
nodejs抓取动态网页
nodejs抓取动态网页(用nodejs配置代理服务器,我们需要借助两个npm包,一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-28 17:04
题图 From Geek Time From Clm
前端开发人员在工作中经常会遇到跨域问题。一般来说,我们主要使用以下方法来解决跨域问题:
1、jsonp
2、cors
3、配置代理服务器。
jsonp 不是很灵活。它只能发送 get 请求,但不能发送 psot 请求。虽然cors可以支持多种请求格式,但是如果请求携带cookies,需要分别配置服务端和客户端,也很麻烦。
与前两者相比,使用代理服务器解决跨域问题要简单得多。
由于同源策略,浏览器在不同域名之间发送ajax请求,响应数据不会被浏览器加载。服务器到服务器的请求不受同源策略的限制。
下图是代理服务器的原理:
代理服务器只起中继作用。配置代理服务器的方式有很多种,比如使用apache、nginx、tomcat等,今天给大家介绍一下用nodejs配置代理服务器,用nodejs配置代理服务器。我们需要用到两个npm包,一个是web开发框架express,一个是express中间件http-proxy-middleware。
第一步用express搭建两台服务器,一台端口号为3000的静态资源服务器和一台端口号为5000的接口服务器。静态资源服务器代码如下:
var express = require(express);var app = express();app.use(express.static(./public));app.listen(3000);
并在public文件夹下创建一个.html,在页面中使用jquery,并使用jquery发送ajax向接口服务器发送测试请求。
a.html代码如下:
然后搭建一个接口服务器,接口服务器的端口号为5000,代码如下:
看代码,我们设计了三个接口,都是get请求,只是url不同。
此时启动静态资源服务器和接口服务器,然后访问静态资源服务器下的a.html。结果如下:
如图所示,出现跨域。此时,http-proxy-middleware中间件安装在静态资源服务器中,并集成到静态资源服务器中。
代码显示如下:
此时重启静态资源服务器,在a.html页面中稍微更改发送ajax的地址,如图:
观察代码:我们的代码原来是直接请求5000端口服务器的数据,现在改成相对路径。与当前网页所在的服务器相比,当前网页所在的静态服务器端口为3000。
当我们访问 ::3000/a.html 时,结果如下:
看看ajax请求的地址是怎么拼接的:
结论:相对路径是自动连接的。
查看请求的结果,是成功的:
跨域成功,当然这个不严谨,浏览器不参与跨域,但是页面中ajax请求的地址还是3000端口的服务,但是3000端口的服务接收到请求并转发给5000端口服务,5000端口服务结果原封不动返回给浏览器。
回看上面的代码,我们只是在静态资源服务器中应用了 http-proxy-middleware 中间件。这个中间件的使用非常简单,可以分为以下几个步骤:
1、安装并导入到项目中。
2、通过 app.use 挂载中间件。这里需要注意的是,在挂载这个中间件的时候,app.use需要设置一个pre-route来和项目的原创路由区分开来。
调用该中间件时,需要设置几个常用参数:
1、target,指的是目标网站,或者代理的网站。
2、changeOrigin 是否改变主机。默认为 false,不被覆盖。
3、pathRewrite 路径重写,这个特性取决于需求。
简单配置:
如果这样配置,当在a.html中发送请求时,写:
这个请求会被静态资源服务器翻译成:
:5000/api/a
也就是说,如果没有设置pathRewrite,页面中的请求地址会原封不动地追加到目的服务器地址上。
而如果真正的接口地址是这样的:
:5000/b
如何配置代理服务器?
此时在页面中发送请求:
此时根据代理服务的重写规则,最终的请求地址为:
:5000/b
以上就是pathRewrite的作用。
然后看changeOrigin的作用。当我们将 changeOrigin 设置为 true 时,我们在接口服务器上打印 req.headers 以查看结果是什么:
仔细观察host是localhost:5000,把changeOrigin改成false?再次打印 req.headers :
此时检查主机是否为localhost:3000,
changeOrigin 是是否重写请求头中的主机。代理服务器会在请求头中添加对应的Host头,然后目标服务器可以根据这个头来区分要访问的站点。如果你在本地80端口设置一个apache服务器,则服务器配备两个虚拟站点,设置代理后changeOrigin为true。至此,就可以正确访问虚拟主机下的文档内容了。否则访问 ab 站点就相当于访问 localhost。当然,如果你的服务器没有配置虚拟主机,你可以省略这个参数,就像上面演示的代码一样,你可以完全省略这个参数。因为接口服务器没有设置虚拟主机。
以上就是用nodejs搭建代理服务器的知识。这个 http-proxy-middleware 中间件被广泛使用。这个中间件内置在 vue-cli 或 create-react-app 生成的项目中。配置规则基本和上面一样,有什么问题可以留言。
每天进步一点点,大家互相鼓励,虽然是假期,但也不能放松。
代码地址 查看全部
nodejs抓取动态网页(用nodejs配置代理服务器,我们需要借助两个npm包,一个)
题图 From Geek Time From Clm
前端开发人员在工作中经常会遇到跨域问题。一般来说,我们主要使用以下方法来解决跨域问题:
1、jsonp
2、cors
3、配置代理服务器。
jsonp 不是很灵活。它只能发送 get 请求,但不能发送 psot 请求。虽然cors可以支持多种请求格式,但是如果请求携带cookies,需要分别配置服务端和客户端,也很麻烦。
与前两者相比,使用代理服务器解决跨域问题要简单得多。
由于同源策略,浏览器在不同域名之间发送ajax请求,响应数据不会被浏览器加载。服务器到服务器的请求不受同源策略的限制。
下图是代理服务器的原理:
代理服务器只起中继作用。配置代理服务器的方式有很多种,比如使用apache、nginx、tomcat等,今天给大家介绍一下用nodejs配置代理服务器,用nodejs配置代理服务器。我们需要用到两个npm包,一个是web开发框架express,一个是express中间件http-proxy-middleware。
第一步用express搭建两台服务器,一台端口号为3000的静态资源服务器和一台端口号为5000的接口服务器。静态资源服务器代码如下:
var express = require(express);var app = express();app.use(express.static(./public));app.listen(3000);
并在public文件夹下创建一个.html,在页面中使用jquery,并使用jquery发送ajax向接口服务器发送测试请求。
a.html代码如下:
然后搭建一个接口服务器,接口服务器的端口号为5000,代码如下:
看代码,我们设计了三个接口,都是get请求,只是url不同。
此时启动静态资源服务器和接口服务器,然后访问静态资源服务器下的a.html。结果如下:
如图所示,出现跨域。此时,http-proxy-middleware中间件安装在静态资源服务器中,并集成到静态资源服务器中。
代码显示如下:
此时重启静态资源服务器,在a.html页面中稍微更改发送ajax的地址,如图:
观察代码:我们的代码原来是直接请求5000端口服务器的数据,现在改成相对路径。与当前网页所在的服务器相比,当前网页所在的静态服务器端口为3000。
当我们访问 ::3000/a.html 时,结果如下:
看看ajax请求的地址是怎么拼接的:
结论:相对路径是自动连接的。
查看请求的结果,是成功的:
跨域成功,当然这个不严谨,浏览器不参与跨域,但是页面中ajax请求的地址还是3000端口的服务,但是3000端口的服务接收到请求并转发给5000端口服务,5000端口服务结果原封不动返回给浏览器。
回看上面的代码,我们只是在静态资源服务器中应用了 http-proxy-middleware 中间件。这个中间件的使用非常简单,可以分为以下几个步骤:
1、安装并导入到项目中。
2、通过 app.use 挂载中间件。这里需要注意的是,在挂载这个中间件的时候,app.use需要设置一个pre-route来和项目的原创路由区分开来。
调用该中间件时,需要设置几个常用参数:
1、target,指的是目标网站,或者代理的网站。
2、changeOrigin 是否改变主机。默认为 false,不被覆盖。
3、pathRewrite 路径重写,这个特性取决于需求。
简单配置:
如果这样配置,当在a.html中发送请求时,写:
这个请求会被静态资源服务器翻译成:
:5000/api/a
也就是说,如果没有设置pathRewrite,页面中的请求地址会原封不动地追加到目的服务器地址上。
而如果真正的接口地址是这样的:
:5000/b
如何配置代理服务器?
此时在页面中发送请求:
此时根据代理服务的重写规则,最终的请求地址为:
:5000/b
以上就是pathRewrite的作用。
然后看changeOrigin的作用。当我们将 changeOrigin 设置为 true 时,我们在接口服务器上打印 req.headers 以查看结果是什么:
仔细观察host是localhost:5000,把changeOrigin改成false?再次打印 req.headers :
此时检查主机是否为localhost:3000,
changeOrigin 是是否重写请求头中的主机。代理服务器会在请求头中添加对应的Host头,然后目标服务器可以根据这个头来区分要访问的站点。如果你在本地80端口设置一个apache服务器,则服务器配备两个虚拟站点,设置代理后changeOrigin为true。至此,就可以正确访问虚拟主机下的文档内容了。否则访问 ab 站点就相当于访问 localhost。当然,如果你的服务器没有配置虚拟主机,你可以省略这个参数,就像上面演示的代码一样,你可以完全省略这个参数。因为接口服务器没有设置虚拟主机。
以上就是用nodejs搭建代理服务器的知识。这个 http-proxy-middleware 中间件被广泛使用。这个中间件内置在 vue-cli 或 create-react-app 生成的项目中。配置规则基本和上面一样,有什么问题可以留言。
每天进步一点点,大家互相鼓励,虽然是假期,但也不能放松。
代码地址
nodejs抓取动态网页(selenium1.使用selenium抓取动态图片本次抓取的流程确认)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-03-28 15:24
文章目录
本章将带你使用selenium抓取一些动态加载的页面,让你体会到selenium的用处
1.使用selenium抓取动态图片
本次拍摄的图片是百度图片中安吉拉的相关图片
import time
import requests # 使用requests下载图片
from urllib import request # 下载图片
from bs4 import BeautifulSoup # 使用bs4解析
from selenium import webdriver # 自动化测试工具
# 配置下载的图片的地址, 文件夹需要先创建好
IMAGE_PATH = './images/'
# 实例化驱动程序的Chrome对象, driverpath: 驱动的路径
browser = webdriver.Chrome(r'driverpath')
# 定制请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
"Chrome/74.0.3729.108 Safari/537.36",
}
# 打开百度图片页面
browser.get('https://image.baidu.com/')
# 获取输入框并向输入框内输入数据
input_box = browser.find_element_by_id('kw')
input_box.send_keys('安琪拉')
time.sleep(2)
# 点击搜索按钮获取响应输入
button = browser.find_element_by_class_name('s_search')
button.click()
time.sleep(1)
# 下拉滚动条, 循环多次下拉, 可以获取到更多的图片
for i in range(3):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1.5)
# 获取网页的str源代码
response = browser.page_source
# 实现数据解析--使用测试工具获取到的源码就是str类型,不需要再使用text获取文本数据
soup = BeautifulSoup(response, 'lxml')
li_list = soup.select('.imgpage ul li')
for li in li_list:
# li内的data-objurl属性存储的是图片的地址
href = li['data-objurl']
# 首先使用urllib模块下的request.urlretrieve下载, 此处我注释了, 大家可以尝试一下
# request.urlretrieve(href, IMAGE_PATH+'%s.jpg' % li_list.index(li))
# print('正在下载地址为%s的图片...' % href)
# time.sleep(0.5)
# 使用requests模块下载 -- 需要自己写入文件,因为requests没有自带的下载方法
image_response = requests.get(url=href, headers=headers)
# 写入文件必须使用二进制写入
with open(IMAGE_PATH + "%s.jpg" % li_list.index(li), 'wb') as f:
# 访问的是图片页面,图片是二进制流,使用content获取
f.write(image_response.content)
# 循环下载完成后退出
browser.quit()
2.使用 selenium 捕获动态数据
我要找的是雪球网爬取动态数据,爬取雪球网首页推荐数据,雪球网地址
2.1 分析爬虫页面,制定爬虫流程
确认网址
我这里看到的数据一样,就是当前的url,可以点击Headers复制url
如上图,数据已经有了,但是低头看抓包区会发现只有几条数据,所以需要用selenium打开当前页面并配合js下拉页面获取更多数据
分析获取的数据(xpath或者bs4),得到需要的数据
对数据进行封装和持久化,存储在文件或数据库中(后面会讲到)
2.2 编写爬虫代码爬取页面
import time
import json # 用于格式化存入文件
from selenium import webdriver # 自动化测试工具
from lxml import etree # 使用xpath解析
def spider_snowball():
"""
1.爬取雪球网,获取url
2.使用自动化测试工具打开雪球网
3.需要使用自动化测试工具循环下拉滚动条三次,获取到动态加载的数据
4.然后使用自动化测试工具点击加载更多的button按钮,来获取到更多的数据
5.对获取到的数据进行解析,拿取需要的数据
6.将数据循环以词典添加到列表中
7.将列表数据写入到文件中,并且需要将列表转换为json字符串
"""
# 开始时间, 用于测试爬虫的时长
start_time = time.time()
# 雪球网的url, 默认就为推荐数据
url = 'https://xueqiu.com'
# 定制请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
"Chrome/74.0.3729.108 Safari/537.36",
}
# 实例化浏览器对象,以谷歌浏览器运行, driverpath: 自己驱动的存放路径
browser = webdriver.Chrome(r'driverpath')
# 打开对应的url
browser.get(url)
# 下拉滚动条三次, 三次之后就需要点击加载更多的按钮, 可自己下拉查看
for i in range(3):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1.5)
# 获取加载更多的按钮
button = browser.find_element_by_class_name('AnonymousHome_home__timeline__more_6RI')
try:
# 循环点击这个按钮,并且下拉获取到更多的数据, 此处循环自行设置, 可以不必循环太多次
for i in range(100):
# 点击这个按钮
button.click()
# 点击按钮之后会展示更多的数据,然后继续下拉滚动条来获取加载更多按钮
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(2)
except Exception as e:
print('出错了:', e)
else:
# 如果没有出错,那么则获取到了全部(大量)的数据,下面要对数据进行解析,取出所需数据
# 获取到的网页源码就是str类型,不需要再使用text获取html文本数据
tree = etree.HTML(browser.page_source)
# 获取到所有的a标签
a_list = tree.xpath('//div[@class="AnonymousHome_home__timeline__item_3vU"]/h3/a')
result_list = []
for a in a_list:
result_dict = dict()
# 标签中的文字可直接使用text获取文本或者再次使用xpath匹配
title = a.text
# 因为xpath匹配出来后的数据是放在列表中,所以要从列表中拿出来
href = url + a.xpath('./@href')[0]
# 将数据添加到字典中
result_dict["title"] = title
result_dict["url"] = href
# 将字典添加到列表中
result_list.append(result_dict)
# 此处循环完毕后,列表中有多个字典,可以将列表写入文件(数据库)中,以便查看数据
with open('xue_qiu.json', 'w', encoding='utf-8') as f:
# 写入文件要将python格式转换为json字符串写入
f.write(json.dumps(result_list, ensure_ascii=False, indent=2))
# 退出浏览器
browser.quit()
end_time = time.time()
# 打印爬取数据的总时长
print("总耗时:%d" % (end_time-start_time))
if __name__ == '__main__':
spider_snowball()
3.总结
如果你自己用上面的代码去抓取数据,相信你就会知道selenium的方便之处。如果不使用selenium来抓一些数据,可能大家抓起来很不方便,但是selenium也有自己的弊端,就是效率不高,就像上面的抓雪球网一样,我自己测试了一下220s,有时候也可以选择抓取js包进行数据分析(后面会有案例),当然如果用其他方法获取不到数据,使用selenium也是一个不错的选择。 查看全部
nodejs抓取动态网页(selenium1.使用selenium抓取动态图片本次抓取的流程确认)
文章目录
本章将带你使用selenium抓取一些动态加载的页面,让你体会到selenium的用处
1.使用selenium抓取动态图片
本次拍摄的图片是百度图片中安吉拉的相关图片
import time
import requests # 使用requests下载图片
from urllib import request # 下载图片
from bs4 import BeautifulSoup # 使用bs4解析
from selenium import webdriver # 自动化测试工具
# 配置下载的图片的地址, 文件夹需要先创建好
IMAGE_PATH = './images/'
# 实例化驱动程序的Chrome对象, driverpath: 驱动的路径
browser = webdriver.Chrome(r'driverpath')
# 定制请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
"Chrome/74.0.3729.108 Safari/537.36",
}
# 打开百度图片页面
browser.get('https://image.baidu.com/')
# 获取输入框并向输入框内输入数据
input_box = browser.find_element_by_id('kw')
input_box.send_keys('安琪拉')
time.sleep(2)
# 点击搜索按钮获取响应输入
button = browser.find_element_by_class_name('s_search')
button.click()
time.sleep(1)
# 下拉滚动条, 循环多次下拉, 可以获取到更多的图片
for i in range(3):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1.5)
# 获取网页的str源代码
response = browser.page_source
# 实现数据解析--使用测试工具获取到的源码就是str类型,不需要再使用text获取文本数据
soup = BeautifulSoup(response, 'lxml')
li_list = soup.select('.imgpage ul li')
for li in li_list:
# li内的data-objurl属性存储的是图片的地址
href = li['data-objurl']
# 首先使用urllib模块下的request.urlretrieve下载, 此处我注释了, 大家可以尝试一下
# request.urlretrieve(href, IMAGE_PATH+'%s.jpg' % li_list.index(li))
# print('正在下载地址为%s的图片...' % href)
# time.sleep(0.5)
# 使用requests模块下载 -- 需要自己写入文件,因为requests没有自带的下载方法
image_response = requests.get(url=href, headers=headers)
# 写入文件必须使用二进制写入
with open(IMAGE_PATH + "%s.jpg" % li_list.index(li), 'wb') as f:
# 访问的是图片页面,图片是二进制流,使用content获取
f.write(image_response.content)
# 循环下载完成后退出
browser.quit()
2.使用 selenium 捕获动态数据
我要找的是雪球网爬取动态数据,爬取雪球网首页推荐数据,雪球网地址
2.1 分析爬虫页面,制定爬虫流程
确认网址
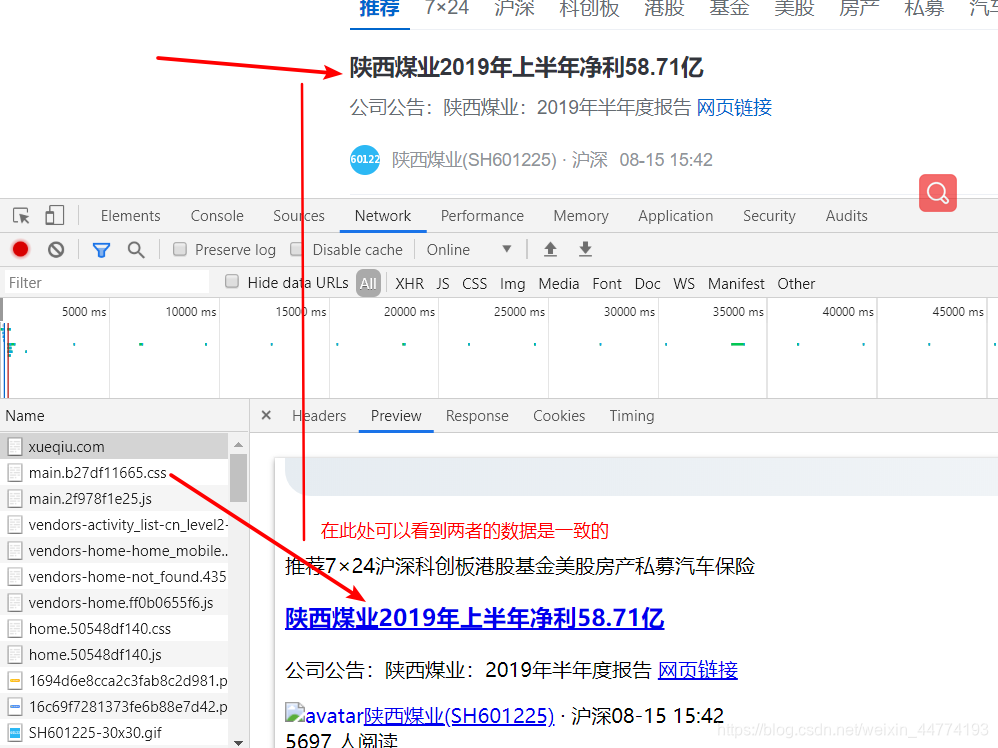
我这里看到的数据一样,就是当前的url,可以点击Headers复制url
如上图,数据已经有了,但是低头看抓包区会发现只有几条数据,所以需要用selenium打开当前页面并配合js下拉页面获取更多数据
分析获取的数据(xpath或者bs4),得到需要的数据
对数据进行封装和持久化,存储在文件或数据库中(后面会讲到)
2.2 编写爬虫代码爬取页面
import time
import json # 用于格式化存入文件
from selenium import webdriver # 自动化测试工具
from lxml import etree # 使用xpath解析
def spider_snowball():
"""
1.爬取雪球网,获取url
2.使用自动化测试工具打开雪球网
3.需要使用自动化测试工具循环下拉滚动条三次,获取到动态加载的数据
4.然后使用自动化测试工具点击加载更多的button按钮,来获取到更多的数据
5.对获取到的数据进行解析,拿取需要的数据
6.将数据循环以词典添加到列表中
7.将列表数据写入到文件中,并且需要将列表转换为json字符串
"""
# 开始时间, 用于测试爬虫的时长
start_time = time.time()
# 雪球网的url, 默认就为推荐数据
url = 'https://xueqiu.com'
# 定制请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
"Chrome/74.0.3729.108 Safari/537.36",
}
# 实例化浏览器对象,以谷歌浏览器运行, driverpath: 自己驱动的存放路径
browser = webdriver.Chrome(r'driverpath')
# 打开对应的url
browser.get(url)
# 下拉滚动条三次, 三次之后就需要点击加载更多的按钮, 可自己下拉查看
for i in range(3):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1.5)
# 获取加载更多的按钮
button = browser.find_element_by_class_name('AnonymousHome_home__timeline__more_6RI')
try:
# 循环点击这个按钮,并且下拉获取到更多的数据, 此处循环自行设置, 可以不必循环太多次
for i in range(100):
# 点击这个按钮
button.click()
# 点击按钮之后会展示更多的数据,然后继续下拉滚动条来获取加载更多按钮
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(2)
except Exception as e:
print('出错了:', e)
else:
# 如果没有出错,那么则获取到了全部(大量)的数据,下面要对数据进行解析,取出所需数据
# 获取到的网页源码就是str类型,不需要再使用text获取html文本数据
tree = etree.HTML(browser.page_source)
# 获取到所有的a标签
a_list = tree.xpath('//div[@class="AnonymousHome_home__timeline__item_3vU"]/h3/a')
result_list = []
for a in a_list:
result_dict = dict()
# 标签中的文字可直接使用text获取文本或者再次使用xpath匹配
title = a.text
# 因为xpath匹配出来后的数据是放在列表中,所以要从列表中拿出来
href = url + a.xpath('./@href')[0]
# 将数据添加到字典中
result_dict["title"] = title
result_dict["url"] = href
# 将字典添加到列表中
result_list.append(result_dict)
# 此处循环完毕后,列表中有多个字典,可以将列表写入文件(数据库)中,以便查看数据
with open('xue_qiu.json', 'w', encoding='utf-8') as f:
# 写入文件要将python格式转换为json字符串写入
f.write(json.dumps(result_list, ensure_ascii=False, indent=2))
# 退出浏览器
browser.quit()
end_time = time.time()
# 打印爬取数据的总时长
print("总耗时:%d" % (end_time-start_time))
if __name__ == '__main__':
spider_snowball()
3.总结
如果你自己用上面的代码去抓取数据,相信你就会知道selenium的方便之处。如果不使用selenium来抓一些数据,可能大家抓起来很不方便,但是selenium也有自己的弊端,就是效率不高,就像上面的抓雪球网一样,我自己测试了一下220s,有时候也可以选择抓取js包进行数据分析(后面会有案例),当然如果用其他方法获取不到数据,使用selenium也是一个不错的选择。
nodejs抓取动态网页(我能够成功地抓取一个网页,然后提取我需要的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-28 15:21
这就是我想要完成的。我能够成功抓取一个网页,然后提取我需要的信息,我已经在几个 网站 上运行了这个页面,其中分页链接在 href 属性中很容易获得。我的问题是当分页变量是动态的时如何导航到下一页:
1
2
Next Page
到目前为止,这里的代码是我为其他网站工作
所做的
var request = require('request'), // simplified HTTP request client
cheerio = require('cheerio'), // lean implementation of core jQuery
Xray = require('x-ray'), //
x = Xray(),
fs = require('fs'); // file system i/o
/*
TODO: Make this feature dynamic, to take in the URL of the page
var pageUrl;
*/
var status = 'for sale';
var counter = 0;
x('http://www.example.com/results/1', '.results', [{
id: '[email protected]', // extracts the value from the attribute id
title: 'div.info h2',
category: 'span.category',
price: 'p.price',
count: counter+1, // why doesnt this update? this never shows in the json
status: status // this value never shows up in the json
}])
.paginate(whatShouldThisBe)
.limit(800)
.write('products.json');
此外,count和status的值永远不会显示在生成的JSON文件中。不确定我在这里做错了什么,但我们将不胜感激。
谢谢! 查看全部
nodejs抓取动态网页(我能够成功地抓取一个网页,然后提取我需要的信息)
这就是我想要完成的。我能够成功抓取一个网页,然后提取我需要的信息,我已经在几个 网站 上运行了这个页面,其中分页链接在 href 属性中很容易获得。我的问题是当分页变量是动态的时如何导航到下一页:
1
2
Next Page
到目前为止,这里的代码是我为其他网站工作
所做的
var request = require('request'), // simplified HTTP request client
cheerio = require('cheerio'), // lean implementation of core jQuery
Xray = require('x-ray'), //
x = Xray(),
fs = require('fs'); // file system i/o
/*
TODO: Make this feature dynamic, to take in the URL of the page
var pageUrl;
*/
var status = 'for sale';
var counter = 0;
x('http://www.example.com/results/1', '.results', [{
id: '[email protected]', // extracts the value from the attribute id
title: 'div.info h2',
category: 'span.category',
price: 'p.price',
count: counter+1, // why doesnt this update? this never shows in the json
status: status // this value never shows up in the json
}])
.paginate(whatShouldThisBe)
.limit(800)
.write('products.json');
此外,count和status的值永远不会显示在生成的JSON文件中。不确定我在这里做错了什么,但我们将不胜感激。
谢谢!
nodejs抓取动态网页(使用nodejs写爬虫过程中常用模块和一些必须掌握的js语法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-25 19:11
本文是使用nodejs编写爬虫系列教程的第一篇。介绍了使用nodejs编写爬虫过程中常用的模块以及一些必须掌握的js语法
常用模块
常用模块如下:
fs-extrasuperagentcheeriolog4jssequelizechalkpuppeteerfs-extra
使用async/await的前提是接口必须封装成promise,看一个简单的例子:
const sleep = (milliseconds) => {
return new Promise((resolve, reject) => {
setTimeout(() => resolve(), milliseconds)
})
}
const main = async () => {
await sleep(5000);
console.log('5秒后...');
}
main();
在 async 函数中使用 await + promise 来组织异步代码就像同步代码一样,非常自然,有助于我们分析代码的执行流程。
在 node 中,fs 模块是一个非常常见的用于操作文件的原生模块。fs(文件系统)模块提供了一些与文件系统相关的同步和异步API。有时需要使用同步 API。当一个自写的模块在访问文件后导出一些接口时,这个时候使用同步api是很实用的。看一个例子:
const path = require('path');
const fs = require('fs-extra');
const { log4js } = require('../../config/log4jsConfig');
const log = log4js.getLogger('qupingce');
const createModels = () => {
const models = {};
const fileNames = fs.readdirSync(path.resolve(__dirname, '.'));
fileNames
.filter(fileName => fileName !== 'index.js')
.map(fileName => fileName.slice(0, -3))
.forEach(modelName => {
log.info(`Sequelize define model ${modelName}!`);
models[modelName] = require(path.resolve(__dirname, `./${modelName}.js`));
})
return models;
}
module.exports = createModels();
该模块访问当前目录中的所有模型模块并导出模型。如果使用异步接口,即fs.readdir,则无法通过在其他模块中导入该模块来获取模型。原因是 require 是一个同步操作。虽然接口是异步的,但同步代码不能立即获得异步操作的结果。
为了充分发挥节点异步的优势,我们应该尽量使用异步接口。
我们可以使用 fs-extra 模块代替 fs 模块,类似的模块是 mz。fs-extra 收录了 fs 模块的所有接口,也为每个异步接口提供了 Promise 支持。更好的是 fs-extra 还提供了一些其他有用的文件操作功能,比如删除和移动文件的操作。更详细的介绍请查看官方仓库 fs-extra。
超级代理
superagent是一个节点的http客户端,可以类比java中的httpclient和okhttp,python中的requests。允许我们模拟 http 请求。superagent 库有很多有用的特性。
superagent会根据response的content-type自动序列化,序列化后的返回内容可以通过response.body获取。这个库会自动缓存和发送cookies,所以我们不需要手动管理cookies然后它的api是链式调用样式,调用起来很爽,但是在使用的时候要注意调用顺序。它的异步 api 都返回承诺。
有木头很方便。官方文档是一个很长的页面,目录清晰,很容易搜索到自己需要的内容。最后,superagent 还支持插件集成。例如,如果您需要在超时后自动重新发送,您可以使用 superagent-retry。更多插件可以去npm官网搜索关键词superagent-。更多详细信息,请参见官方文档 superagent
// 官方文档的一个调用示例
request
.post('/api/pet')
.send({ name: 'Manny', species: 'cat' })
.set('X-API-Key', 'foobar')
.set('Accept', 'application/json')
.then(res => {
alert('yay got ' + JSON.stringify(res.body));
});
切里奥
写过爬虫的人都知道,我们经常有解析html的需求,从网页的源代码中爬取信息应该是最基本的爬取方式。python中有beautifulsoup,java中有jsoup,node中有cheerio。
Cheerio 专为服务器端设计,为您提供近乎完整的 jquery 体验。使用cheerio解析html获取元素,调用方式与jquery操作dom元素的用法一模一样。而且它还提供了一些方便的接口,比如获取html,看一个例子:
const cheerio = require('cheerio')
const $ = cheerio.load('Hello world')
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
$.html()
//=> Hello there!
官方仓库:cheerio
log4js
log4j 是为 node 设计的日志模块。在简单的场景中,考虑使用调试模块。log4js 更符合我对日志库的需求。其实他们的定位是不一样的。debug 模块是为调试而设计的,而 log4js 是一个日志库。它必须提供文件输出和分类等常规功能。
log4js模块的名字有点符合java中著名的日志库log4j的节奏。log4j 具有以下特点:
您可以自定义 appender(输出目标),lo4js 甚至提供了输出到目标(例如邮件)的 appender。通过组合不同的appender,可以达到不同目的的记录器(loggers)提供日志分类功能。官方FAQ中提到如果要实现appender的级别过滤,可以使用logLevelFilter提供滚动日志和自定义输出格式
让我们通过我最新的爬虫项目的配置文件来感受一下这个库的以下特点:
const log4js = require('log4js');
const path = require('path');
const fs = require('fs-extra');
const infoFilePath = path.resolve(__dirname, '../out/log/info.log');
const errorFilePath = path.resolve(__dirname, '../out/log/error.log');
log4js.configure({
appenders: {
dateFile: {
type: 'dateFile',
filename: infoFilePath,
pattern: 'yyyy-MM-dd',
compress: false
},
errorDateFile: {
type: 'dateFile',
filename: errorFilePath,
pattern: 'yyyy-MM-dd',
compress: false,
},
justErrorsToFile: {
type: 'logLevelFilter',
appender: 'errorDateFile',
level: 'error'
},
out: {
type: 'console'
}
},
categories: {
default: {
appenders: ['out'],
level: 'trace'
},
qupingce: {
appenders: ['out', 'dateFile', 'justErrorsToFile'],
level: 'trace'
}
}
});
const clear = async () => {
const files = await fs.readdir(path.resolve(__dirname, '../out/log'));
for (const fileName of files) {
fs.remove(path.resolve(__dirname, `../out/log/${fileName}`));
}
}
module.exports = {
log4js,
clear
}
续集
在编写项目时,我们经常有持久的需求。在简单的场景中,可以使用 JSON 来保存数据。如果数据量比较大,又容易管理,那么就要考虑使用数据库了。如果是操作mysql和sqllite,推荐使用sequelize。如果是mongodb,我推荐使用专门为mongodb设计的mongoose
sequelize中还有一些我觉得还不是很好的点,比如默认生成的id(主键)、createdAt和updatedAt。
除了一些自己造成的故障外,sequelize 设计得很好。内置的操作符、钩子和验证器很有趣。sequelize 还提供了 Promise 和 typescript 支持。如果你使用 typescript 开发项目,还有一个不错的 orm 选择:typeorm。更多信息参见官方文档:sequelize
粉笔
chalk 的中文意思是粉笔。该模块是node的一个非常有特色和实用的模块。它可以为您的输出内容添加颜色、下划线、背景颜色和其他装饰。我们在写项目的时候,经常需要记录一些步骤和事件,比如打开数据库链接、发起http请求等等。我们可以适当地使用粉笔来突出显示某些内容,例如在请求的 url 下划线。
const logRequest = (response, isDetailed = false) => {
const URL = chalk.underline.yellow(response.request.url);
const basicInfo = `${response.request.method} Status: ${response.status} Content-Type: ${response.type} URL=${URL}`;
if (!isDetailed) {
logger.info(basicInfo);
} else {
const detailInfo = `${basicInfo}\ntext: ${response.text}`;
logger.info(detailInfo);
}
};
调用上面的 logRequest 效果:
有关更多信息,请参阅官方存储库粉笔
傀儡师
如果您还没有听说过这个库,那么您可能听说过 selenium。puppeteer 是 Google Chrome 团队开源的一个节点模块,用于通过 devtools 协议操作 chrome 或 Chromium。由 Google 制造,质量有保证。该模块提供了一些高级 API。默认情况下,这个库操作的浏览器的用户是看不到界面的,也就是所谓的无头浏览器。当然也可以通过配置一些参数来启动interfaced模式。在chrome中也有一些记录puppeteer操作的扩展,比如Puppeteer Recorder。使用这个库,我们可以用来获取一些由 js 呈现的信息,而不是直接呈现在页面源代码中。比如spa页面,页面的内容是js渲染的。这时候puppeteer就为我们解决了这个问题。我们可以调用 puppeteer 来获取页面上某个标签出现时渲染出来的 html。事实上,很多高难度爬虫解决的终极法宝就是操纵浏览器。
前置 js 语法 async/await
首先要提的是async/await,因为node在很早的时候就已经支持async/await了(node 8 LTS),现在没有理由写没有async/await的后端项目。使用 async/await 可以将我们从回调炼狱中解放出来。这里主要提一下使用async/await时可能遇到的问题
如何同时使用异步/等待?
看一段测试代码:
const sleep = (milliseconds) => {
return new Promise((resolve, reject) => {
setTimeout(() => resolve(), milliseconds)
})
}
const test1 = async () => {
for (let i = 0, max = 3; i {
Array.from({length: 3}).forEach(async () => {
await sleep(1000);
});
}
const main = async () => {
console.time('测试 for 循环使用 await');
await test1();
console.timeEnd('测试 for 循环使用 await');
console.time('测试 forEach 调用 async 函数')
await test2();
console.timeEnd('测试 forEach 调用 async 函数')
}
main();
运行的结果是:
测试 for 循环使用 await: 3003.905ms
测试 forEach 调用 async 函数: 0.372ms
我想有些人可能会认为测试 forEach 的结果会是 1 秒左右,其实测试 2 等价于如下代码:
const test2 = async () => {
// Array.from({length: 3}).forEach(async () => {
// await sleep(1000);
// });
Array.from({length: 3}).forEach(() => {
sleep(1000);
});
}
从上面的运行结果也可以看出,直接在for循环中使用await+promise相当于同步调用,所以耗时3秒左右。如果要并发,应该直接调用promise,因为forEach不会帮你await,所以相当于上面的代码,三个任务直接异步并发。
处理多个异步任务
上面的代码还有一个问题,就是在测试2中,并没有等到三个任务都执行完就直接结束了。有时我们需要等待多个并发任务结束后再执行后续任务。其实很简单,使用 Promise 提供的几个工具功能就可以了。
const sleep = (milliseconds, id='') => {
return new Promise((resolve, reject) => {
setTimeout(() => {
console.log(`任务${id}执行结束`)
resolve(id);
}, milliseconds)
})
}
const test2 = async () => {
const tasks = Array.from({length: 3}).map((ele, index) => sleep(1000, index));
const resultArray = await Promise.all(tasks);
console.log({ resultArray} )
console.log('所有任务执行结束');
}
const main = async () => {
console.time('使用 Promise.all 处理多个并发任务')
await test2();
console.timeEnd('使用 Promise.all 处理多个并发任务')
}
main()
运行结果:
任务0执行结束
任务1执行结束
任务2执行结束
{ resultArray: [ 0, 1, 2 ] }
所有任务执行结束
使用 Promise.all 处理多个并发任务: 1018.628ms
除了 Promise.all,Promise 还有race等接口,但最常用的就是all和race。
正则表达式
正则表达式是处理字符串的强大工具。核心是匹配,从中衍生出抽取、查找、替换等操作。
有时当我们通过cheerio获取标签中的文本时,我们需要提取一些信息,这时正则表达式就应该发挥作用了。正则表达式的相关语法在此不做详述。初学者,推荐看廖雪峰的正则表达式教程。让我们看一个例子:
// 服务器返回的 img url 是: /GetFile/getUploadImg?fileName=9b1cc22c74bc44c8af78b46e0ca4c352.png
// 现在我只想提取文件名,后缀名也不要
const imgUrl = '/GetFile/getUploadImg?fileName=9b1cc22c74bc44c8af78b46e0ca4c352.png';
const imgReg = /\/GetFile\/getUploadImg\?fileName=(.+)\..+/;
const imgName = imgUrl.match(imgReg)[1];
console.log(imgName); // => 9b1cc22c74bc44c8af78b46e0ca4c352
暂时就介绍到这里,以后会增加更多的内容。
本文为原创的内容,首发于我的个人博客。转载请注明出处。如有任何问题,请发邮件骚扰。 查看全部
nodejs抓取动态网页(使用nodejs写爬虫过程中常用模块和一些必须掌握的js语法)
本文是使用nodejs编写爬虫系列教程的第一篇。介绍了使用nodejs编写爬虫过程中常用的模块以及一些必须掌握的js语法
常用模块
常用模块如下:
fs-extrasuperagentcheeriolog4jssequelizechalkpuppeteerfs-extra
使用async/await的前提是接口必须封装成promise,看一个简单的例子:
const sleep = (milliseconds) => {
return new Promise((resolve, reject) => {
setTimeout(() => resolve(), milliseconds)
})
}
const main = async () => {
await sleep(5000);
console.log('5秒后...');
}
main();
在 async 函数中使用 await + promise 来组织异步代码就像同步代码一样,非常自然,有助于我们分析代码的执行流程。
在 node 中,fs 模块是一个非常常见的用于操作文件的原生模块。fs(文件系统)模块提供了一些与文件系统相关的同步和异步API。有时需要使用同步 API。当一个自写的模块在访问文件后导出一些接口时,这个时候使用同步api是很实用的。看一个例子:
const path = require('path');
const fs = require('fs-extra');
const { log4js } = require('../../config/log4jsConfig');
const log = log4js.getLogger('qupingce');
const createModels = () => {
const models = {};
const fileNames = fs.readdirSync(path.resolve(__dirname, '.'));
fileNames
.filter(fileName => fileName !== 'index.js')
.map(fileName => fileName.slice(0, -3))
.forEach(modelName => {
log.info(`Sequelize define model ${modelName}!`);
models[modelName] = require(path.resolve(__dirname, `./${modelName}.js`));
})
return models;
}
module.exports = createModels();
该模块访问当前目录中的所有模型模块并导出模型。如果使用异步接口,即fs.readdir,则无法通过在其他模块中导入该模块来获取模型。原因是 require 是一个同步操作。虽然接口是异步的,但同步代码不能立即获得异步操作的结果。
为了充分发挥节点异步的优势,我们应该尽量使用异步接口。
我们可以使用 fs-extra 模块代替 fs 模块,类似的模块是 mz。fs-extra 收录了 fs 模块的所有接口,也为每个异步接口提供了 Promise 支持。更好的是 fs-extra 还提供了一些其他有用的文件操作功能,比如删除和移动文件的操作。更详细的介绍请查看官方仓库 fs-extra。
超级代理
superagent是一个节点的http客户端,可以类比java中的httpclient和okhttp,python中的requests。允许我们模拟 http 请求。superagent 库有很多有用的特性。
superagent会根据response的content-type自动序列化,序列化后的返回内容可以通过response.body获取。这个库会自动缓存和发送cookies,所以我们不需要手动管理cookies然后它的api是链式调用样式,调用起来很爽,但是在使用的时候要注意调用顺序。它的异步 api 都返回承诺。
有木头很方便。官方文档是一个很长的页面,目录清晰,很容易搜索到自己需要的内容。最后,superagent 还支持插件集成。例如,如果您需要在超时后自动重新发送,您可以使用 superagent-retry。更多插件可以去npm官网搜索关键词superagent-。更多详细信息,请参见官方文档 superagent
// 官方文档的一个调用示例
request
.post('/api/pet')
.send({ name: 'Manny', species: 'cat' })
.set('X-API-Key', 'foobar')
.set('Accept', 'application/json')
.then(res => {
alert('yay got ' + JSON.stringify(res.body));
});
切里奥
写过爬虫的人都知道,我们经常有解析html的需求,从网页的源代码中爬取信息应该是最基本的爬取方式。python中有beautifulsoup,java中有jsoup,node中有cheerio。
Cheerio 专为服务器端设计,为您提供近乎完整的 jquery 体验。使用cheerio解析html获取元素,调用方式与jquery操作dom元素的用法一模一样。而且它还提供了一些方便的接口,比如获取html,看一个例子:
const cheerio = require('cheerio')
const $ = cheerio.load('Hello world')
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
$.html()
//=> Hello there!
官方仓库:cheerio
log4js
log4j 是为 node 设计的日志模块。在简单的场景中,考虑使用调试模块。log4js 更符合我对日志库的需求。其实他们的定位是不一样的。debug 模块是为调试而设计的,而 log4js 是一个日志库。它必须提供文件输出和分类等常规功能。
log4js模块的名字有点符合java中著名的日志库log4j的节奏。log4j 具有以下特点:
您可以自定义 appender(输出目标),lo4js 甚至提供了输出到目标(例如邮件)的 appender。通过组合不同的appender,可以达到不同目的的记录器(loggers)提供日志分类功能。官方FAQ中提到如果要实现appender的级别过滤,可以使用logLevelFilter提供滚动日志和自定义输出格式
让我们通过我最新的爬虫项目的配置文件来感受一下这个库的以下特点:
const log4js = require('log4js');
const path = require('path');
const fs = require('fs-extra');
const infoFilePath = path.resolve(__dirname, '../out/log/info.log');
const errorFilePath = path.resolve(__dirname, '../out/log/error.log');
log4js.configure({
appenders: {
dateFile: {
type: 'dateFile',
filename: infoFilePath,
pattern: 'yyyy-MM-dd',
compress: false
},
errorDateFile: {
type: 'dateFile',
filename: errorFilePath,
pattern: 'yyyy-MM-dd',
compress: false,
},
justErrorsToFile: {
type: 'logLevelFilter',
appender: 'errorDateFile',
level: 'error'
},
out: {
type: 'console'
}
},
categories: {
default: {
appenders: ['out'],
level: 'trace'
},
qupingce: {
appenders: ['out', 'dateFile', 'justErrorsToFile'],
level: 'trace'
}
}
});
const clear = async () => {
const files = await fs.readdir(path.resolve(__dirname, '../out/log'));
for (const fileName of files) {
fs.remove(path.resolve(__dirname, `../out/log/${fileName}`));
}
}
module.exports = {
log4js,
clear
}
续集
在编写项目时,我们经常有持久的需求。在简单的场景中,可以使用 JSON 来保存数据。如果数据量比较大,又容易管理,那么就要考虑使用数据库了。如果是操作mysql和sqllite,推荐使用sequelize。如果是mongodb,我推荐使用专门为mongodb设计的mongoose
sequelize中还有一些我觉得还不是很好的点,比如默认生成的id(主键)、createdAt和updatedAt。
除了一些自己造成的故障外,sequelize 设计得很好。内置的操作符、钩子和验证器很有趣。sequelize 还提供了 Promise 和 typescript 支持。如果你使用 typescript 开发项目,还有一个不错的 orm 选择:typeorm。更多信息参见官方文档:sequelize
粉笔
chalk 的中文意思是粉笔。该模块是node的一个非常有特色和实用的模块。它可以为您的输出内容添加颜色、下划线、背景颜色和其他装饰。我们在写项目的时候,经常需要记录一些步骤和事件,比如打开数据库链接、发起http请求等等。我们可以适当地使用粉笔来突出显示某些内容,例如在请求的 url 下划线。
const logRequest = (response, isDetailed = false) => {
const URL = chalk.underline.yellow(response.request.url);
const basicInfo = `${response.request.method} Status: ${response.status} Content-Type: ${response.type} URL=${URL}`;
if (!isDetailed) {
logger.info(basicInfo);
} else {
const detailInfo = `${basicInfo}\ntext: ${response.text}`;
logger.info(detailInfo);
}
};
调用上面的 logRequest 效果:

有关更多信息,请参阅官方存储库粉笔
傀儡师
如果您还没有听说过这个库,那么您可能听说过 selenium。puppeteer 是 Google Chrome 团队开源的一个节点模块,用于通过 devtools 协议操作 chrome 或 Chromium。由 Google 制造,质量有保证。该模块提供了一些高级 API。默认情况下,这个库操作的浏览器的用户是看不到界面的,也就是所谓的无头浏览器。当然也可以通过配置一些参数来启动interfaced模式。在chrome中也有一些记录puppeteer操作的扩展,比如Puppeteer Recorder。使用这个库,我们可以用来获取一些由 js 呈现的信息,而不是直接呈现在页面源代码中。比如spa页面,页面的内容是js渲染的。这时候puppeteer就为我们解决了这个问题。我们可以调用 puppeteer 来获取页面上某个标签出现时渲染出来的 html。事实上,很多高难度爬虫解决的终极法宝就是操纵浏览器。
前置 js 语法 async/await
首先要提的是async/await,因为node在很早的时候就已经支持async/await了(node 8 LTS),现在没有理由写没有async/await的后端项目。使用 async/await 可以将我们从回调炼狱中解放出来。这里主要提一下使用async/await时可能遇到的问题
如何同时使用异步/等待?
看一段测试代码:
const sleep = (milliseconds) => {
return new Promise((resolve, reject) => {
setTimeout(() => resolve(), milliseconds)
})
}
const test1 = async () => {
for (let i = 0, max = 3; i {
Array.from({length: 3}).forEach(async () => {
await sleep(1000);
});
}
const main = async () => {
console.time('测试 for 循环使用 await');
await test1();
console.timeEnd('测试 for 循环使用 await');
console.time('测试 forEach 调用 async 函数')
await test2();
console.timeEnd('测试 forEach 调用 async 函数')
}
main();
运行的结果是:
测试 for 循环使用 await: 3003.905ms
测试 forEach 调用 async 函数: 0.372ms
我想有些人可能会认为测试 forEach 的结果会是 1 秒左右,其实测试 2 等价于如下代码:
const test2 = async () => {
// Array.from({length: 3}).forEach(async () => {
// await sleep(1000);
// });
Array.from({length: 3}).forEach(() => {
sleep(1000);
});
}
从上面的运行结果也可以看出,直接在for循环中使用await+promise相当于同步调用,所以耗时3秒左右。如果要并发,应该直接调用promise,因为forEach不会帮你await,所以相当于上面的代码,三个任务直接异步并发。
处理多个异步任务
上面的代码还有一个问题,就是在测试2中,并没有等到三个任务都执行完就直接结束了。有时我们需要等待多个并发任务结束后再执行后续任务。其实很简单,使用 Promise 提供的几个工具功能就可以了。
const sleep = (milliseconds, id='') => {
return new Promise((resolve, reject) => {
setTimeout(() => {
console.log(`任务${id}执行结束`)
resolve(id);
}, milliseconds)
})
}
const test2 = async () => {
const tasks = Array.from({length: 3}).map((ele, index) => sleep(1000, index));
const resultArray = await Promise.all(tasks);
console.log({ resultArray} )
console.log('所有任务执行结束');
}
const main = async () => {
console.time('使用 Promise.all 处理多个并发任务')
await test2();
console.timeEnd('使用 Promise.all 处理多个并发任务')
}
main()
运行结果:
任务0执行结束
任务1执行结束
任务2执行结束
{ resultArray: [ 0, 1, 2 ] }
所有任务执行结束
使用 Promise.all 处理多个并发任务: 1018.628ms
除了 Promise.all,Promise 还有race等接口,但最常用的就是all和race。
正则表达式
正则表达式是处理字符串的强大工具。核心是匹配,从中衍生出抽取、查找、替换等操作。
有时当我们通过cheerio获取标签中的文本时,我们需要提取一些信息,这时正则表达式就应该发挥作用了。正则表达式的相关语法在此不做详述。初学者,推荐看廖雪峰的正则表达式教程。让我们看一个例子:
// 服务器返回的 img url 是: /GetFile/getUploadImg?fileName=9b1cc22c74bc44c8af78b46e0ca4c352.png
// 现在我只想提取文件名,后缀名也不要
const imgUrl = '/GetFile/getUploadImg?fileName=9b1cc22c74bc44c8af78b46e0ca4c352.png';
const imgReg = /\/GetFile\/getUploadImg\?fileName=(.+)\..+/;
const imgName = imgUrl.match(imgReg)[1];
console.log(imgName); // => 9b1cc22c74bc44c8af78b46e0ca4c352
暂时就介绍到这里,以后会增加更多的内容。
本文为原创的内容,首发于我的个人博客。转载请注明出处。如有任何问题,请发邮件骚扰。
nodejs抓取动态网页(如何判断一个前端渲染的页面是否为抓取动态的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-24 09:19
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面使用js渲染。对于爬虫来说,这种页面比较烦人:只提取 HTML 内容,往往无法获取有效信息。那么如何处理这种页面呢?一般有两种方法:
爬取阶段,爬虫内置浏览器内核,爬取前执行js渲染页面。这方面的相应工具是 Selenium、HtmlUnit 或 PhantomJs。但这些工具都存在一定的效率问题,同时也不是那么稳定。优点是编写规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本上都是通过AJAX获取的,所以分析AJAX请求,找到数据对应的请求也是可行的。而且相对于页面样式,这个界面是不太可能改变的。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较大量的分析经验。
比较这两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种更为可靠。对于某些网站,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,而第二种方法会很复杂。
对于第一种方法,webmagic-selenium就是这样一种尝试,它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium的配置比较复杂,和平台和版本有关,没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。我希望你会发现解析一个前端渲染的页面并没有那么复杂。这里我们以AngularJS中文社区为例。
如何判断前端渲染
判断页面是否为js渲染的方式比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果没有找到有效信息,基本上就是js渲染了。
本例中在源码中找不到页面中的标题“优符计算机网-前端攻城师”,因此可以断定是js渲染,这个数据是通过AJAX获取的。
分析请求
现在我们到了最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是浏览器中的开发者工具查看网络请求。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是一个下拉页面,总之所有的操作你觉得可能会触发新的数据)),那就记得保留场景,一一分析请求!
这一步需要一点耐心,但不是随机的。首先可以帮助我们的是上面的分类过滤器(All、Document 和其他选项)。如果是普通的 AJAX,会显示在 XHR 标签下,而 JSONP 请求会显示在 Scripts 标签下。这是两种更常见的数据类型。
然后你可以根据数据的大小来判断。一般来说,较大的结果更有可能是返回数据的接口。其余的基本上都是凭经验。比如这里的“latest?p=1&s=20”,一看就很可疑……
对于可疑地址,此时可以查看响应正文的内容。在这里的开发者工具中并不清楚。我们将URL复制到地址栏,再次请求(如果Chrome推荐安装jsonviewer,查看AJAX结果非常方便)。查看结果,看起来我们找到了我们想要的东西。
同样的方法,我们进入帖子详情页面,找到具体内容的请求:.
编程
回顾之前列表+目标页面的例子,你会发现我们这次的需求和之前的差不多,只是换成了AJAX方法——AJAX方法列表,AJAX方法数据,返回的数据变成了JSON。那么,我们仍然可以使用最后一种方式,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求由一些固定的url加上这个id组成。所以在这一步中,我们手动构造URL,并将其添加到待爬取队列中。这里我们使用 JsonPath 选择语言来选择数据(webmagic-extension 包中提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了 URL,解析目标数据其实很简单,因为 JSON 数据是完全结构化的,所以我们省去了分析页面和编写 XPath 的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见 AngularJSProcessor.java
总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。事实上,动态网页抓取的最大区别在于它使链接发现更加困难。我们比较一下两种开发模式:
后端渲染页面
下载二级页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能是在页面HTML中预先输出,也可能是通过AJAX请求,甚至是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂的多,所以这其实就是动态页面爬取的难点所在。
本节的这个例子希望实现的是在分析请求后为此类爬虫的编写提供一个模式,即发现辅助数据 => 构建链接 => 下载并分析目标 AJAX 模式。
PS:
WebMagic 0.5.0 稍后会为链式 API 添加 Json 支持,您可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析 AJAX 请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。 查看全部
nodejs抓取动态网页(如何判断一个前端渲染的页面是否为抓取动态的方式)
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面使用js渲染。对于爬虫来说,这种页面比较烦人:只提取 HTML 内容,往往无法获取有效信息。那么如何处理这种页面呢?一般有两种方法:
爬取阶段,爬虫内置浏览器内核,爬取前执行js渲染页面。这方面的相应工具是 Selenium、HtmlUnit 或 PhantomJs。但这些工具都存在一定的效率问题,同时也不是那么稳定。优点是编写规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本上都是通过AJAX获取的,所以分析AJAX请求,找到数据对应的请求也是可行的。而且相对于页面样式,这个界面是不太可能改变的。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较大量的分析经验。
比较这两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种更为可靠。对于某些网站,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,而第二种方法会很复杂。
对于第一种方法,webmagic-selenium就是这样一种尝试,它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium的配置比较复杂,和平台和版本有关,没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。我希望你会发现解析一个前端渲染的页面并没有那么复杂。这里我们以AngularJS中文社区为例。
如何判断前端渲染
判断页面是否为js渲染的方式比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果没有找到有效信息,基本上就是js渲染了。


本例中在源码中找不到页面中的标题“优符计算机网-前端攻城师”,因此可以断定是js渲染,这个数据是通过AJAX获取的。
分析请求
现在我们到了最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是浏览器中的开发者工具查看网络请求。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是一个下拉页面,总之所有的操作你觉得可能会触发新的数据)),那就记得保留场景,一一分析请求!
这一步需要一点耐心,但不是随机的。首先可以帮助我们的是上面的分类过滤器(All、Document 和其他选项)。如果是普通的 AJAX,会显示在 XHR 标签下,而 JSONP 请求会显示在 Scripts 标签下。这是两种更常见的数据类型。
然后你可以根据数据的大小来判断。一般来说,较大的结果更有可能是返回数据的接口。其余的基本上都是凭经验。比如这里的“latest?p=1&s=20”,一看就很可疑……

对于可疑地址,此时可以查看响应正文的内容。在这里的开发者工具中并不清楚。我们将URL复制到地址栏,再次请求(如果Chrome推荐安装jsonviewer,查看AJAX结果非常方便)。查看结果,看起来我们找到了我们想要的东西。

同样的方法,我们进入帖子详情页面,找到具体内容的请求:.
编程
回顾之前列表+目标页面的例子,你会发现我们这次的需求和之前的差不多,只是换成了AJAX方法——AJAX方法列表,AJAX方法数据,返回的数据变成了JSON。那么,我们仍然可以使用最后一种方式,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求由一些固定的url加上这个id组成。所以在这一步中,我们手动构造URL,并将其添加到待爬取队列中。这里我们使用 JsonPath 选择语言来选择数据(webmagic-extension 包中提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了 URL,解析目标数据其实很简单,因为 JSON 数据是完全结构化的,所以我们省去了分析页面和编写 XPath 的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见 AngularJSProcessor.java
总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。事实上,动态网页抓取的最大区别在于它使链接发现更加困难。我们比较一下两种开发模式:
后端渲染页面
下载二级页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能是在页面HTML中预先输出,也可能是通过AJAX请求,甚至是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂的多,所以这其实就是动态页面爬取的难点所在。
本节的这个例子希望实现的是在分析请求后为此类爬虫的编写提供一个模式,即发现辅助数据 => 构建链接 => 下载并分析目标 AJAX 模式。
PS:
WebMagic 0.5.0 稍后会为链式 API 添加 Json 支持,您可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析 AJAX 请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。
nodejs抓取动态网页(下phantomjs,具体过程是怎么实现的呢?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2022-03-21 22:19
最近在研究phantomjs,但只是第一次,谈不上深入研究。首先介绍一下phantomjs是什么。
官网上的介绍是:“PhantomJS 是一个可以用 JavaScript API 编写脚本的无头 WebKit。它对各种 Web 标准有快速和原生的支持:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。” 服务器端 JavaScript API。它完全支持没有浏览器支持的 Web,它速度快,原生支持各种 Web 标准:DOM 操作、CSS 选择器、JSON、Canvas 和 SVG。” PhantomJS 可用于页面自动化、Web 监控、网页截图和无接口测试。
本文结合nodejs,使用phantomjs网页截图功能,对多个URL进行批量截图操作,将图片上传到七牛服务器,批量获取图片下载地址,并保存在本地文件中。
下面开始说一下这个demo的具体流程是如何实现的。
一、安装
1、nodejs
nodejs的安装在之前的文章中已经提到过,这里不再赘述。详情请参考nodejs官网:;
2、幻影
关于phantomjs的安装,这里是windows环境下的安装方法:
首先去官网下载phantomjs压缩包,解压到本地磁盘。比如我电脑上解压后存储的地址是:D:\Program files\phantomjs-2.1.1;
二、配置环境变量。将解压后的phantomjs目录下bin目录的路径(比如我本地bin目录的位置是:D:\Program files\phantomjs-2.1.1\bin)添加到系统中变量路径变量中间;
然后,打开cmd,输入“phantomjs --version”命令查看phantomjs是否安装成功。如果出现版本号信息,则安装成功。如果报错,需要重启电脑。
结果如下所示:
二、设计理念
首先说一下写这个demo的初衷。因为我在工作中每次发邮件都需要用到一些截图,不想每次都手动拍多张,所以想用一个自动化的批处理工具来自动截图,不过这只是为了完成截图,使用的时候还是要上传图片。我还是觉得麻烦,所以想在截图完成后自动将这些图片上传到七牛服务器,然后从服务器获取图片下载地址,然后就可以直接使用图片下载地址了。好的。以下是具体的设计思路。
对于上图中的截图设备,具体程序流程为:
三、编码
1、模拟Echarts图表生成的工程代码和启动方法不再详述。请参考我在github上发布的源码:
2、截图
2.1、capture.js
主要使用phantomjs进行截图操作
1 var page=require('webpage').create();//创建一个网页对象;
2 var system=require('system');
3 var address,fileName;
4 // page.viewportSize={width:1024,height:800};//设置窗口的大小为1024*800;
5 // page.clipRect={top:0,left:0,width:1024,height:800};//截取从{0,0}为起点的1024*800大小的图像;
6 // //禁止Javascript,允许图片载入;
7 // // 并将userAgent改为"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.31 (KHTML, like Gecko) PhantomJS/19.0";
8 // page.settings={
9 // javascriptEnabled: false,
10 // loadImages: true,
11 // userAgent: 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.31 (KHTML, like Gecko) PhantomJS/19.0'
12 // };
13
14 if (system.args.length === 1) {
15 console.log('Try to pass some args when invoking this script!');
16 phantom.exit(1);
17 }else{
18 //获取指令传递的参数,参数是以数组的形式传递的;
19 address=system.args[1];
20 fileName=system.args[2];
21 count=system.args[3];
22 max=system.args[4];
23 //打开一个网页;
24 page.open(address,function(status){
25 console.log(status);
26 if(status==='success'){
27 //成功后将页面存储为图片并放在指定的位置;
28 page.render('./pictures/'+fileName+'.png');
29 }
30 // page.close();//释放;
31 //退出;
32 phantom.exit();
33 });
34 }
2.2、phantom.js
Nodejs 启动一个新的子进程并发送 phantomjs 命令进行截图。截图成功后,发送图片上传命令上传图片:
1 /**
2 * Created by Administrator on 2016/5/5.
3 */
4 var urls=["http://localhost:3000/","http://localhost:3000/table","http://www.baidu.com"];
5 var count=0;
6 var max=urls.length;
7 if(urls.length!=0){
8 capture(urls[0]);
9 }
10 //生成随机字符串作为图片名称;
11 function createRandomName(len){
12 len = len || 32;
13 /****默认去掉了容易混淆的字符oOLl,9gq,Vv,Uu,I1****/
14 var $chars = 'ABCDEFGHJKMNPQRSTWXYZabcdefhijkmnprstwxyz2345678';
15 var maxPos = $chars.length;
16 var pwd = '';
17 for (i = 0; i < len; i++) {
18 pwd += $chars.charAt(Math.floor(Math.random() * maxPos));
19 }
20 return pwd;
21 }
22 //开始执行截图命令;
23 function capture(url){
24 var randomPicName='test'+createRandomName(Math.random()*8);
25 console.log("获取的随机名称="+randomPicName);
26 var spawn=require('child_process').spawn;
27 var process=spawn('phantomjs',['capture.js',url,randomPicName,count,max],{cwd:'./routes/'});
28 process.stdout.setEncoding('utf8');
29
30 process.stdout.on("data",function(data){
31 console.log(data);
32 console.log("spawnSTDOUT:"+JSON.stringify(data));
33 var code=data.replace(/[\r\n]/g,"");
34 console.log(code);
35 if(code=='success'){
36 var execFile=require('child_process').execFile;
37 var filePath='./pictures/'+randomPicName+'.png';
38 var execProcess=execFile('node',['upload.js',filePath,randomPicName,count,JSON.stringify(urls)],{cwd:'./routes/'},
39 function(err,stdout,stderr){
40 console.log("execFileSTDOUT:", stdout);
41 console.log("execFileSTDERR:", stderr);
42 });
43 }
44 });
45 process.stderr.on('data',function(data){
46 console.log("stderr"+data);
47 });
48 process.on('close',function(code){
49 if (code == 1) {
50 console.log('child process异常结束。目标:' + url);
51 }
52 });
53 process.on('exit',function(code){
54 console.log('child process exited with code ' + code);
55 count++;
56 if(count!=urls.length){
57 capture(urls[count]);
58 }
59 });
60 }
2.3、上传.js
主要是将图片上传到七牛并获取图片的下载地址,并将结果存入本地txt文件:
1 /**
2 * Created by Administrator on 2016/5/6.
3 */
4 var qiniu = require("qiniu");
5 var config=require('./config');
6 var argvs=process.argv.splice(2);
7 var fs=require("fs");
8 console.log(argvs);
9
10 filePath=argvs[0];
11 key=argvs[1]+'.png';
12 //count;
13 var count=parseInt(argvs[2]);
14 //urls;
15 var urls=JSON.parse(argvs[3]);
16 var max=urls.length;
17 console.log("get the arguments:"+filePath+"---"+key+"--"+count+"---"+max);
18 /**
19 * 第一步:初始化
20 * @type {string}
21 */
22 //需要填写你的 Access Key 和 Secret Key
23 qiniu.conf.ACCESS_KEY = config.qiniu.ACCESS_KEY;
24 qiniu.conf.SECRET_KEY = config.qiniu.SECRET_KEY;
25 //要上传的空间
26 bucket = config.qiniu.Bucket_Name;
27
28 /**
29 * 第二步:获取上传的token
30 * @param bucket
31 * @param key
32 */
33 //构建上传策略函数,设置回调的url以及需要回调给业务服务器的数据
34 function uptoken(bucket, key) {
35 var putPolicy = new qiniu.rs.PutPolicy(bucket+":"+key);
36 console.log("token= "+putPolicy.token());
37 return putPolicy.token();
38 }
39 //生成上传 Token
40 token = uptoken(bucket, key);
41 /**
42 * 第三步:上传图片
43 * @type {string}
44 */
45
46 //构造上传函数
47 function uploadFile(uptoken, key, localFile,count,max) {
48 var extra = new qiniu.io.PutExtra();
49 qiniu.io.putFile(uptoken, key, localFile, extra, function(err, ret) {
50 if(!err) {
51 console.log("上传成功-------------------");
52 // 上传成功, 处理返回值
53 // console.log(ret.hash, ret.key, ret.persistentId);
54 //构建私有空间的链接
55 url = config.qiniu.Domain+ret.key;
56 var policy = new qiniu.rs.GetPolicy();
57 //生成下载链接url
58 var downloadUrl = policy.makeRequest(url);
59 //打印下载的url
60 console.log("downloadUrl= "+downloadUrl);
61 var date=new Date();
62 var dateString=date.toLocaleDateString();//日期;
63 var timeString=date.toLocaleTimeString();//时间;
64 var time=date.toLocaleDateString()+" "+date.toLocaleTimeString();
65 console.log(time);
66 var signalArray={
67 "编号":count+1,
68 "被截屏的路径地址":urls[count],
69 "上传七牛后的图片名称":key,
70 "下载地址":downloadUrl,
71 "截图时间":time
72 };
73 if(count==0){
74 // fs.appendFile(__dirname+'/downloadUrl.txt',"\r\n-----------------"+dateString+" "+timeString+"------------操作开始----------------------\r\n",function(err){
75 // if(err){console.log('fail')}
76 // });
77 fs.appendFileSync(__dirname+'/downloadUrl.txt',"\r\n-----------------"+dateString+" "+timeString+"------------操作开始----------------------\r\n",{encoding:'utf8'});
78 }
79 fs.appendFile(__dirname+'/downloadUrl.txt',JSON.stringify(signalArray)+'\r\n',function(err){
80 if(err){console.log("fail")}
81 });
82 // fs.appendFileSync(__dirname+'/downloadUrl.txt',JSON.stringify(signalArray)+'\r\n',{encoding:'utf8'});
83
84 // if((count+1)==max){
85 // fs.appendFile(__dirname+'/downloadUrl.txt',"\r\n-----------------"+dateString+" "+timeString+"------------操作结束----------------------\r\n",function(err){
86 // if(err){console.log('fail')}
87 // });
88 // fs.appendFileSync(__dirname+'/downloadUrl.txt',"\r\n-----------------"+dateString+" "+timeString+"------------操作结束----------------------\r\n\n",{encoding:'utf8'});
89 // }
90 } else {
91 // 上传失败, 处理返回代码
92 console.log(err);
93 }
94 });
95 }
96 //调用uploadFile上传,并返回下载地址;
97 uploadFile(token, key, filePath,count,max);
2.4、执行:
首先, npm install 安装所需的包。二、直接输入“node routes/phantom.js”,回车,程序开始执行。我们来看看执行结果:
2.4.1、/图片:
这个目录下还有更多的图片文件,这些是phantomjs截图的图片;
2.4.2、七牛服务器
网页登录七牛后,在自己的bucket中可以看到已经添加了很多图片文件,说明我们已经上传成功了:
2.4.3、本地下载Url.txt文件
然后我们测试下载地址是否可以正确下载图片:
以上就是使用nodejs+phantomjs+七牛实现截图操作的完整方法,将截图上传到七牛,并将下载地址保存在本地磁盘。
PS:但是有一个问题,七牛的token是有有效期的,也就是说过了有效期,之前的url就不能用了。你可以重新上传一遍,或者直接在七牛上下载之前的图片。
如果需要源码,可以到我的github下载。下载地址为:
Phantomjs_pic 项目(生成echarts图表等):;
phantomjsScreenCapture 项目(实现截图和上传图片):;
ps:这次只是对phantomjs的一个简单应用。如果您有什么意见和建议,欢迎指出,谢谢! 查看全部
nodejs抓取动态网页(下phantomjs,具体过程是怎么实现的呢?(一))
最近在研究phantomjs,但只是第一次,谈不上深入研究。首先介绍一下phantomjs是什么。
官网上的介绍是:“PhantomJS 是一个可以用 JavaScript API 编写脚本的无头 WebKit。它对各种 Web 标准有快速和原生的支持:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。” 服务器端 JavaScript API。它完全支持没有浏览器支持的 Web,它速度快,原生支持各种 Web 标准:DOM 操作、CSS 选择器、JSON、Canvas 和 SVG。” PhantomJS 可用于页面自动化、Web 监控、网页截图和无接口测试。
本文结合nodejs,使用phantomjs网页截图功能,对多个URL进行批量截图操作,将图片上传到七牛服务器,批量获取图片下载地址,并保存在本地文件中。
下面开始说一下这个demo的具体流程是如何实现的。
一、安装
1、nodejs
nodejs的安装在之前的文章中已经提到过,这里不再赘述。详情请参考nodejs官网:;
2、幻影
关于phantomjs的安装,这里是windows环境下的安装方法:
首先去官网下载phantomjs压缩包,解压到本地磁盘。比如我电脑上解压后存储的地址是:D:\Program files\phantomjs-2.1.1;
二、配置环境变量。将解压后的phantomjs目录下bin目录的路径(比如我本地bin目录的位置是:D:\Program files\phantomjs-2.1.1\bin)添加到系统中变量路径变量中间;
然后,打开cmd,输入“phantomjs --version”命令查看phantomjs是否安装成功。如果出现版本号信息,则安装成功。如果报错,需要重启电脑。
结果如下所示:

二、设计理念
首先说一下写这个demo的初衷。因为我在工作中每次发邮件都需要用到一些截图,不想每次都手动拍多张,所以想用一个自动化的批处理工具来自动截图,不过这只是为了完成截图,使用的时候还是要上传图片。我还是觉得麻烦,所以想在截图完成后自动将这些图片上传到七牛服务器,然后从服务器获取图片下载地址,然后就可以直接使用图片下载地址了。好的。以下是具体的设计思路。

对于上图中的截图设备,具体程序流程为:

三、编码
1、模拟Echarts图表生成的工程代码和启动方法不再详述。请参考我在github上发布的源码:
2、截图
2.1、capture.js
主要使用phantomjs进行截图操作
1 var page=require('webpage').create();//创建一个网页对象;
2 var system=require('system');
3 var address,fileName;
4 // page.viewportSize={width:1024,height:800};//设置窗口的大小为1024*800;
5 // page.clipRect={top:0,left:0,width:1024,height:800};//截取从{0,0}为起点的1024*800大小的图像;
6 // //禁止Javascript,允许图片载入;
7 // // 并将userAgent改为"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.31 (KHTML, like Gecko) PhantomJS/19.0";
8 // page.settings={
9 // javascriptEnabled: false,
10 // loadImages: true,
11 // userAgent: 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.31 (KHTML, like Gecko) PhantomJS/19.0'
12 // };
13
14 if (system.args.length === 1) {
15 console.log('Try to pass some args when invoking this script!');
16 phantom.exit(1);
17 }else{
18 //获取指令传递的参数,参数是以数组的形式传递的;
19 address=system.args[1];
20 fileName=system.args[2];
21 count=system.args[3];
22 max=system.args[4];
23 //打开一个网页;
24 page.open(address,function(status){
25 console.log(status);
26 if(status==='success'){
27 //成功后将页面存储为图片并放在指定的位置;
28 page.render('./pictures/'+fileName+'.png');
29 }
30 // page.close();//释放;
31 //退出;
32 phantom.exit();
33 });
34 }
2.2、phantom.js
Nodejs 启动一个新的子进程并发送 phantomjs 命令进行截图。截图成功后,发送图片上传命令上传图片:
1 /**
2 * Created by Administrator on 2016/5/5.
3 */
4 var urls=["http://localhost:3000/","http://localhost:3000/table","http://www.baidu.com"];
5 var count=0;
6 var max=urls.length;
7 if(urls.length!=0){
8 capture(urls[0]);
9 }
10 //生成随机字符串作为图片名称;
11 function createRandomName(len){
12 len = len || 32;
13 /****默认去掉了容易混淆的字符oOLl,9gq,Vv,Uu,I1****/
14 var $chars = 'ABCDEFGHJKMNPQRSTWXYZabcdefhijkmnprstwxyz2345678';
15 var maxPos = $chars.length;
16 var pwd = '';
17 for (i = 0; i < len; i++) {
18 pwd += $chars.charAt(Math.floor(Math.random() * maxPos));
19 }
20 return pwd;
21 }
22 //开始执行截图命令;
23 function capture(url){
24 var randomPicName='test'+createRandomName(Math.random()*8);
25 console.log("获取的随机名称="+randomPicName);
26 var spawn=require('child_process').spawn;
27 var process=spawn('phantomjs',['capture.js',url,randomPicName,count,max],{cwd:'./routes/'});
28 process.stdout.setEncoding('utf8');
29
30 process.stdout.on("data",function(data){
31 console.log(data);
32 console.log("spawnSTDOUT:"+JSON.stringify(data));
33 var code=data.replace(/[\r\n]/g,"");
34 console.log(code);
35 if(code=='success'){
36 var execFile=require('child_process').execFile;
37 var filePath='./pictures/'+randomPicName+'.png';
38 var execProcess=execFile('node',['upload.js',filePath,randomPicName,count,JSON.stringify(urls)],{cwd:'./routes/'},
39 function(err,stdout,stderr){
40 console.log("execFileSTDOUT:", stdout);
41 console.log("execFileSTDERR:", stderr);
42 });
43 }
44 });
45 process.stderr.on('data',function(data){
46 console.log("stderr"+data);
47 });
48 process.on('close',function(code){
49 if (code == 1) {
50 console.log('child process异常结束。目标:' + url);
51 }
52 });
53 process.on('exit',function(code){
54 console.log('child process exited with code ' + code);
55 count++;
56 if(count!=urls.length){
57 capture(urls[count]);
58 }
59 });
60 }
2.3、上传.js
主要是将图片上传到七牛并获取图片的下载地址,并将结果存入本地txt文件:
1 /**
2 * Created by Administrator on 2016/5/6.
3 */
4 var qiniu = require("qiniu");
5 var config=require('./config');
6 var argvs=process.argv.splice(2);
7 var fs=require("fs");
8 console.log(argvs);
9
10 filePath=argvs[0];
11 key=argvs[1]+'.png';
12 //count;
13 var count=parseInt(argvs[2]);
14 //urls;
15 var urls=JSON.parse(argvs[3]);
16 var max=urls.length;
17 console.log("get the arguments:"+filePath+"---"+key+"--"+count+"---"+max);
18 /**
19 * 第一步:初始化
20 * @type {string}
21 */
22 //需要填写你的 Access Key 和 Secret Key
23 qiniu.conf.ACCESS_KEY = config.qiniu.ACCESS_KEY;
24 qiniu.conf.SECRET_KEY = config.qiniu.SECRET_KEY;
25 //要上传的空间
26 bucket = config.qiniu.Bucket_Name;
27
28 /**
29 * 第二步:获取上传的token
30 * @param bucket
31 * @param key
32 */
33 //构建上传策略函数,设置回调的url以及需要回调给业务服务器的数据
34 function uptoken(bucket, key) {
35 var putPolicy = new qiniu.rs.PutPolicy(bucket+":"+key);
36 console.log("token= "+putPolicy.token());
37 return putPolicy.token();
38 }
39 //生成上传 Token
40 token = uptoken(bucket, key);
41 /**
42 * 第三步:上传图片
43 * @type {string}
44 */
45
46 //构造上传函数
47 function uploadFile(uptoken, key, localFile,count,max) {
48 var extra = new qiniu.io.PutExtra();
49 qiniu.io.putFile(uptoken, key, localFile, extra, function(err, ret) {
50 if(!err) {
51 console.log("上传成功-------------------");
52 // 上传成功, 处理返回值
53 // console.log(ret.hash, ret.key, ret.persistentId);
54 //构建私有空间的链接
55 url = config.qiniu.Domain+ret.key;
56 var policy = new qiniu.rs.GetPolicy();
57 //生成下载链接url
58 var downloadUrl = policy.makeRequest(url);
59 //打印下载的url
60 console.log("downloadUrl= "+downloadUrl);
61 var date=new Date();
62 var dateString=date.toLocaleDateString();//日期;
63 var timeString=date.toLocaleTimeString();//时间;
64 var time=date.toLocaleDateString()+" "+date.toLocaleTimeString();
65 console.log(time);
66 var signalArray={
67 "编号":count+1,
68 "被截屏的路径地址":urls[count],
69 "上传七牛后的图片名称":key,
70 "下载地址":downloadUrl,
71 "截图时间":time
72 };
73 if(count==0){
74 // fs.appendFile(__dirname+'/downloadUrl.txt',"\r\n-----------------"+dateString+" "+timeString+"------------操作开始----------------------\r\n",function(err){
75 // if(err){console.log('fail')}
76 // });
77 fs.appendFileSync(__dirname+'/downloadUrl.txt',"\r\n-----------------"+dateString+" "+timeString+"------------操作开始----------------------\r\n",{encoding:'utf8'});
78 }
79 fs.appendFile(__dirname+'/downloadUrl.txt',JSON.stringify(signalArray)+'\r\n',function(err){
80 if(err){console.log("fail")}
81 });
82 // fs.appendFileSync(__dirname+'/downloadUrl.txt',JSON.stringify(signalArray)+'\r\n',{encoding:'utf8'});
83
84 // if((count+1)==max){
85 // fs.appendFile(__dirname+'/downloadUrl.txt',"\r\n-----------------"+dateString+" "+timeString+"------------操作结束----------------------\r\n",function(err){
86 // if(err){console.log('fail')}
87 // });
88 // fs.appendFileSync(__dirname+'/downloadUrl.txt',"\r\n-----------------"+dateString+" "+timeString+"------------操作结束----------------------\r\n\n",{encoding:'utf8'});
89 // }
90 } else {
91 // 上传失败, 处理返回代码
92 console.log(err);
93 }
94 });
95 }
96 //调用uploadFile上传,并返回下载地址;
97 uploadFile(token, key, filePath,count,max);
2.4、执行:
首先, npm install 安装所需的包。二、直接输入“node routes/phantom.js”,回车,程序开始执行。我们来看看执行结果:
2.4.1、/图片:
这个目录下还有更多的图片文件,这些是phantomjs截图的图片;
2.4.2、七牛服务器
网页登录七牛后,在自己的bucket中可以看到已经添加了很多图片文件,说明我们已经上传成功了:

2.4.3、本地下载Url.txt文件

然后我们测试下载地址是否可以正确下载图片:

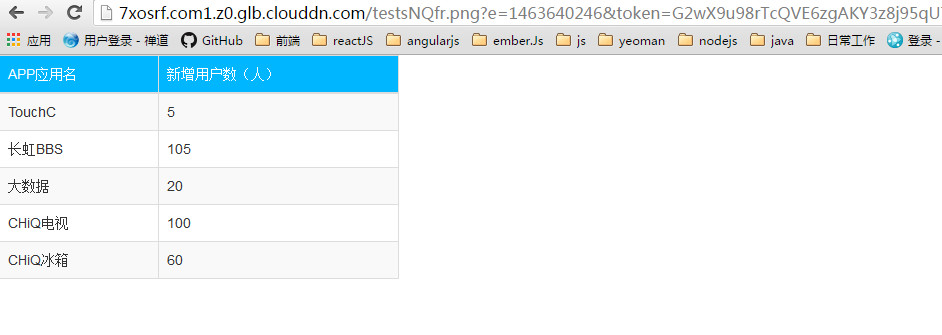

以上就是使用nodejs+phantomjs+七牛实现截图操作的完整方法,将截图上传到七牛,并将下载地址保存在本地磁盘。
PS:但是有一个问题,七牛的token是有有效期的,也就是说过了有效期,之前的url就不能用了。你可以重新上传一遍,或者直接在七牛上下载之前的图片。
如果需要源码,可以到我的github下载。下载地址为:
Phantomjs_pic 项目(生成echarts图表等):;
phantomjsScreenCapture 项目(实现截图和上传图片):;
ps:这次只是对phantomjs的一个简单应用。如果您有什么意见和建议,欢迎指出,谢谢!
nodejs抓取动态网页(一个网页的内容.write()介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-20 00:19
网页的内容其实是一个字符串,response.write()可以接受一个字符串作为参数,所以显然你只需要将网页的内容作为参数传递给response.write()。例如:
var http = require('http');
http.createServer(function(req, res){
var html = ''
+''
+'nodejs'
+''
+''
+ 'hello world! 1234'
+''
+'';
res.writeHead(200,{'Content-Type' : 'text/html'});
res.write(html);
res.end();
}).listen(8888);
在浏览器地址栏输入127.0.0.1:8888查看结果,打开控制台,可以发现网页的所有内容都已经收录了在浏览器中。
一个网页一般收录css样式文件和javascript脚本文件,上例中没有两个文件。现在你可以添加简单的css和javascript文件来看看效果:
var http = require('http');
http.createServer(function(req, res){
var html = ''
+''
+'nodejs'
+''
+''
+''
+''
+ 'hello world!hello world! 1234'
+''
+'';
res.writeHead(200,{'Content-Type' : 'text/html'});
res.write(html);
res.end();
}).listen(8888);
你会发现css文件和javascript文件都没有正确下载。这是因为这段代码中指定的'Content-Type'都是'text/html'类型,而且所有的响应内容都是一样的,当然看不到想要的效果。
我们知道有很多不同的方式来引入 CSS 样式和 javascript 脚本。CSS 样式可以使用外部样式、内部样式和内联样式,而 JavaScript 可以同时使用外部和内部样式。由于无法正确显示外线,您可以尝试其他方法。通过测试可以发现,在网页上无论是css内部样式还是内联样式都可以看到,javascript也是如此。
可以看到浏览器中的文字显示为红色。
但是现代 Web 开发并不提倡这两种方法。现代 Web 开发提倡使用 css 样式和 javascript 来使用 outreach 来方便管理和重用。css文件和javascript文件都是静态文件,我们可以尝试搭建一个简单的静态文件服务,这样就可以在网页中正确使用出站文件。 查看全部
nodejs抓取动态网页(一个网页的内容.write()介绍)
网页的内容其实是一个字符串,response.write()可以接受一个字符串作为参数,所以显然你只需要将网页的内容作为参数传递给response.write()。例如:
var http = require('http');
http.createServer(function(req, res){
var html = ''
+''
+'nodejs'
+''
+''
+ 'hello world! 1234'
+''
+'';
res.writeHead(200,{'Content-Type' : 'text/html'});
res.write(html);
res.end();
}).listen(8888);
在浏览器地址栏输入127.0.0.1:8888查看结果,打开控制台,可以发现网页的所有内容都已经收录了在浏览器中。
一个网页一般收录css样式文件和javascript脚本文件,上例中没有两个文件。现在你可以添加简单的css和javascript文件来看看效果:
var http = require('http');
http.createServer(function(req, res){
var html = ''
+''
+'nodejs'
+''
+''
+''
+''
+ 'hello world!hello world! 1234'
+''
+'';
res.writeHead(200,{'Content-Type' : 'text/html'});
res.write(html);
res.end();
}).listen(8888);
你会发现css文件和javascript文件都没有正确下载。这是因为这段代码中指定的'Content-Type'都是'text/html'类型,而且所有的响应内容都是一样的,当然看不到想要的效果。
我们知道有很多不同的方式来引入 CSS 样式和 javascript 脚本。CSS 样式可以使用外部样式、内部样式和内联样式,而 JavaScript 可以同时使用外部和内部样式。由于无法正确显示外线,您可以尝试其他方法。通过测试可以发现,在网页上无论是css内部样式还是内联样式都可以看到,javascript也是如此。
可以看到浏览器中的文字显示为红色。
但是现代 Web 开发并不提倡这两种方法。现代 Web 开发提倡使用 css 样式和 javascript 来使用 outreach 来方便管理和重用。css文件和javascript文件都是静态文件,我们可以尝试搭建一个简单的静态文件服务,这样就可以在网页中正确使用出站文件。
nodejs抓取动态网页(网站采用动态网页技术可以实现更多的功能,VisualStudio)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-19 19:26
网站使用动态网页技术可以实现更多的功能,比如用户注册、用户登录、在线调查、用户管理、订单管理等。下面我们来看看什么是动态网页设计。
动态网页设计是以Web应用开发项目为基础,以项目开发组织为指导,以XHTML标记语言、ASP动态网站开发技术、VBScript脚本语言、JavaScript客户端脚本语言、ADO数据库访问技术为手段,理论与实践相结合,全面展示了项目分析、设计、制作、总结和评估的过程。
此外,动态网页设计还具有以下特点:
1、增强的性能。编译后的公共语言运行时代码在服务器上运行。利用早期绑定、即时编译、本地优化和开箱即用缓存服务。这相当于在编写单行代码之前显着提高了性能。
2、世界级的工具支持。框架补充了 Visual Studio 集成开发环境中的工具箱和设计器。WYSIWYG 编辑、拖放服务器控件和自动部署只是这个强大工具提供的一些功能。
3、力量和灵活性。因为它基于公共语言运行时,Web 应用程序开发人员可以利用整个平台的强大功能和灵活性。
4、动态网页基于数据库技术,可以大大减少网站维护的工作量。网站使用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等。 查看全部
nodejs抓取动态网页(网站采用动态网页技术可以实现更多的功能,VisualStudio)
网站使用动态网页技术可以实现更多的功能,比如用户注册、用户登录、在线调查、用户管理、订单管理等。下面我们来看看什么是动态网页设计。
动态网页设计是以Web应用开发项目为基础,以项目开发组织为指导,以XHTML标记语言、ASP动态网站开发技术、VBScript脚本语言、JavaScript客户端脚本语言、ADO数据库访问技术为手段,理论与实践相结合,全面展示了项目分析、设计、制作、总结和评估的过程。
此外,动态网页设计还具有以下特点:
1、增强的性能。编译后的公共语言运行时代码在服务器上运行。利用早期绑定、即时编译、本地优化和开箱即用缓存服务。这相当于在编写单行代码之前显着提高了性能。
2、世界级的工具支持。框架补充了 Visual Studio 集成开发环境中的工具箱和设计器。WYSIWYG 编辑、拖放服务器控件和自动部署只是这个强大工具提供的一些功能。
3、力量和灵活性。因为它基于公共语言运行时,Web 应用程序开发人员可以利用整个平台的强大功能和灵活性。
4、动态网页基于数据库技术,可以大大减少网站维护的工作量。网站使用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等。
nodejs抓取动态网页(年前无心工作,上班刷知乎发现一篇分享python爬虫的文章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-17 08:26
多年前无意工作,在工作中发现一篇文章分享python爬虫刷知乎的文章。
感觉他爬的网站里面的妹子都好看,很喜欢这里,个个都是美女。
不幸的是,虽然python已经使用了很长时间,但是它已经被废弃太久了。最近在用nodejs重构后台界面,所以尝试用nodejs实现爬虫。
好吧,让我们开始吧,男孩!
准备好工作了:
系统环境:mac
运行环境:节点
所需模块:request-promise、cheerio、fs
编辑:vscode(谁用谁知道)
简单看一下这些 nodejs 模块:
var request = require('request-promise');
request('http://www.google.com')
.then(function (htmlString) {
console.log(htmlString)
})
.catch(function (err) {
});
任何响应都可以输出到文件流:
request('http://google.com/doodle.png').pipe(
fs.createWriteStream('doodle.png')
)
api类似jQuery,使用超级简单
const cheerio = require('cheerio')
const $ = cheerio.load('Hello world')
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
$.html()
//=> Hello there!
您可以在本地创建目录、创建文件、读取文件等。
网页分析:
分析目标的相册网址网站
因为python文章的作者已经详细分析过网站,我就简单分析一下。
随意打开几张相册,可以看到规则如下:
"https://www.****.com/g/****/"
所以我们可以确定要爬取的base url:
const base_url = 'https://www.****.com/g/';//爬取相册网页的基本网址
然后看几乎每张专辑底部的页码,而我们要抓取整张专辑,所以需要考虑分页情况,点击分页,我们看到分页的url是这样的:
"https://www.****.com/g/****/*.html"
商业逻辑:
实际代码:
app.js 轮询和代码结构
const nvshens = require('./co');
const base_url = 'https://www.nvshens.com/g/';//爬取相册网页的基本网址
let index = 1;
let start = 25380;
const end = 30000;
const main = async (URL) => {
//1.请求网址
const data = await nvshens.getPage(URL);
//2.判断是否存在相册
if (nvshens.getTitle((data.res))) {
//3.下载照片
await nvshens.download(data.res);
//4.请求分页
index++;
const new_url = `${base_url}${start}/${index}.html`;
main(new_url);
} else {
index = 1;
console.log(`${base_url}${start}页面已完成`)
start++;
if (start < end) {
//5.请求下一个网址
main(base_url + start);
} else {
console.log(`${base_url}${end}所有页面已完成`)
}
}
};
main(base_url + start);
co.js //业务代码
var request = require('request-promise'); //网络请求
const cheerio = require("cheerio");//操作dom
const fs = require("fs");//读写文件
const headers = {
"Referer": "https://www.nvshens.com/g/24656/"
}
//因为一些网站在解决盗链问题时是根据Referer的值来判断的,所以在请求头上添加Referer属性就好(可以填爬取网站的地址)。
//另外Referer携带的数据 是用来告诉服务器当前请求是从哪个页面请求过来的。
const basePath = "/Users/用户名/Desktop/mm/";
//自定义mac本地下载目录,需预先创建,windows路径可参考"D:/Users/mm/"
let downloadPath;
let pageIndex = 1;
module.exports = {
//请求页面
async getPage(url) {
const data = {
url,
res: await request({
url: url
})
}
return data;
},
//判断页面是否存在相册
getTitle(data) {
const $ = cheerio.load(data);
if ($("#htilte").text()) {
downloadPath = basePath + $("#htilte").text();
//创建相册
if (!fs.existsSync(downloadPath)) {
fs.mkdirSync(downloadPath);
console.log(`${downloadPath}文件夹创建成功`)
}
return true;
} else {
return false;
}
},
//下载相册照片
async download(data) {
if (data) {
var $ = cheerio.load(data);
$("#hgallery").children().each(async (i, elem) => {
const imgSrc = $(elem).attr('src');
const imgPath = "/" + imgSrc.split("/").pop().split(".")[0] + "." + imgSrc.split(".").pop();
console.log(`${downloadPath + imgPath}下载中`)
const imgData = await request({
uri: imgSrc,
resolveWithFullResponse: true,
headers,
}).pipe(fs.createWriteStream(downloadPath + imgPath));
})
console.log("page done")
}
},
}
开始运行
node app.js
可以实现几个功能,是不是很简单? 查看全部
nodejs抓取动态网页(年前无心工作,上班刷知乎发现一篇分享python爬虫的文章)
多年前无意工作,在工作中发现一篇文章分享python爬虫刷知乎的文章。
感觉他爬的网站里面的妹子都好看,很喜欢这里,个个都是美女。
不幸的是,虽然python已经使用了很长时间,但是它已经被废弃太久了。最近在用nodejs重构后台界面,所以尝试用nodejs实现爬虫。
好吧,让我们开始吧,男孩!
准备好工作了:
系统环境:mac
运行环境:节点
所需模块:request-promise、cheerio、fs
编辑:vscode(谁用谁知道)
简单看一下这些 nodejs 模块:
var request = require('request-promise');
request('http://www.google.com')
.then(function (htmlString) {
console.log(htmlString)
})
.catch(function (err) {
});
任何响应都可以输出到文件流:
request('http://google.com/doodle.png').pipe(
fs.createWriteStream('doodle.png')
)
api类似jQuery,使用超级简单
const cheerio = require('cheerio')
const $ = cheerio.load('Hello world')
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
$.html()
//=> Hello there!
您可以在本地创建目录、创建文件、读取文件等。
网页分析:
分析目标的相册网址网站
因为python文章的作者已经详细分析过网站,我就简单分析一下。
随意打开几张相册,可以看到规则如下:
"https://www.****.com/g/****/"
所以我们可以确定要爬取的base url:
const base_url = 'https://www.****.com/g/';//爬取相册网页的基本网址
然后看几乎每张专辑底部的页码,而我们要抓取整张专辑,所以需要考虑分页情况,点击分页,我们看到分页的url是这样的:
"https://www.****.com/g/****/*.html"
商业逻辑:
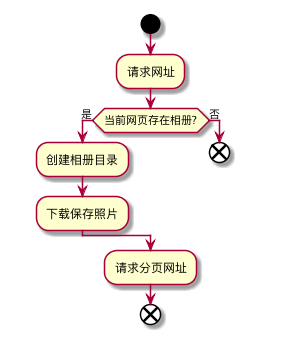
实际代码:
app.js 轮询和代码结构
const nvshens = require('./co');
const base_url = 'https://www.nvshens.com/g/';//爬取相册网页的基本网址
let index = 1;
let start = 25380;
const end = 30000;
const main = async (URL) => {
//1.请求网址
const data = await nvshens.getPage(URL);
//2.判断是否存在相册
if (nvshens.getTitle((data.res))) {
//3.下载照片
await nvshens.download(data.res);
//4.请求分页
index++;
const new_url = `${base_url}${start}/${index}.html`;
main(new_url);
} else {
index = 1;
console.log(`${base_url}${start}页面已完成`)
start++;
if (start < end) {
//5.请求下一个网址
main(base_url + start);
} else {
console.log(`${base_url}${end}所有页面已完成`)
}
}
};
main(base_url + start);
co.js //业务代码
var request = require('request-promise'); //网络请求
const cheerio = require("cheerio");//操作dom
const fs = require("fs");//读写文件
const headers = {
"Referer": "https://www.nvshens.com/g/24656/"
}
//因为一些网站在解决盗链问题时是根据Referer的值来判断的,所以在请求头上添加Referer属性就好(可以填爬取网站的地址)。
//另外Referer携带的数据 是用来告诉服务器当前请求是从哪个页面请求过来的。
const basePath = "/Users/用户名/Desktop/mm/";
//自定义mac本地下载目录,需预先创建,windows路径可参考"D:/Users/mm/"
let downloadPath;
let pageIndex = 1;
module.exports = {
//请求页面
async getPage(url) {
const data = {
url,
res: await request({
url: url
})
}
return data;
},
//判断页面是否存在相册
getTitle(data) {
const $ = cheerio.load(data);
if ($("#htilte").text()) {
downloadPath = basePath + $("#htilte").text();
//创建相册
if (!fs.existsSync(downloadPath)) {
fs.mkdirSync(downloadPath);
console.log(`${downloadPath}文件夹创建成功`)
}
return true;
} else {
return false;
}
},
//下载相册照片
async download(data) {
if (data) {
var $ = cheerio.load(data);
$("#hgallery").children().each(async (i, elem) => {
const imgSrc = $(elem).attr('src');
const imgPath = "/" + imgSrc.split("/").pop().split(".")[0] + "." + imgSrc.split(".").pop();
console.log(`${downloadPath + imgPath}下载中`)
const imgData = await request({
uri: imgSrc,
resolveWithFullResponse: true,
headers,
}).pipe(fs.createWriteStream(downloadPath + imgPath));
})
console.log("page done")
}
},
}
开始运行
node app.js
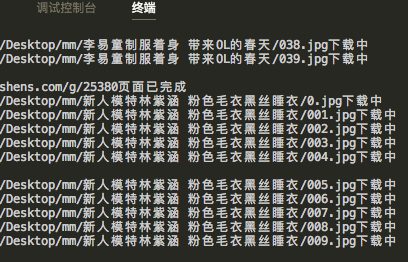
可以实现几个功能,是不是很简单?
nodejs抓取动态网页(基础概念SSR:即服务端渲染(ServerSide)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-17 06:02
基本概念
SSR:服务器端渲染(Server Side Render) 传统的服务器端渲染可以使用Java、php等开发语言来实现。随着Node.js及相关前端技术的不断进步,前端同学也可以使用这个完整的独立服务端渲染。
流程:浏览器发送请求->服务器运行react代码生成页面->服务器返回页面->浏览器下载HTML文档->页面就绪,即:当前页面由服务器生成并发送给浏览器。
对应CSR:客户端渲染过程:浏览器发送请求->服务器返回空白HTML(HTML收录根节点和js文件)->浏览器下载js文件->浏览器运行React代码->页面就绪:当前页面内容由js渲染
如何区分页面是否为服务端渲染:右键->显示网页源代码。如果页面内容在 HTML 文档中,则为服务器端渲染,否则为客户端渲染。
比较
为什么要使用服务器端渲染
首屏加载时间优化,因为SSR直接返回生成内容的HTML,而普通CSR先返回空白HTML,然后浏览器动态加载JavaScript脚本并在页面有内容之前渲染;所以SSR首屏加载更快,减少白屏时间,用户体验更好。
SEO(Search Engine Optimization),搜索关键词时的排名,对于大多数搜索引擎来说,不识别JavaScript内容,只识别HTML内容。 (注:原则上最好不要使用服务端渲染,所以如果只有SEO需求,可以使用预渲染等技术代替)
构建服务器渲染项目
(1)使用Node.js作为服务端和客户端的中间层,承担代理代理,处理cookies等操作。
(2) hydra的使用:在服务端渲染的情况下,使用hydra代替render。它的作用是把相关的事件注入到HTML页面中(即:让React组件的数据跟随HTML 文档一起传递给浏览器页面),可以保持服务器端数据与浏览器端一致,避免闪屏,让首次加载体验更加高效流畅。
ReactDom.hydrate(, document.getElementById('root'));
(3)服务端代码webpack编译:一般会构建一个webpack.server.js文件。除了常规的参数配置外,target参数需要设置为'node'。
const serverConfig = {
target: 'node',
entry: './src/server/index.js',
output: {
filename: 'bundle.js',
path: path.resolve(__dirname, '../dist')
},
externals: [nodeExternals()],
module: {
rules: [{
test: /\.js?$/,
loader: 'babel-loader',
exclude: [
path.join(__dirname, './node_modules')
]
}
...
]
}
(此处省略样式打包,代码压缩,运行坏境配置等等...)
...
};
(4) 使用 react-dom/server 下的 renderToString 方法,将各种复杂的组件和代码在服务器上转换成 HTML 字符串返回给浏览器,并在初始请求上发送标签以加快页面加载速度并允许搜索引擎抓取页面以进行 SEO。
const render = (store, routes, req, context) => {
const content = renderToString((
{renderRoutes(routes)}
));
return `
ssr
${content}
`;
}
app.get('*', function (req, res) {
...
const html = render(store, routes, req, context);
res.send(html);
});
renderToString 的类似函数: i. renderToStaticMarkup:不同的是,renderToStaticMarkup 渲染的是纯 HTML,没有 data-reactid。 JavaScript 加载完成后,由于无法识别之前服务器渲染的内容,重新渲染(可能页面会闪退)。
二。 renderToNodeStream:将 React 元素渲染为其初始 HTML,返回一个可读的输出 HTML 字符串流。
三。 renderToStaticNodeStream:类似于renderToNodeStream,除了这不会创建React内部使用的额外DOM属性,例如data-reactroot。
(5) 使用redux来承担数据准备和状态维护的职责,通常用react-redux、redux-thunk(中间件:发送异步请求到action)。(这个猿目前用的比较多的是Redux和 Mobx,这里以 Redux 为例)。 A. 创建一个 store(服务端需要为每个请求创建一次,客户端只创建一次):
const reducer = combineReducers({
home: homeReducer,
page1: page1Reducer,
page2: page2Reducer
});
export const getStore = (req) => {
return createStore(reducer, applyMiddleware(thunk.withExtraArgument(serverAxios(req))));
}
export const getClientStore = () => {
return createStore(reducer, window.STATE_FROM_SERVER, applyMiddleware(thunk.withExtraArgument(clientAxios)));
}
B. action:负责将数据从应用程序传输到商店,是商店数据的唯一来源
export const getData = () => {
return (dispatch, getState, axiosInstance) => {
return axiosInstance.get('interfaceUrl/xxx')
.then((res) => {
dispatch({
type: 'HOME_LIST',
list: res.list
})
});
}
}
C. reducer:接收旧的状态和动作,返回新的状态,响应动作并发送给store。
export default (state = { list: [] }, action) => {
switch(action.type) {
case 'HOME_LIST':
return {
...state,
list: action.list
}
default:
return state;
}
}
export default (state = { list: [] }, action) => {
switch(action.type) {
case 'HOME_LIST':
return {
...state,
list: action.list
}
default:
return state;
}
}
D. Provider 使用 react-redux 的 connect 将组件连接到 store
Provider 将之前创建的 store 作为 prop 传递给 Provider
const content = renderToString((
{renderRoutes(routes)}
));
connect([mapStateToProps], [mapDispatchToProps], [mergeProps], [options]) 接收四个参数。前两个属性是常用的。 mapStateToProps 函数允许我们将 store 中的数据作为 props 绑定到组件。 mapDispatchToProps 将 Actions 作为 props 绑定到组件
connect(mapStateToProps(),mapDispatchToProps())(MyComponent)
(6) 使用react-router承担路由职责。服务端路由和客户端路由不同。它是无状态的。React提供了一个无状态组件StaticRouter,它将当前URL传递给StaticRouter和调用 ReactDOMServer.renderToString() 来匹配路由视图。
服务器
import { StaticRouter } from 'react-router-dom';
import { renderRoutes } from 'react-router-config'
import routes from './router.js'
{renderRoutes(routes)}
浏览器端
import { BrowserRouter } from 'react-router-dom';
import { renderRoutes } from 'react-router-config'
import routes from './router.js'
{renderRoutes(routes)}
当浏览器的地址栏发生变化时,前端会匹配路由视图,而由于req.path发生变化,服务器会匹配路由视图,保持了前后端路由的一致性意见。页面刷新后,当前视图仍能正常显示。如果只有浏览器端路由,使用BrowserRouter,当页面地址改变后刷新页面时,会因为没有对应的html而找不到页面。返回一个完整的html给客户端,页面依旧正常显示。推荐使用react-router-config插件,然后在StaticRouter和BrowserRouter标签的子元素中添加renderRoutes(routes)如上:创建router.js文件
const routes = [{ component: Root,
routes: [
{ path: '/',
exact: true,
component: Home,
loadData: Home.loadData
},
{ path: '/child/:id',
component: Child,
loadData: Child.loadData
routes: [
path: '/child/:id/grand-child',
component: GrandChild,
loadData: GrandChild.loadData
]
}
]
}];
当浏览器请求一个地址时,server.js可以在实际渲染之前通过matchRouters判断要渲染的内容,调用loaderData函数进行action dispatch,返回promise->promiseAll->renderToString,最后生成HTML文档返回。
import { matchRoutes } from 'react-router-config'
const loadBranchData = (location) => {
const branch = matchRoutes(routes, location.pathname)
const promises = branch.map(({ route, match }) => {
return route.loadData
? route.loadData(match)
: Promise.resolve(null)
})
return Promise.all(promises)
}
(7)写组件的时候注意代码同构(即:一组React代码在服务端执行一次,在客户端执行一次)由于服务端绑定事件无效,服务端只返回Page样式(&灌水数据),同时返回JavaScript文件,该事件只有在浏览器下载执行JavaScript时才能绑定,我们希望这个过程只需要写代码一次,此时会用到同构和服务,客户端渲染样式,客户端执行时绑定事件。
优点:共享前端代码,节省开发时间缺点:由于服务器端和浏览器环境的不同,会出现一些问题,比如找不到document等对象,DOM计算错误,不一致前端渲染和服务端渲染之间的内容等;前端可以做非常复杂的请求合并和延迟处理,但是对于同构来说,所有这些请求只有在提前得到结果时才会渲染。
以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Script Home。 查看全部
nodejs抓取动态网页(基础概念SSR:即服务端渲染(ServerSide)(图))
基本概念
SSR:服务器端渲染(Server Side Render) 传统的服务器端渲染可以使用Java、php等开发语言来实现。随着Node.js及相关前端技术的不断进步,前端同学也可以使用这个完整的独立服务端渲染。
流程:浏览器发送请求->服务器运行react代码生成页面->服务器返回页面->浏览器下载HTML文档->页面就绪,即:当前页面由服务器生成并发送给浏览器。

对应CSR:客户端渲染过程:浏览器发送请求->服务器返回空白HTML(HTML收录根节点和js文件)->浏览器下载js文件->浏览器运行React代码->页面就绪:当前页面内容由js渲染

如何区分页面是否为服务端渲染:右键->显示网页源代码。如果页面内容在 HTML 文档中,则为服务器端渲染,否则为客户端渲染。
比较
为什么要使用服务器端渲染
首屏加载时间优化,因为SSR直接返回生成内容的HTML,而普通CSR先返回空白HTML,然后浏览器动态加载JavaScript脚本并在页面有内容之前渲染;所以SSR首屏加载更快,减少白屏时间,用户体验更好。
SEO(Search Engine Optimization),搜索关键词时的排名,对于大多数搜索引擎来说,不识别JavaScript内容,只识别HTML内容。 (注:原则上最好不要使用服务端渲染,所以如果只有SEO需求,可以使用预渲染等技术代替)
构建服务器渲染项目
(1)使用Node.js作为服务端和客户端的中间层,承担代理代理,处理cookies等操作。
(2) hydra的使用:在服务端渲染的情况下,使用hydra代替render。它的作用是把相关的事件注入到HTML页面中(即:让React组件的数据跟随HTML 文档一起传递给浏览器页面),可以保持服务器端数据与浏览器端一致,避免闪屏,让首次加载体验更加高效流畅。
ReactDom.hydrate(, document.getElementById('root'));
(3)服务端代码webpack编译:一般会构建一个webpack.server.js文件。除了常规的参数配置外,target参数需要设置为'node'。
const serverConfig = {
target: 'node',
entry: './src/server/index.js',
output: {
filename: 'bundle.js',
path: path.resolve(__dirname, '../dist')
},
externals: [nodeExternals()],
module: {
rules: [{
test: /\.js?$/,
loader: 'babel-loader',
exclude: [
path.join(__dirname, './node_modules')
]
}
...
]
}
(此处省略样式打包,代码压缩,运行坏境配置等等...)
...
};
(4) 使用 react-dom/server 下的 renderToString 方法,将各种复杂的组件和代码在服务器上转换成 HTML 字符串返回给浏览器,并在初始请求上发送标签以加快页面加载速度并允许搜索引擎抓取页面以进行 SEO。
const render = (store, routes, req, context) => {
const content = renderToString((
{renderRoutes(routes)}
));
return `
ssr
${content}
`;
}
app.get('*', function (req, res) {
...
const html = render(store, routes, req, context);
res.send(html);
});
renderToString 的类似函数: i. renderToStaticMarkup:不同的是,renderToStaticMarkup 渲染的是纯 HTML,没有 data-reactid。 JavaScript 加载完成后,由于无法识别之前服务器渲染的内容,重新渲染(可能页面会闪退)。
二。 renderToNodeStream:将 React 元素渲染为其初始 HTML,返回一个可读的输出 HTML 字符串流。
三。 renderToStaticNodeStream:类似于renderToNodeStream,除了这不会创建React内部使用的额外DOM属性,例如data-reactroot。
(5) 使用redux来承担数据准备和状态维护的职责,通常用react-redux、redux-thunk(中间件:发送异步请求到action)。(这个猿目前用的比较多的是Redux和 Mobx,这里以 Redux 为例)。 A. 创建一个 store(服务端需要为每个请求创建一次,客户端只创建一次):
const reducer = combineReducers({
home: homeReducer,
page1: page1Reducer,
page2: page2Reducer
});
export const getStore = (req) => {
return createStore(reducer, applyMiddleware(thunk.withExtraArgument(serverAxios(req))));
}
export const getClientStore = () => {
return createStore(reducer, window.STATE_FROM_SERVER, applyMiddleware(thunk.withExtraArgument(clientAxios)));
}
B. action:负责将数据从应用程序传输到商店,是商店数据的唯一来源
export const getData = () => {
return (dispatch, getState, axiosInstance) => {
return axiosInstance.get('interfaceUrl/xxx')
.then((res) => {
dispatch({
type: 'HOME_LIST',
list: res.list
})
});
}
}
C. reducer:接收旧的状态和动作,返回新的状态,响应动作并发送给store。
export default (state = { list: [] }, action) => {
switch(action.type) {
case 'HOME_LIST':
return {
...state,
list: action.list
}
default:
return state;
}
}
export default (state = { list: [] }, action) => {
switch(action.type) {
case 'HOME_LIST':
return {
...state,
list: action.list
}
default:
return state;
}
}
D. Provider 使用 react-redux 的 connect 将组件连接到 store
Provider 将之前创建的 store 作为 prop 传递给 Provider
const content = renderToString((
{renderRoutes(routes)}
));
connect([mapStateToProps], [mapDispatchToProps], [mergeProps], [options]) 接收四个参数。前两个属性是常用的。 mapStateToProps 函数允许我们将 store 中的数据作为 props 绑定到组件。 mapDispatchToProps 将 Actions 作为 props 绑定到组件
connect(mapStateToProps(),mapDispatchToProps())(MyComponent)
(6) 使用react-router承担路由职责。服务端路由和客户端路由不同。它是无状态的。React提供了一个无状态组件StaticRouter,它将当前URL传递给StaticRouter和调用 ReactDOMServer.renderToString() 来匹配路由视图。
服务器
import { StaticRouter } from 'react-router-dom';
import { renderRoutes } from 'react-router-config'
import routes from './router.js'
{renderRoutes(routes)}
浏览器端
import { BrowserRouter } from 'react-router-dom';
import { renderRoutes } from 'react-router-config'
import routes from './router.js'
{renderRoutes(routes)}
当浏览器的地址栏发生变化时,前端会匹配路由视图,而由于req.path发生变化,服务器会匹配路由视图,保持了前后端路由的一致性意见。页面刷新后,当前视图仍能正常显示。如果只有浏览器端路由,使用BrowserRouter,当页面地址改变后刷新页面时,会因为没有对应的html而找不到页面。返回一个完整的html给客户端,页面依旧正常显示。推荐使用react-router-config插件,然后在StaticRouter和BrowserRouter标签的子元素中添加renderRoutes(routes)如上:创建router.js文件
const routes = [{ component: Root,
routes: [
{ path: '/',
exact: true,
component: Home,
loadData: Home.loadData
},
{ path: '/child/:id',
component: Child,
loadData: Child.loadData
routes: [
path: '/child/:id/grand-child',
component: GrandChild,
loadData: GrandChild.loadData
]
}
]
}];
当浏览器请求一个地址时,server.js可以在实际渲染之前通过matchRouters判断要渲染的内容,调用loaderData函数进行action dispatch,返回promise->promiseAll->renderToString,最后生成HTML文档返回。
import { matchRoutes } from 'react-router-config'
const loadBranchData = (location) => {
const branch = matchRoutes(routes, location.pathname)
const promises = branch.map(({ route, match }) => {
return route.loadData
? route.loadData(match)
: Promise.resolve(null)
})
return Promise.all(promises)
}
(7)写组件的时候注意代码同构(即:一组React代码在服务端执行一次,在客户端执行一次)由于服务端绑定事件无效,服务端只返回Page样式(&灌水数据),同时返回JavaScript文件,该事件只有在浏览器下载执行JavaScript时才能绑定,我们希望这个过程只需要写代码一次,此时会用到同构和服务,客户端渲染样式,客户端执行时绑定事件。
优点:共享前端代码,节省开发时间缺点:由于服务器端和浏览器环境的不同,会出现一些问题,比如找不到document等对象,DOM计算错误,不一致前端渲染和服务端渲染之间的内容等;前端可以做非常复杂的请求合并和延迟处理,但是对于同构来说,所有这些请求只有在提前得到结果时才会渲染。
以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Script Home。
nodejs抓取动态网页(一下如何抓取动态页面?抓取一个页面的方法十分简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-17 05:20
当我们要抓取一个页面的内容时,首先要做的不是写代码,而是分析页面,判断是静态页面还是动态页面。抓取静态页面的方法很简单。可以直接解析html源码,然后分析解析。不明白的可以参考我上一篇文章Scrapy抓取豆瓣电影资料。这里我主要介绍如何抓取。动态页面。
抓取动态页面有两种方法:
第一种方法是使用第三方工具模拟浏览器的行为来加载数据。例如:Selenium、PhantomJs。这种方法的优点是不必考虑动态页面的各种变化,但性能较低。
第二种方法是分析页面,找到对应的请求接口,直接获取数据。这种方式的优点是性能高,但缺点也很明显,就是获取API接口比较麻烦。
我这里用第二种方法爬取动态页面。
1.浏览器打开页面,查看网页源码,发现源码中没有图片信息。这是一个动态加载的页面,它是一个动态页面的异步ajax请求。
2.分析页面,提取API接口,通过F12可以找到review元素。
3.打开上面的url,发现传入的数据是json格式的,所以我们拿到response响应后,首先要使用json.loads()来解析数据。
4.观察API接口,可以发现有几个参数,ch、sn、listtype、temp,通过改变这些参数的值可以得到不同的内容。
通过分析发现,ch参数代表图片的分类,比如beauty代表漂亮的图片,sn代表图片的数量,比如0代表1到30之间的图片,30代表31到60之间的图片。
分析完这些参数,我们就确定了我们需要请求的url地址。这里的url不像静态页面中程序自动获取的a标签中的href,而是我们需要自动设置。我们可以重写 start_requests 方法。指定要检索的 url。
5.写我们的蜘蛛
# -*- coding: utf-8 -*-
from json import loads
import scrapy
from urllib.parse import urlencode
from image360.items import BeautyItem
class ImageSpider(scrapy.Spider):
name = 'image'
allowed_domains = ['image.so.com']
# 重写Spider中的start_requests方法:指定开始url
def start_requests(self):
base_url = 'http://image.so.com/zj?'
param = {'ch': 'beauty', 'listtype': 'new', 'temp': '1'}
# 可以根据需要爬取不同数量的图片,此处只爬取60张图片
for page in range(2):
param['sn'] = page * 30
full_url = base_url + urlencode(param)
yield scrapy.Request(url=full_url, callback=self.parse)
def parse(self, response):
# 获取到的内容是json数据
# 用json.loads()解析数据
# 此处的response没有content
model_dict = loads(response.text)
for elem in model_dict['list']:
item = BeautyItem()
item['title'] = elem['group_title']
item['tag'] = elem['tag']
item['height'] = elem['cover_width']
item['width'] = elem['cover_height']
item['url'] = elem['qhimg_url']
yield item
6.写入项目并定义保存的字段
import scrapy
class BeautyItem(scrapy.Item):
title = scrapy.Field()
tag = scrapy.Field()
height = scrapy.Field()
width = scrapy.Field()
url = scrapy.Field()
7.写一个管道完成数据持久化操作,包括下载图片和保存图片信息到mongo。
Scrapy 提供了一个项目管道来下载属于特定项目的图像。比如你在抓产品的时候,也想把他们的图片下载到本地,这可以通过图片管道来实现。这是在 ImagesPipenine 类中实现的,该类提供了一种方便的方法以及附加功能来在本地下载和存储图像。该类提供了许多处理图像的方法。具体可以查看官方文档的中文版。
# -*- coding: utf-8 -*-
import logging
import pymongo
import scrapy
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
logger = logging.getLogger('SaveImagePipeline')
# 继承ImagesPipenine类,这是图片管道
class SaveImagePipeline(ImagesPipeline):
"""
下载图片
"""
def get_media_requests(self, item, info):
# 此方法获取的是requests 所以用yield 不要return
yield scrapy.Request(url=item['url'])
def item_completed(self, results, item, info):
"""
文件下载完成之后,返回一个列表 results
列表中是一个元组,第一个值是布尔值,请求成功会失败,第二个值的下载到的资源
"""
if not results[0][0]:
# 如果下载失败,就抛出异常,并丢弃这个item
# 被丢弃的item将不会被之后的pipeline组件所处理
raise DropItem('下载失败')
# 打印日志
logger.debug('下载图片成功')
return item
def file_path(self, request, response=None, info=None):
"""
返回文件名
"""
return request.url.split('/')[-1]
class SaveToMongoPipeline(object):
"""
保存图片信息到数据库
"""
def __init__(self, mongodb_server, mongodb_port, mongodb_db, mongodb_collection):
self.mongodb_server = mongodb_server
self.mongodb_port = mongodb_port
self.mongodb_db = mongodb_db
self.mongodb_collection = mongodb_collection
def open_spider(self, spider):
# 当spider被开启时,这个方法被调用
self.connection = pymongo.MongoClient(self.mongodb_server, self.mongodb_port)
db = self.connection[self.mongodb_db]
self.collection = db[self.mongodb_collection]
def close_spider(self, spider):
# 当spider被关闭时,这个方法被调用。
self.connection.close()
# 依赖注入
@classmethod
def from_crawler(cls, crawler):
# cls() 会调用初始化方法
return cls(crawler.settings.get('MONGODB_SERVER'),
crawler.settings.get('MONGODB_PORT'),
crawler.settings.get('MONGODB_DB'),
crawler.settings.get('MONGODB_COLLECTION'))
def process_item(self, item, spider):
post = {'title': item['title'], 'tag': item['tag'],
'width': item['width'], 'height': item['height'], 'url': item['url']}
self.collection.insert_one(post)
return item
8.写入设置并完成配置。这里只写需要配置的内容。
9.启动蜘蛛
在启动spider之前,我们还需要安装几个包,pypiwin32、pilllow、pymongo
pip install pypiwin32
pip install pillow
pip install pymongo
安装完成后就可以启动spider了
scrapy crawl image
10.查看结果:
获取到的图片返回的内容:
将图片保存到指定路径:
一个爬取动态页面和下载图片的爬虫就完成了。其实写起来很简单。关键是分析API接口,重写start_requests方法。 查看全部
nodejs抓取动态网页(一下如何抓取动态页面?抓取一个页面的方法十分简单)
当我们要抓取一个页面的内容时,首先要做的不是写代码,而是分析页面,判断是静态页面还是动态页面。抓取静态页面的方法很简单。可以直接解析html源码,然后分析解析。不明白的可以参考我上一篇文章Scrapy抓取豆瓣电影资料。这里我主要介绍如何抓取。动态页面。
抓取动态页面有两种方法:
第一种方法是使用第三方工具模拟浏览器的行为来加载数据。例如:Selenium、PhantomJs。这种方法的优点是不必考虑动态页面的各种变化,但性能较低。
第二种方法是分析页面,找到对应的请求接口,直接获取数据。这种方式的优点是性能高,但缺点也很明显,就是获取API接口比较麻烦。
我这里用第二种方法爬取动态页面。
1.浏览器打开页面,查看网页源码,发现源码中没有图片信息。这是一个动态加载的页面,它是一个动态页面的异步ajax请求。
2.分析页面,提取API接口,通过F12可以找到review元素。

3.打开上面的url,发现传入的数据是json格式的,所以我们拿到response响应后,首先要使用json.loads()来解析数据。

4.观察API接口,可以发现有几个参数,ch、sn、listtype、temp,通过改变这些参数的值可以得到不同的内容。
通过分析发现,ch参数代表图片的分类,比如beauty代表漂亮的图片,sn代表图片的数量,比如0代表1到30之间的图片,30代表31到60之间的图片。
分析完这些参数,我们就确定了我们需要请求的url地址。这里的url不像静态页面中程序自动获取的a标签中的href,而是我们需要自动设置。我们可以重写 start_requests 方法。指定要检索的 url。
5.写我们的蜘蛛
# -*- coding: utf-8 -*-
from json import loads
import scrapy
from urllib.parse import urlencode
from image360.items import BeautyItem
class ImageSpider(scrapy.Spider):
name = 'image'
allowed_domains = ['image.so.com']
# 重写Spider中的start_requests方法:指定开始url
def start_requests(self):
base_url = 'http://image.so.com/zj?'
param = {'ch': 'beauty', 'listtype': 'new', 'temp': '1'}
# 可以根据需要爬取不同数量的图片,此处只爬取60张图片
for page in range(2):
param['sn'] = page * 30
full_url = base_url + urlencode(param)
yield scrapy.Request(url=full_url, callback=self.parse)
def parse(self, response):
# 获取到的内容是json数据
# 用json.loads()解析数据
# 此处的response没有content
model_dict = loads(response.text)
for elem in model_dict['list']:
item = BeautyItem()
item['title'] = elem['group_title']
item['tag'] = elem['tag']
item['height'] = elem['cover_width']
item['width'] = elem['cover_height']
item['url'] = elem['qhimg_url']
yield item
6.写入项目并定义保存的字段
import scrapy
class BeautyItem(scrapy.Item):
title = scrapy.Field()
tag = scrapy.Field()
height = scrapy.Field()
width = scrapy.Field()
url = scrapy.Field()
7.写一个管道完成数据持久化操作,包括下载图片和保存图片信息到mongo。
Scrapy 提供了一个项目管道来下载属于特定项目的图像。比如你在抓产品的时候,也想把他们的图片下载到本地,这可以通过图片管道来实现。这是在 ImagesPipenine 类中实现的,该类提供了一种方便的方法以及附加功能来在本地下载和存储图像。该类提供了许多处理图像的方法。具体可以查看官方文档的中文版。
# -*- coding: utf-8 -*-
import logging
import pymongo
import scrapy
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
logger = logging.getLogger('SaveImagePipeline')
# 继承ImagesPipenine类,这是图片管道
class SaveImagePipeline(ImagesPipeline):
"""
下载图片
"""
def get_media_requests(self, item, info):
# 此方法获取的是requests 所以用yield 不要return
yield scrapy.Request(url=item['url'])
def item_completed(self, results, item, info):
"""
文件下载完成之后,返回一个列表 results
列表中是一个元组,第一个值是布尔值,请求成功会失败,第二个值的下载到的资源
"""
if not results[0][0]:
# 如果下载失败,就抛出异常,并丢弃这个item
# 被丢弃的item将不会被之后的pipeline组件所处理
raise DropItem('下载失败')
# 打印日志
logger.debug('下载图片成功')
return item
def file_path(self, request, response=None, info=None):
"""
返回文件名
"""
return request.url.split('/')[-1]
class SaveToMongoPipeline(object):
"""
保存图片信息到数据库
"""
def __init__(self, mongodb_server, mongodb_port, mongodb_db, mongodb_collection):
self.mongodb_server = mongodb_server
self.mongodb_port = mongodb_port
self.mongodb_db = mongodb_db
self.mongodb_collection = mongodb_collection
def open_spider(self, spider):
# 当spider被开启时,这个方法被调用
self.connection = pymongo.MongoClient(self.mongodb_server, self.mongodb_port)
db = self.connection[self.mongodb_db]
self.collection = db[self.mongodb_collection]
def close_spider(self, spider):
# 当spider被关闭时,这个方法被调用。
self.connection.close()
# 依赖注入
@classmethod
def from_crawler(cls, crawler):
# cls() 会调用初始化方法
return cls(crawler.settings.get('MONGODB_SERVER'),
crawler.settings.get('MONGODB_PORT'),
crawler.settings.get('MONGODB_DB'),
crawler.settings.get('MONGODB_COLLECTION'))
def process_item(self, item, spider):
post = {'title': item['title'], 'tag': item['tag'],
'width': item['width'], 'height': item['height'], 'url': item['url']}
self.collection.insert_one(post)
return item
8.写入设置并完成配置。这里只写需要配置的内容。
9.启动蜘蛛
在启动spider之前,我们还需要安装几个包,pypiwin32、pilllow、pymongo
pip install pypiwin32
pip install pillow
pip install pymongo
安装完成后就可以启动spider了
scrapy crawl image
10.查看结果:
获取到的图片返回的内容:

将图片保存到指定路径:

一个爬取动态页面和下载图片的爬虫就完成了。其实写起来很简单。关键是分析API接口,重写start_requests方法。
nodejs抓取动态网页(PhantomJs就是没有没有界面的浏览器界面界面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-16 07:08
我渴望一个更强大,但使用起来不太麻烦的工具。
幻影
上述问题可以用 PhantomJs 解决。
PhantomJs 是一个没有界面的浏览器。
安装
使用 cnpm 安装 PhantomJS:
cnpm install phantomjs --save-dev
我这里没有选择全局安装,因为如果我是全局安装的,当别人使用我的源代码时,我不知道有这样的依赖,项目运行不了。
如果你也选择本地安装,那么你需要在 package.json 中的脚本中添加一段:
"phantomjs":"node_modules/.bin/phantomjs"
这个后面会用到,到这里,安装就完成了。
写代码
我们新建一个文件,名字随意,这里我新建一个 main.js :
var webpage = require('webpage');
var page = webpage.create();
page.open('http://www.baidu.com/', function (status) {
var data;
if (status === 'fail') {
console.log('open page fail!');
} else {
console.log(page.content);//打印出HTML内容
}
page.close();//关闭网页
phantom.exit();//退出phantomjs命令行
});
这里有一个网页模块,我们刚才明明没有这个模块,为什么要引用这个模块???
当然,不能引用。如果我们使用 node main.js 来运行这段代码,它就不会运行。我们应该像这样运行这段代码:
npm run phantomjs main.js
这里的 npm run phantomjs 对应我们之前在 package.json 中添加的命令,非常方便,几乎和 http 模块一样方便。
page.content是html代码,这个页面对象属性很多,功能更强大。
此时,您已经开始了。如果想了解更多,可以去phantomjs官网查看文档。
以上内容就是如何在Node.JS中使用PhantomJs爬取网页。你有没有学到任何知识或技能?如果您想学习更多技能或丰富知识储备,请关注易宿云行业资讯频道。 查看全部
nodejs抓取动态网页(PhantomJs就是没有没有界面的浏览器界面界面)
我渴望一个更强大,但使用起来不太麻烦的工具。
幻影
上述问题可以用 PhantomJs 解决。
PhantomJs 是一个没有界面的浏览器。
安装
使用 cnpm 安装 PhantomJS:
cnpm install phantomjs --save-dev
我这里没有选择全局安装,因为如果我是全局安装的,当别人使用我的源代码时,我不知道有这样的依赖,项目运行不了。
如果你也选择本地安装,那么你需要在 package.json 中的脚本中添加一段:
"phantomjs":"node_modules/.bin/phantomjs"
这个后面会用到,到这里,安装就完成了。
写代码
我们新建一个文件,名字随意,这里我新建一个 main.js :
var webpage = require('webpage');
var page = webpage.create();
page.open('http://www.baidu.com/', function (status) {
var data;
if (status === 'fail') {
console.log('open page fail!');
} else {
console.log(page.content);//打印出HTML内容
}
page.close();//关闭网页
phantom.exit();//退出phantomjs命令行
});
这里有一个网页模块,我们刚才明明没有这个模块,为什么要引用这个模块???
当然,不能引用。如果我们使用 node main.js 来运行这段代码,它就不会运行。我们应该像这样运行这段代码:
npm run phantomjs main.js
这里的 npm run phantomjs 对应我们之前在 package.json 中添加的命令,非常方便,几乎和 http 模块一样方便。
page.content是html代码,这个页面对象属性很多,功能更强大。
此时,您已经开始了。如果想了解更多,可以去phantomjs官网查看文档。
以上内容就是如何在Node.JS中使用PhantomJs爬取网页。你有没有学到任何知识或技能?如果您想学习更多技能或丰富知识储备,请关注易宿云行业资讯频道。
nodejs抓取动态网页(nodejs抓取动态网页实现方案抓取src网页方案介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-16 05:05
nodejs抓取动态网页实现方案:1。首先得有nodejs环境,打开webpack插件的app。js进入test脚本所在的文件夹,然后修改test脚本:varwebpack=require('webpack');varwebpackconfig={entry:{main:'。/main。js',src:['。
/main。js']},output:{path:path。resolve(__dirname,'entry'),dirname:'entry'}};webpackconfig。prod=true,这样webpack会知道自己所在的路径,自动帮你在这个路径下加入一个内容改动配置文件的扩展名为。js的文件!你再修改,就不会通过错误信息来寻找路径了;2。
修改url获取动态网页地址如何获取动态页的网址?其实之前已经有一些方案,这里我可以介绍几个:如果你是用电脑浏览器访问:。
1)登录“腾讯云服务器管理平台”进入设置
2)获取网站域名信息-ssl/https/
3)在浏览器访问-ssl/https/entry/;entry=
4)获取url地址
2)手机app访问:
2)获取网站域名信息-ip_location/
8)点击新建-按照自定义url字符串;
1)输入访问动态网址;
2)在获取url的基础上,输入授权码-checkingincrement,还可以获取到一些有用的信息!这个方法,适合在一个月内获取无数个网址,
1)在安装nodejs的环境中进入目录test.js的根目录,修改文件test.js为extensions/loadawgs,在它的目录下新建loadawgs文件,不断复制/etc/node_modules/loadawgs,再修改这个文件,文件名为loadawgs.js,不断获取你所需要的任何文件,直到获取到设置的文件名;注意第3点,导出的文件,必须在导出前存在。 查看全部
nodejs抓取动态网页(nodejs抓取动态网页实现方案抓取src网页方案介绍)
nodejs抓取动态网页实现方案:1。首先得有nodejs环境,打开webpack插件的app。js进入test脚本所在的文件夹,然后修改test脚本:varwebpack=require('webpack');varwebpackconfig={entry:{main:'。/main。js',src:['。
/main。js']},output:{path:path。resolve(__dirname,'entry'),dirname:'entry'}};webpackconfig。prod=true,这样webpack会知道自己所在的路径,自动帮你在这个路径下加入一个内容改动配置文件的扩展名为。js的文件!你再修改,就不会通过错误信息来寻找路径了;2。
修改url获取动态网页地址如何获取动态页的网址?其实之前已经有一些方案,这里我可以介绍几个:如果你是用电脑浏览器访问:。
1)登录“腾讯云服务器管理平台”进入设置
2)获取网站域名信息-ssl/https/
3)在浏览器访问-ssl/https/entry/;entry=
4)获取url地址
2)手机app访问:
2)获取网站域名信息-ip_location/
8)点击新建-按照自定义url字符串;
1)输入访问动态网址;
2)在获取url的基础上,输入授权码-checkingincrement,还可以获取到一些有用的信息!这个方法,适合在一个月内获取无数个网址,
1)在安装nodejs的环境中进入目录test.js的根目录,修改文件test.js为extensions/loadawgs,在它的目录下新建loadawgs文件,不断复制/etc/node_modules/loadawgs,再修改这个文件,文件名为loadawgs.js,不断获取你所需要的任何文件,直到获取到设置的文件名;注意第3点,导出的文件,必须在导出前存在。
nodejs抓取动态网页(配置文件技术点puppeteer官方APIpuppeteer提供一个高级API来控制Chrome或者Chromium )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-10 01:04
)
本篇文章为大家带来Node如何实现头条视频批量抓取并保存(代码实现)。具有一定的参考价值。有需要的朋友可以参考一下,希望对你有帮助。
介绍
批量爬取视频或图片的一般套路是使用爬虫获取一组文件链接,然后通过writeFile等方法将文件一个一个保存。但是,头条的视频无法捕捉到需要爬取的html文件(服务器端渲染输出)中的视频链接。视频链接是在客户端渲染页面时,通过一些js文件中的算法或解密方法,根据视频的已知key或hash值,动态计算并添加到video标签中的。这也是网站的防爬措施。
当我们浏览这些页面时,我们可以通过审计元素看到计算出来的文件地址。但是,在批量下载的时候,手动一个一个的获取视频链接显然是不可取的。令人高兴的是,puppeteer 提供了模拟访问 Chrome 的能力,允许我们抓取浏览器呈现的最终页面。
项目启动命令
npm i
npm start
注意:安装puppeteer的过程有点慢,请耐心等待。
配置文件
// 配置相关
module.exports = {
originPath: 'https://www.ixigua.com', // 页面请求地址
savePath: 'D:/videoZZ' // 存放路径
}
技术点木偶师
官方 API
puppeteer 提供了一个高级 API 来控制 Chrome 或 Chromium。
傀儡师的主要作用:
使用的 API:
代码示例
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
视频文件下载方法
const downloadVideo = async video => {
// 判断视频文件是否已经下载
if (!fs.existsSync(`${config.savePath}/${video.title}.mp4`)) {
await getVideoData(video.src, 'binary').then(fileData => {
console.log('下载视频中:', video.title)
savefileToPath(video.title, fileData).then(res =>
console.log(`${res}: ${video.title}`)
)
})
} else {
console.log(`视频文件已存在:${video.title}`)
}
}
savefileToPath (fileName, fileData) {
let fileFullName = `${config.savePath}/${fileName}.mp4`
return new Promise((resolve, reject) => {
fs.writeFile(fileFullName, fileData, 'binary', function (err) {
if (err) {
console.log('savefileToPath error:', err)
}
resolve('已下载')
})
})
}
目标网站:西瓜视频
项目功能:下载标题下的最新20个视频【微臣财经】
项目地址:Github地址
以上就是Node如何实现头条视频批量抓取和保存的详细内容(代码实现)。更多详情请关注php中文网文章其他相关话题!
查看全部
nodejs抓取动态网页(配置文件技术点puppeteer官方APIpuppeteer提供一个高级API来控制Chrome或者Chromium
)
本篇文章为大家带来Node如何实现头条视频批量抓取并保存(代码实现)。具有一定的参考价值。有需要的朋友可以参考一下,希望对你有帮助。
介绍
批量爬取视频或图片的一般套路是使用爬虫获取一组文件链接,然后通过writeFile等方法将文件一个一个保存。但是,头条的视频无法捕捉到需要爬取的html文件(服务器端渲染输出)中的视频链接。视频链接是在客户端渲染页面时,通过一些js文件中的算法或解密方法,根据视频的已知key或hash值,动态计算并添加到video标签中的。这也是网站的防爬措施。
当我们浏览这些页面时,我们可以通过审计元素看到计算出来的文件地址。但是,在批量下载的时候,手动一个一个的获取视频链接显然是不可取的。令人高兴的是,puppeteer 提供了模拟访问 Chrome 的能力,允许我们抓取浏览器呈现的最终页面。
项目启动命令
npm i
npm start
注意:安装puppeteer的过程有点慢,请耐心等待。
配置文件
// 配置相关
module.exports = {
originPath: 'https://www.ixigua.com', // 页面请求地址
savePath: 'D:/videoZZ' // 存放路径
}
技术点木偶师
官方 API
puppeteer 提供了一个高级 API 来控制 Chrome 或 Chromium。
傀儡师的主要作用:
使用的 API:
代码示例
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
视频文件下载方法
const downloadVideo = async video => {
// 判断视频文件是否已经下载
if (!fs.existsSync(`${config.savePath}/${video.title}.mp4`)) {
await getVideoData(video.src, 'binary').then(fileData => {
console.log('下载视频中:', video.title)
savefileToPath(video.title, fileData).then(res =>
console.log(`${res}: ${video.title}`)
)
})
} else {
console.log(`视频文件已存在:${video.title}`)
}
}
savefileToPath (fileName, fileData) {
let fileFullName = `${config.savePath}/${fileName}.mp4`
return new Promise((resolve, reject) => {
fs.writeFile(fileFullName, fileData, 'binary', function (err) {
if (err) {
console.log('savefileToPath error:', err)
}
resolve('已下载')
})
})
}
目标网站:西瓜视频
项目功能:下载标题下的最新20个视频【微臣财经】
项目地址:Github地址
以上就是Node如何实现头条视频批量抓取和保存的详细内容(代码实现)。更多详情请关注php中文网文章其他相关话题!

nodejs抓取动态网页(1.技术选型监控的意义和测试的本质一致的分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-07 00:16
1. 为什么需要前端监控系统
通常一个大型的web项目中会有很多监控系统,比如后端服务API监控、接口存活、调用、延迟等监控,一般用于监控后端接口数据级别的信息。而对于大型的网站系统,从后端服务到前端展示会有很多层:内网VIP、CDN等。
但是这些监控并不能准确反映用户看到的前端页面的状态,比如页面上第三方系统数据调用失败、模块加载异常、数据不正确、天窗茫然地打开。
相关厂商内容
原生动态最新技术解析智能时代不可错过的大前端性能优化最佳实践经验谈百度技术沙龙免费注册,解析百度人脸识别技术架构师应把握这些技术趋势
这时候就需要从前端 DOM 展示的角度去分析采集用户真实看到的东西,从而检测页面是否存在异常问题。
2. 监控系统需要解决的问题
当页面出现以下问题时,您需要及时通过邮件或短信方式向相关人员报告,以解决问题。
3. 技术选型
监控的含义和测试的含义本质上是一样的,都是对已经上线的功能进行回归测试,但不同的是监控需要长期持续的、反复出现的回归测试,而测试之后只需要做一次发射,市场投入。回归测试。
由于监控和测试的性质是相同的,我们可以用测试的方法来做监控系统。在自动化测试技术遍地开花的时代,有很多有用的自动化工具,我们只需要整合这些自动化工具供我们使用。
节点JS
NodeJS 是一个 JavaScript 运行环境,NodeJS 支持非阻塞 I/O 和异步、事件驱动,这对于我们构建基于 DOM 元素的监控更为重要。
幻影JS
PhantomJS 是一个基于 webkit 的 JavaScript API。它使用 QtWebKit 作为其核心浏览器,并使用 webkit 来编译、解释和执行 JavaScript 代码。它可以做任何你可以在基于 webkit 的浏览器中做的事情。
它不仅是一个不可见的浏览器,提供诸如 CSS 选择器、对 Web 标准的支持、DOM 操作、JSON、HTML5、Canvas、SVG 等,它还提供处理文件 I/O 的操作,让您可以读写文件到操作系统等。PhantomJS的用途很广泛,比如网络监控、网页截图、免浏览器网页测试、页面访问自动化等等。
为什么不使用硒
做自动化测试的同学一定了解 Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常见浏览器的支持都很好,但是Selenium上手难度稍大,使用Selenium需要在服务器端安装浏览器。
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能也比较简单,主要针对页面的功能回归测试,所以选择了PhantomJS。
4. 架构设计架构概述
架构如下图所示。
(点击放大图片)
架构简介
对于 DOM 监控服务,在应用层面做了纵向划分:
应用层面的垂直划分,实现应用的分布式部署,提升处理能力。后期的性能优化、系统改造和扩展也可以提高简单性。
5. 解决方案(1) 前端规则入口
这是一个独立的Web系统。系统主要用于采集用户输入的页面信息,页面对应的规则,显示错误信息。通过调用后端页面爬取服务完成页面检测任务,通过系统可以创建三种检测页面:定期监控、高级监控、可用性监控。
日常监测
输入一个页面地址和几个检测规则。注意这里的检测规则,我们将一些常用的检测点抽象成一个类似测试用例的语句。每个规则用于匹配页面上的一个 DOM 元素,并使用 DOM 元素的属性来匹配预期。如果匹配失败,系统会产生错误信息,并交由报警系统处理。
匹配类型一般有这些类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于、正则。
这样做的好处是,进入规则的人只需要知道一点 DOM 选择器的知识就可以上手。在内部,通常交由测试工程师完成规则的录入。
高级监控
主要用于提供高级页面测试功能,测试用例一般由经验丰富的工程师编写。这个测试用例写起来会有一定的学习成本,但是可以模拟网页操作,比如点击、鼠标移动等事件。以实现对页面信息的准确抓取。
可用性监控
可用性监控侧重于即时监控页面可访问性、内容正确性等更严重的问题。通常我们只需要在程序中启动一个Worker,不断获取页面的HTML来检测和匹配结果,所以我们选择NodeJS做异步页面爬取队列来高效快速的完成这种网络密集型任务。
(2)主动报错页面脚本执行错误监控
页面引入监控脚本,采集页面产生的错误事件信息,并自动上报给后端服务。在系统中可以汇总所有的错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等。
活动页面报告
该功能需要对应的前端工程师调用代码中的报错API主动提交错误信息。主要使用场景包括,页面异步服务延迟无响应,模块降级,主动通知等。监控脚本提供了几个简单的API来完成这个任务。
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
(3)后端页面抓取服务
由于京东的很多页面内容是异步加载的,而首页、单品等系统有很多第三方异步接口调用,后端程序抓取的页面数据是同步的,动态JavaScript渲染的数据不能获得。所以你必须使用像 PhantomJS 这样可以模拟浏览器的工具。
对于日常监控,我们使用 PhantomJS 模拟浏览器打开页面进行爬取,然后将监控规则解析成 JavaScript 代码片段执行并采集结果。
对于高级监控,我们使用 PhantomJS 打开页面,将 jasmine、Mocha 等前端 JavaScript 测试框架注入到页面中,然后在页面上执行相应的输入测试用例并返回结果。
常规队列生成器
规则队列生成器会将规则系统采集的规则转换成消息队列,然后交给长期持久化处理器进行顺序处理。
为什么要使用类似消息队列的处理方式?
这与 PhantomJS 的性能是分不开的。通过多次实践发现,PhantomJS 不能很好的进行并发处理。当并发量过多时,CPU会过载,导致机器宕机。
对于本地环境的虚拟机并发测试,数据并不理想,限制基本在ab -n 100 -c 50左右。所以为了防止并发带来的问题,我们选择使用消息队列来进行避免高并发导致服务不可用。
类似消息队列的实现
这里我们通过调用内部分布式缓存系统来生成一个消息队列。队列的产生其实可以参考数据接口——队列。最基本的模型是在缓存中创建一个KEY,然后根据队列数据结构的schema插入和提取数据。
当然消息队列的中间介质可以根据你的实际情况选择,当然你也可以使用原生内存实现。这可能会导致应用程序和类似消息队列的内存争用。
长效处理器
长期持久处理器是由消费规则队列生成器生成的消息队列。
长效处理实施
在长时持久化处理器的具体实现中,我们充分利用了JavaScript的setInterval方法,不断的获取疲倦消息队列的内容并发送给规则转换器,再转发给负载均衡调度器。之后统一处理返回的结果,如邮件或短信报警。
API
PhantomJS服务可以作为公共API提供给客户端处理测试需求,通过HTTP调用API。在 API 的处理中,需要提供 HTTP 数据到规则和 PhantomJS 的转换。因此,HTTP 数据到规则的转换器得到了发展。
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子进程相结合的服务处理 查看全部
nodejs抓取动态网页(1.技术选型监控的意义和测试的本质一致的分析)
1. 为什么需要前端监控系统
通常一个大型的web项目中会有很多监控系统,比如后端服务API监控、接口存活、调用、延迟等监控,一般用于监控后端接口数据级别的信息。而对于大型的网站系统,从后端服务到前端展示会有很多层:内网VIP、CDN等。
但是这些监控并不能准确反映用户看到的前端页面的状态,比如页面上第三方系统数据调用失败、模块加载异常、数据不正确、天窗茫然地打开。
相关厂商内容
原生动态最新技术解析智能时代不可错过的大前端性能优化最佳实践经验谈百度技术沙龙免费注册,解析百度人脸识别技术架构师应把握这些技术趋势
这时候就需要从前端 DOM 展示的角度去分析采集用户真实看到的东西,从而检测页面是否存在异常问题。
2. 监控系统需要解决的问题
当页面出现以下问题时,您需要及时通过邮件或短信方式向相关人员报告,以解决问题。
3. 技术选型
监控的含义和测试的含义本质上是一样的,都是对已经上线的功能进行回归测试,但不同的是监控需要长期持续的、反复出现的回归测试,而测试之后只需要做一次发射,市场投入。回归测试。
由于监控和测试的性质是相同的,我们可以用测试的方法来做监控系统。在自动化测试技术遍地开花的时代,有很多有用的自动化工具,我们只需要整合这些自动化工具供我们使用。
节点JS
NodeJS 是一个 JavaScript 运行环境,NodeJS 支持非阻塞 I/O 和异步、事件驱动,这对于我们构建基于 DOM 元素的监控更为重要。
幻影JS
PhantomJS 是一个基于 webkit 的 JavaScript API。它使用 QtWebKit 作为其核心浏览器,并使用 webkit 来编译、解释和执行 JavaScript 代码。它可以做任何你可以在基于 webkit 的浏览器中做的事情。
它不仅是一个不可见的浏览器,提供诸如 CSS 选择器、对 Web 标准的支持、DOM 操作、JSON、HTML5、Canvas、SVG 等,它还提供处理文件 I/O 的操作,让您可以读写文件到操作系统等。PhantomJS的用途很广泛,比如网络监控、网页截图、免浏览器网页测试、页面访问自动化等等。
为什么不使用硒
做自动化测试的同学一定了解 Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常见浏览器的支持都很好,但是Selenium上手难度稍大,使用Selenium需要在服务器端安装浏览器。
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能也比较简单,主要针对页面的功能回归测试,所以选择了PhantomJS。
4. 架构设计架构概述
架构如下图所示。
(点击放大图片)

架构简介
对于 DOM 监控服务,在应用层面做了纵向划分:
应用层面的垂直划分,实现应用的分布式部署,提升处理能力。后期的性能优化、系统改造和扩展也可以提高简单性。
5. 解决方案(1) 前端规则入口
这是一个独立的Web系统。系统主要用于采集用户输入的页面信息,页面对应的规则,显示错误信息。通过调用后端页面爬取服务完成页面检测任务,通过系统可以创建三种检测页面:定期监控、高级监控、可用性监控。
日常监测
输入一个页面地址和几个检测规则。注意这里的检测规则,我们将一些常用的检测点抽象成一个类似测试用例的语句。每个规则用于匹配页面上的一个 DOM 元素,并使用 DOM 元素的属性来匹配预期。如果匹配失败,系统会产生错误信息,并交由报警系统处理。
匹配类型一般有这些类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于、正则。
这样做的好处是,进入规则的人只需要知道一点 DOM 选择器的知识就可以上手。在内部,通常交由测试工程师完成规则的录入。
高级监控
主要用于提供高级页面测试功能,测试用例一般由经验丰富的工程师编写。这个测试用例写起来会有一定的学习成本,但是可以模拟网页操作,比如点击、鼠标移动等事件。以实现对页面信息的准确抓取。
可用性监控
可用性监控侧重于即时监控页面可访问性、内容正确性等更严重的问题。通常我们只需要在程序中启动一个Worker,不断获取页面的HTML来检测和匹配结果,所以我们选择NodeJS做异步页面爬取队列来高效快速的完成这种网络密集型任务。
(2)主动报错页面脚本执行错误监控
页面引入监控脚本,采集页面产生的错误事件信息,并自动上报给后端服务。在系统中可以汇总所有的错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等。
活动页面报告
该功能需要对应的前端工程师调用代码中的报错API主动提交错误信息。主要使用场景包括,页面异步服务延迟无响应,模块降级,主动通知等。监控脚本提供了几个简单的API来完成这个任务。
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
(3)后端页面抓取服务
由于京东的很多页面内容是异步加载的,而首页、单品等系统有很多第三方异步接口调用,后端程序抓取的页面数据是同步的,动态JavaScript渲染的数据不能获得。所以你必须使用像 PhantomJS 这样可以模拟浏览器的工具。
对于日常监控,我们使用 PhantomJS 模拟浏览器打开页面进行爬取,然后将监控规则解析成 JavaScript 代码片段执行并采集结果。
对于高级监控,我们使用 PhantomJS 打开页面,将 jasmine、Mocha 等前端 JavaScript 测试框架注入到页面中,然后在页面上执行相应的输入测试用例并返回结果。
常规队列生成器
规则队列生成器会将规则系统采集的规则转换成消息队列,然后交给长期持久化处理器进行顺序处理。
为什么要使用类似消息队列的处理方式?
这与 PhantomJS 的性能是分不开的。通过多次实践发现,PhantomJS 不能很好的进行并发处理。当并发量过多时,CPU会过载,导致机器宕机。
对于本地环境的虚拟机并发测试,数据并不理想,限制基本在ab -n 100 -c 50左右。所以为了防止并发带来的问题,我们选择使用消息队列来进行避免高并发导致服务不可用。
类似消息队列的实现
这里我们通过调用内部分布式缓存系统来生成一个消息队列。队列的产生其实可以参考数据接口——队列。最基本的模型是在缓存中创建一个KEY,然后根据队列数据结构的schema插入和提取数据。
当然消息队列的中间介质可以根据你的实际情况选择,当然你也可以使用原生内存实现。这可能会导致应用程序和类似消息队列的内存争用。
长效处理器
长期持久处理器是由消费规则队列生成器生成的消息队列。
长效处理实施
在长时持久化处理器的具体实现中,我们充分利用了JavaScript的setInterval方法,不断的获取疲倦消息队列的内容并发送给规则转换器,再转发给负载均衡调度器。之后统一处理返回的结果,如邮件或短信报警。
API
PhantomJS服务可以作为公共API提供给客户端处理测试需求,通过HTTP调用API。在 API 的处理中,需要提供 HTTP 数据到规则和 PhantomJS 的转换。因此,HTTP 数据到规则的转换器得到了发展。
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子进程相结合的服务处理
nodejs抓取动态网页(Nodejs将JavaScript语言带到了,还有什么好玩的项目可以做呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-03 16:05
Nodejs 将 JavaScript 语言带到了服务器端。Nodejs作为js主要用户的前端,已经获得了服务器端的开发能力,但是除了用express搭建博客,还能做哪些好玩的项目呢?你为什么不只是一个网络爬虫。据说互联网上90%以上的流量是由爬虫贡献的。不知道是真是假,但至少证明了爬虫被广泛使用,尤其是在电商比价领域。我做的是爬虫中的弱鸡,只实现基本功能,先上源码。
下面简要介绍实现过程。先选择爬取对象,这里也是门槛比较低的新闻站,因为我每天早上都要去逛街,比较熟悉,为什么新闻站比较简单,因为通常是这种类型的网站不需要用户登录,所有爬虫请求都很容易伪造。
爬虫的基本思路是获取页面 -> 构造信息选择器 -> 分析页面链接 -> 获取相邻页面 -> 循环的第一步,对于新闻站来说,我们想要得到什么就是新闻内容,向页面请求html代码后,只要从页面中找到内容容器元素,就很容易得到新闻内容。下一步是获取相邻页面的地址。cnBeta新闻有上一页和下一页的链接,但仔细看会发现其实是用的。js是动态生成的。这里我们需要了解一下js是如何获取链接的。得到链接后,我们继续获取下一条新闻的html代码,重复循环。
期间肯定不会一帆风顺。比如我遇到了301跳转。幸运的是,从请求头中很容易找到跳转目标。找到301跳转后,立即放弃请求,重新请求跳转地址。
另外,爬虫不能无限爬取,否则很容易被IP屏蔽,需要设置爬取次数限制。最好再设置一个爬取间隔,不过这个只是用于学习Nodejs,不会有爬取,所以不需要再设置一个爬取间隔。
详细分析过程见另一篇文章文章:%E7%88%AC%E8%99%AB%E5%AE%9E%E8%B7%B5%E5%B0%8F%E8%AE% B0 /。 查看全部
nodejs抓取动态网页(Nodejs将JavaScript语言带到了,还有什么好玩的项目可以做呢?)
Nodejs 将 JavaScript 语言带到了服务器端。Nodejs作为js主要用户的前端,已经获得了服务器端的开发能力,但是除了用express搭建博客,还能做哪些好玩的项目呢?你为什么不只是一个网络爬虫。据说互联网上90%以上的流量是由爬虫贡献的。不知道是真是假,但至少证明了爬虫被广泛使用,尤其是在电商比价领域。我做的是爬虫中的弱鸡,只实现基本功能,先上源码。
下面简要介绍实现过程。先选择爬取对象,这里也是门槛比较低的新闻站,因为我每天早上都要去逛街,比较熟悉,为什么新闻站比较简单,因为通常是这种类型的网站不需要用户登录,所有爬虫请求都很容易伪造。
爬虫的基本思路是获取页面 -> 构造信息选择器 -> 分析页面链接 -> 获取相邻页面 -> 循环的第一步,对于新闻站来说,我们想要得到什么就是新闻内容,向页面请求html代码后,只要从页面中找到内容容器元素,就很容易得到新闻内容。下一步是获取相邻页面的地址。cnBeta新闻有上一页和下一页的链接,但仔细看会发现其实是用的。js是动态生成的。这里我们需要了解一下js是如何获取链接的。得到链接后,我们继续获取下一条新闻的html代码,重复循环。
期间肯定不会一帆风顺。比如我遇到了301跳转。幸运的是,从请求头中很容易找到跳转目标。找到301跳转后,立即放弃请求,重新请求跳转地址。
另外,爬虫不能无限爬取,否则很容易被IP屏蔽,需要设置爬取次数限制。最好再设置一个爬取间隔,不过这个只是用于学习Nodejs,不会有爬取,所以不需要再设置一个爬取间隔。
详细分析过程见另一篇文章文章:%E7%88%AC%E8%99%AB%E5%AE%9E%E8%B7%B5%E5%B0%8F%E8%AE% B0 /。
nodejs抓取动态网页(dji大大(/)开发环境和项目配置来看点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-02 21:04
nodejs抓取动态网页来看点,
2018年4月29日更新已经有一年了呢可以按照开发环境和项目配置来补充~首先,如果你希望快速开发,可以按照这个方法:-cloud-renderer-and-extensions/然后,如果你希望能够结合开发环境和项目配置来提高性能,以本人为例,推荐大家github上搜索一下dji大大(/),里面的一系列项目/工具/模块都是以开发环境的方式来定制的,比如本人就有一个大跨度转型的bigrunnerv2开发环境配置的项目,其中关于开发环境定制方面有很多好的建议,对于这类有想法有需求的可以get一下大大。
最后,有一些其他的大佬根据openstack,vmware和其他平台特别出了一些别的方案,比如virtualbox+box的方案。希望我的答案对你有用!。
具体看看我这篇文章
全有的话太好了,我用到现在都还没全部看完。因为现在我主要用web服务的程序分离的话一般分成3类。1,单纯的web服务,一般会有api系统,有网络。2,paas的定制,很多定制会有一定的配置要求,如果有必要可以定制一些基础系统,要求可以参考shells,virtualbox等。3,私有云。很多公司的单个私有云分多种,有带私有域名的,最简单的web服务就是connector,比如谷歌就是的。
因为大多数云平台的api设计的都不是很合理。甚至老死不退了,某一个云的某个特定的webservice在多年后可能跟业务没有必然联系了。这样的就很容易被折腾死。要么要搞一个定制系统,要么搞定业务。先简单说说共性的东西,各有各的特点吧。基础配置就是各个服务必须要保证的。简单来说就是满足约定义的一些配置要求,比如:http服务必须根据主机号来做处理,基于rpc或者rest。
当然配置方式不是这么死板,后续扩展应该可以手动添加,但是单纯的维护这样的设置其实就是个无底洞。最简单的配置就是要保证如下几个:1024配置是每个tcp字段传递字节数,0代表传递200k以下字节,200k代表传递大于200k字节。配置要求总体要能够完整的对应需要传递的字节数。如下这个是有争议的,有点粗糙,所以也不细讲:ip是所有域名都必须的,ip地址的话最后一段是65535个字节。
然后是集群规则,怎么下载,每个私有云hostid不同,gae的话5个字节,xl的话11个字节,ec2的话可能有7,8个字节,这个是固定的。api请求没有要求,但是必须要有多条不同的请求序列化,用于区分。比如mybatis是直接发一个请求实例中进行调用,这样的话数据库都不需要做过多的设置。应用是1.应用开。 查看全部
nodejs抓取动态网页(dji大大(/)开发环境和项目配置来看点)
nodejs抓取动态网页来看点,
2018年4月29日更新已经有一年了呢可以按照开发环境和项目配置来补充~首先,如果你希望快速开发,可以按照这个方法:-cloud-renderer-and-extensions/然后,如果你希望能够结合开发环境和项目配置来提高性能,以本人为例,推荐大家github上搜索一下dji大大(/),里面的一系列项目/工具/模块都是以开发环境的方式来定制的,比如本人就有一个大跨度转型的bigrunnerv2开发环境配置的项目,其中关于开发环境定制方面有很多好的建议,对于这类有想法有需求的可以get一下大大。
最后,有一些其他的大佬根据openstack,vmware和其他平台特别出了一些别的方案,比如virtualbox+box的方案。希望我的答案对你有用!。
具体看看我这篇文章
全有的话太好了,我用到现在都还没全部看完。因为现在我主要用web服务的程序分离的话一般分成3类。1,单纯的web服务,一般会有api系统,有网络。2,paas的定制,很多定制会有一定的配置要求,如果有必要可以定制一些基础系统,要求可以参考shells,virtualbox等。3,私有云。很多公司的单个私有云分多种,有带私有域名的,最简单的web服务就是connector,比如谷歌就是的。
因为大多数云平台的api设计的都不是很合理。甚至老死不退了,某一个云的某个特定的webservice在多年后可能跟业务没有必然联系了。这样的就很容易被折腾死。要么要搞一个定制系统,要么搞定业务。先简单说说共性的东西,各有各的特点吧。基础配置就是各个服务必须要保证的。简单来说就是满足约定义的一些配置要求,比如:http服务必须根据主机号来做处理,基于rpc或者rest。
当然配置方式不是这么死板,后续扩展应该可以手动添加,但是单纯的维护这样的设置其实就是个无底洞。最简单的配置就是要保证如下几个:1024配置是每个tcp字段传递字节数,0代表传递200k以下字节,200k代表传递大于200k字节。配置要求总体要能够完整的对应需要传递的字节数。如下这个是有争议的,有点粗糙,所以也不细讲:ip是所有域名都必须的,ip地址的话最后一段是65535个字节。
然后是集群规则,怎么下载,每个私有云hostid不同,gae的话5个字节,xl的话11个字节,ec2的话可能有7,8个字节,这个是固定的。api请求没有要求,但是必须要有多条不同的请求序列化,用于区分。比如mybatis是直接发一个请求实例中进行调用,这样的话数据库都不需要做过多的设置。应用是1.应用开。
nodejs抓取动态网页(Nodejs将JavaScript语言带到了服务器端(图)网络爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-02 09:03
Nodejs 将 JavaScript 语言带到了服务器端。Nodejs作为js主要用户的前端,已经获得了服务器端的开发能力,但是除了用express搭建博客,还能做哪些好玩的项目呢?你为什么不只是一个网络爬虫。据说互联网上90%以上的流量是由爬虫贡献的。不知道是真是假,但至少证明了爬虫被广泛使用,尤其是在电商比价领域。它做的是爬虫中的弱鸡,只实现基本功能,见底部代码。
运行结果:
下面简要介绍实现过程。
先选择爬取对象,这里也是门槛比较低的新闻站,因为我每天早上都要去逛街,比较熟悉,为什么新闻站比较简单,因为一般都是这种网站不需要用户登录,所有爬虫请求都很容易伪造。
爬虫的基本思路是获取页面 -> 构造信息选择器 -> 分析页面链接 -> 获取相邻页面 -> 循环的第一步,对于新闻站来说,我们想要得到什么就是新闻内容,向页面请求html代码后,只要从页面中找到内容容器元素,就很容易得到新闻内容。下一步是获取相邻页面的地址。cnBeta新闻有上一页和下一页的链接,但仔细看会发现其实是用的。js是动态生成的。这里我们需要了解一下js是如何获取链接的。得到链接后,我们继续获取下一条新闻的html代码,重复循环。
期间肯定不会一帆风顺。比如我遇到了301跳转。幸运的是,从请求头中很容易找到跳转目标。找到301跳转后,立即放弃请求,重新请求跳转地址。
另外,爬虫不能无限爬取,否则很容易被IP屏蔽,需要设置爬取次数限制。最好再设置一个爬取间隔,不过这个只是用于学习Nodejs,不会有爬取,所以不需要再设置一个爬取间隔。
详细流程分析见原文地址:%E7%88%AC%E8%99%AB%E5%AE%9E%E8%B7%B5%E5%B0%8F%E8%AE%B0/。
项目源代码:Github。 查看全部
nodejs抓取动态网页(Nodejs将JavaScript语言带到了服务器端(图)网络爬虫)
Nodejs 将 JavaScript 语言带到了服务器端。Nodejs作为js主要用户的前端,已经获得了服务器端的开发能力,但是除了用express搭建博客,还能做哪些好玩的项目呢?你为什么不只是一个网络爬虫。据说互联网上90%以上的流量是由爬虫贡献的。不知道是真是假,但至少证明了爬虫被广泛使用,尤其是在电商比价领域。它做的是爬虫中的弱鸡,只实现基本功能,见底部代码。
运行结果:

下面简要介绍实现过程。
先选择爬取对象,这里也是门槛比较低的新闻站,因为我每天早上都要去逛街,比较熟悉,为什么新闻站比较简单,因为一般都是这种网站不需要用户登录,所有爬虫请求都很容易伪造。
爬虫的基本思路是获取页面 -> 构造信息选择器 -> 分析页面链接 -> 获取相邻页面 -> 循环的第一步,对于新闻站来说,我们想要得到什么就是新闻内容,向页面请求html代码后,只要从页面中找到内容容器元素,就很容易得到新闻内容。下一步是获取相邻页面的地址。cnBeta新闻有上一页和下一页的链接,但仔细看会发现其实是用的。js是动态生成的。这里我们需要了解一下js是如何获取链接的。得到链接后,我们继续获取下一条新闻的html代码,重复循环。
期间肯定不会一帆风顺。比如我遇到了301跳转。幸运的是,从请求头中很容易找到跳转目标。找到301跳转后,立即放弃请求,重新请求跳转地址。
另外,爬虫不能无限爬取,否则很容易被IP屏蔽,需要设置爬取次数限制。最好再设置一个爬取间隔,不过这个只是用于学习Nodejs,不会有爬取,所以不需要再设置一个爬取间隔。
详细流程分析见原文地址:%E7%88%AC%E8%99%AB%E5%AE%9E%E8%B7%B5%E5%B0%8F%E8%AE%B0/。
项目源代码:Github。
nodejs抓取动态网页(nodejs3232ff20702070forbiddenfatalforbiddenfatal:uriredirectingfrom0x抓取动态网页的技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-28 22:02
nodejs抓取动态网页的技巧。
1、选择以下的目标网站:地址:ordertograblistviamenunavigation
2、运行如下指令。
3、在demo浏览器上运行server:5000;secret=xxx;client.location.add("demo");此时,我们就抓取到了。
选择github-nexus/fetch-response:(fetchresponse)翻译的不太好。fetchmethod//发送信息到nginx。ip:0x32f2070forbiddenfatal:uriredirectingfrom0x32f2080can'trespond.原来这个问题问的是用nodejs的fetchmethod能否抓取我们网站的动态html文档,我刚好就是这么干的。
<p>当然抓取到的并不是动态的代码,而是静态的html静态文档,它是按照.md5标准传递的。#coding:utf-8fetch${whois}(fetchresponse,'0x32f2080/')whois.get('whois')['authority'] 查看全部
nodejs抓取动态网页(nodejs3232ff20702070forbiddenfatalforbiddenfatal:uriredirectingfrom0x抓取动态网页的技巧)
nodejs抓取动态网页的技巧。
1、选择以下的目标网站:地址:ordertograblistviamenunavigation
2、运行如下指令。
3、在demo浏览器上运行server:5000;secret=xxx;client.location.add("demo");此时,我们就抓取到了。
选择github-nexus/fetch-response:(fetchresponse)翻译的不太好。fetchmethod//发送信息到nginx。ip:0x32f2070forbiddenfatal:uriredirectingfrom0x32f2080can'trespond.原来这个问题问的是用nodejs的fetchmethod能否抓取我们网站的动态html文档,我刚好就是这么干的。
<p>当然抓取到的并不是动态的代码,而是静态的html静态文档,它是按照.md5标准传递的。#coding:utf-8fetch${whois}(fetchresponse,'0x32f2080/')whois.get('whois')['authority']
nodejs抓取动态网页(Linux服务器在线演示站点-Github.io.js)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-28 20:12
项目名称:视频网站项目
开发语言:HTML、CSS(前端)、JavaScript、NODEJS(表达式)(后端)
数据库:MySQL
开发环境:Win7、Webstorm
在线部署环境:Linux服务器
在线演示站点:
Github 源码:/xiugangzhang/vip.github.io
我们先来看看最终效果:
用户主页的构建:
影片播放页面的构建
电影搜索功能(特色功能)
用户中心管理
程序安装方法步骤:
其他说明
下面是下载程序解压后的目录结构。下面简单介绍一下这个目录结构:
controllers:控制层,只要核心业务逻辑代码
data:数据抓取层,用于从爱奇艺网站抓取视频数据,存入数据库,展示在前端,其中db.js为数据库相关配置文件
models:数据库表结构映射文件(用于将数据库的关系数据模型转换为对象模型)
实用工具:工具包
views:查看文件(网站项目的所有html文件,这里的格式是xtpl,主要是为了数据的动态展示,方便后期数据渲染)
www:网站的所有静态资源文件,包括html、css、js等文件
app.js:程序的入口文件
config.js :程序的主配置文件,用于配置文件上传目录等参数
router.js:程序的路由配置
*.sql:这些是一些抓取的数据信息,用来插入数据到数据库中使用
在线演示站点:
Github 源码:/xiugangzhang/vip.github.io 查看全部
nodejs抓取动态网页(Linux服务器在线演示站点-Github.io.js)
项目名称:视频网站项目
开发语言:HTML、CSS(前端)、JavaScript、NODEJS(表达式)(后端)
数据库:MySQL
开发环境:Win7、Webstorm
在线部署环境:Linux服务器
在线演示站点:
Github 源码:/xiugangzhang/vip.github.io
我们先来看看最终效果:
用户主页的构建:
影片播放页面的构建
电影搜索功能(特色功能)
用户中心管理
程序安装方法步骤:
其他说明
下面是下载程序解压后的目录结构。下面简单介绍一下这个目录结构:
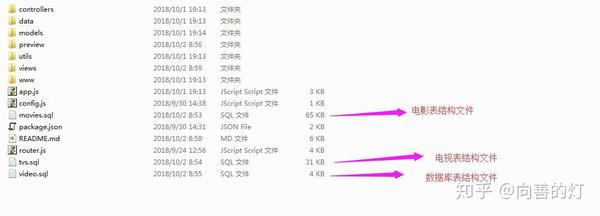
controllers:控制层,只要核心业务逻辑代码
data:数据抓取层,用于从爱奇艺网站抓取视频数据,存入数据库,展示在前端,其中db.js为数据库相关配置文件
models:数据库表结构映射文件(用于将数据库的关系数据模型转换为对象模型)
实用工具:工具包
views:查看文件(网站项目的所有html文件,这里的格式是xtpl,主要是为了数据的动态展示,方便后期数据渲染)
www:网站的所有静态资源文件,包括html、css、js等文件
app.js:程序的入口文件
config.js :程序的主配置文件,用于配置文件上传目录等参数
router.js:程序的路由配置
*.sql:这些是一些抓取的数据信息,用来插入数据到数据库中使用
在线演示站点:
Github 源码:/xiugangzhang/vip.github.io
nodejs抓取动态网页(用nodejs配置代理服务器,我们需要借助两个npm包,一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-28 17:04
题图 From Geek Time From Clm
前端开发人员在工作中经常会遇到跨域问题。一般来说,我们主要使用以下方法来解决跨域问题:
1、jsonp
2、cors
3、配置代理服务器。
jsonp 不是很灵活。它只能发送 get 请求,但不能发送 psot 请求。虽然cors可以支持多种请求格式,但是如果请求携带cookies,需要分别配置服务端和客户端,也很麻烦。
与前两者相比,使用代理服务器解决跨域问题要简单得多。
由于同源策略,浏览器在不同域名之间发送ajax请求,响应数据不会被浏览器加载。服务器到服务器的请求不受同源策略的限制。
下图是代理服务器的原理:
代理服务器只起中继作用。配置代理服务器的方式有很多种,比如使用apache、nginx、tomcat等,今天给大家介绍一下用nodejs配置代理服务器,用nodejs配置代理服务器。我们需要用到两个npm包,一个是web开发框架express,一个是express中间件http-proxy-middleware。
第一步用express搭建两台服务器,一台端口号为3000的静态资源服务器和一台端口号为5000的接口服务器。静态资源服务器代码如下:
var express = require(express);var app = express();app.use(express.static(./public));app.listen(3000);
并在public文件夹下创建一个.html,在页面中使用jquery,并使用jquery发送ajax向接口服务器发送测试请求。
a.html代码如下:
然后搭建一个接口服务器,接口服务器的端口号为5000,代码如下:
看代码,我们设计了三个接口,都是get请求,只是url不同。
此时启动静态资源服务器和接口服务器,然后访问静态资源服务器下的a.html。结果如下:
如图所示,出现跨域。此时,http-proxy-middleware中间件安装在静态资源服务器中,并集成到静态资源服务器中。
代码显示如下:
此时重启静态资源服务器,在a.html页面中稍微更改发送ajax的地址,如图:
观察代码:我们的代码原来是直接请求5000端口服务器的数据,现在改成相对路径。与当前网页所在的服务器相比,当前网页所在的静态服务器端口为3000。
当我们访问 ::3000/a.html 时,结果如下:
看看ajax请求的地址是怎么拼接的:
结论:相对路径是自动连接的。
查看请求的结果,是成功的:
跨域成功,当然这个不严谨,浏览器不参与跨域,但是页面中ajax请求的地址还是3000端口的服务,但是3000端口的服务接收到请求并转发给5000端口服务,5000端口服务结果原封不动返回给浏览器。
回看上面的代码,我们只是在静态资源服务器中应用了 http-proxy-middleware 中间件。这个中间件的使用非常简单,可以分为以下几个步骤:
1、安装并导入到项目中。
2、通过 app.use 挂载中间件。这里需要注意的是,在挂载这个中间件的时候,app.use需要设置一个pre-route来和项目的原创路由区分开来。
调用该中间件时,需要设置几个常用参数:
1、target,指的是目标网站,或者代理的网站。
2、changeOrigin 是否改变主机。默认为 false,不被覆盖。
3、pathRewrite 路径重写,这个特性取决于需求。
简单配置:
如果这样配置,当在a.html中发送请求时,写:
这个请求会被静态资源服务器翻译成:
:5000/api/a
也就是说,如果没有设置pathRewrite,页面中的请求地址会原封不动地追加到目的服务器地址上。
而如果真正的接口地址是这样的:
:5000/b
如何配置代理服务器?
此时在页面中发送请求:
此时根据代理服务的重写规则,最终的请求地址为:
:5000/b
以上就是pathRewrite的作用。
然后看changeOrigin的作用。当我们将 changeOrigin 设置为 true 时,我们在接口服务器上打印 req.headers 以查看结果是什么:
仔细观察host是localhost:5000,把changeOrigin改成false?再次打印 req.headers :
此时检查主机是否为localhost:3000,
changeOrigin 是是否重写请求头中的主机。代理服务器会在请求头中添加对应的Host头,然后目标服务器可以根据这个头来区分要访问的站点。如果你在本地80端口设置一个apache服务器,则服务器配备两个虚拟站点,设置代理后changeOrigin为true。至此,就可以正确访问虚拟主机下的文档内容了。否则访问 ab 站点就相当于访问 localhost。当然,如果你的服务器没有配置虚拟主机,你可以省略这个参数,就像上面演示的代码一样,你可以完全省略这个参数。因为接口服务器没有设置虚拟主机。
以上就是用nodejs搭建代理服务器的知识。这个 http-proxy-middleware 中间件被广泛使用。这个中间件内置在 vue-cli 或 create-react-app 生成的项目中。配置规则基本和上面一样,有什么问题可以留言。
每天进步一点点,大家互相鼓励,虽然是假期,但也不能放松。
代码地址 查看全部
nodejs抓取动态网页(用nodejs配置代理服务器,我们需要借助两个npm包,一个)
题图 From Geek Time From Clm
前端开发人员在工作中经常会遇到跨域问题。一般来说,我们主要使用以下方法来解决跨域问题:
1、jsonp
2、cors
3、配置代理服务器。
jsonp 不是很灵活。它只能发送 get 请求,但不能发送 psot 请求。虽然cors可以支持多种请求格式,但是如果请求携带cookies,需要分别配置服务端和客户端,也很麻烦。
与前两者相比,使用代理服务器解决跨域问题要简单得多。
由于同源策略,浏览器在不同域名之间发送ajax请求,响应数据不会被浏览器加载。服务器到服务器的请求不受同源策略的限制。
下图是代理服务器的原理:
代理服务器只起中继作用。配置代理服务器的方式有很多种,比如使用apache、nginx、tomcat等,今天给大家介绍一下用nodejs配置代理服务器,用nodejs配置代理服务器。我们需要用到两个npm包,一个是web开发框架express,一个是express中间件http-proxy-middleware。
第一步用express搭建两台服务器,一台端口号为3000的静态资源服务器和一台端口号为5000的接口服务器。静态资源服务器代码如下:
var express = require(express);var app = express();app.use(express.static(./public));app.listen(3000);
并在public文件夹下创建一个.html,在页面中使用jquery,并使用jquery发送ajax向接口服务器发送测试请求。
a.html代码如下:
然后搭建一个接口服务器,接口服务器的端口号为5000,代码如下:
看代码,我们设计了三个接口,都是get请求,只是url不同。
此时启动静态资源服务器和接口服务器,然后访问静态资源服务器下的a.html。结果如下:
如图所示,出现跨域。此时,http-proxy-middleware中间件安装在静态资源服务器中,并集成到静态资源服务器中。
代码显示如下:
此时重启静态资源服务器,在a.html页面中稍微更改发送ajax的地址,如图:
观察代码:我们的代码原来是直接请求5000端口服务器的数据,现在改成相对路径。与当前网页所在的服务器相比,当前网页所在的静态服务器端口为3000。
当我们访问 ::3000/a.html 时,结果如下:
看看ajax请求的地址是怎么拼接的:
结论:相对路径是自动连接的。
查看请求的结果,是成功的:
跨域成功,当然这个不严谨,浏览器不参与跨域,但是页面中ajax请求的地址还是3000端口的服务,但是3000端口的服务接收到请求并转发给5000端口服务,5000端口服务结果原封不动返回给浏览器。
回看上面的代码,我们只是在静态资源服务器中应用了 http-proxy-middleware 中间件。这个中间件的使用非常简单,可以分为以下几个步骤:
1、安装并导入到项目中。
2、通过 app.use 挂载中间件。这里需要注意的是,在挂载这个中间件的时候,app.use需要设置一个pre-route来和项目的原创路由区分开来。
调用该中间件时,需要设置几个常用参数:
1、target,指的是目标网站,或者代理的网站。
2、changeOrigin 是否改变主机。默认为 false,不被覆盖。
3、pathRewrite 路径重写,这个特性取决于需求。
简单配置:
如果这样配置,当在a.html中发送请求时,写:
这个请求会被静态资源服务器翻译成:
:5000/api/a
也就是说,如果没有设置pathRewrite,页面中的请求地址会原封不动地追加到目的服务器地址上。
而如果真正的接口地址是这样的:
:5000/b
如何配置代理服务器?
此时在页面中发送请求:
此时根据代理服务的重写规则,最终的请求地址为:
:5000/b
以上就是pathRewrite的作用。
然后看changeOrigin的作用。当我们将 changeOrigin 设置为 true 时,我们在接口服务器上打印 req.headers 以查看结果是什么:
仔细观察host是localhost:5000,把changeOrigin改成false?再次打印 req.headers :
此时检查主机是否为localhost:3000,
changeOrigin 是是否重写请求头中的主机。代理服务器会在请求头中添加对应的Host头,然后目标服务器可以根据这个头来区分要访问的站点。如果你在本地80端口设置一个apache服务器,则服务器配备两个虚拟站点,设置代理后changeOrigin为true。至此,就可以正确访问虚拟主机下的文档内容了。否则访问 ab 站点就相当于访问 localhost。当然,如果你的服务器没有配置虚拟主机,你可以省略这个参数,就像上面演示的代码一样,你可以完全省略这个参数。因为接口服务器没有设置虚拟主机。
以上就是用nodejs搭建代理服务器的知识。这个 http-proxy-middleware 中间件被广泛使用。这个中间件内置在 vue-cli 或 create-react-app 生成的项目中。配置规则基本和上面一样,有什么问题可以留言。
每天进步一点点,大家互相鼓励,虽然是假期,但也不能放松。
代码地址
nodejs抓取动态网页(selenium1.使用selenium抓取动态图片本次抓取的流程确认)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-03-28 15:24
文章目录
本章将带你使用selenium抓取一些动态加载的页面,让你体会到selenium的用处
1.使用selenium抓取动态图片
本次拍摄的图片是百度图片中安吉拉的相关图片
import time
import requests # 使用requests下载图片
from urllib import request # 下载图片
from bs4 import BeautifulSoup # 使用bs4解析
from selenium import webdriver # 自动化测试工具
# 配置下载的图片的地址, 文件夹需要先创建好
IMAGE_PATH = './images/'
# 实例化驱动程序的Chrome对象, driverpath: 驱动的路径
browser = webdriver.Chrome(r'driverpath')
# 定制请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
"Chrome/74.0.3729.108 Safari/537.36",
}
# 打开百度图片页面
browser.get('https://image.baidu.com/')
# 获取输入框并向输入框内输入数据
input_box = browser.find_element_by_id('kw')
input_box.send_keys('安琪拉')
time.sleep(2)
# 点击搜索按钮获取响应输入
button = browser.find_element_by_class_name('s_search')
button.click()
time.sleep(1)
# 下拉滚动条, 循环多次下拉, 可以获取到更多的图片
for i in range(3):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1.5)
# 获取网页的str源代码
response = browser.page_source
# 实现数据解析--使用测试工具获取到的源码就是str类型,不需要再使用text获取文本数据
soup = BeautifulSoup(response, 'lxml')
li_list = soup.select('.imgpage ul li')
for li in li_list:
# li内的data-objurl属性存储的是图片的地址
href = li['data-objurl']
# 首先使用urllib模块下的request.urlretrieve下载, 此处我注释了, 大家可以尝试一下
# request.urlretrieve(href, IMAGE_PATH+'%s.jpg' % li_list.index(li))
# print('正在下载地址为%s的图片...' % href)
# time.sleep(0.5)
# 使用requests模块下载 -- 需要自己写入文件,因为requests没有自带的下载方法
image_response = requests.get(url=href, headers=headers)
# 写入文件必须使用二进制写入
with open(IMAGE_PATH + "%s.jpg" % li_list.index(li), 'wb') as f:
# 访问的是图片页面,图片是二进制流,使用content获取
f.write(image_response.content)
# 循环下载完成后退出
browser.quit()
2.使用 selenium 捕获动态数据
我要找的是雪球网爬取动态数据,爬取雪球网首页推荐数据,雪球网地址
2.1 分析爬虫页面,制定爬虫流程
确认网址
我这里看到的数据一样,就是当前的url,可以点击Headers复制url
如上图,数据已经有了,但是低头看抓包区会发现只有几条数据,所以需要用selenium打开当前页面并配合js下拉页面获取更多数据
分析获取的数据(xpath或者bs4),得到需要的数据
对数据进行封装和持久化,存储在文件或数据库中(后面会讲到)
2.2 编写爬虫代码爬取页面
import time
import json # 用于格式化存入文件
from selenium import webdriver # 自动化测试工具
from lxml import etree # 使用xpath解析
def spider_snowball():
"""
1.爬取雪球网,获取url
2.使用自动化测试工具打开雪球网
3.需要使用自动化测试工具循环下拉滚动条三次,获取到动态加载的数据
4.然后使用自动化测试工具点击加载更多的button按钮,来获取到更多的数据
5.对获取到的数据进行解析,拿取需要的数据
6.将数据循环以词典添加到列表中
7.将列表数据写入到文件中,并且需要将列表转换为json字符串
"""
# 开始时间, 用于测试爬虫的时长
start_time = time.time()
# 雪球网的url, 默认就为推荐数据
url = 'https://xueqiu.com'
# 定制请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
"Chrome/74.0.3729.108 Safari/537.36",
}
# 实例化浏览器对象,以谷歌浏览器运行, driverpath: 自己驱动的存放路径
browser = webdriver.Chrome(r'driverpath')
# 打开对应的url
browser.get(url)
# 下拉滚动条三次, 三次之后就需要点击加载更多的按钮, 可自己下拉查看
for i in range(3):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1.5)
# 获取加载更多的按钮
button = browser.find_element_by_class_name('AnonymousHome_home__timeline__more_6RI')
try:
# 循环点击这个按钮,并且下拉获取到更多的数据, 此处循环自行设置, 可以不必循环太多次
for i in range(100):
# 点击这个按钮
button.click()
# 点击按钮之后会展示更多的数据,然后继续下拉滚动条来获取加载更多按钮
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(2)
except Exception as e:
print('出错了:', e)
else:
# 如果没有出错,那么则获取到了全部(大量)的数据,下面要对数据进行解析,取出所需数据
# 获取到的网页源码就是str类型,不需要再使用text获取html文本数据
tree = etree.HTML(browser.page_source)
# 获取到所有的a标签
a_list = tree.xpath('//div[@class="AnonymousHome_home__timeline__item_3vU"]/h3/a')
result_list = []
for a in a_list:
result_dict = dict()
# 标签中的文字可直接使用text获取文本或者再次使用xpath匹配
title = a.text
# 因为xpath匹配出来后的数据是放在列表中,所以要从列表中拿出来
href = url + a.xpath('./@href')[0]
# 将数据添加到字典中
result_dict["title"] = title
result_dict["url"] = href
# 将字典添加到列表中
result_list.append(result_dict)
# 此处循环完毕后,列表中有多个字典,可以将列表写入文件(数据库)中,以便查看数据
with open('xue_qiu.json', 'w', encoding='utf-8') as f:
# 写入文件要将python格式转换为json字符串写入
f.write(json.dumps(result_list, ensure_ascii=False, indent=2))
# 退出浏览器
browser.quit()
end_time = time.time()
# 打印爬取数据的总时长
print("总耗时:%d" % (end_time-start_time))
if __name__ == '__main__':
spider_snowball()
3.总结
如果你自己用上面的代码去抓取数据,相信你就会知道selenium的方便之处。如果不使用selenium来抓一些数据,可能大家抓起来很不方便,但是selenium也有自己的弊端,就是效率不高,就像上面的抓雪球网一样,我自己测试了一下220s,有时候也可以选择抓取js包进行数据分析(后面会有案例),当然如果用其他方法获取不到数据,使用selenium也是一个不错的选择。 查看全部
nodejs抓取动态网页(selenium1.使用selenium抓取动态图片本次抓取的流程确认)
文章目录
本章将带你使用selenium抓取一些动态加载的页面,让你体会到selenium的用处
1.使用selenium抓取动态图片
本次拍摄的图片是百度图片中安吉拉的相关图片
import time
import requests # 使用requests下载图片
from urllib import request # 下载图片
from bs4 import BeautifulSoup # 使用bs4解析
from selenium import webdriver # 自动化测试工具
# 配置下载的图片的地址, 文件夹需要先创建好
IMAGE_PATH = './images/'
# 实例化驱动程序的Chrome对象, driverpath: 驱动的路径
browser = webdriver.Chrome(r'driverpath')
# 定制请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
"Chrome/74.0.3729.108 Safari/537.36",
}
# 打开百度图片页面
browser.get('https://image.baidu.com/')
# 获取输入框并向输入框内输入数据
input_box = browser.find_element_by_id('kw')
input_box.send_keys('安琪拉')
time.sleep(2)
# 点击搜索按钮获取响应输入
button = browser.find_element_by_class_name('s_search')
button.click()
time.sleep(1)
# 下拉滚动条, 循环多次下拉, 可以获取到更多的图片
for i in range(3):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1.5)
# 获取网页的str源代码
response = browser.page_source
# 实现数据解析--使用测试工具获取到的源码就是str类型,不需要再使用text获取文本数据
soup = BeautifulSoup(response, 'lxml')
li_list = soup.select('.imgpage ul li')
for li in li_list:
# li内的data-objurl属性存储的是图片的地址
href = li['data-objurl']
# 首先使用urllib模块下的request.urlretrieve下载, 此处我注释了, 大家可以尝试一下
# request.urlretrieve(href, IMAGE_PATH+'%s.jpg' % li_list.index(li))
# print('正在下载地址为%s的图片...' % href)
# time.sleep(0.5)
# 使用requests模块下载 -- 需要自己写入文件,因为requests没有自带的下载方法
image_response = requests.get(url=href, headers=headers)
# 写入文件必须使用二进制写入
with open(IMAGE_PATH + "%s.jpg" % li_list.index(li), 'wb') as f:
# 访问的是图片页面,图片是二进制流,使用content获取
f.write(image_response.content)
# 循环下载完成后退出
browser.quit()
2.使用 selenium 捕获动态数据
我要找的是雪球网爬取动态数据,爬取雪球网首页推荐数据,雪球网地址
2.1 分析爬虫页面,制定爬虫流程
确认网址
我这里看到的数据一样,就是当前的url,可以点击Headers复制url
如上图,数据已经有了,但是低头看抓包区会发现只有几条数据,所以需要用selenium打开当前页面并配合js下拉页面获取更多数据
分析获取的数据(xpath或者bs4),得到需要的数据
对数据进行封装和持久化,存储在文件或数据库中(后面会讲到)
2.2 编写爬虫代码爬取页面
import time
import json # 用于格式化存入文件
from selenium import webdriver # 自动化测试工具
from lxml import etree # 使用xpath解析
def spider_snowball():
"""
1.爬取雪球网,获取url
2.使用自动化测试工具打开雪球网
3.需要使用自动化测试工具循环下拉滚动条三次,获取到动态加载的数据
4.然后使用自动化测试工具点击加载更多的button按钮,来获取到更多的数据
5.对获取到的数据进行解析,拿取需要的数据
6.将数据循环以词典添加到列表中
7.将列表数据写入到文件中,并且需要将列表转换为json字符串
"""
# 开始时间, 用于测试爬虫的时长
start_time = time.time()
# 雪球网的url, 默认就为推荐数据
url = 'https://xueqiu.com'
# 定制请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
"Chrome/74.0.3729.108 Safari/537.36",
}
# 实例化浏览器对象,以谷歌浏览器运行, driverpath: 自己驱动的存放路径
browser = webdriver.Chrome(r'driverpath')
# 打开对应的url
browser.get(url)
# 下拉滚动条三次, 三次之后就需要点击加载更多的按钮, 可自己下拉查看
for i in range(3):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1.5)
# 获取加载更多的按钮
button = browser.find_element_by_class_name('AnonymousHome_home__timeline__more_6RI')
try:
# 循环点击这个按钮,并且下拉获取到更多的数据, 此处循环自行设置, 可以不必循环太多次
for i in range(100):
# 点击这个按钮
button.click()
# 点击按钮之后会展示更多的数据,然后继续下拉滚动条来获取加载更多按钮
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(2)
except Exception as e:
print('出错了:', e)
else:
# 如果没有出错,那么则获取到了全部(大量)的数据,下面要对数据进行解析,取出所需数据
# 获取到的网页源码就是str类型,不需要再使用text获取html文本数据
tree = etree.HTML(browser.page_source)
# 获取到所有的a标签
a_list = tree.xpath('//div[@class="AnonymousHome_home__timeline__item_3vU"]/h3/a')
result_list = []
for a in a_list:
result_dict = dict()
# 标签中的文字可直接使用text获取文本或者再次使用xpath匹配
title = a.text
# 因为xpath匹配出来后的数据是放在列表中,所以要从列表中拿出来
href = url + a.xpath('./@href')[0]
# 将数据添加到字典中
result_dict["title"] = title
result_dict["url"] = href
# 将字典添加到列表中
result_list.append(result_dict)
# 此处循环完毕后,列表中有多个字典,可以将列表写入文件(数据库)中,以便查看数据
with open('xue_qiu.json', 'w', encoding='utf-8') as f:
# 写入文件要将python格式转换为json字符串写入
f.write(json.dumps(result_list, ensure_ascii=False, indent=2))
# 退出浏览器
browser.quit()
end_time = time.time()
# 打印爬取数据的总时长
print("总耗时:%d" % (end_time-start_time))
if __name__ == '__main__':
spider_snowball()
3.总结
如果你自己用上面的代码去抓取数据,相信你就会知道selenium的方便之处。如果不使用selenium来抓一些数据,可能大家抓起来很不方便,但是selenium也有自己的弊端,就是效率不高,就像上面的抓雪球网一样,我自己测试了一下220s,有时候也可以选择抓取js包进行数据分析(后面会有案例),当然如果用其他方法获取不到数据,使用selenium也是一个不错的选择。
nodejs抓取动态网页(我能够成功地抓取一个网页,然后提取我需要的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-28 15:21
这就是我想要完成的。我能够成功抓取一个网页,然后提取我需要的信息,我已经在几个 网站 上运行了这个页面,其中分页链接在 href 属性中很容易获得。我的问题是当分页变量是动态的时如何导航到下一页:
1
2
Next Page
到目前为止,这里的代码是我为其他网站工作
所做的
var request = require('request'), // simplified HTTP request client
cheerio = require('cheerio'), // lean implementation of core jQuery
Xray = require('x-ray'), //
x = Xray(),
fs = require('fs'); // file system i/o
/*
TODO: Make this feature dynamic, to take in the URL of the page
var pageUrl;
*/
var status = 'for sale';
var counter = 0;
x('http://www.example.com/results/1', '.results', [{
id: '[email protected]', // extracts the value from the attribute id
title: 'div.info h2',
category: 'span.category',
price: 'p.price',
count: counter+1, // why doesnt this update? this never shows in the json
status: status // this value never shows up in the json
}])
.paginate(whatShouldThisBe)
.limit(800)
.write('products.json');
此外,count和status的值永远不会显示在生成的JSON文件中。不确定我在这里做错了什么,但我们将不胜感激。
谢谢! 查看全部
nodejs抓取动态网页(我能够成功地抓取一个网页,然后提取我需要的信息)
这就是我想要完成的。我能够成功抓取一个网页,然后提取我需要的信息,我已经在几个 网站 上运行了这个页面,其中分页链接在 href 属性中很容易获得。我的问题是当分页变量是动态的时如何导航到下一页:
1
2
Next Page
到目前为止,这里的代码是我为其他网站工作
所做的
var request = require('request'), // simplified HTTP request client
cheerio = require('cheerio'), // lean implementation of core jQuery
Xray = require('x-ray'), //
x = Xray(),
fs = require('fs'); // file system i/o
/*
TODO: Make this feature dynamic, to take in the URL of the page
var pageUrl;
*/
var status = 'for sale';
var counter = 0;
x('http://www.example.com/results/1', '.results', [{
id: '[email protected]', // extracts the value from the attribute id
title: 'div.info h2',
category: 'span.category',
price: 'p.price',
count: counter+1, // why doesnt this update? this never shows in the json
status: status // this value never shows up in the json
}])
.paginate(whatShouldThisBe)
.limit(800)
.write('products.json');
此外,count和status的值永远不会显示在生成的JSON文件中。不确定我在这里做错了什么,但我们将不胜感激。
谢谢!
nodejs抓取动态网页(使用nodejs写爬虫过程中常用模块和一些必须掌握的js语法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-25 19:11
本文是使用nodejs编写爬虫系列教程的第一篇。介绍了使用nodejs编写爬虫过程中常用的模块以及一些必须掌握的js语法
常用模块
常用模块如下:
fs-extrasuperagentcheeriolog4jssequelizechalkpuppeteerfs-extra
使用async/await的前提是接口必须封装成promise,看一个简单的例子:
const sleep = (milliseconds) => {
return new Promise((resolve, reject) => {
setTimeout(() => resolve(), milliseconds)
})
}
const main = async () => {
await sleep(5000);
console.log('5秒后...');
}
main();
在 async 函数中使用 await + promise 来组织异步代码就像同步代码一样,非常自然,有助于我们分析代码的执行流程。
在 node 中,fs 模块是一个非常常见的用于操作文件的原生模块。fs(文件系统)模块提供了一些与文件系统相关的同步和异步API。有时需要使用同步 API。当一个自写的模块在访问文件后导出一些接口时,这个时候使用同步api是很实用的。看一个例子:
const path = require('path');
const fs = require('fs-extra');
const { log4js } = require('../../config/log4jsConfig');
const log = log4js.getLogger('qupingce');
const createModels = () => {
const models = {};
const fileNames = fs.readdirSync(path.resolve(__dirname, '.'));
fileNames
.filter(fileName => fileName !== 'index.js')
.map(fileName => fileName.slice(0, -3))
.forEach(modelName => {
log.info(`Sequelize define model ${modelName}!`);
models[modelName] = require(path.resolve(__dirname, `./${modelName}.js`));
})
return models;
}
module.exports = createModels();
该模块访问当前目录中的所有模型模块并导出模型。如果使用异步接口,即fs.readdir,则无法通过在其他模块中导入该模块来获取模型。原因是 require 是一个同步操作。虽然接口是异步的,但同步代码不能立即获得异步操作的结果。
为了充分发挥节点异步的优势,我们应该尽量使用异步接口。
我们可以使用 fs-extra 模块代替 fs 模块,类似的模块是 mz。fs-extra 收录了 fs 模块的所有接口,也为每个异步接口提供了 Promise 支持。更好的是 fs-extra 还提供了一些其他有用的文件操作功能,比如删除和移动文件的操作。更详细的介绍请查看官方仓库 fs-extra。
超级代理
superagent是一个节点的http客户端,可以类比java中的httpclient和okhttp,python中的requests。允许我们模拟 http 请求。superagent 库有很多有用的特性。
superagent会根据response的content-type自动序列化,序列化后的返回内容可以通过response.body获取。这个库会自动缓存和发送cookies,所以我们不需要手动管理cookies然后它的api是链式调用样式,调用起来很爽,但是在使用的时候要注意调用顺序。它的异步 api 都返回承诺。
有木头很方便。官方文档是一个很长的页面,目录清晰,很容易搜索到自己需要的内容。最后,superagent 还支持插件集成。例如,如果您需要在超时后自动重新发送,您可以使用 superagent-retry。更多插件可以去npm官网搜索关键词superagent-。更多详细信息,请参见官方文档 superagent
// 官方文档的一个调用示例
request
.post('/api/pet')
.send({ name: 'Manny', species: 'cat' })
.set('X-API-Key', 'foobar')
.set('Accept', 'application/json')
.then(res => {
alert('yay got ' + JSON.stringify(res.body));
});
切里奥
写过爬虫的人都知道,我们经常有解析html的需求,从网页的源代码中爬取信息应该是最基本的爬取方式。python中有beautifulsoup,java中有jsoup,node中有cheerio。
Cheerio 专为服务器端设计,为您提供近乎完整的 jquery 体验。使用cheerio解析html获取元素,调用方式与jquery操作dom元素的用法一模一样。而且它还提供了一些方便的接口,比如获取html,看一个例子:
const cheerio = require('cheerio')
const $ = cheerio.load('Hello world')
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
$.html()
//=> Hello there!
官方仓库:cheerio
log4js
log4j 是为 node 设计的日志模块。在简单的场景中,考虑使用调试模块。log4js 更符合我对日志库的需求。其实他们的定位是不一样的。debug 模块是为调试而设计的,而 log4js 是一个日志库。它必须提供文件输出和分类等常规功能。
log4js模块的名字有点符合java中著名的日志库log4j的节奏。log4j 具有以下特点:
您可以自定义 appender(输出目标),lo4js 甚至提供了输出到目标(例如邮件)的 appender。通过组合不同的appender,可以达到不同目的的记录器(loggers)提供日志分类功能。官方FAQ中提到如果要实现appender的级别过滤,可以使用logLevelFilter提供滚动日志和自定义输出格式
让我们通过我最新的爬虫项目的配置文件来感受一下这个库的以下特点:
const log4js = require('log4js');
const path = require('path');
const fs = require('fs-extra');
const infoFilePath = path.resolve(__dirname, '../out/log/info.log');
const errorFilePath = path.resolve(__dirname, '../out/log/error.log');
log4js.configure({
appenders: {
dateFile: {
type: 'dateFile',
filename: infoFilePath,
pattern: 'yyyy-MM-dd',
compress: false
},
errorDateFile: {
type: 'dateFile',
filename: errorFilePath,
pattern: 'yyyy-MM-dd',
compress: false,
},
justErrorsToFile: {
type: 'logLevelFilter',
appender: 'errorDateFile',
level: 'error'
},
out: {
type: 'console'
}
},
categories: {
default: {
appenders: ['out'],
level: 'trace'
},
qupingce: {
appenders: ['out', 'dateFile', 'justErrorsToFile'],
level: 'trace'
}
}
});
const clear = async () => {
const files = await fs.readdir(path.resolve(__dirname, '../out/log'));
for (const fileName of files) {
fs.remove(path.resolve(__dirname, `../out/log/${fileName}`));
}
}
module.exports = {
log4js,
clear
}
续集
在编写项目时,我们经常有持久的需求。在简单的场景中,可以使用 JSON 来保存数据。如果数据量比较大,又容易管理,那么就要考虑使用数据库了。如果是操作mysql和sqllite,推荐使用sequelize。如果是mongodb,我推荐使用专门为mongodb设计的mongoose
sequelize中还有一些我觉得还不是很好的点,比如默认生成的id(主键)、createdAt和updatedAt。
除了一些自己造成的故障外,sequelize 设计得很好。内置的操作符、钩子和验证器很有趣。sequelize 还提供了 Promise 和 typescript 支持。如果你使用 typescript 开发项目,还有一个不错的 orm 选择:typeorm。更多信息参见官方文档:sequelize
粉笔
chalk 的中文意思是粉笔。该模块是node的一个非常有特色和实用的模块。它可以为您的输出内容添加颜色、下划线、背景颜色和其他装饰。我们在写项目的时候,经常需要记录一些步骤和事件,比如打开数据库链接、发起http请求等等。我们可以适当地使用粉笔来突出显示某些内容,例如在请求的 url 下划线。
const logRequest = (response, isDetailed = false) => {
const URL = chalk.underline.yellow(response.request.url);
const basicInfo = `${response.request.method} Status: ${response.status} Content-Type: ${response.type} URL=${URL}`;
if (!isDetailed) {
logger.info(basicInfo);
} else {
const detailInfo = `${basicInfo}\ntext: ${response.text}`;
logger.info(detailInfo);
}
};
调用上面的 logRequest 效果:
有关更多信息,请参阅官方存储库粉笔
傀儡师
如果您还没有听说过这个库,那么您可能听说过 selenium。puppeteer 是 Google Chrome 团队开源的一个节点模块,用于通过 devtools 协议操作 chrome 或 Chromium。由 Google 制造,质量有保证。该模块提供了一些高级 API。默认情况下,这个库操作的浏览器的用户是看不到界面的,也就是所谓的无头浏览器。当然也可以通过配置一些参数来启动interfaced模式。在chrome中也有一些记录puppeteer操作的扩展,比如Puppeteer Recorder。使用这个库,我们可以用来获取一些由 js 呈现的信息,而不是直接呈现在页面源代码中。比如spa页面,页面的内容是js渲染的。这时候puppeteer就为我们解决了这个问题。我们可以调用 puppeteer 来获取页面上某个标签出现时渲染出来的 html。事实上,很多高难度爬虫解决的终极法宝就是操纵浏览器。
前置 js 语法 async/await
首先要提的是async/await,因为node在很早的时候就已经支持async/await了(node 8 LTS),现在没有理由写没有async/await的后端项目。使用 async/await 可以将我们从回调炼狱中解放出来。这里主要提一下使用async/await时可能遇到的问题
如何同时使用异步/等待?
看一段测试代码:
const sleep = (milliseconds) => {
return new Promise((resolve, reject) => {
setTimeout(() => resolve(), milliseconds)
})
}
const test1 = async () => {
for (let i = 0, max = 3; i {
Array.from({length: 3}).forEach(async () => {
await sleep(1000);
});
}
const main = async () => {
console.time('测试 for 循环使用 await');
await test1();
console.timeEnd('测试 for 循环使用 await');
console.time('测试 forEach 调用 async 函数')
await test2();
console.timeEnd('测试 forEach 调用 async 函数')
}
main();
运行的结果是:
测试 for 循环使用 await: 3003.905ms
测试 forEach 调用 async 函数: 0.372ms
我想有些人可能会认为测试 forEach 的结果会是 1 秒左右,其实测试 2 等价于如下代码:
const test2 = async () => {
// Array.from({length: 3}).forEach(async () => {
// await sleep(1000);
// });
Array.from({length: 3}).forEach(() => {
sleep(1000);
});
}
从上面的运行结果也可以看出,直接在for循环中使用await+promise相当于同步调用,所以耗时3秒左右。如果要并发,应该直接调用promise,因为forEach不会帮你await,所以相当于上面的代码,三个任务直接异步并发。
处理多个异步任务
上面的代码还有一个问题,就是在测试2中,并没有等到三个任务都执行完就直接结束了。有时我们需要等待多个并发任务结束后再执行后续任务。其实很简单,使用 Promise 提供的几个工具功能就可以了。
const sleep = (milliseconds, id='') => {
return new Promise((resolve, reject) => {
setTimeout(() => {
console.log(`任务${id}执行结束`)
resolve(id);
}, milliseconds)
})
}
const test2 = async () => {
const tasks = Array.from({length: 3}).map((ele, index) => sleep(1000, index));
const resultArray = await Promise.all(tasks);
console.log({ resultArray} )
console.log('所有任务执行结束');
}
const main = async () => {
console.time('使用 Promise.all 处理多个并发任务')
await test2();
console.timeEnd('使用 Promise.all 处理多个并发任务')
}
main()
运行结果:
任务0执行结束
任务1执行结束
任务2执行结束
{ resultArray: [ 0, 1, 2 ] }
所有任务执行结束
使用 Promise.all 处理多个并发任务: 1018.628ms
除了 Promise.all,Promise 还有race等接口,但最常用的就是all和race。
正则表达式
正则表达式是处理字符串的强大工具。核心是匹配,从中衍生出抽取、查找、替换等操作。
有时当我们通过cheerio获取标签中的文本时,我们需要提取一些信息,这时正则表达式就应该发挥作用了。正则表达式的相关语法在此不做详述。初学者,推荐看廖雪峰的正则表达式教程。让我们看一个例子:
// 服务器返回的 img url 是: /GetFile/getUploadImg?fileName=9b1cc22c74bc44c8af78b46e0ca4c352.png
// 现在我只想提取文件名,后缀名也不要
const imgUrl = '/GetFile/getUploadImg?fileName=9b1cc22c74bc44c8af78b46e0ca4c352.png';
const imgReg = /\/GetFile\/getUploadImg\?fileName=(.+)\..+/;
const imgName = imgUrl.match(imgReg)[1];
console.log(imgName); // => 9b1cc22c74bc44c8af78b46e0ca4c352
暂时就介绍到这里,以后会增加更多的内容。
本文为原创的内容,首发于我的个人博客。转载请注明出处。如有任何问题,请发邮件骚扰。 查看全部
nodejs抓取动态网页(使用nodejs写爬虫过程中常用模块和一些必须掌握的js语法)
本文是使用nodejs编写爬虫系列教程的第一篇。介绍了使用nodejs编写爬虫过程中常用的模块以及一些必须掌握的js语法
常用模块
常用模块如下:
fs-extrasuperagentcheeriolog4jssequelizechalkpuppeteerfs-extra
使用async/await的前提是接口必须封装成promise,看一个简单的例子:
const sleep = (milliseconds) => {
return new Promise((resolve, reject) => {
setTimeout(() => resolve(), milliseconds)
})
}
const main = async () => {
await sleep(5000);
console.log('5秒后...');
}
main();
在 async 函数中使用 await + promise 来组织异步代码就像同步代码一样,非常自然,有助于我们分析代码的执行流程。
