协议等页面。这些页面在搜索引擎优化方面影响不大。这时候就需要使用Disallow命令来禁止这些页面被搜索引擎搜索。抓住。
2)动态页面,企业类站点屏蔽动态页面,有利于网站安全。并且如果多个URL访问同一个页面,权重就会分散。因此,一般情况下,阻塞动态页面并保留静态或伪静态页面。
3) 网站后台页面,网站后台页面也可以归为无用页面。禁止收录百利而无一害。
在这种情况下,有一条灰线表示 robots.txt 正在运行。只是收录网站的地址栏:
Robots.txt 设置禁止搜索引擎访问指令 查看全部
php禁止网页抓取(robots协议Robots协议(也称为爬虫协议、机器人协议等))
机器人协议
Robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站通过Robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
 http://www.sujianbao.com/wp-co ... 0.jpg 300w, http://www.sujianbao.com/wp-co ... 2.jpg 220w" />
http://www.sujianbao.com/wp-co ... 0.jpg 300w, http://www.sujianbao.com/wp-co ... 2.jpg 220w" />机器人.txt
1. 什么是robots.txt?
搜索蜘蛛访问站点时,首先会检查站点根目录下是否存在robots.txt。如果存在,搜索机器人会根据文件内容确定访问范围;如果该文件不存在,所有 'S 搜索蜘蛛将能够访问 网站 上所有不受密码保护的页面。从表面上看,这个功能是有限的。从搜索引擎优化的角度来看,集中权重的效果可以通过拦截页面来实现,这也是优化者最重要的地方。
这个文件必须放在网站的根目录下,并且有字母大小限制,文件名必须是小写字母。所有命令的第一个字母必须大写,其余的必须小写。并且命令后必须有一个英文字符空格。
2.网站设置robots.txt的几个原因
1)设置访问权限以保护网站安全。
2) 禁止搜索引擎抓取无效页面,权重集中在主页面。
3.如何编写标准语法的robots.txt协议?
有几个概念需要掌握。
User-agent表示定义的是哪个搜索引擎,比如User-agent:Baiduspider,定义了百度蜘蛛。
Disallow 表示禁止访问。
允许意味着运行访问。
通过以上三个命令,你可以组合出多种写法,允许哪个搜索引擎访问或者禁止哪个页面。
1) 允许所有搜索引擎访问网站的所有部分
Robots.txt 的写法如下:
用户代理: *
不允许:
或者
用户代理: *
允许: /
注意:第一个英文必须大写。当冒号是英文时,冒号后面有一个空格。这几点不能错。
2)禁止所有搜索引擎访问网站的所有部分
Robots.txt 的写法如下:
用户代理: *
不允许: /
3)允许或禁止访问搜索引擎
禁止访问搜索引擎,例如禁止访问谷歌搜索引擎
用户代理:Googlebot
不允许: /
允许访问某个搜索引擎,例如允许访问百度搜索引擎
用户代理:百度蜘蛛
允许: /
4) 你只需要禁止蜘蛛访问某个目录,比如禁止admin、css、images等目录被索引
Robots.txt 的写法如下:
用户代理: *
禁止:/css/
禁止:/管理员/
禁止:/图像/
注意:路径后面有斜线和不带斜线的区别:比如Disallow:/images/带斜线是禁止抓取整个文件夹的图片,Disallow:/images不带斜线表示有/images路径@> 中的关键词将被阻止。
5) 阻止文件夹 /templets,但可以抓取其中一个文件:/templets/main
Robots.txt 的写法如下:
用户代理: *
禁止:/templets
允许:/main
6) 禁止访问/html/目录(包括子目录)中所有后缀为“.php”的URL
Robots.txt 的写法如下:
用户代理: *
禁止:/html/*.php
7) 只允许访问某个目录下有某个后缀的文件,使用“$”
Robots.txt 的写法如下:
用户代理: *
允许:.html$
不允许: /
8)禁止索引网站中的所有动态页面
例如,带有“?”的域名 这里被限制了,比如index.php?id=1
Robots.txt 的写法如下:
用户代理: *
不允许: /*?*
9)禁止搜索引擎抓取我们网站上的所有图片(如果您的网站使用了其他后缀的图片名称,您也可以在这里直接添加)
有时,为了节省服务器资源,我们需要禁止各种搜索引擎在网站上索引我们的图片。这里的方法除了使用“Disallow:/images/”直接屏蔽文件夹之外。也可以直接屏蔽图片后缀名。
Robots.txt 的写法如下:
用户代理: *
禁止:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
 http://www.sujianbao.com/wp-co ... 4.jpg 300w, http://www.sujianbao.com/wp-co ... 3.jpg 220w" />
http://www.sujianbao.com/wp-co ... 4.jpg 300w, http://www.sujianbao.com/wp-co ... 3.jpg 220w" />SEO(搜索引擎优化)
4. 写robots.txt要注意什么
1) 第一个英文要大写。当冒号是英文时,冒号后面有一个空格。这几点不能错。
2)斜线:/代表整个网站
3) 如果“/”后面有多余的空格,整个网站都会被阻塞
4)不要禁止正常内容
5) 生效时间是几天到两个月
5. 我什么时候需要使用这个协议?
1)无用页面,很多网站都有联系我们、用户协议等页面。这些页面在搜索引擎优化方面影响不大。这时候就需要使用Disallow命令来禁止这些页面被搜索引擎搜索。抓住。
2)动态页面,企业类站点屏蔽动态页面,有利于网站安全。并且如果多个URL访问同一个页面,权重就会分散。因此,一般情况下,阻塞动态页面并保留静态或伪静态页面。
3) 网站后台页面,网站后台页面也可以归为无用页面。禁止收录百利而无一害。
在这种情况下,有一条灰线表示 robots.txt 正在运行。只是收录网站的地址栏:
 http://www.sujianbao.com/wp-co ... 5.png 300w, http://www.sujianbao.com/wp-co ... 4.png 220w" />
http://www.sujianbao.com/wp-co ... 5.png 300w, http://www.sujianbao.com/wp-co ... 4.png 220w" />Robots.txt 设置禁止搜索引擎访问指令
php禁止网页抓取(张力博客不是:403Forbidden错误的原因以及怎么解决的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-01 19:17
张立博客不提供WordPress相关的付费服务吗?经常有朋友来找我说网站出现403错误,怎么解决,今天给大家带来一个朋友的文章,让你了解403 Forbidden错误的原因和解决方法它。
原文如下:
这几天刚接手一批新做的网站。访问网站时,时不时会出现403 Forbidden错误,浏览器会给出403 Forbidden错误信息,列在Open Access Error中,输出URL后,出现如下错误:
403 禁地
拒绝访问服务器上的此资源!
技术支持 LiteSpeed 网络服务器
LiteSpeed Technologies 不对本网站的管理和内容负责!
403错误是网站访问过程中常见的错误提示。资源不可用,服务器理解客户端的请求,但拒绝处理。通常是由于服务器上的文件或目录的权限设置,例如IIS或apache的访问权限不当造成的。一般会出现如下提示:
一、403 禁止是什么意思?
403 Forbidden 是 HTTP 协议中的一个状态码(Status Code)。可以简单理解为无权访问本站。此状态表示服务器理解请求但拒绝执行任务,不应将请求重新发送到服务器。当 HTTP 请求方法不是“HEAD”,并且服务器想让客户端知道它为什么没有权限时,服务器应该在返回的信息中描述拒绝的原因。在服务器不想提供任何反馈信息的情况下,服务器可以使用 404 Not Found 而不是 403 Forbidden。
二、403错误码分类介绍
403.1
403.1 该错误是由于禁止“执行”访问引起的。如果您尝试从目录中执行 CGI、ISAPI 或其他可执行程序,但该目录不允许该程序执行,则会出现此错误。
403.2
403.2 错误是由“读”访问被禁止引起的。该错误是因为该目录没有默认的网页并且没有开启目录浏览,或者要显示的HTML页面所在的目录只标记了“可执行”或“脚本”权限。
403.3
403.3 该错误是由于禁止“写”访问引起的。尝试将文件上传到目录或修改目录中的文件时会出现此类错误,但该目录不允许“写入”访问错误。
403.4
403.4 错误是由 SSL 的要求引起的。您必须在要查看的网页地址中使用“https”。
403.5
403.5 错误是由需要 128 位加密算法的 Web 浏览器引起的。如果您的浏览器不支持 128 位加密算法,则会出现此错误。您可以连接到 Microsoft网站 执行浏览器升级。
403.6
403.6 错误是由IP地址被拒绝引起的。如果服务器有无法访问站点的IP地址列表,并且您使用的IP地址在列表中,您将返回此错误信息。
403.7
403.7 错误是因为需要客户端证书。当需要访问的资源要求浏览器具有服务器可以识别的安全套接字层 (SSL) 客户端证书时,将返回此错误。
403.8
403.8 错误是由于禁止站点访问引起的。如果服务器有无法访问站点的DNS名称列表,并且您使用的DNS名称在列表中,则会返回此信息。请注意,403.6 和 403.8 的区别是错误的。
403.9
403.9 错误是因为连接的用户太多。当Web服务器很忙,由于流量太大而无法处理请求时,将返回此错误。
403.10
403.10 错误是无效配置导致的错误。当您尝试从目录中执行 CGI、ISAPI 或其他可执行程序,但该目录不允许该程序执行时,将返回此错误。
403.11
403.11 错误是由于密码更改,用户无权查看页面。
403.12
403.12 错误是由映射器拒绝访问引起的。要查看的网页需要有效的客户端证书,当您的客户端证书映射没有访问该网站的权限时,会返回映射器拒绝访问的错误。
403.13
403.13错误是由于要查看的网页需要使用有效的客户端证书,或者无法确定证书是否已被吊销,导致使用的客户端证书已被吊销。
403.14
403.14 错误 Web 服务器配置为不列出此目录的内容并拒绝目录列表。
403.15
403.15 错误是客户端访问权限过多造成的。当服务器超过其客户端访问权限限制时,将返回此错误。
403.16
403.16 错误是由不受信任或无效的客户端证书引起的。
403.17
403.17 错误是因为客户端证书已过期或尚未生效。
三、403错误的主要原因
1、你的IP被列入黑名单。
2、您在一定时间内访问过这个网站(通常是使用采集程序),您的访问被防火墙拒绝。
3、网站 域名解析到空间,但空间没有绑定到这个域名。
4、您的网页脚本文件在当前目录没有执行权限。
5、在不允许写入/创建文件的目录中执行了文件创建/写入操作。 查看全部
php禁止网页抓取(张力博客不是:403Forbidden错误的原因以及怎么解决的方法)
张立博客不提供WordPress相关的付费服务吗?经常有朋友来找我说网站出现403错误,怎么解决,今天给大家带来一个朋友的文章,让你了解403 Forbidden错误的原因和解决方法它。
原文如下:
这几天刚接手一批新做的网站。访问网站时,时不时会出现403 Forbidden错误,浏览器会给出403 Forbidden错误信息,列在Open Access Error中,输出URL后,出现如下错误:
403 禁地
拒绝访问服务器上的此资源!
技术支持 LiteSpeed 网络服务器
LiteSpeed Technologies 不对本网站的管理和内容负责!
403错误是网站访问过程中常见的错误提示。资源不可用,服务器理解客户端的请求,但拒绝处理。通常是由于服务器上的文件或目录的权限设置,例如IIS或apache的访问权限不当造成的。一般会出现如下提示:
 https://zhangliseo.com/wp-cont ... 5.png 768w" />
https://zhangliseo.com/wp-cont ... 5.png 768w" />一、403 禁止是什么意思?
403 Forbidden 是 HTTP 协议中的一个状态码(Status Code)。可以简单理解为无权访问本站。此状态表示服务器理解请求但拒绝执行任务,不应将请求重新发送到服务器。当 HTTP 请求方法不是“HEAD”,并且服务器想让客户端知道它为什么没有权限时,服务器应该在返回的信息中描述拒绝的原因。在服务器不想提供任何反馈信息的情况下,服务器可以使用 404 Not Found 而不是 403 Forbidden。
二、403错误码分类介绍
403.1
403.1 该错误是由于禁止“执行”访问引起的。如果您尝试从目录中执行 CGI、ISAPI 或其他可执行程序,但该目录不允许该程序执行,则会出现此错误。
403.2
403.2 错误是由“读”访问被禁止引起的。该错误是因为该目录没有默认的网页并且没有开启目录浏览,或者要显示的HTML页面所在的目录只标记了“可执行”或“脚本”权限。
403.3
403.3 该错误是由于禁止“写”访问引起的。尝试将文件上传到目录或修改目录中的文件时会出现此类错误,但该目录不允许“写入”访问错误。
403.4
403.4 错误是由 SSL 的要求引起的。您必须在要查看的网页地址中使用“https”。
403.5
403.5 错误是由需要 128 位加密算法的 Web 浏览器引起的。如果您的浏览器不支持 128 位加密算法,则会出现此错误。您可以连接到 Microsoft网站 执行浏览器升级。
403.6
403.6 错误是由IP地址被拒绝引起的。如果服务器有无法访问站点的IP地址列表,并且您使用的IP地址在列表中,您将返回此错误信息。
403.7
403.7 错误是因为需要客户端证书。当需要访问的资源要求浏览器具有服务器可以识别的安全套接字层 (SSL) 客户端证书时,将返回此错误。
403.8
403.8 错误是由于禁止站点访问引起的。如果服务器有无法访问站点的DNS名称列表,并且您使用的DNS名称在列表中,则会返回此信息。请注意,403.6 和 403.8 的区别是错误的。
403.9
403.9 错误是因为连接的用户太多。当Web服务器很忙,由于流量太大而无法处理请求时,将返回此错误。
403.10
403.10 错误是无效配置导致的错误。当您尝试从目录中执行 CGI、ISAPI 或其他可执行程序,但该目录不允许该程序执行时,将返回此错误。
403.11
403.11 错误是由于密码更改,用户无权查看页面。
403.12
403.12 错误是由映射器拒绝访问引起的。要查看的网页需要有效的客户端证书,当您的客户端证书映射没有访问该网站的权限时,会返回映射器拒绝访问的错误。
403.13
403.13错误是由于要查看的网页需要使用有效的客户端证书,或者无法确定证书是否已被吊销,导致使用的客户端证书已被吊销。
403.14
403.14 错误 Web 服务器配置为不列出此目录的内容并拒绝目录列表。
403.15
403.15 错误是客户端访问权限过多造成的。当服务器超过其客户端访问权限限制时,将返回此错误。
403.16
403.16 错误是由不受信任或无效的客户端证书引起的。
403.17
403.17 错误是因为客户端证书已过期或尚未生效。
三、403错误的主要原因

1、你的IP被列入黑名单。
2、您在一定时间内访问过这个网站(通常是使用采集程序),您的访问被防火墙拒绝。
3、网站 域名解析到空间,但空间没有绑定到这个域名。
4、您的网页脚本文件在当前目录没有执行权限。
5、在不允许写入/创建文件的目录中执行了文件创建/写入操作。
php禁止网页抓取(PHP中可以轻松的使用下面的语句实现禁止页面缓存)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-30 11:07
在 PHP 中,您可以轻松地使用以下语句来禁止页面缓存,但是为了您的方便,很难记住和组织它。
核心代码:
复制代码代码如下:
header("Expires: Mon, 26 Jul 1997 05:00:00 GMT");
header("上次修改:".gmdate("D, d MYH:i:s")." GMT");
header("缓存控制:无缓存,必须重新验证");
header("Pramga: 无缓存");
这对于一些页面很有用,比如:验证码,因为每次生成的验证码肯定是不一样的,否则验证码没有意义,所以可以用上面的语句禁止缓存。
又如:“每次发帖换一张漂亮的图片”,页面缓存必须关闭,否则会返回缓存中相同的图片。
最近在百度联盟看到《英雄联盟》——《如何让网友爱上你的网站》(主要讨论如何提升用户体验),想到一件事:
以论坛为例。用户登录时,会显示登录后的页面,如“管理”、“修改信息”等。当用户退出论坛时,他将再次返回上一页。
还有“管理”、“修改信息”等(因为返回的是缓存页面),虽然此时cookie已经被清空了,但是“管理”、“修改信息”等都没有效果。
但是,用户仍然认为这是一个有效的页面,以便其他人也可以“管理”、“修改信息”等,认为网站 是不安全的(虽然它实际上是安全的)。这时候,在需要进行cookie验证的页面添加以上代码就非常有用了,至少可以消除对用户心理的负面影响。
以上就是PHP禁止页面缓存代码的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php禁止网页抓取(PHP中可以轻松的使用下面的语句实现禁止页面缓存)
在 PHP 中,您可以轻松地使用以下语句来禁止页面缓存,但是为了您的方便,很难记住和组织它。
核心代码:
复制代码代码如下:
header("Expires: Mon, 26 Jul 1997 05:00:00 GMT");
header("上次修改:".gmdate("D, d MYH:i:s")." GMT");
header("缓存控制:无缓存,必须重新验证");
header("Pramga: 无缓存");
这对于一些页面很有用,比如:验证码,因为每次生成的验证码肯定是不一样的,否则验证码没有意义,所以可以用上面的语句禁止缓存。
又如:“每次发帖换一张漂亮的图片”,页面缓存必须关闭,否则会返回缓存中相同的图片。
最近在百度联盟看到《英雄联盟》——《如何让网友爱上你的网站》(主要讨论如何提升用户体验),想到一件事:
以论坛为例。用户登录时,会显示登录后的页面,如“管理”、“修改信息”等。当用户退出论坛时,他将再次返回上一页。
还有“管理”、“修改信息”等(因为返回的是缓存页面),虽然此时cookie已经被清空了,但是“管理”、“修改信息”等都没有效果。
但是,用户仍然认为这是一个有效的页面,以便其他人也可以“管理”、“修改信息”等,认为网站 是不安全的(虽然它实际上是安全的)。这时候,在需要进行cookie验证的页面添加以上代码就非常有用了,至少可以消除对用户心理的负面影响。
以上就是PHP禁止页面缓存代码的详细内容。更多详情请关注其他相关html中文网站文章!
php禁止网页抓取(robots写法大全和robots.txt.语法的作用!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-25 22:12
如何编写robots.txt以及robots.txt语法的作用
1 如果允许所有搜索引擎访问网站的所有部分,我们可以创建一个空白文本文档,命名为robots.txt,并将其放在网站的根目录中。
Robots.txt 的写法如下:
用户代理: *
不允许:
或者
用户代理: *
允许: /
2如果我们禁止所有搜索引擎访问网站的所有部分
Robots.txt 的写法如下:
用户代理: *
不允许: /
3 如果我们需要搜索引擎抓取,比如百度,百度是禁止索引我们的网站词
Robots.txt 的写法如下:
用户代理:百度蜘蛛
不允许: /
4 如果我们禁止谷歌索引我们的网站,其实和例3一样,就是把User-agent:头文件中蜘蛛的名字改成谷歌的Googlebot
能
Robots.txt 的写法如下:
用户代理:Googlebot
不允许: /
5 如果我们禁止除 Google 之外的所有搜索引擎将我们的 网站 词编入索引
Robots.txt 的写法如下:
用户代理:Googlebot
不允许:
用户代理: *
不允许: /
6 如果我们禁止除百度以外的所有搜索引擎索引我们的网站
Robots.txt 的写法如下:
用户代理:百度蜘蛛
不允许:
用户代理: *
不允许: /
7 如果我们需要禁止蜘蛛访问某个目录,比如禁止admin、css、images等目录被索引
Robots.txt 的写法如下:
用户代理: *
禁止:/css/
禁止:/管理员/
禁止:/图像/
8 如果我们允许蜘蛛访问我们网站的某个目录中的某些特定URL
Robots.txt 的写法如下:
用户代理: *
允许:/css/my
允许:/admin/html
允许:/图像/索引
禁止:/css/
禁止:/管理员/
禁止:/图像/
9 我们在一些网站的robots.txt中看到Disallow或Allow中的一些符号,例如问号和星号。如果使用“”,主要是限制访问某个后缀的域名,禁止访问/html/目录(包括子目录)中所有后缀为“.htm”的URL。
Robots.txt 的写法如下:
用户代理: *
禁止:/html/.htm
10 如果我们使用“”,我们只允许访问某个目录中带有某个后缀的文件robots.txt。写法如下: User-agent:∗Allow:.asp" 表示只允许访问某个目录下带有某个后缀的文件robots.txt 写法如下: User-agent:*Allow:.asp"表示只允许访问特定目录中具有特定后缀的文件。Robots.txt 的写法如下: User-agent:∗Allow:.asp
不允许: /
11 如果我们禁止索引网站中的所有动态页面(此处限制带“?”的域名,例如index.asp?id=1)
Robots.txt 的写法如下:
用户代理: *
不允许: /?
有时,为了节省服务器资源,我们需要禁止各种搜索引擎在网站上索引我们的图片。这里的方法除了使用“Disallow:/images/”直接屏蔽文件夹之外。也可以直接屏蔽图片后缀名。
例 12
如果我们禁止Google搜索引擎抓取我们网站上的所有图片(如果您的网站使用了其他后缀的图片名称,您也可以在这里直接添加)
Robots.txt 的写法如下:
用户代理:Googlebot
禁止:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
13 如果我们禁止百度搜索引擎抓取我们网站上的所有图片
Robots.txt 的写法如下:
用户代理:百度蜘蛛
禁止:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
14 除百度和谷歌外,其他搜索引擎禁止抓取您的图片网站
(注意这里,为了让大家看得更清楚,用了一个比较笨的方法——对单个搜索引擎单独定义。)
Robots.txt 的写法如下:
用户代理:百度蜘蛛
允许:.jpeg$
允许:.gif$
允许:.png$
允许:.bmp$
用户代理:Googlebot
允许:.jpeg$
允许:.gif$
允许:.png$
允许:.bmp$
用户代理: *
禁止:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
15 只允许百度抓取网站上的“JPG”格式文件
(其他搜索引擎的方法与此相同,只需修改搜索引擎的蜘蛛名称即可)
Robots.txt 的写法如下:
用户代理:百度蜘蛛
允许:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
16只禁止百度爬取网站上的“JPG”格式文件
Robots.txt 的写法如下:
用户代理:百度蜘蛛
禁止:.jpg$
17如果?代表一个会话 ID,您可以排除所有收录该 ID 的网址,以确保 Googlebot 不会抓取重复的页面。但是,网址以什么结尾?可能是您要收录的页面版本。在这种情况下,可以将 Vaughan 与 Allow 命令结合使用。
Robots.txt 的写法如下:
用户代理:*
允许:/?$
不允许:/?
不允许:/?
一行将阻止收录?(具体来说,它将阻止所有以您的域名开头,后跟任何字符串,然后是问号 (?),然后是任何字符串的 URL)。Allow: /?$ 将允许任何以? (具体来说,它将允许所有以您的域名开头,后跟任何字符串,然后是问号 (?) 的 URL,问号 URL 后没有任何字符)。
18 如果我们想禁止搜索引擎访问某些目录或某些网址,我们可以截取一些名称
Robots.txt 的写法如下:
用户代理:*
不允许:/plus/feedback.php?
以上内容供大家参考。 查看全部
php禁止网页抓取(robots写法大全和robots.txt.语法的作用!)
如何编写robots.txt以及robots.txt语法的作用
1 如果允许所有搜索引擎访问网站的所有部分,我们可以创建一个空白文本文档,命名为robots.txt,并将其放在网站的根目录中。
Robots.txt 的写法如下:
用户代理: *
不允许:
或者
用户代理: *
允许: /
2如果我们禁止所有搜索引擎访问网站的所有部分
Robots.txt 的写法如下:
用户代理: *
不允许: /
3 如果我们需要搜索引擎抓取,比如百度,百度是禁止索引我们的网站词
Robots.txt 的写法如下:
用户代理:百度蜘蛛
不允许: /
4 如果我们禁止谷歌索引我们的网站,其实和例3一样,就是把User-agent:头文件中蜘蛛的名字改成谷歌的Googlebot
能
Robots.txt 的写法如下:
用户代理:Googlebot
不允许: /
5 如果我们禁止除 Google 之外的所有搜索引擎将我们的 网站 词编入索引
Robots.txt 的写法如下:
用户代理:Googlebot
不允许:
用户代理: *
不允许: /
6 如果我们禁止除百度以外的所有搜索引擎索引我们的网站
Robots.txt 的写法如下:
用户代理:百度蜘蛛
不允许:
用户代理: *
不允许: /
7 如果我们需要禁止蜘蛛访问某个目录,比如禁止admin、css、images等目录被索引
Robots.txt 的写法如下:
用户代理: *
禁止:/css/
禁止:/管理员/
禁止:/图像/
8 如果我们允许蜘蛛访问我们网站的某个目录中的某些特定URL
Robots.txt 的写法如下:
用户代理: *
允许:/css/my
允许:/admin/html
允许:/图像/索引
禁止:/css/
禁止:/管理员/
禁止:/图像/
9 我们在一些网站的robots.txt中看到Disallow或Allow中的一些符号,例如问号和星号。如果使用“”,主要是限制访问某个后缀的域名,禁止访问/html/目录(包括子目录)中所有后缀为“.htm”的URL。
Robots.txt 的写法如下:
用户代理: *
禁止:/html/.htm
10 如果我们使用“”,我们只允许访问某个目录中带有某个后缀的文件robots.txt。写法如下: User-agent:∗Allow:.asp" 表示只允许访问某个目录下带有某个后缀的文件robots.txt 写法如下: User-agent:*Allow:.asp"表示只允许访问特定目录中具有特定后缀的文件。Robots.txt 的写法如下: User-agent:∗Allow:.asp
不允许: /
11 如果我们禁止索引网站中的所有动态页面(此处限制带“?”的域名,例如index.asp?id=1)
Robots.txt 的写法如下:
用户代理: *
不允许: /?
有时,为了节省服务器资源,我们需要禁止各种搜索引擎在网站上索引我们的图片。这里的方法除了使用“Disallow:/images/”直接屏蔽文件夹之外。也可以直接屏蔽图片后缀名。
例 12
如果我们禁止Google搜索引擎抓取我们网站上的所有图片(如果您的网站使用了其他后缀的图片名称,您也可以在这里直接添加)
Robots.txt 的写法如下:
用户代理:Googlebot
禁止:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
13 如果我们禁止百度搜索引擎抓取我们网站上的所有图片
Robots.txt 的写法如下:
用户代理:百度蜘蛛
禁止:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
14 除百度和谷歌外,其他搜索引擎禁止抓取您的图片网站
(注意这里,为了让大家看得更清楚,用了一个比较笨的方法——对单个搜索引擎单独定义。)
Robots.txt 的写法如下:
用户代理:百度蜘蛛
允许:.jpeg$
允许:.gif$
允许:.png$
允许:.bmp$
用户代理:Googlebot
允许:.jpeg$
允许:.gif$
允许:.png$
允许:.bmp$
用户代理: *
禁止:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
15 只允许百度抓取网站上的“JPG”格式文件
(其他搜索引擎的方法与此相同,只需修改搜索引擎的蜘蛛名称即可)
Robots.txt 的写法如下:
用户代理:百度蜘蛛
允许:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
16只禁止百度爬取网站上的“JPG”格式文件
Robots.txt 的写法如下:
用户代理:百度蜘蛛
禁止:.jpg$
17如果?代表一个会话 ID,您可以排除所有收录该 ID 的网址,以确保 Googlebot 不会抓取重复的页面。但是,网址以什么结尾?可能是您要收录的页面版本。在这种情况下,可以将 Vaughan 与 Allow 命令结合使用。
Robots.txt 的写法如下:
用户代理:*
允许:/?$
不允许:/?
不允许:/?
一行将阻止收录?(具体来说,它将阻止所有以您的域名开头,后跟任何字符串,然后是问号 (?),然后是任何字符串的 URL)。Allow: /?$ 将允许任何以? (具体来说,它将允许所有以您的域名开头,后跟任何字符串,然后是问号 (?) 的 URL,问号 URL 后没有任何字符)。
18 如果我们想禁止搜索引擎访问某些目录或某些网址,我们可以截取一些名称
Robots.txt 的写法如下:
用户代理:*
不允许:/plus/feedback.php?
以上内容供大家参考。
php禁止网页抓取(我写技术博客有两个原因:CDN服务提供商会分配给你若干个节点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-24 01:01
我写技术博客有两个原因:一是总结我最近的研究成果,二是把这些成果分享给大家。所以就我而言,我还是更喜欢写文章让更多人看到。我最近注意到我博客的大部分流量来自谷歌,几乎没有来自百度。而本文旨在提出这个问题并试图解决它。当然,换成云主机服务商可以很直接很清楚的解决这个问题,但这不是本文的重点,暂不提及。
为什么在 Github Pages 上禁用了百度爬虫?
关于这个问题,我联系了Github Support部门,得到的答复是这样的:
嗨,杰瑞,
很抱歉给您带来麻烦。我们目前正在阻止百度用户代理抓取 GitHub Pages 站点,以响应该用户代理对过多请求负责,这导致了其他 GitHub 客户的可用性问题。
这不太可能很快改变,因此如果您需要百度用户代理能够抓取您的网站,您将需要将其托管在其他地方。
再次对给您带来的不便表示歉意。
干杯,
亚历克斯
简单来说,百度爬虫爬的太猛了,给很多Github用户造成了可用性问题,禁用百度爬虫的举动可能还会继续。(不知道跟之前的大炮有没有关系)
因此,我只能自己做,才能得到足够的温饱。让我们讨论解决这个问题的方法。
解决问题-CDN
那么我们先来了解一下CDN的原理。
CDN原理
CDN的全称是Content Delivery Network,即内容分发网络,一般用于分发静态内容,如图片、视频、CSS、JS文件等。
如果不使用 CDN,所有用户请求将被定向到单个源服务器。如果启用了 CDN 服务,CDN 服务提供商会为您分配多个节点。以上图为例,例如3个东海岸节点和3个西海岸节点分配给您的服务器。
这时,用户不会直接向源服务器发送请求,而是向边缘服务器发送请求。再看下图。当您第一次访问资源 foo.png 时,边缘服务器没有 foo.png 的缓存。所以它会向原创服务器发送请求并获取 foo.png。下一次所有通过这个节点的请求,因为有缓存,不需要再次向源服务器发送请求,而边缘服务器直接返回文件的缓存。这样可以大大减少时延,减少源站的压力。
CDN 服务如何确定您从哪个边缘服务器获取资源?实际上,在发送DNS请求时,您要访问的域名会映射到最近节点的IP。确定哪个是最近的节点,最简单的策略是基于IP,但是每个CDN服务商可能有不同的策略,这里就不展开讨论了。
CDN 的局限性
CDN确实可以解决很多问题,但也有一定的局限性。最重要的一点是:永远不要使用 CDN 来缓存动态内容。
我们来看一个例子,假设服务器端有这样一个PHP文件hello.php:
如果 CDN 缓存了这个文件,将会产生非常糟糕的后果。例如,Jerry 首先访问 hello.php 页面,获取了 Hello, Jerry 的内容。此时内容已经缓存到节点A,Tom离节点A最近,所以当Tom访问hello.php时,会直接得到缓存的内容:Hello, Jerry。这时候,汤姆的心一定是崩溃了。
您还应该避免在以下情况下使用 CDN: 根据用户代理选择返回移动版或桌面版页面。UA判断这对解决我们的问题很重要,下面会提到。当然,Github Pages上部署的网站都是静态站点,所有用户进来看到的内容大体是一样的。所以通过CDN缓存整个站点是没有问题的。
可行性分析
Github使用UA判断百度爬虫,返回403 Forbidden。百度爬虫的UA大致是这样的:
Mozilla/5.0(兼容;Baiduspider/2.0;+)
那么使用CDN解决这个问题的关键就是让百度爬虫不直接向Github服务器发送请求,而是通过CDN边缘服务器的缓存抓取网站的内容。边缘服务器本身不关心UA,所以问题解决了。
但问题真的这么简单吗?
