
nodejs抓取动态网页
nodejs抓取动态网页(nodejs抓取动态网页快速、轻量的动态(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-06 07:00
nodejs抓取动态网页快速、轻量的动态网页是javascript代码可以传输请求,比如bootstrap+ejs+mysql,体积和效率都会大幅度提升,因此很多开发者都喜欢用nodejs来写。其中bootstrap+ejs+mysql也是用javascript写的,因此这几个库与用什么其他动态网页框架比起来来还不错,这是基本情况。
这几个库都是做中文网页的,但是不同模块之间还是有一些小差别,在这里不对每个库的具体差别做介绍,主要是为了对比一下它们之间的主要差别。首先是网页网址。官方文档列出了主要用到的框架和一些简单的用法说明,bootstrap可以抓取不同网站的静态页面,不建议用。但是bootstrap+mysql是可以直接抓的动态页面,在这里我分享一下我的抓取流程,希望对你有帮助。
先放结论:我根据实际的使用感受主要从如下几个方面对它们进行对比,还是比较客观的。爬虫和分析能力:bootstrap确实强于mysql,两者是四核i7主机10g内存硬盘(2t)的配置,爬虫能力差不多(网站的完整路径为,即没有后缀名),用mysqlpostgis也能抓取,即使是未经正常测试,这里网站简单,从简单到完整一一对比,mysql的性能优势不突出。
爬虫和sql对比:在基于mysqlpostgis爬虫的爬取测试中,分析mysql相对于esdrupal等新一代postgis的优势主要体现在哪些方面,由于mysql等引擎已经成熟,sql更成熟一些,但不得不说postgis的各种功能如exposure等在模拟sql数据库(nodejs可以直接模拟执行sql)时都对mysql的有着巨大的优势,比如json、aof、el-connect等等,可能其他的postgis引擎也能模拟执行sql并响应请求,但是sql开发者的优势就是掌握sql的关键手段sql的优势在mysql,这里不再赘述。
开发效率:react+vue的高性能和可拓展性和mysql\sql\postgis兼容性如何取舍,还是一个问题,试想如果react和angular不兼容,那mysql能不能正常发挥出优势这就有待商榷了。bootstrap的建议是reactmysql就行,这个我们在理解三者用法上直接对比react的用法,他同时也是对mysql、sql语法的一个补充,不是全部。
性能问题:bootstrap的性能大约等于reactexpress,不能再高了,let,filter,resultset这些同样是支持多个模块对应不同数据库,sqlmap,filter2d这些同样也支持多个模块对应不同数据库,不用多余折腾。mysqlpostgis来看看大概和reactexpress多大差距。
一个简单的页面,一个人进行注册后产生一张人脸表classname表。而mysqlpostgis来看看大概和reactexpress的速度对比。大致差距。从一个简单的页面抓取我。 查看全部
nodejs抓取动态网页(nodejs抓取动态网页快速、轻量的动态(图))
nodejs抓取动态网页快速、轻量的动态网页是javascript代码可以传输请求,比如bootstrap+ejs+mysql,体积和效率都会大幅度提升,因此很多开发者都喜欢用nodejs来写。其中bootstrap+ejs+mysql也是用javascript写的,因此这几个库与用什么其他动态网页框架比起来来还不错,这是基本情况。
这几个库都是做中文网页的,但是不同模块之间还是有一些小差别,在这里不对每个库的具体差别做介绍,主要是为了对比一下它们之间的主要差别。首先是网页网址。官方文档列出了主要用到的框架和一些简单的用法说明,bootstrap可以抓取不同网站的静态页面,不建议用。但是bootstrap+mysql是可以直接抓的动态页面,在这里我分享一下我的抓取流程,希望对你有帮助。
先放结论:我根据实际的使用感受主要从如下几个方面对它们进行对比,还是比较客观的。爬虫和分析能力:bootstrap确实强于mysql,两者是四核i7主机10g内存硬盘(2t)的配置,爬虫能力差不多(网站的完整路径为,即没有后缀名),用mysqlpostgis也能抓取,即使是未经正常测试,这里网站简单,从简单到完整一一对比,mysql的性能优势不突出。
爬虫和sql对比:在基于mysqlpostgis爬虫的爬取测试中,分析mysql相对于esdrupal等新一代postgis的优势主要体现在哪些方面,由于mysql等引擎已经成熟,sql更成熟一些,但不得不说postgis的各种功能如exposure等在模拟sql数据库(nodejs可以直接模拟执行sql)时都对mysql的有着巨大的优势,比如json、aof、el-connect等等,可能其他的postgis引擎也能模拟执行sql并响应请求,但是sql开发者的优势就是掌握sql的关键手段sql的优势在mysql,这里不再赘述。
开发效率:react+vue的高性能和可拓展性和mysql\sql\postgis兼容性如何取舍,还是一个问题,试想如果react和angular不兼容,那mysql能不能正常发挥出优势这就有待商榷了。bootstrap的建议是reactmysql就行,这个我们在理解三者用法上直接对比react的用法,他同时也是对mysql、sql语法的一个补充,不是全部。
性能问题:bootstrap的性能大约等于reactexpress,不能再高了,let,filter,resultset这些同样是支持多个模块对应不同数据库,sqlmap,filter2d这些同样也支持多个模块对应不同数据库,不用多余折腾。mysqlpostgis来看看大概和reactexpress多大差距。
一个简单的页面,一个人进行注册后产生一张人脸表classname表。而mysqlpostgis来看看大概和reactexpress的速度对比。大致差距。从一个简单的页面抓取我。
nodejs抓取动态网页(一个网络爬虫的开发过程及实现过程原理目标分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-06 05:20
)
Nodejs 将前端开发语言移植到了服务端。如今,前端开发者可以轻松地使用 Nodejs 实现网络爬虫,这在以前是不可想象的。本文介绍了一个简单的Nodejs爬虫开发过程,只想看代码拉到最后。
爬行原理目标分析
这次爬取的目标选择是观察cnBeta的新闻详情页收录到相邻页面的链接,但是通过查看源码,发现这个链接是由Js生成的:
这是一种常见的反爬虫措施。关联页面的链接通过异步请求获取,然后由js动态生成。查看网络面板,您可以看到该页面确实发送了一个异步请求。结果具有我们想要的关联页面 ID:
接下来分析这个请求,可以发现有两个参数,这两个参数都可以在HTML中找到:
第一个参数_csrf很容易直接在源码中搜索:
第二个参数全文搜索找不到:
观察这个参数的结构,发现数据被两个逗号分隔成三段,所以猜测数据是由于多部分拼接造成的,单独搜索真的找到了:
但是我只找到了最后两段数据,开头是1,不知道是哪里来的。由于只有一个字符,检索起来比较困难,观察到这个请求在很多页面中都是以1开头的,所以这里干脆写死了。. .
至此,对目标的分析结束,下面将执行爬虫。
实施过程程序结构
大体思路是从起始页开始爬取,异步获取上一个新闻页面的链接继续爬取,并设置最大爬取次数,防止陷入死循环。伪代码如下:
功能点
关键是保存内容。首先,获取页面的 HTML 代码。主要使用http模块,如下:
const http = require('http');
http.get(pageUrl, function(res){
let html='';
res.setEncoding('utf8');
res.on('data', (chunk) => {
html += chunk;
});
res.on('end', () => {
console.log(html); //这里得到完整的HTML字符串
});
})
复制代码
要从 HTML 获取信息,您可以使用常规匹配,或使用cheerio。Cheerio 可以说实现了一个 Nodejs 端的 jQuery。它和jQuery的区别在于它需要先生成一个实例,然后像jQuery一样使用它:
const cheerio = require('cheerio');
const $ = cheerio.load(html);
let news_title = $('.cnbeta-article .title h1').text().trim().replace(/\//g, '-');
复制代码
fs模块主要用于保存文件,如下:
const fs = require('fs');
fs.writeFile(FilePath, FileContent, 'utf-8', function(err) {
if (err) {
console.log(err);
}
});
复制代码
这里有个坑。我们希望将文章的文本保存为与标题同名的txt文本,但标题可能收录斜线(/)。保存这样的文件时,程序会把标题斜线前的部分误认为是路径,报错,所以需要替换标题中的斜线。
保存图片与保存文本大致相同。主要区别在于写入格式,需要以二进制方式写入:
http.get(img_src, function(res) {
let imgData = "";
res.setEncoding("binary"); //注意格式
res.on("data", function(chunk) {
imgData += chunk;
});
res.on("end", function() {
fs.writeFile(imgSavePath, imgData, "binary", function(err) { //注意格式
if (err) {
console.log(err);
}
});
});
复制代码
程序的结构和主要功能基本是这样的。
后记
实现爬虫说起来容易,但是健壮性真的很难保证。在爬cnBeta的过程中,又发现了一个301跳坑。URL跳转时,程序抓取的HTML为空,无法获取。因此,请求得到响应后,需要判断响应头是否为301,如果是,则需要从响应信息中找到重定向后的URL,重新发起请求。好在cnBeta不需要用户登录,如果是必须登录才能访问的网站,爬虫会很麻烦。
本项目完整代码见Nodejs爬虫,感谢cnBeta^^。
查看全部
nodejs抓取动态网页(一个网络爬虫的开发过程及实现过程原理目标分析
)
Nodejs 将前端开发语言移植到了服务端。如今,前端开发者可以轻松地使用 Nodejs 实现网络爬虫,这在以前是不可想象的。本文介绍了一个简单的Nodejs爬虫开发过程,只想看代码拉到最后。
爬行原理目标分析
这次爬取的目标选择是观察cnBeta的新闻详情页收录到相邻页面的链接,但是通过查看源码,发现这个链接是由Js生成的:
这是一种常见的反爬虫措施。关联页面的链接通过异步请求获取,然后由js动态生成。查看网络面板,您可以看到该页面确实发送了一个异步请求。结果具有我们想要的关联页面 ID:
接下来分析这个请求,可以发现有两个参数,这两个参数都可以在HTML中找到:
第一个参数_csrf很容易直接在源码中搜索:
第二个参数全文搜索找不到:
观察这个参数的结构,发现数据被两个逗号分隔成三段,所以猜测数据是由于多部分拼接造成的,单独搜索真的找到了:
但是我只找到了最后两段数据,开头是1,不知道是哪里来的。由于只有一个字符,检索起来比较困难,观察到这个请求在很多页面中都是以1开头的,所以这里干脆写死了。. .
至此,对目标的分析结束,下面将执行爬虫。
实施过程程序结构
大体思路是从起始页开始爬取,异步获取上一个新闻页面的链接继续爬取,并设置最大爬取次数,防止陷入死循环。伪代码如下:
功能点
关键是保存内容。首先,获取页面的 HTML 代码。主要使用http模块,如下:
const http = require('http');
http.get(pageUrl, function(res){
let html='';
res.setEncoding('utf8');
res.on('data', (chunk) => {
html += chunk;
});
res.on('end', () => {
console.log(html); //这里得到完整的HTML字符串
});
})
复制代码
要从 HTML 获取信息,您可以使用常规匹配,或使用cheerio。Cheerio 可以说实现了一个 Nodejs 端的 jQuery。它和jQuery的区别在于它需要先生成一个实例,然后像jQuery一样使用它:
const cheerio = require('cheerio');
const $ = cheerio.load(html);
let news_title = $('.cnbeta-article .title h1').text().trim().replace(/\//g, '-');
复制代码
fs模块主要用于保存文件,如下:
const fs = require('fs');
fs.writeFile(FilePath, FileContent, 'utf-8', function(err) {
if (err) {
console.log(err);
}
});
复制代码
这里有个坑。我们希望将文章的文本保存为与标题同名的txt文本,但标题可能收录斜线(/)。保存这样的文件时,程序会把标题斜线前的部分误认为是路径,报错,所以需要替换标题中的斜线。
保存图片与保存文本大致相同。主要区别在于写入格式,需要以二进制方式写入:
http.get(img_src, function(res) {
let imgData = "";
res.setEncoding("binary"); //注意格式
res.on("data", function(chunk) {
imgData += chunk;
});
res.on("end", function() {
fs.writeFile(imgSavePath, imgData, "binary", function(err) { //注意格式
if (err) {
console.log(err);
}
});
});
复制代码
程序的结构和主要功能基本是这样的。
后记
实现爬虫说起来容易,但是健壮性真的很难保证。在爬cnBeta的过程中,又发现了一个301跳坑。URL跳转时,程序抓取的HTML为空,无法获取。因此,请求得到响应后,需要判断响应头是否为301,如果是,则需要从响应信息中找到重定向后的URL,重新发起请求。好在cnBeta不需要用户登录,如果是必须登录才能访问的网站,爬虫会很麻烦。
本项目完整代码见Nodejs爬虫,感谢cnBeta^^。
nodejs抓取动态网页(聊聊:到底应该如何做好一个不错的交互互动网站?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-03 12:09
聊天:如何做好互动互动网站?
对于HTML5,作为一个新推出的标准,大多数人都喜欢它。学习和认知新事物是大多数人感兴趣的。但是你了解HTML5的优点和缺点吗?在我们选择一个新事物之前,首先要了解这个事物的优缺点,这样才容易做出正确的选择。这里分析一下H5互动网站的优势?
先来说说:H5互动企业网站有什么优势?你知道多少?
1、 的优势在于良好的用户体验。
H5页面更适合用户使用移动应用浏览网页。由于手机的手机界面有限,这种类型的页面可以让用户无需翻页就可以清楚地看到自己喜欢的网页。可以从上到下快速来回滚动,大大减少了用户翻页的时间。
2、H5页面代码的优点是比较简单。
H5页面有各种空白。这种页面的冗余代码比传统页面少很多,方便用户使用,也方便网页开发者和设计者。
3、的优势 方便拓展用户渠道。
H5页面最大的不同就是支持多端口适配。无论是大屏PC终端、手机终端,还是平板终端,都能根据屏幕大小自动缩放。
4、H5网站的优点是更容易优化。
H5页面对搜索引擎非常友好。这个页面非常方便蜘蛛爬取爬取,也有利于网站优化器的优化。这种页面也叫Easy收录,也有助于原创作者保护自己的原创。
5、的优点 全新标签,网站更丰富的定义。
与旧版H5页面相比,html5增加了很多语义标签,网站定义更方便,更详细。
6、 的优点是支持多媒体元素。
H5页面可以支持视频、音频、flash动画等多媒体元素,以往图片和视频过多不仅不利于网站的加载速度,而且不利于网页的爬取和搜索。搜索引擎。现在出现H5页面。,你可以随意在网站中添加各种多媒体元素,完全不受限制。
7、H5页面开发成本较低的优势。
由于HTML5网站的良好兼容性,用户在开发一个网站后不需要再开发另一个移动站,在一定程度上节省了大量资金。
那我们再说一遍:如何做好H5互动网站的建设?
一、分析公司竞争对手的H5交互网站
① 一般来自对手的H5互动网站头衔设置
② 一般情况下,H5交互网站页面的布局来自比赛的另一端
③ 一般来自对手的H5交互网站目录设置
④ 一般来自对手的H5交互网站用户界面体验
⑤ 一般来自对手H5互动网站内链设定
⑥ 一般H5互动网站外链由竞赛对方发布
⑦ 是否有来自对方H5互动网站的友情链接一般
⑧ 一般来自H5交互网站参赛对手常用站点设置(robots.txt;nofollow;网站的伪静态;网站地图)
二、来自公司企业H5交互的设计开发分析网站
公司企业H5交互网站界面风格分析:
有喜欢的H5互动参考网站吗?或者其他行业的H5交互参考网站?H5 Interactive 网站 是专注于基础展示?还是专注于品牌创意展示?还是专注于营销转化?公司主色网站是深红色吗?黄色?海军蓝?还是其他颜色?H5 Interactive网站想要给用户什么样的感受?简单?专业形象?小而新鲜?高大上?或者是其他东西?
公司H5互动网站栏目规划分析:
看看H5互动网站公司是否需要这些栏目?
这里分享一个品牌策划行业公司的官网栏目结构策划,可以适当参考! 查看全部
nodejs抓取动态网页(聊聊:到底应该如何做好一个不错的交互互动网站?)
聊天:如何做好互动互动网站?
对于HTML5,作为一个新推出的标准,大多数人都喜欢它。学习和认知新事物是大多数人感兴趣的。但是你了解HTML5的优点和缺点吗?在我们选择一个新事物之前,首先要了解这个事物的优缺点,这样才容易做出正确的选择。这里分析一下H5互动网站的优势?
先来说说:H5互动企业网站有什么优势?你知道多少?
1、 的优势在于良好的用户体验。
H5页面更适合用户使用移动应用浏览网页。由于手机的手机界面有限,这种类型的页面可以让用户无需翻页就可以清楚地看到自己喜欢的网页。可以从上到下快速来回滚动,大大减少了用户翻页的时间。
2、H5页面代码的优点是比较简单。
H5页面有各种空白。这种页面的冗余代码比传统页面少很多,方便用户使用,也方便网页开发者和设计者。
3、的优势 方便拓展用户渠道。
H5页面最大的不同就是支持多端口适配。无论是大屏PC终端、手机终端,还是平板终端,都能根据屏幕大小自动缩放。
4、H5网站的优点是更容易优化。
H5页面对搜索引擎非常友好。这个页面非常方便蜘蛛爬取爬取,也有利于网站优化器的优化。这种页面也叫Easy收录,也有助于原创作者保护自己的原创。
5、的优点 全新标签,网站更丰富的定义。
与旧版H5页面相比,html5增加了很多语义标签,网站定义更方便,更详细。
6、 的优点是支持多媒体元素。
H5页面可以支持视频、音频、flash动画等多媒体元素,以往图片和视频过多不仅不利于网站的加载速度,而且不利于网页的爬取和搜索。搜索引擎。现在出现H5页面。,你可以随意在网站中添加各种多媒体元素,完全不受限制。
7、H5页面开发成本较低的优势。
由于HTML5网站的良好兼容性,用户在开发一个网站后不需要再开发另一个移动站,在一定程度上节省了大量资金。
那我们再说一遍:如何做好H5互动网站的建设?
一、分析公司竞争对手的H5交互网站
① 一般来自对手的H5互动网站头衔设置
② 一般情况下,H5交互网站页面的布局来自比赛的另一端
③ 一般来自对手的H5交互网站目录设置
④ 一般来自对手的H5交互网站用户界面体验
⑤ 一般来自对手H5互动网站内链设定
⑥ 一般H5互动网站外链由竞赛对方发布
⑦ 是否有来自对方H5互动网站的友情链接一般
⑧ 一般来自H5交互网站参赛对手常用站点设置(robots.txt;nofollow;网站的伪静态;网站地图)
二、来自公司企业H5交互的设计开发分析网站
公司企业H5交互网站界面风格分析:
有喜欢的H5互动参考网站吗?或者其他行业的H5交互参考网站?H5 Interactive 网站 是专注于基础展示?还是专注于品牌创意展示?还是专注于营销转化?公司主色网站是深红色吗?黄色?海军蓝?还是其他颜色?H5 Interactive网站想要给用户什么样的感受?简单?专业形象?小而新鲜?高大上?或者是其他东西?
公司H5互动网站栏目规划分析:
看看H5互动网站公司是否需要这些栏目?
这里分享一个品牌策划行业公司的官网栏目结构策划,可以适当参考!
nodejs抓取动态网页(-spider页面(PS:最后面还有彩蛋))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-03 12:08
前言
之前研究过数据,写了一些数据爬虫的爬虫,不过写的比较随意。现在看来不合理的地方很多。这段时间比较闲,本来想重构一下之前的项目。
后来利用这个周末,干脆重新写了一个项目,这个项目guwen-spider。目前这个爬虫还是比较简单的类型。它直接抓取页面,然后从页面中提取数据,并将数据保存到数据库中。
对比我之前写的,我觉得难点在于整个程序的健壮性和相应的容错机制。昨天写代码的过程中,其实反映了真正的主代码其实写的很快,花了大部分时间
做稳定性调试,寻求更合理的方式处理数据与过程控制的关系。
背景
该项目的背景是抓取一个一级页面,它是一个内容列表。单击目录是章节和长度的列表。点击章节或长度是进入具体内容页面。
概述
本项目github地址:[guwen-spider](yangfan0095/guwen-spider)(PS:最后还有彩蛋~~逃跑
项目技术细节
项目使用了大量的ES7 async函数,更直观的反映了程序的流程。为方便起见,在数据遍历的过程中直接使用了著名的async库,所以必然会用到回调promise,因为数据的处理发生在回调函数中,难免会遇到一些数据传输的问题,其实,也可以直接用ES7的async await写一个方法来实现同样的功能。其实这里最好的一点就是使用Class的静态方法来封装数据库的操作。顾名思义,静态方法与原型相同,不占用额外空间。
该项目主要用于
* 1 ES7 的 async await 协程做异步逻辑处理。
* 2 使用 npm 的 async 库做循环遍历和并发请求操作。
* 3 使用log4js进行日志处理
* 4 使用cheerio处理dom操作。
* 5 使用mongoose连接mongoDB进行数据存储和操作。
目录结构
├── bin//入口
│ ├── booklist.js// 抢书逻辑
│ ├── Chapterlist.js// 抓取章节逻辑
│ ├── content.js// 抓取内容逻辑
│ └── index.js// 程序入口
├── config//配置文件
├── dbhelper// 数据库操作方法目录
├── logs// 项目日志目录
├── model// mongoDB 集合操作示例
├── node_modules
├── utils// 工具函数
├── package.json
项目实现计划分析
该项目是典型的多级爬取案例,目前只有三个层次,分别是书单、书目对应的章节列表、章节链接对应的内容。有两种方法可以捕获这样的结构。一种是直接从外层抓到内层,抓到内层后再执行下一个外层,另一种是先将外层保存到数据库中。,然后根据外层抓取到所有内层章节的链接,再次保存,然后从数据库中查询对应的链接单元来抓取内容。这两种方案各有利弊。其实这两种方法我都试过了。后者有一个优势,因为三个层次是分别捕获的,以便更方便,尽可能保存到相关章节。数据。试想一下,如果按照正常逻辑使用前者
遍历一级目录抓取对应的二级章节列表,再遍历章节列表抓取内容。当三级内容单元被捕获并需要保存时,如果你需要大量一级目录信息,你需要在这些分层数据之间进行数据传输,这实际上应该是一个比较复杂的考虑。因此,单独保存数据在一定程度上避免了不必要和复杂的数据传输。
目前,我们认为我们要捕捉的古籍数量并不多,涵盖各种历史的古籍大约只有180本左右。它和章节内容本身是一小块数据,即一个集合中有180个文档记录。这180本书的所有章节共有16000章,对应爬取相应内容需要访问的16000页。所以选择第二个应该是合理的。
项目实现
主程序有bookListInit、chapterListInit、contentListInit三个方法,分别是抓取图书目录、章节列表、图书内容的初始化方法。通过async,可以控制这三种方法的运行过程。图书目录抓取完成后,将数据保存到数据库中,然后将执行结果返回给主程序。如果主程序运行成功,会根据书单抓取章节列表。,同样抢书的内容。
项目主入口
/**
* 爬虫抓取主入口
*/
const start = async() => {
let booklistRes = await bookListInit();
if (!booklistRes) {
logger.warn('书籍列表抓取出错,程序终止...');
return;
}
logger.info('书籍列表抓取成功,现在进行书籍章节抓取...');
let chapterlistRes = await chapterListInit();
if (!chapterlistRes) {
logger.warn('书籍章节列表抓取出错,程序终止...');
return;
}
logger.info('书籍章节列表抓取成功,现在进行书籍内容抓取...');
let contentListRes = await contentListInit();
if (!contentListRes) {
logger.warn('书籍章节内容抓取出错,程序终止...');
return;
}
logger.info('书籍内容抓取成功');
}
// 开始入口
if (typeof bookListInit === 'function' && typeof chapterListInit === 'function') {
// 开始抓取
start();
}
介绍bookListInit、chapterListInit、contentListInit,三个方法
书单.js
/**
* 初始化方法 返回抓取结果 true 抓取成果 false 抓取失败
*/
const bookListInit = async() => {
logger.info('抓取书籍列表开始...');
const pageUrlList = getPageUrlList(totalListPage, baseUrl);
let res = await getBookList(pageUrlList);
return res;
}
章节列表.js
/**
* 初始化入口
*/
const chapterListInit = async() => {
const list = await bookHelper.getBookList(bookListModel);
if (!list) {
logger.error('初始化查询书籍目录失败');
}
logger.info('开始抓取书籍章节列表,书籍目录共:' + list.length + '条');
let res = await asyncGetChapter(list);
return res;
};
内容.js
/**
* 初始化入口
*/
const contentListInit = async() => {
//获取书籍列表
const list = await bookHelper.getBookLi(bookListModel);
if (!list) {
logger.error('初始化查询书籍目录失败');
return;
}
const res = await mapBookList(list);
if (!res) {
logger.error('抓取章节信息,调用 getCurBookSectionList() 进行串行遍历操作,执行完成回调出错,错误信息已打印,请查看日志!');
return;
}
return res;
}
关于内容抓取的想法
图书目录爬取的逻辑其实很简单。你只需要使用 async.mapLimit 做一次遍历保存数据,但是我们保存内容时的简化逻辑其实就是遍历章节列表去抓取链接中的内容。但实际情况是链接数多达数万。从内存使用的角度来看,我们无法将它们全部保存到一个数组中然后遍历它们,因此我们需要将内容捕获进行单元化。
常见的遍历方法是每次查询一定数量进行爬取。缺点是只用一定数量进行分类,数据之间没有相关性,插入是分批进行的。如果出现错误,容错方面会出现一些小问题,我们认为将一本书作为采集会遇到问题。因此,我们使用第二种方法以书为单位捕获和保存内容。
这里使用了方法`async.mapLimit(list, 1, (series, callback) => {})` 来遍历。回调是不可避免的使用,感觉很恶心。async.mapLimit() 的第二个参数可以设置同时请求的数量。
/*
* 内容抓取步骤:
* 第一步得到书籍列表, 通过书籍列表查到一条书籍记录下 对应的所有章节列表,
* 第二步 对章节列表进行遍历获取内容保存到数据库中
* 第三步 保存完数据后 回到第一步 进行下一步书籍的内容抓取和保存
*/
/**
* 初始化入口
*/
const contentListInit = async() => {
//获取书籍列表
const list = await bookHelper.getBookList(bookListModel);
if (!list) {
logger.error('初始化查询书籍目录失败');
return;
}
const res = await mapBookList(list);
if (!res) {
logger.error('抓取章节信息,调用 getCurBookSectionList() 进行串行遍历操作,执行完成回调出错,错误信息已打印,请查看日志!');
return;
}
return res;
}
/**
* 遍历书籍目录下的章节列表
* @param {*} list
*/
const mapBookList = (list) => {
return new Promise((resolve, reject) => {
async.mapLimit(list, 1, (series, callback) => {
let doc = series._doc;
getCurBookSectionList(doc, callback);
}, (err, result) => {
if (err) {
logger.error('书籍目录抓取异步执行出错!');
logger.error(err);
reject(false); return;
}
resolve(true);
})
})
}
/**
* 获取单本书籍下章节列表 调用章节列表遍历进行抓取内容
* @param {*} series
* @param {*} callback
*/
const getCurBookSectionList = async(series, callback) => {
let num = Math.random() * 1000 + 1000;
await sleep(num);
let key = series.key;
const res = await bookHelper.querySectionList(chapterListModel, {
key: key
});
if (!res) {
logger.error('获取当前书籍: ' + series.bookName + ' 章节内容失败,进入下一部书籍内容抓取!');
callback(null, null);
return;
}
//判断当前数据是否已经存在
const bookItemModel = getModel(key);
const contentLength = await bookHelper.getCollectionLength(bookItemModel, {});
if (contentLength === res.length) {
logger.info('当前书籍:' + series.bookName + '数据库已经抓取完成,进入下一条数据任务');
callback(null, null);
return;
}
await mapSectionList(res);
callback(null, null);
}
抓包后如何保存数据是个问题
这里我们使用key对数据进行分类。每次我们拿到link,根据key遍历,这样做的好处是保存的数据是一个整体。现在我们正在考虑数据存储的问题。
1 可整体插入
优点:数据库操作快,不浪费时间。
缺点:有些书可能有几百章,这意味着几百页的内容在插入之前必须保存。这也会消耗内存并可能导致程序运行不稳定。
2可以以每篇文章文章的形式插入到数据库中。
优点:页面抓取保存的方式,可以及时保存数据,即使出现后续错误,也无需重新保存之前的章节。
缺点:明显慢。想爬几万个页面,做几万次*N的数据库操作,想一想。在这里,您还可以创建一个缓冲区来一次保存一定数量的条目。当条目数达到条目数时,再次保存。好的选择。
/**
* 遍历单条书籍下所有章节 调用内容抓取方法
* @param {*} list
*/
const mapSectionList = (list) => {
return new Promise((resolve, reject) => {
async.mapLimit(list, 1, (series, callback) => {
let doc = series._doc;
getContent(doc, callback)
}, (err, result) => {
if (err) {
logger.error('书籍目录抓取异步执行出错!');
logger.error(err);
reject(false);
return;
}
const bookName = list[0].bookName;
const key = list[0].key;
// 以整体为单元进行保存
saveAllContentToDB(result, bookName, key, resolve);
//以每篇文章作为单元进行保存
// logger.info(bookName + '数据抓取完成,进入下一部书籍抓取函数...');
// resolve(true);
})
})
}
两者都有其优点和缺点,我们都在这里尝试过。准备了两个错误保存集合,errContentModel 和 error采集Model。插入错误时,信息会保存到相应的集合中。您可以选择两者之一。添加集合保存数据的原因是为了方便一次性查看和后续操作,无需查看日志。
(PS,其实可以完全使用error采集Model集合,errContentModel集合完全可以保存章节信息)
//保存出错的数据名称
const errorSpider = mongoose.Schema({
chapter: String,
section: String,
url: String,
key: String,
bookName: String,
author: String,
})
// 保存出错的数据名称 只保留key 和 bookName信息
const errorCollection = mongoose.Schema({
key: String,
bookName: String,
})
我们把每本书信息的内容放到一个新的集合中,集合以key命名。
总结
其实,编写这个项目的主要难点在于程序稳定性的控制,容错机制的设置,以及错误的记录。目前这个项目基本上可以一次直接运行整个流程。但是,程序设计肯定存在很多问题。请指正并交流。
复活节彩蛋
写完这个项目,做了一个基于React的前端网站用于页面浏览,一个基于koa2.x的服务器。整体技术栈相当于React+Redux+Koa2,前后端服务分开部署,各自独立可以更好的去除前后端服务之间的耦合。例如,同一组服务器端代码不仅可以为 Web 提供支持,还可以为移动和应用程序提供支持。目前整套还很简陋,但是可以满足基本的查询和浏览功能。希望以后有时间来充实这个项目。
本项目地址:[guwen-spider](yangfan0095/guwen-spider)
对应前端React+Redux+semantic-ui地址:[guwen-react](yangfan0095/guwen-react)
对应节点koa2.2+猫鼬地址:[guwen-node](yangfan0095/guwen-node)
项目很简单,但是从前端到服务器端,多了一个学习和研发的环境。
谢谢阅读!
