
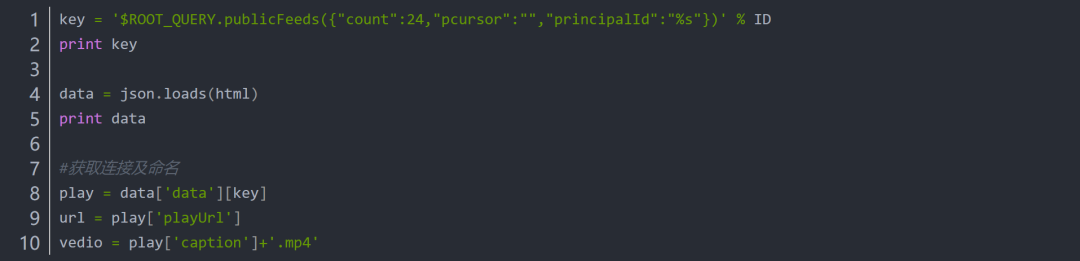
chrome网页视频抓取
chrome网页视频抓取( 谷歌浏览器仅支持H264编码,但是视频流的编码可能不一样)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-14 20:25
谷歌浏览器仅支持H264编码,但是视频流的编码可能不一样)
某些 MP4 视频无法在 Google Chrome 中播放
本质上,html 使用标签来播放视频,我相信大多数浏览器都支持。
但是我今天遇到了一个问题。我在APP上拍了两个视频,一个可以播放,另一个失败。
排除服务器和文件存储服务器的问题。怀疑是前端代码写错了。疑似网速受限,视频被截断。
没想到,原来是mp4视频流格式问题,谷歌浏览器不支持。
mp4都是mp4,但这只是让操作系统识别哪些应用程序可以播放。实际内容取决于视频流的格式或编码,但视频流的编码可能不同。
据说谷歌浏览器只支持H264编码,因为支持视频编码需要专利费,所以只支持这个。
原因
由于之前的文章文章已经基本查清了服务器的原因,这次还是发现视频播放失败,所以重点放在了前端和网络上。
通过控制台发现视频数据已经取到了,但是仍然显示“播放失败”。
怀疑:
第一点是从日志来看,没有看到错误日志;
第二点是从前端控制台检查,发现传输完成;
三、 第四(PS:因为前端人手不足所以做了原来的改动)因为经验有限,请前端小姐姐帮忙查一下。
找方向
但是前台小姐很忙,不能坐等死。决定继续考虑。
怀疑是视频问题,直接通过url下载视频。下载到本地就可以正常播放了,说明视频本身是完整的。
所以我写了一个tag-only html,写了视频源,分别用edge和google打开。
Sorry, your browser doesn't support embedded videos.
原来edge可以正常播放,google却不能。那只能是视频本身的问题。
找到方向后,启动google(这个google不是别的google)。发现经常有这样的问题,结论是谷歌只支持h264。
视频格式和编码
相关介绍见文章:Chrome使用视频无法正常播放MP4视频的解决方法-Yellow_ice-博客园()
验证猜想
既然怀疑是视频编码问题,需要验证一下。如何查看视频的编码?我不能直接看到它。
这里需要用到ffmpeg软件。
从官网下载解压后,将“安装目录/bin”写入系统变量Path。
ffmpeg -i 0b9a8a522ae84fa69e15068cbf044c1e.mp4
无法播放的视频输出 hevc(别名 H265):
可以播放的输出是h264:
验证解决方案
用这个软件把hevc转成264扔到OBS服务器上,确认能不能正常播放。
结论自然是可以的。
综上所述
结论是视频拍摄完成后APP端存储的编码有误。因为这次拍摄的是第二个视频,所以和上一个不同。一个是h264可以播放,一个是hevc不能播放。
请在前端更改视频编码,应该没问题。
无底线
如果无法解析,否则OBS服务器会自动转码。
然后服务器需要在拉取视频后进行转码。
目前google了一下,发现有两种说法:
其实这两种方法本质上是一样的。前者需要您自己在服务器或本地计算机上安装软件。后者不如前者灵活,但可以直接使用。
因为本质是调用ffmpeg,所以视频流必须保存在服务器上,代表的是File文件。
因此,原创文件和转换后的文件需要经过内存、服务器,然后才能删除,占用内存和时间。
所以尽量统一编码格式。
该工具包是:GitHub-a-schild/jave2:JAVE(Java 音频视频编码器)库是 ffmpeg 项目上的 Java 包装器
参考链接
Chrome无法正常使用视频播放MP4视频-Yellow_ice-博客园()
GitHub-a-schild/jave2: JAVE(Java 音频视频编码器)库是 ffmpeg 项目上的 Java 包装器 查看全部
chrome网页视频抓取(
谷歌浏览器仅支持H264编码,但是视频流的编码可能不一样)
某些 MP4 视频无法在 Google Chrome 中播放
本质上,html 使用标签来播放视频,我相信大多数浏览器都支持。
但是我今天遇到了一个问题。我在APP上拍了两个视频,一个可以播放,另一个失败。
排除服务器和文件存储服务器的问题。怀疑是前端代码写错了。疑似网速受限,视频被截断。
没想到,原来是mp4视频流格式问题,谷歌浏览器不支持。
mp4都是mp4,但这只是让操作系统识别哪些应用程序可以播放。实际内容取决于视频流的格式或编码,但视频流的编码可能不同。
据说谷歌浏览器只支持H264编码,因为支持视频编码需要专利费,所以只支持这个。
原因
由于之前的文章文章已经基本查清了服务器的原因,这次还是发现视频播放失败,所以重点放在了前端和网络上。
通过控制台发现视频数据已经取到了,但是仍然显示“播放失败”。
怀疑:
第一点是从日志来看,没有看到错误日志;
第二点是从前端控制台检查,发现传输完成;
三、 第四(PS:因为前端人手不足所以做了原来的改动)因为经验有限,请前端小姐姐帮忙查一下。
找方向
但是前台小姐很忙,不能坐等死。决定继续考虑。
怀疑是视频问题,直接通过url下载视频。下载到本地就可以正常播放了,说明视频本身是完整的。
所以我写了一个tag-only html,写了视频源,分别用edge和google打开。
Sorry, your browser doesn't support embedded videos.
原来edge可以正常播放,google却不能。那只能是视频本身的问题。
找到方向后,启动google(这个google不是别的google)。发现经常有这样的问题,结论是谷歌只支持h264。
视频格式和编码
相关介绍见文章:Chrome使用视频无法正常播放MP4视频的解决方法-Yellow_ice-博客园()
验证猜想
既然怀疑是视频编码问题,需要验证一下。如何查看视频的编码?我不能直接看到它。
这里需要用到ffmpeg软件。
从官网下载解压后,将“安装目录/bin”写入系统变量Path。
ffmpeg -i 0b9a8a522ae84fa69e15068cbf044c1e.mp4
无法播放的视频输出 hevc(别名 H265):

可以播放的输出是h264:

验证解决方案
用这个软件把hevc转成264扔到OBS服务器上,确认能不能正常播放。
结论自然是可以的。
综上所述
结论是视频拍摄完成后APP端存储的编码有误。因为这次拍摄的是第二个视频,所以和上一个不同。一个是h264可以播放,一个是hevc不能播放。
请在前端更改视频编码,应该没问题。
无底线
如果无法解析,否则OBS服务器会自动转码。
然后服务器需要在拉取视频后进行转码。
目前google了一下,发现有两种说法:
其实这两种方法本质上是一样的。前者需要您自己在服务器或本地计算机上安装软件。后者不如前者灵活,但可以直接使用。
因为本质是调用ffmpeg,所以视频流必须保存在服务器上,代表的是File文件。
因此,原创文件和转换后的文件需要经过内存、服务器,然后才能删除,占用内存和时间。
所以尽量统一编码格式。
该工具包是:GitHub-a-schild/jave2:JAVE(Java 音频视频编码器)库是 ffmpeg 项目上的 Java 包装器
参考链接
Chrome无法正常使用视频播放MP4视频-Yellow_ice-博客园()
GitHub-a-schild/jave2: JAVE(Java 音频视频编码器)库是 ffmpeg 项目上的 Java 包装器
chrome网页视频抓取(Chrome的Downloader-从任何网站下载视频的最简单,最快的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-04 15:21
适用于 Chrome 的视频下载器 - 从任何 网站 下载视频的最简单、最快捷的方式。此扩展程序允许您从几乎任何页面下载视频文件,以便在您的计算机上进一步查看。它支持许多网站,包括Facebook、Dailymotion、Vimeo、Blip、Metacafe、Break 和其他数千个网站-从任何网站下载和保存视频-同时下载多个视频- 检测并保存任何媒体类型(.3gp、.mp4、.wmv、.flv、.swf、.mp3...)-最快和最简单的视频下载扩展 *重要** 请注意,Chrome 的视频下载器我们不是对您下载的媒体内容负责。我们建议在下载特定视频或音频之前检查媒体的版权许可。请小心!感谢您使用它,如果您喜欢它,请给 Chrome 扩展视频下载器 5 颗星!支持语言:Deutsch、English、English(UK)、English(美国)、Français、Norsk、español、italiano、português(巴西)、português(葡萄牙)、slovenský、suomi、русский、Japanese 查看全部
chrome网页视频抓取(Chrome的Downloader-从任何网站下载视频的最简单,最快的方法)
适用于 Chrome 的视频下载器 - 从任何 网站 下载视频的最简单、最快捷的方式。此扩展程序允许您从几乎任何页面下载视频文件,以便在您的计算机上进一步查看。它支持许多网站,包括Facebook、Dailymotion、Vimeo、Blip、Metacafe、Break 和其他数千个网站-从任何网站下载和保存视频-同时下载多个视频- 检测并保存任何媒体类型(.3gp、.mp4、.wmv、.flv、.swf、.mp3...)-最快和最简单的视频下载扩展 *重要** 请注意,Chrome 的视频下载器我们不是对您下载的媒体内容负责。我们建议在下载特定视频或音频之前检查媒体的版权许可。请小心!感谢您使用它,如果您喜欢它,请给 Chrome 扩展视频下载器 5 颗星!支持语言:Deutsch、English、English(UK)、English(美国)、Français、Norsk、español、italiano、português(巴西)、português(葡萄牙)、slovenský、suomi、русский、Japanese
chrome网页视频抓取(网页文字抓取工具使用方法输入网址后与url链接介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-28 04:13
网页文字抓取工具是一款简单实用的工具。用户只需输入目标链接网站,即可快速抓取相关网页上的所有文字,支持复制或导出为txt文件。欢迎有需要的朋友下载使用!
特征
1、绿色软件,无需安装。
2、 支持键盘ctrl、alt、shift+鼠标左键、中键、右键操作。
3、无法复制的文字可以抓取,但是图片不能抓取。
4、 支持复制常规静态对话框、系统消息和程序选项卡等表单文本。
5、支持鼠标快捷键,Ctrl、Alt、Shift和鼠标左/中/右键的任意组合。
6、 支持在 Chrome 中抓取网页图片替代文本和 url 链接。
指示
输入网址后,点击抓取按钮,就OK了。!
软件亮点
网页文字抓取器是一款小巧精致的网页文字提取软件,可以让您轻松抓取和复制禁止选择和复制的网页上的文字。对于内容被大面积广告覆盖而无法看到的网页,网上有很多禁止复制的html文件。抓取网页文本抓取器并阅读它也是一个很好的解决方案。
相关新闻
现在IE被边缘化了,我们使用的浏览器大多是WebKit核心,所以当你发现网站设置了禁止复制的权限时,不妨试试把网址拖到IE浏览器上。接下来,说不定会有惊喜哦~
还有一点需要注意的是,现在国内很多浏览器都是双核的。“兼容模式”是IE的核心。也可以点击切换试试看。复制到 IE 是一种效果。 查看全部
chrome网页视频抓取(网页文字抓取工具使用方法输入网址后与url链接介绍)
网页文字抓取工具是一款简单实用的工具。用户只需输入目标链接网站,即可快速抓取相关网页上的所有文字,支持复制或导出为txt文件。欢迎有需要的朋友下载使用!

特征
1、绿色软件,无需安装。
2、 支持键盘ctrl、alt、shift+鼠标左键、中键、右键操作。
3、无法复制的文字可以抓取,但是图片不能抓取。
4、 支持复制常规静态对话框、系统消息和程序选项卡等表单文本。
5、支持鼠标快捷键,Ctrl、Alt、Shift和鼠标左/中/右键的任意组合。
6、 支持在 Chrome 中抓取网页图片替代文本和 url 链接。
指示
输入网址后,点击抓取按钮,就OK了。!
软件亮点
网页文字抓取器是一款小巧精致的网页文字提取软件,可以让您轻松抓取和复制禁止选择和复制的网页上的文字。对于内容被大面积广告覆盖而无法看到的网页,网上有很多禁止复制的html文件。抓取网页文本抓取器并阅读它也是一个很好的解决方案。
相关新闻
现在IE被边缘化了,我们使用的浏览器大多是WebKit核心,所以当你发现网站设置了禁止复制的权限时,不妨试试把网址拖到IE浏览器上。接下来,说不定会有惊喜哦~
还有一点需要注意的是,现在国内很多浏览器都是双核的。“兼容模式”是IE的核心。也可以点击切换试试看。复制到 IE 是一种效果。
chrome网页视频抓取(猫抓支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
网站优化 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-11-21 06:19
猫抓
Mozhao 是一个扩展,支持所有 Chrome 内核浏览器的网络媒体嗅探和抓取。
它可以一键抓取任何站点的任何视频/音频数据,使用起来非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮可以看到页面上的资源信息。
然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地。
猫扎支持优酷、搜狐、腾讯、微博、B站等几乎所有国内网站视频文件嗅探。
当多个媒体资源出现在同一页面时,您还可以对其进行快速批量操作。
一般来说,这类嗅探工具支持的视频文件是未加密的。当面对一些加密的视频时,会有一定的失败几率。
但是,从市场反馈来看,猫筹可以捕捉到很多其他IDM无法嗅探的媒体资源。
这也是其竞争激烈的拓展店能拥有超过5万用户的原因之一。
此外,毛爪还支持对所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间音乐。
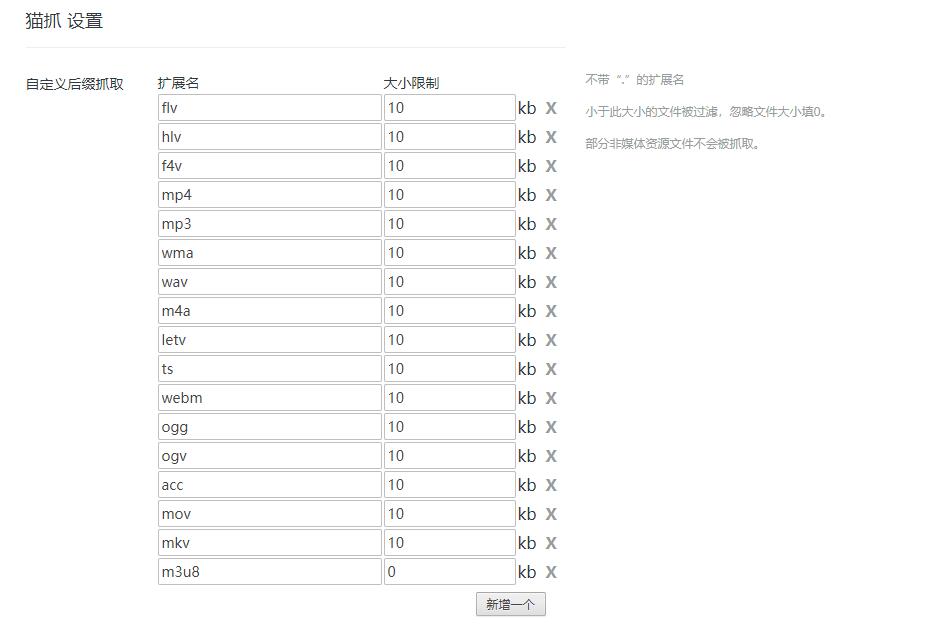
在【选项】中,用户还可以自定义采集的视频和音频格式,还支持使用正则表达式自定义采集的内容。
网络嗅探器最初是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。Sniffer 也是很多程序员在编写网络程序时捕捉和测试的工具。
近年来,网络嗅探器广泛应用于用户的日常行为中,成为捕捉视频、音频等内容的工具。
下载:/extension/jfedfbgedapdagkghmgibemcoggfppbb 查看全部
chrome网页视频抓取(猫抓支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
猫抓
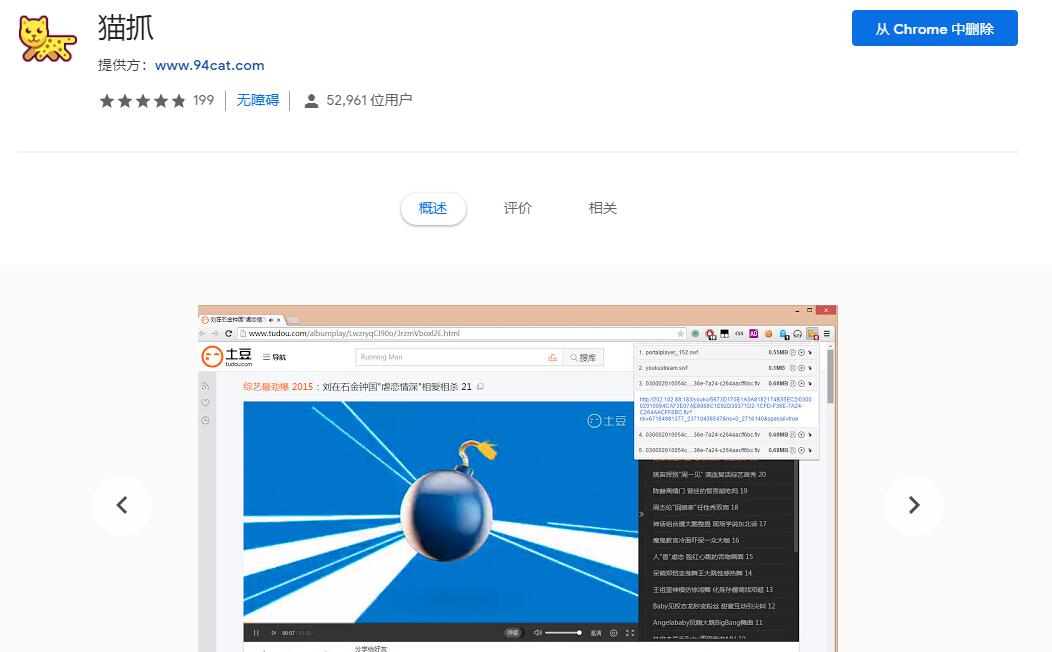
Mozhao 是一个扩展,支持所有 Chrome 内核浏览器的网络媒体嗅探和抓取。
它可以一键抓取任何站点的任何视频/音频数据,使用起来非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮可以看到页面上的资源信息。
然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地。
猫扎支持优酷、搜狐、腾讯、微博、B站等几乎所有国内网站视频文件嗅探。
当多个媒体资源出现在同一页面时,您还可以对其进行快速批量操作。
一般来说,这类嗅探工具支持的视频文件是未加密的。当面对一些加密的视频时,会有一定的失败几率。
但是,从市场反馈来看,猫筹可以捕捉到很多其他IDM无法嗅探的媒体资源。
这也是其竞争激烈的拓展店能拥有超过5万用户的原因之一。
此外,毛爪还支持对所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,还支持使用正则表达式自定义采集的内容。
网络嗅探器最初是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。Sniffer 也是很多程序员在编写网络程序时捕捉和测试的工具。
近年来,网络嗅探器广泛应用于用户的日常行为中,成为捕捉视频、音频等内容的工具。
下载:/extension/jfedfbgedapdagkghmgibemcoggfppbb
chrome网页视频抓取(来个图:浏览器扩展需要注意的是,本站推荐的扩展)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-11 16:22
文章内容
在日常使用中,我们总是希望能够在浏览器上执行除浏览以外的某些动作,比如爬取网络视频、爬取网络图片、高速下载等。据统计,80%以上的网民从来没有使用过浏览器扩展,这是一种真正的浪费。相信本期介绍的这几点会对你有所帮助。当然,它们都是免费和开源的。
这是一张图片:
浏览器扩展
需要注意的是,本站推荐的浏览器扩展仅在谷歌Chrome浏览器中进行了测试。当然,这些扩展中的大多数都有其他浏览器的适用版本。需要的可以到相关地址下载安装。
一、IDM 集成模块
准确的说,这个扩展不是一个独立的扩展,而是一个配套的扩展。历史上最强的多线程下载工具 IDM 使用了它。在实际使用中,它可以以几何倍数提高您的下载速度。简单的解释就是,正常情况下,你的浏览器下载速度是单线程的,但是有了IDM,你的下载速度会是多线程的。简单的说,一个下载任务被拆分成多个部分,然后IDM可以同时下载这多个不同的部分。例如:
100M文件不拆分时,下载速度5M/S,下载时间20S。拆分成5份时,每份20M,每份下载速度也是5M/s。由于是同时下载,所以只需要4S就可以完成下载。这就是IDM的力量。
但残酷的事实是:IDM 是有偿的。
不过浏览器除了使用IDM之外,还有自己的多线程下载。您可以通过以下操作打开浏览器的多线程下载:
直接在浏览器顶部的搜索栏中搜索
找到此项,在右边选择Enabled,点击右下角的Relaunch【重启浏览器】二、Image Picka
这个扩展是一个可以大大加快我使用过程中效率的工具。是一款网页图片批量下载工具。它可以直接从浏览缓存中抓取您看到的图片并下载它们,或者简单地拖放。图片来自网页下载。
这是一个开源免费插件,你可以在这里找到它:
如何使用:只需单击要抓取图像的 URL 上的扩展名
需要注意的是,该插件仅兼容谷歌浏览器和火狐浏览器。目前尚不清楚在某些国产浏览器上是否可以正常使用。你可以试试。
在 Google Chrome 上安装需要以下步骤:
下载扩展的压缩包,解压压缩包,在谷歌浏览器的管理扩展中选择加载解压的扩展
加载解压后的扩展三、微信公众号同步助手
同样,这也是一款开源免费软件,可以帮助您快速将您的文章同步到各种自媒体平台。需要注意的是,过去传过来的文章是草稿的形式。需要注意的是,同步过去的文章默认会有扩展名的签名。您可以通过右键单击扩展-选项-配置并选择关闭签名来执行此操作。
你可以在这里找到它:#howtouse,它支持许多不同的平台和许多不同的浏览器
微信公众号同步助手官网
支持的平台
微信公众号同步助手
关闭扩展同步时底部的签名文章
四、Chrome 语法
这个插件可以帮助在网上英语写作过程中纠正语法和纠正英语写作错误。我们在和国外客户聊天的时候,可以避免有时对某个词写生不熟,造成乌龙事件。推荐给第一次使用英语与他人交流的人。虽然扩展是付费的,付费功能会改善语义和句子表达,但一般来说,除非你真的需要,否则没有必要使用付费版本。
影响
扩展需要从谷歌扩展商店安装,如下:
五、灯塔
这个是做网页测试用的,对于普通人来说,不太好用。主要是评价网站的质量。如速度、SEO、网页结构等,安装在谷歌浏览器扩展商店中。
也可以直接点击地址:
灯塔扩展六、返回顶部扩展
这是一个轻量级的扩展程序,非常好用。使用方法:在网页任意位置右击选择返回顶部,或者点击右上角的返回顶部扩展。
安装可以在谷歌浏览器扩展商店安装,也可以点击下方链接进行安装:
安装:%E7%BD%AE%E9%A1%B6%EF%BC%88totop%EF%BC%89/eoecceliiajignmnmnehakdagafjigdj
相关推荐:Chevereto WP前端上传适配效果展示B2主题WordPress主题设置阿里云邮件推送配置指南详解网站备案和不备案的区别,以及为什么要备案wordpress极致优化-预加载WP 内核进入内存 中速生成页面 查看全部
chrome网页视频抓取(来个图:浏览器扩展需要注意的是,本站推荐的扩展)
文章内容
在日常使用中,我们总是希望能够在浏览器上执行除浏览以外的某些动作,比如爬取网络视频、爬取网络图片、高速下载等。据统计,80%以上的网民从来没有使用过浏览器扩展,这是一种真正的浪费。相信本期介绍的这几点会对你有所帮助。当然,它们都是免费和开源的。
这是一张图片:

浏览器扩展
需要注意的是,本站推荐的浏览器扩展仅在谷歌Chrome浏览器中进行了测试。当然,这些扩展中的大多数都有其他浏览器的适用版本。需要的可以到相关地址下载安装。
一、IDM 集成模块
准确的说,这个扩展不是一个独立的扩展,而是一个配套的扩展。历史上最强的多线程下载工具 IDM 使用了它。在实际使用中,它可以以几何倍数提高您的下载速度。简单的解释就是,正常情况下,你的浏览器下载速度是单线程的,但是有了IDM,你的下载速度会是多线程的。简单的说,一个下载任务被拆分成多个部分,然后IDM可以同时下载这多个不同的部分。例如:
100M文件不拆分时,下载速度5M/S,下载时间20S。拆分成5份时,每份20M,每份下载速度也是5M/s。由于是同时下载,所以只需要4S就可以完成下载。这就是IDM的力量。
但残酷的事实是:IDM 是有偿的。
不过浏览器除了使用IDM之外,还有自己的多线程下载。您可以通过以下操作打开浏览器的多线程下载:

直接在浏览器顶部的搜索栏中搜索

找到此项,在右边选择Enabled,点击右下角的Relaunch【重启浏览器】二、Image Picka
这个扩展是一个可以大大加快我使用过程中效率的工具。是一款网页图片批量下载工具。它可以直接从浏览缓存中抓取您看到的图片并下载它们,或者简单地拖放。图片来自网页下载。
这是一个开源免费插件,你可以在这里找到它:

如何使用:只需单击要抓取图像的 URL 上的扩展名
需要注意的是,该插件仅兼容谷歌浏览器和火狐浏览器。目前尚不清楚在某些国产浏览器上是否可以正常使用。你可以试试。
在 Google Chrome 上安装需要以下步骤:
下载扩展的压缩包,解压压缩包,在谷歌浏览器的管理扩展中选择加载解压的扩展

加载解压后的扩展三、微信公众号同步助手
同样,这也是一款开源免费软件,可以帮助您快速将您的文章同步到各种自媒体平台。需要注意的是,过去传过来的文章是草稿的形式。需要注意的是,同步过去的文章默认会有扩展名的签名。您可以通过右键单击扩展-选项-配置并选择关闭签名来执行此操作。
你可以在这里找到它:#howtouse,它支持许多不同的平台和许多不同的浏览器

微信公众号同步助手官网

支持的平台

微信公众号同步助手

关闭扩展同步时底部的签名文章
四、Chrome 语法
这个插件可以帮助在网上英语写作过程中纠正语法和纠正英语写作错误。我们在和国外客户聊天的时候,可以避免有时对某个词写生不熟,造成乌龙事件。推荐给第一次使用英语与他人交流的人。虽然扩展是付费的,付费功能会改善语义和句子表达,但一般来说,除非你真的需要,否则没有必要使用付费版本。

影响
扩展需要从谷歌扩展商店安装,如下:
五、灯塔
这个是做网页测试用的,对于普通人来说,不太好用。主要是评价网站的质量。如速度、SEO、网页结构等,安装在谷歌浏览器扩展商店中。
也可以直接点击地址:

灯塔扩展六、返回顶部扩展
这是一个轻量级的扩展程序,非常好用。使用方法:在网页任意位置右击选择返回顶部,或者点击右上角的返回顶部扩展。
安装可以在谷歌浏览器扩展商店安装,也可以点击下方链接进行安装:
安装:%E7%BD%AE%E9%A1%B6%EF%BC%88totop%EF%BC%89/eoecceliiajignmnmnehakdagafjigdj
相关推荐:Chevereto WP前端上传适配效果展示B2主题WordPress主题设置阿里云邮件推送配置指南详解网站备案和不备案的区别,以及为什么要备案wordpress极致优化-预加载WP 内核进入内存 中速生成页面
chrome网页视频抓取( 如何开启Chrome实时字幕的详细设置(图)!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2021-11-10 19:09
如何开启Chrome实时字幕的详细设置(图)!)
谷歌近日发布了新版Chrome 89,带来了一项新的黑科技——实时字幕!顾名思义,这个功能可以为网络视频实时生成字幕。当您打开视频网站 并播放视频时,Chrome 会自动识别其中的音频并生成字幕!虽然目前的功能只支持英文,但考虑到谷歌本身就是最高质量的自动翻译功能的提供者,未来这个功能会与谷歌实时翻译结合,一定会更上一层楼!今天我们就来看看如何在Chrome中开启实时字幕功能。
首先,我们需要更新到Chrome 89。打开Chrome,点击工具栏上的菜单按钮,在“帮助”栏中找到“关于谷歌浏览器”。将显示当前 Chrome 的版本信息并自动检查更新。Chrome更新使用国内CDN,所以网络连接不成问题。
首先需要更新到 Chrome 89
然后,转到 Chrome 的设置菜单,在“高级”中找到“辅助功能”。在其中,您可以看到“字幕”选项。
在这里找到“字幕”
点击“字幕”对实时字幕功能进行各种设置。开启实时字幕开关后,Chrome会自动下载所需资源,完成后实时字幕功能生效!并且在这个页面上还可以设置字幕的文字大小、字体、颜色、透明度等特性,可以根据需要进行自定义。
实时字幕的详细设置
我们来看看实时字幕的效果。实时字幕功能可以通过识别网页中的视频自动激活,不限于特定的网站。国外的YouTube、中国的Bilibili等都可以使用Chrome的实时字幕,当我们在B站打开一段英文视频时,可以看到浏览器底部出现了浮动的实时字幕。准确率相当不错!
自动生成的字幕
总的来说,Chrome的实时字幕功能还是比较不错的。其实类似的功能已经在安卓系统中配备了,部分国产手机也支持相应的功能,甚至还支持中文。希望Chrome的实时字幕也能尽快支持中文甚至翻译,带来更好的体验!
【编辑推荐】
和姐姐聊Java 16的新特性,真香!IT项目太多,太难管理?不!因为这七招你都学了五年没学Python,这些网站让我相见晚了,快来看看Java都到了16了,你为什么还在用8呢?情况越来越糟。是吗?太奇妙了!Windows 10的这些黑科技功能你都用过了吗? 查看全部
chrome网页视频抓取(
如何开启Chrome实时字幕的详细设置(图)!)

谷歌近日发布了新版Chrome 89,带来了一项新的黑科技——实时字幕!顾名思义,这个功能可以为网络视频实时生成字幕。当您打开视频网站 并播放视频时,Chrome 会自动识别其中的音频并生成字幕!虽然目前的功能只支持英文,但考虑到谷歌本身就是最高质量的自动翻译功能的提供者,未来这个功能会与谷歌实时翻译结合,一定会更上一层楼!今天我们就来看看如何在Chrome中开启实时字幕功能。
首先,我们需要更新到Chrome 89。打开Chrome,点击工具栏上的菜单按钮,在“帮助”栏中找到“关于谷歌浏览器”。将显示当前 Chrome 的版本信息并自动检查更新。Chrome更新使用国内CDN,所以网络连接不成问题。

首先需要更新到 Chrome 89
然后,转到 Chrome 的设置菜单,在“高级”中找到“辅助功能”。在其中,您可以看到“字幕”选项。

在这里找到“字幕”
点击“字幕”对实时字幕功能进行各种设置。开启实时字幕开关后,Chrome会自动下载所需资源,完成后实时字幕功能生效!并且在这个页面上还可以设置字幕的文字大小、字体、颜色、透明度等特性,可以根据需要进行自定义。

实时字幕的详细设置
我们来看看实时字幕的效果。实时字幕功能可以通过识别网页中的视频自动激活,不限于特定的网站。国外的YouTube、中国的Bilibili等都可以使用Chrome的实时字幕,当我们在B站打开一段英文视频时,可以看到浏览器底部出现了浮动的实时字幕。准确率相当不错!