并不真地。
来看看,我使用百度站长工具进行爬行诊断测试结果:
结果只是偶尔能爬成功,结果很失望吧?下面我们来分析一下原因,先列举一些我目前知道的:
所有成功爬取的页面都访问了209.9.130.5个节点
所有爬取失败的页面都访问了209.9.130.6个节点
我的本地ping会ping到209.9.130.8个节点
嗯,细心的同学应该已经发现问题了。大部分百度爬虫请求都指向了209.9.130.6节点,但是这个节点上没有页面缓存。!!如果百度爬虫是页面的第一个访问者,CDN的边缘服务器会使用百度爬虫的UA向Github服务器请求,结果自然是拒绝。
最终我们通过CDN得到了解决这个问题的必要条件:你的博客必须有巨大的流量!只有这样才能保证CDN的每个边缘服务器上都有任意页面的缓存。我认为几乎不可能满足这个要求,除非有像 React 主页这样的 网站。
最后一句话总结:CDN方案不靠谱。
当然,我没有放弃,我做了一些奇怪的事情......首先我找到了所有的BaiduSpider IP,然后我想假装是这些IP来请求内容,以便在所有百度蜘蛛的边缘服务器上可能会爬行。建立缓存。
函数卷曲($url,$ip){
$ch = curl_init();
curl_setopt_array($ch, [
CURLOPT_URL => $url,
CURLOPT_TIMEOUT => 10,
CURLOPT_HEADER => 真, 查看全部
php禁止网页抓取(我写技术博客有两个原因:CDN服务提供商会分配给你若干个节点)
我写技术博客有两个原因:一是总结我最近的研究成果,二是把这些成果分享给大家。所以就我而言,我还是更喜欢写文章让更多人看到。我最近注意到我博客的大部分流量来自谷歌,几乎没有来自百度。而本文旨在提出这个问题并试图解决它。当然,换成云主机服务商可以很直接很清楚的解决这个问题,但这不是本文的重点,暂不提及。
为什么在 Github Pages 上禁用了百度爬虫?
关于这个问题,我联系了Github Support部门,得到的答复是这样的:
嗨,杰瑞,
很抱歉给您带来麻烦。我们目前正在阻止百度用户代理抓取 GitHub Pages 站点,以响应该用户代理对过多请求负责,这导致了其他 GitHub 客户的可用性问题。
这不太可能很快改变,因此如果您需要百度用户代理能够抓取您的网站,您将需要将其托管在其他地方。
再次对给您带来的不便表示歉意。
干杯,
亚历克斯
简单来说,百度爬虫爬的太猛了,给很多Github用户造成了可用性问题,禁用百度爬虫的举动可能还会继续。(不知道跟之前的大炮有没有关系)
因此,我只能自己做,才能得到足够的温饱。让我们讨论解决这个问题的方法。
解决问题-CDN
那么我们先来了解一下CDN的原理。
CDN原理
CDN的全称是Content Delivery Network,即内容分发网络,一般用于分发静态内容,如图片、视频、CSS、JS文件等。

如果不使用 CDN,所有用户请求将被定向到单个源服务器。如果启用了 CDN 服务,CDN 服务提供商会为您分配多个节点。以上图为例,例如3个东海岸节点和3个西海岸节点分配给您的服务器。
这时,用户不会直接向源服务器发送请求,而是向边缘服务器发送请求。再看下图。当您第一次访问资源 foo.png 时,边缘服务器没有 foo.png 的缓存。所以它会向原创服务器发送请求并获取 foo.png。下一次所有通过这个节点的请求,因为有缓存,不需要再次向源服务器发送请求,而边缘服务器直接返回文件的缓存。这样可以大大减少时延,减少源站的压力。

CDN 服务如何确定您从哪个边缘服务器获取资源?实际上,在发送DNS请求时,您要访问的域名会映射到最近节点的IP。确定哪个是最近的节点,最简单的策略是基于IP,但是每个CDN服务商可能有不同的策略,这里就不展开讨论了。
CDN 的局限性
CDN确实可以解决很多问题,但也有一定的局限性。最重要的一点是:永远不要使用 CDN 来缓存动态内容。
我们来看一个例子,假设服务器端有这样一个PHP文件hello.php:
如果 CDN 缓存了这个文件,将会产生非常糟糕的后果。例如,Jerry 首先访问 hello.php 页面,获取了 Hello, Jerry 的内容。此时内容已经缓存到节点A,Tom离节点A最近,所以当Tom访问hello.php时,会直接得到缓存的内容:Hello, Jerry。这时候,汤姆的心一定是崩溃了。
您还应该避免在以下情况下使用 CDN: 根据用户代理选择返回移动版或桌面版页面。UA判断这对解决我们的问题很重要,下面会提到。当然,Github Pages上部署的网站都是静态站点,所有用户进来看到的内容大体是一样的。所以通过CDN缓存整个站点是没有问题的。
可行性分析
Github使用UA判断百度爬虫,返回403 Forbidden。百度爬虫的UA大致是这样的:
Mozilla/5.0(兼容;Baiduspider/2.0;+)
那么使用CDN解决这个问题的关键就是让百度爬虫不直接向Github服务器发送请求,而是通过CDN边缘服务器的缓存抓取网站的内容。边缘服务器本身不关心UA,所以问题解决了。
但问题真的这么简单吗?
并不真地。
来看看,我使用百度站长工具进行爬行诊断测试结果:

结果只是偶尔能爬成功,结果很失望吧?下面我们来分析一下原因,先列举一些我目前知道的:
所有成功爬取的页面都访问了209.9.130.5个节点
所有爬取失败的页面都访问了209.9.130.6个节点
我的本地ping会ping到209.9.130.8个节点
嗯,细心的同学应该已经发现问题了。大部分百度爬虫请求都指向了209.9.130.6节点,但是这个节点上没有页面缓存。!!如果百度爬虫是页面的第一个访问者,CDN的边缘服务器会使用百度爬虫的UA向Github服务器请求,结果自然是拒绝。
最终我们通过CDN得到了解决这个问题的必要条件:你的博客必须有巨大的流量!只有这样才能保证CDN的每个边缘服务器上都有任意页面的缓存。我认为几乎不可能满足这个要求,除非有像 React 主页这样的 网站。
最后一句话总结:CDN方案不靠谱。
当然,我没有放弃,我做了一些奇怪的事情......首先我找到了所有的BaiduSpider IP,然后我想假装是这些IP来请求内容,以便在所有百度蜘蛛的边缘服务器上可能会爬行。建立缓存。
函数卷曲($url,$ip){
$ch = curl_init();
curl_setopt_array($ch, [
CURLOPT_URL => $url,
CURLOPT_TIMEOUT => 10,
CURLOPT_HEADER => 真,
php禁止网页抓取(PHP代码找到如下类似位置,重启Apache即可:找到 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-20 00:14
)
找到如下类似的位置,按照如下代码添加/修改,然后重启Apache:
DocumentRoot /home/wwwroot/xxx
SetEnvIfNoCase User-Agent ".*(FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms)" BADBOT
Order allow,deny
Allow from all
deny from env=BADBOT
二、Nginx 代码
进入nginx安装目录下的conf目录,将以下代码保存为agent_deny.conf
cd /usr/local/nginx/conf
vimagent_deny.conf
#禁止Scrapy等工具的抓取
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
return 403;
}
#禁止指定UA及UA为空的访问
if ($http_user_agent ~ "FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" ) {
return 403;
}
#禁止非GET|HEAD|POST方式的抓取
if ($request_method !~ ^(GET|HEAD|POST)$) {
return 403;
}
然后,在网站位置/{在相关配置中插入以下代码:
include agent_deny.conf;
比如张哥博客的配置:
[[email protected]_Server ~]$ cat /usr/local/nginx/conf/zhangge.conf
location / {
try_files $uri $uri/ /index.php?$args;
#这个位置新增1行:
include agent_deny.conf;
rewrite ^/sitemap_360_sp.txt$ /sitemap_360_sp.php last;
rewrite ^/sitemap_baidu_sp.xml$ /sitemap_baidu_sp.php last;
rewrite ^/sitemap_m.xml$ /sitemap_m.php last;
保存后执行如下命令顺利重启nginx:
/usr/local/nginx/sbin/nginx -s reload
三、PHP 代码
将下面的方法放到网站
入口文件index.php中的第一个
//获取UA信息
$ua = $_SERVER['HTTP_USER_AGENT'];
//将恶意USER_AGENT存入数组
$now_ua = array('FeedDemon ','BOT/0.1 (BOT for JCE)','CrawlDaddy ','Java','Feedly','UniversalFeedParser','ApacheBench','Swiftbot','ZmEu','Indy Library','oBot','jaunty','YandexBot','AhrefsBot','YisouSpider','jikeSpider','MJ12bot','WinHttp','EasouSpider','HttpClient','Microsoft URL Control','YYSpider','jaunty','Python-urllib','lightDeckReports Bot');
//禁止空USER_AGENT,dedecms等主流采集程序都是空USER_AGENT,部分sql注入工具也是空USER_AGENT
if(!$ua) {
header("Content-type: text/html; charset=utf-8");
wp_die('请勿采集本站,因为采集的站长木有小JJ!');
}else{
foreach($now_ua as $value )
//判断是否是数组中存在的UA
if(eregi($value,$ua)) {
header("Content-type: text/html; charset=utf-8");
wp_die('请勿采集本站,因为采集的站长木有小JJ!');
}
}
四、测试结果
如果是vps的话就很简单了,用curl -A模拟爬行就可以了,比如:
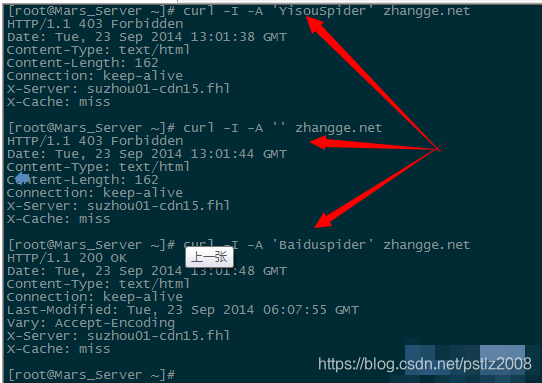
模拟一搜蜘蛛爬行:
curl -I -A 'YisouSpider' zhangge.net
用空的 UA 模拟爬行:
curl -I -A '' zhangge.net
模拟百度蜘蛛爬行:
curl -I -A 'Baiduspider' zhangge.net
三个抓取结果截图如下:
可以看出,如果一搜蜘蛛和UA为空,则返回403禁止标志,而百度蜘蛛成功返回200,说明生效!
补充:第二天查看nginx日志效果截图:
①、UA信息为空的垃圾采集被拦截:
②,被禁止的UA被屏蔽了:
因此,对于垃圾蜘蛛的采集,我们可以通过分析网站的访问日志,找出一些我们之前没有见过的蜘蛛的名字。查询无误后,我们可以将它们添加到前面代码的禁止列表中,起到禁止爬取的作用。
五、附录:UA 合集
以下是网上常见的垃圾邮件UA列表,仅供参考,也欢迎大家补充。
FeedDemon 内容采集
BOT/0.1 (BOT for JCE) sql注入
CrawlDaddy sql注入
Java 内容采集
Jullo 内容采集
Feedly 内容采集
UniversalFeedParser 内容采集
ApacheBench cc攻击器
Swiftbot 无用爬虫
YandexBot 无用爬虫
AhrefsBot 无用爬虫
YisouSpider 无用爬虫
jikeSpider 无用爬虫
MJ12bot 无用爬虫
ZmEu phpmyadmin 漏洞扫描
WinHttp 采集cc攻击
EasouSpider 无用爬虫
HttpClient tcp攻击
Microsoft URL Control 扫描
YYSpider 无用爬虫
jaunty wordpress爆破扫描器
oBot 无用爬虫
Python-urllib 内容采集
Indy Library 扫描
FlightDeckReports Bot 无用爬虫
Linguee Bot 无用爬虫 查看全部
php禁止网页抓取(PHP代码找到如下类似位置,重启Apache即可:找到
)
找到如下类似的位置,按照如下代码添加/修改,然后重启Apache:
DocumentRoot /home/wwwroot/xxx
SetEnvIfNoCase User-Agent ".*(FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms)" BADBOT
Order allow,deny
Allow from all
deny from env=BADBOT
二、Nginx 代码
进入nginx安装目录下的conf目录,将以下代码保存为agent_deny.conf
cd /usr/local/nginx/conf
vimagent_deny.conf
#禁止Scrapy等工具的抓取
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
return 403;
}
#禁止指定UA及UA为空的访问
if ($http_user_agent ~ "FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" ) {
return 403;
}
#禁止非GET|HEAD|POST方式的抓取
if ($request_method !~ ^(GET|HEAD|POST)$) {
return 403;
}
然后,在网站位置/{在相关配置中插入以下代码:
include agent_deny.conf;
比如张哥博客的配置:
[[email protected]_Server ~]$ cat /usr/local/nginx/conf/zhangge.conf
location / {
try_files $uri $uri/ /index.php?$args;
#这个位置新增1行:
include agent_deny.conf;
rewrite ^/sitemap_360_sp.txt$ /sitemap_360_sp.php last;
rewrite ^/sitemap_baidu_sp.xml$ /sitemap_baidu_sp.php last;
rewrite ^/sitemap_m.xml$ /sitemap_m.php last;
保存后执行如下命令顺利重启nginx:
/usr/local/nginx/sbin/nginx -s reload
三、PHP 代码
将下面的方法放到网站
入口文件index.php中的第一个
//获取UA信息
$ua = $_SERVER['HTTP_USER_AGENT'];
//将恶意USER_AGENT存入数组
$now_ua = array('FeedDemon ','BOT/0.1 (BOT for JCE)','CrawlDaddy ','Java','Feedly','UniversalFeedParser','ApacheBench','Swiftbot','ZmEu','Indy Library','oBot','jaunty','YandexBot','AhrefsBot','YisouSpider','jikeSpider','MJ12bot','WinHttp','EasouSpider','HttpClient','Microsoft URL Control','YYSpider','jaunty','Python-urllib','lightDeckReports Bot');
//禁止空USER_AGENT,dedecms等主流采集程序都是空USER_AGENT,部分sql注入工具也是空USER_AGENT
if(!$ua) {
header("Content-type: text/html; charset=utf-8");
wp_die('请勿采集本站,因为采集的站长木有小JJ!');
}else{
foreach($now_ua as $value )
//判断是否是数组中存在的UA
if(eregi($value,$ua)) {
header("Content-type: text/html; charset=utf-8");
wp_die('请勿采集本站,因为采集的站长木有小JJ!');
}
}
四、测试结果
如果是vps的话就很简单了,用curl -A模拟爬行就可以了,比如:
模拟一搜蜘蛛爬行:
curl -I -A 'YisouSpider' zhangge.net
用空的 UA 模拟爬行:
curl -I -A '' zhangge.net
模拟百度蜘蛛爬行:
curl -I -A 'Baiduspider' zhangge.net
三个抓取结果截图如下:
可以看出,如果一搜蜘蛛和UA为空,则返回403禁止标志,而百度蜘蛛成功返回200,说明生效!
补充:第二天查看nginx日志效果截图:
①、UA信息为空的垃圾采集被拦截:
②,被禁止的UA被屏蔽了:
因此,对于垃圾蜘蛛的采集,我们可以通过分析网站的访问日志,找出一些我们之前没有见过的蜘蛛的名字。查询无误后,我们可以将它们添加到前面代码的禁止列表中,起到禁止爬取的作用。
五、附录:UA 合集
以下是网上常见的垃圾邮件UA列表,仅供参考,也欢迎大家补充。
FeedDemon 内容采集
BOT/0.1 (BOT for JCE) sql注入
CrawlDaddy sql注入
Java 内容采集
Jullo 内容采集
Feedly 内容采集
UniversalFeedParser 内容采集
ApacheBench cc攻击器
Swiftbot 无用爬虫
YandexBot 无用爬虫
AhrefsBot 无用爬虫
YisouSpider 无用爬虫
jikeSpider 无用爬虫
MJ12bot 无用爬虫
ZmEu phpmyadmin 漏洞扫描
WinHttp 采集cc攻击
EasouSpider 无用爬虫
HttpClient tcp攻击
Microsoft URL Control 扫描
YYSpider 无用爬虫
jaunty wordpress爆破扫描器
oBot 无用爬虫
Python-urllib 内容采集
Indy Library 扫描
FlightDeckReports Bot 无用爬虫
Linguee Bot 无用爬虫
php禁止网页抓取(网站反爬虫的原因常见手段设置站点配置文件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-20 00:12
)
一、概述网站反爬虫常见反爬虫手段的原因
1. 根据IP访问频率封锁IP
2. 设置账号登录时长,账号访问过多被阻塞 设置账号登录限制,只登录显示内容 设置账号登录时长,时间到自动注销
3. 弹出数字验证码和图片确认验证码 爬虫访问次数过多,弹出验证码需要输入
4. API接口限制 限制一个登录账号每天调用后端api接口的次数,对后端api返回的信息进行加密
二、nginx 反爬设置站点配置文件
因为user-agent标记了Bytespider爬虫,所以可以通过Nginx规则限制流氓爬虫的访问,直接返回403错误。修改对应的站点配置文件(注意是在服务器中)
添加红色部分
server {
listen 80 default_server;
listen [::]:80 default_server;
index index.html index.htm index.nginx-debian.html;
server_name _;
location / {
try_files $uri $uri/ =404;
}
#forbidden Scrapy
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
return 403;
}
#forbidden UA
if ($http_user_agent ~ "Bytespider|FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|python-requests|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" ) {
return 403;
}
#forbidden not GET|HEAD|POST method access
if ($request_method !~ ^(GET|HEAD|POST)$) {
return 403;
}
}
附录:UA 集合
FeedDemon 内容采集
BOT/0.1 (BOT for JCE) sql注入
CrawlDaddy sql注入
Java 内容采集
Jullo 内容采集
Feedly 内容采集
UniversalFeedParser 内容采集
ApacheBench cc攻击器
Swiftbot 无用爬虫
YandexBot 无用爬虫
AhrefsBot 无用爬虫
YisouSpider 无用爬虫(已被UC神马搜索收购,此蜘蛛可以放开!)
jikeSpider 无用爬虫
MJ12bot 无用爬虫
ZmEu phpmyadmin 漏洞扫描
WinHttp 采集cc攻击
EasouSpider 无用爬虫
HttpClient tcp攻击
Microsoft URL Control 扫描
YYSpider 无用爬虫
jaunty wordpress爆破扫描器
oBot 无用爬虫
Python-urllib 内容采集
Python-requests 内容采集
Indy Library 扫描
FlightDeckReports Bot 无用爬虫
Linguee Bot 无用爬虫
使用python验证
蟒蛇验证
使用请求模块
import requests
# 最基本的不带参数的get请求
r = requests.get('http://192.168.28.229')
print(r.content)
使用 urllib 模块
import urllib.request
response = urllib.request.urlopen('http://192.168.28.229/')
print(response.read().decode('utf-8'))
返回 403 意味着它有效。
b'\r\n403 Forbidden\r\n\r\n403 Forbidden\r\nnginx\r\n\r\n\r\n'
三、全站防护设置示意图 第一层robots.txt
Robots是网站和爬虫之间的协议。它使用简单直接的txt格式文本方式告诉对应的爬虫允许的权限,也就是说robots.txt是在搜索引擎中访问网站时查看的第一个文件。
注:只是协议规定,是否允许爬取数据收录,不影响网页访问。
注:对于手动履带技术人员,一般直接忽略。
如果所有爬虫蜘蛛都不允许访问,内容如下:
User-agent: *
Disallow: /
第二层useragent特征拦截
因为user-agent标记了Bytespider爬虫,所以可以通过Nginx规则限制流氓爬虫的访问,直接返回403错误。
具体操作请查看上面的nginx配置。
注意:这可以阻止一些爬虫访问,以及初级爬虫。
第三层JS发送鼠标点击事件
对于某些网站,您可以从浏览器打开一个普通页面,但请求中会要求您输入验证码或重定向到其他页面。原理:点击登录时触发js加密码,复杂加密算法参数+时间戳+sig值,参数+时限在后台执行。验证成功后即可登录。
备注:爬虫高手需要模拟浏览器的行为,加载js代码和图片识别,才能正常登录。
第四层后台界面限制
1. 根据IP访问频率屏蔽IP(注意:频率一定要控制好,否则容易误伤。) 2. 设置帐号登录时间,帐号访问被屏蔽太多。设置账号登录限制,只有登录才能显示内容。设置账号登录时长,时间一到自动退出。@4.API 接口的限制。日常登录账号,在请求后端api接口时,限制调用次数。对后台api返回的信息进行加密
通过这4层设置,可以有效保护数据安全。
本文参考链接: 查看全部
php禁止网页抓取(网站反爬虫的原因常见手段设置站点配置文件
)
一、概述网站反爬虫常见反爬虫手段的原因
1. 根据IP访问频率封锁IP
2. 设置账号登录时长,账号访问过多被阻塞 设置账号登录限制,只登录显示内容 设置账号登录时长,时间到自动注销
3. 弹出数字验证码和图片确认验证码 爬虫访问次数过多,弹出验证码需要输入
4. API接口限制 限制一个登录账号每天调用后端api接口的次数,对后端api返回的信息进行加密
二、nginx 反爬设置站点配置文件
因为user-agent标记了Bytespider爬虫,所以可以通过Nginx规则限制流氓爬虫的访问,直接返回403错误。修改对应的站点配置文件(注意是在服务器中)
添加红色部分
server {
listen 80 default_server;
listen [::]:80 default_server;
index index.html index.htm index.nginx-debian.html;
server_name _;
location / {
try_files $uri $uri/ =404;
}
#forbidden Scrapy
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
return 403;
}
#forbidden UA
if ($http_user_agent ~ "Bytespider|FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|python-requests|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" ) {
return 403;
}
#forbidden not GET|HEAD|POST method access
if ($request_method !~ ^(GET|HEAD|POST)$) {
return 403;
}
}
附录:UA 集合
FeedDemon 内容采集
BOT/0.1 (BOT for JCE) sql注入
CrawlDaddy sql注入
Java 内容采集
Jullo 内容采集
Feedly 内容采集
UniversalFeedParser 内容采集
ApacheBench cc攻击器
Swiftbot 无用爬虫
YandexBot 无用爬虫
AhrefsBot 无用爬虫
YisouSpider 无用爬虫(已被UC神马搜索收购,此蜘蛛可以放开!)
jikeSpider 无用爬虫
MJ12bot 无用爬虫
ZmEu phpmyadmin 漏洞扫描
WinHttp 采集cc攻击
EasouSpider 无用爬虫
HttpClient tcp攻击
Microsoft URL Control 扫描
YYSpider 无用爬虫
jaunty wordpress爆破扫描器
oBot 无用爬虫
Python-urllib 内容采集
Python-requests 内容采集
Indy Library 扫描
FlightDeckReports Bot 无用爬虫
Linguee Bot 无用爬虫
使用python验证
蟒蛇验证
使用请求模块
import requests
# 最基本的不带参数的get请求
r = requests.get('http://192.168.28.229')
print(r.content)
使用 urllib 模块
import urllib.request
response = urllib.request.urlopen('http://192.168.28.229/')
print(response.read().decode('utf-8'))
返回 403 意味着它有效。
b'\r\n403 Forbidden\r\n\r\n403 Forbidden\r\nnginx\r\n\r\n\r\n'
三、全站防护设置示意图 第一层robots.txt
Robots是网站和爬虫之间的协议。它使用简单直接的txt格式文本方式告诉对应的爬虫允许的权限,也就是说robots.txt是在搜索引擎中访问网站时查看的第一个文件。
注:只是协议规定,是否允许爬取数据收录,不影响网页访问。
注:对于手动履带技术人员,一般直接忽略。
如果所有爬虫蜘蛛都不允许访问,内容如下:
User-agent: *
Disallow: /
第二层useragent特征拦截
因为user-agent标记了Bytespider爬虫,所以可以通过Nginx规则限制流氓爬虫的访问,直接返回403错误。
具体操作请查看上面的nginx配置。
注意:这可以阻止一些爬虫访问,以及初级爬虫。
第三层JS发送鼠标点击事件
对于某些网站,您可以从浏览器打开一个普通页面,但请求中会要求您输入验证码或重定向到其他页面。原理:点击登录时触发js加密码,复杂加密算法参数+时间戳+sig值,参数+时限在后台执行。验证成功后即可登录。
备注:爬虫高手需要模拟浏览器的行为,加载js代码和图片识别,才能正常登录。
第四层后台界面限制
1. 根据IP访问频率屏蔽IP(注意:频率一定要控制好,否则容易误伤。) 2. 设置帐号登录时间,帐号访问被屏蔽太多。设置账号登录限制,只有登录才能显示内容。设置账号登录时长,时间一到自动退出。@4.API 接口的限制。日常登录账号,在请求后端api接口时,限制调用次数。对后台api返回的信息进行加密
通过这4层设置,可以有效保护数据安全。
本文参考链接:
php禁止网页抓取(搜索引擎使用spider程序自动访问互联网上的网页并获取网页信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-14 03:12
搜索引擎使用蜘蛛程序自动访问互联网上的网页并获取网页信息。当蜘蛛访问一个网站时,它首先会检查网站的根域下是否有一个名为robots.txt的纯文本文件。这个文件是用来指定蜘蛛在你的网站 爬取范围上的。您可以在您的网站中创建一个robots.txt,并在文件中声明网站中不想被搜索引擎收录搜索的部分或指定搜索引擎只是收录 特定部分。
请注意,只有当您的 网站 收录您不想被 收录 搜索的内容时,您才需要使用 robots.txt 文件。如果您想要搜索引擎收录网站 上的所有内容,请不要创建robots.txt 文件。
2. robots.txt 文件在哪里?
robots.txt文件应该放在网站的根目录下。例如,当蜘蛛访问一个网站(例如)时,它会首先检查网站中是否存在该文件。如果蜘蛛找到该文件,它会根据文件的内容确定其访问权限的范围。
网站 URL 对应robots.txt URL
:80/
:80/robots.txt
: 1234/
:1234/robots.txt
3.我在robots.txt中设置了禁止百度收录I网站,为什么还是出现在百度搜索结果中?
如果您的robots.txt文件中设置了禁止收录的其他网站链接,这些网页可能仍会出现在百度的搜索结果中,但您网页上的内容将不会被抓取,索引和显示,百度搜索结果中显示的只是您相关网页的其他网站描述。
4. 禁止搜索引擎跟踪网页链接,只索引网页
如果您不希望搜索引擎跟踪此页面上的链接并且不传递链接的权重,请将此元标记放置在页面的一部分中:
如果您不想让百度跟踪特定链接,百度也支持更精确的控制,请直接在链接上写下这个标记:
登入
要允许其他搜索引擎跟踪,但只阻止百度跟踪指向您页面的链接,请将此元标记放在页面的一部分中:
5. 禁止搜索引擎在搜索结果中显示网页快照,只索引网页
为了防止所有搜索引擎显示您的 网站 快照,请将此元标记放在页面的一部分中:
要允许其他搜索引擎显示快照,但只阻止百度显示,请使用以下标签:
注意:此标签仅禁止百度显示网页快照。百度将继续对网页进行索引,并在搜索结果中显示网页摘要。
6. 我想禁止百度图片搜索收录 部分图片,如何设置?
禁止百度蜘蛛抓取网站上的所有图片,禁止或允许百度蜘蛛抓取网站上特定格式的图片文件可以通过设置robots实现,请参考“robots.txt文件使用示例”示例10、11、12。
7. Robots.txt 文件格式
“robots.txt”文件收录一个或多个记录,由空行分隔(以CR、CR/NL 或NL 作为终止符)。每条记录的格式如下:
":"
可以在这个文件中使用#做注释,具体用法同UNIX中的约定。此文件中的记录通常以一行或多行 User-agent 开头,后跟几行 Disallow 和 Allow 行,详细信息如下:
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被“robots.txt”限制。对于此文件,必须至少有一个用户代理记录。如果此项的值设置为*,则对任何机器人都有效。在“robots.txt”文件中,只能有“User-agent:*”等一条记录。如果您在“robots.txt”文件中添加“User-agent:SomeBot”和几行禁止和允许行,则名称“SomeBot”仅受“User-agent: SomeBot”之后的禁止和允许行的限制。
不允许:
该项的值用于描述一组不想被访问的 URL。该值可以是完整路径或路径的非空前缀。机器人不会访问以 Disallow 项的值开头的 URL。例如,“Disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,而“Disallow:/help/”则允许机器人访问/help.html、/helpabc。 html,而不是访问 /help/index.html。“禁止:”表示允许机器人访问网站的所有URL。“/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”不存在或者是一个空文件,这个网站 对所有搜索引擎机器人都是开放的。
允许:
此项的值用于描述您要访问的一组 URL。与 Disallow 项类似,该值可以是完整路径或路径前缀。机器人可以访问以 Allow 项的值开头的 URL。例如,“Allow:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。一个网站的所有URL默认都是Allow,所以Allow通常和Disallow结合使用,实现允许访问某些网页同时禁止访问其他所有URL的功能。
使用“*”和“$”:
百度蜘蛛支持使用通配符“*”和“$”来模糊匹配URL。
"$" 匹配行尾。
“*”匹配 0 个或多个任意字符。
注:我们将严格遵守机器人的相关协议。请注意区分您不想被抓取的目录或收录 的情况。我们会处理robots中写的文件,你不想被爬取和收录的目录做精确匹配,否则robots协议不会生效。
8. URL 匹配示例
值为 Allow 或 Disallow 的 URL 匹配结果
/tmp
/tmp
是的
/tmp
/tmp.html
是的
/tmp
/tmp/a.html
是的
/tmp
/tmhoho
不
/你好*
/你好.html
是的
/He*lo
/你好,哈哈
是的
/堆*lo
/你好,哈哈
不
html$
/tmpa.html
是的
/a.html$
/a.html
是的
htm$
/a.html
不
9. robots.txt 文件使用示例
示例 1. 禁止所有搜索引擎访问 网站 的任何部分
下载 robots.txt 文件
用户代理: *
不允许: /
示例 2. 允许所有机器人访问
(或者你可以创建一个空文件“/robots.txt”)
用户代理: *
允许: /
比如3.只禁止百度蜘蛛访问你的网站
用户代理:百度蜘蛛
不允许: /
示例 4. 只允许百度蜘蛛访问您的 网站
用户代理:百度蜘蛛
允许: /
用户代理: *
不允许: /
示例 5. 只允许百度蜘蛛和谷歌机器人访问
用户代理:百度蜘蛛
允许: /
用户代理:Googlebot
允许: /
用户代理: *
不允许: /
示例 6. 禁止蜘蛛访问特定目录
本例中网站有3个目录限制搜索引擎访问,即robot不会访问这3个目录。需要注意的是,每个目录必须单独声明,不能写成“Disallow: /cgi-bin/ /tmp/”。
用户代理: *
禁止:/cgi-bin/
禁止:/tmp/
禁止:/~joe/
示例 7. 允许访问特定目录中的某些 URL
用户代理: *
允许:/cgi-bin/see
允许:/tmp/hi
允许:/~joe/look
禁止:/cgi-bin/
禁止:/tmp/
禁止:/~joe/
示例 8. 使用“*”限制对 url 的访问
禁止访问/cgi-bin/目录下所有后缀为“.htm”的URL(包括子目录)。
用户代理: *
禁止:/cgi-bin/*.htm
示例 9. 使用“$”限制对 url 的访问
只允许访问带有“.htm”后缀的 URL。
用户代理: *
允许:/*.htm$
不允许: /
示例1 0.禁止访问网站中的所有动态页面
用户代理: *
不允许: /*?*
示例11.禁止百度蜘蛛抓取网站上的所有图片
只允许抓取网页,不允许抓取图片。
用户代理:百度蜘蛛
禁止:/*.jpg$
禁止:/*.jpeg$
禁止:/*.gif$
禁止:/*.png$
禁止:/*.bmp$
示例12.只允许百度蜘蛛抓取.gif格式的网页和图片
允许抓取网页和gif格式的图片,但不允许抓取其他格式的图片
用户代理:百度蜘蛛
允许:/*.gif$
禁止:/*.jpg$
禁止:/*.jpeg$
禁止:/*.png$
禁止:/*.bmp$
示例13.仅禁止百度蜘蛛抓取.jpg格式的图片
用户代理:百度蜘蛛
禁止:/*.jpg$
10. robots.txt 文件参考
关于robots.txt文件更具体的设置,请参考以下链接:
机器人排除协议的 Web 服务器管理员指南
机器人排除协议的 HTML 作者指南
最初的 1994 年协议描述,目前已部署
修订后的 Internet-Draft 规范,尚未完成或实施 查看全部
php禁止网页抓取(搜索引擎使用spider程序自动访问互联网上的网页并获取网页信息)
搜索引擎使用蜘蛛程序自动访问互联网上的网页并获取网页信息。当蜘蛛访问一个网站时,它首先会检查网站的根域下是否有一个名为robots.txt的纯文本文件。这个文件是用来指定蜘蛛在你的网站 爬取范围上的。您可以在您的网站中创建一个robots.txt,并在文件中声明网站中不想被搜索引擎收录搜索的部分或指定搜索引擎只是收录 特定部分。
请注意,只有当您的 网站 收录您不想被 收录 搜索的内容时,您才需要使用 robots.txt 文件。如果您想要搜索引擎收录网站 上的所有内容,请不要创建robots.txt 文件。
2. robots.txt 文件在哪里?
robots.txt文件应该放在网站的根目录下。例如,当蜘蛛访问一个网站(例如)时,它会首先检查网站中是否存在该文件。如果蜘蛛找到该文件,它会根据文件的内容确定其访问权限的范围。
网站 URL 对应robots.txt URL
:80/
:80/robots.txt
: 1234/
:1234/robots.txt
3.我在robots.txt中设置了禁止百度收录I网站,为什么还是出现在百度搜索结果中?