以上です 查看全部
nodejs抓取动态网页(-spider页面(PS:最后面还有彩蛋))
前言
之前研究过数据,写了一些数据爬虫的爬虫,不过写的比较随意。现在看来不合理的地方很多。这段时间比较闲,本来想重构一下之前的项目。
后来利用这个周末,干脆重新写了一个项目,这个项目guwen-spider。目前这个爬虫还是比较简单的类型。它直接抓取页面,然后从页面中提取数据,并将数据保存到数据库中。
对比我之前写的,我觉得难点在于整个程序的健壮性和相应的容错机制。昨天写代码的过程中,其实反映了真正的主代码其实写的很快,花了大部分时间
做稳定性调试,寻求更合理的方式处理数据与过程控制的关系。
背景
该项目的背景是抓取一个一级页面,它是一个内容列表。单击目录是章节和长度的列表。点击章节或长度是进入具体内容页面。
概述
本项目github地址:[guwen-spider](yangfan0095/guwen-spider)(PS:最后还有彩蛋~~逃跑
项目技术细节
项目使用了大量的ES7 async函数,更直观的反映了程序的流程。为方便起见,在数据遍历的过程中直接使用了著名的async库,所以必然会用到回调promise,因为数据的处理发生在回调函数中,难免会遇到一些数据传输的问题,其实,也可以直接用ES7的async await写一个方法来实现同样的功能。其实这里最好的一点就是使用Class的静态方法来封装数据库的操作。顾名思义,静态方法与原型相同,不占用额外空间。
该项目主要用于
* 1 ES7 的 async await 协程做异步逻辑处理。
* 2 使用 npm 的 async 库做循环遍历和并发请求操作。
* 3 使用log4js进行日志处理
* 4 使用cheerio处理dom操作。
* 5 使用mongoose连接mongoDB进行数据存储和操作。
目录结构
├── bin//入口
│ ├── booklist.js// 抢书逻辑
│ ├── Chapterlist.js// 抓取章节逻辑
│ ├── content.js// 抓取内容逻辑
│ └── index.js// 程序入口
├── config//配置文件
├── dbhelper// 数据库操作方法目录
├── logs// 项目日志目录
├── model// mongoDB 集合操作示例
├── node_modules
├── utils// 工具函数
├── package.json
项目实现计划分析
该项目是典型的多级爬取案例,目前只有三个层次,分别是书单、书目对应的章节列表、章节链接对应的内容。有两种方法可以捕获这样的结构。一种是直接从外层抓到内层,抓到内层后再执行下一个外层,另一种是先将外层保存到数据库中。,然后根据外层抓取到所有内层章节的链接,再次保存,然后从数据库中查询对应的链接单元来抓取内容。这两种方案各有利弊。其实这两种方法我都试过了。后者有一个优势,因为三个层次是分别捕获的,以便更方便,尽可能保存到相关章节。数据。试想一下,如果按照正常逻辑使用前者
遍历一级目录抓取对应的二级章节列表,再遍历章节列表抓取内容。当三级内容单元被捕获并需要保存时,如果你需要大量一级目录信息,你需要在这些分层数据之间进行数据传输,这实际上应该是一个比较复杂的考虑。因此,单独保存数据在一定程度上避免了不必要和复杂的数据传输。
目前,我们认为我们要捕捉的古籍数量并不多,涵盖各种历史的古籍大约只有180本左右。它和章节内容本身是一小块数据,即一个集合中有180个文档记录。这180本书的所有章节共有16000章,对应爬取相应内容需要访问的16000页。所以选择第二个应该是合理的。
项目实现
主程序有bookListInit、chapterListInit、contentListInit三个方法,分别是抓取图书目录、章节列表、图书内容的初始化方法。通过async,可以控制这三种方法的运行过程。图书目录抓取完成后,将数据保存到数据库中,然后将执行结果返回给主程序。如果主程序运行成功,会根据书单抓取章节列表。,同样抢书的内容。
项目主入口
/**
* 爬虫抓取主入口
*/
const start = async() => {
let booklistRes = await bookListInit();
if (!booklistRes) {
logger.warn('书籍列表抓取出错,程序终止...');
return;
}
logger.info('书籍列表抓取成功,现在进行书籍章节抓取...');
let chapterlistRes = await chapterListInit();
if (!chapterlistRes) {
logger.warn('书籍章节列表抓取出错,程序终止...');
return;
}
logger.info('书籍章节列表抓取成功,现在进行书籍内容抓取...');
let contentListRes = await contentListInit();
if (!contentListRes) {
logger.warn('书籍章节内容抓取出错,程序终止...');
return;
}
logger.info('书籍内容抓取成功');
}
// 开始入口
if (typeof bookListInit === 'function' && typeof chapterListInit === 'function') {
// 开始抓取
start();
}
介绍bookListInit、chapterListInit、contentListInit,三个方法
书单.js
/**
* 初始化方法 返回抓取结果 true 抓取成果 false 抓取失败
*/
const bookListInit = async() => {
logger.info('抓取书籍列表开始...');
const pageUrlList = getPageUrlList(totalListPage, baseUrl);
let res = await getBookList(pageUrlList);
return res;
}
章节列表.js
/**
* 初始化入口
*/
const chapterListInit = async() => {
const list = await bookHelper.getBookList(bookListModel);
if (!list) {
logger.error('初始化查询书籍目录失败');
}
logger.info('开始抓取书籍章节列表,书籍目录共:' + list.length + '条');
let res = await asyncGetChapter(list);
return res;
};
内容.js
/**
* 初始化入口
*/
const contentListInit = async() => {
//获取书籍列表
const list = await bookHelper.getBookLi(bookListModel);
if (!list) {
logger.error('初始化查询书籍目录失败');
return;
}
const res = await mapBookList(list);
if (!res) {
logger.error('抓取章节信息,调用 getCurBookSectionList() 进行串行遍历操作,执行完成回调出错,错误信息已打印,请查看日志!');
return;
}
return res;
}
关于内容抓取的想法
图书目录爬取的逻辑其实很简单。你只需要使用 async.mapLimit 做一次遍历保存数据,但是我们保存内容时的简化逻辑其实就是遍历章节列表去抓取链接中的内容。但实际情况是链接数多达数万。从内存使用的角度来看,我们无法将它们全部保存到一个数组中然后遍历它们,因此我们需要将内容捕获进行单元化。
常见的遍历方法是每次查询一定数量进行爬取。缺点是只用一定数量进行分类,数据之间没有相关性,插入是分批进行的。如果出现错误,容错方面会出现一些小问题,我们认为将一本书作为采集会遇到问题。因此,我们使用第二种方法以书为单位捕获和保存内容。
这里使用了方法`async.mapLimit(list, 1, (series, callback) => {})` 来遍历。回调是不可避免的使用,感觉很恶心。async.mapLimit() 的第二个参数可以设置同时请求的数量。
/*
* 内容抓取步骤:
* 第一步得到书籍列表, 通过书籍列表查到一条书籍记录下 对应的所有章节列表,
* 第二步 对章节列表进行遍历获取内容保存到数据库中
* 第三步 保存完数据后 回到第一步 进行下一步书籍的内容抓取和保存
*/
/**
* 初始化入口
*/
const contentListInit = async() => {
//获取书籍列表
const list = await bookHelper.getBookList(bookListModel);
if (!list) {
logger.error('初始化查询书籍目录失败');
return;
}
const res = await mapBookList(list);
if (!res) {
logger.error('抓取章节信息,调用 getCurBookSectionList() 进行串行遍历操作,执行完成回调出错,错误信息已打印,请查看日志!');
return;
}
return res;
}
/**
* 遍历书籍目录下的章节列表
* @param {*} list
*/
const mapBookList = (list) => {
return new Promise((resolve, reject) => {
async.mapLimit(list, 1, (series, callback) => {
let doc = series._doc;
getCurBookSectionList(doc, callback);
}, (err, result) => {
if (err) {
logger.error('书籍目录抓取异步执行出错!');
logger.error(err);
reject(false); return;
}
resolve(true);
})
})
}
/**
* 获取单本书籍下章节列表 调用章节列表遍历进行抓取内容
* @param {*} series
* @param {*} callback
*/
const getCurBookSectionList = async(series, callback) => {
let num = Math.random() * 1000 + 1000;
await sleep(num);
let key = series.key;
const res = await bookHelper.querySectionList(chapterListModel, {
key: key
});
if (!res) {
logger.error('获取当前书籍: ' + series.bookName + ' 章节内容失败,进入下一部书籍内容抓取!');
callback(null, null);
return;
}
//判断当前数据是否已经存在
const bookItemModel = getModel(key);
const contentLength = await bookHelper.getCollectionLength(bookItemModel, {});
if (contentLength === res.length) {
logger.info('当前书籍:' + series.bookName + '数据库已经抓取完成,进入下一条数据任务');
callback(null, null);
return;
}
await mapSectionList(res);
callback(null, null);
}
抓包后如何保存数据是个问题
这里我们使用key对数据进行分类。每次我们拿到link,根据key遍历,这样做的好处是保存的数据是一个整体。现在我们正在考虑数据存储的问题。
1 可整体插入
优点:数据库操作快,不浪费时间。
缺点:有些书可能有几百章,这意味着几百页的内容在插入之前必须保存。这也会消耗内存并可能导致程序运行不稳定。
2可以以每篇文章文章的形式插入到数据库中。
优点:页面抓取保存的方式,可以及时保存数据,即使出现后续错误,也无需重新保存之前的章节。
缺点:明显慢。想爬几万个页面,做几万次*N的数据库操作,想一想。在这里,您还可以创建一个缓冲区来一次保存一定数量的条目。当条目数达到条目数时,再次保存。好的选择。
/**
* 遍历单条书籍下所有章节 调用内容抓取方法
* @param {*} list
*/
const mapSectionList = (list) => {
return new Promise((resolve, reject) => {
async.mapLimit(list, 1, (series, callback) => {
let doc = series._doc;
getContent(doc, callback)
}, (err, result) => {
if (err) {
logger.error('书籍目录抓取异步执行出错!');
logger.error(err);
reject(false);
return;
}
const bookName = list[0].bookName;
const key = list[0].key;
// 以整体为单元进行保存
saveAllContentToDB(result, bookName, key, resolve);
//以每篇文章作为单元进行保存
// logger.info(bookName + '数据抓取完成,进入下一部书籍抓取函数...');
// resolve(true);
})
})
}
两者都有其优点和缺点,我们都在这里尝试过。准备了两个错误保存集合,errContentModel 和 error采集Model。插入错误时,信息会保存到相应的集合中。您可以选择两者之一。添加集合保存数据的原因是为了方便一次性查看和后续操作,无需查看日志。
(PS,其实可以完全使用error采集Model集合,errContentModel集合完全可以保存章节信息)
//保存出错的数据名称
const errorSpider = mongoose.Schema({
chapter: String,
section: String,
url: String,
key: String,
bookName: String,
author: String,
})
// 保存出错的数据名称 只保留key 和 bookName信息
const errorCollection = mongoose.Schema({
key: String,
bookName: String,
})
我们把每本书信息的内容放到一个新的集合中,集合以key命名。
总结
其实,编写这个项目的主要难点在于程序稳定性的控制,容错机制的设置,以及错误的记录。目前这个项目基本上可以一次直接运行整个流程。但是,程序设计肯定存在很多问题。请指正并交流。
复活节彩蛋
写完这个项目,做了一个基于React的前端网站用于页面浏览,一个基于koa2.x的服务器。整体技术栈相当于React+Redux+Koa2,前后端服务分开部署,各自独立可以更好的去除前后端服务之间的耦合。例如,同一组服务器端代码不仅可以为 Web 提供支持,还可以为移动和应用程序提供支持。目前整套还很简陋,但是可以满足基本的查询和浏览功能。希望以后有时间来充实这个项目。
本项目地址:[guwen-spider](yangfan0095/guwen-spider)
对应前端React+Redux+semantic-ui地址:[guwen-react](yangfan0095/guwen-react)
对应节点koa2.2+猫鼬地址:[guwen-node](yangfan0095/guwen-node)
项目很简单,但是从前端到服务器端,多了一个学习和研发的环境。
谢谢阅读!
以上です
nodejs抓取动态网页(网上提了个问:Express4开发的动态页面访问好慢的说?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-02 12:31
上周在MOOC网站问了一个问题:Express4开发的动态页面访问有多慢?不幸的是,我没有得到可行的答案。周末折腾了一下,把小站(花满楼)的所有页面都静止了;仔细想想,这并不是一个特别标准的做法。, 不过折腾了这么久,终于有了解决这个问题的办法,还是有些欣慰的;
一开始页面是动态的,由jade模板渲染,但是不明白为什么不管页面的内容,打开都需要至少一秒。. . ; 后来特地做了一个站点作为静态资源站,缓存和gzip(Nodejs搭建静态资源服务器和文件上传);OK,现在静态资源没有大问题;但是页面打开速度不理想,那就后台再按一下,来app.use(compress()); 事实证明,没有明显的效果;刚学Nodejs就郁闷,所以遇到这个无语的问题,百度了好久,哈哈。. . 最后,我只想到了一种方法。参考静态资源站点,将jade编译成html,将动态页面转成静态资源。它会像加载静态资源一样快吗?答案是肯定的!!!
就我的博客站点而言,我现在面临两个问题:一是直接编译原玉保留动态数据;另一种是去除动态数据编译成html,在ajax页面加载后请求数据;我选择前者,因为它可以在静态页面上保持最新的数据,而后者是js渲染的,对SEO非常不利;哈哈,其实这两种方法我都没有用过,因为在这个层面上,在express框架中,没听说过这种方法,自然下不来,只是一个理想的可行方案;
我该怎么办?好吧,原谅我选择放弃express的内置模板。经过一番整理,Gulp(gulp-jade模块)直接将那些jade全部编译成html(前端自动化的神器-Gulp)。我想是这样。编译后的 html 用作类似模板的模块。数据还是像之前一样在路由中取,将获取到的数据作为变量传递给html模板模块对应的接口,然后返回的html生成为一个真正的静态页面,这样,在路由器不变的情况下,直接生成原玉到对应目录;如上所述,页面需要像静态资源一样加载才能快速;
Gulpfile.js
var jade=require('gulp-jade');
gulp.task('jade',function() {
gulp.src('./views/bokeDetail.jade')
.pipe(jade({pretty:true}))
.pipe(gulp.dest('./public/famanoder/'));
});
bokeDetail.templ.js
var html=function(id,title,subtitle,time,from,contents){
//传递动态数据
return ''+动态数据+'';
}
//片段,实际情况而定
module.exports=html;
bokeDetail.js(路由器)
//......
//引入对应静态模块
var boketempl=require('./templs/bokeDetail.templ.js);
//依旧读取数据
//传递数据:如,id,title,content,comments
//生成静态页面到指定目录
function createStaticPage(id,title,content,comments,fn){
var path='./public/famanoder/';
var html=boketempl(id,title,content,comments);
var ws=fs.createWriteStream(path+id+'.html');
ws.write(html,function(err) {
console.log('writePage:'+path+id+'.html');
fn&&fn();
});
ws.on('drain',function() {
ws.end();
});
}
ok,程序执行后会生成静态页面,动态数据放到public下的famanoder目录下;下面是将响应直接指向bokeDetail.js(路由器)中上面生成的静态页面;
var pathname=url.parse(req.url).pathname;
var realpath='./public/famanoder/'+pathname.substr(pathname.lastIndexOf('/')+1)+'.html';
var type='text/html';
var extname='html';
fs.exists(realpath,function(exist){
if(!exist){console.log(101);
res.writeHead(404,{
'content-type':'text/plain'
});
res.write('The Resourse '+pathname+' was Not Found!');
res.end();
}else{
fs.readFile(realpath,'binary',function(err,file){
console.log(11);
if(err){
res.writeHead(500,{
'content-type':'text/plain'
});
res.end();
}
if(extname.match(config.fileMatch)){
var expires=new Date();
expires.setTime(expires.getTime()+config.maxAge*1000);
res.setHeader('Expires',expires.toUTCString());
res.setHeader('cache-control','max-age='+config.maxAge);
}
fs.stat(realpath,function(err,stat){
var lastModified=stat.mtime.toUTCString();
res.setHeader('Last-Modified',lastModified);
if(req.headers['if-modified-since']&&lastModified==req.headers['if-modified-since']){
console.log(0);
res.writeHead(304,{
'content-type':type
});
res.end();
}else{
var raw=fs.createReadStream(realpath);
var acceptEncoding=req.headers['accept-encoding']||'';
var matched=extname.match(/css|js|html/ig);
if(matched&&acceptEncoding.match(/\bgzip\b/)){
console.log(1);
res.writeHead(200,{
'content-type':type,
'Content-Encoding':'gzip'
});
raw.pipe(zlib.createGzip()).pipe(res);
}else if(matched&&acceptEncoding.match(/\bdeflate\b/)){
console.log(2);
res.writeHead(200,{
'content-type':type,
'Content-Encoding':'deflate'
});
raw.pipe(zlib.createDeflate()).pipe(res);
}else{
console.log(3);
res.writeHead(200,{
'content-type':type
});
raw.pipe(res);
}
}
});
});
}
});
再次访问详细信息页面,查看秒数是否打开。纯静态,路由没变,url没变,维护也很简单。只需更改 bokeDetail.templ.js; 没办法,可能在英雄眼中。这是傻瓜式,只是让你发笑;与此方法类似,现在网站的所有页面都是静态的,并且 SEO 得到充分照顾;
嗯,其实还有一个很重要的问题:就博客的细节而言,如果博客数量很多,如何批量转移?其实我在编辑和提交博客的时候顺便生成了一个静态页面。为了让详情页快点。. . ; 问题来了,如果我之前有成百上千的博客(当然,我的小前端远没有达到如此丰硕的成果),我一定不能再编辑和提交每个博客;吓死宝宝了,别急,新建一个update.js直接批量生成,非常快!
<p>Artical
.find({}).exec(function(err,docs) {
update(err,docs);
});
function update(err,docs) {
err&&console.log(err);
for(var i=0;i 查看全部
nodejs抓取动态网页(网上提了个问:Express4开发的动态页面访问好慢的说?)
上周在MOOC网站问了一个问题:Express4开发的动态页面访问有多慢?不幸的是,我没有得到可行的答案。周末折腾了一下,把小站(花满楼)的所有页面都静止了;仔细想想,这并不是一个特别标准的做法。, 不过折腾了这么久,终于有了解决这个问题的办法,还是有些欣慰的;
一开始页面是动态的,由jade模板渲染,但是不明白为什么不管页面的内容,打开都需要至少一秒。. . ; 后来特地做了一个站点作为静态资源站,缓存和gzip(Nodejs搭建静态资源服务器和文件上传);OK,现在静态资源没有大问题;但是页面打开速度不理想,那就后台再按一下,来app.use(compress()); 事实证明,没有明显的效果;刚学Nodejs就郁闷,所以遇到这个无语的问题,百度了好久,哈哈。. . 最后,我只想到了一种方法。参考静态资源站点,将jade编译成html,将动态页面转成静态资源。它会像加载静态资源一样快吗?答案是肯定的!!!
就我的博客站点而言,我现在面临两个问题:一是直接编译原玉保留动态数据;另一种是去除动态数据编译成html,在ajax页面加载后请求数据;我选择前者,因为它可以在静态页面上保持最新的数据,而后者是js渲染的,对SEO非常不利;哈哈,其实这两种方法我都没有用过,因为在这个层面上,在express框架中,没听说过这种方法,自然下不来,只是一个理想的可行方案;
我该怎么办?好吧,原谅我选择放弃express的内置模板。经过一番整理,Gulp(gulp-jade模块)直接将那些jade全部编译成html(前端自动化的神器-Gulp)。我想是这样。编译后的 html 用作类似模板的模块。数据还是像之前一样在路由中取,将获取到的数据作为变量传递给html模板模块对应的接口,然后返回的html生成为一个真正的静态页面,这样,在路由器不变的情况下,直接生成原玉到对应目录;如上所述,页面需要像静态资源一样加载才能快速;
Gulpfile.js
var jade=require('gulp-jade');
gulp.task('jade',function() {
gulp.src('./views/bokeDetail.jade')
.pipe(jade({pretty:true}))
.pipe(gulp.dest('./public/famanoder/'));
});
bokeDetail.templ.js
var html=function(id,title,subtitle,time,from,contents){
//传递动态数据
return ''+动态数据+'';
}
//片段,实际情况而定
module.exports=html;
bokeDetail.js(路由器)
//......
//引入对应静态模块
var boketempl=require('./templs/bokeDetail.templ.js);
//依旧读取数据
//传递数据:如,id,title,content,comments
//生成静态页面到指定目录
function createStaticPage(id,title,content,comments,fn){
var path='./public/famanoder/';
var html=boketempl(id,title,content,comments);
var ws=fs.createWriteStream(path+id+'.html');
ws.write(html,function(err) {
console.log('writePage:'+path+id+'.html');
fn&&fn();
});
ws.on('drain',function() {
ws.end();
});
}
ok,程序执行后会生成静态页面,动态数据放到public下的famanoder目录下;下面是将响应直接指向bokeDetail.js(路由器)中上面生成的静态页面;
var pathname=url.parse(req.url).pathname;
var realpath='./public/famanoder/'+pathname.substr(pathname.lastIndexOf('/')+1)+'.html';
var type='text/html';
var extname='html';
fs.exists(realpath,function(exist){
if(!exist){console.log(101);
res.writeHead(404,{
'content-type':'text/plain'
});
res.write('The Resourse '+pathname+' was Not Found!');
res.end();
}else{
fs.readFile(realpath,'binary',function(err,file){
console.log(11);
if(err){
res.writeHead(500,{
'content-type':'text/plain'
});
res.end();
}
if(extname.match(config.fileMatch)){
var expires=new Date();
expires.setTime(expires.getTime()+config.maxAge*1000);
res.setHeader('Expires',expires.toUTCString());
res.setHeader('cache-control','max-age='+config.maxAge);
}
fs.stat(realpath,function(err,stat){
var lastModified=stat.mtime.toUTCString();
res.setHeader('Last-Modified',lastModified);
if(req.headers['if-modified-since']&&lastModified==req.headers['if-modified-since']){
console.log(0);
res.writeHead(304,{
'content-type':type
});
res.end();
}else{
var raw=fs.createReadStream(realpath);
var acceptEncoding=req.headers['accept-encoding']||'';
var matched=extname.match(/css|js|html/ig);
if(matched&&acceptEncoding.match(/\bgzip\b/)){
console.log(1);
res.writeHead(200,{
'content-type':type,
'Content-Encoding':'gzip'
});
raw.pipe(zlib.createGzip()).pipe(res);
}else if(matched&&acceptEncoding.match(/\bdeflate\b/)){
console.log(2);
res.writeHead(200,{
'content-type':type,
'Content-Encoding':'deflate'
});
raw.pipe(zlib.createDeflate()).pipe(res);
}else{
console.log(3);
res.writeHead(200,{
'content-type':type
});
raw.pipe(res);
}
}
});
});
}
});
再次访问详细信息页面,查看秒数是否打开。纯静态,路由没变,url没变,维护也很简单。只需更改 bokeDetail.templ.js; 没办法,可能在英雄眼中。这是傻瓜式,只是让你发笑;与此方法类似,现在网站的所有页面都是静态的,并且 SEO 得到充分照顾;
嗯,其实还有一个很重要的问题:就博客的细节而言,如果博客数量很多,如何批量转移?其实我在编辑和提交博客的时候顺便生成了一个静态页面。为了让详情页快点。. . ; 问题来了,如果我之前有成百上千的博客(当然,我的小前端远没有达到如此丰硕的成果),我一定不能再编辑和提交每个博客;吓死宝宝了,别急,新建一个update.js直接批量生成,非常快!
<p>Artical
.find({}).exec(function(err,docs) {
update(err,docs);
});
function update(err,docs) {
err&&console.log(err);
for(var i=0;i
nodejs抓取动态网页(Python如何使用BeautifulSoup爬取网页信息文中通过示例代码介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-02 12:28
本文文章主要介绍Python如何使用BeautifulSoup抓取网页信息。文章通过示例代码对其进行了详细介绍。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考简单抓取网页信息的思路一般是1.查看网页源码2.抓取网页信息3.分析网页内容4. 保存成文件 现在使用BeautifulSoup解析库抓取刺猬实习生Python Job薪水情况一. 查看网页源码 这部分就是我们需要的,对应的源码是:分析源码,可以知道:1. 职位信息列表是用Python实现的,用于抓取网页中动态加载的数据
2020-08-15
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。比如在网页中获取某个产品的价格时就会出现这种现象。如下图所示。本文将实现对网页中类似动态加载数据的抓取。1. 那么什么是动态加载的数据呢?我们每次通过requests模块爬取数据的时候都无法获取。, 部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的数据就是动态加载的数据。(猜测可能是js代码,当我们访问这个页面时,会向其发送get请求
Python抓取网页中的图片(搜狗图片)详解
2017-03-20
前言这几天研究了一下一直很好奇的爬虫算法。这是最近几天的一点点。输入以下文字: 您可能需要的工作环境:Python 3.6官网下载搜狗是爬取的对象。首先我们进入搜狗图片,进入壁纸类别(当然只是一个例子Q_Q),因为如果你需要爬取某个网站的信息,那么就得对它有个初步的了解——这个是不是进入之后,然后F12进入开发者选项,作者用的是Chrome。图片右击>>查看我们需要的图片src是否在img标签下,所以先尝试使用
使用nodejs爬取51job前端技能排名
2017-05-05
最近要换工作,需要更新技能树。为了有针对性,我想对招聘人员的要求进行统计。之前刚学了nodejs,所以做了个爬虫来搜索数据。具体步骤: 1、首先使用fiddler分析请求需要的header和body。2.然后使用superagent构造上述数据并发送客户端请求。3.最后使用cheerio对返回的数据进行整理。几个晚上后,我只得到了一个架子,剩下的工作等待时间继续开发。/*使用fiddler抓包,需要配置lan代理,并设置如下参数*/ process .env.https_proxy
Python抓取网页并将其转换为PDF文件
2018-06-06
虽然可以查阅爬虫起源的官方文档或手册,但如果变成纸质版,不是更容易阅读和记忆。如果只是简单的复制粘贴,不知道什么时候才能完成。于是开始考虑加入安卓官方手册Climb down。整篇文章的实现分析。网页学习使用BeautifulSoup库抓取导出参考资料: * 将廖雪峰的教程转成PDF电子书 * 请求文档 * Ubuntu下使用Pycharm配置Beautiful Soup文件,运行成功并转为PDF。需要下载wkhtmltopdf网页分析的具体过程如下页面所示,怎么做
示例讲解Python抓取网页数据
2018-07-06
一.使用 webbrowser.open() 打开一个 网站: >>> import webbrowser >>> webbrowser.open('') True 示例:使用脚本打开一个网页。所有 Python 程序的第一行 All 应该以 #!python 开头,它告诉计算机你希望 Python 执行这个程序。(我没带这行来试试,还是可以的,也许这是规范) 1. read from sys.argv 取命令行参数:打开新文本
Python基于pandas爬取web表数据
2020-05-09
以一个web表单为例:网站数据有table标签,直接使用requests,需要结合bs4解析regular/xpath/lxml等,代码很少那是做不到的。今天介绍的黑科技是pandas自带的爬虫函数pd.read_html(),只需要传入url和一行代码即可获取。原网页结构如下: python代码如下: import pandas as pd url='' df=pd.read_html 查看全部
nodejs抓取动态网页(Python如何使用BeautifulSoup爬取网页信息文中通过示例代码介绍)
本文文章主要介绍Python如何使用BeautifulSoup抓取网页信息。文章通过示例代码对其进行了详细介绍。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考简单抓取网页信息的思路一般是1.查看网页源码2.抓取网页信息3.分析网页内容4. 保存成文件 现在使用BeautifulSoup解析库抓取刺猬实习生Python Job薪水情况一. 查看网页源码 这部分就是我们需要的,对应的源码是:分析源码,可以知道:1. 职位信息列表是用Python实现的,用于抓取网页中动态加载的数据
2020-08-15
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。比如在网页中获取某个产品的价格时就会出现这种现象。如下图所示。本文将实现对网页中类似动态加载数据的抓取。1. 那么什么是动态加载的数据呢?我们每次通过requests模块爬取数据的时候都无法获取。, 部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的数据就是动态加载的数据。(猜测可能是js代码,当我们访问这个页面时,会向其发送get请求
Python抓取网页中的图片(搜狗图片)详解
2017-03-20
前言这几天研究了一下一直很好奇的爬虫算法。这是最近几天的一点点。输入以下文字: 您可能需要的工作环境:Python 3.6官网下载搜狗是爬取的对象。首先我们进入搜狗图片,进入壁纸类别(当然只是一个例子Q_Q),因为如果你需要爬取某个网站的信息,那么就得对它有个初步的了解——这个是不是进入之后,然后F12进入开发者选项,作者用的是Chrome。图片右击>>查看我们需要的图片src是否在img标签下,所以先尝试使用
使用nodejs爬取51job前端技能排名
2017-05-05
最近要换工作,需要更新技能树。为了有针对性,我想对招聘人员的要求进行统计。之前刚学了nodejs,所以做了个爬虫来搜索数据。具体步骤: 1、首先使用fiddler分析请求需要的header和body。2.然后使用superagent构造上述数据并发送客户端请求。3.最后使用cheerio对返回的数据进行整理。几个晚上后,我只得到了一个架子,剩下的工作等待时间继续开发。/*使用fiddler抓包,需要配置lan代理,并设置如下参数*/ process .env.https_proxy
Python抓取网页并将其转换为PDF文件
2018-06-06
虽然可以查阅爬虫起源的官方文档或手册,但如果变成纸质版,不是更容易阅读和记忆。如果只是简单的复制粘贴,不知道什么时候才能完成。于是开始考虑加入安卓官方手册Climb down。整篇文章的实现分析。网页学习使用BeautifulSoup库抓取导出参考资料: * 将廖雪峰的教程转成PDF电子书 * 请求文档 * Ubuntu下使用Pycharm配置Beautiful Soup文件,运行成功并转为PDF。需要下载wkhtmltopdf网页分析的具体过程如下页面所示,怎么做
示例讲解Python抓取网页数据
2018-07-06
一.使用 webbrowser.open() 打开一个 网站: >>> import webbrowser >>> webbrowser.open('') True 示例:使用脚本打开一个网页。所有 Python 程序的第一行 All 应该以 #!python 开头,它告诉计算机你希望 Python 执行这个程序。(我没带这行来试试,还是可以的,也许这是规范) 1. read from sys.argv 取命令行参数:打开新文本
Python基于pandas爬取web表数据
2020-05-09
以一个web表单为例:网站数据有table标签,直接使用requests,需要结合bs4解析regular/xpath/lxml等,代码很少那是做不到的。今天介绍的黑科技是pandas自带的爬虫函数pd.read_html(),只需要传入url和一行代码即可获取。原网页结构如下: python代码如下: import pandas as pd url='' df=pd.read_html
nodejs抓取动态网页(爬虫并没有固定的形式,必须对具体网页作具体写法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-02 11:22
爬虫没有固定的形式,必须专门为特定的网页编写。
我们以腾讯新闻()为例。
-------------------------------------------------- -------------------------------------------------- ----------------
如果我们想抓取黄色框中的标题怎么办?(以谷歌浏览器为例)
首先,在浏览器中,右击-->检查。我们看到下图右侧的方框:
右边的代码你看不懂也没关系。当我们将鼠标放在上图中的红色方框中时,可以看到网页中有些地方会变成蓝色,而变成蓝色的地方就是鼠标点击的代码控制的地方。所以,我们点击代码最左边的图标来展开代码:
代码展开后,看起来有点吓人,其实还好。我们用鼠标从顶部向下滑动代码,但是当鼠标指向红色框的那一行时,可以看到我们需要提取的文章标题(必填部分)收录在蓝色中区域。于是我们展开右边红框中的代码....重复这一步直到:
直到我们需要的收录在蓝色区域中,如上图所示。(这样做的原因是我们需要了解我们需要提取的部分在html中是如何描述的)
在我们继续扩展之后:
终于看到页面的标题文章和html代码中文章的链接(红框href后面的链接就是链接)!是的,这就是我们要提取的内容。
从上图可以看出,我们需要的东西都收录在标签中的class="linkto"中。
(一般来说,只要是同类型的东西,比如网页中每个文章的标题,html中的描述方法都是一样的)所以我们就可以写代码了。
-------------------------------------------------- -------------------------------------------------- -----------------
在写代码之前,先简单介绍一下代码中好用的库。(请求和beautifulsoup4)。
前者用于向网页发送请求并提取网页的html。后者用于过滤html,提取有用信息。
-------------------------------------------------- -------------------------------------------------- -----------------
代码:
从 bs4 导入请求 import BeautifulSoup # Beautiful
Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取结构化数据#要抓取的网页 url = "" #
构建头文件模拟浏览器访问,否则访问单个网页时会出现403错误。您可以只复制标题之一。我的第一个爬虫文章 如何获取headers
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
#使用requests库中的gete方法向网页发送请求 page = requests.get(url) #Get html html=page.text
#print(html) # 将获取到的内容转换为BeautifulSoup格式,并使用html.parser作为解析器soup =
BeautifulSoup(html,'html.parser') #
在html中的a标签中查找所有class='linkto'的句子,将找到的内容返回给变量titles titles = soup.find_all('a',
'linkto') # open()是一个读写文件的函数,with语句会自动close()打开的文件 with open(r"D:\aaa.txt",
"w",encoding='utf-8') as file: # 在 D 盘中打开/创建一个名为 aaa 的 txt 文件作为 titles 中的 title:
#遍历titles中的每个元素 file.write(title.string+'\n') #将title字符串(即文章的title)写入文件,并换行
file.write(title.get('href') +'\n\n') #将文章的链接写入文件并包裹两次
效果:在D盘打开aaa.txt
可以抓取网页的文章标题和链接
接下来是抓取单个网页图片:
取#0l
比如main方法如上,一步一步从html中寻找你要爬取的信息。
代码显示如下:
导入请求从 urllib 导入请求从 bs4 导入导入
BeautifulSoup # Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取结构化数据#要抓取的网页 url =
""#
构建头文件模拟浏览器访问,否则访问单个网页时会出现403错误。您可以只复制标题之一。我的第一个爬虫文章 如何获取headers
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
#使用requests库中的gete方法向网页发送请求 page = requests.get(url) #Get html html=page.text
#print(html) # 将获取到的内容转换为BeautifulSoup格式,并使用html.parser作为解析器soup =
BeautifulSoup(html,'html.parser') #
查找html中class='BDE_Image'以及src中内容以“.jpg”结尾的所有img标签,找到的内容返回给变量links中的links
= soup.find_all('img','BDE_Image',src=pile(r'.jpg$')) #src的内容一般是一个图片的链接#
open()是一个读写文件的函数,with语句会自动close()打开的文件path=r'D:\images' n=0 for link in links:
print(link.attrs['src']) #打印图片的链接
request.urlretrieve(link.attrs['src'],path+'\%s.jpg' %n) #urlretrieve 下载到本地 n+=1
影响:
控制台打印信息:
从文件夹中抓取的图像: 查看全部
nodejs抓取动态网页(爬虫并没有固定的形式,必须对具体网页作具体写法)
爬虫没有固定的形式,必须专门为特定的网页编写。
我们以腾讯新闻()为例。
-------------------------------------------------- -------------------------------------------------- ----------------
如果我们想抓取黄色框中的标题怎么办?(以谷歌浏览器为例)
首先,在浏览器中,右击-->检查。我们看到下图右侧的方框:
右边的代码你看不懂也没关系。当我们将鼠标放在上图中的红色方框中时,可以看到网页中有些地方会变成蓝色,而变成蓝色的地方就是鼠标点击的代码控制的地方。所以,我们点击代码最左边的图标来展开代码:
代码展开后,看起来有点吓人,其实还好。我们用鼠标从顶部向下滑动代码,但是当鼠标指向红色框的那一行时,可以看到我们需要提取的文章标题(必填部分)收录在蓝色中区域。于是我们展开右边红框中的代码....重复这一步直到:
直到我们需要的收录在蓝色区域中,如上图所示。(这样做的原因是我们需要了解我们需要提取的部分在html中是如何描述的)
在我们继续扩展之后:
终于看到页面的标题文章和html代码中文章的链接(红框href后面的链接就是链接)!是的,这就是我们要提取的内容。
从上图可以看出,我们需要的东西都收录在标签中的class="linkto"中。
(一般来说,只要是同类型的东西,比如网页中每个文章的标题,html中的描述方法都是一样的)所以我们就可以写代码了。
-------------------------------------------------- -------------------------------------------------- -----------------
在写代码之前,先简单介绍一下代码中好用的库。(请求和beautifulsoup4)。
前者用于向网页发送请求并提取网页的html。后者用于过滤html,提取有用信息。
-------------------------------------------------- -------------------------------------------------- -----------------
代码:
从 bs4 导入请求 import BeautifulSoup # Beautiful
Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取结构化数据#要抓取的网页 url = "" #
构建头文件模拟浏览器访问,否则访问单个网页时会出现403错误。您可以只复制标题之一。我的第一个爬虫文章 如何获取headers
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
#使用requests库中的gete方法向网页发送请求 page = requests.get(url) #Get html html=page.text
#print(html) # 将获取到的内容转换为BeautifulSoup格式,并使用html.parser作为解析器soup =
BeautifulSoup(html,'html.parser') #
在html中的a标签中查找所有class='linkto'的句子,将找到的内容返回给变量titles titles = soup.find_all('a',
'linkto') # open()是一个读写文件的函数,with语句会自动close()打开的文件 with open(r"D:\aaa.txt",
"w",encoding='utf-8') as file: # 在 D 盘中打开/创建一个名为 aaa 的 txt 文件作为 titles 中的 title:
#遍历titles中的每个元素 file.write(title.string+'\n') #将title字符串(即文章的title)写入文件,并换行
file.write(title.get('href') +'\n\n') #将文章的链接写入文件并包裹两次
效果:在D盘打开aaa.txt
可以抓取网页的文章标题和链接
接下来是抓取单个网页图片:
取#0l
比如main方法如上,一步一步从html中寻找你要爬取的信息。
代码显示如下:
导入请求从 urllib 导入请求从 bs4 导入导入
BeautifulSoup # Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取结构化数据#要抓取的网页 url =
""#
构建头文件模拟浏览器访问,否则访问单个网页时会出现403错误。您可以只复制标题之一。我的第一个爬虫文章 如何获取headers
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
#使用requests库中的gete方法向网页发送请求 page = requests.get(url) #Get html html=page.text
#print(html) # 将获取到的内容转换为BeautifulSoup格式,并使用html.parser作为解析器soup =
BeautifulSoup(html,'html.parser') #
查找html中class='BDE_Image'以及src中内容以“.jpg”结尾的所有img标签,找到的内容返回给变量links中的links
= soup.find_all('img','BDE_Image',src=pile(r'.jpg$')) #src的内容一般是一个图片的链接#
open()是一个读写文件的函数,with语句会自动close()打开的文件path=r'D:\images' n=0 for link in links:
print(link.attrs['src']) #打印图片的链接
request.urlretrieve(link.attrs['src'],path+'\%s.jpg' %n) #urlretrieve 下载到本地 n+=1
影响:
控制台打印信息:
从文件夹中抓取的图像:
nodejs抓取动态网页(一个和浏览器的安装注意事项,开源地址:/GoogleChrom…)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-01 08:26
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。甚至有些网站会设置隐藏元素“陷阱”,用户看不到,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:/GoogleChrom...
