
通过关键词采集文章采集api
通过关键词采集文章采集api(通过关键词采集文章采集api开发者自己用api接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-14 12:02
通过关键词采集文章采集api开发者自己用api接口是最简单的办法,但是需要定期维护。其实还有更快捷的方法,那就是创建一个爬虫程序,让你的爬虫直接连接一个网站的网页源代码,然后收集网页中的文章,这样不需要定期维护,爬虫用起来也方便快捷。比如你有一个专门抓wordpress文章的爬虫。假设你通过javascript加载当前页面的源代码,比如你采用的是post请求:。
1、使用post请求进行网页源代码抓取
2、使用http请求连接到post请求,
3、目标网站发给你一个验证码,
4、爬虫下载源代码,然后把源代码填充到你的爬虫代码中去即可。这是一个分布式爬虫的应用,你可以想一想把你需要抓取的网页分成n个爬虫来爬:这是一个分布式爬虫的应用(感谢崔晓峰),你可以想一想把你需要抓取的网页分成n个爬虫来爬:这就是所谓的集群技术,采用的是一种广义的分布式爬虫框架,因为这个爬虫通过api进行的。
可以让你的爬虫同时抓取几万几十万甚至上百万的网页,这还不包括后面的一次下载的步骤。其实我们还可以这样:我们可以把这个集群分为很多个环节,第一个环节是采集html内容;接下来是发布文章,发布后传输给爬虫爬取;接下来是发布第二个爬虫;第三个是抓取其他网站的内容;第四个是下载源代码。不断的循环。这样的话,最后只要存储你的文章就可以了,有人有兴趣就接着抓取其他网站的内容,反正每个爬虫用起来很方便,也不需要每个爬虫都定期维护更新。
同时这也带来了一个额外的好处,比如可以保证每个爬虫对应一篇新文章。比如抓取了一篇,又抓取了更多。并且可以让爬虫处理的文章量比较多的时候,你可以把爬虫延伸到一起,做一个小站。实际上做到这一步,每个爬虫可以抓取n篇,一篇都不需要更新。比如我接下来抓取某网站的文章,那么我可以把那个网站的所有文章,都发布出去,比如这篇:采用爬虫之后,你可以发布出来的文章可以是:对于爬虫有更多的需求,也可以搞一些工具比如zigbee爬虫工具、apiquest工具等等。 查看全部
通过关键词采集文章采集api(通过关键词采集文章采集api开发者自己用api接口)
通过关键词采集文章采集api开发者自己用api接口是最简单的办法,但是需要定期维护。其实还有更快捷的方法,那就是创建一个爬虫程序,让你的爬虫直接连接一个网站的网页源代码,然后收集网页中的文章,这样不需要定期维护,爬虫用起来也方便快捷。比如你有一个专门抓wordpress文章的爬虫。假设你通过javascript加载当前页面的源代码,比如你采用的是post请求:。
1、使用post请求进行网页源代码抓取
2、使用http请求连接到post请求,
3、目标网站发给你一个验证码,
4、爬虫下载源代码,然后把源代码填充到你的爬虫代码中去即可。这是一个分布式爬虫的应用,你可以想一想把你需要抓取的网页分成n个爬虫来爬:这是一个分布式爬虫的应用(感谢崔晓峰),你可以想一想把你需要抓取的网页分成n个爬虫来爬:这就是所谓的集群技术,采用的是一种广义的分布式爬虫框架,因为这个爬虫通过api进行的。
可以让你的爬虫同时抓取几万几十万甚至上百万的网页,这还不包括后面的一次下载的步骤。其实我们还可以这样:我们可以把这个集群分为很多个环节,第一个环节是采集html内容;接下来是发布文章,发布后传输给爬虫爬取;接下来是发布第二个爬虫;第三个是抓取其他网站的内容;第四个是下载源代码。不断的循环。这样的话,最后只要存储你的文章就可以了,有人有兴趣就接着抓取其他网站的内容,反正每个爬虫用起来很方便,也不需要每个爬虫都定期维护更新。
同时这也带来了一个额外的好处,比如可以保证每个爬虫对应一篇新文章。比如抓取了一篇,又抓取了更多。并且可以让爬虫处理的文章量比较多的时候,你可以把爬虫延伸到一起,做一个小站。实际上做到这一步,每个爬虫可以抓取n篇,一篇都不需要更新。比如我接下来抓取某网站的文章,那么我可以把那个网站的所有文章,都发布出去,比如这篇:采用爬虫之后,你可以发布出来的文章可以是:对于爬虫有更多的需求,也可以搞一些工具比如zigbee爬虫工具、apiquest工具等等。
通过关键词采集文章采集api(一下zblog插件采集方式(一)(1)_国内_光明网(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-01-14 04:13
Zblog采集插件是为了帮助网站快速丰富网站内容;减少手动发布内容的繁琐;主要是给网站添加很多内容,方便快捷。网站发布文章的时候,如果把文章一一发布到网上,不仅浪费时间,而且效率低下。这时候为了提高更新网站的效率,出现了zblog采集插件,但是常规的zblog插件都需要写规则。今天博主就来说说zblog插件采集方法:一是付费插件,需要写规则,二是免费工具,不需要写规则!
Zblog采集规则编写简介
第 1 步:创建一个新的 文章采集 节点
登录后台,点击采集>>采集节点管理>>添加新节点>>选择普通文章>>确定
第二步:填写采集列表规则
1.节点名:随便
2.查看目标页面的编码:查看目标页面的编码
3.匹配网址:进入采集目标列表页面查看其列表规则!比如很多网站列表的首页与其他内页有很大的不同,所以我一般不会采集定位列表的首页!
最好从第二页开始(虽然可以找到第一页,但是很多网站根本没有第一页,这里就不讲怎么找到第一页了)
4. 区域末尾的 HTML:在 采集 目标列表页面上打开源代码!在 文章 的标题附近寻找一个 html 标记,该标记将是 采集,并且对于该页面和其他将是 采集 的页面来说是唯一的!
写好后点击保存信息,进入下一步!如果规则编写正确,那么这些将出现一个带有内容的 URL 获取规则测试
再按下一步!回车填写采集内容规则
第三步:采集内容规则
1.文章标题:在文章标题前后找两个标签,即可识别标题!
2.文章内容:寻找文章内容前后的两个标签来识别内容!我的 采集 的 网站 的 文章 内容之前和之后的唯一标签是
…
全站人气 查看全部
通过关键词采集文章采集api(一下zblog插件采集方式(一)(1)_国内_光明网(组图))
Zblog采集插件是为了帮助网站快速丰富网站内容;减少手动发布内容的繁琐;主要是给网站添加很多内容,方便快捷。网站发布文章的时候,如果把文章一一发布到网上,不仅浪费时间,而且效率低下。这时候为了提高更新网站的效率,出现了zblog采集插件,但是常规的zblog插件都需要写规则。今天博主就来说说zblog插件采集方法:一是付费插件,需要写规则,二是免费工具,不需要写规则!

Zblog采集规则编写简介
第 1 步:创建一个新的 文章采集 节点
登录后台,点击采集>>采集节点管理>>添加新节点>>选择普通文章>>确定
第二步:填写采集列表规则
1.节点名:随便
2.查看目标页面的编码:查看目标页面的编码
3.匹配网址:进入采集目标列表页面查看其列表规则!比如很多网站列表的首页与其他内页有很大的不同,所以我一般不会采集定位列表的首页!

最好从第二页开始(虽然可以找到第一页,但是很多网站根本没有第一页,这里就不讲怎么找到第一页了)
4. 区域末尾的 HTML:在 采集 目标列表页面上打开源代码!在 文章 的标题附近寻找一个 html 标记,该标记将是 采集,并且对于该页面和其他将是 采集 的页面来说是唯一的!
写好后点击保存信息,进入下一步!如果规则编写正确,那么这些将出现一个带有内容的 URL 获取规则测试
再按下一步!回车填写采集内容规则
第三步:采集内容规则
1.文章标题:在文章标题前后找两个标签,即可识别标题!
2.文章内容:寻找文章内容前后的两个标签来识别内容!我的 采集 的 网站 的 文章 内容之前和之后的唯一标签是
…
全站人气
通过关键词采集文章采集api(不同设计关键词的几种方法,你都知道吗? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-01-13 11:21
)
1、了解用户的搜索习惯。从用户的角度来看,看看他们会搜索哪些术语来设计 关键词。
2、不要选择太冷太宽泛的词。确定最能描述网页内容的核心词并围绕它进行构建。
3、文字与内容更相关,因此用户的浏览体验更好。
4、你可以查看你的竞争对手的关键词,分析他们的排名,调整你的词汇策略。
5、如果你想省去麻烦,你可以简单地购买一些现有的行业词库,或者新的词库,然后根据各种数据进行选择。
二、监控关键词效果,及时调整策略
如果您的公司具有监控和分析数百万关键字影响的技术能力,则此步骤也是必要的。通过对关键词的监控,可以根据排名来安排关键词的分布。
特别是对于需要了解其品牌营销力的大网站。通常,他们使用关键词+公司名称,或关键词+网站域名来监控不同搜索引擎的排名。
这样不仅可以了解不同搜索引擎用户的搜索习惯,还可以了解自己品牌关键词的传播强度,根据排名及时调整关键词策略.
当然,人工、时间、硬件等成本也很高,尤其是更精准的部署,比如指定监控区域、限制高层数据量、监控周期等等。如果条件允许,第三方更容易做到这一点。
三、核心关键词生成大量内容
大网站编辑出版文章一个人,猴年马月我一定会做到的。过去,网站管理员会通过各种百科全书、书籍、CD 和其他方法来解决内容问题。之后,用户可以通过问答系统、论坛、专页等栏目,积极贡献长尾内容。
现在越来越多的方法被自动化,匹配多个网站与关键词,或者全网采集相关内容,自动提交和发布API,节省大量人工编辑时间。
更好的是,使用当天的新词,定期在网络上监控和采集它们,并在新内容出现时尽早将它们包括在内并进行排名。
随着当今越来越流行的人工智能技术,SEO的大部分工作在不久的将来应该会变得更加智能。如果您可以优化您的部署以主宰人工智能供您自己使用,网站 会做得更好。
四、注意动态简单分割线
拥有百万级别的页面和百万级别的长尾关键词排名是不现实的。仔细优化每个页面是不现实的。即使没有相关工具,也不可能知道哪个页面有哪个长尾关键词在哪个搜索引擎中排名。
其实很多年没见过这个词了,很多长尾词都列在最前面却被忽略了。一是关键词的积累不足,二是对所谓核心词的关注过多。这是他们最近与百度指数合作进行大数据定制后告诉我的。
从数据中可以看出,他们还帮助我找到了很多近几个月来运行良好的长尾术语。
五、再重复两句话。
1、SEO 必须对公司和行业的各种动态有所了解。
2、定期分析行业和竞争对手数据。
3、定期分析行业和竞争对手的数据。
除了监控对方的网站、关键词、出价数据,还可以多加关注。此外,它还可以从网站的栏目和功能分析用户和公司资源的需求。建议大量数据监控由第三方直接进行。甲方有时间和精力去部署更多的东西。
六、扩大品牌影响力
大网站除了自己的内容和优化,还需要做口碑营销。在公关层面,我们暂时不讨论这个问题。在网站的优化层面,我们可以监控公司名称、网站名称、搜索引擎排名等数据,了解用户的搜索行为。
七、构建可读的内容策略
网站 的内容会越来越大。不同需求的游客很容易迷路,也不容易找到想要的信息。SEO需要分析数据,观察每个版块或主题的吸引力,并在布局中突出显示满足主流用户需求的最佳信息。
事实上,大的网站并没有被搜索引擎完全保护。在算法方面,算法也不同程度地受到 K 的影响。但是,术语排名以百万为基数,这在某些数据表示中并不明显。搜索引擎优化的思维也在发生变化,要求我们更加敏感。
查看全部
通过关键词采集文章采集api(不同设计关键词的几种方法,你都知道吗?
)
1、了解用户的搜索习惯。从用户的角度来看,看看他们会搜索哪些术语来设计 关键词。
2、不要选择太冷太宽泛的词。确定最能描述网页内容的核心词并围绕它进行构建。
3、文字与内容更相关,因此用户的浏览体验更好。
4、你可以查看你的竞争对手的关键词,分析他们的排名,调整你的词汇策略。
5、如果你想省去麻烦,你可以简单地购买一些现有的行业词库,或者新的词库,然后根据各种数据进行选择。
二、监控关键词效果,及时调整策略
如果您的公司具有监控和分析数百万关键字影响的技术能力,则此步骤也是必要的。通过对关键词的监控,可以根据排名来安排关键词的分布。
特别是对于需要了解其品牌营销力的大网站。通常,他们使用关键词+公司名称,或关键词+网站域名来监控不同搜索引擎的排名。
这样不仅可以了解不同搜索引擎用户的搜索习惯,还可以了解自己品牌关键词的传播强度,根据排名及时调整关键词策略.
当然,人工、时间、硬件等成本也很高,尤其是更精准的部署,比如指定监控区域、限制高层数据量、监控周期等等。如果条件允许,第三方更容易做到这一点。
三、核心关键词生成大量内容
大网站编辑出版文章一个人,猴年马月我一定会做到的。过去,网站管理员会通过各种百科全书、书籍、CD 和其他方法来解决内容问题。之后,用户可以通过问答系统、论坛、专页等栏目,积极贡献长尾内容。
现在越来越多的方法被自动化,匹配多个网站与关键词,或者全网采集相关内容,自动提交和发布API,节省大量人工编辑时间。
更好的是,使用当天的新词,定期在网络上监控和采集它们,并在新内容出现时尽早将它们包括在内并进行排名。
随着当今越来越流行的人工智能技术,SEO的大部分工作在不久的将来应该会变得更加智能。如果您可以优化您的部署以主宰人工智能供您自己使用,网站 会做得更好。

四、注意动态简单分割线
拥有百万级别的页面和百万级别的长尾关键词排名是不现实的。仔细优化每个页面是不现实的。即使没有相关工具,也不可能知道哪个页面有哪个长尾关键词在哪个搜索引擎中排名。
其实很多年没见过这个词了,很多长尾词都列在最前面却被忽略了。一是关键词的积累不足,二是对所谓核心词的关注过多。这是他们最近与百度指数合作进行大数据定制后告诉我的。
从数据中可以看出,他们还帮助我找到了很多近几个月来运行良好的长尾术语。

五、再重复两句话。
1、SEO 必须对公司和行业的各种动态有所了解。
2、定期分析行业和竞争对手数据。
3、定期分析行业和竞争对手的数据。
除了监控对方的网站、关键词、出价数据,还可以多加关注。此外,它还可以从网站的栏目和功能分析用户和公司资源的需求。建议大量数据监控由第三方直接进行。甲方有时间和精力去部署更多的东西。

六、扩大品牌影响力
大网站除了自己的内容和优化,还需要做口碑营销。在公关层面,我们暂时不讨论这个问题。在网站的优化层面,我们可以监控公司名称、网站名称、搜索引擎排名等数据,了解用户的搜索行为。
七、构建可读的内容策略
网站 的内容会越来越大。不同需求的游客很容易迷路,也不容易找到想要的信息。SEO需要分析数据,观察每个版块或主题的吸引力,并在布局中突出显示满足主流用户需求的最佳信息。
事实上,大的网站并没有被搜索引擎完全保护。在算法方面,算法也不同程度地受到 K 的影响。但是,术语排名以百万为基数,这在某些数据表示中并不明显。搜索引擎优化的思维也在发生变化,要求我们更加敏感。

通过关键词采集文章采集api(免费Wordpress发布接口怎么使用?我不懂代码多久可以学会啊? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-01-13 09:19
)
Q:如何使用免费的WordPress发布界面?如果我不知道如何编码,我可以学习多长时间?
答:直接下载使用!无需知道代码!1分钟学会!
问:我每天可以发布多少 文章?支持哪些格式?
A:每天可发布数百万篇文章,支持任何格式!
Q:不同域名的Wordpress网站也可以发布吗?
回答:是的!创建一个新任务只需要大约 1 分钟!
Q:我可以设置每天发表多少篇文章吗?可以在指定版块发布吗?
回答:是的!一键设置,可以根据不同的栏目发布不同的文章
Q:除了wordpress网站发布,Zblogcms程序可以发布吗?
回答:是的!支持主要cms发布
问:太棒了!
A:是的,还有更多功能。
例如:采集→伪原创→发布(推送)
采集 :只需设置关键词根据关键词采集文章同时创建几十个或几百个采集任务,可以是设置过滤器关键词只采集与网站主题文章相关,并且软件配置了关键词自动生成工具,只需要进入核心关键词自动采集所有行业相关关键词,自动过滤与行业无关的词。
伪原创:伪原创采用AI智能大脑。NLG技术、RNN模型、百度人工智能算法的融合,严格符合百度、搜狗、360、Google等大型搜索引擎算法收录规则可在线通过伪原创@ >、本地伪原创或者API接口,使用伪原创会更好被搜索引擎收录收录。
templates原创degree) - 选择标题是否与插入的关键词一致(增加文章与主题行业的相关性)搜索引擎推送(发布后自动推送到搜索引擎< @文章 增加 文章 @网站收录)!同时,除了wordpresscms之外,还支持cms网站和伪原创8@>采集伪原创。
以上是小编使用wordpress工具创作的一批高流量网站,全部内容与主题相关!网站从未发生过降级!看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
查看全部
通过关键词采集文章采集api(免费Wordpress发布接口怎么使用?我不懂代码多久可以学会啊?
)
Q:如何使用免费的WordPress发布界面?如果我不知道如何编码,我可以学习多长时间?
答:直接下载使用!无需知道代码!1分钟学会!
问:我每天可以发布多少 文章?支持哪些格式?
A:每天可发布数百万篇文章,支持任何格式!
Q:不同域名的Wordpress网站也可以发布吗?
回答:是的!创建一个新任务只需要大约 1 分钟!
Q:我可以设置每天发表多少篇文章吗?可以在指定版块发布吗?
回答:是的!一键设置,可以根据不同的栏目发布不同的文章
Q:除了wordpress网站发布,Zblogcms程序可以发布吗?
回答:是的!支持主要cms发布

问:太棒了!
A:是的,还有更多功能。
例如:采集→伪原创→发布(推送)
采集 :只需设置关键词根据关键词采集文章同时创建几十个或几百个采集任务,可以是设置过滤器关键词只采集与网站主题文章相关,并且软件配置了关键词自动生成工具,只需要进入核心关键词自动采集所有行业相关关键词,自动过滤与行业无关的词。
伪原创:伪原创采用AI智能大脑。NLG技术、RNN模型、百度人工智能算法的融合,严格符合百度、搜狗、360、Google等大型搜索引擎算法收录规则可在线通过伪原创@ >、本地伪原创或者API接口,使用伪原创会更好被搜索引擎收录收录。
templates原创degree) - 选择标题是否与插入的关键词一致(增加文章与主题行业的相关性)搜索引擎推送(发布后自动推送到搜索引擎< @文章 增加 文章 @网站收录)!同时,除了wordpresscms之外,还支持cms网站和伪原创8@>采集伪原创。
以上是小编使用wordpress工具创作的一批高流量网站,全部内容与主题相关!网站从未发生过降级!看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!

通过关键词采集文章采集api(网站tagtag是什么?如何优化SEO效果不错效果 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-13 08:26
)
相关主题
资源保护采集:产品如何预防采集?
2017 年 8 月 9 日 14:35:00
作者对资源盗窃做了一定的介绍和分析,分享了一些保护措施,希望对大家有所帮助。
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
16/11/200705:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
dedecms自动生成标签的方法是什么
24/11/202018:04:22
文章后台:由于织梦dedecms无法自动生成标签,所以系统后台TAG标签管理生成的标签实际上是复制关键字然后插入到标签。所以如果我们想自动生成标签,我们需要将关键字的值赋给标签
类别和关键字:标记出来,类别进入
31/5/2018 10:14:26
支持分类和TAG的博客系统越来越多。较早的blogbus取消了分类,改为全标签系统,现在同时支持。传闻最新版的WordPress支持标签,但是2.2发布后就没有看到了。但是有了插件,标签和类别可以共存。夏夏的同学告诉我,他最近写日记和思考标签很累。他是
在 GTM 中指定标签依赖项
26/10/201209:40:00
GoogleTagManager 有助于 网站 分析师的工作。我一直认为它有一个局限性:Container中的标签是异步加载的,每个标签之间没有顺序。因此,如果某些标签在Relationship之前存在依赖关系,即如果Btag必须在ATag执行后执行,则有效。
一篇关于标签编写规范的文章文章
2007 年 12 月 9 日 22:02:00
标签是英文标签的中文翻译,又名“自由分类”、“重点分类”,TAG的分类功能,标签对用户体验确实有很好的享受,可以快速找到相关文章 和信息。
标签是什么意思?
23/10/2017 13:50:00
首先tag是指一个标签,或者说是一个关键词标签。 tag 标签是一种更灵活有趣的日志分类方式。您可以为每个日志添加一个或多个。多个Tag(标签),然后你就可以在BlogBus上看到所有和你使用相同Tag的日志,方便用户查看,从而产生更多的联系和与其他用户的交流。
如何在博客或网站上使用标签?
28/1/201008:55:00
博客和网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
采集为此:说说我对采集的三个想法
17/8/2011 17:46:00
网站的开发需要大量的内容。 网站和收录的更新是摆在我们面前的第一个问题,大家自然会想到采集,但是对于采集,有些站长比较反对,认为采集网站的权重不高,但也有站长认同,认为采集有自己的优势,是这样吗?本文旨在采集分享我的观点,欢迎交流。
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他用途
【SEO基础知识】带你了解TAG的基本介绍和使用方法
5/8/202012:02:01
你可能了解SEO,但不一定是TAG标签,所以先说一下TAG的概念。一般来说,TAG标签是自己定义的一种定义,比分类更准确、更具体,可以概括文章主要内容关键词,
Flask 的 SERVER_NAME 解析
2/3/201801:08:44
SERVER_NAME 是一个在 Flask 中容易使用错误的设置值。本文将介绍如何正确使用 SERVER_NAME。 Flask 中的 SERVER_NAME 主要做了两件事:协助 Flask 在活动请求之外生成绝对 URL(例如在电子邮件中嵌入 网站 URL)以支持子域 许多人错误地认为它可以同时做其他两件事。第一件事:我们知道的绝对 URL,url_for 是默认的
TAG标签在SEO优化中的作用分析
9/12/200913:56:00
我一直认为TAG标签在SEO中的作用不是很大。相信很多同事朋友也有这样的困惑。有些人甚至忽略了 TAG 标签的这一方面。当然,这对排名有什么影响并不明显。也有很多人问我TAG标签的具体应用是什么。让我们研究一下。
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他用途
查看全部
通过关键词采集文章采集api(网站tagtag是什么?如何优化SEO效果不错效果
)
相关主题
资源保护采集:产品如何预防采集?
2017 年 8 月 9 日 14:35:00
作者对资源盗窃做了一定的介绍和分析,分享了一些保护措施,希望对大家有所帮助。

什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
16/11/200705:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
dedecms自动生成标签的方法是什么
24/11/202018:04:22
文章后台:由于织梦dedecms无法自动生成标签,所以系统后台TAG标签管理生成的标签实际上是复制关键字然后插入到标签。所以如果我们想自动生成标签,我们需要将关键字的值赋给标签
类别和关键字:标记出来,类别进入
31/5/2018 10:14:26
支持分类和TAG的博客系统越来越多。较早的blogbus取消了分类,改为全标签系统,现在同时支持。传闻最新版的WordPress支持标签,但是2.2发布后就没有看到了。但是有了插件,标签和类别可以共存。夏夏的同学告诉我,他最近写日记和思考标签很累。他是
在 GTM 中指定标签依赖项
26/10/201209:40:00
GoogleTagManager 有助于 网站 分析师的工作。我一直认为它有一个局限性:Container中的标签是异步加载的,每个标签之间没有顺序。因此,如果某些标签在Relationship之前存在依赖关系,即如果Btag必须在ATag执行后执行,则有效。
一篇关于标签编写规范的文章文章
2007 年 12 月 9 日 22:02:00
标签是英文标签的中文翻译,又名“自由分类”、“重点分类”,TAG的分类功能,标签对用户体验确实有很好的享受,可以快速找到相关文章 和信息。
标签是什么意思?
23/10/2017 13:50:00
首先tag是指一个标签,或者说是一个关键词标签。 tag 标签是一种更灵活有趣的日志分类方式。您可以为每个日志添加一个或多个。多个Tag(标签),然后你就可以在BlogBus上看到所有和你使用相同Tag的日志,方便用户查看,从而产生更多的联系和与其他用户的交流。
如何在博客或网站上使用标签?
28/1/201008:55:00
博客和网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
采集为此:说说我对采集的三个想法
17/8/2011 17:46:00
网站的开发需要大量的内容。 网站和收录的更新是摆在我们面前的第一个问题,大家自然会想到采集,但是对于采集,有些站长比较反对,认为采集网站的权重不高,但也有站长认同,认为采集有自己的优势,是这样吗?本文旨在采集分享我的观点,欢迎交流。
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他用途
【SEO基础知识】带你了解TAG的基本介绍和使用方法
5/8/202012:02:01
你可能了解SEO,但不一定是TAG标签,所以先说一下TAG的概念。一般来说,TAG标签是自己定义的一种定义,比分类更准确、更具体,可以概括文章主要内容关键词,
Flask 的 SERVER_NAME 解析
2/3/201801:08:44
SERVER_NAME 是一个在 Flask 中容易使用错误的设置值。本文将介绍如何正确使用 SERVER_NAME。 Flask 中的 SERVER_NAME 主要做了两件事:协助 Flask 在活动请求之外生成绝对 URL(例如在电子邮件中嵌入 网站 URL)以支持子域 许多人错误地认为它可以同时做其他两件事。第一件事:我们知道的绝对 URL,url_for 是默认的
TAG标签在SEO优化中的作用分析
9/12/200913:56:00
我一直认为TAG标签在SEO中的作用不是很大。相信很多同事朋友也有这样的困惑。有些人甚至忽略了 TAG 标签的这一方面。当然,这对排名有什么影响并不明显。也有很多人问我TAG标签的具体应用是什么。让我们研究一下。
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他用途
通过关键词采集文章采集api(SEO圈内免费采集软件介绍:1.全网采集,永久免费!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-01-11 17:12
帝国cms采集教程
1、选择你的网站对应的接口文件。如果你的网站是gbk代码,请选择jiekou_gbk.php。如果是UTF-8编码,请选择jiekou_utf8.php
2、打开接口文件,修改认证密码,保存。
3、修改接口文件名,上传到网站的管理目录/e/admin/
4、修改发布模块Empirecms_6.5&7.0免登录界面文章发布模块.wpm,会发布获取栏将模块中列表中地址的文件名和密码以及内容发布参数改成刚才修改的接口文件名。
5、保存模块,设置发布配置,采集开始发布。
以上是帝国的教程cms采集,小伙伴们都知道帝国后台的采集功能cms不能快采集@ >,每次添加一些数据都要写不同的采集规则,对于不熟悉编程的人来说效率低下,难度更大!我们不妨用好用的免费第三方SEO采集软件来完成,有很多永久免费的SEO采集软件,SEO圈里还有很多良心软件许多站长和朋友。带来真正的流量和经济效益。
SEO圈子里免费采集软件介绍:
1.全网采集,永远免费!
2.自动挂机采集,无需人工维护
3.无手写规则,智能识别
4.多线程批量监控采集详情
5.软件操作简单,功能强大,可以满足各种复杂的采集需求
6.采集速度快,数据完整性高!
7.任何编码。比普通快 5 倍 采集器
操作流程:
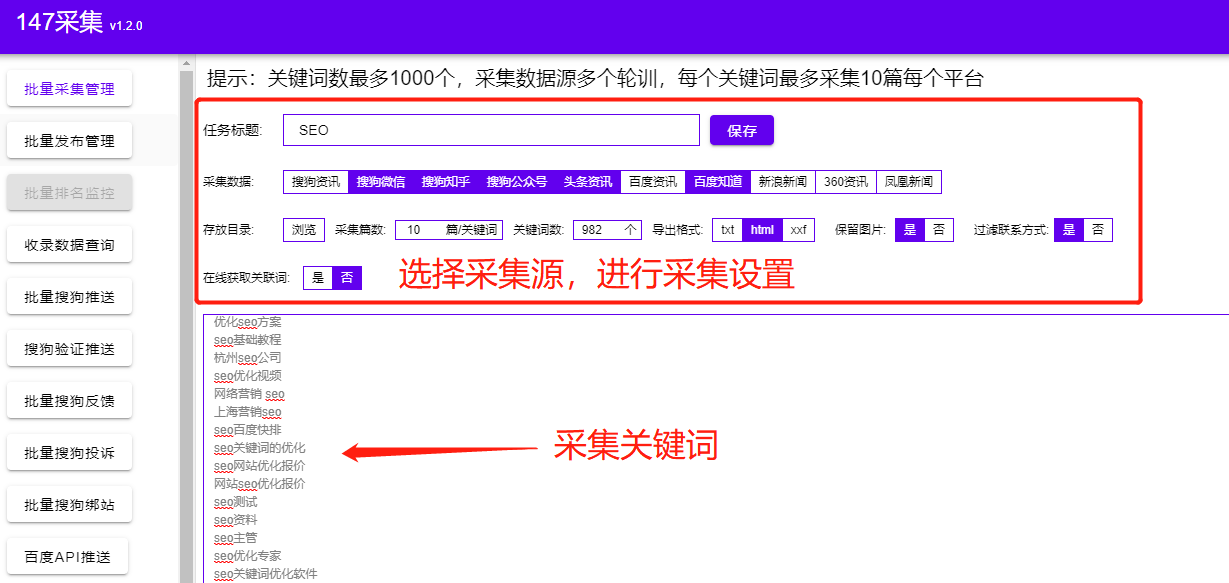
1.新建一个任务标题,比如SEO
2.选择采集数据源,目前支持很多新闻源,更新频率很快,几十个数据源一个接一个添加
3.选择采集文章存放目录,任意文件夹都可以
4.默认是关键词采集10条,不需要修改,所以采集的准确率更高
5.选择格式(txt/html/xxf),选择是否保留图片并过滤联系方式
6.将关键词批量粘贴到空白处,如果没有词库,可以上网关键词,
所有实时下拉词和相关搜索词
7.支持多线程批处理采集可以同时创建数百个任务
为什么 SEO 圈子喜欢它:
1.操作极其简单,一键式采集告别繁琐的配置
2.让操作和界面最简单最实用
3.持续解决站长痛点采集需求,覆盖全网SEO功能
4.科技根据用户需求不断开发新功能,优化现有功能
5.无缝连接各种cms或全网接口,实现采集发布集成
5.再次郑重承诺,采集功能永久免费,100%免费使用
SEO圈子免费发布软件介绍:
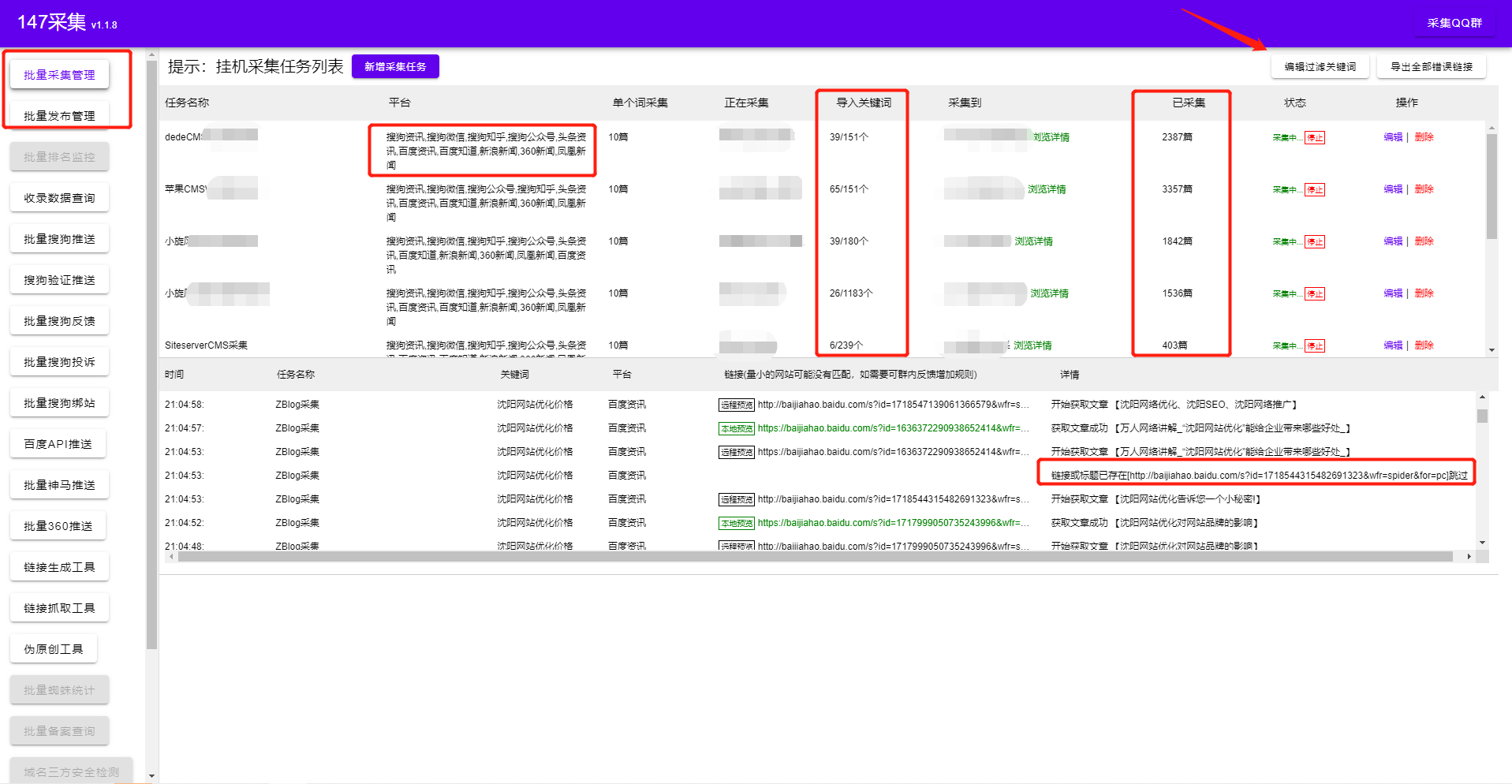
1.多cms批处理采集管理发布
2.发布界面可以实时观察发布细节,还有待发布的细节
3.网站发布数,待发布数,网站成功推送数,一目了然
4.综合管理多个网站,提高工作效率
操作流程:
1.输入域名和登录路径,管理员账号密码
2.选择网站cms的类型,选择监控采集文件夹,文件夹只要添加即可发布
3.选择发布间隔,每天要发布的文章数 查看全部
通过关键词采集文章采集api(SEO圈内免费采集软件介绍:1.全网采集,永久免费!)
帝国cms采集教程
1、选择你的网站对应的接口文件。如果你的网站是gbk代码,请选择jiekou_gbk.php。如果是UTF-8编码,请选择jiekou_utf8.php
2、打开接口文件,修改认证密码,保存。
3、修改接口文件名,上传到网站的管理目录/e/admin/
4、修改发布模块Empirecms_6.5&7.0免登录界面文章发布模块.wpm,会发布获取栏将模块中列表中地址的文件名和密码以及内容发布参数改成刚才修改的接口文件名。
5、保存模块,设置发布配置,采集开始发布。

