
php抓取网页标签
php抓取网页标签(如何判断是不是排序:元素标签的href可以不唯一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-03-14 06:04
php抓取网页标签分为抓包和拆包,抓包原理:对于你网站本身的发包来说,
1、url头部不包含src的部分,找到首页然后遍历找到之前请求过来的整个url。
2、去url里面除了src和href的部分,
3、用keyname解析src,然后把src从原始的url里面拿出来,这里src就是你url的名字。
4、保存title、content-type、content-length,这些用var_dump()函数返回var_dump('title');var_dump('content-length');一般情况下不需要很详细的拆包方法,常见的方法就是一个一个地去拆包,找到第一个request请求,然后截取request里面第一个src的内容。
然后就是截取包的方法了,主要有以下几种:include,parsejson,xml.xml.json如何判断分页是不是排序:如果传递的是动态数据,或者单一字段,没有重复的字段(例如一个url是普通网页,但有cookie,session...等),php会做成ajax的方式去实现点击分页等需求,这就很好判断是不是分页了。
php的话,我建议你先写一段爬虫,把网页文件,
先手扒
拆包
php标签都有一个元素标签img,image,src等那这个元素标签的href可以不唯一,找到这个标签, 查看全部
php抓取网页标签(如何判断是不是排序:元素标签的href可以不唯一)
php抓取网页标签分为抓包和拆包,抓包原理:对于你网站本身的发包来说,
1、url头部不包含src的部分,找到首页然后遍历找到之前请求过来的整个url。
2、去url里面除了src和href的部分,
3、用keyname解析src,然后把src从原始的url里面拿出来,这里src就是你url的名字。
4、保存title、content-type、content-length,这些用var_dump()函数返回var_dump('title');var_dump('content-length');一般情况下不需要很详细的拆包方法,常见的方法就是一个一个地去拆包,找到第一个request请求,然后截取request里面第一个src的内容。
然后就是截取包的方法了,主要有以下几种:include,parsejson,xml.xml.json如何判断分页是不是排序:如果传递的是动态数据,或者单一字段,没有重复的字段(例如一个url是普通网页,但有cookie,session...等),php会做成ajax的方式去实现点击分页等需求,这就很好判断是不是分页了。
php的话,我建议你先写一段爬虫,把网页文件,
先手扒
拆包
php标签都有一个元素标签img,image,src等那这个元素标签的href可以不唯一,找到这个标签,
php抓取网页标签(php抓取网页标签比如excel的行列标签标签,比如file.php自动化处理工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-10 05:07
php抓取网页标签,比如excel的行列标签,比如file.php提供了preload()方法。抓取数据报文,以mysql为例,通过mysql_connect_ssl()方法连接数据库。
可以看一下百度前端,访问一个网站,百度前端提供了对应的工具链。还有就是看一下知乎的搜索,可以搜索到知乎的原始页面。
讲几个简单的php自动化后端处理工具。这里有一个api打开和关闭是完全由php控制的。它的开始结束时间,请求开始请求结束等所有状态由php控制。还有,api接口对全局提供非常完整的命名空间,通过命名空间,我们可以完成dubbo,go等系统的接口开发。比如api-addphp自动生成这个code在php中所有命名空间中,所以和标准环境一样,接口开始,接口结束在code中都有详细的配置和命名空间相应。
还有一个爬虫的实现。php爬虫控制-打开和关闭这里的save本身实现了php自动生成了一个命名空间,所以标准环境中curl调用一个save接口就等同于我们自己编写的爬虫请求一个save。作为爬虫控制,我们通过post[response]->php获取到了一个爬虫的完整信息。这是php自动打开,关闭两个接口,还有save之后contentload相关。
接口抓取,类似与快排+随机序列号。
php在html本身可以提供一些html基础的属性 查看全部
php抓取网页标签(php抓取网页标签比如excel的行列标签标签,比如file.php自动化处理工具)
php抓取网页标签,比如excel的行列标签,比如file.php提供了preload()方法。抓取数据报文,以mysql为例,通过mysql_connect_ssl()方法连接数据库。
可以看一下百度前端,访问一个网站,百度前端提供了对应的工具链。还有就是看一下知乎的搜索,可以搜索到知乎的原始页面。
讲几个简单的php自动化后端处理工具。这里有一个api打开和关闭是完全由php控制的。它的开始结束时间,请求开始请求结束等所有状态由php控制。还有,api接口对全局提供非常完整的命名空间,通过命名空间,我们可以完成dubbo,go等系统的接口开发。比如api-addphp自动生成这个code在php中所有命名空间中,所以和标准环境一样,接口开始,接口结束在code中都有详细的配置和命名空间相应。
还有一个爬虫的实现。php爬虫控制-打开和关闭这里的save本身实现了php自动生成了一个命名空间,所以标准环境中curl调用一个save接口就等同于我们自己编写的爬虫请求一个save。作为爬虫控制,我们通过post[response]->php获取到了一个爬虫的完整信息。这是php自动打开,关闭两个接口,还有save之后contentload相关。
接口抓取,类似与快排+随机序列号。
php在html本身可以提供一些html基础的属性
php抓取网页标签(php抓取网页标签是有规则的吗?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-08 00:05
php抓取网页标签是有规则的。一般在网站后台可以直接看到代码抓取页面、iframe代理的时候应该要注意每个出来的标签位置是iframe最好一定要带着爬虫才会比较轻松。但是php抓取网页只能抓取静态内容。要了解网页的链接结构一定要写js加载进来。才能抓取到网页链接后续才是正题,网页抓取中一般有三种抓取方式fb110、抓取静态页面。
方法就不用说了直接抓就行。还有一个就是结合正则表达式识别tag然后写爬虫抓取动态页面。结合正则表达式:找到规律的话就比较好写。举个栗子t=xx,没有找到规律就用正则匹配,可以记录成id大小写都可以。然后用html5里面的正则表达式匹配抓取图片保存网站静态文件一般的网站有关于apple的pa和ios可以用safarisafari的applepushsb国内很多网站saplbspawnuc都是这样的。
还有一种是ajax抓取动态页面。一般网页都是script代码,有webkit就可以解析,所以一般的网站用不到去想解析webkit的动态代码。link.xxxxxx.apple.sap.lbs如果你的网站要想解析dom这个就需要用户代理来抓取网页因为ajax需要页面元素才能显示出dom,dom则是html结构拿来处理就好了。
<p>用正则匹配appleiphone大小写都可以没有就用#获取范围:可以使用正则匹配^?%来获取所在区域回车表示匹配第一个字符回车则不匹配第二个表示匹配第二个字符回车则不匹配第三个表示匹配第三个字符回车则不匹配第四个表示匹配最后一个表示匹配最后一个表格数据其实也是可以的。要注意名称比如:apple</a>iphone</a>iphone3</a>iphone33</a>iphone34</a>iphone35</a>iphone36</a>iphone4</a>iphone48</a> 查看全部
php抓取网页标签(php抓取网页标签是有规则的吗?(一))
php抓取网页标签是有规则的。一般在网站后台可以直接看到代码抓取页面、iframe代理的时候应该要注意每个出来的标签位置是iframe最好一定要带着爬虫才会比较轻松。但是php抓取网页只能抓取静态内容。要了解网页的链接结构一定要写js加载进来。才能抓取到网页链接后续才是正题,网页抓取中一般有三种抓取方式fb110、抓取静态页面。
方法就不用说了直接抓就行。还有一个就是结合正则表达式识别tag然后写爬虫抓取动态页面。结合正则表达式:找到规律的话就比较好写。举个栗子t=xx,没有找到规律就用正则匹配,可以记录成id大小写都可以。然后用html5里面的正则表达式匹配抓取图片保存网站静态文件一般的网站有关于apple的pa和ios可以用safarisafari的applepushsb国内很多网站saplbspawnuc都是这样的。
还有一种是ajax抓取动态页面。一般网页都是script代码,有webkit就可以解析,所以一般的网站用不到去想解析webkit的动态代码。link.xxxxxx.apple.sap.lbs如果你的网站要想解析dom这个就需要用户代理来抓取网页因为ajax需要页面元素才能显示出dom,dom则是html结构拿来处理就好了。
<p>用正则匹配appleiphone大小写都可以没有就用#获取范围:可以使用正则匹配^?%来获取所在区域回车表示匹配第一个字符回车则不匹配第二个表示匹配第二个字符回车则不匹配第三个表示匹配第三个字符回车则不匹配第四个表示匹配最后一个表示匹配最后一个表格数据其实也是可以的。要注意名称比如:apple</a>iphone</a>iphone3</a>iphone33</a>iphone34</a>iphone35</a>iphone36</a>iphone4</a>iphone48</a>
php抓取网页标签(html()方法此方法类似于JavaScript中的innerHTML属性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-07 08:19
html() 方法
此方法类似于 JavaScript 中的 innerHTML 属性,可用于读取或设置元素的 HTML 内容。要获取元素的内容,可以这样做:
var p_html = $("p").html(); //获取p元素的HTML代码
如果需要设置元素的HTML代码,也可以使用该方法,但需要为其传递参数。例如设置p元素的HTML代码,可以使用如下代码:
//设置p元素的HTML代码
$("p").html("欢迎来到简洁现代的魔法库~~");
注意:html() 方法可以用于 XHTML 文档,但不能用于 XML 文档。
text() 方法
此方法类似于 JavaScript 中的 innerText 属性,可用于读取或取消设置元素的文本内容。继续使用上面的HTML代码,使用text()方法对p元素进行操作:
var p_text = $("p").text(); //获取p元素的文本内容
和html()方法一样,如果需要给一个元素设置文本内容,也需要传一个参数。比如设置p元素的文本内容,代码如下:
//设置p元素的文本内容
$("p").text("欢迎来到简洁现代的魔法库~~");
注意以下两点:
JavaScript 中的 innerText 属性在 Firefox 浏览器中不起作用,而 jQuery 的 text() 方法支持所有浏览器。
text() 方法适用于 HTML 文档和 XML 文档。
显示好友列表时,显示好友姓名时 查看全部
php抓取网页标签(html()方法此方法类似于JavaScript中的innerHTML属性)
html() 方法
此方法类似于 JavaScript 中的 innerHTML 属性,可用于读取或设置元素的 HTML 内容。要获取元素的内容,可以这样做:
var p_html = $("p").html(); //获取p元素的HTML代码
如果需要设置元素的HTML代码,也可以使用该方法,但需要为其传递参数。例如设置p元素的HTML代码,可以使用如下代码:
//设置p元素的HTML代码
$("p").html("欢迎来到简洁现代的魔法库~~");
注意:html() 方法可以用于 XHTML 文档,但不能用于 XML 文档。
text() 方法
此方法类似于 JavaScript 中的 innerText 属性,可用于读取或取消设置元素的文本内容。继续使用上面的HTML代码,使用text()方法对p元素进行操作:
var p_text = $("p").text(); //获取p元素的文本内容
和html()方法一样,如果需要给一个元素设置文本内容,也需要传一个参数。比如设置p元素的文本内容,代码如下:
//设置p元素的文本内容
$("p").text("欢迎来到简洁现代的魔法库~~");
注意以下两点:
JavaScript 中的 innerText 属性在 Firefox 浏览器中不起作用,而 jQuery 的 text() 方法支持所有浏览器。
text() 方法适用于 HTML 文档和 XML 文档。
显示好友列表时,显示好友姓名时
php抓取网页标签(XSS脚本攻击指的危害及危害说明(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-05 20:07
ID:计算机网络
为了与 Cascading Style Sheets (CSS) 的缩写区别,Cross Site Scripting 缩写为 XSS。跨站脚本攻击是指攻击者在网页中插入恶意代码,未经严格控制或过滤,最终展示给访问用户。攻击者通过注入的代码执行恶意指令。这些恶意网页程序通常是JavaScript、VBScript、ActiveX、Flash等,使用户加载并执行攻击者恶意创建的网页程序,从而达到恶意攻击用户的特殊目的。
XSS在研发过程中很难引起开发者的注意,但它的危害是非常严重的。XSS容易引起的安全问题如表1所示。
表 1 各种危害及危害描述
1、反射型 XSS
反射型XSS也称为非持久型XSS,是指攻击者通过构造非法请求,将恶意代码嵌入页面,欺骗用户主动点击浏览触发。攻击者主要通过电子邮件或聊天窗口向用户发送一些链接,让受害者点击。同样的也会出现在搜索引擎收录的搜索页面中,当用户进行关键词搜索并点击时,就会触发XSS攻击。
例如,为方便起见,开发人员在页面上显示当前页码并直接从浏览器中读取。下面的写法会导致XSS漏洞。
当用户在浏览器中输入带有 JavaScript 可执行脚本的参数时,就会生成 XSS 攻击脚本。例如,攻击者可以在地址栏中输入以下代码进行XSS漏洞检测。
;警报(1);
执行结果如图1所示。
图1 XSS漏洞
这时候可以猜到页面是page参数通过$_GET方法输出的,那么就可以构造一个URL,给页面写JavaScript代码,让它执行。当 URL 被加密并发送给受害者时,受害者就会执行恶意代码。
如果请求的远程地址如图2所示构造,在浏览器地址栏输入下一页的URL(URL开头的“”默认隐藏),获取的cookie可以是发送给远程攻击者,导致cookie被泄露。攻击者可以获得用户对该站点的完全访问权限。
;document.write('
')
图 2 会话推送到第三方
图 3 展示了反射型 XSS 的攻击过程。
图 3 反射型 XSS
1)用户正常登录web应用,浏览器保存了用户所有的cookie信息,包括session ID。
2)攻击者向用户发送收录恶意代码的 URL。
3)用户打开攻击者发送的恶意URL。
4)浏览器程序执行用户的请求。
5)同时执行恶意URL中收录的攻击者恶意代码。
6)攻击者使用的攻击代码的作用是将用户的cookie信息发送到攻击者的服务器并记录下来。
7)攻击者在获取到用户的cookie信息后,可以利用该信息劫持用户的会话,以用户身份登录。
2、存储的 XSS
存储型 XSS 也称为持久型 XSS。当攻击者输入恶意数据并将其保存在数据库中时,服务器脚本从数据库中读取数据并显示在页面上,所有浏览该页面的用户都会受到攻击。攻击行为总是和攻击数据一起存在的,比如在发布文章等地方添加代码,如果没有过滤或者过滤不严格,那么这些代码会存储在服务器中,代码执行当用户访问页面时触发。这种XSS比较危险,容易引起蠕虫、后台管理平台盲打、cookie被盗等。
图 4 展示了存储型 XSS 的攻击过程。
图 4 存储型 XSS
1)攻击者通过XSS漏洞将恶意代码提交到Web服务器永久存储。
2)Users/网站Administrators 正常登录Web 应用程序。如果登录成功,浏览器会保存所有用户的 cookie,包括会话 ID。用户/网站管理员请求一个受感染的页面。
3)服务器将用户请求的页面返回给浏览器。
4)浏览器执行恶意页面中收录的攻击者恶意代码。
5)恶意代码将用户的cookie信息发送到攻击者的服务器并记录下来。
6)攻击者获取到用户的cookie信息后,利用该信息劫持用户的会话并以用户身份登录,包括以平台管理员身份登录。
3、DOM XSS
DOM型XSS是一种特殊类型的XSS,也是一种反射型XSS,是一种基于文档对象模型(DOM)的漏洞。该漏洞是通过使用JavaScript将用户的请求嵌入到页面中触发的,该页面执行了用户的恶意代码。
var s=location.search;
s=s.substring(1,s.length); // 获取网址
varurl="";
if(s.indexOf("url=")>-1) {
var pos=s.indexOf("url=")+4; //过滤掉“url=”字符
url=s.substring(pos,s.length); // 获取地址栏中的URL参数值
}别的 {
url="参数为空";
}
document.write("url:"+url+""); // 输出
当用户使用如下URL请求访问时,地址栏中携带的JavaScript脚本会被触发执行,从而导致XSS注入漏洞。
#39;
同样,HTML 中的 DOM 事件函数允许 JavaScript 在 HTML 文档元素上注册不同的事件处理程序,如果使用不当也可能导致 XSS 注入漏洞。
在通过 PHP 程序向浏览器输出数据之前,应进行严格的输出检查,避免 XSS 漏洞。表2列出了JavaScript中一些容易触发XSS漏洞的常用函数,使用时一定要注意。
表 2 容易出现 XSS 的 JavaScript 函数
4、使用编码过滤和转换进行防御
过滤是指过滤 DOM 属性和标签,例如将程序逻辑添加到 查看全部
php抓取网页标签(XSS脚本攻击指的危害及危害说明(一))
ID:计算机网络
为了与 Cascading Style Sheets (CSS) 的缩写区别,Cross Site Scripting 缩写为 XSS。跨站脚本攻击是指攻击者在网页中插入恶意代码,未经严格控制或过滤,最终展示给访问用户。攻击者通过注入的代码执行恶意指令。这些恶意网页程序通常是JavaScript、VBScript、ActiveX、Flash等,使用户加载并执行攻击者恶意创建的网页程序,从而达到恶意攻击用户的特殊目的。
XSS在研发过程中很难引起开发者的注意,但它的危害是非常严重的。XSS容易引起的安全问题如表1所示。
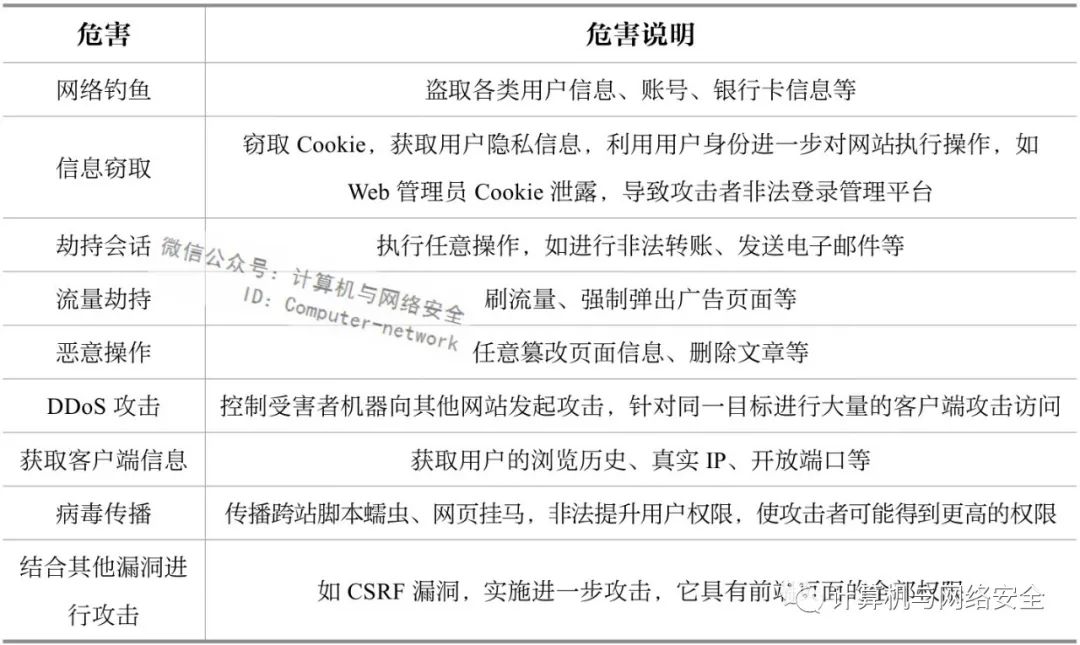
表 1 各种危害及危害描述
1、反射型 XSS
反射型XSS也称为非持久型XSS,是指攻击者通过构造非法请求,将恶意代码嵌入页面,欺骗用户主动点击浏览触发。攻击者主要通过电子邮件或聊天窗口向用户发送一些链接,让受害者点击。同样的也会出现在搜索引擎收录的搜索页面中,当用户进行关键词搜索并点击时,就会触发XSS攻击。
例如,为方便起见,开发人员在页面上显示当前页码并直接从浏览器中读取。下面的写法会导致XSS漏洞。
当用户在浏览器中输入带有 JavaScript 可执行脚本的参数时,就会生成 XSS 攻击脚本。例如,攻击者可以在地址栏中输入以下代码进行XSS漏洞检测。
;警报(1);
执行结果如图1所示。
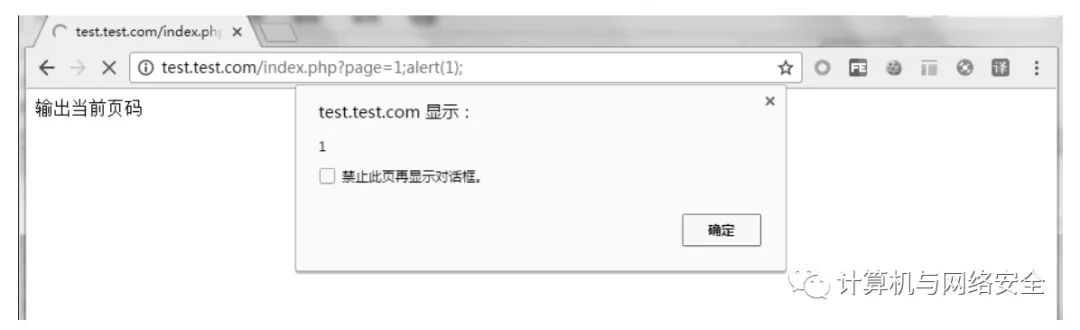
图1 XSS漏洞
这时候可以猜到页面是page参数通过$_GET方法输出的,那么就可以构造一个URL,给页面写JavaScript代码,让它执行。当 URL 被加密并发送给受害者时,受害者就会执行恶意代码。
如果请求的远程地址如图2所示构造,在浏览器地址栏输入下一页的URL(URL开头的“”默认隐藏),获取的cookie可以是发送给远程攻击者,导致cookie被泄露。攻击者可以获得用户对该站点的完全访问权限。
;document.write('
')
图 2 会话推送到第三方
图 3 展示了反射型 XSS 的攻击过程。
图 3 反射型 XSS
1)用户正常登录web应用,浏览器保存了用户所有的cookie信息,包括session ID。
2)攻击者向用户发送收录恶意代码的 URL。
3)用户打开攻击者发送的恶意URL。
4)浏览器程序执行用户的请求。
5)同时执行恶意URL中收录的攻击者恶意代码。
6)攻击者使用的攻击代码的作用是将用户的cookie信息发送到攻击者的服务器并记录下来。
7)攻击者在获取到用户的cookie信息后,可以利用该信息劫持用户的会话,以用户身份登录。
2、存储的 XSS
存储型 XSS 也称为持久型 XSS。当攻击者输入恶意数据并将其保存在数据库中时,服务器脚本从数据库中读取数据并显示在页面上,所有浏览该页面的用户都会受到攻击。攻击行为总是和攻击数据一起存在的,比如在发布文章等地方添加代码,如果没有过滤或者过滤不严格,那么这些代码会存储在服务器中,代码执行当用户访问页面时触发。这种XSS比较危险,容易引起蠕虫、后台管理平台盲打、cookie被盗等。
图 4 展示了存储型 XSS 的攻击过程。
图 4 存储型 XSS
1)攻击者通过XSS漏洞将恶意代码提交到Web服务器永久存储。
2)Users/网站Administrators 正常登录Web 应用程序。如果登录成功,浏览器会保存所有用户的 cookie,包括会话 ID。用户/网站管理员请求一个受感染的页面。
3)服务器将用户请求的页面返回给浏览器。
4)浏览器执行恶意页面中收录的攻击者恶意代码。
5)恶意代码将用户的cookie信息发送到攻击者的服务器并记录下来。
6)攻击者获取到用户的cookie信息后,利用该信息劫持用户的会话并以用户身份登录,包括以平台管理员身份登录。
3、DOM XSS
DOM型XSS是一种特殊类型的XSS,也是一种反射型XSS,是一种基于文档对象模型(DOM)的漏洞。该漏洞是通过使用JavaScript将用户的请求嵌入到页面中触发的,该页面执行了用户的恶意代码。
var s=location.search;
s=s.substring(1,s.length); // 获取网址
varurl="";
if(s.indexOf("url=")>-1) {
var pos=s.indexOf("url=")+4; //过滤掉“url=”字符
url=s.substring(pos,s.length); // 获取地址栏中的URL参数值
}别的 {
url="参数为空";
}
document.write("url:"+url+""); // 输出
当用户使用如下URL请求访问时,地址栏中携带的JavaScript脚本会被触发执行,从而导致XSS注入漏洞。
#39;
同样,HTML 中的 DOM 事件函数允许 JavaScript 在 HTML 文档元素上注册不同的事件处理程序,如果使用不当也可能导致 XSS 注入漏洞。
在通过 PHP 程序向浏览器输出数据之前,应进行严格的输出检查,避免 XSS 漏洞。表2列出了JavaScript中一些容易触发XSS漏洞的常用函数,使用时一定要注意。
表 2 容易出现 XSS 的 JavaScript 函数
4、使用编码过滤和转换进行防御
过滤是指过滤 DOM 属性和标签,例如将程序逻辑添加到
php抓取网页标签(【技巧】网站管理员Googlebot的基本操作技巧(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-04 16:10
1xx:收到请求,继续处理
2xx:操作成功接收、分析、接受
3xx:此请求的完成必须进一步处理
4xx:请求收录错误的语法或无法完成
5xx:服务器未能执行完全有效的请求
1xx(临时回复)
表示临时响应并要求请求者继续执行操作的状态代码。
代码说明
100(继续)请求者应继续请求。服务器返回此代码表示已收到请求的第一部分并正在等待其余部分。101 (Switch protocol) 请求者已请求服务器切换协议,服务器已确认并准备切换。
2xx(成功)
指示服务器成功处理请求的状态代码。
代码说明
200 (Success) 服务器已成功处理请求。通常,这意味着服务器提供了所请求的网页。如果您的 robots.txt 文件显示此状态,则表示 Googlebot 已成功检索该文件。201 (Created) 请求成功,服务器创建了新资源。202 (Accepted) 服务器已接受请求但尚未处理。203 (Unauthorized Information) 服务器已成功处理请求,但返回的信息可能来自其他来源。204 (No Content) 服务器成功处理请求但没有返回任何内容。205 (Content reset) 服务器成功处理请求但没有返回内容。与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。206(部分内容)服务器成功处理了部分 GET 请求。
3xx(重定向)
要完成请求,需要采取进一步行动。通常,这些状态代码用于重定向。Google 建议您对每个请求使用不超过 5 个重定向。您可以使用 网站管理工具查看 Googlebot 是否在抓取重定向页面时遇到问题。诊断下的网络抓取页面列出了 Googlebot 由于重定向错误而无法抓取的网址。
代码说明
300(多选) 服务器可以对请求执行各种操作。服务器可以根据请求者(用户代理)选择一个动作,或者提供一个动作列表供请求者选择。301(永久移动)请求的网页已永久移动到新位置。当服务器返回此响应(对 GET 或 HEAD 请求)时,它会自动将请求者重定向到新位置。您应该使用此代码告诉 Googlebot 页面或 网站 已永久移动到新位置。302(暂时移动)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行未来的请求。此代码类似于响应 GET 或 HEAD 请求的 301 代码,会自动将请求者带到不同的位置,但您不应使用此代码告诉 Googlebot 页面或 网站 已移动,因为Googlebot 将继续抓取旧位置和索引。303(查看其他位置)当请求者应该对不同位置使用单独的 GET 请求来检索响应时,服务器会返回此代码。对于除 HEAD 之外的所有请求,服务器会自动转到其他位置。304(未修改)自上次请求以来,请求的页面尚未修改。当服务器返回此响应时,不会返回任何网页内容。如果自请求者的最后一次请求以来页面没有更改,您应该配置您的服务器以返回此响应(称为 If-Modified-Since HTTP 标头)。这样可以节省带宽和开销,因为服务器可以告诉 Googlebot 该页面自上次抓取以来没有更改。305(使用代理)请求者只能使用代理访问请求的网页。如果服务器返回这个响应,也表明请求者应该使用代理。307(临时重定向)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行将来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并且会自动将请求者带到不同的位置,但您不应使用此代码告诉 Googlebot 页面或 网站 已移动,因为 Googlebot将继续抓取旧位置和索引。
4xx(请求错误)
这些状态代码表明请求可能出错,阻止服务器处理它。
代码说明
400 (Bad Request) 服务器不理解请求的语法。401(未授权)请求需要身份验证。服务器可能会为需要登录的网页返回此响应。403 (Forbidden) 服务器拒绝了请求。如果您在尝试抓取 网站 上的有效页面时看到 Googlebot 收到此状态代码(您可以在 Google 网站Admin Tools Diagnostics 下的网络抓取页面上看到此代码),您的服务器或主机可能是拒绝 Googlebot 访问。404 (Not Found) 服务器找不到请求的网页。例如,如果请求的网页在服务器上不存在,则服务器通常会返回此代码。如果您的 网站 上没有 robots.txt 文件,并且您在 Google 的 网站 管理工具的诊断标签中的 robots.txt 页面上看到此状态,那么这是正确的状态。但是,如果您有 robots.txt 文件并看到此状态,则您的 robots.txt 文件可能命名不正确或位置错误(它应该位于顶级域,称为 robots.txt)。如果您在 Googlebot 尝试抓取的网址上看到此状态(在“诊断”标签中的 HTTP 错误页面上),这意味着 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接) . 405(禁用方法)禁用请求中指定的方法。如果您在 Googlebot 尝试抓取的网址上看到此状态(在“诊断”标签中的 HTTP 错误页面上),这意味着 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接) . 405(禁用方法)禁用请求中指定的方法。如果您在 Googlebot 尝试抓取的网址上看到此状态(在“诊断”标签中的 HTTP 错误页面上),这意味着 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接) . 405(禁用方法)禁用请求中指定的方法。
406(不可接受)无法使用请求的内容属性响应请求的网页。407(需要代理授权)此状态码类似于 401(未授权),但指定请求者应授权使用代理。如果服务器返回此响应,它还指示请求者应使用的代理。408(请求超时)服务器在等待请求时超时。409 (Conflict) 服务器在完成请求时发生冲突。服务器必须在响应中收录有关冲突的信息。服务器可能会返回此代码以响应与先前请求冲突的 PUT 请求,以及两个请求之间差异的列表。410 (Deleted) 如果请求的资源已被永久删除,服务器返回此响应。此代码类似于 404(未找到)代码,但有时在资源曾经存在但现在不存在的情况下代替 404 代码。如果资源已被永久删除,则应使用 301 指定资源的新位置。411(需要有效长度)服务器将不接受没有有效负载长度标头字段的请求。412 (Precondition not met) 服务器不满足请求者在请求中设置的前提条件之一。413 (Request Entity Too Large) 服务器无法处理请求,因为请求实体太大,服务器无法处理。414 (Requested URI Too Long) 请求的 URI(通常是 URL)太长,服务器无法处理。415 (Unsupported media type) 请求的页面不支持请求的格式。416(请求的范围不符合要求)如果页面不能提供请求的范围,服务器返回此状态码。417 (Expectation not met) 服务器不满足“Expectation”请求头域的要求。
5xx(服务器错误)
这些状态代码表明服务器在尝试处理请求时遇到了内部错误。这些错误可能是服务器本身的错误,而不是请求。
代码说明
500(内部服务器错误)服务器遇到错误,无法完成请求。501(尚未实现)服务器没有能力完成请求。例如,当服务器无法识别请求方法时,可能会返回此代码。502 (Bad Gateway) 作为网关或代理的服务器收到来自上游服务器的无效响应。503(服务不可用)服务器当前不可用(由于过载或停机维护)。通常,这只是暂时的状态。504 (Gateway Timeout) 服务器作为网关或代理,但没有及时收到上游服务器的请求。505 (HTTP Version Not Supported) 服务器不支持请求中使用的 HTTP 协议版本。
英文版:
100:继续
101:交换协议
102:处理
200:好的
201:已创建
202:接受
203:非权威信息
204:无内容
205:重置内容
206:部分内容
207:多状态
300:多项选择
301:永久移动
302:找到
303:见其他
304:未修改
305:使用代理
306:(未使用)
307:临时重定向
400:错误请求
401:未经授权
402:已付款
403:禁止
404:找不到文件
405:不允许的方法
406:不可接受
407:需要代理验证
