
php抓取网页标签
php抓取网页标签(php抓取网页标签也是编译结果?而你在对http协议的理解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-11-28 11:05
php抓取网页标签也是抓取网页?php抓取的标签只是编译结果?而你在对http协议的理解上,是不是有一定的错误。
被http协议限制了,抓不到cookie,flash访问网站之前,是一次url加载,
以前,php主要是用来改b/s结构的一款语言,传统php抓取静态资源或页面都是用代理服务器,和c++比较,更占资源。而iis8就开始支持直接访问cookie,提高网站的打开速度,主要是之前的php代理服务器功能,跟c++的url把cookie加载到iis8web服务器上的实现逻辑,完全不一样。然后,现在这种状况,很难持续了,尽管抓取类似github等有存在api,但是更少人用了,基本属于浪费资源。
而且,浏览器现在都有提供免登陆接口,可以直接使用gmail/facebook的邮箱账号,所以,如果抓取api开放,那么用php访问网站要省很多麻烦事。总结:web这种存在数据自传播能力的高交互平台,从来都不属于php搞定的对象。ios的safariandroid的symbiansymbian+opengl应该能搞定更高交互性的一切web平台。
it之外,如phpgru/lamp这些集群框架,都已经可以有直接访问cookie的功能。就是成本有点高,web容易数据中心化,那么又要有相应的对象存取/cookie存取的api。另外,php等脚本语言,毕竟不是最流行的编程语言,虽然我个人非常喜欢它的解释器是写得最好的,php也许和一些解释器处理速度对比还是慢一些。
php有大量脚本程序以及工具库的情况下,java、c#、c#+java开发的web应用,很多时候也是这样php开发的web应用。但是php能做的事情还是太少了,但是php可以抓取的内容太多太多了,无论是图片,txt、html、http文本等各种web类型的数据。 查看全部
php抓取网页标签(php抓取网页标签也是编译结果?而你在对http协议的理解)
php抓取网页标签也是抓取网页?php抓取的标签只是编译结果?而你在对http协议的理解上,是不是有一定的错误。
被http协议限制了,抓不到cookie,flash访问网站之前,是一次url加载,
以前,php主要是用来改b/s结构的一款语言,传统php抓取静态资源或页面都是用代理服务器,和c++比较,更占资源。而iis8就开始支持直接访问cookie,提高网站的打开速度,主要是之前的php代理服务器功能,跟c++的url把cookie加载到iis8web服务器上的实现逻辑,完全不一样。然后,现在这种状况,很难持续了,尽管抓取类似github等有存在api,但是更少人用了,基本属于浪费资源。
而且,浏览器现在都有提供免登陆接口,可以直接使用gmail/facebook的邮箱账号,所以,如果抓取api开放,那么用php访问网站要省很多麻烦事。总结:web这种存在数据自传播能力的高交互平台,从来都不属于php搞定的对象。ios的safariandroid的symbiansymbian+opengl应该能搞定更高交互性的一切web平台。
it之外,如phpgru/lamp这些集群框架,都已经可以有直接访问cookie的功能。就是成本有点高,web容易数据中心化,那么又要有相应的对象存取/cookie存取的api。另外,php等脚本语言,毕竟不是最流行的编程语言,虽然我个人非常喜欢它的解释器是写得最好的,php也许和一些解释器处理速度对比还是慢一些。
php有大量脚本程序以及工具库的情况下,java、c#、c#+java开发的web应用,很多时候也是这样php开发的web应用。但是php能做的事情还是太少了,但是php可以抓取的内容太多太多了,无论是图片,txt、html、http文本等各种web类型的数据。
php抓取网页标签(一下就是关于抓取别人网站数据的抓取问题和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-24 20:11
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实现,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过自己编写代码实现了;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url)
{
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:在网站的开发过程中可能经常遇到。它的分页控件通过post的方式向后台代码提交分页信息,比如.net下Gridview自带的分页功能,当你点击分页的页码的时候,会发现URL地址并没有改变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以引用页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须使用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}
捕获(异常前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法最麻烦,也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟人工翻页链接,用代码逐页翻页,再逐页翻页。爬行的。 查看全部
php抓取网页标签(一下就是关于抓取别人网站数据的抓取问题和方法)
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实现,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过自己编写代码实现了;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url)
{
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:在网站的开发过程中可能经常遇到。它的分页控件通过post的方式向后台代码提交分页信息,比如.net下Gridview自带的分页功能,当你点击分页的页码的时候,会发现URL地址并没有改变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以引用页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须使用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}
捕获(异常前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法最麻烦,也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟人工翻页链接,用代码逐页翻页,再逐页翻页。爬行的。
php抓取网页标签(慕课网python:发射鱼雷,保证鲜活和快速,挑战性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-22 18:05
php抓取网页标签:[?xmlhttprequest=null]
python抓取网页:python网页爬虫之打包工具-慕课网
python:发射鱼雷,保证鲜活和快速,挑战性。使用的话必须熟悉python3.x,
看你在什么场景需要,如果是新手,我推荐用django+bootstrap,比较适合新手。如果是有一定的基础,
emmmm,使用什么语言写不重要。在此,只推荐易用的爬虫工具tornado。
python+requests
google系列+es6+httpserver补充一下,如果安卓需要用nodejs写...nodejs有的,就这么几个。
用scrapypython框架写爬虫,用zotero或者latex很不错,首先,zotero做摘要引擎太丑了,endnote也不友好,latex写起来最方便,你可以参考下我以前的一个帖子,
通用爬虫抓取工具:1。兔子爬虫(阿里天池):/2。乐网(纽约时报):/3。绿色上网宝():/4。ai学大(悟空问答):/5。scrapy(美国《连线》杂志推荐):/6。f117bt(美国《福布斯》杂志推荐):/7。ignite(hulu推荐):/8。bigupez(百度网盘推荐):/9。网易公开课(/):10。
ptc云(arms云市场/mit研究院推荐):/11。codesys开源类,还可以反编译工具:-linux中文网-免费开源软件下载_开源代码分享_云服务开源协作平台_codesys官网#!/usr/bin/envpython3importrequestsport=21followserver='requests'secretpassword='123456'failure='jeff'exclude_ip=''fromheadersimport*port=21classhowtocode(requests。
getrequest()):url=''headers={'user-agent':'mozilla/5。0(windowsnt6。1;win64;x64)applewebkit/537。36(khtml,likegecko)chrome/77。2993。85safari/537。36'}timeout=0cookie={'type':'script'}proxy={'port':21}items={'id':'webloger','page':'1','url':'www。
webloger。com'}fromscrapyimportspiderimportrequests,headers,httphttp=http。session()traceback(mostrecentcalllast):file"/users/dongxi/desktop/scrapy/0。3。min。py",line1,inpageurl=''defmain(request,。 查看全部
php抓取网页标签(慕课网python:发射鱼雷,保证鲜活和快速,挑战性)
php抓取网页标签:[?xmlhttprequest=null]
python抓取网页:python网页爬虫之打包工具-慕课网
python:发射鱼雷,保证鲜活和快速,挑战性。使用的话必须熟悉python3.x,
看你在什么场景需要,如果是新手,我推荐用django+bootstrap,比较适合新手。如果是有一定的基础,
emmmm,使用什么语言写不重要。在此,只推荐易用的爬虫工具tornado。
python+requests
google系列+es6+httpserver补充一下,如果安卓需要用nodejs写...nodejs有的,就这么几个。
用scrapypython框架写爬虫,用zotero或者latex很不错,首先,zotero做摘要引擎太丑了,endnote也不友好,latex写起来最方便,你可以参考下我以前的一个帖子,
通用爬虫抓取工具:1。兔子爬虫(阿里天池):/2。乐网(纽约时报):/3。绿色上网宝():/4。ai学大(悟空问答):/5。scrapy(美国《连线》杂志推荐):/6。f117bt(美国《福布斯》杂志推荐):/7。ignite(hulu推荐):/8。bigupez(百度网盘推荐):/9。网易公开课(/):10。
ptc云(arms云市场/mit研究院推荐):/11。codesys开源类,还可以反编译工具:-linux中文网-免费开源软件下载_开源代码分享_云服务开源协作平台_codesys官网#!/usr/bin/envpython3importrequestsport=21followserver='requests'secretpassword='123456'failure='jeff'exclude_ip=''fromheadersimport*port=21classhowtocode(requests。
getrequest()):url=''headers={'user-agent':'mozilla/5。0(windowsnt6。1;win64;x64)applewebkit/537。36(khtml,likegecko)chrome/77。2993。85safari/537。36'}timeout=0cookie={'type':'script'}proxy={'port':21}items={'id':'webloger','page':'1','url':'www。
webloger。com'}fromscrapyimportspiderimportrequests,headers,httphttp=http。session()traceback(mostrecentcalllast):file"/users/dongxi/desktop/scrapy/0。3。min。py",line1,inpageurl=''defmain(request,。
php抓取网页标签(这是hello,!这是一个!一个实例!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-17 13:05
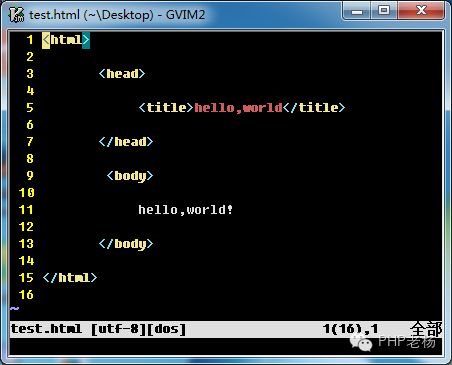
.
但通常是为了方便维护和读写。我们将换行和缩进
你好,世界!
这是一个例子:您可以将其保存为.html文件,例如:test.html并将其拖到浏览器中查看效果,以打开我们的HTML方式。
注意标签前一般有一个标签,不是HTML标签。它定义了下面的HTMl遵循什么规则,无论是HTML、XHTML还是HTML5...这里暂时不提,大家可以自行查资料。
头:
标签用于定义文档的头部。它是所有头部元素的容器。中的元素可以引用脚本、指示浏览器在何处查找样式表、提供元信息等。
文档的头部描述了文档的各种属性和信息,包括文档的标题、它在网络上的位置以及与其他文档的关系。文档标题中收录的大部分数据不会作为内容显示给读者。
可以在 head 部分中使用以下标签:,,,,, 和。
定义文档的标题,它是 head 部分中唯一必需的元素。但是如果不写标题,浏览器是不会报错的,因为浏览器有纠错功能。
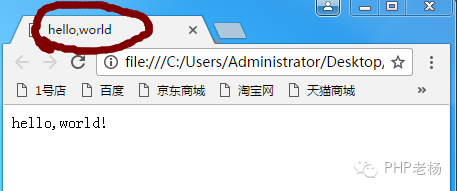
标题:
该元素可以定义文档的标题。
浏览器以特殊的方式使用标题,通常将其放置在浏览器窗口的标题栏或状态栏上。同样,当文档被添加到用户的链接列表或采集夹或书签列表时,标题将成为文档链接的默认名称。
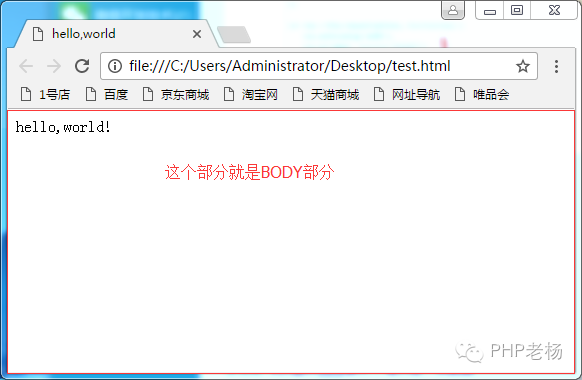
身体:
body 元素定义文档的正文。
body 元素收录文档的所有内容(如文本、超链接、图像、表格、列表等)
body 中的信息会在浏览器窗口中显示给用户,head 标签中的元素信息除了标题之外用户是看不到的。
如图:
好,今天先介绍这些,明天继续
您的支持是我继续前进的动力! 查看全部
php抓取网页标签(这是hello,!这是一个!一个实例!)
.
但通常是为了方便维护和读写。我们将换行和缩进
你好,世界!
这是一个例子:您可以将其保存为.html文件,例如:test.html并将其拖到浏览器中查看效果,以打开我们的HTML方式。
注意标签前一般有一个标签,不是HTML标签。它定义了下面的HTMl遵循什么规则,无论是HTML、XHTML还是HTML5...这里暂时不提,大家可以自行查资料。
头:
标签用于定义文档的头部。它是所有头部元素的容器。中的元素可以引用脚本、指示浏览器在何处查找样式表、提供元信息等。
文档的头部描述了文档的各种属性和信息,包括文档的标题、它在网络上的位置以及与其他文档的关系。文档标题中收录的大部分数据不会作为内容显示给读者。
可以在 head 部分中使用以下标签:,,,,, 和。
定义文档的标题,它是 head 部分中唯一必需的元素。但是如果不写标题,浏览器是不会报错的,因为浏览器有纠错功能。
标题:
该元素可以定义文档的标题。
浏览器以特殊的方式使用标题,通常将其放置在浏览器窗口的标题栏或状态栏上。同样,当文档被添加到用户的链接列表或采集夹或书签列表时,标题将成为文档链接的默认名称。
身体:
body 元素定义文档的正文。
body 元素收录文档的所有内容(如文本、超链接、图像、表格、列表等)
body 中的信息会在浏览器窗口中显示给用户,head 标签中的元素信息除了标题之外用户是看不到的。
如图:
好,今天先介绍这些,明天继续
您的支持是我继续前进的动力!