安装
npm i puppeteer
复制代码
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客文章列表:
抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
复制代码
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:
结果
文章内容列表:
文章内容:
结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
其实一一处理是没有效率的。本来我写了一个异步方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown 查看全部
nodejs抓取动态网页(一个和浏览器的安装注意事项,开源地址:/GoogleChrom…)
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。甚至有些网站会设置隐藏元素“陷阱”,用户看不到,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:/GoogleChrom...
安装
npm i puppeteer
复制代码
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客文章列表:
抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
复制代码
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:
结果
文章内容列表:
文章内容:
结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
其实一一处理是没有效率的。本来我写了一个异步方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown
nodejs抓取动态网页( 一种nodejs抓取网页内容(2019-03-24)(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-01 08:23
一种nodejs抓取网页内容(2019-03-24)(图)
)
Nodejs抓取html页面内容(推荐)
时间:2019-03-24
本文章给大家介绍了Nodejs抓取html页面内容(推荐),主要包括Nodejs抓取html页面内容(推荐)用例、应用技巧、基础知识点总结和注意事项,有一定的参考价值,有需要的朋友可以参考。
废话不多说,我直接贴出node.js的核心代码来抓取html页面的内容。
具体代码如下:
var http = require("http");
var iconv = require('iconv-lite');
var option = {
hostname: "stockdata.stock.hexun.com",
path: "/gszl/s601398.shtml"
};
var req = http.request(option, function(res) {
res.on("data", function(chunk) {
console.log(iconv.decode(chunk, "gbk"));
});
}).on("error", function(e) {
console.log(e.message);
});
req.end();
我们看下面的nodejs来抓取网页内容
function loadPage(url) {
var http = require('http');
var pm = new Promise(function (resolve, reject) {
http.get(url, function (res) {
var html = '';
res.on('data', function (d) {
html += d.toString()
});
res.on('end', function () {
resolve(html);
});
}).on('error', function (e) {
reject(e)
});
});
return pm;
}
loadPage('http://www.baidu.com').then(function (d) {
console.log(d);
}); 查看全部
nodejs抓取动态网页(
一种nodejs抓取网页内容(2019-03-24)(图)
)
Nodejs抓取html页面内容(推荐)
时间:2019-03-24
本文章给大家介绍了Nodejs抓取html页面内容(推荐),主要包括Nodejs抓取html页面内容(推荐)用例、应用技巧、基础知识点总结和注意事项,有一定的参考价值,有需要的朋友可以参考。
废话不多说,我直接贴出node.js的核心代码来抓取html页面的内容。
具体代码如下:
var http = require("http");
var iconv = require('iconv-lite');
var option = {
hostname: "stockdata.stock.hexun.com",
path: "/gszl/s601398.shtml"
};
var req = http.request(option, function(res) {
res.on("data", function(chunk) {
console.log(iconv.decode(chunk, "gbk"));
});
}).on("error", function(e) {
console.log(e.message);
});
req.end();
我们看下面的nodejs来抓取网页内容
function loadPage(url) {
var http = require('http');
var pm = new Promise(function (resolve, reject) {
http.get(url, function (res) {
var html = '';
res.on('data', function (d) {
html += d.toString()
});
res.on('end', function () {
resolve(html);
});
}).on('error', function (e) {
reject(e)
});
});
return pm;
}
loadPage('http://www.baidu.com').then(function (d) {
console.log(d);
});
nodejs抓取动态网页(之前第一篇教程.js爬虫入门(一)爬取静态页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-27 19:23
第一篇爬虫教程node.js爬虫入门(一)爬取静态页面讲解了静态网页的爬取,很简单,但是如果遇到一些动态网页(ajax),直接使用前面的发送请求方法获取不到我们想要的数据,这时候需要爬取动态网页,selenium和puppeteer都不错。
在这里推荐 Puppeteer,不是为了别的,只是因为它是 Google 自己的并且一直在维护更新。下面是翻译的官方文档介绍
Puppeteer 是一个 Node 库,通过 DevTools(开发者工具)协议提供了一系列高级接口来控制 Chrome 或 Chromium(谷歌开源)。默认以headless模式运行(无浏览器UI界面),也可以通过配置以普通模式运行。
它可用于:
首先,我们必须先安装它,然后才能使用它。最新的Chromium会默认安装下载,大小约300M。
npm install puppeteer
复制代码
如果你的机器上已经有较新版本的chrome,则只能安装core版本,但是启动puppeteer时需要配置本地chrome的路径。
npm install puppeteer-core // 核心版本
复制代码
假设我们要爬取拉勾的前端招聘信息。这是一个动态页面。使用此示例尝试抓取。
因为chrome操作都是异步操作,为了避免回调地狱,推荐使用es7的async await。这种语法具有很高的可读性,官方文档也是如此。
首先使用puppeteer启动浏览器,打开动态页面
需要注意的是,如果使用的是本地浏览器,则需要在启动浏览器配置中传入本地chrome路径
const browser = await puppeteer.launch({
executablePath: 'C:/Users/Administrator/AppData/Local/Google/Chrome/Application/chrome.exe'
})
复制代码
在chrome环境中执行函数,获取需要的数据,然后返回到node的执行环境
上图可以看到我们需要的数据的dom位置。在chrome环境执行的函数中,我们需要获取和整理需要的数据。
let list = document.querySelectorAll('.s_position_list .item_con_list li')
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
name: list[i].getAttribute('data-positionname'),
company: list[i].getAttribute('data-company'),
salary: list[i].getAttribute('data-salary'),
require: list[i].querySelector('.li_b_l').childNodes[4].textContent.replace(/ |\n/g, ''),
})
}
return res
复制代码
这里有一个调试技巧,我们可以在chrome控制台中直接编写获取数据的函数,方便调试
最后附上完整代码
const puppeteer = require('puppeteer');
(async () => {
// 启动浏览器
const browser = await puppeteer.launch({
headless: false, // 默认是无头模式,这里为了示范所以使用正常模式
})
// 控制浏览器打开新标签页面
const page = await browser.newPage()
// 在新标签中打开要爬取的网页
await page.goto('https://www.lagou.com/jobs/list_web%E5%89%8D%E7%AB%AF?px=new&city=%E5%B9%BF%E5%B7%9E')
// 使用evaluate方法在浏览器中执行传入函数(完全的浏览器环境,所以函数内可以直接使用window、document等所有对象和方法)
let data = await page.evaluate(() => {
let list = document.querySelectorAll('.s_position_list .item_con_list li')
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
name: list[i].getAttribute('data-positionname'),
company: list[i].getAttribute('data-company'),
salary: list[i].getAttribute('data-salary'),
require: list[i].querySelector('.li_b_l').childNodes[4].textContent.replace(/ |\n/g, ''),
})
}
return res
})
console.log(data)
})()
复制代码
操作结果
到这里,动态网页的爬取也已经完成了,但是puppeteer的功能远不止这些。它还具有许多可以使用的强大 API。您可以移至官方文档。
第三期会讲如何定时执行爬虫并存入数据库。 查看全部
nodejs抓取动态网页(之前第一篇教程.js爬虫入门(一)爬取静态页面)
第一篇爬虫教程node.js爬虫入门(一)爬取静态页面讲解了静态网页的爬取,很简单,但是如果遇到一些动态网页(ajax),直接使用前面的发送请求方法获取不到我们想要的数据,这时候需要爬取动态网页,selenium和puppeteer都不错。
在这里推荐 Puppeteer,不是为了别的,只是因为它是 Google 自己的并且一直在维护更新。下面是翻译的官方文档介绍
Puppeteer 是一个 Node 库,通过 DevTools(开发者工具)协议提供了一系列高级接口来控制 Chrome 或 Chromium(谷歌开源)。默认以headless模式运行(无浏览器UI界面),也可以通过配置以普通模式运行。
它可用于:
首先,我们必须先安装它,然后才能使用它。最新的Chromium会默认安装下载,大小约300M。
npm install puppeteer
复制代码
如果你的机器上已经有较新版本的chrome,则只能安装core版本,但是启动puppeteer时需要配置本地chrome的路径。
npm install puppeteer-core // 核心版本
复制代码
假设我们要爬取拉勾的前端招聘信息。这是一个动态页面。使用此示例尝试抓取。
因为chrome操作都是异步操作,为了避免回调地狱,推荐使用es7的async await。这种语法具有很高的可读性,官方文档也是如此。
首先使用puppeteer启动浏览器,打开动态页面
需要注意的是,如果使用的是本地浏览器,则需要在启动浏览器配置中传入本地chrome路径
const browser = await puppeteer.launch({
executablePath: 'C:/Users/Administrator/AppData/Local/Google/Chrome/Application/chrome.exe'
})
复制代码
在chrome环境中执行函数,获取需要的数据,然后返回到node的执行环境
上图可以看到我们需要的数据的dom位置。在chrome环境执行的函数中,我们需要获取和整理需要的数据。
let list = document.querySelectorAll('.s_position_list .item_con_list li')
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
name: list[i].getAttribute('data-positionname'),
company: list[i].getAttribute('data-company'),
salary: list[i].getAttribute('data-salary'),
require: list[i].querySelector('.li_b_l').childNodes[4].textContent.replace(/ |\n/g, ''),
})
}
return res
复制代码
这里有一个调试技巧,我们可以在chrome控制台中直接编写获取数据的函数,方便调试
最后附上完整代码
const puppeteer = require('puppeteer');
(async () => {
// 启动浏览器
const browser = await puppeteer.launch({
headless: false, // 默认是无头模式,这里为了示范所以使用正常模式
})
// 控制浏览器打开新标签页面
const page = await browser.newPage()
// 在新标签中打开要爬取的网页
await page.goto('https://www.lagou.com/jobs/list_web%E5%89%8D%E7%AB%AF?px=new&city=%E5%B9%BF%E5%B7%9E')
// 使用evaluate方法在浏览器中执行传入函数(完全的浏览器环境,所以函数内可以直接使用window、document等所有对象和方法)
let data = await page.evaluate(() => {
let list = document.querySelectorAll('.s_position_list .item_con_list li')
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
name: list[i].getAttribute('data-positionname'),
company: list[i].getAttribute('data-company'),
salary: list[i].getAttribute('data-salary'),
require: list[i].querySelector('.li_b_l').childNodes[4].textContent.replace(/ |\n/g, ''),
})
}
return res
})
console.log(data)
})()
复制代码
操作结果
到这里,动态网页的爬取也已经完成了,但是puppeteer的功能远不止这些。它还具有许多可以使用的强大 API。您可以移至官方文档。
第三期会讲如何定时执行爬虫并存入数据库。
nodejs抓取动态网页(记录一下西瓜视频MP4地址的获取步骤(1)_ )
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-25 03:07
)
记录获取西瓜视频MP4地址的步骤
目标:
指定西瓜视频的地址,例如获取其视频MP4文件的下载地址
以下使用chrome浏览器
开始分析:
首先在浏览器中打开视频页面,打开review元素(右键->review元素或F12)刷新页面查看网络选项中抓包
提示 1:
由于我们得到的是视频文件的下载地址,而视频文件一般都比较大,可以使用网络包列表中的Size来对最大的包进行排序
如图:
在这里我们可以轻松确定视频文件的地址
(你得到的地址可能和我得到的不一样,但URL路径中的最后一串应该是一样的)
接下来,我们将找出获取地址的位置。一般的做法是截取url中比较有代表性的部分(这个靠经验,你应该明白)进行搜索,搜索可以使用chrome评论元素的Search功能
此搜索将在网络列中找到所有数据包的响应内容。如果找到,我们就可以确定视频文件地址的来源。
你为什么这么做?
按照正常思路,首先获取视频文件的请求是由浏览器发起的,所以浏览器在发起之前肯定已经获取到了视频文件的地址,那么地址在哪里呢?一般来说,无非就是直接写
在网页源码中获取视频地址或者使用ajax请求之类的,所以这个地址必须在我们目前能看到的网络列表中的包中。
但是,在这个例子中,搜索结果是空的。尝试220f87599d445a14a53803fd01d86816e971157c7a70000cab5121742cc、5cc4c0ae0f7d6f87014dc0f0058257e>@k
无法搜索。
好吧,既然找不到,那就用暴力的方法吧。好在这个网页上的网络包并不多,我们就一一寻找。搜索过程一般可以忽略css、图片、多媒体等文档,
先查看json格式的文件
下面手动查看。. .
再次检查后,我发现了一个可疑的链接
首先这个url是可疑的,里面收录了各种敏感的关键词,比如mp4、urls等。
二、内容可疑:
video_list 出来了,但还能是谁呢?但是,如果仔细观察,该内容中的 URL 格式是不正确的。乍一看,好像是加密过的。难怪你找不到它。
下面是找个解密方法来验证我们这里看到的就是我们想要的视频地址
让我们先来看看这个想法。我们找到的数据是浏览器请求的。既然是请求数据,那肯定有用。让我们找出数据在哪里使用,如何找到它,或搜索。使用这些数据中的变量名称进行搜索
这些数据中有两个可疑的变量:backup_url_1、main_url。第一个乍一看是备份,所以让我们搜索第二个。
搜索结果如下:
下面找到这些包中 main_url 所在的代码。幸运的是,第一个就是我们想要的(tt-video.js)
如图:
从代码中我们可以看出main_url使用base64decode进行解密。下面使用代码验证(请自行验证)。果然,我们得到了想要的视频地址。
至此,我们已经有了从这个数据包中获取视频地址的方法,那么接下来的问题是,这个数据包的地址是如何生成的呢?
首先分析一下这个包的url的组成:
先去掉不相关的参数,方法很简单,直接在浏览器中打开url,然后尝试删除参数,继续测试。删除的url如下
然后我发现有三件事我不知道它们来自哪里。让我们继续使用我们的搜索工具来一一查找。
(注:当你按照文章一步一步来的时候,你看到的参数可能和我这里写的参数不一样,请按实际搜索)
首先是v02004bd0000bc9po7aj2boojm5cta5g,搜索结果如下:
原来这个参数是视频的videoId,直接在网页源码中。好的,第一个就完成了。
看看第二个参数8795045找不到
来看看第三个参数 3128215333 找不到
后两个参数是不可搜索的,可能是实时生成的,也可能是加密的,所以换个思路,用url前半部分的关键词搜索一下,看看用在什么地方
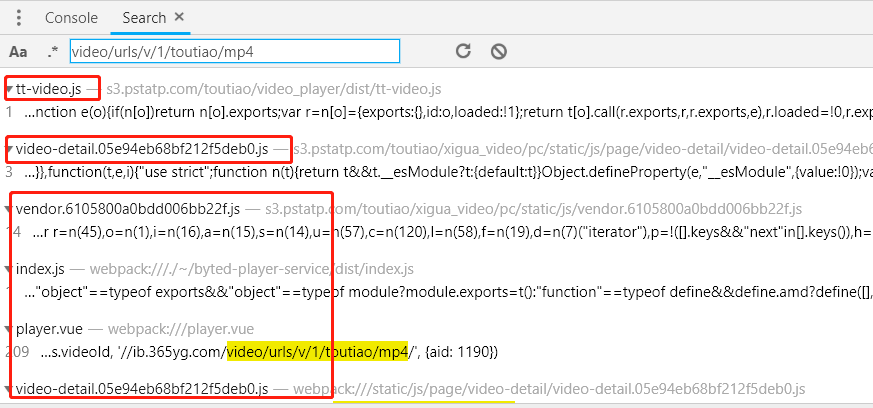
关于关键词 当然越长越准确,所以我选择的搜索词是video/urls/v/1/toutiao/mp4,搜索结果如下:
这里只能一一打开源代码。. .
查看源代码时,注意以下几点:
1、查看上下文,查看文件的功能
2、想想我们在寻找什么。比如在这个例子中,我们搜索的是一个视频资源的URL,所以一定要特别注意视频相关的关键词、函数名等
哈哈,幸运的是,我在第一个文件(tt-video.js)中发现了可疑代码
这都与视频有关。更可疑的是 getVideosJson 函数的名称。然后我发现一个 crc32 函数使用了目标 url。我们来看看crc32函数是在哪里定义的。
(PS:标准的crc32是一种公共算法,用于为一段数据生成校验码,但一般这些反爬虫前端工程师会自己实现,所以以JS代码为准)
通过搜索crc32关键词,可以定位到如下代码:
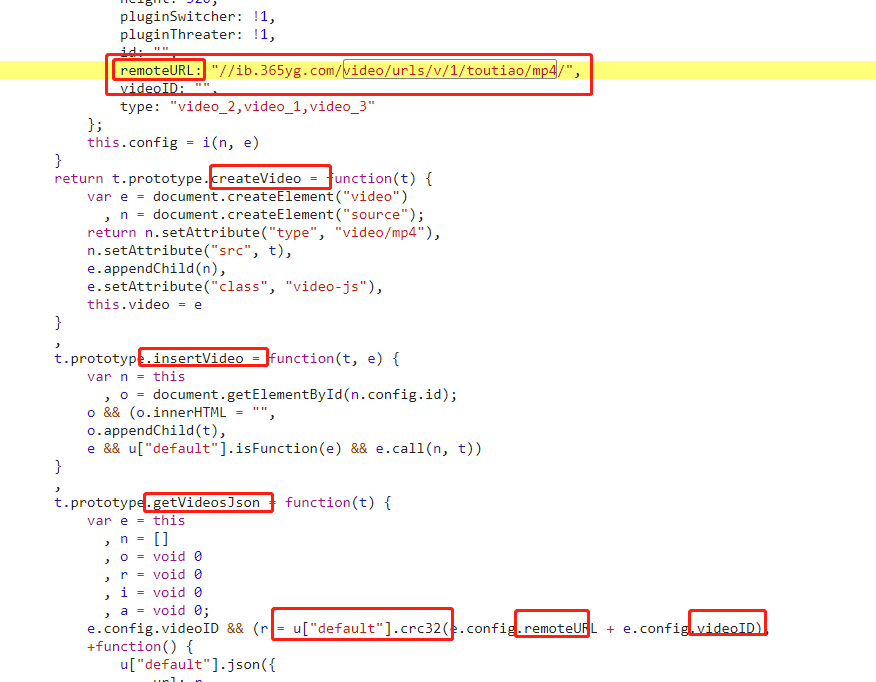
专注于图中的红色区域。我们找不到的 r 和 s 参数出现在这里。这说明我们的想法应该是正确的。然后我们发现r的值是随机生成的。这很容易处理。我们也会只随机生成一个,最好完全按照JS代码模拟。
但是s的值似乎有点复杂。那么,现在是测试你的脑力的时候了。
s 的值是由函数 o 生成的,但是 o 的代码非常复杂。我该怎么办?
第一种方法:
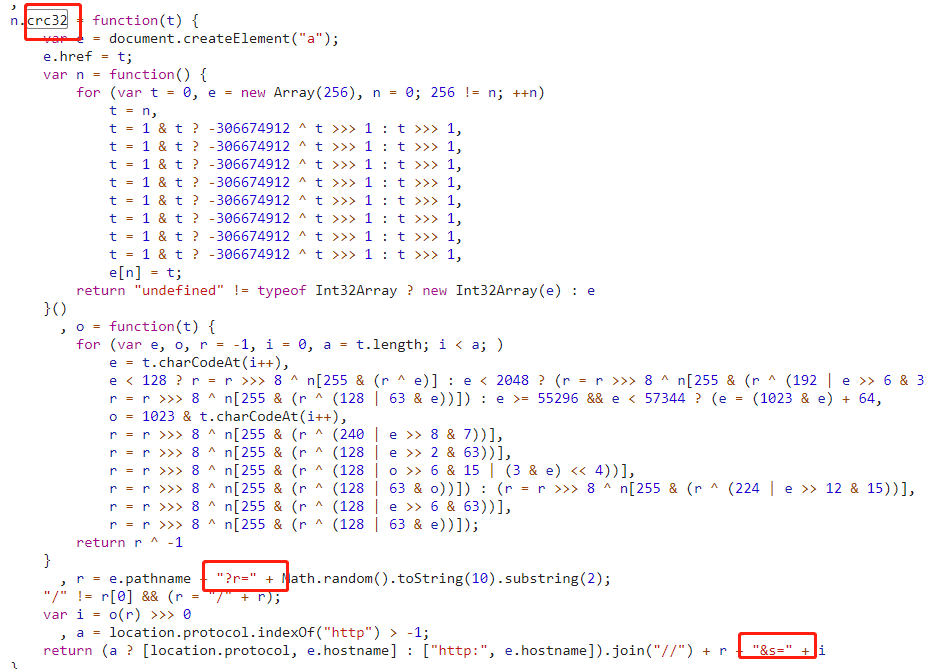
不好说,js代码的算法完全是模拟出来的,可以用其他语言尝试计算,或者用pyv8、nodejs等js引擎来执行
第二种方法:
怎么说呢,换个角度想想。如果你是写这段代码的前端工程师,你会怎么做?您会从头开始实施验证算法吗?? ? (当然不可否认,确实有些情况下算法是自创的)由于这个函数是
对于像crc32这样的公共算法,每种语言基本上都有一个标准库实现,所以可以直接调用标准库来测试。如果加密结果一致,大家开心不一致,请参考第一种方法。
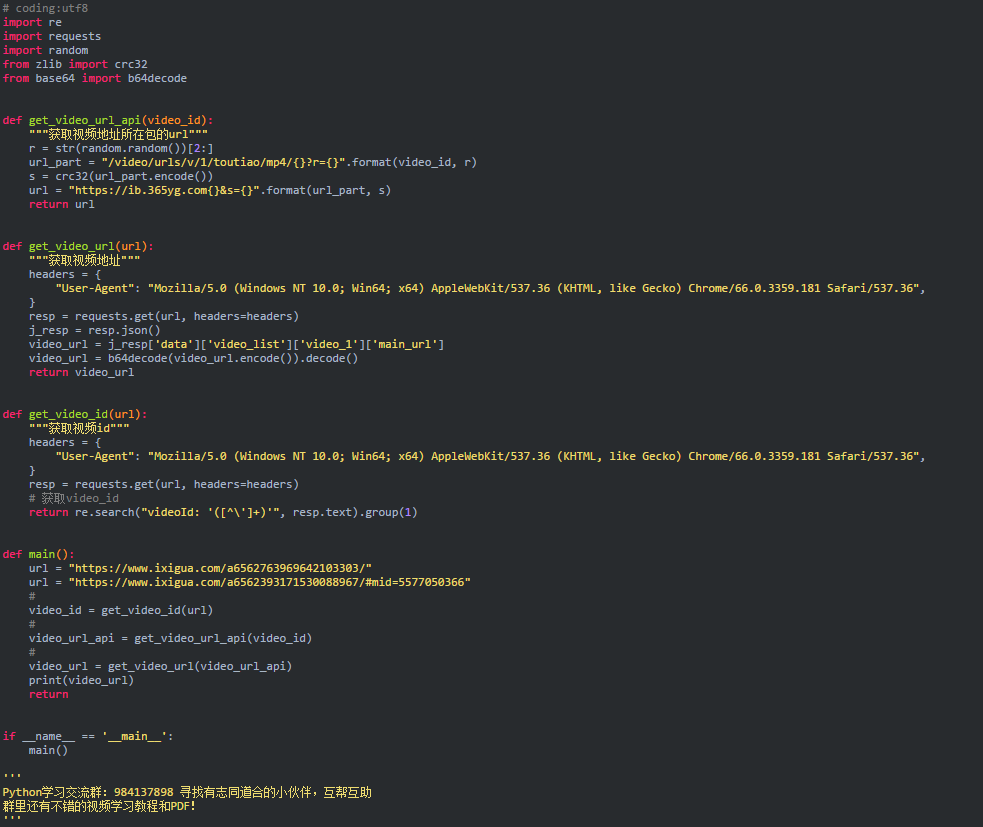
好了,到此为止,分析已经完成了,现在是时候编写代码了。代码显示如下:
查看全部
nodejs抓取动态网页(记录一下西瓜视频MP4地址的获取步骤(1)_
)
记录获取西瓜视频MP4地址的步骤
目标:
指定西瓜视频的地址,例如获取其视频MP4文件的下载地址
以下使用chrome浏览器
开始分析:
首先在浏览器中打开视频页面,打开review元素(右键->review元素或F12)刷新页面查看网络选项中抓包
提示 1:
由于我们得到的是视频文件的下载地址,而视频文件一般都比较大,可以使用网络包列表中的Size来对最大的包进行排序
如图:

在这里我们可以轻松确定视频文件的地址
(你得到的地址可能和我得到的不一样,但URL路径中的最后一串应该是一样的)
接下来,我们将找出获取地址的位置。一般的做法是截取url中比较有代表性的部分(这个靠经验,你应该明白)进行搜索,搜索可以使用chrome评论元素的Search功能

此搜索将在网络列中找到所有数据包的响应内容。如果找到,我们就可以确定视频文件地址的来源。
你为什么这么做?
按照正常思路,首先获取视频文件的请求是由浏览器发起的,所以浏览器在发起之前肯定已经获取到了视频文件的地址,那么地址在哪里呢?一般来说,无非就是直接写
在网页源码中获取视频地址或者使用ajax请求之类的,所以这个地址必须在我们目前能看到的网络列表中的包中。
但是,在这个例子中,搜索结果是空的。尝试220f87599d445a14a53803fd01d86816e971157c7a70000cab5121742cc、5cc4c0ae0f7d6f87014dc0f0058257e>@k
无法搜索。
好吧,既然找不到,那就用暴力的方法吧。好在这个网页上的网络包并不多,我们就一一寻找。搜索过程一般可以忽略css、图片、多媒体等文档,
先查看json格式的文件
下面手动查看。. .
再次检查后,我发现了一个可疑的链接
首先这个url是可疑的,里面收录了各种敏感的关键词,比如mp4、urls等。
二、内容可疑:
video_list 出来了,但还能是谁呢?但是,如果仔细观察,该内容中的 URL 格式是不正确的。乍一看,好像是加密过的。难怪你找不到它。
下面是找个解密方法来验证我们这里看到的就是我们想要的视频地址
让我们先来看看这个想法。我们找到的数据是浏览器请求的。既然是请求数据,那肯定有用。让我们找出数据在哪里使用,如何找到它,或搜索。使用这些数据中的变量名称进行搜索
这些数据中有两个可疑的变量:backup_url_1、main_url。第一个乍一看是备份,所以让我们搜索第二个。
搜索结果如下:
下面找到这些包中 main_url 所在的代码。幸运的是,第一个就是我们想要的(tt-video.js)
如图:
从代码中我们可以看出main_url使用base64decode进行解密。下面使用代码验证(请自行验证)。果然,我们得到了想要的视频地址。
至此,我们已经有了从这个数据包中获取视频地址的方法,那么接下来的问题是,这个数据包的地址是如何生成的呢?
首先分析一下这个包的url的组成:
先去掉不相关的参数,方法很简单,直接在浏览器中打开url,然后尝试删除参数,继续测试。删除的url如下
然后我发现有三件事我不知道它们来自哪里。让我们继续使用我们的搜索工具来一一查找。
(注:当你按照文章一步一步来的时候,你看到的参数可能和我这里写的参数不一样,请按实际搜索)
首先是v02004bd0000bc9po7aj2boojm5cta5g,搜索结果如下:
原来这个参数是视频的videoId,直接在网页源码中。好的,第一个就完成了。
看看第二个参数8795045找不到
来看看第三个参数 3128215333 找不到
后两个参数是不可搜索的,可能是实时生成的,也可能是加密的,所以换个思路,用url前半部分的关键词搜索一下,看看用在什么地方
关于关键词 当然越长越准确,所以我选择的搜索词是video/urls/v/1/toutiao/mp4,搜索结果如下:
这里只能一一打开源代码。. .
查看源代码时,注意以下几点:
1、查看上下文,查看文件的功能
2、想想我们在寻找什么。比如在这个例子中,我们搜索的是一个视频资源的URL,所以一定要特别注意视频相关的关键词、函数名等
哈哈,幸运的是,我在第一个文件(tt-video.js)中发现了可疑代码
这都与视频有关。更可疑的是 getVideosJson 函数的名称。然后我发现一个 crc32 函数使用了目标 url。我们来看看crc32函数是在哪里定义的。
(PS:标准的crc32是一种公共算法,用于为一段数据生成校验码,但一般这些反爬虫前端工程师会自己实现,所以以JS代码为准)
通过搜索crc32关键词,可以定位到如下代码:
专注于图中的红色区域。我们找不到的 r 和 s 参数出现在这里。这说明我们的想法应该是正确的。然后我们发现r的值是随机生成的。这很容易处理。我们也会只随机生成一个,最好完全按照JS代码模拟。
但是s的值似乎有点复杂。那么,现在是测试你的脑力的时候了。
s 的值是由函数 o 生成的,但是 o 的代码非常复杂。我该怎么办?