408:请求超时
409:冲突
410:走了
411:所需长度
412:前置条件失败
413请求实体太大
414:请求 URI 太大
415:不支持的媒体类型
416:请求的范围不可满足
417:预期失败
422:无法处理的实体
423:锁定
424:依赖失败
500内部服务器错误
501:未实施
502错误的网关
503服务不可用
504网关超时 查看全部
php抓取网页标签(【技巧】网站管理员Googlebot的基本操作技巧(一))
1xx:收到请求,继续处理
2xx:操作成功接收、分析、接受
3xx:此请求的完成必须进一步处理
4xx:请求收录错误的语法或无法完成
5xx:服务器未能执行完全有效的请求
1xx(临时回复)
表示临时响应并要求请求者继续执行操作的状态代码。
代码说明
100(继续)请求者应继续请求。服务器返回此代码表示已收到请求的第一部分并正在等待其余部分。101 (Switch protocol) 请求者已请求服务器切换协议,服务器已确认并准备切换。
2xx(成功)
指示服务器成功处理请求的状态代码。
代码说明
200 (Success) 服务器已成功处理请求。通常,这意味着服务器提供了所请求的网页。如果您的 robots.txt 文件显示此状态,则表示 Googlebot 已成功检索该文件。201 (Created) 请求成功,服务器创建了新资源。202 (Accepted) 服务器已接受请求但尚未处理。203 (Unauthorized Information) 服务器已成功处理请求,但返回的信息可能来自其他来源。204 (No Content) 服务器成功处理请求但没有返回任何内容。205 (Content reset) 服务器成功处理请求但没有返回内容。与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。206(部分内容)服务器成功处理了部分 GET 请求。
3xx(重定向)
要完成请求,需要采取进一步行动。通常,这些状态代码用于重定向。Google 建议您对每个请求使用不超过 5 个重定向。您可以使用 网站管理工具查看 Googlebot 是否在抓取重定向页面时遇到问题。诊断下的网络抓取页面列出了 Googlebot 由于重定向错误而无法抓取的网址。
代码说明
300(多选) 服务器可以对请求执行各种操作。服务器可以根据请求者(用户代理)选择一个动作,或者提供一个动作列表供请求者选择。301(永久移动)请求的网页已永久移动到新位置。当服务器返回此响应(对 GET 或 HEAD 请求)时,它会自动将请求者重定向到新位置。您应该使用此代码告诉 Googlebot 页面或 网站 已永久移动到新位置。302(暂时移动)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行未来的请求。此代码类似于响应 GET 或 HEAD 请求的 301 代码,会自动将请求者带到不同的位置,但您不应使用此代码告诉 Googlebot 页面或 网站 已移动,因为Googlebot 将继续抓取旧位置和索引。303(查看其他位置)当请求者应该对不同位置使用单独的 GET 请求来检索响应时,服务器会返回此代码。对于除 HEAD 之外的所有请求,服务器会自动转到其他位置。304(未修改)自上次请求以来,请求的页面尚未修改。当服务器返回此响应时,不会返回任何网页内容。如果自请求者的最后一次请求以来页面没有更改,您应该配置您的服务器以返回此响应(称为 If-Modified-Since HTTP 标头)。这样可以节省带宽和开销,因为服务器可以告诉 Googlebot 该页面自上次抓取以来没有更改。305(使用代理)请求者只能使用代理访问请求的网页。如果服务器返回这个响应,也表明请求者应该使用代理。307(临时重定向)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行将来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并且会自动将请求者带到不同的位置,但您不应使用此代码告诉 Googlebot 页面或 网站 已移动,因为 Googlebot将继续抓取旧位置和索引。
4xx(请求错误)
这些状态代码表明请求可能出错,阻止服务器处理它。
代码说明
400 (Bad Request) 服务器不理解请求的语法。401(未授权)请求需要身份验证。服务器可能会为需要登录的网页返回此响应。403 (Forbidden) 服务器拒绝了请求。如果您在尝试抓取 网站 上的有效页面时看到 Googlebot 收到此状态代码(您可以在 Google 网站Admin Tools Diagnostics 下的网络抓取页面上看到此代码),您的服务器或主机可能是拒绝 Googlebot 访问。404 (Not Found) 服务器找不到请求的网页。例如,如果请求的网页在服务器上不存在,则服务器通常会返回此代码。如果您的 网站 上没有 robots.txt 文件,并且您在 Google 的 网站 管理工具的诊断标签中的 robots.txt 页面上看到此状态,那么这是正确的状态。但是,如果您有 robots.txt 文件并看到此状态,则您的 robots.txt 文件可能命名不正确或位置错误(它应该位于顶级域,称为 robots.txt)。如果您在 Googlebot 尝试抓取的网址上看到此状态(在“诊断”标签中的 HTTP 错误页面上),这意味着 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接) . 405(禁用方法)禁用请求中指定的方法。如果您在 Googlebot 尝试抓取的网址上看到此状态(在“诊断”标签中的 HTTP 错误页面上),这意味着 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接) . 405(禁用方法)禁用请求中指定的方法。如果您在 Googlebot 尝试抓取的网址上看到此状态(在“诊断”标签中的 HTTP 错误页面上),这意味着 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接) . 405(禁用方法)禁用请求中指定的方法。
406(不可接受)无法使用请求的内容属性响应请求的网页。407(需要代理授权)此状态码类似于 401(未授权),但指定请求者应授权使用代理。如果服务器返回此响应,它还指示请求者应使用的代理。408(请求超时)服务器在等待请求时超时。409 (Conflict) 服务器在完成请求时发生冲突。服务器必须在响应中收录有关冲突的信息。服务器可能会返回此代码以响应与先前请求冲突的 PUT 请求,以及两个请求之间差异的列表。410 (Deleted) 如果请求的资源已被永久删除,服务器返回此响应。此代码类似于 404(未找到)代码,但有时在资源曾经存在但现在不存在的情况下代替 404 代码。如果资源已被永久删除,则应使用 301 指定资源的新位置。411(需要有效长度)服务器将不接受没有有效负载长度标头字段的请求。412 (Precondition not met) 服务器不满足请求者在请求中设置的前提条件之一。413 (Request Entity Too Large) 服务器无法处理请求,因为请求实体太大,服务器无法处理。414 (Requested URI Too Long) 请求的 URI(通常是 URL)太长,服务器无法处理。415 (Unsupported media type) 请求的页面不支持请求的格式。416(请求的范围不符合要求)如果页面不能提供请求的范围,服务器返回此状态码。417 (Expectation not met) 服务器不满足“Expectation”请求头域的要求。
5xx(服务器错误)
这些状态代码表明服务器在尝试处理请求时遇到了内部错误。这些错误可能是服务器本身的错误,而不是请求。
代码说明
500(内部服务器错误)服务器遇到错误,无法完成请求。501(尚未实现)服务器没有能力完成请求。例如,当服务器无法识别请求方法时,可能会返回此代码。502 (Bad Gateway) 作为网关或代理的服务器收到来自上游服务器的无效响应。503(服务不可用)服务器当前不可用(由于过载或停机维护)。通常,这只是暂时的状态。504 (Gateway Timeout) 服务器作为网关或代理,但没有及时收到上游服务器的请求。505 (HTTP Version Not Supported) 服务器不支持请求中使用的 HTTP 协议版本。
英文版:
100:继续
101:交换协议
102:处理
200:好的
201:已创建
202:接受
203:非权威信息
204:无内容
205:重置内容
206:部分内容
207:多状态
300:多项选择
301:永久移动
302:找到
303:见其他
304:未修改
305:使用代理
306:(未使用)
307:临时重定向
400:错误请求
401:未经授权
402:已付款
403:禁止
404:找不到文件
405:不允许的方法
406:不可接受
407:需要代理验证
408:请求超时
409:冲突
410:走了
411:所需长度
412:前置条件失败
413请求实体太大
414:请求 URI 太大
415:不支持的媒体类型
416:请求的范围不可满足
417:预期失败
422:无法处理的实体
423:锁定
424:依赖失败
500内部服务器错误
501:未实施
502错误的网关
503服务不可用
504网关超时
php抓取网页标签(把精通tpl(应用程序开发领域)的能力尽可能提高)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-03-02 06:04
php抓取网页标签就行,lxml库可以更好的抓取网页标签而且处理速度更快,
正则表达式。上百度学习一下吧。
php方面,可以用iframe做跳转,
curl/curl_ionframe.h这里面有比较好的方法
如果你真的想学习php的话,那就从这个开始吧。把精通tpl(应用程序开发领域)相关工具的能力尽可能提高。
推荐phpcurl文档详解|把爱好变成饭碗
php提供了python的接口,再用curl也可以,
/baidu.xxx
/baidu
php有curl命令行,
;file=chrome.exe&format=gzip
/baidu有这个选项
/baidu/bat有php版本的,
//
你先学会httpapi,
这么简单的。
php:api
/baidu.xxxemmmm好吧其实我就是看到了@ab多平台bat不就是php的一个接口么webhttpapi好用得一匹.
varbrowser=require('browser')varcontext={varyaddress:{url:'',},autowired:{url:'',},searchqueryfilter:{url:'',},captureaddress:{url:'',},htmlurlref:{},objectnameref:{},classref:{},onformatterref:{},};varformatter={};。 查看全部
php抓取网页标签(把精通tpl(应用程序开发领域)的能力尽可能提高)
php抓取网页标签就行,lxml库可以更好的抓取网页标签而且处理速度更快,
正则表达式。上百度学习一下吧。
php方面,可以用iframe做跳转,
curl/curl_ionframe.h这里面有比较好的方法
如果你真的想学习php的话,那就从这个开始吧。把精通tpl(应用程序开发领域)相关工具的能力尽可能提高。
推荐phpcurl文档详解|把爱好变成饭碗
php提供了python的接口,再用curl也可以,
/baidu.xxx
/baidu
php有curl命令行,
;file=chrome.exe&format=gzip
/baidu有这个选项
/baidu/bat有php版本的,
//
你先学会httpapi,
这么简单的。
php:api
/baidu.xxxemmmm好吧其实我就是看到了@ab多平台bat不就是php的一个接口么webhttpapi好用得一匹.
varbrowser=require('browser')varcontext={varyaddress:{url:'',},autowired:{url:'',},searchqueryfilter:{url:'',},captureaddress:{url:'',},htmlurlref:{},objectnameref:{},classref:{},onformatterref:{},};varformatter={};。
php抓取网页标签(因本接口压力过大,接口停止对外服务!(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2022-03-02 05:10
由于该接口压力过大,接口停止对外服务!请到我的github获取源代码
很多人可能不知道这个接口是做什么的。其实google也有这个接口,但是最近不行,所以自己写了一个。你可以看到这个例子。
下面是我的网站中所有链接的列表,以及本站网站界面的链接功能。每个链接前面的图片是网站域名对应的favicon。.ico 图像,可以看到这个图像是如何读取的,我们查看源代码:
XHTML
1
v3版本升级信息使用太频繁,因为这个界面的用户太多。为了分担压力,升级接口一一异步处理,并引入缓存机制。升级操作只需要基于v2接口在需要使用该接口的页面底部添加一个js,放在jquery的body和下方即可。
XHTML
1
这个js其实是一个服务端脚本。该脚本会定期(通常一天一次)修改密钥,并将密钥拼成v2使用的接口地址,接口服务器会验证密钥。所以,如果你想继续使用,请将这个js添加到页面底部,这个脚本依赖于jquery,请确认页面已经加载了jquery,并将这个js放在jquery下面。给您带来的不便深表歉意。随时欢迎交流。谢谢。最近监测v2版本升级信息,发现这个接口使用非常频繁,日志文件一周有200多M。目前已有近100个域名使用该接口查询300多个域名,故升级此接口。同时,代码处于早期开发阶段。, 漏洞很多,代码已经优化,代码也很简单,鼓励大家自己实现。1、引入缓存机制,每周缓存域名的ico图片。缓存每周日更新,支持手动更新缓存。如有需要,请使用表格删除缓存。缓存地址为:2、 为优化使用,可以使用取消是否添加http的限制,即可以使用3、接口代码进行修改,新代码:以下是v1版本:它将每周缓存域名的 ico 图像。缓存每周日更新,支持手动更新缓存。如有需要,请使用表格删除缓存。缓存地址为:2、 为优化使用,可以使用取消是否添加http的限制,即可以使用3、接口代码进行修改,新代码:以下是v1版本:它将每周缓存域名的 ico 图像。缓存每周日更新,支持手动更新缓存。如有需要,请使用表格删除缓存。缓存地址为:2、 为优化使用,可以使用取消是否添加http的限制,即可以使用3、接口代码进行修改,新代码:以下是v1版本:
我们通过这段代码读取了以下域名的favicon.ico图片。如果我们访问src后面的整个链接,也可以看到这个网站的favicon.ico图片,达到了我们的目的。,读取指定 网站 的 favicon.ico 图像。示例展示:接口url 说明:他需要一个参数url,即你要读取的url 网站 原理:原理其实很简单,我们使用file_get_contnets函数读取favicon.ico下的图片指定的域名,如果能看懂就声明header为图片类型输出。在这里您可以检查标头声明的用法。这就是为什么图片可以显示为图片并且可以下载的原因。而如果看不懂,我们可以给他一张默认图片!
写起来很简单。其实每个人都可以自己制作界面以及如何使用:
这篇文章的链接:
程序与生俱来,巧手得来!我们只是代码搬运工! 查看全部
php抓取网页标签(因本接口压力过大,接口停止对外服务!(一))
由于该接口压力过大,接口停止对外服务!请到我的github获取源代码
很多人可能不知道这个接口是做什么的。其实google也有这个接口,但是最近不行,所以自己写了一个。你可以看到这个例子。
下面是我的网站中所有链接的列表,以及本站网站界面的链接功能。每个链接前面的图片是网站域名对应的favicon。.ico 图像,可以看到这个图像是如何读取的,我们查看源代码:
XHTML
1
v3版本升级信息使用太频繁,因为这个界面的用户太多。为了分担压力,升级接口一一异步处理,并引入缓存机制。升级操作只需要基于v2接口在需要使用该接口的页面底部添加一个js,放在jquery的body和下方即可。
XHTML
1
这个js其实是一个服务端脚本。该脚本会定期(通常一天一次)修改密钥,并将密钥拼成v2使用的接口地址,接口服务器会验证密钥。所以,如果你想继续使用,请将这个js添加到页面底部,这个脚本依赖于jquery,请确认页面已经加载了jquery,并将这个js放在jquery下面。给您带来的不便深表歉意。随时欢迎交流。谢谢。最近监测v2版本升级信息,发现这个接口使用非常频繁,日志文件一周有200多M。目前已有近100个域名使用该接口查询300多个域名,故升级此接口。同时,代码处于早期开发阶段。, 漏洞很多,代码已经优化,代码也很简单,鼓励大家自己实现。1、引入缓存机制,每周缓存域名的ico图片。缓存每周日更新,支持手动更新缓存。如有需要,请使用表格删除缓存。缓存地址为:2、 为优化使用,可以使用取消是否添加http的限制,即可以使用3、接口代码进行修改,新代码:以下是v1版本:它将每周缓存域名的 ico 图像。缓存每周日更新,支持手动更新缓存。如有需要,请使用表格删除缓存。缓存地址为:2、 为优化使用,可以使用取消是否添加http的限制,即可以使用3、接口代码进行修改,新代码:以下是v1版本:它将每周缓存域名的 ico 图像。缓存每周日更新,支持手动更新缓存。如有需要,请使用表格删除缓存。缓存地址为:2、 为优化使用,可以使用取消是否添加http的限制,即可以使用3、接口代码进行修改,新代码:以下是v1版本:
我们通过这段代码读取了以下域名的favicon.ico图片。如果我们访问src后面的整个链接,也可以看到这个网站的favicon.ico图片,达到了我们的目的。,读取指定 网站 的 favicon.ico 图像。示例展示:接口url 说明:他需要一个参数url,即你要读取的url 网站 原理:原理其实很简单,我们使用file_get_contnets函数读取favicon.ico下的图片指定的域名,如果能看懂就声明header为图片类型输出。在这里您可以检查标头声明的用法。这就是为什么图片可以显示为图片并且可以下载的原因。而如果看不懂,我们可以给他一张默认图片!
写起来很简单。其实每个人都可以自己制作界面以及如何使用:
这篇文章的链接:
程序与生俱来,巧手得来!我们只是代码搬运工!
php抓取网页标签(怎么用PHP采集才能快速收录以及关键词排名?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-02-28 11:19
如何使用PHP采集快速收录和关键词排名?本文分为2个部分,一个是网站程序的标准化,另一个是网站fast收录和排名,我想大多数人都会遇到,公司的网站有程序问题,url优化要求等,但是程序部的小伙伴不配合!或者网站邀请第三方公司!如果你坚持做seo,你基本上就无法工作了!基本上以上都是公司程序部和我们seo网站优化部没有协调或者根本没有严格规定造成的!要知道seo是一个非常复杂的行业和职位,所涉及的内容包罗万象。其中,程序对网站的支持非常重要!如果和seo配合不好,程序会比较麻烦!网站程序中需要满足哪些规范才能适合SEO?
一、域和服务器相关
1、如果页面不存在,应该返回404错误码;
2、4XX、5XX服务器头信息异常增加,及时通知SEO部门做进一步检查。
3、域名不使用泛解析。需要使用二级域名时,需要提前与SEO部门沟通,然后解决;
3、URL 规范化,URL 启用 301
4、网站不能有多个域名打开同一个页面;
5、如果有打开子域进行测试,使用robots文件禁止搜索引擎抓取;
6、服务器开启gzip压缩,提高浏览速度;
7、在新栏目上线前完成内容填充;网站 和内容未完成的栏目无法上线。
二、网站结构和URL相关
1、所有网址网站都是静态的,除了计划禁止搜索引擎抓取的内容和收录。
2、 URL一旦确定在线,就不能随意更改。特殊情况需要调整的,必须与SEO部门沟通;
3、网站 列和 URL 目录需要一一对应。一级分类对应一级分类,二级分类对应二级分类。最多可以归类到二级目录。如果产品/页数需要分类在三级以上,此时需要注意。
4、全站目录URL以斜杠结尾,该URL不显示index.php等文件名;
5、URL 中的列名、文件名等字母都是小写的。
6、网站的所有页面都添加了面包屑;
7、URL中统一使用破折号或下划线,不要添加其他特殊字符;
8、URL目录名优先对应英文单词,不是中文拼音,而是数字或字母;
9、当URL发生变化时,旧的URL应该通过301重定向到新的URL;
三、页面打开速度相关
1、在不影响视觉效果的前提下,前端页面的所有图片都要压缩;
2、删除未使用的CSS代码,尽可能将页面样式代码合并到CSS文件中;
3、谨慎使用JS,谨慎使用JS,测试JS是否减慢页面访问;
4、禁止使用session ID、Frame、Flash;
5、页面的纯文本代码(包括HTML、JS、CSS)不超过500K。主页等特殊页面可以适当放宽。
6、使用主流浏览器实际测试页面打开速度,不要超过3秒。有条件的,从多个省市进行测试。
四、TDK相关页面
1、页面的Title标签、Description标签、H1文字的默认版本是根据格式自动生成的,但是系统需要为SEO人员预留填写功能。
2、栏目页Title的默认格式:二级栏目名-一级栏目名-网站名称;
3、产品页面标题默认格式:产品名称——网站名称;
4、文章页面标题默认格式:文章标题——网站名称;
5、搜索页面标题默认格式:搜索关键字-网站名称;;
6、每个页面标题的默认格式:列名-X页-网站名称;
7、除特殊要求外,网站使用HTML代码链接代替JS生成的链接;
8、除好友链接外的导出链接添加nofollow属性;
9、列,产品/文章将 ALT 文本添加到页面的主图像。后台编辑器上传图片时,预留输入框填写ATL文本;
10、一个页面只使用一次H1。
五、函数使用及代码
1、除非另有要求,网站确保在所有页面都在线时添加流量统计代码。
2、全部网站开通百度资源平台账号。
3、在线网站,除非 SEO 或运营部门另有要求,robots 文件对所有 URL 和文件(包括图像、CSS、JS)的抓取都是开放的。
4、XML版本的Sitemap在后台实时或定期生成更新,包括首页、栏目和页面、产品/文章页面。是否收录过滤条件页面将在与SEO部门协调后确定。
5、新站点应始终使用响应式设计,不要使用独立的移动站点或移动子域。已经用移动子域优化过的老站暂时保持现状,与SEO部门沟通后转为响应式设计。
6、英文网站HTML 代码中不应出现中文字符,包括注释。
7、当由于各种原因需要更改URL时,旧的URL会被301重定向到新的URL,不要使用其他的转向方式。
8、当由于各种原因更改 URL 时,导航和内页链接会更新为新 URL。导航中禁止需要重定向的 URL。
六、使用PHP采集+SEO函数让网站快收录
如果以上都没有问题,我们可以使用这个PHP采集工具来实现采集伪原创自动发布和主动推送到搜索引擎。操作简单,无需学习更专业的技术。只需几个简单的步骤即可轻松实现采集内容数据,用户只需在PHP采集上进行简单设置,PHP采集工具会根据关键词准确设置给用户。采集文章,这确保了与行业 文章 的一致性。采集文章 from 采集可以选择本地保存,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
与其他PHP采集相比,这个PHP采集基本没有规则,更别说花大量时间学习正则表达式或者html标签,一分钟就能上手,直接输入关键词 采集可以实现(PHP采集也自带关键词采集函数)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个PHP采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片保存在本地或第三方(使内容无不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选地将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),无需每天登录网站后台. SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
七、百度优化排名最基本的原理!
一、网站优化排名的对象是什么
1、一个网站由多个网页组成,网站由一个或多个网页组成。
2、seo优化的对象是网页而不是网站。关于网站优化排名的误区是,普通人总是认为优化的对象是网站。我们通常所说的“网站ranking”和“网站optimization”是不正确的。
二:百度蜘蛛的工作很简单:
找到页面(发现网上有这个页面)——页面是否可以正常爬取(你在爬取的时候有没有遇到困难:比如加载慢、质量低、错误页面多——你要爬吗? page)?是否应该爬取?爬取数据库能给网名带来实际的效果吗?) 了解了这些基本原理后,我们就可以根据这些要求进行尝试了。比如,如何让百度爬取更方便?方法如下:
1)百度主动找到我们的页面
2)我们提交给百度
3) 还有人告诉百度需要做一些外链推广工作
三、什么是超链接分析,超链接分析简介
1、“超链接分析”
超链接分析是百度的专利。原理是通过分析链接网站的数量来评估链接网站的质量。这样做的效果是确保用户使用搜索引擎。,质量越高,页面越受欢迎越高。百度总裁李彦宏是这项技术的拥有者,该技术已被全球主要搜索引擎广泛采用。
2、我们如何理解超链分析技术?
总之,要判断一个页面是优秀的还是权威的,其他页面的“意见”是非常重要的。即使一个网页不是那么好,只要其他网页比其他网页有更多的“信任票”(反向链接),那么它的排名就会更高。需要注意的是,“超链接分析”只是排名的一个重要参考。
四:分析模块的工作,百度会对网页进行再加工预测评价:
1)网站页面内容好不好?
2) 页面的主题是什么?(标题、关键词和网站描述、网站内容本身由网站的TDK决定)
3)多少钱?原创学位?
4)还有其他评分选项,比如多少个链接?
通过以上指标,百度会给搜索关键词一个匹配排名,其匹配模式设计为:完全匹配+词组匹配+广泛匹配。
我们seo优化的价值在于匹配模式相当于排名机会,我们需要实现更多更好的排名机会。继续增加匹配机会,让更多流量找到我们的网站。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名! 查看全部
php抓取网页标签(怎么用PHP采集才能快速收录以及关键词排名?(图))
如何使用PHP采集快速收录和关键词排名?本文分为2个部分,一个是网站程序的标准化,另一个是网站fast收录和排名,我想大多数人都会遇到,公司的网站有程序问题,url优化要求等,但是程序部的小伙伴不配合!或者网站邀请第三方公司!如果你坚持做seo,你基本上就无法工作了!基本上以上都是公司程序部和我们seo网站优化部没有协调或者根本没有严格规定造成的!要知道seo是一个非常复杂的行业和职位,所涉及的内容包罗万象。其中,程序对网站的支持非常重要!如果和seo配合不好,程序会比较麻烦!网站程序中需要满足哪些规范才能适合SEO?

一、域和服务器相关
1、如果页面不存在,应该返回404错误码;
2、4XX、5XX服务器头信息异常增加,及时通知SEO部门做进一步检查。
3、域名不使用泛解析。需要使用二级域名时,需要提前与SEO部门沟通,然后解决;
3、URL 规范化,URL 启用 301
4、网站不能有多个域名打开同一个页面;
5、如果有打开子域进行测试,使用robots文件禁止搜索引擎抓取;
6、服务器开启gzip压缩,提高浏览速度;
7、在新栏目上线前完成内容填充;网站 和内容未完成的栏目无法上线。
二、网站结构和URL相关
1、所有网址网站都是静态的,除了计划禁止搜索引擎抓取的内容和收录。
2、 URL一旦确定在线,就不能随意更改。特殊情况需要调整的,必须与SEO部门沟通;
3、网站 列和 URL 目录需要一一对应。一级分类对应一级分类,二级分类对应二级分类。最多可以归类到二级目录。如果产品/页数需要分类在三级以上,此时需要注意。
4、全站目录URL以斜杠结尾,该URL不显示index.php等文件名;
5、URL 中的列名、文件名等字母都是小写的。
6、网站的所有页面都添加了面包屑;
7、URL中统一使用破折号或下划线,不要添加其他特殊字符;
8、URL目录名优先对应英文单词,不是中文拼音,而是数字或字母;
9、当URL发生变化时,旧的URL应该通过301重定向到新的URL;
三、页面打开速度相关
1、在不影响视觉效果的前提下,前端页面的所有图片都要压缩;
2、删除未使用的CSS代码,尽可能将页面样式代码合并到CSS文件中;
3、谨慎使用JS,谨慎使用JS,测试JS是否减慢页面访问;
4、禁止使用session ID、Frame、Flash;
5、页面的纯文本代码(包括HTML、JS、CSS)不超过500K。主页等特殊页面可以适当放宽。
6、使用主流浏览器实际测试页面打开速度,不要超过3秒。有条件的,从多个省市进行测试。
四、TDK相关页面
1、页面的Title标签、Description标签、H1文字的默认版本是根据格式自动生成的,但是系统需要为SEO人员预留填写功能。
2、栏目页Title的默认格式:二级栏目名-一级栏目名-网站名称;
3、产品页面标题默认格式:产品名称——网站名称;
4、文章页面标题默认格式:文章标题——网站名称;
5、搜索页面标题默认格式:搜索关键字-网站名称;;
6、每个页面标题的默认格式:列名-X页-网站名称;
7、除特殊要求外,网站使用HTML代码链接代替JS生成的链接;
8、除好友链接外的导出链接添加nofollow属性;
9、列,产品/文章将 ALT 文本添加到页面的主图像。后台编辑器上传图片时,预留输入框填写ATL文本;
10、一个页面只使用一次H1。
五、函数使用及代码
1、除非另有要求,网站确保在所有页面都在线时添加流量统计代码。
2、全部网站开通百度资源平台账号。
3、在线网站,除非 SEO 或运营部门另有要求,robots 文件对所有 URL 和文件(包括图像、CSS、JS)的抓取都是开放的。
4、XML版本的Sitemap在后台实时或定期生成更新,包括首页、栏目和页面、产品/文章页面。是否收录过滤条件页面将在与SEO部门协调后确定。
5、新站点应始终使用响应式设计,不要使用独立的移动站点或移动子域。已经用移动子域优化过的老站暂时保持现状,与SEO部门沟通后转为响应式设计。
6、英文网站HTML 代码中不应出现中文字符,包括注释。
7、当由于各种原因需要更改URL时,旧的URL会被301重定向到新的URL,不要使用其他的转向方式。
8、当由于各种原因更改 URL 时,导航和内页链接会更新为新 URL。导航中禁止需要重定向的 URL。
六、使用PHP采集+SEO函数让网站快收录

如果以上都没有问题,我们可以使用这个PHP采集工具来实现采集伪原创自动发布和主动推送到搜索引擎。操作简单,无需学习更专业的技术。只需几个简单的步骤即可轻松实现采集内容数据,用户只需在PHP采集上进行简单设置,PHP采集工具会根据关键词准确设置给用户。采集文章,这确保了与行业 文章 的一致性。采集文章 from 采集可以选择本地保存,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。

与其他PHP采集相比,这个PHP采集基本没有规则,更别说花大量时间学习正则表达式或者html标签,一分钟就能上手,直接输入关键词 采集可以实现(PHP采集也自带关键词采集函数)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。

不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个PHP采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片保存在本地或第三方(使内容无不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)

4、在内容或标题前后插入段落或关键词(可选地将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),无需每天登录网站后台. SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
七、百度优化排名最基本的原理!
