
chrome网页视频抓取
chrome网页视频抓取( Python中一个非常成熟的库——selenium专栏(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-31 19:20
Python中一个非常成熟的库——selenium专栏(组图))
本系列文章收录在公众号:数据宇宙>py爬虫>Selenium
转发本文并私信我“python”,可以获得Python资料及更多系列文章(持续更新)
作为“数据玩家”,手头没有数据怎么办?当然,用代码自动化采集数据,但现在“爬虫”可没那么容易了,其中最难的是突破网站的各种反爬机制。本系列将全面讲解Python中一个非常成熟的库——selenium,并教你如何使用它在网络上爬取你需要的数据
虽然自动爬虫很方便,但希望大家可以考虑到网站服务器的承受能力,不要频繁访问网站。永远不要采集敏感数据!!否则很容易“从入门到监狱”
本系列大部分案例都是selenium和pyppeteer库同时讲解的,并且有Python和C#2语言的实现文章,详情请到公众号目录。
当你得到数据时,你还需要对数据进行处理和分析。我的 pandas 专栏是高级教程的最佳介绍。
前言
学习任何库,首先要了解库的机制和流程。今天,我们将从一个小例子开始我们的学习之旅。
搜索和采集结果的标题
要求如下:
硒的问题
这个系列一直围绕着一个点:“用代码操作浏览器”,我们来看看整个过程:
然而,市面上的浏览器种类繁多,甚至一个厂商的浏览器版本也不同。我们如何保证我们的代码只需要编写一次就可以控制不同的浏览器?
更深入的流程图如下:
“案子怎么还没开始,就说硒不是?我还在学吗?”
他有以下优点:
缺点:
如果觉得不能接受selenium的缺点,可以查看pyppeteer的相关文章(公众号:大数据宇宙>py爬虫>pyppeteer)
得到驱动
现在让我们开始使用 selenium 来解决我们的需求。
首先,使用 pip 安装 selenium
由于我在本地安装了谷歌Chrome浏览器,打开浏览器查看浏览器的版本:
然后去相关的网站(私信我“python”)下载对应的驱动:
一切都准备好了
看过我相关教学文章的人都知道,我喜欢从语义的角度去理解和学习图书馆。
Selenium 本质上控制着浏览器,所以我们在使用它的时候,代码的语义应该类似于手动操作浏览器的过程。
首先导入一些包:
让我们看看如何使用代码来描述我们的手动操作。
打开浏览器:
没错,我们只是下载了驱动程序,但是 Python 怎么知道在哪里可以找到该驱动程序呢?
我们可以在实例化浏览器对象的时候传入一个文件路径,告诉他程序的具体位置:
输入百度搜索的网址:
将鼠标移动到输入框,点击一次,然后输入内容“爬虫”:
这里的问题是,如何在代码中表达“鼠标到输入框,点击一次”?
其实selenium确实可以模拟鼠标移动等操作(网站的一些登录验证码需要用鼠标拉动拼图来模拟),但是目前的情况下,我们不应该模拟鼠标,而是根据html标签定位。.
此时,我们可以使用浏览器的“开发者功能”进行定位。
限于篇幅,本文不详细讲解“开发者功能”的所有操作,详细讲解会放在公众号目录:数据宇宙>爬虫工具>系列文章
下面用一张动态图来展示操作过程:
看一下代码:
接下来,输入内容“爬虫”:
我们继续模拟点击输入框右侧的“百度点击”按钮。
同样使用“开发人员功能”,找到元素并复制 css 选择器表达式字符串:
所有结果的主标题:
这对初学者来说可能有点困难,因为这一次我们需要同时选择多个元素(多个搜索结果的主标题),并查看定位到的标签:
仔细看看我们需要的主要标题在哪里:
所以,现在我们将使用 CSS 选择器来表达以下语义: 在 div 内部 (id=content_left),在 h3 标记内部的 a 标记文本。div 和 h3 之间可能有多层嵌套。
生成的选择器表达式如下:
调用代码如下:
Python基础教程教材 Python编程从零基础到实际项目实例
¥59
买
代码执行太快
上面的代码之所以没有得到任何结果,是因为执行第10行的代码时,页面上还没有加载任何结果。
如果一个人正在操作浏览器,那么你应该对他说:嘿,直到你看到那些结果,你去提取主标题。
怎么说“直到你看到那些结果”?,selenium有一种特殊的等待元素出现的机制,代码如下:
用控件关闭浏览器,完整代码如下:
总结
使用代码控制 selenium 与手动操作基本相同。一般流程是:
下一节,我们将介绍更多的selenium技能,敬请期待!!
私信我“python”获取本系列所有相关资料和源码文章 查看全部
chrome网页视频抓取(
Python中一个非常成熟的库——selenium专栏(组图))
本系列文章收录在公众号:数据宇宙>py爬虫>Selenium
转发本文并私信我“python”,可以获得Python资料及更多系列文章(持续更新)
作为“数据玩家”,手头没有数据怎么办?当然,用代码自动化采集数据,但现在“爬虫”可没那么容易了,其中最难的是突破网站的各种反爬机制。本系列将全面讲解Python中一个非常成熟的库——selenium,并教你如何使用它在网络上爬取你需要的数据
虽然自动爬虫很方便,但希望大家可以考虑到网站服务器的承受能力,不要频繁访问网站。永远不要采集敏感数据!!否则很容易“从入门到监狱”
本系列大部分案例都是selenium和pyppeteer库同时讲解的,并且有Python和C#2语言的实现文章,详情请到公众号目录。
当你得到数据时,你还需要对数据进行处理和分析。我的 pandas 专栏是高级教程的最佳介绍。
前言
学习任何库,首先要了解库的机制和流程。今天,我们将从一个小例子开始我们的学习之旅。
搜索和采集结果的标题
要求如下:
硒的问题
这个系列一直围绕着一个点:“用代码操作浏览器”,我们来看看整个过程:
然而,市面上的浏览器种类繁多,甚至一个厂商的浏览器版本也不同。我们如何保证我们的代码只需要编写一次就可以控制不同的浏览器?
更深入的流程图如下:
“案子怎么还没开始,就说硒不是?我还在学吗?”
他有以下优点:
缺点:
如果觉得不能接受selenium的缺点,可以查看pyppeteer的相关文章(公众号:大数据宇宙>py爬虫>pyppeteer)
得到驱动
现在让我们开始使用 selenium 来解决我们的需求。
首先,使用 pip 安装 selenium
由于我在本地安装了谷歌Chrome浏览器,打开浏览器查看浏览器的版本:
然后去相关的网站(私信我“python”)下载对应的驱动:
一切都准备好了
看过我相关教学文章的人都知道,我喜欢从语义的角度去理解和学习图书馆。
Selenium 本质上控制着浏览器,所以我们在使用它的时候,代码的语义应该类似于手动操作浏览器的过程。
首先导入一些包:
让我们看看如何使用代码来描述我们的手动操作。
打开浏览器:
没错,我们只是下载了驱动程序,但是 Python 怎么知道在哪里可以找到该驱动程序呢?
我们可以在实例化浏览器对象的时候传入一个文件路径,告诉他程序的具体位置:
输入百度搜索的网址:
将鼠标移动到输入框,点击一次,然后输入内容“爬虫”:
这里的问题是,如何在代码中表达“鼠标到输入框,点击一次”?
其实selenium确实可以模拟鼠标移动等操作(网站的一些登录验证码需要用鼠标拉动拼图来模拟),但是目前的情况下,我们不应该模拟鼠标,而是根据html标签定位。.
此时,我们可以使用浏览器的“开发者功能”进行定位。
限于篇幅,本文不详细讲解“开发者功能”的所有操作,详细讲解会放在公众号目录:数据宇宙>爬虫工具>系列文章
下面用一张动态图来展示操作过程:
看一下代码:
接下来,输入内容“爬虫”:
我们继续模拟点击输入框右侧的“百度点击”按钮。
同样使用“开发人员功能”,找到元素并复制 css 选择器表达式字符串:
所有结果的主标题:
这对初学者来说可能有点困难,因为这一次我们需要同时选择多个元素(多个搜索结果的主标题),并查看定位到的标签:
仔细看看我们需要的主要标题在哪里:
所以,现在我们将使用 CSS 选择器来表达以下语义: 在 div 内部 (id=content_left),在 h3 标记内部的 a 标记文本。div 和 h3 之间可能有多层嵌套。
生成的选择器表达式如下:
调用代码如下:
Python基础教程教材 Python编程从零基础到实际项目实例
¥59
买
代码执行太快
上面的代码之所以没有得到任何结果,是因为执行第10行的代码时,页面上还没有加载任何结果。
如果一个人正在操作浏览器,那么你应该对他说:嘿,直到你看到那些结果,你去提取主标题。
怎么说“直到你看到那些结果”?,selenium有一种特殊的等待元素出现的机制,代码如下:
用控件关闭浏览器,完整代码如下:
总结
使用代码控制 selenium 与手动操作基本相同。一般流程是:
下一节,我们将介绍更多的selenium技能,敬请期待!!
私信我“python”获取本系列所有相关资料和源码文章
chrome网页视频抓取(相似软件版本说明软件地址功能介绍-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-31 09:17
Chrome SPY 正式版是一款针对谷歌浏览器的网页元素分析工具。使用最新版本的Chrome SPY,用户可以获得元素矩阵、元素坐标、参考代码、tagName、代码关键字等元素信息。Chrome SPY 正式版可以提取元素属性,保存文本,查看谷歌浏览器的网页属性。同时支持标签选择,查看当前网页的标签内容。
类似软件
印记
软件地址
Chrome SPY 功能介绍
1、Chrome SPY提供网页元素分析功能,通过本软件可以立即读取元素;
2、可以提取元素属性,可以保存文本;
3、可以查看谷歌浏览器的网页属性;
4、可以在软件界面启动浏览器;
5、支持标签选择,查看当前网页的标签内容;
6、左侧代码展示,查看当前元素的参考代码;
7、支持代码关键字查看和标签名查看。
Chrome SPY 软件功能
1、Chrome SPY免费使用,打开即可识别浏览器;
2、可以查看谷歌浏览器的网页元素;
3、 立即在窗口中显示元素信息,方便复制使用;
4、可以提取多个元素,可以查看元素矩阵和元素坐标。
Chrome SPY 使用说明
1、打开Chrome_SPY.exe软件快速识别谷歌浏览器;
2、点击启动浏览器,使其立即运行,从而在浏览器中查看网页内容;
3、访问网页时,可以在软件界面查看标签,选择一个标签即可查看内容;
4、获取到标签后,会在此处显示网页的相关内容,获取的内容可以复制。支持元素矩形、元素坐标、参考代码、标签名、代码关键字;
5、提取元素功能,在软件界面中提取你需要的数据并保存为文本。
Chrome SPY 软件相关
Web 元素是您在浏览 Internet 时看到的一切。一个页面,称为网页,由多个网页网站 组成。网站 的第一页称为主页。
首页是所有网页的索引页,其他网页可以通过点击首页上的超链接打开。正是由于主页在网站中的特殊作用,人们经常用主页来指代所有的网页,而将个别的网站称为“个人主页”。主题 网站 称为“Web Production”。
网页元素包括:文本、图片、音频、动画和视频。文字,符合排版要求。图片、音频、动画、视频满足网络传输和专题需要,需要选择。
Chrome SPY 安装步骤
1.从pc下载网下载最新的软件包
2.解压软件,运行“EXE.file”
3.双击打开,进入软件界面
4. 本软件为绿色版,无需安装即可使用
Chrome 间谍更新日志
日夜工作只为让你更快乐
妈咪咪咪哄~虫子全没了!
小编推荐:使用Chrome SPY后,我想你可能还需要QQ助手、百度关键词优化软件、汇汇购物助手等软件,快来pc下载网下载使用吧! 查看全部
chrome网页视频抓取(相似软件版本说明软件地址功能介绍-苏州安嘉)
Chrome SPY 正式版是一款针对谷歌浏览器的网页元素分析工具。使用最新版本的Chrome SPY,用户可以获得元素矩阵、元素坐标、参考代码、tagName、代码关键字等元素信息。Chrome SPY 正式版可以提取元素属性,保存文本,查看谷歌浏览器的网页属性。同时支持标签选择,查看当前网页的标签内容。
类似软件
印记
软件地址

Chrome SPY 功能介绍
1、Chrome SPY提供网页元素分析功能,通过本软件可以立即读取元素;
2、可以提取元素属性,可以保存文本;
3、可以查看谷歌浏览器的网页属性;
4、可以在软件界面启动浏览器;
5、支持标签选择,查看当前网页的标签内容;
6、左侧代码展示,查看当前元素的参考代码;
7、支持代码关键字查看和标签名查看。
Chrome SPY 软件功能
1、Chrome SPY免费使用,打开即可识别浏览器;
2、可以查看谷歌浏览器的网页元素;
3、 立即在窗口中显示元素信息,方便复制使用;
4、可以提取多个元素,可以查看元素矩阵和元素坐标。
Chrome SPY 使用说明
1、打开Chrome_SPY.exe软件快速识别谷歌浏览器;
2、点击启动浏览器,使其立即运行,从而在浏览器中查看网页内容;
3、访问网页时,可以在软件界面查看标签,选择一个标签即可查看内容;
4、获取到标签后,会在此处显示网页的相关内容,获取的内容可以复制。支持元素矩形、元素坐标、参考代码、标签名、代码关键字;
5、提取元素功能,在软件界面中提取你需要的数据并保存为文本。
Chrome SPY 软件相关
Web 元素是您在浏览 Internet 时看到的一切。一个页面,称为网页,由多个网页网站 组成。网站 的第一页称为主页。
首页是所有网页的索引页,其他网页可以通过点击首页上的超链接打开。正是由于主页在网站中的特殊作用,人们经常用主页来指代所有的网页,而将个别的网站称为“个人主页”。主题 网站 称为“Web Production”。
网页元素包括:文本、图片、音频、动画和视频。文字,符合排版要求。图片、音频、动画、视频满足网络传输和专题需要,需要选择。
Chrome SPY 安装步骤
1.从pc下载网下载最新的软件包
2.解压软件,运行“EXE.file”
3.双击打开,进入软件界面

4. 本软件为绿色版,无需安装即可使用
Chrome 间谍更新日志
日夜工作只为让你更快乐
妈咪咪咪哄~虫子全没了!
小编推荐:使用Chrome SPY后,我想你可能还需要QQ助手、百度关键词优化软件、汇汇购物助手等软件,快来pc下载网下载使用吧!
chrome网页视频抓取(网页视频字幕插件插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-01-29 21:04
Dualsub(Universal Subtitle Renderer)官方安装版是一款优秀的网络视频字幕插件。Dualsub不仅可以帮助用户在页面上同时显示两个字幕,而且还有丰富的样式可以自由选择,非常方便。
特殊功能
1、原生渲染:其实就是把字幕作为第二行插入到原文中,字体设置为更小。
2、任何字幕语言:可选语言由视频本身提供,也可以自动翻译成另一种语言。
3、合并算法优化:使用一点算法来避免重叠和处理不一致的时间线。
使用教程
1、首先,从当前页面下载扩展,安装完成后,可以打开你想看的YouTube外语视频,页面会显示Dualsub工具栏。
2、然后,通过原生视频设置页面,打开字幕显示,选择原生语言类型。
3、 接下来通过Dualsub的设置框选择替代字幕的语言,语言类型多样化。第一个选项通常是英语,第二个选项是您需要翻译成的语言。
4、另外,你可以设置字幕位置。
双字幕:第一行是原生播放器字幕,第二行是Dualsub插件提供的备用字幕。
Dual subtitles (swap):Dualsub插件提供的备用字幕在第一行,原生播放器字幕在第二行。
单字幕:仅显示 Dualsub 插件提供的备用字幕。
5、另外,它支持字幕选择和保存到本地。通过CSS,还可以在字幕样式栏中添加代码来调整字幕的样式。 查看全部
chrome网页视频抓取(网页视频字幕插件插件)
Dualsub(Universal Subtitle Renderer)官方安装版是一款优秀的网络视频字幕插件。Dualsub不仅可以帮助用户在页面上同时显示两个字幕,而且还有丰富的样式可以自由选择,非常方便。
特殊功能
1、原生渲染:其实就是把字幕作为第二行插入到原文中,字体设置为更小。
2、任何字幕语言:可选语言由视频本身提供,也可以自动翻译成另一种语言。
3、合并算法优化:使用一点算法来避免重叠和处理不一致的时间线。
使用教程
1、首先,从当前页面下载扩展,安装完成后,可以打开你想看的YouTube外语视频,页面会显示Dualsub工具栏。
2、然后,通过原生视频设置页面,打开字幕显示,选择原生语言类型。
3、 接下来通过Dualsub的设置框选择替代字幕的语言,语言类型多样化。第一个选项通常是英语,第二个选项是您需要翻译成的语言。

4、另外,你可以设置字幕位置。
双字幕:第一行是原生播放器字幕,第二行是Dualsub插件提供的备用字幕。
Dual subtitles (swap):Dualsub插件提供的备用字幕在第一行,原生播放器字幕在第二行。
单字幕:仅显示 Dualsub 插件提供的备用字幕。
5、另外,它支持字幕选择和保存到本地。通过CSS,还可以在字幕样式栏中添加代码来调整字幕的样式。
chrome网页视频抓取(腾讯视频格式格式最为突出,工作效率提升N倍,你值得拥有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-29 15:03
)
作为一名资深的IT行业从业者,我们在工作中总是会遇到找各种视频素材的问题,但是由于专业网站的要求不一致,我们会发现很多网站都有自己的格式,尤其是腾讯视频的QLV格式最为突出。苏老师刚开始工作时,为了转换腾讯视频的高清格式,花钱买TB买了各种小玩意儿。没用,那种感觉心里真的有点绝望。后来终于让苏老师找到了这样一个神器,提高了N倍的工作效率,在此分享给大家。
苏老师心情
苏老师当时的心情
准备工具:浏览器、猫抓插件
浏览器:市面上主流的浏览器主要分为两大类:chorme-based和ie-based浏览器,以及chromium-based浏览器,典型的特点是速度快。360出来的浏览器有两种,一种是常见的360安全浏览器,基于IE内核,IE内核版本应该是ie8,另一种是360超快浏览器,也就是360 Chrome浏览器,根据中国人的习惯集成了多个插件,支持chromium内核。用ie内核切换,可以添加chrome store中的所有插件。如果要搭建适合自己的chromium内核的浏览器,建议使用原版chrome浏览器,自己安装插件,自己打磨。
Catscratch 插件:Catscratch 插件是一个支持嗅探和抓取安装在所有 chrome 内核浏览器中的网络视频链接的插件。您可以从任何站点获取任何视频数据。使用此插件,您可以一键获取您需要的链接并自动抓取并保存。使用很方便,打开需要下载文件的网站。可以在这个页面抓取所有自定义设置的内容,然后选择要下载的内容下载到本地电脑,使用方便!
运营流程
1.打开基于chorme内核的浏览器(这里以360极速浏览器为例),选择扩展中心
2.点击进入,在搜索框搜索猫抓app
3.点击安装按钮安装猫抓应用
4.打开你要下载的视频的网站,以腾讯视频为例,选择你要下载的视频,点击播放
5.点击右上角的猫抓按钮,等待抓取页面的视频信息加载完毕。加载完成后,选择内容(体验)较大的视频,点击保存,即可在本地加载本页高清视频。,并且不需要转码。
查看全部
chrome网页视频抓取(腾讯视频格式格式最为突出,工作效率提升N倍,你值得拥有
)
作为一名资深的IT行业从业者,我们在工作中总是会遇到找各种视频素材的问题,但是由于专业网站的要求不一致,我们会发现很多网站都有自己的格式,尤其是腾讯视频的QLV格式最为突出。苏老师刚开始工作时,为了转换腾讯视频的高清格式,花钱买TB买了各种小玩意儿。没用,那种感觉心里真的有点绝望。后来终于让苏老师找到了这样一个神器,提高了N倍的工作效率,在此分享给大家。

苏老师心情
苏老师当时的心情
准备工具:浏览器、猫抓插件
浏览器:市面上主流的浏览器主要分为两大类:chorme-based和ie-based浏览器,以及chromium-based浏览器,典型的特点是速度快。360出来的浏览器有两种,一种是常见的360安全浏览器,基于IE内核,IE内核版本应该是ie8,另一种是360超快浏览器,也就是360 Chrome浏览器,根据中国人的习惯集成了多个插件,支持chromium内核。用ie内核切换,可以添加chrome store中的所有插件。如果要搭建适合自己的chromium内核的浏览器,建议使用原版chrome浏览器,自己安装插件,自己打磨。

Catscratch 插件:Catscratch 插件是一个支持嗅探和抓取安装在所有 chrome 内核浏览器中的网络视频链接的插件。您可以从任何站点获取任何视频数据。使用此插件,您可以一键获取您需要的链接并自动抓取并保存。使用很方便,打开需要下载文件的网站。可以在这个页面抓取所有自定义设置的内容,然后选择要下载的内容下载到本地电脑,使用方便!