自动生成的字幕
总的来说,Chrome的实时字幕功能还是比较不错的。其实类似的功能已经在安卓系统中配备了,部分国产手机也支持相应的功能,甚至还支持中文。希望Chrome的实时字幕也能尽快支持中文甚至翻译,带来更好的体验!
【编辑推荐】
和姐姐聊Java 16的新特性,真香!IT项目太多,太难管理?不!因为这七招你都学了五年没学Python,这些网站让我相见晚了,快来看看Java都到了16了,你为什么还在用8呢?情况越来越糟。是吗?太奇妙了!Windows 10的这些黑科技功能你都用过了吗?
chrome网页视频抓取(有关使用BeautifulSoup和Selenium进行网页爬取的相关资料关注)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-09 01:22
摘要 今天小编就为大家讲解使用BeautifulSoup和Selenium进行网络爬虫。我相信你应该关注这个话题。小编还采集了一些
今天给大家讲解一下使用BeautifulSoup和Selenium进行网络爬虫。我相信你应该关注这个话题。我还采集了有关使用 BeautifulSoup 和 Selenium 进行网络爬虫的相关信息。合作伙伴看起来很有帮助。
出自:开源中国翻译频道英文原文概览
HTML 几乎是直截了当的。CSS 是一个很大的改进。它清楚地区分了页面的结构和外观。JavaScript 增添了一些魅力。理论上,情况确实如此。现实世界仍然有些不同。
在本教程中,您将了解您在浏览器中看到的内容是如何实际呈现的,以及如何在必要时抓取它。特别是,您将学习如何计算 Disqus 评论。我们的工具是 Python 和这种语言的优秀包,例如 request、BeautifulSoup 和 Selenium。
什么时候应该使用网络爬虫?
网络爬虫是一种自动获取网页内容的实践,旨在使人类用户能够相互交互、解析它们并提取一些信息(可能是指向其他页面的链接)。如果没有其他方法可以提取必要的网页信息,网络爬虫是一种必要且有效的技术方法。理想情况下,应用程序依靠提供良好的专用 API 以编程方式自动获取网页数据。但在以下情况下,最好不要使用网页抓取技术:
正在爬取的网页是脆弱的(您正在爬取的网页可能会经常更改)。
禁止爬行(某些 Web 应用程序具有禁止爬行的策略)。
爬取速度可能很慢,爬取的内容过于复杂(如果你需要在大量无用信息中寻找和涉猎你想要的东西)。
了解真实的网页
让我们通过查看一些常见的 Web 应用程序代码的实现来了解我们面临的问题。比如在《Vagrant 技术介绍》(链接:)页面底部有一些 Disqus 评论。为了抓取这些评论,我们需要先在页面上找到它们。
查看页面代码
从 1990 年代开始,每个浏览器都支持查看当前页面的 html 代码。以下是源代码视图中查看的“Vagrant 技术简介”帖子对应的源代码片段。本源代码以大量压缩丑陋的 JavaScript 代码开头,与本文内容无关。这是“小”部分之一:
这是页面中的一些实际 html 代码:
代码看起来很乱。在页面的源代码中找不到Disqus的评论,这让你有点意外。
强大的内联框架
原创页面是一个“混搭”,Disqus 评论嵌入在 iframe(内联框架)元素中。可以在评论区右击找到,在那里可以看到框架信息和源码。这是有道理的。将第三方内容嵌入到 iframe 中是使用 iframe 的主要应用场景之一。让我们在主页源代码中找到 iframe 标签。就是这样!主页源中没有 iframe 标记。
JavaScript 生成的标签
之所以省略,是因为查看页面源显示的是从服务器获取的内容。但是最终浏览器渲染出来的DOM(文档对象模型)可能会有很大的不同。JavaScript 开始工作并且可以随意操作 DOM。无法找到 iframe,因为从服务器检索页面时它不存在。
静态抓取与动态抓取
静态抓取会忽略 JavaScript,它可以直接从服务器获取网页代码,不依赖浏览器。这就是你通过“查看源代码”看到的,然后就可以提取信息了。如果要查找源代码中已经存在的内容,则无需进一步操作。但是,如果您要查找的内容像上面的 Disqus 评论一样嵌入在 iframe 中,则必须使用动态抓取来获取内容。
动态爬取使用真实浏览器(或非接口浏览器),首先让页面中的JavaScript运行,完成动态内容的处理和加载。之后,它会查询 DOM 以获取它要查找的内容。有时,您还需要让浏览器自动模拟人工操作来获取您需要的内容。
使用 Requests 和 BeautifulSoup 进行静态抓取
下面我们来看看如何使用两个经典的 Python 包进行静态爬取:requests 用于爬取网页内容。BeautifulSoup 用于解析 html。
安装 Requests 和 BeautifulSoup
先安装pipenv,然后运行命令:pipenv install requests beautifulsoup4
它首先为你创建一个虚拟环境,然后在虚拟环境中安装这两个包。如果你的代码在 gitlab 上,你可以使用命令 pipenv install 来安装它。
获取网页内容
只需要一行代码就可以抓取带有请求的网页内容:
r = requests.get(url)。
该代码返回一个响应对象,其中收录许多有用的属性。最重要的属性是 ok 和 content。如果请求失败, r.ok 为 False 并且 r.content 收录错误消息。content 代表一个字节流,作为 text 处理时最好解码成utf-8.
>>> r = requests.get('')>>> r.okFalse>>> 打印(r.content.decode('utf-8'))未找到
在此服务器上找不到请求的 URL /ggg。
端口 80 的 Apache/2.0.52 (CentOS) 服务器
如果代码正常返回并且没有报错,那么r.content会收录所请求网页的源代码(也就是你在“查看源代码”中看到的)。
使用 BeautifulSoup 查找元素
下面的 get_page() 函数会获取给定 URL 的网页源代码,然后将其解码为 utf-8,最后将内容传递给 BeautifulSoup 对象并返回。BeautifulSoup 使用 html 解析器进行解析。
def get_page(url): r = requests.get(url) content = r.content.decode('utf-8') return BeautifulSoup(content,'html.parser')
拿到 BeautifulSoup 对象后,我们就可以开始解析需要的信息了。
BeautifulSoup 提供了多种搜索方法来定位网页中的元素,并且可以深入挖掘嵌套元素。
Tuts+ 网站 里面有很多培训教程,这里()是我的主页。每个页面最多收录 12 个教程。如果您已经获得了12个教程,您可以转到下一页。一篇文章 文章 被标签包围。下面的功能是找到页面中所有的文章元素,然后找到对应的链接,最后提取教程的网址。
page = get_page('')articles = get_page_articles(page)prefix =''for a in article: print(a[len(prefix):]) 输出:building-games-with-python-3-and-pygame-part -5--cms-30085building-games-with-python-3-and-pygame-part-4--cms-30084building-games-with-python-3-and-pygame-part -3--cms-30083building-games-with-python-3-and-pygame-part-2--cms-30082building-games-with-python-3-and-pygame-part -1--cms-30081mastering-the-react-lifecycle-methods--cms-29849testing-data-integrated-code-with-go-part-5--cms- 29852testing-data-密集型代码与go-part-4--cms-29851testing-data-密集型代码与go-part-3--cms-29850testing-data-密集型代码与go-part-2--cms-29848testing-data-密集型代码与go-part-1--cms-29847 make-your-go-programs-lightning-fast-with-profiling--cms-29809 使用Selenium动态爬取
静态爬取非常适合一系列的文章,但是正如我们之前看到的,Disqus 的评论是由 JavaScript 写在 iframe 中的。为了获得这些注释,我们需要让浏览器自动与 DOM 交互。做这种事情的最好的工具之一是 Selenium。
Selenium 主要用于 Web 应用程序自动化测试,但它也是一个很好的通用浏览器自动化工具。
安装硒
使用以下命令安装 Selenium:
pipenv install selenium 选择您的网络驱动程序
Selenium 需要一个 Web 驱动程序(用于自动化的浏览器)。对于网络爬虫,您通常不需要关心您选择的驱动程序。我建议使用 Chrome 驱动程序。Selenium手册中有相关介绍。
比较 Chrome 和 Phantomjs
在某些情况下,您可能想要使用无头浏览器。理论上,Phantomjs 正是那个 Web 驱动程序。但实际上,有人报告了一些只有在 Phantomjs 中才会出现的问题。Selenium 使用 Chrome 或 Firefox 时不会出现这些问题。我喜欢从等式中删除这个变量以使用实际的 Web 浏览器驱动程序。 查看全部
chrome网页视频抓取(有关使用BeautifulSoup和Selenium进行网页爬取的相关资料关注)
摘要 今天小编就为大家讲解使用BeautifulSoup和Selenium进行网络爬虫。我相信你应该关注这个话题。小编还采集了一些
今天给大家讲解一下使用BeautifulSoup和Selenium进行网络爬虫。我相信你应该关注这个话题。我还采集了有关使用 BeautifulSoup 和 Selenium 进行网络爬虫的相关信息。合作伙伴看起来很有帮助。
出自:开源中国翻译频道英文原文概览
HTML 几乎是直截了当的。CSS 是一个很大的改进。它清楚地区分了页面的结构和外观。JavaScript 增添了一些魅力。理论上,情况确实如此。现实世界仍然有些不同。
在本教程中,您将了解您在浏览器中看到的内容是如何实际呈现的,以及如何在必要时抓取它。特别是,您将学习如何计算 Disqus 评论。我们的工具是 Python 和这种语言的优秀包,例如 request、BeautifulSoup 和 Selenium。
什么时候应该使用网络爬虫?
网络爬虫是一种自动获取网页内容的实践,旨在使人类用户能够相互交互、解析它们并提取一些信息(可能是指向其他页面的链接)。如果没有其他方法可以提取必要的网页信息,网络爬虫是一种必要且有效的技术方法。理想情况下,应用程序依靠提供良好的专用 API 以编程方式自动获取网页数据。但在以下情况下,最好不要使用网页抓取技术:
正在爬取的网页是脆弱的(您正在爬取的网页可能会经常更改)。
禁止爬行(某些 Web 应用程序具有禁止爬行的策略)。
爬取速度可能很慢,爬取的内容过于复杂(如果你需要在大量无用信息中寻找和涉猎你想要的东西)。
了解真实的网页
让我们通过查看一些常见的 Web 应用程序代码的实现来了解我们面临的问题。比如在《Vagrant 技术介绍》(链接:)页面底部有一些 Disqus 评论。为了抓取这些评论,我们需要先在页面上找到它们。
查看页面代码
从 1990 年代开始,每个浏览器都支持查看当前页面的 html 代码。以下是源代码视图中查看的“Vagrant 技术简介”帖子对应的源代码片段。本源代码以大量压缩丑陋的 JavaScript 代码开头,与本文内容无关。这是“小”部分之一:
这是页面中的一些实际 html 代码:
代码看起来很乱。在页面的源代码中找不到Disqus的评论,这让你有点意外。
强大的内联框架
原创页面是一个“混搭”,Disqus 评论嵌入在 iframe(内联框架)元素中。可以在评论区右击找到,在那里可以看到框架信息和源码。这是有道理的。将第三方内容嵌入到 iframe 中是使用 iframe 的主要应用场景之一。让我们在主页源代码中找到 iframe 标签。就是这样!主页源中没有 iframe 标记。
JavaScript 生成的标签
之所以省略,是因为查看页面源显示的是从服务器获取的内容。但是最终浏览器渲染出来的DOM(文档对象模型)可能会有很大的不同。JavaScript 开始工作并且可以随意操作 DOM。无法找到 iframe,因为从服务器检索页面时它不存在。
静态抓取与动态抓取
静态抓取会忽略 JavaScript,它可以直接从服务器获取网页代码,不依赖浏览器。这就是你通过“查看源代码”看到的,然后就可以提取信息了。如果要查找源代码中已经存在的内容,则无需进一步操作。但是,如果您要查找的内容像上面的 Disqus 评论一样嵌入在 iframe 中,则必须使用动态抓取来获取内容。
动态爬取使用真实浏览器(或非接口浏览器),首先让页面中的JavaScript运行,完成动态内容的处理和加载。之后,它会查询 DOM 以获取它要查找的内容。有时,您还需要让浏览器自动模拟人工操作来获取您需要的内容。
使用 Requests 和 BeautifulSoup 进行静态抓取
下面我们来看看如何使用两个经典的 Python 包进行静态爬取:requests 用于爬取网页内容。BeautifulSoup 用于解析 html。
安装 Requests 和 BeautifulSoup
先安装pipenv,然后运行命令:pipenv install requests beautifulsoup4
它首先为你创建一个虚拟环境,然后在虚拟环境中安装这两个包。如果你的代码在 gitlab 上,你可以使用命令 pipenv install 来安装它。
获取网页内容
只需要一行代码就可以抓取带有请求的网页内容:
r = requests.get(url)。
该代码返回一个响应对象,其中收录许多有用的属性。最重要的属性是 ok 和 content。如果请求失败, r.ok 为 False 并且 r.content 收录错误消息。content 代表一个字节流,作为 text 处理时最好解码成utf-8.
>>> r = requests.get('')>>> r.okFalse>>> 打印(r.content.decode('utf-8'))未找到
在此服务器上找不到请求的 URL /ggg。
端口 80 的 Apache/2.0.52 (CentOS) 服务器
如果代码正常返回并且没有报错,那么r.content会收录所请求网页的源代码(也就是你在“查看源代码”中看到的)。
使用 BeautifulSoup 查找元素
下面的 get_page() 函数会获取给定 URL 的网页源代码,然后将其解码为 utf-8,最后将内容传递给 BeautifulSoup 对象并返回。BeautifulSoup 使用 html 解析器进行解析。
def get_page(url): r = requests.get(url) content = r.content.decode('utf-8') return BeautifulSoup(content,'html.parser')
拿到 BeautifulSoup 对象后,我们就可以开始解析需要的信息了。
BeautifulSoup 提供了多种搜索方法来定位网页中的元素,并且可以深入挖掘嵌套元素。
Tuts+ 网站 里面有很多培训教程,这里()是我的主页。每个页面最多收录 12 个教程。如果您已经获得了12个教程,您可以转到下一页。一篇文章 文章 被标签包围。下面的功能是找到页面中所有的文章元素,然后找到对应的链接,最后提取教程的网址。
page = get_page('')articles = get_page_articles(page)prefix =''for a in article: print(a[len(prefix):]) 输出:building-games-with-python-3-and-pygame-part -5--cms-30085building-games-with-python-3-and-pygame-part-4--cms-30084building-games-with-python-3-and-pygame-part -3--cms-30083building-games-with-python-3-and-pygame-part-2--cms-30082building-games-with-python-3-and-pygame-part -1--cms-30081mastering-the-react-lifecycle-methods--cms-29849testing-data-integrated-code-with-go-part-5--cms- 29852testing-data-密集型代码与go-part-4--cms-29851testing-data-密集型代码与go-part-3--cms-29850testing-data-密集型代码与go-part-2--cms-29848testing-data-密集型代码与go-part-1--cms-29847 make-your-go-programs-lightning-fast-with-profiling--cms-29809 使用Selenium动态爬取
静态爬取非常适合一系列的文章,但是正如我们之前看到的,Disqus 的评论是由 JavaScript 写在 iframe 中的。为了获得这些注释,我们需要让浏览器自动与 DOM 交互。做这种事情的最好的工具之一是 Selenium。
Selenium 主要用于 Web 应用程序自动化测试,但它也是一个很好的通用浏览器自动化工具。
安装硒
使用以下命令安装 Selenium:
pipenv install selenium 选择您的网络驱动程序
Selenium 需要一个 Web 驱动程序(用于自动化的浏览器)。对于网络爬虫,您通常不需要关心您选择的驱动程序。我建议使用 Chrome 驱动程序。Selenium手册中有相关介绍。
比较 Chrome 和 Phantomjs
在某些情况下,您可能想要使用无头浏览器。理论上,Phantomjs 正是那个 Web 驱动程序。但实际上,有人报告了一些只有在 Phantomjs 中才会出现的问题。Selenium 使用 Chrome 或 Firefox 时不会出现这些问题。我喜欢从等式中删除这个变量以使用实际的 Web 浏览器驱动程序。
chrome网页视频抓取(Python实现抓取B站视频弹幕评论,废话不多说 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-09 01:21
)
前言
用Python捕捉B站视频弹幕评论,废话不多说。
让我们愉快的开始吧~
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文以爬取视频《“这是我见过最拽的中国奥运冠军”》为例,讲解如何爬取B站视频的弹幕和评论!
目标地址
https://www.bilibili.com/video/BV1wq4y1Q7dp
抢弹幕
网络分析
B站视频的弹幕不像TXSP。播放视频会触发弹幕数据包。他需要点击网页右侧弹幕列表行展开,然后点击查看历史弹幕,获取视频弹幕开始日期到结束日期链接:
在链接的末尾,使用oid和开始日期形成弹幕日期URL:
https://api.bilibili.com/x/v2/ ... 21-08
在此基础上,点击任一生效日期,即可获得该日期的弹幕数据包。里面的内容目前无法读取。之所以确定是弹幕数据包,是因为日期是点击他刚加载出来的,链接和上一个链接有关系:
获取到的网址:
https://api.bilibili.com/x/v2/ ... 08-08
URL中的oid是视频弹幕链接的id值;data参数是刚才的日期,要获取视频的所有弹幕内容,只需要修改data参数即可。data参数可以从上面弹幕日期url中获取,也可以自己构造;网页数据格式为json格式
代码
import requests\
import pandas as pd\
import re\
\
def data_resposen(url):\
headers = {\
"cookie": "你的cookie",\
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36"\
}\
resposen = requests.get(url, headers=headers)\
return resposen\
\
def main(oid, month):\
df = pd.DataFrame()\
url = f'https://api.bilibili.com/x/v2/dm/history/index?type=1&oid={oid}&month={month}'\
list_data = data_resposen(url).json()['data'] # 拿到所有日期\
print(list_data)\
for data in list_data:\
urls = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid={oid}&date={data}'\
text = re.findall(".*?([\u4E00-\u9FA5]+).*?", data_resposen(urls).text)\
for e in text:\
print(e)\
data = pd.DataFrame({'弹幕': [e]})\
df = pd.concat([df, data])\
df.to_csv('弹幕.csv', encoding='utf-8', index=False, mode='a+')\
\
if __name__ == '__main__':\
oid = '384801460' # 视频弹幕链接的id值\
month = '2021-08' # 开始日期\
main(oid, month)
显示结果
查看全部
chrome网页视频抓取(Python实现抓取B站视频弹幕评论,废话不多说
)
前言
用Python捕捉B站视频弹幕评论,废话不多说。
让我们愉快的开始吧~
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文以爬取视频《“这是我见过最拽的中国奥运冠军”》为例,讲解如何爬取B站视频的弹幕和评论!
目标地址
https://www.bilibili.com/video/BV1wq4y1Q7dp
抢弹幕
网络分析
B站视频的弹幕不像TXSP。播放视频会触发弹幕数据包。他需要点击网页右侧弹幕列表行展开,然后点击查看历史弹幕,获取视频弹幕开始日期到结束日期链接:

在链接的末尾,使用oid和开始日期形成弹幕日期URL:
https://api.bilibili.com/x/v2/ ... 21-08
在此基础上,点击任一生效日期,即可获得该日期的弹幕数据包。里面的内容目前无法读取。之所以确定是弹幕数据包,是因为日期是点击他刚加载出来的,链接和上一个链接有关系:

获取到的网址:
https://api.bilibili.com/x/v2/ ... 08-08
URL中的oid是视频弹幕链接的id值;data参数是刚才的日期,要获取视频的所有弹幕内容,只需要修改data参数即可。data参数可以从上面弹幕日期url中获取,也可以自己构造;网页数据格式为json格式
代码
import requests\
import pandas as pd\
import re\
\
def data_resposen(url):\
headers = {\
"cookie": "你的cookie",\
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36"\
}\
resposen = requests.get(url, headers=headers)\
return resposen\
\
def main(oid, month):\
df = pd.DataFrame()\
url = f'https://api.bilibili.com/x/v2/dm/history/index?type=1&oid={oid}&month={month}'\
list_data = data_resposen(url).json()['data'] # 拿到所有日期\
print(list_data)\
for data in list_data:\
urls = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid={oid}&date={data}'\
text = re.findall(".*?([\u4E00-\u9FA5]+).*?", data_resposen(urls).text)\
for e in text:\
print(e)\
data = pd.DataFrame({'弹幕': [e]})\
df = pd.concat([df, data])\
df.to_csv('弹幕.csv', encoding='utf-8', index=False, mode='a+')\
\
if __name__ == '__main__':\
oid = '384801460' # 视频弹幕链接的id值\
month = '2021-08' # 开始日期\
main(oid, month)
显示结果