第一种方法:
不好说,js代码的算法完全是模拟出来的,可以用其他语言尝试计算,或者用pyv8、nodejs等js引擎来执行
第二种方法:
怎么说呢,换个角度想想。如果你是写这段代码的前端工程师,你会怎么做?您会从头开始实施验证算法吗?? ? (当然不可否认,确实有些情况下算法是自创的)由于这个函数是
对于像crc32这样的公共算法,每种语言基本上都有一个标准库实现,所以可以直接调用标准库来测试。如果加密结果一致,大家开心不一致,请参考第一种方法。
好了,到此为止,分析已经完成了,现在是时候编写代码了。代码显示如下:
nodejs抓取动态网页(ajax和Chrome的内核性能相对Trident较好,性能你懂的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-20 20:31
在Ajax时代,许多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的HTML
跳过了JS加载部分,即爬虫抓取的网页不完整、不完整。你可以看到下面博客花园的首页
从主页加载中,我们可以看到页面呈现后,将有五个Ajax异步请求。默认情况下,爬虫程序无法抓取Ajax生成的内容
此时,如果要获取这些动态页面,必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎有三个支柱
三叉戟:即内核。WebBrowser基于此内核,但其可加载性较差
壁虎:FF的内核比Trident有更好的性能
WebKit:Safari和chrome的内核性能,你知道,在真实场景中仍然基于它
好吧,为了简单和方便,让我们使用WebBrowser来玩。使用WebBrowser时,我们应注意以下几点:
第一:因为WebBrowser是system.windows.forms中的WinForm控件,所以我们需要设置StatThread标志
第二:WinForm是事件驱动的,控制台不响应事件。所有事件都在windows的消息队列中等待执行。为了不让程序假装死亡
我们需要调用Doevents方法来转移控制,并让操作系统执行其他事件
第三:我们需要使用domdocument而不是documenttext来查看WebBrowser中的内容
通常有两种方法来判断是否加载了动态网页:
① : 在这里设置一个最大值,因为每次异步加载JS时,都会触发导航和documentcompleted事件,所以我们需要
只需将计数值记录在
② : 当然,除了通过判断最大值来判断加载是否完成外,我们还可以通过设置定时器来判断,如3S、4S、5S等
是否已加载web浏览器 查看全部
nodejs抓取动态网页(ajax和Chrome的内核性能相对Trident较好,性能你懂的)
在Ajax时代,许多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的HTML
跳过了JS加载部分,即爬虫抓取的网页不完整、不完整。你可以看到下面博客花园的首页

从主页加载中,我们可以看到页面呈现后,将有五个Ajax异步请求。默认情况下,爬虫程序无法抓取Ajax生成的内容
此时,如果要获取这些动态页面,必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎有三个支柱
三叉戟:即内核。WebBrowser基于此内核,但其可加载性较差
壁虎:FF的内核比Trident有更好的性能
WebKit:Safari和chrome的内核性能,你知道,在真实场景中仍然基于它
好吧,为了简单和方便,让我们使用WebBrowser来玩。使用WebBrowser时,我们应注意以下几点:
第一:因为WebBrowser是system.windows.forms中的WinForm控件,所以我们需要设置StatThread标志
第二:WinForm是事件驱动的,控制台不响应事件。所有事件都在windows的消息队列中等待执行。为了不让程序假装死亡
我们需要调用Doevents方法来转移控制,并让操作系统执行其他事件
第三:我们需要使用domdocument而不是documenttext来查看WebBrowser中的内容
通常有两种方法来判断是否加载了动态网页:
① : 在这里设置一个最大值,因为每次异步加载JS时,都会触发导航和documentcompleted事件,所以我们需要
只需将计数值记录在
② : 当然,除了通过判断最大值来判断加载是否完成外,我们还可以通过设置定时器来判断,如3S、4S、5S等
是否已加载web浏览器
nodejs抓取动态网页(本发明基于Web动态信息抓取技术的详情页面自动生成方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-20 03:07
本发明涉及一种基于Web动态信息捕获技术的细节页面自动生成方法
背景技术:
目前,国内主流爬虫直接使用HTTP协议下载指定URL的静态HTML内容,并对内容进行分析和提取。该方法已广泛应用于搜索引擎、舆情监控、垂直门户网站等领域
但在电子商务领域,考虑到安全性、加载速度、页面静态等因素,商品页面中网站的价格、商品规格、图形细节等大部分都是通过JS和Ajax加载的动态HTML内容。这使得传统的网络爬虫系统无法有效地自动获取商品信息
随着互联网的发展,中国大量线下零售企业开始建设自己的电商平台,如广百百货的广百汇、广州友谊商城的线上商城等,实现线上线下商品的一体化销售。然而,传统零售企业要想在网上销售大量商品,需要记录每种商品的详细商品图形信息,工作量非常巨大。例如,在冰箱、洗衣机、彩电和空调四大类中,有8000至10000种常用型号。如果一个人按照5人的输入团队,每小时输入4台PC产品+4台移动产品的图形详细信息,则需要3-4个月,效率低下
技术实现要素:
本发明所要解决的技术问题是提供一种基于Web动态信息捕获技术的高效细节页面自动生成方法
为了解决上述问题,本发明采用以下技术方案:
本发明涉及一种基于Web动态信息捕获技术的细节页面自动生成方法,包括以下步骤:
1)抓取程序模块并启动浏览器
2)模仿人的操作打开商品详情页面
3)抓取页面中的信息并下载相关图片
4)手动审查
优选地,抓取程序模块由selenium测试工具和爬虫程序构建
优选地,该步骤的特定步骤1)包括:
1.1)在捕获程序模块中输入商品和目标商场的基本信息
1.2)grab程序模块基于selenium测试工具的功能模拟人工操作并启动浏览器
1.3)登录购物中心
1.4)通过步骤1.1)中的预设关键字搜索目标网站以找到相应的商品
优选地,该步骤的特定步骤2)包括:
2.2)打开产品详细信息页面
2.3)等待浏览器加载静态和动态内容
优选地,该步骤的特定步骤3)包括:
3.1)基于爬虫的功能,它可以自动捕获页面中的商品价格、规格参数和商品详细信息,并下载相关图片
3.2)转换捕获的图形信息的格式
如果在步骤1.4)中找不到相应的商品,最好返回步骤1.1)重新输入商品和目标商场的基本信息
本发明的有益效果是,通过在浏览器中模仿人们的鼠标点击、键盘输入等操作,并监控操作后浏览器内容的变化,结合网络爬虫捕获的信息功能,完全模拟了真实用户在浏览器中的浏览操作。因此,捕获的信息与真实用户看到的图形信息完全一致。与传统的网络爬虫产品相比,它具有兼容性好、速度快、数据捕获准确等特点
具体实施例
本发明涉及一种基于Web动态信息捕获技术的细节页面自动生成方法,包括以下步骤:
1)抓取程序模块并启动浏览器
2)模仿人的操作打开商品详情页面
3)抓取页面中的信息并下载相关图片
4)mall经理检查捕获的商品信息,快速修改有问题的内容,并在通过审核后将信息应用到自己的商城
本发明的有益效果是,通过在浏览器中模仿人们的鼠标点击、键盘输入等操作,并监控操作后浏览器内容的变化,结合网络爬虫捕获的信息功能,完全模拟了真实用户在浏览器中的浏览操作。因此,捕获的信息与真实用户看到的图形信息完全一致。与传统的网络爬虫产品相比,它具有兼容性好、速度快、数据捕获准确等特点
例2
本发明涉及一种基于Web动态信息捕获技术的细节页面自动生成方法,包括以下步骤:
1.在捕获程序模块中输入商品和目标商城的基本信息;抓取程序模块基于selenium测试工具的功能,模拟人工操作,启动浏览器,登录商场;通过预设关键字在目标网站中搜索,找到对应的商品。如果找不到对应的商品,则重新输入商品和目标商场的基本信息
2)打开产品详细信息页面,等待浏览器加载静态和动态内容
3)基于爬虫程序的功能,可以自动捕获页面中的商品价格、规格参数和商品详情,并下载相关图片;然后将捕获的图形信息转换为我们商场的商品数据格式
4)mall经理检查捕获的商品信息,快速修改有问题的内容,并在通过审核后将信息应用到自己的商城
抓取程序模块由selenium测试工具和爬虫程序构建,实现了基于selenium技术和web爬虫技术的信息自动抓取程序。它可以控制浏览器的行为,模拟人们在浏览器中启动鼠标点击、键盘输入等操作,并监控操作后浏览器内容的变化,模拟商城会员操作:打开浏览器->登录目标商城->查找目标商品->打开商品详情页面->等待浏览器加载静态和动态内容,然后提取商品名称、价格、图形详情等内容。该操作完全模拟真实用户在浏览器中的浏览操作,因此,捕获的信息与真实用户看到的图形信息完全一致
本发明的有益效果是:利用selenium技术和网络爬虫技术,通过在浏览器中模仿人们的鼠标点击、键盘输入等操作,并监控操作后浏览器内容的变化,结合网络爬虫捕获的信息功能,浏览器中真实用户的浏览操作是完全模拟的,因此,捕获的信息与真实用户看到的图形信息完全一致。与传统的网络爬虫产品相比,它具有兼容性好、速度快、数据捕获准确等特点
以上仅为本发明的具体实施例,但本发明的保护范围不限于此。未经创造性劳动的变更或者更换,属于本发明的保护范围 查看全部
nodejs抓取动态网页(本发明基于Web动态信息抓取技术的详情页面自动生成方法)
本发明涉及一种基于Web动态信息捕获技术的细节页面自动生成方法
背景技术:
目前,国内主流爬虫直接使用HTTP协议下载指定URL的静态HTML内容,并对内容进行分析和提取。该方法已广泛应用于搜索引擎、舆情监控、垂直门户网站等领域
但在电子商务领域,考虑到安全性、加载速度、页面静态等因素,商品页面中网站的价格、商品规格、图形细节等大部分都是通过JS和Ajax加载的动态HTML内容。这使得传统的网络爬虫系统无法有效地自动获取商品信息
随着互联网的发展,中国大量线下零售企业开始建设自己的电商平台,如广百百货的广百汇、广州友谊商城的线上商城等,实现线上线下商品的一体化销售。然而,传统零售企业要想在网上销售大量商品,需要记录每种商品的详细商品图形信息,工作量非常巨大。例如,在冰箱、洗衣机、彩电和空调四大类中,有8000至10000种常用型号。如果一个人按照5人的输入团队,每小时输入4台PC产品+4台移动产品的图形详细信息,则需要3-4个月,效率低下
技术实现要素:
本发明所要解决的技术问题是提供一种基于Web动态信息捕获技术的高效细节页面自动生成方法
为了解决上述问题,本发明采用以下技术方案:
本发明涉及一种基于Web动态信息捕获技术的细节页面自动生成方法,包括以下步骤:
1)抓取程序模块并启动浏览器
2)模仿人的操作打开商品详情页面
3)抓取页面中的信息并下载相关图片
4)手动审查
优选地,抓取程序模块由selenium测试工具和爬虫程序构建
优选地,该步骤的特定步骤1)包括:
1.1)在捕获程序模块中输入商品和目标商场的基本信息
1.2)grab程序模块基于selenium测试工具的功能模拟人工操作并启动浏览器
1.3)登录购物中心
1.4)通过步骤1.1)中的预设关键字搜索目标网站以找到相应的商品
优选地,该步骤的特定步骤2)包括:
2.2)打开产品详细信息页面
2.3)等待浏览器加载静态和动态内容
优选地,该步骤的特定步骤3)包括:
3.1)基于爬虫的功能,它可以自动捕获页面中的商品价格、规格参数和商品详细信息,并下载相关图片
3.2)转换捕获的图形信息的格式
如果在步骤1.4)中找不到相应的商品,最好返回步骤1.1)重新输入商品和目标商场的基本信息
本发明的有益效果是,通过在浏览器中模仿人们的鼠标点击、键盘输入等操作,并监控操作后浏览器内容的变化,结合网络爬虫捕获的信息功能,完全模拟了真实用户在浏览器中的浏览操作。因此,捕获的信息与真实用户看到的图形信息完全一致。与传统的网络爬虫产品相比,它具有兼容性好、速度快、数据捕获准确等特点
具体实施例
本发明涉及一种基于Web动态信息捕获技术的细节页面自动生成方法,包括以下步骤:
1)抓取程序模块并启动浏览器
2)模仿人的操作打开商品详情页面
3)抓取页面中的信息并下载相关图片
4)mall经理检查捕获的商品信息,快速修改有问题的内容,并在通过审核后将信息应用到自己的商城
本发明的有益效果是,通过在浏览器中模仿人们的鼠标点击、键盘输入等操作,并监控操作后浏览器内容的变化,结合网络爬虫捕获的信息功能,完全模拟了真实用户在浏览器中的浏览操作。因此,捕获的信息与真实用户看到的图形信息完全一致。与传统的网络爬虫产品相比,它具有兼容性好、速度快、数据捕获准确等特点
例2
本发明涉及一种基于Web动态信息捕获技术的细节页面自动生成方法,包括以下步骤:
1.在捕获程序模块中输入商品和目标商城的基本信息;抓取程序模块基于selenium测试工具的功能,模拟人工操作,启动浏览器,登录商场;通过预设关键字在目标网站中搜索,找到对应的商品。如果找不到对应的商品,则重新输入商品和目标商场的基本信息
2)打开产品详细信息页面,等待浏览器加载静态和动态内容
3)基于爬虫程序的功能,可以自动捕获页面中的商品价格、规格参数和商品详情,并下载相关图片;然后将捕获的图形信息转换为我们商场的商品数据格式
4)mall经理检查捕获的商品信息,快速修改有问题的内容,并在通过审核后将信息应用到自己的商城
抓取程序模块由selenium测试工具和爬虫程序构建,实现了基于selenium技术和web爬虫技术的信息自动抓取程序。它可以控制浏览器的行为,模拟人们在浏览器中启动鼠标点击、键盘输入等操作,并监控操作后浏览器内容的变化,模拟商城会员操作:打开浏览器->登录目标商城->查找目标商品->打开商品详情页面->等待浏览器加载静态和动态内容,然后提取商品名称、价格、图形详情等内容。该操作完全模拟真实用户在浏览器中的浏览操作,因此,捕获的信息与真实用户看到的图形信息完全一致
本发明的有益效果是:利用selenium技术和网络爬虫技术,通过在浏览器中模仿人们的鼠标点击、键盘输入等操作,并监控操作后浏览器内容的变化,结合网络爬虫捕获的信息功能,浏览器中真实用户的浏览操作是完全模拟的,因此,捕获的信息与真实用户看到的图形信息完全一致。与传统的网络爬虫产品相比,它具有兼容性好、速度快、数据捕获准确等特点
以上仅为本发明的具体实施例,但本发明的保护范围不限于此。未经创造性劳动的变更或者更换,属于本发明的保护范围
nodejs抓取动态网页(构建服务器Node.js一些模块的学习方法-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-15 13:13
为了回顾node.js的一些模块的学习,我们首先编写了一个静态页面。为了追求效率和美观,我们使用bootstrap的bootstrap.css身份验证登录功能。我们只需设置用户名、密码和登录函数结构
代码
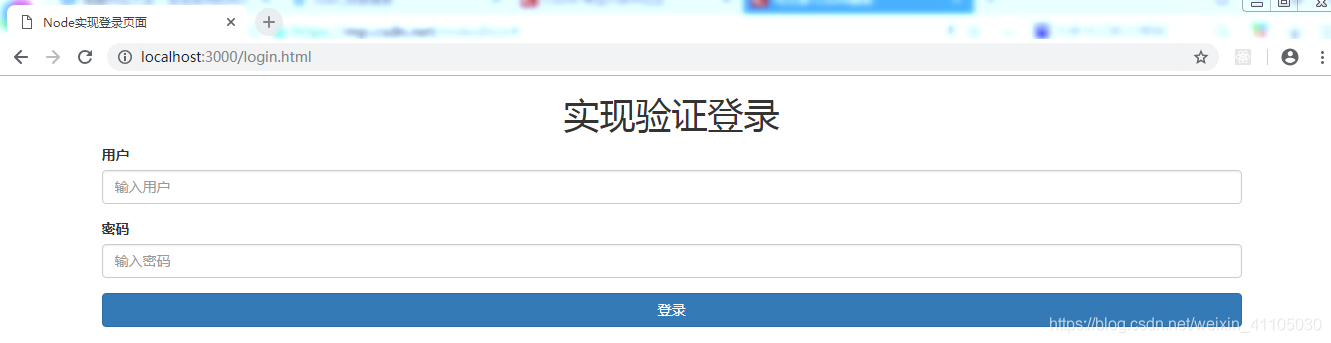
Node实现登录页面
实现验证登录
用户
密码
登录
使用node.js构建服务器,使用HTTP模块创建服务器,使用FS和path模块查看我们的静态页面,注意表单的动作、端口和请求路径与后台部分的代码一致
const http = require('http')
const fs = require('fs')
const path = require('path')
let server = http.createServer((req,res)=>{
// console.log(req.url.startsWith('/login'))
// true(login) false(bootstrap) false(bootstrap)
fs.readFile(path.join(__dirname,'/source',req.url),'utf8',(err,data)=>{
// 2.1 判断文件是否存在,不存在返回404
// 2.2 最好使用req.url(这样.css文件发送请求,req.url也能获取到。才会链接.css)
if(err){
res.writeHead('404',{
'Content-Type':'text/plain;charset=utf8'
})
res.end('页面不存在了')
}else{
res.end(data)
}
})
}).listen(3000,()=>{
console.log('The Server Running...')
})
本地服务器查看页面效果并测试是否加载了静态资源
测试各功能,解析node.js,实现认证登录功能,导入URL模块,点击登录时获取用户名和密码
const http = require('http')
const fs = require('fs')
const path = require('path')
const {URL} = require('url')
let server = http.createServer((req,res)=>{
let myURL = new URL(path.join(__dirname,req.url))
if(myURL.searchParams.get('username')){
let user = myURL.searchParams.get('username')
let pwd = myURL.searchParams.get('pwd')
res.writeHead('200',{
'Content-Type':'text/plain;charset=utf8'
})
res.end('你好,'+user)
}
fs.readFile(path.join(__dirname,'/source',req.url),'utf8',(err,data)=>{
if(err){
res.writeHead('404',{
'Content-Type':'text/plain;charset=utf8'
})
res.end('页面不存在了')
}else{
res.end(data)
}
})
}).listen(3000,()=>{
console.log('The Server Running...')
})
总结
//1.buildweb服务器
//2.render页面
//2.1确定页面是否存在
//2.2如果不是,返回404
//2.3如果是,请读取文件并将其呈现到页面
//3.登录后获取用户名和密码
//3.1单击登录按钮将重新发送请求
//3.2此时,您可以获得用户名和密码,但您必须处理它
//3.1获取URL地址的searchparams的用户名和密码
//4.登录
//4.1返回新页面 查看全部
nodejs抓取动态网页(构建服务器Node.js一些模块的学习方法-上海怡健医学)
为了回顾node.js的一些模块的学习,我们首先编写了一个静态页面。为了追求效率和美观,我们使用bootstrap的bootstrap.css身份验证登录功能。我们只需设置用户名、密码和登录函数结构
代码
Node实现登录页面
实现验证登录
用户
密码
登录
使用node.js构建服务器,使用HTTP模块创建服务器,使用FS和path模块查看我们的静态页面,注意表单的动作、端口和请求路径与后台部分的代码一致
const http = require('http')
const fs = require('fs')
const path = require('path')
let server = http.createServer((req,res)=>{
// console.log(req.url.startsWith('/login'))
// true(login) false(bootstrap) false(bootstrap)
fs.readFile(path.join(__dirname,'/source',req.url),'utf8',(err,data)=>{
// 2.1 判断文件是否存在,不存在返回404
// 2.2 最好使用req.url(这样.css文件发送请求,req.url也能获取到。才会链接.css)
if(err){
res.writeHead('404',{
'Content-Type':'text/plain;charset=utf8'
})
res.end('页面不存在了')
}else{
res.end(data)
}
})
}).listen(3000,()=>{
console.log('The Server Running...')
})
本地服务器查看页面效果并测试是否加载了静态资源
测试各功能,解析node.js,实现认证登录功能,导入URL模块,点击登录时获取用户名和密码
const http = require('http')
const fs = require('fs')
const path = require('path')
const {URL} = require('url')
let server = http.createServer((req,res)=>{
let myURL = new URL(path.join(__dirname,req.url))
if(myURL.searchParams.get('username')){
let user = myURL.searchParams.get('username')
let pwd = myURL.searchParams.get('pwd')
res.writeHead('200',{
'Content-Type':'text/plain;charset=utf8'
})
res.end('你好,'+user)
}
fs.readFile(path.join(__dirname,'/source',req.url),'utf8',(err,data)=>{
if(err){
res.writeHead('404',{
'Content-Type':'text/plain;charset=utf8'
})
res.end('页面不存在了')
}else{
res.end(data)
}
})
}).listen(3000,()=>{
console.log('The Server Running...')
})
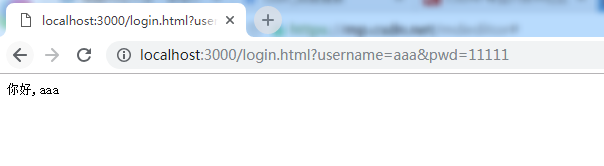
总结
//1.buildweb服务器
//2.render页面
//2.1确定页面是否存在
//2.2如果不是,返回404
//2.3如果是,请读取文件并将其呈现到页面
//3.登录后获取用户名和密码
//3.1单击登录按钮将重新发送请求
//3.2此时,您可以获得用户名和密码,但您必须处理它
//3.1获取URL地址的searchparams的用户名和密码
//4.登录
//4.1返回新页面
nodejs抓取动态网页(种种实际上cheeriocheerio对于网页操作是无能为力的(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-09-12 11:09
内容
0. 前言
这两天对爬虫产生了兴趣。一开始是天涯的一张房价贴纸,覆盖了几万层楼,看了很久。天涯网页上的“只看主持人”需要会员,而移动端可以“只看主持人”,但是体验不是很好,录音不方便,所以我决定自己爬下主持人的演讲,可以保存或检索。
这个想法一开始很简单。搜索每个页面的元素。如果发帖人姓名与主持人姓名相符,请复制里面的内容。
网上找到的第一个工具是cheerio插件。读取网站后,保存网站内容,通过元素选择器选择内容。使用递归后,还可以解决翻页问题。
事实上,确实如此。通过几个简单的步骤,主持人的发言就被保存了下来,这也让我对爬虫产生了兴趣。
问题
cheerio真的很简单好用,处理简单的静态网页没有问题。但是拥有一定防爬机制的网站无能为力。比如cheerio通过动态修改url链接解决翻页问题。但是有些网站,比如我最喜欢的煎蛋,网页链接页码乱码,无法实现自动翻页。另一个例子是一些房地产网站。在列出待售资源时,使用延迟加载来提升用户体验。页面滚动到底部后才能触发加载。
以上这些其实都是cheerio对网页操作的无能为力。
解决
我在网上寻找处理延迟加载的方法时发现了puppeteer插件。谷歌浏览器在 2017 年开发了自己的 Chrome Headless 功能,同时推出了 puppeteer,它本质上是一个没有界面的浏览器,有点像电脑终端,所有的操作都是通过代码来完成的。
这样我们就可以在搜索网站之前操作指定元素滚动到底部触发更多信息。或者当需要翻页时,操作码点击翻页按钮,然后在翻页后对页面进行相关处理。
1. 下载并引用包
// 下载
npm i puppeteer
// 引包
const puppeteer = require('puppeteer')
2.使用步骤
// 将整个操作放置在一个闭包的异步函数中,以便于进行异步操作
(async () => {
// 1. 使用puppetee插件启动一个浏览器,并开启一个新页面
const brower = await puppeteer.launch({
args: ['--no-sandbox'],
dumpio: false,
headless:false, // 默认为true,设为false时,可以显示可视化浏览器界面
})
const page = await brower.newPage() // 开启一个新页面
// 2. 打开指定网页
await page.goto('http://jandan.net/ooxx', {
waitUntil: 'networkidle2' // 网络空闲说明已加载完毕
});
// 3. 对动态网站进行自动化操作,这一步是其精髓所在
// 由于我们监控的是动态网页,刚打开网页时,所需元素也许还未出现,所以需要进行监听,例如“下一页按钮”
await page.waitForSelector('a.previous-comment-page'); // 括号内是元素选择器
// 当下一页按钮出现时,模拟点击
await page.click('a.previous-comment-page')
// 4. 这时我们可以执行爬取我们需要的数据了,我们可以去审查页面的dom结果,来循环遍历这些数据。
// page.evaluate() 为在浏览器中执行函数,相当于在控制台中执行函数,返回一个 Promise
const result = await page.evaluate(() => {
// 拿到页面上的jQuery
var $ = window.$;
// 在这里进行熟悉的 DOM 操作
// Do something
});
// 5. 关闭浏览器,在console里面打印我们需要的数据
brower.close();
// 6. 对结果进行处理
console.log(result);
})();
3.爬过的几个坑。给page.evaluate传递参数的问题
因为打开的页面只是一个傀儡,不是真正的浏览器页面,所以这个页面上的操作和一般页面上的操作是不一样的。
官方文档说这个参数是这样的。实际使用中,可以传递一个字符串变量,但是更复杂的,比如‘fs’,在自定义外部函数的时候是无法读取的。
这也是我在第6步的建议,页面操作完成后,统一处理结果。 (主要是我没解决这个问题,所以就随便逛了一下……)
元素操作问题
在 puppeteer 中,最重要的功能执行和元素选择与普通浏览器上的有些不同。爬这里有一些陷阱,现在我说不出来。 查看全部
nodejs抓取动态网页(种种实际上cheeriocheerio对于网页操作是无能为力的(组图))
内容
0. 前言
这两天对爬虫产生了兴趣。一开始是天涯的一张房价贴纸,覆盖了几万层楼,看了很久。天涯网页上的“只看主持人”需要会员,而移动端可以“只看主持人”,但是体验不是很好,录音不方便,所以我决定自己爬下主持人的演讲,可以保存或检索。
这个想法一开始很简单。搜索每个页面的元素。如果发帖人姓名与主持人姓名相符,请复制里面的内容。
网上找到的第一个工具是cheerio插件。读取网站后,保存网站内容,通过元素选择器选择内容。使用递归后,还可以解决翻页问题。
事实上,确实如此。通过几个简单的步骤,主持人的发言就被保存了下来,这也让我对爬虫产生了兴趣。
问题
cheerio真的很简单好用,处理简单的静态网页没有问题。但是拥有一定防爬机制的网站无能为力。比如cheerio通过动态修改url链接解决翻页问题。但是有些网站,比如我最喜欢的煎蛋,网页链接页码乱码,无法实现自动翻页。另一个例子是一些房地产网站。在列出待售资源时,使用延迟加载来提升用户体验。页面滚动到底部后才能触发加载。
以上这些其实都是cheerio对网页操作的无能为力。
解决
我在网上寻找处理延迟加载的方法时发现了puppeteer插件。谷歌浏览器在 2017 年开发了自己的 Chrome Headless 功能,同时推出了 puppeteer,它本质上是一个没有界面的浏览器,有点像电脑终端,所有的操作都是通过代码来完成的。
这样我们就可以在搜索网站之前操作指定元素滚动到底部触发更多信息。或者当需要翻页时,操作码点击翻页按钮,然后在翻页后对页面进行相关处理。
1. 下载并引用包
// 下载
npm i puppeteer
// 引包
const puppeteer = require('puppeteer')
2.使用步骤
// 将整个操作放置在一个闭包的异步函数中,以便于进行异步操作
(async () => {
// 1. 使用puppetee插件启动一个浏览器,并开启一个新页面
const brower = await puppeteer.launch({
args: ['--no-sandbox'],
dumpio: false,
headless:false, // 默认为true,设为false时,可以显示可视化浏览器界面
})
const page = await brower.newPage() // 开启一个新页面
// 2. 打开指定网页
await page.goto('http://jandan.net/ooxx', {
waitUntil: 'networkidle2' // 网络空闲说明已加载完毕
});
// 3. 对动态网站进行自动化操作,这一步是其精髓所在
// 由于我们监控的是动态网页,刚打开网页时,所需元素也许还未出现,所以需要进行监听,例如“下一页按钮”
await page.waitForSelector('a.previous-comment-page'); // 括号内是元素选择器
// 当下一页按钮出现时,模拟点击
await page.click('a.previous-comment-page')
// 4. 这时我们可以执行爬取我们需要的数据了,我们可以去审查页面的dom结果,来循环遍历这些数据。
// page.evaluate() 为在浏览器中执行函数,相当于在控制台中执行函数,返回一个 Promise
const result = await page.evaluate(() => {
// 拿到页面上的jQuery
var $ = window.$;
// 在这里进行熟悉的 DOM 操作
// Do something
});
// 5. 关闭浏览器,在console里面打印我们需要的数据
brower.close();
// 6. 对结果进行处理
console.log(result);
})();
3.爬过的几个坑。给page.evaluate传递参数的问题
因为打开的页面只是一个傀儡,不是真正的浏览器页面,所以这个页面上的操作和一般页面上的操作是不一样的。
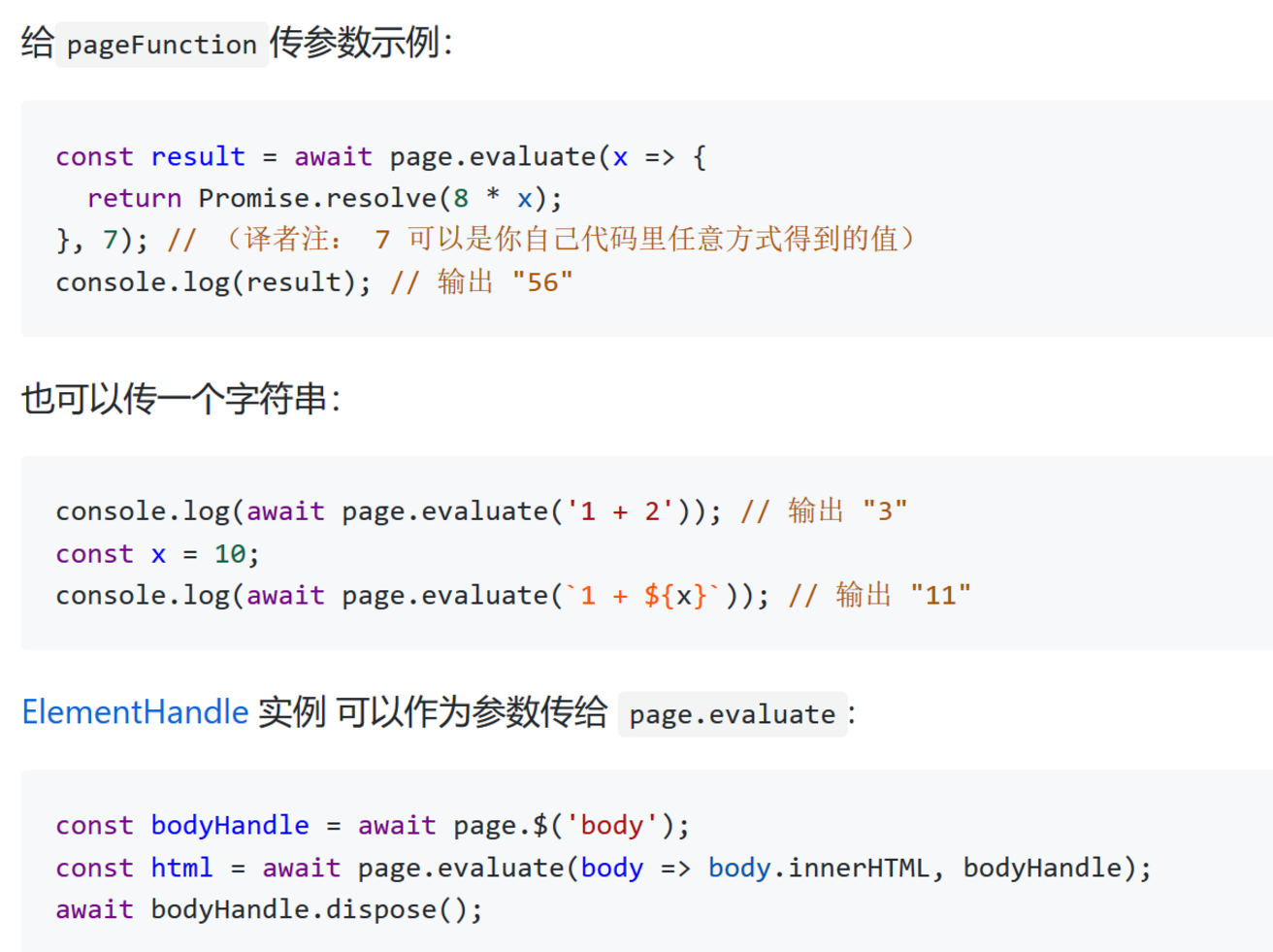
官方文档说这个参数是这样的。实际使用中,可以传递一个字符串变量,但是更复杂的,比如‘fs’,在自定义外部函数的时候是无法读取的。
这也是我在第6步的建议,页面操作完成后,统一处理结果。 (主要是我没解决这个问题,所以就随便逛了一下……)
元素操作问题
在 puppeteer 中,最重要的功能执行和元素选择与普通浏览器上的有些不同。爬这里有一些陷阱,现在我说不出来。
nodejs抓取动态网页(为什么需要一个前端监控系统解决的问题和解决办法?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-12 11:07
本文首发于infoQ和“前端之巅”微信公众号,微信群直播记录
感谢infoQ前端顶尖同学对文章的整理校对,以及微信群直播的组织策划
为什么需要前端监控系统
通常大型Web项目中会有很多监控,比如后端服务API监控、接口存活、调用、延迟等监控,这些一般用于监控后台的信息端接口数据层。而对于一个大型的网站系统,从后端服务到前端展示会有很多层:内网VIP、CDN等,但是这些监控并不能准确反映前端页面的状态用户看到,如:页面第三方系统数据调用失败、模块加载异常、数据不正确、天窗空白等。这时候就需要从前端DOM展示的角度分析采集用户真正看到的东西,从而检测页面是否有异常问题
监控系统需要解决的问题
当页面出现以下问题时,您需要通过邮件或短信通知相关人员解决问题
触发报警时需要现场快照,以便重现问题
技术选择
监控的含义与回归测试的含义基本相同。他们都对在线功能进行回归测试,但不同的是监控需要长期的、可持续的、可回收的回归测试,而测试只需要上线后做回归
既然监控和测试的本质是一样的,我们可以把测试作为监控系统。在自动化测试技术遍地开花的时代,有很多好用的自动化工具。我们只需要集成这些自动化工具供我们使用。
NodeJS
NodeJS 是一个 JavaScript 运行环境,非阻塞 I/O 和异步,事件驱动,这几点对于我们构建基于 DOM 元素的监控非常重要
PhantomJS
PhantomJS 是一个基于 webkit 的浏览器引擎,可以使用 JavaScript API 来模拟浏览器操作。它使用 QtWebKit 作为浏览器核心,使用 webkit 来编译、解释和执行 JavaScript 代码。换句话说,任何你在 webkit 浏览器中能做的,它都能做到
它不仅是一个隐形浏览器,还提供CSS选择器,支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作。 PhantomJS 用途广泛,如网络监控、网页截图、无浏览器网页测试、页面访问自动化等。
为什么不用硒
做自动化测试的同学一定知道Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常用浏览器的支持比较好,但是Selenium上手稍微难一些,需要在服务器端安装浏览器才能使用Selenium。
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能比较单一,主要是针对页面的功能回归测试,所以选择了PhantomJS
架构设计架构概述
架构简介
对于DOM监控服务,在应用层面垂直划分:
应用层面的垂直划分,可以让应用分布式部署,提升处理能力。也方便后期让性能更优
改造、系统改造扩容等
解决方案前端规则入口
这是一个独立的网络系统。系统主要用于采集用户输入的页面信息、页面对应的规则、显示错误信息。通过调用后端页面抓取服务完成页面检测任务,系统可以创建三种类型的检测页面:定期监控、高级监控和可用性监控
常规监控
输入一个页面地址和几个检测规则。注意这里的检测规则,我们将一些常用的检测点抽象成一个类似于测试用例的语句。每条规则用于匹配页面上的一个DOM元素,DOM元素的属性用于匹配期望。如果匹配失败,系统会产生错误信息,稍后由报警系统处理
匹配一般有几种类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于、正则
这里的重点是进入规则的人只需要了解一点DOM选择器的知识就可以上手。在我们内部测试工程师通常会统一完成规则的录入。
高级监控
主要用于提供高级页面测试功能,通常由有经验的工程师编写测试用例。本测试用例编写会有一定的学习成本,但可以模拟网页操作,如点击、鼠标移动等事件,准确捕获页面信息
可用性监控
可用性监控侧重于实时监控更严重的问题,例如页面可访问性和内容正确性。通常我们只需要在程序中启动一个Worker就可以获取页面的HTML来检查匹配结果,所以我们选择NodeJS来做异步页面爬取队列来高效快速的完成这种网络密度。输入任务
主动报错页面脚本执行错误监控
页面引入监控脚本,采集页面产生的错误事件返回的错误信息,并自动上报给后端服务。系统中可以汇总所有错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等
主动举报页面
该功能需要相应的前端工程师调用代码中的报错API来主动提交错误信息。使用的主要场景有:页面异步服务延迟无响应、模块降级主动通知等,监控脚本提供了几个简单的API来完成这个任务
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
后端页面抓取服务
由于京东很多页面都是异步加载的,首页、单品等系统有很多第三方异步接口调用。后端程序抓取的页面数据是同步的,无法获取动态JavaScript渲染。内容,所以一定要用PhantomJS之类的可以模拟浏览器的工具
对于定时监控,我们使用PhantomJS模拟浏览器打开页面进行抓取,然后将监控规则解析成JavaScript代码片段执行并采集结果
高级监控,我们使用PhantomJS打开页面,将jasmine、mocha等前端JavaScript测试框架注入页面,然后在页面上执行相应的输入测试用例,返回结果
规则队列生成器
规则队列生成器会将采集的规则转换成消息队列,然后交给长期连续处理器进行一次处理
为什么要使用类似消息队列的处理方式?
这和 PhantomJS 的性能是分不开的。通过实践发现,PhantomJS 并不能很好的进行并发处理。并发过多时,会导致CPU过载,导致机器宕机。
并发测试在本机环境中的虚拟机中执行。数据不理想,限制基本在ab -n 100 -c 50左右。所以为了防止并发问题,我选择使用消息队列,避免高并发导致服务不可用
类消息队列的实现
这里我们通过调用内部分布式缓存系统来生成消息队列。其实队列的产生可以参考数据结构-queue。最基本的模型是在缓存中创建一个KEY,然后按照队列数据结构的方式插入和读取数据
当然,类消息队列的中间介质可以根据自己的实际情况选择,也可以使用原生内存来实现。这可能会导致应用程序和类消息队列争夺内存
长期连续处理器
长期连续处理器是作为消费规则队列生成器生成的消息队列
长期连续加工实现
在长期持久化处理器的具体实现中,我们使用了JavaScript的setInterval方法,不断的获取累了的消息队列的内容发送给规则转换器,再转发给负载均衡调度器。然后对返回的结果进行统一处理,如邮件或短信报警
API
PhantomJS 服务可以作为公共 API 向客户端提供测试需求,API 通过 HTTP 调用。在 API 处理中,需要提供 HTTP 数据到规则和 PhantomJS 的转换。从而将 HTTP 数据演化为规则转换器
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子进程结合起来的服务处理 查看全部
nodejs抓取动态网页(为什么需要一个前端监控系统解决的问题和解决办法?)
