
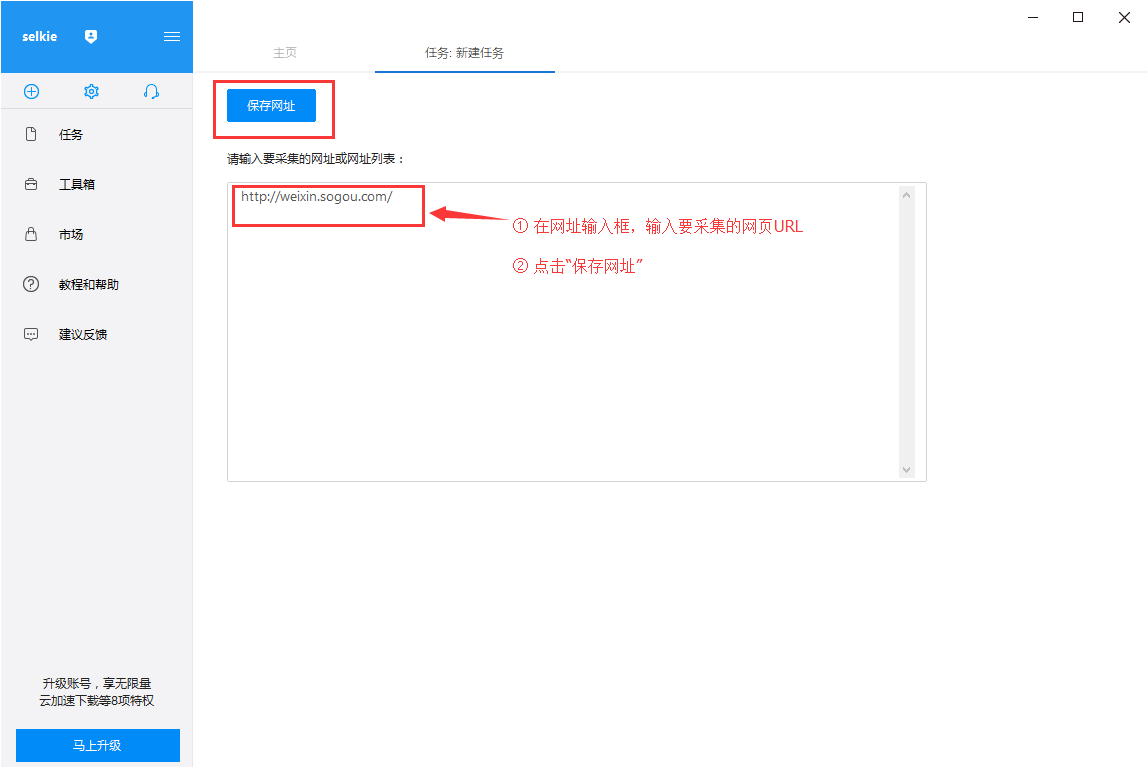
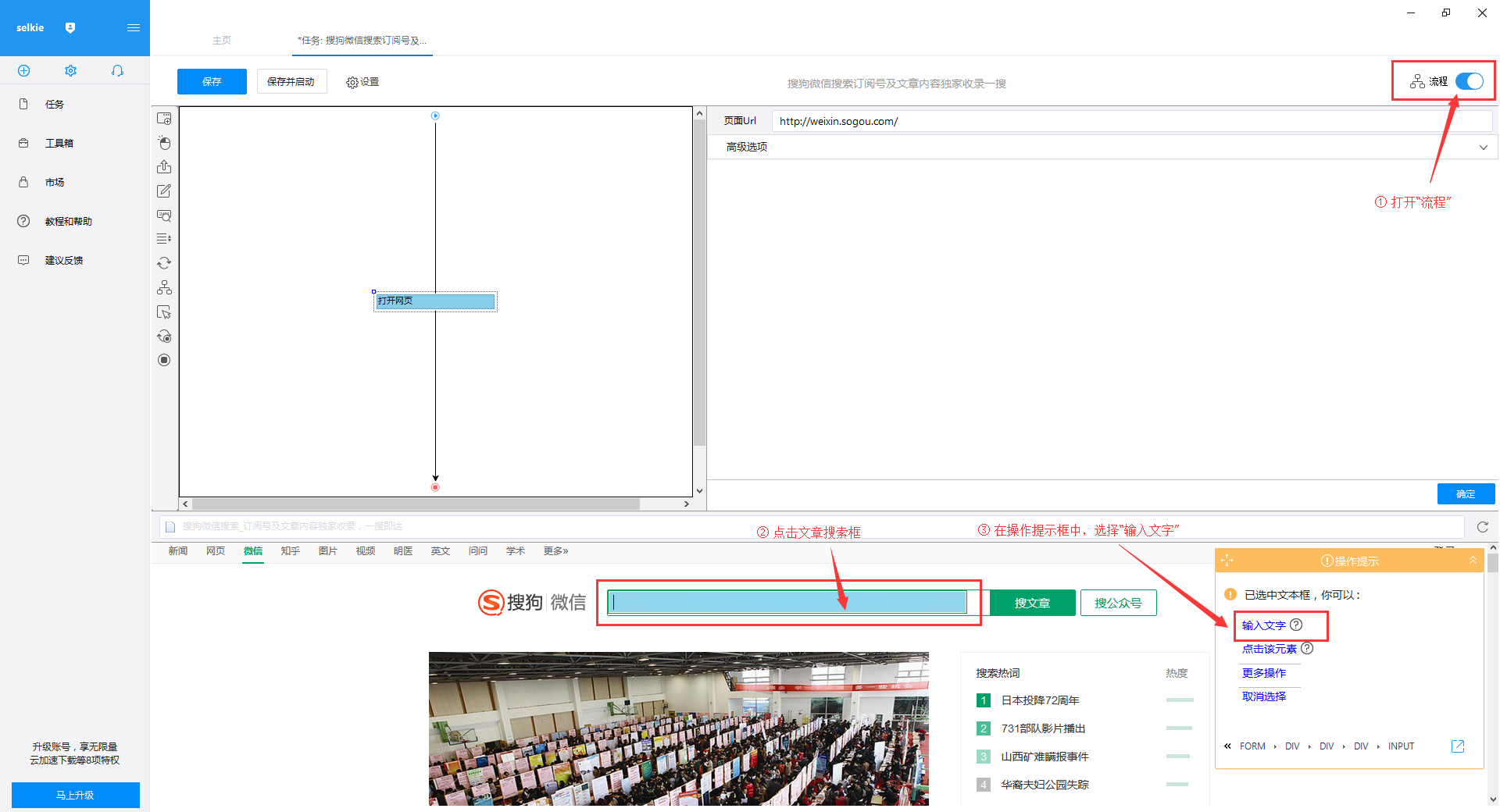
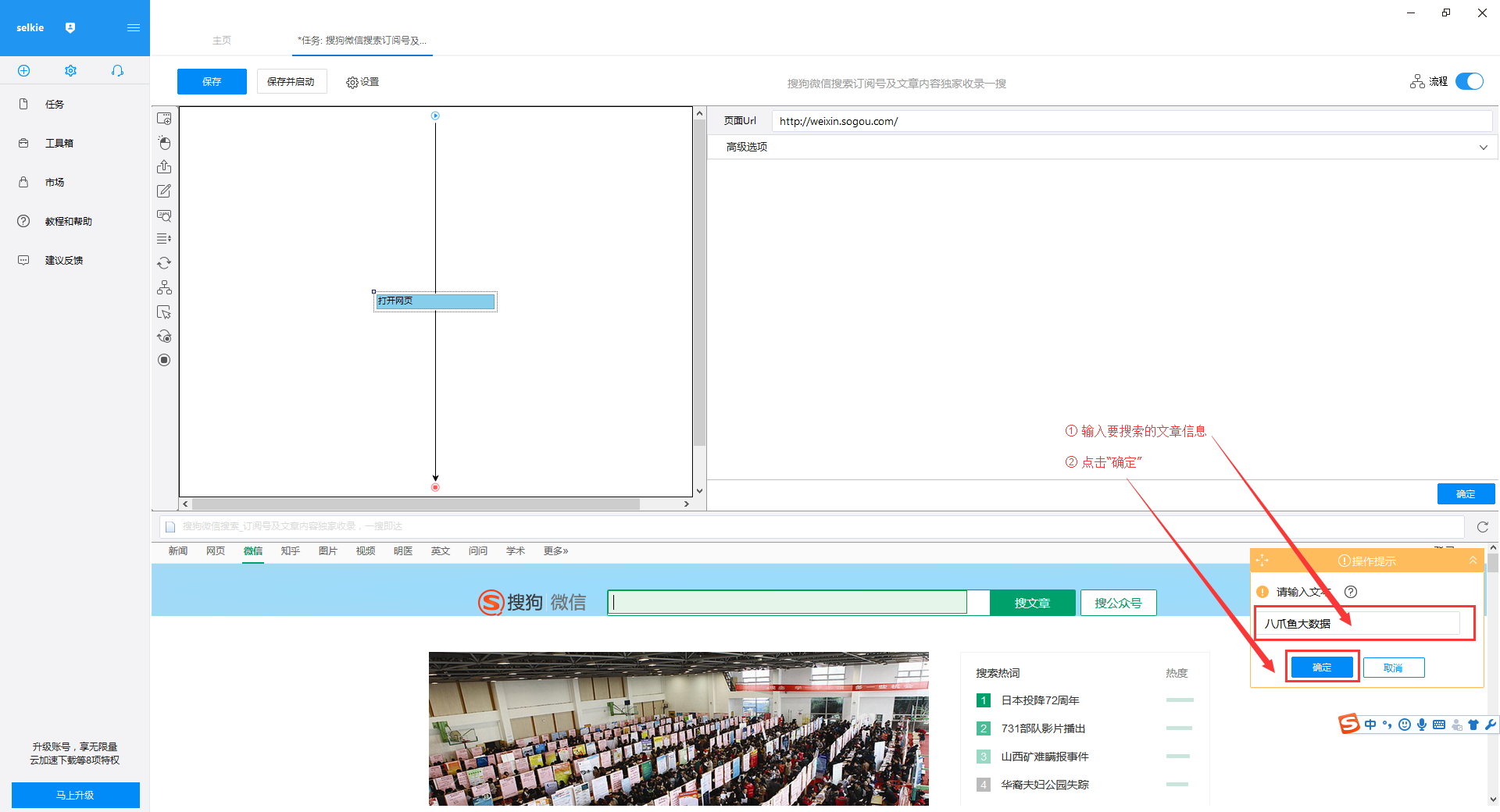
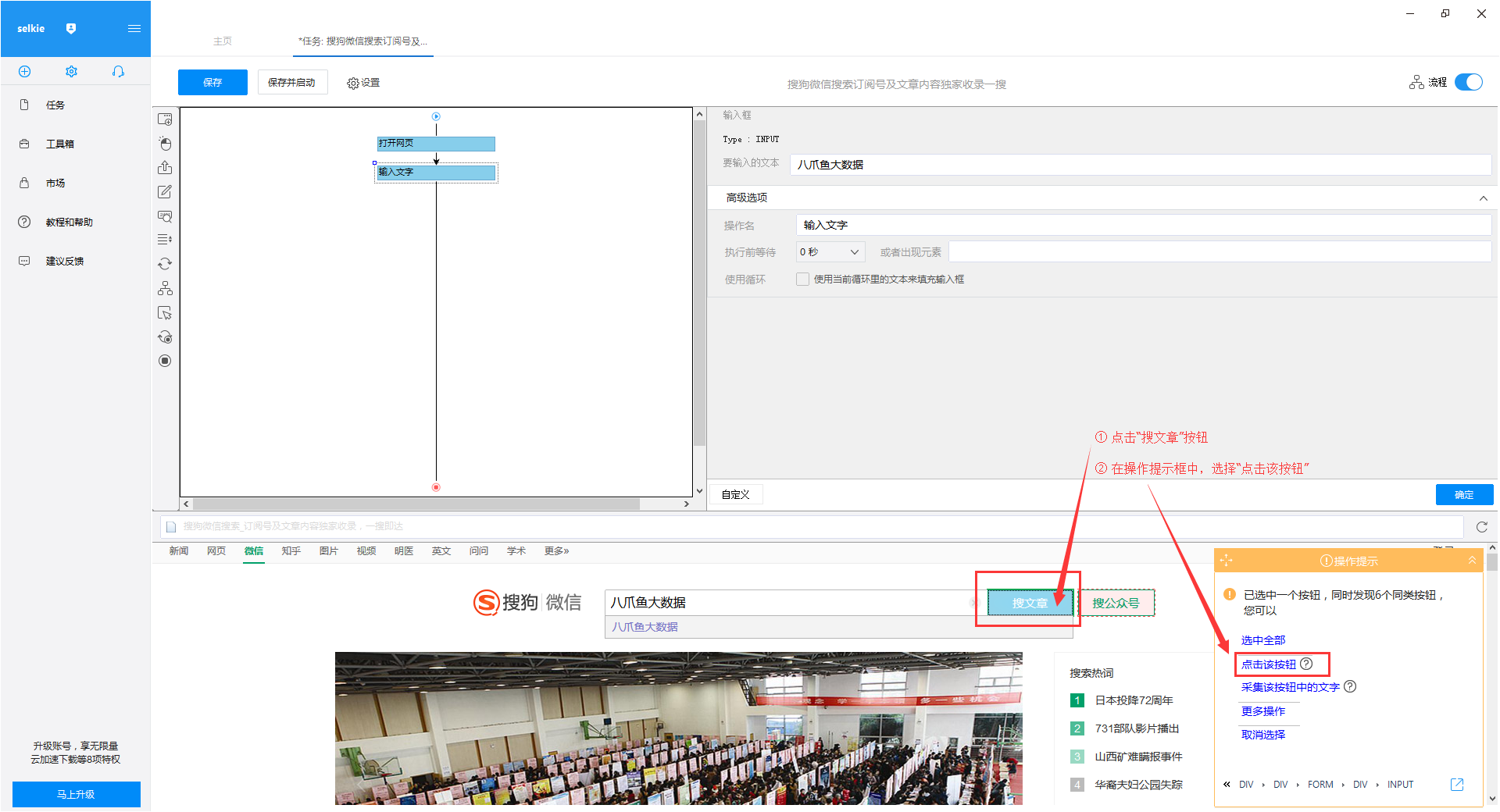
通过关键词采集文章采集api
通过关键词采集文章采集api(网络爬虫系统的原理和工作流程及注意事项介绍-乐题库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-17 13:02
网络数据采集指通过网络爬虫或网站公共API从网站获取数据信息。该方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图片、音频、视频和其他文件或附件采集,附件可以自动与身体关联
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据
在大数据时代,网络爬虫是从互联网获取采集数据的有利工具。目前已知的网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类
本部分首先简要介绍了网络爬虫的原理和工作流程,然后讨论了网络爬虫的爬虫策略,最后描述了典型的网络工具
网络爬虫原理
网络爬虫是一个程序或脚本,根据一定的规则自动抓取网络信息
网络爬虫可以自动采集他们可以访问的所有页面内容,并为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般有三个功能:数据采集、处理和存储,如图1所示
图1网络爬虫示意图
除了供用户阅读的文本信息外,网页还收录一些超链接信息
网络爬虫系统正是通过网页中的超链接信息,不断地获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL获取初始网页上的URL。在抓取网页的过程中,它不断地从当前网页中提取新的URL并将其放入队列,直到满足系统的某些停止条件
网络爬虫系统通常选择一些具有大量网站链接(网页中的超链接)的重要URL作为种子URL集合
网络爬虫系统将这些种子集作为初始URL来开始数据获取。因为网页收录链接信息,所以您将通过现有网页的URL获得一些新的URL
网页之间的指向结构可以看作是一个森林,每个种子URL对应的网页是森林中树的根节点,因此网络爬虫系统可以根据广度优先搜索算法或深度优先搜索算法遍历所有网页
由于深度优先搜索算法可能会使爬虫系统陷入网站内部,不利于搜索靠近网站主页的网页信息,因此一般采用广度优先搜索算法采集网页
网络爬虫系统首先将种子URL放入下载队列,然后简单地从队列头部获取一个URL来下载其相应的网页,获取网页内容并存储。解析网页中的链接信息后,可以获得一些新的URL
其次,根据一定的网页分析算法,过滤掉与主题无关的链接,保留有用的链接,并将其放入等待获取的URL队列中
最后,取出一个URL,下载相应的网页,然后解析它。重复此操作,直到遍历整个网络或满足某些条件
网络爬虫工作流
如图2所示,web爬虫的基本工作流程如下
1)首先选择一些种子URL
2)将这些URL放入要获取的URL队列
3)从待取URL队列中取出待取URL,解析DNS,获取主机IP地址,下载该URL对应的网页,保存在下载的网页库中。此外,将这些URL放入已爬网的URL队列
4)分析爬网URL队列中的URL,分析其他URL,并将这些URL放入要爬网的URL队列中,以便进入下一个周期
图2网络爬虫的基本工作流程
网络爬虫爬行策略
谷歌和百度等通用搜索引擎捕获的网页数量通常以数十亿计。因此,面对如此多的web页面,如何使web爬虫尽可能地遍历所有的web页面,从而尽可能地扩大web信息的捕获范围,这是web爬虫系统面临的一个关键问题。在网络爬虫系统中,爬行策略决定了网页的爬行顺序
本节首先简要介绍web爬虫捕获策略中使用的基本概念
1)web页面之间的关系模型
从互联网的结构来看,网页通过若干超链接相互连接,形成一个庞大而复杂的相互关联的有向图
如图3所示,如果将网页视为图中的一个节点,并将与网页中其他网页的链接视为该节点与其他节点的边,则很容易将整个Internet上的网页建模为一个有向图
理论上,通过遍历算法遍历图形,几乎可以访问Internet上的所有网页
图3网页关系模型示意图
2)web页面分类
通过从爬虫的角度划分互联网,互联网的所有页面可以分为五个部分:下载和过期页面、下载和过期页面、要下载的页面、已知页面和未知页面,如图4所示
捕获本地网页实际上是互联网内容的镜像和备份。互联网是动态的。当Internet上的部分内容发生更改时,本地网页将过期。因此,下载的网页分为已下载但未过期的网页和已下载和过期的网页
图4网页分类
要下载的网页是指URL队列中要获取的网页
可以看出,网页是指尚未爬网且不在要爬网的URL队列中的网页,但可以通过分析已爬网的网页或与要爬网的URL对应的网页来获得
还有一些网页是网络爬虫无法直接抓取和下载的,称为不可知网页
以下重点介绍几种常见的捕获策略
1.universalwebcrawler
通用网络爬虫,也称为全网爬虫,从一些种子URL向全网爬网,主要用于门户网站搜索引擎和大型web服务提供商采集数据
为了提高工作效率,一般的网络爬虫都会采用一定的爬行策略。常用的爬行策略有深度优先策略和广度优先策略
1)深度优先战略
深度优先策略意味着网络爬虫将从起始页开始,一个链接一个链接地跟踪它,直到它无法继续
完成爬网分支后,web爬虫将返回到上一个链接节点以进一步搜索其他链接。遍历所有链接后,爬网任务结束
这种策略更适合于垂直搜索或现场搜索,但对收录深层页面内容的网站进行爬网会造成巨大的资源浪费
以图3为例,遍历路径为1→ 2.→ 5.→ 6.→ 3.→ 7.→ 4.→ 八,
在深度优先策略中,当搜索节点时,节点的子节点和子节点的后续节点都优先于节点的兄弟节点。深度优先策略将在搜索空间时尽可能深入。仅当无法找到节点的后续节点时,才会考虑其兄弟节点
这种策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到最优解
如果没有限制,它将沿着一条路径无限扩展,这将“落入”大量数据。通常,使用深度优先策略会选择合适的深度,然后重复搜索直到找到解决方案,因此搜索效率会降低。因此,当搜索数据量相对较小时,通常使用深度优先策略
2)广度优先战略
广度优先策略根据web内容目录级别的深度抓取页面,浅层目录级别的页面首先被抓取。在对同一级别的页面进行爬网后,爬虫程序将深入到下一级别继续爬网
仍然以图3为例,遍历路径为1→ 2.→ 3.→ 4.→ 5.→ 6.→ 7.→ 八,
由于广度优先策略在N层节点扩展完成后进入N+1层,因此可以保证找到路径最短的解
该策略可以有效地控制页面的爬行深度,避免了当遇到无限深的分支时爬行无法结束的问题。它易于实现,并且不需要存储大量中间节点。缺点是爬行到具有深层目录级别的页面需要很长时间
如果搜索中存在过多的分支,即节点的后续节点过多,算法将耗尽资源,无法在可用空间中找到解决方案
2.关注网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫
@基于内容评价的1)crawling策略
Debra将文本相似度的计算方法引入到网络爬虫中,提出了fish搜索算法
该算法以用户输入的查询词为主题,收录 查看全部
通过关键词采集文章采集api(网络爬虫系统的原理和工作流程及注意事项介绍-乐题库)
网络数据采集指通过网络爬虫或网站公共API从网站获取数据信息。该方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图片、音频、视频和其他文件或附件采集,附件可以自动与身体关联
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据
在大数据时代,网络爬虫是从互联网获取采集数据的有利工具。目前已知的网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类
本部分首先简要介绍了网络爬虫的原理和工作流程,然后讨论了网络爬虫的爬虫策略,最后描述了典型的网络工具
网络爬虫原理
网络爬虫是一个程序或脚本,根据一定的规则自动抓取网络信息
网络爬虫可以自动采集他们可以访问的所有页面内容,并为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般有三个功能:数据采集、处理和存储,如图1所示
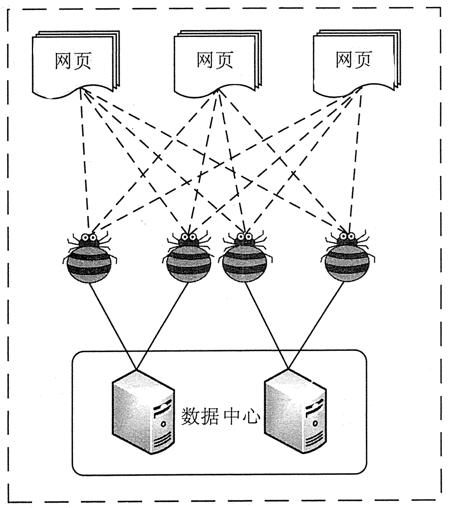
图1网络爬虫示意图
除了供用户阅读的文本信息外,网页还收录一些超链接信息
网络爬虫系统正是通过网页中的超链接信息,不断地获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL获取初始网页上的URL。在抓取网页的过程中,它不断地从当前网页中提取新的URL并将其放入队列,直到满足系统的某些停止条件
网络爬虫系统通常选择一些具有大量网站链接(网页中的超链接)的重要URL作为种子URL集合
网络爬虫系统将这些种子集作为初始URL来开始数据获取。因为网页收录链接信息,所以您将通过现有网页的URL获得一些新的URL
网页之间的指向结构可以看作是一个森林,每个种子URL对应的网页是森林中树的根节点,因此网络爬虫系统可以根据广度优先搜索算法或深度优先搜索算法遍历所有网页
由于深度优先搜索算法可能会使爬虫系统陷入网站内部,不利于搜索靠近网站主页的网页信息,因此一般采用广度优先搜索算法采集网页
网络爬虫系统首先将种子URL放入下载队列,然后简单地从队列头部获取一个URL来下载其相应的网页,获取网页内容并存储。解析网页中的链接信息后,可以获得一些新的URL
其次,根据一定的网页分析算法,过滤掉与主题无关的链接,保留有用的链接,并将其放入等待获取的URL队列中
最后,取出一个URL,下载相应的网页,然后解析它。重复此操作,直到遍历整个网络或满足某些条件
网络爬虫工作流
如图2所示,web爬虫的基本工作流程如下
1)首先选择一些种子URL
2)将这些URL放入要获取的URL队列
3)从待取URL队列中取出待取URL,解析DNS,获取主机IP地址,下载该URL对应的网页,保存在下载的网页库中。此外,将这些URL放入已爬网的URL队列
4)分析爬网URL队列中的URL,分析其他URL,并将这些URL放入要爬网的URL队列中,以便进入下一个周期
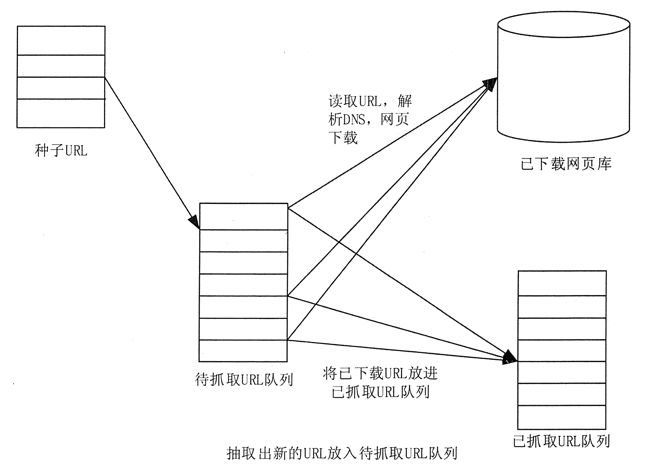
图2网络爬虫的基本工作流程
网络爬虫爬行策略
谷歌和百度等通用搜索引擎捕获的网页数量通常以数十亿计。因此,面对如此多的web页面,如何使web爬虫尽可能地遍历所有的web页面,从而尽可能地扩大web信息的捕获范围,这是web爬虫系统面临的一个关键问题。在网络爬虫系统中,爬行策略决定了网页的爬行顺序
本节首先简要介绍web爬虫捕获策略中使用的基本概念
1)web页面之间的关系模型
从互联网的结构来看,网页通过若干超链接相互连接,形成一个庞大而复杂的相互关联的有向图
如图3所示,如果将网页视为图中的一个节点,并将与网页中其他网页的链接视为该节点与其他节点的边,则很容易将整个Internet上的网页建模为一个有向图
理论上,通过遍历算法遍历图形,几乎可以访问Internet上的所有网页
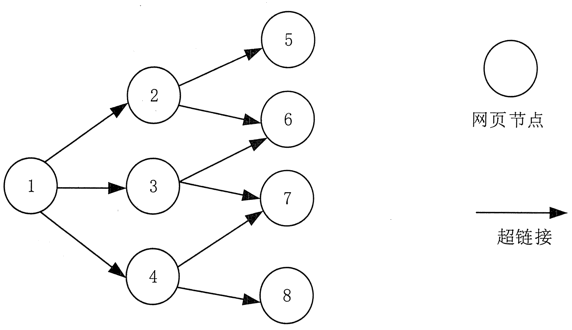
图3网页关系模型示意图
2)web页面分类
通过从爬虫的角度划分互联网,互联网的所有页面可以分为五个部分:下载和过期页面、下载和过期页面、要下载的页面、已知页面和未知页面,如图4所示
捕获本地网页实际上是互联网内容的镜像和备份。互联网是动态的。当Internet上的部分内容发生更改时,本地网页将过期。因此,下载的网页分为已下载但未过期的网页和已下载和过期的网页
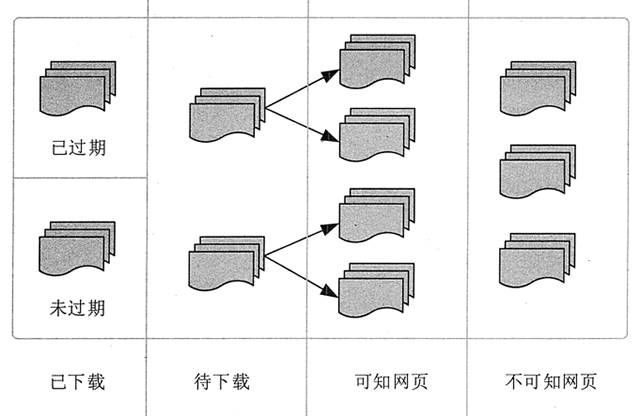
图4网页分类
要下载的网页是指URL队列中要获取的网页
可以看出,网页是指尚未爬网且不在要爬网的URL队列中的网页,但可以通过分析已爬网的网页或与要爬网的URL对应的网页来获得
还有一些网页是网络爬虫无法直接抓取和下载的,称为不可知网页
以下重点介绍几种常见的捕获策略
1.universalwebcrawler
通用网络爬虫,也称为全网爬虫,从一些种子URL向全网爬网,主要用于门户网站搜索引擎和大型web服务提供商采集数据
为了提高工作效率,一般的网络爬虫都会采用一定的爬行策略。常用的爬行策略有深度优先策略和广度优先策略
1)深度优先战略
深度优先策略意味着网络爬虫将从起始页开始,一个链接一个链接地跟踪它,直到它无法继续
完成爬网分支后,web爬虫将返回到上一个链接节点以进一步搜索其他链接。遍历所有链接后,爬网任务结束
这种策略更适合于垂直搜索或现场搜索,但对收录深层页面内容的网站进行爬网会造成巨大的资源浪费
以图3为例,遍历路径为1→ 2.→ 5.→ 6.→ 3.→ 7.→ 4.→ 八,
在深度优先策略中,当搜索节点时,节点的子节点和子节点的后续节点都优先于节点的兄弟节点。深度优先策略将在搜索空间时尽可能深入。仅当无法找到节点的后续节点时,才会考虑其兄弟节点
这种策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到最优解
如果没有限制,它将沿着一条路径无限扩展,这将“落入”大量数据。通常,使用深度优先策略会选择合适的深度,然后重复搜索直到找到解决方案,因此搜索效率会降低。因此,当搜索数据量相对较小时,通常使用深度优先策略
2)广度优先战略
广度优先策略根据web内容目录级别的深度抓取页面,浅层目录级别的页面首先被抓取。在对同一级别的页面进行爬网后,爬虫程序将深入到下一级别继续爬网
仍然以图3为例,遍历路径为1→ 2.→ 3.→ 4.→ 5.→ 6.→ 7.→ 八,
由于广度优先策略在N层节点扩展完成后进入N+1层,因此可以保证找到路径最短的解
该策略可以有效地控制页面的爬行深度,避免了当遇到无限深的分支时爬行无法结束的问题。它易于实现,并且不需要存储大量中间节点。缺点是爬行到具有深层目录级别的页面需要很长时间
如果搜索中存在过多的分支,即节点的后续节点过多,算法将耗尽资源,无法在可用空间中找到解决方案
2.关注网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫
@基于内容评价的1)crawling策略
Debra将文本相似度的计算方法引入到网络爬虫中,提出了fish搜索算法
该算法以用户输入的查询词为主题,收录
通过关键词采集文章采集api(这个问题需要分几种情况来解答第一种辑)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-09-17 10:17
这个问题需要在几种情况下得到回答
首先,您只需要下载并再次编辑它。这个方法很简单。一般来说,你知道你想要的文章,也就是说,你知道文章的访问地址。一般来说,它可以在采集器的帮助下下载,无论是保存为word还是其他格式都没有问题
第二个需要自动同步到您的平台。这很麻烦,因为您不知道下载地址(无法手动输入)
一、1、通过搜索犬浏览器搜索您的官方帐户名称,调用其界面,如果2、存在,则通过第二个界面查询官方帐户下的历史记录文章。获取文章链接,通过程序下载,然后保存到您的后台
这种方法的优点是它是半自动的,无需手动输入文章link。缺点:@1、如果您经常发送请求,搜狗会提示验证码。这需要手动处理,因此2、不能完全自动,文章链接是临时的,需要在有效期内下载3、只能获取最近十个历史文章,4、需要定期执行,不能实时更新。更新太频繁,被验证码拦截,频率太低,更新延迟太大
mode二、@1、按程序模拟官方帐户的登录管理页面。2、通过模拟调用编辑材料3、使用模拟编辑和插入链接的功能,4、调用搜索官方账号界面,查询官方账号获取传真。5、调用另一个接口,通过获取的factid获取文章列表。此文章列表中有链接
这种方法的优点是:@1、没有验证码,但也有封条,但频率较低2、你可以得到下面列出的所有文章名单官方账号。3、文章链接永久有效。缺点是:@1、仍然存在接口调用被阻止的情况。自动解封需要一些时间2、需要定期执行,不能实时更新。更新太频繁,并被验证代码阻止。频率太低,更新延迟太大
方法三、@1、通过实时推送,您只需提供API接口即可接收链接,将文章链接实时推送至顶层接口,获取链接并将下载内容保存到您自己的平台
此方法的优点:@1、不密封,2、不需要输入验证码,3、技术难度低4、文章更新及时且延迟低,最多三到五分钟4、文章链接是永久有效的。它可以实现真正的全自动化。缺点:您需要有自己的开发人员和API来接收参数
如果有更好的方法,请联系我,互相学习。如果您需要技术支持,也可以与我联系。上述方法已亲自试用过。有源代码(仅限Java) 查看全部
通过关键词采集文章采集api(这个问题需要分几种情况来解答第一种辑)
这个问题需要在几种情况下得到回答
首先,您只需要下载并再次编辑它。这个方法很简单。一般来说,你知道你想要的文章,也就是说,你知道文章的访问地址。一般来说,它可以在采集器的帮助下下载,无论是保存为word还是其他格式都没有问题
第二个需要自动同步到您的平台。这很麻烦,因为您不知道下载地址(无法手动输入)
一、1、通过搜索犬浏览器搜索您的官方帐户名称,调用其界面,如果2、存在,则通过第二个界面查询官方帐户下的历史记录文章。获取文章链接,通过程序下载,然后保存到您的后台
这种方法的优点是它是半自动的,无需手动输入文章link。缺点:@1、如果您经常发送请求,搜狗会提示验证码。这需要手动处理,因此2、不能完全自动,文章链接是临时的,需要在有效期内下载3、只能获取最近十个历史文章,4、需要定期执行,不能实时更新。更新太频繁,被验证码拦截,频率太低,更新延迟太大
mode二、@1、按程序模拟官方帐户的登录管理页面。2、通过模拟调用编辑材料3、使用模拟编辑和插入链接的功能,4、调用搜索官方账号界面,查询官方账号获取传真。5、调用另一个接口,通过获取的factid获取文章列表。此文章列表中有链接
这种方法的优点是:@1、没有验证码,但也有封条,但频率较低2、你可以得到下面列出的所有文章名单官方账号。3、文章链接永久有效。缺点是:@1、仍然存在接口调用被阻止的情况。自动解封需要一些时间2、需要定期执行,不能实时更新。更新太频繁,并被验证代码阻止。频率太低,更新延迟太大
方法三、@1、通过实时推送,您只需提供API接口即可接收链接,将文章链接实时推送至顶层接口,获取链接并将下载内容保存到您自己的平台
此方法的优点:@1、不密封,2、不需要输入验证码,3、技术难度低4、文章更新及时且延迟低,最多三到五分钟4、文章链接是永久有效的。它可以实现真正的全自动化。缺点:您需要有自己的开发人员和API来接收参数
如果有更好的方法,请联系我,互相学习。如果您需要技术支持,也可以与我联系。上述方法已亲自试用过。有源代码(仅限Java)
通过关键词采集文章采集api(通过关键词采集文章采集api集成模板库:百度凤巢)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-13 16:05
通过关键词采集文章采集api集成模板库:百度凤巢集成sites.wk任务相关:top20w页搜录收录问题
2、采集的文章页面是一次性采集到的么?(因为页面内容不可修改,
3、对采集的效率、稳定性、一致性有影响么?
4、百度api集成本身能够解决一系列的问题,例如seo,如何解决需要自己开发的问题?目前百度api应该是解决前几页的问题,对接后都能够解决,最怕的是如何保证复用性,多个系统不能互相对接,页面不能集成到指定的集成库(sites。wk),所以建议你自己开发一个,开发完成后都会出现问题的,建议技术实力过硬的话自己做,或者外包。
百度站长api在javascript方面可以做的工作,其实是很有限的,只能做到限制cookie就可以限制绝大多数页面的ip了。就像头条,虽然可以通过内容采集在爬行的过程中找到爬虫的特定位置,但是这个有一定概率会被爬虫发现,然后封掉。就算被发现,也有足够的心理去操作,不去做这么尴尬的事情。百度做为bat三巨头之一,找人来做这事不是自找死路嘛?虽然很多人同意在基础上可以,但是可以非常可以,也是肯定可以,只是现在没必要了,因为一是已经有,百度一下就知道了,二是高估了自己的技术,找了一个前辈,感觉技术都是没有问题的。
毕竟是人来开发,解决一系列业务逻辑可能都不是很顺,没有把技术交给任何人是坏事,但是如果是开发一个demo就搞定业务,那也没必要了。我觉得现在的话,想要实现采集,还是找一些创业公司来做比较好,他们肯定有技术实力来搞采集。 查看全部
通过关键词采集文章采集api(通过关键词采集文章采集api集成模板库:百度凤巢)
通过关键词采集文章采集api集成模板库:百度凤巢集成sites.wk任务相关:top20w页搜录收录问题
2、采集的文章页面是一次性采集到的么?(因为页面内容不可修改,
3、对采集的效率、稳定性、一致性有影响么?
4、百度api集成本身能够解决一系列的问题,例如seo,如何解决需要自己开发的问题?目前百度api应该是解决前几页的问题,对接后都能够解决,最怕的是如何保证复用性,多个系统不能互相对接,页面不能集成到指定的集成库(sites。wk),所以建议你自己开发一个,开发完成后都会出现问题的,建议技术实力过硬的话自己做,或者外包。
百度站长api在javascript方面可以做的工作,其实是很有限的,只能做到限制cookie就可以限制绝大多数页面的ip了。就像头条,虽然可以通过内容采集在爬行的过程中找到爬虫的特定位置,但是这个有一定概率会被爬虫发现,然后封掉。就算被发现,也有足够的心理去操作,不去做这么尴尬的事情。百度做为bat三巨头之一,找人来做这事不是自找死路嘛?虽然很多人同意在基础上可以,但是可以非常可以,也是肯定可以,只是现在没必要了,因为一是已经有,百度一下就知道了,二是高估了自己的技术,找了一个前辈,感觉技术都是没有问题的。
毕竟是人来开发,解决一系列业务逻辑可能都不是很顺,没有把技术交给任何人是坏事,但是如果是开发一个demo就搞定业务,那也没必要了。我觉得现在的话,想要实现采集,还是找一些创业公司来做比较好,他们肯定有技术实力来搞采集。
通过关键词采集文章采集api(基于5.的FPGA开发板上位机Demo实现本设计(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-09-12 20:10
)
1.概览
本设计采用FPGA技术将CMOS摄像头(DVP接口)的视频数据采集通过以太网(UDP方式)传输到PC,上位机DEMO通过socket编程实时显示视频。在屏幕上。
2.硬件系统框图
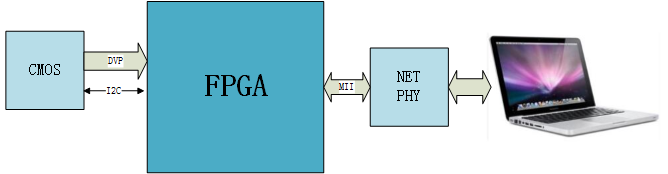
CMOS采用OV7670(30万像素),FPGA采用CYCLONE IV,以太网卡采用100M网卡芯片。
硬件平台采用ETree的FPGA开发板(某宝提供),如下图:
3.UDP/IP 协议
UDP(User Datagram Protocol)是OSI参考模型中的无连接传输层协议,提供面向事务的简单不可靠的信息传输服务。每个数据包的前8个字节用于收录头信息,其余字节用于收录特定的传输数据。 UDP协议常用于数据传输速度较高的场合,如图像传输、网络监控数据交换等。
UDP 消息格式
0 15
16 31
源端口号
目的端口号
消息长度
校验和
数据
IP(Internet Protoco)数据包位于网络层,其功能是将数据包发送到目标网络或主机。所有 TCP、UDP、IMCP、IGCP 数据均以 IP 数据格式传输。
在以太网数据帧的传输过程中,包长一般为46~1500字节,这里UDP包长度设计为:(8+20+640*2)=1308字节以提高传输效率。
4.FPGA 逻辑设计
FPGA各部分逻辑模块如下图所示:
以下是OV7670的初始配置代码:
<p>//file name: i2c_cfg_par.v
//creator: shugen.yin
//date: 2017-4-21
//function: i2c registers
//log: VGA RAW/25FPS, XCLK=24M
module i2c_cfg_par(
input [07:0] lut_index,
output reg [15:0] lut_data
);
always @(*)
begin
case(lut_index)
//ov7670 RAW 25Fps 24M input
'd0 : lut_data 查看全部
通过关键词采集文章采集api(基于5.的FPGA开发板上位机Demo实现本设计(组图)
)
1.概览
本设计采用FPGA技术将CMOS摄像头(DVP接口)的视频数据采集通过以太网(UDP方式)传输到PC,上位机DEMO通过socket编程实时显示视频。在屏幕上。
2.硬件系统框图
CMOS采用OV7670(30万像素),FPGA采用CYCLONE IV,以太网卡采用100M网卡芯片。
硬件平台采用ETree的FPGA开发板(某宝提供),如下图:

3.UDP/IP 协议
UDP(User Datagram Protocol)是OSI参考模型中的无连接传输层协议,提供面向事务的简单不可靠的信息传输服务。每个数据包的前8个字节用于收录头信息,其余字节用于收录特定的传输数据。 UDP协议常用于数据传输速度较高的场合,如图像传输、网络监控数据交换等。
UDP 消息格式
0 15
16 31
源端口号
目的端口号
消息长度
校验和
数据
IP(Internet Protoco)数据包位于网络层,其功能是将数据包发送到目标网络或主机。所有 TCP、UDP、IMCP、IGCP 数据均以 IP 数据格式传输。

在以太网数据帧的传输过程中,包长一般为46~1500字节,这里UDP包长度设计为:(8+20+640*2)=1308字节以提高传输效率。
4.FPGA 逻辑设计
FPGA各部分逻辑模块如下图所示:

以下是OV7670的初始配置代码:
<p>//file name: i2c_cfg_par.v
//creator: shugen.yin
//date: 2017-4-21
//function: i2c registers
//log: VGA RAW/25FPS, XCLK=24M
module i2c_cfg_par(
input [07:0] lut_index,
output reg [15:0] lut_data
);
always @(*)
begin
case(lut_index)
//ov7670 RAW 25Fps 24M input
'd0 : lut_data
通过关键词采集文章采集api(网络爬虫系统的原理和工作流程及注意事项介绍-乐题库 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-12 20:08
)
网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
在大数据时代,网络爬虫更像是来自采集data 的互联网工具。已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图 1 网络爬虫示意图
网页中除了供用户阅读的文字信息外,还收录一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,不断地从当前页面中提取新的URL并将其放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些比较重要的网站 URL,外展度(网页中超链接的数量)较高作为种子URL集合。
网络爬虫系统使用这些种子集合作为初始 URL 来开始数据爬取。由于网页收录链接信息,所以会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法进行搜索或者深度优先搜索算法遍历所有网页。
因为深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索更接近网站首页的网页信息,所以广度优先搜索算法采集页一般使用。
网络爬虫系统首先将种子URL放入下载队列,简单地从队列头部取出一个URL下载对应的网页,获取网页内容并存储,解析链接后网页中的信息,你可以得到一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后取出一个网址,下载对应的网页,然后解析,不断迭代,直到遍历全网或满足一定条件,才会停止。
网络爬虫工作流程
如图2所示,网络爬虫的基本工作流程如下。
1) 首先选择种子 URL 的一部分。
2) 将这些 URL 放入 URL 队列进行抓取。
3)从待爬取的URL队列中取出待爬取的URL,解析DNS得到主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入抓取到的网址队列中。
4)对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
图 2 网络爬虫的基本工作流程
网络爬虫抓取策略
谷歌、百度等通用搜索引擎抓取的网页数量通常以亿为单位计算。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页,从而尽可能扩大网页信息的覆盖范围呢?这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,抓取策略决定了抓取网页的顺序。
本节先简单介绍一下网络爬虫的爬取策略中用到的基本概念。
1)网页关系模型
从互联网的结构来看,网页通过不同数量的超链接相互连接,形成一个庞大而复杂的有向图,相互关联。
如图3所示,如果一个网页被视为图中的某个节点,而该网页中其他网页的链接被视为该节点到其他节点的边,那么我们可以很容易地认为整个网页Internet 上的页面被建模为有向图。
理论上,通过遍历算法遍历图,几乎可以访问互联网上的所有网页。
图 3 网页关系模型图
2)Web 分类
从爬虫的角度来划分互联网,互联网上的所有页面可以分为5个部分:已下载但未过期页面、已下载已过期页面、已下载页面、已知页面和未知页面,如图4. 显示。
抓取的本地网页实际上是互联网内容的镜像和备份。互联网是动态变化的。当互联网上的部分内容发生变化时,抓取到的本地网页就会失效。因此,下载的网页分为两种:下载的未过期网页和下载的过期网页。
图 4 网页分类
待下载的网页是指在URL队列中待抓取的页面。
可以看出,网页指的是未被抓取的网页,也不在待抓取的URL队列中,但可以通过分析抓取的页面或要抓取的URL对应的页面获取已抓取。
还有一些网页是网络爬虫无法直接抓取下载的,称为不可知网页。
以下重点介绍几种常见的抓取策略。
1.通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集data。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个跟踪链接,直到无法再深入。
网络爬虫在完成一个爬行分支后返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。
此策略更适合垂直搜索或站点搜索,但在抓取页面内容更深层次的站点时会造成资源的巨大浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间的时候,会尽可能的深入,只有在找不到一个节点的后继节点时才考虑它的兄弟节点。
这样的策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它会沿着一条路径无限扩展,从而“陷入”海量数据。一般情况下,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样就降低了搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度抓取网页。首先抓取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。
仍以图3为例,遍历路径为1→2→3→4→5→6→7→8
因为广度优先策略是在第N层节点扩展完成后进入第N+1层,所以可以保证找到路径最短的解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支无法结束爬取的问题,实现方便,无需存储大量中间节点。缺点是爬到目录需要很长时间。更深的页面。
如果搜索过程中分支过多,即节点的后继节点过多,算法会耗尽资源,在可用空间中找不到解。
2.专注于网络爬虫
焦点网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入到网络爬虫中,并提出了 Fish Search 算法。
算法以用户输入的查询词为主题,将收录查询词的页面视为主题相关页面。它的局限性在于它无法评估页面与主题的相关性。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面与主题的相关性。
使用基于连续值计算链接值的方法,不仅可以计算出哪些抓取的链接与主题相关,还可以量化相关性的大小。
2)基于链接结构评估的爬行策略
网页不同于一般文本。它是一个收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面上的链接表示页面之间的相互关系。基于链接结构的搜索策略模型利用这些结构特征来评估页面和链接的重要性来确定搜索顺序。其中,PageRank算法是这类搜索策略模型的代表。
PageRank 算法的基本原理是,如果一个网页被多次引用,它可能是一个非常重要的网页。如果一个网页没有被多次引用,但被一个重要的网页引用,那么它也可能是一个重要的网页。一个网页的重要性均匀地传递给它所引用的网页。
将某个页面的PageRank除以该页面存在的前向链接,并将得到的值与前向链接指向的页面的PageRank相加,得到链接页面的PageRank .
如图 5 所示,PageRank 值为 100 的网页将其重要性平均转移到它引用的两个页面上,每个页面得到 50。同样,PageRank 值为 9 的网页引用它为 3 个页面中的每个页面传递的值是 3。
PageRank 值为 53 的页面的值来自引用它的两个页面传递的值。
,
图 5 PageRank 算法示例
3) 基于强化学习的爬行策略
Rennie 和 McCallum 将增强学习引入聚焦爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性,从而确定链接访问的顺序。
4)基于上下文映射的爬行策略
Diligenti 等人。提出了一种爬行策略,通过建立上下文映射来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面和相关网页之间的距离。最先访问最近页面中的链接。
3.增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只抓取新生成或更改的网页的爬虫。可以在一定程度上保证抓取到的页面尽可能的新鲜。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要重新访问网页以更新本地页面集中页面的内容。常用的方法有统一更新法、个体更新法和基于分类的更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先策略、PageRank 优先策略等。
4. 深网爬虫
网页按存在方式可分为表面网页和深层网页。
深网爬虫架构包括6个基本功能模块(爬虫控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS)面。
其中,LVS(LabelValueSet)表示标签和值的集合,用于表示填写表单的数据源。在爬虫过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。
查看全部
通过关键词采集文章采集api(网络爬虫系统的原理和工作流程及注意事项介绍-乐题库
)
网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
在大数据时代,网络爬虫更像是来自采集data 的互联网工具。已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。

图 1 网络爬虫示意图
网页中除了供用户阅读的文字信息外,还收录一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,不断地从当前页面中提取新的URL并将其放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些比较重要的网站 URL,外展度(网页中超链接的数量)较高作为种子URL集合。
网络爬虫系统使用这些种子集合作为初始 URL 来开始数据爬取。由于网页收录链接信息,所以会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法进行搜索或者深度优先搜索算法遍历所有网页。
因为深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索更接近网站首页的网页信息,所以广度优先搜索算法采集页一般使用。
网络爬虫系统首先将种子URL放入下载队列,简单地从队列头部取出一个URL下载对应的网页,获取网页内容并存储,解析链接后网页中的信息,你可以得到一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后取出一个网址,下载对应的网页,然后解析,不断迭代,直到遍历全网或满足一定条件,才会停止。
网络爬虫工作流程
如图2所示,网络爬虫的基本工作流程如下。
1) 首先选择种子 URL 的一部分。
2) 将这些 URL 放入 URL 队列进行抓取。
3)从待爬取的URL队列中取出待爬取的URL,解析DNS得到主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入抓取到的网址队列中。
4)对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。

图 2 网络爬虫的基本工作流程
网络爬虫抓取策略
谷歌、百度等通用搜索引擎抓取的网页数量通常以亿为单位计算。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页,从而尽可能扩大网页信息的覆盖范围呢?这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,抓取策略决定了抓取网页的顺序。
本节先简单介绍一下网络爬虫的爬取策略中用到的基本概念。
1)网页关系模型
从互联网的结构来看,网页通过不同数量的超链接相互连接,形成一个庞大而复杂的有向图,相互关联。
如图3所示,如果一个网页被视为图中的某个节点,而该网页中其他网页的链接被视为该节点到其他节点的边,那么我们可以很容易地认为整个网页Internet 上的页面被建模为有向图。
理论上,通过遍历算法遍历图,几乎可以访问互联网上的所有网页。

图 3 网页关系模型图
2)Web 分类
从爬虫的角度来划分互联网,互联网上的所有页面可以分为5个部分:已下载但未过期页面、已下载已过期页面、已下载页面、已知页面和未知页面,如图4. 显示。
抓取的本地网页实际上是互联网内容的镜像和备份。互联网是动态变化的。当互联网上的部分内容发生变化时,抓取到的本地网页就会失效。因此,下载的网页分为两种:下载的未过期网页和下载的过期网页。

图 4 网页分类
待下载的网页是指在URL队列中待抓取的页面。
可以看出,网页指的是未被抓取的网页,也不在待抓取的URL队列中,但可以通过分析抓取的页面或要抓取的URL对应的页面获取已抓取。
还有一些网页是网络爬虫无法直接抓取下载的,称为不可知网页。
以下重点介绍几种常见的抓取策略。
1.通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集data。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个跟踪链接,直到无法再深入。
网络爬虫在完成一个爬行分支后返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。
此策略更适合垂直搜索或站点搜索,但在抓取页面内容更深层次的站点时会造成资源的巨大浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间的时候,会尽可能的深入,只有在找不到一个节点的后继节点时才考虑它的兄弟节点。
这样的策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它会沿着一条路径无限扩展,从而“陷入”海量数据。一般情况下,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样就降低了搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度抓取网页。首先抓取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。
仍以图3为例,遍历路径为1→2→3→4→5→6→7→8
因为广度优先策略是在第N层节点扩展完成后进入第N+1层,所以可以保证找到路径最短的解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支无法结束爬取的问题,实现方便,无需存储大量中间节点。缺点是爬到目录需要很长时间。更深的页面。
如果搜索过程中分支过多,即节点的后继节点过多,算法会耗尽资源,在可用空间中找不到解。
2.专注于网络爬虫
焦点网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入到网络爬虫中,并提出了 Fish Search 算法。
算法以用户输入的查询词为主题,将收录查询词的页面视为主题相关页面。它的局限性在于它无法评估页面与主题的相关性。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面与主题的相关性。
使用基于连续值计算链接值的方法,不仅可以计算出哪些抓取的链接与主题相关,还可以量化相关性的大小。
2)基于链接结构评估的爬行策略
网页不同于一般文本。它是一个收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面上的链接表示页面之间的相互关系。基于链接结构的搜索策略模型利用这些结构特征来评估页面和链接的重要性来确定搜索顺序。其中,PageRank算法是这类搜索策略模型的代表。
PageRank 算法的基本原理是,如果一个网页被多次引用,它可能是一个非常重要的网页。如果一个网页没有被多次引用,但被一个重要的网页引用,那么它也可能是一个重要的网页。一个网页的重要性均匀地传递给它所引用的网页。
将某个页面的PageRank除以该页面存在的前向链接,并将得到的值与前向链接指向的页面的PageRank相加,得到链接页面的PageRank .
如图 5 所示,PageRank 值为 100 的网页将其重要性平均转移到它引用的两个页面上,每个页面得到 50。同样,PageRank 值为 9 的网页引用它为 3 个页面中的每个页面传递的值是 3。
PageRank 值为 53 的页面的值来自引用它的两个页面传递的值。

,
图 5 PageRank 算法示例
3) 基于强化学习的爬行策略
Rennie 和 McCallum 将增强学习引入聚焦爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性,从而确定链接访问的顺序。
4)基于上下文映射的爬行策略
Diligenti 等人。提出了一种爬行策略,通过建立上下文映射来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面和相关网页之间的距离。最先访问最近页面中的链接。
3.增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只抓取新生成或更改的网页的爬虫。可以在一定程度上保证抓取到的页面尽可能的新鲜。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要重新访问网页以更新本地页面集中页面的内容。常用的方法有统一更新法、个体更新法和基于分类的更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先策略、PageRank 优先策略等。
4. 深网爬虫
网页按存在方式可分为表面网页和深层网页。
深网爬虫架构包括6个基本功能模块(爬虫控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS)面。
其中,LVS(LabelValueSet)表示标签和值的集合,用于表示填写表单的数据源。在爬虫过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。

