
chrome网页视频抓取
chrome网页视频抓取(一下后大所开发环境lKaliLinuxAPI寻找ampamp)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-09-29 15:14
小编将与大家分享如何使用Python网络爬虫捕捉视频。我希望你读了这篇文章后会收获很多。让我们一起讨论吧
准备:
彩色浏览器
利维姆
Lpython3开发环境
lKali Linux
API find&;amp;amp;提取
1、我们通过F12打开开发者模式
2、再次检查headers属性
3、再看一看请求URL属性值
代码实现
编写脚本并使用爬虫下载剪辑
##导入的两个模块,其中requests模块需要自行下载
from multiprocessing import Pool
import requests
##定义一个涵数
def demo(i):
##定义了一个url,后面%3d就是截取后面三位给他加0,以防止i的参数是1的时候参数对不上号,所以是1的时候就变成了001
url="https://vip.okokbo.com/2018011 ... B%25i
##定义了请求头信息
headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36"}
##构建自定义请求对象
req=requests.get(url,headers=headers)
##将文件保存在当前目录的mp4文件中,名字以url后十位数起名
with open('./mp4/ {}'.format(url[-10:]), 'wb') as f:
f.write(req.content)
##程序代码的入口
if __name__=='__main__':
##定义一个进程池,可以同时执行二十个任务,不然一个一个下载太慢
pool = Pool(20)
##执行任务的代码
for i in range(100):
pool.apply_async(demo, (i,))
pool.close()
pool.join()
复制电影存储路径
用于进入windows命令行模式并粘贴地址
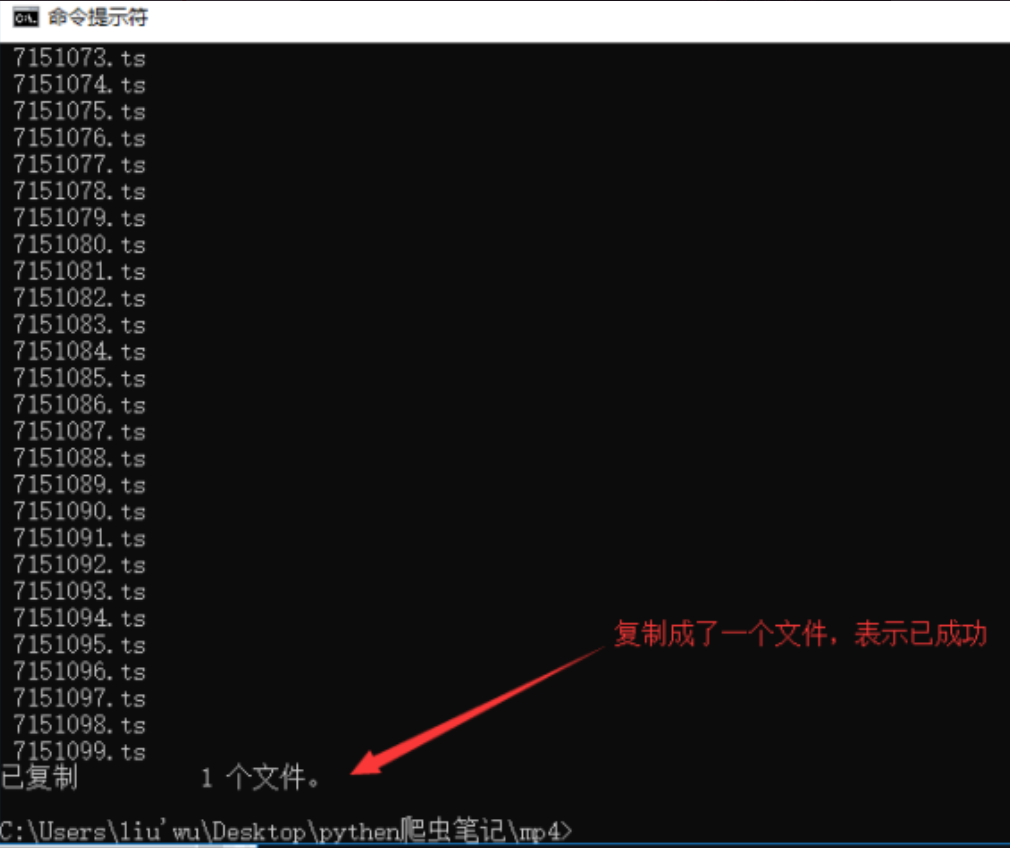
复制以*结尾的所有文件。将此目录中的Ts合并到一个文件中
合并
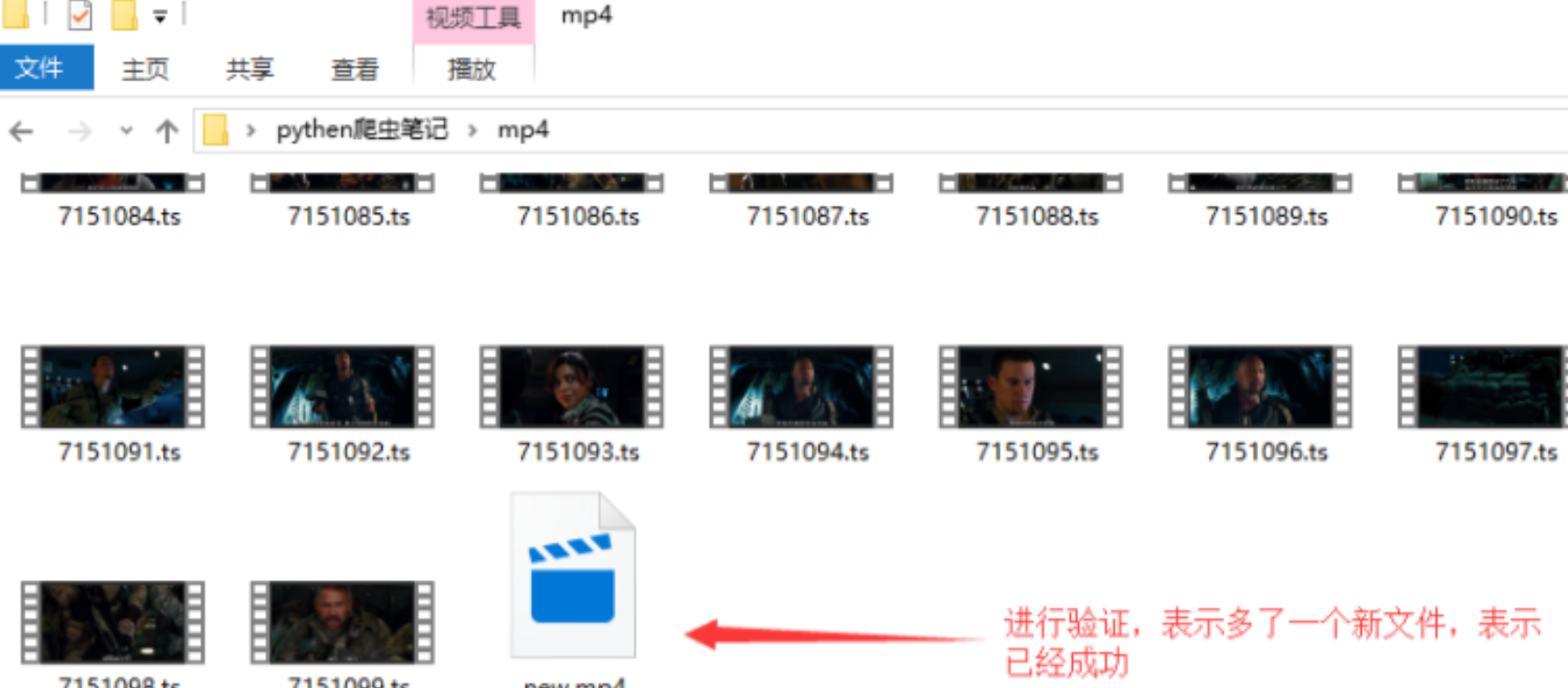
核实
读完这篇文章,我相信您对如何使用Python web crawler捕获视频有了一定的了解。如果您想了解更多,欢迎关注益苏云行业信息频道。谢谢你的阅读 查看全部
chrome网页视频抓取(一下后大所开发环境lKaliLinuxAPI寻找ampamp)
小编将与大家分享如何使用Python网络爬虫捕捉视频。我希望你读了这篇文章后会收获很多。让我们一起讨论吧
准备:
彩色浏览器
利维姆
Lpython3开发环境
lKali Linux
API find&;amp;amp;提取
1、我们通过F12打开开发者模式
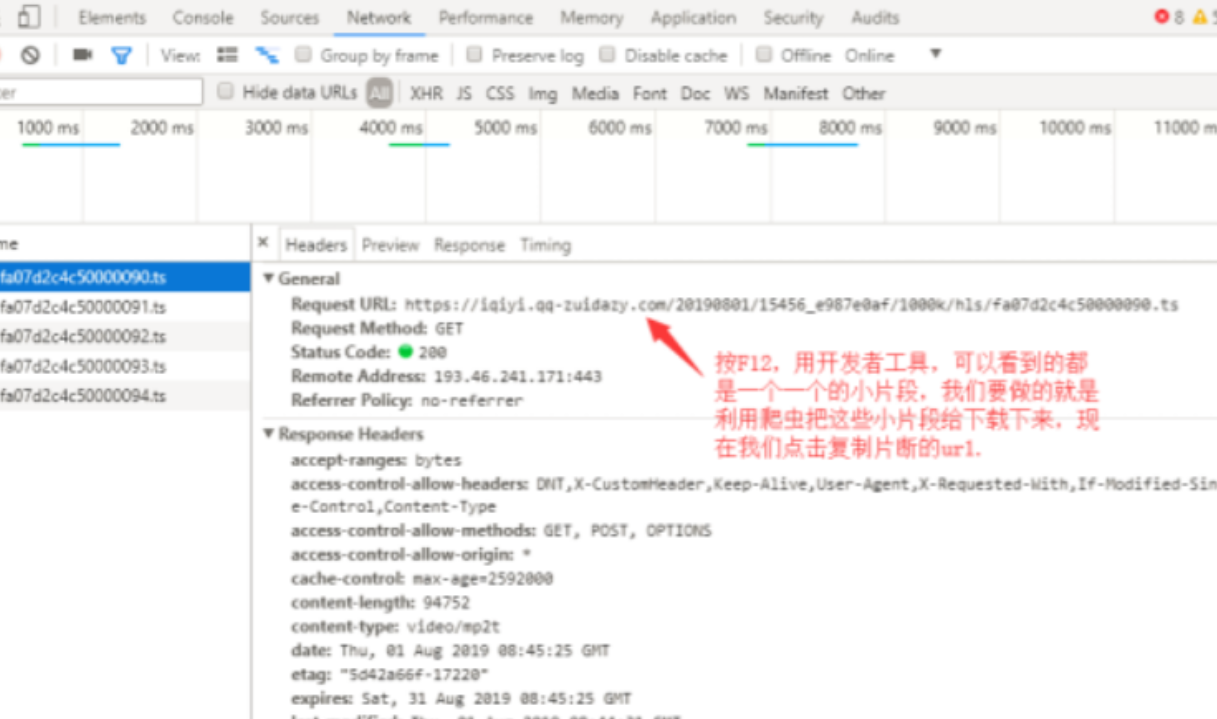
2、再次检查headers属性
3、再看一看请求URL属性值
代码实现
编写脚本并使用爬虫下载剪辑
##导入的两个模块,其中requests模块需要自行下载
from multiprocessing import Pool
import requests
##定义一个涵数
def demo(i):
##定义了一个url,后面%3d就是截取后面三位给他加0,以防止i的参数是1的时候参数对不上号,所以是1的时候就变成了001
url="https://vip.okokbo.com/2018011 ... B%25i
##定义了请求头信息
headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36"}
##构建自定义请求对象
req=requests.get(url,headers=headers)
##将文件保存在当前目录的mp4文件中,名字以url后十位数起名
with open('./mp4/ {}'.format(url[-10:]), 'wb') as f:
f.write(req.content)
##程序代码的入口
if __name__=='__main__':
##定义一个进程池,可以同时执行二十个任务,不然一个一个下载太慢
pool = Pool(20)
##执行任务的代码
for i in range(100):
pool.apply_async(demo, (i,))
pool.close()
pool.join()
复制电影存储路径
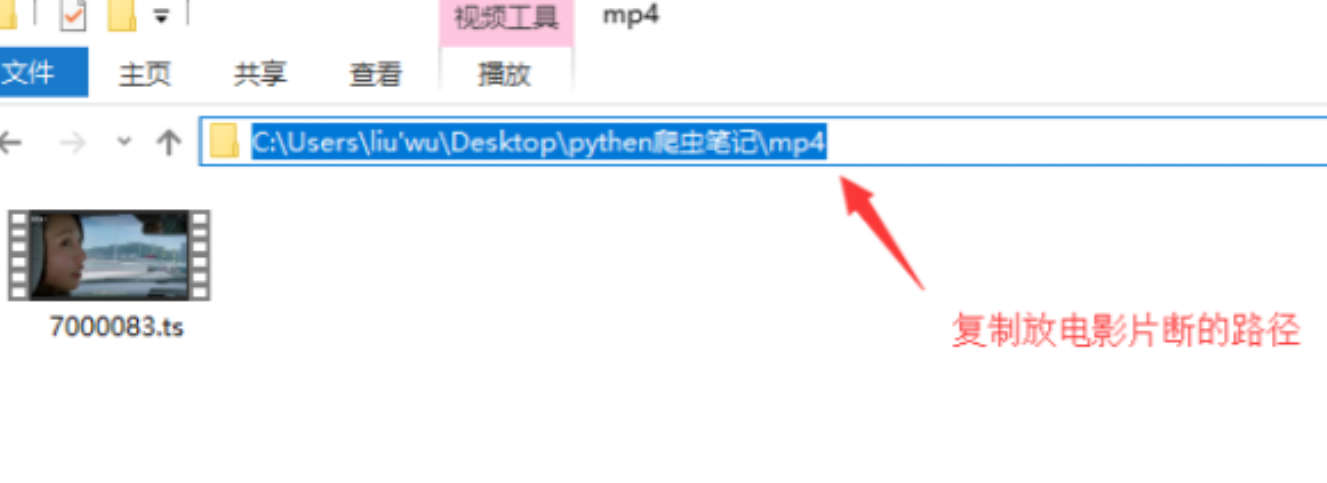
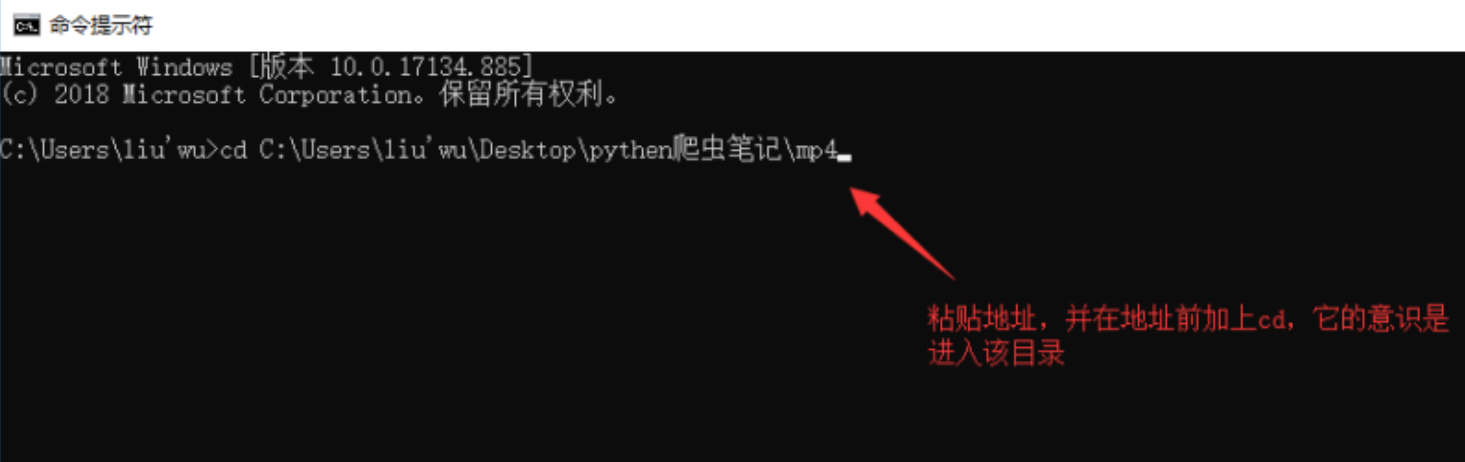
用于进入windows命令行模式并粘贴地址
复制以*结尾的所有文件。将此目录中的Ts合并到一个文件中
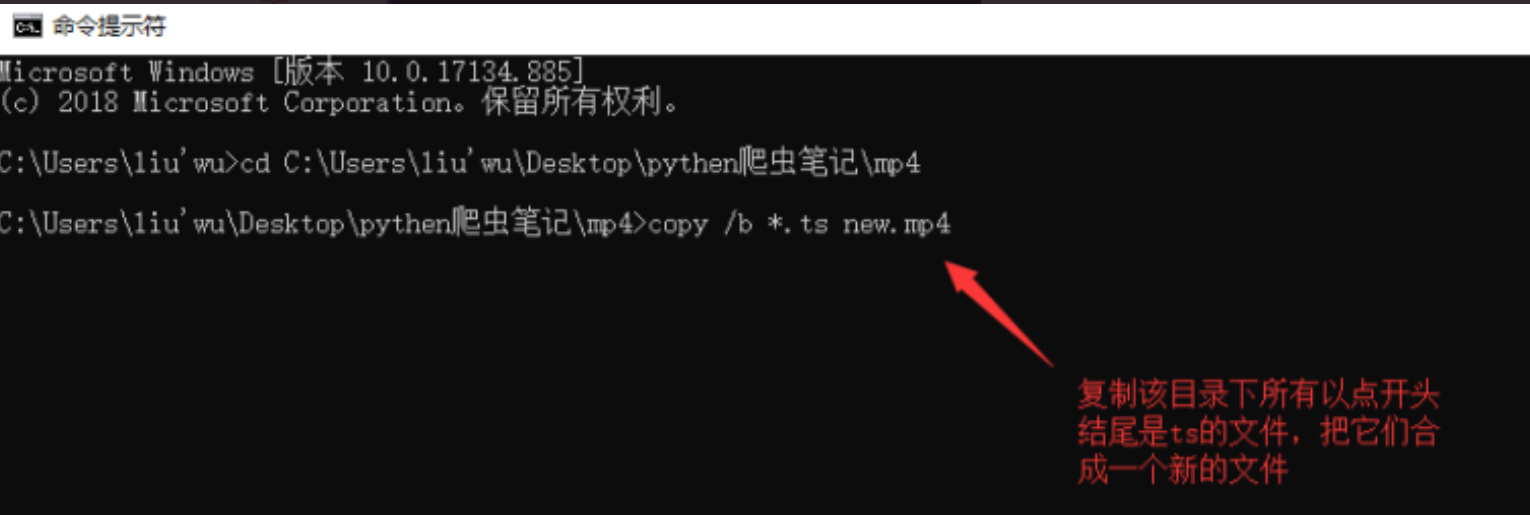