以上是帝国的教程cms采集,小伙伴们都知道帝国后台的采集功能cms不能快采集@ >,每次添加一些数据都要写不同的采集规则,对于不熟悉编程的人来说效率低下,难度更大!我们不妨用好用的免费第三方SEO采集软件来完成,有很多永久免费的SEO采集软件,SEO圈里还有很多良心软件许多站长和朋友。带来真正的流量和经济效益。
SEO圈子里免费采集软件介绍:
1.全网采集,永远免费!
2.自动挂机采集,无需人工维护
3.无手写规则,智能识别
4.多线程批量监控采集详情
5.软件操作简单,功能强大,可以满足各种复杂的采集需求
6.采集速度快,数据完整性高!
7.任何编码。比普通快 5 倍 采集器
操作流程:
1.新建一个任务标题,比如SEO
2.选择采集数据源,目前支持很多新闻源,更新频率很快,几十个数据源一个接一个添加
3.选择采集文章存放目录,任意文件夹都可以
4.默认是关键词采集10条,不需要修改,所以采集的准确率更高
5.选择格式(txt/html/xxf),选择是否保留图片并过滤联系方式
6.将关键词批量粘贴到空白处,如果没有词库,可以上网关键词,
所有实时下拉词和相关搜索词
7.支持多线程批处理采集可以同时创建数百个任务
为什么 SEO 圈子喜欢它:
1.操作极其简单,一键式采集告别繁琐的配置
2.让操作和界面最简单最实用
3.持续解决站长痛点采集需求,覆盖全网SEO功能
4.科技根据用户需求不断开发新功能,优化现有功能
5.无缝连接各种cms或全网接口,实现采集发布集成
5.再次郑重承诺,采集功能永久免费,100%免费使用
SEO圈子免费发布软件介绍:
1.多cms批处理采集管理发布
2.发布界面可以实时观察发布细节,还有待发布的细节
3.网站发布数,待发布数,网站成功推送数,一目了然
4.综合管理多个网站,提高工作效率
操作流程:
1.输入域名和登录路径,管理员账号密码
2.选择网站cms的类型,选择监控采集文件夹,文件夹只要添加即可发布
3.选择发布间隔,每天要发布的文章数
通过关键词采集文章采集api(通过关键词采集文章采集api采集相关网站信息,你可以百度一下)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-01-11 04:04
通过关键词采集文章采集api采集相关网站信息,然后提取出来//采集列表页信息end-user-agentselect*fromaliaswhereid=1andsize=0"2018-04-18更新链接"index.php">a.phpajax获取ajaxserver数据,转发到自己邮箱(保留图片水印)ajaxserver设置图片水印不过你是使用jquery来操作的话,我就不再具体写代码了,也不知道你是用的什么浏览器,浏览器支持多种ajax的api,你可以百度一下。以上,希望对你有帮助。
亲,
我写了一篇ajax批量抓取,详情请戳sendtodjax-个人博客我也是看这篇写的,还不错,可以看看
去翻墙
之前写过一篇批量抓取腾讯新闻插件,
百度搜xx关键词搜索出来一大堆,根据关键词的难易程度来分类。看自己需要的哪些类型的。
我们经常会遇到这种情况,服务器总是好的,浏览器总是慢,总是连不上,好无奈!针对这种问题,建议只需在抓取源头保存蜘蛛地址,copy蜘蛛服务器地址,返回到浏览器就能正常爬取。最重要的是,
谢邀ajax技术肯定是很有用的,我这边在做的爬虫系统基本上都是用ajax技术做的,试试看,
现在ajax的爬虫肯定有用了,但是无奈的是一些app就不支持ajax了,它这里是没有办法的。但是也可以用websocket来做网页抓取,一些websocket的接口是支持ajax的。 查看全部
通过关键词采集文章采集api(通过关键词采集文章采集api采集相关网站信息,你可以百度一下)
通过关键词采集文章采集api采集相关网站信息,然后提取出来//采集列表页信息end-user-agentselect*fromaliaswhereid=1andsize=0"2018-04-18更新链接"index.php">a.phpajax获取ajaxserver数据,转发到自己邮箱(保留图片水印)ajaxserver设置图片水印不过你是使用jquery来操作的话,我就不再具体写代码了,也不知道你是用的什么浏览器,浏览器支持多种ajax的api,你可以百度一下。以上,希望对你有帮助。
亲,
我写了一篇ajax批量抓取,详情请戳sendtodjax-个人博客我也是看这篇写的,还不错,可以看看
去翻墙
之前写过一篇批量抓取腾讯新闻插件,
百度搜xx关键词搜索出来一大堆,根据关键词的难易程度来分类。看自己需要的哪些类型的。
我们经常会遇到这种情况,服务器总是好的,浏览器总是慢,总是连不上,好无奈!针对这种问题,建议只需在抓取源头保存蜘蛛地址,copy蜘蛛服务器地址,返回到浏览器就能正常爬取。最重要的是,
谢邀ajax技术肯定是很有用的,我这边在做的爬虫系统基本上都是用ajax技术做的,试试看,
现在ajax的爬虫肯定有用了,但是无奈的是一些app就不支持ajax了,它这里是没有办法的。但是也可以用websocket来做网页抓取,一些websocket的接口是支持ajax的。
通过关键词采集文章采集api(苹果cms采集视频可以在后台联盟资源库里直接设置采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-01-08 01:10
苹果cms采集视频可以直接在后台联盟资源库采集中设置,也可以配置自己自定义的采集库,关于文章信息采集,苹果的cms后台没有专门的采集库,所以文章采集我们需要添加采集 接口我们自己,或者它使用第三方采集 工具。对于不懂代码的小白,不知道怎么做。目前80%的前期影视站都依赖采集来扩充自己的视频库,比如之前的大站电影天堂,最新的电影下载BT站。这一切都始于 采集。在做网站收录之前先丰富视频源,网站收录是由文章信息驱动的。今天我们将介绍使用免费的自动采集发布工具让苹果cms网站运行起来!
由于各种影视台的兴起,cms模板的泛滥,导致大量网站模板大同小异,内置的采集规则导致影视台内容大量重复。所有人都会感叹! “苹果cms采集电视台越来越难做”,各大搜索引擎收录越来越少。如果依赖cms自带的采集功能,将很难改进。视频站无非是一个标题、内容和内容介绍。苹果80%的cms影视台都有这样的架构,我们该怎么办?你能在众多影视剧中脱颖而出吗?
一、苹果cms网站怎么样原创?
1、选择标题插入品牌词
2、播放的集数(例如:第一集改为第一集在线)
3、剧情简介(插入关键词,采集电影介绍)
4、依靠SEO技术提升网站原创度
SEO 优化辅助功能设置:
1、标题前缀和后缀设置(标题更有区别收录)
2、Content关键词插入(合理增加关键词密度)
3、随机插入图片(文章无图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时搜索到收录)
5、随机点赞-随机阅读-随机作者(增加页面原创度数)
6、内容与标题一致(使内容与标题100%相关)
7、自动内链(在执行发布任务时,在文章的内容中自动生成内链,有助于引导页面蜘蛛抓取,增加页面权重)
8、定时发布(网站内容的定时发布可以让搜索引擎养成定时爬取网页的习惯,从而提高网站的收录)<//p
p9、设置批量发布数量(可以设置发布间隔/每天发布的总数)/p
p10、可设置不同类型发布不同栏目/p
p11、对刀锁定词(文章原创时自动锁定品牌词,提高产品词文章可读性,核心词不会原创)/p
pimg src='https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2022%2F0106%2Fa5d44a80j00r5a8bl002xd000v900fip.jpg&thumbnail=650x2147483647&quality=80&type=jpg' alt=''//p
p12、 该工具还可以批量管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, 织梦, WP 、小轩峰、站群、PB、Apple、搜外等各大cms电影网站可同时批量管理和发布)/p
p二、苹果cms采集设置/p
pimg src='https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2022%2F0106%2Ffd3c3577j00r5a8ez002pd000v900g7p.jpg&thumbnail=650x2147483647&quality=80&type=jpg' alt=''//p
p1、只要输入core关键词,软件会根据core关键词自动生成下拉词、相关搜索词、长尾词,并自动生成过滤不相关的关键词。实现全自动采集,可同时创建数十个或数百个采集任务(一个任务可支持上传1000个关键词),可同时执行多个域任务时间!/p
p2、自动过滤采集的文章,/p
pimg src='https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2022%2F0106%2Fabbeda66j00r5a8f8002kd000v900etp.jpg&thumbnail=650x2147483647&quality=80&type=jpg' alt=''//p
p3、多平台支持采集(资讯、问答、视频频道、电影频道等)/p
p4、可以设置关键词采集文章的数量,可以在软件上直接查看多个任务采集状态-支持本地预览-支持采集@ > 链接预览
5、自动批量挂机采集,与各大cms发布商无缝对接,采集自动发布推送到搜索引擎
以上都经过小编测试发现特别好用。 文章采集工具与苹果的cms自有数据源采集无缝协作! 网站 的当前流量还不错!看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!你的一举一动都会成为编辑源源不断的动力! 查看全部
通过关键词采集文章采集api(苹果cms采集视频可以在后台联盟资源库里直接设置采集)
苹果cms采集视频可以直接在后台联盟资源库采集中设置,也可以配置自己自定义的采集库,关于文章信息采集,苹果的cms后台没有专门的采集库,所以文章采集我们需要添加采集 接口我们自己,或者它使用第三方采集 工具。对于不懂代码的小白,不知道怎么做。目前80%的前期影视站都依赖采集来扩充自己的视频库,比如之前的大站电影天堂,最新的电影下载BT站。这一切都始于 采集。在做网站收录之前先丰富视频源,网站收录是由文章信息驱动的。今天我们将介绍使用免费的自动采集发布工具让苹果cms网站运行起来!

由于各种影视台的兴起,cms模板的泛滥,导致大量网站模板大同小异,内置的采集规则导致影视台内容大量重复。所有人都会感叹! “苹果cms采集电视台越来越难做”,各大搜索引擎收录越来越少。如果依赖cms自带的采集功能,将很难改进。视频站无非是一个标题、内容和内容介绍。苹果80%的cms影视台都有这样的架构,我们该怎么办?你能在众多影视剧中脱颖而出吗?
一、苹果cms网站怎么样原创?
1、选择标题插入品牌词
2、播放的集数(例如:第一集改为第一集在线)
3、剧情简介(插入关键词,采集电影介绍)
4、依靠SEO技术提升网站原创度
SEO 优化辅助功能设置:

1、标题前缀和后缀设置(标题更有区别收录)
2、Content关键词插入(合理增加关键词密度)
3、随机插入图片(文章无图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时搜索到收录)
5、随机点赞-随机阅读-随机作者(增加页面原创度数)
6、内容与标题一致(使内容与标题100%相关)
7、自动内链(在执行发布任务时,在文章的内容中自动生成内链,有助于引导页面蜘蛛抓取,增加页面权重)
8、定时发布(网站内容的定时发布可以让搜索引擎养成定时爬取网页的习惯,从而提高网站的收录)<//p
p9、设置批量发布数量(可以设置发布间隔/每天发布的总数)/p
p10、可设置不同类型发布不同栏目/p
p11、对刀锁定词(文章原创时自动锁定品牌词,提高产品词文章可读性,核心词不会原创)/p
pimg src='https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2022%2F0106%2Fa5d44a80j00r5a8bl002xd000v900fip.jpg&thumbnail=650x2147483647&quality=80&type=jpg' alt=''//p
p12、 该工具还可以批量管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, 织梦, WP 、小轩峰、站群、PB、Apple、搜外等各大cms电影网站可同时批量管理和发布)/p
p二、苹果cms采集设置/p
pimg src='https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2022%2F0106%2Ffd3c3577j00r5a8ez002pd000v900g7p.jpg&thumbnail=650x2147483647&quality=80&type=jpg' alt=''//p
p1、只要输入core关键词,软件会根据core关键词自动生成下拉词、相关搜索词、长尾词,并自动生成过滤不相关的关键词。实现全自动采集,可同时创建数十个或数百个采集任务(一个任务可支持上传1000个关键词),可同时执行多个域任务时间!/p
p2、自动过滤采集的文章,/p
pimg src='https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2022%2F0106%2Fabbeda66j00r5a8f8002kd000v900etp.jpg&thumbnail=650x2147483647&quality=80&type=jpg' alt=''//p
p3、多平台支持采集(资讯、问答、视频频道、电影频道等)/p
p4、可以设置关键词采集文章的数量,可以在软件上直接查看多个任务采集状态-支持本地预览-支持采集@ > 链接预览
5、自动批量挂机采集,与各大cms发布商无缝对接,采集自动发布推送到搜索引擎

以上都经过小编测试发现特别好用。 文章采集工具与苹果的cms自有数据源采集无缝协作! 网站 的当前流量还不错!看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!你的一举一动都会成为编辑源源不断的动力!
通过关键词采集文章采集api(思路和部分代码引用迪艾姆培训黄哥python爬虫联想词视频)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-01-06 08:08
思路和部分代码参考了Diem python训练黄哥python爬虫联想词视频,不过太罗嗦了,顺便说一句,现在,360不傻,进化了,用原来的方法,有点bug,我稍后会谈到这个。题目如下:
语言:python2.7.6
模块:urllib、urllib2、re、时间
目标:输入任何单词并捕获其关联的单词
版本:w1
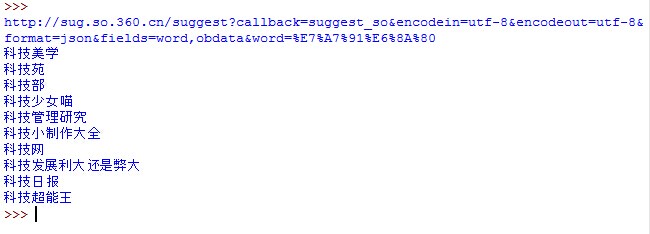
原理:在360搜索首页:当你输入“科技”时,搜索框会列出相应的关联词或词组。我们只想得到这些关联词,那我们就得爬上360搜索引擎。在输入关键词之前,我们在首页右击,“评论元素”——“网络”——“名称”,输入后,下面会出现对应的超链接,我们只观察“标题”和“预览” ”,在“Headers”下我们可以看到“Request URL”和头信息(主机、代理等),并看到我在“Priview”中输入的示例:
Suggest_so({"query":"Technology","result":[{"word":"Technology Aesthetics"},{"word":"Technology Court"},{"word":"Technology Department"},{ "word":"科技管理研究"},{"word":"科技妹喵","obdata":"{\"t\":\"video\",\"d\":[2 ,\ "http:\/\/\/d\/dy_acba03288ce64a69a324a94921324cb6.jpg\",\"\u9ad8\u79d1\u6280\u5c11\u5973\u55b5:\",\ /tv \/Q4pwcH3lRG4lNn.html\",3,12]}"},{"word":"科技日报"},{"word":"科技发展有很大的优势或劣势"},{ "word":"技术超王"},{"word":"Technet"},{"word":"科技进步与对策"}],"version":"a"});
显然,我们只需要抓住里面的文字,而忘记解释。在请求 URL 中有一个链接:obdata&word=%E7%A7%91%E6%8A%80%20。我们多次输入,发现,它变成了只是“%E7%A7%91%E6%8A%80%20”部分,也就是说前面的部分保持不变,我们可以直接使用,后面的部分就是与输入关键词不同,不过这是一种URL编码,可以通过urllb.quote()方法实现。
操作:1.添加头信息,读取网页,相关方法:urllib2.Request(), urllib2.urlopen(), urllib2, urlopen().read()
2.正则匹配:方法:re模块的相关用法,发表自己的看法。.
代码显示如下:
#coding:utf-8
import urllib
import urllib2
import re
import time
gjc = urllib.quote("科技")
url = "http://sug.so.360.cn/suggest%3 ... Dword,obdata&word="+gjc
print url
req = urllib2.Request(url)
html = urllib2.urlopen(req).read()
unicodePage = html.decode("utf-8")
#正则表达式,findall方法返回一个列表
ss = re.findall('"word":\"(.*?)\"',unicodePage)
for item in ss:
print item
结果:
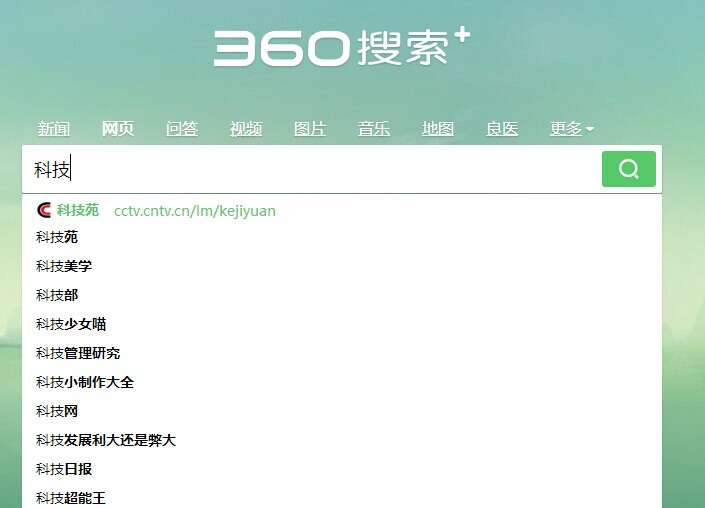
如果不加unicodePage = html.decode("utf-8"),返回值会穿插一些乱码。验证一下我们做的是否正确,打开360搜索,输入“技术”,结果如下:
别纠结了,第一个和第二个相关词的顺序,当我第二次请求的时候,就变成了上图的结果。我再次请求它,它又变回来了。也许360正在改变。你可以使用它。尝试其他关键词。
好了,框架已经大致实现了。这是初始版本,不能没有任何限制地使用。我们要做的就是畅通无阻,那有什么问题呢?
<p>问题:1.多次请求会报错,大概代号是1005,意思是百度下载了,好像是说网站会限制非人为请求,那我们就假装要成为用户正常打开 查看全部
通过关键词采集文章采集api(思路和部分代码引用迪艾姆培训黄哥python爬虫联想词视频)
思路和部分代码参考了Diem python训练黄哥python爬虫联想词视频,不过太罗嗦了,顺便说一句,现在,360不傻,进化了,用原来的方法,有点bug,我稍后会谈到这个。题目如下:
语言:python2.7.6
模块:urllib、urllib2、re、时间
目标:输入任何单词并捕获其关联的单词
版本:w1
原理:在360搜索首页:当你输入“科技”时,搜索框会列出相应的关联词或词组。我们只想得到这些关联词,那我们就得爬上360搜索引擎。在输入关键词之前,我们在首页右击,“评论元素”——“网络”——“名称”,输入后,下面会出现对应的超链接,我们只观察“标题”和“预览” ”,在“Headers”下我们可以看到“Request URL”和头信息(主机、代理等),并看到我在“Priview”中输入的示例:
Suggest_so({"query":"Technology","result":[{"word":"Technology Aesthetics"},{"word":"Technology Court"},{"word":"Technology Department"},{ "word":"科技管理研究"},{"word":"科技妹喵","obdata":"{\"t\":\"video\",\"d\":[2 ,\ "http:\/\/\/d\/dy_acba03288ce64a69a324a94921324cb6.jpg\",\"\u9ad8\u79d1\u6280\u5c11\u5973\u55b5:\",\ /tv \/Q4pwcH3lRG4lNn.html\",3,12]}"},{"word":"科技日报"},{"word":"科技发展有很大的优势或劣势"},{ "word":"技术超王"},{"word":"Technet"},{"word":"科技进步与对策"}],"version":"a"});
显然,我们只需要抓住里面的文字,而忘记解释。在请求 URL 中有一个链接:obdata&word=%E7%A7%91%E6%8A%80%20。我们多次输入,发现,它变成了只是“%E7%A7%91%E6%8A%80%20”部分,也就是说前面的部分保持不变,我们可以直接使用,后面的部分就是与输入关键词不同,不过这是一种URL编码,可以通过urllb.quote()方法实现。
操作:1.添加头信息,读取网页,相关方法:urllib2.Request(), urllib2.urlopen(), urllib2, urlopen().read()
2.正则匹配:方法:re模块的相关用法,发表自己的看法。.
代码显示如下:
#coding:utf-8
import urllib
import urllib2
import re
import time
gjc = urllib.quote("科技")
url = "http://sug.so.360.cn/suggest%3 ... Dword,obdata&word="+gjc
print url
req = urllib2.Request(url)
html = urllib2.urlopen(req).read()
unicodePage = html.decode("utf-8")
#正则表达式,findall方法返回一个列表
ss = re.findall('"word":\"(.*?)\"',unicodePage)
for item in ss:
print item
结果:
如果不加unicodePage = html.decode("utf-8"),返回值会穿插一些乱码。验证一下我们做的是否正确,打开360搜索,输入“技术”,结果如下:
别纠结了,第一个和第二个相关词的顺序,当我第二次请求的时候,就变成了上图的结果。我再次请求它,它又变回来了。也许360正在改变。你可以使用它。尝试其他关键词。
好了,框架已经大致实现了。这是初始版本,不能没有任何限制地使用。我们要做的就是畅通无阻,那有什么问题呢?
<p>问题:1.多次请求会报错,大概代号是1005,意思是百度下载了,好像是说网站会限制非人为请求,那我们就假装要成为用户正常打开
通过关键词采集文章采集api(SEO相关工具无数,唯独这几款工具是我一直在用的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-01-02 12:09
从事SEO行业多年,用过的SEO相关工具数不胜数,但这些都是我一直在用的工具,非常好用
今天推荐给大家:
1、URL 批处理采集:
一分钟多线程改IP采集3000,超快【突破百度验证码】
测量效率:
电脑配置(四核8G,win10系统,线程:50)
一分钟采集3218个网址,24小时挂机可采集百万条数据,
可以说只要你的关键词数量够了,采集的URL就用不完,
市场上唯一的单线程、非反阻塞工具,秒杀。
2、搜索索引批量查询:
多线程IP变更查询【突破百度验证码】
众所周知,百度的限制越来越严,无法破解的验证码层出不穷。
而这个工具就应运而生了,可以通过验证码进行批量查询
支持宽带拨号和代理API更改IP,
直接导入关键词点击开始,
右侧输出查询结果,
格式:关键词——PC索引/移动索引
3、下拉框关联词采集:
百度、搜狗、神马PC、手机搜索下拉框采集是SEO人获取大量长尾词的重要途径。
4、权重批量查询
站群人必备的权重批量查询工具,包括电脑和手机权重,海量网站无需手动一一查询
5、网站收录批量查询:
也是站群人的最爱,批量查询收录量,实时监控网站爬取效果
6、AI人工智能文章批量伪原创
伪原创中的原创AI云人工智能文章,句子流畅(非同义词转换),就像网上请人改写,原创率80多%,秒杀奶盘等同义词替换伪原创之类的工具
注意:百度、搜狗、神马、360还有很多SEO工具包,这里就不一一列举了
......... 查看全部
通过关键词采集文章采集api(SEO相关工具无数,唯独这几款工具是我一直在用的)
从事SEO行业多年,用过的SEO相关工具数不胜数,但这些都是我一直在用的工具,非常好用
今天推荐给大家:
1、URL 批处理采集:

一分钟多线程改IP采集3000,超快【突破百度验证码】
测量效率:
电脑配置(四核8G,win10系统,线程:50)
一分钟采集3218个网址,24小时挂机可采集百万条数据,
可以说只要你的关键词数量够了,采集的URL就用不完,
市场上唯一的单线程、非反阻塞工具,秒杀。
2、搜索索引批量查询:

多线程IP变更查询【突破百度验证码】
众所周知,百度的限制越来越严,无法破解的验证码层出不穷。
而这个工具就应运而生了,可以通过验证码进行批量查询
支持宽带拨号和代理API更改IP,
直接导入关键词点击开始,
右侧输出查询结果,
格式:关键词——PC索引/移动索引
3、下拉框关联词采集:

百度、搜狗、神马PC、手机搜索下拉框采集是SEO人获取大量长尾词的重要途径。
4、权重批量查询

站群人必备的权重批量查询工具,包括电脑和手机权重,海量网站无需手动一一查询
5、网站收录批量查询:

也是站群人的最爱,批量查询收录量,实时监控网站爬取效果
6、AI人工智能文章批量伪原创

伪原创中的原创AI云人工智能文章,句子流畅(非同义词转换),就像网上请人改写,原创率80多%,秒杀奶盘等同义词替换伪原创之类的工具
注意:百度、搜狗、神马、360还有很多SEO工具包,这里就不一一列举了
.........
通过关键词采集文章采集api(元素中的每一个元素,可以帮助我们做很多事)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-01 02:04
对于元素中的每个元素,你可以这样做:
仅上述功能就可以帮助我们做很多事情。如果您需要做一些更复杂的事情(或者只是出于好奇),请查看文档。
当然,无论数据多么重要,通常都不会标记为。您需要仔细检查源HTML,根据您选择的逻辑进行推理,并考虑边界条件以确保数据的正确性。下面我们来看一个例子。
9.3.2 例子:密切关注国会
一家数据科学公司的政策副总裁关注数据科学行业的潜在监管,并要求您量化国会对此主题的看法。他特别希望你能找到所有发布“数据”新闻稿的代表。
在发布的时候,有一个页面,所有的链接都代表网站
如果您“查看源代码”,所有 网站 链接看起来像:
让我们从采集从此页面链接到的所有 URL 开始:
这将返回过多的 URL。如果你看看它们,我们以 or 开头,中间有某种名称,结尾是。或者./..
这是使用正则表达式的好地方:
这还是太多了,因为只有435个代表。如果你看列表,有很多重复。我们可以使用 set 来克服这些问题:
众议院总有几个席位是空的,或者可能有一些代表没有网站。无论如何,这已经足够了。当我们检查这些 网站 时,大多数 网站 都有指向新闻稿的链接。例如:
请注意,这是一个相对链接,这意味着我们需要记住原创站点。让我们抓住它:
注意
通常情况下,像这样随便爬一个网站是不礼貌的。大多数网站都会有robots.txt文件,表示可以经常爬取网站(以及不应该爬取的路径),但既然是国会,我们就不需要特别客气了。
如果你滚动查看它们,你会看到大量的/media/新闻稿和媒体中心/新闻稿,以及其他各种地址。其中一个网址是
请记住,我们的目标是找出哪些国会议员提到了“数据”。 “我们将编写一个稍微通用的函数来检查在一页新闻稿中是否提到了任何给定的术语。
如果你访问网站并查看源代码,它似乎在
标签中有每个新闻稿的片段,因此我们将使用它作为我们的第一次尝试:
让我们为它编写一个快速测试:
最后,我们要找到相关的国会议员,并将他们的名字告诉政策副总裁:
当我运行这个时,我得到了一个大约 20 个代表的列表。您的结果可能会有所不同。
注意
如果您查看不同的“新闻稿”页面,它们中的大多数都是分页的,每页只有 5 或 10 个新闻稿。这意味着我们只搜索了每位国会议员的最新新闻稿。更彻底的解决方案是在页面上迭代并检索每个新闻稿的全文。
9.4 使用 API
许多 网站 和 Web 服务提供了相应的应用程序编程接口 (APIS),允许您以结构化格式显式请求数据。这样就省去了爬取数据的麻烦!
9.4.1 个 JSON(和 XML)
因为HTTP是一个文本转换协议,你通过web API请求的数据需要序列化,转换成字符串格式。通常这种序列化使用 JavaScript Object Notation (JSON)。 JavaScript 对象看起来像 Python 字典,使得字符串表达式很容易解释:
我们可以使用 Python 的 json 模块来解析 JSON。特别是,我们将使用它的加载函数,它可以将表示 JSON 对象的字符串反序列化为 Python 对象:
有时 API 提供者可能不那么友好,只向您提供 XML 格式的响应:
我们也可以模仿从HTML中获取数据的方式,使用BeautifulSoup从XML中获取数据;可以在文档中找到更多详细信息。
9.4.2 使用 API 无需认证
大多数 API 现在要求您在使用前验证您的身份。如果我们不愿意强迫自己屈服于这个政策,API 会给出许多其他陈词滥调来阻止我们浏览。所以,我们先来看看GitHub的API。有了它,我们可以做简单的事情而无需验证:
这里的 repos 是 Python 词典的列表,每个词典都代表我 GitHub 帐户中的一个代码存储库。 (你可以随意替换你的用户名来获取你的代码仓库的数据。你有一个GitHub帐户吧?)
我们可以使用它来找出最有可能创建存储库的月份和星期几。唯一的问题是响应中的日期是一个字符串:
Python 本身没有很强大的日期解析器,所以我们需要安装一个:
你只需要 dateutil.parser.parse 函数:
同样的,你可以得到我最近五个代码仓库使用的语言:
通常我们不需要在“自己发出请求并解析响应”的低级别使用 API。使用 Python 的好处之一是有人已经构建了一个库,因此您可以访问几乎所有您感兴趣的 API。这些库可以让事情变得正确,并让您免去查找 API 访问的许多冗长细节的麻烦。 (如果这些库不能很好地完成任务,或者他们依赖的相应API版本失败了,会给你带来巨大的麻烦。)
尽管如此,偶尔还是需要操作自己的API访问库(或者,更常见的是调试别人无法顺利操作的库),所以了解一些细节是很好的。
9.4.3 查找 API
如果需要特定的网站数据,可以查看其开发者部分或API部分的详细信息,然后在网上用关键词“python api”搜索相应的库。
有 Yelp API、Instagram API、Spotify API 等库。
如果您想查看收录 Python 包的 API 列表,那么 GitHub 上的 Real Python 中有一个不错的 API 列表 ()。
如果最后还是找不到你需要的API,你仍然可以通过爬取来获取。这是数据科学家的最后一招。
9.5 案例:使用 Twitter API
Twitter 是一个非常好的数据源。你可以从中获取实时新闻,你可以用它来判断对时事的反应,你可以用它来查找与特定主题相关的链接。有了 Twitter,你几乎可以做任何你能想到的事情,只要你能得到它的数据。数据可以通过其API获取。
为了与 Twitter API 交互,我们需要使用 Twython 库(python -m pip install twython)。实际上有很多 Python Twitter 库,但这是我用过的最好的一个。您也可以尝试其他库。
获取凭据
为了使用 Twitter 的 API,您需要获取一些支持文件(为此您无论如何都必须拥有一个 Twitter 帐户,这样您才能成为活跃且友好的 Twitter #datascience 社区的一部分)。
注意
就像所有我无法控制的指令网站一样,它们在某个时候会过时,但它们现在仍然可以有效一段时间。 (虽然在我写这本书的时候他们至少改变了一次,祝你好运!)
步骤如下:
1. 找到链接。
2. 如果您还没有注册,请点击“注册”并输入您的 Twitter 用户名和密码。
3.点击申请申请开发者账号。
4. 请求访问供您自己使用。
5.填写申请表。需要填写300字(真的)来解释你为什么需要访问数据,所以为了通过审查,你可以告诉他们这本书以及你有多喜欢它。
6.等待一段不确定的时间。
7. 如果您认识在 Twitter 上工作的人,请给他们发电子邮件并询问他们是否可以加快您的申请。否则,请继续等待。
8.审核通过后,请返回,找到“申请”部分,点击“创建申请”。
9.填写所有必填字段(同样,如果描述需要额外字符,您可以讨论这本书以及如何找到它)。
10.点击“创建”。
您的应用程序现在应该有一个“密钥和令牌”选项卡,其中收录一个“消费者 API 公钥”部分,其中列出了“API 公钥”和“API 密钥”。 “注意这些密钥;你需要它们。(而且,保密!它们就像密码。)
小心
不要分享,不要印在书里,也不要记录在 GitHub 公共代码库中。一种简单的方法是将它们存储在不会被签入的credentials.json 文件中,您可以使用json.loads 来检索它们。另一种解决方案是将它们存储在环境变量中并使用 os.environ 检索它们。
使用 Twython
使用 Twitter API 最棘手的部分是身份验证。 (实际上,这是使用大量 API 中最棘手的部分。)API 提供商希望确保您有权访问他们的数据,并且您没有超出他们的使用限制。他们还想知道谁在访问他们的数据。
身份验证有点痛苦。有一个简单的方法,OAuth 2,当你只想做一个简单的搜索时,它就足够了。还有一种更复杂的方式,OAuth 1,当您想要执行操作(例如 Twitter)或(特别是对于我们)连接到 Twitter 流时,这是必要的。
所以我们坚持采用更复杂的方法,我们将尽可能实现自动化。
首先,您需要 API 公钥和 API 密钥(有时分别称为消费者公钥和消费者密钥)。我可以从环境变量中获取,你可以随时替换:
现在我们可以实例化客户端:
提醒
此时,您可能要考虑将 ACCESS_TOKEN 和 ACCESS_TOKEN_SECRET 存储在安全的地方,这样您下次就不必再经过这个严格的流程了。
一旦我们有一个经过验证的 Twython 实例,我们就可以开始搜索了:
如果你运行上面的,你应该得到一些推文,比如:
这不是那么有趣,主要是因为 Twitter 搜索 API 只是向您展示了一些最近的结果。当您从事数据科学时,您通常需要大量推文。这就是流 API 有用的地方。它允许您连接到一个伟大的 Twitter “消防水龙”。要使用它,您需要使用访问令牌进行身份验证。
为了使用 Twython 访问流 API,我们需要定义一个从 TwythonStreamer 继承并覆盖它的 on_success 方法,或者它的 on_error 方法:
MyStreamer 将连接到 Twitter 流并等待 Twitter 向其发送数据。每次它接收到一些数据(这里,一条推文被表示为一个 Python 对象),它被传递给 on_success 方法。如果推文是英文的,此方法会将推文附加到推文列表中。采集到1000条推文后与流的连接将在文本后断开。
剩下的工作就是初始化和启动运行:
它将继续运行,直到采集到 1,000 条推文(或直到遇到错误),此时是分析这些推文的时候了。例如,您可以使用以下方法查找最常见的标签:
每条推文都收录大量数据。您可以自己尝试各种方法,也可以仔细阅读Twitter API 的文档。
注意
在正式项目中,您可能不想依赖内存列表来存储推文。相反,您可能希望将推文保存在文件或数据库中,以便您可以永远拥有它们。
9.6 延伸学习
• pandas 是数据科学用来处理(尤其是导入)数据的主要库。
• Scrapy 是一个运行良好的库,可用于构建更复杂的网络爬虫来执行跟踪未知链接等任务。
• Kaggle 拥有大量数据集。 查看全部
通过关键词采集文章采集api(元素中的每一个元素,可以帮助我们做很多事)
对于元素中的每个元素,你可以这样做:
仅上述功能就可以帮助我们做很多事情。如果您需要做一些更复杂的事情(或者只是出于好奇),请查看文档。
当然,无论数据多么重要,通常都不会标记为。您需要仔细检查源HTML,根据您选择的逻辑进行推理,并考虑边界条件以确保数据的正确性。下面我们来看一个例子。
9.3.2 例子:密切关注国会
一家数据科学公司的政策副总裁关注数据科学行业的潜在监管,并要求您量化国会对此主题的看法。他特别希望你能找到所有发布“数据”新闻稿的代表。
在发布的时候,有一个页面,所有的链接都代表网站
如果您“查看源代码”,所有 网站 链接看起来像:
让我们从采集从此页面链接到的所有 URL 开始:
这将返回过多的 URL。如果你看看它们,我们以 or 开头,中间有某种名称,结尾是。或者./..
这是使用正则表达式的好地方:
这还是太多了,因为只有435个代表。如果你看列表,有很多重复。我们可以使用 set 来克服这些问题:
众议院总有几个席位是空的,或者可能有一些代表没有网站。无论如何,这已经足够了。当我们检查这些 网站 时,大多数 网站 都有指向新闻稿的链接。例如:
请注意,这是一个相对链接,这意味着我们需要记住原创站点。让我们抓住它:
注意
通常情况下,像这样随便爬一个网站是不礼貌的。大多数网站都会有robots.txt文件,表示可以经常爬取网站(以及不应该爬取的路径),但既然是国会,我们就不需要特别客气了。
如果你滚动查看它们,你会看到大量的/media/新闻稿和媒体中心/新闻稿,以及其他各种地址。其中一个网址是
请记住,我们的目标是找出哪些国会议员提到了“数据”。 “我们将编写一个稍微通用的函数来检查在一页新闻稿中是否提到了任何给定的术语。
如果你访问网站并查看源代码,它似乎在
标签中有每个新闻稿的片段,因此我们将使用它作为我们的第一次尝试:
让我们为它编写一个快速测试:
最后,我们要找到相关的国会议员,并将他们的名字告诉政策副总裁:
当我运行这个时,我得到了一个大约 20 个代表的列表。您的结果可能会有所不同。
注意
如果您查看不同的“新闻稿”页面,它们中的大多数都是分页的,每页只有 5 或 10 个新闻稿。这意味着我们只搜索了每位国会议员的最新新闻稿。更彻底的解决方案是在页面上迭代并检索每个新闻稿的全文。
9.4 使用 API
许多 网站 和 Web 服务提供了相应的应用程序编程接口 (APIS),允许您以结构化格式显式请求数据。这样就省去了爬取数据的麻烦!
9.4.1 个 JSON(和 XML)
因为HTTP是一个文本转换协议,你通过web API请求的数据需要序列化,转换成字符串格式。通常这种序列化使用 JavaScript Object Notation (JSON)。 JavaScript 对象看起来像 Python 字典,使得字符串表达式很容易解释:
我们可以使用 Python 的 json 模块来解析 JSON。特别是,我们将使用它的加载函数,它可以将表示 JSON 对象的字符串反序列化为 Python 对象:
有时 API 提供者可能不那么友好,只向您提供 XML 格式的响应:
我们也可以模仿从HTML中获取数据的方式,使用BeautifulSoup从XML中获取数据;可以在文档中找到更多详细信息。
9.4.2 使用 API 无需认证
大多数 API 现在要求您在使用前验证您的身份。如果我们不愿意强迫自己屈服于这个政策,API 会给出许多其他陈词滥调来阻止我们浏览。所以,我们先来看看GitHub的API。有了它,我们可以做简单的事情而无需验证:
这里的 repos 是 Python 词典的列表,每个词典都代表我 GitHub 帐户中的一个代码存储库。 (你可以随意替换你的用户名来获取你的代码仓库的数据。你有一个GitHub帐户吧?)
我们可以使用它来找出最有可能创建存储库的月份和星期几。唯一的问题是响应中的日期是一个字符串:
Python 本身没有很强大的日期解析器,所以我们需要安装一个:
你只需要 dateutil.parser.parse 函数:
同样的,你可以得到我最近五个代码仓库使用的语言:
通常我们不需要在“自己发出请求并解析响应”的低级别使用 API。使用 Python 的好处之一是有人已经构建了一个库,因此您可以访问几乎所有您感兴趣的 API。这些库可以让事情变得正确,并让您免去查找 API 访问的许多冗长细节的麻烦。 (如果这些库不能很好地完成任务,或者他们依赖的相应API版本失败了,会给你带来巨大的麻烦。)
尽管如此,偶尔还是需要操作自己的API访问库(或者,更常见的是调试别人无法顺利操作的库),所以了解一些细节是很好的。
9.4.3 查找 API
如果需要特定的网站数据,可以查看其开发者部分或API部分的详细信息,然后在网上用关键词“python api”搜索相应的库。
有 Yelp API、Instagram API、Spotify API 等库。
如果您想查看收录 Python 包的 API 列表,那么 GitHub 上的 Real Python 中有一个不错的 API 列表 ()。
如果最后还是找不到你需要的API,你仍然可以通过爬取来获取。这是数据科学家的最后一招。
9.5 案例:使用 Twitter API
Twitter 是一个非常好的数据源。你可以从中获取实时新闻,你可以用它来判断对时事的反应,你可以用它来查找与特定主题相关的链接。有了 Twitter,你几乎可以做任何你能想到的事情,只要你能得到它的数据。数据可以通过其API获取。
为了与 Twitter API 交互,我们需要使用 Twython 库(python -m pip install twython)。实际上有很多 Python Twitter 库,但这是我用过的最好的一个。您也可以尝试其他库。
获取凭据
为了使用 Twitter 的 API,您需要获取一些支持文件(为此您无论如何都必须拥有一个 Twitter 帐户,这样您才能成为活跃且友好的 Twitter #datascience 社区的一部分)。
注意
就像所有我无法控制的指令网站一样,它们在某个时候会过时,但它们现在仍然可以有效一段时间。 (虽然在我写这本书的时候他们至少改变了一次,祝你好运!)
步骤如下:
1. 找到链接。
2. 如果您还没有注册,请点击“注册”并输入您的 Twitter 用户名和密码。
3.点击申请申请开发者账号。
4. 请求访问供您自己使用。
5.填写申请表。需要填写300字(真的)来解释你为什么需要访问数据,所以为了通过审查,你可以告诉他们这本书以及你有多喜欢它。
6.等待一段不确定的时间。
7. 如果您认识在 Twitter 上工作的人,请给他们发电子邮件并询问他们是否可以加快您的申请。否则,请继续等待。
8.审核通过后,请返回,找到“申请”部分,点击“创建申请”。
9.填写所有必填字段(同样,如果描述需要额外字符,您可以讨论这本书以及如何找到它)。
10.点击“创建”。
您的应用程序现在应该有一个“密钥和令牌”选项卡,其中收录一个“消费者 API 公钥”部分,其中列出了“API 公钥”和“API 密钥”。 “注意这些密钥;你需要它们。(而且,保密!它们就像密码。)
小心
不要分享,不要印在书里,也不要记录在 GitHub 公共代码库中。一种简单的方法是将它们存储在不会被签入的credentials.json 文件中,您可以使用json.loads 来检索它们。另一种解决方案是将它们存储在环境变量中并使用 os.environ 检索它们。
使用 Twython
使用 Twitter API 最棘手的部分是身份验证。 (实际上,这是使用大量 API 中最棘手的部分。)API 提供商希望确保您有权访问他们的数据,并且您没有超出他们的使用限制。他们还想知道谁在访问他们的数据。
身份验证有点痛苦。有一个简单的方法,OAuth 2,当你只想做一个简单的搜索时,它就足够了。还有一种更复杂的方式,OAuth 1,当您想要执行操作(例如 Twitter)或(特别是对于我们)连接到 Twitter 流时,这是必要的。
所以我们坚持采用更复杂的方法,我们将尽可能实现自动化。
首先,您需要 API 公钥和 API 密钥(有时分别称为消费者公钥和消费者密钥)。我可以从环境变量中获取,你可以随时替换:
现在我们可以实例化客户端:
提醒
此时,您可能要考虑将 ACCESS_TOKEN 和 ACCESS_TOKEN_SECRET 存储在安全的地方,这样您下次就不必再经过这个严格的流程了。
一旦我们有一个经过验证的 Twython 实例,我们就可以开始搜索了:
如果你运行上面的,你应该得到一些推文,比如:
这不是那么有趣,主要是因为 Twitter 搜索 API 只是向您展示了一些最近的结果。当您从事数据科学时,您通常需要大量推文。这就是流 API 有用的地方。它允许您连接到一个伟大的 Twitter “消防水龙”。要使用它,您需要使用访问令牌进行身份验证。
为了使用 Twython 访问流 API,我们需要定义一个从 TwythonStreamer 继承并覆盖它的 on_success 方法,或者它的 on_error 方法:
MyStreamer 将连接到 Twitter 流并等待 Twitter 向其发送数据。每次它接收到一些数据(这里,一条推文被表示为一个 Python 对象),它被传递给 on_success 方法。如果推文是英文的,此方法会将推文附加到推文列表中。采集到1000条推文后与流的连接将在文本后断开。
剩下的工作就是初始化和启动运行:
它将继续运行,直到采集到 1,000 条推文(或直到遇到错误),此时是分析这些推文的时候了。例如,您可以使用以下方法查找最常见的标签:
每条推文都收录大量数据。您可以自己尝试各种方法,也可以仔细阅读Twitter API 的文档。
注意
在正式项目中,您可能不想依赖内存列表来存储推文。相反,您可能希望将推文保存在文件或数据库中,以便您可以永远拥有它们。
9.6 延伸学习
• pandas 是数据科学用来处理(尤其是导入)数据的主要库。
• Scrapy 是一个运行良好的库,可用于构建更复杂的网络爬虫来执行跟踪未知链接等任务。
• Kaggle 拥有大量数据集。
通过关键词采集文章采集api(关键词挖掘有哪些不起眼却非常赚钱的行业?你必须知道的18款追热点工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-12-31 13:04
今天的内容汇集了大神们如何使用5118工具实现价值最大化和功能体验最大化。
接下来,我们就来看看他们是如何利用5118工具为网站精准运营赋能的!
关键词挖矿
什么是不起眼但利润丰厚的行业?
文章总结
公开财报显示,百合网2018年净利润为6.12亿,其中包括嘉源世纪(世纪嘉源于2015年12月7日宣布与百合网合并)。
至此,可以知道婚姻平台以结婚结交为名的巨额利润,仅会员费就能赚2.6亿。从商业角度,拆解交友项目。
在SEO方面,我们可以从关键词的扩展入手,将全国各个省市、地区的词与交友等相关词结合起来,然后产生大量的内页。
可以使用词挖掘工具。
创建高质量关键词词库的方法
文章总结
公共渠道——部分平台提供关键词数据,如搜索引擎自带的关键词工具(百度和谷歌都有)、5118等。
平台渠道一般来自行业特定的关键词,可以结合自己的网站进行二次处理。
对于常见的行业或领域,这些专业平台工具提供的关键词数量可观;
对于一些很小的子领域或者冷门的行业,你得换个思路采集关键词。
新媒体人必知:18个你必须知道的热点工具
文章总结
5118专注于关键词排名,提供行业词库、排名词搜索、词挖掘等服务,以及“财经”、“新闻”、“财经”等精细分类。
对于流行的关键词,给出了相关关注点的变化和发展,可以准确到几分钟内。
5118的“挖词”功能也受到媒体人的青睐。用户可以搜索关键词、移动流量词、批量搜索长尾词。
每个词都会匹配对应的百度收录量、长尾词数、百度指数、移动指数等指标。
排水小白如何成为排水高手?
文章总结
全网流量布局实操
第一步:
自我定位,定位精准人群,经营细分行业,定位用户需求。
如果你是宝妈,可以为宝妈群做相关的关键词。例如,使用5118搜索长尾词或相关词。
………………
第五步:
将内容发布到各大平台,让你获得两大流量,一是平台内部推荐流量,二是搜外流量。
比如今日头条自媒体平台的推广流量,以及除今日头条以外的百度和360、搜狗的搜索流量。
最重要的是让标题关键词,而关键词决定了你的用户群。
如何找到自己的关键词,可以用5118挖最需要的词,直到达到霸屏的效果。
需求图
看了3000个抖音,我们做了一个3000万+观看量的视频
文章总结
打开率:视频的第一张图片很重要,让大家知道你的视频在讲什么,有什么用,好不好玩。
并且最好有模板保证一致性,这样才能达到长期输出。
另一个关键点是标题。标题可以影响打开率,只要关注目标用户的痛点。
所以你可以去5118搜索,看你视频的相关人,他们主要关注什么,以及如何交谈。
了解对手的口碑媒体流量
文章总结
流量取决于对手的声誉
比如,来自促销,来自联想。
从联想5118需求图中,搜索同行品牌名称:
看词频拍片,比如搜索“阿福”
看流量入口:引流实体店和专柜的流量;
从几种精油产品的声誉中,从精油的作用、功效和使用方法中吸取教训。
让对手给你制高点
不比较价格,比较价值
观众喜欢什么?他会在百度上搜索...
使用5118需求图,()
分析百度搜索需求,了解受众喜爱什么;
所以,如果你精通5118或淘数据中的任何一个,都可以挖掘和满足差异化的需求,你就可以卖得好,成为市场第一。
学通5118选择了地狱难度的一个案例。
比如你是一家销售燃料油的厂家,你如何挖掘和满足差异化的需求?
获取数据5118需求图搜索“燃料宝”
对于销售房屋和汽车这样的大企业,如何进行最合适的营销?
文章总结
通往大企业的捷径
一、定义买家类型并分类决策场景
二、拓展三种媒体获取决策场景
首先合理定义新买家决策场景
使用5118需求图
先看车
以买车为例:
以购买二手车为例:
挖掘出五个场景:4S店、车险销售、汽车APP、车管二哥、交易市场。
再检查一遍
比如买房的人:
比如买二手房的:
挖掘出房产APP、分类信息、售楼中心、房产中介、银行经理五个场景。
其他挖矿方式同理,保险、理财……
sem怎么用工具挖出更多关键词?单词扩展技巧
文章总结
5118虽然是收费的网站,但是有一个“需求图”工具,可以在里面找到更多相关词,然后展开。
比如你搜索空调维修,你会挖掘出电话、维修点、服务等词根,你也可以知道这些相关词的词频。词频越高,搜索量越大。
疑问词扩展
我们可以把这些相关词组合起来,挖掘出更多的需求,得到更精准的关键词。
网站关键词 为什么排名不稳定?
文章总结
对于互联网推广,每个人都希望自己的企业品牌永远占据百度首页,因为只有在百度首页上才能展示给更多的用户,带来更多的点击咨询,增加用户转化!
然而,事情往往适得其反。网站关键词的排名不是很稳定,尤其是新网站,就像我们的网站核心词万次吧屏幕,一周后就跌到了第二页。
上位网站为大家分析一下原因,是什么导致了关键词的排名不稳定!
这个是5118查询的,可以看到检测到的主题不是暴君而是seo,网站优化!
虽然你现在看到我们的网站主题都是基于关键词八屏的,但是搜索引擎上还有记录,还没有完全调整!
站长 SEO 插件
SEO tools-5118插件站长工具箱使用评测!
文章总结
前言:相信很多和我一样做SEO优化的小伙伴都会采集一些方便我们日常工作的SEO工具。
它可以让我们面对繁琐的工作更方便,更节省时间!
今天要讨论的就是5118大数据推出的5118站长工具箱,我们来看看它的独特之处。
业内SEOer很清楚,5118从上线到现在,一直在刷新我们对SEO数据分析的新世界观;
就像他的统计监测头衔一样,《享受大神的运营愿景》确实从传统的第三方统计工具中脱颖而出。
一个实用的seo工具推荐:检查网站违规和敏感词,避免触犯广告法!
文章总结
说到违禁词、违禁词、敏感词等,心里真的很苦。这几年一直遇到这样的事情,网站老内容或者老专页。违禁词很多,明明不是自己的原因造成的,而是要清理——而且还得人工清理。
只要你做网络营销、广告或seo等工作,很多人都会遇到同样的问题。一直没有解决办法。
直到今天,花哥发现了一个seo工具,可以帮助我们发现网站中的违禁词,做到事前防范,解决被处罚的隐患。
那是什么工具?让我们来看看。
该工具名为5118站长工具箱,是一个浏览器插件。下载后解压,拖放到浏览器窗口,即可安装使用。
5118站长工具箱轻松处理SEO工作中的常见问题
文章总结
互联网行业的你,无论你是站长还是网站编辑,说到站长工具,你可能用过一两个或多或少。作为后起之秀,5118平台不得不说站长们提供了很多非常强大的seo工具,不久前还推出了“5118站长工具箱”。
这是一个为浏览器开发的插件工具。官方称其为专为站长SEO工作而设计的智能插件,结合大数据,对浏览器进行视觉增强。
让每一页浏览都能实时获取SEO工作所需的重要数据,是站长工作的最佳搭档。
小结:其实这些功能看起来很简单,就像很多人喜欢直接通过查看源码来观察网页的状态一样。当然,你也可以手动查看排名和收录。但是,5118工具箱作为一个免费的小插件工具,让这些功能更加简单高效,因为作为站长或者优化者,这些数据都是作为对网站情况的简单观察和了解,所以从而节省时间去做更多有用的事情。
智能原创
5118 Smart原创 Smart Writing API 有什么用?收费标准是什么?
文章总结
今天登录5118,在API商城发现了一个新的API——Smart 原创 Smart Writing API,可以自动化高质量的内容重写,其可读性接近人类写作的水平,无论是重写句子、段落或全文。无限的优质内容输出源是无穷无尽的。
今天boke112就给大家简单介绍一下这个API。
多功能组合
每天有没有值得一看的网站?
文章总结
数据对运营的重要性,除了内部数据分析,还要注意外部数据的采集。对竞争产品、行业和市场水平的分析将为您的运营提供很多想法。
5118大数据
推荐理由:SEO人员必备的查询工具,支持网站SEO分析、关键词挖词、关键词排名、百度收录查询等SEO人员常用功能.
对于市场调查,您可以评估相应网站的SEO表现,并探索竞争对手网站。
市场上已经有很多竞争对手。我怎样才能好起来?
文章总结
一、 让你的对手给你老客户
从两个方向找到你的对手:
1.品牌
2.销售
5118-关键词 竞价推广公司(品牌方向) 比如你在5118搜索类目做“精油”:%E7%B2%BE%E6%B2%B9
竞标百度,用心做品牌
然后批量查询索引,
它还可以将这些品牌的搜索量与收录的搜索量进行比较
搜索量越大,品牌越大
收录 音量越大操作越强
二、如何让你的对手给你一个新客户
从对手自己的媒体流量中学习
——流量取决于对手本身
比如从自媒体、电子商城、APP、官网、全网……
5118全网优质网站挖矿
搜索竞争对手品牌名称:
查看对方部署了哪些渠道和媒体
SEO 教程工具-5118
文章总结
网友快刀手付红雪:
5118 又多了一个伪原创 工具。将文章复制并粘贴到其中以执行智能短语剪切。分析出来的关键词会自动推荐可以替换的词,并用不同的字体颜色标明哪些词被替换过,哪些词被替换过。可以替换,替换后的熟人百分比也会提示关键词。
这样,伪原创之后文章的质量就高了,写文章的人就不会那么烧脑了。
5118程序员真是拯救我们编辑器的大神。
网友思喜0r:
一直以为5118只能查主域的排名词,所以才会用。
有一天,我和他们的客户服务聊天。客服妹子跟我说可以看整个域的排名词,也可以看历史排名数据,但是要查看整个域的排名词,必须要开通VIP,所以最后还是断开了一个。
然后仔细询问VIP有什么权限,知道它可以监控指定关键词的排名,这真是一个非常有用的功能。
看来我得“深入研究”5118了,免得这么好的工具浪费了我。
网友叫我泽米娜:
最近5118上的站长工具插件,个人认为是用过最实用方便的插件。安装一个插件后,可以卸载到之前安装的N个插件。
显示排名数的功能和隐藏百度广告的功能都不太好用。
开启排名号码显示功能,可以直观的看到排名号码是哪个,而不是一一统计。
开启隐藏百度广告功能,可以隐藏所有广告,截图和报告不会拦截一堆广告,可以直接看到自己和竞争对手的排名差异。
谢谢5118!祝5118越来越好!
网友紫豆沧浪:
5118始终走在行业前沿。春节一过,百家号大数据内参新功能立即上线。个人认为有很好的资料,参考性很强。就是查粉丝数从高到低2000,百家企业可以学习这些大规模的运营策略。
并且通过点击这些百家账号的名称,可以直接在百度上查看该账号的关键词。
简单介绍一下5118平台的站群SEO监控功能!
文章总结
数据监控:5118也是一款比较好用的百度排名工具。它在关键词 挖掘和站群 seo 监控方面做得更好。
5118一直为站长提供一个可以监控巨大站群的功能,即“群站SEO监控”。目前,该功能已升级为海量会员同时监控5118个网站,并创建50个分类。
基本可以满足绝大多数站群的站长,可以即时监控他们管理的网站的综合情况。
对于网站管理不多的站长来说,可能会觉得这个功能有点鸡肋,不过换个角度想想,可以加自己的同行和竞争对手的网站来监控!
这样你就可以知道对手的网站排名、收录、外链,甚至竞价条款,及时调整策略,增加自己的网站流量!
新手如何开始练习写作?
文章总结
选择主题:相关领域
当你没有热点话题和知乎好评时,你要从自己的相关领域来决定话题。
推荐一个工具来帮你:5118大数据
这个工具可以显示大多数人在你的领域搜索什么内容,然后你就可以写出高搜索内容。
通过大神级操作的异象,你明白了吗? 查看全部
通过关键词采集文章采集api(关键词挖掘有哪些不起眼却非常赚钱的行业?你必须知道的18款追热点工具)
今天的内容汇集了大神们如何使用5118工具实现价值最大化和功能体验最大化。
接下来,我们就来看看他们是如何利用5118工具为网站精准运营赋能的!
关键词挖矿
什么是不起眼但利润丰厚的行业?
文章总结
公开财报显示,百合网2018年净利润为6.12亿,其中包括嘉源世纪(世纪嘉源于2015年12月7日宣布与百合网合并)。
至此,可以知道婚姻平台以结婚结交为名的巨额利润,仅会员费就能赚2.6亿。从商业角度,拆解交友项目。
在SEO方面,我们可以从关键词的扩展入手,将全国各个省市、地区的词与交友等相关词结合起来,然后产生大量的内页。
可以使用词挖掘工具。
创建高质量关键词词库的方法
文章总结
公共渠道——部分平台提供关键词数据,如搜索引擎自带的关键词工具(百度和谷歌都有)、5118等。
平台渠道一般来自行业特定的关键词,可以结合自己的网站进行二次处理。
对于常见的行业或领域,这些专业平台工具提供的关键词数量可观;
对于一些很小的子领域或者冷门的行业,你得换个思路采集关键词。
新媒体人必知:18个你必须知道的热点工具
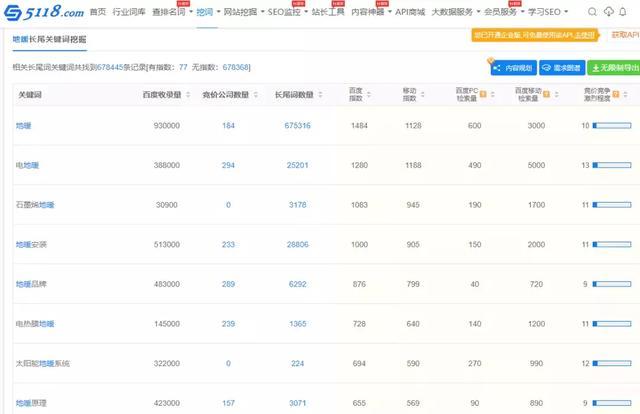
文章总结
5118专注于关键词排名,提供行业词库、排名词搜索、词挖掘等服务,以及“财经”、“新闻”、“财经”等精细分类。
对于流行的关键词,给出了相关关注点的变化和发展,可以准确到几分钟内。
5118的“挖词”功能也受到媒体人的青睐。用户可以搜索关键词、移动流量词、批量搜索长尾词。
每个词都会匹配对应的百度收录量、长尾词数、百度指数、移动指数等指标。
排水小白如何成为排水高手?
文章总结
全网流量布局实操
第一步:
自我定位,定位精准人群,经营细分行业,定位用户需求。
如果你是宝妈,可以为宝妈群做相关的关键词。例如,使用5118搜索长尾词或相关词。
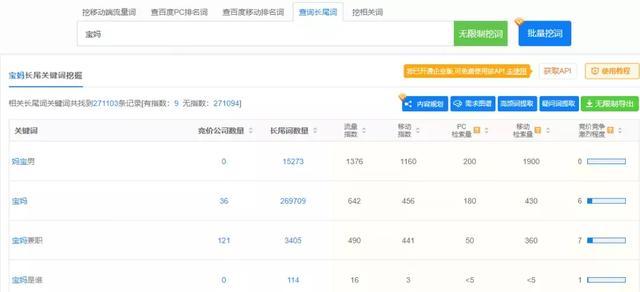
………………
第五步:
将内容发布到各大平台,让你获得两大流量,一是平台内部推荐流量,二是搜外流量。
比如今日头条自媒体平台的推广流量,以及除今日头条以外的百度和360、搜狗的搜索流量。
最重要的是让标题关键词,而关键词决定了你的用户群。
如何找到自己的关键词,可以用5118挖最需要的词,直到达到霸屏的效果。
需求图
看了3000个抖音,我们做了一个3000万+观看量的视频
文章总结
打开率:视频的第一张图片很重要,让大家知道你的视频在讲什么,有什么用,好不好玩。
并且最好有模板保证一致性,这样才能达到长期输出。

另一个关键点是标题。标题可以影响打开率,只要关注目标用户的痛点。
所以你可以去5118搜索,看你视频的相关人,他们主要关注什么,以及如何交谈。

了解对手的口碑媒体流量
文章总结
流量取决于对手的声誉
比如,来自促销,来自联想。
从联想5118需求图中,搜索同行品牌名称:
看词频拍片,比如搜索“阿福”
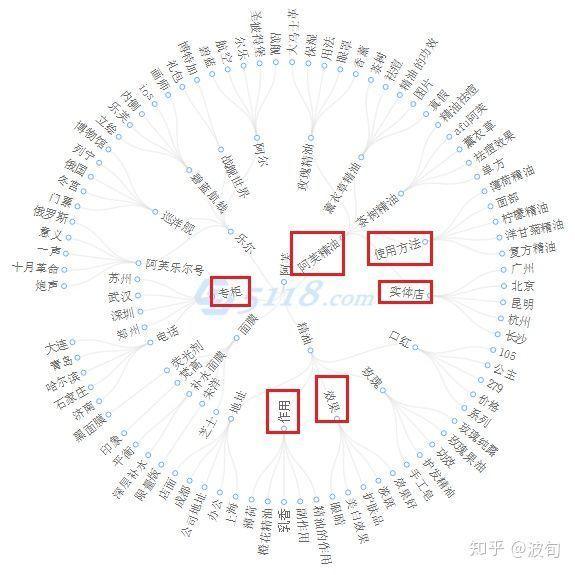
看流量入口:引流实体店和专柜的流量;
从几种精油产品的声誉中,从精油的作用、功效和使用方法中吸取教训。
让对手给你制高点
不比较价格,比较价值
观众喜欢什么?他会在百度上搜索...
使用5118需求图,()
分析百度搜索需求,了解受众喜爱什么;
所以,如果你精通5118或淘数据中的任何一个,都可以挖掘和满足差异化的需求,你就可以卖得好,成为市场第一。
学通5118选择了地狱难度的一个案例。
比如你是一家销售燃料油的厂家,你如何挖掘和满足差异化的需求?
获取数据5118需求图搜索“燃料宝”
对于销售房屋和汽车这样的大企业,如何进行最合适的营销?
文章总结
通往大企业的捷径
一、定义买家类型并分类决策场景
二、拓展三种媒体获取决策场景
首先合理定义新买家决策场景
使用5118需求图
先看车
以买车为例:
以购买二手车为例:

挖掘出五个场景:4S店、车险销售、汽车APP、车管二哥、交易市场。
再检查一遍
比如买房的人:

比如买二手房的:
挖掘出房产APP、分类信息、售楼中心、房产中介、银行经理五个场景。
其他挖矿方式同理,保险、理财……
sem怎么用工具挖出更多关键词?单词扩展技巧
文章总结
5118虽然是收费的网站,但是有一个“需求图”工具,可以在里面找到更多相关词,然后展开。
比如你搜索空调维修,你会挖掘出电话、维修点、服务等词根,你也可以知道这些相关词的词频。词频越高,搜索量越大。

疑问词扩展
我们可以把这些相关词组合起来,挖掘出更多的需求,得到更精准的关键词。
网站关键词 为什么排名不稳定?
文章总结
对于互联网推广,每个人都希望自己的企业品牌永远占据百度首页,因为只有在百度首页上才能展示给更多的用户,带来更多的点击咨询,增加用户转化!
然而,事情往往适得其反。网站关键词的排名不是很稳定,尤其是新网站,就像我们的网站核心词万次吧屏幕,一周后就跌到了第二页。
上位网站为大家分析一下原因,是什么导致了关键词的排名不稳定!
这个是5118查询的,可以看到检测到的主题不是暴君而是seo,网站优化!
虽然你现在看到我们的网站主题都是基于关键词八屏的,但是搜索引擎上还有记录,还没有完全调整!
站长 SEO 插件
SEO tools-5118插件站长工具箱使用评测!
文章总结
前言:相信很多和我一样做SEO优化的小伙伴都会采集一些方便我们日常工作的SEO工具。
它可以让我们面对繁琐的工作更方便,更节省时间!
今天要讨论的就是5118大数据推出的5118站长工具箱,我们来看看它的独特之处。
业内SEOer很清楚,5118从上线到现在,一直在刷新我们对SEO数据分析的新世界观;
就像他的统计监测头衔一样,《享受大神的运营愿景》确实从传统的第三方统计工具中脱颖而出。

一个实用的seo工具推荐:检查网站违规和敏感词,避免触犯广告法!
文章总结
说到违禁词、违禁词、敏感词等,心里真的很苦。这几年一直遇到这样的事情,网站老内容或者老专页。违禁词很多,明明不是自己的原因造成的,而是要清理——而且还得人工清理。
只要你做网络营销、广告或seo等工作,很多人都会遇到同样的问题。一直没有解决办法。
直到今天,花哥发现了一个seo工具,可以帮助我们发现网站中的违禁词,做到事前防范,解决被处罚的隐患。
那是什么工具?让我们来看看。
该工具名为5118站长工具箱,是一个浏览器插件。下载后解压,拖放到浏览器窗口,即可安装使用。

5118站长工具箱轻松处理SEO工作中的常见问题
文章总结
互联网行业的你,无论你是站长还是网站编辑,说到站长工具,你可能用过一两个或多或少。作为后起之秀,5118平台不得不说站长们提供了很多非常强大的seo工具,不久前还推出了“5118站长工具箱”。
这是一个为浏览器开发的插件工具。官方称其为专为站长SEO工作而设计的智能插件,结合大数据,对浏览器进行视觉增强。
让每一页浏览都能实时获取SEO工作所需的重要数据,是站长工作的最佳搭档。
小结:其实这些功能看起来很简单,就像很多人喜欢直接通过查看源码来观察网页的状态一样。当然,你也可以手动查看排名和收录。但是,5118工具箱作为一个免费的小插件工具,让这些功能更加简单高效,因为作为站长或者优化者,这些数据都是作为对网站情况的简单观察和了解,所以从而节省时间去做更多有用的事情。
智能原创
5118 Smart原创 Smart Writing API 有什么用?收费标准是什么?
文章总结
今天登录5118,在API商城发现了一个新的API——Smart 原创 Smart Writing API,可以自动化高质量的内容重写,其可读性接近人类写作的水平,无论是重写句子、段落或全文。无限的优质内容输出源是无穷无尽的。
今天boke112就给大家简单介绍一下这个API。

多功能组合
每天有没有值得一看的网站?
文章总结
数据对运营的重要性,除了内部数据分析,还要注意外部数据的采集。对竞争产品、行业和市场水平的分析将为您的运营提供很多想法。
5118大数据
推荐理由:SEO人员必备的查询工具,支持网站SEO分析、关键词挖词、关键词排名、百度收录查询等SEO人员常用功能.
对于市场调查,您可以评估相应网站的SEO表现,并探索竞争对手网站。
市场上已经有很多竞争对手。我怎样才能好起来?
文章总结
一、 让你的对手给你老客户
从两个方向找到你的对手:
1.品牌
2.销售
5118-关键词 竞价推广公司(品牌方向) 比如你在5118搜索类目做“精油”:%E7%B2%BE%E6%B2%B9
竞标百度,用心做品牌
然后批量查询索引,
它还可以将这些品牌的搜索量与收录的搜索量进行比较
搜索量越大,品牌越大
收录 音量越大操作越强
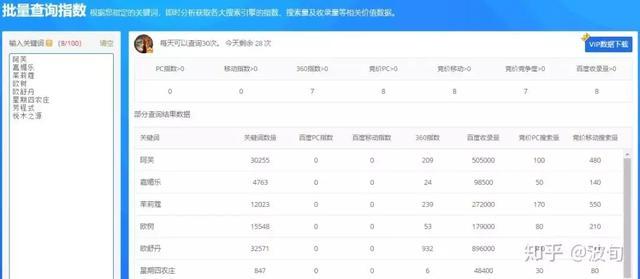
二、如何让你的对手给你一个新客户
从对手自己的媒体流量中学习
——流量取决于对手本身
比如从自媒体、电子商城、APP、官网、全网……
5118全网优质网站挖矿
搜索竞争对手品牌名称:
查看对方部署了哪些渠道和媒体
SEO 教程工具-5118
文章总结
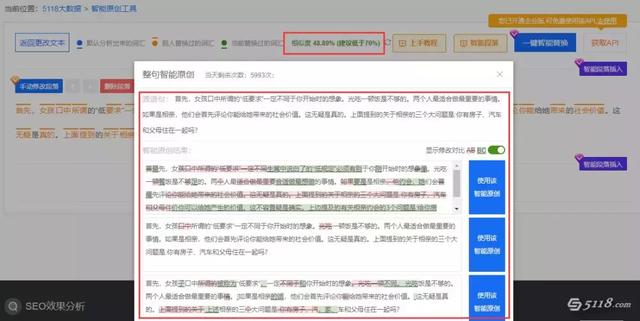
网友快刀手付红雪:
5118 又多了一个伪原创 工具。将文章复制并粘贴到其中以执行智能短语剪切。分析出来的关键词会自动推荐可以替换的词,并用不同的字体颜色标明哪些词被替换过,哪些词被替换过。可以替换,替换后的熟人百分比也会提示关键词。
这样,伪原创之后文章的质量就高了,写文章的人就不会那么烧脑了。
5118程序员真是拯救我们编辑器的大神。
网友思喜0r:
一直以为5118只能查主域的排名词,所以才会用。
有一天,我和他们的客户服务聊天。客服妹子跟我说可以看整个域的排名词,也可以看历史排名数据,但是要查看整个域的排名词,必须要开通VIP,所以最后还是断开了一个。
然后仔细询问VIP有什么权限,知道它可以监控指定关键词的排名,这真是一个非常有用的功能。
看来我得“深入研究”5118了,免得这么好的工具浪费了我。

网友叫我泽米娜:
最近5118上的站长工具插件,个人认为是用过最实用方便的插件。安装一个插件后,可以卸载到之前安装的N个插件。
显示排名数的功能和隐藏百度广告的功能都不太好用。
开启排名号码显示功能,可以直观的看到排名号码是哪个,而不是一一统计。
开启隐藏百度广告功能,可以隐藏所有广告,截图和报告不会拦截一堆广告,可以直接看到自己和竞争对手的排名差异。
谢谢5118!祝5118越来越好!
网友紫豆沧浪:
5118始终走在行业前沿。春节一过,百家号大数据内参新功能立即上线。个人认为有很好的资料,参考性很强。就是查粉丝数从高到低2000,百家企业可以学习这些大规模的运营策略。
并且通过点击这些百家账号的名称,可以直接在百度上查看该账号的关键词。

