
php抓取网页标签
php抓取网页标签(XHTML+CSS设计网页的属性及用法做详细的介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-04-12 22:27
我们一直在强调文章中的语义,那么如何使用HTML标签呢?它们一般用在什么地方?
刚接触XHTML+CSS设计网页的时候,对标签的使用没有经验,很随意。但是随着对搜索引擎优化知识的深入学习和了解,发现标签的使用其实也是一种知识。
这里就不详细介绍CSS中各个标签的属性和用法了,重点介绍在网页中的应用,希望对大家有所帮助。
一、DIV
DIV 对于 XHTML 建站的朋友应该不陌生。许多网站 和材质也被称为Web 标准网站 构造为DIV+CSS网站 构造。这么称呼也不无道理,因为W3C不建议在网页布局中使用Table标签,而作为布局标签的DIV自然会承担布局的重任。
DIV也可以说是一个大容器。除了网页的整体结构布局外,建议对网页中看似相对独立的区域进行划分。就像报纸一样,DIV 的作用是分割一个收录不同内容的大容器。在不同的地区,根据具体情况选择合适的标签。
二、H 标签
H标签是一个标题标签,经常用在段落之前,表示该段落想要表达什么。根据显示的层次和要表达的意义,可分为H1~H6。
H1 是最重要的,通常用于表达对整个网站 的角色和性质的描述,或者表明网站 的受众。其他选项卡用于显示部分的名称,或介绍性文本段落的一般描述,具体取决于级别。
因为它代表了对网站或某段文字的概括描述,所以H标签相对于搜索引擎具有很高的价值。但这并不意味着它可以随意使用。例如,一些网站使用H标签在一段文字中显示关键词,以刻意追求特定关键词的排名。或者干脆使用 H 标签作为容器来布局网页。这完全混淆了H标签的作用,不推荐。
三、P
P 是一个段落标签,用于区分一组文本的不同段落。第一个 P 标签中的文本在搜索引擎的抓取顺序中也具有很高的价值。比如百度,它忽略了Meta标签描述(description)中的文字,抓取第一个P标签中的内容(不是绝对的)。
一些网站在切分时会使用<br />标签,以便让搜索引擎抓取更多内容,为用户提供浏览体验。这并不是说不可能,有时甚至根本达不到预期的效果。对于严格类型(Strict)的文档,<br /> 是一种表达标签形式,不允许使用。
尽管大多数 网站 使用过渡文档类型,但我不建议将它们用于文本段落。
四、UL 和 LI 标签
这是一个无序列表,UL标签是列表的声明,LI是列表项。由于其item的相对独立性,常用于导航、新闻或文章列表等地方。UL 也可以作为容器来区分不同的列表。
有的网站可以追求“Web标准”,将Table转换为UL和LI,这使得网页难以阅读和维护,错误的理解正好违背了Web标准传达给我们的概念。
五、表
Table的用法我这里就不过多介绍了,只是想说Web标准并没有说以后不能用Table,但是不推荐用Table来布局,而且是仅在显示数据时使用。因此,Web 页面和 Table 标签的使用并不矛盾。
六、 搜索引擎标签
(1)Title:网页的标题,对网站的描述。子标签对搜索引擎也很有价值,通常包括目标关键字。
(2)元关键字:网页中的主要关键字。本来是为了方便搜索引擎对网站进行分类而准备的,后来由于很多网站为了使关键字排名更好 有利的是,这个标签经常被用来作弊,所以现在这个标签对搜索引擎几乎没有意义。
(3)Meta's Description: 网页的描述。和关键词一样,最初是为了方便搜索引擎分类而设计的。也因为很多网站使用这个标签作弊,所以搜索不到了引擎。如此重要。目前主流搜索引擎中只有谷歌还在抓取其内容,但几乎没有根据其内容确定关键词。
事实上,对于搜索引擎来说,最重要的是内容的质量。同样,我们所做的网站 是向观众宣传我们自己。请不要因为短期而忘记基本面。毕竟用户关心的是信息是否是他们需要的,而不是你的网站排名。
«
» 查看全部
php抓取网页标签(XHTML+CSS设计网页的属性及用法做详细的介绍)
我们一直在强调文章中的语义,那么如何使用HTML标签呢?它们一般用在什么地方?
刚接触XHTML+CSS设计网页的时候,对标签的使用没有经验,很随意。但是随着对搜索引擎优化知识的深入学习和了解,发现标签的使用其实也是一种知识。
这里就不详细介绍CSS中各个标签的属性和用法了,重点介绍在网页中的应用,希望对大家有所帮助。
一、DIV
DIV 对于 XHTML 建站的朋友应该不陌生。许多网站 和材质也被称为Web 标准网站 构造为DIV+CSS网站 构造。这么称呼也不无道理,因为W3C不建议在网页布局中使用Table标签,而作为布局标签的DIV自然会承担布局的重任。
DIV也可以说是一个大容器。除了网页的整体结构布局外,建议对网页中看似相对独立的区域进行划分。就像报纸一样,DIV 的作用是分割一个收录不同内容的大容器。在不同的地区,根据具体情况选择合适的标签。
二、H 标签
H标签是一个标题标签,经常用在段落之前,表示该段落想要表达什么。根据显示的层次和要表达的意义,可分为H1~H6。
H1 是最重要的,通常用于表达对整个网站 的角色和性质的描述,或者表明网站 的受众。其他选项卡用于显示部分的名称,或介绍性文本段落的一般描述,具体取决于级别。
因为它代表了对网站或某段文字的概括描述,所以H标签相对于搜索引擎具有很高的价值。但这并不意味着它可以随意使用。例如,一些网站使用H标签在一段文字中显示关键词,以刻意追求特定关键词的排名。或者干脆使用 H 标签作为容器来布局网页。这完全混淆了H标签的作用,不推荐。
三、P
P 是一个段落标签,用于区分一组文本的不同段落。第一个 P 标签中的文本在搜索引擎的抓取顺序中也具有很高的价值。比如百度,它忽略了Meta标签描述(description)中的文字,抓取第一个P标签中的内容(不是绝对的)。
一些网站在切分时会使用<br />标签,以便让搜索引擎抓取更多内容,为用户提供浏览体验。这并不是说不可能,有时甚至根本达不到预期的效果。对于严格类型(Strict)的文档,<br /> 是一种表达标签形式,不允许使用。
尽管大多数 网站 使用过渡文档类型,但我不建议将它们用于文本段落。
四、UL 和 LI 标签
这是一个无序列表,UL标签是列表的声明,LI是列表项。由于其item的相对独立性,常用于导航、新闻或文章列表等地方。UL 也可以作为容器来区分不同的列表。
有的网站可以追求“Web标准”,将Table转换为UL和LI,这使得网页难以阅读和维护,错误的理解正好违背了Web标准传达给我们的概念。
五、表
Table的用法我这里就不过多介绍了,只是想说Web标准并没有说以后不能用Table,但是不推荐用Table来布局,而且是仅在显示数据时使用。因此,Web 页面和 Table 标签的使用并不矛盾。
六、 搜索引擎标签
(1)Title:网页的标题,对网站的描述。子标签对搜索引擎也很有价值,通常包括目标关键字。
(2)元关键字:网页中的主要关键字。本来是为了方便搜索引擎对网站进行分类而准备的,后来由于很多网站为了使关键字排名更好 有利的是,这个标签经常被用来作弊,所以现在这个标签对搜索引擎几乎没有意义。
(3)Meta's Description: 网页的描述。和关键词一样,最初是为了方便搜索引擎分类而设计的。也因为很多网站使用这个标签作弊,所以搜索不到了引擎。如此重要。目前主流搜索引擎中只有谷歌还在抓取其内容,但几乎没有根据其内容确定关键词。
事实上,对于搜索引擎来说,最重要的是内容的质量。同样,我们所做的网站 是向观众宣传我们自己。请不要因为短期而忘记基本面。毕竟用户关心的是信息是否是他们需要的,而不是你的网站排名。
«
»
php抓取网页标签(反馈您可以通过推送后返回的状态码和字段来判断数据是否成功)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-04-12 22:25
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
回显 $result;
4)ruby 推送示例
需要'net/http'
网址 = ['#39;, '#39;]
uri = URI.parse('
site=&token=eTk7ychrWZP1pDQD')
req = Net::HTTP::Post.new(uri.request_uri)
req.body = urls.join("\n")
req.content_type = '文本/纯文本'
res = Net::HTTP.start(uri.hostname, uri.port) { |http| http.request(req) }
puts res.body 如何查看推送反馈
可以通过推送后返回的状态码和字段判断数据是否推送成功。
1,状态码为200,表示推送成功,可能返回以下字段:
字段
是否需要
参数类型
说明
成功
是的
int
成功推送的网址数
留下
是的
int
当天剩余的可推送网址数
not_same_site
没有
数组
未处理的网址列表,因为它们不是本网站的网址
无效
没有
数组
非法网址列表
成功返回示例:
{
“剩余”:4999998,
“成功”:2,
"not_same_site":[],
"not_valid":[]
}
2、状态码为4XX或500,表示推送失败,返回字段为:
字段
是否需要
类型
说明
错误
是的
int
错误码,同状态码
消息
是的
字符串
错误描述
常见推送失败返回示例说明:
错误
消息
意义
400
网站错误
网站未经站长平台验证
空内容
帖子内容为空
一次只允许 2000 个网址
一次最多只能提交 2000 个链接
超额
超过每日限额,超过限额后提交无效
401
令牌无效
令牌错误
404
找不到
接口地址填写错误
500
内部错误,请稍后再试
偶尔服务器异常,一般重试会成功
1、与原来的sitemap提交界面有什么区别?
答:状态反馈更及时。本来,提交后需要登录站长平台查看是否提交成功。目前只能根据提交后返回的数据来判断。
2、现有提交站点地图数据的程序代码需要修改什么?
回答:主要有两个变化。第一点是提交的接口需要修改;第二点是需要对接口返回的信息进行处理。失败后,需要根据错误进行处理。报错链接无法提交成功
3、为什么提交成功后看不到数据变化?
回答:我们的反馈是新提交的链接数量。如果您提交的链接之前已经提交过(即重复提交),则不计入内
4。什么时候使用主动推送提交功能最有效?
回答:页面链接生成或发布时立即提交,这样效果最好
5、一次提交一份数据和多份数据有什么区别?
答案:没有区别
6。重新提交已经发布的链接有什么问题?
A:会有两种效果。首先,您提交的配额将被浪费。每个站点每天可以提交的提交数量是有限制的。如果您提交了旧链接,当有新链接时,您可能会因为配额用尽而无法提交。二、如果您频繁重复提交旧链接,我们会减少您的配额,您可能会失去主动推送功能的权限
7、主动推送可以推送多少个链接?
回答:主动推送可以提交的链接数量上限是根据您提交的新生成的有价值链接的数量来确定的。百度会根据提交新链接的数量不时调整上限。链接数越多,可以提交的链接数限制就越高。
站点地图是您的 网站 上的页面列表。创建和提交站点地图有助于百度发现和了解您 网站 上的所有页面。您也可以通过 Sitemap 提供关于您的其他信息网站,例如最后更新日期、Sitemap 文件的更新频率等,供百度蜘蛛参考。
百度不保证所有网址都会被抓取并索引提交的数据。但是,我们会使用 Sitemap 中的数据来了解 网站 的结构,这可以帮助我们改进我们的抓取策略,并在未来更好地抓取 网站。
此外,站点地图对搜索排名没有影响。
百度Sitemap协议支持三种格式:文本格式、xml格式、Sitemap索引格式。您可以根据自己的情况选择任何格式来组织站点地图。具体格式说明及示例如下:
以txt文本列出需要提交给百度的链接地址,通过站长平台提交txt文本文件
此文本文件需要以下准则:
·文本文件每行必须有一个URL。 URL 中不能有换行符。
·不应收录除 URL 列表以外的任何信息。
·你必须写完整的URL,包括http。
·每个文本文件最多可收录 50,000 个 URL,并且应小于 10MB(10,485,760 字节)。如果 网站 收录超过 50,000 个 URL,您可以将列表拆分为多个文本文件并单独添加每个文件。
·文本文件需要使用UTF-8编码或者GBK编码。
单个xml数据的格式如下:
2009-12-14
每天
0.8
2010-05-01
每天
0.8
以上Sitemap向百度提交了一个url:
如果有多个url,按照上面的格式重复分段,列出所有url地址,打包成xml文件,提交给站长平台。
首先,站点地图文件收录的网址不得超过 50,000 个,并且大小不得超过 10 MB。如果您的站点地图超出这些限制,请将其拆分为几个较小的站点地图。这些限制有助于确保您的网络服务器不会因提供大文件而过载。
其次,站点支持的站点地图文件数量必须少于 50,000 个。如果sitemap文件数量超过50000个,则不处理,并提示“链接数过多”。
第三,如果网站的主域被验证,Sitemap文件可以收录网站主域下的所有URL。
第一步是制作要提交到站点地图文件中的网页列表。文件格式请阅读百度站点地图协议支持哪些格式。
第二步是将Sitemap文件放到网站目录下。比如你的网站是,你已经创建了sitemap_example.xml的Sitemap文件,上传sitemap_example.xml到网站根目录或者/sitemap_example.xml
第三步,登录百度站长平台,确保提交Sitemap数据的网站已经验证了归属。
第四步,进入Sitemap工具,点击“Add New Data”,文件类型选择“URL List”,并填写爬取周期和Sitemap文件地址
最后,提交后,可以在Sitemap列表中看到提交的Sitemap文件。如果Sitemap文件中有新的网站链接,可以选中该文件,点击Update进行选择,即更新网站链接。 @网站链接已提交。
百度推出了移动站点地图协议,用于将 URL 提交到移动搜索收录。百度手机Sitemap协议是在标准Sitemap协议的基础上制定的,增加了标签。它有四个值:
没有上述标签,表示为PC网页
下面的例子相当于向百度手机搜索提交了一个手机网页:,
向 PC Search 提交了一个传统网页:,
向移动和 PC 搜索提交了自适应网页:
xmlns:mobile="">
2009-12-14
每天
0.8
2009-12-14
每天
0.8
2009-12-14
每天
0.8
2009-12-14
每天
0.8
按照Mobile Sitemap协议完成Sitemap后,在Sitemap工具中点击Add New Data提交,与提交普通Sitemap相同。
百度蜘蛛会参考设置周期抓取Sitemap文件,请根据Sitemap文件内容的更新进行设置(如添加新的url)。请注意,如果url保持不变,只是更新了url对应的页面内容(例如论坛发帖页面有新回复),则不在本次更新范围内。 Sitemap 工具无法解决页面更新问题。
Sitemap数据提交后,百度一般会在1小时内开始处理。在以后的定时爬取中,如果您的站点地图支持etag,我们会更频繁地爬取站点地图文件,及时发现内容更新;否则,爬取周期会更长。
百度不保证提交的数据会被抓取到收录所有的网址。 收录 是否与页面质量有关。
是的。请使用 gzip 压缩站点地图。站点地图应小于 10MB(10,485,759 字节),无论是否压缩。
没有。 Sitemap 中的“优先级”提示仅表明该 URL 相对于您自己 网站 上的其他 URL 的重要性,不会影响页面在搜索结果中的排名。
没有。站点地图中 URL 的位置不会影响百度识别或使用它的方式。
由于转码问题,建议不要收录中文。
【特别提醒】本工具暂时下线,如恢复,将另行通知。
自动推送JS代码是百度站长平台最新推出的轻量级链接提交组件。站长只需要将自动推送的JS代码放置在网站各个页面的源码中即可。当页面被访问时,页面链接会自动推送到百度,有利于百度更快发现新页面。
为了更快速地发现网站每天产生的最新内容,百度站长平台推出了主动推送工具。产品上线后,有站长反映使用主动推送的技术门槛比较高,所以我们顺势推出了成本更低的JS自动推送工具。一步安装,实现页面自动推送,成本低,利润高。
站长需要在每个页面的HTML代码中收录如下自动推送JS代码:
如果站长使用PHP语言开发的网站,可以按照以下步骤进行:
1、创建一个名为“baidu_js_push.php”的文件,文件内容为上述自动推送JS代码;
2、在每个PHP模板页面文件的标签后添加一行代码:
基于自动推送的实现原理,每次浏览新页面,页面URL都会自动推送到百度,无需站长聚合URL再进行主动推送操作。
利用用户的浏览行为触发推送动作,节省站长手动操作的时间。
链接提交中已经使用主动推送(或站点地图)的网站是否还需要部署自动推送代码?
两者不冲突,相得益彰。已经使用主动推送的站点仍然可以部署自动推送的JS代码,两者可以一起使用。
自动推送适用于技术能力相对较弱,无法支持全天候实时主动推送方案的站长,因为实施方便,后续维护成本低。
站长只需要部署一次自动推送JS代码的操作,就可以实现浏览时推送新页面的效果,低成本实现链接的自动提交。
同时我们也支持使用主动推送和自动推送代码,两者互不影响。 查看全部
php抓取网页标签(反馈您可以通过推送后返回的状态码和字段来判断数据是否成功)
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
回显 $result;
4)ruby 推送示例
需要'net/http'
网址 = ['#39;, '#39;]
uri = URI.parse('
site=&token=eTk7ychrWZP1pDQD')
req = Net::HTTP::Post.new(uri.request_uri)
req.body = urls.join("\n")
req.content_type = '文本/纯文本'
res = Net::HTTP.start(uri.hostname, uri.port) { |http| http.request(req) }
puts res.body 如何查看推送反馈
可以通过推送后返回的状态码和字段判断数据是否推送成功。
1,状态码为200,表示推送成功,可能返回以下字段:
字段
是否需要
参数类型
说明
成功
是的
int
成功推送的网址数
留下
是的
int
当天剩余的可推送网址数
not_same_site
没有
数组
未处理的网址列表,因为它们不是本网站的网址
无效
没有
数组
非法网址列表
成功返回示例:
{
“剩余”:4999998,
“成功”:2,
"not_same_site":[],
"not_valid":[]
}
2、状态码为4XX或500,表示推送失败,返回字段为:
字段
是否需要
类型
说明
错误
是的
int
错误码,同状态码
消息
是的
字符串
错误描述
常见推送失败返回示例说明:
错误
消息
意义
400
网站错误
网站未经站长平台验证
空内容
帖子内容为空
一次只允许 2000 个网址
一次最多只能提交 2000 个链接
超额
超过每日限额,超过限额后提交无效
401
令牌无效
令牌错误
404
找不到
接口地址填写错误
500
内部错误,请稍后再试
偶尔服务器异常,一般重试会成功
1、与原来的sitemap提交界面有什么区别?
答:状态反馈更及时。本来,提交后需要登录站长平台查看是否提交成功。目前只能根据提交后返回的数据来判断。
2、现有提交站点地图数据的程序代码需要修改什么?
回答:主要有两个变化。第一点是提交的接口需要修改;第二点是需要对接口返回的信息进行处理。失败后,需要根据错误进行处理。报错链接无法提交成功
3、为什么提交成功后看不到数据变化?
回答:我们的反馈是新提交的链接数量。如果您提交的链接之前已经提交过(即重复提交),则不计入内
4。什么时候使用主动推送提交功能最有效?
回答:页面链接生成或发布时立即提交,这样效果最好
5、一次提交一份数据和多份数据有什么区别?
答案:没有区别
6。重新提交已经发布的链接有什么问题?
A:会有两种效果。首先,您提交的配额将被浪费。每个站点每天可以提交的提交数量是有限制的。如果您提交了旧链接,当有新链接时,您可能会因为配额用尽而无法提交。二、如果您频繁重复提交旧链接,我们会减少您的配额,您可能会失去主动推送功能的权限
7、主动推送可以推送多少个链接?
回答:主动推送可以提交的链接数量上限是根据您提交的新生成的有价值链接的数量来确定的。百度会根据提交新链接的数量不时调整上限。链接数越多,可以提交的链接数限制就越高。
站点地图是您的 网站 上的页面列表。创建和提交站点地图有助于百度发现和了解您 网站 上的所有页面。您也可以通过 Sitemap 提供关于您的其他信息网站,例如最后更新日期、Sitemap 文件的更新频率等,供百度蜘蛛参考。
百度不保证所有网址都会被抓取并索引提交的数据。但是,我们会使用 Sitemap 中的数据来了解 网站 的结构,这可以帮助我们改进我们的抓取策略,并在未来更好地抓取 网站。
此外,站点地图对搜索排名没有影响。
百度Sitemap协议支持三种格式:文本格式、xml格式、Sitemap索引格式。您可以根据自己的情况选择任何格式来组织站点地图。具体格式说明及示例如下:
以txt文本列出需要提交给百度的链接地址,通过站长平台提交txt文本文件
此文本文件需要以下准则:
·文本文件每行必须有一个URL。 URL 中不能有换行符。
·不应收录除 URL 列表以外的任何信息。
·你必须写完整的URL,包括http。
·每个文本文件最多可收录 50,000 个 URL,并且应小于 10MB(10,485,760 字节)。如果 网站 收录超过 50,000 个 URL,您可以将列表拆分为多个文本文件并单独添加每个文件。
·文本文件需要使用UTF-8编码或者GBK编码。
单个xml数据的格式如下:
2009-12-14
每天
0.8
2010-05-01
每天
0.8
以上Sitemap向百度提交了一个url:
如果有多个url,按照上面的格式重复分段,列出所有url地址,打包成xml文件,提交给站长平台。
首先,站点地图文件收录的网址不得超过 50,000 个,并且大小不得超过 10 MB。如果您的站点地图超出这些限制,请将其拆分为几个较小的站点地图。这些限制有助于确保您的网络服务器不会因提供大文件而过载。
其次,站点支持的站点地图文件数量必须少于 50,000 个。如果sitemap文件数量超过50000个,则不处理,并提示“链接数过多”。
第三,如果网站的主域被验证,Sitemap文件可以收录网站主域下的所有URL。
第一步是制作要提交到站点地图文件中的网页列表。文件格式请阅读百度站点地图协议支持哪些格式。
第二步是将Sitemap文件放到网站目录下。比如你的网站是,你已经创建了sitemap_example.xml的Sitemap文件,上传sitemap_example.xml到网站根目录或者/sitemap_example.xml
第三步,登录百度站长平台,确保提交Sitemap数据的网站已经验证了归属。
第四步,进入Sitemap工具,点击“Add New Data”,文件类型选择“URL List”,并填写爬取周期和Sitemap文件地址
最后,提交后,可以在Sitemap列表中看到提交的Sitemap文件。如果Sitemap文件中有新的网站链接,可以选中该文件,点击Update进行选择,即更新网站链接。 @网站链接已提交。
百度推出了移动站点地图协议,用于将 URL 提交到移动搜索收录。百度手机Sitemap协议是在标准Sitemap协议的基础上制定的,增加了标签。它有四个值:
没有上述标签,表示为PC网页
下面的例子相当于向百度手机搜索提交了一个手机网页:,
向 PC Search 提交了一个传统网页:,
向移动和 PC 搜索提交了自适应网页:
xmlns:mobile="">
2009-12-14
每天
0.8
2009-12-14
每天
0.8
2009-12-14
每天
0.8
2009-12-14
每天
0.8
按照Mobile Sitemap协议完成Sitemap后,在Sitemap工具中点击Add New Data提交,与提交普通Sitemap相同。
百度蜘蛛会参考设置周期抓取Sitemap文件,请根据Sitemap文件内容的更新进行设置(如添加新的url)。请注意,如果url保持不变,只是更新了url对应的页面内容(例如论坛发帖页面有新回复),则不在本次更新范围内。 Sitemap 工具无法解决页面更新问题。
Sitemap数据提交后,百度一般会在1小时内开始处理。在以后的定时爬取中,如果您的站点地图支持etag,我们会更频繁地爬取站点地图文件,及时发现内容更新;否则,爬取周期会更长。
百度不保证提交的数据会被抓取到收录所有的网址。 收录 是否与页面质量有关。
是的。请使用 gzip 压缩站点地图。站点地图应小于 10MB(10,485,759 字节),无论是否压缩。
没有。 Sitemap 中的“优先级”提示仅表明该 URL 相对于您自己 网站 上的其他 URL 的重要性,不会影响页面在搜索结果中的排名。
没有。站点地图中 URL 的位置不会影响百度识别或使用它的方式。
由于转码问题,建议不要收录中文。
【特别提醒】本工具暂时下线,如恢复,将另行通知。
自动推送JS代码是百度站长平台最新推出的轻量级链接提交组件。站长只需要将自动推送的JS代码放置在网站各个页面的源码中即可。当页面被访问时,页面链接会自动推送到百度,有利于百度更快发现新页面。
为了更快速地发现网站每天产生的最新内容,百度站长平台推出了主动推送工具。产品上线后,有站长反映使用主动推送的技术门槛比较高,所以我们顺势推出了成本更低的JS自动推送工具。一步安装,实现页面自动推送,成本低,利润高。
站长需要在每个页面的HTML代码中收录如下自动推送JS代码:
如果站长使用PHP语言开发的网站,可以按照以下步骤进行:
1、创建一个名为“baidu_js_push.php”的文件,文件内容为上述自动推送JS代码;
2、在每个PHP模板页面文件的标签后添加一行代码:
基于自动推送的实现原理,每次浏览新页面,页面URL都会自动推送到百度,无需站长聚合URL再进行主动推送操作。
利用用户的浏览行为触发推送动作,节省站长手动操作的时间。
链接提交中已经使用主动推送(或站点地图)的网站是否还需要部署自动推送代码?
两者不冲突,相得益彰。已经使用主动推送的站点仍然可以部署自动推送的JS代码,两者可以一起使用。
自动推送适用于技术能力相对较弱,无法支持全天候实时主动推送方案的站长,因为实施方便,后续维护成本低。
站长只需要部署一次自动推送JS代码的操作,就可以实现浏览时推送新页面的效果,低成本实现链接的自动提交。
同时我们也支持使用主动推送和自动推送代码,两者互不影响。
php抓取网页标签( PHP中常用的实现页面自动跳转的方法有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-04-12 19:33
PHP中常用的实现页面自动跳转的方法有哪些?)
PHP页面跳转实现技巧
在 Web 系统中,从一个网页跳转到另一个网页是 LAMP 项目中最常用的技术之一。页面跳转可能是用户点击链接、按钮等引起的,也可能是系统自动生成的。下面介绍PHP中实现自动页面跳转的常用方法。我希望它对你有帮助。更多新闻,请关注应届毕业生网站!
PHP页面跳转一、header()函数
header() 函数是 PHP 中一个非常简单的页面跳转方法。header()函数的主要作用是将HTTP协议头(header)输出到浏览器。
header() 函数定义如下:
void header (string string [,bool replace [,int http_response_code]]) 可选参数replace表示是替换之前的相似头还是添加相同类型的头。默认为替换。
第二个可选参数 http_response_code 将 HTTP 响应代码强制为指定值。header函数中Location类型的header是一个特殊的header调用,常用于实现页面跳转。注意:1.location 和“:”之间不能有空格,否则不会跳转。
2.在使用标头之前必须没有输出。
3. 标头之后的 PHP 代码也将被执行。比如将浏览器重定向到Lamp Brothers官方论坛 <?php// 重定向浏览器
标题(“位置:
");
// 确保重定向后不会执行后续代码
出口;
PHP页面跳转二、元标记
Meta 标签是 HTML 中的标签,负责提供文档元信息。在PHP程序中使用这个标签也可以实现页面跳转。如果http-equiv定义为refresh,当页面打开时,会在一定时间内根据内容指定的值跳转到对应的页面。
如果设置 content="seconds;url=URL",它定义了页面跳转到指定 URL 后的时间。比如使用meta标签实现疫苗后,页面自动跳转到LAMP兄弟官方论坛。 查看全部
php抓取网页标签(
PHP中常用的实现页面自动跳转的方法有哪些?)
PHP页面跳转实现技巧
在 Web 系统中,从一个网页跳转到另一个网页是 LAMP 项目中最常用的技术之一。页面跳转可能是用户点击链接、按钮等引起的,也可能是系统自动生成的。下面介绍PHP中实现自动页面跳转的常用方法。我希望它对你有帮助。更多新闻,请关注应届毕业生网站!