合并
核实
读完这篇文章,我相信您对如何使用Python web crawler捕获视频有了一定的了解。如果您想了解更多,欢迎关注益苏云行业信息频道。谢谢你的阅读
chrome网页视频抓取( 基于python写的一个爬虫程序--实现简单的网页图片下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-26 15:08
基于python写的一个爬虫程序--实现简单的网页图片下载)
网页图片抓取的python爬虫方法
更新时间:2018-07-16 17:03:01 作者:JentZhang
最近在学习python的东西。今天给大家分享一个基于python的爬虫程序,可以实现简单的网页图片下载。具体的示例代码可以参考这篇文章。
一、简介
这段时间我一直在学习Python。我听说过 Python 爬虫有多强大。我现在才在这里学习。跟着小乌龟的Python视频写了一个爬虫程序,可以实现简单的网页图片下载。
二、代码
__author__ = "JentZhang"
import urllib.request
import os
import random
import re
def url_open(url):
'''
打开网页
:param url:
:return:
'''
req = urllib.request.Request(url)
req.add_header('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36')
# 应用代理
'''
proxyies = ["111.155.116.237:8123","101.236.23.202:8866","122.114.31.177:808"]
proxy = random.choice(proxyies)
proxy_support = urllib.request.ProxyHandler({"http": proxy})
opener = urllib.request.build_opener(proxy_support)
urllib.request.install_opener(opener)
'''
response = urllib.request.urlopen(url)
html = response.read()
return html
def save_img(folder, img_addrs):
'''
保存图片
:param folder: 要保存的文件夹
:param img_addrs: 图片地址(列表)
:return:
'''
# 创建文件夹用来存放图片
if not os.path.exists(folder):
os.mkdir(folder)
os.chdir(folder)
for each in img_addrs:
filename = each.split('/')[-1]
try:
with open(filename, 'wb') as f:
img = url_open("http:" + each)
f.write(img)
except urllib.error.HTTPError as e:
# print(e.reason)
pass
print('完毕!')
def find_imgs(url):
'''
获取全部的图片链接
:param url: 连接地址
:return: 图片地址的列表
'''
html = url_open(url).decode("utf-8")
img_addrs = re.findall(r'src="(.+?\.gif)', html)
return img_addrs
def get_page(url):
'''
获取当前一共有多少页的图片
:param url: 网页地址
:return:
'''
html = url_open(url).decode('utf-8')
a = html.find("current-comment-page") + 23
b = html.find("]", a)
return html[a:b]
def download_mm(url="http://jandan.net/ooxx/", folder="OOXX", pages=1):
'''
主程序(下载图片)
:param folder:默认存放的文件夹
:param pages: 下载的页数
:return:
'''
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = url + "page-" + str(page_num) + "#comments"
img_addrs = find_imgs(page_url)
save_img(folder, img_addrs)
if __name__ == "__main__":
download_mm()
三、总结
因为代码中访问的URL已经使用了反爬虫算法。所以爬不出来我想要的图片,所以,就做个爬虫的笔记吧。仅供学习参考【捂脸】。. . .