运营流程
1.打开基于chorme内核的浏览器(这里以360极速浏览器为例),选择扩展中心
2.点击进入,在搜索框搜索猫抓app
3.点击安装按钮安装猫抓应用

4.打开你要下载的视频的网站,以腾讯视频为例,选择你要下载的视频,点击播放

5.点击右上角的猫抓按钮,等待抓取页面的视频信息加载完毕。加载完成后,选择内容(体验)较大的视频,点击保存,即可在本地加载本页高清视频。,并且不需要转码。
chrome网页视频抓取(PDFlux浏览器插件一键拷贝到Word、Excel、PPT中的安装方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-27 16:06
PDFlux 浏览器插件目前支持基于 Chromium 内核的 Chrome 浏览器和 Edge 浏览器。
PDFlux Chrome插件(PDF表格智能提取神器)目前支持macOS、Windows系统、小程序和浏览器插件,但PDFlux可以智能识别PDF中的表格并一键复制到Word、Excel、PPT 有需要的朋友快来下载体验吧。
安装方法
1、在本地下载PDFlux插件并解压;
2、在“更多工具”中打开“扩展”,确保“开发者模式”已开启;
3、在浏览器“扩展”界面点击“加载解压扩展”按钮,选择解压后的PDFlux插件文件夹;
4、刷新您的浏览器以开始使用。
如何使用
浏览网页时,例如在“巨潮资讯网”,点击右上角的PDFlux图标,扫码登录,网页上会出现“在PDFlux中打开”按钮.
点击“在PDFlux中打开”按钮,对应的PDF文件将上传到PDFlux,上传完成后即可在PDFluxWebtool中打开文件。
支持网站
目前支持网站
1、巨潮资讯网
2、上海证券交易所(含科创板)
3、孔雀开屏(中国银行同业交易商协会)
4、香港交易所披露
5、东方财富网
程序支持网站
1、证监会
2、新三板
3、SHCH
4、中国外汇交易中心和全国银行间同业拆借中心
5、北京金融资产交易所
6、中国债券信息网
7、新交所
8、SEC 查看全部
chrome网页视频抓取(PDFlux浏览器插件一键拷贝到Word、Excel、PPT中的安装方法)
PDFlux 浏览器插件目前支持基于 Chromium 内核的 Chrome 浏览器和 Edge 浏览器。
PDFlux Chrome插件(PDF表格智能提取神器)目前支持macOS、Windows系统、小程序和浏览器插件,但PDFlux可以智能识别PDF中的表格并一键复制到Word、Excel、PPT 有需要的朋友快来下载体验吧。
安装方法
1、在本地下载PDFlux插件并解压;
2、在“更多工具”中打开“扩展”,确保“开发者模式”已开启;
3、在浏览器“扩展”界面点击“加载解压扩展”按钮,选择解压后的PDFlux插件文件夹;
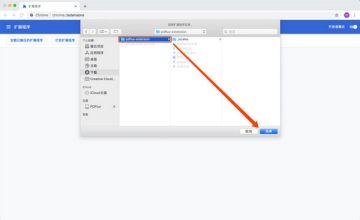
4、刷新您的浏览器以开始使用。
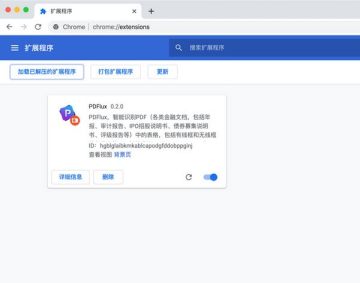
如何使用
浏览网页时,例如在“巨潮资讯网”,点击右上角的PDFlux图标,扫码登录,网页上会出现“在PDFlux中打开”按钮.
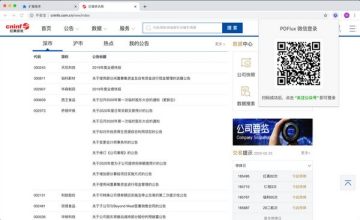
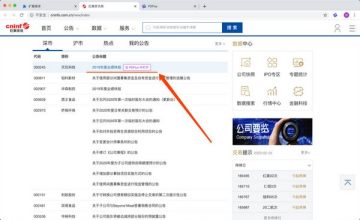
点击“在PDFlux中打开”按钮,对应的PDF文件将上传到PDFlux,上传完成后即可在PDFluxWebtool中打开文件。
支持网站
目前支持网站
1、巨潮资讯网
2、上海证券交易所(含科创板)
3、孔雀开屏(中国银行同业交易商协会)
4、香港交易所披露
5、东方财富网
程序支持网站
1、证监会
2、新三板
3、SHCH
4、中国外汇交易中心和全国银行间同业拆借中心
5、北京金融资产交易所
6、中国债券信息网
7、新交所
8、SEC
chrome网页视频抓取(有type,记录如下流程状态->入库(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-24 04:23
背景说明
由于目标页面是用vue结构写的,通过urlConnection获取连接后无法使用Document/Jsoup解析。页面元素通过js动态呈现。后来尝试通过webMagic框架和selenium\Chrome来抓取和整理基础数据。
加工
设计标记表结构,记录捕获的状态和数据,配置selenium相关环境,分析页面dom元素的工具,编码和解析html进程,编码,集成和调试处理器和管道层webmagic 框架。数据存储操作
步骤解剖
1. 标记表结构设计,示例表如下
<br />CREATE TABLE `data` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL COMMENT 'dataname',
`type` tinyint(4) DEFAULT NULL COMMENT '类型',
`xx` int(11) DEFAULT '0' COMMENT '修订',
`xx` ...
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8 COMMENT='数据标记'
制作这张表的初衷是对抓取的数据做一个基本的保留,提取过程中的核心数据用于后期的统计和验证处理。因为不信任抓取数据的结果【可能是网络中断,页面无法正常打开,页面打开后布局混乱,并发情况下浏览器窗口意外关闭,页面修改元素添加和更改。获取目标数据]。所以有一个type字段来记录下面的进程状态
抓取 -> 打开 -> 操作 -> 解析 -> 库存 -> 抓取
其中
1.爬取 是指抓取根路径或者获取到页面上的目标url路径;
2.打开 是指通过Chrome driver打开url的过程;
3.操作 是指需要通过selenium模拟点击、跳转、输入等操作;
4.解析 是指到达目标页面后对html元素进行解析并获取有效内容
5.入库 将内容进行持久化操作
6.爬取 获取下一级链接,循环此操作
这里最不可控的一步是2、3、4。由于各种原因,可能会出现各种问题。因此,需要记录当前数据的执行状态。当然,如果数据对你来说是可丢失的、可重复的、可信的,你可以忽略部分数据,以量取胜。
2. Selenium 相关环境配置
先引入jar,下载浏览器对应驱动并配置
org.seleniumhq.selenium
selenium-java
3.9.1
org.seleniumhq.selenium
selenium-server
3.9.1
org.yaml
snakeyaml
上面是pom配置,下面是驱动变量设置,
static
{
System.getProperties().setProperty("webdriver.chrome.driver", "/Users/chenhailong/Downloads/tools/nessarytool/chromedriver");
}
运行以下代码时,浏览器可以正常打开,说明配置正常
WebDriver w = new ChromeDriver();
w.get("https://www.deathearth.com");
# 控制台会输出以下信息
Starting ChromeDriver 2.38.552518 (183d19265345f54ce39cbb94cf81ba5f15905011) on port 33558
Only local connections are allowed.
八月 23, 2019 5:02:46 下午 org.openqa.selenium.remote.ProtocolHandshake createSession
信息: Detected dialect: OSS
这种环境下最容易出现的问题就是浏览器版本和驱动版本不一致,导致程序无法打开浏览器。或者浏览器自动升级的影响。只需仔细配置即可。
3. 解析页面上的html元素
一个。这里最麻烦的就是页面修改问题。我只是写了一套匹配规则来处理它。但是,目标网站经常会改变布局,调整按钮的功能。因此,基本上需要随着目标网站的变化而变化。没门。
湾。其次,存在分析效率问题。我遇到过两种情况。一种是在抓取长文本类型(超过10w字节)的文章的内容时,通过父元素的text()方法读取,内容被截断。导致信息不完整。这是通过循环子标签来处理的。如下
<p>
...
...
修改前: w.findElements(By.id("content")).getText()
修改后:List ls = w.findElements(By.xpath("div"))
for(int i = 0;i 查看全部
chrome网页视频抓取(有type,记录如下流程状态->入库(组图))
背景说明
由于目标页面是用vue结构写的,通过urlConnection获取连接后无法使用Document/Jsoup解析。页面元素通过js动态呈现。后来尝试通过webMagic框架和selenium\Chrome来抓取和整理基础数据。
加工
设计标记表结构,记录捕获的状态和数据,配置selenium相关环境,分析页面dom元素的工具,编码和解析html进程,编码,集成和调试处理器和管道层webmagic 框架。数据存储操作
步骤解剖
1. 标记表结构设计,示例表如下
<br />CREATE TABLE `data` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL COMMENT 'dataname',
`type` tinyint(4) DEFAULT NULL COMMENT '类型',
`xx` int(11) DEFAULT '0' COMMENT '修订',
`xx` ...
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8 COMMENT='数据标记'
制作这张表的初衷是对抓取的数据做一个基本的保留,提取过程中的核心数据用于后期的统计和验证处理。因为不信任抓取数据的结果【可能是网络中断,页面无法正常打开,页面打开后布局混乱,并发情况下浏览器窗口意外关闭,页面修改元素添加和更改。获取目标数据]。所以有一个type字段来记录下面的进程状态
抓取 -> 打开 -> 操作 -> 解析 -> 库存 -> 抓取
其中
1.爬取 是指抓取根路径或者获取到页面上的目标url路径;
2.打开 是指通过Chrome driver打开url的过程;
3.操作 是指需要通过selenium模拟点击、跳转、输入等操作;
4.解析 是指到达目标页面后对html元素进行解析并获取有效内容
5.入库 将内容进行持久化操作
6.爬取 获取下一级链接,循环此操作
这里最不可控的一步是2、3、4。由于各种原因,可能会出现各种问题。因此,需要记录当前数据的执行状态。当然,如果数据对你来说是可丢失的、可重复的、可信的,你可以忽略部分数据,以量取胜。
2. Selenium 相关环境配置
先引入jar,下载浏览器对应驱动并配置
org.seleniumhq.selenium
selenium-java
3.9.1
org.seleniumhq.selenium
selenium-server
3.9.1
org.yaml
snakeyaml
上面是pom配置,下面是驱动变量设置,
static
{
System.getProperties().setProperty("webdriver.chrome.driver", "/Users/chenhailong/Downloads/tools/nessarytool/chromedriver");
}
运行以下代码时,浏览器可以正常打开,说明配置正常
WebDriver w = new ChromeDriver();
w.get("https://www.deathearth.com";);
# 控制台会输出以下信息
Starting ChromeDriver 2.38.552518 (183d19265345f54ce39cbb94cf81ba5f15905011) on port 33558
Only local connections are allowed.
八月 23, 2019 5:02:46 下午 org.openqa.selenium.remote.ProtocolHandshake createSession
信息: Detected dialect: OSS
这种环境下最容易出现的问题就是浏览器版本和驱动版本不一致,导致程序无法打开浏览器。或者浏览器自动升级的影响。只需仔细配置即可。
3. 解析页面上的html元素
一个。这里最麻烦的就是页面修改问题。我只是写了一套匹配规则来处理它。但是,目标网站经常会改变布局,调整按钮的功能。因此,基本上需要随着目标网站的变化而变化。没门。
湾。其次,存在分析效率问题。我遇到过两种情况。一种是在抓取长文本类型(超过10w字节)的文章的内容时,通过父元素的text()方法读取,内容被截断。导致信息不完整。这是通过循环子标签来处理的。如下
<p>
...
...
修改前: w.findElements(By.id("content")).getText()
修改后:List ls = w.findElements(By.xpath("div"))
for(int i = 0;i
chrome网页视频抓取(我在google中出现的bugNotNotloadlocalresource )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-14 09:04
)
具体教程是我在google上找到的:
教程:
这里我只做一个具体的实现,并说明具体操作中的bug:
不允许加载本地资源
使用视频作为网页背景
video#bgvid {
position: fixed; right: 0; bottom: 0;
min-width: 100%; min-height: 100%;
width: auto; height: 90%; z-index: -100;
/*background: url(G:\javaweb\前端\bideo.js-master\20140906061602621.jpg) no-repeat;*/
background-size: 80px 60px;
}
#polina {
font-family: Agenda-Light, Agenda Light, Agenda, Arial Narrow, sans-serif;
font-weight: 100;
background: rgba(0,0,0,0.3);
color: white;
padding: 2rem;
width: 33%;
margin: 2rem;
float: right;
font-size: 1.2rem;
}
POLINA
<p>filmed by Alexander Wagner 2011
</p>
这个可以作为静态页面在本地访问,直接打开对应的html,但是我放到项目中的时候,出现了无法访问本地资源的bug:
不允许加载本地资源
经过搜索,发现是因为安全原因设置了google浏览器,所以为了能够成功访问,我在项目的xml中配置了对应的路径:
然后路径改为:
在html头部添加basePath的配置:
****
这样以后google就不会直接访问本地资源了,这样就可以在项目页面播放视频了~~~:
查看全部
chrome网页视频抓取(我在google中出现的bugNotNotloadlocalresource
)
具体教程是我在google上找到的:
教程:
这里我只做一个具体的实现,并说明具体操作中的bug:
不允许加载本地资源
使用视频作为网页背景
video#bgvid {
position: fixed; right: 0; bottom: 0;
min-width: 100%; min-height: 100%;
width: auto; height: 90%; z-index: -100;
/*background: url(G:\javaweb\前端\bideo.js-master\20140906061602621.jpg) no-repeat;*/
background-size: 80px 60px;
}
#polina {
font-family: Agenda-Light, Agenda Light, Agenda, Arial Narrow, sans-serif;
font-weight: 100;
background: rgba(0,0,0,0.3);
color: white;
padding: 2rem;
width: 33%;
margin: 2rem;
float: right;
font-size: 1.2rem;
}
POLINA
<p>filmed by Alexander Wagner 2011
</p>
这个可以作为静态页面在本地访问,直接打开对应的html,但是我放到项目中的时候,出现了无法访问本地资源的bug:
不允许加载本地资源
经过搜索,发现是因为安全原因设置了google浏览器,所以为了能够成功访问,我在项目的xml中配置了对应的路径:

然后路径改为:

在html头部添加basePath的配置:
****
这样以后google就不会直接访问本地资源了,这样就可以在项目页面播放视频了~~~:

chrome网页视频抓取(本文Chrome浏览器HTML5性能测试从Chrome的众多特点中摘出来)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-14 09:02
编者按:我们都知道HTML5有两大特点:增强网页性能和为Web应用程序增加本地数据库等功能。性能函数的渲染问题想必是绝大多数Chrome浏览器用户选择使用Chrome的主要原因之一。了解HTML5架构,追求在线视频在浏览器上高清播放能力和浏览器性能稳定的玩家,更关心Chrome浏览器的HTML5性能表现。
点击下载:
网页会爆 Chrome浏览器HTML5性能评测
那么,在这篇文章中,笔者从Chrome的众多特性中提取了Chrome浏览器HTML5性能测试,进行了更详细的测试,并通过评测分享给Chrome玩家。
目前,随着业界对HTML5的热议以及各大浏览器厂商对HTML5标准的重视,越来越多的人开始关注HTML5。不仅有WEB开发者,还有很多普通用户。提到 HTML5 标准,大多数人首先想到的可能就是 HTML5 视频标准。但是,用户需要注意的是,HTML5 带来的不仅仅是一个新的视频 Web 标准,它还引入了许多将对 Web 未来发展方向产生巨大影响的元素和属性。
测试项目介绍:本文主要测试Chrome浏览器在Web服务协议测试、网络视频性能、HTML5性能测试、扩展网页性能模拟重力系统测试等方面的性能。
温馨提示:本站页面均基于HTML5优化。建议您使用完美兼容的 HTML5 浏览,以获得最佳的阅读体验! () 查看全部
chrome网页视频抓取(本文Chrome浏览器HTML5性能测试从Chrome的众多特点中摘出来)
编者按:我们都知道HTML5有两大特点:增强网页性能和为Web应用程序增加本地数据库等功能。性能函数的渲染问题想必是绝大多数Chrome浏览器用户选择使用Chrome的主要原因之一。了解HTML5架构,追求在线视频在浏览器上高清播放能力和浏览器性能稳定的玩家,更关心Chrome浏览器的HTML5性能表现。
点击下载:

网页会爆 Chrome浏览器HTML5性能评测
那么,在这篇文章中,笔者从Chrome的众多特性中提取了Chrome浏览器HTML5性能测试,进行了更详细的测试,并通过评测分享给Chrome玩家。
目前,随着业界对HTML5的热议以及各大浏览器厂商对HTML5标准的重视,越来越多的人开始关注HTML5。不仅有WEB开发者,还有很多普通用户。提到 HTML5 标准,大多数人首先想到的可能就是 HTML5 视频标准。但是,用户需要注意的是,HTML5 带来的不仅仅是一个新的视频 Web 标准,它还引入了许多将对 Web 未来发展方向产生巨大影响的元素和属性。
测试项目介绍:本文主要测试Chrome浏览器在Web服务协议测试、网络视频性能、HTML5性能测试、扩展网页性能模拟重力系统测试等方面的性能。
温馨提示:本站页面均基于HTML5优化。建议您使用完美兼容的 HTML5 浏览,以获得最佳的阅读体验! ()
chrome网页视频抓取( 猫抓是一款支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-01-09 17:02
猫抓是一款支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
猫渣是一个支持所有Chrome核心浏览器的网络媒体嗅探和抓取的扩展。
可以一键抓取任意站点的任意视频/音频数据,使用非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮,就可以在这个页面看到资源信息了。
然后可以对资源进行三个操作:复制链接地址,小窗口播放,下载到本地电脑。
猫扎支持优酷、搜狐、腾讯、微博、B站等国内几乎所有网站的视频文件嗅探。
当您在同一页面上遇到多个属性时,您还可以对它们进行快速批量操作。
此类嗅探工具支持的短视频文件一般都是未加密的。面对一些加密视频时,会有一定的失败概率。
不过从市场反馈来看,猫爪可以抢到很多其他扩展,包括IDM都无法嗅到的媒体资源。
这就是它在竞争性扩展商店中拥有超过 50,000 名用户的原因之一。
此外,猫爪还支持所有音乐网站的音频文件嗅探,包括Qzone的SWF模块和音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,也支持使用正则表达式自定义采集的内容。
网络嗅探器原本是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。嗅探器也是许多程序员在编写网络程序时捕获和测试数据包的工具。
近年来,网络嗅探器已广泛应用于用户的日常行为,成为捕捉视频、音频等内容的工具。
资源下载 本资源为免费资源,请先登录 查看全部
chrome网页视频抓取(
猫抓是一款支持所有Chrome内核浏览器的网页媒体嗅探的扩展)

猫渣是一个支持所有Chrome核心浏览器的网络媒体嗅探和抓取的扩展。
可以一键抓取任意站点的任意视频/音频数据,使用非常方便。

安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮,就可以在这个页面看到资源信息了。
然后可以对资源进行三个操作:复制链接地址,小窗口播放,下载到本地电脑。

猫扎支持优酷、搜狐、腾讯、微博、B站等国内几乎所有网站的视频文件嗅探。
当您在同一页面上遇到多个属性时,您还可以对它们进行快速批量操作。

此类嗅探工具支持的短视频文件一般都是未加密的。面对一些加密视频时,会有一定的失败概率。
不过从市场反馈来看,猫爪可以抢到很多其他扩展,包括IDM都无法嗅到的媒体资源。
这就是它在竞争性扩展商店中拥有超过 50,000 名用户的原因之一。

此外,猫爪还支持所有音乐网站的音频文件嗅探,包括Qzone的SWF模块和音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,也支持使用正则表达式自定义采集的内容。

网络嗅探器原本是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。嗅探器也是许多程序员在编写网络程序时捕获和测试数据包的工具。
近年来,网络嗅探器已广泛应用于用户的日常行为,成为捕捉视频、音频等内容的工具。
资源下载 本资源为免费资源,请先登录
chrome网页视频抓取(下载GoogleChrome15也许很多注重浏览器页面排版(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-08 16:04
人们在使用电脑浏览网页时,往往会用到网页的排版功能。说到这种排版的功能,大家应该都有自己的感受。也就是说,布局模式在很大程度上取决于用户浏览网页所使用的浏览器。点击下载谷歌浏览器 15
或许很多专注于浏览器页面布局的用户对WebKit引擎的理解并不深入,但又不想对浏览器做太多的手动辅助设置,从而可以自由浏览页面。其实这些烦恼都可以通过使用Chrome浏览器轻松解决。目前几乎所有的浏览器都集成了网页自适应排版模式,但是这种HTML排版能力的强弱因浏览器而异。未来本文将分析Chrome浏览器自动识别网页和HTML智能排版的强大实力。
Chrome浏览器页面调整
解析 WebKit 引擎
WebKit 的前身是 KDE 组的 KHTML。WebKit 中收录的 WebCore 排版引擎和 JSCore 引擎是从 KDE 的 KHTML 和 KJS 衍生而来的。在比较了 Gecko 和 KHTML 之后,Apple 还是选择了后者,因为它的源码结构清晰,渲染速度极快。Apple 进一步推动了 KHTML 并推出了 Safari,这是一款配备 KHTML 改进的 WebKit 引擎的浏览器。
在 Google Chrome 中手动缩放网页
谷歌浏览器使用 WebKit 引擎。WebKit 简单、紧凑、高效地使用内存,符合 Google 的理念,并且对于新开发人员来说相当容易使用。浏览错误建议 当 URL 无法解析或连接失败时,谷歌浏览器将尝试确定它想要访问的网页并提供建议。浏览器会将您尝试浏览的页面的 URL 传输给 Google,以便建议替代页面或类似页面。
简短而强大的是 Webkit。事实上,作为Windows平台的后起之秀,Webkit进入Windows平台的时间并不长,但在短短的时间之后,Webkit就可以进入其他三个老牌核心同台竞技的水平,包括带有 Trident 内核的 Microsoft IE。浏览器,带有Gecko内核的Firefox浏览器,带有Presto内核的Opera浏览器,当然WebKit内核的代表是Google Chrome和Apple Safari浏览器
总结:笔者在之前的文章中对Chrome浏览器的HTML5兼容性做了详细的评测,从评测结果中得出,Chrome浏览器和HTML5可以说是相得益彰,符合当前浏览器的发展技术。需求,同时为未来进一步的技术发展创造机会。但是HTML5在页面布局、视频、色彩渲染等方面都表现不错,因此Chrome浏览器对HTML智能布局的依赖能力很强;在自动识别网页方面,由于Chrome浏览器使用了Webkit架构引擎,所以网页识别自然是有保障的。
温馨提示:本站页面均基于HTML5优化。建议您使用完美兼容的 HTML5 浏览,以获得最佳的阅读体验!() 查看全部
chrome网页视频抓取(下载GoogleChrome15也许很多注重浏览器页面排版(组图))
人们在使用电脑浏览网页时,往往会用到网页的排版功能。说到这种排版的功能,大家应该都有自己的感受。也就是说,布局模式在很大程度上取决于用户浏览网页所使用的浏览器。点击下载谷歌浏览器 15
或许很多专注于浏览器页面布局的用户对WebKit引擎的理解并不深入,但又不想对浏览器做太多的手动辅助设置,从而可以自由浏览页面。其实这些烦恼都可以通过使用Chrome浏览器轻松解决。目前几乎所有的浏览器都集成了网页自适应排版模式,但是这种HTML排版能力的强弱因浏览器而异。未来本文将分析Chrome浏览器自动识别网页和HTML智能排版的强大实力。
Chrome浏览器页面调整
解析 WebKit 引擎
WebKit 的前身是 KDE 组的 KHTML。WebKit 中收录的 WebCore 排版引擎和 JSCore 引擎是从 KDE 的 KHTML 和 KJS 衍生而来的。在比较了 Gecko 和 KHTML 之后,Apple 还是选择了后者,因为它的源码结构清晰,渲染速度极快。Apple 进一步推动了 KHTML 并推出了 Safari,这是一款配备 KHTML 改进的 WebKit 引擎的浏览器。
在 Google Chrome 中手动缩放网页
谷歌浏览器使用 WebKit 引擎。WebKit 简单、紧凑、高效地使用内存,符合 Google 的理念,并且对于新开发人员来说相当容易使用。浏览错误建议 当 URL 无法解析或连接失败时,谷歌浏览器将尝试确定它想要访问的网页并提供建议。浏览器会将您尝试浏览的页面的 URL 传输给 Google,以便建议替代页面或类似页面。
简短而强大的是 Webkit。事实上,作为Windows平台的后起之秀,Webkit进入Windows平台的时间并不长,但在短短的时间之后,Webkit就可以进入其他三个老牌核心同台竞技的水平,包括带有 Trident 内核的 Microsoft IE。浏览器,带有Gecko内核的Firefox浏览器,带有Presto内核的Opera浏览器,当然WebKit内核的代表是Google Chrome和Apple Safari浏览器
总结:笔者在之前的文章中对Chrome浏览器的HTML5兼容性做了详细的评测,从评测结果中得出,Chrome浏览器和HTML5可以说是相得益彰,符合当前浏览器的发展技术。需求,同时为未来进一步的技术发展创造机会。但是HTML5在页面布局、视频、色彩渲染等方面都表现不错,因此Chrome浏览器对HTML智能布局的依赖能力很强;在自动识别网页方面,由于Chrome浏览器使用了Webkit架构引擎,所以网页识别自然是有保障的。
温馨提示:本站页面均基于HTML5优化。建议您使用完美兼容的 HTML5 浏览,以获得最佳的阅读体验!()
chrome网页视频抓取(ChromeSPY是一款网页元素分析工具,下载体验吧!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-05 08:07
Chrome SPY 是一个网页元素分析工具。该软件可以帮助用户分析网页元素,帮助用户获取引用代码、tagName、代码关键字等元素信息,方便用户根据自己的需要查询获取信息,喜欢就下载吧并体验它!
软件介绍
网页元素是您在 Internet 上浏览时看到的所有内容。页面称为网页,许多网页构成一个网站。网站 的第一个网页称为主页。
首页是所有网页的索引页。您可以通过单击主页上的超链接打开其他网页。正是由于首页在网站中的特殊作用,人们经常使用首页来指代所有网页。个人网站被称为“个人主页”,个人网站将被建立和生产。主题网站 被称为“网页创建”。
网页元素包括:文字、图片、音频、动画和视频。文字符合排版要求。图片、音频、动画、视频满足网络传输和专题需要,需要选择。
软件功能
1、Chrome SPY 提供网页元素分析功能,您可以通过该软件立即读取元素;
2、 可以提取元素属性并保存文本;
3、可以查看谷歌浏览器的网页属性;
4、可以在软件界面启动浏览器;
5、支持标签选择,查看当前网页的标签内容;
6、 显示左边的代码,查看当前元素的引用代码;
7、支持代码关键字查看,支持标签名称查看。
指示
1、打开Chrome_SPY.exe软件,快速识别谷歌浏览器;
2、 点击启动浏览器,即可立即运行,以便在浏览器中查看网页内容;
3、 访问网页时,可以在软件界面查看标签,选择标签查看内容;
4、 获取tag时,会在此处显示网页的相关内容,获取的内容可以复制,支持元素矩形,元素坐标,引用代码,tagName,code关键字;
5、 提取元素功能,在软件界面中提取您需要的数据,并保存为文本。
更新日志
1.修复已知错误
2.优化操作体验 查看全部
chrome网页视频抓取(ChromeSPY是一款网页元素分析工具,下载体验吧!)
Chrome SPY 是一个网页元素分析工具。该软件可以帮助用户分析网页元素,帮助用户获取引用代码、tagName、代码关键字等元素信息,方便用户根据自己的需要查询获取信息,喜欢就下载吧并体验它!
软件介绍
网页元素是您在 Internet 上浏览时看到的所有内容。页面称为网页,许多网页构成一个网站。网站 的第一个网页称为主页。
首页是所有网页的索引页。您可以通过单击主页上的超链接打开其他网页。正是由于首页在网站中的特殊作用,人们经常使用首页来指代所有网页。个人网站被称为“个人主页”,个人网站将被建立和生产。主题网站 被称为“网页创建”。
网页元素包括:文字、图片、音频、动画和视频。文字符合排版要求。图片、音频、动画、视频满足网络传输和专题需要,需要选择。