chrome网页视频抓取(流媒体的插件....)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-11-03 14:11
在线视频网站 视频是一种流媒体。
1.
那么什么是流媒体?
【流媒体】是指将一系列媒体数据进行压缩,通过网络将数据分段传输,并在网络上实时传输视频和音频以供观看的技术和过程。该技术使数据包像流水一样发送;如果您不使用此技术,则必须在使用前下载整个媒体文件。流媒体可以传输实时视频或存储在服务器上的视频。当观众在观看这些视频文件时,视频数据将通过特定的播放软件(如Windows Media Player、Real Player 或QuickTime Player)进行播放。--维基百科]
简单地说,在线播放的视频和音乐被视为流媒体。它采用新的编码和压缩方式,在互联网上传输,然后当您观看时,播放器将再次解码和解压缩以进行播放。你说得对,播放的时候电脑上确实生成了一个缓存文件,但是这个缓存文件不是直接的媒体文件,所以不能直接播放。并且因为缓存是在播放过程中分段完成的,所以并不完整。
2.
Chrome有不少下载在线视频数据的插件,不过貌似是因为谷歌官方不允许这种插件出现在chrome应用商店中,所以过段时间大部分都失效了。
其实下载优酷的视频或者其他网站的视频在自己的客户端都有这个功能,比如优酷的iku,可以支持自己下载网站的视频。
或者装个火狐,它有个插件叫NetVideohunter,拦截流媒体的能力简直绝了…… 查看全部
chrome网页视频抓取(流媒体的插件....)
在线视频网站 视频是一种流媒体。
1.
那么什么是流媒体?
【流媒体】是指将一系列媒体数据进行压缩,通过网络将数据分段传输,并在网络上实时传输视频和音频以供观看的技术和过程。该技术使数据包像流水一样发送;如果您不使用此技术,则必须在使用前下载整个媒体文件。流媒体可以传输实时视频或存储在服务器上的视频。当观众在观看这些视频文件时,视频数据将通过特定的播放软件(如Windows Media Player、Real Player 或QuickTime Player)进行播放。--维基百科]
简单地说,在线播放的视频和音乐被视为流媒体。它采用新的编码和压缩方式,在互联网上传输,然后当您观看时,播放器将再次解码和解压缩以进行播放。你说得对,播放的时候电脑上确实生成了一个缓存文件,但是这个缓存文件不是直接的媒体文件,所以不能直接播放。并且因为缓存是在播放过程中分段完成的,所以并不完整。
2.
Chrome有不少下载在线视频数据的插件,不过貌似是因为谷歌官方不允许这种插件出现在chrome应用商店中,所以过段时间大部分都失效了。
其实下载优酷的视频或者其他网站的视频在自己的客户端都有这个功能,比如优酷的iku,可以支持自己下载网站的视频。
或者装个火狐,它有个插件叫NetVideohunter,拦截流媒体的能力简直绝了……
chrome网页视频抓取(插件安装方法安装包的方法和软件特色)
网站优化 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2021-10-29 21:04
从常用的 GET 和 POST 到 RESTful PUT、DELETE...等。您甚至可以发送文件和发送额外的标头。
2、采集功能(测试采集)
通过集合的分类,我们可以对软件提供的API进行分类和测试。还可以导入或共享集合,以便团队中的每个人都可以共享您构建的集合。
3、人性化响应组织
一般在使用其他工具进行测试时,响应的内容通常是纯文本的raw,但是如果是JSON,则打包成一整行JSON。这会造成阅读障碍,Postman 可以自动美化响应内容的格式。JSON、XML 或 HTML 将被组织成我们可以阅读的格式
4、内置测试脚本语言
支持编写测试脚本,可以快速查看请求结果,并返回测试结果
5、设置变量和环境
Postman 可以自由设置变量和环境。一般在编辑请求和验证响应时,我们总是需要重新输入某些字符,比如url,这允许我们设置变量来保存这些值。并将变量保存在不同的环境中。
软件特点
1、支持多种请求类型:get、post、put、patch、delete等。
2、 支持数据在线存储,数据可以通过账号迁移。
3、 支持设置请求头和请求参数非常方便。
4、支持不同的认证机制,包括Basic Auth、Digest Auth、OAuth 1.0、OAuth 2.0等。
5、 响应数据根据语法格式自动高亮显示,包括 HTML、JSON 和 XML。
安装方法
安装本地包
1、打开下载的postman谷歌插件安装包,解压到本地,打开应用,直接点击图标中的蓝色字体部分,直接进入Postman主界面。
2、如下图,这是Postman的主界面。
Chrome浏览器邮递员插件安装
由于chrome在2018年初停止支持chrome应用,目前可以安装postman插件,但是已经不能正常使用了。如果要安装Postman插件(本页下载包内有插件),谷歌浏览器插件的通用安装方法在这里~
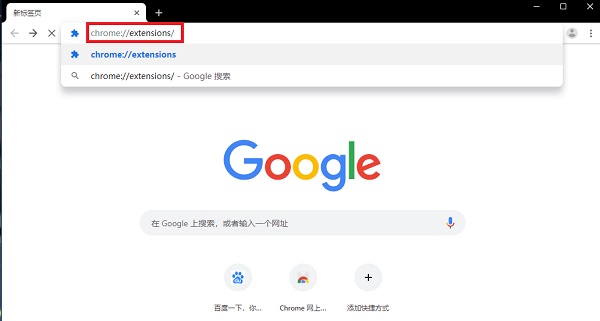
1、 在本地解压插件,打开谷歌浏览器,打开扩展程序界面,在chrome地址栏直接输入chrome://extensions/
2、 进入扩展页面,打开开发者模式,加载解压后的扩展,选择解压文件夹,安装成功后就可以看到postman了。
使用教程
当开发者需要调试网页是否正常运行时,不仅仅是调试网页的HTML、CSS、脚本等信息是否正常运行。更重要的是网页可以正确处理各种HTTP请求。毕竟网页的HTTP请求是网站与用户交互的一个非常重要的方式。在动态网站中,大部分用户的数据需要通过HTTP请求与服务器交互。
Postman 插件充当此交互方法的“桥梁”。它可以通过Chrome插件的形式,将模拟用户HTTP请求的各种数据发送到服务器,以便开发者及时做出正确的响应,或者发布产品。对之前的错误信息进行提前处理,保证产品上线后的稳定性和安全性。
在Chrome中安装Postman插件后,用户只需在调试网站时启动Postman插件,进行一些简单的配置即可修改网站的基本信息,发送各种类型网站,在发送HTTP数据时,用户可以在写入相关测试数据时添加一定的参数信息,使测试数据更加准确,Postman将完美支持这一切。
开发者在使用Postman时可能需要同时调试同一个网站或多个网站。每次Postman插件都要重新设置会很麻烦,Postman也考虑了满足用户的个性化需求,所以在Postman配置页面,用户可以自动添加或管理多个网站用户启动 Postman 时打开相应的设置。 查看全部
chrome网页视频抓取(插件安装方法安装包的方法和软件特色)
从常用的 GET 和 POST 到 RESTful PUT、DELETE...等。您甚至可以发送文件和发送额外的标头。
2、采集功能(测试采集)
通过集合的分类,我们可以对软件提供的API进行分类和测试。还可以导入或共享集合,以便团队中的每个人都可以共享您构建的集合。
3、人性化响应组织
一般在使用其他工具进行测试时,响应的内容通常是纯文本的raw,但是如果是JSON,则打包成一整行JSON。这会造成阅读障碍,Postman 可以自动美化响应内容的格式。JSON、XML 或 HTML 将被组织成我们可以阅读的格式
4、内置测试脚本语言
支持编写测试脚本,可以快速查看请求结果,并返回测试结果
5、设置变量和环境
Postman 可以自由设置变量和环境。一般在编辑请求和验证响应时,我们总是需要重新输入某些字符,比如url,这允许我们设置变量来保存这些值。并将变量保存在不同的环境中。
软件特点
1、支持多种请求类型:get、post、put、patch、delete等。
2、 支持数据在线存储,数据可以通过账号迁移。
3、 支持设置请求头和请求参数非常方便。
4、支持不同的认证机制,包括Basic Auth、Digest Auth、OAuth 1.0、OAuth 2.0等。
5、 响应数据根据语法格式自动高亮显示,包括 HTML、JSON 和 XML。
安装方法
安装本地包
1、打开下载的postman谷歌插件安装包,解压到本地,打开应用,直接点击图标中的蓝色字体部分,直接进入Postman主界面。
2、如下图,这是Postman的主界面。
Chrome浏览器邮递员插件安装
由于chrome在2018年初停止支持chrome应用,目前可以安装postman插件,但是已经不能正常使用了。如果要安装Postman插件(本页下载包内有插件),谷歌浏览器插件的通用安装方法在这里~
1、 在本地解压插件,打开谷歌浏览器,打开扩展程序界面,在chrome地址栏直接输入chrome://extensions/
2、 进入扩展页面,打开开发者模式,加载解压后的扩展,选择解压文件夹,安装成功后就可以看到postman了。
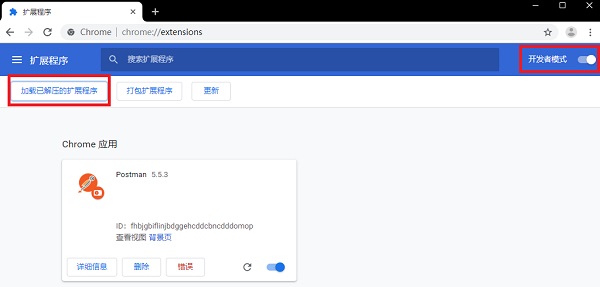
使用教程
当开发者需要调试网页是否正常运行时,不仅仅是调试网页的HTML、CSS、脚本等信息是否正常运行。更重要的是网页可以正确处理各种HTTP请求。毕竟网页的HTTP请求是网站与用户交互的一个非常重要的方式。在动态网站中,大部分用户的数据需要通过HTTP请求与服务器交互。
Postman 插件充当此交互方法的“桥梁”。它可以通过Chrome插件的形式,将模拟用户HTTP请求的各种数据发送到服务器,以便开发者及时做出正确的响应,或者发布产品。对之前的错误信息进行提前处理,保证产品上线后的稳定性和安全性。
在Chrome中安装Postman插件后,用户只需在调试网站时启动Postman插件,进行一些简单的配置即可修改网站的基本信息,发送各种类型网站,在发送HTTP数据时,用户可以在写入相关测试数据时添加一定的参数信息,使测试数据更加准确,Postman将完美支持这一切。
开发者在使用Postman时可能需要同时调试同一个网站或多个网站。每次Postman插件都要重新设置会很麻烦,Postman也考虑了满足用户的个性化需求,所以在Postman配置页面,用户可以自动添加或管理多个网站用户启动 Postman 时打开相应的设置。
chrome网页视频抓取(WebScraper(chrome网页最新版浏览器)插件安装使用使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2021-10-11 01:14
Web Scraper(最新版的chrome网页为Web Scraper(最新版的chrome网页来自网页的最新版规则,以便快速提取网页中需要的内容。Web Scraper (最新版chrome网页的整个爬取逻辑都是从设置一级Selector(dian)开始,选择爬取范围,然后一级Selector设置二级Selector后,再次选择抓取字段,然后就可以抓取Web Scraper(最新版chrome网页了。插件抓取数据后,还可以将数据(chu)导出为CSV文件,欢迎免费下载。
Web Scraper(最新版chrome网页介绍
1. 抓取多个页面2、 读取的数据存储在本地存储或 CouchDB 中。Scraper(最新版chrome网页ipt+AJAX)5、浏览抓取的数据6、导出为CSV7、导入、导出站点地图8、只依赖于Web Scraper(最新版chrome浏览器,插件安装使用一、Install1、小编这里是Web Scraper(最新版chrome浏览器,先进入Web Scraper(最新版的chrome网页)://extensions/:进入Web Scraper(最新版chrome网页扩展,解压Web Scraper(你在本页下载的最新版chrome网页,拖入扩展页面。 2、 安装完成后抓紧时间)尝试插件的具体功能。3、当然可以先在设置页面设置插件的存储设置和存储类型功能。二、 使用抓取功能安装完成后,只需四步即可完成抓取操作。具体流程如下:1、打开Web Scraper(最新版chrome网页首先需要使用此插件进行Web Scraper(最新版chrome网页需要在开发者工具模式下使用,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 使用抓取功能安装完成后,只需四步即可完成抓取操作。具体流程如下:1、打开Web Scraper(最新版chrome网页首先需要使用此插件进行Web Scraper(最新版chrome网页需要在开发者工具模式下使用,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 使用抓取功能安装完成后,只需四步即可完成抓取操作。具体流程如下:1、打开Web Scraper(最新版chrome网页首先需要使用此插件进行Web Scraper(最新版chrome网页需要在开发者工具模式下使用,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。
我抓取今日头条的数据,然后用今日头条来命名;Web Scraper(chrome网页最新版itWeb Scraper(chrome网页最新版网址:将网页链接复制到星号网址栏,例如图中,我把“吴晓波频道”的首页链接复制到这个栏,然后点击下面的Web Scraper(最新版chrome网页te satWeb Scraper(最新版chrome网页新建SitWeb Scraper(chrome最新版网站)。
3、 设置这个SitWeb Scraper(最新版chrome网页和整个Web Scraper(最新版chrome网页有如下爬取逻辑:设置一级Selector,选择爬取范围;在一级SelectWeb Scraper(最新版chrome网页)设置二级Selector,选择捕获字段,然后捕获。对于文章,一级Selector意味着你要圈住这个文章的元素@>,这个元素可能包括标题、作者、发布时间、评论数等,然后我们在二级Selector中挑出我们想要的元素,比如标题、作者、阅读次数。我们来拆解一下这个设置主次选择器的工作流程:(1)点击Add nWeb Scraper(最新版chrome网页创建一级Selector。然后按照以下步骤操作:-输入id:id代表你抓取的整个范围,例如这里是文章 ,我们可以命名为wuxiWeb Scraper(最新版chrome网页-文章;-Select Type:类型代表你抓取的部分的类型,比如element/text/link,因为这是整个文章元素范围,我们需要先Use Element全选(如果这个网页需要滑动加载更多,则选择ElementWeb Scraper(最新版chrome网页ll Down);-check Multiple:勾选中的小框前面的Multiple,因为要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮我们识别多篇同类型的文章文章;-保留设置:其余未提及部分保留默认设置。
所以你可以学习该领域的英语。比如我要选择“作者”,我就写“作者”;-选择类型:选择文本,因为你要抓取的是文本;-不要勾选多个:不要勾选前面的小方框多个,因为我们将在这里抓取单个元素;-保留设置:保留其余未提及部分的默认设置。(4)点击选择,然后点击要爬取的字段,按照以下步骤操作: -选择一个字段:这里要爬取的字段为单个字段,点击用鼠标抓取字段,比如要爬取标题,鼠标点击某篇文章文章的标题,当字段所在的区域变成红色时,即被选中; -Complete选择:
(5)重复以上操作,直到选中要爬取的字段。4、爬网爬虫(chrome网页最新版本后,只需要设置好所有的Selectors,启动:点击Web Scraper(最新版的chrome网页,然后点击StartWeb Scraper(最新版的chrome网页),弹出一个小窗口后,爬虫就开始工作了。你会得到一个列表所有你想要的数据。(2)如果你想对数据进行排序,比如按阅读、喜欢、作者等指标排序,让数据更清晰,那么你可以点击Export DatWeb Scraper(最新的版本的chrome网页,并导入到Excel表格中。(3)导入Excel表格后,可以过滤数据。
Web Scraper(最新版chrome网页摘要
网络爬虫(chrome网页V4.60是一款适用于ios版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友: 查看全部
chrome网页视频抓取(WebScraper(chrome网页最新版浏览器)插件安装使用使用方法)
Web Scraper(最新版的chrome网页为Web Scraper(最新版的chrome网页来自网页的最新版规则,以便快速提取网页中需要的内容。Web Scraper (最新版chrome网页的整个爬取逻辑都是从设置一级Selector(dian)开始,选择爬取范围,然后一级Selector设置二级Selector后,再次选择抓取字段,然后就可以抓取Web Scraper(最新版chrome网页了。插件抓取数据后,还可以将数据(chu)导出为CSV文件,欢迎免费下载。
Web Scraper(最新版chrome网页介绍
1. 抓取多个页面2、 读取的数据存储在本地存储或 CouchDB 中。Scraper(最新版chrome网页ipt+AJAX)5、浏览抓取的数据6、导出为CSV7、导入、导出站点地图8、只依赖于Web Scraper(最新版chrome浏览器,插件安装使用一、Install1、小编这里是Web Scraper(最新版chrome浏览器,先进入Web Scraper(最新版的chrome网页)://extensions/:进入Web Scraper(最新版chrome网页扩展,解压Web Scraper(你在本页下载的最新版chrome网页,拖入扩展页面。 2、 安装完成后抓紧时间)尝试插件的具体功能。3、当然可以先在设置页面设置插件的存储设置和存储类型功能。二、 使用抓取功能安装完成后,只需四步即可完成抓取操作。具体流程如下:1、打开Web Scraper(最新版chrome网页首先需要使用此插件进行Web Scraper(最新版chrome网页需要在开发者工具模式下使用,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 使用抓取功能安装完成后,只需四步即可完成抓取操作。具体流程如下:1、打开Web Scraper(最新版chrome网页首先需要使用此插件进行Web Scraper(最新版chrome网页需要在开发者工具模式下使用,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 使用抓取功能安装完成后,只需四步即可完成抓取操作。具体流程如下:1、打开Web Scraper(最新版chrome网页首先需要使用此插件进行Web Scraper(最新版chrome网页需要在开发者工具模式下使用,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。
我抓取今日头条的数据,然后用今日头条来命名;Web Scraper(chrome网页最新版itWeb Scraper(chrome网页最新版网址:将网页链接复制到星号网址栏,例如图中,我把“吴晓波频道”的首页链接复制到这个栏,然后点击下面的Web Scraper(最新版chrome网页te satWeb Scraper(最新版chrome网页新建SitWeb Scraper(chrome最新版网站)。
3、 设置这个SitWeb Scraper(最新版chrome网页和整个Web Scraper(最新版chrome网页有如下爬取逻辑:设置一级Selector,选择爬取范围;在一级SelectWeb Scraper(最新版chrome网页)设置二级Selector,选择捕获字段,然后捕获。对于文章,一级Selector意味着你要圈住这个文章的元素@>,这个元素可能包括标题、作者、发布时间、评论数等,然后我们在二级Selector中挑出我们想要的元素,比如标题、作者、阅读次数。我们来拆解一下这个设置主次选择器的工作流程:(1)点击Add nWeb Scraper(最新版chrome网页创建一级Selector。然后按照以下步骤操作:-输入id:id代表你抓取的整个范围,例如这里是文章 ,我们可以命名为wuxiWeb Scraper(最新版chrome网页-文章;-Select Type:类型代表你抓取的部分的类型,比如element/text/link,因为这是整个文章元素范围,我们需要先Use Element全选(如果这个网页需要滑动加载更多,则选择ElementWeb Scraper(最新版chrome网页ll Down);-check Multiple:勾选中的小框前面的Multiple,因为要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮我们识别多篇同类型的文章文章;-保留设置:其余未提及部分保留默认设置。
所以你可以学习该领域的英语。比如我要选择“作者”,我就写“作者”;-选择类型:选择文本,因为你要抓取的是文本;-不要勾选多个:不要勾选前面的小方框多个,因为我们将在这里抓取单个元素;-保留设置:保留其余未提及部分的默认设置。(4)点击选择,然后点击要爬取的字段,按照以下步骤操作: -选择一个字段:这里要爬取的字段为单个字段,点击用鼠标抓取字段,比如要爬取标题,鼠标点击某篇文章文章的标题,当字段所在的区域变成红色时,即被选中; -Complete选择:
(5)重复以上操作,直到选中要爬取的字段。4、爬网爬虫(chrome网页最新版本后,只需要设置好所有的Selectors,启动:点击Web Scraper(最新版的chrome网页,然后点击StartWeb Scraper(最新版的chrome网页),弹出一个小窗口后,爬虫就开始工作了。你会得到一个列表所有你想要的数据。(2)如果你想对数据进行排序,比如按阅读、喜欢、作者等指标排序,让数据更清晰,那么你可以点击Export DatWeb Scraper(最新的版本的chrome网页,并导入到Excel表格中。(3)导入Excel表格后,可以过滤数据。
Web Scraper(最新版chrome网页摘要
网络爬虫(chrome网页V4.60是一款适用于ios版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:
chrome网页视频抓取( 谷歌开发一种可以自动将网页转换为短视频的AI系统URL2Video)
网站优化 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-10-08 16:35
谷歌开发一种可以自动将网页转换为短视频的AI系统URL2Video)
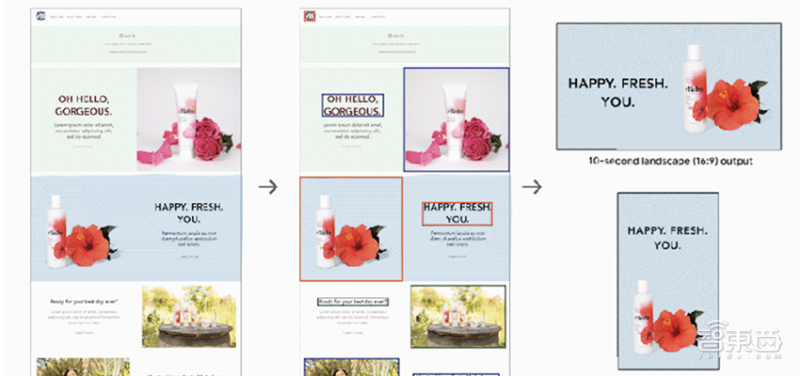
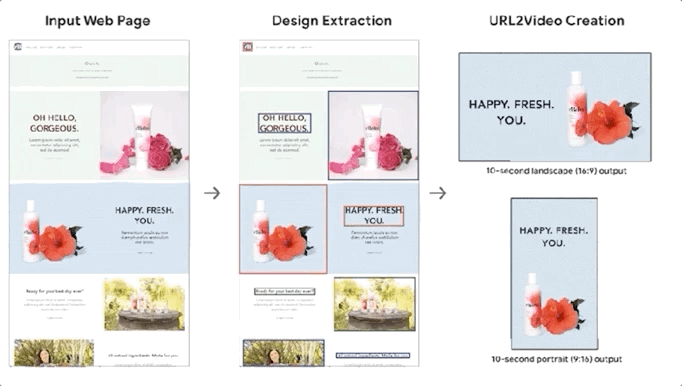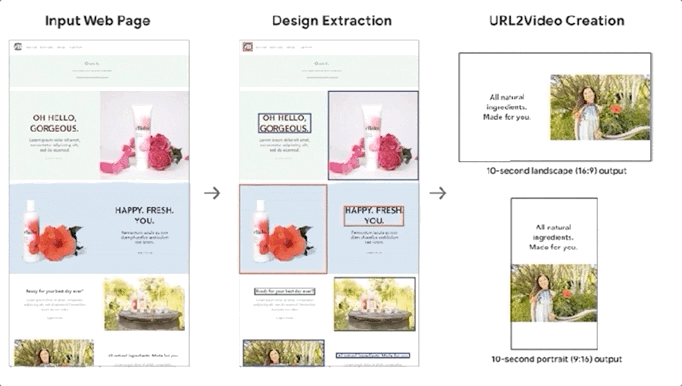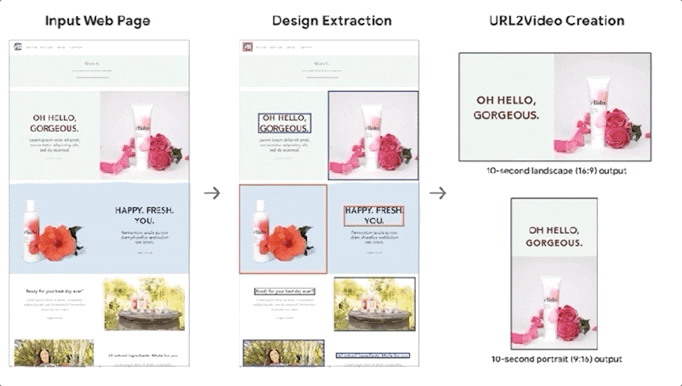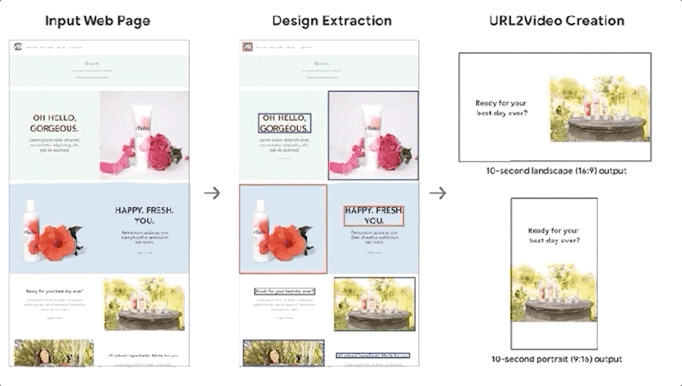
Smart Things 10 月 30 日报道称,谷歌表示正在开发一个 AI 系统 URL2Video,可以自动将网页转换为短视频。系统可以自动从HTML中提取文本、图片、字体、颜色、布局等设计模板,并将这些元素组合成与原创网页相似的视频。
该系统主要针对有产品和服务的详细网页介绍,但还没有提供视频介绍的公司。
谷歌表示,通过 URL2Video 处理网络信息将使产品和服务以视频的形式接触到更多的受众。而相对于传统视频制作需要几天到几周的制作周期和880到1200美元的制作成本,URL2Video有着无可比拟的优势。
URL2Video 在与专业编辑讨论的基础上,采用启发式方法确定视频编辑模板,包括内容级别、视频信息量和每个元素的时长。URL2Video 使用这种方法来解析网页,分析内容,选择关键文本或图像,保留相似的设计风格,并根据用户的具体需求进行修改。
如果我们看看这个神奇功能背后的原理,就会发现视频转换技术离不开网页元素的分类排序。
URL2Video 会从每个网页中提取文档对象模型信息和多媒体资料,并将视觉上可区分的内容标记为视频中的可用元素,包括标题、产品图片、文字说明和外部链接。
URL2Video 提取的每个元素(即文本和多媒体文件)和网页相关信息(HTML 标签、CSS 样式等)都会根据它们在原创网页上的重要性进行排序和注释,以获得不同的优先级,例如在网页顶部 占据较大区域的元素将获得更高的分数和优先级。
基于上述元素排名和启发式视频编辑模板,URL2Video可以得到视频中每个元素的最佳停留时间和位置分布。
将网页转换为视频的最后一步是格式调整。URL2Video 将图片的大小转换成适合视频屏幕的纵横比,根据风格和主题确定视频使用的字体和颜色,然后转换成MPEG-4格式。
为了使视频简洁,URL2Video 只显示网页的主要元素,如标题和主要产品图片,并且会限制每个元素在视频中的停留时间。
谷歌表示,在用户研究和测试中,URL2Video已经能够高效地从网页中提取元素,并通过交互功能键辅助用户进行编辑。
谷歌科学家 Peggy Chi 和 Irfan Essa 在他们的博客中写道:“虽然目前的研究重点是视觉呈现,但我们正在研究视频编辑中的音轨和画外音等技术。总之,我们认为方便的视频剪辑是大势所趋,而机器学习模型可以以交互的形式给剪辑师排版和排版的建议,从而快速制作出多个高质量的视频。” 查看全部
chrome网页视频抓取(
谷歌开发一种可以自动将网页转换为短视频的AI系统URL2Video)
Smart Things 10 月 30 日报道称,谷歌表示正在开发一个 AI 系统 URL2Video,可以自动将网页转换为短视频。系统可以自动从HTML中提取文本、图片、字体、颜色、布局等设计模板,并将这些元素组合成与原创网页相似的视频。

该系统主要针对有产品和服务的详细网页介绍,但还没有提供视频介绍的公司。
谷歌表示,通过 URL2Video 处理网络信息将使产品和服务以视频的形式接触到更多的受众。而相对于传统视频制作需要几天到几周的制作周期和880到1200美元的制作成本,URL2Video有着无可比拟的优势。
URL2Video 在与专业编辑讨论的基础上,采用启发式方法确定视频编辑模板,包括内容级别、视频信息量和每个元素的时长。URL2Video 使用这种方法来解析网页,分析内容,选择关键文本或图像,保留相似的设计风格,并根据用户的具体需求进行修改。
如果我们看看这个神奇功能背后的原理,就会发现视频转换技术离不开网页元素的分类排序。
URL2Video 会从每个网页中提取文档对象模型信息和多媒体资料,并将视觉上可区分的内容标记为视频中的可用元素,包括标题、产品图片、文字说明和外部链接。
URL2Video 提取的每个元素(即文本和多媒体文件)和网页相关信息(HTML 标签、CSS 样式等)都会根据它们在原创网页上的重要性进行排序和注释,以获得不同的优先级,例如在网页顶部 占据较大区域的元素将获得更高的分数和优先级。
基于上述元素排名和启发式视频编辑模板,URL2Video可以得到视频中每个元素的最佳停留时间和位置分布。
将网页转换为视频的最后一步是格式调整。URL2Video 将图片的大小转换成适合视频屏幕的纵横比,根据风格和主题确定视频使用的字体和颜色,然后转换成MPEG-4格式。
为了使视频简洁,URL2Video 只显示网页的主要元素,如标题和主要产品图片,并且会限制每个元素在视频中的停留时间。
谷歌表示,在用户研究和测试中,URL2Video已经能够高效地从网页中提取元素,并通过交互功能键辅助用户进行编辑。
谷歌科学家 Peggy Chi 和 Irfan Essa 在他们的博客中写道:“虽然目前的研究重点是视觉呈现,但我们正在研究视频编辑中的音轨和画外音等技术。总之,我们认为方便的视频剪辑是大势所趋,而机器学习模型可以以交互的形式给剪辑师排版和排版的建议,从而快速制作出多个高质量的视频。”
chrome网页视频抓取(猫抓这款Chrome插件的特色亮点及特色功能介绍(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 344 次浏览 • 2021-10-06 16:08
当我想下载音乐视频但没有下载选项或下载限制时,我该怎么办?那么你需要一个网络媒体捕捉器。当您想下载但受到限制时,它将帮助您捕获页面上的所有媒体。您可以选择自己喜欢的内容进行下载。抓住这个Chrome插件就有这样的功能。
猫扎是一款网页媒体嗅探工具插件,可以嗅探获取任意网页中的视频链接等数据,一键获取所需链接并自动保存。使用非常方便,打开需要下载文件的网站。可以抓取页面收录的所有链接内容,然后选择要下载的内容下载到本地电脑,方便使用!
插件功能
1、 支持从任何站点抓取任何数据;
2、多个站点可以同时更新;
3、 支持使用正则表达式自定义要抓取的内容。
精选亮点
1、是一款Chrome嗅探音乐视频插件,大小只有几十k。
2、 无论是看视频还是听音乐,都可以使用猫爪插件进行抓拍,只需点击下载即可。
3、也可以在设置中自定义配置,还可以抓取图片、文档等各种资源文件。
4、当然还有更多,可以和IDM一起使用。这么多素材来源,慢慢练习就能成为剪辑大师。
指示
将下载的插件添加到Chrome浏览器后,它会一直帮你在打开的网页中抓取可下载的网页媒体。如果当前网页可以下载媒体,打开右上角的插件列表就会打开。显示没有捕获到资源。
当然,如果有西苑可供下载,就会显示数量。当您单击要捕获媒体的页面时,您可以看到猫的图标上显示一个数字。该数字表示当前页面上捕获的媒体数量。打开后,将显示可下载的媒体。您可以选择如果要下载,只需下载即可。如下所示
如果有视频可以下载,后面会有观看图标,可以查看是否是你要下载的内容然后下载
很多媒体往往可以在一个页面上抓取,当数量很大时,你也可以批量处理这些下载
快来下载猫咪体验吧~
插件下载地址: 查看全部
chrome网页视频抓取(猫抓这款Chrome插件的特色亮点及特色功能介绍(图))
当我想下载音乐视频但没有下载选项或下载限制时,我该怎么办?那么你需要一个网络媒体捕捉器。当您想下载但受到限制时,它将帮助您捕获页面上的所有媒体。您可以选择自己喜欢的内容进行下载。抓住这个Chrome插件就有这样的功能。
猫扎是一款网页媒体嗅探工具插件,可以嗅探获取任意网页中的视频链接等数据,一键获取所需链接并自动保存。使用非常方便,打开需要下载文件的网站。可以抓取页面收录的所有链接内容,然后选择要下载的内容下载到本地电脑,方便使用!
插件功能
1、 支持从任何站点抓取任何数据;
2、多个站点可以同时更新;
3、 支持使用正则表达式自定义要抓取的内容。
精选亮点
1、是一款Chrome嗅探音乐视频插件,大小只有几十k。
2、 无论是看视频还是听音乐,都可以使用猫爪插件进行抓拍,只需点击下载即可。
3、也可以在设置中自定义配置,还可以抓取图片、文档等各种资源文件。
4、当然还有更多,可以和IDM一起使用。这么多素材来源,慢慢练习就能成为剪辑大师。
指示
将下载的插件添加到Chrome浏览器后,它会一直帮你在打开的网页中抓取可下载的网页媒体。如果当前网页可以下载媒体,打开右上角的插件列表就会打开。显示没有捕获到资源。
当然,如果有西苑可供下载,就会显示数量。当您单击要捕获媒体的页面时,您可以看到猫的图标上显示一个数字。该数字表示当前页面上捕获的媒体数量。打开后,将显示可下载的媒体。您可以选择如果要下载,只需下载即可。如下所示
如果有视频可以下载,后面会有观看图标,可以查看是否是你要下载的内容然后下载
很多媒体往往可以在一个页面上抓取,当数量很大时,你也可以批量处理这些下载
快来下载猫咪体验吧~
插件下载地址:
chrome网页视频抓取(猫抓支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
网站优化 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2021-10-06 06:19
猫抓
Mozhao 是一个扩展,支持所有 Chrome 内核浏览器的网络媒体嗅探和抓取。
它可以一键抓取任何站点的任何视频/音频数据,使用起来非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮可以看到页面上的资源信息。
然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地。
猫扎支持优酷、搜狐、腾讯、微博、B站等几乎所有国内网站视频文件嗅探。
当多个媒体资源出现在同一页面时,您还可以对其进行快速批量操作。
一般来说,这类嗅探工具支持的视频文件是未加密的。当面对一些加密的视频时,会有一定的失败几率。
但是,从市场反馈来看,猫筹可以抢到很多其他IDM无法嗅探的媒体资源。
这也是其竞争激烈的拓展店能拥有超过5万用户的原因之一。
此外,毛爪还支持所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,还支持使用正则表达式自定义采集的内容。
网络嗅探器最初是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。Sniffer 也是很多程序员在编写网络程序时捕捉和测试的工具。
近年来,网络嗅探器被广泛应用于用户的日常行为中,成为捕捉视频、音频等内容的工具。
点击这里下载
Github地址 查看全部
chrome网页视频抓取(猫抓支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
猫抓

Mozhao 是一个扩展,支持所有 Chrome 内核浏览器的网络媒体嗅探和抓取。
它可以一键抓取任何站点的任何视频/音频数据,使用起来非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮可以看到页面上的资源信息。
然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地。
猫扎支持优酷、搜狐、腾讯、微博、B站等几乎所有国内网站视频文件嗅探。
当多个媒体资源出现在同一页面时,您还可以对其进行快速批量操作。
一般来说,这类嗅探工具支持的视频文件是未加密的。当面对一些加密的视频时,会有一定的失败几率。
但是,从市场反馈来看,猫筹可以抢到很多其他IDM无法嗅探的媒体资源。
这也是其竞争激烈的拓展店能拥有超过5万用户的原因之一。
此外,毛爪还支持所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,还支持使用正则表达式自定义采集的内容。
网络嗅探器最初是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。Sniffer 也是很多程序员在编写网络程序时捕捉和测试的工具。
近年来,网络嗅探器被广泛应用于用户的日常行为中,成为捕捉视频、音频等内容的工具。
点击这里下载
Github地址
chrome网页视频抓取(和入门ffmpeg开FFmpeg官方网站有了神器何不自己写个工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-06 04:33
前几天有同学说想下载网站的视频,找不到连接。他问我是否可以做些什么。当时觉得应该很简单,就说抽空看看。然后它分析了目标网页,并试图从网页的源代码中找到链接,但失败了。F12调出开发者工具,进入NetWrok,看到网页是通过ajax发起的xhr请求获取的视频连接。难怪页面元素里没有下载地址。请求是一个 m3u8 格式的文件。我查了一下这是一个支离破碎的流媒体。文件,然后到处找工具下载这个格式文件,不是很理想。很多都是分片后直接下载的ts文件,但是这个网站 已加密,无法直接播放。终于找到了ffmpeg视频插件神器,视频转码、剪切、合并、播放。不用说,它还支持多个平台。
FFmpeg 介绍和入门 FFmpeg
ffmpeg开启FFmpeg官方网站
有了神器,何不自己写个工具自己下载。当您准备好这样做时,您首先会被如何获得连接的问题所阻碍。本来只是想写个小爬虫,爬取网页连接。结果不起作用。Ajax动态发起的请求的网页元素中没有数据,对js不熟悉。我不知道如何获得这种数据。同学们可以手动打开浏览器F12找到连接吗?这不是我的风格:) 然后继续各种搜索,得到结果,自己实现浏览器,拦截网页的所有请求,你一定会得到的。筛选后得到三个选项:
1.WebBrowser.
2.GeokoFx.
3.CefSharp.
第一次尝试WebBrowser,目标网站无法直接打开网页,于是换了谷歌浏览器,修改了UserAgent打开,但是网页没有完全显示出来,就放弃了。然后,可以直接打开GeokoFx,速度还不错,但是有些连接点击没有反应,只能放弃。最后用CefSharp测试达到了预期的目的,就是无法打开flash和H264视频。折腾了一天,官方说不支持版权问题,需要自己修改。我找到了一个修改过的库。我找到了一个支持flash和H264视频的库:
提取码:dfdr
是nupkg的安装包,查看nupkg的安装方法
然后编写代码:
获取视频地址,继承和集成默认抽象类DefaultRequestHandler就够了。
public class MyRequestHandler : DefaultRequestHandler
{
public override CefReturnValue OnBeforeResourceLoad(IWebBrowser browserControl, IBrowser browser, IFrame frame, IRequest request, IRequestCallback callback)
{
//拿到url后再判断下是不是视频文件
string url = request.Url;
}
}
然后在初始化浏览器时指定它。
chromeBrowser.RequestHandler = new MyRequestHandler(callback);
这里我从url中提取文件名,然后判断扩展名来判断是否是视频文件。不知道有没有更通用的方法。无法判断ResourceType == ResourceType.Media。在许多情况下,返回的值是 xhr。
FFmpeg部分就是直接命令行调用下,有时间再研究下这个神器的lib方式。
下面是折腾了几天的结果。
在这里可以下载、播放等操作,界面有点丑,功能实现了。
下载支持续传,但是m3u8分片文件没有保存断点,所以关闭软件后续传无法恢复,必须重启。直播流的大小无法预测,因此不显示进度,但会及时更新下载的数据大小。
一般情况下不需要下载ts文件,直接下载m3u8,程序会自动分析ts片段文件,下载完所有文件后自动合成一个mp4文件。
软件下载: 链接:
提取码:n6q4
如果还是不行,请下载安装NET Framework4.6.1 查看全部
chrome网页视频抓取(和入门ffmpeg开FFmpeg官方网站有了神器何不自己写个工具)
前几天有同学说想下载网站的视频,找不到连接。他问我是否可以做些什么。当时觉得应该很简单,就说抽空看看。然后它分析了目标网页,并试图从网页的源代码中找到链接,但失败了。F12调出开发者工具,进入NetWrok,看到网页是通过ajax发起的xhr请求获取的视频连接。难怪页面元素里没有下载地址。请求是一个 m3u8 格式的文件。我查了一下这是一个支离破碎的流媒体。文件,然后到处找工具下载这个格式文件,不是很理想。很多都是分片后直接下载的ts文件,但是这个网站 已加密,无法直接播放。终于找到了ffmpeg视频插件神器,视频转码、剪切、合并、播放。不用说,它还支持多个平台。
FFmpeg 介绍和入门 FFmpeg
ffmpeg开启FFmpeg官方网站
有了神器,何不自己写个工具自己下载。当您准备好这样做时,您首先会被如何获得连接的问题所阻碍。本来只是想写个小爬虫,爬取网页连接。结果不起作用。Ajax动态发起的请求的网页元素中没有数据,对js不熟悉。我不知道如何获得这种数据。同学们可以手动打开浏览器F12找到连接吗?这不是我的风格:) 然后继续各种搜索,得到结果,自己实现浏览器,拦截网页的所有请求,你一定会得到的。筛选后得到三个选项:
1.WebBrowser.
2.GeokoFx.
3.CefSharp.
第一次尝试WebBrowser,目标网站无法直接打开网页,于是换了谷歌浏览器,修改了UserAgent打开,但是网页没有完全显示出来,就放弃了。然后,可以直接打开GeokoFx,速度还不错,但是有些连接点击没有反应,只能放弃。最后用CefSharp测试达到了预期的目的,就是无法打开flash和H264视频。折腾了一天,官方说不支持版权问题,需要自己修改。我找到了一个修改过的库。我找到了一个支持flash和H264视频的库:
提取码:dfdr
是nupkg的安装包,查看nupkg的安装方法
然后编写代码:
获取视频地址,继承和集成默认抽象类DefaultRequestHandler就够了。
public class MyRequestHandler : DefaultRequestHandler
{
public override CefReturnValue OnBeforeResourceLoad(IWebBrowser browserControl, IBrowser browser, IFrame frame, IRequest request, IRequestCallback callback)
{
//拿到url后再判断下是不是视频文件
string url = request.Url;
}
}
然后在初始化浏览器时指定它。
chromeBrowser.RequestHandler = new MyRequestHandler(callback);
这里我从url中提取文件名,然后判断扩展名来判断是否是视频文件。不知道有没有更通用的方法。无法判断ResourceType == ResourceType.Media。在许多情况下,返回的值是 xhr。
FFmpeg部分就是直接命令行调用下,有时间再研究下这个神器的lib方式。
下面是折腾了几天的结果。