如果您的robots.txt文件中设置了禁止收录的其他网站链接,这些网页可能仍会出现在百度的搜索结果中,但您网页上的内容将不会被抓取,索引和显示,百度搜索结果中显示的只是您相关网页的其他网站描述。
4. 禁止搜索引擎跟踪网页链接,只索引网页
如果您不希望搜索引擎跟踪此页面上的链接并且不传递链接的权重,请将此元标记放置在页面的一部分中:
如果您不想让百度跟踪特定链接,百度也支持更精确的控制,请直接在链接上写下这个标记:
登入
要允许其他搜索引擎跟踪,但只阻止百度跟踪指向您页面的链接,请将此元标记放在页面的一部分中:
5. 禁止搜索引擎在搜索结果中显示网页快照,只索引网页
为了防止所有搜索引擎显示您的 网站 快照,请将此元标记放在页面的一部分中:
要允许其他搜索引擎显示快照,但只阻止百度显示,请使用以下标签:
注意:此标签仅禁止百度显示网页快照。百度将继续对网页进行索引,并在搜索结果中显示网页摘要。
6. 我想禁止百度图片搜索收录 部分图片,如何设置?
禁止百度蜘蛛抓取网站上的所有图片,禁止或允许百度蜘蛛抓取网站上特定格式的图片文件可以通过设置robots实现,请参考“robots.txt文件使用示例”示例10、11、12。
7. Robots.txt 文件格式
“robots.txt”文件收录一个或多个记录,由空行分隔(以CR、CR/NL 或NL 作为终止符)。每条记录的格式如下:
":"
可以在这个文件中使用#做注释,具体用法同UNIX中的约定。此文件中的记录通常以一行或多行 User-agent 开头,后跟几行 Disallow 和 Allow 行,详细信息如下:
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被“robots.txt”限制。对于此文件,必须至少有一个用户代理记录。如果此项的值设置为*,则对任何机器人都有效。在“robots.txt”文件中,只能有“User-agent:*”等一条记录。如果您在“robots.txt”文件中添加“User-agent:SomeBot”和几行禁止和允许行,则名称“SomeBot”仅受“User-agent: SomeBot”之后的禁止和允许行的限制。
不允许:
该项的值用于描述一组不想被访问的 URL。该值可以是完整路径或路径的非空前缀。机器人不会访问以 Disallow 项的值开头的 URL。例如,“Disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,而“Disallow:/help/”则允许机器人访问/help.html、/helpabc。 html,而不是访问 /help/index.html。“禁止:”表示允许机器人访问网站的所有URL。“/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”不存在或者是一个空文件,这个网站 对所有搜索引擎机器人都是开放的。
允许:
此项的值用于描述您要访问的一组 URL。与 Disallow 项类似,该值可以是完整路径或路径前缀。机器人可以访问以 Allow 项的值开头的 URL。例如,“Allow:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。一个网站的所有URL默认都是Allow,所以Allow通常和Disallow结合使用,实现允许访问某些网页同时禁止访问其他所有URL的功能。
使用“*”和“$”:
百度蜘蛛支持使用通配符“*”和“$”来模糊匹配URL。
"$" 匹配行尾。
“*”匹配 0 个或多个任意字符。
注:我们将严格遵守机器人的相关协议。请注意区分您不想被抓取的目录或收录 的情况。我们会处理robots中写的文件,你不想被爬取和收录的目录做精确匹配,否则robots协议不会生效。
8. URL 匹配示例
值为 Allow 或 Disallow 的 URL 匹配结果
/tmp
/tmp
是的
/tmp
/tmp.html
是的
/tmp
/tmp/a.html
是的
/tmp
/tmhoho
不
/你好*
/你好.html
是的
/He*lo
/你好,哈哈
是的
/堆*lo
/你好,哈哈
不
html$
/tmpa.html
是的
/a.html$
/a.html
是的
htm$
/a.html
不
9. robots.txt 文件使用示例
示例 1. 禁止所有搜索引擎访问 网站 的任何部分
下载 robots.txt 文件
用户代理: *
不允许: /
示例 2. 允许所有机器人访问
(或者你可以创建一个空文件“/robots.txt”)
用户代理: *
允许: /
比如3.只禁止百度蜘蛛访问你的网站
用户代理:百度蜘蛛
不允许: /
示例 4. 只允许百度蜘蛛访问您的 网站
用户代理:百度蜘蛛
允许: /
用户代理: *
不允许: /
示例 5. 只允许百度蜘蛛和谷歌机器人访问
用户代理:百度蜘蛛
允许: /
用户代理:Googlebot
允许: /
用户代理: *
不允许: /
示例 6. 禁止蜘蛛访问特定目录
本例中网站有3个目录限制搜索引擎访问,即robot不会访问这3个目录。需要注意的是,每个目录必须单独声明,不能写成“Disallow: /cgi-bin/ /tmp/”。
用户代理: *
禁止:/cgi-bin/
禁止:/tmp/
禁止:/~joe/
示例 7. 允许访问特定目录中的某些 URL
用户代理: *
允许:/cgi-bin/see
允许:/tmp/hi
允许:/~joe/look
禁止:/cgi-bin/
禁止:/tmp/
禁止:/~joe/
示例 8. 使用“*”限制对 url 的访问
禁止访问/cgi-bin/目录下所有后缀为“.htm”的URL(包括子目录)。
用户代理: *
禁止:/cgi-bin/*.htm
示例 9. 使用“$”限制对 url 的访问
只允许访问带有“.htm”后缀的 URL。
用户代理: *
允许:/*.htm$
不允许: /
示例1 0.禁止访问网站中的所有动态页面
用户代理: *
不允许: /*?*
示例11.禁止百度蜘蛛抓取网站上的所有图片
只允许抓取网页,不允许抓取图片。
用户代理:百度蜘蛛
禁止:/*.jpg$
禁止:/*.jpeg$
禁止:/*.gif$
禁止:/*.png$
禁止:/*.bmp$
示例12.只允许百度蜘蛛抓取.gif格式的网页和图片
允许抓取网页和gif格式的图片,但不允许抓取其他格式的图片
用户代理:百度蜘蛛
允许:/*.gif$
禁止:/*.jpg$
禁止:/*.jpeg$
禁止:/*.png$
禁止:/*.bmp$
示例13.仅禁止百度蜘蛛抓取.jpg格式的图片
用户代理:百度蜘蛛
禁止:/*.jpg$
10. robots.txt 文件参考
关于robots.txt文件更具体的设置,请参考以下链接:
机器人排除协议的 Web 服务器管理员指南
机器人排除协议的 HTML 作者指南
最初的 1994 年协议描述,目前已部署
修订后的 Internet-Draft 规范,尚未完成或实施
php禁止网页抓取(开发小伙伴们要记住的两点:robots.txt是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-11 22:17
“爬虫玩得好,监狱早进;爬虫快乐爬,监狱要坐;数据播放,监狱伙食就够了。” 这种在技术圈广为流传的嘲讽并非危言耸听,因为近年来太多优秀的爬虫程序员为此面临牢狱之灾!
为了避免一些不必要的麻烦,开发伙伴必须牢记以下两点:
一、robots.txt 是什么?
robots.txt 是纯文本文件。在这个文件中,网站管理者可以声明网站中不被搜索引擎访问的部分,或者指定搜索引擎只访问收录指定的内容。
当搜索引擎(也称为搜索机器人或蜘蛛程序)访问一个站点时,它会首先检查站点根目录中是否存在robots.txt。如果存在,搜索机器人会根据文件Scope的内容判断访问;如果文件不存在,搜索机器人会沿着链接爬行。
二、robots.txt的作用
1、引导搜索引擎蜘蛛抓取指定的栏目或内容;
2、网站 修改或URL重写优化时屏蔽对搜索引擎不友好的链接;
3、 屏蔽死链接和404错误页面;
4、 屏蔽没有内容和价值的页面;
5、 屏蔽重复页面,例如评论页和搜索结果页;
6、阻止任何不想成为收录的页面;
7、引导蜘蛛抓取地图网站;
三、Robots 语法(三种语法和两种通配符)
三种语法如下:
1、用户代理:(定义搜索引擎)
例子:
用户代理:*(定义所有搜索引擎)
User-agent:Googlebot(定义谷歌,只允许谷歌蜘蛛抓取)
User-agent: 百度蜘蛛(定义百度,只允许百度蜘蛛爬取)
不同搜索引擎的搜索机器人名称不同,谷歌:Googlebot,百度:Baiduspider,MSN:MSNbot,雅虎:Slurp。
2、Disallow:(用于定义不允许蜘蛛爬取的页面或目录)
例子:
Disallow:/(禁止蜘蛛爬取网站的所有目录,“/”表示根目录)
Disallow: /admin(禁止蜘蛛爬取管理目录)
Disallow: /abc.html(禁止蜘蛛爬到abc.html页面)
Disallow: /help.html(禁止蜘蛛爬到help.html页面)
3、Allow:(用于定义允许蜘蛛爬取的页面或子目录)
例子:
Allow:/admin/test/(允许蜘蛛爬取admin下的test目录)
允许:/admin/abc.html(允许蜘蛛爬到admin目录下的abc.html页面)
两个通配符如下:
4、匹配字符“$”
$ 通配符:匹配 URL 末尾的字符
5、通配符“*”
* 通配符:匹配0个或多个任意字符
四、robots.txt 综合示例
1、禁止搜索引擎抓取特定目录
在这个例子中,网站有三个限制搜索引擎访问的目录,即搜索引擎不会访问这三个目录。
用户代理:* 禁止:/admin/
禁止:/tmp/
禁止:/abc/
2、禁止admin目录,但允许爬取admin目录下的seo子目录
用户代理:* 允许:/admin/seo/
禁止:/管理员/
3、禁止抓取/abc/目录(包括子目录)中所有后缀为“.htm”的URL
用户代理:* 禁止:/abc/*.htm$
4、禁止抓取网站中的所有动态页面
用户代理:* 禁止:/?
用“?”阻止所有文件,以便阻止所有动态路径。
5、百度蜘蛛禁止爬取网站所有图片:
用户代理:百度蜘蛛
禁止:/.jpg$
禁止:/.jpeg$
禁止:/.gif$
禁止:/.png$
禁止:/*.bmp$
6、为了防止 网站 页面被抓取,同时这些页面上仍然展示 AdSense 广告
用户代理:* 禁止:/folder1/
用户代理:Mediapartners-Google
允许:/folder1/
请禁止除 Mediapartners-Google 之外的所有机器人。这可以防止页面出现在搜索结果中,同时允许 Mediapartners-Google 机器人分析页面以确定要显示哪些广告。Mediapartners-Google 机器人不会与其他 Google 用户代理共享网页。
五、备注
1、robots.txt文件必须放在网站的根目录下,不能放在子目录下。
以吴俊泽的博客网站为例:比如可以访问robots.txt文件。
2、robots.txt 文件名必须小写,记得给robot加上“s”。
3、User-agent, Allow, Disallow 的“:”后跟一个字符空格。
4、 路径后加斜线“/”和不加斜线是有区别的
禁止:/帮助
防止蜘蛛访问 /help.html、/helpabc.html、/help/index.html
禁止:/帮助/
防止蜘蛛访问 /help/index.html。但允许访问 /help.html, /helpabc.html
5、Disallow 和 Allow 行的顺序是有意义的:
例如:
允许蜘蛛访问/admin/目录下的seo文件夹
用户代理:* 允许:/admin/seo/
禁止:/管理员/
如果 Allow 和 Disallow 的顺序颠倒:
用户代理:* 禁止:/admin/
允许:/admin/seo/
蜘蛛无法访问/admin/目录下的seo文件夹,因为第一个Disallow:/admin/已经匹配成功。
六、关于机器人元
Robots.txt 文件主要是限制搜索引擎对整个站点或目录的访问,而Robots Meta 标签主要是针对特定页面的。与其他META标签(如使用的语言、页面描述、关键词等)一样,Robots Meta标签也放置在页面上,专门告诉搜索引擎ROBOTS如何抓取内容页面的。
Robots Meta标签没有大小写区分,name="Robots"表示所有搜索引擎,可以针对特定的搜索引擎(如google)编写,内容部分有四个命令选项:index、noindex、 follow, nofollow , 并且说明之间用“,”隔开。
Index指令告诉搜索机器人抓取页面;
NoIndex 命令:告诉搜索引擎不要抓取这个页面
跟随指令意味着搜索机器人可以沿着页面上的链接继续爬行;
NoFollow 命令:告诉搜索引擎不允许从此页面找到链接并拒绝其继续访问。
Robots Meta标签的默认值为Index和Follow;
根据上面的命令,我们有以下四种组合:
你可以抓取这个页面,你可以继续索引这个页面上的其他链接=
您无权抓取此页面,但您可以抓取此页面上的其他链接并将其编入索引
您可以抓取此页面,但不允许抓取此页面上的其他链接并将其编入索引
您不得抓取此页面,也不得沿此页面抓取以索引其他链接。
七、关于
将“nofollow”放在超链接中以告诉搜索引擎不要抓取特定链接。 查看全部
php禁止网页抓取(开发小伙伴们要记住的两点:robots.txt是什么?)
“爬虫玩得好,监狱早进;爬虫快乐爬,监狱要坐;数据播放,监狱伙食就够了。” 这种在技术圈广为流传的嘲讽并非危言耸听,因为近年来太多优秀的爬虫程序员为此面临牢狱之灾!
为了避免一些不必要的麻烦,开发伙伴必须牢记以下两点:
一、robots.txt 是什么?
robots.txt 是纯文本文件。在这个文件中,网站管理者可以声明网站中不被搜索引擎访问的部分,或者指定搜索引擎只访问收录指定的内容。
当搜索引擎(也称为搜索机器人或蜘蛛程序)访问一个站点时,它会首先检查站点根目录中是否存在robots.txt。如果存在,搜索机器人会根据文件Scope的内容判断访问;如果文件不存在,搜索机器人会沿着链接爬行。
二、robots.txt的作用
1、引导搜索引擎蜘蛛抓取指定的栏目或内容;
2、网站 修改或URL重写优化时屏蔽对搜索引擎不友好的链接;
3、 屏蔽死链接和404错误页面;
4、 屏蔽没有内容和价值的页面;
5、 屏蔽重复页面,例如评论页和搜索结果页;
6、阻止任何不想成为收录的页面;
7、引导蜘蛛抓取地图网站;
三、Robots 语法(三种语法和两种通配符)
三种语法如下:
1、用户代理:(定义搜索引擎)
例子:
用户代理:*(定义所有搜索引擎)
User-agent:Googlebot(定义谷歌,只允许谷歌蜘蛛抓取)
User-agent: 百度蜘蛛(定义百度,只允许百度蜘蛛爬取)
不同搜索引擎的搜索机器人名称不同,谷歌:Googlebot,百度:Baiduspider,MSN:MSNbot,雅虎:Slurp。
2、Disallow:(用于定义不允许蜘蛛爬取的页面或目录)
例子:
Disallow:/(禁止蜘蛛爬取网站的所有目录,“/”表示根目录)
Disallow: /admin(禁止蜘蛛爬取管理目录)
Disallow: /abc.html(禁止蜘蛛爬到abc.html页面)
Disallow: /help.html(禁止蜘蛛爬到help.html页面)
3、Allow:(用于定义允许蜘蛛爬取的页面或子目录)
例子:
Allow:/admin/test/(允许蜘蛛爬取admin下的test目录)
允许:/admin/abc.html(允许蜘蛛爬到admin目录下的abc.html页面)
两个通配符如下:
4、匹配字符“$”
$ 通配符:匹配 URL 末尾的字符
5、通配符“*”
* 通配符:匹配0个或多个任意字符
四、robots.txt 综合示例
1、禁止搜索引擎抓取特定目录
在这个例子中,网站有三个限制搜索引擎访问的目录,即搜索引擎不会访问这三个目录。
用户代理:* 禁止:/admin/
禁止:/tmp/
禁止:/abc/
2、禁止admin目录,但允许爬取admin目录下的seo子目录
用户代理:* 允许:/admin/seo/
禁止:/管理员/
3、禁止抓取/abc/目录(包括子目录)中所有后缀为“.htm”的URL
用户代理:* 禁止:/abc/*.htm$
4、禁止抓取网站中的所有动态页面
用户代理:* 禁止:/?
用“?”阻止所有文件,以便阻止所有动态路径。
5、百度蜘蛛禁止爬取网站所有图片:
用户代理:百度蜘蛛
禁止:/.jpg$
禁止:/.jpeg$
禁止:/.gif$
禁止:/.png$
禁止:/*.bmp$
6、为了防止 网站 页面被抓取,同时这些页面上仍然展示 AdSense 广告
用户代理:* 禁止:/folder1/
用户代理:Mediapartners-Google
允许:/folder1/
请禁止除 Mediapartners-Google 之外的所有机器人。这可以防止页面出现在搜索结果中,同时允许 Mediapartners-Google 机器人分析页面以确定要显示哪些广告。Mediapartners-Google 机器人不会与其他 Google 用户代理共享网页。
五、备注
1、robots.txt文件必须放在网站的根目录下,不能放在子目录下。
以吴俊泽的博客网站为例:比如可以访问robots.txt文件。
2、robots.txt 文件名必须小写,记得给robot加上“s”。
3、User-agent, Allow, Disallow 的“:”后跟一个字符空格。
4、 路径后加斜线“/”和不加斜线是有区别的
禁止:/帮助
防止蜘蛛访问 /help.html、/helpabc.html、/help/index.html
禁止:/帮助/
防止蜘蛛访问 /help/index.html。但允许访问 /help.html, /helpabc.html
5、Disallow 和 Allow 行的顺序是有意义的:
例如:
允许蜘蛛访问/admin/目录下的seo文件夹
用户代理:* 允许:/admin/seo/
禁止:/管理员/
如果 Allow 和 Disallow 的顺序颠倒:
用户代理:* 禁止:/admin/
允许:/admin/seo/
蜘蛛无法访问/admin/目录下的seo文件夹,因为第一个Disallow:/admin/已经匹配成功。
六、关于机器人元
Robots.txt 文件主要是限制搜索引擎对整个站点或目录的访问,而Robots Meta 标签主要是针对特定页面的。与其他META标签(如使用的语言、页面描述、关键词等)一样,Robots Meta标签也放置在页面上,专门告诉搜索引擎ROBOTS如何抓取内容页面的。
Robots Meta标签没有大小写区分,name="Robots"表示所有搜索引擎,可以针对特定的搜索引擎(如google)编写,内容部分有四个命令选项:index、noindex、 follow, nofollow , 并且说明之间用“,”隔开。
Index指令告诉搜索机器人抓取页面;
NoIndex 命令:告诉搜索引擎不要抓取这个页面
跟随指令意味着搜索机器人可以沿着页面上的链接继续爬行;
NoFollow 命令:告诉搜索引擎不允许从此页面找到链接并拒绝其继续访问。
Robots Meta标签的默认值为Index和Follow;
根据上面的命令,我们有以下四种组合:
你可以抓取这个页面,你可以继续索引这个页面上的其他链接=
您无权抓取此页面,但您可以抓取此页面上的其他链接并将其编入索引
您可以抓取此页面,但不允许抓取此页面上的其他链接并将其编入索引
您不得抓取此页面,也不得沿此页面抓取以索引其他链接。
七、关于
将“nofollow”放在超链接中以告诉搜索引擎不要抓取特定链接。
php禁止网页抓取(selenium裸浏览器启动配置参数接收是怎样的?【】 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-09 15:10
)
每次selenium启动chrome浏览器的时候,chrome浏览器都很干净,没有插件,没有采集,也没有历史。这是因为 selenium 启动裸浏览器是为了保证启动 chrome 时的最快运行效率。这就是为什么我们需要配置参数,但有时我们需要的不仅仅是一个裸浏览器。
Selenium启动配置参数接收的是ChromeOptions类,创建如下:
from selenium import webdriver
option = webdriver.ChromeOptions()
创建 ChromeOptions 类后,添加参数。添加参数的具体方法有几种,分别对应添加不同类型的配置项。
设置chrome二进制文件位置(binary_location)
from selenium import webdriver
option = webdriver.ChromeOptions()
# 添加启动参数
option.add_argument()
# 添加扩展应用
option.add_extension()
option.add_encoded_extension()
# 添加实验性质的设置参数
option.add_experimental_option()
# 设置调试器地址
option.debugger_address()
常用配置参数:
from selenium import webdriver
option = webdriver.ChromeOptions()
# 添加UA
options.add_argument('user-agent="MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1"')
# 指定浏览器分辨率
options.add_argument('window-size=1920x3000')
# 谷歌文档提到需要加上这个属性来规避bug
chrome_options.add_argument('--disable-gpu')
# 隐藏滚动条, 应对一些特殊页面
options.add_argument('--hide-scrollbars')
# 不加载图片, 提升速度
options.add_argument('blink-settings=imagesEnabled=false')
# 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
options.add_argument('--headless')
# 以最高权限运行
options.add_argument('--no-sandbox')
# 手动指定使用的浏览器位置
options.binary_location = r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe"
#添加crx插件
option.add_extension('d:\crx\AdBlock_v2.17.crx')
# 禁用JavaScript
option.add_argument("--disable-javascript")
# 设置开发者模式启动,该模式下webdriver属性为正常值
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 禁用浏览器弹窗
prefs = {
'profile.default_content_setting_values' : {
'notifications' : 2
}
}
options.add_experimental_option('prefs',prefs)
driver=webdriver.Chrome(chrome_options=chrome_options)
浏览器地址栏参数:
在浏览器地址栏输入以下命令获取相应信息
about:version - 显示当前版本
about:memory - 显示本机浏览器内存使用状况
about:plugins - 显示已安装插件
about:histograms - 显示历史记录
about:dns - 显示DNS状态
about:cache - 显示缓存页面
about:gpu -是否有硬件加速
chrome://extensions/ - 查看已经安装的扩展
其他配置项目参数
–user-data-dir=”[PATH]”
# 指定用户文件夹User Data路径,可以把书签这样的用户数据保存在系统分区以外的分区
–disk-cache-dir=”[PATH]“
# 指定缓存Cache路径
–disk-cache-size=
# 指定Cache大小,单位Byte
–first run
# 重置到初始状态,第一次运行
–incognito
# 隐身模式启动
–disable-javascript
# 禁用Javascript
--omnibox-popup-count="num"
# 将地址栏弹出的提示菜单数量改为num个
--user-agent="xxxxxxxx"
# 修改HTTP请求头部的Agent字符串,可以通过about:version页面查看修改效果
--disable-plugins
# 禁止加载所有插件,可以增加速度。可以通过about:plugins页面查看效果
--disable-javascript
# 禁用JavaScript,如果觉得速度慢在加上这个
--disable-java
# 禁用java
--start-maximized
# 启动就最大化
--no-sandbox
# 取消沙盒模式
--single-process
# 单进程运行
--process-per-tab
# 每个标签使用单独进程
--process-per-site
# 每个站点使用单独进程
--in-process-plugins
# 插件不启用单独进程
--disable-popup-blocking
# 禁用弹出拦截
--disable-plugins
# 禁用插件
--disable-images
# 禁用图像
--incognito
# 启动进入隐身模式
--enable-udd-profiles
# 启用账户切换菜单
--proxy-pac-url
# 使用pac代理 [via 1/2]
--lang=zh-CN
# 设置语言为简体中文
--disk-cache-dir
# 自定义缓存目录
--disk-cache-size
# 自定义缓存最大值(单位byte)
--media-cache-size
# 自定义多媒体缓存最大值(单位byte)
--bookmark-menu
# 在工具 栏增加一个书签按钮
--enable-sync
# 启用书签同步 查看全部
php禁止网页抓取(selenium裸浏览器启动配置参数接收是怎样的?【】
)
每次selenium启动chrome浏览器的时候,chrome浏览器都很干净,没有插件,没有采集,也没有历史。这是因为 selenium 启动裸浏览器是为了保证启动 chrome 时的最快运行效率。这就是为什么我们需要配置参数,但有时我们需要的不仅仅是一个裸浏览器。
Selenium启动配置参数接收的是ChromeOptions类,创建如下:
from selenium import webdriver
option = webdriver.ChromeOptions()
创建 ChromeOptions 类后,添加参数。添加参数的具体方法有几种,分别对应添加不同类型的配置项。
设置chrome二进制文件位置(binary_location)
from selenium import webdriver
option = webdriver.ChromeOptions()
# 添加启动参数
option.add_argument()
# 添加扩展应用
option.add_extension()
option.add_encoded_extension()
# 添加实验性质的设置参数
option.add_experimental_option()
# 设置调试器地址
option.debugger_address()
常用配置参数:
from selenium import webdriver
option = webdriver.ChromeOptions()
# 添加UA
options.add_argument('user-agent="MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1"')
# 指定浏览器分辨率
options.add_argument('window-size=1920x3000')
# 谷歌文档提到需要加上这个属性来规避bug
chrome_options.add_argument('--disable-gpu')
# 隐藏滚动条, 应对一些特殊页面
options.add_argument('--hide-scrollbars')
# 不加载图片, 提升速度
options.add_argument('blink-settings=imagesEnabled=false')
# 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
options.add_argument('--headless')
# 以最高权限运行
options.add_argument('--no-sandbox')
# 手动指定使用的浏览器位置
options.binary_location = r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe"
#添加crx插件
option.add_extension('d:\crx\AdBlock_v2.17.crx')
# 禁用JavaScript
option.add_argument("--disable-javascript")
# 设置开发者模式启动,该模式下webdriver属性为正常值
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 禁用浏览器弹窗
prefs = {
'profile.default_content_setting_values' : {
'notifications' : 2
}
}
options.add_experimental_option('prefs',prefs)
driver=webdriver.Chrome(chrome_options=chrome_options)
浏览器地址栏参数:
在浏览器地址栏输入以下命令获取相应信息
about:version - 显示当前版本
about:memory - 显示本机浏览器内存使用状况
about:plugins - 显示已安装插件
about:histograms - 显示历史记录
about:dns - 显示DNS状态
about:cache - 显示缓存页面
about:gpu -是否有硬件加速
chrome://extensions/ - 查看已经安装的扩展

其他配置项目参数
–user-data-dir=”[PATH]”
# 指定用户文件夹User Data路径,可以把书签这样的用户数据保存在系统分区以外的分区
–disk-cache-dir=”[PATH]“
# 指定缓存Cache路径
–disk-cache-size=
# 指定Cache大小,单位Byte
–first run
# 重置到初始状态,第一次运行
–incognito
# 隐身模式启动
–disable-javascript
# 禁用Javascript
--omnibox-popup-count="num"
# 将地址栏弹出的提示菜单数量改为num个
--user-agent="xxxxxxxx"
# 修改HTTP请求头部的Agent字符串,可以通过about:version页面查看修改效果
--disable-plugins
# 禁止加载所有插件,可以增加速度。可以通过about:plugins页面查看效果
--disable-javascript
# 禁用JavaScript,如果觉得速度慢在加上这个
--disable-java
# 禁用java
--start-maximized
# 启动就最大化
--no-sandbox
# 取消沙盒模式
--single-process
# 单进程运行
--process-per-tab
# 每个标签使用单独进程
--process-per-site
# 每个站点使用单独进程
--in-process-plugins
# 插件不启用单独进程
--disable-popup-blocking
# 禁用弹出拦截
--disable-plugins
# 禁用插件
--disable-images
# 禁用图像
--incognito
# 启动进入隐身模式
--enable-udd-profiles
# 启用账户切换菜单
--proxy-pac-url
# 使用pac代理 [via 1/2]
--lang=zh-CN
# 设置语言为简体中文
--disk-cache-dir
# 自定义缓存目录
--disk-cache-size
# 自定义缓存最大值(单位byte)
--media-cache-size
# 自定义多媒体缓存最大值(单位byte)
--bookmark-menu
# 在工具 栏增加一个书签按钮
--enable-sync
# 启用书签同步
php禁止网页抓取(php禁止访问方法:在php文件头部写上“if($_SERVER)后面的两种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-12 17:17
今天PHP爱好者给大家带来一个禁止PHP访问的方法:1、在PHP文件的头部写上“if( $_SERVER['HTTP_REFERER'] == "" ){...}”;2、在程序中定义一个标识变量;3、 获取 config.php 中的变量。我希望能有所帮助。
本文运行环境:Windows7系统,PHP7.版本1,DELL G3电脑
php如何禁止访问方法?