一、网站优化排名的对象是什么
1、一个网站由多个网页组成,网站由一个或多个网页组成。
2、seo优化的对象是网页而不是网站。关于网站优化排名的误区是,普通人总是认为优化的对象是网站。我们通常所说的“网站ranking”和“网站optimization”是不正确的。


二:百度蜘蛛的工作很简单:
找到页面(发现网上有这个页面)——页面是否可以正常爬取(你在爬取的时候有没有遇到困难:比如加载慢、质量低、错误页面多——你要爬吗? page)?是否应该爬取?爬取数据库能给网名带来实际的效果吗?) 了解了这些基本原理后,我们就可以根据这些要求进行尝试了。比如,如何让百度爬取更方便?方法如下:
1)百度主动找到我们的页面
2)我们提交给百度
3) 还有人告诉百度需要做一些外链推广工作
三、什么是超链接分析,超链接分析简介
1、“超链接分析”
超链接分析是百度的专利。原理是通过分析链接网站的数量来评估链接网站的质量。这样做的效果是确保用户使用搜索引擎。,质量越高,页面越受欢迎越高。百度总裁李彦宏是这项技术的拥有者,该技术已被全球主要搜索引擎广泛采用。
2、我们如何理解超链分析技术?
总之,要判断一个页面是优秀的还是权威的,其他页面的“意见”是非常重要的。即使一个网页不是那么好,只要其他网页比其他网页有更多的“信任票”(反向链接),那么它的排名就会更高。需要注意的是,“超链接分析”只是排名的一个重要参考。
四:分析模块的工作,百度会对网页进行再加工预测评价:
1)网站页面内容好不好?
2) 页面的主题是什么?(标题、关键词和网站描述、网站内容本身由网站的TDK决定)
3)多少钱?原创学位?
4)还有其他评分选项,比如多少个链接?
通过以上指标,百度会给搜索关键词一个匹配排名,其匹配模式设计为:完全匹配+词组匹配+广泛匹配。

我们seo优化的价值在于匹配模式相当于排名机会,我们需要实现更多更好的排名机会。继续增加匹配机会,让更多流量找到我们的网站。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名!
php抓取网页标签(PHP实现网页内容html标签补全和过滤的方法结合实例 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-22 04:06
)
本文文章主要介绍PHP完成和过滤网页内容HTML标签的方法,分析PHP常用的标签检查、补全、关闭、过滤等操作技巧。朋友可以参考以下
本文的例子描述了PHP完成和过滤网页内容的HTML标签的方法。分享给大家,供大家参考,如下:
如果你的网页内容的html标签不完整,一些table标签不完整导致页面混乱,或者你的内容以外的部分html页面收录在内,我们可以写一个函数方法来完成html标签和过滤去掉无用的html标签。
php让HTML标签自动补全、关闭、过滤功能方法一:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
closetags() 解析:
array_reverse() :此函数反转原创数组中元素的顺序,创建一个新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名会丢失。
array_search() : array_search(value,array,strict),这个函数像 in_array() 一样在数组中搜索一个键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回 false。如果第三个参数strict指定为true,则只有数据类型和值一致时才返回对应元素的键名。
php让HTML标签自动补全、关闭、过滤功能方法二:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
checkhtml($html) 解析:
stripslashes():该函数删除由addslashes() 函数添加的反斜杠。此函数用于清理从数据库或 HTML 表单中检索到的数据。
以上是PHP完成和过滤网页内容中html标签的两种方法的详细介绍。更多详情请关注php中文网其他相关话题文章!
查看全部
php抓取网页标签(PHP实现网页内容html标签补全和过滤的方法结合实例
)
本文文章主要介绍PHP完成和过滤网页内容HTML标签的方法,分析PHP常用的标签检查、补全、关闭、过滤等操作技巧。朋友可以参考以下
本文的例子描述了PHP完成和过滤网页内容的HTML标签的方法。分享给大家,供大家参考,如下:
如果你的网页内容的html标签不完整,一些table标签不完整导致页面混乱,或者你的内容以外的部分html页面收录在内,我们可以写一个函数方法来完成html标签和过滤去掉无用的html标签。
php让HTML标签自动补全、关闭、过滤功能方法一:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
closetags() 解析:
array_reverse() :此函数反转原创数组中元素的顺序,创建一个新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名会丢失。
array_search() : array_search(value,array,strict),这个函数像 in_array() 一样在数组中搜索一个键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回 false。如果第三个参数strict指定为true,则只有数据类型和值一致时才返回对应元素的键名。
php让HTML标签自动补全、关闭、过滤功能方法二:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
checkhtml($html) 解析:
stripslashes():该函数删除由addslashes() 函数添加的反斜杠。此函数用于清理从数据库或 HTML 表单中检索到的数据。
以上是PHP完成和过滤网页内容中html标签的两种方法的详细介绍。更多详情请关注php中文网其他相关话题文章!

php抓取网页标签(php抓取网页标签抓取+云音乐歌词+转发按钮按钮)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-20 08:03
php抓取网页标签首先是打开浏览器,
php主要抓取html,我也在探索如何php抓取。
知乎好多类似的问题
php需要提供url头数据,可以通过get或者post实现,建议用dll封装一层path_to_array.至于如何封装,稍加研究就可以了.
php大神们的回答:百度一下
推荐你看看今天刚更新的自己写的php爬虫网页数据抓取+云音乐歌词抓取+转发按钮
这个有个问题,
php抓取网页主要是靠url头来抓取的,style="getheader('class','none')"。
这里有一个爬取网页的教程,
.url
这个问题还是蛮困惑的,我也不懂。还在研究中。
我也碰到过这个问题。抓取了别人的网站,然后都没有对应的名称,也没有源文件。看了其他的大神的回答,都不是抓取主要的数据,有点搞笑。
同样。同样搞定了,去github看了一圈,没有发现成功的。把我的抓取代码放到github上,cat~winflu_php0112534.php,抓取了我的网站,还是不对,没有对应的名称,没有源文件。思考了一下:1,使用curl来对我的网站做抓取时候没有对应的数据。2,服务器端是基于我的服务器上配置上的各种数据类型进行操作,如果没有对应数据类型,是没有办法判断我的url的数据类型的。
没有type_string.text='something'这种类型的数据。就像没有text这种类型的文本数据。所以我就继续等待这个问题的解决。 查看全部
php抓取网页标签(php抓取网页标签抓取+云音乐歌词+转发按钮按钮)
php抓取网页标签首先是打开浏览器,
php主要抓取html,我也在探索如何php抓取。
知乎好多类似的问题
php需要提供url头数据,可以通过get或者post实现,建议用dll封装一层path_to_array.至于如何封装,稍加研究就可以了.
php大神们的回答:百度一下
推荐你看看今天刚更新的自己写的php爬虫网页数据抓取+云音乐歌词抓取+转发按钮
这个有个问题,
php抓取网页主要是靠url头来抓取的,style="getheader('class','none')"。
这里有一个爬取网页的教程,
.url
这个问题还是蛮困惑的,我也不懂。还在研究中。
我也碰到过这个问题。抓取了别人的网站,然后都没有对应的名称,也没有源文件。看了其他的大神的回答,都不是抓取主要的数据,有点搞笑。
同样。同样搞定了,去github看了一圈,没有发现成功的。把我的抓取代码放到github上,cat~winflu_php0112534.php,抓取了我的网站,还是不对,没有对应的名称,没有源文件。思考了一下:1,使用curl来对我的网站做抓取时候没有对应的数据。2,服务器端是基于我的服务器上配置上的各种数据类型进行操作,如果没有对应数据类型,是没有办法判断我的url的数据类型的。
没有type_string.text='something'这种类型的数据。就像没有text这种类型的文本数据。所以我就继续等待这个问题的解决。
php抓取网页标签(html标签不能是什么事都不能十全十美,就这样了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-19 03:25
)
日志一般需要生成摘要,手动填写太麻烦,所以使用mb_substr自动拦截,问题来了。如果纯文本还是基本准确的,如果html代码太多,拦截就太糟糕了。例如,如果摘要设置为 300 字,则前面的空格和 html 代码可能占 100 字。怎么做?你最好的办法是遇到html代码,跳过它,不计较。这样更准确,当然美中不足的是,如果是img标签呢?没有什么是完美的,仅此而已。
utf编码,unicode字符1-6个字节都是可以的,但是html码肯定是1个字节,而且以<开头>结尾,所以后面分析出来。但是有一个问题,html标签不能关闭。比如300字满的时候,后面还有几个html标签,导致标签打不开,页面布局完全乱了。我记得php有一个扩展库,专门检查html规范,但是一般主机没有安装,所以我试着写了。逻辑挺复杂的,看到就头晕,觉得有些地方是多余的,但是没找到别的办法。
在这几天的测试中,可以正确处理未封闭的 html 标签。但是如果使用php过滤器会比较麻烦,php代码中可能会有很多<和>,目前的解决方案是,如果输入格式中收录php过滤器,则不进行处理。如果字符串中没有html标签,直接调用mb_substr进行处理,其中收录抽象截取标记,优先从标记截取。
这是代码: 查看全部
php抓取网页标签(html标签不能是什么事都不能十全十美,就这样了
)
日志一般需要生成摘要,手动填写太麻烦,所以使用mb_substr自动拦截,问题来了。如果纯文本还是基本准确的,如果html代码太多,拦截就太糟糕了。例如,如果摘要设置为 300 字,则前面的空格和 html 代码可能占 100 字。怎么做?你最好的办法是遇到html代码,跳过它,不计较。这样更准确,当然美中不足的是,如果是img标签呢?没有什么是完美的,仅此而已。
utf编码,unicode字符1-6个字节都是可以的,但是html码肯定是1个字节,而且以<开头>结尾,所以后面分析出来。但是有一个问题,html标签不能关闭。比如300字满的时候,后面还有几个html标签,导致标签打不开,页面布局完全乱了。我记得php有一个扩展库,专门检查html规范,但是一般主机没有安装,所以我试着写了。逻辑挺复杂的,看到就头晕,觉得有些地方是多余的,但是没找到别的办法。
在这几天的测试中,可以正确处理未封闭的 html 标签。但是如果使用php过滤器会比较麻烦,php代码中可能会有很多<和>,目前的解决方案是,如果输入格式中收录php过滤器,则不进行处理。如果字符串中没有html标签,直接调用mb_substr进行处理,其中收录抽象截取标记,优先从标记截取。
这是代码:
php抓取网页标签(网页制作软件dw最新版新增功能无缝实时编辑(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-18 16:07
)
Dreamweaver 2020 for Mac,简称“DW”,是Mac上最好的网页设计软件之一。dw cc2020 mac版增加了新的界面,快速灵活的编码引擎,对Git的支持和更直观的可视化CSS编辑工具,功能更完善,dw mac版可以帮助用户创建、编码和管理美观的< @网站更快更好,这里是最新版的网页制作软件dw,由于DW 2020和谐版还没有上线,所以还是正式版,请稍等...
Adobe Dreamweaver CC 2020 for mac 官方介绍
<p>Adobe Dreamweaver,简称“DW”,中文名“Dream Weaver”,最初为美国开发,2005年被收购。DW是一个所见即所得的网页代码编辑器,集网页创建和管理为一体 查看全部
php抓取网页标签(网页制作软件dw最新版新增功能无缝实时编辑(组图)
)
Dreamweaver 2020 for Mac,简称“DW”,是Mac上最好的网页设计软件之一。dw cc2020 mac版增加了新的界面,快速灵活的编码引擎,对Git的支持和更直观的可视化CSS编辑工具,功能更完善,dw mac版可以帮助用户创建、编码和管理美观的< @网站更快更好,这里是最新版的网页制作软件dw,由于DW 2020和谐版还没有上线,所以还是正式版,请稍等...
Adobe Dreamweaver CC 2020 for mac 官方介绍
<p>Adobe Dreamweaver,简称“DW”,中文名“Dream Weaver”,最初为美国开发,2005年被收购。DW是一个所见即所得的网页代码编辑器,集网页创建和管理为一体
php抓取网页标签(GoogleSearch如何使用.txt?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-18 13:27
并非所有网络机器人都遵循 robots.txt。坏人(例如电子邮件地址抓取工具)构建不遵循此协议的机器人。事实上,一些不良行为者使用 robots.txt 文件来查找您的私人内容所在的位置。虽然阻止爬虫访问私人页面(如登录和管理页面)似乎合乎逻辑,因此它们不会出现在索引中,但将这些 URL 的位置放在可公开访问的 robots.txt 文件中也意味着恶意软件可以更容易地找到它们。最好对这些页面进行 NoIndex 并将它们保留在登录表单后面,而不是将它们放在您的 robots.txt 文件中。
您可以在我们学习中心的 robots.txt 部分阅读更多详细信息。
在 GSC 中定义 URL 参数
一些 网站(在电子商务中最常见)通过将某些参数附加到 URL 来使相同的内容在多个不同的 URL 上可用。如果您曾经在网上购物,您可能已经使用过滤器缩小了搜索范围。例如,您可以在亚马逊上搜索“鞋子”,然后按尺码、颜色和款式细化您的搜索。每次优化时,URL 都会略有变化:
https://www.example.com/produc ... id%3D 32&highlight=green+dress&cat_id=1&sessionid=123$affid=43
Google 如何知道向搜索者提供哪个版本的 URL?Google 在确定代表 URL 本身方面做得很好,但您可以使用 Google Search Console 中的 URL 参数功能告诉 Google 您希望他们如何处理您的页面。如果您使用此功能告诉 Googlebot“不要抓取带有 ___ 参数的网址”,您实际上是在要求 Googlebot 对 Googlebot 隐藏此内容,这可能会导致这些网页从搜索结果中删除。如果这些参数创建重复页面,这就是您想要的,但如果您希望这些页面被索引,则不理想。
爬虫能找到你所有的重要内容吗?
既然您已经了解了一些使搜索引擎爬虫远离您不重要的内容的策略,那么让我们来看看可以帮助 Googlebot 找到您的重要页面的优化。
有时,搜索引擎将能够抓取您的 网站 的某些部分,但其他页面或部分可能由于某种原因而被遮挡。确保搜索引擎可以发现您想要索引的所有内容,而不仅仅是您的主页,这一点很重要。
问问自己这个问题:机器人可以爬过你的 网站,而不仅仅是在上面吗? 查看全部
php抓取网页标签(GoogleSearch如何使用.txt?)
并非所有网络机器人都遵循 robots.txt。坏人(例如电子邮件地址抓取工具)构建不遵循此协议的机器人。事实上,一些不良行为者使用 robots.txt 文件来查找您的私人内容所在的位置。虽然阻止爬虫访问私人页面(如登录和管理页面)似乎合乎逻辑,因此它们不会出现在索引中,但将这些 URL 的位置放在可公开访问的 robots.txt 文件中也意味着恶意软件可以更容易地找到它们。最好对这些页面进行 NoIndex 并将它们保留在登录表单后面,而不是将它们放在您的 robots.txt 文件中。
您可以在我们学习中心的 robots.txt 部分阅读更多详细信息。
在 GSC 中定义 URL 参数
一些 网站(在电子商务中最常见)通过将某些参数附加到 URL 来使相同的内容在多个不同的 URL 上可用。如果您曾经在网上购物,您可能已经使用过滤器缩小了搜索范围。例如,您可以在亚马逊上搜索“鞋子”,然后按尺码、颜色和款式细化您的搜索。每次优化时,URL 都会略有变化:
https://www.example.com/produc ... id%3D 32&highlight=green+dress&cat_id=1&sessionid=123$affid=43
Google 如何知道向搜索者提供哪个版本的 URL?Google 在确定代表 URL 本身方面做得很好,但您可以使用 Google Search Console 中的 URL 参数功能告诉 Google 您希望他们如何处理您的页面。如果您使用此功能告诉 Googlebot“不要抓取带有 ___ 参数的网址”,您实际上是在要求 Googlebot 对 Googlebot 隐藏此内容,这可能会导致这些网页从搜索结果中删除。如果这些参数创建重复页面,这就是您想要的,但如果您希望这些页面被索引,则不理想。
爬虫能找到你所有的重要内容吗?
既然您已经了解了一些使搜索引擎爬虫远离您不重要的内容的策略,那么让我们来看看可以帮助 Googlebot 找到您的重要页面的优化。
有时,搜索引擎将能够抓取您的 网站 的某些部分,但其他页面或部分可能由于某种原因而被遮挡。确保搜索引擎可以发现您想要索引的所有内容,而不仅仅是您的主页,这一点很重要。
问问自己这个问题:机器人可以爬过你的 网站,而不仅仅是在上面吗?
php抓取网页标签(php的开发者来说源码,远程抓取图片并保存到本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-02-18 13:24
作为一个模仿站点工作者,当网站 有版权甚至加密时,WEBZIP 也会关闭。如何扣除网页上的图片和背景图片?有时,您可能会想到使用 Firefox。这个浏览器似乎是一个强大的错误。 文章 有版权,右键被屏蔽,Firefox 完全不受影响。
但是作为一个热爱php的开发者,我更喜欢自己做。于是,我写了如下源码,php远程抓图小程序。您可以读取 css 文件并在 css 代码中获取背景图像。下面的代码也是为了抓取css中的图片而写的。
如果不出意外,你会发现你指定的文件夹里全是图片,哈哈..
ps:php获取远程图片并下载并保存在本地
分享一个使用php获取远程图片并将远程图片下载保存到本地的功能代码:
/*
*功能:php完美实现下载远程图片保存到本地
*参数:文件url,保存文件目录,保存文件名称,使用的下载方式
*当保存文件名称为空时则使用远程文件原来的名称
*/
function getImage($url,$save_dir='',$filename='',$type=0){
if(trim($url)==''){
return array('file_name'=>'','save_path'=>'','error'=>1);
}
if(trim($save_dir)==''){
$save_dir='./';
}
if(trim($filename)==''){//保存文件名
$ext=strrchr($url,'.');
if($ext!='.gif'&&$ext!='.jpg'){
return array('file_name'=>'','save_path'=>'','error'=>3);
}
$filename=time().$ext;
}
if(0!==strrpos($save_dir,'/')){
$save_dir.='/';
}
//创建保存目录
if(!file_exists($save_dir)&&!mkdir($save_dir,0777,true)){
return array('file_name'=>'','save_path'=>'','error'=>5);
}
//获取远程文件所采用的方法
if($type){
$ch=curl_init();
$timeout=5;
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_CONNECTTIMEOUT,$timeout);
$img=curl_exec($ch);
curl_close($ch);
}else{
ob_start();
readfile($url);
$img=ob_get_contents();
ob_end_clean();
}
//$size=strlen($img);
//文件大小
$fp2=@fopen($save_dir.$filename,'a');
fwrite($fp2,$img);
fclose($fp2);
unset($img,$url);
return array('file_name'=>$filename,'save_path'=>$save_dir.$filename,'error'=>0);
}
以上内容是小编分享给大家的PHP源码批量抓取远程网页图片并保存到本地的实现方法。希望你喜欢。 查看全部
php抓取网页标签(php的开发者来说源码,远程抓取图片并保存到本地)
作为一个模仿站点工作者,当网站 有版权甚至加密时,WEBZIP 也会关闭。如何扣除网页上的图片和背景图片?有时,您可能会想到使用 Firefox。这个浏览器似乎是一个强大的错误。 文章 有版权,右键被屏蔽,Firefox 完全不受影响。
但是作为一个热爱php的开发者,我更喜欢自己做。于是,我写了如下源码,php远程抓图小程序。您可以读取 css 文件并在 css 代码中获取背景图像。下面的代码也是为了抓取css中的图片而写的。
如果不出意外,你会发现你指定的文件夹里全是图片,哈哈..
ps:php获取远程图片并下载并保存在本地
分享一个使用php获取远程图片并将远程图片下载保存到本地的功能代码:
/*
*功能:php完美实现下载远程图片保存到本地
*参数:文件url,保存文件目录,保存文件名称,使用的下载方式
*当保存文件名称为空时则使用远程文件原来的名称
*/
function getImage($url,$save_dir='',$filename='',$type=0){
if(trim($url)==''){
return array('file_name'=>'','save_path'=>'','error'=>1);
}
if(trim($save_dir)==''){
$save_dir='./';
}
if(trim($filename)==''){//保存文件名
$ext=strrchr($url,'.');
if($ext!='.gif'&&$ext!='.jpg'){
return array('file_name'=>'','save_path'=>'','error'=>3);
}
$filename=time().$ext;
}
if(0!==strrpos($save_dir,'/')){
$save_dir.='/';
}
//创建保存目录
if(!file_exists($save_dir)&&!mkdir($save_dir,0777,true)){
return array('file_name'=>'','save_path'=>'','error'=>5);
}
//获取远程文件所采用的方法
if($type){
$ch=curl_init();
$timeout=5;
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_CONNECTTIMEOUT,$timeout);
$img=curl_exec($ch);
curl_close($ch);
}else{
ob_start();
readfile($url);
$img=ob_get_contents();
ob_end_clean();
}
//$size=strlen($img);
//文件大小
$fp2=@fopen($save_dir.$filename,'a');
fwrite($fp2,$img);
fclose($fp2);
unset($img,$url);
return array('file_name'=>$filename,'save_path'=>$save_dir.$filename,'error'=>0);
}
以上内容是小编分享给大家的PHP源码批量抓取远程网页图片并保存到本地的实现方法。希望你喜欢。
php抓取网页标签( Sitemap(站点地图)(文件格式))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-16 06:08
Sitemap(站点地图)(文件格式))
提交站点地图
站点地图是一个文件,它允许网站管理员列出 网站 上的网页并告知搜索引擎有关 网站 内容的组织。
神马等搜索引擎网络爬虫会读取这个文件,更智能地抓取网站内容
理想情况下,如果您的 网站 页面正确链接,Whatsminer 的网络爬虫将能够发现其中的大部分。即便如此,提交站点地图也可以帮助搜索引擎更高效地抓取网站,尤其是在满足网站以下条件之一的情况下:
1.网站 是一个新的 网站 并且没有很多指向这个 网站 的外部链接。搜索引擎的网络爬虫通过跟踪它们之间的链接来抓取网页,如果没有其他网站指向您页面的链接,则可能无法发现您的页面。
2.网站规模很大。在这种情况下,Whatsminer 的网络爬虫在爬取时可能会漏掉一些新页面。
3.网站 中的大量内容页面断开连接或缺少有效链接。如果您的 网站 页面不能自然地相互引用,您可以在站点地图中列出它们,以确保搜索引擎不会错过您的页面。
需要注意的是,神马搜索会按照正常流程对Sitemap进行分析处理,但不保证会对您提交的所有网址进行抓取和索引,也不保证其在搜索结果中的排名。站点地图格式:
WhatsMiner 支持的站点地图文件包括标准 xml 文件和索引 xml 文件。一个标准的 xml 文件最多收录 10,000 个 URL。如果 URL 超过 10,000,则可以使用索引 xml 文件。被索引的 xml 文件被限制为不超过三层。
标准xml文件格式示例:
2014-05-01
每天
0.5
2014-05-01
每天
0.8
索引xml文件格式示例:
1.顶级站点地图格式 查看全部
php抓取网页标签(
Sitemap(站点地图)(文件格式))
提交站点地图
站点地图是一个文件,它允许网站管理员列出 网站 上的网页并告知搜索引擎有关 网站 内容的组织。
神马等搜索引擎网络爬虫会读取这个文件,更智能地抓取网站内容
理想情况下,如果您的 网站 页面正确链接,Whatsminer 的网络爬虫将能够发现其中的大部分。即便如此,提交站点地图也可以帮助搜索引擎更高效地抓取网站,尤其是在满足网站以下条件之一的情况下:
1.网站 是一个新的 网站 并且没有很多指向这个 网站 的外部链接。搜索引擎的网络爬虫通过跟踪它们之间的链接来抓取网页,如果没有其他网站指向您页面的链接,则可能无法发现您的页面。
2.网站规模很大。在这种情况下,Whatsminer 的网络爬虫在爬取时可能会漏掉一些新页面。
3.网站 中的大量内容页面断开连接或缺少有效链接。如果您的 网站 页面不能自然地相互引用,您可以在站点地图中列出它们,以确保搜索引擎不会错过您的页面。
需要注意的是,神马搜索会按照正常流程对Sitemap进行分析处理,但不保证会对您提交的所有网址进行抓取和索引,也不保证其在搜索结果中的排名。站点地图格式:
WhatsMiner 支持的站点地图文件包括标准 xml 文件和索引 xml 文件。一个标准的 xml 文件最多收录 10,000 个 URL。如果 URL 超过 10,000,则可以使用索引 xml 文件。被索引的 xml 文件被限制为不超过三层。
标准xml文件格式示例:
2014-05-01
每天
0.5
2014-05-01
每天
0.8
索引xml文件格式示例:
1.顶级站点地图格式
php抓取网页标签(方维网络记录一下采集过程中的几个要点需要注意的地方)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-02-05 20:19
PHP网站在生产中经常需要采集其他网站数据,一些细节会造成很大的麻烦。维网记录采集过程中需要注意的几个点
1、首先,你需要获取对方网站的所有内容。你可能会想到使用 file_gets_contents 来获取它,但是这个函数不适合获取远程文件。打开本地txt文件非常有用。那么用什么来获取呢?curl,这个php扩展来处理。以下是获取网页内容的简单基本配置。更多参数配置可以在线搜索。
2、在采集网页匹配数据时,尤其是列表页,可以先把对方的空格、换行等html标签全部去掉,这样会容易很多写正则表达式。这是一个函数:
3、正则匹配会在获取到对方数据后开始。以下是一些常见的匹配规则:
一个是任意字符(.*?),一个是([\s\S]*?) 表示任意字符,包括换行符,在匹配过程中就足够了。然后选择匹配模式 i。
4、介绍采集的思路。您可以下载与页面匹配的数据并保存为txt文件,然后在本地进行处理。另外,为了避免频繁访问对方网站或者数据丢失,可以加一个while(){}循环或者sleep()暂停几秒来处理。封装相关的数据库处理函数,直接调用。
5、还有一个重要的事情很多人可能会忽略,那就是页面的编码。如果对方网站是gbk的编码,对应的php文件或者提交条件的html文件也会是gbk的编码。但是会有一个问题,就是gbk的html向gbk的php页面提交中文数据的时候,gbk的php文件可能没有响应你。如果用这些中文数据来匹配,就会遇到问题。所以我们要换个思路,utf-8是最好的编码方式,所以要使用utf-8编码,而对方是gbk,怎么办呢?
$allcontent =iconv('gbk', 'utf-8',removetag(curl_exec($ch)));
上面的转换就ok了!全部使用 utf-8 查看全部
php抓取网页标签(方维网络记录一下采集过程中的几个要点需要注意的地方)
PHP网站在生产中经常需要采集其他网站数据,一些细节会造成很大的麻烦。维网记录采集过程中需要注意的几个点
1、首先,你需要获取对方网站的所有内容。你可能会想到使用 file_gets_contents 来获取它,但是这个函数不适合获取远程文件。打开本地txt文件非常有用。那么用什么来获取呢?curl,这个php扩展来处理。以下是获取网页内容的简单基本配置。更多参数配置可以在线搜索。

2、在采集网页匹配数据时,尤其是列表页,可以先把对方的空格、换行等html标签全部去掉,这样会容易很多写正则表达式。这是一个函数:

3、正则匹配会在获取到对方数据后开始。以下是一些常见的匹配规则:
一个是任意字符(.*?),一个是([\s\S]*?) 表示任意字符,包括换行符,在匹配过程中就足够了。然后选择匹配模式 i。
4、介绍采集的思路。您可以下载与页面匹配的数据并保存为txt文件,然后在本地进行处理。另外,为了避免频繁访问对方网站或者数据丢失,可以加一个while(){}循环或者sleep()暂停几秒来处理。封装相关的数据库处理函数,直接调用。
5、还有一个重要的事情很多人可能会忽略,那就是页面的编码。如果对方网站是gbk的编码,对应的php文件或者提交条件的html文件也会是gbk的编码。但是会有一个问题,就是gbk的html向gbk的php页面提交中文数据的时候,gbk的php文件可能没有响应你。如果用这些中文数据来匹配,就会遇到问题。所以我们要换个思路,utf-8是最好的编码方式,所以要使用utf-8编码,而对方是gbk,怎么办呢?
$allcontent =iconv('gbk', 'utf-8',removetag(curl_exec($ch)));
上面的转换就ok了!全部使用 utf-8
php抓取网页标签(常见爬取网页时,提取数据的方法有xpath,正则提取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-05 16:32
2021-08-14 抓取网页时,提取数据的方法有xpath和正则提取。对于json数据,使用函数jsonpath提取,scrapy中使用css提取。标题在这么多提取方法中,这次我们使用xpath来模拟我们所面临的数据,用于一般和特殊的数据提取。
网址:
文章使用这个 网站 从 xpath 中提取数据。
一、对于简单的数据,可以直接查看网页的源码,然后复制其xpath的路径(提示:7、8%的网页可以通过这种方式直接提取)
第一步:鼠标右击,查看网页,也可以使用快捷键F12
2.第二步:
点击你要的信息:点击后,下面会自动跳转到对应的位置,然后复制路径。
这种方法非常快。准确率一般,毕竟自己写最准确。
墙破解推荐一个谷歌插件,xpath-helper插件可以实时查看自己的xpath路径对应的信息。
二、如有特殊要求,xpath会响应
还是这个网站,我现在在想,从后面的所有类别爬取,我不要所有这个模块
这是使用xpath中的position(位置)方法,position处理这种情况比较快
/html/body/div/div[1]/div[6]/div/div[3]/div[1]/div[2]/a[1]/text()
这个 xpath 提取的就是全部
/html/body/div/div[1]/div[6]/div/div[3]/div[1]/div[2]/a[position()>1]/text()
此 xpath 提取所有后续模块
使用方法:顾名思义,位置(position),我们只需要替换递归标签中的这个字段就可以从选中的行中提取数据
翻页并提取页面的URL
我们可以发现网页的下一页的位置正在发生变化。如果要定位,不能使用常规方法,因为每一页的位置都不一样。这就是我们要使用的 last()
/html/body/div/div[1]/div[8]/div/a[last()-1]/@href
像这样,很容易理解,差不多就是递归标签内修改position,last()代表最后一个标签,last()-1,代表倒数第二个标签,其余同理
或者翻转标签,也可以使用 content() 方法进行定位:
/html/body/div/div[1]/div[8]/div/a[contains(string(.),'next')]/@href
还有一些其他的方法,下次继续,有什么问题可以留言交流!!!