最后:我把jpg格式改成gif,还是可以爬到很烂的gif:
第一个是反爬虫机制的图片占位符,完全没有任何内容
总结
以上就是小编为大家介绍的Python爬虫抓取网页图片的方法。我希望它会对你有所帮助。如果有什么问题,请给我留言,小编会及时回复您。非常感谢您对脚本之家网站的支持! 查看全部
chrome网页视频抓取(
基于python写的一个爬虫程序--实现简单的网页图片下载)
网页图片抓取的python爬虫方法
更新时间:2018-07-16 17:03:01 作者:JentZhang
最近在学习python的东西。今天给大家分享一个基于python的爬虫程序,可以实现简单的网页图片下载。具体的示例代码可以参考这篇文章。
一、简介
这段时间我一直在学习Python。我听说过 Python 爬虫有多强大。我现在才在这里学习。跟着小乌龟的Python视频写了一个爬虫程序,可以实现简单的网页图片下载。
二、代码
__author__ = "JentZhang"
import urllib.request
import os
import random
import re
def url_open(url):
'''
打开网页
:param url:
:return:
'''
req = urllib.request.Request(url)
req.add_header('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36')
# 应用代理
'''
proxyies = ["111.155.116.237:8123","101.236.23.202:8866","122.114.31.177:808"]
proxy = random.choice(proxyies)
proxy_support = urllib.request.ProxyHandler({"http": proxy})
opener = urllib.request.build_opener(proxy_support)
urllib.request.install_opener(opener)
'''
response = urllib.request.urlopen(url)
html = response.read()
return html
def save_img(folder, img_addrs):
'''
保存图片
:param folder: 要保存的文件夹
:param img_addrs: 图片地址(列表)
:return:
'''
# 创建文件夹用来存放图片
if not os.path.exists(folder):
os.mkdir(folder)
os.chdir(folder)
for each in img_addrs:
filename = each.split('/')[-1]
try:
with open(filename, 'wb') as f:
img = url_open("http:" + each)
f.write(img)
except urllib.error.HTTPError as e:
# print(e.reason)
pass
print('完毕!')
def find_imgs(url):
'''
获取全部的图片链接
:param url: 连接地址
:return: 图片地址的列表
'''
html = url_open(url).decode("utf-8")
img_addrs = re.findall(r'src="(.+?\.gif)', html)
return img_addrs
def get_page(url):
'''
获取当前一共有多少页的图片
:param url: 网页地址
:return:
'''
html = url_open(url).decode('utf-8')
a = html.find("current-comment-page") + 23
b = html.find("]", a)
return html[a:b]
def download_mm(url="http://jandan.net/ooxx/", folder="OOXX", pages=1):
'''
主程序(下载图片)
:param folder:默认存放的文件夹
:param pages: 下载的页数
:return:
'''
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = url + "page-" + str(page_num) + "#comments"
img_addrs = find_imgs(page_url)
save_img(folder, img_addrs)
if __name__ == "__main__":
download_mm()
三、总结
因为代码中访问的URL已经使用了反爬虫算法。所以爬不出来我想要的图片,所以,就做个爬虫的笔记吧。仅供学习参考【捂脸】。. . .