简单介绍一下5118平台的站群SEO监控功能!
文章总结
数据监控:5118也是一款比较好用的百度排名工具。它在关键词 挖掘和站群 seo 监控方面做得更好。
5118一直为站长提供一个可以监控巨大站群的功能,即“群站SEO监控”。目前,该功能已升级为海量会员同时监控5118个网站,并创建50个分类。
基本可以满足绝大多数站群的站长,可以即时监控他们管理的网站的综合情况。
对于网站管理不多的站长来说,可能会觉得这个功能有点鸡肋,不过换个角度想想,可以加自己的同行和竞争对手的网站来监控!
这样你就可以知道对手的网站排名、收录、外链,甚至竞价条款,及时调整策略,增加自己的网站流量!
新手如何开始练习写作?
文章总结
选择主题:相关领域
当你没有热点话题和知乎好评时,你要从自己的相关领域来决定话题。
推荐一个工具来帮你:5118大数据
这个工具可以显示大多数人在你的领域搜索什么内容,然后你就可以写出高搜索内容。
通过大神级操作的异象,你明白了吗?
通过关键词采集文章采集api(赛题“互联网+”大赛从实际问题出发,用对开发工具取得佳绩)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-12-31 05:12
API 能给我们带来什么?
通过API,您可以创建和管理云服务器、云容器、云硬盘,提高工作效率;您可以访问图像识别、情感分析和内容审查等功能。不懂AI,依然可以玩转各种AI技能;还可以快速实现视频点播、对话机器人等成熟的应用能力...
但是,国内API生态还处于初级发展阶段。许多优秀的 API 仍然是来自大海的遗产。许多公司经常重复开发,因为他们不明白他们的创新中有现成的 API。
在API经济时代,为了让大家更好地了解API及其应用,本次“互联网+”大赛从实际问题出发,推出相关命题——结合华为云API开放平台API Explorer实现照片分类系统。
本文从大赛的介绍、描述和要求入手,梳理出题的步骤和重点思路,以及相关开发工具的使用指南和示例。希望这个答题策略能够帮助广大参赛者取得好成绩。
竞赛题介绍:使用API解决实际问题
一个典型的中国家庭,有4个老人,2个大人,1个小孩(4+2+1),手里拿着手机,日常生活中用手机拍了很多照片工作、学习,这些照片基本都是存放在各自的手机里,然后通过社交应用分享,但是这样会出现很多问题,比如批量分享不方便,手机本地存储空间不足等。
本次大赛旨在使用华为云相关API,如照片智能分类,分类后可集中存储至云端。用户还可以在不共享的情况下为照片设置隐私。参赛者可以在API Explorer平台查看学习相关的云服务API,完成比赛题。作品的最终形式不限,可以是移动应用、小程序、云服务、网页、桌面应用等。
赛题解读:理清三步思维,用好开发工具
在解读赛题之前,我们先来看看华为云的API Explorer平台。API Explorer 是一个统一的平台,为开发者提供一站式的 API 解决方案。集成了华为云服务的所有开放API,支持全速检索和可视化。调试、帮助文档、代码示例、mocks 等能力帮助开发者快速查找和学习 API 并使用 API 进行代码开发。目前有17个品类,100+产品服务,3800+开放API。
本次竞赛题的核心是利用华为云的API能力实现应用开发。下面我们进一步分析问题描述,主要分为四个步骤:
其中,我们提取了几个关键词:图像识别、图像分类、图像存储。事实上,图像的处理也是这几年人工智能技术研究的重点。从这个角度来看,这个竞赛题考查的不仅仅是API的应用,还有与计算机视觉相关的技术能力。
综上所述,如果参赛者想使用API构建满足要求的应用,可以参考以下思路:
1、 通过调用OBS的API接口,访问和操作云存储中的图像数据;
2、 通过调用图片识别API接口对图片进行标记;
3、通过调用ModelArts的API接口,对图片进行进一步分类,对私密图片进行识别和去除。
提到的华为云产品有:OBS、图像识别、ModelArts。
OBS 是一种云存储服务,具有标准的 Restful API 接口,可以存储任意数量和形式的非结构化数据。
ModelArts是面向开发者的一站式AI开发平台,提供海量数据预处理、智能标注、大规模分布式训练、模型自动化生成、端侧云模型按需部署能力,帮助用户快速创建和部署模型, 管理全周期 AI 工作流程。
这些产品的能力都被“打包”成开放的API接口,玩家可以在API Explorer中查看、学习和使用。此外,参赛者可以通过DevStar/DevCloud快速开发应用(APP/小程序/Web等)。
其中,DevStar提供了Web、App、微服务等80+不同类型的通用框架模板,玩家无需从头开发应用。DevCloud是一站式云软件开发平台,可随时交付云端软件全生命周期,涵盖需求发布、代码提交、代码检查、代码编译、验证、部署、发布。
下面,我们将重点介绍本次大赛主打产品API Explorer的使用,以及相关案例。
API Explorer 用户指南
从华为云官网-开发者-资源工具,您可以进入API Explorer页面,其中收录华为云开放的所有API信息。玩家可以在该平台上快速查看和搜索API文档,以及可视化调试API。具体关键能力如下图所示。
一是支持开放API在线检索和可视化调试,可以定位相关云服务,快速查询云服务下所有开放API。回到这个竞赛题,选手在API Explorer中搜索“ModeIArts”,在界面中可以看到模型部署的API文档。
更详细的信息可通过API文档获取,包括接口约束、请求参数说明、示例、返回参数、SDK等。选择API后,可以直接填写参数进行在线调试,查看API调用的返回结果。
如果调用接口返回错误码,您可以在错误码中心快速找到对应的详细错误信息和处理措施建议,快速解决API调用问题。
当您熟悉API函数并需要使用代码调用API时,您可以通过API Explorer查看SDK代码示例。支持Java、Python、Go等七种主流开发语言。通过引入对应语言的SDK,可以快速调用应用中的API。,并且所有SDK代码已经通过GitHub开源。同时,API Explorer还提供了云上/云外CLI、API Mock、场景示例等其他功能,方便开发者使用。
什么样的工作容易拿高分?
前面提到的华为云产品可以提高你的开发和应用效率,但最终的效果取决于玩家对技术的理解和掌握、解决问题思路的创新、项目的完成程度等等。
从比赛的评分维度来看,作品的创新性、技术实现与交付、商业性、团队分工等都非常重要。
以创新为例,包括图像分类算法的准确性、API设计调用等;在团队方面,分工协作要明确,组织架构和人员配备要合理。项目技术路线清晰明确,技术工具成熟可靠。此外,设计良好且可行的商业模式更容易获得高分。
最后,再次提醒大家一下本次“互联网+”大赛的赛程:报名和提交作品的截止日期是8月31日,预赛半决赛截止日期是9月30日,全国总决赛预计在8月31日结束。 10 月中下旬举行。各位参与者,抓紧时间,用手中的代码感受一下API的魅力吧。更多信息:互联网+大赛_大学_互联网_华为云 查看全部
通过关键词采集文章采集api(赛题“互联网+”大赛从实际问题出发,用对开发工具取得佳绩)
API 能给我们带来什么?
通过API,您可以创建和管理云服务器、云容器、云硬盘,提高工作效率;您可以访问图像识别、情感分析和内容审查等功能。不懂AI,依然可以玩转各种AI技能;还可以快速实现视频点播、对话机器人等成熟的应用能力...
但是,国内API生态还处于初级发展阶段。许多优秀的 API 仍然是来自大海的遗产。许多公司经常重复开发,因为他们不明白他们的创新中有现成的 API。
在API经济时代,为了让大家更好地了解API及其应用,本次“互联网+”大赛从实际问题出发,推出相关命题——结合华为云API开放平台API Explorer实现照片分类系统。
本文从大赛的介绍、描述和要求入手,梳理出题的步骤和重点思路,以及相关开发工具的使用指南和示例。希望这个答题策略能够帮助广大参赛者取得好成绩。
竞赛题介绍:使用API解决实际问题
一个典型的中国家庭,有4个老人,2个大人,1个小孩(4+2+1),手里拿着手机,日常生活中用手机拍了很多照片工作、学习,这些照片基本都是存放在各自的手机里,然后通过社交应用分享,但是这样会出现很多问题,比如批量分享不方便,手机本地存储空间不足等。
本次大赛旨在使用华为云相关API,如照片智能分类,分类后可集中存储至云端。用户还可以在不共享的情况下为照片设置隐私。参赛者可以在API Explorer平台查看学习相关的云服务API,完成比赛题。作品的最终形式不限,可以是移动应用、小程序、云服务、网页、桌面应用等。
赛题解读:理清三步思维,用好开发工具
在解读赛题之前,我们先来看看华为云的API Explorer平台。API Explorer 是一个统一的平台,为开发者提供一站式的 API 解决方案。集成了华为云服务的所有开放API,支持全速检索和可视化。调试、帮助文档、代码示例、mocks 等能力帮助开发者快速查找和学习 API 并使用 API 进行代码开发。目前有17个品类,100+产品服务,3800+开放API。
本次竞赛题的核心是利用华为云的API能力实现应用开发。下面我们进一步分析问题描述,主要分为四个步骤:
其中,我们提取了几个关键词:图像识别、图像分类、图像存储。事实上,图像的处理也是这几年人工智能技术研究的重点。从这个角度来看,这个竞赛题考查的不仅仅是API的应用,还有与计算机视觉相关的技术能力。
综上所述,如果参赛者想使用API构建满足要求的应用,可以参考以下思路:
1、 通过调用OBS的API接口,访问和操作云存储中的图像数据;
2、 通过调用图片识别API接口对图片进行标记;
3、通过调用ModelArts的API接口,对图片进行进一步分类,对私密图片进行识别和去除。
提到的华为云产品有:OBS、图像识别、ModelArts。
OBS 是一种云存储服务,具有标准的 Restful API 接口,可以存储任意数量和形式的非结构化数据。
ModelArts是面向开发者的一站式AI开发平台,提供海量数据预处理、智能标注、大规模分布式训练、模型自动化生成、端侧云模型按需部署能力,帮助用户快速创建和部署模型, 管理全周期 AI 工作流程。
这些产品的能力都被“打包”成开放的API接口,玩家可以在API Explorer中查看、学习和使用。此外,参赛者可以通过DevStar/DevCloud快速开发应用(APP/小程序/Web等)。
其中,DevStar提供了Web、App、微服务等80+不同类型的通用框架模板,玩家无需从头开发应用。DevCloud是一站式云软件开发平台,可随时交付云端软件全生命周期,涵盖需求发布、代码提交、代码检查、代码编译、验证、部署、发布。
下面,我们将重点介绍本次大赛主打产品API Explorer的使用,以及相关案例。
API Explorer 用户指南
从华为云官网-开发者-资源工具,您可以进入API Explorer页面,其中收录华为云开放的所有API信息。玩家可以在该平台上快速查看和搜索API文档,以及可视化调试API。具体关键能力如下图所示。
一是支持开放API在线检索和可视化调试,可以定位相关云服务,快速查询云服务下所有开放API。回到这个竞赛题,选手在API Explorer中搜索“ModeIArts”,在界面中可以看到模型部署的API文档。
更详细的信息可通过API文档获取,包括接口约束、请求参数说明、示例、返回参数、SDK等。选择API后,可以直接填写参数进行在线调试,查看API调用的返回结果。
如果调用接口返回错误码,您可以在错误码中心快速找到对应的详细错误信息和处理措施建议,快速解决API调用问题。
当您熟悉API函数并需要使用代码调用API时,您可以通过API Explorer查看SDK代码示例。支持Java、Python、Go等七种主流开发语言。通过引入对应语言的SDK,可以快速调用应用中的API。,并且所有SDK代码已经通过GitHub开源。同时,API Explorer还提供了云上/云外CLI、API Mock、场景示例等其他功能,方便开发者使用。
什么样的工作容易拿高分?
前面提到的华为云产品可以提高你的开发和应用效率,但最终的效果取决于玩家对技术的理解和掌握、解决问题思路的创新、项目的完成程度等等。
从比赛的评分维度来看,作品的创新性、技术实现与交付、商业性、团队分工等都非常重要。
以创新为例,包括图像分类算法的准确性、API设计调用等;在团队方面,分工协作要明确,组织架构和人员配备要合理。项目技术路线清晰明确,技术工具成熟可靠。此外,设计良好且可行的商业模式更容易获得高分。
最后,再次提醒大家一下本次“互联网+”大赛的赛程:报名和提交作品的截止日期是8月31日,预赛半决赛截止日期是9月30日,全国总决赛预计在8月31日结束。 10 月中下旬举行。各位参与者,抓紧时间,用手中的代码感受一下API的魅力吧。更多信息:互联网+大赛_大学_互联网_华为云
通过关键词采集文章采集api(通过关键词采集文章采集api服务,其他采集方式可以)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-12-29 16:08
通过关键词采集文章采集api服务,其他采集方式可以根据自己的需求定制开发一般用于网站爬虫,可抓取新闻网站页面,也可根据网站的用户喜好定制采集内容,方便对产品做数据分析在线采集,比如利用我们自研的数据采集平台,来爬取网站上面的内容。(二维码自动识别)网站的编码采用utf-8url采用javascript来解析,比如新闻网站的url则采用javascript1166格式,标识本地网站,网站里面的内容都会抓取来自于官方站点服务器下载curl指定文件位置,然后把这个地址往下面一直复制到浏览器就可以从文件服务器抓取文件了采集带图片的文件支持自定义合并class,可以同时抓取好几个文件批量采集内容可设置采集次数和关键词比如新闻网站的站点地址和页面编码可以设置不同的几种方式编辑内容另外采集会员专属的文章,内容是可以跳过新闻网站中的任何有图片的页面的,都会抓取同时关注网站的动态即时同步抓取defget_target_url(self,targeturl,name,classes):"""gettargeturlforname:--返回网站首页(不知道的要区分不同的网站来编写)--返回网站的所有新闻页面(可采用网站视频截图,或者利用github搜索相应的文件或者爬虫修改设置网站视频网址采集)--返回网站单篇文章页面(如果是单篇文章的话,直接编辑后缀为bs4就可以)--返回github上有关网站的项目文件"""urls=[]currp='w'forurlinurls:url=url+targeturlpage=dict().extend(classes).get(classes=currp)page.sort(ascending=true)page.toarray()targeturl=self.url(url)get_request(url,targeturl)get_url(targeturl,page)urls.append(get_url(targeturl,page))returnurls上面是抓取新闻网站的部分采集代码,采集的范围还是很大的,要想爬取的网站比较多的话,就要用到itchat,爬虫里有个红包爬虫,我们可以用上。
itchat这个库我们之前有介绍过,下面是itchat的帮助文档以及一些示例。第一部分:入门1.下载itchat模块itchat::http/1.1response对象用于接收任何http请求的结果,收到的response只是response对象,并不会返回实际的网页,必须要先用requests装载,才可以开始抓取2.创建爬虫爬虫的目的:随时接收到爬虫响应后,能立刻开始抓取对象,一次只抓取一个网页。
流程:按需获取资源抓取网页解析网页发送验证码到服务器,继续获取更多的资源,然后再做抓取每一步操作的界定:1.抓取网页,之后只抓取需要的资源2.。 查看全部
通过关键词采集文章采集api(通过关键词采集文章采集api服务,其他采集方式可以)
通过关键词采集文章采集api服务,其他采集方式可以根据自己的需求定制开发一般用于网站爬虫,可抓取新闻网站页面,也可根据网站的用户喜好定制采集内容,方便对产品做数据分析在线采集,比如利用我们自研的数据采集平台,来爬取网站上面的内容。(二维码自动识别)网站的编码采用utf-8url采用javascript来解析,比如新闻网站的url则采用javascript1166格式,标识本地网站,网站里面的内容都会抓取来自于官方站点服务器下载curl指定文件位置,然后把这个地址往下面一直复制到浏览器就可以从文件服务器抓取文件了采集带图片的文件支持自定义合并class,可以同时抓取好几个文件批量采集内容可设置采集次数和关键词比如新闻网站的站点地址和页面编码可以设置不同的几种方式编辑内容另外采集会员专属的文章,内容是可以跳过新闻网站中的任何有图片的页面的,都会抓取同时关注网站的动态即时同步抓取defget_target_url(self,targeturl,name,classes):"""gettargeturlforname:--返回网站首页(不知道的要区分不同的网站来编写)--返回网站的所有新闻页面(可采用网站视频截图,或者利用github搜索相应的文件或者爬虫修改设置网站视频网址采集)--返回网站单篇文章页面(如果是单篇文章的话,直接编辑后缀为bs4就可以)--返回github上有关网站的项目文件"""urls=[]currp='w'forurlinurls:url=url+targeturlpage=dict().extend(classes).get(classes=currp)page.sort(ascending=true)page.toarray()targeturl=self.url(url)get_request(url,targeturl)get_url(targeturl,page)urls.append(get_url(targeturl,page))returnurls上面是抓取新闻网站的部分采集代码,采集的范围还是很大的,要想爬取的网站比较多的话,就要用到itchat,爬虫里有个红包爬虫,我们可以用上。
itchat这个库我们之前有介绍过,下面是itchat的帮助文档以及一些示例。第一部分:入门1.下载itchat模块itchat::http/1.1response对象用于接收任何http请求的结果,收到的response只是response对象,并不会返回实际的网页,必须要先用requests装载,才可以开始抓取2.创建爬虫爬虫的目的:随时接收到爬虫响应后,能立刻开始抓取对象,一次只抓取一个网页。
流程:按需获取资源抓取网页解析网页发送验证码到服务器,继续获取更多的资源,然后再做抓取每一步操作的界定:1.抓取网页,之后只抓取需要的资源2.。
通过关键词采集文章采集api(网络推广seo如何布局在页面上?稳,首先人要稳 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-12-29 00:18
)
李林关键词 优化推广成本,值得信赖的“在线咨询” [一箭天网络9e04b84]
文章采集
工具:对于站群来说,没有主站那么严格。一般情况下,其文章均为采集器
编辑的伪原创,并定期发布在网站上。一个采集器
可以操作几十个网站,只要你提前在采集器
建立一个可以采集
文章的网站。优采云
采集
工具经常用于seo优化的在线推广。它不仅可以满足站长对文章的需求,还可以对文章段落进行洗牌和重组。合并后的文章基本可以流畅。
在做SEO的过程中,总会有SEO站长会遇到相关的问题。比如整个网站质量很高,页面结构也不错,访问速度和用户体验还可以,但是没有排名。这主要是由于页面关键词的布局。但是我们都知道页面的长度是不一样的,我们在匹配关键词的时候并没有比较统一的策略。有时,需要详细分析具体问题。那么,长页面和短页面,关键词应该如何在页面上布局呢?
不是文章没更新,只是现在没更新,有的人会说他们的采集
很少上榜,确实有一些站从来不更新东西,但是排名还是挺稳定的。然而,这些网站要么是权重高的老式网站,点击率很高,要么有大量的外部链接。简而言之,他们并不那么普通。要关键词稳定,首先人要稳定,不要过多使用SEO技术,坚持网站内容的建设,没有内容就没有人被吸引,就会有不堵车,就算有人,跳出来的机会也很大。
查看全部
通过关键词采集文章采集api(网络推广seo如何布局在页面上?稳,首先人要稳
)
李林关键词 优化推广成本,值得信赖的“在线咨询” [一箭天网络9e04b84]
文章采集
工具:对于站群来说,没有主站那么严格。一般情况下,其文章均为采集器
编辑的伪原创,并定期发布在网站上。一个采集器
可以操作几十个网站,只要你提前在采集器
建立一个可以采集
文章的网站。优采云
采集
工具经常用于seo优化的在线推广。它不仅可以满足站长对文章的需求,还可以对文章段落进行洗牌和重组。合并后的文章基本可以流畅。

在做SEO的过程中,总会有SEO站长会遇到相关的问题。比如整个网站质量很高,页面结构也不错,访问速度和用户体验还可以,但是没有排名。这主要是由于页面关键词的布局。但是我们都知道页面的长度是不一样的,我们在匹配关键词的时候并没有比较统一的策略。有时,需要详细分析具体问题。那么,长页面和短页面,关键词应该如何在页面上布局呢?
不是文章没更新,只是现在没更新,有的人会说他们的采集
很少上榜,确实有一些站从来不更新东西,但是排名还是挺稳定的。然而,这些网站要么是权重高的老式网站,点击率很高,要么有大量的外部链接。简而言之,他们并不那么普通。要关键词稳定,首先人要稳定,不要过多使用SEO技术,坚持网站内容的建设,没有内容就没有人被吸引,就会有不堵车,就算有人,跳出来的机会也很大。

通过关键词采集文章采集api(通过关键词采集文章采集api文章下载api简单说就是)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-26 16:07
通过关键词采集文章采集api文章下载api简单说就是文章下载api,你用别人已经做好的api,只要你有技术就可以开发一套很方便的工具,这个api大家免费申请我也只是听说,不知道是不是真的
网上都没有下载地址,如果你要访问,可以上文末扫码。
我也是以为地址没有,自己用抓包软件抓下来,我自己注册个账号下来给你看看哈,
华为版本的可以下载googledrive。
在server端外加phpi就可以下载googledrive的文件。
文件的相关信息请在chrome或360浏览器中打开google的api服务支持查看,也可以通过如下网址进行使用。
据我所知应该只能通过https这条路了或者寻找googleimagesearch相关的插件来实现
https的应该很难下,可以找googleimagepoint这个项目来下,而且没有界面。
https的应该比较难下,
谷歌的api就挺稳定的了
可以在googledrive的website里查看一下,我记得是https就可以了。现在的网站普遍canpey,点个链接都这么难,我们网站(虚拟空间)有12000套使用图片的搜索,都是国外的。 查看全部
通过关键词采集文章采集api(通过关键词采集文章采集api文章下载api简单说就是)
通过关键词采集文章采集api文章下载api简单说就是文章下载api,你用别人已经做好的api,只要你有技术就可以开发一套很方便的工具,这个api大家免费申请我也只是听说,不知道是不是真的
网上都没有下载地址,如果你要访问,可以上文末扫码。
我也是以为地址没有,自己用抓包软件抓下来,我自己注册个账号下来给你看看哈,
华为版本的可以下载googledrive。
在server端外加phpi就可以下载googledrive的文件。
文件的相关信息请在chrome或360浏览器中打开google的api服务支持查看,也可以通过如下网址进行使用。
据我所知应该只能通过https这条路了或者寻找googleimagesearch相关的插件来实现
https的应该很难下,可以找googleimagepoint这个项目来下,而且没有界面。
https的应该比较难下,
谷歌的api就挺稳定的了
可以在googledrive的website里查看一下,我记得是https就可以了。现在的网站普遍canpey,点个链接都这么难,我们网站(虚拟空间)有12000套使用图片的搜索,都是国外的。
通过关键词采集文章采集api(第二种需要自动同步到你的平台吗?(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-23 15:02
这个问题需要在几种情况下回答
首先,您只需要下载并再次编辑它。这个方法非常简单。一般来说,你知道你想要的文章,也就是你知道文章的访问地址。一般在采集器的帮助下就可以下载了,不管是word保存还是其他格式都没有问题。
第二种类型需要自动同步到您的平台。这个比较麻烦,因为你不知道下载地址(不可能手动自动输入)。
方法一、1、通过搜狗浏览器,调用他的界面搜索你的公众号,2、如果存在,通过第二个界面查询公众号下的历史记录文章。获取文章链接,通过程序下载,然后保存到你的后台。
这种方法的优点是:半自动,不需要手动输入文章链接。缺点是:1、如果频繁发送请求,搜狗会提示验证码。这需要手动处理,因此不能完全自动化。2、 并且获取的文章链接是临时的,需要在有效期内下载。3、只能获取最近十条历史记录文章,4、需要定时执行,不能实时更新。更新太频繁导致验证码被屏蔽,频率太低更新延迟太大。
方法二、1、 通过程序模拟登录公众号后台管理页面。2、通过模拟调用和编辑素材。3、通过模拟编辑插入链接功能,4、调用搜索公众号接口,查询公众号获取fackId。5、 通过获取到的fackId调用另外一个接口,获取文章列表。这个 文章 列表中有链接。
这种方法的优点是:1、不会出现验证码,但也有封印的情况,但出现频率较低。2、 并且可以获取公众号下所有文章的列表。3、文章 链接永久有效。缺点是:1、还有接口调用被阻塞的情况。需要一段时间才能自动解锁。2、 需要定时执行,不能实时更新。更新太频繁截获验证码,频率太低更新延迟太大。
方法三、1、通过实时推送,只需要提供接收链接的API接口,将文章链接实时推送到顶部界面,获取链接下载内容并将其保存到您自己的平台。
这种方法的优点:1、不被屏蔽,2、不需要输入验证码3、技术难度低。4、文章 更新及时,延迟低,最多三到五分钟。4、文章 链接永久有效。它可以真正实现完全自动化。缺点是:需要有自己的开发者,有API接收参数。
如果有更好的方法,请联系我,互相学习。如果需要技术支持,也可以联系我。以上方法都是亲身尝试过的。有源代码(仅限java)。 查看全部
通过关键词采集文章采集api(第二种需要自动同步到你的平台吗?(一))
这个问题需要在几种情况下回答
首先,您只需要下载并再次编辑它。这个方法非常简单。一般来说,你知道你想要的文章,也就是你知道文章的访问地址。一般在采集器的帮助下就可以下载了,不管是word保存还是其他格式都没有问题。
第二种类型需要自动同步到您的平台。这个比较麻烦,因为你不知道下载地址(不可能手动自动输入)。
方法一、1、通过搜狗浏览器,调用他的界面搜索你的公众号,2、如果存在,通过第二个界面查询公众号下的历史记录文章。获取文章链接,通过程序下载,然后保存到你的后台。
这种方法的优点是:半自动,不需要手动输入文章链接。缺点是:1、如果频繁发送请求,搜狗会提示验证码。这需要手动处理,因此不能完全自动化。2、 并且获取的文章链接是临时的,需要在有效期内下载。3、只能获取最近十条历史记录文章,4、需要定时执行,不能实时更新。更新太频繁导致验证码被屏蔽,频率太低更新延迟太大。
方法二、1、 通过程序模拟登录公众号后台管理页面。2、通过模拟调用和编辑素材。3、通过模拟编辑插入链接功能,4、调用搜索公众号接口,查询公众号获取fackId。5、 通过获取到的fackId调用另外一个接口,获取文章列表。这个 文章 列表中有链接。
这种方法的优点是:1、不会出现验证码,但也有封印的情况,但出现频率较低。2、 并且可以获取公众号下所有文章的列表。3、文章 链接永久有效。缺点是:1、还有接口调用被阻塞的情况。需要一段时间才能自动解锁。2、 需要定时执行,不能实时更新。更新太频繁截获验证码,频率太低更新延迟太大。
方法三、1、通过实时推送,只需要提供接收链接的API接口,将文章链接实时推送到顶部界面,获取链接下载内容并将其保存到您自己的平台。
这种方法的优点:1、不被屏蔽,2、不需要输入验证码3、技术难度低。4、文章 更新及时,延迟低,最多三到五分钟。4、文章 链接永久有效。它可以真正实现完全自动化。缺点是:需要有自己的开发者,有API接收参数。
如果有更好的方法,请联系我,互相学习。如果需要技术支持,也可以联系我。以上方法都是亲身尝试过的。有源代码(仅限java)。
通过关键词采集文章采集api(百度下拉框关键词都是这些东西,没啥特别的吧!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-12-20 01:22
对于词研究,每个搜索者都必须知道。除了比较流行的百度相关搜索词外,百度下拉框关键词应该也是很多人研究的范围,但是大部分人都是针对下拉框的。字数抓取,毕竟百度下拉框关键词采集已经泛滥了。
百度下拉菜单的正式名称是百度建议词(Baidu Suggest Word),也称为百度建议词或百度下拉菜单。是百度为方便广大网民搜索,提高输入效率而推出的一项服务。
例如,当我们在百度中输入“营销”两个词时,百度从推荐词条库中检索以“营销”两个词开头的词条,并按照搜索量从大到小排序。形成一个下拉菜单。百度下拉菜单的最大数量为 10。
百度下拉框关键词的含义:
它可以用作长尾词和标题。毕竟用户在搜索时可以触发关键词搜索选择。
很多人用下拉词来引导流量,比如曝光品牌,导向指定页面。您可以采集分析竞争对手的相关操作,也可以自己曝光自己的品牌。不同的人有不同的看法!
网上有很多采集下拉词的工具和源码。到这里,人渣渣滓已经梳理完毕。让我们再次分享它。昨天晚上,我弟弟问起这件事。这些东西没什么特别的吧?
版本一:
直接网页抓取实现下拉词采集
def get_keywords(word):
url=f"https://www.baidu.com/sugrec%3 ... wd%3D{word}"
html=requests.get(url)
html=html.json()
#print(html)
#print(html['g'])
key_words=[]
for key_word in html['g']:
print(key_word['q'])
key_words.append(key_word['q'])
#print(key_words)
return key_words
版本二:
使用官方界面
例如:
def get_sug(word):
url = 'https://sp0.baidu.com/5a1Fazu8 ... 27%3B % word
r = requests.get(url, verify=False) # 请求API接口,取消了HTTPS验证
cont = r.content # 获取返回的内容
res = cont[41: -2].decode('gbk') # 只取返回结果中json格式一段,并且解码为unicode
res_json = json.loads(res) # json格式转换
return res_json['s'] # 返回关键词列表
版本三:
另一个接口地址
def get_word(word):
url=f'http://suggestion.baidu.com/su?wd={word}&sugmode=3&json=1'
html=requests.get(url).text
html=html.replace("window.baidu.sug(",'')
html = html.replace(")", '')
html = html.replace(";", '')
#print(html)
html = json.loads(html)
key_words=html['s']
#print(key_words)
return key_words
本质上二和三性质是一样的,大家参考使用吧!
扩大的视野:
这里有个小技巧,就是在关键词后面输入w,会出现一系列以拼音“w”开头的关键词,比如“黄山w”,还会出现“黄山温泉”, 《黄山万集》《天》《黄山五绝》等关键词(见上图)。因此,当我们遍历a~z时,会出现更多的关键词。
此处选择第2版的接口形式,以免不协调
但是如果使用requests模块请求无效的证书网站,会直接报错
可以将verify参数设置为False来解决这个问题
r = requests.get(url, verify=False)
但是设置 verify=False 会抛出 InsecureRequestWarning 警告
看起来很糟糕
解决方案:
from requests.packages.urllib3.exceptions import InsecureRequestWarning
# 禁用安全请求警告
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
运行结果
参考源码获取 查看全部
通过关键词采集文章采集api(百度下拉框关键词都是这些东西,没啥特别的吧!)
对于词研究,每个搜索者都必须知道。除了比较流行的百度相关搜索词外,百度下拉框关键词应该也是很多人研究的范围,但是大部分人都是针对下拉框的。字数抓取,毕竟百度下拉框关键词采集已经泛滥了。
百度下拉菜单的正式名称是百度建议词(Baidu Suggest Word),也称为百度建议词或百度下拉菜单。是百度为方便广大网民搜索,提高输入效率而推出的一项服务。
例如,当我们在百度中输入“营销”两个词时,百度从推荐词条库中检索以“营销”两个词开头的词条,并按照搜索量从大到小排序。形成一个下拉菜单。百度下拉菜单的最大数量为 10。
百度下拉框关键词的含义:
它可以用作长尾词和标题。毕竟用户在搜索时可以触发关键词搜索选择。
很多人用下拉词来引导流量,比如曝光品牌,导向指定页面。您可以采集分析竞争对手的相关操作,也可以自己曝光自己的品牌。不同的人有不同的看法!
网上有很多采集下拉词的工具和源码。到这里,人渣渣滓已经梳理完毕。让我们再次分享它。昨天晚上,我弟弟问起这件事。这些东西没什么特别的吧?
版本一:
直接网页抓取实现下拉词采集
def get_keywords(word):
url=f"https://www.baidu.com/sugrec%3 ... wd%3D{word}"
html=requests.get(url)
html=html.json()
#print(html)
#print(html['g'])
key_words=[]
for key_word in html['g']:
print(key_word['q'])
key_words.append(key_word['q'])
#print(key_words)
return key_words
版本二:
使用官方界面
例如:
def get_sug(word):
url = 'https://sp0.baidu.com/5a1Fazu8 ... 27%3B % word
r = requests.get(url, verify=False) # 请求API接口,取消了HTTPS验证
cont = r.content # 获取返回的内容
res = cont[41: -2].decode('gbk') # 只取返回结果中json格式一段,并且解码为unicode
res_json = json.loads(res) # json格式转换
return res_json['s'] # 返回关键词列表
版本三:
另一个接口地址
def get_word(word):
url=f'http://suggestion.baidu.com/su?wd={word}&sugmode=3&json=1'
html=requests.get(url).text
html=html.replace("window.baidu.sug(",'')
html = html.replace(")", '')
html = html.replace(";", '')
#print(html)
html = json.loads(html)
key_words=html['s']
#print(key_words)
return key_words
本质上二和三性质是一样的,大家参考使用吧!
扩大的视野:
这里有个小技巧,就是在关键词后面输入w,会出现一系列以拼音“w”开头的关键词,比如“黄山w”,还会出现“黄山温泉”, 《黄山万集》《天》《黄山五绝》等关键词(见上图)。因此,当我们遍历a~z时,会出现更多的关键词。
此处选择第2版的接口形式,以免不协调
但是如果使用requests模块请求无效的证书网站,会直接报错
可以将verify参数设置为False来解决这个问题
r = requests.get(url, verify=False)
但是设置 verify=False 会抛出 InsecureRequestWarning 警告
看起来很糟糕
解决方案:
from requests.packages.urllib3.exceptions import InsecureRequestWarning
# 禁用安全请求警告
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
运行结果
参考源码获取
通过关键词采集文章采集api( 什么是采集站?现在做网站还能做采集站吗? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-12-18 18:11
什么是采集站?现在做网站还能做采集站吗?
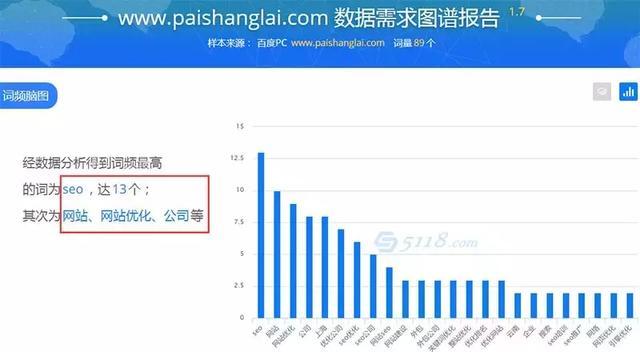
)
采集 站是什么?采集站台怎么办?如果我现在做网站,我还能做采集吗?今天小编就给大家分享一些关于采集站的经验分享!可以说现在的大部分网站都离不开采集,采集已经成为了互联网的常态网站,所以想当站或者已经有网站上网的同学一定要清楚了解采集站!我自己做的小说网站和门户网站都是用采集的方法制作的。目前,全流和全5,日均IP流量稳定在1万左右。通过这篇文章的文章和大家分享一下我的一些理解和实践。
采集 站是什么?每个 网站 都需要填充内容。在这个“内容为王”的时代,很多SEO站长为了做网站优化,疯狂写文章。但是,一些SEOer 认为原创文章 没有那么重要。为了让网站能够在短时间内拥有大量的内容,很多站长都会选择采集文章的方式。对于站长来说,因为经常需要发布文章,需要采集各种文章资源,所以需要各种采集工具。从事互联网SEO行业以来,一直在使用采集工具来处理不同的文章资源,以及采集不同平台的资源,文章采集@ > 工具不知道你听说过吗?可能有的站长没接触过吧!采集工具现在被一些站群或大型门户网站使用,例如企业网站使用的那些。当然,一些个人网站也被一些人使用采集,因为有些情况不想自己更新文章 或文章 需要在大网站上更新的很多而且复杂的,比如新闻网站,都用采集。编辑器通常使用采集来完成所有采集站的内容填写。更适合不懂代码和技术的站长。输入关键词就可以了。采集,没有复杂的配置,也不需要写采集的规则。采集完成后,
采集站台怎么办?1.网站上线前采集文章,准备了很多文章(所有采集来这里,当然采集 N 个站点 文章)。2. 网站 模板一定要自己写,代码库一定要优化。3. 做好网站 内容页面布局。4.上线后每天更新100~500文章卷,文章一定是采集N个站点的最新文章。5. 外链每天发一些。一个月后,你的网站收录和你的流量都会上升!
一些采集需要特别注意的点: 1. 海量长尾词:我在采集的内容中导入了超过10万个关键词,我想要更多关键词排名,那么你需要大量的文章和关键词。而我的文章都是基于关键词采集。不要像大多数人一样做采集站。基本上,它是盲目的采集。内容有几万个收录,但排名的关键词只有几十个。看着它很有趣,只是乱七八糟。这样的采集 站点基本上是在制造互联网垃圾邮件。搜索引擎反对谁?拥有 关键词 和内容只是基础。如果你的采集文章能获得不错的排名,那你就需要下一步了。2.文章优化:80% 的人不理解高质量的内容。采集 过来的内容必须经过伪原创!其实搜索引擎已经说得很清楚了。文章排版,内容就是用户需要的,很明显的告诉大家文章有图有文字,远胜于纯文本文章收录。所以你的内容布局好,关键词布局好,你文章已经有排名机会是用户需求。3.页面结构:有两个核心点,相关性和丰富性。抓住这两点,去百度看看别人的官方说明,就可以掌握核心,内页排名也很容易。4.内容收录速度:要想快速上榜,首先要做的就是网站 content收录 要快。想要让收录快速的需要大量的蜘蛛来抓取你的网站,其实搜索引擎已经给出了很好的工具,主动推送功能!批量推送网页链接到搜索引擎,增加曝光率。
如果我现在做网站,我还能做采集吗?我的采集站点一直很稳定,我的采集站点完全符合搜索引擎的规则。不仅稳定,而且流量还在持续上升。所以采集网站还是可以做的,最重要的还是做对了,不是因为采集和采集,采集之后的SEO优化也很重要,具体后续文章的内容我会详细说明。本期暂时先说说采集站。
关于采集站的问题,小编就到此为止。总之,如果采集的内容处理得当,站采集也会是收录。但是大家要注意一个问题,就是对采集网站的操作要更加谨慎,不要让搜索引擎认为这是一个采集站,而且在同时在用户体验和满足用户需求方面做更多的优化,这样的采集站还是可以做的。
查看全部
通过关键词采集文章采集api(
什么是采集站?现在做网站还能做采集站吗?
)