通过关键词采集文章采集api(【干货】注册CDN的几种方法,你了解吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 288 次浏览 • 2021-09-12 00:00
1、真实IP地址采集
CDN 介绍
CDN的全称是Content Delivery Network,即内容分发网络
网址:
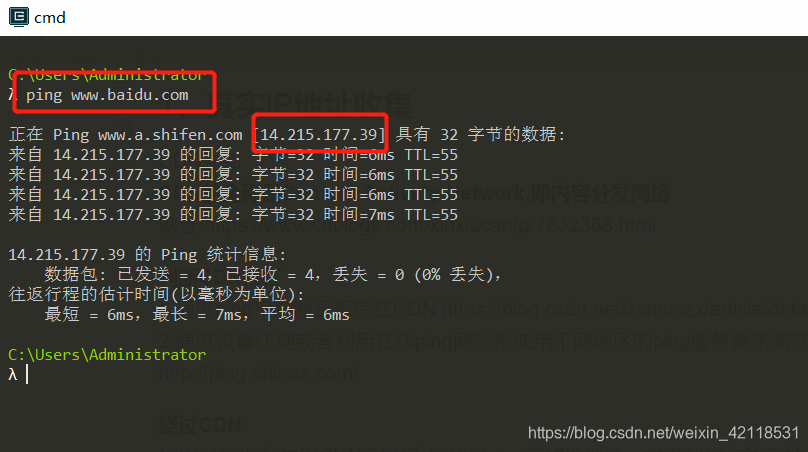
判断CDN是否存在
例如:百度有CDN服务器地址14.215.177.39
绕过 CDN
如果目标不使用CDN,可以直接使用ping 获取IP地址。或者在线使用网站
验证 IP 地址
使用IP地址访问网站,如果正常,就是真实IP地址。否则就不是真的。
2、shodan 介绍
信息采集方式
1.Active 信息采集:直接与目标交互,在交互过程中采集信息
2.Passive 信息采集:通过第三方引擎与目标交互,或者不允许目标交互查询数据库获取目标信息
Shodan 搜索引擎介绍
虽然目前人们认为谷歌是最强的搜索引擎,但shodan是互联网上最可怕的搜索引擎。与谷歌不同的是,Shodan不会在互联网上搜索网址,而是直接进入互联网的后台渠道。 Shodan可以说是一个“黑暗”的谷歌,寻找所有与互联网相关的服务器、摄像头、打印机、路由器等。
Shodan 网址:
Shodan 注册和登录:获取 API 密钥以供使用
API 密钥:pde7mB56vGwCWh2yKjj87z9ucYDiPwYg
shodan 搜索
1.在资源管理器搜索框中输入网络摄像头进行搜索(摄像头)
2.通过关键字port指定一个具体的端口号。
3.通过关键字host指定一个具体的IP地址。
4.通过关键字city指定特定城市的搜索内容。
3、shodan 安装命令行
pip 安装 shodan
shodan 初始化命令行:shoden 的 API key:pde7mB56vGwCWh2yKjj87z9ucYDiPwYg
shodan init pde7mB56vGwCWh2yKjj87z9ucYDiPwYg
查找特定服务的数量
1>查看Apache服务器数量
2>查看Tomcat服务器数量
Shodan 命令行搜索功能
shodan 搜索 microsoft iis 6.0
Shodan获取指定IP地址信息
shodan 主机 ip 地址
Shodan 获取帐户信息
shodan 信息
Shodan 获取自己的外部 IP 地址
shodan myip
示例如下:
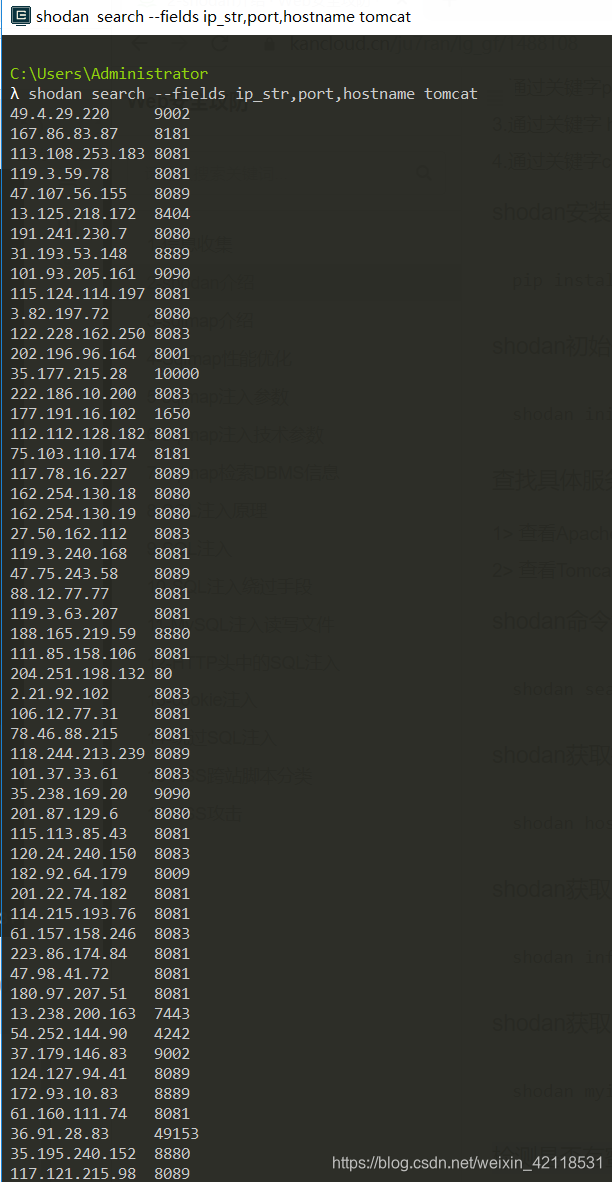
搜索关键字段的tomcat
4、检测是否有蜜罐保护
蜜罐技术
蜜罐技术本质上是一种欺骗攻击者的技术。通过布置一些主机、网络服务或信息作为诱饵,可以诱导攻击者对其进行攻击,从而捕获和分析攻击行为。 , 了解攻击者使用的工具和方法,并猜测攻击的意图和动机,可以让防御者清楚地了解他们面临的安全威胁,并利用技术和管理方法来增强实际系统的安全防护能力.
shodan honeyscore 123.59.161.39 #ip是百合网
5、Python-shodan 使用
导入 shodan
SHODAN_API_KEY = ‘pde7mB56vGwCWh2yKjj87z9ucYDiPwYg’
api = shodan.Shodan(SHODAN_API_KEY)
查看参数并返回结果
返回的结果数据为json格式
6、sqlmap 介绍
Sqlmap 介绍
Sqlmap 是一个开源渗透工具,可以自动化检测和利用 SQL 注入缺陷并接管数据库服务器的过程。他拥有强大的检测引擎,许多适合终极渗透测试的小众特性和广泛的开关,从数据库指纹、从数据库中获取数据到访问底层文件系统以及通过带外在操作系统上执行命令连接。
官网:
Sqlmap 特性
Sqlmap的下载(不需要最新版本)
7、渗透测试环境安装配置
SQL注入需要使用phpstudy软件,phpstudy功能:在本地快速搭建web项目,打开服务,打开Apache、MySQL等(需要安装phpstudy2018版本,否则与后面安装的软件不兼容)
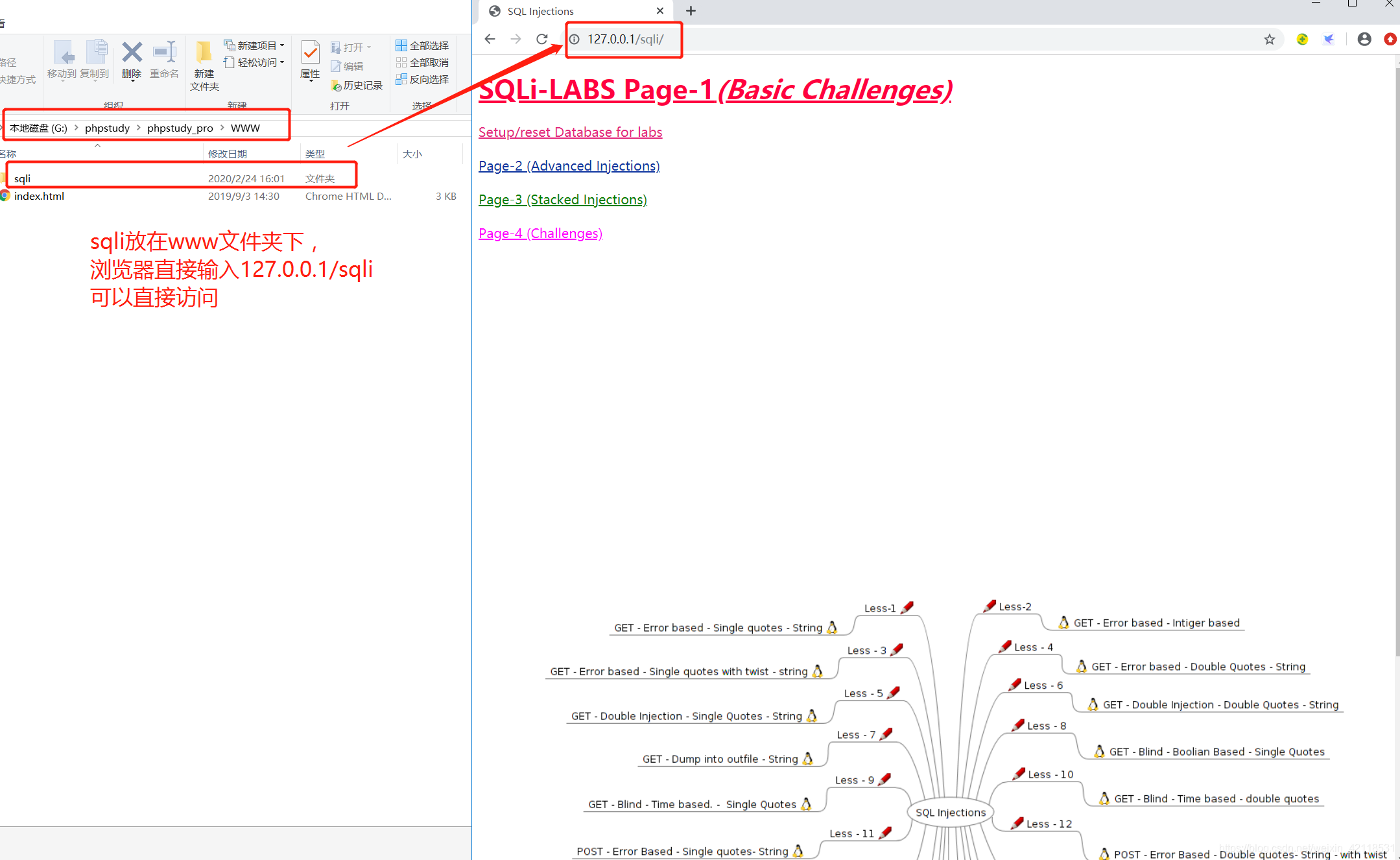
安装软件后,路径G:\phpstudy\phpstudy_pro\WWW就是后面创建WEB项目的路径
还需要安装一个软件sqli-labs-master,将解压后的文件夹放到phpstudy软件的G:\phpstudy\phpstudy_pro\WWW文件夹中,重命名为sqli(方便访问)。本地直接访问:
浏览器输入:127.0.0.1/sqli 本地直接访问
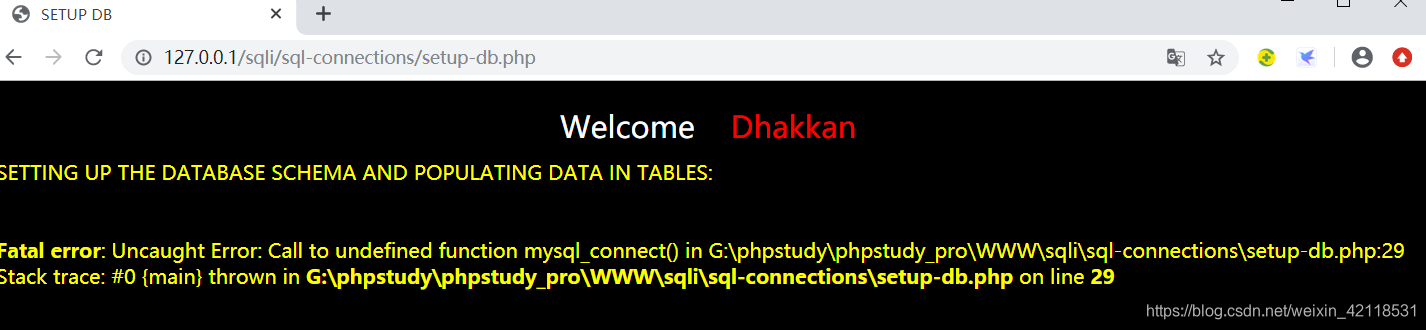
此时设置成功!
此时还不能链接数据库,显示错误
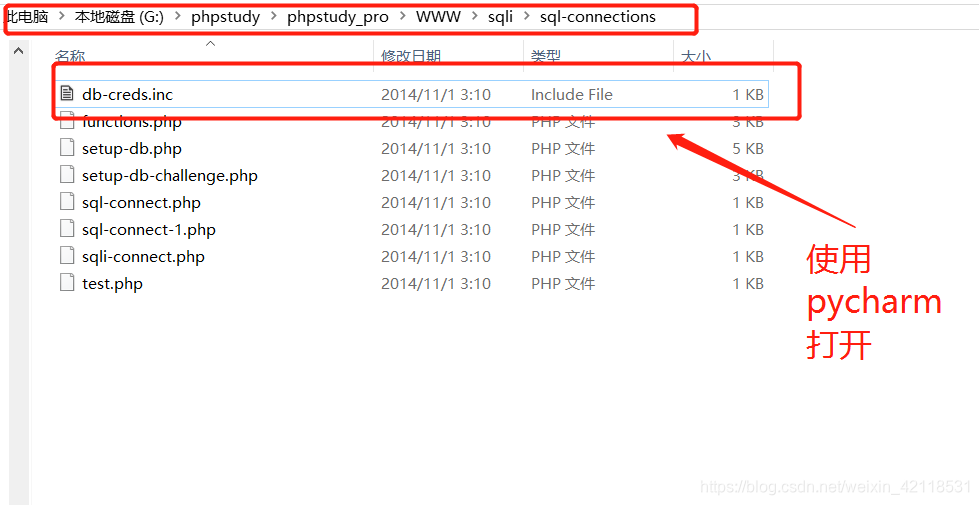
需要在G:\phpstudy\phpstudy_pro\WWW\sqli\sql-connections路径下找到db-creds.inc文件,使用pycharm打开该文件
文件内容如下:修改数据库密码(一般是初始root),保存关闭。再次验证 SQL 是否开启
验证方法:
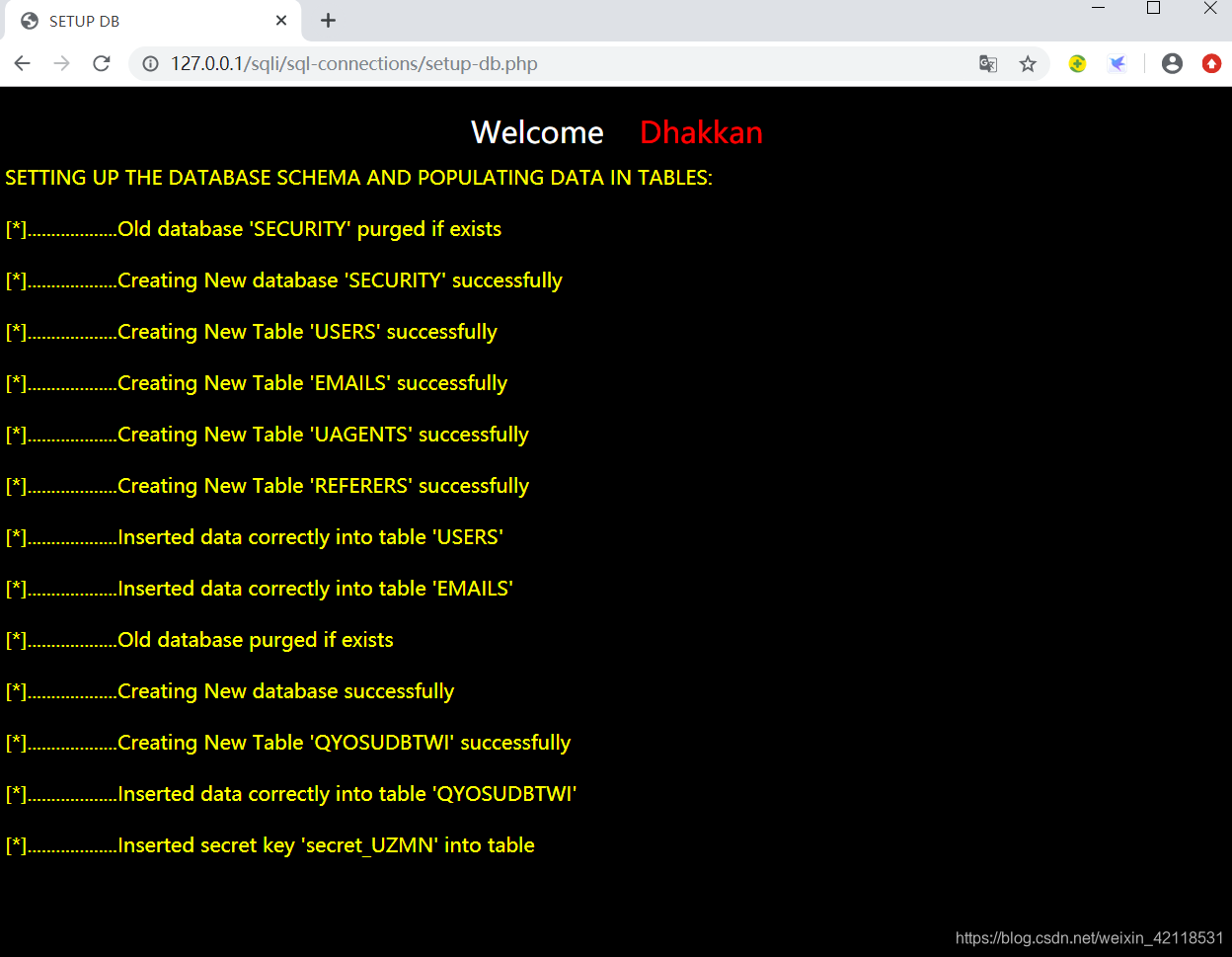
刷新网页
显示如下图:表示连接成功
点击后如下图:
另一种验证方法:打开phpstudy2018的MySQL命令行
如下图:如果数据库信息匹配,则证明连接成功。
还需要安装一个软件DVWA-master,将解压后的文件夹放到phpstudy软件的G:\phpstudy\phpstudy_pro\WWW文件夹中,重命名为DVWA(方便访问),然后就可以直接访问:
浏览器输入:127.0.0.1/dwa 直接访问(windows系统下不区分大小写)
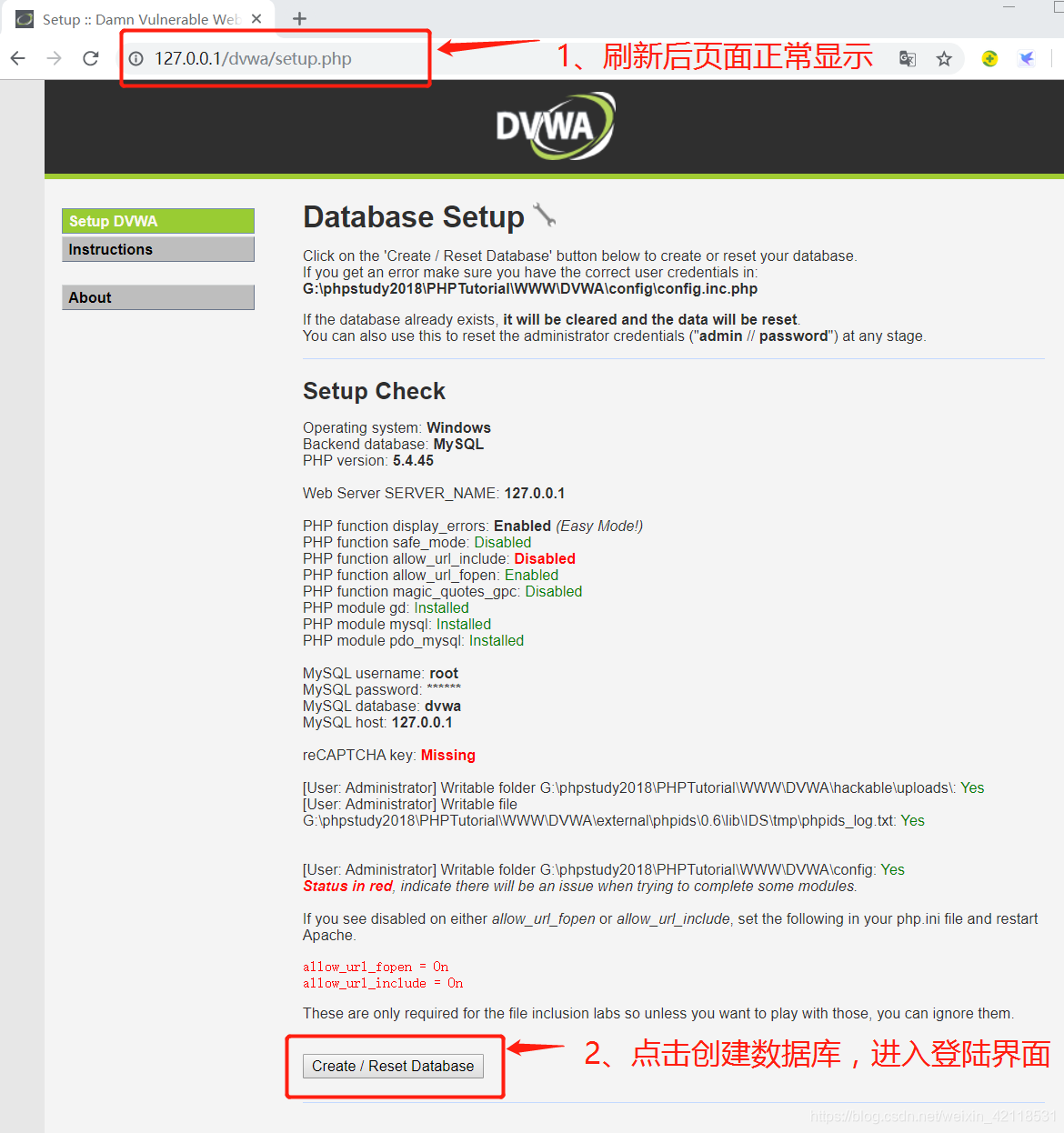
以上连接说明G:\phpstudy2018\PHPTutorial\WWW\DVWA\config路径下的文件配置不正确,需要对文件config.inc.php.dist进行如下操作:
使用pycharm打开上面修改的2号文件config.inc.php,继续修改参数如下:
刷新之前的127.0.0.1/dwa界面,显示可以创建数据库,点击进入登录界面
下图显示创建成功:
到此,渗透测试环境搭建完毕! 查看全部
通过关键词采集文章采集api(【干货】注册CDN的几种方法,你了解吗?)
1、真实IP地址采集
CDN 介绍
CDN的全称是Content Delivery Network,即内容分发网络
网址:
判断CDN是否存在
例如:百度有CDN服务器地址14.215.177.39
绕过 CDN
如果目标不使用CDN,可以直接使用ping 获取IP地址。或者在线使用网站
验证 IP 地址
使用IP地址访问网站,如果正常,就是真实IP地址。否则就不是真的。
2、shodan 介绍
信息采集方式
1.Active 信息采集:直接与目标交互,在交互过程中采集信息
2.Passive 信息采集:通过第三方引擎与目标交互,或者不允许目标交互查询数据库获取目标信息
Shodan 搜索引擎介绍
虽然目前人们认为谷歌是最强的搜索引擎,但shodan是互联网上最可怕的搜索引擎。与谷歌不同的是,Shodan不会在互联网上搜索网址,而是直接进入互联网的后台渠道。 Shodan可以说是一个“黑暗”的谷歌,寻找所有与互联网相关的服务器、摄像头、打印机、路由器等。
Shodan 网址:
Shodan 注册和登录:获取 API 密钥以供使用
API 密钥:pde7mB56vGwCWh2yKjj87z9ucYDiPwYg
shodan 搜索
1.在资源管理器搜索框中输入网络摄像头进行搜索(摄像头)
2.通过关键字port指定一个具体的端口号。
3.通过关键字host指定一个具体的IP地址。
4.通过关键字city指定特定城市的搜索内容。

3、shodan 安装命令行
pip 安装 shodan
shodan 初始化命令行:shoden 的 API key:pde7mB56vGwCWh2yKjj87z9ucYDiPwYg
shodan init pde7mB56vGwCWh2yKjj87z9ucYDiPwYg
查找特定服务的数量
1>查看Apache服务器数量
2>查看Tomcat服务器数量
Shodan 命令行搜索功能
shodan 搜索 microsoft iis 6.0
Shodan获取指定IP地址信息
shodan 主机 ip 地址
Shodan 获取帐户信息
shodan 信息
Shodan 获取自己的外部 IP 地址
shodan myip
示例如下:
搜索关键字段的tomcat
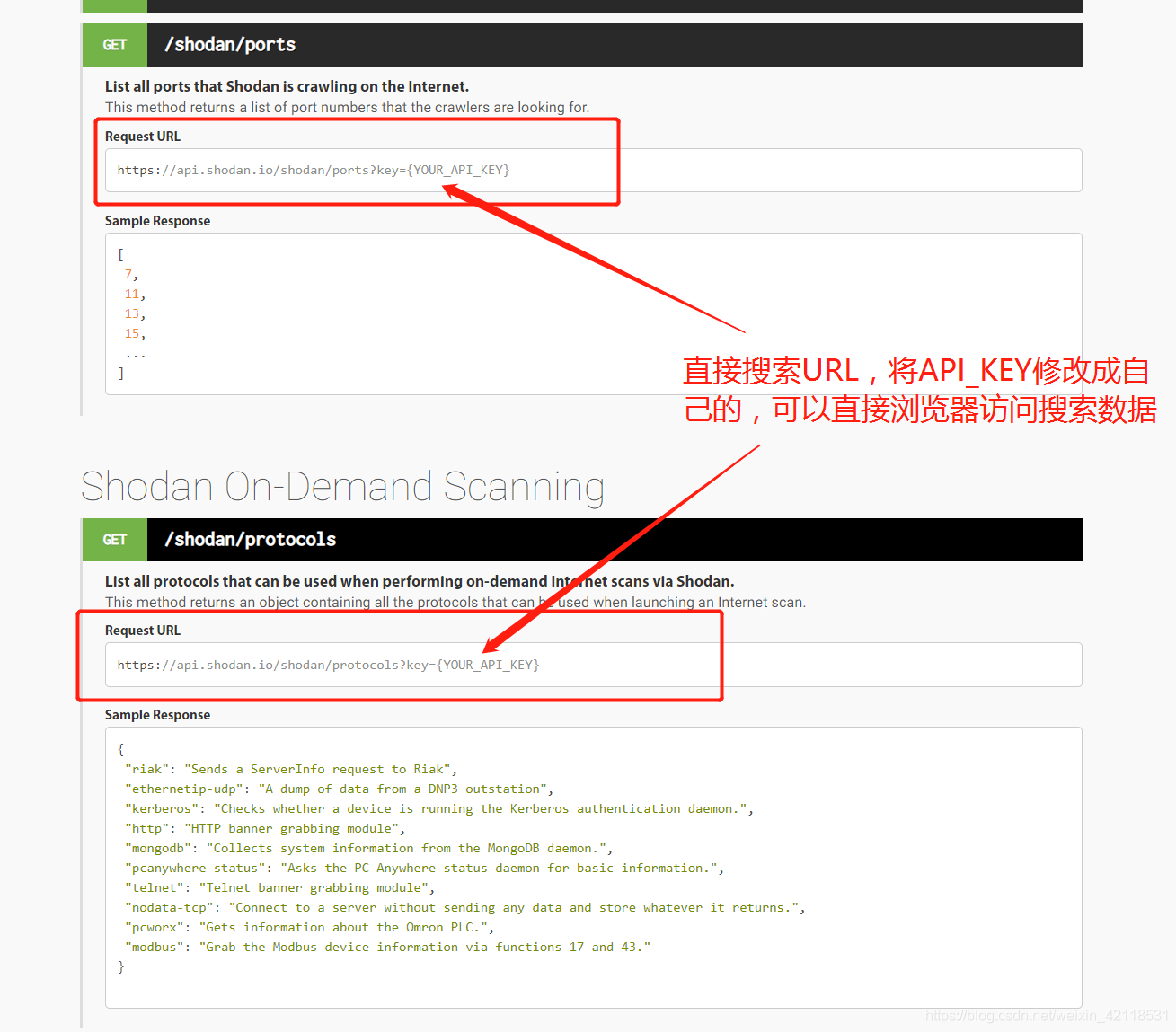
4、检测是否有蜜罐保护
蜜罐技术
蜜罐技术本质上是一种欺骗攻击者的技术。通过布置一些主机、网络服务或信息作为诱饵,可以诱导攻击者对其进行攻击,从而捕获和分析攻击行为。 , 了解攻击者使用的工具和方法,并猜测攻击的意图和动机,可以让防御者清楚地了解他们面临的安全威胁,并利用技术和管理方法来增强实际系统的安全防护能力.
shodan honeyscore 123.59.161.39 #ip是百合网
5、Python-shodan 使用
导入 shodan
SHODAN_API_KEY = ‘pde7mB56vGwCWh2yKjj87z9ucYDiPwYg’
api = shodan.Shodan(SHODAN_API_KEY)
查看参数并返回结果
返回的结果数据为json格式
6、sqlmap 介绍
Sqlmap 介绍
Sqlmap 是一个开源渗透工具,可以自动化检测和利用 SQL 注入缺陷并接管数据库服务器的过程。他拥有强大的检测引擎,许多适合终极渗透测试的小众特性和广泛的开关,从数据库指纹、从数据库中获取数据到访问底层文件系统以及通过带外在操作系统上执行命令连接。
官网:
Sqlmap 特性
Sqlmap的下载(不需要最新版本)
7、渗透测试环境安装配置
SQL注入需要使用phpstudy软件,phpstudy功能:在本地快速搭建web项目,打开服务,打开Apache、MySQL等(需要安装phpstudy2018版本,否则与后面安装的软件不兼容)
安装软件后,路径G:\phpstudy\phpstudy_pro\WWW就是后面创建WEB项目的路径
还需要安装一个软件sqli-labs-master,将解压后的文件夹放到phpstudy软件的G:\phpstudy\phpstudy_pro\WWW文件夹中,重命名为sqli(方便访问)。本地直接访问:
浏览器输入:127.0.0.1/sqli 本地直接访问
此时设置成功!

此时还不能链接数据库,显示错误
需要在G:\phpstudy\phpstudy_pro\WWW\sqli\sql-connections路径下找到db-creds.inc文件,使用pycharm打开该文件
文件内容如下:修改数据库密码(一般是初始root),保存关闭。再次验证 SQL 是否开启
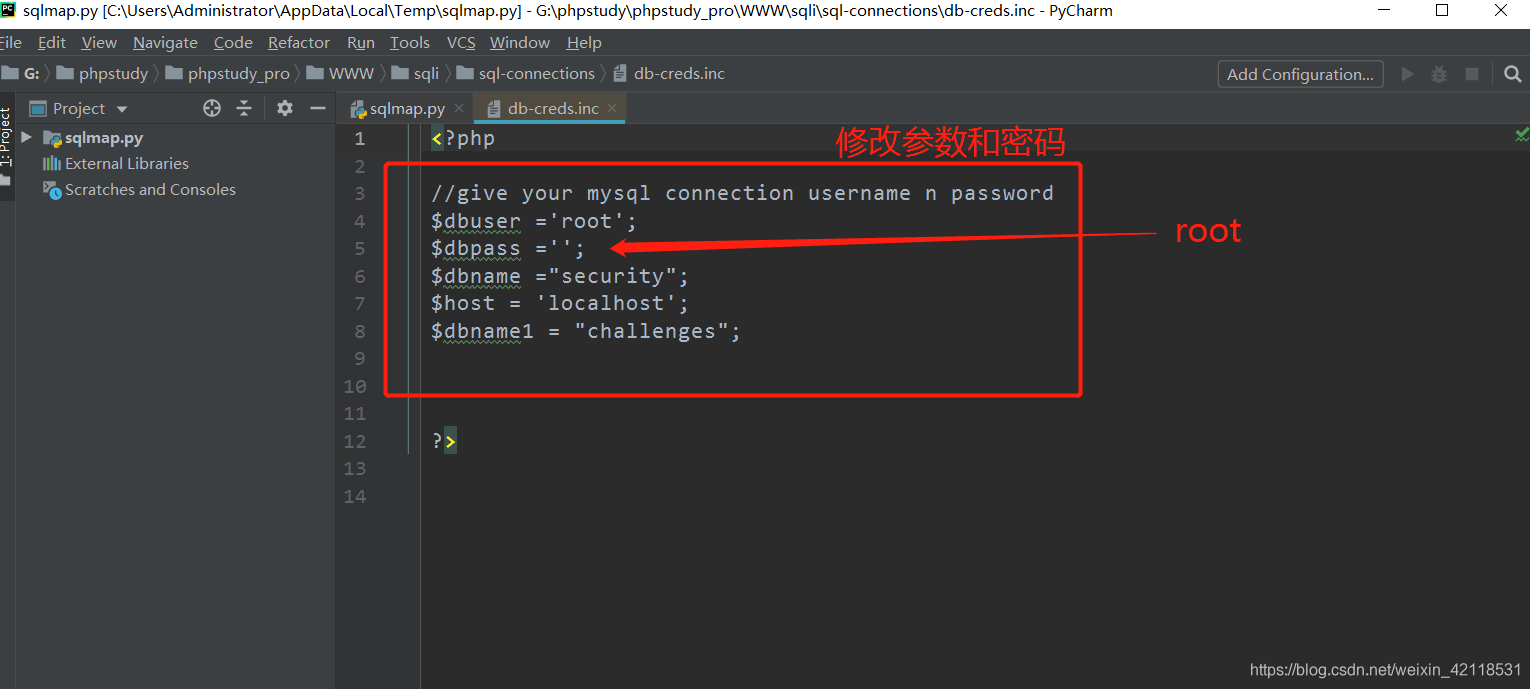
验证方法:
刷新网页
显示如下图:表示连接成功
点击后如下图:
另一种验证方法:打开phpstudy2018的MySQL命令行

如下图:如果数据库信息匹配,则证明连接成功。
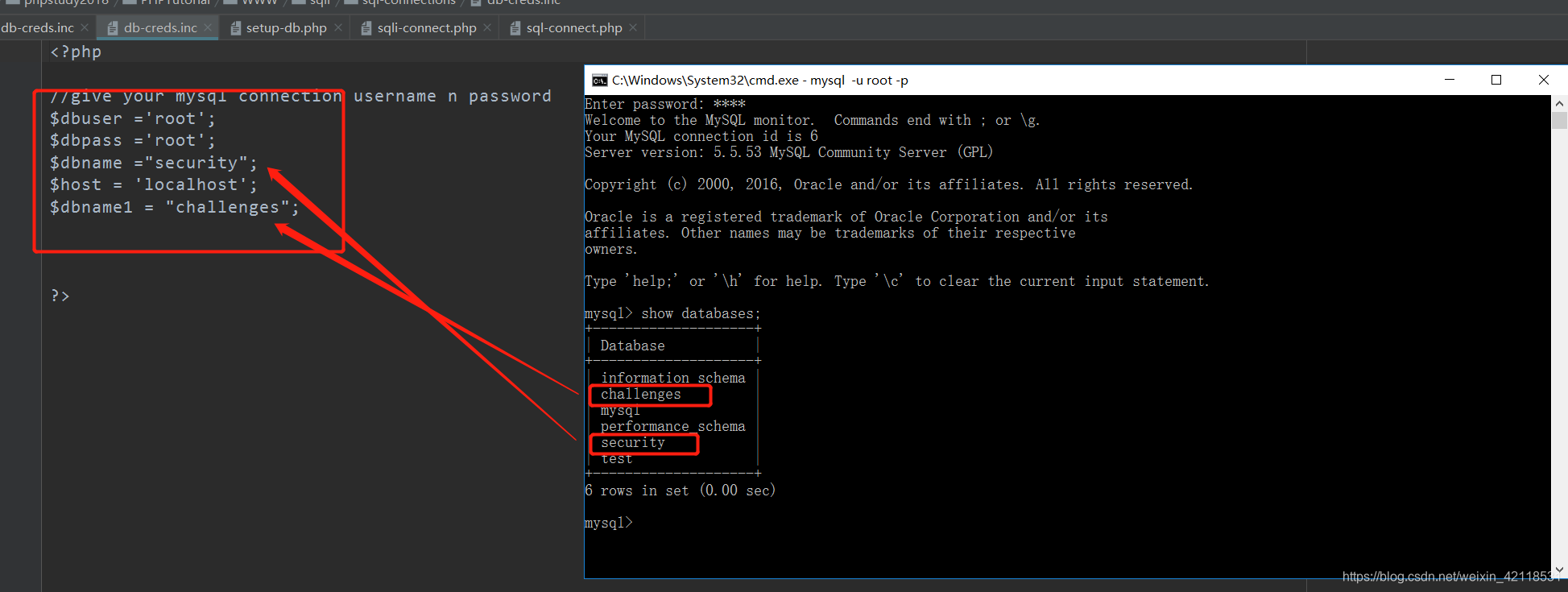
还需要安装一个软件DVWA-master,将解压后的文件夹放到phpstudy软件的G:\phpstudy\phpstudy_pro\WWW文件夹中,重命名为DVWA(方便访问),然后就可以直接访问:
浏览器输入:127.0.0.1/dwa 直接访问(windows系统下不区分大小写)
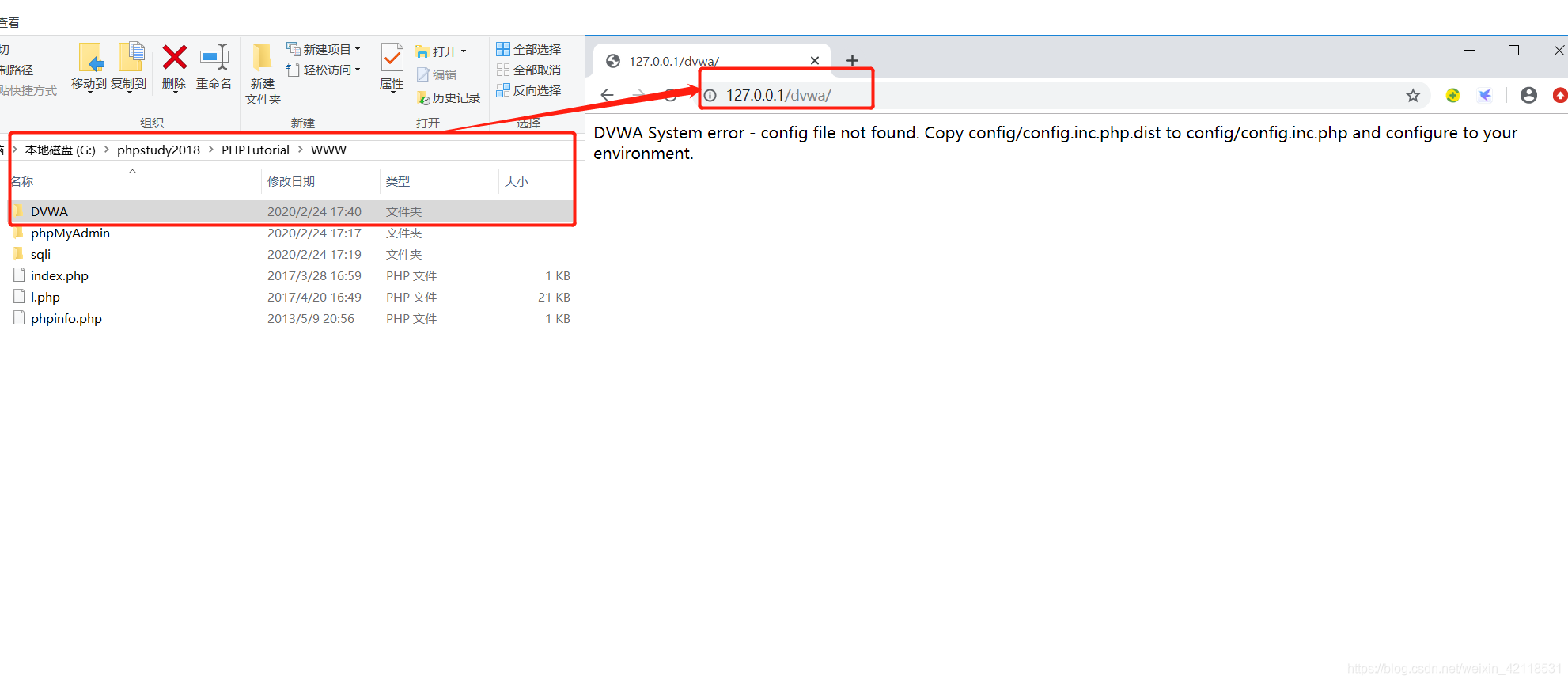
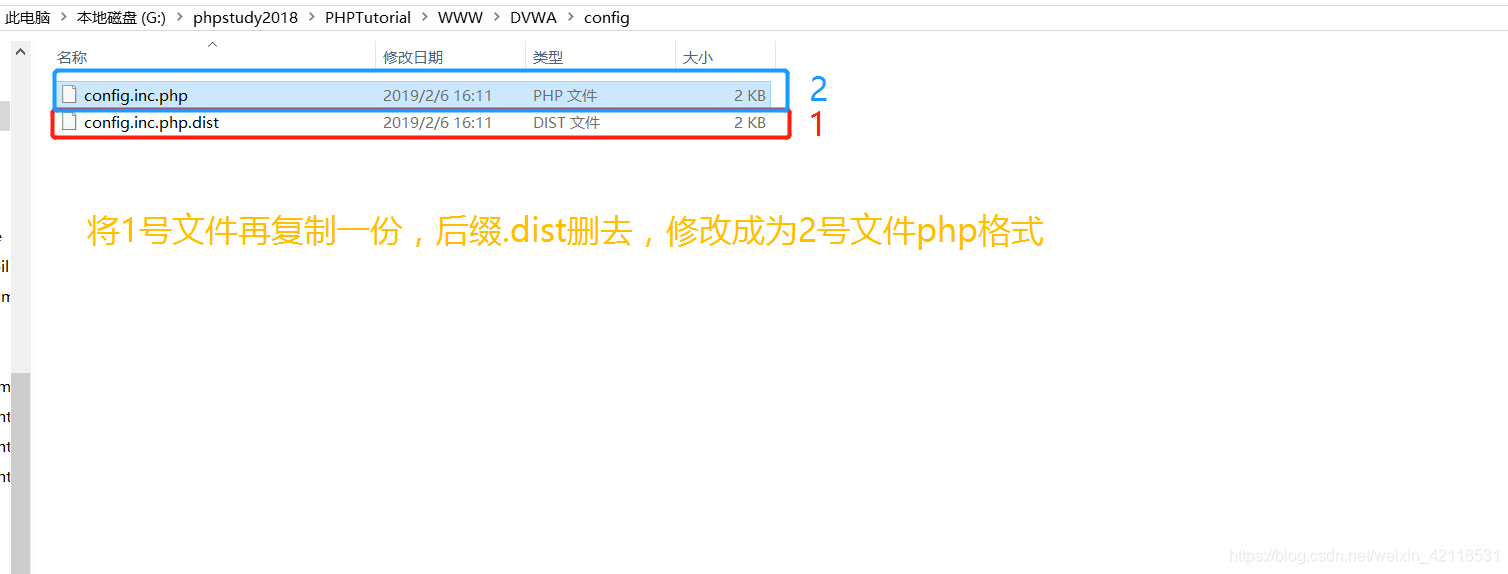
以上连接说明G:\phpstudy2018\PHPTutorial\WWW\DVWA\config路径下的文件配置不正确,需要对文件config.inc.php.dist进行如下操作:
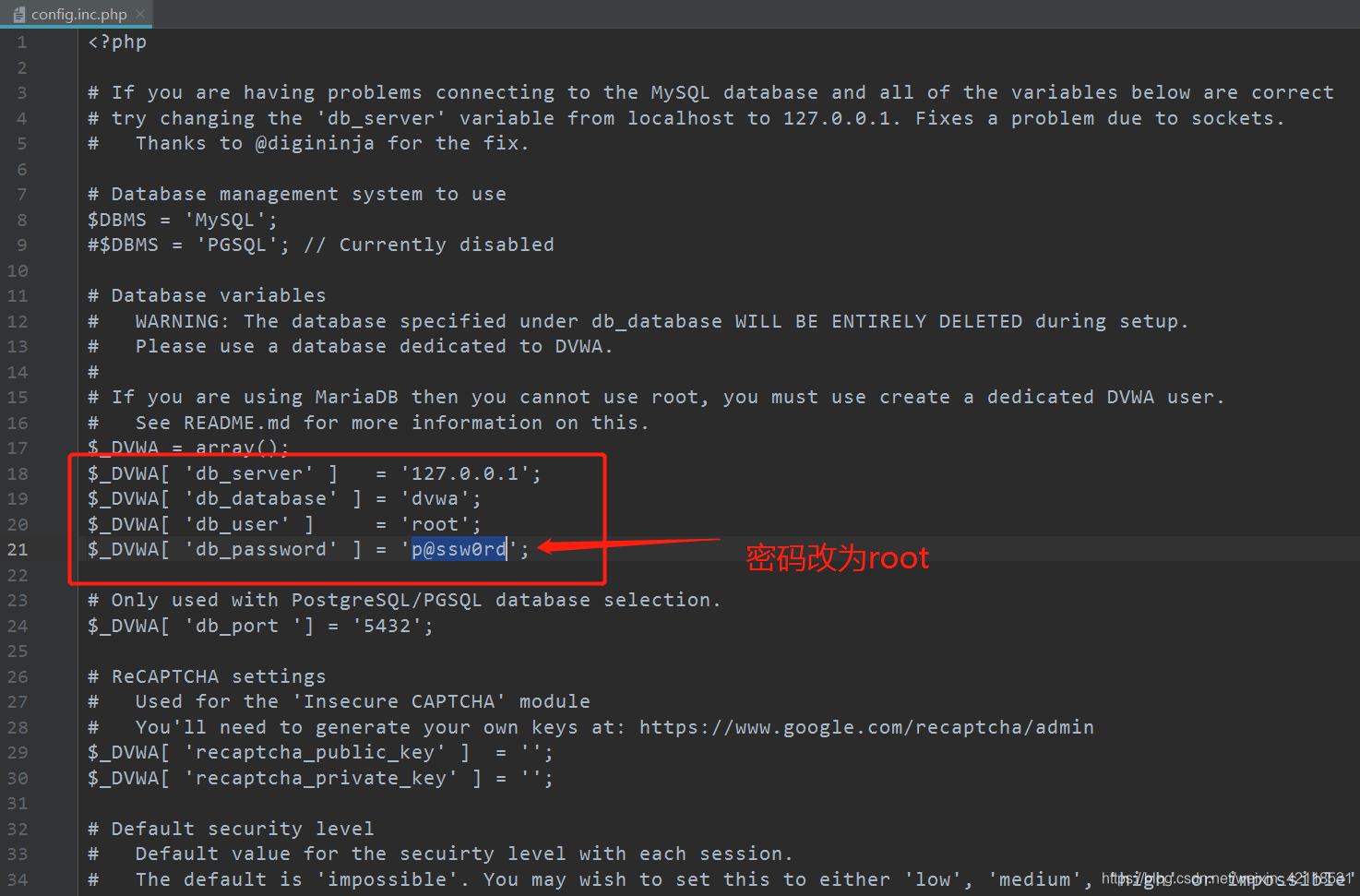
使用pycharm打开上面修改的2号文件config.inc.php,继续修改参数如下:
刷新之前的127.0.0.1/dwa界面,显示可以创建数据库,点击进入登录界面