分类:
技术要点:
相关文章: 查看全部
php抓取网页标签(常见爬取网页时,提取数据的方法有xpath,正则提取)
2021-08-14 抓取网页时,提取数据的方法有xpath和正则提取。对于json数据,使用函数jsonpath提取,scrapy中使用css提取。标题在这么多提取方法中,这次我们使用xpath来模拟我们所面临的数据,用于一般和特殊的数据提取。
网址:
文章使用这个 网站 从 xpath 中提取数据。
一、对于简单的数据,可以直接查看网页的源码,然后复制其xpath的路径(提示:7、8%的网页可以通过这种方式直接提取)
第一步:鼠标右击,查看网页,也可以使用快捷键F12
2.第二步:
点击你要的信息:点击后,下面会自动跳转到对应的位置,然后复制路径。
这种方法非常快。准确率一般,毕竟自己写最准确。
墙破解推荐一个谷歌插件,xpath-helper插件可以实时查看自己的xpath路径对应的信息。
二、如有特殊要求,xpath会响应
还是这个网站,我现在在想,从后面的所有类别爬取,我不要所有这个模块
这是使用xpath中的position(位置)方法,position处理这种情况比较快
/html/body/div/div[1]/div[6]/div/div[3]/div[1]/div[2]/a[1]/text()
这个 xpath 提取的就是全部
/html/body/div/div[1]/div[6]/div/div[3]/div[1]/div[2]/a[position()>1]/text()
此 xpath 提取所有后续模块
使用方法:顾名思义,位置(position),我们只需要替换递归标签中的这个字段就可以从选中的行中提取数据
翻页并提取页面的URL
我们可以发现网页的下一页的位置正在发生变化。如果要定位,不能使用常规方法,因为每一页的位置都不一样。这就是我们要使用的 last()
/html/body/div/div[1]/div[8]/div/a[last()-1]/@href
像这样,很容易理解,差不多就是递归标签内修改position,last()代表最后一个标签,last()-1,代表倒数第二个标签,其余同理
或者翻转标签,也可以使用 content() 方法进行定位:
/html/body/div/div[1]/div[8]/div/a[contains(string(.),'next')]/@href
还有一些其他的方法,下次继续,有什么问题可以留言交流!!!
分类:
技术要点:
相关文章:
php抓取网页标签(WordPress主题影响SEO效果的几个方面方面SEO标签结构化数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-02-05 16:28
很多网友都在咨询或讨论WordPress主题是否会影响SEO优化。要理解这个问题,并不难,首先要了解SEO与哪些方面有关,这些方面是否与WordPress主题有关。本文将讨论主题的哪些方面影响 SEO。
由于WordPress主题与写作内容无关,原创、写作质量、专业度等本文将不予讨论,虽然这些是最影响搜索引擎收录和排名的。
WordPress主题影响SEO效果的几个方面SEO标签结构化数据页面加载速度页面渲染速度页面代码错误1、SEO标签
许多主题都会带有一些 SEO 标签,通常包括以下内容:
机器人META标签
上述标签告诉搜索引擎允许抓取该页面并允许以下链接。
inindex,follow:允许爬取这个页面,允许关注链接。index,nofollow:允许抓取此页面,但不允许以下链接。noindex,follow:禁止抓取该页面,但允许以下链接。noindex,nofllow:禁止爬取该页面,禁止在该页面点击链接。rel =“规范”标签
本页应用示例:
早在 2009 年 2 月,Google、Yahoo 和 live search 就宣布支持 Link 的新属性 Canonical。主要目的是帮助搜索引擎解决存在多个版本的网站内容,制定标准化的链接,防止同一个内容重复收录。
这个标签在 WordPress 中很重要,因为 WordPress 可能有伪静态 URL,默认 ?p=123 URL,或者其他一些参数后缀,但是它们的内容是完全一样的,通过 rel=”canonical” 标签可以避免重复 收录,现在所有主要搜索引擎都支持它。
描述 META 标签
例子:
描述标签,顾名思义,就是对网页的简单描述/摘录,可以让搜索引擎更快地掌握网页的基本内容。曾经有关键字标签(定义 关键词),但现在正在逐步淘汰。
标题标签
例子:
WordPress主题会不会影响SEO优化? - 天使之家
对于SEO来说,最重要的是标题标签,每个页面必须有一个,而且只有一个。这个标签定义了网页的标题,也是上述所有标签中对SEO最重要的标签,最好能反映网页的关键词或关键词。但是不要滥用标题标签,如果文字错误,可能会被搜索引擎视为作弊。
额外提一下,H1、H2、H3...这种类型的标签对SEO也有帮助,但基本上与WordPress主题无关,需要在编写内容时添加。在主页和列表页,文章 标题在一般主题中会标有 H2。因为在一个页面中,H1只能使用一次,否则也会造成SEO不当。
2、结构化数据
说白了,结构化数据就是网页除了title、url、description这三个要素外,还可以向搜索引擎提交更多的信息,在搜索结果页展示更多的信息,获得更好的排名。
结构化数据代码分为三种类型:JSON-LD、微数据和 RDFa。无论是谷歌还是百度,都推荐使用 JSON-LD 格式。
一般的 WordPress 主题不会自动生成结构化数据,除非您自己添加相应的代码,或者使用 SEO 插件。强烈建议使用 Yoast SEO 或 Rank Math SEO 来生成规范的结构化数据。其中,Rank Math PRO可以自定义结构化数据的内容,这样除了结构化数据外,还可以添加百度尊重的结构化数据代码。或者在文章页面模板中添加如下代码,添加百度结构化数据。
{
"@context": "https://ziyuan.baidu.com/conte ... ot%3B,
"@id": "",
"title": "",
"images": [
""
],
"description":"",
"pubDate": "",
"upDate":""
}
注:是 Google、Bing、Yandex 和 Yahoo! 合作的结果 它已被包括百度在内的几乎所有主要搜索引擎支持。只是百度目前更喜欢上面例子的结构化数据,未来可能会改变这种看法。
3、网页加载速度
无论是哪个搜索引擎,网页和相关静态资源的加载速度都非常重要。WordPress主题对这方面的影响分为两部分,一是动态加载速度,二是静态缓存后的加载速度。
动态加载速度
对于不使用静态缓存的网页,程序代码的编码质量、服务器性能、服务器运行环境、网络带宽、网络状况等因素都会影响动态加载速度。因为每次访问网页,都是由后端的PHP程序生成前端网页,然后传递给浏览器。整个过程比较缓慢。
虽然 WordPress 有很多静态缓存方案,但有些情况不适合缓存,比如:用 WooCommerce 搭建的商店、需要动态展示的网页、具有交互功能的网页等。
在上面提到的影响动态加载速度的因素中,与主题相关的主要是程序代码的编码质量。这个话题比较大,不能一两句话完全解释清楚,但是有以下几个原则供大家参考。便于选择优质主题的参考。
静态缓存后的加载速度
静态缓存之后的术语对于 WordPress 站长来说一定很熟悉。WordPress本身不支持静态,但是有很多插件可以实现网页的静态缓存。例如:WP Rocket、W3 Total Cache、WP Super Cache 等。
经过静态缓存处理后,用户在访问网页时不需要像动态网页那样在后端临时生成前端页面。尤其是上面提到的三个缓存插件,无论是 Nginx 还是 Apache,都可以直接调用缓存的内容交付,无需 PHP 处理。PS:WP Rocket 需要在 Nginx 环境中额外安装 Rocket-Nginx。
这样,静态缓存后的网页加载速度大大提高,基本上只取决于网络带宽、网络条件和服务器静态资源的并发性能。也就是说,对于 WordPress 主题,只要不加载太多、庞大的静态资产,就可以获得良好的加载速度。
看到这里,基本可以得出一个结论,只要大部分主题都是静态缓存处理的,加载速度不会有太大影响。使用静态缓存,这不太可能成为影响 SEO 的条件。
4、网页渲染速度
网页渲染速度和加载速度不同,加载完成不代表渲染完成。浏览器在默认加载网页的静态资源时,是按顺序加载的,浏览器会延迟页面的渲染,直到完成加载、解析并执行完页面中引用的所有CSS文件。推荐阅读“什么是关键路径 CSS?”一文。
还有一些js文件,同样会阻塞页面渲染过程,但是可以通过异步加载进行优化。
网页渲染速度对SEO的影响也很大,但是对百度搜索的影响稍微小一些,因为百度还是使用了爬虫机制,而且GoogleSpider做了调整,这意味着谷歌不仅会爬取渲染后的网页同时,还分析了网页渲染的过程和速度,从而判断网页的浏览体验。
虽然百度在这方面有些落后,但也只是时间问题,因为百度的移动爬虫已经做了很大的调整。
在这一点上,国外的主题大多处理得很好,因为开发者一般使用 PageSpeed Insights 分数作为衡量标准。
5、网页代码是否有错误
这是一个基本要求。如果网页出现代码错误或者调用某些404资源,都会严重影响SEO。稍微成熟的 WordPress 主题不会有这个问题,但是需要提醒的是,一些国外的主题可能会加载一些在大陆无法正常访问的资源,比如谷歌字体、谷歌前端公共库等,仍然会不利。搜索引擎优化。
综上所述
如果阅读本文,WordPress 主题对 SEO 有影响吗?有什么影响?结论已经揭晓。
第一个和第二个方面可以通过额外的 SEO 插件来解决。第三点可以通过静态缓存进行优化。第四点需要下功夫打磨,有很多功能插件可以优化PageSpeed Insights分数。最后,第5点。使用国外主题时,建议仔细检查是否加载了谷歌的部分公共资源。建议将谷歌前端公共库和谷歌字体注释掉,或者通过插件禁用。
内容为王,其他手段只起到辅助作用,所以我劝大家不要本末倒置。做好用户需要的内容,提升用户体验,是最重要的SEO优化。 查看全部
php抓取网页标签(WordPress主题影响SEO效果的几个方面方面SEO标签结构化数据)
很多网友都在咨询或讨论WordPress主题是否会影响SEO优化。要理解这个问题,并不难,首先要了解SEO与哪些方面有关,这些方面是否与WordPress主题有关。本文将讨论主题的哪些方面影响 SEO。
由于WordPress主题与写作内容无关,原创、写作质量、专业度等本文将不予讨论,虽然这些是最影响搜索引擎收录和排名的。
WordPress主题影响SEO效果的几个方面SEO标签结构化数据页面加载速度页面渲染速度页面代码错误1、SEO标签
许多主题都会带有一些 SEO 标签,通常包括以下内容:
机器人META标签
上述标签告诉搜索引擎允许抓取该页面并允许以下链接。
inindex,follow:允许爬取这个页面,允许关注链接。index,nofollow:允许抓取此页面,但不允许以下链接。noindex,follow:禁止抓取该页面,但允许以下链接。noindex,nofllow:禁止爬取该页面,禁止在该页面点击链接。rel =“规范”标签
本页应用示例:
早在 2009 年 2 月,Google、Yahoo 和 live search 就宣布支持 Link 的新属性 Canonical。主要目的是帮助搜索引擎解决存在多个版本的网站内容,制定标准化的链接,防止同一个内容重复收录。
这个标签在 WordPress 中很重要,因为 WordPress 可能有伪静态 URL,默认 ?p=123 URL,或者其他一些参数后缀,但是它们的内容是完全一样的,通过 rel=”canonical” 标签可以避免重复 收录,现在所有主要搜索引擎都支持它。
描述 META 标签
例子:
描述标签,顾名思义,就是对网页的简单描述/摘录,可以让搜索引擎更快地掌握网页的基本内容。曾经有关键字标签(定义 关键词),但现在正在逐步淘汰。
标题标签
例子:
WordPress主题会不会影响SEO优化? - 天使之家
对于SEO来说,最重要的是标题标签,每个页面必须有一个,而且只有一个。这个标签定义了网页的标题,也是上述所有标签中对SEO最重要的标签,最好能反映网页的关键词或关键词。但是不要滥用标题标签,如果文字错误,可能会被搜索引擎视为作弊。
额外提一下,H1、H2、H3...这种类型的标签对SEO也有帮助,但基本上与WordPress主题无关,需要在编写内容时添加。在主页和列表页,文章 标题在一般主题中会标有 H2。因为在一个页面中,H1只能使用一次,否则也会造成SEO不当。
2、结构化数据
说白了,结构化数据就是网页除了title、url、description这三个要素外,还可以向搜索引擎提交更多的信息,在搜索结果页展示更多的信息,获得更好的排名。
结构化数据代码分为三种类型:JSON-LD、微数据和 RDFa。无论是谷歌还是百度,都推荐使用 JSON-LD 格式。
一般的 WordPress 主题不会自动生成结构化数据,除非您自己添加相应的代码,或者使用 SEO 插件。强烈建议使用 Yoast SEO 或 Rank Math SEO 来生成规范的结构化数据。其中,Rank Math PRO可以自定义结构化数据的内容,这样除了结构化数据外,还可以添加百度尊重的结构化数据代码。或者在文章页面模板中添加如下代码,添加百度结构化数据。
{
"@context": "https://ziyuan.baidu.com/conte ... ot%3B,
"@id": "",
"title": "",
"images": [
""
],
"description":"",
"pubDate": "",
"upDate":""
}
注:是 Google、Bing、Yandex 和 Yahoo! 合作的结果 它已被包括百度在内的几乎所有主要搜索引擎支持。只是百度目前更喜欢上面例子的结构化数据,未来可能会改变这种看法。
3、网页加载速度
无论是哪个搜索引擎,网页和相关静态资源的加载速度都非常重要。WordPress主题对这方面的影响分为两部分,一是动态加载速度,二是静态缓存后的加载速度。
动态加载速度
对于不使用静态缓存的网页,程序代码的编码质量、服务器性能、服务器运行环境、网络带宽、网络状况等因素都会影响动态加载速度。因为每次访问网页,都是由后端的PHP程序生成前端网页,然后传递给浏览器。整个过程比较缓慢。
虽然 WordPress 有很多静态缓存方案,但有些情况不适合缓存,比如:用 WooCommerce 搭建的商店、需要动态展示的网页、具有交互功能的网页等。
在上面提到的影响动态加载速度的因素中,与主题相关的主要是程序代码的编码质量。这个话题比较大,不能一两句话完全解释清楚,但是有以下几个原则供大家参考。便于选择优质主题的参考。
静态缓存后的加载速度
静态缓存之后的术语对于 WordPress 站长来说一定很熟悉。WordPress本身不支持静态,但是有很多插件可以实现网页的静态缓存。例如:WP Rocket、W3 Total Cache、WP Super Cache 等。
经过静态缓存处理后,用户在访问网页时不需要像动态网页那样在后端临时生成前端页面。尤其是上面提到的三个缓存插件,无论是 Nginx 还是 Apache,都可以直接调用缓存的内容交付,无需 PHP 处理。PS:WP Rocket 需要在 Nginx 环境中额外安装 Rocket-Nginx。
这样,静态缓存后的网页加载速度大大提高,基本上只取决于网络带宽、网络条件和服务器静态资源的并发性能。也就是说,对于 WordPress 主题,只要不加载太多、庞大的静态资产,就可以获得良好的加载速度。
看到这里,基本可以得出一个结论,只要大部分主题都是静态缓存处理的,加载速度不会有太大影响。使用静态缓存,这不太可能成为影响 SEO 的条件。
4、网页渲染速度
网页渲染速度和加载速度不同,加载完成不代表渲染完成。浏览器在默认加载网页的静态资源时,是按顺序加载的,浏览器会延迟页面的渲染,直到完成加载、解析并执行完页面中引用的所有CSS文件。推荐阅读“什么是关键路径 CSS?”一文。
还有一些js文件,同样会阻塞页面渲染过程,但是可以通过异步加载进行优化。
网页渲染速度对SEO的影响也很大,但是对百度搜索的影响稍微小一些,因为百度还是使用了爬虫机制,而且GoogleSpider做了调整,这意味着谷歌不仅会爬取渲染后的网页同时,还分析了网页渲染的过程和速度,从而判断网页的浏览体验。
虽然百度在这方面有些落后,但也只是时间问题,因为百度的移动爬虫已经做了很大的调整。
在这一点上,国外的主题大多处理得很好,因为开发者一般使用 PageSpeed Insights 分数作为衡量标准。
5、网页代码是否有错误
这是一个基本要求。如果网页出现代码错误或者调用某些404资源,都会严重影响SEO。稍微成熟的 WordPress 主题不会有这个问题,但是需要提醒的是,一些国外的主题可能会加载一些在大陆无法正常访问的资源,比如谷歌字体、谷歌前端公共库等,仍然会不利。搜索引擎优化。
综上所述
如果阅读本文,WordPress 主题对 SEO 有影响吗?有什么影响?结论已经揭晓。
第一个和第二个方面可以通过额外的 SEO 插件来解决。第三点可以通过静态缓存进行优化。第四点需要下功夫打磨,有很多功能插件可以优化PageSpeed Insights分数。最后,第5点。使用国外主题时,建议仔细检查是否加载了谷歌的部分公共资源。建议将谷歌前端公共库和谷歌字体注释掉,或者通过插件禁用。
内容为王,其他手段只起到辅助作用,所以我劝大家不要本末倒置。做好用户需要的内容,提升用户体验,是最重要的SEO优化。
php抓取网页标签(WordPress主题是否会影响SEO效果的几个方面SEO标签数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-01-30 17:08
WordPress 主题是否会影响 SEO 优化。要理解这个问题,并不难,首先要了解SEO与哪些方面有关,这些方面是否与WordPress主题有关。本文将讨论主题的哪些方面影响 SEO。
因为WordPress主题与写作内容无关,原创、写作质量、专业性等本文将不予讨论,虽然这些是最影响搜索引擎收录和排名的。
WordPress主题影响SEO效果的几个方面SEO标签结构化数据页面加载速度页面渲染速度页面代码错误1、SEO标签
许多主题都会带有一些 SEO 标签,通常包括以下内容:
机器人META标签
上述标签告诉搜索引擎允许抓取该页面并允许以下链接。
inindex,follow:允许爬取这个页面,允许关注链接。index,nofollow:允许抓取此页面,但不允许以下链接。noindex,follow:禁止抓取该页面,但允许以下链接。noindex,nofllow:禁止爬取该页面,禁止在该页面点击链接。rel =“规范”标签
本页应用示例:
早在 2009 年 2 月,Google、Yahoo 和 live search 就宣布支持 Link 的新属性 Canonical。主要目的是帮助搜索引擎解决存在多个版本的网站内容,制定标准化的链接,防止同一个内容重复收录。
这个标签在 WordPress 中很重要,因为 WordPress 可能有伪静态 URL,默认 ?p=123 URL,或者其他一些参数后缀,但是它们的内容是完全一样的,通过 rel=”canonical” 标签可以避免重复 收录,现在所有主要搜索引擎都支持它。
描述 META 标签
例子:
描述标签,顾名思义,就是对网页的简单描述/摘录,可以让搜索引擎更快地掌握网页的基本内容。曾经有关键字标签(定义 关键词),但现在正在逐步淘汰。
标题标签
例子:
WordPress主题是否会影响SEO效果 - 站长帮
对于SEO来说,最重要的是标题标签,每个页面必须有一个,而且只有一个。这个标签定义了网页的标题,也是上述所有标签中对SEO最重要的标签,最好能反映网页的关键词或关键词。但是不要滥用标题标签,如果文字错误,可能会被搜索引擎视为作弊。
额外提一下,H1、H2、H3...这种类型的标签对SEO也有帮助,但基本上与WordPress主题无关,需要在编写内容时添加。在主页和列表页,文章 标题在一般主题中会标有 H2。因为在一个页面中,H1只能使用一次,否则也会造成SEO不当。
2、结构化数据
说白了,结构化数据就是网页除了title、url、description这三个要素外,还可以向搜索引擎提交更多的信息,在搜索结果页展示更多的信息,获得更好的排名。
结构化数据代码分为三种类型:JSON-LD、微数据和 RDFa。无论是谷歌还是百度,都推荐使用 JSON-LD 格式。
一般的 WordPress 主题不会自动生成结构化数据,除非您自己添加相应的代码,或者使用 SEO 插件。强烈建议使用 Yoast SEO 或 Rank Math SEO 来生成规范的结构化数据。其中,Rank Math PRO可以自定义结构化数据的内容,这样除了结构化数据外,还可以添加百度尊重的结构化数据代码。或者在文章页面模板中添加如下代码,添加百度结构化数据。
{
"@context": "https://ziyuan.baidu.com/conte ... ot%3B,
"@id": "",
"title": "",
"images": [
""
],
"description":"",
"pubDate": "",
"upDate":""
}
注:是 Google、Bing、Yandex 和 Yahoo! 合作的结果 它已被包括百度在内的几乎所有主要搜索引擎支持。只是百度目前更喜欢上面例子的结构化数据,未来可能会改变这种看法。
3、网页加载速度
无论是哪个搜索引擎,网页和相关静态资源的加载速度都非常重要。WordPress主题对这方面的影响分为两部分,一是动态加载速度,二是静态缓存后的加载速度。
动态加载速度
对于不使用静态缓存的网页,程序代码的编码质量、服务器性能、服务器运行环境、网络带宽、网络状况等因素都会影响动态加载速度。因为每次访问网页,都是由后端的PHP程序生成前端网页,然后传递给浏览器。整个过程比较缓慢。
虽然 WordPress 有很多静态缓存方案,但有些情况不适合缓存,比如:用 WooCommerce 搭建的商店、需要动态展示的网页、具有交互功能的网页等。
在上面提到的影响动态加载速度的因素中,与主题相关的主要是程序代码的编码质量。这个话题比较大,不能一两句话完全解释清楚,但是有以下几个原则供大家参考。便于选择优质主题的参考。
静态缓存后的加载速度
静态缓存之后的术语对于 WordPress 站长来说一定很熟悉。WordPress本身不支持静态,但是有很多插件可以实现网页的静态缓存。例如:WP Rocket、W3 Total Cache、WP Super Cache 等。
经过静态缓存处理后,用户在访问网页时不需要像动态网页那样在后端临时生成前端页面。尤其是上面提到的三个缓存插件,无论是 Nginx 还是 Apache,都可以直接调用缓存的内容交付,无需 PHP 处理。PS:WP Rocket 需要在 Nginx 环境中额外安装 Rocket-Nginx。
这样,静态缓存后的网页加载速度大大提高,基本上只取决于网络带宽、网络条件和服务器静态资源的并发性能。也就是说,对于 WordPress 主题,只要不加载太多、庞大的静态资产,就可以获得良好的加载速度。
看到这里,基本可以得出一个结论,只要大部分主题都是静态缓存处理的,加载速度不会有太大影响。使用静态缓存,这不太可能成为影响 SEO 的条件。
4、网页渲染速度
网页渲染速度和加载速度不同,加载完成不代表渲染完成。浏览器在默认加载网页的静态资源时,是按顺序加载的,浏览器会延迟页面的渲染,直到完成加载、解析并执行完页面中引用的所有CSS文件。
还有一些js文件,同样会阻塞页面渲染过程,但是可以通过异步加载进行优化。
网页渲染速度对SEO的影响也很大,但是对百度搜索的影响稍微小一些,因为百度仍然使用爬虫机制,而且GoogleSpider已经调整,这意味着谷歌不仅会在渲染完成后抓取网页. 同时还分析了网页渲染的过程和速度,从而判断网页的浏览体验。
虽然百度在这方面有些落后,但也只是时间问题,因为百度的移动爬虫已经做了很大的调整。
在这一点上,国外的主题大多处理得很好,因为开发者一般使用 PageSpeed Insights 分数作为衡量标准。
5、网页代码是否有错误
这是一个基本要求。如果网页出现代码错误或者调用某些404资源,都会严重影响SEO。稍微成熟的WordPress主题不会有这个问题,但是需要提醒的是,一些国外的主题可能会加载一些在大陆无法正常访问的资源,比如谷歌字体、谷歌前端公共库等,仍然会不利。搜索引擎优化。
综上所述
如果阅读本文,WordPress 主题对 SEO 有影响吗?有什么影响?结论已经揭晓。
第一个和第二个方面可以通过额外的 SEO 插件来解决。第三点可以通过静态缓存进行优化。第四点需要下功夫打磨,有很多功能插件可以优化PageSpeed Insights分数。最后,第5点。使用国外主题时,建议仔细检查是否加载了谷歌的部分公共资源。建议将谷歌前端公共库和谷歌字体注释掉,或者通过插件禁用。
内容为王,其他手段只起到辅助作用,所以我劝大家不要本末倒置。做好用户需要的内容,提升用户体验,是最重要的SEO优化。 查看全部
php抓取网页标签(WordPress主题是否会影响SEO效果的几个方面SEO标签数据)
WordPress 主题是否会影响 SEO 优化。要理解这个问题,并不难,首先要了解SEO与哪些方面有关,这些方面是否与WordPress主题有关。本文将讨论主题的哪些方面影响 SEO。
因为WordPress主题与写作内容无关,原创、写作质量、专业性等本文将不予讨论,虽然这些是最影响搜索引擎收录和排名的。
WordPress主题影响SEO效果的几个方面SEO标签结构化数据页面加载速度页面渲染速度页面代码错误1、SEO标签
许多主题都会带有一些 SEO 标签,通常包括以下内容:
机器人META标签
上述标签告诉搜索引擎允许抓取该页面并允许以下链接。
inindex,follow:允许爬取这个页面,允许关注链接。index,nofollow:允许抓取此页面,但不允许以下链接。noindex,follow:禁止抓取该页面,但允许以下链接。noindex,nofllow:禁止爬取该页面,禁止在该页面点击链接。rel =“规范”标签
本页应用示例:
早在 2009 年 2 月,Google、Yahoo 和 live search 就宣布支持 Link 的新属性 Canonical。主要目的是帮助搜索引擎解决存在多个版本的网站内容,制定标准化的链接,防止同一个内容重复收录。
这个标签在 WordPress 中很重要,因为 WordPress 可能有伪静态 URL,默认 ?p=123 URL,或者其他一些参数后缀,但是它们的内容是完全一样的,通过 rel=”canonical” 标签可以避免重复 收录,现在所有主要搜索引擎都支持它。
描述 META 标签
例子:
描述标签,顾名思义,就是对网页的简单描述/摘录,可以让搜索引擎更快地掌握网页的基本内容。曾经有关键字标签(定义 关键词),但现在正在逐步淘汰。
标题标签
例子:
WordPress主题是否会影响SEO效果 - 站长帮
对于SEO来说,最重要的是标题标签,每个页面必须有一个,而且只有一个。这个标签定义了网页的标题,也是上述所有标签中对SEO最重要的标签,最好能反映网页的关键词或关键词。但是不要滥用标题标签,如果文字错误,可能会被搜索引擎视为作弊。
额外提一下,H1、H2、H3...这种类型的标签对SEO也有帮助,但基本上与WordPress主题无关,需要在编写内容时添加。在主页和列表页,文章 标题在一般主题中会标有 H2。因为在一个页面中,H1只能使用一次,否则也会造成SEO不当。
2、结构化数据
说白了,结构化数据就是网页除了title、url、description这三个要素外,还可以向搜索引擎提交更多的信息,在搜索结果页展示更多的信息,获得更好的排名。
结构化数据代码分为三种类型:JSON-LD、微数据和 RDFa。无论是谷歌还是百度,都推荐使用 JSON-LD 格式。
一般的 WordPress 主题不会自动生成结构化数据,除非您自己添加相应的代码,或者使用 SEO 插件。强烈建议使用 Yoast SEO 或 Rank Math SEO 来生成规范的结构化数据。其中,Rank Math PRO可以自定义结构化数据的内容,这样除了结构化数据外,还可以添加百度尊重的结构化数据代码。或者在文章页面模板中添加如下代码,添加百度结构化数据。
{
"@context": "https://ziyuan.baidu.com/conte ... ot%3B,
"@id": "",
"title": "",
"images": [
""
],
"description":"",
"pubDate": "",
"upDate":""
}
注:是 Google、Bing、Yandex 和 Yahoo! 合作的结果 它已被包括百度在内的几乎所有主要搜索引擎支持。只是百度目前更喜欢上面例子的结构化数据,未来可能会改变这种看法。
3、网页加载速度
无论是哪个搜索引擎,网页和相关静态资源的加载速度都非常重要。WordPress主题对这方面的影响分为两部分,一是动态加载速度,二是静态缓存后的加载速度。
动态加载速度
对于不使用静态缓存的网页,程序代码的编码质量、服务器性能、服务器运行环境、网络带宽、网络状况等因素都会影响动态加载速度。因为每次访问网页,都是由后端的PHP程序生成前端网页,然后传递给浏览器。整个过程比较缓慢。
虽然 WordPress 有很多静态缓存方案,但有些情况不适合缓存,比如:用 WooCommerce 搭建的商店、需要动态展示的网页、具有交互功能的网页等。
在上面提到的影响动态加载速度的因素中,与主题相关的主要是程序代码的编码质量。这个话题比较大,不能一两句话完全解释清楚,但是有以下几个原则供大家参考。便于选择优质主题的参考。
静态缓存后的加载速度
静态缓存之后的术语对于 WordPress 站长来说一定很熟悉。WordPress本身不支持静态,但是有很多插件可以实现网页的静态缓存。例如:WP Rocket、W3 Total Cache、WP Super Cache 等。
经过静态缓存处理后,用户在访问网页时不需要像动态网页那样在后端临时生成前端页面。尤其是上面提到的三个缓存插件,无论是 Nginx 还是 Apache,都可以直接调用缓存的内容交付,无需 PHP 处理。PS:WP Rocket 需要在 Nginx 环境中额外安装 Rocket-Nginx。
这样,静态缓存后的网页加载速度大大提高,基本上只取决于网络带宽、网络条件和服务器静态资源的并发性能。也就是说,对于 WordPress 主题,只要不加载太多、庞大的静态资产,就可以获得良好的加载速度。
看到这里,基本可以得出一个结论,只要大部分主题都是静态缓存处理的,加载速度不会有太大影响。使用静态缓存,这不太可能成为影响 SEO 的条件。
4、网页渲染速度
网页渲染速度和加载速度不同,加载完成不代表渲染完成。浏览器在默认加载网页的静态资源时,是按顺序加载的,浏览器会延迟页面的渲染,直到完成加载、解析并执行完页面中引用的所有CSS文件。
还有一些js文件,同样会阻塞页面渲染过程,但是可以通过异步加载进行优化。
网页渲染速度对SEO的影响也很大,但是对百度搜索的影响稍微小一些,因为百度仍然使用爬虫机制,而且GoogleSpider已经调整,这意味着谷歌不仅会在渲染完成后抓取网页. 同时还分析了网页渲染的过程和速度,从而判断网页的浏览体验。
虽然百度在这方面有些落后,但也只是时间问题,因为百度的移动爬虫已经做了很大的调整。
在这一点上,国外的主题大多处理得很好,因为开发者一般使用 PageSpeed Insights 分数作为衡量标准。
5、网页代码是否有错误
这是一个基本要求。如果网页出现代码错误或者调用某些404资源,都会严重影响SEO。稍微成熟的WordPress主题不会有这个问题,但是需要提醒的是,一些国外的主题可能会加载一些在大陆无法正常访问的资源,比如谷歌字体、谷歌前端公共库等,仍然会不利。搜索引擎优化。
综上所述
如果阅读本文,WordPress 主题对 SEO 有影响吗?有什么影响?结论已经揭晓。
第一个和第二个方面可以通过额外的 SEO 插件来解决。第三点可以通过静态缓存进行优化。第四点需要下功夫打磨,有很多功能插件可以优化PageSpeed Insights分数。最后,第5点。使用国外主题时,建议仔细检查是否加载了谷歌的部分公共资源。建议将谷歌前端公共库和谷歌字体注释掉,或者通过插件禁用。
内容为王,其他手段只起到辅助作用,所以我劝大家不要本末倒置。做好用户需要的内容,提升用户体验,是最重要的SEO优化。
php抓取网页标签(如何判断是不是排序:元素标签的href可以不唯一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-03-14 06:04
php抓取网页标签分为抓包和拆包,抓包原理:对于你网站本身的发包来说,
1、url头部不包含src的部分,找到首页然后遍历找到之前请求过来的整个url。
2、去url里面除了src和href的部分,
3、用keyname解析src,然后把src从原始的url里面拿出来,这里src就是你url的名字。
4、保存title、content-type、content-length,这些用var_dump()函数返回var_dump('title');var_dump('content-length');一般情况下不需要很详细的拆包方法,常见的方法就是一个一个地去拆包,找到第一个request请求,然后截取request里面第一个src的内容。
然后就是截取包的方法了,主要有以下几种:include,parsejson,xml.xml.json如何判断分页是不是排序:如果传递的是动态数据,或者单一字段,没有重复的字段(例如一个url是普通网页,但有cookie,session...等),php会做成ajax的方式去实现点击分页等需求,这就很好判断是不是分页了。
php的话,我建议你先写一段爬虫,把网页文件,
先手扒
拆包
php标签都有一个元素标签img,image,src等那这个元素标签的href可以不唯一,找到这个标签, 查看全部
php抓取网页标签(如何判断是不是排序:元素标签的href可以不唯一)
php抓取网页标签分为抓包和拆包,抓包原理:对于你网站本身的发包来说,
1、url头部不包含src的部分,找到首页然后遍历找到之前请求过来的整个url。
2、去url里面除了src和href的部分,
3、用keyname解析src,然后把src从原始的url里面拿出来,这里src就是你url的名字。
4、保存title、content-type、content-length,这些用var_dump()函数返回var_dump('title');var_dump('content-length');一般情况下不需要很详细的拆包方法,常见的方法就是一个一个地去拆包,找到第一个request请求,然后截取request里面第一个src的内容。
然后就是截取包的方法了,主要有以下几种:include,parsejson,xml.xml.json如何判断分页是不是排序:如果传递的是动态数据,或者单一字段,没有重复的字段(例如一个url是普通网页,但有cookie,session...等),php会做成ajax的方式去实现点击分页等需求,这就很好判断是不是分页了。
php的话,我建议你先写一段爬虫,把网页文件,
先手扒
拆包
php标签都有一个元素标签img,image,src等那这个元素标签的href可以不唯一,找到这个标签,
php抓取网页标签(php抓取网页标签比如excel的行列标签标签,比如file.php自动化处理工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-10 05:07
php抓取网页标签,比如excel的行列标签,比如file.php提供了preload()方法。抓取数据报文,以mysql为例,通过mysql_connect_ssl()方法连接数据库。
可以看一下百度前端,访问一个网站,百度前端提供了对应的工具链。还有就是看一下知乎的搜索,可以搜索到知乎的原始页面。
讲几个简单的php自动化后端处理工具。这里有一个api打开和关闭是完全由php控制的。它的开始结束时间,请求开始请求结束等所有状态由php控制。还有,api接口对全局提供非常完整的命名空间,通过命名空间,我们可以完成dubbo,go等系统的接口开发。比如api-addphp自动生成这个code在php中所有命名空间中,所以和标准环境一样,接口开始,接口结束在code中都有详细的配置和命名空间相应。
还有一个爬虫的实现。php爬虫控制-打开和关闭这里的save本身实现了php自动生成了一个命名空间,所以标准环境中curl调用一个save接口就等同于我们自己编写的爬虫请求一个save。作为爬虫控制,我们通过post[response]->php获取到了一个爬虫的完整信息。这是php自动打开,关闭两个接口,还有save之后contentload相关。
接口抓取,类似与快排+随机序列号。
php在html本身可以提供一些html基础的属性 查看全部
php抓取网页标签(php抓取网页标签比如excel的行列标签标签,比如file.php自动化处理工具)
php抓取网页标签,比如excel的行列标签,比如file.php提供了preload()方法。抓取数据报文,以mysql为例,通过mysql_connect_ssl()方法连接数据库。
可以看一下百度前端,访问一个网站,百度前端提供了对应的工具链。还有就是看一下知乎的搜索,可以搜索到知乎的原始页面。