在 node 中,fs 模块是一个非常常见的用于操作文件的原生模块。fs(文件系统)模块提供了一些与文件系统相关的同步和异步API。有时需要使用同步 API。当一个自写的模块在访问文件后导出一些接口时,这个时候使用同步api是很实用的。看一个例子:
const path = require('path');
const fs = require('fs-extra');
const { log4js } = require('../../config/log4jsConfig');
const log = log4js.getLogger('qupingce');
const createModels = () => {
const models = {};
const fileNames = fs.readdirSync(path.resolve(__dirname, '.'));
fileNames
.filter(fileName => fileName !== 'index.js')
.map(fileName => fileName.slice(0, -3))
.forEach(modelName => {
log.info(`Sequelize define model ${modelName}!`);
models[modelName] = require(path.resolve(__dirname, `./${modelName}.js`));
})
return models;
}
module.exports = createModels();
该模块访问当前目录中的所有模型模块并导出模型。如果使用异步接口,即fs.readdir,则无法通过在其他模块中导入该模块来获取模型。原因是 require 是一个同步操作。虽然接口是异步的,但同步代码不能立即获得异步操作的结果。
为了充分发挥节点异步的优势,我们应该尽量使用异步接口。
我们可以使用 fs-extra 模块代替 fs 模块,类似的模块是 mz。fs-extra 收录了 fs 模块的所有接口,也为每个异步接口提供了 Promise 支持。更好的是 fs-extra 还提供了一些其他有用的文件操作功能,比如删除和移动文件的操作。更详细的介绍请查看官方仓库 fs-extra。
超级代理
superagent是一个节点的http客户端,可以类比java中的httpclient和okhttp,python中的requests。允许我们模拟 http 请求。superagent 库有很多有用的特性。
superagent会根据response的content-type自动序列化,序列化后的返回内容可以通过response.body获取。这个库会自动缓存和发送cookies,所以我们不需要手动管理cookies然后它的api是链式调用样式,调用起来很爽,但是在使用的时候要注意调用顺序。它的异步 api 都返回承诺。
有木头很方便。官方文档是一个很长的页面,目录清晰,很容易搜索到自己需要的内容。最后,superagent 还支持插件集成。例如,如果您需要在超时后自动重新发送,您可以使用 superagent-retry。更多插件可以去npm官网搜索关键词superagent-。更多详细信息,请参见官方文档 superagent
// 官方文档的一个调用示例
request
.post('/api/pet')
.send({ name: 'Manny', species: 'cat' })
.set('X-API-Key', 'foobar')
.set('Accept', 'application/json')
.then(res => {
alert('yay got ' + JSON.stringify(res.body));
});
切里奥
写过爬虫的人都知道,我们经常有解析html的需求,从网页的源代码中爬取信息应该是最基本的爬取方式。python中有beautifulsoup,java中有jsoup,node中有cheerio。
Cheerio 专为服务器端设计,为您提供近乎完整的 jquery 体验。使用cheerio解析html获取元素,调用方式与jquery操作dom元素的用法一模一样。而且它还提供了一些方便的接口,比如获取html,看一个例子:
const cheerio = require('cheerio')
const $ = cheerio.load('Hello world')
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
$.html()
//=> Hello there!
官方仓库:cheerio
log4js
log4j 是为 node 设计的日志模块。在简单的场景中,考虑使用调试模块。log4js 更符合我对日志库的需求。其实他们的定位是不一样的。debug 模块是为调试而设计的,而 log4js 是一个日志库。它必须提供文件输出和分类等常规功能。
log4js模块的名字有点符合java中著名的日志库log4j的节奏。log4j 具有以下特点:
您可以自定义 appender(输出目标),lo4js 甚至提供了输出到目标(例如邮件)的 appender。通过组合不同的appender,可以达到不同目的的记录器(loggers)提供日志分类功能。官方FAQ中提到如果要实现appender的级别过滤,可以使用logLevelFilter提供滚动日志和自定义输出格式
让我们通过我最新的爬虫项目的配置文件来感受一下这个库的以下特点:
const log4js = require('log4js');
const path = require('path');
const fs = require('fs-extra');
const infoFilePath = path.resolve(__dirname, '../out/log/info.log');
const errorFilePath = path.resolve(__dirname, '../out/log/error.log');
log4js.configure({
appenders: {
dateFile: {
type: 'dateFile',
filename: infoFilePath,
pattern: 'yyyy-MM-dd',
compress: false
},
errorDateFile: {
type: 'dateFile',
filename: errorFilePath,
pattern: 'yyyy-MM-dd',
compress: false,
},
justErrorsToFile: {
type: 'logLevelFilter',
appender: 'errorDateFile',
level: 'error'
},
out: {
type: 'console'
}
},
categories: {
default: {
appenders: ['out'],
level: 'trace'
},
qupingce: {
appenders: ['out', 'dateFile', 'justErrorsToFile'],
level: 'trace'
}
}
});
const clear = async () => {
const files = await fs.readdir(path.resolve(__dirname, '../out/log'));
for (const fileName of files) {
fs.remove(path.resolve(__dirname, `../out/log/${fileName}`));
}
}
module.exports = {
log4js,
clear
}
续集
在编写项目时,我们经常有持久的需求。在简单的场景中,可以使用 JSON 来保存数据。如果数据量比较大,又容易管理,那么就要考虑使用数据库了。如果是操作mysql和sqllite,推荐使用sequelize。如果是mongodb,我推荐使用专门为mongodb设计的mongoose
sequelize中还有一些我觉得还不是很好的点,比如默认生成的id(主键)、createdAt和updatedAt。
除了一些自己造成的故障外,sequelize 设计得很好。内置的操作符、钩子和验证器很有趣。sequelize 还提供了 Promise 和 typescript 支持。如果你使用 typescript 开发项目,还有一个不错的 orm 选择:typeorm。更多信息参见官方文档:sequelize
粉笔
chalk 的中文意思是粉笔。该模块是node的一个非常有特色和实用的模块。它可以为您的输出内容添加颜色、下划线、背景颜色和其他装饰。我们在写项目的时候,经常需要记录一些步骤和事件,比如打开数据库链接、发起http请求等等。我们可以适当地使用粉笔来突出显示某些内容,例如在请求的 url 下划线。
const logRequest = (response, isDetailed = false) => {
const URL = chalk.underline.yellow(response.request.url);
const basicInfo = `${response.request.method} Status: ${response.status} Content-Type: ${response.type} URL=${URL}`;
if (!isDetailed) {
logger.info(basicInfo);
} else {
const detailInfo = `${basicInfo}\ntext: ${response.text}`;
logger.info(detailInfo);
}
};
调用上面的 logRequest 效果:
有关更多信息,请参阅官方存储库粉笔
傀儡师
如果您还没有听说过这个库,那么您可能听说过 selenium。puppeteer 是 Google Chrome 团队开源的一个节点模块,用于通过 devtools 协议操作 chrome 或 Chromium。由 Google 制造,质量有保证。该模块提供了一些高级 API。默认情况下,这个库操作的浏览器的用户是看不到界面的,也就是所谓的无头浏览器。当然也可以通过配置一些参数来启动interfaced模式。在chrome中也有一些记录puppeteer操作的扩展,比如Puppeteer Recorder。使用这个库,我们可以用来获取一些由 js 呈现的信息,而不是直接呈现在页面源代码中。比如spa页面,页面的内容是js渲染的。这时候puppeteer就为我们解决了这个问题。我们可以调用 puppeteer 来获取页面上某个标签出现时渲染出来的 html。事实上,很多高难度爬虫解决的终极法宝就是操纵浏览器。
前置 js 语法 async/await
首先要提的是async/await,因为node在很早的时候就已经支持async/await了(node 8 LTS),现在没有理由写没有async/await的后端项目。使用 async/await 可以将我们从回调炼狱中解放出来。这里主要提一下使用async/await时可能遇到的问题
如何同时使用异步/等待?
看一段测试代码:
const sleep = (milliseconds) => {
return new Promise((resolve, reject) => {
setTimeout(() => resolve(), milliseconds)
})
}
const test1 = async () => {
for (let i = 0, max = 3; i {
Array.from({length: 3}).forEach(async () => {
await sleep(1000);
});
}
const main = async () => {
console.time('测试 for 循环使用 await');
await test1();
console.timeEnd('测试 for 循环使用 await');
console.time('测试 forEach 调用 async 函数')
await test2();
console.timeEnd('测试 forEach 调用 async 函数')
}
main();
运行的结果是:
测试 for 循环使用 await: 3003.905ms
测试 forEach 调用 async 函数: 0.372ms
我想有些人可能会认为测试 forEach 的结果会是 1 秒左右,其实测试 2 等价于如下代码:
const test2 = async () => {
// Array.from({length: 3}).forEach(async () => {
// await sleep(1000);
// });
Array.from({length: 3}).forEach(() => {
sleep(1000);
});
}
从上面的运行结果也可以看出,直接在for循环中使用await+promise相当于同步调用,所以耗时3秒左右。如果要并发,应该直接调用promise,因为forEach不会帮你await,所以相当于上面的代码,三个任务直接异步并发。
处理多个异步任务
上面的代码还有一个问题,就是在测试2中,并没有等到三个任务都执行完就直接结束了。有时我们需要等待多个并发任务结束后再执行后续任务。其实很简单,使用 Promise 提供的几个工具功能就可以了。
const sleep = (milliseconds, id='') => {
return new Promise((resolve, reject) => {
setTimeout(() => {
console.log(`任务${id}执行结束`)
resolve(id);
}, milliseconds)
})
}
const test2 = async () => {
const tasks = Array.from({length: 3}).map((ele, index) => sleep(1000, index));
const resultArray = await Promise.all(tasks);
console.log({ resultArray} )
console.log('所有任务执行结束');
}
const main = async () => {
console.time('使用 Promise.all 处理多个并发任务')
await test2();
console.timeEnd('使用 Promise.all 处理多个并发任务')
}
main()
运行结果:
任务0执行结束
任务1执行结束
任务2执行结束
{ resultArray: [ 0, 1, 2 ] }
所有任务执行结束
使用 Promise.all 处理多个并发任务: 1018.628ms
除了 Promise.all,Promise 还有race等接口,但最常用的就是all和race。
正则表达式
正则表达式是处理字符串的强大工具。核心是匹配,从中衍生出抽取、查找、替换等操作。
有时当我们通过cheerio获取标签中的文本时,我们需要提取一些信息,这时正则表达式就应该发挥作用了。正则表达式的相关语法在此不做详述。初学者,推荐看廖雪峰的正则表达式教程。让我们看一个例子:
// 服务器返回的 img url 是: /GetFile/getUploadImg?fileName=9b1cc22c74bc44c8af78b46e0ca4c352.png
// 现在我只想提取文件名,后缀名也不要
const imgUrl = '/GetFile/getUploadImg?fileName=9b1cc22c74bc44c8af78b46e0ca4c352.png';
const imgReg = /\/GetFile\/getUploadImg\?fileName=(.+)\..+/;
const imgName = imgUrl.match(imgReg)[1];
console.log(imgName); // => 9b1cc22c74bc44c8af78b46e0ca4c352
暂时就介绍到这里,以后会增加更多的内容。
本文为原创的内容,首发于我的个人博客。转载请注明出处。如有任何问题,请发邮件骚扰。
nodejs抓取动态网页(如何判断一个前端渲染的页面是否为抓取动态的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-24 09:19
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面使用js渲染。对于爬虫来说,这种页面比较烦人:只提取 HTML 内容,往往无法获取有效信息。那么如何处理这种页面呢?一般有两种方法:
爬取阶段,爬虫内置浏览器内核,爬取前执行js渲染页面。这方面的相应工具是 Selenium、HtmlUnit 或 PhantomJs。但这些工具都存在一定的效率问题,同时也不是那么稳定。优点是编写规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本上都是通过AJAX获取的,所以分析AJAX请求,找到数据对应的请求也是可行的。而且相对于页面样式,这个界面是不太可能改变的。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较大量的分析经验。
比较这两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种更为可靠。对于某些网站,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,而第二种方法会很复杂。
对于第一种方法,webmagic-selenium就是这样一种尝试,它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium的配置比较复杂,和平台和版本有关,没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。我希望你会发现解析一个前端渲染的页面并没有那么复杂。这里我们以AngularJS中文社区为例。
如何判断前端渲染
判断页面是否为js渲染的方式比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果没有找到有效信息,基本上就是js渲染了。
本例中在源码中找不到页面中的标题“优符计算机网-前端攻城师”,因此可以断定是js渲染,这个数据是通过AJAX获取的。
分析请求
现在我们到了最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是浏览器中的开发者工具查看网络请求。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是一个下拉页面,总之所有的操作你觉得可能会触发新的数据)),那就记得保留场景,一一分析请求!
这一步需要一点耐心,但不是随机的。首先可以帮助我们的是上面的分类过滤器(All、Document 和其他选项)。如果是普通的 AJAX,会显示在 XHR 标签下,而 JSONP 请求会显示在 Scripts 标签下。这是两种更常见的数据类型。
然后你可以根据数据的大小来判断。一般来说,较大的结果更有可能是返回数据的接口。其余的基本上都是凭经验。比如这里的“latest?p=1&s=20”,一看就很可疑……
对于可疑地址,此时可以查看响应正文的内容。在这里的开发者工具中并不清楚。我们将URL复制到地址栏,再次请求(如果Chrome推荐安装jsonviewer,查看AJAX结果非常方便)。查看结果,看起来我们找到了我们想要的东西。
同样的方法,我们进入帖子详情页面,找到具体内容的请求:.
编程
回顾之前列表+目标页面的例子,你会发现我们这次的需求和之前的差不多,只是换成了AJAX方法——AJAX方法列表,AJAX方法数据,返回的数据变成了JSON。那么,我们仍然可以使用最后一种方式,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求由一些固定的url加上这个id组成。所以在这一步中,我们手动构造URL,并将其添加到待爬取队列中。这里我们使用 JsonPath 选择语言来选择数据(webmagic-extension 包中提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了 URL,解析目标数据其实很简单,因为 JSON 数据是完全结构化的,所以我们省去了分析页面和编写 XPath 的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见 AngularJSProcessor.java
总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。事实上,动态网页抓取的最大区别在于它使链接发现更加困难。我们比较一下两种开发模式:
后端渲染页面
下载二级页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能是在页面HTML中预先输出,也可能是通过AJAX请求,甚至是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂的多,所以这其实就是动态页面爬取的难点所在。
本节的这个例子希望实现的是在分析请求后为此类爬虫的编写提供一个模式,即发现辅助数据 => 构建链接 => 下载并分析目标 AJAX 模式。
PS:
WebMagic 0.5.0 稍后会为链式 API 添加 Json 支持,您可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析 AJAX 请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。 查看全部
nodejs抓取动态网页(如何判断一个前端渲染的页面是否为抓取动态的方式)
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面使用js渲染。对于爬虫来说,这种页面比较烦人:只提取 HTML 内容,往往无法获取有效信息。那么如何处理这种页面呢?一般有两种方法:
爬取阶段,爬虫内置浏览器内核,爬取前执行js渲染页面。这方面的相应工具是 Selenium、HtmlUnit 或 PhantomJs。但这些工具都存在一定的效率问题,同时也不是那么稳定。优点是编写规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本上都是通过AJAX获取的,所以分析AJAX请求,找到数据对应的请求也是可行的。而且相对于页面样式,这个界面是不太可能改变的。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较大量的分析经验。
比较这两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种更为可靠。对于某些网站,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,而第二种方法会很复杂。
对于第一种方法,webmagic-selenium就是这样一种尝试,它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium的配置比较复杂,和平台和版本有关,没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。我希望你会发现解析一个前端渲染的页面并没有那么复杂。这里我们以AngularJS中文社区为例。
如何判断前端渲染
判断页面是否为js渲染的方式比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果没有找到有效信息,基本上就是js渲染了。
本例中在源码中找不到页面中的标题“优符计算机网-前端攻城师”,因此可以断定是js渲染,这个数据是通过AJAX获取的。
分析请求
现在我们到了最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是浏览器中的开发者工具查看网络请求。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是一个下拉页面,总之所有的操作你觉得可能会触发新的数据)),那就记得保留场景,一一分析请求!
这一步需要一点耐心,但不是随机的。首先可以帮助我们的是上面的分类过滤器(All、Document 和其他选项)。如果是普通的 AJAX,会显示在 XHR 标签下,而 JSONP 请求会显示在 Scripts 标签下。这是两种更常见的数据类型。
然后你可以根据数据的大小来判断。一般来说,较大的结果更有可能是返回数据的接口。其余的基本上都是凭经验。比如这里的“latest?p=1&s=20”,一看就很可疑……
对于可疑地址,此时可以查看响应正文的内容。在这里的开发者工具中并不清楚。我们将URL复制到地址栏,再次请求(如果Chrome推荐安装jsonviewer,查看AJAX结果非常方便)。查看结果,看起来我们找到了我们想要的东西。
同样的方法,我们进入帖子详情页面,找到具体内容的请求:.
编程
回顾之前列表+目标页面的例子,你会发现我们这次的需求和之前的差不多,只是换成了AJAX方法——AJAX方法列表,AJAX方法数据,返回的数据变成了JSON。那么,我们仍然可以使用最后一种方式,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求由一些固定的url加上这个id组成。所以在这一步中,我们手动构造URL,并将其添加到待爬取队列中。这里我们使用 JsonPath 选择语言来选择数据(webmagic-extension 包中提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了 URL,解析目标数据其实很简单,因为 JSON 数据是完全结构化的,所以我们省去了分析页面和编写 XPath 的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见 AngularJSProcessor.java
总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。事实上,动态网页抓取的最大区别在于它使链接发现更加困难。我们比较一下两种开发模式:
后端渲染页面
下载二级页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能是在页面HTML中预先输出,也可能是通过AJAX请求,甚至是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂的多,所以这其实就是动态页面爬取的难点所在。
本节的这个例子希望实现的是在分析请求后为此类爬虫的编写提供一个模式,即发现辅助数据 => 构建链接 => 下载并分析目标 AJAX 模式。
PS:
WebMagic 0.5.0 稍后会为链式 API 添加 Json 支持,您可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析 AJAX 请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。
nodejs抓取动态网页(下phantomjs,具体过程是怎么实现的呢?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2022-03-21 22:19
最近在研究phantomjs,但只是第一次,谈不上深入研究。首先介绍一下phantomjs是什么。
官网上的介绍是:“PhantomJS 是一个可以用 JavaScript API 编写脚本的无头 WebKit。它对各种 Web 标准有快速和原生的支持:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。” 服务器端 JavaScript API。它完全支持没有浏览器支持的 Web,它速度快,原生支持各种 Web 标准:DOM 操作、CSS 选择器、JSON、Canvas 和 SVG。” PhantomJS 可用于页面自动化、Web 监控、网页截图和无接口测试。
本文结合nodejs,使用phantomjs网页截图功能,对多个URL进行批量截图操作,将图片上传到七牛服务器,批量获取图片下载地址,并保存在本地文件中。
下面开始说一下这个demo的具体流程是如何实现的。
一、安装
1、nodejs
nodejs的安装在之前的文章中已经提到过,这里不再赘述。详情请参考nodejs官网:;
2、幻影
关于phantomjs的安装,这里是windows环境下的安装方法:
首先去官网下载phantomjs压缩包,解压到本地磁盘。比如我电脑上解压后存储的地址是:D:\Program files\phantomjs-2.1.1;
二、配置环境变量。将解压后的phantomjs目录下bin目录的路径(比如我本地bin目录的位置是:D:\Program files\phantomjs-2.1.1\bin)添加到系统中变量路径变量中间;
然后,打开cmd,输入“phantomjs --version”命令查看phantomjs是否安装成功。如果出现版本号信息,则安装成功。如果报错,需要重启电脑。
结果如下所示:
二、设计理念
首先说一下写这个demo的初衷。因为我在工作中每次发邮件都需要用到一些截图,不想每次都手动拍多张,所以想用一个自动化的批处理工具来自动截图,不过这只是为了完成截图,使用的时候还是要上传图片。我还是觉得麻烦,所以想在截图完成后自动将这些图片上传到七牛服务器,然后从服务器获取图片下载地址,然后就可以直接使用图片下载地址了。好的。以下是具体的设计思路。
对于上图中的截图设备,具体程序流程为:
三、编码
1、模拟Echarts图表生成的工程代码和启动方法不再详述。请参考我在github上发布的源码:
2、截图
2.1、capture.js
主要使用phantomjs进行截图操作
1 var page=require('webpage').create();//创建一个网页对象;
2 var system=require('system');
3 var address,fileName;
4 // page.viewportSize={width:1024,height:800};//设置窗口的大小为1024*800;
5 // page.clipRect={top:0,left:0,width:1024,height:800};//截取从{0,0}为起点的1024*800大小的图像;
6 // //禁止Javascript,允许图片载入;
7 // // 并将userAgent改为"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.31 (KHTML, like Gecko) PhantomJS/19.0";
8 // page.settings={
9 // javascriptEnabled: false,
10 // loadImages: true,
11 // userAgent: 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.31 (KHTML, like Gecko) PhantomJS/19.0'
12 // };
13
14 if (system.args.length === 1) {
15 console.log('Try to pass some args when invoking this script!');
16 phantom.exit(1);
17 }else{
18 //获取指令传递的参数,参数是以数组的形式传递的;
19 address=system.args[1];
20 fileName=system.args[2];
21 count=system.args[3];
22 max=system.args[4];
23 //打开一个网页;
24 page.open(address,function(status){
25 console.log(status);
26 if(status==='success'){
27 //成功后将页面存储为图片并放在指定的位置;
28 page.render('./pictures/'+fileName+'.png');
29 }
30 // page.close();//释放;
31 //退出;
32 phantom.exit();
33 });
34 }
2.2、phantom.js
Nodejs 启动一个新的子进程并发送 phantomjs 命令进行截图。截图成功后,发送图片上传命令上传图片:
1 /**
2 * Created by Administrator on 2016/5/5.
3 */
4 var urls=["http://localhost:3000/","http://localhost:3000/table","http://www.baidu.com"];
5 var count=0;
6 var max=urls.length;
7 if(urls.length!=0){
8 capture(urls[0]);
9 }
10 //生成随机字符串作为图片名称;
11 function createRandomName(len){
12 len = len || 32;
13 /****默认去掉了容易混淆的字符oOLl,9gq,Vv,Uu,I1****/
14 var $chars = 'ABCDEFGHJKMNPQRSTWXYZabcdefhijkmnprstwxyz2345678';
15 var maxPos = $chars.length;
16 var pwd = '';
17 for (i = 0; i < len; i++) {
18 pwd += $chars.charAt(Math.floor(Math.random() * maxPos));
19 }
20 return pwd;
21 }
22 //开始执行截图命令;
23 function capture(url){
24 var randomPicName='test'+createRandomName(Math.random()*8);
25 console.log("获取的随机名称="+randomPicName);
26 var spawn=require('child_process').spawn;
27 var process=spawn('phantomjs',['capture.js',url,randomPicName,count,max],{cwd:'./routes/'});
28 process.stdout.setEncoding('utf8');
29
30 process.stdout.on("data",function(data){
31 console.log(data);
32 console.log("spawnSTDOUT:"+JSON.stringify(data));
33 var code=data.replace(/[\r\n]/g,"");
34 console.log(code);
35 if(code=='success'){
36 var execFile=require('child_process').execFile;
37 var filePath='./pictures/'+randomPicName+'.png';
38 var execProcess=execFile('node',['upload.js',filePath,randomPicName,count,JSON.stringify(urls)],{cwd:'./routes/'},
39 function(err,stdout,stderr){
40 console.log("execFileSTDOUT:", stdout);
41 console.log("execFileSTDERR:", stderr);
42 });
43 }
44 });
45 process.stderr.on('data',function(data){
46 console.log("stderr"+data);
47 });
48 process.on('close',function(code){
49 if (code == 1) {
50 console.log('child process异常结束。目标:' + url);
51 }
52 });
53 process.on('exit',function(code){
54 console.log('child process exited with code ' + code);
55 count++;
56 if(count!=urls.length){
57 capture(urls[count]);
58 }
59 });
60 }
2.3、上传.js
主要是将图片上传到七牛并获取图片的下载地址,并将结果存入本地txt文件:
1 /**
2 * Created by Administrator on 2016/5/6.
3 */
4 var qiniu = require("qiniu");
5 var config=require('./config');
6 var argvs=process.argv.splice(2);
7 var fs=require("fs");
8 console.log(argvs);
9
10 filePath=argvs[0];
11 key=argvs[1]+'.png';
12 //count;
13 var count=parseInt(argvs[2]);
14 //urls;
15 var urls=JSON.parse(argvs[3]);
16 var max=urls.length;
17 console.log("get the arguments:"+filePath+"---"+key+"--"+count+"---"+max);
18 /**
19 * 第一步:初始化
20 * @type {string}
21 */
22 //需要填写你的 Access Key 和 Secret Key
23 qiniu.conf.ACCESS_KEY = config.qiniu.ACCESS_KEY;
24 qiniu.conf.SECRET_KEY = config.qiniu.SECRET_KEY;
25 //要上传的空间
26 bucket = config.qiniu.Bucket_Name;
27
28 /**
29 * 第二步:获取上传的token
30 * @param bucket
31 * @param key
32 */
33 //构建上传策略函数,设置回调的url以及需要回调给业务服务器的数据
34 function uptoken(bucket, key) {
35 var putPolicy = new qiniu.rs.PutPolicy(bucket+":"+key);
36 console.log("token= "+putPolicy.token());
37 return putPolicy.token();
38 }
39 //生成上传 Token
40 token = uptoken(bucket, key);
41 /**
42 * 第三步:上传图片
43 * @type {string}
44 */
45
46 //构造上传函数
47 function uploadFile(uptoken, key, localFile,count,max) {
48 var extra = new qiniu.io.PutExtra();
49 qiniu.io.putFile(uptoken, key, localFile, extra, function(err, ret) {
50 if(!err) {
51 console.log("上传成功-------------------");
52 // 上传成功, 处理返回值
53 // console.log(ret.hash, ret.key, ret.persistentId);
54 //构建私有空间的链接
55 url = config.qiniu.Domain+ret.key;
56 var policy = new qiniu.rs.GetPolicy();
57 //生成下载链接url
58 var downloadUrl = policy.makeRequest(url);
59 //打印下载的url
60 console.log("downloadUrl= "+downloadUrl);
61 var date=new Date();
62 var dateString=date.toLocaleDateString();//日期;
63 var timeString=date.toLocaleTimeString();//时间;
64 var time=date.toLocaleDateString()+" "+date.toLocaleTimeString();
65 console.log(time);
66 var signalArray={
67 "编号":count+1,
68 "被截屏的路径地址":urls[count],
69 "上传七牛后的图片名称":key,
70 "下载地址":downloadUrl,
71 "截图时间":time
72 };
73 if(count==0){
74 // fs.appendFile(__dirname+'/downloadUrl.txt',"\r\n-----------------"+dateString+" "+timeString+"------------操作开始----------------------\r\n",function(err){
75 // if(err){console.log('fail')}
76 // });
77 fs.appendFileSync(__dirname+'/downloadUrl.txt',"\r\n-----------------"+dateString+" "+timeString+"------------操作开始----------------------\r\n",{encoding:'utf8'});
78 }
79 fs.appendFile(__dirname+'/downloadUrl.txt',JSON.stringify(signalArray)+'\r\n',function(err){
80 if(err){console.log("fail")}
81 });
82 // fs.appendFileSync(__dirname+'/downloadUrl.txt',JSON.stringify(signalArray)+'\r\n',{encoding:'utf8'});
83
84 // if((count+1)==max){
85 // fs.appendFile(__dirname+'/downloadUrl.txt',"\r\n-----------------"+dateString+" "+timeString+"------------操作结束----------------------\r\n",function(err){
86 // if(err){console.log('fail')}
87 // });
88 // fs.appendFileSync(__dirname+'/downloadUrl.txt',"\r\n-----------------"+dateString+" "+timeString+"------------操作结束----------------------\r\n\n",{encoding:'utf8'});
89 // }
90 } else {
91 // 上传失败, 处理返回代码
92 console.log(err);
93 }
94 });
95 }
96 //调用uploadFile上传,并返回下载地址;
97 uploadFile(token, key, filePath,count,max);
2.4、执行:
首先, npm install 安装所需的包。二、直接输入“node routes/phantom.js”,回车,程序开始执行。我们来看看执行结果:
2.4.1、/图片:
这个目录下还有更多的图片文件,这些是phantomjs截图的图片;
2.4.2、七牛服务器
网页登录七牛后,在自己的bucket中可以看到已经添加了很多图片文件,说明我们已经上传成功了:
2.4.3、本地下载Url.txt文件
然后我们测试下载地址是否可以正确下载图片:
以上就是使用nodejs+phantomjs+七牛实现截图操作的完整方法,将截图上传到七牛,并将下载地址保存在本地磁盘。
PS:但是有一个问题,七牛的token是有有效期的,也就是说过了有效期,之前的url就不能用了。你可以重新上传一遍,或者直接在七牛上下载之前的图片。
如果需要源码,可以到我的github下载。下载地址为:
Phantomjs_pic 项目(生成echarts图表等):;
phantomjsScreenCapture 项目(实现截图和上传图片):;
ps:这次只是对phantomjs的一个简单应用。如果您有什么意见和建议,欢迎指出,谢谢! 查看全部
nodejs抓取动态网页(下phantomjs,具体过程是怎么实现的呢?(一))
最近在研究phantomjs,但只是第一次,谈不上深入研究。首先介绍一下phantomjs是什么。
官网上的介绍是:“PhantomJS 是一个可以用 JavaScript API 编写脚本的无头 WebKit。它对各种 Web 标准有快速和原生的支持:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。” 服务器端 JavaScript API。它完全支持没有浏览器支持的 Web,它速度快,原生支持各种 Web 标准:DOM 操作、CSS 选择器、JSON、Canvas 和 SVG。” PhantomJS 可用于页面自动化、Web 监控、网页截图和无接口测试。
本文结合nodejs,使用phantomjs网页截图功能,对多个URL进行批量截图操作,将图片上传到七牛服务器,批量获取图片下载地址,并保存在本地文件中。
下面开始说一下这个demo的具体流程是如何实现的。
一、安装
1、nodejs
nodejs的安装在之前的文章中已经提到过,这里不再赘述。详情请参考nodejs官网:;
2、幻影
关于phantomjs的安装,这里是windows环境下的安装方法:
首先去官网下载phantomjs压缩包,解压到本地磁盘。比如我电脑上解压后存储的地址是:D:\Program files\phantomjs-2.1.1;
二、配置环境变量。将解压后的phantomjs目录下bin目录的路径(比如我本地bin目录的位置是:D:\Program files\phantomjs-2.1.1\bin)添加到系统中变量路径变量中间;
然后,打开cmd,输入“phantomjs --version”命令查看phantomjs是否安装成功。如果出现版本号信息,则安装成功。如果报错,需要重启电脑。
结果如下所示:
二、设计理念
首先说一下写这个demo的初衷。因为我在工作中每次发邮件都需要用到一些截图,不想每次都手动拍多张,所以想用一个自动化的批处理工具来自动截图,不过这只是为了完成截图,使用的时候还是要上传图片。我还是觉得麻烦,所以想在截图完成后自动将这些图片上传到七牛服务器,然后从服务器获取图片下载地址,然后就可以直接使用图片下载地址了。好的。以下是具体的设计思路。
对于上图中的截图设备,具体程序流程为:
三、编码
1、模拟Echarts图表生成的工程代码和启动方法不再详述。请参考我在github上发布的源码:
2、截图
2.1、capture.js
主要使用phantomjs进行截图操作
1 var page=require('webpage').create();//创建一个网页对象;
2 var system=require('system');
3 var address,fileName;
4 // page.viewportSize={width:1024,height:800};//设置窗口的大小为1024*800;
5 // page.clipRect={top:0,left:0,width:1024,height:800};//截取从{0,0}为起点的1024*800大小的图像;
6 // //禁止Javascript,允许图片载入;
7 // // 并将userAgent改为"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.31 (KHTML, like Gecko) PhantomJS/19.0";
8 // page.settings={
9 // javascriptEnabled: false,
10 // loadImages: true,
11 // userAgent: 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.31 (KHTML, like Gecko) PhantomJS/19.0'
12 // };
13
14 if (system.args.length === 1) {
15 console.log('Try to pass some args when invoking this script!');
16 phantom.exit(1);
17 }else{
18 //获取指令传递的参数,参数是以数组的形式传递的;
19 address=system.args[1];
20 fileName=system.args[2];
21 count=system.args[3];
22 max=system.args[4];
23 //打开一个网页;
24 page.open(address,function(status){
25 console.log(status);
26 if(status==='success'){
27 //成功后将页面存储为图片并放在指定的位置;
28 page.render('./pictures/'+fileName+'.png');
29 }
30 // page.close();//释放;
31 //退出;
32 phantom.exit();
33 });
34 }
2.2、phantom.js
Nodejs 启动一个新的子进程并发送 phantomjs 命令进行截图。截图成功后,发送图片上传命令上传图片:
1 /**
2 * Created by Administrator on 2016/5/5.
3 */
4 var urls=["http://localhost:3000/","http://localhost:3000/table","http://www.baidu.com"];
5 var count=0;
6 var max=urls.length;
7 if(urls.length!=0){
8 capture(urls[0]);
9 }
10 //生成随机字符串作为图片名称;
11 function createRandomName(len){
12 len = len || 32;
13 /****默认去掉了容易混淆的字符oOLl,9gq,Vv,Uu,I1****/
14 var $chars = 'ABCDEFGHJKMNPQRSTWXYZabcdefhijkmnprstwxyz2345678';
15 var maxPos = $chars.length;
16 var pwd = '';
17 for (i = 0; i < len; i++) {
18 pwd += $chars.charAt(Math.floor(Math.random() * maxPos));
19 }
20 return pwd;
21 }
22 //开始执行截图命令;
23 function capture(url){
24 var randomPicName='test'+createRandomName(Math.random()*8);
25 console.log("获取的随机名称="+randomPicName);
26 var spawn=require('child_process').spawn;
27 var process=spawn('phantomjs',['capture.js',url,randomPicName,count,max],{cwd:'./routes/'});
28 process.stdout.setEncoding('utf8');
29
30 process.stdout.on("data",function(data){
31 console.log(data);
32 console.log("spawnSTDOUT:"+JSON.stringify(data));
33 var code=data.replace(/[\r\n]/g,"");
34 console.log(code);
35 if(code=='success'){
36 var execFile=require('child_process').execFile;
37 var filePath='./pictures/'+randomPicName+'.png';
38 var execProcess=execFile('node',['upload.js',filePath,randomPicName,count,JSON.stringify(urls)],{cwd:'./routes/'},
39 function(err,stdout,stderr){
40 console.log("execFileSTDOUT:", stdout);
41 console.log("execFileSTDERR:", stderr);
42 });
43 }
44 });
45 process.stderr.on('data',function(data){
46 console.log("stderr"+data);
47 });
48 process.on('close',function(code){
49 if (code == 1) {
50 console.log('child process异常结束。目标:' + url);
51 }
52 });
53 process.on('exit',function(code){
54 console.log('child process exited with code ' + code);
55 count++;
56 if(count!=urls.length){
57 capture(urls[count]);
58 }
59 });
60 }
2.3、上传.js
主要是将图片上传到七牛并获取图片的下载地址,并将结果存入本地txt文件:
1 /**
2 * Created by Administrator on 2016/5/6.
3 */
4 var qiniu = require("qiniu");
5 var config=require('./config');
6 var argvs=process.argv.splice(2);
7 var fs=require("fs");
8 console.log(argvs);
9
10 filePath=argvs[0];
11 key=argvs[1]+'.png';
12 //count;
13 var count=parseInt(argvs[2]);
14 //urls;
15 var urls=JSON.parse(argvs[3]);
16 var max=urls.length;
17 console.log("get the arguments:"+filePath+"---"+key+"--"+count+"---"+max);
18 /**
19 * 第一步:初始化
20 * @type {string}
21 */
22 //需要填写你的 Access Key 和 Secret Key
23 qiniu.conf.ACCESS_KEY = config.qiniu.ACCESS_KEY;
24 qiniu.conf.SECRET_KEY = config.qiniu.SECRET_KEY;
25 //要上传的空间
26 bucket = config.qiniu.Bucket_Name;
27
28 /**
29 * 第二步:获取上传的token
30 * @param bucket
31 * @param key
32 */
33 //构建上传策略函数,设置回调的url以及需要回调给业务服务器的数据
34 function uptoken(bucket, key) {
35 var putPolicy = new qiniu.rs.PutPolicy(bucket+":"+key);
36 console.log("token= "+putPolicy.token());
37 return putPolicy.token();
38 }
39 //生成上传 Token
40 token = uptoken(bucket, key);
41 /**
42 * 第三步:上传图片
43 * @type {string}
44 */
45
46 //构造上传函数
47 function uploadFile(uptoken, key, localFile,count,max) {
48 var extra = new qiniu.io.PutExtra();
49 qiniu.io.putFile(uptoken, key, localFile, extra, function(err, ret) {
50 if(!err) {
51 console.log("上传成功-------------------");
52 // 上传成功, 处理返回值
53 // console.log(ret.hash, ret.key, ret.persistentId);
54 //构建私有空间的链接
55 url = config.qiniu.Domain+ret.key;
56 var policy = new qiniu.rs.GetPolicy();
57 //生成下载链接url
58 var downloadUrl = policy.makeRequest(url);
59 //打印下载的url
60 console.log("downloadUrl= "+downloadUrl);
61 var date=new Date();
62 var dateString=date.toLocaleDateString();//日期;
63 var timeString=date.toLocaleTimeString();//时间;
64 var time=date.toLocaleDateString()+" "+date.toLocaleTimeString();
65 console.log(time);