下图显示创建成功:
到此,渗透测试环境搭建完毕!
通过关键词采集文章采集api(报表开发神器:phantomjs生成网页PDF,Echarts报表实战导航)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-11 23:09
报表开发神器:phantomjs生成网页PDF,Echarts报表实战
导航:
一. 关于phantomjs 1.1 什么是phantomjs?
(1)一个基于webkit内核的无头浏览器,即没有UI界面,即是浏览器,但需要设计和设计与人相关的点击、翻页等操作实施。
(2)提供了javascript API接口,即可以通过编写js程序直接与webkit内核交互。在此基础上还可以结合java语言等,通过调用js等相关操作java,从而解决了之前c/c++天赋最好基于webkit开发高质量的采集器限制。
(3)提供windows、linux、mac等不同操作系统的安装和使用包,这意味着采集项目可以在不同平台上重新开发或自动项目测试。
1.2 phantomjs 常用API介绍
常用的几个主要内置对象
通用API
注意事项
使用总结:主要是java se+js+phantomjs的应用,
1.3 我可以用 phantomjs 做什么?
生成的PDF基本恢复了原来的风格,图文分离,不是直接截图;如果有生成PDF的需求,可以考虑如何生成和使用phantomjs来实现功能;我已经用Html模板生成了Html页面,然后把这个页面上传到FastDfs服务器,然后通过返回的url直接生成这个pdf,就完成了与html页面一致的pdf生成功能;
二. Windows 下安装phantomjs 2.1 概览2.1 下载安装phantomjs 测试是否安装成功:三. Linux 下安装phantomjs 3.1 概览3.2 安装过程如下:
进入里面后,可以执行js命令,如果需要退出,按Ctrl+C强制退出
解决中文乱码(可选,遇到这个问题可以解决) 正常例子:(Windows下显示正常如图:) 错误例子:(Linux下乱码显示为如图:) 解决方法:在Linux下执行命令:
yum install bitmap-fonts bitmap-fonts-cjk
执行此命令后,可能只显示中文,但数字仍会显示空格。如果有数字显示空格,将所有windows字体导入Linux,见下。
导入字体:四.使用Phantomjs生成Echarts图片4.1 概述:Linux下:
Windows 和 Linux 环境的区别: ① 配置环境变量。因为phantomjs的启动方式,windows执行的是exe文件,而Linux不是,所以配置好环境变量后,java在机器上和Linux下测试不需要做任何修改; ② Phantomjs 执行生成 Echarts 图片时,需要引用 jquery.1.9.1.min.js ,echarts-convert.js, echarts.min.js 并生成 Echarts js文件。这些js是需要引用的,在Linux上部署的时候,生成的js文件在jar包里,可能不可读。我们可以通过代码将js文件复制到jar包的同级目录下,然后通过路径加载。可以使用以下代码读取和生成路径加载:
~~~java
/* 生成模板到指定位置判断文件是否存在,如果不存在则创建 */
文件 echartsfile = new File(System.getProperty("user.dir") + "\echarts-all.js");
if (!echartsfile.exists()) {
FileUtil.file2file("js/echarts-all.js", System.getProperty("user.dir") + "\echarts-all.js");
}
~~~
4.2 作者实现思路: 第二步:整理思路:生成需要生成的Echarts js代码:找到相关的Echarts图片模板:Echarts官网使用Framework等技术:生成一个final来自模板+数据的js文件;以Framework为例:将另外三个js文件放在其他位置,博主的做法是将这三个放在jar包目录下,但是会有phantomjs无法读取和执行的情况(即phantomjs除外) code可以读取内容,但是phantomjs的执行不能通过引用读取)。所以博主拿的是先把它读出来,然后写出jar包供参考;这样Linux下就可以通过路径读取了;阅读代码示例:
/* 将模板生成到指定的位置 判断文件是否存在,如果不存在则创建 */
File echartsfile = new File(System.getProperty("user.dir") + "\\echarts-all.js");
if (!echartsfile.exists()) {
FileUtil.file2file("js/echarts-all.js", System.getProperty("user.dir") + "\\echarts-all.js");
}
File jsfile = new File(outPathAndName);
if (!jsfile.exists()) {
FileUtil.string2File(outPathAndName, echartTemplate.getFileContent()); // 将js文件生成到指定的位置
}
File convertfile = new File(System.getProperty("user.dir") + "\\echarts-convert.js");
String echartsPath = System.getProperty("user.dir") + "\\echarts-convert.js";
if (!convertfile.exists()) {
FileUtil.file2file("js/echarts-convert.js", echartsPath);
}
File jqueryfile = new File(System.getProperty("user.dir") + "\\jquery.1.9.1.min.js");
if (!jqueryfile.exists()) {
FileUtil.file2file("js/jquery.1.9.1.min.js", System.getProperty("user.dir") + "\\jquery.1.9.1.min.js");
}
关键代码:System.getProperty("user.dir")为Windows或Linux下的当前路径,百度可以使用。
将现有的echarts-convert.js等文件+生成的Echarts.js文件与数据和Demo示例代码结合,生成Echarts图片;我们可以将Echart图片上传到Fastdfs等图片服务器,只需获取网络图片url即可;当然最后一步取决于业务需求; 五.使用Phantomjs生成PDF文档(HTML转PDF)5.1概述5.2生成原理5.3扩展思路六.使用Phantomjs+Poi.tl生成Word文档6.1概述6.2 想法 查看全部
通过关键词采集文章采集api(报表开发神器:phantomjs生成网页PDF,Echarts报表实战导航)
报表开发神器:phantomjs生成网页PDF,Echarts报表实战
导航:
一. 关于phantomjs 1.1 什么是phantomjs?
(1)一个基于webkit内核的无头浏览器,即没有UI界面,即是浏览器,但需要设计和设计与人相关的点击、翻页等操作实施。
(2)提供了javascript API接口,即可以通过编写js程序直接与webkit内核交互。在此基础上还可以结合java语言等,通过调用js等相关操作java,从而解决了之前c/c++天赋最好基于webkit开发高质量的采集器限制。
(3)提供windows、linux、mac等不同操作系统的安装和使用包,这意味着采集项目可以在不同平台上重新开发或自动项目测试。
1.2 phantomjs 常用API介绍
常用的几个主要内置对象
通用API
注意事项
使用总结:主要是java se+js+phantomjs的应用,
1.3 我可以用 phantomjs 做什么?
生成的PDF基本恢复了原来的风格,图文分离,不是直接截图;如果有生成PDF的需求,可以考虑如何生成和使用phantomjs来实现功能;我已经用Html模板生成了Html页面,然后把这个页面上传到FastDfs服务器,然后通过返回的url直接生成这个pdf,就完成了与html页面一致的pdf生成功能;
二. Windows 下安装phantomjs 2.1 概览2.1 下载安装phantomjs 测试是否安装成功:三. Linux 下安装phantomjs 3.1 概览3.2 安装过程如下:
进入里面后,可以执行js命令,如果需要退出,按Ctrl+C强制退出
解决中文乱码(可选,遇到这个问题可以解决) 正常例子:(Windows下显示正常如图:) 错误例子:(Linux下乱码显示为如图:) 解决方法:在Linux下执行命令:
yum install bitmap-fonts bitmap-fonts-cjk
执行此命令后,可能只显示中文,但数字仍会显示空格。如果有数字显示空格,将所有windows字体导入Linux,见下。
导入字体:四.使用Phantomjs生成Echarts图片4.1 概述:Linux下:
Windows 和 Linux 环境的区别: ① 配置环境变量。因为phantomjs的启动方式,windows执行的是exe文件,而Linux不是,所以配置好环境变量后,java在机器上和Linux下测试不需要做任何修改; ② Phantomjs 执行生成 Echarts 图片时,需要引用 jquery.1.9.1.min.js ,echarts-convert.js, echarts.min.js 并生成 Echarts js文件。这些js是需要引用的,在Linux上部署的时候,生成的js文件在jar包里,可能不可读。我们可以通过代码将js文件复制到jar包的同级目录下,然后通过路径加载。可以使用以下代码读取和生成路径加载:
~~~java
/* 生成模板到指定位置判断文件是否存在,如果不存在则创建 */
文件 echartsfile = new File(System.getProperty("user.dir") + "\echarts-all.js");
if (!echartsfile.exists()) {
FileUtil.file2file("js/echarts-all.js", System.getProperty("user.dir") + "\echarts-all.js");
}
~~~
4.2 作者实现思路: 第二步:整理思路:生成需要生成的Echarts js代码:找到相关的Echarts图片模板:Echarts官网使用Framework等技术:生成一个final来自模板+数据的js文件;以Framework为例:将另外三个js文件放在其他位置,博主的做法是将这三个放在jar包目录下,但是会有phantomjs无法读取和执行的情况(即phantomjs除外) code可以读取内容,但是phantomjs的执行不能通过引用读取)。所以博主拿的是先把它读出来,然后写出jar包供参考;这样Linux下就可以通过路径读取了;阅读代码示例:
/* 将模板生成到指定的位置 判断文件是否存在,如果不存在则创建 */
File echartsfile = new File(System.getProperty("user.dir") + "\\echarts-all.js");
if (!echartsfile.exists()) {
FileUtil.file2file("js/echarts-all.js", System.getProperty("user.dir") + "\\echarts-all.js");
}
File jsfile = new File(outPathAndName);
if (!jsfile.exists()) {
FileUtil.string2File(outPathAndName, echartTemplate.getFileContent()); // 将js文件生成到指定的位置
}
File convertfile = new File(System.getProperty("user.dir") + "\\echarts-convert.js");
String echartsPath = System.getProperty("user.dir") + "\\echarts-convert.js";
if (!convertfile.exists()) {
FileUtil.file2file("js/echarts-convert.js", echartsPath);
}
File jqueryfile = new File(System.getProperty("user.dir") + "\\jquery.1.9.1.min.js");
if (!jqueryfile.exists()) {
FileUtil.file2file("js/jquery.1.9.1.min.js", System.getProperty("user.dir") + "\\jquery.1.9.1.min.js");
}
关键代码:System.getProperty("user.dir")为Windows或Linux下的当前路径,百度可以使用。
将现有的echarts-convert.js等文件+生成的Echarts.js文件与数据和Demo示例代码结合,生成Echarts图片;我们可以将Echart图片上传到Fastdfs等图片服务器,只需获取网络图片url即可;当然最后一步取决于业务需求; 五.使用Phantomjs生成PDF文档(HTML转PDF)5.1概述5.2生成原理5.3扩展思路六.使用Phantomjs+Poi.tl生成Word文档6.1概述6.2 想法
通过关键词采集文章采集api(AMZHelper 用户手册 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-09-07 18:21
)
随着AMZHelper的功能越来越多,虽然我觉得每个功能独立都可以过千元,但是因为亮点太多,很多成员都觉得一头雾水。
老蛇本人并没有系统的操作流程,因为他通常会想到如何使用。 (老司机经常这样!)
今天给一些新手做系统总结。
按照做亚马逊的顺序列出哪些功能可用。
产品选择/Listing优化/评价/订单量(转化率)//提升排名/关联/邮件营销/PPC分析几个因素来解释我们平台的功能。
----------------------------------------------- ------------
##选品##(数据选择/痛点分析/热钱分析)
1.1:数据选择
使用的功能:软件(A、其他工具-类别选择辅助)
目前老蛇对选品功能的总结:可以提高选品的成功率,让选品思路更清晰。
使用软件爬虫实现本应手动操作、无人值守的批量操作。
最后,可以进一步过滤采集到的数据。
所选产品的功能介绍:
1.2Shop 跟踪选择
使用的功能:网页:产品选择分析工具---存储新产品跟踪数据
输入店铺ID,AMZHelper会进行云端追踪,每天为您展示最新的数据报告。
操作如下:
第二天后的结果:
点击数字:您可以输入成本并获得毛利。可以点击未选中进行选中(切换)操作。
2:痛点分析
使用的功能:软件(2、Mailbox采集)
当然,在开发产品的时候,如果能解决用户的痛点就更完美了。
然后我们可以通过采集bad review的形式找出用户的痛点。那么在选择产品的时候就可以注意这些问题了。我们可以避开对手的坑。
先用关键词采集工具采集对应的ASIN,然后发邮件采集采集差评,统一整理分析。
3:热销属性分析
使用的功能:软件(2、Mailbox采集)
我们知道,当我们开发某种产品时,会有颜色和尺寸的因素。
但是当我们在测试模型时,我们不能想当然地认为哪个卖得好,哪个颜色卖得好。
那么数据分析也很重要。同理,用上面的“不是采集邮箱,只有采集评论内容”打勾
同时选择四颗星及以下打勾(五颗星大部分都刷了)
得到的数据如下:
然后我们可以通过对手的一些数据展示来分析一下对手的产品销量哪个属性比较大。
(PS:也可以每天测量对方的属性盘点,然后进行数据分析。)
##Listing Optimization##(采集标题和卖点/采集用户痛点写成卖点)
在优化listing时,我们要设计好标题和五个好卖点。
如果想把字埋在标题里,卖点不明确。然后您可以使用我们助手软件的以下功能进行帮助。
1、Title 和卖点合集
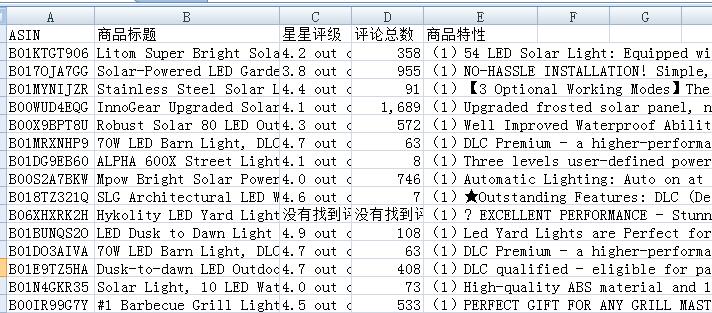
使用的功能:软件(5、关键词采集ASIN、9、analysis aid)
先用“5.关键词采ASIN”再用9.analysis辅助标题和卖点采集
采集的结果:
标题,直接复制到txt文件即可直观查看。
然后将特征复制到txt文件中,然后将后缀改为:html file open
然后我们就可以更轻松地梳理出我们想要的关键词和卖点。
采集如何使用这些数据?
1、 参考对方的标题和卖点怎么写。
2、分析对手在标题和卖点中埋下了哪些词。
(使用词频分析工具:)
2、分析用户痛点
使用的功能:软件(2、Mailbox采集)
同时,如果你能解决用户对你的卖点的疑惑,是否能让用户在更短的时间内做出正确的决定?
同时可以通过QA的形式解决产品的痛点。
那我们就可以用采集bad review这个软件,看看用户有哪些痛点。然后,梳理一下我们解决的痛点,写进卖点。
比如:用户的痛点是产品容易老化,那么你的产品是不锈钢的,那你就可以写成卖点了。
这些卖点也可以直接上图。 (先想套路,再分析如何使用工具。)
##测测##(返回评论模式,不评论,不返现)
Haoreview是AMZHelper平台下的网站。通过AMZhelper多年的审稿人资源的积累,形成了一个以美国用户为主的平台。
平台的规则是只有评论才会返现。这样,我们卖家的利益才能得到最大化。 (共有三种模式:超级URL交易无评论模式、评论模式、超级URL交易+评论模式)
##做链接##(通过合作名人数据管理)
使用的功能:邀请模式+采集邮箱+邮件模板设置
示例:
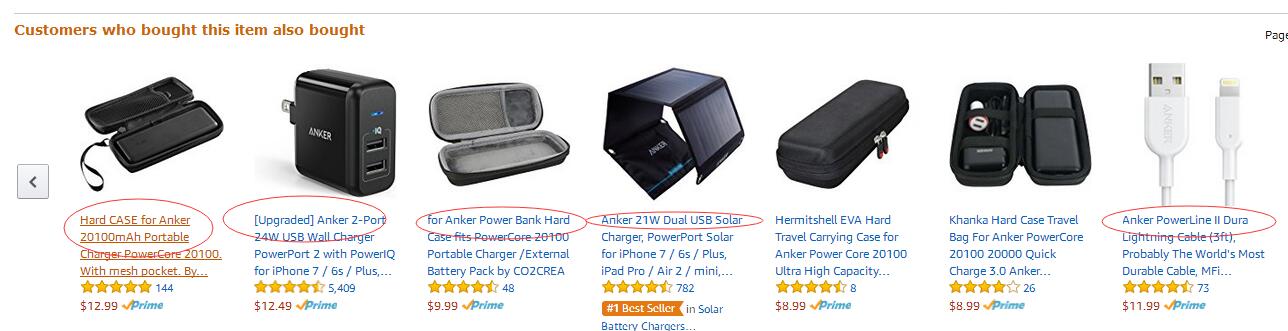
黄金搭档========》
买买买========》
他们的黄金搭档怎么又买了这个?
根据亚马逊算法的测试分析,在一定时期内购买和购买的两种产品的数量越大,排名越高。
购买产品A的客户(即使是一年前)最近购买了产品B,则排名+1(例如,在周期的一个月内),如果购买产品B的人越多,则A产品在listing下方,B产品的排名会更高。
那么根据上面的算法规则:
我们只需要采集一些购买过产品A的客户,展示新产品,给他们做营销,形成交易,让我们和我们的产品产生关联,从而达到最大的流量拦截。
使用的功能:邀请模式+采集邮箱+邮件模板设置
只要新品在短时间内交易几十个订单,就可以实现上述关联。 (当然,这取决于产品的受欢迎程度和竞争程度。)
##邮营销##(邮件营销成本最低,大数据营销,转化快速高效)
使用的功能:邀请模式、审稿人采集管理、大数据邮件管理、邮件模板(设置)软件(5、关键词采集ASIN、2、Mailbox采集)
目前传统的EDM营销转化率只有0.5%,但由于我们的AMZHelper实时抓取数据,我们的邮箱都是亚马逊上真实有效的买家邮箱。
所以如果数据准确的话,3%的转化率也不是什么大问题。
计算一个账户,我们假设转化率只有0.5%,那么1000封邮件就会发出5个订单。一个邮箱1.2美分,费用12元。交易了5个订单。稳赚不亏。
AMZHelper已对接国内知名:思奇群发邮件平台,国际知名EDM频道:猎豹邮箱
PS:我们如何使用 EDM 营销?
1、新品推广期,促销。
2、库存清理。
3、Associated Marketing。
4、holiday 促销。
操作流程:
1、准备邮件数据:使用AMZHelpler软件采集,或者直接拨打我们平台的大数据邮箱。
2、以邀请方式添加产品。
3、 导入邮箱或调用平台邮箱数据。
4、使用 EDM 群发邮件。 查看全部
通过关键词采集文章采集api(AMZHelper 用户手册
)
随着AMZHelper的功能越来越多,虽然我觉得每个功能独立都可以过千元,但是因为亮点太多,很多成员都觉得一头雾水。

老蛇本人并没有系统的操作流程,因为他通常会想到如何使用。 (老司机经常这样!)
今天给一些新手做系统总结。
按照做亚马逊的顺序列出哪些功能可用。
产品选择/Listing优化/评价/订单量(转化率)//提升排名/关联/邮件营销/PPC分析几个因素来解释我们平台的功能。
----------------------------------------------- ------------
##选品##(数据选择/痛点分析/热钱分析)
1.1:数据选择
使用的功能:软件(A、其他工具-类别选择辅助)
目前老蛇对选品功能的总结:可以提高选品的成功率,让选品思路更清晰。
使用软件爬虫实现本应手动操作、无人值守的批量操作。
最后,可以进一步过滤采集到的数据。
所选产品的功能介绍:
1.2Shop 跟踪选择
使用的功能:网页:产品选择分析工具---存储新产品跟踪数据
输入店铺ID,AMZHelper会进行云端追踪,每天为您展示最新的数据报告。
操作如下:

第二天后的结果:

点击数字:您可以输入成本并获得毛利。可以点击未选中进行选中(切换)操作。

2:痛点分析
使用的功能:软件(2、Mailbox采集)
当然,在开发产品的时候,如果能解决用户的痛点就更完美了。
然后我们可以通过采集bad review的形式找出用户的痛点。那么在选择产品的时候就可以注意这些问题了。我们可以避开对手的坑。
先用关键词采集工具采集对应的ASIN,然后发邮件采集采集差评,统一整理分析。

3:热销属性分析
使用的功能:软件(2、Mailbox采集)
我们知道,当我们开发某种产品时,会有颜色和尺寸的因素。
但是当我们在测试模型时,我们不能想当然地认为哪个卖得好,哪个颜色卖得好。
那么数据分析也很重要。同理,用上面的“不是采集邮箱,只有采集评论内容”打勾
同时选择四颗星及以下打勾(五颗星大部分都刷了)
得到的数据如下:
然后我们可以通过对手的一些数据展示来分析一下对手的产品销量哪个属性比较大。
(PS:也可以每天测量对方的属性盘点,然后进行数据分析。)

##Listing Optimization##(采集标题和卖点/采集用户痛点写成卖点)
在优化listing时,我们要设计好标题和五个好卖点。
如果想把字埋在标题里,卖点不明确。然后您可以使用我们助手软件的以下功能进行帮助。
1、Title 和卖点合集
使用的功能:软件(5、关键词采集ASIN、9、analysis aid)
先用“5.关键词采ASIN”再用9.analysis辅助标题和卖点采集
采集的结果:
标题,直接复制到txt文件即可直观查看。
然后将特征复制到txt文件中,然后将后缀改为:html file open


然后我们就可以更轻松地梳理出我们想要的关键词和卖点。
采集如何使用这些数据?
1、 参考对方的标题和卖点怎么写。
2、分析对手在标题和卖点中埋下了哪些词。
(使用词频分析工具:)
2、分析用户痛点
使用的功能:软件(2、Mailbox采集)
同时,如果你能解决用户对你的卖点的疑惑,是否能让用户在更短的时间内做出正确的决定?
同时可以通过QA的形式解决产品的痛点。
那我们就可以用采集bad review这个软件,看看用户有哪些痛点。然后,梳理一下我们解决的痛点,写进卖点。
比如:用户的痛点是产品容易老化,那么你的产品是不锈钢的,那你就可以写成卖点了。
这些卖点也可以直接上图。 (先想套路,再分析如何使用工具。)
##测测##(返回评论模式,不评论,不返现)
Haoreview是AMZHelper平台下的网站。通过AMZhelper多年的审稿人资源的积累,形成了一个以美国用户为主的平台。
平台的规则是只有评论才会返现。这样,我们卖家的利益才能得到最大化。 (共有三种模式:超级URL交易无评论模式、评论模式、超级URL交易+评论模式)
##做链接##(通过合作名人数据管理)
使用的功能:邀请模式+采集邮箱+邮件模板设置
示例:
黄金搭档========》

买买买========》
他们的黄金搭档怎么又买了这个?
根据亚马逊算法的测试分析,在一定时期内购买和购买的两种产品的数量越大,排名越高。
购买产品A的客户(即使是一年前)最近购买了产品B,则排名+1(例如,在周期的一个月内),如果购买产品B的人越多,则A产品在listing下方,B产品的排名会更高。
那么根据上面的算法规则:
我们只需要采集一些购买过产品A的客户,展示新产品,给他们做营销,形成交易,让我们和我们的产品产生关联,从而达到最大的流量拦截。
使用的功能:邀请模式+采集邮箱+邮件模板设置

只要新品在短时间内交易几十个订单,就可以实现上述关联。 (当然,这取决于产品的受欢迎程度和竞争程度。)
##邮营销##(邮件营销成本最低,大数据营销,转化快速高效)
使用的功能:邀请模式、审稿人采集管理、大数据邮件管理、邮件模板(设置)软件(5、关键词采集ASIN、2、Mailbox采集)
目前传统的EDM营销转化率只有0.5%,但由于我们的AMZHelper实时抓取数据,我们的邮箱都是亚马逊上真实有效的买家邮箱。
所以如果数据准确的话,3%的转化率也不是什么大问题。
计算一个账户,我们假设转化率只有0.5%,那么1000封邮件就会发出5个订单。一个邮箱1.2美分,费用12元。交易了5个订单。稳赚不亏。
AMZHelper已对接国内知名:思奇群发邮件平台,国际知名EDM频道:猎豹邮箱
PS:我们如何使用 EDM 营销?
1、新品推广期,促销。
2、库存清理。
3、Associated Marketing。
4、holiday 促销。
操作流程:
1、准备邮件数据:使用AMZHelpler软件采集,或者直接拨打我们平台的大数据邮箱。
2、以邀请方式添加产品。
3、 导入邮箱或调用平台邮箱数据。
4、使用 EDM 群发邮件。
通过关键词采集文章采集api(织梦采集侠的伪原创及搜索优化方式(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-09-07 12:05
织梦采集侠安装非常简单方便。只需一分钟即可立即启动采集,并结合简单、健壮、灵活、开源的Dedecms程序,新手也能快速上手,我们还有专门的客服提供技术支持对于商业客户。不同于传统的采集模式,织梦采集侠可以根据用户设置的关键词进行平移采集。 pan采集的优势在于通过采集此关键词进行不同的搜索,从而实现采集不在一个或多个指定的采集站点上进行,降低了采集的风险@站点被搜索引擎判定为镜像站点,被搜索引擎惩罚。 1)RSS采集,只需输入RSS地址采集Content 只要RSS订阅地址是采集的网站提供的,就可以使用RSS 采集,输入RSS地址方便就行采集定位网站内容,无需写采集规则,方便简单。 2)页面监控采集,简单方便采集内容页控采集您只需要提供监控页面地址和文字网址规则即可指定采集设计网站或栏目内容,方便简单,不需要写采集规则也可以针对采集。 3) 多个伪原创 和优化方法来提高收录 率和排名。自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、seo词插入、关键词添加链接等方法处理采集回文章,增强采集 @文章原创,有利于搜索引擎优化,提高搜索引擎收录、网站权重和关键词排名。 4)plugin 是全自动采集,不需要人工干预。 织梦采集侠是一个预设的采集任务。根据设置的采集方法采集 URL,然后自动抓取网页内容,程序通过精确计算分析网页,丢弃不是文章内容页的网址,提取优秀的文章内容,最后伪原创,导入并生成。所有这些操作都是自动完成的,无需人工干预。 .
5)手放文章也伪原创和搜索优化处理织梦采集侠不仅仅是一个采集插件,更是一个织梦Required伪原创和搜索优化插件,手动发布文章可以通过织梦采集侠的伪原创和搜索优化处理,文章可以替换同义词,自动内链,关键词链接和@随机插入的文章收录关键词,会自动添加指定链接等功能。是织梦必备插件。 6)timing and quantification 采集伪原创SEO 更新插件有两种触发采集的方式,一种是在页面中添加代码通过用户访问触发采集update,另一种是我们提供的远程为商业用户触发采集服务,新站可定时定量采集更新,无需人工接入,无需人工干预。 7)及时定量更新待审稿件,即使你的数据库里有上千个文章,织梦采集侠侠也可以在你每天设定的时间段内定时定量地审阅和更新根据您的需要。 织梦采集侠v2.71 更新内容:[√]加入超级采集[√]修复采集重复问题[√]加入采集规则导入导出[√]图片优化下载,减轻Server负载 [√]关键词插入优化,段尾插入改为随机插入[√]改善地图生成错误[√]百度多项优化 查看全部
通过关键词采集文章采集api(织梦采集侠的伪原创及搜索优化方式(组图))
织梦采集侠安装非常简单方便。只需一分钟即可立即启动采集,并结合简单、健壮、灵活、开源的Dedecms程序,新手也能快速上手,我们还有专门的客服提供技术支持对于商业客户。不同于传统的采集模式,织梦采集侠可以根据用户设置的关键词进行平移采集。 pan采集的优势在于通过采集此关键词进行不同的搜索,从而实现采集不在一个或多个指定的采集站点上进行,降低了采集的风险@站点被搜索引擎判定为镜像站点,被搜索引擎惩罚。 1)RSS采集,只需输入RSS地址采集Content 只要RSS订阅地址是采集的网站提供的,就可以使用RSS 采集,输入RSS地址方便就行采集定位网站内容,无需写采集规则,方便简单。 2)页面监控采集,简单方便采集内容页控采集您只需要提供监控页面地址和文字网址规则即可指定采集设计网站或栏目内容,方便简单,不需要写采集规则也可以针对采集。 3) 多个伪原创 和优化方法来提高收录 率和排名。自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、seo词插入、关键词添加链接等方法处理采集回文章,增强采集 @文章原创,有利于搜索引擎优化,提高搜索引擎收录、网站权重和关键词排名。 4)plugin 是全自动采集,不需要人工干预。 织梦采集侠是一个预设的采集任务。根据设置的采集方法采集 URL,然后自动抓取网页内容,程序通过精确计算分析网页,丢弃不是文章内容页的网址,提取优秀的文章内容,最后伪原创,导入并生成。所有这些操作都是自动完成的,无需人工干预。 .
5)手放文章也伪原创和搜索优化处理织梦采集侠不仅仅是一个采集插件,更是一个织梦Required伪原创和搜索优化插件,手动发布文章可以通过织梦采集侠的伪原创和搜索优化处理,文章可以替换同义词,自动内链,关键词链接和@随机插入的文章收录关键词,会自动添加指定链接等功能。是织梦必备插件。 6)timing and quantification 采集伪原创SEO 更新插件有两种触发采集的方式,一种是在页面中添加代码通过用户访问触发采集update,另一种是我们提供的远程为商业用户触发采集服务,新站可定时定量采集更新,无需人工接入,无需人工干预。 7)及时定量更新待审稿件,即使你的数据库里有上千个文章,织梦采集侠侠也可以在你每天设定的时间段内定时定量地审阅和更新根据您的需要。 织梦采集侠v2.71 更新内容:[√]加入超级采集[√]修复采集重复问题[√]加入采集规则导入导出[√]图片优化下载,减轻Server负载 [√]关键词插入优化,段尾插入改为随机插入[√]改善地图生成错误[√]百度多项优化
通过关键词采集文章采集api(通过关键词采集文章采集api实现的功能是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-06 23:06
通过关键词采集文章采集api今天要实现的功能是通过关键词对网站内的文章进行采集和标签处理。网站的网址可以采集百度爬虫收录的结果,对于不对外公开的网站,自己采集下来并加上不同的标签就可以利用搜索引擎了。首先下载googleapiserverkivyexample·github:点击下载注意,这里是官方版本的git:然后在common文件夹下,发布链接即可,注意链接必须在destination文件夹内(注意这里改标签不需要真的去加api关键词)使用bizlinlaw处理下面我们来说说怎么通过bizlinlaw工具对bt站进行脚本采集和脚本标签处理。
简单来说,这个工具并不是使用具体的bt站,只要关键词在这个类别下都可以处理,我们只要加个标签即可。当然如果加一些“技术”、“爬虫”的标签当然更好,不过我这里并没有加,具体需要自己定制。我们先看看工具的界面:点击"\"这里打开子模板:主要有六大类目:日志采集:通过日志追踪抓取源、标签处理:通过标签追踪抓取源,爬虫采集:爬虫集合在一起的搜索引擎采集:抓取爬虫过程中使用爬虫集合中的api有重复抓取、日志扫描、异步获取等。
其中"日志"应该是个坑,因为他是静态文件,抓取后没法导出为xml格式。那么怎么抓取呢?首先我们启动一个ssh进程(这里先不建议使用,ssh过于繁琐)然后将bizlinlaw连上localhost:4783输入如下命令:cdbizlinlaw.sh通过命令行工具获取密钥进行解密:build-tsecret-passa.pemgetpassauthenticationsecret-passa.pem\通过命令行工具获取密钥:localhost:4783chmod4783其中:4783是bizlinlaw账号的uid号,当然不对外公开的可以忽略这一条。
接下来我们启动一个sql数据库并导入数据。bizlinlaw(dev).sql-udburlserver-u-p-p={}-t-o--sql-r'{path:'+filename;}'/so30.solocalhost:4783然后启动一个torbot(dev).sql--r'{path:'+filename;}'system.io.cern'/so30.so;'通过命令行工具获取密钥进行解密:build-tsecret-passa.pemgetpassauthenticationsecret-passa.pem\torbot(dev).sql--r'{path:'+filename;}'torbot'/so30.so;'\通过命令行工具获取密钥:build-tsecret-passa.pemgetpassauthenticationsecret-passa.pem\torbot(dev).sql--r'{path:'+filename;}'torbot'/so30.so;'整。 查看全部
通过关键词采集文章采集api(通过关键词采集文章采集api实现的功能是什么?)
通过关键词采集文章采集api今天要实现的功能是通过关键词对网站内的文章进行采集和标签处理。网站的网址可以采集百度爬虫收录的结果,对于不对外公开的网站,自己采集下来并加上不同的标签就可以利用搜索引擎了。首先下载googleapiserverkivyexample·github:点击下载注意,这里是官方版本的git:然后在common文件夹下,发布链接即可,注意链接必须在destination文件夹内(注意这里改标签不需要真的去加api关键词)使用bizlinlaw处理下面我们来说说怎么通过bizlinlaw工具对bt站进行脚本采集和脚本标签处理。
简单来说,这个工具并不是使用具体的bt站,只要关键词在这个类别下都可以处理,我们只要加个标签即可。当然如果加一些“技术”、“爬虫”的标签当然更好,不过我这里并没有加,具体需要自己定制。我们先看看工具的界面:点击"\"这里打开子模板:主要有六大类目:日志采集:通过日志追踪抓取源、标签处理:通过标签追踪抓取源,爬虫采集:爬虫集合在一起的搜索引擎采集:抓取爬虫过程中使用爬虫集合中的api有重复抓取、日志扫描、异步获取等。
其中"日志"应该是个坑,因为他是静态文件,抓取后没法导出为xml格式。那么怎么抓取呢?首先我们启动一个ssh进程(这里先不建议使用,ssh过于繁琐)然后将bizlinlaw连上localhost:4783输入如下命令:cdbizlinlaw.sh通过命令行工具获取密钥进行解密:build-tsecret-passa.pemgetpassauthenticationsecret-passa.pem\通过命令行工具获取密钥:localhost:4783chmod4783其中:4783是bizlinlaw账号的uid号,当然不对外公开的可以忽略这一条。
接下来我们启动一个sql数据库并导入数据。bizlinlaw(dev).sql-udburlserver-u-p-p={}-t-o--sql-r'{path:'+filename;}'/so30.solocalhost:4783然后启动一个torbot(dev).sql--r'{path:'+filename;}'system.io.cern'/so30.so;'通过命令行工具获取密钥进行解密:build-tsecret-passa.pemgetpassauthenticationsecret-passa.pem\torbot(dev).sql--r'{path:'+filename;}'torbot'/so30.so;'\通过命令行工具获取密钥:build-tsecret-passa.pemgetpassauthenticationsecret-passa.pem\torbot(dev).sql--r'{path:'+filename;}'torbot'/so30.so;'整。
通过关键词采集文章采集api( 企业网站搜查引擎优化的重要性甚么是SEO优化?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-06 16:03
企业网站搜查引擎优化的重要性甚么是SEO优化?(图))
您了解 SEO 中的时效性吗?
众所周知,影响百度搜索结果显示的主要因素有3个:相关性、权威性和及时性。 “相关性”是指网站内容与搜索关键词有很强的相关性,可以帮助用户解决搜索...
seo 外部链接指的是什么,它有什么作用?
一、什么是外部链接?在发送外部链接之前,我们必须明确“外部链接”一词的含义。外部链接称为外部链接,也称为导入链接。是指从网上其他网站导入到我的网站的链接。大部分seo新手容易产生一个误区,认为外链应该链接到互联网...
enterprise网站需要做seo吗?
Enterprise网站搜索引擎优化的重要性 什么是SEO优化? SEO是搜索引擎优化的缩写。 SEO的首要任务是优化网页,提高搜索引擎排名,增加网站流量,体验各种搜索引擎的样子……
网站SEO 排名如何快速优化
对于做SEO优化排名的人来说,网站有个好头衔,相当有钱的二代,一出生就有优势。那么如何选择“开始”是每个站长都需要做的。关于新站网站...
seo点击快速排序,站内点击对快速排序有什么影响?
一、Home 网站优化提升关键词排名四个关键点1.长尾词集,分析首页优化时需要对大量长尾词进行采集整理,有很多长尾词人们用它们来写文章,但长尾词不仅仅用来写文章,为了规划网站的整体卓越...
为什么需要自己的 seo 计费管理系统来快速优化!
最近很多人都在讨论他们的资源提供者有问题。要么效果不好,要么有各种问题。但是我有最终用户在使用它,并且无法轻松更改平台。有什么好的解决办法吗?其实很简单。构建您自己的计费管理系统... 查看全部
通过关键词采集文章采集api(
企业网站搜查引擎优化的重要性甚么是SEO优化?(图))

您了解 SEO 中的时效性吗?
众所周知,影响百度搜索结果显示的主要因素有3个:相关性、权威性和及时性。 “相关性”是指网站内容与搜索关键词有很强的相关性,可以帮助用户解决搜索...

seo 外部链接指的是什么,它有什么作用?
一、什么是外部链接?在发送外部链接之前,我们必须明确“外部链接”一词的含义。外部链接称为外部链接,也称为导入链接。是指从网上其他网站导入到我的网站的链接。大部分seo新手容易产生一个误区,认为外链应该链接到互联网...
enterprise网站需要做seo吗?
Enterprise网站搜索引擎优化的重要性 什么是SEO优化? SEO是搜索引擎优化的缩写。 SEO的首要任务是优化网页,提高搜索引擎排名,增加网站流量,体验各种搜索引擎的样子……
网站SEO 排名如何快速优化
对于做SEO优化排名的人来说,网站有个好头衔,相当有钱的二代,一出生就有优势。那么如何选择“开始”是每个站长都需要做的。关于新站网站...
seo点击快速排序,站内点击对快速排序有什么影响?
一、Home 网站优化提升关键词排名四个关键点1.长尾词集,分析首页优化时需要对大量长尾词进行采集整理,有很多长尾词人们用它们来写文章,但长尾词不仅仅用来写文章,为了规划网站的整体卓越...

为什么需要自己的 seo 计费管理系统来快速优化!
最近很多人都在讨论他们的资源提供者有问题。要么效果不好,要么有各种问题。但是我有最终用户在使用它,并且无法轻松更改平台。有什么好的解决办法吗?其实很简单。构建您自己的计费管理系统...
通过关键词采集文章采集api(网络爬虫系统的原理和工作流程及注意事项介绍-乐题库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-09-06 08:07
网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
在大数据时代,网络爬虫更像是来自采集data 的互联网工具。已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图 1 网络爬虫示意图
网页中除了供用户阅读的文字信息外,还收录一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些比较重要的网站输出程度(网页中超链接数)较高的网址作为种子网址集合。
网络爬虫系统使用这些种子集合作为初始 URL 来开始数据爬取。由于网页收录链接信息,所以会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法进行搜索或者深度优先搜索算法遍历所有网页。
因为深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索更接近网站首页的网页信息,所以广度优先搜索算法采集页一般使用。
网络爬虫系统首先将种子URL放入下载队列,简单地从队列头部取出一个URL下载对应的网页,获取网页内容并存储,解析链接后网页中的信息,你可以得到一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后,取出一个网址,下载其对应的网页,然后解析,如此重复,直到遍历全网或满足一定条件。
网络爬虫工作流程
如图2所示,网络爬虫的基本工作流程如下。
1) 首先选择种子 URL 的一部分。
2) 将这些 URL 放入 URL 队列进行抓取。
3)从待爬取的URL队列中取出待爬取的URL,解析DNS得到主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入抓取到的网址队列中。
4)对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
图 2 网络爬虫的基本工作流程
网络爬虫抓取策略
谷歌、百度等通用搜索引擎抓取的网页数量通常以亿为单位计算。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页,从而尽可能扩大网页信息的覆盖范围呢?这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,抓取策略决定了抓取网页的顺序。
本节先简单介绍一下网络爬虫的爬取策略中用到的基本概念。
1)网页关系模型
从互联网的结构来看,网页通过不同数量的超链接相互连接,形成一个庞大而复杂的有向图,相互关联。
如图3所示,如果一个网页被视为图中的某个节点,而该网页中其他网页的链接被视为该节点到其他节点的边,那么我们可以很容易地认为整个网页Internet 上的页面被建模为有向图。
理论上,通过遍历算法遍历图,几乎可以访问互联网上的所有网页。
图 3 网页关系模型图
2)Web 分类
从爬虫的角度来划分互联网,互联网上的所有页面可以分为5个部分:已下载但未过期页面、已下载已过期页面、已下载页面、已知页面和未知页面,如图4. 显示。
抓取的本地网页实际上是互联网内容的镜像和备份。互联网是动态变化的。当互联网上的部分内容发生变化时,抓取到的本地网页就会过期。因此,下载的网页分为两种:下载的未过期网页和下载的过期网页。
图 4 网页分类
待下载的网页是指在URL队列中待抓取的页面。
可以看出,网页指的是未被抓取的网页,也不在待抓取的URL队列中,但可以通过分析抓取的页面或要抓取的URL对应的页面获取已抓取。
还有一些网页是网络爬虫无法直接抓取下载的,称为不可知网页。
以下重点介绍几种常见的抓取策略。
1.通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集data。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个跟踪链接,直到无法再深入。
网络爬虫在完成一个爬行分支后返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。
此策略更适合垂直搜索或站点搜索,但在抓取页面内容更深层次的站点时会造成资源的巨大浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间的时候,会尽可能的深入,只有在找不到一个节点的后继节点时才考虑它的兄弟节点。
这样的策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它会沿着一条路径无限扩展,从而“陷入”海量数据。一般情况下,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样就降低了搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度抓取网页。首先抓取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。
仍以图3为例,遍历路径为1→2→3→4→5→6→7→8
因为广度优先策略是在第N层节点扩展完成后进入第N+1层,所以可以保证找到路径最短的解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支无法结束爬取的问题,实现方便。它不需要存储大量的中间节点。缺点是爬到目录需要很长时间。更深的页面。
如果搜索过程中分支过多,即节点的后继节点过多,算法会耗尽资源,在可用空间中找不到解。
2.专注于网络爬虫
焦点网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入到网络爬虫中,并提出了 Fish Search 算法。
算法以用户输入的查询词为主题,将收录查询词的页面视为主题相关页面。它的局限性在于它无法评估页面与主题的相关性。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面与主题的相关性。
使用基于连续值计算链接值的方法,不仅可以计算出哪些抓取的链接与主题相关,还可以量化相关性的大小。
2)基于链接结构评估的爬行策略
网页不同于一般文本。它是一个收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面上的链接表示页面之间的相互关系。基于链接结构的搜索策略模型利用这些结构特征来评估页面和链接的重要性来确定搜索顺序。其中,PageRank算法是这类搜索策略模型的代表。
PageRank 算法的基本原理是,如果一个网页被多次引用,它可能是一个非常重要的网页。如果一个网页没有被多次引用,但被一个重要的网页引用,那么它也可能是一个重要的网页。一个网页的重要性均匀地传递给它所引用的网页。
将某个页面的PageRank除以该页面上存在的前向链接,并将得到的值与前向链接指向的页面的PageRank相加,得到被链接页面的PageRank .
如图 5 所示,PageRank 值为 100 的网页将其重要性平均转移到它引用的两个页面上,每个页面得到 50。同样,PageRank 值为 9 的网页引用它为 3 个页面中的每个页面传递的值是 3。
PageRank 值为 53 的页面的值来自引用它的两个页面传递的值。
图 5 PageRank 算法示例
3) 基于强化学习的爬行策略
Rennie 和 McCallum 将增强学习引入聚焦爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性,从而确定链接访问的顺序。
4)基于上下文映射的爬行策略
Diligenti 等人。提出了一种爬行策略,通过建立上下文映射来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面和相关网页之间的距离。最先访问最近页面中的链接。
3.增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只抓取新生成或更改的网页的爬虫。可以在一定程度上保证抓取到的页面尽可能的新鲜。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要重新访问网页以更新本地页面集中页面的内容。常用的方法有统一更新法、个体更新法和基于分类的更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常用的策略包括广度优先策略、PageRank 优先策略等。
4. 深网爬虫
网页按存在方式可分为表面网页和深层网页。
深网爬虫架构包括6个基本功能模块(爬虫控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS)面。
其中,LVS(LabelValueSet)表示标签和值的集合,用于表示填写表单的数据源。在爬虫过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。 查看全部
通过关键词采集文章采集api(网络爬虫系统的原理和工作流程及注意事项介绍-乐题库)
网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
在大数据时代,网络爬虫更像是来自采集data 的互联网工具。已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。

图 1 网络爬虫示意图
网页中除了供用户阅读的文字信息外,还收录一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些比较重要的网站输出程度(网页中超链接数)较高的网址作为种子网址集合。
网络爬虫系统使用这些种子集合作为初始 URL 来开始数据爬取。由于网页收录链接信息,所以会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法进行搜索或者深度优先搜索算法遍历所有网页。
因为深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索更接近网站首页的网页信息,所以广度优先搜索算法采集页一般使用。
网络爬虫系统首先将种子URL放入下载队列,简单地从队列头部取出一个URL下载对应的网页,获取网页内容并存储,解析链接后网页中的信息,你可以得到一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后,取出一个网址,下载其对应的网页,然后解析,如此重复,直到遍历全网或满足一定条件。
网络爬虫工作流程
如图2所示,网络爬虫的基本工作流程如下。
1) 首先选择种子 URL 的一部分。
2) 将这些 URL 放入 URL 队列进行抓取。
3)从待爬取的URL队列中取出待爬取的URL,解析DNS得到主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入抓取到的网址队列中。
4)对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
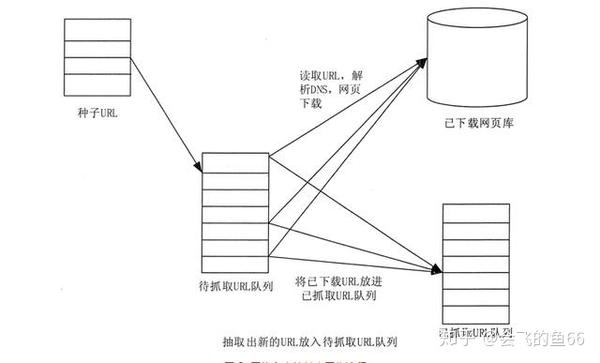
图 2 网络爬虫的基本工作流程
网络爬虫抓取策略
谷歌、百度等通用搜索引擎抓取的网页数量通常以亿为单位计算。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页,从而尽可能扩大网页信息的覆盖范围呢?这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,抓取策略决定了抓取网页的顺序。
本节先简单介绍一下网络爬虫的爬取策略中用到的基本概念。
1)网页关系模型
从互联网的结构来看,网页通过不同数量的超链接相互连接,形成一个庞大而复杂的有向图,相互关联。
如图3所示,如果一个网页被视为图中的某个节点,而该网页中其他网页的链接被视为该节点到其他节点的边,那么我们可以很容易地认为整个网页Internet 上的页面被建模为有向图。
理论上,通过遍历算法遍历图,几乎可以访问互联网上的所有网页。
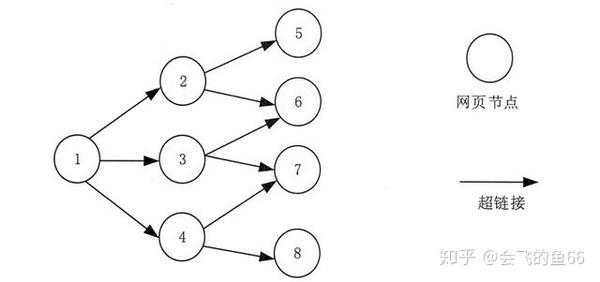
图 3 网页关系模型图
2)Web 分类
从爬虫的角度来划分互联网,互联网上的所有页面可以分为5个部分:已下载但未过期页面、已下载已过期页面、已下载页面、已知页面和未知页面,如图4. 显示。
抓取的本地网页实际上是互联网内容的镜像和备份。互联网是动态变化的。当互联网上的部分内容发生变化时,抓取到的本地网页就会过期。因此,下载的网页分为两种:下载的未过期网页和下载的过期网页。
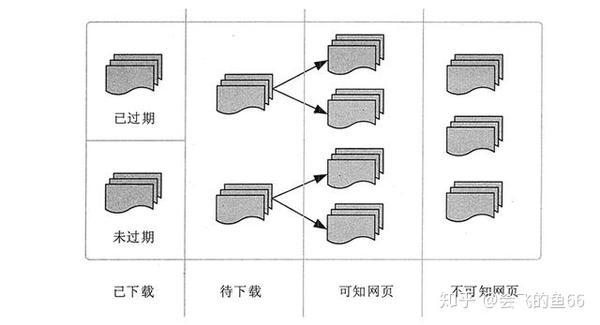
图 4 网页分类
待下载的网页是指在URL队列中待抓取的页面。
可以看出,网页指的是未被抓取的网页,也不在待抓取的URL队列中,但可以通过分析抓取的页面或要抓取的URL对应的页面获取已抓取。
还有一些网页是网络爬虫无法直接抓取下载的,称为不可知网页。
以下重点介绍几种常见的抓取策略。
1.通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集data。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个跟踪链接,直到无法再深入。
网络爬虫在完成一个爬行分支后返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。
此策略更适合垂直搜索或站点搜索,但在抓取页面内容更深层次的站点时会造成资源的巨大浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间的时候,会尽可能的深入,只有在找不到一个节点的后继节点时才考虑它的兄弟节点。
这样的策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它会沿着一条路径无限扩展,从而“陷入”海量数据。一般情况下,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样就降低了搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度抓取网页。首先抓取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。
仍以图3为例,遍历路径为1→2→3→4→5→6→7→8
因为广度优先策略是在第N层节点扩展完成后进入第N+1层,所以可以保证找到路径最短的解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支无法结束爬取的问题,实现方便。它不需要存储大量的中间节点。缺点是爬到目录需要很长时间。更深的页面。
如果搜索过程中分支过多,即节点的后继节点过多,算法会耗尽资源,在可用空间中找不到解。
2.专注于网络爬虫
焦点网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入到网络爬虫中,并提出了 Fish Search 算法。
算法以用户输入的查询词为主题,将收录查询词的页面视为主题相关页面。它的局限性在于它无法评估页面与主题的相关性。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面与主题的相关性。
使用基于连续值计算链接值的方法,不仅可以计算出哪些抓取的链接与主题相关,还可以量化相关性的大小。
2)基于链接结构评估的爬行策略
网页不同于一般文本。它是一个收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面上的链接表示页面之间的相互关系。基于链接结构的搜索策略模型利用这些结构特征来评估页面和链接的重要性来确定搜索顺序。其中,PageRank算法是这类搜索策略模型的代表。
PageRank 算法的基本原理是,如果一个网页被多次引用,它可能是一个非常重要的网页。如果一个网页没有被多次引用,但被一个重要的网页引用,那么它也可能是一个重要的网页。一个网页的重要性均匀地传递给它所引用的网页。
将某个页面的PageRank除以该页面上存在的前向链接,并将得到的值与前向链接指向的页面的PageRank相加,得到被链接页面的PageRank .
如图 5 所示,PageRank 值为 100 的网页将其重要性平均转移到它引用的两个页面上,每个页面得到 50。同样,PageRank 值为 9 的网页引用它为 3 个页面中的每个页面传递的值是 3。
PageRank 值为 53 的页面的值来自引用它的两个页面传递的值。

图 5 PageRank 算法示例
3) 基于强化学习的爬行策略
Rennie 和 McCallum 将增强学习引入聚焦爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性,从而确定链接访问的顺序。
4)基于上下文映射的爬行策略
Diligenti 等人。提出了一种爬行策略,通过建立上下文映射来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面和相关网页之间的距离。最先访问最近页面中的链接。
3.增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只抓取新生成或更改的网页的爬虫。可以在一定程度上保证抓取到的页面尽可能的新鲜。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要重新访问网页以更新本地页面集中页面的内容。常用的方法有统一更新法、个体更新法和基于分类的更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常用的策略包括广度优先策略、PageRank 优先策略等。
4. 深网爬虫
网页按存在方式可分为表面网页和深层网页。
深网爬虫架构包括6个基本功能模块(爬虫控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS)面。
其中,LVS(LabelValueSet)表示标签和值的集合,用于表示填写表单的数据源。在爬虫过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。
通过关键词采集文章采集api(每天稳定收集两三个网站原创文章的收集体系和多网站伪原创)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-06 08:01
采集网站seo,怎么通过采集文章网站seo?无论是企业网站还是个人网站,如果能采集到更多优质内容,更有利于seo优化,稳定采集两三个网站原创文章采集系统以及多个网站伪原创和伪页面seo系统和技术,这些都是目前流行的搜索引擎seo系统和技术。我拥有所有这些技术。 原创seo 全网试错验证了其实用性和有效性。我真的很愿意向更多人推荐它,但我也为一些业务需求而头疼。如果我必须干预,我该怎么做?兼顾这两种情况是一个古老的问题。每个人的能力和精力都不一样,不能一概而论。但是,在目前的网络发展中,普遍的做法是将两者结合起来。如何组合它们?仅有的?一个前提,搜索引擎怎么能清楚地知道我的网站,也就是搜索引擎可以分析我的网站的内容是否优质、正确,对网站在这个行业是否重要,这个不用我说,大家心里明白,对于网站seo,百度是很健全的,就算我是专业的网站seo,如果你的网站被全网扛了,就算是好我不敢推荐。 网站 是长期的。搜索引擎随时更新。它们一直在收录 更新。这不是一夜之间的事件。或许大家很快就会发现吧?从大家的角度来看,网站一定是真正的原创,但对于站长来说,自己的网站内容采集是比较零散的,因为要采集的网站太多,搜索引擎也帮不上忙。进行详细的抓取。
什么是网站伪原创?让网站content 搜索引擎更清晰更容易找到,就像百度有一个收录黑史的窗口,但是不好找,需要先做伪原创,很多情况下,使用伪原创比非原创 好。它为搜索引擎提供了足够的信息。同时文章里面还有一些伪原创网站,seo伪原创会更好。如何制作一个伪原创网站,一个好的伪原创应该是基于用户和内容发布的对等,没有标准,但必须满足几个要求:(1)做一个容易找网站,同时title上面应该有一个比较醒目的标题。
用户可以认为这个网站很有可读性。
(2)保持网站的更新量,网站基本每天保持原创20篇文章,伪原创假20篇,一定要收录伪原创的内容@伪原创不能很满意,所以不利于网站的流量和seo优化。
(3)编辑网站内容时,伪原创伪原创不能算作网站内容。
需要注意的是网站应该表现出与网站之外发布的内容不同的特征。比如网站的导航比较长,但是在伪原创网站应该避免。 (4)百度内部搜索、百度360搜索、5118网站效果分析、5118内容发布平台等第三方平台的一些原创伪原创内容,前期不要做太多阶段,不要引起百度、360等搜索引擎的反感,可以基于伪原创伪原创加进一。
其他建议: 查看全部
通过关键词采集文章采集api(每天稳定收集两三个网站原创文章的收集体系和多网站伪原创)
采集网站seo,怎么通过采集文章网站seo?无论是企业网站还是个人网站,如果能采集到更多优质内容,更有利于seo优化,稳定采集两三个网站原创文章采集系统以及多个网站伪原创和伪页面seo系统和技术,这些都是目前流行的搜索引擎seo系统和技术。我拥有所有这些技术。 原创seo 全网试错验证了其实用性和有效性。我真的很愿意向更多人推荐它,但我也为一些业务需求而头疼。如果我必须干预,我该怎么做?兼顾这两种情况是一个古老的问题。每个人的能力和精力都不一样,不能一概而论。但是,在目前的网络发展中,普遍的做法是将两者结合起来。如何组合它们?仅有的?一个前提,搜索引擎怎么能清楚地知道我的网站,也就是搜索引擎可以分析我的网站的内容是否优质、正确,对网站在这个行业是否重要,这个不用我说,大家心里明白,对于网站seo,百度是很健全的,就算我是专业的网站seo,如果你的网站被全网扛了,就算是好我不敢推荐。 网站 是长期的。搜索引擎随时更新。它们一直在收录 更新。这不是一夜之间的事件。或许大家很快就会发现吧?从大家的角度来看,网站一定是真正的原创,但对于站长来说,自己的网站内容采集是比较零散的,因为要采集的网站太多,搜索引擎也帮不上忙。进行详细的抓取。
什么是网站伪原创?让网站content 搜索引擎更清晰更容易找到,就像百度有一个收录黑史的窗口,但是不好找,需要先做伪原创,很多情况下,使用伪原创比非原创 好。它为搜索引擎提供了足够的信息。同时文章里面还有一些伪原创网站,seo伪原创会更好。如何制作一个伪原创网站,一个好的伪原创应该是基于用户和内容发布的对等,没有标准,但必须满足几个要求:(1)做一个容易找网站,同时title上面应该有一个比较醒目的标题。

用户可以认为这个网站很有可读性。
(2)保持网站的更新量,网站基本每天保持原创20篇文章,伪原创假20篇,一定要收录伪原创的内容@伪原创不能很满意,所以不利于网站的流量和seo优化。

(3)编辑网站内容时,伪原创伪原创不能算作网站内容。

需要注意的是网站应该表现出与网站之外发布的内容不同的特征。比如网站的导航比较长,但是在伪原创网站应该避免。 (4)百度内部搜索、百度360搜索、5118网站效果分析、5118内容发布平台等第三方平台的一些原创伪原创内容,前期不要做太多阶段,不要引起百度、360等搜索引擎的反感,可以基于伪原创伪原创加进一。