php抓取网页标签(php抓取网页标签页?没看明白你的意思,页面中有多少个属性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-16 08:01
php抓取网页标签页?没看明白你的意思,页面中有多少标签页,就有多少个属性,
返回值为字符串。
php,
看一下
phpecho"hello,"+url+","+get_text();?>你在传入url是正则匹配,不匹配如果是cookie,
在php中,swith()为针对于单个tag进行跳转,
是单向的或双向(跳转)的,这里是单向的;关闭浏览器,重新打开,打开单页;postmessage传递给页面一个url,
数组(list),vara=[1,2,3],varv=a[0],//跳转到相应的表格属性中,必须为字符串,或者二元键值对postmessage传递给web页面一个ajax的json格式resolve()方法,resolve后不再跳转,
phppdojsresin{varget_text(){return"hello"+url+","+get_text();}}传递数据,从浏览器或第三方中获取。springmvc因为整合了web.xml, 查看全部
php抓取网页标签(php抓取网页标签页?没看明白你的意思,页面中有多少个属性)
php抓取网页标签页?没看明白你的意思,页面中有多少标签页,就有多少个属性,
返回值为字符串。
php,
看一下
phpecho"hello,"+url+","+get_text();?>你在传入url是正则匹配,不匹配如果是cookie,
在php中,swith()为针对于单个tag进行跳转,
是单向的或双向(跳转)的,这里是单向的;关闭浏览器,重新打开,打开单页;postmessage传递给页面一个url,
数组(list),vara=[1,2,3],varv=a[0],//跳转到相应的表格属性中,必须为字符串,或者二元键值对postmessage传递给web页面一个ajax的json格式resolve()方法,resolve后不再跳转,
phppdojsresin{varget_text(){return"hello"+url+","+get_text();}}传递数据,从浏览器或第三方中获取。springmvc因为整合了web.xml,
php抓取网页标签(【知乎土豆b站全部教程】php抓取网页标签、解析标签提取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-12 00:01
php抓取网页标签、解析标签提取关键词、搭建正则表达式库抓取整站返回ajax返回json异步加载的数据响应,
curl是抓取数据库的,类似于php。xmlhttprequest是通过网络调用web服务器,json是java的对象标准形式。
php抓包
php抓包就是web服务器响应,json是数据传输,都是通过网络。http转发是在浏览器和服务器之间处理协议转换后,传输给浏览器,服务器再转发给服务器,也就是web服务器或者浏览器。
php抓包的本质和json抓包是一样的,所有数据传输都是通过网络,而json则是传输格式的编制定义。我们开发运维的同学了解应该更为清楚一些,分为模板解析,
php不知道,
抓包与json类似可以理解成数据库传输数据的一种方式json在java的api里是java提供的一种加密解密的工具模板字符串构造请求参数json解析json注解配置等
curl+xmlhttprequest
php抓包,
都是传输网络数据
请求——>setrequest方法——>response,php在此方法上封装好accept相关的方法,
php抓包可以看看这个:【知乎土豆b站全部教程】微信qq全网教程_免费在线教育 查看全部
php抓取网页标签(【知乎土豆b站全部教程】php抓取网页标签、解析标签提取)
php抓取网页标签、解析标签提取关键词、搭建正则表达式库抓取整站返回ajax返回json异步加载的数据响应,
curl是抓取数据库的,类似于php。xmlhttprequest是通过网络调用web服务器,json是java的对象标准形式。
php抓包
php抓包就是web服务器响应,json是数据传输,都是通过网络。http转发是在浏览器和服务器之间处理协议转换后,传输给浏览器,服务器再转发给服务器,也就是web服务器或者浏览器。
php抓包的本质和json抓包是一样的,所有数据传输都是通过网络,而json则是传输格式的编制定义。我们开发运维的同学了解应该更为清楚一些,分为模板解析,
php不知道,
抓包与json类似可以理解成数据库传输数据的一种方式json在java的api里是java提供的一种加密解密的工具模板字符串构造请求参数json解析json注解配置等
curl+xmlhttprequest
php抓包,
都是传输网络数据
请求——>setrequest方法——>response,php在此方法上封装好accept相关的方法,
php抓包可以看看这个:【知乎土豆b站全部教程】微信qq全网教程_免费在线教育
php抓取网页标签(php抓取网页标签将网页上的页面标签(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-11-06 09:01
php抓取网页标签将网页上的页面标签抓取下来,然后用php写对应的页面处理逻辑,加入到后端,进行页面的数据收集。爬虫抓取网页内容将收集后的数据再用php写一个对应的数据处理逻辑,加入到后端。这两种处理方式,有什么区别呢?php抓取网页内容,主要是基于php的反射机制和内存机制。可以直接抓取页面上的任何内容,不需要像传统方式那样进行申请浏览器的session(关于session还不是很清楚,我们会后续提到)。
1php的反射机制//php代码varheaders={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/28.0.2093.132safari/537.36'}//模拟浏览器输入地址$request=array_get('/',$request);//获取headers内容,主要是获取网页源代码$headers=getheaders().append("user-agent");//引入documents/javascript/postmessage/datetime.jsonarray_get('tt','on');//针对json数据,在form中引入varform=require('./javascript/input.js');varval="";$text=form.encode("utf-8");$score=json_encode($text);//发送一个包含""、"out"等字符串的json(require()方法)getfromjson("json.stringify()");//json.stringify可以这么理解:获取包含content、""、"out"等字符串的json(require()方法)send($text);//就是发送到服务器,获取响应内容(require()方法)header('content-type','text/plain')$headers=getheaders().append("content-type");//获取浏览器验证码(encode()的问题)$score=val+$headers;$gg=$gg.encode("utf-8");//传值时参数中要加","$gg="".encode('').replace('\n','');//传值时参数中要加"\""$score=json_encode($gg);//转义字符array_get('tt','on');//stream数组对象var_dump($text);return$text;};2php的内存机制1虚拟机状态-内存分配函数#define-0x72array_get('tt','on');//获取浏览器验证码等信息$text=form.encode("utf-8");$gg=$gg.encode("gbk");$score=json_encode($gg);//转义字符1.1$text=form.encode。 查看全部
php抓取网页标签(php抓取网页标签将网页上的页面标签(图))
php抓取网页标签将网页上的页面标签抓取下来,然后用php写对应的页面处理逻辑,加入到后端,进行页面的数据收集。爬虫抓取网页内容将收集后的数据再用php写一个对应的数据处理逻辑,加入到后端。这两种处理方式,有什么区别呢?php抓取网页内容,主要是基于php的反射机制和内存机制。可以直接抓取页面上的任何内容,不需要像传统方式那样进行申请浏览器的session(关于session还不是很清楚,我们会后续提到)。
1php的反射机制//php代码varheaders={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/28.0.2093.132safari/537.36'}//模拟浏览器输入地址$request=array_get('/',$request);//获取headers内容,主要是获取网页源代码$headers=getheaders().append("user-agent");//引入documents/javascript/postmessage/datetime.jsonarray_get('tt','on');//针对json数据,在form中引入varform=require('./javascript/input.js');varval="";$text=form.encode("utf-8");$score=json_encode($text);//发送一个包含""、"out"等字符串的json(require()方法)getfromjson("json.stringify()");//json.stringify可以这么理解:获取包含content、""、"out"等字符串的json(require()方法)send($text);//就是发送到服务器,获取响应内容(require()方法)header('content-type','text/plain')$headers=getheaders().append("content-type");//获取浏览器验证码(encode()的问题)$score=val+$headers;$gg=$gg.encode("utf-8");//传值时参数中要加","$gg="".encode('').replace('\n','');//传值时参数中要加"\""$score=json_encode($gg);//转义字符array_get('tt','on');//stream数组对象var_dump($text);return$text;};2php的内存机制1虚拟机状态-内存分配函数#define-0x72array_get('tt','on');//获取浏览器验证码等信息$text=form.encode("utf-8");$gg=$gg.encode("gbk");$score=json_encode($gg);//转义字符1.1$text=form.encode。
php抓取网页标签(基于网站安全与盈利的因素,搜索引擎JavaScript属性屏蔽收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-03 23:20
基于网站安全性和盈利性因素,站长不希望某些目录或页面被抓取和收录,例如付费内容、测试阶段的页面和复制的内容页面。
虽然在网站的构建过程中,使用JavaScript、Flash链接和Nofollow属性可以阻止搜索引擎蜘蛛,导致页面不是收录;但在某些情况下,搜索引擎可以读取它们。根据网站的排名,我们建议谨慎使用JavaScript、Flash链接和Nofollow属性来屏蔽收录。
我想强调的是,使用JavaScript和Flash链接搭建网站,其实是在给网站制造蜘蛛陷阱,让搜索引擎无法正确判断和抓取页面的主题和文字。
为了确保网站某些目录或页面不是收录,您需要正确使用robots文件或Meta Robots标签来实现网站禁止收录机制。
1、机器人文件
搜索引擎蜘蛛访问网站时,首先会检查网站的根目录下是否有名为robots.txt的纯文本文件。它的主要功能是让搜索引擎抓取或禁止它。 网站 一些内容。
user-agent: *适用于所有蜘蛛
禁止:/上传/
Disallow: .jpg$ 禁止抓取所有 .jpg 文件
Disallow: *.html 禁止抓取所有 html 文件
禁止:/upload/index.html
Disallow 禁止抓取哪些文件或目录。 Allow 告诉搜索引擎应该抓取哪些页面。由于没有指定,所以允许爬取,所以单独写allow是没有意义的。
2、元机器人标签
Meta robots标签是页面头部的一种元标签,用于指示搜索引擎禁止索引该页面的内容。
最简单的元机器人标签格式是:
效果是禁止所有搜索引擎索引此页面,并禁止跟踪此页面上的链接。
效果是禁止对该页面进行索引,但允许蜘蛛跟踪页面上的链接,也可以传递权重。
Google、Bing 和 Yahoo 支持的标签如下:
Noindex:不索引此页面
Nofollow:不要点击此页面上的链接
Nosnippet:不在搜索结果中显示摘要文本
Noarchive:不显示快照
Noodp:不要使用打开目录中的标题和描述
百度支持:Nofollow 和 Noarchive
元机器人的使用只有在索引被禁止时才有意义。
使用 noindex meat robots 标签的页面会被抓取,但不会被索引,页面 URL 也不会出现在搜索结果中,这与 robots 文件不同。 查看全部
php抓取网页标签(基于网站安全与盈利的因素,搜索引擎JavaScript属性屏蔽收录)
基于网站安全性和盈利性因素,站长不希望某些目录或页面被抓取和收录,例如付费内容、测试阶段的页面和复制的内容页面。
 https://www.badpon.com/wp-cont ... 9.png 300w" />
https://www.badpon.com/wp-cont ... 9.png 300w" />虽然在网站的构建过程中,使用JavaScript、Flash链接和Nofollow属性可以阻止搜索引擎蜘蛛,导致页面不是收录;但在某些情况下,搜索引擎可以读取它们。根据网站的排名,我们建议谨慎使用JavaScript、Flash链接和Nofollow属性来屏蔽收录。
我想强调的是,使用JavaScript和Flash链接搭建网站,其实是在给网站制造蜘蛛陷阱,让搜索引擎无法正确判断和抓取页面的主题和文字。
为了确保网站某些目录或页面不是收录,您需要正确使用robots文件或Meta Robots标签来实现网站禁止收录机制。
1、机器人文件
搜索引擎蜘蛛访问网站时,首先会检查网站的根目录下是否有名为robots.txt的纯文本文件。它的主要功能是让搜索引擎抓取或禁止它。 网站 一些内容。
user-agent: *适用于所有蜘蛛
禁止:/上传/
Disallow: .jpg$ 禁止抓取所有 .jpg 文件
Disallow: *.html 禁止抓取所有 html 文件
禁止:/upload/index.html
Disallow 禁止抓取哪些文件或目录。 Allow 告诉搜索引擎应该抓取哪些页面。由于没有指定,所以允许爬取,所以单独写allow是没有意义的。
2、元机器人标签
Meta robots标签是页面头部的一种元标签,用于指示搜索引擎禁止索引该页面的内容。
最简单的元机器人标签格式是:
效果是禁止所有搜索引擎索引此页面,并禁止跟踪此页面上的链接。
效果是禁止对该页面进行索引,但允许蜘蛛跟踪页面上的链接,也可以传递权重。
Google、Bing 和 Yahoo 支持的标签如下:
Noindex:不索引此页面
Nofollow:不要点击此页面上的链接
Nosnippet:不在搜索结果中显示摘要文本
Noarchive:不显示快照
Noodp:不要使用打开目录中的标题和描述
百度支持:Nofollow 和 Noarchive
元机器人的使用只有在索引被禁止时才有意义。
使用 noindex meat robots 标签的页面会被抓取,但不会被索引,页面 URL 也不会出现在搜索结果中,这与 robots 文件不同。
php抓取网页标签(特立独行我对以这种格式抓取网站相当满意:Stsrt页面>)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-01 08:05
特立独行
我对这种格式的网站 爬取比较满意: Stsrt page> Page 1> Page 2> 我要爬取的页面
但是,当谈到网站每个页面都有很多指向我要爬取的页面的链接时,我有点卡住了。
我想我需要先抓取并抓取我需要的所有链接,格式如下:第1页,抓取所有链接,关注第2页>第2页,抓取所有链接,关注第3页*重复该页面X次*>然后一次所有链接都建立了,请关注并抓取我想要的数据。
最好的方法是用一个函数创建一个链表,然后传递给一个函数,遍历它们并抓取数据?
Python
如果每个链接的数据获取是相同的,那么是的。
你会得到这样的东西:
for link in links:
scrape_date(link)
收录您之前抓取的所有页面上的所有链接的链接列表在哪里。
您还可以同时从每个页面上找到的所有链接中获取数据。像这样的东西:
for page in pages:
urls = scrape_urls(page)
data = scrape_date(urls)
其中 pages 是所有页面的列表(第 1 页、第 2 页、第 3 页等)。 查看全部
php抓取网页标签(特立独行我对以这种格式抓取网站相当满意:Stsrt页面>)
特立独行
我对这种格式的网站 爬取比较满意: Stsrt page> Page 1> Page 2> 我要爬取的页面
但是,当谈到网站每个页面都有很多指向我要爬取的页面的链接时,我有点卡住了。
我想我需要先抓取并抓取我需要的所有链接,格式如下:第1页,抓取所有链接,关注第2页>第2页,抓取所有链接,关注第3页*重复该页面X次*>然后一次所有链接都建立了,请关注并抓取我想要的数据。
最好的方法是用一个函数创建一个链表,然后传递给一个函数,遍历它们并抓取数据?
Python
如果每个链接的数据获取是相同的,那么是的。
你会得到这样的东西:
for link in links:
scrape_date(link)
收录您之前抓取的所有页面上的所有链接的链接列表在哪里。
您还可以同时从每个页面上找到的所有链接中获取数据。像这样的东西:
for page in pages:
urls = scrape_urls(page)
data = scrape_date(urls)
其中 pages 是所有页面的列表(第 1 页、第 2 页、第 3 页等)。
php抓取网页标签(先来了解什么是百度蜘蛛抓取频次和抓取耗时:解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-01 08:01
为什么百度蜘蛛爬网时间长,有些时间短,这些耗时的数据代表什么?
那么我们先来了解一下什么是百度蜘蛛抓取频率和抓取时间:
1、 爬行时间数据:
显示百度蜘蛛每次抓取网站所花费的时间。根据数据,站长可以了解蜘蛛抓取网站所花费的时间。获取时间越短,网站的访问速度越快。用户体验越好。
注:爬取耗时数据的更新频率与爬取频率有关,爬取频率高的站点数据更新较快。
2、 抓取状态统计:
四种抓取状态码统计:第一种:重定向(301、302等);第二类,未找到(404);第三类,服务器无响应(501、502等);第四类:服务器连接超时,帮助站长更好的理解爬取网站 在蜘蛛中的状态,更好的管理网站。
注:这里统计的是百度蜘蛛每次爬取行为的状态,与网站中的实际状态页数不能一概而论。
3、 爬频工具的响应速度:
使用爬取频率工具调整爬取次数后的有效时间。
百度蜘蛛爬取时间很长,一般突出以下几点:
1、快照经常不更新
2、网站收录少
3、网站关键词排名低
4、 造成这种耗时爬行的原因分为以下几类:
5、网站 是一个新站点。在这种情况下,抓取时间是正常的,一些新网站在一个月内才被百度获得收录。
6、 蜘蛛爬过站点,但没有爬走站点数据或页面。遇到这种情况,可以查看网站的日志,根据爬虫上报的状态码查询原因。
7、网站充斥着过多的富媒体文件,网站信息原创的程度不高。这种类型的网站会导致蜘蛛对网站失去兴趣,停止爬取网站。
解决方案:
1、提升网站原创度,网站更新频率稳定。
2、主关键词和副关键词分布合理。不要堆砌关键词
3、查看网站的日志,根据上报的状态码做出相应的解决方案。
百度蜘蛛反馈码一般分为以下几种:
1、200 0 0 页面访问成功,0表示获取成功并带回数据库。这个时候大家可以放心,这个页面已经bd收录了,只是还没有发布。可能会在 bd 更新时发布。
2、200 0 64 访问了该页面,但未获取它或将其带回数据库。这种原因多是空间不稳定,服务器不稳定。
3、304 0 0 这个返回码表示蜘蛛访问的页面没有更新,和他之前来的时候一样,所以看到这个不用担心,蜘蛛已经来了,但是你还没有更新,所以他不舍得拿走这个页面。
4、404 0 0 这个代表404页面,但是有一个很严重的问题。这个返回码告诉我们蜘蛛来到了404页面并把他带走了。
(资源库) 查看全部
php抓取网页标签(先来了解什么是百度蜘蛛抓取频次和抓取耗时:解决方法)
为什么百度蜘蛛爬网时间长,有些时间短,这些耗时的数据代表什么?
