
通过关键词采集文章采集api
通过关键词采集文章采集api(SEO从业者是怎么产生的?频道上线你有项目来A5招商吧 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-29 01:20
)
创业项目频道上线,A5有招商项目吗?
作为13年的资深SEO司机,我经常思考SEO的本质?对于大多数SEO优化者来说,大多数人都理解SEO=外链+内容。其实这是一个很简单的理解。这是从一个非常低的角度来看SEO工作。
SEO的全称是Search Engine Optimization,帮助搜索引擎优化。SEO 正在帮助百度、谷歌和 360 改进他们的内容。从这个角度思考,你会发现SEO实际上是在做一个伟大的生意,而不是白天和黑夜。交换链接和伪原创。
搜索引擎是怎么来的?
当 Internet 首次出现时,每台计算机都是一个信息孤岛。为了让这些岛屿上的信息查询速度更快,一些聪明人编写了一个简单的爬虫程序,对分布在网络上每台计算机上的文件进行索引。然后通过一个简单的搜索框,用户可以快速搜索孤岛信息,造福人类。
搜索引擎最怕什么?
我最怕我的用户找不到他们想要的结果。希望从各个信息孤岛中,尽可能多地找到用户可能感兴趣的内容,并继续放到自己的索引中,让用户下次搜索时可以满意的离开。
SEO从业者是帮助搜索引擎优化的人。这并不意味着每天都会生成无数的垃圾邮件,或者它们在提供帮助。不是每天建立无数的友情链接来帮助它,而是帮助搜索引擎解决他们的实际问题。感觉很棒吗?
如果你不能意识到这一点,实际上你可能无法适应SEO优化领域。这不是鲁莽的早期时代。如果一直依赖链接和伪原创,只会觉得SEO真的很可笑!
我们怎样才能做得更好?
1.拥有最全面准确的行业词库
当我们经营某个网站或某专栏时,我们往往是垂直于一个行业。每个行业都有自己的范围。总的来说,每个行业其实都有自己的一批核心关键词+长尾词。这些词定义了一个行业的范围,所以有一个行业词库是完全掌握一个行业的必备。
例如,围绕理财行业的核心词如下:
理财行业核心词下的长尾词列表如下:
2.用词库找出搜索引擎最需要什么
当我们掌握了一个行业的所有词汇,才能真正了解这个行业,了解这个行业用户的需求。
接下来,我们要在这近百万的金融词汇中找出最能带来流量的词。这里我们使用百度PC指数、360指数、百度移动指数、竞价策划者PC搜索量、竞价策划者移动搜索量和竞价策划者竞争程度:
通过上面的公式,我们可以筛选出一批业内最能带来流量的词,从百万词库中筛选出104635个流量词。
3.通过API关键词过滤掉搜索引擎最缺乏的内容
通过上面过滤掉的104635个流量词,我们可以把它们放到百度、360等搜索引擎中进行模拟查询,了解前20个网页的URL级别和标题,了解搜索引擎是否内容饱和.
通过API商城的百度PC端TOP 50排名API(www 5118 com/apistore),我们可以方便的获取JSON格式的排名。
下图中,我们以“什么是指数基金”这个词为例,得到TOP20搜索结果的排名:
返回的排名信息中还有两个比较重要的信息,域名权重信息和Title信息。
域名权重信息表示前50个域名是否都是权重相对较低的域名,让您有机会挤进去。
对Title信息的分析,是指网络上这个关键词的内容是否饱和,还是百度为了填充信息,选择了一些补充信息来填充搜索结果。
通过分析这两条信息,我们可以判断这个关键词是否值得优先考虑。
让我们在这里做一个假设。如果我的网站5118的权重是A,那么我们要找出TOP20排名结果中是否有很多5118权重B级甚至C级网站的排名结果。如果有那么我们还有机会占据他们的位置。
还有另一种情况。如果不能通过域名找到机会,还有另一个机会。事实上,这些高权重域名的内容并不完全符合搜索要求,这意味着搜索结果中的某些内容标题并不完全匹配 关键词 。
比如上图中的Title并没有完全收录“什么是指数基金”这个词,只是搜索引擎为了补充结果而放置的一个指数,那么我们也可以将这些仓位标记为机会。
通过类似上面的算法,我们可以得到每个词的机会分数。我们可以设置一个筛选阈值,比如设置为8。如果TOP 20结果中有超过8个机会位置,我们会将这些关键词保留,进入第四阶段。
4.帮助搜索引擎改进这些内容
通过前三步筛选出性价比最高的SEO关键词后,我们可以安排编辑撰写文章或者专题,或者安排技术部进行文章采集,或安排运营部门指导用户创作内容。
通过这四步逐层过滤,我们的内容运营工作就会很有针对性。虽然上面写了这么多字,但其实是以下三个目的:
5. 监控 SEO 效果
随着内容的不断完善,我们需要对上面确定的内容策略的有效性进行整体评估,可能需要对一些参数、阈值甚至算法进行微调:
借助百度站长后台(),了解爬虫的爬取次数和爬取时间,了解爬虫遇到的异常次数。
因为只有监控这些参数才能知道百度爬虫在你的内容制作完成后是否如期到达,没有遇到任何障碍,从而保证你的内容策略不会因为其他技术操作导致策略失败和维修干扰因素。
使用5118PC收录检测功能或百度PC收录API检测制造内容是否为收录。
收录 是排名的先决条件。如果内容不能是收录,那么再多的爬虫都没有意义。如果内容没有做成收录,对内容策略也是一个打击,所以对收录的监控也很重要。
检查排名是否按预期增长
随着内容和收录的不断增加,我们SEO的最终目标是获得好的排名。
跟踪整体趋势,确保整体内容策略正确。
2. 监控个别关键词 排名,以评估每个内容制作工作的稳定性并关注细节。
▲可以使用5118关键词监控自行添加关键词进行批量监控
▲ 也可以使用 5118关键词ranking采集 API 来监控
如果公司有开发能力,可以直接使用5118提供的关键词排名查询API进行排名数据采集,并集成到其现有的管理系统中。
最后总结:
现代人类文明的发展是一个追求极致自动化的过程。无人工厂、无人超市、无人机,作为大数据时代的SEO管理者,也需要追求SEO自动化,与时俱进,实现自我突破。
通过这个内容生产过程,我们可以逐步优化我们的内容策略,最大限度地发挥内容生产流量的效果。还等什么,赶快使用这些大数据API,让你轻松推广。
查看全部
通过关键词采集文章采集api(SEO从业者是怎么产生的?频道上线你有项目来A5招商吧
)
创业项目频道上线,A5有招商项目吗?
作为13年的资深SEO司机,我经常思考SEO的本质?对于大多数SEO优化者来说,大多数人都理解SEO=外链+内容。其实这是一个很简单的理解。这是从一个非常低的角度来看SEO工作。
SEO的全称是Search Engine Optimization,帮助搜索引擎优化。SEO 正在帮助百度、谷歌和 360 改进他们的内容。从这个角度思考,你会发现SEO实际上是在做一个伟大的生意,而不是白天和黑夜。交换链接和伪原创。
搜索引擎是怎么来的?
当 Internet 首次出现时,每台计算机都是一个信息孤岛。为了让这些岛屿上的信息查询速度更快,一些聪明人编写了一个简单的爬虫程序,对分布在网络上每台计算机上的文件进行索引。然后通过一个简单的搜索框,用户可以快速搜索孤岛信息,造福人类。
搜索引擎最怕什么?
我最怕我的用户找不到他们想要的结果。希望从各个信息孤岛中,尽可能多地找到用户可能感兴趣的内容,并继续放到自己的索引中,让用户下次搜索时可以满意的离开。
SEO从业者是帮助搜索引擎优化的人。这并不意味着每天都会生成无数的垃圾邮件,或者它们在提供帮助。不是每天建立无数的友情链接来帮助它,而是帮助搜索引擎解决他们的实际问题。感觉很棒吗?
如果你不能意识到这一点,实际上你可能无法适应SEO优化领域。这不是鲁莽的早期时代。如果一直依赖链接和伪原创,只会觉得SEO真的很可笑!

我们怎样才能做得更好?
1.拥有最全面准确的行业词库
当我们经营某个网站或某专栏时,我们往往是垂直于一个行业。每个行业都有自己的范围。总的来说,每个行业其实都有自己的一批核心关键词+长尾词。这些词定义了一个行业的范围,所以有一个行业词库是完全掌握一个行业的必备。
例如,围绕理财行业的核心词如下:

理财行业核心词下的长尾词列表如下:


2.用词库找出搜索引擎最需要什么
当我们掌握了一个行业的所有词汇,才能真正了解这个行业,了解这个行业用户的需求。
接下来,我们要在这近百万的金融词汇中找出最能带来流量的词。这里我们使用百度PC指数、360指数、百度移动指数、竞价策划者PC搜索量、竞价策划者移动搜索量和竞价策划者竞争程度:

通过上面的公式,我们可以筛选出一批业内最能带来流量的词,从百万词库中筛选出104635个流量词。

3.通过API关键词过滤掉搜索引擎最缺乏的内容
通过上面过滤掉的104635个流量词,我们可以把它们放到百度、360等搜索引擎中进行模拟查询,了解前20个网页的URL级别和标题,了解搜索引擎是否内容饱和.
通过API商城的百度PC端TOP 50排名API(www 5118 com/apistore),我们可以方便的获取JSON格式的排名。
下图中,我们以“什么是指数基金”这个词为例,得到TOP20搜索结果的排名:

返回的排名信息中还有两个比较重要的信息,域名权重信息和Title信息。
域名权重信息表示前50个域名是否都是权重相对较低的域名,让您有机会挤进去。
对Title信息的分析,是指网络上这个关键词的内容是否饱和,还是百度为了填充信息,选择了一些补充信息来填充搜索结果。
通过分析这两条信息,我们可以判断这个关键词是否值得优先考虑。
让我们在这里做一个假设。如果我的网站5118的权重是A,那么我们要找出TOP20排名结果中是否有很多5118权重B级甚至C级网站的排名结果。如果有那么我们还有机会占据他们的位置。

还有另一种情况。如果不能通过域名找到机会,还有另一个机会。事实上,这些高权重域名的内容并不完全符合搜索要求,这意味着搜索结果中的某些内容标题并不完全匹配 关键词 。

比如上图中的Title并没有完全收录“什么是指数基金”这个词,只是搜索引擎为了补充结果而放置的一个指数,那么我们也可以将这些仓位标记为机会。
通过类似上面的算法,我们可以得到每个词的机会分数。我们可以设置一个筛选阈值,比如设置为8。如果TOP 20结果中有超过8个机会位置,我们会将这些关键词保留,进入第四阶段。
4.帮助搜索引擎改进这些内容
通过前三步筛选出性价比最高的SEO关键词后,我们可以安排编辑撰写文章或者专题,或者安排技术部进行文章采集,或安排运营部门指导用户创作内容。
通过这四步逐层过滤,我们的内容运营工作就会很有针对性。虽然上面写了这么多字,但其实是以下三个目的:

5. 监控 SEO 效果
随着内容的不断完善,我们需要对上面确定的内容策略的有效性进行整体评估,可能需要对一些参数、阈值甚至算法进行微调:
借助百度站长后台(),了解爬虫的爬取次数和爬取时间,了解爬虫遇到的异常次数。
因为只有监控这些参数才能知道百度爬虫在你的内容制作完成后是否如期到达,没有遇到任何障碍,从而保证你的内容策略不会因为其他技术操作导致策略失败和维修干扰因素。


使用5118PC收录检测功能或百度PC收录API检测制造内容是否为收录。
收录 是排名的先决条件。如果内容不能是收录,那么再多的爬虫都没有意义。如果内容没有做成收录,对内容策略也是一个打击,所以对收录的监控也很重要。

检查排名是否按预期增长
随着内容和收录的不断增加,我们SEO的最终目标是获得好的排名。
跟踪整体趋势,确保整体内容策略正确。

2. 监控个别关键词 排名,以评估每个内容制作工作的稳定性并关注细节。
▲可以使用5118关键词监控自行添加关键词进行批量监控

▲ 也可以使用 5118关键词ranking采集 API 来监控
如果公司有开发能力,可以直接使用5118提供的关键词排名查询API进行排名数据采集,并集成到其现有的管理系统中。

最后总结:
现代人类文明的发展是一个追求极致自动化的过程。无人工厂、无人超市、无人机,作为大数据时代的SEO管理者,也需要追求SEO自动化,与时俱进,实现自我突破。
通过这个内容生产过程,我们可以逐步优化我们的内容策略,最大限度地发挥内容生产流量的效果。还等什么,赶快使用这些大数据API,让你轻松推广。

通过关键词采集文章采集api(这款论坛采集软件完美支持采集所有编码格式的网页程序)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-26 20:11
论坛采集软件是一款非常优秀的专业网络数据采集工具软件,论坛采集软件适用于有采集挖矿需求的各类群体和用户可以使用本软件对各种论坛的信息进行数据采集,抓取结构化文本、图片、文件等资源信息,进行编辑过滤,自动增量更新发布到网站后台,每个在类文件或其他数据库系统中,软件操作非常方便,可以简单的执行各种网站数据采集,本论坛采集软件完美支持采集对于所有编码格式的网页,程序还可以自动识别网页编码,支持目前所有主流和非主流cms、BBS等网站节目,并能实现采集器和网站节目的完美结合,我来告诉你怎么做使用它,我希望它可以帮助你。
论坛采集软件使用图1
它具有以下特点:
1. 支持采集标题、内容、用户名、注册时间、签名、头像、附件等,支持添加采集字段;支持自动回复,方便选择回复帖和隐藏附件。支持帖子回复
2.支持回复部分的增量采集,可以采集新建回复并发布。可以处理论坛、贴吧、连载更新问题;智能生成采集规则,系统内置多个常用论坛自动识别规则,可自动生成采集规则
3.支持网站自动登录,支持当前主流Discuz、PHPWind论坛,暂不支持验证码登录;界面支持自动注册账号、处理头像、处理话题和回复,官方界面不断更新维护
4.支持下载文件,支持翻译、分词、代理等功能优采云采集器;支持插件开发,接口灵活,可以采集更复杂的网站数据,做数据处理
5.可以搜索关键词采集帖子网址,可以批量设置关键词查询类型采集
论坛采集 专家特色:
主要用于数据采集挖掘、垂直搜索、信息聚合与门户、企业网络信息聚合、商业智能、论坛或博客迁移、智能信息代理、个人信息检索等领域,适用于各种数据采集和挖掘需求组。
论坛采集高手使用方法:
1.解压并启动软件
2.第一次运行需要导入采集规则
论坛采集软件使用图2
3.可以添加需要采集的网站
论坛采集软件使用图3
4.选择采集的内容,点击开始,会自动继续采集
论坛采集 软件使用情况图4 查看全部
通过关键词采集文章采集api(这款论坛采集软件完美支持采集所有编码格式的网页程序)
论坛采集软件是一款非常优秀的专业网络数据采集工具软件,论坛采集软件适用于有采集挖矿需求的各类群体和用户可以使用本软件对各种论坛的信息进行数据采集,抓取结构化文本、图片、文件等资源信息,进行编辑过滤,自动增量更新发布到网站后台,每个在类文件或其他数据库系统中,软件操作非常方便,可以简单的执行各种网站数据采集,本论坛采集软件完美支持采集对于所有编码格式的网页,程序还可以自动识别网页编码,支持目前所有主流和非主流cms、BBS等网站节目,并能实现采集器和网站节目的完美结合,我来告诉你怎么做使用它,我希望它可以帮助你。

论坛采集软件使用图1
它具有以下特点:
1. 支持采集标题、内容、用户名、注册时间、签名、头像、附件等,支持添加采集字段;支持自动回复,方便选择回复帖和隐藏附件。支持帖子回复
2.支持回复部分的增量采集,可以采集新建回复并发布。可以处理论坛、贴吧、连载更新问题;智能生成采集规则,系统内置多个常用论坛自动识别规则,可自动生成采集规则
3.支持网站自动登录,支持当前主流Discuz、PHPWind论坛,暂不支持验证码登录;界面支持自动注册账号、处理头像、处理话题和回复,官方界面不断更新维护
4.支持下载文件,支持翻译、分词、代理等功能优采云采集器;支持插件开发,接口灵活,可以采集更复杂的网站数据,做数据处理
5.可以搜索关键词采集帖子网址,可以批量设置关键词查询类型采集
论坛采集 专家特色:
主要用于数据采集挖掘、垂直搜索、信息聚合与门户、企业网络信息聚合、商业智能、论坛或博客迁移、智能信息代理、个人信息检索等领域,适用于各种数据采集和挖掘需求组。
论坛采集高手使用方法:
1.解压并启动软件
2.第一次运行需要导入采集规则
论坛采集软件使用图2
3.可以添加需要采集的网站
论坛采集软件使用图3
4.选择采集的内容,点击开始,会自动继续采集
论坛采集 软件使用情况图4
通过关键词采集文章采集api(搜狗链接提交工具为站长提供链接)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-18 14:10
大哥要什么,估计用不着吧,哈哈哈!!!
之前这个人渣写了很多百度提交的工具脚本收录。这里分享一下搜狗链接提交工具脚本Gou。与百度api提交不同,搜狗的提交是网页提交,限制为20个。条码打印一次,必须同时输入code。你害怕的可能性大吗?!还是因为服务器资源不足?!
链接提交:
链接提交工具为站长提供了一个链接提交通道,帮助搜狗蜘蛛抓取你的网站。您可以通过本工具提交您想成为搜狗收录的链接,搜狗将按照自己的标准进行处理,不保证您提交的收录内容得到保障。
工具地址:
限制:
您一次最多可以提交 20 个链接,每行一个;
仅支持提交页面对应链接,不支持以sitemap形式提交文件。
与百度搜索提交不同的是,需要输入验证码。关键是这个验证码的处理!
要点1.session的使用
既然需要提交验证码,就需要维护一个会话链接,直接使用请求的会话即可!
#实例化session
session = requests.session()
2.验证码处理
这个人渣粗心大意,以为验证码只是一个png图片,直接下载就行了。没想到搜狗的验证码图片是svg格式的,但是不干扰处理。原理还是一样的,直接下载就好了,然后转换格式,这里适用于python的第三方库:cairosvg!
cairosvg 库安装:
pip install cairosvg
如何使用 cairosvg 格式化和 svg 到 png,
cairosvg.svg2png(
url="code.svg", write_to="code.png")
但是需要注意的是,有一个错误需要处理。好在大佬们已经给出了完美的解决方案!
需要安装gtk2-runtime-2.24.33-2021-01-30-ts-win64.exe,同时重启编辑器!
具体解决方法可以查看:python将svg html转换为png图片
附上gtk2-runtime-2.24.33-2021-01-30-ts-win64.exe安装包,文末提供!
3.获取验证码
获取验证码其实很简单,和访问下载一样!
code_url="https://zhanzhang.sogou.com/ap ... ot%3B
r=session.get(url=code_url,headers=headers,timeout=5)
with open('code.svg','wb')as f:
f.write(r.content)
print("下载验证码成功!")
4.显示验证码图片,手动编码
展示验证码图片,这里应用的是第三方库PIL!
from PIL import Image
im = Image.open('code.png')
im.show()
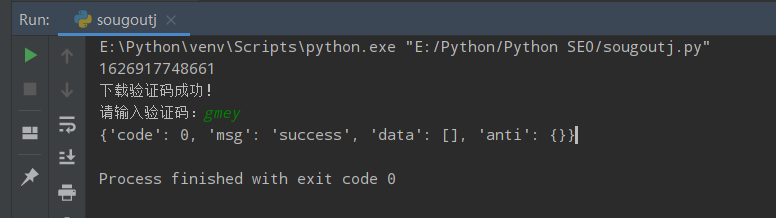
code=input("请输入验证码:")
Python提交效果:
提交成功:
错误的验证码:
扩张
如果要实现自动,即自动编码,可以考虑第三方编码接口,或者使用深度学习!
我没试过这里的人渣。可以试试上面人渣推荐的百度ocr界面。当然是付费的,但是新用户有一定的权限,相信够用了!
演示脚本源代码
涵盖验证码获取和手动编码
建议学习思考
完整的脚本工具源代码免费提供
获得方法
转发这条推文到朋友圈截图 查看全部
通过关键词采集文章采集api(搜狗链接提交工具为站长提供链接)
大哥要什么,估计用不着吧,哈哈哈!!!
之前这个人渣写了很多百度提交的工具脚本收录。这里分享一下搜狗链接提交工具脚本Gou。与百度api提交不同,搜狗的提交是网页提交,限制为20个。条码打印一次,必须同时输入code。你害怕的可能性大吗?!还是因为服务器资源不足?!
链接提交:
链接提交工具为站长提供了一个链接提交通道,帮助搜狗蜘蛛抓取你的网站。您可以通过本工具提交您想成为搜狗收录的链接,搜狗将按照自己的标准进行处理,不保证您提交的收录内容得到保障。
工具地址:
限制:
您一次最多可以提交 20 个链接,每行一个;
仅支持提交页面对应链接,不支持以sitemap形式提交文件。

与百度搜索提交不同的是,需要输入验证码。关键是这个验证码的处理!
要点1.session的使用
既然需要提交验证码,就需要维护一个会话链接,直接使用请求的会话即可!
#实例化session
session = requests.session()
2.验证码处理
这个人渣粗心大意,以为验证码只是一个png图片,直接下载就行了。没想到搜狗的验证码图片是svg格式的,但是不干扰处理。原理还是一样的,直接下载就好了,然后转换格式,这里适用于python的第三方库:cairosvg!
cairosvg 库安装:
pip install cairosvg
如何使用 cairosvg 格式化和 svg 到 png,
cairosvg.svg2png(
url="code.svg", write_to="code.png")
但是需要注意的是,有一个错误需要处理。好在大佬们已经给出了完美的解决方案!
需要安装gtk2-runtime-2.24.33-2021-01-30-ts-win64.exe,同时重启编辑器!

具体解决方法可以查看:python将svg html转换为png图片
附上gtk2-runtime-2.24.33-2021-01-30-ts-win64.exe安装包,文末提供!
3.获取验证码
获取验证码其实很简单,和访问下载一样!
code_url="https://zhanzhang.sogou.com/ap ... ot%3B
r=session.get(url=code_url,headers=headers,timeout=5)
with open('code.svg','wb')as f:
f.write(r.content)
print("下载验证码成功!")
4.显示验证码图片,手动编码
展示验证码图片,这里应用的是第三方库PIL!
from PIL import Image
im = Image.open('code.png')
im.show()
code=input("请输入验证码:")
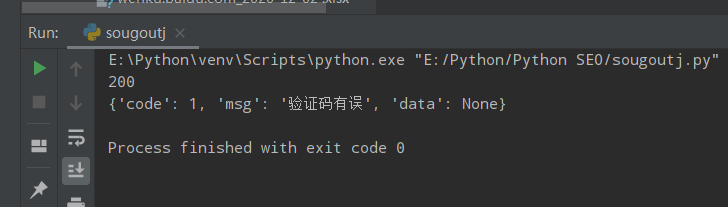
Python提交效果:

提交成功:
错误的验证码:
扩张
如果要实现自动,即自动编码,可以考虑第三方编码接口,或者使用深度学习!
我没试过这里的人渣。可以试试上面人渣推荐的百度ocr界面。当然是付费的,但是新用户有一定的权限,相信够用了!
演示脚本源代码
涵盖验证码获取和手动编码
建议学习思考
完整的脚本工具源代码免费提供
获得方法