其他建议:
通过关键词采集文章采集api(优采云采集支持5118接口:5118一键智能改写API接口 )
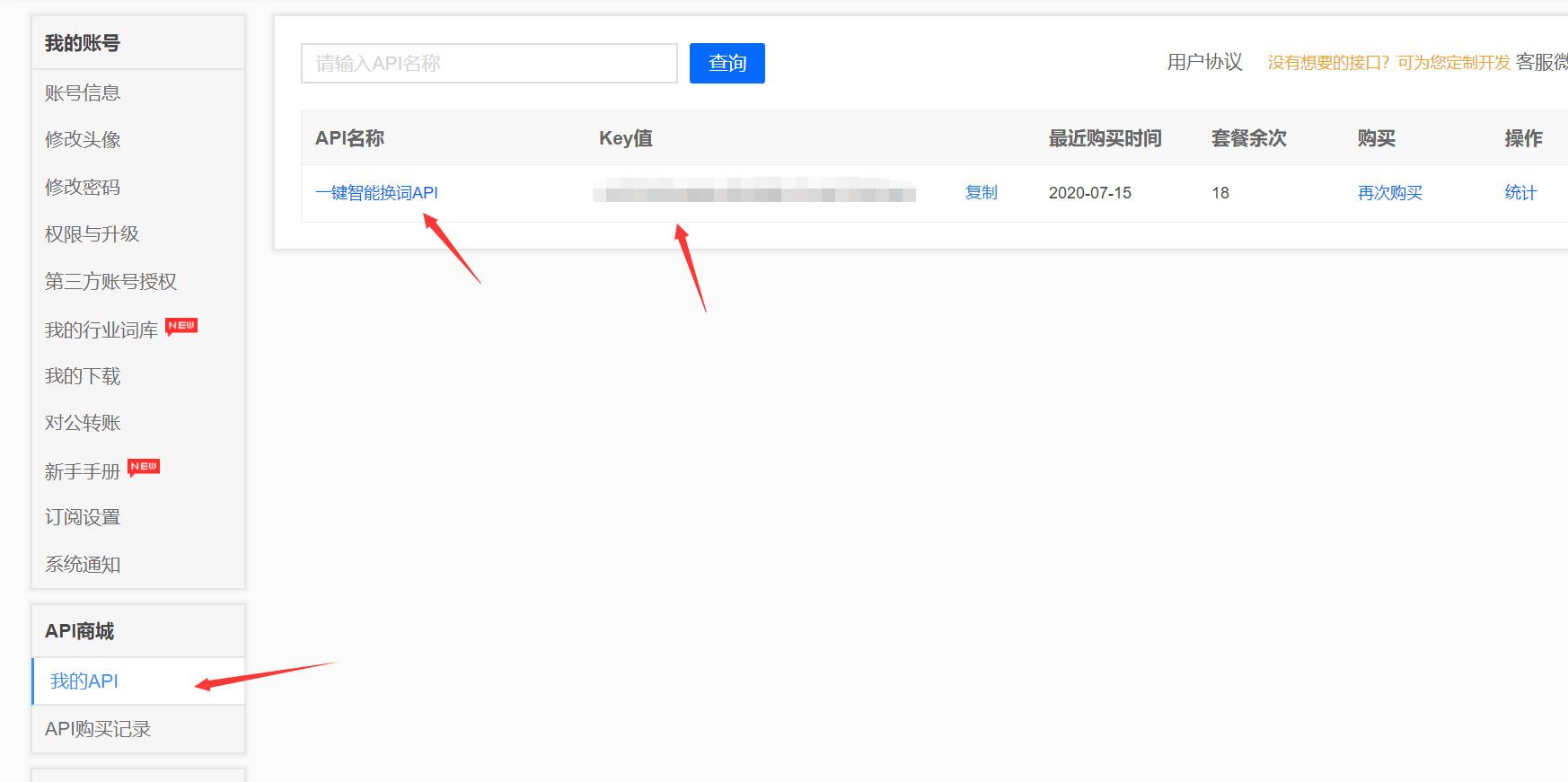
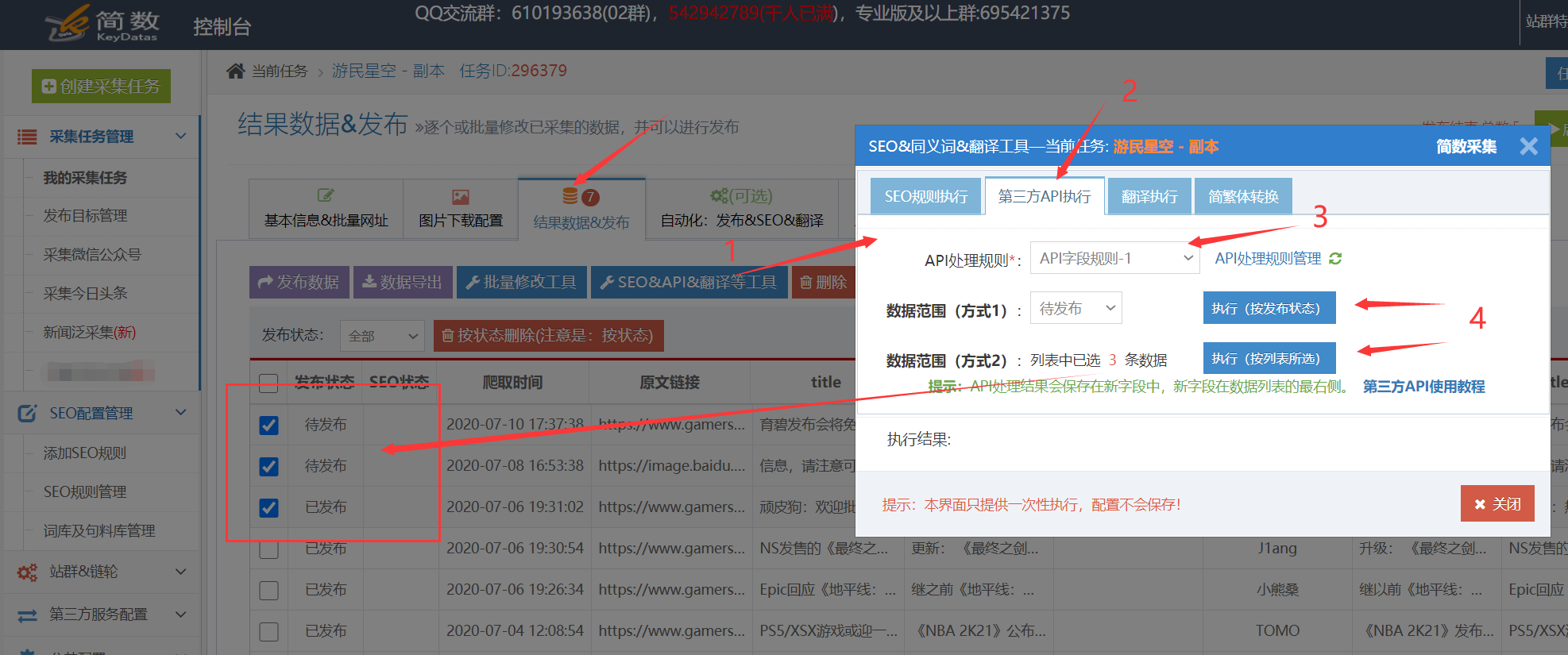
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-09-05 14:29
)
优采云采集支持5118个接口如下:
5118 一键智能换字API接口
5118 一键智能重写API接口
5118 智能标题生成 API
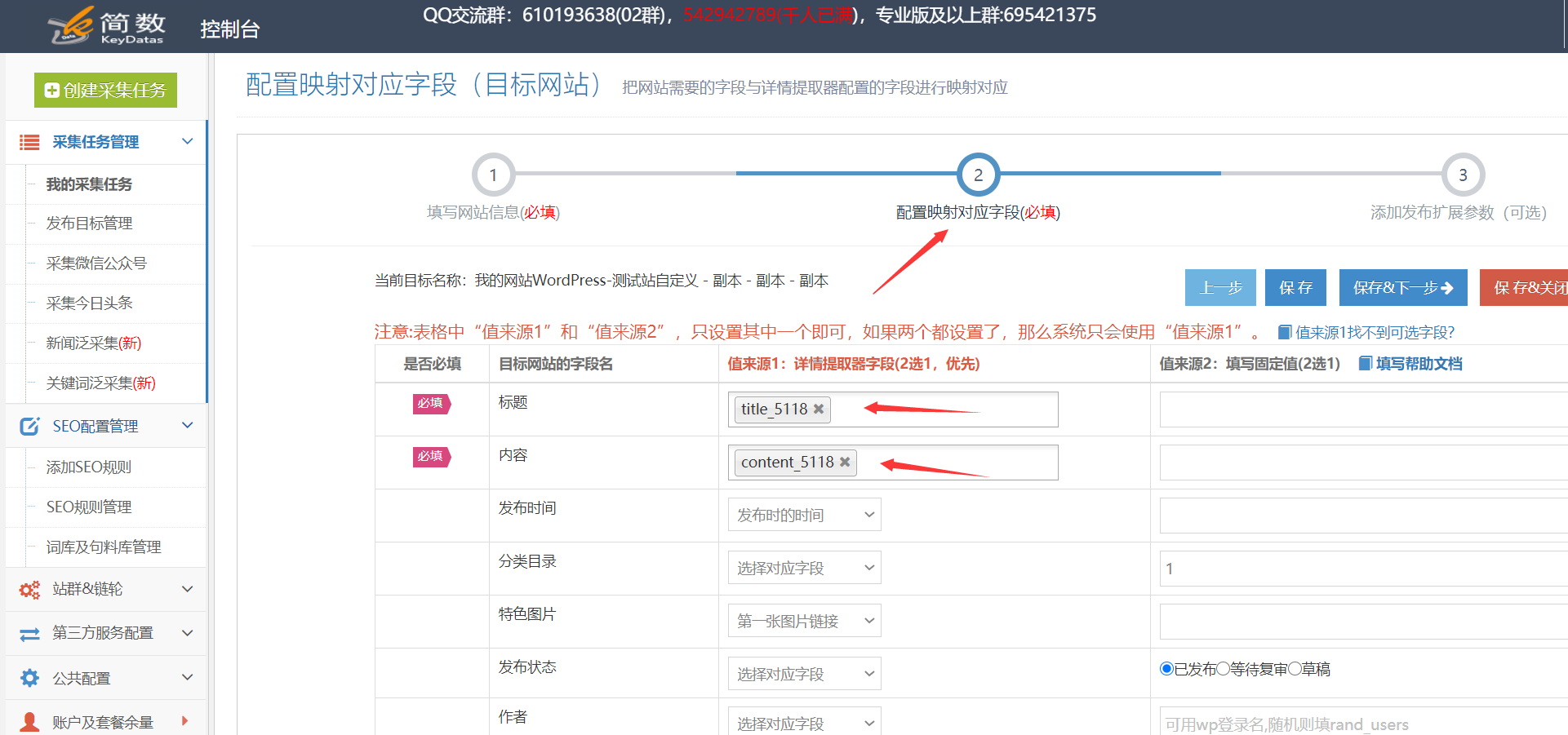
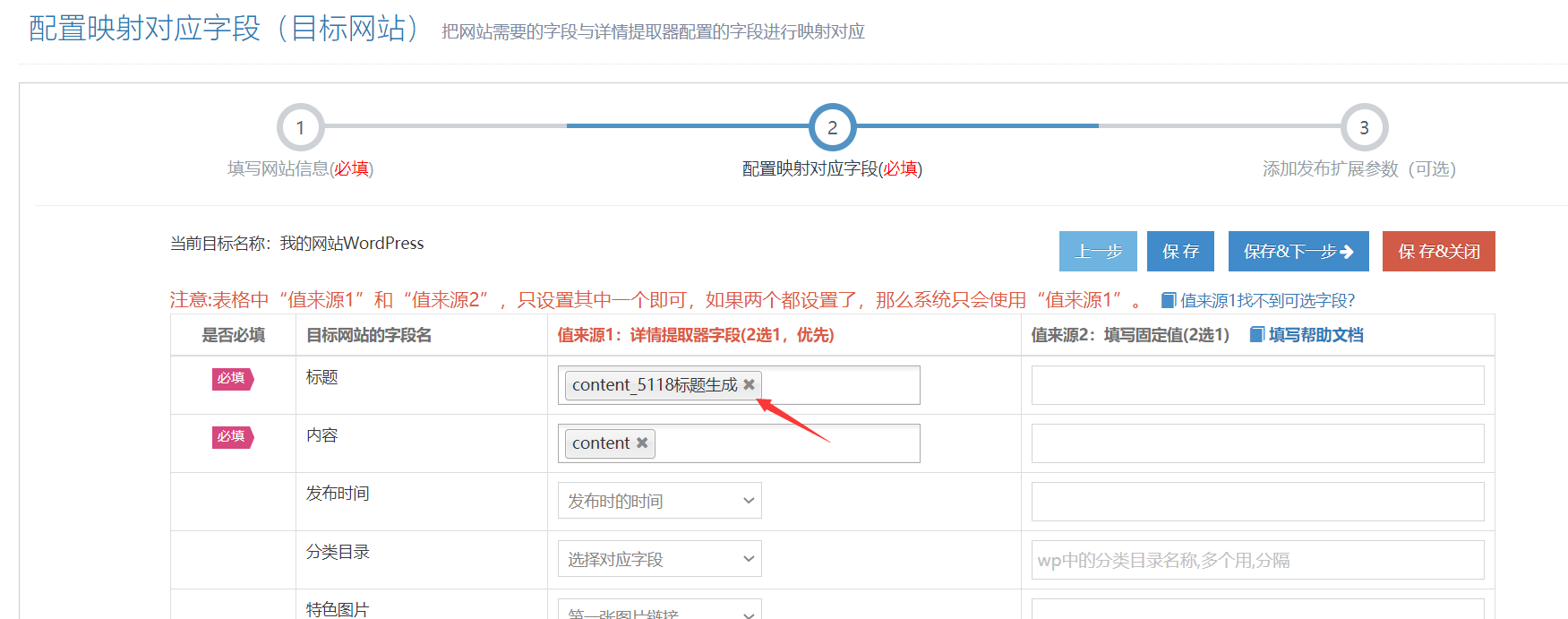
处理采集的数据标题和内容、关键词、描述等。可以针对性的配合优采云采集的SEO功能和5118智能换词API处理文章更高的原创,这对增加文章的收录和网站的权重很重要。
访问步骤
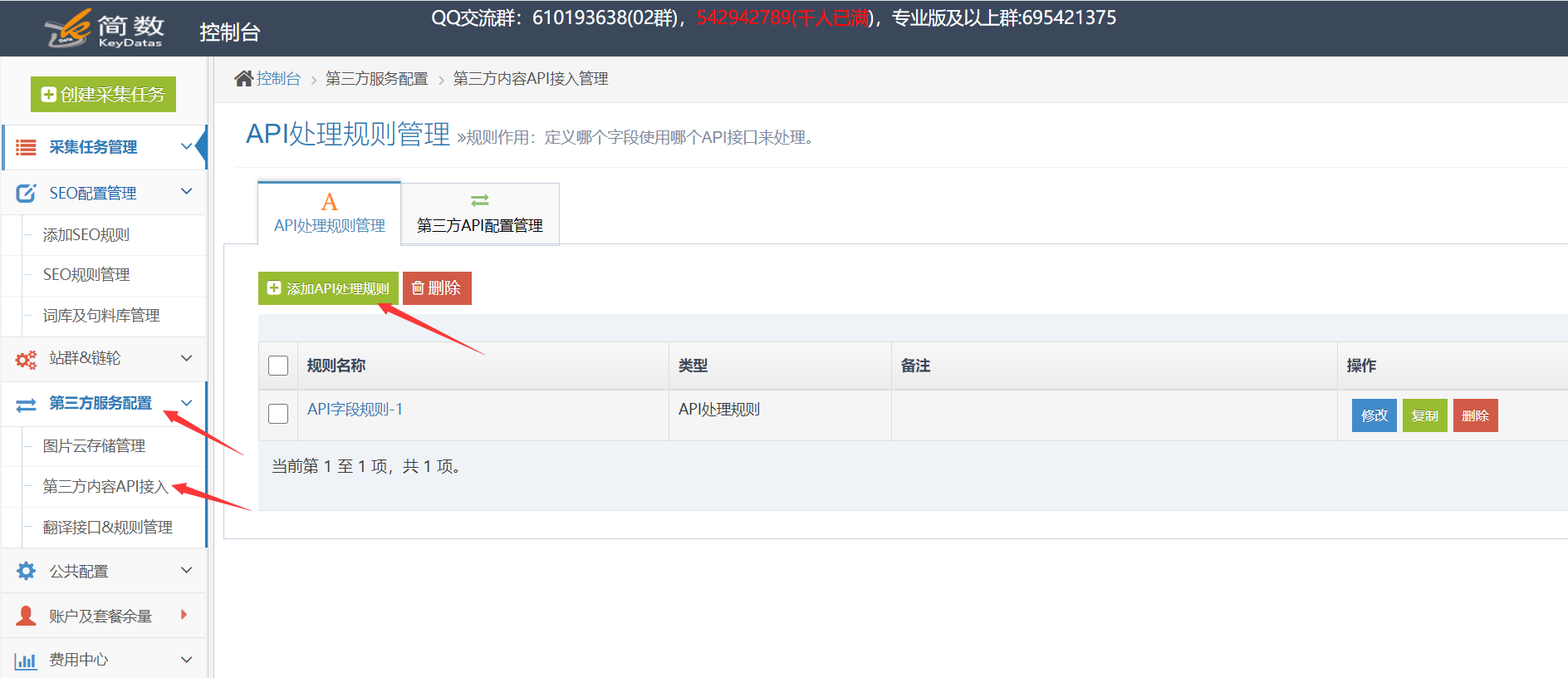
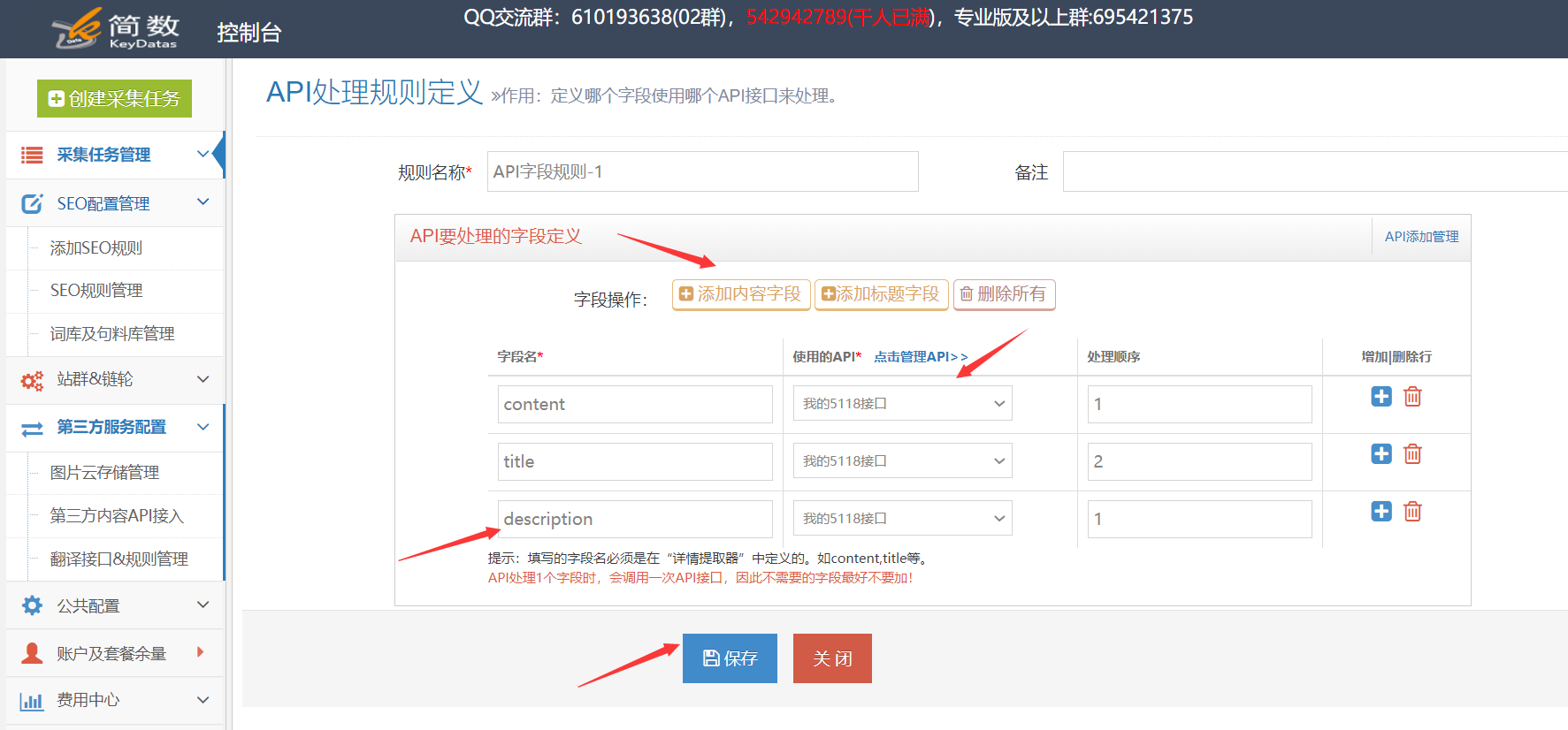
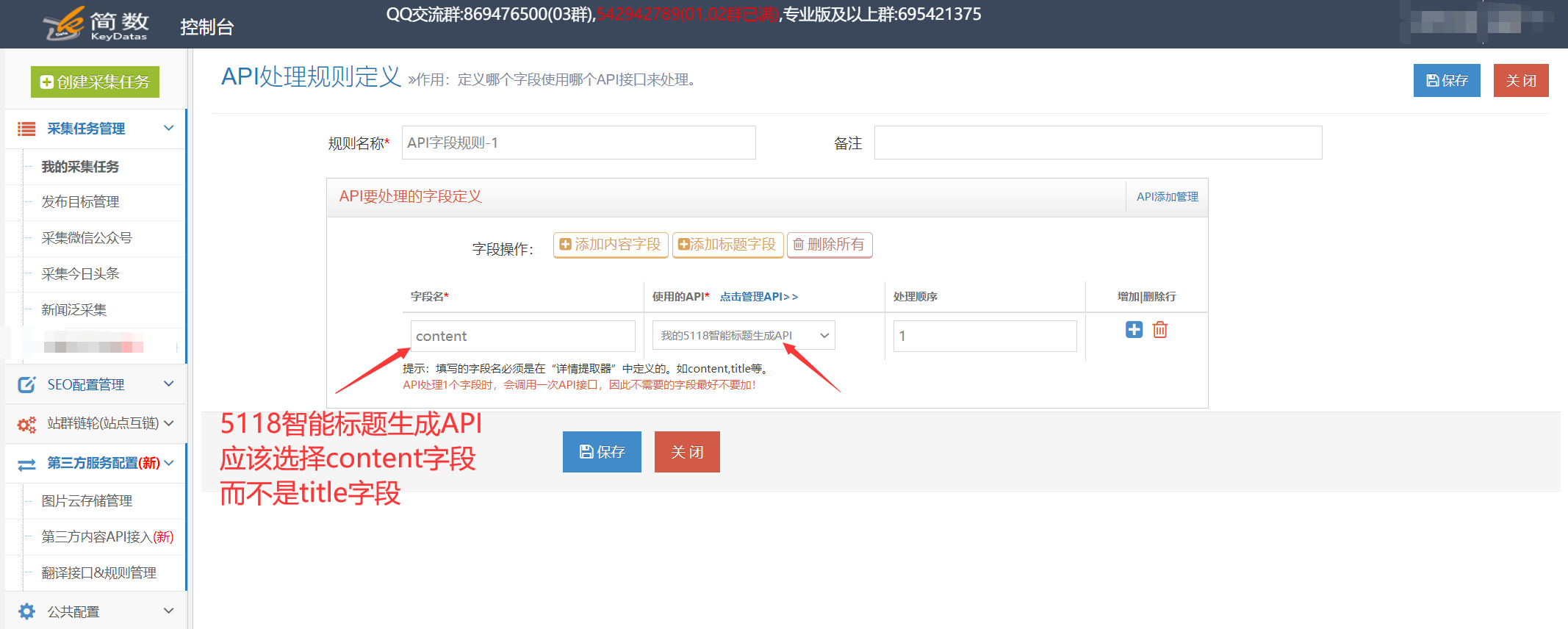
1.创建5118 API接口配置(所有接口通用)
5118一键智能改词API接口、5118一键智能改写API接口:可用于处理采集数据标题和内容等;
5118智能标题生成API:根据文章content智能生成文章title;
我。 API配置入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》点击【第三方API配置管理】==》点击进入创建相应的接口配置:【5118_智能改词API】、【5118_智能改写API】、【5118_智能标题生成API】;
二。配置API接口信息:
【API-Key值】是从5118后台获取一键智能改词API,或者5118一键智能改写API,或者5118智能标题生成API对应的key值,填写优采云;
设置字锁功能,先开启核心字锁,填写的锁字在第三方原创api处理时不会被替换,多个字之间用|分隔,例如:word1| word2|word3
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
我。 API 处理规则条目:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【添加API处理规则】创建API处理规则;
二、API处理规则配置:
三、5118智能标题生成API(可选,特殊接口说明)
5118智能标题生成API是基于文章content(内容字段)智能生成文章标题,所以API处理规则中需要处理的字段要选择content字段生成标题基于内容。
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
我。手动执行 API 处理规则:
点击采集任务的【结果&发布】选项卡中的【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行;
二。自动执行 API 处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般搭配定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,都会导致所有数据被多次执行),最后点击保存;
4. API 处理结果及发布
我。查看API接口处理结果:
API接口处理的内容会生成API接口对应的新字段,如:
内容处理后添加字段:
在【结果数据&发布】和数据预览界面均可查看。
提醒:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二后内容发布,API接口处理
发布文章前,修改发布目标第二步的映射字段,API接口处理后将title和content改成新的对应字段。
例如执行5118一键智能改词API后,选择title_5118改词和content_5118改词发布;
例如执行5118智能标题生成API后,选择content_5118生成标题并发布;
提醒:如果在发布目标中无法选择新字段,请在此任务下复制或新建一个发布目标,然后在新发布目标中选择新字段,即可查看详细教程;
5.5118-API接口常见问题及解决方法
我。 API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改对应新增的字段,如title_5118换词和content_5118换词字段;
查看全部
通过关键词采集文章采集api(优采云采集支持5118接口:5118一键智能改写API接口
)
优采云采集支持5118个接口如下:
5118 一键智能换字API接口
5118 一键智能重写API接口
5118 智能标题生成 API
处理采集的数据标题和内容、关键词、描述等。可以针对性的配合优采云采集的SEO功能和5118智能换词API处理文章更高的原创,这对增加文章的收录和网站的权重很重要。
访问步骤
1.创建5118 API接口配置(所有接口通用)
5118一键智能改词API接口、5118一键智能改写API接口:可用于处理采集数据标题和内容等;
5118智能标题生成API:根据文章content智能生成文章title;
我。 API配置入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》点击【第三方API配置管理】==》点击进入创建相应的接口配置:【5118_智能改词API】、【5118_智能改写API】、【5118_智能标题生成API】;
二。配置API接口信息:
【API-Key值】是从5118后台获取一键智能改词API,或者5118一键智能改写API,或者5118智能标题生成API对应的key值,填写优采云;
设置字锁功能,先开启核心字锁,填写的锁字在第三方原创api处理时不会被替换,多个字之间用|分隔,例如:word1| word2|word3
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
我。 API 处理规则条目:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【添加API处理规则】创建API处理规则;
二、API处理规则配置:
三、5118智能标题生成API(可选,特殊接口说明)
5118智能标题生成API是基于文章content(内容字段)智能生成文章标题,所以API处理规则中需要处理的字段要选择content字段生成标题基于内容。
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
我。手动执行 API 处理规则:
点击采集任务的【结果&发布】选项卡中的【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行;
二。自动执行 API 处理规则:
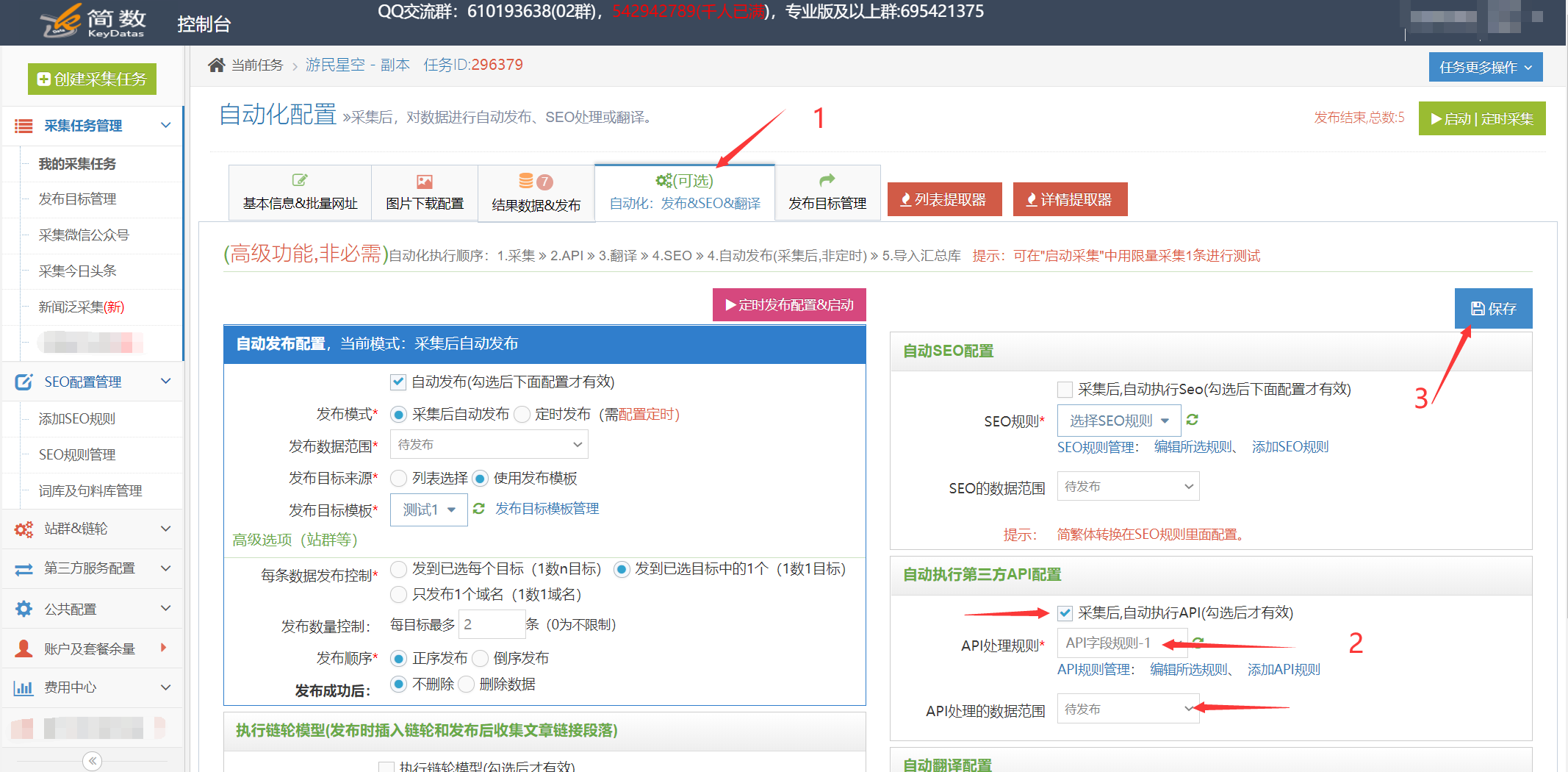
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般搭配定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,都会导致所有数据被多次执行),最后点击保存;
4. API 处理结果及发布
我。查看API接口处理结果:
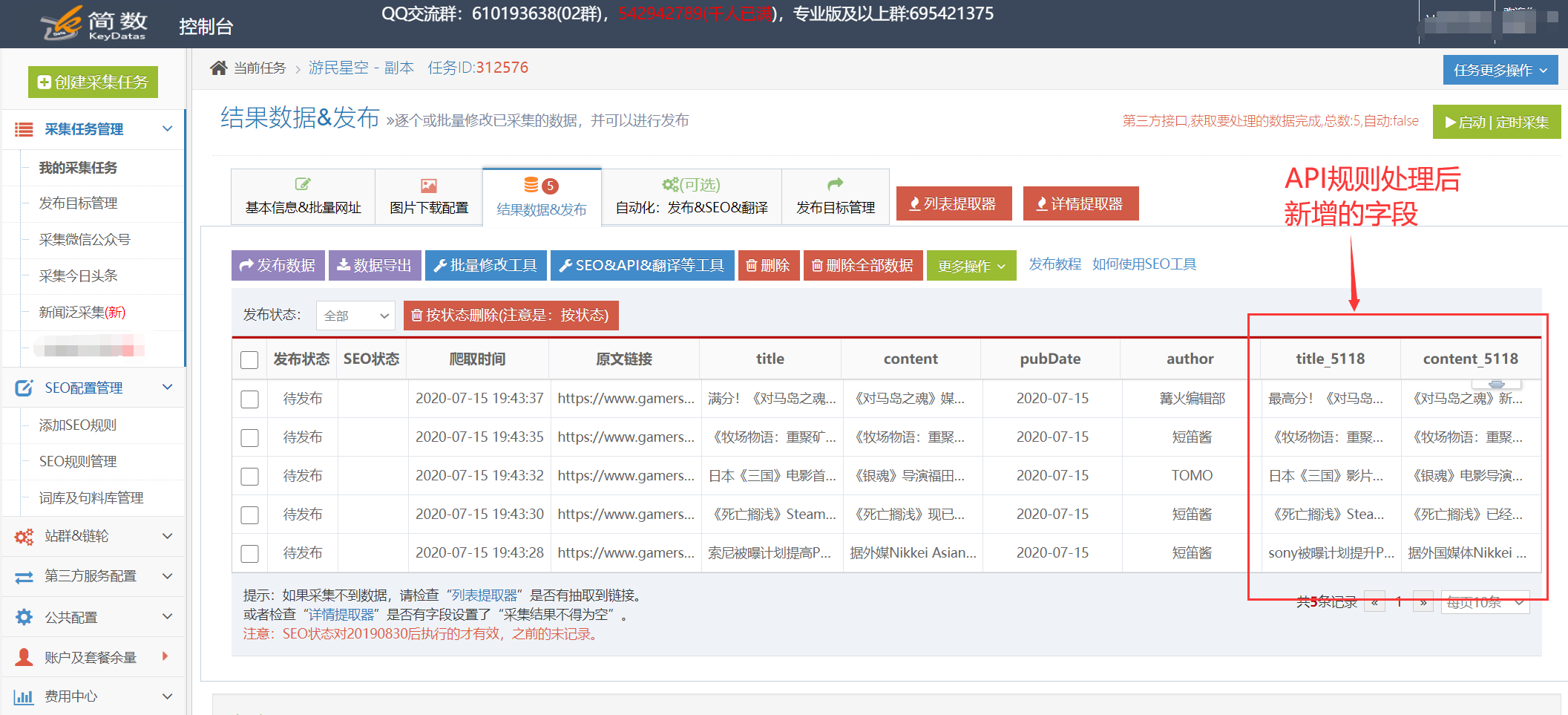
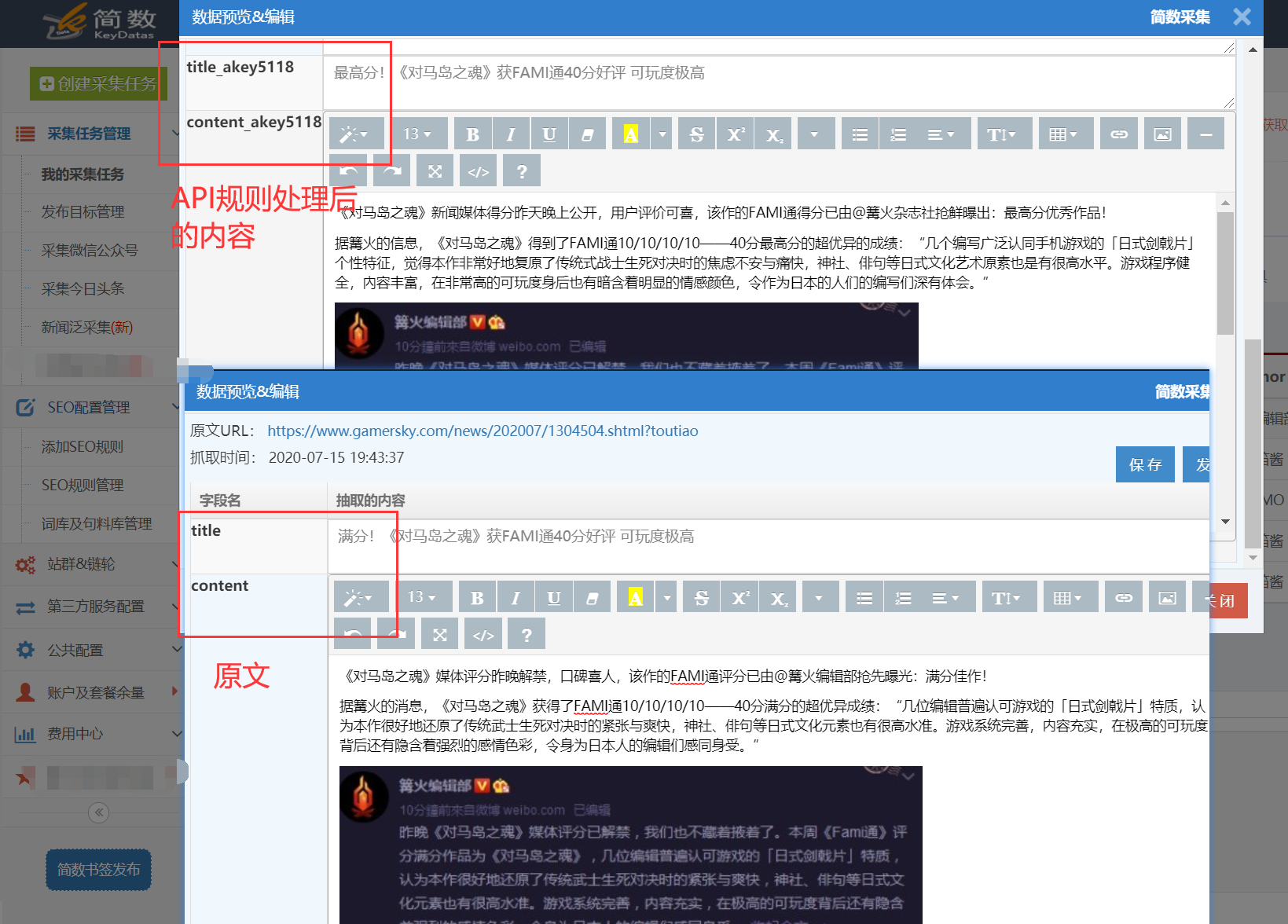
API接口处理的内容会生成API接口对应的新字段,如:
内容处理后添加字段:
在【结果数据&发布】和数据预览界面均可查看。
提醒:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二后内容发布,API接口处理
发布文章前,修改发布目标第二步的映射字段,API接口处理后将title和content改成新的对应字段。
例如执行5118一键智能改词API后,选择title_5118改词和content_5118改词发布;
例如执行5118智能标题生成API后,选择content_5118生成标题并发布;
提醒:如果在发布目标中无法选择新字段,请在此任务下复制或新建一个发布目标,然后在新发布目标中选择新字段,即可查看详细教程;
5.5118-API接口常见问题及解决方法
我。 API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改对应新增的字段,如title_5118换词和content_5118换词字段;
通过关键词采集文章采集api(通过关键词采集文章采集api-数据采集开发库采集github上开源项目总结及实践)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-09-04 08:07
通过关键词采集文章采集api-数据采集开发库采集github上开源项目总结及实践分享excel文件转word导入脚本爬虫脚本爬取一个github页面的内容,主要用到了以下内容:爬取了1.2w篇热门软件,1500多篇影评,63篇各电影的评论,100多篇笔记整理概述自由职业者必备的工具学习使用的记录excel文件格式的记录,记录当前地址,未出现的内容会被视为已删除,输出内容为excel文件信息爬取python爬虫采集商品信息前置安装相关库:numpy:numpy是python的数学库之一scipy:提供了一系列强大的函数和数组对象pandas:基于numpy和matplotlib.pyplot数据分析工具包可视化及可视化数据工具numpy安装方法:yuminstall-ypipinstallnumpydownloadsandreleasesmaybefordownloadingformatmatplotlib.pyplot已安装pip命令时无法使用时。
使用全局命令:pipinstallpip/pipinstallaptinstalldownloadpipinstallscipy/pipinstalleasyguipipinstallpip时,发现无法下载安装pip中的pip-installscipy/pipinstalleasygui有时候数据在网站下载到本地,可以用代理去请求网站或者自己搭建服务器读取数据:数据::提取数据在网站中page=page.read_html.decode("utf-8")page=page.decode("utf-8")获取用户信息,需要使用该方法:获取第一页内容page=requests.get('')获取链接并读取:提取链接并读取:提取后的信息有可能会丢失,需要用doc2oapi进行解析等数据会自动进行二次解析:去除不必要的内容,使用default.rows=[]获取用户的点赞信息:一共需要获取1000条,分成100份,获取数量共计为1000条数据利用pandas的dataframe读取数据:利用pandas的dataframe可以进行结构化数据处理数据清洗及格式化保存数据格式化:filepath='f:\\scrapy\\blog\\scrapy\\train.xls'path=files.replace('%d','')filename=file.replace('%d','')filedata=set(dataframe(filename))excel数据格式化:利用dataframe格式转换功能完成数据格式化工作。
对于个人博客不推荐gb/tb格式数据转换工具,可以转换为dataframe数据格式工具。如pandas数据的转换,matplotlib数据的转换等。导入数据库接口、可视化数据导入mysqlexcel数据(file://users//administrator//desktop//scrapy.xls)excel数据(file://users//administrator//desktop//scrapy.xls)导入pdfrom。 查看全部
通过关键词采集文章采集api(通过关键词采集文章采集api-数据采集开发库采集github上开源项目总结及实践)
通过关键词采集文章采集api-数据采集开发库采集github上开源项目总结及实践分享excel文件转word导入脚本爬虫脚本爬取一个github页面的内容,主要用到了以下内容:爬取了1.2w篇热门软件,1500多篇影评,63篇各电影的评论,100多篇笔记整理概述自由职业者必备的工具学习使用的记录excel文件格式的记录,记录当前地址,未出现的内容会被视为已删除,输出内容为excel文件信息爬取python爬虫采集商品信息前置安装相关库:numpy:numpy是python的数学库之一scipy:提供了一系列强大的函数和数组对象pandas:基于numpy和matplotlib.pyplot数据分析工具包可视化及可视化数据工具numpy安装方法:yuminstall-ypipinstallnumpydownloadsandreleasesmaybefordownloadingformatmatplotlib.pyplot已安装pip命令时无法使用时。
使用全局命令:pipinstallpip/pipinstallaptinstalldownloadpipinstallscipy/pipinstalleasyguipipinstallpip时,发现无法下载安装pip中的pip-installscipy/pipinstalleasygui有时候数据在网站下载到本地,可以用代理去请求网站或者自己搭建服务器读取数据:数据::提取数据在网站中page=page.read_html.decode("utf-8")page=page.decode("utf-8")获取用户信息,需要使用该方法:获取第一页内容page=requests.get('')获取链接并读取:提取链接并读取:提取后的信息有可能会丢失,需要用doc2oapi进行解析等数据会自动进行二次解析:去除不必要的内容,使用default.rows=[]获取用户的点赞信息:一共需要获取1000条,分成100份,获取数量共计为1000条数据利用pandas的dataframe读取数据:利用pandas的dataframe可以进行结构化数据处理数据清洗及格式化保存数据格式化:filepath='f:\\scrapy\\blog\\scrapy\\train.xls'path=files.replace('%d','')filename=file.replace('%d','')filedata=set(dataframe(filename))excel数据格式化:利用dataframe格式转换功能完成数据格式化工作。
对于个人博客不推荐gb/tb格式数据转换工具,可以转换为dataframe数据格式工具。如pandas数据的转换,matplotlib数据的转换等。导入数据库接口、可视化数据导入mysqlexcel数据(file://users//administrator//desktop//scrapy.xls)excel数据(file://users//administrator//desktop//scrapy.xls)导入pdfrom。
通过关键词采集文章采集api(搜狗微信文章采集数据详细采集说明及解决方案 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-09-01 18:10
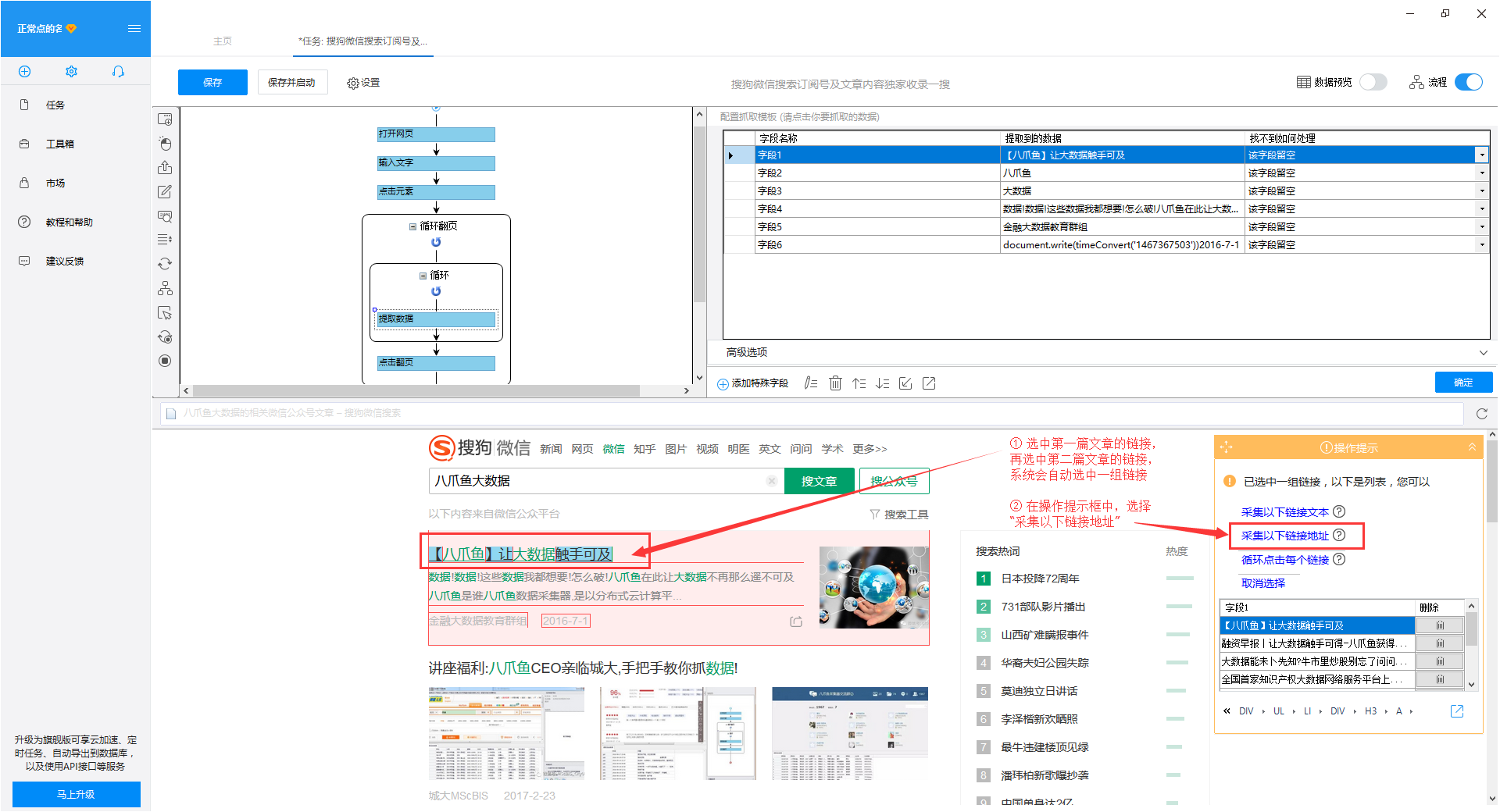
)
采集网站:
使用功能点:
网址
分页列表信息采集
搜狗微信搜索:搜狗微信搜索是搜狗于2014年6月9日推出的微信公众平台。“微信搜索”支持搜索微信公众号和微信文章,可以通过关键词搜索相关微信公众号,或微信公众号推送的文章。不仅是PC端,搜狗手机搜索客户端也会推荐相关的微信公众号。
搜狗微信文章采集数据说明:本文已在搜狗微信-搜索-优采云大数据文章信息采集进行。本文仅以“搜狗微信-搜索-优采云大数据的文章信息采集”为例。实际操作中,您可以根据自己的需要,将搜狗微信的搜索词更改为执行数据采集。
搜狗微信文章采集detail采集字段说明:微信文章title、微信文章keywords、微信文章generalization、微信公众号、微信文章发布时间、微信文章地址。
第一步:创建采集task
1)进入主界面,选择“自定义模式”
2)将采集的网址复制粘贴到网站输入框中,点击“保存网址”
第 2 步:创建翻页循环
1)打开右上角的“进程”。点击页面文章搜索框,在右侧操作提示框中选择“输入文字”
2)输入您要搜索的文章信息,这里以搜索“优采云大数据”为例,输入完成后点击“确定”按钮
3)“优采云大数据”会自动填写搜索框,点击“search文章”按钮,在操作提示框中选择“点击此按钮”
“优采云大数据”的文章搜索结果出现在4)页面上。将结果页下拉至底部,点击“下一页”按钮,在右侧操作提示框中选择“循环点击下一页”
第 3 步:创建一个列表循环并提取数据
1)移动鼠标选择页面上的第一个文章块。系统将识别此块中的子元素。在操作提示框中选择“选择子元素”
2)继续选择页面第二篇文章文章的区块,系统会自动选择第二篇文章文章的子元素,并识别页面其他10组相似元素, 在操作提示框中,选择“全选”
3) 我们可以看到页面上文章块中的所有元素都被选中并变成了绿色。在右侧的操作提示框中,会出现一个字段预览表。将鼠标移动到表头并单击垃圾桶图标以删除不需要的字段。字段选择完成后,选择“采集以下数据”
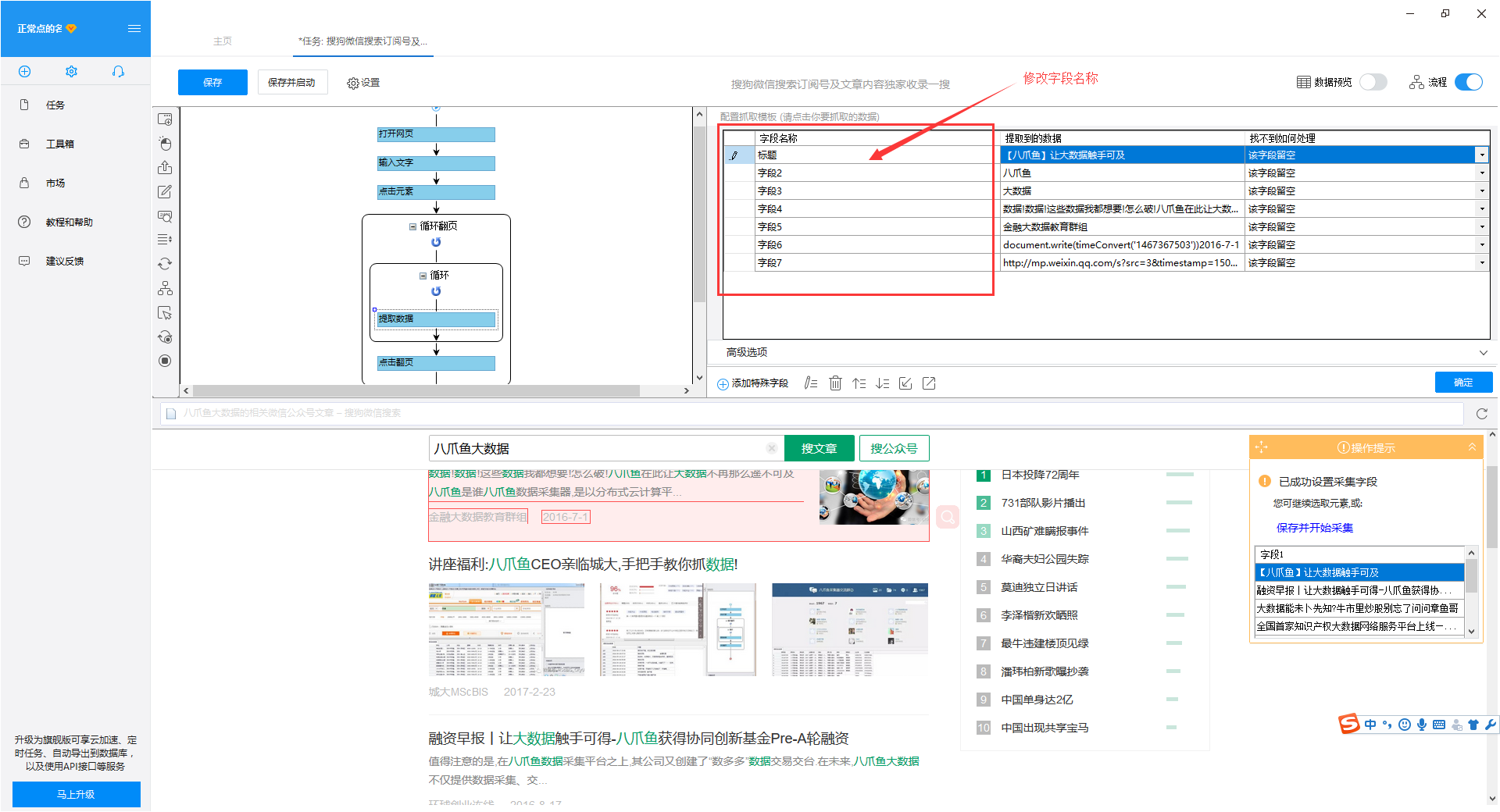
4) 由于我们还想要每个采集文章的URL,所以我们需要再提取一个字段。点击第一篇文章文章的链接,再点击第二篇文章文章的链接,系统会自动在页面上选择一组文章链接。在右侧的操作提示框中选择“采集以下链接地址”
5)字段选择完成后,选择对应的字段,自定义字段的命名。完成后点击左上角的“保存并开始”开始采集task
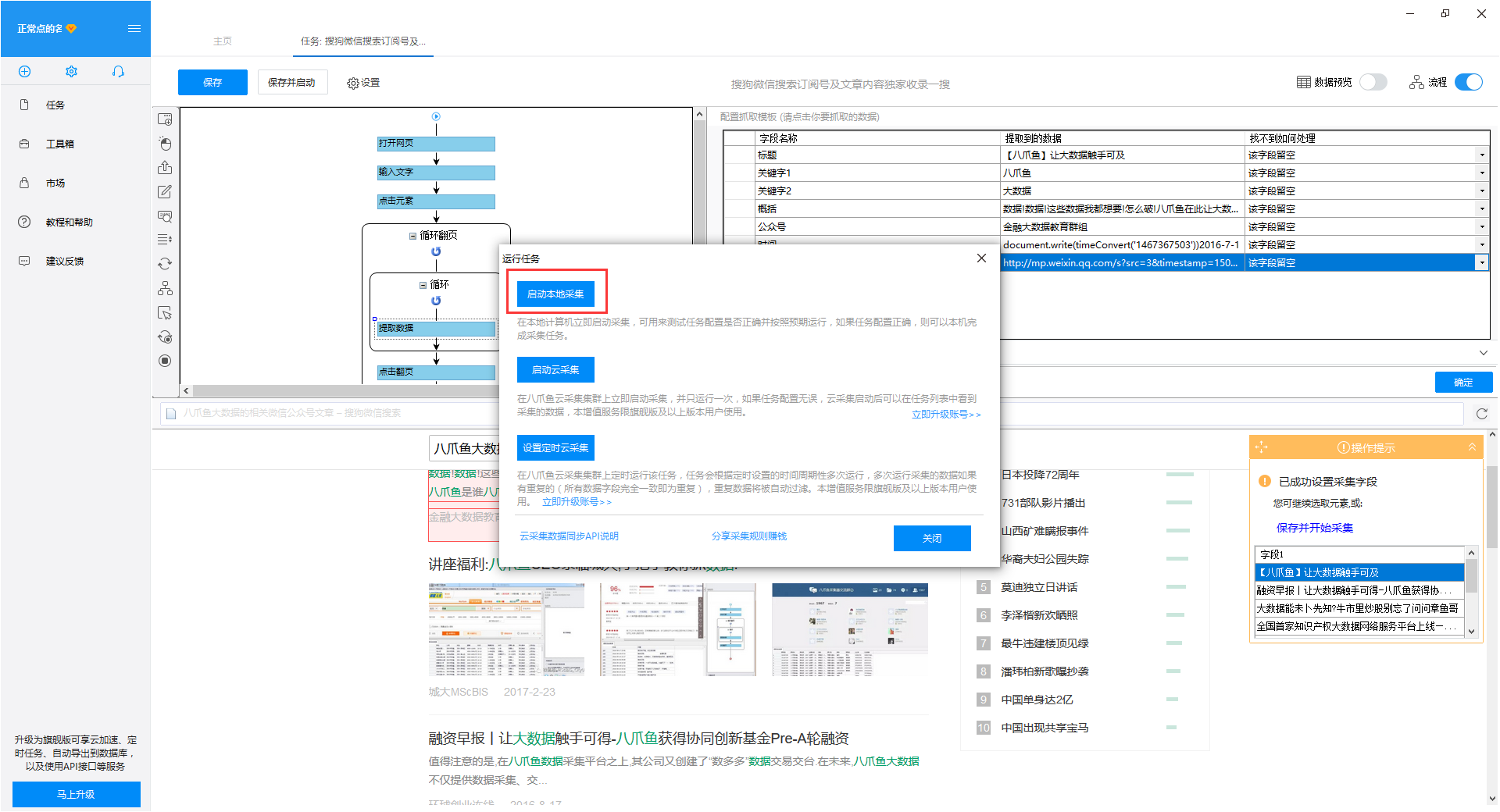
6)选择“启动本地采集”
第四步:数据采集并导出
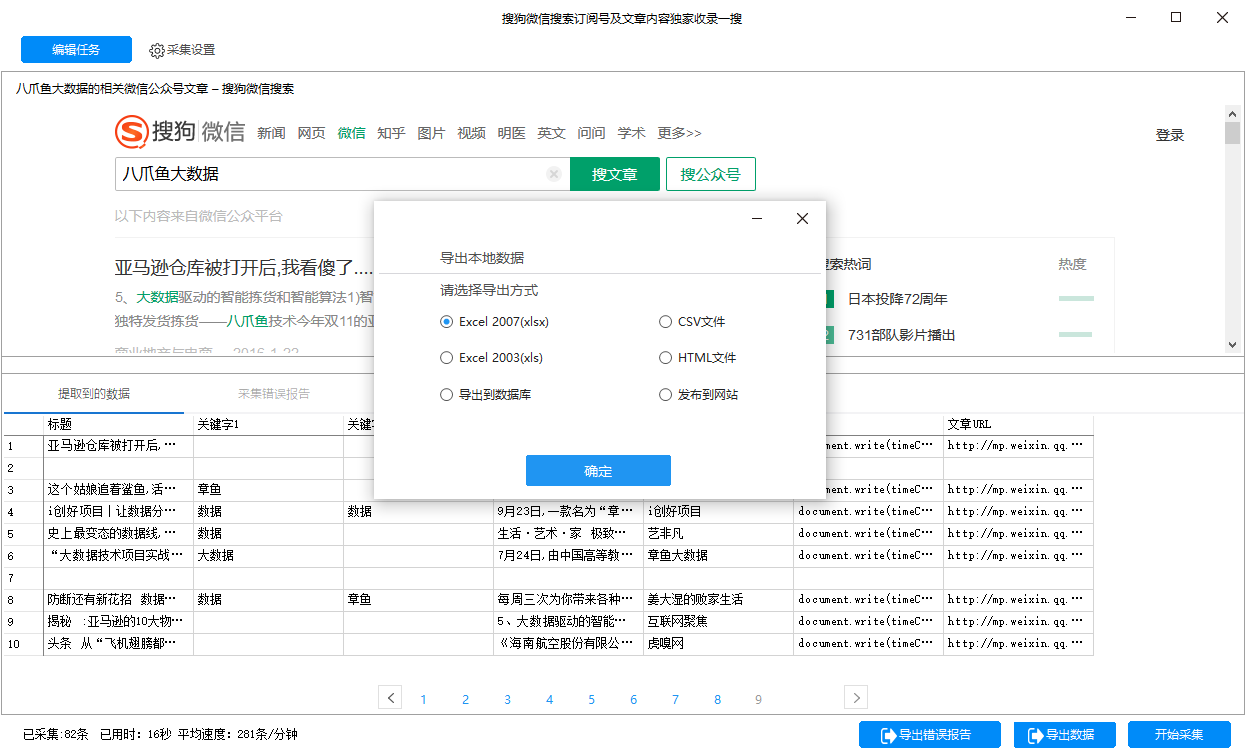
1)采集完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,导出采集好搜狗微信文章的数据
2)这里我们选择excel作为导出格式,导出数据如下图
查看全部
通过关键词采集文章采集api(搜狗微信文章采集数据详细采集说明及解决方案
)
采集网站:
使用功能点:
网址
分页列表信息采集
搜狗微信搜索:搜狗微信搜索是搜狗于2014年6月9日推出的微信公众平台。“微信搜索”支持搜索微信公众号和微信文章,可以通过关键词搜索相关微信公众号,或微信公众号推送的文章。不仅是PC端,搜狗手机搜索客户端也会推荐相关的微信公众号。
搜狗微信文章采集数据说明:本文已在搜狗微信-搜索-优采云大数据文章信息采集进行。本文仅以“搜狗微信-搜索-优采云大数据的文章信息采集”为例。实际操作中,您可以根据自己的需要,将搜狗微信的搜索词更改为执行数据采集。
搜狗微信文章采集detail采集字段说明:微信文章title、微信文章keywords、微信文章generalization、微信公众号、微信文章发布时间、微信文章地址。
第一步:创建采集task
1)进入主界面,选择“自定义模式”
2)将采集的网址复制粘贴到网站输入框中,点击“保存网址”
第 2 步:创建翻页循环
1)打开右上角的“进程”。点击页面文章搜索框,在右侧操作提示框中选择“输入文字”
2)输入您要搜索的文章信息,这里以搜索“优采云大数据”为例,输入完成后点击“确定”按钮
3)“优采云大数据”会自动填写搜索框,点击“search文章”按钮,在操作提示框中选择“点击此按钮”
“优采云大数据”的文章搜索结果出现在4)页面上。将结果页下拉至底部,点击“下一页”按钮,在右侧操作提示框中选择“循环点击下一页”
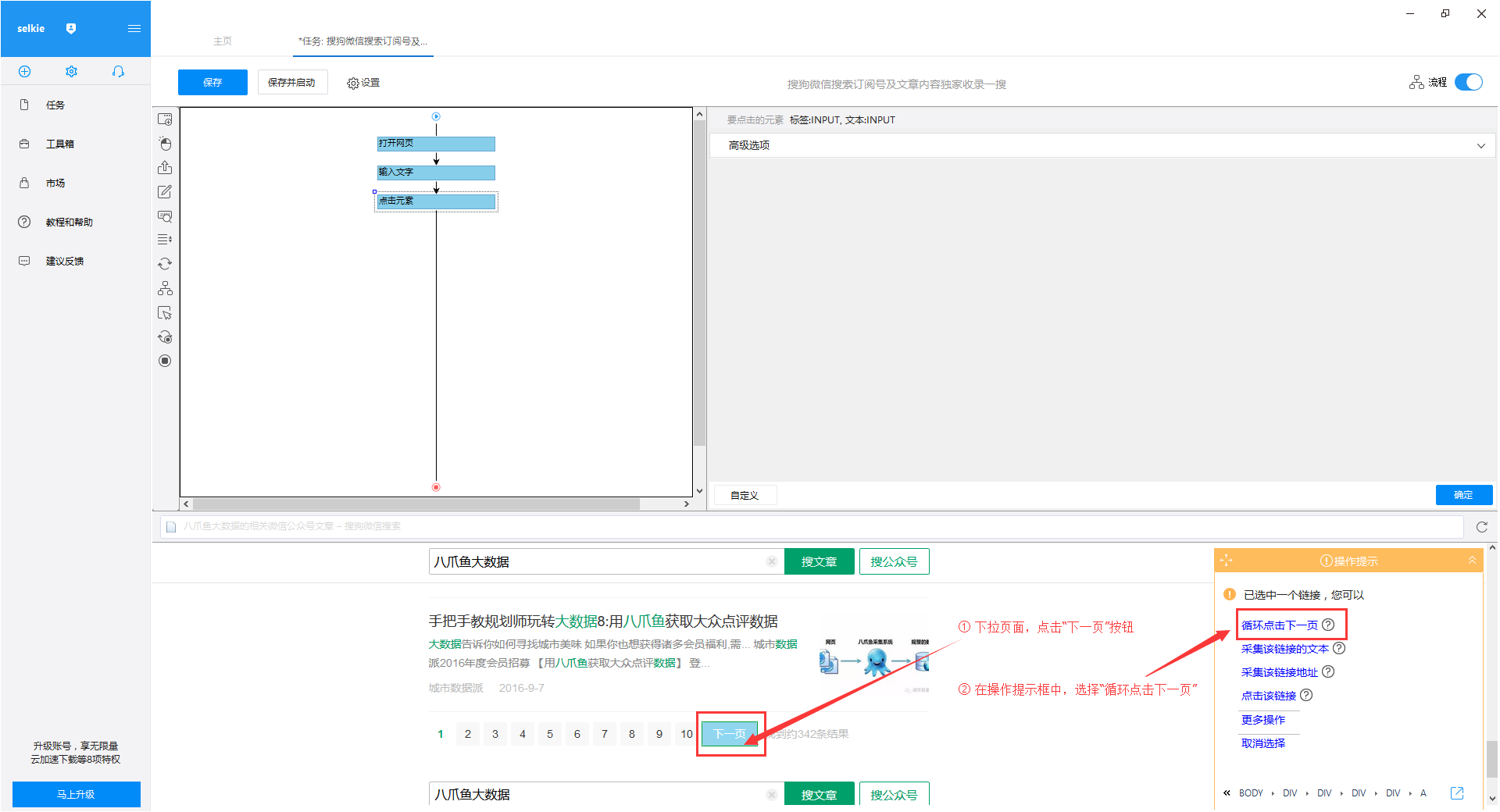
第 3 步:创建一个列表循环并提取数据
1)移动鼠标选择页面上的第一个文章块。系统将识别此块中的子元素。在操作提示框中选择“选择子元素”
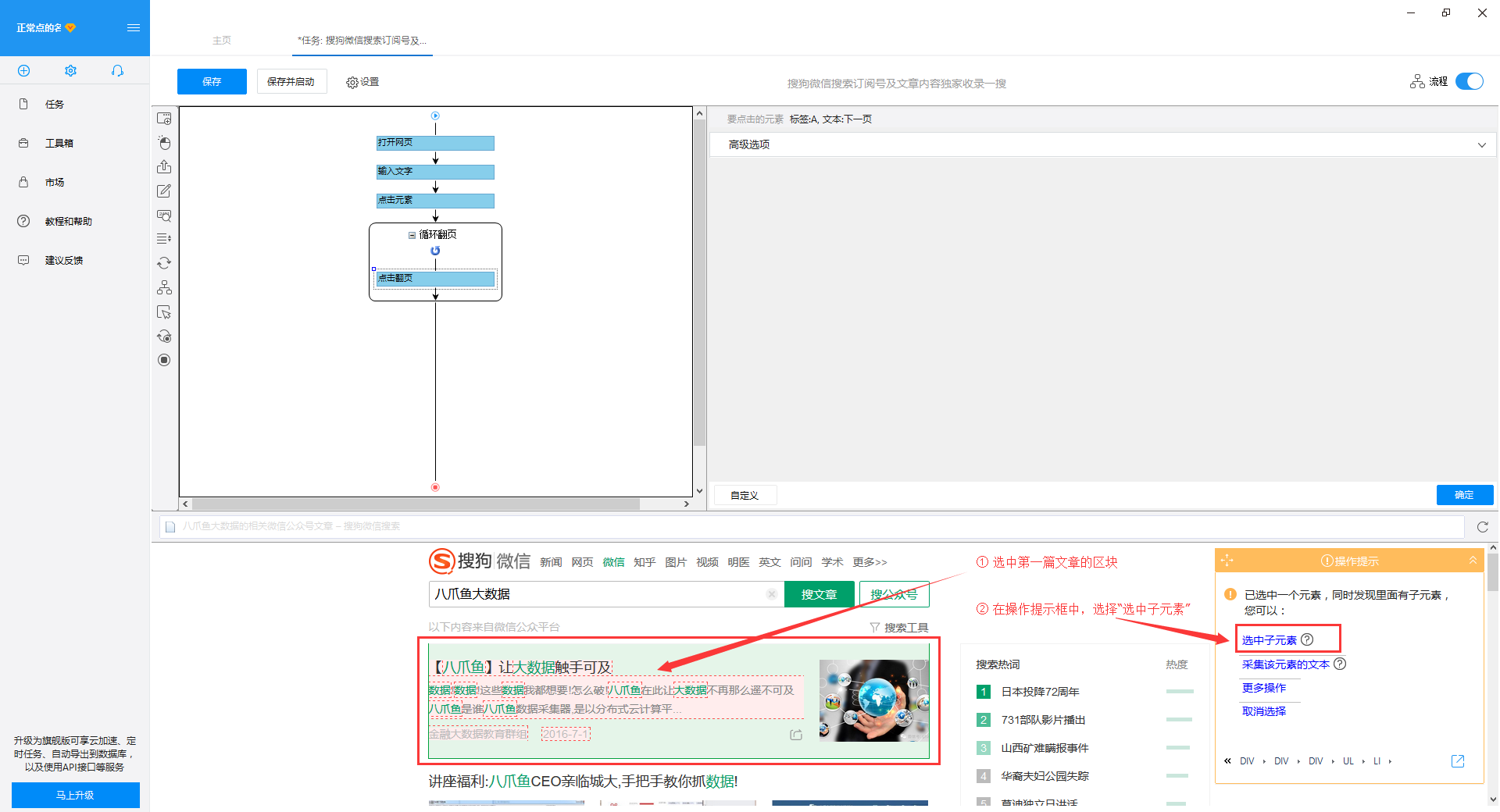
2)继续选择页面第二篇文章文章的区块,系统会自动选择第二篇文章文章的子元素,并识别页面其他10组相似元素, 在操作提示框中,选择“全选”
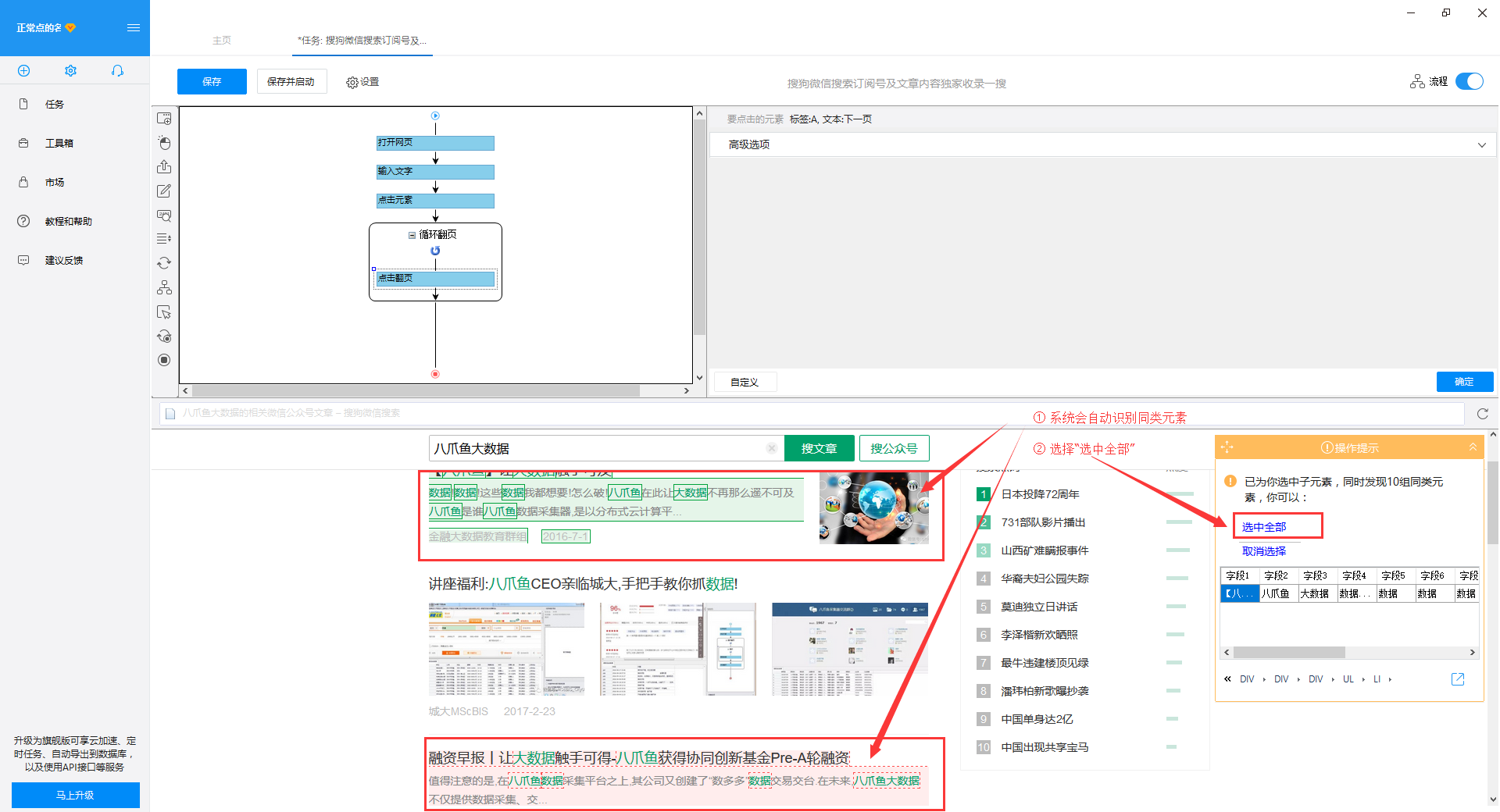
3) 我们可以看到页面上文章块中的所有元素都被选中并变成了绿色。在右侧的操作提示框中,会出现一个字段预览表。将鼠标移动到表头并单击垃圾桶图标以删除不需要的字段。字段选择完成后,选择“采集以下数据”
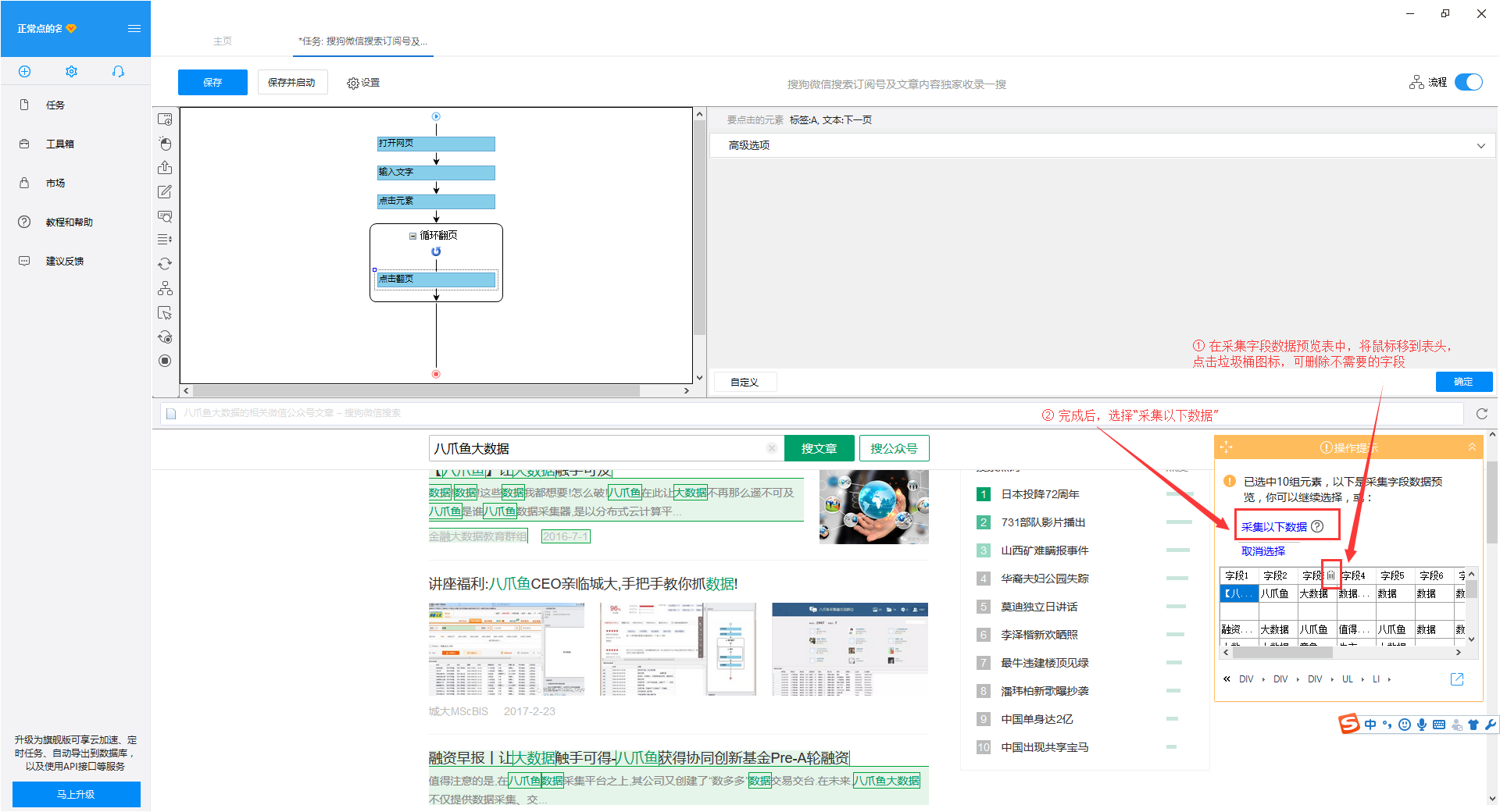
4) 由于我们还想要每个采集文章的URL,所以我们需要再提取一个字段。点击第一篇文章文章的链接,再点击第二篇文章文章的链接,系统会自动在页面上选择一组文章链接。在右侧的操作提示框中选择“采集以下链接地址”
5)字段选择完成后,选择对应的字段,自定义字段的命名。完成后点击左上角的“保存并开始”开始采集task
6)选择“启动本地采集”
第四步:数据采集并导出
1)采集完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,导出采集好搜狗微信文章的数据
2)这里我们选择excel作为导出格式,导出数据如下图
通过关键词采集文章采集api(百度站长平台原创提交工具下载使用百度原创工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-08-31 13:05
百度站长平台原创提交工具是一款可以帮助站长朋友提交到百度站长平台原创的工具,下载并使用这个百度原创提交工具可以让你的原创内容得到有效保护,立即下载并使用这个百度原创提交者。
百度站长平台是全球最大的面向中国互联网管理者、移动开发者和创业者的搜索流量管理官方平台。提供提交和分析工具,帮助搜索引擎捕捉收录、SEO优化建议等;为移动开发者提供百度官方API接口,以及多端适配能力和服务;及时发布百度权威数据和算法、工具等升级推送新信息。通过多种线上线下互动渠道,在为互联网多终端运营商增加用户和流量的同时,也为海量用户创造更好的搜索体验,携手双方共同打造移动时代的绿色搜索生态互联网。
软件功能
1.[更容易成为百度收录] 大量推送希望收录的数据到百度,网站会更容易成为百度收录,无论是添加还是删除数据,它百度知道的会更快。
2.【百度官方数据】在百度上查询网站的准确数据,方便分析网站的流量是否异常,搜索引擎是否友好。
3.【搜索结果个性化展示】通过使用站点子链、官网图、结构化数据等工具,网站可以在百度搜索结果页面更加个性化展示,获取更多交通。
4.【流量异常快速反馈】通过反馈中心快速反馈网站问题,随时跟踪进度,快速解决。
5.【新闻源申请与管理】信息站点或频道可在站长平台申请加入新闻源。新闻源站可以通过站长平台了解收录,反馈问题,接收相关新闻提醒。
6.【App和搜索流量打通】移动开发者可以通过AppLink等产品将搜索用户转化为自己的用户,打破App的封闭性,更容易获取用户。 查看全部
通过关键词采集文章采集api(百度站长平台原创提交工具下载使用百度原创工具)
百度站长平台原创提交工具是一款可以帮助站长朋友提交到百度站长平台原创的工具,下载并使用这个百度原创提交工具可以让你的原创内容得到有效保护,立即下载并使用这个百度原创提交者。
百度站长平台是全球最大的面向中国互联网管理者、移动开发者和创业者的搜索流量管理官方平台。提供提交和分析工具,帮助搜索引擎捕捉收录、SEO优化建议等;为移动开发者提供百度官方API接口,以及多端适配能力和服务;及时发布百度权威数据和算法、工具等升级推送新信息。通过多种线上线下互动渠道,在为互联网多终端运营商增加用户和流量的同时,也为海量用户创造更好的搜索体验,携手双方共同打造移动时代的绿色搜索生态互联网。
软件功能
1.[更容易成为百度收录] 大量推送希望收录的数据到百度,网站会更容易成为百度收录,无论是添加还是删除数据,它百度知道的会更快。
2.【百度官方数据】在百度上查询网站的准确数据,方便分析网站的流量是否异常,搜索引擎是否友好。
3.【搜索结果个性化展示】通过使用站点子链、官网图、结构化数据等工具,网站可以在百度搜索结果页面更加个性化展示,获取更多交通。
4.【流量异常快速反馈】通过反馈中心快速反馈网站问题,随时跟踪进度,快速解决。
5.【新闻源申请与管理】信息站点或频道可在站长平台申请加入新闻源。新闻源站可以通过站长平台了解收录,反馈问题,接收相关新闻提醒。
6.【App和搜索流量打通】移动开发者可以通过AppLink等产品将搜索用户转化为自己的用户,打破App的封闭性,更容易获取用户。
通过关键词采集文章采集api(讲讲等境外社交数据采集的新姿势→(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-08-31 07:01
在《Facebook、Twitter、YouTube、Ins等海外社交数据采集新姿势→》一文中,我们介绍了海外社交数据的主要采集场景和采集方式。
另外,一定有很多你关心的、想详细了解的问题。本文将结合与客户合作过程中的经验,详细讲解海外社交数据采集的一些问题。
问题清单:
01 所有海外社交网络网站采集都可以吗?
02 网站 是所有可用的数据采集吗?
03 你能采集所有历史数据吗?
04 是否可以实现对新增数据的实时采集?
05 如何稳定采集海外社交数据?
06采集到达的数据能否实时导出?
07 支持哪些类型的交付?
08 从确定需求到上线交付需要多长时间?
01 所有海外社交网络网站采集都可以吗?
是的。只要能正常访问的网站,就可以使用优采云quick采集。包括但不限于 Twitter、Facebook、YouTube、Instagram、LinkedIn、Pinterest、Google+、Tumblr、VK、Flickr、MySpace、Tagged、Ask.fm、Meetup 等。
不过有些网站防采集比较严格,自己试试采集容易出问题。如果您有采集海外社交数据需求,建议联系优采云官网()客服协助您进行采集测试。
02 网站 是所有可用的数据采集吗?
是的。 网站默认显示的数据,或者登录/点击等交互后显示的数据,都可以是采集。
Twitter、Facebook、YouTube、Instagram等社交网站虽然主要内容形式不同,但都属于社交媒体平台,其庞大的结构和功能都比较相似。 采集场景也有很多共性,最常见的采集场景的三种类型是:
① 指定账号采集下更新的推文/图片/视频;
②特定关键词采集的实时搜索结果;
③ 在推文/图片/视频下评论采集。
03 你能采集所有历史数据吗?
需要根据网页的情况来分析。有些网站可以看到所有的历史数据,你可以采集。有的网站只显示某段时间的数据,有的则隐藏,不能采集。
和推特首页一样,瀑布流加载新数据(向下滚动加载新数据),滚动不限次数,无法查看之前发布的所有历史数据。如果需要历史数据,可以从现在开始,定时更新数据多次采集,不断积累。
04 是否可以实现对新增数据的实时采集?
是的。 优采云专属cloud采集,支持灵活定时策略设置,采用分布式云采集方式,可在极短时间内完成采集多个海外社交数据源的数据更新。
例如,我们有一位客户需要在采集Twitter 上实时更新 3000 多个指定帐户的推文。怎么做首先将3000+账号按照更新频率分组,然后合理分配云节点采集每个组,最后帮助客户实现3000+的实时采集用于更新数据的数据源。
05 如何稳定采集海外社交数据?
在进行海外社交数据采集时,我们可能会遇到以下稳定性问题: ①部分网站需要特定国家/地区IP才能访问; ②采集数据量大时可能会遇到IP阻塞; ③ 存在云节点宕机、数据泄露的情况。
相应地,我们采取了一系列措施来有效解决上述问题: ①购买海外云集群,使用大量海外云节点访问和采集数据; ② 支持导入不同国家的优质IP,然后根据IP采集数据接入合并; ③ 在云端搭建监控系统,一旦节点停止挖矿,数据泄露会及时报警。
06采集到达的数据能否实时导出?
是的。 优采云提供高负载、高吞吐量的API接口,可以秒级将采集结果同步到企业数据库或内部系统。
除了API的使用,还有定时自动存储功能,无需技术人员即可实现数据的自动存储。目前支持SqlServer、MySql、Oracle 三种数据库。
07 支持哪些类型的交付?
我们提供各种交付方式,例如 SaaS 软件、私有化部署和数据服务。
SaaS软件:购买优采云SaaS软件,用于海外社交数据采集。
私有化部署:将优采云软件部署到企业服务器,支持二次开发,数据安全性极高,可与企业业务系统高度集成。
数据服务:数据直送,包括数据采集、数据清洗到数据导出等一站式数据服务。
08 从确认需求到上线发货需要多长时间?
需要根据你的需求具体评估,但总体来说还是很快的。
整个流程主要是确认需求→集中检测→采购事宜→在线发货→售后支持。我们会有一对一的专属客户经理跟进,确保每个环节的顺利进行。
比较耗时的部分是密集测试,包括制定采集规则,测试采集效果等任务。由于很好地服务了类似需求的客户,积累了大量海外社交网站采集规则和采集模板,可以直接投入测试,项目进度比较快。我们已经帮助创业团队在5天内完成了4个网站近30+采集任务在Twitter、Facebook、YouTube和Instagram上的任务创建和测试,并协助他们的项目快速上线。
以上是进行海外社交数据采集时最常见的一些问题。
想了解更多,请咨询我们的客服~ 查看全部
通过关键词采集文章采集api(讲讲等境外社交数据采集的新姿势→(二))
在《Facebook、Twitter、YouTube、Ins等海外社交数据采集新姿势→》一文中,我们介绍了海外社交数据的主要采集场景和采集方式。
另外,一定有很多你关心的、想详细了解的问题。本文将结合与客户合作过程中的经验,详细讲解海外社交数据采集的一些问题。
问题清单:
01 所有海外社交网络网站采集都可以吗?
02 网站 是所有可用的数据采集吗?
03 你能采集所有历史数据吗?
04 是否可以实现对新增数据的实时采集?
05 如何稳定采集海外社交数据?
06采集到达的数据能否实时导出?
07 支持哪些类型的交付?
08 从确定需求到上线交付需要多长时间?
01 所有海外社交网络网站采集都可以吗?
是的。只要能正常访问的网站,就可以使用优采云quick采集。包括但不限于 Twitter、Facebook、YouTube、Instagram、LinkedIn、Pinterest、Google+、Tumblr、VK、Flickr、MySpace、Tagged、Ask.fm、Meetup 等。