软件功能
1、Chrome SPY 提供网页元素分析功能,您可以通过该软件立即读取元素;
2、 可以提取元素属性并保存文本;
3、可以查看谷歌浏览器的网页属性;
4、可以在软件界面启动浏览器;
5、支持标签选择,查看当前网页的标签内容;
6、 显示左边的代码,查看当前元素的引用代码;
7、支持代码关键字查看,支持标签名称查看。
指示
1、打开Chrome_SPY.exe软件,快速识别谷歌浏览器;
2、 点击启动浏览器,即可立即运行,以便在浏览器中查看网页内容;
3、 访问网页时,可以在软件界面查看标签,选择标签查看内容;
4、 获取tag时,会在此处显示网页的相关内容,获取的内容可以复制,支持元素矩形,元素坐标,引用代码,tagName,code关键字;
5、 提取元素功能,在软件界面中提取您需要的数据,并保存为文本。
更新日志
1.修复已知错误
2.优化操作体验
chrome网页视频抓取(愉阅(chrome网页内容抓取插件)v免费软件介绍插件安装使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-31 20:15
快乐阅读(chrome网页内容捕捉插件)v免费软件是一款简单实用的快乐阅读(chrome网页内容捕捉插件)v免费软件,主要帮助你快速享受(chrome网页内容捕捉插件) v各种免费软件中的图片和文字内容放在单独的阅读页面上,供(xing)浏览。这些图片解压后可以批量下载(xia),也可以在文章@阅读>有时间自动提取下一页文字,欢迎(ying)免费下载。
悦悦(chrome网页内容抓取插件)v免费软件介绍
1. 插件安装与使用1、 小编这里使用的是360极速浏览器,先在标签页v免费软件进入快感(chrome网页内容抓取插件):/ /myextensions/ extensions/:进入扩展页面,解压你在本页面下载的鱼悦(chrome网页内容抓取插件)v免费软件插件,拖入扩展页面。 2、安装完成后,试试插件的效果。 3、 插件安装后,页面右侧会自动出现爬虫助手按钮。 4、 点击图片欣赏(chrome网页内容抓取插件) v 所有可以在免费软件上抓取的图片,抓取后也可以批量下载这些图片。 5、 并且点击正文会提取页面内容文章@> 整洁的界面集中阅读,按图片大小分组查看图片2、炫酷的幻灯片模式浏览图片< @3、优质文字提取,清爽阅读4、自动提取下一页文字,开启“超级下一页”突破任何限制5、登录账号并采集文章 @>,同步配置到云端6、下载安卓客户端,随时随地阅读采集内容。
悦悦(chrome网页内容抓取插件)v免费软件总结
YueYue(chrome网页内容抓取插件)vV2.20是一款适用于ios版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友: 查看全部
chrome网页视频抓取(愉阅(chrome网页内容抓取插件)v免费软件介绍插件安装使用)
快乐阅读(chrome网页内容捕捉插件)v免费软件是一款简单实用的快乐阅读(chrome网页内容捕捉插件)v免费软件,主要帮助你快速享受(chrome网页内容捕捉插件) v各种免费软件中的图片和文字内容放在单独的阅读页面上,供(xing)浏览。这些图片解压后可以批量下载(xia),也可以在文章@阅读>有时间自动提取下一页文字,欢迎(ying)免费下载。
悦悦(chrome网页内容抓取插件)v免费软件介绍
1. 插件安装与使用1、 小编这里使用的是360极速浏览器,先在标签页v免费软件进入快感(chrome网页内容抓取插件):/ /myextensions/ extensions/:进入扩展页面,解压你在本页面下载的鱼悦(chrome网页内容抓取插件)v免费软件插件,拖入扩展页面。 2、安装完成后,试试插件的效果。 3、 插件安装后,页面右侧会自动出现爬虫助手按钮。 4、 点击图片欣赏(chrome网页内容抓取插件) v 所有可以在免费软件上抓取的图片,抓取后也可以批量下载这些图片。 5、 并且点击正文会提取页面内容文章@> 整洁的界面集中阅读,按图片大小分组查看图片2、炫酷的幻灯片模式浏览图片< @3、优质文字提取,清爽阅读4、自动提取下一页文字,开启“超级下一页”突破任何限制5、登录账号并采集文章 @>,同步配置到云端6、下载安卓客户端,随时随地阅读采集内容。
悦悦(chrome网页内容抓取插件)v免费软件总结
YueYue(chrome网页内容抓取插件)vV2.20是一款适用于ios版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:
chrome网页视频抓取(文中代码滚动到底部时头条通过ajax更多文章(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-31 16:20
文中代码只是部分说明,完整代码放在文章的最后。
首先,实际感受一下我们想要捕捉到什么好处?点击今日头条,在搜索栏中输入“街拍”二字,点击任意一篇文章文章,里面的图片就是我们要抓取的内容。
可以看到搜索结果默认返回20篇文章。当页面滚动到底部时,标题通过ajax加载更多文章,在浏览器中按F12打开调试工具(我的是Chrome),点击网络选项,尝试加载更多文章,可以看到相关的http请求:
可以看到请求的URL(Request URL)为:,其请求参数为:
很容易猜到offset代表的是偏移量,也就是已经请求的文章的个数;format是返回格式,这里是json格式的数据;关键字是我们的搜索关键字;autoload 应该是自动加载的一个指标,无所谓;count 是请求的新 文章 的数量;_ 应该是请求发起时的时间戳。将请求的 URL 和这些查询参数结合起来,形成一个完整的请求 URL。比如这次的Request URL是:%E8%A1%97%E6%8B%8D&autoload=true&count=20&_=92。
我们先来看看这个请求为我们返回了什么样的数据。
导入json
从 pprint 导入 pprint
从 urllib 导入请求
url = ";format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&_=92"
以 request.urlopen(url) 作为资源:
d = json.loads(res.read().decode())
打印(四)
这里我们首先通过request.urlopen(url)向这个url发送请求,返回的数据存放在res中,res是一个HttpResponse对象,实际返回的内容是通过调用其read方法获取的,因为read方法返回的是Python bytes 类型的字符串,调用其decode方法将其编码为字符串类型的字符串,默认为UTF-8编码。由于数据是以json格式返回的,所以通过json.load方法转换成Python字典形式。
打印出这个字典,可以看到字典中有一个键'data'对应一个由字典组成的列表的值。分析表明该值是所有文章的返回数据列表。稍微修改一下代码。看看'data'的值对应的是什么:
以 request.urlopen(url) 作为资源:
d = json.loads(res.read().decode())
d = d.get('数据')
打印(d)
在这里,pprint 用于使字典打印的值更加格式化,以便于分析。你可以看到这是一个字典列表。列表中的每一项代表一块文章,里面收录了文章的所有基本数据,比如标题、文章的URL等,这样我们就可以得到URL我们这次请求的所有 文章 的列表如下:
urls = [article.get('article_url') for article in d if article.get('article_url')]
这里使用了list comprehension,循环文章列表,通过get('article_url')获取文章的URL,加上if判断条件是为了防止文章因为缺失数据导致空的文章 @> 网址。我们将继续请求这些文章 URL,阅读它们的内容,并提取图片并将它们保存到我们的硬盘中。
我们先处理一个文章,看看如何提取文章中的所有图片。
只需点击一个文章链接,按F12查看网页源代码,可以看到文章的主体部分位于
在div里面。在这个div下面,有一个h1标签,代表文章的标题,还有一系列img标签,其src属性存储了图片所在的链接,所以我们通过访问这些链接下载图片,看到怎么做: 查看全部
chrome网页视频抓取(文中代码滚动到底部时头条通过ajax更多文章(图))
文中代码只是部分说明,完整代码放在文章的最后。
首先,实际感受一下我们想要捕捉到什么好处?点击今日头条,在搜索栏中输入“街拍”二字,点击任意一篇文章文章,里面的图片就是我们要抓取的内容。
可以看到搜索结果默认返回20篇文章。当页面滚动到底部时,标题通过ajax加载更多文章,在浏览器中按F12打开调试工具(我的是Chrome),点击网络选项,尝试加载更多文章,可以看到相关的http请求:
可以看到请求的URL(Request URL)为:,其请求参数为:
很容易猜到offset代表的是偏移量,也就是已经请求的文章的个数;format是返回格式,这里是json格式的数据;关键字是我们的搜索关键字;autoload 应该是自动加载的一个指标,无所谓;count 是请求的新 文章 的数量;_ 应该是请求发起时的时间戳。将请求的 URL 和这些查询参数结合起来,形成一个完整的请求 URL。比如这次的Request URL是:%E8%A1%97%E6%8B%8D&autoload=true&count=20&_=92。
我们先来看看这个请求为我们返回了什么样的数据。
导入json
从 pprint 导入 pprint
从 urllib 导入请求
url = ";format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&_=92"
以 request.urlopen(url) 作为资源:
d = json.loads(res.read().decode())
打印(四)
这里我们首先通过request.urlopen(url)向这个url发送请求,返回的数据存放在res中,res是一个HttpResponse对象,实际返回的内容是通过调用其read方法获取的,因为read方法返回的是Python bytes 类型的字符串,调用其decode方法将其编码为字符串类型的字符串,默认为UTF-8编码。由于数据是以json格式返回的,所以通过json.load方法转换成Python字典形式。
打印出这个字典,可以看到字典中有一个键'data'对应一个由字典组成的列表的值。分析表明该值是所有文章的返回数据列表。稍微修改一下代码。看看'data'的值对应的是什么:
以 request.urlopen(url) 作为资源:
d = json.loads(res.read().decode())
d = d.get('数据')
打印(d)
在这里,pprint 用于使字典打印的值更加格式化,以便于分析。你可以看到这是一个字典列表。列表中的每一项代表一块文章,里面收录了文章的所有基本数据,比如标题、文章的URL等,这样我们就可以得到URL我们这次请求的所有 文章 的列表如下:
urls = [article.get('article_url') for article in d if article.get('article_url')]
这里使用了list comprehension,循环文章列表,通过get('article_url')获取文章的URL,加上if判断条件是为了防止文章因为缺失数据导致空的文章 @> 网址。我们将继续请求这些文章 URL,阅读它们的内容,并提取图片并将它们保存到我们的硬盘中。
我们先处理一个文章,看看如何提取文章中的所有图片。
只需点击一个文章链接,按F12查看网页源代码,可以看到文章的主体部分位于
在div里面。在这个div下面,有一个h1标签,代表文章的标题,还有一系列img标签,其src属性存储了图片所在的链接,所以我们通过访问这些链接下载图片,看到怎么做:
chrome网页视频抓取(浏览器在线下载视频需要会员?找不到下载的地方?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-28 22:01
需要会员在浏览器中在线下载视频?找不到下载的地方?这时候需要网络嗅探才能下载
Chrome是最常用的浏览器,上面的插件和脚本极其丰富,所以首先想到了Chrome插件。查了一下,比较有名的好像是一个叫“Video DownloadHelper”的插件。立即下载安装,效果确实不错,下载的视频确实是网页的清晰度。
但问题也来了。当我下载第二个视频时,用英文提示我在120分钟内只允许下载一个视频。付费升级是无限的,太无聊了!所以删除它并寻找其他解决方案。
我从Chrome App Store下载了一些插件进行试用。我不记得细节,但他们中的许多人无法成功嗅探视频。简而言之,我留下了其中两个:Stream Video Downloader 和 Flash Video Downloader。这两个插件经测试成功嗅探到下载地址,并将原视频保存到本地。更推荐前者。后者下载的视频虽然分辨率最好,但在本地播放时会卡顿,这可能不是标准码率的问题。
许多人无法访问 Google 的 Chrome 网上应用店。这里我导出了原创
的crx文件,方便本地安装。打开Chrome,更多工具-扩展,将Stream Video Downloader或Flash Video Downloader的crx文件拖入安装。然后打开视频播放页面。如果右上角出现一个明亮的下载图标,则表示嗅探已成功。点击它,你会发现你嗅到了各种分辨率的视频文件,比如360p、480p、720p,甚至1080p。选择对应的版本下载,它会自动下载分段的视频并合并成一个完整的视频文件。
下载链接 查看全部
chrome网页视频抓取(浏览器在线下载视频需要会员?找不到下载的地方?)
需要会员在浏览器中在线下载视频?找不到下载的地方?这时候需要网络嗅探才能下载
Chrome是最常用的浏览器,上面的插件和脚本极其丰富,所以首先想到了Chrome插件。查了一下,比较有名的好像是一个叫“Video DownloadHelper”的插件。立即下载安装,效果确实不错,下载的视频确实是网页的清晰度。
但问题也来了。当我下载第二个视频时,用英文提示我在120分钟内只允许下载一个视频。付费升级是无限的,太无聊了!所以删除它并寻找其他解决方案。
我从Chrome App Store下载了一些插件进行试用。我不记得细节,但他们中的许多人无法成功嗅探视频。简而言之,我留下了其中两个:Stream Video Downloader 和 Flash Video Downloader。这两个插件经测试成功嗅探到下载地址,并将原视频保存到本地。更推荐前者。后者下载的视频虽然分辨率最好,但在本地播放时会卡顿,这可能不是标准码率的问题。
许多人无法访问 Google 的 Chrome 网上应用店。这里我导出了原创
的crx文件,方便本地安装。打开Chrome,更多工具-扩展,将Stream Video Downloader或Flash Video Downloader的crx文件拖入安装。然后打开视频播放页面。如果右上角出现一个明亮的下载图标,则表示嗅探已成功。点击它,你会发现你嗅到了各种分辨率的视频文件,比如360p、480p、720p,甚至1080p。选择对应的版本下载,它会自动下载分段的视频并合并成一个完整的视频文件。
下载链接
chrome网页视频抓取(实践应用类(非知识讲解)本文介绍selenium库和chrome浏览器实现自动抓取网页元素)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-23 21:01
概括
最后更新时间:2020.08.20(实验部分待更新)
本文类型:实际应用(非知识讲解)
本文介绍了selenium库和chrome浏览器自动抓取网页元素,定位并填写表单数据,可以实现自动填写,节省大量人力。为了方便使用selenium库,方便处理运行中的错误,本文将对selenium库进行一定程度的重新封装,以便读者在了解selenium库后能够快速上手编程。
一、本文知识点:1.安装selenium库,2.selenium库查找元素的方式,3.重新打包selenium库
二、本文结构:1.先简单介绍一下知识点,2.把复制后可以直接运行的调试代码以完整段落的形式贴出来,让读者可以调试发布的每一段代码。
三、 本文方法实现:以百度主页为控制网页,以谷歌浏览器为实验平台,使用python+selenium进行网页操作。ps:其他对应的爬网实验会更新。
四、本文实验:1.
后台自动登录百度贴吧
, 2.
后台QQ邮箱阅读最新邮件
, 等待其他实验更新(均提供详细代码和注释,文末有对应链接)
温馨提示:以下为本文文章内容,以下案例可供参考
一、安装selenium库及相关文件
Selenium 库是python 爬取网站 的自动化工具。支持的浏览器包括Chrome、Firefox、Safari等主流界面浏览器。它还支持Windows、Linux、IOS、Android等多种操作系统。
1.安装硒库
(1)点击win10的开始菜单,直接输入cmd右键以管理员身份运行
(2)如果安装python时勾选了添加路径的选项,可以直接输入命令
pip 安装硒
(如果没有添加,建议卸载python,重新安装,查看添加路径。这个建议慎选,因为需要重新安装之前下载的库)
(3)网络连接下等待完成。如果提示超时,可以尝试以下命令切换下载源并重新安装:
pip 安装硒 -i
2.下载谷歌浏览器相关文件
本文使用的浏览器是谷歌浏览器,所以只介绍谷歌浏览器的爬取方法。其他浏览器的方法类似。
(1)
点击下载谷歌浏览器
(2)安装谷歌浏览器后,查看谷歌浏览器的版本号,点击谷歌浏览器右上角的三个点,选择——
帮助
——
关于谷歌浏览器
——
查看版本号
.
如图,本文版本号为
84.0.4147.125
(3)
点击下载谷歌浏览器驱动
打开驱动下载页面,找到版本号对应的驱动版本,
84.0.4147.125
, 所以寻找
84.0
一开始点击打开驱动下载对应的系统驱动。然后将其解压到您要编写项目的文件夹中。
不要放在python目录或者浏览器安装目录下。如果这样做,移植到另一台计算机时会出现各种BUG。根本原因是你的电脑已经安装了相应的库文件和驱动,但是端口是 电脑可能没有安装。
二、selenium 快速入门
1.元素定位的八种方式
(1)
ID
(2)
名称
(3)
路径
(4)
链接文字
(5)
部分链接文本
(6)
标签名称
(7)
班级名称
(8)
css 选择器
2. id 方法
(1) 在 selenium 中通过
ID
定位一个元素:
find_element_by_id
以百度的页面为例,其百度输入框的页面源码如下:
......
在,
是输入框的网页代码,
百度网页代码
通过id查找元素的代码和注释如下:
导入操作系统
导入系统
导入时间
从硒导入网络驱动程序
##此方法获取的工作文件夹路径在py文件下或封装exe后有效。##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动器路径##
Google Drive Drive = 当前工作主路径 + "/" + "chromedriver.exe"
##初始化硒控制##
浏览器驱动程序 = webdriver.Chrome(executable_path=Google Drive 驱动程序)
##打开链接,改成其他网址,请注意开头##
浏览器驱动程序.get("")
##按id搜索清除搜索框内容##
浏览器 driver.find_element_by_id("kw").clear()
##搜索并按id输入搜索框内容##
浏览器驱动.find_element_by_id("kw").send_keys("python+selenium库实现抓取网页数据内容并自动填表的解决方案,并附上已经交付给甲方的代码实际稳定运行")
##按id搜索,点击百度搜索##
浏览器 driver.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭并退出浏览器
浏览器 driver.quit()
3. 命名方法
还是以百度输入框为例,通过selenium
名称
定位一个元素:
find_element_by_name
代码和注释如下:
导入操作系统
导入系统
导入时间
从硒导入网络驱动程序
##此方法获取的工作文件夹路径在py文件下或封装exe后有效。##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动器路径##
Google Drive Drive = 当前工作主路径 + "/" + "chromedriver.exe"
##初始化硒控制##
浏览器驱动程序 = webdriver.Chrome(executable_path=Google Drive 驱动程序)
##打开链接,改成其他网址,请注意开头##
浏览器驱动程序.get("")
##按名称搜索清除搜索框内容##
浏览器 driver.find_element_by_name("wd").clear()
##按名称搜索并输入搜索框的内容##
浏览器驱动.find_element_by_name("wd").send_keys("python+selenium库实现爬虫抓取网页数据内容并自动填表的解决方案,并附上已经交付给甲方的代码实际稳定运行")
##按id搜索,点击百度搜索##
浏览器 driver.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭并退出浏览器
浏览器 driver.quit()
4. xpath 方式
还是以百度输入框为例,通过selenium
路径
定位一个元素:
find_element_by_xpath
. 但是这种方法不适合在网页中的位置会发生变化的表格元素,因为xpath方法指向的是固定的行列,无法检测行列内容的变化。
首先在谷歌浏览器中打开百度,在空白处
鼠标右键
,选择
检查 (N)
有了这个选择,就可以进入网页的开发者模式了,如图。然后在百度输入框
鼠标右键
, 再次点击
检查 (N)
选择,可以发现右边代码框自动选中的部分已经变成了百度输入框的代码。最后,在右侧自动选中的代码片段
右键点击
-选择
复制
-选择
复制 Xpath
, 百度输入框
路径
为了
//*[@id="kw"]
, 百度
路径
为了
//*[@id="su"]
接下来,使用此值执行百度搜索。代码和注释如下。
导入操作系统
导入系统
导入时间
从硒导入网络驱动程序
##此方法获取的工作文件夹路径在py文件下或封装exe后有效。##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动器路径##
Google Drive Drive = 当前工作主路径 + "/" + "chromedriver.exe"
##初始化硒控制##
浏览器驱动程序 = webdriver.Chrome(executable_path=Google Drive 驱动程序)
##打开链接,改成其他网址,请注意开头##
浏览器驱动程序.get("")
##通过xpath搜索清除搜索框内容,注意单引号和双引号的混合使用##
浏览器 driver.find_element_by_xpath('//*[@id="kw"]').clear()
##通过xpath搜索并输入搜索框的内容,注意单引号和双引号的混合使用##
Browser driver.find_element_by_xpath('//*[@id="kw"]').send_keys("python+selenium库实现了爬虫抓取网页数据内容并自动填表的解决方案,并附有实际稳定性已交付给甲方运行代码")
##通过xpath搜索,点击百度搜索,注意单引号和双引号的混合使用##
浏览器 driver.find_element_by_xpath('//*[@id="su"]').click()
##保持5s时间
time.sleep(5)
###关闭并退出浏览器
浏览器 driver.quit()
5. 链接文本和部分链接文本方法 查看全部
chrome网页视频抓取(实践应用类(非知识讲解)本文介绍selenium库和chrome浏览器实现自动抓取网页元素)
概括
最后更新时间:2020.08.20(实验部分待更新)
本文类型:实际应用(非知识讲解)
本文介绍了selenium库和chrome浏览器自动抓取网页元素,定位并填写表单数据,可以实现自动填写,节省大量人力。为了方便使用selenium库,方便处理运行中的错误,本文将对selenium库进行一定程度的重新封装,以便读者在了解selenium库后能够快速上手编程。
一、本文知识点:1.安装selenium库,2.selenium库查找元素的方式,3.重新打包selenium库
二、本文结构:1.先简单介绍一下知识点,2.把复制后可以直接运行的调试代码以完整段落的形式贴出来,让读者可以调试发布的每一段代码。
三、 本文方法实现:以百度主页为控制网页,以谷歌浏览器为实验平台,使用python+selenium进行网页操作。ps:其他对应的爬网实验会更新。
四、本文实验:1.
后台自动登录百度贴吧
, 2.
后台QQ邮箱阅读最新邮件
, 等待其他实验更新(均提供详细代码和注释,文末有对应链接)
温馨提示:以下为本文文章内容,以下案例可供参考
一、安装selenium库及相关文件
Selenium 库是python 爬取网站 的自动化工具。支持的浏览器包括Chrome、Firefox、Safari等主流界面浏览器。它还支持Windows、Linux、IOS、Android等多种操作系统。
1.安装硒库
(1)点击win10的开始菜单,直接输入cmd右键以管理员身份运行
(2)如果安装python时勾选了添加路径的选项,可以直接输入命令
pip 安装硒
(如果没有添加,建议卸载python,重新安装,查看添加路径。这个建议慎选,因为需要重新安装之前下载的库)
(3)网络连接下等待完成。如果提示超时,可以尝试以下命令切换下载源并重新安装:
pip 安装硒 -i
2.下载谷歌浏览器相关文件
本文使用的浏览器是谷歌浏览器,所以只介绍谷歌浏览器的爬取方法。其他浏览器的方法类似。
(1)
点击下载谷歌浏览器
(2)安装谷歌浏览器后,查看谷歌浏览器的版本号,点击谷歌浏览器右上角的三个点,选择——
帮助
——
关于谷歌浏览器
——
查看版本号
.
如图,本文版本号为
84.0.4147.125
(3)
点击下载谷歌浏览器驱动
打开驱动下载页面,找到版本号对应的驱动版本,
84.0.4147.125
, 所以寻找
84.0
一开始点击打开驱动下载对应的系统驱动。然后将其解压到您要编写项目的文件夹中。
不要放在python目录或者浏览器安装目录下。如果这样做,移植到另一台计算机时会出现各种BUG。根本原因是你的电脑已经安装了相应的库文件和驱动,但是端口是 电脑可能没有安装。
二、selenium 快速入门
1.元素定位的八种方式
(1)
ID
(2)
名称
(3)
路径
(4)
链接文字
(5)
部分链接文本
(6)
标签名称
(7)
班级名称
(8)
css 选择器
2. id 方法
(1) 在 selenium 中通过
ID
定位一个元素:
find_element_by_id
以百度的页面为例,其百度输入框的页面源码如下:
......
在,
是输入框的网页代码,
百度网页代码
通过id查找元素的代码和注释如下:
导入操作系统
导入系统
导入时间
从硒导入网络驱动程序
##此方法获取的工作文件夹路径在py文件下或封装exe后有效。##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动器路径##
Google Drive Drive = 当前工作主路径 + "/" + "chromedriver.exe"
##初始化硒控制##
浏览器驱动程序 = webdriver.Chrome(executable_path=Google Drive 驱动程序)
##打开链接,改成其他网址,请注意开头##
浏览器驱动程序.get("")
##按id搜索清除搜索框内容##
浏览器 driver.find_element_by_id("kw").clear()
##搜索并按id输入搜索框内容##
浏览器驱动.find_element_by_id("kw").send_keys("python+selenium库实现抓取网页数据内容并自动填表的解决方案,并附上已经交付给甲方的代码实际稳定运行")
##按id搜索,点击百度搜索##
浏览器 driver.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭并退出浏览器
浏览器 driver.quit()
3. 命名方法
还是以百度输入框为例,通过selenium
名称
定位一个元素:
find_element_by_name
代码和注释如下:
导入操作系统
导入系统
导入时间
从硒导入网络驱动程序
##此方法获取的工作文件夹路径在py文件下或封装exe后有效。##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动器路径##
Google Drive Drive = 当前工作主路径 + "/" + "chromedriver.exe"
##初始化硒控制##
浏览器驱动程序 = webdriver.Chrome(executable_path=Google Drive 驱动程序)
##打开链接,改成其他网址,请注意开头##
浏览器驱动程序.get("")
##按名称搜索清除搜索框内容##
浏览器 driver.find_element_by_name("wd").clear()
##按名称搜索并输入搜索框的内容##
浏览器驱动.find_element_by_name("wd").send_keys("python+selenium库实现爬虫抓取网页数据内容并自动填表的解决方案,并附上已经交付给甲方的代码实际稳定运行")
##按id搜索,点击百度搜索##
浏览器 driver.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭并退出浏览器
浏览器 driver.quit()
4. xpath 方式
还是以百度输入框为例,通过selenium
路径
定位一个元素:
find_element_by_xpath
. 但是这种方法不适合在网页中的位置会发生变化的表格元素,因为xpath方法指向的是固定的行列,无法检测行列内容的变化。
首先在谷歌浏览器中打开百度,在空白处
鼠标右键
,选择
检查 (N)
有了这个选择,就可以进入网页的开发者模式了,如图。然后在百度输入框
鼠标右键
, 再次点击
检查 (N)
选择,可以发现右边代码框自动选中的部分已经变成了百度输入框的代码。最后,在右侧自动选中的代码片段
右键点击
-选择
复制
-选择
复制 Xpath
, 百度输入框
路径
为了
//*[@id="kw"]
, 百度
路径
为了
//*[@id="su"]
接下来,使用此值执行百度搜索。代码和注释如下。
导入操作系统
导入系统
导入时间
从硒导入网络驱动程序
##此方法获取的工作文件夹路径在py文件下或封装exe后有效。##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动器路径##
Google Drive Drive = 当前工作主路径 + "/" + "chromedriver.exe"
##初始化硒控制##
浏览器驱动程序 = webdriver.Chrome(executable_path=Google Drive 驱动程序)
##打开链接,改成其他网址,请注意开头##
浏览器驱动程序.get("")
##通过xpath搜索清除搜索框内容,注意单引号和双引号的混合使用##
浏览器 driver.find_element_by_xpath('//*[@id="kw"]').clear()
##通过xpath搜索并输入搜索框的内容,注意单引号和双引号的混合使用##
Browser driver.find_element_by_xpath('//*[@id="kw"]').send_keys("python+selenium库实现了爬虫抓取网页数据内容并自动填表的解决方案,并附有实际稳定性已交付给甲方运行代码")
##通过xpath搜索,点击百度搜索,注意单引号和双引号的混合使用##
浏览器 driver.find_element_by_xpath('//*[@id="su"]').click()
##保持5s时间
time.sleep(5)
###关闭并退出浏览器
浏览器 driver.quit()
5. 链接文本和部分链接文本方法
chrome网页视频抓取(谷歌浏览器扩展插件安装方法.zip文件2.打开(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-20 21:21
谷歌浏览器截图插件是一款浏览器辅助软件。每个人在浏览网页时可能都需要截图。那么这个小插件可以快速拦截网页,方便快捷,可以拦截任何页面,非常方便,有需要的赶紧下载试试吧!
插件介绍:
谷歌浏览器网页截图扩展允许浏览器截图,可以对整个网页进行截图,包括带有滚动条的窗口,可以对网页的任意区域进行截图。网页上出现的浮动元素只在截图后出现一次。捕获的图像提供突出显示、校正和用于编辑的文本工具。
特征:
只需单击一下,您就可以将整个页面另存为 PNG 图像。
快速轻松地捕获整个网页。即使是很长的页面也可以保存为图像文件。
在截屏之前,您可以选择让扩展程序先帮助调整窗口大小。
该扩展程序只运行在本机上,这意味着该扩展程序不会向任何服务器发送任何信息,它甚至可以在没有网络连接的情况下工作。因此,您的隐私永远不会被泄露。
如何安装 Google Chrome 扩展程序
1.解压.zip文件
2.打开浏览器扩展选项,选择解压后的扩展
3.选择你解压后的文件路径,点击确定
4.加载成功
编辑评论
将网页截取为图片,支持窗口截屏、区域截屏、整页截屏三种方式。支持横竖翻页拦截大网页,新版本引入了自动截图保存功能。 查看全部
chrome网页视频抓取(谷歌浏览器扩展插件安装方法.zip文件2.打开(组图))
谷歌浏览器截图插件是一款浏览器辅助软件。每个人在浏览网页时可能都需要截图。那么这个小插件可以快速拦截网页,方便快捷,可以拦截任何页面,非常方便,有需要的赶紧下载试试吧!
插件介绍:
谷歌浏览器网页截图扩展允许浏览器截图,可以对整个网页进行截图,包括带有滚动条的窗口,可以对网页的任意区域进行截图。网页上出现的浮动元素只在截图后出现一次。捕获的图像提供突出显示、校正和用于编辑的文本工具。
特征:
只需单击一下,您就可以将整个页面另存为 PNG 图像。
快速轻松地捕获整个网页。即使是很长的页面也可以保存为图像文件。
在截屏之前,您可以选择让扩展程序先帮助调整窗口大小。
该扩展程序只运行在本机上,这意味着该扩展程序不会向任何服务器发送任何信息,它甚至可以在没有网络连接的情况下工作。因此,您的隐私永远不会被泄露。
如何安装 Google Chrome 扩展程序
1.解压.zip文件
2.打开浏览器扩展选项,选择解压后的扩展
3.选择你解压后的文件路径,点击确定
4.加载成功
编辑评论
将网页截取为图片,支持窗口截屏、区域截屏、整页截屏三种方式。支持横竖翻页拦截大网页,新版本引入了自动截图保存功能。
chrome网页视频抓取(从Chromium的源码third_Chrome中的媒体播放架构图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-20 20:11
Linux
新增的视频/音频标签提供了直接在网页上播放音频和视频的能力,无需任何插件。因此,可以使用 HTML5 开发媒体播放器。互联网上也出现了许多 HTML5 播放器,例如 jPlayer。但是,各种浏览器支持的 HTML5 音频和视频格式非常有限。比如IE9只支持H.264,Firefox只支持VP8和Theora。谷歌浏览器被认为拥有最全面的支持格式。支持的视频格式包括H.264、VP8、Theora,音频包括Vorbis、MP3、AAC、WAV。这些格式对于播放网络在线音视频基本足够了(不包括flash),但是如果我们要播放本地音视频,就会遇到很多不支持的格式,比如rmvb视频,在国内很流行,而且高- 定义视频是最常见的 mkv 和 avi 格式目前并非所有浏览器都支持。从这一点来看,目前基于HTML5的播放器无法替代QQ视频和射击播放器等传统播放器。
是否可以向浏览器添加对更多音频和视频格式的支持?分析了谷歌的开源浏览器Chromium,发现它的音视频解码是由FFmpeg提供的(代码在第三方\ffmpeg\),和Chrome是一样的,所以可以添加对更多类型的音频和音频的支持视频格式转换为 Chrome。
Chrome 中的媒体播放架构如下图所示:
Pipeline 是 Google 为 Chrome 开发的媒体框架引擎。 HTML5 视频/音频标签用于实现媒体播放。 FFmpeg 在其中提供了解复用器和解码器。所以需要添加对音视频格式的支持,主要是修改FFmpeg。 .
从Chromium源代码third_party\ffmpeg\chromium\config\Chrome\linux\ia32\config.h可以知道Chrome使用的FFmpeg配置选项。在原来的配置选项后添加以下选项:
--enable-decoder='rv10,rv20,rv30,rv40,cook,h263,h263i,mpeg4,msmpeg4v1,msmpeg4v2,msmpeg4v3,amrnb,amrwb,ac3,flv' --enable-demuxer='rm,mpegvideo ,avi,avisynth,h263,aac,amr,ac3,flv,mpegts,mpegtsraw' --enable-parser='mpegvideo,rv30,rv40,h263,mpeg4video,ac3'
使用新的配置选项重新配置编译FFmpeg,并使用生成的3个动态链接库avcodec-54.dll, avformat-54.dll, avutil-51. dll 替换 Chrome 中的原创文件。请注意,用于编译 FFmpeg 的 Chromium 源代码版本应与 Chrome 的版本相似。如果差异过大,更换库可能会导致Chrome无法正常运行。在Windows上编译FFmpeg的方法请参考我的另一篇文档《在Windows上用Chromium编译FFmpeg》。
这样修改FFmpeg后,就可以在Chrome中使用HTML5 video/audio标签播放更多格式的音视频了。可以播放最常见的mkv、avi、flv、mov、amr。但是rmvb还是不能播放。用Visual Studio 2010跟踪后,我找到了原因。原来常见的rmvb电影视频编码是RV40,音频编码是COOK。这两种编解码器类型在 Chrome 中没有定义。它们将在解析 rmvb 时使用。认为是未知的编解码类型(kUnknownVideoCodec和kUnknownAudioCodec),为此需要修改media\base\video_decoder_config.h和media\base\audio_decoder_config.h,将这两种格式分别添加到枚举类型VideoCodec和AudioCodec中,然后也如果要修改media\ffmpeg\,具体修改方法就不赘述了,直接看代码即可。经过这次修改,Chrome的媒体引擎可以识别RV40和COOK两种格式,普通的rmvb电影也可以播放了。
由此可见,Chrome 播放更多格式的音视频并不难。当然,这只是第一步。还有很多问题。比如播放rmvb电影的时候,拖动进度条就会乱屏。兼容性和稳定性需要做更多的工作。
窗口
在 Windows 上的 Chromium 中编译 FFmpeg
在谷歌开源浏览器Chromium中,HTML5音视频标签的实现使用开源多媒体软件FFmpeg提供解码,与Chrome相同。 FFmpeg源码位于Chromium源码树的third_party\ffmpeg\,但是在Windows上用Visual Studio 2010编译Chromium时,这部分FFmpeg代码不参与编译,而是直接使用预编译好的3个动态链接库(位于third_party\ffmpeg\chromium\binaries\Chromium\win\ia32\)。谷歌文档指出,目前Windows上的这部分FFmpeg代码只能借助MinGW手动编译。参考文档,经过实际验证,现将编译步骤总结如下。
Google 对 FFmpeg 进行了修改。修改后的代码部分以patch的形式放在third_party\ffmpeg\chromium\patches\中。下载的Chromium源代码中的这些补丁已经打好了,可以直接编译FFmpeg。
以下步骤在Windows7 64位验证,前提是安装并配置了Chromium开发环境,包括Visual Studio 2010、depot_tools等,假设所有软件安装在C盘,Chromium源代码位于C:\Chromium\。
1. 从...下载 4 个文件... /third_party/mingw/: README.chromium, mingw-get-inst-20101030.exe, pthreads-w32-2-8-0- release .tar.gz、pthreads-w32.patch.txt。 README.chromium 是本文引用的主要文档。 mingw-get-inst-20101030.exe是MinGW的安装文件,版本比较老,可以到MinGW官网下载最新版本。
2. 运行mingw-get-inst-20101030.exe,将MinGW安装到C:\MinGW\,安装时检查以下3项:
C++ 编译器
MSYS 基础系统
MinGW 开发者工具包
3. 下载并解压到 C:
4. 修改系统环境变量PATH,添加如下路径:C:\MinGW\bin;C:\MinGW\msys\1.0\bin;C:\yasm-1.2.0
5. 将第一步下载的pthreads-w32-2-8-0-release.tar.gz解压到C:
6. 将第一步下载的pthreads-w32.patch.txt复制到C:\
7.在Windows命令行窗口依次运行以下命令:
c:
cd pthreads-w32-2-8-0-release
补丁 -p0
使干净的 GC 成为静态
cp pthread.h sched.h /mingw/include
cp libpthreadGC2.a /mingw/lib
调用“c:\Program Files (x86)\Microsoft Visual Studio 10.0\VC\bin\vcvars32.bat”
c:\MinGW\msys\1.0\msys.bat
8. 出现MinGW/MSYS命令行窗口,在里面运行如下命令:
cd /c/yasm-1.2.0/
./configure
制作
cd /c/chromium/src/third_party/ffmpeg/
./configure --disable-everything --enable-fft --enable-rdft --disable-network --disable-bzlib --disable-zlib --disable-swscale --disable-amd3dnow --disable- amd3dnowext --enable-shared --optflags=-O2 --enable-decoder='theora,vorbis,vp8' --enable-decoder='pcm_u8,pcm_s16le,pcm_f32le' --enable-demuxer='ogg,matroska,wav '--enable-parser=vp8 --arch=i686 --enable-yasm --extra-cflags=-m32 --extra-ldflags=-m32 --enable-pic
make -j4
FFmpeg的配置参数来自third_party\ffmpeg\chromium\config\Chromium\linux\ia32\config.h
编译完成后会生成3个动态链接库:avcodec-54.dll、avformat-54.dll、avutil-51.dll,会用到当 Chromium 运行时。音频和视频解码。目前,Chromium 中的 FFmpeg 仅支持 Vorbis、Theora 和 VP8 解码器。除了这三个之外,Chrome中的FFmpeg还支持H.264、AAC和MP3。如果我们想让 Chromium 的 HTML5 音频/视频标签支持更多的媒体格式,需要做的一件事就是重新配置和编译 FFmpeg。可以参考我的另一篇文章文章《让Chromium支持H.264视频。
参考资料
1)third_party\ffmpeg\chromium\README.chromium
2)third_party\ffmpeg\chromium\patches\README.chromium
3) ... ngw/README.chromium 查看全部
chrome网页视频抓取(从Chromium的源码third_Chrome中的媒体播放架构图)
Linux
新增的视频/音频标签提供了直接在网页上播放音频和视频的能力,无需任何插件。因此,可以使用 HTML5 开发媒体播放器。互联网上也出现了许多 HTML5 播放器,例如 jPlayer。但是,各种浏览器支持的 HTML5 音频和视频格式非常有限。比如IE9只支持H.264,Firefox只支持VP8和Theora。谷歌浏览器被认为拥有最全面的支持格式。支持的视频格式包括H.264、VP8、Theora,音频包括Vorbis、MP3、AAC、WAV。这些格式对于播放网络在线音视频基本足够了(不包括flash),但是如果我们要播放本地音视频,就会遇到很多不支持的格式,比如rmvb视频,在国内很流行,而且高- 定义视频是最常见的 mkv 和 avi 格式目前并非所有浏览器都支持。从这一点来看,目前基于HTML5的播放器无法替代QQ视频和射击播放器等传统播放器。
是否可以向浏览器添加对更多音频和视频格式的支持?分析了谷歌的开源浏览器Chromium,发现它的音视频解码是由FFmpeg提供的(代码在第三方\ffmpeg\),和Chrome是一样的,所以可以添加对更多类型的音频和音频的支持视频格式转换为 Chrome。
Chrome 中的媒体播放架构如下图所示:

Pipeline 是 Google 为 Chrome 开发的媒体框架引擎。 HTML5 视频/音频标签用于实现媒体播放。 FFmpeg 在其中提供了解复用器和解码器。所以需要添加对音视频格式的支持,主要是修改FFmpeg。 .
从Chromium源代码third_party\ffmpeg\chromium\config\Chrome\linux\ia32\config.h可以知道Chrome使用的FFmpeg配置选项。在原来的配置选项后添加以下选项:
--enable-decoder='rv10,rv20,rv30,rv40,cook,h263,h263i,mpeg4,msmpeg4v1,msmpeg4v2,msmpeg4v3,amrnb,amrwb,ac3,flv' --enable-demuxer='rm,mpegvideo ,avi,avisynth,h263,aac,amr,ac3,flv,mpegts,mpegtsraw' --enable-parser='mpegvideo,rv30,rv40,h263,mpeg4video,ac3'
使用新的配置选项重新配置编译FFmpeg,并使用生成的3个动态链接库avcodec-54.dll, avformat-54.dll, avutil-51. dll 替换 Chrome 中的原创文件。请注意,用于编译 FFmpeg 的 Chromium 源代码版本应与 Chrome 的版本相似。如果差异过大,更换库可能会导致Chrome无法正常运行。在Windows上编译FFmpeg的方法请参考我的另一篇文档《在Windows上用Chromium编译FFmpeg》。
这样修改FFmpeg后,就可以在Chrome中使用HTML5 video/audio标签播放更多格式的音视频了。可以播放最常见的mkv、avi、flv、mov、amr。但是rmvb还是不能播放。用Visual Studio 2010跟踪后,我找到了原因。原来常见的rmvb电影视频编码是RV40,音频编码是COOK。这两种编解码器类型在 Chrome 中没有定义。它们将在解析 rmvb 时使用。认为是未知的编解码类型(kUnknownVideoCodec和kUnknownAudioCodec),为此需要修改media\base\video_decoder_config.h和media\base\audio_decoder_config.h,将这两种格式分别添加到枚举类型VideoCodec和AudioCodec中,然后也如果要修改media\ffmpeg\,具体修改方法就不赘述了,直接看代码即可。经过这次修改,Chrome的媒体引擎可以识别RV40和COOK两种格式,普通的rmvb电影也可以播放了。
由此可见,Chrome 播放更多格式的音视频并不难。当然,这只是第一步。还有很多问题。比如播放rmvb电影的时候,拖动进度条就会乱屏。兼容性和稳定性需要做更多的工作。
窗口
在 Windows 上的 Chromium 中编译 FFmpeg
在谷歌开源浏览器Chromium中,HTML5音视频标签的实现使用开源多媒体软件FFmpeg提供解码,与Chrome相同。 FFmpeg源码位于Chromium源码树的third_party\ffmpeg\,但是在Windows上用Visual Studio 2010编译Chromium时,这部分FFmpeg代码不参与编译,而是直接使用预编译好的3个动态链接库(位于third_party\ffmpeg\chromium\binaries\Chromium\win\ia32\)。谷歌文档指出,目前Windows上的这部分FFmpeg代码只能借助MinGW手动编译。参考文档,经过实际验证,现将编译步骤总结如下。
Google 对 FFmpeg 进行了修改。修改后的代码部分以patch的形式放在third_party\ffmpeg\chromium\patches\中。下载的Chromium源代码中的这些补丁已经打好了,可以直接编译FFmpeg。
以下步骤在Windows7 64位验证,前提是安装并配置了Chromium开发环境,包括Visual Studio 2010、depot_tools等,假设所有软件安装在C盘,Chromium源代码位于C:\Chromium\。
1. 从...下载 4 个文件... /third_party/mingw/: README.chromium, mingw-get-inst-20101030.exe, pthreads-w32-2-8-0- release .tar.gz、pthreads-w32.patch.txt。 README.chromium 是本文引用的主要文档。 mingw-get-inst-20101030.exe是MinGW的安装文件,版本比较老,可以到MinGW官网下载最新版本。
2. 运行mingw-get-inst-20101030.exe,将MinGW安装到C:\MinGW\,安装时检查以下3项:
C++ 编译器
MSYS 基础系统
MinGW 开发者工具包
3. 下载并解压到 C:
4. 修改系统环境变量PATH,添加如下路径:C:\MinGW\bin;C:\MinGW\msys\1.0\bin;C:\yasm-1.2.0
5. 将第一步下载的pthreads-w32-2-8-0-release.tar.gz解压到C:
6. 将第一步下载的pthreads-w32.patch.txt复制到C:\
7.在Windows命令行窗口依次运行以下命令:
c:
cd pthreads-w32-2-8-0-release
补丁 -p0
使干净的 GC 成为静态
cp pthread.h sched.h /mingw/include
cp libpthreadGC2.a /mingw/lib
调用“c:\Program Files (x86)\Microsoft Visual Studio 10.0\VC\bin\vcvars32.bat”
c:\MinGW\msys\1.0\msys.bat
8. 出现MinGW/MSYS命令行窗口,在里面运行如下命令:
cd /c/yasm-1.2.0/
./configure
制作
cd /c/chromium/src/third_party/ffmpeg/
./configure --disable-everything --enable-fft --enable-rdft --disable-network --disable-bzlib --disable-zlib --disable-swscale --disable-amd3dnow --disable- amd3dnowext --enable-shared --optflags=-O2 --enable-decoder='theora,vorbis,vp8' --enable-decoder='pcm_u8,pcm_s16le,pcm_f32le' --enable-demuxer='ogg,matroska,wav '--enable-parser=vp8 --arch=i686 --enable-yasm --extra-cflags=-m32 --extra-ldflags=-m32 --enable-pic
make -j4
FFmpeg的配置参数来自third_party\ffmpeg\chromium\config\Chromium\linux\ia32\config.h
编译完成后会生成3个动态链接库:avcodec-54.dll、avformat-54.dll、avutil-51.dll,会用到当 Chromium 运行时。音频和视频解码。目前,Chromium 中的 FFmpeg 仅支持 Vorbis、Theora 和 VP8 解码器。除了这三个之外,Chrome中的FFmpeg还支持H.264、AAC和MP3。如果我们想让 Chromium 的 HTML5 音频/视频标签支持更多的媒体格式,需要做的一件事就是重新配置和编译 FFmpeg。可以参考我的另一篇文章文章《让Chromium支持H.264视频。
参考资料
1)third_party\ffmpeg\chromium\README.chromium
2)third_party\ffmpeg\chromium\patches\README.chromium
3) ... ngw/README.chromium
chrome网页视频抓取( 优点扩展下载地址:Pinbox跨平台收藏工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-18 21:03
优点扩展下载地址:Pinbox跨平台收藏工具)
Pinbox 是一款谷歌浏览器插件,可以让用户的 Chrome 书签更加生动。用户在Chrome中安装Pinbox插件后,只需点击扩展按钮,即可自动为您保存当前网页至Pinbox。保存网页时,同时将当前网页的缩略图保存在采集夹中,方便用户通过采集夹中的缩略图快速了解网页内容。
Pinbox插件不仅支持一些常见的文字或图片类型网站,还可以将视频类型网站保存在采集中,用户还可以通过Pinbox快速分享保存的采集。
优势
扩展下载链接:Pinbox 跨平台采集工具
口袋
Pocket 是一个非常好的网页保存工具。使用起来非常方便。您只需要点击扩展按钮,就会自动为您保存当前网页到Pocket,以网格形式显示,您可以对其进行标记。排序、归档等操作,但国内使用较慢。
优势
扩展下载链接:Pocket
Instapaper
Instapaper 是一种类似于 Pocket 的网络采集服务。也可以一键采集网页,但是在显示上有很大的不同。在Pocket中,采用卡片网格格式的布局,以图片为主体,而在Instapaper中,则采用文本列表的形式,显示更多的文本信息,界面比Pocket更简单,布局比 Pocket 更漂亮。很多,比较适合文字阅读。
优势
扩展下载链接:Instapaper 查看全部
chrome网页视频抓取(
优点扩展下载地址:Pinbox跨平台收藏工具)

Pinbox 是一款谷歌浏览器插件,可以让用户的 Chrome 书签更加生动。用户在Chrome中安装Pinbox插件后,只需点击扩展按钮,即可自动为您保存当前网页至Pinbox。保存网页时,同时将当前网页的缩略图保存在采集夹中,方便用户通过采集夹中的缩略图快速了解网页内容。
Pinbox插件不仅支持一些常见的文字或图片类型网站,还可以将视频类型网站保存在采集中,用户还可以通过Pinbox快速分享保存的采集。
优势
扩展下载链接:Pinbox 跨平台采集工具
口袋

Pocket 是一个非常好的网页保存工具。使用起来非常方便。您只需要点击扩展按钮,就会自动为您保存当前网页到Pocket,以网格形式显示,您可以对其进行标记。排序、归档等操作,但国内使用较慢。
优势
扩展下载链接:Pocket
Instapaper