PHP禁止从浏览器直接输入地址访问.php文件的方法:
具体实现方法如下:
一般来说,我们不希望用户直接输入地址来访问一些重要的文件,我们需要为此做一些设置。下面总结了一些禁止通过浏览器输入地址直接访问.PHP文件的PHP方法,非常实用。
比如我不想让别人直接从浏览器输入地址来访问这个文件。
但是如果从任何网站连接都无法访问,则即使建立连接并跳转到另一个地址也无法访问该机器。
1. 在 xx.php 文件的头部写入如下代码。
代码显示如下:
<p style="line-height: 2em; text-indent: 2em; text-align: left;">$fromurl="https://www.jb51.net/"; //跳转往这个地址。<br style="text-indent: 2em; text-align: left;"/>if( $_SERVER['HTTP_REFERER'] == "" )<br style="text-indent: 2em; text-align: left;"/>{<br style="text-indent: 2em; text-align: left;"/>header("Location:".$fromurl); exit;<br style="text-indent: 2em; text-align: left;"/>}<br style="text-indent: 2em; text-align: left;"/></p>
这样,我们只需要简单地伪造源头即可。为此,我们还可以执行以下操作:
2. 在程序中定义一个标识变量
代码显示如下:
<p style="line-height: 2em; text-indent: 2em; text-align: left;">define('IN_SYS', TRUE);<br style="text-indent: 2em; text-align: left;"/></p>
3. 在 config.php 中获取这个变量
代码显示如下:
<p style="line-height: 2em; text-indent: 2em; text-align: left;">if(!defined('IN_SYS')) { <br style="text-indent: 2em; text-align: left;"/>exit('禁止访问'); <br style="text-indent: 2em; text-align: left;"/>}<br style="text-indent: 2em; text-align: left;"/></p>
后两种方法是我们在很多cms中遇到的。
以上就是如何禁止php访问的详细内容,请其他相关php爱好者关注文章! 查看全部
php禁止网页抓取(php禁止访问方法:在php文件头部写上“if($_SERVER)后面的两种方法)
今天PHP爱好者给大家带来一个禁止PHP访问的方法:1、在PHP文件的头部写上“if( $_SERVER['HTTP_REFERER'] == "" ){...}”;2、在程序中定义一个标识变量;3、 获取 config.php 中的变量。我希望能有所帮助。
本文运行环境:Windows7系统,PHP7.版本1,DELL G3电脑
php如何禁止访问方法?
PHP禁止从浏览器直接输入地址访问.php文件的方法:
具体实现方法如下:
一般来说,我们不希望用户直接输入地址来访问一些重要的文件,我们需要为此做一些设置。下面总结了一些禁止通过浏览器输入地址直接访问.PHP文件的PHP方法,非常实用。
比如我不想让别人直接从浏览器输入地址来访问这个文件。
但是如果从任何网站连接都无法访问,则即使建立连接并跳转到另一个地址也无法访问该机器。
1. 在 xx.php 文件的头部写入如下代码。
代码显示如下:
<p style="line-height: 2em; text-indent: 2em; text-align: left;">$fromurl="https://www.jb51.net/"; //跳转往这个地址。<br style="text-indent: 2em; text-align: left;"/>if( $_SERVER['HTTP_REFERER'] == "" )<br style="text-indent: 2em; text-align: left;"/>{<br style="text-indent: 2em; text-align: left;"/>header("Location:".$fromurl); exit;<br style="text-indent: 2em; text-align: left;"/>}<br style="text-indent: 2em; text-align: left;"/></p>
这样,我们只需要简单地伪造源头即可。为此,我们还可以执行以下操作:
2. 在程序中定义一个标识变量
代码显示如下:
<p style="line-height: 2em; text-indent: 2em; text-align: left;">define('IN_SYS', TRUE);<br style="text-indent: 2em; text-align: left;"/></p>
3. 在 config.php 中获取这个变量
代码显示如下:
<p style="line-height: 2em; text-indent: 2em; text-align: left;">if(!defined('IN_SYS')) { <br style="text-indent: 2em; text-align: left;"/>exit('禁止访问'); <br style="text-indent: 2em; text-align: left;"/>}<br style="text-indent: 2em; text-align: left;"/></p>
后两种方法是我们在很多cms中遇到的。
以上就是如何禁止php访问的详细内容,请其他相关php爱好者关注文章!
php禁止网页抓取(先来了解一下什么是跨域?笙学术平台的认可)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-10 14:25
我们先来了解什么是跨域:
1.什么是跨域?跨域:即浏览器不能执行其他网站脚本。它是由浏览器的同源策略引起的,是浏览器对 javascript 施加的安全限制。例如:页面a想要获取页面b的资源。如果a和b页面的协议、域名、端口、子域不同,则执行的访问动作都是跨域的,浏览器一般出于安全原因限制跨域访问,即跨域请求资源不允许。注意:跨域访问限制实际上是浏览器限制。了解这一点很重要!!!同源策略:即协议、域名、端口必须相同,其中之一会导致跨域;
如果使用jsonp,则没有跨域限制
限制域名
1、允许单域名访问
header('Access-Control-Allow-Origin:https://www.baidu.com');
2、允许多个域访问
$origin = isset($_SERVER['HTTP_ORIGIN'])? $_SERVER['HTTP_ORIGIN'] : '';
$allow_origin = array('https://blog.oioweb.cn','https://my.oioweb.cn');
if(in_array($origin, $allow_origin)){
header('Access-Control-Allow-Origin:'.$origin);
}
3、允许所有域名访问
header('Access-Control-Allow-Origin:*');
转载:感谢您对良生学术平台的认可,感谢您对我们原创作品和文章的青睐。欢迎各位朋友分享到您的个人站长或朋友圈,但转载请注明文章出处“梁生学术”。
这很棒!(1) 查看全部
php禁止网页抓取(先来了解一下什么是跨域?笙学术平台的认可)
我们先来了解什么是跨域:
1.什么是跨域?跨域:即浏览器不能执行其他网站脚本。它是由浏览器的同源策略引起的,是浏览器对 javascript 施加的安全限制。例如:页面a想要获取页面b的资源。如果a和b页面的协议、域名、端口、子域不同,则执行的访问动作都是跨域的,浏览器一般出于安全原因限制跨域访问,即跨域请求资源不允许。注意:跨域访问限制实际上是浏览器限制。了解这一点很重要!!!同源策略:即协议、域名、端口必须相同,其中之一会导致跨域;
如果使用jsonp,则没有跨域限制
限制域名
1、允许单域名访问
header('Access-Control-Allow-Origin:https://www.baidu.com');
2、允许多个域访问
$origin = isset($_SERVER['HTTP_ORIGIN'])? $_SERVER['HTTP_ORIGIN'] : '';
$allow_origin = array('https://blog.oioweb.cn','https://my.oioweb.cn');
if(in_array($origin, $allow_origin)){
header('Access-Control-Allow-Origin:'.$origin);
}
3、允许所有域名访问
header('Access-Control-Allow-Origin:*');
转载:感谢您对良生学术平台的认可,感谢您对我们原创作品和文章的青睐。欢迎各位朋友分享到您的个人站长或朋友圈,但转载请注明文章出处“梁生学术”。
这很棒!(1)
php禁止网页抓取(PHP完整Curl数据函数:伪造客户端IP地址,伪造访问referer )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-08 12:19
)
1、伪造客户端IP地址,伪造访问referer:(一般这样可以访问数据)
curl_setopt($curl, CURLOPT_HTTPHEADER, ['X-FORWARDED-FOR:110.85.108.185', 'CLIENT-IP:110.85.108.185']);
curl_setopt($curl, CURLOPT_REFERER, 'http://www.demo.com/test.php');
2、如果以上还是不行,可能是别人抓到了真实IP。这个时候我们会使用代理访问。
# 详细方式
curl_setopt($curl, CURLOPT_PROXY, '112.85.209.72'); //代理服务器地址
curl_setopt($curl, CURLOPT_PROXYPORT, 80); //代理服务器端口
//curl_setopt($curl, CURLOPT_PROXYUSERPWD, ':''); //http代理认证帐号,username:password的格式
curl_setopt($curl, CURLOPT_PROXYTYPE, CURLPROXY_HTTP); //使用http代理模式
# 简写方式
curl_setopt($curl, CURLOPT_PROXY, 'http://112.85.209.72:80');
3、 还有另一种类型可以用浏览器访问,但不能用 curl。 (对方检查了useragent,如果没有,则认为是非法来源等)
$useragent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 ';
$useragent.= '(KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36';
curl_setopt($curl, CURLOPT_USERAGENT, $useragent);
PHP完整的Curl抓取数据功能:
/**
* 请求接口
* @access public
* @param string $url 请求地址
* @param array $data 提交参数 没有get 有post
* @return bean|array
*/
public function send($url='')
{
set_time_limit(0);
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($curl, CURLOPT_HTTPHEADER, ['X-FORWARDED-FOR:127.0.1.1', 'CLIENT-IP:127.0.1.1']);
curl_setopt($curl, CURLOPT_REFERER, 'http://www.demo.com/demo.php');
curl_setopt($curl, CURLOPT_PROXY, 'http://127.0.0.1:80');
$useragent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 ';
$useragent.= '(KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36';
curl_setopt($curl, CURLOPT_USERAGENT, $useragent);
if(!empty($data) && is_array($data)){
curl_setopt($curl, CURLOPT_POST, true);
curl_setopt($curl, CURLOPT_POSTFIELDS, $data);
}
$html = curl_exec($curl);
if($error=curl_errno($curl)){
return false;
}
curl_close($curl);
return $html;
} 查看全部
php禁止网页抓取(PHP完整Curl数据函数:伪造客户端IP地址,伪造访问referer
)
1、伪造客户端IP地址,伪造访问referer:(一般这样可以访问数据)
curl_setopt($curl, CURLOPT_HTTPHEADER, ['X-FORWARDED-FOR:110.85.108.185', 'CLIENT-IP:110.85.108.185']);
curl_setopt($curl, CURLOPT_REFERER, 'http://www.demo.com/test.php');
2、如果以上还是不行,可能是别人抓到了真实IP。这个时候我们会使用代理访问。
# 详细方式
curl_setopt($curl, CURLOPT_PROXY, '112.85.209.72'); //代理服务器地址
curl_setopt($curl, CURLOPT_PROXYPORT, 80); //代理服务器端口
//curl_setopt($curl, CURLOPT_PROXYUSERPWD, ':''); //http代理认证帐号,username:password的格式
curl_setopt($curl, CURLOPT_PROXYTYPE, CURLPROXY_HTTP); //使用http代理模式
# 简写方式
curl_setopt($curl, CURLOPT_PROXY, 'http://112.85.209.72:80');
3、 还有另一种类型可以用浏览器访问,但不能用 curl。 (对方检查了useragent,如果没有,则认为是非法来源等)
$useragent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 ';
$useragent.= '(KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36';
curl_setopt($curl, CURLOPT_USERAGENT, $useragent);
PHP完整的Curl抓取数据功能:
/**
* 请求接口
* @access public
* @param string $url 请求地址
* @param array $data 提交参数 没有get 有post
* @return bean|array
*/
public function send($url='')
{
set_time_limit(0);
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($curl, CURLOPT_HTTPHEADER, ['X-FORWARDED-FOR:127.0.1.1', 'CLIENT-IP:127.0.1.1']);
curl_setopt($curl, CURLOPT_REFERER, 'http://www.demo.com/demo.php');
curl_setopt($curl, CURLOPT_PROXY, 'http://127.0.0.1:80');
$useragent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 ';
$useragent.= '(KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36';
curl_setopt($curl, CURLOPT_USERAGENT, $useragent);
if(!empty($data) && is_array($data)){
curl_setopt($curl, CURLOPT_POST, true);
curl_setopt($curl, CURLOPT_POSTFIELDS, $data);
}
$html = curl_exec($curl);
if($error=curl_errno($curl)){
return false;
}
curl_close($curl);
return $html;
}
php禁止网页抓取(浙江四HB源码SEO与您分享SEO优化如何禁止捕捉和记录机制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-05 23:14
在网站,搜索引擎优化的过程中,并不是所有的页面和内容都被搜索引擎抓取和索引。例如,如果复制的内容被捕获,则会对网站产生负面影响。例如,一些电商平台为了用户更好地搜索和过滤产品而屏蔽了大量页面,以及布局格式的页面。如果抓取了大量这样的页面,就会浪费搜索和引擎分配给网站的总爬取时间,进而影响搜索和引擎真正想要抓取的页面,记录。网站管理员可以通过查询网站来访问日志。如果出现类似情况,大量无用页面被抓取,重要内容从未抓取,网站
今天浙江四HB源码SEO与大家分享SEO优化如何禁止抓拍和记录机制,希望对大家有所帮助。
在前面的章节中,熟悉的JavaScript、flash links、nofollow等方法并不能保证页面不会被收录。在其他情况下,由于未知原因,可能存在导入的外部链接导致页面被收录。浙江SEO将在本文中讨论机器人文档和非索引元机器人标签。前者确保不捕获页面,而后者确保不收录页面。
文本文件
机器人。网站的根目录中存在.txt文件。它的指令用于禁止引擎、搜索、蜘蛛抓取某些页面内容或允许抓取某些内容。蜘蛛在搜索、引擎或爬取网站上爬取时,会先检查这个文件的权限。
机器人文件不存在或文件中没有内容。默认情况下,搜索引擎和引擎可以抓取网站的所有页面。如果需要禁止捕获某些信息,则必须专门编写机器人文件。另外,浙江SEO建议,如果允许爬取网站的所有内容,还应该在根目录下放置一个空的robots.txt文件。因为如果由于设置问题导致robot文件不存在,有些服务器会返回200状态码和其他一些错误信息,而不是404状态码,所以搜索引擎误解了robot的信息。下面简单介绍一下如何写robot文件:
用户代理:*
不允许:/
以上是机器人文件的简要说明。根据一些英文单词,大家会更容易理解和记忆。例如,允许和禁止。以上描述可以分为: User Agent:指定以下规则适用于哪个搜索引擎蜘蛛。*通配符表示所有蜘蛛。如果仅适用于百度蜘蛛,请将通配符替换为百度蜘蛛*
用户代理:百度蜘蛛
以下规则仅适用于百度蜘蛛
禁止:提醒人们不允许蜘蛛抓取内容。后缀文件或者目录名就够了,可以在以后的学习实践中详细学习,浙江seo这里有个提示,禁止文件和目录写在同一行。文件或目录需要占一行,每行必须先写Disallow:指令。
没有indexmeta机器人标签
虽然robot文件可以禁止搜索引擎抓取特定的URL,搜索引擎也会做同样的事情,但是在一些导入链接的作用下,虽然搜索引擎没有抓取到该URL,但是该URL还是会出现在一些相关的链接。在查询的结果页面,标题和描述会显示您获得的相关信息。如果你想完全禁止 URL 出现在搜索结果中,你需要使用现在提到的没有索引的元机器人标签。
元机器人标签是页面头部的元标签之一。它的作用是告诉搜索引擎和引擎禁止索引这个页面的内容。
简单的元机器人标签格式如下
这意味着禁止所有搜索蜘蛛索引该页面,并且禁止跟踪该页面上的所有链接。
有时使用上述标签。指令是禁止蜘蛛索引,但它可以跟踪页面上的链接。
浙江seo提醒,学习这个文章需要注意的内容是爬取和索引或者采集是两个不同的概念。使用robot文件可以禁止爬取,但不会影响索引;index用于禁止Index,但可以检索。另外,为了让Meta NOindex标签起作用,必须允许蜘蛛抓取页面,否则禁止索引的标签根本看不到。
以上就是浙江四HB源码seo关于SEO禁止爬取、索引、采集机制的知识。感谢您的阅读。 查看全部
php禁止网页抓取(浙江四HB源码SEO与您分享SEO优化如何禁止捕捉和记录机制)
在网站,搜索引擎优化的过程中,并不是所有的页面和内容都被搜索引擎抓取和索引。例如,如果复制的内容被捕获,则会对网站产生负面影响。例如,一些电商平台为了用户更好地搜索和过滤产品而屏蔽了大量页面,以及布局格式的页面。如果抓取了大量这样的页面,就会浪费搜索和引擎分配给网站的总爬取时间,进而影响搜索和引擎真正想要抓取的页面,记录。网站管理员可以通过查询网站来访问日志。如果出现类似情况,大量无用页面被抓取,重要内容从未抓取,网站
今天浙江四HB源码SEO与大家分享SEO优化如何禁止抓拍和记录机制,希望对大家有所帮助。
在前面的章节中,熟悉的JavaScript、flash links、nofollow等方法并不能保证页面不会被收录。在其他情况下,由于未知原因,可能存在导入的外部链接导致页面被收录。浙江SEO将在本文中讨论机器人文档和非索引元机器人标签。前者确保不捕获页面,而后者确保不收录页面。
文本文件
机器人。网站的根目录中存在.txt文件。它的指令用于禁止引擎、搜索、蜘蛛抓取某些页面内容或允许抓取某些内容。蜘蛛在搜索、引擎或爬取网站上爬取时,会先检查这个文件的权限。
机器人文件不存在或文件中没有内容。默认情况下,搜索引擎和引擎可以抓取网站的所有页面。如果需要禁止捕获某些信息,则必须专门编写机器人文件。另外,浙江SEO建议,如果允许爬取网站的所有内容,还应该在根目录下放置一个空的robots.txt文件。因为如果由于设置问题导致robot文件不存在,有些服务器会返回200状态码和其他一些错误信息,而不是404状态码,所以搜索引擎误解了robot的信息。下面简单介绍一下如何写robot文件:
用户代理:*
不允许:/
以上是机器人文件的简要说明。根据一些英文单词,大家会更容易理解和记忆。例如,允许和禁止。以上描述可以分为: User Agent:指定以下规则适用于哪个搜索引擎蜘蛛。*通配符表示所有蜘蛛。如果仅适用于百度蜘蛛,请将通配符替换为百度蜘蛛*
用户代理:百度蜘蛛
以下规则仅适用于百度蜘蛛
禁止:提醒人们不允许蜘蛛抓取内容。后缀文件或者目录名就够了,可以在以后的学习实践中详细学习,浙江seo这里有个提示,禁止文件和目录写在同一行。文件或目录需要占一行,每行必须先写Disallow:指令。
没有indexmeta机器人标签
虽然robot文件可以禁止搜索引擎抓取特定的URL,搜索引擎也会做同样的事情,但是在一些导入链接的作用下,虽然搜索引擎没有抓取到该URL,但是该URL还是会出现在一些相关的链接。在查询的结果页面,标题和描述会显示您获得的相关信息。如果你想完全禁止 URL 出现在搜索结果中,你需要使用现在提到的没有索引的元机器人标签。
元机器人标签是页面头部的元标签之一。它的作用是告诉搜索引擎和引擎禁止索引这个页面的内容。
简单的元机器人标签格式如下
这意味着禁止所有搜索蜘蛛索引该页面,并且禁止跟踪该页面上的所有链接。
有时使用上述标签。指令是禁止蜘蛛索引,但它可以跟踪页面上的链接。
https://wwwhhhhbbbbcom.oss-cn- ... ality,q_50%2Fresize,m_fill,w_300,h_200 300w" />浙江seo提醒,学习这个文章需要注意的内容是爬取和索引或者采集是两个不同的概念。使用robot文件可以禁止爬取,但不会影响索引;index用于禁止Index,但可以检索。另外,为了让Meta NOindex标签起作用,必须允许蜘蛛抓取页面,否则禁止索引的标签根本看不到。
以上就是浙江四HB源码seo关于SEO禁止爬取、索引、采集机制的知识。感谢您的阅读。
php禁止网页抓取(浏览器端负责解析php禁止网页抓取任何内容是个坑)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-05 01:03
php禁止网页抓取任何内容是个坑。
意思是禁止蜘蛛访问该网页。
最后打个补丁的关系。
curl就是一个http客户端请求就是发出去一次。浏览器端负责解析跳转就是跳转到用户设定好的页面客户端发送请求,服务器端获取响应,返回内容,接着发送过来一样就是请求和响应过程中,
出现过getlib,就是类似websocket的东西。就像http2的getpost。
出现过opener,
只有必要时使用,
curl
iis的话叫做httpoverhttps
chrome的话叫做filebasedpagetransferprotocol
以php为例,用request建立tcp连接,控制其过程使用new的一对参数,以init()方法初始化为每一次的用户请求httpframe但是每一次http请求并不是首次发出的请求,还有requestscope的问题while(true){assertrequest。http。createsession();//只有在请求有了sessionpost(request,assertrequest。
http。createsession())//并不能把session状态写到结果}try{try。assertrequest。http。createsession();}catch(exceptione){}request。close();//关闭连接。 查看全部
php禁止网页抓取(浏览器端负责解析php禁止网页抓取任何内容是个坑)
php禁止网页抓取任何内容是个坑。
意思是禁止蜘蛛访问该网页。
最后打个补丁的关系。
curl就是一个http客户端请求就是发出去一次。浏览器端负责解析跳转就是跳转到用户设定好的页面客户端发送请求,服务器端获取响应,返回内容,接着发送过来一样就是请求和响应过程中,
出现过getlib,就是类似websocket的东西。就像http2的getpost。
出现过opener,
只有必要时使用,
curl
iis的话叫做httpoverhttps
chrome的话叫做filebasedpagetransferprotocol
以php为例,用request建立tcp连接,控制其过程使用new的一对参数,以init()方法初始化为每一次的用户请求httpframe但是每一次http请求并不是首次发出的请求,还有requestscope的问题while(true){assertrequest。http。createsession();//只有在请求有了sessionpost(request,assertrequest。
http。createsession())//并不能把session状态写到结果}try{try。assertrequest。http。createsession();}catch(exceptione){}request。close();//关闭连接。
php禁止网页抓取( 什么是robots.txt文件?搜索引擎使用spider程序自动访问互联网上的网页并获取网页信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-02 15:11
什么是robots.txt文件?搜索引擎使用spider程序自动访问互联网上的网页并获取网页信息)
禁止搜索引擎的方法收录
禁止搜索引擎的方法收录
什么是 robots.txt 文件?
搜索引擎使用蜘蛛程序自动访问互联网上的网页并获取网页信息。当蜘蛛访问一个网站时,它首先会检查网站的根域下是否有一个名为robots.txt的纯文本文件。这个文件是用来指定蜘蛛在你的网站 爬取范围上的。您可以在您的网站中创建一个robots.txt,并在文件中声明网站中不想被搜索引擎收录搜索到的部分或指定搜索引擎仅是 收录 特定部分。
请注意,只有当您的网站收录您不想被收录搜索的内容时,您才需要使用robots.txt文件。如果您想要搜索引擎收录网站 上的所有内容,请不要创建robots.txt 文件。
robots.txt 文件在哪里?
robots.txt文件应该放在网站的根目录下。例如,当蜘蛛访问一个网站(例如)时,它会首先检查网站中是否存在该文件。如果蜘蛛找到该文件,它会根据文件的内容确定其访问权限的范围。
网站 robots.txt:///robots.txt:80/:80/robots.txt:1234/:1234/robots.txt:///robots.txt的URL对应的URL
我在robots.txt中设置了禁止百度收录me网站,为什么还是出现在百度搜索结果中?
如果您的robots.txt文件中设置了禁止收录的其他网站链接,这些网页可能仍会出现在百度的搜索结果中,但您网页上的内容将不会被抓取,索引和显示,百度搜索结果中显示的只是您相关网页的其他网站描述。
禁止搜索引擎关注网页链接,仅索引网页
如果您不希望搜索引擎跟踪此页面上的链接并且不传递链接的权重,请将此元标记放在页面的一部分中:
如果您不想让百度跟踪特定链接,百度也支持更精确的控制,请直接在链接上写下这个标记:
登入
要允许其他搜索引擎跟踪,但仅阻止百度跟踪指向您页面的链接,请将此元标记放置在页面的一部分中:
防止搜索引擎在搜索结果中显示网页快照,只索引网页
为了防止所有搜索引擎显示您的 网站 快照,请将此元标记放在页面的一部分中:
要允许其他搜索引擎显示快照,但只阻止百度显示,请使用以下标签:
注意:此标签仅禁止百度显示网页快照。百度将继续对网页进行索引,并在搜索结果中显示网页摘要。
我想禁止百度图片搜索收录中的一些图片,我该如何设置?
禁止百度蜘蛛抓取网站上的所有图片,禁止或允许百度蜘蛛抓取网站上特定格式的图片文件可以通过设置robots实现,请参考“robots.txt文件使用示例”示例10、11、12。
robots.txt 文件的格式
“robots.txt”文件收录一个或多个记录,由空行分隔(以CR、CR/NL或NL作为终止符)。每条记录的格式如下:
“:”。
可以在这个文件中使用#做注释,具体用法同UNIX中的约定。此文件中的记录通常以一行或多行 User-agent 开头,后跟几行 Disallow 和 Allow 行。详细情况如下:
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被“robots.txt”限制。对于此文件,必须至少有一个用户代理记录。如果此项的值设置为*,则对任何机器人都有效。在“robots.txt”文件中,只能有“User-agent:*”这样的一条记录。如果您在“robots.txt”文件中添加“User-agent:SomeBot”和几行禁止和允许行,则名称“SomeBot”仅受“User-agent: SomeBot”后的禁止和允许行的限制。
不允许:
该项的值用于描述一组不想被访问的 URL。该值可以是完整路径或路径的非空前缀。机器人不会访问以 Disallow 项的值开头的 URL。例如,“Disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,“Disallow:/help/”允许机器人访问/help.html、/helpabc。 html,而不是访问 /help/index.html。“禁止:”表示允许机器人访问网站的所有URL。“/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”不存在或为空文件,则此网站 对所有搜索引擎机器人开放。
允许:
此项的值用于描述您要访问的一组 URL。与 Disallow 项类似,该值可以是完整路径或路径前缀。允许机器人访问以 Allow 项的值开头的 URL。例如,“Allow:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。网站 的所有 URL 默认都是 Allow 的,所以 Allow 通常与 Disallow 结合使用,允许访问某些网页,同时禁止访问所有其他 URL。
需要注意的是,Disallow 和 Allow 行的顺序是有意义的,机器人会根据第一个匹配成功的 Allow 或 Disallow 行来决定是否访问 URL。
使用“*”和“$”:
百度蜘蛛支持使用通配符“*”和“$”来模糊匹配URL。
"$" 匹配行尾。
“*”匹配 0 个或多个任意字符。
URL匹配示例
Allow 或 Disallow 值的 URL 匹配结果 /tmp/tmpyes/tmp/tmp.htmlyes/tmp/tmp/a.htmlyes/tmp//tmpno/tmp//tmphohono/tmp//tmp/a.htmlyes/Hello*/Hello .htmlyes/He*lo/Hello,loloyes/Heap*lo/Hello,lolonohtml$/tmpa.htmlyes/a.html$/a.htmlyeshtm$/a.htmlno
需要注意的是,每个目录必须单独声明,不能写成“Disallow: /cgi-bin/ /tmp/”。User-agent: *Disallow: /cgi-bin/Disallow: /tmp/Disallow: /~joe/Example6. 允许访问特定目录中的部分 url User-agent: *Allow: /cgi- bin/seeAllow: /tmp/hiAllow: /~joe/lookDisallow: /cgi-bin/Disallow: /tmp/Disallow: /~joe/Example 7. 使用“*”来限制访问url,禁止访问/cgi-bin/ 后缀为“.htm”的所有 URL(包括子目录)。
User-agent: *Disallow: /cgi-bin/*.htm 示例 8. 使用“$”限制对 URL 的访问,只允许访问带有“.htm”后缀的 URL。User-agent: *Allow: .htm$Disallow: /example9. 禁止访问网站 中的所有动态页面 User-agent: *Disallow: /*?*Example 10. 禁止百度蜘蛛抓取了网站上的所有图片。只允许抓取网页,不允许抓取图片。用户代理:BaiduspiderDisallow: /*.jpg$Disallow: /*.jpeg$Disallow: /*.gif$Disallow: /*.png$Disallow: /*.bmp$Example 11. 只允许Baiduspider抓取网页和.gif格式的图片允许抓取gif格式的网页和图片,但不允许抓取其他格式的图片。用户代理:BaiduspiderAllow: /*.gif$Disallow: /*.jpg$Disallow: /*.
robots.txt 文件参考
关于robots.txt文件更具体的设置,请参考以下链接:
· 机器人排除协议的 Web 服务器管理员指南
· 机器人排除协议的 HTML 作者指南
· 1994 年的原创协议描述,如当前部署
· 修订后的 Internet-Draft 规范,尚未完成或实施 查看全部
php禁止网页抓取(
什么是robots.txt文件?搜索引擎使用spider程序自动访问互联网上的网页并获取网页信息)
禁止搜索引擎的方法收录
禁止搜索引擎的方法收录
什么是 robots.txt 文件?
搜索引擎使用蜘蛛程序自动访问互联网上的网页并获取网页信息。当蜘蛛访问一个网站时,它首先会检查网站的根域下是否有一个名为robots.txt的纯文本文件。这个文件是用来指定蜘蛛在你的网站 爬取范围上的。您可以在您的网站中创建一个robots.txt,并在文件中声明网站中不想被搜索引擎收录搜索到的部分或指定搜索引擎仅是 收录 特定部分。
请注意,只有当您的网站收录您不想被收录搜索的内容时,您才需要使用robots.txt文件。如果您想要搜索引擎收录网站 上的所有内容,请不要创建robots.txt 文件。
robots.txt 文件在哪里?
robots.txt文件应该放在网站的根目录下。例如,当蜘蛛访问一个网站(例如)时,它会首先检查网站中是否存在该文件。如果蜘蛛找到该文件,它会根据文件的内容确定其访问权限的范围。
网站 robots.txt:///robots.txt:80/:80/robots.txt:1234/:1234/robots.txt:///robots.txt的URL对应的URL
我在robots.txt中设置了禁止百度收录me网站,为什么还是出现在百度搜索结果中?
如果您的robots.txt文件中设置了禁止收录的其他网站链接,这些网页可能仍会出现在百度的搜索结果中,但您网页上的内容将不会被抓取,索引和显示,百度搜索结果中显示的只是您相关网页的其他网站描述。
禁止搜索引擎关注网页链接,仅索引网页
如果您不希望搜索引擎跟踪此页面上的链接并且不传递链接的权重,请将此元标记放在页面的一部分中:
如果您不想让百度跟踪特定链接,百度也支持更精确的控制,请直接在链接上写下这个标记:
登入
要允许其他搜索引擎跟踪,但仅阻止百度跟踪指向您页面的链接,请将此元标记放置在页面的一部分中:
防止搜索引擎在搜索结果中显示网页快照,只索引网页
为了防止所有搜索引擎显示您的 网站 快照,请将此元标记放在页面的一部分中:
要允许其他搜索引擎显示快照,但只阻止百度显示,请使用以下标签:
注意:此标签仅禁止百度显示网页快照。百度将继续对网页进行索引,并在搜索结果中显示网页摘要。
我想禁止百度图片搜索收录中的一些图片,我该如何设置?