最后:我把jpg格式改成gif,还是可以爬到很烂的gif:
第一个是反爬虫机制的图片占位符,完全没有任何内容
总结
以上就是小编为大家介绍的Python爬虫抓取网页图片的方法。我希望它会对你有所帮助。如果有什么问题,请给我留言,小编会及时回复您。非常感谢您对脚本之家网站的支持!
chrome网页视频抓取(chrome浏览器官网下载地址2020google浏览器20202020)
网站优化 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-09-25 10:05
很多时候,当我们想要搜索一些视频时,我们通常可以通过Chrome浏览器完成它们。搜索速度快,操作简单。但是,有些用户希望在Chrome浏览器中下载网络视频,那么如何在Chrome浏览器中下载网络视频呢?接下来,小编将告诉你如何从chrome下载网络视频
谷歌浏览器官方网站下载谷歌浏览器官方网站下载地址2020
作为一种流行且功能强大的网络搜索工具,谷歌浏览器2020的最新版本,加上各种实用的扩展,对Chrome浏览器本身的影响小于Firefox的扩展。同时,它可以满足人们对书签、浏览记录同步等的强烈需求,这也使得Chrome的浏览器市场占有率达到60%以上,基本立于不败之地。有需要的用户可以下载并安装
具体方法:
1、首先打开任何视频页面。这里,以一个小视频为例
2、按F12键或打开浏览器右上角的菜单按钮,以查找开发人员选项
3、单击网络,然后刷新页面。此时,您可以在review元素中看到每个元素的加载情况,在type下找到视频格式(如video/MP4),然后单击打开文件
4、单击标题并复制以下HTTP地址
5、在浏览器中打开页面
6、将网页另存为后,视频下载完成,然后可以打开并在本地播放
以上是从chrome下载网络视频的操作方法。有需要的用户可以按照小编的步骤操作。我希望它能对你有所帮助 查看全部
chrome网页视频抓取(chrome浏览器官网下载地址2020google浏览器20202020)
很多时候,当我们想要搜索一些视频时,我们通常可以通过Chrome浏览器完成它们。搜索速度快,操作简单。但是,有些用户希望在Chrome浏览器中下载网络视频,那么如何在Chrome浏览器中下载网络视频呢?接下来,小编将告诉你如何从chrome下载网络视频

谷歌浏览器官方网站下载谷歌浏览器官方网站下载地址2020
作为一种流行且功能强大的网络搜索工具,谷歌浏览器2020的最新版本,加上各种实用的扩展,对Chrome浏览器本身的影响小于Firefox的扩展。同时,它可以满足人们对书签、浏览记录同步等的强烈需求,这也使得Chrome的浏览器市场占有率达到60%以上,基本立于不败之地。有需要的用户可以下载并安装
具体方法:
1、首先打开任何视频页面。这里,以一个小视频为例

2、按F12键或打开浏览器右上角的菜单按钮,以查找开发人员选项

3、单击网络,然后刷新页面。此时,您可以在review元素中看到每个元素的加载情况,在type下找到视频格式(如video/MP4),然后单击打开文件

4、单击标题并复制以下HTTP地址

5、在浏览器中打开页面

6、将网页另存为后,视频下载完成,然后可以打开并在本地播放


以上是从chrome下载网络视频的操作方法。有需要的用户可以按照小编的步骤操作。我希望它能对你有所帮助
chrome网页视频抓取(VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器缓存)
网站优化 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-09-23 04:13
我们有一个浏览器缓存我们上网时,有时我们要下载视频,不需要查找种子和地址,使用VideoCacheview下载视频在浏览器下载下载,这非常方便。
VideoCacheview根据基于Mozilla的Web浏览器(包括Firefox)自动扫描Internet Explorer和整个缓存,以查找当前存储在那里的所有视频文件。它允许您轻松复制缓存视频文件或其他目录以在将来播放和观看。如果您有与FLV文件关联的视频播放器,则还可以在缓存中播放视频文件。
VideoCacheview是绿色软件,您无需安装DLL链接库,只需执行VideoCacheview.exe文件。运行视频库之后,它会自动扫描IE或Mozilla浏览器的缓存目录,等待5-30秒扫描后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口的视频文件列表后,根据视频文件是否保存在本地缓存中,您可以选择以下不同意见:
如果视频文件存在于缓存中,则可以选择“播放所选文件”,“将所选文件复制到”等;
如果视频文件未存储在缓存中,则可以选择“在浏览器中的打开下载URL”,“复制下载URL”等。 查看全部
chrome网页视频抓取(VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器缓存)
我们有一个浏览器缓存我们上网时,有时我们要下载视频,不需要查找种子和地址,使用VideoCacheview下载视频在浏览器下载下载,这非常方便。
VideoCacheview根据基于Mozilla的Web浏览器(包括Firefox)自动扫描Internet Explorer和整个缓存,以查找当前存储在那里的所有视频文件。它允许您轻松复制缓存视频文件或其他目录以在将来播放和观看。如果您有与FLV文件关联的视频播放器,则还可以在缓存中播放视频文件。
VideoCacheview是绿色软件,您无需安装DLL链接库,只需执行VideoCacheview.exe文件。运行视频库之后,它会自动扫描IE或Mozilla浏览器的缓存目录,等待5-30秒扫描后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口的视频文件列表后,根据视频文件是否保存在本地缓存中,您可以选择以下不同意见:
如果视频文件存在于缓存中,则可以选择“播放所选文件”,“将所选文件复制到”等;
如果视频文件未存储在缓存中,则可以选择“在浏览器中的打开下载URL”,“复制下载URL”等。
chrome网页视频抓取(五款Music:识别网页正在播放的音乐观看视频视频 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-09-16 18:01
)
当我们浏览网页时,有没有遇到过这样的情况:漂亮的图片或视频不能通过右键直接保存,我们不知道什么叫好音乐?有些文本不支持直接复制。当你看到好看的字体时,你知道字体名吗?今天推出的五个chrome扩展可以帮助您一起解决这五个难点
优采云directory fatkun批量下载图片:批量下载网页图片
网页上有两种图片。一个可以右键单击直接保存到本地,另一个仅限于右键单击操作。第二,如果图片没有被多余的文本覆盖,我们可以直接保存屏幕截图。一旦文本被覆盖,我们就很难获得原创图片。此时,法特昆图片批量下载工具可以帮助您
Fatkun批量下载图片是用于批量下载网页图片的扩展工具。它将显示当前页面或所有打开页面上的所有图片元素,并在图片下方显示其分辨率,以便于过滤分辨率较小的图片。接下来,您可以选择下载一些图片或全部图片。一些图片也可以直接拖动和下载,省去了右键单击的步骤
此外,fatkun还具有大图像分析功能。对于一些常见的网站,如微博、空间、天猫,即使网站目前只有缩略图,您也可以通过关键词替换找到原创图像链接。Fatkun的智能脚本可以智能地过滤出用户想要的图片
视频下载专业版:自动捕获网络视频
与图片相比,视频更难下载,尤其是一些网页中嵌入的视频或微博上的视频。视频下载器可用于轻松下载
以腾讯主页上的显示视频为例。此处,它显示在文本下方作为背景,不能通过右键单击保存。通过扩展,可以直接抓取到下载地址进行下载。同样,微博上的视频也可以保存
需要注意的是,在拍摄视频时,我们必须注意版权问题,即是否允许二次创作或发布到其他平台
AHA音乐:识别网页上播放的音乐
当你观看视频和听到美丽的BGM时,你可能会发出一个弹幕,问BGM是什么,但回答可能是“BGM爱自杀,再次请求支持”。此时,您可以在手机上打开音乐,但有一种更简单的方法可以让您在不离开浏览器的情况下直接知道歌曲名称,即使用AHA音乐分机
当网页播放声音时,单击展开以识别背景音乐,每个识别历史将自动保存。单击识别结果后面的YouTube图标,打开相应歌曲的YouTube视频。然而,链接到Youtube似乎毫无用处。如果你可以链接到网易云音乐或音乐,它可能更实用
Copyfish:图像文本的OCR识别
网页上的文本通常可以复制,但也有一些特殊情况。例如,文本有一个超链接,该超链接只能单击到链接中而不能被选择,或者设置为未选择,或者图片中的某些文本不能直接复制。此时,OCR字符识别可以解决上述问题
Copyfish是网页字符识别的扩展。一般来说,只要文本背景不太复杂,就可以正确识别。例如,“爱凡纳,让未来触手可及”,其中“爱凡纳”的背景太复杂,无法识别为文本,后续文本被正确识别。识别的文本可以复制或翻译成谷歌翻译
此外,copyfish还提供pro和pro+版本,价格为19.$95/月和29.$95/月。增加了自动OCR语言识别和pro vision OCR,即更好的OCR识别技术,甚至可以很好地识别笔迹。如果您想识别本地图片或PDF文件,请在chrome中打开它们并使用copyfish进行识别
Fontface忍者:识别网页字体和段落格式
对于那些从事设计的人来说,他们总是希望从好作品中获得灵感。字体是设计的重要组成部分。此时,当你看到一个好看的字体时,你总是想知道字体名称。Fontface Ninja不仅可以列出当前页面中的所有字体,还可以链接到其字体网站以显示特定信息,包括是否免费用于商业用途、购买价格等
单独选择文本段落还可以显示单独的字体名称和段落信息,包括字体大小、行距、字距和文本颜色编号。对于从事文章排版的人来说,有一定的参考意义。例如,如果你看到一个微信推送,觉得排版很好,你可以用浏览器打开它,查看它的字体大小、行距等信息
通过浏览器的扩展,我们可以看到网页中更深层次的信息,就像使用显微镜挖掘网页中的所有元素一样。最后,值得一提的是,当我们使用这些材料时,我们必须注意它们的版权信息。某些图片、视频或字体不能免费使用。否则,有朝一日我们可能会收到视觉中国或方正字体的律师来信
查看全部
chrome网页视频抓取(五款Music:识别网页正在播放的音乐观看视频视频
)