PHP页面跳转一、header()函数
header() 函数是 PHP 中一个非常简单的页面跳转方法。header()函数的主要作用是将HTTP协议头(header)输出到浏览器。
header() 函数定义如下:
void header (string string [,bool replace [,int http_response_code]]) 可选参数replace表示是替换之前的相似头还是添加相同类型的头。默认为替换。
第二个可选参数 http_response_code 将 HTTP 响应代码强制为指定值。header函数中Location类型的header是一个特殊的header调用,常用于实现页面跳转。注意:1.location 和“:”之间不能有空格,否则不会跳转。
2.在使用标头之前必须没有输出。
3. 标头之后的 PHP 代码也将被执行。比如将浏览器重定向到Lamp Brothers官方论坛 <?php// 重定向浏览器
标题(“位置:
");
// 确保重定向后不会执行后续代码
出口;
PHP页面跳转二、元标记
Meta 标签是 HTML 中的标签,负责提供文档元信息。在PHP程序中使用这个标签也可以实现页面跳转。如果http-equiv定义为refresh,当页面打开时,会在一定时间内根据内容指定的值跳转到对应的页面。
如果设置 content="seconds;url=URL",它定义了页面跳转到指定 URL 后的时间。比如使用meta标签实现疫苗后,页面自动跳转到LAMP兄弟官方论坛。
php抓取网页标签( 有哪些方法可以实现php页面跳转跳转?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-04-11 19:07
有哪些方法可以实现php页面跳转跳转?(图))
PHP跳转到指定页面的问题,一般见于构造网站需求。例如,我们需要从一个页面跳转到另一个页面来实现某种功能或效果。其实PHP中实现页面跳转的方式有很多种,那么这篇文章文章就给大家介绍一下,有哪些方法可以实现PHP页面跳转呢?
首先我们需要了解两个知识点:
一:header()函数是PHP中一种非常简单的页面跳转方法。 header()函数的主要作用是将HTTP协议头(header)输出到浏览器。
第二:Meta标签是HTML中负责提供文档元信息的标签。在PHP程序中使用这个标签也可以实现页面跳转。如果http-equiv定义为refresh,当页面打开时,会在一定时间内根据内容指定的值跳转到对应的页面。如果设置 content="seconds;url=URL",它定义了页面跳转到指定 URL 后的时间。
然后php跳转到指定页面的header()函数。具体示例代码如下:
void header(string string [,bool replace [,int http_response_code]])//header()函数的定义
//重定向浏览器
header("位置:");
//保证重定向后不会执行后续代码
退出;
php 跳转到指定页面的 Meta 标签。具体示例代码如下:
“刷新”内容=“1;url=http://”> 查看全部
php抓取网页标签(
有哪些方法可以实现php页面跳转跳转?(图))

PHP跳转到指定页面的问题,一般见于构造网站需求。例如,我们需要从一个页面跳转到另一个页面来实现某种功能或效果。其实PHP中实现页面跳转的方式有很多种,那么这篇文章文章就给大家介绍一下,有哪些方法可以实现PHP页面跳转呢?
首先我们需要了解两个知识点:
一:header()函数是PHP中一种非常简单的页面跳转方法。 header()函数的主要作用是将HTTP协议头(header)输出到浏览器。
第二:Meta标签是HTML中负责提供文档元信息的标签。在PHP程序中使用这个标签也可以实现页面跳转。如果http-equiv定义为refresh,当页面打开时,会在一定时间内根据内容指定的值跳转到对应的页面。如果设置 content="seconds;url=URL",它定义了页面跳转到指定 URL 后的时间。
然后php跳转到指定页面的header()函数。具体示例代码如下:
void header(string string [,bool replace [,int http_response_code]])//header()函数的定义
//重定向浏览器
header("位置:");
//保证重定向后不会执行后续代码
退出;
php 跳转到指定页面的 Meta 标签。具体示例代码如下:
“刷新”内容=“1;url=http://”>
php抓取网页标签(php开发者来说源码,远程抓取图片小程序-小编分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-10 11:35
作为一个模仿站点工作者,当网站 有版权甚至加密时,WEBZIP 也会关闭。如何扣除网页上的图片和背景图片?有时,您可能会想到使用 Firefox。这个浏览器似乎是一个强大的错误。 文章 有版权,右键被屏蔽,Firefox 完全不受影响。
但是作为一个热爱php的开发者,我更喜欢自己做。于是,我写了如下源码,php远程抓图小程序。您可以读取 css 文件并在 css 代码中获取背景图像。下面的代码也是为了抓取css中的图片而写的。
array ( 'follow_location' => false // don't follow redirects ) ) ); //请确保php.ini中的fopen wrappers已经激活 readfile( $url,false,$context); $img = ob_get_contents(); ob_end_clean(); $fp2 = @fopen($filename,"a"); fwrite($fp2,$img); fclose($fp2); echo $filename." ok √
"; } &#63;>
如果不出意外,你会发现你指定的文件夹里全是图片,哈哈..
ps:php获取远程图片并下载并保存在本地
分享一个使用php获取远程图片并将远程图片下载保存到本地的功能代码:
/* *功能:php完美实现下载远程图片保存到本地 *参数:文件url,保存文件目录,保存文件名称,使用的下载方式 *当保存文件名称为空时则使用远程文件原来的名称 */ function getImage($url,$save_dir='',$filename='',$type=0){ if(trim($url)==''){ return array('file_name'=>'','save_path'=>'','error'=>1); } if(trim($save_dir)==''){ $save_dir='./'; } if(trim($filename)==''){//保存文件名 $ext=strrchr($url,'.'); if($ext!='.gif'&&$ext!='.jpg'){ return array('file_name'=>'','save_path'=>'','error'=>3); } $filename=time().$ext; } if(0!==strrpos($save_dir,'/')){ $save_dir.='/'; } //创建保存目录 if(!file_exists($save_dir)&&!mkdir($save_dir,0777,true)){ return array('file_name'=>'','save_path'=>'','error'=>5); } //获取远程文件所采用的方法 if($type){ $ch=curl_init(); $timeout=5; curl_setopt($ch,CURLOPT_URL,$url); curl_setopt($ch,CURLOPT_RETURNTRANSFER,1); curl_setopt($ch,CURLOPT_CONNECTTIMEOUT,$timeout); $img=curl_exec($ch); curl_close($ch); }else{ ob_start(); readfile($url); $img=ob_get_contents(); ob_end_clean(); } //$size=strlen($img); //文件大小 $fp2=@fopen($save_dir.$filename,'a'); fwrite($fp2,$img); fclose($fp2); unset($img,$url); return array('file_name'=>$filename,'save_path'=>$save_dir.$filename,'error'=>0); }
以上内容是小编分享给大家的PHP源码批量抓取远程网页图片并保存到本地的实现方法。希望你喜欢。
推荐内容:免费高清PNG素材下载 查看全部
php抓取网页标签(php开发者来说源码,远程抓取图片小程序-小编分享)
作为一个模仿站点工作者,当网站 有版权甚至加密时,WEBZIP 也会关闭。如何扣除网页上的图片和背景图片?有时,您可能会想到使用 Firefox。这个浏览器似乎是一个强大的错误。 文章 有版权,右键被屏蔽,Firefox 完全不受影响。
但是作为一个热爱php的开发者,我更喜欢自己做。于是,我写了如下源码,php远程抓图小程序。您可以读取 css 文件并在 css 代码中获取背景图像。下面的代码也是为了抓取css中的图片而写的。
array ( 'follow_location' => false // don't follow redirects ) ) ); //请确保php.ini中的fopen wrappers已经激活 readfile( $url,false,$context); $img = ob_get_contents(); ob_end_clean(); $fp2 = @fopen($filename,"a"); fwrite($fp2,$img); fclose($fp2); echo $filename." ok √
"; } &#63;>
如果不出意外,你会发现你指定的文件夹里全是图片,哈哈..
ps:php获取远程图片并下载并保存在本地
分享一个使用php获取远程图片并将远程图片下载保存到本地的功能代码:
/* *功能:php完美实现下载远程图片保存到本地 *参数:文件url,保存文件目录,保存文件名称,使用的下载方式 *当保存文件名称为空时则使用远程文件原来的名称 */ function getImage($url,$save_dir='',$filename='',$type=0){ if(trim($url)==''){ return array('file_name'=>'','save_path'=>'','error'=>1); } if(trim($save_dir)==''){ $save_dir='./'; } if(trim($filename)==''){//保存文件名 $ext=strrchr($url,'.'); if($ext!='.gif'&&$ext!='.jpg'){ return array('file_name'=>'','save_path'=>'','error'=>3); } $filename=time().$ext; } if(0!==strrpos($save_dir,'/')){ $save_dir.='/'; } //创建保存目录 if(!file_exists($save_dir)&&!mkdir($save_dir,0777,true)){ return array('file_name'=>'','save_path'=>'','error'=>5); } //获取远程文件所采用的方法 if($type){ $ch=curl_init(); $timeout=5; curl_setopt($ch,CURLOPT_URL,$url); curl_setopt($ch,CURLOPT_RETURNTRANSFER,1); curl_setopt($ch,CURLOPT_CONNECTTIMEOUT,$timeout); $img=curl_exec($ch); curl_close($ch); }else{ ob_start(); readfile($url); $img=ob_get_contents(); ob_end_clean(); } //$size=strlen($img); //文件大小 $fp2=@fopen($save_dir.$filename,'a'); fwrite($fp2,$img); fclose($fp2); unset($img,$url); return array('file_name'=>$filename,'save_path'=>$save_dir.$filename,'error'=>0); }
以上内容是小编分享给大家的PHP源码批量抓取远程网页图片并保存到本地的实现方法。希望你喜欢。
推荐内容:免费高清PNG素材下载
php抓取网页标签(php抓取网页标签的方法,使用php的selenium库抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-04-05 05:04
php抓取网页标签的方法
1、使用php的selenium库抓取index.php页面1.1安装phpwindlib:wgetphpinfo:phpwindlibphpinfo:phpwindlib1.2定位需要爬取的标签网址
2、使用正则表达式抓取网页标签的路径2.1安装python的正则表达式库dom4j2.2获取<a>标签
3、获取<a>标签的关键字3.1获取<a>标签的数组3.2获取<a>标签下的所有<a>标签并列举出来3.3获取<a>标签</a>标签的子标签
可以选择python3抓取网页js代码最后sqlite导出关键字页面。
python数据抓取|python从入门到实战网易云课堂下个专栏学python爬虫网易云课堂的python爬虫,有讲解各个主流框架如requests+beautifulsoup+selenium等,想要学的抓紧看。也有关于python3抓取数据(包括已有的datetime)也很赞。
一、将数据采集到localserver目录中可以采用pymongo库,爬取中文数据的话推荐pymongo-pymongo-python3.5.1documentation和pymongo-pymongo-python3.5.1documentation(github)用pymongo的两个主要原因是因为它的线程模型和一致,pymongo提供了`open`函数,对于一个爬虫程序来说,这个函数定义需要使用pymongo_close模块来关闭线程。open用于开始爬虫,stop关闭线程。
二、pandas提供了series存储数据以及dataframe功能不过一般情况下我们也不建议专门用pandas来爬取数据,比如要么想要抓取股票交易,要么想要爬取全国各个县市的数据,可以用numpy(numericalpreprocessing)。在这一块我写过一个爬虫:python爬虫实战第一章:我该往哪里找数据_野生python爱好者社区_python3.6.1documentation。同时github上也有pandas官方的教程:pandas3.4学习笔记-csdn博客。
三、python3.4及以上版本提供的一些nlp和research方法可以考虑,例如nlp中的query转换gif, 查看全部
php抓取网页标签(php抓取网页标签的方法,使用php的selenium库抓取)
php抓取网页标签的方法
1、使用php的selenium库抓取index.php页面1.1安装phpwindlib:wgetphpinfo:phpwindlibphpinfo:phpwindlib1.2定位需要爬取的标签网址
2、使用正则表达式抓取网页标签的路径2.1安装python的正则表达式库dom4j2.2获取<a>标签
3、获取<a>标签的关键字3.1获取<a>标签的数组3.2获取<a>标签下的所有<a>标签并列举出来3.3获取<a>标签</a>标签的子标签
可以选择python3抓取网页js代码最后sqlite导出关键字页面。
python数据抓取|python从入门到实战网易云课堂下个专栏学python爬虫网易云课堂的python爬虫,有讲解各个主流框架如requests+beautifulsoup+selenium等,想要学的抓紧看。也有关于python3抓取数据(包括已有的datetime)也很赞。
一、将数据采集到localserver目录中可以采用pymongo库,爬取中文数据的话推荐pymongo-pymongo-python3.5.1documentation和pymongo-pymongo-python3.5.1documentation(github)用pymongo的两个主要原因是因为它的线程模型和一致,pymongo提供了`open`函数,对于一个爬虫程序来说,这个函数定义需要使用pymongo_close模块来关闭线程。open用于开始爬虫,stop关闭线程。
二、pandas提供了series存储数据以及dataframe功能不过一般情况下我们也不建议专门用pandas来爬取数据,比如要么想要抓取股票交易,要么想要爬取全国各个县市的数据,可以用numpy(numericalpreprocessing)。在这一块我写过一个爬虫:python爬虫实战第一章:我该往哪里找数据_野生python爱好者社区_python3.6.1documentation。同时github上也有pandas官方的教程:pandas3.4学习笔记-csdn博客。
三、python3.4及以上版本提供的一些nlp和research方法可以考虑,例如nlp中的query转换gif,
php抓取网页标签(如何可能难到程序猿的图片采集方式怎么可能猿呢 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-03-31 06:05
)
有时候我们有这样的需求,在一系列的html页面中,提取整个img标签,或者提取img标签中的src属性,也就是我们需要的图片链接,不多说直接粘贴代码,代码如下:
function extract_img($tag) {
preg_match_all('/(id|alt|title|src)=("[^"]*")/i', $tag, $matches);
$ret = array();
foreach($matches[1] as $i => $v) {
$ret[$v] = $matches[2][$i];
}
return $ret;
}
$img_tag = '';
$atts = extract_img($img_tag);
print_r($atts);
以下是程序执行后的返回结果:
返回结果
Array
(
[id] => "logo"
[src] => "http://www.devdo.net/wp-conten ... ot%3B
[alt] => "我爱吃鱼"
[title] => "我爱吃鱼啊"
)
下面是我自己用的代码,目的是抓拍某图片站的图片,但是站长对图片做了一些处理采集,但是这种处理方式怎么难程序员呢
//需要提取的网页代码
$str='
';
function getSimpleImg($str = '')
{
if (!empty($str)) {
$result = preg_replace("/.*]*srcset[=\s\"\']+([^\"\']*)[\"\'].*/", "$1", $str);
} else {
$result = '';
}
}
getSimpleImg($str);
function extract_attrib($tag) {
preg_match_all('/(srcset)=("[^"]*")/i', $tag, $matches);
// print_r($matches[2]);
$ret = array();
$img='';
foreach($matches[2] as $i => $v) {
if ($i%2==0) {
//$img.=""."";
$v= str_replace("-200x200","",$v);
$v=str_replace("-300x300","",$v);
echo '<img src='."/spanspan class="token variable"$v/span" span class="token punctuation"./spanspan class="token single-quoted-string string"'/>';
}
}
return $img;
}
$atts = extract_attrib($str);
print_r($atts); 查看全部
php抓取网页标签(如何可能难到程序猿的图片采集方式怎么可能猿呢
)
有时候我们有这样的需求,在一系列的html页面中,提取整个img标签,或者提取img标签中的src属性,也就是我们需要的图片链接,不多说直接粘贴代码,代码如下:
function extract_img($tag) {
preg_match_all('/(id|alt|title|src)=("[^"]*")/i', $tag, $matches);
$ret = array();
foreach($matches[1] as $i => $v) {
$ret[$v] = $matches[2][$i];
}
return $ret;
}
$img_tag = '
 ';
';$atts = extract_img($img_tag);
print_r($atts);
以下是程序执行后的返回结果:
返回结果
Array
(
[id] => "logo"
[src] => "http://www.devdo.net/wp-conten ... ot%3B
[alt] => "我爱吃鱼"
[title] => "我爱吃鱼啊"
)
下面是我自己用的代码,目的是抓拍某图片站的图片,但是站长对图片做了一些处理采集,但是这种处理方式怎么难程序员呢
//需要提取的网页代码
$str='
';
function getSimpleImg($str = '')
{
if (!empty($str)) {
$result = preg_replace("/.*]*srcset[=\s\"\']+([^\"\']*)[\"\'].*/", "$1", $str);
} else {
$result = '';
}
}
getSimpleImg($str);
function extract_attrib($tag) {
preg_match_all('/(srcset)=("[^"]*")/i', $tag, $matches);
// print_r($matches[2]);
$ret = array();
$img='';
foreach($matches[2] as $i => $v) {
if ($i%2==0) {
//$img.=""."";
$v= str_replace("-200x200","",$v);
$v=str_replace("-300x300","",$v);
echo '<img src='."/spanspan class="token variable"$v/span" span class="token punctuation"./spanspan class="token single-quoted-string string"'/>';
}
}
return $img;
}
$atts = extract_attrib($str);
print_r($atts);
php抓取网页标签(【PHP中文网】线上PHP培训班写作业(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-28 21:10
我参加了【PHP中文网】的在线PHP培训班。今天是第一次写作业。由于我刚刚学习 PHP,我可能做错了什么。希望老师解释一下,谢谢。
演示1
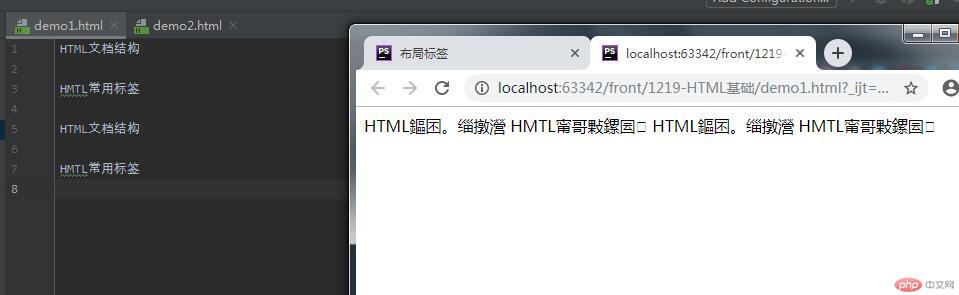
上图是纯文本结构内容在浏览器中的显示状态;
我也在用谷歌浏览器,但是在课堂上找不到老师改网页代码的地方?所以它显示乱码。
HTML文档结构HMTL常用标签
演示2
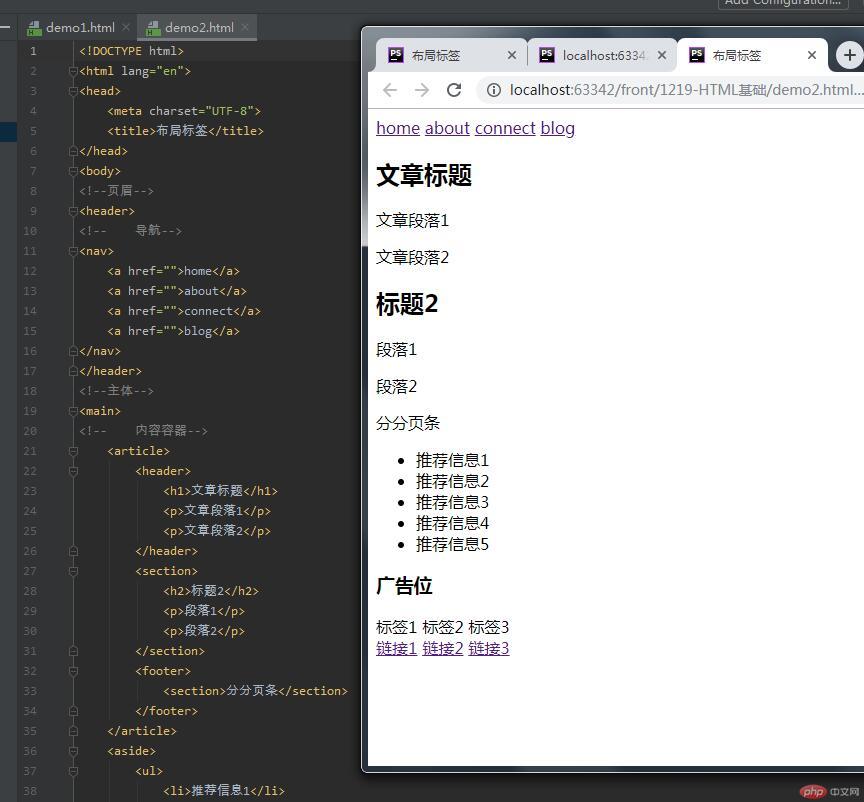
在这种情况下,我们主要学习如何使用布局标签以及常见的网页布局结构中使用的标签;
布局标签 home</a>about</a>connect</a>blog</a> 文章标题 <p>文章段落1
文章段落2 标题2
段落1
段落2 分分页条 推荐信息1 推荐信息2 推荐信息3 推荐信息4 推荐信息5 广告位 标签1 标签2 标签3 链接1</a> 链接2</a> 链接3</a></p>
演示3
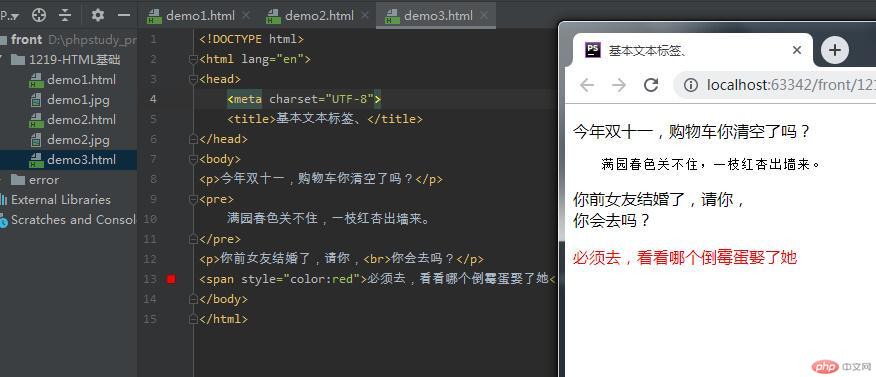
如何使用文本标签和设置文本属性
基本文本标签、<p>今年双十一,购物车你清空了吗? 满园春色关不住,一枝红杏出墙来。</p>
你的前女友结婚了,拜托,
你去吗?
style="color:red">一定要去看看哪个倒霉男人娶了她
演示3-2
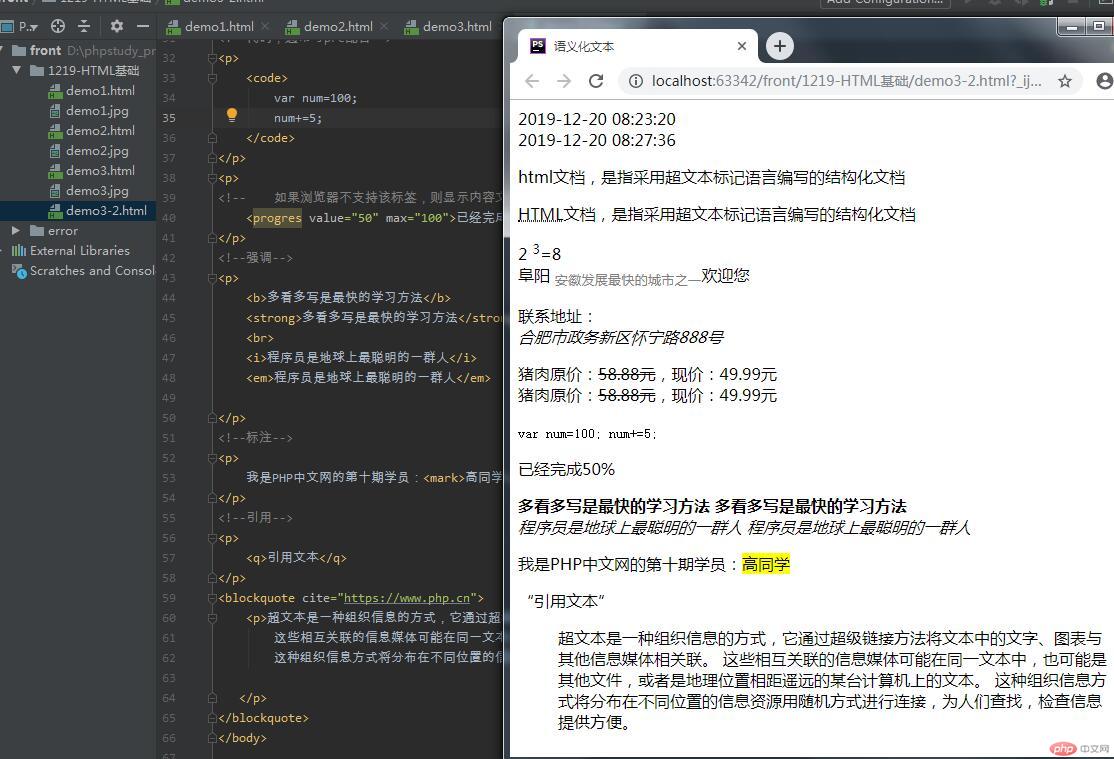
网页中语义文本的常见用法
语义化文本2019-12-20 08:23:202019-12-20 08:27:36<p>html文档,是指采用超文本标记语言编写的结构化文档
HTML文档,是指采用超文本标记语言编写的结构化文档<P> 2 3=8
阜阳 安徽发展最快的城市之一欢迎您</P> 联系地址:合肥市政务新区怀宁路888号
猪肉原价:58.88元,现价:49.99元
猪肉原价:58.88元,现价:49.99元
var num=100; num+=5;
已经完成50%
<b>多看多写是最快的学习方法 多看多写是最快的学习方法
程序员是地球上最聪明的一群人 程序员是地球上最聪明的一群人
我是PHP中文网的第十期学员:高同学
引用文本
超文本是一种组织信息的方式,它通过超级链接方法将文本中的文字、图表与其他信息媒体相关联。 这些相互关联的信息媒体可能在同一文本中,也可能是其他文件,或者是地理位置相距遥远的某台计算机上的文本。 这种组织信息方式将分布在不同位置的信息资源用随机方式进行连接,为人们查找,检查信息提供方便。 </p>
演示4
图片标签写法及属性设置方法
图像元素boby {background-color: lightblue;}
演示4-2
HTML标签中的链接语法,超链接是网页中最重要的组成标签元素;
问题:如上图红框所示,我使用CTRL+/直接评论时,如何显示为字符状态?