转发这条推文到朋友圈截图
通过关键词采集文章采集api(如何通过关键词采集文章采集api搬运工?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-10-17 14:01
通过关键词采集文章采集api,用户通过自己的帐号加入采集列表(保存在本地),点击采集按钮,会跳转到对应的指定网站,经过解析后,就可以通过对应的api接口自动化把内容发布到该网站的某一页面上。
如果你想做到的是他们的方式,需要有,一些特别的技术。比如对网页内容进行标记,下标和内容标题或者标签进行分割。需要具备高级技术。这里也是一个靠博客积累经验的方式。
ip,但你要明白这是垃圾链接,而不是他们说的那么复杂,所以一定要注意,网站收录不了就是你们网站的大原则问题,重在原则,但你的网站不可能是个全新的网站,现在肯定都有收录的,如果不收录就联系我,
哈哈哈我有这个能力
b站搬运工,
在b站下app我之前曾搜过英语
怎么说呢,贴吧现在清理文章还是挺多的,让我感到让b站被炒起来之前被扒了一些内容,然后不是所有的up主都有原创作品,有时候很多新发的视频是原来的问题,而且每次搬运也要排队,做的都是无效率的工作,b站好的一点就是你把自己的作品发出来就能解决,不用重复做无效率的工作,还有就是这种方式其实真的也就是二次元能火一点,因为其他的会有很多黑幕,不过我觉得在慢慢发展吧。 查看全部
通过关键词采集文章采集api(如何通过关键词采集文章采集api搬运工?)
通过关键词采集文章采集api,用户通过自己的帐号加入采集列表(保存在本地),点击采集按钮,会跳转到对应的指定网站,经过解析后,就可以通过对应的api接口自动化把内容发布到该网站的某一页面上。
如果你想做到的是他们的方式,需要有,一些特别的技术。比如对网页内容进行标记,下标和内容标题或者标签进行分割。需要具备高级技术。这里也是一个靠博客积累经验的方式。
ip,但你要明白这是垃圾链接,而不是他们说的那么复杂,所以一定要注意,网站收录不了就是你们网站的大原则问题,重在原则,但你的网站不可能是个全新的网站,现在肯定都有收录的,如果不收录就联系我,
哈哈哈我有这个能力
b站搬运工,
在b站下app我之前曾搜过英语
怎么说呢,贴吧现在清理文章还是挺多的,让我感到让b站被炒起来之前被扒了一些内容,然后不是所有的up主都有原创作品,有时候很多新发的视频是原来的问题,而且每次搬运也要排队,做的都是无效率的工作,b站好的一点就是你把自己的作品发出来就能解决,不用重复做无效率的工作,还有就是这种方式其实真的也就是二次元能火一点,因为其他的会有很多黑幕,不过我觉得在慢慢发展吧。
通过关键词采集文章采集api(论坛新手站长和网站编辑必备的discuz插件实现的功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-17 00:03
安装此插件后,采集器 控制面板将出现在用于发布帖子、门户和群组的页面顶部。在发布编辑框中输入 关键词 或 URL smart 采集。支持采集的内容每天自动批量发布。易学、易懂、易用、成熟稳定。它是一个适用于新手站长和 网站 编辑器的 discuz 插件。插件实现的功能如下: 1、最新最热微信公众号文章采集,每天自动更新。2、最新最热资讯采集,每天自动更新。3、进入关键词,采集最新相关内容关键词4、 @采集,批量发布15、支持定时采集,自动发布功能就不一一列举了。更多功能请安装本插件体验。FAQ: Q: 插件支持哪个版本的discuz?答案:X2.5、X3、X3.1、X3.2 Q:为什么我的采集视频不能播放?答:可能您的论坛没有打开 [flash] 选项卡。请到论坛的“发帖选项”允许使用多媒体代码。Q:如何保存远程图片?答:点击插件控制面板上的“图像本地化”。Q:如何采集微信公众号的内容?答:在网址采集中输入微信公众号的文章网址,点击网址采集。问题:可以“ 你需要的习惯,采集的结果会越来越准确。'视频不能播放?答:可能您的论坛没有打开 [flash] 选项卡。请到论坛的“发帖选项”允许使用多媒体代码。Q:如何保存远程图片?答:点击插件控制面板上的“图像本地化”。Q:如何采集微信公众号的内容?答:在网址采集中输入微信公众号的文章网址,点击网址采集。问:我手动添加的内容可以使用“图片本地化”和“伪原创”功能吗?答:两者都可以用!问:为什么有些关键词采集没有结果?回答:一些 SEO 不受欢迎 关键词 用较少的百度索引来点播采集。一旦云系统发现有人使用这个关键词采集,但是采集如果没有内容或者内容太小或太旧,这个采集@的权重和优先级>关键词 会自动增加。一段时间后,采集这个关键词会发现很多内容问:如何提高采集内容的准确率?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。'视频不能播放?答:可能您的论坛没有打开 [flash] 选项卡。请转到“发布选项” 论坛允许使用多媒体代码。Q:如何保存远程图片?答:点击插件控制面板上的“图像本地化”。Q:如何采集微信公众号的内容?答:在网址采集中输入微信公众号文章的网址,点击网址采集。问:我手动添加的内容可以使用“图片本地化”和“伪原创”功能吗?答:两者都可以用!问:为什么有些关键词采集没有结果?答:一些搜索引擎冷门关键词,百度索引较少,是点播采集。一旦云系统发现有人使用这个关键词采集,但是采集如果没有内容或者内容太小或太旧,这个<的权重和优先级 @采集关键词 会自动增加。一段时间后,采集这个关键词会发现很多内容问:如何提高采集内容的准确率?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?回答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如何提高采集内容的准确率?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如何提高采集内容的准确率?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。 查看全部
通过关键词采集文章采集api(论坛新手站长和网站编辑必备的discuz插件实现的功能)
安装此插件后,采集器 控制面板将出现在用于发布帖子、门户和群组的页面顶部。在发布编辑框中输入 关键词 或 URL smart 采集。支持采集的内容每天自动批量发布。易学、易懂、易用、成熟稳定。它是一个适用于新手站长和 网站 编辑器的 discuz 插件。插件实现的功能如下: 1、最新最热微信公众号文章采集,每天自动更新。2、最新最热资讯采集,每天自动更新。3、进入关键词,采集最新相关内容关键词4、 @采集,批量发布15、支持定时采集,自动发布功能就不一一列举了。更多功能请安装本插件体验。FAQ: Q: 插件支持哪个版本的discuz?答案:X2.5、X3、X3.1、X3.2 Q:为什么我的采集视频不能播放?答:可能您的论坛没有打开 [flash] 选项卡。请到论坛的“发帖选项”允许使用多媒体代码。Q:如何保存远程图片?答:点击插件控制面板上的“图像本地化”。Q:如何采集微信公众号的内容?答:在网址采集中输入微信公众号的文章网址,点击网址采集。问题:可以“ 你需要的习惯,采集的结果会越来越准确。'视频不能播放?答:可能您的论坛没有打开 [flash] 选项卡。请到论坛的“发帖选项”允许使用多媒体代码。Q:如何保存远程图片?答:点击插件控制面板上的“图像本地化”。Q:如何采集微信公众号的内容?答:在网址采集中输入微信公众号的文章网址,点击网址采集。问:我手动添加的内容可以使用“图片本地化”和“伪原创”功能吗?答:两者都可以用!问:为什么有些关键词采集没有结果?回答:一些 SEO 不受欢迎 关键词 用较少的百度索引来点播采集。一旦云系统发现有人使用这个关键词采集,但是采集如果没有内容或者内容太小或太旧,这个采集@的权重和优先级>关键词 会自动增加。一段时间后,采集这个关键词会发现很多内容问:如何提高采集内容的准确率?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。'视频不能播放?答:可能您的论坛没有打开 [flash] 选项卡。请转到“发布选项” 论坛允许使用多媒体代码。Q:如何保存远程图片?答:点击插件控制面板上的“图像本地化”。Q:如何采集微信公众号的内容?答:在网址采集中输入微信公众号文章的网址,点击网址采集。问:我手动添加的内容可以使用“图片本地化”和“伪原创”功能吗?答:两者都可以用!问:为什么有些关键词采集没有结果?答:一些搜索引擎冷门关键词,百度索引较少,是点播采集。一旦云系统发现有人使用这个关键词采集,但是采集如果没有内容或者内容太小或太旧,这个<的权重和优先级 @采集关键词 会自动增加。一段时间后,采集这个关键词会发现很多内容问:如何提高采集内容的准确率?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?回答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如何提高采集内容的准确率?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如何提高采集内容的准确率?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。
通过关键词采集文章采集api(互联网产品获得长尾流量的根本原因是怎样的?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-10-16 03:03
通过关键词采集文章采集api等各种挖掘用户需求才是互联网产品获得长尾流量的根本。比如同样是做文章阅读,今日头条以图文形式,迅速积累大量文章;百度则靠文字、图片搜索快速积累流量;微信则靠扫码、附近、朋友圈等日活跃用户等通过对用户行为的分析和机器学习来获取长尾流量。所以大公司通过挖掘用户在购物、社交、游戏、电商等场景中的行为习惯,再辅助产品定位就更容易抓住长尾流量了。
而小公司则可以有更多选择,比如利用大公司不愿意分享出来的特色服务,比如上下游企业的合作等来获取长尾流量。
我来抛砖引玉。在我所了解的范围内,adwords帮助企业引流推广是比较有效的,但在互联网发展的初期,服务和现状却不那么理想,无论是是流量、转化率还是客单价都不高。首先,我们来回顾下adwords与整个互联网的关系:从支付渠道看:paypalmoney,麦肯锡money,vivomoney等,所以其实在传统互联网时代,adwords用于企业与客户的沟通推广是不错的,因为adwords支持以低成本聚集大量客户,而且客户转化率比较高。
转化方式上看:搜索广告之所以流量足,用户量大,在于整个搜索app都有它的身影,大到360浏览器、小到安卓手机里的百度,几乎我们每个人每天都会用到搜索app。而搜索更是承载着我们获取信息、商机、生活服务的需求。商机太多了,在互联网的每个场景下面,整合的商机太多了,而且最为重要的是,商机的可持续性也越来越强,不像到当下市场饱和,竞争激烈,商机往往是持续性的。
即便是当下流量的天花板,大家的分成已经趋于透明,前几年做搜索引擎的靠砸钱的方式已经很难再做了,也无法带来大规模客户。那么我们该怎么办?大家都知道,流量的获取很简单,各大流量平台给你免费导量,什么花钱送的;转化呢?我们知道传统的转化路径是先付费锁定目标客户、然后再到他的渠道去做转化,现在已经逐渐发展到你完全不用操心这块,你只需要在渠道上拿出一定的钱即可获得对方的转化。
这就是adwords的盈利模式。回到adwords,其实说白了还是流量的采集、过滤以及匹配的过程,其中关键点还是在于如何在资源紧张的情况下还能达到盈利。关于免费流量采集、过滤以及匹配,我总结了几点:。
1、收益率高:单价高、转化高,
2、转化率高:流量的确精准,且在渠道上单价较低,
3、门槛低:不需要懂得技术支持;
4、独立开发:团队人员充足且专业。
adwords可以说是一个最好也是最坏的时代,
1、竞争激烈:竞争的主要原因是:价格的竞争;
2、劣币驱逐良币:流量 查看全部
通过关键词采集文章采集api(互联网产品获得长尾流量的根本原因是怎样的?)
通过关键词采集文章采集api等各种挖掘用户需求才是互联网产品获得长尾流量的根本。比如同样是做文章阅读,今日头条以图文形式,迅速积累大量文章;百度则靠文字、图片搜索快速积累流量;微信则靠扫码、附近、朋友圈等日活跃用户等通过对用户行为的分析和机器学习来获取长尾流量。所以大公司通过挖掘用户在购物、社交、游戏、电商等场景中的行为习惯,再辅助产品定位就更容易抓住长尾流量了。
而小公司则可以有更多选择,比如利用大公司不愿意分享出来的特色服务,比如上下游企业的合作等来获取长尾流量。
我来抛砖引玉。在我所了解的范围内,adwords帮助企业引流推广是比较有效的,但在互联网发展的初期,服务和现状却不那么理想,无论是是流量、转化率还是客单价都不高。首先,我们来回顾下adwords与整个互联网的关系:从支付渠道看:paypalmoney,麦肯锡money,vivomoney等,所以其实在传统互联网时代,adwords用于企业与客户的沟通推广是不错的,因为adwords支持以低成本聚集大量客户,而且客户转化率比较高。
转化方式上看:搜索广告之所以流量足,用户量大,在于整个搜索app都有它的身影,大到360浏览器、小到安卓手机里的百度,几乎我们每个人每天都会用到搜索app。而搜索更是承载着我们获取信息、商机、生活服务的需求。商机太多了,在互联网的每个场景下面,整合的商机太多了,而且最为重要的是,商机的可持续性也越来越强,不像到当下市场饱和,竞争激烈,商机往往是持续性的。
即便是当下流量的天花板,大家的分成已经趋于透明,前几年做搜索引擎的靠砸钱的方式已经很难再做了,也无法带来大规模客户。那么我们该怎么办?大家都知道,流量的获取很简单,各大流量平台给你免费导量,什么花钱送的;转化呢?我们知道传统的转化路径是先付费锁定目标客户、然后再到他的渠道去做转化,现在已经逐渐发展到你完全不用操心这块,你只需要在渠道上拿出一定的钱即可获得对方的转化。
这就是adwords的盈利模式。回到adwords,其实说白了还是流量的采集、过滤以及匹配的过程,其中关键点还是在于如何在资源紧张的情况下还能达到盈利。关于免费流量采集、过滤以及匹配,我总结了几点:。
1、收益率高:单价高、转化高,
2、转化率高:流量的确精准,且在渠道上单价较低,
3、门槛低:不需要懂得技术支持;
4、独立开发:团队人员充足且专业。
adwords可以说是一个最好也是最坏的时代,
1、竞争激烈:竞争的主要原因是:价格的竞争;
2、劣币驱逐良币:流量
通过关键词采集文章采集api(为什么学爬虫?机器帮助你快速爬取数据!(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-10-15 18:05
【为什么要学爬?】
1、爬虫上手容易,深入难。如何编写高效的爬虫,如何编写高度灵活和可扩展的爬虫是一项技术任务。另外,在爬取过程中,经常容易遇到反爬虫,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,可以学习这门课!
2、如果你是其他行业的开发者,比如app开发,web开发,学习爬虫可以加强你对技术的理解,并且能够开发出更安全的软件和网站
【课程设计】
一个完整的爬虫程序,无论大小,大体上可以分为三个步骤,即:
网络请求:模拟浏览器从互联网获取数据的行为。数据分析:过滤请求的数据,提取我们想要的数据。数据存储:将提取的数据存储到硬盘或内存中。比如使用mysql数据库或者redis。
然后本课程也按照这些步骤一步步讲解,引导学生充分掌握每一步的技术。另外,由于爬虫的多样性,在爬取过程中可能会出现反爬和效率低下的情况。因此,我们又增加了两章来提高爬虫程序的灵活性,即:
爬虫进阶:包括IP代理、多线程爬虫、图形验证码识别、JS加解密、动态网页爬虫、字体反爬识别等。 Scrapy及分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫、等等。
通过爬虫的高级知识点,我们可以应对大量的反爬网站,而Scrapy框架是一个专业的爬虫框架,使用它可以快速提高我们的爬虫程序的效率和速度。另外,如果一台机器不能满足你的需求,我们可以使用分布式爬虫,让多台机器帮你快速抓取数据。
从基础爬虫到商业应用爬虫,这套课程满足你的所有需求!
【课程服务】
专属付费社区+定期问答 查看全部
通过关键词采集文章采集api(为什么学爬虫?机器帮助你快速爬取数据!(上))
【为什么要学爬?】
1、爬虫上手容易,深入难。如何编写高效的爬虫,如何编写高度灵活和可扩展的爬虫是一项技术任务。另外,在爬取过程中,经常容易遇到反爬虫,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,可以学习这门课!
2、如果你是其他行业的开发者,比如app开发,web开发,学习爬虫可以加强你对技术的理解,并且能够开发出更安全的软件和网站
【课程设计】
一个完整的爬虫程序,无论大小,大体上可以分为三个步骤,即:
网络请求:模拟浏览器从互联网获取数据的行为。数据分析:过滤请求的数据,提取我们想要的数据。数据存储:将提取的数据存储到硬盘或内存中。比如使用mysql数据库或者redis。
然后本课程也按照这些步骤一步步讲解,引导学生充分掌握每一步的技术。另外,由于爬虫的多样性,在爬取过程中可能会出现反爬和效率低下的情况。因此,我们又增加了两章来提高爬虫程序的灵活性,即:
爬虫进阶:包括IP代理、多线程爬虫、图形验证码识别、JS加解密、动态网页爬虫、字体反爬识别等。 Scrapy及分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫、等等。
通过爬虫的高级知识点,我们可以应对大量的反爬网站,而Scrapy框架是一个专业的爬虫框架,使用它可以快速提高我们的爬虫程序的效率和速度。另外,如果一台机器不能满足你的需求,我们可以使用分布式爬虫,让多台机器帮你快速抓取数据。
从基础爬虫到商业应用爬虫,这套课程满足你的所有需求!
【课程服务】
专属付费社区+定期问答
通过关键词采集文章采集api(网络爬虫简单来说就是指通过爬虫程序访问网站的API连接获取数据 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-14 02:27
)
简单来说,网络爬虫是指通过爬虫程序访问网站的API连接,获取数据信息。爬虫程序可以从网页中检索所需的数据信息,然后将其存储在新创建的文档中。网络爬虫支持各种数据采集、文件、图片。视频等可以是采集,但不能是采集非法经营。互联网大数据时代,网络爬虫主要为搜索引擎提供最全面、最新的数据,网络爬虫也是从采集互联网数据中爬取的。
我们还可以利用网络爬虫来采集舆情数据,以及采集新闻、社交、论坛、博客等信息数据。这也是获取舆情数据的常用方案之一。一般爬虫程序会使用爬虫代理IP对一些有意义的网站进行数据采集。舆情数据也可以在数据交换市场购买,或者从专业的舆情分析团队获取,但一般来说,专业的舆情分析团队也是通过爬虫使用代理IP去采集相关数据进行舆情数据分析。
由于短视频的火爆,抖音、快手这两个主流短视频APP,我们也可以使用爬虫程序采集抖音、快手来分析舆情数据。生成统计数据表,作为数据报告提供给大家。也可以参考下面的采集程序代码:
// 要访问的目标页面
string targetUrl = "http://httpbin.org/ip";
// 代理服务器(产品官网 www.16yun.cn)
string proxyHost = "http://t.16yun.cn";
string proxyPort = "31111";
// 代理验证信息
string proxyUser = "username";
string proxyPass = "password";
// 设置代理服务器
WebProxy proxy = new WebProxy(string.Format("{0}:{1}", proxyHost, proxyPort), true);
ServicePointManager.Expect100Continue = false;
var request = WebRequest.Create(targetUrl) as HttpWebRequest;
request.AllowAutoRedirect = true;
request.KeepAlive = true;
request.Method = "GET";
request.Proxy = proxy;
//request.Proxy.Credentials = CredentialCache.DefaultCredentials;
request.Proxy.Credentials = new System.Net.NetworkCredential(proxyUser, proxyPass);
// 设置Proxy Tunnel
// Random ran=new Random();
// int tunnel =ran.Next(1,10000);
// request.Headers.Add("Proxy-Tunnel", String.valueOf(tunnel));
//request.Timeout = 20000;
//request.ServicePoint.ConnectionLimit = 512;
//request.UserAgent = "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.82 Safari/537.36";
//request.Headers.Add("Cache-Control", "max-age=0");
//request.Headers.Add("DNT", "1");
//String encoded = System.Convert.ToBase64String(System.Text.Encoding.GetEncoding("ISO-8859-1").GetBytes(proxyUser + ":" + proxyPass));
//request.Headers.Add("Proxy-Authorization", "Basic " + encoded);
using (var response = request.GetResponse() as HttpWebResponse)
using (var sr = new StreamReader(response.GetResponseStream(), Encoding.UTF8))
{
string htmlStr = sr.ReadToEnd();
}
复制代码 查看全部
通过关键词采集文章采集api(网络爬虫简单来说就是指通过爬虫程序访问网站的API连接获取数据
)
简单来说,网络爬虫是指通过爬虫程序访问网站的API连接,获取数据信息。爬虫程序可以从网页中检索所需的数据信息,然后将其存储在新创建的文档中。网络爬虫支持各种数据采集、文件、图片。视频等可以是采集,但不能是采集非法经营。互联网大数据时代,网络爬虫主要为搜索引擎提供最全面、最新的数据,网络爬虫也是从采集互联网数据中爬取的。
我们还可以利用网络爬虫来采集舆情数据,以及采集新闻、社交、论坛、博客等信息数据。这也是获取舆情数据的常用方案之一。一般爬虫程序会使用爬虫代理IP对一些有意义的网站进行数据采集。舆情数据也可以在数据交换市场购买,或者从专业的舆情分析团队获取,但一般来说,专业的舆情分析团队也是通过爬虫使用代理IP去采集相关数据进行舆情数据分析。
由于短视频的火爆,抖音、快手这两个主流短视频APP,我们也可以使用爬虫程序采集抖音、快手来分析舆情数据。生成统计数据表,作为数据报告提供给大家。也可以参考下面的采集程序代码:
// 要访问的目标页面
string targetUrl = "http://httpbin.org/ip";
// 代理服务器(产品官网 www.16yun.cn)
string proxyHost = "http://t.16yun.cn";
string proxyPort = "31111";
// 代理验证信息
string proxyUser = "username";
string proxyPass = "password";
// 设置代理服务器
WebProxy proxy = new WebProxy(string.Format("{0}:{1}", proxyHost, proxyPort), true);
ServicePointManager.Expect100Continue = false;
var request = WebRequest.Create(targetUrl) as HttpWebRequest;
request.AllowAutoRedirect = true;
request.KeepAlive = true;
request.Method = "GET";
request.Proxy = proxy;
//request.Proxy.Credentials = CredentialCache.DefaultCredentials;
request.Proxy.Credentials = new System.Net.NetworkCredential(proxyUser, proxyPass);
// 设置Proxy Tunnel
// Random ran=new Random();
// int tunnel =ran.Next(1,10000);
// request.Headers.Add("Proxy-Tunnel", String.valueOf(tunnel));
//request.Timeout = 20000;
//request.ServicePoint.ConnectionLimit = 512;
//request.UserAgent = "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.82 Safari/537.36";
//request.Headers.Add("Cache-Control", "max-age=0");
//request.Headers.Add("DNT", "1");
//String encoded = System.Convert.ToBase64String(System.Text.Encoding.GetEncoding("ISO-8859-1").GetBytes(proxyUser + ":" + proxyPass));
//request.Headers.Add("Proxy-Authorization", "Basic " + encoded);
using (var response = request.GetResponse() as HttpWebResponse)
using (var sr = new StreamReader(response.GetResponseStream(), Encoding.UTF8))
{
string htmlStr = sr.ReadToEnd();
}
复制代码
通过关键词采集文章采集api(软件采集规则子规则,采集示例:使用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-11 13:14
描述
模板介绍:
本模板用于通过关键字搜索采集企查网站的公司专利列表。字段包括:公司名称、链接、专利名称、申请人、发表日期等列表字段。
采集 字段示例:
指示:
1. 购买模板后,将模板文件导入到采集器。该模板分为两个子规则。规则1使用关键词采集公司链接;规则 2 使用公司链接批量处理 采集 各种证书。
2.输入公司名称或关键词,先采集公司链接,支持关键词批量导入,然后使用公司链接到采集各个证书内容,也支持批量采集。
3.请点击【保存并开始】继续采集。
获取模板:
用户在该页面下单后,可以自动获取模板文件(*.otd)的下载地址,点击下载保存到自己的电脑上使用。
提示:
对采集器软件不熟悉,上手难度较大。下面有丰富的教程。您可能会遇到的问题在这里都有解答。打开后采集起来,遇到问题就来学习:
用户下单时,必须阅读、理解并同意以下条款:
本店购买的所有商品均为虚拟商品或定制服务,恕不退换。用户应根据自身需求进行详细咨询,确认满足需求后再下单。
本店出售的所有软件或视频教程均归本店原创所有,拥有独家知识产权。用户购买后,仅限于用户自己的学习和研究。未经本店书面许可,不得复制、分发或用于任何商业盈利。
第三方采集器如优采云、优采云等以及本店开发的定制软件均为市场上合法合法的软件。用户在本店的付费定制基于以上采集器软件的采集规则(模板)必须在相应的国家法律法规下使用,不得使用本软件或采集模板未经许可不得修改或破解,未经书面许可不得使用。复制,并保证采集规则模板用于数据采集的应用应遵循相关互联网数据爬取规范,所获取的数据仅限于学习和研究的目的。
本店有义务告知:若超出以上规格或获取的数据适用于以上范围,则视为未遵守本店协议,由此产生的后果由买家自行承担,可能产生的纠纷或法律后果与本店无关。如发生损害本店利益的,本店有权要求用户承担相关损失。 查看全部
通过关键词采集文章采集api(软件采集规则子规则,采集示例:使用方法)
描述
模板介绍:
本模板用于通过关键字搜索采集企查网站的公司专利列表。字段包括:公司名称、链接、专利名称、申请人、发表日期等列表字段。
采集 字段示例:
 https://www.futaike.net/wp-con ... 9.jpg 300w, https://www.futaike.net/wp-con ... 6.jpg 768w, https://www.futaike.net/wp-con ... 5.jpg 1024w, https://www.futaike.net/wp-con ... 8.jpg 600w" />
https://www.futaike.net/wp-con ... 9.jpg 300w, https://www.futaike.net/wp-con ... 6.jpg 768w, https://www.futaike.net/wp-con ... 5.jpg 1024w, https://www.futaike.net/wp-con ... 8.jpg 600w" />指示:
1. 购买模板后,将模板文件导入到采集器。该模板分为两个子规则。规则1使用关键词采集公司链接;规则 2 使用公司链接批量处理 采集 各种证书。
2.输入公司名称或关键词,先采集公司链接,支持关键词批量导入,然后使用公司链接到采集各个证书内容,也支持批量采集。
3.请点击【保存并开始】继续采集。
获取模板:
用户在该页面下单后,可以自动获取模板文件(*.otd)的下载地址,点击下载保存到自己的电脑上使用。
提示:
对采集器软件不熟悉,上手难度较大。下面有丰富的教程。您可能会遇到的问题在这里都有解答。打开后采集起来,遇到问题就来学习:
用户下单时,必须阅读、理解并同意以下条款:
本店购买的所有商品均为虚拟商品或定制服务,恕不退换。用户应根据自身需求进行详细咨询,确认满足需求后再下单。
本店出售的所有软件或视频教程均归本店原创所有,拥有独家知识产权。用户购买后,仅限于用户自己的学习和研究。未经本店书面许可,不得复制、分发或用于任何商业盈利。
第三方采集器如优采云、优采云等以及本店开发的定制软件均为市场上合法合法的软件。用户在本店的付费定制基于以上采集器软件的采集规则(模板)必须在相应的国家法律法规下使用,不得使用本软件或采集模板未经许可不得修改或破解,未经书面许可不得使用。复制,并保证采集规则模板用于数据采集的应用应遵循相关互联网数据爬取规范,所获取的数据仅限于学习和研究的目的。
本店有义务告知:若超出以上规格或获取的数据适用于以上范围,则视为未遵守本店协议,由此产生的后果由买家自行承担,可能产生的纠纷或法律后果与本店无关。如发生损害本店利益的,本店有权要求用户承担相关损失。
通过关键词采集文章采集api(站长快车采集器v4.0更新内容:更新的内容与发布程序)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-10-10 09:22
<p>站长快车是主要主流文章系统、论坛系统等多线程会员注册、内容采集及发布程序。海量内容,迅速提高论坛的知名度。其丰富的规则模板和灵活的自定义模块可以适用于各种内容发布系统。系统收录自定义规则采集、智能采集、批量会员注册、批量发帖、转发等多项功能。内容库可在系统界面直接管理,实时浏览、可视化修改、输入SQL命令运行操作、批量替换等操作。软件中的优化功能让您更得心应手。它可以生成标签 < @关键词、删除重复记录、非法 查看全部
通过关键词采集文章采集api(举例说明网络数据在不同行业的利用价值分析与应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-08 03:11
据赛迪顾问统计,在最近一万件技术领域专利中最常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热门的词汇。其中,data采集是被提及最多的词。
数据采集是大数据分析的前提和必要条件,在整个数据利用过程中占有重要地位。数据采集方法分为系统日志采集方法、网络数据采集方法、其他数据采集方法三种。随着Web2.0的发展,整个Web系统覆盖了大量有价值的数据。目前Web系统采集的数据通常是通过网络爬虫实现的。本文将进行网络数据和网络爬虫。系统规范。
什么是网络数据
网络数据是指非传统的数据来源,比如通过搜索引擎爬取获得的不同形式的数据。网络数据也可以是从数据聚合商或搜索引擎网站购买的数据,以提高目标营销。这种类型的数据可以是结构化的或非结构化的(更有可能),可以由网络链接、文本数据、数据表、图像、视频等组成。
互联网构成了当今提供给我们的大部分数据,根据许多研究,非结构化数据占其中的 80%。尽管较早时忽略了这些形式的数据,但竞争加剧和对更多数据的需求需要使用尽可能多的数据源。
网络数据可以用来做什么
互联网拥有数十亿页的数据。网络数据作为一种潜在的数据来源,对于行业的战略业务发展具有巨大的潜力。
下面举例说明网络数据在不同行业的使用价值:
此外,在《Web Scraping is Transforming the World with its Applications》文章中,详细列出了网络数据在制造、金融研究、风险管理等领域的价值。
如何采集网络数据
目前网页数据采集有两种方法:一种是API,一种是网络爬虫。API又称应用程序接口,是网站的管理者为了方便用户而编写的一种编程接口。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关demo可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制日常接口调用的上限,给我们带来很大的不便。为此,我们通常采用第二种方法——网络爬虫。
使用爬虫技术采集网络数据
网络爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集的图片、音频、视频等文件或附件,可以自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。在大数据时代,网络爬虫对于采集来自互联网的数据来说更是一种优势工具。
网络爬虫的原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有三个功能:网络数据采集、处理和存储,如图:
网络爬虫采集
网络爬虫通过定义采集字段来抓取网页中的文字信息、图片信息等。此外,网页中还收录一些超链接信息,网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。爬虫提取并保存网页中需要提取的资源,同时提取存在于网站 Link中的其他网站,发送请求后,接收网站的响应@> 并再次解析页面,然后从网页中提取所需的资源...等等,
数据处理
数据处理是分析和处理数据(包括数值和非数值)的技术过程。网络爬虫抓取的初始数据需要“清洗”。在数据处理环节,对各种原创数据进行分析、整理、计算、编辑等处理和处理,从大量、杂乱、难以理解的数据中提取并推导出有价值、有意义的数据。
数据中心
所谓数据中心,也就是数据存储,就是指在获取到需要的数据并分解成有用的组件后,采用可扩展的方式,将所有提取解析出来的数据存储在一个数据库或集群中,然后创建一个允许用户及时查找相关数据集或提取函数。
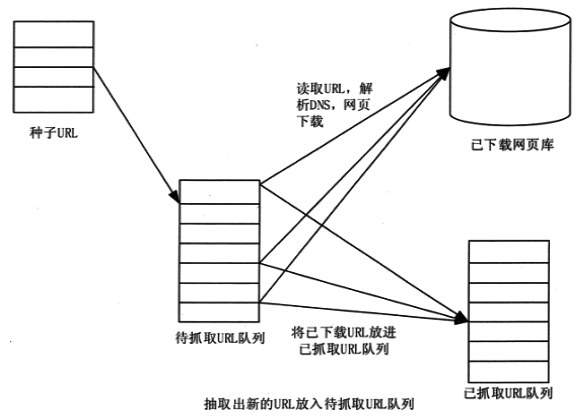
网络爬虫工作流程
如下图所示,一个网络爬虫的基本工作流程如下。首先选择种子 URL 的一部分。
总结
当前,网络大数据规模和复杂度的快速增长,对现有IT架构的处理和计算能力提出了挑战。根据IDC发布的一份研究报告,预计到2020年,网络大数据总量将达到35ZB。大数据将成为行业数字化、信息化的重要推动者。返回搜狐查看更多 查看全部
通过关键词采集文章采集api(举例说明网络数据在不同行业的利用价值分析与应用)
据赛迪顾问统计,在最近一万件技术领域专利中最常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热门的词汇。其中,data采集是被提及最多的词。