禁止百度蜘蛛抓取网站上的所有图片,禁止或允许百度蜘蛛抓取网站上特定格式的图片文件可以通过设置robots实现,请参考“robots.txt文件使用示例”示例10、11、12。
robots.txt 文件的格式
“robots.txt”文件收录一个或多个记录,由空行分隔(以CR、CR/NL或NL作为终止符)。每条记录的格式如下:
“:”。
可以在这个文件中使用#做注释,具体用法同UNIX中的约定。此文件中的记录通常以一行或多行 User-agent 开头,后跟几行 Disallow 和 Allow 行。详细情况如下:
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被“robots.txt”限制。对于此文件,必须至少有一个用户代理记录。如果此项的值设置为*,则对任何机器人都有效。在“robots.txt”文件中,只能有“User-agent:*”这样的一条记录。如果您在“robots.txt”文件中添加“User-agent:SomeBot”和几行禁止和允许行,则名称“SomeBot”仅受“User-agent: SomeBot”后的禁止和允许行的限制。
不允许:
该项的值用于描述一组不想被访问的 URL。该值可以是完整路径或路径的非空前缀。机器人不会访问以 Disallow 项的值开头的 URL。例如,“Disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,“Disallow:/help/”允许机器人访问/help.html、/helpabc。 html,而不是访问 /help/index.html。“禁止:”表示允许机器人访问网站的所有URL。“/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”不存在或为空文件,则此网站 对所有搜索引擎机器人开放。
允许:
此项的值用于描述您要访问的一组 URL。与 Disallow 项类似,该值可以是完整路径或路径前缀。允许机器人访问以 Allow 项的值开头的 URL。例如,“Allow:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。网站 的所有 URL 默认都是 Allow 的,所以 Allow 通常与 Disallow 结合使用,允许访问某些网页,同时禁止访问所有其他 URL。
需要注意的是,Disallow 和 Allow 行的顺序是有意义的,机器人会根据第一个匹配成功的 Allow 或 Disallow 行来决定是否访问 URL。
使用“*”和“$”:
百度蜘蛛支持使用通配符“*”和“$”来模糊匹配URL。
"$" 匹配行尾。
“*”匹配 0 个或多个任意字符。
URL匹配示例
Allow 或 Disallow 值的 URL 匹配结果 /tmp/tmpyes/tmp/tmp.htmlyes/tmp/tmp/a.htmlyes/tmp//tmpno/tmp//tmphohono/tmp//tmp/a.htmlyes/Hello*/Hello .htmlyes/He*lo/Hello,loloyes/Heap*lo/Hello,lolonohtml$/tmpa.htmlyes/a.html$/a.htmlyeshtm$/a.htmlno
需要注意的是,每个目录必须单独声明,不能写成“Disallow: /cgi-bin/ /tmp/”。User-agent: *Disallow: /cgi-bin/Disallow: /tmp/Disallow: /~joe/Example6. 允许访问特定目录中的部分 url User-agent: *Allow: /cgi- bin/seeAllow: /tmp/hiAllow: /~joe/lookDisallow: /cgi-bin/Disallow: /tmp/Disallow: /~joe/Example 7. 使用“*”来限制访问url,禁止访问/cgi-bin/ 后缀为“.htm”的所有 URL(包括子目录)。
User-agent: *Disallow: /cgi-bin/*.htm 示例 8. 使用“$”限制对 URL 的访问,只允许访问带有“.htm”后缀的 URL。User-agent: *Allow: .htm$Disallow: /example9. 禁止访问网站 中的所有动态页面 User-agent: *Disallow: /*?*Example 10. 禁止百度蜘蛛抓取了网站上的所有图片。只允许抓取网页,不允许抓取图片。用户代理:BaiduspiderDisallow: /*.jpg$Disallow: /*.jpeg$Disallow: /*.gif$Disallow: /*.png$Disallow: /*.bmp$Example 11. 只允许Baiduspider抓取网页和.gif格式的图片允许抓取gif格式的网页和图片,但不允许抓取其他格式的图片。用户代理:BaiduspiderAllow: /*.gif$Disallow: /*.jpg$Disallow: /*.
robots.txt 文件参考
关于robots.txt文件更具体的设置,请参考以下链接:
· 机器人排除协议的 Web 服务器管理员指南
· 机器人排除协议的 HTML 作者指南
· 1994 年的原创协议描述,如当前部署
· 修订后的 Internet-Draft 规范,尚未完成或实施
php禁止网页抓取(代码添加一个屏蔽功能更为方便方便!!! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-02 05:05
)
由于 WordPress 是一个开源博客程序,因此受到世界各地许多用户的喜爱。也会有很多个性化的需求。
比如有些文章我们可能不想让搜索引擎抓取,这个可以通过robots实现,但是很麻烦。代码中加入阻塞函数更方便
一、设置方法
方法还是很简单的,就几段代码。我们在主题文件中找到了“functions.php”文件。我们不保证每个主题文件的名称完全相同,但大部分都是一样的。
然后将以下代码添加到“functions.php”文件中。提示:如果您的 WordPress 站点启用了页面缓存,则此功能将不起作用!!
// 站点开启了页面缓存,此功能无效
function ludouse_add_custom_box() {
if (function_exists('add_meta_box')) {
add_meta_box('ludou_allow_se', '搜索引擎', 'ludou_allow_se', 'post', 'side', 'low');
add_meta_box('ludou_allow_se', '搜索引擎', 'ludou_allow_se', 'page', 'side', 'low');
}
}
add_action('add_meta_boxes', 'ludouse_add_custom_box');
function ludou_allow_se() {
global $post;
//添加验证字段
wp_nonce_field('ludou_allow_se', 'ludou_allow_se_nonce');
$meta_value = get_post_meta($post->ID, 'ludou_allow_se', true);
if($meta_value)
echo ' 屏蔽搜索引擎';
else
echo ' 屏蔽搜索引擎';
}
// 保存选项设置
function ludouse_save_postdata($post_id) {
// 验证
if ( !isset( $_POST['ludou_allow_se_nonce']))
return $post_id;
$nonce = $_POST['ludou_allow_se_nonce'];
// 验证字段是否合法
if (!wp_verify_nonce( $nonce, 'ludou_allow_se'))
return $post_id;
// 判断是否自动保存
if (defined('DOING_AUTOSAVE') && DOING_AUTOSAVE)
return $post_id;
// 验证用户权限
if ('page' == $_POST['post_type']) {
if ( !current_user_can('edit_page', $post_id))
return $post_id;
}
else {
if (!current_user_can('edit_post', $post_id))
return $post_id;
}
// 更新设置
if(!empty($_POST['ludou-allow-se']))
update_post_meta($post_id, 'ludou_allow_se', '1');
else
update_post_meta($post_id, 'ludou_allow_se', '0');
}
add_action('save_post', 'ludouse_save_postdata');
// 对于设置不允许抓取文章和页面
// 禁止搜索引擎抓取,返回404
function do_ludou_allow_se() {
// 本功能只对文章和页面有效
if(is_singular()) {
global $post;
$is_robots = 0;
$ludou_allow_se = get_post_meta($post->ID, 'ludou_allow_se', true);
if(!empty($ludou_allow_se)) {
// 下面是爬虫Agent判断关键字数组
// 有点简单,自己优化一下吧
$bots = array(
'spider',
'bot',
'crawl',
'Slurp',
'yahoo-blogs',
'Yandex',
'Yeti',
'blogsearch',
'ia_archive',
'Google',
'baidu'
);
$useragent = $_SERVER['HTTP_USER_AGENT'];
if(!empty($useragent)) {
foreach ($bots as $lookfor) {
if (stristr($useragent, $lookfor) !== false) {
$is_robots = 1;
break;
}
}
}
// 如果当前文章/页面禁止搜索引擎抓取,返回404
// 当然你可以改成403
if($is_robots) {
status_header(404);
exit;
}
}
}
}
add_action('wp', 'do_ludou_allow_se');
二、优化方法
当我们将上述代码添加到主题“functions.php”中时,WordPress后台的文章编辑页面会出现一个文件拦截搜索引擎按钮。如果你想要某篇文章文章不要检查它是否被搜索引擎抓取。
但是上面的代码是勾选时,被勾选的文章在被搜索引擎访问时会返回404状态。如果您担心返回404死链接会影响SEO,那么我们可以使用以下代码。
但前提是你先在主题文件的“header.php”中添加一个meta语句告诉搜索引擎不要收录这个页面。
并且以下代码必须在您的主题 header.php 文件中:
wp_head();
然后在主题“functions.php”文件中添加如下优化代码。当然,如果有问题,我们可以选择不使用优化后的代码,因为你设置不为收录的页面肯定很少,所以不会对搜索引擎造成太大影响。
// 站点开启了页面缓存,此功能无效
function ludouse_add_custom_box() {
if (function_exists('add_meta_box')) {
add_meta_box('ludou_allow_se', '搜索引擎', 'ludou_allow_se', 'post', 'side', 'low');
add_meta_box('ludou_allow_se', '搜索引擎', 'ludou_allow_se', 'page', 'side', 'low');
}
}
add_action('add_meta_boxes', 'ludouse_add_custom_box');
function ludou_allow_se() {
global $post;
//添加验证字段
wp_nonce_field('ludou_allow_se', 'ludou_allow_se_nonce');
$meta_value = get_post_meta($post->ID, 'ludou_allow_se', true);
if($meta_value)
echo ' 屏蔽搜索引擎';
else
echo ' 屏蔽搜索引擎';
}
// 保存选项设置
function ludouse_save_postdata($post_id) {
// 验证
if ( !isset( $_POST['ludou_allow_se_nonce']))
return $post_id;
$nonce = $_POST['ludou_allow_se_nonce'];
// 验证字段是否合法
if (!wp_verify_nonce( $nonce, 'ludou_allow_se'))
return $post_id;
// 判断是否自动保存
if (defined('DOING_AUTOSAVE') && DOING_AUTOSAVE)
return $post_id;
// 验证用户权限
if ('page' == $_POST['post_type']) {
if ( !current_user_can('edit_page', $post_id))
return $post_id;
}
else {
if (!current_user_can('edit_post', $post_id))
return $post_id;
}
// 更新设置
if(!empty($_POST['ludou-allow-se']))
update_post_meta($post_id, 'ludou_allow_se', '1');
else
update_post_meta($post_id, 'ludou_allow_se', '0');
}
add_action('save_post', 'ludouse_save_postdata');
// 对于设置不允许抓取文章和页面
// 禁止搜索引擎抓取,返回404
function do_ludou_allow_se() {
// 本功能只对文章和页面有效
if(is_singular()) {
global $post;
$is_robots = 0;
$ludou_allow_se = get_post_meta($post->ID, 'ludou_allow_se', true);
if(!empty($ludou_allow_se)) {
// 下面是爬虫Agent判断关键字数组
// 有点简单,自己优化一下吧
$bots = array(
'spider',
'bot',
'crawl',
'Slurp',
'yahoo-blogs',
'Yandex',
'Yeti',
'blogsearch',
'ia_archive',
'Google',
'baidu'
);
$useragent = $_SERVER['HTTP_USER_AGENT'];
if(!empty($useragent)) {
foreach ($bots as $lookfor) {
if (stristr($useragent, $lookfor) !== false) {
$is_robots = 1;
break;
}
}
}
// 如果当前文章/页面禁止搜索引擎抓取,返回404
// 当然你可以改成403
if($is_robots) {
echo "\n";
}
}
}
}
add_action('wp_head', 'do_ludou_allow_se'); 查看全部
php禁止网页抓取(代码添加一个屏蔽功能更为方便方便!!!
)
由于 WordPress 是一个开源博客程序,因此受到世界各地许多用户的喜爱。也会有很多个性化的需求。
比如有些文章我们可能不想让搜索引擎抓取,这个可以通过robots实现,但是很麻烦。代码中加入阻塞函数更方便
一、设置方法
方法还是很简单的,就几段代码。我们在主题文件中找到了“functions.php”文件。我们不保证每个主题文件的名称完全相同,但大部分都是一样的。
然后将以下代码添加到“functions.php”文件中。提示:如果您的 WordPress 站点启用了页面缓存,则此功能将不起作用!!
// 站点开启了页面缓存,此功能无效
function ludouse_add_custom_box() {
if (function_exists('add_meta_box')) {
add_meta_box('ludou_allow_se', '搜索引擎', 'ludou_allow_se', 'post', 'side', 'low');
add_meta_box('ludou_allow_se', '搜索引擎', 'ludou_allow_se', 'page', 'side', 'low');
}
}
add_action('add_meta_boxes', 'ludouse_add_custom_box');
function ludou_allow_se() {
global $post;
//添加验证字段
wp_nonce_field('ludou_allow_se', 'ludou_allow_se_nonce');
$meta_value = get_post_meta($post->ID, 'ludou_allow_se', true);
if($meta_value)
echo ' 屏蔽搜索引擎';
else
echo ' 屏蔽搜索引擎';
}
// 保存选项设置
function ludouse_save_postdata($post_id) {
// 验证
if ( !isset( $_POST['ludou_allow_se_nonce']))
return $post_id;
$nonce = $_POST['ludou_allow_se_nonce'];
// 验证字段是否合法
if (!wp_verify_nonce( $nonce, 'ludou_allow_se'))
return $post_id;
// 判断是否自动保存
if (defined('DOING_AUTOSAVE') && DOING_AUTOSAVE)
return $post_id;
// 验证用户权限
if ('page' == $_POST['post_type']) {
if ( !current_user_can('edit_page', $post_id))
return $post_id;
}
else {
if (!current_user_can('edit_post', $post_id))
return $post_id;
}
// 更新设置
if(!empty($_POST['ludou-allow-se']))
update_post_meta($post_id, 'ludou_allow_se', '1');
else
update_post_meta($post_id, 'ludou_allow_se', '0');
}
add_action('save_post', 'ludouse_save_postdata');
// 对于设置不允许抓取文章和页面
// 禁止搜索引擎抓取,返回404
function do_ludou_allow_se() {
// 本功能只对文章和页面有效
if(is_singular()) {
global $post;
$is_robots = 0;
$ludou_allow_se = get_post_meta($post->ID, 'ludou_allow_se', true);
if(!empty($ludou_allow_se)) {
// 下面是爬虫Agent判断关键字数组
// 有点简单,自己优化一下吧
$bots = array(
'spider',
'bot',
'crawl',
'Slurp',
'yahoo-blogs',
'Yandex',
'Yeti',
'blogsearch',
'ia_archive',
'Google',
'baidu'
);
$useragent = $_SERVER['HTTP_USER_AGENT'];
if(!empty($useragent)) {
foreach ($bots as $lookfor) {
if (stristr($useragent, $lookfor) !== false) {
$is_robots = 1;
break;
}
}
}
// 如果当前文章/页面禁止搜索引擎抓取,返回404
// 当然你可以改成403
if($is_robots) {
status_header(404);
exit;
}
}
}
}
add_action('wp', 'do_ludou_allow_se');
二、优化方法
当我们将上述代码添加到主题“functions.php”中时,WordPress后台的文章编辑页面会出现一个文件拦截搜索引擎按钮。如果你想要某篇文章文章不要检查它是否被搜索引擎抓取。
但是上面的代码是勾选时,被勾选的文章在被搜索引擎访问时会返回404状态。如果您担心返回404死链接会影响SEO,那么我们可以使用以下代码。
但前提是你先在主题文件的“header.php”中添加一个meta语句告诉搜索引擎不要收录这个页面。
并且以下代码必须在您的主题 header.php 文件中:
wp_head();
然后在主题“functions.php”文件中添加如下优化代码。当然,如果有问题,我们可以选择不使用优化后的代码,因为你设置不为收录的页面肯定很少,所以不会对搜索引擎造成太大影响。
// 站点开启了页面缓存,此功能无效
function ludouse_add_custom_box() {
if (function_exists('add_meta_box')) {
add_meta_box('ludou_allow_se', '搜索引擎', 'ludou_allow_se', 'post', 'side', 'low');
add_meta_box('ludou_allow_se', '搜索引擎', 'ludou_allow_se', 'page', 'side', 'low');
}
}
add_action('add_meta_boxes', 'ludouse_add_custom_box');
function ludou_allow_se() {
global $post;
//添加验证字段
wp_nonce_field('ludou_allow_se', 'ludou_allow_se_nonce');
$meta_value = get_post_meta($post->ID, 'ludou_allow_se', true);
if($meta_value)
echo ' 屏蔽搜索引擎';
else
echo ' 屏蔽搜索引擎';
}
// 保存选项设置
function ludouse_save_postdata($post_id) {
// 验证
if ( !isset( $_POST['ludou_allow_se_nonce']))
return $post_id;
$nonce = $_POST['ludou_allow_se_nonce'];
// 验证字段是否合法
if (!wp_verify_nonce( $nonce, 'ludou_allow_se'))
return $post_id;
// 判断是否自动保存
if (defined('DOING_AUTOSAVE') && DOING_AUTOSAVE)
return $post_id;
// 验证用户权限
if ('page' == $_POST['post_type']) {
if ( !current_user_can('edit_page', $post_id))
return $post_id;
}
else {
if (!current_user_can('edit_post', $post_id))
return $post_id;
}
// 更新设置
if(!empty($_POST['ludou-allow-se']))
update_post_meta($post_id, 'ludou_allow_se', '1');
else
update_post_meta($post_id, 'ludou_allow_se', '0');
}
add_action('save_post', 'ludouse_save_postdata');
// 对于设置不允许抓取文章和页面
// 禁止搜索引擎抓取,返回404
function do_ludou_allow_se() {
// 本功能只对文章和页面有效
if(is_singular()) {
global $post;
$is_robots = 0;
$ludou_allow_se = get_post_meta($post->ID, 'ludou_allow_se', true);
if(!empty($ludou_allow_se)) {
// 下面是爬虫Agent判断关键字数组
// 有点简单,自己优化一下吧
$bots = array(
'spider',
'bot',
'crawl',
'Slurp',
'yahoo-blogs',
'Yandex',
'Yeti',
'blogsearch',
'ia_archive',
'Google',
'baidu'
);
$useragent = $_SERVER['HTTP_USER_AGENT'];
if(!empty($useragent)) {
foreach ($bots as $lookfor) {
if (stristr($useragent, $lookfor) !== false) {
$is_robots = 1;
break;
}
}
}
// 如果当前文章/页面禁止搜索引擎抓取,返回404
// 当然你可以改成403
if($is_robots) {
echo "\n";
}
}
}
}
add_action('wp_head', 'do_ludou_allow_se');
php禁止网页抓取(如何禁止搜索引擎抓取我们网站的动态网址呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-02 05:02
所谓动态网址是指收录?、&等字符的网址,如news.php?lang=cn&class=1&id=2。当我们开启网站的伪静态时,对于@网站 SEO,要避免搜索引擎爬取我们的动态网址网站。
你为什么要这样做?因为搜索引擎在对同一个页面爬了两次但最终确定是同一个页面后会触发网站。具体处罚不明确。,总之,不利于整个网站的SEO。那么如何禁止搜索引擎抓取我们的动态网址网站呢?
可以使用robots.txt文件来解决这个问题,具体操作请看下面。
我们知道动态页面有一个共同的特点,就是会有一个“?” 链接中的问号符号,因此我们可以在robots.txt文件中写入以下规则:
用户代理: *
不允许: /*?*
这将禁止搜索引擎抓取网站的整个动态链接。另外,如果我们只想让搜索引擎抓取特定类型的文件,比如html格式的静态页面,我们可以在robots.txt中加入如下规则:
用户代理: *
允许:.html$
不允许: /
另外,记得把你写的robots.txt文件放在你的网站的根目录下,否则是不行的。此外,还有一个简单的快捷方式来编写规则。登录google网站管理员工具,在里面写规则,生成robots.txt文件即可。 查看全部
php禁止网页抓取(如何禁止搜索引擎抓取我们网站的动态网址呢?(图))
所谓动态网址是指收录?、&等字符的网址,如news.php?lang=cn&class=1&id=2。当我们开启网站的伪静态时,对于@网站 SEO,要避免搜索引擎爬取我们的动态网址网站。
你为什么要这样做?因为搜索引擎在对同一个页面爬了两次但最终确定是同一个页面后会触发网站。具体处罚不明确。,总之,不利于整个网站的SEO。那么如何禁止搜索引擎抓取我们的动态网址网站呢?
可以使用robots.txt文件来解决这个问题,具体操作请看下面。
我们知道动态页面有一个共同的特点,就是会有一个“?” 链接中的问号符号,因此我们可以在robots.txt文件中写入以下规则:
用户代理: *
不允许: /*?*
这将禁止搜索引擎抓取网站的整个动态链接。另外,如果我们只想让搜索引擎抓取特定类型的文件,比如html格式的静态页面,我们可以在robots.txt中加入如下规则:
用户代理: *
允许:.html$
不允许: /
另外,记得把你写的robots.txt文件放在你的网站的根目录下,否则是不行的。此外,还有一个简单的快捷方式来编写规则。登录google网站管理员工具,在里面写规则,生成robots.txt文件即可。
php禁止网页抓取(怎么禁止这些不遵循robots协议的搜索引擎我们不想的评判)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-02 05:00
相信大家还记得,360搜索引擎刚出来的时候,因为没有遵守robots协议,就被百度抓到了。我们不会判断谁对谁错。今天我们要讨论的是如何禁止这些不遵守机器人协议的搜索。引擎抓取我们不希望它们抓取的内容。
前不久,WordPress官方插件目录中新增了一个名为Blackhole for Bad Bots的插件。这个插件就是用来清理这些不守规矩的搜索引擎蜘蛛的。插件的原理很有意思。一个虚拟链接被添加到 robots.txt 文件中。一旦蜘蛛试图访问它,插件就会禁止蜘蛛访问网站中的其他页面。遵守规则的蜘蛛自然不会访问此链接,可以畅通无阻地抓取网站允许搜索引擎收录的页面。
这相当于设置了一个巧妙的陷阱。如果你遵守规则,我自然欢迎你。你已经踏入了我不守规矩布置的圈套。哈哈,对不起,这里不欢迎你。更棒的是普通用户看不到这个隐藏链接,遵循robots协议的搜索引擎不受影响。
特征
如果你的网站不是基于WordPress的,没关系,只要你使用的语言是PHP,通过Blackhole的独立PHP版本就可以实现同样的功能!
白名单
默认情况下,该插件不会屏蔽以下任何主流搜索引擎。以下搜索引擎默认添加到插件的白名单中。该插件还允许我们在设置中手动将其他搜索引擎添加到白名单中。
如果您的 网站 不是基于 WordPress 构建的,您也可以使用该插件的 PHP 版本。 查看全部
php禁止网页抓取(怎么禁止这些不遵循robots协议的搜索引擎我们不想的评判)
相信大家还记得,360搜索引擎刚出来的时候,因为没有遵守robots协议,就被百度抓到了。我们不会判断谁对谁错。今天我们要讨论的是如何禁止这些不遵守机器人协议的搜索。引擎抓取我们不希望它们抓取的内容。
前不久,WordPress官方插件目录中新增了一个名为Blackhole for Bad Bots的插件。这个插件就是用来清理这些不守规矩的搜索引擎蜘蛛的。插件的原理很有意思。一个虚拟链接被添加到 robots.txt 文件中。一旦蜘蛛试图访问它,插件就会禁止蜘蛛访问网站中的其他页面。遵守规则的蜘蛛自然不会访问此链接,可以畅通无阻地抓取网站允许搜索引擎收录的页面。
这相当于设置了一个巧妙的陷阱。如果你遵守规则,我自然欢迎你。你已经踏入了我不守规矩布置的圈套。哈哈,对不起,这里不欢迎你。更棒的是普通用户看不到这个隐藏链接,遵循robots协议的搜索引擎不受影响。
特征
如果你的网站不是基于WordPress的,没关系,只要你使用的语言是PHP,通过Blackhole的独立PHP版本就可以实现同样的功能!
白名单
默认情况下,该插件不会屏蔽以下任何主流搜索引擎。以下搜索引擎默认添加到插件的白名单中。该插件还允许我们在设置中手动将其他搜索引擎添加到白名单中。
如果您的 网站 不是基于 WordPress 构建的,您也可以使用该插件的 PHP 版本。
php禁止网页抓取(利于网站优化的robots.txt使用技巧及注意事项!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-01 19:22
这篇文章有更多资源!
需要登录才能下载或查看,还没有账号?立即注册
X
Robots.txt 是搜索引擎蜘蛛抓取您的网站时查看的第一个文件。这个文件告诉搜索引擎的蜘蛛程序你网站上哪些文件可以查看,哪些不可以查看。现在主流的搜索引擎还是遵守这个规则的。
robots.txt 是一个文本文件。它必须命名为“robots.txt”并上传到站点的根目录。上传到子目录是无效的,因为搜索引擎机器人只会在你的域名文档的根目录中找到这个。
一、使用针对网站优化的robots.txt的提示
1、在线建站提供了便捷的途径。当我们把域名解析到服务器后,就可以访问站点了,但是此时站点还没有布局,meta标签还是乱七八糟的。如果此时的站点被搜索引擎蜘蛛收录 抓取,则此时更改它不利于 SEO 优化。这时候可以使用robots.txt文件设置所有搜索引擎蜘蛛不查询网站的所有内容。语法格式为:
用户代理: *
不允许: /
复制代码
2、自定义搜索引擎蜘蛛抓取特定内容,让您根据网站情况选择如何处理搜索引擎。这里有两层意思。
(1)自定义搜索引擎。如果你不屑杜娘的做法,你可以让它只盯着你看。语法格式是:
用户代理:baiduspider
不允许: /
复制代码
注意:常见的搜索引擎机器人名称。
名称搜索引擎
百度蜘蛛
小型摩托车
ia_archiver
谷歌机器人
FAST-WebCrawler
啜饮
MSNBOT
(2)自定义站点内容。也就是说可以指定一个目录允许蜘蛛爬行,一个目录禁止爬行。比如所有的搜索引擎蜘蛛都允许爬取的内容目录abc,禁止目录def。如下内容,其语法格式为:
用户代理: *
允许:/abc/
禁止:/def/
复制代码
3、引导搜索引擎获取网站内容。这里最典型的做法是
(1)引导蜘蛛抓取你的网站地图,语法格式为:
用户代理: *
站点地图:站点地图-url
复制代码
(2)防止蜘蛛抓取您的网站重复内容。
4、404 错误页面问题。如果你的服务器响应404错误页面,没有在你站点的根目录配置robots.txt文件,搜索引擎蜘蛛会把它当成robots.txt文件,影响搜索引擎对你的处理<页面的@网站 收录。
二、用特定程序建网站的robots.txt的写法。这里只是提供一个大概的写法,具体情况自己考虑吧!
1、如何为WordPress网站编写robots.txt文件
用户代理: *
禁止:/wp-admin
禁止:/wp-content/plugins
禁止:/wp-content/themes
禁止:/wp-includes
禁止:/?s=
站点地图:***.com/sitemap.xml
复制代码
2、Discuz论坛如何写robots.txt文件
用户代理: *
允许:/redirect.php
允许:/viewthread.php
允许:/forumdisplay.php
不允许: /?
禁止:/*.php
复制代码
有人说设置robots.txt文件会带来被“一厢情愿者”攻击的危险,但既然你是“一厢情愿的人”,那你就没有问题(这不仅仅是建站程序本身,还有服务器安全等)。 查看全部
php禁止网页抓取(利于网站优化的robots.txt使用技巧及注意事项!)
这篇文章有更多资源!
需要登录才能下载或查看,还没有账号?立即注册
X
Robots.txt 是搜索引擎蜘蛛抓取您的网站时查看的第一个文件。这个文件告诉搜索引擎的蜘蛛程序你网站上哪些文件可以查看,哪些不可以查看。现在主流的搜索引擎还是遵守这个规则的。
robots.txt 是一个文本文件。它必须命名为“robots.txt”并上传到站点的根目录。上传到子目录是无效的,因为搜索引擎机器人只会在你的域名文档的根目录中找到这个。
一、使用针对网站优化的robots.txt的提示
1、在线建站提供了便捷的途径。当我们把域名解析到服务器后,就可以访问站点了,但是此时站点还没有布局,meta标签还是乱七八糟的。如果此时的站点被搜索引擎蜘蛛收录 抓取,则此时更改它不利于 SEO 优化。这时候可以使用robots.txt文件设置所有搜索引擎蜘蛛不查询网站的所有内容。语法格式为:
用户代理: *
不允许: /
复制代码
2、自定义搜索引擎蜘蛛抓取特定内容,让您根据网站情况选择如何处理搜索引擎。这里有两层意思。
(1)自定义搜索引擎。如果你不屑杜娘的做法,你可以让它只盯着你看。语法格式是:
用户代理:baiduspider
不允许: /
复制代码
注意:常见的搜索引擎机器人名称。
名称搜索引擎
百度蜘蛛
小型摩托车
ia_archiver
谷歌机器人
FAST-WebCrawler
啜饮
MSNBOT
(2)自定义站点内容。也就是说可以指定一个目录允许蜘蛛爬行,一个目录禁止爬行。比如所有的搜索引擎蜘蛛都允许爬取的内容目录abc,禁止目录def。如下内容,其语法格式为:
用户代理: *
允许:/abc/
禁止:/def/
复制代码
3、引导搜索引擎获取网站内容。这里最典型的做法是
(1)引导蜘蛛抓取你的网站地图,语法格式为:
用户代理: *
站点地图:站点地图-url
复制代码
(2)防止蜘蛛抓取您的网站重复内容。
4、404 错误页面问题。如果你的服务器响应404错误页面,没有在你站点的根目录配置robots.txt文件,搜索引擎蜘蛛会把它当成robots.txt文件,影响搜索引擎对你的处理<页面的@网站 收录。
二、用特定程序建网站的robots.txt的写法。这里只是提供一个大概的写法,具体情况自己考虑吧!
1、如何为WordPress网站编写robots.txt文件
用户代理: *
禁止:/wp-admin
禁止:/wp-content/plugins
禁止:/wp-content/themes
禁止:/wp-includes
禁止:/?s=
站点地图:***.com/sitemap.xml
复制代码
2、Discuz论坛如何写robots.txt文件
用户代理: *
允许:/redirect.php
允许:/viewthread.php
允许:/forumdisplay.php
不允许: /?
禁止:/*.php
复制代码
有人说设置robots.txt文件会带来被“一厢情愿者”攻击的危险,但既然你是“一厢情愿的人”,那你就没有问题(这不仅仅是建站程序本身,还有服务器安全等)。
php禁止网页抓取(robots协议Robots协议(也称为爬虫协议、机器人协议等))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-01 19:20
机器人协议
Robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站通过Robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
机器人.txt
1. 什么是robots.txt?
搜索蜘蛛访问站点时,首先会检查站点根目录下是否存在robots.txt。如果存在,搜索机器人会根据文件内容确定访问范围;如果该文件不存在,所有 'S 搜索蜘蛛将能够访问 网站 上所有不受密码保护的页面。从表面上看,这个功能是有限的。从搜索引擎优化的角度来看,集中权重的效果可以通过拦截页面来实现,这也是优化者最重要的地方。
这个文件必须放在网站的根目录下,并且有字母大小限制,文件名必须是小写字母。所有命令的第一个字母必须大写,其余的必须小写。并且命令后必须有一个英文字符空格。
2.网站设置robots.txt的几个原因
1)设置访问权限以保护网站安全。
2) 禁止搜索引擎抓取无效页面,权重集中在主页面。
3.如何编写标准语法的robots.txt协议?