不过有些网站防采集比较严格,自己试试采集容易出问题。如果您有采集海外社交数据需求,建议联系优采云官网()客服协助您进行采集测试。
02 网站 是所有可用的数据采集吗?
是的。 网站默认显示的数据,或者登录/点击等交互后显示的数据,都可以是采集。
Twitter、Facebook、YouTube、Instagram等社交网站虽然主要内容形式不同,但都属于社交媒体平台,其庞大的结构和功能都比较相似。 采集场景也有很多共性,最常见的采集场景的三种类型是:
① 指定账号采集下更新的推文/图片/视频;
②特定关键词采集的实时搜索结果;
③ 在推文/图片/视频下评论采集。

03 你能采集所有历史数据吗?
需要根据网页的情况来分析。有些网站可以看到所有的历史数据,你可以采集。有的网站只显示某段时间的数据,有的则隐藏,不能采集。
和推特首页一样,瀑布流加载新数据(向下滚动加载新数据),滚动不限次数,无法查看之前发布的所有历史数据。如果需要历史数据,可以从现在开始,定时更新数据多次采集,不断积累。
04 是否可以实现对新增数据的实时采集?
是的。 优采云专属cloud采集,支持灵活定时策略设置,采用分布式云采集方式,可在极短时间内完成采集多个海外社交数据源的数据更新。
例如,我们有一位客户需要在采集Twitter 上实时更新 3000 多个指定帐户的推文。怎么做首先将3000+账号按照更新频率分组,然后合理分配云节点采集每个组,最后帮助客户实现3000+的实时采集用于更新数据的数据源。

05 如何稳定采集海外社交数据?
在进行海外社交数据采集时,我们可能会遇到以下稳定性问题: ①部分网站需要特定国家/地区IP才能访问; ②采集数据量大时可能会遇到IP阻塞; ③ 存在云节点宕机、数据泄露的情况。
相应地,我们采取了一系列措施来有效解决上述问题: ①购买海外云集群,使用大量海外云节点访问和采集数据; ② 支持导入不同国家的优质IP,然后根据IP采集数据接入合并; ③ 在云端搭建监控系统,一旦节点停止挖矿,数据泄露会及时报警。

06采集到达的数据能否实时导出?
是的。 优采云提供高负载、高吞吐量的API接口,可以秒级将采集结果同步到企业数据库或内部系统。
除了API的使用,还有定时自动存储功能,无需技术人员即可实现数据的自动存储。目前支持SqlServer、MySql、Oracle 三种数据库。
07 支持哪些类型的交付?
我们提供各种交付方式,例如 SaaS 软件、私有化部署和数据服务。
SaaS软件:购买优采云SaaS软件,用于海外社交数据采集。
私有化部署:将优采云软件部署到企业服务器,支持二次开发,数据安全性极高,可与企业业务系统高度集成。
数据服务:数据直送,包括数据采集、数据清洗到数据导出等一站式数据服务。

08 从确认需求到上线发货需要多长时间?
需要根据你的需求具体评估,但总体来说还是很快的。
整个流程主要是确认需求→集中检测→采购事宜→在线发货→售后支持。我们会有一对一的专属客户经理跟进,确保每个环节的顺利进行。
比较耗时的部分是密集测试,包括制定采集规则,测试采集效果等任务。由于很好地服务了类似需求的客户,积累了大量海外社交网站采集规则和采集模板,可以直接投入测试,项目进度比较快。我们已经帮助创业团队在5天内完成了4个网站近30+采集任务在Twitter、Facebook、YouTube和Instagram上的任务创建和测试,并协助他们的项目快速上线。
以上是进行海外社交数据采集时最常见的一些问题。
想了解更多,请咨询我们的客服~
通过关键词采集文章采集api(【每日一题】网页源代码的案例教程(二) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-08-30 23:13
)
内容
前言
大家好,我叫山念。
这是我的第二篇博客,也是第一个技术博客。希望大家多多支持,让我更有动力更新一些python爬虫案例教程。
开始
建立目标网址:点击进入
进入跳转页面:
你可以看到我们需要一些音乐
分析(x0)
这些音乐的源文件地址是否在我们的网页元素中,然后检查网页源代码中是否收录我们需要的内容。 (注:网页元素和网页源代码不一定相同。网页元素是浏览器渲染的源代码,源代码纯粹是服务器发送给我们的原创数据)
网页元素中只有封面图片的资源,不使用音频源文件地址:
网页的源代码中也没有我们需要的东西:
分析(x1)
其实没有也很正常(网站这么大的数据不会让你这么轻易就抢到了.....只是带大家走一遍流程,分析其他网站这样的
那我们开始播放音乐来抓包,看看能不能抓到数据:
果然,在播放按钮被触发后,服务器将其发送给我们的客户端。 (阿贾克斯)
还有我们抓到的源文件地址
除了这两个段落,其他的都应该修复。
分析(x2)
然后我假设这两个段落是我第一次访问这首歌的页面时生成的。比如这首音乐在服务器数据库中的ID值是多少?
假设是合理的,但由于我们已经检查了源代码并且网页元素找不到这些值,我不会在这里浪费时间。
分析(x3)
这里告诉你,我们向服务器发送一个URL请求,服务器返回给我们的数据包不止一个,一般是N个数据包。当我们看到没有源代码时,可能是通过ajax悄悄传递给我们的?
Ajax 网上有很多解释,但大家可能看不懂。从服务器获取源代码数据,然后执行JavaScript通过浏览器渲染获取一些数据(音乐)。
这样大家应该就明白了,接下来我们开始抓取当前页面的包:
Ajax 异步请求数据将在 XHR 中。所以直接过滤就好了。我抓到了这个包,获取请求并查看返回值。
果然这个包数据都是对应的,那就打开看看里面有没有音乐源文件地址:
没有,但是出现了两次。
分析(x4)
那是我们音乐的ID(index)值吗?
看下面的包:
这个get请求很重要,它在参数中使用了我们的rid值
而他的返回值恰好有我们的音乐源文件地址:
通过分析获取音乐
通过我们的分析,我们可以理清思路。
先抓住这个包裹摆脱
然后通过rid来请求这个包获取音乐文件地址
JavaScript 绕过参数冗余
可以看到这个rid得到的地址中的key值是经过url编码的,很容易解码:
import requests
keywords = '%E5%BE%80%E4%BA%8B%E9%9A%8F%E9%A3%8E'
print(requests.utils.unquote(keywords))
# 往事随风
而pn=1表示第一页,30表示本页共有30首音乐数据,1表示状态码请求成功,最后如何获取reqId的值?
如果你有逆向JavaScript的能力,我们把这里的参数全部删掉,我们也可以访问我们的rid。为什么?
当您访问百度时
可以看到有很多你看不懂的多余参数,这些参数其实可以直接删除!
结果是一样的,这就是所谓的参数冗余。
CSRF攻防
当我们直接访问这个链接时,会出现这个画面吗?
而如果我们把所有的请求头都放在我们的pycharm中,用Python模拟发送请求,就可以成功(自测)
可以看到请求中有一个参数叫csrf,叫做反跨站攻击。
这很容易理解。当我们直接用浏览器访问时,虽然可以带cookies,但是不能带这个参数。而当我们完整复制请求头,在pycharm中用Python运行时,我们可以携带这个参数,然后就可以访问了。
目的是为了保护这个api,防止在任何情况下被随意访问。
这个 csrf 参数不是我们 cookie 中的值吗?那么我们需要先获取cookie吗?因为cookies会过期,为了让你的程序永远有效,那么最好的办法就是自动获取cookies
总结
那么所有的原理就可以想通了
先访问首页获取cookies,然后绕过JavaScript删除多余的参数进行摆脱,最后通过rid访问获取音乐源地址(这里的参数也可以删除),最后保存数据!
全程干货,解析网站反拔手段,Python采集全站任乐!
代码
"""
author: 善念
date: 2021-04-12
"""
import requests
import jsonpath
from urllib.request import urlretrieve
import urllib.parse
def get_csrf():
# 保持cookies 维持客户端与服务器之间的会话
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1618229629; _ga=GA1.2.1951895595.1618229638; _gid=GA1.2.369506281.1618229638; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1618230532; kw_token=ZOMA0RIOLV',
'Host': 'www.kuwo.cn',
'Pragma': 'no-cache',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
}
s.get('http://www.kuwo.cn/', headers=headers)
url = f'http://www.kuwo.cn/api/www/sea ... ey%3D{keyword}&pn=1&rn=30&httpsStatus=1&reqId=a3b6cb30-9b8a-11eb-bc04-b33703ed2ebb'
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1618229629; _ga=GA1.2.1951895595.1618229638; _gid=GA1.2.369506281.1618229638; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1618229710; kw_token=UTBATXE1HY',
'csrf': s.cookies.get_dict()['kw_token'],
'Host': 'www.kuwo.cn',
'Pragma': 'no-cache',
'Referer': f'http://www.kuwo.cn/search/list?key={keyword}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
}
r = s.get(url, headers=headers)
print(r.text)
rid = jsonpath.jsonpath(r.json(), '$..rid')[0]
print(rid)
return rid
def get_music_url(rid):
url = f'http://www.kuwo.cn/url?format=mp3&rid={rid}&response=url&type=convert_url3&br=128kmp3&from=web&httpsStatus=1'
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1618231398; _ga=GA1.2.52993118.1618231399; _gid=GA1.2.889494894.1618231399; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1618231413; _gat=1; kw_token=VBM6N1XEG4P',
'Host': 'www.kuwo.cn',
'Pragma': 'no-cache',
'Referer': f'http://www.kuwo.cn/search/list?key={keyword}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
}
music_url = s.get(url, headers=headers).json().get('url')
print(music_url)
return music_url
def get_music(music_url):
urlretrieve(music_url, f'{urllib.parse.unquote(keyword)}'+'.mp3')
def go():
rid = get_csrf()
music_url = get_music_url(rid)
get_music(music_url)
if __name__ == '__main__':
s = requests.session()
keyword = input('请输入您要下载的音乐名字:')
keyword = urllib.parse.quote(keyword)
go()
文章到此结束,感谢阅读,但我想对读者说几句。
emmmmm今天无话可说——我心里没有女人,代码自然☺
查看全部
通过关键词采集文章采集api(【每日一题】网页源代码的案例教程(二)
)
内容
前言
大家好,我叫山念。
这是我的第二篇博客,也是第一个技术博客。希望大家多多支持,让我更有动力更新一些python爬虫案例教程。

开始
建立目标网址:点击进入
进入跳转页面:
你可以看到我们需要一些音乐
分析(x0)
这些音乐的源文件地址是否在我们的网页元素中,然后检查网页源代码中是否收录我们需要的内容。 (注:网页元素和网页源代码不一定相同。网页元素是浏览器渲染的源代码,源代码纯粹是服务器发送给我们的原创数据)
网页元素中只有封面图片的资源,不使用音频源文件地址:
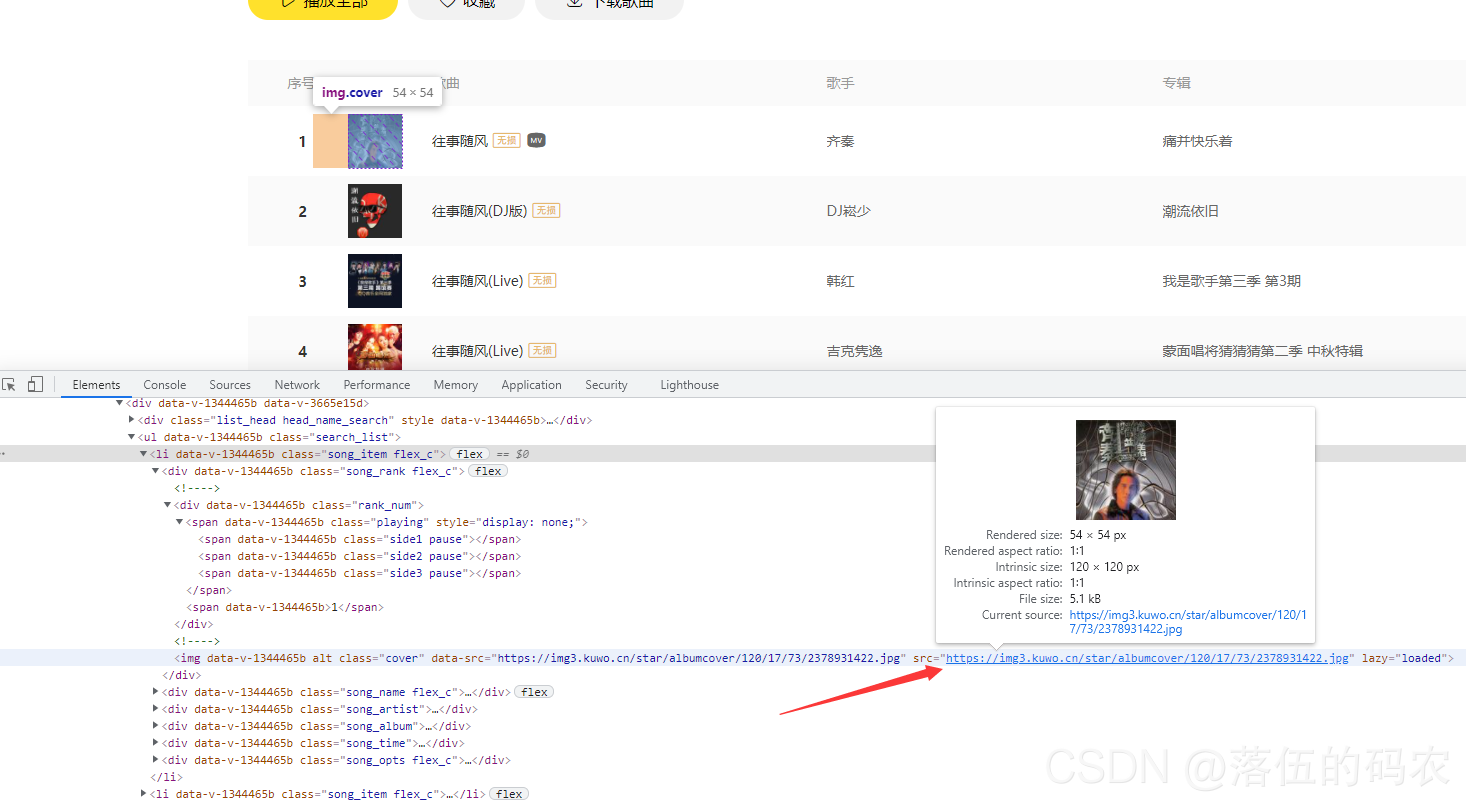
网页的源代码中也没有我们需要的东西:

分析(x1)
其实没有也很正常(网站这么大的数据不会让你这么轻易就抢到了.....只是带大家走一遍流程,分析其他网站这样的
那我们开始播放音乐来抓包,看看能不能抓到数据:
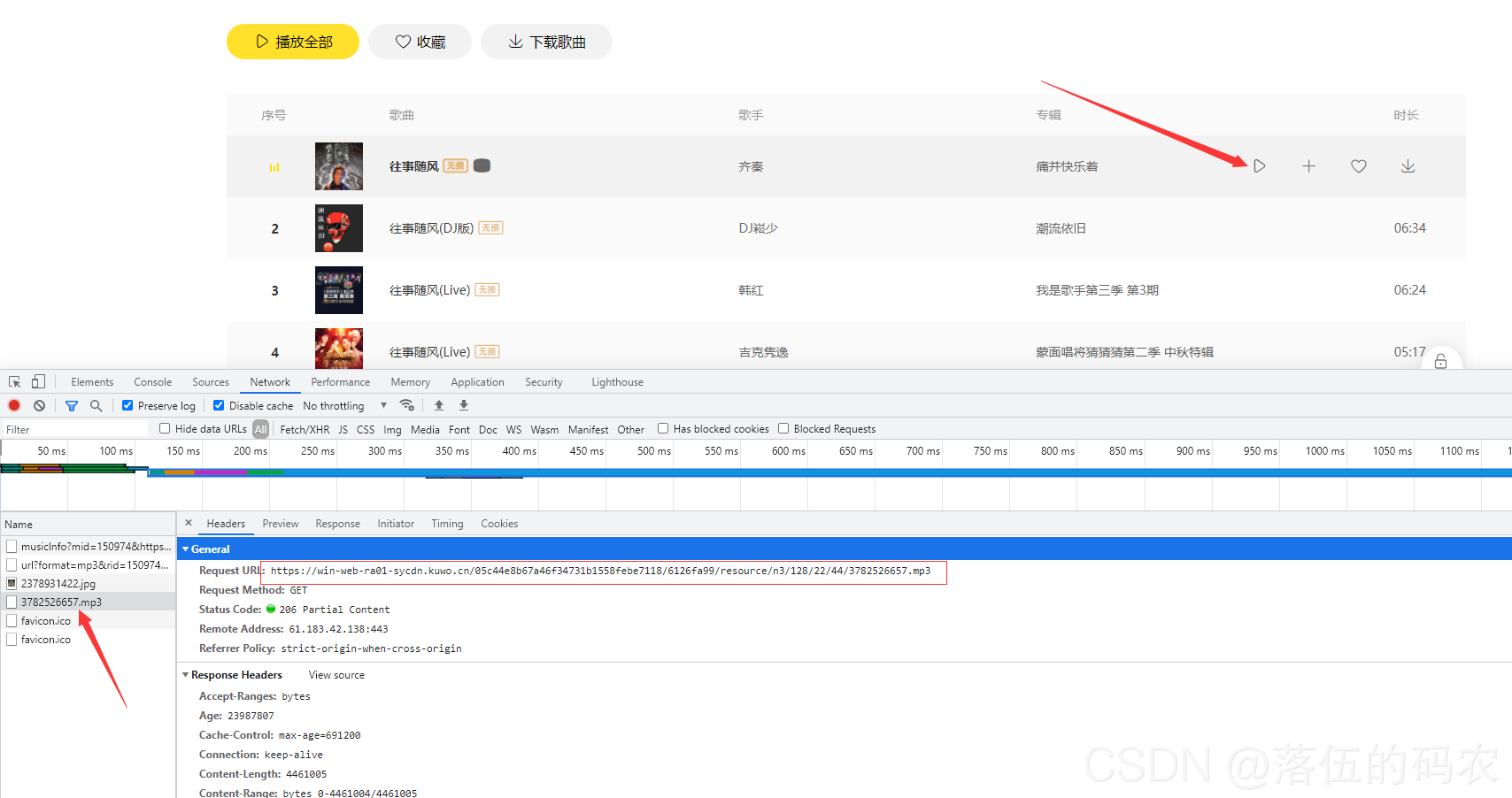
果然,在播放按钮被触发后,服务器将其发送给我们的客户端。 (阿贾克斯)
还有我们抓到的源文件地址
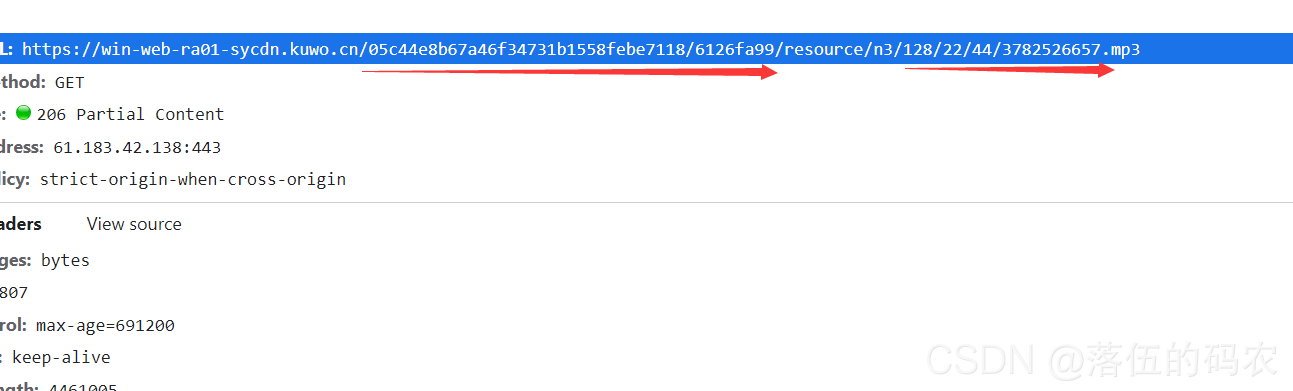
除了这两个段落,其他的都应该修复。
分析(x2)
然后我假设这两个段落是我第一次访问这首歌的页面时生成的。比如这首音乐在服务器数据库中的ID值是多少?
假设是合理的,但由于我们已经检查了源代码并且网页元素找不到这些值,我不会在这里浪费时间。
分析(x3)
这里告诉你,我们向服务器发送一个URL请求,服务器返回给我们的数据包不止一个,一般是N个数据包。当我们看到没有源代码时,可能是通过ajax悄悄传递给我们的?
Ajax 网上有很多解释,但大家可能看不懂。从服务器获取源代码数据,然后执行JavaScript通过浏览器渲染获取一些数据(音乐)。
这样大家应该就明白了,接下来我们开始抓取当前页面的包:
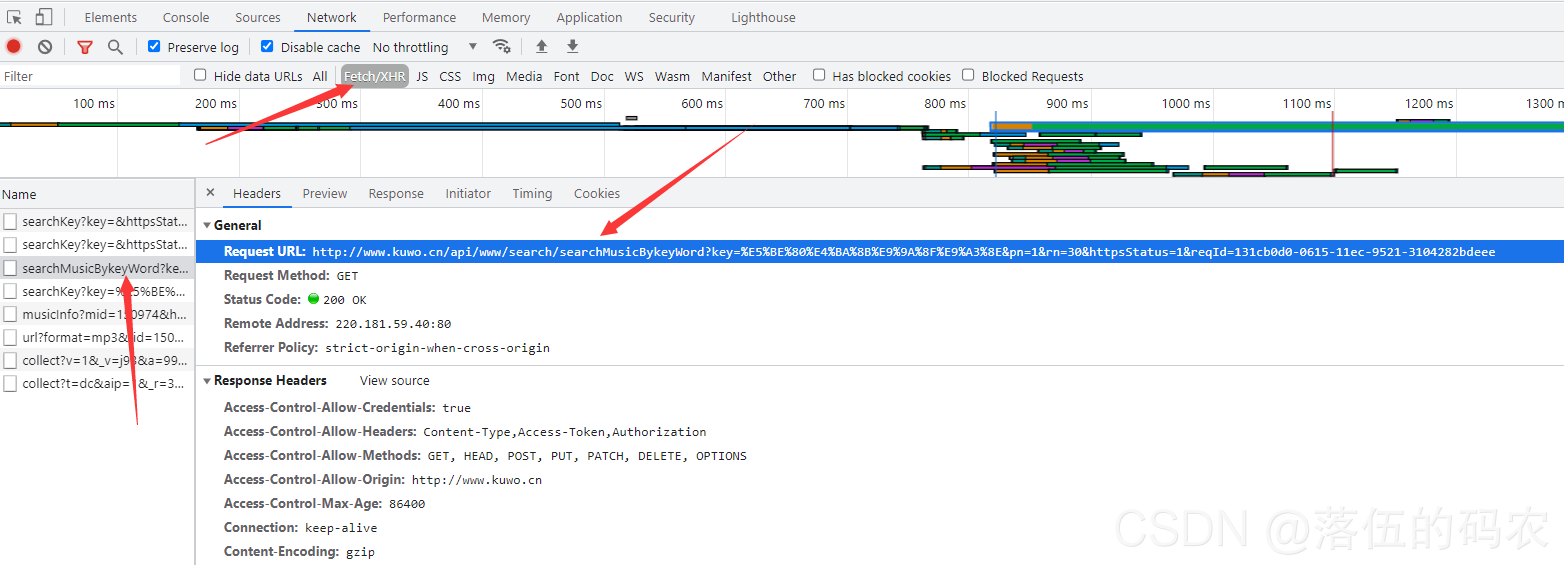
Ajax 异步请求数据将在 XHR 中。所以直接过滤就好了。我抓到了这个包,获取请求并查看返回值。
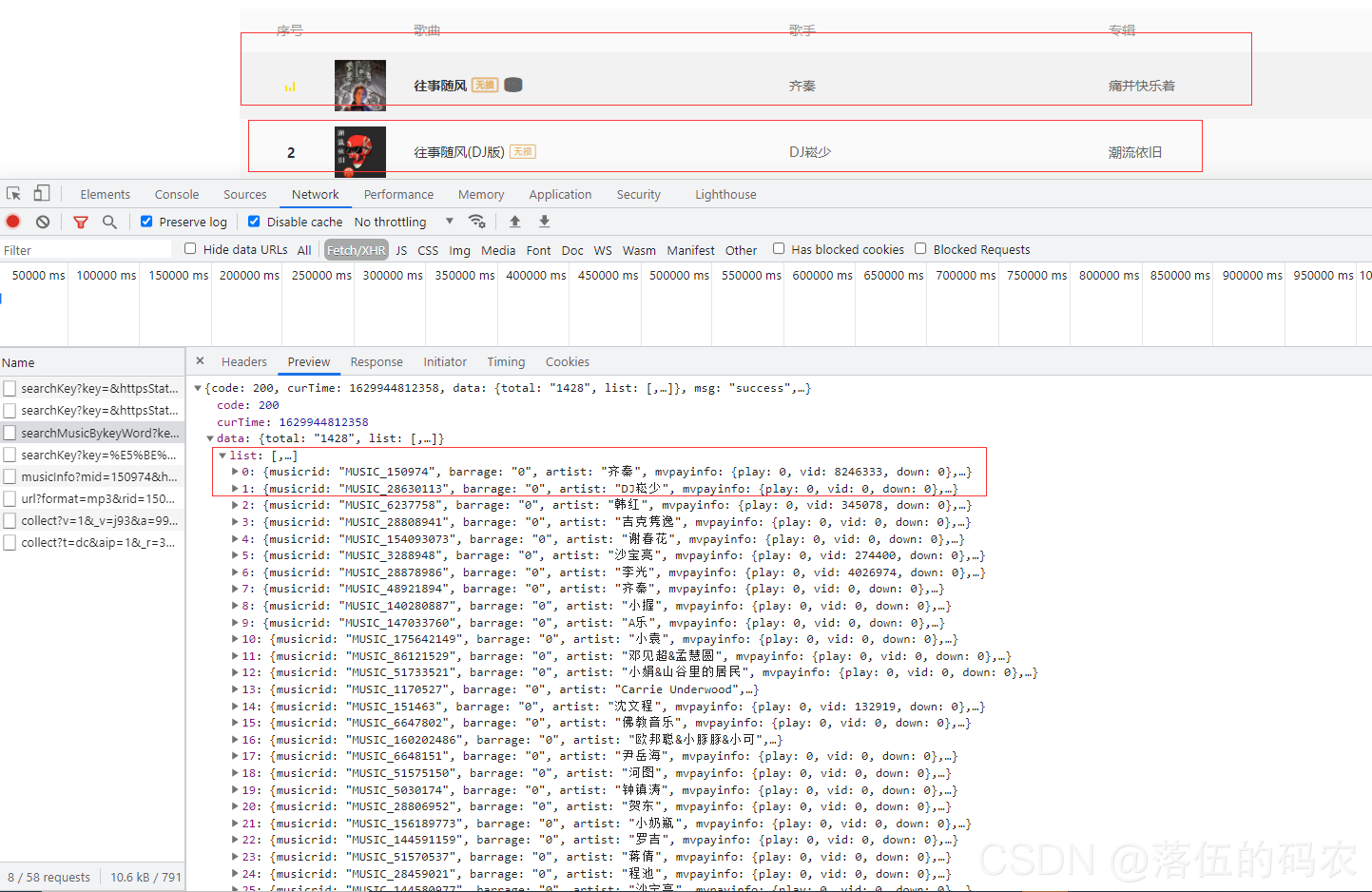
果然这个包数据都是对应的,那就打开看看里面有没有音乐源文件地址:
没有,但是出现了两次。
分析(x4)
那是我们音乐的ID(index)值吗?
看下面的包:
这个get请求很重要,它在参数中使用了我们的rid值
而他的返回值恰好有我们的音乐源文件地址:
通过分析获取音乐
通过我们的分析,我们可以理清思路。
先抓住这个包裹摆脱
然后通过rid来请求这个包获取音乐文件地址
JavaScript 绕过参数冗余
可以看到这个rid得到的地址中的key值是经过url编码的,很容易解码:
import requests
keywords = '%E5%BE%80%E4%BA%8B%E9%9A%8F%E9%A3%8E'
print(requests.utils.unquote(keywords))
# 往事随风
而pn=1表示第一页,30表示本页共有30首音乐数据,1表示状态码请求成功,最后如何获取reqId的值?
如果你有逆向JavaScript的能力,我们把这里的参数全部删掉,我们也可以访问我们的rid。为什么?
当您访问百度时

可以看到有很多你看不懂的多余参数,这些参数其实可以直接删除!
结果是一样的,这就是所谓的参数冗余。
CSRF攻防
当我们直接访问这个链接时,会出现这个画面吗?
而如果我们把所有的请求头都放在我们的pycharm中,用Python模拟发送请求,就可以成功(自测)
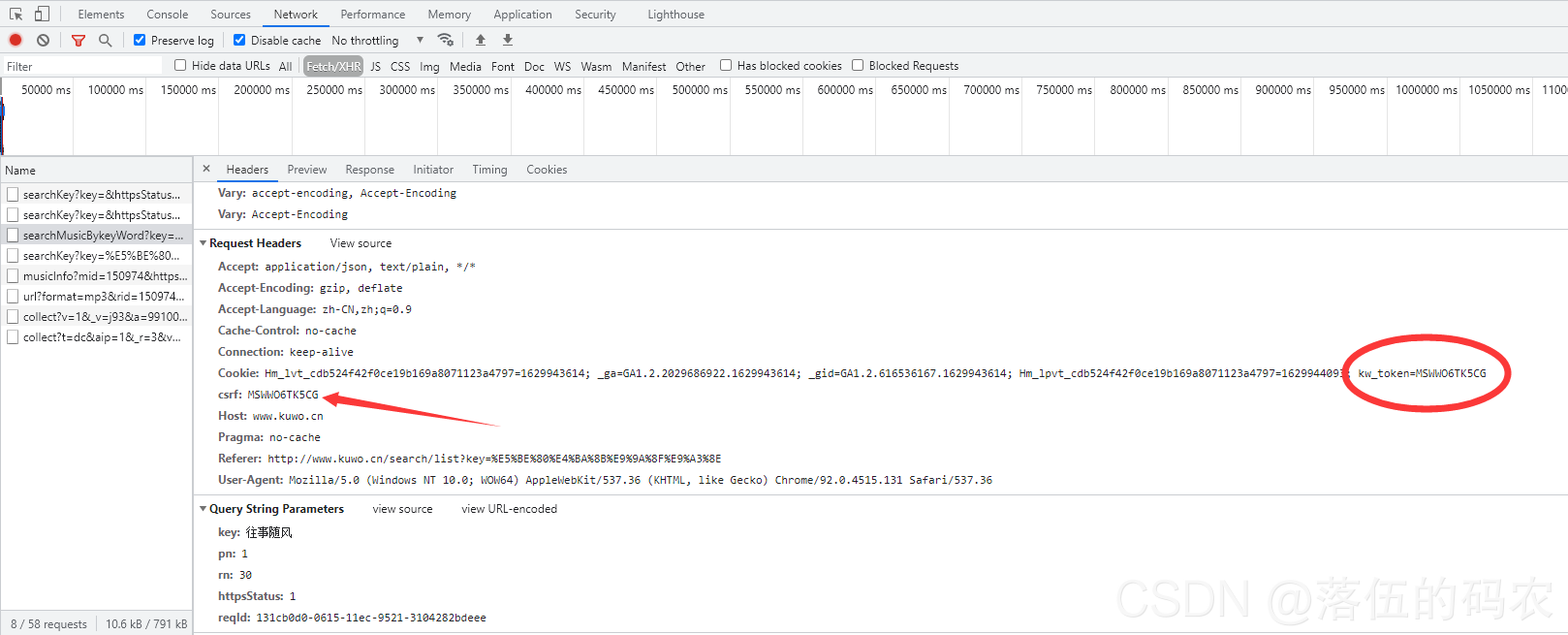
可以看到请求中有一个参数叫csrf,叫做反跨站攻击。
这很容易理解。当我们直接用浏览器访问时,虽然可以带cookies,但是不能带这个参数。而当我们完整复制请求头,在pycharm中用Python运行时,我们可以携带这个参数,然后就可以访问了。
目的是为了保护这个api,防止在任何情况下被随意访问。
这个 csrf 参数不是我们 cookie 中的值吗?那么我们需要先获取cookie吗?因为cookies会过期,为了让你的程序永远有效,那么最好的办法就是自动获取cookies
总结
那么所有的原理就可以想通了
先访问首页获取cookies,然后绕过JavaScript删除多余的参数进行摆脱,最后通过rid访问获取音乐源地址(这里的参数也可以删除),最后保存数据!
全程干货,解析网站反拔手段,Python采集全站任乐!
代码
"""
author: 善念
date: 2021-04-12
"""
import requests
import jsonpath
from urllib.request import urlretrieve
import urllib.parse
def get_csrf():
# 保持cookies 维持客户端与服务器之间的会话
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1618229629; _ga=GA1.2.1951895595.1618229638; _gid=GA1.2.369506281.1618229638; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1618230532; kw_token=ZOMA0RIOLV',
'Host': 'www.kuwo.cn',
'Pragma': 'no-cache',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
}
s.get('http://www.kuwo.cn/', headers=headers)
url = f'http://www.kuwo.cn/api/www/sea ... ey%3D{keyword}&pn=1&rn=30&httpsStatus=1&reqId=a3b6cb30-9b8a-11eb-bc04-b33703ed2ebb'
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1618229629; _ga=GA1.2.1951895595.1618229638; _gid=GA1.2.369506281.1618229638; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1618229710; kw_token=UTBATXE1HY',
'csrf': s.cookies.get_dict()['kw_token'],
'Host': 'www.kuwo.cn',
'Pragma': 'no-cache',
'Referer': f'http://www.kuwo.cn/search/list?key={keyword}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
}
r = s.get(url, headers=headers)
print(r.text)
rid = jsonpath.jsonpath(r.json(), '$..rid')[0]
print(rid)
return rid
def get_music_url(rid):
url = f'http://www.kuwo.cn/url?format=mp3&rid={rid}&response=url&type=convert_url3&br=128kmp3&from=web&httpsStatus=1'
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1618231398; _ga=GA1.2.52993118.1618231399; _gid=GA1.2.889494894.1618231399; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1618231413; _gat=1; kw_token=VBM6N1XEG4P',
'Host': 'www.kuwo.cn',
'Pragma': 'no-cache',
'Referer': f'http://www.kuwo.cn/search/list?key={keyword}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
}
music_url = s.get(url, headers=headers).json().get('url')
print(music_url)
return music_url
def get_music(music_url):
urlretrieve(music_url, f'{urllib.parse.unquote(keyword)}'+'.mp3')
def go():
rid = get_csrf()
music_url = get_music_url(rid)
get_music(music_url)
if __name__ == '__main__':
s = requests.session()
keyword = input('请输入您要下载的音乐名字:')
keyword = urllib.parse.quote(keyword)
go()