当我们浏览网页时,有没有遇到过这样的情况:漂亮的图片或视频不能通过右键直接保存,我们不知道什么叫好音乐?有些文本不支持直接复制。当你看到好看的字体时,你知道字体名吗?今天推出的五个chrome扩展可以帮助您一起解决这五个难点
优采云directory fatkun批量下载图片:批量下载网页图片
网页上有两种图片。一个可以右键单击直接保存到本地,另一个仅限于右键单击操作。第二,如果图片没有被多余的文本覆盖,我们可以直接保存屏幕截图。一旦文本被覆盖,我们就很难获得原创图片。此时,法特昆图片批量下载工具可以帮助您
 https://s3.ifanr.com/wp-conten ... 3.jpg 360w, https://s3.ifanr.com/wp-conten ... 9.jpg 768w" />
https://s3.ifanr.com/wp-conten ... 3.jpg 360w, https://s3.ifanr.com/wp-conten ... 9.jpg 768w" />Fatkun批量下载图片是用于批量下载网页图片的扩展工具。它将显示当前页面或所有打开页面上的所有图片元素,并在图片下方显示其分辨率,以便于过滤分辨率较小的图片。接下来,您可以选择下载一些图片或全部图片。一些图片也可以直接拖动和下载,省去了右键单击的步骤
 https://s3.ifanr.com/wp-conten ... 5.jpg 360w, https://s3.ifanr.com/wp-conten ... 0.jpg 768w" />
https://s3.ifanr.com/wp-conten ... 5.jpg 360w, https://s3.ifanr.com/wp-conten ... 0.jpg 768w" />此外,fatkun还具有大图像分析功能。对于一些常见的网站,如微博、空间、天猫,即使网站目前只有缩略图,您也可以通过关键词替换找到原创图像链接。Fatkun的智能脚本可以智能地过滤出用户想要的图片
视频下载专业版:自动捕获网络视频
与图片相比,视频更难下载,尤其是一些网页中嵌入的视频或微博上的视频。视频下载器可用于轻松下载
 https://s3.ifanr.com/wp-conten ... 5.jpg 360w, https://s3.ifanr.com/wp-conten ... 0.jpg 768w" />
https://s3.ifanr.com/wp-conten ... 5.jpg 360w, https://s3.ifanr.com/wp-conten ... 0.jpg 768w" />以腾讯主页上的显示视频为例。此处,它显示在文本下方作为背景,不能通过右键单击保存。通过扩展,可以直接抓取到下载地址进行下载。同样,微博上的视频也可以保存
需要注意的是,在拍摄视频时,我们必须注意版权问题,即是否允许二次创作或发布到其他平台
AHA音乐:识别网页上播放的音乐
当你观看视频和听到美丽的BGM时,你可能会发出一个弹幕,问BGM是什么,但回答可能是“BGM爱自杀,再次请求支持”。此时,您可以在手机上打开音乐,但有一种更简单的方法可以让您在不离开浏览器的情况下直接知道歌曲名称,即使用AHA音乐分机
 https://s3.ifanr.com/wp-conten ... 5.jpg 360w, https://s3.ifanr.com/wp-conten ... 0.jpg 768w" />
https://s3.ifanr.com/wp-conten ... 5.jpg 360w, https://s3.ifanr.com/wp-conten ... 0.jpg 768w" />当网页播放声音时,单击展开以识别背景音乐,每个识别历史将自动保存。单击识别结果后面的YouTube图标,打开相应歌曲的YouTube视频。然而,链接到Youtube似乎毫无用处。如果你可以链接到网易云音乐或音乐,它可能更实用
Copyfish:图像文本的OCR识别
网页上的文本通常可以复制,但也有一些特殊情况。例如,文本有一个超链接,该超链接只能单击到链接中而不能被选择,或者设置为未选择,或者图片中的某些文本不能直接复制。此时,OCR字符识别可以解决上述问题
 https://s3.ifanr.com/wp-conten ... 5.jpg 360w, https://s3.ifanr.com/wp-conten ... 0.jpg 768w" />
https://s3.ifanr.com/wp-conten ... 5.jpg 360w, https://s3.ifanr.com/wp-conten ... 0.jpg 768w" />Copyfish是网页字符识别的扩展。一般来说,只要文本背景不太复杂,就可以正确识别。例如,“爱凡纳,让未来触手可及”,其中“爱凡纳”的背景太复杂,无法识别为文本,后续文本被正确识别。识别的文本可以复制或翻译成谷歌翻译
 https://s3.ifanr.com/wp-conten ... 8.jpg 360w, https://s3.ifanr.com/wp-conten ... 6.jpg 768w" />
https://s3.ifanr.com/wp-conten ... 8.jpg 360w, https://s3.ifanr.com/wp-conten ... 6.jpg 768w" />此外,copyfish还提供pro和pro+版本,价格为19.$95/月和29.$95/月。增加了自动OCR语言识别和pro vision OCR,即更好的OCR识别技术,甚至可以很好地识别笔迹。如果您想识别本地图片或PDF文件,请在chrome中打开它们并使用copyfish进行识别
Fontface忍者:识别网页字体和段落格式
对于那些从事设计的人来说,他们总是希望从好作品中获得灵感。字体是设计的重要组成部分。此时,当你看到一个好看的字体时,你总是想知道字体名称。Fontface Ninja不仅可以列出当前页面中的所有字体,还可以链接到其字体网站以显示特定信息,包括是否免费用于商业用途、购买价格等
 https://s3.ifanr.com/wp-conten ... 0.jpg 360w, https://s3.ifanr.com/wp-conten ... 3.jpg 768w" />
https://s3.ifanr.com/wp-conten ... 0.jpg 360w, https://s3.ifanr.com/wp-conten ... 3.jpg 768w" />单独选择文本段落还可以显示单独的字体名称和段落信息,包括字体大小、行距、字距和文本颜色编号。对于从事文章排版的人来说,有一定的参考意义。例如,如果你看到一个微信推送,觉得排版很好,你可以用浏览器打开它,查看它的字体大小、行距等信息
 https://s3.ifanr.com/wp-conten ... 0.jpg 360w, https://s3.ifanr.com/wp-conten ... 3.jpg 768w" />
https://s3.ifanr.com/wp-conten ... 0.jpg 360w, https://s3.ifanr.com/wp-conten ... 3.jpg 768w" />通过浏览器的扩展,我们可以看到网页中更深层次的信息,就像使用显微镜挖掘网页中的所有元素一样。最后,值得一提的是,当我们使用这些材料时,我们必须注意它们的版权信息。某些图片、视频或字体不能免费使用。否则,有朝一日我们可能会收到视觉中国或方正字体的律师来信
 https://s3.ifanr.com/wp-conten ... 5.png 360w, https://s3.ifanr.com/wp-conten ... 1.png 768w, https://s3.ifanr.com/wp-conten ... 1.png 1024w" />
https://s3.ifanr.com/wp-conten ... 5.png 360w, https://s3.ifanr.com/wp-conten ... 1.png 768w, https://s3.ifanr.com/wp-conten ... 1.png 1024w" /> chrome网页视频抓取(一下后大所开发环境lKaliLinuxAPI寻找ampamp)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-09-29 15:14
小编将与大家分享如何使用Python网络爬虫捕捉视频。我希望你读了这篇文章后会收获很多。让我们一起讨论吧
准备:
彩色浏览器
利维姆
Lpython3开发环境
lKali Linux
API find&;amp;amp;提取
1、我们通过F12打开开发者模式
2、再次检查headers属性
3、再看一看请求URL属性值
代码实现
编写脚本并使用爬虫下载剪辑
##导入的两个模块,其中requests模块需要自行下载
from multiprocessing import Pool
import requests
##定义一个涵数
def demo(i):
##定义了一个url,后面%3d就是截取后面三位给他加0,以防止i的参数是1的时候参数对不上号,所以是1的时候就变成了001
url="https://vip.okokbo.com/2018011 ... B%25i
##定义了请求头信息
headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36"}
##构建自定义请求对象
req=requests.get(url,headers=headers)
##将文件保存在当前目录的mp4文件中,名字以url后十位数起名
with open('./mp4/ {}'.format(url[-10:]), 'wb') as f:
f.write(req.content)
##程序代码的入口
if __name__=='__main__':
##定义一个进程池,可以同时执行二十个任务,不然一个一个下载太慢
pool = Pool(20)
##执行任务的代码
for i in range(100):
pool.apply_async(demo, (i,))
pool.close()
pool.join()
复制电影存储路径
用于进入windows命令行模式并粘贴地址
复制以*结尾的所有文件。将此目录中的Ts合并到一个文件中
合并
核实