那么我们先来了解一下什么是百度蜘蛛抓取频率和抓取时间:
1、 爬行时间数据:
显示百度蜘蛛每次抓取网站所花费的时间。根据数据,站长可以了解蜘蛛抓取网站所花费的时间。获取时间越短,网站的访问速度越快。用户体验越好。
注:爬取耗时数据的更新频率与爬取频率有关,爬取频率高的站点数据更新较快。
2、 抓取状态统计:
四种抓取状态码统计:第一种:重定向(301、302等);第二类,未找到(404);第三类,服务器无响应(501、502等);第四类:服务器连接超时,帮助站长更好的理解爬取网站 在蜘蛛中的状态,更好的管理网站。
注:这里统计的是百度蜘蛛每次爬取行为的状态,与网站中的实际状态页数不能一概而论。
3、 爬频工具的响应速度:
使用爬取频率工具调整爬取次数后的有效时间。
百度蜘蛛爬取时间很长,一般突出以下几点:
1、快照经常不更新
2、网站收录少
3、网站关键词排名低
4、 造成这种耗时爬行的原因分为以下几类:
5、网站 是一个新站点。在这种情况下,抓取时间是正常的,一些新网站在一个月内才被百度获得收录。
6、 蜘蛛爬过站点,但没有爬走站点数据或页面。遇到这种情况,可以查看网站的日志,根据爬虫上报的状态码查询原因。
7、网站充斥着过多的富媒体文件,网站信息原创的程度不高。这种类型的网站会导致蜘蛛对网站失去兴趣,停止爬取网站。
解决方案:
1、提升网站原创度,网站更新频率稳定。
2、主关键词和副关键词分布合理。不要堆砌关键词
3、查看网站的日志,根据上报的状态码做出相应的解决方案。
百度蜘蛛反馈码一般分为以下几种:
1、200 0 0 页面访问成功,0表示获取成功并带回数据库。这个时候大家可以放心,这个页面已经bd收录了,只是还没有发布。可能会在 bd 更新时发布。
2、200 0 64 访问了该页面,但未获取它或将其带回数据库。这种原因多是空间不稳定,服务器不稳定。
3、304 0 0 这个返回码表示蜘蛛访问的页面没有更新,和他之前来的时候一样,所以看到这个不用担心,蜘蛛已经来了,但是你还没有更新,所以他不舍得拿走这个页面。
4、404 0 0 这个代表404页面,但是有一个很严重的问题。这个返回码告诉我们蜘蛛来到了404页面并把他带走了。
(资源库)
php抓取网页标签(PHP利用Curl可以完成各种传送文件操作,访问多个url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-31 19:15
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,开发爬虫程序的效率不高,所以经常需要使用 Curl Multi Functions。实现多线程并发访问多个URL地址的函数,实现网页的并发多线程爬取或下载文件
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面这段代码是抓取多个网址,然后将抓取到的网址的页面代码写入指定文件
$urls = array( 'https://www.html.cn/', 'http://www.google.com/', 'http://www.example.com/' ); // 设置要抓取的页面URL $save_to='/test.txt'; // 把抓取的代码写入该文件 $st = fopen($save_to,"a"); $mh = curl_multi_init(); foreach ($urls as $i => $url) { $conn[$i] = curl_init($url); curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i], CURLOPT_HEADER ,0); curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 curl_multi_add_handle ($mh,$conn[$i]); } // 初始化 do { curl_multi_exec($mh,$active); } while ($active); // 执行 foreach ($urls as $i => $url) { curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); } // 结束清理 curl_multi_close($mh); fclose($st);
(2)下面的代码和上面的意思一样,只不过这个地方先把获取到的代码放入变量中,然后将获取到的内容写入指定文件
$urls = array( 'https://www.html.cn/', 'http://www.google.com/', 'http://www.example.com/' ); $save_to='/test.txt'; // 把抓取的代码写入该文件 $st = fopen($save_to,"a"); $mh = curl_multi_init(); foreach ($urls as $i => $url) { $conn[$i] = curl_init($url); curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i], CURLOPT_HEADER ,0); curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 curl_multi_add_handle ($mh,$conn[$i]); } do { curl_multi_exec($mh,$active); } while ($active); foreach ($urls as $i => $url) { $data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 fwrite($st,$data); // 将字符串写入文件 } // 获得数据变量,并写入文件 foreach ($urls as $i => $url) { curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); } curl_multi_close($mh); fclose($st);
(3) 下面一段代码实现了使用PHP的Curl Functions实现文件的并发多线程下载
$urls=array( 'https://www.html.cn/5w.zip', 'https://www.html.cn/5w.zip', 'https://www.html.cn/5w.zip' ); $save_to='./home/'; $mh=curl_multi_init(); foreach($urls as $i=>$url){ $g=$save_to.basename($url); if(!is_file($g)){ $conn[$i]=curl_init($url); $fp[$i]=fopen($g,"w"); curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]); curl_setopt($conn[$i],CURLOPT_HEADER ,0); curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60); curl_multi_add_handle($mh,$conn[$i]); } } do{ $n=curl_multi_exec($mh,$active); }while($active); foreach($urls as $i=>$url){ curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); fclose($fp[$i]); } curl_multi_close($mh);$urls=array( 'https://www.html.cn/5w.zip', 'https://www.html.cn/5w.zip', 'https://www.html.cn/5w.zip' ); $save_to='./home/'; $mh=curl_multi_init(); foreach($urls as $i=>$url){ $g=$save_to.basename($url); if(!is_file($g)){ $conn[$i]=curl_init($url); $fp[$i]=fopen($g,"w"); curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]); curl_setopt($conn[$i],CURLOPT_HEADER ,0); curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60); curl_multi_add_handle($mh,$conn[$i]); } } do{ $n=curl_multi_exec($mh,$active); }while($active); foreach($urls as $i=>$url){ curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); fclose($fp[$i]); } curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
以上就是php结合curl实现多线程爬取的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php抓取网页标签(PHP利用Curl可以完成各种传送文件操作,访问多个url)
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,开发爬虫程序的效率不高,所以经常需要使用 Curl Multi Functions。实现多线程并发访问多个URL地址的函数,实现网页的并发多线程爬取或下载文件
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面这段代码是抓取多个网址,然后将抓取到的网址的页面代码写入指定文件
$urls = array( 'https://www.html.cn/', 'http://www.google.com/', 'http://www.example.com/' ); // 设置要抓取的页面URL $save_to='/test.txt'; // 把抓取的代码写入该文件 $st = fopen($save_to,"a"); $mh = curl_multi_init(); foreach ($urls as $i => $url) { $conn[$i] = curl_init($url); curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i], CURLOPT_HEADER ,0); curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 curl_multi_add_handle ($mh,$conn[$i]); } // 初始化 do { curl_multi_exec($mh,$active); } while ($active); // 执行 foreach ($urls as $i => $url) { curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); } // 结束清理 curl_multi_close($mh); fclose($st);
(2)下面的代码和上面的意思一样,只不过这个地方先把获取到的代码放入变量中,然后将获取到的内容写入指定文件
$urls = array( 'https://www.html.cn/', 'http://www.google.com/', 'http://www.example.com/' ); $save_to='/test.txt'; // 把抓取的代码写入该文件 $st = fopen($save_to,"a"); $mh = curl_multi_init(); foreach ($urls as $i => $url) { $conn[$i] = curl_init($url); curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i], CURLOPT_HEADER ,0); curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 curl_multi_add_handle ($mh,$conn[$i]); } do { curl_multi_exec($mh,$active); } while ($active); foreach ($urls as $i => $url) { $data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 fwrite($st,$data); // 将字符串写入文件 } // 获得数据变量,并写入文件 foreach ($urls as $i => $url) { curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); } curl_multi_close($mh); fclose($st);
(3) 下面一段代码实现了使用PHP的Curl Functions实现文件的并发多线程下载
$urls=array( 'https://www.html.cn/5w.zip', 'https://www.html.cn/5w.zip', 'https://www.html.cn/5w.zip' ); $save_to='./home/'; $mh=curl_multi_init(); foreach($urls as $i=>$url){ $g=$save_to.basename($url); if(!is_file($g)){ $conn[$i]=curl_init($url); $fp[$i]=fopen($g,"w"); curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]); curl_setopt($conn[$i],CURLOPT_HEADER ,0); curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60); curl_multi_add_handle($mh,$conn[$i]); } } do{ $n=curl_multi_exec($mh,$active); }while($active); foreach($urls as $i=>$url){ curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); fclose($fp[$i]); } curl_multi_close($mh);$urls=array( 'https://www.html.cn/5w.zip', 'https://www.html.cn/5w.zip', 'https://www.html.cn/5w.zip' ); $save_to='./home/'; $mh=curl_multi_init(); foreach($urls as $i=>$url){ $g=$save_to.basename($url); if(!is_file($g)){ $conn[$i]=curl_init($url); $fp[$i]=fopen($g,"w"); curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]); curl_setopt($conn[$i],CURLOPT_HEADER ,0); curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60); curl_multi_add_handle($mh,$conn[$i]); } } do{ $n=curl_multi_exec($mh,$active); }while($active); foreach($urls as $i=>$url){ curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); fclose($fp[$i]); } curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
以上就是php结合curl实现多线程爬取的详细内容。更多详情请关注其他相关html中文网站文章!
php抓取网页标签(有一定的参考价值,有需要的朋友可以参考一下!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-27 08:13
本文文章的内容是介绍使用js获取页面所有标签的方法(详细代码解释)。有一定的参考价值,有需要的朋友可以参考一下,希望对你有帮助。
前两天看到一个问题,问如何从页面中获取所有标签并查看它们的编号。感觉还是有点意思,就给大家做一下吧。
我们先从页面获取标签的思路开始。不用说,我们肯定会想到DOM操作。拿到之后,我们不确定一个元素是否有子元素。我们应该做什么?我肯定会想到递归
既然有了DOM操作和递归,就很容易了,直接写代码就行了。下面是代码,有注释,可以拉下来参考。
Document
var map = {};
//采用递归调用的方法,比较方便和简单。
function fds(node) {
if (node.nodeType === 1) {
//这里我们用nodeName属性,直接获取节点的节点名称
var tagName = node.nodeName;
//判断对象中存在不存在同类的节点,若存在则添加,不存在则添加并赋值为1
map[tagName] = map[tagName] ? map[tagName] + 1 : 1;
}
//获取该元素节点的所有子节点
var children = node.childNodes;
for (var i = 0; i < children.length; i++) {
//递归调用
fds(children[i])
}
}
fds(document);
console.log(map)
以上就是使用js获取页面所有标签的方法的详细内容(详细代码解释)。更多详情请关注php中文网其他相关文章!
免责声明:本文转载于:博客园,如有侵权,请联系删除 查看全部
php抓取网页标签(有一定的参考价值,有需要的朋友可以参考一下!)
本文文章的内容是介绍使用js获取页面所有标签的方法(详细代码解释)。有一定的参考价值,有需要的朋友可以参考一下,希望对你有帮助。
前两天看到一个问题,问如何从页面中获取所有标签并查看它们的编号。感觉还是有点意思,就给大家做一下吧。
我们先从页面获取标签的思路开始。不用说,我们肯定会想到DOM操作。拿到之后,我们不确定一个元素是否有子元素。我们应该做什么?我肯定会想到递归
既然有了DOM操作和递归,就很容易了,直接写代码就行了。下面是代码,有注释,可以拉下来参考。
Document
var map = {};
//采用递归调用的方法,比较方便和简单。
function fds(node) {
if (node.nodeType === 1) {
//这里我们用nodeName属性,直接获取节点的节点名称
var tagName = node.nodeName;
//判断对象中存在不存在同类的节点,若存在则添加,不存在则添加并赋值为1
map[tagName] = map[tagName] ? map[tagName] + 1 : 1;
}
//获取该元素节点的所有子节点
var children = node.childNodes;
for (var i = 0; i < children.length; i++) {
//递归调用
fds(children[i])
}
}
fds(document);
console.log(map)
以上就是使用js获取页面所有标签的方法的详细内容(详细代码解释)。更多详情请关注php中文网其他相关文章!

免责声明:本文转载于:博客园,如有侵权,请联系删除
php抓取网页标签(使用js获取页面上的所有标签的方法(代码详解))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-21 04:13
本文文章的内容是介绍使用js获取页面所有标签的方法(详细代码解释)。有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
前两天看到一个问题,问如何从页面中获取所有标签并查看它们的编号。感觉还是有点意思,就给大家做一下吧。
我们先从页面获取标签的思路开始。不用说,我们肯定会想到 DOM 操作。拿到之后,我们不确定一个元素是否有子元素。我们应该做什么?我肯定会想到递归
既然有了DOM操作和递归,就很容易了,直接写代码就行了。下面是代码,有注释,可以拉下来参考。
文档
无功映射 = {};
//递归调用的方法更方便简单。
函数 fds(节点){
if (node.nodeType === 1) {
//这里我们使用nodeName属性直接获取节点的节点名
var tagName = node.nodeName;
//判断对象中没有同类节点,如果存在则添加,如果不存在则添加并赋值为1
地图[标签名] = 地图[标签名]?地图[标签名] + 1: 1;
}
//获取元素节点的所有子节点
var children = node.childNodes;
for (var i = 0; i <children.length; i++) {
//递归调用
fds(儿童[i])
}
}
fds(文件);
控制台日志(地图) 查看全部
php抓取网页标签(使用js获取页面上的所有标签的方法(代码详解))
本文文章的内容是介绍使用js获取页面所有标签的方法(详细代码解释)。有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
前两天看到一个问题,问如何从页面中获取所有标签并查看它们的编号。感觉还是有点意思,就给大家做一下吧。
我们先从页面获取标签的思路开始。不用说,我们肯定会想到 DOM 操作。拿到之后,我们不确定一个元素是否有子元素。我们应该做什么?我肯定会想到递归
既然有了DOM操作和递归,就很容易了,直接写代码就行了。下面是代码,有注释,可以拉下来参考。
文档
无功映射 = {};
//递归调用的方法更方便简单。
函数 fds(节点){
if (node.nodeType === 1) {
//这里我们使用nodeName属性直接获取节点的节点名
var tagName = node.nodeName;
//判断对象中没有同类节点,如果存在则添加,如果不存在则添加并赋值为1
地图[标签名] = 地图[标签名]?地图[标签名] + 1: 1;
}
//获取元素节点的所有子节点
var children = node.childNodes;
for (var i = 0; i <children.length; i++) {
//递归调用
fds(儿童[i])
}
}
fds(文件);
控制台日志(地图)
php抓取网页标签( 2018-12-27())
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-10-16 00:27
2018-12-27())
Jsoup抓取页面A标签中的href路径
时间:2018-12-27
本文章为大家介绍Jsoup抓取到页面A标签的href路径,主要包括Jsoup抓取到页面A标签的href路径的使用示例、应用技巧、基础知识点总结及注意事项需要注意。有一定的参考价值,有需要的朋友可以参考。
直接上代码,注释很全
<p>
public static void main(String[] args)throws Exception{
//抓取的网址
String url = "http://www.stats.gov.cn/tjsj/t ... 3B%3B
//编码格式的转换
Document document = Jsoup.parse(new URL(url).openStream(), "GBK", url);
//根据class获取到 页面的 元素内容
Elements tables = document.getElementsByClass("provincetr");
//根据td标签来划分
Elements td = tables.select("td");
for(int j=0;j 查看全部
php抓取网页标签(
2018-12-27())
Jsoup抓取页面A标签中的href路径
时间:2018-12-27
本文章为大家介绍Jsoup抓取到页面A标签的href路径,主要包括Jsoup抓取到页面A标签的href路径的使用示例、应用技巧、基础知识点总结及注意事项需要注意。有一定的参考价值,有需要的朋友可以参考。
直接上代码,注释很全
<p>
public static void main(String[] args)throws Exception{
//抓取的网址
String url = "http://www.stats.gov.cn/tjsj/t ... 3B%3B
//编码格式的转换
Document document = Jsoup.parse(new URL(url).openStream(), "GBK", url);
//根据class获取到 页面的 元素内容
Elements tables = document.getElementsByClass("provincetr");
//根据td标签来划分
Elements td = tables.select("td");
for(int j=0;j
php抓取网页标签( PHP实现网页内容html标签补全和过滤的方法实例解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 36 次浏览 • 2021-09-26 12:07
PHP实现网页内容html标签补全和过滤的方法实例解析)