文章到此结束,感谢阅读,但我想对读者说几句。
emmmmm今天无话可说——我心里没有女人,代码自然☺

通过关键词采集文章采集api(发送图片微博、更新用户资料与头像、API自动授权)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-08-29 10:14
5、发送图片到微博,更新用户信息和头像,API自动授权
二、博客平台:
1、博客管理,轻松搞定
2、各大博客平台(BSP)从注册到激活自动完成
3、 将您的博文同步发送至所有博客平台,多博客维护从此轻松自在
4、关键词管理将相关词汇添加到您设置的超链接中以改进网站外链
三、portal 社区:
1、阳光门网站发帖准确到二级栏目,在线推广,准确有效
2、多条内容随机回复,随机词组自由组合
3、指定帖子回复,专业抢沙发,批量马甲制作
4、猫扑、天涯、新浪、腾讯、网易、搜狐等都支持
四、综合论坛:
1、内置网址,海量论坛
2、cloud 上万个网址库,随时更新与同步
3、用户网址库无限空间,无限导入
4、Forum 采集工具,让整个互联网论坛都可以加载到网址库中
5、Intelligent A power,模式码识别,注册问答识别
6、plug-in,补丁修改,论坛任务自动处理
五、问答平台:
1、我发现问题并准确回答
2、根据关键字搜索任何领域未解答的问题
3、精准匹配系统,回复并给出正确答案,答案就是你所问
4、多题分批提问,多题自答
商科推广专家软件功能
一、信息发布功能
二、信息搜索功能
三、群发邮件功能
四、邮件采集功能
五、Engine 登录及增强排名功能
六、繁-简体自动转换
七、生成交付报告
八、发布成功率高
九、自动保存功能
十、网站推荐功能
十一、设置维护功能
十二、自动在线升级 查看全部
通过关键词采集文章采集api(发送图片微博、更新用户资料与头像、API自动授权)
5、发送图片到微博,更新用户信息和头像,API自动授权
二、博客平台:
1、博客管理,轻松搞定
2、各大博客平台(BSP)从注册到激活自动完成
3、 将您的博文同步发送至所有博客平台,多博客维护从此轻松自在
4、关键词管理将相关词汇添加到您设置的超链接中以改进网站外链
三、portal 社区:
1、阳光门网站发帖准确到二级栏目,在线推广,准确有效
2、多条内容随机回复,随机词组自由组合
3、指定帖子回复,专业抢沙发,批量马甲制作
4、猫扑、天涯、新浪、腾讯、网易、搜狐等都支持
四、综合论坛:
1、内置网址,海量论坛
2、cloud 上万个网址库,随时更新与同步
3、用户网址库无限空间,无限导入
4、Forum 采集工具,让整个互联网论坛都可以加载到网址库中
5、Intelligent A power,模式码识别,注册问答识别
6、plug-in,补丁修改,论坛任务自动处理
五、问答平台:
1、我发现问题并准确回答
2、根据关键字搜索任何领域未解答的问题
3、精准匹配系统,回复并给出正确答案,答案就是你所问
4、多题分批提问,多题自答
商科推广专家软件功能
一、信息发布功能
二、信息搜索功能
三、群发邮件功能
四、邮件采集功能
五、Engine 登录及增强排名功能
六、繁-简体自动转换
七、生成交付报告
八、发布成功率高
九、自动保存功能
十、网站推荐功能
十一、设置维护功能
十二、自动在线升级
通过关键词采集文章采集api(网络爬虫系统的原理和工作流程及注意事项介绍-乐题库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-17 13:02
网络数据采集指通过网络爬虫或网站公共API从网站获取数据信息。该方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图片、音频、视频和其他文件或附件采集,附件可以自动与身体关联
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据
在大数据时代,网络爬虫是从互联网获取采集数据的有利工具。目前已知的网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类
本部分首先简要介绍了网络爬虫的原理和工作流程,然后讨论了网络爬虫的爬虫策略,最后描述了典型的网络工具
网络爬虫原理
网络爬虫是一个程序或脚本,根据一定的规则自动抓取网络信息
网络爬虫可以自动采集他们可以访问的所有页面内容,并为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般有三个功能:数据采集、处理和存储,如图1所示
图1网络爬虫示意图
除了供用户阅读的文本信息外,网页还收录一些超链接信息
网络爬虫系统正是通过网页中的超链接信息,不断地获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL获取初始网页上的URL。在抓取网页的过程中,它不断地从当前网页中提取新的URL并将其放入队列,直到满足系统的某些停止条件
网络爬虫系统通常选择一些具有大量网站链接(网页中的超链接)的重要URL作为种子URL集合
网络爬虫系统将这些种子集作为初始URL来开始数据获取。因为网页收录链接信息,所以您将通过现有网页的URL获得一些新的URL
网页之间的指向结构可以看作是一个森林,每个种子URL对应的网页是森林中树的根节点,因此网络爬虫系统可以根据广度优先搜索算法或深度优先搜索算法遍历所有网页
由于深度优先搜索算法可能会使爬虫系统陷入网站内部,不利于搜索靠近网站主页的网页信息,因此一般采用广度优先搜索算法采集网页
网络爬虫系统首先将种子URL放入下载队列,然后简单地从队列头部获取一个URL来下载其相应的网页,获取网页内容并存储。解析网页中的链接信息后,可以获得一些新的URL
其次,根据一定的网页分析算法,过滤掉与主题无关的链接,保留有用的链接,并将其放入等待获取的URL队列中
最后,取出一个URL,下载相应的网页,然后解析它。重复此操作,直到遍历整个网络或满足某些条件
网络爬虫工作流
如图2所示,web爬虫的基本工作流程如下
1)首先选择一些种子URL
2)将这些URL放入要获取的URL队列
3)从待取URL队列中取出待取URL,解析DNS,获取主机IP地址,下载该URL对应的网页,保存在下载的网页库中。此外,将这些URL放入已爬网的URL队列
4)分析爬网URL队列中的URL,分析其他URL,并将这些URL放入要爬网的URL队列中,以便进入下一个周期
图2网络爬虫的基本工作流程
网络爬虫爬行策略
谷歌和百度等通用搜索引擎捕获的网页数量通常以数十亿计。因此,面对如此多的web页面,如何使web爬虫尽可能地遍历所有的web页面,从而尽可能地扩大web信息的捕获范围,这是web爬虫系统面临的一个关键问题。在网络爬虫系统中,爬行策略决定了网页的爬行顺序
本节首先简要介绍web爬虫捕获策略中使用的基本概念
1)web页面之间的关系模型
从互联网的结构来看,网页通过若干超链接相互连接,形成一个庞大而复杂的相互关联的有向图
如图3所示,如果将网页视为图中的一个节点,并将与网页中其他网页的链接视为该节点与其他节点的边,则很容易将整个Internet上的网页建模为一个有向图
理论上,通过遍历算法遍历图形,几乎可以访问Internet上的所有网页
图3网页关系模型示意图
2)web页面分类
通过从爬虫的角度划分互联网,互联网的所有页面可以分为五个部分:下载和过期页面、下载和过期页面、要下载的页面、已知页面和未知页面,如图4所示
捕获本地网页实际上是互联网内容的镜像和备份。互联网是动态的。当Internet上的部分内容发生更改时,本地网页将过期。因此,下载的网页分为已下载但未过期的网页和已下载和过期的网页
图4网页分类
要下载的网页是指URL队列中要获取的网页
可以看出,网页是指尚未爬网且不在要爬网的URL队列中的网页,但可以通过分析已爬网的网页或与要爬网的URL对应的网页来获得
还有一些网页是网络爬虫无法直接抓取和下载的,称为不可知网页
以下重点介绍几种常见的捕获策略
1.universalwebcrawler
通用网络爬虫,也称为全网爬虫,从一些种子URL向全网爬网,主要用于门户网站搜索引擎和大型web服务提供商采集数据
为了提高工作效率,一般的网络爬虫都会采用一定的爬行策略。常用的爬行策略有深度优先策略和广度优先策略
1)深度优先战略
深度优先策略意味着网络爬虫将从起始页开始,一个链接一个链接地跟踪它,直到它无法继续
完成爬网分支后,web爬虫将返回到上一个链接节点以进一步搜索其他链接。遍历所有链接后,爬网任务结束
这种策略更适合于垂直搜索或现场搜索,但对收录深层页面内容的网站进行爬网会造成巨大的资源浪费
以图3为例,遍历路径为1→ 2.→ 5.→ 6.→ 3.→ 7.→ 4.→ 八,
在深度优先策略中,当搜索节点时,节点的子节点和子节点的后续节点都优先于节点的兄弟节点。深度优先策略将在搜索空间时尽可能深入。仅当无法找到节点的后续节点时,才会考虑其兄弟节点
这种策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到最优解
如果没有限制,它将沿着一条路径无限扩展,这将“落入”大量数据。通常,使用深度优先策略会选择合适的深度,然后重复搜索直到找到解决方案,因此搜索效率会降低。因此,当搜索数据量相对较小时,通常使用深度优先策略
2)广度优先战略
广度优先策略根据web内容目录级别的深度抓取页面,浅层目录级别的页面首先被抓取。在对同一级别的页面进行爬网后,爬虫程序将深入到下一级别继续爬网
仍然以图3为例,遍历路径为1→ 2.→ 3.→ 4.→ 5.→ 6.→ 7.→ 八,
由于广度优先策略在N层节点扩展完成后进入N+1层,因此可以保证找到路径最短的解
该策略可以有效地控制页面的爬行深度,避免了当遇到无限深的分支时爬行无法结束的问题。它易于实现,并且不需要存储大量中间节点。缺点是爬行到具有深层目录级别的页面需要很长时间
如果搜索中存在过多的分支,即节点的后续节点过多,算法将耗尽资源,无法在可用空间中找到解决方案
2.关注网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫
@基于内容评价的1)crawling策略
Debra将文本相似度的计算方法引入到网络爬虫中,提出了fish搜索算法
该算法以用户输入的查询词为主题,收录 查看全部
通过关键词采集文章采集api(网络爬虫系统的原理和工作流程及注意事项介绍-乐题库)
网络数据采集指通过网络爬虫或网站公共API从网站获取数据信息。该方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图片、音频、视频和其他文件或附件采集,附件可以自动与身体关联
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据
在大数据时代,网络爬虫是从互联网获取采集数据的有利工具。目前已知的网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类
本部分首先简要介绍了网络爬虫的原理和工作流程,然后讨论了网络爬虫的爬虫策略,最后描述了典型的网络工具
网络爬虫原理
网络爬虫是一个程序或脚本,根据一定的规则自动抓取网络信息
网络爬虫可以自动采集他们可以访问的所有页面内容,并为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般有三个功能:数据采集、处理和存储,如图1所示
图1网络爬虫示意图
除了供用户阅读的文本信息外,网页还收录一些超链接信息
网络爬虫系统正是通过网页中的超链接信息,不断地获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL获取初始网页上的URL。在抓取网页的过程中,它不断地从当前网页中提取新的URL并将其放入队列,直到满足系统的某些停止条件
网络爬虫系统通常选择一些具有大量网站链接(网页中的超链接)的重要URL作为种子URL集合
网络爬虫系统将这些种子集作为初始URL来开始数据获取。因为网页收录链接信息,所以您将通过现有网页的URL获得一些新的URL
网页之间的指向结构可以看作是一个森林,每个种子URL对应的网页是森林中树的根节点,因此网络爬虫系统可以根据广度优先搜索算法或深度优先搜索算法遍历所有网页
由于深度优先搜索算法可能会使爬虫系统陷入网站内部,不利于搜索靠近网站主页的网页信息,因此一般采用广度优先搜索算法采集网页
网络爬虫系统首先将种子URL放入下载队列,然后简单地从队列头部获取一个URL来下载其相应的网页,获取网页内容并存储。解析网页中的链接信息后,可以获得一些新的URL
其次,根据一定的网页分析算法,过滤掉与主题无关的链接,保留有用的链接,并将其放入等待获取的URL队列中
最后,取出一个URL,下载相应的网页,然后解析它。重复此操作,直到遍历整个网络或满足某些条件
网络爬虫工作流
如图2所示,web爬虫的基本工作流程如下
1)首先选择一些种子URL
2)将这些URL放入要获取的URL队列
3)从待取URL队列中取出待取URL,解析DNS,获取主机IP地址,下载该URL对应的网页,保存在下载的网页库中。此外,将这些URL放入已爬网的URL队列
4)分析爬网URL队列中的URL,分析其他URL,并将这些URL放入要爬网的URL队列中,以便进入下一个周期
图2网络爬虫的基本工作流程
网络爬虫爬行策略
谷歌和百度等通用搜索引擎捕获的网页数量通常以数十亿计。因此,面对如此多的web页面,如何使web爬虫尽可能地遍历所有的web页面,从而尽可能地扩大web信息的捕获范围,这是web爬虫系统面临的一个关键问题。在网络爬虫系统中,爬行策略决定了网页的爬行顺序
本节首先简要介绍web爬虫捕获策略中使用的基本概念
1)web页面之间的关系模型
从互联网的结构来看,网页通过若干超链接相互连接,形成一个庞大而复杂的相互关联的有向图
如图3所示,如果将网页视为图中的一个节点,并将与网页中其他网页的链接视为该节点与其他节点的边,则很容易将整个Internet上的网页建模为一个有向图
理论上,通过遍历算法遍历图形,几乎可以访问Internet上的所有网页
图3网页关系模型示意图
2)web页面分类
通过从爬虫的角度划分互联网,互联网的所有页面可以分为五个部分:下载和过期页面、下载和过期页面、要下载的页面、已知页面和未知页面,如图4所示
捕获本地网页实际上是互联网内容的镜像和备份。互联网是动态的。当Internet上的部分内容发生更改时,本地网页将过期。因此,下载的网页分为已下载但未过期的网页和已下载和过期的网页
图4网页分类
要下载的网页是指URL队列中要获取的网页
可以看出,网页是指尚未爬网且不在要爬网的URL队列中的网页,但可以通过分析已爬网的网页或与要爬网的URL对应的网页来获得
还有一些网页是网络爬虫无法直接抓取和下载的,称为不可知网页
以下重点介绍几种常见的捕获策略
1.universalwebcrawler
通用网络爬虫,也称为全网爬虫,从一些种子URL向全网爬网,主要用于门户网站搜索引擎和大型web服务提供商采集数据
为了提高工作效率,一般的网络爬虫都会采用一定的爬行策略。常用的爬行策略有深度优先策略和广度优先策略
1)深度优先战略
深度优先策略意味着网络爬虫将从起始页开始,一个链接一个链接地跟踪它,直到它无法继续
完成爬网分支后,web爬虫将返回到上一个链接节点以进一步搜索其他链接。遍历所有链接后,爬网任务结束
这种策略更适合于垂直搜索或现场搜索,但对收录深层页面内容的网站进行爬网会造成巨大的资源浪费
以图3为例,遍历路径为1→ 2.→ 5.→ 6.→ 3.→ 7.→ 4.→ 八,
在深度优先策略中,当搜索节点时,节点的子节点和子节点的后续节点都优先于节点的兄弟节点。深度优先策略将在搜索空间时尽可能深入。仅当无法找到节点的后续节点时,才会考虑其兄弟节点
这种策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到最优解
如果没有限制,它将沿着一条路径无限扩展,这将“落入”大量数据。通常,使用深度优先策略会选择合适的深度,然后重复搜索直到找到解决方案,因此搜索效率会降低。因此,当搜索数据量相对较小时,通常使用深度优先策略
2)广度优先战略
广度优先策略根据web内容目录级别的深度抓取页面,浅层目录级别的页面首先被抓取。在对同一级别的页面进行爬网后,爬虫程序将深入到下一级别继续爬网
仍然以图3为例,遍历路径为1→ 2.→ 3.→ 4.→ 5.→ 6.→ 7.→ 八,
由于广度优先策略在N层节点扩展完成后进入N+1层,因此可以保证找到路径最短的解
该策略可以有效地控制页面的爬行深度,避免了当遇到无限深的分支时爬行无法结束的问题。它易于实现,并且不需要存储大量中间节点。缺点是爬行到具有深层目录级别的页面需要很长时间
如果搜索中存在过多的分支,即节点的后续节点过多,算法将耗尽资源,无法在可用空间中找到解决方案
2.关注网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫
@基于内容评价的1)crawling策略
Debra将文本相似度的计算方法引入到网络爬虫中,提出了fish搜索算法
该算法以用户输入的查询词为主题,收录
通过关键词采集文章采集api(这个问题需要分几种情况来解答第一种辑)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-09-17 10:17
这个问题需要在几种情况下得到回答
首先,您只需要下载并再次编辑它。这个方法很简单。一般来说,你知道你想要的文章,也就是说,你知道文章的访问地址。一般来说,它可以在采集器的帮助下下载,无论是保存为word还是其他格式都没有问题
第二个需要自动同步到您的平台。这很麻烦,因为您不知道下载地址(无法手动输入)
一、1、通过搜索犬浏览器搜索您的官方帐户名称,调用其界面,如果2、存在,则通过第二个界面查询官方帐户下的历史记录文章。获取文章链接,通过程序下载,然后保存到您的后台
这种方法的优点是它是半自动的,无需手动输入文章link。缺点:@1、如果您经常发送请求,搜狗会提示验证码。这需要手动处理,因此2、不能完全自动,文章链接是临时的,需要在有效期内下载3、只能获取最近十个历史文章,4、需要定期执行,不能实时更新。更新太频繁,被验证码拦截,频率太低,更新延迟太大
mode二、@1、按程序模拟官方帐户的登录管理页面。2、通过模拟调用编辑材料3、使用模拟编辑和插入链接的功能,4、调用搜索官方账号界面,查询官方账号获取传真。5、调用另一个接口,通过获取的factid获取文章列表。此文章列表中有链接
这种方法的优点是:@1、没有验证码,但也有封条,但频率较低2、你可以得到下面列出的所有文章名单官方账号。3、文章链接永久有效。缺点是:@1、仍然存在接口调用被阻止的情况。自动解封需要一些时间2、需要定期执行,不能实时更新。更新太频繁,并被验证代码阻止。频率太低,更新延迟太大
方法三、@1、通过实时推送,您只需提供API接口即可接收链接,将文章链接实时推送至顶层接口,获取链接并将下载内容保存到您自己的平台
此方法的优点:@1、不密封,2、不需要输入验证码,3、技术难度低4、文章更新及时且延迟低,最多三到五分钟4、文章链接是永久有效的。它可以实现真正的全自动化。缺点:您需要有自己的开发人员和API来接收参数
如果有更好的方法,请联系我,互相学习。如果您需要技术支持,也可以与我联系。上述方法已亲自试用过。有源代码(仅限Java) 查看全部
通过关键词采集文章采集api(这个问题需要分几种情况来解答第一种辑)
这个问题需要在几种情况下得到回答
首先,您只需要下载并再次编辑它。这个方法很简单。一般来说,你知道你想要的文章,也就是说,你知道文章的访问地址。一般来说,它可以在采集器的帮助下下载,无论是保存为word还是其他格式都没有问题
第二个需要自动同步到您的平台。这很麻烦,因为您不知道下载地址(无法手动输入)
一、1、通过搜索犬浏览器搜索您的官方帐户名称,调用其界面,如果2、存在,则通过第二个界面查询官方帐户下的历史记录文章。获取文章链接,通过程序下载,然后保存到您的后台
这种方法的优点是它是半自动的,无需手动输入文章link。缺点:@1、如果您经常发送请求,搜狗会提示验证码。这需要手动处理,因此2、不能完全自动,文章链接是临时的,需要在有效期内下载3、只能获取最近十个历史文章,4、需要定期执行,不能实时更新。更新太频繁,被验证码拦截,频率太低,更新延迟太大
mode二、@1、按程序模拟官方帐户的登录管理页面。2、通过模拟调用编辑材料3、使用模拟编辑和插入链接的功能,4、调用搜索官方账号界面,查询官方账号获取传真。5、调用另一个接口,通过获取的factid获取文章列表。此文章列表中有链接
这种方法的优点是:@1、没有验证码,但也有封条,但频率较低2、你可以得到下面列出的所有文章名单官方账号。3、文章链接永久有效。缺点是:@1、仍然存在接口调用被阻止的情况。自动解封需要一些时间2、需要定期执行,不能实时更新。更新太频繁,并被验证代码阻止。频率太低,更新延迟太大
方法三、@1、通过实时推送,您只需提供API接口即可接收链接,将文章链接实时推送至顶层接口,获取链接并将下载内容保存到您自己的平台
此方法的优点:@1、不密封,2、不需要输入验证码,3、技术难度低4、文章更新及时且延迟低,最多三到五分钟4、文章链接是永久有效的。它可以实现真正的全自动化。缺点:您需要有自己的开发人员和API来接收参数
如果有更好的方法,请联系我,互相学习。如果您需要技术支持,也可以与我联系。上述方法已亲自试用过。有源代码(仅限Java)
通过关键词采集文章采集api(通过关键词采集文章采集api集成模板库:百度凤巢)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-13 16:05
通过关键词采集文章采集api集成模板库:百度凤巢集成sites.wk任务相关:top20w页搜录收录问题
2、采集的文章页面是一次性采集到的么?(因为页面内容不可修改,
3、对采集的效率、稳定性、一致性有影响么?
4、百度api集成本身能够解决一系列的问题,例如seo,如何解决需要自己开发的问题?目前百度api应该是解决前几页的问题,对接后都能够解决,最怕的是如何保证复用性,多个系统不能互相对接,页面不能集成到指定的集成库(sites。wk),所以建议你自己开发一个,开发完成后都会出现问题的,建议技术实力过硬的话自己做,或者外包。
百度站长api在javascript方面可以做的工作,其实是很有限的,只能做到限制cookie就可以限制绝大多数页面的ip了。就像头条,虽然可以通过内容采集在爬行的过程中找到爬虫的特定位置,但是这个有一定概率会被爬虫发现,然后封掉。就算被发现,也有足够的心理去操作,不去做这么尴尬的事情。百度做为bat三巨头之一,找人来做这事不是自找死路嘛?虽然很多人同意在基础上可以,但是可以非常可以,也是肯定可以,只是现在没必要了,因为一是已经有,百度一下就知道了,二是高估了自己的技术,找了一个前辈,感觉技术都是没有问题的。
毕竟是人来开发,解决一系列业务逻辑可能都不是很顺,没有把技术交给任何人是坏事,但是如果是开发一个demo就搞定业务,那也没必要了。我觉得现在的话,想要实现采集,还是找一些创业公司来做比较好,他们肯定有技术实力来搞采集。 查看全部
通过关键词采集文章采集api(通过关键词采集文章采集api集成模板库:百度凤巢)
通过关键词采集文章采集api集成模板库:百度凤巢集成sites.wk任务相关:top20w页搜录收录问题
2、采集的文章页面是一次性采集到的么?(因为页面内容不可修改,
3、对采集的效率、稳定性、一致性有影响么?
4、百度api集成本身能够解决一系列的问题,例如seo,如何解决需要自己开发的问题?目前百度api应该是解决前几页的问题,对接后都能够解决,最怕的是如何保证复用性,多个系统不能互相对接,页面不能集成到指定的集成库(sites。wk),所以建议你自己开发一个,开发完成后都会出现问题的,建议技术实力过硬的话自己做,或者外包。
百度站长api在javascript方面可以做的工作,其实是很有限的,只能做到限制cookie就可以限制绝大多数页面的ip了。就像头条,虽然可以通过内容采集在爬行的过程中找到爬虫的特定位置,但是这个有一定概率会被爬虫发现,然后封掉。就算被发现,也有足够的心理去操作,不去做这么尴尬的事情。百度做为bat三巨头之一,找人来做这事不是自找死路嘛?虽然很多人同意在基础上可以,但是可以非常可以,也是肯定可以,只是现在没必要了,因为一是已经有,百度一下就知道了,二是高估了自己的技术,找了一个前辈,感觉技术都是没有问题的。
毕竟是人来开发,解决一系列业务逻辑可能都不是很顺,没有把技术交给任何人是坏事,但是如果是开发一个demo就搞定业务,那也没必要了。我觉得现在的话,想要实现采集,还是找一些创业公司来做比较好,他们肯定有技术实力来搞采集。
通过关键词采集文章采集api(基于5.的FPGA开发板上位机Demo实现本设计(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-09-12 20:10
)
1.概览
本设计采用FPGA技术将CMOS摄像头(DVP接口)的视频数据采集通过以太网(UDP方式)传输到PC,上位机DEMO通过socket编程实时显示视频。在屏幕上。
2.硬件系统框图
CMOS采用OV7670(30万像素),FPGA采用CYCLONE IV,以太网卡采用100M网卡芯片。
硬件平台采用ETree的FPGA开发板(某宝提供),如下图:
3.UDP/IP 协议
UDP(User Datagram Protocol)是OSI参考模型中的无连接传输层协议,提供面向事务的简单不可靠的信息传输服务。每个数据包的前8个字节用于收录头信息,其余字节用于收录特定的传输数据。 UDP协议常用于数据传输速度较高的场合,如图像传输、网络监控数据交换等。
UDP 消息格式
0 15
16 31
源端口号
目的端口号
消息长度
校验和
数据
IP(Internet Protoco)数据包位于网络层,其功能是将数据包发送到目标网络或主机。所有 TCP、UDP、IMCP、IGCP 数据均以 IP 数据格式传输。
在以太网数据帧的传输过程中,包长一般为46~1500字节,这里UDP包长度设计为:(8+20+640*2)=1308字节以提高传输效率。
4.FPGA 逻辑设计
FPGA各部分逻辑模块如下图所示:
以下是OV7670的初始配置代码:
<p>//file name: i2c_cfg_par.v
//creator: shugen.yin
//date: 2017-4-21
//function: i2c registers
//log: VGA RAW/25FPS, XCLK=24M
module i2c_cfg_par(
input [07:0] lut_index,
output reg [15:0] lut_data
);
always @(*)
begin
case(lut_index)
//ov7670 RAW 25Fps 24M input
'd0 : lut_data 查看全部
通过关键词采集文章采集api(基于5.的FPGA开发板上位机Demo实现本设计(组图)
)
1.概览
本设计采用FPGA技术将CMOS摄像头(DVP接口)的视频数据采集通过以太网(UDP方式)传输到PC,上位机DEMO通过socket编程实时显示视频。在屏幕上。
2.硬件系统框图
CMOS采用OV7670(30万像素),FPGA采用CYCLONE IV,以太网卡采用100M网卡芯片。
硬件平台采用ETree的FPGA开发板(某宝提供),如下图:
3.UDP/IP 协议
UDP(User Datagram Protocol)是OSI参考模型中的无连接传输层协议,提供面向事务的简单不可靠的信息传输服务。每个数据包的前8个字节用于收录头信息,其余字节用于收录特定的传输数据。 UDP协议常用于数据传输速度较高的场合,如图像传输、网络监控数据交换等。
UDP 消息格式
0 15
16 31
源端口号
目的端口号
消息长度
校验和
数据
IP(Internet Protoco)数据包位于网络层,其功能是将数据包发送到目标网络或主机。所有 TCP、UDP、IMCP、IGCP 数据均以 IP 数据格式传输。
在以太网数据帧的传输过程中,包长一般为46~1500字节,这里UDP包长度设计为:(8+20+640*2)=1308字节以提高传输效率。
4.FPGA 逻辑设计
FPGA各部分逻辑模块如下图所示:
以下是OV7670的初始配置代码:
<p>//file name: i2c_cfg_par.v
//creator: shugen.yin
//date: 2017-4-21
//function: i2c registers
//log: VGA RAW/25FPS, XCLK=24M
module i2c_cfg_par(
input [07:0] lut_index,
output reg [15:0] lut_data
);
always @(*)
begin
case(lut_index)
//ov7670 RAW 25Fps 24M input
'd0 : lut_data
通过关键词采集文章采集api(网络爬虫系统的原理和工作流程及注意事项介绍-乐题库 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-12 20:08
)
网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
在大数据时代,网络爬虫更像是来自采集data 的互联网工具。已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图 1 网络爬虫示意图
网页中除了供用户阅读的文字信息外,还收录一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,不断地从当前页面中提取新的URL并将其放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些比较重要的网站 URL,外展度(网页中超链接的数量)较高作为种子URL集合。
网络爬虫系统使用这些种子集合作为初始 URL 来开始数据爬取。由于网页收录链接信息,所以会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法进行搜索或者深度优先搜索算法遍历所有网页。
因为深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索更接近网站首页的网页信息,所以广度优先搜索算法采集页一般使用。
网络爬虫系统首先将种子URL放入下载队列,简单地从队列头部取出一个URL下载对应的网页,获取网页内容并存储,解析链接后网页中的信息,你可以得到一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后取出一个网址,下载对应的网页,然后解析,不断迭代,直到遍历全网或满足一定条件,才会停止。
网络爬虫工作流程
如图2所示,网络爬虫的基本工作流程如下。
1) 首先选择种子 URL 的一部分。
2) 将这些 URL 放入 URL 队列进行抓取。
3)从待爬取的URL队列中取出待爬取的URL,解析DNS得到主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入抓取到的网址队列中。
4)对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
图 2 网络爬虫的基本工作流程
网络爬虫抓取策略
谷歌、百度等通用搜索引擎抓取的网页数量通常以亿为单位计算。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页,从而尽可能扩大网页信息的覆盖范围呢?这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,抓取策略决定了抓取网页的顺序。
本节先简单介绍一下网络爬虫的爬取策略中用到的基本概念。
1)网页关系模型
从互联网的结构来看,网页通过不同数量的超链接相互连接,形成一个庞大而复杂的有向图,相互关联。
如图3所示,如果一个网页被视为图中的某个节点,而该网页中其他网页的链接被视为该节点到其他节点的边,那么我们可以很容易地认为整个网页Internet 上的页面被建模为有向图。
理论上,通过遍历算法遍历图,几乎可以访问互联网上的所有网页。
图 3 网页关系模型图
2)Web 分类
从爬虫的角度来划分互联网,互联网上的所有页面可以分为5个部分:已下载但未过期页面、已下载已过期页面、已下载页面、已知页面和未知页面,如图4. 显示。
抓取的本地网页实际上是互联网内容的镜像和备份。互联网是动态变化的。当互联网上的部分内容发生变化时,抓取到的本地网页就会失效。因此,下载的网页分为两种:下载的未过期网页和下载的过期网页。
图 4 网页分类
待下载的网页是指在URL队列中待抓取的页面。
可以看出,网页指的是未被抓取的网页,也不在待抓取的URL队列中,但可以通过分析抓取的页面或要抓取的URL对应的页面获取已抓取。
还有一些网页是网络爬虫无法直接抓取下载的,称为不可知网页。
以下重点介绍几种常见的抓取策略。
1.通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集data。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个跟踪链接,直到无法再深入。
网络爬虫在完成一个爬行分支后返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。
此策略更适合垂直搜索或站点搜索,但在抓取页面内容更深层次的站点时会造成资源的巨大浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间的时候,会尽可能的深入,只有在找不到一个节点的后继节点时才考虑它的兄弟节点。
这样的策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它会沿着一条路径无限扩展,从而“陷入”海量数据。一般情况下,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样就降低了搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度抓取网页。首先抓取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。
仍以图3为例,遍历路径为1→2→3→4→5→6→7→8
因为广度优先策略是在第N层节点扩展完成后进入第N+1层,所以可以保证找到路径最短的解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支无法结束爬取的问题,实现方便,无需存储大量中间节点。缺点是爬到目录需要很长时间。更深的页面。
如果搜索过程中分支过多,即节点的后继节点过多,算法会耗尽资源,在可用空间中找不到解。
2.专注于网络爬虫
焦点网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入到网络爬虫中,并提出了 Fish Search 算法。
算法以用户输入的查询词为主题,将收录查询词的页面视为主题相关页面。它的局限性在于它无法评估页面与主题的相关性。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面与主题的相关性。
使用基于连续值计算链接值的方法,不仅可以计算出哪些抓取的链接与主题相关,还可以量化相关性的大小。
2)基于链接结构评估的爬行策略
网页不同于一般文本。它是一个收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面上的链接表示页面之间的相互关系。基于链接结构的搜索策略模型利用这些结构特征来评估页面和链接的重要性来确定搜索顺序。其中,PageRank算法是这类搜索策略模型的代表。
PageRank 算法的基本原理是,如果一个网页被多次引用,它可能是一个非常重要的网页。如果一个网页没有被多次引用,但被一个重要的网页引用,那么它也可能是一个重要的网页。一个网页的重要性均匀地传递给它所引用的网页。
将某个页面的PageRank除以该页面存在的前向链接,并将得到的值与前向链接指向的页面的PageRank相加,得到链接页面的PageRank .
如图 5 所示,PageRank 值为 100 的网页将其重要性平均转移到它引用的两个页面上,每个页面得到 50。同样,PageRank 值为 9 的网页引用它为 3 个页面中的每个页面传递的值是 3。
PageRank 值为 53 的页面的值来自引用它的两个页面传递的值。
,
图 5 PageRank 算法示例
3) 基于强化学习的爬行策略
Rennie 和 McCallum 将增强学习引入聚焦爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性,从而确定链接访问的顺序。
4)基于上下文映射的爬行策略
Diligenti 等人。提出了一种爬行策略,通过建立上下文映射来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面和相关网页之间的距离。最先访问最近页面中的链接。
3.增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只抓取新生成或更改的网页的爬虫。可以在一定程度上保证抓取到的页面尽可能的新鲜。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要重新访问网页以更新本地页面集中页面的内容。常用的方法有统一更新法、个体更新法和基于分类的更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先策略、PageRank 优先策略等。
4. 深网爬虫
网页按存在方式可分为表面网页和深层网页。
深网爬虫架构包括6个基本功能模块(爬虫控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS)面。
其中,LVS(LabelValueSet)表示标签和值的集合,用于表示填写表单的数据源。在爬虫过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。
查看全部
通过关键词采集文章采集api(网络爬虫系统的原理和工作流程及注意事项介绍-乐题库
)
网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
在大数据时代,网络爬虫更像是来自采集data 的互联网工具。已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图 1 网络爬虫示意图
网页中除了供用户阅读的文字信息外,还收录一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,不断地从当前页面中提取新的URL并将其放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些比较重要的网站 URL,外展度(网页中超链接的数量)较高作为种子URL集合。
网络爬虫系统使用这些种子集合作为初始 URL 来开始数据爬取。由于网页收录链接信息,所以会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法进行搜索或者深度优先搜索算法遍历所有网页。
因为深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索更接近网站首页的网页信息,所以广度优先搜索算法采集页一般使用。
网络爬虫系统首先将种子URL放入下载队列,简单地从队列头部取出一个URL下载对应的网页,获取网页内容并存储,解析链接后网页中的信息,你可以得到一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后取出一个网址,下载对应的网页,然后解析,不断迭代,直到遍历全网或满足一定条件,才会停止。
网络爬虫工作流程
如图2所示,网络爬虫的基本工作流程如下。
1) 首先选择种子 URL 的一部分。
2) 将这些 URL 放入 URL 队列进行抓取。
3)从待爬取的URL队列中取出待爬取的URL,解析DNS得到主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入抓取到的网址队列中。
4)对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
图 2 网络爬虫的基本工作流程
网络爬虫抓取策略
谷歌、百度等通用搜索引擎抓取的网页数量通常以亿为单位计算。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页,从而尽可能扩大网页信息的覆盖范围呢?这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,抓取策略决定了抓取网页的顺序。
本节先简单介绍一下网络爬虫的爬取策略中用到的基本概念。
1)网页关系模型
从互联网的结构来看,网页通过不同数量的超链接相互连接,形成一个庞大而复杂的有向图,相互关联。
如图3所示,如果一个网页被视为图中的某个节点,而该网页中其他网页的链接被视为该节点到其他节点的边,那么我们可以很容易地认为整个网页Internet 上的页面被建模为有向图。
理论上,通过遍历算法遍历图,几乎可以访问互联网上的所有网页。
图 3 网页关系模型图
2)Web 分类
从爬虫的角度来划分互联网,互联网上的所有页面可以分为5个部分:已下载但未过期页面、已下载已过期页面、已下载页面、已知页面和未知页面,如图4. 显示。
抓取的本地网页实际上是互联网内容的镜像和备份。互联网是动态变化的。当互联网上的部分内容发生变化时,抓取到的本地网页就会失效。因此,下载的网页分为两种:下载的未过期网页和下载的过期网页。
图 4 网页分类
待下载的网页是指在URL队列中待抓取的页面。
可以看出,网页指的是未被抓取的网页,也不在待抓取的URL队列中,但可以通过分析抓取的页面或要抓取的URL对应的页面获取已抓取。
还有一些网页是网络爬虫无法直接抓取下载的,称为不可知网页。
以下重点介绍几种常见的抓取策略。
1.通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集data。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个跟踪链接,直到无法再深入。
网络爬虫在完成一个爬行分支后返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。
此策略更适合垂直搜索或站点搜索,但在抓取页面内容更深层次的站点时会造成资源的巨大浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间的时候,会尽可能的深入,只有在找不到一个节点的后继节点时才考虑它的兄弟节点。
这样的策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它会沿着一条路径无限扩展,从而“陷入”海量数据。一般情况下,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样就降低了搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度抓取网页。首先抓取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。
仍以图3为例,遍历路径为1→2→3→4→5→6→7→8
因为广度优先策略是在第N层节点扩展完成后进入第N+1层,所以可以保证找到路径最短的解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支无法结束爬取的问题,实现方便,无需存储大量中间节点。缺点是爬到目录需要很长时间。更深的页面。
如果搜索过程中分支过多,即节点的后继节点过多,算法会耗尽资源,在可用空间中找不到解。
2.专注于网络爬虫
焦点网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入到网络爬虫中,并提出了 Fish Search 算法。
算法以用户输入的查询词为主题,将收录查询词的页面视为主题相关页面。它的局限性在于它无法评估页面与主题的相关性。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面与主题的相关性。
使用基于连续值计算链接值的方法,不仅可以计算出哪些抓取的链接与主题相关,还可以量化相关性的大小。
2)基于链接结构评估的爬行策略
网页不同于一般文本。它是一个收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面上的链接表示页面之间的相互关系。基于链接结构的搜索策略模型利用这些结构特征来评估页面和链接的重要性来确定搜索顺序。其中,PageRank算法是这类搜索策略模型的代表。
PageRank 算法的基本原理是,如果一个网页被多次引用,它可能是一个非常重要的网页。如果一个网页没有被多次引用,但被一个重要的网页引用,那么它也可能是一个重要的网页。一个网页的重要性均匀地传递给它所引用的网页。
将某个页面的PageRank除以该页面存在的前向链接,并将得到的值与前向链接指向的页面的PageRank相加,得到链接页面的PageRank .
如图 5 所示,PageRank 值为 100 的网页将其重要性平均转移到它引用的两个页面上,每个页面得到 50。同样,PageRank 值为 9 的网页引用它为 3 个页面中的每个页面传递的值是 3。
PageRank 值为 53 的页面的值来自引用它的两个页面传递的值。
,
图 5 PageRank 算法示例
3) 基于强化学习的爬行策略
Rennie 和 McCallum 将增强学习引入聚焦爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性,从而确定链接访问的顺序。
4)基于上下文映射的爬行策略
Diligenti 等人。提出了一种爬行策略,通过建立上下文映射来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面和相关网页之间的距离。最先访问最近页面中的链接。
3.增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只抓取新生成或更改的网页的爬虫。可以在一定程度上保证抓取到的页面尽可能的新鲜。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要重新访问网页以更新本地页面集中页面的内容。常用的方法有统一更新法、个体更新法和基于分类的更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先策略、PageRank 优先策略等。
4. 深网爬虫
网页按存在方式可分为表面网页和深层网页。
深网爬虫架构包括6个基本功能模块(爬虫控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS)面。
其中,LVS(LabelValueSet)表示标签和值的集合,用于表示填写表单的数据源。在爬虫过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。
通过关键词采集文章采集api(【干货】注册CDN的几种方法,你了解吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 288 次浏览 • 2021-09-12 00:00
1、真实IP地址采集
CDN 介绍
CDN的全称是Content Delivery Network,即内容分发网络
网址:
判断CDN是否存在
例如:百度有CDN服务器地址14.215.177.39
绕过 CDN
如果目标不使用CDN,可以直接使用ping 获取IP地址。或者在线使用网站
验证 IP 地址
使用IP地址访问网站,如果正常,就是真实IP地址。否则就不是真的。
2、shodan 介绍
信息采集方式
1.Active 信息采集:直接与目标交互,在交互过程中采集信息
2.Passive 信息采集:通过第三方引擎与目标交互,或者不允许目标交互查询数据库获取目标信息
Shodan 搜索引擎介绍
虽然目前人们认为谷歌是最强的搜索引擎,但shodan是互联网上最可怕的搜索引擎。与谷歌不同的是,Shodan不会在互联网上搜索网址,而是直接进入互联网的后台渠道。 Shodan可以说是一个“黑暗”的谷歌,寻找所有与互联网相关的服务器、摄像头、打印机、路由器等。
Shodan 网址:
Shodan 注册和登录:获取 API 密钥以供使用
API 密钥:pde7mB56vGwCWh2yKjj87z9ucYDiPwYg
shodan 搜索
1.在资源管理器搜索框中输入网络摄像头进行搜索(摄像头)
2.通过关键字port指定一个具体的端口号。
3.通过关键字host指定一个具体的IP地址。
4.通过关键字city指定特定城市的搜索内容。
3、shodan 安装命令行
pip 安装 shodan
shodan 初始化命令行:shoden 的 API key:pde7mB56vGwCWh2yKjj87z9ucYDiPwYg
shodan init pde7mB56vGwCWh2yKjj87z9ucYDiPwYg
查找特定服务的数量
1>查看Apache服务器数量
2>查看Tomcat服务器数量
Shodan 命令行搜索功能
shodan 搜索 microsoft iis 6.0
Shodan获取指定IP地址信息
shodan 主机 ip 地址
Shodan 获取帐户信息
shodan 信息
Shodan 获取自己的外部 IP 地址
shodan myip
示例如下:
搜索关键字段的tomcat
4、检测是否有蜜罐保护
蜜罐技术
蜜罐技术本质上是一种欺骗攻击者的技术。通过布置一些主机、网络服务或信息作为诱饵,可以诱导攻击者对其进行攻击,从而捕获和分析攻击行为。 , 了解攻击者使用的工具和方法,并猜测攻击的意图和动机,可以让防御者清楚地了解他们面临的安全威胁,并利用技术和管理方法来增强实际系统的安全防护能力.
shodan honeyscore 123.59.161.39 #ip是百合网
5、Python-shodan 使用
导入 shodan
SHODAN_API_KEY = ‘pde7mB56vGwCWh2yKjj87z9ucYDiPwYg’
api = shodan.Shodan(SHODAN_API_KEY)
查看参数并返回结果
返回的结果数据为json格式
6、sqlmap 介绍
Sqlmap 介绍
Sqlmap 是一个开源渗透工具,可以自动化检测和利用 SQL 注入缺陷并接管数据库服务器的过程。他拥有强大的检测引擎,许多适合终极渗透测试的小众特性和广泛的开关,从数据库指纹、从数据库中获取数据到访问底层文件系统以及通过带外在操作系统上执行命令连接。
官网:
Sqlmap 特性
Sqlmap的下载(不需要最新版本)
7、渗透测试环境安装配置
SQL注入需要使用phpstudy软件,phpstudy功能:在本地快速搭建web项目,打开服务,打开Apache、MySQL等(需要安装phpstudy2018版本,否则与后面安装的软件不兼容)
安装软件后,路径G:\phpstudy\phpstudy_pro\WWW就是后面创建WEB项目的路径
还需要安装一个软件sqli-labs-master,将解压后的文件夹放到phpstudy软件的G:\phpstudy\phpstudy_pro\WWW文件夹中,重命名为sqli(方便访问)。本地直接访问:
浏览器输入:127.0.0.1/sqli 本地直接访问
此时设置成功!
此时还不能链接数据库,显示错误
需要在G:\phpstudy\phpstudy_pro\WWW\sqli\sql-connections路径下找到db-creds.inc文件,使用pycharm打开该文件
文件内容如下:修改数据库密码(一般是初始root),保存关闭。再次验证 SQL 是否开启
验证方法:
刷新网页
显示如下图:表示连接成功
点击后如下图:
另一种验证方法:打开phpstudy2018的MySQL命令行
如下图:如果数据库信息匹配,则证明连接成功。
还需要安装一个软件DVWA-master,将解压后的文件夹放到phpstudy软件的G:\phpstudy\phpstudy_pro\WWW文件夹中,重命名为DVWA(方便访问),然后就可以直接访问:
浏览器输入:127.0.0.1/dwa 直接访问(windows系统下不区分大小写)
以上连接说明G:\phpstudy2018\PHPTutorial\WWW\DVWA\config路径下的文件配置不正确,需要对文件config.inc.php.dist进行如下操作:
使用pycharm打开上面修改的2号文件config.inc.php,继续修改参数如下:
刷新之前的127.0.0.1/dwa界面,显示可以创建数据库,点击进入登录界面
下图显示创建成功:
到此,渗透测试环境搭建完毕! 查看全部
通过关键词采集文章采集api(【干货】注册CDN的几种方法,你了解吗?)
1、真实IP地址采集
CDN 介绍
CDN的全称是Content Delivery Network,即内容分发网络
网址:
判断CDN是否存在
例如:百度有CDN服务器地址14.215.177.39
绕过 CDN
如果目标不使用CDN,可以直接使用ping 获取IP地址。或者在线使用网站
验证 IP 地址
使用IP地址访问网站,如果正常,就是真实IP地址。否则就不是真的。
2、shodan 介绍
信息采集方式
1.Active 信息采集:直接与目标交互,在交互过程中采集信息
2.Passive 信息采集:通过第三方引擎与目标交互,或者不允许目标交互查询数据库获取目标信息
Shodan 搜索引擎介绍
虽然目前人们认为谷歌是最强的搜索引擎,但shodan是互联网上最可怕的搜索引擎。与谷歌不同的是,Shodan不会在互联网上搜索网址,而是直接进入互联网的后台渠道。 Shodan可以说是一个“黑暗”的谷歌,寻找所有与互联网相关的服务器、摄像头、打印机、路由器等。
Shodan 网址:
Shodan 注册和登录:获取 API 密钥以供使用
API 密钥:pde7mB56vGwCWh2yKjj87z9ucYDiPwYg
shodan 搜索
1.在资源管理器搜索框中输入网络摄像头进行搜索(摄像头)
2.通过关键字port指定一个具体的端口号。
3.通过关键字host指定一个具体的IP地址。
4.通过关键字city指定特定城市的搜索内容。
3、shodan 安装命令行
pip 安装 shodan
shodan 初始化命令行:shoden 的 API key:pde7mB56vGwCWh2yKjj87z9ucYDiPwYg
shodan init pde7mB56vGwCWh2yKjj87z9ucYDiPwYg
查找特定服务的数量
1>查看Apache服务器数量
2>查看Tomcat服务器数量
Shodan 命令行搜索功能
shodan 搜索 microsoft iis 6.0
Shodan获取指定IP地址信息
shodan 主机 ip 地址
Shodan 获取帐户信息
shodan 信息
Shodan 获取自己的外部 IP 地址
shodan myip
示例如下:
搜索关键字段的tomcat
4、检测是否有蜜罐保护
蜜罐技术
蜜罐技术本质上是一种欺骗攻击者的技术。通过布置一些主机、网络服务或信息作为诱饵,可以诱导攻击者对其进行攻击,从而捕获和分析攻击行为。 , 了解攻击者使用的工具和方法,并猜测攻击的意图和动机,可以让防御者清楚地了解他们面临的安全威胁,并利用技术和管理方法来增强实际系统的安全防护能力.
shodan honeyscore 123.59.161.39 #ip是百合网
5、Python-shodan 使用
导入 shodan
SHODAN_API_KEY = ‘pde7mB56vGwCWh2yKjj87z9ucYDiPwYg’
api = shodan.Shodan(SHODAN_API_KEY)
查看参数并返回结果
返回的结果数据为json格式
6、sqlmap 介绍
Sqlmap 介绍
Sqlmap 是一个开源渗透工具,可以自动化检测和利用 SQL 注入缺陷并接管数据库服务器的过程。他拥有强大的检测引擎,许多适合终极渗透测试的小众特性和广泛的开关,从数据库指纹、从数据库中获取数据到访问底层文件系统以及通过带外在操作系统上执行命令连接。
官网:
Sqlmap 特性
Sqlmap的下载(不需要最新版本)
7、渗透测试环境安装配置
SQL注入需要使用phpstudy软件,phpstudy功能:在本地快速搭建web项目,打开服务,打开Apache、MySQL等(需要安装phpstudy2018版本,否则与后面安装的软件不兼容)
安装软件后,路径G:\phpstudy\phpstudy_pro\WWW就是后面创建WEB项目的路径
还需要安装一个软件sqli-labs-master,将解压后的文件夹放到phpstudy软件的G:\phpstudy\phpstudy_pro\WWW文件夹中,重命名为sqli(方便访问)。本地直接访问:
浏览器输入:127.0.0.1/sqli 本地直接访问
此时设置成功!
此时还不能链接数据库,显示错误
需要在G:\phpstudy\phpstudy_pro\WWW\sqli\sql-connections路径下找到db-creds.inc文件,使用pycharm打开该文件
文件内容如下:修改数据库密码(一般是初始root),保存关闭。再次验证 SQL 是否开启
验证方法:
刷新网页
显示如下图:表示连接成功
点击后如下图:
另一种验证方法:打开phpstudy2018的MySQL命令行
如下图:如果数据库信息匹配,则证明连接成功。
还需要安装一个软件DVWA-master,将解压后的文件夹放到phpstudy软件的G:\phpstudy\phpstudy_pro\WWW文件夹中,重命名为DVWA(方便访问),然后就可以直接访问:
浏览器输入:127.0.0.1/dwa 直接访问(windows系统下不区分大小写)
以上连接说明G:\phpstudy2018\PHPTutorial\WWW\DVWA\config路径下的文件配置不正确,需要对文件config.inc.php.dist进行如下操作:
使用pycharm打开上面修改的2号文件config.inc.php,继续修改参数如下:
刷新之前的127.0.0.1/dwa界面,显示可以创建数据库,点击进入登录界面
下图显示创建成功:
到此,渗透测试环境搭建完毕!
通过关键词采集文章采集api(报表开发神器:phantomjs生成网页PDF,Echarts报表实战导航)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-11 23:09
报表开发神器:phantomjs生成网页PDF,Echarts报表实战
导航:
一. 关于phantomjs 1.1 什么是phantomjs?
(1)一个基于webkit内核的无头浏览器,即没有UI界面,即是浏览器,但需要设计和设计与人相关的点击、翻页等操作实施。
(2)提供了javascript API接口,即可以通过编写js程序直接与webkit内核交互。在此基础上还可以结合java语言等,通过调用js等相关操作java,从而解决了之前c/c++天赋最好基于webkit开发高质量的采集器限制。
(3)提供windows、linux、mac等不同操作系统的安装和使用包,这意味着采集项目可以在不同平台上重新开发或自动项目测试。
1.2 phantomjs 常用API介绍
常用的几个主要内置对象
通用API
注意事项
使用总结:主要是java se+js+phantomjs的应用,
1.3 我可以用 phantomjs 做什么?
生成的PDF基本恢复了原来的风格,图文分离,不是直接截图;如果有生成PDF的需求,可以考虑如何生成和使用phantomjs来实现功能;我已经用Html模板生成了Html页面,然后把这个页面上传到FastDfs服务器,然后通过返回的url直接生成这个pdf,就完成了与html页面一致的pdf生成功能;
二. Windows 下安装phantomjs 2.1 概览2.1 下载安装phantomjs 测试是否安装成功:三. Linux 下安装phantomjs 3.1 概览3.2 安装过程如下:
进入里面后,可以执行js命令,如果需要退出,按Ctrl+C强制退出
解决中文乱码(可选,遇到这个问题可以解决) 正常例子:(Windows下显示正常如图:) 错误例子:(Linux下乱码显示为如图:) 解决方法:在Linux下执行命令:
yum install bitmap-fonts bitmap-fonts-cjk
执行此命令后,可能只显示中文,但数字仍会显示空格。如果有数字显示空格,将所有windows字体导入Linux,见下。
导入字体:四.使用Phantomjs生成Echarts图片4.1 概述:Linux下:
Windows 和 Linux 环境的区别: ① 配置环境变量。因为phantomjs的启动方式,windows执行的是exe文件,而Linux不是,所以配置好环境变量后,java在机器上和Linux下测试不需要做任何修改; ② Phantomjs 执行生成 Echarts 图片时,需要引用 jquery.1.9.1.min.js ,echarts-convert.js, echarts.min.js 并生成 Echarts js文件。这些js是需要引用的,在Linux上部署的时候,生成的js文件在jar包里,可能不可读。我们可以通过代码将js文件复制到jar包的同级目录下,然后通过路径加载。可以使用以下代码读取和生成路径加载:
~~~java
/* 生成模板到指定位置判断文件是否存在,如果不存在则创建 */
文件 echartsfile = new File(System.getProperty("user.dir") + "\echarts-all.js");
if (!echartsfile.exists()) {
FileUtil.file2file("js/echarts-all.js", System.getProperty("user.dir") + "\echarts-all.js");
}
~~~
4.2 作者实现思路: 第二步:整理思路:生成需要生成的Echarts js代码:找到相关的Echarts图片模板:Echarts官网使用Framework等技术:生成一个final来自模板+数据的js文件;以Framework为例:将另外三个js文件放在其他位置,博主的做法是将这三个放在jar包目录下,但是会有phantomjs无法读取和执行的情况(即phantomjs除外) code可以读取内容,但是phantomjs的执行不能通过引用读取)。所以博主拿的是先把它读出来,然后写出jar包供参考;这样Linux下就可以通过路径读取了;阅读代码示例:
/* 将模板生成到指定的位置 判断文件是否存在,如果不存在则创建 */
File echartsfile = new File(System.getProperty("user.dir") + "\\echarts-all.js");
if (!echartsfile.exists()) {
FileUtil.file2file("js/echarts-all.js", System.getProperty("user.dir") + "\\echarts-all.js");
}
File jsfile = new File(outPathAndName);
if (!jsfile.exists()) {
FileUtil.string2File(outPathAndName, echartTemplate.getFileContent()); // 将js文件生成到指定的位置
}
File convertfile = new File(System.getProperty("user.dir") + "\\echarts-convert.js");
String echartsPath = System.getProperty("user.dir") + "\\echarts-convert.js";
if (!convertfile.exists()) {
FileUtil.file2file("js/echarts-convert.js", echartsPath);
}
File jqueryfile = new File(System.getProperty("user.dir") + "\\jquery.1.9.1.min.js");
if (!jqueryfile.exists()) {
FileUtil.file2file("js/jquery.1.9.1.min.js", System.getProperty("user.dir") + "\\jquery.1.9.1.min.js");
}
关键代码:System.getProperty("user.dir")为Windows或Linux下的当前路径,百度可以使用。
将现有的echarts-convert.js等文件+生成的Echarts.js文件与数据和Demo示例代码结合,生成Echarts图片;我们可以将Echart图片上传到Fastdfs等图片服务器,只需获取网络图片url即可;当然最后一步取决于业务需求; 五.使用Phantomjs生成PDF文档(HTML转PDF)5.1概述5.2生成原理5.3扩展思路六.使用Phantomjs+Poi.tl生成Word文档6.1概述6.2 想法 查看全部
通过关键词采集文章采集api(报表开发神器:phantomjs生成网页PDF,Echarts报表实战导航)
报表开发神器:phantomjs生成网页PDF,Echarts报表实战
导航:
一. 关于phantomjs 1.1 什么是phantomjs?
(1)一个基于webkit内核的无头浏览器,即没有UI界面,即是浏览器,但需要设计和设计与人相关的点击、翻页等操作实施。
(2)提供了javascript API接口,即可以通过编写js程序直接与webkit内核交互。在此基础上还可以结合java语言等,通过调用js等相关操作java,从而解决了之前c/c++天赋最好基于webkit开发高质量的采集器限制。
(3)提供windows、linux、mac等不同操作系统的安装和使用包,这意味着采集项目可以在不同平台上重新开发或自动项目测试。
1.2 phantomjs 常用API介绍
常用的几个主要内置对象
通用API
注意事项
使用总结:主要是java se+js+phantomjs的应用,
1.3 我可以用 phantomjs 做什么?
生成的PDF基本恢复了原来的风格,图文分离,不是直接截图;如果有生成PDF的需求,可以考虑如何生成和使用phantomjs来实现功能;我已经用Html模板生成了Html页面,然后把这个页面上传到FastDfs服务器,然后通过返回的url直接生成这个pdf,就完成了与html页面一致的pdf生成功能;
二. Windows 下安装phantomjs 2.1 概览2.1 下载安装phantomjs 测试是否安装成功:三. Linux 下安装phantomjs 3.1 概览3.2 安装过程如下:
进入里面后,可以执行js命令,如果需要退出,按Ctrl+C强制退出
解决中文乱码(可选,遇到这个问题可以解决) 正常例子:(Windows下显示正常如图:) 错误例子:(Linux下乱码显示为如图:) 解决方法:在Linux下执行命令:
yum install bitmap-fonts bitmap-fonts-cjk
执行此命令后,可能只显示中文,但数字仍会显示空格。如果有数字显示空格,将所有windows字体导入Linux,见下。
导入字体:四.使用Phantomjs生成Echarts图片4.1 概述:Linux下:
Windows 和 Linux 环境的区别: ① 配置环境变量。因为phantomjs的启动方式,windows执行的是exe文件,而Linux不是,所以配置好环境变量后,java在机器上和Linux下测试不需要做任何修改; ② Phantomjs 执行生成 Echarts 图片时,需要引用 jquery.1.9.1.min.js ,echarts-convert.js, echarts.min.js 并生成 Echarts js文件。这些js是需要引用的,在Linux上部署的时候,生成的js文件在jar包里,可能不可读。我们可以通过代码将js文件复制到jar包的同级目录下,然后通过路径加载。可以使用以下代码读取和生成路径加载:
~~~java
/* 生成模板到指定位置判断文件是否存在,如果不存在则创建 */
文件 echartsfile = new File(System.getProperty("user.dir") + "\echarts-all.js");
if (!echartsfile.exists()) {
FileUtil.file2file("js/echarts-all.js", System.getProperty("user.dir") + "\echarts-all.js");
}
~~~
4.2 作者实现思路: 第二步:整理思路:生成需要生成的Echarts js代码:找到相关的Echarts图片模板:Echarts官网使用Framework等技术:生成一个final来自模板+数据的js文件;以Framework为例:将另外三个js文件放在其他位置,博主的做法是将这三个放在jar包目录下,但是会有phantomjs无法读取和执行的情况(即phantomjs除外) code可以读取内容,但是phantomjs的执行不能通过引用读取)。所以博主拿的是先把它读出来,然后写出jar包供参考;这样Linux下就可以通过路径读取了;阅读代码示例:
/* 将模板生成到指定的位置 判断文件是否存在,如果不存在则创建 */
File echartsfile = new File(System.getProperty("user.dir") + "\\echarts-all.js");
if (!echartsfile.exists()) {
FileUtil.file2file("js/echarts-all.js", System.getProperty("user.dir") + "\\echarts-all.js");
}
File jsfile = new File(outPathAndName);
if (!jsfile.exists()) {
FileUtil.string2File(outPathAndName, echartTemplate.getFileContent()); // 将js文件生成到指定的位置
}
File convertfile = new File(System.getProperty("user.dir") + "\\echarts-convert.js");
String echartsPath = System.getProperty("user.dir") + "\\echarts-convert.js";
if (!convertfile.exists()) {
FileUtil.file2file("js/echarts-convert.js", echartsPath);
}
File jqueryfile = new File(System.getProperty("user.dir") + "\\jquery.1.9.1.min.js");
if (!jqueryfile.exists()) {
FileUtil.file2file("js/jquery.1.9.1.min.js", System.getProperty("user.dir") + "\\jquery.1.9.1.min.js");
}
关键代码:System.getProperty("user.dir")为Windows或Linux下的当前路径,百度可以使用。
将现有的echarts-convert.js等文件+生成的Echarts.js文件与数据和Demo示例代码结合,生成Echarts图片;我们可以将Echart图片上传到Fastdfs等图片服务器,只需获取网络图片url即可;当然最后一步取决于业务需求; 五.使用Phantomjs生成PDF文档(HTML转PDF)5.1概述5.2生成原理5.3扩展思路六.使用Phantomjs+Poi.tl生成Word文档6.1概述6.2 想法
通过关键词采集文章采集api(AMZHelper 用户手册 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-09-07 18:21
)
随着AMZHelper的功能越来越多,虽然我觉得每个功能独立都可以过千元,但是因为亮点太多,很多成员都觉得一头雾水。
老蛇本人并没有系统的操作流程,因为他通常会想到如何使用。 (老司机经常这样!)
今天给一些新手做系统总结。
按照做亚马逊的顺序列出哪些功能可用。
产品选择/Listing优化/评价/订单量(转化率)//提升排名/关联/邮件营销/PPC分析几个因素来解释我们平台的功能。
----------------------------------------------- ------------
##选品##(数据选择/痛点分析/热钱分析)
1.1:数据选择
使用的功能:软件(A、其他工具-类别选择辅助)
目前老蛇对选品功能的总结:可以提高选品的成功率,让选品思路更清晰。
使用软件爬虫实现本应手动操作、无人值守的批量操作。
最后,可以进一步过滤采集到的数据。
所选产品的功能介绍:
1.2Shop 跟踪选择
使用的功能:网页:产品选择分析工具---存储新产品跟踪数据
输入店铺ID,AMZHelper会进行云端追踪,每天为您展示最新的数据报告。
操作如下:
第二天后的结果:
点击数字:您可以输入成本并获得毛利。可以点击未选中进行选中(切换)操作。
2:痛点分析
使用的功能:软件(2、Mailbox采集)
当然,在开发产品的时候,如果能解决用户的痛点就更完美了。
然后我们可以通过采集bad review的形式找出用户的痛点。那么在选择产品的时候就可以注意这些问题了。我们可以避开对手的坑。
先用关键词采集工具采集对应的ASIN,然后发邮件采集采集差评,统一整理分析。
3:热销属性分析
使用的功能:软件(2、Mailbox采集)
我们知道,当我们开发某种产品时,会有颜色和尺寸的因素。
但是当我们在测试模型时,我们不能想当然地认为哪个卖得好,哪个颜色卖得好。
那么数据分析也很重要。同理,用上面的“不是采集邮箱,只有采集评论内容”打勾
同时选择四颗星及以下打勾(五颗星大部分都刷了)
得到的数据如下:
然后我们可以通过对手的一些数据展示来分析一下对手的产品销量哪个属性比较大。
(PS:也可以每天测量对方的属性盘点,然后进行数据分析。)
##Listing Optimization##(采集标题和卖点/采集用户痛点写成卖点)
在优化listing时,我们要设计好标题和五个好卖点。
如果想把字埋在标题里,卖点不明确。然后您可以使用我们助手软件的以下功能进行帮助。
1、Title 和卖点合集
使用的功能:软件(5、关键词采集ASIN、9、analysis aid)
先用“5.关键词采ASIN”再用9.analysis辅助标题和卖点采集
采集的结果:
标题,直接复制到txt文件即可直观查看。
然后将特征复制到txt文件中,然后将后缀改为:html file open
然后我们就可以更轻松地梳理出我们想要的关键词和卖点。
采集如何使用这些数据?
1、 参考对方的标题和卖点怎么写。
2、分析对手在标题和卖点中埋下了哪些词。
(使用词频分析工具:)
2、分析用户痛点
使用的功能:软件(2、Mailbox采集)
同时,如果你能解决用户对你的卖点的疑惑,是否能让用户在更短的时间内做出正确的决定?
同时可以通过QA的形式解决产品的痛点。
那我们就可以用采集bad review这个软件,看看用户有哪些痛点。然后,梳理一下我们解决的痛点,写进卖点。
比如:用户的痛点是产品容易老化,那么你的产品是不锈钢的,那你就可以写成卖点了。
这些卖点也可以直接上图。 (先想套路,再分析如何使用工具。)
##测测##(返回评论模式,不评论,不返现)
Haoreview是AMZHelper平台下的网站。通过AMZhelper多年的审稿人资源的积累,形成了一个以美国用户为主的平台。
平台的规则是只有评论才会返现。这样,我们卖家的利益才能得到最大化。 (共有三种模式:超级URL交易无评论模式、评论模式、超级URL交易+评论模式)
##做链接##(通过合作名人数据管理)
使用的功能:邀请模式+采集邮箱+邮件模板设置
示例:
黄金搭档========》
买买买========》
他们的黄金搭档怎么又买了这个?
根据亚马逊算法的测试分析,在一定时期内购买和购买的两种产品的数量越大,排名越高。
购买产品A的客户(即使是一年前)最近购买了产品B,则排名+1(例如,在周期的一个月内),如果购买产品B的人越多,则A产品在listing下方,B产品的排名会更高。
那么根据上面的算法规则:
我们只需要采集一些购买过产品A的客户,展示新产品,给他们做营销,形成交易,让我们和我们的产品产生关联,从而达到最大的流量拦截。
使用的功能:邀请模式+采集邮箱+邮件模板设置
只要新品在短时间内交易几十个订单,就可以实现上述关联。 (当然,这取决于产品的受欢迎程度和竞争程度。)
##邮营销##(邮件营销成本最低,大数据营销,转化快速高效)
使用的功能:邀请模式、审稿人采集管理、大数据邮件管理、邮件模板(设置)软件(5、关键词采集ASIN、2、Mailbox采集)
目前传统的EDM营销转化率只有0.5%,但由于我们的AMZHelper实时抓取数据,我们的邮箱都是亚马逊上真实有效的买家邮箱。
所以如果数据准确的话,3%的转化率也不是什么大问题。
计算一个账户,我们假设转化率只有0.5%,那么1000封邮件就会发出5个订单。一个邮箱1.2美分,费用12元。交易了5个订单。稳赚不亏。
AMZHelper已对接国内知名:思奇群发邮件平台,国际知名EDM频道:猎豹邮箱
PS:我们如何使用 EDM 营销?
1、新品推广期,促销。
2、库存清理。
3、Associated Marketing。
4、holiday 促销。
操作流程:
1、准备邮件数据:使用AMZHelpler软件采集,或者直接拨打我们平台的大数据邮箱。
2、以邀请方式添加产品。
3、 导入邮箱或调用平台邮箱数据。
4、使用 EDM 群发邮件。 查看全部
通过关键词采集文章采集api(AMZHelper 用户手册
)
随着AMZHelper的功能越来越多,虽然我觉得每个功能独立都可以过千元,但是因为亮点太多,很多成员都觉得一头雾水。
老蛇本人并没有系统的操作流程,因为他通常会想到如何使用。 (老司机经常这样!)
今天给一些新手做系统总结。
按照做亚马逊的顺序列出哪些功能可用。
产品选择/Listing优化/评价/订单量(转化率)//提升排名/关联/邮件营销/PPC分析几个因素来解释我们平台的功能。
----------------------------------------------- ------------
##选品##(数据选择/痛点分析/热钱分析)
1.1:数据选择
使用的功能:软件(A、其他工具-类别选择辅助)
目前老蛇对选品功能的总结:可以提高选品的成功率,让选品思路更清晰。
使用软件爬虫实现本应手动操作、无人值守的批量操作。
最后,可以进一步过滤采集到的数据。
所选产品的功能介绍:
1.2Shop 跟踪选择
使用的功能:网页:产品选择分析工具---存储新产品跟踪数据
输入店铺ID,AMZHelper会进行云端追踪,每天为您展示最新的数据报告。
操作如下:
第二天后的结果:
点击数字:您可以输入成本并获得毛利。可以点击未选中进行选中(切换)操作。
2:痛点分析
使用的功能:软件(2、Mailbox采集)
当然,在开发产品的时候,如果能解决用户的痛点就更完美了。
然后我们可以通过采集bad review的形式找出用户的痛点。那么在选择产品的时候就可以注意这些问题了。我们可以避开对手的坑。
先用关键词采集工具采集对应的ASIN,然后发邮件采集采集差评,统一整理分析。
3:热销属性分析
使用的功能:软件(2、Mailbox采集)
我们知道,当我们开发某种产品时,会有颜色和尺寸的因素。
但是当我们在测试模型时,我们不能想当然地认为哪个卖得好,哪个颜色卖得好。
那么数据分析也很重要。同理,用上面的“不是采集邮箱,只有采集评论内容”打勾
同时选择四颗星及以下打勾(五颗星大部分都刷了)
得到的数据如下:
然后我们可以通过对手的一些数据展示来分析一下对手的产品销量哪个属性比较大。
(PS:也可以每天测量对方的属性盘点,然后进行数据分析。)
##Listing Optimization##(采集标题和卖点/采集用户痛点写成卖点)
在优化listing时,我们要设计好标题和五个好卖点。
如果想把字埋在标题里,卖点不明确。然后您可以使用我们助手软件的以下功能进行帮助。
1、Title 和卖点合集
使用的功能:软件(5、关键词采集ASIN、9、analysis aid)
先用“5.关键词采ASIN”再用9.analysis辅助标题和卖点采集
采集的结果:
标题,直接复制到txt文件即可直观查看。
然后将特征复制到txt文件中,然后将后缀改为:html file open
然后我们就可以更轻松地梳理出我们想要的关键词和卖点。
采集如何使用这些数据?
1、 参考对方的标题和卖点怎么写。
2、分析对手在标题和卖点中埋下了哪些词。
(使用词频分析工具:)
2、分析用户痛点
使用的功能:软件(2、Mailbox采集)
同时,如果你能解决用户对你的卖点的疑惑,是否能让用户在更短的时间内做出正确的决定?
同时可以通过QA的形式解决产品的痛点。
那我们就可以用采集bad review这个软件,看看用户有哪些痛点。然后,梳理一下我们解决的痛点,写进卖点。
比如:用户的痛点是产品容易老化,那么你的产品是不锈钢的,那你就可以写成卖点了。
这些卖点也可以直接上图。 (先想套路,再分析如何使用工具。)
##测测##(返回评论模式,不评论,不返现)
Haoreview是AMZHelper平台下的网站。通过AMZhelper多年的审稿人资源的积累,形成了一个以美国用户为主的平台。
平台的规则是只有评论才会返现。这样,我们卖家的利益才能得到最大化。 (共有三种模式:超级URL交易无评论模式、评论模式、超级URL交易+评论模式)
##做链接##(通过合作名人数据管理)
使用的功能:邀请模式+采集邮箱+邮件模板设置
示例:
黄金搭档========》
买买买========》
他们的黄金搭档怎么又买了这个?
根据亚马逊算法的测试分析,在一定时期内购买和购买的两种产品的数量越大,排名越高。
购买产品A的客户(即使是一年前)最近购买了产品B,则排名+1(例如,在周期的一个月内),如果购买产品B的人越多,则A产品在listing下方,B产品的排名会更高。
那么根据上面的算法规则:
我们只需要采集一些购买过产品A的客户,展示新产品,给他们做营销,形成交易,让我们和我们的产品产生关联,从而达到最大的流量拦截。
使用的功能:邀请模式+采集邮箱+邮件模板设置
只要新品在短时间内交易几十个订单,就可以实现上述关联。 (当然,这取决于产品的受欢迎程度和竞争程度。)
##邮营销##(邮件营销成本最低,大数据营销,转化快速高效)
使用的功能:邀请模式、审稿人采集管理、大数据邮件管理、邮件模板(设置)软件(5、关键词采集ASIN、2、Mailbox采集)
目前传统的EDM营销转化率只有0.5%,但由于我们的AMZHelper实时抓取数据,我们的邮箱都是亚马逊上真实有效的买家邮箱。
所以如果数据准确的话,3%的转化率也不是什么大问题。
计算一个账户,我们假设转化率只有0.5%,那么1000封邮件就会发出5个订单。一个邮箱1.2美分,费用12元。交易了5个订单。稳赚不亏。
AMZHelper已对接国内知名:思奇群发邮件平台,国际知名EDM频道:猎豹邮箱
PS:我们如何使用 EDM 营销?
1、新品推广期,促销。
2、库存清理。
3、Associated Marketing。
4、holiday 促销。
操作流程:
1、准备邮件数据:使用AMZHelpler软件采集,或者直接拨打我们平台的大数据邮箱。
2、以邀请方式添加产品。
3、 导入邮箱或调用平台邮箱数据。
4、使用 EDM 群发邮件。
通过关键词采集文章采集api(织梦采集侠的伪原创及搜索优化方式(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-09-07 12:05
织梦采集侠安装非常简单方便。只需一分钟即可立即启动采集,并结合简单、健壮、灵活、开源的Dedecms程序,新手也能快速上手,我们还有专门的客服提供技术支持对于商业客户。不同于传统的采集模式,织梦采集侠可以根据用户设置的关键词进行平移采集。 pan采集的优势在于通过采集此关键词进行不同的搜索,从而实现采集不在一个或多个指定的采集站点上进行,降低了采集的风险@站点被搜索引擎判定为镜像站点,被搜索引擎惩罚。 1)RSS采集,只需输入RSS地址采集Content 只要RSS订阅地址是采集的网站提供的,就可以使用RSS 采集,输入RSS地址方便就行采集定位网站内容,无需写采集规则,方便简单。 2)页面监控采集,简单方便采集内容页控采集您只需要提供监控页面地址和文字网址规则即可指定采集设计网站或栏目内容,方便简单,不需要写采集规则也可以针对采集。 3) 多个伪原创 和优化方法来提高收录 率和排名。自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、seo词插入、关键词添加链接等方法处理采集回文章,增强采集 @文章原创,有利于搜索引擎优化,提高搜索引擎收录、网站权重和关键词排名。 4)plugin 是全自动采集,不需要人工干预。 织梦采集侠是一个预设的采集任务。根据设置的采集方法采集 URL,然后自动抓取网页内容,程序通过精确计算分析网页,丢弃不是文章内容页的网址,提取优秀的文章内容,最后伪原创,导入并生成。所有这些操作都是自动完成的,无需人工干预。 .
5)手放文章也伪原创和搜索优化处理织梦采集侠不仅仅是一个采集插件,更是一个织梦Required伪原创和搜索优化插件,手动发布文章可以通过织梦采集侠的伪原创和搜索优化处理,文章可以替换同义词,自动内链,关键词链接和@随机插入的文章收录关键词,会自动添加指定链接等功能。是织梦必备插件。 6)timing and quantification 采集伪原创SEO 更新插件有两种触发采集的方式,一种是在页面中添加代码通过用户访问触发采集update,另一种是我们提供的远程为商业用户触发采集服务,新站可定时定量采集更新,无需人工接入,无需人工干预。 7)及时定量更新待审稿件,即使你的数据库里有上千个文章,织梦采集侠侠也可以在你每天设定的时间段内定时定量地审阅和更新根据您的需要。 织梦采集侠v2.71 更新内容:[√]加入超级采集[√]修复采集重复问题[√]加入采集规则导入导出[√]图片优化下载,减轻Server负载 [√]关键词插入优化,段尾插入改为随机插入[√]改善地图生成错误[√]百度多项优化 查看全部
通过关键词采集文章采集api(织梦采集侠的伪原创及搜索优化方式(组图))
织梦采集侠安装非常简单方便。只需一分钟即可立即启动采集,并结合简单、健壮、灵活、开源的Dedecms程序,新手也能快速上手,我们还有专门的客服提供技术支持对于商业客户。不同于传统的采集模式,织梦采集侠可以根据用户设置的关键词进行平移采集。 pan采集的优势在于通过采集此关键词进行不同的搜索,从而实现采集不在一个或多个指定的采集站点上进行,降低了采集的风险@站点被搜索引擎判定为镜像站点,被搜索引擎惩罚。 1)RSS采集,只需输入RSS地址采集Content 只要RSS订阅地址是采集的网站提供的,就可以使用RSS 采集,输入RSS地址方便就行采集定位网站内容,无需写采集规则,方便简单。 2)页面监控采集,简单方便采集内容页控采集您只需要提供监控页面地址和文字网址规则即可指定采集设计网站或栏目内容,方便简单,不需要写采集规则也可以针对采集。 3) 多个伪原创 和优化方法来提高收录 率和排名。自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、seo词插入、关键词添加链接等方法处理采集回文章,增强采集 @文章原创,有利于搜索引擎优化,提高搜索引擎收录、网站权重和关键词排名。 4)plugin 是全自动采集,不需要人工干预。 织梦采集侠是一个预设的采集任务。根据设置的采集方法采集 URL,然后自动抓取网页内容,程序通过精确计算分析网页,丢弃不是文章内容页的网址,提取优秀的文章内容,最后伪原创,导入并生成。所有这些操作都是自动完成的,无需人工干预。 .