66 var signalArray={
67 "编号":count+1,
68 "被截屏的路径地址":urls[count],
69 "上传七牛后的图片名称":key,
70 "下载地址":downloadUrl,
71 "截图时间":time
72 };
73 if(count==0){
74 // fs.appendFile(__dirname+'/downloadUrl.txt',"\r\n-----------------"+dateString+" "+timeString+"------------操作开始----------------------\r\n",function(err){
75 // if(err){console.log('fail')}
76 // });
77 fs.appendFileSync(__dirname+'/downloadUrl.txt',"\r\n-----------------"+dateString+" "+timeString+"------------操作开始----------------------\r\n",{encoding:'utf8'});
78 }
79 fs.appendFile(__dirname+'/downloadUrl.txt',JSON.stringify(signalArray)+'\r\n',function(err){
80 if(err){console.log("fail")}
81 });
82 // fs.appendFileSync(__dirname+'/downloadUrl.txt',JSON.stringify(signalArray)+'\r\n',{encoding:'utf8'});
83
84 // if((count+1)==max){
85 // fs.appendFile(__dirname+'/downloadUrl.txt',"\r\n-----------------"+dateString+" "+timeString+"------------操作结束----------------------\r\n",function(err){
86 // if(err){console.log('fail')}
87 // });
88 // fs.appendFileSync(__dirname+'/downloadUrl.txt',"\r\n-----------------"+dateString+" "+timeString+"------------操作结束----------------------\r\n\n",{encoding:'utf8'});
89 // }
90 } else {
91 // 上传失败, 处理返回代码
92 console.log(err);
93 }
94 });
95 }
96 //调用uploadFile上传,并返回下载地址;
97 uploadFile(token, key, filePath,count,max);
2.4、执行:
首先, npm install 安装所需的包。二、直接输入“node routes/phantom.js”,回车,程序开始执行。我们来看看执行结果:
2.4.1、/图片:
这个目录下还有更多的图片文件,这些是phantomjs截图的图片;
2.4.2、七牛服务器
网页登录七牛后,在自己的bucket中可以看到已经添加了很多图片文件,说明我们已经上传成功了:
2.4.3、本地下载Url.txt文件
然后我们测试下载地址是否可以正确下载图片:
以上就是使用nodejs+phantomjs+七牛实现截图操作的完整方法,将截图上传到七牛,并将下载地址保存在本地磁盘。
PS:但是有一个问题,七牛的token是有有效期的,也就是说过了有效期,之前的url就不能用了。你可以重新上传一遍,或者直接在七牛上下载之前的图片。
如果需要源码,可以到我的github下载。下载地址为:
Phantomjs_pic 项目(生成echarts图表等):;
phantomjsScreenCapture 项目(实现截图和上传图片):;
ps:这次只是对phantomjs的一个简单应用。如果您有什么意见和建议,欢迎指出,谢谢!
nodejs抓取动态网页(一个网页的内容.write()介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-20 00:19
网页的内容其实是一个字符串,response.write()可以接受一个字符串作为参数,所以显然你只需要将网页的内容作为参数传递给response.write()。例如:
var http = require('http');
http.createServer(function(req, res){
var html = ''
+''
+'nodejs'
+''
+''
+ 'hello world! 1234'
+''
+'';
res.writeHead(200,{'Content-Type' : 'text/html'});
res.write(html);
res.end();
}).listen(8888);
在浏览器地址栏输入127.0.0.1:8888查看结果,打开控制台,可以发现网页的所有内容都已经收录了在浏览器中。
一个网页一般收录css样式文件和javascript脚本文件,上例中没有两个文件。现在你可以添加简单的css和javascript文件来看看效果:
var http = require('http');
http.createServer(function(req, res){
var html = ''
+''
+'nodejs'
+''
+''
+''
+''
+ 'hello world!hello world! 1234'
+''
+'';
res.writeHead(200,{'Content-Type' : 'text/html'});
res.write(html);
res.end();
}).listen(8888);
你会发现css文件和javascript文件都没有正确下载。这是因为这段代码中指定的'Content-Type'都是'text/html'类型,而且所有的响应内容都是一样的,当然看不到想要的效果。
我们知道有很多不同的方式来引入 CSS 样式和 javascript 脚本。CSS 样式可以使用外部样式、内部样式和内联样式,而 JavaScript 可以同时使用外部和内部样式。由于无法正确显示外线,您可以尝试其他方法。通过测试可以发现,在网页上无论是css内部样式还是内联样式都可以看到,javascript也是如此。
可以看到浏览器中的文字显示为红色。
但是现代 Web 开发并不提倡这两种方法。现代 Web 开发提倡使用 css 样式和 javascript 来使用 outreach 来方便管理和重用。css文件和javascript文件都是静态文件,我们可以尝试搭建一个简单的静态文件服务,这样就可以在网页中正确使用出站文件。 查看全部
nodejs抓取动态网页(一个网页的内容.write()介绍)
网页的内容其实是一个字符串,response.write()可以接受一个字符串作为参数,所以显然你只需要将网页的内容作为参数传递给response.write()。例如:
var http = require('http');
http.createServer(function(req, res){
var html = ''
+''
+'nodejs'
+''
+''
+ 'hello world! 1234'
+''
+'';
res.writeHead(200,{'Content-Type' : 'text/html'});
res.write(html);
res.end();
}).listen(8888);
在浏览器地址栏输入127.0.0.1:8888查看结果,打开控制台,可以发现网页的所有内容都已经收录了在浏览器中。
一个网页一般收录css样式文件和javascript脚本文件,上例中没有两个文件。现在你可以添加简单的css和javascript文件来看看效果:
var http = require('http');
http.createServer(function(req, res){
var html = ''
+''
+'nodejs'
+''
+''
+''
+''
+ 'hello world!hello world! 1234'
+''
+'';
res.writeHead(200,{'Content-Type' : 'text/html'});
res.write(html);
res.end();
}).listen(8888);
你会发现css文件和javascript文件都没有正确下载。这是因为这段代码中指定的'Content-Type'都是'text/html'类型,而且所有的响应内容都是一样的,当然看不到想要的效果。
我们知道有很多不同的方式来引入 CSS 样式和 javascript 脚本。CSS 样式可以使用外部样式、内部样式和内联样式,而 JavaScript 可以同时使用外部和内部样式。由于无法正确显示外线,您可以尝试其他方法。通过测试可以发现,在网页上无论是css内部样式还是内联样式都可以看到,javascript也是如此。
可以看到浏览器中的文字显示为红色。
但是现代 Web 开发并不提倡这两种方法。现代 Web 开发提倡使用 css 样式和 javascript 来使用 outreach 来方便管理和重用。css文件和javascript文件都是静态文件,我们可以尝试搭建一个简单的静态文件服务,这样就可以在网页中正确使用出站文件。
nodejs抓取动态网页(网站采用动态网页技术可以实现更多的功能,VisualStudio)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-19 19:26
网站使用动态网页技术可以实现更多的功能,比如用户注册、用户登录、在线调查、用户管理、订单管理等。下面我们来看看什么是动态网页设计。
动态网页设计是以Web应用开发项目为基础,以项目开发组织为指导,以XHTML标记语言、ASP动态网站开发技术、VBScript脚本语言、JavaScript客户端脚本语言、ADO数据库访问技术为手段,理论与实践相结合,全面展示了项目分析、设计、制作、总结和评估的过程。
此外,动态网页设计还具有以下特点:
1、增强的性能。编译后的公共语言运行时代码在服务器上运行。利用早期绑定、即时编译、本地优化和开箱即用缓存服务。这相当于在编写单行代码之前显着提高了性能。
2、世界级的工具支持。框架补充了 Visual Studio 集成开发环境中的工具箱和设计器。WYSIWYG 编辑、拖放服务器控件和自动部署只是这个强大工具提供的一些功能。
3、力量和灵活性。因为它基于公共语言运行时,Web 应用程序开发人员可以利用整个平台的强大功能和灵活性。
4、动态网页基于数据库技术,可以大大减少网站维护的工作量。网站使用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等。 查看全部
nodejs抓取动态网页(网站采用动态网页技术可以实现更多的功能,VisualStudio)
网站使用动态网页技术可以实现更多的功能,比如用户注册、用户登录、在线调查、用户管理、订单管理等。下面我们来看看什么是动态网页设计。
动态网页设计是以Web应用开发项目为基础,以项目开发组织为指导,以XHTML标记语言、ASP动态网站开发技术、VBScript脚本语言、JavaScript客户端脚本语言、ADO数据库访问技术为手段,理论与实践相结合,全面展示了项目分析、设计、制作、总结和评估的过程。
此外,动态网页设计还具有以下特点:
1、增强的性能。编译后的公共语言运行时代码在服务器上运行。利用早期绑定、即时编译、本地优化和开箱即用缓存服务。这相当于在编写单行代码之前显着提高了性能。
2、世界级的工具支持。框架补充了 Visual Studio 集成开发环境中的工具箱和设计器。WYSIWYG 编辑、拖放服务器控件和自动部署只是这个强大工具提供的一些功能。
3、力量和灵活性。因为它基于公共语言运行时,Web 应用程序开发人员可以利用整个平台的强大功能和灵活性。
4、动态网页基于数据库技术,可以大大减少网站维护的工作量。网站使用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等。
nodejs抓取动态网页(年前无心工作,上班刷知乎发现一篇分享python爬虫的文章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-17 08:26
多年前无意工作,在工作中发现一篇文章分享python爬虫刷知乎的文章。
感觉他爬的网站里面的妹子都好看,很喜欢这里,个个都是美女。
不幸的是,虽然python已经使用了很长时间,但是它已经被废弃太久了。最近在用nodejs重构后台界面,所以尝试用nodejs实现爬虫。
好吧,让我们开始吧,男孩!
准备好工作了:
系统环境:mac
运行环境:节点
所需模块:request-promise、cheerio、fs
编辑:vscode(谁用谁知道)
简单看一下这些 nodejs 模块:
var request = require('request-promise');
request('http://www.google.com')
.then(function (htmlString) {
console.log(htmlString)
})
.catch(function (err) {
});
任何响应都可以输出到文件流:
request('http://google.com/doodle.png').pipe(
fs.createWriteStream('doodle.png')
)
api类似jQuery,使用超级简单
const cheerio = require('cheerio')
const $ = cheerio.load('Hello world')
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
$.html()
//=> Hello there!
您可以在本地创建目录、创建文件、读取文件等。
网页分析:
分析目标的相册网址网站
因为python文章的作者已经详细分析过网站,我就简单分析一下。
随意打开几张相册,可以看到规则如下:
"https://www.****.com/g/****/"
所以我们可以确定要爬取的base url:
const base_url = 'https://www.****.com/g/';//爬取相册网页的基本网址
然后看几乎每张专辑底部的页码,而我们要抓取整张专辑,所以需要考虑分页情况,点击分页,我们看到分页的url是这样的:
"https://www.****.com/g/****/*.html"
商业逻辑:
实际代码:
app.js 轮询和代码结构
const nvshens = require('./co');
const base_url = 'https://www.nvshens.com/g/';//爬取相册网页的基本网址
let index = 1;
let start = 25380;
const end = 30000;
const main = async (URL) => {
//1.请求网址
const data = await nvshens.getPage(URL);
//2.判断是否存在相册
if (nvshens.getTitle((data.res))) {
//3.下载照片
await nvshens.download(data.res);
//4.请求分页
index++;
const new_url = `${base_url}${start}/${index}.html`;
main(new_url);
} else {
index = 1;
console.log(`${base_url}${start}页面已完成`)
start++;
if (start < end) {
//5.请求下一个网址
main(base_url + start);
} else {
console.log(`${base_url}${end}所有页面已完成`)
}
}
};
main(base_url + start);
co.js //业务代码
var request = require('request-promise'); //网络请求
const cheerio = require("cheerio");//操作dom
const fs = require("fs");//读写文件
const headers = {
"Referer": "https://www.nvshens.com/g/24656/"
}
//因为一些网站在解决盗链问题时是根据Referer的值来判断的,所以在请求头上添加Referer属性就好(可以填爬取网站的地址)。
//另外Referer携带的数据 是用来告诉服务器当前请求是从哪个页面请求过来的。
const basePath = "/Users/用户名/Desktop/mm/";
//自定义mac本地下载目录,需预先创建,windows路径可参考"D:/Users/mm/"
let downloadPath;
let pageIndex = 1;
module.exports = {
//请求页面
async getPage(url) {
const data = {
url,
res: await request({
url: url
})
}
return data;
},
//判断页面是否存在相册
getTitle(data) {
const $ = cheerio.load(data);
if ($("#htilte").text()) {
downloadPath = basePath + $("#htilte").text();
//创建相册
if (!fs.existsSync(downloadPath)) {
fs.mkdirSync(downloadPath);
console.log(`${downloadPath}文件夹创建成功`)
}
return true;
} else {
return false;
}
},
//下载相册照片
async download(data) {
if (data) {
var $ = cheerio.load(data);
$("#hgallery").children().each(async (i, elem) => {
const imgSrc = $(elem).attr('src');
const imgPath = "/" + imgSrc.split("/").pop().split(".")[0] + "." + imgSrc.split(".").pop();
console.log(`${downloadPath + imgPath}下载中`)
const imgData = await request({
uri: imgSrc,
resolveWithFullResponse: true,
headers,
}).pipe(fs.createWriteStream(downloadPath + imgPath));
})
console.log("page done")
}
},
}
开始运行
node app.js
可以实现几个功能,是不是很简单? 查看全部
nodejs抓取动态网页(年前无心工作,上班刷知乎发现一篇分享python爬虫的文章)
多年前无意工作,在工作中发现一篇文章分享python爬虫刷知乎的文章。
感觉他爬的网站里面的妹子都好看,很喜欢这里,个个都是美女。
不幸的是,虽然python已经使用了很长时间,但是它已经被废弃太久了。最近在用nodejs重构后台界面,所以尝试用nodejs实现爬虫。
好吧,让我们开始吧,男孩!
准备好工作了:
系统环境:mac
运行环境:节点
所需模块:request-promise、cheerio、fs
编辑:vscode(谁用谁知道)
简单看一下这些 nodejs 模块:
var request = require('request-promise');
request('http://www.google.com')
.then(function (htmlString) {
console.log(htmlString)
})
.catch(function (err) {
});
任何响应都可以输出到文件流:
request('http://google.com/doodle.png').pipe(
fs.createWriteStream('doodle.png')
)
api类似jQuery,使用超级简单
const cheerio = require('cheerio')
const $ = cheerio.load('Hello world')
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
$.html()
//=> Hello there!
您可以在本地创建目录、创建文件、读取文件等。
网页分析:
分析目标的相册网址网站
因为python文章的作者已经详细分析过网站,我就简单分析一下。
随意打开几张相册,可以看到规则如下:
"https://www.****.com/g/****/"
所以我们可以确定要爬取的base url:
const base_url = 'https://www.****.com/g/';//爬取相册网页的基本网址
然后看几乎每张专辑底部的页码,而我们要抓取整张专辑,所以需要考虑分页情况,点击分页,我们看到分页的url是这样的:
"https://www.****.com/g/****/*.html"
商业逻辑:
实际代码:
app.js 轮询和代码结构
const nvshens = require('./co');
const base_url = 'https://www.nvshens.com/g/';//爬取相册网页的基本网址
let index = 1;
let start = 25380;
const end = 30000;
const main = async (URL) => {
//1.请求网址
const data = await nvshens.getPage(URL);
//2.判断是否存在相册
if (nvshens.getTitle((data.res))) {
//3.下载照片
await nvshens.download(data.res);
//4.请求分页
index++;
const new_url = `${base_url}${start}/${index}.html`;
main(new_url);
} else {
index = 1;
console.log(`${base_url}${start}页面已完成`)
start++;
if (start < end) {
//5.请求下一个网址
main(base_url + start);
} else {
console.log(`${base_url}${end}所有页面已完成`)
}
}
};
main(base_url + start);
co.js //业务代码
var request = require('request-promise'); //网络请求
const cheerio = require("cheerio");//操作dom
const fs = require("fs");//读写文件
const headers = {
"Referer": "https://www.nvshens.com/g/24656/"
}
//因为一些网站在解决盗链问题时是根据Referer的值来判断的,所以在请求头上添加Referer属性就好(可以填爬取网站的地址)。
//另外Referer携带的数据 是用来告诉服务器当前请求是从哪个页面请求过来的。
const basePath = "/Users/用户名/Desktop/mm/";
//自定义mac本地下载目录,需预先创建,windows路径可参考"D:/Users/mm/"
let downloadPath;
let pageIndex = 1;
module.exports = {
//请求页面
async getPage(url) {
const data = {
url,
res: await request({
url: url
})
}
return data;
},
//判断页面是否存在相册
getTitle(data) {
const $ = cheerio.load(data);
if ($("#htilte").text()) {
downloadPath = basePath + $("#htilte").text();
//创建相册
if (!fs.existsSync(downloadPath)) {
fs.mkdirSync(downloadPath);
console.log(`${downloadPath}文件夹创建成功`)
}
return true;
} else {
return false;
}
},
//下载相册照片
async download(data) {
if (data) {
var $ = cheerio.load(data);
$("#hgallery").children().each(async (i, elem) => {
const imgSrc = $(elem).attr('src');
const imgPath = "/" + imgSrc.split("/").pop().split(".")[0] + "." + imgSrc.split(".").pop();
console.log(`${downloadPath + imgPath}下载中`)
const imgData = await request({
uri: imgSrc,
resolveWithFullResponse: true,
headers,
}).pipe(fs.createWriteStream(downloadPath + imgPath));
})
console.log("page done")
}
},
}
开始运行
node app.js
可以实现几个功能,是不是很简单?
nodejs抓取动态网页(基础概念SSR:即服务端渲染(ServerSide)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-17 06:02
基本概念
SSR:服务器端渲染(Server Side Render) 传统的服务器端渲染可以使用Java、php等开发语言来实现。随着Node.js及相关前端技术的不断进步,前端同学也可以使用这个完整的独立服务端渲染。
流程:浏览器发送请求->服务器运行react代码生成页面->服务器返回页面->浏览器下载HTML文档->页面就绪,即:当前页面由服务器生成并发送给浏览器。
对应CSR:客户端渲染过程:浏览器发送请求->服务器返回空白HTML(HTML收录根节点和js文件)->浏览器下载js文件->浏览器运行React代码->页面就绪:当前页面内容由js渲染
如何区分页面是否为服务端渲染:右键->显示网页源代码。如果页面内容在 HTML 文档中,则为服务器端渲染,否则为客户端渲染。
比较
为什么要使用服务器端渲染
首屏加载时间优化,因为SSR直接返回生成内容的HTML,而普通CSR先返回空白HTML,然后浏览器动态加载JavaScript脚本并在页面有内容之前渲染;所以SSR首屏加载更快,减少白屏时间,用户体验更好。
SEO(Search Engine Optimization),搜索关键词时的排名,对于大多数搜索引擎来说,不识别JavaScript内容,只识别HTML内容。 (注:原则上最好不要使用服务端渲染,所以如果只有SEO需求,可以使用预渲染等技术代替)
构建服务器渲染项目
(1)使用Node.js作为服务端和客户端的中间层,承担代理代理,处理cookies等操作。
(2) hydra的使用:在服务端渲染的情况下,使用hydra代替render。它的作用是把相关的事件注入到HTML页面中(即:让React组件的数据跟随HTML 文档一起传递给浏览器页面),可以保持服务器端数据与浏览器端一致,避免闪屏,让首次加载体验更加高效流畅。
ReactDom.hydrate(, document.getElementById('root'));
(3)服务端代码webpack编译:一般会构建一个webpack.server.js文件。除了常规的参数配置外,target参数需要设置为'node'。
const serverConfig = {
target: 'node',
entry: './src/server/index.js',
output: {
filename: 'bundle.js',
path: path.resolve(__dirname, '../dist')
},
externals: [nodeExternals()],
module: {
rules: [{
test: /\.js?$/,
loader: 'babel-loader',
exclude: [
path.join(__dirname, './node_modules')
]
}
...
]
}
(此处省略样式打包,代码压缩,运行坏境配置等等...)
...
};
(4) 使用 react-dom/server 下的 renderToString 方法,将各种复杂的组件和代码在服务器上转换成 HTML 字符串返回给浏览器,并在初始请求上发送标签以加快页面加载速度并允许搜索引擎抓取页面以进行 SEO。
const render = (store, routes, req, context) => {
const content = renderToString((
{renderRoutes(routes)}
));
return `
ssr
${content}
`;
}
app.get('*', function (req, res) {
...
const html = render(store, routes, req, context);
res.send(html);
});
renderToString 的类似函数: i. renderToStaticMarkup:不同的是,renderToStaticMarkup 渲染的是纯 HTML,没有 data-reactid。 JavaScript 加载完成后,由于无法识别之前服务器渲染的内容,重新渲染(可能页面会闪退)。
二。 renderToNodeStream:将 React 元素渲染为其初始 HTML,返回一个可读的输出 HTML 字符串流。
三。 renderToStaticNodeStream:类似于renderToNodeStream,除了这不会创建React内部使用的额外DOM属性,例如data-reactroot。
(5) 使用redux来承担数据准备和状态维护的职责,通常用react-redux、redux-thunk(中间件:发送异步请求到action)。(这个猿目前用的比较多的是Redux和 Mobx,这里以 Redux 为例)。 A. 创建一个 store(服务端需要为每个请求创建一次,客户端只创建一次):
const reducer = combineReducers({
home: homeReducer,
page1: page1Reducer,
page2: page2Reducer
});
export const getStore = (req) => {
return createStore(reducer, applyMiddleware(thunk.withExtraArgument(serverAxios(req))));
}
export const getClientStore = () => {
return createStore(reducer, window.STATE_FROM_SERVER, applyMiddleware(thunk.withExtraArgument(clientAxios)));
}
B. action:负责将数据从应用程序传输到商店,是商店数据的唯一来源
export const getData = () => {
return (dispatch, getState, axiosInstance) => {
return axiosInstance.get('interfaceUrl/xxx')
.then((res) => {
dispatch({
type: 'HOME_LIST',
list: res.list
})
});
}
}
C. reducer:接收旧的状态和动作,返回新的状态,响应动作并发送给store。
export default (state = { list: [] }, action) => {
switch(action.type) {
case 'HOME_LIST':
return {
...state,
list: action.list
}
default:
return state;
}
}
export default (state = { list: [] }, action) => {
switch(action.type) {
case 'HOME_LIST':
return {
...state,
list: action.list
}
default:
return state;
}
}
D. Provider 使用 react-redux 的 connect 将组件连接到 store
Provider 将之前创建的 store 作为 prop 传递给 Provider
const content = renderToString((
{renderRoutes(routes)}
));
connect([mapStateToProps], [mapDispatchToProps], [mergeProps], [options]) 接收四个参数。前两个属性是常用的。 mapStateToProps 函数允许我们将 store 中的数据作为 props 绑定到组件。 mapDispatchToProps 将 Actions 作为 props 绑定到组件
connect(mapStateToProps(),mapDispatchToProps())(MyComponent)
(6) 使用react-router承担路由职责。服务端路由和客户端路由不同。它是无状态的。React提供了一个无状态组件StaticRouter,它将当前URL传递给StaticRouter和调用 ReactDOMServer.renderToString() 来匹配路由视图。
服务器
import { StaticRouter } from 'react-router-dom';
import { renderRoutes } from 'react-router-config'
import routes from './router.js'
{renderRoutes(routes)}
浏览器端
import { BrowserRouter } from 'react-router-dom';
import { renderRoutes } from 'react-router-config'
import routes from './router.js'
{renderRoutes(routes)}
当浏览器的地址栏发生变化时,前端会匹配路由视图,而由于req.path发生变化,服务器会匹配路由视图,保持了前后端路由的一致性意见。页面刷新后,当前视图仍能正常显示。如果只有浏览器端路由,使用BrowserRouter,当页面地址改变后刷新页面时,会因为没有对应的html而找不到页面。返回一个完整的html给客户端,页面依旧正常显示。推荐使用react-router-config插件,然后在StaticRouter和BrowserRouter标签的子元素中添加renderRoutes(routes)如上:创建router.js文件
const routes = [{ component: Root,
routes: [
{ path: '/',
exact: true,
component: Home,
loadData: Home.loadData
},
{ path: '/child/:id',
component: Child,
loadData: Child.loadData
routes: [
path: '/child/:id/grand-child',
component: GrandChild,
loadData: GrandChild.loadData
]
}
]
}];
当浏览器请求一个地址时,server.js可以在实际渲染之前通过matchRouters判断要渲染的内容,调用loaderData函数进行action dispatch,返回promise->promiseAll->renderToString,最后生成HTML文档返回。
import { matchRoutes } from 'react-router-config'
const loadBranchData = (location) => {
const branch = matchRoutes(routes, location.pathname)
const promises = branch.map(({ route, match }) => {
return route.loadData
? route.loadData(match)
: Promise.resolve(null)
})
return Promise.all(promises)
}
(7)写组件的时候注意代码同构(即:一组React代码在服务端执行一次,在客户端执行一次)由于服务端绑定事件无效,服务端只返回Page样式(&灌水数据),同时返回JavaScript文件,该事件只有在浏览器下载执行JavaScript时才能绑定,我们希望这个过程只需要写代码一次,此时会用到同构和服务,客户端渲染样式,客户端执行时绑定事件。
优点:共享前端代码,节省开发时间缺点:由于服务器端和浏览器环境的不同,会出现一些问题,比如找不到document等对象,DOM计算错误,不一致前端渲染和服务端渲染之间的内容等;前端可以做非常复杂的请求合并和延迟处理,但是对于同构来说,所有这些请求只有在提前得到结果时才会渲染。
以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Script Home。 查看全部
nodejs抓取动态网页(基础概念SSR:即服务端渲染(ServerSide)(图))
基本概念
SSR:服务器端渲染(Server Side Render) 传统的服务器端渲染可以使用Java、php等开发语言来实现。随着Node.js及相关前端技术的不断进步,前端同学也可以使用这个完整的独立服务端渲染。
流程:浏览器发送请求->服务器运行react代码生成页面->服务器返回页面->浏览器下载HTML文档->页面就绪,即:当前页面由服务器生成并发送给浏览器。
对应CSR:客户端渲染过程:浏览器发送请求->服务器返回空白HTML(HTML收录根节点和js文件)->浏览器下载js文件->浏览器运行React代码->页面就绪:当前页面内容由js渲染
如何区分页面是否为服务端渲染:右键->显示网页源代码。如果页面内容在 HTML 文档中,则为服务器端渲染,否则为客户端渲染。
比较
为什么要使用服务器端渲染
首屏加载时间优化,因为SSR直接返回生成内容的HTML,而普通CSR先返回空白HTML,然后浏览器动态加载JavaScript脚本并在页面有内容之前渲染;所以SSR首屏加载更快,减少白屏时间,用户体验更好。
SEO(Search Engine Optimization),搜索关键词时的排名,对于大多数搜索引擎来说,不识别JavaScript内容,只识别HTML内容。 (注:原则上最好不要使用服务端渲染,所以如果只有SEO需求,可以使用预渲染等技术代替)
构建服务器渲染项目
(1)使用Node.js作为服务端和客户端的中间层,承担代理代理,处理cookies等操作。
(2) hydra的使用:在服务端渲染的情况下,使用hydra代替render。它的作用是把相关的事件注入到HTML页面中(即:让React组件的数据跟随HTML 文档一起传递给浏览器页面),可以保持服务器端数据与浏览器端一致,避免闪屏,让首次加载体验更加高效流畅。
ReactDom.hydrate(, document.getElementById('root'));
(3)服务端代码webpack编译:一般会构建一个webpack.server.js文件。除了常规的参数配置外,target参数需要设置为'node'。
const serverConfig = {
target: 'node',
entry: './src/server/index.js',
output: {
filename: 'bundle.js',
path: path.resolve(__dirname, '../dist')
},
externals: [nodeExternals()],
module: {
rules: [{
test: /\.js?$/,
loader: 'babel-loader',
exclude: [
path.join(__dirname, './node_modules')
]
}
...
]
}
(此处省略样式打包,代码压缩,运行坏境配置等等...)
...
};
(4) 使用 react-dom/server 下的 renderToString 方法,将各种复杂的组件和代码在服务器上转换成 HTML 字符串返回给浏览器,并在初始请求上发送标签以加快页面加载速度并允许搜索引擎抓取页面以进行 SEO。
const render = (store, routes, req, context) => {
const content = renderToString((
{renderRoutes(routes)}
));
return `
ssr
${content}
`;
}
app.get('*', function (req, res) {
...
const html = render(store, routes, req, context);
res.send(html);
});
renderToString 的类似函数: i. renderToStaticMarkup:不同的是,renderToStaticMarkup 渲染的是纯 HTML,没有 data-reactid。 JavaScript 加载完成后,由于无法识别之前服务器渲染的内容,重新渲染(可能页面会闪退)。
二。 renderToNodeStream:将 React 元素渲染为其初始 HTML,返回一个可读的输出 HTML 字符串流。
三。 renderToStaticNodeStream:类似于renderToNodeStream,除了这不会创建React内部使用的额外DOM属性,例如data-reactroot。
(5) 使用redux来承担数据准备和状态维护的职责,通常用react-redux、redux-thunk(中间件:发送异步请求到action)。(这个猿目前用的比较多的是Redux和 Mobx,这里以 Redux 为例)。 A. 创建一个 store(服务端需要为每个请求创建一次,客户端只创建一次):
const reducer = combineReducers({
home: homeReducer,
page1: page1Reducer,
page2: page2Reducer
});
export const getStore = (req) => {
return createStore(reducer, applyMiddleware(thunk.withExtraArgument(serverAxios(req))));
}
export const getClientStore = () => {
return createStore(reducer, window.STATE_FROM_SERVER, applyMiddleware(thunk.withExtraArgument(clientAxios)));
}
B. action:负责将数据从应用程序传输到商店,是商店数据的唯一来源
export const getData = () => {
return (dispatch, getState, axiosInstance) => {
return axiosInstance.get('interfaceUrl/xxx')
.then((res) => {
dispatch({
type: 'HOME_LIST',
list: res.list
})
});
}
}
C. reducer:接收旧的状态和动作,返回新的状态,响应动作并发送给store。
export default (state = { list: [] }, action) => {
switch(action.type) {
case 'HOME_LIST':
return {
...state,
list: action.list
}
default:
return state;
}
}
export default (state = { list: [] }, action) => {
switch(action.type) {
case 'HOME_LIST':
return {
...state,
list: action.list
}
default:
return state;
}
}
D. Provider 使用 react-redux 的 connect 将组件连接到 store
Provider 将之前创建的 store 作为 prop 传递给 Provider
const content = renderToString((
{renderRoutes(routes)}
));
connect([mapStateToProps], [mapDispatchToProps], [mergeProps], [options]) 接收四个参数。前两个属性是常用的。 mapStateToProps 函数允许我们将 store 中的数据作为 props 绑定到组件。 mapDispatchToProps 将 Actions 作为 props 绑定到组件
connect(mapStateToProps(),mapDispatchToProps())(MyComponent)
(6) 使用react-router承担路由职责。服务端路由和客户端路由不同。它是无状态的。React提供了一个无状态组件StaticRouter,它将当前URL传递给StaticRouter和调用 ReactDOMServer.renderToString() 来匹配路由视图。
服务器
import { StaticRouter } from 'react-router-dom';
import { renderRoutes } from 'react-router-config'
import routes from './router.js'
{renderRoutes(routes)}
浏览器端
import { BrowserRouter } from 'react-router-dom';
import { renderRoutes } from 'react-router-config'
import routes from './router.js'
{renderRoutes(routes)}
当浏览器的地址栏发生变化时,前端会匹配路由视图,而由于req.path发生变化,服务器会匹配路由视图,保持了前后端路由的一致性意见。页面刷新后,当前视图仍能正常显示。如果只有浏览器端路由,使用BrowserRouter,当页面地址改变后刷新页面时,会因为没有对应的html而找不到页面。返回一个完整的html给客户端,页面依旧正常显示。推荐使用react-router-config插件,然后在StaticRouter和BrowserRouter标签的子元素中添加renderRoutes(routes)如上:创建router.js文件
const routes = [{ component: Root,
routes: [
{ path: '/',
exact: true,
component: Home,
loadData: Home.loadData
},
{ path: '/child/:id',
component: Child,
loadData: Child.loadData
routes: [
path: '/child/:id/grand-child',
component: GrandChild,
loadData: GrandChild.loadData
]
}
]
}];
当浏览器请求一个地址时,server.js可以在实际渲染之前通过matchRouters判断要渲染的内容,调用loaderData函数进行action dispatch,返回promise->promiseAll->renderToString,最后生成HTML文档返回。
import { matchRoutes } from 'react-router-config'
const loadBranchData = (location) => {
const branch = matchRoutes(routes, location.pathname)
const promises = branch.map(({ route, match }) => {
return route.loadData
? route.loadData(match)
: Promise.resolve(null)
})
return Promise.all(promises)
}
(7)写组件的时候注意代码同构(即:一组React代码在服务端执行一次,在客户端执行一次)由于服务端绑定事件无效,服务端只返回Page样式(&灌水数据),同时返回JavaScript文件,该事件只有在浏览器下载执行JavaScript时才能绑定,我们希望这个过程只需要写代码一次,此时会用到同构和服务,客户端渲染样式,客户端执行时绑定事件。
优点:共享前端代码,节省开发时间缺点:由于服务器端和浏览器环境的不同,会出现一些问题,比如找不到document等对象,DOM计算错误,不一致前端渲染和服务端渲染之间的内容等;前端可以做非常复杂的请求合并和延迟处理,但是对于同构来说,所有这些请求只有在提前得到结果时才会渲染。
以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Script Home。
nodejs抓取动态网页(一下如何抓取动态页面?抓取一个页面的方法十分简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-17 05:20
当我们要抓取一个页面的内容时,首先要做的不是写代码,而是分析页面,判断是静态页面还是动态页面。抓取静态页面的方法很简单。可以直接解析html源码,然后分析解析。不明白的可以参考我上一篇文章Scrapy抓取豆瓣电影资料。这里我主要介绍如何抓取。动态页面。
抓取动态页面有两种方法:
第一种方法是使用第三方工具模拟浏览器的行为来加载数据。例如:Selenium、PhantomJs。这种方法的优点是不必考虑动态页面的各种变化,但性能较低。
第二种方法是分析页面,找到对应的请求接口,直接获取数据。这种方式的优点是性能高,但缺点也很明显,就是获取API接口比较麻烦。
我这里用第二种方法爬取动态页面。
1.浏览器打开页面,查看网页源码,发现源码中没有图片信息。这是一个动态加载的页面,它是一个动态页面的异步ajax请求。
2.分析页面,提取API接口,通过F12可以找到review元素。
3.打开上面的url,发现传入的数据是json格式的,所以我们拿到response响应后,首先要使用json.loads()来解析数据。
4.观察API接口,可以发现有几个参数,ch、sn、listtype、temp,通过改变这些参数的值可以得到不同的内容。
通过分析发现,ch参数代表图片的分类,比如beauty代表漂亮的图片,sn代表图片的数量,比如0代表1到30之间的图片,30代表31到60之间的图片。
分析完这些参数,我们就确定了我们需要请求的url地址。这里的url不像静态页面中程序自动获取的a标签中的href,而是我们需要自动设置。我们可以重写 start_requests 方法。指定要检索的 url。
5.写我们的蜘蛛
# -*- coding: utf-8 -*-
from json import loads
import scrapy
from urllib.parse import urlencode
from image360.items import BeautyItem
class ImageSpider(scrapy.Spider):
name = 'image'
allowed_domains = ['image.so.com']
# 重写Spider中的start_requests方法:指定开始url
def start_requests(self):
base_url = 'http://image.so.com/zj?'
param = {'ch': 'beauty', 'listtype': 'new', 'temp': '1'}
# 可以根据需要爬取不同数量的图片,此处只爬取60张图片
for page in range(2):
param['sn'] = page * 30
full_url = base_url + urlencode(param)
yield scrapy.Request(url=full_url, callback=self.parse)
def parse(self, response):
# 获取到的内容是json数据
# 用json.loads()解析数据
# 此处的response没有content
model_dict = loads(response.text)
for elem in model_dict['list']:
item = BeautyItem()
item['title'] = elem['group_title']
item['tag'] = elem['tag']
item['height'] = elem['cover_width']
item['width'] = elem['cover_height']
item['url'] = elem['qhimg_url']
yield item
6.写入项目并定义保存的字段
import scrapy
class BeautyItem(scrapy.Item):
title = scrapy.Field()
tag = scrapy.Field()
height = scrapy.Field()
width = scrapy.Field()
url = scrapy.Field()
7.写一个管道完成数据持久化操作,包括下载图片和保存图片信息到mongo。
Scrapy 提供了一个项目管道来下载属于特定项目的图像。比如你在抓产品的时候,也想把他们的图片下载到本地,这可以通过图片管道来实现。这是在 ImagesPipenine 类中实现的,该类提供了一种方便的方法以及附加功能来在本地下载和存储图像。该类提供了许多处理图像的方法。具体可以查看官方文档的中文版。
# -*- coding: utf-8 -*-
import logging
import pymongo
import scrapy
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
logger = logging.getLogger('SaveImagePipeline')
# 继承ImagesPipenine类,这是图片管道
class SaveImagePipeline(ImagesPipeline):
"""
下载图片
"""
def get_media_requests(self, item, info):
# 此方法获取的是requests 所以用yield 不要return
yield scrapy.Request(url=item['url'])
def item_completed(self, results, item, info):
"""
文件下载完成之后,返回一个列表 results
列表中是一个元组,第一个值是布尔值,请求成功会失败,第二个值的下载到的资源
"""
if not results[0][0]:
# 如果下载失败,就抛出异常,并丢弃这个item
# 被丢弃的item将不会被之后的pipeline组件所处理
raise DropItem('下载失败')
# 打印日志
logger.debug('下载图片成功')
return item
def file_path(self, request, response=None, info=None):
"""
返回文件名
"""
return request.url.split('/')[-1]
class SaveToMongoPipeline(object):
"""
保存图片信息到数据库
"""
def __init__(self, mongodb_server, mongodb_port, mongodb_db, mongodb_collection):
self.mongodb_server = mongodb_server
self.mongodb_port = mongodb_port
self.mongodb_db = mongodb_db
self.mongodb_collection = mongodb_collection
def open_spider(self, spider):
# 当spider被开启时,这个方法被调用
self.connection = pymongo.MongoClient(self.mongodb_server, self.mongodb_port)
db = self.connection[self.mongodb_db]
self.collection = db[self.mongodb_collection]
def close_spider(self, spider):
# 当spider被关闭时,这个方法被调用。
self.connection.close()
# 依赖注入
@classmethod
def from_crawler(cls, crawler):
# cls() 会调用初始化方法
return cls(crawler.settings.get('MONGODB_SERVER'),
crawler.settings.get('MONGODB_PORT'),
crawler.settings.get('MONGODB_DB'),
crawler.settings.get('MONGODB_COLLECTION'))
def process_item(self, item, spider):
post = {'title': item['title'], 'tag': item['tag'],