在这里可以下载、播放等操作,界面有点丑,功能实现了。
下载支持续传,但是m3u8分片文件没有保存断点,所以关闭软件后续传无法恢复,必须重启。直播流的大小无法预测,因此不显示进度,但会及时更新下载的数据大小。
一般情况下不需要下载ts文件,直接下载m3u8,程序会自动分析ts片段文件,下载完所有文件后自动合成一个mp4文件。
软件下载: 链接:
提取码:n6q4
如果还是不行,请下载安装NET Framework4.6.1
chrome网页视频抓取(除了手动安装扩展还可以安装个谷歌助手(微信edge))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-05 09:01
第285章原创文章苏生不服,把这个公众号设为star,第一时间看到最新的文章。
换句话说,没有扩展的浏览器是没有灵魂的。我分享了几篇关于Chrome扩展文章的文章(微信edge也可以安装使用),这里是第六篇:
除了手动安装扩展,你还可以安装一个谷歌助手(在公众号后台回复浏览器获取扩展),这样你就可以直接打开谷歌商店进行安装。
猫抓
这是一个音乐和视频资源嗅探神器,但它已被chrome删除。下载后只能手动安装。播放完视频后,点击扩展程序下载视频。如果部分视频无法下载,请参考文章
另存为 MHT
我以前共享过扩展单文件。这个也可以完美离线下载导出网页,直接将网页打包保存成文件(保留排版、图片、动图等格式),扩展地址,比如保存这篇文章文章@的效果>:
窗口标签管理器
一次打开太多窗口,占用资源?遇到麻烦不敢关掉,怕找不到?本扩展支持一键保存和打开所有网页,支持书签、历史记录和标签、扩展地址的聚合搜索
石脑油计划
本扩展可以选择、复制、编辑、翻译图片中嵌入的文字(仅支持英文),扩展地址
代理 SwitchyOmega
此扩展可以帮助您轻松快速地管理和切换多个代理设置、扩展地址
潮汐
这是一款白噪声专注定时器,可帮助您保持专注,提高工作和学习效率,扩展您的地址,并在您工作太累时聆听海浪的声音。
梦词翻译
这是为阅读和学习外语而开发的翻译和单词搜索工具。它汇集了数十种在线词典和在线翻译。扩展地址为 %E6%A2%A6%E6%83%B3%E5%88%92%E8 %AF%8D%E7%BF%BB%E8%AF%91%E2%80%94%E8%81 %9A%E5%90%88%E8%AF%8D%E5%85%B8%E6%90%9C%E7%B4%A2/odfgigmpkhhhieicogijogfobfipijjh?hl=zh-CN
浏览器标签
虽然IE浏览器已经被微软抛弃了,但有些网站(税务/教育系统和网银网站)只兼容IE,我该怎么办?如果你想在Chrome浏览器中继续使用这些网站,你可以试试这个IE Tab扩展。当然,使用edge浏览器会更方便。在设置中,将“允许在 Internet Explorer 模式下重新加载”更改为“允许”,然后右键单击并选择在 Internet Explorer 模式下重新加载。 查看全部
chrome网页视频抓取(除了手动安装扩展还可以安装个谷歌助手(微信edge))
第285章原创文章苏生不服,把这个公众号设为star,第一时间看到最新的文章。
换句话说,没有扩展的浏览器是没有灵魂的。我分享了几篇关于Chrome扩展文章的文章(微信edge也可以安装使用),这里是第六篇:
除了手动安装扩展,你还可以安装一个谷歌助手(在公众号后台回复浏览器获取扩展),这样你就可以直接打开谷歌商店进行安装。
猫抓
这是一个音乐和视频资源嗅探神器,但它已被chrome删除。下载后只能手动安装。播放完视频后,点击扩展程序下载视频。如果部分视频无法下载,请参考文章
另存为 MHT
我以前共享过扩展单文件。这个也可以完美离线下载导出网页,直接将网页打包保存成文件(保留排版、图片、动图等格式),扩展地址,比如保存这篇文章文章@的效果>:
窗口标签管理器
一次打开太多窗口,占用资源?遇到麻烦不敢关掉,怕找不到?本扩展支持一键保存和打开所有网页,支持书签、历史记录和标签、扩展地址的聚合搜索
石脑油计划
本扩展可以选择、复制、编辑、翻译图片中嵌入的文字(仅支持英文),扩展地址
代理 SwitchyOmega
此扩展可以帮助您轻松快速地管理和切换多个代理设置、扩展地址
潮汐
这是一款白噪声专注定时器,可帮助您保持专注,提高工作和学习效率,扩展您的地址,并在您工作太累时聆听海浪的声音。
梦词翻译
这是为阅读和学习外语而开发的翻译和单词搜索工具。它汇集了数十种在线词典和在线翻译。扩展地址为 %E6%A2%A6%E6%83%B3%E5%88%92%E8 %AF%8D%E7%BF%BB%E8%AF%91%E2%80%94%E8%81 %9A%E5%90%88%E8%AF%8D%E5%85%B8%E6%90%9C%E7%B4%A2/odfgigmpkhhhieicogijogfobfipijjh?hl=zh-CN
浏览器标签
虽然IE浏览器已经被微软抛弃了,但有些网站(税务/教育系统和网银网站)只兼容IE,我该怎么办?如果你想在Chrome浏览器中继续使用这些网站,你可以试试这个IE Tab扩展。当然,使用edge浏览器会更方便。在设置中,将“允许在 Internet Explorer 模式下重新加载”更改为“允许”,然后右键单击并选择在 Internet Explorer 模式下重新加载。
chrome网页视频抓取(流媒体的插件....)
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-04 10:12
在线视频网站 视频是一种流媒体。
1.
那么什么是流媒体?
【流媒体】是指将一系列媒体数据进行压缩,通过网络将数据分段传输,并在网络上实时传输视频和音频以供观看的技术和过程。该技术使数据包像流水一样发送;如果您不使用此技术,则必须在使用前下载整个媒体文件。流媒体可以传输实时视频或存储在服务器上的视频。当观众在观看这些视频文件时,视频数据将通过特定的播放软件(如Windows Media Player、Real Player 或QuickTime Player)进行播放。--维基百科]
简单地说,在线播放的视频和音乐被视为流媒体。它采用新的编码和压缩方式,在互联网上传输,然后当您观看时,播放器将再次解码和解压缩以进行播放。你说得对,播放的时候电脑上确实生成了一个缓存文件,但是这个缓存文件不是直接的媒体文件,所以不能直接播放。并且因为缓存是在播放过程中分段完成的,所以并不完整。
2.
Chrome中有很多下载在线视频数据的插件,不过貌似是因为谷歌官方不允许此类插件出现在chrome应用商店中,所以过一段时间后大部分都会失效。
其实下载优酷的视频或者其他网站的视频在自己的客户端都有这个功能,比如优酷的iku,可以支持自己下载网站的视频。
或者装个火狐,它有个插件叫NetVideohunter,拦截流媒体的能力简直绝了…… 查看全部
chrome网页视频抓取(流媒体的插件....)
在线视频网站 视频是一种流媒体。
1.
那么什么是流媒体?
【流媒体】是指将一系列媒体数据进行压缩,通过网络将数据分段传输,并在网络上实时传输视频和音频以供观看的技术和过程。该技术使数据包像流水一样发送;如果您不使用此技术,则必须在使用前下载整个媒体文件。流媒体可以传输实时视频或存储在服务器上的视频。当观众在观看这些视频文件时,视频数据将通过特定的播放软件(如Windows Media Player、Real Player 或QuickTime Player)进行播放。--维基百科]
简单地说,在线播放的视频和音乐被视为流媒体。它采用新的编码和压缩方式,在互联网上传输,然后当您观看时,播放器将再次解码和解压缩以进行播放。你说得对,播放的时候电脑上确实生成了一个缓存文件,但是这个缓存文件不是直接的媒体文件,所以不能直接播放。并且因为缓存是在播放过程中分段完成的,所以并不完整。
2.
Chrome中有很多下载在线视频数据的插件,不过貌似是因为谷歌官方不允许此类插件出现在chrome应用商店中,所以过一段时间后大部分都会失效。
其实下载优酷的视频或者其他网站的视频在自己的客户端都有这个功能,比如优酷的iku,可以支持自己下载网站的视频。
或者装个火狐,它有个插件叫NetVideohunter,拦截流媒体的能力简直绝了……
chrome网页视频抓取( 四.Python自动化下载视频讨论网络查找很多获取中 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-10-04 10:11
四.Python自动化下载视频讨论网络查找很多获取中
)
第二步:在“全部”中找到一个以“MP4”结尾的文件,即要下载的视频文件,点击“Header”查看相应的视频地址。注意:在视频执行过程中,请尝试单击“下一个暂停”,否则将跳转到下一个视频
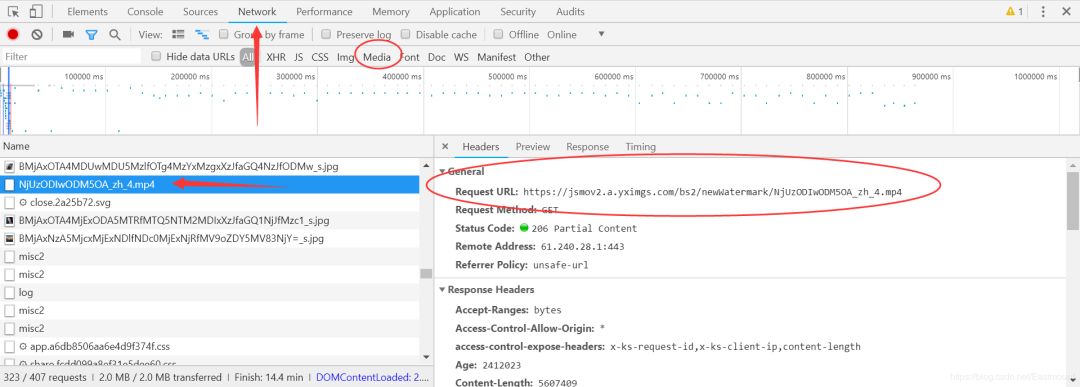
请求URL:
请求方法:获取
状态代码:206部分内容
远程地址:61.240.28.1:443
推荐人策略:不安全的url
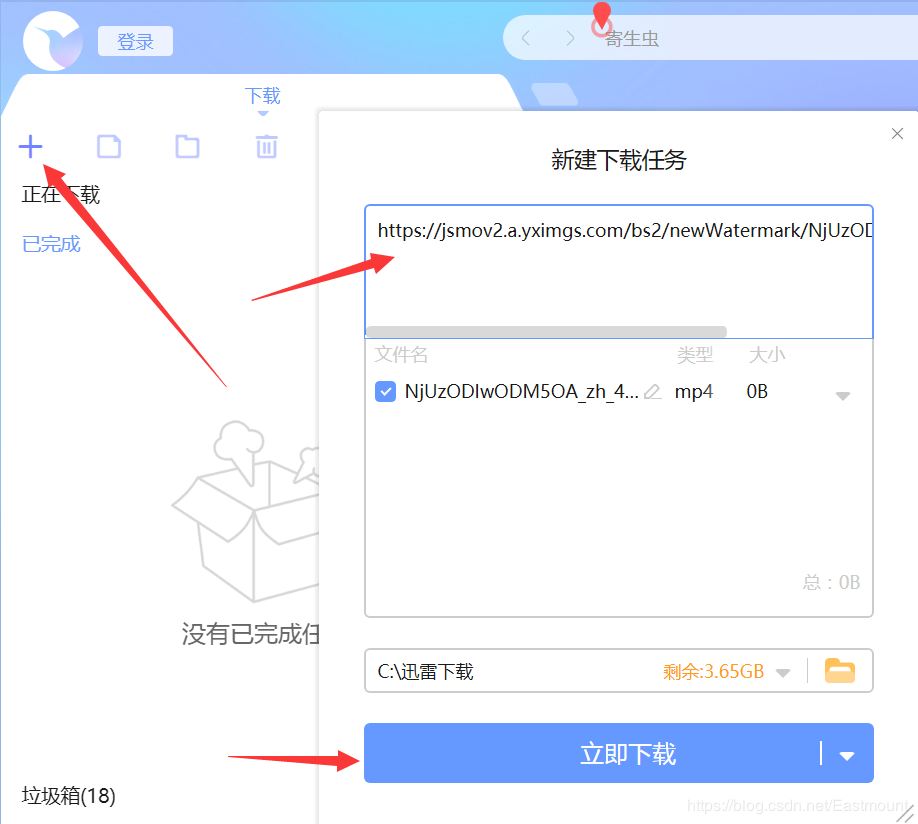
第三步:打开迅雷,将复制的视频URL添加到“新下载任务”中,下载视频
步骤4:视频已成功下载到本地并可以打开
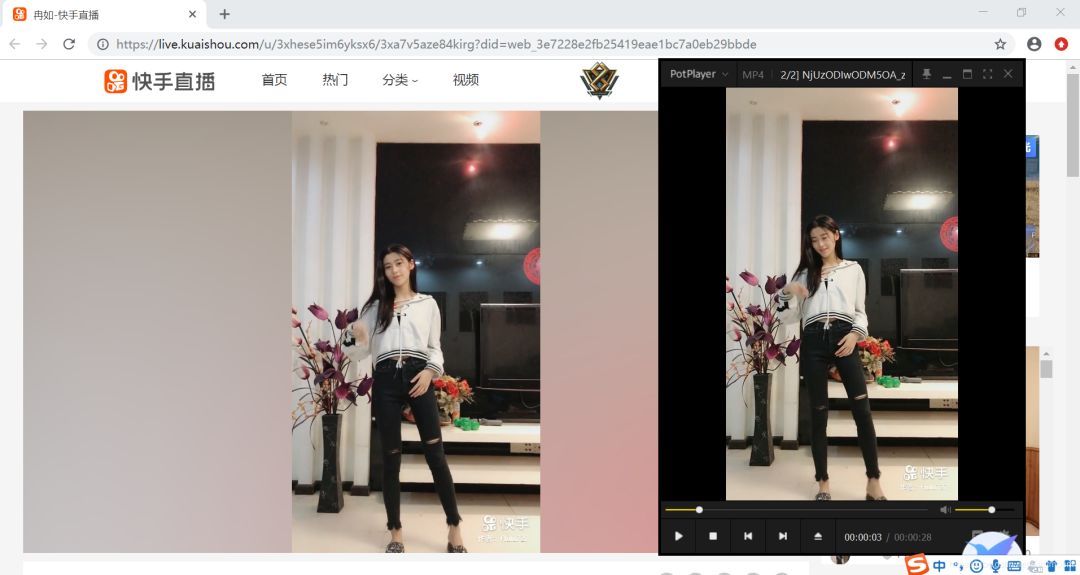
你可能会想:
你能直接分析HTML源代码并找到视频的链接吗。否,视频是动态加载的。我能想到的方法是通过python获取网络中的所有资源,然后找到“MP4”对应的超链接,但最终还是没有解决。后续部分将对此进行详细讨论
三.Python下载视频
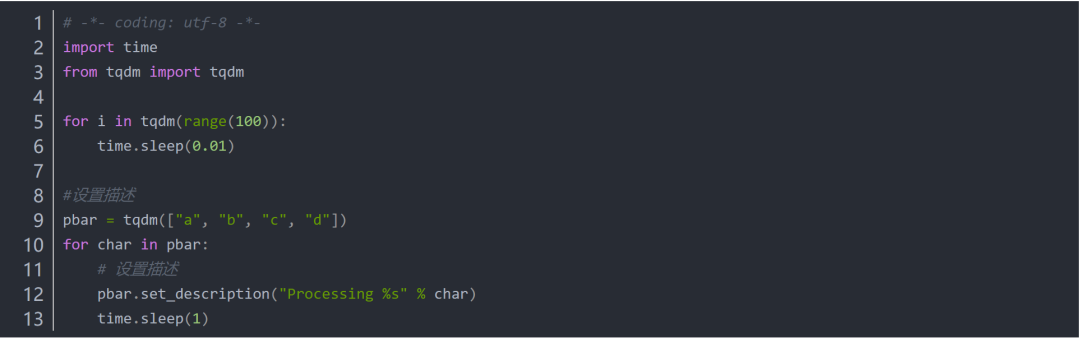
TQM是一个python进度条库。可以在python长循环中添加进度提示。用法:TQM(迭代器)
示例代码:
输出结果如下图所示:
下面是将视频下载到本地服务器的代码
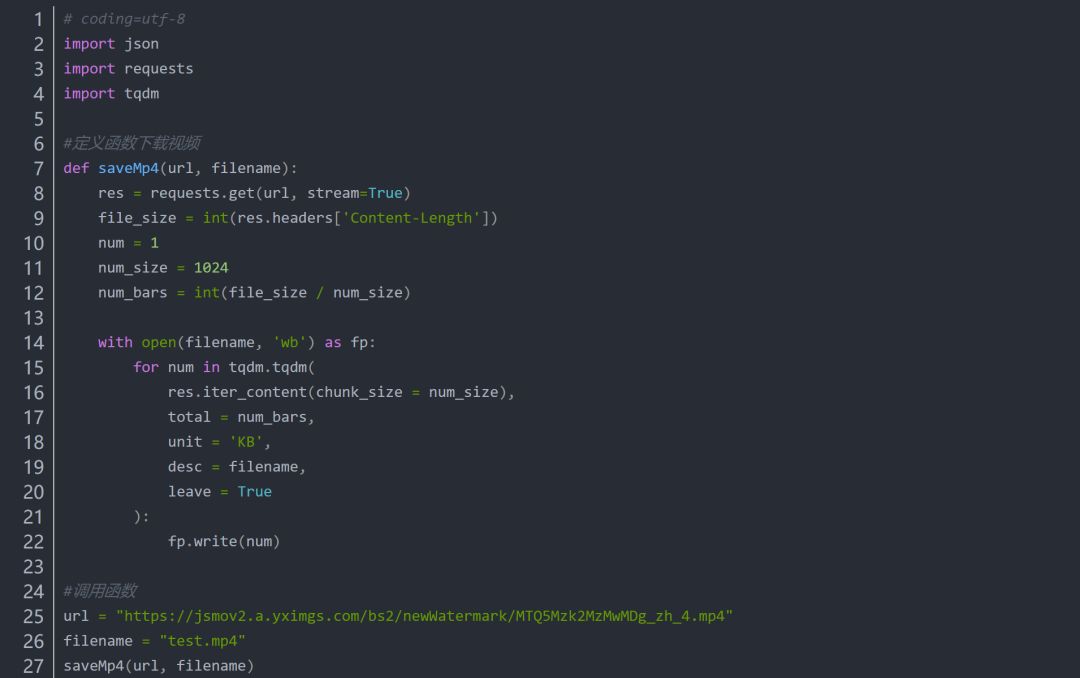
如下图所示:
如果读者想下载一位葵花大师的所有视频,请点击他们的个人主页,如下所示。p>
主播主页:
写了这里之后,您可能想知道是否可以编写一个爬虫程序来抓取所有web链接中与“MP4”对应的地址,然后进行统一的爬网。让我们做一个简单的分析,但最终的结果失败了
四.Python自动捕获视频讨论
有很多网络搜索。没有有效的答案来获取网络中的所有网络请求URL和XHR响应结果,包括GitHub的代码。例如:
这里有一些讨论。我想到的第一种方法包括两个基本操作,即:
1.设置标头和请求的参数数据,并调用requests()函数请求连接。请注意,视频是一种get方法
2.通过调用JSON解析返回的数据。Load()函数,并获取指定的字段
# -*- coding: utf-8 -*- import jsondata = { 'id' : 1, 'name' : 'test1', 'age' : '1' } data2 = [{ 'id' : 1, 'name' : 'test1', 'age' : '1' },{ 'id' : 2, 'name' : 'test2', 'age' : '2' }] #python字典类型转换为json对象 json_str = json.dumps(data) print(u"python原始数据:") print(repr(data)) print (u"json对象:") print(json_str) print("") json_str2 = json.dumps(data2) print (u"python原始数据:") print(repr(data2)) print (u"json对象:") print(json_str2) print("") # 将json对象转换为python字典 data3 = json.loads(json_str) print(data3) print("data3['name']: ", data3['name']) print("data3['age']: ", data3['age'])
输出结果如下图所示:
下面是一个简单的尝试:
步骤1:调用请求以获取数据
最重要的输出是最后一个脚本代码
视频URL代码收录在这里
步骤2:尝试解析JSON数据并使用以下代码定位链接
但最重要的一步是如何定位和解析JSON位置
五.总结
稍后,我们将学习Fiddler的移动数据包捕获和代理设置
Github:
原创链接:
查看全部
chrome网页视频抓取(
四.Python自动化下载视频讨论网络查找很多获取中
)
第二步:在“全部”中找到一个以“MP4”结尾的文件,即要下载的视频文件,点击“Header”查看相应的视频地址。注意:在视频执行过程中,请尝试单击“下一个暂停”,否则将跳转到下一个视频
请求URL:
请求方法:获取
状态代码:206部分内容
远程地址:61.240.28.1:443
推荐人策略:不安全的url
第三步:打开迅雷,将复制的视频URL添加到“新下载任务”中,下载视频
步骤4:视频已成功下载到本地并可以打开
你可能会想:
你能直接分析HTML源代码并找到视频的链接吗。否,视频是动态加载的。我能想到的方法是通过python获取网络中的所有资源,然后找到“MP4”对应的超链接,但最终还是没有解决。后续部分将对此进行详细讨论

三.Python下载视频
TQM是一个python进度条库。可以在python长循环中添加进度提示。用法:TQM(迭代器)
示例代码:
输出结果如下图所示:

下面是将视频下载到本地服务器的代码
如下图所示:

如果读者想下载一位葵花大师的所有视频,请点击他们的个人主页,如下所示。p>
主播主页:
写了这里之后,您可能想知道是否可以编写一个爬虫程序来抓取所有web链接中与“MP4”对应的地址,然后进行统一的爬网。让我们做一个简单的分析,但最终的结果失败了
四.Python自动捕获视频讨论
有很多网络搜索。没有有效的答案来获取网络中的所有网络请求URL和XHR响应结果,包括GitHub的代码。例如:
这里有一些讨论。我想到的第一种方法包括两个基本操作,即:
1.设置标头和请求的参数数据,并调用requests()函数请求连接。请注意,视频是一种get方法

2.通过调用JSON解析返回的数据。Load()函数,并获取指定的字段
# -*- coding: utf-8 -*- import jsondata = { 'id' : 1, 'name' : 'test1', 'age' : '1' } data2 = [{ 'id' : 1, 'name' : 'test1', 'age' : '1' },{ 'id' : 2, 'name' : 'test2', 'age' : '2' }] #python字典类型转换为json对象 json_str = json.dumps(data) print(u"python原始数据:") print(repr(data)) print (u"json对象:") print(json_str) print("") json_str2 = json.dumps(data2) print (u"python原始数据:") print(repr(data2)) print (u"json对象:") print(json_str2) print("") # 将json对象转换为python字典 data3 = json.loads(json_str) print(data3) print("data3['name']: ", data3['name']) print("data3['age']: ", data3['age'])
输出结果如下图所示:

下面是一个简单的尝试:
步骤1:调用请求以获取数据
最重要的输出是最后一个脚本代码
视频URL代码收录在这里

步骤2:尝试解析JSON数据并使用以下代码定位链接
但最重要的一步是如何定位和解析JSON位置
五.总结
稍后,我们将学习Fiddler的移动数据包捕获和代理设置
Github:
原创链接:



chrome网页视频抓取(爬虫北京二手车数据的过程及应用方法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-10-04 07:29
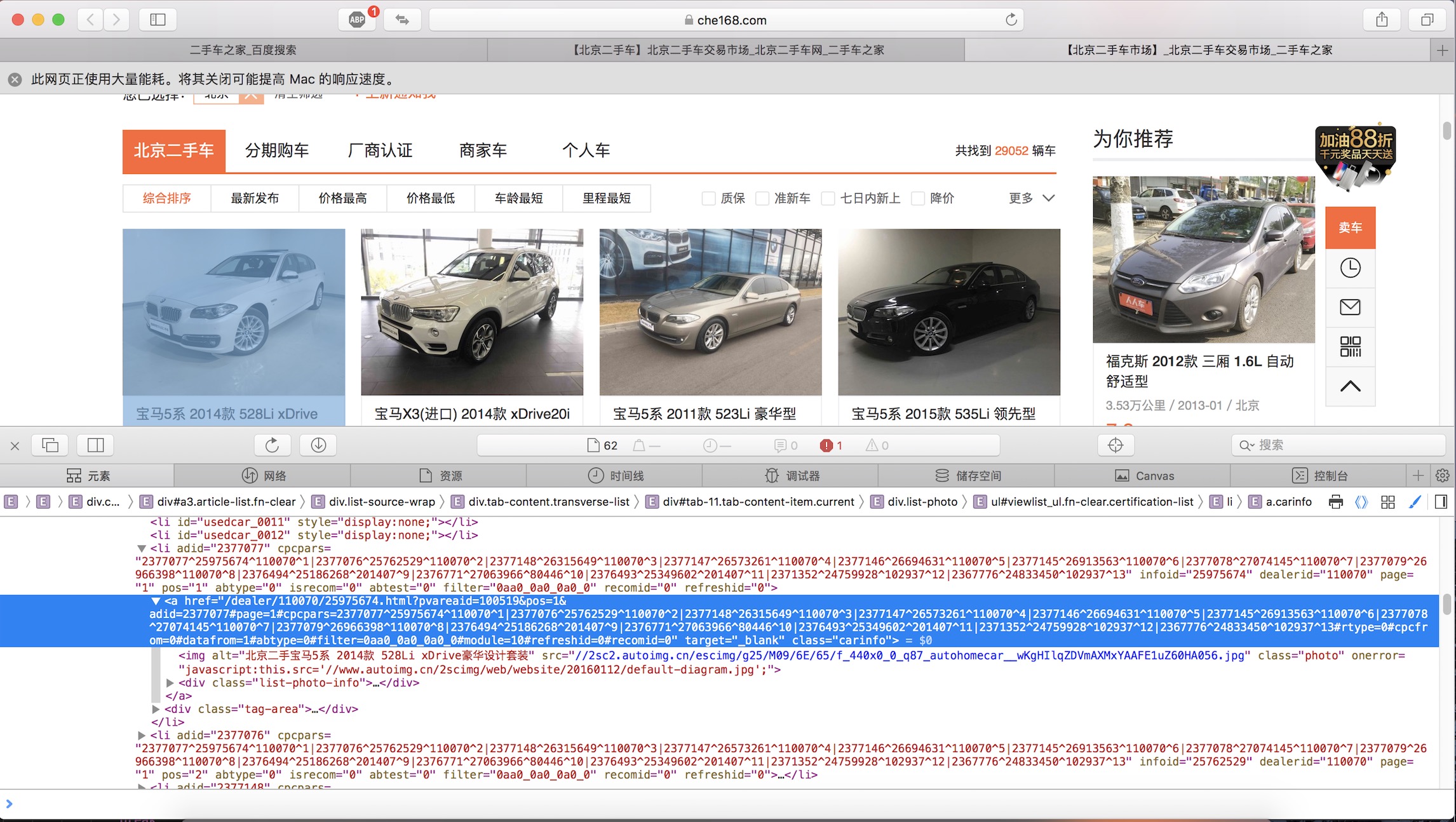
基于golang的爬虫实战前言
爬虫本来就是蟒蛇的强项。早期学习scrapy,写了一些简单的爬虫小程序。但是后来突然对golang产生了兴趣,决定写爬虫来练手。由于我是golang新手,有错误请指正。
下载依赖包需要的库gopkg.in/gomail.v2缺点的大致思路
go get github.com/tebeka/selenium
go get gopkg.in/gomail.v2
代码
// StartChrome 启动谷歌浏览器headless模式
func StartChrome() {
opts := []selenium.ServiceOption{}
caps := selenium.Capabilities{
"browserName": "chrome",
}
// 禁止加载图片,加快渲染速度
imagCaps := map[string]interface{}{
"profile.managed_default_content_settings.images": 2,
}
chromeCaps := chrome.Capabilities{
Prefs: imagCaps,
Path: "",
Args: []string{
"--headless", // 设置Chrome无头模式
"--no-sandbox",
"--user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/604.4.7 (KHTML, like Gecko) Version/11.0.2 Safari/604.4.7", // 模拟user-agent,防反爬
},
}
caps.AddChrome(chromeCaps)
// 启动chromedriver,端口号可自定义
service, err = selenium.NewChromeDriverService("/opt/google/chrome/chromedriver", 9515, opts...)
if err != nil {
log.Printf("Error starting the ChromeDriver server: %v", err)
}
// 调起chrome浏览器
webDriver, err = selenium.NewRemote(caps, fmt.Sprintf("http://localhost:%d/wd/hub", 9515))
if err != nil {
panic(err)
}
// 这是目标网站留下的坑,不加这个在linux系统中会显示手机网页,每个网站的策略不一样,需要区别处理。
webDriver.AddCookie(&selenium.Cookie{
Name: "defaultJumpDomain",
Value: "www",
})
// 导航到目标网站
err = webDriver.Get(urlBeijing)
if err != nil {
panic(fmt.Sprintf("Failed to load page: %s\n", err))
}
log.Println(webDriver.Title())
}
通过上面的代码,可以通过代码启动Chrome,跳转到目标网站,方便下一步的数据采集。
// SetupWriter 初始化CSV
func SetupWriter() {
dateTime = time.Now().Format("2006-01-02 15:04:05") // 格式字符串是固定的,据说是go语言诞生时间,谷歌的恶趣味...
os.Mkdir("data", os.ModePerm)
csvFile, err := os.Create(fmt.Sprintf("data/%s.csv", dateTime))
if err != nil {
panic(err)
}
csvFile.WriteString("\xEF\xBB\xBF")
writer = csv.NewWriter(csvFile)
writer.Write([]string{"车型", "行驶里程", "首次上牌", "价格", "所在地", "门店"})
}
数据抓取
这部分是核心业务。每个网站都有不同的爬取方式,但是思路是一样的。通过xpath、css选择器、className、tagName等获取元素的内容,selenium的api可以实现大部分操作功能可以通过selenium源码看到。核心 API 包括 WebDriver 和 WebElement。下面是从北京二手车之家抓取二手车数据的过程。其他网站请参考修改过程。
const urlBeijing = "https://www.che168.com/beijing ... ot%3B
鼠标指向这句话右键,依次复制-XPath,就可以得到改变元素所在的xpath属性
//*[@id="viewlist_ul"]
然后通过代码
listContainer, err := webDriver.FindElement(selenium.ByXPATH, "//*[@id=\"viewlist_ul\"]")
可以获取html修改部分的WebElement对象。不难看出,这是所有数据的父容器。为了获取具体的数据,需要定位到每个元素子集,通过开发模式可以看出。
可以通过开发者工具获取类为carinfo,因为有多个元素,所以通过
lists, err := listContainer.FindElements(selenium.ByClassName, "carinfo")
您可以获得所有元素子集的集合。获取每个子集中的元素数据,需要遍历集合
for i := 0; i < len(lists); i++ {
var urlElem selenium.WebElement
if pageIndex == 1 {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+13))
} else {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+1))
}
if err != nil {
break
}
// 因为有些数据在次级页面,需要跳转
url, err := urlElem.GetAttribute("href")
if err != nil {
break
}
webDriver.Get(url)
title, _ := webDriver.Title()
log.Printf("当前页面标题:%s\n", title)
// 获取车辆型号
modelElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[1]/h2")
var model string
if err != nil {
log.Println(err)
model = "暂无"
} else {
model, _ = modelElem.Text()
}
log.Printf("model=[%s]\n", model)
...
// 数据写入CSV
writer.Write([]string{model, miles, date, price, position, store})
writer.Flush()
webDriver.Back() // 回退到上级页面重复步骤抓取
}
所有源码如下,初学者,轻喷~~
// StartCrawler 开始爬取数据
func StartCrawler() {
log.Println("Start Crawling at ", time.Now().Format("2006-01-02 15:04:05"))
pageIndex := 0
for {
listContainer, err := webDriver.FindElement(selenium.ByXPATH, "//*[@id=\"viewlist_ul\"]")
if err != nil {
panic(err)
}
lists, err := listContainer.FindElements(selenium.ByClassName, "carinfo")
if err != nil {
panic(err)
}
log.Println("数据量:", len(lists))
pageIndex++
log.Printf("正在抓取第%d页数据...\n", pageIndex)
for i := 0; i < len(lists); i++ {
var urlElem selenium.WebElement
if pageIndex == 1 {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+13))
} else {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+1))
}
if err != nil {
break
}
url, err := urlElem.GetAttribute("href")
if err != nil {
break
}
webDriver.Get(url)
title, _ := webDriver.Title()
log.Printf("当前页面标题:%s\n", title)
modelElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[1]/h2")
var model string
if err != nil {
log.Println(err)
model = "暂无"
} else {
model, _ = modelElem.Text()
}
log.Printf("model=[%s]\n", model)
priceElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[2]/div/ins")
var price string
if err != nil {
log.Println(err)
price = "暂无"
} else {
price, _ = priceElem.Text()
price = fmt.Sprintf("%s万", price)
}
log.Printf("price=[%s]\n", price)
milesElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[4]/ul/li[1]/span")
var miles string
if err != nil {
log.Println(err)
milesElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[3]/ul/li[1]/span")
if err != nil {
log.Println(err)
miles = "暂无"
} else {
miles, _ = milesElem.Text()
}
} else {
miles, _ = milesElem.Text()
}
log.Printf("miles=[%s]\n", miles)
timeElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[4]/ul/li[2]/span")
var date string
if err != nil {
log.Println(err)
timeElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[3]/ul/li[2]/span")
if err != nil {
log.Println(err)
date = "暂无"
} else {
date, _ = timeElem.Text()
}
} else {
date, _ = timeElem.Text()
}
log.Printf("time=[%s]\n", date)
positionElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[4]/ul/li[4]/span")
var position string
if err != nil {
log.Println(err)
positionElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[3]/ul/li[4]/span")
if err != nil {
log.Println(err)
position = "暂无"
} else {
position, _ = positionElem.Text()
}
} else {
position, _ = positionElem.Text()
}
log.Printf("position=[%s]\n", position)
storeElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[1]/div/div/div")
var store string
if err != nil {
log.Println(err)
store = "暂无"
} else {
store, _ = storeElem.Text()
store = strings.Replace(store, "商家|", "", -1)
if strings.Contains(store, "金牌店铺") {
store = strings.Replace(store, "金牌店铺", "", -1)
}
}
log.Printf("store=[%s]\n", store)
writer.Write([]string{model, miles, date, price, position, store})
writer.Flush()
webDriver.Back()
}
log.Printf("第%d页数据已经抓取完毕,开始下一页...\n", pageIndex)
nextButton, err := webDriver.FindElement(selenium.ByClassName, "page-item-next")
if err != nil {
log.Println("所有数据抓取完毕!")
break
}
nextButton.Click()
}
log.Println("Crawling Finished at ", time.Now().Format("2006-01-02 15:04:05"))
sendResult(dateTime)
}
整个代码如下,比较简单,不再赘述
func sendResult(fileName string) {
email := gomail.NewMessage()
email.SetAddressHeader("From", "re**ng@163.com", "张**")
email.SetHeader("To", email.FormatAddress("li**yang@163.com", "李**"))
email.SetHeader("Cc", email.FormatAddress("zhang**tao@163.net", "张**"))
email.SetHeader("Subject", "二手车之家-北京-二手车信息")
email.SetBody("text/plain;charset=UTF-8", "本周抓取到的二手车信息数据,请注意查收!\n")
email.Attach(fmt.Sprintf("data/%s.csv", fileName))
dialer := &gomail.Dialer{
Host: "smtp.163.com",
Port: 25,
Username: ${your_email}, // 替换自己的邮箱地址
Password: ${smtp_password}, // 自定义smtp服务器密码
SSL: false,
}
if err := dialer.DialAndSend(email); err != nil {
log.Println("邮件发送失败!err: ", err)
return
}
log.Println("邮件发送成功!")
}
defer service.Stop() // 停止chromedriver
defer webDriver.Quit() // 关闭浏览器
defer csvFile.Close() // 关闭文件流
总结 查看全部
chrome网页视频抓取(爬虫北京二手车数据的过程及应用方法(一))
基于golang的爬虫实战前言
爬虫本来就是蟒蛇的强项。早期学习scrapy,写了一些简单的爬虫小程序。但是后来突然对golang产生了兴趣,决定写爬虫来练手。由于我是golang新手,有错误请指正。
下载依赖包需要的库gopkg.in/gomail.v2缺点的大致思路
go get github.com/tebeka/selenium
go get gopkg.in/gomail.v2
代码
// StartChrome 启动谷歌浏览器headless模式
func StartChrome() {
opts := []selenium.ServiceOption{}
caps := selenium.Capabilities{
"browserName": "chrome",
}
// 禁止加载图片,加快渲染速度
imagCaps := map[string]interface{}{
"profile.managed_default_content_settings.images": 2,
}
chromeCaps := chrome.Capabilities{
Prefs: imagCaps,
Path: "",
Args: []string{
"--headless", // 设置Chrome无头模式
"--no-sandbox",
"--user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/604.4.7 (KHTML, like Gecko) Version/11.0.2 Safari/604.4.7", // 模拟user-agent,防反爬
},
}
caps.AddChrome(chromeCaps)
// 启动chromedriver,端口号可自定义
service, err = selenium.NewChromeDriverService("/opt/google/chrome/chromedriver", 9515, opts...)
if err != nil {
log.Printf("Error starting the ChromeDriver server: %v", err)
}
// 调起chrome浏览器
webDriver, err = selenium.NewRemote(caps, fmt.Sprintf("http://localhost:%d/wd/hub", 9515))
if err != nil {
panic(err)
}
// 这是目标网站留下的坑,不加这个在linux系统中会显示手机网页,每个网站的策略不一样,需要区别处理。
webDriver.AddCookie(&selenium.Cookie{
Name: "defaultJumpDomain",
Value: "www",
})
// 导航到目标网站
err = webDriver.Get(urlBeijing)
if err != nil {
panic(fmt.Sprintf("Failed to load page: %s\n", err))
}
log.Println(webDriver.Title())
}
通过上面的代码,可以通过代码启动Chrome,跳转到目标网站,方便下一步的数据采集。
// SetupWriter 初始化CSV
func SetupWriter() {
dateTime = time.Now().Format("2006-01-02 15:04:05") // 格式字符串是固定的,据说是go语言诞生时间,谷歌的恶趣味...
os.Mkdir("data", os.ModePerm)
csvFile, err := os.Create(fmt.Sprintf("data/%s.csv", dateTime))
if err != nil {
panic(err)
}
csvFile.WriteString("\xEF\xBB\xBF")
writer = csv.NewWriter(csvFile)
writer.Write([]string{"车型", "行驶里程", "首次上牌", "价格", "所在地", "门店"})
}
数据抓取
这部分是核心业务。每个网站都有不同的爬取方式,但是思路是一样的。通过xpath、css选择器、className、tagName等获取元素的内容,selenium的api可以实现大部分操作功能可以通过selenium源码看到。核心 API 包括 WebDriver 和 WebElement。下面是从北京二手车之家抓取二手车数据的过程。其他网站请参考修改过程。
const urlBeijing = "https://www.che168.com/beijing ... ot%3B
鼠标指向这句话右键,依次复制-XPath,就可以得到改变元素所在的xpath属性
//*[@id="viewlist_ul"]
然后通过代码
listContainer, err := webDriver.FindElement(selenium.ByXPATH, "//*[@id=\"viewlist_ul\"]")
可以获取html修改部分的WebElement对象。不难看出,这是所有数据的父容器。为了获取具体的数据,需要定位到每个元素子集,通过开发模式可以看出。
可以通过开发者工具获取类为carinfo,因为有多个元素,所以通过
lists, err := listContainer.FindElements(selenium.ByClassName, "carinfo")
您可以获得所有元素子集的集合。获取每个子集中的元素数据,需要遍历集合
for i := 0; i < len(lists); i++ {
var urlElem selenium.WebElement
if pageIndex == 1 {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+13))
} else {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+1))
}
if err != nil {
break
}
// 因为有些数据在次级页面,需要跳转
url, err := urlElem.GetAttribute("href")
if err != nil {
break
}
webDriver.Get(url)
title, _ := webDriver.Title()
log.Printf("当前页面标题:%s\n", title)
// 获取车辆型号
modelElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[1]/h2")
var model string
if err != nil {
log.Println(err)
model = "暂无"
} else {
model, _ = modelElem.Text()
}
log.Printf("model=[%s]\n", model)
...
// 数据写入CSV
writer.Write([]string{model, miles, date, price, position, store})
writer.Flush()
webDriver.Back() // 回退到上级页面重复步骤抓取
}
所有源码如下,初学者,轻喷~~
// StartCrawler 开始爬取数据
func StartCrawler() {
log.Println("Start Crawling at ", time.Now().Format("2006-01-02 15:04:05"))
pageIndex := 0
for {
listContainer, err := webDriver.FindElement(selenium.ByXPATH, "//*[@id=\"viewlist_ul\"]")
if err != nil {
panic(err)
}
lists, err := listContainer.FindElements(selenium.ByClassName, "carinfo")
if err != nil {
panic(err)
}
log.Println("数据量:", len(lists))
pageIndex++
log.Printf("正在抓取第%d页数据...\n", pageIndex)
for i := 0; i < len(lists); i++ {
var urlElem selenium.WebElement
if pageIndex == 1 {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+13))
} else {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+1))
}
if err != nil {
break
}
url, err := urlElem.GetAttribute("href")
if err != nil {
break
}
webDriver.Get(url)
title, _ := webDriver.Title()
log.Printf("当前页面标题:%s\n", title)
modelElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[1]/h2")
var model string
if err != nil {
log.Println(err)
model = "暂无"
} else {
model, _ = modelElem.Text()
}
log.Printf("model=[%s]\n", model)
priceElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[2]/div/ins")
var price string
if err != nil {
log.Println(err)
price = "暂无"
} else {
price, _ = priceElem.Text()
price = fmt.Sprintf("%s万", price)
}
log.Printf("price=[%s]\n", price)
milesElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[4]/ul/li[1]/span")
var miles string
if err != nil {
log.Println(err)
milesElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[3]/ul/li[1]/span")
if err != nil {
log.Println(err)
miles = "暂无"
} else {
miles, _ = milesElem.Text()
}
} else {
miles, _ = milesElem.Text()
}
log.Printf("miles=[%s]\n", miles)
timeElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[4]/ul/li[2]/span")
var date string
if err != nil {
log.Println(err)
timeElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[3]/ul/li[2]/span")
if err != nil {
log.Println(err)
date = "暂无"
} else {
date, _ = timeElem.Text()
}
} else {
date, _ = timeElem.Text()
}
log.Printf("time=[%s]\n", date)
positionElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[4]/ul/li[4]/span")
var position string
if err != nil {
log.Println(err)
positionElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[3]/ul/li[4]/span")
if err != nil {
log.Println(err)
position = "暂无"
} else {
position, _ = positionElem.Text()
}
} else {
position, _ = positionElem.Text()
}
log.Printf("position=[%s]\n", position)
storeElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[1]/div/div/div")
var store string
if err != nil {
log.Println(err)
store = "暂无"
} else {
store, _ = storeElem.Text()
store = strings.Replace(store, "商家|", "", -1)
if strings.Contains(store, "金牌店铺") {
store = strings.Replace(store, "金牌店铺", "", -1)
}
}
log.Printf("store=[%s]\n", store)
writer.Write([]string{model, miles, date, price, position, store})
writer.Flush()
webDriver.Back()
}
log.Printf("第%d页数据已经抓取完毕,开始下一页...\n", pageIndex)
nextButton, err := webDriver.FindElement(selenium.ByClassName, "page-item-next")
if err != nil {
log.Println("所有数据抓取完毕!")
break
}
nextButton.Click()
}
log.Println("Crawling Finished at ", time.Now().Format("2006-01-02 15:04:05"))
sendResult(dateTime)
}
整个代码如下,比较简单,不再赘述
func sendResult(fileName string) {
email := gomail.NewMessage()
email.SetAddressHeader("From", "re**ng@163.com", "张**")
email.SetHeader("To", email.FormatAddress("li**yang@163.com", "李**"))
email.SetHeader("Cc", email.FormatAddress("zhang**tao@163.net", "张**"))
email.SetHeader("Subject", "二手车之家-北京-二手车信息")
email.SetBody("text/plain;charset=UTF-8", "本周抓取到的二手车信息数据,请注意查收!\n")
email.Attach(fmt.Sprintf("data/%s.csv", fileName))
dialer := &gomail.Dialer{
Host: "smtp.163.com",
Port: 25,
Username: ${your_email}, // 替换自己的邮箱地址
Password: ${smtp_password}, // 自定义smtp服务器密码
SSL: false,
}
if err := dialer.DialAndSend(email); err != nil {
log.Println("邮件发送失败!err: ", err)
return
}
log.Println("邮件发送成功!")
}
defer service.Stop() // 停止chromedriver
defer webDriver.Quit() // 关闭浏览器
defer csvFile.Close() // 关闭文件流
总结
chrome网页视频抓取(Google把杀死网页上那些令人讨厌的自动播放视频内容作为2018年首要大事)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-29 15:17
全球新的浏览器之王谷歌浏览器将清除网页上那些烦人的自动播放视频内容作为2018年的首要任务,并承诺将于2018年1月21日至2018年1月27日推出该功能两个版本之间的 Chrome 64。
在某些新闻内容页面上,默认情况下会自动播放与内容相关的视频。它们总是在不适当的场合播放,这会给用户带来混乱,需要额外的手动设置来阻止它们。
在 Chrome 64 中,将不允许自动播放内容自动进行。通常,有些广告喜欢使用自动播放模式。这种类型的广告不仅让用户感到不舒服,而且在浏览网页时也会干扰用户的注意力。当然,不仅仅是广告,一些网站也希望通过这种方式来增加网络小视频的播放量,让用户的注意力停留在编辑想要的地方。
Chrome 将使自动播放的内容成为一种用户友好的体验,并允许用户对这些媒体内容有更多的自主控制权。用户只在需要观看视频播放时点击。当然,您仍然可以将其设置为默认自动播放,也可以将其设置为打开网页一段时间后自动播放。
谷歌计划在年底发布 Chrome 63 时添加一些小功能作为过渡。它会在页面上弹出一个气泡,允许用户静音选择。过去,谷歌只是在带有自动播放内容的网页标签上放一个小的扬声器标记。
苹果在最新的Safari 11上推出了每个站点和全网的自动播放控制功能。该版本将于9月25日与macOS High Sierra一起发布。返回搜狐查看更多 查看全部
chrome网页视频抓取(Google把杀死网页上那些令人讨厌的自动播放视频内容作为2018年首要大事)
全球新的浏览器之王谷歌浏览器将清除网页上那些烦人的自动播放视频内容作为2018年的首要任务,并承诺将于2018年1月21日至2018年1月27日推出该功能两个版本之间的 Chrome 64。