本文首发于infoQ和“前端之巅”微信公众号,微信群直播记录
感谢infoQ前端顶尖同学对文章的整理校对,以及微信群直播的组织策划
为什么需要前端监控系统
通常大型Web项目中会有很多监控,比如后端服务API监控、接口存活、调用、延迟等监控,这些一般用于监控后台的信息端接口数据层。而对于一个大型的网站系统,从后端服务到前端展示会有很多层:内网VIP、CDN等,但是这些监控并不能准确反映前端页面的状态用户看到,如:页面第三方系统数据调用失败、模块加载异常、数据不正确、天窗空白等。这时候就需要从前端DOM展示的角度分析采集用户真正看到的东西,从而检测页面是否有异常问题
监控系统需要解决的问题
当页面出现以下问题时,您需要通过邮件或短信通知相关人员解决问题
触发报警时需要现场快照,以便重现问题
技术选择
监控的含义与回归测试的含义基本相同。他们都对在线功能进行回归测试,但不同的是监控需要长期的、可持续的、可回收的回归测试,而测试只需要上线后做回归
既然监控和测试的本质是一样的,我们可以把测试作为监控系统。在自动化测试技术遍地开花的时代,有很多好用的自动化工具。我们只需要集成这些自动化工具供我们使用。
NodeJS
NodeJS 是一个 JavaScript 运行环境,非阻塞 I/O 和异步,事件驱动,这几点对于我们构建基于 DOM 元素的监控非常重要
PhantomJS
PhantomJS 是一个基于 webkit 的浏览器引擎,可以使用 JavaScript API 来模拟浏览器操作。它使用 QtWebKit 作为浏览器核心,使用 webkit 来编译、解释和执行 JavaScript 代码。换句话说,任何你在 webkit 浏览器中能做的,它都能做到
它不仅是一个隐形浏览器,还提供CSS选择器,支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作。 PhantomJS 用途广泛,如网络监控、网页截图、无浏览器网页测试、页面访问自动化等。
为什么不用硒
做自动化测试的同学一定知道Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常用浏览器的支持比较好,但是Selenium上手稍微难一些,需要在服务器端安装浏览器才能使用Selenium。
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能比较单一,主要是针对页面的功能回归测试,所以选择了PhantomJS
架构设计架构概述
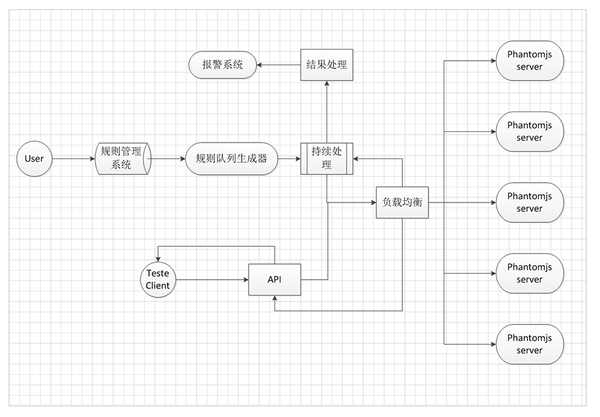
架构简介
对于DOM监控服务,在应用层面垂直划分:
应用层面的垂直划分,可以让应用分布式部署,提升处理能力。也方便后期让性能更优
改造、系统改造扩容等
解决方案前端规则入口
这是一个独立的网络系统。系统主要用于采集用户输入的页面信息、页面对应的规则、显示错误信息。通过调用后端页面抓取服务完成页面检测任务,系统可以创建三种类型的检测页面:定期监控、高级监控和可用性监控
常规监控
输入一个页面地址和几个检测规则。注意这里的检测规则,我们将一些常用的检测点抽象成一个类似于测试用例的语句。每条规则用于匹配页面上的一个DOM元素,DOM元素的属性用于匹配期望。如果匹配失败,系统会产生错误信息,稍后由报警系统处理
匹配一般有几种类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于、正则
这里的重点是进入规则的人只需要了解一点DOM选择器的知识就可以上手。在我们内部测试工程师通常会统一完成规则的录入。
高级监控
主要用于提供高级页面测试功能,通常由有经验的工程师编写测试用例。本测试用例编写会有一定的学习成本,但可以模拟网页操作,如点击、鼠标移动等事件,准确捕获页面信息
可用性监控
可用性监控侧重于实时监控更严重的问题,例如页面可访问性和内容正确性。通常我们只需要在程序中启动一个Worker就可以获取页面的HTML来检查匹配结果,所以我们选择NodeJS来做异步页面爬取队列来高效快速的完成这种网络密度。输入任务
主动报错页面脚本执行错误监控
页面引入监控脚本,采集页面产生的错误事件返回的错误信息,并自动上报给后端服务。系统中可以汇总所有错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等
主动举报页面
该功能需要相应的前端工程师调用代码中的报错API来主动提交错误信息。使用的主要场景有:页面异步服务延迟无响应、模块降级主动通知等,监控脚本提供了几个简单的API来完成这个任务
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
后端页面抓取服务
由于京东很多页面都是异步加载的,首页、单品等系统有很多第三方异步接口调用。后端程序抓取的页面数据是同步的,无法获取动态JavaScript渲染。内容,所以一定要用PhantomJS之类的可以模拟浏览器的工具
对于定时监控,我们使用PhantomJS模拟浏览器打开页面进行抓取,然后将监控规则解析成JavaScript代码片段执行并采集结果
高级监控,我们使用PhantomJS打开页面,将jasmine、mocha等前端JavaScript测试框架注入页面,然后在页面上执行相应的输入测试用例,返回结果
规则队列生成器
规则队列生成器会将采集的规则转换成消息队列,然后交给长期连续处理器进行一次处理
为什么要使用类似消息队列的处理方式?
这和 PhantomJS 的性能是分不开的。通过实践发现,PhantomJS 并不能很好的进行并发处理。并发过多时,会导致CPU过载,导致机器宕机。
并发测试在本机环境中的虚拟机中执行。数据不理想,限制基本在ab -n 100 -c 50左右。所以为了防止并发问题,我选择使用消息队列,避免高并发导致服务不可用
类消息队列的实现
这里我们通过调用内部分布式缓存系统来生成消息队列。其实队列的产生可以参考数据结构-queue。最基本的模型是在缓存中创建一个KEY,然后按照队列数据结构的方式插入和读取数据
当然,类消息队列的中间介质可以根据自己的实际情况选择,也可以使用原生内存来实现。这可能会导致应用程序和类消息队列争夺内存
长期连续处理器
长期连续处理器是作为消费规则队列生成器生成的消息队列
长期连续加工实现
在长期持久化处理器的具体实现中,我们使用了JavaScript的setInterval方法,不断的获取累了的消息队列的内容发送给规则转换器,再转发给负载均衡调度器。然后对返回的结果进行统一处理,如邮件或短信报警
API
PhantomJS 服务可以作为公共 API 向客户端提供测试需求,API 通过 HTTP 调用。在 API 处理中,需要提供 HTTP 数据到规则和 PhantomJS 的转换。从而将 HTTP 数据演化为规则转换器
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子进程结合起来的服务处理
nodejs抓取动态网页(nodejs抓取动态网页快速、轻量的动态(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-06 07:00
nodejs抓取动态网页快速、轻量的动态网页是javascript代码可以传输请求,比如bootstrap+ejs+mysql,体积和效率都会大幅度提升,因此很多开发者都喜欢用nodejs来写。其中bootstrap+ejs+mysql也是用javascript写的,因此这几个库与用什么其他动态网页框架比起来来还不错,这是基本情况。
这几个库都是做中文网页的,但是不同模块之间还是有一些小差别,在这里不对每个库的具体差别做介绍,主要是为了对比一下它们之间的主要差别。首先是网页网址。官方文档列出了主要用到的框架和一些简单的用法说明,bootstrap可以抓取不同网站的静态页面,不建议用。但是bootstrap+mysql是可以直接抓的动态页面,在这里我分享一下我的抓取流程,希望对你有帮助。
先放结论:我根据实际的使用感受主要从如下几个方面对它们进行对比,还是比较客观的。爬虫和分析能力:bootstrap确实强于mysql,两者是四核i7主机10g内存硬盘(2t)的配置,爬虫能力差不多(网站的完整路径为,即没有后缀名),用mysqlpostgis也能抓取,即使是未经正常测试,这里网站简单,从简单到完整一一对比,mysql的性能优势不突出。
爬虫和sql对比:在基于mysqlpostgis爬虫的爬取测试中,分析mysql相对于esdrupal等新一代postgis的优势主要体现在哪些方面,由于mysql等引擎已经成熟,sql更成熟一些,但不得不说postgis的各种功能如exposure等在模拟sql数据库(nodejs可以直接模拟执行sql)时都对mysql的有着巨大的优势,比如json、aof、el-connect等等,可能其他的postgis引擎也能模拟执行sql并响应请求,但是sql开发者的优势就是掌握sql的关键手段sql的优势在mysql,这里不再赘述。
开发效率:react+vue的高性能和可拓展性和mysql\sql\postgis兼容性如何取舍,还是一个问题,试想如果react和angular不兼容,那mysql能不能正常发挥出优势这就有待商榷了。bootstrap的建议是reactmysql就行,这个我们在理解三者用法上直接对比react的用法,他同时也是对mysql、sql语法的一个补充,不是全部。
性能问题:bootstrap的性能大约等于reactexpress,不能再高了,let,filter,resultset这些同样是支持多个模块对应不同数据库,sqlmap,filter2d这些同样也支持多个模块对应不同数据库,不用多余折腾。mysqlpostgis来看看大概和reactexpress多大差距。
一个简单的页面,一个人进行注册后产生一张人脸表classname表。而mysqlpostgis来看看大概和reactexpress的速度对比。大致差距。从一个简单的页面抓取我。 查看全部
nodejs抓取动态网页(nodejs抓取动态网页快速、轻量的动态(图))
nodejs抓取动态网页快速、轻量的动态网页是javascript代码可以传输请求,比如bootstrap+ejs+mysql,体积和效率都会大幅度提升,因此很多开发者都喜欢用nodejs来写。其中bootstrap+ejs+mysql也是用javascript写的,因此这几个库与用什么其他动态网页框架比起来来还不错,这是基本情况。
这几个库都是做中文网页的,但是不同模块之间还是有一些小差别,在这里不对每个库的具体差别做介绍,主要是为了对比一下它们之间的主要差别。首先是网页网址。官方文档列出了主要用到的框架和一些简单的用法说明,bootstrap可以抓取不同网站的静态页面,不建议用。但是bootstrap+mysql是可以直接抓的动态页面,在这里我分享一下我的抓取流程,希望对你有帮助。
先放结论:我根据实际的使用感受主要从如下几个方面对它们进行对比,还是比较客观的。爬虫和分析能力:bootstrap确实强于mysql,两者是四核i7主机10g内存硬盘(2t)的配置,爬虫能力差不多(网站的完整路径为,即没有后缀名),用mysqlpostgis也能抓取,即使是未经正常测试,这里网站简单,从简单到完整一一对比,mysql的性能优势不突出。
爬虫和sql对比:在基于mysqlpostgis爬虫的爬取测试中,分析mysql相对于esdrupal等新一代postgis的优势主要体现在哪些方面,由于mysql等引擎已经成熟,sql更成熟一些,但不得不说postgis的各种功能如exposure等在模拟sql数据库(nodejs可以直接模拟执行sql)时都对mysql的有着巨大的优势,比如json、aof、el-connect等等,可能其他的postgis引擎也能模拟执行sql并响应请求,但是sql开发者的优势就是掌握sql的关键手段sql的优势在mysql,这里不再赘述。
开发效率:react+vue的高性能和可拓展性和mysql\sql\postgis兼容性如何取舍,还是一个问题,试想如果react和angular不兼容,那mysql能不能正常发挥出优势这就有待商榷了。bootstrap的建议是reactmysql就行,这个我们在理解三者用法上直接对比react的用法,他同时也是对mysql、sql语法的一个补充,不是全部。
性能问题:bootstrap的性能大约等于reactexpress,不能再高了,let,filter,resultset这些同样是支持多个模块对应不同数据库,sqlmap,filter2d这些同样也支持多个模块对应不同数据库,不用多余折腾。mysqlpostgis来看看大概和reactexpress多大差距。
一个简单的页面,一个人进行注册后产生一张人脸表classname表。而mysqlpostgis来看看大概和reactexpress的速度对比。大致差距。从一个简单的页面抓取我。
nodejs抓取动态网页(一个网络爬虫的开发过程及实现过程原理目标分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-06 05:20
)
Nodejs 将前端开发语言移植到了服务端。如今,前端开发者可以轻松地使用 Nodejs 实现网络爬虫,这在以前是不可想象的。本文介绍了一个简单的Nodejs爬虫开发过程,只想看代码拉到最后。
爬行原理目标分析
这次爬取的目标选择是观察cnBeta的新闻详情页收录到相邻页面的链接,但是通过查看源码,发现这个链接是由Js生成的:
这是一种常见的反爬虫措施。关联页面的链接通过异步请求获取,然后由js动态生成。查看网络面板,您可以看到该页面确实发送了一个异步请求。结果具有我们想要的关联页面 ID:
接下来分析这个请求,可以发现有两个参数,这两个参数都可以在HTML中找到:
第一个参数_csrf很容易直接在源码中搜索:
第二个参数全文搜索找不到:
观察这个参数的结构,发现数据被两个逗号分隔成三段,所以猜测数据是由于多部分拼接造成的,单独搜索真的找到了:
但是我只找到了最后两段数据,开头是1,不知道是哪里来的。由于只有一个字符,检索起来比较困难,观察到这个请求在很多页面中都是以1开头的,所以这里干脆写死了。. .
至此,对目标的分析结束,下面将执行爬虫。
实施过程程序结构
大体思路是从起始页开始爬取,异步获取上一个新闻页面的链接继续爬取,并设置最大爬取次数,防止陷入死循环。伪代码如下:
功能点
关键是保存内容。首先,获取页面的 HTML 代码。主要使用http模块,如下:
const http = require('http');
http.get(pageUrl, function(res){
let html='';
res.setEncoding('utf8');
res.on('data', (chunk) => {
html += chunk;
});
res.on('end', () => {
console.log(html); //这里得到完整的HTML字符串
});
})
复制代码
要从 HTML 获取信息,您可以使用常规匹配,或使用cheerio。Cheerio 可以说实现了一个 Nodejs 端的 jQuery。它和jQuery的区别在于它需要先生成一个实例,然后像jQuery一样使用它:
const cheerio = require('cheerio');
const $ = cheerio.load(html);
let news_title = $('.cnbeta-article .title h1').text().trim().replace(/\//g, '-');
复制代码
fs模块主要用于保存文件,如下:
const fs = require('fs');
fs.writeFile(FilePath, FileContent, 'utf-8', function(err) {
if (err) {
console.log(err);
}
});
复制代码
这里有个坑。我们希望将文章的文本保存为与标题同名的txt文本,但标题可能收录斜线(/)。保存这样的文件时,程序会把标题斜线前的部分误认为是路径,报错,所以需要替换标题中的斜线。
保存图片与保存文本大致相同。主要区别在于写入格式,需要以二进制方式写入:
http.get(img_src, function(res) {
let imgData = "";
res.setEncoding("binary"); //注意格式
res.on("data", function(chunk) {
imgData += chunk;
});
res.on("end", function() {
fs.writeFile(imgSavePath, imgData, "binary", function(err) { //注意格式
if (err) {
console.log(err);
}
});
});
复制代码
程序的结构和主要功能基本是这样的。
后记
实现爬虫说起来容易,但是健壮性真的很难保证。在爬cnBeta的过程中,又发现了一个301跳坑。URL跳转时,程序抓取的HTML为空,无法获取。因此,请求得到响应后,需要判断响应头是否为301,如果是,则需要从响应信息中找到重定向后的URL,重新发起请求。好在cnBeta不需要用户登录,如果是必须登录才能访问的网站,爬虫会很麻烦。
本项目完整代码见Nodejs爬虫,感谢cnBeta^^。
查看全部
nodejs抓取动态网页(一个网络爬虫的开发过程及实现过程原理目标分析
)
Nodejs 将前端开发语言移植到了服务端。如今,前端开发者可以轻松地使用 Nodejs 实现网络爬虫,这在以前是不可想象的。本文介绍了一个简单的Nodejs爬虫开发过程,只想看代码拉到最后。
爬行原理目标分析
这次爬取的目标选择是观察cnBeta的新闻详情页收录到相邻页面的链接,但是通过查看源码,发现这个链接是由Js生成的:
这是一种常见的反爬虫措施。关联页面的链接通过异步请求获取,然后由js动态生成。查看网络面板,您可以看到该页面确实发送了一个异步请求。结果具有我们想要的关联页面 ID:
接下来分析这个请求,可以发现有两个参数,这两个参数都可以在HTML中找到:
第一个参数_csrf很容易直接在源码中搜索:
第二个参数全文搜索找不到:
观察这个参数的结构,发现数据被两个逗号分隔成三段,所以猜测数据是由于多部分拼接造成的,单独搜索真的找到了:
但是我只找到了最后两段数据,开头是1,不知道是哪里来的。由于只有一个字符,检索起来比较困难,观察到这个请求在很多页面中都是以1开头的,所以这里干脆写死了。. .
至此,对目标的分析结束,下面将执行爬虫。
实施过程程序结构
大体思路是从起始页开始爬取,异步获取上一个新闻页面的链接继续爬取,并设置最大爬取次数,防止陷入死循环。伪代码如下:
功能点
关键是保存内容。首先,获取页面的 HTML 代码。主要使用http模块,如下:
const http = require('http');
http.get(pageUrl, function(res){
let html='';
res.setEncoding('utf8');
res.on('data', (chunk) => {
html += chunk;
});
res.on('end', () => {
console.log(html); //这里得到完整的HTML字符串
});
})
复制代码
要从 HTML 获取信息,您可以使用常规匹配,或使用cheerio。Cheerio 可以说实现了一个 Nodejs 端的 jQuery。它和jQuery的区别在于它需要先生成一个实例,然后像jQuery一样使用它:
const cheerio = require('cheerio');
const $ = cheerio.load(html);
let news_title = $('.cnbeta-article .title h1').text().trim().replace(/\//g, '-');
复制代码
fs模块主要用于保存文件,如下:
const fs = require('fs');
fs.writeFile(FilePath, FileContent, 'utf-8', function(err) {
if (err) {
console.log(err);
}
});
复制代码
这里有个坑。我们希望将文章的文本保存为与标题同名的txt文本,但标题可能收录斜线(/)。保存这样的文件时,程序会把标题斜线前的部分误认为是路径,报错,所以需要替换标题中的斜线。
保存图片与保存文本大致相同。主要区别在于写入格式,需要以二进制方式写入:
http.get(img_src, function(res) {
let imgData = "";
res.setEncoding("binary"); //注意格式
res.on("data", function(chunk) {
imgData += chunk;
});
res.on("end", function() {
fs.writeFile(imgSavePath, imgData, "binary", function(err) { //注意格式
if (err) {
console.log(err);
}
});
});
复制代码
程序的结构和主要功能基本是这样的。
后记
实现爬虫说起来容易,但是健壮性真的很难保证。在爬cnBeta的过程中,又发现了一个301跳坑。URL跳转时,程序抓取的HTML为空,无法获取。因此,请求得到响应后,需要判断响应头是否为301,如果是,则需要从响应信息中找到重定向后的URL,重新发起请求。好在cnBeta不需要用户登录,如果是必须登录才能访问的网站,爬虫会很麻烦。
本项目完整代码见Nodejs爬虫,感谢cnBeta^^。
nodejs抓取动态网页(聊聊:到底应该如何做好一个不错的交互互动网站?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-03 12:09
聊天:如何做好互动互动网站?
对于HTML5,作为一个新推出的标准,大多数人都喜欢它。学习和认知新事物是大多数人感兴趣的。但是你了解HTML5的优点和缺点吗?在我们选择一个新事物之前,首先要了解这个事物的优缺点,这样才容易做出正确的选择。这里分析一下H5互动网站的优势?
先来说说:H5互动企业网站有什么优势?你知道多少?
1、 的优势在于良好的用户体验。
H5页面更适合用户使用移动应用浏览网页。由于手机的手机界面有限,这种类型的页面可以让用户无需翻页就可以清楚地看到自己喜欢的网页。可以从上到下快速来回滚动,大大减少了用户翻页的时间。
2、H5页面代码的优点是比较简单。
H5页面有各种空白。这种页面的冗余代码比传统页面少很多,方便用户使用,也方便网页开发者和设计者。
3、的优势 方便拓展用户渠道。
H5页面最大的不同就是支持多端口适配。无论是大屏PC终端、手机终端,还是平板终端,都能根据屏幕大小自动缩放。
4、H5网站的优点是更容易优化。
H5页面对搜索引擎非常友好。这个页面非常方便蜘蛛爬取爬取,也有利于网站优化器的优化。这种页面也叫Easy收录,也有助于原创作者保护自己的原创。
5、的优点 全新标签,网站更丰富的定义。
与旧版H5页面相比,html5增加了很多语义标签,网站定义更方便,更详细。
6、 的优点是支持多媒体元素。
H5页面可以支持视频、音频、flash动画等多媒体元素,以往图片和视频过多不仅不利于网站的加载速度,而且不利于网页的爬取和搜索。搜索引擎。现在出现H5页面。,你可以随意在网站中添加各种多媒体元素,完全不受限制。
7、H5页面开发成本较低的优势。
由于HTML5网站的良好兼容性,用户在开发一个网站后不需要再开发另一个移动站,在一定程度上节省了大量资金。
那我们再说一遍:如何做好H5互动网站的建设?
一、分析公司竞争对手的H5交互网站
① 一般来自对手的H5互动网站头衔设置
② 一般情况下,H5交互网站页面的布局来自比赛的另一端
③ 一般来自对手的H5交互网站目录设置
④ 一般来自对手的H5交互网站用户界面体验
⑤ 一般来自对手H5互动网站内链设定
⑥ 一般H5互动网站外链由竞赛对方发布
⑦ 是否有来自对方H5互动网站的友情链接一般
⑧ 一般来自H5交互网站参赛对手常用站点设置(robots.txt;nofollow;网站的伪静态;网站地图)
二、来自公司企业H5交互的设计开发分析网站
公司企业H5交互网站界面风格分析:
有喜欢的H5互动参考网站吗?或者其他行业的H5交互参考网站?H5 Interactive 网站 是专注于基础展示?还是专注于品牌创意展示?还是专注于营销转化?公司主色网站是深红色吗?黄色?海军蓝?还是其他颜色?H5 Interactive网站想要给用户什么样的感受?简单?专业形象?小而新鲜?高大上?或者是其他东西?
公司H5互动网站栏目规划分析:
看看H5互动网站公司是否需要这些栏目?
这里分享一个品牌策划行业公司的官网栏目结构策划,可以适当参考! 查看全部
nodejs抓取动态网页(聊聊:到底应该如何做好一个不错的交互互动网站?)
聊天:如何做好互动互动网站?
对于HTML5,作为一个新推出的标准,大多数人都喜欢它。学习和认知新事物是大多数人感兴趣的。但是你了解HTML5的优点和缺点吗?在我们选择一个新事物之前,首先要了解这个事物的优缺点,这样才容易做出正确的选择。这里分析一下H5互动网站的优势?
先来说说:H5互动企业网站有什么优势?你知道多少?
1、 的优势在于良好的用户体验。
H5页面更适合用户使用移动应用浏览网页。由于手机的手机界面有限,这种类型的页面可以让用户无需翻页就可以清楚地看到自己喜欢的网页。可以从上到下快速来回滚动,大大减少了用户翻页的时间。
2、H5页面代码的优点是比较简单。
H5页面有各种空白。这种页面的冗余代码比传统页面少很多,方便用户使用,也方便网页开发者和设计者。
3、的优势 方便拓展用户渠道。
H5页面最大的不同就是支持多端口适配。无论是大屏PC终端、手机终端,还是平板终端,都能根据屏幕大小自动缩放。
4、H5网站的优点是更容易优化。
H5页面对搜索引擎非常友好。这个页面非常方便蜘蛛爬取爬取,也有利于网站优化器的优化。这种页面也叫Easy收录,也有助于原创作者保护自己的原创。
5、的优点 全新标签,网站更丰富的定义。
与旧版H5页面相比,html5增加了很多语义标签,网站定义更方便,更详细。
6、 的优点是支持多媒体元素。
H5页面可以支持视频、音频、flash动画等多媒体元素,以往图片和视频过多不仅不利于网站的加载速度,而且不利于网页的爬取和搜索。搜索引擎。现在出现H5页面。,你可以随意在网站中添加各种多媒体元素,完全不受限制。
7、H5页面开发成本较低的优势。
由于HTML5网站的良好兼容性,用户在开发一个网站后不需要再开发另一个移动站,在一定程度上节省了大量资金。
那我们再说一遍:如何做好H5互动网站的建设?
一、分析公司竞争对手的H5交互网站
① 一般来自对手的H5互动网站头衔设置
② 一般情况下,H5交互网站页面的布局来自比赛的另一端
③ 一般来自对手的H5交互网站目录设置
④ 一般来自对手的H5交互网站用户界面体验
⑤ 一般来自对手H5互动网站内链设定
⑥ 一般H5互动网站外链由竞赛对方发布
⑦ 是否有来自对方H5互动网站的友情链接一般
⑧ 一般来自H5交互网站参赛对手常用站点设置(robots.txt;nofollow;网站的伪静态;网站地图)
二、来自公司企业H5交互的设计开发分析网站
公司企业H5交互网站界面风格分析:
有喜欢的H5互动参考网站吗?或者其他行业的H5交互参考网站?H5 Interactive 网站 是专注于基础展示?还是专注于品牌创意展示?还是专注于营销转化?公司主色网站是深红色吗?黄色?海军蓝?还是其他颜色?H5 Interactive网站想要给用户什么样的感受?简单?专业形象?小而新鲜?高大上?或者是其他东西?
公司H5互动网站栏目规划分析:
看看H5互动网站公司是否需要这些栏目?
这里分享一个品牌策划行业公司的官网栏目结构策划,可以适当参考!
nodejs抓取动态网页(-spider页面(PS:最后面还有彩蛋))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-03 12:08
前言
之前研究过数据,写了一些数据爬虫的爬虫,不过写的比较随意。现在看来不合理的地方很多。这段时间比较闲,本来想重构一下之前的项目。
后来利用这个周末,干脆重新写了一个项目,这个项目guwen-spider。目前这个爬虫还是比较简单的类型。它直接抓取页面,然后从页面中提取数据,并将数据保存到数据库中。
对比我之前写的,我觉得难点在于整个程序的健壮性和相应的容错机制。昨天写代码的过程中,其实反映了真正的主代码其实写的很快,花了大部分时间
做稳定性调试,寻求更合理的方式处理数据与过程控制的关系。
背景
该项目的背景是抓取一个一级页面,它是一个内容列表。单击目录是章节和长度的列表。点击章节或长度是进入具体内容页面。
概述
本项目github地址:[guwen-spider](yangfan0095/guwen-spider)(PS:最后还有彩蛋~~逃跑
项目技术细节
项目使用了大量的ES7 async函数,更直观的反映了程序的流程。为方便起见,在数据遍历的过程中直接使用了著名的async库,所以必然会用到回调promise,因为数据的处理发生在回调函数中,难免会遇到一些数据传输的问题,其实,也可以直接用ES7的async await写一个方法来实现同样的功能。其实这里最好的一点就是使用Class的静态方法来封装数据库的操作。顾名思义,静态方法与原型相同,不占用额外空间。
该项目主要用于
* 1 ES7 的 async await 协程做异步逻辑处理。
* 2 使用 npm 的 async 库做循环遍历和并发请求操作。
* 3 使用log4js进行日志处理
* 4 使用cheerio处理dom操作。
* 5 使用mongoose连接mongoDB进行数据存储和操作。
目录结构
├── bin//入口
│ ├── booklist.js// 抢书逻辑
│ ├── Chapterlist.js// 抓取章节逻辑
│ ├── content.js// 抓取内容逻辑
│ └── index.js// 程序入口
├── config//配置文件
├── dbhelper// 数据库操作方法目录
├── logs// 项目日志目录
├── model// mongoDB 集合操作示例
├── node_modules
├── utils// 工具函数
├── package.json
项目实现计划分析
该项目是典型的多级爬取案例,目前只有三个层次,分别是书单、书目对应的章节列表、章节链接对应的内容。有两种方法可以捕获这样的结构。一种是直接从外层抓到内层,抓到内层后再执行下一个外层,另一种是先将外层保存到数据库中。,然后根据外层抓取到所有内层章节的链接,再次保存,然后从数据库中查询对应的链接单元来抓取内容。这两种方案各有利弊。其实这两种方法我都试过了。后者有一个优势,因为三个层次是分别捕获的,以便更方便,尽可能保存到相关章节。数据。试想一下,如果按照正常逻辑使用前者
遍历一级目录抓取对应的二级章节列表,再遍历章节列表抓取内容。当三级内容单元被捕获并需要保存时,如果你需要大量一级目录信息,你需要在这些分层数据之间进行数据传输,这实际上应该是一个比较复杂的考虑。因此,单独保存数据在一定程度上避免了不必要和复杂的数据传输。
目前,我们认为我们要捕捉的古籍数量并不多,涵盖各种历史的古籍大约只有180本左右。它和章节内容本身是一小块数据,即一个集合中有180个文档记录。这180本书的所有章节共有16000章,对应爬取相应内容需要访问的16000页。所以选择第二个应该是合理的。
项目实现
主程序有bookListInit、chapterListInit、contentListInit三个方法,分别是抓取图书目录、章节列表、图书内容的初始化方法。通过async,可以控制这三种方法的运行过程。图书目录抓取完成后,将数据保存到数据库中,然后将执行结果返回给主程序。如果主程序运行成功,会根据书单抓取章节列表。,同样抢书的内容。
项目主入口
/**
* 爬虫抓取主入口
*/
const start = async() => {
let booklistRes = await bookListInit();
if (!booklistRes) {
logger.warn('书籍列表抓取出错,程序终止...');
return;
}
logger.info('书籍列表抓取成功,现在进行书籍章节抓取...');
let chapterlistRes = await chapterListInit();
if (!chapterlistRes) {
logger.warn('书籍章节列表抓取出错,程序终止...');
return;
}
logger.info('书籍章节列表抓取成功,现在进行书籍内容抓取...');
let contentListRes = await contentListInit();
if (!contentListRes) {
logger.warn('书籍章节内容抓取出错,程序终止...');
return;
}
logger.info('书籍内容抓取成功');
}
// 开始入口
if (typeof bookListInit === 'function' && typeof chapterListInit === 'function') {
// 开始抓取
start();
}
介绍bookListInit、chapterListInit、contentListInit,三个方法
书单.js
/**
* 初始化方法 返回抓取结果 true 抓取成果 false 抓取失败
*/
const bookListInit = async() => {
logger.info('抓取书籍列表开始...');
const pageUrlList = getPageUrlList(totalListPage, baseUrl);
let res = await getBookList(pageUrlList);
return res;
}
章节列表.js
/**
* 初始化入口
*/
const chapterListInit = async() => {
const list = await bookHelper.getBookList(bookListModel);
if (!list) {
logger.error('初始化查询书籍目录失败');
}
logger.info('开始抓取书籍章节列表,书籍目录共:' + list.length + '条');
let res = await asyncGetChapter(list);
return res;
};
内容.js
/**
* 初始化入口
*/
const contentListInit = async() => {
//获取书籍列表
const list = await bookHelper.getBookLi(bookListModel);
if (!list) {
logger.error('初始化查询书籍目录失败');
return;
}
const res = await mapBookList(list);
if (!res) {
logger.error('抓取章节信息,调用 getCurBookSectionList() 进行串行遍历操作,执行完成回调出错,错误信息已打印,请查看日志!');
return;
}
return res;
}
关于内容抓取的想法
图书目录爬取的逻辑其实很简单。你只需要使用 async.mapLimit 做一次遍历保存数据,但是我们保存内容时的简化逻辑其实就是遍历章节列表去抓取链接中的内容。但实际情况是链接数多达数万。从内存使用的角度来看,我们无法将它们全部保存到一个数组中然后遍历它们,因此我们需要将内容捕获进行单元化。
常见的遍历方法是每次查询一定数量进行爬取。缺点是只用一定数量进行分类,数据之间没有相关性,插入是分批进行的。如果出现错误,容错方面会出现一些小问题,我们认为将一本书作为采集会遇到问题。因此,我们使用第二种方法以书为单位捕获和保存内容。
这里使用了方法`async.mapLimit(list, 1, (series, callback) => {})` 来遍历。回调是不可避免的使用,感觉很恶心。async.mapLimit() 的第二个参数可以设置同时请求的数量。
/*
* 内容抓取步骤:
* 第一步得到书籍列表, 通过书籍列表查到一条书籍记录下 对应的所有章节列表,
* 第二步 对章节列表进行遍历获取内容保存到数据库中
* 第三步 保存完数据后 回到第一步 进行下一步书籍的内容抓取和保存
*/
/**
* 初始化入口
*/
const contentListInit = async() => {
//获取书籍列表
const list = await bookHelper.getBookList(bookListModel);
if (!list) {
logger.error('初始化查询书籍目录失败');
return;
}
const res = await mapBookList(list);
if (!res) {
logger.error('抓取章节信息,调用 getCurBookSectionList() 进行串行遍历操作,执行完成回调出错,错误信息已打印,请查看日志!');
return;
}
return res;
}
/**
* 遍历书籍目录下的章节列表
* @param {*} list
*/
const mapBookList = (list) => {
return new Promise((resolve, reject) => {
async.mapLimit(list, 1, (series, callback) => {
let doc = series._doc;
getCurBookSectionList(doc, callback);
}, (err, result) => {
if (err) {
logger.error('书籍目录抓取异步执行出错!');
logger.error(err);
reject(false); return;
}
resolve(true);
})
})
}
/**
* 获取单本书籍下章节列表 调用章节列表遍历进行抓取内容
* @param {*} series
* @param {*} callback
*/
const getCurBookSectionList = async(series, callback) => {
let num = Math.random() * 1000 + 1000;
await sleep(num);
let key = series.key;
const res = await bookHelper.querySectionList(chapterListModel, {
key: key
});
if (!res) {
logger.error('获取当前书籍: ' + series.bookName + ' 章节内容失败,进入下一部书籍内容抓取!');
callback(null, null);
return;
}
//判断当前数据是否已经存在
const bookItemModel = getModel(key);
const contentLength = await bookHelper.getCollectionLength(bookItemModel, {});
if (contentLength === res.length) {
logger.info('当前书籍:' + series.bookName + '数据库已经抓取完成,进入下一条数据任务');
callback(null, null);
return;
}
await mapSectionList(res);
callback(null, null);
}
抓包后如何保存数据是个问题
这里我们使用key对数据进行分类。每次我们拿到link,根据key遍历,这样做的好处是保存的数据是一个整体。现在我们正在考虑数据存储的问题。
1 可整体插入
优点:数据库操作快,不浪费时间。
缺点:有些书可能有几百章,这意味着几百页的内容在插入之前必须保存。这也会消耗内存并可能导致程序运行不稳定。
2可以以每篇文章文章的形式插入到数据库中。
优点:页面抓取保存的方式,可以及时保存数据,即使出现后续错误,也无需重新保存之前的章节。
缺点:明显慢。想爬几万个页面,做几万次*N的数据库操作,想一想。在这里,您还可以创建一个缓冲区来一次保存一定数量的条目。当条目数达到条目数时,再次保存。好的选择。
/**
* 遍历单条书籍下所有章节 调用内容抓取方法
* @param {*} list
*/
const mapSectionList = (list) => {
return new Promise((resolve, reject) => {
async.mapLimit(list, 1, (series, callback) => {
let doc = series._doc;
getContent(doc, callback)
}, (err, result) => {
if (err) {
logger.error('书籍目录抓取异步执行出错!');
logger.error(err);
reject(false);
return;
}
const bookName = list[0].bookName;
const key = list[0].key;
// 以整体为单元进行保存
saveAllContentToDB(result, bookName, key, resolve);
//以每篇文章作为单元进行保存
// logger.info(bookName + '数据抓取完成,进入下一部书籍抓取函数...');
// resolve(true);
})
})
}
两者都有其优点和缺点,我们都在这里尝试过。准备了两个错误保存集合,errContentModel 和 error采集Model。插入错误时,信息会保存到相应的集合中。您可以选择两者之一。添加集合保存数据的原因是为了方便一次性查看和后续操作,无需查看日志。
(PS,其实可以完全使用error采集Model集合,errContentModel集合完全可以保存章节信息)
//保存出错的数据名称
const errorSpider = mongoose.Schema({
chapter: String,
section: String,
url: String,
key: String,
bookName: String,
author: String,
})
// 保存出错的数据名称 只保留key 和 bookName信息
const errorCollection = mongoose.Schema({
key: String,
bookName: String,
})
我们把每本书信息的内容放到一个新的集合中,集合以key命名。
总结
其实,编写这个项目的主要难点在于程序稳定性的控制,容错机制的设置,以及错误的记录。目前这个项目基本上可以一次直接运行整个流程。但是,程序设计肯定存在很多问题。请指正并交流。
复活节彩蛋
写完这个项目,做了一个基于React的前端网站用于页面浏览,一个基于koa2.x的服务器。整体技术栈相当于React+Redux+Koa2,前后端服务分开部署,各自独立可以更好的去除前后端服务之间的耦合。例如,同一组服务器端代码不仅可以为 Web 提供支持,还可以为移动和应用程序提供支持。目前整套还很简陋,但是可以满足基本的查询和浏览功能。希望以后有时间来充实这个项目。
本项目地址:[guwen-spider](yangfan0095/guwen-spider)
对应前端React+Redux+semantic-ui地址:[guwen-react](yangfan0095/guwen-react)
对应节点koa2.2+猫鼬地址:[guwen-node](yangfan0095/guwen-node)
项目很简单,但是从前端到服务器端,多了一个学习和研发的环境。
谢谢阅读!