'width': item['width'], 'height': item['height'], 'url': item['url']}
self.collection.insert_one(post)
return item
8.写入设置并完成配置。这里只写需要配置的内容。
9.启动蜘蛛
在启动spider之前,我们还需要安装几个包,pypiwin32、pilllow、pymongo
pip install pypiwin32
pip install pillow
pip install pymongo
安装完成后就可以启动spider了
scrapy crawl image
10.查看结果:
获取到的图片返回的内容:
将图片保存到指定路径:
一个爬取动态页面和下载图片的爬虫就完成了。其实写起来很简单。关键是分析API接口,重写start_requests方法。 查看全部
nodejs抓取动态网页(一下如何抓取动态页面?抓取一个页面的方法十分简单)
当我们要抓取一个页面的内容时,首先要做的不是写代码,而是分析页面,判断是静态页面还是动态页面。抓取静态页面的方法很简单。可以直接解析html源码,然后分析解析。不明白的可以参考我上一篇文章Scrapy抓取豆瓣电影资料。这里我主要介绍如何抓取。动态页面。
抓取动态页面有两种方法:
第一种方法是使用第三方工具模拟浏览器的行为来加载数据。例如:Selenium、PhantomJs。这种方法的优点是不必考虑动态页面的各种变化,但性能较低。
第二种方法是分析页面,找到对应的请求接口,直接获取数据。这种方式的优点是性能高,但缺点也很明显,就是获取API接口比较麻烦。
我这里用第二种方法爬取动态页面。
1.浏览器打开页面,查看网页源码,发现源码中没有图片信息。这是一个动态加载的页面,它是一个动态页面的异步ajax请求。
2.分析页面,提取API接口,通过F12可以找到review元素。
3.打开上面的url,发现传入的数据是json格式的,所以我们拿到response响应后,首先要使用json.loads()来解析数据。
4.观察API接口,可以发现有几个参数,ch、sn、listtype、temp,通过改变这些参数的值可以得到不同的内容。
通过分析发现,ch参数代表图片的分类,比如beauty代表漂亮的图片,sn代表图片的数量,比如0代表1到30之间的图片,30代表31到60之间的图片。
分析完这些参数,我们就确定了我们需要请求的url地址。这里的url不像静态页面中程序自动获取的a标签中的href,而是我们需要自动设置。我们可以重写 start_requests 方法。指定要检索的 url。
5.写我们的蜘蛛
# -*- coding: utf-8 -*-
from json import loads
import scrapy
from urllib.parse import urlencode
from image360.items import BeautyItem
class ImageSpider(scrapy.Spider):
name = 'image'
allowed_domains = ['image.so.com']
# 重写Spider中的start_requests方法:指定开始url
def start_requests(self):
base_url = 'http://image.so.com/zj?'
param = {'ch': 'beauty', 'listtype': 'new', 'temp': '1'}
# 可以根据需要爬取不同数量的图片,此处只爬取60张图片
for page in range(2):
param['sn'] = page * 30
full_url = base_url + urlencode(param)
yield scrapy.Request(url=full_url, callback=self.parse)
def parse(self, response):
# 获取到的内容是json数据
# 用json.loads()解析数据
# 此处的response没有content
model_dict = loads(response.text)
for elem in model_dict['list']:
item = BeautyItem()
item['title'] = elem['group_title']
item['tag'] = elem['tag']
item['height'] = elem['cover_width']
item['width'] = elem['cover_height']
item['url'] = elem['qhimg_url']
yield item
6.写入项目并定义保存的字段
import scrapy
class BeautyItem(scrapy.Item):
title = scrapy.Field()
tag = scrapy.Field()
height = scrapy.Field()
width = scrapy.Field()
url = scrapy.Field()
7.写一个管道完成数据持久化操作,包括下载图片和保存图片信息到mongo。
Scrapy 提供了一个项目管道来下载属于特定项目的图像。比如你在抓产品的时候,也想把他们的图片下载到本地,这可以通过图片管道来实现。这是在 ImagesPipenine 类中实现的,该类提供了一种方便的方法以及附加功能来在本地下载和存储图像。该类提供了许多处理图像的方法。具体可以查看官方文档的中文版。
# -*- coding: utf-8 -*-
import logging
import pymongo
import scrapy
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
logger = logging.getLogger('SaveImagePipeline')
# 继承ImagesPipenine类,这是图片管道
class SaveImagePipeline(ImagesPipeline):
"""
下载图片
"""
def get_media_requests(self, item, info):
# 此方法获取的是requests 所以用yield 不要return
yield scrapy.Request(url=item['url'])
def item_completed(self, results, item, info):
"""
文件下载完成之后,返回一个列表 results
列表中是一个元组,第一个值是布尔值,请求成功会失败,第二个值的下载到的资源
"""
if not results[0][0]:
# 如果下载失败,就抛出异常,并丢弃这个item
# 被丢弃的item将不会被之后的pipeline组件所处理
raise DropItem('下载失败')
# 打印日志
logger.debug('下载图片成功')
return item
def file_path(self, request, response=None, info=None):
"""
返回文件名
"""
return request.url.split('/')[-1]
class SaveToMongoPipeline(object):
"""
保存图片信息到数据库
"""
def __init__(self, mongodb_server, mongodb_port, mongodb_db, mongodb_collection):
self.mongodb_server = mongodb_server
self.mongodb_port = mongodb_port
self.mongodb_db = mongodb_db
self.mongodb_collection = mongodb_collection
def open_spider(self, spider):
# 当spider被开启时,这个方法被调用
self.connection = pymongo.MongoClient(self.mongodb_server, self.mongodb_port)
db = self.connection[self.mongodb_db]
self.collection = db[self.mongodb_collection]
def close_spider(self, spider):
# 当spider被关闭时,这个方法被调用。
self.connection.close()
# 依赖注入
@classmethod
def from_crawler(cls, crawler):
# cls() 会调用初始化方法
return cls(crawler.settings.get('MONGODB_SERVER'),
crawler.settings.get('MONGODB_PORT'),
crawler.settings.get('MONGODB_DB'),
crawler.settings.get('MONGODB_COLLECTION'))
def process_item(self, item, spider):
post = {'title': item['title'], 'tag': item['tag'],
'width': item['width'], 'height': item['height'], 'url': item['url']}
self.collection.insert_one(post)
return item
8.写入设置并完成配置。这里只写需要配置的内容。
9.启动蜘蛛
在启动spider之前,我们还需要安装几个包,pypiwin32、pilllow、pymongo
pip install pypiwin32
pip install pillow
pip install pymongo
安装完成后就可以启动spider了
scrapy crawl image
10.查看结果:
获取到的图片返回的内容:
将图片保存到指定路径:
一个爬取动态页面和下载图片的爬虫就完成了。其实写起来很简单。关键是分析API接口,重写start_requests方法。
nodejs抓取动态网页(PhantomJs就是没有没有界面的浏览器界面界面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-16 07:08
我渴望一个更强大,但使用起来不太麻烦的工具。
幻影
上述问题可以用 PhantomJs 解决。
PhantomJs 是一个没有界面的浏览器。
安装
使用 cnpm 安装 PhantomJS:
cnpm install phantomjs --save-dev
我这里没有选择全局安装,因为如果我是全局安装的,当别人使用我的源代码时,我不知道有这样的依赖,项目运行不了。
如果你也选择本地安装,那么你需要在 package.json 中的脚本中添加一段:
"phantomjs":"node_modules/.bin/phantomjs"
这个后面会用到,到这里,安装就完成了。
写代码
我们新建一个文件,名字随意,这里我新建一个 main.js :
var webpage = require('webpage');
var page = webpage.create();
page.open('http://www.baidu.com/', function (status) {
var data;
if (status === 'fail') {
console.log('open page fail!');
} else {
console.log(page.content);//打印出HTML内容
}
page.close();//关闭网页
phantom.exit();//退出phantomjs命令行
});
这里有一个网页模块,我们刚才明明没有这个模块,为什么要引用这个模块???
当然,不能引用。如果我们使用 node main.js 来运行这段代码,它就不会运行。我们应该像这样运行这段代码:
npm run phantomjs main.js
这里的 npm run phantomjs 对应我们之前在 package.json 中添加的命令,非常方便,几乎和 http 模块一样方便。
page.content是html代码,这个页面对象属性很多,功能更强大。
此时,您已经开始了。如果想了解更多,可以去phantomjs官网查看文档。
以上内容就是如何在Node.JS中使用PhantomJs爬取网页。你有没有学到任何知识或技能?如果您想学习更多技能或丰富知识储备,请关注易宿云行业资讯频道。 查看全部
nodejs抓取动态网页(PhantomJs就是没有没有界面的浏览器界面界面)
我渴望一个更强大,但使用起来不太麻烦的工具。
幻影
上述问题可以用 PhantomJs 解决。
PhantomJs 是一个没有界面的浏览器。
安装
使用 cnpm 安装 PhantomJS:
cnpm install phantomjs --save-dev
我这里没有选择全局安装,因为如果我是全局安装的,当别人使用我的源代码时,我不知道有这样的依赖,项目运行不了。
如果你也选择本地安装,那么你需要在 package.json 中的脚本中添加一段:
"phantomjs":"node_modules/.bin/phantomjs"
这个后面会用到,到这里,安装就完成了。
写代码
我们新建一个文件,名字随意,这里我新建一个 main.js :
var webpage = require('webpage');
var page = webpage.create();
page.open('http://www.baidu.com/', function (status) {
var data;
if (status === 'fail') {
console.log('open page fail!');
} else {
console.log(page.content);//打印出HTML内容
}
page.close();//关闭网页
phantom.exit();//退出phantomjs命令行
});
这里有一个网页模块,我们刚才明明没有这个模块,为什么要引用这个模块???
当然,不能引用。如果我们使用 node main.js 来运行这段代码,它就不会运行。我们应该像这样运行这段代码:
npm run phantomjs main.js
这里的 npm run phantomjs 对应我们之前在 package.json 中添加的命令,非常方便,几乎和 http 模块一样方便。
page.content是html代码,这个页面对象属性很多,功能更强大。
此时,您已经开始了。如果想了解更多,可以去phantomjs官网查看文档。
以上内容就是如何在Node.JS中使用PhantomJs爬取网页。你有没有学到任何知识或技能?如果您想学习更多技能或丰富知识储备,请关注易宿云行业资讯频道。
nodejs抓取动态网页(nodejs抓取动态网页实现方案抓取src网页方案介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-16 05:05
nodejs抓取动态网页实现方案:1。首先得有nodejs环境,打开webpack插件的app。js进入test脚本所在的文件夹,然后修改test脚本:varwebpack=require('webpack');varwebpackconfig={entry:{main:'。/main。js',src:['。
/main。js']},output:{path:path。resolve(__dirname,'entry'),dirname:'entry'}};webpackconfig。prod=true,这样webpack会知道自己所在的路径,自动帮你在这个路径下加入一个内容改动配置文件的扩展名为。js的文件!你再修改,就不会通过错误信息来寻找路径了;2。
修改url获取动态网页地址如何获取动态页的网址?其实之前已经有一些方案,这里我可以介绍几个:如果你是用电脑浏览器访问:。
1)登录“腾讯云服务器管理平台”进入设置
2)获取网站域名信息-ssl/https/
3)在浏览器访问-ssl/https/entry/;entry=
4)获取url地址
2)手机app访问:
2)获取网站域名信息-ip_location/
8)点击新建-按照自定义url字符串;
1)输入访问动态网址;
2)在获取url的基础上,输入授权码-checkingincrement,还可以获取到一些有用的信息!这个方法,适合在一个月内获取无数个网址,
1)在安装nodejs的环境中进入目录test.js的根目录,修改文件test.js为extensions/loadawgs,在它的目录下新建loadawgs文件,不断复制/etc/node_modules/loadawgs,再修改这个文件,文件名为loadawgs.js,不断获取你所需要的任何文件,直到获取到设置的文件名;注意第3点,导出的文件,必须在导出前存在。 查看全部
nodejs抓取动态网页(nodejs抓取动态网页实现方案抓取src网页方案介绍)
nodejs抓取动态网页实现方案:1。首先得有nodejs环境,打开webpack插件的app。js进入test脚本所在的文件夹,然后修改test脚本:varwebpack=require('webpack');varwebpackconfig={entry:{main:'。/main。js',src:['。
/main。js']},output:{path:path。resolve(__dirname,'entry'),dirname:'entry'}};webpackconfig。prod=true,这样webpack会知道自己所在的路径,自动帮你在这个路径下加入一个内容改动配置文件的扩展名为。js的文件!你再修改,就不会通过错误信息来寻找路径了;2。
修改url获取动态网页地址如何获取动态页的网址?其实之前已经有一些方案,这里我可以介绍几个:如果你是用电脑浏览器访问:。
1)登录“腾讯云服务器管理平台”进入设置
2)获取网站域名信息-ssl/https/
3)在浏览器访问-ssl/https/entry/;entry=
4)获取url地址
2)手机app访问:
2)获取网站域名信息-ip_location/
8)点击新建-按照自定义url字符串;
1)输入访问动态网址;
2)在获取url的基础上,输入授权码-checkingincrement,还可以获取到一些有用的信息!这个方法,适合在一个月内获取无数个网址,
1)在安装nodejs的环境中进入目录test.js的根目录,修改文件test.js为extensions/loadawgs,在它的目录下新建loadawgs文件,不断复制/etc/node_modules/loadawgs,再修改这个文件,文件名为loadawgs.js,不断获取你所需要的任何文件,直到获取到设置的文件名;注意第3点,导出的文件,必须在导出前存在。
nodejs抓取动态网页(配置文件技术点puppeteer官方APIpuppeteer提供一个高级API来控制Chrome或者Chromium )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-10 01:04
)
本篇文章为大家带来Node如何实现头条视频批量抓取并保存(代码实现)。具有一定的参考价值。有需要的朋友可以参考一下,希望对你有帮助。
介绍
批量爬取视频或图片的一般套路是使用爬虫获取一组文件链接,然后通过writeFile等方法将文件一个一个保存。但是,头条的视频无法捕捉到需要爬取的html文件(服务器端渲染输出)中的视频链接。视频链接是在客户端渲染页面时,通过一些js文件中的算法或解密方法,根据视频的已知key或hash值,动态计算并添加到video标签中的。这也是网站的防爬措施。
当我们浏览这些页面时,我们可以通过审计元素看到计算出来的文件地址。但是,在批量下载的时候,手动一个一个的获取视频链接显然是不可取的。令人高兴的是,puppeteer 提供了模拟访问 Chrome 的能力,允许我们抓取浏览器呈现的最终页面。
项目启动命令
npm i
npm start
注意:安装puppeteer的过程有点慢,请耐心等待。
配置文件
// 配置相关
module.exports = {
originPath: 'https://www.ixigua.com', // 页面请求地址
savePath: 'D:/videoZZ' // 存放路径
}
技术点木偶师
官方 API
puppeteer 提供了一个高级 API 来控制 Chrome 或 Chromium。
傀儡师的主要作用:
使用的 API:
代码示例
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
视频文件下载方法
const downloadVideo = async video => {
// 判断视频文件是否已经下载
if (!fs.existsSync(`${config.savePath}/${video.title}.mp4`)) {
await getVideoData(video.src, 'binary').then(fileData => {
console.log('下载视频中:', video.title)
savefileToPath(video.title, fileData).then(res =>
console.log(`${res}: ${video.title}`)
)
})
} else {
console.log(`视频文件已存在:${video.title}`)
}
}
savefileToPath (fileName, fileData) {
let fileFullName = `${config.savePath}/${fileName}.mp4`
return new Promise((resolve, reject) => {
fs.writeFile(fileFullName, fileData, 'binary', function (err) {
if (err) {
console.log('savefileToPath error:', err)
}
resolve('已下载')
})
})
}
目标网站:西瓜视频
项目功能:下载标题下的最新20个视频【微臣财经】
项目地址:Github地址
以上就是Node如何实现头条视频批量抓取和保存的详细内容(代码实现)。更多详情请关注php中文网文章其他相关话题!
查看全部
nodejs抓取动态网页(配置文件技术点puppeteer官方APIpuppeteer提供一个高级API来控制Chrome或者Chromium
)
本篇文章为大家带来Node如何实现头条视频批量抓取并保存(代码实现)。具有一定的参考价值。有需要的朋友可以参考一下,希望对你有帮助。
介绍
批量爬取视频或图片的一般套路是使用爬虫获取一组文件链接,然后通过writeFile等方法将文件一个一个保存。但是,头条的视频无法捕捉到需要爬取的html文件(服务器端渲染输出)中的视频链接。视频链接是在客户端渲染页面时,通过一些js文件中的算法或解密方法,根据视频的已知key或hash值,动态计算并添加到video标签中的。这也是网站的防爬措施。
当我们浏览这些页面时,我们可以通过审计元素看到计算出来的文件地址。但是,在批量下载的时候,手动一个一个的获取视频链接显然是不可取的。令人高兴的是,puppeteer 提供了模拟访问 Chrome 的能力,允许我们抓取浏览器呈现的最终页面。
项目启动命令
npm i
npm start
注意:安装puppeteer的过程有点慢,请耐心等待。
配置文件
// 配置相关
module.exports = {
originPath: 'https://www.ixigua.com', // 页面请求地址
savePath: 'D:/videoZZ' // 存放路径
}
技术点木偶师
官方 API
puppeteer 提供了一个高级 API 来控制 Chrome 或 Chromium。
傀儡师的主要作用:
使用的 API:
代码示例
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
视频文件下载方法
const downloadVideo = async video => {
// 判断视频文件是否已经下载
if (!fs.existsSync(`${config.savePath}/${video.title}.mp4`)) {
await getVideoData(video.src, 'binary').then(fileData => {
console.log('下载视频中:', video.title)
savefileToPath(video.title, fileData).then(res =>
console.log(`${res}: ${video.title}`)
)
})
} else {
console.log(`视频文件已存在:${video.title}`)
}
}
savefileToPath (fileName, fileData) {
let fileFullName = `${config.savePath}/${fileName}.mp4`
return new Promise((resolve, reject) => {
fs.writeFile(fileFullName, fileData, 'binary', function (err) {
if (err) {
console.log('savefileToPath error:', err)
}
resolve('已下载')
})
})
}
目标网站:西瓜视频
项目功能:下载标题下的最新20个视频【微臣财经】
项目地址:Github地址
以上就是Node如何实现头条视频批量抓取和保存的详细内容(代码实现)。更多详情请关注php中文网文章其他相关话题!
nodejs抓取动态网页(1.技术选型监控的意义和测试的本质一致的分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-07 00:16
1. 为什么需要前端监控系统
通常一个大型的web项目中会有很多监控系统,比如后端服务API监控、接口存活、调用、延迟等监控,一般用于监控后端接口数据级别的信息。而对于大型的网站系统,从后端服务到前端展示会有很多层:内网VIP、CDN等。
但是这些监控并不能准确反映用户看到的前端页面的状态,比如页面上第三方系统数据调用失败、模块加载异常、数据不正确、天窗茫然地打开。
相关厂商内容
原生动态最新技术解析智能时代不可错过的大前端性能优化最佳实践经验谈百度技术沙龙免费注册,解析百度人脸识别技术架构师应把握这些技术趋势
这时候就需要从前端 DOM 展示的角度去分析采集用户真实看到的东西,从而检测页面是否存在异常问题。
2. 监控系统需要解决的问题
当页面出现以下问题时,您需要及时通过邮件或短信方式向相关人员报告,以解决问题。
3. 技术选型
监控的含义和测试的含义本质上是一样的,都是对已经上线的功能进行回归测试,但不同的是监控需要长期持续的、反复出现的回归测试,而测试之后只需要做一次发射,市场投入。回归测试。
由于监控和测试的性质是相同的,我们可以用测试的方法来做监控系统。在自动化测试技术遍地开花的时代,有很多有用的自动化工具,我们只需要整合这些自动化工具供我们使用。
节点JS
NodeJS 是一个 JavaScript 运行环境,NodeJS 支持非阻塞 I/O 和异步、事件驱动,这对于我们构建基于 DOM 元素的监控更为重要。
幻影JS
PhantomJS 是一个基于 webkit 的 JavaScript API。它使用 QtWebKit 作为其核心浏览器,并使用 webkit 来编译、解释和执行 JavaScript 代码。它可以做任何你可以在基于 webkit 的浏览器中做的事情。
它不仅是一个不可见的浏览器,提供诸如 CSS 选择器、对 Web 标准的支持、DOM 操作、JSON、HTML5、Canvas、SVG 等,它还提供处理文件 I/O 的操作,让您可以读写文件到操作系统等。PhantomJS的用途很广泛,比如网络监控、网页截图、免浏览器网页测试、页面访问自动化等等。
为什么不使用硒
做自动化测试的同学一定了解 Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常见浏览器的支持都很好,但是Selenium上手难度稍大,使用Selenium需要在服务器端安装浏览器。
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能也比较简单,主要针对页面的功能回归测试,所以选择了PhantomJS。
4. 架构设计架构概述
架构如下图所示。
(点击放大图片)
架构简介
对于 DOM 监控服务,在应用层面做了纵向划分:
应用层面的垂直划分,实现应用的分布式部署,提升处理能力。后期的性能优化、系统改造和扩展也可以提高简单性。
5. 解决方案(1) 前端规则入口
这是一个独立的Web系统。系统主要用于采集用户输入的页面信息,页面对应的规则,显示错误信息。通过调用后端页面爬取服务完成页面检测任务,通过系统可以创建三种检测页面:定期监控、高级监控、可用性监控。
日常监测
输入一个页面地址和几个检测规则。注意这里的检测规则,我们将一些常用的检测点抽象成一个类似测试用例的语句。每个规则用于匹配页面上的一个 DOM 元素,并使用 DOM 元素的属性来匹配预期。如果匹配失败,系统会产生错误信息,并交由报警系统处理。
匹配类型一般有这些类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于、正则。
这样做的好处是,进入规则的人只需要知道一点 DOM 选择器的知识就可以上手。在内部,通常交由测试工程师完成规则的录入。
高级监控
主要用于提供高级页面测试功能,测试用例一般由经验丰富的工程师编写。这个测试用例写起来会有一定的学习成本,但是可以模拟网页操作,比如点击、鼠标移动等事件。以实现对页面信息的准确抓取。
可用性监控
可用性监控侧重于即时监控页面可访问性、内容正确性等更严重的问题。通常我们只需要在程序中启动一个Worker,不断获取页面的HTML来检测和匹配结果,所以我们选择NodeJS做异步页面爬取队列来高效快速的完成这种网络密集型任务。
(2)主动报错页面脚本执行错误监控
页面引入监控脚本,采集页面产生的错误事件信息,并自动上报给后端服务。在系统中可以汇总所有的错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等。
活动页面报告
该功能需要对应的前端工程师调用代码中的报错API主动提交错误信息。主要使用场景包括,页面异步服务延迟无响应,模块降级,主动通知等。监控脚本提供了几个简单的API来完成这个任务。
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
(3)后端页面抓取服务
由于京东的很多页面内容是异步加载的,而首页、单品等系统有很多第三方异步接口调用,后端程序抓取的页面数据是同步的,动态JavaScript渲染的数据不能获得。所以你必须使用像 PhantomJS 这样可以模拟浏览器的工具。
对于日常监控,我们使用 PhantomJS 模拟浏览器打开页面进行爬取,然后将监控规则解析成 JavaScript 代码片段执行并采集结果。
对于高级监控,我们使用 PhantomJS 打开页面,将 jasmine、Mocha 等前端 JavaScript 测试框架注入到页面中,然后在页面上执行相应的输入测试用例并返回结果。
常规队列生成器
规则队列生成器会将规则系统采集的规则转换成消息队列,然后交给长期持久化处理器进行顺序处理。
为什么要使用类似消息队列的处理方式?
这与 PhantomJS 的性能是分不开的。通过多次实践发现,PhantomJS 不能很好的进行并发处理。当并发量过多时,CPU会过载,导致机器宕机。
对于本地环境的虚拟机并发测试,数据并不理想,限制基本在ab -n 100 -c 50左右。所以为了防止并发带来的问题,我们选择使用消息队列来进行避免高并发导致服务不可用。
类似消息队列的实现
这里我们通过调用内部分布式缓存系统来生成一个消息队列。队列的产生其实可以参考数据接口——队列。最基本的模型是在缓存中创建一个KEY,然后根据队列数据结构的schema插入和提取数据。
当然消息队列的中间介质可以根据你的实际情况选择,当然你也可以使用原生内存实现。这可能会导致应用程序和类似消息队列的内存争用。
长效处理器
长期持久处理器是由消费规则队列生成器生成的消息队列。
长效处理实施
在长时持久化处理器的具体实现中,我们充分利用了JavaScript的setInterval方法,不断的获取疲倦消息队列的内容并发送给规则转换器,再转发给负载均衡调度器。之后统一处理返回的结果,如邮件或短信报警。
API
PhantomJS服务可以作为公共API提供给客户端处理测试需求,通过HTTP调用API。在 API 的处理中,需要提供 HTTP 数据到规则和 PhantomJS 的转换。因此,HTTP 数据到规则的转换器得到了发展。
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子进程相结合的服务处理 查看全部
nodejs抓取动态网页(1.技术选型监控的意义和测试的本质一致的分析)
1. 为什么需要前端监控系统
通常一个大型的web项目中会有很多监控系统,比如后端服务API监控、接口存活、调用、延迟等监控,一般用于监控后端接口数据级别的信息。而对于大型的网站系统,从后端服务到前端展示会有很多层:内网VIP、CDN等。
但是这些监控并不能准确反映用户看到的前端页面的状态,比如页面上第三方系统数据调用失败、模块加载异常、数据不正确、天窗茫然地打开。
相关厂商内容
原生动态最新技术解析智能时代不可错过的大前端性能优化最佳实践经验谈百度技术沙龙免费注册,解析百度人脸识别技术架构师应把握这些技术趋势
这时候就需要从前端 DOM 展示的角度去分析采集用户真实看到的东西,从而检测页面是否存在异常问题。
2. 监控系统需要解决的问题
当页面出现以下问题时,您需要及时通过邮件或短信方式向相关人员报告,以解决问题。
3. 技术选型
监控的含义和测试的含义本质上是一样的,都是对已经上线的功能进行回归测试,但不同的是监控需要长期持续的、反复出现的回归测试,而测试之后只需要做一次发射,市场投入。回归测试。
由于监控和测试的性质是相同的,我们可以用测试的方法来做监控系统。在自动化测试技术遍地开花的时代,有很多有用的自动化工具,我们只需要整合这些自动化工具供我们使用。
节点JS
NodeJS 是一个 JavaScript 运行环境,NodeJS 支持非阻塞 I/O 和异步、事件驱动,这对于我们构建基于 DOM 元素的监控更为重要。
幻影JS
PhantomJS 是一个基于 webkit 的 JavaScript API。它使用 QtWebKit 作为其核心浏览器,并使用 webkit 来编译、解释和执行 JavaScript 代码。它可以做任何你可以在基于 webkit 的浏览器中做的事情。
它不仅是一个不可见的浏览器,提供诸如 CSS 选择器、对 Web 标准的支持、DOM 操作、JSON、HTML5、Canvas、SVG 等,它还提供处理文件 I/O 的操作,让您可以读写文件到操作系统等。PhantomJS的用途很广泛,比如网络监控、网页截图、免浏览器网页测试、页面访问自动化等等。
为什么不使用硒
做自动化测试的同学一定了解 Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常见浏览器的支持都很好,但是Selenium上手难度稍大,使用Selenium需要在服务器端安装浏览器。
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能也比较简单,主要针对页面的功能回归测试,所以选择了PhantomJS。
4. 架构设计架构概述
架构如下图所示。
(点击放大图片)
架构简介
对于 DOM 监控服务,在应用层面做了纵向划分:
应用层面的垂直划分,实现应用的分布式部署,提升处理能力。后期的性能优化、系统改造和扩展也可以提高简单性。
5. 解决方案(1) 前端规则入口
这是一个独立的Web系统。系统主要用于采集用户输入的页面信息,页面对应的规则,显示错误信息。通过调用后端页面爬取服务完成页面检测任务,通过系统可以创建三种检测页面:定期监控、高级监控、可用性监控。
日常监测
输入一个页面地址和几个检测规则。注意这里的检测规则,我们将一些常用的检测点抽象成一个类似测试用例的语句。每个规则用于匹配页面上的一个 DOM 元素,并使用 DOM 元素的属性来匹配预期。如果匹配失败,系统会产生错误信息,并交由报警系统处理。
匹配类型一般有这些类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于、正则。
这样做的好处是,进入规则的人只需要知道一点 DOM 选择器的知识就可以上手。在内部,通常交由测试工程师完成规则的录入。
高级监控
主要用于提供高级页面测试功能,测试用例一般由经验丰富的工程师编写。这个测试用例写起来会有一定的学习成本,但是可以模拟网页操作,比如点击、鼠标移动等事件。以实现对页面信息的准确抓取。
可用性监控
可用性监控侧重于即时监控页面可访问性、内容正确性等更严重的问题。通常我们只需要在程序中启动一个Worker,不断获取页面的HTML来检测和匹配结果,所以我们选择NodeJS做异步页面爬取队列来高效快速的完成这种网络密集型任务。
(2)主动报错页面脚本执行错误监控
页面引入监控脚本,采集页面产生的错误事件信息,并自动上报给后端服务。在系统中可以汇总所有的错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等。
活动页面报告
该功能需要对应的前端工程师调用代码中的报错API主动提交错误信息。主要使用场景包括,页面异步服务延迟无响应,模块降级,主动通知等。监控脚本提供了几个简单的API来完成这个任务。
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
(3)后端页面抓取服务
由于京东的很多页面内容是异步加载的,而首页、单品等系统有很多第三方异步接口调用,后端程序抓取的页面数据是同步的,动态JavaScript渲染的数据不能获得。所以你必须使用像 PhantomJS 这样可以模拟浏览器的工具。
对于日常监控,我们使用 PhantomJS 模拟浏览器打开页面进行爬取,然后将监控规则解析成 JavaScript 代码片段执行并采集结果。
对于高级监控,我们使用 PhantomJS 打开页面,将 jasmine、Mocha 等前端 JavaScript 测试框架注入到页面中,然后在页面上执行相应的输入测试用例并返回结果。
常规队列生成器
规则队列生成器会将规则系统采集的规则转换成消息队列,然后交给长期持久化处理器进行顺序处理。
为什么要使用类似消息队列的处理方式?
这与 PhantomJS 的性能是分不开的。通过多次实践发现,PhantomJS 不能很好的进行并发处理。当并发量过多时,CPU会过载,导致机器宕机。
对于本地环境的虚拟机并发测试,数据并不理想,限制基本在ab -n 100 -c 50左右。所以为了防止并发带来的问题,我们选择使用消息队列来进行避免高并发导致服务不可用。
类似消息队列的实现
这里我们通过调用内部分布式缓存系统来生成一个消息队列。队列的产生其实可以参考数据接口——队列。最基本的模型是在缓存中创建一个KEY,然后根据队列数据结构的schema插入和提取数据。
当然消息队列的中间介质可以根据你的实际情况选择,当然你也可以使用原生内存实现。这可能会导致应用程序和类似消息队列的内存争用。
长效处理器
长期持久处理器是由消费规则队列生成器生成的消息队列。
长效处理实施
在长时持久化处理器的具体实现中,我们充分利用了JavaScript的setInterval方法,不断的获取疲倦消息队列的内容并发送给规则转换器,再转发给负载均衡调度器。之后统一处理返回的结果,如邮件或短信报警。
API
PhantomJS服务可以作为公共API提供给客户端处理测试需求,通过HTTP调用API。在 API 的处理中,需要提供 HTTP 数据到规则和 PhantomJS 的转换。因此,HTTP 数据到规则的转换器得到了发展。
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子进程相结合的服务处理
nodejs抓取动态网页(Nodejs将JavaScript语言带到了,还有什么好玩的项目可以做呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-03 16:05
Nodejs 将 JavaScript 语言带到了服务器端。Nodejs作为js主要用户的前端,已经获得了服务器端的开发能力,但是除了用express搭建博客,还能做哪些好玩的项目呢?你为什么不只是一个网络爬虫。据说互联网上90%以上的流量是由爬虫贡献的。不知道是真是假,但至少证明了爬虫被广泛使用,尤其是在电商比价领域。我做的是爬虫中的弱鸡,只实现基本功能,先上源码。
下面简要介绍实现过程。先选择爬取对象,这里也是门槛比较低的新闻站,因为我每天早上都要去逛街,比较熟悉,为什么新闻站比较简单,因为通常是这种类型的网站不需要用户登录,所有爬虫请求都很容易伪造。
爬虫的基本思路是获取页面 -> 构造信息选择器 -> 分析页面链接 -> 获取相邻页面 -> 循环的第一步,对于新闻站来说,我们想要得到什么就是新闻内容,向页面请求html代码后,只要从页面中找到内容容器元素,就很容易得到新闻内容。下一步是获取相邻页面的地址。cnBeta新闻有上一页和下一页的链接,但仔细看会发现其实是用的。js是动态生成的。这里我们需要了解一下js是如何获取链接的。得到链接后,我们继续获取下一条新闻的html代码,重复循环。
期间肯定不会一帆风顺。比如我遇到了301跳转。幸运的是,从请求头中很容易找到跳转目标。找到301跳转后,立即放弃请求,重新请求跳转地址。
另外,爬虫不能无限爬取,否则很容易被IP屏蔽,需要设置爬取次数限制。最好再设置一个爬取间隔,不过这个只是用于学习Nodejs,不会有爬取,所以不需要再设置一个爬取间隔。
详细分析过程见另一篇文章文章:%E7%88%AC%E8%99%AB%E5%AE%9E%E8%B7%B5%E5%B0%8F%E8%AE% B0 /。 查看全部
nodejs抓取动态网页(Nodejs将JavaScript语言带到了,还有什么好玩的项目可以做呢?)
Nodejs 将 JavaScript 语言带到了服务器端。Nodejs作为js主要用户的前端,已经获得了服务器端的开发能力,但是除了用express搭建博客,还能做哪些好玩的项目呢?你为什么不只是一个网络爬虫。据说互联网上90%以上的流量是由爬虫贡献的。不知道是真是假,但至少证明了爬虫被广泛使用,尤其是在电商比价领域。我做的是爬虫中的弱鸡,只实现基本功能,先上源码。
下面简要介绍实现过程。先选择爬取对象,这里也是门槛比较低的新闻站,因为我每天早上都要去逛街,比较熟悉,为什么新闻站比较简单,因为通常是这种类型的网站不需要用户登录,所有爬虫请求都很容易伪造。
爬虫的基本思路是获取页面 -> 构造信息选择器 -> 分析页面链接 -> 获取相邻页面 -> 循环的第一步,对于新闻站来说,我们想要得到什么就是新闻内容,向页面请求html代码后,只要从页面中找到内容容器元素,就很容易得到新闻内容。下一步是获取相邻页面的地址。cnBeta新闻有上一页和下一页的链接,但仔细看会发现其实是用的。js是动态生成的。这里我们需要了解一下js是如何获取链接的。得到链接后,我们继续获取下一条新闻的html代码,重复循环。
期间肯定不会一帆风顺。比如我遇到了301跳转。幸运的是,从请求头中很容易找到跳转目标。找到301跳转后,立即放弃请求,重新请求跳转地址。
另外,爬虫不能无限爬取,否则很容易被IP屏蔽,需要设置爬取次数限制。最好再设置一个爬取间隔,不过这个只是用于学习Nodejs,不会有爬取,所以不需要再设置一个爬取间隔。
详细分析过程见另一篇文章文章:%E7%88%AC%E8%99%AB%E5%AE%9E%E8%B7%B5%E5%B0%8F%E8%AE% B0 /。
nodejs抓取动态网页(dji大大(/)开发环境和项目配置来看点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-02 21:04
nodejs抓取动态网页来看点,
2018年4月29日更新已经有一年了呢可以按照开发环境和项目配置来补充~首先,如果你希望快速开发,可以按照这个方法:-cloud-renderer-and-extensions/然后,如果你希望能够结合开发环境和项目配置来提高性能,以本人为例,推荐大家github上搜索一下dji大大(/),里面的一系列项目/工具/模块都是以开发环境的方式来定制的,比如本人就有一个大跨度转型的bigrunnerv2开发环境配置的项目,其中关于开发环境定制方面有很多好的建议,对于这类有想法有需求的可以get一下大大。
最后,有一些其他的大佬根据openstack,vmware和其他平台特别出了一些别的方案,比如virtualbox+box的方案。希望我的答案对你有用!。
具体看看我这篇文章
全有的话太好了,我用到现在都还没全部看完。因为现在我主要用web服务的程序分离的话一般分成3类。1,单纯的web服务,一般会有api系统,有网络。2,paas的定制,很多定制会有一定的配置要求,如果有必要可以定制一些基础系统,要求可以参考shells,virtualbox等。3,私有云。很多公司的单个私有云分多种,有带私有域名的,最简单的web服务就是connector,比如谷歌就是的。
因为大多数云平台的api设计的都不是很合理。甚至老死不退了,某一个云的某个特定的webservice在多年后可能跟业务没有必然联系了。这样的就很容易被折腾死。要么要搞一个定制系统,要么搞定业务。先简单说说共性的东西,各有各的特点吧。基础配置就是各个服务必须要保证的。简单来说就是满足约定义的一些配置要求,比如:http服务必须根据主机号来做处理,基于rpc或者rest。
当然配置方式不是这么死板,后续扩展应该可以手动添加,但是单纯的维护这样的设置其实就是个无底洞。最简单的配置就是要保证如下几个:1024配置是每个tcp字段传递字节数,0代表传递200k以下字节,200k代表传递大于200k字节。配置要求总体要能够完整的对应需要传递的字节数。如下这个是有争议的,有点粗糙,所以也不细讲:ip是所有域名都必须的,ip地址的话最后一段是65535个字节。
然后是集群规则,怎么下载,每个私有云hostid不同,gae的话5个字节,xl的话11个字节,ec2的话可能有7,8个字节,这个是固定的。api请求没有要求,但是必须要有多条不同的请求序列化,用于区分。比如mybatis是直接发一个请求实例中进行调用,这样的话数据库都不需要做过多的设置。应用是1.应用开。 查看全部
nodejs抓取动态网页(dji大大(/)开发环境和项目配置来看点)
nodejs抓取动态网页来看点,
2018年4月29日更新已经有一年了呢可以按照开发环境和项目配置来补充~首先,如果你希望快速开发,可以按照这个方法:-cloud-renderer-and-extensions/然后,如果你希望能够结合开发环境和项目配置来提高性能,以本人为例,推荐大家github上搜索一下dji大大(/),里面的一系列项目/工具/模块都是以开发环境的方式来定制的,比如本人就有一个大跨度转型的bigrunnerv2开发环境配置的项目,其中关于开发环境定制方面有很多好的建议,对于这类有想法有需求的可以get一下大大。
最后,有一些其他的大佬根据openstack,vmware和其他平台特别出了一些别的方案,比如virtualbox+box的方案。希望我的答案对你有用!。
具体看看我这篇文章
全有的话太好了,我用到现在都还没全部看完。因为现在我主要用web服务的程序分离的话一般分成3类。1,单纯的web服务,一般会有api系统,有网络。2,paas的定制,很多定制会有一定的配置要求,如果有必要可以定制一些基础系统,要求可以参考shells,virtualbox等。3,私有云。很多公司的单个私有云分多种,有带私有域名的,最简单的web服务就是connector,比如谷歌就是的。
因为大多数云平台的api设计的都不是很合理。甚至老死不退了,某一个云的某个特定的webservice在多年后可能跟业务没有必然联系了。这样的就很容易被折腾死。要么要搞一个定制系统,要么搞定业务。先简单说说共性的东西,各有各的特点吧。基础配置就是各个服务必须要保证的。简单来说就是满足约定义的一些配置要求,比如:http服务必须根据主机号来做处理,基于rpc或者rest。
当然配置方式不是这么死板,后续扩展应该可以手动添加,但是单纯的维护这样的设置其实就是个无底洞。最简单的配置就是要保证如下几个:1024配置是每个tcp字段传递字节数,0代表传递200k以下字节,200k代表传递大于200k字节。配置要求总体要能够完整的对应需要传递的字节数。如下这个是有争议的,有点粗糙,所以也不细讲:ip是所有域名都必须的,ip地址的话最后一段是65535个字节。
然后是集群规则,怎么下载,每个私有云hostid不同,gae的话5个字节,xl的话11个字节,ec2的话可能有7,8个字节,这个是固定的。api请求没有要求,但是必须要有多条不同的请求序列化,用于区分。比如mybatis是直接发一个请求实例中进行调用,这样的话数据库都不需要做过多的设置。应用是1.应用开。
nodejs抓取动态网页(Nodejs将JavaScript语言带到了服务器端(图)网络爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-02 09:03
Nodejs 将 JavaScript 语言带到了服务器端。Nodejs作为js主要用户的前端,已经获得了服务器端的开发能力,但是除了用express搭建博客,还能做哪些好玩的项目呢?你为什么不只是一个网络爬虫。据说互联网上90%以上的流量是由爬虫贡献的。不知道是真是假,但至少证明了爬虫被广泛使用,尤其是在电商比价领域。它做的是爬虫中的弱鸡,只实现基本功能,见底部代码。
运行结果:
下面简要介绍实现过程。
先选择爬取对象,这里也是门槛比较低的新闻站,因为我每天早上都要去逛街,比较熟悉,为什么新闻站比较简单,因为一般都是这种网站不需要用户登录,所有爬虫请求都很容易伪造。
爬虫的基本思路是获取页面 -> 构造信息选择器 -> 分析页面链接 -> 获取相邻页面 -> 循环的第一步,对于新闻站来说,我们想要得到什么就是新闻内容,向页面请求html代码后,只要从页面中找到内容容器元素,就很容易得到新闻内容。下一步是获取相邻页面的地址。cnBeta新闻有上一页和下一页的链接,但仔细看会发现其实是用的。js是动态生成的。这里我们需要了解一下js是如何获取链接的。得到链接后,我们继续获取下一条新闻的html代码,重复循环。
期间肯定不会一帆风顺。比如我遇到了301跳转。幸运的是,从请求头中很容易找到跳转目标。找到301跳转后,立即放弃请求,重新请求跳转地址。
另外,爬虫不能无限爬取,否则很容易被IP屏蔽,需要设置爬取次数限制。最好再设置一个爬取间隔,不过这个只是用于学习Nodejs,不会有爬取,所以不需要再设置一个爬取间隔。
详细流程分析见原文地址:%E7%88%AC%E8%99%AB%E5%AE%9E%E8%B7%B5%E5%B0%8F%E8%AE%B0/。
项目源代码:Github。 查看全部
nodejs抓取动态网页(Nodejs将JavaScript语言带到了服务器端(图)网络爬虫)
Nodejs 将 JavaScript 语言带到了服务器端。Nodejs作为js主要用户的前端,已经获得了服务器端的开发能力,但是除了用express搭建博客,还能做哪些好玩的项目呢?你为什么不只是一个网络爬虫。据说互联网上90%以上的流量是由爬虫贡献的。不知道是真是假,但至少证明了爬虫被广泛使用,尤其是在电商比价领域。它做的是爬虫中的弱鸡,只实现基本功能,见底部代码。
运行结果:
下面简要介绍实现过程。
先选择爬取对象,这里也是门槛比较低的新闻站,因为我每天早上都要去逛街,比较熟悉,为什么新闻站比较简单,因为一般都是这种网站不需要用户登录,所有爬虫请求都很容易伪造。
爬虫的基本思路是获取页面 -> 构造信息选择器 -> 分析页面链接 -> 获取相邻页面 -> 循环的第一步,对于新闻站来说,我们想要得到什么就是新闻内容,向页面请求html代码后,只要从页面中找到内容容器元素,就很容易得到新闻内容。下一步是获取相邻页面的地址。cnBeta新闻有上一页和下一页的链接,但仔细看会发现其实是用的。js是动态生成的。这里我们需要了解一下js是如何获取链接的。得到链接后,我们继续获取下一条新闻的html代码,重复循环。
期间肯定不会一帆风顺。比如我遇到了301跳转。幸运的是,从请求头中很容易找到跳转目标。找到301跳转后,立即放弃请求,重新请求跳转地址。
另外,爬虫不能无限爬取,否则很容易被IP屏蔽,需要设置爬取次数限制。最好再设置一个爬取间隔,不过这个只是用于学习Nodejs,不会有爬取,所以不需要再设置一个爬取间隔。
详细流程分析见原文地址:%E7%88%AC%E8%99%AB%E5%AE%9E%E8%B7%B5%E5%B0%8F%E8%AE%B0/。
项目源代码:Github。
nodejs抓取动态网页(nodejs3232ff20702070forbiddenfatalforbiddenfatal:uriredirectingfrom0x抓取动态网页的技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-28 22:02
nodejs抓取动态网页的技巧。
1、选择以下的目标网站:地址:ordertograblistviamenunavigation
2、运行如下指令。
3、在demo浏览器上运行server:5000;secret=xxx;client.location.add("demo");此时,我们就抓取到了。
选择github-nexus/fetch-response:(fetchresponse)翻译的不太好。fetchmethod//发送信息到nginx。ip:0x32f2070forbiddenfatal:uriredirectingfrom0x32f2080can'trespond.原来这个问题问的是用nodejs的fetchmethod能否抓取我们网站的动态html文档,我刚好就是这么干的。
<p>当然抓取到的并不是动态的代码,而是静态的html静态文档,它是按照.md5标准传递的。#coding:utf-8fetch${whois}(fetchresponse,'0x32f2080/')whois.get('whois')['authority'] 查看全部
nodejs抓取动态网页(nodejs3232ff20702070forbiddenfatalforbiddenfatal:uriredirectingfrom0x抓取动态网页的技巧)
nodejs抓取动态网页的技巧。
1、选择以下的目标网站:地址:ordertograblistviamenunavigation
2、运行如下指令。
3、在demo浏览器上运行server:5000;secret=xxx;client.location.add("demo");此时,我们就抓取到了。
选择github-nexus/fetch-response:(fetchresponse)翻译的不太好。fetchmethod//发送信息到nginx。ip:0x32f2070forbiddenfatal:uriredirectingfrom0x32f2080can'trespond.原来这个问题问的是用nodejs的fetchmethod能否抓取我们网站的动态html文档,我刚好就是这么干的。
<p>当然抓取到的并不是动态的代码,而是静态的html静态文档,它是按照.md5标准传递的。#coding:utf-8fetch${whois}(fetchresponse,'0x32f2080/')whois.get('whois')['authority']
nodejs抓取动态网页(Linux服务器在线演示站点-Github.io.js)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-28 20:12
项目名称:视频网站项目
开发语言:HTML、CSS(前端)、JavaScript、NODEJS(表达式)(后端)
数据库:MySQL
开发环境:Win7、Webstorm
在线部署环境:Linux服务器
在线演示站点:
Github 源码:/xiugangzhang/vip.github.io
我们先来看看最终效果:
用户主页的构建:
影片播放页面的构建
电影搜索功能(特色功能)
用户中心管理
程序安装方法步骤:
其他说明
下面是下载程序解压后的目录结构。下面简单介绍一下这个目录结构:
controllers:控制层,只要核心业务逻辑代码
data:数据抓取层,用于从爱奇艺网站抓取视频数据,存入数据库,展示在前端,其中db.js为数据库相关配置文件
models:数据库表结构映射文件(用于将数据库的关系数据模型转换为对象模型)
实用工具:工具包
views:查看文件(网站项目的所有html文件,这里的格式是xtpl,主要是为了数据的动态展示,方便后期数据渲染)
www:网站的所有静态资源文件,包括html、css、js等文件
app.js:程序的入口文件
config.js :程序的主配置文件,用于配置文件上传目录等参数
router.js:程序的路由配置
*.sql:这些是一些抓取的数据信息,用来插入数据到数据库中使用
在线演示站点:
Github 源码:/xiugangzhang/vip.github.io 查看全部
nodejs抓取动态网页(Linux服务器在线演示站点-Github.io.js)
项目名称:视频网站项目
开发语言:HTML、CSS(前端)、JavaScript、NODEJS(表达式)(后端)
数据库:MySQL
开发环境:Win7、Webstorm
在线部署环境:Linux服务器
在线演示站点:
Github 源码:/xiugangzhang/vip.github.io
我们先来看看最终效果:
用户主页的构建:
影片播放页面的构建
电影搜索功能(特色功能)
用户中心管理
程序安装方法步骤:
其他说明
下面是下载程序解压后的目录结构。下面简单介绍一下这个目录结构:
controllers:控制层,只要核心业务逻辑代码
data:数据抓取层,用于从爱奇艺网站抓取视频数据,存入数据库,展示在前端,其中db.js为数据库相关配置文件
models:数据库表结构映射文件(用于将数据库的关系数据模型转换为对象模型)
实用工具:工具包
views:查看文件(网站项目的所有html文件,这里的格式是xtpl,主要是为了数据的动态展示,方便后期数据渲染)
www:网站的所有静态资源文件,包括html、css、js等文件
app.js:程序的入口文件
config.js :程序的主配置文件,用于配置文件上传目录等参数
router.js:程序的路由配置
*.sql:这些是一些抓取的数据信息,用来插入数据到数据库中使用
在线演示站点:
Github 源码:/xiugangzhang/vip.github.io