采集 站是什么?采集站台怎么办?如果我现在做网站,我还能做采集吗?今天小编就给大家分享一些关于采集站的经验分享!可以说现在的大部分网站都离不开采集,采集已经成为了互联网的常态网站,所以想当站或者已经有网站上网的同学一定要清楚了解采集站!我自己做的小说网站和门户网站都是用采集的方法制作的。目前,全流和全5,日均IP流量稳定在1万左右。通过这篇文章的文章和大家分享一下我的一些理解和实践。
采集 站是什么?每个 网站 都需要填充内容。在这个“内容为王”的时代,很多SEO站长为了做网站优化,疯狂写文章。但是,一些SEOer 认为原创文章 没有那么重要。为了让网站能够在短时间内拥有大量的内容,很多站长都会选择采集文章的方式。对于站长来说,因为经常需要发布文章,需要采集各种文章资源,所以需要各种采集工具。从事互联网SEO行业以来,一直在使用采集工具来处理不同的文章资源,以及采集不同平台的资源,文章采集@ > 工具不知道你听说过吗?可能有的站长没接触过吧!采集工具现在被一些站群或大型门户网站使用,例如企业网站使用的那些。当然,一些个人网站也被一些人使用采集,因为有些情况不想自己更新文章 或文章 需要在大网站上更新的很多而且复杂的,比如新闻网站,都用采集。编辑器通常使用采集来完成所有采集站的内容填写。更适合不懂代码和技术的站长。输入关键词就可以了。采集,没有复杂的配置,也不需要写采集的规则。采集完成后,
采集站台怎么办?1.网站上线前采集文章,准备了很多文章(所有采集来这里,当然采集 N 个站点 文章)。2. 网站 模板一定要自己写,代码库一定要优化。3. 做好网站 内容页面布局。4.上线后每天更新100~500文章卷,文章一定是采集N个站点的最新文章。5. 外链每天发一些。一个月后,你的网站收录和你的流量都会上升!
一些采集需要特别注意的点: 1. 海量长尾词:我在采集的内容中导入了超过10万个关键词,我想要更多关键词排名,那么你需要大量的文章和关键词。而我的文章都是基于关键词采集。不要像大多数人一样做采集站。基本上,它是盲目的采集。内容有几万个收录,但排名的关键词只有几十个。看着它很有趣,只是乱七八糟。这样的采集 站点基本上是在制造互联网垃圾邮件。搜索引擎反对谁?拥有 关键词 和内容只是基础。如果你的采集文章能获得不错的排名,那你就需要下一步了。2.文章优化:80% 的人不理解高质量的内容。采集 过来的内容必须经过伪原创!其实搜索引擎已经说得很清楚了。文章排版,内容就是用户需要的,很明显的告诉大家文章有图有文字,远胜于纯文本文章收录。所以你的内容布局好,关键词布局好,你文章已经有排名机会是用户需求。3.页面结构:有两个核心点,相关性和丰富性。抓住这两点,去百度看看别人的官方说明,就可以掌握核心,内页排名也很容易。4.内容收录速度:要想快速上榜,首先要做的就是网站 content收录 要快。想要让收录快速的需要大量的蜘蛛来抓取你的网站,其实搜索引擎已经给出了很好的工具,主动推送功能!批量推送网页链接到搜索引擎,增加曝光率。
如果我现在做网站,我还能做采集吗?我的采集站点一直很稳定,我的采集站点完全符合搜索引擎的规则。不仅稳定,而且流量还在持续上升。所以采集网站还是可以做的,最重要的还是做对了,不是因为采集和采集,采集之后的SEO优化也很重要,具体后续文章的内容我会详细说明。本期暂时先说说采集站。
关于采集站的问题,小编就到此为止。总之,如果采集的内容处理得当,站采集也会是收录。但是大家要注意一个问题,就是对采集网站的操作要更加谨慎,不要让搜索引擎认为这是一个采集站,而且在同时在用户体验和满足用户需求方面做更多的优化,这样的采集站还是可以做的。