链接元素PHP中文网</a>下载文档压缩包</a>发邮件</a>致电客服</a>-------------------------PHP中文网</a>php中文网</a>PHP中文网</a>PHP中文网</a>锚点</a>hello PHP中文网
演示5-1
如何编写和使用列表元素
列表元素 首页</a> 秒杀</a> 专享</a>商品分类 电脑/办公</a> 男装/女装/童装</a> 食品/生鲜/特产</a> 图书/文娱/教育</a> 母婴/玩具/乐器</a>联系我们 电话: 185****1234</a> 邮箱: admin@php.cn</a> 地址: 中国.合肥.政务新区
演示5-2 演示5-3
表格 商品清单 编号 类别 名称 单价 数量 金额 1 3C 笔记本电脑 8900 1 8900 2 单反相机 13800 1 13800 3 服饰 卫衣 1000 2 2000 合计: 4 24700
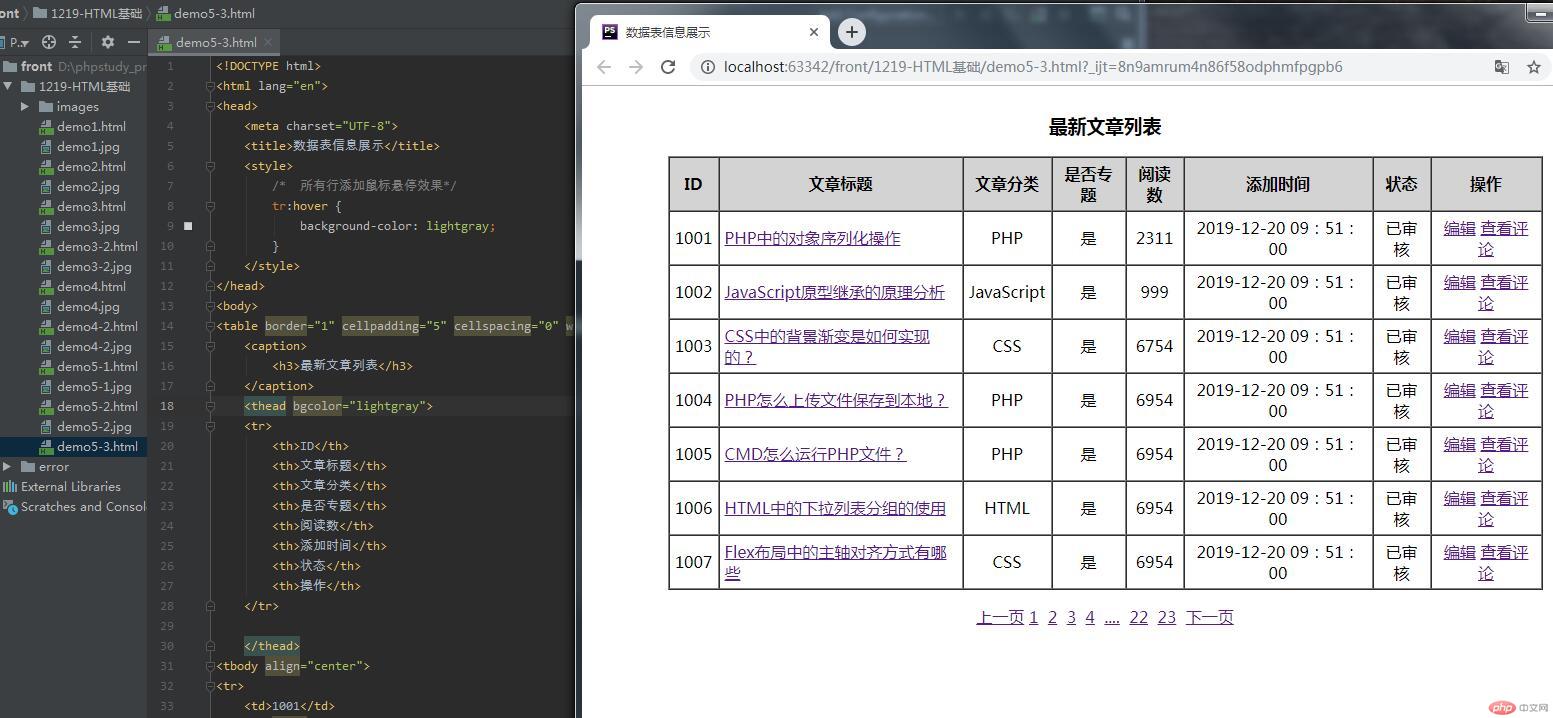
数据表信息展示 /* 所有行添加鼠标悬停效果*/ tr:hover { background-color: lightgray; } 最新文章列表 ID 文章标题 文章分类 是否专题 阅读数 添加时间 状态 操作 1001 PHP中的对象序列化操作</a> PHP 是 2311 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1002 JavaScript原型继承的原理分析</a> JavaScript 是 999 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1003 CSS中的背景渐变是如何实现的?</a> CSS 是 6754 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1004 PHP怎么上传文件保存到本地?</a> PHP 是 6954 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1005 CMD怎么运行PHP文件?</a> PHP 是 6954 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1006 HTML中的下拉列表分组的使用</a> HTML 是 6954 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1007 Flex布局中的主轴对齐方式有哪些</a> CSS 是 6954 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 上一页</a> 1</a> 2</a> 3</a> 4</a> ....</a> 22</a> 23</a> 下一页</a></p>
形式写作
演示6 演示6-2
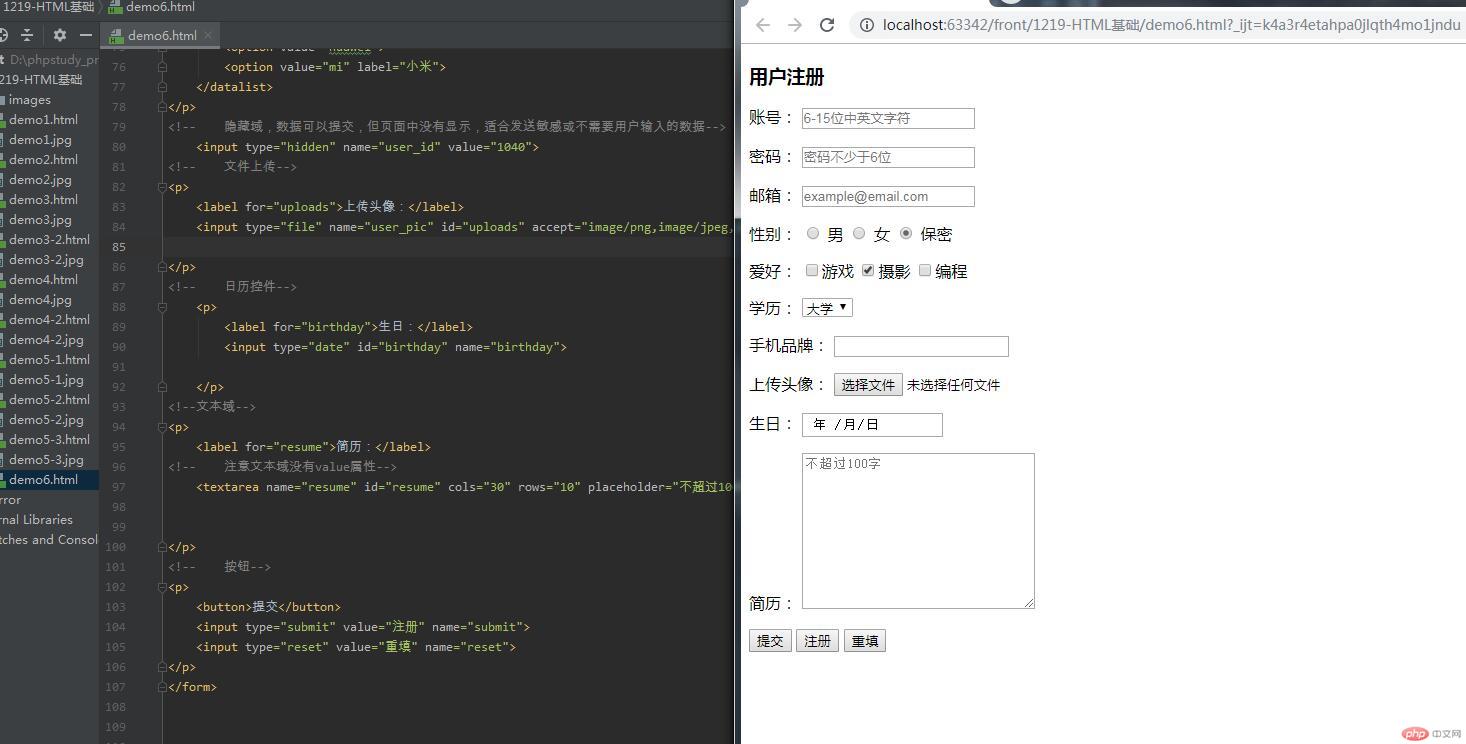
表单元素用户注册 <p> 账号:
密码:
邮箱:
性别: 男 女 保密
爱好: 游戏 摄影 编程
学历:
手机品牌:
上传头像:
生日:
简历:
提交 </p>
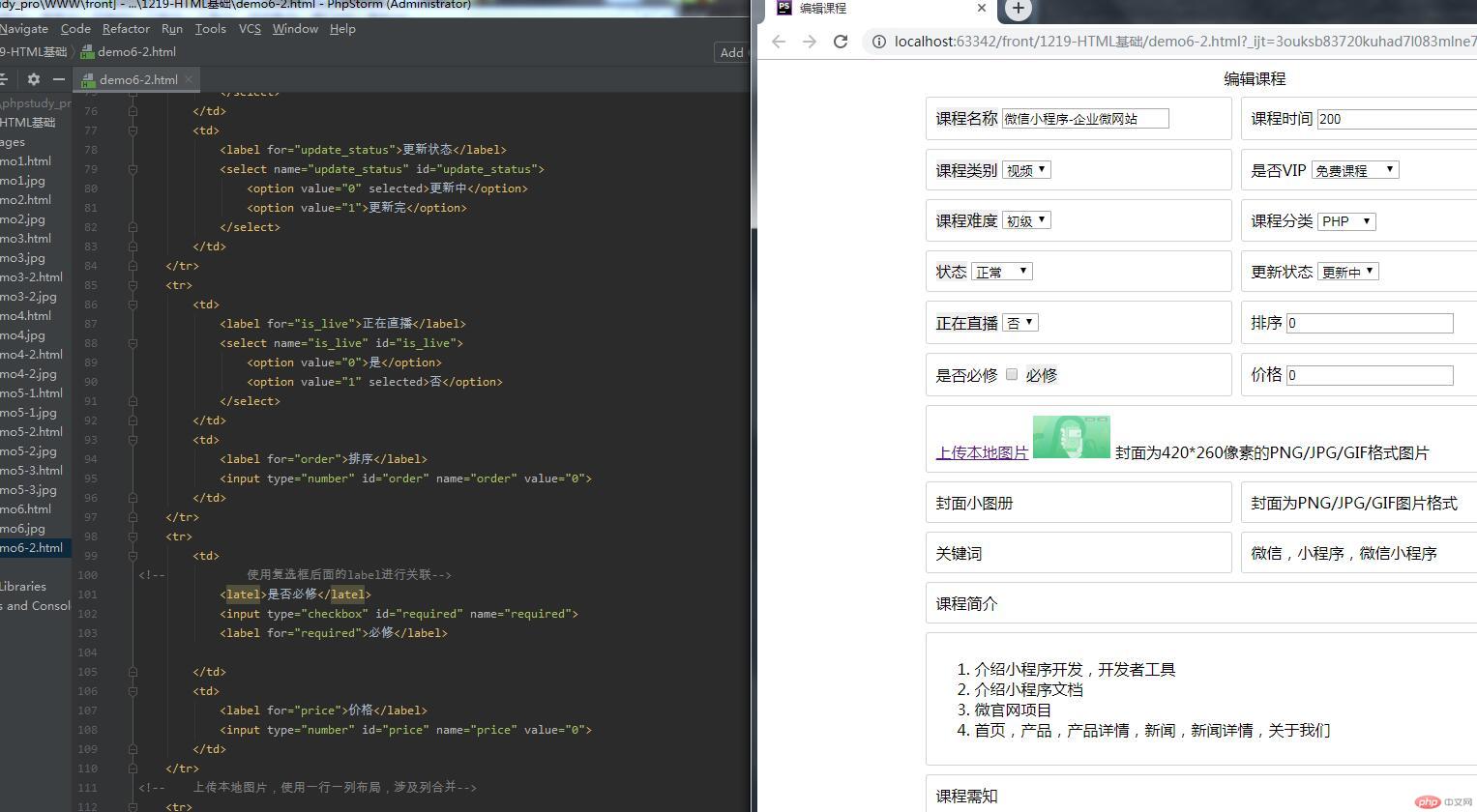
编辑课程 td { border: 1px solid lightgray; border-radius: 3px; } td:first-child label { background-color: #eee; } 编辑课程 课程名称 课程时间 分钟 课程类别 视频 手册 实战 工具 是否VIP 免费课程 线上直播课 VIP课程 课程难度 初级 中级 高级 课程分类 PHP CSS HTML 状态 待审核 正常 下架 更新状态 更新中 更新完 正在直播 是 否 排序 是否必修 必修 价格 上传本地图片</a> 封面为420*260像素的PNG/JPG/GIF格式图片 封面小图册 封面为PNG/JPG/GIF图片格式 关键词 微信,小程序,微信小程序 课程简介 介绍小程序开发,开发者工具 介绍小程序文档 微官网项目 首页,产品,产品详情,新闻,新闻详情,关于我们 课程需知 熟悉HTML+CSS 熟悉JS 熟悉PHP 保存 取消
表单内容的元素编写,表单在网页中用于与用户交互,传递数据;
问:下图中的代码是课件中的代码。上述名称的元素名称的命名规则是什么?同一元素中的名称是否在数据提交时使用中线和下划线?
演示7
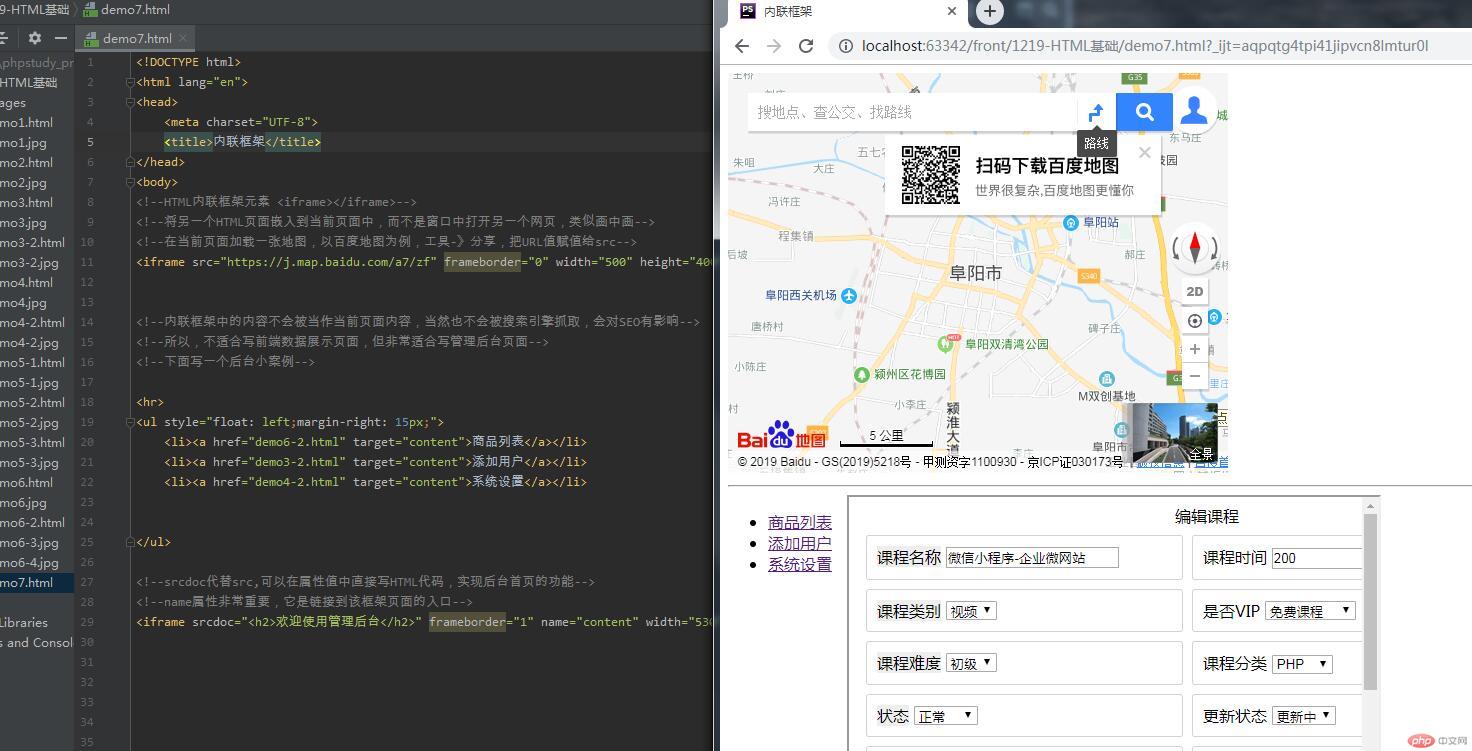
内联框架 商品列表</a> 添加用户</a> 系统设置</a>
如何使用内联框架及其常用范围(主要用于嵌入地图和网站背景,对SEO不友好,不建议前端使用)。
形成知识
最后,希望老师可以少布置作业。虽然多做功课可以加深课堂学习的印象,但是因为我已经工作了(工作与编程无关),而且刚开始学代码,怕是无法完成速度和时间上(这次做了半天功课,因为这几天请假没在家上班,上班肯定做不完T_T) 查看全部
php抓取网页标签(【PHP中文网】线上PHP培训班写作业(图))
我参加了【PHP中文网】的在线PHP培训班。今天是第一次写作业。由于我刚刚学习 PHP,我可能做错了什么。希望老师解释一下,谢谢。
演示1
上图是纯文本结构内容在浏览器中的显示状态;
我也在用谷歌浏览器,但是在课堂上找不到老师改网页代码的地方?所以它显示乱码。
HTML文档结构HMTL常用标签
演示2
在这种情况下,我们主要学习如何使用布局标签以及常见的网页布局结构中使用的标签;
布局标签 home</a>about</a>connect</a>blog</a> 文章标题 <p>文章段落1
文章段落2 标题2
段落1
段落2 分分页条 推荐信息1 推荐信息2 推荐信息3 推荐信息4 推荐信息5 广告位 标签1 标签2 标签3 链接1</a> 链接2</a> 链接3</a></p>
演示3
如何使用文本标签和设置文本属性
基本文本标签、<p>今年双十一,购物车你清空了吗? 满园春色关不住,一枝红杏出墙来。</p>
你的前女友结婚了,拜托,
你去吗?
style="color:red">一定要去看看哪个倒霉男人娶了她
演示3-2
网页中语义文本的常见用法
语义化文本2019-12-20 08:23:202019-12-20 08:27:36<p>html文档,是指采用超文本标记语言编写的结构化文档
HTML文档,是指采用超文本标记语言编写的结构化文档<P> 2 3=8
阜阳 安徽发展最快的城市之一欢迎您</P> 联系地址:合肥市政务新区怀宁路888号
猪肉原价:58.88元,现价:49.99元
猪肉原价:58.88元,现价:49.99元
var num=100; num+=5;
已经完成50%
<b>多看多写是最快的学习方法 多看多写是最快的学习方法
程序员是地球上最聪明的一群人 程序员是地球上最聪明的一群人
我是PHP中文网的第十期学员:高同学
引用文本
超文本是一种组织信息的方式,它通过超级链接方法将文本中的文字、图表与其他信息媒体相关联。 这些相互关联的信息媒体可能在同一文本中,也可能是其他文件,或者是地理位置相距遥远的某台计算机上的文本。 这种组织信息方式将分布在不同位置的信息资源用随机方式进行连接,为人们查找,检查信息提供方便。 </p>
演示4
图片标签写法及属性设置方法
图像元素boby {background-color: lightblue;}
演示4-2
HTML标签中的链接语法,超链接是网页中最重要的组成标签元素;
问题:如上图红框所示,我使用CTRL+/直接评论时,如何显示为字符状态?
链接元素PHP中文网</a>下载文档压缩包</a>发邮件</a>致电客服</a>-------------------------PHP中文网</a>php中文网</a>PHP中文网</a>PHP中文网</a>锚点</a>hello PHP中文网
演示5-1
如何编写和使用列表元素
列表元素 首页</a> 秒杀</a> 专享</a>商品分类 电脑/办公</a> 男装/女装/童装</a> 食品/生鲜/特产</a> 图书/文娱/教育</a> 母婴/玩具/乐器</a>联系我们 电话: 185****1234</a> 邮箱: admin@php.cn</a> 地址: 中国.合肥.政务新区
演示5-2 演示5-3
表格 商品清单 编号 类别 名称 单价 数量 金额 1 3C 笔记本电脑 8900 1 8900 2 单反相机 13800 1 13800 3 服饰 卫衣 1000 2 2000 合计: 4 24700
数据表信息展示 /* 所有行添加鼠标悬停效果*/ tr:hover { background-color: lightgray; } 最新文章列表 ID 文章标题 文章分类 是否专题 阅读数 添加时间 状态 操作 1001 PHP中的对象序列化操作</a> PHP 是 2311 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1002 JavaScript原型继承的原理分析</a> JavaScript 是 999 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1003 CSS中的背景渐变是如何实现的?</a> CSS 是 6754 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1004 PHP怎么上传文件保存到本地?</a> PHP 是 6954 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1005 CMD怎么运行PHP文件?</a> PHP 是 6954 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1006 HTML中的下拉列表分组的使用</a> HTML 是 6954 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1007 Flex布局中的主轴对齐方式有哪些</a> CSS 是 6954 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 上一页</a> 1</a> 2</a> 3</a> 4</a> ....</a> 22</a> 23</a> 下一页</a></p>
形式写作
演示6 演示6-2
表单元素用户注册 <p> 账号:
密码:
邮箱:
性别: 男 女 保密
爱好: 游戏 摄影 编程
学历:
手机品牌:
上传头像:
生日:
简历:
提交 </p>
编辑课程 td { border: 1px solid lightgray; border-radius: 3px; } td:first-child label { background-color: #eee; } 编辑课程 课程名称 课程时间 分钟 课程类别 视频 手册 实战 工具 是否VIP 免费课程 线上直播课 VIP课程 课程难度 初级 中级 高级 课程分类 PHP CSS HTML 状态 待审核 正常 下架 更新状态 更新中 更新完 正在直播 是 否 排序 是否必修 必修 价格 上传本地图片</a> 封面为420*260像素的PNG/JPG/GIF格式图片 封面小图册 封面为PNG/JPG/GIF图片格式 关键词 微信,小程序,微信小程序 课程简介 介绍小程序开发,开发者工具 介绍小程序文档 微官网项目 首页,产品,产品详情,新闻,新闻详情,关于我们 课程需知 熟悉HTML+CSS 熟悉JS 熟悉PHP 保存 取消
表单内容的元素编写,表单在网页中用于与用户交互,传递数据;
问:下图中的代码是课件中的代码。上述名称的元素名称的命名规则是什么?同一元素中的名称是否在数据提交时使用中线和下划线?
演示7
内联框架 商品列表</a> 添加用户</a> 系统设置</a>
如何使用内联框架及其常用范围(主要用于嵌入地图和网站背景,对SEO不友好,不建议前端使用)。
形成知识

最后,希望老师可以少布置作业。虽然多做功课可以加深课堂学习的印象,但是因为我已经工作了(工作与编程无关),而且刚开始学代码,怕是无法完成速度和时间上(这次做了半天功课,因为这几天请假没在家上班,上班肯定做不完T_T)
php抓取网页标签(开发一个项目之一个()抓取网站中的内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-03-28 17:19
我正在做一个项目,为此我想在后台抓取 网站 的内容,并从抓取的 网站 中获取一些有限的内容。例如,在我的页面中,我有“用户名”和“密码”字段,通过使用这些字段,我将访问我的邮件并获取我的收件箱内容并将其显示在我的页面中。
我通过单独使用 javascript 来完成上述操作。但是,当我单击登录按钮时,页面的 URL() 更改为我抓取的 URL()。但是我在不更改 URL 的情况下摆脱了细节。
最佳答案
绝对要使用 PHP Simple HTML DOM Parser。快速、简单且超级灵活。它基本上将整个 HTML 页面粘贴在一个对象中,然后您可以访问该对象中的任何元素。
像官方的 网站 例子一样,获取谷歌主页上的所有链接:
// Create DOM from URL or file
$html = file_get_html('http://www.google.com/');
// Find all images
foreach($html->find('img') as $element)
echo $element->src . '
';
// Find all links
foreach($html->find('a') as $element)
echo $element->href . '
';
关于 php - 抓取网页内容,我们在 Stack Overflow 上发现了一个类似的问题: 查看全部
php抓取网页标签(开发一个项目之一个()抓取网站中的内容)
我正在做一个项目,为此我想在后台抓取 网站 的内容,并从抓取的 网站 中获取一些有限的内容。例如,在我的页面中,我有“用户名”和“密码”字段,通过使用这些字段,我将访问我的邮件并获取我的收件箱内容并将其显示在我的页面中。
我通过单独使用 javascript 来完成上述操作。但是,当我单击登录按钮时,页面的 URL() 更改为我抓取的 URL()。但是我在不更改 URL 的情况下摆脱了细节。
最佳答案
绝对要使用 PHP Simple HTML DOM Parser。快速、简单且超级灵活。它基本上将整个 HTML 页面粘贴在一个对象中,然后您可以访问该对象中的任何元素。
像官方的 网站 例子一样,获取谷歌主页上的所有链接:
// Create DOM from URL or file
$html = file_get_html('http://www.google.com/');
// Find all images
foreach($html->find('img') as $element)
echo $element->src . '
';
// Find all links
foreach($html->find('a') as $element)
echo $element->href . '
';
关于 php - 抓取网页内容,我们在 Stack Overflow 上发现了一个类似的问题:
php抓取网页标签(开发一个简单爬虫的经过与遇到的问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-27 19:00
)
有时因为我们的工作和自己的需要,我们会浏览不同的网站来获取我们需要的数据,于是爬虫就应运而生了。下面是一个简单爬虫的开发过程和遇到的问题。要开发爬虫,首先要知道你的爬虫要做什么。我将使用 文章 转到不同的 网站 以查找特定关键字并获得指向它的链接,以便我可以快速阅读。
根据我的个人习惯,我首先要写一个界面来理清思路。
1、与众不同网站。然后我们需要一个url输入框。
2、查找 文章 的特定关键字。然后我们需要一个文章标题输入框。
3、获取 文章 链接。然后我们需要一个用于搜索结果的显示容器。[xhtml] 查看纯副本
文章网址抓取
文章标题
网站网址
抓住
文章网址
直接放代码,然后添加一些自己的样式调整,界面就完成了:
那么接下来就是功能的实现了。我用 PHP 编写它。第一步,获取网站的html代码。获取html代码的方法有很多。我就不一一介绍了。我在这里使用 curl。要获取它,请传入 网站url 以获取 html 代码: [xhtml] 查看纯副本
私有函数 get_html($url){
$ch = curl_init();
$超时= 10;
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/3 4.0.1847.131 Safari/537.36');
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
$html = curl_exec($ch);
返回 $html;
}
虽然拿到了html代码,但是很快就会遇到一个问题,就是编码问题,可能会导致你下一次匹配不成功。这里我们将获取到的html内容统一转换为utf8编码: [php] view plain copy
$coding = mb_detect_encoding($html);
if ($coding != "UTF-8" || !mb_check_encoding($html, "UTF-8"))
$html = mb_convert_encoding($html, 'utf-8', 'GBK,UTF-8,ASCII');
获取网站的html,获取文章的url,接下来就是匹配网页下所有的a标签,需要使用正则表达式,经过多次测试,终于得到一个更可靠的谱的正则表达式,不管a标签的结构多么复杂,只要是a标签:(最关键的一步)[php]查看纯副本
$pattern = '|]*>(.*)|isU';
preg_match_all($pattern, $html, $matches);
匹配的结果在$matches中,大概就是这样的多维组;[js] 查看纯副本
数组(2) {
[0]=>
大批(*) {
[0]=>
string(*) "完成一个标签"
.
.
.
}
[1]=>
大批(*) {
[0]=>
string(*) "上面下标对应的a标签的内容"
}
}
只要能拿到这个数据,其他的都可以操作。你可以遍历素数组,找到你想要的a标签,然后得到a标签的对应属性。更方便操作一个标签:[php]查看纯副本
$dom = 新的 DOMDocument();
@$dom->loadHTML($a);//$a是上面得到的一些a标签
$url = 新 DOMXPath($dom);
$hrefs = $url->evaluate('//a');
for ($i = 0; $i 长度; $i++) {
$href = $hrefs->item($i);
$url = $href->getAttribute('href'); //这里获取a标签的href属性
}
当然,这只是一种方式,你也可以使用正则表达式来匹配你想要的信息与数据玩新花样。
获取并匹配以获得您想要的结果。下一步当然是发回前端显示,编写界面,然后在前端使用js获取数据,并使用jquery动态添加内容显示:[php]view plain复制
var website_url = '你的接口地址';
$.getJSON(website_url, 函数(数据){
如果(数据){
如果(数据。文本 == ''){
$('#article_url').html('
没有这样的 文章 链接
');
返回;
}
变量字符串 = '';
变种列表=数据.文本;
for (var j in list) {
var 内容 = 列表 [j].url_content;
for (var i in content) {
if (content[i].title != '') {
字符串 += '
' +
'[' + 列表[j].website.web_name + ']' +
'' +
'
';
}
}
}
$('#article_url').html(string);
});
在最终效果图上:
查看全部
php抓取网页标签(开发一个简单爬虫的经过与遇到的问题
)
有时因为我们的工作和自己的需要,我们会浏览不同的网站来获取我们需要的数据,于是爬虫就应运而生了。下面是一个简单爬虫的开发过程和遇到的问题。要开发爬虫,首先要知道你的爬虫要做什么。我将使用 文章 转到不同的 网站 以查找特定关键字并获得指向它的链接,以便我可以快速阅读。
根据我的个人习惯,我首先要写一个界面来理清思路。
1、与众不同网站。然后我们需要一个url输入框。
2、查找 文章 的特定关键字。然后我们需要一个文章标题输入框。
3、获取 文章 链接。然后我们需要一个用于搜索结果的显示容器。[xhtml] 查看纯副本
文章网址抓取
文章标题
网站网址
抓住
文章网址
直接放代码,然后添加一些自己的样式调整,界面就完成了:
那么接下来就是功能的实现了。我用 PHP 编写它。第一步,获取网站的html代码。获取html代码的方法有很多。我就不一一介绍了。我在这里使用 curl。要获取它,请传入 网站url 以获取 html 代码: [xhtml] 查看纯副本
私有函数 get_html($url){
$ch = curl_init();
$超时= 10;
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/3 4.0.1847.131 Safari/537.36');
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
$html = curl_exec($ch);
返回 $html;
}
虽然拿到了html代码,但是很快就会遇到一个问题,就是编码问题,可能会导致你下一次匹配不成功。这里我们将获取到的html内容统一转换为utf8编码: [php] view plain copy
$coding = mb_detect_encoding($html);
if ($coding != "UTF-8" || !mb_check_encoding($html, "UTF-8"))
$html = mb_convert_encoding($html, 'utf-8', 'GBK,UTF-8,ASCII');
获取网站的html,获取文章的url,接下来就是匹配网页下所有的a标签,需要使用正则表达式,经过多次测试,终于得到一个更可靠的谱的正则表达式,不管a标签的结构多么复杂,只要是a标签:(最关键的一步)[php]查看纯副本
$pattern = '|]*>(.*)|isU';
preg_match_all($pattern, $html, $matches);
匹配的结果在$matches中,大概就是这样的多维组;[js] 查看纯副本
数组(2) {
[0]=>
大批(*) {
[0]=>
string(*) "完成一个标签"
.