讲几个简单的php自动化后端处理工具。这里有一个api打开和关闭是完全由php控制的。它的开始结束时间,请求开始请求结束等所有状态由php控制。还有,api接口对全局提供非常完整的命名空间,通过命名空间,我们可以完成dubbo,go等系统的接口开发。比如api-addphp自动生成这个code在php中所有命名空间中,所以和标准环境一样,接口开始,接口结束在code中都有详细的配置和命名空间相应。
还有一个爬虫的实现。php爬虫控制-打开和关闭这里的save本身实现了php自动生成了一个命名空间,所以标准环境中curl调用一个save接口就等同于我们自己编写的爬虫请求一个save。作为爬虫控制,我们通过post[response]->php获取到了一个爬虫的完整信息。这是php自动打开,关闭两个接口,还有save之后contentload相关。
接口抓取,类似与快排+随机序列号。
php在html本身可以提供一些html基础的属性
php抓取网页标签(php抓取网页标签是有规则的吗?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-08 00:05
php抓取网页标签是有规则的。一般在网站后台可以直接看到代码抓取页面、iframe代理的时候应该要注意每个出来的标签位置是iframe最好一定要带着爬虫才会比较轻松。但是php抓取网页只能抓取静态内容。要了解网页的链接结构一定要写js加载进来。才能抓取到网页链接后续才是正题,网页抓取中一般有三种抓取方式fb110、抓取静态页面。
方法就不用说了直接抓就行。还有一个就是结合正则表达式识别tag然后写爬虫抓取动态页面。结合正则表达式:找到规律的话就比较好写。举个栗子t=xx,没有找到规律就用正则匹配,可以记录成id大小写都可以。然后用html5里面的正则表达式匹配抓取图片保存网站静态文件一般的网站有关于apple的pa和ios可以用safarisafari的applepushsb国内很多网站saplbspawnuc都是这样的。
还有一种是ajax抓取动态页面。一般网页都是script代码,有webkit就可以解析,所以一般的网站用不到去想解析webkit的动态代码。link.xxxxxx.apple.sap.lbs如果你的网站要想解析dom这个就需要用户代理来抓取网页因为ajax需要页面元素才能显示出dom,dom则是html结构拿来处理就好了。
<p>用正则匹配appleiphone大小写都可以没有就用#获取范围:可以使用正则匹配^?%来获取所在区域回车表示匹配第一个字符回车则不匹配第二个表示匹配第二个字符回车则不匹配第三个表示匹配第三个字符回车则不匹配第四个表示匹配最后一个表示匹配最后一个表格数据其实也是可以的。要注意名称比如:apple</a>iphone</a>iphone3</a>iphone33</a>iphone34</a>iphone35</a>iphone36</a>iphone4</a>iphone48</a> 查看全部
php抓取网页标签(php抓取网页标签是有规则的吗?(一))
php抓取网页标签是有规则的。一般在网站后台可以直接看到代码抓取页面、iframe代理的时候应该要注意每个出来的标签位置是iframe最好一定要带着爬虫才会比较轻松。但是php抓取网页只能抓取静态内容。要了解网页的链接结构一定要写js加载进来。才能抓取到网页链接后续才是正题,网页抓取中一般有三种抓取方式fb110、抓取静态页面。
方法就不用说了直接抓就行。还有一个就是结合正则表达式识别tag然后写爬虫抓取动态页面。结合正则表达式:找到规律的话就比较好写。举个栗子t=xx,没有找到规律就用正则匹配,可以记录成id大小写都可以。然后用html5里面的正则表达式匹配抓取图片保存网站静态文件一般的网站有关于apple的pa和ios可以用safarisafari的applepushsb国内很多网站saplbspawnuc都是这样的。
还有一种是ajax抓取动态页面。一般网页都是script代码,有webkit就可以解析,所以一般的网站用不到去想解析webkit的动态代码。link.xxxxxx.apple.sap.lbs如果你的网站要想解析dom这个就需要用户代理来抓取网页因为ajax需要页面元素才能显示出dom,dom则是html结构拿来处理就好了。
<p>用正则匹配appleiphone大小写都可以没有就用#获取范围:可以使用正则匹配^?%来获取所在区域回车表示匹配第一个字符回车则不匹配第二个表示匹配第二个字符回车则不匹配第三个表示匹配第三个字符回车则不匹配第四个表示匹配最后一个表示匹配最后一个表格数据其实也是可以的。要注意名称比如:apple</a>iphone</a>iphone3</a>iphone33</a>iphone34</a>iphone35</a>iphone36</a>iphone4</a>iphone48</a>
php抓取网页标签(html()方法此方法类似于JavaScript中的innerHTML属性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-07 08:19
html() 方法
此方法类似于 JavaScript 中的 innerHTML 属性,可用于读取或设置元素的 HTML 内容。要获取元素的内容,可以这样做:
var p_html = $("p").html(); //获取p元素的HTML代码
如果需要设置元素的HTML代码,也可以使用该方法,但需要为其传递参数。例如设置p元素的HTML代码,可以使用如下代码:
//设置p元素的HTML代码
$("p").html("欢迎来到简洁现代的魔法库~~");
注意:html() 方法可以用于 XHTML 文档,但不能用于 XML 文档。
text() 方法
此方法类似于 JavaScript 中的 innerText 属性,可用于读取或取消设置元素的文本内容。继续使用上面的HTML代码,使用text()方法对p元素进行操作:
var p_text = $("p").text(); //获取p元素的文本内容
和html()方法一样,如果需要给一个元素设置文本内容,也需要传一个参数。比如设置p元素的文本内容,代码如下:
//设置p元素的文本内容
$("p").text("欢迎来到简洁现代的魔法库~~");
注意以下两点:
JavaScript 中的 innerText 属性在 Firefox 浏览器中不起作用,而 jQuery 的 text() 方法支持所有浏览器。
text() 方法适用于 HTML 文档和 XML 文档。
显示好友列表时,显示好友姓名时 查看全部
php抓取网页标签(html()方法此方法类似于JavaScript中的innerHTML属性)
html() 方法
此方法类似于 JavaScript 中的 innerHTML 属性,可用于读取或设置元素的 HTML 内容。要获取元素的内容,可以这样做:
var p_html = $("p").html(); //获取p元素的HTML代码
如果需要设置元素的HTML代码,也可以使用该方法,但需要为其传递参数。例如设置p元素的HTML代码,可以使用如下代码:
//设置p元素的HTML代码
$("p").html("欢迎来到简洁现代的魔法库~~");
注意:html() 方法可以用于 XHTML 文档,但不能用于 XML 文档。
text() 方法
此方法类似于 JavaScript 中的 innerText 属性,可用于读取或取消设置元素的文本内容。继续使用上面的HTML代码,使用text()方法对p元素进行操作:
var p_text = $("p").text(); //获取p元素的文本内容
和html()方法一样,如果需要给一个元素设置文本内容,也需要传一个参数。比如设置p元素的文本内容,代码如下:
//设置p元素的文本内容
$("p").text("欢迎来到简洁现代的魔法库~~");
注意以下两点:
JavaScript 中的 innerText 属性在 Firefox 浏览器中不起作用,而 jQuery 的 text() 方法支持所有浏览器。
text() 方法适用于 HTML 文档和 XML 文档。
显示好友列表时,显示好友姓名时
php抓取网页标签(XSS脚本攻击指的危害及危害说明(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-05 20:07
ID:计算机网络
为了与 Cascading Style Sheets (CSS) 的缩写区别,Cross Site Scripting 缩写为 XSS。跨站脚本攻击是指攻击者在网页中插入恶意代码,未经严格控制或过滤,最终展示给访问用户。攻击者通过注入的代码执行恶意指令。这些恶意网页程序通常是JavaScript、VBScript、ActiveX、Flash等,使用户加载并执行攻击者恶意创建的网页程序,从而达到恶意攻击用户的特殊目的。
XSS在研发过程中很难引起开发者的注意,但它的危害是非常严重的。XSS容易引起的安全问题如表1所示。
表 1 各种危害及危害描述
1、反射型 XSS
反射型XSS也称为非持久型XSS,是指攻击者通过构造非法请求,将恶意代码嵌入页面,欺骗用户主动点击浏览触发。攻击者主要通过电子邮件或聊天窗口向用户发送一些链接,让受害者点击。同样的也会出现在搜索引擎收录的搜索页面中,当用户进行关键词搜索并点击时,就会触发XSS攻击。
例如,为方便起见,开发人员在页面上显示当前页码并直接从浏览器中读取。下面的写法会导致XSS漏洞。
当用户在浏览器中输入带有 JavaScript 可执行脚本的参数时,就会生成 XSS 攻击脚本。例如,攻击者可以在地址栏中输入以下代码进行XSS漏洞检测。
;警报(1);
执行结果如图1所示。
图1 XSS漏洞
这时候可以猜到页面是page参数通过$_GET方法输出的,那么就可以构造一个URL,给页面写JavaScript代码,让它执行。当 URL 被加密并发送给受害者时,受害者就会执行恶意代码。
如果请求的远程地址如图2所示构造,在浏览器地址栏输入下一页的URL(URL开头的“”默认隐藏),获取的cookie可以是发送给远程攻击者,导致cookie被泄露。攻击者可以获得用户对该站点的完全访问权限。
;document.write('
')
图 2 会话推送到第三方
图 3 展示了反射型 XSS 的攻击过程。
图 3 反射型 XSS
1)用户正常登录web应用,浏览器保存了用户所有的cookie信息,包括session ID。
2)攻击者向用户发送收录恶意代码的 URL。
3)用户打开攻击者发送的恶意URL。
4)浏览器程序执行用户的请求。
5)同时执行恶意URL中收录的攻击者恶意代码。
6)攻击者使用的攻击代码的作用是将用户的cookie信息发送到攻击者的服务器并记录下来。
7)攻击者在获取到用户的cookie信息后,可以利用该信息劫持用户的会话,以用户身份登录。
2、存储的 XSS
存储型 XSS 也称为持久型 XSS。当攻击者输入恶意数据并将其保存在数据库中时,服务器脚本从数据库中读取数据并显示在页面上,所有浏览该页面的用户都会受到攻击。攻击行为总是和攻击数据一起存在的,比如在发布文章等地方添加代码,如果没有过滤或者过滤不严格,那么这些代码会存储在服务器中,代码执行当用户访问页面时触发。这种XSS比较危险,容易引起蠕虫、后台管理平台盲打、cookie被盗等。
图 4 展示了存储型 XSS 的攻击过程。
图 4 存储型 XSS
1)攻击者通过XSS漏洞将恶意代码提交到Web服务器永久存储。
2)Users/网站Administrators 正常登录Web 应用程序。如果登录成功,浏览器会保存所有用户的 cookie,包括会话 ID。用户/网站管理员请求一个受感染的页面。
3)服务器将用户请求的页面返回给浏览器。
4)浏览器执行恶意页面中收录的攻击者恶意代码。
5)恶意代码将用户的cookie信息发送到攻击者的服务器并记录下来。
6)攻击者获取到用户的cookie信息后,利用该信息劫持用户的会话并以用户身份登录,包括以平台管理员身份登录。
3、DOM XSS
DOM型XSS是一种特殊类型的XSS,也是一种反射型XSS,是一种基于文档对象模型(DOM)的漏洞。该漏洞是通过使用JavaScript将用户的请求嵌入到页面中触发的,该页面执行了用户的恶意代码。
var s=location.search;
s=s.substring(1,s.length); // 获取网址
varurl="";
if(s.indexOf("url=")>-1) {
var pos=s.indexOf("url=")+4; //过滤掉“url=”字符
url=s.substring(pos,s.length); // 获取地址栏中的URL参数值
}别的 {
url="参数为空";
}
document.write("url:"+url+""); // 输出
当用户使用如下URL请求访问时,地址栏中携带的JavaScript脚本会被触发执行,从而导致XSS注入漏洞。
#39;
同样,HTML 中的 DOM 事件函数允许 JavaScript 在 HTML 文档元素上注册不同的事件处理程序,如果使用不当也可能导致 XSS 注入漏洞。
在通过 PHP 程序向浏览器输出数据之前,应进行严格的输出检查,避免 XSS 漏洞。表2列出了JavaScript中一些容易触发XSS漏洞的常用函数,使用时一定要注意。
表 2 容易出现 XSS 的 JavaScript 函数
4、使用编码过滤和转换进行防御
过滤是指过滤 DOM 属性和标签,例如将程序逻辑添加到 查看全部
php抓取网页标签(XSS脚本攻击指的危害及危害说明(一))
ID:计算机网络
为了与 Cascading Style Sheets (CSS) 的缩写区别,Cross Site Scripting 缩写为 XSS。跨站脚本攻击是指攻击者在网页中插入恶意代码,未经严格控制或过滤,最终展示给访问用户。攻击者通过注入的代码执行恶意指令。这些恶意网页程序通常是JavaScript、VBScript、ActiveX、Flash等,使用户加载并执行攻击者恶意创建的网页程序,从而达到恶意攻击用户的特殊目的。
XSS在研发过程中很难引起开发者的注意,但它的危害是非常严重的。XSS容易引起的安全问题如表1所示。
表 1 各种危害及危害描述
1、反射型 XSS
反射型XSS也称为非持久型XSS,是指攻击者通过构造非法请求,将恶意代码嵌入页面,欺骗用户主动点击浏览触发。攻击者主要通过电子邮件或聊天窗口向用户发送一些链接,让受害者点击。同样的也会出现在搜索引擎收录的搜索页面中,当用户进行关键词搜索并点击时,就会触发XSS攻击。
例如,为方便起见,开发人员在页面上显示当前页码并直接从浏览器中读取。下面的写法会导致XSS漏洞。
当用户在浏览器中输入带有 JavaScript 可执行脚本的参数时,就会生成 XSS 攻击脚本。例如,攻击者可以在地址栏中输入以下代码进行XSS漏洞检测。
;警报(1);
执行结果如图1所示。
图1 XSS漏洞
这时候可以猜到页面是page参数通过$_GET方法输出的,那么就可以构造一个URL,给页面写JavaScript代码,让它执行。当 URL 被加密并发送给受害者时,受害者就会执行恶意代码。
如果请求的远程地址如图2所示构造,在浏览器地址栏输入下一页的URL(URL开头的“”默认隐藏),获取的cookie可以是发送给远程攻击者,导致cookie被泄露。攻击者可以获得用户对该站点的完全访问权限。
;document.write('
')
图 2 会话推送到第三方
图 3 展示了反射型 XSS 的攻击过程。
图 3 反射型 XSS
1)用户正常登录web应用,浏览器保存了用户所有的cookie信息,包括session ID。
2)攻击者向用户发送收录恶意代码的 URL。
3)用户打开攻击者发送的恶意URL。
4)浏览器程序执行用户的请求。
5)同时执行恶意URL中收录的攻击者恶意代码。
6)攻击者使用的攻击代码的作用是将用户的cookie信息发送到攻击者的服务器并记录下来。
7)攻击者在获取到用户的cookie信息后,可以利用该信息劫持用户的会话,以用户身份登录。
2、存储的 XSS
存储型 XSS 也称为持久型 XSS。当攻击者输入恶意数据并将其保存在数据库中时,服务器脚本从数据库中读取数据并显示在页面上,所有浏览该页面的用户都会受到攻击。攻击行为总是和攻击数据一起存在的,比如在发布文章等地方添加代码,如果没有过滤或者过滤不严格,那么这些代码会存储在服务器中,代码执行当用户访问页面时触发。这种XSS比较危险,容易引起蠕虫、后台管理平台盲打、cookie被盗等。
图 4 展示了存储型 XSS 的攻击过程。
图 4 存储型 XSS
1)攻击者通过XSS漏洞将恶意代码提交到Web服务器永久存储。
2)Users/网站Administrators 正常登录Web 应用程序。如果登录成功,浏览器会保存所有用户的 cookie,包括会话 ID。用户/网站管理员请求一个受感染的页面。
3)服务器将用户请求的页面返回给浏览器。
4)浏览器执行恶意页面中收录的攻击者恶意代码。
5)恶意代码将用户的cookie信息发送到攻击者的服务器并记录下来。
6)攻击者获取到用户的cookie信息后,利用该信息劫持用户的会话并以用户身份登录,包括以平台管理员身份登录。
3、DOM XSS
DOM型XSS是一种特殊类型的XSS,也是一种反射型XSS,是一种基于文档对象模型(DOM)的漏洞。该漏洞是通过使用JavaScript将用户的请求嵌入到页面中触发的,该页面执行了用户的恶意代码。
var s=location.search;
s=s.substring(1,s.length); // 获取网址
varurl="";
if(s.indexOf("url=")>-1) {
var pos=s.indexOf("url=")+4; //过滤掉“url=”字符
url=s.substring(pos,s.length); // 获取地址栏中的URL参数值
}别的 {
url="参数为空";
}
document.write("url:"+url+""); // 输出
当用户使用如下URL请求访问时,地址栏中携带的JavaScript脚本会被触发执行,从而导致XSS注入漏洞。
#39;
同样,HTML 中的 DOM 事件函数允许 JavaScript 在 HTML 文档元素上注册不同的事件处理程序,如果使用不当也可能导致 XSS 注入漏洞。
在通过 PHP 程序向浏览器输出数据之前,应进行严格的输出检查,避免 XSS 漏洞。表2列出了JavaScript中一些容易触发XSS漏洞的常用函数,使用时一定要注意。
表 2 容易出现 XSS 的 JavaScript 函数
4、使用编码过滤和转换进行防御
过滤是指过滤 DOM 属性和标签,例如将程序逻辑添加到
php抓取网页标签(【技巧】网站管理员Googlebot的基本操作技巧(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-04 16:10
1xx:收到请求,继续处理
2xx:操作成功接收、分析、接受
3xx:此请求的完成必须进一步处理
4xx:请求收录错误的语法或无法完成
5xx:服务器未能执行完全有效的请求
1xx(临时回复)
表示临时响应并要求请求者继续执行操作的状态代码。
代码说明
100(继续)请求者应继续请求。服务器返回此代码表示已收到请求的第一部分并正在等待其余部分。101 (Switch protocol) 请求者已请求服务器切换协议,服务器已确认并准备切换。
2xx(成功)
指示服务器成功处理请求的状态代码。
代码说明
200 (Success) 服务器已成功处理请求。通常,这意味着服务器提供了所请求的网页。如果您的 robots.txt 文件显示此状态,则表示 Googlebot 已成功检索该文件。201 (Created) 请求成功,服务器创建了新资源。202 (Accepted) 服务器已接受请求但尚未处理。203 (Unauthorized Information) 服务器已成功处理请求,但返回的信息可能来自其他来源。204 (No Content) 服务器成功处理请求但没有返回任何内容。205 (Content reset) 服务器成功处理请求但没有返回内容。与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。206(部分内容)服务器成功处理了部分 GET 请求。
3xx(重定向)
要完成请求,需要采取进一步行动。通常,这些状态代码用于重定向。Google 建议您对每个请求使用不超过 5 个重定向。您可以使用 网站管理工具查看 Googlebot 是否在抓取重定向页面时遇到问题。诊断下的网络抓取页面列出了 Googlebot 由于重定向错误而无法抓取的网址。
代码说明
300(多选) 服务器可以对请求执行各种操作。服务器可以根据请求者(用户代理)选择一个动作,或者提供一个动作列表供请求者选择。301(永久移动)请求的网页已永久移动到新位置。当服务器返回此响应(对 GET 或 HEAD 请求)时,它会自动将请求者重定向到新位置。您应该使用此代码告诉 Googlebot 页面或 网站 已永久移动到新位置。302(暂时移动)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行未来的请求。此代码类似于响应 GET 或 HEAD 请求的 301 代码,会自动将请求者带到不同的位置,但您不应使用此代码告诉 Googlebot 页面或 网站 已移动,因为Googlebot 将继续抓取旧位置和索引。303(查看其他位置)当请求者应该对不同位置使用单独的 GET 请求来检索响应时,服务器会返回此代码。对于除 HEAD 之外的所有请求,服务器会自动转到其他位置。304(未修改)自上次请求以来,请求的页面尚未修改。当服务器返回此响应时,不会返回任何网页内容。如果自请求者的最后一次请求以来页面没有更改,您应该配置您的服务器以返回此响应(称为 If-Modified-Since HTTP 标头)。这样可以节省带宽和开销,因为服务器可以告诉 Googlebot 该页面自上次抓取以来没有更改。305(使用代理)请求者只能使用代理访问请求的网页。如果服务器返回这个响应,也表明请求者应该使用代理。307(临时重定向)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行将来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并且会自动将请求者带到不同的位置,但您不应使用此代码告诉 Googlebot 页面或 网站 已移动,因为 Googlebot将继续抓取旧位置和索引。
4xx(请求错误)
这些状态代码表明请求可能出错,阻止服务器处理它。
代码说明
400 (Bad Request) 服务器不理解请求的语法。401(未授权)请求需要身份验证。服务器可能会为需要登录的网页返回此响应。403 (Forbidden) 服务器拒绝了请求。如果您在尝试抓取 网站 上的有效页面时看到 Googlebot 收到此状态代码(您可以在 Google 网站Admin Tools Diagnostics 下的网络抓取页面上看到此代码),您的服务器或主机可能是拒绝 Googlebot 访问。404 (Not Found) 服务器找不到请求的网页。例如,如果请求的网页在服务器上不存在,则服务器通常会返回此代码。如果您的 网站 上没有 robots.txt 文件,并且您在 Google 的 网站 管理工具的诊断标签中的 robots.txt 页面上看到此状态,那么这是正确的状态。但是,如果您有 robots.txt 文件并看到此状态,则您的 robots.txt 文件可能命名不正确或位置错误(它应该位于顶级域,称为 robots.txt)。如果您在 Googlebot 尝试抓取的网址上看到此状态(在“诊断”标签中的 HTTP 错误页面上),这意味着 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接) . 405(禁用方法)禁用请求中指定的方法。如果您在 Googlebot 尝试抓取的网址上看到此状态(在“诊断”标签中的 HTTP 错误页面上),这意味着 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接) . 405(禁用方法)禁用请求中指定的方法。如果您在 Googlebot 尝试抓取的网址上看到此状态(在“诊断”标签中的 HTTP 错误页面上),这意味着 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接) . 405(禁用方法)禁用请求中指定的方法。
406(不可接受)无法使用请求的内容属性响应请求的网页。407(需要代理授权)此状态码类似于 401(未授权),但指定请求者应授权使用代理。如果服务器返回此响应,它还指示请求者应使用的代理。408(请求超时)服务器在等待请求时超时。409 (Conflict) 服务器在完成请求时发生冲突。服务器必须在响应中收录有关冲突的信息。服务器可能会返回此代码以响应与先前请求冲突的 PUT 请求,以及两个请求之间差异的列表。410 (Deleted) 如果请求的资源已被永久删除,服务器返回此响应。此代码类似于 404(未找到)代码,但有时在资源曾经存在但现在不存在的情况下代替 404 代码。如果资源已被永久删除,则应使用 301 指定资源的新位置。411(需要有效长度)服务器将不接受没有有效负载长度标头字段的请求。412 (Precondition not met) 服务器不满足请求者在请求中设置的前提条件之一。413 (Request Entity Too Large) 服务器无法处理请求,因为请求实体太大,服务器无法处理。414 (Requested URI Too Long) 请求的 URI(通常是 URL)太长,服务器无法处理。415 (Unsupported media type) 请求的页面不支持请求的格式。416(请求的范围不符合要求)如果页面不能提供请求的范围,服务器返回此状态码。417 (Expectation not met) 服务器不满足“Expectation”请求头域的要求。
5xx(服务器错误)
这些状态代码表明服务器在尝试处理请求时遇到了内部错误。这些错误可能是服务器本身的错误,而不是请求。
代码说明
500(内部服务器错误)服务器遇到错误,无法完成请求。501(尚未实现)服务器没有能力完成请求。例如,当服务器无法识别请求方法时,可能会返回此代码。502 (Bad Gateway) 作为网关或代理的服务器收到来自上游服务器的无效响应。503(服务不可用)服务器当前不可用(由于过载或停机维护)。通常,这只是暂时的状态。504 (Gateway Timeout) 服务器作为网关或代理,但没有及时收到上游服务器的请求。505 (HTTP Version Not Supported) 服务器不支持请求中使用的 HTTP 协议版本。
英文版:
100:继续
101:交换协议
102:处理
200:好的
201:已创建
202:接受
203:非权威信息
204:无内容
205:重置内容
206:部分内容
207:多状态
300:多项选择
301:永久移动
302:找到
303:见其他
304:未修改
305:使用代理
306:(未使用)
307:临时重定向
400:错误请求
401:未经授权
402:已付款
403:禁止
404:找不到文件
405:不允许的方法
406:不可接受
407:需要代理验证
408:请求超时
409:冲突
410:走了
411:所需长度
412:前置条件失败
413请求实体太大
414:请求 URI 太大
415:不支持的媒体类型
416:请求的范围不可满足
417:预期失败
422:无法处理的实体
423:锁定
424:依赖失败
500内部服务器错误
501:未实施
502错误的网关
503服务不可用
504网关超时 查看全部
php抓取网页标签(【技巧】网站管理员Googlebot的基本操作技巧(一))
1xx:收到请求,继续处理
2xx:操作成功接收、分析、接受
3xx:此请求的完成必须进一步处理
4xx:请求收录错误的语法或无法完成
5xx:服务器未能执行完全有效的请求
1xx(临时回复)
表示临时响应并要求请求者继续执行操作的状态代码。
代码说明
100(继续)请求者应继续请求。服务器返回此代码表示已收到请求的第一部分并正在等待其余部分。101 (Switch protocol) 请求者已请求服务器切换协议,服务器已确认并准备切换。
2xx(成功)
指示服务器成功处理请求的状态代码。
代码说明
200 (Success) 服务器已成功处理请求。通常,这意味着服务器提供了所请求的网页。如果您的 robots.txt 文件显示此状态,则表示 Googlebot 已成功检索该文件。201 (Created) 请求成功,服务器创建了新资源。202 (Accepted) 服务器已接受请求但尚未处理。203 (Unauthorized Information) 服务器已成功处理请求,但返回的信息可能来自其他来源。204 (No Content) 服务器成功处理请求但没有返回任何内容。205 (Content reset) 服务器成功处理请求但没有返回内容。与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。206(部分内容)服务器成功处理了部分 GET 请求。
3xx(重定向)
要完成请求,需要采取进一步行动。通常,这些状态代码用于重定向。Google 建议您对每个请求使用不超过 5 个重定向。您可以使用 网站管理工具查看 Googlebot 是否在抓取重定向页面时遇到问题。诊断下的网络抓取页面列出了 Googlebot 由于重定向错误而无法抓取的网址。
代码说明
300(多选) 服务器可以对请求执行各种操作。服务器可以根据请求者(用户代理)选择一个动作,或者提供一个动作列表供请求者选择。301(永久移动)请求的网页已永久移动到新位置。当服务器返回此响应(对 GET 或 HEAD 请求)时,它会自动将请求者重定向到新位置。您应该使用此代码告诉 Googlebot 页面或 网站 已永久移动到新位置。302(暂时移动)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行未来的请求。此代码类似于响应 GET 或 HEAD 请求的 301 代码,会自动将请求者带到不同的位置,但您不应使用此代码告诉 Googlebot 页面或 网站 已移动,因为Googlebot 将继续抓取旧位置和索引。303(查看其他位置)当请求者应该对不同位置使用单独的 GET 请求来检索响应时,服务器会返回此代码。对于除 HEAD 之外的所有请求,服务器会自动转到其他位置。304(未修改)自上次请求以来,请求的页面尚未修改。当服务器返回此响应时,不会返回任何网页内容。如果自请求者的最后一次请求以来页面没有更改,您应该配置您的服务器以返回此响应(称为 If-Modified-Since HTTP 标头)。这样可以节省带宽和开销,因为服务器可以告诉 Googlebot 该页面自上次抓取以来没有更改。305(使用代理)请求者只能使用代理访问请求的网页。如果服务器返回这个响应,也表明请求者应该使用代理。307(临时重定向)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行将来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并且会自动将请求者带到不同的位置,但您不应使用此代码告诉 Googlebot 页面或 网站 已移动,因为 Googlebot将继续抓取旧位置和索引。
4xx(请求错误)
这些状态代码表明请求可能出错,阻止服务器处理它。
代码说明
400 (Bad Request) 服务器不理解请求的语法。401(未授权)请求需要身份验证。服务器可能会为需要登录的网页返回此响应。403 (Forbidden) 服务器拒绝了请求。如果您在尝试抓取 网站 上的有效页面时看到 Googlebot 收到此状态代码(您可以在 Google 网站Admin Tools Diagnostics 下的网络抓取页面上看到此代码),您的服务器或主机可能是拒绝 Googlebot 访问。404 (Not Found) 服务器找不到请求的网页。例如,如果请求的网页在服务器上不存在,则服务器通常会返回此代码。如果您的 网站 上没有 robots.txt 文件,并且您在 Google 的 网站 管理工具的诊断标签中的 robots.txt 页面上看到此状态,那么这是正确的状态。但是,如果您有 robots.txt 文件并看到此状态,则您的 robots.txt 文件可能命名不正确或位置错误(它应该位于顶级域,称为 robots.txt)。如果您在 Googlebot 尝试抓取的网址上看到此状态(在“诊断”标签中的 HTTP 错误页面上),这意味着 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接) . 405(禁用方法)禁用请求中指定的方法。如果您在 Googlebot 尝试抓取的网址上看到此状态(在“诊断”标签中的 HTTP 错误页面上),这意味着 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接) . 405(禁用方法)禁用请求中指定的方法。如果您在 Googlebot 尝试抓取的网址上看到此状态(在“诊断”标签中的 HTTP 错误页面上),这意味着 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接) . 405(禁用方法)禁用请求中指定的方法。
406(不可接受)无法使用请求的内容属性响应请求的网页。407(需要代理授权)此状态码类似于 401(未授权),但指定请求者应授权使用代理。如果服务器返回此响应,它还指示请求者应使用的代理。408(请求超时)服务器在等待请求时超时。409 (Conflict) 服务器在完成请求时发生冲突。服务器必须在响应中收录有关冲突的信息。服务器可能会返回此代码以响应与先前请求冲突的 PUT 请求,以及两个请求之间差异的列表。410 (Deleted) 如果请求的资源已被永久删除,服务器返回此响应。此代码类似于 404(未找到)代码,但有时在资源曾经存在但现在不存在的情况下代替 404 代码。如果资源已被永久删除,则应使用 301 指定资源的新位置。411(需要有效长度)服务器将不接受没有有效负载长度标头字段的请求。412 (Precondition not met) 服务器不满足请求者在请求中设置的前提条件之一。413 (Request Entity Too Large) 服务器无法处理请求,因为请求实体太大,服务器无法处理。414 (Requested URI Too Long) 请求的 URI(通常是 URL)太长,服务器无法处理。415 (Unsupported media type) 请求的页面不支持请求的格式。416(请求的范围不符合要求)如果页面不能提供请求的范围,服务器返回此状态码。417 (Expectation not met) 服务器不满足“Expectation”请求头域的要求。
5xx(服务器错误)
这些状态代码表明服务器在尝试处理请求时遇到了内部错误。这些错误可能是服务器本身的错误,而不是请求。
代码说明
500(内部服务器错误)服务器遇到错误,无法完成请求。501(尚未实现)服务器没有能力完成请求。例如,当服务器无法识别请求方法时,可能会返回此代码。502 (Bad Gateway) 作为网关或代理的服务器收到来自上游服务器的无效响应。503(服务不可用)服务器当前不可用(由于过载或停机维护)。通常,这只是暂时的状态。504 (Gateway Timeout) 服务器作为网关或代理,但没有及时收到上游服务器的请求。505 (HTTP Version Not Supported) 服务器不支持请求中使用的 HTTP 协议版本。
英文版:
100:继续
101:交换协议
102:处理
200:好的
201:已创建
202:接受
203:非权威信息
204:无内容
205:重置内容
206:部分内容
207:多状态
300:多项选择
301:永久移动
302:找到
303:见其他
304:未修改
305:使用代理
306:(未使用)
307:临时重定向
400:错误请求
401:未经授权
402:已付款
403:禁止
404:找不到文件
405:不允许的方法
406:不可接受
407:需要代理验证
408:请求超时
409:冲突
410:走了
411:所需长度
412:前置条件失败
413请求实体太大
414:请求 URI 太大
415:不支持的媒体类型
416:请求的范围不可满足
417:预期失败
422:无法处理的实体
423:锁定
424:依赖失败
500内部服务器错误
501:未实施
502错误的网关
503服务不可用
504网关超时
php抓取网页标签(把精通tpl(应用程序开发领域)的能力尽可能提高)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-03-02 06:04
php抓取网页标签就行,lxml库可以更好的抓取网页标签而且处理速度更快,
正则表达式。上百度学习一下吧。
php方面,可以用iframe做跳转,
curl/curl_ionframe.h这里面有比较好的方法
如果你真的想学习php的话,那就从这个开始吧。把精通tpl(应用程序开发领域)相关工具的能力尽可能提高。
推荐phpcurl文档详解|把爱好变成饭碗
php提供了python的接口,再用curl也可以,
/baidu.xxx
/baidu
php有curl命令行,
;file=chrome.exe&format=gzip
/baidu有这个选项
/baidu/bat有php版本的,
//
你先学会httpapi,
这么简单的。
php:api
/baidu.xxxemmmm好吧其实我就是看到了@ab多平台bat不就是php的一个接口么webhttpapi好用得一匹.