用PHP完成和过滤网页内容HTML标记的方法摘要[2种方法]
更新时间:2017年4月27日10:58:53作者:网站
本文章主要介绍了PHP中HTML标记完成和web内容过滤的方法,并以实例的形式分析了PHP常见的标记检查、完成、关闭、过滤等相关操作技巧。有需要的朋友可以参考
本文介绍了在PHP中完成HTML标记和过滤网页内容的方法。与您分享,供您参考,如下所示:
如果网页内容的HTML标记未完全显示,某些表标记不完整,导致页面混乱,或者收录内容之外的本地HTML页面,我们可以编写一个函数方法来完成HTML标记并过滤掉无用的HTML标记
PHP使HTML标记完整并自动关闭。过滤函数方法1:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
Closetags()解析:
array_u;Reverse():此函数反转原创数组中的元素,创建新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名将丢失
array_usearch():array_usearch(value,array,strict),与类似array()中的相同,在数组中查找键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回false。如果第三个参数strict指定为true,则仅当数据类型和值一致时,才会返回相应元素的键名
PHP使HTML标记完整并自动关闭。过滤函数方法2:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
Checkhtml($HTML)解析:
Stripsplashes():函数删除addslashes()函数添加的反斜杠。此函数用于清理从数据库或HTML表单检索的数据
有关PHP的更多信息,感兴趣的读者可以查看本网站上的主题:PHP数据结构和算法教程、PHP编程算法摘要、PHP排序算法摘要、PHP常见遍历算法和技能摘要、PHP数学运算技能摘要、PHP数组运算技能、,PHP字符串用法总结,以及PHP中常见数据库操作技巧总结
我希望这篇文章能对你的PHP编程有所帮助 查看全部
php抓取网页标签(
PHP实现网页内容html标签补全和过滤的方法实例解析)
用PHP完成和过滤网页内容HTML标记的方法摘要[2种方法]
更新时间:2017年4月27日10:58:53作者:网站
本文章主要介绍了PHP中HTML标记完成和web内容过滤的方法,并以实例的形式分析了PHP常见的标记检查、完成、关闭、过滤等相关操作技巧。有需要的朋友可以参考
本文介绍了在PHP中完成HTML标记和过滤网页内容的方法。与您分享,供您参考,如下所示:
如果网页内容的HTML标记未完全显示,某些表标记不完整,导致页面混乱,或者收录内容之外的本地HTML页面,我们可以编写一个函数方法来完成HTML标记并过滤掉无用的HTML标记
PHP使HTML标记完整并自动关闭。过滤函数方法1:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
Closetags()解析:
array_u;Reverse():此函数反转原创数组中的元素,创建新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名将丢失
array_usearch():array_usearch(value,array,strict),与类似array()中的相同,在数组中查找键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回false。如果第三个参数strict指定为true,则仅当数据类型和值一致时,才会返回相应元素的键名
PHP使HTML标记完整并自动关闭。过滤函数方法2:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
Checkhtml($HTML)解析:
Stripsplashes():函数删除addslashes()函数添加的反斜杠。此函数用于清理从数据库或HTML表单检索的数据
有关PHP的更多信息,感兴趣的读者可以查看本网站上的主题:PHP数据结构和算法教程、PHP编程算法摘要、PHP排序算法摘要、PHP常见遍历算法和技能摘要、PHP数学运算技能摘要、PHP数组运算技能、,PHP字符串用法总结,以及PHP中常见数据库操作技巧总结
我希望这篇文章能对你的PHP编程有所帮助
php抓取网页标签(对阅读全文网页重构应该避免的10大CSS糟糕用法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-19 19:23
阿里云>;云气社区>;主题地图>;P>;PHP从网页中获取标记
建议的活动:
更多优惠>
当前主题:PHP从网页中获取标记并将其添加到采集夹中
相关主题:
PHP从网页中获取标签以查看更多博客
标准化标签对搜索引擎优化的影响
作者:1005人参观了优惠活动。评论数量:2002年之前
规范标签:初学者的简单指南。想知道什么是规范标记以及如何使用它们来避免可怕的重复内容问题吗?规格标签不是新的。自2009年以来,这是十年来最好的一年。百度、360和搜狗共同创造了它们。他们的目标是什么?为网站所有者提供一种快速简便的方法来解决重复内容问题
阅读全文
HTML基本标记()
作者:听音乐睡觉709人浏览评论:04年前
HTML标记:1、tag,短文本引用注释:引用短文本,如古人的一句话。请注意,引用的文本不需要双引号。标签的真正关键点不是其默认的双引号样式(效果与手动双引号相同,但含义不同),而是其语义
阅读全文
网页重构中应避免的十种错误CSS用法
作者:黄伟的世界1207观评论:05年前
对于网页重建,CSS Zen garden标志着网页布局已从表格更改为HTML+CSS。多年来,随着我们的网站变得越来越复杂:HTML5、CSS3、新技术和新特性,越来越多的开发人员开始思考并尝试提高他们的CSS技能。那么我们从哪里开始呢?对
阅读全文
如何优化网页性能
作者:bill.kang1019观点评论:2008年之前
原创地址:本文将讨论浏览器渲染的加载过程,目的有两个:
阅读全文
有条理dedecms标签完整,易于查找
作者:YTCAHCOM1263观点评论:2005年前
常用dedecmsDevelopment经常使用一些标记,尤其是主页、专栏页和内容页。这些页面将使用标签的调用,如标题、关键字、描述、Arclist、field.body等。为了便于搜索,ytkah专门对它们进行了分类dedecmsLabel,各位
阅读全文
Python爬虫入门教程8-100蜂鸟网图片爬虫3
作者:梦橡皮擦1259观点评论:02年前
1.hummingbird pictures-冗长的两句话几天前的教程容量很大。今天,我写了一篇相对简单的文章。蜂鸟仍在爬行,aiohttp仍在使用。我希望你喜欢在网页上爬行。本教程仍然基于**学习**的目的。为什么选择蜂鸟?不可能。我盲目地选择它
阅读全文
第86天:HTML5应用程序标签和智能表单
作者:半指温柔音乐937人浏览评论:03年前
一、HTML5应用程序标签1、datalist数据载体的输入列表属性必须指向数据源2、progress进度条WebKit外观:无/*如果要更改默认样式,请先取消默认样式*/。我的进展:-
阅读全文
[Python学习]只需抓取Wikipedia程序语言消息框
作者:肖洛洛1432观点点评:2006年之前
文章主要描述如何通过python抓取Wikipedia的Infobox,主要是通过正则表达式和urllib;下面的文章可能描述了通过BeautifulSoup爬行网页的知识。既然在这方面文章还很少,我希望能提供一些想法和方法来帮助你
阅读全文
PHP从网页中获取标签并提出问题
[JavaScript学习桶]100位阿里巴巴技术专家解答了934个流行JavaScript问题
作者:管理北碚5207人,观点和评论数量:13年前
阿里巴巴极客公益活动:也许你开夜车只是为了解决一个问题,也许你不明白,只是问一个答案,也许你绞尽脑汁只是因为一个未知的问题,所以他们来了。阿里巴巴的技术专家来到云琦为您解答技术问题,他们的用户自己的技术帮助用户成长。本次活动特别邀请了100位阿里巴巴技术专家
阅读全文 查看全部
php抓取网页标签(对阅读全文网页重构应该避免的10大CSS糟糕用法)
阿里云>;云气社区>;主题地图>;P>;PHP从网页中获取标记

建议的活动:
更多优惠>
当前主题:PHP从网页中获取标记并将其添加到采集夹中
相关主题:
PHP从网页中获取标签以查看更多博客
标准化标签对搜索引擎优化的影响


作者:1005人参观了优惠活动。评论数量:2002年之前
规范标签:初学者的简单指南。想知道什么是规范标记以及如何使用它们来避免可怕的重复内容问题吗?规格标签不是新的。自2009年以来,这是十年来最好的一年。百度、360和搜狗共同创造了它们。他们的目标是什么?为网站所有者提供一种快速简便的方法来解决重复内容问题
阅读全文
HTML基本标记()


作者:听音乐睡觉709人浏览评论:04年前
HTML标记:1、tag,短文本引用注释:引用短文本,如古人的一句话。请注意,引用的文本不需要双引号。标签的真正关键点不是其默认的双引号样式(效果与手动双引号相同,但含义不同),而是其语义
阅读全文
网页重构中应避免的十种错误CSS用法


作者:黄伟的世界1207观评论:05年前
对于网页重建,CSS Zen garden标志着网页布局已从表格更改为HTML+CSS。多年来,随着我们的网站变得越来越复杂:HTML5、CSS3、新技术和新特性,越来越多的开发人员开始思考并尝试提高他们的CSS技能。那么我们从哪里开始呢?对
阅读全文
如何优化网页性能


作者:bill.kang1019观点评论:2008年之前
原创地址:本文将讨论浏览器渲染的加载过程,目的有两个:
阅读全文
有条理dedecms标签完整,易于查找


作者:YTCAHCOM1263观点评论:2005年前
常用dedecmsDevelopment经常使用一些标记,尤其是主页、专栏页和内容页。这些页面将使用标签的调用,如标题、关键字、描述、Arclist、field.body等。为了便于搜索,ytkah专门对它们进行了分类dedecmsLabel,各位
阅读全文
Python爬虫入门教程8-100蜂鸟网图片爬虫3


作者:梦橡皮擦1259观点评论:02年前
1.hummingbird pictures-冗长的两句话几天前的教程容量很大。今天,我写了一篇相对简单的文章。蜂鸟仍在爬行,aiohttp仍在使用。我希望你喜欢在网页上爬行。本教程仍然基于**学习**的目的。为什么选择蜂鸟?不可能。我盲目地选择它
阅读全文
第86天:HTML5应用程序标签和智能表单


作者:半指温柔音乐937人浏览评论:03年前
一、HTML5应用程序标签1、datalist数据载体的输入列表属性必须指向数据源2、progress进度条WebKit外观:无/*如果要更改默认样式,请先取消默认样式*/。我的进展:-
阅读全文
[Python学习]只需抓取Wikipedia程序语言消息框

作者:肖洛洛1432观点点评:2006年之前
文章主要描述如何通过python抓取Wikipedia的Infobox,主要是通过正则表达式和urllib;下面的文章可能描述了通过BeautifulSoup爬行网页的知识。既然在这方面文章还很少,我希望能提供一些想法和方法来帮助你
阅读全文
PHP从网页中获取标签并提出问题
[JavaScript学习桶]100位阿里巴巴技术专家解答了934个流行JavaScript问题

作者:管理北碚5207人,观点和评论数量:13年前
阿里巴巴极客公益活动:也许你开夜车只是为了解决一个问题,也许你不明白,只是问一个答案,也许你绞尽脑汁只是因为一个未知的问题,所以他们来了。阿里巴巴的技术专家来到云琦为您解答技术问题,他们的用户自己的技术帮助用户成长。本次活动特别邀请了100位阿里巴巴技术专家
阅读全文
php抓取网页标签( 裕轩汪这篇文章主要介绍了的相关资料,非常不错)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-09-19 19:20
裕轩汪这篇文章主要介绍了的相关资料,非常不错)
PHP正则表达式获取标记的特定属性值的方法
更新时间:2016年7月14日10:09:11作者:于玄旺
本文文章主要介绍了用PHP正则表达式捕获标签特定属性值的方法的相关资料。这是非常好的,具有参考价值。有需要的朋友可以参考
PHP学习了几天regular并获取了一些网站的数据,因此我发现每次再次编写regular都很麻烦,所以我想编写一个通用接口来获取具有特定属性值的特定标记并直接编写代码
//$html-被查找的字符串 $tag-被查找的标签 $attr-被查找的属性名 $value-被查找的属性值
function get_tag_data($html,$tag,$attr,$value){
$regex = "/(.*?)/is";
echo $regex."
";
preg_match_all($regex,$html,$matches,PREG_PATTERN_ORDER);
return $matches[1];
}
//返回值为数组 查找到的标签内的内容
这里有一个例子
header("Content-type: text/html; charset=utf-8");
$temp = '
首页
日志
LOFTER
相册
博友
关于我
';
$result = get_tag_data($temp,"a","class","fc01");
var_dump($result);
输出结果为
array(6) { [0]=> string(6) "首页" [1]=> string(6) "日志" [2]=> string(6) "LOFTER" [3]=> string(6) "相册" [4]=> string(6) "博友" [5]=> string(9) "关于我" }
检查源代码以查看
array(6) {
[0]=>
string(6) "首页"
[1]=>
string(6) "日志"
[2]=>
string(6) "LOFTER"
[3]=>
string(6) "相册"
[4]=>
string(6) "博友"
[5]=>
string(9) "关于我"
}
第一次写博客很紧张。哈哈哈,希望对你有用。我也希望你能指出代码中的问题。没有太多的测试~~
上面是小编介绍的用PHP正则表达式获取标签特定属性值的方法。我希望这对你有帮助。如果您有任何问题,请给我留言,小编会及时回复您。非常感谢您对脚本屋网站的支持@ 查看全部
php抓取网页标签(
裕轩汪这篇文章主要介绍了的相关资料,非常不错)
PHP正则表达式获取标记的特定属性值的方法
更新时间:2016年7月14日10:09:11作者:于玄旺
本文文章主要介绍了用PHP正则表达式捕获标签特定属性值的方法的相关资料。这是非常好的,具有参考价值。有需要的朋友可以参考
PHP学习了几天regular并获取了一些网站的数据,因此我发现每次再次编写regular都很麻烦,所以我想编写一个通用接口来获取具有特定属性值的特定标记并直接编写代码
//$html-被查找的字符串 $tag-被查找的标签 $attr-被查找的属性名 $value-被查找的属性值
function get_tag_data($html,$tag,$attr,$value){
$regex = "/(.*?)/is";
echo $regex."
";
preg_match_all($regex,$html,$matches,PREG_PATTERN_ORDER);
return $matches[1];
}
//返回值为数组 查找到的标签内的内容
这里有一个例子
header("Content-type: text/html; charset=utf-8");
$temp = '
首页
日志
LOFTER
相册
博友
关于我
';
$result = get_tag_data($temp,"a","class","fc01");
var_dump($result);
输出结果为
array(6) { [0]=> string(6) "首页" [1]=> string(6) "日志" [2]=> string(6) "LOFTER" [3]=> string(6) "相册" [4]=> string(6) "博友" [5]=> string(9) "关于我" }
检查源代码以查看
array(6) {
[0]=>
string(6) "首页"
[1]=>
string(6) "日志"
[2]=>
string(6) "LOFTER"
[3]=>
string(6) "相册"
[4]=>
string(6) "博友"
[5]=>
string(9) "关于我"
}
第一次写博客很紧张。哈哈哈,希望对你有用。我也希望你能指出代码中的问题。没有太多的测试~~
上面是小编介绍的用PHP正则表达式获取标签特定属性值的方法。我希望这对你有帮助。如果您有任何问题,请给我留言,小编会及时回复您。非常感谢您对脚本屋网站的支持@
php抓取网页标签(基于PHP的服务端开源项目之phpQuery采集文章列表介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-15 10:01
phpQuery是一个基于PHP的服务端开源项目,它可以让PHP开发人员轻松处理DOM文档内容,比如获取某新闻网站的头条信息。更有意思的是,它采用了jQuery的思想,你可以像使用jQuery一样处理页面内容,获取你想要的页面信息。
采集头条
先看一实例,现在我要采集新浪网国内新闻的头条,代码如下:
include'phpQuery/phpQuery.php';phpQuery::newDocumentFile('#39;);echopq(".blkToph1:eq(0)")->html();
简单的三行代码,就可以获取头条内容。首先在程序中收录phpQuery.php核心程序,然后调用读取目标网页,最后输出对应标签下的内容。
pq()是一个功能强大的方法,跟jQuery的$()如出一辙,jQuery的选择器基本上都能使用在phpQuery上,只要把“.”变成“->”。如上例中,pq(".blkTop
h1:eq(0)")抓取了页面class属性为blkTop的DIV元素,并找到该DIV内部的第一个h1标签,然后用html()方法获取h1标签里的内容(带html标签),也就是我们要获取的头条信息,如果使用text()方法,则只获取头条的文本内容。当然要使用好phpQuery,关键是要找对文档中对应内容的节点。
采集文章列表
下面再来看一个例子,获取网站的blog列表,请看代码:
include'phpQuery/phpQuery.php';phpQuery::newDocumentFile('#39;);$artlist=pq(".blog_li");foreach($artlistas$li){echopq($li)->find('h2')->html()."";}
通过循环列表中的DIV,找出文章标题并输出,就是这么简单。
解析XML文档
假设现在有一个这样的test.xml文档: 查看全部
php抓取网页标签(基于PHP的服务端开源项目之phpQuery采集文章列表介绍)
phpQuery是一个基于PHP的服务端开源项目,它可以让PHP开发人员轻松处理DOM文档内容,比如获取某新闻网站的头条信息。更有意思的是,它采用了jQuery的思想,你可以像使用jQuery一样处理页面内容,获取你想要的页面信息。
采集头条
先看一实例,现在我要采集新浪网国内新闻的头条,代码如下:
include'phpQuery/phpQuery.php';phpQuery::newDocumentFile('#39;);echopq(".blkToph1:eq(0)")->html();
简单的三行代码,就可以获取头条内容。首先在程序中收录phpQuery.php核心程序,然后调用读取目标网页,最后输出对应标签下的内容。
pq()是一个功能强大的方法,跟jQuery的$()如出一辙,jQuery的选择器基本上都能使用在phpQuery上,只要把“.”变成“->”。如上例中,pq(".blkTop
h1:eq(0)")抓取了页面class属性为blkTop的DIV元素,并找到该DIV内部的第一个h1标签,然后用html()方法获取h1标签里的内容(带html标签),也就是我们要获取的头条信息,如果使用text()方法,则只获取头条的文本内容。当然要使用好phpQuery,关键是要找对文档中对应内容的节点。
采集文章列表
下面再来看一个例子,获取网站的blog列表,请看代码:
include'phpQuery/phpQuery.php';phpQuery::newDocumentFile('#39;);$artlist=pq(".blog_li");foreach($artlistas$li){echopq($li)->find('h2')->html()."";}
通过循环列表中的DIV,找出文章标题并输出,就是这么简单。
解析XML文档
假设现在有一个这样的test.xml文档:
php抓取网页标签(html()方法此方法类似于JavaScript中的innerHTML属性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-09-15 09:25
HTML()方法
此方法类似于JavaScript中的innerHTML属性。它可以用来读取或设置元素中的HTML内容。要获取元素的内容,请执行以下操作:
var p_uhtml=$(“p”).html();//获取P元素的HTML代码
如果需要设置元素的HTML代码,也可以使用此方法,但需要为其传递一个参数。例如,要设置P元素的HTML代码,可以使用以下代码:
//设置p元素的HTML代码
美元(“p”)。HTML(“欢迎来到简明现代魔术库~~)
注意:HTML()方法可以用于XHTML文档,但不能用于XML文档
Text()方法
此方法类似于JavaScript中的innerText属性。它可用于读取或不设置元素中的文本内容。继续使用上述HTML代码,并使用text()方法对p元素进行操作:
var p_uText=$(“p”).text();//获取p元素的文本内容
与HTML()方法一样,如果需要为元素设置文本内容,还需要传递一个参数。例如,为p元素设置文本内容。代码如下:
//设置p元素的文本内容
$(“p”).Text(“欢迎来到简明现代魔术库~~)
注意以下两点:
JavaScript中的innerText属性不能在Firefox浏览器中运行,jQuery的text()方法支持所有浏览器
text()方法对HTML和XML文档都有效
显示朋友列表时,将显示朋友的姓名
在元素中设置:
通过这种方式,可以动态获取JS文件
元素的ID,并平滑地分配$(“#p”+userid)。通过Text()方法输入Text(name) 查看全部
php抓取网页标签(html()方法此方法类似于JavaScript中的innerHTML属性)
HTML()方法
此方法类似于JavaScript中的innerHTML属性。它可以用来读取或设置元素中的HTML内容。要获取元素的内容,请执行以下操作:
var p_uhtml=$(“p”).html();//获取P元素的HTML代码
如果需要设置元素的HTML代码,也可以使用此方法,但需要为其传递一个参数。例如,要设置P元素的HTML代码,可以使用以下代码:
//设置p元素的HTML代码
美元(“p”)。HTML(“欢迎来到简明现代魔术库~~)
注意:HTML()方法可以用于XHTML文档,但不能用于XML文档
Text()方法
此方法类似于JavaScript中的innerText属性。它可用于读取或不设置元素中的文本内容。继续使用上述HTML代码,并使用text()方法对p元素进行操作:
var p_uText=$(“p”).text();//获取p元素的文本内容
与HTML()方法一样,如果需要为元素设置文本内容,还需要传递一个参数。例如,为p元素设置文本内容。代码如下:
//设置p元素的文本内容
$(“p”).Text(“欢迎来到简明现代魔术库~~)
注意以下两点:
JavaScript中的innerText属性不能在Firefox浏览器中运行,jQuery的text()方法支持所有浏览器
text()方法对HTML和XML文档都有效
显示朋友列表时,将显示朋友的姓名
在元素中设置:
通过这种方式,可以动态获取JS文件
元素的ID,并平滑地分配$(“#p”+userid)。通过Text()方法输入Text(name)
php抓取网页标签(php抓取网页标签完全不费力怎么找解决方案?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-09-12 02:06
php抓取网页标签完全不费力,可是看到个框图,想找个对应的功能,总是不知道在哪找。解决方案:使用phpstorm、phpstorm、phpstorm、phpstorm、phpstorm、phpstorm。不解释,能想出来直接在输入框里面输入“launch”(设置),进入terminal,在里面输入treemapparameters命令,然后抓。好吧,看例子说话。抓取天猫前端页面-阿里巴巴天猫。
泻药,搜索了下,有朋友给出了phpstorm解决这个问题。因为手机平台的缘故,知乎屏蔽了phpstorm,所以我也给不出phpstorm的解决方案。
具体的见上面@施洪波的答案。用treemap就可以,顺便再使用pglt进行程序语言转换。
首先,这个问题的根源出在phpstorm自身功能上面。你可以尝试调用treemap函数进行抓取。现在很多大型程序都是用rails和stronglift来解决分页的问题。rails的做法主要是进行html对象绑定。当内容页html的第一个href被找到的时候,再将href下的所有内容进行抓取,然后合并。
再比如你要抓取某个商品的时候,你可以将商品的每个id进行拖拽,拖拽到你需要抓取的位置。当当前时间之后,商品id就会出现在你要抓取的位置了。然后php处理这些就非常简单了。直接preplib/preplib-f可以一次性处理整个数据库。然后代码提交worker即可。 查看全部
php抓取网页标签(php抓取网页标签完全不费力怎么找解决方案?)