数据采集是大数据分析的前提和必要条件,在整个数据利用过程中占有重要地位。数据采集方法分为系统日志采集方法、网络数据采集方法、其他数据采集方法三种。随着Web2.0的发展,整个Web系统覆盖了大量有价值的数据。目前Web系统采集的数据通常是通过网络爬虫实现的。本文将进行网络数据和网络爬虫。系统规范。
什么是网络数据
网络数据是指非传统的数据来源,比如通过搜索引擎爬取获得的不同形式的数据。网络数据也可以是从数据聚合商或搜索引擎网站购买的数据,以提高目标营销。这种类型的数据可以是结构化的或非结构化的(更有可能),可以由网络链接、文本数据、数据表、图像、视频等组成。
互联网构成了当今提供给我们的大部分数据,根据许多研究,非结构化数据占其中的 80%。尽管较早时忽略了这些形式的数据,但竞争加剧和对更多数据的需求需要使用尽可能多的数据源。
网络数据可以用来做什么
互联网拥有数十亿页的数据。网络数据作为一种潜在的数据来源,对于行业的战略业务发展具有巨大的潜力。
下面举例说明网络数据在不同行业的使用价值:

此外,在《Web Scraping is Transforming the World with its Applications》文章中,详细列出了网络数据在制造、金融研究、风险管理等领域的价值。
如何采集网络数据
目前网页数据采集有两种方法:一种是API,一种是网络爬虫。API又称应用程序接口,是网站的管理者为了方便用户而编写的一种编程接口。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关demo可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制日常接口调用的上限,给我们带来很大的不便。为此,我们通常采用第二种方法——网络爬虫。
使用爬虫技术采集网络数据
网络爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集的图片、音频、视频等文件或附件,可以自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。在大数据时代,网络爬虫对于采集来自互联网的数据来说更是一种优势工具。
网络爬虫的原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有三个功能:网络数据采集、处理和存储,如图:

网络爬虫采集
网络爬虫通过定义采集字段来抓取网页中的文字信息、图片信息等。此外,网页中还收录一些超链接信息,网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。爬虫提取并保存网页中需要提取的资源,同时提取存在于网站 Link中的其他网站,发送请求后,接收网站的响应@> 并再次解析页面,然后从网页中提取所需的资源...等等,
数据处理
数据处理是分析和处理数据(包括数值和非数值)的技术过程。网络爬虫抓取的初始数据需要“清洗”。在数据处理环节,对各种原创数据进行分析、整理、计算、编辑等处理和处理,从大量、杂乱、难以理解的数据中提取并推导出有价值、有意义的数据。
数据中心
所谓数据中心,也就是数据存储,就是指在获取到需要的数据并分解成有用的组件后,采用可扩展的方式,将所有提取解析出来的数据存储在一个数据库或集群中,然后创建一个允许用户及时查找相关数据集或提取函数。
网络爬虫工作流程
如下图所示,一个网络爬虫的基本工作流程如下。首先选择种子 URL 的一部分。
总结
当前,网络大数据规模和复杂度的快速增长,对现有IT架构的处理和计算能力提出了挑战。根据IDC发布的一份研究报告,预计到2020年,网络大数据总量将达到35ZB。大数据将成为行业数字化、信息化的重要推动者。返回搜狐查看更多
通过关键词采集文章采集api(京东商品标题关键词的采集方法有一个意义让消费者一眼)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-04 10:12
优化产品标题,相信这是很多商家都在努力做的事情,毕竟产品的排名跟标题优化是息息相关的。可以说标题优化好了,那么自然搜索产品的排名也会上升。当然,这只是标题优化的主要功能,并不是全部。我们优化标题的另一个意义是让消费者第一眼就了解产品,而这个标题也收录了这样的关键词。那么接下来小编就给大家分享一下京东商品标题关键词的一些采集方法。
关键词采集店铺相关关键词制作成产品关键词表是标题优化的第一步。这里简单介绍三种采集关键词方式:首页采集,即在京东首页的搜索栏中输入关键词,以及关键词与输入词相关的内容会出现在下拉框中。
搜索栏下拉框中的匹配方式主要有“前向匹配”和“首字母匹配”两种。而且,推荐词的排序规则是根据词的流行度和相关性来确定的,而且是周期性的,所以我们需要经常观察和替换。
快递采集,即通过京东快递筛选出精准的产品关键词,给出的词也会反映其竞争指数,让商家对关键词有很大的判断力对于关键词的帮助,如果关键词的星级比较高就好了。这里小编强烈建议在核心扩展中输入一些大字,这样中长字会比较多。
第三方,也就是通过一些第三方软件如京东商务智能、金豆云等,可以查看商家行业的数据,然后可以使用第三方软件中的索引来进行选择那些需要制作的产品关键词。搜索索引越高,搜索此关键词的用户就越多。
当然,搜索指数比较高的基本都是那些宽泛的词,转化率较高的关键词多是搜索量中等的精准词,比如行业暴涨的热词,基本都是季节性的关键词许多。
以上三种关键词采集方法可以说是商家比较常用的。总之,关键词的选择需要考虑的方面很多,不能单靠一个方向发展。毕竟关键词的质量会直接影响到产品的曝光度和流量。 查看全部
通过关键词采集文章采集api(京东商品标题关键词的采集方法有一个意义让消费者一眼)
优化产品标题,相信这是很多商家都在努力做的事情,毕竟产品的排名跟标题优化是息息相关的。可以说标题优化好了,那么自然搜索产品的排名也会上升。当然,这只是标题优化的主要功能,并不是全部。我们优化标题的另一个意义是让消费者第一眼就了解产品,而这个标题也收录了这样的关键词。那么接下来小编就给大家分享一下京东商品标题关键词的一些采集方法。

关键词采集店铺相关关键词制作成产品关键词表是标题优化的第一步。这里简单介绍三种采集关键词方式:首页采集,即在京东首页的搜索栏中输入关键词,以及关键词与输入词相关的内容会出现在下拉框中。
搜索栏下拉框中的匹配方式主要有“前向匹配”和“首字母匹配”两种。而且,推荐词的排序规则是根据词的流行度和相关性来确定的,而且是周期性的,所以我们需要经常观察和替换。
快递采集,即通过京东快递筛选出精准的产品关键词,给出的词也会反映其竞争指数,让商家对关键词有很大的判断力对于关键词的帮助,如果关键词的星级比较高就好了。这里小编强烈建议在核心扩展中输入一些大字,这样中长字会比较多。
第三方,也就是通过一些第三方软件如京东商务智能、金豆云等,可以查看商家行业的数据,然后可以使用第三方软件中的索引来进行选择那些需要制作的产品关键词。搜索索引越高,搜索此关键词的用户就越多。
当然,搜索指数比较高的基本都是那些宽泛的词,转化率较高的关键词多是搜索量中等的精准词,比如行业暴涨的热词,基本都是季节性的关键词许多。
以上三种关键词采集方法可以说是商家比较常用的。总之,关键词的选择需要考虑的方面很多,不能单靠一个方向发展。毕竟关键词的质量会直接影响到产品的曝光度和流量。
通过关键词采集文章采集api(第二种需要自动同步到你的平台吗?(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-10-01 18:07
这个问题需要在几种情况下回答
首先,您只需要下载并再次编辑它。这个方法非常简单。一般来说,你知道你想要的文章,也就是你知道文章的访问地址。一般在采集器的帮助下就可以下载了,不管是保存成word还是其他格式都没有问题。
第二个需要自动同步到您的平台。这个比较麻烦,因为你不知道下载地址(不可能手动自动输入)。
方法一、1、通过搜狗浏览器,调用他的界面搜索你的公众号,2、如果存在,通过第二个界面查询公众号下的历史记录文章。获取文章链接,通过程序下载,然后保存到你的后台。
这种方法的优点是:半自动,不需要手动输入文章链接。缺点是:1、如果频繁发送请求,搜狗会提示验证码。这需要手动处理,因此不能完全自动化。2、 并且获取的文章链接是临时的,需要在有效期内下载。3、只能获取最近十条历史记录文章,4、需要定时执行,不能实时更新。更新太频繁导致验证码被屏蔽,频率太低更新延迟太大。
方法二、1、 通过程序模拟登录公众号后台管理页面。2、通过模拟调用和编辑素材。3、通过模拟编辑插入链接功能,4、调用搜索公众号接口,查询公众号获取fackId。5、 通过获取到的 fackId 调用另一个接口获取文章 列表。这个 文章 列表中有链接。
这种方式的优点是:1、不会出现验证码,但也有封印的情况,但出现频率较低。2、 并且可以获取公众号下的所有文章列表。3、文章 链接永久有效。缺点是:1、还有接口调用被阻塞的情况。需要一段时间才能自动解锁。2、 需要定时执行,不能实时更新。更新太频繁截获验证码,频率太低更新延迟太大。
方法三、1、通过实时推送,只需要提供API接口接收链接,将文章链接实时推送到顶部界面,获取链接下载内容并将其保存到您自己的平台。
这种方法的优点:1、不被屏蔽,2、不需要输入验证码3、技术难度低。4、文章 及时更新,延迟低,最多三到五分钟。4、文章 链接永久有效。它可以真正实现完全自动化。缺点是需要有自己的开发者,有API接收参数。
如果有更好的方法,请联系我,互相学习。如果需要技术支持,也可以联系我。以上方法都是亲身尝试过的。有源代码(仅限java)。 查看全部
通过关键词采集文章采集api(第二种需要自动同步到你的平台吗?(一))
这个问题需要在几种情况下回答
首先,您只需要下载并再次编辑它。这个方法非常简单。一般来说,你知道你想要的文章,也就是你知道文章的访问地址。一般在采集器的帮助下就可以下载了,不管是保存成word还是其他格式都没有问题。
第二个需要自动同步到您的平台。这个比较麻烦,因为你不知道下载地址(不可能手动自动输入)。
方法一、1、通过搜狗浏览器,调用他的界面搜索你的公众号,2、如果存在,通过第二个界面查询公众号下的历史记录文章。获取文章链接,通过程序下载,然后保存到你的后台。
这种方法的优点是:半自动,不需要手动输入文章链接。缺点是:1、如果频繁发送请求,搜狗会提示验证码。这需要手动处理,因此不能完全自动化。2、 并且获取的文章链接是临时的,需要在有效期内下载。3、只能获取最近十条历史记录文章,4、需要定时执行,不能实时更新。更新太频繁导致验证码被屏蔽,频率太低更新延迟太大。
方法二、1、 通过程序模拟登录公众号后台管理页面。2、通过模拟调用和编辑素材。3、通过模拟编辑插入链接功能,4、调用搜索公众号接口,查询公众号获取fackId。5、 通过获取到的 fackId 调用另一个接口获取文章 列表。这个 文章 列表中有链接。
这种方式的优点是:1、不会出现验证码,但也有封印的情况,但出现频率较低。2、 并且可以获取公众号下的所有文章列表。3、文章 链接永久有效。缺点是:1、还有接口调用被阻塞的情况。需要一段时间才能自动解锁。2、 需要定时执行,不能实时更新。更新太频繁截获验证码,频率太低更新延迟太大。
方法三、1、通过实时推送,只需要提供API接口接收链接,将文章链接实时推送到顶部界面,获取链接下载内容并将其保存到您自己的平台。
这种方法的优点:1、不被屏蔽,2、不需要输入验证码3、技术难度低。4、文章 及时更新,延迟低,最多三到五分钟。4、文章 链接永久有效。它可以真正实现完全自动化。缺点是需要有自己的开发者,有API接收参数。
如果有更好的方法,请联系我,互相学习。如果需要技术支持,也可以联系我。以上方法都是亲身尝试过的。有源代码(仅限java)。
通过关键词采集文章采集api(推荐10个最好用的数据采集工具10款用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 386 次浏览 • 2021-10-01 07:22
推荐10个最好的数据采集工具
10个最好的数据采集工具,免费采集工具,网站网页采集工具,各行各业采集工具,目前比较好的一些免费数据采集 工具,希望对大家有帮助。
, 优采云采集器 优采云是基于运营商实名制,融合网络数据采集、移动互联网数据、API接口服务等服务的数据服务。互联网。平台。它最大的特点是可以在不了解网络爬虫技术的情况下轻松完成采集。
2、优采云采集器 优采云采集器是目前最流行的互联网数据采集软件。凭借灵活的配置和强大的性能,在国内同类产品中处于领先地位,获得了众多用户的一致认可。只是现在各大平台都设置了严格的反爬,很难获得有价值的数据。
3、靠近中国金坛中国数据服务平台拥有多种专业数据采集工具。开发者上传的采集工具很多,而且很多都是免费的。无论是采集国内外网站、行业网站、政府网站、app、微博、搜索引擎、公众号、小程序等数据,还是其他数据,几乎涵盖了业界99%的采集软件,近期即可完成采集。对技术含量要求高的高强度防爬或裂缝有专业的技术解决方案。如果要考专业度,近探的专业度是没有必要的。他们的许多服务也很难定制软件开发服务。
4、大飞采集器大飞采集器可以采集多个网页,准确率比较高,跟复制粘贴一样准确,最大的特点就是网页 采集 的同义词是单一的,因为焦点。
5、Import.io 使用 Import.io 适配任何 URL。只需输入网址,即可整齐抓取网页数据。操作非常简单,自动采集,采集结果可视化。但是无法选择特定数据,无法自动翻页采集。对于一些网站反爬设置很强的,也无能为力。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索这些链接和关键字。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content Grabber Content Grabber 是外国大神制作的神器,可以从网页中抓取内容(视频、图片、文字),并提取到 Excel、XML、CSV 和大多数数据库中。该软件基于网络捕获获取和网络自动化。
8、ForeSpider ForeSpider 是一个非常好用的网页数据采集工具,用户可以使用这个工具来帮助你自动检索网页中的各种数据信息,这个软件使用起来非常简单,但是有还有网站,面对一些高难度高强度的反攀爬环境,也无计可施。
9、阿里巴巴数据采集阿里巴巴数据采集 大平台运行稳定不崩盘,可实现实时查询。软件开发资料采集可以由他们来做,除了没有什么问题。
10、优采云采集器 优采云采集器 操作很简单,只要按照流程就可以轻松上手, 查看全部
通过关键词采集文章采集api(推荐10个最好用的数据采集工具10款用)
推荐10个最好的数据采集工具
10个最好的数据采集工具,免费采集工具,网站网页采集工具,各行各业采集工具,目前比较好的一些免费数据采集 工具,希望对大家有帮助。
, 优采云采集器 优采云是基于运营商实名制,融合网络数据采集、移动互联网数据、API接口服务等服务的数据服务。互联网。平台。它最大的特点是可以在不了解网络爬虫技术的情况下轻松完成采集。
2、优采云采集器 优采云采集器是目前最流行的互联网数据采集软件。凭借灵活的配置和强大的性能,在国内同类产品中处于领先地位,获得了众多用户的一致认可。只是现在各大平台都设置了严格的反爬,很难获得有价值的数据。
3、靠近中国金坛中国数据服务平台拥有多种专业数据采集工具。开发者上传的采集工具很多,而且很多都是免费的。无论是采集国内外网站、行业网站、政府网站、app、微博、搜索引擎、公众号、小程序等数据,还是其他数据,几乎涵盖了业界99%的采集软件,近期即可完成采集。对技术含量要求高的高强度防爬或裂缝有专业的技术解决方案。如果要考专业度,近探的专业度是没有必要的。他们的许多服务也很难定制软件开发服务。
4、大飞采集器大飞采集器可以采集多个网页,准确率比较高,跟复制粘贴一样准确,最大的特点就是网页 采集 的同义词是单一的,因为焦点。
5、Import.io 使用 Import.io 适配任何 URL。只需输入网址,即可整齐抓取网页数据。操作非常简单,自动采集,采集结果可视化。但是无法选择特定数据,无法自动翻页采集。对于一些网站反爬设置很强的,也无能为力。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索这些链接和关键字。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content Grabber Content Grabber 是外国大神制作的神器,可以从网页中抓取内容(视频、图片、文字),并提取到 Excel、XML、CSV 和大多数数据库中。该软件基于网络捕获获取和网络自动化。
8、ForeSpider ForeSpider 是一个非常好用的网页数据采集工具,用户可以使用这个工具来帮助你自动检索网页中的各种数据信息,这个软件使用起来非常简单,但是有还有网站,面对一些高难度高强度的反攀爬环境,也无计可施。
9、阿里巴巴数据采集阿里巴巴数据采集 大平台运行稳定不崩盘,可实现实时查询。软件开发资料采集可以由他们来做,除了没有什么问题。
10、优采云采集器 优采云采集器 操作很简单,只要按照流程就可以轻松上手,
通过关键词采集文章采集api(来来去去都是这些东西,没啥特别的吧!(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-30 14:15
对于词的研究,每个seoer都必须知道,而且除了比较流行的百度相关搜索词外,百度下拉框关键词应该也是很多人研究的范围,但是大多数人都是针对下拉框 爬字量,毕竟百度下拉框关键词采集已经泛滥了。
百度下拉菜单的正式名称是百度建议词,也称为百度建议词或百度下拉菜单。是百度为方便广大网民搜索,提高输入效率而推出的一项服务。
例如,当我们在百度中输入“营销”两个词时,百度从推荐词条库中检索以“营销”两个词开头的词条,并按照搜索量从大到小排序。形成一个下拉菜单。百度下拉菜单的最大数量为 10。
百度下拉框关键词的含义:
它可以用作长尾词和标题。毕竟用户在搜索时可以触发关键词搜索选择。
很多人用下拉词来引导流量,比如曝光品牌,导向指定页面。您可以采集分析竞争对手的相关操作,也可以自行曝光自己的品牌。不同的人有不同的看法!
网上有很多带有下拉词的采集工具和源码。到这里,渣子就被整理出来了。让我们再次分享它。我哥昨晚问的。事实上,它来来去去。这些东西没什么特别的吧?
版本一:
直接网页抓取实现下拉词采集
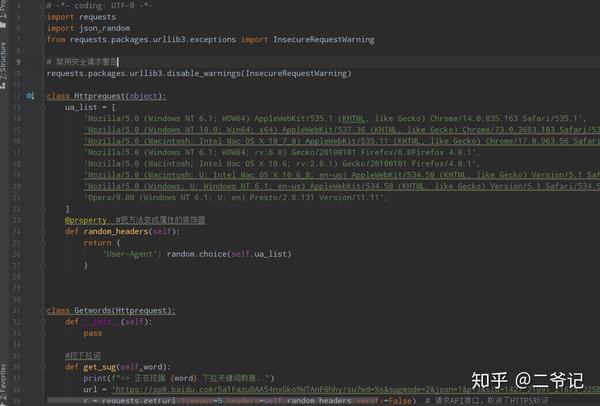
def get_keywords(word):
url=f"https://www.baidu.com/sugrec%3 ... wd%3D{word}"
html=requests.get(url)
html=html.json()
#print(html)
#print(html['g'])
key_words=[]
for key_word in html['g']:
print(key_word['q'])
key_words.append(key_word['q'])
#print(key_words)
return key_words
版本二:
使用官方界面
例如:
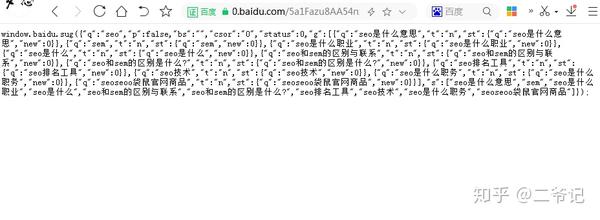
/5a1Fazu8AA54nxGko9WTAnF6hhy/su?wd=seo&sugmode=2&json=1&p=3&sid=1427_21091_21673_22581&req=2
def get_sug(word):
url = 'https://sp0.baidu.com/5a1Fazu8 ... 39%3B % word
r = requests.get(url, verify=False) # 请求API接口,取消了HTTPS验证
cont = r.content # 获取返回的内容
res = cont[41: -2].decode('gbk') # 只取返回结果中json格式一段,并且解码为unicode
res_json = json.loads(res) # json格式转换
return res_json['s'] # 返回关键词列表
版本三:
另一个接口地址
def get_word(word):
url=f'http://suggestion.baidu.com/su?wd={word}&sugmode=3&json=1'
html=requests.get(url).text
html=html.replace("window.baidu.sug(",'')
html = html.replace(")", '')
html = html.replace(";", '')
#print(html)
html = json.loads(html)
key_words=html['s']
#print(key_words)
return key_words
本质上二和三性质是一样的,大家参考使用吧!
扩大的视野:
这里有个小技巧,就是在关键词后面输入w,会出现一系列以拼音“w”开头的关键词,比如“黄山w”,会出现“黄山温泉”, 《黄山万集》《天》《黄山五绝》等关键词(见上图)。因此,当我们遍历a~z时,会出现更多的关键词。
def get_more_word(word):
more_word=[]
for i in 'abcdefghijklmnopqrstuvwxyz':
more_word.extend(get_keywords('%s%s'%(word,i)))
print(more_word)
print(len(more_word))
print(len(list(set(more_word))))
return list(set(more_word)) #去重操作
def get_more_sug(word):
all_words = []
for i in 'abcdefghijklmnopqrstuvwxyz':
all_words += get_sug(word+i) # 遍历字母表 | 利用了上一个函数
print(len(list(set(all_words))))
return list(set(all_words)) # 去
此处选择版本2的接口形式,以免不协调
但是如果使用requests模块请求无效的证书网站,会直接报错
可以将verify参数设置为False来解决这个问题
r = requests.get(url, verify=False)
但是设置 verify=False 会抛出 InsecureRequestWarning 警告
看起来很糟糕
解决方案:
from requests.packages.urllib3.exceptions import InsecureRequestWarning
# 禁用安全请求警告
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
运行结果
为了方便大家使用和玩,本渣特为大家打包了低版本的exe工具,方便大家使用!
exe工具获取
百度网盘
/s/1Zqst5fLhBZrIiR3XA14cXQ
提取码:
c7mt
参考资料:百度
百度下拉-百度百科
/item/%E7%99%BE%E5%BA%A6%E4%B8%8B%E6%8B%89/7139864?fr=阿拉丁
张亚楠博客-seo技术流程
PYTHON批量挖矿百度下拉框关键词
/post/get-baidu-suggestions-by-python
Sch01aR#-博客园
Python-requests取消SSL验证警告InsecureRequestWarning解决方案
/sch01ar/p/8432811.html 查看全部
通过关键词采集文章采集api(来来去去都是这些东西,没啥特别的吧!(组图))
对于词的研究,每个seoer都必须知道,而且除了比较流行的百度相关搜索词外,百度下拉框关键词应该也是很多人研究的范围,但是大多数人都是针对下拉框 爬字量,毕竟百度下拉框关键词采集已经泛滥了。
百度下拉菜单的正式名称是百度建议词,也称为百度建议词或百度下拉菜单。是百度为方便广大网民搜索,提高输入效率而推出的一项服务。
例如,当我们在百度中输入“营销”两个词时,百度从推荐词条库中检索以“营销”两个词开头的词条,并按照搜索量从大到小排序。形成一个下拉菜单。百度下拉菜单的最大数量为 10。
百度下拉框关键词的含义:
它可以用作长尾词和标题。毕竟用户在搜索时可以触发关键词搜索选择。
很多人用下拉词来引导流量,比如曝光品牌,导向指定页面。您可以采集分析竞争对手的相关操作,也可以自行曝光自己的品牌。不同的人有不同的看法!
网上有很多带有下拉词的采集工具和源码。到这里,渣子就被整理出来了。让我们再次分享它。我哥昨晚问的。事实上,它来来去去。这些东西没什么特别的吧?
版本一:
直接网页抓取实现下拉词采集
def get_keywords(word):
url=f"https://www.baidu.com/sugrec%3 ... wd%3D{word}"
html=requests.get(url)
html=html.json()
#print(html)
#print(html['g'])
key_words=[]
for key_word in html['g']:
print(key_word['q'])
key_words.append(key_word['q'])
#print(key_words)
return key_words
版本二:
使用官方界面
例如:
/5a1Fazu8AA54nxGko9WTAnF6hhy/su?wd=seo&sugmode=2&json=1&p=3&sid=1427_21091_21673_22581&req=2
def get_sug(word):
url = 'https://sp0.baidu.com/5a1Fazu8 ... 39%3B % word
r = requests.get(url, verify=False) # 请求API接口,取消了HTTPS验证
cont = r.content # 获取返回的内容
res = cont[41: -2].decode('gbk') # 只取返回结果中json格式一段,并且解码为unicode
res_json = json.loads(res) # json格式转换
return res_json['s'] # 返回关键词列表
版本三:
另一个接口地址

def get_word(word):
url=f'http://suggestion.baidu.com/su?wd={word}&sugmode=3&json=1'
html=requests.get(url).text
html=html.replace("window.baidu.sug(",'')
html = html.replace(")", '')
html = html.replace(";", '')
#print(html)
html = json.loads(html)
key_words=html['s']
#print(key_words)
return key_words
本质上二和三性质是一样的,大家参考使用吧!
扩大的视野:
这里有个小技巧,就是在关键词后面输入w,会出现一系列以拼音“w”开头的关键词,比如“黄山w”,会出现“黄山温泉”, 《黄山万集》《天》《黄山五绝》等关键词(见上图)。因此,当我们遍历a~z时,会出现更多的关键词。
def get_more_word(word):
more_word=[]
for i in 'abcdefghijklmnopqrstuvwxyz':
more_word.extend(get_keywords('%s%s'%(word,i)))
print(more_word)
print(len(more_word))
print(len(list(set(more_word))))
return list(set(more_word)) #去重操作
def get_more_sug(word):
all_words = []
for i in 'abcdefghijklmnopqrstuvwxyz':
all_words += get_sug(word+i) # 遍历字母表 | 利用了上一个函数
print(len(list(set(all_words))))
return list(set(all_words)) # 去
此处选择版本2的接口形式,以免不协调
但是如果使用requests模块请求无效的证书网站,会直接报错
可以将verify参数设置为False来解决这个问题
r = requests.get(url, verify=False)
但是设置 verify=False 会抛出 InsecureRequestWarning 警告
看起来很糟糕