varbrowser=require('browser')varcontext={varyaddress:{url:'',},autowired:{url:'',},searchqueryfilter:{url:'',},captureaddress:{url:'',},htmlurlref:{},objectnameref:{},classref:{},onformatterref:{},};varformatter={};。 查看全部
php抓取网页标签(把精通tpl(应用程序开发领域)的能力尽可能提高)
php抓取网页标签就行,lxml库可以更好的抓取网页标签而且处理速度更快,
正则表达式。上百度学习一下吧。
php方面,可以用iframe做跳转,
curl/curl_ionframe.h这里面有比较好的方法
如果你真的想学习php的话,那就从这个开始吧。把精通tpl(应用程序开发领域)相关工具的能力尽可能提高。
推荐phpcurl文档详解|把爱好变成饭碗
php提供了python的接口,再用curl也可以,
/baidu.xxx
/baidu
php有curl命令行,
;file=chrome.exe&format=gzip
/baidu有这个选项
/baidu/bat有php版本的,
//
你先学会httpapi,
这么简单的。
php:api
/baidu.xxxemmmm好吧其实我就是看到了@ab多平台bat不就是php的一个接口么webhttpapi好用得一匹.
varbrowser=require('browser')varcontext={varyaddress:{url:'',},autowired:{url:'',},searchqueryfilter:{url:'',},captureaddress:{url:'',},htmlurlref:{},objectnameref:{},classref:{},onformatterref:{},};varformatter={};。
php抓取网页标签(因本接口压力过大,接口停止对外服务!(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2022-03-02 05:10
由于该接口压力过大,接口停止对外服务!请到我的github获取源代码
很多人可能不知道这个接口是做什么的。其实google也有这个接口,但是最近不行,所以自己写了一个。你可以看到这个例子。
下面是我的网站中所有链接的列表,以及本站网站界面的链接功能。每个链接前面的图片是网站域名对应的favicon。.ico 图像,可以看到这个图像是如何读取的,我们查看源代码:
XHTML
1
v3版本升级信息使用太频繁,因为这个界面的用户太多。为了分担压力,升级接口一一异步处理,并引入缓存机制。升级操作只需要基于v2接口在需要使用该接口的页面底部添加一个js,放在jquery的body和下方即可。
XHTML
1
这个js其实是一个服务端脚本。该脚本会定期(通常一天一次)修改密钥,并将密钥拼成v2使用的接口地址,接口服务器会验证密钥。所以,如果你想继续使用,请将这个js添加到页面底部,这个脚本依赖于jquery,请确认页面已经加载了jquery,并将这个js放在jquery下面。给您带来的不便深表歉意。随时欢迎交流。谢谢。最近监测v2版本升级信息,发现这个接口使用非常频繁,日志文件一周有200多M。目前已有近100个域名使用该接口查询300多个域名,故升级此接口。同时,代码处于早期开发阶段。, 漏洞很多,代码已经优化,代码也很简单,鼓励大家自己实现。1、引入缓存机制,每周缓存域名的ico图片。缓存每周日更新,支持手动更新缓存。如有需要,请使用表格删除缓存。缓存地址为:2、 为优化使用,可以使用取消是否添加http的限制,即可以使用3、接口代码进行修改,新代码:以下是v1版本:它将每周缓存域名的 ico 图像。缓存每周日更新,支持手动更新缓存。如有需要,请使用表格删除缓存。缓存地址为:2、 为优化使用,可以使用取消是否添加http的限制,即可以使用3、接口代码进行修改,新代码:以下是v1版本:它将每周缓存域名的 ico 图像。缓存每周日更新,支持手动更新缓存。如有需要,请使用表格删除缓存。缓存地址为:2、 为优化使用,可以使用取消是否添加http的限制,即可以使用3、接口代码进行修改,新代码:以下是v1版本:
我们通过这段代码读取了以下域名的favicon.ico图片。如果我们访问src后面的整个链接,也可以看到这个网站的favicon.ico图片,达到了我们的目的。,读取指定 网站 的 favicon.ico 图像。示例展示:接口url 说明:他需要一个参数url,即你要读取的url 网站 原理:原理其实很简单,我们使用file_get_contnets函数读取favicon.ico下的图片指定的域名,如果能看懂就声明header为图片类型输出。在这里您可以检查标头声明的用法。这就是为什么图片可以显示为图片并且可以下载的原因。而如果看不懂,我们可以给他一张默认图片!
写起来很简单。其实每个人都可以自己制作界面以及如何使用:
这篇文章的链接:
程序与生俱来,巧手得来!我们只是代码搬运工! 查看全部
php抓取网页标签(因本接口压力过大,接口停止对外服务!(一))
由于该接口压力过大,接口停止对外服务!请到我的github获取源代码
很多人可能不知道这个接口是做什么的。其实google也有这个接口,但是最近不行,所以自己写了一个。你可以看到这个例子。
下面是我的网站中所有链接的列表,以及本站网站界面的链接功能。每个链接前面的图片是网站域名对应的favicon。.ico 图像,可以看到这个图像是如何读取的,我们查看源代码:
XHTML
1
v3版本升级信息使用太频繁,因为这个界面的用户太多。为了分担压力,升级接口一一异步处理,并引入缓存机制。升级操作只需要基于v2接口在需要使用该接口的页面底部添加一个js,放在jquery的body和下方即可。
XHTML
1
这个js其实是一个服务端脚本。该脚本会定期(通常一天一次)修改密钥,并将密钥拼成v2使用的接口地址,接口服务器会验证密钥。所以,如果你想继续使用,请将这个js添加到页面底部,这个脚本依赖于jquery,请确认页面已经加载了jquery,并将这个js放在jquery下面。给您带来的不便深表歉意。随时欢迎交流。谢谢。最近监测v2版本升级信息,发现这个接口使用非常频繁,日志文件一周有200多M。目前已有近100个域名使用该接口查询300多个域名,故升级此接口。同时,代码处于早期开发阶段。, 漏洞很多,代码已经优化,代码也很简单,鼓励大家自己实现。1、引入缓存机制,每周缓存域名的ico图片。缓存每周日更新,支持手动更新缓存。如有需要,请使用表格删除缓存。缓存地址为:2、 为优化使用,可以使用取消是否添加http的限制,即可以使用3、接口代码进行修改,新代码:以下是v1版本:它将每周缓存域名的 ico 图像。缓存每周日更新,支持手动更新缓存。如有需要,请使用表格删除缓存。缓存地址为:2、 为优化使用,可以使用取消是否添加http的限制,即可以使用3、接口代码进行修改,新代码:以下是v1版本:它将每周缓存域名的 ico 图像。缓存每周日更新,支持手动更新缓存。如有需要,请使用表格删除缓存。缓存地址为:2、 为优化使用,可以使用取消是否添加http的限制,即可以使用3、接口代码进行修改,新代码:以下是v1版本:
我们通过这段代码读取了以下域名的favicon.ico图片。如果我们访问src后面的整个链接,也可以看到这个网站的favicon.ico图片,达到了我们的目的。,读取指定 网站 的 favicon.ico 图像。示例展示:接口url 说明:他需要一个参数url,即你要读取的url 网站 原理:原理其实很简单,我们使用file_get_contnets函数读取favicon.ico下的图片指定的域名,如果能看懂就声明header为图片类型输出。在这里您可以检查标头声明的用法。这就是为什么图片可以显示为图片并且可以下载的原因。而如果看不懂,我们可以给他一张默认图片!
写起来很简单。其实每个人都可以自己制作界面以及如何使用:
这篇文章的链接:
程序与生俱来,巧手得来!我们只是代码搬运工!
php抓取网页标签(怎么用PHP采集才能快速收录以及关键词排名?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-02-28 11:19
如何使用PHP采集快速收录和关键词排名?本文分为2个部分,一个是网站程序的标准化,另一个是网站fast收录和排名,我想大多数人都会遇到,公司的网站有程序问题,url优化要求等,但是程序部的小伙伴不配合!或者网站邀请第三方公司!如果你坚持做seo,你基本上就无法工作了!基本上以上都是公司程序部和我们seo网站优化部没有协调或者根本没有严格规定造成的!要知道seo是一个非常复杂的行业和职位,所涉及的内容包罗万象。其中,程序对网站的支持非常重要!如果和seo配合不好,程序会比较麻烦!网站程序中需要满足哪些规范才能适合SEO?
一、域和服务器相关
1、如果页面不存在,应该返回404错误码;
2、4XX、5XX服务器头信息异常增加,及时通知SEO部门做进一步检查。
3、域名不使用泛解析。需要使用二级域名时,需要提前与SEO部门沟通,然后解决;
3、URL 规范化,URL 启用 301
4、网站不能有多个域名打开同一个页面;
5、如果有打开子域进行测试,使用robots文件禁止搜索引擎抓取;
6、服务器开启gzip压缩,提高浏览速度;
7、在新栏目上线前完成内容填充;网站 和内容未完成的栏目无法上线。
二、网站结构和URL相关
1、所有网址网站都是静态的,除了计划禁止搜索引擎抓取的内容和收录。
2、 URL一旦确定在线,就不能随意更改。特殊情况需要调整的,必须与SEO部门沟通;
3、网站 列和 URL 目录需要一一对应。一级分类对应一级分类,二级分类对应二级分类。最多可以归类到二级目录。如果产品/页数需要分类在三级以上,此时需要注意。
4、全站目录URL以斜杠结尾,该URL不显示index.php等文件名;
5、URL 中的列名、文件名等字母都是小写的。
6、网站的所有页面都添加了面包屑;
7、URL中统一使用破折号或下划线,不要添加其他特殊字符;
8、URL目录名优先对应英文单词,不是中文拼音,而是数字或字母;
9、当URL发生变化时,旧的URL应该通过301重定向到新的URL;
三、页面打开速度相关
1、在不影响视觉效果的前提下,前端页面的所有图片都要压缩;
2、删除未使用的CSS代码,尽可能将页面样式代码合并到CSS文件中;
3、谨慎使用JS,谨慎使用JS,测试JS是否减慢页面访问;
4、禁止使用session ID、Frame、Flash;
5、页面的纯文本代码(包括HTML、JS、CSS)不超过500K。主页等特殊页面可以适当放宽。
6、使用主流浏览器实际测试页面打开速度,不要超过3秒。有条件的,从多个省市进行测试。
四、TDK相关页面
1、页面的Title标签、Description标签、H1文字的默认版本是根据格式自动生成的,但是系统需要为SEO人员预留填写功能。
2、栏目页Title的默认格式:二级栏目名-一级栏目名-网站名称;
3、产品页面标题默认格式:产品名称——网站名称;
4、文章页面标题默认格式:文章标题——网站名称;
5、搜索页面标题默认格式:搜索关键字-网站名称;;
6、每个页面标题的默认格式:列名-X页-网站名称;
7、除特殊要求外,网站使用HTML代码链接代替JS生成的链接;
8、除好友链接外的导出链接添加nofollow属性;
9、列,产品/文章将 ALT 文本添加到页面的主图像。后台编辑器上传图片时,预留输入框填写ATL文本;
10、一个页面只使用一次H1。
五、函数使用及代码
1、除非另有要求,网站确保在所有页面都在线时添加流量统计代码。
2、全部网站开通百度资源平台账号。
3、在线网站,除非 SEO 或运营部门另有要求,robots 文件对所有 URL 和文件(包括图像、CSS、JS)的抓取都是开放的。
4、XML版本的Sitemap在后台实时或定期生成更新,包括首页、栏目和页面、产品/文章页面。是否收录过滤条件页面将在与SEO部门协调后确定。
5、新站点应始终使用响应式设计,不要使用独立的移动站点或移动子域。已经用移动子域优化过的老站暂时保持现状,与SEO部门沟通后转为响应式设计。
6、英文网站HTML 代码中不应出现中文字符,包括注释。
7、当由于各种原因需要更改URL时,旧的URL会被301重定向到新的URL,不要使用其他的转向方式。
8、当由于各种原因更改 URL 时,导航和内页链接会更新为新 URL。导航中禁止需要重定向的 URL。
六、使用PHP采集+SEO函数让网站快收录
如果以上都没有问题,我们可以使用这个PHP采集工具来实现采集伪原创自动发布和主动推送到搜索引擎。操作简单,无需学习更专业的技术。只需几个简单的步骤即可轻松实现采集内容数据,用户只需在PHP采集上进行简单设置,PHP采集工具会根据关键词准确设置给用户。采集文章,这确保了与行业 文章 的一致性。采集文章 from 采集可以选择本地保存,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
与其他PHP采集相比,这个PHP采集基本没有规则,更别说花大量时间学习正则表达式或者html标签,一分钟就能上手,直接输入关键词 采集可以实现(PHP采集也自带关键词采集函数)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个PHP采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片保存在本地或第三方(使内容无不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选地将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),无需每天登录网站后台. SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
七、百度优化排名最基本的原理!
一、网站优化排名的对象是什么
1、一个网站由多个网页组成,网站由一个或多个网页组成。
2、seo优化的对象是网页而不是网站。关于网站优化排名的误区是,普通人总是认为优化的对象是网站。我们通常所说的“网站ranking”和“网站optimization”是不正确的。
二:百度蜘蛛的工作很简单:
找到页面(发现网上有这个页面)——页面是否可以正常爬取(你在爬取的时候有没有遇到困难:比如加载慢、质量低、错误页面多——你要爬吗? page)?是否应该爬取?爬取数据库能给网名带来实际的效果吗?) 了解了这些基本原理后,我们就可以根据这些要求进行尝试了。比如,如何让百度爬取更方便?方法如下:
1)百度主动找到我们的页面
2)我们提交给百度
3) 还有人告诉百度需要做一些外链推广工作
三、什么是超链接分析,超链接分析简介
1、“超链接分析”
超链接分析是百度的专利。原理是通过分析链接网站的数量来评估链接网站的质量。这样做的效果是确保用户使用搜索引擎。,质量越高,页面越受欢迎越高。百度总裁李彦宏是这项技术的拥有者,该技术已被全球主要搜索引擎广泛采用。
2、我们如何理解超链分析技术?
总之,要判断一个页面是优秀的还是权威的,其他页面的“意见”是非常重要的。即使一个网页不是那么好,只要其他网页比其他网页有更多的“信任票”(反向链接),那么它的排名就会更高。需要注意的是,“超链接分析”只是排名的一个重要参考。
四:分析模块的工作,百度会对网页进行再加工预测评价:
1)网站页面内容好不好?
2) 页面的主题是什么?(标题、关键词和网站描述、网站内容本身由网站的TDK决定)
3)多少钱?原创学位?
4)还有其他评分选项,比如多少个链接?
通过以上指标,百度会给搜索关键词一个匹配排名,其匹配模式设计为:完全匹配+词组匹配+广泛匹配。
我们seo优化的价值在于匹配模式相当于排名机会,我们需要实现更多更好的排名机会。继续增加匹配机会,让更多流量找到我们的网站。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名! 查看全部
php抓取网页标签(怎么用PHP采集才能快速收录以及关键词排名?(图))
如何使用PHP采集快速收录和关键词排名?本文分为2个部分,一个是网站程序的标准化,另一个是网站fast收录和排名,我想大多数人都会遇到,公司的网站有程序问题,url优化要求等,但是程序部的小伙伴不配合!或者网站邀请第三方公司!如果你坚持做seo,你基本上就无法工作了!基本上以上都是公司程序部和我们seo网站优化部没有协调或者根本没有严格规定造成的!要知道seo是一个非常复杂的行业和职位,所涉及的内容包罗万象。其中,程序对网站的支持非常重要!如果和seo配合不好,程序会比较麻烦!网站程序中需要满足哪些规范才能适合SEO?
一、域和服务器相关
1、如果页面不存在,应该返回404错误码;
2、4XX、5XX服务器头信息异常增加,及时通知SEO部门做进一步检查。
3、域名不使用泛解析。需要使用二级域名时,需要提前与SEO部门沟通,然后解决;
3、URL 规范化,URL 启用 301
4、网站不能有多个域名打开同一个页面;
5、如果有打开子域进行测试,使用robots文件禁止搜索引擎抓取;
6、服务器开启gzip压缩,提高浏览速度;
7、在新栏目上线前完成内容填充;网站 和内容未完成的栏目无法上线。
二、网站结构和URL相关
1、所有网址网站都是静态的,除了计划禁止搜索引擎抓取的内容和收录。
2、 URL一旦确定在线,就不能随意更改。特殊情况需要调整的,必须与SEO部门沟通;
3、网站 列和 URL 目录需要一一对应。一级分类对应一级分类,二级分类对应二级分类。最多可以归类到二级目录。如果产品/页数需要分类在三级以上,此时需要注意。
4、全站目录URL以斜杠结尾,该URL不显示index.php等文件名;
5、URL 中的列名、文件名等字母都是小写的。
6、网站的所有页面都添加了面包屑;
7、URL中统一使用破折号或下划线,不要添加其他特殊字符;
8、URL目录名优先对应英文单词,不是中文拼音,而是数字或字母;
9、当URL发生变化时,旧的URL应该通过301重定向到新的URL;
三、页面打开速度相关
1、在不影响视觉效果的前提下,前端页面的所有图片都要压缩;
2、删除未使用的CSS代码,尽可能将页面样式代码合并到CSS文件中;
3、谨慎使用JS,谨慎使用JS,测试JS是否减慢页面访问;
4、禁止使用session ID、Frame、Flash;
5、页面的纯文本代码(包括HTML、JS、CSS)不超过500K。主页等特殊页面可以适当放宽。
6、使用主流浏览器实际测试页面打开速度,不要超过3秒。有条件的,从多个省市进行测试。
四、TDK相关页面
1、页面的Title标签、Description标签、H1文字的默认版本是根据格式自动生成的,但是系统需要为SEO人员预留填写功能。
2、栏目页Title的默认格式:二级栏目名-一级栏目名-网站名称;
3、产品页面标题默认格式:产品名称——网站名称;
4、文章页面标题默认格式:文章标题——网站名称;
5、搜索页面标题默认格式:搜索关键字-网站名称;;
6、每个页面标题的默认格式:列名-X页-网站名称;
7、除特殊要求外,网站使用HTML代码链接代替JS生成的链接;
8、除好友链接外的导出链接添加nofollow属性;
9、列,产品/文章将 ALT 文本添加到页面的主图像。后台编辑器上传图片时,预留输入框填写ATL文本;
10、一个页面只使用一次H1。
五、函数使用及代码
1、除非另有要求,网站确保在所有页面都在线时添加流量统计代码。
2、全部网站开通百度资源平台账号。
3、在线网站,除非 SEO 或运营部门另有要求,robots 文件对所有 URL 和文件(包括图像、CSS、JS)的抓取都是开放的。
4、XML版本的Sitemap在后台实时或定期生成更新,包括首页、栏目和页面、产品/文章页面。是否收录过滤条件页面将在与SEO部门协调后确定。
5、新站点应始终使用响应式设计,不要使用独立的移动站点或移动子域。已经用移动子域优化过的老站暂时保持现状,与SEO部门沟通后转为响应式设计。
6、英文网站HTML 代码中不应出现中文字符,包括注释。
7、当由于各种原因需要更改URL时,旧的URL会被301重定向到新的URL,不要使用其他的转向方式。
8、当由于各种原因更改 URL 时,导航和内页链接会更新为新 URL。导航中禁止需要重定向的 URL。
六、使用PHP采集+SEO函数让网站快收录
如果以上都没有问题,我们可以使用这个PHP采集工具来实现采集伪原创自动发布和主动推送到搜索引擎。操作简单,无需学习更专业的技术。只需几个简单的步骤即可轻松实现采集内容数据,用户只需在PHP采集上进行简单设置,PHP采集工具会根据关键词准确设置给用户。采集文章,这确保了与行业 文章 的一致性。采集文章 from 采集可以选择本地保存,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
与其他PHP采集相比,这个PHP采集基本没有规则,更别说花大量时间学习正则表达式或者html标签,一分钟就能上手,直接输入关键词 采集可以实现(PHP采集也自带关键词采集函数)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个PHP采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片保存在本地或第三方(使内容无不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选地将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),无需每天登录网站后台. SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
七、百度优化排名最基本的原理!
一、网站优化排名的对象是什么
1、一个网站由多个网页组成,网站由一个或多个网页组成。
2、seo优化的对象是网页而不是网站。关于网站优化排名的误区是,普通人总是认为优化的对象是网站。我们通常所说的“网站ranking”和“网站optimization”是不正确的。
二:百度蜘蛛的工作很简单:
找到页面(发现网上有这个页面)——页面是否可以正常爬取(你在爬取的时候有没有遇到困难:比如加载慢、质量低、错误页面多——你要爬吗? page)?是否应该爬取?爬取数据库能给网名带来实际的效果吗?) 了解了这些基本原理后,我们就可以根据这些要求进行尝试了。比如,如何让百度爬取更方便?方法如下:
1)百度主动找到我们的页面
2)我们提交给百度
3) 还有人告诉百度需要做一些外链推广工作
三、什么是超链接分析,超链接分析简介
1、“超链接分析”
超链接分析是百度的专利。原理是通过分析链接网站的数量来评估链接网站的质量。这样做的效果是确保用户使用搜索引擎。,质量越高,页面越受欢迎越高。百度总裁李彦宏是这项技术的拥有者,该技术已被全球主要搜索引擎广泛采用。
2、我们如何理解超链分析技术?
总之,要判断一个页面是优秀的还是权威的,其他页面的“意见”是非常重要的。即使一个网页不是那么好,只要其他网页比其他网页有更多的“信任票”(反向链接),那么它的排名就会更高。需要注意的是,“超链接分析”只是排名的一个重要参考。
四:分析模块的工作,百度会对网页进行再加工预测评价:
1)网站页面内容好不好?