读完这篇文章,我相信您对如何使用Python web crawler捕获视频有了一定的了解。如果您想了解更多,欢迎关注益苏云行业信息频道。谢谢你的阅读 查看全部
chrome网页视频抓取(一下后大所开发环境lKaliLinuxAPI寻找ampamp)
小编将与大家分享如何使用Python网络爬虫捕捉视频。我希望你读了这篇文章后会收获很多。让我们一起讨论吧
准备:
彩色浏览器
利维姆
Lpython3开发环境
lKali Linux
API find&;amp;amp;提取
1、我们通过F12打开开发者模式
2、再次检查headers属性
3、再看一看请求URL属性值
代码实现
编写脚本并使用爬虫下载剪辑
##导入的两个模块,其中requests模块需要自行下载
from multiprocessing import Pool
import requests
##定义一个涵数
def demo(i):
##定义了一个url,后面%3d就是截取后面三位给他加0,以防止i的参数是1的时候参数对不上号,所以是1的时候就变成了001
url="https://vip.okokbo.com/2018011 ... B%25i
##定义了请求头信息
headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36"}
##构建自定义请求对象
req=requests.get(url,headers=headers)
##将文件保存在当前目录的mp4文件中,名字以url后十位数起名
with open('./mp4/ {}'.format(url[-10:]), 'wb') as f:
f.write(req.content)
##程序代码的入口
if __name__=='__main__':
##定义一个进程池,可以同时执行二十个任务,不然一个一个下载太慢
pool = Pool(20)
##执行任务的代码
for i in range(100):
pool.apply_async(demo, (i,))
pool.close()
pool.join()
复制电影存储路径
用于进入windows命令行模式并粘贴地址
复制以*结尾的所有文件。将此目录中的Ts合并到一个文件中
合并
核实
读完这篇文章,我相信您对如何使用Python web crawler捕获视频有了一定的了解。如果您想了解更多,欢迎关注益苏云行业信息频道。谢谢你的阅读
chrome网页视频抓取( 基于python写的一个爬虫程序--实现简单的网页图片下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-26 15:08
基于python写的一个爬虫程序--实现简单的网页图片下载)
网页图片抓取的python爬虫方法
更新时间:2018-07-16 17:03:01 作者:JentZhang
最近在学习python的东西。今天给大家分享一个基于python的爬虫程序,可以实现简单的网页图片下载。具体的示例代码可以参考这篇文章。
一、简介
这段时间我一直在学习Python。我听说过 Python 爬虫有多强大。我现在才在这里学习。跟着小乌龟的Python视频写了一个爬虫程序,可以实现简单的网页图片下载。
二、代码
__author__ = "JentZhang"
import urllib.request
import os
import random
import re
def url_open(url):
'''
打开网页
:param url:
:return:
'''
req = urllib.request.Request(url)
req.add_header('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36')
# 应用代理
'''
proxyies = ["111.155.116.237:8123","101.236.23.202:8866","122.114.31.177:808"]
proxy = random.choice(proxyies)
proxy_support = urllib.request.ProxyHandler({"http": proxy})
opener = urllib.request.build_opener(proxy_support)
urllib.request.install_opener(opener)
'''
response = urllib.request.urlopen(url)
html = response.read()
return html
def save_img(folder, img_addrs):
'''
保存图片
:param folder: 要保存的文件夹
:param img_addrs: 图片地址(列表)
:return:
'''
# 创建文件夹用来存放图片
if not os.path.exists(folder):
os.mkdir(folder)
os.chdir(folder)
for each in img_addrs:
filename = each.split('/')[-1]
try:
with open(filename, 'wb') as f:
img = url_open("http:" + each)
f.write(img)
except urllib.error.HTTPError as e:
# print(e.reason)
pass
print('完毕!')
def find_imgs(url):
'''
获取全部的图片链接
:param url: 连接地址
:return: 图片地址的列表
'''
html = url_open(url).decode("utf-8")
img_addrs = re.findall(r'src="(.+?\.gif)', html)
return img_addrs
def get_page(url):
'''
获取当前一共有多少页的图片
:param url: 网页地址
:return:
'''
html = url_open(url).decode('utf-8')
a = html.find("current-comment-page") + 23
b = html.find("]", a)
return html[a:b]
def download_mm(url="http://jandan.net/ooxx/", folder="OOXX", pages=1):
'''
主程序(下载图片)
:param folder:默认存放的文件夹
:param pages: 下载的页数
:return:
'''
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = url + "page-" + str(page_num) + "#comments"
img_addrs = find_imgs(page_url)
save_img(folder, img_addrs)
if __name__ == "__main__":
download_mm()
三、总结
因为代码中访问的URL已经使用了反爬虫算法。所以爬不出来我想要的图片,所以,就做个爬虫的笔记吧。仅供学习参考【捂脸】。. . .
最后:我把jpg格式改成gif,还是可以爬到很烂的gif:
第一个是反爬虫机制的图片占位符,完全没有任何内容
总结
以上就是小编为大家介绍的Python爬虫抓取网页图片的方法。我希望它会对你有所帮助。如果有什么问题,请给我留言,小编会及时回复您。非常感谢您对脚本之家网站的支持! 查看全部
chrome网页视频抓取(
基于python写的一个爬虫程序--实现简单的网页图片下载)
网页图片抓取的python爬虫方法
更新时间:2018-07-16 17:03:01 作者:JentZhang
最近在学习python的东西。今天给大家分享一个基于python的爬虫程序,可以实现简单的网页图片下载。具体的示例代码可以参考这篇文章。
一、简介
这段时间我一直在学习Python。我听说过 Python 爬虫有多强大。我现在才在这里学习。跟着小乌龟的Python视频写了一个爬虫程序,可以实现简单的网页图片下载。
二、代码
__author__ = "JentZhang"
import urllib.request
import os
import random
import re
def url_open(url):
'''
打开网页
:param url:
:return:
'''
req = urllib.request.Request(url)
req.add_header('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36')
# 应用代理
'''
proxyies = ["111.155.116.237:8123","101.236.23.202:8866","122.114.31.177:808"]
proxy = random.choice(proxyies)
proxy_support = urllib.request.ProxyHandler({"http": proxy})
opener = urllib.request.build_opener(proxy_support)
urllib.request.install_opener(opener)
'''
response = urllib.request.urlopen(url)
html = response.read()
return html
def save_img(folder, img_addrs):
'''
保存图片
:param folder: 要保存的文件夹
:param img_addrs: 图片地址(列表)
:return:
'''
# 创建文件夹用来存放图片
if not os.path.exists(folder):
os.mkdir(folder)
os.chdir(folder)
for each in img_addrs:
filename = each.split('/')[-1]
try:
with open(filename, 'wb') as f:
img = url_open("http:" + each)
f.write(img)
except urllib.error.HTTPError as e:
# print(e.reason)
pass
print('完毕!')