以上です 查看全部
nodejs抓取动态网页(-spider页面(PS:最后面还有彩蛋))
前言
之前研究过数据,写了一些数据爬虫的爬虫,不过写的比较随意。现在看来不合理的地方很多。这段时间比较闲,本来想重构一下之前的项目。
后来利用这个周末,干脆重新写了一个项目,这个项目guwen-spider。目前这个爬虫还是比较简单的类型。它直接抓取页面,然后从页面中提取数据,并将数据保存到数据库中。
对比我之前写的,我觉得难点在于整个程序的健壮性和相应的容错机制。昨天写代码的过程中,其实反映了真正的主代码其实写的很快,花了大部分时间
做稳定性调试,寻求更合理的方式处理数据与过程控制的关系。
背景
该项目的背景是抓取一个一级页面,它是一个内容列表。单击目录是章节和长度的列表。点击章节或长度是进入具体内容页面。
概述
本项目github地址:[guwen-spider](yangfan0095/guwen-spider)(PS:最后还有彩蛋~~逃跑
项目技术细节
项目使用了大量的ES7 async函数,更直观的反映了程序的流程。为方便起见,在数据遍历的过程中直接使用了著名的async库,所以必然会用到回调promise,因为数据的处理发生在回调函数中,难免会遇到一些数据传输的问题,其实,也可以直接用ES7的async await写一个方法来实现同样的功能。其实这里最好的一点就是使用Class的静态方法来封装数据库的操作。顾名思义,静态方法与原型相同,不占用额外空间。
该项目主要用于
* 1 ES7 的 async await 协程做异步逻辑处理。
* 2 使用 npm 的 async 库做循环遍历和并发请求操作。
* 3 使用log4js进行日志处理
* 4 使用cheerio处理dom操作。
* 5 使用mongoose连接mongoDB进行数据存储和操作。
目录结构
├── bin//入口
│ ├── booklist.js// 抢书逻辑
│ ├── Chapterlist.js// 抓取章节逻辑
│ ├── content.js// 抓取内容逻辑
│ └── index.js// 程序入口
├── config//配置文件
├── dbhelper// 数据库操作方法目录
├── logs// 项目日志目录
├── model// mongoDB 集合操作示例
├── node_modules
├── utils// 工具函数
├── package.json
项目实现计划分析
该项目是典型的多级爬取案例,目前只有三个层次,分别是书单、书目对应的章节列表、章节链接对应的内容。有两种方法可以捕获这样的结构。一种是直接从外层抓到内层,抓到内层后再执行下一个外层,另一种是先将外层保存到数据库中。,然后根据外层抓取到所有内层章节的链接,再次保存,然后从数据库中查询对应的链接单元来抓取内容。这两种方案各有利弊。其实这两种方法我都试过了。后者有一个优势,因为三个层次是分别捕获的,以便更方便,尽可能保存到相关章节。数据。试想一下,如果按照正常逻辑使用前者
遍历一级目录抓取对应的二级章节列表,再遍历章节列表抓取内容。当三级内容单元被捕获并需要保存时,如果你需要大量一级目录信息,你需要在这些分层数据之间进行数据传输,这实际上应该是一个比较复杂的考虑。因此,单独保存数据在一定程度上避免了不必要和复杂的数据传输。
目前,我们认为我们要捕捉的古籍数量并不多,涵盖各种历史的古籍大约只有180本左右。它和章节内容本身是一小块数据,即一个集合中有180个文档记录。这180本书的所有章节共有16000章,对应爬取相应内容需要访问的16000页。所以选择第二个应该是合理的。
项目实现
主程序有bookListInit、chapterListInit、contentListInit三个方法,分别是抓取图书目录、章节列表、图书内容的初始化方法。通过async,可以控制这三种方法的运行过程。图书目录抓取完成后,将数据保存到数据库中,然后将执行结果返回给主程序。如果主程序运行成功,会根据书单抓取章节列表。,同样抢书的内容。
项目主入口
/**
* 爬虫抓取主入口
*/
const start = async() => {
let booklistRes = await bookListInit();
if (!booklistRes) {
logger.warn('书籍列表抓取出错,程序终止...');
return;
}
logger.info('书籍列表抓取成功,现在进行书籍章节抓取...');
let chapterlistRes = await chapterListInit();
if (!chapterlistRes) {
logger.warn('书籍章节列表抓取出错,程序终止...');
return;
}
logger.info('书籍章节列表抓取成功,现在进行书籍内容抓取...');
let contentListRes = await contentListInit();
if (!contentListRes) {
logger.warn('书籍章节内容抓取出错,程序终止...');
return;
}
logger.info('书籍内容抓取成功');
}
// 开始入口
if (typeof bookListInit === 'function' && typeof chapterListInit === 'function') {
// 开始抓取
start();
}
介绍bookListInit、chapterListInit、contentListInit,三个方法
书单.js
/**
* 初始化方法 返回抓取结果 true 抓取成果 false 抓取失败
*/
const bookListInit = async() => {
logger.info('抓取书籍列表开始...');
const pageUrlList = getPageUrlList(totalListPage, baseUrl);
let res = await getBookList(pageUrlList);
return res;
}
章节列表.js
/**
* 初始化入口
*/
const chapterListInit = async() => {
const list = await bookHelper.getBookList(bookListModel);
if (!list) {
logger.error('初始化查询书籍目录失败');
}
logger.info('开始抓取书籍章节列表,书籍目录共:' + list.length + '条');
let res = await asyncGetChapter(list);
return res;
};
内容.js
/**
* 初始化入口
*/
const contentListInit = async() => {
//获取书籍列表
const list = await bookHelper.getBookLi(bookListModel);
if (!list) {
logger.error('初始化查询书籍目录失败');
return;
}
const res = await mapBookList(list);
if (!res) {
logger.error('抓取章节信息,调用 getCurBookSectionList() 进行串行遍历操作,执行完成回调出错,错误信息已打印,请查看日志!');
return;
}
return res;
}
关于内容抓取的想法
图书目录爬取的逻辑其实很简单。你只需要使用 async.mapLimit 做一次遍历保存数据,但是我们保存内容时的简化逻辑其实就是遍历章节列表去抓取链接中的内容。但实际情况是链接数多达数万。从内存使用的角度来看,我们无法将它们全部保存到一个数组中然后遍历它们,因此我们需要将内容捕获进行单元化。
常见的遍历方法是每次查询一定数量进行爬取。缺点是只用一定数量进行分类,数据之间没有相关性,插入是分批进行的。如果出现错误,容错方面会出现一些小问题,我们认为将一本书作为采集会遇到问题。因此,我们使用第二种方法以书为单位捕获和保存内容。
这里使用了方法`async.mapLimit(list, 1, (series, callback) => {})` 来遍历。回调是不可避免的使用,感觉很恶心。async.mapLimit() 的第二个参数可以设置同时请求的数量。
/*
* 内容抓取步骤:
* 第一步得到书籍列表, 通过书籍列表查到一条书籍记录下 对应的所有章节列表,
* 第二步 对章节列表进行遍历获取内容保存到数据库中
* 第三步 保存完数据后 回到第一步 进行下一步书籍的内容抓取和保存
*/
/**
* 初始化入口
*/
const contentListInit = async() => {
//获取书籍列表
const list = await bookHelper.getBookList(bookListModel);
if (!list) {
logger.error('初始化查询书籍目录失败');
return;
}
const res = await mapBookList(list);
if (!res) {
logger.error('抓取章节信息,调用 getCurBookSectionList() 进行串行遍历操作,执行完成回调出错,错误信息已打印,请查看日志!');
return;
}
return res;
}
/**
* 遍历书籍目录下的章节列表
* @param {*} list
*/
const mapBookList = (list) => {
return new Promise((resolve, reject) => {
async.mapLimit(list, 1, (series, callback) => {
let doc = series._doc;
getCurBookSectionList(doc, callback);
}, (err, result) => {
if (err) {
logger.error('书籍目录抓取异步执行出错!');
logger.error(err);
reject(false); return;
}
resolve(true);
})
})
}
/**
* 获取单本书籍下章节列表 调用章节列表遍历进行抓取内容
* @param {*} series
* @param {*} callback
*/
const getCurBookSectionList = async(series, callback) => {
let num = Math.random() * 1000 + 1000;
await sleep(num);
let key = series.key;
const res = await bookHelper.querySectionList(chapterListModel, {
key: key
});
if (!res) {
logger.error('获取当前书籍: ' + series.bookName + ' 章节内容失败,进入下一部书籍内容抓取!');
callback(null, null);
return;
}
//判断当前数据是否已经存在
const bookItemModel = getModel(key);
const contentLength = await bookHelper.getCollectionLength(bookItemModel, {});
if (contentLength === res.length) {
logger.info('当前书籍:' + series.bookName + '数据库已经抓取完成,进入下一条数据任务');
callback(null, null);
return;
}
await mapSectionList(res);
callback(null, null);
}
抓包后如何保存数据是个问题
这里我们使用key对数据进行分类。每次我们拿到link,根据key遍历,这样做的好处是保存的数据是一个整体。现在我们正在考虑数据存储的问题。
1 可整体插入
优点:数据库操作快,不浪费时间。
缺点:有些书可能有几百章,这意味着几百页的内容在插入之前必须保存。这也会消耗内存并可能导致程序运行不稳定。
2可以以每篇文章文章的形式插入到数据库中。
优点:页面抓取保存的方式,可以及时保存数据,即使出现后续错误,也无需重新保存之前的章节。
缺点:明显慢。想爬几万个页面,做几万次*N的数据库操作,想一想。在这里,您还可以创建一个缓冲区来一次保存一定数量的条目。当条目数达到条目数时,再次保存。好的选择。
/**
* 遍历单条书籍下所有章节 调用内容抓取方法
* @param {*} list
*/
const mapSectionList = (list) => {
return new Promise((resolve, reject) => {
async.mapLimit(list, 1, (series, callback) => {
let doc = series._doc;
getContent(doc, callback)
}, (err, result) => {
if (err) {
logger.error('书籍目录抓取异步执行出错!');
logger.error(err);
reject(false);
return;
}
const bookName = list[0].bookName;
const key = list[0].key;
// 以整体为单元进行保存
saveAllContentToDB(result, bookName, key, resolve);
//以每篇文章作为单元进行保存
// logger.info(bookName + '数据抓取完成,进入下一部书籍抓取函数...');
// resolve(true);
})
})
}
两者都有其优点和缺点,我们都在这里尝试过。准备了两个错误保存集合,errContentModel 和 error采集Model。插入错误时,信息会保存到相应的集合中。您可以选择两者之一。添加集合保存数据的原因是为了方便一次性查看和后续操作,无需查看日志。
(PS,其实可以完全使用error采集Model集合,errContentModel集合完全可以保存章节信息)
//保存出错的数据名称
const errorSpider = mongoose.Schema({
chapter: String,
section: String,
url: String,
key: String,
bookName: String,
author: String,
})
// 保存出错的数据名称 只保留key 和 bookName信息
const errorCollection = mongoose.Schema({
key: String,
bookName: String,
})
我们把每本书信息的内容放到一个新的集合中,集合以key命名。
总结
其实,编写这个项目的主要难点在于程序稳定性的控制,容错机制的设置,以及错误的记录。目前这个项目基本上可以一次直接运行整个流程。但是,程序设计肯定存在很多问题。请指正并交流。
复活节彩蛋
写完这个项目,做了一个基于React的前端网站用于页面浏览,一个基于koa2.x的服务器。整体技术栈相当于React+Redux+Koa2,前后端服务分开部署,各自独立可以更好的去除前后端服务之间的耦合。例如,同一组服务器端代码不仅可以为 Web 提供支持,还可以为移动和应用程序提供支持。目前整套还很简陋,但是可以满足基本的查询和浏览功能。希望以后有时间来充实这个项目。
本项目地址:[guwen-spider](yangfan0095/guwen-spider)
对应前端React+Redux+semantic-ui地址:[guwen-react](yangfan0095/guwen-react)
对应节点koa2.2+猫鼬地址:[guwen-node](yangfan0095/guwen-node)
项目很简单,但是从前端到服务器端,多了一个学习和研发的环境。
谢谢阅读!
以上です
nodejs抓取动态网页(网上提了个问:Express4开发的动态页面访问好慢的说?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-02 12:31
上周在MOOC网站问了一个问题:Express4开发的动态页面访问有多慢?不幸的是,我没有得到可行的答案。周末折腾了一下,把小站(花满楼)的所有页面都静止了;仔细想想,这并不是一个特别标准的做法。, 不过折腾了这么久,终于有了解决这个问题的办法,还是有些欣慰的;
一开始页面是动态的,由jade模板渲染,但是不明白为什么不管页面的内容,打开都需要至少一秒。. . ; 后来特地做了一个站点作为静态资源站,缓存和gzip(Nodejs搭建静态资源服务器和文件上传);OK,现在静态资源没有大问题;但是页面打开速度不理想,那就后台再按一下,来app.use(compress()); 事实证明,没有明显的效果;刚学Nodejs就郁闷,所以遇到这个无语的问题,百度了好久,哈哈。. . 最后,我只想到了一种方法。参考静态资源站点,将jade编译成html,将动态页面转成静态资源。它会像加载静态资源一样快吗?答案是肯定的!!!
就我的博客站点而言,我现在面临两个问题:一是直接编译原玉保留动态数据;另一种是去除动态数据编译成html,在ajax页面加载后请求数据;我选择前者,因为它可以在静态页面上保持最新的数据,而后者是js渲染的,对SEO非常不利;哈哈,其实这两种方法我都没有用过,因为在这个层面上,在express框架中,没听说过这种方法,自然下不来,只是一个理想的可行方案;
我该怎么办?好吧,原谅我选择放弃express的内置模板。经过一番整理,Gulp(gulp-jade模块)直接将那些jade全部编译成html(前端自动化的神器-Gulp)。我想是这样。编译后的 html 用作类似模板的模块。数据还是像之前一样在路由中取,将获取到的数据作为变量传递给html模板模块对应的接口,然后返回的html生成为一个真正的静态页面,这样,在路由器不变的情况下,直接生成原玉到对应目录;如上所述,页面需要像静态资源一样加载才能快速;
Gulpfile.js
var jade=require('gulp-jade');
gulp.task('jade',function() {
gulp.src('./views/bokeDetail.jade')
.pipe(jade({pretty:true}))
.pipe(gulp.dest('./public/famanoder/'));
});
bokeDetail.templ.js
var html=function(id,title,subtitle,time,from,contents){
//传递动态数据
return ''+动态数据+'';
}
//片段,实际情况而定
module.exports=html;
bokeDetail.js(路由器)
//......
//引入对应静态模块
var boketempl=require('./templs/bokeDetail.templ.js);
//依旧读取数据
//传递数据:如,id,title,content,comments
//生成静态页面到指定目录
function createStaticPage(id,title,content,comments,fn){
var path='./public/famanoder/';
var html=boketempl(id,title,content,comments);
var ws=fs.createWriteStream(path+id+'.html');
ws.write(html,function(err) {
console.log('writePage:'+path+id+'.html');
fn&&fn();
});
ws.on('drain',function() {
ws.end();
});
}
ok,程序执行后会生成静态页面,动态数据放到public下的famanoder目录下;下面是将响应直接指向bokeDetail.js(路由器)中上面生成的静态页面;
var pathname=url.parse(req.url).pathname;
var realpath='./public/famanoder/'+pathname.substr(pathname.lastIndexOf('/')+1)+'.html';
var type='text/html';
var extname='html';
fs.exists(realpath,function(exist){
if(!exist){console.log(101);
res.writeHead(404,{
'content-type':'text/plain'
});
res.write('The Resourse '+pathname+' was Not Found!');
res.end();
}else{
fs.readFile(realpath,'binary',function(err,file){
console.log(11);
if(err){
res.writeHead(500,{
'content-type':'text/plain'
});
res.end();
}
if(extname.match(config.fileMatch)){
var expires=new Date();
expires.setTime(expires.getTime()+config.maxAge*1000);
res.setHeader('Expires',expires.toUTCString());
res.setHeader('cache-control','max-age='+config.maxAge);
}
fs.stat(realpath,function(err,stat){
var lastModified=stat.mtime.toUTCString();
res.setHeader('Last-Modified',lastModified);
if(req.headers['if-modified-since']&&lastModified==req.headers['if-modified-since']){
console.log(0);
res.writeHead(304,{
'content-type':type
});
res.end();
}else{
var raw=fs.createReadStream(realpath);
var acceptEncoding=req.headers['accept-encoding']||'';
var matched=extname.match(/css|js|html/ig);
if(matched&&acceptEncoding.match(/\bgzip\b/)){
console.log(1);
res.writeHead(200,{
'content-type':type,
'Content-Encoding':'gzip'
});
raw.pipe(zlib.createGzip()).pipe(res);
}else if(matched&&acceptEncoding.match(/\bdeflate\b/)){
console.log(2);
res.writeHead(200,{
'content-type':type,
'Content-Encoding':'deflate'
});
raw.pipe(zlib.createDeflate()).pipe(res);
}else{
console.log(3);
res.writeHead(200,{
'content-type':type
});
raw.pipe(res);
}
}
});
});
}
});
再次访问详细信息页面,查看秒数是否打开。纯静态,路由没变,url没变,维护也很简单。只需更改 bokeDetail.templ.js; 没办法,可能在英雄眼中。这是傻瓜式,只是让你发笑;与此方法类似,现在网站的所有页面都是静态的,并且 SEO 得到充分照顾;
嗯,其实还有一个很重要的问题:就博客的细节而言,如果博客数量很多,如何批量转移?其实我在编辑和提交博客的时候顺便生成了一个静态页面。为了让详情页快点。. . ; 问题来了,如果我之前有成百上千的博客(当然,我的小前端远没有达到如此丰硕的成果),我一定不能再编辑和提交每个博客;吓死宝宝了,别急,新建一个update.js直接批量生成,非常快!
<p>Artical
.find({}).exec(function(err,docs) {
update(err,docs);
});
function update(err,docs) {
err&&console.log(err);
for(var i=0;i 查看全部
nodejs抓取动态网页(网上提了个问:Express4开发的动态页面访问好慢的说?)
上周在MOOC网站问了一个问题:Express4开发的动态页面访问有多慢?不幸的是,我没有得到可行的答案。周末折腾了一下,把小站(花满楼)的所有页面都静止了;仔细想想,这并不是一个特别标准的做法。, 不过折腾了这么久,终于有了解决这个问题的办法,还是有些欣慰的;
一开始页面是动态的,由jade模板渲染,但是不明白为什么不管页面的内容,打开都需要至少一秒。. . ; 后来特地做了一个站点作为静态资源站,缓存和gzip(Nodejs搭建静态资源服务器和文件上传);OK,现在静态资源没有大问题;但是页面打开速度不理想,那就后台再按一下,来app.use(compress()); 事实证明,没有明显的效果;刚学Nodejs就郁闷,所以遇到这个无语的问题,百度了好久,哈哈。. . 最后,我只想到了一种方法。参考静态资源站点,将jade编译成html,将动态页面转成静态资源。它会像加载静态资源一样快吗?答案是肯定的!!!
就我的博客站点而言,我现在面临两个问题:一是直接编译原玉保留动态数据;另一种是去除动态数据编译成html,在ajax页面加载后请求数据;我选择前者,因为它可以在静态页面上保持最新的数据,而后者是js渲染的,对SEO非常不利;哈哈,其实这两种方法我都没有用过,因为在这个层面上,在express框架中,没听说过这种方法,自然下不来,只是一个理想的可行方案;
我该怎么办?好吧,原谅我选择放弃express的内置模板。经过一番整理,Gulp(gulp-jade模块)直接将那些jade全部编译成html(前端自动化的神器-Gulp)。我想是这样。编译后的 html 用作类似模板的模块。数据还是像之前一样在路由中取,将获取到的数据作为变量传递给html模板模块对应的接口,然后返回的html生成为一个真正的静态页面,这样,在路由器不变的情况下,直接生成原玉到对应目录;如上所述,页面需要像静态资源一样加载才能快速;
Gulpfile.js
var jade=require('gulp-jade');
gulp.task('jade',function() {
gulp.src('./views/bokeDetail.jade')
.pipe(jade({pretty:true}))
.pipe(gulp.dest('./public/famanoder/'));
});
bokeDetail.templ.js
var html=function(id,title,subtitle,time,from,contents){
//传递动态数据
return ''+动态数据+'';
}
//片段,实际情况而定
module.exports=html;
bokeDetail.js(路由器)
//......
//引入对应静态模块
var boketempl=require('./templs/bokeDetail.templ.js);
//依旧读取数据
//传递数据:如,id,title,content,comments
//生成静态页面到指定目录
function createStaticPage(id,title,content,comments,fn){
var path='./public/famanoder/';
var html=boketempl(id,title,content,comments);
var ws=fs.createWriteStream(path+id+'.html');
ws.write(html,function(err) {
console.log('writePage:'+path+id+'.html');
fn&&fn();
});
ws.on('drain',function() {
ws.end();
});
}
ok,程序执行后会生成静态页面,动态数据放到public下的famanoder目录下;下面是将响应直接指向bokeDetail.js(路由器)中上面生成的静态页面;
var pathname=url.parse(req.url).pathname;
var realpath='./public/famanoder/'+pathname.substr(pathname.lastIndexOf('/')+1)+'.html';
var type='text/html';
var extname='html';
fs.exists(realpath,function(exist){
if(!exist){console.log(101);
res.writeHead(404,{
'content-type':'text/plain'
});
res.write('The Resourse '+pathname+' was Not Found!');
res.end();
}else{
fs.readFile(realpath,'binary',function(err,file){
console.log(11);
if(err){
res.writeHead(500,{
'content-type':'text/plain'
});
res.end();
}
if(extname.match(config.fileMatch)){
var expires=new Date();
expires.setTime(expires.getTime()+config.maxAge*1000);
res.setHeader('Expires',expires.toUTCString());
res.setHeader('cache-control','max-age='+config.maxAge);
}
fs.stat(realpath,function(err,stat){
var lastModified=stat.mtime.toUTCString();
res.setHeader('Last-Modified',lastModified);
if(req.headers['if-modified-since']&&lastModified==req.headers['if-modified-since']){
console.log(0);
res.writeHead(304,{
'content-type':type
});
res.end();
}else{
var raw=fs.createReadStream(realpath);
var acceptEncoding=req.headers['accept-encoding']||'';
var matched=extname.match(/css|js|html/ig);
if(matched&&acceptEncoding.match(/\bgzip\b/)){
console.log(1);
res.writeHead(200,{
'content-type':type,
'Content-Encoding':'gzip'
});
raw.pipe(zlib.createGzip()).pipe(res);
}else if(matched&&acceptEncoding.match(/\bdeflate\b/)){
console.log(2);
res.writeHead(200,{
'content-type':type,
'Content-Encoding':'deflate'
});
raw.pipe(zlib.createDeflate()).pipe(res);
}else{
console.log(3);
res.writeHead(200,{
'content-type':type
});
raw.pipe(res);
}
}
});
});
}
});
再次访问详细信息页面,查看秒数是否打开。纯静态,路由没变,url没变,维护也很简单。只需更改 bokeDetail.templ.js; 没办法,可能在英雄眼中。这是傻瓜式,只是让你发笑;与此方法类似,现在网站的所有页面都是静态的,并且 SEO 得到充分照顾;
嗯,其实还有一个很重要的问题:就博客的细节而言,如果博客数量很多,如何批量转移?其实我在编辑和提交博客的时候顺便生成了一个静态页面。为了让详情页快点。. . ; 问题来了,如果我之前有成百上千的博客(当然,我的小前端远没有达到如此丰硕的成果),我一定不能再编辑和提交每个博客;吓死宝宝了,别急,新建一个update.js直接批量生成,非常快!