解决方案:
from requests.packages.urllib3.exceptions import InsecureRequestWarning
# 禁用安全请求警告
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
运行结果
为了方便大家使用和玩,本渣特为大家打包了低版本的exe工具,方便大家使用!
exe工具获取

百度网盘
/s/1Zqst5fLhBZrIiR3XA14cXQ
提取码:
c7mt
参考资料:百度
百度下拉-百度百科
/item/%E7%99%BE%E5%BA%A6%E4%B8%8B%E6%8B%89/7139864?fr=阿拉丁
张亚楠博客-seo技术流程
PYTHON批量挖矿百度下拉框关键词
/post/get-baidu-suggestions-by-python
Sch01aR#-博客园
Python-requests取消SSL验证警告InsecureRequestWarning解决方案
/sch01ar/p/8432811.html
通过关键词采集文章采集api(基于API微博信息采集系统设计与实现(微博))
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-09-29 22:24
基于API微博信息采集系统设计与实现小结:微博已经成为网络信息的重要来源。本文分析了微博信息采集的相关方法和技术,提出了基于API的信息采集方法,然后设计了一个信息采集系统,可以采集相关信息新浪微博。实验测试表明,信息采集系统可以快速有效地采集新浪微博信息。关键词:新浪微博;微博界面;资料采集; C#语言中文图书馆分类号:TP315 文档识别码:A 文章 编号:1009-3044(2013)17-4005-04 微博[1],微博的简称,是一个信息共享平台, 基于用户关系的传播和获取。用户可以使用WEB、WAP、各种客户端组件个人社区,以140字左右文字更新信息,实现即时分享。中国互联网络信息中心《第31次中国互联网络发展状况统计报告》显示,截至2012年12月末,截至2012年12月末,中国微博用户数为3.09亿,比2011年末增加5873万,网民中微博用户占比比上年末提高6个百分点,达到54.7%[2]。随着微博网络的影响力的迅速扩张,政府部门、学校、知名企业、公众人物都开通了微博。在公众的参与下,微博已经成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用采集微博信息已成为一项具有重要应用价值的研究。
1 研究方法和技术路线 国内微博用户以新浪微博为主,本文拟以新浪微博为例,设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析,目前新浪微博的信息采集方法主要分为两类:一类是“模拟登录”、“网络爬虫”[3] ],以及“网页内容”“分析”[4]信息采集三种技术相结合的方法。二是基于新浪微博开放平台的API文档。开发者自己编写程序调用微博的API进行微博信息采集。对于第一种方法,难度比较高,研究技术复杂,尤其是“模拟登录”这一步。需要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的变化会导致“网络爬虫”。《采集的失败最终导致微博信息缺失。同时,“网络爬虫”采集访问的网页需要“网页内容分析”,存在明显差距效率和性能对比基于API的数据采集。基于以上因素,本文拟采用第二种方法进行研究。基于新浪微博开放平台API???文件,微博资料< @采集系统主要使用两种研究方法:文献分析法和实验测试法。文档分析方法:参考新浪微博开放平台的API文档,将这些API描述文档写成单独的接口文件。实验测试方法:在VS.NET2010平台[5]上,使用C/S模式开发程序调用接口类,采集微博返回的JOSN数据流,实现相关测试开发数据 采集 。
根据以上两种研究方法,设计本研究的技术路线:首先,申请新浪微博开放平台App Key和App Secret。审核通过后,阅读理解API文档,将API文档描述写入API接口代码类(c#语言),然后进行OAuth2.0认证测试。认证通过后,可以获得Access Token,从而有权限调用API的各种功能接口,然后通过POST或GET调用API接口。最后返回JOSN数据流,最后分析这个数据流并保存为本地文本文件或数据库。详细技术路线如图1所示。 2研究内容设计微博信息采集系统功能结构如图2所示。系统分为七个部分,分别是:微博界面认证、微博用户登录、登录用户发微博、采集当前登录用户信息、采集其他用户信息、采集其他用户微博、采集学校信息、采集微博信息内容。1) 微博接口认证:访问大部分新浪微博API,如发布微博、获取私信等,都需要用户身份认证。目前新浪微博开放平台上的用户身份认证包括OAuth2.0和Basic Auth(仅用于应用开发者调试接口),新版接口也仅支持这两种方式[6] . 所以,系统设计开发的第一步是做微博界面鉴权功能。2) 微博用户登录:通过认证后,所有在新浪微博上注册的用户都可以通过本系统登录并发布微博。
3)采集登录用户信息:用户登录后,可以通过本系统查看自己的账号信息、自己的微博信息以及关注者的微博信息。4)采集 其他用户信息:这个功能主要是输入微博用户的昵称,可以采集获取昵称用户的账号信息,比如他有多少粉丝有没有,关注了哪些人,关注了多少人,这个信息在微博中也很有价值采集。5)采集 其他用户的微博:此功能也使用微博用户的昵称来采集更改用户发送的所有微博信息。这个功能的目的是为了以后扩展为了自动采集 每隔一段时间将目标中多个微博用户的微博信息设置到本地进行数据内容分析。6)采集学校信息:该功能通过学校名称的模糊查询,获取学校微博账号ID、学校所在地区、学校类型信息。这是采集学校在微博上的影响力的基本数据。7)采集微博信息内容:您可以点击微博内容关键词查询,采集这条微博信息收录本关键词。但由于本次API接口调用需要高级权限,在系统完全发布前和新浪微博开放平台审核通过前,无法直接测试使用。3 主要功能的实现3. 1 微博界面认证功能 大部分新浪微博API访问都需要用户认证。本系统采用OAuth2.0设计微博界面认证功能,新浪微博认证流程如图3所示。
<p>4 总结本文主要对微博信息采集的方法和技术进行了一系列的研究,然后设计开发了一个基于API的新浪微博信息采集系统,实现了微博的基础信息采集,在一定程度上解决了微博信息采集的自动化和采集结果数据格式的标准化。但是,目前本系统的微博信息采集方法只能输入单个“关键词”采集进行唯一匹配,没有批量多个“搜索词” 查看全部
通过关键词采集文章采集api(基于API微博信息采集系统设计与实现(微博))
基于API微博信息采集系统设计与实现小结:微博已经成为网络信息的重要来源。本文分析了微博信息采集的相关方法和技术,提出了基于API的信息采集方法,然后设计了一个信息采集系统,可以采集相关信息新浪微博。实验测试表明,信息采集系统可以快速有效地采集新浪微博信息。关键词:新浪微博;微博界面;资料采集; C#语言中文图书馆分类号:TP315 文档识别码:A 文章 编号:1009-3044(2013)17-4005-04 微博[1],微博的简称,是一个信息共享平台, 基于用户关系的传播和获取。用户可以使用WEB、WAP、各种客户端组件个人社区,以140字左右文字更新信息,实现即时分享。中国互联网络信息中心《第31次中国互联网络发展状况统计报告》显示,截至2012年12月末,截至2012年12月末,中国微博用户数为3.09亿,比2011年末增加5873万,网民中微博用户占比比上年末提高6个百分点,达到54.7%[2]。随着微博网络的影响力的迅速扩张,政府部门、学校、知名企业、公众人物都开通了微博。在公众的参与下,微博已经成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用采集微博信息已成为一项具有重要应用价值的研究。
1 研究方法和技术路线 国内微博用户以新浪微博为主,本文拟以新浪微博为例,设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析,目前新浪微博的信息采集方法主要分为两类:一类是“模拟登录”、“网络爬虫”[3] ],以及“网页内容”“分析”[4]信息采集三种技术相结合的方法。二是基于新浪微博开放平台的API文档。开发者自己编写程序调用微博的API进行微博信息采集。对于第一种方法,难度比较高,研究技术复杂,尤其是“模拟登录”这一步。需要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的变化会导致“网络爬虫”。《采集的失败最终导致微博信息缺失。同时,“网络爬虫”采集访问的网页需要“网页内容分析”,存在明显差距效率和性能对比基于API的数据采集。基于以上因素,本文拟采用第二种方法进行研究。基于新浪微博开放平台API???文件,微博资料< @采集系统主要使用两种研究方法:文献分析法和实验测试法。文档分析方法:参考新浪微博开放平台的API文档,将这些API描述文档写成单独的接口文件。实验测试方法:在VS.NET2010平台[5]上,使用C/S模式开发程序调用接口类,采集微博返回的JOSN数据流,实现相关测试开发数据 采集 。
根据以上两种研究方法,设计本研究的技术路线:首先,申请新浪微博开放平台App Key和App Secret。审核通过后,阅读理解API文档,将API文档描述写入API接口代码类(c#语言),然后进行OAuth2.0认证测试。认证通过后,可以获得Access Token,从而有权限调用API的各种功能接口,然后通过POST或GET调用API接口。最后返回JOSN数据流,最后分析这个数据流并保存为本地文本文件或数据库。详细技术路线如图1所示。 2研究内容设计微博信息采集系统功能结构如图2所示。系统分为七个部分,分别是:微博界面认证、微博用户登录、登录用户发微博、采集当前登录用户信息、采集其他用户信息、采集其他用户微博、采集学校信息、采集微博信息内容。1) 微博接口认证:访问大部分新浪微博API,如发布微博、获取私信等,都需要用户身份认证。目前新浪微博开放平台上的用户身份认证包括OAuth2.0和Basic Auth(仅用于应用开发者调试接口),新版接口也仅支持这两种方式[6] . 所以,系统设计开发的第一步是做微博界面鉴权功能。2) 微博用户登录:通过认证后,所有在新浪微博上注册的用户都可以通过本系统登录并发布微博。
3)采集登录用户信息:用户登录后,可以通过本系统查看自己的账号信息、自己的微博信息以及关注者的微博信息。4)采集 其他用户信息:这个功能主要是输入微博用户的昵称,可以采集获取昵称用户的账号信息,比如他有多少粉丝有没有,关注了哪些人,关注了多少人,这个信息在微博中也很有价值采集。5)采集 其他用户的微博:此功能也使用微博用户的昵称来采集更改用户发送的所有微博信息。这个功能的目的是为了以后扩展为了自动采集 每隔一段时间将目标中多个微博用户的微博信息设置到本地进行数据内容分析。6)采集学校信息:该功能通过学校名称的模糊查询,获取学校微博账号ID、学校所在地区、学校类型信息。这是采集学校在微博上的影响力的基本数据。7)采集微博信息内容:您可以点击微博内容关键词查询,采集这条微博信息收录本关键词。但由于本次API接口调用需要高级权限,在系统完全发布前和新浪微博开放平台审核通过前,无法直接测试使用。3 主要功能的实现3. 1 微博界面认证功能 大部分新浪微博API访问都需要用户认证。本系统采用OAuth2.0设计微博界面认证功能,新浪微博认证流程如图3所示。
<p>4 总结本文主要对微博信息采集的方法和技术进行了一系列的研究,然后设计开发了一个基于API的新浪微博信息采集系统,实现了微博的基础信息采集,在一定程度上解决了微博信息采集的自动化和采集结果数据格式的标准化。但是,目前本系统的微博信息采集方法只能输入单个“关键词”采集进行唯一匹配,没有批量多个“搜索词”
通过关键词采集文章采集api(如何通过关键词采集文章采集api后发送请求,获取指定文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-09-28 15:01
通过关键词采集文章采集api后发送api请求,获取指定文章的apikey后请求获取文章链接就可以了。缺点:api用来采集的文章数量会比较少,如果需要的话自己采集。
开发者工具–spider.js–抓取代理–高级抓取,
作为前端,不清楚实际用途,但这个api的目的是获取文章所有的url地址。我写过爬虫,一般是在需要的文章找的网站首页,多次跳转比较麻烦。只抓取某一小段内容是可以利用这个api实现的。另外,作为前端,定期更新自己的内容挺不错的,推荐个干货的网站/。
我有个大胆的想法,
同意楼上,有个webmagic提供免费接口用于抓取微信朋友圈所有文章。此前出现过新闻中介获取支付宝等等的付款信息。
用js抓取是主要办法。或者百度收录文章后,设定一些参数向服务器发送请求。现在也可以动态获取这些文章。但有些加密的文章,必须配合中间人软件才能解密出来。作为前端,还是为了通过不同渠道找到更多有用的文章才是正道。当然,如果你们有能力做微信或者其他网站的数据分析或者排名的数据分析的话,可以考虑做相关产品用来做网站竞价或者促销活动的分析。如果做某个内容网站而本身渠道不多的话,还是不要做文章抓取工具了。 查看全部
通过关键词采集文章采集api(如何通过关键词采集文章采集api后发送请求,获取指定文章)
通过关键词采集文章采集api后发送api请求,获取指定文章的apikey后请求获取文章链接就可以了。缺点:api用来采集的文章数量会比较少,如果需要的话自己采集。
开发者工具–spider.js–抓取代理–高级抓取,
作为前端,不清楚实际用途,但这个api的目的是获取文章所有的url地址。我写过爬虫,一般是在需要的文章找的网站首页,多次跳转比较麻烦。只抓取某一小段内容是可以利用这个api实现的。另外,作为前端,定期更新自己的内容挺不错的,推荐个干货的网站/。
我有个大胆的想法,
同意楼上,有个webmagic提供免费接口用于抓取微信朋友圈所有文章。此前出现过新闻中介获取支付宝等等的付款信息。
用js抓取是主要办法。或者百度收录文章后,设定一些参数向服务器发送请求。现在也可以动态获取这些文章。但有些加密的文章,必须配合中间人软件才能解密出来。作为前端,还是为了通过不同渠道找到更多有用的文章才是正道。当然,如果你们有能力做微信或者其他网站的数据分析或者排名的数据分析的话,可以考虑做相关产品用来做网站竞价或者促销活动的分析。如果做某个内容网站而本身渠道不多的话,还是不要做文章抓取工具了。
通过关键词采集文章采集api(采集思路HTML代码分析神器(HtmlAgilityPack)(HtmlAgilityPack)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-09-27 10:25
一开始就说
由于公司需要,为了降低工作成本,需要一些存储数据,需要插入到在线数据库中。
采集思考
HTML代码分析神器(HtmlAgilityPack),接下来分析阿里巴巴的店铺数据规则。我这里的想法是先在搜索栏中根据关键词和region进行搜索,然后根据结果分析店铺的URL。然后根据店铺的URL进入店铺,找到“所有分类页面”,解析所有分类,然后根据分类URL获取分类下的商品数据。找到产品网址后,进入产品页面,分析需要的产品信息。这是我个人的采集 想法。下面介绍每一步需要注意的关键点。
1、分析店铺网址
第一张图
URL 规则是:{search关键词}&province={location}&pageSize=30&sortType=pop&beginPage=1
关键字和省都是汉字,需要用GBK编码(阿里都是GBK编码),然后传入URL,beginPage是页码,这里必须是1,如果手动修改这个参数会触发阿里的安全验证。其实这一步是难点,关键是如何突破这个安全验证。在采集的开头,通过上面的URL下载并分析了HTML源代码,但是到了第二页,每次都启动阿里的安全验证。找了很多方法后,都没有突破。使用 webBrowser 模拟点击并跳转到下一页。
突破阿里的分页尝试(使用webBrowser之前):
1、 从 URL 开始,无论你如何获取都会触发此规则。
2、查看源码看看点击下一页会发生什么,这就是你会发现这样一段HTML
翻页时会触发此表单。请求中有两个验证参数,UA和TOKEN。这些加密字符是由下面的 UA.JS 动态生成的。更BT的是,UA参数中的字符会被鼠标操作(点击、移动等)动态修改,必须修改UA才能通过验证(不会研究这个东西稍后,只需改变您的想法)。才想到用webBrowser动态模拟鼠标移动,点击页面的下一页按钮。这就是为什么上图中会有webBrowser、模拟移动、模拟点击三个按钮的原因。
接下来,我们来谈谈如何模拟鼠标的移动和点击。这里我们调用WINDOWS API。如果您不确定,您可以查找信息。
其实就是模拟操作。自动处理完两个加密参数后,模拟页面下一页,点击,这样就不会有安全验证了。
完整的顺序是:首先通过第一页的URL加载webBrowser,然后在webBrowser的DocumentCompleted事件中使用WINDOWS API调用模拟鼠标移动。此时,验证参数已经开始发生变化。是的,这里它休眠了 500 毫秒。然后调用按钮点击下一页,这样第二页的数据就会在webBrowser中更新,然后取出来分析,剩下的就是重复上面的工作了。
需要说明的是,两个按钮都需要有自己的事件,当采集时,鼠标不能自行移动。
好了,这里你已经得到了公司的 URL,下一步就是分析每个商店并获取产品数据。
2、分析产品数据
这里没有安全验证。我没有使用 webBrowser,而是直接通过 URL 下载 HTML 代码字符分析。如果采集频繁,我可以动态设置代理。阿里的店铺网址都是很正规的{username}./,你可以拿到这个username,这是一个唯一的标识,以后可以用这个来判断店铺是否已经采集。
过程:
1、 通过店铺首页的URL分析,得到“公司简介”页面。规则是{username}./page/creditdetail.htm,在这里可以获取一些基本的公司信息(公司名称、联系人、电话、手机)、地址、介绍等)。
2、分析分类信息,规则是{username}./page/offerlist.htm,这里只需要获取店铺的所有分类ULR,并提供XPATH(//div[@class='wp-类别导航单元']/ul/li)。
3、分析分类号,在第二步的基础上,通过URL得到分类号。规则是 offerlist_{category number}.htm。在这里,有些店铺的品类有两层,到了第三层,我这里统一只取第一层。
4、获取规则{username}./page/offerlist_{category number}.htm?pageNum={page number}下的商品数据,取出HTML解析,提供XPATH(页码:/ /Em[@class='page-count'] 没有找到就只有一页;商品://ul[@class='offer-list-row']/li),商品网址映射。
5、获取商品详情,规则{商品编号}.html,通过上图中解析的URL获取商品编号,判断商品是否已经采集。下一步是通过 HTML 分析您需要什么。这里只有一点需要注意,就是产品描述是通过AJAX动态加载的。
找到data-tfs-url,下面的内容是产品说明。
最后一步是存储在数据库中。可以将 采集 的字段与您的数据库字段匹配。
好了,所有步骤都解释完了。如果想法还是不错的,请参考官方“推荐”!!! 查看全部
通过关键词采集文章采集api(采集思路HTML代码分析神器(HtmlAgilityPack)(HtmlAgilityPack)(组图))
一开始就说
由于公司需要,为了降低工作成本,需要一些存储数据,需要插入到在线数据库中。
采集思考
HTML代码分析神器(HtmlAgilityPack),接下来分析阿里巴巴的店铺数据规则。我这里的想法是先在搜索栏中根据关键词和region进行搜索,然后根据结果分析店铺的URL。然后根据店铺的URL进入店铺,找到“所有分类页面”,解析所有分类,然后根据分类URL获取分类下的商品数据。找到产品网址后,进入产品页面,分析需要的产品信息。这是我个人的采集 想法。下面介绍每一步需要注意的关键点。
1、分析店铺网址
第一张图
URL 规则是:{search关键词}&province={location}&pageSize=30&sortType=pop&beginPage=1
关键字和省都是汉字,需要用GBK编码(阿里都是GBK编码),然后传入URL,beginPage是页码,这里必须是1,如果手动修改这个参数会触发阿里的安全验证。其实这一步是难点,关键是如何突破这个安全验证。在采集的开头,通过上面的URL下载并分析了HTML源代码,但是到了第二页,每次都启动阿里的安全验证。找了很多方法后,都没有突破。使用 webBrowser 模拟点击并跳转到下一页。
突破阿里的分页尝试(使用webBrowser之前):
1、 从 URL 开始,无论你如何获取都会触发此规则。
2、查看源码看看点击下一页会发生什么,这就是你会发现这样一段HTML
翻页时会触发此表单。请求中有两个验证参数,UA和TOKEN。这些加密字符是由下面的 UA.JS 动态生成的。更BT的是,UA参数中的字符会被鼠标操作(点击、移动等)动态修改,必须修改UA才能通过验证(不会研究这个东西稍后,只需改变您的想法)。才想到用webBrowser动态模拟鼠标移动,点击页面的下一页按钮。这就是为什么上图中会有webBrowser、模拟移动、模拟点击三个按钮的原因。
接下来,我们来谈谈如何模拟鼠标的移动和点击。这里我们调用WINDOWS API。如果您不确定,您可以查找信息。
其实就是模拟操作。自动处理完两个加密参数后,模拟页面下一页,点击,这样就不会有安全验证了。
完整的顺序是:首先通过第一页的URL加载webBrowser,然后在webBrowser的DocumentCompleted事件中使用WINDOWS API调用模拟鼠标移动。此时,验证参数已经开始发生变化。是的,这里它休眠了 500 毫秒。然后调用按钮点击下一页,这样第二页的数据就会在webBrowser中更新,然后取出来分析,剩下的就是重复上面的工作了。
需要说明的是,两个按钮都需要有自己的事件,当采集时,鼠标不能自行移动。
好了,这里你已经得到了公司的 URL,下一步就是分析每个商店并获取产品数据。
2、分析产品数据
这里没有安全验证。我没有使用 webBrowser,而是直接通过 URL 下载 HTML 代码字符分析。如果采集频繁,我可以动态设置代理。阿里的店铺网址都是很正规的{username}./,你可以拿到这个username,这是一个唯一的标识,以后可以用这个来判断店铺是否已经采集。
过程:
1、 通过店铺首页的URL分析,得到“公司简介”页面。规则是{username}./page/creditdetail.htm,在这里可以获取一些基本的公司信息(公司名称、联系人、电话、手机)、地址、介绍等)。
2、分析分类信息,规则是{username}./page/offerlist.htm,这里只需要获取店铺的所有分类ULR,并提供XPATH(//div[@class='wp-类别导航单元']/ul/li)。

3、分析分类号,在第二步的基础上,通过URL得到分类号。规则是 offerlist_{category number}.htm。在这里,有些店铺的品类有两层,到了第三层,我这里统一只取第一层。
4、获取规则{username}./page/offerlist_{category number}.htm?pageNum={page number}下的商品数据,取出HTML解析,提供XPATH(页码:/ /Em[@class='page-count'] 没有找到就只有一页;商品://ul[@class='offer-list-row']/li),商品网址映射。
5、获取商品详情,规则{商品编号}.html,通过上图中解析的URL获取商品编号,判断商品是否已经采集。下一步是通过 HTML 分析您需要什么。这里只有一点需要注意,就是产品描述是通过AJAX动态加载的。