Instapaper 是一种类似于 Pocket 的网络采集服务。也可以一键采集网页,但是在显示上有很大的不同。在Pocket中,采用卡片网格格式的布局,以图片为主体,而在Instapaper中,则采用文本列表的形式,显示更多的文本信息,界面比Pocket更简单,布局比 Pocket 更漂亮。很多,比较适合文字阅读。
优势
扩展下载链接:Instapaper
chrome网页视频抓取(挖一下crx插件可以根据用户需求快速准确地抓取网页上的图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-18 21:00
Dig it crx插件是一款基于Chrome浏览器的图片批量下载插件。这个挖的插件可以根据用户需要快速准确的抓取网页图片(包括网页中的css背景图片和嵌入iframe的图片),根据您的需要过滤和批量下载图片,并支持整个截图网页。无论是工作还是娱乐,都能有效帮助您节省更多时间。
特征:
1、精准高效的网页图片抓取功能,无论是CSS背景图片还是嵌入的IFRAME图片,准确率都在99.9%以上。
2、 便捷的网页截图功能,支持当前可视区域截图和整个网页区域截图。
3、 实用的图片遮挡功能,自动过滤被遮挡的图片,结果更准确。
4、自定义图片保存路径,根据当前日期分类保存。
5、图片保存到云端,随时随地访问。
离线安装插件:
如果无法访问谷歌应用商店,可以下载crx插件包到本地,安装方法:
1、拖放到Chrome浏览器。
2、使用开发模式,将下载的crx改为zip,解压到一个文件夹
菜单->更多工具->扩展
检查开发者模式
加载解压后的扩展...,选择刚刚解压的文件夹路径
更新日志:
1、采用新的LOGO
2、 增加云存储功能,可以访问采集的图片
3、修复几个bug
细节 查看全部
chrome网页视频抓取(挖一下crx插件可以根据用户需求快速准确地抓取网页上的图片)
Dig it crx插件是一款基于Chrome浏览器的图片批量下载插件。这个挖的插件可以根据用户需要快速准确的抓取网页图片(包括网页中的css背景图片和嵌入iframe的图片),根据您的需要过滤和批量下载图片,并支持整个截图网页。无论是工作还是娱乐,都能有效帮助您节省更多时间。
特征:
1、精准高效的网页图片抓取功能,无论是CSS背景图片还是嵌入的IFRAME图片,准确率都在99.9%以上。
2、 便捷的网页截图功能,支持当前可视区域截图和整个网页区域截图。
3、 实用的图片遮挡功能,自动过滤被遮挡的图片,结果更准确。
4、自定义图片保存路径,根据当前日期分类保存。
5、图片保存到云端,随时随地访问。
离线安装插件:
如果无法访问谷歌应用商店,可以下载crx插件包到本地,安装方法:
1、拖放到Chrome浏览器。
2、使用开发模式,将下载的crx改为zip,解压到一个文件夹
菜单->更多工具->扩展
检查开发者模式
加载解压后的扩展...,选择刚刚解压的文件夹路径
更新日志:
1、采用新的LOGO
2、 增加云存储功能,可以访问采集的图片
3、修复几个bug
细节
chrome网页视频抓取(imacros系统自然环境规定Windows10,Windows8/8.1(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-16 08:02
imacros破解版下载是一款功能强大的浏览器组件,可以完成对网页的抓取、检测等实际操作。另外,填写网页表单信息和自动下载文件图片也很方便。它适用于多种浏览器。,热忱欢迎有兴趣的朋友下载安装本站软件!
imacros中文版APP详细介绍
iMacros 是 Mozilla Firefox 浏览器的附加组件。它的主要功能是帮助您创建用于登录URL、社区论坛和Internet 邮箱的姿势宏以查看电子邮件。它还允许我们创建其他姿势宏,例如:保存网页、存储网页上的组件(例如:照片)、打印输出...
imacros系统自然环境法规
Windows 10、Windows 8/8.1、Windows 7、Windows XP SP3、Windows Server 2003/2008/2008R2/2012/2012R2
Windows 32 位(x86) 和 64 位(x64)
Microsoft Internet Explorer 9、10 或 11(Windows XP 也适用于 ie8)
Mozilla Firefox 版本 21 或更高版本(可选,仅适用于 iMacros Firefox Add-On)
Google chrome Version 22 或更高版本号(可选,仅适用于 iMacros Chrome Add-On)
RAM:256MB(强烈推荐512MB)
电脑硬盘:30MB
imacros动作特征
1、MacrosWeb 浏览器 API
iMacros 的脚本套接字可以对 Web 浏览器进行可编程控制。因此,您可以编写脚本来执行复杂的日常任务。iMacros 的 32/64 位 API 可以远程操作浏览器。
2、数据信息获取
iMacros不仅可以填写网页表单信息,还可以获取信息。例如:从网站上搜索并获取文字、图片(如价格、产品介绍、股票价格等)。iMacros 应用Unicode 文件格式和所有语言表达(包括多字节语言表达,如中文)。
3、网页检测
iMacros可以进行Web应用软件的软件性能测试、功能测试和可用性测试。iMacros 是唯一可以在浏览器(如 IE、Firefox 和 Chrome)中立即检测的专用工具。它可以在java/Flash/Flex/Silverlight 程序流和所有AJAX 元素中进行测试。iMacros 内置了命令命令,可以准确捕捉到 Web 每次的响应时间。
4、网络自动化技术
自动化技术填写表格可以满足最终产品用户的要求。您可以更好地在线下载和提交文本、照片、文档和网页,还可以解析PDF文档和屏幕截图。
您可以从 CSV/XML 文档、数据库查询或其他 Web 应用程序启动和导出数据。
您可以浏览网页。
iMacros 可以帮助您查看网址、记住登录密码、填写网络表单,让您摆脱繁琐的工作。是唯一一款可以自动填写网页表单的APP。它将所有信息存储在文本文件中,以便于编辑和阅读。登录密码使用 256 位 AES 加密算法。
5、.NET Web 浏览器组件
.NET Web 浏览器组件可以快速将自动化技术程序流添加到您的应用程序软件中。它在检测和调节方面拥有十多年的关键技术。现阶段已有超过50万名客户在申请。 查看全部
chrome网页视频抓取(imacros系统自然环境规定Windows10,Windows8/8.1(组图))
imacros破解版下载是一款功能强大的浏览器组件,可以完成对网页的抓取、检测等实际操作。另外,填写网页表单信息和自动下载文件图片也很方便。它适用于多种浏览器。,热忱欢迎有兴趣的朋友下载安装本站软件!
imacros中文版APP详细介绍
iMacros 是 Mozilla Firefox 浏览器的附加组件。它的主要功能是帮助您创建用于登录URL、社区论坛和Internet 邮箱的姿势宏以查看电子邮件。它还允许我们创建其他姿势宏,例如:保存网页、存储网页上的组件(例如:照片)、打印输出...
imacros系统自然环境法规
Windows 10、Windows 8/8.1、Windows 7、Windows XP SP3、Windows Server 2003/2008/2008R2/2012/2012R2
Windows 32 位(x86) 和 64 位(x64)
Microsoft Internet Explorer 9、10 或 11(Windows XP 也适用于 ie8)
Mozilla Firefox 版本 21 或更高版本(可选,仅适用于 iMacros Firefox Add-On)
Google chrome Version 22 或更高版本号(可选,仅适用于 iMacros Chrome Add-On)
RAM:256MB(强烈推荐512MB)
电脑硬盘:30MB
imacros动作特征
1、MacrosWeb 浏览器 API
iMacros 的脚本套接字可以对 Web 浏览器进行可编程控制。因此,您可以编写脚本来执行复杂的日常任务。iMacros 的 32/64 位 API 可以远程操作浏览器。
2、数据信息获取
iMacros不仅可以填写网页表单信息,还可以获取信息。例如:从网站上搜索并获取文字、图片(如价格、产品介绍、股票价格等)。iMacros 应用Unicode 文件格式和所有语言表达(包括多字节语言表达,如中文)。
3、网页检测
iMacros可以进行Web应用软件的软件性能测试、功能测试和可用性测试。iMacros 是唯一可以在浏览器(如 IE、Firefox 和 Chrome)中立即检测的专用工具。它可以在java/Flash/Flex/Silverlight 程序流和所有AJAX 元素中进行测试。iMacros 内置了命令命令,可以准确捕捉到 Web 每次的响应时间。
4、网络自动化技术
自动化技术填写表格可以满足最终产品用户的要求。您可以更好地在线下载和提交文本、照片、文档和网页,还可以解析PDF文档和屏幕截图。
您可以从 CSV/XML 文档、数据库查询或其他 Web 应用程序启动和导出数据。
您可以浏览网页。
iMacros 可以帮助您查看网址、记住登录密码、填写网络表单,让您摆脱繁琐的工作。是唯一一款可以自动填写网页表单的APP。它将所有信息存储在文本文件中,以便于编辑和阅读。登录密码使用 256 位 AES 加密算法。
5、.NET Web 浏览器组件
.NET Web 浏览器组件可以快速将自动化技术程序流添加到您的应用程序软件中。它在检测和调节方面拥有十多年的关键技术。现阶段已有超过50万名客户在申请。
chrome网页视频抓取( Python中一个非常成熟的库——selenium专栏(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-31 19:20
Python中一个非常成熟的库——selenium专栏(组图))
本系列文章收录在公众号:数据宇宙>py爬虫>Selenium
转发本文并私信我“python”,可以获得Python资料及更多系列文章(持续更新)
作为“数据玩家”,手头没有数据怎么办?当然,用代码自动化采集数据,但现在“爬虫”可没那么容易了,其中最难的是突破网站的各种反爬机制。本系列将全面讲解Python中一个非常成熟的库——selenium,并教你如何使用它在网络上爬取你需要的数据
虽然自动爬虫很方便,但希望大家可以考虑到网站服务器的承受能力,不要频繁访问网站。永远不要采集敏感数据!!否则很容易“从入门到监狱”
本系列大部分案例都是selenium和pyppeteer库同时讲解的,并且有Python和C#2语言的实现文章,详情请到公众号目录。
当你得到数据时,你还需要对数据进行处理和分析。我的 pandas 专栏是高级教程的最佳介绍。
前言
学习任何库,首先要了解库的机制和流程。今天,我们将从一个小例子开始我们的学习之旅。
搜索和采集结果的标题
要求如下:
硒的问题
这个系列一直围绕着一个点:“用代码操作浏览器”,我们来看看整个过程:
然而,市面上的浏览器种类繁多,甚至一个厂商的浏览器版本也不同。我们如何保证我们的代码只需要编写一次就可以控制不同的浏览器?
更深入的流程图如下:
“案子怎么还没开始,就说硒不是?我还在学吗?”
他有以下优点:
缺点:
如果觉得不能接受selenium的缺点,可以查看pyppeteer的相关文章(公众号:大数据宇宙>py爬虫>pyppeteer)
得到驱动
现在让我们开始使用 selenium 来解决我们的需求。
首先,使用 pip 安装 selenium
由于我在本地安装了谷歌Chrome浏览器,打开浏览器查看浏览器的版本:
然后去相关的网站(私信我“python”)下载对应的驱动:
一切都准备好了
看过我相关教学文章的人都知道,我喜欢从语义的角度去理解和学习图书馆。
Selenium 本质上控制着浏览器,所以我们在使用它的时候,代码的语义应该类似于手动操作浏览器的过程。
首先导入一些包:
让我们看看如何使用代码来描述我们的手动操作。
打开浏览器:
没错,我们只是下载了驱动程序,但是 Python 怎么知道在哪里可以找到该驱动程序呢?
我们可以在实例化浏览器对象的时候传入一个文件路径,告诉他程序的具体位置:
输入百度搜索的网址:
将鼠标移动到输入框,点击一次,然后输入内容“爬虫”:
这里的问题是,如何在代码中表达“鼠标到输入框,点击一次”?
其实selenium确实可以模拟鼠标移动等操作(网站的一些登录验证码需要用鼠标拉动拼图来模拟),但是目前的情况下,我们不应该模拟鼠标,而是根据html标签定位。.
此时,我们可以使用浏览器的“开发者功能”进行定位。
限于篇幅,本文不详细讲解“开发者功能”的所有操作,详细讲解会放在公众号目录:数据宇宙>爬虫工具>系列文章
下面用一张动态图来展示操作过程:
看一下代码:
接下来,输入内容“爬虫”:
我们继续模拟点击输入框右侧的“百度点击”按钮。
同样使用“开发人员功能”,找到元素并复制 css 选择器表达式字符串:
所有结果的主标题:
这对初学者来说可能有点困难,因为这一次我们需要同时选择多个元素(多个搜索结果的主标题),并查看定位到的标签:
仔细看看我们需要的主要标题在哪里:
所以,现在我们将使用 CSS 选择器来表达以下语义: 在 div 内部 (id=content_left),在 h3 标记内部的 a 标记文本。div 和 h3 之间可能有多层嵌套。
生成的选择器表达式如下:
调用代码如下:
Python基础教程教材 Python编程从零基础到实际项目实例
¥59
买
代码执行太快
上面的代码之所以没有得到任何结果,是因为执行第10行的代码时,页面上还没有加载任何结果。
如果一个人正在操作浏览器,那么你应该对他说:嘿,直到你看到那些结果,你去提取主标题。
怎么说“直到你看到那些结果”?,selenium有一种特殊的等待元素出现的机制,代码如下:
用控件关闭浏览器,完整代码如下:
总结
使用代码控制 selenium 与手动操作基本相同。一般流程是:
下一节,我们将介绍更多的selenium技能,敬请期待!!
私信我“python”获取本系列所有相关资料和源码文章 查看全部
chrome网页视频抓取(
Python中一个非常成熟的库——selenium专栏(组图))
本系列文章收录在公众号:数据宇宙>py爬虫>Selenium
转发本文并私信我“python”,可以获得Python资料及更多系列文章(持续更新)
作为“数据玩家”,手头没有数据怎么办?当然,用代码自动化采集数据,但现在“爬虫”可没那么容易了,其中最难的是突破网站的各种反爬机制。本系列将全面讲解Python中一个非常成熟的库——selenium,并教你如何使用它在网络上爬取你需要的数据
虽然自动爬虫很方便,但希望大家可以考虑到网站服务器的承受能力,不要频繁访问网站。永远不要采集敏感数据!!否则很容易“从入门到监狱”
本系列大部分案例都是selenium和pyppeteer库同时讲解的,并且有Python和C#2语言的实现文章,详情请到公众号目录。
当你得到数据时,你还需要对数据进行处理和分析。我的 pandas 专栏是高级教程的最佳介绍。
前言
学习任何库,首先要了解库的机制和流程。今天,我们将从一个小例子开始我们的学习之旅。
搜索和采集结果的标题
要求如下:
硒的问题
这个系列一直围绕着一个点:“用代码操作浏览器”,我们来看看整个过程:
然而,市面上的浏览器种类繁多,甚至一个厂商的浏览器版本也不同。我们如何保证我们的代码只需要编写一次就可以控制不同的浏览器?
更深入的流程图如下:
“案子怎么还没开始,就说硒不是?我还在学吗?”
他有以下优点:
缺点:
如果觉得不能接受selenium的缺点,可以查看pyppeteer的相关文章(公众号:大数据宇宙>py爬虫>pyppeteer)
得到驱动
现在让我们开始使用 selenium 来解决我们的需求。
首先,使用 pip 安装 selenium
由于我在本地安装了谷歌Chrome浏览器,打开浏览器查看浏览器的版本:
然后去相关的网站(私信我“python”)下载对应的驱动:
一切都准备好了
看过我相关教学文章的人都知道,我喜欢从语义的角度去理解和学习图书馆。
Selenium 本质上控制着浏览器,所以我们在使用它的时候,代码的语义应该类似于手动操作浏览器的过程。
首先导入一些包:
让我们看看如何使用代码来描述我们的手动操作。
打开浏览器:
没错,我们只是下载了驱动程序,但是 Python 怎么知道在哪里可以找到该驱动程序呢?
我们可以在实例化浏览器对象的时候传入一个文件路径,告诉他程序的具体位置:
输入百度搜索的网址:
将鼠标移动到输入框,点击一次,然后输入内容“爬虫”:
这里的问题是,如何在代码中表达“鼠标到输入框,点击一次”?
其实selenium确实可以模拟鼠标移动等操作(网站的一些登录验证码需要用鼠标拉动拼图来模拟),但是目前的情况下,我们不应该模拟鼠标,而是根据html标签定位。.
此时,我们可以使用浏览器的“开发者功能”进行定位。
限于篇幅,本文不详细讲解“开发者功能”的所有操作,详细讲解会放在公众号目录:数据宇宙>爬虫工具>系列文章
下面用一张动态图来展示操作过程:
看一下代码:
接下来,输入内容“爬虫”:
我们继续模拟点击输入框右侧的“百度点击”按钮。
同样使用“开发人员功能”,找到元素并复制 css 选择器表达式字符串:
所有结果的主标题:
这对初学者来说可能有点困难,因为这一次我们需要同时选择多个元素(多个搜索结果的主标题),并查看定位到的标签:
仔细看看我们需要的主要标题在哪里:
所以,现在我们将使用 CSS 选择器来表达以下语义: 在 div 内部 (id=content_left),在 h3 标记内部的 a 标记文本。div 和 h3 之间可能有多层嵌套。
生成的选择器表达式如下:
调用代码如下:
Python基础教程教材 Python编程从零基础到实际项目实例
¥59
买
代码执行太快
上面的代码之所以没有得到任何结果,是因为执行第10行的代码时,页面上还没有加载任何结果。
如果一个人正在操作浏览器,那么你应该对他说:嘿,直到你看到那些结果,你去提取主标题。
怎么说“直到你看到那些结果”?,selenium有一种特殊的等待元素出现的机制,代码如下:
用控件关闭浏览器,完整代码如下:
总结
使用代码控制 selenium 与手动操作基本相同。一般流程是:
下一节,我们将介绍更多的selenium技能,敬请期待!!
私信我“python”获取本系列所有相关资料和源码文章
chrome网页视频抓取(相似软件版本说明软件地址功能介绍-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-31 09:17
Chrome SPY 正式版是一款针对谷歌浏览器的网页元素分析工具。使用最新版本的Chrome SPY,用户可以获得元素矩阵、元素坐标、参考代码、tagName、代码关键字等元素信息。Chrome SPY 正式版可以提取元素属性,保存文本,查看谷歌浏览器的网页属性。同时支持标签选择,查看当前网页的标签内容。
类似软件
印记
软件地址
Chrome SPY 功能介绍
1、Chrome SPY提供网页元素分析功能,通过本软件可以立即读取元素;
2、可以提取元素属性,可以保存文本;
3、可以查看谷歌浏览器的网页属性;
4、可以在软件界面启动浏览器;
5、支持标签选择,查看当前网页的标签内容;
6、左侧代码展示,查看当前元素的参考代码;
7、支持代码关键字查看和标签名查看。
Chrome SPY 软件功能
1、Chrome SPY免费使用,打开即可识别浏览器;
2、可以查看谷歌浏览器的网页元素;
3、 立即在窗口中显示元素信息,方便复制使用;
4、可以提取多个元素,可以查看元素矩阵和元素坐标。
Chrome SPY 使用说明
1、打开Chrome_SPY.exe软件快速识别谷歌浏览器;
2、点击启动浏览器,使其立即运行,从而在浏览器中查看网页内容;
3、访问网页时,可以在软件界面查看标签,选择一个标签即可查看内容;
4、获取到标签后,会在此处显示网页的相关内容,获取的内容可以复制。支持元素矩形、元素坐标、参考代码、标签名、代码关键字;
5、提取元素功能,在软件界面中提取你需要的数据并保存为文本。
Chrome SPY 软件相关
Web 元素是您在浏览 Internet 时看到的一切。一个页面,称为网页,由多个网页网站 组成。网站 的第一页称为主页。
首页是所有网页的索引页,其他网页可以通过点击首页上的超链接打开。正是由于主页在网站中的特殊作用,人们经常用主页来指代所有的网页,而将个别的网站称为“个人主页”。主题 网站 称为“Web Production”。
网页元素包括:文本、图片、音频、动画和视频。文字,符合排版要求。图片、音频、动画、视频满足网络传输和专题需要,需要选择。
Chrome SPY 安装步骤
1.从pc下载网下载最新的软件包
2.解压软件,运行“EXE.file”
3.双击打开,进入软件界面
4. 本软件为绿色版,无需安装即可使用
Chrome 间谍更新日志
日夜工作只为让你更快乐
妈咪咪咪哄~虫子全没了!
小编推荐:使用Chrome SPY后,我想你可能还需要QQ助手、百度关键词优化软件、汇汇购物助手等软件,快来pc下载网下载使用吧! 查看全部
chrome网页视频抓取(相似软件版本说明软件地址功能介绍-苏州安嘉)
Chrome SPY 正式版是一款针对谷歌浏览器的网页元素分析工具。使用最新版本的Chrome SPY,用户可以获得元素矩阵、元素坐标、参考代码、tagName、代码关键字等元素信息。Chrome SPY 正式版可以提取元素属性,保存文本,查看谷歌浏览器的网页属性。同时支持标签选择,查看当前网页的标签内容。
类似软件
印记
软件地址
Chrome SPY 功能介绍
1、Chrome SPY提供网页元素分析功能,通过本软件可以立即读取元素;
2、可以提取元素属性,可以保存文本;
3、可以查看谷歌浏览器的网页属性;
4、可以在软件界面启动浏览器;
5、支持标签选择,查看当前网页的标签内容;
6、左侧代码展示,查看当前元素的参考代码;
7、支持代码关键字查看和标签名查看。
Chrome SPY 软件功能
1、Chrome SPY免费使用,打开即可识别浏览器;
2、可以查看谷歌浏览器的网页元素;
3、 立即在窗口中显示元素信息,方便复制使用;
4、可以提取多个元素,可以查看元素矩阵和元素坐标。
Chrome SPY 使用说明
1、打开Chrome_SPY.exe软件快速识别谷歌浏览器;
2、点击启动浏览器,使其立即运行,从而在浏览器中查看网页内容;
3、访问网页时,可以在软件界面查看标签,选择一个标签即可查看内容;
4、获取到标签后,会在此处显示网页的相关内容,获取的内容可以复制。支持元素矩形、元素坐标、参考代码、标签名、代码关键字;
5、提取元素功能,在软件界面中提取你需要的数据并保存为文本。
Chrome SPY 软件相关
Web 元素是您在浏览 Internet 时看到的一切。一个页面,称为网页,由多个网页网站 组成。网站 的第一页称为主页。
首页是所有网页的索引页,其他网页可以通过点击首页上的超链接打开。正是由于主页在网站中的特殊作用,人们经常用主页来指代所有的网页,而将个别的网站称为“个人主页”。主题 网站 称为“Web Production”。
网页元素包括:文本、图片、音频、动画和视频。文字,符合排版要求。图片、音频、动画、视频满足网络传输和专题需要,需要选择。
Chrome SPY 安装步骤
1.从pc下载网下载最新的软件包
2.解压软件,运行“EXE.file”
3.双击打开,进入软件界面
4. 本软件为绿色版,无需安装即可使用
Chrome 间谍更新日志
日夜工作只为让你更快乐
妈咪咪咪哄~虫子全没了!
小编推荐:使用Chrome SPY后,我想你可能还需要QQ助手、百度关键词优化软件、汇汇购物助手等软件,快来pc下载网下载使用吧!
chrome网页视频抓取(网页视频字幕插件插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-01-29 21:04
Dualsub(Universal Subtitle Renderer)官方安装版是一款优秀的网络视频字幕插件。Dualsub不仅可以帮助用户在页面上同时显示两个字幕,而且还有丰富的样式可以自由选择,非常方便。
特殊功能
1、原生渲染:其实就是把字幕作为第二行插入到原文中,字体设置为更小。
2、任何字幕语言:可选语言由视频本身提供,也可以自动翻译成另一种语言。
3、合并算法优化:使用一点算法来避免重叠和处理不一致的时间线。
使用教程
1、首先,从当前页面下载扩展,安装完成后,可以打开你想看的YouTube外语视频,页面会显示Dualsub工具栏。
2、然后,通过原生视频设置页面,打开字幕显示,选择原生语言类型。
3、 接下来通过Dualsub的设置框选择替代字幕的语言,语言类型多样化。第一个选项通常是英语,第二个选项是您需要翻译成的语言。
4、另外,你可以设置字幕位置。
双字幕:第一行是原生播放器字幕,第二行是Dualsub插件提供的备用字幕。
Dual subtitles (swap):Dualsub插件提供的备用字幕在第一行,原生播放器字幕在第二行。
单字幕:仅显示 Dualsub 插件提供的备用字幕。
5、另外,它支持字幕选择和保存到本地。通过CSS,还可以在字幕样式栏中添加代码来调整字幕的样式。 查看全部
chrome网页视频抓取(网页视频字幕插件插件)
Dualsub(Universal Subtitle Renderer)官方安装版是一款优秀的网络视频字幕插件。Dualsub不仅可以帮助用户在页面上同时显示两个字幕,而且还有丰富的样式可以自由选择,非常方便。
特殊功能
1、原生渲染:其实就是把字幕作为第二行插入到原文中,字体设置为更小。
2、任何字幕语言:可选语言由视频本身提供,也可以自动翻译成另一种语言。
3、合并算法优化:使用一点算法来避免重叠和处理不一致的时间线。
使用教程
1、首先,从当前页面下载扩展,安装完成后,可以打开你想看的YouTube外语视频,页面会显示Dualsub工具栏。
2、然后,通过原生视频设置页面,打开字幕显示,选择原生语言类型。
3、 接下来通过Dualsub的设置框选择替代字幕的语言,语言类型多样化。第一个选项通常是英语,第二个选项是您需要翻译成的语言。
4、另外,你可以设置字幕位置。
双字幕:第一行是原生播放器字幕,第二行是Dualsub插件提供的备用字幕。
Dual subtitles (swap):Dualsub插件提供的备用字幕在第一行,原生播放器字幕在第二行。
单字幕:仅显示 Dualsub 插件提供的备用字幕。
5、另外,它支持字幕选择和保存到本地。通过CSS,还可以在字幕样式栏中添加代码来调整字幕的样式。
chrome网页视频抓取(腾讯视频格式格式最为突出,工作效率提升N倍,你值得拥有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-29 15:03
)
作为一名资深的IT行业从业者,我们在工作中总是会遇到找各种视频素材的问题,但是由于专业网站的要求不一致,我们会发现很多网站都有自己的格式,尤其是腾讯视频的QLV格式最为突出。苏老师刚开始工作时,为了转换腾讯视频的高清格式,花钱买TB买了各种小玩意儿。没用,那种感觉心里真的有点绝望。后来终于让苏老师找到了这样一个神器,提高了N倍的工作效率,在此分享给大家。
苏老师心情
苏老师当时的心情
准备工具:浏览器、猫抓插件
浏览器:市面上主流的浏览器主要分为两大类:chorme-based和ie-based浏览器,以及chromium-based浏览器,典型的特点是速度快。360出来的浏览器有两种,一种是常见的360安全浏览器,基于IE内核,IE内核版本应该是ie8,另一种是360超快浏览器,也就是360 Chrome浏览器,根据中国人的习惯集成了多个插件,支持chromium内核。用ie内核切换,可以添加chrome store中的所有插件。如果要搭建适合自己的chromium内核的浏览器,建议使用原版chrome浏览器,自己安装插件,自己打磨。
Catscratch 插件:Catscratch 插件是一个支持嗅探和抓取安装在所有 chrome 内核浏览器中的网络视频链接的插件。您可以从任何站点获取任何视频数据。使用此插件,您可以一键获取您需要的链接并自动抓取并保存。使用很方便,打开需要下载文件的网站。可以在这个页面抓取所有自定义设置的内容,然后选择要下载的内容下载到本地电脑,使用方便!
运营流程
1.打开基于chorme内核的浏览器(这里以360极速浏览器为例),选择扩展中心
2.点击进入,在搜索框搜索猫抓app
3.点击安装按钮安装猫抓应用
4.打开你要下载的视频的网站,以腾讯视频为例,选择你要下载的视频,点击播放
5.点击右上角的猫抓按钮,等待抓取页面的视频信息加载完毕。加载完成后,选择内容(体验)较大的视频,点击保存,即可在本地加载本页高清视频。,并且不需要转码。
查看全部
chrome网页视频抓取(腾讯视频格式格式最为突出,工作效率提升N倍,你值得拥有
)
作为一名资深的IT行业从业者,我们在工作中总是会遇到找各种视频素材的问题,但是由于专业网站的要求不一致,我们会发现很多网站都有自己的格式,尤其是腾讯视频的QLV格式最为突出。苏老师刚开始工作时,为了转换腾讯视频的高清格式,花钱买TB买了各种小玩意儿。没用,那种感觉心里真的有点绝望。后来终于让苏老师找到了这样一个神器,提高了N倍的工作效率,在此分享给大家。
苏老师心情
苏老师当时的心情
准备工具:浏览器、猫抓插件
浏览器:市面上主流的浏览器主要分为两大类:chorme-based和ie-based浏览器,以及chromium-based浏览器,典型的特点是速度快。360出来的浏览器有两种,一种是常见的360安全浏览器,基于IE内核,IE内核版本应该是ie8,另一种是360超快浏览器,也就是360 Chrome浏览器,根据中国人的习惯集成了多个插件,支持chromium内核。用ie内核切换,可以添加chrome store中的所有插件。如果要搭建适合自己的chromium内核的浏览器,建议使用原版chrome浏览器,自己安装插件,自己打磨。
Catscratch 插件:Catscratch 插件是一个支持嗅探和抓取安装在所有 chrome 内核浏览器中的网络视频链接的插件。您可以从任何站点获取任何视频数据。使用此插件,您可以一键获取您需要的链接并自动抓取并保存。使用很方便,打开需要下载文件的网站。可以在这个页面抓取所有自定义设置的内容,然后选择要下载的内容下载到本地电脑,使用方便!
运营流程
1.打开基于chorme内核的浏览器(这里以360极速浏览器为例),选择扩展中心
2.点击进入,在搜索框搜索猫抓app
3.点击安装按钮安装猫抓应用
4.打开你要下载的视频的网站,以腾讯视频为例,选择你要下载的视频,点击播放
5.点击右上角的猫抓按钮,等待抓取页面的视频信息加载完毕。加载完成后,选择内容(体验)较大的视频,点击保存,即可在本地加载本页高清视频。,并且不需要转码。
chrome网页视频抓取(PDFlux浏览器插件一键拷贝到Word、Excel、PPT中的安装方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-27 16:06
PDFlux 浏览器插件目前支持基于 Chromium 内核的 Chrome 浏览器和 Edge 浏览器。
PDFlux Chrome插件(PDF表格智能提取神器)目前支持macOS、Windows系统、小程序和浏览器插件,但PDFlux可以智能识别PDF中的表格并一键复制到Word、Excel、PPT 有需要的朋友快来下载体验吧。
安装方法
1、在本地下载PDFlux插件并解压;
2、在“更多工具”中打开“扩展”,确保“开发者模式”已开启;
3、在浏览器“扩展”界面点击“加载解压扩展”按钮,选择解压后的PDFlux插件文件夹;
4、刷新您的浏览器以开始使用。
如何使用
浏览网页时,例如在“巨潮资讯网”,点击右上角的PDFlux图标,扫码登录,网页上会出现“在PDFlux中打开”按钮.
点击“在PDFlux中打开”按钮,对应的PDF文件将上传到PDFlux,上传完成后即可在PDFluxWebtool中打开文件。
支持网站
目前支持网站
1、巨潮资讯网
2、上海证券交易所(含科创板)
3、孔雀开屏(中国银行同业交易商协会)
4、香港交易所披露
5、东方财富网
程序支持网站
1、证监会
2、新三板
3、SHCH