有几个概念需要掌握。
User-agent表示定义的是哪个搜索引擎,比如User-agent:Baiduspider,定义了百度蜘蛛。
Disallow 表示禁止访问。
允许意味着运行访问。
通过以上三个命令,你可以组合出多种写法,允许哪个搜索引擎访问或者禁止哪个页面。
1) 允许所有搜索引擎访问网站的所有部分
Robots.txt 的写法如下:
用户代理: *
不允许:
或者
用户代理: *
允许: /
注意:第一个英文必须大写。当冒号是英文时,冒号后面有一个空格。这几点不能错。
2)禁止所有搜索引擎访问网站的所有部分
Robots.txt 的写法如下:
用户代理: *
不允许: /
3)允许或禁止访问搜索引擎
禁止访问搜索引擎,例如禁止访问谷歌搜索引擎
用户代理:Googlebot
不允许: /
允许访问某个搜索引擎,例如允许访问百度搜索引擎
用户代理:百度蜘蛛
允许: /
4) 你只需要禁止蜘蛛访问某个目录,比如禁止admin、css、images等目录被索引
Robots.txt 的写法如下:
用户代理: *
禁止:/css/
禁止:/管理员/
禁止:/图像/
注意:路径后面有斜线和不带斜线的区别:比如Disallow:/images/带斜线是禁止抓取整个文件夹的图片,Disallow:/images不带斜线表示有/images路径@> 中的关键词将被阻止。
5) 阻止文件夹 /templets,但可以抓取其中一个文件:/templets/main
Robots.txt 的写法如下:
用户代理: *
禁止:/templets
允许:/main
6) 禁止访问/html/目录(包括子目录)中所有后缀为“.php”的URL
Robots.txt 的写法如下:
用户代理: *
禁止:/html/*.php
7) 只允许访问某个目录下有某个后缀的文件,使用“$”
Robots.txt 的写法如下:
用户代理: *
允许:.html$
不允许: /
8)禁止索引网站中的所有动态页面
例如,带有“?”的域名 这里被限制了,比如index.php?id=1
Robots.txt 的写法如下:
用户代理: *
不允许: /*?*
9)禁止搜索引擎抓取我们网站上的所有图片(如果您的网站使用了其他后缀的图片名称,您也可以在这里直接添加)
有时,为了节省服务器资源,我们需要禁止各种搜索引擎在网站上索引我们的图片。这里的方法除了使用“Disallow:/images/”直接屏蔽文件夹之外。也可以直接屏蔽图片后缀名。
Robots.txt 的写法如下:
用户代理: *
禁止:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
SEO(搜索引擎优化)
4. 写robots.txt要注意什么
1) 第一个英文要大写。当冒号是英文时,冒号后面有一个空格。这几点不能错。
2)斜线:/代表整个网站
3) 如果“/”后面有多余的空格,整个网站都会被阻塞
4)不要禁止正常内容
5) 生效时间是几天到两个月
5. 我什么时候需要使用这个协议?
1)无用页面,很多网站都有联系我们、用户协议等页面。这些页面在搜索引擎优化方面影响不大。这时候就需要使用Disallow命令来禁止这些页面被搜索引擎搜索。抓住。
2)动态页面,企业类站点屏蔽动态页面,有利于网站安全。并且如果多个URL访问同一个页面,权重就会分散。因此,一般情况下,阻塞动态页面并保留静态或伪静态页面。
3) 网站后台页面,网站后台页面也可以归为无用页面。禁止收录百利而无一害。
在这种情况下,有一条灰线表示 robots.txt 正在运行。只是收录网站的地址栏:
Robots.txt 设置禁止搜索引擎访问指令 查看全部
php禁止网页抓取(robots协议Robots协议(也称为爬虫协议、机器人协议等))
机器人协议
Robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站通过Robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
http://www.sujianbao.com/wp-co ... 0.jpg 300w, http://www.sujianbao.com/wp-co ... 2.jpg 220w" />机器人.txt
1. 什么是robots.txt?
搜索蜘蛛访问站点时,首先会检查站点根目录下是否存在robots.txt。如果存在,搜索机器人会根据文件内容确定访问范围;如果该文件不存在,所有 'S 搜索蜘蛛将能够访问 网站 上所有不受密码保护的页面。从表面上看,这个功能是有限的。从搜索引擎优化的角度来看,集中权重的效果可以通过拦截页面来实现,这也是优化者最重要的地方。
这个文件必须放在网站的根目录下,并且有字母大小限制,文件名必须是小写字母。所有命令的第一个字母必须大写,其余的必须小写。并且命令后必须有一个英文字符空格。
2.网站设置robots.txt的几个原因
1)设置访问权限以保护网站安全。
2) 禁止搜索引擎抓取无效页面,权重集中在主页面。
3.如何编写标准语法的robots.txt协议?
有几个概念需要掌握。
User-agent表示定义的是哪个搜索引擎,比如User-agent:Baiduspider,定义了百度蜘蛛。
Disallow 表示禁止访问。
允许意味着运行访问。
通过以上三个命令,你可以组合出多种写法,允许哪个搜索引擎访问或者禁止哪个页面。
1) 允许所有搜索引擎访问网站的所有部分
Robots.txt 的写法如下:
用户代理: *
不允许:
或者
用户代理: *
允许: /
注意:第一个英文必须大写。当冒号是英文时,冒号后面有一个空格。这几点不能错。
2)禁止所有搜索引擎访问网站的所有部分
Robots.txt 的写法如下:
用户代理: *
不允许: /
3)允许或禁止访问搜索引擎
禁止访问搜索引擎,例如禁止访问谷歌搜索引擎
用户代理:Googlebot
不允许: /
允许访问某个搜索引擎,例如允许访问百度搜索引擎
用户代理:百度蜘蛛
允许: /
4) 你只需要禁止蜘蛛访问某个目录,比如禁止admin、css、images等目录被索引
Robots.txt 的写法如下:
用户代理: *
禁止:/css/
禁止:/管理员/
禁止:/图像/
注意:路径后面有斜线和不带斜线的区别:比如Disallow:/images/带斜线是禁止抓取整个文件夹的图片,Disallow:/images不带斜线表示有/images路径@> 中的关键词将被阻止。
5) 阻止文件夹 /templets,但可以抓取其中一个文件:/templets/main
Robots.txt 的写法如下:
用户代理: *
禁止:/templets
允许:/main
6) 禁止访问/html/目录(包括子目录)中所有后缀为“.php”的URL
Robots.txt 的写法如下:
用户代理: *
禁止:/html/*.php
7) 只允许访问某个目录下有某个后缀的文件,使用“$”
Robots.txt 的写法如下:
用户代理: *
允许:.html$
不允许: /
8)禁止索引网站中的所有动态页面
例如,带有“?”的域名 这里被限制了,比如index.php?id=1
Robots.txt 的写法如下:
用户代理: *
不允许: /*?*
9)禁止搜索引擎抓取我们网站上的所有图片(如果您的网站使用了其他后缀的图片名称,您也可以在这里直接添加)
有时,为了节省服务器资源,我们需要禁止各种搜索引擎在网站上索引我们的图片。这里的方法除了使用“Disallow:/images/”直接屏蔽文件夹之外。也可以直接屏蔽图片后缀名。
Robots.txt 的写法如下:
用户代理: *
禁止:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
http://www.sujianbao.com/wp-co ... 4.jpg 300w, http://www.sujianbao.com/wp-co ... 3.jpg 220w" />SEO(搜索引擎优化)
4. 写robots.txt要注意什么
1) 第一个英文要大写。当冒号是英文时,冒号后面有一个空格。这几点不能错。
2)斜线:/代表整个网站
3) 如果“/”后面有多余的空格,整个网站都会被阻塞
4)不要禁止正常内容
5) 生效时间是几天到两个月
5. 我什么时候需要使用这个协议?
1)无用页面,很多网站都有联系我们、用户协议等页面。这些页面在搜索引擎优化方面影响不大。这时候就需要使用Disallow命令来禁止这些页面被搜索引擎搜索。抓住。
2)动态页面,企业类站点屏蔽动态页面,有利于网站安全。并且如果多个URL访问同一个页面,权重就会分散。因此,一般情况下,阻塞动态页面并保留静态或伪静态页面。
3) 网站后台页面,网站后台页面也可以归为无用页面。禁止收录百利而无一害。
在这种情况下,有一条灰线表示 robots.txt 正在运行。只是收录网站的地址栏:
http://www.sujianbao.com/wp-co ... 5.png 300w, http://www.sujianbao.com/wp-co ... 4.png 220w" />Robots.txt 设置禁止搜索引擎访问指令
php禁止网页抓取(张力博客不是:403Forbidden错误的原因以及怎么解决的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-01 19:17
张立博客不提供WordPress相关的付费服务吗?经常有朋友来找我说网站出现403错误,怎么解决,今天给大家带来一个朋友的文章,让你了解403 Forbidden错误的原因和解决方法它。
原文如下:
这几天刚接手一批新做的网站。访问网站时,时不时会出现403 Forbidden错误,浏览器会给出403 Forbidden错误信息,列在Open Access Error中,输出URL后,出现如下错误:
403 禁地
拒绝访问服务器上的此资源!
技术支持 LiteSpeed 网络服务器
LiteSpeed Technologies 不对本网站的管理和内容负责!
403错误是网站访问过程中常见的错误提示。资源不可用,服务器理解客户端的请求,但拒绝处理。通常是由于服务器上的文件或目录的权限设置,例如IIS或apache的访问权限不当造成的。一般会出现如下提示:
一、403 禁止是什么意思?
403 Forbidden 是 HTTP 协议中的一个状态码(Status Code)。可以简单理解为无权访问本站。此状态表示服务器理解请求但拒绝执行任务,不应将请求重新发送到服务器。当 HTTP 请求方法不是“HEAD”,并且服务器想让客户端知道它为什么没有权限时,服务器应该在返回的信息中描述拒绝的原因。在服务器不想提供任何反馈信息的情况下,服务器可以使用 404 Not Found 而不是 403 Forbidden。
二、403错误码分类介绍
403.1
403.1 该错误是由于禁止“执行”访问引起的。如果您尝试从目录中执行 CGI、ISAPI 或其他可执行程序,但该目录不允许该程序执行,则会出现此错误。
403.2
403.2 错误是由“读”访问被禁止引起的。该错误是因为该目录没有默认的网页并且没有开启目录浏览,或者要显示的HTML页面所在的目录只标记了“可执行”或“脚本”权限。
403.3
403.3 该错误是由于禁止“写”访问引起的。尝试将文件上传到目录或修改目录中的文件时会出现此类错误,但该目录不允许“写入”访问错误。
403.4
403.4 错误是由 SSL 的要求引起的。您必须在要查看的网页地址中使用“https”。
403.5
403.5 错误是由需要 128 位加密算法的 Web 浏览器引起的。如果您的浏览器不支持 128 位加密算法,则会出现此错误。您可以连接到 Microsoft网站 执行浏览器升级。
403.6
403.6 错误是由IP地址被拒绝引起的。如果服务器有无法访问站点的IP地址列表,并且您使用的IP地址在列表中,您将返回此错误信息。
403.7
403.7 错误是因为需要客户端证书。当需要访问的资源要求浏览器具有服务器可以识别的安全套接字层 (SSL) 客户端证书时,将返回此错误。
403.8
403.8 错误是由于禁止站点访问引起的。如果服务器有无法访问站点的DNS名称列表,并且您使用的DNS名称在列表中,则会返回此信息。请注意,403.6 和 403.8 的区别是错误的。
403.9
403.9 错误是因为连接的用户太多。当Web服务器很忙,由于流量太大而无法处理请求时,将返回此错误。
403.10
403.10 错误是无效配置导致的错误。当您尝试从目录中执行 CGI、ISAPI 或其他可执行程序,但该目录不允许该程序执行时,将返回此错误。
403.11
403.11 错误是由于密码更改,用户无权查看页面。
403.12
403.12 错误是由映射器拒绝访问引起的。要查看的网页需要有效的客户端证书,当您的客户端证书映射没有访问该网站的权限时,会返回映射器拒绝访问的错误。
403.13
403.13错误是由于要查看的网页需要使用有效的客户端证书,或者无法确定证书是否已被吊销,导致使用的客户端证书已被吊销。
403.14
403.14 错误 Web 服务器配置为不列出此目录的内容并拒绝目录列表。
403.15
403.15 错误是客户端访问权限过多造成的。当服务器超过其客户端访问权限限制时,将返回此错误。
403.16
403.16 错误是由不受信任或无效的客户端证书引起的。
403.17
403.17 错误是因为客户端证书已过期或尚未生效。
三、403错误的主要原因
1、你的IP被列入黑名单。
2、您在一定时间内访问过这个网站(通常是使用采集程序),您的访问被防火墙拒绝。
3、网站 域名解析到空间,但空间没有绑定到这个域名。
4、您的网页脚本文件在当前目录没有执行权限。
5、在不允许写入/创建文件的目录中执行了文件创建/写入操作。 查看全部
php禁止网页抓取(张力博客不是:403Forbidden错误的原因以及怎么解决的方法)
张立博客不提供WordPress相关的付费服务吗?经常有朋友来找我说网站出现403错误,怎么解决,今天给大家带来一个朋友的文章,让你了解403 Forbidden错误的原因和解决方法它。
原文如下:
这几天刚接手一批新做的网站。访问网站时,时不时会出现403 Forbidden错误,浏览器会给出403 Forbidden错误信息,列在Open Access Error中,输出URL后,出现如下错误:
403 禁地
拒绝访问服务器上的此资源!
技术支持 LiteSpeed 网络服务器
LiteSpeed Technologies 不对本网站的管理和内容负责!
403错误是网站访问过程中常见的错误提示。资源不可用,服务器理解客户端的请求,但拒绝处理。通常是由于服务器上的文件或目录的权限设置,例如IIS或apache的访问权限不当造成的。一般会出现如下提示:
https://zhangliseo.com/wp-cont ... 5.png 768w" />一、403 禁止是什么意思?
403 Forbidden 是 HTTP 协议中的一个状态码(Status Code)。可以简单理解为无权访问本站。此状态表示服务器理解请求但拒绝执行任务,不应将请求重新发送到服务器。当 HTTP 请求方法不是“HEAD”,并且服务器想让客户端知道它为什么没有权限时,服务器应该在返回的信息中描述拒绝的原因。在服务器不想提供任何反馈信息的情况下,服务器可以使用 404 Not Found 而不是 403 Forbidden。
二、403错误码分类介绍
403.1
403.1 该错误是由于禁止“执行”访问引起的。如果您尝试从目录中执行 CGI、ISAPI 或其他可执行程序,但该目录不允许该程序执行,则会出现此错误。
403.2
403.2 错误是由“读”访问被禁止引起的。该错误是因为该目录没有默认的网页并且没有开启目录浏览,或者要显示的HTML页面所在的目录只标记了“可执行”或“脚本”权限。
403.3
403.3 该错误是由于禁止“写”访问引起的。尝试将文件上传到目录或修改目录中的文件时会出现此类错误,但该目录不允许“写入”访问错误。
403.4
403.4 错误是由 SSL 的要求引起的。您必须在要查看的网页地址中使用“https”。
403.5
403.5 错误是由需要 128 位加密算法的 Web 浏览器引起的。如果您的浏览器不支持 128 位加密算法,则会出现此错误。您可以连接到 Microsoft网站 执行浏览器升级。
403.6
403.6 错误是由IP地址被拒绝引起的。如果服务器有无法访问站点的IP地址列表,并且您使用的IP地址在列表中,您将返回此错误信息。
403.7
403.7 错误是因为需要客户端证书。当需要访问的资源要求浏览器具有服务器可以识别的安全套接字层 (SSL) 客户端证书时,将返回此错误。
403.8
403.8 错误是由于禁止站点访问引起的。如果服务器有无法访问站点的DNS名称列表,并且您使用的DNS名称在列表中,则会返回此信息。请注意,403.6 和 403.8 的区别是错误的。
403.9
403.9 错误是因为连接的用户太多。当Web服务器很忙,由于流量太大而无法处理请求时,将返回此错误。
403.10
403.10 错误是无效配置导致的错误。当您尝试从目录中执行 CGI、ISAPI 或其他可执行程序,但该目录不允许该程序执行时,将返回此错误。
403.11
403.11 错误是由于密码更改,用户无权查看页面。
403.12
403.12 错误是由映射器拒绝访问引起的。要查看的网页需要有效的客户端证书,当您的客户端证书映射没有访问该网站的权限时,会返回映射器拒绝访问的错误。
403.13
403.13错误是由于要查看的网页需要使用有效的客户端证书,或者无法确定证书是否已被吊销,导致使用的客户端证书已被吊销。
403.14
403.14 错误 Web 服务器配置为不列出此目录的内容并拒绝目录列表。
403.15
403.15 错误是客户端访问权限过多造成的。当服务器超过其客户端访问权限限制时,将返回此错误。
403.16
403.16 错误是由不受信任或无效的客户端证书引起的。
403.17
403.17 错误是因为客户端证书已过期或尚未生效。
三、403错误的主要原因
1、你的IP被列入黑名单。
2、您在一定时间内访问过这个网站(通常是使用采集程序),您的访问被防火墙拒绝。
3、网站 域名解析到空间,但空间没有绑定到这个域名。
4、您的网页脚本文件在当前目录没有执行权限。
5、在不允许写入/创建文件的目录中执行了文件创建/写入操作。
php禁止网页抓取(PHP中可以轻松的使用下面的语句实现禁止页面缓存)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-30 11:07
在 PHP 中,您可以轻松地使用以下语句来禁止页面缓存,但是为了您的方便,很难记住和组织它。
核心代码:
复制代码代码如下:
header("Expires: Mon, 26 Jul 1997 05:00:00 GMT");
header("上次修改:".gmdate("D, d MYH:i:s")." GMT");
header("缓存控制:无缓存,必须重新验证");
header("Pramga: 无缓存");
这对于一些页面很有用,比如:验证码,因为每次生成的验证码肯定是不一样的,否则验证码没有意义,所以可以用上面的语句禁止缓存。
又如:“每次发帖换一张漂亮的图片”,页面缓存必须关闭,否则会返回缓存中相同的图片。
最近在百度联盟看到《英雄联盟》——《如何让网友爱上你的网站》(主要讨论如何提升用户体验),想到一件事:
以论坛为例。用户登录时,会显示登录后的页面,如“管理”、“修改信息”等。当用户退出论坛时,他将再次返回上一页。
还有“管理”、“修改信息”等(因为返回的是缓存页面),虽然此时cookie已经被清空了,但是“管理”、“修改信息”等都没有效果。
但是,用户仍然认为这是一个有效的页面,以便其他人也可以“管理”、“修改信息”等,认为网站 是不安全的(虽然它实际上是安全的)。这时候,在需要进行cookie验证的页面添加以上代码就非常有用了,至少可以消除对用户心理的负面影响。
以上就是PHP禁止页面缓存代码的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php禁止网页抓取(PHP中可以轻松的使用下面的语句实现禁止页面缓存)
在 PHP 中,您可以轻松地使用以下语句来禁止页面缓存,但是为了您的方便,很难记住和组织它。
核心代码:
复制代码代码如下:
header("Expires: Mon, 26 Jul 1997 05:00:00 GMT");
header("上次修改:".gmdate("D, d MYH:i:s")." GMT");
header("缓存控制:无缓存,必须重新验证");
header("Pramga: 无缓存");
这对于一些页面很有用,比如:验证码,因为每次生成的验证码肯定是不一样的,否则验证码没有意义,所以可以用上面的语句禁止缓存。
又如:“每次发帖换一张漂亮的图片”,页面缓存必须关闭,否则会返回缓存中相同的图片。
最近在百度联盟看到《英雄联盟》——《如何让网友爱上你的网站》(主要讨论如何提升用户体验),想到一件事:
以论坛为例。用户登录时,会显示登录后的页面,如“管理”、“修改信息”等。当用户退出论坛时,他将再次返回上一页。
还有“管理”、“修改信息”等(因为返回的是缓存页面),虽然此时cookie已经被清空了,但是“管理”、“修改信息”等都没有效果。
但是,用户仍然认为这是一个有效的页面,以便其他人也可以“管理”、“修改信息”等,认为网站 是不安全的(虽然它实际上是安全的)。这时候,在需要进行cookie验证的页面添加以上代码就非常有用了,至少可以消除对用户心理的负面影响。
以上就是PHP禁止页面缓存代码的详细内容。更多详情请关注其他相关html中文网站文章!
php禁止网页抓取(robots写法大全和robots.txt.语法的作用!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-25 22:12
如何编写robots.txt以及robots.txt语法的作用
1 如果允许所有搜索引擎访问网站的所有部分,我们可以创建一个空白文本文档,命名为robots.txt,并将其放在网站的根目录中。
Robots.txt 的写法如下:
用户代理: *
不允许:
或者
用户代理: *
允许: /
2如果我们禁止所有搜索引擎访问网站的所有部分
Robots.txt 的写法如下:
用户代理: *
不允许: /
3 如果我们需要搜索引擎抓取,比如百度,百度是禁止索引我们的网站词
Robots.txt 的写法如下:
用户代理:百度蜘蛛
不允许: /
4 如果我们禁止谷歌索引我们的网站,其实和例3一样,就是把User-agent:头文件中蜘蛛的名字改成谷歌的Googlebot
能
Robots.txt 的写法如下:
用户代理:Googlebot
不允许: /
5 如果我们禁止除 Google 之外的所有搜索引擎将我们的 网站 词编入索引
Robots.txt 的写法如下:
用户代理:Googlebot
不允许:
用户代理: *
不允许: /
6 如果我们禁止除百度以外的所有搜索引擎索引我们的网站
Robots.txt 的写法如下:
用户代理:百度蜘蛛
不允许:
用户代理: *
不允许: /
7 如果我们需要禁止蜘蛛访问某个目录,比如禁止admin、css、images等目录被索引
Robots.txt 的写法如下:
用户代理: *
禁止:/css/
禁止:/管理员/
禁止:/图像/
8 如果我们允许蜘蛛访问我们网站的某个目录中的某些特定URL
Robots.txt 的写法如下:
用户代理: *
允许:/css/my
允许:/admin/html
允许:/图像/索引
禁止:/css/
禁止:/管理员/
禁止:/图像/
9 我们在一些网站的robots.txt中看到Disallow或Allow中的一些符号,例如问号和星号。如果使用“”,主要是限制访问某个后缀的域名,禁止访问/html/目录(包括子目录)中所有后缀为“.htm”的URL。
Robots.txt 的写法如下:
用户代理: *
禁止:/html/.htm
10 如果我们使用“”,我们只允许访问某个目录中带有某个后缀的文件robots.txt。写法如下: User-agent:∗Allow:.asp" 表示只允许访问某个目录下带有某个后缀的文件robots.txt 写法如下: User-agent:*Allow:.asp"表示只允许访问特定目录中具有特定后缀的文件。Robots.txt 的写法如下: User-agent:∗Allow:.asp
不允许: /
11 如果我们禁止索引网站中的所有动态页面(此处限制带“?”的域名,例如index.asp?id=1)
Robots.txt 的写法如下:
用户代理: *
不允许: /?
有时,为了节省服务器资源,我们需要禁止各种搜索引擎在网站上索引我们的图片。这里的方法除了使用“Disallow:/images/”直接屏蔽文件夹之外。也可以直接屏蔽图片后缀名。
例 12
如果我们禁止Google搜索引擎抓取我们网站上的所有图片(如果您的网站使用了其他后缀的图片名称,您也可以在这里直接添加)
Robots.txt 的写法如下:
用户代理:Googlebot
禁止:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
13 如果我们禁止百度搜索引擎抓取我们网站上的所有图片
Robots.txt 的写法如下:
用户代理:百度蜘蛛
禁止:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
14 除百度和谷歌外,其他搜索引擎禁止抓取您的图片网站
(注意这里,为了让大家看得更清楚,用了一个比较笨的方法——对单个搜索引擎单独定义。)
Robots.txt 的写法如下:
用户代理:百度蜘蛛
允许:.jpeg$
允许:.gif$
允许:.png$
允许:.bmp$
用户代理:Googlebot
允许:.jpeg$
允许:.gif$
允许:.png$
允许:.bmp$
用户代理: *
禁止:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
15 只允许百度抓取网站上的“JPG”格式文件
(其他搜索引擎的方法与此相同,只需修改搜索引擎的蜘蛛名称即可)
Robots.txt 的写法如下:
用户代理:百度蜘蛛
允许:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
16只禁止百度爬取网站上的“JPG”格式文件
Robots.txt 的写法如下:
用户代理:百度蜘蛛
禁止:.jpg$
17如果?代表一个会话 ID,您可以排除所有收录该 ID 的网址,以确保 Googlebot 不会抓取重复的页面。但是,网址以什么结尾?可能是您要收录的页面版本。在这种情况下,可以将 Vaughan 与 Allow 命令结合使用。
Robots.txt 的写法如下:
用户代理:*
允许:/?$
不允许:/?
不允许:/?
一行将阻止收录?(具体来说,它将阻止所有以您的域名开头,后跟任何字符串,然后是问号 (?),然后是任何字符串的 URL)。Allow: /?$ 将允许任何以? (具体来说,它将允许所有以您的域名开头,后跟任何字符串,然后是问号 (?) 的 URL,问号 URL 后没有任何字符)。
18 如果我们想禁止搜索引擎访问某些目录或某些网址,我们可以截取一些名称
Robots.txt 的写法如下:
用户代理:*
不允许:/plus/feedback.php?
以上内容供大家参考。 查看全部
php禁止网页抓取(robots写法大全和robots.txt.语法的作用!)
如何编写robots.txt以及robots.txt语法的作用
1 如果允许所有搜索引擎访问网站的所有部分,我们可以创建一个空白文本文档,命名为robots.txt,并将其放在网站的根目录中。
Robots.txt 的写法如下:
用户代理: *
不允许:
或者
用户代理: *
允许: /
2如果我们禁止所有搜索引擎访问网站的所有部分
Robots.txt 的写法如下:
用户代理: *
不允许: /
3 如果我们需要搜索引擎抓取,比如百度,百度是禁止索引我们的网站词
Robots.txt 的写法如下:
用户代理:百度蜘蛛
不允许: /
4 如果我们禁止谷歌索引我们的网站,其实和例3一样,就是把User-agent:头文件中蜘蛛的名字改成谷歌的Googlebot
能
Robots.txt 的写法如下:
用户代理:Googlebot
不允许: /
5 如果我们禁止除 Google 之外的所有搜索引擎将我们的 网站 词编入索引
Robots.txt 的写法如下:
用户代理:Googlebot
不允许:
用户代理: *
不允许: /
6 如果我们禁止除百度以外的所有搜索引擎索引我们的网站
Robots.txt 的写法如下:
用户代理:百度蜘蛛
不允许:
用户代理: *
不允许: /
7 如果我们需要禁止蜘蛛访问某个目录,比如禁止admin、css、images等目录被索引
Robots.txt 的写法如下:
用户代理: *
禁止:/css/
禁止:/管理员/
禁止:/图像/
8 如果我们允许蜘蛛访问我们网站的某个目录中的某些特定URL
Robots.txt 的写法如下:
用户代理: *
允许:/css/my
允许:/admin/html
允许:/图像/索引
禁止:/css/
禁止:/管理员/
禁止:/图像/
9 我们在一些网站的robots.txt中看到Disallow或Allow中的一些符号,例如问号和星号。如果使用“”,主要是限制访问某个后缀的域名,禁止访问/html/目录(包括子目录)中所有后缀为“.htm”的URL。
Robots.txt 的写法如下:
用户代理: *
禁止:/html/.htm
10 如果我们使用“”,我们只允许访问某个目录中带有某个后缀的文件robots.txt。写法如下: User-agent:∗Allow:.asp" 表示只允许访问某个目录下带有某个后缀的文件robots.txt 写法如下: User-agent:*Allow:.asp"表示只允许访问特定目录中具有特定后缀的文件。Robots.txt 的写法如下: User-agent:∗Allow:.asp
不允许: /
11 如果我们禁止索引网站中的所有动态页面(此处限制带“?”的域名,例如index.asp?id=1)
Robots.txt 的写法如下:
用户代理: *
不允许: /?
有时,为了节省服务器资源,我们需要禁止各种搜索引擎在网站上索引我们的图片。这里的方法除了使用“Disallow:/images/”直接屏蔽文件夹之外。也可以直接屏蔽图片后缀名。
例 12
如果我们禁止Google搜索引擎抓取我们网站上的所有图片(如果您的网站使用了其他后缀的图片名称,您也可以在这里直接添加)
Robots.txt 的写法如下:
用户代理:Googlebot
禁止:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
13 如果我们禁止百度搜索引擎抓取我们网站上的所有图片
Robots.txt 的写法如下:
用户代理:百度蜘蛛
禁止:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
14 除百度和谷歌外,其他搜索引擎禁止抓取您的图片网站
(注意这里,为了让大家看得更清楚,用了一个比较笨的方法——对单个搜索引擎单独定义。)
Robots.txt 的写法如下:
用户代理:百度蜘蛛
允许:.jpeg$
允许:.gif$
允许:.png$
允许:.bmp$
用户代理:Googlebot
允许:.jpeg$
允许:.gif$
允许:.png$
允许:.bmp$
用户代理: *
禁止:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
15 只允许百度抓取网站上的“JPG”格式文件
(其他搜索引擎的方法与此相同,只需修改搜索引擎的蜘蛛名称即可)
Robots.txt 的写法如下:
用户代理:百度蜘蛛
允许:.jpg$
禁止:.jpeg$
禁止:.gif$
禁止:.png$
禁止:.bmp$
16只禁止百度爬取网站上的“JPG”格式文件
Robots.txt 的写法如下:
用户代理:百度蜘蛛
禁止:.jpg$
17如果?代表一个会话 ID,您可以排除所有收录该 ID 的网址,以确保 Googlebot 不会抓取重复的页面。但是,网址以什么结尾?可能是您要收录的页面版本。在这种情况下,可以将 Vaughan 与 Allow 命令结合使用。
Robots.txt 的写法如下:
用户代理:*
允许:/?$
不允许:/?
不允许:/?
一行将阻止收录?(具体来说,它将阻止所有以您的域名开头,后跟任何字符串,然后是问号 (?),然后是任何字符串的 URL)。Allow: /?$ 将允许任何以? (具体来说,它将允许所有以您的域名开头,后跟任何字符串,然后是问号 (?) 的 URL,问号 URL 后没有任何字符)。
18 如果我们想禁止搜索引擎访问某些目录或某些网址,我们可以截取一些名称
Robots.txt 的写法如下:
用户代理:*
不允许:/plus/feedback.php?
以上内容供大家参考。
php禁止网页抓取(我写技术博客有两个原因:CDN服务提供商会分配给你若干个节点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-24 01:01
我写技术博客有两个原因:一是总结我最近的研究成果,二是把这些成果分享给大家。所以就我而言,我还是更喜欢写文章让更多人看到。我最近注意到我博客的大部分流量来自谷歌,几乎没有来自百度。而本文旨在提出这个问题并试图解决它。当然,换成云主机服务商可以很直接很清楚的解决这个问题,但这不是本文的重点,暂不提及。
为什么在 Github Pages 上禁用了百度爬虫?