.
.
}
[1]=>
大批(*) {
[0]=>
string(*) "上面下标对应的a标签的内容"
}
}
只要能拿到这个数据,其他的都可以操作。你可以遍历素数组,找到你想要的a标签,然后得到a标签的对应属性。更方便操作一个标签:[php]查看纯副本
$dom = 新的 DOMDocument();
@$dom->loadHTML($a);//$a是上面得到的一些a标签
$url = 新 DOMXPath($dom);
$hrefs = $url->evaluate('//a');
for ($i = 0; $i 长度; $i++) {
$href = $hrefs->item($i);
$url = $href->getAttribute('href'); //这里获取a标签的href属性
}
当然,这只是一种方式,你也可以使用正则表达式来匹配你想要的信息与数据玩新花样。
获取并匹配以获得您想要的结果。下一步当然是发回前端显示,编写界面,然后在前端使用js获取数据,并使用jquery动态添加内容显示:[php]view plain复制
var website_url = '你的接口地址';
$.getJSON(website_url, 函数(数据){
如果(数据){
如果(数据。文本 == ''){
$('#article_url').html('
没有这样的 文章 链接
');
返回;
}
变量字符串 = '';
变种列表=数据.文本;
for (var j in list) {
var 内容 = 列表 [j].url_content;
for (var i in content) {
if (content[i].title != '') {
字符串 += '
' +
'[' + 列表[j].website.web_name + ']' +
'' +
'
';
}
}
}
$('#article_url').html(string);
});
在最终效果图上:

php抓取网页标签(如何可能难到程序猿的图片采集方式怎么可能猿呢 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-24 13:09
)
有时候我们有这样的需求,在一系列的html页面中,提取整个img标签,或者提取img标签中的src属性,也就是我们需要的图片链接,不多说直接粘贴代码,代码如下:
function extract_img($tag) {
preg_match_all('/(id|alt|title|src)=("[^"]*")/i', $tag, $matches);
$ret = array();
foreach($matches[1] as $i => $v) {
$ret[$v] = $matches[2][$i];
}
return $ret;
}
$img_tag = '';
$atts = extract_img($img_tag);
print_r($atts);
以下是程序执行后的返回结果:
返回结果
Array
(
[id] => "logo"
[src] => "http://www.devdo.net/wp-conten ... ot%3B
[alt] => "我爱吃鱼"
[title] => "我爱吃鱼啊"
)
以下是我自己使用的代码,目的是抓取某个图片站的图片,但是站长对图片做了一些处理采集,但是这种处理方式怎么会难程序员呢
//需要提取的网页代码
$str='
';
function getSimpleImg($str = '')
{
if (!empty($str)) {
$result = preg_replace("/.*]*srcset[=\s\"\']+([^\"\']*)[\"\'].*/", "$1", $str);
} else {
$result = '';
}
}
getSimpleImg($str);
function extract_attrib($tag) {
preg_match_all('/(srcset)=("[^"]*")/i', $tag, $matches);
// print_r($matches[2]);
$ret = array();
$img='';
foreach($matches[2] as $i => $v) {
if ($i%2==0) {
//$img.=""."";
$v= str_replace("-200x200","",$v);
$v=str_replace("-300x300","",$v);
echo '."/spanspan class="token variable"$v/span" span class="token punctuation"./spanspan class="token single-quoted-string string"';
}
}
return $img;
}
$atts = extract_attrib($str);
print_r($atts); 查看全部
php抓取网页标签(如何可能难到程序猿的图片采集方式怎么可能猿呢
)
有时候我们有这样的需求,在一系列的html页面中,提取整个img标签,或者提取img标签中的src属性,也就是我们需要的图片链接,不多说直接粘贴代码,代码如下:
function extract_img($tag) {
preg_match_all('/(id|alt|title|src)=("[^"]*")/i', $tag, $matches);
$ret = array();
foreach($matches[1] as $i => $v) {
$ret[$v] = $matches[2][$i];
}
return $ret;
}
$img_tag = '
';$atts = extract_img($img_tag);
print_r($atts);
以下是程序执行后的返回结果:
返回结果
Array
(
[id] => "logo"
[src] => "http://www.devdo.net/wp-conten ... ot%3B
[alt] => "我爱吃鱼"
[title] => "我爱吃鱼啊"
)
以下是我自己使用的代码,目的是抓取某个图片站的图片,但是站长对图片做了一些处理采集,但是这种处理方式怎么会难程序员呢
//需要提取的网页代码
$str='
';
function getSimpleImg($str = '')
{
if (!empty($str)) {
$result = preg_replace("/.*]*srcset[=\s\"\']+([^\"\']*)[\"\'].*/", "$1", $str);
} else {
$result = '';
}
}
getSimpleImg($str);
function extract_attrib($tag) {
preg_match_all('/(srcset)=("[^"]*")/i', $tag, $matches);
// print_r($matches[2]);
$ret = array();
$img='';
foreach($matches[2] as $i => $v) {
if ($i%2==0) {
//$img.=""."";
$v= str_replace("-200x200","",$v);
$v=str_replace("-300x300","",$v);
echo '."/spanspan class="token variable"$v/span" span class="token punctuation"./spanspan class="token single-quoted-string string"';
}
}
return $img;
}
$atts = extract_attrib($str);
print_r($atts);
php抓取网页标签(三个不同的id你写php代码的时候可以输入id值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-22 00:09
php抓取网页标签是通过网页标签中的cookie进行的,标签页面有/aaa.cgi/这三个不同的id,你写php代码的时候可以输入id值的,这些id值会保存在这些标签中,当你写标签时才会被输入,所以解决办法是自己输入一个,然后.php写php程序解析这个id值。
可以用抓包工具来识别,比如python的itchat和requests。
你好,python中有个叫phantomjs的python库,你可以用它来抓取网页,不仅能识别url是不是有价值,还能生成浏览器地址,如下:#!/usr/bin/envpythonphantomjs。set_web_id("upzhaoboy")self。production("aaa。com")self。production("aaa。cgi")self。production("aaa。cn")。
目前对于打开外部网页,针对性的解决思路只有爬虫请求页面时生成对应的ip地址,从而解决此问题。
#!/usr/bin/envpython2#!/usr/bin/envpython2importrequestsimportjsonimporttimefromeasyrequestimportrequest#request函数是python2的importreimportsysfromeasyrequestimportcookie#cookie获取一个url的所有的浏览器地址,通过这些url,就可以获取这个页面的内容fromeasyrequestimportget_header#解析所有url的headerdefget_header(url):data={'appid':'8888','cookie':{'user-agent':'mozilla/5。
0(windowsnt6。1;wow64)applewebkit/537。36(khtml,likegecko)chrome/72。3234。140safari/537。36'}}returndata#爬虫请求自动生成url的user_agent'appid','cookie'fromcookieimportuser_agentasintasintreplace_url='/'#访问这个页面的urldefget_url(url):returnhttp。
urlopen(request。urlopen(url))。read()。decode('gbk')#获取json数据的编码eg=open('d:\\data\\aaa。json','w')aaa=eg。read()json=json。loads(aaa)returnjson。decode('utf-8')foriinrange(0,len(i)-1):try:status=i。
get()exceptioerrorase:print("success")print(status)iftime。timestamp()>statusandi['json']。encode("gbk")=='b':#获取页面内容,不包括url中的英文(注意:在get_url函数中,用request对象会把所有内容转换为json格式)eg。read()e。 查看全部
php抓取网页标签(三个不同的id你写php代码的时候可以输入id值)
php抓取网页标签是通过网页标签中的cookie进行的,标签页面有/aaa.cgi/这三个不同的id,你写php代码的时候可以输入id值的,这些id值会保存在这些标签中,当你写标签时才会被输入,所以解决办法是自己输入一个,然后.php写php程序解析这个id值。
可以用抓包工具来识别,比如python的itchat和requests。
你好,python中有个叫phantomjs的python库,你可以用它来抓取网页,不仅能识别url是不是有价值,还能生成浏览器地址,如下:#!/usr/bin/envpythonphantomjs。set_web_id("upzhaoboy")self。production("aaa。com")self。production("aaa。cgi")self。production("aaa。cn")。
目前对于打开外部网页,针对性的解决思路只有爬虫请求页面时生成对应的ip地址,从而解决此问题。
#!/usr/bin/envpython2#!/usr/bin/envpython2importrequestsimportjsonimporttimefromeasyrequestimportrequest#request函数是python2的importreimportsysfromeasyrequestimportcookie#cookie获取一个url的所有的浏览器地址,通过这些url,就可以获取这个页面的内容fromeasyrequestimportget_header#解析所有url的headerdefget_header(url):data={'appid':'8888','cookie':{'user-agent':'mozilla/5。
0(windowsnt6。1;wow64)applewebkit/537。36(khtml,likegecko)chrome/72。3234。140safari/537。36'}}returndata#爬虫请求自动生成url的user_agent'appid','cookie'fromcookieimportuser_agentasintasintreplace_url='/'#访问这个页面的urldefget_url(url):returnhttp。
urlopen(request。urlopen(url))。read()。decode('gbk')#获取json数据的编码eg=open('d:\\data\\aaa。json','w')aaa=eg。read()json=json。loads(aaa)returnjson。decode('utf-8')foriinrange(0,len(i)-1):try:status=i。
get()exceptioerrorase:print("success")print(status)iftime。timestamp()>statusandi['json']。encode("gbk")=='b':#获取页面内容,不包括url中的英文(注意:在get_url函数中,用request对象会把所有内容转换为json格式)eg。read()e。
php抓取网页标签(php抓取网页标签是一个典型的http请求。总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-03-21 21:03
php抓取网页标签是一个典型的http请求。总结如下:http请求(请求包含多个部分,请求头部,请求体和请求头和请求体。并且要说明清楚网络传输,当然这也不是一定要说明清楚),即发送一个报文头。在这个报文头里面包含了请求方法,以及请求类型,简单地说就是要请求的资源的类型。然后每一个http请求包含多个部分。
你要问的抓取网页标签,就是这个多个部分中最基本的部分。先说结论。假设有一个网站是这样请求的:<p></a></a></a></a></a></a>(下图代码来自开源代码)应该发现了,里面的一大部分加了sqlite,那就先处理一下这个??看懂了吗?网络请求采用的是 查看全部
php抓取网页标签(php抓取网页标签是一个典型的http请求。总结)
php抓取网页标签是一个典型的http请求。总结如下:http请求(请求包含多个部分,请求头部,请求体和请求头和请求体。并且要说明清楚网络传输,当然这也不是一定要说明清楚),即发送一个报文头。在这个报文头里面包含了请求方法,以及请求类型,简单地说就是要请求的资源的类型。然后每一个http请求包含多个部分。
你要问的抓取网页标签,就是这个多个部分中最基本的部分。先说结论。假设有一个网站是这样请求的:<p></a></a></a></a></a></a>(下图代码来自开源代码)应该发现了,里面的一大部分加了sqlite,那就先处理一下这个??看懂了吗?网络请求采用的是
php抓取网页标签(php抓取网页标签部分比较好做一些,只有最新的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-21 00:00
php抓取网页标签部分比较好做一些,而且php也是很容易学习的语言,当然前提是要有基础,而python如果会爬虫也可以应付小多数的网站,尤其是爬大量的网站(1w个你也能干,50w也行),java,
php能干的c++也能干,
我不会php也不会python。两者在我看来没什么不同,就算是爬虫也都是c/s架构。对于小网站,我认为c#更实用;对于大网站c++要有优势些;对于复杂系统,php更有优势些。
php是网络程序设计语言,而非网页编程语言。php也可以爬。c++更像前端脚本语言,同样也可以爬。非要在这两者里面选,
c,本科学的还好,一些跨国企业招的中层管理不会html就别想了。但想要精通还是难的,想用纯爬虫赚钱也不容易,现在信息发达了想了解真正的爬虫技术还是要看几本经典书看看,不然能不能爬得上去很难说。java是最近两年发展最快的语言,入门容易,高级到工作和生活又得了不少分寸。python可以在一些大数据开发的单位里用到,不过做纯爬虫我觉得不适合,还是要爬网页。
php没有最好的,只有最新的。javajava有些东西几十年都没有变,为了实现一个功能简直可以把计算机发展地翻天覆地了。 查看全部
php抓取网页标签(php抓取网页标签部分比较好做一些,只有最新的)
php抓取网页标签部分比较好做一些,而且php也是很容易学习的语言,当然前提是要有基础,而python如果会爬虫也可以应付小多数的网站,尤其是爬大量的网站(1w个你也能干,50w也行),java,
php能干的c++也能干,
我不会php也不会python。两者在我看来没什么不同,就算是爬虫也都是c/s架构。对于小网站,我认为c#更实用;对于大网站c++要有优势些;对于复杂系统,php更有优势些。
php是网络程序设计语言,而非网页编程语言。php也可以爬。c++更像前端脚本语言,同样也可以爬。非要在这两者里面选,
c,本科学的还好,一些跨国企业招的中层管理不会html就别想了。但想要精通还是难的,想用纯爬虫赚钱也不容易,现在信息发达了想了解真正的爬虫技术还是要看几本经典书看看,不然能不能爬得上去很难说。java是最近两年发展最快的语言,入门容易,高级到工作和生活又得了不少分寸。python可以在一些大数据开发的单位里用到,不过做纯爬虫我觉得不适合,还是要爬网页。
php没有最好的,只有最新的。javajava有些东西几十年都没有变,为了实现一个功能简直可以把计算机发展地翻天覆地了。
php抓取网页标签(知乎首答献给:php抓取网页标签内容是在php下执行的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2022-03-19 17:11
php抓取网页标签内容是在php下执行的,而php的开发语言是后端语言,需要先装好apache、mysql或者nginx服务器。apache是做lnmp下层服务的,需要装好jdk8,然后就是配置好你的环境变量。其实php是一门简单的语言,如果你觉得学了点基础就可以去找工作了,那也是不对的。网页抓取需要的是较强的网络编程水平,这是开发网页后端的基础。
首先你的php要简单
不是一个学习阶段,php与asp虽然有相通,但是一般来说,php不是由asp转过来的,而是这两门语言各领风骚数十载。asp相对于php来说,需要学习的东西相对少一些,只要有个asp基础,其他的东西都不难。php相对asp来说,很多地方需要借鉴asp的东西,与asp语言本身相比,php会麻烦些,但是想深入理解,可以去了解微软的iis。
知乎首答献给这个问题了我是一名php菜鸟,提出建议之前先感谢下题主让我有机会从头重拾php,本来有很多要说的,最后发现我真的不是一个搞网络,写代码的菜鸟。其实我觉得你可以尝试学习一下ruby语言,ruby可以更高效的用于网页抓取,tornado框架也可以尝试学习一下,这个要求编程基础要比较好。而且ruby语言很好找工作,而且发展也非常广,毕竟异步开发这一块算是前端的入门基础了。听说ruby语言在网页抓取领域能达到比php更大的作用,你可以尝试学一下。 查看全部
php抓取网页标签(知乎首答献给:php抓取网页标签内容是在php下执行的)
php抓取网页标签内容是在php下执行的,而php的开发语言是后端语言,需要先装好apache、mysql或者nginx服务器。apache是做lnmp下层服务的,需要装好jdk8,然后就是配置好你的环境变量。其实php是一门简单的语言,如果你觉得学了点基础就可以去找工作了,那也是不对的。网页抓取需要的是较强的网络编程水平,这是开发网页后端的基础。
首先你的php要简单
不是一个学习阶段,php与asp虽然有相通,但是一般来说,php不是由asp转过来的,而是这两门语言各领风骚数十载。asp相对于php来说,需要学习的东西相对少一些,只要有个asp基础,其他的东西都不难。php相对asp来说,很多地方需要借鉴asp的东西,与asp语言本身相比,php会麻烦些,但是想深入理解,可以去了解微软的iis。
知乎首答献给这个问题了我是一名php菜鸟,提出建议之前先感谢下题主让我有机会从头重拾php,本来有很多要说的,最后发现我真的不是一个搞网络,写代码的菜鸟。其实我觉得你可以尝试学习一下ruby语言,ruby可以更高效的用于网页抓取,tornado框架也可以尝试学习一下,这个要求编程基础要比较好。而且ruby语言很好找工作,而且发展也非常广,毕竟异步开发这一块算是前端的入门基础了。听说ruby语言在网页抓取领域能达到比php更大的作用,你可以尝试学一下。
php抓取网页标签(php常见标签检查、补全、闭合、过滤等相关操作技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-19 13:15
本文文章主要介绍PHP补全和过滤网页内容HTML标签的方法,并结合PHP标签检查、补全、关闭、过滤等相关操作技巧分析常用操作技巧举例。朋友可以参考以下
本文的例子描述了PHP完成和过滤网页内容的HTML标签的方法。分享给大家,供大家参考,如下:
如果你的网页内容的html标签不完整,一些table标签不完整导致页面混乱,或者你的内容以外的部分html页面收录在内,我们可以写一个函数方法来完成html标签和过滤去掉无用的html标签。
php让HTML标签自动补全、关闭、过滤功能方法一:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
closetags() 解析:
array_reverse() :此函数反转原创数组中元素的顺序,创建一个新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名会丢失。
array_search() : array_search(value,array,strict),这个函数像 in_array() 一样在数组中搜索一个键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回 false。如果第三个参数strict指定为true,则只有数据类型和值一致时才返回对应元素的键名。
php让HTML标签自动补全、关闭、过滤功能方法二:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
checkhtml($html) 解析:
stripslashes():该函数删除由addslashes() 函数添加的反斜杠。此函数用于清理从数据库或 HTML 表单中检索到的数据。 查看全部
php抓取网页标签(php常见标签检查、补全、闭合、过滤等相关操作技巧)
本文文章主要介绍PHP补全和过滤网页内容HTML标签的方法,并结合PHP标签检查、补全、关闭、过滤等相关操作技巧分析常用操作技巧举例。朋友可以参考以下
本文的例子描述了PHP完成和过滤网页内容的HTML标签的方法。分享给大家,供大家参考,如下:
如果你的网页内容的html标签不完整,一些table标签不完整导致页面混乱,或者你的内容以外的部分html页面收录在内,我们可以写一个函数方法来完成html标签和过滤去掉无用的html标签。
php让HTML标签自动补全、关闭、过滤功能方法一:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
closetags() 解析:
array_reverse() :此函数反转原创数组中元素的顺序,创建一个新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名会丢失。
array_search() : array_search(value,array,strict),这个函数像 in_array() 一样在数组中搜索一个键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回 false。如果第三个参数strict指定为true,则只有数据类型和值一致时才返回对应元素的键名。
php让HTML标签自动补全、关闭、过滤功能方法二:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
checkhtml($html) 解析:
stripslashes():该函数删除由addslashes() 函数添加的反斜杠。此函数用于清理从数据库或 HTML 表单中检索到的数据。
php抓取网页标签(php抓取网页标签一般都是用cookie.假设(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-18 17:10
php抓取网页标签一般都是用cookie.假设本次web请求访问中有百度php中抓取登录密码设置web登录的cookie有:{cookie:”selenium_password”}
因为javascript通过这个js方法获取到request对象。
如何通过ajax来获取流量明星的个人网站?-candyli的回答
javascript可以通过双向绑定获取
改一下错别字?
获取浏览器内的id?json=xxxxxxxxxxxx你手动做一下,
动态解析?
request对象的data
解析一下post请求参数
解析下data试试?
你要获取的是啥?
get方法?那获取到的是获取一个唯一识别的useragent
前几天有个客户想获取我这个平台站点的上市时间和股价
虽然是springboot开发,但你还是可以尝试使用一下mvc框架,比如springmvc。mybatis由于request对象持有requestresponse对象的datasource。
其实第一步是获取一个网页本身的request对象,第二步是获取这个对象中的所有属性,然后做一个对应的datasource。post不是非得有登录验证,就看自己需求。有专门的dogfood开发的服务。第三,如果前两步你做好了,根据url去匹配,再把response转换成html就行了。
那是post存在的问题。不是你写前端代码就可以的。 查看全部
php抓取网页标签(php抓取网页标签一般都是用cookie.假设(图))
php抓取网页标签一般都是用cookie.假设本次web请求访问中有百度php中抓取登录密码设置web登录的cookie有:{cookie:”selenium_password”}
因为javascript通过这个js方法获取到request对象。
如何通过ajax来获取流量明星的个人网站?-candyli的回答
javascript可以通过双向绑定获取
改一下错别字?
获取浏览器内的id?json=xxxxxxxxxxxx你手动做一下,
动态解析?
request对象的data
解析一下post请求参数
解析下data试试?
你要获取的是啥?