php抓取网页标签完全不费力,可是看到个框图,想找个对应的功能,总是不知道在哪找。解决方案:使用phpstorm、phpstorm、phpstorm、phpstorm、phpstorm、phpstorm。不解释,能想出来直接在输入框里面输入“launch”(设置),进入terminal,在里面输入treemapparameters命令,然后抓。好吧,看例子说话。抓取天猫前端页面-阿里巴巴天猫。
泻药,搜索了下,有朋友给出了phpstorm解决这个问题。因为手机平台的缘故,知乎屏蔽了phpstorm,所以我也给不出phpstorm的解决方案。
具体的见上面@施洪波的答案。用treemap就可以,顺便再使用pglt进行程序语言转换。
首先,这个问题的根源出在phpstorm自身功能上面。你可以尝试调用treemap函数进行抓取。现在很多大型程序都是用rails和stronglift来解决分页的问题。rails的做法主要是进行html对象绑定。当内容页html的第一个href被找到的时候,再将href下的所有内容进行抓取,然后合并。
再比如你要抓取某个商品的时候,你可以将商品的每个id进行拖拽,拖拽到你需要抓取的位置。当当前时间之后,商品id就会出现在你要抓取的位置了。然后php处理这些就非常简单了。直接preplib/preplib-f可以一次性处理整个数据库。然后代码提交worker即可。
php抓取网页标签(php抓取网页标签也是编译结果?而你在对http协议的理解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-11-28 11:05
php抓取网页标签也是抓取网页?php抓取的标签只是编译结果?而你在对http协议的理解上,是不是有一定的错误。
被http协议限制了,抓不到cookie,flash访问网站之前,是一次url加载,
以前,php主要是用来改b/s结构的一款语言,传统php抓取静态资源或页面都是用代理服务器,和c++比较,更占资源。而iis8就开始支持直接访问cookie,提高网站的打开速度,主要是之前的php代理服务器功能,跟c++的url把cookie加载到iis8web服务器上的实现逻辑,完全不一样。然后,现在这种状况,很难持续了,尽管抓取类似github等有存在api,但是更少人用了,基本属于浪费资源。
而且,浏览器现在都有提供免登陆接口,可以直接使用gmail/facebook的邮箱账号,所以,如果抓取api开放,那么用php访问网站要省很多麻烦事。总结:web这种存在数据自传播能力的高交互平台,从来都不属于php搞定的对象。ios的safariandroid的symbiansymbian+opengl应该能搞定更高交互性的一切web平台。
it之外,如phpgru/lamp这些集群框架,都已经可以有直接访问cookie的功能。就是成本有点高,web容易数据中心化,那么又要有相应的对象存取/cookie存取的api。另外,php等脚本语言,毕竟不是最流行的编程语言,虽然我个人非常喜欢它的解释器是写得最好的,php也许和一些解释器处理速度对比还是慢一些。
php有大量脚本程序以及工具库的情况下,java、c#、c#+java开发的web应用,很多时候也是这样php开发的web应用。但是php能做的事情还是太少了,但是php可以抓取的内容太多太多了,无论是图片,txt、html、http文本等各种web类型的数据。 查看全部
php抓取网页标签(php抓取网页标签也是编译结果?而你在对http协议的理解)
php抓取网页标签也是抓取网页?php抓取的标签只是编译结果?而你在对http协议的理解上,是不是有一定的错误。
被http协议限制了,抓不到cookie,flash访问网站之前,是一次url加载,
以前,php主要是用来改b/s结构的一款语言,传统php抓取静态资源或页面都是用代理服务器,和c++比较,更占资源。而iis8就开始支持直接访问cookie,提高网站的打开速度,主要是之前的php代理服务器功能,跟c++的url把cookie加载到iis8web服务器上的实现逻辑,完全不一样。然后,现在这种状况,很难持续了,尽管抓取类似github等有存在api,但是更少人用了,基本属于浪费资源。
而且,浏览器现在都有提供免登陆接口,可以直接使用gmail/facebook的邮箱账号,所以,如果抓取api开放,那么用php访问网站要省很多麻烦事。总结:web这种存在数据自传播能力的高交互平台,从来都不属于php搞定的对象。ios的safariandroid的symbiansymbian+opengl应该能搞定更高交互性的一切web平台。
it之外,如phpgru/lamp这些集群框架,都已经可以有直接访问cookie的功能。就是成本有点高,web容易数据中心化,那么又要有相应的对象存取/cookie存取的api。另外,php等脚本语言,毕竟不是最流行的编程语言,虽然我个人非常喜欢它的解释器是写得最好的,php也许和一些解释器处理速度对比还是慢一些。
php有大量脚本程序以及工具库的情况下,java、c#、c#+java开发的web应用,很多时候也是这样php开发的web应用。但是php能做的事情还是太少了,但是php可以抓取的内容太多太多了,无论是图片,txt、html、http文本等各种web类型的数据。
php抓取网页标签(一下就是关于抓取别人网站数据的抓取问题和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-24 20:11
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实现,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过自己编写代码实现了;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url)
{
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:在网站的开发过程中可能经常遇到。它的分页控件通过post的方式向后台代码提交分页信息,比如.net下Gridview自带的分页功能,当你点击分页的页码的时候,会发现URL地址并没有改变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以引用页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须使用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}
捕获(异常前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法最麻烦,也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟人工翻页链接,用代码逐页翻页,再逐页翻页。爬行的。 查看全部
php抓取网页标签(一下就是关于抓取别人网站数据的抓取问题和方法)
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实现,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过自己编写代码实现了;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url)
{
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:在网站的开发过程中可能经常遇到。它的分页控件通过post的方式向后台代码提交分页信息,比如.net下Gridview自带的分页功能,当你点击分页的页码的时候,会发现URL地址并没有改变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以引用页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须使用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}
捕获(异常前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法最麻烦,也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟人工翻页链接,用代码逐页翻页,再逐页翻页。爬行的。
php抓取网页标签(慕课网python:发射鱼雷,保证鲜活和快速,挑战性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-22 18:05
php抓取网页标签:[?xmlhttprequest=null]
python抓取网页:python网页爬虫之打包工具-慕课网
python:发射鱼雷,保证鲜活和快速,挑战性。使用的话必须熟悉python3.x,
看你在什么场景需要,如果是新手,我推荐用django+bootstrap,比较适合新手。如果是有一定的基础,
emmmm,使用什么语言写不重要。在此,只推荐易用的爬虫工具tornado。
python+requests
google系列+es6+httpserver补充一下,如果安卓需要用nodejs写...nodejs有的,就这么几个。
用scrapypython框架写爬虫,用zotero或者latex很不错,首先,zotero做摘要引擎太丑了,endnote也不友好,latex写起来最方便,你可以参考下我以前的一个帖子,
通用爬虫抓取工具:1。兔子爬虫(阿里天池):/2。乐网(纽约时报):/3。绿色上网宝():/4。ai学大(悟空问答):/5。scrapy(美国《连线》杂志推荐):/6。f117bt(美国《福布斯》杂志推荐):/7。ignite(hulu推荐):/8。bigupez(百度网盘推荐):/9。网易公开课(/):10。
ptc云(arms云市场/mit研究院推荐):/11。codesys开源类,还可以反编译工具:-linux中文网-免费开源软件下载_开源代码分享_云服务开源协作平台_codesys官网#!/usr/bin/envpython3importrequestsport=21followserver='requests'secretpassword='123456'failure='jeff'exclude_ip=''fromheadersimport*port=21classhowtocode(requests。
getrequest()):url=''headers={'user-agent':'mozilla/5。0(windowsnt6。1;win64;x64)applewebkit/537。36(khtml,likegecko)chrome/77。2993。85safari/537。36'}timeout=0cookie={'type':'script'}proxy={'port':21}items={'id':'webloger','page':'1','url':'www。
webloger。com'}fromscrapyimportspiderimportrequests,headers,httphttp=http。session()traceback(mostrecentcalllast):file"/users/dongxi/desktop/scrapy/0。3。min。py",line1,inpageurl=''defmain(request,。 查看全部
php抓取网页标签(慕课网python:发射鱼雷,保证鲜活和快速,挑战性)
php抓取网页标签:[?xmlhttprequest=null]
python抓取网页:python网页爬虫之打包工具-慕课网
python:发射鱼雷,保证鲜活和快速,挑战性。使用的话必须熟悉python3.x,
看你在什么场景需要,如果是新手,我推荐用django+bootstrap,比较适合新手。如果是有一定的基础,
emmmm,使用什么语言写不重要。在此,只推荐易用的爬虫工具tornado。
python+requests
google系列+es6+httpserver补充一下,如果安卓需要用nodejs写...nodejs有的,就这么几个。
用scrapypython框架写爬虫,用zotero或者latex很不错,首先,zotero做摘要引擎太丑了,endnote也不友好,latex写起来最方便,你可以参考下我以前的一个帖子,
通用爬虫抓取工具:1。兔子爬虫(阿里天池):/2。乐网(纽约时报):/3。绿色上网宝():/4。ai学大(悟空问答):/5。scrapy(美国《连线》杂志推荐):/6。f117bt(美国《福布斯》杂志推荐):/7。ignite(hulu推荐):/8。bigupez(百度网盘推荐):/9。网易公开课(/):10。
ptc云(arms云市场/mit研究院推荐):/11。codesys开源类,还可以反编译工具:-linux中文网-免费开源软件下载_开源代码分享_云服务开源协作平台_codesys官网#!/usr/bin/envpython3importrequestsport=21followserver='requests'secretpassword='123456'failure='jeff'exclude_ip=''fromheadersimport*port=21classhowtocode(requests。
getrequest()):url=''headers={'user-agent':'mozilla/5。0(windowsnt6。1;win64;x64)applewebkit/537。36(khtml,likegecko)chrome/77。2993。85safari/537。36'}timeout=0cookie={'type':'script'}proxy={'port':21}items={'id':'webloger','page':'1','url':'www。
webloger。com'}fromscrapyimportspiderimportrequests,headers,httphttp=http。session()traceback(mostrecentcalllast):file"/users/dongxi/desktop/scrapy/0。3。min。py",line1,inpageurl=''defmain(request,。
php抓取网页标签(这是hello,!这是一个!一个实例!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-17 13:05
.
但通常是为了方便维护和读写。我们将换行和缩进
你好,世界!
这是一个例子:您可以将其保存为.html文件,例如:test.html并将其拖到浏览器中查看效果,以打开我们的HTML方式。
注意标签前一般有一个标签,不是HTML标签。它定义了下面的HTMl遵循什么规则,无论是HTML、XHTML还是HTML5...这里暂时不提,大家可以自行查资料。
头:
标签用于定义文档的头部。它是所有头部元素的容器。中的元素可以引用脚本、指示浏览器在何处查找样式表、提供元信息等。
文档的头部描述了文档的各种属性和信息,包括文档的标题、它在网络上的位置以及与其他文档的关系。文档标题中收录的大部分数据不会作为内容显示给读者。
可以在 head 部分中使用以下标签:,,,,, 和。
定义文档的标题,它是 head 部分中唯一必需的元素。但是如果不写标题,浏览器是不会报错的,因为浏览器有纠错功能。
标题:
该元素可以定义文档的标题。
浏览器以特殊的方式使用标题,通常将其放置在浏览器窗口的标题栏或状态栏上。同样,当文档被添加到用户的链接列表或采集夹或书签列表时,标题将成为文档链接的默认名称。
身体:
body 元素定义文档的正文。
body 元素收录文档的所有内容(如文本、超链接、图像、表格、列表等)
body 中的信息会在浏览器窗口中显示给用户,head 标签中的元素信息除了标题之外用户是看不到的。
如图:
好,今天先介绍这些,明天继续
您的支持是我继续前进的动力! 查看全部
php抓取网页标签(这是hello,!这是一个!一个实例!)
.
但通常是为了方便维护和读写。我们将换行和缩进
你好,世界!
这是一个例子:您可以将其保存为.html文件,例如:test.html并将其拖到浏览器中查看效果,以打开我们的HTML方式。
注意标签前一般有一个标签,不是HTML标签。它定义了下面的HTMl遵循什么规则,无论是HTML、XHTML还是HTML5...这里暂时不提,大家可以自行查资料。
头:
标签用于定义文档的头部。它是所有头部元素的容器。中的元素可以引用脚本、指示浏览器在何处查找样式表、提供元信息等。
文档的头部描述了文档的各种属性和信息,包括文档的标题、它在网络上的位置以及与其他文档的关系。文档标题中收录的大部分数据不会作为内容显示给读者。
可以在 head 部分中使用以下标签:,,,,, 和。
定义文档的标题,它是 head 部分中唯一必需的元素。但是如果不写标题,浏览器是不会报错的,因为浏览器有纠错功能。
标题:
该元素可以定义文档的标题。
浏览器以特殊的方式使用标题,通常将其放置在浏览器窗口的标题栏或状态栏上。同样,当文档被添加到用户的链接列表或采集夹或书签列表时,标题将成为文档链接的默认名称。
身体:
body 元素定义文档的正文。
body 元素收录文档的所有内容(如文本、超链接、图像、表格、列表等)
body 中的信息会在浏览器窗口中显示给用户,head 标签中的元素信息除了标题之外用户是看不到的。
如图:
好,今天先介绍这些,明天继续
您的支持是我继续前进的动力!