在某些新闻内容页面上,默认情况下会自动播放与内容相关的视频。它们总是在不适当的场合播放,这会给用户带来混乱,需要额外的手动设置来阻止它们。
在 Chrome 64 中,将不允许自动播放内容自动进行。通常,有些广告喜欢使用自动播放模式。这种类型的广告不仅让用户感到不舒服,而且在浏览网页时也会干扰用户的注意力。当然,不仅仅是广告,一些网站也希望通过这种方式来增加网络小视频的播放量,让用户的注意力停留在编辑想要的地方。
Chrome 将使自动播放的内容成为一种用户友好的体验,并允许用户对这些媒体内容有更多的自主控制权。用户只在需要观看视频播放时点击。当然,您仍然可以将其设置为默认自动播放,也可以将其设置为打开网页一段时间后自动播放。
谷歌计划在年底发布 Chrome 63 时添加一些小功能作为过渡。它会在页面上弹出一个气泡,允许用户静音选择。过去,谷歌只是在带有自动播放内容的网页标签上放一个小的扬声器标记。
苹果在最新的Safari 11上推出了每个站点和全网的自动播放控制功能。该版本将于9月25日与macOS High Sierra一起发布。返回搜狐查看更多
chrome网页视频抓取( 谷歌浏览器仅支持H264编码,但是视频流的编码可能不一样)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-14 20:25
谷歌浏览器仅支持H264编码,但是视频流的编码可能不一样)
某些 MP4 视频无法在 Google Chrome 中播放
本质上,html 使用标签来播放视频,我相信大多数浏览器都支持。
但是我今天遇到了一个问题。我在APP上拍了两个视频,一个可以播放,另一个失败。
排除服务器和文件存储服务器的问题。怀疑是前端代码写错了。疑似网速受限,视频被截断。
没想到,原来是mp4视频流格式问题,谷歌浏览器不支持。
mp4都是mp4,但这只是让操作系统识别哪些应用程序可以播放。实际内容取决于视频流的格式或编码,但视频流的编码可能不同。
据说谷歌浏览器只支持H264编码,因为支持视频编码需要专利费,所以只支持这个。
原因
由于之前的文章文章已经基本查清了服务器的原因,这次还是发现视频播放失败,所以重点放在了前端和网络上。
通过控制台发现视频数据已经取到了,但是仍然显示“播放失败”。
怀疑:
第一点是从日志来看,没有看到错误日志;
第二点是从前端控制台检查,发现传输完成;
三、 第四(PS:因为前端人手不足所以做了原来的改动)因为经验有限,请前端小姐姐帮忙查一下。
找方向
但是前台小姐很忙,不能坐等死。决定继续考虑。
怀疑是视频问题,直接通过url下载视频。下载到本地就可以正常播放了,说明视频本身是完整的。
所以我写了一个tag-only html,写了视频源,分别用edge和google打开。
Sorry, your browser doesn't support embedded videos.
原来edge可以正常播放,google却不能。那只能是视频本身的问题。
找到方向后,启动google(这个google不是别的google)。发现经常有这样的问题,结论是谷歌只支持h264。
视频格式和编码
相关介绍见文章:Chrome使用视频无法正常播放MP4视频的解决方法-Yellow_ice-博客园()
验证猜想
既然怀疑是视频编码问题,需要验证一下。如何查看视频的编码?我不能直接看到它。
这里需要用到ffmpeg软件。
从官网下载解压后,将“安装目录/bin”写入系统变量Path。
ffmpeg -i 0b9a8a522ae84fa69e15068cbf044c1e.mp4
无法播放的视频输出 hevc(别名 H265):
可以播放的输出是h264:
验证解决方案
用这个软件把hevc转成264扔到OBS服务器上,确认能不能正常播放。
结论自然是可以的。
综上所述
结论是视频拍摄完成后APP端存储的编码有误。因为这次拍摄的是第二个视频,所以和上一个不同。一个是h264可以播放,一个是hevc不能播放。
请在前端更改视频编码,应该没问题。
无底线
如果无法解析,否则OBS服务器会自动转码。
然后服务器需要在拉取视频后进行转码。
目前google了一下,发现有两种说法:
其实这两种方法本质上是一样的。前者需要您自己在服务器或本地计算机上安装软件。后者不如前者灵活,但可以直接使用。
因为本质是调用ffmpeg,所以视频流必须保存在服务器上,代表的是File文件。
因此,原创文件和转换后的文件需要经过内存、服务器,然后才能删除,占用内存和时间。
所以尽量统一编码格式。
该工具包是:GitHub-a-schild/jave2:JAVE(Java 音频视频编码器)库是 ffmpeg 项目上的 Java 包装器
参考链接
Chrome无法正常使用视频播放MP4视频-Yellow_ice-博客园()
GitHub-a-schild/jave2: JAVE(Java 音频视频编码器)库是 ffmpeg 项目上的 Java 包装器 查看全部
chrome网页视频抓取(
谷歌浏览器仅支持H264编码,但是视频流的编码可能不一样)
某些 MP4 视频无法在 Google Chrome 中播放
本质上,html 使用标签来播放视频,我相信大多数浏览器都支持。
但是我今天遇到了一个问题。我在APP上拍了两个视频,一个可以播放,另一个失败。
排除服务器和文件存储服务器的问题。怀疑是前端代码写错了。疑似网速受限,视频被截断。
没想到,原来是mp4视频流格式问题,谷歌浏览器不支持。
mp4都是mp4,但这只是让操作系统识别哪些应用程序可以播放。实际内容取决于视频流的格式或编码,但视频流的编码可能不同。
据说谷歌浏览器只支持H264编码,因为支持视频编码需要专利费,所以只支持这个。
原因
由于之前的文章文章已经基本查清了服务器的原因,这次还是发现视频播放失败,所以重点放在了前端和网络上。
通过控制台发现视频数据已经取到了,但是仍然显示“播放失败”。
怀疑:
第一点是从日志来看,没有看到错误日志;
第二点是从前端控制台检查,发现传输完成;
三、 第四(PS:因为前端人手不足所以做了原来的改动)因为经验有限,请前端小姐姐帮忙查一下。
找方向
但是前台小姐很忙,不能坐等死。决定继续考虑。
怀疑是视频问题,直接通过url下载视频。下载到本地就可以正常播放了,说明视频本身是完整的。
所以我写了一个tag-only html,写了视频源,分别用edge和google打开。
Sorry, your browser doesn't support embedded videos.
原来edge可以正常播放,google却不能。那只能是视频本身的问题。
找到方向后,启动google(这个google不是别的google)。发现经常有这样的问题,结论是谷歌只支持h264。
视频格式和编码
相关介绍见文章:Chrome使用视频无法正常播放MP4视频的解决方法-Yellow_ice-博客园()
验证猜想
既然怀疑是视频编码问题,需要验证一下。如何查看视频的编码?我不能直接看到它。
这里需要用到ffmpeg软件。
从官网下载解压后,将“安装目录/bin”写入系统变量Path。
ffmpeg -i 0b9a8a522ae84fa69e15068cbf044c1e.mp4
无法播放的视频输出 hevc(别名 H265):
可以播放的输出是h264:
验证解决方案
用这个软件把hevc转成264扔到OBS服务器上,确认能不能正常播放。
结论自然是可以的。
综上所述
结论是视频拍摄完成后APP端存储的编码有误。因为这次拍摄的是第二个视频,所以和上一个不同。一个是h264可以播放,一个是hevc不能播放。
请在前端更改视频编码,应该没问题。
无底线
如果无法解析,否则OBS服务器会自动转码。
然后服务器需要在拉取视频后进行转码。
目前google了一下,发现有两种说法:
其实这两种方法本质上是一样的。前者需要您自己在服务器或本地计算机上安装软件。后者不如前者灵活,但可以直接使用。
因为本质是调用ffmpeg,所以视频流必须保存在服务器上,代表的是File文件。
因此,原创文件和转换后的文件需要经过内存、服务器,然后才能删除,占用内存和时间。
所以尽量统一编码格式。
该工具包是:GitHub-a-schild/jave2:JAVE(Java 音频视频编码器)库是 ffmpeg 项目上的 Java 包装器
参考链接
Chrome无法正常使用视频播放MP4视频-Yellow_ice-博客园()
GitHub-a-schild/jave2: JAVE(Java 音频视频编码器)库是 ffmpeg 项目上的 Java 包装器
chrome网页视频抓取(Chrome的Downloader-从任何网站下载视频的最简单,最快的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-04 15:21
适用于 Chrome 的视频下载器 - 从任何 网站 下载视频的最简单、最快捷的方式。此扩展程序允许您从几乎任何页面下载视频文件,以便在您的计算机上进一步查看。它支持许多网站,包括Facebook、Dailymotion、Vimeo、Blip、Metacafe、Break 和其他数千个网站-从任何网站下载和保存视频-同时下载多个视频- 检测并保存任何媒体类型(.3gp、.mp4、.wmv、.flv、.swf、.mp3...)-最快和最简单的视频下载扩展 *重要** 请注意,Chrome 的视频下载器我们不是对您下载的媒体内容负责。我们建议在下载特定视频或音频之前检查媒体的版权许可。请小心!感谢您使用它,如果您喜欢它,请给 Chrome 扩展视频下载器 5 颗星!支持语言:Deutsch、English、English(UK)、English(美国)、Français、Norsk、español、italiano、português(巴西)、português(葡萄牙)、slovenský、suomi、русский、Japanese 查看全部
chrome网页视频抓取(Chrome的Downloader-从任何网站下载视频的最简单,最快的方法)
适用于 Chrome 的视频下载器 - 从任何 网站 下载视频的最简单、最快捷的方式。此扩展程序允许您从几乎任何页面下载视频文件,以便在您的计算机上进一步查看。它支持许多网站,包括Facebook、Dailymotion、Vimeo、Blip、Metacafe、Break 和其他数千个网站-从任何网站下载和保存视频-同时下载多个视频- 检测并保存任何媒体类型(.3gp、.mp4、.wmv、.flv、.swf、.mp3...)-最快和最简单的视频下载扩展 *重要** 请注意,Chrome 的视频下载器我们不是对您下载的媒体内容负责。我们建议在下载特定视频或音频之前检查媒体的版权许可。请小心!感谢您使用它,如果您喜欢它,请给 Chrome 扩展视频下载器 5 颗星!支持语言:Deutsch、English、English(UK)、English(美国)、Français、Norsk、español、italiano、português(巴西)、português(葡萄牙)、slovenský、suomi、русский、Japanese
chrome网页视频抓取(网页文字抓取工具使用方法输入网址后与url链接介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-28 04:13
网页文字抓取工具是一款简单实用的工具。用户只需输入目标链接网站,即可快速抓取相关网页上的所有文字,支持复制或导出为txt文件。欢迎有需要的朋友下载使用!
特征
1、绿色软件,无需安装。
2、 支持键盘ctrl、alt、shift+鼠标左键、中键、右键操作。
3、无法复制的文字可以抓取,但是图片不能抓取。
4、 支持复制常规静态对话框、系统消息和程序选项卡等表单文本。
5、支持鼠标快捷键,Ctrl、Alt、Shift和鼠标左/中/右键的任意组合。
6、 支持在 Chrome 中抓取网页图片替代文本和 url 链接。
指示
输入网址后,点击抓取按钮,就OK了。!
软件亮点
网页文字抓取器是一款小巧精致的网页文字提取软件,可以让您轻松抓取和复制禁止选择和复制的网页上的文字。对于内容被大面积广告覆盖而无法看到的网页,网上有很多禁止复制的html文件。抓取网页文本抓取器并阅读它也是一个很好的解决方案。
相关新闻
现在IE被边缘化了,我们使用的浏览器大多是WebKit核心,所以当你发现网站设置了禁止复制的权限时,不妨试试把网址拖到IE浏览器上。接下来,说不定会有惊喜哦~
还有一点需要注意的是,现在国内很多浏览器都是双核的。“兼容模式”是IE的核心。也可以点击切换试试看。复制到 IE 是一种效果。 查看全部
chrome网页视频抓取(网页文字抓取工具使用方法输入网址后与url链接介绍)
网页文字抓取工具是一款简单实用的工具。用户只需输入目标链接网站,即可快速抓取相关网页上的所有文字,支持复制或导出为txt文件。欢迎有需要的朋友下载使用!
特征
1、绿色软件,无需安装。
2、 支持键盘ctrl、alt、shift+鼠标左键、中键、右键操作。
3、无法复制的文字可以抓取,但是图片不能抓取。
4、 支持复制常规静态对话框、系统消息和程序选项卡等表单文本。
5、支持鼠标快捷键,Ctrl、Alt、Shift和鼠标左/中/右键的任意组合。
6、 支持在 Chrome 中抓取网页图片替代文本和 url 链接。
指示
输入网址后,点击抓取按钮,就OK了。!
软件亮点
网页文字抓取器是一款小巧精致的网页文字提取软件,可以让您轻松抓取和复制禁止选择和复制的网页上的文字。对于内容被大面积广告覆盖而无法看到的网页,网上有很多禁止复制的html文件。抓取网页文本抓取器并阅读它也是一个很好的解决方案。
相关新闻
现在IE被边缘化了,我们使用的浏览器大多是WebKit核心,所以当你发现网站设置了禁止复制的权限时,不妨试试把网址拖到IE浏览器上。接下来,说不定会有惊喜哦~
还有一点需要注意的是,现在国内很多浏览器都是双核的。“兼容模式”是IE的核心。也可以点击切换试试看。复制到 IE 是一种效果。
chrome网页视频抓取(猫抓支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
网站优化 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-11-21 06:19
猫抓
Mozhao 是一个扩展,支持所有 Chrome 内核浏览器的网络媒体嗅探和抓取。
它可以一键抓取任何站点的任何视频/音频数据,使用起来非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮可以看到页面上的资源信息。
然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地。
猫扎支持优酷、搜狐、腾讯、微博、B站等几乎所有国内网站视频文件嗅探。
当多个媒体资源出现在同一页面时,您还可以对其进行快速批量操作。
一般来说,这类嗅探工具支持的视频文件是未加密的。当面对一些加密的视频时,会有一定的失败几率。
但是,从市场反馈来看,猫筹可以捕捉到很多其他IDM无法嗅探的媒体资源。
这也是其竞争激烈的拓展店能拥有超过5万用户的原因之一。
此外,毛爪还支持对所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,还支持使用正则表达式自定义采集的内容。
网络嗅探器最初是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。Sniffer 也是很多程序员在编写网络程序时捕捉和测试的工具。
近年来,网络嗅探器广泛应用于用户的日常行为中,成为捕捉视频、音频等内容的工具。
下载:/extension/jfedfbgedapdagkghmgibemcoggfppbb 查看全部
chrome网页视频抓取(猫抓支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
猫抓
Mozhao 是一个扩展,支持所有 Chrome 内核浏览器的网络媒体嗅探和抓取。
它可以一键抓取任何站点的任何视频/音频数据,使用起来非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮可以看到页面上的资源信息。
然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地。
猫扎支持优酷、搜狐、腾讯、微博、B站等几乎所有国内网站视频文件嗅探。
当多个媒体资源出现在同一页面时,您还可以对其进行快速批量操作。
一般来说,这类嗅探工具支持的视频文件是未加密的。当面对一些加密的视频时,会有一定的失败几率。
但是,从市场反馈来看,猫筹可以捕捉到很多其他IDM无法嗅探的媒体资源。
这也是其竞争激烈的拓展店能拥有超过5万用户的原因之一。
此外,毛爪还支持对所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,还支持使用正则表达式自定义采集的内容。
网络嗅探器最初是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。Sniffer 也是很多程序员在编写网络程序时捕捉和测试的工具。
近年来,网络嗅探器广泛应用于用户的日常行为中,成为捕捉视频、音频等内容的工具。
下载:/extension/jfedfbgedapdagkghmgibemcoggfppbb
chrome网页视频抓取(来个图:浏览器扩展需要注意的是,本站推荐的扩展)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-11 16:22
文章内容
在日常使用中,我们总是希望能够在浏览器上执行除浏览以外的某些动作,比如爬取网络视频、爬取网络图片、高速下载等。据统计,80%以上的网民从来没有使用过浏览器扩展,这是一种真正的浪费。相信本期介绍的这几点会对你有所帮助。当然,它们都是免费和开源的。
这是一张图片:
浏览器扩展
需要注意的是,本站推荐的浏览器扩展仅在谷歌Chrome浏览器中进行了测试。当然,这些扩展中的大多数都有其他浏览器的适用版本。需要的可以到相关地址下载安装。
一、IDM 集成模块
准确的说,这个扩展不是一个独立的扩展,而是一个配套的扩展。历史上最强的多线程下载工具 IDM 使用了它。在实际使用中,它可以以几何倍数提高您的下载速度。简单的解释就是,正常情况下,你的浏览器下载速度是单线程的,但是有了IDM,你的下载速度会是多线程的。简单的说,一个下载任务被拆分成多个部分,然后IDM可以同时下载这多个不同的部分。例如:
100M文件不拆分时,下载速度5M/S,下载时间20S。拆分成5份时,每份20M,每份下载速度也是5M/s。由于是同时下载,所以只需要4S就可以完成下载。这就是IDM的力量。
但残酷的事实是:IDM 是有偿的。
不过浏览器除了使用IDM之外,还有自己的多线程下载。您可以通过以下操作打开浏览器的多线程下载:
直接在浏览器顶部的搜索栏中搜索
找到此项,在右边选择Enabled,点击右下角的Relaunch【重启浏览器】二、Image Picka
这个扩展是一个可以大大加快我使用过程中效率的工具。是一款网页图片批量下载工具。它可以直接从浏览缓存中抓取您看到的图片并下载它们,或者简单地拖放。图片来自网页下载。
这是一个开源免费插件,你可以在这里找到它:
如何使用:只需单击要抓取图像的 URL 上的扩展名
需要注意的是,该插件仅兼容谷歌浏览器和火狐浏览器。目前尚不清楚在某些国产浏览器上是否可以正常使用。你可以试试。
在 Google Chrome 上安装需要以下步骤:
下载扩展的压缩包,解压压缩包,在谷歌浏览器的管理扩展中选择加载解压的扩展
加载解压后的扩展三、微信公众号同步助手
同样,这也是一款开源免费软件,可以帮助您快速将您的文章同步到各种自媒体平台。需要注意的是,过去传过来的文章是草稿的形式。需要注意的是,同步过去的文章默认会有扩展名的签名。您可以通过右键单击扩展-选项-配置并选择关闭签名来执行此操作。
你可以在这里找到它:#howtouse,它支持许多不同的平台和许多不同的浏览器
微信公众号同步助手官网
支持的平台
微信公众号同步助手
关闭扩展同步时底部的签名文章
四、Chrome 语法
这个插件可以帮助在网上英语写作过程中纠正语法和纠正英语写作错误。我们在和国外客户聊天的时候,可以避免有时对某个词写生不熟,造成乌龙事件。推荐给第一次使用英语与他人交流的人。虽然扩展是付费的,付费功能会改善语义和句子表达,但一般来说,除非你真的需要,否则没有必要使用付费版本。
影响
扩展需要从谷歌扩展商店安装,如下:
五、灯塔
这个是做网页测试用的,对于普通人来说,不太好用。主要是评价网站的质量。如速度、SEO、网页结构等,安装在谷歌浏览器扩展商店中。
也可以直接点击地址:
灯塔扩展六、返回顶部扩展
这是一个轻量级的扩展程序,非常好用。使用方法:在网页任意位置右击选择返回顶部,或者点击右上角的返回顶部扩展。
安装可以在谷歌浏览器扩展商店安装,也可以点击下方链接进行安装:
安装:%E7%BD%AE%E9%A1%B6%EF%BC%88totop%EF%BC%89/eoecceliiajignmnmnehakdagafjigdj
相关推荐:Chevereto WP前端上传适配效果展示B2主题WordPress主题设置阿里云邮件推送配置指南详解网站备案和不备案的区别,以及为什么要备案wordpress极致优化-预加载WP 内核进入内存 中速生成页面 查看全部
chrome网页视频抓取(来个图:浏览器扩展需要注意的是,本站推荐的扩展)
文章内容
在日常使用中,我们总是希望能够在浏览器上执行除浏览以外的某些动作,比如爬取网络视频、爬取网络图片、高速下载等。据统计,80%以上的网民从来没有使用过浏览器扩展,这是一种真正的浪费。相信本期介绍的这几点会对你有所帮助。当然,它们都是免费和开源的。
这是一张图片:
浏览器扩展
需要注意的是,本站推荐的浏览器扩展仅在谷歌Chrome浏览器中进行了测试。当然,这些扩展中的大多数都有其他浏览器的适用版本。需要的可以到相关地址下载安装。
一、IDM 集成模块
准确的说,这个扩展不是一个独立的扩展,而是一个配套的扩展。历史上最强的多线程下载工具 IDM 使用了它。在实际使用中,它可以以几何倍数提高您的下载速度。简单的解释就是,正常情况下,你的浏览器下载速度是单线程的,但是有了IDM,你的下载速度会是多线程的。简单的说,一个下载任务被拆分成多个部分,然后IDM可以同时下载这多个不同的部分。例如:
100M文件不拆分时,下载速度5M/S,下载时间20S。拆分成5份时,每份20M,每份下载速度也是5M/s。由于是同时下载,所以只需要4S就可以完成下载。这就是IDM的力量。
但残酷的事实是:IDM 是有偿的。
不过浏览器除了使用IDM之外,还有自己的多线程下载。您可以通过以下操作打开浏览器的多线程下载:
直接在浏览器顶部的搜索栏中搜索
找到此项,在右边选择Enabled,点击右下角的Relaunch【重启浏览器】二、Image Picka
这个扩展是一个可以大大加快我使用过程中效率的工具。是一款网页图片批量下载工具。它可以直接从浏览缓存中抓取您看到的图片并下载它们,或者简单地拖放。图片来自网页下载。
这是一个开源免费插件,你可以在这里找到它:
如何使用:只需单击要抓取图像的 URL 上的扩展名
需要注意的是,该插件仅兼容谷歌浏览器和火狐浏览器。目前尚不清楚在某些国产浏览器上是否可以正常使用。你可以试试。
在 Google Chrome 上安装需要以下步骤:
下载扩展的压缩包,解压压缩包,在谷歌浏览器的管理扩展中选择加载解压的扩展
加载解压后的扩展三、微信公众号同步助手
同样,这也是一款开源免费软件,可以帮助您快速将您的文章同步到各种自媒体平台。需要注意的是,过去传过来的文章是草稿的形式。需要注意的是,同步过去的文章默认会有扩展名的签名。您可以通过右键单击扩展-选项-配置并选择关闭签名来执行此操作。
你可以在这里找到它:#howtouse,它支持许多不同的平台和许多不同的浏览器
微信公众号同步助手官网
支持的平台
微信公众号同步助手
关闭扩展同步时底部的签名文章
四、Chrome 语法
这个插件可以帮助在网上英语写作过程中纠正语法和纠正英语写作错误。我们在和国外客户聊天的时候,可以避免有时对某个词写生不熟,造成乌龙事件。推荐给第一次使用英语与他人交流的人。虽然扩展是付费的,付费功能会改善语义和句子表达,但一般来说,除非你真的需要,否则没有必要使用付费版本。
影响
扩展需要从谷歌扩展商店安装,如下:
五、灯塔
这个是做网页测试用的,对于普通人来说,不太好用。主要是评价网站的质量。如速度、SEO、网页结构等,安装在谷歌浏览器扩展商店中。
也可以直接点击地址:
灯塔扩展六、返回顶部扩展
这是一个轻量级的扩展程序,非常好用。使用方法:在网页任意位置右击选择返回顶部,或者点击右上角的返回顶部扩展。
安装可以在谷歌浏览器扩展商店安装,也可以点击下方链接进行安装:
安装:%E7%BD%AE%E9%A1%B6%EF%BC%88totop%EF%BC%89/eoecceliiajignmnmnehakdagafjigdj
相关推荐:Chevereto WP前端上传适配效果展示B2主题WordPress主题设置阿里云邮件推送配置指南详解网站备案和不备案的区别,以及为什么要备案wordpress极致优化-预加载WP 内核进入内存 中速生成页面
chrome网页视频抓取( 如何开启Chrome实时字幕的详细设置(图)!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2021-11-10 19:09
如何开启Chrome实时字幕的详细设置(图)!)
谷歌近日发布了新版Chrome 89,带来了一项新的黑科技——实时字幕!顾名思义,这个功能可以为网络视频实时生成字幕。当您打开视频网站 并播放视频时,Chrome 会自动识别其中的音频并生成字幕!虽然目前的功能只支持英文,但考虑到谷歌本身就是最高质量的自动翻译功能的提供者,未来这个功能会与谷歌实时翻译结合,一定会更上一层楼!今天我们就来看看如何在Chrome中开启实时字幕功能。
首先,我们需要更新到Chrome 89。打开Chrome,点击工具栏上的菜单按钮,在“帮助”栏中找到“关于谷歌浏览器”。将显示当前 Chrome 的版本信息并自动检查更新。Chrome更新使用国内CDN,所以网络连接不成问题。
首先需要更新到 Chrome 89
然后,转到 Chrome 的设置菜单,在“高级”中找到“辅助功能”。在其中,您可以看到“字幕”选项。
在这里找到“字幕”
点击“字幕”对实时字幕功能进行各种设置。开启实时字幕开关后,Chrome会自动下载所需资源,完成后实时字幕功能生效!并且在这个页面上还可以设置字幕的文字大小、字体、颜色、透明度等特性,可以根据需要进行自定义。
实时字幕的详细设置
我们来看看实时字幕的效果。实时字幕功能可以通过识别网页中的视频自动激活,不限于特定的网站。国外的YouTube、中国的Bilibili等都可以使用Chrome的实时字幕,当我们在B站打开一段英文视频时,可以看到浏览器底部出现了浮动的实时字幕。准确率相当不错!
自动生成的字幕
总的来说,Chrome的实时字幕功能还是比较不错的。其实类似的功能已经在安卓系统中配备了,部分国产手机也支持相应的功能,甚至还支持中文。希望Chrome的实时字幕也能尽快支持中文甚至翻译,带来更好的体验!
【编辑推荐】
和姐姐聊Java 16的新特性,真香!IT项目太多,太难管理?不!因为这七招你都学了五年没学Python,这些网站让我相见晚了,快来看看Java都到了16了,你为什么还在用8呢?情况越来越糟。是吗?太奇妙了!Windows 10的这些黑科技功能你都用过了吗? 查看全部
chrome网页视频抓取(
如何开启Chrome实时字幕的详细设置(图)!)
谷歌近日发布了新版Chrome 89,带来了一项新的黑科技——实时字幕!顾名思义,这个功能可以为网络视频实时生成字幕。当您打开视频网站 并播放视频时,Chrome 会自动识别其中的音频并生成字幕!虽然目前的功能只支持英文,但考虑到谷歌本身就是最高质量的自动翻译功能的提供者,未来这个功能会与谷歌实时翻译结合,一定会更上一层楼!今天我们就来看看如何在Chrome中开启实时字幕功能。
首先,我们需要更新到Chrome 89。打开Chrome,点击工具栏上的菜单按钮,在“帮助”栏中找到“关于谷歌浏览器”。将显示当前 Chrome 的版本信息并自动检查更新。Chrome更新使用国内CDN,所以网络连接不成问题。
首先需要更新到 Chrome 89
然后,转到 Chrome 的设置菜单,在“高级”中找到“辅助功能”。在其中,您可以看到“字幕”选项。
在这里找到“字幕”
点击“字幕”对实时字幕功能进行各种设置。开启实时字幕开关后,Chrome会自动下载所需资源,完成后实时字幕功能生效!并且在这个页面上还可以设置字幕的文字大小、字体、颜色、透明度等特性,可以根据需要进行自定义。
实时字幕的详细设置
我们来看看实时字幕的效果。实时字幕功能可以通过识别网页中的视频自动激活,不限于特定的网站。国外的YouTube、中国的Bilibili等都可以使用Chrome的实时字幕,当我们在B站打开一段英文视频时,可以看到浏览器底部出现了浮动的实时字幕。准确率相当不错!
自动生成的字幕
总的来说,Chrome的实时字幕功能还是比较不错的。其实类似的功能已经在安卓系统中配备了,部分国产手机也支持相应的功能,甚至还支持中文。希望Chrome的实时字幕也能尽快支持中文甚至翻译,带来更好的体验!
【编辑推荐】
和姐姐聊Java 16的新特性,真香!IT项目太多,太难管理?不!因为这七招你都学了五年没学Python,这些网站让我相见晚了,快来看看Java都到了16了,你为什么还在用8呢?情况越来越糟。是吗?太奇妙了!Windows 10的这些黑科技功能你都用过了吗?
chrome网页视频抓取(有关使用BeautifulSoup和Selenium进行网页爬取的相关资料关注)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-09 01:22
摘要 今天小编就为大家讲解使用BeautifulSoup和Selenium进行网络爬虫。我相信你应该关注这个话题。小编还采集了一些
今天给大家讲解一下使用BeautifulSoup和Selenium进行网络爬虫。我相信你应该关注这个话题。我还采集了有关使用 BeautifulSoup 和 Selenium 进行网络爬虫的相关信息。合作伙伴看起来很有帮助。
出自:开源中国翻译频道英文原文概览
HTML 几乎是直截了当的。CSS 是一个很大的改进。它清楚地区分了页面的结构和外观。JavaScript 增添了一些魅力。理论上,情况确实如此。现实世界仍然有些不同。
在本教程中,您将了解您在浏览器中看到的内容是如何实际呈现的,以及如何在必要时抓取它。特别是,您将学习如何计算 Disqus 评论。我们的工具是 Python 和这种语言的优秀包,例如 request、BeautifulSoup 和 Selenium。
什么时候应该使用网络爬虫?
网络爬虫是一种自动获取网页内容的实践,旨在使人类用户能够相互交互、解析它们并提取一些信息(可能是指向其他页面的链接)。如果没有其他方法可以提取必要的网页信息,网络爬虫是一种必要且有效的技术方法。理想情况下,应用程序依靠提供良好的专用 API 以编程方式自动获取网页数据。但在以下情况下,最好不要使用网页抓取技术:
正在爬取的网页是脆弱的(您正在爬取的网页可能会经常更改)。
禁止爬行(某些 Web 应用程序具有禁止爬行的策略)。
爬取速度可能很慢,爬取的内容过于复杂(如果你需要在大量无用信息中寻找和涉猎你想要的东西)。
了解真实的网页
让我们通过查看一些常见的 Web 应用程序代码的实现来了解我们面临的问题。比如在《Vagrant 技术介绍》(链接:)页面底部有一些 Disqus 评论。为了抓取这些评论,我们需要先在页面上找到它们。
查看页面代码
从 1990 年代开始,每个浏览器都支持查看当前页面的 html 代码。以下是源代码视图中查看的“Vagrant 技术简介”帖子对应的源代码片段。本源代码以大量压缩丑陋的 JavaScript 代码开头,与本文内容无关。这是“小”部分之一:
这是页面中的一些实际 html 代码:
代码看起来很乱。在页面的源代码中找不到Disqus的评论,这让你有点意外。
强大的内联框架
原创页面是一个“混搭”,Disqus 评论嵌入在 iframe(内联框架)元素中。可以在评论区右击找到,在那里可以看到框架信息和源码。这是有道理的。将第三方内容嵌入到 iframe 中是使用 iframe 的主要应用场景之一。让我们在主页源代码中找到 iframe 标签。就是这样!主页源中没有 iframe 标记。
JavaScript 生成的标签
之所以省略,是因为查看页面源显示的是从服务器获取的内容。但是最终浏览器渲染出来的DOM(文档对象模型)可能会有很大的不同。JavaScript 开始工作并且可以随意操作 DOM。无法找到 iframe,因为从服务器检索页面时它不存在。
静态抓取与动态抓取
静态抓取会忽略 JavaScript,它可以直接从服务器获取网页代码,不依赖浏览器。这就是你通过“查看源代码”看到的,然后就可以提取信息了。如果要查找源代码中已经存在的内容,则无需进一步操作。但是,如果您要查找的内容像上面的 Disqus 评论一样嵌入在 iframe 中,则必须使用动态抓取来获取内容。
动态爬取使用真实浏览器(或非接口浏览器),首先让页面中的JavaScript运行,完成动态内容的处理和加载。之后,它会查询 DOM 以获取它要查找的内容。有时,您还需要让浏览器自动模拟人工操作来获取您需要的内容。
使用 Requests 和 BeautifulSoup 进行静态抓取
下面我们来看看如何使用两个经典的 Python 包进行静态爬取:requests 用于爬取网页内容。BeautifulSoup 用于解析 html。
安装 Requests 和 BeautifulSoup
先安装pipenv,然后运行命令:pipenv install requests beautifulsoup4
它首先为你创建一个虚拟环境,然后在虚拟环境中安装这两个包。如果你的代码在 gitlab 上,你可以使用命令 pipenv install 来安装它。
获取网页内容
只需要一行代码就可以抓取带有请求的网页内容:
r = requests.get(url)。
该代码返回一个响应对象,其中收录许多有用的属性。最重要的属性是 ok 和 content。如果请求失败, r.ok 为 False 并且 r.content 收录错误消息。content 代表一个字节流,作为 text 处理时最好解码成utf-8.
>>> r = requests.get('')>>> r.okFalse>>> 打印(r.content.decode('utf-8'))未找到
在此服务器上找不到请求的 URL /ggg。
端口 80 的 Apache/2.0.52 (CentOS) 服务器
如果代码正常返回并且没有报错,那么r.content会收录所请求网页的源代码(也就是你在“查看源代码”中看到的)。
使用 BeautifulSoup 查找元素
下面的 get_page() 函数会获取给定 URL 的网页源代码,然后将其解码为 utf-8,最后将内容传递给 BeautifulSoup 对象并返回。BeautifulSoup 使用 html 解析器进行解析。
def get_page(url): r = requests.get(url) content = r.content.decode('utf-8') return BeautifulSoup(content,'html.parser')
拿到 BeautifulSoup 对象后,我们就可以开始解析需要的信息了。
BeautifulSoup 提供了多种搜索方法来定位网页中的元素,并且可以深入挖掘嵌套元素。
Tuts+ 网站 里面有很多培训教程,这里()是我的主页。每个页面最多收录 12 个教程。如果您已经获得了12个教程,您可以转到下一页。一篇文章 文章 被标签包围。下面的功能是找到页面中所有的文章元素,然后找到对应的链接,最后提取教程的网址。
page = get_page('')articles = get_page_articles(page)prefix =''for a in article: print(a[len(prefix):]) 输出:building-games-with-python-3-and-pygame-part -5--cms-30085building-games-with-python-3-and-pygame-part-4--cms-30084building-games-with-python-3-and-pygame-part -3--cms-30083building-games-with-python-3-and-pygame-part-2--cms-30082building-games-with-python-3-and-pygame-part -1--cms-30081mastering-the-react-lifecycle-methods--cms-29849testing-data-integrated-code-with-go-part-5--cms- 29852testing-data-密集型代码与go-part-4--cms-29851testing-data-密集型代码与go-part-3--cms-29850testing-data-密集型代码与go-part-2--cms-29848testing-data-密集型代码与go-part-1--cms-29847 make-your-go-programs-lightning-fast-with-profiling--cms-29809 使用Selenium动态爬取