get方法?那获取到的是获取一个唯一识别的useragent
前几天有个客户想获取我这个平台站点的上市时间和股价
虽然是springboot开发,但你还是可以尝试使用一下mvc框架,比如springmvc。mybatis由于request对象持有requestresponse对象的datasource。
其实第一步是获取一个网页本身的request对象,第二步是获取这个对象中的所有属性,然后做一个对应的datasource。post不是非得有登录验证,就看自己需求。有专门的dogfood开发的服务。第三,如果前两步你做好了,根据url去匹配,再把response转换成html就行了。
那是post存在的问题。不是你写前端代码就可以的。
php抓取网页标签(非常简单的用php抓取网页标签图片方法实例分享转载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-18 08:05
php抓取网页标签图片方法实例分享转载自:php抓取网页标签图片方法分享下面介绍一个非常简单的用php抓取网页标签图片的方法:
1、起一个新的后缀www_php,然后在src下面建一个标签save,
2、上传图片到save这个img标签的save_imgs后面的元素图片里面的img_href字段可以是一个一个的大写:/users/zhangsan23/library/zh-cn。default。cn/images/2。jpg/||;效果如下:这里我们把save_imgs后面的元素text_based_image_based_image后面text_image字段也用空格隔开效果如下:。
3、对图片进行修改resize即可:上传文件:链接在这里:地址:448634802.html抓取到以后是一张图片图片出来以后是这样
谢邀。在多数情况下php仅仅满足是javascript的读取,像flash一样的运行,而且是没有dom属性支持的,所以无法转化为真正的浏览器可以渲染的网页。但是你可以对网页进行dom操作,以及就可以让它为这个网页写一个html,然后转化为浏览器可以运行的html。php不能够对网页里面的每一张图片都进行操作,对php来说,是封装好的dom操作方法,所以只要写好接口就可以实现。你可以上网找找php对网页的操作的方法。 查看全部
php抓取网页标签(非常简单的用php抓取网页标签图片方法实例分享转载)
php抓取网页标签图片方法实例分享转载自:php抓取网页标签图片方法分享下面介绍一个非常简单的用php抓取网页标签图片的方法:
1、起一个新的后缀www_php,然后在src下面建一个标签save,
2、上传图片到save这个img标签的save_imgs后面的元素图片里面的img_href字段可以是一个一个的大写:/users/zhangsan23/library/zh-cn。default。cn/images/2。jpg/||;效果如下:这里我们把save_imgs后面的元素text_based_image_based_image后面text_image字段也用空格隔开效果如下:。
3、对图片进行修改resize即可:上传文件:链接在这里:地址:448634802.html抓取到以后是一张图片图片出来以后是这样
谢邀。在多数情况下php仅仅满足是javascript的读取,像flash一样的运行,而且是没有dom属性支持的,所以无法转化为真正的浏览器可以渲染的网页。但是你可以对网页进行dom操作,以及就可以让它为这个网页写一个html,然后转化为浏览器可以运行的html。php不能够对网页里面的每一张图片都进行操作,对php来说,是封装好的dom操作方法,所以只要写好接口就可以实现。你可以上网找找php对网页的操作的方法。
php抓取网页标签(伪造模拟客户端COOKIE登陆采集抓取远程网址相关的页面内容 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-03-17 17:20
)
在正常开发中,我们经常会遇到爬取某个页面的内容,但是有时候有些页面需要登录才能访问,最常见的就是论坛,这时候我们就需要使用curl来模拟登录了。
以下讨论与伪造模拟客户端 cookie login采集 以爬取远程 URL 有关。通过伪造和模拟客户端cookie登录到采集爬取远程URL页面内容教程文章,内容为本站精挑细选的教程,希望对广大网友有所帮助,以下是详细内容:
php模拟登录
在正常开发中,我们经常会遇到爬取某个页面的内容,但是有时候有些页面需要登录才能访问,最常见的就是论坛,这时候我们就需要使用curl来模拟登录了。大致思路:需要先请求提取cookies并保存,然后使用保存的cookies再次发送请求,获取页面内容。我们直接看下面的代码。
<?php
/**
* Brief PHP读取Curl模拟登陆,获取cookie,带cookie进行请求
* Date:2016/10/20
* Time:9:41
*/
//设置cookie保存位置
$cookieFile=dirname(__FILE__).'cookie.curl.tmp';
//第一步:获取cookie
$url='https://www.hfxskyyj.com/;
$data=array(
'username'=>'aseoe',
'password'=>'aseoe',
);
//curl初始化
$ch=curl_init();
curl_setopt($ch,CURLOPT_URL,$url);
//设置为post请求
curl_setopt($ch,CURLOPT_POST,true);
//设置附带返回header信息为空
curl_setopt($ch,CURLOPT_HEADER,0);
//post数据
curl_setopt($ch,CURLOPT_POSTFIELDS,$data);
//cookie保存文件位置
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookieFile);
//设置数据返回作为变量储存,而不是直接输出
curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);
//执行请求
$ret=curl_exec($ch);
//关闭连接
curl_close($ch);
//第二步:附带cookie请求需要登陆的页面
$url='https://www.hfxskyyj.com/';
//curl初始化
$ch=curl_init();
curl_setopt($ch,CURLOPT_URL,$url);
//设置为post请求
curl_setopt($ch,CURLOPT_POST,true);
//设置附带返回header信息为空
curl_setopt($ch,CURLOPT_HEADER,0);
//设置cookie信息文件位置,注意与第二步中的获取不同,这里是读取
curl_setopt($ch,CURLOPT_COOKIEFILE,$cookieFile);
//设置数据返回作为变量储存,而不是直接输出
curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);
//执行请求
$ret=curl_exec($ch);
//关闭连接
curl_close($ch);
//打印抓取内容
var_dump($ret);
这样,我们爬取了需要登录才能访问页面的内容。注意上面的地址只是一个例子,需要替换成你要爬取的页面的地址。
在正常开发中,我们经常会遇到爬取某个页面的内容,但是有时候有些页面需要登录才能访问,最常见的就是论坛,这时候我们就需要使用curl来模拟登录了。总体思路:需要先请求提取cookie并保存,再使用保存。
查看全部
php抓取网页标签(伪造模拟客户端COOKIE登陆采集抓取远程网址相关的页面内容
)
在正常开发中,我们经常会遇到爬取某个页面的内容,但是有时候有些页面需要登录才能访问,最常见的就是论坛,这时候我们就需要使用curl来模拟登录了。
以下讨论与伪造模拟客户端 cookie login采集 以爬取远程 URL 有关。通过伪造和模拟客户端cookie登录到采集爬取远程URL页面内容教程文章,内容为本站精挑细选的教程,希望对广大网友有所帮助,以下是详细内容:
php模拟登录
在正常开发中,我们经常会遇到爬取某个页面的内容,但是有时候有些页面需要登录才能访问,最常见的就是论坛,这时候我们就需要使用curl来模拟登录了。大致思路:需要先请求提取cookies并保存,然后使用保存的cookies再次发送请求,获取页面内容。我们直接看下面的代码。
<?php
/**
* Brief PHP读取Curl模拟登陆,获取cookie,带cookie进行请求
* Date:2016/10/20
* Time:9:41
*/
//设置cookie保存位置
$cookieFile=dirname(__FILE__).'cookie.curl.tmp';
//第一步:获取cookie
$url='https://www.hfxskyyj.com/;
$data=array(
'username'=>'aseoe',
'password'=>'aseoe',
);
//curl初始化
$ch=curl_init();
curl_setopt($ch,CURLOPT_URL,$url);
//设置为post请求
curl_setopt($ch,CURLOPT_POST,true);
//设置附带返回header信息为空
curl_setopt($ch,CURLOPT_HEADER,0);
//post数据
curl_setopt($ch,CURLOPT_POSTFIELDS,$data);
//cookie保存文件位置
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookieFile);
//设置数据返回作为变量储存,而不是直接输出
curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);
//执行请求
$ret=curl_exec($ch);
//关闭连接
curl_close($ch);
//第二步:附带cookie请求需要登陆的页面
$url='https://www.hfxskyyj.com/';
//curl初始化
$ch=curl_init();
curl_setopt($ch,CURLOPT_URL,$url);
//设置为post请求
curl_setopt($ch,CURLOPT_POST,true);
//设置附带返回header信息为空
curl_setopt($ch,CURLOPT_HEADER,0);
//设置cookie信息文件位置,注意与第二步中的获取不同,这里是读取
curl_setopt($ch,CURLOPT_COOKIEFILE,$cookieFile);
//设置数据返回作为变量储存,而不是直接输出
curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);
//执行请求
$ret=curl_exec($ch);
//关闭连接
curl_close($ch);
//打印抓取内容
var_dump($ret);
这样,我们爬取了需要登录才能访问页面的内容。注意上面的地址只是一个例子,需要替换成你要爬取的页面的地址。
在正常开发中,我们经常会遇到爬取某个页面的内容,但是有时候有些页面需要登录才能访问,最常见的就是论坛,这时候我们就需要使用curl来模拟登录了。总体思路:需要先请求提取cookie并保存,再使用保存。

php抓取网页标签(萧萧python教学之Python3.7流程及教学方法汇总(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2022-03-15 14:07
晓晓蟒蛇教学
1 环境
Windows7 x64
Python 3.7
2 过程
i) 配置相关库
ii) 抓取网页源代码信息
iii) 使用函数爬取特定标签中不同参数的文本
3 代码
3.1 配置相关库(请求和BS4)
进入
from urllib.request import urlopen #获取用于请求打开网页的库
from bs4 import BeautifulSoup #获取网页解析库
输出
导入爬虫相关库
3.2 爬取网页源代码
进入
html=urlopen("") #获取html结构和内容
bs0bj=BeautifulSoup(html) #提取名称信息
输出
爬取特定网页的结构和内容
BeautifulSoup从网页源码中爬取名字信息
评论
name 属性用于标识提交给服务器的表单数据,或者通过 JavaScript 在客户端引用表单数据。
只有设置了 name 属性的表单元素才能在提交表单时传递其值。
3.3 爬取特定标签中不同参数的文本
BeautifulSoup 中的 find() 和 findAll() 函数可以通过标签的不同属性找到想要的标签组或单个标签
标签
3.3.1 文本参数文本
进入
nameList=bs0bj.findAll(text="the Prince") #在网页中查找收录“王子”内容的标签
print(len(nameList)) #统计字符“王子”出现的次数
输出
在收录“王子”的网页上查找并打印标签
计算字符“王子”的出现次数
评论
text 使用标签的文本内容来匹配,而不是标签属性
len() 函数返回字符串的长度或项目数(当变量收录多个项目/元素时)
3.3.2 关键词参数关键字
进入
allText = bs0bj.findAll(id="text") #关键词参数关键字,可以选择指定属性的标签
打印(allText[0].get_text())
输出
打印网页的所有文本内容
评论
关键词参数关键字可以选择具有指定属性的标签
3.3.3标签参数标签
进入
tagList=bs0bj.findAll({"h1","h2"})#返回HTML文档h1标题标签的列表
打印(tagList[0].get_text())
输出
返回收录 HTML 文档中的 h1、h2 标题标签的列表
评论
标记参数标记可以传递一个或多个标记名称的 Python 列表作为标记参数
3.3.4个属性参数属性
进入
nameList=bs0bj.findAll("span",{"class":"green"}) #提取所有span标签下的绿色文字内容
for name in nameList: #注意for的用法:遍历列表中的所有名字
print(name.get_text()) #清除标签信息,打印字符名称列表
输出
使用 bs0bj.findAll(tagName, tagAttributes) 提取仅收录在
span> 标签中的文本,获取战争与和平角色名称列表
评论
bs0bj.tagName 只能获取页面中第一个指定的标签,而 bs0bj.findAll(tagName,
tagAttributes) 获取页面中所有指定的标签
name.get_text() 将清除 HTML 文档中的所有标签、超链接和段落,并返回一个没有标签的字符串
文本,因此通常在打印、存储和操作数据时最后使用。一般来说,HTML 文档的标记应该被保留
签名结构便于 BeautifulSoup 对象搜索。
注意 for 的用法:遍历列表中的所有名称
4 全文
代码全文如下:
################################################# #############################
# 爬虫
# 作者:莱诺克斯
# 数据:2019.09.30
# 许可证:BSD 3.0
################################################# #############################
# 配置相关库
from urllib.request import urlopen #获取请求打开网页的库
from bs4 import BeautifulSoup #获取网页解析库
# 抓取网页源代码信息
html=urlopen("")#获取html结构和内容
bs0bj=美汤(html)
# 爬取特定标签中不同参数的文本
#文本参数文本
nameList=bs0bj.findAll(text="the Prince")#在网页中查找收录“王子”内容的标签
print(len(nameList)) #统计字符“王子”出现的次数
# 关键词参数关键字
allText = bs0bj.findAll(id="text")#关键词参数关键字,可以选择指定属性的标签
打印(allText[0].get_text())
#标签参数标签
tagList=bs0bj.findAll({"h1","h2"})#返回HTML文档h1标题标签的列表
打印(tagList[0].get_text())
# 属性参数属性
nameList=bs0bj.findAll("span",{"class":"green"})#提取所有span标签下的绿色文字内容
for name in nameList: #注意for的用法,遍历列表中的所有名字
print(name.get_text()) #清除标签信息,打印字符名称列表 查看全部
php抓取网页标签(萧萧python教学之Python3.7流程及教学方法汇总(一))
晓晓蟒蛇教学
1 环境
Windows7 x64
Python 3.7
2 过程
i) 配置相关库
ii) 抓取网页源代码信息
iii) 使用函数爬取特定标签中不同参数的文本
3 代码
3.1 配置相关库(请求和BS4)
进入
from urllib.request import urlopen #获取用于请求打开网页的库
from bs4 import BeautifulSoup #获取网页解析库
输出
导入爬虫相关库
3.2 爬取网页源代码
进入
html=urlopen("") #获取html结构和内容
bs0bj=BeautifulSoup(html) #提取名称信息
输出
爬取特定网页的结构和内容
BeautifulSoup从网页源码中爬取名字信息
评论
name 属性用于标识提交给服务器的表单数据,或者通过 JavaScript 在客户端引用表单数据。
只有设置了 name 属性的表单元素才能在提交表单时传递其值。
3.3 爬取特定标签中不同参数的文本
BeautifulSoup 中的 find() 和 findAll() 函数可以通过标签的不同属性找到想要的标签组或单个标签
标签
3.3.1 文本参数文本
进入
nameList=bs0bj.findAll(text="the Prince") #在网页中查找收录“王子”内容的标签
print(len(nameList)) #统计字符“王子”出现的次数
输出
在收录“王子”的网页上查找并打印标签
计算字符“王子”的出现次数
评论
text 使用标签的文本内容来匹配,而不是标签属性
len() 函数返回字符串的长度或项目数(当变量收录多个项目/元素时)
3.3.2 关键词参数关键字
进入
allText = bs0bj.findAll(id="text") #关键词参数关键字,可以选择指定属性的标签
打印(allText[0].get_text())
输出
打印网页的所有文本内容
评论
关键词参数关键字可以选择具有指定属性的标签
3.3.3标签参数标签
进入
tagList=bs0bj.findAll({"h1","h2"})#返回HTML文档h1标题标签的列表
打印(tagList[0].get_text())
输出
返回收录 HTML 文档中的 h1、h2 标题标签的列表
评论
标记参数标记可以传递一个或多个标记名称的 Python 列表作为标记参数
3.3.4个属性参数属性
进入
nameList=bs0bj.findAll("span",{"class":"green"}) #提取所有span标签下的绿色文字内容
for name in nameList: #注意for的用法:遍历列表中的所有名字
print(name.get_text()) #清除标签信息,打印字符名称列表
输出
使用 bs0bj.findAll(tagName, tagAttributes) 提取仅收录在
span> 标签中的文本,获取战争与和平角色名称列表
评论
bs0bj.tagName 只能获取页面中第一个指定的标签,而 bs0bj.findAll(tagName,
tagAttributes) 获取页面中所有指定的标签
name.get_text() 将清除 HTML 文档中的所有标签、超链接和段落,并返回一个没有标签的字符串
文本,因此通常在打印、存储和操作数据时最后使用。一般来说,HTML 文档的标记应该被保留
签名结构便于 BeautifulSoup 对象搜索。
注意 for 的用法:遍历列表中的所有名称
4 全文
代码全文如下:
################################################# #############################
# 爬虫
# 作者:莱诺克斯
# 数据:2019.09.30
# 许可证:BSD 3.0
################################################# #############################
# 配置相关库
from urllib.request import urlopen #获取请求打开网页的库
from bs4 import BeautifulSoup #获取网页解析库
# 抓取网页源代码信息
html=urlopen("")#获取html结构和内容
bs0bj=美汤(html)
# 爬取特定标签中不同参数的文本
#文本参数文本
nameList=bs0bj.findAll(text="the Prince")#在网页中查找收录“王子”内容的标签
print(len(nameList)) #统计字符“王子”出现的次数
# 关键词参数关键字
allText = bs0bj.findAll(id="text")#关键词参数关键字,可以选择指定属性的标签
打印(allText[0].get_text())
#标签参数标签
tagList=bs0bj.findAll({"h1","h2"})#返回HTML文档h1标题标签的列表
打印(tagList[0].get_text())
# 属性参数属性
nameList=bs0bj.findAll("span",{"class":"green"})#提取所有span标签下的绿色文字内容
for name in nameList: #注意for的用法,遍历列表中的所有名字
print(name.get_text()) #清除标签信息,打印字符名称列表
php抓取网页标签(XHTML+CSS设计网页的属性及用法做详细的介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-04-12 22:27
我们一直在强调文章中的语义,那么如何使用HTML标签呢?它们一般用在什么地方?
刚接触XHTML+CSS设计网页的时候,对标签的使用没有经验,很随意。但是随着对搜索引擎优化知识的深入学习和了解,发现标签的使用其实也是一种知识。
这里就不详细介绍CSS中各个标签的属性和用法了,重点介绍在网页中的应用,希望对大家有所帮助。
一、DIV
DIV 对于 XHTML 建站的朋友应该不陌生。许多网站 和材质也被称为Web 标准网站 构造为DIV+CSS网站 构造。这么称呼也不无道理,因为W3C不建议在网页布局中使用Table标签,而作为布局标签的DIV自然会承担布局的重任。
DIV也可以说是一个大容器。除了网页的整体结构布局外,建议对网页中看似相对独立的区域进行划分。就像报纸一样,DIV 的作用是分割一个收录不同内容的大容器。在不同的地区,根据具体情况选择合适的标签。
二、H 标签
H标签是一个标题标签,经常用在段落之前,表示该段落想要表达什么。根据显示的层次和要表达的意义,可分为H1~H6。
H1 是最重要的,通常用于表达对整个网站 的角色和性质的描述,或者表明网站 的受众。其他选项卡用于显示部分的名称,或介绍性文本段落的一般描述,具体取决于级别。
因为它代表了对网站或某段文字的概括描述,所以H标签相对于搜索引擎具有很高的价值。但这并不意味着它可以随意使用。例如,一些网站使用H标签在一段文字中显示关键词,以刻意追求特定关键词的排名。或者干脆使用 H 标签作为容器来布局网页。这完全混淆了H标签的作用,不推荐。
三、P
P 是一个段落标签,用于区分一组文本的不同段落。第一个 P 标签中的文本在搜索引擎的抓取顺序中也具有很高的价值。比如百度,它忽略了Meta标签描述(description)中的文字,抓取第一个P标签中的内容(不是绝对的)。
一些网站在切分时会使用<br />标签,以便让搜索引擎抓取更多内容,为用户提供浏览体验。这并不是说不可能,有时甚至根本达不到预期的效果。对于严格类型(Strict)的文档,<br /> 是一种表达标签形式,不允许使用。
尽管大多数 网站 使用过渡文档类型,但我不建议将它们用于文本段落。
四、UL 和 LI 标签
这是一个无序列表,UL标签是列表的声明,LI是列表项。由于其item的相对独立性,常用于导航、新闻或文章列表等地方。UL 也可以作为容器来区分不同的列表。
有的网站可以追求“Web标准”,将Table转换为UL和LI,这使得网页难以阅读和维护,错误的理解正好违背了Web标准传达给我们的概念。
五、表
Table的用法我这里就不过多介绍了,只是想说Web标准并没有说以后不能用Table,但是不推荐用Table来布局,而且是仅在显示数据时使用。因此,Web 页面和 Table 标签的使用并不矛盾。
六、 搜索引擎标签
(1)Title:网页的标题,对网站的描述。子标签对搜索引擎也很有价值,通常包括目标关键字。
(2)元关键字:网页中的主要关键字。本来是为了方便搜索引擎对网站进行分类而准备的,后来由于很多网站为了使关键字排名更好 有利的是,这个标签经常被用来作弊,所以现在这个标签对搜索引擎几乎没有意义。
(3)Meta's Description: 网页的描述。和关键词一样,最初是为了方便搜索引擎分类而设计的。也因为很多网站使用这个标签作弊,所以搜索不到了引擎。如此重要。目前主流搜索引擎中只有谷歌还在抓取其内容,但几乎没有根据其内容确定关键词。
事实上,对于搜索引擎来说,最重要的是内容的质量。同样,我们所做的网站 是向观众宣传我们自己。请不要因为短期而忘记基本面。毕竟用户关心的是信息是否是他们需要的,而不是你的网站排名。
«
» 查看全部
php抓取网页标签(XHTML+CSS设计网页的属性及用法做详细的介绍)
我们一直在强调文章中的语义,那么如何使用HTML标签呢?它们一般用在什么地方?
刚接触XHTML+CSS设计网页的时候,对标签的使用没有经验,很随意。但是随着对搜索引擎优化知识的深入学习和了解,发现标签的使用其实也是一种知识。
这里就不详细介绍CSS中各个标签的属性和用法了,重点介绍在网页中的应用,希望对大家有所帮助。
一、DIV
DIV 对于 XHTML 建站的朋友应该不陌生。许多网站 和材质也被称为Web 标准网站 构造为DIV+CSS网站 构造。这么称呼也不无道理,因为W3C不建议在网页布局中使用Table标签,而作为布局标签的DIV自然会承担布局的重任。
DIV也可以说是一个大容器。除了网页的整体结构布局外,建议对网页中看似相对独立的区域进行划分。就像报纸一样,DIV 的作用是分割一个收录不同内容的大容器。在不同的地区,根据具体情况选择合适的标签。
二、H 标签
H标签是一个标题标签,经常用在段落之前,表示该段落想要表达什么。根据显示的层次和要表达的意义,可分为H1~H6。
H1 是最重要的,通常用于表达对整个网站 的角色和性质的描述,或者表明网站 的受众。其他选项卡用于显示部分的名称,或介绍性文本段落的一般描述,具体取决于级别。
因为它代表了对网站或某段文字的概括描述,所以H标签相对于搜索引擎具有很高的价值。但这并不意味着它可以随意使用。例如,一些网站使用H标签在一段文字中显示关键词,以刻意追求特定关键词的排名。或者干脆使用 H 标签作为容器来布局网页。这完全混淆了H标签的作用,不推荐。
三、P
P 是一个段落标签,用于区分一组文本的不同段落。第一个 P 标签中的文本在搜索引擎的抓取顺序中也具有很高的价值。比如百度,它忽略了Meta标签描述(description)中的文字,抓取第一个P标签中的内容(不是绝对的)。
一些网站在切分时会使用<br />标签,以便让搜索引擎抓取更多内容,为用户提供浏览体验。这并不是说不可能,有时甚至根本达不到预期的效果。对于严格类型(Strict)的文档,<br /> 是一种表达标签形式,不允许使用。
尽管大多数 网站 使用过渡文档类型,但我不建议将它们用于文本段落。
四、UL 和 LI 标签
这是一个无序列表,UL标签是列表的声明,LI是列表项。由于其item的相对独立性,常用于导航、新闻或文章列表等地方。UL 也可以作为容器来区分不同的列表。
有的网站可以追求“Web标准”,将Table转换为UL和LI,这使得网页难以阅读和维护,错误的理解正好违背了Web标准传达给我们的概念。
五、表
Table的用法我这里就不过多介绍了,只是想说Web标准并没有说以后不能用Table,但是不推荐用Table来布局,而且是仅在显示数据时使用。因此,Web 页面和 Table 标签的使用并不矛盾。
六、 搜索引擎标签
(1)Title:网页的标题,对网站的描述。子标签对搜索引擎也很有价值,通常包括目标关键字。
(2)元关键字:网页中的主要关键字。本来是为了方便搜索引擎对网站进行分类而准备的,后来由于很多网站为了使关键字排名更好 有利的是,这个标签经常被用来作弊,所以现在这个标签对搜索引擎几乎没有意义。
(3)Meta's Description: 网页的描述。和关键词一样,最初是为了方便搜索引擎分类而设计的。也因为很多网站使用这个标签作弊,所以搜索不到了引擎。如此重要。目前主流搜索引擎中只有谷歌还在抓取其内容,但几乎没有根据其内容确定关键词。
事实上,对于搜索引擎来说,最重要的是内容的质量。同样,我们所做的网站 是向观众宣传我们自己。请不要因为短期而忘记基本面。毕竟用户关心的是信息是否是他们需要的,而不是你的网站排名。
«
»
php抓取网页标签(反馈您可以通过推送后返回的状态码和字段来判断数据是否成功)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-04-12 22:25
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
回显 $result;
4)ruby 推送示例
需要'net/http'
网址 = ['#39;, '#39;]
uri = URI.parse('
site=&token=eTk7ychrWZP1pDQD')
req = Net::HTTP::Post.new(uri.request_uri)
req.body = urls.join("\n")
req.content_type = '文本/纯文本'
res = Net::HTTP.start(uri.hostname, uri.port) { |http| http.request(req) }
puts res.body 如何查看推送反馈
可以通过推送后返回的状态码和字段判断数据是否推送成功。
1,状态码为200,表示推送成功,可能返回以下字段:
字段
是否需要
参数类型
说明
成功
是的
int
成功推送的网址数
留下
是的
int
当天剩余的可推送网址数
not_same_site
没有
数组
未处理的网址列表,因为它们不是本网站的网址
无效
没有
数组
非法网址列表
成功返回示例:
{
“剩余”:4999998,
“成功”:2,
"not_same_site":[],
"not_valid":[]
}
2、状态码为4XX或500,表示推送失败,返回字段为:
字段
是否需要
类型
说明
错误
是的
int
错误码,同状态码
消息
是的
字符串
错误描述
常见推送失败返回示例说明:
错误
消息
意义
400
网站错误
网站未经站长平台验证
空内容
帖子内容为空
一次只允许 2000 个网址
一次最多只能提交 2000 个链接
超额
超过每日限额,超过限额后提交无效
401
令牌无效
令牌错误
404
找不到
接口地址填写错误
500
内部错误,请稍后再试
偶尔服务器异常,一般重试会成功
1、与原来的sitemap提交界面有什么区别?
答:状态反馈更及时。本来,提交后需要登录站长平台查看是否提交成功。目前只能根据提交后返回的数据来判断。
2、现有提交站点地图数据的程序代码需要修改什么?
回答:主要有两个变化。第一点是提交的接口需要修改;第二点是需要对接口返回的信息进行处理。失败后,需要根据错误进行处理。报错链接无法提交成功
3、为什么提交成功后看不到数据变化?
回答:我们的反馈是新提交的链接数量。如果您提交的链接之前已经提交过(即重复提交),则不计入内
4。什么时候使用主动推送提交功能最有效?
回答:页面链接生成或发布时立即提交,这样效果最好
5、一次提交一份数据和多份数据有什么区别?
答案:没有区别
6。重新提交已经发布的链接有什么问题?
A:会有两种效果。首先,您提交的配额将被浪费。每个站点每天可以提交的提交数量是有限制的。如果您提交了旧链接,当有新链接时,您可能会因为配额用尽而无法提交。二、如果您频繁重复提交旧链接,我们会减少您的配额,您可能会失去主动推送功能的权限
7、主动推送可以推送多少个链接?
回答:主动推送可以提交的链接数量上限是根据您提交的新生成的有价值链接的数量来确定的。百度会根据提交新链接的数量不时调整上限。链接数越多,可以提交的链接数限制就越高。
站点地图是您的 网站 上的页面列表。创建和提交站点地图有助于百度发现和了解您 网站 上的所有页面。您也可以通过 Sitemap 提供关于您的其他信息网站,例如最后更新日期、Sitemap 文件的更新频率等,供百度蜘蛛参考。
百度不保证所有网址都会被抓取并索引提交的数据。但是,我们会使用 Sitemap 中的数据来了解 网站 的结构,这可以帮助我们改进我们的抓取策略,并在未来更好地抓取 网站。
此外,站点地图对搜索排名没有影响。
百度Sitemap协议支持三种格式:文本格式、xml格式、Sitemap索引格式。您可以根据自己的情况选择任何格式来组织站点地图。具体格式说明及示例如下:
以txt文本列出需要提交给百度的链接地址,通过站长平台提交txt文本文件
此文本文件需要以下准则:
·文本文件每行必须有一个URL。 URL 中不能有换行符。
·不应收录除 URL 列表以外的任何信息。
·你必须写完整的URL,包括http。
·每个文本文件最多可收录 50,000 个 URL,并且应小于 10MB(10,485,760 字节)。如果 网站 收录超过 50,000 个 URL,您可以将列表拆分为多个文本文件并单独添加每个文件。
·文本文件需要使用UTF-8编码或者GBK编码。
单个xml数据的格式如下:
2009-12-14
每天
0.8
2010-05-01
每天
0.8
以上Sitemap向百度提交了一个url:
如果有多个url,按照上面的格式重复分段,列出所有url地址,打包成xml文件,提交给站长平台。
首先,站点地图文件收录的网址不得超过 50,000 个,并且大小不得超过 10 MB。如果您的站点地图超出这些限制,请将其拆分为几个较小的站点地图。这些限制有助于确保您的网络服务器不会因提供大文件而过载。
其次,站点支持的站点地图文件数量必须少于 50,000 个。如果sitemap文件数量超过50000个,则不处理,并提示“链接数过多”。
第三,如果网站的主域被验证,Sitemap文件可以收录网站主域下的所有URL。
第一步是制作要提交到站点地图文件中的网页列表。文件格式请阅读百度站点地图协议支持哪些格式。
第二步是将Sitemap文件放到网站目录下。比如你的网站是,你已经创建了sitemap_example.xml的Sitemap文件,上传sitemap_example.xml到网站根目录或者/sitemap_example.xml
第三步,登录百度站长平台,确保提交Sitemap数据的网站已经验证了归属。
第四步,进入Sitemap工具,点击“Add New Data”,文件类型选择“URL List”,并填写爬取周期和Sitemap文件地址
最后,提交后,可以在Sitemap列表中看到提交的Sitemap文件。如果Sitemap文件中有新的网站链接,可以选中该文件,点击Update进行选择,即更新网站链接。 @网站链接已提交。
百度推出了移动站点地图协议,用于将 URL 提交到移动搜索收录。百度手机Sitemap协议是在标准Sitemap协议的基础上制定的,增加了标签。它有四个值:
没有上述标签,表示为PC网页
下面的例子相当于向百度手机搜索提交了一个手机网页:,
向 PC Search 提交了一个传统网页:,
向移动和 PC 搜索提交了自适应网页:
xmlns:mobile="">
2009-12-14
每天
0.8
2009-12-14
每天
0.8
2009-12-14
每天
0.8
2009-12-14
每天
0.8
按照Mobile Sitemap协议完成Sitemap后,在Sitemap工具中点击Add New Data提交,与提交普通Sitemap相同。
百度蜘蛛会参考设置周期抓取Sitemap文件,请根据Sitemap文件内容的更新进行设置(如添加新的url)。请注意,如果url保持不变,只是更新了url对应的页面内容(例如论坛发帖页面有新回复),则不在本次更新范围内。 Sitemap 工具无法解决页面更新问题。
Sitemap数据提交后,百度一般会在1小时内开始处理。在以后的定时爬取中,如果您的站点地图支持etag,我们会更频繁地爬取站点地图文件,及时发现内容更新;否则,爬取周期会更长。
百度不保证提交的数据会被抓取到收录所有的网址。 收录 是否与页面质量有关。
是的。请使用 gzip 压缩站点地图。站点地图应小于 10MB(10,485,759 字节),无论是否压缩。
没有。 Sitemap 中的“优先级”提示仅表明该 URL 相对于您自己 网站 上的其他 URL 的重要性,不会影响页面在搜索结果中的排名。
没有。站点地图中 URL 的位置不会影响百度识别或使用它的方式。
由于转码问题,建议不要收录中文。
【特别提醒】本工具暂时下线,如恢复,将另行通知。
自动推送JS代码是百度站长平台最新推出的轻量级链接提交组件。站长只需要将自动推送的JS代码放置在网站各个页面的源码中即可。当页面被访问时,页面链接会自动推送到百度,有利于百度更快发现新页面。
为了更快速地发现网站每天产生的最新内容,百度站长平台推出了主动推送工具。产品上线后,有站长反映使用主动推送的技术门槛比较高,所以我们顺势推出了成本更低的JS自动推送工具。一步安装,实现页面自动推送,成本低,利润高。
站长需要在每个页面的HTML代码中收录如下自动推送JS代码:
如果站长使用PHP语言开发的网站,可以按照以下步骤进行:
1、创建一个名为“baidu_js_push.php”的文件,文件内容为上述自动推送JS代码;
2、在每个PHP模板页面文件的标签后添加一行代码:
基于自动推送的实现原理,每次浏览新页面,页面URL都会自动推送到百度,无需站长聚合URL再进行主动推送操作。
利用用户的浏览行为触发推送动作,节省站长手动操作的时间。
链接提交中已经使用主动推送(或站点地图)的网站是否还需要部署自动推送代码?
两者不冲突,相得益彰。已经使用主动推送的站点仍然可以部署自动推送的JS代码,两者可以一起使用。
自动推送适用于技术能力相对较弱,无法支持全天候实时主动推送方案的站长,因为实施方便,后续维护成本低。
站长只需要部署一次自动推送JS代码的操作,就可以实现浏览时推送新页面的效果,低成本实现链接的自动提交。
同时我们也支持使用主动推送和自动推送代码,两者互不影响。 查看全部
php抓取网页标签(反馈您可以通过推送后返回的状态码和字段来判断数据是否成功)
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
回显 $result;
4)ruby 推送示例
需要'net/http'
网址 = ['#39;, '#39;]
uri = URI.parse('
site=&token=eTk7ychrWZP1pDQD')
req = Net::HTTP::Post.new(uri.request_uri)
req.body = urls.join("\n")
req.content_type = '文本/纯文本'
res = Net::HTTP.start(uri.hostname, uri.port) { |http| http.request(req) }
puts res.body 如何查看推送反馈
可以通过推送后返回的状态码和字段判断数据是否推送成功。
1,状态码为200,表示推送成功,可能返回以下字段:
字段
是否需要
参数类型
说明
成功
是的
int
成功推送的网址数
留下
是的
int
当天剩余的可推送网址数
not_same_site
没有
数组
未处理的网址列表,因为它们不是本网站的网址
无效
没有
数组
非法网址列表
成功返回示例:
{
“剩余”:4999998,
“成功”:2,
"not_same_site":[],
"not_valid":[]
}
2、状态码为4XX或500,表示推送失败,返回字段为:
字段
是否需要
类型
说明
错误
是的
int
错误码,同状态码
消息
是的
字符串
错误描述
常见推送失败返回示例说明:
错误
消息
意义
400
网站错误
网站未经站长平台验证
空内容
帖子内容为空
一次只允许 2000 个网址
一次最多只能提交 2000 个链接
超额
超过每日限额,超过限额后提交无效
401
令牌无效
令牌错误
404
找不到
接口地址填写错误
500
内部错误,请稍后再试
偶尔服务器异常,一般重试会成功
1、与原来的sitemap提交界面有什么区别?