2) 页面的主题是什么?(标题、关键词和网站描述、网站内容本身由网站的TDK决定)
3)多少钱?原创学位?
4)还有其他评分选项,比如多少个链接?
通过以上指标,百度会给搜索关键词一个匹配排名,其匹配模式设计为:完全匹配+词组匹配+广泛匹配。
我们seo优化的价值在于匹配模式相当于排名机会,我们需要实现更多更好的排名机会。继续增加匹配机会,让更多流量找到我们的网站。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名!
php抓取网页标签(PHP实现网页内容html标签补全和过滤的方法结合实例 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-22 04:06
)
本文文章主要介绍PHP完成和过滤网页内容HTML标签的方法,分析PHP常用的标签检查、补全、关闭、过滤等操作技巧。朋友可以参考以下
本文的例子描述了PHP完成和过滤网页内容的HTML标签的方法。分享给大家,供大家参考,如下:
如果你的网页内容的html标签不完整,一些table标签不完整导致页面混乱,或者你的内容以外的部分html页面收录在内,我们可以写一个函数方法来完成html标签和过滤去掉无用的html标签。
php让HTML标签自动补全、关闭、过滤功能方法一:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
closetags() 解析:
array_reverse() :此函数反转原创数组中元素的顺序,创建一个新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名会丢失。
array_search() : array_search(value,array,strict),这个函数像 in_array() 一样在数组中搜索一个键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回 false。如果第三个参数strict指定为true,则只有数据类型和值一致时才返回对应元素的键名。
php让HTML标签自动补全、关闭、过滤功能方法二:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
checkhtml($html) 解析:
stripslashes():该函数删除由addslashes() 函数添加的反斜杠。此函数用于清理从数据库或 HTML 表单中检索到的数据。
以上是PHP完成和过滤网页内容中html标签的两种方法的详细介绍。更多详情请关注php中文网其他相关话题文章!
查看全部
php抓取网页标签(PHP实现网页内容html标签补全和过滤的方法结合实例
)
本文文章主要介绍PHP完成和过滤网页内容HTML标签的方法,分析PHP常用的标签检查、补全、关闭、过滤等操作技巧。朋友可以参考以下
本文的例子描述了PHP完成和过滤网页内容的HTML标签的方法。分享给大家,供大家参考,如下:
如果你的网页内容的html标签不完整,一些table标签不完整导致页面混乱,或者你的内容以外的部分html页面收录在内,我们可以写一个函数方法来完成html标签和过滤去掉无用的html标签。
php让HTML标签自动补全、关闭、过滤功能方法一:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
closetags() 解析:
array_reverse() :此函数反转原创数组中元素的顺序,创建一个新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名会丢失。
array_search() : array_search(value,array,strict),这个函数像 in_array() 一样在数组中搜索一个键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回 false。如果第三个参数strict指定为true,则只有数据类型和值一致时才返回对应元素的键名。
php让HTML标签自动补全、关闭、过滤功能方法二:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
checkhtml($html) 解析:
stripslashes():该函数删除由addslashes() 函数添加的反斜杠。此函数用于清理从数据库或 HTML 表单中检索到的数据。
以上是PHP完成和过滤网页内容中html标签的两种方法的详细介绍。更多详情请关注php中文网其他相关话题文章!
php抓取网页标签(php抓取网页标签抓取+云音乐歌词+转发按钮按钮)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-20 08:03
php抓取网页标签首先是打开浏览器,
php主要抓取html,我也在探索如何php抓取。
知乎好多类似的问题
php需要提供url头数据,可以通过get或者post实现,建议用dll封装一层path_to_array.至于如何封装,稍加研究就可以了.
php大神们的回答:百度一下
推荐你看看今天刚更新的自己写的php爬虫网页数据抓取+云音乐歌词抓取+转发按钮
这个有个问题,
php抓取网页主要是靠url头来抓取的,style="getheader('class','none')"。
这里有一个爬取网页的教程,
.url
这个问题还是蛮困惑的,我也不懂。还在研究中。
我也碰到过这个问题。抓取了别人的网站,然后都没有对应的名称,也没有源文件。看了其他的大神的回答,都不是抓取主要的数据,有点搞笑。
同样。同样搞定了,去github看了一圈,没有发现成功的。把我的抓取代码放到github上,cat~winflu_php0112534.php,抓取了我的网站,还是不对,没有对应的名称,没有源文件。思考了一下:1,使用curl来对我的网站做抓取时候没有对应的数据。2,服务器端是基于我的服务器上配置上的各种数据类型进行操作,如果没有对应数据类型,是没有办法判断我的url的数据类型的。
没有type_string.text='something'这种类型的数据。就像没有text这种类型的文本数据。所以我就继续等待这个问题的解决。 查看全部
php抓取网页标签(php抓取网页标签抓取+云音乐歌词+转发按钮按钮)
php抓取网页标签首先是打开浏览器,
php主要抓取html,我也在探索如何php抓取。
知乎好多类似的问题
php需要提供url头数据,可以通过get或者post实现,建议用dll封装一层path_to_array.至于如何封装,稍加研究就可以了.
php大神们的回答:百度一下
推荐你看看今天刚更新的自己写的php爬虫网页数据抓取+云音乐歌词抓取+转发按钮
这个有个问题,
php抓取网页主要是靠url头来抓取的,style="getheader('class','none')"。
这里有一个爬取网页的教程,
.url
这个问题还是蛮困惑的,我也不懂。还在研究中。
我也碰到过这个问题。抓取了别人的网站,然后都没有对应的名称,也没有源文件。看了其他的大神的回答,都不是抓取主要的数据,有点搞笑。
同样。同样搞定了,去github看了一圈,没有发现成功的。把我的抓取代码放到github上,cat~winflu_php0112534.php,抓取了我的网站,还是不对,没有对应的名称,没有源文件。思考了一下:1,使用curl来对我的网站做抓取时候没有对应的数据。2,服务器端是基于我的服务器上配置上的各种数据类型进行操作,如果没有对应数据类型,是没有办法判断我的url的数据类型的。
没有type_string.text='something'这种类型的数据。就像没有text这种类型的文本数据。所以我就继续等待这个问题的解决。
php抓取网页标签(html标签不能是什么事都不能十全十美,就这样了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-19 03:25
)
日志一般需要生成摘要,手动填写太麻烦,所以使用mb_substr自动拦截,问题来了。如果纯文本还是基本准确的,如果html代码太多,拦截就太糟糕了。例如,如果摘要设置为 300 字,则前面的空格和 html 代码可能占 100 字。怎么做?你最好的办法是遇到html代码,跳过它,不计较。这样更准确,当然美中不足的是,如果是img标签呢?没有什么是完美的,仅此而已。
utf编码,unicode字符1-6个字节都是可以的,但是html码肯定是1个字节,而且以<开头>结尾,所以后面分析出来。但是有一个问题,html标签不能关闭。比如300字满的时候,后面还有几个html标签,导致标签打不开,页面布局完全乱了。我记得php有一个扩展库,专门检查html规范,但是一般主机没有安装,所以我试着写了。逻辑挺复杂的,看到就头晕,觉得有些地方是多余的,但是没找到别的办法。
在这几天的测试中,可以正确处理未封闭的 html 标签。但是如果使用php过滤器会比较麻烦,php代码中可能会有很多<和>,目前的解决方案是,如果输入格式中收录php过滤器,则不进行处理。如果字符串中没有html标签,直接调用mb_substr进行处理,其中收录抽象截取标记,优先从标记截取。
这是代码: 查看全部
php抓取网页标签(html标签不能是什么事都不能十全十美,就这样了
)
日志一般需要生成摘要,手动填写太麻烦,所以使用mb_substr自动拦截,问题来了。如果纯文本还是基本准确的,如果html代码太多,拦截就太糟糕了。例如,如果摘要设置为 300 字,则前面的空格和 html 代码可能占 100 字。怎么做?你最好的办法是遇到html代码,跳过它,不计较。这样更准确,当然美中不足的是,如果是img标签呢?没有什么是完美的,仅此而已。
utf编码,unicode字符1-6个字节都是可以的,但是html码肯定是1个字节,而且以<开头>结尾,所以后面分析出来。但是有一个问题,html标签不能关闭。比如300字满的时候,后面还有几个html标签,导致标签打不开,页面布局完全乱了。我记得php有一个扩展库,专门检查html规范,但是一般主机没有安装,所以我试着写了。逻辑挺复杂的,看到就头晕,觉得有些地方是多余的,但是没找到别的办法。
在这几天的测试中,可以正确处理未封闭的 html 标签。但是如果使用php过滤器会比较麻烦,php代码中可能会有很多<和>,目前的解决方案是,如果输入格式中收录php过滤器,则不进行处理。如果字符串中没有html标签,直接调用mb_substr进行处理,其中收录抽象截取标记,优先从标记截取。
这是代码:
php抓取网页标签(网页制作软件dw最新版新增功能无缝实时编辑(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-18 16:07
)
Dreamweaver 2020 for Mac,简称“DW”,是Mac上最好的网页设计软件之一。dw cc2020 mac版增加了新的界面,快速灵活的编码引擎,对Git的支持和更直观的可视化CSS编辑工具,功能更完善,dw mac版可以帮助用户创建、编码和管理美观的< @网站更快更好,这里是最新版的网页制作软件dw,由于DW 2020和谐版还没有上线,所以还是正式版,请稍等...
Adobe Dreamweaver CC 2020 for mac 官方介绍
<p>Adobe Dreamweaver,简称“DW”,中文名“Dream Weaver”,最初为美国开发,2005年被收购。DW是一个所见即所得的网页代码编辑器,集网页创建和管理为一体 查看全部
php抓取网页标签(网页制作软件dw最新版新增功能无缝实时编辑(组图)
)
Dreamweaver 2020 for Mac,简称“DW”,是Mac上最好的网页设计软件之一。dw cc2020 mac版增加了新的界面,快速灵活的编码引擎,对Git的支持和更直观的可视化CSS编辑工具,功能更完善,dw mac版可以帮助用户创建、编码和管理美观的< @网站更快更好,这里是最新版的网页制作软件dw,由于DW 2020和谐版还没有上线,所以还是正式版,请稍等...
Adobe Dreamweaver CC 2020 for mac 官方介绍
<p>Adobe Dreamweaver,简称“DW”,中文名“Dream Weaver”,最初为美国开发,2005年被收购。DW是一个所见即所得的网页代码编辑器,集网页创建和管理为一体
php抓取网页标签(GoogleSearch如何使用.txt?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-18 13:27
并非所有网络机器人都遵循 robots.txt。坏人(例如电子邮件地址抓取工具)构建不遵循此协议的机器人。事实上,一些不良行为者使用 robots.txt 文件来查找您的私人内容所在的位置。虽然阻止爬虫访问私人页面(如登录和管理页面)似乎合乎逻辑,因此它们不会出现在索引中,但将这些 URL 的位置放在可公开访问的 robots.txt 文件中也意味着恶意软件可以更容易地找到它们。最好对这些页面进行 NoIndex 并将它们保留在登录表单后面,而不是将它们放在您的 robots.txt 文件中。
您可以在我们学习中心的 robots.txt 部分阅读更多详细信息。
在 GSC 中定义 URL 参数
一些 网站(在电子商务中最常见)通过将某些参数附加到 URL 来使相同的内容在多个不同的 URL 上可用。如果您曾经在网上购物,您可能已经使用过滤器缩小了搜索范围。例如,您可以在亚马逊上搜索“鞋子”,然后按尺码、颜色和款式细化您的搜索。每次优化时,URL 都会略有变化:
https://www.example.com/produc ... id%3D 32&highlight=green+dress&cat_id=1&sessionid=123$affid=43
Google 如何知道向搜索者提供哪个版本的 URL?Google 在确定代表 URL 本身方面做得很好,但您可以使用 Google Search Console 中的 URL 参数功能告诉 Google 您希望他们如何处理您的页面。如果您使用此功能告诉 Googlebot“不要抓取带有 ___ 参数的网址”,您实际上是在要求 Googlebot 对 Googlebot 隐藏此内容,这可能会导致这些网页从搜索结果中删除。如果这些参数创建重复页面,这就是您想要的,但如果您希望这些页面被索引,则不理想。
爬虫能找到你所有的重要内容吗?
既然您已经了解了一些使搜索引擎爬虫远离您不重要的内容的策略,那么让我们来看看可以帮助 Googlebot 找到您的重要页面的优化。
有时,搜索引擎将能够抓取您的 网站 的某些部分,但其他页面或部分可能由于某种原因而被遮挡。确保搜索引擎可以发现您想要索引的所有内容,而不仅仅是您的主页,这一点很重要。
问问自己这个问题:机器人可以爬过你的 网站,而不仅仅是在上面吗? 查看全部
php抓取网页标签(GoogleSearch如何使用.txt?)
并非所有网络机器人都遵循 robots.txt。坏人(例如电子邮件地址抓取工具)构建不遵循此协议的机器人。事实上,一些不良行为者使用 robots.txt 文件来查找您的私人内容所在的位置。虽然阻止爬虫访问私人页面(如登录和管理页面)似乎合乎逻辑,因此它们不会出现在索引中,但将这些 URL 的位置放在可公开访问的 robots.txt 文件中也意味着恶意软件可以更容易地找到它们。最好对这些页面进行 NoIndex 并将它们保留在登录表单后面,而不是将它们放在您的 robots.txt 文件中。
您可以在我们学习中心的 robots.txt 部分阅读更多详细信息。
在 GSC 中定义 URL 参数
一些 网站(在电子商务中最常见)通过将某些参数附加到 URL 来使相同的内容在多个不同的 URL 上可用。如果您曾经在网上购物,您可能已经使用过滤器缩小了搜索范围。例如,您可以在亚马逊上搜索“鞋子”,然后按尺码、颜色和款式细化您的搜索。每次优化时,URL 都会略有变化:
https://www.example.com/produc ... id%3D 32&highlight=green+dress&cat_id=1&sessionid=123$affid=43
Google 如何知道向搜索者提供哪个版本的 URL?Google 在确定代表 URL 本身方面做得很好,但您可以使用 Google Search Console 中的 URL 参数功能告诉 Google 您希望他们如何处理您的页面。如果您使用此功能告诉 Googlebot“不要抓取带有 ___ 参数的网址”,您实际上是在要求 Googlebot 对 Googlebot 隐藏此内容,这可能会导致这些网页从搜索结果中删除。如果这些参数创建重复页面,这就是您想要的,但如果您希望这些页面被索引,则不理想。
爬虫能找到你所有的重要内容吗?
既然您已经了解了一些使搜索引擎爬虫远离您不重要的内容的策略,那么让我们来看看可以帮助 Googlebot 找到您的重要页面的优化。
有时,搜索引擎将能够抓取您的 网站 的某些部分,但其他页面或部分可能由于某种原因而被遮挡。确保搜索引擎可以发现您想要索引的所有内容,而不仅仅是您的主页,这一点很重要。
问问自己这个问题:机器人可以爬过你的 网站,而不仅仅是在上面吗?
php抓取网页标签(php的开发者来说源码,远程抓取图片并保存到本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-02-18 13:24
作为一个模仿站点工作者,当网站 有版权甚至加密时,WEBZIP 也会关闭。如何扣除网页上的图片和背景图片?有时,您可能会想到使用 Firefox。这个浏览器似乎是一个强大的错误。 文章 有版权,右键被屏蔽,Firefox 完全不受影响。
但是作为一个热爱php的开发者,我更喜欢自己做。于是,我写了如下源码,php远程抓图小程序。您可以读取 css 文件并在 css 代码中获取背景图像。下面的代码也是为了抓取css中的图片而写的。
如果不出意外,你会发现你指定的文件夹里全是图片,哈哈..
ps:php获取远程图片并下载并保存在本地
分享一个使用php获取远程图片并将远程图片下载保存到本地的功能代码:
/*
*功能:php完美实现下载远程图片保存到本地
*参数:文件url,保存文件目录,保存文件名称,使用的下载方式
*当保存文件名称为空时则使用远程文件原来的名称
*/
function getImage($url,$save_dir='',$filename='',$type=0){
if(trim($url)==''){
return array('file_name'=>'','save_path'=>'','error'=>1);
}
if(trim($save_dir)==''){
$save_dir='./';
}
if(trim($filename)==''){//保存文件名
$ext=strrchr($url,'.');
if($ext!='.gif'&&$ext!='.jpg'){
return array('file_name'=>'','save_path'=>'','error'=>3);
}
$filename=time().$ext;
}
if(0!==strrpos($save_dir,'/')){
$save_dir.='/';
}
//创建保存目录
if(!file_exists($save_dir)&&!mkdir($save_dir,0777,true)){
return array('file_name'=>'','save_path'=>'','error'=>5);
}
//获取远程文件所采用的方法
if($type){
$ch=curl_init();
$timeout=5;
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_CONNECTTIMEOUT,$timeout);
$img=curl_exec($ch);
curl_close($ch);
}else{
ob_start();
readfile($url);
$img=ob_get_contents();
ob_end_clean();
}
//$size=strlen($img);
//文件大小
$fp2=@fopen($save_dir.$filename,'a');
fwrite($fp2,$img);
fclose($fp2);
unset($img,$url);
return array('file_name'=>$filename,'save_path'=>$save_dir.$filename,'error'=>0);
}
以上内容是小编分享给大家的PHP源码批量抓取远程网页图片并保存到本地的实现方法。希望你喜欢。 查看全部
php抓取网页标签(php的开发者来说源码,远程抓取图片并保存到本地)
作为一个模仿站点工作者,当网站 有版权甚至加密时,WEBZIP 也会关闭。如何扣除网页上的图片和背景图片?有时,您可能会想到使用 Firefox。这个浏览器似乎是一个强大的错误。 文章 有版权,右键被屏蔽,Firefox 完全不受影响。
但是作为一个热爱php的开发者,我更喜欢自己做。于是,我写了如下源码,php远程抓图小程序。您可以读取 css 文件并在 css 代码中获取背景图像。下面的代码也是为了抓取css中的图片而写的。
如果不出意外,你会发现你指定的文件夹里全是图片,哈哈..
ps:php获取远程图片并下载并保存在本地
分享一个使用php获取远程图片并将远程图片下载保存到本地的功能代码:
/*
*功能:php完美实现下载远程图片保存到本地
*参数:文件url,保存文件目录,保存文件名称,使用的下载方式
*当保存文件名称为空时则使用远程文件原来的名称
*/
function getImage($url,$save_dir='',$filename='',$type=0){
if(trim($url)==''){
return array('file_name'=>'','save_path'=>'','error'=>1);
}
if(trim($save_dir)==''){
$save_dir='./';
}
if(trim($filename)==''){//保存文件名
$ext=strrchr($url,'.');
if($ext!='.gif'&&$ext!='.jpg'){
return array('file_name'=>'','save_path'=>'','error'=>3);
}
$filename=time().$ext;
}
if(0!==strrpos($save_dir,'/')){
$save_dir.='/';
}
//创建保存目录
if(!file_exists($save_dir)&&!mkdir($save_dir,0777,true)){
return array('file_name'=>'','save_path'=>'','error'=>5);
}
//获取远程文件所采用的方法
if($type){
$ch=curl_init();
$timeout=5;
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_CONNECTTIMEOUT,$timeout);
$img=curl_exec($ch);
curl_close($ch);
}else{
ob_start();
readfile($url);
$img=ob_get_contents();
ob_end_clean();
}
//$size=strlen($img);
//文件大小
$fp2=@fopen($save_dir.$filename,'a');
fwrite($fp2,$img);
fclose($fp2);
unset($img,$url);
return array('file_name'=>$filename,'save_path'=>$save_dir.$filename,'error'=>0);
}
以上内容是小编分享给大家的PHP源码批量抓取远程网页图片并保存到本地的实现方法。希望你喜欢。
php抓取网页标签( Sitemap(站点地图)(文件格式))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-16 06:08
Sitemap(站点地图)(文件格式))
提交站点地图
站点地图是一个文件,它允许网站管理员列出 网站 上的网页并告知搜索引擎有关 网站 内容的组织。
神马等搜索引擎网络爬虫会读取这个文件,更智能地抓取网站内容
理想情况下,如果您的 网站 页面正确链接,Whatsminer 的网络爬虫将能够发现其中的大部分。即便如此,提交站点地图也可以帮助搜索引擎更高效地抓取网站,尤其是在满足网站以下条件之一的情况下:
1.网站 是一个新的 网站 并且没有很多指向这个 网站 的外部链接。搜索引擎的网络爬虫通过跟踪它们之间的链接来抓取网页,如果没有其他网站指向您页面的链接,则可能无法发现您的页面。
2.网站规模很大。在这种情况下,Whatsminer 的网络爬虫在爬取时可能会漏掉一些新页面。
3.网站 中的大量内容页面断开连接或缺少有效链接。如果您的 网站 页面不能自然地相互引用,您可以在站点地图中列出它们,以确保搜索引擎不会错过您的页面。
需要注意的是,神马搜索会按照正常流程对Sitemap进行分析处理,但不保证会对您提交的所有网址进行抓取和索引,也不保证其在搜索结果中的排名。站点地图格式:
WhatsMiner 支持的站点地图文件包括标准 xml 文件和索引 xml 文件。一个标准的 xml 文件最多收录 10,000 个 URL。如果 URL 超过 10,000,则可以使用索引 xml 文件。被索引的 xml 文件被限制为不超过三层。
标准xml文件格式示例:
2014-05-01
每天
0.5
2014-05-01
每天
0.8
索引xml文件格式示例:
1.顶级站点地图格式 查看全部
php抓取网页标签(
Sitemap(站点地图)(文件格式))
提交站点地图
站点地图是一个文件,它允许网站管理员列出 网站 上的网页并告知搜索引擎有关 网站 内容的组织。
神马等搜索引擎网络爬虫会读取这个文件,更智能地抓取网站内容
理想情况下,如果您的 网站 页面正确链接,Whatsminer 的网络爬虫将能够发现其中的大部分。即便如此,提交站点地图也可以帮助搜索引擎更高效地抓取网站,尤其是在满足网站以下条件之一的情况下:
1.网站 是一个新的 网站 并且没有很多指向这个 网站 的外部链接。搜索引擎的网络爬虫通过跟踪它们之间的链接来抓取网页,如果没有其他网站指向您页面的链接,则可能无法发现您的页面。
2.网站规模很大。在这种情况下,Whatsminer 的网络爬虫在爬取时可能会漏掉一些新页面。
3.网站 中的大量内容页面断开连接或缺少有效链接。如果您的 网站 页面不能自然地相互引用,您可以在站点地图中列出它们,以确保搜索引擎不会错过您的页面。
需要注意的是,神马搜索会按照正常流程对Sitemap进行分析处理,但不保证会对您提交的所有网址进行抓取和索引,也不保证其在搜索结果中的排名。站点地图格式:
WhatsMiner 支持的站点地图文件包括标准 xml 文件和索引 xml 文件。一个标准的 xml 文件最多收录 10,000 个 URL。如果 URL 超过 10,000,则可以使用索引 xml 文件。被索引的 xml 文件被限制为不超过三层。
标准xml文件格式示例:
2014-05-01
每天
0.5
2014-05-01
每天
0.8
索引xml文件格式示例:
1.顶级站点地图格式
php抓取网页标签(方维网络记录一下采集过程中的几个要点需要注意的地方)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-02-05 20:19
PHP网站在生产中经常需要采集其他网站数据,一些细节会造成很大的麻烦。维网记录采集过程中需要注意的几个点
1、首先,你需要获取对方网站的所有内容。你可能会想到使用 file_gets_contents 来获取它,但是这个函数不适合获取远程文件。打开本地txt文件非常有用。那么用什么来获取呢?curl,这个php扩展来处理。以下是获取网页内容的简单基本配置。更多参数配置可以在线搜索。
2、在采集网页匹配数据时,尤其是列表页,可以先把对方的空格、换行等html标签全部去掉,这样会容易很多写正则表达式。这是一个函数:
3、正则匹配会在获取到对方数据后开始。以下是一些常见的匹配规则:
一个是任意字符(.*?),一个是([\s\S]*?) 表示任意字符,包括换行符,在匹配过程中就足够了。然后选择匹配模式 i。
4、介绍采集的思路。您可以下载与页面匹配的数据并保存为txt文件,然后在本地进行处理。另外,为了避免频繁访问对方网站或者数据丢失,可以加一个while(){}循环或者sleep()暂停几秒来处理。封装相关的数据库处理函数,直接调用。
5、还有一个重要的事情很多人可能会忽略,那就是页面的编码。如果对方网站是gbk的编码,对应的php文件或者提交条件的html文件也会是gbk的编码。但是会有一个问题,就是gbk的html向gbk的php页面提交中文数据的时候,gbk的php文件可能没有响应你。如果用这些中文数据来匹配,就会遇到问题。所以我们要换个思路,utf-8是最好的编码方式,所以要使用utf-8编码,而对方是gbk,怎么办呢?
$allcontent =iconv('gbk', 'utf-8',removetag(curl_exec($ch)));
上面的转换就ok了!全部使用 utf-8 查看全部
php抓取网页标签(方维网络记录一下采集过程中的几个要点需要注意的地方)
PHP网站在生产中经常需要采集其他网站数据,一些细节会造成很大的麻烦。维网记录采集过程中需要注意的几个点
1、首先,你需要获取对方网站的所有内容。你可能会想到使用 file_gets_contents 来获取它,但是这个函数不适合获取远程文件。打开本地txt文件非常有用。那么用什么来获取呢?curl,这个php扩展来处理。以下是获取网页内容的简单基本配置。更多参数配置可以在线搜索。
2、在采集网页匹配数据时,尤其是列表页,可以先把对方的空格、换行等html标签全部去掉,这样会容易很多写正则表达式。这是一个函数:
3、正则匹配会在获取到对方数据后开始。以下是一些常见的匹配规则:
一个是任意字符(.*?),一个是([\s\S]*?) 表示任意字符,包括换行符,在匹配过程中就足够了。然后选择匹配模式 i。
4、介绍采集的思路。您可以下载与页面匹配的数据并保存为txt文件,然后在本地进行处理。另外,为了避免频繁访问对方网站或者数据丢失,可以加一个while(){}循环或者sleep()暂停几秒来处理。封装相关的数据库处理函数,直接调用。
5、还有一个重要的事情很多人可能会忽略,那就是页面的编码。如果对方网站是gbk的编码,对应的php文件或者提交条件的html文件也会是gbk的编码。但是会有一个问题,就是gbk的html向gbk的php页面提交中文数据的时候,gbk的php文件可能没有响应你。如果用这些中文数据来匹配,就会遇到问题。所以我们要换个思路,utf-8是最好的编码方式,所以要使用utf-8编码,而对方是gbk,怎么办呢?
$allcontent =iconv('gbk', 'utf-8',removetag(curl_exec($ch)));
上面的转换就ok了!全部使用 utf-8
php抓取网页标签(常见爬取网页时,提取数据的方法有xpath,正则提取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-05 16:32
2021-08-14 抓取网页时,提取数据的方法有xpath和正则提取。对于json数据,使用函数jsonpath提取,scrapy中使用css提取。标题在这么多提取方法中,这次我们使用xpath来模拟我们所面临的数据,用于一般和特殊的数据提取。
网址:
文章使用这个 网站 从 xpath 中提取数据。
一、对于简单的数据,可以直接查看网页的源码,然后复制其xpath的路径(提示:7、8%的网页可以通过这种方式直接提取)
第一步:鼠标右击,查看网页,也可以使用快捷键F12
2.第二步:
点击你要的信息:点击后,下面会自动跳转到对应的位置,然后复制路径。
这种方法非常快。准确率一般,毕竟自己写最准确。
墙破解推荐一个谷歌插件,xpath-helper插件可以实时查看自己的xpath路径对应的信息。
二、如有特殊要求,xpath会响应
还是这个网站,我现在在想,从后面的所有类别爬取,我不要所有这个模块
这是使用xpath中的position(位置)方法,position处理这种情况比较快
/html/body/div/div[1]/div[6]/div/div[3]/div[1]/div[2]/a[1]/text()
这个 xpath 提取的就是全部
/html/body/div/div[1]/div[6]/div/div[3]/div[1]/div[2]/a[position()>1]/text()
此 xpath 提取所有后续模块
使用方法:顾名思义,位置(position),我们只需要替换递归标签中的这个字段就可以从选中的行中提取数据
翻页并提取页面的URL
我们可以发现网页的下一页的位置正在发生变化。如果要定位,不能使用常规方法,因为每一页的位置都不一样。这就是我们要使用的 last()
/html/body/div/div[1]/div[8]/div/a[last()-1]/@href
像这样,很容易理解,差不多就是递归标签内修改position,last()代表最后一个标签,last()-1,代表倒数第二个标签,其余同理
或者翻转标签,也可以使用 content() 方法进行定位:
/html/body/div/div[1]/div[8]/div/a[contains(string(.),'next')]/@href
还有一些其他的方法,下次继续,有什么问题可以留言交流!!!
分类:
技术要点:
相关文章: 查看全部
php抓取网页标签(常见爬取网页时,提取数据的方法有xpath,正则提取)
2021-08-14 抓取网页时,提取数据的方法有xpath和正则提取。对于json数据,使用函数jsonpath提取,scrapy中使用css提取。标题在这么多提取方法中,这次我们使用xpath来模拟我们所面临的数据,用于一般和特殊的数据提取。
网址:
文章使用这个 网站 从 xpath 中提取数据。
一、对于简单的数据,可以直接查看网页的源码,然后复制其xpath的路径(提示:7、8%的网页可以通过这种方式直接提取)
第一步:鼠标右击,查看网页,也可以使用快捷键F12
2.第二步:
点击你要的信息:点击后,下面会自动跳转到对应的位置,然后复制路径。
这种方法非常快。准确率一般,毕竟自己写最准确。
墙破解推荐一个谷歌插件,xpath-helper插件可以实时查看自己的xpath路径对应的信息。
二、如有特殊要求,xpath会响应
还是这个网站,我现在在想,从后面的所有类别爬取,我不要所有这个模块
这是使用xpath中的position(位置)方法,position处理这种情况比较快
/html/body/div/div[1]/div[6]/div/div[3]/div[1]/div[2]/a[1]/text()
这个 xpath 提取的就是全部
/html/body/div/div[1]/div[6]/div/div[3]/div[1]/div[2]/a[position()>1]/text()
此 xpath 提取所有后续模块
使用方法:顾名思义,位置(position),我们只需要替换递归标签中的这个字段就可以从选中的行中提取数据
翻页并提取页面的URL
我们可以发现网页的下一页的位置正在发生变化。如果要定位,不能使用常规方法,因为每一页的位置都不一样。这就是我们要使用的 last()
/html/body/div/div[1]/div[8]/div/a[last()-1]/@href
像这样,很容易理解,差不多就是递归标签内修改position,last()代表最后一个标签,last()-1,代表倒数第二个标签,其余同理
或者翻转标签,也可以使用 content() 方法进行定位:
/html/body/div/div[1]/div[8]/div/a[contains(string(.),'next')]/@href
还有一些其他的方法,下次继续,有什么问题可以留言交流!!!