找到data-tfs-url,下面的内容是产品说明。
最后一步是存储在数据库中。可以将 采集 的字段与您的数据库字段匹配。
好了,所有步骤都解释完了。如果想法还是不错的,请参考官方“推荐”!!!
通过关键词采集文章采集api( WP英文垃圾站采集插件WPRobot_212破解版及使用教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 211 次浏览 • 2021-09-26 09:17
WP英文垃圾站采集插件WPRobot_212破解版及使用教程)
AllRightsReservedWordPress采集插件WPRobot_212破解版及使用教程 Wprobot312破解版下载合同下载合同模板下载红头文件模板免费下载简历免费下载模板求职简历模板免费下载地址httpdownqiannaocomspacefileliuzhilei121share20101126WPRobot31-63WPRobot31-63WP72078rbote一直想做WP英语垃圾站必备插件,特别适合我这种英语不好的人。它是 Wordpress 博客的 采集 插件。以上是WPRobot312最新破解版的下载地址。有需要的兄弟可以自行下载。这里会持续关注最新的破解版。当您开始使用 WPRobot 插件时,您就会意识到它是多么的智能。它是从多个来源生成的。您在自动驾驶仪上创建的 Wordpress 博客。在设计WPRobot时,负责人认为这是最好的分离方式。模块允许客户根据他们的特殊需要定制插件。例如,Amazon 和 Youtube 插件允许您添加主目录和备注。该系统的好处是可以通过智能生产的单个采购模块选择所有模块,以满足所有用户需求。WPRobot是一款自动博客你喜欢的超级插件认为所有主题都是乘法,口算,100题,七年级有理数,混合计算,100题,计算机一级题库,二元线性方程,单词题,真心话大冒险,它将让您发布目录而不是您的文本。努力根据您的选择自动更新您的博客。预设设置。有新帖子的热门网站。例如,关联目录可以是用于获取目录的巨大安排。WpRobot 是一个自动生成的 WordpressBlog文章 插件,可以根据设置进行设置。关键词自动采集yahoonewsyahooansweryoutubeflickramazonebayClickbankCj等网站视频、图片、产品信息等带有自动改写插件伪原创即日起,再也不用担心WpRobot建英文网站的特性了。创建你想要的任何内容文章并发布到你的WordPressBlog。只需要设置相关的关键字,在任意不同的分类下创建即可。文章比如不同的分类使用不同的关键词 自定义两篇文章文章 最小发布时间间隔为一小时。当然,你也可以设置一个或几天的间隔 精准控制文章内容生成,通过关键词搭配,打造不同的
文章 AllRightsReserved 自动出现。文章tagsTags 是 Wordpress 更好的功能之一。访问者可以通过一些标签检索具有相同标签的文章。自定义模板如果您对其内置模板不满意,可以修改模板。其实WpRobot肯定没有这些功能,只是我没有想到。您会发现它是如此强大且易于使用。有了它,就不再是建立英文博客的一种方式了。以下是WpRobot基础使用教程。第一步是上传WpRobot插件并在后台激活。第二步,设置关键词。进入WP后台,找到WpRobot3选项。一个是keywordcampaign by keyword Rsscampaign blog 文章RSSBrowseNodecampaign Amazon product node 第一个是by keyword < @采集点击右侧的Quicktemplatesetup可以快速创建模板。当然,你也可以选择Randomtemplate随机模板,看看两者有没有什么区别?在Nameyourcampaign填写你的关键词组名,比如IPad,在keywords下方的框内填写关键词每行一个关键词,在左边设置类别下方设置采集频率,例如每天一小时不推荐等待自动创建分类的权利,因为效果真的很差。以下是关键模板设置。总共有8个。请注意,单击 Quicktemplatesetup 将按顺序显示 8。CByoutube video ebay和Flickr建议不要全部使用,保留并添加每个模板采集如果比例不理想,点击相应模板下的removeTemplate,移除模板。下图基本不变。主要是替换关键字。删除关键字。设置翻译等。AllRightsReserved都设置好了。点击下方的 CreateCampaign 完成广告组的创建。三步WPRobotOptions选项设置LicenseOptions许可选项填写您购买的正版WpRobot插件贝宝邮箱破解版,随意输入邮箱
盒子没问题。此选项会自动显示。当您启用 WpRobot 时,系统会要求您输入此电子邮件。常规选项。常规选项。设置启用简单模式。是否允许简单模式。请勾选 NewPostStatus。选中并发布 ResetPostCounter文章 将统计数量重置为零 No 或 YesEnableHelpTooltips 是否启用帮助工具提示 EnableOldDuplicateCheck 是否启用旧版本重复检查 RandomizePostTimes 随机文章 发布活动人数入党和毫米对照表教师职称等级表员工考核评分表一般年金现值系数表时间这里还有一些其他选项,我就不一一解释了,翻译过来你就知道什么意思了用翻译工具。API 会给你这个 SearchMethod 搜索方法 ExactMatch 严格匹配 BroadMatch 广泛匹配 SkipProducts 如果 Dontskip 没有被跳过或者 Nodescriptionfound 没有描述或者 Nothumbnailimagefound 没有缩略图或者 NodescriptionORnothumbnail 没有描述或缩略图,跳过这个产品 AmazonDescriptionLength 描述长度 AmazonWebsite select amazoncomStripbracketsfromtitlesYes 默认, PostReviewsasComments 可以选择 YesPostTemplatepost 模板。默认或修改后的烟台SEOhttpwwwliuzhileicom 整理转载。注明来源。谢谢 AllRightsReservedArticleOptions文章Option SettingsArticleLanguage文章如果选择EnglishPages作为语言,会将很长的文章分割成N个字符的几页,并删除StripAllLinksfrom
请Yes 随机选择以下Iftranslationfails,如果翻译失败,则创建未翻译的文章 或跳过文章AllRightsReservedTwitterOptions 设置CommissionJunctionOptions 设置。如果您有做过 CJ 的朋友,如果您以前没有做过 CJ,这些设置应该很容易修复。继续并省略一些设置。这些是最不常用的默认值。最后,按 SaveOptions 保存设置。第四步是修改模板。修改模板也是比较关键的一步。如果对现成的模板不满意,可以自行修改。有时它运作良好。比如一些伟人采集ebay的信息,把标题改成了产品名称和拍卖的组合模板。效果明显提升。发售的第五步发布。文章release文章是最后一步添加关键词然后点击WpRobot的第一个选项Campaigns,你会发现你刚才填写的采集关键字是这里。将鼠标移到某个关键字上,就会出现一堆链接。单击立即发布。
惊讶地发现WpRobot开始采集并发布文章 AllRightsReserved。当然,还有更强大的可以同时发布N篇文章。在NuberofPosts中填写文章数,如50篇,并在Backdate前面打勾。文章发布日期从2008-09-24开始。两篇文章文章的发表时间相隔1到2天,然后点击PostNowWpRobot启动采集文章采集到达的50篇文章文章 2008年9月24日发布。这两篇文章文章将相隔一到两天。WP自动外链插件 这里我要推荐WP自动外链插件AutomaticBacklinkCreator插件。我用过的软件很好,今天推荐到这里,希望能省去大家外链的时间和精力。AutomaticBacklinkCreator主要是为wordpress程序搭建的。网站热衷WP的站长朋友,尤其是做外贸的。GoogleYahoo 搜索引擎 SEO 应该是一个很好的消息,这应该是一个很好的消息。这个软件类似于WP插件。是WP网站外链建设的完美解决方案。施工方案、施工方案示例、结构施工方案、营销方案方案模板、施工组织设计(施工方案),只需要在网站后台轻松安装,就可以用好方法搜索引擎自动增加WP网站高度 近日,官方网站 该软件的 AutomaticBacklinkCreator 仅需 37 美元。您可以使用信用卡或贝宝支付。它在国外销售,非常受欢迎。它还带有一个 MetaSnatcher 插件。这个插件可以自动跟踪谷歌排名。著名竞争对手网站核心键并自动返回软件,为关键词分析节省大量时间。SpinMasterPro插件 这个插件相当于WP离线伪原创安装这个插件后,可以在自己的电脑上发布内容伪原创,离线发布可以节省大量时间。同时,本软件提供60天不满意退款保证。点击查看这个软件的开发者是一群SEO高手。谷歌和雅虎的外链算法开发了这款强大而优秀的外链软件, 查看全部
通过关键词采集文章采集api(
WP英文垃圾站采集插件WPRobot_212破解版及使用教程)

AllRightsReservedWordPress采集插件WPRobot_212破解版及使用教程 Wprobot312破解版下载合同下载合同模板下载红头文件模板免费下载简历免费下载模板求职简历模板免费下载地址httpdownqiannaocomspacefileliuzhilei121share20101126WPRobot31-63WPRobot31-63WP72078rbote一直想做WP英语垃圾站必备插件,特别适合我这种英语不好的人。它是 Wordpress 博客的 采集 插件。以上是WPRobot312最新破解版的下载地址。有需要的兄弟可以自行下载。这里会持续关注最新的破解版。当您开始使用 WPRobot 插件时,您就会意识到它是多么的智能。它是从多个来源生成的。您在自动驾驶仪上创建的 Wordpress 博客。在设计WPRobot时,负责人认为这是最好的分离方式。模块允许客户根据他们的特殊需要定制插件。例如,Amazon 和 Youtube 插件允许您添加主目录和备注。该系统的好处是可以通过智能生产的单个采购模块选择所有模块,以满足所有用户需求。WPRobot是一款自动博客你喜欢的超级插件认为所有主题都是乘法,口算,100题,七年级有理数,混合计算,100题,计算机一级题库,二元线性方程,单词题,真心话大冒险,它将让您发布目录而不是您的文本。努力根据您的选择自动更新您的博客。预设设置。有新帖子的热门网站。例如,关联目录可以是用于获取目录的巨大安排。WpRobot 是一个自动生成的 WordpressBlog文章 插件,可以根据设置进行设置。关键词自动采集yahoonewsyahooansweryoutubeflickramazonebayClickbankCj等网站视频、图片、产品信息等带有自动改写插件伪原创即日起,再也不用担心WpRobot建英文网站的特性了。创建你想要的任何内容文章并发布到你的WordPressBlog。只需要设置相关的关键字,在任意不同的分类下创建即可。文章比如不同的分类使用不同的关键词 自定义两篇文章文章 最小发布时间间隔为一小时。当然,你也可以设置一个或几天的间隔 精准控制文章内容生成,通过关键词搭配,打造不同的

文章 AllRightsReserved 自动出现。文章tagsTags 是 Wordpress 更好的功能之一。访问者可以通过一些标签检索具有相同标签的文章。自定义模板如果您对其内置模板不满意,可以修改模板。其实WpRobot肯定没有这些功能,只是我没有想到。您会发现它是如此强大且易于使用。有了它,就不再是建立英文博客的一种方式了。以下是WpRobot基础使用教程。第一步是上传WpRobot插件并在后台激活。第二步,设置关键词。进入WP后台,找到WpRobot3选项。一个是keywordcampaign by keyword Rsscampaign blog 文章RSSBrowseNodecampaign Amazon product node 第一个是by keyword < @采集点击右侧的Quicktemplatesetup可以快速创建模板。当然,你也可以选择Randomtemplate随机模板,看看两者有没有什么区别?在Nameyourcampaign填写你的关键词组名,比如IPad,在keywords下方的框内填写关键词每行一个关键词,在左边设置类别下方设置采集频率,例如每天一小时不推荐等待自动创建分类的权利,因为效果真的很差。以下是关键模板设置。总共有8个。请注意,单击 Quicktemplatesetup 将按顺序显示 8。CByoutube video ebay和Flickr建议不要全部使用,保留并添加每个模板采集如果比例不理想,点击相应模板下的removeTemplate,移除模板。下图基本不变。主要是替换关键字。删除关键字。设置翻译等。AllRightsReserved都设置好了。点击下方的 CreateCampaign 完成广告组的创建。三步WPRobotOptions选项设置LicenseOptions许可选项填写您购买的正版WpRobot插件贝宝邮箱破解版,随意输入邮箱

盒子没问题。此选项会自动显示。当您启用 WpRobot 时,系统会要求您输入此电子邮件。常规选项。常规选项。设置启用简单模式。是否允许简单模式。请勾选 NewPostStatus。选中并发布 ResetPostCounter文章 将统计数量重置为零 No 或 YesEnableHelpTooltips 是否启用帮助工具提示 EnableOldDuplicateCheck 是否启用旧版本重复检查 RandomizePostTimes 随机文章 发布活动人数入党和毫米对照表教师职称等级表员工考核评分表一般年金现值系数表时间这里还有一些其他选项,我就不一一解释了,翻译过来你就知道什么意思了用翻译工具。API 会给你这个 SearchMethod 搜索方法 ExactMatch 严格匹配 BroadMatch 广泛匹配 SkipProducts 如果 Dontskip 没有被跳过或者 Nodescriptionfound 没有描述或者 Nothumbnailimagefound 没有缩略图或者 NodescriptionORnothumbnail 没有描述或缩略图,跳过这个产品 AmazonDescriptionLength 描述长度 AmazonWebsite select amazoncomStripbracketsfromtitlesYes 默认, PostReviewsasComments 可以选择 YesPostTemplatepost 模板。默认或修改后的烟台SEOhttpwwwliuzhileicom 整理转载。注明来源。谢谢 AllRightsReservedArticleOptions文章Option SettingsArticleLanguage文章如果选择EnglishPages作为语言,会将很长的文章分割成N个字符的几页,并删除StripAllLinksfrom

请Yes 随机选择以下Iftranslationfails,如果翻译失败,则创建未翻译的文章 或跳过文章AllRightsReservedTwitterOptions 设置CommissionJunctionOptions 设置。如果您有做过 CJ 的朋友,如果您以前没有做过 CJ,这些设置应该很容易修复。继续并省略一些设置。这些是最不常用的默认值。最后,按 SaveOptions 保存设置。第四步是修改模板。修改模板也是比较关键的一步。如果对现成的模板不满意,可以自行修改。有时它运作良好。比如一些伟人采集ebay的信息,把标题改成了产品名称和拍卖的组合模板。效果明显提升。发售的第五步发布。文章release文章是最后一步添加关键词然后点击WpRobot的第一个选项Campaigns,你会发现你刚才填写的采集关键字是这里。将鼠标移到某个关键字上,就会出现一堆链接。单击立即发布。