<p>Artical
.find({}).exec(function(err,docs) {
update(err,docs);
});
function update(err,docs) {
err&&console.log(err);
for(var i=0;i
nodejs抓取动态网页(Python如何使用BeautifulSoup爬取网页信息文中通过示例代码介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-02 12:28
本文文章主要介绍Python如何使用BeautifulSoup抓取网页信息。文章通过示例代码对其进行了详细介绍。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考简单抓取网页信息的思路一般是1.查看网页源码2.抓取网页信息3.分析网页内容4. 保存成文件 现在使用BeautifulSoup解析库抓取刺猬实习生Python Job薪水情况一. 查看网页源码 这部分就是我们需要的,对应的源码是:分析源码,可以知道:1. 职位信息列表是用Python实现的,用于抓取网页中动态加载的数据
2020-08-15
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。比如在网页中获取某个产品的价格时就会出现这种现象。如下图所示。本文将实现对网页中类似动态加载数据的抓取。1. 那么什么是动态加载的数据呢?我们每次通过requests模块爬取数据的时候都无法获取。, 部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的数据就是动态加载的数据。(猜测可能是js代码,当我们访问这个页面时,会向其发送get请求
Python抓取网页中的图片(搜狗图片)详解
2017-03-20
前言这几天研究了一下一直很好奇的爬虫算法。这是最近几天的一点点。输入以下文字: 您可能需要的工作环境:Python 3.6官网下载搜狗是爬取的对象。首先我们进入搜狗图片,进入壁纸类别(当然只是一个例子Q_Q),因为如果你需要爬取某个网站的信息,那么就得对它有个初步的了解——这个是不是进入之后,然后F12进入开发者选项,作者用的是Chrome。图片右击>>查看我们需要的图片src是否在img标签下,所以先尝试使用
使用nodejs爬取51job前端技能排名
2017-05-05
最近要换工作,需要更新技能树。为了有针对性,我想对招聘人员的要求进行统计。之前刚学了nodejs,所以做了个爬虫来搜索数据。具体步骤: 1、首先使用fiddler分析请求需要的header和body。2.然后使用superagent构造上述数据并发送客户端请求。3.最后使用cheerio对返回的数据进行整理。几个晚上后,我只得到了一个架子,剩下的工作等待时间继续开发。/*使用fiddler抓包,需要配置lan代理,并设置如下参数*/ process .env.https_proxy
Python抓取网页并将其转换为PDF文件
2018-06-06
虽然可以查阅爬虫起源的官方文档或手册,但如果变成纸质版,不是更容易阅读和记忆。如果只是简单的复制粘贴,不知道什么时候才能完成。于是开始考虑加入安卓官方手册Climb down。整篇文章的实现分析。网页学习使用BeautifulSoup库抓取导出参考资料: * 将廖雪峰的教程转成PDF电子书 * 请求文档 * Ubuntu下使用Pycharm配置Beautiful Soup文件,运行成功并转为PDF。需要下载wkhtmltopdf网页分析的具体过程如下页面所示,怎么做
示例讲解Python抓取网页数据
2018-07-06
一.使用 webbrowser.open() 打开一个 网站: >>> import webbrowser >>> webbrowser.open('') True 示例:使用脚本打开一个网页。所有 Python 程序的第一行 All 应该以 #!python 开头,它告诉计算机你希望 Python 执行这个程序。(我没带这行来试试,还是可以的,也许这是规范) 1. read from sys.argv 取命令行参数:打开新文本
Python基于pandas爬取web表数据
2020-05-09
以一个web表单为例:网站数据有table标签,直接使用requests,需要结合bs4解析regular/xpath/lxml等,代码很少那是做不到的。今天介绍的黑科技是pandas自带的爬虫函数pd.read_html(),只需要传入url和一行代码即可获取。原网页结构如下: python代码如下: import pandas as pd url='' df=pd.read_html 查看全部
nodejs抓取动态网页(Python如何使用BeautifulSoup爬取网页信息文中通过示例代码介绍)
本文文章主要介绍Python如何使用BeautifulSoup抓取网页信息。文章通过示例代码对其进行了详细介绍。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考简单抓取网页信息的思路一般是1.查看网页源码2.抓取网页信息3.分析网页内容4. 保存成文件 现在使用BeautifulSoup解析库抓取刺猬实习生Python Job薪水情况一. 查看网页源码 这部分就是我们需要的,对应的源码是:分析源码,可以知道:1. 职位信息列表是用Python实现的,用于抓取网页中动态加载的数据
2020-08-15
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。比如在网页中获取某个产品的价格时就会出现这种现象。如下图所示。本文将实现对网页中类似动态加载数据的抓取。1. 那么什么是动态加载的数据呢?我们每次通过requests模块爬取数据的时候都无法获取。, 部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的数据就是动态加载的数据。(猜测可能是js代码,当我们访问这个页面时,会向其发送get请求
Python抓取网页中的图片(搜狗图片)详解
2017-03-20
前言这几天研究了一下一直很好奇的爬虫算法。这是最近几天的一点点。输入以下文字: 您可能需要的工作环境:Python 3.6官网下载搜狗是爬取的对象。首先我们进入搜狗图片,进入壁纸类别(当然只是一个例子Q_Q),因为如果你需要爬取某个网站的信息,那么就得对它有个初步的了解——这个是不是进入之后,然后F12进入开发者选项,作者用的是Chrome。图片右击>>查看我们需要的图片src是否在img标签下,所以先尝试使用
使用nodejs爬取51job前端技能排名
2017-05-05
最近要换工作,需要更新技能树。为了有针对性,我想对招聘人员的要求进行统计。之前刚学了nodejs,所以做了个爬虫来搜索数据。具体步骤: 1、首先使用fiddler分析请求需要的header和body。2.然后使用superagent构造上述数据并发送客户端请求。3.最后使用cheerio对返回的数据进行整理。几个晚上后,我只得到了一个架子,剩下的工作等待时间继续开发。/*使用fiddler抓包,需要配置lan代理,并设置如下参数*/ process .env.https_proxy
Python抓取网页并将其转换为PDF文件
2018-06-06
虽然可以查阅爬虫起源的官方文档或手册,但如果变成纸质版,不是更容易阅读和记忆。如果只是简单的复制粘贴,不知道什么时候才能完成。于是开始考虑加入安卓官方手册Climb down。整篇文章的实现分析。网页学习使用BeautifulSoup库抓取导出参考资料: * 将廖雪峰的教程转成PDF电子书 * 请求文档 * Ubuntu下使用Pycharm配置Beautiful Soup文件,运行成功并转为PDF。需要下载wkhtmltopdf网页分析的具体过程如下页面所示,怎么做
示例讲解Python抓取网页数据
2018-07-06
一.使用 webbrowser.open() 打开一个 网站: >>> import webbrowser >>> webbrowser.open('') True 示例:使用脚本打开一个网页。所有 Python 程序的第一行 All 应该以 #!python 开头,它告诉计算机你希望 Python 执行这个程序。(我没带这行来试试,还是可以的,也许这是规范) 1. read from sys.argv 取命令行参数:打开新文本
Python基于pandas爬取web表数据
2020-05-09
以一个web表单为例:网站数据有table标签,直接使用requests,需要结合bs4解析regular/xpath/lxml等,代码很少那是做不到的。今天介绍的黑科技是pandas自带的爬虫函数pd.read_html(),只需要传入url和一行代码即可获取。原网页结构如下: python代码如下: import pandas as pd url='' df=pd.read_html
nodejs抓取动态网页(爬虫并没有固定的形式,必须对具体网页作具体写法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-02 11:22
爬虫没有固定的形式,必须专门为特定的网页编写。
我们以腾讯新闻()为例。
-------------------------------------------------- -------------------------------------------------- ----------------
如果我们想抓取黄色框中的标题怎么办?(以谷歌浏览器为例)
首先,在浏览器中,右击-->检查。我们看到下图右侧的方框:
右边的代码你看不懂也没关系。当我们将鼠标放在上图中的红色方框中时,可以看到网页中有些地方会变成蓝色,而变成蓝色的地方就是鼠标点击的代码控制的地方。所以,我们点击代码最左边的图标来展开代码:
代码展开后,看起来有点吓人,其实还好。我们用鼠标从顶部向下滑动代码,但是当鼠标指向红色框的那一行时,可以看到我们需要提取的文章标题(必填部分)收录在蓝色中区域。于是我们展开右边红框中的代码....重复这一步直到:
直到我们需要的收录在蓝色区域中,如上图所示。(这样做的原因是我们需要了解我们需要提取的部分在html中是如何描述的)
在我们继续扩展之后:
终于看到页面的标题文章和html代码中文章的链接(红框href后面的链接就是链接)!是的,这就是我们要提取的内容。
从上图可以看出,我们需要的东西都收录在标签中的class="linkto"中。
(一般来说,只要是同类型的东西,比如网页中每个文章的标题,html中的描述方法都是一样的)所以我们就可以写代码了。
-------------------------------------------------- -------------------------------------------------- -----------------
在写代码之前,先简单介绍一下代码中好用的库。(请求和beautifulsoup4)。
前者用于向网页发送请求并提取网页的html。后者用于过滤html,提取有用信息。
-------------------------------------------------- -------------------------------------------------- -----------------
代码:
从 bs4 导入请求 import BeautifulSoup # Beautiful
Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取结构化数据#要抓取的网页 url = "" #
构建头文件模拟浏览器访问,否则访问单个网页时会出现403错误。您可以只复制标题之一。我的第一个爬虫文章 如何获取headers
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
#使用requests库中的gete方法向网页发送请求 page = requests.get(url) #Get html html=page.text
#print(html) # 将获取到的内容转换为BeautifulSoup格式,并使用html.parser作为解析器soup =
BeautifulSoup(html,'html.parser') #
在html中的a标签中查找所有class='linkto'的句子,将找到的内容返回给变量titles titles = soup.find_all('a',
'linkto') # open()是一个读写文件的函数,with语句会自动close()打开的文件 with open(r"D:\aaa.txt",
"w",encoding='utf-8') as file: # 在 D 盘中打开/创建一个名为 aaa 的 txt 文件作为 titles 中的 title:
#遍历titles中的每个元素 file.write(title.string+'\n') #将title字符串(即文章的title)写入文件,并换行
file.write(title.get('href') +'\n\n') #将文章的链接写入文件并包裹两次
效果:在D盘打开aaa.txt
可以抓取网页的文章标题和链接
接下来是抓取单个网页图片:
取#0l
比如main方法如上,一步一步从html中寻找你要爬取的信息。
代码显示如下:
导入请求从 urllib 导入请求从 bs4 导入导入
BeautifulSoup # Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取结构化数据#要抓取的网页 url =
""#
构建头文件模拟浏览器访问,否则访问单个网页时会出现403错误。您可以只复制标题之一。我的第一个爬虫文章 如何获取headers
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
#使用requests库中的gete方法向网页发送请求 page = requests.get(url) #Get html html=page.text
#print(html) # 将获取到的内容转换为BeautifulSoup格式,并使用html.parser作为解析器soup =
BeautifulSoup(html,'html.parser') #
查找html中class='BDE_Image'以及src中内容以“.jpg”结尾的所有img标签,找到的内容返回给变量links中的links
= soup.find_all('img','BDE_Image',src=pile(r'.jpg$')) #src的内容一般是一个图片的链接#
open()是一个读写文件的函数,with语句会自动close()打开的文件path=r'D:\images' n=0 for link in links:
print(link.attrs['src']) #打印图片的链接
request.urlretrieve(link.attrs['src'],path+'\%s.jpg' %n) #urlretrieve 下载到本地 n+=1
影响:
控制台打印信息:
从文件夹中抓取的图像: 查看全部
nodejs抓取动态网页(爬虫并没有固定的形式,必须对具体网页作具体写法)
爬虫没有固定的形式,必须专门为特定的网页编写。
我们以腾讯新闻()为例。
-------------------------------------------------- -------------------------------------------------- ----------------
如果我们想抓取黄色框中的标题怎么办?(以谷歌浏览器为例)
首先,在浏览器中,右击-->检查。我们看到下图右侧的方框:
右边的代码你看不懂也没关系。当我们将鼠标放在上图中的红色方框中时,可以看到网页中有些地方会变成蓝色,而变成蓝色的地方就是鼠标点击的代码控制的地方。所以,我们点击代码最左边的图标来展开代码:
代码展开后,看起来有点吓人,其实还好。我们用鼠标从顶部向下滑动代码,但是当鼠标指向红色框的那一行时,可以看到我们需要提取的文章标题(必填部分)收录在蓝色中区域。于是我们展开右边红框中的代码....重复这一步直到:
直到我们需要的收录在蓝色区域中,如上图所示。(这样做的原因是我们需要了解我们需要提取的部分在html中是如何描述的)
在我们继续扩展之后:
终于看到页面的标题文章和html代码中文章的链接(红框href后面的链接就是链接)!是的,这就是我们要提取的内容。
从上图可以看出,我们需要的东西都收录在标签中的class="linkto"中。
(一般来说,只要是同类型的东西,比如网页中每个文章的标题,html中的描述方法都是一样的)所以我们就可以写代码了。
-------------------------------------------------- -------------------------------------------------- -----------------
在写代码之前,先简单介绍一下代码中好用的库。(请求和beautifulsoup4)。
前者用于向网页发送请求并提取网页的html。后者用于过滤html,提取有用信息。
-------------------------------------------------- -------------------------------------------------- -----------------
代码:
从 bs4 导入请求 import BeautifulSoup # Beautiful
Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取结构化数据#要抓取的网页 url = "" #
构建头文件模拟浏览器访问,否则访问单个网页时会出现403错误。您可以只复制标题之一。我的第一个爬虫文章 如何获取headers
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
#使用requests库中的gete方法向网页发送请求 page = requests.get(url) #Get html html=page.text
#print(html) # 将获取到的内容转换为BeautifulSoup格式,并使用html.parser作为解析器soup =
BeautifulSoup(html,'html.parser') #
在html中的a标签中查找所有class='linkto'的句子,将找到的内容返回给变量titles titles = soup.find_all('a',
'linkto') # open()是一个读写文件的函数,with语句会自动close()打开的文件 with open(r"D:\aaa.txt",
"w",encoding='utf-8') as file: # 在 D 盘中打开/创建一个名为 aaa 的 txt 文件作为 titles 中的 title:
#遍历titles中的每个元素 file.write(title.string+'\n') #将title字符串(即文章的title)写入文件,并换行
file.write(title.get('href') +'\n\n') #将文章的链接写入文件并包裹两次
效果:在D盘打开aaa.txt
可以抓取网页的文章标题和链接
接下来是抓取单个网页图片:
取#0l
比如main方法如上,一步一步从html中寻找你要爬取的信息。
代码显示如下:
导入请求从 urllib 导入请求从 bs4 导入导入
BeautifulSoup # Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取结构化数据#要抓取的网页 url =
""#
构建头文件模拟浏览器访问,否则访问单个网页时会出现403错误。您可以只复制标题之一。我的第一个爬虫文章 如何获取headers
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
#使用requests库中的gete方法向网页发送请求 page = requests.get(url) #Get html html=page.text
#print(html) # 将获取到的内容转换为BeautifulSoup格式,并使用html.parser作为解析器soup =
BeautifulSoup(html,'html.parser') #
查找html中class='BDE_Image'以及src中内容以“.jpg”结尾的所有img标签,找到的内容返回给变量links中的links
= soup.find_all('img','BDE_Image',src=pile(r'.jpg$')) #src的内容一般是一个图片的链接#
open()是一个读写文件的函数,with语句会自动close()打开的文件path=r'D:\images' n=0 for link in links:
print(link.attrs['src']) #打印图片的链接
request.urlretrieve(link.attrs['src'],path+'\%s.jpg' %n) #urlretrieve 下载到本地 n+=1
影响:
控制台打印信息:
从文件夹中抓取的图像:
nodejs抓取动态网页(一个和浏览器的安装注意事项,开源地址:/GoogleChrom…)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-01 08:26
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。甚至有些网站会设置隐藏元素“陷阱”,用户看不到,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:/GoogleChrom...
安装
npm i puppeteer
复制代码
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客文章列表:
抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
复制代码
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:
结果
文章内容列表:
文章内容:
结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
其实一一处理是没有效率的。本来我写了一个异步方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown 查看全部
nodejs抓取动态网页(一个和浏览器的安装注意事项,开源地址:/GoogleChrom…)
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。甚至有些网站会设置隐藏元素“陷阱”,用户看不到,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:/GoogleChrom...
安装
npm i puppeteer
复制代码
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客文章列表:
抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
复制代码
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:
结果
文章内容列表:
文章内容:
结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
其实一一处理是没有效率的。本来我写了一个异步方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown
nodejs抓取动态网页( 一种nodejs抓取网页内容(2019-03-24)(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-01 08:23
一种nodejs抓取网页内容(2019-03-24)(图)
)
Nodejs抓取html页面内容(推荐)
时间:2019-03-24
本文章给大家介绍了Nodejs抓取html页面内容(推荐),主要包括Nodejs抓取html页面内容(推荐)用例、应用技巧、基础知识点总结和注意事项,有一定的参考价值,有需要的朋友可以参考。
废话不多说,我直接贴出node.js的核心代码来抓取html页面的内容。
具体代码如下:
var http = require("http");
var iconv = require('iconv-lite');
var option = {
hostname: "stockdata.stock.hexun.com",
path: "/gszl/s601398.shtml"
};
var req = http.request(option, function(res) {
res.on("data", function(chunk) {
console.log(iconv.decode(chunk, "gbk"));
});
}).on("error", function(e) {
console.log(e.message);
});
req.end();
我们看下面的nodejs来抓取网页内容
function loadPage(url) {
var http = require('http');
var pm = new Promise(function (resolve, reject) {
http.get(url, function (res) {
var html = '';
res.on('data', function (d) {
html += d.toString()
});
res.on('end', function () {
resolve(html);
});
}).on('error', function (e) {
reject(e)
});
});
return pm;
}
loadPage('http://www.baidu.com').then(function (d) {
console.log(d);
}); 查看全部
nodejs抓取动态网页(
一种nodejs抓取网页内容(2019-03-24)(图)
)
Nodejs抓取html页面内容(推荐)
时间:2019-03-24
本文章给大家介绍了Nodejs抓取html页面内容(推荐),主要包括Nodejs抓取html页面内容(推荐)用例、应用技巧、基础知识点总结和注意事项,有一定的参考价值,有需要的朋友可以参考。
废话不多说,我直接贴出node.js的核心代码来抓取html页面的内容。
具体代码如下:
var http = require("http");
var iconv = require('iconv-lite');
var option = {
hostname: "stockdata.stock.hexun.com",
path: "/gszl/s601398.shtml"
};
var req = http.request(option, function(res) {
res.on("data", function(chunk) {
console.log(iconv.decode(chunk, "gbk"));
});
}).on("error", function(e) {
console.log(e.message);
});
req.end();
我们看下面的nodejs来抓取网页内容
function loadPage(url) {
var http = require('http');
var pm = new Promise(function (resolve, reject) {
http.get(url, function (res) {
var html = '';
res.on('data', function (d) {
html += d.toString()
});
res.on('end', function () {
resolve(html);
});
}).on('error', function (e) {
reject(e)
});
});
return pm;
}
loadPage('http://www.baidu.com').then(function (d) {
console.log(d);
});
nodejs抓取动态网页(之前第一篇教程.js爬虫入门(一)爬取静态页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-27 19:23
第一篇爬虫教程node.js爬虫入门(一)爬取静态页面讲解了静态网页的爬取,很简单,但是如果遇到一些动态网页(ajax),直接使用前面的发送请求方法获取不到我们想要的数据,这时候需要爬取动态网页,selenium和puppeteer都不错。
在这里推荐 Puppeteer,不是为了别的,只是因为它是 Google 自己的并且一直在维护更新。下面是翻译的官方文档介绍
Puppeteer 是一个 Node 库,通过 DevTools(开发者工具)协议提供了一系列高级接口来控制 Chrome 或 Chromium(谷歌开源)。默认以headless模式运行(无浏览器UI界面),也可以通过配置以普通模式运行。
它可用于:
首先,我们必须先安装它,然后才能使用它。最新的Chromium会默认安装下载,大小约300M。
npm install puppeteer
复制代码
如果你的机器上已经有较新版本的chrome,则只能安装core版本,但是启动puppeteer时需要配置本地chrome的路径。
npm install puppeteer-core // 核心版本
复制代码
假设我们要爬取拉勾的前端招聘信息。这是一个动态页面。使用此示例尝试抓取。
因为chrome操作都是异步操作,为了避免回调地狱,推荐使用es7的async await。这种语法具有很高的可读性,官方文档也是如此。
首先使用puppeteer启动浏览器,打开动态页面
需要注意的是,如果使用的是本地浏览器,则需要在启动浏览器配置中传入本地chrome路径
const browser = await puppeteer.launch({
executablePath: 'C:/Users/Administrator/AppData/Local/Google/Chrome/Application/chrome.exe'
})
复制代码
在chrome环境中执行函数,获取需要的数据,然后返回到node的执行环境
上图可以看到我们需要的数据的dom位置。在chrome环境执行的函数中,我们需要获取和整理需要的数据。
let list = document.querySelectorAll('.s_position_list .item_con_list li')
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
name: list[i].getAttribute('data-positionname'),
company: list[i].getAttribute('data-company'),
salary: list[i].getAttribute('data-salary'),
require: list[i].querySelector('.li_b_l').childNodes[4].textContent.replace(/ |\n/g, ''),
})
}
return res
复制代码
这里有一个调试技巧,我们可以在chrome控制台中直接编写获取数据的函数,方便调试
最后附上完整代码
const puppeteer = require('puppeteer');
(async () => {
// 启动浏览器
const browser = await puppeteer.launch({
headless: false, // 默认是无头模式,这里为了示范所以使用正常模式
})
// 控制浏览器打开新标签页面
const page = await browser.newPage()
// 在新标签中打开要爬取的网页
await page.goto('https://www.lagou.com/jobs/list_web%E5%89%8D%E7%AB%AF?px=new&city=%E5%B9%BF%E5%B7%9E')
// 使用evaluate方法在浏览器中执行传入函数(完全的浏览器环境,所以函数内可以直接使用window、document等所有对象和方法)
let data = await page.evaluate(() => {
let list = document.querySelectorAll('.s_position_list .item_con_list li')
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
name: list[i].getAttribute('data-positionname'),
company: list[i].getAttribute('data-company'),
salary: list[i].getAttribute('data-salary'),
require: list[i].querySelector('.li_b_l').childNodes[4].textContent.replace(/ |\n/g, ''),
})
}
return res
})
console.log(data)
})()
复制代码
操作结果
到这里,动态网页的爬取也已经完成了,但是puppeteer的功能远不止这些。它还具有许多可以使用的强大 API。您可以移至官方文档。
第三期会讲如何定时执行爬虫并存入数据库。 查看全部
nodejs抓取动态网页(之前第一篇教程.js爬虫入门(一)爬取静态页面)
第一篇爬虫教程node.js爬虫入门(一)爬取静态页面讲解了静态网页的爬取,很简单,但是如果遇到一些动态网页(ajax),直接使用前面的发送请求方法获取不到我们想要的数据,这时候需要爬取动态网页,selenium和puppeteer都不错。
在这里推荐 Puppeteer,不是为了别的,只是因为它是 Google 自己的并且一直在维护更新。下面是翻译的官方文档介绍
Puppeteer 是一个 Node 库,通过 DevTools(开发者工具)协议提供了一系列高级接口来控制 Chrome 或 Chromium(谷歌开源)。默认以headless模式运行(无浏览器UI界面),也可以通过配置以普通模式运行。
它可用于:
首先,我们必须先安装它,然后才能使用它。最新的Chromium会默认安装下载,大小约300M。
npm install puppeteer
复制代码
如果你的机器上已经有较新版本的chrome,则只能安装core版本,但是启动puppeteer时需要配置本地chrome的路径。
npm install puppeteer-core // 核心版本
复制代码
假设我们要爬取拉勾的前端招聘信息。这是一个动态页面。使用此示例尝试抓取。
因为chrome操作都是异步操作,为了避免回调地狱,推荐使用es7的async await。这种语法具有很高的可读性,官方文档也是如此。
首先使用puppeteer启动浏览器,打开动态页面
需要注意的是,如果使用的是本地浏览器,则需要在启动浏览器配置中传入本地chrome路径
const browser = await puppeteer.launch({
executablePath: 'C:/Users/Administrator/AppData/Local/Google/Chrome/Application/chrome.exe'
})
复制代码
在chrome环境中执行函数,获取需要的数据,然后返回到node的执行环境
上图可以看到我们需要的数据的dom位置。在chrome环境执行的函数中,我们需要获取和整理需要的数据。
let list = document.querySelectorAll('.s_position_list .item_con_list li')
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
name: list[i].getAttribute('data-positionname'),
company: list[i].getAttribute('data-company'),
salary: list[i].getAttribute('data-salary'),
require: list[i].querySelector('.li_b_l').childNodes[4].textContent.replace(/ |\n/g, ''),
})
}
return res
复制代码
这里有一个调试技巧,我们可以在chrome控制台中直接编写获取数据的函数,方便调试
最后附上完整代码
const puppeteer = require('puppeteer');
(async () => {
// 启动浏览器
const browser = await puppeteer.launch({
headless: false, // 默认是无头模式,这里为了示范所以使用正常模式
})
// 控制浏览器打开新标签页面
const page = await browser.newPage()
// 在新标签中打开要爬取的网页
await page.goto('https://www.lagou.com/jobs/list_web%E5%89%8D%E7%AB%AF?px=new&city=%E5%B9%BF%E5%B7%9E')
// 使用evaluate方法在浏览器中执行传入函数(完全的浏览器环境,所以函数内可以直接使用window、document等所有对象和方法)
let data = await page.evaluate(() => {
let list = document.querySelectorAll('.s_position_list .item_con_list li')
let res = []
for (let i = 0; i < list.length; i++) {
res.push({
name: list[i].getAttribute('data-positionname'),
company: list[i].getAttribute('data-company'),
salary: list[i].getAttribute('data-salary'),
require: list[i].querySelector('.li_b_l').childNodes[4].textContent.replace(/ |\n/g, ''),
})
}
return res
})
console.log(data)
})()
复制代码
操作结果
到这里,动态网页的爬取也已经完成了,但是puppeteer的功能远不止这些。它还具有许多可以使用的强大 API。您可以移至官方文档。
第三期会讲如何定时执行爬虫并存入数据库。
nodejs抓取动态网页(记录一下西瓜视频MP4地址的获取步骤(1)_ )
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-25 03:07
)
记录获取西瓜视频MP4地址的步骤
目标:
指定西瓜视频的地址,例如获取其视频MP4文件的下载地址
以下使用chrome浏览器
开始分析:
首先在浏览器中打开视频页面,打开review元素(右键->review元素或F12)刷新页面查看网络选项中抓包
提示 1:
由于我们得到的是视频文件的下载地址,而视频文件一般都比较大,可以使用网络包列表中的Size来对最大的包进行排序
如图:
在这里我们可以轻松确定视频文件的地址
(你得到的地址可能和我得到的不一样,但URL路径中的最后一串应该是一样的)
接下来,我们将找出获取地址的位置。一般的做法是截取url中比较有代表性的部分(这个靠经验,你应该明白)进行搜索,搜索可以使用chrome评论元素的Search功能
此搜索将在网络列中找到所有数据包的响应内容。如果找到,我们就可以确定视频文件地址的来源。
你为什么这么做?
按照正常思路,首先获取视频文件的请求是由浏览器发起的,所以浏览器在发起之前肯定已经获取到了视频文件的地址,那么地址在哪里呢?一般来说,无非就是直接写
在网页源码中获取视频地址或者使用ajax请求之类的,所以这个地址必须在我们目前能看到的网络列表中的包中。
但是,在这个例子中,搜索结果是空的。尝试220f87599d445a14a53803fd01d86816e971157c7a70000cab5121742cc、5cc4c0ae0f7d6f87014dc0f0058257e>@k
无法搜索。
好吧,既然找不到,那就用暴力的方法吧。好在这个网页上的网络包并不多,我们就一一寻找。搜索过程一般可以忽略css、图片、多媒体等文档,
先查看json格式的文件
下面手动查看。. .
再次检查后,我发现了一个可疑的链接
首先这个url是可疑的,里面收录了各种敏感的关键词,比如mp4、urls等。
二、内容可疑:
video_list 出来了,但还能是谁呢?但是,如果仔细观察,该内容中的 URL 格式是不正确的。乍一看,好像是加密过的。难怪你找不到它。
下面是找个解密方法来验证我们这里看到的就是我们想要的视频地址
让我们先来看看这个想法。我们找到的数据是浏览器请求的。既然是请求数据,那肯定有用。让我们找出数据在哪里使用,如何找到它,或搜索。使用这些数据中的变量名称进行搜索
这些数据中有两个可疑的变量:backup_url_1、main_url。第一个乍一看是备份,所以让我们搜索第二个。
搜索结果如下:
下面找到这些包中 main_url 所在的代码。幸运的是,第一个就是我们想要的(tt-video.js)
如图:
从代码中我们可以看出main_url使用base64decode进行解密。下面使用代码验证(请自行验证)。果然,我们得到了想要的视频地址。
至此,我们已经有了从这个数据包中获取视频地址的方法,那么接下来的问题是,这个数据包的地址是如何生成的呢?
首先分析一下这个包的url的组成:
先去掉不相关的参数,方法很简单,直接在浏览器中打开url,然后尝试删除参数,继续测试。删除的url如下
然后我发现有三件事我不知道它们来自哪里。让我们继续使用我们的搜索工具来一一查找。
(注:当你按照文章一步一步来的时候,你看到的参数可能和我这里写的参数不一样,请按实际搜索)
首先是v02004bd0000bc9po7aj2boojm5cta5g,搜索结果如下:
原来这个参数是视频的videoId,直接在网页源码中。好的,第一个就完成了。
看看第二个参数8795045找不到
来看看第三个参数 3128215333 找不到
后两个参数是不可搜索的,可能是实时生成的,也可能是加密的,所以换个思路,用url前半部分的关键词搜索一下,看看用在什么地方
关于关键词 当然越长越准确,所以我选择的搜索词是video/urls/v/1/toutiao/mp4,搜索结果如下:
这里只能一一打开源代码。. .
查看源代码时,注意以下几点:
1、查看上下文,查看文件的功能
2、想想我们在寻找什么。比如在这个例子中,我们搜索的是一个视频资源的URL,所以一定要特别注意视频相关的关键词、函数名等
哈哈,幸运的是,我在第一个文件(tt-video.js)中发现了可疑代码
这都与视频有关。更可疑的是 getVideosJson 函数的名称。然后我发现一个 crc32 函数使用了目标 url。我们来看看crc32函数是在哪里定义的。
(PS:标准的crc32是一种公共算法,用于为一段数据生成校验码,但一般这些反爬虫前端工程师会自己实现,所以以JS代码为准)
通过搜索crc32关键词,可以定位到如下代码:
专注于图中的红色区域。我们找不到的 r 和 s 参数出现在这里。这说明我们的想法应该是正确的。然后我们发现r的值是随机生成的。这很容易处理。我们也会只随机生成一个,最好完全按照JS代码模拟。
但是s的值似乎有点复杂。那么,现在是测试你的脑力的时候了。
s 的值是由函数 o 生成的,但是 o 的代码非常复杂。我该怎么办?
第一种方法:
不好说,js代码的算法完全是模拟出来的,可以用其他语言尝试计算,或者用pyv8、nodejs等js引擎来执行
第二种方法:
怎么说呢,换个角度想想。如果你是写这段代码的前端工程师,你会怎么做?您会从头开始实施验证算法吗?? ? (当然不可否认,确实有些情况下算法是自创的)由于这个函数是
对于像crc32这样的公共算法,每种语言基本上都有一个标准库实现,所以可以直接调用标准库来测试。如果加密结果一致,大家开心不一致,请参考第一种方法。
好了,到此为止,分析已经完成了,现在是时候编写代码了。代码显示如下:
查看全部
nodejs抓取动态网页(记录一下西瓜视频MP4地址的获取步骤(1)_
)
记录获取西瓜视频MP4地址的步骤
目标:
指定西瓜视频的地址,例如获取其视频MP4文件的下载地址
以下使用chrome浏览器
开始分析:
首先在浏览器中打开视频页面,打开review元素(右键->review元素或F12)刷新页面查看网络选项中抓包
提示 1:
由于我们得到的是视频文件的下载地址,而视频文件一般都比较大,可以使用网络包列表中的Size来对最大的包进行排序
如图:
在这里我们可以轻松确定视频文件的地址
(你得到的地址可能和我得到的不一样,但URL路径中的最后一串应该是一样的)
接下来,我们将找出获取地址的位置。一般的做法是截取url中比较有代表性的部分(这个靠经验,你应该明白)进行搜索,搜索可以使用chrome评论元素的Search功能
此搜索将在网络列中找到所有数据包的响应内容。如果找到,我们就可以确定视频文件地址的来源。
你为什么这么做?
按照正常思路,首先获取视频文件的请求是由浏览器发起的,所以浏览器在发起之前肯定已经获取到了视频文件的地址,那么地址在哪里呢?一般来说,无非就是直接写
在网页源码中获取视频地址或者使用ajax请求之类的,所以这个地址必须在我们目前能看到的网络列表中的包中。
但是,在这个例子中,搜索结果是空的。尝试220f87599d445a14a53803fd01d86816e971157c7a70000cab5121742cc、5cc4c0ae0f7d6f87014dc0f0058257e>@k
无法搜索。
好吧,既然找不到,那就用暴力的方法吧。好在这个网页上的网络包并不多,我们就一一寻找。搜索过程一般可以忽略css、图片、多媒体等文档,
先查看json格式的文件
下面手动查看。. .
再次检查后,我发现了一个可疑的链接
首先这个url是可疑的,里面收录了各种敏感的关键词,比如mp4、urls等。
二、内容可疑:
video_list 出来了,但还能是谁呢?但是,如果仔细观察,该内容中的 URL 格式是不正确的。乍一看,好像是加密过的。难怪你找不到它。
下面是找个解密方法来验证我们这里看到的就是我们想要的视频地址
让我们先来看看这个想法。我们找到的数据是浏览器请求的。既然是请求数据,那肯定有用。让我们找出数据在哪里使用,如何找到它,或搜索。使用这些数据中的变量名称进行搜索
这些数据中有两个可疑的变量:backup_url_1、main_url。第一个乍一看是备份,所以让我们搜索第二个。
搜索结果如下:
下面找到这些包中 main_url 所在的代码。幸运的是,第一个就是我们想要的(tt-video.js)
如图:
从代码中我们可以看出main_url使用base64decode进行解密。下面使用代码验证(请自行验证)。果然,我们得到了想要的视频地址。
至此,我们已经有了从这个数据包中获取视频地址的方法,那么接下来的问题是,这个数据包的地址是如何生成的呢?
首先分析一下这个包的url的组成:
先去掉不相关的参数,方法很简单,直接在浏览器中打开url,然后尝试删除参数,继续测试。删除的url如下
然后我发现有三件事我不知道它们来自哪里。让我们继续使用我们的搜索工具来一一查找。
(注:当你按照文章一步一步来的时候,你看到的参数可能和我这里写的参数不一样,请按实际搜索)
首先是v02004bd0000bc9po7aj2boojm5cta5g,搜索结果如下:
原来这个参数是视频的videoId,直接在网页源码中。好的,第一个就完成了。
看看第二个参数8795045找不到
来看看第三个参数 3128215333 找不到
后两个参数是不可搜索的,可能是实时生成的,也可能是加密的,所以换个思路,用url前半部分的关键词搜索一下,看看用在什么地方
关于关键词 当然越长越准确,所以我选择的搜索词是video/urls/v/1/toutiao/mp4,搜索结果如下:
这里只能一一打开源代码。. .
查看源代码时,注意以下几点:
1、查看上下文,查看文件的功能
2、想想我们在寻找什么。比如在这个例子中,我们搜索的是一个视频资源的URL,所以一定要特别注意视频相关的关键词、函数名等
哈哈,幸运的是,我在第一个文件(tt-video.js)中发现了可疑代码
这都与视频有关。更可疑的是 getVideosJson 函数的名称。然后我发现一个 crc32 函数使用了目标 url。我们来看看crc32函数是在哪里定义的。
(PS:标准的crc32是一种公共算法,用于为一段数据生成校验码,但一般这些反爬虫前端工程师会自己实现,所以以JS代码为准)
通过搜索crc32关键词,可以定位到如下代码:
专注于图中的红色区域。我们找不到的 r 和 s 参数出现在这里。这说明我们的想法应该是正确的。然后我们发现r的值是随机生成的。这很容易处理。我们也会只随机生成一个,最好完全按照JS代码模拟。
但是s的值似乎有点复杂。那么,现在是测试你的脑力的时候了。
s 的值是由函数 o 生成的,但是 o 的代码非常复杂。我该怎么办?