关于这个问题,我联系了Github Support部门,得到的答复是这样的:
嗨,杰瑞,
很抱歉给您带来麻烦。我们目前正在阻止百度用户代理抓取 GitHub Pages 站点,以响应该用户代理对过多请求负责,这导致了其他 GitHub 客户的可用性问题。
这不太可能很快改变,因此如果您需要百度用户代理能够抓取您的网站,您将需要将其托管在其他地方。
再次对给您带来的不便表示歉意。
干杯,
亚历克斯
简单来说,百度爬虫爬的太猛了,给很多Github用户造成了可用性问题,禁用百度爬虫的举动可能还会继续。(不知道跟之前的大炮有没有关系)
因此,我只能自己做,才能得到足够的温饱。让我们讨论解决这个问题的方法。
解决问题-CDN
那么我们先来了解一下CDN的原理。
CDN原理
CDN的全称是Content Delivery Network,即内容分发网络,一般用于分发静态内容,如图片、视频、CSS、JS文件等。
如果不使用 CDN,所有用户请求将被定向到单个源服务器。如果启用了 CDN 服务,CDN 服务提供商会为您分配多个节点。以上图为例,例如3个东海岸节点和3个西海岸节点分配给您的服务器。
这时,用户不会直接向源服务器发送请求,而是向边缘服务器发送请求。再看下图。当您第一次访问资源 foo.png 时,边缘服务器没有 foo.png 的缓存。所以它会向原创服务器发送请求并获取 foo.png。下一次所有通过这个节点的请求,因为有缓存,不需要再次向源服务器发送请求,而边缘服务器直接返回文件的缓存。这样可以大大减少时延,减少源站的压力。
CDN 服务如何确定您从哪个边缘服务器获取资源?实际上,在发送DNS请求时,您要访问的域名会映射到最近节点的IP。确定哪个是最近的节点,最简单的策略是基于IP,但是每个CDN服务商可能有不同的策略,这里就不展开讨论了。
CDN 的局限性
CDN确实可以解决很多问题,但也有一定的局限性。最重要的一点是:永远不要使用 CDN 来缓存动态内容。
我们来看一个例子,假设服务器端有这样一个PHP文件hello.php:
如果 CDN 缓存了这个文件,将会产生非常糟糕的后果。例如,Jerry 首先访问 hello.php 页面,获取了 Hello, Jerry 的内容。此时内容已经缓存到节点A,Tom离节点A最近,所以当Tom访问hello.php时,会直接得到缓存的内容:Hello, Jerry。这时候,汤姆的心一定是崩溃了。
您还应该避免在以下情况下使用 CDN: 根据用户代理选择返回移动版或桌面版页面。UA判断这对解决我们的问题很重要,下面会提到。当然,Github Pages上部署的网站都是静态站点,所有用户进来看到的内容大体是一样的。所以通过CDN缓存整个站点是没有问题的。
可行性分析
Github使用UA判断百度爬虫,返回403 Forbidden。百度爬虫的UA大致是这样的:
Mozilla/5.0(兼容;Baiduspider/2.0;+)
那么使用CDN解决这个问题的关键就是让百度爬虫不直接向Github服务器发送请求,而是通过CDN边缘服务器的缓存抓取网站的内容。边缘服务器本身不关心UA,所以问题解决了。
但问题真的这么简单吗?
并不真地。
来看看,我使用百度站长工具进行爬行诊断测试结果:
结果只是偶尔能爬成功,结果很失望吧?下面我们来分析一下原因,先列举一些我目前知道的:
所有成功爬取的页面都访问了209.9.130.5个节点
所有爬取失败的页面都访问了209.9.130.6个节点
我的本地ping会ping到209.9.130.8个节点
嗯,细心的同学应该已经发现问题了。大部分百度爬虫请求都指向了209.9.130.6节点,但是这个节点上没有页面缓存。!!如果百度爬虫是页面的第一个访问者,CDN的边缘服务器会使用百度爬虫的UA向Github服务器请求,结果自然是拒绝。
最终我们通过CDN得到了解决这个问题的必要条件:你的博客必须有巨大的流量!只有这样才能保证CDN的每个边缘服务器上都有任意页面的缓存。我认为几乎不可能满足这个要求,除非有像 React 主页这样的 网站。
最后一句话总结:CDN方案不靠谱。
当然,我没有放弃,我做了一些奇怪的事情......首先我找到了所有的BaiduSpider IP,然后我想假装是这些IP来请求内容,以便在所有百度蜘蛛的边缘服务器上可能会爬行。建立缓存。
函数卷曲($url,$ip){
$ch = curl_init();
curl_setopt_array($ch, [
CURLOPT_URL => $url,
CURLOPT_TIMEOUT => 10,
CURLOPT_HEADER => 真, 查看全部
php禁止网页抓取(我写技术博客有两个原因:CDN服务提供商会分配给你若干个节点)
我写技术博客有两个原因:一是总结我最近的研究成果,二是把这些成果分享给大家。所以就我而言,我还是更喜欢写文章让更多人看到。我最近注意到我博客的大部分流量来自谷歌,几乎没有来自百度。而本文旨在提出这个问题并试图解决它。当然,换成云主机服务商可以很直接很清楚的解决这个问题,但这不是本文的重点,暂不提及。
为什么在 Github Pages 上禁用了百度爬虫?
关于这个问题,我联系了Github Support部门,得到的答复是这样的:
嗨,杰瑞,
很抱歉给您带来麻烦。我们目前正在阻止百度用户代理抓取 GitHub Pages 站点,以响应该用户代理对过多请求负责,这导致了其他 GitHub 客户的可用性问题。
这不太可能很快改变,因此如果您需要百度用户代理能够抓取您的网站,您将需要将其托管在其他地方。
再次对给您带来的不便表示歉意。
干杯,
亚历克斯
简单来说,百度爬虫爬的太猛了,给很多Github用户造成了可用性问题,禁用百度爬虫的举动可能还会继续。(不知道跟之前的大炮有没有关系)
因此,我只能自己做,才能得到足够的温饱。让我们讨论解决这个问题的方法。
解决问题-CDN
那么我们先来了解一下CDN的原理。
CDN原理
CDN的全称是Content Delivery Network,即内容分发网络,一般用于分发静态内容,如图片、视频、CSS、JS文件等。
如果不使用 CDN,所有用户请求将被定向到单个源服务器。如果启用了 CDN 服务,CDN 服务提供商会为您分配多个节点。以上图为例,例如3个东海岸节点和3个西海岸节点分配给您的服务器。
这时,用户不会直接向源服务器发送请求,而是向边缘服务器发送请求。再看下图。当您第一次访问资源 foo.png 时,边缘服务器没有 foo.png 的缓存。所以它会向原创服务器发送请求并获取 foo.png。下一次所有通过这个节点的请求,因为有缓存,不需要再次向源服务器发送请求,而边缘服务器直接返回文件的缓存。这样可以大大减少时延,减少源站的压力。
CDN 服务如何确定您从哪个边缘服务器获取资源?实际上,在发送DNS请求时,您要访问的域名会映射到最近节点的IP。确定哪个是最近的节点,最简单的策略是基于IP,但是每个CDN服务商可能有不同的策略,这里就不展开讨论了。
CDN 的局限性
CDN确实可以解决很多问题,但也有一定的局限性。最重要的一点是:永远不要使用 CDN 来缓存动态内容。
我们来看一个例子,假设服务器端有这样一个PHP文件hello.php:
如果 CDN 缓存了这个文件,将会产生非常糟糕的后果。例如,Jerry 首先访问 hello.php 页面,获取了 Hello, Jerry 的内容。此时内容已经缓存到节点A,Tom离节点A最近,所以当Tom访问hello.php时,会直接得到缓存的内容:Hello, Jerry。这时候,汤姆的心一定是崩溃了。
您还应该避免在以下情况下使用 CDN: 根据用户代理选择返回移动版或桌面版页面。UA判断这对解决我们的问题很重要,下面会提到。当然,Github Pages上部署的网站都是静态站点,所有用户进来看到的内容大体是一样的。所以通过CDN缓存整个站点是没有问题的。
可行性分析
Github使用UA判断百度爬虫,返回403 Forbidden。百度爬虫的UA大致是这样的:
Mozilla/5.0(兼容;Baiduspider/2.0;+)
那么使用CDN解决这个问题的关键就是让百度爬虫不直接向Github服务器发送请求,而是通过CDN边缘服务器的缓存抓取网站的内容。边缘服务器本身不关心UA,所以问题解决了。
但问题真的这么简单吗?
并不真地。
来看看,我使用百度站长工具进行爬行诊断测试结果:
结果只是偶尔能爬成功,结果很失望吧?下面我们来分析一下原因,先列举一些我目前知道的:
所有成功爬取的页面都访问了209.9.130.5个节点
所有爬取失败的页面都访问了209.9.130.6个节点
我的本地ping会ping到209.9.130.8个节点
嗯,细心的同学应该已经发现问题了。大部分百度爬虫请求都指向了209.9.130.6节点,但是这个节点上没有页面缓存。!!如果百度爬虫是页面的第一个访问者,CDN的边缘服务器会使用百度爬虫的UA向Github服务器请求,结果自然是拒绝。
最终我们通过CDN得到了解决这个问题的必要条件:你的博客必须有巨大的流量!只有这样才能保证CDN的每个边缘服务器上都有任意页面的缓存。我认为几乎不可能满足这个要求,除非有像 React 主页这样的 网站。
最后一句话总结:CDN方案不靠谱。
当然,我没有放弃,我做了一些奇怪的事情......首先我找到了所有的BaiduSpider IP,然后我想假装是这些IP来请求内容,以便在所有百度蜘蛛的边缘服务器上可能会爬行。建立缓存。
函数卷曲($url,$ip){
$ch = curl_init();
curl_setopt_array($ch, [
CURLOPT_URL => $url,
CURLOPT_TIMEOUT => 10,
CURLOPT_HEADER => 真,
php禁止网页抓取(PHP代码找到如下类似位置,重启Apache即可:找到 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-20 00:14
)
找到如下类似的位置,按照如下代码添加/修改,然后重启Apache:
DocumentRoot /home/wwwroot/xxx
SetEnvIfNoCase User-Agent ".*(FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms)" BADBOT
Order allow,deny
Allow from all
deny from env=BADBOT
二、Nginx 代码
进入nginx安装目录下的conf目录,将以下代码保存为agent_deny.conf
cd /usr/local/nginx/conf
vimagent_deny.conf
#禁止Scrapy等工具的抓取
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
return 403;
}
#禁止指定UA及UA为空的访问
if ($http_user_agent ~ "FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" ) {
return 403;
}
#禁止非GET|HEAD|POST方式的抓取
if ($request_method !~ ^(GET|HEAD|POST)$) {
return 403;
}
然后,在网站位置/{在相关配置中插入以下代码:
include agent_deny.conf;
比如张哥博客的配置:
[[email protected]_Server ~]$ cat /usr/local/nginx/conf/zhangge.conf
location / {
try_files $uri $uri/ /index.php?$args;
#这个位置新增1行:
include agent_deny.conf;
rewrite ^/sitemap_360_sp.txt$ /sitemap_360_sp.php last;
rewrite ^/sitemap_baidu_sp.xml$ /sitemap_baidu_sp.php last;
rewrite ^/sitemap_m.xml$ /sitemap_m.php last;
保存后执行如下命令顺利重启nginx:
/usr/local/nginx/sbin/nginx -s reload
三、PHP 代码
将下面的方法放到网站
入口文件index.php中的第一个
//获取UA信息
$ua = $_SERVER['HTTP_USER_AGENT'];
//将恶意USER_AGENT存入数组
$now_ua = array('FeedDemon ','BOT/0.1 (BOT for JCE)','CrawlDaddy ','Java','Feedly','UniversalFeedParser','ApacheBench','Swiftbot','ZmEu','Indy Library','oBot','jaunty','YandexBot','AhrefsBot','YisouSpider','jikeSpider','MJ12bot','WinHttp','EasouSpider','HttpClient','Microsoft URL Control','YYSpider','jaunty','Python-urllib','lightDeckReports Bot');
//禁止空USER_AGENT,dedecms等主流采集程序都是空USER_AGENT,部分sql注入工具也是空USER_AGENT
if(!$ua) {
header("Content-type: text/html; charset=utf-8");
wp_die('请勿采集本站,因为采集的站长木有小JJ!');
}else{
foreach($now_ua as $value )
//判断是否是数组中存在的UA
if(eregi($value,$ua)) {
header("Content-type: text/html; charset=utf-8");
wp_die('请勿采集本站,因为采集的站长木有小JJ!');
}
}
四、测试结果
如果是vps的话就很简单了,用curl -A模拟爬行就可以了,比如:
模拟一搜蜘蛛爬行:
curl -I -A 'YisouSpider' zhangge.net
用空的 UA 模拟爬行:
curl -I -A '' zhangge.net
模拟百度蜘蛛爬行:
curl -I -A 'Baiduspider' zhangge.net
三个抓取结果截图如下:
可以看出,如果一搜蜘蛛和UA为空,则返回403禁止标志,而百度蜘蛛成功返回200,说明生效!
补充:第二天查看nginx日志效果截图:
①、UA信息为空的垃圾采集被拦截:
②,被禁止的UA被屏蔽了:
因此,对于垃圾蜘蛛的采集,我们可以通过分析网站的访问日志,找出一些我们之前没有见过的蜘蛛的名字。查询无误后,我们可以将它们添加到前面代码的禁止列表中,起到禁止爬取的作用。
五、附录:UA 合集
以下是网上常见的垃圾邮件UA列表,仅供参考,也欢迎大家补充。
FeedDemon 内容采集
BOT/0.1 (BOT for JCE) sql注入
CrawlDaddy sql注入
Java 内容采集
Jullo 内容采集
Feedly 内容采集
UniversalFeedParser 内容采集
ApacheBench cc攻击器
Swiftbot 无用爬虫
YandexBot 无用爬虫
AhrefsBot 无用爬虫
YisouSpider 无用爬虫
jikeSpider 无用爬虫
MJ12bot 无用爬虫
ZmEu phpmyadmin 漏洞扫描
WinHttp 采集cc攻击
EasouSpider 无用爬虫
HttpClient tcp攻击
Microsoft URL Control 扫描
YYSpider 无用爬虫
jaunty wordpress爆破扫描器
oBot 无用爬虫
Python-urllib 内容采集
Indy Library 扫描
FlightDeckReports Bot 无用爬虫
Linguee Bot 无用爬虫 查看全部
php禁止网页抓取(PHP代码找到如下类似位置,重启Apache即可:找到
)
找到如下类似的位置,按照如下代码添加/修改,然后重启Apache:
DocumentRoot /home/wwwroot/xxx
SetEnvIfNoCase User-Agent ".*(FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms)" BADBOT
Order allow,deny
Allow from all
deny from env=BADBOT
二、Nginx 代码
进入nginx安装目录下的conf目录,将以下代码保存为agent_deny.conf
cd /usr/local/nginx/conf
vimagent_deny.conf
#禁止Scrapy等工具的抓取
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
return 403;
}
#禁止指定UA及UA为空的访问
if ($http_user_agent ~ "FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" ) {
return 403;
}
#禁止非GET|HEAD|POST方式的抓取
if ($request_method !~ ^(GET|HEAD|POST)$) {
return 403;
}
然后,在网站位置/{在相关配置中插入以下代码:
include agent_deny.conf;
比如张哥博客的配置:
[[email protected]_Server ~]$ cat /usr/local/nginx/conf/zhangge.conf
location / {
try_files $uri $uri/ /index.php?$args;
#这个位置新增1行:
include agent_deny.conf;
rewrite ^/sitemap_360_sp.txt$ /sitemap_360_sp.php last;
rewrite ^/sitemap_baidu_sp.xml$ /sitemap_baidu_sp.php last;
rewrite ^/sitemap_m.xml$ /sitemap_m.php last;
保存后执行如下命令顺利重启nginx:
/usr/local/nginx/sbin/nginx -s reload
三、PHP 代码
将下面的方法放到网站
入口文件index.php中的第一个
//获取UA信息
$ua = $_SERVER['HTTP_USER_AGENT'];
//将恶意USER_AGENT存入数组
$now_ua = array('FeedDemon ','BOT/0.1 (BOT for JCE)','CrawlDaddy ','Java','Feedly','UniversalFeedParser','ApacheBench','Swiftbot','ZmEu','Indy Library','oBot','jaunty','YandexBot','AhrefsBot','YisouSpider','jikeSpider','MJ12bot','WinHttp','EasouSpider','HttpClient','Microsoft URL Control','YYSpider','jaunty','Python-urllib','lightDeckReports Bot');
//禁止空USER_AGENT,dedecms等主流采集程序都是空USER_AGENT,部分sql注入工具也是空USER_AGENT
if(!$ua) {
header("Content-type: text/html; charset=utf-8");
wp_die('请勿采集本站,因为采集的站长木有小JJ!');
}else{
foreach($now_ua as $value )
//判断是否是数组中存在的UA
if(eregi($value,$ua)) {
header("Content-type: text/html; charset=utf-8");
wp_die('请勿采集本站,因为采集的站长木有小JJ!');
}
}
四、测试结果
如果是vps的话就很简单了,用curl -A模拟爬行就可以了,比如:
模拟一搜蜘蛛爬行:
curl -I -A 'YisouSpider' zhangge.net
用空的 UA 模拟爬行:
curl -I -A '' zhangge.net
模拟百度蜘蛛爬行:
curl -I -A 'Baiduspider' zhangge.net
三个抓取结果截图如下:
可以看出,如果一搜蜘蛛和UA为空,则返回403禁止标志,而百度蜘蛛成功返回200,说明生效!
补充:第二天查看nginx日志效果截图:
①、UA信息为空的垃圾采集被拦截:
②,被禁止的UA被屏蔽了:
因此,对于垃圾蜘蛛的采集,我们可以通过分析网站的访问日志,找出一些我们之前没有见过的蜘蛛的名字。查询无误后,我们可以将它们添加到前面代码的禁止列表中,起到禁止爬取的作用。
五、附录:UA 合集
以下是网上常见的垃圾邮件UA列表,仅供参考,也欢迎大家补充。
FeedDemon 内容采集
BOT/0.1 (BOT for JCE) sql注入
CrawlDaddy sql注入
Java 内容采集
Jullo 内容采集
Feedly 内容采集
UniversalFeedParser 内容采集
ApacheBench cc攻击器
Swiftbot 无用爬虫
YandexBot 无用爬虫
AhrefsBot 无用爬虫
YisouSpider 无用爬虫
jikeSpider 无用爬虫
MJ12bot 无用爬虫
ZmEu phpmyadmin 漏洞扫描
WinHttp 采集cc攻击
EasouSpider 无用爬虫
HttpClient tcp攻击
Microsoft URL Control 扫描
YYSpider 无用爬虫
jaunty wordpress爆破扫描器
oBot 无用爬虫
Python-urllib 内容采集
Indy Library 扫描
FlightDeckReports Bot 无用爬虫
Linguee Bot 无用爬虫
php禁止网页抓取(网站反爬虫的原因常见手段设置站点配置文件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-20 00:12
)
一、概述网站反爬虫常见反爬虫手段的原因
1. 根据IP访问频率封锁IP
2. 设置账号登录时长,账号访问过多被阻塞 设置账号登录限制,只登录显示内容 设置账号登录时长,时间到自动注销
3. 弹出数字验证码和图片确认验证码 爬虫访问次数过多,弹出验证码需要输入
4. API接口限制 限制一个登录账号每天调用后端api接口的次数,对后端api返回的信息进行加密
二、nginx 反爬设置站点配置文件
因为user-agent标记了Bytespider爬虫,所以可以通过Nginx规则限制流氓爬虫的访问,直接返回403错误。修改对应的站点配置文件(注意是在服务器中)
添加红色部分
server {
listen 80 default_server;
listen [::]:80 default_server;
index index.html index.htm index.nginx-debian.html;
server_name _;
location / {
try_files $uri $uri/ =404;
}
#forbidden Scrapy
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
return 403;
}
#forbidden UA
if ($http_user_agent ~ "Bytespider|FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|python-requests|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" ) {
return 403;
}
#forbidden not GET|HEAD|POST method access
if ($request_method !~ ^(GET|HEAD|POST)$) {
return 403;
}
}
附录:UA 集合
FeedDemon 内容采集
BOT/0.1 (BOT for JCE) sql注入
CrawlDaddy sql注入
Java 内容采集
Jullo 内容采集
Feedly 内容采集
UniversalFeedParser 内容采集
ApacheBench cc攻击器
Swiftbot 无用爬虫
YandexBot 无用爬虫
AhrefsBot 无用爬虫
YisouSpider 无用爬虫(已被UC神马搜索收购,此蜘蛛可以放开!)
jikeSpider 无用爬虫
MJ12bot 无用爬虫
ZmEu phpmyadmin 漏洞扫描
WinHttp 采集cc攻击
EasouSpider 无用爬虫
HttpClient tcp攻击
Microsoft URL Control 扫描
YYSpider 无用爬虫
jaunty wordpress爆破扫描器
oBot 无用爬虫
Python-urllib 内容采集
Python-requests 内容采集
Indy Library 扫描
FlightDeckReports Bot 无用爬虫
Linguee Bot 无用爬虫
使用python验证
蟒蛇验证
使用请求模块
import requests
# 最基本的不带参数的get请求
r = requests.get('http://192.168.28.229')
print(r.content)
使用 urllib 模块
import urllib.request
response = urllib.request.urlopen('http://192.168.28.229/')
print(response.read().decode('utf-8'))
返回 403 意味着它有效。
b'\r\n403 Forbidden\r\n\r\n403 Forbidden\r\nnginx\r\n\r\n\r\n'
三、全站防护设置示意图 第一层robots.txt
Robots是网站和爬虫之间的协议。它使用简单直接的txt格式文本方式告诉对应的爬虫允许的权限,也就是说robots.txt是在搜索引擎中访问网站时查看的第一个文件。
注:只是协议规定,是否允许爬取数据收录,不影响网页访问。
注:对于手动履带技术人员,一般直接忽略。
如果所有爬虫蜘蛛都不允许访问,内容如下:
User-agent: *
Disallow: /
第二层useragent特征拦截
因为user-agent标记了Bytespider爬虫,所以可以通过Nginx规则限制流氓爬虫的访问,直接返回403错误。
具体操作请查看上面的nginx配置。
注意:这可以阻止一些爬虫访问,以及初级爬虫。
第三层JS发送鼠标点击事件
对于某些网站,您可以从浏览器打开一个普通页面,但请求中会要求您输入验证码或重定向到其他页面。原理:点击登录时触发js加密码,复杂加密算法参数+时间戳+sig值,参数+时限在后台执行。验证成功后即可登录。
备注:爬虫高手需要模拟浏览器的行为,加载js代码和图片识别,才能正常登录。
第四层后台界面限制
1. 根据IP访问频率屏蔽IP(注意:频率一定要控制好,否则容易误伤。) 2. 设置帐号登录时间,帐号访问被屏蔽太多。设置账号登录限制,只有登录才能显示内容。设置账号登录时长,时间一到自动退出。@4.API 接口的限制。日常登录账号,在请求后端api接口时,限制调用次数。对后台api返回的信息进行加密
通过这4层设置,可以有效保护数据安全。
本文参考链接: 查看全部
php禁止网页抓取(网站反爬虫的原因常见手段设置站点配置文件
)
一、概述网站反爬虫常见反爬虫手段的原因
1. 根据IP访问频率封锁IP
2. 设置账号登录时长,账号访问过多被阻塞 设置账号登录限制,只登录显示内容 设置账号登录时长,时间到自动注销
3. 弹出数字验证码和图片确认验证码 爬虫访问次数过多,弹出验证码需要输入
4. API接口限制 限制一个登录账号每天调用后端api接口的次数,对后端api返回的信息进行加密
二、nginx 反爬设置站点配置文件
因为user-agent标记了Bytespider爬虫,所以可以通过Nginx规则限制流氓爬虫的访问,直接返回403错误。修改对应的站点配置文件(注意是在服务器中)
添加红色部分
server {
listen 80 default_server;
listen [::]:80 default_server;
index index.html index.htm index.nginx-debian.html;
server_name _;
location / {
try_files $uri $uri/ =404;
}
#forbidden Scrapy
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
return 403;
}
#forbidden UA
if ($http_user_agent ~ "Bytespider|FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|python-requests|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" ) {
return 403;
}
#forbidden not GET|HEAD|POST method access
if ($request_method !~ ^(GET|HEAD|POST)$) {
return 403;
}
}
附录:UA 集合
FeedDemon 内容采集
BOT/0.1 (BOT for JCE) sql注入
CrawlDaddy sql注入
Java 内容采集
Jullo 内容采集
Feedly 内容采集
UniversalFeedParser 内容采集
ApacheBench cc攻击器
Swiftbot 无用爬虫
YandexBot 无用爬虫
AhrefsBot 无用爬虫
YisouSpider 无用爬虫(已被UC神马搜索收购,此蜘蛛可以放开!)
jikeSpider 无用爬虫
MJ12bot 无用爬虫
ZmEu phpmyadmin 漏洞扫描
WinHttp 采集cc攻击
EasouSpider 无用爬虫
HttpClient tcp攻击
Microsoft URL Control 扫描
YYSpider 无用爬虫
jaunty wordpress爆破扫描器
oBot 无用爬虫
Python-urllib 内容采集
Python-requests 内容采集
Indy Library 扫描
FlightDeckReports Bot 无用爬虫
Linguee Bot 无用爬虫
使用python验证
蟒蛇验证
使用请求模块
import requests
# 最基本的不带参数的get请求
r = requests.get('http://192.168.28.229')
print(r.content)
使用 urllib 模块
import urllib.request
response = urllib.request.urlopen('http://192.168.28.229/')
print(response.read().decode('utf-8'))
返回 403 意味着它有效。
b'\r\n403 Forbidden\r\n\r\n403 Forbidden\r\nnginx\r\n\r\n\r\n'
三、全站防护设置示意图 第一层robots.txt
Robots是网站和爬虫之间的协议。它使用简单直接的txt格式文本方式告诉对应的爬虫允许的权限,也就是说robots.txt是在搜索引擎中访问网站时查看的第一个文件。
注:只是协议规定,是否允许爬取数据收录,不影响网页访问。
注:对于手动履带技术人员,一般直接忽略。
如果所有爬虫蜘蛛都不允许访问,内容如下:
User-agent: *
Disallow: /
第二层useragent特征拦截
因为user-agent标记了Bytespider爬虫,所以可以通过Nginx规则限制流氓爬虫的访问,直接返回403错误。
具体操作请查看上面的nginx配置。
注意:这可以阻止一些爬虫访问,以及初级爬虫。
第三层JS发送鼠标点击事件
对于某些网站,您可以从浏览器打开一个普通页面,但请求中会要求您输入验证码或重定向到其他页面。原理:点击登录时触发js加密码,复杂加密算法参数+时间戳+sig值,参数+时限在后台执行。验证成功后即可登录。
备注:爬虫高手需要模拟浏览器的行为,加载js代码和图片识别,才能正常登录。
第四层后台界面限制
1. 根据IP访问频率屏蔽IP(注意:频率一定要控制好,否则容易误伤。) 2. 设置帐号登录时间,帐号访问被屏蔽太多。设置账号登录限制,只有登录才能显示内容。设置账号登录时长,时间一到自动退出。@4.API 接口的限制。日常登录账号,在请求后端api接口时,限制调用次数。对后台api返回的信息进行加密
通过这4层设置,可以有效保护数据安全。
本文参考链接:
php禁止网页抓取(搜索引擎使用spider程序自动访问互联网上的网页并获取网页信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-14 03:12
搜索引擎使用蜘蛛程序自动访问互联网上的网页并获取网页信息。当蜘蛛访问一个网站时,它首先会检查网站的根域下是否有一个名为robots.txt的纯文本文件。这个文件是用来指定蜘蛛在你的网站 爬取范围上的。您可以在您的网站中创建一个robots.txt,并在文件中声明网站中不想被搜索引擎收录搜索的部分或指定搜索引擎只是收录 特定部分。
请注意,只有当您的 网站 收录您不想被 收录 搜索的内容时,您才需要使用 robots.txt 文件。如果您想要搜索引擎收录网站 上的所有内容,请不要创建robots.txt 文件。
2. robots.txt 文件在哪里?
robots.txt文件应该放在网站的根目录下。例如,当蜘蛛访问一个网站(例如)时,它会首先检查网站中是否存在该文件。如果蜘蛛找到该文件,它会根据文件的内容确定其访问权限的范围。
网站 URL 对应robots.txt URL
:80/
:80/robots.txt
: 1234/
:1234/robots.txt
3.我在robots.txt中设置了禁止百度收录I网站,为什么还是出现在百度搜索结果中?
如果您的robots.txt文件中设置了禁止收录的其他网站链接,这些网页可能仍会出现在百度的搜索结果中,但您网页上的内容将不会被抓取,索引和显示,百度搜索结果中显示的只是您相关网页的其他网站描述。
4. 禁止搜索引擎跟踪网页链接,只索引网页
如果您不希望搜索引擎跟踪此页面上的链接并且不传递链接的权重,请将此元标记放置在页面的一部分中:
如果您不想让百度跟踪特定链接,百度也支持更精确的控制,请直接在链接上写下这个标记:
登入
要允许其他搜索引擎跟踪,但只阻止百度跟踪指向您页面的链接,请将此元标记放在页面的一部分中:
5. 禁止搜索引擎在搜索结果中显示网页快照,只索引网页
为了防止所有搜索引擎显示您的 网站 快照,请将此元标记放在页面的一部分中:
要允许其他搜索引擎显示快照,但只阻止百度显示,请使用以下标签:
注意:此标签仅禁止百度显示网页快照。百度将继续对网页进行索引,并在搜索结果中显示网页摘要。
6. 我想禁止百度图片搜索收录 部分图片,如何设置?