php抓取网页标签(php抓取网页标签页?没看明白你的意思,页面中有多少个属性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-16 08:01
php抓取网页标签页?没看明白你的意思,页面中有多少标签页,就有多少个属性,
返回值为字符串。
php,
看一下
phpecho"hello,"+url+","+get_text();?>你在传入url是正则匹配,不匹配如果是cookie,
在php中,swith()为针对于单个tag进行跳转,
是单向的或双向(跳转)的,这里是单向的;关闭浏览器,重新打开,打开单页;postmessage传递给页面一个url,
数组(list),vara=[1,2,3],varv=a[0],//跳转到相应的表格属性中,必须为字符串,或者二元键值对postmessage传递给web页面一个ajax的json格式resolve()方法,resolve后不再跳转,
phppdojsresin{varget_text(){return"hello"+url+","+get_text();}}传递数据,从浏览器或第三方中获取。springmvc因为整合了web.xml, 查看全部
php抓取网页标签(php抓取网页标签页?没看明白你的意思,页面中有多少个属性)
php抓取网页标签页?没看明白你的意思,页面中有多少标签页,就有多少个属性,
返回值为字符串。
php,
看一下
phpecho"hello,"+url+","+get_text();?>你在传入url是正则匹配,不匹配如果是cookie,
在php中,swith()为针对于单个tag进行跳转,
是单向的或双向(跳转)的,这里是单向的;关闭浏览器,重新打开,打开单页;postmessage传递给页面一个url,
数组(list),vara=[1,2,3],varv=a[0],//跳转到相应的表格属性中,必须为字符串,或者二元键值对postmessage传递给web页面一个ajax的json格式resolve()方法,resolve后不再跳转,
phppdojsresin{varget_text(){return"hello"+url+","+get_text();}}传递数据,从浏览器或第三方中获取。springmvc因为整合了web.xml,
php抓取网页标签(【知乎土豆b站全部教程】php抓取网页标签、解析标签提取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-12 00:01
php抓取网页标签、解析标签提取关键词、搭建正则表达式库抓取整站返回ajax返回json异步加载的数据响应,
curl是抓取数据库的,类似于php。xmlhttprequest是通过网络调用web服务器,json是java的对象标准形式。
php抓包
php抓包就是web服务器响应,json是数据传输,都是通过网络。http转发是在浏览器和服务器之间处理协议转换后,传输给浏览器,服务器再转发给服务器,也就是web服务器或者浏览器。
php抓包的本质和json抓包是一样的,所有数据传输都是通过网络,而json则是传输格式的编制定义。我们开发运维的同学了解应该更为清楚一些,分为模板解析,
php不知道,
抓包与json类似可以理解成数据库传输数据的一种方式json在java的api里是java提供的一种加密解密的工具模板字符串构造请求参数json解析json注解配置等
curl+xmlhttprequest
php抓包,
都是传输网络数据
请求——>setrequest方法——>response,php在此方法上封装好accept相关的方法,
php抓包可以看看这个:【知乎土豆b站全部教程】微信qq全网教程_免费在线教育 查看全部
php抓取网页标签(【知乎土豆b站全部教程】php抓取网页标签、解析标签提取)
php抓取网页标签、解析标签提取关键词、搭建正则表达式库抓取整站返回ajax返回json异步加载的数据响应,
curl是抓取数据库的,类似于php。xmlhttprequest是通过网络调用web服务器,json是java的对象标准形式。
php抓包
php抓包就是web服务器响应,json是数据传输,都是通过网络。http转发是在浏览器和服务器之间处理协议转换后,传输给浏览器,服务器再转发给服务器,也就是web服务器或者浏览器。
php抓包的本质和json抓包是一样的,所有数据传输都是通过网络,而json则是传输格式的编制定义。我们开发运维的同学了解应该更为清楚一些,分为模板解析,
php不知道,
抓包与json类似可以理解成数据库传输数据的一种方式json在java的api里是java提供的一种加密解密的工具模板字符串构造请求参数json解析json注解配置等
curl+xmlhttprequest
php抓包,
都是传输网络数据
请求——>setrequest方法——>response,php在此方法上封装好accept相关的方法,
php抓包可以看看这个:【知乎土豆b站全部教程】微信qq全网教程_免费在线教育
php抓取网页标签(php抓取网页标签将网页上的页面标签(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-11-06 09:01
php抓取网页标签将网页上的页面标签抓取下来,然后用php写对应的页面处理逻辑,加入到后端,进行页面的数据收集。爬虫抓取网页内容将收集后的数据再用php写一个对应的数据处理逻辑,加入到后端。这两种处理方式,有什么区别呢?php抓取网页内容,主要是基于php的反射机制和内存机制。可以直接抓取页面上的任何内容,不需要像传统方式那样进行申请浏览器的session(关于session还不是很清楚,我们会后续提到)。
1php的反射机制//php代码varheaders={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/28.0.2093.132safari/537.36'}//模拟浏览器输入地址$request=array_get('/',$request);//获取headers内容,主要是获取网页源代码$headers=getheaders().append("user-agent");//引入documents/javascript/postmessage/datetime.jsonarray_get('tt','on');//针对json数据,在form中引入varform=require('./javascript/input.js');varval="";$text=form.encode("utf-8");$score=json_encode($text);//发送一个包含""、"out"等字符串的json(require()方法)getfromjson("json.stringify()");//json.stringify可以这么理解:获取包含content、""、"out"等字符串的json(require()方法)send($text);//就是发送到服务器,获取响应内容(require()方法)header('content-type','text/plain')$headers=getheaders().append("content-type");//获取浏览器验证码(encode()的问题)$score=val+$headers;$gg=$gg.encode("utf-8");//传值时参数中要加","$gg="".encode('').replace('\n','');//传值时参数中要加"\""$score=json_encode($gg);//转义字符array_get('tt','on');//stream数组对象var_dump($text);return$text;};2php的内存机制1虚拟机状态-内存分配函数#define-0x72array_get('tt','on');//获取浏览器验证码等信息$text=form.encode("utf-8");$gg=$gg.encode("gbk");$score=json_encode($gg);//转义字符1.1$text=form.encode。 查看全部
php抓取网页标签(php抓取网页标签将网页上的页面标签(图))
php抓取网页标签将网页上的页面标签抓取下来,然后用php写对应的页面处理逻辑,加入到后端,进行页面的数据收集。爬虫抓取网页内容将收集后的数据再用php写一个对应的数据处理逻辑,加入到后端。这两种处理方式,有什么区别呢?php抓取网页内容,主要是基于php的反射机制和内存机制。可以直接抓取页面上的任何内容,不需要像传统方式那样进行申请浏览器的session(关于session还不是很清楚,我们会后续提到)。
1php的反射机制//php代码varheaders={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/28.0.2093.132safari/537.36'}//模拟浏览器输入地址$request=array_get('/',$request);//获取headers内容,主要是获取网页源代码$headers=getheaders().append("user-agent");//引入documents/javascript/postmessage/datetime.jsonarray_get('tt','on');//针对json数据,在form中引入varform=require('./javascript/input.js');varval="";$text=form.encode("utf-8");$score=json_encode($text);//发送一个包含""、"out"等字符串的json(require()方法)getfromjson("json.stringify()");//json.stringify可以这么理解:获取包含content、""、"out"等字符串的json(require()方法)send($text);//就是发送到服务器,获取响应内容(require()方法)header('content-type','text/plain')$headers=getheaders().append("content-type");//获取浏览器验证码(encode()的问题)$score=val+$headers;$gg=$gg.encode("utf-8");//传值时参数中要加","$gg="".encode('').replace('\n','');//传值时参数中要加"\""$score=json_encode($gg);//转义字符array_get('tt','on');//stream数组对象var_dump($text);return$text;};2php的内存机制1虚拟机状态-内存分配函数#define-0x72array_get('tt','on');//获取浏览器验证码等信息$text=form.encode("utf-8");$gg=$gg.encode("gbk");$score=json_encode($gg);//转义字符1.1$text=form.encode。
php抓取网页标签(基于网站安全与盈利的因素,搜索引擎JavaScript属性屏蔽收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-03 23:20
基于网站安全性和盈利性因素,站长不希望某些目录或页面被抓取和收录,例如付费内容、测试阶段的页面和复制的内容页面。
虽然在网站的构建过程中,使用JavaScript、Flash链接和Nofollow属性可以阻止搜索引擎蜘蛛,导致页面不是收录;但在某些情况下,搜索引擎可以读取它们。根据网站的排名,我们建议谨慎使用JavaScript、Flash链接和Nofollow属性来屏蔽收录。
我想强调的是,使用JavaScript和Flash链接搭建网站,其实是在给网站制造蜘蛛陷阱,让搜索引擎无法正确判断和抓取页面的主题和文字。
为了确保网站某些目录或页面不是收录,您需要正确使用robots文件或Meta Robots标签来实现网站禁止收录机制。
1、机器人文件
搜索引擎蜘蛛访问网站时,首先会检查网站的根目录下是否有名为robots.txt的纯文本文件。它的主要功能是让搜索引擎抓取或禁止它。 网站 一些内容。
user-agent: *适用于所有蜘蛛
禁止:/上传/
Disallow: .jpg$ 禁止抓取所有 .jpg 文件
Disallow: *.html 禁止抓取所有 html 文件
禁止:/upload/index.html
Disallow 禁止抓取哪些文件或目录。 Allow 告诉搜索引擎应该抓取哪些页面。由于没有指定,所以允许爬取,所以单独写allow是没有意义的。
2、元机器人标签
Meta robots标签是页面头部的一种元标签,用于指示搜索引擎禁止索引该页面的内容。
最简单的元机器人标签格式是:
效果是禁止所有搜索引擎索引此页面,并禁止跟踪此页面上的链接。
效果是禁止对该页面进行索引,但允许蜘蛛跟踪页面上的链接,也可以传递权重。
Google、Bing 和 Yahoo 支持的标签如下:
Noindex:不索引此页面
Nofollow:不要点击此页面上的链接
Nosnippet:不在搜索结果中显示摘要文本
Noarchive:不显示快照
Noodp:不要使用打开目录中的标题和描述
百度支持:Nofollow 和 Noarchive
元机器人的使用只有在索引被禁止时才有意义。
使用 noindex meat robots 标签的页面会被抓取,但不会被索引,页面 URL 也不会出现在搜索结果中,这与 robots 文件不同。 查看全部
php抓取网页标签(基于网站安全与盈利的因素,搜索引擎JavaScript属性屏蔽收录)
基于网站安全性和盈利性因素,站长不希望某些目录或页面被抓取和收录,例如付费内容、测试阶段的页面和复制的内容页面。
https://www.badpon.com/wp-cont ... 9.png 300w" />虽然在网站的构建过程中,使用JavaScript、Flash链接和Nofollow属性可以阻止搜索引擎蜘蛛,导致页面不是收录;但在某些情况下,搜索引擎可以读取它们。根据网站的排名,我们建议谨慎使用JavaScript、Flash链接和Nofollow属性来屏蔽收录。
我想强调的是,使用JavaScript和Flash链接搭建网站,其实是在给网站制造蜘蛛陷阱,让搜索引擎无法正确判断和抓取页面的主题和文字。
为了确保网站某些目录或页面不是收录,您需要正确使用robots文件或Meta Robots标签来实现网站禁止收录机制。
1、机器人文件
搜索引擎蜘蛛访问网站时,首先会检查网站的根目录下是否有名为robots.txt的纯文本文件。它的主要功能是让搜索引擎抓取或禁止它。 网站 一些内容。
user-agent: *适用于所有蜘蛛
禁止:/上传/
Disallow: .jpg$ 禁止抓取所有 .jpg 文件
Disallow: *.html 禁止抓取所有 html 文件
禁止:/upload/index.html
Disallow 禁止抓取哪些文件或目录。 Allow 告诉搜索引擎应该抓取哪些页面。由于没有指定,所以允许爬取,所以单独写allow是没有意义的。
2、元机器人标签
Meta robots标签是页面头部的一种元标签,用于指示搜索引擎禁止索引该页面的内容。
最简单的元机器人标签格式是:
效果是禁止所有搜索引擎索引此页面,并禁止跟踪此页面上的链接。
效果是禁止对该页面进行索引,但允许蜘蛛跟踪页面上的链接,也可以传递权重。
Google、Bing 和 Yahoo 支持的标签如下:
Noindex:不索引此页面
Nofollow:不要点击此页面上的链接
Nosnippet:不在搜索结果中显示摘要文本
Noarchive:不显示快照
Noodp:不要使用打开目录中的标题和描述
百度支持:Nofollow 和 Noarchive
元机器人的使用只有在索引被禁止时才有意义。
使用 noindex meat robots 标签的页面会被抓取,但不会被索引,页面 URL 也不会出现在搜索结果中,这与 robots 文件不同。
php抓取网页标签(特立独行我对以这种格式抓取网站相当满意:Stsrt页面>)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-01 08:05
特立独行
我对这种格式的网站 爬取比较满意: Stsrt page> Page 1> Page 2> 我要爬取的页面
但是,当谈到网站每个页面都有很多指向我要爬取的页面的链接时,我有点卡住了。
我想我需要先抓取并抓取我需要的所有链接,格式如下:第1页,抓取所有链接,关注第2页>第2页,抓取所有链接,关注第3页*重复该页面X次*>然后一次所有链接都建立了,请关注并抓取我想要的数据。
最好的方法是用一个函数创建一个链表,然后传递给一个函数,遍历它们并抓取数据?
Python
如果每个链接的数据获取是相同的,那么是的。
你会得到这样的东西:
for link in links:
scrape_date(link)
收录您之前抓取的所有页面上的所有链接的链接列表在哪里。
您还可以同时从每个页面上找到的所有链接中获取数据。像这样的东西:
for page in pages:
urls = scrape_urls(page)
data = scrape_date(urls)
其中 pages 是所有页面的列表(第 1 页、第 2 页、第 3 页等)。 查看全部
php抓取网页标签(特立独行我对以这种格式抓取网站相当满意:Stsrt页面>)
特立独行
我对这种格式的网站 爬取比较满意: Stsrt page> Page 1> Page 2> 我要爬取的页面
但是,当谈到网站每个页面都有很多指向我要爬取的页面的链接时,我有点卡住了。
我想我需要先抓取并抓取我需要的所有链接,格式如下:第1页,抓取所有链接,关注第2页>第2页,抓取所有链接,关注第3页*重复该页面X次*>然后一次所有链接都建立了,请关注并抓取我想要的数据。
最好的方法是用一个函数创建一个链表,然后传递给一个函数,遍历它们并抓取数据?
Python
如果每个链接的数据获取是相同的,那么是的。
你会得到这样的东西:
for link in links:
scrape_date(link)
收录您之前抓取的所有页面上的所有链接的链接列表在哪里。
您还可以同时从每个页面上找到的所有链接中获取数据。像这样的东西:
for page in pages:
urls = scrape_urls(page)
data = scrape_date(urls)
其中 pages 是所有页面的列表(第 1 页、第 2 页、第 3 页等)。
php抓取网页标签(先来了解什么是百度蜘蛛抓取频次和抓取耗时:解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-01 08:01
为什么百度蜘蛛爬网时间长,有些时间短,这些耗时的数据代表什么?
那么我们先来了解一下什么是百度蜘蛛抓取频率和抓取时间:
1、 爬行时间数据:
显示百度蜘蛛每次抓取网站所花费的时间。根据数据,站长可以了解蜘蛛抓取网站所花费的时间。获取时间越短,网站的访问速度越快。用户体验越好。
注:爬取耗时数据的更新频率与爬取频率有关,爬取频率高的站点数据更新较快。
2、 抓取状态统计:
四种抓取状态码统计:第一种:重定向(301、302等);第二类,未找到(404);第三类,服务器无响应(501、502等);第四类:服务器连接超时,帮助站长更好的理解爬取网站 在蜘蛛中的状态,更好的管理网站。
注:这里统计的是百度蜘蛛每次爬取行为的状态,与网站中的实际状态页数不能一概而论。
3、 爬频工具的响应速度:
使用爬取频率工具调整爬取次数后的有效时间。
百度蜘蛛爬取时间很长,一般突出以下几点:
1、快照经常不更新
2、网站收录少
3、网站关键词排名低
4、 造成这种耗时爬行的原因分为以下几类:
5、网站 是一个新站点。在这种情况下,抓取时间是正常的,一些新网站在一个月内才被百度获得收录。
6、 蜘蛛爬过站点,但没有爬走站点数据或页面。遇到这种情况,可以查看网站的日志,根据爬虫上报的状态码查询原因。
7、网站充斥着过多的富媒体文件,网站信息原创的程度不高。这种类型的网站会导致蜘蛛对网站失去兴趣,停止爬取网站。
解决方案:
1、提升网站原创度,网站更新频率稳定。
2、主关键词和副关键词分布合理。不要堆砌关键词
3、查看网站的日志,根据上报的状态码做出相应的解决方案。
百度蜘蛛反馈码一般分为以下几种:
1、200 0 0 页面访问成功,0表示获取成功并带回数据库。这个时候大家可以放心,这个页面已经bd收录了,只是还没有发布。可能会在 bd 更新时发布。
2、200 0 64 访问了该页面,但未获取它或将其带回数据库。这种原因多是空间不稳定,服务器不稳定。
3、304 0 0 这个返回码表示蜘蛛访问的页面没有更新,和他之前来的时候一样,所以看到这个不用担心,蜘蛛已经来了,但是你还没有更新,所以他不舍得拿走这个页面。
4、404 0 0 这个代表404页面,但是有一个很严重的问题。这个返回码告诉我们蜘蛛来到了404页面并把他带走了。
(资源库) 查看全部
php抓取网页标签(先来了解什么是百度蜘蛛抓取频次和抓取耗时:解决方法)
为什么百度蜘蛛爬网时间长,有些时间短,这些耗时的数据代表什么?
那么我们先来了解一下什么是百度蜘蛛抓取频率和抓取时间:
1、 爬行时间数据:
显示百度蜘蛛每次抓取网站所花费的时间。根据数据,站长可以了解蜘蛛抓取网站所花费的时间。获取时间越短,网站的访问速度越快。用户体验越好。
注:爬取耗时数据的更新频率与爬取频率有关,爬取频率高的站点数据更新较快。
2、 抓取状态统计:
四种抓取状态码统计:第一种:重定向(301、302等);第二类,未找到(404);第三类,服务器无响应(501、502等);第四类:服务器连接超时,帮助站长更好的理解爬取网站 在蜘蛛中的状态,更好的管理网站。
注:这里统计的是百度蜘蛛每次爬取行为的状态,与网站中的实际状态页数不能一概而论。
3、 爬频工具的响应速度:
使用爬取频率工具调整爬取次数后的有效时间。
百度蜘蛛爬取时间很长,一般突出以下几点:
1、快照经常不更新
2、网站收录少
3、网站关键词排名低
4、 造成这种耗时爬行的原因分为以下几类:
5、网站 是一个新站点。在这种情况下,抓取时间是正常的,一些新网站在一个月内才被百度获得收录。
6、 蜘蛛爬过站点,但没有爬走站点数据或页面。遇到这种情况,可以查看网站的日志,根据爬虫上报的状态码查询原因。
7、网站充斥着过多的富媒体文件,网站信息原创的程度不高。这种类型的网站会导致蜘蛛对网站失去兴趣,停止爬取网站。
解决方案:
1、提升网站原创度,网站更新频率稳定。
2、主关键词和副关键词分布合理。不要堆砌关键词
3、查看网站的日志,根据上报的状态码做出相应的解决方案。
百度蜘蛛反馈码一般分为以下几种:
1、200 0 0 页面访问成功,0表示获取成功并带回数据库。这个时候大家可以放心,这个页面已经bd收录了,只是还没有发布。可能会在 bd 更新时发布。
2、200 0 64 访问了该页面,但未获取它或将其带回数据库。这种原因多是空间不稳定,服务器不稳定。
3、304 0 0 这个返回码表示蜘蛛访问的页面没有更新,和他之前来的时候一样,所以看到这个不用担心,蜘蛛已经来了,但是你还没有更新,所以他不舍得拿走这个页面。
4、404 0 0 这个代表404页面,但是有一个很严重的问题。这个返回码告诉我们蜘蛛来到了404页面并把他带走了。
(资源库)
php抓取网页标签(PHP利用Curl可以完成各种传送文件操作,访问多个url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-31 19:15
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,开发爬虫程序的效率不高,所以经常需要使用 Curl Multi Functions。实现多线程并发访问多个URL地址的函数,实现网页的并发多线程爬取或下载文件
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面这段代码是抓取多个网址,然后将抓取到的网址的页面代码写入指定文件
$urls = array( 'https://www.html.cn/', 'http://www.google.com/', 'http://www.example.com/' ); // 设置要抓取的页面URL $save_to='/test.txt'; // 把抓取的代码写入该文件 $st = fopen($save_to,"a"); $mh = curl_multi_init(); foreach ($urls as $i => $url) { $conn[$i] = curl_init($url); curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i], CURLOPT_HEADER ,0); curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 curl_multi_add_handle ($mh,$conn[$i]); } // 初始化 do { curl_multi_exec($mh,$active); } while ($active); // 执行 foreach ($urls as $i => $url) { curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); } // 结束清理 curl_multi_close($mh); fclose($st);
(2)下面的代码和上面的意思一样,只不过这个地方先把获取到的代码放入变量中,然后将获取到的内容写入指定文件
$urls = array( 'https://www.html.cn/', 'http://www.google.com/', 'http://www.example.com/' ); $save_to='/test.txt'; // 把抓取的代码写入该文件 $st = fopen($save_to,"a"); $mh = curl_multi_init(); foreach ($urls as $i => $url) { $conn[$i] = curl_init($url); curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i], CURLOPT_HEADER ,0); curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 curl_multi_add_handle ($mh,$conn[$i]); } do { curl_multi_exec($mh,$active); } while ($active); foreach ($urls as $i => $url) { $data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 fwrite($st,$data); // 将字符串写入文件 } // 获得数据变量,并写入文件 foreach ($urls as $i => $url) { curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); } curl_multi_close($mh); fclose($st);
(3) 下面一段代码实现了使用PHP的Curl Functions实现文件的并发多线程下载
$urls=array( 'https://www.html.cn/5w.zip', 'https://www.html.cn/5w.zip', 'https://www.html.cn/5w.zip' ); $save_to='./home/'; $mh=curl_multi_init(); foreach($urls as $i=>$url){ $g=$save_to.basename($url); if(!is_file($g)){ $conn[$i]=curl_init($url); $fp[$i]=fopen($g,"w"); curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]); curl_setopt($conn[$i],CURLOPT_HEADER ,0); curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60); curl_multi_add_handle($mh,$conn[$i]); } } do{ $n=curl_multi_exec($mh,$active); }while($active); foreach($urls as $i=>$url){ curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); fclose($fp[$i]); } curl_multi_close($mh);$urls=array( 'https://www.html.cn/5w.zip', 'https://www.html.cn/5w.zip', 'https://www.html.cn/5w.zip' ); $save_to='./home/'; $mh=curl_multi_init(); foreach($urls as $i=>$url){ $g=$save_to.basename($url); if(!is_file($g)){ $conn[$i]=curl_init($url); $fp[$i]=fopen($g,"w"); curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]); curl_setopt($conn[$i],CURLOPT_HEADER ,0); curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60); curl_multi_add_handle($mh,$conn[$i]); } } do{ $n=curl_multi_exec($mh,$active); }while($active); foreach($urls as $i=>$url){ curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); fclose($fp[$i]); } curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
以上就是php结合curl实现多线程爬取的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php抓取网页标签(PHP利用Curl可以完成各种传送文件操作,访问多个url)
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,开发爬虫程序的效率不高,所以经常需要使用 Curl Multi Functions。实现多线程并发访问多个URL地址的函数,实现网页的并发多线程爬取或下载文件
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面这段代码是抓取多个网址,然后将抓取到的网址的页面代码写入指定文件
$urls = array( 'https://www.html.cn/', 'http://www.google.com/', 'http://www.example.com/' ); // 设置要抓取的页面URL $save_to='/test.txt'; // 把抓取的代码写入该文件 $st = fopen($save_to,"a"); $mh = curl_multi_init(); foreach ($urls as $i => $url) { $conn[$i] = curl_init($url); curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i], CURLOPT_HEADER ,0); curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 curl_multi_add_handle ($mh,$conn[$i]); } // 初始化 do { curl_multi_exec($mh,$active); } while ($active); // 执行 foreach ($urls as $i => $url) { curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); } // 结束清理 curl_multi_close($mh); fclose($st);
(2)下面的代码和上面的意思一样,只不过这个地方先把获取到的代码放入变量中,然后将获取到的内容写入指定文件
$urls = array( 'https://www.html.cn/', 'http://www.google.com/', 'http://www.example.com/' ); $save_to='/test.txt'; // 把抓取的代码写入该文件 $st = fopen($save_to,"a"); $mh = curl_multi_init(); foreach ($urls as $i => $url) { $conn[$i] = curl_init($url); curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i], CURLOPT_HEADER ,0); curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 curl_multi_add_handle ($mh,$conn[$i]); } do { curl_multi_exec($mh,$active); } while ($active); foreach ($urls as $i => $url) { $data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 fwrite($st,$data); // 将字符串写入文件 } // 获得数据变量,并写入文件 foreach ($urls as $i => $url) { curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); } curl_multi_close($mh); fclose($st);
(3) 下面一段代码实现了使用PHP的Curl Functions实现文件的并发多线程下载
$urls=array( 'https://www.html.cn/5w.zip', 'https://www.html.cn/5w.zip', 'https://www.html.cn/5w.zip' ); $save_to='./home/'; $mh=curl_multi_init(); foreach($urls as $i=>$url){ $g=$save_to.basename($url); if(!is_file($g)){ $conn[$i]=curl_init($url); $fp[$i]=fopen($g,"w"); curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]); curl_setopt($conn[$i],CURLOPT_HEADER ,0); curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60); curl_multi_add_handle($mh,$conn[$i]); } } do{ $n=curl_multi_exec($mh,$active); }while($active); foreach($urls as $i=>$url){ curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); fclose($fp[$i]); } curl_multi_close($mh);$urls=array( 'https://www.html.cn/5w.zip', 'https://www.html.cn/5w.zip', 'https://www.html.cn/5w.zip' ); $save_to='./home/'; $mh=curl_multi_init(); foreach($urls as $i=>$url){ $g=$save_to.basename($url); if(!is_file($g)){ $conn[$i]=curl_init($url); $fp[$i]=fopen($g,"w"); curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]); curl_setopt($conn[$i],CURLOPT_HEADER ,0); curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60); curl_multi_add_handle($mh,$conn[$i]); } } do{ $n=curl_multi_exec($mh,$active); }while($active); foreach($urls as $i=>$url){ curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); fclose($fp[$i]); } curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
以上就是php结合curl实现多线程爬取的详细内容。更多详情请关注其他相关html中文网站文章!