def find_imgs(url):
'''
获取全部的图片链接
:param url: 连接地址
:return: 图片地址的列表
'''
html = url_open(url).decode("utf-8")
img_addrs = re.findall(r'src="(.+?\.gif)', html)
return img_addrs
def get_page(url):
'''
获取当前一共有多少页的图片
:param url: 网页地址
:return:
'''
html = url_open(url).decode('utf-8')
a = html.find("current-comment-page") + 23
b = html.find("]", a)
return html[a:b]
def download_mm(url="http://jandan.net/ooxx/", folder="OOXX", pages=1):
'''
主程序(下载图片)
:param folder:默认存放的文件夹
:param pages: 下载的页数
:return:
'''
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = url + "page-" + str(page_num) + "#comments"
img_addrs = find_imgs(page_url)
save_img(folder, img_addrs)
if __name__ == "__main__":
download_mm()
三、总结
因为代码中访问的URL已经使用了反爬虫算法。所以爬不出来我想要的图片,所以,就做个爬虫的笔记吧。仅供学习参考【捂脸】。. . .
最后:我把jpg格式改成gif,还是可以爬到很烂的gif:
第一个是反爬虫机制的图片占位符,完全没有任何内容
总结
以上就是小编为大家介绍的Python爬虫抓取网页图片的方法。我希望它会对你有所帮助。如果有什么问题,请给我留言,小编会及时回复您。非常感谢您对脚本之家网站的支持!
chrome网页视频抓取(chrome浏览器官网下载地址2020google浏览器20202020)
网站优化 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-09-25 10:05
很多时候,当我们想要搜索一些视频时,我们通常可以通过Chrome浏览器完成它们。搜索速度快,操作简单。但是,有些用户希望在Chrome浏览器中下载网络视频,那么如何在Chrome浏览器中下载网络视频呢?接下来,小编将告诉你如何从chrome下载网络视频
谷歌浏览器官方网站下载谷歌浏览器官方网站下载地址2020
作为一种流行且功能强大的网络搜索工具,谷歌浏览器2020的最新版本,加上各种实用的扩展,对Chrome浏览器本身的影响小于Firefox的扩展。同时,它可以满足人们对书签、浏览记录同步等的强烈需求,这也使得Chrome的浏览器市场占有率达到60%以上,基本立于不败之地。有需要的用户可以下载并安装
具体方法:
1、首先打开任何视频页面。这里,以一个小视频为例
2、按F12键或打开浏览器右上角的菜单按钮,以查找开发人员选项
3、单击网络,然后刷新页面。此时,您可以在review元素中看到每个元素的加载情况,在type下找到视频格式(如video/MP4),然后单击打开文件
4、单击标题并复制以下HTTP地址
5、在浏览器中打开页面
6、将网页另存为后,视频下载完成,然后可以打开并在本地播放
以上是从chrome下载网络视频的操作方法。有需要的用户可以按照小编的步骤操作。我希望它能对你有所帮助 查看全部
chrome网页视频抓取(chrome浏览器官网下载地址2020google浏览器20202020)
很多时候,当我们想要搜索一些视频时,我们通常可以通过Chrome浏览器完成它们。搜索速度快,操作简单。但是,有些用户希望在Chrome浏览器中下载网络视频,那么如何在Chrome浏览器中下载网络视频呢?接下来,小编将告诉你如何从chrome下载网络视频
谷歌浏览器官方网站下载谷歌浏览器官方网站下载地址2020
作为一种流行且功能强大的网络搜索工具,谷歌浏览器2020的最新版本,加上各种实用的扩展,对Chrome浏览器本身的影响小于Firefox的扩展。同时,它可以满足人们对书签、浏览记录同步等的强烈需求,这也使得Chrome的浏览器市场占有率达到60%以上,基本立于不败之地。有需要的用户可以下载并安装
具体方法:
1、首先打开任何视频页面。这里,以一个小视频为例
2、按F12键或打开浏览器右上角的菜单按钮,以查找开发人员选项
3、单击网络,然后刷新页面。此时,您可以在review元素中看到每个元素的加载情况,在type下找到视频格式(如video/MP4),然后单击打开文件
4、单击标题并复制以下HTTP地址
5、在浏览器中打开页面
6、将网页另存为后,视频下载完成,然后可以打开并在本地播放
以上是从chrome下载网络视频的操作方法。有需要的用户可以按照小编的步骤操作。我希望它能对你有所帮助
chrome网页视频抓取(VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器缓存)
网站优化 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-09-23 04:13
我们有一个浏览器缓存我们上网时,有时我们要下载视频,不需要查找种子和地址,使用VideoCacheview下载视频在浏览器下载下载,这非常方便。
VideoCacheview根据基于Mozilla的Web浏览器(包括Firefox)自动扫描Internet Explorer和整个缓存,以查找当前存储在那里的所有视频文件。它允许您轻松复制缓存视频文件或其他目录以在将来播放和观看。如果您有与FLV文件关联的视频播放器,则还可以在缓存中播放视频文件。
VideoCacheview是绿色软件,您无需安装DLL链接库,只需执行VideoCacheview.exe文件。运行视频库之后,它会自动扫描IE或Mozilla浏览器的缓存目录,等待5-30秒扫描后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口的视频文件列表后,根据视频文件是否保存在本地缓存中,您可以选择以下不同意见:
如果视频文件存在于缓存中,则可以选择“播放所选文件”,“将所选文件复制到”等;
如果视频文件未存储在缓存中,则可以选择“在浏览器中的打开下载URL”,“复制下载URL”等。 查看全部
chrome网页视频抓取(VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器缓存)
我们有一个浏览器缓存我们上网时,有时我们要下载视频,不需要查找种子和地址,使用VideoCacheview下载视频在浏览器下载下载,这非常方便。
VideoCacheview根据基于Mozilla的Web浏览器(包括Firefox)自动扫描Internet Explorer和整个缓存,以查找当前存储在那里的所有视频文件。它允许您轻松复制缓存视频文件或其他目录以在将来播放和观看。如果您有与FLV文件关联的视频播放器,则还可以在缓存中播放视频文件。
VideoCacheview是绿色软件,您无需安装DLL链接库,只需执行VideoCacheview.exe文件。运行视频库之后,它会自动扫描IE或Mozilla浏览器的缓存目录,等待5-30秒扫描后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口的视频文件列表后,根据视频文件是否保存在本地缓存中,您可以选择以下不同意见:
如果视频文件存在于缓存中,则可以选择“播放所选文件”,“将所选文件复制到”等;
如果视频文件未存储在缓存中,则可以选择“在浏览器中的打开下载URL”,“复制下载URL”等。
chrome网页视频抓取(五款Music:识别网页正在播放的音乐观看视频视频 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-09-16 18:01
)
当我们浏览网页时,有没有遇到过这样的情况:漂亮的图片或视频不能通过右键直接保存,我们不知道什么叫好音乐?有些文本不支持直接复制。当你看到好看的字体时,你知道字体名吗?今天推出的五个chrome扩展可以帮助您一起解决这五个难点
优采云directory fatkun批量下载图片:批量下载网页图片
网页上有两种图片。一个可以右键单击直接保存到本地,另一个仅限于右键单击操作。第二,如果图片没有被多余的文本覆盖,我们可以直接保存屏幕截图。一旦文本被覆盖,我们就很难获得原创图片。此时,法特昆图片批量下载工具可以帮助您
Fatkun批量下载图片是用于批量下载网页图片的扩展工具。它将显示当前页面或所有打开页面上的所有图片元素,并在图片下方显示其分辨率,以便于过滤分辨率较小的图片。接下来,您可以选择下载一些图片或全部图片。一些图片也可以直接拖动和下载,省去了右键单击的步骤