4、中国外汇交易中心和全国银行间同业拆借中心
5、北京金融资产交易所
6、中国债券信息网
7、新交所
8、SEC 查看全部
chrome网页视频抓取(PDFlux浏览器插件一键拷贝到Word、Excel、PPT中的安装方法)
PDFlux 浏览器插件目前支持基于 Chromium 内核的 Chrome 浏览器和 Edge 浏览器。
PDFlux Chrome插件(PDF表格智能提取神器)目前支持macOS、Windows系统、小程序和浏览器插件,但PDFlux可以智能识别PDF中的表格并一键复制到Word、Excel、PPT 有需要的朋友快来下载体验吧。
安装方法
1、在本地下载PDFlux插件并解压;
2、在“更多工具”中打开“扩展”,确保“开发者模式”已开启;
3、在浏览器“扩展”界面点击“加载解压扩展”按钮,选择解压后的PDFlux插件文件夹;
4、刷新您的浏览器以开始使用。
如何使用
浏览网页时,例如在“巨潮资讯网”,点击右上角的PDFlux图标,扫码登录,网页上会出现“在PDFlux中打开”按钮.
点击“在PDFlux中打开”按钮,对应的PDF文件将上传到PDFlux,上传完成后即可在PDFluxWebtool中打开文件。
支持网站
目前支持网站
1、巨潮资讯网
2、上海证券交易所(含科创板)
3、孔雀开屏(中国银行同业交易商协会)
4、香港交易所披露
5、东方财富网
程序支持网站
1、证监会
2、新三板
3、SHCH
4、中国外汇交易中心和全国银行间同业拆借中心
5、北京金融资产交易所
6、中国债券信息网
7、新交所
8、SEC
chrome网页视频抓取(有type,记录如下流程状态->入库(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-24 04:23
背景说明
由于目标页面是用vue结构写的,通过urlConnection获取连接后无法使用Document/Jsoup解析。页面元素通过js动态呈现。后来尝试通过webMagic框架和selenium\Chrome来抓取和整理基础数据。
加工
设计标记表结构,记录捕获的状态和数据,配置selenium相关环境,分析页面dom元素的工具,编码和解析html进程,编码,集成和调试处理器和管道层webmagic 框架。数据存储操作
步骤解剖
1. 标记表结构设计,示例表如下
<br />CREATE TABLE `data` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL COMMENT 'dataname',
`type` tinyint(4) DEFAULT NULL COMMENT '类型',
`xx` int(11) DEFAULT '0' COMMENT '修订',
`xx` ...
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8 COMMENT='数据标记'
制作这张表的初衷是对抓取的数据做一个基本的保留,提取过程中的核心数据用于后期的统计和验证处理。因为不信任抓取数据的结果【可能是网络中断,页面无法正常打开,页面打开后布局混乱,并发情况下浏览器窗口意外关闭,页面修改元素添加和更改。获取目标数据]。所以有一个type字段来记录下面的进程状态
抓取 -> 打开 -> 操作 -> 解析 -> 库存 -> 抓取
其中
1.爬取 是指抓取根路径或者获取到页面上的目标url路径;
2.打开 是指通过Chrome driver打开url的过程;
3.操作 是指需要通过selenium模拟点击、跳转、输入等操作;
4.解析 是指到达目标页面后对html元素进行解析并获取有效内容
5.入库 将内容进行持久化操作
6.爬取 获取下一级链接,循环此操作
这里最不可控的一步是2、3、4。由于各种原因,可能会出现各种问题。因此,需要记录当前数据的执行状态。当然,如果数据对你来说是可丢失的、可重复的、可信的,你可以忽略部分数据,以量取胜。
2. Selenium 相关环境配置
先引入jar,下载浏览器对应驱动并配置
org.seleniumhq.selenium
selenium-java
3.9.1
org.seleniumhq.selenium
selenium-server
3.9.1
org.yaml
snakeyaml
上面是pom配置,下面是驱动变量设置,
static
{
System.getProperties().setProperty("webdriver.chrome.driver", "/Users/chenhailong/Downloads/tools/nessarytool/chromedriver");
}
运行以下代码时,浏览器可以正常打开,说明配置正常
WebDriver w = new ChromeDriver();
w.get("https://www.deathearth.com");
# 控制台会输出以下信息
Starting ChromeDriver 2.38.552518 (183d19265345f54ce39cbb94cf81ba5f15905011) on port 33558
Only local connections are allowed.
八月 23, 2019 5:02:46 下午 org.openqa.selenium.remote.ProtocolHandshake createSession
信息: Detected dialect: OSS
这种环境下最容易出现的问题就是浏览器版本和驱动版本不一致,导致程序无法打开浏览器。或者浏览器自动升级的影响。只需仔细配置即可。
3. 解析页面上的html元素
一个。这里最麻烦的就是页面修改问题。我只是写了一套匹配规则来处理它。但是,目标网站经常会改变布局,调整按钮的功能。因此,基本上需要随着目标网站的变化而变化。没门。
湾。其次,存在分析效率问题。我遇到过两种情况。一种是在抓取长文本类型(超过10w字节)的文章的内容时,通过父元素的text()方法读取,内容被截断。导致信息不完整。这是通过循环子标签来处理的。如下
<p>
...
...
修改前: w.findElements(By.id("content")).getText()
修改后:List ls = w.findElements(By.xpath("div"))
for(int i = 0;i 查看全部
chrome网页视频抓取(有type,记录如下流程状态->入库(组图))
背景说明
由于目标页面是用vue结构写的,通过urlConnection获取连接后无法使用Document/Jsoup解析。页面元素通过js动态呈现。后来尝试通过webMagic框架和selenium\Chrome来抓取和整理基础数据。
加工
设计标记表结构,记录捕获的状态和数据,配置selenium相关环境,分析页面dom元素的工具,编码和解析html进程,编码,集成和调试处理器和管道层webmagic 框架。数据存储操作
步骤解剖
1. 标记表结构设计,示例表如下
<br />CREATE TABLE `data` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL COMMENT 'dataname',
`type` tinyint(4) DEFAULT NULL COMMENT '类型',
`xx` int(11) DEFAULT '0' COMMENT '修订',
`xx` ...
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8 COMMENT='数据标记'
制作这张表的初衷是对抓取的数据做一个基本的保留,提取过程中的核心数据用于后期的统计和验证处理。因为不信任抓取数据的结果【可能是网络中断,页面无法正常打开,页面打开后布局混乱,并发情况下浏览器窗口意外关闭,页面修改元素添加和更改。获取目标数据]。所以有一个type字段来记录下面的进程状态
抓取 -> 打开 -> 操作 -> 解析 -> 库存 -> 抓取
其中
1.爬取 是指抓取根路径或者获取到页面上的目标url路径;
2.打开 是指通过Chrome driver打开url的过程;
3.操作 是指需要通过selenium模拟点击、跳转、输入等操作;
4.解析 是指到达目标页面后对html元素进行解析并获取有效内容
5.入库 将内容进行持久化操作
6.爬取 获取下一级链接,循环此操作
这里最不可控的一步是2、3、4。由于各种原因,可能会出现各种问题。因此,需要记录当前数据的执行状态。当然,如果数据对你来说是可丢失的、可重复的、可信的,你可以忽略部分数据,以量取胜。
2. Selenium 相关环境配置
先引入jar,下载浏览器对应驱动并配置
org.seleniumhq.selenium
selenium-java
3.9.1
org.seleniumhq.selenium
selenium-server
3.9.1
org.yaml
snakeyaml
上面是pom配置,下面是驱动变量设置,
static
{
System.getProperties().setProperty("webdriver.chrome.driver", "/Users/chenhailong/Downloads/tools/nessarytool/chromedriver");
}
运行以下代码时,浏览器可以正常打开,说明配置正常
WebDriver w = new ChromeDriver();
w.get("https://www.deathearth.com";);
# 控制台会输出以下信息
Starting ChromeDriver 2.38.552518 (183d19265345f54ce39cbb94cf81ba5f15905011) on port 33558
Only local connections are allowed.
八月 23, 2019 5:02:46 下午 org.openqa.selenium.remote.ProtocolHandshake createSession
信息: Detected dialect: OSS
这种环境下最容易出现的问题就是浏览器版本和驱动版本不一致,导致程序无法打开浏览器。或者浏览器自动升级的影响。只需仔细配置即可。
3. 解析页面上的html元素
一个。这里最麻烦的就是页面修改问题。我只是写了一套匹配规则来处理它。但是,目标网站经常会改变布局,调整按钮的功能。因此,基本上需要随着目标网站的变化而变化。没门。
湾。其次,存在分析效率问题。我遇到过两种情况。一种是在抓取长文本类型(超过10w字节)的文章的内容时,通过父元素的text()方法读取,内容被截断。导致信息不完整。这是通过循环子标签来处理的。如下
<p>
...
...
修改前: w.findElements(By.id("content")).getText()
修改后:List ls = w.findElements(By.xpath("div"))
for(int i = 0;i
chrome网页视频抓取(我在google中出现的bugNotNotloadlocalresource )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-14 09:04
)
具体教程是我在google上找到的:
教程:
这里我只做一个具体的实现,并说明具体操作中的bug:
不允许加载本地资源
使用视频作为网页背景
video#bgvid {
position: fixed; right: 0; bottom: 0;
min-width: 100%; min-height: 100%;
width: auto; height: 90%; z-index: -100;
/*background: url(G:\javaweb\前端\bideo.js-master\20140906061602621.jpg) no-repeat;*/
background-size: 80px 60px;
}
#polina {
font-family: Agenda-Light, Agenda Light, Agenda, Arial Narrow, sans-serif;
font-weight: 100;
background: rgba(0,0,0,0.3);
color: white;
padding: 2rem;
width: 33%;
margin: 2rem;
float: right;
font-size: 1.2rem;
}
POLINA
<p>filmed by Alexander Wagner 2011
</p>
这个可以作为静态页面在本地访问,直接打开对应的html,但是我放到项目中的时候,出现了无法访问本地资源的bug:
不允许加载本地资源
经过搜索,发现是因为安全原因设置了google浏览器,所以为了能够成功访问,我在项目的xml中配置了对应的路径:
然后路径改为:
在html头部添加basePath的配置:
****
这样以后google就不会直接访问本地资源了,这样就可以在项目页面播放视频了~~~:
查看全部
chrome网页视频抓取(我在google中出现的bugNotNotloadlocalresource
)
具体教程是我在google上找到的:
教程:
这里我只做一个具体的实现,并说明具体操作中的bug:
不允许加载本地资源
使用视频作为网页背景
video#bgvid {
position: fixed; right: 0; bottom: 0;
min-width: 100%; min-height: 100%;
width: auto; height: 90%; z-index: -100;
/*background: url(G:\javaweb\前端\bideo.js-master\20140906061602621.jpg) no-repeat;*/
background-size: 80px 60px;
}
#polina {
font-family: Agenda-Light, Agenda Light, Agenda, Arial Narrow, sans-serif;
font-weight: 100;
background: rgba(0,0,0,0.3);
color: white;
padding: 2rem;
width: 33%;
margin: 2rem;
float: right;
font-size: 1.2rem;
}
POLINA
<p>filmed by Alexander Wagner 2011
</p>
这个可以作为静态页面在本地访问,直接打开对应的html,但是我放到项目中的时候,出现了无法访问本地资源的bug:
不允许加载本地资源
经过搜索,发现是因为安全原因设置了google浏览器,所以为了能够成功访问,我在项目的xml中配置了对应的路径:
然后路径改为:
在html头部添加basePath的配置:
****
这样以后google就不会直接访问本地资源了,这样就可以在项目页面播放视频了~~~:
chrome网页视频抓取(本文Chrome浏览器HTML5性能测试从Chrome的众多特点中摘出来)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-14 09:02
编者按:我们都知道HTML5有两大特点:增强网页性能和为Web应用程序增加本地数据库等功能。性能函数的渲染问题想必是绝大多数Chrome浏览器用户选择使用Chrome的主要原因之一。了解HTML5架构,追求在线视频在浏览器上高清播放能力和浏览器性能稳定的玩家,更关心Chrome浏览器的HTML5性能表现。
点击下载:
网页会爆 Chrome浏览器HTML5性能评测
那么,在这篇文章中,笔者从Chrome的众多特性中提取了Chrome浏览器HTML5性能测试,进行了更详细的测试,并通过评测分享给Chrome玩家。
目前,随着业界对HTML5的热议以及各大浏览器厂商对HTML5标准的重视,越来越多的人开始关注HTML5。不仅有WEB开发者,还有很多普通用户。提到 HTML5 标准,大多数人首先想到的可能就是 HTML5 视频标准。但是,用户需要注意的是,HTML5 带来的不仅仅是一个新的视频 Web 标准,它还引入了许多将对 Web 未来发展方向产生巨大影响的元素和属性。
测试项目介绍:本文主要测试Chrome浏览器在Web服务协议测试、网络视频性能、HTML5性能测试、扩展网页性能模拟重力系统测试等方面的性能。
温馨提示:本站页面均基于HTML5优化。建议您使用完美兼容的 HTML5 浏览,以获得最佳的阅读体验! () 查看全部
chrome网页视频抓取(本文Chrome浏览器HTML5性能测试从Chrome的众多特点中摘出来)
编者按:我们都知道HTML5有两大特点:增强网页性能和为Web应用程序增加本地数据库等功能。性能函数的渲染问题想必是绝大多数Chrome浏览器用户选择使用Chrome的主要原因之一。了解HTML5架构,追求在线视频在浏览器上高清播放能力和浏览器性能稳定的玩家,更关心Chrome浏览器的HTML5性能表现。
点击下载:
网页会爆 Chrome浏览器HTML5性能评测
那么,在这篇文章中,笔者从Chrome的众多特性中提取了Chrome浏览器HTML5性能测试,进行了更详细的测试,并通过评测分享给Chrome玩家。
目前,随着业界对HTML5的热议以及各大浏览器厂商对HTML5标准的重视,越来越多的人开始关注HTML5。不仅有WEB开发者,还有很多普通用户。提到 HTML5 标准,大多数人首先想到的可能就是 HTML5 视频标准。但是,用户需要注意的是,HTML5 带来的不仅仅是一个新的视频 Web 标准,它还引入了许多将对 Web 未来发展方向产生巨大影响的元素和属性。
测试项目介绍:本文主要测试Chrome浏览器在Web服务协议测试、网络视频性能、HTML5性能测试、扩展网页性能模拟重力系统测试等方面的性能。
温馨提示:本站页面均基于HTML5优化。建议您使用完美兼容的 HTML5 浏览,以获得最佳的阅读体验! ()
chrome网页视频抓取( 猫抓是一款支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-01-09 17:02
猫抓是一款支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
猫渣是一个支持所有Chrome核心浏览器的网络媒体嗅探和抓取的扩展。
可以一键抓取任意站点的任意视频/音频数据,使用非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮,就可以在这个页面看到资源信息了。
然后可以对资源进行三个操作:复制链接地址,小窗口播放,下载到本地电脑。
猫扎支持优酷、搜狐、腾讯、微博、B站等国内几乎所有网站的视频文件嗅探。
当您在同一页面上遇到多个属性时,您还可以对它们进行快速批量操作。
此类嗅探工具支持的短视频文件一般都是未加密的。面对一些加密视频时,会有一定的失败概率。
不过从市场反馈来看,猫爪可以抢到很多其他扩展,包括IDM都无法嗅到的媒体资源。
这就是它在竞争性扩展商店中拥有超过 50,000 名用户的原因之一。
此外,猫爪还支持所有音乐网站的音频文件嗅探,包括Qzone的SWF模块和音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,也支持使用正则表达式自定义采集的内容。
网络嗅探器原本是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。嗅探器也是许多程序员在编写网络程序时捕获和测试数据包的工具。
近年来,网络嗅探器已广泛应用于用户的日常行为,成为捕捉视频、音频等内容的工具。
资源下载 本资源为免费资源,请先登录 查看全部
chrome网页视频抓取(
猫抓是一款支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
猫渣是一个支持所有Chrome核心浏览器的网络媒体嗅探和抓取的扩展。
可以一键抓取任意站点的任意视频/音频数据,使用非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮,就可以在这个页面看到资源信息了。
然后可以对资源进行三个操作:复制链接地址,小窗口播放,下载到本地电脑。
猫扎支持优酷、搜狐、腾讯、微博、B站等国内几乎所有网站的视频文件嗅探。
当您在同一页面上遇到多个属性时,您还可以对它们进行快速批量操作。
此类嗅探工具支持的短视频文件一般都是未加密的。面对一些加密视频时,会有一定的失败概率。
不过从市场反馈来看,猫爪可以抢到很多其他扩展,包括IDM都无法嗅到的媒体资源。
这就是它在竞争性扩展商店中拥有超过 50,000 名用户的原因之一。
此外,猫爪还支持所有音乐网站的音频文件嗅探,包括Qzone的SWF模块和音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,也支持使用正则表达式自定义采集的内容。
网络嗅探器原本是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。嗅探器也是许多程序员在编写网络程序时捕获和测试数据包的工具。
近年来,网络嗅探器已广泛应用于用户的日常行为,成为捕捉视频、音频等内容的工具。
资源下载 本资源为免费资源,请先登录
chrome网页视频抓取(下载GoogleChrome15也许很多注重浏览器页面排版(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-08 16:04
人们在使用电脑浏览网页时,往往会用到网页的排版功能。说到这种排版的功能,大家应该都有自己的感受。也就是说,布局模式在很大程度上取决于用户浏览网页所使用的浏览器。点击下载谷歌浏览器 15
或许很多专注于浏览器页面布局的用户对WebKit引擎的理解并不深入,但又不想对浏览器做太多的手动辅助设置,从而可以自由浏览页面。其实这些烦恼都可以通过使用Chrome浏览器轻松解决。目前几乎所有的浏览器都集成了网页自适应排版模式,但是这种HTML排版能力的强弱因浏览器而异。未来本文将分析Chrome浏览器自动识别网页和HTML智能排版的强大实力。
Chrome浏览器页面调整
解析 WebKit 引擎
WebKit 的前身是 KDE 组的 KHTML。WebKit 中收录的 WebCore 排版引擎和 JSCore 引擎是从 KDE 的 KHTML 和 KJS 衍生而来的。在比较了 Gecko 和 KHTML 之后,Apple 还是选择了后者,因为它的源码结构清晰,渲染速度极快。Apple 进一步推动了 KHTML 并推出了 Safari,这是一款配备 KHTML 改进的 WebKit 引擎的浏览器。
在 Google Chrome 中手动缩放网页
谷歌浏览器使用 WebKit 引擎。WebKit 简单、紧凑、高效地使用内存,符合 Google 的理念,并且对于新开发人员来说相当容易使用。浏览错误建议 当 URL 无法解析或连接失败时,谷歌浏览器将尝试确定它想要访问的网页并提供建议。浏览器会将您尝试浏览的页面的 URL 传输给 Google,以便建议替代页面或类似页面。
简短而强大的是 Webkit。事实上,作为Windows平台的后起之秀,Webkit进入Windows平台的时间并不长,但在短短的时间之后,Webkit就可以进入其他三个老牌核心同台竞技的水平,包括带有 Trident 内核的 Microsoft IE。浏览器,带有Gecko内核的Firefox浏览器,带有Presto内核的Opera浏览器,当然WebKit内核的代表是Google Chrome和Apple Safari浏览器
总结:笔者在之前的文章中对Chrome浏览器的HTML5兼容性做了详细的评测,从评测结果中得出,Chrome浏览器和HTML5可以说是相得益彰,符合当前浏览器的发展技术。需求,同时为未来进一步的技术发展创造机会。但是HTML5在页面布局、视频、色彩渲染等方面都表现不错,因此Chrome浏览器对HTML智能布局的依赖能力很强;在自动识别网页方面,由于Chrome浏览器使用了Webkit架构引擎,所以网页识别自然是有保障的。
温馨提示:本站页面均基于HTML5优化。建议您使用完美兼容的 HTML5 浏览,以获得最佳的阅读体验!() 查看全部
chrome网页视频抓取(下载GoogleChrome15也许很多注重浏览器页面排版(组图))
人们在使用电脑浏览网页时,往往会用到网页的排版功能。说到这种排版的功能,大家应该都有自己的感受。也就是说,布局模式在很大程度上取决于用户浏览网页所使用的浏览器。点击下载谷歌浏览器 15
或许很多专注于浏览器页面布局的用户对WebKit引擎的理解并不深入,但又不想对浏览器做太多的手动辅助设置,从而可以自由浏览页面。其实这些烦恼都可以通过使用Chrome浏览器轻松解决。目前几乎所有的浏览器都集成了网页自适应排版模式,但是这种HTML排版能力的强弱因浏览器而异。未来本文将分析Chrome浏览器自动识别网页和HTML智能排版的强大实力。
Chrome浏览器页面调整
解析 WebKit 引擎
WebKit 的前身是 KDE 组的 KHTML。WebKit 中收录的 WebCore 排版引擎和 JSCore 引擎是从 KDE 的 KHTML 和 KJS 衍生而来的。在比较了 Gecko 和 KHTML 之后,Apple 还是选择了后者,因为它的源码结构清晰,渲染速度极快。Apple 进一步推动了 KHTML 并推出了 Safari,这是一款配备 KHTML 改进的 WebKit 引擎的浏览器。
在 Google Chrome 中手动缩放网页
谷歌浏览器使用 WebKit 引擎。WebKit 简单、紧凑、高效地使用内存,符合 Google 的理念,并且对于新开发人员来说相当容易使用。浏览错误建议 当 URL 无法解析或连接失败时,谷歌浏览器将尝试确定它想要访问的网页并提供建议。浏览器会将您尝试浏览的页面的 URL 传输给 Google,以便建议替代页面或类似页面。
简短而强大的是 Webkit。事实上,作为Windows平台的后起之秀,Webkit进入Windows平台的时间并不长,但在短短的时间之后,Webkit就可以进入其他三个老牌核心同台竞技的水平,包括带有 Trident 内核的 Microsoft IE。浏览器,带有Gecko内核的Firefox浏览器,带有Presto内核的Opera浏览器,当然WebKit内核的代表是Google Chrome和Apple Safari浏览器
总结:笔者在之前的文章中对Chrome浏览器的HTML5兼容性做了详细的评测,从评测结果中得出,Chrome浏览器和HTML5可以说是相得益彰,符合当前浏览器的发展技术。需求,同时为未来进一步的技术发展创造机会。但是HTML5在页面布局、视频、色彩渲染等方面都表现不错,因此Chrome浏览器对HTML智能布局的依赖能力很强;在自动识别网页方面,由于Chrome浏览器使用了Webkit架构引擎,所以网页识别自然是有保障的。
温馨提示:本站页面均基于HTML5优化。建议您使用完美兼容的 HTML5 浏览,以获得最佳的阅读体验!()
chrome网页视频抓取(ChromeSPY是一款网页元素分析工具,下载体验吧!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-05 08:07
Chrome SPY 是一个网页元素分析工具。该软件可以帮助用户分析网页元素,帮助用户获取引用代码、tagName、代码关键字等元素信息,方便用户根据自己的需要查询获取信息,喜欢就下载吧并体验它!
软件介绍
网页元素是您在 Internet 上浏览时看到的所有内容。页面称为网页,许多网页构成一个网站。网站 的第一个网页称为主页。
首页是所有网页的索引页。您可以通过单击主页上的超链接打开其他网页。正是由于首页在网站中的特殊作用,人们经常使用首页来指代所有网页。个人网站被称为“个人主页”,个人网站将被建立和生产。主题网站 被称为“网页创建”。
网页元素包括:文字、图片、音频、动画和视频。文字符合排版要求。图片、音频、动画、视频满足网络传输和专题需要,需要选择。
软件功能
1、Chrome SPY 提供网页元素分析功能,您可以通过该软件立即读取元素;
2、 可以提取元素属性并保存文本;
3、可以查看谷歌浏览器的网页属性;
4、可以在软件界面启动浏览器;
5、支持标签选择,查看当前网页的标签内容;
6、 显示左边的代码,查看当前元素的引用代码;
7、支持代码关键字查看,支持标签名称查看。
指示
1、打开Chrome_SPY.exe软件,快速识别谷歌浏览器;
2、 点击启动浏览器,即可立即运行,以便在浏览器中查看网页内容;
3、 访问网页时,可以在软件界面查看标签,选择标签查看内容;
4、 获取tag时,会在此处显示网页的相关内容,获取的内容可以复制,支持元素矩形,元素坐标,引用代码,tagName,code关键字;
5、 提取元素功能,在软件界面中提取您需要的数据,并保存为文本。
更新日志
1.修复已知错误
2.优化操作体验 查看全部
chrome网页视频抓取(ChromeSPY是一款网页元素分析工具,下载体验吧!)
Chrome SPY 是一个网页元素分析工具。该软件可以帮助用户分析网页元素,帮助用户获取引用代码、tagName、代码关键字等元素信息,方便用户根据自己的需要查询获取信息,喜欢就下载吧并体验它!
软件介绍
网页元素是您在 Internet 上浏览时看到的所有内容。页面称为网页,许多网页构成一个网站。网站 的第一个网页称为主页。
首页是所有网页的索引页。您可以通过单击主页上的超链接打开其他网页。正是由于首页在网站中的特殊作用,人们经常使用首页来指代所有网页。个人网站被称为“个人主页”,个人网站将被建立和生产。主题网站 被称为“网页创建”。
网页元素包括:文字、图片、音频、动画和视频。文字符合排版要求。图片、音频、动画、视频满足网络传输和专题需要,需要选择。
软件功能
1、Chrome SPY 提供网页元素分析功能,您可以通过该软件立即读取元素;
2、 可以提取元素属性并保存文本;
3、可以查看谷歌浏览器的网页属性;
4、可以在软件界面启动浏览器;
5、支持标签选择,查看当前网页的标签内容;
6、 显示左边的代码,查看当前元素的引用代码;
7、支持代码关键字查看,支持标签名称查看。
指示
1、打开Chrome_SPY.exe软件,快速识别谷歌浏览器;
2、 点击启动浏览器,即可立即运行,以便在浏览器中查看网页内容;
3、 访问网页时,可以在软件界面查看标签,选择标签查看内容;
4、 获取tag时,会在此处显示网页的相关内容,获取的内容可以复制,支持元素矩形,元素坐标,引用代码,tagName,code关键字;
5、 提取元素功能,在软件界面中提取您需要的数据,并保存为文本。
更新日志
1.修复已知错误
2.优化操作体验
chrome网页视频抓取(愉阅(chrome网页内容抓取插件)v免费软件介绍插件安装使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-31 20:15
快乐阅读(chrome网页内容捕捉插件)v免费软件是一款简单实用的快乐阅读(chrome网页内容捕捉插件)v免费软件,主要帮助你快速享受(chrome网页内容捕捉插件) v各种免费软件中的图片和文字内容放在单独的阅读页面上,供(xing)浏览。这些图片解压后可以批量下载(xia),也可以在文章@阅读>有时间自动提取下一页文字,欢迎(ying)免费下载。
悦悦(chrome网页内容抓取插件)v免费软件介绍
1. 插件安装与使用1、 小编这里使用的是360极速浏览器,先在标签页v免费软件进入快感(chrome网页内容抓取插件):/ /myextensions/ extensions/:进入扩展页面,解压你在本页面下载的鱼悦(chrome网页内容抓取插件)v免费软件插件,拖入扩展页面。 2、安装完成后,试试插件的效果。 3、 插件安装后,页面右侧会自动出现爬虫助手按钮。 4、 点击图片欣赏(chrome网页内容抓取插件) v 所有可以在免费软件上抓取的图片,抓取后也可以批量下载这些图片。 5、 并且点击正文会提取页面内容文章@> 整洁的界面集中阅读,按图片大小分组查看图片2、炫酷的幻灯片模式浏览图片< @3、优质文字提取,清爽阅读4、自动提取下一页文字,开启“超级下一页”突破任何限制5、登录账号并采集文章 @>,同步配置到云端6、下载安卓客户端,随时随地阅读采集内容。