第一种方法:
不好说,js代码的算法完全是模拟出来的,可以用其他语言尝试计算,或者用pyv8、nodejs等js引擎来执行
第二种方法:
怎么说呢,换个角度想想。如果你是写这段代码的前端工程师,你会怎么做?您会从头开始实施验证算法吗?? ? (当然不可否认,确实有些情况下算法是自创的)由于这个函数是
对于像crc32这样的公共算法,每种语言基本上都有一个标准库实现,所以可以直接调用标准库来测试。如果加密结果一致,大家开心不一致,请参考第一种方法。
好了,到此为止,分析已经完成了,现在是时候编写代码了。代码显示如下:
nodejs抓取动态网页(ajax和Chrome的内核性能相对Trident较好,性能你懂的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-20 20:31
在Ajax时代,许多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的HTML
跳过了JS加载部分,即爬虫抓取的网页不完整、不完整。你可以看到下面博客花园的首页
从主页加载中,我们可以看到页面呈现后,将有五个Ajax异步请求。默认情况下,爬虫程序无法抓取Ajax生成的内容
此时,如果要获取这些动态页面,必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎有三个支柱
三叉戟:即内核。WebBrowser基于此内核,但其可加载性较差
壁虎:FF的内核比Trident有更好的性能
WebKit:Safari和chrome的内核性能,你知道,在真实场景中仍然基于它
好吧,为了简单和方便,让我们使用WebBrowser来玩。使用WebBrowser时,我们应注意以下几点:
第一:因为WebBrowser是system.windows.forms中的WinForm控件,所以我们需要设置StatThread标志
第二:WinForm是事件驱动的,控制台不响应事件。所有事件都在windows的消息队列中等待执行。为了不让程序假装死亡
我们需要调用Doevents方法来转移控制,并让操作系统执行其他事件
第三:我们需要使用domdocument而不是documenttext来查看WebBrowser中的内容
通常有两种方法来判断是否加载了动态网页:
① : 在这里设置一个最大值,因为每次异步加载JS时,都会触发导航和documentcompleted事件,所以我们需要
只需将计数值记录在
② : 当然,除了通过判断最大值来判断加载是否完成外,我们还可以通过设置定时器来判断,如3S、4S、5S等
是否已加载web浏览器 查看全部
nodejs抓取动态网页(ajax和Chrome的内核性能相对Trident较好,性能你懂的)
在Ajax时代,许多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的HTML
跳过了JS加载部分,即爬虫抓取的网页不完整、不完整。你可以看到下面博客花园的首页
从主页加载中,我们可以看到页面呈现后,将有五个Ajax异步请求。默认情况下,爬虫程序无法抓取Ajax生成的内容
此时,如果要获取这些动态页面,必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎有三个支柱
三叉戟:即内核。WebBrowser基于此内核,但其可加载性较差
壁虎:FF的内核比Trident有更好的性能
WebKit:Safari和chrome的内核性能,你知道,在真实场景中仍然基于它
好吧,为了简单和方便,让我们使用WebBrowser来玩。使用WebBrowser时,我们应注意以下几点:
第一:因为WebBrowser是system.windows.forms中的WinForm控件,所以我们需要设置StatThread标志
第二:WinForm是事件驱动的,控制台不响应事件。所有事件都在windows的消息队列中等待执行。为了不让程序假装死亡
我们需要调用Doevents方法来转移控制,并让操作系统执行其他事件
第三:我们需要使用domdocument而不是documenttext来查看WebBrowser中的内容
通常有两种方法来判断是否加载了动态网页:
① : 在这里设置一个最大值,因为每次异步加载JS时,都会触发导航和documentcompleted事件,所以我们需要
只需将计数值记录在
② : 当然,除了通过判断最大值来判断加载是否完成外,我们还可以通过设置定时器来判断,如3S、4S、5S等
是否已加载web浏览器
nodejs抓取动态网页(本发明基于Web动态信息抓取技术的详情页面自动生成方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-20 03:07
本发明涉及一种基于Web动态信息捕获技术的细节页面自动生成方法
背景技术:
目前,国内主流爬虫直接使用HTTP协议下载指定URL的静态HTML内容,并对内容进行分析和提取。该方法已广泛应用于搜索引擎、舆情监控、垂直门户网站等领域
但在电子商务领域,考虑到安全性、加载速度、页面静态等因素,商品页面中网站的价格、商品规格、图形细节等大部分都是通过JS和Ajax加载的动态HTML内容。这使得传统的网络爬虫系统无法有效地自动获取商品信息
随着互联网的发展,中国大量线下零售企业开始建设自己的电商平台,如广百百货的广百汇、广州友谊商城的线上商城等,实现线上线下商品的一体化销售。然而,传统零售企业要想在网上销售大量商品,需要记录每种商品的详细商品图形信息,工作量非常巨大。例如,在冰箱、洗衣机、彩电和空调四大类中,有8000至10000种常用型号。如果一个人按照5人的输入团队,每小时输入4台PC产品+4台移动产品的图形详细信息,则需要3-4个月,效率低下
技术实现要素:
本发明所要解决的技术问题是提供一种基于Web动态信息捕获技术的高效细节页面自动生成方法
为了解决上述问题,本发明采用以下技术方案:
本发明涉及一种基于Web动态信息捕获技术的细节页面自动生成方法,包括以下步骤:
1)抓取程序模块并启动浏览器
2)模仿人的操作打开商品详情页面
3)抓取页面中的信息并下载相关图片
4)手动审查
优选地,抓取程序模块由selenium测试工具和爬虫程序构建
优选地,该步骤的特定步骤1)包括:
1.1)在捕获程序模块中输入商品和目标商场的基本信息
1.2)grab程序模块基于selenium测试工具的功能模拟人工操作并启动浏览器
1.3)登录购物中心
1.4)通过步骤1.1)中的预设关键字搜索目标网站以找到相应的商品
优选地,该步骤的特定步骤2)包括:
2.2)打开产品详细信息页面
2.3)等待浏览器加载静态和动态内容
优选地,该步骤的特定步骤3)包括:
3.1)基于爬虫的功能,它可以自动捕获页面中的商品价格、规格参数和商品详细信息,并下载相关图片
3.2)转换捕获的图形信息的格式
如果在步骤1.4)中找不到相应的商品,最好返回步骤1.1)重新输入商品和目标商场的基本信息
本发明的有益效果是,通过在浏览器中模仿人们的鼠标点击、键盘输入等操作,并监控操作后浏览器内容的变化,结合网络爬虫捕获的信息功能,完全模拟了真实用户在浏览器中的浏览操作。因此,捕获的信息与真实用户看到的图形信息完全一致。与传统的网络爬虫产品相比,它具有兼容性好、速度快、数据捕获准确等特点
具体实施例
本发明涉及一种基于Web动态信息捕获技术的细节页面自动生成方法,包括以下步骤:
1)抓取程序模块并启动浏览器
2)模仿人的操作打开商品详情页面
3)抓取页面中的信息并下载相关图片
4)mall经理检查捕获的商品信息,快速修改有问题的内容,并在通过审核后将信息应用到自己的商城
本发明的有益效果是,通过在浏览器中模仿人们的鼠标点击、键盘输入等操作,并监控操作后浏览器内容的变化,结合网络爬虫捕获的信息功能,完全模拟了真实用户在浏览器中的浏览操作。因此,捕获的信息与真实用户看到的图形信息完全一致。与传统的网络爬虫产品相比,它具有兼容性好、速度快、数据捕获准确等特点
例2
本发明涉及一种基于Web动态信息捕获技术的细节页面自动生成方法,包括以下步骤:
1.在捕获程序模块中输入商品和目标商城的基本信息;抓取程序模块基于selenium测试工具的功能,模拟人工操作,启动浏览器,登录商场;通过预设关键字在目标网站中搜索,找到对应的商品。如果找不到对应的商品,则重新输入商品和目标商场的基本信息
2)打开产品详细信息页面,等待浏览器加载静态和动态内容
3)基于爬虫程序的功能,可以自动捕获页面中的商品价格、规格参数和商品详情,并下载相关图片;然后将捕获的图形信息转换为我们商场的商品数据格式
4)mall经理检查捕获的商品信息,快速修改有问题的内容,并在通过审核后将信息应用到自己的商城
抓取程序模块由selenium测试工具和爬虫程序构建,实现了基于selenium技术和web爬虫技术的信息自动抓取程序。它可以控制浏览器的行为,模拟人们在浏览器中启动鼠标点击、键盘输入等操作,并监控操作后浏览器内容的变化,模拟商城会员操作:打开浏览器->登录目标商城->查找目标商品->打开商品详情页面->等待浏览器加载静态和动态内容,然后提取商品名称、价格、图形详情等内容。该操作完全模拟真实用户在浏览器中的浏览操作,因此,捕获的信息与真实用户看到的图形信息完全一致
本发明的有益效果是:利用selenium技术和网络爬虫技术,通过在浏览器中模仿人们的鼠标点击、键盘输入等操作,并监控操作后浏览器内容的变化,结合网络爬虫捕获的信息功能,浏览器中真实用户的浏览操作是完全模拟的,因此,捕获的信息与真实用户看到的图形信息完全一致。与传统的网络爬虫产品相比,它具有兼容性好、速度快、数据捕获准确等特点
以上仅为本发明的具体实施例,但本发明的保护范围不限于此。未经创造性劳动的变更或者更换,属于本发明的保护范围 查看全部
nodejs抓取动态网页(本发明基于Web动态信息抓取技术的详情页面自动生成方法)
本发明涉及一种基于Web动态信息捕获技术的细节页面自动生成方法
背景技术:
目前,国内主流爬虫直接使用HTTP协议下载指定URL的静态HTML内容,并对内容进行分析和提取。该方法已广泛应用于搜索引擎、舆情监控、垂直门户网站等领域
但在电子商务领域,考虑到安全性、加载速度、页面静态等因素,商品页面中网站的价格、商品规格、图形细节等大部分都是通过JS和Ajax加载的动态HTML内容。这使得传统的网络爬虫系统无法有效地自动获取商品信息
随着互联网的发展,中国大量线下零售企业开始建设自己的电商平台,如广百百货的广百汇、广州友谊商城的线上商城等,实现线上线下商品的一体化销售。然而,传统零售企业要想在网上销售大量商品,需要记录每种商品的详细商品图形信息,工作量非常巨大。例如,在冰箱、洗衣机、彩电和空调四大类中,有8000至10000种常用型号。如果一个人按照5人的输入团队,每小时输入4台PC产品+4台移动产品的图形详细信息,则需要3-4个月,效率低下
技术实现要素:
本发明所要解决的技术问题是提供一种基于Web动态信息捕获技术的高效细节页面自动生成方法
为了解决上述问题,本发明采用以下技术方案:
本发明涉及一种基于Web动态信息捕获技术的细节页面自动生成方法,包括以下步骤:
1)抓取程序模块并启动浏览器
2)模仿人的操作打开商品详情页面
3)抓取页面中的信息并下载相关图片
4)手动审查
优选地,抓取程序模块由selenium测试工具和爬虫程序构建
优选地,该步骤的特定步骤1)包括:
1.1)在捕获程序模块中输入商品和目标商场的基本信息
1.2)grab程序模块基于selenium测试工具的功能模拟人工操作并启动浏览器
1.3)登录购物中心
1.4)通过步骤1.1)中的预设关键字搜索目标网站以找到相应的商品
优选地,该步骤的特定步骤2)包括:
2.2)打开产品详细信息页面
2.3)等待浏览器加载静态和动态内容
优选地,该步骤的特定步骤3)包括:
3.1)基于爬虫的功能,它可以自动捕获页面中的商品价格、规格参数和商品详细信息,并下载相关图片
3.2)转换捕获的图形信息的格式
如果在步骤1.4)中找不到相应的商品,最好返回步骤1.1)重新输入商品和目标商场的基本信息
本发明的有益效果是,通过在浏览器中模仿人们的鼠标点击、键盘输入等操作,并监控操作后浏览器内容的变化,结合网络爬虫捕获的信息功能,完全模拟了真实用户在浏览器中的浏览操作。因此,捕获的信息与真实用户看到的图形信息完全一致。与传统的网络爬虫产品相比,它具有兼容性好、速度快、数据捕获准确等特点
具体实施例
本发明涉及一种基于Web动态信息捕获技术的细节页面自动生成方法,包括以下步骤:
1)抓取程序模块并启动浏览器
2)模仿人的操作打开商品详情页面
3)抓取页面中的信息并下载相关图片
4)mall经理检查捕获的商品信息,快速修改有问题的内容,并在通过审核后将信息应用到自己的商城
本发明的有益效果是,通过在浏览器中模仿人们的鼠标点击、键盘输入等操作,并监控操作后浏览器内容的变化,结合网络爬虫捕获的信息功能,完全模拟了真实用户在浏览器中的浏览操作。因此,捕获的信息与真实用户看到的图形信息完全一致。与传统的网络爬虫产品相比,它具有兼容性好、速度快、数据捕获准确等特点
例2
本发明涉及一种基于Web动态信息捕获技术的细节页面自动生成方法,包括以下步骤:
1.在捕获程序模块中输入商品和目标商城的基本信息;抓取程序模块基于selenium测试工具的功能,模拟人工操作,启动浏览器,登录商场;通过预设关键字在目标网站中搜索,找到对应的商品。如果找不到对应的商品,则重新输入商品和目标商场的基本信息
2)打开产品详细信息页面,等待浏览器加载静态和动态内容
3)基于爬虫程序的功能,可以自动捕获页面中的商品价格、规格参数和商品详情,并下载相关图片;然后将捕获的图形信息转换为我们商场的商品数据格式
4)mall经理检查捕获的商品信息,快速修改有问题的内容,并在通过审核后将信息应用到自己的商城
抓取程序模块由selenium测试工具和爬虫程序构建,实现了基于selenium技术和web爬虫技术的信息自动抓取程序。它可以控制浏览器的行为,模拟人们在浏览器中启动鼠标点击、键盘输入等操作,并监控操作后浏览器内容的变化,模拟商城会员操作:打开浏览器->登录目标商城->查找目标商品->打开商品详情页面->等待浏览器加载静态和动态内容,然后提取商品名称、价格、图形详情等内容。该操作完全模拟真实用户在浏览器中的浏览操作,因此,捕获的信息与真实用户看到的图形信息完全一致
本发明的有益效果是:利用selenium技术和网络爬虫技术,通过在浏览器中模仿人们的鼠标点击、键盘输入等操作,并监控操作后浏览器内容的变化,结合网络爬虫捕获的信息功能,浏览器中真实用户的浏览操作是完全模拟的,因此,捕获的信息与真实用户看到的图形信息完全一致。与传统的网络爬虫产品相比,它具有兼容性好、速度快、数据捕获准确等特点
以上仅为本发明的具体实施例,但本发明的保护范围不限于此。未经创造性劳动的变更或者更换,属于本发明的保护范围
nodejs抓取动态网页(构建服务器Node.js一些模块的学习方法-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-15 13:13
为了回顾node.js的一些模块的学习,我们首先编写了一个静态页面。为了追求效率和美观,我们使用bootstrap的bootstrap.css身份验证登录功能。我们只需设置用户名、密码和登录函数结构
代码
Node实现登录页面
实现验证登录
用户
密码
登录
使用node.js构建服务器,使用HTTP模块创建服务器,使用FS和path模块查看我们的静态页面,注意表单的动作、端口和请求路径与后台部分的代码一致
const http = require('http')
const fs = require('fs')
const path = require('path')
let server = http.createServer((req,res)=>{
// console.log(req.url.startsWith('/login'))
// true(login) false(bootstrap) false(bootstrap)
fs.readFile(path.join(__dirname,'/source',req.url),'utf8',(err,data)=>{
// 2.1 判断文件是否存在,不存在返回404
// 2.2 最好使用req.url(这样.css文件发送请求,req.url也能获取到。才会链接.css)
if(err){
res.writeHead('404',{
'Content-Type':'text/plain;charset=utf8'
})
res.end('页面不存在了')
}else{
res.end(data)
}
})
}).listen(3000,()=>{
console.log('The Server Running...')
})
本地服务器查看页面效果并测试是否加载了静态资源
测试各功能,解析node.js,实现认证登录功能,导入URL模块,点击登录时获取用户名和密码
const http = require('http')
const fs = require('fs')
const path = require('path')
const {URL} = require('url')
let server = http.createServer((req,res)=>{
let myURL = new URL(path.join(__dirname,req.url))
if(myURL.searchParams.get('username')){
let user = myURL.searchParams.get('username')
let pwd = myURL.searchParams.get('pwd')
res.writeHead('200',{
'Content-Type':'text/plain;charset=utf8'
})
res.end('你好,'+user)
}
fs.readFile(path.join(__dirname,'/source',req.url),'utf8',(err,data)=>{
if(err){
res.writeHead('404',{
'Content-Type':'text/plain;charset=utf8'
})
res.end('页面不存在了')
}else{
res.end(data)
}
})
}).listen(3000,()=>{
console.log('The Server Running...')
})
总结
//1.buildweb服务器
//2.render页面
//2.1确定页面是否存在
//2.2如果不是,返回404
//2.3如果是,请读取文件并将其呈现到页面
//3.登录后获取用户名和密码
//3.1单击登录按钮将重新发送请求
//3.2此时,您可以获得用户名和密码,但您必须处理它
//3.1获取URL地址的searchparams的用户名和密码
//4.登录
//4.1返回新页面 查看全部
nodejs抓取动态网页(构建服务器Node.js一些模块的学习方法-上海怡健医学)
为了回顾node.js的一些模块的学习,我们首先编写了一个静态页面。为了追求效率和美观,我们使用bootstrap的bootstrap.css身份验证登录功能。我们只需设置用户名、密码和登录函数结构
代码
Node实现登录页面
实现验证登录
用户
密码
登录
使用node.js构建服务器,使用HTTP模块创建服务器,使用FS和path模块查看我们的静态页面,注意表单的动作、端口和请求路径与后台部分的代码一致
const http = require('http')
const fs = require('fs')
const path = require('path')
let server = http.createServer((req,res)=>{
// console.log(req.url.startsWith('/login'))
// true(login) false(bootstrap) false(bootstrap)
fs.readFile(path.join(__dirname,'/source',req.url),'utf8',(err,data)=>{
// 2.1 判断文件是否存在,不存在返回404
// 2.2 最好使用req.url(这样.css文件发送请求,req.url也能获取到。才会链接.css)
if(err){
res.writeHead('404',{
'Content-Type':'text/plain;charset=utf8'
})
res.end('页面不存在了')
}else{
res.end(data)
}
})
}).listen(3000,()=>{
console.log('The Server Running...')
})
本地服务器查看页面效果并测试是否加载了静态资源
测试各功能,解析node.js,实现认证登录功能,导入URL模块,点击登录时获取用户名和密码
const http = require('http')
const fs = require('fs')
const path = require('path')
const {URL} = require('url')
let server = http.createServer((req,res)=>{
let myURL = new URL(path.join(__dirname,req.url))
if(myURL.searchParams.get('username')){
let user = myURL.searchParams.get('username')
let pwd = myURL.searchParams.get('pwd')
res.writeHead('200',{
'Content-Type':'text/plain;charset=utf8'
})
res.end('你好,'+user)
}
fs.readFile(path.join(__dirname,'/source',req.url),'utf8',(err,data)=>{
if(err){
res.writeHead('404',{
'Content-Type':'text/plain;charset=utf8'
})
res.end('页面不存在了')
}else{
res.end(data)
}
})
}).listen(3000,()=>{
console.log('The Server Running...')
})
总结
//1.buildweb服务器
//2.render页面
//2.1确定页面是否存在
//2.2如果不是,返回404
//2.3如果是,请读取文件并将其呈现到页面
//3.登录后获取用户名和密码
//3.1单击登录按钮将重新发送请求
//3.2此时,您可以获得用户名和密码,但您必须处理它
//3.1获取URL地址的searchparams的用户名和密码
//4.登录
//4.1返回新页面
nodejs抓取动态网页(种种实际上cheeriocheerio对于网页操作是无能为力的(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-09-12 11:09
内容
0. 前言
这两天对爬虫产生了兴趣。一开始是天涯的一张房价贴纸,覆盖了几万层楼,看了很久。天涯网页上的“只看主持人”需要会员,而移动端可以“只看主持人”,但是体验不是很好,录音不方便,所以我决定自己爬下主持人的演讲,可以保存或检索。
这个想法一开始很简单。搜索每个页面的元素。如果发帖人姓名与主持人姓名相符,请复制里面的内容。
网上找到的第一个工具是cheerio插件。读取网站后,保存网站内容,通过元素选择器选择内容。使用递归后,还可以解决翻页问题。
事实上,确实如此。通过几个简单的步骤,主持人的发言就被保存了下来,这也让我对爬虫产生了兴趣。
问题
cheerio真的很简单好用,处理简单的静态网页没有问题。但是拥有一定防爬机制的网站无能为力。比如cheerio通过动态修改url链接解决翻页问题。但是有些网站,比如我最喜欢的煎蛋,网页链接页码乱码,无法实现自动翻页。另一个例子是一些房地产网站。在列出待售资源时,使用延迟加载来提升用户体验。页面滚动到底部后才能触发加载。
以上这些其实都是cheerio对网页操作的无能为力。
解决
我在网上寻找处理延迟加载的方法时发现了puppeteer插件。谷歌浏览器在 2017 年开发了自己的 Chrome Headless 功能,同时推出了 puppeteer,它本质上是一个没有界面的浏览器,有点像电脑终端,所有的操作都是通过代码来完成的。
这样我们就可以在搜索网站之前操作指定元素滚动到底部触发更多信息。或者当需要翻页时,操作码点击翻页按钮,然后在翻页后对页面进行相关处理。
1. 下载并引用包
// 下载
npm i puppeteer
// 引包
const puppeteer = require('puppeteer')
2.使用步骤
// 将整个操作放置在一个闭包的异步函数中,以便于进行异步操作
(async () => {
// 1. 使用puppetee插件启动一个浏览器,并开启一个新页面
const brower = await puppeteer.launch({
args: ['--no-sandbox'],
dumpio: false,
headless:false, // 默认为true,设为false时,可以显示可视化浏览器界面
})
const page = await brower.newPage() // 开启一个新页面
// 2. 打开指定网页
await page.goto('http://jandan.net/ooxx', {
waitUntil: 'networkidle2' // 网络空闲说明已加载完毕
});
// 3. 对动态网站进行自动化操作,这一步是其精髓所在
// 由于我们监控的是动态网页,刚打开网页时,所需元素也许还未出现,所以需要进行监听,例如“下一页按钮”
await page.waitForSelector('a.previous-comment-page'); // 括号内是元素选择器
// 当下一页按钮出现时,模拟点击
await page.click('a.previous-comment-page')
// 4. 这时我们可以执行爬取我们需要的数据了,我们可以去审查页面的dom结果,来循环遍历这些数据。
// page.evaluate() 为在浏览器中执行函数,相当于在控制台中执行函数,返回一个 Promise
const result = await page.evaluate(() => {
// 拿到页面上的jQuery
var $ = window.$;
// 在这里进行熟悉的 DOM 操作
// Do something
});
// 5. 关闭浏览器,在console里面打印我们需要的数据
brower.close();
// 6. 对结果进行处理
console.log(result);
})();
3.爬过的几个坑。给page.evaluate传递参数的问题
因为打开的页面只是一个傀儡,不是真正的浏览器页面,所以这个页面上的操作和一般页面上的操作是不一样的。
官方文档说这个参数是这样的。实际使用中,可以传递一个字符串变量,但是更复杂的,比如‘fs’,在自定义外部函数的时候是无法读取的。
这也是我在第6步的建议,页面操作完成后,统一处理结果。 (主要是我没解决这个问题,所以就随便逛了一下……)
元素操作问题
在 puppeteer 中,最重要的功能执行和元素选择与普通浏览器上的有些不同。爬这里有一些陷阱,现在我说不出来。 查看全部
nodejs抓取动态网页(种种实际上cheeriocheerio对于网页操作是无能为力的(组图))
内容
0. 前言
这两天对爬虫产生了兴趣。一开始是天涯的一张房价贴纸,覆盖了几万层楼,看了很久。天涯网页上的“只看主持人”需要会员,而移动端可以“只看主持人”,但是体验不是很好,录音不方便,所以我决定自己爬下主持人的演讲,可以保存或检索。
这个想法一开始很简单。搜索每个页面的元素。如果发帖人姓名与主持人姓名相符,请复制里面的内容。
网上找到的第一个工具是cheerio插件。读取网站后,保存网站内容,通过元素选择器选择内容。使用递归后,还可以解决翻页问题。
事实上,确实如此。通过几个简单的步骤,主持人的发言就被保存了下来,这也让我对爬虫产生了兴趣。
问题
cheerio真的很简单好用,处理简单的静态网页没有问题。但是拥有一定防爬机制的网站无能为力。比如cheerio通过动态修改url链接解决翻页问题。但是有些网站,比如我最喜欢的煎蛋,网页链接页码乱码,无法实现自动翻页。另一个例子是一些房地产网站。在列出待售资源时,使用延迟加载来提升用户体验。页面滚动到底部后才能触发加载。
以上这些其实都是cheerio对网页操作的无能为力。
解决
我在网上寻找处理延迟加载的方法时发现了puppeteer插件。谷歌浏览器在 2017 年开发了自己的 Chrome Headless 功能,同时推出了 puppeteer,它本质上是一个没有界面的浏览器,有点像电脑终端,所有的操作都是通过代码来完成的。
这样我们就可以在搜索网站之前操作指定元素滚动到底部触发更多信息。或者当需要翻页时,操作码点击翻页按钮,然后在翻页后对页面进行相关处理。
1. 下载并引用包
// 下载
npm i puppeteer
// 引包
const puppeteer = require('puppeteer')
2.使用步骤
// 将整个操作放置在一个闭包的异步函数中,以便于进行异步操作
(async () => {
// 1. 使用puppetee插件启动一个浏览器,并开启一个新页面
const brower = await puppeteer.launch({
args: ['--no-sandbox'],
dumpio: false,
headless:false, // 默认为true,设为false时,可以显示可视化浏览器界面
})
const page = await brower.newPage() // 开启一个新页面
// 2. 打开指定网页
await page.goto('http://jandan.net/ooxx', {
waitUntil: 'networkidle2' // 网络空闲说明已加载完毕
});
// 3. 对动态网站进行自动化操作,这一步是其精髓所在
// 由于我们监控的是动态网页,刚打开网页时,所需元素也许还未出现,所以需要进行监听,例如“下一页按钮”
await page.waitForSelector('a.previous-comment-page'); // 括号内是元素选择器
// 当下一页按钮出现时,模拟点击
await page.click('a.previous-comment-page')
// 4. 这时我们可以执行爬取我们需要的数据了,我们可以去审查页面的dom结果,来循环遍历这些数据。
// page.evaluate() 为在浏览器中执行函数,相当于在控制台中执行函数,返回一个 Promise
const result = await page.evaluate(() => {
// 拿到页面上的jQuery
var $ = window.$;
// 在这里进行熟悉的 DOM 操作
// Do something
});
// 5. 关闭浏览器,在console里面打印我们需要的数据
brower.close();
// 6. 对结果进行处理
console.log(result);
})();
3.爬过的几个坑。给page.evaluate传递参数的问题
因为打开的页面只是一个傀儡,不是真正的浏览器页面,所以这个页面上的操作和一般页面上的操作是不一样的。
官方文档说这个参数是这样的。实际使用中,可以传递一个字符串变量,但是更复杂的,比如‘fs’,在自定义外部函数的时候是无法读取的。
这也是我在第6步的建议,页面操作完成后,统一处理结果。 (主要是我没解决这个问题,所以就随便逛了一下……)
元素操作问题
在 puppeteer 中,最重要的功能执行和元素选择与普通浏览器上的有些不同。爬这里有一些陷阱,现在我说不出来。
nodejs抓取动态网页(为什么需要一个前端监控系统解决的问题和解决办法?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-12 11:07
本文首发于infoQ和“前端之巅”微信公众号,微信群直播记录
感谢infoQ前端顶尖同学对文章的整理校对,以及微信群直播的组织策划
为什么需要前端监控系统
通常大型Web项目中会有很多监控,比如后端服务API监控、接口存活、调用、延迟等监控,这些一般用于监控后台的信息端接口数据层。而对于一个大型的网站系统,从后端服务到前端展示会有很多层:内网VIP、CDN等,但是这些监控并不能准确反映前端页面的状态用户看到,如:页面第三方系统数据调用失败、模块加载异常、数据不正确、天窗空白等。这时候就需要从前端DOM展示的角度分析采集用户真正看到的东西,从而检测页面是否有异常问题
监控系统需要解决的问题
当页面出现以下问题时,您需要通过邮件或短信通知相关人员解决问题
触发报警时需要现场快照,以便重现问题
技术选择
监控的含义与回归测试的含义基本相同。他们都对在线功能进行回归测试,但不同的是监控需要长期的、可持续的、可回收的回归测试,而测试只需要上线后做回归
既然监控和测试的本质是一样的,我们可以把测试作为监控系统。在自动化测试技术遍地开花的时代,有很多好用的自动化工具。我们只需要集成这些自动化工具供我们使用。
NodeJS
NodeJS 是一个 JavaScript 运行环境,非阻塞 I/O 和异步,事件驱动,这几点对于我们构建基于 DOM 元素的监控非常重要
PhantomJS
PhantomJS 是一个基于 webkit 的浏览器引擎,可以使用 JavaScript API 来模拟浏览器操作。它使用 QtWebKit 作为浏览器核心,使用 webkit 来编译、解释和执行 JavaScript 代码。换句话说,任何你在 webkit 浏览器中能做的,它都能做到
它不仅是一个隐形浏览器,还提供CSS选择器,支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作。 PhantomJS 用途广泛,如网络监控、网页截图、无浏览器网页测试、页面访问自动化等。
为什么不用硒
做自动化测试的同学一定知道Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常用浏览器的支持比较好,但是Selenium上手稍微难一些,需要在服务器端安装浏览器才能使用Selenium。
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能比较单一,主要是针对页面的功能回归测试,所以选择了PhantomJS
架构设计架构概述
架构简介
对于DOM监控服务,在应用层面垂直划分:
应用层面的垂直划分,可以让应用分布式部署,提升处理能力。也方便后期让性能更优
改造、系统改造扩容等
解决方案前端规则入口
这是一个独立的网络系统。系统主要用于采集用户输入的页面信息、页面对应的规则、显示错误信息。通过调用后端页面抓取服务完成页面检测任务,系统可以创建三种类型的检测页面:定期监控、高级监控和可用性监控
常规监控
输入一个页面地址和几个检测规则。注意这里的检测规则,我们将一些常用的检测点抽象成一个类似于测试用例的语句。每条规则用于匹配页面上的一个DOM元素,DOM元素的属性用于匹配期望。如果匹配失败,系统会产生错误信息,稍后由报警系统处理
匹配一般有几种类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于、正则
这里的重点是进入规则的人只需要了解一点DOM选择器的知识就可以上手。在我们内部测试工程师通常会统一完成规则的录入。
高级监控
主要用于提供高级页面测试功能,通常由有经验的工程师编写测试用例。本测试用例编写会有一定的学习成本,但可以模拟网页操作,如点击、鼠标移动等事件,准确捕获页面信息
可用性监控
可用性监控侧重于实时监控更严重的问题,例如页面可访问性和内容正确性。通常我们只需要在程序中启动一个Worker就可以获取页面的HTML来检查匹配结果,所以我们选择NodeJS来做异步页面爬取队列来高效快速的完成这种网络密度。输入任务
主动报错页面脚本执行错误监控
页面引入监控脚本,采集页面产生的错误事件返回的错误信息,并自动上报给后端服务。系统中可以汇总所有错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等
主动举报页面
该功能需要相应的前端工程师调用代码中的报错API来主动提交错误信息。使用的主要场景有:页面异步服务延迟无响应、模块降级主动通知等,监控脚本提供了几个简单的API来完成这个任务
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
后端页面抓取服务
由于京东很多页面都是异步加载的,首页、单品等系统有很多第三方异步接口调用。后端程序抓取的页面数据是同步的,无法获取动态JavaScript渲染。内容,所以一定要用PhantomJS之类的可以模拟浏览器的工具
对于定时监控,我们使用PhantomJS模拟浏览器打开页面进行抓取,然后将监控规则解析成JavaScript代码片段执行并采集结果
高级监控,我们使用PhantomJS打开页面,将jasmine、mocha等前端JavaScript测试框架注入页面,然后在页面上执行相应的输入测试用例,返回结果
规则队列生成器
规则队列生成器会将采集的规则转换成消息队列,然后交给长期连续处理器进行一次处理
为什么要使用类似消息队列的处理方式?
这和 PhantomJS 的性能是分不开的。通过实践发现,PhantomJS 并不能很好的进行并发处理。并发过多时,会导致CPU过载,导致机器宕机。
并发测试在本机环境中的虚拟机中执行。数据不理想,限制基本在ab -n 100 -c 50左右。所以为了防止并发问题,我选择使用消息队列,避免高并发导致服务不可用
类消息队列的实现
这里我们通过调用内部分布式缓存系统来生成消息队列。其实队列的产生可以参考数据结构-queue。最基本的模型是在缓存中创建一个KEY,然后按照队列数据结构的方式插入和读取数据
当然,类消息队列的中间介质可以根据自己的实际情况选择,也可以使用原生内存来实现。这可能会导致应用程序和类消息队列争夺内存
长期连续处理器
长期连续处理器是作为消费规则队列生成器生成的消息队列
长期连续加工实现
在长期持久化处理器的具体实现中,我们使用了JavaScript的setInterval方法,不断的获取累了的消息队列的内容发送给规则转换器,再转发给负载均衡调度器。然后对返回的结果进行统一处理,如邮件或短信报警
API
PhantomJS 服务可以作为公共 API 向客户端提供测试需求,API 通过 HTTP 调用。在 API 处理中,需要提供 HTTP 数据到规则和 PhantomJS 的转换。从而将 HTTP 数据演化为规则转换器
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子进程结合起来的服务处理 查看全部
nodejs抓取动态网页(为什么需要一个前端监控系统解决的问题和解决办法?)
本文首发于infoQ和“前端之巅”微信公众号,微信群直播记录
感谢infoQ前端顶尖同学对文章的整理校对,以及微信群直播的组织策划
为什么需要前端监控系统
通常大型Web项目中会有很多监控,比如后端服务API监控、接口存活、调用、延迟等监控,这些一般用于监控后台的信息端接口数据层。而对于一个大型的网站系统,从后端服务到前端展示会有很多层:内网VIP、CDN等,但是这些监控并不能准确反映前端页面的状态用户看到,如:页面第三方系统数据调用失败、模块加载异常、数据不正确、天窗空白等。这时候就需要从前端DOM展示的角度分析采集用户真正看到的东西,从而检测页面是否有异常问题
监控系统需要解决的问题
当页面出现以下问题时,您需要通过邮件或短信通知相关人员解决问题
触发报警时需要现场快照,以便重现问题
技术选择
监控的含义与回归测试的含义基本相同。他们都对在线功能进行回归测试,但不同的是监控需要长期的、可持续的、可回收的回归测试,而测试只需要上线后做回归
既然监控和测试的本质是一样的,我们可以把测试作为监控系统。在自动化测试技术遍地开花的时代,有很多好用的自动化工具。我们只需要集成这些自动化工具供我们使用。
NodeJS
NodeJS 是一个 JavaScript 运行环境,非阻塞 I/O 和异步,事件驱动,这几点对于我们构建基于 DOM 元素的监控非常重要
PhantomJS
PhantomJS 是一个基于 webkit 的浏览器引擎,可以使用 JavaScript API 来模拟浏览器操作。它使用 QtWebKit 作为浏览器核心,使用 webkit 来编译、解释和执行 JavaScript 代码。换句话说,任何你在 webkit 浏览器中能做的,它都能做到
它不仅是一个隐形浏览器,还提供CSS选择器,支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作。 PhantomJS 用途广泛,如网络监控、网页截图、无浏览器网页测试、页面访问自动化等。
为什么不用硒
做自动化测试的同学一定知道Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常用浏览器的支持比较好,但是Selenium上手稍微难一些,需要在服务器端安装浏览器才能使用Selenium。
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能比较单一,主要是针对页面的功能回归测试,所以选择了PhantomJS
架构设计架构概述
架构简介
对于DOM监控服务,在应用层面垂直划分:
应用层面的垂直划分,可以让应用分布式部署,提升处理能力。也方便后期让性能更优
改造、系统改造扩容等
解决方案前端规则入口
这是一个独立的网络系统。系统主要用于采集用户输入的页面信息、页面对应的规则、显示错误信息。通过调用后端页面抓取服务完成页面检测任务,系统可以创建三种类型的检测页面:定期监控、高级监控和可用性监控
常规监控
输入一个页面地址和几个检测规则。注意这里的检测规则,我们将一些常用的检测点抽象成一个类似于测试用例的语句。每条规则用于匹配页面上的一个DOM元素,DOM元素的属性用于匹配期望。如果匹配失败,系统会产生错误信息,稍后由报警系统处理
匹配一般有几种类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于、正则
这里的重点是进入规则的人只需要了解一点DOM选择器的知识就可以上手。在我们内部测试工程师通常会统一完成规则的录入。
高级监控
主要用于提供高级页面测试功能,通常由有经验的工程师编写测试用例。本测试用例编写会有一定的学习成本,但可以模拟网页操作,如点击、鼠标移动等事件,准确捕获页面信息
可用性监控
可用性监控侧重于实时监控更严重的问题,例如页面可访问性和内容正确性。通常我们只需要在程序中启动一个Worker就可以获取页面的HTML来检查匹配结果,所以我们选择NodeJS来做异步页面爬取队列来高效快速的完成这种网络密度。输入任务
主动报错页面脚本执行错误监控
页面引入监控脚本,采集页面产生的错误事件返回的错误信息,并自动上报给后端服务。系统中可以汇总所有错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等
主动举报页面
该功能需要相应的前端工程师调用代码中的报错API来主动提交错误信息。使用的主要场景有:页面异步服务延迟无响应、模块降级主动通知等,监控脚本提供了几个简单的API来完成这个任务
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
后端页面抓取服务
由于京东很多页面都是异步加载的,首页、单品等系统有很多第三方异步接口调用。后端程序抓取的页面数据是同步的,无法获取动态JavaScript渲染。内容,所以一定要用PhantomJS之类的可以模拟浏览器的工具
对于定时监控,我们使用PhantomJS模拟浏览器打开页面进行抓取,然后将监控规则解析成JavaScript代码片段执行并采集结果
高级监控,我们使用PhantomJS打开页面,将jasmine、mocha等前端JavaScript测试框架注入页面,然后在页面上执行相应的输入测试用例,返回结果
规则队列生成器
规则队列生成器会将采集的规则转换成消息队列,然后交给长期连续处理器进行一次处理
为什么要使用类似消息队列的处理方式?
这和 PhantomJS 的性能是分不开的。通过实践发现,PhantomJS 并不能很好的进行并发处理。并发过多时,会导致CPU过载,导致机器宕机。
并发测试在本机环境中的虚拟机中执行。数据不理想,限制基本在ab -n 100 -c 50左右。所以为了防止并发问题,我选择使用消息队列,避免高并发导致服务不可用
类消息队列的实现
这里我们通过调用内部分布式缓存系统来生成消息队列。其实队列的产生可以参考数据结构-queue。最基本的模型是在缓存中创建一个KEY,然后按照队列数据结构的方式插入和读取数据
当然,类消息队列的中间介质可以根据自己的实际情况选择,也可以使用原生内存来实现。这可能会导致应用程序和类消息队列争夺内存
长期连续处理器
长期连续处理器是作为消费规则队列生成器生成的消息队列
长期连续加工实现
在长期持久化处理器的具体实现中,我们使用了JavaScript的setInterval方法,不断的获取累了的消息队列的内容发送给规则转换器,再转发给负载均衡调度器。然后对返回的结果进行统一处理,如邮件或短信报警
API
PhantomJS 服务可以作为公共 API 向客户端提供测试需求,API 通过 HTTP 调用。在 API 处理中,需要提供 HTTP 数据到规则和 PhantomJS 的转换。从而将 HTTP 数据演化为规则转换器
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子进程结合起来的服务处理