答:状态反馈更及时。本来,提交后需要登录站长平台查看是否提交成功。目前只能根据提交后返回的数据来判断。
2、现有提交站点地图数据的程序代码需要修改什么?
回答:主要有两个变化。第一点是提交的接口需要修改;第二点是需要对接口返回的信息进行处理。失败后,需要根据错误进行处理。报错链接无法提交成功
3、为什么提交成功后看不到数据变化?
回答:我们的反馈是新提交的链接数量。如果您提交的链接之前已经提交过(即重复提交),则不计入内
4。什么时候使用主动推送提交功能最有效?
回答:页面链接生成或发布时立即提交,这样效果最好
5、一次提交一份数据和多份数据有什么区别?
答案:没有区别
6。重新提交已经发布的链接有什么问题?
A:会有两种效果。首先,您提交的配额将被浪费。每个站点每天可以提交的提交数量是有限制的。如果您提交了旧链接,当有新链接时,您可能会因为配额用尽而无法提交。二、如果您频繁重复提交旧链接,我们会减少您的配额,您可能会失去主动推送功能的权限
7、主动推送可以推送多少个链接?
回答:主动推送可以提交的链接数量上限是根据您提交的新生成的有价值链接的数量来确定的。百度会根据提交新链接的数量不时调整上限。链接数越多,可以提交的链接数限制就越高。
站点地图是您的 网站 上的页面列表。创建和提交站点地图有助于百度发现和了解您 网站 上的所有页面。您也可以通过 Sitemap 提供关于您的其他信息网站,例如最后更新日期、Sitemap 文件的更新频率等,供百度蜘蛛参考。
百度不保证所有网址都会被抓取并索引提交的数据。但是,我们会使用 Sitemap 中的数据来了解 网站 的结构,这可以帮助我们改进我们的抓取策略,并在未来更好地抓取 网站。
此外,站点地图对搜索排名没有影响。
百度Sitemap协议支持三种格式:文本格式、xml格式、Sitemap索引格式。您可以根据自己的情况选择任何格式来组织站点地图。具体格式说明及示例如下:
以txt文本列出需要提交给百度的链接地址,通过站长平台提交txt文本文件
此文本文件需要以下准则:
·文本文件每行必须有一个URL。 URL 中不能有换行符。
·不应收录除 URL 列表以外的任何信息。
·你必须写完整的URL,包括http。
·每个文本文件最多可收录 50,000 个 URL,并且应小于 10MB(10,485,760 字节)。如果 网站 收录超过 50,000 个 URL,您可以将列表拆分为多个文本文件并单独添加每个文件。
·文本文件需要使用UTF-8编码或者GBK编码。
单个xml数据的格式如下:
2009-12-14
每天
0.8
2010-05-01
每天
0.8
以上Sitemap向百度提交了一个url:
如果有多个url,按照上面的格式重复分段,列出所有url地址,打包成xml文件,提交给站长平台。
首先,站点地图文件收录的网址不得超过 50,000 个,并且大小不得超过 10 MB。如果您的站点地图超出这些限制,请将其拆分为几个较小的站点地图。这些限制有助于确保您的网络服务器不会因提供大文件而过载。
其次,站点支持的站点地图文件数量必须少于 50,000 个。如果sitemap文件数量超过50000个,则不处理,并提示“链接数过多”。
第三,如果网站的主域被验证,Sitemap文件可以收录网站主域下的所有URL。
第一步是制作要提交到站点地图文件中的网页列表。文件格式请阅读百度站点地图协议支持哪些格式。
第二步是将Sitemap文件放到网站目录下。比如你的网站是,你已经创建了sitemap_example.xml的Sitemap文件,上传sitemap_example.xml到网站根目录或者/sitemap_example.xml
第三步,登录百度站长平台,确保提交Sitemap数据的网站已经验证了归属。
第四步,进入Sitemap工具,点击“Add New Data”,文件类型选择“URL List”,并填写爬取周期和Sitemap文件地址
最后,提交后,可以在Sitemap列表中看到提交的Sitemap文件。如果Sitemap文件中有新的网站链接,可以选中该文件,点击Update进行选择,即更新网站链接。 @网站链接已提交。
百度推出了移动站点地图协议,用于将 URL 提交到移动搜索收录。百度手机Sitemap协议是在标准Sitemap协议的基础上制定的,增加了标签。它有四个值:
没有上述标签,表示为PC网页
下面的例子相当于向百度手机搜索提交了一个手机网页:,
向 PC Search 提交了一个传统网页:,
向移动和 PC 搜索提交了自适应网页:
xmlns:mobile="">
2009-12-14
每天
0.8
2009-12-14
每天
0.8
2009-12-14
每天
0.8
2009-12-14
每天
0.8
按照Mobile Sitemap协议完成Sitemap后,在Sitemap工具中点击Add New Data提交,与提交普通Sitemap相同。
百度蜘蛛会参考设置周期抓取Sitemap文件,请根据Sitemap文件内容的更新进行设置(如添加新的url)。请注意,如果url保持不变,只是更新了url对应的页面内容(例如论坛发帖页面有新回复),则不在本次更新范围内。 Sitemap 工具无法解决页面更新问题。
Sitemap数据提交后,百度一般会在1小时内开始处理。在以后的定时爬取中,如果您的站点地图支持etag,我们会更频繁地爬取站点地图文件,及时发现内容更新;否则,爬取周期会更长。
百度不保证提交的数据会被抓取到收录所有的网址。 收录 是否与页面质量有关。
是的。请使用 gzip 压缩站点地图。站点地图应小于 10MB(10,485,759 字节),无论是否压缩。
没有。 Sitemap 中的“优先级”提示仅表明该 URL 相对于您自己 网站 上的其他 URL 的重要性,不会影响页面在搜索结果中的排名。
没有。站点地图中 URL 的位置不会影响百度识别或使用它的方式。
由于转码问题,建议不要收录中文。
【特别提醒】本工具暂时下线,如恢复,将另行通知。
自动推送JS代码是百度站长平台最新推出的轻量级链接提交组件。站长只需要将自动推送的JS代码放置在网站各个页面的源码中即可。当页面被访问时,页面链接会自动推送到百度,有利于百度更快发现新页面。
为了更快速地发现网站每天产生的最新内容,百度站长平台推出了主动推送工具。产品上线后,有站长反映使用主动推送的技术门槛比较高,所以我们顺势推出了成本更低的JS自动推送工具。一步安装,实现页面自动推送,成本低,利润高。
站长需要在每个页面的HTML代码中收录如下自动推送JS代码:
如果站长使用PHP语言开发的网站,可以按照以下步骤进行:
1、创建一个名为“baidu_js_push.php”的文件,文件内容为上述自动推送JS代码;
2、在每个PHP模板页面文件的标签后添加一行代码:
基于自动推送的实现原理,每次浏览新页面,页面URL都会自动推送到百度,无需站长聚合URL再进行主动推送操作。
利用用户的浏览行为触发推送动作,节省站长手动操作的时间。
链接提交中已经使用主动推送(或站点地图)的网站是否还需要部署自动推送代码?
两者不冲突,相得益彰。已经使用主动推送的站点仍然可以部署自动推送的JS代码,两者可以一起使用。
自动推送适用于技术能力相对较弱,无法支持全天候实时主动推送方案的站长,因为实施方便,后续维护成本低。
站长只需要部署一次自动推送JS代码的操作,就可以实现浏览时推送新页面的效果,低成本实现链接的自动提交。
同时我们也支持使用主动推送和自动推送代码,两者互不影响。
php抓取网页标签( PHP中常用的实现页面自动跳转的方法有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-04-12 19:33
PHP中常用的实现页面自动跳转的方法有哪些?)
PHP页面跳转实现技巧
在 Web 系统中,从一个网页跳转到另一个网页是 LAMP 项目中最常用的技术之一。页面跳转可能是用户点击链接、按钮等引起的,也可能是系统自动生成的。下面介绍PHP中实现自动页面跳转的常用方法。我希望它对你有帮助。更多新闻,请关注应届毕业生网站!
PHP页面跳转一、header()函数
header() 函数是 PHP 中一个非常简单的页面跳转方法。header()函数的主要作用是将HTTP协议头(header)输出到浏览器。
header() 函数定义如下:
void header (string string [,bool replace [,int http_response_code]]) 可选参数replace表示是替换之前的相似头还是添加相同类型的头。默认为替换。
第二个可选参数 http_response_code 将 HTTP 响应代码强制为指定值。header函数中Location类型的header是一个特殊的header调用,常用于实现页面跳转。注意:1.location 和“:”之间不能有空格,否则不会跳转。
2.在使用标头之前必须没有输出。
3. 标头之后的 PHP 代码也将被执行。比如将浏览器重定向到Lamp Brothers官方论坛 <?php// 重定向浏览器
标题(“位置:
");
// 确保重定向后不会执行后续代码
出口;
PHP页面跳转二、元标记
Meta 标签是 HTML 中的标签,负责提供文档元信息。在PHP程序中使用这个标签也可以实现页面跳转。如果http-equiv定义为refresh,当页面打开时,会在一定时间内根据内容指定的值跳转到对应的页面。
如果设置 content="seconds;url=URL",它定义了页面跳转到指定 URL 后的时间。比如使用meta标签实现疫苗后,页面自动跳转到LAMP兄弟官方论坛。 查看全部
php抓取网页标签(
PHP中常用的实现页面自动跳转的方法有哪些?)
PHP页面跳转实现技巧
在 Web 系统中,从一个网页跳转到另一个网页是 LAMP 项目中最常用的技术之一。页面跳转可能是用户点击链接、按钮等引起的,也可能是系统自动生成的。下面介绍PHP中实现自动页面跳转的常用方法。我希望它对你有帮助。更多新闻,请关注应届毕业生网站!
PHP页面跳转一、header()函数
header() 函数是 PHP 中一个非常简单的页面跳转方法。header()函数的主要作用是将HTTP协议头(header)输出到浏览器。
header() 函数定义如下:
void header (string string [,bool replace [,int http_response_code]]) 可选参数replace表示是替换之前的相似头还是添加相同类型的头。默认为替换。
第二个可选参数 http_response_code 将 HTTP 响应代码强制为指定值。header函数中Location类型的header是一个特殊的header调用,常用于实现页面跳转。注意:1.location 和“:”之间不能有空格,否则不会跳转。
2.在使用标头之前必须没有输出。
3. 标头之后的 PHP 代码也将被执行。比如将浏览器重定向到Lamp Brothers官方论坛 <?php// 重定向浏览器
标题(“位置:
");
// 确保重定向后不会执行后续代码
出口;
PHP页面跳转二、元标记
Meta 标签是 HTML 中的标签,负责提供文档元信息。在PHP程序中使用这个标签也可以实现页面跳转。如果http-equiv定义为refresh,当页面打开时,会在一定时间内根据内容指定的值跳转到对应的页面。
如果设置 content="seconds;url=URL",它定义了页面跳转到指定 URL 后的时间。比如使用meta标签实现疫苗后,页面自动跳转到LAMP兄弟官方论坛。
php抓取网页标签( 有哪些方法可以实现php页面跳转跳转?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-04-11 19:07
有哪些方法可以实现php页面跳转跳转?(图))
PHP跳转到指定页面的问题,一般见于构造网站需求。例如,我们需要从一个页面跳转到另一个页面来实现某种功能或效果。其实PHP中实现页面跳转的方式有很多种,那么这篇文章文章就给大家介绍一下,有哪些方法可以实现PHP页面跳转呢?
首先我们需要了解两个知识点:
一:header()函数是PHP中一种非常简单的页面跳转方法。 header()函数的主要作用是将HTTP协议头(header)输出到浏览器。
第二:Meta标签是HTML中负责提供文档元信息的标签。在PHP程序中使用这个标签也可以实现页面跳转。如果http-equiv定义为refresh,当页面打开时,会在一定时间内根据内容指定的值跳转到对应的页面。如果设置 content="seconds;url=URL",它定义了页面跳转到指定 URL 后的时间。
然后php跳转到指定页面的header()函数。具体示例代码如下:
void header(string string [,bool replace [,int http_response_code]])//header()函数的定义
//重定向浏览器
header("位置:");
//保证重定向后不会执行后续代码
退出;
php 跳转到指定页面的 Meta 标签。具体示例代码如下:
“刷新”内容=“1;url=http://”> 查看全部
php抓取网页标签(
有哪些方法可以实现php页面跳转跳转?(图))
PHP跳转到指定页面的问题,一般见于构造网站需求。例如,我们需要从一个页面跳转到另一个页面来实现某种功能或效果。其实PHP中实现页面跳转的方式有很多种,那么这篇文章文章就给大家介绍一下,有哪些方法可以实现PHP页面跳转呢?
首先我们需要了解两个知识点:
一:header()函数是PHP中一种非常简单的页面跳转方法。 header()函数的主要作用是将HTTP协议头(header)输出到浏览器。
第二:Meta标签是HTML中负责提供文档元信息的标签。在PHP程序中使用这个标签也可以实现页面跳转。如果http-equiv定义为refresh,当页面打开时,会在一定时间内根据内容指定的值跳转到对应的页面。如果设置 content="seconds;url=URL",它定义了页面跳转到指定 URL 后的时间。
然后php跳转到指定页面的header()函数。具体示例代码如下:
void header(string string [,bool replace [,int http_response_code]])//header()函数的定义
//重定向浏览器
header("位置:");
//保证重定向后不会执行后续代码
退出;
php 跳转到指定页面的 Meta 标签。具体示例代码如下:
“刷新”内容=“1;url=http://”>
php抓取网页标签(php开发者来说源码,远程抓取图片小程序-小编分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-10 11:35
作为一个模仿站点工作者,当网站 有版权甚至加密时,WEBZIP 也会关闭。如何扣除网页上的图片和背景图片?有时,您可能会想到使用 Firefox。这个浏览器似乎是一个强大的错误。 文章 有版权,右键被屏蔽,Firefox 完全不受影响。
但是作为一个热爱php的开发者,我更喜欢自己做。于是,我写了如下源码,php远程抓图小程序。您可以读取 css 文件并在 css 代码中获取背景图像。下面的代码也是为了抓取css中的图片而写的。
array ( 'follow_location' => false // don't follow redirects ) ) ); //请确保php.ini中的fopen wrappers已经激活 readfile( $url,false,$context); $img = ob_get_contents(); ob_end_clean(); $fp2 = @fopen($filename,"a"); fwrite($fp2,$img); fclose($fp2); echo $filename." ok √
"; } &#63;>
如果不出意外,你会发现你指定的文件夹里全是图片,哈哈..
ps:php获取远程图片并下载并保存在本地
分享一个使用php获取远程图片并将远程图片下载保存到本地的功能代码:
/* *功能:php完美实现下载远程图片保存到本地 *参数:文件url,保存文件目录,保存文件名称,使用的下载方式 *当保存文件名称为空时则使用远程文件原来的名称 */ function getImage($url,$save_dir='',$filename='',$type=0){ if(trim($url)==''){ return array('file_name'=>'','save_path'=>'','error'=>1); } if(trim($save_dir)==''){ $save_dir='./'; } if(trim($filename)==''){//保存文件名 $ext=strrchr($url,'.'); if($ext!='.gif'&&$ext!='.jpg'){ return array('file_name'=>'','save_path'=>'','error'=>3); } $filename=time().$ext; } if(0!==strrpos($save_dir,'/')){ $save_dir.='/'; } //创建保存目录 if(!file_exists($save_dir)&&!mkdir($save_dir,0777,true)){ return array('file_name'=>'','save_path'=>'','error'=>5); } //获取远程文件所采用的方法 if($type){ $ch=curl_init(); $timeout=5; curl_setopt($ch,CURLOPT_URL,$url); curl_setopt($ch,CURLOPT_RETURNTRANSFER,1); curl_setopt($ch,CURLOPT_CONNECTTIMEOUT,$timeout); $img=curl_exec($ch); curl_close($ch); }else{ ob_start(); readfile($url); $img=ob_get_contents(); ob_end_clean(); } //$size=strlen($img); //文件大小 $fp2=@fopen($save_dir.$filename,'a'); fwrite($fp2,$img); fclose($fp2); unset($img,$url); return array('file_name'=>$filename,'save_path'=>$save_dir.$filename,'error'=>0); }
以上内容是小编分享给大家的PHP源码批量抓取远程网页图片并保存到本地的实现方法。希望你喜欢。
推荐内容:免费高清PNG素材下载 查看全部
php抓取网页标签(php开发者来说源码,远程抓取图片小程序-小编分享)
作为一个模仿站点工作者,当网站 有版权甚至加密时,WEBZIP 也会关闭。如何扣除网页上的图片和背景图片?有时,您可能会想到使用 Firefox。这个浏览器似乎是一个强大的错误。 文章 有版权,右键被屏蔽,Firefox 完全不受影响。
但是作为一个热爱php的开发者,我更喜欢自己做。于是,我写了如下源码,php远程抓图小程序。您可以读取 css 文件并在 css 代码中获取背景图像。下面的代码也是为了抓取css中的图片而写的。
array ( 'follow_location' => false // don't follow redirects ) ) ); //请确保php.ini中的fopen wrappers已经激活 readfile( $url,false,$context); $img = ob_get_contents(); ob_end_clean(); $fp2 = @fopen($filename,"a"); fwrite($fp2,$img); fclose($fp2); echo $filename." ok √
"; } &#63;>
如果不出意外,你会发现你指定的文件夹里全是图片,哈哈..
ps:php获取远程图片并下载并保存在本地
分享一个使用php获取远程图片并将远程图片下载保存到本地的功能代码:
/* *功能:php完美实现下载远程图片保存到本地 *参数:文件url,保存文件目录,保存文件名称,使用的下载方式 *当保存文件名称为空时则使用远程文件原来的名称 */ function getImage($url,$save_dir='',$filename='',$type=0){ if(trim($url)==''){ return array('file_name'=>'','save_path'=>'','error'=>1); } if(trim($save_dir)==''){ $save_dir='./'; } if(trim($filename)==''){//保存文件名 $ext=strrchr($url,'.'); if($ext!='.gif'&&$ext!='.jpg'){ return array('file_name'=>'','save_path'=>'','error'=>3); } $filename=time().$ext; } if(0!==strrpos($save_dir,'/')){ $save_dir.='/'; } //创建保存目录 if(!file_exists($save_dir)&&!mkdir($save_dir,0777,true)){ return array('file_name'=>'','save_path'=>'','error'=>5); } //获取远程文件所采用的方法 if($type){ $ch=curl_init(); $timeout=5; curl_setopt($ch,CURLOPT_URL,$url); curl_setopt($ch,CURLOPT_RETURNTRANSFER,1); curl_setopt($ch,CURLOPT_CONNECTTIMEOUT,$timeout); $img=curl_exec($ch); curl_close($ch); }else{ ob_start(); readfile($url); $img=ob_get_contents(); ob_end_clean(); } //$size=strlen($img); //文件大小 $fp2=@fopen($save_dir.$filename,'a'); fwrite($fp2,$img); fclose($fp2); unset($img,$url); return array('file_name'=>$filename,'save_path'=>$save_dir.$filename,'error'=>0); }
以上内容是小编分享给大家的PHP源码批量抓取远程网页图片并保存到本地的实现方法。希望你喜欢。
推荐内容:免费高清PNG素材下载
php抓取网页标签(php抓取网页标签的方法,使用php的selenium库抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-04-05 05:04
php抓取网页标签的方法
1、使用php的selenium库抓取index.php页面1.1安装phpwindlib:wgetphpinfo:phpwindlibphpinfo:phpwindlib1.2定位需要爬取的标签网址
2、使用正则表达式抓取网页标签的路径2.1安装python的正则表达式库dom4j2.2获取<a>标签
3、获取<a>标签的关键字3.1获取<a>标签的数组3.2获取<a>标签下的所有<a>标签并列举出来3.3获取<a>标签</a>标签的子标签
可以选择python3抓取网页js代码最后sqlite导出关键字页面。
python数据抓取|python从入门到实战网易云课堂下个专栏学python爬虫网易云课堂的python爬虫,有讲解各个主流框架如requests+beautifulsoup+selenium等,想要学的抓紧看。也有关于python3抓取数据(包括已有的datetime)也很赞。
一、将数据采集到localserver目录中可以采用pymongo库,爬取中文数据的话推荐pymongo-pymongo-python3.5.1documentation和pymongo-pymongo-python3.5.1documentation(github)用pymongo的两个主要原因是因为它的线程模型和一致,pymongo提供了`open`函数,对于一个爬虫程序来说,这个函数定义需要使用pymongo_close模块来关闭线程。open用于开始爬虫,stop关闭线程。
二、pandas提供了series存储数据以及dataframe功能不过一般情况下我们也不建议专门用pandas来爬取数据,比如要么想要抓取股票交易,要么想要爬取全国各个县市的数据,可以用numpy(numericalpreprocessing)。在这一块我写过一个爬虫:python爬虫实战第一章:我该往哪里找数据_野生python爱好者社区_python3.6.1documentation。同时github上也有pandas官方的教程:pandas3.4学习笔记-csdn博客。
三、python3.4及以上版本提供的一些nlp和research方法可以考虑,例如nlp中的query转换gif, 查看全部
php抓取网页标签(php抓取网页标签的方法,使用php的selenium库抓取)
php抓取网页标签的方法
1、使用php的selenium库抓取index.php页面1.1安装phpwindlib:wgetphpinfo:phpwindlibphpinfo:phpwindlib1.2定位需要爬取的标签网址
2、使用正则表达式抓取网页标签的路径2.1安装python的正则表达式库dom4j2.2获取<a>标签
3、获取<a>标签的关键字3.1获取<a>标签的数组3.2获取<a>标签下的所有<a>标签并列举出来3.3获取<a>标签</a>标签的子标签
可以选择python3抓取网页js代码最后sqlite导出关键字页面。
python数据抓取|python从入门到实战网易云课堂下个专栏学python爬虫网易云课堂的python爬虫,有讲解各个主流框架如requests+beautifulsoup+selenium等,想要学的抓紧看。也有关于python3抓取数据(包括已有的datetime)也很赞。
一、将数据采集到localserver目录中可以采用pymongo库,爬取中文数据的话推荐pymongo-pymongo-python3.5.1documentation和pymongo-pymongo-python3.5.1documentation(github)用pymongo的两个主要原因是因为它的线程模型和一致,pymongo提供了`open`函数,对于一个爬虫程序来说,这个函数定义需要使用pymongo_close模块来关闭线程。open用于开始爬虫,stop关闭线程。
二、pandas提供了series存储数据以及dataframe功能不过一般情况下我们也不建议专门用pandas来爬取数据,比如要么想要抓取股票交易,要么想要爬取全国各个县市的数据,可以用numpy(numericalpreprocessing)。在这一块我写过一个爬虫:python爬虫实战第一章:我该往哪里找数据_野生python爱好者社区_python3.6.1documentation。同时github上也有pandas官方的教程:pandas3.4学习笔记-csdn博客。
三、python3.4及以上版本提供的一些nlp和research方法可以考虑,例如nlp中的query转换gif,
php抓取网页标签(如何可能难到程序猿的图片采集方式怎么可能猿呢 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-03-31 06:05
)
有时候我们有这样的需求,在一系列的html页面中,提取整个img标签,或者提取img标签中的src属性,也就是我们需要的图片链接,不多说直接粘贴代码,代码如下:
function extract_img($tag) {
preg_match_all('/(id|alt|title|src)=("[^"]*")/i', $tag, $matches);
$ret = array();
foreach($matches[1] as $i => $v) {
$ret[$v] = $matches[2][$i];
}
return $ret;
}
$img_tag = '';
$atts = extract_img($img_tag);
print_r($atts);
以下是程序执行后的返回结果:
返回结果
Array
(
[id] => "logo"
[src] => "http://www.devdo.net/wp-conten ... ot%3B
[alt] => "我爱吃鱼"
[title] => "我爱吃鱼啊"
)
下面是我自己用的代码,目的是抓拍某图片站的图片,但是站长对图片做了一些处理采集,但是这种处理方式怎么难程序员呢
//需要提取的网页代码
$str='
';
function getSimpleImg($str = '')
{
if (!empty($str)) {
$result = preg_replace("/.*]*srcset[=\s\"\']+([^\"\']*)[\"\'].*/", "$1", $str);
} else {
$result = '';
}
}
getSimpleImg($str);
function extract_attrib($tag) {
preg_match_all('/(srcset)=("[^"]*")/i', $tag, $matches);
// print_r($matches[2]);
$ret = array();
$img='';
foreach($matches[2] as $i => $v) {
if ($i%2==0) {
//$img.=""."";
$v= str_replace("-200x200","",$v);
$v=str_replace("-300x300","",$v);
echo '<img src='."/spanspan class="token variable"$v/span" span class="token punctuation"./spanspan class="token single-quoted-string string"'/>';
}
}
return $img;
}
$atts = extract_attrib($str);
print_r($atts); 查看全部
php抓取网页标签(如何可能难到程序猿的图片采集方式怎么可能猿呢
)
有时候我们有这样的需求,在一系列的html页面中,提取整个img标签,或者提取img标签中的src属性,也就是我们需要的图片链接,不多说直接粘贴代码,代码如下:
function extract_img($tag) {
preg_match_all('/(id|alt|title|src)=("[^"]*")/i', $tag, $matches);
$ret = array();
foreach($matches[1] as $i => $v) {
$ret[$v] = $matches[2][$i];
}
return $ret;
}
$img_tag = '
';$atts = extract_img($img_tag);
print_r($atts);
以下是程序执行后的返回结果:
返回结果
Array
(
[id] => "logo"
[src] => "http://www.devdo.net/wp-conten ... ot%3B
[alt] => "我爱吃鱼"
[title] => "我爱吃鱼啊"
)
下面是我自己用的代码,目的是抓拍某图片站的图片,但是站长对图片做了一些处理采集,但是这种处理方式怎么难程序员呢
//需要提取的网页代码
$str='
';
function getSimpleImg($str = '')
{
if (!empty($str)) {
$result = preg_replace("/.*]*srcset[=\s\"\']+([^\"\']*)[\"\'].*/", "$1", $str);
} else {
$result = '';
}
}
getSimpleImg($str);
function extract_attrib($tag) {
preg_match_all('/(srcset)=("[^"]*")/i', $tag, $matches);
// print_r($matches[2]);
$ret = array();
$img='';
foreach($matches[2] as $i => $v) {
if ($i%2==0) {
//$img.=""."";
$v= str_replace("-200x200","",$v);
$v=str_replace("-300x300","",$v);
echo '<img src='."/spanspan class="token variable"$v/span" span class="token punctuation"./spanspan class="token single-quoted-string string"'/>';
}
}
return $img;
}
$atts = extract_attrib($str);
print_r($atts);
php抓取网页标签(【PHP中文网】线上PHP培训班写作业(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-28 21:10
我参加了【PHP中文网】的在线PHP培训班。今天是第一次写作业。由于我刚刚学习 PHP,我可能做错了什么。希望老师解释一下,谢谢。
演示1
上图是纯文本结构内容在浏览器中的显示状态;
我也在用谷歌浏览器,但是在课堂上找不到老师改网页代码的地方?所以它显示乱码。
HTML文档结构HMTL常用标签
演示2
在这种情况下,我们主要学习如何使用布局标签以及常见的网页布局结构中使用的标签;
布局标签 home</a>about</a>connect</a>blog</a> 文章标题 <p>文章段落1
文章段落2 标题2
段落1
段落2 分分页条 推荐信息1 推荐信息2 推荐信息3 推荐信息4 推荐信息5 广告位 标签1 标签2 标签3 链接1</a> 链接2</a> 链接3</a></p>
演示3
如何使用文本标签和设置文本属性
基本文本标签、<p>今年双十一,购物车你清空了吗? 满园春色关不住,一枝红杏出墙来。</p>
你的前女友结婚了,拜托,
你去吗?
style="color:red">一定要去看看哪个倒霉男人娶了她
演示3-2
网页中语义文本的常见用法
语义化文本2019-12-20 08:23:202019-12-20 08:27:36<p>html文档,是指采用超文本标记语言编写的结构化文档
HTML文档,是指采用超文本标记语言编写的结构化文档<P> 2 3=8
阜阳 安徽发展最快的城市之一欢迎您</P> 联系地址:合肥市政务新区怀宁路888号
猪肉原价:58.88元,现价:49.99元
猪肉原价:58.88元,现价:49.99元
var num=100; num+=5;
已经完成50%
<b>多看多写是最快的学习方法 多看多写是最快的学习方法
程序员是地球上最聪明的一群人 程序员是地球上最聪明的一群人
我是PHP中文网的第十期学员:高同学
引用文本
超文本是一种组织信息的方式,它通过超级链接方法将文本中的文字、图表与其他信息媒体相关联。 这些相互关联的信息媒体可能在同一文本中,也可能是其他文件,或者是地理位置相距遥远的某台计算机上的文本。 这种组织信息方式将分布在不同位置的信息资源用随机方式进行连接,为人们查找,检查信息提供方便。 </p>
演示4
图片标签写法及属性设置方法
图像元素boby {background-color: lightblue;}
演示4-2
HTML标签中的链接语法,超链接是网页中最重要的组成标签元素;
问题:如上图红框所示,我使用CTRL+/直接评论时,如何显示为字符状态?