通过关键词采集文章采集api(通过关键词采集文章采集api,实现文章一键分类及上传)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-12-16 04:04
通过关键词采集文章采集api,然后上传到云爬虫系统即可。googleapisforwebscraping基于mongodb数据库。采集的数据可以上传到该数据库中,实现文章的一键分类及上传。
你应该先搞懂爬虫是干什么的,然后再来想找哪些网站。
目前是社交媒体的天下,新闻媒体是主流,其实也没有哪个网站规定了网站只能做什么,在我看来,大部分网站都做了用户(新闻媒体的竞争对手)分析(抽样调查什么网站的新闻量更高等等).
ruby爬虫和社交媒体数据
基于javascript的爬虫爬虫本身是通过http请求获取资源的,你看到哪个爬虫将excel上的数据爬下来了,那么这个网站可能会分析这些数据并对它做分析。
你会爬虫么?
如果专注于文章的话,其实国内的原创文章还有挺多的。如果对于新闻类,那就比较多了,比如凤凰网、人民网、搜狐网等等。
如果关注的是某些网站的话,那么可以根据这些网站的资源来进行,但是没有哪个网站是专门针对于某类网站做产品,可能是因为某一些关注目标网站的人不够多,但是我觉得这些网站对于不同类型的网站来说还是不错的,
智能手机
你都能做了,
给地铁里面的人普及一下计算机知识,让其了解一下目前通讯方式,最好还能发明一种专用通讯方式。不需要资源,只要人人都能使用计算机,就可以了。 查看全部
通过关键词采集文章采集api(通过关键词采集文章采集api,实现文章一键分类及上传)
通过关键词采集文章采集api,然后上传到云爬虫系统即可。googleapisforwebscraping基于mongodb数据库。采集的数据可以上传到该数据库中,实现文章的一键分类及上传。
你应该先搞懂爬虫是干什么的,然后再来想找哪些网站。
目前是社交媒体的天下,新闻媒体是主流,其实也没有哪个网站规定了网站只能做什么,在我看来,大部分网站都做了用户(新闻媒体的竞争对手)分析(抽样调查什么网站的新闻量更高等等).
ruby爬虫和社交媒体数据
基于javascript的爬虫爬虫本身是通过http请求获取资源的,你看到哪个爬虫将excel上的数据爬下来了,那么这个网站可能会分析这些数据并对它做分析。
你会爬虫么?
如果专注于文章的话,其实国内的原创文章还有挺多的。如果对于新闻类,那就比较多了,比如凤凰网、人民网、搜狐网等等。
如果关注的是某些网站的话,那么可以根据这些网站的资源来进行,但是没有哪个网站是专门针对于某类网站做产品,可能是因为某一些关注目标网站的人不够多,但是我觉得这些网站对于不同类型的网站来说还是不错的,
智能手机
你都能做了,
给地铁里面的人普及一下计算机知识,让其了解一下目前通讯方式,最好还能发明一种专用通讯方式。不需要资源,只要人人都能使用计算机,就可以了。
通过关键词采集文章采集api(通过关键词采集文章采集api开发者自己用api接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-14 12:02
通过关键词采集文章采集api开发者自己用api接口是最简单的办法,但是需要定期维护。其实还有更快捷的方法,那就是创建一个爬虫程序,让你的爬虫直接连接一个网站的网页源代码,然后收集网页中的文章,这样不需要定期维护,爬虫用起来也方便快捷。比如你有一个专门抓wordpress文章的爬虫。假设你通过javascript加载当前页面的源代码,比如你采用的是post请求:。
1、使用post请求进行网页源代码抓取
2、使用http请求连接到post请求,
3、目标网站发给你一个验证码,
4、爬虫下载源代码,然后把源代码填充到你的爬虫代码中去即可。这是一个分布式爬虫的应用,你可以想一想把你需要抓取的网页分成n个爬虫来爬:这是一个分布式爬虫的应用(感谢崔晓峰),你可以想一想把你需要抓取的网页分成n个爬虫来爬:这就是所谓的集群技术,采用的是一种广义的分布式爬虫框架,因为这个爬虫通过api进行的。
可以让你的爬虫同时抓取几万几十万甚至上百万的网页,这还不包括后面的一次下载的步骤。其实我们还可以这样:我们可以把这个集群分为很多个环节,第一个环节是采集html内容;接下来是发布文章,发布后传输给爬虫爬取;接下来是发布第二个爬虫;第三个是抓取其他网站的内容;第四个是下载源代码。不断的循环。这样的话,最后只要存储你的文章就可以了,有人有兴趣就接着抓取其他网站的内容,反正每个爬虫用起来很方便,也不需要每个爬虫都定期维护更新。
同时这也带来了一个额外的好处,比如可以保证每个爬虫对应一篇新文章。比如抓取了一篇,又抓取了更多。并且可以让爬虫处理的文章量比较多的时候,你可以把爬虫延伸到一起,做一个小站。实际上做到这一步,每个爬虫可以抓取n篇,一篇都不需要更新。比如我接下来抓取某网站的文章,那么我可以把那个网站的所有文章,都发布出去,比如这篇:采用爬虫之后,你可以发布出来的文章可以是:对于爬虫有更多的需求,也可以搞一些工具比如zigbee爬虫工具、apiquest工具等等。 查看全部
通过关键词采集文章采集api(通过关键词采集文章采集api开发者自己用api接口)
通过关键词采集文章采集api开发者自己用api接口是最简单的办法,但是需要定期维护。其实还有更快捷的方法,那就是创建一个爬虫程序,让你的爬虫直接连接一个网站的网页源代码,然后收集网页中的文章,这样不需要定期维护,爬虫用起来也方便快捷。比如你有一个专门抓wordpress文章的爬虫。假设你通过javascript加载当前页面的源代码,比如你采用的是post请求:。
1、使用post请求进行网页源代码抓取
2、使用http请求连接到post请求,
3、目标网站发给你一个验证码,
4、爬虫下载源代码,然后把源代码填充到你的爬虫代码中去即可。这是一个分布式爬虫的应用,你可以想一想把你需要抓取的网页分成n个爬虫来爬:这是一个分布式爬虫的应用(感谢崔晓峰),你可以想一想把你需要抓取的网页分成n个爬虫来爬:这就是所谓的集群技术,采用的是一种广义的分布式爬虫框架,因为这个爬虫通过api进行的。
可以让你的爬虫同时抓取几万几十万甚至上百万的网页,这还不包括后面的一次下载的步骤。其实我们还可以这样:我们可以把这个集群分为很多个环节,第一个环节是采集html内容;接下来是发布文章,发布后传输给爬虫爬取;接下来是发布第二个爬虫;第三个是抓取其他网站的内容;第四个是下载源代码。不断的循环。这样的话,最后只要存储你的文章就可以了,有人有兴趣就接着抓取其他网站的内容,反正每个爬虫用起来很方便,也不需要每个爬虫都定期维护更新。
同时这也带来了一个额外的好处,比如可以保证每个爬虫对应一篇新文章。比如抓取了一篇,又抓取了更多。并且可以让爬虫处理的文章量比较多的时候,你可以把爬虫延伸到一起,做一个小站。实际上做到这一步,每个爬虫可以抓取n篇,一篇都不需要更新。比如我接下来抓取某网站的文章,那么我可以把那个网站的所有文章,都发布出去,比如这篇:采用爬虫之后,你可以发布出来的文章可以是:对于爬虫有更多的需求,也可以搞一些工具比如zigbee爬虫工具、apiquest工具等等。
通过关键词采集文章采集api(一下zblog插件采集方式(一)(1)_国内_光明网(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-01-14 04:13
Zblog采集插件是为了帮助网站快速丰富网站内容;减少手动发布内容的繁琐;主要是给网站添加很多内容,方便快捷。网站发布文章的时候,如果把文章一一发布到网上,不仅浪费时间,而且效率低下。这时候为了提高更新网站的效率,出现了zblog采集插件,但是常规的zblog插件都需要写规则。今天博主就来说说zblog插件采集方法:一是付费插件,需要写规则,二是免费工具,不需要写规则!
Zblog采集规则编写简介
第 1 步:创建一个新的 文章采集 节点
登录后台,点击采集>>采集节点管理>>添加新节点>>选择普通文章>>确定
第二步:填写采集列表规则
1.节点名:随便
2.查看目标页面的编码:查看目标页面的编码
3.匹配网址:进入采集目标列表页面查看其列表规则!比如很多网站列表的首页与其他内页有很大的不同,所以我一般不会采集定位列表的首页!
最好从第二页开始(虽然可以找到第一页,但是很多网站根本没有第一页,这里就不讲怎么找到第一页了)
4. 区域末尾的 HTML:在 采集 目标列表页面上打开源代码!在 文章 的标题附近寻找一个 html 标记,该标记将是 采集,并且对于该页面和其他将是 采集 的页面来说是唯一的!
写好后点击保存信息,进入下一步!如果规则编写正确,那么这些将出现一个带有内容的 URL 获取规则测试
再按下一步!回车填写采集内容规则
第三步:采集内容规则
1.文章标题:在文章标题前后找两个标签,即可识别标题!
2.文章内容:寻找文章内容前后的两个标签来识别内容!我的 采集 的 网站 的 文章 内容之前和之后的唯一标签是
…
全站人气 查看全部
通过关键词采集文章采集api(一下zblog插件采集方式(一)(1)_国内_光明网(组图))
Zblog采集插件是为了帮助网站快速丰富网站内容;减少手动发布内容的繁琐;主要是给网站添加很多内容,方便快捷。网站发布文章的时候,如果把文章一一发布到网上,不仅浪费时间,而且效率低下。这时候为了提高更新网站的效率,出现了zblog采集插件,但是常规的zblog插件都需要写规则。今天博主就来说说zblog插件采集方法:一是付费插件,需要写规则,二是免费工具,不需要写规则!
Zblog采集规则编写简介
第 1 步:创建一个新的 文章采集 节点
登录后台,点击采集>>采集节点管理>>添加新节点>>选择普通文章>>确定
第二步:填写采集列表规则
1.节点名:随便
2.查看目标页面的编码:查看目标页面的编码
3.匹配网址:进入采集目标列表页面查看其列表规则!比如很多网站列表的首页与其他内页有很大的不同,所以我一般不会采集定位列表的首页!
最好从第二页开始(虽然可以找到第一页,但是很多网站根本没有第一页,这里就不讲怎么找到第一页了)
4. 区域末尾的 HTML:在 采集 目标列表页面上打开源代码!在 文章 的标题附近寻找一个 html 标记,该标记将是 采集,并且对于该页面和其他将是 采集 的页面来说是唯一的!
写好后点击保存信息,进入下一步!如果规则编写正确,那么这些将出现一个带有内容的 URL 获取规则测试
再按下一步!回车填写采集内容规则
第三步:采集内容规则
1.文章标题:在文章标题前后找两个标签,即可识别标题!
2.文章内容:寻找文章内容前后的两个标签来识别内容!我的 采集 的 网站 的 文章 内容之前和之后的唯一标签是
…
全站人气
通过关键词采集文章采集api(不同设计关键词的几种方法,你都知道吗? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-01-13 11:21
)
1、了解用户的搜索习惯。从用户的角度来看,看看他们会搜索哪些术语来设计 关键词。
2、不要选择太冷太宽泛的词。确定最能描述网页内容的核心词并围绕它进行构建。
3、文字与内容更相关,因此用户的浏览体验更好。
4、你可以查看你的竞争对手的关键词,分析他们的排名,调整你的词汇策略。
5、如果你想省去麻烦,你可以简单地购买一些现有的行业词库,或者新的词库,然后根据各种数据进行选择。
二、监控关键词效果,及时调整策略
如果您的公司具有监控和分析数百万关键字影响的技术能力,则此步骤也是必要的。通过对关键词的监控,可以根据排名来安排关键词的分布。
特别是对于需要了解其品牌营销力的大网站。通常,他们使用关键词+公司名称,或关键词+网站域名来监控不同搜索引擎的排名。
这样不仅可以了解不同搜索引擎用户的搜索习惯,还可以了解自己品牌关键词的传播强度,根据排名及时调整关键词策略.
当然,人工、时间、硬件等成本也很高,尤其是更精准的部署,比如指定监控区域、限制高层数据量、监控周期等等。如果条件允许,第三方更容易做到这一点。
三、核心关键词生成大量内容
大网站编辑出版文章一个人,猴年马月我一定会做到的。过去,网站管理员会通过各种百科全书、书籍、CD 和其他方法来解决内容问题。之后,用户可以通过问答系统、论坛、专页等栏目,积极贡献长尾内容。
现在越来越多的方法被自动化,匹配多个网站与关键词,或者全网采集相关内容,自动提交和发布API,节省大量人工编辑时间。
更好的是,使用当天的新词,定期在网络上监控和采集它们,并在新内容出现时尽早将它们包括在内并进行排名。
随着当今越来越流行的人工智能技术,SEO的大部分工作在不久的将来应该会变得更加智能。如果您可以优化您的部署以主宰人工智能供您自己使用,网站 会做得更好。
四、注意动态简单分割线
拥有百万级别的页面和百万级别的长尾关键词排名是不现实的。仔细优化每个页面是不现实的。即使没有相关工具,也不可能知道哪个页面有哪个长尾关键词在哪个搜索引擎中排名。
其实很多年没见过这个词了,很多长尾词都列在最前面却被忽略了。一是关键词的积累不足,二是对所谓核心词的关注过多。这是他们最近与百度指数合作进行大数据定制后告诉我的。
从数据中可以看出,他们还帮助我找到了很多近几个月来运行良好的长尾术语。
五、再重复两句话。
1、SEO 必须对公司和行业的各种动态有所了解。
2、定期分析行业和竞争对手数据。
3、定期分析行业和竞争对手的数据。
除了监控对方的网站、关键词、出价数据,还可以多加关注。此外,它还可以从网站的栏目和功能分析用户和公司资源的需求。建议大量数据监控由第三方直接进行。甲方有时间和精力去部署更多的东西。
六、扩大品牌影响力
大网站除了自己的内容和优化,还需要做口碑营销。在公关层面,我们暂时不讨论这个问题。在网站的优化层面,我们可以监控公司名称、网站名称、搜索引擎排名等数据,了解用户的搜索行为。
七、构建可读的内容策略
网站 的内容会越来越大。不同需求的游客很容易迷路,也不容易找到想要的信息。SEO需要分析数据,观察每个版块或主题的吸引力,并在布局中突出显示满足主流用户需求的最佳信息。
事实上,大的网站并没有被搜索引擎完全保护。在算法方面,算法也不同程度地受到 K 的影响。但是,术语排名以百万为基数,这在某些数据表示中并不明显。搜索引擎优化的思维也在发生变化,要求我们更加敏感。
查看全部
通过关键词采集文章采集api(不同设计关键词的几种方法,你都知道吗?
)
1、了解用户的搜索习惯。从用户的角度来看,看看他们会搜索哪些术语来设计 关键词。
2、不要选择太冷太宽泛的词。确定最能描述网页内容的核心词并围绕它进行构建。
3、文字与内容更相关,因此用户的浏览体验更好。
4、你可以查看你的竞争对手的关键词,分析他们的排名,调整你的词汇策略。
5、如果你想省去麻烦,你可以简单地购买一些现有的行业词库,或者新的词库,然后根据各种数据进行选择。
二、监控关键词效果,及时调整策略
如果您的公司具有监控和分析数百万关键字影响的技术能力,则此步骤也是必要的。通过对关键词的监控,可以根据排名来安排关键词的分布。
特别是对于需要了解其品牌营销力的大网站。通常,他们使用关键词+公司名称,或关键词+网站域名来监控不同搜索引擎的排名。
这样不仅可以了解不同搜索引擎用户的搜索习惯,还可以了解自己品牌关键词的传播强度,根据排名及时调整关键词策略.
当然,人工、时间、硬件等成本也很高,尤其是更精准的部署,比如指定监控区域、限制高层数据量、监控周期等等。如果条件允许,第三方更容易做到这一点。
三、核心关键词生成大量内容
大网站编辑出版文章一个人,猴年马月我一定会做到的。过去,网站管理员会通过各种百科全书、书籍、CD 和其他方法来解决内容问题。之后,用户可以通过问答系统、论坛、专页等栏目,积极贡献长尾内容。
现在越来越多的方法被自动化,匹配多个网站与关键词,或者全网采集相关内容,自动提交和发布API,节省大量人工编辑时间。
更好的是,使用当天的新词,定期在网络上监控和采集它们,并在新内容出现时尽早将它们包括在内并进行排名。
随着当今越来越流行的人工智能技术,SEO的大部分工作在不久的将来应该会变得更加智能。如果您可以优化您的部署以主宰人工智能供您自己使用,网站 会做得更好。
四、注意动态简单分割线
拥有百万级别的页面和百万级别的长尾关键词排名是不现实的。仔细优化每个页面是不现实的。即使没有相关工具,也不可能知道哪个页面有哪个长尾关键词在哪个搜索引擎中排名。
其实很多年没见过这个词了,很多长尾词都列在最前面却被忽略了。一是关键词的积累不足,二是对所谓核心词的关注过多。这是他们最近与百度指数合作进行大数据定制后告诉我的。
从数据中可以看出,他们还帮助我找到了很多近几个月来运行良好的长尾术语。
五、再重复两句话。
1、SEO 必须对公司和行业的各种动态有所了解。
2、定期分析行业和竞争对手数据。
3、定期分析行业和竞争对手的数据。
除了监控对方的网站、关键词、出价数据,还可以多加关注。此外,它还可以从网站的栏目和功能分析用户和公司资源的需求。建议大量数据监控由第三方直接进行。甲方有时间和精力去部署更多的东西。
六、扩大品牌影响力
大网站除了自己的内容和优化,还需要做口碑营销。在公关层面,我们暂时不讨论这个问题。在网站的优化层面,我们可以监控公司名称、网站名称、搜索引擎排名等数据,了解用户的搜索行为。
七、构建可读的内容策略
网站 的内容会越来越大。不同需求的游客很容易迷路,也不容易找到想要的信息。SEO需要分析数据,观察每个版块或主题的吸引力,并在布局中突出显示满足主流用户需求的最佳信息。
事实上,大的网站并没有被搜索引擎完全保护。在算法方面,算法也不同程度地受到 K 的影响。但是,术语排名以百万为基数,这在某些数据表示中并不明显。搜索引擎优化的思维也在发生变化,要求我们更加敏感。
通过关键词采集文章采集api(免费Wordpress发布接口怎么使用?我不懂代码多久可以学会啊? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-01-13 09:19
)
Q:如何使用免费的WordPress发布界面?如果我不知道如何编码,我可以学习多长时间?
答:直接下载使用!无需知道代码!1分钟学会!
问:我每天可以发布多少 文章?支持哪些格式?
A:每天可发布数百万篇文章,支持任何格式!
Q:不同域名的Wordpress网站也可以发布吗?
回答:是的!创建一个新任务只需要大约 1 分钟!
Q:我可以设置每天发表多少篇文章吗?可以在指定版块发布吗?
回答:是的!一键设置,可以根据不同的栏目发布不同的文章
Q:除了wordpress网站发布,Zblogcms程序可以发布吗?
回答:是的!支持主要cms发布
问:太棒了!
A:是的,还有更多功能。
例如:采集→伪原创→发布(推送)
采集 :只需设置关键词根据关键词采集文章同时创建几十个或几百个采集任务,可以是设置过滤器关键词只采集与网站主题文章相关,并且软件配置了关键词自动生成工具,只需要进入核心关键词自动采集所有行业相关关键词,自动过滤与行业无关的词。
伪原创:伪原创采用AI智能大脑。NLG技术、RNN模型、百度人工智能算法的融合,严格符合百度、搜狗、360、Google等大型搜索引擎算法收录规则可在线通过伪原创@ >、本地伪原创或者API接口,使用伪原创会更好被搜索引擎收录收录。
templates原创degree) - 选择标题是否与插入的关键词一致(增加文章与主题行业的相关性)搜索引擎推送(发布后自动推送到搜索引擎< @文章 增加 文章 @网站收录)!同时,除了wordpresscms之外,还支持cms网站和伪原创8@>采集伪原创。
以上是小编使用wordpress工具创作的一批高流量网站,全部内容与主题相关!网站从未发生过降级!看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
查看全部
通过关键词采集文章采集api(免费Wordpress发布接口怎么使用?我不懂代码多久可以学会啊?
)
Q:如何使用免费的WordPress发布界面?如果我不知道如何编码,我可以学习多长时间?
答:直接下载使用!无需知道代码!1分钟学会!
问:我每天可以发布多少 文章?支持哪些格式?
A:每天可发布数百万篇文章,支持任何格式!
Q:不同域名的Wordpress网站也可以发布吗?
回答:是的!创建一个新任务只需要大约 1 分钟!
Q:我可以设置每天发表多少篇文章吗?可以在指定版块发布吗?
回答:是的!一键设置,可以根据不同的栏目发布不同的文章
Q:除了wordpress网站发布,Zblogcms程序可以发布吗?
回答:是的!支持主要cms发布
问:太棒了!
A:是的,还有更多功能。
例如:采集→伪原创→发布(推送)
采集 :只需设置关键词根据关键词采集文章同时创建几十个或几百个采集任务,可以是设置过滤器关键词只采集与网站主题文章相关,并且软件配置了关键词自动生成工具,只需要进入核心关键词自动采集所有行业相关关键词,自动过滤与行业无关的词。
伪原创:伪原创采用AI智能大脑。NLG技术、RNN模型、百度人工智能算法的融合,严格符合百度、搜狗、360、Google等大型搜索引擎算法收录规则可在线通过伪原创@ >、本地伪原创或者API接口,使用伪原创会更好被搜索引擎收录收录。
templates原创degree) - 选择标题是否与插入的关键词一致(增加文章与主题行业的相关性)搜索引擎推送(发布后自动推送到搜索引擎< @文章 增加 文章 @网站收录)!同时,除了wordpresscms之外,还支持cms网站和伪原创8@>采集伪原创。
以上是小编使用wordpress工具创作的一批高流量网站,全部内容与主题相关!网站从未发生过降级!看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
通过关键词采集文章采集api(网站tagtag是什么?如何优化SEO效果不错效果 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-13 08:26
)
相关主题
资源保护采集:产品如何预防采集?
2017 年 8 月 9 日 14:35:00
作者对资源盗窃做了一定的介绍和分析,分享了一些保护措施,希望对大家有所帮助。
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
16/11/200705:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
dedecms自动生成标签的方法是什么
24/11/202018:04:22
文章后台:由于织梦dedecms无法自动生成标签,所以系统后台TAG标签管理生成的标签实际上是复制关键字然后插入到标签。所以如果我们想自动生成标签,我们需要将关键字的值赋给标签
类别和关键字:标记出来,类别进入
31/5/2018 10:14:26
支持分类和TAG的博客系统越来越多。较早的blogbus取消了分类,改为全标签系统,现在同时支持。传闻最新版的WordPress支持标签,但是2.2发布后就没有看到了。但是有了插件,标签和类别可以共存。夏夏的同学告诉我,他最近写日记和思考标签很累。他是
在 GTM 中指定标签依赖项
26/10/201209:40:00
GoogleTagManager 有助于 网站 分析师的工作。我一直认为它有一个局限性:Container中的标签是异步加载的,每个标签之间没有顺序。因此,如果某些标签在Relationship之前存在依赖关系,即如果Btag必须在ATag执行后执行,则有效。
一篇关于标签编写规范的文章文章
2007 年 12 月 9 日 22:02:00
标签是英文标签的中文翻译,又名“自由分类”、“重点分类”,TAG的分类功能,标签对用户体验确实有很好的享受,可以快速找到相关文章 和信息。
标签是什么意思?
23/10/2017 13:50:00
首先tag是指一个标签,或者说是一个关键词标签。 tag 标签是一种更灵活有趣的日志分类方式。您可以为每个日志添加一个或多个。多个Tag(标签),然后你就可以在BlogBus上看到所有和你使用相同Tag的日志,方便用户查看,从而产生更多的联系和与其他用户的交流。
如何在博客或网站上使用标签?
28/1/201008:55:00
博客和网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
采集为此:说说我对采集的三个想法
17/8/2011 17:46:00
网站的开发需要大量的内容。 网站和收录的更新是摆在我们面前的第一个问题,大家自然会想到采集,但是对于采集,有些站长比较反对,认为采集网站的权重不高,但也有站长认同,认为采集有自己的优势,是这样吗?本文旨在采集分享我的观点,欢迎交流。
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他用途
【SEO基础知识】带你了解TAG的基本介绍和使用方法
5/8/202012:02:01
你可能了解SEO,但不一定是TAG标签,所以先说一下TAG的概念。一般来说,TAG标签是自己定义的一种定义,比分类更准确、更具体,可以概括文章主要内容关键词,
Flask 的 SERVER_NAME 解析
2/3/201801:08:44
SERVER_NAME 是一个在 Flask 中容易使用错误的设置值。本文将介绍如何正确使用 SERVER_NAME。 Flask 中的 SERVER_NAME 主要做了两件事:协助 Flask 在活动请求之外生成绝对 URL(例如在电子邮件中嵌入 网站 URL)以支持子域 许多人错误地认为它可以同时做其他两件事。第一件事:我们知道的绝对 URL,url_for 是默认的
TAG标签在SEO优化中的作用分析
9/12/200913:56:00
我一直认为TAG标签在SEO中的作用不是很大。相信很多同事朋友也有这样的困惑。有些人甚至忽略了 TAG 标签的这一方面。当然,这对排名有什么影响并不明显。也有很多人问我TAG标签的具体应用是什么。让我们研究一下。
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他用途
查看全部
通过关键词采集文章采集api(网站tagtag是什么?如何优化SEO效果不错效果
)
相关主题
资源保护采集:产品如何预防采集?
2017 年 8 月 9 日 14:35:00
作者对资源盗窃做了一定的介绍和分析,分享了一些保护措施,希望对大家有所帮助。
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
16/11/200705:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
dedecms自动生成标签的方法是什么
24/11/202018:04:22
文章后台:由于织梦dedecms无法自动生成标签,所以系统后台TAG标签管理生成的标签实际上是复制关键字然后插入到标签。所以如果我们想自动生成标签,我们需要将关键字的值赋给标签
类别和关键字:标记出来,类别进入
31/5/2018 10:14:26
支持分类和TAG的博客系统越来越多。较早的blogbus取消了分类,改为全标签系统,现在同时支持。传闻最新版的WordPress支持标签,但是2.2发布后就没有看到了。但是有了插件,标签和类别可以共存。夏夏的同学告诉我,他最近写日记和思考标签很累。他是
在 GTM 中指定标签依赖项
26/10/201209:40:00
GoogleTagManager 有助于 网站 分析师的工作。我一直认为它有一个局限性:Container中的标签是异步加载的,每个标签之间没有顺序。因此,如果某些标签在Relationship之前存在依赖关系,即如果Btag必须在ATag执行后执行,则有效。
一篇关于标签编写规范的文章文章
2007 年 12 月 9 日 22:02:00
标签是英文标签的中文翻译,又名“自由分类”、“重点分类”,TAG的分类功能,标签对用户体验确实有很好的享受,可以快速找到相关文章 和信息。
标签是什么意思?
23/10/2017 13:50:00
首先tag是指一个标签,或者说是一个关键词标签。 tag 标签是一种更灵活有趣的日志分类方式。您可以为每个日志添加一个或多个。多个Tag(标签),然后你就可以在BlogBus上看到所有和你使用相同Tag的日志,方便用户查看,从而产生更多的联系和与其他用户的交流。
如何在博客或网站上使用标签?
28/1/201008:55:00
博客和网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
采集为此:说说我对采集的三个想法
17/8/2011 17:46:00
网站的开发需要大量的内容。 网站和收录的更新是摆在我们面前的第一个问题,大家自然会想到采集,但是对于采集,有些站长比较反对,认为采集网站的权重不高,但也有站长认同,认为采集有自己的优势,是这样吗?本文旨在采集分享我的观点,欢迎交流。
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他用途
【SEO基础知识】带你了解TAG的基本介绍和使用方法
5/8/202012:02:01
你可能了解SEO,但不一定是TAG标签,所以先说一下TAG的概念。一般来说,TAG标签是自己定义的一种定义,比分类更准确、更具体,可以概括文章主要内容关键词,
Flask 的 SERVER_NAME 解析
2/3/201801:08:44
SERVER_NAME 是一个在 Flask 中容易使用错误的设置值。本文将介绍如何正确使用 SERVER_NAME。 Flask 中的 SERVER_NAME 主要做了两件事:协助 Flask 在活动请求之外生成绝对 URL(例如在电子邮件中嵌入 网站 URL)以支持子域 许多人错误地认为它可以同时做其他两件事。第一件事:我们知道的绝对 URL,url_for 是默认的
TAG标签在SEO优化中的作用分析
9/12/200913:56:00
我一直认为TAG标签在SEO中的作用不是很大。相信很多同事朋友也有这样的困惑。有些人甚至忽略了 TAG 标签的这一方面。当然,这对排名有什么影响并不明显。也有很多人问我TAG标签的具体应用是什么。让我们研究一下。
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他用途
通过关键词采集文章采集api(SEO圈内免费采集软件介绍:1.全网采集,永久免费!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-01-11 17:12
帝国cms采集教程
1、选择你的网站对应的接口文件。如果你的网站是gbk代码,请选择jiekou_gbk.php。如果是UTF-8编码,请选择jiekou_utf8.php
2、打开接口文件,修改认证密码,保存。
3、修改接口文件名,上传到网站的管理目录/e/admin/
4、修改发布模块Empirecms_6.5&7.0免登录界面文章发布模块.wpm,会发布获取栏将模块中列表中地址的文件名和密码以及内容发布参数改成刚才修改的接口文件名。
5、保存模块,设置发布配置,采集开始发布。
以上是帝国的教程cms采集,小伙伴们都知道帝国后台的采集功能cms不能快采集@ >,每次添加一些数据都要写不同的采集规则,对于不熟悉编程的人来说效率低下,难度更大!我们不妨用好用的免费第三方SEO采集软件来完成,有很多永久免费的SEO采集软件,SEO圈里还有很多良心软件许多站长和朋友。带来真正的流量和经济效益。
SEO圈子里免费采集软件介绍:
1.全网采集,永远免费!
2.自动挂机采集,无需人工维护
3.无手写规则,智能识别
4.多线程批量监控采集详情
5.软件操作简单,功能强大,可以满足各种复杂的采集需求
6.采集速度快,数据完整性高!
7.任何编码。比普通快 5 倍 采集器
操作流程:
1.新建一个任务标题,比如SEO
2.选择采集数据源,目前支持很多新闻源,更新频率很快,几十个数据源一个接一个添加
3.选择采集文章存放目录,任意文件夹都可以
4.默认是关键词采集10条,不需要修改,所以采集的准确率更高
5.选择格式(txt/html/xxf),选择是否保留图片并过滤联系方式
6.将关键词批量粘贴到空白处,如果没有词库,可以上网关键词,
所有实时下拉词和相关搜索词
7.支持多线程批处理采集可以同时创建数百个任务
为什么 SEO 圈子喜欢它:
1.操作极其简单,一键式采集告别繁琐的配置
2.让操作和界面最简单最实用
3.持续解决站长痛点采集需求,覆盖全网SEO功能
4.科技根据用户需求不断开发新功能,优化现有功能
5.无缝连接各种cms或全网接口,实现采集发布集成
5.再次郑重承诺,采集功能永久免费,100%免费使用
SEO圈子免费发布软件介绍:
1.多cms批处理采集管理发布
2.发布界面可以实时观察发布细节,还有待发布的细节
3.网站发布数,待发布数,网站成功推送数,一目了然
4.综合管理多个网站,提高工作效率
操作流程:
1.输入域名和登录路径,管理员账号密码
2.选择网站cms的类型,选择监控采集文件夹,文件夹只要添加即可发布
3.选择发布间隔,每天要发布的文章数 查看全部
通过关键词采集文章采集api(SEO圈内免费采集软件介绍:1.全网采集,永久免费!)
帝国cms采集教程
1、选择你的网站对应的接口文件。如果你的网站是gbk代码,请选择jiekou_gbk.php。如果是UTF-8编码,请选择jiekou_utf8.php
2、打开接口文件,修改认证密码,保存。
3、修改接口文件名,上传到网站的管理目录/e/admin/
4、修改发布模块Empirecms_6.5&7.0免登录界面文章发布模块.wpm,会发布获取栏将模块中列表中地址的文件名和密码以及内容发布参数改成刚才修改的接口文件名。
5、保存模块,设置发布配置,采集开始发布。
以上是帝国的教程cms采集,小伙伴们都知道帝国后台的采集功能cms不能快采集@ >,每次添加一些数据都要写不同的采集规则,对于不熟悉编程的人来说效率低下,难度更大!我们不妨用好用的免费第三方SEO采集软件来完成,有很多永久免费的SEO采集软件,SEO圈里还有很多良心软件许多站长和朋友。带来真正的流量和经济效益。
SEO圈子里免费采集软件介绍:
1.全网采集,永远免费!
2.自动挂机采集,无需人工维护
3.无手写规则,智能识别
4.多线程批量监控采集详情
5.软件操作简单,功能强大,可以满足各种复杂的采集需求
6.采集速度快,数据完整性高!
7.任何编码。比普通快 5 倍 采集器
操作流程:
1.新建一个任务标题,比如SEO
2.选择采集数据源,目前支持很多新闻源,更新频率很快,几十个数据源一个接一个添加
3.选择采集文章存放目录,任意文件夹都可以
4.默认是关键词采集10条,不需要修改,所以采集的准确率更高
5.选择格式(txt/html/xxf),选择是否保留图片并过滤联系方式
6.将关键词批量粘贴到空白处,如果没有词库,可以上网关键词,
所有实时下拉词和相关搜索词
7.支持多线程批处理采集可以同时创建数百个任务
为什么 SEO 圈子喜欢它:
1.操作极其简单,一键式采集告别繁琐的配置
2.让操作和界面最简单最实用
3.持续解决站长痛点采集需求,覆盖全网SEO功能
4.科技根据用户需求不断开发新功能,优化现有功能
5.无缝连接各种cms或全网接口,实现采集发布集成
5.再次郑重承诺,采集功能永久免费,100%免费使用
SEO圈子免费发布软件介绍:
1.多cms批处理采集管理发布
2.发布界面可以实时观察发布细节,还有待发布的细节
3.网站发布数,待发布数,网站成功推送数,一目了然
4.综合管理多个网站,提高工作效率
操作流程:
1.输入域名和登录路径,管理员账号密码
2.选择网站cms的类型,选择监控采集文件夹,文件夹只要添加即可发布
3.选择发布间隔,每天要发布的文章数
通过关键词采集文章采集api(通过关键词采集文章采集api采集相关网站信息,你可以百度一下)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-01-11 04:04
通过关键词采集文章采集api采集相关网站信息,然后提取出来//采集列表页信息end-user-agentselect*fromaliaswhereid=1andsize=0"2018-04-18更新链接"index.php">a.phpajax获取ajaxserver数据,转发到自己邮箱(保留图片水印)ajaxserver设置图片水印不过你是使用jquery来操作的话,我就不再具体写代码了,也不知道你是用的什么浏览器,浏览器支持多种ajax的api,你可以百度一下。以上,希望对你有帮助。
亲,
我写了一篇ajax批量抓取,详情请戳sendtodjax-个人博客我也是看这篇写的,还不错,可以看看
去翻墙
之前写过一篇批量抓取腾讯新闻插件,
百度搜xx关键词搜索出来一大堆,根据关键词的难易程度来分类。看自己需要的哪些类型的。
我们经常会遇到这种情况,服务器总是好的,浏览器总是慢,总是连不上,好无奈!针对这种问题,建议只需在抓取源头保存蜘蛛地址,copy蜘蛛服务器地址,返回到浏览器就能正常爬取。最重要的是,
谢邀ajax技术肯定是很有用的,我这边在做的爬虫系统基本上都是用ajax技术做的,试试看,
现在ajax的爬虫肯定有用了,但是无奈的是一些app就不支持ajax了,它这里是没有办法的。但是也可以用websocket来做网页抓取,一些websocket的接口是支持ajax的。 查看全部
通过关键词采集文章采集api(通过关键词采集文章采集api采集相关网站信息,你可以百度一下)
通过关键词采集文章采集api采集相关网站信息,然后提取出来//采集列表页信息end-user-agentselect*fromaliaswhereid=1andsize=0"2018-04-18更新链接"index.php">a.phpajax获取ajaxserver数据,转发到自己邮箱(保留图片水印)ajaxserver设置图片水印不过你是使用jquery来操作的话,我就不再具体写代码了,也不知道你是用的什么浏览器,浏览器支持多种ajax的api,你可以百度一下。以上,希望对你有帮助。
亲,
我写了一篇ajax批量抓取,详情请戳sendtodjax-个人博客我也是看这篇写的,还不错,可以看看
去翻墙
之前写过一篇批量抓取腾讯新闻插件,
百度搜xx关键词搜索出来一大堆,根据关键词的难易程度来分类。看自己需要的哪些类型的。
我们经常会遇到这种情况,服务器总是好的,浏览器总是慢,总是连不上,好无奈!针对这种问题,建议只需在抓取源头保存蜘蛛地址,copy蜘蛛服务器地址,返回到浏览器就能正常爬取。最重要的是,
谢邀ajax技术肯定是很有用的,我这边在做的爬虫系统基本上都是用ajax技术做的,试试看,
现在ajax的爬虫肯定有用了,但是无奈的是一些app就不支持ajax了,它这里是没有办法的。但是也可以用websocket来做网页抓取,一些websocket的接口是支持ajax的。
通过关键词采集文章采集api(苹果cms采集视频可以在后台联盟资源库里直接设置采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-01-08 01:10
苹果cms采集视频可以直接在后台联盟资源库采集中设置,也可以配置自己自定义的采集库,关于文章信息采集,苹果的cms后台没有专门的采集库,所以文章采集我们需要添加采集 接口我们自己,或者它使用第三方采集 工具。对于不懂代码的小白,不知道怎么做。目前80%的前期影视站都依赖采集来扩充自己的视频库,比如之前的大站电影天堂,最新的电影下载BT站。这一切都始于 采集。在做网站收录之前先丰富视频源,网站收录是由文章信息驱动的。今天我们将介绍使用免费的自动采集发布工具让苹果cms网站运行起来!
由于各种影视台的兴起,cms模板的泛滥,导致大量网站模板大同小异,内置的采集规则导致影视台内容大量重复。所有人都会感叹! “苹果cms采集电视台越来越难做”,各大搜索引擎收录越来越少。如果依赖cms自带的采集功能,将很难改进。视频站无非是一个标题、内容和内容介绍。苹果80%的cms影视台都有这样的架构,我们该怎么办?你能在众多影视剧中脱颖而出吗?
一、苹果cms网站怎么样原创?
1、选择标题插入品牌词
2、播放的集数(例如:第一集改为第一集在线)
3、剧情简介(插入关键词,采集电影介绍)
4、依靠SEO技术提升网站原创度
SEO 优化辅助功能设置:
1、标题前缀和后缀设置(标题更有区别收录)
2、Content关键词插入(合理增加关键词密度)
3、随机插入图片(文章无图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时搜索到收录)
5、随机点赞-随机阅读-随机作者(增加页面原创度数)
6、内容与标题一致(使内容与标题100%相关)
7、自动内链(在执行发布任务时,在文章的内容中自动生成内链,有助于引导页面蜘蛛抓取,增加页面权重)
8、定时发布(网站内容的定时发布可以让搜索引擎养成定时爬取网页的习惯,从而提高网站的收录)<//p
p9、设置批量发布数量(可以设置发布间隔/每天发布的总数)/p
p10、可设置不同类型发布不同栏目/p
p11、对刀锁定词(文章原创时自动锁定品牌词,提高产品词文章可读性,核心词不会原创)/p
pimg src='https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2022%2F0106%2Fa5d44a80j00r5a8bl002xd000v900fip.jpg&thumbnail=650x2147483647&quality=80&type=jpg' alt=''//p
p12、 该工具还可以批量管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, 织梦, WP 、小轩峰、站群、PB、Apple、搜外等各大cms电影网站可同时批量管理和发布)/p
p二、苹果cms采集设置/p
pimg src='https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2022%2F0106%2Ffd3c3577j00r5a8ez002pd000v900g7p.jpg&thumbnail=650x2147483647&quality=80&type=jpg' alt=''//p
p1、只要输入core关键词,软件会根据core关键词自动生成下拉词、相关搜索词、长尾词,并自动生成过滤不相关的关键词。实现全自动采集,可同时创建数十个或数百个采集任务(一个任务可支持上传1000个关键词),可同时执行多个域任务时间!/p
p2、自动过滤采集的文章,/p
pimg src='https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2022%2F0106%2Fabbeda66j00r5a8f8002kd000v900etp.jpg&thumbnail=650x2147483647&quality=80&type=jpg' alt=''//p
p3、多平台支持采集(资讯、问答、视频频道、电影频道等)/p
p4、可以设置关键词采集文章的数量,可以在软件上直接查看多个任务采集状态-支持本地预览-支持采集@ > 链接预览
5、自动批量挂机采集,与各大cms发布商无缝对接,采集自动发布推送到搜索引擎
以上都经过小编测试发现特别好用。 文章采集工具与苹果的cms自有数据源采集无缝协作! 网站 的当前流量还不错!看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!你的一举一动都会成为编辑源源不断的动力! 查看全部
通过关键词采集文章采集api(苹果cms采集视频可以在后台联盟资源库里直接设置采集)
苹果cms采集视频可以直接在后台联盟资源库采集中设置,也可以配置自己自定义的采集库,关于文章信息采集,苹果的cms后台没有专门的采集库,所以文章采集我们需要添加采集 接口我们自己,或者它使用第三方采集 工具。对于不懂代码的小白,不知道怎么做。目前80%的前期影视站都依赖采集来扩充自己的视频库,比如之前的大站电影天堂,最新的电影下载BT站。这一切都始于 采集。在做网站收录之前先丰富视频源,网站收录是由文章信息驱动的。今天我们将介绍使用免费的自动采集发布工具让苹果cms网站运行起来!
由于各种影视台的兴起,cms模板的泛滥,导致大量网站模板大同小异,内置的采集规则导致影视台内容大量重复。所有人都会感叹! “苹果cms采集电视台越来越难做”,各大搜索引擎收录越来越少。如果依赖cms自带的采集功能,将很难改进。视频站无非是一个标题、内容和内容介绍。苹果80%的cms影视台都有这样的架构,我们该怎么办?你能在众多影视剧中脱颖而出吗?
一、苹果cms网站怎么样原创?
1、选择标题插入品牌词
2、播放的集数(例如:第一集改为第一集在线)
3、剧情简介(插入关键词,采集电影介绍)
4、依靠SEO技术提升网站原创度
SEO 优化辅助功能设置:
1、标题前缀和后缀设置(标题更有区别收录)
2、Content关键词插入(合理增加关键词密度)
3、随机插入图片(文章无图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时搜索到收录)
5、随机点赞-随机阅读-随机作者(增加页面原创度数)
6、内容与标题一致(使内容与标题100%相关)
7、自动内链(在执行发布任务时,在文章的内容中自动生成内链,有助于引导页面蜘蛛抓取,增加页面权重)
8、定时发布(网站内容的定时发布可以让搜索引擎养成定时爬取网页的习惯,从而提高网站的收录)<//p
p9、设置批量发布数量(可以设置发布间隔/每天发布的总数)/p
p10、可设置不同类型发布不同栏目/p
p11、对刀锁定词(文章原创时自动锁定品牌词,提高产品词文章可读性,核心词不会原创)/p
pimg src='https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2022%2F0106%2Fa5d44a80j00r5a8bl002xd000v900fip.jpg&thumbnail=650x2147483647&quality=80&type=jpg' alt=''//p
p12、 该工具还可以批量管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, 织梦, WP 、小轩峰、站群、PB、Apple、搜外等各大cms电影网站可同时批量管理和发布)/p
p二、苹果cms采集设置/p
pimg src='https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2022%2F0106%2Ffd3c3577j00r5a8ez002pd000v900g7p.jpg&thumbnail=650x2147483647&quality=80&type=jpg' alt=''//p
p1、只要输入core关键词,软件会根据core关键词自动生成下拉词、相关搜索词、长尾词,并自动生成过滤不相关的关键词。实现全自动采集,可同时创建数十个或数百个采集任务(一个任务可支持上传1000个关键词),可同时执行多个域任务时间!/p
p2、自动过滤采集的文章,/p
pimg src='https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2022%2F0106%2Fabbeda66j00r5a8f8002kd000v900etp.jpg&thumbnail=650x2147483647&quality=80&type=jpg' alt=''//p
p3、多平台支持采集(资讯、问答、视频频道、电影频道等)/p
p4、可以设置关键词采集文章的数量,可以在软件上直接查看多个任务采集状态-支持本地预览-支持采集@ > 链接预览
5、自动批量挂机采集,与各大cms发布商无缝对接,采集自动发布推送到搜索引擎
以上都经过小编测试发现特别好用。 文章采集工具与苹果的cms自有数据源采集无缝协作! 网站 的当前流量还不错!看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!你的一举一动都会成为编辑源源不断的动力!
通过关键词采集文章采集api(思路和部分代码引用迪艾姆培训黄哥python爬虫联想词视频)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-01-06 08:08
思路和部分代码参考了Diem python训练黄哥python爬虫联想词视频,不过太罗嗦了,顺便说一句,现在,360不傻,进化了,用原来的方法,有点bug,我稍后会谈到这个。题目如下:
语言:python2.7.6
模块:urllib、urllib2、re、时间
目标:输入任何单词并捕获其关联的单词
版本:w1
原理:在360搜索首页:当你输入“科技”时,搜索框会列出相应的关联词或词组。我们只想得到这些关联词,那我们就得爬上360搜索引擎。在输入关键词之前,我们在首页右击,“评论元素”——“网络”——“名称”,输入后,下面会出现对应的超链接,我们只观察“标题”和“预览” ”,在“Headers”下我们可以看到“Request URL”和头信息(主机、代理等),并看到我在“Priview”中输入的示例:
Suggest_so({"query":"Technology","result":[{"word":"Technology Aesthetics"},{"word":"Technology Court"},{"word":"Technology Department"},{ "word":"科技管理研究"},{"word":"科技妹喵","obdata":"{\"t\":\"video\",\"d\":[2 ,\ "http:\/\/\/d\/dy_acba03288ce64a69a324a94921324cb6.jpg\",\"\u9ad8\u79d1\u6280\u5c11\u5973\u55b5:\",\ /tv \/Q4pwcH3lRG4lNn.html\",3,12]}"},{"word":"科技日报"},{"word":"科技发展有很大的优势或劣势"},{ "word":"技术超王"},{"word":"Technet"},{"word":"科技进步与对策"}],"version":"a"});