5)手放文章也伪原创和搜索优化处理织梦采集侠不仅仅是一个采集插件,更是一个织梦Required伪原创和搜索优化插件,手动发布文章可以通过织梦采集侠的伪原创和搜索优化处理,文章可以替换同义词,自动内链,关键词链接和@随机插入的文章收录关键词,会自动添加指定链接等功能。是织梦必备插件。 6)timing and quantification 采集伪原创SEO 更新插件有两种触发采集的方式,一种是在页面中添加代码通过用户访问触发采集update,另一种是我们提供的远程为商业用户触发采集服务,新站可定时定量采集更新,无需人工接入,无需人工干预。 7)及时定量更新待审稿件,即使你的数据库里有上千个文章,织梦采集侠侠也可以在你每天设定的时间段内定时定量地审阅和更新根据您的需要。 织梦采集侠v2.71 更新内容:[√]加入超级采集[√]修复采集重复问题[√]加入采集规则导入导出[√]图片优化下载,减轻Server负载 [√]关键词插入优化,段尾插入改为随机插入[√]改善地图生成错误[√]百度多项优化
通过关键词采集文章采集api(通过关键词采集文章采集api实现的功能是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-06 23:06
通过关键词采集文章采集api今天要实现的功能是通过关键词对网站内的文章进行采集和标签处理。网站的网址可以采集百度爬虫收录的结果,对于不对外公开的网站,自己采集下来并加上不同的标签就可以利用搜索引擎了。首先下载googleapiserverkivyexample·github:点击下载注意,这里是官方版本的git:然后在common文件夹下,发布链接即可,注意链接必须在destination文件夹内(注意这里改标签不需要真的去加api关键词)使用bizlinlaw处理下面我们来说说怎么通过bizlinlaw工具对bt站进行脚本采集和脚本标签处理。
简单来说,这个工具并不是使用具体的bt站,只要关键词在这个类别下都可以处理,我们只要加个标签即可。当然如果加一些“技术”、“爬虫”的标签当然更好,不过我这里并没有加,具体需要自己定制。我们先看看工具的界面:点击"\"这里打开子模板:主要有六大类目:日志采集:通过日志追踪抓取源、标签处理:通过标签追踪抓取源,爬虫采集:爬虫集合在一起的搜索引擎采集:抓取爬虫过程中使用爬虫集合中的api有重复抓取、日志扫描、异步获取等。
其中"日志"应该是个坑,因为他是静态文件,抓取后没法导出为xml格式。那么怎么抓取呢?首先我们启动一个ssh进程(这里先不建议使用,ssh过于繁琐)然后将bizlinlaw连上localhost:4783输入如下命令:cdbizlinlaw.sh通过命令行工具获取密钥进行解密:build-tsecret-passa.pemgetpassauthenticationsecret-passa.pem\通过命令行工具获取密钥:localhost:4783chmod4783其中:4783是bizlinlaw账号的uid号,当然不对外公开的可以忽略这一条。
接下来我们启动一个sql数据库并导入数据。bizlinlaw(dev).sql-udburlserver-u-p-p={}-t-o--sql-r'{path:'+filename;}'/so30.solocalhost:4783然后启动一个torbot(dev).sql--r'{path:'+filename;}'system.io.cern'/so30.so;'通过命令行工具获取密钥进行解密:build-tsecret-passa.pemgetpassauthenticationsecret-passa.pem\torbot(dev).sql--r'{path:'+filename;}'torbot'/so30.so;'\通过命令行工具获取密钥:build-tsecret-passa.pemgetpassauthenticationsecret-passa.pem\torbot(dev).sql--r'{path:'+filename;}'torbot'/so30.so;'整。 查看全部
通过关键词采集文章采集api(通过关键词采集文章采集api实现的功能是什么?)
通过关键词采集文章采集api今天要实现的功能是通过关键词对网站内的文章进行采集和标签处理。网站的网址可以采集百度爬虫收录的结果,对于不对外公开的网站,自己采集下来并加上不同的标签就可以利用搜索引擎了。首先下载googleapiserverkivyexample·github:点击下载注意,这里是官方版本的git:然后在common文件夹下,发布链接即可,注意链接必须在destination文件夹内(注意这里改标签不需要真的去加api关键词)使用bizlinlaw处理下面我们来说说怎么通过bizlinlaw工具对bt站进行脚本采集和脚本标签处理。
简单来说,这个工具并不是使用具体的bt站,只要关键词在这个类别下都可以处理,我们只要加个标签即可。当然如果加一些“技术”、“爬虫”的标签当然更好,不过我这里并没有加,具体需要自己定制。我们先看看工具的界面:点击"\"这里打开子模板:主要有六大类目:日志采集:通过日志追踪抓取源、标签处理:通过标签追踪抓取源,爬虫采集:爬虫集合在一起的搜索引擎采集:抓取爬虫过程中使用爬虫集合中的api有重复抓取、日志扫描、异步获取等。
其中"日志"应该是个坑,因为他是静态文件,抓取后没法导出为xml格式。那么怎么抓取呢?首先我们启动一个ssh进程(这里先不建议使用,ssh过于繁琐)然后将bizlinlaw连上localhost:4783输入如下命令:cdbizlinlaw.sh通过命令行工具获取密钥进行解密:build-tsecret-passa.pemgetpassauthenticationsecret-passa.pem\通过命令行工具获取密钥:localhost:4783chmod4783其中:4783是bizlinlaw账号的uid号,当然不对外公开的可以忽略这一条。
接下来我们启动一个sql数据库并导入数据。bizlinlaw(dev).sql-udburlserver-u-p-p={}-t-o--sql-r'{path:'+filename;}'/so30.solocalhost:4783然后启动一个torbot(dev).sql--r'{path:'+filename;}'system.io.cern'/so30.so;'通过命令行工具获取密钥进行解密:build-tsecret-passa.pemgetpassauthenticationsecret-passa.pem\torbot(dev).sql--r'{path:'+filename;}'torbot'/so30.so;'\通过命令行工具获取密钥:build-tsecret-passa.pemgetpassauthenticationsecret-passa.pem\torbot(dev).sql--r'{path:'+filename;}'torbot'/so30.so;'整。
通过关键词采集文章采集api( 企业网站搜查引擎优化的重要性甚么是SEO优化?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-06 16:03
企业网站搜查引擎优化的重要性甚么是SEO优化?(图))
您了解 SEO 中的时效性吗?
众所周知,影响百度搜索结果显示的主要因素有3个:相关性、权威性和及时性。 “相关性”是指网站内容与搜索关键词有很强的相关性,可以帮助用户解决搜索...
seo 外部链接指的是什么,它有什么作用?
一、什么是外部链接?在发送外部链接之前,我们必须明确“外部链接”一词的含义。外部链接称为外部链接,也称为导入链接。是指从网上其他网站导入到我的网站的链接。大部分seo新手容易产生一个误区,认为外链应该链接到互联网...
enterprise网站需要做seo吗?
Enterprise网站搜索引擎优化的重要性 什么是SEO优化? SEO是搜索引擎优化的缩写。 SEO的首要任务是优化网页,提高搜索引擎排名,增加网站流量,体验各种搜索引擎的样子……
网站SEO 排名如何快速优化
对于做SEO优化排名的人来说,网站有个好头衔,相当有钱的二代,一出生就有优势。那么如何选择“开始”是每个站长都需要做的。关于新站网站...
seo点击快速排序,站内点击对快速排序有什么影响?
一、Home 网站优化提升关键词排名四个关键点1.长尾词集,分析首页优化时需要对大量长尾词进行采集整理,有很多长尾词人们用它们来写文章,但长尾词不仅仅用来写文章,为了规划网站的整体卓越...
为什么需要自己的 seo 计费管理系统来快速优化!
最近很多人都在讨论他们的资源提供者有问题。要么效果不好,要么有各种问题。但是我有最终用户在使用它,并且无法轻松更改平台。有什么好的解决办法吗?其实很简单。构建您自己的计费管理系统... 查看全部
通过关键词采集文章采集api(
企业网站搜查引擎优化的重要性甚么是SEO优化?(图))
您了解 SEO 中的时效性吗?
众所周知,影响百度搜索结果显示的主要因素有3个:相关性、权威性和及时性。 “相关性”是指网站内容与搜索关键词有很强的相关性,可以帮助用户解决搜索...
seo 外部链接指的是什么,它有什么作用?
一、什么是外部链接?在发送外部链接之前,我们必须明确“外部链接”一词的含义。外部链接称为外部链接,也称为导入链接。是指从网上其他网站导入到我的网站的链接。大部分seo新手容易产生一个误区,认为外链应该链接到互联网...
enterprise网站需要做seo吗?
Enterprise网站搜索引擎优化的重要性 什么是SEO优化? SEO是搜索引擎优化的缩写。 SEO的首要任务是优化网页,提高搜索引擎排名,增加网站流量,体验各种搜索引擎的样子……
网站SEO 排名如何快速优化
对于做SEO优化排名的人来说,网站有个好头衔,相当有钱的二代,一出生就有优势。那么如何选择“开始”是每个站长都需要做的。关于新站网站...
seo点击快速排序,站内点击对快速排序有什么影响?
一、Home 网站优化提升关键词排名四个关键点1.长尾词集,分析首页优化时需要对大量长尾词进行采集整理,有很多长尾词人们用它们来写文章,但长尾词不仅仅用来写文章,为了规划网站的整体卓越...
为什么需要自己的 seo 计费管理系统来快速优化!
最近很多人都在讨论他们的资源提供者有问题。要么效果不好,要么有各种问题。但是我有最终用户在使用它,并且无法轻松更改平台。有什么好的解决办法吗?其实很简单。构建您自己的计费管理系统...
通过关键词采集文章采集api(网络爬虫系统的原理和工作流程及注意事项介绍-乐题库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-09-06 08:07
网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
在大数据时代,网络爬虫更像是来自采集data 的互联网工具。已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图 1 网络爬虫示意图
网页中除了供用户阅读的文字信息外,还收录一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些比较重要的网站输出程度(网页中超链接数)较高的网址作为种子网址集合。
网络爬虫系统使用这些种子集合作为初始 URL 来开始数据爬取。由于网页收录链接信息,所以会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法进行搜索或者深度优先搜索算法遍历所有网页。
因为深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索更接近网站首页的网页信息,所以广度优先搜索算法采集页一般使用。
网络爬虫系统首先将种子URL放入下载队列,简单地从队列头部取出一个URL下载对应的网页,获取网页内容并存储,解析链接后网页中的信息,你可以得到一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后,取出一个网址,下载其对应的网页,然后解析,如此重复,直到遍历全网或满足一定条件。
网络爬虫工作流程
如图2所示,网络爬虫的基本工作流程如下。
1) 首先选择种子 URL 的一部分。
2) 将这些 URL 放入 URL 队列进行抓取。
3)从待爬取的URL队列中取出待爬取的URL,解析DNS得到主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入抓取到的网址队列中。
4)对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
图 2 网络爬虫的基本工作流程
网络爬虫抓取策略
谷歌、百度等通用搜索引擎抓取的网页数量通常以亿为单位计算。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页,从而尽可能扩大网页信息的覆盖范围呢?这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,抓取策略决定了抓取网页的顺序。
本节先简单介绍一下网络爬虫的爬取策略中用到的基本概念。
1)网页关系模型
从互联网的结构来看,网页通过不同数量的超链接相互连接,形成一个庞大而复杂的有向图,相互关联。
如图3所示,如果一个网页被视为图中的某个节点,而该网页中其他网页的链接被视为该节点到其他节点的边,那么我们可以很容易地认为整个网页Internet 上的页面被建模为有向图。
理论上,通过遍历算法遍历图,几乎可以访问互联网上的所有网页。
图 3 网页关系模型图
2)Web 分类
从爬虫的角度来划分互联网,互联网上的所有页面可以分为5个部分:已下载但未过期页面、已下载已过期页面、已下载页面、已知页面和未知页面,如图4. 显示。
抓取的本地网页实际上是互联网内容的镜像和备份。互联网是动态变化的。当互联网上的部分内容发生变化时,抓取到的本地网页就会过期。因此,下载的网页分为两种:下载的未过期网页和下载的过期网页。
图 4 网页分类
待下载的网页是指在URL队列中待抓取的页面。
可以看出,网页指的是未被抓取的网页,也不在待抓取的URL队列中,但可以通过分析抓取的页面或要抓取的URL对应的页面获取已抓取。
还有一些网页是网络爬虫无法直接抓取下载的,称为不可知网页。
以下重点介绍几种常见的抓取策略。
1.通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集data。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个跟踪链接,直到无法再深入。
网络爬虫在完成一个爬行分支后返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。
此策略更适合垂直搜索或站点搜索,但在抓取页面内容更深层次的站点时会造成资源的巨大浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间的时候,会尽可能的深入,只有在找不到一个节点的后继节点时才考虑它的兄弟节点。
这样的策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它会沿着一条路径无限扩展,从而“陷入”海量数据。一般情况下,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样就降低了搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度抓取网页。首先抓取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。
仍以图3为例,遍历路径为1→2→3→4→5→6→7→8
因为广度优先策略是在第N层节点扩展完成后进入第N+1层,所以可以保证找到路径最短的解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支无法结束爬取的问题,实现方便。它不需要存储大量的中间节点。缺点是爬到目录需要很长时间。更深的页面。
如果搜索过程中分支过多,即节点的后继节点过多,算法会耗尽资源,在可用空间中找不到解。
2.专注于网络爬虫
焦点网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入到网络爬虫中,并提出了 Fish Search 算法。
算法以用户输入的查询词为主题,将收录查询词的页面视为主题相关页面。它的局限性在于它无法评估页面与主题的相关性。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面与主题的相关性。
使用基于连续值计算链接值的方法,不仅可以计算出哪些抓取的链接与主题相关,还可以量化相关性的大小。
2)基于链接结构评估的爬行策略
网页不同于一般文本。它是一个收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面上的链接表示页面之间的相互关系。基于链接结构的搜索策略模型利用这些结构特征来评估页面和链接的重要性来确定搜索顺序。其中,PageRank算法是这类搜索策略模型的代表。
PageRank 算法的基本原理是,如果一个网页被多次引用,它可能是一个非常重要的网页。如果一个网页没有被多次引用,但被一个重要的网页引用,那么它也可能是一个重要的网页。一个网页的重要性均匀地传递给它所引用的网页。
将某个页面的PageRank除以该页面上存在的前向链接,并将得到的值与前向链接指向的页面的PageRank相加,得到被链接页面的PageRank .
如图 5 所示,PageRank 值为 100 的网页将其重要性平均转移到它引用的两个页面上,每个页面得到 50。同样,PageRank 值为 9 的网页引用它为 3 个页面中的每个页面传递的值是 3。
PageRank 值为 53 的页面的值来自引用它的两个页面传递的值。
图 5 PageRank 算法示例
3) 基于强化学习的爬行策略
Rennie 和 McCallum 将增强学习引入聚焦爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性,从而确定链接访问的顺序。
4)基于上下文映射的爬行策略
Diligenti 等人。提出了一种爬行策略,通过建立上下文映射来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面和相关网页之间的距离。最先访问最近页面中的链接。
3.增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只抓取新生成或更改的网页的爬虫。可以在一定程度上保证抓取到的页面尽可能的新鲜。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要重新访问网页以更新本地页面集中页面的内容。常用的方法有统一更新法、个体更新法和基于分类的更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常用的策略包括广度优先策略、PageRank 优先策略等。
4. 深网爬虫
网页按存在方式可分为表面网页和深层网页。
深网爬虫架构包括6个基本功能模块(爬虫控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS)面。
其中,LVS(LabelValueSet)表示标签和值的集合,用于表示填写表单的数据源。在爬虫过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。 查看全部
通过关键词采集文章采集api(网络爬虫系统的原理和工作流程及注意事项介绍-乐题库)
网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
在大数据时代,网络爬虫更像是来自采集data 的互联网工具。已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图 1 网络爬虫示意图
网页中除了供用户阅读的文字信息外,还收录一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些比较重要的网站输出程度(网页中超链接数)较高的网址作为种子网址集合。
网络爬虫系统使用这些种子集合作为初始 URL 来开始数据爬取。由于网页收录链接信息,所以会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法进行搜索或者深度优先搜索算法遍历所有网页。
因为深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索更接近网站首页的网页信息,所以广度优先搜索算法采集页一般使用。
网络爬虫系统首先将种子URL放入下载队列,简单地从队列头部取出一个URL下载对应的网页,获取网页内容并存储,解析链接后网页中的信息,你可以得到一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后,取出一个网址,下载其对应的网页,然后解析,如此重复,直到遍历全网或满足一定条件。
网络爬虫工作流程
如图2所示,网络爬虫的基本工作流程如下。
1) 首先选择种子 URL 的一部分。
2) 将这些 URL 放入 URL 队列进行抓取。
3)从待爬取的URL队列中取出待爬取的URL,解析DNS得到主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入抓取到的网址队列中。
4)对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
图 2 网络爬虫的基本工作流程
网络爬虫抓取策略
谷歌、百度等通用搜索引擎抓取的网页数量通常以亿为单位计算。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页,从而尽可能扩大网页信息的覆盖范围呢?这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,抓取策略决定了抓取网页的顺序。
本节先简单介绍一下网络爬虫的爬取策略中用到的基本概念。
1)网页关系模型
从互联网的结构来看,网页通过不同数量的超链接相互连接,形成一个庞大而复杂的有向图,相互关联。
如图3所示,如果一个网页被视为图中的某个节点,而该网页中其他网页的链接被视为该节点到其他节点的边,那么我们可以很容易地认为整个网页Internet 上的页面被建模为有向图。
理论上,通过遍历算法遍历图,几乎可以访问互联网上的所有网页。
图 3 网页关系模型图
2)Web 分类
从爬虫的角度来划分互联网,互联网上的所有页面可以分为5个部分:已下载但未过期页面、已下载已过期页面、已下载页面、已知页面和未知页面,如图4. 显示。
抓取的本地网页实际上是互联网内容的镜像和备份。互联网是动态变化的。当互联网上的部分内容发生变化时,抓取到的本地网页就会过期。因此,下载的网页分为两种:下载的未过期网页和下载的过期网页。
图 4 网页分类
待下载的网页是指在URL队列中待抓取的页面。
可以看出,网页指的是未被抓取的网页,也不在待抓取的URL队列中,但可以通过分析抓取的页面或要抓取的URL对应的页面获取已抓取。
还有一些网页是网络爬虫无法直接抓取下载的,称为不可知网页。
以下重点介绍几种常见的抓取策略。
1.通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集data。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个跟踪链接,直到无法再深入。
网络爬虫在完成一个爬行分支后返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。
此策略更适合垂直搜索或站点搜索,但在抓取页面内容更深层次的站点时会造成资源的巨大浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间的时候,会尽可能的深入,只有在找不到一个节点的后继节点时才考虑它的兄弟节点。
这样的策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它会沿着一条路径无限扩展,从而“陷入”海量数据。一般情况下,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样就降低了搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度抓取网页。首先抓取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。
仍以图3为例,遍历路径为1→2→3→4→5→6→7→8
因为广度优先策略是在第N层节点扩展完成后进入第N+1层,所以可以保证找到路径最短的解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支无法结束爬取的问题,实现方便。它不需要存储大量的中间节点。缺点是爬到目录需要很长时间。更深的页面。
如果搜索过程中分支过多,即节点的后继节点过多,算法会耗尽资源,在可用空间中找不到解。
2.专注于网络爬虫
焦点网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入到网络爬虫中,并提出了 Fish Search 算法。
算法以用户输入的查询词为主题,将收录查询词的页面视为主题相关页面。它的局限性在于它无法评估页面与主题的相关性。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面与主题的相关性。
使用基于连续值计算链接值的方法,不仅可以计算出哪些抓取的链接与主题相关,还可以量化相关性的大小。
2)基于链接结构评估的爬行策略
网页不同于一般文本。它是一个收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面上的链接表示页面之间的相互关系。基于链接结构的搜索策略模型利用这些结构特征来评估页面和链接的重要性来确定搜索顺序。其中,PageRank算法是这类搜索策略模型的代表。
PageRank 算法的基本原理是,如果一个网页被多次引用,它可能是一个非常重要的网页。如果一个网页没有被多次引用,但被一个重要的网页引用,那么它也可能是一个重要的网页。一个网页的重要性均匀地传递给它所引用的网页。
将某个页面的PageRank除以该页面上存在的前向链接,并将得到的值与前向链接指向的页面的PageRank相加,得到被链接页面的PageRank .
如图 5 所示,PageRank 值为 100 的网页将其重要性平均转移到它引用的两个页面上,每个页面得到 50。同样,PageRank 值为 9 的网页引用它为 3 个页面中的每个页面传递的值是 3。
PageRank 值为 53 的页面的值来自引用它的两个页面传递的值。
图 5 PageRank 算法示例
3) 基于强化学习的爬行策略
Rennie 和 McCallum 将增强学习引入聚焦爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性,从而确定链接访问的顺序。
4)基于上下文映射的爬行策略
Diligenti 等人。提出了一种爬行策略,通过建立上下文映射来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面和相关网页之间的距离。最先访问最近页面中的链接。
3.增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只抓取新生成或更改的网页的爬虫。可以在一定程度上保证抓取到的页面尽可能的新鲜。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要重新访问网页以更新本地页面集中页面的内容。常用的方法有统一更新法、个体更新法和基于分类的更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常用的策略包括广度优先策略、PageRank 优先策略等。
4. 深网爬虫
网页按存在方式可分为表面网页和深层网页。
深网爬虫架构包括6个基本功能模块(爬虫控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS)面。
其中,LVS(LabelValueSet)表示标签和值的集合,用于表示填写表单的数据源。在爬虫过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。
通过关键词采集文章采集api(每天稳定收集两三个网站原创文章的收集体系和多网站伪原创)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-06 08:01
采集网站seo,怎么通过采集文章网站seo?无论是企业网站还是个人网站,如果能采集到更多优质内容,更有利于seo优化,稳定采集两三个网站原创文章采集系统以及多个网站伪原创和伪页面seo系统和技术,这些都是目前流行的搜索引擎seo系统和技术。我拥有所有这些技术。 原创seo 全网试错验证了其实用性和有效性。我真的很愿意向更多人推荐它,但我也为一些业务需求而头疼。如果我必须干预,我该怎么做?兼顾这两种情况是一个古老的问题。每个人的能力和精力都不一样,不能一概而论。但是,在目前的网络发展中,普遍的做法是将两者结合起来。如何组合它们?仅有的?一个前提,搜索引擎怎么能清楚地知道我的网站,也就是搜索引擎可以分析我的网站的内容是否优质、正确,对网站在这个行业是否重要,这个不用我说,大家心里明白,对于网站seo,百度是很健全的,就算我是专业的网站seo,如果你的网站被全网扛了,就算是好我不敢推荐。 网站 是长期的。搜索引擎随时更新。它们一直在收录 更新。这不是一夜之间的事件。或许大家很快就会发现吧?从大家的角度来看,网站一定是真正的原创,但对于站长来说,自己的网站内容采集是比较零散的,因为要采集的网站太多,搜索引擎也帮不上忙。进行详细的抓取。
什么是网站伪原创?让网站content 搜索引擎更清晰更容易找到,就像百度有一个收录黑史的窗口,但是不好找,需要先做伪原创,很多情况下,使用伪原创比非原创 好。它为搜索引擎提供了足够的信息。同时文章里面还有一些伪原创网站,seo伪原创会更好。如何制作一个伪原创网站,一个好的伪原创应该是基于用户和内容发布的对等,没有标准,但必须满足几个要求:(1)做一个容易找网站,同时title上面应该有一个比较醒目的标题。
用户可以认为这个网站很有可读性。
(2)保持网站的更新量,网站基本每天保持原创20篇文章,伪原创假20篇,一定要收录伪原创的内容@伪原创不能很满意,所以不利于网站的流量和seo优化。
(3)编辑网站内容时,伪原创伪原创不能算作网站内容。
需要注意的是网站应该表现出与网站之外发布的内容不同的特征。比如网站的导航比较长,但是在伪原创网站应该避免。 (4)百度内部搜索、百度360搜索、5118网站效果分析、5118内容发布平台等第三方平台的一些原创伪原创内容,前期不要做太多阶段,不要引起百度、360等搜索引擎的反感,可以基于伪原创伪原创加进一。
其他建议: 查看全部
通过关键词采集文章采集api(每天稳定收集两三个网站原创文章的收集体系和多网站伪原创)
采集网站seo,怎么通过采集文章网站seo?无论是企业网站还是个人网站,如果能采集到更多优质内容,更有利于seo优化,稳定采集两三个网站原创文章采集系统以及多个网站伪原创和伪页面seo系统和技术,这些都是目前流行的搜索引擎seo系统和技术。我拥有所有这些技术。 原创seo 全网试错验证了其实用性和有效性。我真的很愿意向更多人推荐它,但我也为一些业务需求而头疼。如果我必须干预,我该怎么做?兼顾这两种情况是一个古老的问题。每个人的能力和精力都不一样,不能一概而论。但是,在目前的网络发展中,普遍的做法是将两者结合起来。如何组合它们?仅有的?一个前提,搜索引擎怎么能清楚地知道我的网站,也就是搜索引擎可以分析我的网站的内容是否优质、正确,对网站在这个行业是否重要,这个不用我说,大家心里明白,对于网站seo,百度是很健全的,就算我是专业的网站seo,如果你的网站被全网扛了,就算是好我不敢推荐。 网站 是长期的。搜索引擎随时更新。它们一直在收录 更新。这不是一夜之间的事件。或许大家很快就会发现吧?从大家的角度来看,网站一定是真正的原创,但对于站长来说,自己的网站内容采集是比较零散的,因为要采集的网站太多,搜索引擎也帮不上忙。进行详细的抓取。
什么是网站伪原创?让网站content 搜索引擎更清晰更容易找到,就像百度有一个收录黑史的窗口,但是不好找,需要先做伪原创,很多情况下,使用伪原创比非原创 好。它为搜索引擎提供了足够的信息。同时文章里面还有一些伪原创网站,seo伪原创会更好。如何制作一个伪原创网站,一个好的伪原创应该是基于用户和内容发布的对等,没有标准,但必须满足几个要求:(1)做一个容易找网站,同时title上面应该有一个比较醒目的标题。
用户可以认为这个网站很有可读性。
(2)保持网站的更新量,网站基本每天保持原创20篇文章,伪原创假20篇,一定要收录伪原创的内容@伪原创不能很满意,所以不利于网站的流量和seo优化。
(3)编辑网站内容时,伪原创伪原创不能算作网站内容。
需要注意的是网站应该表现出与网站之外发布的内容不同的特征。比如网站的导航比较长,但是在伪原创网站应该避免。 (4)百度内部搜索、百度360搜索、5118网站效果分析、5118内容发布平台等第三方平台的一些原创伪原创内容,前期不要做太多阶段,不要引起百度、360等搜索引擎的反感,可以基于伪原创伪原创加进一。
其他建议:
通过关键词采集文章采集api(优采云采集支持5118接口:5118一键智能改写API接口 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-09-05 14:29
)
优采云采集支持5118个接口如下:
5118 一键智能换字API接口
5118 一键智能重写API接口
5118 智能标题生成 API
处理采集的数据标题和内容、关键词、描述等。可以针对性的配合优采云采集的SEO功能和5118智能换词API处理文章更高的原创,这对增加文章的收录和网站的权重很重要。
访问步骤
1.创建5118 API接口配置(所有接口通用)
5118一键智能改词API接口、5118一键智能改写API接口:可用于处理采集数据标题和内容等;
5118智能标题生成API:根据文章content智能生成文章title;
我。 API配置入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》点击【第三方API配置管理】==》点击进入创建相应的接口配置:【5118_智能改词API】、【5118_智能改写API】、【5118_智能标题生成API】;
二。配置API接口信息:
【API-Key值】是从5118后台获取一键智能改词API,或者5118一键智能改写API,或者5118智能标题生成API对应的key值,填写优采云;
设置字锁功能,先开启核心字锁,填写的锁字在第三方原创api处理时不会被替换,多个字之间用|分隔,例如:word1| word2|word3
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
我。 API 处理规则条目:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【添加API处理规则】创建API处理规则;
二、API处理规则配置:
三、5118智能标题生成API(可选,特殊接口说明)
5118智能标题生成API是基于文章content(内容字段)智能生成文章标题,所以API处理规则中需要处理的字段要选择content字段生成标题基于内容。
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
我。手动执行 API 处理规则:
点击采集任务的【结果&发布】选项卡中的【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行;
二。自动执行 API 处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般搭配定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,都会导致所有数据被多次执行),最后点击保存;
4. API 处理结果及发布
我。查看API接口处理结果:
API接口处理的内容会生成API接口对应的新字段,如:
内容处理后添加字段:
在【结果数据&发布】和数据预览界面均可查看。
提醒:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二后内容发布,API接口处理
发布文章前,修改发布目标第二步的映射字段,API接口处理后将title和content改成新的对应字段。
例如执行5118一键智能改词API后,选择title_5118改词和content_5118改词发布;
例如执行5118智能标题生成API后,选择content_5118生成标题并发布;
提醒:如果在发布目标中无法选择新字段,请在此任务下复制或新建一个发布目标,然后在新发布目标中选择新字段,即可查看详细教程;
5.5118-API接口常见问题及解决方法
我。 API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改对应新增的字段,如title_5118换词和content_5118换词字段;
查看全部
通过关键词采集文章采集api(优采云采集支持5118接口:5118一键智能改写API接口
)
优采云采集支持5118个接口如下:
5118 一键智能换字API接口
5118 一键智能重写API接口
5118 智能标题生成 API
处理采集的数据标题和内容、关键词、描述等。可以针对性的配合优采云采集的SEO功能和5118智能换词API处理文章更高的原创,这对增加文章的收录和网站的权重很重要。
访问步骤
1.创建5118 API接口配置(所有接口通用)
5118一键智能改词API接口、5118一键智能改写API接口:可用于处理采集数据标题和内容等;
5118智能标题生成API:根据文章content智能生成文章title;
我。 API配置入口:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》点击【第三方API配置管理】==》点击进入创建相应的接口配置:【5118_智能改词API】、【5118_智能改写API】、【5118_智能标题生成API】;
二。配置API接口信息:
【API-Key值】是从5118后台获取一键智能改词API,或者5118一键智能改写API,或者5118智能标题生成API对应的key值,填写优采云;
设置字锁功能,先开启核心字锁,填写的锁字在第三方原创api处理时不会被替换,多个字之间用|分隔,例如:word1| word2|word3
2. 创建 API 处理规则
API处理规则,可设置调用API接口处理哪些字段的内容;
我。 API 处理规则条目:
点击控制台左侧列表中的【第三方服务配置】==》点击【第三方内容API访问】==》进入【API处理规则管理】页面,最后点击【添加API处理规则】创建API处理规则;
二、API处理规则配置:
三、5118智能标题生成API(可选,特殊接口说明)
5118智能标题生成API是基于文章content(内容字段)智能生成文章标题,所以API处理规则中需要处理的字段要选择content字段生成标题基于内容。
3. API 处理规则使用
API处理规则的使用方式有两种:手动执行和自动执行:
我。手动执行 API 处理规则:
点击采集任务的【结果&发布】选项卡中的【SEO&API&翻译工具】按钮==》选择【第三方API执行】栏==》选择对应的API处理规则==》执行;
二。自动执行 API 处理规则:
启用 API 处理的自动执行。任务完成采集后,会自动执行API处理。一般搭配定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡中,【自动执行第三方API配置】==》勾选【采集,自动执行API】选项==》选择要执行的API处理规则==》选择API接口处理的数据范围(一般选择“待发布”,都会导致所有数据被多次执行),最后点击保存;
4. API 处理结果及发布
我。查看API接口处理结果:
API接口处理的内容会生成API接口对应的新字段,如:
内容处理后添加字段:
在【结果数据&发布】和数据预览界面均可查看。
提醒:API处理规则执行需要一段时间,执行后页面会自动刷新,API接口处理的新字段会出现;
二后内容发布,API接口处理
发布文章前,修改发布目标第二步的映射字段,API接口处理后将title和content改成新的对应字段。
例如执行5118一键智能改词API后,选择title_5118改词和content_5118改词发布;
例如执行5118智能标题生成API后,选择content_5118生成标题并发布;
提醒:如果在发布目标中无法选择新字段,请在此任务下复制或新建一个发布目标,然后在新发布目标中选择新字段,即可查看详细教程;
5.5118-API接口常见问题及解决方法
我。 API处理规则和SEO规则如何搭配使用?
系统默认对title和content字段进行SEO功能,需要在SEO规则中修改对应新增的字段,如title_5118换词和content_5118换词字段;
通过关键词采集文章采集api(通过关键词采集文章采集api-数据采集开发库采集github上开源项目总结及实践)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-09-04 08:07
通过关键词采集文章采集api-数据采集开发库采集github上开源项目总结及实践分享excel文件转word导入脚本爬虫脚本爬取一个github页面的内容,主要用到了以下内容:爬取了1.2w篇热门软件,1500多篇影评,63篇各电影的评论,100多篇笔记整理概述自由职业者必备的工具学习使用的记录excel文件格式的记录,记录当前地址,未出现的内容会被视为已删除,输出内容为excel文件信息爬取python爬虫采集商品信息前置安装相关库:numpy:numpy是python的数学库之一scipy:提供了一系列强大的函数和数组对象pandas:基于numpy和matplotlib.pyplot数据分析工具包可视化及可视化数据工具numpy安装方法:yuminstall-ypipinstallnumpydownloadsandreleasesmaybefordownloadingformatmatplotlib.pyplot已安装pip命令时无法使用时。
使用全局命令:pipinstallpip/pipinstallaptinstalldownloadpipinstallscipy/pipinstalleasyguipipinstallpip时,发现无法下载安装pip中的pip-installscipy/pipinstalleasygui有时候数据在网站下载到本地,可以用代理去请求网站或者自己搭建服务器读取数据:数据::提取数据在网站中page=page.read_html.decode("utf-8")page=page.decode("utf-8")获取用户信息,需要使用该方法:获取第一页内容page=requests.get('')获取链接并读取:提取链接并读取:提取后的信息有可能会丢失,需要用doc2oapi进行解析等数据会自动进行二次解析:去除不必要的内容,使用default.rows=[]获取用户的点赞信息:一共需要获取1000条,分成100份,获取数量共计为1000条数据利用pandas的dataframe读取数据:利用pandas的dataframe可以进行结构化数据处理数据清洗及格式化保存数据格式化:filepath='f:\\scrapy\\blog\\scrapy\\train.xls'path=files.replace('%d','')filename=file.replace('%d','')filedata=set(dataframe(filename))excel数据格式化:利用dataframe格式转换功能完成数据格式化工作。
对于个人博客不推荐gb/tb格式数据转换工具,可以转换为dataframe数据格式工具。如pandas数据的转换,matplotlib数据的转换等。导入数据库接口、可视化数据导入mysqlexcel数据(file://users//administrator//desktop//scrapy.xls)excel数据(file://users//administrator//desktop//scrapy.xls)导入pdfrom。 查看全部
通过关键词采集文章采集api(通过关键词采集文章采集api-数据采集开发库采集github上开源项目总结及实践)
通过关键词采集文章采集api-数据采集开发库采集github上开源项目总结及实践分享excel文件转word导入脚本爬虫脚本爬取一个github页面的内容,主要用到了以下内容:爬取了1.2w篇热门软件,1500多篇影评,63篇各电影的评论,100多篇笔记整理概述自由职业者必备的工具学习使用的记录excel文件格式的记录,记录当前地址,未出现的内容会被视为已删除,输出内容为excel文件信息爬取python爬虫采集商品信息前置安装相关库:numpy:numpy是python的数学库之一scipy:提供了一系列强大的函数和数组对象pandas:基于numpy和matplotlib.pyplot数据分析工具包可视化及可视化数据工具numpy安装方法:yuminstall-ypipinstallnumpydownloadsandreleasesmaybefordownloadingformatmatplotlib.pyplot已安装pip命令时无法使用时。
使用全局命令:pipinstallpip/pipinstallaptinstalldownloadpipinstallscipy/pipinstalleasyguipipinstallpip时,发现无法下载安装pip中的pip-installscipy/pipinstalleasygui有时候数据在网站下载到本地,可以用代理去请求网站或者自己搭建服务器读取数据:数据::提取数据在网站中page=page.read_html.decode("utf-8")page=page.decode("utf-8")获取用户信息,需要使用该方法:获取第一页内容page=requests.get('')获取链接并读取:提取链接并读取:提取后的信息有可能会丢失,需要用doc2oapi进行解析等数据会自动进行二次解析:去除不必要的内容,使用default.rows=[]获取用户的点赞信息:一共需要获取1000条,分成100份,获取数量共计为1000条数据利用pandas的dataframe读取数据:利用pandas的dataframe可以进行结构化数据处理数据清洗及格式化保存数据格式化:filepath='f:\\scrapy\\blog\\scrapy\\train.xls'path=files.replace('%d','')filename=file.replace('%d','')filedata=set(dataframe(filename))excel数据格式化:利用dataframe格式转换功能完成数据格式化工作。
对于个人博客不推荐gb/tb格式数据转换工具,可以转换为dataframe数据格式工具。如pandas数据的转换,matplotlib数据的转换等。导入数据库接口、可视化数据导入mysqlexcel数据(file://users//administrator//desktop//scrapy.xls)excel数据(file://users//administrator//desktop//scrapy.xls)导入pdfrom。
通过关键词采集文章采集api(搜狗微信文章采集数据详细采集说明及解决方案 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-09-01 18:10
)
采集网站:
使用功能点:
网址
分页列表信息采集
搜狗微信搜索:搜狗微信搜索是搜狗于2014年6月9日推出的微信公众平台。“微信搜索”支持搜索微信公众号和微信文章,可以通过关键词搜索相关微信公众号,或微信公众号推送的文章。不仅是PC端,搜狗手机搜索客户端也会推荐相关的微信公众号。
搜狗微信文章采集数据说明:本文已在搜狗微信-搜索-优采云大数据文章信息采集进行。本文仅以“搜狗微信-搜索-优采云大数据的文章信息采集”为例。实际操作中,您可以根据自己的需要,将搜狗微信的搜索词更改为执行数据采集。
搜狗微信文章采集detail采集字段说明:微信文章title、微信文章keywords、微信文章generalization、微信公众号、微信文章发布时间、微信文章地址。
第一步:创建采集task
1)进入主界面,选择“自定义模式”
2)将采集的网址复制粘贴到网站输入框中,点击“保存网址”
第 2 步:创建翻页循环
1)打开右上角的“进程”。点击页面文章搜索框,在右侧操作提示框中选择“输入文字”
2)输入您要搜索的文章信息,这里以搜索“优采云大数据”为例,输入完成后点击“确定”按钮
3)“优采云大数据”会自动填写搜索框,点击“search文章”按钮,在操作提示框中选择“点击此按钮”
“优采云大数据”的文章搜索结果出现在4)页面上。将结果页下拉至底部,点击“下一页”按钮,在右侧操作提示框中选择“循环点击下一页”
第 3 步:创建一个列表循环并提取数据
1)移动鼠标选择页面上的第一个文章块。系统将识别此块中的子元素。在操作提示框中选择“选择子元素”
2)继续选择页面第二篇文章文章的区块,系统会自动选择第二篇文章文章的子元素,并识别页面其他10组相似元素, 在操作提示框中,选择“全选”
3) 我们可以看到页面上文章块中的所有元素都被选中并变成了绿色。在右侧的操作提示框中,会出现一个字段预览表。将鼠标移动到表头并单击垃圾桶图标以删除不需要的字段。字段选择完成后,选择“采集以下数据”
4) 由于我们还想要每个采集文章的URL,所以我们需要再提取一个字段。点击第一篇文章文章的链接,再点击第二篇文章文章的链接,系统会自动在页面上选择一组文章链接。在右侧的操作提示框中选择“采集以下链接地址”
5)字段选择完成后,选择对应的字段,自定义字段的命名。完成后点击左上角的“保存并开始”开始采集task
6)选择“启动本地采集”
第四步:数据采集并导出
1)采集完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,导出采集好搜狗微信文章的数据
2)这里我们选择excel作为导出格式,导出数据如下图
查看全部
通过关键词采集文章采集api(搜狗微信文章采集数据详细采集说明及解决方案
)
采集网站:
使用功能点:
网址
分页列表信息采集
搜狗微信搜索:搜狗微信搜索是搜狗于2014年6月9日推出的微信公众平台。“微信搜索”支持搜索微信公众号和微信文章,可以通过关键词搜索相关微信公众号,或微信公众号推送的文章。不仅是PC端,搜狗手机搜索客户端也会推荐相关的微信公众号。
搜狗微信文章采集数据说明:本文已在搜狗微信-搜索-优采云大数据文章信息采集进行。本文仅以“搜狗微信-搜索-优采云大数据的文章信息采集”为例。实际操作中,您可以根据自己的需要,将搜狗微信的搜索词更改为执行数据采集。
搜狗微信文章采集detail采集字段说明:微信文章title、微信文章keywords、微信文章generalization、微信公众号、微信文章发布时间、微信文章地址。
第一步:创建采集task
1)进入主界面,选择“自定义模式”
2)将采集的网址复制粘贴到网站输入框中,点击“保存网址”
第 2 步:创建翻页循环
1)打开右上角的“进程”。点击页面文章搜索框,在右侧操作提示框中选择“输入文字”
2)输入您要搜索的文章信息,这里以搜索“优采云大数据”为例,输入完成后点击“确定”按钮
3)“优采云大数据”会自动填写搜索框,点击“search文章”按钮,在操作提示框中选择“点击此按钮”
“优采云大数据”的文章搜索结果出现在4)页面上。将结果页下拉至底部,点击“下一页”按钮,在右侧操作提示框中选择“循环点击下一页”
第 3 步:创建一个列表循环并提取数据
1)移动鼠标选择页面上的第一个文章块。系统将识别此块中的子元素。在操作提示框中选择“选择子元素”
2)继续选择页面第二篇文章文章的区块,系统会自动选择第二篇文章文章的子元素,并识别页面其他10组相似元素, 在操作提示框中,选择“全选”
3) 我们可以看到页面上文章块中的所有元素都被选中并变成了绿色。在右侧的操作提示框中,会出现一个字段预览表。将鼠标移动到表头并单击垃圾桶图标以删除不需要的字段。字段选择完成后,选择“采集以下数据”
4) 由于我们还想要每个采集文章的URL,所以我们需要再提取一个字段。点击第一篇文章文章的链接,再点击第二篇文章文章的链接,系统会自动在页面上选择一组文章链接。在右侧的操作提示框中选择“采集以下链接地址”
5)字段选择完成后,选择对应的字段,自定义字段的命名。完成后点击左上角的“保存并开始”开始采集task
6)选择“启动本地采集”
第四步:数据采集并导出
1)采集完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,导出采集好搜狗微信文章的数据
2)这里我们选择excel作为导出格式,导出数据如下图
通过关键词采集文章采集api(百度站长平台原创提交工具下载使用百度原创工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-08-31 13:05
百度站长平台原创提交工具是一款可以帮助站长朋友提交到百度站长平台原创的工具,下载并使用这个百度原创提交工具可以让你的原创内容得到有效保护,立即下载并使用这个百度原创提交者。
百度站长平台是全球最大的面向中国互联网管理者、移动开发者和创业者的搜索流量管理官方平台。提供提交和分析工具,帮助搜索引擎捕捉收录、SEO优化建议等;为移动开发者提供百度官方API接口,以及多端适配能力和服务;及时发布百度权威数据和算法、工具等升级推送新信息。通过多种线上线下互动渠道,在为互联网多终端运营商增加用户和流量的同时,也为海量用户创造更好的搜索体验,携手双方共同打造移动时代的绿色搜索生态互联网。
软件功能
1.[更容易成为百度收录] 大量推送希望收录的数据到百度,网站会更容易成为百度收录,无论是添加还是删除数据,它百度知道的会更快。
2.【百度官方数据】在百度上查询网站的准确数据,方便分析网站的流量是否异常,搜索引擎是否友好。
3.【搜索结果个性化展示】通过使用站点子链、官网图、结构化数据等工具,网站可以在百度搜索结果页面更加个性化展示,获取更多交通。
4.【流量异常快速反馈】通过反馈中心快速反馈网站问题,随时跟踪进度,快速解决。
5.【新闻源申请与管理】信息站点或频道可在站长平台申请加入新闻源。新闻源站可以通过站长平台了解收录,反馈问题,接收相关新闻提醒。
6.【App和搜索流量打通】移动开发者可以通过AppLink等产品将搜索用户转化为自己的用户,打破App的封闭性,更容易获取用户。 查看全部
通过关键词采集文章采集api(百度站长平台原创提交工具下载使用百度原创工具)
百度站长平台原创提交工具是一款可以帮助站长朋友提交到百度站长平台原创的工具,下载并使用这个百度原创提交工具可以让你的原创内容得到有效保护,立即下载并使用这个百度原创提交者。
百度站长平台是全球最大的面向中国互联网管理者、移动开发者和创业者的搜索流量管理官方平台。提供提交和分析工具,帮助搜索引擎捕捉收录、SEO优化建议等;为移动开发者提供百度官方API接口,以及多端适配能力和服务;及时发布百度权威数据和算法、工具等升级推送新信息。通过多种线上线下互动渠道,在为互联网多终端运营商增加用户和流量的同时,也为海量用户创造更好的搜索体验,携手双方共同打造移动时代的绿色搜索生态互联网。
软件功能
1.[更容易成为百度收录] 大量推送希望收录的数据到百度,网站会更容易成为百度收录,无论是添加还是删除数据,它百度知道的会更快。
2.【百度官方数据】在百度上查询网站的准确数据,方便分析网站的流量是否异常,搜索引擎是否友好。
3.【搜索结果个性化展示】通过使用站点子链、官网图、结构化数据等工具,网站可以在百度搜索结果页面更加个性化展示,获取更多交通。
4.【流量异常快速反馈】通过反馈中心快速反馈网站问题,随时跟踪进度,快速解决。
5.【新闻源申请与管理】信息站点或频道可在站长平台申请加入新闻源。新闻源站可以通过站长平台了解收录,反馈问题,接收相关新闻提醒。
6.【App和搜索流量打通】移动开发者可以通过AppLink等产品将搜索用户转化为自己的用户,打破App的封闭性,更容易获取用户。
通过关键词采集文章采集api(讲讲等境外社交数据采集的新姿势→(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-08-31 07:01
在《Facebook、Twitter、YouTube、Ins等海外社交数据采集新姿势→》一文中,我们介绍了海外社交数据的主要采集场景和采集方式。
另外,一定有很多你关心的、想详细了解的问题。本文将结合与客户合作过程中的经验,详细讲解海外社交数据采集的一些问题。
问题清单:
01 所有海外社交网络网站采集都可以吗?
02 网站 是所有可用的数据采集吗?
03 你能采集所有历史数据吗?
04 是否可以实现对新增数据的实时采集?
05 如何稳定采集海外社交数据?
06采集到达的数据能否实时导出?
07 支持哪些类型的交付?
08 从确定需求到上线交付需要多长时间?
01 所有海外社交网络网站采集都可以吗?
是的。只要能正常访问的网站,就可以使用优采云quick采集。包括但不限于 Twitter、Facebook、YouTube、Instagram、LinkedIn、Pinterest、Google+、Tumblr、VK、Flickr、MySpace、Tagged、Ask.fm、Meetup 等。
不过有些网站防采集比较严格,自己试试采集容易出问题。如果您有采集海外社交数据需求,建议联系优采云官网()客服协助您进行采集测试。
02 网站 是所有可用的数据采集吗?
是的。 网站默认显示的数据,或者登录/点击等交互后显示的数据,都可以是采集。
Twitter、Facebook、YouTube、Instagram等社交网站虽然主要内容形式不同,但都属于社交媒体平台,其庞大的结构和功能都比较相似。 采集场景也有很多共性,最常见的采集场景的三种类型是:
① 指定账号采集下更新的推文/图片/视频;
②特定关键词采集的实时搜索结果;
③ 在推文/图片/视频下评论采集。
03 你能采集所有历史数据吗?
需要根据网页的情况来分析。有些网站可以看到所有的历史数据,你可以采集。有的网站只显示某段时间的数据,有的则隐藏,不能采集。
和推特首页一样,瀑布流加载新数据(向下滚动加载新数据),滚动不限次数,无法查看之前发布的所有历史数据。如果需要历史数据,可以从现在开始,定时更新数据多次采集,不断积累。
04 是否可以实现对新增数据的实时采集?
是的。 优采云专属cloud采集,支持灵活定时策略设置,采用分布式云采集方式,可在极短时间内完成采集多个海外社交数据源的数据更新。
例如,我们有一位客户需要在采集Twitter 上实时更新 3000 多个指定帐户的推文。怎么做首先将3000+账号按照更新频率分组,然后合理分配云节点采集每个组,最后帮助客户实现3000+的实时采集用于更新数据的数据源。
05 如何稳定采集海外社交数据?
在进行海外社交数据采集时,我们可能会遇到以下稳定性问题: ①部分网站需要特定国家/地区IP才能访问; ②采集数据量大时可能会遇到IP阻塞; ③ 存在云节点宕机、数据泄露的情况。
相应地,我们采取了一系列措施来有效解决上述问题: ①购买海外云集群,使用大量海外云节点访问和采集数据; ② 支持导入不同国家的优质IP,然后根据IP采集数据接入合并; ③ 在云端搭建监控系统,一旦节点停止挖矿,数据泄露会及时报警。
06采集到达的数据能否实时导出?
是的。 优采云提供高负载、高吞吐量的API接口,可以秒级将采集结果同步到企业数据库或内部系统。
除了API的使用,还有定时自动存储功能,无需技术人员即可实现数据的自动存储。目前支持SqlServer、MySql、Oracle 三种数据库。
07 支持哪些类型的交付?
我们提供各种交付方式,例如 SaaS 软件、私有化部署和数据服务。
SaaS软件:购买优采云SaaS软件,用于海外社交数据采集。
私有化部署:将优采云软件部署到企业服务器,支持二次开发,数据安全性极高,可与企业业务系统高度集成。
数据服务:数据直送,包括数据采集、数据清洗到数据导出等一站式数据服务。
08 从确认需求到上线发货需要多长时间?
需要根据你的需求具体评估,但总体来说还是很快的。
整个流程主要是确认需求→集中检测→采购事宜→在线发货→售后支持。我们会有一对一的专属客户经理跟进,确保每个环节的顺利进行。
比较耗时的部分是密集测试,包括制定采集规则,测试采集效果等任务。由于很好地服务了类似需求的客户,积累了大量海外社交网站采集规则和采集模板,可以直接投入测试,项目进度比较快。我们已经帮助创业团队在5天内完成了4个网站近30+采集任务在Twitter、Facebook、YouTube和Instagram上的任务创建和测试,并协助他们的项目快速上线。
以上是进行海外社交数据采集时最常见的一些问题。
想了解更多,请咨询我们的客服~ 查看全部
通过关键词采集文章采集api(讲讲等境外社交数据采集的新姿势→(二))
在《Facebook、Twitter、YouTube、Ins等海外社交数据采集新姿势→》一文中,我们介绍了海外社交数据的主要采集场景和采集方式。
另外,一定有很多你关心的、想详细了解的问题。本文将结合与客户合作过程中的经验,详细讲解海外社交数据采集的一些问题。
问题清单:
01 所有海外社交网络网站采集都可以吗?
02 网站 是所有可用的数据采集吗?
03 你能采集所有历史数据吗?
04 是否可以实现对新增数据的实时采集?
05 如何稳定采集海外社交数据?
06采集到达的数据能否实时导出?
07 支持哪些类型的交付?
08 从确定需求到上线交付需要多长时间?
01 所有海外社交网络网站采集都可以吗?
是的。只要能正常访问的网站,就可以使用优采云quick采集。包括但不限于 Twitter、Facebook、YouTube、Instagram、LinkedIn、Pinterest、Google+、Tumblr、VK、Flickr、MySpace、Tagged、Ask.fm、Meetup 等。
不过有些网站防采集比较严格,自己试试采集容易出问题。如果您有采集海外社交数据需求,建议联系优采云官网()客服协助您进行采集测试。
02 网站 是所有可用的数据采集吗?
是的。 网站默认显示的数据,或者登录/点击等交互后显示的数据,都可以是采集。
Twitter、Facebook、YouTube、Instagram等社交网站虽然主要内容形式不同,但都属于社交媒体平台,其庞大的结构和功能都比较相似。 采集场景也有很多共性,最常见的采集场景的三种类型是:
① 指定账号采集下更新的推文/图片/视频;
②特定关键词采集的实时搜索结果;
③ 在推文/图片/视频下评论采集。
03 你能采集所有历史数据吗?
需要根据网页的情况来分析。有些网站可以看到所有的历史数据,你可以采集。有的网站只显示某段时间的数据,有的则隐藏,不能采集。
和推特首页一样,瀑布流加载新数据(向下滚动加载新数据),滚动不限次数,无法查看之前发布的所有历史数据。如果需要历史数据,可以从现在开始,定时更新数据多次采集,不断积累。
04 是否可以实现对新增数据的实时采集?
是的。 优采云专属cloud采集,支持灵活定时策略设置,采用分布式云采集方式,可在极短时间内完成采集多个海外社交数据源的数据更新。
例如,我们有一位客户需要在采集Twitter 上实时更新 3000 多个指定帐户的推文。怎么做首先将3000+账号按照更新频率分组,然后合理分配云节点采集每个组,最后帮助客户实现3000+的实时采集用于更新数据的数据源。
05 如何稳定采集海外社交数据?
在进行海外社交数据采集时,我们可能会遇到以下稳定性问题: ①部分网站需要特定国家/地区IP才能访问; ②采集数据量大时可能会遇到IP阻塞; ③ 存在云节点宕机、数据泄露的情况。
相应地,我们采取了一系列措施来有效解决上述问题: ①购买海外云集群,使用大量海外云节点访问和采集数据; ② 支持导入不同国家的优质IP,然后根据IP采集数据接入合并; ③ 在云端搭建监控系统,一旦节点停止挖矿,数据泄露会及时报警。
06采集到达的数据能否实时导出?
是的。 优采云提供高负载、高吞吐量的API接口,可以秒级将采集结果同步到企业数据库或内部系统。
除了API的使用,还有定时自动存储功能,无需技术人员即可实现数据的自动存储。目前支持SqlServer、MySql、Oracle 三种数据库。
07 支持哪些类型的交付?
我们提供各种交付方式,例如 SaaS 软件、私有化部署和数据服务。
SaaS软件:购买优采云SaaS软件,用于海外社交数据采集。
私有化部署:将优采云软件部署到企业服务器,支持二次开发,数据安全性极高,可与企业业务系统高度集成。
数据服务:数据直送,包括数据采集、数据清洗到数据导出等一站式数据服务。
08 从确认需求到上线发货需要多长时间?
需要根据你的需求具体评估,但总体来说还是很快的。
整个流程主要是确认需求→集中检测→采购事宜→在线发货→售后支持。我们会有一对一的专属客户经理跟进,确保每个环节的顺利进行。
比较耗时的部分是密集测试,包括制定采集规则,测试采集效果等任务。由于很好地服务了类似需求的客户,积累了大量海外社交网站采集规则和采集模板,可以直接投入测试,项目进度比较快。我们已经帮助创业团队在5天内完成了4个网站近30+采集任务在Twitter、Facebook、YouTube和Instagram上的任务创建和测试,并协助他们的项目快速上线。
以上是进行海外社交数据采集时最常见的一些问题。
想了解更多,请咨询我们的客服~
通过关键词采集文章采集api(【每日一题】网页源代码的案例教程(二) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-08-30 23:13
)
内容
前言
大家好,我叫山念。
这是我的第二篇博客,也是第一个技术博客。希望大家多多支持,让我更有动力更新一些python爬虫案例教程。
开始
建立目标网址:点击进入
进入跳转页面:
你可以看到我们需要一些音乐
分析(x0)
这些音乐的源文件地址是否在我们的网页元素中,然后检查网页源代码中是否收录我们需要的内容。 (注:网页元素和网页源代码不一定相同。网页元素是浏览器渲染的源代码,源代码纯粹是服务器发送给我们的原创数据)
网页元素中只有封面图片的资源,不使用音频源文件地址:
网页的源代码中也没有我们需要的东西:
分析(x1)
其实没有也很正常(网站这么大的数据不会让你这么轻易就抢到了.....只是带大家走一遍流程,分析其他网站这样的
那我们开始播放音乐来抓包,看看能不能抓到数据:
果然,在播放按钮被触发后,服务器将其发送给我们的客户端。 (阿贾克斯)
还有我们抓到的源文件地址
除了这两个段落,其他的都应该修复。
分析(x2)
然后我假设这两个段落是我第一次访问这首歌的页面时生成的。比如这首音乐在服务器数据库中的ID值是多少?
假设是合理的,但由于我们已经检查了源代码并且网页元素找不到这些值,我不会在这里浪费时间。
分析(x3)
这里告诉你,我们向服务器发送一个URL请求,服务器返回给我们的数据包不止一个,一般是N个数据包。当我们看到没有源代码时,可能是通过ajax悄悄传递给我们的?
Ajax 网上有很多解释,但大家可能看不懂。从服务器获取源代码数据,然后执行JavaScript通过浏览器渲染获取一些数据(音乐)。
这样大家应该就明白了,接下来我们开始抓取当前页面的包:
Ajax 异步请求数据将在 XHR 中。所以直接过滤就好了。我抓到了这个包,获取请求并查看返回值。
果然这个包数据都是对应的,那就打开看看里面有没有音乐源文件地址:
没有,但是出现了两次。
分析(x4)
那是我们音乐的ID(index)值吗?
看下面的包:
这个get请求很重要,它在参数中使用了我们的rid值
而他的返回值恰好有我们的音乐源文件地址:
通过分析获取音乐
通过我们的分析,我们可以理清思路。
先抓住这个包裹摆脱
然后通过rid来请求这个包获取音乐文件地址
JavaScript 绕过参数冗余
可以看到这个rid得到的地址中的key值是经过url编码的,很容易解码:
import requests
keywords = '%E5%BE%80%E4%BA%8B%E9%9A%8F%E9%A3%8E'
print(requests.utils.unquote(keywords))
# 往事随风
而pn=1表示第一页,30表示本页共有30首音乐数据,1表示状态码请求成功,最后如何获取reqId的值?
如果你有逆向JavaScript的能力,我们把这里的参数全部删掉,我们也可以访问我们的rid。为什么?
当您访问百度时
可以看到有很多你看不懂的多余参数,这些参数其实可以直接删除!
结果是一样的,这就是所谓的参数冗余。
CSRF攻防
当我们直接访问这个链接时,会出现这个画面吗?
而如果我们把所有的请求头都放在我们的pycharm中,用Python模拟发送请求,就可以成功(自测)
可以看到请求中有一个参数叫csrf,叫做反跨站攻击。
这很容易理解。当我们直接用浏览器访问时,虽然可以带cookies,但是不能带这个参数。而当我们完整复制请求头,在pycharm中用Python运行时,我们可以携带这个参数,然后就可以访问了。
目的是为了保护这个api,防止在任何情况下被随意访问。
这个 csrf 参数不是我们 cookie 中的值吗?那么我们需要先获取cookie吗?因为cookies会过期,为了让你的程序永远有效,那么最好的办法就是自动获取cookies
总结
那么所有的原理就可以想通了
先访问首页获取cookies,然后绕过JavaScript删除多余的参数进行摆脱,最后通过rid访问获取音乐源地址(这里的参数也可以删除),最后保存数据!
全程干货,解析网站反拔手段,Python采集全站任乐!
代码
"""
author: 善念
date: 2021-04-12
"""
import requests
import jsonpath
from urllib.request import urlretrieve
import urllib.parse
def get_csrf():
# 保持cookies 维持客户端与服务器之间的会话
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1618229629; _ga=GA1.2.1951895595.1618229638; _gid=GA1.2.369506281.1618229638; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1618230532; kw_token=ZOMA0RIOLV',
'Host': 'www.kuwo.cn',
'Pragma': 'no-cache',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
}
s.get('http://www.kuwo.cn/', headers=headers)
url = f'http://www.kuwo.cn/api/www/sea ... ey%3D{keyword}&pn=1&rn=30&httpsStatus=1&reqId=a3b6cb30-9b8a-11eb-bc04-b33703ed2ebb'
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1618229629; _ga=GA1.2.1951895595.1618229638; _gid=GA1.2.369506281.1618229638; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1618229710; kw_token=UTBATXE1HY',
'csrf': s.cookies.get_dict()['kw_token'],
'Host': 'www.kuwo.cn',
'Pragma': 'no-cache',
'Referer': f'http://www.kuwo.cn/search/list?key={keyword}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
}
r = s.get(url, headers=headers)
print(r.text)
rid = jsonpath.jsonpath(r.json(), '$..rid')[0]
print(rid)
return rid
def get_music_url(rid):
url = f'http://www.kuwo.cn/url?format=mp3&rid={rid}&response=url&type=convert_url3&br=128kmp3&from=web&httpsStatus=1'
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1618231398; _ga=GA1.2.52993118.1618231399; _gid=GA1.2.889494894.1618231399; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1618231413; _gat=1; kw_token=VBM6N1XEG4P',
'Host': 'www.kuwo.cn',
'Pragma': 'no-cache',
'Referer': f'http://www.kuwo.cn/search/list?key={keyword}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
}
music_url = s.get(url, headers=headers).json().get('url')
print(music_url)
return music_url
def get_music(music_url):
urlretrieve(music_url, f'{urllib.parse.unquote(keyword)}'+'.mp3')
def go():
rid = get_csrf()
music_url = get_music_url(rid)
get_music(music_url)
if __name__ == '__main__':
s = requests.session()
keyword = input('请输入您要下载的音乐名字:')
keyword = urllib.parse.quote(keyword)
go()
文章到此结束,感谢阅读,但我想对读者说几句。
emmmmm今天无话可说——我心里没有女人,代码自然☺
查看全部
通过关键词采集文章采集api(【每日一题】网页源代码的案例教程(二)
)
内容
前言
大家好,我叫山念。
这是我的第二篇博客,也是第一个技术博客。希望大家多多支持,让我更有动力更新一些python爬虫案例教程。
开始
建立目标网址:点击进入
进入跳转页面:
你可以看到我们需要一些音乐
分析(x0)
这些音乐的源文件地址是否在我们的网页元素中,然后检查网页源代码中是否收录我们需要的内容。 (注:网页元素和网页源代码不一定相同。网页元素是浏览器渲染的源代码,源代码纯粹是服务器发送给我们的原创数据)
网页元素中只有封面图片的资源,不使用音频源文件地址:
网页的源代码中也没有我们需要的东西:
分析(x1)
其实没有也很正常(网站这么大的数据不会让你这么轻易就抢到了.....只是带大家走一遍流程,分析其他网站这样的
那我们开始播放音乐来抓包,看看能不能抓到数据:
果然,在播放按钮被触发后,服务器将其发送给我们的客户端。 (阿贾克斯)
还有我们抓到的源文件地址
除了这两个段落,其他的都应该修复。
分析(x2)
然后我假设这两个段落是我第一次访问这首歌的页面时生成的。比如这首音乐在服务器数据库中的ID值是多少?
假设是合理的,但由于我们已经检查了源代码并且网页元素找不到这些值,我不会在这里浪费时间。
分析(x3)
这里告诉你,我们向服务器发送一个URL请求,服务器返回给我们的数据包不止一个,一般是N个数据包。当我们看到没有源代码时,可能是通过ajax悄悄传递给我们的?
Ajax 网上有很多解释,但大家可能看不懂。从服务器获取源代码数据,然后执行JavaScript通过浏览器渲染获取一些数据(音乐)。
这样大家应该就明白了,接下来我们开始抓取当前页面的包:
Ajax 异步请求数据将在 XHR 中。所以直接过滤就好了。我抓到了这个包,获取请求并查看返回值。
果然这个包数据都是对应的,那就打开看看里面有没有音乐源文件地址:
没有,但是出现了两次。
分析(x4)
那是我们音乐的ID(index)值吗?
看下面的包:
这个get请求很重要,它在参数中使用了我们的rid值
而他的返回值恰好有我们的音乐源文件地址:
通过分析获取音乐
通过我们的分析,我们可以理清思路。
先抓住这个包裹摆脱
然后通过rid来请求这个包获取音乐文件地址
JavaScript 绕过参数冗余
可以看到这个rid得到的地址中的key值是经过url编码的,很容易解码:
import requests
keywords = '%E5%BE%80%E4%BA%8B%E9%9A%8F%E9%A3%8E'
print(requests.utils.unquote(keywords))
# 往事随风
而pn=1表示第一页,30表示本页共有30首音乐数据,1表示状态码请求成功,最后如何获取reqId的值?
如果你有逆向JavaScript的能力,我们把这里的参数全部删掉,我们也可以访问我们的rid。为什么?
当您访问百度时
可以看到有很多你看不懂的多余参数,这些参数其实可以直接删除!
结果是一样的,这就是所谓的参数冗余。
CSRF攻防
当我们直接访问这个链接时,会出现这个画面吗?
而如果我们把所有的请求头都放在我们的pycharm中,用Python模拟发送请求,就可以成功(自测)
可以看到请求中有一个参数叫csrf,叫做反跨站攻击。
这很容易理解。当我们直接用浏览器访问时,虽然可以带cookies,但是不能带这个参数。而当我们完整复制请求头,在pycharm中用Python运行时,我们可以携带这个参数,然后就可以访问了。
目的是为了保护这个api,防止在任何情况下被随意访问。
这个 csrf 参数不是我们 cookie 中的值吗?那么我们需要先获取cookie吗?因为cookies会过期,为了让你的程序永远有效,那么最好的办法就是自动获取cookies
总结
那么所有的原理就可以想通了
先访问首页获取cookies,然后绕过JavaScript删除多余的参数进行摆脱,最后通过rid访问获取音乐源地址(这里的参数也可以删除),最后保存数据!
全程干货,解析网站反拔手段,Python采集全站任乐!
代码
"""
author: 善念
date: 2021-04-12
"""
import requests
import jsonpath
from urllib.request import urlretrieve
import urllib.parse
def get_csrf():
# 保持cookies 维持客户端与服务器之间的会话
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1618229629; _ga=GA1.2.1951895595.1618229638; _gid=GA1.2.369506281.1618229638; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1618230532; kw_token=ZOMA0RIOLV',
'Host': 'www.kuwo.cn',
'Pragma': 'no-cache',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
}
s.get('http://www.kuwo.cn/', headers=headers)
url = f'http://www.kuwo.cn/api/www/sea ... ey%3D{keyword}&pn=1&rn=30&httpsStatus=1&reqId=a3b6cb30-9b8a-11eb-bc04-b33703ed2ebb'
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1618229629; _ga=GA1.2.1951895595.1618229638; _gid=GA1.2.369506281.1618229638; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1618229710; kw_token=UTBATXE1HY',
'csrf': s.cookies.get_dict()['kw_token'],
'Host': 'www.kuwo.cn',
'Pragma': 'no-cache',
'Referer': f'http://www.kuwo.cn/search/list?key={keyword}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
}
r = s.get(url, headers=headers)
print(r.text)
rid = jsonpath.jsonpath(r.json(), '$..rid')[0]
print(rid)
return rid
def get_music_url(rid):
url = f'http://www.kuwo.cn/url?format=mp3&rid={rid}&response=url&type=convert_url3&br=128kmp3&from=web&httpsStatus=1'
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1618231398; _ga=GA1.2.52993118.1618231399; _gid=GA1.2.889494894.1618231399; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1618231413; _gat=1; kw_token=VBM6N1XEG4P',
'Host': 'www.kuwo.cn',
'Pragma': 'no-cache',
'Referer': f'http://www.kuwo.cn/search/list?key={keyword}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
}
music_url = s.get(url, headers=headers).json().get('url')
print(music_url)
return music_url
def get_music(music_url):
urlretrieve(music_url, f'{urllib.parse.unquote(keyword)}'+'.mp3')
def go():
rid = get_csrf()
music_url = get_music_url(rid)
get_music(music_url)
if __name__ == '__main__':
s = requests.session()
keyword = input('请输入您要下载的音乐名字:')
keyword = urllib.parse.quote(keyword)
go()
文章到此结束,感谢阅读,但我想对读者说几句。
emmmmm今天无话可说——我心里没有女人,代码自然☺
通过关键词采集文章采集api(发送图片微博、更新用户资料与头像、API自动授权)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-08-29 10:14
5、发送图片到微博,更新用户信息和头像,API自动授权
二、博客平台:
1、博客管理,轻松搞定
2、各大博客平台(BSP)从注册到激活自动完成
3、 将您的博文同步发送至所有博客平台,多博客维护从此轻松自在
4、关键词管理将相关词汇添加到您设置的超链接中以改进网站外链
三、portal 社区:
1、阳光门网站发帖准确到二级栏目,在线推广,准确有效
2、多条内容随机回复,随机词组自由组合
3、指定帖子回复,专业抢沙发,批量马甲制作
4、猫扑、天涯、新浪、腾讯、网易、搜狐等都支持
四、综合论坛:
1、内置网址,海量论坛
2、cloud 上万个网址库,随时更新与同步
3、用户网址库无限空间,无限导入
4、Forum 采集工具,让整个互联网论坛都可以加载到网址库中
5、Intelligent A power,模式码识别,注册问答识别
6、plug-in,补丁修改,论坛任务自动处理
五、问答平台:
1、我发现问题并准确回答
2、根据关键字搜索任何领域未解答的问题
3、精准匹配系统,回复并给出正确答案,答案就是你所问
4、多题分批提问,多题自答
商科推广专家软件功能
一、信息发布功能
二、信息搜索功能
三、群发邮件功能
四、邮件采集功能
五、Engine 登录及增强排名功能
六、繁-简体自动转换
七、生成交付报告
八、发布成功率高
九、自动保存功能
十、网站推荐功能
十一、设置维护功能
十二、自动在线升级 查看全部
通过关键词采集文章采集api(发送图片微博、更新用户资料与头像、API自动授权)
5、发送图片到微博,更新用户信息和头像,API自动授权
二、博客平台:
1、博客管理,轻松搞定
2、各大博客平台(BSP)从注册到激活自动完成
3、 将您的博文同步发送至所有博客平台,多博客维护从此轻松自在
4、关键词管理将相关词汇添加到您设置的超链接中以改进网站外链
三、portal 社区:
1、阳光门网站发帖准确到二级栏目,在线推广,准确有效
2、多条内容随机回复,随机词组自由组合
3、指定帖子回复,专业抢沙发,批量马甲制作
4、猫扑、天涯、新浪、腾讯、网易、搜狐等都支持
四、综合论坛:
1、内置网址,海量论坛
2、cloud 上万个网址库,随时更新与同步
3、用户网址库无限空间,无限导入
4、Forum 采集工具,让整个互联网论坛都可以加载到网址库中
5、Intelligent A power,模式码识别,注册问答识别
6、plug-in,补丁修改,论坛任务自动处理
五、问答平台:
1、我发现问题并准确回答
2、根据关键字搜索任何领域未解答的问题
3、精准匹配系统,回复并给出正确答案,答案就是你所问
4、多题分批提问,多题自答
商科推广专家软件功能
一、信息发布功能
二、信息搜索功能
三、群发邮件功能
四、邮件采集功能
五、Engine 登录及增强排名功能
六、繁-简体自动转换
七、生成交付报告
八、发布成功率高
九、自动保存功能
十、网站推荐功能
十一、设置维护功能
十二、自动在线升级