分类:
技术要点:
相关文章:
php抓取网页标签(WordPress主题影响SEO效果的几个方面方面SEO标签结构化数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-02-05 16:28
很多网友都在咨询或讨论WordPress主题是否会影响SEO优化。要理解这个问题,并不难,首先要了解SEO与哪些方面有关,这些方面是否与WordPress主题有关。本文将讨论主题的哪些方面影响 SEO。
由于WordPress主题与写作内容无关,原创、写作质量、专业度等本文将不予讨论,虽然这些是最影响搜索引擎收录和排名的。
WordPress主题影响SEO效果的几个方面SEO标签结构化数据页面加载速度页面渲染速度页面代码错误1、SEO标签
许多主题都会带有一些 SEO 标签,通常包括以下内容:
机器人META标签
上述标签告诉搜索引擎允许抓取该页面并允许以下链接。
inindex,follow:允许爬取这个页面,允许关注链接。index,nofollow:允许抓取此页面,但不允许以下链接。noindex,follow:禁止抓取该页面,但允许以下链接。noindex,nofllow:禁止爬取该页面,禁止在该页面点击链接。rel =“规范”标签
本页应用示例:
早在 2009 年 2 月,Google、Yahoo 和 live search 就宣布支持 Link 的新属性 Canonical。主要目的是帮助搜索引擎解决存在多个版本的网站内容,制定标准化的链接,防止同一个内容重复收录。
这个标签在 WordPress 中很重要,因为 WordPress 可能有伪静态 URL,默认 ?p=123 URL,或者其他一些参数后缀,但是它们的内容是完全一样的,通过 rel=”canonical” 标签可以避免重复 收录,现在所有主要搜索引擎都支持它。
描述 META 标签
例子:
描述标签,顾名思义,就是对网页的简单描述/摘录,可以让搜索引擎更快地掌握网页的基本内容。曾经有关键字标签(定义 关键词),但现在正在逐步淘汰。
标题标签
例子:
WordPress主题会不会影响SEO优化? - 天使之家
对于SEO来说,最重要的是标题标签,每个页面必须有一个,而且只有一个。这个标签定义了网页的标题,也是上述所有标签中对SEO最重要的标签,最好能反映网页的关键词或关键词。但是不要滥用标题标签,如果文字错误,可能会被搜索引擎视为作弊。
额外提一下,H1、H2、H3...这种类型的标签对SEO也有帮助,但基本上与WordPress主题无关,需要在编写内容时添加。在主页和列表页,文章 标题在一般主题中会标有 H2。因为在一个页面中,H1只能使用一次,否则也会造成SEO不当。
2、结构化数据
说白了,结构化数据就是网页除了title、url、description这三个要素外,还可以向搜索引擎提交更多的信息,在搜索结果页展示更多的信息,获得更好的排名。
结构化数据代码分为三种类型:JSON-LD、微数据和 RDFa。无论是谷歌还是百度,都推荐使用 JSON-LD 格式。
一般的 WordPress 主题不会自动生成结构化数据,除非您自己添加相应的代码,或者使用 SEO 插件。强烈建议使用 Yoast SEO 或 Rank Math SEO 来生成规范的结构化数据。其中,Rank Math PRO可以自定义结构化数据的内容,这样除了结构化数据外,还可以添加百度尊重的结构化数据代码。或者在文章页面模板中添加如下代码,添加百度结构化数据。
{
"@context": "https://ziyuan.baidu.com/conte ... ot%3B,
"@id": "",
"title": "",
"images": [
""
],
"description":"",
"pubDate": "",
"upDate":""
}
注:是 Google、Bing、Yandex 和 Yahoo! 合作的结果 它已被包括百度在内的几乎所有主要搜索引擎支持。只是百度目前更喜欢上面例子的结构化数据,未来可能会改变这种看法。
3、网页加载速度
无论是哪个搜索引擎,网页和相关静态资源的加载速度都非常重要。WordPress主题对这方面的影响分为两部分,一是动态加载速度,二是静态缓存后的加载速度。
动态加载速度
对于不使用静态缓存的网页,程序代码的编码质量、服务器性能、服务器运行环境、网络带宽、网络状况等因素都会影响动态加载速度。因为每次访问网页,都是由后端的PHP程序生成前端网页,然后传递给浏览器。整个过程比较缓慢。
虽然 WordPress 有很多静态缓存方案,但有些情况不适合缓存,比如:用 WooCommerce 搭建的商店、需要动态展示的网页、具有交互功能的网页等。
在上面提到的影响动态加载速度的因素中,与主题相关的主要是程序代码的编码质量。这个话题比较大,不能一两句话完全解释清楚,但是有以下几个原则供大家参考。便于选择优质主题的参考。
静态缓存后的加载速度
静态缓存之后的术语对于 WordPress 站长来说一定很熟悉。WordPress本身不支持静态,但是有很多插件可以实现网页的静态缓存。例如:WP Rocket、W3 Total Cache、WP Super Cache 等。
经过静态缓存处理后,用户在访问网页时不需要像动态网页那样在后端临时生成前端页面。尤其是上面提到的三个缓存插件,无论是 Nginx 还是 Apache,都可以直接调用缓存的内容交付,无需 PHP 处理。PS:WP Rocket 需要在 Nginx 环境中额外安装 Rocket-Nginx。
这样,静态缓存后的网页加载速度大大提高,基本上只取决于网络带宽、网络条件和服务器静态资源的并发性能。也就是说,对于 WordPress 主题,只要不加载太多、庞大的静态资产,就可以获得良好的加载速度。
看到这里,基本可以得出一个结论,只要大部分主题都是静态缓存处理的,加载速度不会有太大影响。使用静态缓存,这不太可能成为影响 SEO 的条件。
4、网页渲染速度
网页渲染速度和加载速度不同,加载完成不代表渲染完成。浏览器在默认加载网页的静态资源时,是按顺序加载的,浏览器会延迟页面的渲染,直到完成加载、解析并执行完页面中引用的所有CSS文件。推荐阅读“什么是关键路径 CSS?”一文。
还有一些js文件,同样会阻塞页面渲染过程,但是可以通过异步加载进行优化。
网页渲染速度对SEO的影响也很大,但是对百度搜索的影响稍微小一些,因为百度还是使用了爬虫机制,而且GoogleSpider做了调整,这意味着谷歌不仅会爬取渲染后的网页同时,还分析了网页渲染的过程和速度,从而判断网页的浏览体验。
虽然百度在这方面有些落后,但也只是时间问题,因为百度的移动爬虫已经做了很大的调整。
在这一点上,国外的主题大多处理得很好,因为开发者一般使用 PageSpeed Insights 分数作为衡量标准。
5、网页代码是否有错误
这是一个基本要求。如果网页出现代码错误或者调用某些404资源,都会严重影响SEO。稍微成熟的 WordPress 主题不会有这个问题,但是需要提醒的是,一些国外的主题可能会加载一些在大陆无法正常访问的资源,比如谷歌字体、谷歌前端公共库等,仍然会不利。搜索引擎优化。
综上所述
如果阅读本文,WordPress 主题对 SEO 有影响吗?有什么影响?结论已经揭晓。
第一个和第二个方面可以通过额外的 SEO 插件来解决。第三点可以通过静态缓存进行优化。第四点需要下功夫打磨,有很多功能插件可以优化PageSpeed Insights分数。最后,第5点。使用国外主题时,建议仔细检查是否加载了谷歌的部分公共资源。建议将谷歌前端公共库和谷歌字体注释掉,或者通过插件禁用。
内容为王,其他手段只起到辅助作用,所以我劝大家不要本末倒置。做好用户需要的内容,提升用户体验,是最重要的SEO优化。 查看全部
php抓取网页标签(WordPress主题影响SEO效果的几个方面方面SEO标签结构化数据)
很多网友都在咨询或讨论WordPress主题是否会影响SEO优化。要理解这个问题,并不难,首先要了解SEO与哪些方面有关,这些方面是否与WordPress主题有关。本文将讨论主题的哪些方面影响 SEO。
由于WordPress主题与写作内容无关,原创、写作质量、专业度等本文将不予讨论,虽然这些是最影响搜索引擎收录和排名的。
WordPress主题影响SEO效果的几个方面SEO标签结构化数据页面加载速度页面渲染速度页面代码错误1、SEO标签
许多主题都会带有一些 SEO 标签,通常包括以下内容:
机器人META标签
上述标签告诉搜索引擎允许抓取该页面并允许以下链接。
inindex,follow:允许爬取这个页面,允许关注链接。index,nofollow:允许抓取此页面,但不允许以下链接。noindex,follow:禁止抓取该页面,但允许以下链接。noindex,nofllow:禁止爬取该页面,禁止在该页面点击链接。rel =“规范”标签
本页应用示例:
早在 2009 年 2 月,Google、Yahoo 和 live search 就宣布支持 Link 的新属性 Canonical。主要目的是帮助搜索引擎解决存在多个版本的网站内容,制定标准化的链接,防止同一个内容重复收录。
这个标签在 WordPress 中很重要,因为 WordPress 可能有伪静态 URL,默认 ?p=123 URL,或者其他一些参数后缀,但是它们的内容是完全一样的,通过 rel=”canonical” 标签可以避免重复 收录,现在所有主要搜索引擎都支持它。
描述 META 标签
例子:
描述标签,顾名思义,就是对网页的简单描述/摘录,可以让搜索引擎更快地掌握网页的基本内容。曾经有关键字标签(定义 关键词),但现在正在逐步淘汰。
标题标签
例子:
WordPress主题会不会影响SEO优化? - 天使之家
对于SEO来说,最重要的是标题标签,每个页面必须有一个,而且只有一个。这个标签定义了网页的标题,也是上述所有标签中对SEO最重要的标签,最好能反映网页的关键词或关键词。但是不要滥用标题标签,如果文字错误,可能会被搜索引擎视为作弊。
额外提一下,H1、H2、H3...这种类型的标签对SEO也有帮助,但基本上与WordPress主题无关,需要在编写内容时添加。在主页和列表页,文章 标题在一般主题中会标有 H2。因为在一个页面中,H1只能使用一次,否则也会造成SEO不当。
2、结构化数据
说白了,结构化数据就是网页除了title、url、description这三个要素外,还可以向搜索引擎提交更多的信息,在搜索结果页展示更多的信息,获得更好的排名。
结构化数据代码分为三种类型:JSON-LD、微数据和 RDFa。无论是谷歌还是百度,都推荐使用 JSON-LD 格式。
一般的 WordPress 主题不会自动生成结构化数据,除非您自己添加相应的代码,或者使用 SEO 插件。强烈建议使用 Yoast SEO 或 Rank Math SEO 来生成规范的结构化数据。其中,Rank Math PRO可以自定义结构化数据的内容,这样除了结构化数据外,还可以添加百度尊重的结构化数据代码。或者在文章页面模板中添加如下代码,添加百度结构化数据。
{
"@context": "https://ziyuan.baidu.com/conte ... ot%3B,
"@id": "",
"title": "",
"images": [
""
],
"description":"",
"pubDate": "",
"upDate":""
}
注:是 Google、Bing、Yandex 和 Yahoo! 合作的结果 它已被包括百度在内的几乎所有主要搜索引擎支持。只是百度目前更喜欢上面例子的结构化数据,未来可能会改变这种看法。
3、网页加载速度
无论是哪个搜索引擎,网页和相关静态资源的加载速度都非常重要。WordPress主题对这方面的影响分为两部分,一是动态加载速度,二是静态缓存后的加载速度。
动态加载速度
对于不使用静态缓存的网页,程序代码的编码质量、服务器性能、服务器运行环境、网络带宽、网络状况等因素都会影响动态加载速度。因为每次访问网页,都是由后端的PHP程序生成前端网页,然后传递给浏览器。整个过程比较缓慢。
虽然 WordPress 有很多静态缓存方案,但有些情况不适合缓存,比如:用 WooCommerce 搭建的商店、需要动态展示的网页、具有交互功能的网页等。
在上面提到的影响动态加载速度的因素中,与主题相关的主要是程序代码的编码质量。这个话题比较大,不能一两句话完全解释清楚,但是有以下几个原则供大家参考。便于选择优质主题的参考。
静态缓存后的加载速度
静态缓存之后的术语对于 WordPress 站长来说一定很熟悉。WordPress本身不支持静态,但是有很多插件可以实现网页的静态缓存。例如:WP Rocket、W3 Total Cache、WP Super Cache 等。
经过静态缓存处理后,用户在访问网页时不需要像动态网页那样在后端临时生成前端页面。尤其是上面提到的三个缓存插件,无论是 Nginx 还是 Apache,都可以直接调用缓存的内容交付,无需 PHP 处理。PS:WP Rocket 需要在 Nginx 环境中额外安装 Rocket-Nginx。
这样,静态缓存后的网页加载速度大大提高,基本上只取决于网络带宽、网络条件和服务器静态资源的并发性能。也就是说,对于 WordPress 主题,只要不加载太多、庞大的静态资产,就可以获得良好的加载速度。
看到这里,基本可以得出一个结论,只要大部分主题都是静态缓存处理的,加载速度不会有太大影响。使用静态缓存,这不太可能成为影响 SEO 的条件。
4、网页渲染速度
网页渲染速度和加载速度不同,加载完成不代表渲染完成。浏览器在默认加载网页的静态资源时,是按顺序加载的,浏览器会延迟页面的渲染,直到完成加载、解析并执行完页面中引用的所有CSS文件。推荐阅读“什么是关键路径 CSS?”一文。
还有一些js文件,同样会阻塞页面渲染过程,但是可以通过异步加载进行优化。
网页渲染速度对SEO的影响也很大,但是对百度搜索的影响稍微小一些,因为百度还是使用了爬虫机制,而且GoogleSpider做了调整,这意味着谷歌不仅会爬取渲染后的网页同时,还分析了网页渲染的过程和速度,从而判断网页的浏览体验。
虽然百度在这方面有些落后,但也只是时间问题,因为百度的移动爬虫已经做了很大的调整。
在这一点上,国外的主题大多处理得很好,因为开发者一般使用 PageSpeed Insights 分数作为衡量标准。
5、网页代码是否有错误
这是一个基本要求。如果网页出现代码错误或者调用某些404资源,都会严重影响SEO。稍微成熟的 WordPress 主题不会有这个问题,但是需要提醒的是,一些国外的主题可能会加载一些在大陆无法正常访问的资源,比如谷歌字体、谷歌前端公共库等,仍然会不利。搜索引擎优化。
综上所述
如果阅读本文,WordPress 主题对 SEO 有影响吗?有什么影响?结论已经揭晓。
第一个和第二个方面可以通过额外的 SEO 插件来解决。第三点可以通过静态缓存进行优化。第四点需要下功夫打磨,有很多功能插件可以优化PageSpeed Insights分数。最后,第5点。使用国外主题时,建议仔细检查是否加载了谷歌的部分公共资源。建议将谷歌前端公共库和谷歌字体注释掉,或者通过插件禁用。
内容为王,其他手段只起到辅助作用,所以我劝大家不要本末倒置。做好用户需要的内容,提升用户体验,是最重要的SEO优化。
php抓取网页标签(WordPress主题是否会影响SEO效果的几个方面SEO标签数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-01-30 17:08
WordPress 主题是否会影响 SEO 优化。要理解这个问题,并不难,首先要了解SEO与哪些方面有关,这些方面是否与WordPress主题有关。本文将讨论主题的哪些方面影响 SEO。
因为WordPress主题与写作内容无关,原创、写作质量、专业性等本文将不予讨论,虽然这些是最影响搜索引擎收录和排名的。
WordPress主题影响SEO效果的几个方面SEO标签结构化数据页面加载速度页面渲染速度页面代码错误1、SEO标签
许多主题都会带有一些 SEO 标签,通常包括以下内容:
机器人META标签
上述标签告诉搜索引擎允许抓取该页面并允许以下链接。
inindex,follow:允许爬取这个页面,允许关注链接。index,nofollow:允许抓取此页面,但不允许以下链接。noindex,follow:禁止抓取该页面,但允许以下链接。noindex,nofllow:禁止爬取该页面,禁止在该页面点击链接。rel =“规范”标签
本页应用示例:
早在 2009 年 2 月,Google、Yahoo 和 live search 就宣布支持 Link 的新属性 Canonical。主要目的是帮助搜索引擎解决存在多个版本的网站内容,制定标准化的链接,防止同一个内容重复收录。
这个标签在 WordPress 中很重要,因为 WordPress 可能有伪静态 URL,默认 ?p=123 URL,或者其他一些参数后缀,但是它们的内容是完全一样的,通过 rel=”canonical” 标签可以避免重复 收录,现在所有主要搜索引擎都支持它。
描述 META 标签
例子:
描述标签,顾名思义,就是对网页的简单描述/摘录,可以让搜索引擎更快地掌握网页的基本内容。曾经有关键字标签(定义 关键词),但现在正在逐步淘汰。
标题标签
例子:
WordPress主题是否会影响SEO效果 - 站长帮
对于SEO来说,最重要的是标题标签,每个页面必须有一个,而且只有一个。这个标签定义了网页的标题,也是上述所有标签中对SEO最重要的标签,最好能反映网页的关键词或关键词。但是不要滥用标题标签,如果文字错误,可能会被搜索引擎视为作弊。
额外提一下,H1、H2、H3...这种类型的标签对SEO也有帮助,但基本上与WordPress主题无关,需要在编写内容时添加。在主页和列表页,文章 标题在一般主题中会标有 H2。因为在一个页面中,H1只能使用一次,否则也会造成SEO不当。
2、结构化数据
说白了,结构化数据就是网页除了title、url、description这三个要素外,还可以向搜索引擎提交更多的信息,在搜索结果页展示更多的信息,获得更好的排名。
结构化数据代码分为三种类型:JSON-LD、微数据和 RDFa。无论是谷歌还是百度,都推荐使用 JSON-LD 格式。
一般的 WordPress 主题不会自动生成结构化数据,除非您自己添加相应的代码,或者使用 SEO 插件。强烈建议使用 Yoast SEO 或 Rank Math SEO 来生成规范的结构化数据。其中,Rank Math PRO可以自定义结构化数据的内容,这样除了结构化数据外,还可以添加百度尊重的结构化数据代码。或者在文章页面模板中添加如下代码,添加百度结构化数据。
{
"@context": "https://ziyuan.baidu.com/conte ... ot%3B,
"@id": "",
"title": "",
"images": [
""
],
"description":"",
"pubDate": "",
"upDate":""
}
注:是 Google、Bing、Yandex 和 Yahoo! 合作的结果 它已被包括百度在内的几乎所有主要搜索引擎支持。只是百度目前更喜欢上面例子的结构化数据,未来可能会改变这种看法。
3、网页加载速度
无论是哪个搜索引擎,网页和相关静态资源的加载速度都非常重要。WordPress主题对这方面的影响分为两部分,一是动态加载速度,二是静态缓存后的加载速度。
动态加载速度
对于不使用静态缓存的网页,程序代码的编码质量、服务器性能、服务器运行环境、网络带宽、网络状况等因素都会影响动态加载速度。因为每次访问网页,都是由后端的PHP程序生成前端网页,然后传递给浏览器。整个过程比较缓慢。
虽然 WordPress 有很多静态缓存方案,但有些情况不适合缓存,比如:用 WooCommerce 搭建的商店、需要动态展示的网页、具有交互功能的网页等。
在上面提到的影响动态加载速度的因素中,与主题相关的主要是程序代码的编码质量。这个话题比较大,不能一两句话完全解释清楚,但是有以下几个原则供大家参考。便于选择优质主题的参考。
静态缓存后的加载速度
静态缓存之后的术语对于 WordPress 站长来说一定很熟悉。WordPress本身不支持静态,但是有很多插件可以实现网页的静态缓存。例如:WP Rocket、W3 Total Cache、WP Super Cache 等。
经过静态缓存处理后,用户在访问网页时不需要像动态网页那样在后端临时生成前端页面。尤其是上面提到的三个缓存插件,无论是 Nginx 还是 Apache,都可以直接调用缓存的内容交付,无需 PHP 处理。PS:WP Rocket 需要在 Nginx 环境中额外安装 Rocket-Nginx。
这样,静态缓存后的网页加载速度大大提高,基本上只取决于网络带宽、网络条件和服务器静态资源的并发性能。也就是说,对于 WordPress 主题,只要不加载太多、庞大的静态资产,就可以获得良好的加载速度。
看到这里,基本可以得出一个结论,只要大部分主题都是静态缓存处理的,加载速度不会有太大影响。使用静态缓存,这不太可能成为影响 SEO 的条件。
4、网页渲染速度
网页渲染速度和加载速度不同,加载完成不代表渲染完成。浏览器在默认加载网页的静态资源时,是按顺序加载的,浏览器会延迟页面的渲染,直到完成加载、解析并执行完页面中引用的所有CSS文件。
还有一些js文件,同样会阻塞页面渲染过程,但是可以通过异步加载进行优化。
网页渲染速度对SEO的影响也很大,但是对百度搜索的影响稍微小一些,因为百度仍然使用爬虫机制,而且GoogleSpider已经调整,这意味着谷歌不仅会在渲染完成后抓取网页. 同时还分析了网页渲染的过程和速度,从而判断网页的浏览体验。
虽然百度在这方面有些落后,但也只是时间问题,因为百度的移动爬虫已经做了很大的调整。
在这一点上,国外的主题大多处理得很好,因为开发者一般使用 PageSpeed Insights 分数作为衡量标准。
5、网页代码是否有错误
这是一个基本要求。如果网页出现代码错误或者调用某些404资源,都会严重影响SEO。稍微成熟的WordPress主题不会有这个问题,但是需要提醒的是,一些国外的主题可能会加载一些在大陆无法正常访问的资源,比如谷歌字体、谷歌前端公共库等,仍然会不利。搜索引擎优化。
综上所述
如果阅读本文,WordPress 主题对 SEO 有影响吗?有什么影响?结论已经揭晓。
第一个和第二个方面可以通过额外的 SEO 插件来解决。第三点可以通过静态缓存进行优化。第四点需要下功夫打磨,有很多功能插件可以优化PageSpeed Insights分数。最后,第5点。使用国外主题时,建议仔细检查是否加载了谷歌的部分公共资源。建议将谷歌前端公共库和谷歌字体注释掉,或者通过插件禁用。
内容为王,其他手段只起到辅助作用,所以我劝大家不要本末倒置。做好用户需要的内容,提升用户体验,是最重要的SEO优化。 查看全部
php抓取网页标签(WordPress主题是否会影响SEO效果的几个方面SEO标签数据)
WordPress 主题是否会影响 SEO 优化。要理解这个问题,并不难,首先要了解SEO与哪些方面有关,这些方面是否与WordPress主题有关。本文将讨论主题的哪些方面影响 SEO。
因为WordPress主题与写作内容无关,原创、写作质量、专业性等本文将不予讨论,虽然这些是最影响搜索引擎收录和排名的。
WordPress主题影响SEO效果的几个方面SEO标签结构化数据页面加载速度页面渲染速度页面代码错误1、SEO标签
许多主题都会带有一些 SEO 标签,通常包括以下内容:
机器人META标签
上述标签告诉搜索引擎允许抓取该页面并允许以下链接。
inindex,follow:允许爬取这个页面,允许关注链接。index,nofollow:允许抓取此页面,但不允许以下链接。noindex,follow:禁止抓取该页面,但允许以下链接。noindex,nofllow:禁止爬取该页面,禁止在该页面点击链接。rel =“规范”标签
本页应用示例:
早在 2009 年 2 月,Google、Yahoo 和 live search 就宣布支持 Link 的新属性 Canonical。主要目的是帮助搜索引擎解决存在多个版本的网站内容,制定标准化的链接,防止同一个内容重复收录。
这个标签在 WordPress 中很重要,因为 WordPress 可能有伪静态 URL,默认 ?p=123 URL,或者其他一些参数后缀,但是它们的内容是完全一样的,通过 rel=”canonical” 标签可以避免重复 收录,现在所有主要搜索引擎都支持它。
描述 META 标签
例子:
描述标签,顾名思义,就是对网页的简单描述/摘录,可以让搜索引擎更快地掌握网页的基本内容。曾经有关键字标签(定义 关键词),但现在正在逐步淘汰。
标题标签
例子:
WordPress主题是否会影响SEO效果 - 站长帮
对于SEO来说,最重要的是标题标签,每个页面必须有一个,而且只有一个。这个标签定义了网页的标题,也是上述所有标签中对SEO最重要的标签,最好能反映网页的关键词或关键词。但是不要滥用标题标签,如果文字错误,可能会被搜索引擎视为作弊。
额外提一下,H1、H2、H3...这种类型的标签对SEO也有帮助,但基本上与WordPress主题无关,需要在编写内容时添加。在主页和列表页,文章 标题在一般主题中会标有 H2。因为在一个页面中,H1只能使用一次,否则也会造成SEO不当。
2、结构化数据
说白了,结构化数据就是网页除了title、url、description这三个要素外,还可以向搜索引擎提交更多的信息,在搜索结果页展示更多的信息,获得更好的排名。
结构化数据代码分为三种类型:JSON-LD、微数据和 RDFa。无论是谷歌还是百度,都推荐使用 JSON-LD 格式。
一般的 WordPress 主题不会自动生成结构化数据,除非您自己添加相应的代码,或者使用 SEO 插件。强烈建议使用 Yoast SEO 或 Rank Math SEO 来生成规范的结构化数据。其中,Rank Math PRO可以自定义结构化数据的内容,这样除了结构化数据外,还可以添加百度尊重的结构化数据代码。或者在文章页面模板中添加如下代码,添加百度结构化数据。
{
"@context": "https://ziyuan.baidu.com/conte ... ot%3B,
"@id": "",
"title": "",
"images": [
""
],
"description":"",
"pubDate": "",
"upDate":""
}
注:是 Google、Bing、Yandex 和 Yahoo! 合作的结果 它已被包括百度在内的几乎所有主要搜索引擎支持。只是百度目前更喜欢上面例子的结构化数据,未来可能会改变这种看法。
3、网页加载速度
无论是哪个搜索引擎,网页和相关静态资源的加载速度都非常重要。WordPress主题对这方面的影响分为两部分,一是动态加载速度,二是静态缓存后的加载速度。
动态加载速度
对于不使用静态缓存的网页,程序代码的编码质量、服务器性能、服务器运行环境、网络带宽、网络状况等因素都会影响动态加载速度。因为每次访问网页,都是由后端的PHP程序生成前端网页,然后传递给浏览器。整个过程比较缓慢。
虽然 WordPress 有很多静态缓存方案,但有些情况不适合缓存,比如:用 WooCommerce 搭建的商店、需要动态展示的网页、具有交互功能的网页等。
在上面提到的影响动态加载速度的因素中,与主题相关的主要是程序代码的编码质量。这个话题比较大,不能一两句话完全解释清楚,但是有以下几个原则供大家参考。便于选择优质主题的参考。
静态缓存后的加载速度
静态缓存之后的术语对于 WordPress 站长来说一定很熟悉。WordPress本身不支持静态,但是有很多插件可以实现网页的静态缓存。例如:WP Rocket、W3 Total Cache、WP Super Cache 等。
经过静态缓存处理后,用户在访问网页时不需要像动态网页那样在后端临时生成前端页面。尤其是上面提到的三个缓存插件,无论是 Nginx 还是 Apache,都可以直接调用缓存的内容交付,无需 PHP 处理。PS:WP Rocket 需要在 Nginx 环境中额外安装 Rocket-Nginx。
这样,静态缓存后的网页加载速度大大提高,基本上只取决于网络带宽、网络条件和服务器静态资源的并发性能。也就是说,对于 WordPress 主题,只要不加载太多、庞大的静态资产,就可以获得良好的加载速度。
看到这里,基本可以得出一个结论,只要大部分主题都是静态缓存处理的,加载速度不会有太大影响。使用静态缓存,这不太可能成为影响 SEO 的条件。
4、网页渲染速度
网页渲染速度和加载速度不同,加载完成不代表渲染完成。浏览器在默认加载网页的静态资源时,是按顺序加载的,浏览器会延迟页面的渲染,直到完成加载、解析并执行完页面中引用的所有CSS文件。
还有一些js文件,同样会阻塞页面渲染过程,但是可以通过异步加载进行优化。
网页渲染速度对SEO的影响也很大,但是对百度搜索的影响稍微小一些,因为百度仍然使用爬虫机制,而且GoogleSpider已经调整,这意味着谷歌不仅会在渲染完成后抓取网页. 同时还分析了网页渲染的过程和速度,从而判断网页的浏览体验。
虽然百度在这方面有些落后,但也只是时间问题,因为百度的移动爬虫已经做了很大的调整。
在这一点上,国外的主题大多处理得很好,因为开发者一般使用 PageSpeed Insights 分数作为衡量标准。
5、网页代码是否有错误
这是一个基本要求。如果网页出现代码错误或者调用某些404资源,都会严重影响SEO。稍微成熟的WordPress主题不会有这个问题,但是需要提醒的是,一些国外的主题可能会加载一些在大陆无法正常访问的资源,比如谷歌字体、谷歌前端公共库等,仍然会不利。搜索引擎优化。
综上所述
如果阅读本文,WordPress 主题对 SEO 有影响吗?有什么影响?结论已经揭晓。
第一个和第二个方面可以通过额外的 SEO 插件来解决。第三点可以通过静态缓存进行优化。第四点需要下功夫打磨,有很多功能插件可以优化PageSpeed Insights分数。最后,第5点。使用国外主题时,建议仔细检查是否加载了谷歌的部分公共资源。建议将谷歌前端公共库和谷歌字体注释掉,或者通过插件禁用。
内容为王,其他手段只起到辅助作用,所以我劝大家不要本末倒置。做好用户需要的内容,提升用户体验,是最重要的SEO优化。