显然,我们只需要抓住里面的文字,而忘记解释。在请求 URL 中有一个链接:obdata&word=%E7%A7%91%E6%8A%80%20。我们多次输入,发现,它变成了只是“%E7%A7%91%E6%8A%80%20”部分,也就是说前面的部分保持不变,我们可以直接使用,后面的部分就是与输入关键词不同,不过这是一种URL编码,可以通过urllb.quote()方法实现。
操作:1.添加头信息,读取网页,相关方法:urllib2.Request(), urllib2.urlopen(), urllib2, urlopen().read()
2.正则匹配:方法:re模块的相关用法,发表自己的看法。.
代码显示如下:
#coding:utf-8
import urllib
import urllib2
import re
import time
gjc = urllib.quote("科技")
url = "http://sug.so.360.cn/suggest%3 ... Dword,obdata&word="+gjc
print url
req = urllib2.Request(url)
html = urllib2.urlopen(req).read()
unicodePage = html.decode("utf-8")
#正则表达式,findall方法返回一个列表
ss = re.findall('"word":\"(.*?)\"',unicodePage)
for item in ss:
print item
结果:
如果不加unicodePage = html.decode("utf-8"),返回值会穿插一些乱码。验证一下我们做的是否正确,打开360搜索,输入“技术”,结果如下:
别纠结了,第一个和第二个相关词的顺序,当我第二次请求的时候,就变成了上图的结果。我再次请求它,它又变回来了。也许360正在改变。你可以使用它。尝试其他关键词。
好了,框架已经大致实现了。这是初始版本,不能没有任何限制地使用。我们要做的就是畅通无阻,那有什么问题呢?
<p>问题:1.多次请求会报错,大概代号是1005,意思是百度下载了,好像是说网站会限制非人为请求,那我们就假装要成为用户正常打开 查看全部
通过关键词采集文章采集api(思路和部分代码引用迪艾姆培训黄哥python爬虫联想词视频)
思路和部分代码参考了Diem python训练黄哥python爬虫联想词视频,不过太罗嗦了,顺便说一句,现在,360不傻,进化了,用原来的方法,有点bug,我稍后会谈到这个。题目如下:
语言:python2.7.6
模块:urllib、urllib2、re、时间
目标:输入任何单词并捕获其关联的单词
版本:w1
原理:在360搜索首页:当你输入“科技”时,搜索框会列出相应的关联词或词组。我们只想得到这些关联词,那我们就得爬上360搜索引擎。在输入关键词之前,我们在首页右击,“评论元素”——“网络”——“名称”,输入后,下面会出现对应的超链接,我们只观察“标题”和“预览” ”,在“Headers”下我们可以看到“Request URL”和头信息(主机、代理等),并看到我在“Priview”中输入的示例:
Suggest_so({"query":"Technology","result":[{"word":"Technology Aesthetics"},{"word":"Technology Court"},{"word":"Technology Department"},{ "word":"科技管理研究"},{"word":"科技妹喵","obdata":"{\"t\":\"video\",\"d\":[2 ,\ "http:\/\/\/d\/dy_acba03288ce64a69a324a94921324cb6.jpg\",\"\u9ad8\u79d1\u6280\u5c11\u5973\u55b5:\",\ /tv \/Q4pwcH3lRG4lNn.html\",3,12]}"},{"word":"科技日报"},{"word":"科技发展有很大的优势或劣势"},{ "word":"技术超王"},{"word":"Technet"},{"word":"科技进步与对策"}],"version":"a"});
显然,我们只需要抓住里面的文字,而忘记解释。在请求 URL 中有一个链接:obdata&word=%E7%A7%91%E6%8A%80%20。我们多次输入,发现,它变成了只是“%E7%A7%91%E6%8A%80%20”部分,也就是说前面的部分保持不变,我们可以直接使用,后面的部分就是与输入关键词不同,不过这是一种URL编码,可以通过urllb.quote()方法实现。
操作:1.添加头信息,读取网页,相关方法:urllib2.Request(), urllib2.urlopen(), urllib2, urlopen().read()
2.正则匹配:方法:re模块的相关用法,发表自己的看法。.
代码显示如下:
#coding:utf-8
import urllib
import urllib2
import re
import time
gjc = urllib.quote("科技")
url = "http://sug.so.360.cn/suggest%3 ... Dword,obdata&word="+gjc
print url
req = urllib2.Request(url)
html = urllib2.urlopen(req).read()
unicodePage = html.decode("utf-8")
#正则表达式,findall方法返回一个列表
ss = re.findall('"word":\"(.*?)\"',unicodePage)
for item in ss:
print item
结果:
如果不加unicodePage = html.decode("utf-8"),返回值会穿插一些乱码。验证一下我们做的是否正确,打开360搜索,输入“技术”,结果如下:
别纠结了,第一个和第二个相关词的顺序,当我第二次请求的时候,就变成了上图的结果。我再次请求它,它又变回来了。也许360正在改变。你可以使用它。尝试其他关键词。
好了,框架已经大致实现了。这是初始版本,不能没有任何限制地使用。我们要做的就是畅通无阻,那有什么问题呢?
<p>问题:1.多次请求会报错,大概代号是1005,意思是百度下载了,好像是说网站会限制非人为请求,那我们就假装要成为用户正常打开
通过关键词采集文章采集api(SEO相关工具无数,唯独这几款工具是我一直在用的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-01-02 12:09
从事SEO行业多年,用过的SEO相关工具数不胜数,但这些都是我一直在用的工具,非常好用
今天推荐给大家:
1、URL 批处理采集:
一分钟多线程改IP采集3000,超快【突破百度验证码】
测量效率:
电脑配置(四核8G,win10系统,线程:50)
一分钟采集3218个网址,24小时挂机可采集百万条数据,
可以说只要你的关键词数量够了,采集的URL就用不完,
市场上唯一的单线程、非反阻塞工具,秒杀。
2、搜索索引批量查询:
多线程IP变更查询【突破百度验证码】
众所周知,百度的限制越来越严,无法破解的验证码层出不穷。
而这个工具就应运而生了,可以通过验证码进行批量查询
支持宽带拨号和代理API更改IP,
直接导入关键词点击开始,
右侧输出查询结果,
格式:关键词——PC索引/移动索引
3、下拉框关联词采集:
百度、搜狗、神马PC、手机搜索下拉框采集是SEO人获取大量长尾词的重要途径。
4、权重批量查询
站群人必备的权重批量查询工具,包括电脑和手机权重,海量网站无需手动一一查询
5、网站收录批量查询:
也是站群人的最爱,批量查询收录量,实时监控网站爬取效果
6、AI人工智能文章批量伪原创
伪原创中的原创AI云人工智能文章,句子流畅(非同义词转换),就像网上请人改写,原创率80多%,秒杀奶盘等同义词替换伪原创之类的工具
注意:百度、搜狗、神马、360还有很多SEO工具包,这里就不一一列举了
......... 查看全部
通过关键词采集文章采集api(SEO相关工具无数,唯独这几款工具是我一直在用的)
从事SEO行业多年,用过的SEO相关工具数不胜数,但这些都是我一直在用的工具,非常好用
今天推荐给大家:
1、URL 批处理采集:
一分钟多线程改IP采集3000,超快【突破百度验证码】
测量效率:
电脑配置(四核8G,win10系统,线程:50)
一分钟采集3218个网址,24小时挂机可采集百万条数据,
可以说只要你的关键词数量够了,采集的URL就用不完,
市场上唯一的单线程、非反阻塞工具,秒杀。
2、搜索索引批量查询:
多线程IP变更查询【突破百度验证码】
众所周知,百度的限制越来越严,无法破解的验证码层出不穷。
而这个工具就应运而生了,可以通过验证码进行批量查询
支持宽带拨号和代理API更改IP,
直接导入关键词点击开始,
右侧输出查询结果,
格式:关键词——PC索引/移动索引
3、下拉框关联词采集:
百度、搜狗、神马PC、手机搜索下拉框采集是SEO人获取大量长尾词的重要途径。
4、权重批量查询
站群人必备的权重批量查询工具,包括电脑和手机权重,海量网站无需手动一一查询
5、网站收录批量查询:
也是站群人的最爱,批量查询收录量,实时监控网站爬取效果
6、AI人工智能文章批量伪原创
伪原创中的原创AI云人工智能文章,句子流畅(非同义词转换),就像网上请人改写,原创率80多%,秒杀奶盘等同义词替换伪原创之类的工具
注意:百度、搜狗、神马、360还有很多SEO工具包,这里就不一一列举了
.........
通过关键词采集文章采集api(元素中的每一个元素,可以帮助我们做很多事)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-01 02:04
对于元素中的每个元素,你可以这样做:
仅上述功能就可以帮助我们做很多事情。如果您需要做一些更复杂的事情(或者只是出于好奇),请查看文档。
当然,无论数据多么重要,通常都不会标记为。您需要仔细检查源HTML,根据您选择的逻辑进行推理,并考虑边界条件以确保数据的正确性。下面我们来看一个例子。
9.3.2 例子:密切关注国会
一家数据科学公司的政策副总裁关注数据科学行业的潜在监管,并要求您量化国会对此主题的看法。他特别希望你能找到所有发布“数据”新闻稿的代表。
在发布的时候,有一个页面,所有的链接都代表网站
如果您“查看源代码”,所有 网站 链接看起来像:
让我们从采集从此页面链接到的所有 URL 开始:
这将返回过多的 URL。如果你看看它们,我们以 or 开头,中间有某种名称,结尾是。或者./..
这是使用正则表达式的好地方:
这还是太多了,因为只有435个代表。如果你看列表,有很多重复。我们可以使用 set 来克服这些问题:
众议院总有几个席位是空的,或者可能有一些代表没有网站。无论如何,这已经足够了。当我们检查这些 网站 时,大多数 网站 都有指向新闻稿的链接。例如:
请注意,这是一个相对链接,这意味着我们需要记住原创站点。让我们抓住它:
注意
通常情况下,像这样随便爬一个网站是不礼貌的。大多数网站都会有robots.txt文件,表示可以经常爬取网站(以及不应该爬取的路径),但既然是国会,我们就不需要特别客气了。
如果你滚动查看它们,你会看到大量的/media/新闻稿和媒体中心/新闻稿,以及其他各种地址。其中一个网址是
请记住,我们的目标是找出哪些国会议员提到了“数据”。 “我们将编写一个稍微通用的函数来检查在一页新闻稿中是否提到了任何给定的术语。
如果你访问网站并查看源代码,它似乎在
标签中有每个新闻稿的片段,因此我们将使用它作为我们的第一次尝试:
让我们为它编写一个快速测试:
最后,我们要找到相关的国会议员,并将他们的名字告诉政策副总裁:
当我运行这个时,我得到了一个大约 20 个代表的列表。您的结果可能会有所不同。
注意
如果您查看不同的“新闻稿”页面,它们中的大多数都是分页的,每页只有 5 或 10 个新闻稿。这意味着我们只搜索了每位国会议员的最新新闻稿。更彻底的解决方案是在页面上迭代并检索每个新闻稿的全文。
9.4 使用 API
许多 网站 和 Web 服务提供了相应的应用程序编程接口 (APIS),允许您以结构化格式显式请求数据。这样就省去了爬取数据的麻烦!
9.4.1 个 JSON(和 XML)
因为HTTP是一个文本转换协议,你通过web API请求的数据需要序列化,转换成字符串格式。通常这种序列化使用 JavaScript Object Notation (JSON)。 JavaScript 对象看起来像 Python 字典,使得字符串表达式很容易解释:
我们可以使用 Python 的 json 模块来解析 JSON。特别是,我们将使用它的加载函数,它可以将表示 JSON 对象的字符串反序列化为 Python 对象:
有时 API 提供者可能不那么友好,只向您提供 XML 格式的响应:
我们也可以模仿从HTML中获取数据的方式,使用BeautifulSoup从XML中获取数据;可以在文档中找到更多详细信息。
9.4.2 使用 API 无需认证
大多数 API 现在要求您在使用前验证您的身份。如果我们不愿意强迫自己屈服于这个政策,API 会给出许多其他陈词滥调来阻止我们浏览。所以,我们先来看看GitHub的API。有了它,我们可以做简单的事情而无需验证:
这里的 repos 是 Python 词典的列表,每个词典都代表我 GitHub 帐户中的一个代码存储库。 (你可以随意替换你的用户名来获取你的代码仓库的数据。你有一个GitHub帐户吧?)
我们可以使用它来找出最有可能创建存储库的月份和星期几。唯一的问题是响应中的日期是一个字符串:
Python 本身没有很强大的日期解析器,所以我们需要安装一个:
你只需要 dateutil.parser.parse 函数:
同样的,你可以得到我最近五个代码仓库使用的语言:
通常我们不需要在“自己发出请求并解析响应”的低级别使用 API。使用 Python 的好处之一是有人已经构建了一个库,因此您可以访问几乎所有您感兴趣的 API。这些库可以让事情变得正确,并让您免去查找 API 访问的许多冗长细节的麻烦。 (如果这些库不能很好地完成任务,或者他们依赖的相应API版本失败了,会给你带来巨大的麻烦。)
尽管如此,偶尔还是需要操作自己的API访问库(或者,更常见的是调试别人无法顺利操作的库),所以了解一些细节是很好的。
9.4.3 查找 API
如果需要特定的网站数据,可以查看其开发者部分或API部分的详细信息,然后在网上用关键词“python api”搜索相应的库。
有 Yelp API、Instagram API、Spotify API 等库。
如果您想查看收录 Python 包的 API 列表,那么 GitHub 上的 Real Python 中有一个不错的 API 列表 ()。
如果最后还是找不到你需要的API,你仍然可以通过爬取来获取。这是数据科学家的最后一招。
9.5 案例:使用 Twitter API
Twitter 是一个非常好的数据源。你可以从中获取实时新闻,你可以用它来判断对时事的反应,你可以用它来查找与特定主题相关的链接。有了 Twitter,你几乎可以做任何你能想到的事情,只要你能得到它的数据。数据可以通过其API获取。
为了与 Twitter API 交互,我们需要使用 Twython 库(python -m pip install twython)。实际上有很多 Python Twitter 库,但这是我用过的最好的一个。您也可以尝试其他库。
获取凭据
为了使用 Twitter 的 API,您需要获取一些支持文件(为此您无论如何都必须拥有一个 Twitter 帐户,这样您才能成为活跃且友好的 Twitter #datascience 社区的一部分)。
注意
就像所有我无法控制的指令网站一样,它们在某个时候会过时,但它们现在仍然可以有效一段时间。 (虽然在我写这本书的时候他们至少改变了一次,祝你好运!)
步骤如下:
1. 找到链接。
2. 如果您还没有注册,请点击“注册”并输入您的 Twitter 用户名和密码。
3.点击申请申请开发者账号。
4. 请求访问供您自己使用。
5.填写申请表。需要填写300字(真的)来解释你为什么需要访问数据,所以为了通过审查,你可以告诉他们这本书以及你有多喜欢它。
6.等待一段不确定的时间。
7. 如果您认识在 Twitter 上工作的人,请给他们发电子邮件并询问他们是否可以加快您的申请。否则,请继续等待。
8.审核通过后,请返回,找到“申请”部分,点击“创建申请”。
9.填写所有必填字段(同样,如果描述需要额外字符,您可以讨论这本书以及如何找到它)。
10.点击“创建”。
您的应用程序现在应该有一个“密钥和令牌”选项卡,其中收录一个“消费者 API 公钥”部分,其中列出了“API 公钥”和“API 密钥”。 “注意这些密钥;你需要它们。(而且,保密!它们就像密码。)
小心
不要分享,不要印在书里,也不要记录在 GitHub 公共代码库中。一种简单的方法是将它们存储在不会被签入的credentials.json 文件中,您可以使用json.loads 来检索它们。另一种解决方案是将它们存储在环境变量中并使用 os.environ 检索它们。
使用 Twython
使用 Twitter API 最棘手的部分是身份验证。 (实际上,这是使用大量 API 中最棘手的部分。)API 提供商希望确保您有权访问他们的数据,并且您没有超出他们的使用限制。他们还想知道谁在访问他们的数据。
身份验证有点痛苦。有一个简单的方法,OAuth 2,当你只想做一个简单的搜索时,它就足够了。还有一种更复杂的方式,OAuth 1,当您想要执行操作(例如 Twitter)或(特别是对于我们)连接到 Twitter 流时,这是必要的。
所以我们坚持采用更复杂的方法,我们将尽可能实现自动化。
首先,您需要 API 公钥和 API 密钥(有时分别称为消费者公钥和消费者密钥)。我可以从环境变量中获取,你可以随时替换:
现在我们可以实例化客户端:
提醒
此时,您可能要考虑将 ACCESS_TOKEN 和 ACCESS_TOKEN_SECRET 存储在安全的地方,这样您下次就不必再经过这个严格的流程了。
一旦我们有一个经过验证的 Twython 实例,我们就可以开始搜索了:
如果你运行上面的,你应该得到一些推文,比如:
这不是那么有趣,主要是因为 Twitter 搜索 API 只是向您展示了一些最近的结果。当您从事数据科学时,您通常需要大量推文。这就是流 API 有用的地方。它允许您连接到一个伟大的 Twitter “消防水龙”。要使用它,您需要使用访问令牌进行身份验证。
为了使用 Twython 访问流 API,我们需要定义一个从 TwythonStreamer 继承并覆盖它的 on_success 方法,或者它的 on_error 方法:
MyStreamer 将连接到 Twitter 流并等待 Twitter 向其发送数据。每次它接收到一些数据(这里,一条推文被表示为一个 Python 对象),它被传递给 on_success 方法。如果推文是英文的,此方法会将推文附加到推文列表中。采集到1000条推文后与流的连接将在文本后断开。
剩下的工作就是初始化和启动运行:
它将继续运行,直到采集到 1,000 条推文(或直到遇到错误),此时是分析这些推文的时候了。例如,您可以使用以下方法查找最常见的标签:
每条推文都收录大量数据。您可以自己尝试各种方法,也可以仔细阅读Twitter API 的文档。
注意
在正式项目中,您可能不想依赖内存列表来存储推文。相反,您可能希望将推文保存在文件或数据库中,以便您可以永远拥有它们。
9.6 延伸学习
• pandas 是数据科学用来处理(尤其是导入)数据的主要库。
• Scrapy 是一个运行良好的库,可用于构建更复杂的网络爬虫来执行跟踪未知链接等任务。
• Kaggle 拥有大量数据集。 查看全部
通过关键词采集文章采集api(元素中的每一个元素,可以帮助我们做很多事)
对于元素中的每个元素,你可以这样做:
仅上述功能就可以帮助我们做很多事情。如果您需要做一些更复杂的事情(或者只是出于好奇),请查看文档。
当然,无论数据多么重要,通常都不会标记为。您需要仔细检查源HTML,根据您选择的逻辑进行推理,并考虑边界条件以确保数据的正确性。下面我们来看一个例子。
9.3.2 例子:密切关注国会
一家数据科学公司的政策副总裁关注数据科学行业的潜在监管,并要求您量化国会对此主题的看法。他特别希望你能找到所有发布“数据”新闻稿的代表。
在发布的时候,有一个页面,所有的链接都代表网站
如果您“查看源代码”,所有 网站 链接看起来像:
让我们从采集从此页面链接到的所有 URL 开始:
这将返回过多的 URL。如果你看看它们,我们以 or 开头,中间有某种名称,结尾是。或者./..
这是使用正则表达式的好地方:
这还是太多了,因为只有435个代表。如果你看列表,有很多重复。我们可以使用 set 来克服这些问题:
众议院总有几个席位是空的,或者可能有一些代表没有网站。无论如何,这已经足够了。当我们检查这些 网站 时,大多数 网站 都有指向新闻稿的链接。例如:
请注意,这是一个相对链接,这意味着我们需要记住原创站点。让我们抓住它:
注意
通常情况下,像这样随便爬一个网站是不礼貌的。大多数网站都会有robots.txt文件,表示可以经常爬取网站(以及不应该爬取的路径),但既然是国会,我们就不需要特别客气了。
如果你滚动查看它们,你会看到大量的/media/新闻稿和媒体中心/新闻稿,以及其他各种地址。其中一个网址是
请记住,我们的目标是找出哪些国会议员提到了“数据”。 “我们将编写一个稍微通用的函数来检查在一页新闻稿中是否提到了任何给定的术语。
如果你访问网站并查看源代码,它似乎在
标签中有每个新闻稿的片段,因此我们将使用它作为我们的第一次尝试:
让我们为它编写一个快速测试:
最后,我们要找到相关的国会议员,并将他们的名字告诉政策副总裁:
当我运行这个时,我得到了一个大约 20 个代表的列表。您的结果可能会有所不同。
注意
如果您查看不同的“新闻稿”页面,它们中的大多数都是分页的,每页只有 5 或 10 个新闻稿。这意味着我们只搜索了每位国会议员的最新新闻稿。更彻底的解决方案是在页面上迭代并检索每个新闻稿的全文。
9.4 使用 API
许多 网站 和 Web 服务提供了相应的应用程序编程接口 (APIS),允许您以结构化格式显式请求数据。这样就省去了爬取数据的麻烦!
9.4.1 个 JSON(和 XML)
因为HTTP是一个文本转换协议,你通过web API请求的数据需要序列化,转换成字符串格式。通常这种序列化使用 JavaScript Object Notation (JSON)。 JavaScript 对象看起来像 Python 字典,使得字符串表达式很容易解释:
我们可以使用 Python 的 json 模块来解析 JSON。特别是,我们将使用它的加载函数,它可以将表示 JSON 对象的字符串反序列化为 Python 对象:
有时 API 提供者可能不那么友好,只向您提供 XML 格式的响应:
我们也可以模仿从HTML中获取数据的方式,使用BeautifulSoup从XML中获取数据;可以在文档中找到更多详细信息。
9.4.2 使用 API 无需认证
大多数 API 现在要求您在使用前验证您的身份。如果我们不愿意强迫自己屈服于这个政策,API 会给出许多其他陈词滥调来阻止我们浏览。所以,我们先来看看GitHub的API。有了它,我们可以做简单的事情而无需验证:
这里的 repos 是 Python 词典的列表,每个词典都代表我 GitHub 帐户中的一个代码存储库。 (你可以随意替换你的用户名来获取你的代码仓库的数据。你有一个GitHub帐户吧?)
我们可以使用它来找出最有可能创建存储库的月份和星期几。唯一的问题是响应中的日期是一个字符串:
Python 本身没有很强大的日期解析器,所以我们需要安装一个:
你只需要 dateutil.parser.parse 函数:
同样的,你可以得到我最近五个代码仓库使用的语言:
通常我们不需要在“自己发出请求并解析响应”的低级别使用 API。使用 Python 的好处之一是有人已经构建了一个库,因此您可以访问几乎所有您感兴趣的 API。这些库可以让事情变得正确,并让您免去查找 API 访问的许多冗长细节的麻烦。 (如果这些库不能很好地完成任务,或者他们依赖的相应API版本失败了,会给你带来巨大的麻烦。)
尽管如此,偶尔还是需要操作自己的API访问库(或者,更常见的是调试别人无法顺利操作的库),所以了解一些细节是很好的。
9.4.3 查找 API
如果需要特定的网站数据,可以查看其开发者部分或API部分的详细信息,然后在网上用关键词“python api”搜索相应的库。
有 Yelp API、Instagram API、Spotify API 等库。
如果您想查看收录 Python 包的 API 列表,那么 GitHub 上的 Real Python 中有一个不错的 API 列表 ()。
如果最后还是找不到你需要的API,你仍然可以通过爬取来获取。这是数据科学家的最后一招。
9.5 案例:使用 Twitter API
Twitter 是一个非常好的数据源。你可以从中获取实时新闻,你可以用它来判断对时事的反应,你可以用它来查找与特定主题相关的链接。有了 Twitter,你几乎可以做任何你能想到的事情,只要你能得到它的数据。数据可以通过其API获取。
为了与 Twitter API 交互,我们需要使用 Twython 库(python -m pip install twython)。实际上有很多 Python Twitter 库,但这是我用过的最好的一个。您也可以尝试其他库。
获取凭据
为了使用 Twitter 的 API,您需要获取一些支持文件(为此您无论如何都必须拥有一个 Twitter 帐户,这样您才能成为活跃且友好的 Twitter #datascience 社区的一部分)。
注意
就像所有我无法控制的指令网站一样,它们在某个时候会过时,但它们现在仍然可以有效一段时间。 (虽然在我写这本书的时候他们至少改变了一次,祝你好运!)
步骤如下:
1. 找到链接。
2. 如果您还没有注册,请点击“注册”并输入您的 Twitter 用户名和密码。
3.点击申请申请开发者账号。
4. 请求访问供您自己使用。
5.填写申请表。需要填写300字(真的)来解释你为什么需要访问数据,所以为了通过审查,你可以告诉他们这本书以及你有多喜欢它。
6.等待一段不确定的时间。
7. 如果您认识在 Twitter 上工作的人,请给他们发电子邮件并询问他们是否可以加快您的申请。否则,请继续等待。
8.审核通过后,请返回,找到“申请”部分,点击“创建申请”。
9.填写所有必填字段(同样,如果描述需要额外字符,您可以讨论这本书以及如何找到它)。
10.点击“创建”。
您的应用程序现在应该有一个“密钥和令牌”选项卡,其中收录一个“消费者 API 公钥”部分,其中列出了“API 公钥”和“API 密钥”。 “注意这些密钥;你需要它们。(而且,保密!它们就像密码。)
小心
不要分享,不要印在书里,也不要记录在 GitHub 公共代码库中。一种简单的方法是将它们存储在不会被签入的credentials.json 文件中,您可以使用json.loads 来检索它们。另一种解决方案是将它们存储在环境变量中并使用 os.environ 检索它们。
使用 Twython
使用 Twitter API 最棘手的部分是身份验证。 (实际上,这是使用大量 API 中最棘手的部分。)API 提供商希望确保您有权访问他们的数据,并且您没有超出他们的使用限制。他们还想知道谁在访问他们的数据。
身份验证有点痛苦。有一个简单的方法,OAuth 2,当你只想做一个简单的搜索时,它就足够了。还有一种更复杂的方式,OAuth 1,当您想要执行操作(例如 Twitter)或(特别是对于我们)连接到 Twitter 流时,这是必要的。
所以我们坚持采用更复杂的方法,我们将尽可能实现自动化。
首先,您需要 API 公钥和 API 密钥(有时分别称为消费者公钥和消费者密钥)。我可以从环境变量中获取,你可以随时替换:
现在我们可以实例化客户端:
提醒
此时,您可能要考虑将 ACCESS_TOKEN 和 ACCESS_TOKEN_SECRET 存储在安全的地方,这样您下次就不必再经过这个严格的流程了。
一旦我们有一个经过验证的 Twython 实例,我们就可以开始搜索了:
如果你运行上面的,你应该得到一些推文,比如:
这不是那么有趣,主要是因为 Twitter 搜索 API 只是向您展示了一些最近的结果。当您从事数据科学时,您通常需要大量推文。这就是流 API 有用的地方。它允许您连接到一个伟大的 Twitter “消防水龙”。要使用它,您需要使用访问令牌进行身份验证。
为了使用 Twython 访问流 API,我们需要定义一个从 TwythonStreamer 继承并覆盖它的 on_success 方法,或者它的 on_error 方法:
MyStreamer 将连接到 Twitter 流并等待 Twitter 向其发送数据。每次它接收到一些数据(这里,一条推文被表示为一个 Python 对象),它被传递给 on_success 方法。如果推文是英文的,此方法会将推文附加到推文列表中。采集到1000条推文后与流的连接将在文本后断开。
剩下的工作就是初始化和启动运行:
它将继续运行,直到采集到 1,000 条推文(或直到遇到错误),此时是分析这些推文的时候了。例如,您可以使用以下方法查找最常见的标签:
每条推文都收录大量数据。您可以自己尝试各种方法,也可以仔细阅读Twitter API 的文档。
注意
在正式项目中,您可能不想依赖内存列表来存储推文。相反,您可能希望将推文保存在文件或数据库中,以便您可以永远拥有它们。
9.6 延伸学习
• pandas 是数据科学用来处理(尤其是导入)数据的主要库。
• Scrapy 是一个运行良好的库,可用于构建更复杂的网络爬虫来执行跟踪未知链接等任务。
• Kaggle 拥有大量数据集。
通过关键词采集文章采集api(关键词挖掘有哪些不起眼却非常赚钱的行业?你必须知道的18款追热点工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-12-31 13:04
今天的内容汇集了大神们如何使用5118工具实现价值最大化和功能体验最大化。
接下来,我们就来看看他们是如何利用5118工具为网站精准运营赋能的!
关键词挖矿
什么是不起眼但利润丰厚的行业?
文章总结
公开财报显示,百合网2018年净利润为6.12亿,其中包括嘉源世纪(世纪嘉源于2015年12月7日宣布与百合网合并)。
至此,可以知道婚姻平台以结婚结交为名的巨额利润,仅会员费就能赚2.6亿。从商业角度,拆解交友项目。
在SEO方面,我们可以从关键词的扩展入手,将全国各个省市、地区的词与交友等相关词结合起来,然后产生大量的内页。
可以使用词挖掘工具。
创建高质量关键词词库的方法
文章总结
公共渠道——部分平台提供关键词数据,如搜索引擎自带的关键词工具(百度和谷歌都有)、5118等。
平台渠道一般来自行业特定的关键词,可以结合自己的网站进行二次处理。
对于常见的行业或领域,这些专业平台工具提供的关键词数量可观;
对于一些很小的子领域或者冷门的行业,你得换个思路采集关键词。
新媒体人必知:18个你必须知道的热点工具
文章总结
5118专注于关键词排名,提供行业词库、排名词搜索、词挖掘等服务,以及“财经”、“新闻”、“财经”等精细分类。
对于流行的关键词,给出了相关关注点的变化和发展,可以准确到几分钟内。
5118的“挖词”功能也受到媒体人的青睐。用户可以搜索关键词、移动流量词、批量搜索长尾词。
每个词都会匹配对应的百度收录量、长尾词数、百度指数、移动指数等指标。
排水小白如何成为排水高手?
文章总结
全网流量布局实操
第一步:
自我定位,定位精准人群,经营细分行业,定位用户需求。
如果你是宝妈,可以为宝妈群做相关的关键词。例如,使用5118搜索长尾词或相关词。
………………
第五步:
将内容发布到各大平台,让你获得两大流量,一是平台内部推荐流量,二是搜外流量。
比如今日头条自媒体平台的推广流量,以及除今日头条以外的百度和360、搜狗的搜索流量。
最重要的是让标题关键词,而关键词决定了你的用户群。
如何找到自己的关键词,可以用5118挖最需要的词,直到达到霸屏的效果。
需求图
看了3000个抖音,我们做了一个3000万+观看量的视频
文章总结
打开率:视频的第一张图片很重要,让大家知道你的视频在讲什么,有什么用,好不好玩。
并且最好有模板保证一致性,这样才能达到长期输出。
另一个关键点是标题。标题可以影响打开率,只要关注目标用户的痛点。
所以你可以去5118搜索,看你视频的相关人,他们主要关注什么,以及如何交谈。
了解对手的口碑媒体流量
文章总结
流量取决于对手的声誉
比如,来自促销,来自联想。
从联想5118需求图中,搜索同行品牌名称:
看词频拍片,比如搜索“阿福”
看流量入口:引流实体店和专柜的流量;
从几种精油产品的声誉中,从精油的作用、功效和使用方法中吸取教训。
让对手给你制高点
不比较价格,比较价值
观众喜欢什么?他会在百度上搜索...
使用5118需求图,()
分析百度搜索需求,了解受众喜爱什么;
所以,如果你精通5118或淘数据中的任何一个,都可以挖掘和满足差异化的需求,你就可以卖得好,成为市场第一。
学通5118选择了地狱难度的一个案例。
比如你是一家销售燃料油的厂家,你如何挖掘和满足差异化的需求?
获取数据5118需求图搜索“燃料宝”
对于销售房屋和汽车这样的大企业,如何进行最合适的营销?
文章总结
通往大企业的捷径
一、定义买家类型并分类决策场景
二、拓展三种媒体获取决策场景
首先合理定义新买家决策场景
使用5118需求图
先看车
以买车为例:
以购买二手车为例:
挖掘出五个场景:4S店、车险销售、汽车APP、车管二哥、交易市场。
再检查一遍
比如买房的人:
比如买二手房的:
挖掘出房产APP、分类信息、售楼中心、房产中介、银行经理五个场景。
其他挖矿方式同理,保险、理财……
sem怎么用工具挖出更多关键词?单词扩展技巧
文章总结
5118虽然是收费的网站,但是有一个“需求图”工具,可以在里面找到更多相关词,然后展开。
比如你搜索空调维修,你会挖掘出电话、维修点、服务等词根,你也可以知道这些相关词的词频。词频越高,搜索量越大。
疑问词扩展
我们可以把这些相关词组合起来,挖掘出更多的需求,得到更精准的关键词。
网站关键词 为什么排名不稳定?
文章总结
对于互联网推广,每个人都希望自己的企业品牌永远占据百度首页,因为只有在百度首页上才能展示给更多的用户,带来更多的点击咨询,增加用户转化!
然而,事情往往适得其反。网站关键词的排名不是很稳定,尤其是新网站,就像我们的网站核心词万次吧屏幕,一周后就跌到了第二页。
上位网站为大家分析一下原因,是什么导致了关键词的排名不稳定!
这个是5118查询的,可以看到检测到的主题不是暴君而是seo,网站优化!
虽然你现在看到我们的网站主题都是基于关键词八屏的,但是搜索引擎上还有记录,还没有完全调整!
站长 SEO 插件
SEO tools-5118插件站长工具箱使用评测!
文章总结
前言:相信很多和我一样做SEO优化的小伙伴都会采集一些方便我们日常工作的SEO工具。
它可以让我们面对繁琐的工作更方便,更节省时间!
今天要讨论的就是5118大数据推出的5118站长工具箱,我们来看看它的独特之处。
业内SEOer很清楚,5118从上线到现在,一直在刷新我们对SEO数据分析的新世界观;
就像他的统计监测头衔一样,《享受大神的运营愿景》确实从传统的第三方统计工具中脱颖而出。
一个实用的seo工具推荐:检查网站违规和敏感词,避免触犯广告法!
文章总结
说到违禁词、违禁词、敏感词等,心里真的很苦。这几年一直遇到这样的事情,网站老内容或者老专页。违禁词很多,明明不是自己的原因造成的,而是要清理——而且还得人工清理。
只要你做网络营销、广告或seo等工作,很多人都会遇到同样的问题。一直没有解决办法。
直到今天,花哥发现了一个seo工具,可以帮助我们发现网站中的违禁词,做到事前防范,解决被处罚的隐患。
那是什么工具?让我们来看看。
该工具名为5118站长工具箱,是一个浏览器插件。下载后解压,拖放到浏览器窗口,即可安装使用。
5118站长工具箱轻松处理SEO工作中的常见问题
文章总结
互联网行业的你,无论你是站长还是网站编辑,说到站长工具,你可能用过一两个或多或少。作为后起之秀,5118平台不得不说站长们提供了很多非常强大的seo工具,不久前还推出了“5118站长工具箱”。
这是一个为浏览器开发的插件工具。官方称其为专为站长SEO工作而设计的智能插件,结合大数据,对浏览器进行视觉增强。
让每一页浏览都能实时获取SEO工作所需的重要数据,是站长工作的最佳搭档。
小结:其实这些功能看起来很简单,就像很多人喜欢直接通过查看源码来观察网页的状态一样。当然,你也可以手动查看排名和收录。但是,5118工具箱作为一个免费的小插件工具,让这些功能更加简单高效,因为作为站长或者优化者,这些数据都是作为对网站情况的简单观察和了解,所以从而节省时间去做更多有用的事情。
智能原创
5118 Smart原创 Smart Writing API 有什么用?收费标准是什么?
文章总结
今天登录5118,在API商城发现了一个新的API——Smart 原创 Smart Writing API,可以自动化高质量的内容重写,其可读性接近人类写作的水平,无论是重写句子、段落或全文。无限的优质内容输出源是无穷无尽的。
今天boke112就给大家简单介绍一下这个API。
多功能组合
每天有没有值得一看的网站?
文章总结
数据对运营的重要性,除了内部数据分析,还要注意外部数据的采集。对竞争产品、行业和市场水平的分析将为您的运营提供很多想法。
5118大数据
推荐理由:SEO人员必备的查询工具,支持网站SEO分析、关键词挖词、关键词排名、百度收录查询等SEO人员常用功能.
对于市场调查,您可以评估相应网站的SEO表现,并探索竞争对手网站。
市场上已经有很多竞争对手。我怎样才能好起来?
文章总结
一、 让你的对手给你老客户
从两个方向找到你的对手:
1.品牌
2.销售
5118-关键词 竞价推广公司(品牌方向) 比如你在5118搜索类目做“精油”:%E7%B2%BE%E6%B2%B9
竞标百度,用心做品牌
然后批量查询索引,
它还可以将这些品牌的搜索量与收录的搜索量进行比较
搜索量越大,品牌越大
收录 音量越大操作越强
二、如何让你的对手给你一个新客户
从对手自己的媒体流量中学习
——流量取决于对手本身
比如从自媒体、电子商城、APP、官网、全网……
5118全网优质网站挖矿
搜索竞争对手品牌名称:
查看对方部署了哪些渠道和媒体
SEO 教程工具-5118
文章总结
网友快刀手付红雪:
5118 又多了一个伪原创 工具。将文章复制并粘贴到其中以执行智能短语剪切。分析出来的关键词会自动推荐可以替换的词,并用不同的字体颜色标明哪些词被替换过,哪些词被替换过。可以替换,替换后的熟人百分比也会提示关键词。
这样,伪原创之后文章的质量就高了,写文章的人就不会那么烧脑了。
5118程序员真是拯救我们编辑器的大神。
网友思喜0r:
一直以为5118只能查主域的排名词,所以才会用。
有一天,我和他们的客户服务聊天。客服妹子跟我说可以看整个域的排名词,也可以看历史排名数据,但是要查看整个域的排名词,必须要开通VIP,所以最后还是断开了一个。
然后仔细询问VIP有什么权限,知道它可以监控指定关键词的排名,这真是一个非常有用的功能。
看来我得“深入研究”5118了,免得这么好的工具浪费了我。
网友叫我泽米娜:
最近5118上的站长工具插件,个人认为是用过最实用方便的插件。安装一个插件后,可以卸载到之前安装的N个插件。
显示排名数的功能和隐藏百度广告的功能都不太好用。
开启排名号码显示功能,可以直观的看到排名号码是哪个,而不是一一统计。
开启隐藏百度广告功能,可以隐藏所有广告,截图和报告不会拦截一堆广告,可以直接看到自己和竞争对手的排名差异。
谢谢5118!祝5118越来越好!
网友紫豆沧浪:
5118始终走在行业前沿。春节一过,百家号大数据内参新功能立即上线。个人认为有很好的资料,参考性很强。就是查粉丝数从高到低2000,百家企业可以学习这些大规模的运营策略。
并且通过点击这些百家账号的名称,可以直接在百度上查看该账号的关键词。
简单介绍一下5118平台的站群SEO监控功能!
文章总结
数据监控:5118也是一款比较好用的百度排名工具。它在关键词 挖掘和站群 seo 监控方面做得更好。
5118一直为站长提供一个可以监控巨大站群的功能,即“群站SEO监控”。目前,该功能已升级为海量会员同时监控5118个网站,并创建50个分类。
基本可以满足绝大多数站群的站长,可以即时监控他们管理的网站的综合情况。
对于网站管理不多的站长来说,可能会觉得这个功能有点鸡肋,不过换个角度想想,可以加自己的同行和竞争对手的网站来监控!
这样你就可以知道对手的网站排名、收录、外链,甚至竞价条款,及时调整策略,增加自己的网站流量!
新手如何开始练习写作?
文章总结
选择主题:相关领域
当你没有热点话题和知乎好评时,你要从自己的相关领域来决定话题。
推荐一个工具来帮你:5118大数据
这个工具可以显示大多数人在你的领域搜索什么内容,然后你就可以写出高搜索内容。
通过大神级操作的异象,你明白了吗? 查看全部
通过关键词采集文章采集api(关键词挖掘有哪些不起眼却非常赚钱的行业?你必须知道的18款追热点工具)
今天的内容汇集了大神们如何使用5118工具实现价值最大化和功能体验最大化。
接下来,我们就来看看他们是如何利用5118工具为网站精准运营赋能的!
关键词挖矿
什么是不起眼但利润丰厚的行业?
文章总结
公开财报显示,百合网2018年净利润为6.12亿,其中包括嘉源世纪(世纪嘉源于2015年12月7日宣布与百合网合并)。
至此,可以知道婚姻平台以结婚结交为名的巨额利润,仅会员费就能赚2.6亿。从商业角度,拆解交友项目。
在SEO方面,我们可以从关键词的扩展入手,将全国各个省市、地区的词与交友等相关词结合起来,然后产生大量的内页。
可以使用词挖掘工具。
创建高质量关键词词库的方法
文章总结
公共渠道——部分平台提供关键词数据,如搜索引擎自带的关键词工具(百度和谷歌都有)、5118等。
平台渠道一般来自行业特定的关键词,可以结合自己的网站进行二次处理。
对于常见的行业或领域,这些专业平台工具提供的关键词数量可观;
对于一些很小的子领域或者冷门的行业,你得换个思路采集关键词。
新媒体人必知:18个你必须知道的热点工具
文章总结
5118专注于关键词排名,提供行业词库、排名词搜索、词挖掘等服务,以及“财经”、“新闻”、“财经”等精细分类。
对于流行的关键词,给出了相关关注点的变化和发展,可以准确到几分钟内。
5118的“挖词”功能也受到媒体人的青睐。用户可以搜索关键词、移动流量词、批量搜索长尾词。
每个词都会匹配对应的百度收录量、长尾词数、百度指数、移动指数等指标。
排水小白如何成为排水高手?
文章总结
全网流量布局实操
第一步:
自我定位,定位精准人群,经营细分行业,定位用户需求。
如果你是宝妈,可以为宝妈群做相关的关键词。例如,使用5118搜索长尾词或相关词。
………………
第五步:
将内容发布到各大平台,让你获得两大流量,一是平台内部推荐流量,二是搜外流量。
比如今日头条自媒体平台的推广流量,以及除今日头条以外的百度和360、搜狗的搜索流量。
最重要的是让标题关键词,而关键词决定了你的用户群。
如何找到自己的关键词,可以用5118挖最需要的词,直到达到霸屏的效果。
需求图
看了3000个抖音,我们做了一个3000万+观看量的视频
文章总结
打开率:视频的第一张图片很重要,让大家知道你的视频在讲什么,有什么用,好不好玩。
并且最好有模板保证一致性,这样才能达到长期输出。
另一个关键点是标题。标题可以影响打开率,只要关注目标用户的痛点。
所以你可以去5118搜索,看你视频的相关人,他们主要关注什么,以及如何交谈。
了解对手的口碑媒体流量
文章总结
流量取决于对手的声誉
比如,来自促销,来自联想。
从联想5118需求图中,搜索同行品牌名称:
看词频拍片,比如搜索“阿福”
看流量入口:引流实体店和专柜的流量;
从几种精油产品的声誉中,从精油的作用、功效和使用方法中吸取教训。
让对手给你制高点
不比较价格,比较价值
观众喜欢什么?他会在百度上搜索...
使用5118需求图,()
分析百度搜索需求,了解受众喜爱什么;
所以,如果你精通5118或淘数据中的任何一个,都可以挖掘和满足差异化的需求,你就可以卖得好,成为市场第一。
学通5118选择了地狱难度的一个案例。
比如你是一家销售燃料油的厂家,你如何挖掘和满足差异化的需求?
获取数据5118需求图搜索“燃料宝”
对于销售房屋和汽车这样的大企业,如何进行最合适的营销?
文章总结
通往大企业的捷径
一、定义买家类型并分类决策场景
二、拓展三种媒体获取决策场景
首先合理定义新买家决策场景
使用5118需求图
先看车
以买车为例:
以购买二手车为例:
挖掘出五个场景:4S店、车险销售、汽车APP、车管二哥、交易市场。
再检查一遍
比如买房的人:
比如买二手房的:
挖掘出房产APP、分类信息、售楼中心、房产中介、银行经理五个场景。
其他挖矿方式同理,保险、理财……
sem怎么用工具挖出更多关键词?单词扩展技巧
文章总结
5118虽然是收费的网站,但是有一个“需求图”工具,可以在里面找到更多相关词,然后展开。
比如你搜索空调维修,你会挖掘出电话、维修点、服务等词根,你也可以知道这些相关词的词频。词频越高,搜索量越大。
疑问词扩展
我们可以把这些相关词组合起来,挖掘出更多的需求,得到更精准的关键词。
网站关键词 为什么排名不稳定?
文章总结
对于互联网推广,每个人都希望自己的企业品牌永远占据百度首页,因为只有在百度首页上才能展示给更多的用户,带来更多的点击咨询,增加用户转化!
然而,事情往往适得其反。网站关键词的排名不是很稳定,尤其是新网站,就像我们的网站核心词万次吧屏幕,一周后就跌到了第二页。
上位网站为大家分析一下原因,是什么导致了关键词的排名不稳定!
这个是5118查询的,可以看到检测到的主题不是暴君而是seo,网站优化!
虽然你现在看到我们的网站主题都是基于关键词八屏的,但是搜索引擎上还有记录,还没有完全调整!
站长 SEO 插件
SEO tools-5118插件站长工具箱使用评测!
文章总结
前言:相信很多和我一样做SEO优化的小伙伴都会采集一些方便我们日常工作的SEO工具。
它可以让我们面对繁琐的工作更方便,更节省时间!
今天要讨论的就是5118大数据推出的5118站长工具箱,我们来看看它的独特之处。
业内SEOer很清楚,5118从上线到现在,一直在刷新我们对SEO数据分析的新世界观;
就像他的统计监测头衔一样,《享受大神的运营愿景》确实从传统的第三方统计工具中脱颖而出。
一个实用的seo工具推荐:检查网站违规和敏感词,避免触犯广告法!
文章总结
说到违禁词、违禁词、敏感词等,心里真的很苦。这几年一直遇到这样的事情,网站老内容或者老专页。违禁词很多,明明不是自己的原因造成的,而是要清理——而且还得人工清理。
只要你做网络营销、广告或seo等工作,很多人都会遇到同样的问题。一直没有解决办法。
直到今天,花哥发现了一个seo工具,可以帮助我们发现网站中的违禁词,做到事前防范,解决被处罚的隐患。
那是什么工具?让我们来看看。
该工具名为5118站长工具箱,是一个浏览器插件。下载后解压,拖放到浏览器窗口,即可安装使用。
5118站长工具箱轻松处理SEO工作中的常见问题
文章总结
互联网行业的你,无论你是站长还是网站编辑,说到站长工具,你可能用过一两个或多或少。作为后起之秀,5118平台不得不说站长们提供了很多非常强大的seo工具,不久前还推出了“5118站长工具箱”。
这是一个为浏览器开发的插件工具。官方称其为专为站长SEO工作而设计的智能插件,结合大数据,对浏览器进行视觉增强。
让每一页浏览都能实时获取SEO工作所需的重要数据,是站长工作的最佳搭档。
小结:其实这些功能看起来很简单,就像很多人喜欢直接通过查看源码来观察网页的状态一样。当然,你也可以手动查看排名和收录。但是,5118工具箱作为一个免费的小插件工具,让这些功能更加简单高效,因为作为站长或者优化者,这些数据都是作为对网站情况的简单观察和了解,所以从而节省时间去做更多有用的事情。
智能原创
5118 Smart原创 Smart Writing API 有什么用?收费标准是什么?
文章总结
今天登录5118,在API商城发现了一个新的API——Smart 原创 Smart Writing API,可以自动化高质量的内容重写,其可读性接近人类写作的水平,无论是重写句子、段落或全文。无限的优质内容输出源是无穷无尽的。
今天boke112就给大家简单介绍一下这个API。
多功能组合
每天有没有值得一看的网站?
文章总结
数据对运营的重要性,除了内部数据分析,还要注意外部数据的采集。对竞争产品、行业和市场水平的分析将为您的运营提供很多想法。
5118大数据
推荐理由:SEO人员必备的查询工具,支持网站SEO分析、关键词挖词、关键词排名、百度收录查询等SEO人员常用功能.
对于市场调查,您可以评估相应网站的SEO表现,并探索竞争对手网站。
市场上已经有很多竞争对手。我怎样才能好起来?
文章总结
一、 让你的对手给你老客户
从两个方向找到你的对手:
1.品牌
2.销售
5118-关键词 竞价推广公司(品牌方向) 比如你在5118搜索类目做“精油”:%E7%B2%BE%E6%B2%B9
竞标百度,用心做品牌
然后批量查询索引,