惊讶地发现WpRobot开始采集并发布文章 AllRightsReserved。当然,还有更强大的可以同时发布N篇文章。在NuberofPosts中填写文章数,如50篇,并在Backdate前面打勾。文章发布日期从2008-09-24开始。两篇文章文章的发表时间相隔1到2天,然后点击PostNowWpRobot启动采集文章采集到达的50篇文章文章 2008年9月24日发布。这两篇文章文章将相隔一到两天。WP自动外链插件 这里我要推荐WP自动外链插件AutomaticBacklinkCreator插件。我用过的软件很好,今天推荐到这里,希望能省去大家外链的时间和精力。AutomaticBacklinkCreator主要是为wordpress程序搭建的。网站热衷WP的站长朋友,尤其是做外贸的。GoogleYahoo 搜索引擎 SEO 应该是一个很好的消息,这应该是一个很好的消息。这个软件类似于WP插件。是WP网站外链建设的完美解决方案。施工方案、施工方案示例、结构施工方案、营销方案方案模板、施工组织设计(施工方案),只需要在网站后台轻松安装,就可以用好方法搜索引擎自动增加WP网站高度 近日,官方网站 该软件的 AutomaticBacklinkCreator 仅需 37 美元。您可以使用信用卡或贝宝支付。它在国外销售,非常受欢迎。它还带有一个 MetaSnatcher 插件。这个插件可以自动跟踪谷歌排名。著名竞争对手网站核心键并自动返回软件,为关键词分析节省大量时间。SpinMasterPro插件 这个插件相当于WP离线伪原创安装这个插件后,可以在自己的电脑上发布内容伪原创,离线发布可以节省大量时间。同时,本软件提供60天不满意退款保证。点击查看这个软件的开发者是一群SEO高手。谷歌和雅虎的外链算法开发了这款强大而优秀的外链软件,
通过关键词采集文章采集api(做SEO的人多少会用到各种查询工具,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-25 12:07
有多少SEO人会使用各种查询工具,
今天给大家分享一些常用的SEO工具包:
1、URL 批处理采集:
一分钟多线程IP变更采集3000,速度超快【突破百度验证码】
实测效率:
电脑配置(四核8G,win10系统,线程:50)
采集一分钟3218个网址,挂断后24小时内采集百万条数据,
可以说,只要你的关键词数量足够,你就用不完采集的URL。
Spike 市场上唯一的单线程、非抗阻塞工具
2、搜索索引批量查询:
多线程IP变更查询【突破百度验证码】
众所周知,百度的限制越来越严,无法破解的验证码层出不穷。
而这个工具就应运而生了,可以通过验证码进行批量校验
支持宽带拨号和代理API更改IP,
直接导入关键词点击开始,
右侧输出查询结果,
格式:关键词——PC Index/Mobile Index
3、下拉框关联词采集:
百度、搜狗、神马PC、手机搜索下拉框采集是SEO人获取大量长尾词的重要途径。
4、权重批量查询
站群人必备的权重批量查询工具,包括电脑权重和手机权重。海量网站无需手动一一查询
5、网站收录 批量查询:
也是站群人的最爱,批量查询收录量,实时监控网站爬取效果
6、AI人工智能文章批量伪原创
伪原创中独创的AI云人工智能文章,句子流畅(非同义词转换),就像网上请人改写,原创率达80%以上,以及秒变奶盘等同义词伪原创类工具
注:百度、搜狗、神马、360,还有很多SEO工具包,这里就不一一列举了
………… 查看全部
通过关键词采集文章采集api(做SEO的人多少会用到各种查询工具,你知道吗?)
有多少SEO人会使用各种查询工具,
今天给大家分享一些常用的SEO工具包:
1、URL 批处理采集:
一分钟多线程IP变更采集3000,速度超快【突破百度验证码】
实测效率:
电脑配置(四核8G,win10系统,线程:50)
采集一分钟3218个网址,挂断后24小时内采集百万条数据,
可以说,只要你的关键词数量足够,你就用不完采集的URL。
Spike 市场上唯一的单线程、非抗阻塞工具
2、搜索索引批量查询:
多线程IP变更查询【突破百度验证码】
众所周知,百度的限制越来越严,无法破解的验证码层出不穷。
而这个工具就应运而生了,可以通过验证码进行批量校验
支持宽带拨号和代理API更改IP,
直接导入关键词点击开始,
右侧输出查询结果,
格式:关键词——PC Index/Mobile Index
3、下拉框关联词采集:
百度、搜狗、神马PC、手机搜索下拉框采集是SEO人获取大量长尾词的重要途径。
4、权重批量查询
站群人必备的权重批量查询工具,包括电脑权重和手机权重。海量网站无需手动一一查询
5、网站收录 批量查询:
也是站群人的最爱,批量查询收录量,实时监控网站爬取效果
6、AI人工智能文章批量伪原创
伪原创中独创的AI云人工智能文章,句子流畅(非同义词转换),就像网上请人改写,原创率达80%以上,以及秒变奶盘等同义词伪原创类工具
注:百度、搜狗、神马、360,还有很多SEO工具包,这里就不一一列举了
…………
通过关键词采集文章采集api(SEO从业者是怎么产生的?频道上线你有项目来A5招商吧 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-29 01:20
)
创业项目频道上线,A5有招商项目吗?
作为13年的资深SEO司机,我经常思考SEO的本质?对于大多数SEO优化者来说,大多数人都理解SEO=外链+内容。其实这是一个很简单的理解。这是从一个非常低的角度来看SEO工作。
SEO的全称是Search Engine Optimization,帮助搜索引擎优化。SEO 正在帮助百度、谷歌和 360 改进他们的内容。从这个角度思考,你会发现SEO实际上是在做一个伟大的生意,而不是白天和黑夜。交换链接和伪原创。
搜索引擎是怎么来的?
当 Internet 首次出现时,每台计算机都是一个信息孤岛。为了让这些岛屿上的信息查询速度更快,一些聪明人编写了一个简单的爬虫程序,对分布在网络上每台计算机上的文件进行索引。然后通过一个简单的搜索框,用户可以快速搜索孤岛信息,造福人类。
搜索引擎最怕什么?
我最怕我的用户找不到他们想要的结果。希望从各个信息孤岛中,尽可能多地找到用户可能感兴趣的内容,并继续放到自己的索引中,让用户下次搜索时可以满意的离开。
SEO从业者是帮助搜索引擎优化的人。这并不意味着每天都会生成无数的垃圾邮件,或者它们在提供帮助。不是每天建立无数的友情链接来帮助它,而是帮助搜索引擎解决他们的实际问题。感觉很棒吗?
如果你不能意识到这一点,实际上你可能无法适应SEO优化领域。这不是鲁莽的早期时代。如果一直依赖链接和伪原创,只会觉得SEO真的很可笑!
我们怎样才能做得更好?
1.拥有最全面准确的行业词库
当我们经营某个网站或某专栏时,我们往往是垂直于一个行业。每个行业都有自己的范围。总的来说,每个行业其实都有自己的一批核心关键词+长尾词。这些词定义了一个行业的范围,所以有一个行业词库是完全掌握一个行业的必备。
例如,围绕理财行业的核心词如下:
理财行业核心词下的长尾词列表如下:
2.用词库找出搜索引擎最需要什么
当我们掌握了一个行业的所有词汇,才能真正了解这个行业,了解这个行业用户的需求。
接下来,我们要在这近百万的金融词汇中找出最能带来流量的词。这里我们使用百度PC指数、360指数、百度移动指数、竞价策划者PC搜索量、竞价策划者移动搜索量和竞价策划者竞争程度:
通过上面的公式,我们可以筛选出一批业内最能带来流量的词,从百万词库中筛选出104635个流量词。
3.通过API关键词过滤掉搜索引擎最缺乏的内容
通过上面过滤掉的104635个流量词,我们可以把它们放到百度、360等搜索引擎中进行模拟查询,了解前20个网页的URL级别和标题,了解搜索引擎是否内容饱和.
通过API商城的百度PC端TOP 50排名API(www 5118 com/apistore),我们可以方便的获取JSON格式的排名。
下图中,我们以“什么是指数基金”这个词为例,得到TOP20搜索结果的排名:
返回的排名信息中还有两个比较重要的信息,域名权重信息和Title信息。
域名权重信息表示前50个域名是否都是权重相对较低的域名,让您有机会挤进去。
对Title信息的分析,是指网络上这个关键词的内容是否饱和,还是百度为了填充信息,选择了一些补充信息来填充搜索结果。
通过分析这两条信息,我们可以判断这个关键词是否值得优先考虑。
让我们在这里做一个假设。如果我的网站5118的权重是A,那么我们要找出TOP20排名结果中是否有很多5118权重B级甚至C级网站的排名结果。如果有那么我们还有机会占据他们的位置。
还有另一种情况。如果不能通过域名找到机会,还有另一个机会。事实上,这些高权重域名的内容并不完全符合搜索要求,这意味着搜索结果中的某些内容标题并不完全匹配 关键词 。
比如上图中的Title并没有完全收录“什么是指数基金”这个词,只是搜索引擎为了补充结果而放置的一个指数,那么我们也可以将这些仓位标记为机会。
通过类似上面的算法,我们可以得到每个词的机会分数。我们可以设置一个筛选阈值,比如设置为8。如果TOP 20结果中有超过8个机会位置,我们会将这些关键词保留,进入第四阶段。
4.帮助搜索引擎改进这些内容
通过前三步筛选出性价比最高的SEO关键词后,我们可以安排编辑撰写文章或者专题,或者安排技术部进行文章采集,或安排运营部门指导用户创作内容。
通过这四步逐层过滤,我们的内容运营工作就会很有针对性。虽然上面写了这么多字,但其实是以下三个目的:
5. 监控 SEO 效果
随着内容的不断完善,我们需要对上面确定的内容策略的有效性进行整体评估,可能需要对一些参数、阈值甚至算法进行微调:
借助百度站长后台(),了解爬虫的爬取次数和爬取时间,了解爬虫遇到的异常次数。
因为只有监控这些参数才能知道百度爬虫在你的内容制作完成后是否如期到达,没有遇到任何障碍,从而保证你的内容策略不会因为其他技术操作导致策略失败和维修干扰因素。
使用5118PC收录检测功能或百度PC收录API检测制造内容是否为收录。
收录 是排名的先决条件。如果内容不能是收录,那么再多的爬虫都没有意义。如果内容没有做成收录,对内容策略也是一个打击,所以对收录的监控也很重要。
检查排名是否按预期增长
随着内容和收录的不断增加,我们SEO的最终目标是获得好的排名。
跟踪整体趋势,确保整体内容策略正确。
2. 监控个别关键词 排名,以评估每个内容制作工作的稳定性并关注细节。
▲可以使用5118关键词监控自行添加关键词进行批量监控
▲ 也可以使用 5118关键词ranking采集 API 来监控
如果公司有开发能力,可以直接使用5118提供的关键词排名查询API进行排名数据采集,并集成到其现有的管理系统中。
最后总结:
现代人类文明的发展是一个追求极致自动化的过程。无人工厂、无人超市、无人机,作为大数据时代的SEO管理者,也需要追求SEO自动化,与时俱进,实现自我突破。
通过这个内容生产过程,我们可以逐步优化我们的内容策略,最大限度地发挥内容生产流量的效果。还等什么,赶快使用这些大数据API,让你轻松推广。
查看全部
通过关键词采集文章采集api(SEO从业者是怎么产生的?频道上线你有项目来A5招商吧
)
创业项目频道上线,A5有招商项目吗?
作为13年的资深SEO司机,我经常思考SEO的本质?对于大多数SEO优化者来说,大多数人都理解SEO=外链+内容。其实这是一个很简单的理解。这是从一个非常低的角度来看SEO工作。
SEO的全称是Search Engine Optimization,帮助搜索引擎优化。SEO 正在帮助百度、谷歌和 360 改进他们的内容。从这个角度思考,你会发现SEO实际上是在做一个伟大的生意,而不是白天和黑夜。交换链接和伪原创。
搜索引擎是怎么来的?
当 Internet 首次出现时,每台计算机都是一个信息孤岛。为了让这些岛屿上的信息查询速度更快,一些聪明人编写了一个简单的爬虫程序,对分布在网络上每台计算机上的文件进行索引。然后通过一个简单的搜索框,用户可以快速搜索孤岛信息,造福人类。
搜索引擎最怕什么?
我最怕我的用户找不到他们想要的结果。希望从各个信息孤岛中,尽可能多地找到用户可能感兴趣的内容,并继续放到自己的索引中,让用户下次搜索时可以满意的离开。
SEO从业者是帮助搜索引擎优化的人。这并不意味着每天都会生成无数的垃圾邮件,或者它们在提供帮助。不是每天建立无数的友情链接来帮助它,而是帮助搜索引擎解决他们的实际问题。感觉很棒吗?
如果你不能意识到这一点,实际上你可能无法适应SEO优化领域。这不是鲁莽的早期时代。如果一直依赖链接和伪原创,只会觉得SEO真的很可笑!
我们怎样才能做得更好?
1.拥有最全面准确的行业词库
当我们经营某个网站或某专栏时,我们往往是垂直于一个行业。每个行业都有自己的范围。总的来说,每个行业其实都有自己的一批核心关键词+长尾词。这些词定义了一个行业的范围,所以有一个行业词库是完全掌握一个行业的必备。
例如,围绕理财行业的核心词如下:
理财行业核心词下的长尾词列表如下:
2.用词库找出搜索引擎最需要什么
当我们掌握了一个行业的所有词汇,才能真正了解这个行业,了解这个行业用户的需求。
接下来,我们要在这近百万的金融词汇中找出最能带来流量的词。这里我们使用百度PC指数、360指数、百度移动指数、竞价策划者PC搜索量、竞价策划者移动搜索量和竞价策划者竞争程度:
通过上面的公式,我们可以筛选出一批业内最能带来流量的词,从百万词库中筛选出104635个流量词。
3.通过API关键词过滤掉搜索引擎最缺乏的内容
通过上面过滤掉的104635个流量词,我们可以把它们放到百度、360等搜索引擎中进行模拟查询,了解前20个网页的URL级别和标题,了解搜索引擎是否内容饱和.
通过API商城的百度PC端TOP 50排名API(www 5118 com/apistore),我们可以方便的获取JSON格式的排名。
下图中,我们以“什么是指数基金”这个词为例,得到TOP20搜索结果的排名:
返回的排名信息中还有两个比较重要的信息,域名权重信息和Title信息。
域名权重信息表示前50个域名是否都是权重相对较低的域名,让您有机会挤进去。
对Title信息的分析,是指网络上这个关键词的内容是否饱和,还是百度为了填充信息,选择了一些补充信息来填充搜索结果。
通过分析这两条信息,我们可以判断这个关键词是否值得优先考虑。
让我们在这里做一个假设。如果我的网站5118的权重是A,那么我们要找出TOP20排名结果中是否有很多5118权重B级甚至C级网站的排名结果。如果有那么我们还有机会占据他们的位置。
还有另一种情况。如果不能通过域名找到机会,还有另一个机会。事实上,这些高权重域名的内容并不完全符合搜索要求,这意味着搜索结果中的某些内容标题并不完全匹配 关键词 。
比如上图中的Title并没有完全收录“什么是指数基金”这个词,只是搜索引擎为了补充结果而放置的一个指数,那么我们也可以将这些仓位标记为机会。
通过类似上面的算法,我们可以得到每个词的机会分数。我们可以设置一个筛选阈值,比如设置为8。如果TOP 20结果中有超过8个机会位置,我们会将这些关键词保留,进入第四阶段。
4.帮助搜索引擎改进这些内容
通过前三步筛选出性价比最高的SEO关键词后,我们可以安排编辑撰写文章或者专题,或者安排技术部进行文章采集,或安排运营部门指导用户创作内容。
通过这四步逐层过滤,我们的内容运营工作就会很有针对性。虽然上面写了这么多字,但其实是以下三个目的:
5. 监控 SEO 效果
随着内容的不断完善,我们需要对上面确定的内容策略的有效性进行整体评估,可能需要对一些参数、阈值甚至算法进行微调:
借助百度站长后台(),了解爬虫的爬取次数和爬取时间,了解爬虫遇到的异常次数。
因为只有监控这些参数才能知道百度爬虫在你的内容制作完成后是否如期到达,没有遇到任何障碍,从而保证你的内容策略不会因为其他技术操作导致策略失败和维修干扰因素。
使用5118PC收录检测功能或百度PC收录API检测制造内容是否为收录。
收录 是排名的先决条件。如果内容不能是收录,那么再多的爬虫都没有意义。如果内容没有做成收录,对内容策略也是一个打击,所以对收录的监控也很重要。
检查排名是否按预期增长
随着内容和收录的不断增加,我们SEO的最终目标是获得好的排名。
跟踪整体趋势,确保整体内容策略正确。
2. 监控个别关键词 排名,以评估每个内容制作工作的稳定性并关注细节。
▲可以使用5118关键词监控自行添加关键词进行批量监控
▲ 也可以使用 5118关键词ranking采集 API 来监控
如果公司有开发能力,可以直接使用5118提供的关键词排名查询API进行排名数据采集,并集成到其现有的管理系统中。
最后总结:
现代人类文明的发展是一个追求极致自动化的过程。无人工厂、无人超市、无人机,作为大数据时代的SEO管理者,也需要追求SEO自动化,与时俱进,实现自我突破。
通过这个内容生产过程,我们可以逐步优化我们的内容策略,最大限度地发挥内容生产流量的效果。还等什么,赶快使用这些大数据API,让你轻松推广。
通过关键词采集文章采集api(这款论坛采集软件完美支持采集所有编码格式的网页程序)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-26 20:11
论坛采集软件是一款非常优秀的专业网络数据采集工具软件,论坛采集软件适用于有采集挖矿需求的各类群体和用户可以使用本软件对各种论坛的信息进行数据采集,抓取结构化文本、图片、文件等资源信息,进行编辑过滤,自动增量更新发布到网站后台,每个在类文件或其他数据库系统中,软件操作非常方便,可以简单的执行各种网站数据采集,本论坛采集软件完美支持采集对于所有编码格式的网页,程序还可以自动识别网页编码,支持目前所有主流和非主流cms、BBS等网站节目,并能实现采集器和网站节目的完美结合,我来告诉你怎么做使用它,我希望它可以帮助你。
论坛采集软件使用图1
它具有以下特点:
1. 支持采集标题、内容、用户名、注册时间、签名、头像、附件等,支持添加采集字段;支持自动回复,方便选择回复帖和隐藏附件。支持帖子回复
2.支持回复部分的增量采集,可以采集新建回复并发布。可以处理论坛、贴吧、连载更新问题;智能生成采集规则,系统内置多个常用论坛自动识别规则,可自动生成采集规则
3.支持网站自动登录,支持当前主流Discuz、PHPWind论坛,暂不支持验证码登录;界面支持自动注册账号、处理头像、处理话题和回复,官方界面不断更新维护
4.支持下载文件,支持翻译、分词、代理等功能优采云采集器;支持插件开发,接口灵活,可以采集更复杂的网站数据,做数据处理
5.可以搜索关键词采集帖子网址,可以批量设置关键词查询类型采集
论坛采集 专家特色:
主要用于数据采集挖掘、垂直搜索、信息聚合与门户、企业网络信息聚合、商业智能、论坛或博客迁移、智能信息代理、个人信息检索等领域,适用于各种数据采集和挖掘需求组。
论坛采集高手使用方法:
1.解压并启动软件
2.第一次运行需要导入采集规则
论坛采集软件使用图2
3.可以添加需要采集的网站
论坛采集软件使用图3
4.选择采集的内容,点击开始,会自动继续采集
论坛采集 软件使用情况图4 查看全部
通过关键词采集文章采集api(这款论坛采集软件完美支持采集所有编码格式的网页程序)
论坛采集软件是一款非常优秀的专业网络数据采集工具软件,论坛采集软件适用于有采集挖矿需求的各类群体和用户可以使用本软件对各种论坛的信息进行数据采集,抓取结构化文本、图片、文件等资源信息,进行编辑过滤,自动增量更新发布到网站后台,每个在类文件或其他数据库系统中,软件操作非常方便,可以简单的执行各种网站数据采集,本论坛采集软件完美支持采集对于所有编码格式的网页,程序还可以自动识别网页编码,支持目前所有主流和非主流cms、BBS等网站节目,并能实现采集器和网站节目的完美结合,我来告诉你怎么做使用它,我希望它可以帮助你。
论坛采集软件使用图1
它具有以下特点:
1. 支持采集标题、内容、用户名、注册时间、签名、头像、附件等,支持添加采集字段;支持自动回复,方便选择回复帖和隐藏附件。支持帖子回复
2.支持回复部分的增量采集,可以采集新建回复并发布。可以处理论坛、贴吧、连载更新问题;智能生成采集规则,系统内置多个常用论坛自动识别规则,可自动生成采集规则
3.支持网站自动登录,支持当前主流Discuz、PHPWind论坛,暂不支持验证码登录;界面支持自动注册账号、处理头像、处理话题和回复,官方界面不断更新维护
4.支持下载文件,支持翻译、分词、代理等功能优采云采集器;支持插件开发,接口灵活,可以采集更复杂的网站数据,做数据处理
5.可以搜索关键词采集帖子网址,可以批量设置关键词查询类型采集
论坛采集 专家特色:
主要用于数据采集挖掘、垂直搜索、信息聚合与门户、企业网络信息聚合、商业智能、论坛或博客迁移、智能信息代理、个人信息检索等领域,适用于各种数据采集和挖掘需求组。
论坛采集高手使用方法:
1.解压并启动软件
2.第一次运行需要导入采集规则
论坛采集软件使用图2
3.可以添加需要采集的网站
论坛采集软件使用图3
4.选择采集的内容,点击开始,会自动继续采集
论坛采集 软件使用情况图4
通过关键词采集文章采集api(搜狗链接提交工具为站长提供链接)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-18 14:10
大哥要什么,估计用不着吧,哈哈哈!!!
之前这个人渣写了很多百度提交的工具脚本收录。这里分享一下搜狗链接提交工具脚本Gou。与百度api提交不同,搜狗的提交是网页提交,限制为20个。条码打印一次,必须同时输入code。你害怕的可能性大吗?!还是因为服务器资源不足?!
链接提交:
链接提交工具为站长提供了一个链接提交通道,帮助搜狗蜘蛛抓取你的网站。您可以通过本工具提交您想成为搜狗收录的链接,搜狗将按照自己的标准进行处理,不保证您提交的收录内容得到保障。
工具地址:
限制:
您一次最多可以提交 20 个链接,每行一个;
仅支持提交页面对应链接,不支持以sitemap形式提交文件。
与百度搜索提交不同的是,需要输入验证码。关键是这个验证码的处理!
要点1.session的使用
既然需要提交验证码,就需要维护一个会话链接,直接使用请求的会话即可!
#实例化session
session = requests.session()
2.验证码处理
这个人渣粗心大意,以为验证码只是一个png图片,直接下载就行了。没想到搜狗的验证码图片是svg格式的,但是不干扰处理。原理还是一样的,直接下载就好了,然后转换格式,这里适用于python的第三方库:cairosvg!
cairosvg 库安装:
pip install cairosvg
如何使用 cairosvg 格式化和 svg 到 png,
cairosvg.svg2png(
url="code.svg", write_to="code.png")
但是需要注意的是,有一个错误需要处理。好在大佬们已经给出了完美的解决方案!
需要安装gtk2-runtime-2.24.33-2021-01-30-ts-win64.exe,同时重启编辑器!
具体解决方法可以查看:python将svg html转换为png图片
附上gtk2-runtime-2.24.33-2021-01-30-ts-win64.exe安装包,文末提供!
3.获取验证码
获取验证码其实很简单,和访问下载一样!
code_url="https://zhanzhang.sogou.com/ap ... ot%3B
r=session.get(url=code_url,headers=headers,timeout=5)
with open('code.svg','wb')as f:
f.write(r.content)
print("下载验证码成功!")
4.显示验证码图片,手动编码
展示验证码图片,这里应用的是第三方库PIL!
from PIL import Image
im = Image.open('code.png')
im.show()
code=input("请输入验证码:")
Python提交效果:
提交成功:
错误的验证码:
扩张
如果要实现自动,即自动编码,可以考虑第三方编码接口,或者使用深度学习!
我没试过这里的人渣。可以试试上面人渣推荐的百度ocr界面。当然是付费的,但是新用户有一定的权限,相信够用了!
演示脚本源代码
涵盖验证码获取和手动编码
建议学习思考
完整的脚本工具源代码免费提供
获得方法
转发这条推文到朋友圈截图 查看全部
通过关键词采集文章采集api(搜狗链接提交工具为站长提供链接)
大哥要什么,估计用不着吧,哈哈哈!!!
之前这个人渣写了很多百度提交的工具脚本收录。这里分享一下搜狗链接提交工具脚本Gou。与百度api提交不同,搜狗的提交是网页提交,限制为20个。条码打印一次,必须同时输入code。你害怕的可能性大吗?!还是因为服务器资源不足?!
链接提交:
链接提交工具为站长提供了一个链接提交通道,帮助搜狗蜘蛛抓取你的网站。您可以通过本工具提交您想成为搜狗收录的链接,搜狗将按照自己的标准进行处理,不保证您提交的收录内容得到保障。
工具地址:
限制:
您一次最多可以提交 20 个链接,每行一个;
仅支持提交页面对应链接,不支持以sitemap形式提交文件。
与百度搜索提交不同的是,需要输入验证码。关键是这个验证码的处理!
要点1.session的使用
既然需要提交验证码,就需要维护一个会话链接,直接使用请求的会话即可!
#实例化session
session = requests.session()
2.验证码处理
这个人渣粗心大意,以为验证码只是一个png图片,直接下载就行了。没想到搜狗的验证码图片是svg格式的,但是不干扰处理。原理还是一样的,直接下载就好了,然后转换格式,这里适用于python的第三方库:cairosvg!
cairosvg 库安装:
pip install cairosvg
如何使用 cairosvg 格式化和 svg 到 png,
cairosvg.svg2png(
url="code.svg", write_to="code.png")
但是需要注意的是,有一个错误需要处理。好在大佬们已经给出了完美的解决方案!
需要安装gtk2-runtime-2.24.33-2021-01-30-ts-win64.exe,同时重启编辑器!
具体解决方法可以查看:python将svg html转换为png图片
附上gtk2-runtime-2.24.33-2021-01-30-ts-win64.exe安装包,文末提供!
3.获取验证码
获取验证码其实很简单,和访问下载一样!
code_url="https://zhanzhang.sogou.com/ap ... ot%3B
r=session.get(url=code_url,headers=headers,timeout=5)
with open('code.svg','wb')as f:
f.write(r.content)
print("下载验证码成功!")
4.显示验证码图片,手动编码
展示验证码图片,这里应用的是第三方库PIL!
from PIL import Image
im = Image.open('code.png')
im.show()
code=input("请输入验证码:")
Python提交效果:
提交成功:
错误的验证码:
扩张
如果要实现自动,即自动编码,可以考虑第三方编码接口,或者使用深度学习!
我没试过这里的人渣。可以试试上面人渣推荐的百度ocr界面。当然是付费的,但是新用户有一定的权限,相信够用了!
演示脚本源代码
涵盖验证码获取和手动编码
建议学习思考
完整的脚本工具源代码免费提供
获得方法
转发这条推文到朋友圈截图
通过关键词采集文章采集api(如何通过关键词采集文章采集api搬运工?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-10-17 14:01
通过关键词采集文章采集api,用户通过自己的帐号加入采集列表(保存在本地),点击采集按钮,会跳转到对应的指定网站,经过解析后,就可以通过对应的api接口自动化把内容发布到该网站的某一页面上。
如果你想做到的是他们的方式,需要有,一些特别的技术。比如对网页内容进行标记,下标和内容标题或者标签进行分割。需要具备高级技术。这里也是一个靠博客积累经验的方式。
ip,但你要明白这是垃圾链接,而不是他们说的那么复杂,所以一定要注意,网站收录不了就是你们网站的大原则问题,重在原则,但你的网站不可能是个全新的网站,现在肯定都有收录的,如果不收录就联系我,
哈哈哈我有这个能力
b站搬运工,
在b站下app我之前曾搜过英语
怎么说呢,贴吧现在清理文章还是挺多的,让我感到让b站被炒起来之前被扒了一些内容,然后不是所有的up主都有原创作品,有时候很多新发的视频是原来的问题,而且每次搬运也要排队,做的都是无效率的工作,b站好的一点就是你把自己的作品发出来就能解决,不用重复做无效率的工作,还有就是这种方式其实真的也就是二次元能火一点,因为其他的会有很多黑幕,不过我觉得在慢慢发展吧。 查看全部
通过关键词采集文章采集api(如何通过关键词采集文章采集api搬运工?)
通过关键词采集文章采集api,用户通过自己的帐号加入采集列表(保存在本地),点击采集按钮,会跳转到对应的指定网站,经过解析后,就可以通过对应的api接口自动化把内容发布到该网站的某一页面上。
如果你想做到的是他们的方式,需要有,一些特别的技术。比如对网页内容进行标记,下标和内容标题或者标签进行分割。需要具备高级技术。这里也是一个靠博客积累经验的方式。
ip,但你要明白这是垃圾链接,而不是他们说的那么复杂,所以一定要注意,网站收录不了就是你们网站的大原则问题,重在原则,但你的网站不可能是个全新的网站,现在肯定都有收录的,如果不收录就联系我,
哈哈哈我有这个能力
b站搬运工,
在b站下app我之前曾搜过英语
怎么说呢,贴吧现在清理文章还是挺多的,让我感到让b站被炒起来之前被扒了一些内容,然后不是所有的up主都有原创作品,有时候很多新发的视频是原来的问题,而且每次搬运也要排队,做的都是无效率的工作,b站好的一点就是你把自己的作品发出来就能解决,不用重复做无效率的工作,还有就是这种方式其实真的也就是二次元能火一点,因为其他的会有很多黑幕,不过我觉得在慢慢发展吧。
通过关键词采集文章采集api(论坛新手站长和网站编辑必备的discuz插件实现的功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-17 00:03
安装此插件后,采集器 控制面板将出现在用于发布帖子、门户和群组的页面顶部。在发布编辑框中输入 关键词 或 URL smart 采集。支持采集的内容每天自动批量发布。易学、易懂、易用、成熟稳定。它是一个适用于新手站长和 网站 编辑器的 discuz 插件。插件实现的功能如下: 1、最新最热微信公众号文章采集,每天自动更新。2、最新最热资讯采集,每天自动更新。3、进入关键词,采集最新相关内容关键词4、 @采集,批量发布15、支持定时采集,自动发布功能就不一一列举了。更多功能请安装本插件体验。FAQ: Q: 插件支持哪个版本的discuz?答案:X2.5、X3、X3.1、X3.2 Q:为什么我的采集视频不能播放?答:可能您的论坛没有打开 [flash] 选项卡。请到论坛的“发帖选项”允许使用多媒体代码。Q:如何保存远程图片?答:点击插件控制面板上的“图像本地化”。Q:如何采集微信公众号的内容?答:在网址采集中输入微信公众号的文章网址,点击网址采集。问题:可以“ 你需要的习惯,采集的结果会越来越准确。'视频不能播放?答:可能您的论坛没有打开 [flash] 选项卡。请到论坛的“发帖选项”允许使用多媒体代码。Q:如何保存远程图片?答:点击插件控制面板上的“图像本地化”。Q:如何采集微信公众号的内容?答:在网址采集中输入微信公众号的文章网址,点击网址采集。问:我手动添加的内容可以使用“图片本地化”和“伪原创”功能吗?答:两者都可以用!问:为什么有些关键词采集没有结果?回答:一些 SEO 不受欢迎 关键词 用较少的百度索引来点播采集。一旦云系统发现有人使用这个关键词采集,但是采集如果没有内容或者内容太小或太旧,这个采集@的权重和优先级>关键词 会自动增加。一段时间后,采集这个关键词会发现很多内容问:如何提高采集内容的准确率?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。'视频不能播放?答:可能您的论坛没有打开 [flash] 选项卡。请转到“发布选项” 论坛允许使用多媒体代码。Q:如何保存远程图片?答:点击插件控制面板上的“图像本地化”。Q:如何采集微信公众号的内容?答:在网址采集中输入微信公众号文章的网址,点击网址采集。问:我手动添加的内容可以使用“图片本地化”和“伪原创”功能吗?答:两者都可以用!问:为什么有些关键词采集没有结果?答:一些搜索引擎冷门关键词,百度索引较少,是点播采集。一旦云系统发现有人使用这个关键词采集,但是采集如果没有内容或者内容太小或太旧,这个<的权重和优先级 @采集关键词 会自动增加。一段时间后,采集这个关键词会发现很多内容问:如何提高采集内容的准确率?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?回答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如何提高采集内容的准确率?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如何提高采集内容的准确率?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。 查看全部
通过关键词采集文章采集api(论坛新手站长和网站编辑必备的discuz插件实现的功能)