静态爬取非常适合一系列的文章,但是正如我们之前看到的,Disqus 的评论是由 JavaScript 写在 iframe 中的。为了获得这些注释,我们需要让浏览器自动与 DOM 交互。做这种事情的最好的工具之一是 Selenium。
Selenium 主要用于 Web 应用程序自动化测试,但它也是一个很好的通用浏览器自动化工具。
安装硒
使用以下命令安装 Selenium:
pipenv install selenium 选择您的网络驱动程序
Selenium 需要一个 Web 驱动程序(用于自动化的浏览器)。对于网络爬虫,您通常不需要关心您选择的驱动程序。我建议使用 Chrome 驱动程序。Selenium手册中有相关介绍。
比较 Chrome 和 Phantomjs
在某些情况下,您可能想要使用无头浏览器。理论上,Phantomjs 正是那个 Web 驱动程序。但实际上,有人报告了一些只有在 Phantomjs 中才会出现的问题。Selenium 使用 Chrome 或 Firefox 时不会出现这些问题。我喜欢从等式中删除这个变量以使用实际的 Web 浏览器驱动程序。 查看全部
chrome网页视频抓取(有关使用BeautifulSoup和Selenium进行网页爬取的相关资料关注)
摘要 今天小编就为大家讲解使用BeautifulSoup和Selenium进行网络爬虫。我相信你应该关注这个话题。小编还采集了一些
今天给大家讲解一下使用BeautifulSoup和Selenium进行网络爬虫。我相信你应该关注这个话题。我还采集了有关使用 BeautifulSoup 和 Selenium 进行网络爬虫的相关信息。合作伙伴看起来很有帮助。
出自:开源中国翻译频道英文原文概览
HTML 几乎是直截了当的。CSS 是一个很大的改进。它清楚地区分了页面的结构和外观。JavaScript 增添了一些魅力。理论上,情况确实如此。现实世界仍然有些不同。
在本教程中,您将了解您在浏览器中看到的内容是如何实际呈现的,以及如何在必要时抓取它。特别是,您将学习如何计算 Disqus 评论。我们的工具是 Python 和这种语言的优秀包,例如 request、BeautifulSoup 和 Selenium。
什么时候应该使用网络爬虫?
网络爬虫是一种自动获取网页内容的实践,旨在使人类用户能够相互交互、解析它们并提取一些信息(可能是指向其他页面的链接)。如果没有其他方法可以提取必要的网页信息,网络爬虫是一种必要且有效的技术方法。理想情况下,应用程序依靠提供良好的专用 API 以编程方式自动获取网页数据。但在以下情况下,最好不要使用网页抓取技术:
正在爬取的网页是脆弱的(您正在爬取的网页可能会经常更改)。
禁止爬行(某些 Web 应用程序具有禁止爬行的策略)。
爬取速度可能很慢,爬取的内容过于复杂(如果你需要在大量无用信息中寻找和涉猎你想要的东西)。
了解真实的网页
让我们通过查看一些常见的 Web 应用程序代码的实现来了解我们面临的问题。比如在《Vagrant 技术介绍》(链接:)页面底部有一些 Disqus 评论。为了抓取这些评论,我们需要先在页面上找到它们。
查看页面代码
从 1990 年代开始,每个浏览器都支持查看当前页面的 html 代码。以下是源代码视图中查看的“Vagrant 技术简介”帖子对应的源代码片段。本源代码以大量压缩丑陋的 JavaScript 代码开头,与本文内容无关。这是“小”部分之一:
这是页面中的一些实际 html 代码:
代码看起来很乱。在页面的源代码中找不到Disqus的评论,这让你有点意外。
强大的内联框架
原创页面是一个“混搭”,Disqus 评论嵌入在 iframe(内联框架)元素中。可以在评论区右击找到,在那里可以看到框架信息和源码。这是有道理的。将第三方内容嵌入到 iframe 中是使用 iframe 的主要应用场景之一。让我们在主页源代码中找到 iframe 标签。就是这样!主页源中没有 iframe 标记。
JavaScript 生成的标签
之所以省略,是因为查看页面源显示的是从服务器获取的内容。但是最终浏览器渲染出来的DOM(文档对象模型)可能会有很大的不同。JavaScript 开始工作并且可以随意操作 DOM。无法找到 iframe,因为从服务器检索页面时它不存在。
静态抓取与动态抓取
静态抓取会忽略 JavaScript,它可以直接从服务器获取网页代码,不依赖浏览器。这就是你通过“查看源代码”看到的,然后就可以提取信息了。如果要查找源代码中已经存在的内容,则无需进一步操作。但是,如果您要查找的内容像上面的 Disqus 评论一样嵌入在 iframe 中,则必须使用动态抓取来获取内容。
动态爬取使用真实浏览器(或非接口浏览器),首先让页面中的JavaScript运行,完成动态内容的处理和加载。之后,它会查询 DOM 以获取它要查找的内容。有时,您还需要让浏览器自动模拟人工操作来获取您需要的内容。
使用 Requests 和 BeautifulSoup 进行静态抓取
下面我们来看看如何使用两个经典的 Python 包进行静态爬取:requests 用于爬取网页内容。BeautifulSoup 用于解析 html。
安装 Requests 和 BeautifulSoup
先安装pipenv,然后运行命令:pipenv install requests beautifulsoup4
它首先为你创建一个虚拟环境,然后在虚拟环境中安装这两个包。如果你的代码在 gitlab 上,你可以使用命令 pipenv install 来安装它。
获取网页内容
只需要一行代码就可以抓取带有请求的网页内容:
r = requests.get(url)。
该代码返回一个响应对象,其中收录许多有用的属性。最重要的属性是 ok 和 content。如果请求失败, r.ok 为 False 并且 r.content 收录错误消息。content 代表一个字节流,作为 text 处理时最好解码成utf-8.
>>> r = requests.get('')>>> r.okFalse>>> 打印(r.content.decode('utf-8'))未找到
在此服务器上找不到请求的 URL /ggg。
端口 80 的 Apache/2.0.52 (CentOS) 服务器
如果代码正常返回并且没有报错,那么r.content会收录所请求网页的源代码(也就是你在“查看源代码”中看到的)。
使用 BeautifulSoup 查找元素
下面的 get_page() 函数会获取给定 URL 的网页源代码,然后将其解码为 utf-8,最后将内容传递给 BeautifulSoup 对象并返回。BeautifulSoup 使用 html 解析器进行解析。
def get_page(url): r = requests.get(url) content = r.content.decode('utf-8') return BeautifulSoup(content,'html.parser')
拿到 BeautifulSoup 对象后,我们就可以开始解析需要的信息了。
BeautifulSoup 提供了多种搜索方法来定位网页中的元素,并且可以深入挖掘嵌套元素。
Tuts+ 网站 里面有很多培训教程,这里()是我的主页。每个页面最多收录 12 个教程。如果您已经获得了12个教程,您可以转到下一页。一篇文章 文章 被标签包围。下面的功能是找到页面中所有的文章元素,然后找到对应的链接,最后提取教程的网址。
page = get_page('')articles = get_page_articles(page)prefix =''for a in article: print(a[len(prefix):]) 输出:building-games-with-python-3-and-pygame-part -5--cms-30085building-games-with-python-3-and-pygame-part-4--cms-30084building-games-with-python-3-and-pygame-part -3--cms-30083building-games-with-python-3-and-pygame-part-2--cms-30082building-games-with-python-3-and-pygame-part -1--cms-30081mastering-the-react-lifecycle-methods--cms-29849testing-data-integrated-code-with-go-part-5--cms- 29852testing-data-密集型代码与go-part-4--cms-29851testing-data-密集型代码与go-part-3--cms-29850testing-data-密集型代码与go-part-2--cms-29848testing-data-密集型代码与go-part-1--cms-29847 make-your-go-programs-lightning-fast-with-profiling--cms-29809 使用Selenium动态爬取
静态爬取非常适合一系列的文章,但是正如我们之前看到的,Disqus 的评论是由 JavaScript 写在 iframe 中的。为了获得这些注释,我们需要让浏览器自动与 DOM 交互。做这种事情的最好的工具之一是 Selenium。
Selenium 主要用于 Web 应用程序自动化测试,但它也是一个很好的通用浏览器自动化工具。
安装硒
使用以下命令安装 Selenium:
pipenv install selenium 选择您的网络驱动程序
Selenium 需要一个 Web 驱动程序(用于自动化的浏览器)。对于网络爬虫,您通常不需要关心您选择的驱动程序。我建议使用 Chrome 驱动程序。Selenium手册中有相关介绍。
比较 Chrome 和 Phantomjs
在某些情况下,您可能想要使用无头浏览器。理论上,Phantomjs 正是那个 Web 驱动程序。但实际上,有人报告了一些只有在 Phantomjs 中才会出现的问题。Selenium 使用 Chrome 或 Firefox 时不会出现这些问题。我喜欢从等式中删除这个变量以使用实际的 Web 浏览器驱动程序。
chrome网页视频抓取(Python实现抓取B站视频弹幕评论,废话不多说 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-09 01:21
)
前言
用Python捕捉B站视频弹幕评论,废话不多说。
让我们愉快的开始吧~
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文以爬取视频《“这是我见过最拽的中国奥运冠军”》为例,讲解如何爬取B站视频的弹幕和评论!
目标地址
https://www.bilibili.com/video/BV1wq4y1Q7dp
抢弹幕
网络分析
B站视频的弹幕不像TXSP。播放视频会触发弹幕数据包。他需要点击网页右侧弹幕列表行展开,然后点击查看历史弹幕,获取视频弹幕开始日期到结束日期链接:
在链接的末尾,使用oid和开始日期形成弹幕日期URL:
https://api.bilibili.com/x/v2/ ... 21-08
在此基础上,点击任一生效日期,即可获得该日期的弹幕数据包。里面的内容目前无法读取。之所以确定是弹幕数据包,是因为日期是点击他刚加载出来的,链接和上一个链接有关系:
获取到的网址:
https://api.bilibili.com/x/v2/ ... 08-08
URL中的oid是视频弹幕链接的id值;data参数是刚才的日期,要获取视频的所有弹幕内容,只需要修改data参数即可。data参数可以从上面弹幕日期url中获取,也可以自己构造;网页数据格式为json格式
代码
import requests\
import pandas as pd\
import re\
\
def data_resposen(url):\
headers = {\
"cookie": "你的cookie",\
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36"\
}\
resposen = requests.get(url, headers=headers)\
return resposen\
\
def main(oid, month):\
df = pd.DataFrame()\
url = f'https://api.bilibili.com/x/v2/dm/history/index?type=1&oid={oid}&month={month}'\
list_data = data_resposen(url).json()['data'] # 拿到所有日期\
print(list_data)\
for data in list_data:\
urls = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid={oid}&date={data}'\
text = re.findall(".*?([\u4E00-\u9FA5]+).*?", data_resposen(urls).text)\
for e in text:\
print(e)\
data = pd.DataFrame({'弹幕': [e]})\
df = pd.concat([df, data])\
df.to_csv('弹幕.csv', encoding='utf-8', index=False, mode='a+')\
\
if __name__ == '__main__':\
oid = '384801460' # 视频弹幕链接的id值\
month = '2021-08' # 开始日期\
main(oid, month)
显示结果
查看全部
chrome网页视频抓取(Python实现抓取B站视频弹幕评论,废话不多说
)
前言
用Python捕捉B站视频弹幕评论,废话不多说。
让我们愉快的开始吧~
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文以爬取视频《“这是我见过最拽的中国奥运冠军”》为例,讲解如何爬取B站视频的弹幕和评论!
目标地址
https://www.bilibili.com/video/BV1wq4y1Q7dp
抢弹幕
网络分析
B站视频的弹幕不像TXSP。播放视频会触发弹幕数据包。他需要点击网页右侧弹幕列表行展开,然后点击查看历史弹幕,获取视频弹幕开始日期到结束日期链接:
在链接的末尾,使用oid和开始日期形成弹幕日期URL:
https://api.bilibili.com/x/v2/ ... 21-08
在此基础上,点击任一生效日期,即可获得该日期的弹幕数据包。里面的内容目前无法读取。之所以确定是弹幕数据包,是因为日期是点击他刚加载出来的,链接和上一个链接有关系:
获取到的网址:
https://api.bilibili.com/x/v2/ ... 08-08
URL中的oid是视频弹幕链接的id值;data参数是刚才的日期,要获取视频的所有弹幕内容,只需要修改data参数即可。data参数可以从上面弹幕日期url中获取,也可以自己构造;网页数据格式为json格式
代码
import requests\
import pandas as pd\
import re\
\
def data_resposen(url):\
headers = {\
"cookie": "你的cookie",\
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36"\
}\
resposen = requests.get(url, headers=headers)\
return resposen\
\
def main(oid, month):\
df = pd.DataFrame()\
url = f'https://api.bilibili.com/x/v2/dm/history/index?type=1&oid={oid}&month={month}'\
list_data = data_resposen(url).json()['data'] # 拿到所有日期\
print(list_data)\
for data in list_data:\
urls = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid={oid}&date={data}'\
text = re.findall(".*?([\u4E00-\u9FA5]+).*?", data_resposen(urls).text)\
for e in text:\
print(e)\
data = pd.DataFrame({'弹幕': [e]})\
df = pd.concat([df, data])\
df.to_csv('弹幕.csv', encoding='utf-8', index=False, mode='a+')\
\
if __name__ == '__main__':\
oid = '384801460' # 视频弹幕链接的id值\
month = '2021-08' # 开始日期\
main(oid, month)
显示结果
chrome网页视频抓取(流媒体的插件....)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-11-03 14:11
在线视频网站 视频是一种流媒体。
1.
那么什么是流媒体?
【流媒体】是指将一系列媒体数据进行压缩,通过网络将数据分段传输,并在网络上实时传输视频和音频以供观看的技术和过程。该技术使数据包像流水一样发送;如果您不使用此技术,则必须在使用前下载整个媒体文件。流媒体可以传输实时视频或存储在服务器上的视频。当观众在观看这些视频文件时,视频数据将通过特定的播放软件(如Windows Media Player、Real Player 或QuickTime Player)进行播放。--维基百科]
简单地说,在线播放的视频和音乐被视为流媒体。它采用新的编码和压缩方式,在互联网上传输,然后当您观看时,播放器将再次解码和解压缩以进行播放。你说得对,播放的时候电脑上确实生成了一个缓存文件,但是这个缓存文件不是直接的媒体文件,所以不能直接播放。并且因为缓存是在播放过程中分段完成的,所以并不完整。
2.
Chrome有不少下载在线视频数据的插件,不过貌似是因为谷歌官方不允许这种插件出现在chrome应用商店中,所以过段时间大部分都失效了。
其实下载优酷的视频或者其他网站的视频在自己的客户端都有这个功能,比如优酷的iku,可以支持自己下载网站的视频。
或者装个火狐,它有个插件叫NetVideohunter,拦截流媒体的能力简直绝了…… 查看全部
chrome网页视频抓取(流媒体的插件....)
在线视频网站 视频是一种流媒体。
1.
那么什么是流媒体?
【流媒体】是指将一系列媒体数据进行压缩,通过网络将数据分段传输,并在网络上实时传输视频和音频以供观看的技术和过程。该技术使数据包像流水一样发送;如果您不使用此技术,则必须在使用前下载整个媒体文件。流媒体可以传输实时视频或存储在服务器上的视频。当观众在观看这些视频文件时,视频数据将通过特定的播放软件(如Windows Media Player、Real Player 或QuickTime Player)进行播放。--维基百科]
简单地说,在线播放的视频和音乐被视为流媒体。它采用新的编码和压缩方式,在互联网上传输,然后当您观看时,播放器将再次解码和解压缩以进行播放。你说得对,播放的时候电脑上确实生成了一个缓存文件,但是这个缓存文件不是直接的媒体文件,所以不能直接播放。并且因为缓存是在播放过程中分段完成的,所以并不完整。
2.
Chrome有不少下载在线视频数据的插件,不过貌似是因为谷歌官方不允许这种插件出现在chrome应用商店中,所以过段时间大部分都失效了。
其实下载优酷的视频或者其他网站的视频在自己的客户端都有这个功能,比如优酷的iku,可以支持自己下载网站的视频。
或者装个火狐,它有个插件叫NetVideohunter,拦截流媒体的能力简直绝了……
chrome网页视频抓取(插件安装方法安装包的方法和软件特色)
网站优化 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2021-10-29 21:04
从常用的 GET 和 POST 到 RESTful PUT、DELETE...等。您甚至可以发送文件和发送额外的标头。
2、采集功能(测试采集)
通过集合的分类,我们可以对软件提供的API进行分类和测试。还可以导入或共享集合,以便团队中的每个人都可以共享您构建的集合。
3、人性化响应组织
一般在使用其他工具进行测试时,响应的内容通常是纯文本的raw,但是如果是JSON,则打包成一整行JSON。这会造成阅读障碍,Postman 可以自动美化响应内容的格式。JSON、XML 或 HTML 将被组织成我们可以阅读的格式
4、内置测试脚本语言
支持编写测试脚本,可以快速查看请求结果,并返回测试结果
5、设置变量和环境
Postman 可以自由设置变量和环境。一般在编辑请求和验证响应时,我们总是需要重新输入某些字符,比如url,这允许我们设置变量来保存这些值。并将变量保存在不同的环境中。
软件特点
1、支持多种请求类型:get、post、put、patch、delete等。
2、 支持数据在线存储,数据可以通过账号迁移。
3、 支持设置请求头和请求参数非常方便。
4、支持不同的认证机制,包括Basic Auth、Digest Auth、OAuth 1.0、OAuth 2.0等。
5、 响应数据根据语法格式自动高亮显示,包括 HTML、JSON 和 XML。
安装方法
安装本地包
1、打开下载的postman谷歌插件安装包,解压到本地,打开应用,直接点击图标中的蓝色字体部分,直接进入Postman主界面。
2、如下图,这是Postman的主界面。
Chrome浏览器邮递员插件安装
由于chrome在2018年初停止支持chrome应用,目前可以安装postman插件,但是已经不能正常使用了。如果要安装Postman插件(本页下载包内有插件),谷歌浏览器插件的通用安装方法在这里~
1、 在本地解压插件,打开谷歌浏览器,打开扩展程序界面,在chrome地址栏直接输入chrome://extensions/
2、 进入扩展页面,打开开发者模式,加载解压后的扩展,选择解压文件夹,安装成功后就可以看到postman了。
使用教程
当开发者需要调试网页是否正常运行时,不仅仅是调试网页的HTML、CSS、脚本等信息是否正常运行。更重要的是网页可以正确处理各种HTTP请求。毕竟网页的HTTP请求是网站与用户交互的一个非常重要的方式。在动态网站中,大部分用户的数据需要通过HTTP请求与服务器交互。
Postman 插件充当此交互方法的“桥梁”。它可以通过Chrome插件的形式,将模拟用户HTTP请求的各种数据发送到服务器,以便开发者及时做出正确的响应,或者发布产品。对之前的错误信息进行提前处理,保证产品上线后的稳定性和安全性。
在Chrome中安装Postman插件后,用户只需在调试网站时启动Postman插件,进行一些简单的配置即可修改网站的基本信息,发送各种类型网站,在发送HTTP数据时,用户可以在写入相关测试数据时添加一定的参数信息,使测试数据更加准确,Postman将完美支持这一切。
开发者在使用Postman时可能需要同时调试同一个网站或多个网站。每次Postman插件都要重新设置会很麻烦,Postman也考虑了满足用户的个性化需求,所以在Postman配置页面,用户可以自动添加或管理多个网站用户启动 Postman 时打开相应的设置。 查看全部
chrome网页视频抓取(插件安装方法安装包的方法和软件特色)
从常用的 GET 和 POST 到 RESTful PUT、DELETE...等。您甚至可以发送文件和发送额外的标头。
2、采集功能(测试采集)
通过集合的分类,我们可以对软件提供的API进行分类和测试。还可以导入或共享集合,以便团队中的每个人都可以共享您构建的集合。
3、人性化响应组织
一般在使用其他工具进行测试时,响应的内容通常是纯文本的raw,但是如果是JSON,则打包成一整行JSON。这会造成阅读障碍,Postman 可以自动美化响应内容的格式。JSON、XML 或 HTML 将被组织成我们可以阅读的格式
4、内置测试脚本语言
支持编写测试脚本,可以快速查看请求结果,并返回测试结果
5、设置变量和环境
Postman 可以自由设置变量和环境。一般在编辑请求和验证响应时,我们总是需要重新输入某些字符,比如url,这允许我们设置变量来保存这些值。并将变量保存在不同的环境中。
软件特点
1、支持多种请求类型:get、post、put、patch、delete等。
2、 支持数据在线存储,数据可以通过账号迁移。
3、 支持设置请求头和请求参数非常方便。
4、支持不同的认证机制,包括Basic Auth、Digest Auth、OAuth 1.0、OAuth 2.0等。
5、 响应数据根据语法格式自动高亮显示,包括 HTML、JSON 和 XML。
安装方法
安装本地包
1、打开下载的postman谷歌插件安装包,解压到本地,打开应用,直接点击图标中的蓝色字体部分,直接进入Postman主界面。
2、如下图,这是Postman的主界面。
Chrome浏览器邮递员插件安装
由于chrome在2018年初停止支持chrome应用,目前可以安装postman插件,但是已经不能正常使用了。如果要安装Postman插件(本页下载包内有插件),谷歌浏览器插件的通用安装方法在这里~
1、 在本地解压插件,打开谷歌浏览器,打开扩展程序界面,在chrome地址栏直接输入chrome://extensions/
2、 进入扩展页面,打开开发者模式,加载解压后的扩展,选择解压文件夹,安装成功后就可以看到postman了。
使用教程
当开发者需要调试网页是否正常运行时,不仅仅是调试网页的HTML、CSS、脚本等信息是否正常运行。更重要的是网页可以正确处理各种HTTP请求。毕竟网页的HTTP请求是网站与用户交互的一个非常重要的方式。在动态网站中,大部分用户的数据需要通过HTTP请求与服务器交互。
Postman 插件充当此交互方法的“桥梁”。它可以通过Chrome插件的形式,将模拟用户HTTP请求的各种数据发送到服务器,以便开发者及时做出正确的响应,或者发布产品。对之前的错误信息进行提前处理,保证产品上线后的稳定性和安全性。
在Chrome中安装Postman插件后,用户只需在调试网站时启动Postman插件,进行一些简单的配置即可修改网站的基本信息,发送各种类型网站,在发送HTTP数据时,用户可以在写入相关测试数据时添加一定的参数信息,使测试数据更加准确,Postman将完美支持这一切。
开发者在使用Postman时可能需要同时调试同一个网站或多个网站。每次Postman插件都要重新设置会很麻烦,Postman也考虑了满足用户的个性化需求,所以在Postman配置页面,用户可以自动添加或管理多个网站用户启动 Postman 时打开相应的设置。
chrome网页视频抓取(WebScraper(chrome网页最新版浏览器)插件安装使用使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2021-10-11 01:14
Web Scraper(最新版的chrome网页为Web Scraper(最新版的chrome网页来自网页的最新版规则,以便快速提取网页中需要的内容。Web Scraper (最新版chrome网页的整个爬取逻辑都是从设置一级Selector(dian)开始,选择爬取范围,然后一级Selector设置二级Selector后,再次选择抓取字段,然后就可以抓取Web Scraper(最新版chrome网页了。插件抓取数据后,还可以将数据(chu)导出为CSV文件,欢迎免费下载。
Web Scraper(最新版chrome网页介绍
1. 抓取多个页面2、 读取的数据存储在本地存储或 CouchDB 中。Scraper(最新版chrome网页ipt+AJAX)5、浏览抓取的数据6、导出为CSV7、导入、导出站点地图8、只依赖于Web Scraper(最新版chrome浏览器,插件安装使用一、Install1、小编这里是Web Scraper(最新版chrome浏览器,先进入Web Scraper(最新版的chrome网页)://extensions/:进入Web Scraper(最新版chrome网页扩展,解压Web Scraper(你在本页下载的最新版chrome网页,拖入扩展页面。 2、 安装完成后抓紧时间)尝试插件的具体功能。3、当然可以先在设置页面设置插件的存储设置和存储类型功能。二、 使用抓取功能安装完成后,只需四步即可完成抓取操作。具体流程如下:1、打开Web Scraper(最新版chrome网页首先需要使用此插件进行Web Scraper(最新版chrome网页需要在开发者工具模式下使用,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 使用抓取功能安装完成后,只需四步即可完成抓取操作。具体流程如下:1、打开Web Scraper(最新版chrome网页首先需要使用此插件进行Web Scraper(最新版chrome网页需要在开发者工具模式下使用,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 使用抓取功能安装完成后,只需四步即可完成抓取操作。具体流程如下:1、打开Web Scraper(最新版chrome网页首先需要使用此插件进行Web Scraper(最新版chrome网页需要在开发者工具模式下使用,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。
我抓取今日头条的数据,然后用今日头条来命名;Web Scraper(chrome网页最新版itWeb Scraper(chrome网页最新版网址:将网页链接复制到星号网址栏,例如图中,我把“吴晓波频道”的首页链接复制到这个栏,然后点击下面的Web Scraper(最新版chrome网页te satWeb Scraper(最新版chrome网页新建SitWeb Scraper(chrome最新版网站)。
3、 设置这个SitWeb Scraper(最新版chrome网页和整个Web Scraper(最新版chrome网页有如下爬取逻辑:设置一级Selector,选择爬取范围;在一级SelectWeb Scraper(最新版chrome网页)设置二级Selector,选择捕获字段,然后捕获。对于文章,一级Selector意味着你要圈住这个文章的元素@>,这个元素可能包括标题、作者、发布时间、评论数等,然后我们在二级Selector中挑出我们想要的元素,比如标题、作者、阅读次数。我们来拆解一下这个设置主次选择器的工作流程:(1)点击Add nWeb Scraper(最新版chrome网页创建一级Selector。然后按照以下步骤操作:-输入id:id代表你抓取的整个范围,例如这里是文章 ,我们可以命名为wuxiWeb Scraper(最新版chrome网页-文章;-Select Type:类型代表你抓取的部分的类型,比如element/text/link,因为这是整个文章元素范围,我们需要先Use Element全选(如果这个网页需要滑动加载更多,则选择ElementWeb Scraper(最新版chrome网页ll Down);-check Multiple:勾选中的小框前面的Multiple,因为要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮我们识别多篇同类型的文章文章;-保留设置:其余未提及部分保留默认设置。
所以你可以学习该领域的英语。比如我要选择“作者”,我就写“作者”;-选择类型:选择文本,因为你要抓取的是文本;-不要勾选多个:不要勾选前面的小方框多个,因为我们将在这里抓取单个元素;-保留设置:保留其余未提及部分的默认设置。(4)点击选择,然后点击要爬取的字段,按照以下步骤操作: -选择一个字段:这里要爬取的字段为单个字段,点击用鼠标抓取字段,比如要爬取标题,鼠标点击某篇文章文章的标题,当字段所在的区域变成红色时,即被选中; -Complete选择:
(5)重复以上操作,直到选中要爬取的字段。4、爬网爬虫(chrome网页最新版本后,只需要设置好所有的Selectors,启动:点击Web Scraper(最新版的chrome网页,然后点击StartWeb Scraper(最新版的chrome网页),弹出一个小窗口后,爬虫就开始工作了。你会得到一个列表所有你想要的数据。(2)如果你想对数据进行排序,比如按阅读、喜欢、作者等指标排序,让数据更清晰,那么你可以点击Export DatWeb Scraper(最新的版本的chrome网页,并导入到Excel表格中。(3)导入Excel表格后,可以过滤数据。
Web Scraper(最新版chrome网页摘要
网络爬虫(chrome网页V4.60是一款适用于ios版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友: 查看全部
chrome网页视频抓取(WebScraper(chrome网页最新版浏览器)插件安装使用使用方法)
Web Scraper(最新版的chrome网页为Web Scraper(最新版的chrome网页来自网页的最新版规则,以便快速提取网页中需要的内容。Web Scraper (最新版chrome网页的整个爬取逻辑都是从设置一级Selector(dian)开始,选择爬取范围,然后一级Selector设置二级Selector后,再次选择抓取字段,然后就可以抓取Web Scraper(最新版chrome网页了。插件抓取数据后,还可以将数据(chu)导出为CSV文件,欢迎免费下载。
Web Scraper(最新版chrome网页介绍
1. 抓取多个页面2、 读取的数据存储在本地存储或 CouchDB 中。Scraper(最新版chrome网页ipt+AJAX)5、浏览抓取的数据6、导出为CSV7、导入、导出站点地图8、只依赖于Web Scraper(最新版chrome浏览器,插件安装使用一、Install1、小编这里是Web Scraper(最新版chrome浏览器,先进入Web Scraper(最新版的chrome网页)://extensions/:进入Web Scraper(最新版chrome网页扩展,解压Web Scraper(你在本页下载的最新版chrome网页,拖入扩展页面。 2、 安装完成后抓紧时间)尝试插件的具体功能。3、当然可以先在设置页面设置插件的存储设置和存储类型功能。二、 使用抓取功能安装完成后,只需四步即可完成抓取操作。具体流程如下:1、打开Web Scraper(最新版chrome网页首先需要使用此插件进行Web Scraper(最新版chrome网页需要在开发者工具模式下使用,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 使用抓取功能安装完成后,只需四步即可完成抓取操作。具体流程如下:1、打开Web Scraper(最新版chrome网页首先需要使用此插件进行Web Scraper(最新版chrome网页需要在开发者工具模式下使用,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 使用抓取功能安装完成后,只需四步即可完成抓取操作。具体流程如下:1、打开Web Scraper(最新版chrome网页首先需要使用此插件进行Web Scraper(最新版chrome网页需要在开发者工具模式下使用,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。
我抓取今日头条的数据,然后用今日头条来命名;Web Scraper(chrome网页最新版itWeb Scraper(chrome网页最新版网址:将网页链接复制到星号网址栏,例如图中,我把“吴晓波频道”的首页链接复制到这个栏,然后点击下面的Web Scraper(最新版chrome网页te satWeb Scraper(最新版chrome网页新建SitWeb Scraper(chrome最新版网站)。