悦悦(chrome网页内容抓取插件)v免费软件总结
YueYue(chrome网页内容抓取插件)vV2.20是一款适用于ios版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友: 查看全部
chrome网页视频抓取(愉阅(chrome网页内容抓取插件)v免费软件介绍插件安装使用)
快乐阅读(chrome网页内容捕捉插件)v免费软件是一款简单实用的快乐阅读(chrome网页内容捕捉插件)v免费软件,主要帮助你快速享受(chrome网页内容捕捉插件) v各种免费软件中的图片和文字内容放在单独的阅读页面上,供(xing)浏览。这些图片解压后可以批量下载(xia),也可以在文章@阅读>有时间自动提取下一页文字,欢迎(ying)免费下载。
悦悦(chrome网页内容抓取插件)v免费软件介绍
1. 插件安装与使用1、 小编这里使用的是360极速浏览器,先在标签页v免费软件进入快感(chrome网页内容抓取插件):/ /myextensions/ extensions/:进入扩展页面,解压你在本页面下载的鱼悦(chrome网页内容抓取插件)v免费软件插件,拖入扩展页面。 2、安装完成后,试试插件的效果。 3、 插件安装后,页面右侧会自动出现爬虫助手按钮。 4、 点击图片欣赏(chrome网页内容抓取插件) v 所有可以在免费软件上抓取的图片,抓取后也可以批量下载这些图片。 5、 并且点击正文会提取页面内容文章@> 整洁的界面集中阅读,按图片大小分组查看图片2、炫酷的幻灯片模式浏览图片< @3、优质文字提取,清爽阅读4、自动提取下一页文字,开启“超级下一页”突破任何限制5、登录账号并采集文章 @>,同步配置到云端6、下载安卓客户端,随时随地阅读采集内容。
悦悦(chrome网页内容抓取插件)v免费软件总结
YueYue(chrome网页内容抓取插件)vV2.20是一款适用于ios版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:
chrome网页视频抓取(文中代码滚动到底部时头条通过ajax更多文章(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-31 16:20
文中代码只是部分说明,完整代码放在文章的最后。
首先,实际感受一下我们想要捕捉到什么好处?点击今日头条,在搜索栏中输入“街拍”二字,点击任意一篇文章文章,里面的图片就是我们要抓取的内容。
可以看到搜索结果默认返回20篇文章。当页面滚动到底部时,标题通过ajax加载更多文章,在浏览器中按F12打开调试工具(我的是Chrome),点击网络选项,尝试加载更多文章,可以看到相关的http请求:
可以看到请求的URL(Request URL)为:,其请求参数为:
很容易猜到offset代表的是偏移量,也就是已经请求的文章的个数;format是返回格式,这里是json格式的数据;关键字是我们的搜索关键字;autoload 应该是自动加载的一个指标,无所谓;count 是请求的新 文章 的数量;_ 应该是请求发起时的时间戳。将请求的 URL 和这些查询参数结合起来,形成一个完整的请求 URL。比如这次的Request URL是:%E8%A1%97%E6%8B%8D&autoload=true&count=20&_=92。
我们先来看看这个请求为我们返回了什么样的数据。
导入json
从 pprint 导入 pprint
从 urllib 导入请求
url = ";format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&_=92"
以 request.urlopen(url) 作为资源:
d = json.loads(res.read().decode())
打印(四)
这里我们首先通过request.urlopen(url)向这个url发送请求,返回的数据存放在res中,res是一个HttpResponse对象,实际返回的内容是通过调用其read方法获取的,因为read方法返回的是Python bytes 类型的字符串,调用其decode方法将其编码为字符串类型的字符串,默认为UTF-8编码。由于数据是以json格式返回的,所以通过json.load方法转换成Python字典形式。
打印出这个字典,可以看到字典中有一个键'data'对应一个由字典组成的列表的值。分析表明该值是所有文章的返回数据列表。稍微修改一下代码。看看'data'的值对应的是什么:
以 request.urlopen(url) 作为资源:
d = json.loads(res.read().decode())
d = d.get('数据')
打印(d)
在这里,pprint 用于使字典打印的值更加格式化,以便于分析。你可以看到这是一个字典列表。列表中的每一项代表一块文章,里面收录了文章的所有基本数据,比如标题、文章的URL等,这样我们就可以得到URL我们这次请求的所有 文章 的列表如下:
urls = [article.get('article_url') for article in d if article.get('article_url')]
这里使用了list comprehension,循环文章列表,通过get('article_url')获取文章的URL,加上if判断条件是为了防止文章因为缺失数据导致空的文章 @> 网址。我们将继续请求这些文章 URL,阅读它们的内容,并提取图片并将它们保存到我们的硬盘中。
我们先处理一个文章,看看如何提取文章中的所有图片。
只需点击一个文章链接,按F12查看网页源代码,可以看到文章的主体部分位于
在div里面。在这个div下面,有一个h1标签,代表文章的标题,还有一系列img标签,其src属性存储了图片所在的链接,所以我们通过访问这些链接下载图片,看到怎么做: 查看全部
chrome网页视频抓取(文中代码滚动到底部时头条通过ajax更多文章(图))
文中代码只是部分说明,完整代码放在文章的最后。
首先,实际感受一下我们想要捕捉到什么好处?点击今日头条,在搜索栏中输入“街拍”二字,点击任意一篇文章文章,里面的图片就是我们要抓取的内容。
可以看到搜索结果默认返回20篇文章。当页面滚动到底部时,标题通过ajax加载更多文章,在浏览器中按F12打开调试工具(我的是Chrome),点击网络选项,尝试加载更多文章,可以看到相关的http请求:
可以看到请求的URL(Request URL)为:,其请求参数为:
很容易猜到offset代表的是偏移量,也就是已经请求的文章的个数;format是返回格式,这里是json格式的数据;关键字是我们的搜索关键字;autoload 应该是自动加载的一个指标,无所谓;count 是请求的新 文章 的数量;_ 应该是请求发起时的时间戳。将请求的 URL 和这些查询参数结合起来,形成一个完整的请求 URL。比如这次的Request URL是:%E8%A1%97%E6%8B%8D&autoload=true&count=20&_=92。
我们先来看看这个请求为我们返回了什么样的数据。
导入json
从 pprint 导入 pprint
从 urllib 导入请求
url = ";format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&_=92"
以 request.urlopen(url) 作为资源:
d = json.loads(res.read().decode())
打印(四)
这里我们首先通过request.urlopen(url)向这个url发送请求,返回的数据存放在res中,res是一个HttpResponse对象,实际返回的内容是通过调用其read方法获取的,因为read方法返回的是Python bytes 类型的字符串,调用其decode方法将其编码为字符串类型的字符串,默认为UTF-8编码。由于数据是以json格式返回的,所以通过json.load方法转换成Python字典形式。
打印出这个字典,可以看到字典中有一个键'data'对应一个由字典组成的列表的值。分析表明该值是所有文章的返回数据列表。稍微修改一下代码。看看'data'的值对应的是什么:
以 request.urlopen(url) 作为资源:
d = json.loads(res.read().decode())
d = d.get('数据')
打印(d)
在这里,pprint 用于使字典打印的值更加格式化,以便于分析。你可以看到这是一个字典列表。列表中的每一项代表一块文章,里面收录了文章的所有基本数据,比如标题、文章的URL等,这样我们就可以得到URL我们这次请求的所有 文章 的列表如下:
urls = [article.get('article_url') for article in d if article.get('article_url')]
这里使用了list comprehension,循环文章列表,通过get('article_url')获取文章的URL,加上if判断条件是为了防止文章因为缺失数据导致空的文章 @> 网址。我们将继续请求这些文章 URL,阅读它们的内容,并提取图片并将它们保存到我们的硬盘中。
我们先处理一个文章,看看如何提取文章中的所有图片。
只需点击一个文章链接,按F12查看网页源代码,可以看到文章的主体部分位于
在div里面。在这个div下面,有一个h1标签,代表文章的标题,还有一系列img标签,其src属性存储了图片所在的链接,所以我们通过访问这些链接下载图片,看到怎么做:
chrome网页视频抓取(浏览器在线下载视频需要会员?找不到下载的地方?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-28 22:01
需要会员在浏览器中在线下载视频?找不到下载的地方?这时候需要网络嗅探才能下载
Chrome是最常用的浏览器,上面的插件和脚本极其丰富,所以首先想到了Chrome插件。查了一下,比较有名的好像是一个叫“Video DownloadHelper”的插件。立即下载安装,效果确实不错,下载的视频确实是网页的清晰度。
但问题也来了。当我下载第二个视频时,用英文提示我在120分钟内只允许下载一个视频。付费升级是无限的,太无聊了!所以删除它并寻找其他解决方案。
我从Chrome App Store下载了一些插件进行试用。我不记得细节,但他们中的许多人无法成功嗅探视频。简而言之,我留下了其中两个:Stream Video Downloader 和 Flash Video Downloader。这两个插件经测试成功嗅探到下载地址,并将原视频保存到本地。更推荐前者。后者下载的视频虽然分辨率最好,但在本地播放时会卡顿,这可能不是标准码率的问题。
许多人无法访问 Google 的 Chrome 网上应用店。这里我导出了原创
的crx文件,方便本地安装。打开Chrome,更多工具-扩展,将Stream Video Downloader或Flash Video Downloader的crx文件拖入安装。然后打开视频播放页面。如果右上角出现一个明亮的下载图标,则表示嗅探已成功。点击它,你会发现你嗅到了各种分辨率的视频文件,比如360p、480p、720p,甚至1080p。选择对应的版本下载,它会自动下载分段的视频并合并成一个完整的视频文件。
下载链接 查看全部
chrome网页视频抓取(浏览器在线下载视频需要会员?找不到下载的地方?)
需要会员在浏览器中在线下载视频?找不到下载的地方?这时候需要网络嗅探才能下载
Chrome是最常用的浏览器,上面的插件和脚本极其丰富,所以首先想到了Chrome插件。查了一下,比较有名的好像是一个叫“Video DownloadHelper”的插件。立即下载安装,效果确实不错,下载的视频确实是网页的清晰度。
但问题也来了。当我下载第二个视频时,用英文提示我在120分钟内只允许下载一个视频。付费升级是无限的,太无聊了!所以删除它并寻找其他解决方案。
我从Chrome App Store下载了一些插件进行试用。我不记得细节,但他们中的许多人无法成功嗅探视频。简而言之,我留下了其中两个:Stream Video Downloader 和 Flash Video Downloader。这两个插件经测试成功嗅探到下载地址,并将原视频保存到本地。更推荐前者。后者下载的视频虽然分辨率最好,但在本地播放时会卡顿,这可能不是标准码率的问题。
许多人无法访问 Google 的 Chrome 网上应用店。这里我导出了原创
的crx文件,方便本地安装。打开Chrome,更多工具-扩展,将Stream Video Downloader或Flash Video Downloader的crx文件拖入安装。然后打开视频播放页面。如果右上角出现一个明亮的下载图标,则表示嗅探已成功。点击它,你会发现你嗅到了各种分辨率的视频文件,比如360p、480p、720p,甚至1080p。选择对应的版本下载,它会自动下载分段的视频并合并成一个完整的视频文件。
下载链接
chrome网页视频抓取(实践应用类(非知识讲解)本文介绍selenium库和chrome浏览器实现自动抓取网页元素)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-23 21:01
概括
最后更新时间:2020.08.20(实验部分待更新)
本文类型:实际应用(非知识讲解)
本文介绍了selenium库和chrome浏览器自动抓取网页元素,定位并填写表单数据,可以实现自动填写,节省大量人力。为了方便使用selenium库,方便处理运行中的错误,本文将对selenium库进行一定程度的重新封装,以便读者在了解selenium库后能够快速上手编程。
一、本文知识点:1.安装selenium库,2.selenium库查找元素的方式,3.重新打包selenium库
二、本文结构:1.先简单介绍一下知识点,2.把复制后可以直接运行的调试代码以完整段落的形式贴出来,让读者可以调试发布的每一段代码。
三、 本文方法实现:以百度主页为控制网页,以谷歌浏览器为实验平台,使用python+selenium进行网页操作。ps:其他对应的爬网实验会更新。
四、本文实验:1.
后台自动登录百度贴吧
, 2.
后台QQ邮箱阅读最新邮件
, 等待其他实验更新(均提供详细代码和注释,文末有对应链接)
温馨提示:以下为本文文章内容,以下案例可供参考
一、安装selenium库及相关文件
Selenium 库是python 爬取网站 的自动化工具。支持的浏览器包括Chrome、Firefox、Safari等主流界面浏览器。它还支持Windows、Linux、IOS、Android等多种操作系统。
1.安装硒库
(1)点击win10的开始菜单,直接输入cmd右键以管理员身份运行
(2)如果安装python时勾选了添加路径的选项,可以直接输入命令
pip 安装硒
(如果没有添加,建议卸载python,重新安装,查看添加路径。这个建议慎选,因为需要重新安装之前下载的库)
(3)网络连接下等待完成。如果提示超时,可以尝试以下命令切换下载源并重新安装:
pip 安装硒 -i
2.下载谷歌浏览器相关文件
本文使用的浏览器是谷歌浏览器,所以只介绍谷歌浏览器的爬取方法。其他浏览器的方法类似。
(1)
点击下载谷歌浏览器
(2)安装谷歌浏览器后,查看谷歌浏览器的版本号,点击谷歌浏览器右上角的三个点,选择——
帮助
——
关于谷歌浏览器
——
查看版本号
.
如图,本文版本号为
84.0.4147.125
(3)
点击下载谷歌浏览器驱动
打开驱动下载页面,找到版本号对应的驱动版本,
84.0.4147.125
, 所以寻找
84.0
一开始点击打开驱动下载对应的系统驱动。然后将其解压到您要编写项目的文件夹中。
不要放在python目录或者浏览器安装目录下。如果这样做,移植到另一台计算机时会出现各种BUG。根本原因是你的电脑已经安装了相应的库文件和驱动,但是端口是 电脑可能没有安装。
二、selenium 快速入门
1.元素定位的八种方式
(1)
ID
(2)
名称
(3)
路径
(4)
链接文字
(5)
部分链接文本
(6)
标签名称
(7)
班级名称
(8)
css 选择器
2. id 方法
(1) 在 selenium 中通过
ID
定位一个元素:
find_element_by_id
以百度的页面为例,其百度输入框的页面源码如下:
......
在,
是输入框的网页代码,
百度网页代码
通过id查找元素的代码和注释如下:
导入操作系统
导入系统
导入时间
从硒导入网络驱动程序
##此方法获取的工作文件夹路径在py文件下或封装exe后有效。##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动器路径##
Google Drive Drive = 当前工作主路径 + "/" + "chromedriver.exe"
##初始化硒控制##
浏览器驱动程序 = webdriver.Chrome(executable_path=Google Drive 驱动程序)
##打开链接,改成其他网址,请注意开头##
浏览器驱动程序.get("")
##按id搜索清除搜索框内容##
浏览器 driver.find_element_by_id("kw").clear()
##搜索并按id输入搜索框内容##
浏览器驱动.find_element_by_id("kw").send_keys("python+selenium库实现抓取网页数据内容并自动填表的解决方案,并附上已经交付给甲方的代码实际稳定运行")
##按id搜索,点击百度搜索##
浏览器 driver.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭并退出浏览器
浏览器 driver.quit()
3. 命名方法
还是以百度输入框为例,通过selenium
名称
定位一个元素:
find_element_by_name
代码和注释如下:
导入操作系统
导入系统
导入时间
从硒导入网络驱动程序
##此方法获取的工作文件夹路径在py文件下或封装exe后有效。##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动器路径##
Google Drive Drive = 当前工作主路径 + "/" + "chromedriver.exe"
##初始化硒控制##
浏览器驱动程序 = webdriver.Chrome(executable_path=Google Drive 驱动程序)
##打开链接,改成其他网址,请注意开头##
浏览器驱动程序.get("")
##按名称搜索清除搜索框内容##
浏览器 driver.find_element_by_name("wd").clear()
##按名称搜索并输入搜索框的内容##
浏览器驱动.find_element_by_name("wd").send_keys("python+selenium库实现爬虫抓取网页数据内容并自动填表的解决方案,并附上已经交付给甲方的代码实际稳定运行")
##按id搜索,点击百度搜索##
浏览器 driver.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭并退出浏览器
浏览器 driver.quit()
4. xpath 方式
还是以百度输入框为例,通过selenium
路径
定位一个元素:
find_element_by_xpath
. 但是这种方法不适合在网页中的位置会发生变化的表格元素,因为xpath方法指向的是固定的行列,无法检测行列内容的变化。
首先在谷歌浏览器中打开百度,在空白处
鼠标右键
,选择
检查 (N)
有了这个选择,就可以进入网页的开发者模式了,如图。然后在百度输入框
鼠标右键
, 再次点击
检查 (N)
选择,可以发现右边代码框自动选中的部分已经变成了百度输入框的代码。最后,在右侧自动选中的代码片段
右键点击
-选择
复制
-选择
复制 Xpath
, 百度输入框
路径
为了
//*[@id="kw"]
, 百度
路径
为了
//*[@id="su"]
接下来,使用此值执行百度搜索。代码和注释如下。
导入操作系统
导入系统
导入时间
从硒导入网络驱动程序
##此方法获取的工作文件夹路径在py文件下或封装exe后有效。##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动器路径##
Google Drive Drive = 当前工作主路径 + "/" + "chromedriver.exe"
##初始化硒控制##
浏览器驱动程序 = webdriver.Chrome(executable_path=Google Drive 驱动程序)
##打开链接,改成其他网址,请注意开头##
浏览器驱动程序.get("")
##通过xpath搜索清除搜索框内容,注意单引号和双引号的混合使用##
浏览器 driver.find_element_by_xpath('//*[@id="kw"]').clear()
##通过xpath搜索并输入搜索框的内容,注意单引号和双引号的混合使用##
Browser driver.find_element_by_xpath('//*[@id="kw"]').send_keys("python+selenium库实现了爬虫抓取网页数据内容并自动填表的解决方案,并附有实际稳定性已交付给甲方运行代码")
##通过xpath搜索,点击百度搜索,注意单引号和双引号的混合使用##
浏览器 driver.find_element_by_xpath('//*[@id="su"]').click()
##保持5s时间
time.sleep(5)
###关闭并退出浏览器
浏览器 driver.quit()
5. 链接文本和部分链接文本方法 查看全部
chrome网页视频抓取(实践应用类(非知识讲解)本文介绍selenium库和chrome浏览器实现自动抓取网页元素)
概括
最后更新时间:2020.08.20(实验部分待更新)
本文类型:实际应用(非知识讲解)
本文介绍了selenium库和chrome浏览器自动抓取网页元素,定位并填写表单数据,可以实现自动填写,节省大量人力。为了方便使用selenium库,方便处理运行中的错误,本文将对selenium库进行一定程度的重新封装,以便读者在了解selenium库后能够快速上手编程。
一、本文知识点:1.安装selenium库,2.selenium库查找元素的方式,3.重新打包selenium库
二、本文结构:1.先简单介绍一下知识点,2.把复制后可以直接运行的调试代码以完整段落的形式贴出来,让读者可以调试发布的每一段代码。
三、 本文方法实现:以百度主页为控制网页,以谷歌浏览器为实验平台,使用python+selenium进行网页操作。ps:其他对应的爬网实验会更新。
四、本文实验:1.
后台自动登录百度贴吧
, 2.
后台QQ邮箱阅读最新邮件
, 等待其他实验更新(均提供详细代码和注释,文末有对应链接)
温馨提示:以下为本文文章内容,以下案例可供参考
一、安装selenium库及相关文件
Selenium 库是python 爬取网站 的自动化工具。支持的浏览器包括Chrome、Firefox、Safari等主流界面浏览器。它还支持Windows、Linux、IOS、Android等多种操作系统。
1.安装硒库
(1)点击win10的开始菜单,直接输入cmd右键以管理员身份运行
(2)如果安装python时勾选了添加路径的选项,可以直接输入命令
pip 安装硒
(如果没有添加,建议卸载python,重新安装,查看添加路径。这个建议慎选,因为需要重新安装之前下载的库)
(3)网络连接下等待完成。如果提示超时,可以尝试以下命令切换下载源并重新安装:
pip 安装硒 -i
2.下载谷歌浏览器相关文件
本文使用的浏览器是谷歌浏览器,所以只介绍谷歌浏览器的爬取方法。其他浏览器的方法类似。
(1)
点击下载谷歌浏览器
(2)安装谷歌浏览器后,查看谷歌浏览器的版本号,点击谷歌浏览器右上角的三个点,选择——
帮助
——
关于谷歌浏览器
——
查看版本号
.
如图,本文版本号为
84.0.4147.125
(3)
点击下载谷歌浏览器驱动
打开驱动下载页面,找到版本号对应的驱动版本,
84.0.4147.125
, 所以寻找
84.0
一开始点击打开驱动下载对应的系统驱动。然后将其解压到您要编写项目的文件夹中。
不要放在python目录或者浏览器安装目录下。如果这样做,移植到另一台计算机时会出现各种BUG。根本原因是你的电脑已经安装了相应的库文件和驱动,但是端口是 电脑可能没有安装。
二、selenium 快速入门
1.元素定位的八种方式
(1)
ID
(2)
名称
(3)
路径
(4)
链接文字
(5)
部分链接文本
(6)
标签名称
(7)
班级名称
(8)
css 选择器
2. id 方法
(1) 在 selenium 中通过
ID
定位一个元素:
find_element_by_id
以百度的页面为例,其百度输入框的页面源码如下:
......
在,
是输入框的网页代码,
百度网页代码
通过id查找元素的代码和注释如下:
导入操作系统
导入系统
导入时间
从硒导入网络驱动程序
##此方法获取的工作文件夹路径在py文件下或封装exe后有效。##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动器路径##
Google Drive Drive = 当前工作主路径 + "/" + "chromedriver.exe"
##初始化硒控制##
浏览器驱动程序 = webdriver.Chrome(executable_path=Google Drive 驱动程序)
##打开链接,改成其他网址,请注意开头##
浏览器驱动程序.get("")
##按id搜索清除搜索框内容##
浏览器 driver.find_element_by_id("kw").clear()
##搜索并按id输入搜索框内容##
浏览器驱动.find_element_by_id("kw").send_keys("python+selenium库实现抓取网页数据内容并自动填表的解决方案,并附上已经交付给甲方的代码实际稳定运行")
##按id搜索,点击百度搜索##
浏览器 driver.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭并退出浏览器
浏览器 driver.quit()
3. 命名方法
还是以百度输入框为例,通过selenium
名称
定位一个元素:
find_element_by_name
代码和注释如下:
导入操作系统
导入系统
导入时间
从硒导入网络驱动程序
##此方法获取的工作文件夹路径在py文件下或封装exe后有效。##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动器路径##
Google Drive Drive = 当前工作主路径 + "/" + "chromedriver.exe"
##初始化硒控制##
浏览器驱动程序 = webdriver.Chrome(executable_path=Google Drive 驱动程序)
##打开链接,改成其他网址,请注意开头##
浏览器驱动程序.get("")
##按名称搜索清除搜索框内容##
浏览器 driver.find_element_by_name("wd").clear()
##按名称搜索并输入搜索框的内容##
浏览器驱动.find_element_by_name("wd").send_keys("python+selenium库实现爬虫抓取网页数据内容并自动填表的解决方案,并附上已经交付给甲方的代码实际稳定运行")
##按id搜索,点击百度搜索##
浏览器 driver.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭并退出浏览器
浏览器 driver.quit()
4. xpath 方式
还是以百度输入框为例,通过selenium
路径
定位一个元素:
find_element_by_xpath
. 但是这种方法不适合在网页中的位置会发生变化的表格元素,因为xpath方法指向的是固定的行列,无法检测行列内容的变化。
首先在谷歌浏览器中打开百度,在空白处
鼠标右键
,选择
检查 (N)
有了这个选择,就可以进入网页的开发者模式了,如图。然后在百度输入框
鼠标右键
, 再次点击
检查 (N)
选择,可以发现右边代码框自动选中的部分已经变成了百度输入框的代码。最后,在右侧自动选中的代码片段
右键点击
-选择
复制
-选择
复制 Xpath
, 百度输入框
路径
为了
//*[@id="kw"]
, 百度
路径
为了
//*[@id="su"]
接下来,使用此值执行百度搜索。代码和注释如下。
导入操作系统
导入系统
导入时间
从硒导入网络驱动程序
##此方法获取的工作文件夹路径在py文件下或封装exe后有效。##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动器路径##
Google Drive Drive = 当前工作主路径 + "/" + "chromedriver.exe"
##初始化硒控制##
浏览器驱动程序 = webdriver.Chrome(executable_path=Google Drive 驱动程序)
##打开链接,改成其他网址,请注意开头##
浏览器驱动程序.get("")
##通过xpath搜索清除搜索框内容,注意单引号和双引号的混合使用##
浏览器 driver.find_element_by_xpath('//*[@id="kw"]').clear()
##通过xpath搜索并输入搜索框的内容,注意单引号和双引号的混合使用##
Browser driver.find_element_by_xpath('//*[@id="kw"]').send_keys("python+selenium库实现了爬虫抓取网页数据内容并自动填表的解决方案,并附有实际稳定性已交付给甲方运行代码")
##通过xpath搜索,点击百度搜索,注意单引号和双引号的混合使用##
浏览器 driver.find_element_by_xpath('//*[@id="su"]').click()
##保持5s时间
time.sleep(5)
###关闭并退出浏览器
浏览器 driver.quit()
5. 链接文本和部分链接文本方法
chrome网页视频抓取(谷歌浏览器扩展插件安装方法.zip文件2.打开(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-20 21:21
谷歌浏览器截图插件是一款浏览器辅助软件。每个人在浏览网页时可能都需要截图。那么这个小插件可以快速拦截网页,方便快捷,可以拦截任何页面,非常方便,有需要的赶紧下载试试吧!
插件介绍:
谷歌浏览器网页截图扩展允许浏览器截图,可以对整个网页进行截图,包括带有滚动条的窗口,可以对网页的任意区域进行截图。网页上出现的浮动元素只在截图后出现一次。捕获的图像提供突出显示、校正和用于编辑的文本工具。
特征:
只需单击一下,您就可以将整个页面另存为 PNG 图像。
快速轻松地捕获整个网页。即使是很长的页面也可以保存为图像文件。
在截屏之前,您可以选择让扩展程序先帮助调整窗口大小。
该扩展程序只运行在本机上,这意味着该扩展程序不会向任何服务器发送任何信息,它甚至可以在没有网络连接的情况下工作。因此,您的隐私永远不会被泄露。
如何安装 Google Chrome 扩展程序
1.解压.zip文件
2.打开浏览器扩展选项,选择解压后的扩展
3.选择你解压后的文件路径,点击确定
4.加载成功
编辑评论
将网页截取为图片,支持窗口截屏、区域截屏、整页截屏三种方式。支持横竖翻页拦截大网页,新版本引入了自动截图保存功能。 查看全部
chrome网页视频抓取(谷歌浏览器扩展插件安装方法.zip文件2.打开(组图))
谷歌浏览器截图插件是一款浏览器辅助软件。每个人在浏览网页时可能都需要截图。那么这个小插件可以快速拦截网页,方便快捷,可以拦截任何页面,非常方便,有需要的赶紧下载试试吧!
插件介绍:
谷歌浏览器网页截图扩展允许浏览器截图,可以对整个网页进行截图,包括带有滚动条的窗口,可以对网页的任意区域进行截图。网页上出现的浮动元素只在截图后出现一次。捕获的图像提供突出显示、校正和用于编辑的文本工具。