链接元素PHP中文网</a>下载文档压缩包</a>发邮件</a>致电客服</a>-------------------------PHP中文网</a>php中文网</a>PHP中文网</a>PHP中文网</a>锚点</a>hello PHP中文网
演示5-1
如何编写和使用列表元素
列表元素 首页</a> 秒杀</a> 专享</a>商品分类 电脑/办公</a> 男装/女装/童装</a> 食品/生鲜/特产</a> 图书/文娱/教育</a> 母婴/玩具/乐器</a>联系我们 电话: 185****1234</a> 邮箱: admin@php.cn</a> 地址: 中国.合肥.政务新区
演示5-2 演示5-3
表格 商品清单 编号 类别 名称 单价 数量 金额 1 3C 笔记本电脑 8900 1 8900 2 单反相机 13800 1 13800 3 服饰 卫衣 1000 2 2000 合计: 4 24700
数据表信息展示 /* 所有行添加鼠标悬停效果*/ tr:hover { background-color: lightgray; } 最新文章列表 ID 文章标题 文章分类 是否专题 阅读数 添加时间 状态 操作 1001 PHP中的对象序列化操作</a> PHP 是 2311 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1002 JavaScript原型继承的原理分析</a> JavaScript 是 999 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1003 CSS中的背景渐变是如何实现的?</a> CSS 是 6754 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1004 PHP怎么上传文件保存到本地?</a> PHP 是 6954 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1005 CMD怎么运行PHP文件?</a> PHP 是 6954 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1006 HTML中的下拉列表分组的使用</a> HTML 是 6954 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1007 Flex布局中的主轴对齐方式有哪些</a> CSS 是 6954 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 上一页</a> 1</a> 2</a> 3</a> 4</a> ....</a> 22</a> 23</a> 下一页</a></p>
形式写作
演示6 演示6-2
表单元素用户注册 <p> 账号:
密码:
邮箱:
性别: 男 女 保密
爱好: 游戏 摄影 编程
学历:
手机品牌:
上传头像:
生日:
简历:
提交 </p>
编辑课程 td { border: 1px solid lightgray; border-radius: 3px; } td:first-child label { background-color: #eee; } 编辑课程 课程名称 课程时间 分钟 课程类别 视频 手册 实战 工具 是否VIP 免费课程 线上直播课 VIP课程 课程难度 初级 中级 高级 课程分类 PHP CSS HTML 状态 待审核 正常 下架 更新状态 更新中 更新完 正在直播 是 否 排序 是否必修 必修 价格 上传本地图片</a> 封面为420*260像素的PNG/JPG/GIF格式图片 封面小图册 封面为PNG/JPG/GIF图片格式 关键词 微信,小程序,微信小程序 课程简介 介绍小程序开发,开发者工具 介绍小程序文档 微官网项目 首页,产品,产品详情,新闻,新闻详情,关于我们 课程需知 熟悉HTML+CSS 熟悉JS 熟悉PHP 保存 取消
表单内容的元素编写,表单在网页中用于与用户交互,传递数据;
问:下图中的代码是课件中的代码。上述名称的元素名称的命名规则是什么?同一元素中的名称是否在数据提交时使用中线和下划线?
演示7
内联框架 商品列表</a> 添加用户</a> 系统设置</a>
如何使用内联框架及其常用范围(主要用于嵌入地图和网站背景,对SEO不友好,不建议前端使用)。
形成知识
最后,希望老师可以少布置作业。虽然多做功课可以加深课堂学习的印象,但是因为我已经工作了(工作与编程无关),而且刚开始学代码,怕是无法完成速度和时间上(这次做了半天功课,因为这几天请假没在家上班,上班肯定做不完T_T) 查看全部
php抓取网页标签(【PHP中文网】线上PHP培训班写作业(图))
我参加了【PHP中文网】的在线PHP培训班。今天是第一次写作业。由于我刚刚学习 PHP,我可能做错了什么。希望老师解释一下,谢谢。
演示1
上图是纯文本结构内容在浏览器中的显示状态;
我也在用谷歌浏览器,但是在课堂上找不到老师改网页代码的地方?所以它显示乱码。
HTML文档结构HMTL常用标签
演示2
在这种情况下,我们主要学习如何使用布局标签以及常见的网页布局结构中使用的标签;
布局标签 home</a>about</a>connect</a>blog</a> 文章标题 <p>文章段落1
文章段落2 标题2
段落1
段落2 分分页条 推荐信息1 推荐信息2 推荐信息3 推荐信息4 推荐信息5 广告位 标签1 标签2 标签3 链接1</a> 链接2</a> 链接3</a></p>
演示3
如何使用文本标签和设置文本属性
基本文本标签、<p>今年双十一,购物车你清空了吗? 满园春色关不住,一枝红杏出墙来。</p>
你的前女友结婚了,拜托,
你去吗?
style="color:red">一定要去看看哪个倒霉男人娶了她
演示3-2
网页中语义文本的常见用法
语义化文本2019-12-20 08:23:202019-12-20 08:27:36<p>html文档,是指采用超文本标记语言编写的结构化文档
HTML文档,是指采用超文本标记语言编写的结构化文档<P> 2 3=8
阜阳 安徽发展最快的城市之一欢迎您</P> 联系地址:合肥市政务新区怀宁路888号
猪肉原价:58.88元,现价:49.99元
猪肉原价:58.88元,现价:49.99元
var num=100; num+=5;
已经完成50%
<b>多看多写是最快的学习方法 多看多写是最快的学习方法
程序员是地球上最聪明的一群人 程序员是地球上最聪明的一群人
我是PHP中文网的第十期学员:高同学
引用文本
超文本是一种组织信息的方式,它通过超级链接方法将文本中的文字、图表与其他信息媒体相关联。 这些相互关联的信息媒体可能在同一文本中,也可能是其他文件,或者是地理位置相距遥远的某台计算机上的文本。 这种组织信息方式将分布在不同位置的信息资源用随机方式进行连接,为人们查找,检查信息提供方便。 </p>
演示4
图片标签写法及属性设置方法
图像元素boby {background-color: lightblue;}
演示4-2
HTML标签中的链接语法,超链接是网页中最重要的组成标签元素;
问题:如上图红框所示,我使用CTRL+/直接评论时,如何显示为字符状态?
链接元素PHP中文网</a>下载文档压缩包</a>发邮件</a>致电客服</a>-------------------------PHP中文网</a>php中文网</a>PHP中文网</a>PHP中文网</a>锚点</a>hello PHP中文网
演示5-1
如何编写和使用列表元素
列表元素 首页</a> 秒杀</a> 专享</a>商品分类 电脑/办公</a> 男装/女装/童装</a> 食品/生鲜/特产</a> 图书/文娱/教育</a> 母婴/玩具/乐器</a>联系我们 电话: 185****1234</a> 邮箱: admin@php.cn</a> 地址: 中国.合肥.政务新区
演示5-2 演示5-3
表格 商品清单 编号 类别 名称 单价 数量 金额 1 3C 笔记本电脑 8900 1 8900 2 单反相机 13800 1 13800 3 服饰 卫衣 1000 2 2000 合计: 4 24700
数据表信息展示 /* 所有行添加鼠标悬停效果*/ tr:hover { background-color: lightgray; } 最新文章列表 ID 文章标题 文章分类 是否专题 阅读数 添加时间 状态 操作 1001 PHP中的对象序列化操作</a> PHP 是 2311 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1002 JavaScript原型继承的原理分析</a> JavaScript 是 999 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1003 CSS中的背景渐变是如何实现的?</a> CSS 是 6754 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1004 PHP怎么上传文件保存到本地?</a> PHP 是 6954 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1005 CMD怎么运行PHP文件?</a> PHP 是 6954 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1006 HTML中的下拉列表分组的使用</a> HTML 是 6954 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 1007 Flex布局中的主轴对齐方式有哪些</a> CSS 是 6954 2019-12-20 09:51:00 已审核 编辑</a> 查看评论</a> 上一页</a> 1</a> 2</a> 3</a> 4</a> ....</a> 22</a> 23</a> 下一页</a></p>
形式写作
演示6 演示6-2
表单元素用户注册 <p> 账号:
密码:
邮箱:
性别: 男 女 保密
爱好: 游戏 摄影 编程
学历:
手机品牌:
上传头像:
生日:
简历:
提交 </p>
编辑课程 td { border: 1px solid lightgray; border-radius: 3px; } td:first-child label { background-color: #eee; } 编辑课程 课程名称 课程时间 分钟 课程类别 视频 手册 实战 工具 是否VIP 免费课程 线上直播课 VIP课程 课程难度 初级 中级 高级 课程分类 PHP CSS HTML 状态 待审核 正常 下架 更新状态 更新中 更新完 正在直播 是 否 排序 是否必修 必修 价格 上传本地图片</a> 封面为420*260像素的PNG/JPG/GIF格式图片 封面小图册 封面为PNG/JPG/GIF图片格式 关键词 微信,小程序,微信小程序 课程简介 介绍小程序开发,开发者工具 介绍小程序文档 微官网项目 首页,产品,产品详情,新闻,新闻详情,关于我们 课程需知 熟悉HTML+CSS 熟悉JS 熟悉PHP 保存 取消
表单内容的元素编写,表单在网页中用于与用户交互,传递数据;
问:下图中的代码是课件中的代码。上述名称的元素名称的命名规则是什么?同一元素中的名称是否在数据提交时使用中线和下划线?
演示7
内联框架 商品列表</a> 添加用户</a> 系统设置</a>
如何使用内联框架及其常用范围(主要用于嵌入地图和网站背景,对SEO不友好,不建议前端使用)。
形成知识
最后,希望老师可以少布置作业。虽然多做功课可以加深课堂学习的印象,但是因为我已经工作了(工作与编程无关),而且刚开始学代码,怕是无法完成速度和时间上(这次做了半天功课,因为这几天请假没在家上班,上班肯定做不完T_T)
php抓取网页标签(开发一个项目之一个()抓取网站中的内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-03-28 17:19
我正在做一个项目,为此我想在后台抓取 网站 的内容,并从抓取的 网站 中获取一些有限的内容。例如,在我的页面中,我有“用户名”和“密码”字段,通过使用这些字段,我将访问我的邮件并获取我的收件箱内容并将其显示在我的页面中。
我通过单独使用 javascript 来完成上述操作。但是,当我单击登录按钮时,页面的 URL() 更改为我抓取的 URL()。但是我在不更改 URL 的情况下摆脱了细节。
最佳答案
绝对要使用 PHP Simple HTML DOM Parser。快速、简单且超级灵活。它基本上将整个 HTML 页面粘贴在一个对象中,然后您可以访问该对象中的任何元素。
像官方的 网站 例子一样,获取谷歌主页上的所有链接:
// Create DOM from URL or file
$html = file_get_html('http://www.google.com/');
// Find all images
foreach($html->find('img') as $element)
echo $element->src . '
';
// Find all links
foreach($html->find('a') as $element)
echo $element->href . '
';
关于 php - 抓取网页内容,我们在 Stack Overflow 上发现了一个类似的问题: 查看全部
php抓取网页标签(开发一个项目之一个()抓取网站中的内容)
我正在做一个项目,为此我想在后台抓取 网站 的内容,并从抓取的 网站 中获取一些有限的内容。例如,在我的页面中,我有“用户名”和“密码”字段,通过使用这些字段,我将访问我的邮件并获取我的收件箱内容并将其显示在我的页面中。
我通过单独使用 javascript 来完成上述操作。但是,当我单击登录按钮时,页面的 URL() 更改为我抓取的 URL()。但是我在不更改 URL 的情况下摆脱了细节。
最佳答案
绝对要使用 PHP Simple HTML DOM Parser。快速、简单且超级灵活。它基本上将整个 HTML 页面粘贴在一个对象中,然后您可以访问该对象中的任何元素。
像官方的 网站 例子一样,获取谷歌主页上的所有链接:
// Create DOM from URL or file
$html = file_get_html('http://www.google.com/');
// Find all images
foreach($html->find('img') as $element)
echo $element->src . '
';
// Find all links
foreach($html->find('a') as $element)
echo $element->href . '
';
关于 php - 抓取网页内容,我们在 Stack Overflow 上发现了一个类似的问题:
php抓取网页标签(开发一个简单爬虫的经过与遇到的问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-27 19:00
)
有时因为我们的工作和自己的需要,我们会浏览不同的网站来获取我们需要的数据,于是爬虫就应运而生了。下面是一个简单爬虫的开发过程和遇到的问题。要开发爬虫,首先要知道你的爬虫要做什么。我将使用 文章 转到不同的 网站 以查找特定关键字并获得指向它的链接,以便我可以快速阅读。
根据我的个人习惯,我首先要写一个界面来理清思路。
1、与众不同网站。然后我们需要一个url输入框。
2、查找 文章 的特定关键字。然后我们需要一个文章标题输入框。
3、获取 文章 链接。然后我们需要一个用于搜索结果的显示容器。[xhtml] 查看纯副本
文章网址抓取
文章标题
网站网址
抓住
文章网址
直接放代码,然后添加一些自己的样式调整,界面就完成了:
那么接下来就是功能的实现了。我用 PHP 编写它。第一步,获取网站的html代码。获取html代码的方法有很多。我就不一一介绍了。我在这里使用 curl。要获取它,请传入 网站url 以获取 html 代码: [xhtml] 查看纯副本
私有函数 get_html($url){
$ch = curl_init();
$超时= 10;
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/3 4.0.1847.131 Safari/537.36');
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
$html = curl_exec($ch);
返回 $html;
}
虽然拿到了html代码,但是很快就会遇到一个问题,就是编码问题,可能会导致你下一次匹配不成功。这里我们将获取到的html内容统一转换为utf8编码: [php] view plain copy
$coding = mb_detect_encoding($html);
if ($coding != "UTF-8" || !mb_check_encoding($html, "UTF-8"))
$html = mb_convert_encoding($html, 'utf-8', 'GBK,UTF-8,ASCII');
获取网站的html,获取文章的url,接下来就是匹配网页下所有的a标签,需要使用正则表达式,经过多次测试,终于得到一个更可靠的谱的正则表达式,不管a标签的结构多么复杂,只要是a标签:(最关键的一步)[php]查看纯副本
$pattern = '|]*>(.*)|isU';
preg_match_all($pattern, $html, $matches);
匹配的结果在$matches中,大概就是这样的多维组;[js] 查看纯副本
数组(2) {
[0]=>
大批(*) {
[0]=>
string(*) "完成一个标签"
.
.
.
}
[1]=>
大批(*) {
[0]=>
string(*) "上面下标对应的a标签的内容"
}
}
只要能拿到这个数据,其他的都可以操作。你可以遍历素数组,找到你想要的a标签,然后得到a标签的对应属性。更方便操作一个标签:[php]查看纯副本
$dom = 新的 DOMDocument();
@$dom->loadHTML($a);//$a是上面得到的一些a标签
$url = 新 DOMXPath($dom);
$hrefs = $url->evaluate('//a');
for ($i = 0; $i 长度; $i++) {
$href = $hrefs->item($i);
$url = $href->getAttribute('href'); //这里获取a标签的href属性
}
当然,这只是一种方式,你也可以使用正则表达式来匹配你想要的信息与数据玩新花样。
获取并匹配以获得您想要的结果。下一步当然是发回前端显示,编写界面,然后在前端使用js获取数据,并使用jquery动态添加内容显示:[php]view plain复制
var website_url = '你的接口地址';
$.getJSON(website_url, 函数(数据){
如果(数据){
如果(数据。文本 == ''){
$('#article_url').html('
没有这样的 文章 链接
');
返回;
}
变量字符串 = '';
变种列表=数据.文本;
for (var j in list) {
var 内容 = 列表 [j].url_content;
for (var i in content) {
if (content[i].title != '') {
字符串 += '
' +
'[' + 列表[j].website.web_name + ']' +
'' +
'
';
}
}
}
$('#article_url').html(string);
});
在最终效果图上:
查看全部
php抓取网页标签(开发一个简单爬虫的经过与遇到的问题
)
有时因为我们的工作和自己的需要,我们会浏览不同的网站来获取我们需要的数据,于是爬虫就应运而生了。下面是一个简单爬虫的开发过程和遇到的问题。要开发爬虫,首先要知道你的爬虫要做什么。我将使用 文章 转到不同的 网站 以查找特定关键字并获得指向它的链接,以便我可以快速阅读。
根据我的个人习惯,我首先要写一个界面来理清思路。
1、与众不同网站。然后我们需要一个url输入框。
2、查找 文章 的特定关键字。然后我们需要一个文章标题输入框。
3、获取 文章 链接。然后我们需要一个用于搜索结果的显示容器。[xhtml] 查看纯副本
文章网址抓取
文章标题
网站网址
抓住
文章网址
直接放代码,然后添加一些自己的样式调整,界面就完成了:
那么接下来就是功能的实现了。我用 PHP 编写它。第一步,获取网站的html代码。获取html代码的方法有很多。我就不一一介绍了。我在这里使用 curl。要获取它,请传入 网站url 以获取 html 代码: [xhtml] 查看纯副本
私有函数 get_html($url){
$ch = curl_init();
$超时= 10;
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/3 4.0.1847.131 Safari/537.36');
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
$html = curl_exec($ch);
返回 $html;
}
虽然拿到了html代码,但是很快就会遇到一个问题,就是编码问题,可能会导致你下一次匹配不成功。这里我们将获取到的html内容统一转换为utf8编码: [php] view plain copy
$coding = mb_detect_encoding($html);
if ($coding != "UTF-8" || !mb_check_encoding($html, "UTF-8"))
$html = mb_convert_encoding($html, 'utf-8', 'GBK,UTF-8,ASCII');
获取网站的html,获取文章的url,接下来就是匹配网页下所有的a标签,需要使用正则表达式,经过多次测试,终于得到一个更可靠的谱的正则表达式,不管a标签的结构多么复杂,只要是a标签:(最关键的一步)[php]查看纯副本
$pattern = '|]*>(.*)|isU';
preg_match_all($pattern, $html, $matches);
匹配的结果在$matches中,大概就是这样的多维组;[js] 查看纯副本
数组(2) {
[0]=>
大批(*) {
[0]=>
string(*) "完成一个标签"
.
.
.
}
[1]=>
大批(*) {
[0]=>
string(*) "上面下标对应的a标签的内容"
}
}
只要能拿到这个数据,其他的都可以操作。你可以遍历素数组,找到你想要的a标签,然后得到a标签的对应属性。更方便操作一个标签:[php]查看纯副本
$dom = 新的 DOMDocument();
@$dom->loadHTML($a);//$a是上面得到的一些a标签
$url = 新 DOMXPath($dom);
$hrefs = $url->evaluate('//a');
for ($i = 0; $i 长度; $i++) {
$href = $hrefs->item($i);
$url = $href->getAttribute('href'); //这里获取a标签的href属性
}
当然,这只是一种方式,你也可以使用正则表达式来匹配你想要的信息与数据玩新花样。
获取并匹配以获得您想要的结果。下一步当然是发回前端显示,编写界面,然后在前端使用js获取数据,并使用jquery动态添加内容显示:[php]view plain复制
var website_url = '你的接口地址';
$.getJSON(website_url, 函数(数据){
如果(数据){
如果(数据。文本 == ''){
$('#article_url').html('
没有这样的 文章 链接
');
返回;
}
变量字符串 = '';
变种列表=数据.文本;
for (var j in list) {
var 内容 = 列表 [j].url_content;
for (var i in content) {
if (content[i].title != '') {
字符串 += '
' +
'[' + 列表[j].website.web_name + ']' +
'' +
'
';
}
}
}
$('#article_url').html(string);
});
在最终效果图上:
php抓取网页标签(如何可能难到程序猿的图片采集方式怎么可能猿呢 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-24 13:09
)
有时候我们有这样的需求,在一系列的html页面中,提取整个img标签,或者提取img标签中的src属性,也就是我们需要的图片链接,不多说直接粘贴代码,代码如下:
function extract_img($tag) {
preg_match_all('/(id|alt|title|src)=("[^"]*")/i', $tag, $matches);
$ret = array();
foreach($matches[1] as $i => $v) {
$ret[$v] = $matches[2][$i];
}
return $ret;
}
$img_tag = '';
$atts = extract_img($img_tag);
print_r($atts);
以下是程序执行后的返回结果:
返回结果
Array
(
[id] => "logo"
[src] => "http://www.devdo.net/wp-conten ... ot%3B
[alt] => "我爱吃鱼"
[title] => "我爱吃鱼啊"
)
以下是我自己使用的代码,目的是抓取某个图片站的图片,但是站长对图片做了一些处理采集,但是这种处理方式怎么会难程序员呢
//需要提取的网页代码
$str='
';
function getSimpleImg($str = '')
{
if (!empty($str)) {
$result = preg_replace("/.*]*srcset[=\s\"\']+([^\"\']*)[\"\'].*/", "$1", $str);
} else {
$result = '';
}
}
getSimpleImg($str);
function extract_attrib($tag) {
preg_match_all('/(srcset)=("[^"]*")/i', $tag, $matches);
// print_r($matches[2]);
$ret = array();
$img='';
foreach($matches[2] as $i => $v) {
if ($i%2==0) {
//$img.=""."";
$v= str_replace("-200x200","",$v);
$v=str_replace("-300x300","",$v);
echo '."/spanspan class="token variable"$v/span" span class="token punctuation"./spanspan class="token single-quoted-string string"';
}
}
return $img;
}
$atts = extract_attrib($str);
print_r($atts); 查看全部
php抓取网页标签(如何可能难到程序猿的图片采集方式怎么可能猿呢
)
有时候我们有这样的需求,在一系列的html页面中,提取整个img标签,或者提取img标签中的src属性,也就是我们需要的图片链接,不多说直接粘贴代码,代码如下:
function extract_img($tag) {
preg_match_all('/(id|alt|title|src)=("[^"]*")/i', $tag, $matches);
$ret = array();
foreach($matches[1] as $i => $v) {
$ret[$v] = $matches[2][$i];
}
return $ret;
}
$img_tag = '
';$atts = extract_img($img_tag);
print_r($atts);
以下是程序执行后的返回结果:
返回结果
Array
(
[id] => "logo"
[src] => "http://www.devdo.net/wp-conten ... ot%3B
[alt] => "我爱吃鱼"
[title] => "我爱吃鱼啊"
)
以下是我自己使用的代码,目的是抓取某个图片站的图片,但是站长对图片做了一些处理采集,但是这种处理方式怎么会难程序员呢
//需要提取的网页代码
$str='
';
function getSimpleImg($str = '')
{
if (!empty($str)) {
$result = preg_replace("/.*]*srcset[=\s\"\']+([^\"\']*)[\"\'].*/", "$1", $str);
} else {
$result = '';
}
}
getSimpleImg($str);
function extract_attrib($tag) {
preg_match_all('/(srcset)=("[^"]*")/i', $tag, $matches);
// print_r($matches[2]);
$ret = array();
$img='';
foreach($matches[2] as $i => $v) {
if ($i%2==0) {
//$img.=""."";
$v= str_replace("-200x200","",$v);
$v=str_replace("-300x300","",$v);
echo '."/spanspan class="token variable"$v/span" span class="token punctuation"./spanspan class="token single-quoted-string string"';
}
}
return $img;
}
$atts = extract_attrib($str);
print_r($atts);
php抓取网页标签(三个不同的id你写php代码的时候可以输入id值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-22 00:09
php抓取网页标签是通过网页标签中的cookie进行的,标签页面有/aaa.cgi/这三个不同的id,你写php代码的时候可以输入id值的,这些id值会保存在这些标签中,当你写标签时才会被输入,所以解决办法是自己输入一个,然后.php写php程序解析这个id值。
可以用抓包工具来识别,比如python的itchat和requests。
你好,python中有个叫phantomjs的python库,你可以用它来抓取网页,不仅能识别url是不是有价值,还能生成浏览器地址,如下:#!/usr/bin/envpythonphantomjs。set_web_id("upzhaoboy")self。production("aaa。com")self。production("aaa。cgi")self。production("aaa。cn")。
目前对于打开外部网页,针对性的解决思路只有爬虫请求页面时生成对应的ip地址,从而解决此问题。
#!/usr/bin/envpython2#!/usr/bin/envpython2importrequestsimportjsonimporttimefromeasyrequestimportrequest#request函数是python2的importreimportsysfromeasyrequestimportcookie#cookie获取一个url的所有的浏览器地址,通过这些url,就可以获取这个页面的内容fromeasyrequestimportget_header#解析所有url的headerdefget_header(url):data={'appid':'8888','cookie':{'user-agent':'mozilla/5。
0(windowsnt6。1;wow64)applewebkit/537。36(khtml,likegecko)chrome/72。3234。140safari/537。36'}}returndata#爬虫请求自动生成url的user_agent'appid','cookie'fromcookieimportuser_agentasintasintreplace_url='/'#访问这个页面的urldefget_url(url):returnhttp。
urlopen(request。urlopen(url))。read()。decode('gbk')#获取json数据的编码eg=open('d:\\data\\aaa。json','w')aaa=eg。read()json=json。loads(aaa)returnjson。decode('utf-8')foriinrange(0,len(i)-1):try:status=i。
get()exceptioerrorase:print("success")print(status)iftime。timestamp()>statusandi['json']。encode("gbk")=='b':#获取页面内容,不包括url中的英文(注意:在get_url函数中,用request对象会把所有内容转换为json格式)eg。read()e。 查看全部
php抓取网页标签(三个不同的id你写php代码的时候可以输入id值)
php抓取网页标签是通过网页标签中的cookie进行的,标签页面有/aaa.cgi/这三个不同的id,你写php代码的时候可以输入id值的,这些id值会保存在这些标签中,当你写标签时才会被输入,所以解决办法是自己输入一个,然后.php写php程序解析这个id值。
可以用抓包工具来识别,比如python的itchat和requests。
你好,python中有个叫phantomjs的python库,你可以用它来抓取网页,不仅能识别url是不是有价值,还能生成浏览器地址,如下:#!/usr/bin/envpythonphantomjs。set_web_id("upzhaoboy")self。production("aaa。com")self。production("aaa。cgi")self。production("aaa。cn")。
目前对于打开外部网页,针对性的解决思路只有爬虫请求页面时生成对应的ip地址,从而解决此问题。
#!/usr/bin/envpython2#!/usr/bin/envpython2importrequestsimportjsonimporttimefromeasyrequestimportrequest#request函数是python2的importreimportsysfromeasyrequestimportcookie#cookie获取一个url的所有的浏览器地址,通过这些url,就可以获取这个页面的内容fromeasyrequestimportget_header#解析所有url的headerdefget_header(url):data={'appid':'8888','cookie':{'user-agent':'mozilla/5。
0(windowsnt6。1;wow64)applewebkit/537。36(khtml,likegecko)chrome/72。3234。140safari/537。36'}}returndata#爬虫请求自动生成url的user_agent'appid','cookie'fromcookieimportuser_agentasintasintreplace_url='/'#访问这个页面的urldefget_url(url):returnhttp。
urlopen(request。urlopen(url))。read()。decode('gbk')#获取json数据的编码eg=open('d:\\data\\aaa。json','w')aaa=eg。read()json=json。loads(aaa)returnjson。decode('utf-8')foriinrange(0,len(i)-1):try:status=i。