此外,fatkun还具有大图像分析功能。对于一些常见的网站,如微博、空间、天猫,即使网站目前只有缩略图,您也可以通过关键词替换找到原创图像链接。Fatkun的智能脚本可以智能地过滤出用户想要的图片
视频下载专业版:自动捕获网络视频
与图片相比,视频更难下载,尤其是一些网页中嵌入的视频或微博上的视频。视频下载器可用于轻松下载
以腾讯主页上的显示视频为例。此处,它显示在文本下方作为背景,不能通过右键单击保存。通过扩展,可以直接抓取到下载地址进行下载。同样,微博上的视频也可以保存
需要注意的是,在拍摄视频时,我们必须注意版权问题,即是否允许二次创作或发布到其他平台
AHA音乐:识别网页上播放的音乐
当你观看视频和听到美丽的BGM时,你可能会发出一个弹幕,问BGM是什么,但回答可能是“BGM爱自杀,再次请求支持”。此时,您可以在手机上打开音乐,但有一种更简单的方法可以让您在不离开浏览器的情况下直接知道歌曲名称,即使用AHA音乐分机
当网页播放声音时,单击展开以识别背景音乐,每个识别历史将自动保存。单击识别结果后面的YouTube图标,打开相应歌曲的YouTube视频。然而,链接到Youtube似乎毫无用处。如果你可以链接到网易云音乐或音乐,它可能更实用
Copyfish:图像文本的OCR识别
网页上的文本通常可以复制,但也有一些特殊情况。例如,文本有一个超链接,该超链接只能单击到链接中而不能被选择,或者设置为未选择,或者图片中的某些文本不能直接复制。此时,OCR字符识别可以解决上述问题
Copyfish是网页字符识别的扩展。一般来说,只要文本背景不太复杂,就可以正确识别。例如,“爱凡纳,让未来触手可及”,其中“爱凡纳”的背景太复杂,无法识别为文本,后续文本被正确识别。识别的文本可以复制或翻译成谷歌翻译
此外,copyfish还提供pro和pro+版本,价格为19.$95/月和29.$95/月。增加了自动OCR语言识别和pro vision OCR,即更好的OCR识别技术,甚至可以很好地识别笔迹。如果您想识别本地图片或PDF文件,请在chrome中打开它们并使用copyfish进行识别
Fontface忍者:识别网页字体和段落格式
对于那些从事设计的人来说,他们总是希望从好作品中获得灵感。字体是设计的重要组成部分。此时,当你看到一个好看的字体时,你总是想知道字体名称。Fontface Ninja不仅可以列出当前页面中的所有字体,还可以链接到其字体网站以显示特定信息,包括是否免费用于商业用途、购买价格等
单独选择文本段落还可以显示单独的字体名称和段落信息,包括字体大小、行距、字距和文本颜色编号。对于从事文章排版的人来说,有一定的参考意义。例如,如果你看到一个微信推送,觉得排版很好,你可以用浏览器打开它,查看它的字体大小、行距等信息
通过浏览器的扩展,我们可以看到网页中更深层次的信息,就像使用显微镜挖掘网页中的所有元素一样。最后,值得一提的是,当我们使用这些材料时,我们必须注意它们的版权信息。某些图片、视频或字体不能免费使用。否则,有朝一日我们可能会收到视觉中国或方正字体的律师来信
查看全部
chrome网页视频抓取(五款Music:识别网页正在播放的音乐观看视频视频
)
当我们浏览网页时,有没有遇到过这样的情况:漂亮的图片或视频不能通过右键直接保存,我们不知道什么叫好音乐?有些文本不支持直接复制。当你看到好看的字体时,你知道字体名吗?今天推出的五个chrome扩展可以帮助您一起解决这五个难点
优采云directory fatkun批量下载图片:批量下载网页图片
网页上有两种图片。一个可以右键单击直接保存到本地,另一个仅限于右键单击操作。第二,如果图片没有被多余的文本覆盖,我们可以直接保存屏幕截图。一旦文本被覆盖,我们就很难获得原创图片。此时,法特昆图片批量下载工具可以帮助您
https://s3.ifanr.com/wp-conten ... 3.jpg 360w, https://s3.ifanr.com/wp-conten ... 9.jpg 768w" />Fatkun批量下载图片是用于批量下载网页图片的扩展工具。它将显示当前页面或所有打开页面上的所有图片元素,并在图片下方显示其分辨率,以便于过滤分辨率较小的图片。接下来,您可以选择下载一些图片或全部图片。一些图片也可以直接拖动和下载,省去了右键单击的步骤
https://s3.ifanr.com/wp-conten ... 5.jpg 360w, https://s3.ifanr.com/wp-conten ... 0.jpg 768w" />此外,fatkun还具有大图像分析功能。对于一些常见的网站,如微博、空间、天猫,即使网站目前只有缩略图,您也可以通过关键词替换找到原创图像链接。Fatkun的智能脚本可以智能地过滤出用户想要的图片
视频下载专业版:自动捕获网络视频
与图片相比,视频更难下载,尤其是一些网页中嵌入的视频或微博上的视频。视频下载器可用于轻松下载
https://s3.ifanr.com/wp-conten ... 5.jpg 360w, https://s3.ifanr.com/wp-conten ... 0.jpg 768w" />以腾讯主页上的显示视频为例。此处,它显示在文本下方作为背景,不能通过右键单击保存。通过扩展,可以直接抓取到下载地址进行下载。同样,微博上的视频也可以保存
需要注意的是,在拍摄视频时,我们必须注意版权问题,即是否允许二次创作或发布到其他平台
AHA音乐:识别网页上播放的音乐
当你观看视频和听到美丽的BGM时,你可能会发出一个弹幕,问BGM是什么,但回答可能是“BGM爱自杀,再次请求支持”。此时,您可以在手机上打开音乐,但有一种更简单的方法可以让您在不离开浏览器的情况下直接知道歌曲名称,即使用AHA音乐分机
https://s3.ifanr.com/wp-conten ... 5.jpg 360w, https://s3.ifanr.com/wp-conten ... 0.jpg 768w" />当网页播放声音时,单击展开以识别背景音乐,每个识别历史将自动保存。单击识别结果后面的YouTube图标,打开相应歌曲的YouTube视频。然而,链接到Youtube似乎毫无用处。如果你可以链接到网易云音乐或音乐,它可能更实用
Copyfish:图像文本的OCR识别
网页上的文本通常可以复制,但也有一些特殊情况。例如,文本有一个超链接,该超链接只能单击到链接中而不能被选择,或者设置为未选择,或者图片中的某些文本不能直接复制。此时,OCR字符识别可以解决上述问题
https://s3.ifanr.com/wp-conten ... 5.jpg 360w, https://s3.ifanr.com/wp-conten ... 0.jpg 768w" />Copyfish是网页字符识别的扩展。一般来说,只要文本背景不太复杂,就可以正确识别。例如,“爱凡纳,让未来触手可及”,其中“爱凡纳”的背景太复杂,无法识别为文本,后续文本被正确识别。识别的文本可以复制或翻译成谷歌翻译
https://s3.ifanr.com/wp-conten ... 8.jpg 360w, https://s3.ifanr.com/wp-conten ... 6.jpg 768w" />此外,copyfish还提供pro和pro+版本,价格为19.$95/月和29.$95/月。增加了自动OCR语言识别和pro vision OCR,即更好的OCR识别技术,甚至可以很好地识别笔迹。如果您想识别本地图片或PDF文件,请在chrome中打开它们并使用copyfish进行识别
Fontface忍者:识别网页字体和段落格式
对于那些从事设计的人来说,他们总是希望从好作品中获得灵感。字体是设计的重要组成部分。此时,当你看到一个好看的字体时,你总是想知道字体名称。Fontface Ninja不仅可以列出当前页面中的所有字体,还可以链接到其字体网站以显示特定信息,包括是否免费用于商业用途、购买价格等
https://s3.ifanr.com/wp-conten ... 0.jpg 360w, https://s3.ifanr.com/wp-conten ... 3.jpg 768w" />单独选择文本段落还可以显示单独的字体名称和段落信息,包括字体大小、行距、字距和文本颜色编号。对于从事文章排版的人来说,有一定的参考意义。例如,如果你看到一个微信推送,觉得排版很好,你可以用浏览器打开它,查看它的字体大小、行距等信息
https://s3.ifanr.com/wp-conten ... 0.jpg 360w, https://s3.ifanr.com/wp-conten ... 3.jpg 768w" />通过浏览器的扩展,我们可以看到网页中更深层次的信息,就像使用显微镜挖掘网页中的所有元素一样。最后,值得一提的是,当我们使用这些材料时,我们必须注意它们的版权信息。某些图片、视频或字体不能免费使用。否则,有朝一日我们可能会收到视觉中国或方正字体的律师来信
https://s3.ifanr.com/wp-conten ... 5.png 360w, https://s3.ifanr.com/wp-conten ... 1.png 768w, https://s3.ifanr.com/wp-conten ... 1.png 1024w" /> 