特征:
只需单击一下,您就可以将整个页面另存为 PNG 图像。
快速轻松地捕获整个网页。即使是很长的页面也可以保存为图像文件。
在截屏之前,您可以选择让扩展程序先帮助调整窗口大小。
该扩展程序只运行在本机上,这意味着该扩展程序不会向任何服务器发送任何信息,它甚至可以在没有网络连接的情况下工作。因此,您的隐私永远不会被泄露。
如何安装 Google Chrome 扩展程序
1.解压.zip文件
2.打开浏览器扩展选项,选择解压后的扩展
3.选择你解压后的文件路径,点击确定
4.加载成功
编辑评论
将网页截取为图片,支持窗口截屏、区域截屏、整页截屏三种方式。支持横竖翻页拦截大网页,新版本引入了自动截图保存功能。
chrome网页视频抓取(从Chromium的源码third_Chrome中的媒体播放架构图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-20 20:11
Linux
新增的视频/音频标签提供了直接在网页上播放音频和视频的能力,无需任何插件。因此,可以使用 HTML5 开发媒体播放器。互联网上也出现了许多 HTML5 播放器,例如 jPlayer。但是,各种浏览器支持的 HTML5 音频和视频格式非常有限。比如IE9只支持H.264,Firefox只支持VP8和Theora。谷歌浏览器被认为拥有最全面的支持格式。支持的视频格式包括H.264、VP8、Theora,音频包括Vorbis、MP3、AAC、WAV。这些格式对于播放网络在线音视频基本足够了(不包括flash),但是如果我们要播放本地音视频,就会遇到很多不支持的格式,比如rmvb视频,在国内很流行,而且高- 定义视频是最常见的 mkv 和 avi 格式目前并非所有浏览器都支持。从这一点来看,目前基于HTML5的播放器无法替代QQ视频和射击播放器等传统播放器。
是否可以向浏览器添加对更多音频和视频格式的支持?分析了谷歌的开源浏览器Chromium,发现它的音视频解码是由FFmpeg提供的(代码在第三方\ffmpeg\),和Chrome是一样的,所以可以添加对更多类型的音频和音频的支持视频格式转换为 Chrome。
Chrome 中的媒体播放架构如下图所示:
Pipeline 是 Google 为 Chrome 开发的媒体框架引擎。 HTML5 视频/音频标签用于实现媒体播放。 FFmpeg 在其中提供了解复用器和解码器。所以需要添加对音视频格式的支持,主要是修改FFmpeg。 .
从Chromium源代码third_party\ffmpeg\chromium\config\Chrome\linux\ia32\config.h可以知道Chrome使用的FFmpeg配置选项。在原来的配置选项后添加以下选项:
--enable-decoder='rv10,rv20,rv30,rv40,cook,h263,h263i,mpeg4,msmpeg4v1,msmpeg4v2,msmpeg4v3,amrnb,amrwb,ac3,flv' --enable-demuxer='rm,mpegvideo ,avi,avisynth,h263,aac,amr,ac3,flv,mpegts,mpegtsraw' --enable-parser='mpegvideo,rv30,rv40,h263,mpeg4video,ac3'
使用新的配置选项重新配置编译FFmpeg,并使用生成的3个动态链接库avcodec-54.dll, avformat-54.dll, avutil-51. dll 替换 Chrome 中的原创文件。请注意,用于编译 FFmpeg 的 Chromium 源代码版本应与 Chrome 的版本相似。如果差异过大,更换库可能会导致Chrome无法正常运行。在Windows上编译FFmpeg的方法请参考我的另一篇文档《在Windows上用Chromium编译FFmpeg》。
这样修改FFmpeg后,就可以在Chrome中使用HTML5 video/audio标签播放更多格式的音视频了。可以播放最常见的mkv、avi、flv、mov、amr。但是rmvb还是不能播放。用Visual Studio 2010跟踪后,我找到了原因。原来常见的rmvb电影视频编码是RV40,音频编码是COOK。这两种编解码器类型在 Chrome 中没有定义。它们将在解析 rmvb 时使用。认为是未知的编解码类型(kUnknownVideoCodec和kUnknownAudioCodec),为此需要修改media\base\video_decoder_config.h和media\base\audio_decoder_config.h,将这两种格式分别添加到枚举类型VideoCodec和AudioCodec中,然后也如果要修改media\ffmpeg\,具体修改方法就不赘述了,直接看代码即可。经过这次修改,Chrome的媒体引擎可以识别RV40和COOK两种格式,普通的rmvb电影也可以播放了。
由此可见,Chrome 播放更多格式的音视频并不难。当然,这只是第一步。还有很多问题。比如播放rmvb电影的时候,拖动进度条就会乱屏。兼容性和稳定性需要做更多的工作。
窗口
在 Windows 上的 Chromium 中编译 FFmpeg
在谷歌开源浏览器Chromium中,HTML5音视频标签的实现使用开源多媒体软件FFmpeg提供解码,与Chrome相同。 FFmpeg源码位于Chromium源码树的third_party\ffmpeg\,但是在Windows上用Visual Studio 2010编译Chromium时,这部分FFmpeg代码不参与编译,而是直接使用预编译好的3个动态链接库(位于third_party\ffmpeg\chromium\binaries\Chromium\win\ia32\)。谷歌文档指出,目前Windows上的这部分FFmpeg代码只能借助MinGW手动编译。参考文档,经过实际验证,现将编译步骤总结如下。
Google 对 FFmpeg 进行了修改。修改后的代码部分以patch的形式放在third_party\ffmpeg\chromium\patches\中。下载的Chromium源代码中的这些补丁已经打好了,可以直接编译FFmpeg。
以下步骤在Windows7 64位验证,前提是安装并配置了Chromium开发环境,包括Visual Studio 2010、depot_tools等,假设所有软件安装在C盘,Chromium源代码位于C:\Chromium\。
1. 从...下载 4 个文件... /third_party/mingw/: README.chromium, mingw-get-inst-20101030.exe, pthreads-w32-2-8-0- release .tar.gz、pthreads-w32.patch.txt。 README.chromium 是本文引用的主要文档。 mingw-get-inst-20101030.exe是MinGW的安装文件,版本比较老,可以到MinGW官网下载最新版本。
2. 运行mingw-get-inst-20101030.exe,将MinGW安装到C:\MinGW\,安装时检查以下3项:
C++ 编译器
MSYS 基础系统
MinGW 开发者工具包
3. 下载并解压到 C:
4. 修改系统环境变量PATH,添加如下路径:C:\MinGW\bin;C:\MinGW\msys\1.0\bin;C:\yasm-1.2.0
5. 将第一步下载的pthreads-w32-2-8-0-release.tar.gz解压到C:
6. 将第一步下载的pthreads-w32.patch.txt复制到C:\
7.在Windows命令行窗口依次运行以下命令:
c:
cd pthreads-w32-2-8-0-release
补丁 -p0
使干净的 GC 成为静态
cp pthread.h sched.h /mingw/include
cp libpthreadGC2.a /mingw/lib
调用“c:\Program Files (x86)\Microsoft Visual Studio 10.0\VC\bin\vcvars32.bat”
c:\MinGW\msys\1.0\msys.bat
8. 出现MinGW/MSYS命令行窗口,在里面运行如下命令:
cd /c/yasm-1.2.0/
./configure
制作
cd /c/chromium/src/third_party/ffmpeg/
./configure --disable-everything --enable-fft --enable-rdft --disable-network --disable-bzlib --disable-zlib --disable-swscale --disable-amd3dnow --disable- amd3dnowext --enable-shared --optflags=-O2 --enable-decoder='theora,vorbis,vp8' --enable-decoder='pcm_u8,pcm_s16le,pcm_f32le' --enable-demuxer='ogg,matroska,wav '--enable-parser=vp8 --arch=i686 --enable-yasm --extra-cflags=-m32 --extra-ldflags=-m32 --enable-pic
make -j4
FFmpeg的配置参数来自third_party\ffmpeg\chromium\config\Chromium\linux\ia32\config.h
编译完成后会生成3个动态链接库:avcodec-54.dll、avformat-54.dll、avutil-51.dll,会用到当 Chromium 运行时。音频和视频解码。目前,Chromium 中的 FFmpeg 仅支持 Vorbis、Theora 和 VP8 解码器。除了这三个之外,Chrome中的FFmpeg还支持H.264、AAC和MP3。如果我们想让 Chromium 的 HTML5 音频/视频标签支持更多的媒体格式,需要做的一件事就是重新配置和编译 FFmpeg。可以参考我的另一篇文章文章《让Chromium支持H.264视频。
参考资料
1)third_party\ffmpeg\chromium\README.chromium
2)third_party\ffmpeg\chromium\patches\README.chromium
3) ... ngw/README.chromium 查看全部
chrome网页视频抓取(从Chromium的源码third_Chrome中的媒体播放架构图)
Linux
新增的视频/音频标签提供了直接在网页上播放音频和视频的能力,无需任何插件。因此,可以使用 HTML5 开发媒体播放器。互联网上也出现了许多 HTML5 播放器,例如 jPlayer。但是,各种浏览器支持的 HTML5 音频和视频格式非常有限。比如IE9只支持H.264,Firefox只支持VP8和Theora。谷歌浏览器被认为拥有最全面的支持格式。支持的视频格式包括H.264、VP8、Theora,音频包括Vorbis、MP3、AAC、WAV。这些格式对于播放网络在线音视频基本足够了(不包括flash),但是如果我们要播放本地音视频,就会遇到很多不支持的格式,比如rmvb视频,在国内很流行,而且高- 定义视频是最常见的 mkv 和 avi 格式目前并非所有浏览器都支持。从这一点来看,目前基于HTML5的播放器无法替代QQ视频和射击播放器等传统播放器。
是否可以向浏览器添加对更多音频和视频格式的支持?分析了谷歌的开源浏览器Chromium,发现它的音视频解码是由FFmpeg提供的(代码在第三方\ffmpeg\),和Chrome是一样的,所以可以添加对更多类型的音频和音频的支持视频格式转换为 Chrome。
Chrome 中的媒体播放架构如下图所示:
Pipeline 是 Google 为 Chrome 开发的媒体框架引擎。 HTML5 视频/音频标签用于实现媒体播放。 FFmpeg 在其中提供了解复用器和解码器。所以需要添加对音视频格式的支持,主要是修改FFmpeg。 .
从Chromium源代码third_party\ffmpeg\chromium\config\Chrome\linux\ia32\config.h可以知道Chrome使用的FFmpeg配置选项。在原来的配置选项后添加以下选项:
--enable-decoder='rv10,rv20,rv30,rv40,cook,h263,h263i,mpeg4,msmpeg4v1,msmpeg4v2,msmpeg4v3,amrnb,amrwb,ac3,flv' --enable-demuxer='rm,mpegvideo ,avi,avisynth,h263,aac,amr,ac3,flv,mpegts,mpegtsraw' --enable-parser='mpegvideo,rv30,rv40,h263,mpeg4video,ac3'
使用新的配置选项重新配置编译FFmpeg,并使用生成的3个动态链接库avcodec-54.dll, avformat-54.dll, avutil-51. dll 替换 Chrome 中的原创文件。请注意,用于编译 FFmpeg 的 Chromium 源代码版本应与 Chrome 的版本相似。如果差异过大,更换库可能会导致Chrome无法正常运行。在Windows上编译FFmpeg的方法请参考我的另一篇文档《在Windows上用Chromium编译FFmpeg》。
这样修改FFmpeg后,就可以在Chrome中使用HTML5 video/audio标签播放更多格式的音视频了。可以播放最常见的mkv、avi、flv、mov、amr。但是rmvb还是不能播放。用Visual Studio 2010跟踪后,我找到了原因。原来常见的rmvb电影视频编码是RV40,音频编码是COOK。这两种编解码器类型在 Chrome 中没有定义。它们将在解析 rmvb 时使用。认为是未知的编解码类型(kUnknownVideoCodec和kUnknownAudioCodec),为此需要修改media\base\video_decoder_config.h和media\base\audio_decoder_config.h,将这两种格式分别添加到枚举类型VideoCodec和AudioCodec中,然后也如果要修改media\ffmpeg\,具体修改方法就不赘述了,直接看代码即可。经过这次修改,Chrome的媒体引擎可以识别RV40和COOK两种格式,普通的rmvb电影也可以播放了。
由此可见,Chrome 播放更多格式的音视频并不难。当然,这只是第一步。还有很多问题。比如播放rmvb电影的时候,拖动进度条就会乱屏。兼容性和稳定性需要做更多的工作。
窗口
在 Windows 上的 Chromium 中编译 FFmpeg
在谷歌开源浏览器Chromium中,HTML5音视频标签的实现使用开源多媒体软件FFmpeg提供解码,与Chrome相同。 FFmpeg源码位于Chromium源码树的third_party\ffmpeg\,但是在Windows上用Visual Studio 2010编译Chromium时,这部分FFmpeg代码不参与编译,而是直接使用预编译好的3个动态链接库(位于third_party\ffmpeg\chromium\binaries\Chromium\win\ia32\)。谷歌文档指出,目前Windows上的这部分FFmpeg代码只能借助MinGW手动编译。参考文档,经过实际验证,现将编译步骤总结如下。
Google 对 FFmpeg 进行了修改。修改后的代码部分以patch的形式放在third_party\ffmpeg\chromium\patches\中。下载的Chromium源代码中的这些补丁已经打好了,可以直接编译FFmpeg。
以下步骤在Windows7 64位验证,前提是安装并配置了Chromium开发环境,包括Visual Studio 2010、depot_tools等,假设所有软件安装在C盘,Chromium源代码位于C:\Chromium\。
1. 从...下载 4 个文件... /third_party/mingw/: README.chromium, mingw-get-inst-20101030.exe, pthreads-w32-2-8-0- release .tar.gz、pthreads-w32.patch.txt。 README.chromium 是本文引用的主要文档。 mingw-get-inst-20101030.exe是MinGW的安装文件,版本比较老,可以到MinGW官网下载最新版本。
2. 运行mingw-get-inst-20101030.exe,将MinGW安装到C:\MinGW\,安装时检查以下3项:
C++ 编译器
MSYS 基础系统
MinGW 开发者工具包
3. 下载并解压到 C:
4. 修改系统环境变量PATH,添加如下路径:C:\MinGW\bin;C:\MinGW\msys\1.0\bin;C:\yasm-1.2.0
5. 将第一步下载的pthreads-w32-2-8-0-release.tar.gz解压到C:
6. 将第一步下载的pthreads-w32.patch.txt复制到C:\
7.在Windows命令行窗口依次运行以下命令:
c:
cd pthreads-w32-2-8-0-release
补丁 -p0
使干净的 GC 成为静态
cp pthread.h sched.h /mingw/include
cp libpthreadGC2.a /mingw/lib
调用“c:\Program Files (x86)\Microsoft Visual Studio 10.0\VC\bin\vcvars32.bat”
c:\MinGW\msys\1.0\msys.bat
8. 出现MinGW/MSYS命令行窗口,在里面运行如下命令:
cd /c/yasm-1.2.0/
./configure
制作
cd /c/chromium/src/third_party/ffmpeg/
./configure --disable-everything --enable-fft --enable-rdft --disable-network --disable-bzlib --disable-zlib --disable-swscale --disable-amd3dnow --disable- amd3dnowext --enable-shared --optflags=-O2 --enable-decoder='theora,vorbis,vp8' --enable-decoder='pcm_u8,pcm_s16le,pcm_f32le' --enable-demuxer='ogg,matroska,wav '--enable-parser=vp8 --arch=i686 --enable-yasm --extra-cflags=-m32 --extra-ldflags=-m32 --enable-pic
make -j4
FFmpeg的配置参数来自third_party\ffmpeg\chromium\config\Chromium\linux\ia32\config.h
编译完成后会生成3个动态链接库:avcodec-54.dll、avformat-54.dll、avutil-51.dll,会用到当 Chromium 运行时。音频和视频解码。目前,Chromium 中的 FFmpeg 仅支持 Vorbis、Theora 和 VP8 解码器。除了这三个之外,Chrome中的FFmpeg还支持H.264、AAC和MP3。如果我们想让 Chromium 的 HTML5 音频/视频标签支持更多的媒体格式,需要做的一件事就是重新配置和编译 FFmpeg。可以参考我的另一篇文章文章《让Chromium支持H.264视频。
参考资料
1)third_party\ffmpeg\chromium\README.chromium
2)third_party\ffmpeg\chromium\patches\README.chromium
3) ... ngw/README.chromium
chrome网页视频抓取( 优点扩展下载地址:Pinbox跨平台收藏工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-18 21:03
优点扩展下载地址:Pinbox跨平台收藏工具)
Pinbox 是一款谷歌浏览器插件,可以让用户的 Chrome 书签更加生动。用户在Chrome中安装Pinbox插件后,只需点击扩展按钮,即可自动为您保存当前网页至Pinbox。保存网页时,同时将当前网页的缩略图保存在采集夹中,方便用户通过采集夹中的缩略图快速了解网页内容。
Pinbox插件不仅支持一些常见的文字或图片类型网站,还可以将视频类型网站保存在采集中,用户还可以通过Pinbox快速分享保存的采集。
优势
扩展下载链接:Pinbox 跨平台采集工具
口袋
Pocket 是一个非常好的网页保存工具。使用起来非常方便。您只需要点击扩展按钮,就会自动为您保存当前网页到Pocket,以网格形式显示,您可以对其进行标记。排序、归档等操作,但国内使用较慢。
优势
扩展下载链接:Pocket
Instapaper
Instapaper 是一种类似于 Pocket 的网络采集服务。也可以一键采集网页,但是在显示上有很大的不同。在Pocket中,采用卡片网格格式的布局,以图片为主体,而在Instapaper中,则采用文本列表的形式,显示更多的文本信息,界面比Pocket更简单,布局比 Pocket 更漂亮。很多,比较适合文字阅读。
优势
扩展下载链接:Instapaper 查看全部
chrome网页视频抓取(
优点扩展下载地址:Pinbox跨平台收藏工具)
Pinbox 是一款谷歌浏览器插件,可以让用户的 Chrome 书签更加生动。用户在Chrome中安装Pinbox插件后,只需点击扩展按钮,即可自动为您保存当前网页至Pinbox。保存网页时,同时将当前网页的缩略图保存在采集夹中,方便用户通过采集夹中的缩略图快速了解网页内容。
Pinbox插件不仅支持一些常见的文字或图片类型网站,还可以将视频类型网站保存在采集中,用户还可以通过Pinbox快速分享保存的采集。
优势
扩展下载链接:Pinbox 跨平台采集工具
口袋
Pocket 是一个非常好的网页保存工具。使用起来非常方便。您只需要点击扩展按钮,就会自动为您保存当前网页到Pocket,以网格形式显示,您可以对其进行标记。排序、归档等操作,但国内使用较慢。
优势
扩展下载链接:Pocket
Instapaper
Instapaper 是一种类似于 Pocket 的网络采集服务。也可以一键采集网页,但是在显示上有很大的不同。在Pocket中,采用卡片网格格式的布局,以图片为主体,而在Instapaper中,则采用文本列表的形式,显示更多的文本信息,界面比Pocket更简单,布局比 Pocket 更漂亮。很多,比较适合文字阅读。
优势
扩展下载链接:Instapaper
chrome网页视频抓取(挖一下crx插件可以根据用户需求快速准确地抓取网页上的图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-18 21:00
Dig it crx插件是一款基于Chrome浏览器的图片批量下载插件。这个挖的插件可以根据用户需要快速准确的抓取网页图片(包括网页中的css背景图片和嵌入iframe的图片),根据您的需要过滤和批量下载图片,并支持整个截图网页。无论是工作还是娱乐,都能有效帮助您节省更多时间。
特征:
1、精准高效的网页图片抓取功能,无论是CSS背景图片还是嵌入的IFRAME图片,准确率都在99.9%以上。
2、 便捷的网页截图功能,支持当前可视区域截图和整个网页区域截图。
3、 实用的图片遮挡功能,自动过滤被遮挡的图片,结果更准确。
4、自定义图片保存路径,根据当前日期分类保存。
5、图片保存到云端,随时随地访问。
离线安装插件:
如果无法访问谷歌应用商店,可以下载crx插件包到本地,安装方法:
1、拖放到Chrome浏览器。
2、使用开发模式,将下载的crx改为zip,解压到一个文件夹
菜单->更多工具->扩展
检查开发者模式
加载解压后的扩展...,选择刚刚解压的文件夹路径
更新日志:
1、采用新的LOGO
2、 增加云存储功能,可以访问采集的图片
3、修复几个bug
细节 查看全部
chrome网页视频抓取(挖一下crx插件可以根据用户需求快速准确地抓取网页上的图片)
Dig it crx插件是一款基于Chrome浏览器的图片批量下载插件。这个挖的插件可以根据用户需要快速准确的抓取网页图片(包括网页中的css背景图片和嵌入iframe的图片),根据您的需要过滤和批量下载图片,并支持整个截图网页。无论是工作还是娱乐,都能有效帮助您节省更多时间。
特征:
1、精准高效的网页图片抓取功能,无论是CSS背景图片还是嵌入的IFRAME图片,准确率都在99.9%以上。
2、 便捷的网页截图功能,支持当前可视区域截图和整个网页区域截图。
3、 实用的图片遮挡功能,自动过滤被遮挡的图片,结果更准确。
4、自定义图片保存路径,根据当前日期分类保存。
5、图片保存到云端,随时随地访问。
离线安装插件:
如果无法访问谷歌应用商店,可以下载crx插件包到本地,安装方法:
1、拖放到Chrome浏览器。
2、使用开发模式,将下载的crx改为zip,解压到一个文件夹
菜单->更多工具->扩展
检查开发者模式
加载解压后的扩展...,选择刚刚解压的文件夹路径
更新日志:
1、采用新的LOGO
2、 增加云存储功能,可以访问采集的图片
3、修复几个bug
细节
chrome网页视频抓取(imacros系统自然环境规定Windows10,Windows8/8.1(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-16 08:02
imacros破解版下载是一款功能强大的浏览器组件,可以完成对网页的抓取、检测等实际操作。另外,填写网页表单信息和自动下载文件图片也很方便。它适用于多种浏览器。,热忱欢迎有兴趣的朋友下载安装本站软件!
imacros中文版APP详细介绍
iMacros 是 Mozilla Firefox 浏览器的附加组件。它的主要功能是帮助您创建用于登录URL、社区论坛和Internet 邮箱的姿势宏以查看电子邮件。它还允许我们创建其他姿势宏,例如:保存网页、存储网页上的组件(例如:照片)、打印输出...
imacros系统自然环境法规
Windows 10、Windows 8/8.1、Windows 7、Windows XP SP3、Windows Server 2003/2008/2008R2/2012/2012R2
Windows 32 位(x86) 和 64 位(x64)
Microsoft Internet Explorer 9、10 或 11(Windows XP 也适用于 ie8)
Mozilla Firefox 版本 21 或更高版本(可选,仅适用于 iMacros Firefox Add-On)
Google chrome Version 22 或更高版本号(可选,仅适用于 iMacros Chrome Add-On)
RAM:256MB(强烈推荐512MB)
电脑硬盘:30MB
imacros动作特征
1、MacrosWeb 浏览器 API
iMacros 的脚本套接字可以对 Web 浏览器进行可编程控制。因此,您可以编写脚本来执行复杂的日常任务。iMacros 的 32/64 位 API 可以远程操作浏览器。
2、数据信息获取
iMacros不仅可以填写网页表单信息,还可以获取信息。例如:从网站上搜索并获取文字、图片(如价格、产品介绍、股票价格等)。iMacros 应用Unicode 文件格式和所有语言表达(包括多字节语言表达,如中文)。
3、网页检测
iMacros可以进行Web应用软件的软件性能测试、功能测试和可用性测试。iMacros 是唯一可以在浏览器(如 IE、Firefox 和 Chrome)中立即检测的专用工具。它可以在java/Flash/Flex/Silverlight 程序流和所有AJAX 元素中进行测试。iMacros 内置了命令命令,可以准确捕捉到 Web 每次的响应时间。
4、网络自动化技术
自动化技术填写表格可以满足最终产品用户的要求。您可以更好地在线下载和提交文本、照片、文档和网页,还可以解析PDF文档和屏幕截图。
您可以从 CSV/XML 文档、数据库查询或其他 Web 应用程序启动和导出数据。
您可以浏览网页。
iMacros 可以帮助您查看网址、记住登录密码、填写网络表单,让您摆脱繁琐的工作。是唯一一款可以自动填写网页表单的APP。它将所有信息存储在文本文件中,以便于编辑和阅读。登录密码使用 256 位 AES 加密算法。
5、.NET Web 浏览器组件
.NET Web 浏览器组件可以快速将自动化技术程序流添加到您的应用程序软件中。它在检测和调节方面拥有十多年的关键技术。现阶段已有超过50万名客户在申请。 查看全部
chrome网页视频抓取(imacros系统自然环境规定Windows10,Windows8/8.1(组图))
imacros破解版下载是一款功能强大的浏览器组件,可以完成对网页的抓取、检测等实际操作。另外,填写网页表单信息和自动下载文件图片也很方便。它适用于多种浏览器。,热忱欢迎有兴趣的朋友下载安装本站软件!
imacros中文版APP详细介绍
iMacros 是 Mozilla Firefox 浏览器的附加组件。它的主要功能是帮助您创建用于登录URL、社区论坛和Internet 邮箱的姿势宏以查看电子邮件。它还允许我们创建其他姿势宏,例如:保存网页、存储网页上的组件(例如:照片)、打印输出...
imacros系统自然环境法规
Windows 10、Windows 8/8.1、Windows 7、Windows XP SP3、Windows Server 2003/2008/2008R2/2012/2012R2
Windows 32 位(x86) 和 64 位(x64)
Microsoft Internet Explorer 9、10 或 11(Windows XP 也适用于 ie8)
Mozilla Firefox 版本 21 或更高版本(可选,仅适用于 iMacros Firefox Add-On)
Google chrome Version 22 或更高版本号(可选,仅适用于 iMacros Chrome Add-On)
RAM:256MB(强烈推荐512MB)
电脑硬盘:30MB
imacros动作特征
1、MacrosWeb 浏览器 API
iMacros 的脚本套接字可以对 Web 浏览器进行可编程控制。因此,您可以编写脚本来执行复杂的日常任务。iMacros 的 32/64 位 API 可以远程操作浏览器。
2、数据信息获取
iMacros不仅可以填写网页表单信息,还可以获取信息。例如:从网站上搜索并获取文字、图片(如价格、产品介绍、股票价格等)。iMacros 应用Unicode 文件格式和所有语言表达(包括多字节语言表达,如中文)。
3、网页检测
iMacros可以进行Web应用软件的软件性能测试、功能测试和可用性测试。iMacros 是唯一可以在浏览器(如 IE、Firefox 和 Chrome)中立即检测的专用工具。它可以在java/Flash/Flex/Silverlight 程序流和所有AJAX 元素中进行测试。iMacros 内置了命令命令,可以准确捕捉到 Web 每次的响应时间。
4、网络自动化技术
自动化技术填写表格可以满足最终产品用户的要求。您可以更好地在线下载和提交文本、照片、文档和网页,还可以解析PDF文档和屏幕截图。
您可以从 CSV/XML 文档、数据库查询或其他 Web 应用程序启动和导出数据。
您可以浏览网页。
iMacros 可以帮助您查看网址、记住登录密码、填写网络表单,让您摆脱繁琐的工作。是唯一一款可以自动填写网页表单的APP。它将所有信息存储在文本文件中,以便于编辑和阅读。登录密码使用 256 位 AES 加密算法。
5、.NET Web 浏览器组件
.NET Web 浏览器组件可以快速将自动化技术程序流添加到您的应用程序软件中。它在检测和调节方面拥有十多年的关键技术。现阶段已有超过50万名客户在申请。