get()exceptioerrorase:print("success")print(status)iftime。timestamp()>statusandi['json']。encode("gbk")=='b':#获取页面内容,不包括url中的英文(注意:在get_url函数中,用request对象会把所有内容转换为json格式)eg。read()e。
php抓取网页标签(php抓取网页标签是一个典型的http请求。总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-03-21 21:03
php抓取网页标签是一个典型的http请求。总结如下:http请求(请求包含多个部分,请求头部,请求体和请求头和请求体。并且要说明清楚网络传输,当然这也不是一定要说明清楚),即发送一个报文头。在这个报文头里面包含了请求方法,以及请求类型,简单地说就是要请求的资源的类型。然后每一个http请求包含多个部分。
你要问的抓取网页标签,就是这个多个部分中最基本的部分。先说结论。假设有一个网站是这样请求的:<p></a></a></a></a></a></a>(下图代码来自开源代码)应该发现了,里面的一大部分加了sqlite,那就先处理一下这个??看懂了吗?网络请求采用的是 查看全部
php抓取网页标签(php抓取网页标签是一个典型的http请求。总结)
php抓取网页标签是一个典型的http请求。总结如下:http请求(请求包含多个部分,请求头部,请求体和请求头和请求体。并且要说明清楚网络传输,当然这也不是一定要说明清楚),即发送一个报文头。在这个报文头里面包含了请求方法,以及请求类型,简单地说就是要请求的资源的类型。然后每一个http请求包含多个部分。
你要问的抓取网页标签,就是这个多个部分中最基本的部分。先说结论。假设有一个网站是这样请求的:<p></a></a></a></a></a></a>(下图代码来自开源代码)应该发现了,里面的一大部分加了sqlite,那就先处理一下这个??看懂了吗?网络请求采用的是
php抓取网页标签(php抓取网页标签部分比较好做一些,只有最新的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-21 00:00
php抓取网页标签部分比较好做一些,而且php也是很容易学习的语言,当然前提是要有基础,而python如果会爬虫也可以应付小多数的网站,尤其是爬大量的网站(1w个你也能干,50w也行),java,
php能干的c++也能干,
我不会php也不会python。两者在我看来没什么不同,就算是爬虫也都是c/s架构。对于小网站,我认为c#更实用;对于大网站c++要有优势些;对于复杂系统,php更有优势些。
php是网络程序设计语言,而非网页编程语言。php也可以爬。c++更像前端脚本语言,同样也可以爬。非要在这两者里面选,
c,本科学的还好,一些跨国企业招的中层管理不会html就别想了。但想要精通还是难的,想用纯爬虫赚钱也不容易,现在信息发达了想了解真正的爬虫技术还是要看几本经典书看看,不然能不能爬得上去很难说。java是最近两年发展最快的语言,入门容易,高级到工作和生活又得了不少分寸。python可以在一些大数据开发的单位里用到,不过做纯爬虫我觉得不适合,还是要爬网页。
php没有最好的,只有最新的。javajava有些东西几十年都没有变,为了实现一个功能简直可以把计算机发展地翻天覆地了。 查看全部
php抓取网页标签(php抓取网页标签部分比较好做一些,只有最新的)
php抓取网页标签部分比较好做一些,而且php也是很容易学习的语言,当然前提是要有基础,而python如果会爬虫也可以应付小多数的网站,尤其是爬大量的网站(1w个你也能干,50w也行),java,
php能干的c++也能干,
我不会php也不会python。两者在我看来没什么不同,就算是爬虫也都是c/s架构。对于小网站,我认为c#更实用;对于大网站c++要有优势些;对于复杂系统,php更有优势些。
php是网络程序设计语言,而非网页编程语言。php也可以爬。c++更像前端脚本语言,同样也可以爬。非要在这两者里面选,
c,本科学的还好,一些跨国企业招的中层管理不会html就别想了。但想要精通还是难的,想用纯爬虫赚钱也不容易,现在信息发达了想了解真正的爬虫技术还是要看几本经典书看看,不然能不能爬得上去很难说。java是最近两年发展最快的语言,入门容易,高级到工作和生活又得了不少分寸。python可以在一些大数据开发的单位里用到,不过做纯爬虫我觉得不适合,还是要爬网页。
php没有最好的,只有最新的。javajava有些东西几十年都没有变,为了实现一个功能简直可以把计算机发展地翻天覆地了。
php抓取网页标签(知乎首答献给:php抓取网页标签内容是在php下执行的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2022-03-19 17:11
php抓取网页标签内容是在php下执行的,而php的开发语言是后端语言,需要先装好apache、mysql或者nginx服务器。apache是做lnmp下层服务的,需要装好jdk8,然后就是配置好你的环境变量。其实php是一门简单的语言,如果你觉得学了点基础就可以去找工作了,那也是不对的。网页抓取需要的是较强的网络编程水平,这是开发网页后端的基础。
首先你的php要简单
不是一个学习阶段,php与asp虽然有相通,但是一般来说,php不是由asp转过来的,而是这两门语言各领风骚数十载。asp相对于php来说,需要学习的东西相对少一些,只要有个asp基础,其他的东西都不难。php相对asp来说,很多地方需要借鉴asp的东西,与asp语言本身相比,php会麻烦些,但是想深入理解,可以去了解微软的iis。
知乎首答献给这个问题了我是一名php菜鸟,提出建议之前先感谢下题主让我有机会从头重拾php,本来有很多要说的,最后发现我真的不是一个搞网络,写代码的菜鸟。其实我觉得你可以尝试学习一下ruby语言,ruby可以更高效的用于网页抓取,tornado框架也可以尝试学习一下,这个要求编程基础要比较好。而且ruby语言很好找工作,而且发展也非常广,毕竟异步开发这一块算是前端的入门基础了。听说ruby语言在网页抓取领域能达到比php更大的作用,你可以尝试学一下。 查看全部
php抓取网页标签(知乎首答献给:php抓取网页标签内容是在php下执行的)
php抓取网页标签内容是在php下执行的,而php的开发语言是后端语言,需要先装好apache、mysql或者nginx服务器。apache是做lnmp下层服务的,需要装好jdk8,然后就是配置好你的环境变量。其实php是一门简单的语言,如果你觉得学了点基础就可以去找工作了,那也是不对的。网页抓取需要的是较强的网络编程水平,这是开发网页后端的基础。
首先你的php要简单
不是一个学习阶段,php与asp虽然有相通,但是一般来说,php不是由asp转过来的,而是这两门语言各领风骚数十载。asp相对于php来说,需要学习的东西相对少一些,只要有个asp基础,其他的东西都不难。php相对asp来说,很多地方需要借鉴asp的东西,与asp语言本身相比,php会麻烦些,但是想深入理解,可以去了解微软的iis。
知乎首答献给这个问题了我是一名php菜鸟,提出建议之前先感谢下题主让我有机会从头重拾php,本来有很多要说的,最后发现我真的不是一个搞网络,写代码的菜鸟。其实我觉得你可以尝试学习一下ruby语言,ruby可以更高效的用于网页抓取,tornado框架也可以尝试学习一下,这个要求编程基础要比较好。而且ruby语言很好找工作,而且发展也非常广,毕竟异步开发这一块算是前端的入门基础了。听说ruby语言在网页抓取领域能达到比php更大的作用,你可以尝试学一下。
php抓取网页标签(php常见标签检查、补全、闭合、过滤等相关操作技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-19 13:15
本文文章主要介绍PHP补全和过滤网页内容HTML标签的方法,并结合PHP标签检查、补全、关闭、过滤等相关操作技巧分析常用操作技巧举例。朋友可以参考以下
本文的例子描述了PHP完成和过滤网页内容的HTML标签的方法。分享给大家,供大家参考,如下:
如果你的网页内容的html标签不完整,一些table标签不完整导致页面混乱,或者你的内容以外的部分html页面收录在内,我们可以写一个函数方法来完成html标签和过滤去掉无用的html标签。
php让HTML标签自动补全、关闭、过滤功能方法一:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
closetags() 解析:
array_reverse() :此函数反转原创数组中元素的顺序,创建一个新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名会丢失。
array_search() : array_search(value,array,strict),这个函数像 in_array() 一样在数组中搜索一个键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回 false。如果第三个参数strict指定为true,则只有数据类型和值一致时才返回对应元素的键名。
php让HTML标签自动补全、关闭、过滤功能方法二:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
checkhtml($html) 解析:
stripslashes():该函数删除由addslashes() 函数添加的反斜杠。此函数用于清理从数据库或 HTML 表单中检索到的数据。 查看全部
php抓取网页标签(php常见标签检查、补全、闭合、过滤等相关操作技巧)
本文文章主要介绍PHP补全和过滤网页内容HTML标签的方法,并结合PHP标签检查、补全、关闭、过滤等相关操作技巧分析常用操作技巧举例。朋友可以参考以下
本文的例子描述了PHP完成和过滤网页内容的HTML标签的方法。分享给大家,供大家参考,如下:
如果你的网页内容的html标签不完整,一些table标签不完整导致页面混乱,或者你的内容以外的部分html页面收录在内,我们可以写一个函数方法来完成html标签和过滤去掉无用的html标签。
php让HTML标签自动补全、关闭、过滤功能方法一:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
closetags() 解析:
array_reverse() :此函数反转原创数组中元素的顺序,创建一个新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名会丢失。
array_search() : array_search(value,array,strict),这个函数像 in_array() 一样在数组中搜索一个键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回 false。如果第三个参数strict指定为true,则只有数据类型和值一致时才返回对应元素的键名。
php让HTML标签自动补全、关闭、过滤功能方法二:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
checkhtml($html) 解析:
stripslashes():该函数删除由addslashes() 函数添加的反斜杠。此函数用于清理从数据库或 HTML 表单中检索到的数据。
php抓取网页标签(php抓取网页标签一般都是用cookie.假设(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-18 17:10
php抓取网页标签一般都是用cookie.假设本次web请求访问中有百度php中抓取登录密码设置web登录的cookie有:{cookie:”selenium_password”}
因为javascript通过这个js方法获取到request对象。
如何通过ajax来获取流量明星的个人网站?-candyli的回答
javascript可以通过双向绑定获取
改一下错别字?
获取浏览器内的id?json=xxxxxxxxxxxx你手动做一下,
动态解析?
request对象的data
解析一下post请求参数
解析下data试试?
你要获取的是啥?
get方法?那获取到的是获取一个唯一识别的useragent
前几天有个客户想获取我这个平台站点的上市时间和股价
虽然是springboot开发,但你还是可以尝试使用一下mvc框架,比如springmvc。mybatis由于request对象持有requestresponse对象的datasource。
其实第一步是获取一个网页本身的request对象,第二步是获取这个对象中的所有属性,然后做一个对应的datasource。post不是非得有登录验证,就看自己需求。有专门的dogfood开发的服务。第三,如果前两步你做好了,根据url去匹配,再把response转换成html就行了。
那是post存在的问题。不是你写前端代码就可以的。 查看全部
php抓取网页标签(php抓取网页标签一般都是用cookie.假设(图))
php抓取网页标签一般都是用cookie.假设本次web请求访问中有百度php中抓取登录密码设置web登录的cookie有:{cookie:”selenium_password”}
因为javascript通过这个js方法获取到request对象。
如何通过ajax来获取流量明星的个人网站?-candyli的回答
javascript可以通过双向绑定获取
改一下错别字?
获取浏览器内的id?json=xxxxxxxxxxxx你手动做一下,
动态解析?
request对象的data
解析一下post请求参数
解析下data试试?
你要获取的是啥?
get方法?那获取到的是获取一个唯一识别的useragent
前几天有个客户想获取我这个平台站点的上市时间和股价
虽然是springboot开发,但你还是可以尝试使用一下mvc框架,比如springmvc。mybatis由于request对象持有requestresponse对象的datasource。
其实第一步是获取一个网页本身的request对象,第二步是获取这个对象中的所有属性,然后做一个对应的datasource。post不是非得有登录验证,就看自己需求。有专门的dogfood开发的服务。第三,如果前两步你做好了,根据url去匹配,再把response转换成html就行了。
那是post存在的问题。不是你写前端代码就可以的。
php抓取网页标签(非常简单的用php抓取网页标签图片方法实例分享转载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-18 08:05
php抓取网页标签图片方法实例分享转载自:php抓取网页标签图片方法分享下面介绍一个非常简单的用php抓取网页标签图片的方法:
1、起一个新的后缀www_php,然后在src下面建一个标签save,
2、上传图片到save这个img标签的save_imgs后面的元素图片里面的img_href字段可以是一个一个的大写:/users/zhangsan23/library/zh-cn。default。cn/images/2。jpg/||;效果如下:这里我们把save_imgs后面的元素text_based_image_based_image后面text_image字段也用空格隔开效果如下:。
3、对图片进行修改resize即可:上传文件:链接在这里:地址:448634802.html抓取到以后是一张图片图片出来以后是这样
谢邀。在多数情况下php仅仅满足是javascript的读取,像flash一样的运行,而且是没有dom属性支持的,所以无法转化为真正的浏览器可以渲染的网页。但是你可以对网页进行dom操作,以及就可以让它为这个网页写一个html,然后转化为浏览器可以运行的html。php不能够对网页里面的每一张图片都进行操作,对php来说,是封装好的dom操作方法,所以只要写好接口就可以实现。你可以上网找找php对网页的操作的方法。 查看全部
php抓取网页标签(非常简单的用php抓取网页标签图片方法实例分享转载)
php抓取网页标签图片方法实例分享转载自:php抓取网页标签图片方法分享下面介绍一个非常简单的用php抓取网页标签图片的方法:
1、起一个新的后缀www_php,然后在src下面建一个标签save,
2、上传图片到save这个img标签的save_imgs后面的元素图片里面的img_href字段可以是一个一个的大写:/users/zhangsan23/library/zh-cn。default。cn/images/2。jpg/||;效果如下:这里我们把save_imgs后面的元素text_based_image_based_image后面text_image字段也用空格隔开效果如下:。
3、对图片进行修改resize即可:上传文件:链接在这里:地址:448634802.html抓取到以后是一张图片图片出来以后是这样
谢邀。在多数情况下php仅仅满足是javascript的读取,像flash一样的运行,而且是没有dom属性支持的,所以无法转化为真正的浏览器可以渲染的网页。但是你可以对网页进行dom操作,以及就可以让它为这个网页写一个html,然后转化为浏览器可以运行的html。php不能够对网页里面的每一张图片都进行操作,对php来说,是封装好的dom操作方法,所以只要写好接口就可以实现。你可以上网找找php对网页的操作的方法。
php抓取网页标签(伪造模拟客户端COOKIE登陆采集抓取远程网址相关的页面内容 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-03-17 17:20
)
在正常开发中,我们经常会遇到爬取某个页面的内容,但是有时候有些页面需要登录才能访问,最常见的就是论坛,这时候我们就需要使用curl来模拟登录了。
以下讨论与伪造模拟客户端 cookie login采集 以爬取远程 URL 有关。通过伪造和模拟客户端cookie登录到采集爬取远程URL页面内容教程文章,内容为本站精挑细选的教程,希望对广大网友有所帮助,以下是详细内容:
php模拟登录
在正常开发中,我们经常会遇到爬取某个页面的内容,但是有时候有些页面需要登录才能访问,最常见的就是论坛,这时候我们就需要使用curl来模拟登录了。大致思路:需要先请求提取cookies并保存,然后使用保存的cookies再次发送请求,获取页面内容。我们直接看下面的代码。
<?php
/**
* Brief PHP读取Curl模拟登陆,获取cookie,带cookie进行请求
* Date:2016/10/20
* Time:9:41
*/
//设置cookie保存位置
$cookieFile=dirname(__FILE__).'cookie.curl.tmp';
//第一步:获取cookie
$url='https://www.hfxskyyj.com/;
$data=array(
'username'=>'aseoe',
'password'=>'aseoe',
);
//curl初始化
$ch=curl_init();
curl_setopt($ch,CURLOPT_URL,$url);
//设置为post请求
curl_setopt($ch,CURLOPT_POST,true);
//设置附带返回header信息为空
curl_setopt($ch,CURLOPT_HEADER,0);
//post数据
curl_setopt($ch,CURLOPT_POSTFIELDS,$data);
//cookie保存文件位置
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookieFile);
//设置数据返回作为变量储存,而不是直接输出
curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);
//执行请求
$ret=curl_exec($ch);
//关闭连接
curl_close($ch);
//第二步:附带cookie请求需要登陆的页面
$url='https://www.hfxskyyj.com/';
//curl初始化
$ch=curl_init();
curl_setopt($ch,CURLOPT_URL,$url);
//设置为post请求
curl_setopt($ch,CURLOPT_POST,true);
//设置附带返回header信息为空
curl_setopt($ch,CURLOPT_HEADER,0);
//设置cookie信息文件位置,注意与第二步中的获取不同,这里是读取
curl_setopt($ch,CURLOPT_COOKIEFILE,$cookieFile);
//设置数据返回作为变量储存,而不是直接输出
curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);
//执行请求
$ret=curl_exec($ch);
//关闭连接
curl_close($ch);
//打印抓取内容
var_dump($ret);
这样,我们爬取了需要登录才能访问页面的内容。注意上面的地址只是一个例子,需要替换成你要爬取的页面的地址。
在正常开发中,我们经常会遇到爬取某个页面的内容,但是有时候有些页面需要登录才能访问,最常见的就是论坛,这时候我们就需要使用curl来模拟登录了。总体思路:需要先请求提取cookie并保存,再使用保存。
查看全部
php抓取网页标签(伪造模拟客户端COOKIE登陆采集抓取远程网址相关的页面内容
)
在正常开发中,我们经常会遇到爬取某个页面的内容,但是有时候有些页面需要登录才能访问,最常见的就是论坛,这时候我们就需要使用curl来模拟登录了。
以下讨论与伪造模拟客户端 cookie login采集 以爬取远程 URL 有关。通过伪造和模拟客户端cookie登录到采集爬取远程URL页面内容教程文章,内容为本站精挑细选的教程,希望对广大网友有所帮助,以下是详细内容:
php模拟登录
在正常开发中,我们经常会遇到爬取某个页面的内容,但是有时候有些页面需要登录才能访问,最常见的就是论坛,这时候我们就需要使用curl来模拟登录了。大致思路:需要先请求提取cookies并保存,然后使用保存的cookies再次发送请求,获取页面内容。我们直接看下面的代码。
<?php
/**
* Brief PHP读取Curl模拟登陆,获取cookie,带cookie进行请求
* Date:2016/10/20
* Time:9:41
*/
//设置cookie保存位置
$cookieFile=dirname(__FILE__).'cookie.curl.tmp';
//第一步:获取cookie
$url='https://www.hfxskyyj.com/;
$data=array(
'username'=>'aseoe',
'password'=>'aseoe',
);
//curl初始化
$ch=curl_init();
curl_setopt($ch,CURLOPT_URL,$url);
//设置为post请求
curl_setopt($ch,CURLOPT_POST,true);
//设置附带返回header信息为空
curl_setopt($ch,CURLOPT_HEADER,0);
//post数据
curl_setopt($ch,CURLOPT_POSTFIELDS,$data);
//cookie保存文件位置
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookieFile);
//设置数据返回作为变量储存,而不是直接输出
curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);
//执行请求
$ret=curl_exec($ch);
//关闭连接
curl_close($ch);
//第二步:附带cookie请求需要登陆的页面
$url='https://www.hfxskyyj.com/';
//curl初始化
$ch=curl_init();
curl_setopt($ch,CURLOPT_URL,$url);
//设置为post请求
curl_setopt($ch,CURLOPT_POST,true);
//设置附带返回header信息为空
curl_setopt($ch,CURLOPT_HEADER,0);
//设置cookie信息文件位置,注意与第二步中的获取不同,这里是读取
curl_setopt($ch,CURLOPT_COOKIEFILE,$cookieFile);
//设置数据返回作为变量储存,而不是直接输出
curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);
//执行请求
$ret=curl_exec($ch);
//关闭连接
curl_close($ch);
//打印抓取内容
var_dump($ret);
这样,我们爬取了需要登录才能访问页面的内容。注意上面的地址只是一个例子,需要替换成你要爬取的页面的地址。
在正常开发中,我们经常会遇到爬取某个页面的内容,但是有时候有些页面需要登录才能访问,最常见的就是论坛,这时候我们就需要使用curl来模拟登录了。总体思路:需要先请求提取cookie并保存,再使用保存。
php抓取网页标签(萧萧python教学之Python3.7流程及教学方法汇总(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2022-03-15 14:07
晓晓蟒蛇教学
1 环境
Windows7 x64
Python 3.7
2 过程
i) 配置相关库
ii) 抓取网页源代码信息
iii) 使用函数爬取特定标签中不同参数的文本
3 代码
3.1 配置相关库(请求和BS4)
进入
from urllib.request import urlopen #获取用于请求打开网页的库
from bs4 import BeautifulSoup #获取网页解析库
输出
导入爬虫相关库
3.2 爬取网页源代码
进入
html=urlopen("") #获取html结构和内容
bs0bj=BeautifulSoup(html) #提取名称信息
输出
爬取特定网页的结构和内容
BeautifulSoup从网页源码中爬取名字信息
评论
name 属性用于标识提交给服务器的表单数据,或者通过 JavaScript 在客户端引用表单数据。
只有设置了 name 属性的表单元素才能在提交表单时传递其值。
3.3 爬取特定标签中不同参数的文本
BeautifulSoup 中的 find() 和 findAll() 函数可以通过标签的不同属性找到想要的标签组或单个标签
标签
3.3.1 文本参数文本
进入
nameList=bs0bj.findAll(text="the Prince") #在网页中查找收录“王子”内容的标签
print(len(nameList)) #统计字符“王子”出现的次数
输出
在收录“王子”的网页上查找并打印标签
计算字符“王子”的出现次数
评论
text 使用标签的文本内容来匹配,而不是标签属性
len() 函数返回字符串的长度或项目数(当变量收录多个项目/元素时)
3.3.2 关键词参数关键字
进入
allText = bs0bj.findAll(id="text") #关键词参数关键字,可以选择指定属性的标签
打印(allText[0].get_text())
输出
打印网页的所有文本内容
评论
关键词参数关键字可以选择具有指定属性的标签
3.3.3标签参数标签
进入
tagList=bs0bj.findAll({"h1","h2"})#返回HTML文档h1标题标签的列表
打印(tagList[0].get_text())
输出
返回收录 HTML 文档中的 h1、h2 标题标签的列表
评论
标记参数标记可以传递一个或多个标记名称的 Python 列表作为标记参数
3.3.4个属性参数属性
进入
nameList=bs0bj.findAll("span",{"class":"green"}) #提取所有span标签下的绿色文字内容
for name in nameList: #注意for的用法:遍历列表中的所有名字
print(name.get_text()) #清除标签信息,打印字符名称列表
输出
使用 bs0bj.findAll(tagName, tagAttributes) 提取仅收录在
span> 标签中的文本,获取战争与和平角色名称列表
评论
bs0bj.tagName 只能获取页面中第一个指定的标签,而 bs0bj.findAll(tagName,
tagAttributes) 获取页面中所有指定的标签
name.get_text() 将清除 HTML 文档中的所有标签、超链接和段落,并返回一个没有标签的字符串
文本,因此通常在打印、存储和操作数据时最后使用。一般来说,HTML 文档的标记应该被保留
签名结构便于 BeautifulSoup 对象搜索。
注意 for 的用法:遍历列表中的所有名称
4 全文
代码全文如下:
################################################# #############################
# 爬虫
# 作者:莱诺克斯
# 数据:2019.09.30
# 许可证:BSD 3.0
################################################# #############################
# 配置相关库
from urllib.request import urlopen #获取请求打开网页的库
from bs4 import BeautifulSoup #获取网页解析库
# 抓取网页源代码信息
html=urlopen("")#获取html结构和内容
bs0bj=美汤(html)
# 爬取特定标签中不同参数的文本
#文本参数文本
nameList=bs0bj.findAll(text="the Prince")#在网页中查找收录“王子”内容的标签
print(len(nameList)) #统计字符“王子”出现的次数
# 关键词参数关键字
allText = bs0bj.findAll(id="text")#关键词参数关键字,可以选择指定属性的标签
打印(allText[0].get_text())
#标签参数标签
tagList=bs0bj.findAll({"h1","h2"})#返回HTML文档h1标题标签的列表
打印(tagList[0].get_text())
# 属性参数属性
nameList=bs0bj.findAll("span",{"class":"green"})#提取所有span标签下的绿色文字内容
for name in nameList: #注意for的用法,遍历列表中的所有名字
print(name.get_text()) #清除标签信息,打印字符名称列表 查看全部
php抓取网页标签(萧萧python教学之Python3.7流程及教学方法汇总(一))
晓晓蟒蛇教学
1 环境
Windows7 x64
Python 3.7
2 过程
i) 配置相关库
ii) 抓取网页源代码信息
iii) 使用函数爬取特定标签中不同参数的文本
3 代码
3.1 配置相关库(请求和BS4)
进入
from urllib.request import urlopen #获取用于请求打开网页的库
from bs4 import BeautifulSoup #获取网页解析库
输出
导入爬虫相关库
3.2 爬取网页源代码
进入
html=urlopen("") #获取html结构和内容
bs0bj=BeautifulSoup(html) #提取名称信息
输出
爬取特定网页的结构和内容
BeautifulSoup从网页源码中爬取名字信息
评论
name 属性用于标识提交给服务器的表单数据,或者通过 JavaScript 在客户端引用表单数据。
只有设置了 name 属性的表单元素才能在提交表单时传递其值。
3.3 爬取特定标签中不同参数的文本
BeautifulSoup 中的 find() 和 findAll() 函数可以通过标签的不同属性找到想要的标签组或单个标签
标签
3.3.1 文本参数文本
进入
nameList=bs0bj.findAll(text="the Prince") #在网页中查找收录“王子”内容的标签
print(len(nameList)) #统计字符“王子”出现的次数
输出
在收录“王子”的网页上查找并打印标签
计算字符“王子”的出现次数
评论
text 使用标签的文本内容来匹配,而不是标签属性
len() 函数返回字符串的长度或项目数(当变量收录多个项目/元素时)
3.3.2 关键词参数关键字
进入
allText = bs0bj.findAll(id="text") #关键词参数关键字,可以选择指定属性的标签
打印(allText[0].get_text())
输出
打印网页的所有文本内容
评论
关键词参数关键字可以选择具有指定属性的标签
3.3.3标签参数标签
进入
tagList=bs0bj.findAll({"h1","h2"})#返回HTML文档h1标题标签的列表
打印(tagList[0].get_text())
输出
返回收录 HTML 文档中的 h1、h2 标题标签的列表
评论
标记参数标记可以传递一个或多个标记名称的 Python 列表作为标记参数
3.3.4个属性参数属性
进入
nameList=bs0bj.findAll("span",{"class":"green"}) #提取所有span标签下的绿色文字内容
for name in nameList: #注意for的用法:遍历列表中的所有名字
print(name.get_text()) #清除标签信息,打印字符名称列表
输出
使用 bs0bj.findAll(tagName, tagAttributes) 提取仅收录在
span> 标签中的文本,获取战争与和平角色名称列表
评论
bs0bj.tagName 只能获取页面中第一个指定的标签,而 bs0bj.findAll(tagName,
tagAttributes) 获取页面中所有指定的标签
name.get_text() 将清除 HTML 文档中的所有标签、超链接和段落,并返回一个没有标签的字符串
文本,因此通常在打印、存储和操作数据时最后使用。一般来说,HTML 文档的标记应该被保留
签名结构便于 BeautifulSoup 对象搜索。
注意 for 的用法:遍历列表中的所有名称
4 全文
代码全文如下:
################################################# #############################
# 爬虫
# 作者:莱诺克斯
# 数据:2019.09.30
# 许可证:BSD 3.0
################################################# #############################
# 配置相关库
from urllib.request import urlopen #获取请求打开网页的库
from bs4 import BeautifulSoup #获取网页解析库
# 抓取网页源代码信息
html=urlopen("")#获取html结构和内容
bs0bj=美汤(html)
# 爬取特定标签中不同参数的文本
#文本参数文本
nameList=bs0bj.findAll(text="the Prince")#在网页中查找收录“王子”内容的标签
print(len(nameList)) #统计字符“王子”出现的次数
# 关键词参数关键字
allText = bs0bj.findAll(id="text")#关键词参数关键字,可以选择指定属性的标签
打印(allText[0].get_text())
#标签参数标签
tagList=bs0bj.findAll({"h1","h2"})#返回HTML文档h1标题标签的列表
打印(tagList[0].get_text())
# 属性参数属性
nameList=bs0bj.findAll("span",{"class":"green"})#提取所有span标签下的绿色文字内容
for name in nameList: #注意for的用法,遍历列表中的所有名字
print(name.get_text()) #清除标签信息,打印字符名称列表