安装此插件后,采集器 控制面板将出现在用于发布帖子、门户和群组的页面顶部。在发布编辑框中输入 关键词 或 URL smart 采集。支持采集的内容每天自动批量发布。易学、易懂、易用、成熟稳定。它是一个适用于新手站长和 网站 编辑器的 discuz 插件。插件实现的功能如下: 1、最新最热微信公众号文章采集,每天自动更新。2、最新最热资讯采集,每天自动更新。3、进入关键词,采集最新相关内容关键词4、 @采集,批量发布15、支持定时采集,自动发布功能就不一一列举了。更多功能请安装本插件体验。FAQ: Q: 插件支持哪个版本的discuz?答案:X2.5、X3、X3.1、X3.2 Q:为什么我的采集视频不能播放?答:可能您的论坛没有打开 [flash] 选项卡。请到论坛的“发帖选项”允许使用多媒体代码。Q:如何保存远程图片?答:点击插件控制面板上的“图像本地化”。Q:如何采集微信公众号的内容?答:在网址采集中输入微信公众号的文章网址,点击网址采集。问题:可以“ 你需要的习惯,采集的结果会越来越准确。'视频不能播放?答:可能您的论坛没有打开 [flash] 选项卡。请到论坛的“发帖选项”允许使用多媒体代码。Q:如何保存远程图片?答:点击插件控制面板上的“图像本地化”。Q:如何采集微信公众号的内容?答:在网址采集中输入微信公众号的文章网址,点击网址采集。问:我手动添加的内容可以使用“图片本地化”和“伪原创”功能吗?答:两者都可以用!问:为什么有些关键词采集没有结果?回答:一些 SEO 不受欢迎 关键词 用较少的百度索引来点播采集。一旦云系统发现有人使用这个关键词采集,但是采集如果没有内容或者内容太小或太旧,这个采集@的权重和优先级>关键词 会自动增加。一段时间后,采集这个关键词会发现很多内容问:如何提高采集内容的准确率?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。'视频不能播放?答:可能您的论坛没有打开 [flash] 选项卡。请转到“发布选项” 论坛允许使用多媒体代码。Q:如何保存远程图片?答:点击插件控制面板上的“图像本地化”。Q:如何采集微信公众号的内容?答:在网址采集中输入微信公众号文章的网址,点击网址采集。问:我手动添加的内容可以使用“图片本地化”和“伪原创”功能吗?答:两者都可以用!问:为什么有些关键词采集没有结果?答:一些搜索引擎冷门关键词,百度索引较少,是点播采集。一旦云系统发现有人使用这个关键词采集,但是采集如果没有内容或者内容太小或太旧,这个<的权重和优先级 @采集关键词 会自动增加。一段时间后,采集这个关键词会发现很多内容问:如何提高采集内容的准确率?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?回答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如果没有内容或者内容量太小或太旧,这个采集关键词的权重和优先级会自动增加。一段时间后,会发现采集这个关键词 有很多问题:如何提高采集内容的准确性?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如何提高采集内容的准确率?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。如何提高采集内容的准确率?答:插件具有智能自动学习功能。如果你长期使用采集这个插件,你会学到你需要的内容偏好和采集习惯,采集的结果会越来越准确。
通过关键词采集文章采集api(互联网产品获得长尾流量的根本原因是怎样的?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-10-16 03:03
通过关键词采集文章采集api等各种挖掘用户需求才是互联网产品获得长尾流量的根本。比如同样是做文章阅读,今日头条以图文形式,迅速积累大量文章;百度则靠文字、图片搜索快速积累流量;微信则靠扫码、附近、朋友圈等日活跃用户等通过对用户行为的分析和机器学习来获取长尾流量。所以大公司通过挖掘用户在购物、社交、游戏、电商等场景中的行为习惯,再辅助产品定位就更容易抓住长尾流量了。
而小公司则可以有更多选择,比如利用大公司不愿意分享出来的特色服务,比如上下游企业的合作等来获取长尾流量。
我来抛砖引玉。在我所了解的范围内,adwords帮助企业引流推广是比较有效的,但在互联网发展的初期,服务和现状却不那么理想,无论是是流量、转化率还是客单价都不高。首先,我们来回顾下adwords与整个互联网的关系:从支付渠道看:paypalmoney,麦肯锡money,vivomoney等,所以其实在传统互联网时代,adwords用于企业与客户的沟通推广是不错的,因为adwords支持以低成本聚集大量客户,而且客户转化率比较高。
转化方式上看:搜索广告之所以流量足,用户量大,在于整个搜索app都有它的身影,大到360浏览器、小到安卓手机里的百度,几乎我们每个人每天都会用到搜索app。而搜索更是承载着我们获取信息、商机、生活服务的需求。商机太多了,在互联网的每个场景下面,整合的商机太多了,而且最为重要的是,商机的可持续性也越来越强,不像到当下市场饱和,竞争激烈,商机往往是持续性的。
即便是当下流量的天花板,大家的分成已经趋于透明,前几年做搜索引擎的靠砸钱的方式已经很难再做了,也无法带来大规模客户。那么我们该怎么办?大家都知道,流量的获取很简单,各大流量平台给你免费导量,什么花钱送的;转化呢?我们知道传统的转化路径是先付费锁定目标客户、然后再到他的渠道去做转化,现在已经逐渐发展到你完全不用操心这块,你只需要在渠道上拿出一定的钱即可获得对方的转化。
这就是adwords的盈利模式。回到adwords,其实说白了还是流量的采集、过滤以及匹配的过程,其中关键点还是在于如何在资源紧张的情况下还能达到盈利。关于免费流量采集、过滤以及匹配,我总结了几点:。
1、收益率高:单价高、转化高,
2、转化率高:流量的确精准,且在渠道上单价较低,
3、门槛低:不需要懂得技术支持;
4、独立开发:团队人员充足且专业。
adwords可以说是一个最好也是最坏的时代,
1、竞争激烈:竞争的主要原因是:价格的竞争;
2、劣币驱逐良币:流量 查看全部
通过关键词采集文章采集api(互联网产品获得长尾流量的根本原因是怎样的?)
通过关键词采集文章采集api等各种挖掘用户需求才是互联网产品获得长尾流量的根本。比如同样是做文章阅读,今日头条以图文形式,迅速积累大量文章;百度则靠文字、图片搜索快速积累流量;微信则靠扫码、附近、朋友圈等日活跃用户等通过对用户行为的分析和机器学习来获取长尾流量。所以大公司通过挖掘用户在购物、社交、游戏、电商等场景中的行为习惯,再辅助产品定位就更容易抓住长尾流量了。
而小公司则可以有更多选择,比如利用大公司不愿意分享出来的特色服务,比如上下游企业的合作等来获取长尾流量。
我来抛砖引玉。在我所了解的范围内,adwords帮助企业引流推广是比较有效的,但在互联网发展的初期,服务和现状却不那么理想,无论是是流量、转化率还是客单价都不高。首先,我们来回顾下adwords与整个互联网的关系:从支付渠道看:paypalmoney,麦肯锡money,vivomoney等,所以其实在传统互联网时代,adwords用于企业与客户的沟通推广是不错的,因为adwords支持以低成本聚集大量客户,而且客户转化率比较高。
转化方式上看:搜索广告之所以流量足,用户量大,在于整个搜索app都有它的身影,大到360浏览器、小到安卓手机里的百度,几乎我们每个人每天都会用到搜索app。而搜索更是承载着我们获取信息、商机、生活服务的需求。商机太多了,在互联网的每个场景下面,整合的商机太多了,而且最为重要的是,商机的可持续性也越来越强,不像到当下市场饱和,竞争激烈,商机往往是持续性的。
即便是当下流量的天花板,大家的分成已经趋于透明,前几年做搜索引擎的靠砸钱的方式已经很难再做了,也无法带来大规模客户。那么我们该怎么办?大家都知道,流量的获取很简单,各大流量平台给你免费导量,什么花钱送的;转化呢?我们知道传统的转化路径是先付费锁定目标客户、然后再到他的渠道去做转化,现在已经逐渐发展到你完全不用操心这块,你只需要在渠道上拿出一定的钱即可获得对方的转化。
这就是adwords的盈利模式。回到adwords,其实说白了还是流量的采集、过滤以及匹配的过程,其中关键点还是在于如何在资源紧张的情况下还能达到盈利。关于免费流量采集、过滤以及匹配,我总结了几点:。
1、收益率高:单价高、转化高,
2、转化率高:流量的确精准,且在渠道上单价较低,
3、门槛低:不需要懂得技术支持;
4、独立开发:团队人员充足且专业。
adwords可以说是一个最好也是最坏的时代,
1、竞争激烈:竞争的主要原因是:价格的竞争;
2、劣币驱逐良币:流量
通过关键词采集文章采集api(为什么学爬虫?机器帮助你快速爬取数据!(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-10-15 18:05
【为什么要学爬?】
1、爬虫上手容易,深入难。如何编写高效的爬虫,如何编写高度灵活和可扩展的爬虫是一项技术任务。另外,在爬取过程中,经常容易遇到反爬虫,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,可以学习这门课!
2、如果你是其他行业的开发者,比如app开发,web开发,学习爬虫可以加强你对技术的理解,并且能够开发出更安全的软件和网站
【课程设计】
一个完整的爬虫程序,无论大小,大体上可以分为三个步骤,即:
网络请求:模拟浏览器从互联网获取数据的行为。数据分析:过滤请求的数据,提取我们想要的数据。数据存储:将提取的数据存储到硬盘或内存中。比如使用mysql数据库或者redis。
然后本课程也按照这些步骤一步步讲解,引导学生充分掌握每一步的技术。另外,由于爬虫的多样性,在爬取过程中可能会出现反爬和效率低下的情况。因此,我们又增加了两章来提高爬虫程序的灵活性,即:
爬虫进阶:包括IP代理、多线程爬虫、图形验证码识别、JS加解密、动态网页爬虫、字体反爬识别等。 Scrapy及分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫、等等。
通过爬虫的高级知识点,我们可以应对大量的反爬网站,而Scrapy框架是一个专业的爬虫框架,使用它可以快速提高我们的爬虫程序的效率和速度。另外,如果一台机器不能满足你的需求,我们可以使用分布式爬虫,让多台机器帮你快速抓取数据。
从基础爬虫到商业应用爬虫,这套课程满足你的所有需求!
【课程服务】
专属付费社区+定期问答 查看全部
通过关键词采集文章采集api(为什么学爬虫?机器帮助你快速爬取数据!(上))
【为什么要学爬?】
1、爬虫上手容易,深入难。如何编写高效的爬虫,如何编写高度灵活和可扩展的爬虫是一项技术任务。另外,在爬取过程中,经常容易遇到反爬虫,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,可以学习这门课!
2、如果你是其他行业的开发者,比如app开发,web开发,学习爬虫可以加强你对技术的理解,并且能够开发出更安全的软件和网站
【课程设计】
一个完整的爬虫程序,无论大小,大体上可以分为三个步骤,即:
网络请求:模拟浏览器从互联网获取数据的行为。数据分析:过滤请求的数据,提取我们想要的数据。数据存储:将提取的数据存储到硬盘或内存中。比如使用mysql数据库或者redis。
然后本课程也按照这些步骤一步步讲解,引导学生充分掌握每一步的技术。另外,由于爬虫的多样性,在爬取过程中可能会出现反爬和效率低下的情况。因此,我们又增加了两章来提高爬虫程序的灵活性,即:
爬虫进阶:包括IP代理、多线程爬虫、图形验证码识别、JS加解密、动态网页爬虫、字体反爬识别等。 Scrapy及分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫、等等。
通过爬虫的高级知识点,我们可以应对大量的反爬网站,而Scrapy框架是一个专业的爬虫框架,使用它可以快速提高我们的爬虫程序的效率和速度。另外,如果一台机器不能满足你的需求,我们可以使用分布式爬虫,让多台机器帮你快速抓取数据。
从基础爬虫到商业应用爬虫,这套课程满足你的所有需求!
【课程服务】
专属付费社区+定期问答
通过关键词采集文章采集api(网络爬虫简单来说就是指通过爬虫程序访问网站的API连接获取数据 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-14 02:27
)
简单来说,网络爬虫是指通过爬虫程序访问网站的API连接,获取数据信息。爬虫程序可以从网页中检索所需的数据信息,然后将其存储在新创建的文档中。网络爬虫支持各种数据采集、文件、图片。视频等可以是采集,但不能是采集非法经营。互联网大数据时代,网络爬虫主要为搜索引擎提供最全面、最新的数据,网络爬虫也是从采集互联网数据中爬取的。
我们还可以利用网络爬虫来采集舆情数据,以及采集新闻、社交、论坛、博客等信息数据。这也是获取舆情数据的常用方案之一。一般爬虫程序会使用爬虫代理IP对一些有意义的网站进行数据采集。舆情数据也可以在数据交换市场购买,或者从专业的舆情分析团队获取,但一般来说,专业的舆情分析团队也是通过爬虫使用代理IP去采集相关数据进行舆情数据分析。
由于短视频的火爆,抖音、快手这两个主流短视频APP,我们也可以使用爬虫程序采集抖音、快手来分析舆情数据。生成统计数据表,作为数据报告提供给大家。也可以参考下面的采集程序代码:
// 要访问的目标页面
string targetUrl = "http://httpbin.org/ip";
// 代理服务器(产品官网 www.16yun.cn)
string proxyHost = "http://t.16yun.cn";
string proxyPort = "31111";
// 代理验证信息
string proxyUser = "username";
string proxyPass = "password";
// 设置代理服务器
WebProxy proxy = new WebProxy(string.Format("{0}:{1}", proxyHost, proxyPort), true);
ServicePointManager.Expect100Continue = false;
var request = WebRequest.Create(targetUrl) as HttpWebRequest;
request.AllowAutoRedirect = true;
request.KeepAlive = true;
request.Method = "GET";
request.Proxy = proxy;
//request.Proxy.Credentials = CredentialCache.DefaultCredentials;
request.Proxy.Credentials = new System.Net.NetworkCredential(proxyUser, proxyPass);
// 设置Proxy Tunnel
// Random ran=new Random();
// int tunnel =ran.Next(1,10000);
// request.Headers.Add("Proxy-Tunnel", String.valueOf(tunnel));
//request.Timeout = 20000;
//request.ServicePoint.ConnectionLimit = 512;
//request.UserAgent = "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.82 Safari/537.36";
//request.Headers.Add("Cache-Control", "max-age=0");
//request.Headers.Add("DNT", "1");
//String encoded = System.Convert.ToBase64String(System.Text.Encoding.GetEncoding("ISO-8859-1").GetBytes(proxyUser + ":" + proxyPass));
//request.Headers.Add("Proxy-Authorization", "Basic " + encoded);
using (var response = request.GetResponse() as HttpWebResponse)
using (var sr = new StreamReader(response.GetResponseStream(), Encoding.UTF8))
{
string htmlStr = sr.ReadToEnd();
}
复制代码 查看全部
通过关键词采集文章采集api(网络爬虫简单来说就是指通过爬虫程序访问网站的API连接获取数据
)
简单来说,网络爬虫是指通过爬虫程序访问网站的API连接,获取数据信息。爬虫程序可以从网页中检索所需的数据信息,然后将其存储在新创建的文档中。网络爬虫支持各种数据采集、文件、图片。视频等可以是采集,但不能是采集非法经营。互联网大数据时代,网络爬虫主要为搜索引擎提供最全面、最新的数据,网络爬虫也是从采集互联网数据中爬取的。
我们还可以利用网络爬虫来采集舆情数据,以及采集新闻、社交、论坛、博客等信息数据。这也是获取舆情数据的常用方案之一。一般爬虫程序会使用爬虫代理IP对一些有意义的网站进行数据采集。舆情数据也可以在数据交换市场购买,或者从专业的舆情分析团队获取,但一般来说,专业的舆情分析团队也是通过爬虫使用代理IP去采集相关数据进行舆情数据分析。
由于短视频的火爆,抖音、快手这两个主流短视频APP,我们也可以使用爬虫程序采集抖音、快手来分析舆情数据。生成统计数据表,作为数据报告提供给大家。也可以参考下面的采集程序代码:
// 要访问的目标页面
string targetUrl = "http://httpbin.org/ip";
// 代理服务器(产品官网 www.16yun.cn)
string proxyHost = "http://t.16yun.cn";
string proxyPort = "31111";
// 代理验证信息
string proxyUser = "username";
string proxyPass = "password";
// 设置代理服务器
WebProxy proxy = new WebProxy(string.Format("{0}:{1}", proxyHost, proxyPort), true);
ServicePointManager.Expect100Continue = false;
var request = WebRequest.Create(targetUrl) as HttpWebRequest;
request.AllowAutoRedirect = true;
request.KeepAlive = true;
request.Method = "GET";
request.Proxy = proxy;
//request.Proxy.Credentials = CredentialCache.DefaultCredentials;
request.Proxy.Credentials = new System.Net.NetworkCredential(proxyUser, proxyPass);
// 设置Proxy Tunnel
// Random ran=new Random();
// int tunnel =ran.Next(1,10000);
// request.Headers.Add("Proxy-Tunnel", String.valueOf(tunnel));
//request.Timeout = 20000;
//request.ServicePoint.ConnectionLimit = 512;
//request.UserAgent = "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.82 Safari/537.36";
//request.Headers.Add("Cache-Control", "max-age=0");
//request.Headers.Add("DNT", "1");
//String encoded = System.Convert.ToBase64String(System.Text.Encoding.GetEncoding("ISO-8859-1").GetBytes(proxyUser + ":" + proxyPass));
//request.Headers.Add("Proxy-Authorization", "Basic " + encoded);
using (var response = request.GetResponse() as HttpWebResponse)
using (var sr = new StreamReader(response.GetResponseStream(), Encoding.UTF8))
{
string htmlStr = sr.ReadToEnd();
}
复制代码
通过关键词采集文章采集api(软件采集规则子规则,采集示例:使用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-11 13:14
描述
模板介绍:
本模板用于通过关键字搜索采集企查网站的公司专利列表。字段包括:公司名称、链接、专利名称、申请人、发表日期等列表字段。
采集 字段示例:
指示:
1. 购买模板后,将模板文件导入到采集器。该模板分为两个子规则。规则1使用关键词采集公司链接;规则 2 使用公司链接批量处理 采集 各种证书。
2.输入公司名称或关键词,先采集公司链接,支持关键词批量导入,然后使用公司链接到采集各个证书内容,也支持批量采集。
3.请点击【保存并开始】继续采集。
获取模板:
用户在该页面下单后,可以自动获取模板文件(*.otd)的下载地址,点击下载保存到自己的电脑上使用。
提示:
对采集器软件不熟悉,上手难度较大。下面有丰富的教程。您可能会遇到的问题在这里都有解答。打开后采集起来,遇到问题就来学习:
用户下单时,必须阅读、理解并同意以下条款:
本店购买的所有商品均为虚拟商品或定制服务,恕不退换。用户应根据自身需求进行详细咨询,确认满足需求后再下单。
本店出售的所有软件或视频教程均归本店原创所有,拥有独家知识产权。用户购买后,仅限于用户自己的学习和研究。未经本店书面许可,不得复制、分发或用于任何商业盈利。
第三方采集器如优采云、优采云等以及本店开发的定制软件均为市场上合法合法的软件。用户在本店的付费定制基于以上采集器软件的采集规则(模板)必须在相应的国家法律法规下使用,不得使用本软件或采集模板未经许可不得修改或破解,未经书面许可不得使用。复制,并保证采集规则模板用于数据采集的应用应遵循相关互联网数据爬取规范,所获取的数据仅限于学习和研究的目的。
本店有义务告知:若超出以上规格或获取的数据适用于以上范围,则视为未遵守本店协议,由此产生的后果由买家自行承担,可能产生的纠纷或法律后果与本店无关。如发生损害本店利益的,本店有权要求用户承担相关损失。 查看全部
通过关键词采集文章采集api(软件采集规则子规则,采集示例:使用方法)
描述
模板介绍:
本模板用于通过关键字搜索采集企查网站的公司专利列表。字段包括:公司名称、链接、专利名称、申请人、发表日期等列表字段。
采集 字段示例:
https://www.futaike.net/wp-con ... 9.jpg 300w, https://www.futaike.net/wp-con ... 6.jpg 768w, https://www.futaike.net/wp-con ... 5.jpg 1024w, https://www.futaike.net/wp-con ... 8.jpg 600w" />指示:
1. 购买模板后,将模板文件导入到采集器。该模板分为两个子规则。规则1使用关键词采集公司链接;规则 2 使用公司链接批量处理 采集 各种证书。
2.输入公司名称或关键词,先采集公司链接,支持关键词批量导入,然后使用公司链接到采集各个证书内容,也支持批量采集。
3.请点击【保存并开始】继续采集。
获取模板:
用户在该页面下单后,可以自动获取模板文件(*.otd)的下载地址,点击下载保存到自己的电脑上使用。
提示:
对采集器软件不熟悉,上手难度较大。下面有丰富的教程。您可能会遇到的问题在这里都有解答。打开后采集起来,遇到问题就来学习:
用户下单时,必须阅读、理解并同意以下条款:
本店购买的所有商品均为虚拟商品或定制服务,恕不退换。用户应根据自身需求进行详细咨询,确认满足需求后再下单。
本店出售的所有软件或视频教程均归本店原创所有,拥有独家知识产权。用户购买后,仅限于用户自己的学习和研究。未经本店书面许可,不得复制、分发或用于任何商业盈利。
第三方采集器如优采云、优采云等以及本店开发的定制软件均为市场上合法合法的软件。用户在本店的付费定制基于以上采集器软件的采集规则(模板)必须在相应的国家法律法规下使用,不得使用本软件或采集模板未经许可不得修改或破解,未经书面许可不得使用。复制,并保证采集规则模板用于数据采集的应用应遵循相关互联网数据爬取规范,所获取的数据仅限于学习和研究的目的。
本店有义务告知:若超出以上规格或获取的数据适用于以上范围,则视为未遵守本店协议,由此产生的后果由买家自行承担,可能产生的纠纷或法律后果与本店无关。如发生损害本店利益的,本店有权要求用户承担相关损失。
通过关键词采集文章采集api(站长快车采集器v4.0更新内容:更新的内容与发布程序)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-10-10 09:22
<p>站长快车是主要主流文章系统、论坛系统等多线程会员注册、内容采集及发布程序。海量内容,迅速提高论坛的知名度。其丰富的规则模板和灵活的自定义模块可以适用于各种内容发布系统。系统收录自定义规则采集、智能采集、批量会员注册、批量发帖、转发等多项功能。内容库可在系统界面直接管理,实时浏览、可视化修改、输入SQL命令运行操作、批量替换等操作。软件中的优化功能让您更得心应手。它可以生成标签 < @关键词、删除重复记录、非法 查看全部
通过关键词采集文章采集api(举例说明网络数据在不同行业的利用价值分析与应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-08 03:11
据赛迪顾问统计,在最近一万件技术领域专利中最常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热门的词汇。其中,data采集是被提及最多的词。
数据采集是大数据分析的前提和必要条件,在整个数据利用过程中占有重要地位。数据采集方法分为系统日志采集方法、网络数据采集方法、其他数据采集方法三种。随着Web2.0的发展,整个Web系统覆盖了大量有价值的数据。目前Web系统采集的数据通常是通过网络爬虫实现的。本文将进行网络数据和网络爬虫。系统规范。
什么是网络数据
网络数据是指非传统的数据来源,比如通过搜索引擎爬取获得的不同形式的数据。网络数据也可以是从数据聚合商或搜索引擎网站购买的数据,以提高目标营销。这种类型的数据可以是结构化的或非结构化的(更有可能),可以由网络链接、文本数据、数据表、图像、视频等组成。
互联网构成了当今提供给我们的大部分数据,根据许多研究,非结构化数据占其中的 80%。尽管较早时忽略了这些形式的数据,但竞争加剧和对更多数据的需求需要使用尽可能多的数据源。
网络数据可以用来做什么
互联网拥有数十亿页的数据。网络数据作为一种潜在的数据来源,对于行业的战略业务发展具有巨大的潜力。
下面举例说明网络数据在不同行业的使用价值:
此外,在《Web Scraping is Transforming the World with its Applications》文章中,详细列出了网络数据在制造、金融研究、风险管理等领域的价值。
如何采集网络数据
目前网页数据采集有两种方法:一种是API,一种是网络爬虫。API又称应用程序接口,是网站的管理者为了方便用户而编写的一种编程接口。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关demo可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制日常接口调用的上限,给我们带来很大的不便。为此,我们通常采用第二种方法——网络爬虫。
使用爬虫技术采集网络数据
网络爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集的图片、音频、视频等文件或附件,可以自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。在大数据时代,网络爬虫对于采集来自互联网的数据来说更是一种优势工具。
网络爬虫的原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有三个功能:网络数据采集、处理和存储,如图:
网络爬虫采集
网络爬虫通过定义采集字段来抓取网页中的文字信息、图片信息等。此外,网页中还收录一些超链接信息,网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。爬虫提取并保存网页中需要提取的资源,同时提取存在于网站 Link中的其他网站,发送请求后,接收网站的响应@> 并再次解析页面,然后从网页中提取所需的资源...等等,
数据处理
数据处理是分析和处理数据(包括数值和非数值)的技术过程。网络爬虫抓取的初始数据需要“清洗”。在数据处理环节,对各种原创数据进行分析、整理、计算、编辑等处理和处理,从大量、杂乱、难以理解的数据中提取并推导出有价值、有意义的数据。
数据中心
所谓数据中心,也就是数据存储,就是指在获取到需要的数据并分解成有用的组件后,采用可扩展的方式,将所有提取解析出来的数据存储在一个数据库或集群中,然后创建一个允许用户及时查找相关数据集或提取函数。
网络爬虫工作流程
如下图所示,一个网络爬虫的基本工作流程如下。首先选择种子 URL 的一部分。
总结
当前,网络大数据规模和复杂度的快速增长,对现有IT架构的处理和计算能力提出了挑战。根据IDC发布的一份研究报告,预计到2020年,网络大数据总量将达到35ZB。大数据将成为行业数字化、信息化的重要推动者。返回搜狐查看更多 查看全部
通过关键词采集文章采集api(举例说明网络数据在不同行业的利用价值分析与应用)
据赛迪顾问统计,在最近一万件技术领域专利中最常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热门的词汇。其中,data采集是被提及最多的词。
数据采集是大数据分析的前提和必要条件,在整个数据利用过程中占有重要地位。数据采集方法分为系统日志采集方法、网络数据采集方法、其他数据采集方法三种。随着Web2.0的发展,整个Web系统覆盖了大量有价值的数据。目前Web系统采集的数据通常是通过网络爬虫实现的。本文将进行网络数据和网络爬虫。系统规范。
什么是网络数据
网络数据是指非传统的数据来源,比如通过搜索引擎爬取获得的不同形式的数据。网络数据也可以是从数据聚合商或搜索引擎网站购买的数据,以提高目标营销。这种类型的数据可以是结构化的或非结构化的(更有可能),可以由网络链接、文本数据、数据表、图像、视频等组成。
互联网构成了当今提供给我们的大部分数据,根据许多研究,非结构化数据占其中的 80%。尽管较早时忽略了这些形式的数据,但竞争加剧和对更多数据的需求需要使用尽可能多的数据源。
网络数据可以用来做什么
互联网拥有数十亿页的数据。网络数据作为一种潜在的数据来源,对于行业的战略业务发展具有巨大的潜力。
下面举例说明网络数据在不同行业的使用价值:
此外,在《Web Scraping is Transforming the World with its Applications》文章中,详细列出了网络数据在制造、金融研究、风险管理等领域的价值。
如何采集网络数据
目前网页数据采集有两种方法:一种是API,一种是网络爬虫。API又称应用程序接口,是网站的管理者为了方便用户而编写的一种编程接口。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关demo可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制日常接口调用的上限,给我们带来很大的不便。为此,我们通常采用第二种方法——网络爬虫。
使用爬虫技术采集网络数据
网络爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集的图片、音频、视频等文件或附件,可以自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。在大数据时代,网络爬虫对于采集来自互联网的数据来说更是一种优势工具。
网络爬虫的原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有三个功能:网络数据采集、处理和存储,如图:
网络爬虫采集
网络爬虫通过定义采集字段来抓取网页中的文字信息、图片信息等。此外,网页中还收录一些超链接信息,网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。爬虫提取并保存网页中需要提取的资源,同时提取存在于网站 Link中的其他网站,发送请求后,接收网站的响应@> 并再次解析页面,然后从网页中提取所需的资源...等等,
数据处理
数据处理是分析和处理数据(包括数值和非数值)的技术过程。网络爬虫抓取的初始数据需要“清洗”。在数据处理环节,对各种原创数据进行分析、整理、计算、编辑等处理和处理,从大量、杂乱、难以理解的数据中提取并推导出有价值、有意义的数据。
数据中心
所谓数据中心,也就是数据存储,就是指在获取到需要的数据并分解成有用的组件后,采用可扩展的方式,将所有提取解析出来的数据存储在一个数据库或集群中,然后创建一个允许用户及时查找相关数据集或提取函数。
网络爬虫工作流程
如下图所示,一个网络爬虫的基本工作流程如下。首先选择种子 URL 的一部分。
总结
当前,网络大数据规模和复杂度的快速增长,对现有IT架构的处理和计算能力提出了挑战。根据IDC发布的一份研究报告,预计到2020年,网络大数据总量将达到35ZB。大数据将成为行业数字化、信息化的重要推动者。返回搜狐查看更多
通过关键词采集文章采集api(京东商品标题关键词的采集方法有一个意义让消费者一眼)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-04 10:12
优化产品标题,相信这是很多商家都在努力做的事情,毕竟产品的排名跟标题优化是息息相关的。可以说标题优化好了,那么自然搜索产品的排名也会上升。当然,这只是标题优化的主要功能,并不是全部。我们优化标题的另一个意义是让消费者第一眼就了解产品,而这个标题也收录了这样的关键词。那么接下来小编就给大家分享一下京东商品标题关键词的一些采集方法。
关键词采集店铺相关关键词制作成产品关键词表是标题优化的第一步。这里简单介绍三种采集关键词方式:首页采集,即在京东首页的搜索栏中输入关键词,以及关键词与输入词相关的内容会出现在下拉框中。
搜索栏下拉框中的匹配方式主要有“前向匹配”和“首字母匹配”两种。而且,推荐词的排序规则是根据词的流行度和相关性来确定的,而且是周期性的,所以我们需要经常观察和替换。
快递采集,即通过京东快递筛选出精准的产品关键词,给出的词也会反映其竞争指数,让商家对关键词有很大的判断力对于关键词的帮助,如果关键词的星级比较高就好了。这里小编强烈建议在核心扩展中输入一些大字,这样中长字会比较多。
第三方,也就是通过一些第三方软件如京东商务智能、金豆云等,可以查看商家行业的数据,然后可以使用第三方软件中的索引来进行选择那些需要制作的产品关键词。搜索索引越高,搜索此关键词的用户就越多。
当然,搜索指数比较高的基本都是那些宽泛的词,转化率较高的关键词多是搜索量中等的精准词,比如行业暴涨的热词,基本都是季节性的关键词许多。
以上三种关键词采集方法可以说是商家比较常用的。总之,关键词的选择需要考虑的方面很多,不能单靠一个方向发展。毕竟关键词的质量会直接影响到产品的曝光度和流量。 查看全部
通过关键词采集文章采集api(京东商品标题关键词的采集方法有一个意义让消费者一眼)