php抓取网页标签(有一定的参考价值,有需要的朋友可以参考一下!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-27 08:13
本文文章的内容是介绍使用js获取页面所有标签的方法(详细代码解释)。有一定的参考价值,有需要的朋友可以参考一下,希望对你有帮助。
前两天看到一个问题,问如何从页面中获取所有标签并查看它们的编号。感觉还是有点意思,就给大家做一下吧。
我们先从页面获取标签的思路开始。不用说,我们肯定会想到DOM操作。拿到之后,我们不确定一个元素是否有子元素。我们应该做什么?我肯定会想到递归
既然有了DOM操作和递归,就很容易了,直接写代码就行了。下面是代码,有注释,可以拉下来参考。
Document
var map = {};
//采用递归调用的方法,比较方便和简单。
function fds(node) {
if (node.nodeType === 1) {
//这里我们用nodeName属性,直接获取节点的节点名称
var tagName = node.nodeName;
//判断对象中存在不存在同类的节点,若存在则添加,不存在则添加并赋值为1
map[tagName] = map[tagName] ? map[tagName] + 1 : 1;
}
//获取该元素节点的所有子节点
var children = node.childNodes;
for (var i = 0; i < children.length; i++) {
//递归调用
fds(children[i])
}
}
fds(document);
console.log(map)
以上就是使用js获取页面所有标签的方法的详细内容(详细代码解释)。更多详情请关注php中文网其他相关文章!
免责声明:本文转载于:博客园,如有侵权,请联系删除 查看全部
php抓取网页标签(有一定的参考价值,有需要的朋友可以参考一下!)
本文文章的内容是介绍使用js获取页面所有标签的方法(详细代码解释)。有一定的参考价值,有需要的朋友可以参考一下,希望对你有帮助。
前两天看到一个问题,问如何从页面中获取所有标签并查看它们的编号。感觉还是有点意思,就给大家做一下吧。
我们先从页面获取标签的思路开始。不用说,我们肯定会想到DOM操作。拿到之后,我们不确定一个元素是否有子元素。我们应该做什么?我肯定会想到递归
既然有了DOM操作和递归,就很容易了,直接写代码就行了。下面是代码,有注释,可以拉下来参考。
Document
var map = {};
//采用递归调用的方法,比较方便和简单。
function fds(node) {
if (node.nodeType === 1) {
//这里我们用nodeName属性,直接获取节点的节点名称
var tagName = node.nodeName;
//判断对象中存在不存在同类的节点,若存在则添加,不存在则添加并赋值为1
map[tagName] = map[tagName] ? map[tagName] + 1 : 1;
}
//获取该元素节点的所有子节点
var children = node.childNodes;
for (var i = 0; i < children.length; i++) {
//递归调用
fds(children[i])
}
}
fds(document);
console.log(map)
以上就是使用js获取页面所有标签的方法的详细内容(详细代码解释)。更多详情请关注php中文网其他相关文章!
免责声明:本文转载于:博客园,如有侵权,请联系删除
php抓取网页标签(使用js获取页面上的所有标签的方法(代码详解))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-21 04:13
本文文章的内容是介绍使用js获取页面所有标签的方法(详细代码解释)。有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
前两天看到一个问题,问如何从页面中获取所有标签并查看它们的编号。感觉还是有点意思,就给大家做一下吧。
我们先从页面获取标签的思路开始。不用说,我们肯定会想到 DOM 操作。拿到之后,我们不确定一个元素是否有子元素。我们应该做什么?我肯定会想到递归
既然有了DOM操作和递归,就很容易了,直接写代码就行了。下面是代码,有注释,可以拉下来参考。
文档
无功映射 = {};
//递归调用的方法更方便简单。
函数 fds(节点){
if (node.nodeType === 1) {
//这里我们使用nodeName属性直接获取节点的节点名
var tagName = node.nodeName;
//判断对象中没有同类节点,如果存在则添加,如果不存在则添加并赋值为1
地图[标签名] = 地图[标签名]?地图[标签名] + 1: 1;
}
//获取元素节点的所有子节点
var children = node.childNodes;
for (var i = 0; i <children.length; i++) {
//递归调用
fds(儿童[i])
}
}
fds(文件);
控制台日志(地图) 查看全部
php抓取网页标签(使用js获取页面上的所有标签的方法(代码详解))
本文文章的内容是介绍使用js获取页面所有标签的方法(详细代码解释)。有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
前两天看到一个问题,问如何从页面中获取所有标签并查看它们的编号。感觉还是有点意思,就给大家做一下吧。
我们先从页面获取标签的思路开始。不用说,我们肯定会想到 DOM 操作。拿到之后,我们不确定一个元素是否有子元素。我们应该做什么?我肯定会想到递归
既然有了DOM操作和递归,就很容易了,直接写代码就行了。下面是代码,有注释,可以拉下来参考。
文档
无功映射 = {};
//递归调用的方法更方便简单。
函数 fds(节点){
if (node.nodeType === 1) {
//这里我们使用nodeName属性直接获取节点的节点名
var tagName = node.nodeName;
//判断对象中没有同类节点,如果存在则添加,如果不存在则添加并赋值为1
地图[标签名] = 地图[标签名]?地图[标签名] + 1: 1;
}
//获取元素节点的所有子节点
var children = node.childNodes;
for (var i = 0; i <children.length; i++) {
//递归调用
fds(儿童[i])
}
}
fds(文件);
控制台日志(地图)
php抓取网页标签( 2018-12-27())
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-10-16 00:27
2018-12-27())
Jsoup抓取页面A标签中的href路径
时间:2018-12-27
本文章为大家介绍Jsoup抓取到页面A标签的href路径,主要包括Jsoup抓取到页面A标签的href路径的使用示例、应用技巧、基础知识点总结及注意事项需要注意。有一定的参考价值,有需要的朋友可以参考。
直接上代码,注释很全
<p>
public static void main(String[] args)throws Exception{
//抓取的网址
String url = "http://www.stats.gov.cn/tjsj/t ... 3B%3B
//编码格式的转换
Document document = Jsoup.parse(new URL(url).openStream(), "GBK", url);
//根据class获取到 页面的 元素内容
Elements tables = document.getElementsByClass("provincetr");
//根据td标签来划分
Elements td = tables.select("td");
for(int j=0;j 查看全部
php抓取网页标签(
2018-12-27())
Jsoup抓取页面A标签中的href路径
时间:2018-12-27
本文章为大家介绍Jsoup抓取到页面A标签的href路径,主要包括Jsoup抓取到页面A标签的href路径的使用示例、应用技巧、基础知识点总结及注意事项需要注意。有一定的参考价值,有需要的朋友可以参考。
直接上代码,注释很全
<p>
public static void main(String[] args)throws Exception{
//抓取的网址
String url = "http://www.stats.gov.cn/tjsj/t ... 3B%3B
//编码格式的转换
Document document = Jsoup.parse(new URL(url).openStream(), "GBK", url);
//根据class获取到 页面的 元素内容
Elements tables = document.getElementsByClass("provincetr");
//根据td标签来划分
Elements td = tables.select("td");
for(int j=0;j
php抓取网页标签( PHP实现网页内容html标签补全和过滤的方法实例解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 36 次浏览 • 2021-09-26 12:07
PHP实现网页内容html标签补全和过滤的方法实例解析)
用PHP完成和过滤网页内容HTML标记的方法摘要[2种方法]
更新时间:2017年4月27日10:58:53作者:网站
本文章主要介绍了PHP中HTML标记完成和web内容过滤的方法,并以实例的形式分析了PHP常见的标记检查、完成、关闭、过滤等相关操作技巧。有需要的朋友可以参考
本文介绍了在PHP中完成HTML标记和过滤网页内容的方法。与您分享,供您参考,如下所示:
如果网页内容的HTML标记未完全显示,某些表标记不完整,导致页面混乱,或者收录内容之外的本地HTML页面,我们可以编写一个函数方法来完成HTML标记并过滤掉无用的HTML标记
PHP使HTML标记完整并自动关闭。过滤函数方法1:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
Closetags()解析:
array_u;Reverse():此函数反转原创数组中的元素,创建新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名将丢失
array_usearch():array_usearch(value,array,strict),与类似array()中的相同,在数组中查找键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回false。如果第三个参数strict指定为true,则仅当数据类型和值一致时,才会返回相应元素的键名
PHP使HTML标记完整并自动关闭。过滤函数方法2:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
Checkhtml($HTML)解析:
Stripsplashes():函数删除addslashes()函数添加的反斜杠。此函数用于清理从数据库或HTML表单检索的数据
有关PHP的更多信息,感兴趣的读者可以查看本网站上的主题:PHP数据结构和算法教程、PHP编程算法摘要、PHP排序算法摘要、PHP常见遍历算法和技能摘要、PHP数学运算技能摘要、PHP数组运算技能、,PHP字符串用法总结,以及PHP中常见数据库操作技巧总结
我希望这篇文章能对你的PHP编程有所帮助 查看全部
php抓取网页标签(
PHP实现网页内容html标签补全和过滤的方法实例解析)
用PHP完成和过滤网页内容HTML标记的方法摘要[2种方法]
更新时间:2017年4月27日10:58:53作者:网站
本文章主要介绍了PHP中HTML标记完成和web内容过滤的方法,并以实例的形式分析了PHP常见的标记检查、完成、关闭、过滤等相关操作技巧。有需要的朋友可以参考
本文介绍了在PHP中完成HTML标记和过滤网页内容的方法。与您分享,供您参考,如下所示:
如果网页内容的HTML标记未完全显示,某些表标记不完整,导致页面混乱,或者收录内容之外的本地HTML页面,我们可以编写一个函数方法来完成HTML标记并过滤掉无用的HTML标记
PHP使HTML标记完整并自动关闭。过滤函数方法1:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
Closetags()解析:
array_u;Reverse():此函数反转原创数组中的元素,创建新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名将丢失
array_usearch():array_usearch(value,array,strict),与类似array()中的相同,在数组中查找键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回false。如果第三个参数strict指定为true,则仅当数据类型和值一致时,才会返回相应元素的键名
PHP使HTML标记完整并自动关闭。过滤函数方法2:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
Checkhtml($HTML)解析:
Stripsplashes():函数删除addslashes()函数添加的反斜杠。此函数用于清理从数据库或HTML表单检索的数据
有关PHP的更多信息,感兴趣的读者可以查看本网站上的主题:PHP数据结构和算法教程、PHP编程算法摘要、PHP排序算法摘要、PHP常见遍历算法和技能摘要、PHP数学运算技能摘要、PHP数组运算技能、,PHP字符串用法总结,以及PHP中常见数据库操作技巧总结
我希望这篇文章能对你的PHP编程有所帮助
php抓取网页标签(对阅读全文网页重构应该避免的10大CSS糟糕用法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-19 19:23
阿里云>;云气社区>;主题地图>;P>;PHP从网页中获取标记
建议的活动:
更多优惠>
当前主题:PHP从网页中获取标记并将其添加到采集夹中
相关主题:
PHP从网页中获取标签以查看更多博客
标准化标签对搜索引擎优化的影响
作者:1005人参观了优惠活动。评论数量:2002年之前
规范标签:初学者的简单指南。想知道什么是规范标记以及如何使用它们来避免可怕的重复内容问题吗?规格标签不是新的。自2009年以来,这是十年来最好的一年。百度、360和搜狗共同创造了它们。他们的目标是什么?为网站所有者提供一种快速简便的方法来解决重复内容问题
阅读全文
HTML基本标记()
作者:听音乐睡觉709人浏览评论:04年前
HTML标记:1、tag,短文本引用注释:引用短文本,如古人的一句话。请注意,引用的文本不需要双引号。标签的真正关键点不是其默认的双引号样式(效果与手动双引号相同,但含义不同),而是其语义
阅读全文
网页重构中应避免的十种错误CSS用法
作者:黄伟的世界1207观评论:05年前
对于网页重建,CSS Zen garden标志着网页布局已从表格更改为HTML+CSS。多年来,随着我们的网站变得越来越复杂:HTML5、CSS3、新技术和新特性,越来越多的开发人员开始思考并尝试提高他们的CSS技能。那么我们从哪里开始呢?对
阅读全文
如何优化网页性能
作者:bill.kang1019观点评论:2008年之前
原创地址:本文将讨论浏览器渲染的加载过程,目的有两个:
阅读全文
有条理dedecms标签完整,易于查找
作者:YTCAHCOM1263观点评论:2005年前
常用dedecmsDevelopment经常使用一些标记,尤其是主页、专栏页和内容页。这些页面将使用标签的调用,如标题、关键字、描述、Arclist、field.body等。为了便于搜索,ytkah专门对它们进行了分类dedecmsLabel,各位
阅读全文
Python爬虫入门教程8-100蜂鸟网图片爬虫3
作者:梦橡皮擦1259观点评论:02年前
1.hummingbird pictures-冗长的两句话几天前的教程容量很大。今天,我写了一篇相对简单的文章。蜂鸟仍在爬行,aiohttp仍在使用。我希望你喜欢在网页上爬行。本教程仍然基于**学习**的目的。为什么选择蜂鸟?不可能。我盲目地选择它
阅读全文
第86天:HTML5应用程序标签和智能表单
作者:半指温柔音乐937人浏览评论:03年前
一、HTML5应用程序标签1、datalist数据载体的输入列表属性必须指向数据源2、progress进度条WebKit外观:无/*如果要更改默认样式,请先取消默认样式*/。我的进展:-
阅读全文
[Python学习]只需抓取Wikipedia程序语言消息框
作者:肖洛洛1432观点点评:2006年之前
文章主要描述如何通过python抓取Wikipedia的Infobox,主要是通过正则表达式和urllib;下面的文章可能描述了通过BeautifulSoup爬行网页的知识。既然在这方面文章还很少,我希望能提供一些想法和方法来帮助你
阅读全文
PHP从网页中获取标签并提出问题
[JavaScript学习桶]100位阿里巴巴技术专家解答了934个流行JavaScript问题
作者:管理北碚5207人,观点和评论数量:13年前
阿里巴巴极客公益活动:也许你开夜车只是为了解决一个问题,也许你不明白,只是问一个答案,也许你绞尽脑汁只是因为一个未知的问题,所以他们来了。阿里巴巴的技术专家来到云琦为您解答技术问题,他们的用户自己的技术帮助用户成长。本次活动特别邀请了100位阿里巴巴技术专家
阅读全文 查看全部
php抓取网页标签(对阅读全文网页重构应该避免的10大CSS糟糕用法)
阿里云>;云气社区>;主题地图>;P>;PHP从网页中获取标记
建议的活动:
更多优惠>
当前主题:PHP从网页中获取标记并将其添加到采集夹中
相关主题:
PHP从网页中获取标签以查看更多博客
标准化标签对搜索引擎优化的影响
作者:1005人参观了优惠活动。评论数量:2002年之前
规范标签:初学者的简单指南。想知道什么是规范标记以及如何使用它们来避免可怕的重复内容问题吗?规格标签不是新的。自2009年以来,这是十年来最好的一年。百度、360和搜狗共同创造了它们。他们的目标是什么?为网站所有者提供一种快速简便的方法来解决重复内容问题
阅读全文
HTML基本标记()
作者:听音乐睡觉709人浏览评论:04年前