3、 设置这个SitWeb Scraper(最新版chrome网页和整个Web Scraper(最新版chrome网页有如下爬取逻辑:设置一级Selector,选择爬取范围;在一级SelectWeb Scraper(最新版chrome网页)设置二级Selector,选择捕获字段,然后捕获。对于文章,一级Selector意味着你要圈住这个文章的元素@>,这个元素可能包括标题、作者、发布时间、评论数等,然后我们在二级Selector中挑出我们想要的元素,比如标题、作者、阅读次数。我们来拆解一下这个设置主次选择器的工作流程:(1)点击Add nWeb Scraper(最新版chrome网页创建一级Selector。然后按照以下步骤操作:-输入id:id代表你抓取的整个范围,例如这里是文章 ,我们可以命名为wuxiWeb Scraper(最新版chrome网页-文章;-Select Type:类型代表你抓取的部分的类型,比如element/text/link,因为这是整个文章元素范围,我们需要先Use Element全选(如果这个网页需要滑动加载更多,则选择ElementWeb Scraper(最新版chrome网页ll Down);-check Multiple:勾选中的小框前面的Multiple,因为要选择多个而不是单个元素,我们勾选的时候,爬虫插件会帮我们识别多篇同类型的文章文章;-保留设置:其余未提及部分保留默认设置。
所以你可以学习该领域的英语。比如我要选择“作者”,我就写“作者”;-选择类型:选择文本,因为你要抓取的是文本;-不要勾选多个:不要勾选前面的小方框多个,因为我们将在这里抓取单个元素;-保留设置:保留其余未提及部分的默认设置。(4)点击选择,然后点击要爬取的字段,按照以下步骤操作: -选择一个字段:这里要爬取的字段为单个字段,点击用鼠标抓取字段,比如要爬取标题,鼠标点击某篇文章文章的标题,当字段所在的区域变成红色时,即被选中; -Complete选择:
(5)重复以上操作,直到选中要爬取的字段。4、爬网爬虫(chrome网页最新版本后,只需要设置好所有的Selectors,启动:点击Web Scraper(最新版的chrome网页,然后点击StartWeb Scraper(最新版的chrome网页),弹出一个小窗口后,爬虫就开始工作了。你会得到一个列表所有你想要的数据。(2)如果你想对数据进行排序,比如按阅读、喜欢、作者等指标排序,让数据更清晰,那么你可以点击Export DatWeb Scraper(最新的版本的chrome网页,并导入到Excel表格中。(3)导入Excel表格后,可以过滤数据。
Web Scraper(最新版chrome网页摘要
网络爬虫(chrome网页V4.60是一款适用于ios版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:
chrome网页视频抓取( 谷歌开发一种可以自动将网页转换为短视频的AI系统URL2Video)
网站优化 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-10-08 16:35
谷歌开发一种可以自动将网页转换为短视频的AI系统URL2Video)
Smart Things 10 月 30 日报道称,谷歌表示正在开发一个 AI 系统 URL2Video,可以自动将网页转换为短视频。系统可以自动从HTML中提取文本、图片、字体、颜色、布局等设计模板,并将这些元素组合成与原创网页相似的视频。
该系统主要针对有产品和服务的详细网页介绍,但还没有提供视频介绍的公司。
谷歌表示,通过 URL2Video 处理网络信息将使产品和服务以视频的形式接触到更多的受众。而相对于传统视频制作需要几天到几周的制作周期和880到1200美元的制作成本,URL2Video有着无可比拟的优势。
URL2Video 在与专业编辑讨论的基础上,采用启发式方法确定视频编辑模板,包括内容级别、视频信息量和每个元素的时长。URL2Video 使用这种方法来解析网页,分析内容,选择关键文本或图像,保留相似的设计风格,并根据用户的具体需求进行修改。
如果我们看看这个神奇功能背后的原理,就会发现视频转换技术离不开网页元素的分类排序。
URL2Video 会从每个网页中提取文档对象模型信息和多媒体资料,并将视觉上可区分的内容标记为视频中的可用元素,包括标题、产品图片、文字说明和外部链接。
URL2Video 提取的每个元素(即文本和多媒体文件)和网页相关信息(HTML 标签、CSS 样式等)都会根据它们在原创网页上的重要性进行排序和注释,以获得不同的优先级,例如在网页顶部 占据较大区域的元素将获得更高的分数和优先级。
基于上述元素排名和启发式视频编辑模板,URL2Video可以得到视频中每个元素的最佳停留时间和位置分布。
将网页转换为视频的最后一步是格式调整。URL2Video 将图片的大小转换成适合视频屏幕的纵横比,根据风格和主题确定视频使用的字体和颜色,然后转换成MPEG-4格式。
为了使视频简洁,URL2Video 只显示网页的主要元素,如标题和主要产品图片,并且会限制每个元素在视频中的停留时间。
谷歌表示,在用户研究和测试中,URL2Video已经能够高效地从网页中提取元素,并通过交互功能键辅助用户进行编辑。
谷歌科学家 Peggy Chi 和 Irfan Essa 在他们的博客中写道:“虽然目前的研究重点是视觉呈现,但我们正在研究视频编辑中的音轨和画外音等技术。总之,我们认为方便的视频剪辑是大势所趋,而机器学习模型可以以交互的形式给剪辑师排版和排版的建议,从而快速制作出多个高质量的视频。” 查看全部
chrome网页视频抓取(
谷歌开发一种可以自动将网页转换为短视频的AI系统URL2Video)
Smart Things 10 月 30 日报道称,谷歌表示正在开发一个 AI 系统 URL2Video,可以自动将网页转换为短视频。系统可以自动从HTML中提取文本、图片、字体、颜色、布局等设计模板,并将这些元素组合成与原创网页相似的视频。
该系统主要针对有产品和服务的详细网页介绍,但还没有提供视频介绍的公司。
谷歌表示,通过 URL2Video 处理网络信息将使产品和服务以视频的形式接触到更多的受众。而相对于传统视频制作需要几天到几周的制作周期和880到1200美元的制作成本,URL2Video有着无可比拟的优势。
URL2Video 在与专业编辑讨论的基础上,采用启发式方法确定视频编辑模板,包括内容级别、视频信息量和每个元素的时长。URL2Video 使用这种方法来解析网页,分析内容,选择关键文本或图像,保留相似的设计风格,并根据用户的具体需求进行修改。
如果我们看看这个神奇功能背后的原理,就会发现视频转换技术离不开网页元素的分类排序。
URL2Video 会从每个网页中提取文档对象模型信息和多媒体资料,并将视觉上可区分的内容标记为视频中的可用元素,包括标题、产品图片、文字说明和外部链接。
URL2Video 提取的每个元素(即文本和多媒体文件)和网页相关信息(HTML 标签、CSS 样式等)都会根据它们在原创网页上的重要性进行排序和注释,以获得不同的优先级,例如在网页顶部 占据较大区域的元素将获得更高的分数和优先级。
基于上述元素排名和启发式视频编辑模板,URL2Video可以得到视频中每个元素的最佳停留时间和位置分布。
将网页转换为视频的最后一步是格式调整。URL2Video 将图片的大小转换成适合视频屏幕的纵横比,根据风格和主题确定视频使用的字体和颜色,然后转换成MPEG-4格式。
为了使视频简洁,URL2Video 只显示网页的主要元素,如标题和主要产品图片,并且会限制每个元素在视频中的停留时间。
谷歌表示,在用户研究和测试中,URL2Video已经能够高效地从网页中提取元素,并通过交互功能键辅助用户进行编辑。
谷歌科学家 Peggy Chi 和 Irfan Essa 在他们的博客中写道:“虽然目前的研究重点是视觉呈现,但我们正在研究视频编辑中的音轨和画外音等技术。总之,我们认为方便的视频剪辑是大势所趋,而机器学习模型可以以交互的形式给剪辑师排版和排版的建议,从而快速制作出多个高质量的视频。”
chrome网页视频抓取(猫抓这款Chrome插件的特色亮点及特色功能介绍(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 344 次浏览 • 2021-10-06 16:08
当我想下载音乐视频但没有下载选项或下载限制时,我该怎么办?那么你需要一个网络媒体捕捉器。当您想下载但受到限制时,它将帮助您捕获页面上的所有媒体。您可以选择自己喜欢的内容进行下载。抓住这个Chrome插件就有这样的功能。
猫扎是一款网页媒体嗅探工具插件,可以嗅探获取任意网页中的视频链接等数据,一键获取所需链接并自动保存。使用非常方便,打开需要下载文件的网站。可以抓取页面收录的所有链接内容,然后选择要下载的内容下载到本地电脑,方便使用!
插件功能
1、 支持从任何站点抓取任何数据;
2、多个站点可以同时更新;
3、 支持使用正则表达式自定义要抓取的内容。
精选亮点
1、是一款Chrome嗅探音乐视频插件,大小只有几十k。
2、 无论是看视频还是听音乐,都可以使用猫爪插件进行抓拍,只需点击下载即可。
3、也可以在设置中自定义配置,还可以抓取图片、文档等各种资源文件。
4、当然还有更多,可以和IDM一起使用。这么多素材来源,慢慢练习就能成为剪辑大师。
指示
将下载的插件添加到Chrome浏览器后,它会一直帮你在打开的网页中抓取可下载的网页媒体。如果当前网页可以下载媒体,打开右上角的插件列表就会打开。显示没有捕获到资源。
当然,如果有西苑可供下载,就会显示数量。当您单击要捕获媒体的页面时,您可以看到猫的图标上显示一个数字。该数字表示当前页面上捕获的媒体数量。打开后,将显示可下载的媒体。您可以选择如果要下载,只需下载即可。如下所示
如果有视频可以下载,后面会有观看图标,可以查看是否是你要下载的内容然后下载
很多媒体往往可以在一个页面上抓取,当数量很大时,你也可以批量处理这些下载
快来下载猫咪体验吧~
插件下载地址: 查看全部
chrome网页视频抓取(猫抓这款Chrome插件的特色亮点及特色功能介绍(图))
当我想下载音乐视频但没有下载选项或下载限制时,我该怎么办?那么你需要一个网络媒体捕捉器。当您想下载但受到限制时,它将帮助您捕获页面上的所有媒体。您可以选择自己喜欢的内容进行下载。抓住这个Chrome插件就有这样的功能。
猫扎是一款网页媒体嗅探工具插件,可以嗅探获取任意网页中的视频链接等数据,一键获取所需链接并自动保存。使用非常方便,打开需要下载文件的网站。可以抓取页面收录的所有链接内容,然后选择要下载的内容下载到本地电脑,方便使用!
插件功能
1、 支持从任何站点抓取任何数据;
2、多个站点可以同时更新;
3、 支持使用正则表达式自定义要抓取的内容。
精选亮点
1、是一款Chrome嗅探音乐视频插件,大小只有几十k。
2、 无论是看视频还是听音乐,都可以使用猫爪插件进行抓拍,只需点击下载即可。
3、也可以在设置中自定义配置,还可以抓取图片、文档等各种资源文件。
4、当然还有更多,可以和IDM一起使用。这么多素材来源,慢慢练习就能成为剪辑大师。
指示
将下载的插件添加到Chrome浏览器后,它会一直帮你在打开的网页中抓取可下载的网页媒体。如果当前网页可以下载媒体,打开右上角的插件列表就会打开。显示没有捕获到资源。
当然,如果有西苑可供下载,就会显示数量。当您单击要捕获媒体的页面时,您可以看到猫的图标上显示一个数字。该数字表示当前页面上捕获的媒体数量。打开后,将显示可下载的媒体。您可以选择如果要下载,只需下载即可。如下所示
如果有视频可以下载,后面会有观看图标,可以查看是否是你要下载的内容然后下载
很多媒体往往可以在一个页面上抓取,当数量很大时,你也可以批量处理这些下载
快来下载猫咪体验吧~
插件下载地址:
chrome网页视频抓取(猫抓支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
网站优化 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2021-10-06 06:19
猫抓
Mozhao 是一个扩展,支持所有 Chrome 内核浏览器的网络媒体嗅探和抓取。
它可以一键抓取任何站点的任何视频/音频数据,使用起来非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮可以看到页面上的资源信息。
然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地。
猫扎支持优酷、搜狐、腾讯、微博、B站等几乎所有国内网站视频文件嗅探。
当多个媒体资源出现在同一页面时,您还可以对其进行快速批量操作。
一般来说,这类嗅探工具支持的视频文件是未加密的。当面对一些加密的视频时,会有一定的失败几率。
但是,从市场反馈来看,猫筹可以抢到很多其他IDM无法嗅探的媒体资源。
这也是其竞争激烈的拓展店能拥有超过5万用户的原因之一。
此外,毛爪还支持所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,还支持使用正则表达式自定义采集的内容。
网络嗅探器最初是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。Sniffer 也是很多程序员在编写网络程序时捕捉和测试的工具。
近年来,网络嗅探器被广泛应用于用户的日常行为中,成为捕捉视频、音频等内容的工具。
点击这里下载
Github地址 查看全部
chrome网页视频抓取(猫抓支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
猫抓
Mozhao 是一个扩展,支持所有 Chrome 内核浏览器的网络媒体嗅探和抓取。
它可以一键抓取任何站点的任何视频/音频数据,使用起来非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮可以看到页面上的资源信息。
然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地。
猫扎支持优酷、搜狐、腾讯、微博、B站等几乎所有国内网站视频文件嗅探。
当多个媒体资源出现在同一页面时,您还可以对其进行快速批量操作。
一般来说,这类嗅探工具支持的视频文件是未加密的。当面对一些加密的视频时,会有一定的失败几率。
但是,从市场反馈来看,猫筹可以抢到很多其他IDM无法嗅探的媒体资源。
这也是其竞争激烈的拓展店能拥有超过5万用户的原因之一。
此外,毛爪还支持所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,还支持使用正则表达式自定义采集的内容。
网络嗅探器最初是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。Sniffer 也是很多程序员在编写网络程序时捕捉和测试的工具。
近年来,网络嗅探器被广泛应用于用户的日常行为中,成为捕捉视频、音频等内容的工具。
点击这里下载
Github地址
chrome网页视频抓取(和入门ffmpeg开FFmpeg官方网站有了神器何不自己写个工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-06 04:33
前几天有同学说想下载网站的视频,找不到连接。他问我是否可以做些什么。当时觉得应该很简单,就说抽空看看。然后它分析了目标网页,并试图从网页的源代码中找到链接,但失败了。F12调出开发者工具,进入NetWrok,看到网页是通过ajax发起的xhr请求获取的视频连接。难怪页面元素里没有下载地址。请求是一个 m3u8 格式的文件。我查了一下这是一个支离破碎的流媒体。文件,然后到处找工具下载这个格式文件,不是很理想。很多都是分片后直接下载的ts文件,但是这个网站 已加密,无法直接播放。终于找到了ffmpeg视频插件神器,视频转码、剪切、合并、播放。不用说,它还支持多个平台。
FFmpeg 介绍和入门 FFmpeg
ffmpeg开启FFmpeg官方网站
有了神器,何不自己写个工具自己下载。当您准备好这样做时,您首先会被如何获得连接的问题所阻碍。本来只是想写个小爬虫,爬取网页连接。结果不起作用。Ajax动态发起的请求的网页元素中没有数据,对js不熟悉。我不知道如何获得这种数据。同学们可以手动打开浏览器F12找到连接吗?这不是我的风格:) 然后继续各种搜索,得到结果,自己实现浏览器,拦截网页的所有请求,你一定会得到的。筛选后得到三个选项:
1.WebBrowser.
2.GeokoFx.
3.CefSharp.
第一次尝试WebBrowser,目标网站无法直接打开网页,于是换了谷歌浏览器,修改了UserAgent打开,但是网页没有完全显示出来,就放弃了。然后,可以直接打开GeokoFx,速度还不错,但是有些连接点击没有反应,只能放弃。最后用CefSharp测试达到了预期的目的,就是无法打开flash和H264视频。折腾了一天,官方说不支持版权问题,需要自己修改。我找到了一个修改过的库。我找到了一个支持flash和H264视频的库:
提取码:dfdr
是nupkg的安装包,查看nupkg的安装方法
然后编写代码:
获取视频地址,继承和集成默认抽象类DefaultRequestHandler就够了。
public class MyRequestHandler : DefaultRequestHandler
{
public override CefReturnValue OnBeforeResourceLoad(IWebBrowser browserControl, IBrowser browser, IFrame frame, IRequest request, IRequestCallback callback)
{
//拿到url后再判断下是不是视频文件
string url = request.Url;
}
}
然后在初始化浏览器时指定它。
chromeBrowser.RequestHandler = new MyRequestHandler(callback);
这里我从url中提取文件名,然后判断扩展名来判断是否是视频文件。不知道有没有更通用的方法。无法判断ResourceType == ResourceType.Media。在许多情况下,返回的值是 xhr。
FFmpeg部分就是直接命令行调用下,有时间再研究下这个神器的lib方式。
下面是折腾了几天的结果。
在这里可以下载、播放等操作,界面有点丑,功能实现了。
下载支持续传,但是m3u8分片文件没有保存断点,所以关闭软件后续传无法恢复,必须重启。直播流的大小无法预测,因此不显示进度,但会及时更新下载的数据大小。
一般情况下不需要下载ts文件,直接下载m3u8,程序会自动分析ts片段文件,下载完所有文件后自动合成一个mp4文件。
软件下载: 链接:
提取码:n6q4
如果还是不行,请下载安装NET Framework4.6.1 查看全部
chrome网页视频抓取(和入门ffmpeg开FFmpeg官方网站有了神器何不自己写个工具)
前几天有同学说想下载网站的视频,找不到连接。他问我是否可以做些什么。当时觉得应该很简单,就说抽空看看。然后它分析了目标网页,并试图从网页的源代码中找到链接,但失败了。F12调出开发者工具,进入NetWrok,看到网页是通过ajax发起的xhr请求获取的视频连接。难怪页面元素里没有下载地址。请求是一个 m3u8 格式的文件。我查了一下这是一个支离破碎的流媒体。文件,然后到处找工具下载这个格式文件,不是很理想。很多都是分片后直接下载的ts文件,但是这个网站 已加密,无法直接播放。终于找到了ffmpeg视频插件神器,视频转码、剪切、合并、播放。不用说,它还支持多个平台。
FFmpeg 介绍和入门 FFmpeg
ffmpeg开启FFmpeg官方网站
有了神器,何不自己写个工具自己下载。当您准备好这样做时,您首先会被如何获得连接的问题所阻碍。本来只是想写个小爬虫,爬取网页连接。结果不起作用。Ajax动态发起的请求的网页元素中没有数据,对js不熟悉。我不知道如何获得这种数据。同学们可以手动打开浏览器F12找到连接吗?这不是我的风格:) 然后继续各种搜索,得到结果,自己实现浏览器,拦截网页的所有请求,你一定会得到的。筛选后得到三个选项:
1.WebBrowser.
2.GeokoFx.
3.CefSharp.
第一次尝试WebBrowser,目标网站无法直接打开网页,于是换了谷歌浏览器,修改了UserAgent打开,但是网页没有完全显示出来,就放弃了。然后,可以直接打开GeokoFx,速度还不错,但是有些连接点击没有反应,只能放弃。最后用CefSharp测试达到了预期的目的,就是无法打开flash和H264视频。折腾了一天,官方说不支持版权问题,需要自己修改。我找到了一个修改过的库。我找到了一个支持flash和H264视频的库:
提取码:dfdr
是nupkg的安装包,查看nupkg的安装方法
然后编写代码:
获取视频地址,继承和集成默认抽象类DefaultRequestHandler就够了。
public class MyRequestHandler : DefaultRequestHandler
{
public override CefReturnValue OnBeforeResourceLoad(IWebBrowser browserControl, IBrowser browser, IFrame frame, IRequest request, IRequestCallback callback)
{
//拿到url后再判断下是不是视频文件
string url = request.Url;
}
}
然后在初始化浏览器时指定它。
chromeBrowser.RequestHandler = new MyRequestHandler(callback);
这里我从url中提取文件名,然后判断扩展名来判断是否是视频文件。不知道有没有更通用的方法。无法判断ResourceType == ResourceType.Media。在许多情况下,返回的值是 xhr。
FFmpeg部分就是直接命令行调用下,有时间再研究下这个神器的lib方式。
下面是折腾了几天的结果。
在这里可以下载、播放等操作,界面有点丑,功能实现了。
下载支持续传,但是m3u8分片文件没有保存断点,所以关闭软件后续传无法恢复,必须重启。直播流的大小无法预测,因此不显示进度,但会及时更新下载的数据大小。
一般情况下不需要下载ts文件,直接下载m3u8,程序会自动分析ts片段文件,下载完所有文件后自动合成一个mp4文件。
软件下载: 链接:
提取码:n6q4
如果还是不行,请下载安装NET Framework4.6.1
chrome网页视频抓取(除了手动安装扩展还可以安装个谷歌助手(微信edge))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-05 09:01
第285章原创文章苏生不服,把这个公众号设为star,第一时间看到最新的文章。
换句话说,没有扩展的浏览器是没有灵魂的。我分享了几篇关于Chrome扩展文章的文章(微信edge也可以安装使用),这里是第六篇:
除了手动安装扩展,你还可以安装一个谷歌助手(在公众号后台回复浏览器获取扩展),这样你就可以直接打开谷歌商店进行安装。
猫抓
这是一个音乐和视频资源嗅探神器,但它已被chrome删除。下载后只能手动安装。播放完视频后,点击扩展程序下载视频。如果部分视频无法下载,请参考文章
另存为 MHT
我以前共享过扩展单文件。这个也可以完美离线下载导出网页,直接将网页打包保存成文件(保留排版、图片、动图等格式),扩展地址,比如保存这篇文章文章@的效果>:
窗口标签管理器
一次打开太多窗口,占用资源?遇到麻烦不敢关掉,怕找不到?本扩展支持一键保存和打开所有网页,支持书签、历史记录和标签、扩展地址的聚合搜索
石脑油计划
本扩展可以选择、复制、编辑、翻译图片中嵌入的文字(仅支持英文),扩展地址
代理 SwitchyOmega
此扩展可以帮助您轻松快速地管理和切换多个代理设置、扩展地址
潮汐
这是一款白噪声专注定时器,可帮助您保持专注,提高工作和学习效率,扩展您的地址,并在您工作太累时聆听海浪的声音。
梦词翻译
这是为阅读和学习外语而开发的翻译和单词搜索工具。它汇集了数十种在线词典和在线翻译。扩展地址为 %E6%A2%A6%E6%83%B3%E5%88%92%E8 %AF%8D%E7%BF%BB%E8%AF%91%E2%80%94%E8%81 %9A%E5%90%88%E8%AF%8D%E5%85%B8%E6%90%9C%E7%B4%A2/odfgigmpkhhhieicogijogfobfipijjh?hl=zh-CN
浏览器标签
虽然IE浏览器已经被微软抛弃了,但有些网站(税务/教育系统和网银网站)只兼容IE,我该怎么办?如果你想在Chrome浏览器中继续使用这些网站,你可以试试这个IE Tab扩展。当然,使用edge浏览器会更方便。在设置中,将“允许在 Internet Explorer 模式下重新加载”更改为“允许”,然后右键单击并选择在 Internet Explorer 模式下重新加载。 查看全部
chrome网页视频抓取(除了手动安装扩展还可以安装个谷歌助手(微信edge))
第285章原创文章苏生不服,把这个公众号设为star,第一时间看到最新的文章。
换句话说,没有扩展的浏览器是没有灵魂的。我分享了几篇关于Chrome扩展文章的文章(微信edge也可以安装使用),这里是第六篇:
除了手动安装扩展,你还可以安装一个谷歌助手(在公众号后台回复浏览器获取扩展),这样你就可以直接打开谷歌商店进行安装。
猫抓
这是一个音乐和视频资源嗅探神器,但它已被chrome删除。下载后只能手动安装。播放完视频后,点击扩展程序下载视频。如果部分视频无法下载,请参考文章
另存为 MHT
我以前共享过扩展单文件。这个也可以完美离线下载导出网页,直接将网页打包保存成文件(保留排版、图片、动图等格式),扩展地址,比如保存这篇文章文章@的效果>:
窗口标签管理器
一次打开太多窗口,占用资源?遇到麻烦不敢关掉,怕找不到?本扩展支持一键保存和打开所有网页,支持书签、历史记录和标签、扩展地址的聚合搜索
石脑油计划
本扩展可以选择、复制、编辑、翻译图片中嵌入的文字(仅支持英文),扩展地址
代理 SwitchyOmega
此扩展可以帮助您轻松快速地管理和切换多个代理设置、扩展地址
潮汐
这是一款白噪声专注定时器,可帮助您保持专注,提高工作和学习效率,扩展您的地址,并在您工作太累时聆听海浪的声音。
梦词翻译
这是为阅读和学习外语而开发的翻译和单词搜索工具。它汇集了数十种在线词典和在线翻译。扩展地址为 %E6%A2%A6%E6%83%B3%E5%88%92%E8 %AF%8D%E7%BF%BB%E8%AF%91%E2%80%94%E8%81 %9A%E5%90%88%E8%AF%8D%E5%85%B8%E6%90%9C%E7%B4%A2/odfgigmpkhhhieicogijogfobfipijjh?hl=zh-CN
浏览器标签
虽然IE浏览器已经被微软抛弃了,但有些网站(税务/教育系统和网银网站)只兼容IE,我该怎么办?如果你想在Chrome浏览器中继续使用这些网站,你可以试试这个IE Tab扩展。当然,使用edge浏览器会更方便。在设置中,将“允许在 Internet Explorer 模式下重新加载”更改为“允许”,然后右键单击并选择在 Internet Explorer 模式下重新加载。
chrome网页视频抓取(流媒体的插件....)
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-04 10:12
在线视频网站 视频是一种流媒体。
1.
那么什么是流媒体?
【流媒体】是指将一系列媒体数据进行压缩,通过网络将数据分段传输,并在网络上实时传输视频和音频以供观看的技术和过程。该技术使数据包像流水一样发送;如果您不使用此技术,则必须在使用前下载整个媒体文件。流媒体可以传输实时视频或存储在服务器上的视频。当观众在观看这些视频文件时,视频数据将通过特定的播放软件(如Windows Media Player、Real Player 或QuickTime Player)进行播放。--维基百科]
简单地说,在线播放的视频和音乐被视为流媒体。它采用新的编码和压缩方式,在互联网上传输,然后当您观看时,播放器将再次解码和解压缩以进行播放。你说得对,播放的时候电脑上确实生成了一个缓存文件,但是这个缓存文件不是直接的媒体文件,所以不能直接播放。并且因为缓存是在播放过程中分段完成的,所以并不完整。
2.
Chrome中有很多下载在线视频数据的插件,不过貌似是因为谷歌官方不允许此类插件出现在chrome应用商店中,所以过一段时间后大部分都会失效。
其实下载优酷的视频或者其他网站的视频在自己的客户端都有这个功能,比如优酷的iku,可以支持自己下载网站的视频。
或者装个火狐,它有个插件叫NetVideohunter,拦截流媒体的能力简直绝了…… 查看全部
chrome网页视频抓取(流媒体的插件....)
在线视频网站 视频是一种流媒体。
1.
那么什么是流媒体?
【流媒体】是指将一系列媒体数据进行压缩,通过网络将数据分段传输,并在网络上实时传输视频和音频以供观看的技术和过程。该技术使数据包像流水一样发送;如果您不使用此技术,则必须在使用前下载整个媒体文件。流媒体可以传输实时视频或存储在服务器上的视频。当观众在观看这些视频文件时,视频数据将通过特定的播放软件(如Windows Media Player、Real Player 或QuickTime Player)进行播放。--维基百科]
简单地说,在线播放的视频和音乐被视为流媒体。它采用新的编码和压缩方式,在互联网上传输,然后当您观看时,播放器将再次解码和解压缩以进行播放。你说得对,播放的时候电脑上确实生成了一个缓存文件,但是这个缓存文件不是直接的媒体文件,所以不能直接播放。并且因为缓存是在播放过程中分段完成的,所以并不完整。
2.
Chrome中有很多下载在线视频数据的插件,不过貌似是因为谷歌官方不允许此类插件出现在chrome应用商店中,所以过一段时间后大部分都会失效。
其实下载优酷的视频或者其他网站的视频在自己的客户端都有这个功能,比如优酷的iku,可以支持自己下载网站的视频。
或者装个火狐,它有个插件叫NetVideohunter,拦截流媒体的能力简直绝了……
chrome网页视频抓取( 四.Python自动化下载视频讨论网络查找很多获取中 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-10-04 10:11
四.Python自动化下载视频讨论网络查找很多获取中
)
第二步:在“全部”中找到一个以“MP4”结尾的文件,即要下载的视频文件,点击“Header”查看相应的视频地址。注意:在视频执行过程中,请尝试单击“下一个暂停”,否则将跳转到下一个视频
请求URL:
请求方法:获取
状态代码:206部分内容
远程地址:61.240.28.1:443
推荐人策略:不安全的url
第三步:打开迅雷,将复制的视频URL添加到“新下载任务”中,下载视频
步骤4:视频已成功下载到本地并可以打开
你可能会想:
你能直接分析HTML源代码并找到视频的链接吗。否,视频是动态加载的。我能想到的方法是通过python获取网络中的所有资源,然后找到“MP4”对应的超链接,但最终还是没有解决。后续部分将对此进行详细讨论
三.Python下载视频
TQM是一个python进度条库。可以在python长循环中添加进度提示。用法:TQM(迭代器)
示例代码:
输出结果如下图所示:
下面是将视频下载到本地服务器的代码
如下图所示:
如果读者想下载一位葵花大师的所有视频,请点击他们的个人主页,如下所示。p>
主播主页:
写了这里之后,您可能想知道是否可以编写一个爬虫程序来抓取所有web链接中与“MP4”对应的地址,然后进行统一的爬网。让我们做一个简单的分析,但最终的结果失败了
四.Python自动捕获视频讨论
有很多网络搜索。没有有效的答案来获取网络中的所有网络请求URL和XHR响应结果,包括GitHub的代码。例如:
这里有一些讨论。我想到的第一种方法包括两个基本操作,即:
1.设置标头和请求的参数数据,并调用requests()函数请求连接。请注意,视频是一种get方法
2.通过调用JSON解析返回的数据。Load()函数,并获取指定的字段
# -*- coding: utf-8 -*- import jsondata = { 'id' : 1, 'name' : 'test1', 'age' : '1' } data2 = [{ 'id' : 1, 'name' : 'test1', 'age' : '1' },{ 'id' : 2, 'name' : 'test2', 'age' : '2' }] #python字典类型转换为json对象 json_str = json.dumps(data) print(u"python原始数据:") print(repr(data)) print (u"json对象:") print(json_str) print("") json_str2 = json.dumps(data2) print (u"python原始数据:") print(repr(data2)) print (u"json对象:") print(json_str2) print("") # 将json对象转换为python字典 data3 = json.loads(json_str) print(data3) print("data3['name']: ", data3['name']) print("data3['age']: ", data3['age'])
输出结果如下图所示:
下面是一个简单的尝试:
步骤1:调用请求以获取数据
最重要的输出是最后一个脚本代码
视频URL代码收录在这里
步骤2:尝试解析JSON数据并使用以下代码定位链接
但最重要的一步是如何定位和解析JSON位置
五.总结
稍后,我们将学习Fiddler的移动数据包捕获和代理设置
Github:
原创链接:
查看全部
chrome网页视频抓取(
四.Python自动化下载视频讨论网络查找很多获取中
)
第二步:在“全部”中找到一个以“MP4”结尾的文件,即要下载的视频文件,点击“Header”查看相应的视频地址。注意:在视频执行过程中,请尝试单击“下一个暂停”,否则将跳转到下一个视频
请求URL:
请求方法:获取
状态代码:206部分内容
远程地址:61.240.28.1:443
推荐人策略:不安全的url
第三步:打开迅雷,将复制的视频URL添加到“新下载任务”中,下载视频
步骤4:视频已成功下载到本地并可以打开
你可能会想:
你能直接分析HTML源代码并找到视频的链接吗。否,视频是动态加载的。我能想到的方法是通过python获取网络中的所有资源,然后找到“MP4”对应的超链接,但最终还是没有解决。后续部分将对此进行详细讨论
三.Python下载视频
TQM是一个python进度条库。可以在python长循环中添加进度提示。用法:TQM(迭代器)
示例代码:
输出结果如下图所示:
下面是将视频下载到本地服务器的代码
如下图所示:
如果读者想下载一位葵花大师的所有视频,请点击他们的个人主页,如下所示。p>
主播主页:
写了这里之后,您可能想知道是否可以编写一个爬虫程序来抓取所有web链接中与“MP4”对应的地址,然后进行统一的爬网。让我们做一个简单的分析,但最终的结果失败了
四.Python自动捕获视频讨论
有很多网络搜索。没有有效的答案来获取网络中的所有网络请求URL和XHR响应结果,包括GitHub的代码。例如:
这里有一些讨论。我想到的第一种方法包括两个基本操作,即:
1.设置标头和请求的参数数据,并调用requests()函数请求连接。请注意,视频是一种get方法
2.通过调用JSON解析返回的数据。Load()函数,并获取指定的字段
# -*- coding: utf-8 -*- import jsondata = { 'id' : 1, 'name' : 'test1', 'age' : '1' } data2 = [{ 'id' : 1, 'name' : 'test1', 'age' : '1' },{ 'id' : 2, 'name' : 'test2', 'age' : '2' }] #python字典类型转换为json对象 json_str = json.dumps(data) print(u"python原始数据:") print(repr(data)) print (u"json对象:") print(json_str) print("") json_str2 = json.dumps(data2) print (u"python原始数据:") print(repr(data2)) print (u"json对象:") print(json_str2) print("") # 将json对象转换为python字典 data3 = json.loads(json_str) print(data3) print("data3['name']: ", data3['name']) print("data3['age']: ", data3['age'])
输出结果如下图所示:
下面是一个简单的尝试:
步骤1:调用请求以获取数据
最重要的输出是最后一个脚本代码
视频URL代码收录在这里
步骤2:尝试解析JSON数据并使用以下代码定位链接
但最重要的一步是如何定位和解析JSON位置
五.总结
稍后,我们将学习Fiddler的移动数据包捕获和代理设置
Github:
原创链接:
chrome网页视频抓取(爬虫北京二手车数据的过程及应用方法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-10-04 07:29
基于golang的爬虫实战前言
爬虫本来就是蟒蛇的强项。早期学习scrapy,写了一些简单的爬虫小程序。但是后来突然对golang产生了兴趣,决定写爬虫来练手。由于我是golang新手,有错误请指正。
下载依赖包需要的库gopkg.in/gomail.v2缺点的大致思路
go get github.com/tebeka/selenium
go get gopkg.in/gomail.v2
代码
// StartChrome 启动谷歌浏览器headless模式
func StartChrome() {
opts := []selenium.ServiceOption{}
caps := selenium.Capabilities{
"browserName": "chrome",
}
// 禁止加载图片,加快渲染速度
imagCaps := map[string]interface{}{
"profile.managed_default_content_settings.images": 2,
}
chromeCaps := chrome.Capabilities{
Prefs: imagCaps,
Path: "",
Args: []string{
"--headless", // 设置Chrome无头模式
"--no-sandbox",
"--user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/604.4.7 (KHTML, like Gecko) Version/11.0.2 Safari/604.4.7", // 模拟user-agent,防反爬
},
}
caps.AddChrome(chromeCaps)
// 启动chromedriver,端口号可自定义
service, err = selenium.NewChromeDriverService("/opt/google/chrome/chromedriver", 9515, opts...)
if err != nil {
log.Printf("Error starting the ChromeDriver server: %v", err)
}
// 调起chrome浏览器
webDriver, err = selenium.NewRemote(caps, fmt.Sprintf("http://localhost:%d/wd/hub", 9515))
if err != nil {
panic(err)
}
// 这是目标网站留下的坑,不加这个在linux系统中会显示手机网页,每个网站的策略不一样,需要区别处理。
webDriver.AddCookie(&selenium.Cookie{
Name: "defaultJumpDomain",
Value: "www",
})
// 导航到目标网站
err = webDriver.Get(urlBeijing)
if err != nil {
panic(fmt.Sprintf("Failed to load page: %s\n", err))
}
log.Println(webDriver.Title())
}
通过上面的代码,可以通过代码启动Chrome,跳转到目标网站,方便下一步的数据采集。
// SetupWriter 初始化CSV
func SetupWriter() {
dateTime = time.Now().Format("2006-01-02 15:04:05") // 格式字符串是固定的,据说是go语言诞生时间,谷歌的恶趣味...
os.Mkdir("data", os.ModePerm)
csvFile, err := os.Create(fmt.Sprintf("data/%s.csv", dateTime))
if err != nil {
panic(err)
}
csvFile.WriteString("\xEF\xBB\xBF")
writer = csv.NewWriter(csvFile)
writer.Write([]string{"车型", "行驶里程", "首次上牌", "价格", "所在地", "门店"})
}
数据抓取
这部分是核心业务。每个网站都有不同的爬取方式,但是思路是一样的。通过xpath、css选择器、className、tagName等获取元素的内容,selenium的api可以实现大部分操作功能可以通过selenium源码看到。核心 API 包括 WebDriver 和 WebElement。下面是从北京二手车之家抓取二手车数据的过程。其他网站请参考修改过程。
const urlBeijing = "https://www.che168.com/beijing ... ot%3B
鼠标指向这句话右键,依次复制-XPath,就可以得到改变元素所在的xpath属性
//*[@id="viewlist_ul"]
然后通过代码
listContainer, err := webDriver.FindElement(selenium.ByXPATH, "//*[@id=\"viewlist_ul\"]")
可以获取html修改部分的WebElement对象。不难看出,这是所有数据的父容器。为了获取具体的数据,需要定位到每个元素子集,通过开发模式可以看出。
可以通过开发者工具获取类为carinfo,因为有多个元素,所以通过
lists, err := listContainer.FindElements(selenium.ByClassName, "carinfo")
您可以获得所有元素子集的集合。获取每个子集中的元素数据,需要遍历集合
for i := 0; i < len(lists); i++ {
var urlElem selenium.WebElement
if pageIndex == 1 {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+13))
} else {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+1))
}
if err != nil {
break
}
// 因为有些数据在次级页面,需要跳转
url, err := urlElem.GetAttribute("href")
if err != nil {
break
}
webDriver.Get(url)
title, _ := webDriver.Title()
log.Printf("当前页面标题:%s\n", title)
// 获取车辆型号
modelElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[1]/h2")
var model string
if err != nil {
log.Println(err)
model = "暂无"
} else {
model, _ = modelElem.Text()
}
log.Printf("model=[%s]\n", model)
...
// 数据写入CSV
writer.Write([]string{model, miles, date, price, position, store})
writer.Flush()
webDriver.Back() // 回退到上级页面重复步骤抓取
}
所有源码如下,初学者,轻喷~~
// StartCrawler 开始爬取数据
func StartCrawler() {
log.Println("Start Crawling at ", time.Now().Format("2006-01-02 15:04:05"))
pageIndex := 0
for {
listContainer, err := webDriver.FindElement(selenium.ByXPATH, "//*[@id=\"viewlist_ul\"]")
if err != nil {
panic(err)
}
lists, err := listContainer.FindElements(selenium.ByClassName, "carinfo")
if err != nil {
panic(err)
}
log.Println("数据量:", len(lists))
pageIndex++
log.Printf("正在抓取第%d页数据...\n", pageIndex)
for i := 0; i < len(lists); i++ {
var urlElem selenium.WebElement
if pageIndex == 1 {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+13))
} else {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+1))
}
if err != nil {
break
}
url, err := urlElem.GetAttribute("href")
if err != nil {
break
}
webDriver.Get(url)
title, _ := webDriver.Title()
log.Printf("当前页面标题:%s\n", title)
modelElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[1]/h2")
var model string
if err != nil {
log.Println(err)
model = "暂无"
} else {
model, _ = modelElem.Text()
}
log.Printf("model=[%s]\n", model)
priceElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[2]/div/ins")
var price string
if err != nil {
log.Println(err)
price = "暂无"
} else {
price, _ = priceElem.Text()
price = fmt.Sprintf("%s万", price)
}
log.Printf("price=[%s]\n", price)
milesElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[4]/ul/li[1]/span")
var miles string
if err != nil {
log.Println(err)
milesElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[3]/ul/li[1]/span")
if err != nil {
log.Println(err)
miles = "暂无"
} else {
miles, _ = milesElem.Text()
}
} else {
miles, _ = milesElem.Text()
}
log.Printf("miles=[%s]\n", miles)
timeElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[4]/ul/li[2]/span")
var date string
if err != nil {
log.Println(err)
timeElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[3]/ul/li[2]/span")
if err != nil {
log.Println(err)
date = "暂无"
} else {
date, _ = timeElem.Text()
}
} else {
date, _ = timeElem.Text()
}
log.Printf("time=[%s]\n", date)
positionElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[4]/ul/li[4]/span")
var position string
if err != nil {
log.Println(err)
positionElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[3]/ul/li[4]/span")
if err != nil {
log.Println(err)
position = "暂无"
} else {
position, _ = positionElem.Text()
}
} else {
position, _ = positionElem.Text()
}
log.Printf("position=[%s]\n", position)
storeElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[1]/div/div/div")
var store string
if err != nil {
log.Println(err)
store = "暂无"
} else {
store, _ = storeElem.Text()
store = strings.Replace(store, "商家|", "", -1)
if strings.Contains(store, "金牌店铺") {
store = strings.Replace(store, "金牌店铺", "", -1)
}
}
log.Printf("store=[%s]\n", store)
writer.Write([]string{model, miles, date, price, position, store})
writer.Flush()
webDriver.Back()
}
log.Printf("第%d页数据已经抓取完毕,开始下一页...\n", pageIndex)
nextButton, err := webDriver.FindElement(selenium.ByClassName, "page-item-next")
if err != nil {
log.Println("所有数据抓取完毕!")
break
}
nextButton.Click()
}
log.Println("Crawling Finished at ", time.Now().Format("2006-01-02 15:04:05"))
sendResult(dateTime)
}
整个代码如下,比较简单,不再赘述
func sendResult(fileName string) {
email := gomail.NewMessage()
email.SetAddressHeader("From", "re**ng@163.com", "张**")
email.SetHeader("To", email.FormatAddress("li**yang@163.com", "李**"))
email.SetHeader("Cc", email.FormatAddress("zhang**tao@163.net", "张**"))
email.SetHeader("Subject", "二手车之家-北京-二手车信息")
email.SetBody("text/plain;charset=UTF-8", "本周抓取到的二手车信息数据,请注意查收!\n")
email.Attach(fmt.Sprintf("data/%s.csv", fileName))
dialer := &gomail.Dialer{
Host: "smtp.163.com",
Port: 25,
Username: ${your_email}, // 替换自己的邮箱地址
Password: ${smtp_password}, // 自定义smtp服务器密码
SSL: false,
}
if err := dialer.DialAndSend(email); err != nil {
log.Println("邮件发送失败!err: ", err)
return
}
log.Println("邮件发送成功!")
}
defer service.Stop() // 停止chromedriver
defer webDriver.Quit() // 关闭浏览器
defer csvFile.Close() // 关闭文件流
总结 查看全部
chrome网页视频抓取(爬虫北京二手车数据的过程及应用方法(一))
基于golang的爬虫实战前言
爬虫本来就是蟒蛇的强项。早期学习scrapy,写了一些简单的爬虫小程序。但是后来突然对golang产生了兴趣,决定写爬虫来练手。由于我是golang新手,有错误请指正。
下载依赖包需要的库gopkg.in/gomail.v2缺点的大致思路
go get github.com/tebeka/selenium
go get gopkg.in/gomail.v2
代码
// StartChrome 启动谷歌浏览器headless模式
func StartChrome() {
opts := []selenium.ServiceOption{}
caps := selenium.Capabilities{
"browserName": "chrome",
}
// 禁止加载图片,加快渲染速度
imagCaps := map[string]interface{}{
"profile.managed_default_content_settings.images": 2,
}
chromeCaps := chrome.Capabilities{
Prefs: imagCaps,
Path: "",
Args: []string{
"--headless", // 设置Chrome无头模式
"--no-sandbox",
"--user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/604.4.7 (KHTML, like Gecko) Version/11.0.2 Safari/604.4.7", // 模拟user-agent,防反爬
},
}
caps.AddChrome(chromeCaps)
// 启动chromedriver,端口号可自定义
service, err = selenium.NewChromeDriverService("/opt/google/chrome/chromedriver", 9515, opts...)
if err != nil {
log.Printf("Error starting the ChromeDriver server: %v", err)
}
// 调起chrome浏览器
webDriver, err = selenium.NewRemote(caps, fmt.Sprintf("http://localhost:%d/wd/hub", 9515))
if err != nil {
panic(err)
}
// 这是目标网站留下的坑,不加这个在linux系统中会显示手机网页,每个网站的策略不一样,需要区别处理。
webDriver.AddCookie(&selenium.Cookie{
Name: "defaultJumpDomain",
Value: "www",
})
// 导航到目标网站
err = webDriver.Get(urlBeijing)
if err != nil {
panic(fmt.Sprintf("Failed to load page: %s\n", err))
}
log.Println(webDriver.Title())
}
通过上面的代码,可以通过代码启动Chrome,跳转到目标网站,方便下一步的数据采集。
// SetupWriter 初始化CSV
func SetupWriter() {
dateTime = time.Now().Format("2006-01-02 15:04:05") // 格式字符串是固定的,据说是go语言诞生时间,谷歌的恶趣味...
os.Mkdir("data", os.ModePerm)
csvFile, err := os.Create(fmt.Sprintf("data/%s.csv", dateTime))
if err != nil {
panic(err)
}
csvFile.WriteString("\xEF\xBB\xBF")
writer = csv.NewWriter(csvFile)
writer.Write([]string{"车型", "行驶里程", "首次上牌", "价格", "所在地", "门店"})
}
数据抓取
这部分是核心业务。每个网站都有不同的爬取方式,但是思路是一样的。通过xpath、css选择器、className、tagName等获取元素的内容,selenium的api可以实现大部分操作功能可以通过selenium源码看到。核心 API 包括 WebDriver 和 WebElement。下面是从北京二手车之家抓取二手车数据的过程。其他网站请参考修改过程。
const urlBeijing = "https://www.che168.com/beijing ... ot%3B
鼠标指向这句话右键,依次复制-XPath,就可以得到改变元素所在的xpath属性
//*[@id="viewlist_ul"]
然后通过代码
listContainer, err := webDriver.FindElement(selenium.ByXPATH, "//*[@id=\"viewlist_ul\"]")
可以获取html修改部分的WebElement对象。不难看出,这是所有数据的父容器。为了获取具体的数据,需要定位到每个元素子集,通过开发模式可以看出。
可以通过开发者工具获取类为carinfo,因为有多个元素,所以通过
lists, err := listContainer.FindElements(selenium.ByClassName, "carinfo")
您可以获得所有元素子集的集合。获取每个子集中的元素数据,需要遍历集合
for i := 0; i < len(lists); i++ {
var urlElem selenium.WebElement
if pageIndex == 1 {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+13))
} else {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+1))
}
if err != nil {
break
}
// 因为有些数据在次级页面,需要跳转
url, err := urlElem.GetAttribute("href")
if err != nil {
break
}
webDriver.Get(url)
title, _ := webDriver.Title()
log.Printf("当前页面标题:%s\n", title)
// 获取车辆型号
modelElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[1]/h2")
var model string
if err != nil {
log.Println(err)
model = "暂无"
} else {
model, _ = modelElem.Text()
}
log.Printf("model=[%s]\n", model)
...
// 数据写入CSV
writer.Write([]string{model, miles, date, price, position, store})
writer.Flush()
webDriver.Back() // 回退到上级页面重复步骤抓取
}
所有源码如下,初学者,轻喷~~
// StartCrawler 开始爬取数据
func StartCrawler() {
log.Println("Start Crawling at ", time.Now().Format("2006-01-02 15:04:05"))
pageIndex := 0
for {
listContainer, err := webDriver.FindElement(selenium.ByXPATH, "//*[@id=\"viewlist_ul\"]")
if err != nil {
panic(err)
}
lists, err := listContainer.FindElements(selenium.ByClassName, "carinfo")
if err != nil {
panic(err)
}
log.Println("数据量:", len(lists))
pageIndex++
log.Printf("正在抓取第%d页数据...\n", pageIndex)
for i := 0; i < len(lists); i++ {
var urlElem selenium.WebElement
if pageIndex == 1 {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+13))
} else {
urlElem, err = webDriver.FindElement(selenium.ByXPATH, fmt.Sprintf("//*[@id='viewlist_ul']/li[%d]/a", i+1))
}
if err != nil {
break
}
url, err := urlElem.GetAttribute("href")
if err != nil {
break
}
webDriver.Get(url)
title, _ := webDriver.Title()
log.Printf("当前页面标题:%s\n", title)
modelElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[1]/h2")
var model string
if err != nil {
log.Println(err)
model = "暂无"
} else {
model, _ = modelElem.Text()
}
log.Printf("model=[%s]\n", model)
priceElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[2]/div/ins")
var price string
if err != nil {
log.Println(err)
price = "暂无"
} else {
price, _ = priceElem.Text()
price = fmt.Sprintf("%s万", price)
}
log.Printf("price=[%s]\n", price)
milesElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[4]/ul/li[1]/span")
var miles string
if err != nil {
log.Println(err)
milesElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[3]/ul/li[1]/span")
if err != nil {
log.Println(err)
miles = "暂无"
} else {
miles, _ = milesElem.Text()
}
} else {
miles, _ = milesElem.Text()
}
log.Printf("miles=[%s]\n", miles)
timeElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[4]/ul/li[2]/span")
var date string
if err != nil {
log.Println(err)
timeElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[3]/ul/li[2]/span")
if err != nil {
log.Println(err)
date = "暂无"
} else {
date, _ = timeElem.Text()
}
} else {
date, _ = timeElem.Text()
}
log.Printf("time=[%s]\n", date)
positionElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[4]/ul/li[4]/span")
var position string
if err != nil {
log.Println(err)
positionElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[3]/ul/li[4]/span")
if err != nil {
log.Println(err)
position = "暂无"
} else {
position, _ = positionElem.Text()
}
} else {
position, _ = positionElem.Text()
}
log.Printf("position=[%s]\n", position)
storeElem, err := webDriver.FindElement(selenium.ByXPATH, "/html/body/div[5]/div[2]/div[1]/div/div/div")
var store string
if err != nil {
log.Println(err)
store = "暂无"
} else {
store, _ = storeElem.Text()
store = strings.Replace(store, "商家|", "", -1)
if strings.Contains(store, "金牌店铺") {
store = strings.Replace(store, "金牌店铺", "", -1)
}
}
log.Printf("store=[%s]\n", store)
writer.Write([]string{model, miles, date, price, position, store})
writer.Flush()
webDriver.Back()
}
log.Printf("第%d页数据已经抓取完毕,开始下一页...\n", pageIndex)
nextButton, err := webDriver.FindElement(selenium.ByClassName, "page-item-next")
if err != nil {
log.Println("所有数据抓取完毕!")
break
}
nextButton.Click()
}
log.Println("Crawling Finished at ", time.Now().Format("2006-01-02 15:04:05"))
sendResult(dateTime)
}
整个代码如下,比较简单,不再赘述
func sendResult(fileName string) {
email := gomail.NewMessage()
email.SetAddressHeader("From", "re**ng@163.com", "张**")
email.SetHeader("To", email.FormatAddress("li**yang@163.com", "李**"))
email.SetHeader("Cc", email.FormatAddress("zhang**tao@163.net", "张**"))
email.SetHeader("Subject", "二手车之家-北京-二手车信息")
email.SetBody("text/plain;charset=UTF-8", "本周抓取到的二手车信息数据,请注意查收!\n")
email.Attach(fmt.Sprintf("data/%s.csv", fileName))
dialer := &gomail.Dialer{
Host: "smtp.163.com",
Port: 25,
Username: ${your_email}, // 替换自己的邮箱地址
Password: ${smtp_password}, // 自定义smtp服务器密码
SSL: false,
}
if err := dialer.DialAndSend(email); err != nil {
log.Println("邮件发送失败!err: ", err)
return
}
log.Println("邮件发送成功!")
}
defer service.Stop() // 停止chromedriver
defer webDriver.Quit() // 关闭浏览器
defer csvFile.Close() // 关闭文件流
总结
chrome网页视频抓取(Google把杀死网页上那些令人讨厌的自动播放视频内容作为2018年首要大事)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-29 15:17
全球新的浏览器之王谷歌浏览器将清除网页上那些烦人的自动播放视频内容作为2018年的首要任务,并承诺将于2018年1月21日至2018年1月27日推出该功能两个版本之间的 Chrome 64。
在某些新闻内容页面上,默认情况下会自动播放与内容相关的视频。它们总是在不适当的场合播放,这会给用户带来混乱,需要额外的手动设置来阻止它们。
在 Chrome 64 中,将不允许自动播放内容自动进行。通常,有些广告喜欢使用自动播放模式。这种类型的广告不仅让用户感到不舒服,而且在浏览网页时也会干扰用户的注意力。当然,不仅仅是广告,一些网站也希望通过这种方式来增加网络小视频的播放量,让用户的注意力停留在编辑想要的地方。
Chrome 将使自动播放的内容成为一种用户友好的体验,并允许用户对这些媒体内容有更多的自主控制权。用户只在需要观看视频播放时点击。当然,您仍然可以将其设置为默认自动播放,也可以将其设置为打开网页一段时间后自动播放。
谷歌计划在年底发布 Chrome 63 时添加一些小功能作为过渡。它会在页面上弹出一个气泡,允许用户静音选择。过去,谷歌只是在带有自动播放内容的网页标签上放一个小的扬声器标记。
苹果在最新的Safari 11上推出了每个站点和全网的自动播放控制功能。该版本将于9月25日与macOS High Sierra一起发布。返回搜狐查看更多 查看全部
chrome网页视频抓取(Google把杀死网页上那些令人讨厌的自动播放视频内容作为2018年首要大事)
全球新的浏览器之王谷歌浏览器将清除网页上那些烦人的自动播放视频内容作为2018年的首要任务,并承诺将于2018年1月21日至2018年1月27日推出该功能两个版本之间的 Chrome 64。
在某些新闻内容页面上,默认情况下会自动播放与内容相关的视频。它们总是在不适当的场合播放,这会给用户带来混乱,需要额外的手动设置来阻止它们。
在 Chrome 64 中,将不允许自动播放内容自动进行。通常,有些广告喜欢使用自动播放模式。这种类型的广告不仅让用户感到不舒服,而且在浏览网页时也会干扰用户的注意力。当然,不仅仅是广告,一些网站也希望通过这种方式来增加网络小视频的播放量,让用户的注意力停留在编辑想要的地方。
Chrome 将使自动播放的内容成为一种用户友好的体验,并允许用户对这些媒体内容有更多的自主控制权。用户只在需要观看视频播放时点击。当然,您仍然可以将其设置为默认自动播放,也可以将其设置为打开网页一段时间后自动播放。
谷歌计划在年底发布 Chrome 63 时添加一些小功能作为过渡。它会在页面上弹出一个气泡,允许用户静音选择。过去,谷歌只是在带有自动播放内容的网页标签上放一个小的扬声器标记。
苹果在最新的Safari 11上推出了每个站点和全网的自动播放控制功能。该版本将于9月25日与macOS High Sierra一起发布。返回搜狐查看更多