禁止百度蜘蛛抓取网站上的所有图片,禁止或允许百度蜘蛛抓取网站上特定格式的图片文件可以通过设置robots实现,请参考“robots.txt文件使用示例”示例10、11、12。
7. Robots.txt 文件格式
“robots.txt”文件收录一个或多个记录,由空行分隔(以CR、CR/NL 或NL 作为终止符)。每条记录的格式如下:
":"
可以在这个文件中使用#做注释,具体用法同UNIX中的约定。此文件中的记录通常以一行或多行 User-agent 开头,后跟几行 Disallow 和 Allow 行,详细信息如下:
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被“robots.txt”限制。对于此文件,必须至少有一个用户代理记录。如果此项的值设置为*,则对任何机器人都有效。在“robots.txt”文件中,只能有“User-agent:*”等一条记录。如果您在“robots.txt”文件中添加“User-agent:SomeBot”和几行禁止和允许行,则名称“SomeBot”仅受“User-agent: SomeBot”之后的禁止和允许行的限制。
不允许:
该项的值用于描述一组不想被访问的 URL。该值可以是完整路径或路径的非空前缀。机器人不会访问以 Disallow 项的值开头的 URL。例如,“Disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,而“Disallow:/help/”则允许机器人访问/help.html、/helpabc。 html,而不是访问 /help/index.html。“禁止:”表示允许机器人访问网站的所有URL。“/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”不存在或者是一个空文件,这个网站 对所有搜索引擎机器人都是开放的。
允许:
此项的值用于描述您要访问的一组 URL。与 Disallow 项类似,该值可以是完整路径或路径前缀。机器人可以访问以 Allow 项的值开头的 URL。例如,“Allow:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。一个网站的所有URL默认都是Allow,所以Allow通常和Disallow结合使用,实现允许访问某些网页同时禁止访问其他所有URL的功能。
使用“*”和“$”:
百度蜘蛛支持使用通配符“*”和“$”来模糊匹配URL。
"$" 匹配行尾。
“*”匹配 0 个或多个任意字符。
注:我们将严格遵守机器人的相关协议。请注意区分您不想被抓取的目录或收录 的情况。我们会处理robots中写的文件,你不想被爬取和收录的目录做精确匹配,否则robots协议不会生效。
8. URL 匹配示例
值为 Allow 或 Disallow 的 URL 匹配结果
/tmp
/tmp
是的
/tmp
/tmp.html
是的
/tmp
/tmp/a.html
是的
/tmp
/tmhoho
不
/你好*
/你好.html
是的
/He*lo
/你好,哈哈
是的
/堆*lo
/你好,哈哈
不
html$
/tmpa.html
是的
/a.html$
/a.html
是的
htm$
/a.html
不
9. robots.txt 文件使用示例
示例 1. 禁止所有搜索引擎访问 网站 的任何部分
下载 robots.txt 文件
用户代理: *
不允许: /
示例 2. 允许所有机器人访问
(或者你可以创建一个空文件“/robots.txt”)
用户代理: *
允许: /
比如3.只禁止百度蜘蛛访问你的网站
用户代理:百度蜘蛛
不允许: /
示例 4. 只允许百度蜘蛛访问您的 网站
用户代理:百度蜘蛛
允许: /
用户代理: *
不允许: /
示例 5. 只允许百度蜘蛛和谷歌机器人访问
用户代理:百度蜘蛛
允许: /
用户代理:Googlebot
允许: /
用户代理: *
不允许: /
示例 6. 禁止蜘蛛访问特定目录
本例中网站有3个目录限制搜索引擎访问,即robot不会访问这3个目录。需要注意的是,每个目录必须单独声明,不能写成“Disallow: /cgi-bin/ /tmp/”。
用户代理: *
禁止:/cgi-bin/
禁止:/tmp/
禁止:/~joe/
示例 7. 允许访问特定目录中的某些 URL
用户代理: *
允许:/cgi-bin/see
允许:/tmp/hi
允许:/~joe/look
禁止:/cgi-bin/
禁止:/tmp/
禁止:/~joe/
示例 8. 使用“*”限制对 url 的访问
禁止访问/cgi-bin/目录下所有后缀为“.htm”的URL(包括子目录)。
用户代理: *
禁止:/cgi-bin/*.htm
示例 9. 使用“$”限制对 url 的访问
只允许访问带有“.htm”后缀的 URL。
用户代理: *
允许:/*.htm$
不允许: /
示例1 0.禁止访问网站中的所有动态页面
用户代理: *
不允许: /*?*
示例11.禁止百度蜘蛛抓取网站上的所有图片
只允许抓取网页,不允许抓取图片。
用户代理:百度蜘蛛
禁止:/*.jpg$
禁止:/*.jpeg$
禁止:/*.gif$
禁止:/*.png$
禁止:/*.bmp$
示例12.只允许百度蜘蛛抓取.gif格式的网页和图片
允许抓取网页和gif格式的图片,但不允许抓取其他格式的图片
用户代理:百度蜘蛛
允许:/*.gif$
禁止:/*.jpg$
禁止:/*.jpeg$
禁止:/*.png$
禁止:/*.bmp$
示例13.仅禁止百度蜘蛛抓取.jpg格式的图片
用户代理:百度蜘蛛
禁止:/*.jpg$
10. robots.txt 文件参考
关于robots.txt文件更具体的设置,请参考以下链接:
机器人排除协议的 Web 服务器管理员指南
机器人排除协议的 HTML 作者指南
最初的 1994 年协议描述,目前已部署
修订后的 Internet-Draft 规范,尚未完成或实施 查看全部
php禁止网页抓取(搜索引擎使用spider程序自动访问互联网上的网页并获取网页信息)
搜索引擎使用蜘蛛程序自动访问互联网上的网页并获取网页信息。当蜘蛛访问一个网站时,它首先会检查网站的根域下是否有一个名为robots.txt的纯文本文件。这个文件是用来指定蜘蛛在你的网站 爬取范围上的。您可以在您的网站中创建一个robots.txt,并在文件中声明网站中不想被搜索引擎收录搜索的部分或指定搜索引擎只是收录 特定部分。
请注意,只有当您的 网站 收录您不想被 收录 搜索的内容时,您才需要使用 robots.txt 文件。如果您想要搜索引擎收录网站 上的所有内容,请不要创建robots.txt 文件。
2. robots.txt 文件在哪里?
robots.txt文件应该放在网站的根目录下。例如,当蜘蛛访问一个网站(例如)时,它会首先检查网站中是否存在该文件。如果蜘蛛找到该文件,它会根据文件的内容确定其访问权限的范围。
网站 URL 对应robots.txt URL
:80/
:80/robots.txt
: 1234/
:1234/robots.txt
3.我在robots.txt中设置了禁止百度收录I网站,为什么还是出现在百度搜索结果中?
如果您的robots.txt文件中设置了禁止收录的其他网站链接,这些网页可能仍会出现在百度的搜索结果中,但您网页上的内容将不会被抓取,索引和显示,百度搜索结果中显示的只是您相关网页的其他网站描述。
4. 禁止搜索引擎跟踪网页链接,只索引网页
如果您不希望搜索引擎跟踪此页面上的链接并且不传递链接的权重,请将此元标记放置在页面的一部分中:
如果您不想让百度跟踪特定链接,百度也支持更精确的控制,请直接在链接上写下这个标记:
登入
要允许其他搜索引擎跟踪,但只阻止百度跟踪指向您页面的链接,请将此元标记放在页面的一部分中:
5. 禁止搜索引擎在搜索结果中显示网页快照,只索引网页
为了防止所有搜索引擎显示您的 网站 快照,请将此元标记放在页面的一部分中:
要允许其他搜索引擎显示快照,但只阻止百度显示,请使用以下标签:
注意:此标签仅禁止百度显示网页快照。百度将继续对网页进行索引,并在搜索结果中显示网页摘要。
6. 我想禁止百度图片搜索收录 部分图片,如何设置?
禁止百度蜘蛛抓取网站上的所有图片,禁止或允许百度蜘蛛抓取网站上特定格式的图片文件可以通过设置robots实现,请参考“robots.txt文件使用示例”示例10、11、12。
7. Robots.txt 文件格式
“robots.txt”文件收录一个或多个记录,由空行分隔(以CR、CR/NL 或NL 作为终止符)。每条记录的格式如下:
":"
可以在这个文件中使用#做注释,具体用法同UNIX中的约定。此文件中的记录通常以一行或多行 User-agent 开头,后跟几行 Disallow 和 Allow 行,详细信息如下:
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被“robots.txt”限制。对于此文件,必须至少有一个用户代理记录。如果此项的值设置为*,则对任何机器人都有效。在“robots.txt”文件中,只能有“User-agent:*”等一条记录。如果您在“robots.txt”文件中添加“User-agent:SomeBot”和几行禁止和允许行,则名称“SomeBot”仅受“User-agent: SomeBot”之后的禁止和允许行的限制。
不允许:
该项的值用于描述一组不想被访问的 URL。该值可以是完整路径或路径的非空前缀。机器人不会访问以 Disallow 项的值开头的 URL。例如,“Disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,而“Disallow:/help/”则允许机器人访问/help.html、/helpabc。 html,而不是访问 /help/index.html。“禁止:”表示允许机器人访问网站的所有URL。“/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”不存在或者是一个空文件,这个网站 对所有搜索引擎机器人都是开放的。
允许:
此项的值用于描述您要访问的一组 URL。与 Disallow 项类似,该值可以是完整路径或路径前缀。机器人可以访问以 Allow 项的值开头的 URL。例如,“Allow:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。一个网站的所有URL默认都是Allow,所以Allow通常和Disallow结合使用,实现允许访问某些网页同时禁止访问其他所有URL的功能。
使用“*”和“$”:
百度蜘蛛支持使用通配符“*”和“$”来模糊匹配URL。
"$" 匹配行尾。
“*”匹配 0 个或多个任意字符。
注:我们将严格遵守机器人的相关协议。请注意区分您不想被抓取的目录或收录 的情况。我们会处理robots中写的文件,你不想被爬取和收录的目录做精确匹配,否则robots协议不会生效。
8. URL 匹配示例
值为 Allow 或 Disallow 的 URL 匹配结果
/tmp
/tmp
是的
/tmp
/tmp.html
是的
/tmp
/tmp/a.html
是的
/tmp
/tmhoho
不
/你好*
/你好.html
是的
/He*lo
/你好,哈哈
是的
/堆*lo
/你好,哈哈
不
html$
/tmpa.html
是的
/a.html$
/a.html
是的
htm$
/a.html
不
9. robots.txt 文件使用示例
示例 1. 禁止所有搜索引擎访问 网站 的任何部分
下载 robots.txt 文件
用户代理: *
不允许: /
示例 2. 允许所有机器人访问
(或者你可以创建一个空文件“/robots.txt”)
用户代理: *
允许: /
比如3.只禁止百度蜘蛛访问你的网站
用户代理:百度蜘蛛
不允许: /
示例 4. 只允许百度蜘蛛访问您的 网站
用户代理:百度蜘蛛
允许: /
用户代理: *
不允许: /
示例 5. 只允许百度蜘蛛和谷歌机器人访问
用户代理:百度蜘蛛
允许: /
用户代理:Googlebot
允许: /
用户代理: *
不允许: /
示例 6. 禁止蜘蛛访问特定目录
本例中网站有3个目录限制搜索引擎访问,即robot不会访问这3个目录。需要注意的是,每个目录必须单独声明,不能写成“Disallow: /cgi-bin/ /tmp/”。
用户代理: *
禁止:/cgi-bin/
禁止:/tmp/
禁止:/~joe/
示例 7. 允许访问特定目录中的某些 URL
用户代理: *
允许:/cgi-bin/see
允许:/tmp/hi
允许:/~joe/look
禁止:/cgi-bin/
禁止:/tmp/
禁止:/~joe/
示例 8. 使用“*”限制对 url 的访问
禁止访问/cgi-bin/目录下所有后缀为“.htm”的URL(包括子目录)。
用户代理: *
禁止:/cgi-bin/*.htm
示例 9. 使用“$”限制对 url 的访问
只允许访问带有“.htm”后缀的 URL。
用户代理: *
允许:/*.htm$
不允许: /
示例1 0.禁止访问网站中的所有动态页面
用户代理: *
不允许: /*?*
示例11.禁止百度蜘蛛抓取网站上的所有图片
只允许抓取网页,不允许抓取图片。
用户代理:百度蜘蛛
禁止:/*.jpg$
禁止:/*.jpeg$
禁止:/*.gif$
禁止:/*.png$
禁止:/*.bmp$
示例12.只允许百度蜘蛛抓取.gif格式的网页和图片
允许抓取网页和gif格式的图片,但不允许抓取其他格式的图片
用户代理:百度蜘蛛
允许:/*.gif$
禁止:/*.jpg$
禁止:/*.jpeg$
禁止:/*.png$
禁止:/*.bmp$
示例13.仅禁止百度蜘蛛抓取.jpg格式的图片
用户代理:百度蜘蛛
禁止:/*.jpg$
10. robots.txt 文件参考
关于robots.txt文件更具体的设置,请参考以下链接:
机器人排除协议的 Web 服务器管理员指南
机器人排除协议的 HTML 作者指南
最初的 1994 年协议描述,目前已部署
修订后的 Internet-Draft 规范,尚未完成或实施
php禁止网页抓取(开发小伙伴们要记住的两点:robots.txt是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-11 22:17
“爬虫玩得好,监狱早进;爬虫快乐爬,监狱要坐;数据播放,监狱伙食就够了。” 这种在技术圈广为流传的嘲讽并非危言耸听,因为近年来太多优秀的爬虫程序员为此面临牢狱之灾!
为了避免一些不必要的麻烦,开发伙伴必须牢记以下两点:
一、robots.txt 是什么?
robots.txt 是纯文本文件。在这个文件中,网站管理者可以声明网站中不被搜索引擎访问的部分,或者指定搜索引擎只访问收录指定的内容。
当搜索引擎(也称为搜索机器人或蜘蛛程序)访问一个站点时,它会首先检查站点根目录中是否存在robots.txt。如果存在,搜索机器人会根据文件Scope的内容判断访问;如果文件不存在,搜索机器人会沿着链接爬行。
二、robots.txt的作用
1、引导搜索引擎蜘蛛抓取指定的栏目或内容;
2、网站 修改或URL重写优化时屏蔽对搜索引擎不友好的链接;
3、 屏蔽死链接和404错误页面;
4、 屏蔽没有内容和价值的页面;
5、 屏蔽重复页面,例如评论页和搜索结果页;
6、阻止任何不想成为收录的页面;
7、引导蜘蛛抓取地图网站;
三、Robots 语法(三种语法和两种通配符)
三种语法如下:
1、用户代理:(定义搜索引擎)
例子:
用户代理:*(定义所有搜索引擎)
User-agent:Googlebot(定义谷歌,只允许谷歌蜘蛛抓取)
User-agent: 百度蜘蛛(定义百度,只允许百度蜘蛛爬取)
不同搜索引擎的搜索机器人名称不同,谷歌:Googlebot,百度:Baiduspider,MSN:MSNbot,雅虎:Slurp。
2、Disallow:(用于定义不允许蜘蛛爬取的页面或目录)
例子:
Disallow:/(禁止蜘蛛爬取网站的所有目录,“/”表示根目录)
Disallow: /admin(禁止蜘蛛爬取管理目录)
Disallow: /abc.html(禁止蜘蛛爬到abc.html页面)
Disallow: /help.html(禁止蜘蛛爬到help.html页面)
3、Allow:(用于定义允许蜘蛛爬取的页面或子目录)
例子:
Allow:/admin/test/(允许蜘蛛爬取admin下的test目录)
允许:/admin/abc.html(允许蜘蛛爬到admin目录下的abc.html页面)
两个通配符如下:
4、匹配字符“$”
$ 通配符:匹配 URL 末尾的字符
5、通配符“*”
* 通配符:匹配0个或多个任意字符
四、robots.txt 综合示例
1、禁止搜索引擎抓取特定目录
在这个例子中,网站有三个限制搜索引擎访问的目录,即搜索引擎不会访问这三个目录。
用户代理:* 禁止:/admin/
禁止:/tmp/
禁止:/abc/
2、禁止admin目录,但允许爬取admin目录下的seo子目录
用户代理:* 允许:/admin/seo/
禁止:/管理员/
3、禁止抓取/abc/目录(包括子目录)中所有后缀为“.htm”的URL
用户代理:* 禁止:/abc/*.htm$
4、禁止抓取网站中的所有动态页面
用户代理:* 禁止:/?
用“?”阻止所有文件,以便阻止所有动态路径。
5、百度蜘蛛禁止爬取网站所有图片:
用户代理:百度蜘蛛
禁止:/.jpg$
禁止:/.jpeg$
禁止:/.gif$
禁止:/.png$
禁止:/*.bmp$
6、为了防止 网站 页面被抓取,同时这些页面上仍然展示 AdSense 广告
用户代理:* 禁止:/folder1/
用户代理:Mediapartners-Google
允许:/folder1/
请禁止除 Mediapartners-Google 之外的所有机器人。这可以防止页面出现在搜索结果中,同时允许 Mediapartners-Google 机器人分析页面以确定要显示哪些广告。Mediapartners-Google 机器人不会与其他 Google 用户代理共享网页。
五、备注
1、robots.txt文件必须放在网站的根目录下,不能放在子目录下。
以吴俊泽的博客网站为例:比如可以访问robots.txt文件。
2、robots.txt 文件名必须小写,记得给robot加上“s”。
3、User-agent, Allow, Disallow 的“:”后跟一个字符空格。
4、 路径后加斜线“/”和不加斜线是有区别的
禁止:/帮助
防止蜘蛛访问 /help.html、/helpabc.html、/help/index.html
禁止:/帮助/
防止蜘蛛访问 /help/index.html。但允许访问 /help.html, /helpabc.html
5、Disallow 和 Allow 行的顺序是有意义的:
例如:
允许蜘蛛访问/admin/目录下的seo文件夹
用户代理:* 允许:/admin/seo/
禁止:/管理员/
如果 Allow 和 Disallow 的顺序颠倒:
用户代理:* 禁止:/admin/
允许:/admin/seo/
蜘蛛无法访问/admin/目录下的seo文件夹,因为第一个Disallow:/admin/已经匹配成功。
六、关于机器人元
Robots.txt 文件主要是限制搜索引擎对整个站点或目录的访问,而Robots Meta 标签主要是针对特定页面的。与其他META标签(如使用的语言、页面描述、关键词等)一样,Robots Meta标签也放置在页面上,专门告诉搜索引擎ROBOTS如何抓取内容页面的。
Robots Meta标签没有大小写区分,name="Robots"表示所有搜索引擎,可以针对特定的搜索引擎(如google)编写,内容部分有四个命令选项:index、noindex、 follow, nofollow , 并且说明之间用“,”隔开。
Index指令告诉搜索机器人抓取页面;
NoIndex 命令:告诉搜索引擎不要抓取这个页面
跟随指令意味着搜索机器人可以沿着页面上的链接继续爬行;
NoFollow 命令:告诉搜索引擎不允许从此页面找到链接并拒绝其继续访问。
Robots Meta标签的默认值为Index和Follow;
根据上面的命令,我们有以下四种组合:
你可以抓取这个页面,你可以继续索引这个页面上的其他链接=
您无权抓取此页面,但您可以抓取此页面上的其他链接并将其编入索引
您可以抓取此页面,但不允许抓取此页面上的其他链接并将其编入索引
您不得抓取此页面,也不得沿此页面抓取以索引其他链接。
七、关于
将“nofollow”放在超链接中以告诉搜索引擎不要抓取特定链接。 查看全部
php禁止网页抓取(开发小伙伴们要记住的两点:robots.txt是什么?)
“爬虫玩得好,监狱早进;爬虫快乐爬,监狱要坐;数据播放,监狱伙食就够了。” 这种在技术圈广为流传的嘲讽并非危言耸听,因为近年来太多优秀的爬虫程序员为此面临牢狱之灾!
为了避免一些不必要的麻烦,开发伙伴必须牢记以下两点:
一、robots.txt 是什么?
robots.txt 是纯文本文件。在这个文件中,网站管理者可以声明网站中不被搜索引擎访问的部分,或者指定搜索引擎只访问收录指定的内容。
当搜索引擎(也称为搜索机器人或蜘蛛程序)访问一个站点时,它会首先检查站点根目录中是否存在robots.txt。如果存在,搜索机器人会根据文件Scope的内容判断访问;如果文件不存在,搜索机器人会沿着链接爬行。
二、robots.txt的作用
1、引导搜索引擎蜘蛛抓取指定的栏目或内容;
2、网站 修改或URL重写优化时屏蔽对搜索引擎不友好的链接;
3、 屏蔽死链接和404错误页面;
4、 屏蔽没有内容和价值的页面;
5、 屏蔽重复页面,例如评论页和搜索结果页;
6、阻止任何不想成为收录的页面;
7、引导蜘蛛抓取地图网站;
三、Robots 语法(三种语法和两种通配符)
三种语法如下:
1、用户代理:(定义搜索引擎)
例子:
用户代理:*(定义所有搜索引擎)
User-agent:Googlebot(定义谷歌,只允许谷歌蜘蛛抓取)
User-agent: 百度蜘蛛(定义百度,只允许百度蜘蛛爬取)
不同搜索引擎的搜索机器人名称不同,谷歌:Googlebot,百度:Baiduspider,MSN:MSNbot,雅虎:Slurp。
2、Disallow:(用于定义不允许蜘蛛爬取的页面或目录)
例子:
Disallow:/(禁止蜘蛛爬取网站的所有目录,“/”表示根目录)
Disallow: /admin(禁止蜘蛛爬取管理目录)
Disallow: /abc.html(禁止蜘蛛爬到abc.html页面)
Disallow: /help.html(禁止蜘蛛爬到help.html页面)
3、Allow:(用于定义允许蜘蛛爬取的页面或子目录)
例子:
Allow:/admin/test/(允许蜘蛛爬取admin下的test目录)
允许:/admin/abc.html(允许蜘蛛爬到admin目录下的abc.html页面)
两个通配符如下:
4、匹配字符“$”
$ 通配符:匹配 URL 末尾的字符
5、通配符“*”
* 通配符:匹配0个或多个任意字符
四、robots.txt 综合示例
1、禁止搜索引擎抓取特定目录
在这个例子中,网站有三个限制搜索引擎访问的目录,即搜索引擎不会访问这三个目录。
用户代理:* 禁止:/admin/
禁止:/tmp/
禁止:/abc/
2、禁止admin目录,但允许爬取admin目录下的seo子目录
用户代理:* 允许:/admin/seo/
禁止:/管理员/
3、禁止抓取/abc/目录(包括子目录)中所有后缀为“.htm”的URL
用户代理:* 禁止:/abc/*.htm$
4、禁止抓取网站中的所有动态页面
用户代理:* 禁止:/?
用“?”阻止所有文件,以便阻止所有动态路径。
5、百度蜘蛛禁止爬取网站所有图片:
用户代理:百度蜘蛛
禁止:/.jpg$
禁止:/.jpeg$
禁止:/.gif$
禁止:/.png$
禁止:/*.bmp$
6、为了防止 网站 页面被抓取,同时这些页面上仍然展示 AdSense 广告
用户代理:* 禁止:/folder1/
用户代理:Mediapartners-Google
允许:/folder1/
请禁止除 Mediapartners-Google 之外的所有机器人。这可以防止页面出现在搜索结果中,同时允许 Mediapartners-Google 机器人分析页面以确定要显示哪些广告。Mediapartners-Google 机器人不会与其他 Google 用户代理共享网页。
五、备注
1、robots.txt文件必须放在网站的根目录下,不能放在子目录下。
以吴俊泽的博客网站为例:比如可以访问robots.txt文件。
2、robots.txt 文件名必须小写,记得给robot加上“s”。
3、User-agent, Allow, Disallow 的“:”后跟一个字符空格。
4、 路径后加斜线“/”和不加斜线是有区别的
禁止:/帮助
防止蜘蛛访问 /help.html、/helpabc.html、/help/index.html
禁止:/帮助/
防止蜘蛛访问 /help/index.html。但允许访问 /help.html, /helpabc.html
5、Disallow 和 Allow 行的顺序是有意义的:
例如:
允许蜘蛛访问/admin/目录下的seo文件夹
用户代理:* 允许:/admin/seo/
禁止:/管理员/
如果 Allow 和 Disallow 的顺序颠倒:
用户代理:* 禁止:/admin/
允许:/admin/seo/
蜘蛛无法访问/admin/目录下的seo文件夹,因为第一个Disallow:/admin/已经匹配成功。
六、关于机器人元
Robots.txt 文件主要是限制搜索引擎对整个站点或目录的访问,而Robots Meta 标签主要是针对特定页面的。与其他META标签(如使用的语言、页面描述、关键词等)一样,Robots Meta标签也放置在页面上,专门告诉搜索引擎ROBOTS如何抓取内容页面的。
Robots Meta标签没有大小写区分,name="Robots"表示所有搜索引擎,可以针对特定的搜索引擎(如google)编写,内容部分有四个命令选项:index、noindex、 follow, nofollow , 并且说明之间用“,”隔开。
Index指令告诉搜索机器人抓取页面;
NoIndex 命令:告诉搜索引擎不要抓取这个页面
跟随指令意味着搜索机器人可以沿着页面上的链接继续爬行;
NoFollow 命令:告诉搜索引擎不允许从此页面找到链接并拒绝其继续访问。
Robots Meta标签的默认值为Index和Follow;
根据上面的命令,我们有以下四种组合:
你可以抓取这个页面,你可以继续索引这个页面上的其他链接=
您无权抓取此页面,但您可以抓取此页面上的其他链接并将其编入索引
您可以抓取此页面,但不允许抓取此页面上的其他链接并将其编入索引
您不得抓取此页面,也不得沿此页面抓取以索引其他链接。
七、关于
将“nofollow”放在超链接中以告诉搜索引擎不要抓取特定链接。
php禁止网页抓取(selenium裸浏览器启动配置参数接收是怎样的?【】 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-09 15:10
)
每次selenium启动chrome浏览器的时候,chrome浏览器都很干净,没有插件,没有采集,也没有历史。这是因为 selenium 启动裸浏览器是为了保证启动 chrome 时的最快运行效率。这就是为什么我们需要配置参数,但有时我们需要的不仅仅是一个裸浏览器。
Selenium启动配置参数接收的是ChromeOptions类,创建如下:
from selenium import webdriver
option = webdriver.ChromeOptions()
创建 ChromeOptions 类后,添加参数。添加参数的具体方法有几种,分别对应添加不同类型的配置项。
设置chrome二进制文件位置(binary_location)
from selenium import webdriver
option = webdriver.ChromeOptions()
# 添加启动参数
option.add_argument()
# 添加扩展应用
option.add_extension()
option.add_encoded_extension()
# 添加实验性质的设置参数
option.add_experimental_option()
# 设置调试器地址
option.debugger_address()
常用配置参数:
from selenium import webdriver
option = webdriver.ChromeOptions()
# 添加UA
options.add_argument('user-agent="MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1"')
# 指定浏览器分辨率
options.add_argument('window-size=1920x3000')
# 谷歌文档提到需要加上这个属性来规避bug
chrome_options.add_argument('--disable-gpu')
# 隐藏滚动条, 应对一些特殊页面
options.add_argument('--hide-scrollbars')
# 不加载图片, 提升速度
options.add_argument('blink-settings=imagesEnabled=false')
# 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
options.add_argument('--headless')
# 以最高权限运行
options.add_argument('--no-sandbox')
# 手动指定使用的浏览器位置
options.binary_location = r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe"
#添加crx插件
option.add_extension('d:\crx\AdBlock_v2.17.crx')
# 禁用JavaScript
option.add_argument("--disable-javascript")
# 设置开发者模式启动,该模式下webdriver属性为正常值
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 禁用浏览器弹窗
prefs = {
'profile.default_content_setting_values' : {
'notifications' : 2
}
}
options.add_experimental_option('prefs',prefs)
driver=webdriver.Chrome(chrome_options=chrome_options)
浏览器地址栏参数:
在浏览器地址栏输入以下命令获取相应信息
about:version - 显示当前版本
about:memory - 显示本机浏览器内存使用状况
about:plugins - 显示已安装插件
about:histograms - 显示历史记录
about:dns - 显示DNS状态
about:cache - 显示缓存页面
about:gpu -是否有硬件加速
chrome://extensions/ - 查看已经安装的扩展
其他配置项目参数
–user-data-dir=”[PATH]”
# 指定用户文件夹User Data路径,可以把书签这样的用户数据保存在系统分区以外的分区
–disk-cache-dir=”[PATH]“
# 指定缓存Cache路径
–disk-cache-size=
# 指定Cache大小,单位Byte
–first run
# 重置到初始状态,第一次运行
–incognito
# 隐身模式启动
–disable-javascript
# 禁用Javascript
--omnibox-popup-count="num"
# 将地址栏弹出的提示菜单数量改为num个
--user-agent="xxxxxxxx"
# 修改HTTP请求头部的Agent字符串,可以通过about:version页面查看修改效果
--disable-plugins
# 禁止加载所有插件,可以增加速度。可以通过about:plugins页面查看效果
--disable-javascript
# 禁用JavaScript,如果觉得速度慢在加上这个
--disable-java
# 禁用java
--start-maximized
# 启动就最大化
--no-sandbox
# 取消沙盒模式
--single-process
# 单进程运行
--process-per-tab
# 每个标签使用单独进程
--process-per-site
# 每个站点使用单独进程
--in-process-plugins
# 插件不启用单独进程
--disable-popup-blocking
# 禁用弹出拦截
--disable-plugins
# 禁用插件
--disable-images
# 禁用图像
--incognito
# 启动进入隐身模式
--enable-udd-profiles
# 启用账户切换菜单
--proxy-pac-url
# 使用pac代理 [via 1/2]
--lang=zh-CN
# 设置语言为简体中文
--disk-cache-dir
# 自定义缓存目录
--disk-cache-size
# 自定义缓存最大值(单位byte)
--media-cache-size
# 自定义多媒体缓存最大值(单位byte)
--bookmark-menu
# 在工具 栏增加一个书签按钮
--enable-sync
# 启用书签同步 查看全部
php禁止网页抓取(selenium裸浏览器启动配置参数接收是怎样的?【】
)
每次selenium启动chrome浏览器的时候,chrome浏览器都很干净,没有插件,没有采集,也没有历史。这是因为 selenium 启动裸浏览器是为了保证启动 chrome 时的最快运行效率。这就是为什么我们需要配置参数,但有时我们需要的不仅仅是一个裸浏览器。
Selenium启动配置参数接收的是ChromeOptions类,创建如下:
from selenium import webdriver
option = webdriver.ChromeOptions()
创建 ChromeOptions 类后,添加参数。添加参数的具体方法有几种,分别对应添加不同类型的配置项。
设置chrome二进制文件位置(binary_location)
from selenium import webdriver
option = webdriver.ChromeOptions()
# 添加启动参数
option.add_argument()
# 添加扩展应用
option.add_extension()
option.add_encoded_extension()
# 添加实验性质的设置参数
option.add_experimental_option()
# 设置调试器地址
option.debugger_address()
常用配置参数:
from selenium import webdriver
option = webdriver.ChromeOptions()
# 添加UA
options.add_argument('user-agent="MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1"')
# 指定浏览器分辨率
options.add_argument('window-size=1920x3000')
# 谷歌文档提到需要加上这个属性来规避bug
chrome_options.add_argument('--disable-gpu')
# 隐藏滚动条, 应对一些特殊页面
options.add_argument('--hide-scrollbars')
# 不加载图片, 提升速度
options.add_argument('blink-settings=imagesEnabled=false')
# 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
options.add_argument('--headless')
# 以最高权限运行
options.add_argument('--no-sandbox')
# 手动指定使用的浏览器位置
options.binary_location = r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe"
#添加crx插件
option.add_extension('d:\crx\AdBlock_v2.17.crx')
# 禁用JavaScript
option.add_argument("--disable-javascript")
# 设置开发者模式启动,该模式下webdriver属性为正常值
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 禁用浏览器弹窗
prefs = {
'profile.default_content_setting_values' : {
'notifications' : 2
}
}
options.add_experimental_option('prefs',prefs)
driver=webdriver.Chrome(chrome_options=chrome_options)
浏览器地址栏参数:
在浏览器地址栏输入以下命令获取相应信息
about:version - 显示当前版本
about:memory - 显示本机浏览器内存使用状况
about:plugins - 显示已安装插件
about:histograms - 显示历史记录
about:dns - 显示DNS状态
about:cache - 显示缓存页面
about:gpu -是否有硬件加速
chrome://extensions/ - 查看已经安装的扩展
其他配置项目参数
–user-data-dir=”[PATH]”
# 指定用户文件夹User Data路径,可以把书签这样的用户数据保存在系统分区以外的分区
–disk-cache-dir=”[PATH]“
# 指定缓存Cache路径
–disk-cache-size=
# 指定Cache大小,单位Byte
–first run
# 重置到初始状态,第一次运行
–incognito
# 隐身模式启动
–disable-javascript
# 禁用Javascript
--omnibox-popup-count="num"
# 将地址栏弹出的提示菜单数量改为num个
--user-agent="xxxxxxxx"
# 修改HTTP请求头部的Agent字符串,可以通过about:version页面查看修改效果
--disable-plugins
# 禁止加载所有插件,可以增加速度。可以通过about:plugins页面查看效果
--disable-javascript
# 禁用JavaScript,如果觉得速度慢在加上这个
--disable-java
# 禁用java
--start-maximized
# 启动就最大化
--no-sandbox
# 取消沙盒模式
--single-process
# 单进程运行
--process-per-tab
# 每个标签使用单独进程
--process-per-site
# 每个站点使用单独进程
--in-process-plugins
# 插件不启用单独进程
--disable-popup-blocking
# 禁用弹出拦截
--disable-plugins
# 禁用插件
--disable-images
# 禁用图像
--incognito
# 启动进入隐身模式
--enable-udd-profiles
# 启用账户切换菜单
--proxy-pac-url
# 使用pac代理 [via 1/2]
--lang=zh-CN
# 设置语言为简体中文
--disk-cache-dir
# 自定义缓存目录
--disk-cache-size
# 自定义缓存最大值(单位byte)
--media-cache-size
# 自定义多媒体缓存最大值(单位byte)
--bookmark-menu
# 在工具 栏增加一个书签按钮
--enable-sync
# 启用书签同步