它还可以将这些品牌的搜索量与收录的搜索量进行比较
搜索量越大,品牌越大
收录 音量越大操作越强
二、如何让你的对手给你一个新客户
从对手自己的媒体流量中学习
——流量取决于对手本身
比如从自媒体、电子商城、APP、官网、全网……
5118全网优质网站挖矿
搜索竞争对手品牌名称:
查看对方部署了哪些渠道和媒体
SEO 教程工具-5118
文章总结
网友快刀手付红雪:
5118 又多了一个伪原创 工具。将文章复制并粘贴到其中以执行智能短语剪切。分析出来的关键词会自动推荐可以替换的词,并用不同的字体颜色标明哪些词被替换过,哪些词被替换过。可以替换,替换后的熟人百分比也会提示关键词。
这样,伪原创之后文章的质量就高了,写文章的人就不会那么烧脑了。
5118程序员真是拯救我们编辑器的大神。
网友思喜0r:
一直以为5118只能查主域的排名词,所以才会用。
有一天,我和他们的客户服务聊天。客服妹子跟我说可以看整个域的排名词,也可以看历史排名数据,但是要查看整个域的排名词,必须要开通VIP,所以最后还是断开了一个。
然后仔细询问VIP有什么权限,知道它可以监控指定关键词的排名,这真是一个非常有用的功能。
看来我得“深入研究”5118了,免得这么好的工具浪费了我。
网友叫我泽米娜:
最近5118上的站长工具插件,个人认为是用过最实用方便的插件。安装一个插件后,可以卸载到之前安装的N个插件。
显示排名数的功能和隐藏百度广告的功能都不太好用。
开启排名号码显示功能,可以直观的看到排名号码是哪个,而不是一一统计。
开启隐藏百度广告功能,可以隐藏所有广告,截图和报告不会拦截一堆广告,可以直接看到自己和竞争对手的排名差异。
谢谢5118!祝5118越来越好!
网友紫豆沧浪:
5118始终走在行业前沿。春节一过,百家号大数据内参新功能立即上线。个人认为有很好的资料,参考性很强。就是查粉丝数从高到低2000,百家企业可以学习这些大规模的运营策略。
并且通过点击这些百家账号的名称,可以直接在百度上查看该账号的关键词。
简单介绍一下5118平台的站群SEO监控功能!
文章总结
数据监控:5118也是一款比较好用的百度排名工具。它在关键词 挖掘和站群 seo 监控方面做得更好。
5118一直为站长提供一个可以监控巨大站群的功能,即“群站SEO监控”。目前,该功能已升级为海量会员同时监控5118个网站,并创建50个分类。
基本可以满足绝大多数站群的站长,可以即时监控他们管理的网站的综合情况。
对于网站管理不多的站长来说,可能会觉得这个功能有点鸡肋,不过换个角度想想,可以加自己的同行和竞争对手的网站来监控!
这样你就可以知道对手的网站排名、收录、外链,甚至竞价条款,及时调整策略,增加自己的网站流量!
新手如何开始练习写作?
文章总结
选择主题:相关领域
当你没有热点话题和知乎好评时,你要从自己的相关领域来决定话题。
推荐一个工具来帮你:5118大数据
这个工具可以显示大多数人在你的领域搜索什么内容,然后你就可以写出高搜索内容。
通过大神级操作的异象,你明白了吗?
通过关键词采集文章采集api(赛题“互联网+”大赛从实际问题出发,用对开发工具取得佳绩)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-12-31 05:12
API 能给我们带来什么?
通过API,您可以创建和管理云服务器、云容器、云硬盘,提高工作效率;您可以访问图像识别、情感分析和内容审查等功能。不懂AI,依然可以玩转各种AI技能;还可以快速实现视频点播、对话机器人等成熟的应用能力...
但是,国内API生态还处于初级发展阶段。许多优秀的 API 仍然是来自大海的遗产。许多公司经常重复开发,因为他们不明白他们的创新中有现成的 API。
在API经济时代,为了让大家更好地了解API及其应用,本次“互联网+”大赛从实际问题出发,推出相关命题——结合华为云API开放平台API Explorer实现照片分类系统。
本文从大赛的介绍、描述和要求入手,梳理出题的步骤和重点思路,以及相关开发工具的使用指南和示例。希望这个答题策略能够帮助广大参赛者取得好成绩。
竞赛题介绍:使用API解决实际问题
一个典型的中国家庭,有4个老人,2个大人,1个小孩(4+2+1),手里拿着手机,日常生活中用手机拍了很多照片工作、学习,这些照片基本都是存放在各自的手机里,然后通过社交应用分享,但是这样会出现很多问题,比如批量分享不方便,手机本地存储空间不足等。
本次大赛旨在使用华为云相关API,如照片智能分类,分类后可集中存储至云端。用户还可以在不共享的情况下为照片设置隐私。参赛者可以在API Explorer平台查看学习相关的云服务API,完成比赛题。作品的最终形式不限,可以是移动应用、小程序、云服务、网页、桌面应用等。
赛题解读:理清三步思维,用好开发工具
在解读赛题之前,我们先来看看华为云的API Explorer平台。API Explorer 是一个统一的平台,为开发者提供一站式的 API 解决方案。集成了华为云服务的所有开放API,支持全速检索和可视化。调试、帮助文档、代码示例、mocks 等能力帮助开发者快速查找和学习 API 并使用 API 进行代码开发。目前有17个品类,100+产品服务,3800+开放API。
本次竞赛题的核心是利用华为云的API能力实现应用开发。下面我们进一步分析问题描述,主要分为四个步骤:
其中,我们提取了几个关键词:图像识别、图像分类、图像存储。事实上,图像的处理也是这几年人工智能技术研究的重点。从这个角度来看,这个竞赛题考查的不仅仅是API的应用,还有与计算机视觉相关的技术能力。
综上所述,如果参赛者想使用API构建满足要求的应用,可以参考以下思路:
1、 通过调用OBS的API接口,访问和操作云存储中的图像数据;
2、 通过调用图片识别API接口对图片进行标记;
3、通过调用ModelArts的API接口,对图片进行进一步分类,对私密图片进行识别和去除。
提到的华为云产品有:OBS、图像识别、ModelArts。
OBS 是一种云存储服务,具有标准的 Restful API 接口,可以存储任意数量和形式的非结构化数据。
ModelArts是面向开发者的一站式AI开发平台,提供海量数据预处理、智能标注、大规模分布式训练、模型自动化生成、端侧云模型按需部署能力,帮助用户快速创建和部署模型, 管理全周期 AI 工作流程。
这些产品的能力都被“打包”成开放的API接口,玩家可以在API Explorer中查看、学习和使用。此外,参赛者可以通过DevStar/DevCloud快速开发应用(APP/小程序/Web等)。
其中,DevStar提供了Web、App、微服务等80+不同类型的通用框架模板,玩家无需从头开发应用。DevCloud是一站式云软件开发平台,可随时交付云端软件全生命周期,涵盖需求发布、代码提交、代码检查、代码编译、验证、部署、发布。
下面,我们将重点介绍本次大赛主打产品API Explorer的使用,以及相关案例。
API Explorer 用户指南
从华为云官网-开发者-资源工具,您可以进入API Explorer页面,其中收录华为云开放的所有API信息。玩家可以在该平台上快速查看和搜索API文档,以及可视化调试API。具体关键能力如下图所示。
一是支持开放API在线检索和可视化调试,可以定位相关云服务,快速查询云服务下所有开放API。回到这个竞赛题,选手在API Explorer中搜索“ModeIArts”,在界面中可以看到模型部署的API文档。
更详细的信息可通过API文档获取,包括接口约束、请求参数说明、示例、返回参数、SDK等。选择API后,可以直接填写参数进行在线调试,查看API调用的返回结果。
如果调用接口返回错误码,您可以在错误码中心快速找到对应的详细错误信息和处理措施建议,快速解决API调用问题。
当您熟悉API函数并需要使用代码调用API时,您可以通过API Explorer查看SDK代码示例。支持Java、Python、Go等七种主流开发语言。通过引入对应语言的SDK,可以快速调用应用中的API。,并且所有SDK代码已经通过GitHub开源。同时,API Explorer还提供了云上/云外CLI、API Mock、场景示例等其他功能,方便开发者使用。
什么样的工作容易拿高分?
前面提到的华为云产品可以提高你的开发和应用效率,但最终的效果取决于玩家对技术的理解和掌握、解决问题思路的创新、项目的完成程度等等。
从比赛的评分维度来看,作品的创新性、技术实现与交付、商业性、团队分工等都非常重要。
以创新为例,包括图像分类算法的准确性、API设计调用等;在团队方面,分工协作要明确,组织架构和人员配备要合理。项目技术路线清晰明确,技术工具成熟可靠。此外,设计良好且可行的商业模式更容易获得高分。
最后,再次提醒大家一下本次“互联网+”大赛的赛程:报名和提交作品的截止日期是8月31日,预赛半决赛截止日期是9月30日,全国总决赛预计在8月31日结束。 10 月中下旬举行。各位参与者,抓紧时间,用手中的代码感受一下API的魅力吧。更多信息:互联网+大赛_大学_互联网_华为云 查看全部
通过关键词采集文章采集api(赛题“互联网+”大赛从实际问题出发,用对开发工具取得佳绩)
API 能给我们带来什么?
通过API,您可以创建和管理云服务器、云容器、云硬盘,提高工作效率;您可以访问图像识别、情感分析和内容审查等功能。不懂AI,依然可以玩转各种AI技能;还可以快速实现视频点播、对话机器人等成熟的应用能力...
但是,国内API生态还处于初级发展阶段。许多优秀的 API 仍然是来自大海的遗产。许多公司经常重复开发,因为他们不明白他们的创新中有现成的 API。
在API经济时代,为了让大家更好地了解API及其应用,本次“互联网+”大赛从实际问题出发,推出相关命题——结合华为云API开放平台API Explorer实现照片分类系统。
本文从大赛的介绍、描述和要求入手,梳理出题的步骤和重点思路,以及相关开发工具的使用指南和示例。希望这个答题策略能够帮助广大参赛者取得好成绩。
竞赛题介绍:使用API解决实际问题
一个典型的中国家庭,有4个老人,2个大人,1个小孩(4+2+1),手里拿着手机,日常生活中用手机拍了很多照片工作、学习,这些照片基本都是存放在各自的手机里,然后通过社交应用分享,但是这样会出现很多问题,比如批量分享不方便,手机本地存储空间不足等。
本次大赛旨在使用华为云相关API,如照片智能分类,分类后可集中存储至云端。用户还可以在不共享的情况下为照片设置隐私。参赛者可以在API Explorer平台查看学习相关的云服务API,完成比赛题。作品的最终形式不限,可以是移动应用、小程序、云服务、网页、桌面应用等。
赛题解读:理清三步思维,用好开发工具
在解读赛题之前,我们先来看看华为云的API Explorer平台。API Explorer 是一个统一的平台,为开发者提供一站式的 API 解决方案。集成了华为云服务的所有开放API,支持全速检索和可视化。调试、帮助文档、代码示例、mocks 等能力帮助开发者快速查找和学习 API 并使用 API 进行代码开发。目前有17个品类,100+产品服务,3800+开放API。
本次竞赛题的核心是利用华为云的API能力实现应用开发。下面我们进一步分析问题描述,主要分为四个步骤:
其中,我们提取了几个关键词:图像识别、图像分类、图像存储。事实上,图像的处理也是这几年人工智能技术研究的重点。从这个角度来看,这个竞赛题考查的不仅仅是API的应用,还有与计算机视觉相关的技术能力。
综上所述,如果参赛者想使用API构建满足要求的应用,可以参考以下思路:
1、 通过调用OBS的API接口,访问和操作云存储中的图像数据;
2、 通过调用图片识别API接口对图片进行标记;
3、通过调用ModelArts的API接口,对图片进行进一步分类,对私密图片进行识别和去除。
提到的华为云产品有:OBS、图像识别、ModelArts。
OBS 是一种云存储服务,具有标准的 Restful API 接口,可以存储任意数量和形式的非结构化数据。
ModelArts是面向开发者的一站式AI开发平台,提供海量数据预处理、智能标注、大规模分布式训练、模型自动化生成、端侧云模型按需部署能力,帮助用户快速创建和部署模型, 管理全周期 AI 工作流程。
这些产品的能力都被“打包”成开放的API接口,玩家可以在API Explorer中查看、学习和使用。此外,参赛者可以通过DevStar/DevCloud快速开发应用(APP/小程序/Web等)。
其中,DevStar提供了Web、App、微服务等80+不同类型的通用框架模板,玩家无需从头开发应用。DevCloud是一站式云软件开发平台,可随时交付云端软件全生命周期,涵盖需求发布、代码提交、代码检查、代码编译、验证、部署、发布。
下面,我们将重点介绍本次大赛主打产品API Explorer的使用,以及相关案例。
API Explorer 用户指南
从华为云官网-开发者-资源工具,您可以进入API Explorer页面,其中收录华为云开放的所有API信息。玩家可以在该平台上快速查看和搜索API文档,以及可视化调试API。具体关键能力如下图所示。
一是支持开放API在线检索和可视化调试,可以定位相关云服务,快速查询云服务下所有开放API。回到这个竞赛题,选手在API Explorer中搜索“ModeIArts”,在界面中可以看到模型部署的API文档。
更详细的信息可通过API文档获取,包括接口约束、请求参数说明、示例、返回参数、SDK等。选择API后,可以直接填写参数进行在线调试,查看API调用的返回结果。
如果调用接口返回错误码,您可以在错误码中心快速找到对应的详细错误信息和处理措施建议,快速解决API调用问题。
当您熟悉API函数并需要使用代码调用API时,您可以通过API Explorer查看SDK代码示例。支持Java、Python、Go等七种主流开发语言。通过引入对应语言的SDK,可以快速调用应用中的API。,并且所有SDK代码已经通过GitHub开源。同时,API Explorer还提供了云上/云外CLI、API Mock、场景示例等其他功能,方便开发者使用。
什么样的工作容易拿高分?
前面提到的华为云产品可以提高你的开发和应用效率,但最终的效果取决于玩家对技术的理解和掌握、解决问题思路的创新、项目的完成程度等等。
从比赛的评分维度来看,作品的创新性、技术实现与交付、商业性、团队分工等都非常重要。
以创新为例,包括图像分类算法的准确性、API设计调用等;在团队方面,分工协作要明确,组织架构和人员配备要合理。项目技术路线清晰明确,技术工具成熟可靠。此外,设计良好且可行的商业模式更容易获得高分。
最后,再次提醒大家一下本次“互联网+”大赛的赛程:报名和提交作品的截止日期是8月31日,预赛半决赛截止日期是9月30日,全国总决赛预计在8月31日结束。 10 月中下旬举行。各位参与者,抓紧时间,用手中的代码感受一下API的魅力吧。更多信息:互联网+大赛_大学_互联网_华为云
通过关键词采集文章采集api(通过关键词采集文章采集api服务,其他采集方式可以)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-12-29 16:08
通过关键词采集文章采集api服务,其他采集方式可以根据自己的需求定制开发一般用于网站爬虫,可抓取新闻网站页面,也可根据网站的用户喜好定制采集内容,方便对产品做数据分析在线采集,比如利用我们自研的数据采集平台,来爬取网站上面的内容。(二维码自动识别)网站的编码采用utf-8url采用javascript来解析,比如新闻网站的url则采用javascript1166格式,标识本地网站,网站里面的内容都会抓取来自于官方站点服务器下载curl指定文件位置,然后把这个地址往下面一直复制到浏览器就可以从文件服务器抓取文件了采集带图片的文件支持自定义合并class,可以同时抓取好几个文件批量采集内容可设置采集次数和关键词比如新闻网站的站点地址和页面编码可以设置不同的几种方式编辑内容另外采集会员专属的文章,内容是可以跳过新闻网站中的任何有图片的页面的,都会抓取同时关注网站的动态即时同步抓取defget_target_url(self,targeturl,name,classes):"""gettargeturlforname:--返回网站首页(不知道的要区分不同的网站来编写)--返回网站的所有新闻页面(可采用网站视频截图,或者利用github搜索相应的文件或者爬虫修改设置网站视频网址采集)--返回网站单篇文章页面(如果是单篇文章的话,直接编辑后缀为bs4就可以)--返回github上有关网站的项目文件"""urls=[]currp='w'forurlinurls:url=url+targeturlpage=dict().extend(classes).get(classes=currp)page.sort(ascending=true)page.toarray()targeturl=self.url(url)get_request(url,targeturl)get_url(targeturl,page)urls.append(get_url(targeturl,page))returnurls上面是抓取新闻网站的部分采集代码,采集的范围还是很大的,要想爬取的网站比较多的话,就要用到itchat,爬虫里有个红包爬虫,我们可以用上。
itchat这个库我们之前有介绍过,下面是itchat的帮助文档以及一些示例。第一部分:入门1.下载itchat模块itchat::http/1.1response对象用于接收任何http请求的结果,收到的response只是response对象,并不会返回实际的网页,必须要先用requests装载,才可以开始抓取2.创建爬虫爬虫的目的:随时接收到爬虫响应后,能立刻开始抓取对象,一次只抓取一个网页。
流程:按需获取资源抓取网页解析网页发送验证码到服务器,继续获取更多的资源,然后再做抓取每一步操作的界定:1.抓取网页,之后只抓取需要的资源2.。 查看全部
通过关键词采集文章采集api(通过关键词采集文章采集api服务,其他采集方式可以)
通过关键词采集文章采集api服务,其他采集方式可以根据自己的需求定制开发一般用于网站爬虫,可抓取新闻网站页面,也可根据网站的用户喜好定制采集内容,方便对产品做数据分析在线采集,比如利用我们自研的数据采集平台,来爬取网站上面的内容。(二维码自动识别)网站的编码采用utf-8url采用javascript来解析,比如新闻网站的url则采用javascript1166格式,标识本地网站,网站里面的内容都会抓取来自于官方站点服务器下载curl指定文件位置,然后把这个地址往下面一直复制到浏览器就可以从文件服务器抓取文件了采集带图片的文件支持自定义合并class,可以同时抓取好几个文件批量采集内容可设置采集次数和关键词比如新闻网站的站点地址和页面编码可以设置不同的几种方式编辑内容另外采集会员专属的文章,内容是可以跳过新闻网站中的任何有图片的页面的,都会抓取同时关注网站的动态即时同步抓取defget_target_url(self,targeturl,name,classes):"""gettargeturlforname:--返回网站首页(不知道的要区分不同的网站来编写)--返回网站的所有新闻页面(可采用网站视频截图,或者利用github搜索相应的文件或者爬虫修改设置网站视频网址采集)--返回网站单篇文章页面(如果是单篇文章的话,直接编辑后缀为bs4就可以)--返回github上有关网站的项目文件"""urls=[]currp='w'forurlinurls:url=url+targeturlpage=dict().extend(classes).get(classes=currp)page.sort(ascending=true)page.toarray()targeturl=self.url(url)get_request(url,targeturl)get_url(targeturl,page)urls.append(get_url(targeturl,page))returnurls上面是抓取新闻网站的部分采集代码,采集的范围还是很大的,要想爬取的网站比较多的话,就要用到itchat,爬虫里有个红包爬虫,我们可以用上。
itchat这个库我们之前有介绍过,下面是itchat的帮助文档以及一些示例。第一部分:入门1.下载itchat模块itchat::http/1.1response对象用于接收任何http请求的结果,收到的response只是response对象,并不会返回实际的网页,必须要先用requests装载,才可以开始抓取2.创建爬虫爬虫的目的:随时接收到爬虫响应后,能立刻开始抓取对象,一次只抓取一个网页。
流程:按需获取资源抓取网页解析网页发送验证码到服务器,继续获取更多的资源,然后再做抓取每一步操作的界定:1.抓取网页,之后只抓取需要的资源2.。
通过关键词采集文章采集api(网络推广seo如何布局在页面上?稳,首先人要稳 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-12-29 00:18
)
李林关键词 优化推广成本,值得信赖的“在线咨询” [一箭天网络9e04b84]
文章采集
工具:对于站群来说,没有主站那么严格。一般情况下,其文章均为采集器
编辑的伪原创,并定期发布在网站上。一个采集器
可以操作几十个网站,只要你提前在采集器
建立一个可以采集
文章的网站。优采云
采集
工具经常用于seo优化的在线推广。它不仅可以满足站长对文章的需求,还可以对文章段落进行洗牌和重组。合并后的文章基本可以流畅。
在做SEO的过程中,总会有SEO站长会遇到相关的问题。比如整个网站质量很高,页面结构也不错,访问速度和用户体验还可以,但是没有排名。这主要是由于页面关键词的布局。但是我们都知道页面的长度是不一样的,我们在匹配关键词的时候并没有比较统一的策略。有时,需要详细分析具体问题。那么,长页面和短页面,关键词应该如何在页面上布局呢?
不是文章没更新,只是现在没更新,有的人会说他们的采集
很少上榜,确实有一些站从来不更新东西,但是排名还是挺稳定的。然而,这些网站要么是权重高的老式网站,点击率很高,要么有大量的外部链接。简而言之,他们并不那么普通。要关键词稳定,首先人要稳定,不要过多使用SEO技术,坚持网站内容的建设,没有内容就没有人被吸引,就会有不堵车,就算有人,跳出来的机会也很大。
查看全部
通过关键词采集文章采集api(网络推广seo如何布局在页面上?稳,首先人要稳
)
李林关键词 优化推广成本,值得信赖的“在线咨询” [一箭天网络9e04b84]
文章采集
工具:对于站群来说,没有主站那么严格。一般情况下,其文章均为采集器
编辑的伪原创,并定期发布在网站上。一个采集器
可以操作几十个网站,只要你提前在采集器
建立一个可以采集
文章的网站。优采云
采集
工具经常用于seo优化的在线推广。它不仅可以满足站长对文章的需求,还可以对文章段落进行洗牌和重组。合并后的文章基本可以流畅。
在做SEO的过程中,总会有SEO站长会遇到相关的问题。比如整个网站质量很高,页面结构也不错,访问速度和用户体验还可以,但是没有排名。这主要是由于页面关键词的布局。但是我们都知道页面的长度是不一样的,我们在匹配关键词的时候并没有比较统一的策略。有时,需要详细分析具体问题。那么,长页面和短页面,关键词应该如何在页面上布局呢?
不是文章没更新,只是现在没更新,有的人会说他们的采集
很少上榜,确实有一些站从来不更新东西,但是排名还是挺稳定的。然而,这些网站要么是权重高的老式网站,点击率很高,要么有大量的外部链接。简而言之,他们并不那么普通。要关键词稳定,首先人要稳定,不要过多使用SEO技术,坚持网站内容的建设,没有内容就没有人被吸引,就会有不堵车,就算有人,跳出来的机会也很大。
通过关键词采集文章采集api(通过关键词采集文章采集api文章下载api简单说就是)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-26 16:07
通过关键词采集文章采集api文章下载api简单说就是文章下载api,你用别人已经做好的api,只要你有技术就可以开发一套很方便的工具,这个api大家免费申请我也只是听说,不知道是不是真的
网上都没有下载地址,如果你要访问,可以上文末扫码。
我也是以为地址没有,自己用抓包软件抓下来,我自己注册个账号下来给你看看哈,
华为版本的可以下载googledrive。
在server端外加phpi就可以下载googledrive的文件。
文件的相关信息请在chrome或360浏览器中打开google的api服务支持查看,也可以通过如下网址进行使用。
据我所知应该只能通过https这条路了或者寻找googleimagesearch相关的插件来实现
https的应该很难下,可以找googleimagepoint这个项目来下,而且没有界面。
https的应该比较难下,
谷歌的api就挺稳定的了
可以在googledrive的website里查看一下,我记得是https就可以了。现在的网站普遍canpey,点个链接都这么难,我们网站(虚拟空间)有12000套使用图片的搜索,都是国外的。 查看全部
通过关键词采集文章采集api(通过关键词采集文章采集api文章下载api简单说就是)
通过关键词采集文章采集api文章下载api简单说就是文章下载api,你用别人已经做好的api,只要你有技术就可以开发一套很方便的工具,这个api大家免费申请我也只是听说,不知道是不是真的
网上都没有下载地址,如果你要访问,可以上文末扫码。
我也是以为地址没有,自己用抓包软件抓下来,我自己注册个账号下来给你看看哈,
华为版本的可以下载googledrive。
在server端外加phpi就可以下载googledrive的文件。
文件的相关信息请在chrome或360浏览器中打开google的api服务支持查看,也可以通过如下网址进行使用。
据我所知应该只能通过https这条路了或者寻找googleimagesearch相关的插件来实现
https的应该很难下,可以找googleimagepoint这个项目来下,而且没有界面。
https的应该比较难下,
谷歌的api就挺稳定的了
可以在googledrive的website里查看一下,我记得是https就可以了。现在的网站普遍canpey,点个链接都这么难,我们网站(虚拟空间)有12000套使用图片的搜索,都是国外的。
通过关键词采集文章采集api(第二种需要自动同步到你的平台吗?(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-23 15:02
这个问题需要在几种情况下回答
首先,您只需要下载并再次编辑它。这个方法非常简单。一般来说,你知道你想要的文章,也就是你知道文章的访问地址。一般在采集器的帮助下就可以下载了,不管是word保存还是其他格式都没有问题。
第二种类型需要自动同步到您的平台。这个比较麻烦,因为你不知道下载地址(不可能手动自动输入)。
方法一、1、通过搜狗浏览器,调用他的界面搜索你的公众号,2、如果存在,通过第二个界面查询公众号下的历史记录文章。获取文章链接,通过程序下载,然后保存到你的后台。
这种方法的优点是:半自动,不需要手动输入文章链接。缺点是:1、如果频繁发送请求,搜狗会提示验证码。这需要手动处理,因此不能完全自动化。2、 并且获取的文章链接是临时的,需要在有效期内下载。3、只能获取最近十条历史记录文章,4、需要定时执行,不能实时更新。更新太频繁导致验证码被屏蔽,频率太低更新延迟太大。
方法二、1、 通过程序模拟登录公众号后台管理页面。2、通过模拟调用和编辑素材。3、通过模拟编辑插入链接功能,4、调用搜索公众号接口,查询公众号获取fackId。5、 通过获取到的fackId调用另外一个接口,获取文章列表。这个 文章 列表中有链接。
这种方法的优点是:1、不会出现验证码,但也有封印的情况,但出现频率较低。2、 并且可以获取公众号下所有文章的列表。3、文章 链接永久有效。缺点是:1、还有接口调用被阻塞的情况。需要一段时间才能自动解锁。2、 需要定时执行,不能实时更新。更新太频繁截获验证码,频率太低更新延迟太大。
方法三、1、通过实时推送,只需要提供接收链接的API接口,将文章链接实时推送到顶部界面,获取链接下载内容并将其保存到您自己的平台。
这种方法的优点:1、不被屏蔽,2、不需要输入验证码3、技术难度低。4、文章 更新及时,延迟低,最多三到五分钟。4、文章 链接永久有效。它可以真正实现完全自动化。缺点是:需要有自己的开发者,有API接收参数。
如果有更好的方法,请联系我,互相学习。如果需要技术支持,也可以联系我。以上方法都是亲身尝试过的。有源代码(仅限java)。 查看全部
通过关键词采集文章采集api(第二种需要自动同步到你的平台吗?(一))
这个问题需要在几种情况下回答
首先,您只需要下载并再次编辑它。这个方法非常简单。一般来说,你知道你想要的文章,也就是你知道文章的访问地址。一般在采集器的帮助下就可以下载了,不管是word保存还是其他格式都没有问题。
第二种类型需要自动同步到您的平台。这个比较麻烦,因为你不知道下载地址(不可能手动自动输入)。
方法一、1、通过搜狗浏览器,调用他的界面搜索你的公众号,2、如果存在,通过第二个界面查询公众号下的历史记录文章。获取文章链接,通过程序下载,然后保存到你的后台。
这种方法的优点是:半自动,不需要手动输入文章链接。缺点是:1、如果频繁发送请求,搜狗会提示验证码。这需要手动处理,因此不能完全自动化。2、 并且获取的文章链接是临时的,需要在有效期内下载。3、只能获取最近十条历史记录文章,4、需要定时执行,不能实时更新。更新太频繁导致验证码被屏蔽,频率太低更新延迟太大。
方法二、1、 通过程序模拟登录公众号后台管理页面。2、通过模拟调用和编辑素材。3、通过模拟编辑插入链接功能,4、调用搜索公众号接口,查询公众号获取fackId。5、 通过获取到的fackId调用另外一个接口,获取文章列表。这个 文章 列表中有链接。
这种方法的优点是:1、不会出现验证码,但也有封印的情况,但出现频率较低。2、 并且可以获取公众号下所有文章的列表。3、文章 链接永久有效。缺点是:1、还有接口调用被阻塞的情况。需要一段时间才能自动解锁。2、 需要定时执行,不能实时更新。更新太频繁截获验证码,频率太低更新延迟太大。
方法三、1、通过实时推送,只需要提供接收链接的API接口,将文章链接实时推送到顶部界面,获取链接下载内容并将其保存到您自己的平台。
这种方法的优点:1、不被屏蔽,2、不需要输入验证码3、技术难度低。4、文章 更新及时,延迟低,最多三到五分钟。4、文章 链接永久有效。它可以真正实现完全自动化。缺点是:需要有自己的开发者,有API接收参数。
如果有更好的方法,请联系我,互相学习。如果需要技术支持,也可以联系我。以上方法都是亲身尝试过的。有源代码(仅限java)。
通过关键词采集文章采集api(百度下拉框关键词都是这些东西,没啥特别的吧!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-12-20 01:22
对于词研究,每个搜索者都必须知道。除了比较流行的百度相关搜索词外,百度下拉框关键词应该也是很多人研究的范围,但是大部分人都是针对下拉框的。字数抓取,毕竟百度下拉框关键词采集已经泛滥了。
百度下拉菜单的正式名称是百度建议词(Baidu Suggest Word),也称为百度建议词或百度下拉菜单。是百度为方便广大网民搜索,提高输入效率而推出的一项服务。
例如,当我们在百度中输入“营销”两个词时,百度从推荐词条库中检索以“营销”两个词开头的词条,并按照搜索量从大到小排序。形成一个下拉菜单。百度下拉菜单的最大数量为 10。
百度下拉框关键词的含义:
它可以用作长尾词和标题。毕竟用户在搜索时可以触发关键词搜索选择。
很多人用下拉词来引导流量,比如曝光品牌,导向指定页面。您可以采集分析竞争对手的相关操作,也可以自己曝光自己的品牌。不同的人有不同的看法!
网上有很多采集下拉词的工具和源码。到这里,人渣渣滓已经梳理完毕。让我们再次分享它。昨天晚上,我弟弟问起这件事。这些东西没什么特别的吧?
版本一:
直接网页抓取实现下拉词采集
def get_keywords(word):
url=f"https://www.baidu.com/sugrec%3 ... wd%3D{word}"
html=requests.get(url)
html=html.json()
#print(html)
#print(html['g'])
key_words=[]
for key_word in html['g']:
print(key_word['q'])
key_words.append(key_word['q'])
#print(key_words)
return key_words
版本二:
使用官方界面
例如:
def get_sug(word):
url = 'https://sp0.baidu.com/5a1Fazu8 ... 27%3B % word
r = requests.get(url, verify=False) # 请求API接口,取消了HTTPS验证
cont = r.content # 获取返回的内容
res = cont[41: -2].decode('gbk') # 只取返回结果中json格式一段,并且解码为unicode
res_json = json.loads(res) # json格式转换
return res_json['s'] # 返回关键词列表
版本三:
另一个接口地址
def get_word(word):
url=f'http://suggestion.baidu.com/su?wd={word}&sugmode=3&json=1'
html=requests.get(url).text
html=html.replace("window.baidu.sug(",'')
html = html.replace(")", '')
html = html.replace(";", '')
#print(html)
html = json.loads(html)
key_words=html['s']
#print(key_words)
return key_words
本质上二和三性质是一样的,大家参考使用吧!
扩大的视野:
这里有个小技巧,就是在关键词后面输入w,会出现一系列以拼音“w”开头的关键词,比如“黄山w”,还会出现“黄山温泉”, 《黄山万集》《天》《黄山五绝》等关键词(见上图)。因此,当我们遍历a~z时,会出现更多的关键词。
此处选择第2版的接口形式,以免不协调
但是如果使用requests模块请求无效的证书网站,会直接报错
可以将verify参数设置为False来解决这个问题
r = requests.get(url, verify=False)
但是设置 verify=False 会抛出 InsecureRequestWarning 警告
看起来很糟糕
解决方案:
from requests.packages.urllib3.exceptions import InsecureRequestWarning
# 禁用安全请求警告
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
运行结果
参考源码获取 查看全部
通过关键词采集文章采集api(百度下拉框关键词都是这些东西,没啥特别的吧!)
对于词研究,每个搜索者都必须知道。除了比较流行的百度相关搜索词外,百度下拉框关键词应该也是很多人研究的范围,但是大部分人都是针对下拉框的。字数抓取,毕竟百度下拉框关键词采集已经泛滥了。
百度下拉菜单的正式名称是百度建议词(Baidu Suggest Word),也称为百度建议词或百度下拉菜单。是百度为方便广大网民搜索,提高输入效率而推出的一项服务。
例如,当我们在百度中输入“营销”两个词时,百度从推荐词条库中检索以“营销”两个词开头的词条,并按照搜索量从大到小排序。形成一个下拉菜单。百度下拉菜单的最大数量为 10。
百度下拉框关键词的含义:
它可以用作长尾词和标题。毕竟用户在搜索时可以触发关键词搜索选择。
很多人用下拉词来引导流量,比如曝光品牌,导向指定页面。您可以采集分析竞争对手的相关操作,也可以自己曝光自己的品牌。不同的人有不同的看法!
网上有很多采集下拉词的工具和源码。到这里,人渣渣滓已经梳理完毕。让我们再次分享它。昨天晚上,我弟弟问起这件事。这些东西没什么特别的吧?
版本一:
直接网页抓取实现下拉词采集
def get_keywords(word):
url=f"https://www.baidu.com/sugrec%3 ... wd%3D{word}"
html=requests.get(url)
html=html.json()
#print(html)
#print(html['g'])
key_words=[]
for key_word in html['g']:
print(key_word['q'])
key_words.append(key_word['q'])
#print(key_words)
return key_words
版本二:
使用官方界面
例如:
def get_sug(word):
url = 'https://sp0.baidu.com/5a1Fazu8 ... 27%3B % word
r = requests.get(url, verify=False) # 请求API接口,取消了HTTPS验证
cont = r.content # 获取返回的内容
res = cont[41: -2].decode('gbk') # 只取返回结果中json格式一段,并且解码为unicode
res_json = json.loads(res) # json格式转换
return res_json['s'] # 返回关键词列表
版本三:
另一个接口地址
def get_word(word):
url=f'http://suggestion.baidu.com/su?wd={word}&sugmode=3&json=1'
html=requests.get(url).text
html=html.replace("window.baidu.sug(",'')
html = html.replace(")", '')
html = html.replace(";", '')
#print(html)
html = json.loads(html)
key_words=html['s']
#print(key_words)
return key_words
本质上二和三性质是一样的,大家参考使用吧!
扩大的视野:
这里有个小技巧,就是在关键词后面输入w,会出现一系列以拼音“w”开头的关键词,比如“黄山w”,还会出现“黄山温泉”, 《黄山万集》《天》《黄山五绝》等关键词(见上图)。因此,当我们遍历a~z时,会出现更多的关键词。
此处选择第2版的接口形式,以免不协调
但是如果使用requests模块请求无效的证书网站,会直接报错
可以将verify参数设置为False来解决这个问题
r = requests.get(url, verify=False)
但是设置 verify=False 会抛出 InsecureRequestWarning 警告
看起来很糟糕
解决方案:
from requests.packages.urllib3.exceptions import InsecureRequestWarning
# 禁用安全请求警告
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
运行结果
参考源码获取
通过关键词采集文章采集api( 什么是采集站?现在做网站还能做采集站吗? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-12-18 18:11
什么是采集站?现在做网站还能做采集站吗?
)
采集 站是什么?采集站台怎么办?如果我现在做网站,我还能做采集吗?今天小编就给大家分享一些关于采集站的经验分享!可以说现在的大部分网站都离不开采集,采集已经成为了互联网的常态网站,所以想当站或者已经有网站上网的同学一定要清楚了解采集站!我自己做的小说网站和门户网站都是用采集的方法制作的。目前,全流和全5,日均IP流量稳定在1万左右。通过这篇文章的文章和大家分享一下我的一些理解和实践。
采集 站是什么?每个 网站 都需要填充内容。在这个“内容为王”的时代,很多SEO站长为了做网站优化,疯狂写文章。但是,一些SEOer 认为原创文章 没有那么重要。为了让网站能够在短时间内拥有大量的内容,很多站长都会选择采集文章的方式。对于站长来说,因为经常需要发布文章,需要采集各种文章资源,所以需要各种采集工具。从事互联网SEO行业以来,一直在使用采集工具来处理不同的文章资源,以及采集不同平台的资源,文章采集@ > 工具不知道你听说过吗?可能有的站长没接触过吧!采集工具现在被一些站群或大型门户网站使用,例如企业网站使用的那些。当然,一些个人网站也被一些人使用采集,因为有些情况不想自己更新文章 或文章 需要在大网站上更新的很多而且复杂的,比如新闻网站,都用采集。编辑器通常使用采集来完成所有采集站的内容填写。更适合不懂代码和技术的站长。输入关键词就可以了。采集,没有复杂的配置,也不需要写采集的规则。采集完成后,
采集站台怎么办?1.网站上线前采集文章,准备了很多文章(所有采集来这里,当然采集 N 个站点 文章)。2. 网站 模板一定要自己写,代码库一定要优化。3. 做好网站 内容页面布局。4.上线后每天更新100~500文章卷,文章一定是采集N个站点的最新文章。5. 外链每天发一些。一个月后,你的网站收录和你的流量都会上升!
一些采集需要特别注意的点: 1. 海量长尾词:我在采集的内容中导入了超过10万个关键词,我想要更多关键词排名,那么你需要大量的文章和关键词。而我的文章都是基于关键词采集。不要像大多数人一样做采集站。基本上,它是盲目的采集。内容有几万个收录,但排名的关键词只有几十个。看着它很有趣,只是乱七八糟。这样的采集 站点基本上是在制造互联网垃圾邮件。搜索引擎反对谁?拥有 关键词 和内容只是基础。如果你的采集文章能获得不错的排名,那你就需要下一步了。2.文章优化:80% 的人不理解高质量的内容。采集 过来的内容必须经过伪原创!其实搜索引擎已经说得很清楚了。文章排版,内容就是用户需要的,很明显的告诉大家文章有图有文字,远胜于纯文本文章收录。所以你的内容布局好,关键词布局好,你文章已经有排名机会是用户需求。3.页面结构:有两个核心点,相关性和丰富性。抓住这两点,去百度看看别人的官方说明,就可以掌握核心,内页排名也很容易。4.内容收录速度:要想快速上榜,首先要做的就是网站 content收录 要快。想要让收录快速的需要大量的蜘蛛来抓取你的网站,其实搜索引擎已经给出了很好的工具,主动推送功能!批量推送网页链接到搜索引擎,增加曝光率。
如果我现在做网站,我还能做采集吗?我的采集站点一直很稳定,我的采集站点完全符合搜索引擎的规则。不仅稳定,而且流量还在持续上升。所以采集网站还是可以做的,最重要的还是做对了,不是因为采集和采集,采集之后的SEO优化也很重要,具体后续文章的内容我会详细说明。本期暂时先说说采集站。
关于采集站的问题,小编就到此为止。总之,如果采集的内容处理得当,站采集也会是收录。但是大家要注意一个问题,就是对采集网站的操作要更加谨慎,不要让搜索引擎认为这是一个采集站,而且在同时在用户体验和满足用户需求方面做更多的优化,这样的采集站还是可以做的。
查看全部
通过关键词采集文章采集api(
什么是采集站?现在做网站还能做采集站吗?
)
采集 站是什么?采集站台怎么办?如果我现在做网站,我还能做采集吗?今天小编就给大家分享一些关于采集站的经验分享!可以说现在的大部分网站都离不开采集,采集已经成为了互联网的常态网站,所以想当站或者已经有网站上网的同学一定要清楚了解采集站!我自己做的小说网站和门户网站都是用采集的方法制作的。目前,全流和全5,日均IP流量稳定在1万左右。通过这篇文章的文章和大家分享一下我的一些理解和实践。
采集 站是什么?每个 网站 都需要填充内容。在这个“内容为王”的时代,很多SEO站长为了做网站优化,疯狂写文章。但是,一些SEOer 认为原创文章 没有那么重要。为了让网站能够在短时间内拥有大量的内容,很多站长都会选择采集文章的方式。对于站长来说,因为经常需要发布文章,需要采集各种文章资源,所以需要各种采集工具。从事互联网SEO行业以来,一直在使用采集工具来处理不同的文章资源,以及采集不同平台的资源,文章采集@ > 工具不知道你听说过吗?可能有的站长没接触过吧!采集工具现在被一些站群或大型门户网站使用,例如企业网站使用的那些。当然,一些个人网站也被一些人使用采集,因为有些情况不想自己更新文章 或文章 需要在大网站上更新的很多而且复杂的,比如新闻网站,都用采集。编辑器通常使用采集来完成所有采集站的内容填写。更适合不懂代码和技术的站长。输入关键词就可以了。采集,没有复杂的配置,也不需要写采集的规则。采集完成后,
采集站台怎么办?1.网站上线前采集文章,准备了很多文章(所有采集来这里,当然采集 N 个站点 文章)。2. 网站 模板一定要自己写,代码库一定要优化。3. 做好网站 内容页面布局。4.上线后每天更新100~500文章卷,文章一定是采集N个站点的最新文章。5. 外链每天发一些。一个月后,你的网站收录和你的流量都会上升!
一些采集需要特别注意的点: 1. 海量长尾词:我在采集的内容中导入了超过10万个关键词,我想要更多关键词排名,那么你需要大量的文章和关键词。而我的文章都是基于关键词采集。不要像大多数人一样做采集站。基本上,它是盲目的采集。内容有几万个收录,但排名的关键词只有几十个。看着它很有趣,只是乱七八糟。这样的采集 站点基本上是在制造互联网垃圾邮件。搜索引擎反对谁?拥有 关键词 和内容只是基础。如果你的采集文章能获得不错的排名,那你就需要下一步了。2.文章优化:80% 的人不理解高质量的内容。采集 过来的内容必须经过伪原创!其实搜索引擎已经说得很清楚了。文章排版,内容就是用户需要的,很明显的告诉大家文章有图有文字,远胜于纯文本文章收录。所以你的内容布局好,关键词布局好,你文章已经有排名机会是用户需求。3.页面结构:有两个核心点,相关性和丰富性。抓住这两点,去百度看看别人的官方说明,就可以掌握核心,内页排名也很容易。4.内容收录速度:要想快速上榜,首先要做的就是网站 content收录 要快。想要让收录快速的需要大量的蜘蛛来抓取你的网站,其实搜索引擎已经给出了很好的工具,主动推送功能!批量推送网页链接到搜索引擎,增加曝光率。
如果我现在做网站,我还能做采集吗?我的采集站点一直很稳定,我的采集站点完全符合搜索引擎的规则。不仅稳定,而且流量还在持续上升。所以采集网站还是可以做的,最重要的还是做对了,不是因为采集和采集,采集之后的SEO优化也很重要,具体后续文章的内容我会详细说明。本期暂时先说说采集站。
关于采集站的问题,小编就到此为止。总之,如果采集的内容处理得当,站采集也会是收录。但是大家要注意一个问题,就是对采集网站的操作要更加谨慎,不要让搜索引擎认为这是一个采集站,而且在同时在用户体验和满足用户需求方面做更多的优化,这样的采集站还是可以做的。
通过关键词采集文章采集api(通过关键词采集文章采集api,实现文章一键分类及上传)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-12-16 04:04
通过关键词采集文章采集api,然后上传到云爬虫系统即可。googleapisforwebscraping基于mongodb数据库。采集的数据可以上传到该数据库中,实现文章的一键分类及上传。
你应该先搞懂爬虫是干什么的,然后再来想找哪些网站。
目前是社交媒体的天下,新闻媒体是主流,其实也没有哪个网站规定了网站只能做什么,在我看来,大部分网站都做了用户(新闻媒体的竞争对手)分析(抽样调查什么网站的新闻量更高等等).
ruby爬虫和社交媒体数据
基于javascript的爬虫爬虫本身是通过http请求获取资源的,你看到哪个爬虫将excel上的数据爬下来了,那么这个网站可能会分析这些数据并对它做分析。
你会爬虫么?
如果专注于文章的话,其实国内的原创文章还有挺多的。如果对于新闻类,那就比较多了,比如凤凰网、人民网、搜狐网等等。
如果关注的是某些网站的话,那么可以根据这些网站的资源来进行,但是没有哪个网站是专门针对于某类网站做产品,可能是因为某一些关注目标网站的人不够多,但是我觉得这些网站对于不同类型的网站来说还是不错的,
智能手机
你都能做了,
给地铁里面的人普及一下计算机知识,让其了解一下目前通讯方式,最好还能发明一种专用通讯方式。不需要资源,只要人人都能使用计算机,就可以了。 查看全部
通过关键词采集文章采集api(通过关键词采集文章采集api,实现文章一键分类及上传)
通过关键词采集文章采集api,然后上传到云爬虫系统即可。googleapisforwebscraping基于mongodb数据库。采集的数据可以上传到该数据库中,实现文章的一键分类及上传。
你应该先搞懂爬虫是干什么的,然后再来想找哪些网站。
目前是社交媒体的天下,新闻媒体是主流,其实也没有哪个网站规定了网站只能做什么,在我看来,大部分网站都做了用户(新闻媒体的竞争对手)分析(抽样调查什么网站的新闻量更高等等).
ruby爬虫和社交媒体数据
基于javascript的爬虫爬虫本身是通过http请求获取资源的,你看到哪个爬虫将excel上的数据爬下来了,那么这个网站可能会分析这些数据并对它做分析。
你会爬虫么?
如果专注于文章的话,其实国内的原创文章还有挺多的。如果对于新闻类,那就比较多了,比如凤凰网、人民网、搜狐网等等。
如果关注的是某些网站的话,那么可以根据这些网站的资源来进行,但是没有哪个网站是专门针对于某类网站做产品,可能是因为某一些关注目标网站的人不够多,但是我觉得这些网站对于不同类型的网站来说还是不错的,
智能手机
你都能做了,
给地铁里面的人普及一下计算机知识,让其了解一下目前通讯方式,最好还能发明一种专用通讯方式。不需要资源,只要人人都能使用计算机,就可以了。