HTML标记:1、tag,短文本引用注释:引用短文本,如古人的一句话。请注意,引用的文本不需要双引号。标签的真正关键点不是其默认的双引号样式(效果与手动双引号相同,但含义不同),而是其语义
阅读全文
网页重构中应避免的十种错误CSS用法
作者:黄伟的世界1207观评论:05年前
对于网页重建,CSS Zen garden标志着网页布局已从表格更改为HTML+CSS。多年来,随着我们的网站变得越来越复杂:HTML5、CSS3、新技术和新特性,越来越多的开发人员开始思考并尝试提高他们的CSS技能。那么我们从哪里开始呢?对
阅读全文
如何优化网页性能
作者:bill.kang1019观点评论:2008年之前
原创地址:本文将讨论浏览器渲染的加载过程,目的有两个:
阅读全文
有条理dedecms标签完整,易于查找
作者:YTCAHCOM1263观点评论:2005年前
常用dedecmsDevelopment经常使用一些标记,尤其是主页、专栏页和内容页。这些页面将使用标签的调用,如标题、关键字、描述、Arclist、field.body等。为了便于搜索,ytkah专门对它们进行了分类dedecmsLabel,各位
阅读全文
Python爬虫入门教程8-100蜂鸟网图片爬虫3
作者:梦橡皮擦1259观点评论:02年前
1.hummingbird pictures-冗长的两句话几天前的教程容量很大。今天,我写了一篇相对简单的文章。蜂鸟仍在爬行,aiohttp仍在使用。我希望你喜欢在网页上爬行。本教程仍然基于**学习**的目的。为什么选择蜂鸟?不可能。我盲目地选择它
阅读全文
第86天:HTML5应用程序标签和智能表单
作者:半指温柔音乐937人浏览评论:03年前
一、HTML5应用程序标签1、datalist数据载体的输入列表属性必须指向数据源2、progress进度条WebKit外观:无/*如果要更改默认样式,请先取消默认样式*/。我的进展:-
阅读全文
[Python学习]只需抓取Wikipedia程序语言消息框
作者:肖洛洛1432观点点评:2006年之前
文章主要描述如何通过python抓取Wikipedia的Infobox,主要是通过正则表达式和urllib;下面的文章可能描述了通过BeautifulSoup爬行网页的知识。既然在这方面文章还很少,我希望能提供一些想法和方法来帮助你
阅读全文
PHP从网页中获取标签并提出问题
[JavaScript学习桶]100位阿里巴巴技术专家解答了934个流行JavaScript问题
作者:管理北碚5207人,观点和评论数量:13年前
阿里巴巴极客公益活动:也许你开夜车只是为了解决一个问题,也许你不明白,只是问一个答案,也许你绞尽脑汁只是因为一个未知的问题,所以他们来了。阿里巴巴的技术专家来到云琦为您解答技术问题,他们的用户自己的技术帮助用户成长。本次活动特别邀请了100位阿里巴巴技术专家
阅读全文
php抓取网页标签( 裕轩汪这篇文章主要介绍了的相关资料,非常不错)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-09-19 19:20
裕轩汪这篇文章主要介绍了的相关资料,非常不错)
PHP正则表达式获取标记的特定属性值的方法
更新时间:2016年7月14日10:09:11作者:于玄旺
本文文章主要介绍了用PHP正则表达式捕获标签特定属性值的方法的相关资料。这是非常好的,具有参考价值。有需要的朋友可以参考
PHP学习了几天regular并获取了一些网站的数据,因此我发现每次再次编写regular都很麻烦,所以我想编写一个通用接口来获取具有特定属性值的特定标记并直接编写代码
//$html-被查找的字符串 $tag-被查找的标签 $attr-被查找的属性名 $value-被查找的属性值
function get_tag_data($html,$tag,$attr,$value){
$regex = "/(.*?)/is";
echo $regex."
";
preg_match_all($regex,$html,$matches,PREG_PATTERN_ORDER);
return $matches[1];
}
//返回值为数组 查找到的标签内的内容
这里有一个例子
header("Content-type: text/html; charset=utf-8");
$temp = '
首页
日志
LOFTER
相册
博友
关于我
';
$result = get_tag_data($temp,"a","class","fc01");
var_dump($result);
输出结果为
array(6) { [0]=> string(6) "首页" [1]=> string(6) "日志" [2]=> string(6) "LOFTER" [3]=> string(6) "相册" [4]=> string(6) "博友" [5]=> string(9) "关于我" }
检查源代码以查看
array(6) {
[0]=>
string(6) "首页"
[1]=>
string(6) "日志"
[2]=>
string(6) "LOFTER"
[3]=>
string(6) "相册"
[4]=>
string(6) "博友"
[5]=>
string(9) "关于我"
}
第一次写博客很紧张。哈哈哈,希望对你有用。我也希望你能指出代码中的问题。没有太多的测试~~
上面是小编介绍的用PHP正则表达式获取标签特定属性值的方法。我希望这对你有帮助。如果您有任何问题,请给我留言,小编会及时回复您。非常感谢您对脚本屋网站的支持@ 查看全部
php抓取网页标签(
裕轩汪这篇文章主要介绍了的相关资料,非常不错)
PHP正则表达式获取标记的特定属性值的方法
更新时间:2016年7月14日10:09:11作者:于玄旺
本文文章主要介绍了用PHP正则表达式捕获标签特定属性值的方法的相关资料。这是非常好的,具有参考价值。有需要的朋友可以参考
PHP学习了几天regular并获取了一些网站的数据,因此我发现每次再次编写regular都很麻烦,所以我想编写一个通用接口来获取具有特定属性值的特定标记并直接编写代码
//$html-被查找的字符串 $tag-被查找的标签 $attr-被查找的属性名 $value-被查找的属性值
function get_tag_data($html,$tag,$attr,$value){
$regex = "/(.*?)/is";
echo $regex."
";
preg_match_all($regex,$html,$matches,PREG_PATTERN_ORDER);
return $matches[1];
}
//返回值为数组 查找到的标签内的内容
这里有一个例子
header("Content-type: text/html; charset=utf-8");
$temp = '
首页
日志
LOFTER
相册
博友
关于我
';
$result = get_tag_data($temp,"a","class","fc01");
var_dump($result);
输出结果为
array(6) { [0]=> string(6) "首页" [1]=> string(6) "日志" [2]=> string(6) "LOFTER" [3]=> string(6) "相册" [4]=> string(6) "博友" [5]=> string(9) "关于我" }
检查源代码以查看
array(6) {
[0]=>
string(6) "首页"
[1]=>
string(6) "日志"
[2]=>
string(6) "LOFTER"
[3]=>
string(6) "相册"
[4]=>
string(6) "博友"
[5]=>
string(9) "关于我"
}
第一次写博客很紧张。哈哈哈,希望对你有用。我也希望你能指出代码中的问题。没有太多的测试~~
上面是小编介绍的用PHP正则表达式获取标签特定属性值的方法。我希望这对你有帮助。如果您有任何问题,请给我留言,小编会及时回复您。非常感谢您对脚本屋网站的支持@
php抓取网页标签(基于PHP的服务端开源项目之phpQuery采集文章列表介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-15 10:01
phpQuery是一个基于PHP的服务端开源项目,它可以让PHP开发人员轻松处理DOM文档内容,比如获取某新闻网站的头条信息。更有意思的是,它采用了jQuery的思想,你可以像使用jQuery一样处理页面内容,获取你想要的页面信息。
采集头条
先看一实例,现在我要采集新浪网国内新闻的头条,代码如下:
include'phpQuery/phpQuery.php';phpQuery::newDocumentFile('#39;);echopq(".blkToph1:eq(0)")->html();
简单的三行代码,就可以获取头条内容。首先在程序中收录phpQuery.php核心程序,然后调用读取目标网页,最后输出对应标签下的内容。
pq()是一个功能强大的方法,跟jQuery的$()如出一辙,jQuery的选择器基本上都能使用在phpQuery上,只要把“.”变成“->”。如上例中,pq(".blkTop
h1:eq(0)")抓取了页面class属性为blkTop的DIV元素,并找到该DIV内部的第一个h1标签,然后用html()方法获取h1标签里的内容(带html标签),也就是我们要获取的头条信息,如果使用text()方法,则只获取头条的文本内容。当然要使用好phpQuery,关键是要找对文档中对应内容的节点。
采集文章列表
下面再来看一个例子,获取网站的blog列表,请看代码:
include'phpQuery/phpQuery.php';phpQuery::newDocumentFile('#39;);$artlist=pq(".blog_li");foreach($artlistas$li){echopq($li)->find('h2')->html()."";}
通过循环列表中的DIV,找出文章标题并输出,就是这么简单。
解析XML文档
假设现在有一个这样的test.xml文档: 查看全部
php抓取网页标签(基于PHP的服务端开源项目之phpQuery采集文章列表介绍)
phpQuery是一个基于PHP的服务端开源项目,它可以让PHP开发人员轻松处理DOM文档内容,比如获取某新闻网站的头条信息。更有意思的是,它采用了jQuery的思想,你可以像使用jQuery一样处理页面内容,获取你想要的页面信息。
采集头条
先看一实例,现在我要采集新浪网国内新闻的头条,代码如下:
include'phpQuery/phpQuery.php';phpQuery::newDocumentFile('#39;);echopq(".blkToph1:eq(0)")->html();
简单的三行代码,就可以获取头条内容。首先在程序中收录phpQuery.php核心程序,然后调用读取目标网页,最后输出对应标签下的内容。
pq()是一个功能强大的方法,跟jQuery的$()如出一辙,jQuery的选择器基本上都能使用在phpQuery上,只要把“.”变成“->”。如上例中,pq(".blkTop
h1:eq(0)")抓取了页面class属性为blkTop的DIV元素,并找到该DIV内部的第一个h1标签,然后用html()方法获取h1标签里的内容(带html标签),也就是我们要获取的头条信息,如果使用text()方法,则只获取头条的文本内容。当然要使用好phpQuery,关键是要找对文档中对应内容的节点。
采集文章列表
下面再来看一个例子,获取网站的blog列表,请看代码:
include'phpQuery/phpQuery.php';phpQuery::newDocumentFile('#39;);$artlist=pq(".blog_li");foreach($artlistas$li){echopq($li)->find('h2')->html()."";}
通过循环列表中的DIV,找出文章标题并输出,就是这么简单。
解析XML文档
假设现在有一个这样的test.xml文档:
php抓取网页标签(html()方法此方法类似于JavaScript中的innerHTML属性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-09-15 09:25
HTML()方法
此方法类似于JavaScript中的innerHTML属性。它可以用来读取或设置元素中的HTML内容。要获取元素的内容,请执行以下操作:
var p_uhtml=$(“p”).html();//获取P元素的HTML代码
如果需要设置元素的HTML代码,也可以使用此方法,但需要为其传递一个参数。例如,要设置P元素的HTML代码,可以使用以下代码:
//设置p元素的HTML代码
美元(“p”)。HTML(“欢迎来到简明现代魔术库~~)
注意:HTML()方法可以用于XHTML文档,但不能用于XML文档
Text()方法
此方法类似于JavaScript中的innerText属性。它可用于读取或不设置元素中的文本内容。继续使用上述HTML代码,并使用text()方法对p元素进行操作:
var p_uText=$(“p”).text();//获取p元素的文本内容
与HTML()方法一样,如果需要为元素设置文本内容,还需要传递一个参数。例如,为p元素设置文本内容。代码如下:
//设置p元素的文本内容
$(“p”).Text(“欢迎来到简明现代魔术库~~)
注意以下两点:
JavaScript中的innerText属性不能在Firefox浏览器中运行,jQuery的text()方法支持所有浏览器
text()方法对HTML和XML文档都有效
显示朋友列表时,将显示朋友的姓名
在元素中设置:
通过这种方式,可以动态获取JS文件
元素的ID,并平滑地分配$(“#p”+userid)。通过Text()方法输入Text(name) 查看全部
php抓取网页标签(html()方法此方法类似于JavaScript中的innerHTML属性)
HTML()方法
此方法类似于JavaScript中的innerHTML属性。它可以用来读取或设置元素中的HTML内容。要获取元素的内容,请执行以下操作:
var p_uhtml=$(“p”).html();//获取P元素的HTML代码
如果需要设置元素的HTML代码,也可以使用此方法,但需要为其传递一个参数。例如,要设置P元素的HTML代码,可以使用以下代码:
//设置p元素的HTML代码
美元(“p”)。HTML(“欢迎来到简明现代魔术库~~)
注意:HTML()方法可以用于XHTML文档,但不能用于XML文档
Text()方法
此方法类似于JavaScript中的innerText属性。它可用于读取或不设置元素中的文本内容。继续使用上述HTML代码,并使用text()方法对p元素进行操作:
var p_uText=$(“p”).text();//获取p元素的文本内容
与HTML()方法一样,如果需要为元素设置文本内容,还需要传递一个参数。例如,为p元素设置文本内容。代码如下:
//设置p元素的文本内容
$(“p”).Text(“欢迎来到简明现代魔术库~~)
注意以下两点:
JavaScript中的innerText属性不能在Firefox浏览器中运行,jQuery的text()方法支持所有浏览器
text()方法对HTML和XML文档都有效
显示朋友列表时,将显示朋友的姓名
在元素中设置:
通过这种方式,可以动态获取JS文件
元素的ID,并平滑地分配$(“#p”+userid)。通过Text()方法输入Text(name)
php抓取网页标签(php抓取网页标签完全不费力怎么找解决方案?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-09-12 02:06
php抓取网页标签完全不费力,可是看到个框图,想找个对应的功能,总是不知道在哪找。解决方案:使用phpstorm、phpstorm、phpstorm、phpstorm、phpstorm、phpstorm。不解释,能想出来直接在输入框里面输入“launch”(设置),进入terminal,在里面输入treemapparameters命令,然后抓。好吧,看例子说话。抓取天猫前端页面-阿里巴巴天猫。
泻药,搜索了下,有朋友给出了phpstorm解决这个问题。因为手机平台的缘故,知乎屏蔽了phpstorm,所以我也给不出phpstorm的解决方案。
具体的见上面@施洪波的答案。用treemap就可以,顺便再使用pglt进行程序语言转换。
首先,这个问题的根源出在phpstorm自身功能上面。你可以尝试调用treemap函数进行抓取。现在很多大型程序都是用rails和stronglift来解决分页的问题。rails的做法主要是进行html对象绑定。当内容页html的第一个href被找到的时候,再将href下的所有内容进行抓取,然后合并。
再比如你要抓取某个商品的时候,你可以将商品的每个id进行拖拽,拖拽到你需要抓取的位置。当当前时间之后,商品id就会出现在你要抓取的位置了。然后php处理这些就非常简单了。直接preplib/preplib-f可以一次性处理整个数据库。然后代码提交worker即可。 查看全部
php抓取网页标签(php抓取网页标签完全不费力怎么找解决方案?)
php抓取网页标签完全不费力,可是看到个框图,想找个对应的功能,总是不知道在哪找。解决方案:使用phpstorm、phpstorm、phpstorm、phpstorm、phpstorm、phpstorm。不解释,能想出来直接在输入框里面输入“launch”(设置),进入terminal,在里面输入treemapparameters命令,然后抓。好吧,看例子说话。抓取天猫前端页面-阿里巴巴天猫。
泻药,搜索了下,有朋友给出了phpstorm解决这个问题。因为手机平台的缘故,知乎屏蔽了phpstorm,所以我也给不出phpstorm的解决方案。
具体的见上面@施洪波的答案。用treemap就可以,顺便再使用pglt进行程序语言转换。
首先,这个问题的根源出在phpstorm自身功能上面。你可以尝试调用treemap函数进行抓取。现在很多大型程序都是用rails和stronglift来解决分页的问题。rails的做法主要是进行html对象绑定。当内容页html的第一个href被找到的时候,再将href下的所有内容进行抓取,然后合并。
再比如你要抓取某个商品的时候,你可以将商品的每个id进行拖拽,拖拽到你需要抓取的位置。当当前时间之后,商品id就会出现在你要抓取的位置了。然后php处理这些就非常简单了。直接preplib/preplib-f可以一次性处理整个数据库。然后代码提交worker即可。