优化产品标题,相信这是很多商家都在努力做的事情,毕竟产品的排名跟标题优化是息息相关的。可以说标题优化好了,那么自然搜索产品的排名也会上升。当然,这只是标题优化的主要功能,并不是全部。我们优化标题的另一个意义是让消费者第一眼就了解产品,而这个标题也收录了这样的关键词。那么接下来小编就给大家分享一下京东商品标题关键词的一些采集方法。
关键词采集店铺相关关键词制作成产品关键词表是标题优化的第一步。这里简单介绍三种采集关键词方式:首页采集,即在京东首页的搜索栏中输入关键词,以及关键词与输入词相关的内容会出现在下拉框中。
搜索栏下拉框中的匹配方式主要有“前向匹配”和“首字母匹配”两种。而且,推荐词的排序规则是根据词的流行度和相关性来确定的,而且是周期性的,所以我们需要经常观察和替换。
快递采集,即通过京东快递筛选出精准的产品关键词,给出的词也会反映其竞争指数,让商家对关键词有很大的判断力对于关键词的帮助,如果关键词的星级比较高就好了。这里小编强烈建议在核心扩展中输入一些大字,这样中长字会比较多。
第三方,也就是通过一些第三方软件如京东商务智能、金豆云等,可以查看商家行业的数据,然后可以使用第三方软件中的索引来进行选择那些需要制作的产品关键词。搜索索引越高,搜索此关键词的用户就越多。
当然,搜索指数比较高的基本都是那些宽泛的词,转化率较高的关键词多是搜索量中等的精准词,比如行业暴涨的热词,基本都是季节性的关键词许多。
以上三种关键词采集方法可以说是商家比较常用的。总之,关键词的选择需要考虑的方面很多,不能单靠一个方向发展。毕竟关键词的质量会直接影响到产品的曝光度和流量。
通过关键词采集文章采集api(第二种需要自动同步到你的平台吗?(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-10-01 18:07
这个问题需要在几种情况下回答
首先,您只需要下载并再次编辑它。这个方法非常简单。一般来说,你知道你想要的文章,也就是你知道文章的访问地址。一般在采集器的帮助下就可以下载了,不管是保存成word还是其他格式都没有问题。
第二个需要自动同步到您的平台。这个比较麻烦,因为你不知道下载地址(不可能手动自动输入)。
方法一、1、通过搜狗浏览器,调用他的界面搜索你的公众号,2、如果存在,通过第二个界面查询公众号下的历史记录文章。获取文章链接,通过程序下载,然后保存到你的后台。
这种方法的优点是:半自动,不需要手动输入文章链接。缺点是:1、如果频繁发送请求,搜狗会提示验证码。这需要手动处理,因此不能完全自动化。2、 并且获取的文章链接是临时的,需要在有效期内下载。3、只能获取最近十条历史记录文章,4、需要定时执行,不能实时更新。更新太频繁导致验证码被屏蔽,频率太低更新延迟太大。
方法二、1、 通过程序模拟登录公众号后台管理页面。2、通过模拟调用和编辑素材。3、通过模拟编辑插入链接功能,4、调用搜索公众号接口,查询公众号获取fackId。5、 通过获取到的 fackId 调用另一个接口获取文章 列表。这个 文章 列表中有链接。
这种方式的优点是:1、不会出现验证码,但也有封印的情况,但出现频率较低。2、 并且可以获取公众号下的所有文章列表。3、文章 链接永久有效。缺点是:1、还有接口调用被阻塞的情况。需要一段时间才能自动解锁。2、 需要定时执行,不能实时更新。更新太频繁截获验证码,频率太低更新延迟太大。
方法三、1、通过实时推送,只需要提供API接口接收链接,将文章链接实时推送到顶部界面,获取链接下载内容并将其保存到您自己的平台。
这种方法的优点:1、不被屏蔽,2、不需要输入验证码3、技术难度低。4、文章 及时更新,延迟低,最多三到五分钟。4、文章 链接永久有效。它可以真正实现完全自动化。缺点是需要有自己的开发者,有API接收参数。
如果有更好的方法,请联系我,互相学习。如果需要技术支持,也可以联系我。以上方法都是亲身尝试过的。有源代码(仅限java)。 查看全部
通过关键词采集文章采集api(第二种需要自动同步到你的平台吗?(一))
这个问题需要在几种情况下回答
首先,您只需要下载并再次编辑它。这个方法非常简单。一般来说,你知道你想要的文章,也就是你知道文章的访问地址。一般在采集器的帮助下就可以下载了,不管是保存成word还是其他格式都没有问题。
第二个需要自动同步到您的平台。这个比较麻烦,因为你不知道下载地址(不可能手动自动输入)。
方法一、1、通过搜狗浏览器,调用他的界面搜索你的公众号,2、如果存在,通过第二个界面查询公众号下的历史记录文章。获取文章链接,通过程序下载,然后保存到你的后台。
这种方法的优点是:半自动,不需要手动输入文章链接。缺点是:1、如果频繁发送请求,搜狗会提示验证码。这需要手动处理,因此不能完全自动化。2、 并且获取的文章链接是临时的,需要在有效期内下载。3、只能获取最近十条历史记录文章,4、需要定时执行,不能实时更新。更新太频繁导致验证码被屏蔽,频率太低更新延迟太大。
方法二、1、 通过程序模拟登录公众号后台管理页面。2、通过模拟调用和编辑素材。3、通过模拟编辑插入链接功能,4、调用搜索公众号接口,查询公众号获取fackId。5、 通过获取到的 fackId 调用另一个接口获取文章 列表。这个 文章 列表中有链接。
这种方式的优点是:1、不会出现验证码,但也有封印的情况,但出现频率较低。2、 并且可以获取公众号下的所有文章列表。3、文章 链接永久有效。缺点是:1、还有接口调用被阻塞的情况。需要一段时间才能自动解锁。2、 需要定时执行,不能实时更新。更新太频繁截获验证码,频率太低更新延迟太大。
方法三、1、通过实时推送,只需要提供API接口接收链接,将文章链接实时推送到顶部界面,获取链接下载内容并将其保存到您自己的平台。
这种方法的优点:1、不被屏蔽,2、不需要输入验证码3、技术难度低。4、文章 及时更新,延迟低,最多三到五分钟。4、文章 链接永久有效。它可以真正实现完全自动化。缺点是需要有自己的开发者,有API接收参数。
如果有更好的方法,请联系我,互相学习。如果需要技术支持,也可以联系我。以上方法都是亲身尝试过的。有源代码(仅限java)。
通过关键词采集文章采集api(推荐10个最好用的数据采集工具10款用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 386 次浏览 • 2021-10-01 07:22
推荐10个最好的数据采集工具
10个最好的数据采集工具,免费采集工具,网站网页采集工具,各行各业采集工具,目前比较好的一些免费数据采集 工具,希望对大家有帮助。
, 优采云采集器 优采云是基于运营商实名制,融合网络数据采集、移动互联网数据、API接口服务等服务的数据服务。互联网。平台。它最大的特点是可以在不了解网络爬虫技术的情况下轻松完成采集。
2、优采云采集器 优采云采集器是目前最流行的互联网数据采集软件。凭借灵活的配置和强大的性能,在国内同类产品中处于领先地位,获得了众多用户的一致认可。只是现在各大平台都设置了严格的反爬,很难获得有价值的数据。
3、靠近中国金坛中国数据服务平台拥有多种专业数据采集工具。开发者上传的采集工具很多,而且很多都是免费的。无论是采集国内外网站、行业网站、政府网站、app、微博、搜索引擎、公众号、小程序等数据,还是其他数据,几乎涵盖了业界99%的采集软件,近期即可完成采集。对技术含量要求高的高强度防爬或裂缝有专业的技术解决方案。如果要考专业度,近探的专业度是没有必要的。他们的许多服务也很难定制软件开发服务。
4、大飞采集器大飞采集器可以采集多个网页,准确率比较高,跟复制粘贴一样准确,最大的特点就是网页 采集 的同义词是单一的,因为焦点。
5、Import.io 使用 Import.io 适配任何 URL。只需输入网址,即可整齐抓取网页数据。操作非常简单,自动采集,采集结果可视化。但是无法选择特定数据,无法自动翻页采集。对于一些网站反爬设置很强的,也无能为力。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索这些链接和关键字。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content Grabber Content Grabber 是外国大神制作的神器,可以从网页中抓取内容(视频、图片、文字),并提取到 Excel、XML、CSV 和大多数数据库中。该软件基于网络捕获获取和网络自动化。
8、ForeSpider ForeSpider 是一个非常好用的网页数据采集工具,用户可以使用这个工具来帮助你自动检索网页中的各种数据信息,这个软件使用起来非常简单,但是有还有网站,面对一些高难度高强度的反攀爬环境,也无计可施。
9、阿里巴巴数据采集阿里巴巴数据采集 大平台运行稳定不崩盘,可实现实时查询。软件开发资料采集可以由他们来做,除了没有什么问题。
10、优采云采集器 优采云采集器 操作很简单,只要按照流程就可以轻松上手, 查看全部
通过关键词采集文章采集api(推荐10个最好用的数据采集工具10款用)
推荐10个最好的数据采集工具
10个最好的数据采集工具,免费采集工具,网站网页采集工具,各行各业采集工具,目前比较好的一些免费数据采集 工具,希望对大家有帮助。
, 优采云采集器 优采云是基于运营商实名制,融合网络数据采集、移动互联网数据、API接口服务等服务的数据服务。互联网。平台。它最大的特点是可以在不了解网络爬虫技术的情况下轻松完成采集。
2、优采云采集器 优采云采集器是目前最流行的互联网数据采集软件。凭借灵活的配置和强大的性能,在国内同类产品中处于领先地位,获得了众多用户的一致认可。只是现在各大平台都设置了严格的反爬,很难获得有价值的数据。
3、靠近中国金坛中国数据服务平台拥有多种专业数据采集工具。开发者上传的采集工具很多,而且很多都是免费的。无论是采集国内外网站、行业网站、政府网站、app、微博、搜索引擎、公众号、小程序等数据,还是其他数据,几乎涵盖了业界99%的采集软件,近期即可完成采集。对技术含量要求高的高强度防爬或裂缝有专业的技术解决方案。如果要考专业度,近探的专业度是没有必要的。他们的许多服务也很难定制软件开发服务。
4、大飞采集器大飞采集器可以采集多个网页,准确率比较高,跟复制粘贴一样准确,最大的特点就是网页 采集 的同义词是单一的,因为焦点。
5、Import.io 使用 Import.io 适配任何 URL。只需输入网址,即可整齐抓取网页数据。操作非常简单,自动采集,采集结果可视化。但是无法选择特定数据,无法自动翻页采集。对于一些网站反爬设置很强的,也无能为力。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索这些链接和关键字。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content Grabber Content Grabber 是外国大神制作的神器,可以从网页中抓取内容(视频、图片、文字),并提取到 Excel、XML、CSV 和大多数数据库中。该软件基于网络捕获获取和网络自动化。
8、ForeSpider ForeSpider 是一个非常好用的网页数据采集工具,用户可以使用这个工具来帮助你自动检索网页中的各种数据信息,这个软件使用起来非常简单,但是有还有网站,面对一些高难度高强度的反攀爬环境,也无计可施。
9、阿里巴巴数据采集阿里巴巴数据采集 大平台运行稳定不崩盘,可实现实时查询。软件开发资料采集可以由他们来做,除了没有什么问题。
10、优采云采集器 优采云采集器 操作很简单,只要按照流程就可以轻松上手,
通过关键词采集文章采集api(来来去去都是这些东西,没啥特别的吧!(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-30 14:15
对于词的研究,每个seoer都必须知道,而且除了比较流行的百度相关搜索词外,百度下拉框关键词应该也是很多人研究的范围,但是大多数人都是针对下拉框 爬字量,毕竟百度下拉框关键词采集已经泛滥了。
百度下拉菜单的正式名称是百度建议词,也称为百度建议词或百度下拉菜单。是百度为方便广大网民搜索,提高输入效率而推出的一项服务。
例如,当我们在百度中输入“营销”两个词时,百度从推荐词条库中检索以“营销”两个词开头的词条,并按照搜索量从大到小排序。形成一个下拉菜单。百度下拉菜单的最大数量为 10。
百度下拉框关键词的含义:
它可以用作长尾词和标题。毕竟用户在搜索时可以触发关键词搜索选择。
很多人用下拉词来引导流量,比如曝光品牌,导向指定页面。您可以采集分析竞争对手的相关操作,也可以自行曝光自己的品牌。不同的人有不同的看法!
网上有很多带有下拉词的采集工具和源码。到这里,渣子就被整理出来了。让我们再次分享它。我哥昨晚问的。事实上,它来来去去。这些东西没什么特别的吧?
版本一:
直接网页抓取实现下拉词采集
def get_keywords(word):
url=f"https://www.baidu.com/sugrec%3 ... wd%3D{word}"
html=requests.get(url)
html=html.json()
#print(html)
#print(html['g'])
key_words=[]
for key_word in html['g']:
print(key_word['q'])
key_words.append(key_word['q'])
#print(key_words)
return key_words
版本二:
使用官方界面
例如:
/5a1Fazu8AA54nxGko9WTAnF6hhy/su?wd=seo&sugmode=2&json=1&p=3&sid=1427_21091_21673_22581&req=2
def get_sug(word):
url = 'https://sp0.baidu.com/5a1Fazu8 ... 39%3B % word
r = requests.get(url, verify=False) # 请求API接口,取消了HTTPS验证
cont = r.content # 获取返回的内容
res = cont[41: -2].decode('gbk') # 只取返回结果中json格式一段,并且解码为unicode
res_json = json.loads(res) # json格式转换
return res_json['s'] # 返回关键词列表
版本三:
另一个接口地址
def get_word(word):
url=f'http://suggestion.baidu.com/su?wd={word}&sugmode=3&json=1'
html=requests.get(url).text
html=html.replace("window.baidu.sug(",'')
html = html.replace(")", '')
html = html.replace(";", '')
#print(html)
html = json.loads(html)
key_words=html['s']
#print(key_words)
return key_words
本质上二和三性质是一样的,大家参考使用吧!
扩大的视野:
这里有个小技巧,就是在关键词后面输入w,会出现一系列以拼音“w”开头的关键词,比如“黄山w”,会出现“黄山温泉”, 《黄山万集》《天》《黄山五绝》等关键词(见上图)。因此,当我们遍历a~z时,会出现更多的关键词。
def get_more_word(word):
more_word=[]
for i in 'abcdefghijklmnopqrstuvwxyz':
more_word.extend(get_keywords('%s%s'%(word,i)))
print(more_word)
print(len(more_word))
print(len(list(set(more_word))))
return list(set(more_word)) #去重操作
def get_more_sug(word):
all_words = []
for i in 'abcdefghijklmnopqrstuvwxyz':
all_words += get_sug(word+i) # 遍历字母表 | 利用了上一个函数
print(len(list(set(all_words))))
return list(set(all_words)) # 去
此处选择版本2的接口形式,以免不协调
但是如果使用requests模块请求无效的证书网站,会直接报错
可以将verify参数设置为False来解决这个问题
r = requests.get(url, verify=False)
但是设置 verify=False 会抛出 InsecureRequestWarning 警告
看起来很糟糕
解决方案:
from requests.packages.urllib3.exceptions import InsecureRequestWarning
# 禁用安全请求警告
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
运行结果
为了方便大家使用和玩,本渣特为大家打包了低版本的exe工具,方便大家使用!
exe工具获取
百度网盘
/s/1Zqst5fLhBZrIiR3XA14cXQ
提取码:
c7mt
参考资料:百度
百度下拉-百度百科
/item/%E7%99%BE%E5%BA%A6%E4%B8%8B%E6%8B%89/7139864?fr=阿拉丁
张亚楠博客-seo技术流程
PYTHON批量挖矿百度下拉框关键词
/post/get-baidu-suggestions-by-python
Sch01aR#-博客园
Python-requests取消SSL验证警告InsecureRequestWarning解决方案
/sch01ar/p/8432811.html 查看全部
通过关键词采集文章采集api(来来去去都是这些东西,没啥特别的吧!(组图))
对于词的研究,每个seoer都必须知道,而且除了比较流行的百度相关搜索词外,百度下拉框关键词应该也是很多人研究的范围,但是大多数人都是针对下拉框 爬字量,毕竟百度下拉框关键词采集已经泛滥了。
百度下拉菜单的正式名称是百度建议词,也称为百度建议词或百度下拉菜单。是百度为方便广大网民搜索,提高输入效率而推出的一项服务。
例如,当我们在百度中输入“营销”两个词时,百度从推荐词条库中检索以“营销”两个词开头的词条,并按照搜索量从大到小排序。形成一个下拉菜单。百度下拉菜单的最大数量为 10。
百度下拉框关键词的含义:
它可以用作长尾词和标题。毕竟用户在搜索时可以触发关键词搜索选择。
很多人用下拉词来引导流量,比如曝光品牌,导向指定页面。您可以采集分析竞争对手的相关操作,也可以自行曝光自己的品牌。不同的人有不同的看法!
网上有很多带有下拉词的采集工具和源码。到这里,渣子就被整理出来了。让我们再次分享它。我哥昨晚问的。事实上,它来来去去。这些东西没什么特别的吧?
版本一:
直接网页抓取实现下拉词采集
def get_keywords(word):
url=f"https://www.baidu.com/sugrec%3 ... wd%3D{word}"
html=requests.get(url)
html=html.json()
#print(html)
#print(html['g'])
key_words=[]
for key_word in html['g']:
print(key_word['q'])
key_words.append(key_word['q'])
#print(key_words)
return key_words
版本二:
使用官方界面
例如:
/5a1Fazu8AA54nxGko9WTAnF6hhy/su?wd=seo&sugmode=2&json=1&p=3&sid=1427_21091_21673_22581&req=2
def get_sug(word):
url = 'https://sp0.baidu.com/5a1Fazu8 ... 39%3B % word
r = requests.get(url, verify=False) # 请求API接口,取消了HTTPS验证
cont = r.content # 获取返回的内容
res = cont[41: -2].decode('gbk') # 只取返回结果中json格式一段,并且解码为unicode
res_json = json.loads(res) # json格式转换
return res_json['s'] # 返回关键词列表
版本三:
另一个接口地址
def get_word(word):
url=f'http://suggestion.baidu.com/su?wd={word}&sugmode=3&json=1'
html=requests.get(url).text
html=html.replace("window.baidu.sug(",'')
html = html.replace(")", '')
html = html.replace(";", '')
#print(html)
html = json.loads(html)
key_words=html['s']
#print(key_words)
return key_words
本质上二和三性质是一样的,大家参考使用吧!
扩大的视野:
这里有个小技巧,就是在关键词后面输入w,会出现一系列以拼音“w”开头的关键词,比如“黄山w”,会出现“黄山温泉”, 《黄山万集》《天》《黄山五绝》等关键词(见上图)。因此,当我们遍历a~z时,会出现更多的关键词。
def get_more_word(word):
more_word=[]
for i in 'abcdefghijklmnopqrstuvwxyz':
more_word.extend(get_keywords('%s%s'%(word,i)))
print(more_word)
print(len(more_word))
print(len(list(set(more_word))))
return list(set(more_word)) #去重操作
def get_more_sug(word):
all_words = []
for i in 'abcdefghijklmnopqrstuvwxyz':
all_words += get_sug(word+i) # 遍历字母表 | 利用了上一个函数
print(len(list(set(all_words))))
return list(set(all_words)) # 去
此处选择版本2的接口形式,以免不协调
但是如果使用requests模块请求无效的证书网站,会直接报错
可以将verify参数设置为False来解决这个问题
r = requests.get(url, verify=False)
但是设置 verify=False 会抛出 InsecureRequestWarning 警告
看起来很糟糕
解决方案:
from requests.packages.urllib3.exceptions import InsecureRequestWarning
# 禁用安全请求警告
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
运行结果
为了方便大家使用和玩,本渣特为大家打包了低版本的exe工具,方便大家使用!
exe工具获取
百度网盘
/s/1Zqst5fLhBZrIiR3XA14cXQ
提取码:
c7mt
参考资料:百度
百度下拉-百度百科
/item/%E7%99%BE%E5%BA%A6%E4%B8%8B%E6%8B%89/7139864?fr=阿拉丁
张亚楠博客-seo技术流程
PYTHON批量挖矿百度下拉框关键词
/post/get-baidu-suggestions-by-python
Sch01aR#-博客园
Python-requests取消SSL验证警告InsecureRequestWarning解决方案
/sch01ar/p/8432811.html
通过关键词采集文章采集api(基于API微博信息采集系统设计与实现(微博))
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-09-29 22:24
基于API微博信息采集系统设计与实现小结:微博已经成为网络信息的重要来源。本文分析了微博信息采集的相关方法和技术,提出了基于API的信息采集方法,然后设计了一个信息采集系统,可以采集相关信息新浪微博。实验测试表明,信息采集系统可以快速有效地采集新浪微博信息。关键词:新浪微博;微博界面;资料采集; C#语言中文图书馆分类号:TP315 文档识别码:A 文章 编号:1009-3044(2013)17-4005-04 微博[1],微博的简称,是一个信息共享平台, 基于用户关系的传播和获取。用户可以使用WEB、WAP、各种客户端组件个人社区,以140字左右文字更新信息,实现即时分享。中国互联网络信息中心《第31次中国互联网络发展状况统计报告》显示,截至2012年12月末,截至2012年12月末,中国微博用户数为3.09亿,比2011年末增加5873万,网民中微博用户占比比上年末提高6个百分点,达到54.7%[2]。随着微博网络的影响力的迅速扩张,政府部门、学校、知名企业、公众人物都开通了微博。在公众的参与下,微博已经成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用采集微博信息已成为一项具有重要应用价值的研究。
1 研究方法和技术路线 国内微博用户以新浪微博为主,本文拟以新浪微博为例,设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析,目前新浪微博的信息采集方法主要分为两类:一类是“模拟登录”、“网络爬虫”[3] ],以及“网页内容”“分析”[4]信息采集三种技术相结合的方法。二是基于新浪微博开放平台的API文档。开发者自己编写程序调用微博的API进行微博信息采集。对于第一种方法,难度比较高,研究技术复杂,尤其是“模拟登录”这一步。需要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的变化会导致“网络爬虫”。《采集的失败最终导致微博信息缺失。同时,“网络爬虫”采集访问的网页需要“网页内容分析”,存在明显差距效率和性能对比基于API的数据采集。基于以上因素,本文拟采用第二种方法进行研究。基于新浪微博开放平台API???文件,微博资料< @采集系统主要使用两种研究方法:文献分析法和实验测试法。文档分析方法:参考新浪微博开放平台的API文档,将这些API描述文档写成单独的接口文件。实验测试方法:在VS.NET2010平台[5]上,使用C/S模式开发程序调用接口类,采集微博返回的JOSN数据流,实现相关测试开发数据 采集 。
根据以上两种研究方法,设计本研究的技术路线:首先,申请新浪微博开放平台App Key和App Secret。审核通过后,阅读理解API文档,将API文档描述写入API接口代码类(c#语言),然后进行OAuth2.0认证测试。认证通过后,可以获得Access Token,从而有权限调用API的各种功能接口,然后通过POST或GET调用API接口。最后返回JOSN数据流,最后分析这个数据流并保存为本地文本文件或数据库。详细技术路线如图1所示。 2研究内容设计微博信息采集系统功能结构如图2所示。系统分为七个部分,分别是:微博界面认证、微博用户登录、登录用户发微博、采集当前登录用户信息、采集其他用户信息、采集其他用户微博、采集学校信息、采集微博信息内容。1) 微博接口认证:访问大部分新浪微博API,如发布微博、获取私信等,都需要用户身份认证。目前新浪微博开放平台上的用户身份认证包括OAuth2.0和Basic Auth(仅用于应用开发者调试接口),新版接口也仅支持这两种方式[6] . 所以,系统设计开发的第一步是做微博界面鉴权功能。2) 微博用户登录:通过认证后,所有在新浪微博上注册的用户都可以通过本系统登录并发布微博。
3)采集登录用户信息:用户登录后,可以通过本系统查看自己的账号信息、自己的微博信息以及关注者的微博信息。4)采集 其他用户信息:这个功能主要是输入微博用户的昵称,可以采集获取昵称用户的账号信息,比如他有多少粉丝有没有,关注了哪些人,关注了多少人,这个信息在微博中也很有价值采集。5)采集 其他用户的微博:此功能也使用微博用户的昵称来采集更改用户发送的所有微博信息。这个功能的目的是为了以后扩展为了自动采集 每隔一段时间将目标中多个微博用户的微博信息设置到本地进行数据内容分析。6)采集学校信息:该功能通过学校名称的模糊查询,获取学校微博账号ID、学校所在地区、学校类型信息。这是采集学校在微博上的影响力的基本数据。7)采集微博信息内容:您可以点击微博内容关键词查询,采集这条微博信息收录本关键词。但由于本次API接口调用需要高级权限,在系统完全发布前和新浪微博开放平台审核通过前,无法直接测试使用。3 主要功能的实现3. 1 微博界面认证功能 大部分新浪微博API访问都需要用户认证。本系统采用OAuth2.0设计微博界面认证功能,新浪微博认证流程如图3所示。
<p>4 总结本文主要对微博信息采集的方法和技术进行了一系列的研究,然后设计开发了一个基于API的新浪微博信息采集系统,实现了微博的基础信息采集,在一定程度上解决了微博信息采集的自动化和采集结果数据格式的标准化。但是,目前本系统的微博信息采集方法只能输入单个“关键词”采集进行唯一匹配,没有批量多个“搜索词” 查看全部
通过关键词采集文章采集api(基于API微博信息采集系统设计与实现(微博))
基于API微博信息采集系统设计与实现小结:微博已经成为网络信息的重要来源。本文分析了微博信息采集的相关方法和技术,提出了基于API的信息采集方法,然后设计了一个信息采集系统,可以采集相关信息新浪微博。实验测试表明,信息采集系统可以快速有效地采集新浪微博信息。关键词:新浪微博;微博界面;资料采集; C#语言中文图书馆分类号:TP315 文档识别码:A 文章 编号:1009-3044(2013)17-4005-04 微博[1],微博的简称,是一个信息共享平台, 基于用户关系的传播和获取。用户可以使用WEB、WAP、各种客户端组件个人社区,以140字左右文字更新信息,实现即时分享。中国互联网络信息中心《第31次中国互联网络发展状况统计报告》显示,截至2012年12月末,截至2012年12月末,中国微博用户数为3.09亿,比2011年末增加5873万,网民中微博用户占比比上年末提高6个百分点,达到54.7%[2]。随着微博网络的影响力的迅速扩张,政府部门、学校、知名企业、公众人物都开通了微博。在公众的参与下,微博已经成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用采集微博信息已成为一项具有重要应用价值的研究。
1 研究方法和技术路线 国内微博用户以新浪微博为主,本文拟以新浪微博为例,设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析,目前新浪微博的信息采集方法主要分为两类:一类是“模拟登录”、“网络爬虫”[3] ],以及“网页内容”“分析”[4]信息采集三种技术相结合的方法。二是基于新浪微博开放平台的API文档。开发者自己编写程序调用微博的API进行微博信息采集。对于第一种方法,难度比较高,研究技术复杂,尤其是“模拟登录”这一步。需要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的变化会导致“网络爬虫”。《采集的失败最终导致微博信息缺失。同时,“网络爬虫”采集访问的网页需要“网页内容分析”,存在明显差距效率和性能对比基于API的数据采集。基于以上因素,本文拟采用第二种方法进行研究。基于新浪微博开放平台API???文件,微博资料< @采集系统主要使用两种研究方法:文献分析法和实验测试法。文档分析方法:参考新浪微博开放平台的API文档,将这些API描述文档写成单独的接口文件。实验测试方法:在VS.NET2010平台[5]上,使用C/S模式开发程序调用接口类,采集微博返回的JOSN数据流,实现相关测试开发数据 采集 。
根据以上两种研究方法,设计本研究的技术路线:首先,申请新浪微博开放平台App Key和App Secret。审核通过后,阅读理解API文档,将API文档描述写入API接口代码类(c#语言),然后进行OAuth2.0认证测试。认证通过后,可以获得Access Token,从而有权限调用API的各种功能接口,然后通过POST或GET调用API接口。最后返回JOSN数据流,最后分析这个数据流并保存为本地文本文件或数据库。详细技术路线如图1所示。 2研究内容设计微博信息采集系统功能结构如图2所示。系统分为七个部分,分别是:微博界面认证、微博用户登录、登录用户发微博、采集当前登录用户信息、采集其他用户信息、采集其他用户微博、采集学校信息、采集微博信息内容。1) 微博接口认证:访问大部分新浪微博API,如发布微博、获取私信等,都需要用户身份认证。目前新浪微博开放平台上的用户身份认证包括OAuth2.0和Basic Auth(仅用于应用开发者调试接口),新版接口也仅支持这两种方式[6] . 所以,系统设计开发的第一步是做微博界面鉴权功能。2) 微博用户登录:通过认证后,所有在新浪微博上注册的用户都可以通过本系统登录并发布微博。
3)采集登录用户信息:用户登录后,可以通过本系统查看自己的账号信息、自己的微博信息以及关注者的微博信息。4)采集 其他用户信息:这个功能主要是输入微博用户的昵称,可以采集获取昵称用户的账号信息,比如他有多少粉丝有没有,关注了哪些人,关注了多少人,这个信息在微博中也很有价值采集。5)采集 其他用户的微博:此功能也使用微博用户的昵称来采集更改用户发送的所有微博信息。这个功能的目的是为了以后扩展为了自动采集 每隔一段时间将目标中多个微博用户的微博信息设置到本地进行数据内容分析。6)采集学校信息:该功能通过学校名称的模糊查询,获取学校微博账号ID、学校所在地区、学校类型信息。这是采集学校在微博上的影响力的基本数据。7)采集微博信息内容:您可以点击微博内容关键词查询,采集这条微博信息收录本关键词。但由于本次API接口调用需要高级权限,在系统完全发布前和新浪微博开放平台审核通过前,无法直接测试使用。3 主要功能的实现3. 1 微博界面认证功能 大部分新浪微博API访问都需要用户认证。本系统采用OAuth2.0设计微博界面认证功能,新浪微博认证流程如图3所示。
<p>4 总结本文主要对微博信息采集的方法和技术进行了一系列的研究,然后设计开发了一个基于API的新浪微博信息采集系统,实现了微博的基础信息采集,在一定程度上解决了微博信息采集的自动化和采集结果数据格式的标准化。但是,目前本系统的微博信息采集方法只能输入单个“关键词”采集进行唯一匹配,没有批量多个“搜索词”
通过关键词采集文章采集api(如何通过关键词采集文章采集api后发送请求,获取指定文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-09-28 15:01
通过关键词采集文章采集api后发送api请求,获取指定文章的apikey后请求获取文章链接就可以了。缺点:api用来采集的文章数量会比较少,如果需要的话自己采集。
开发者工具–spider.js–抓取代理–高级抓取,
作为前端,不清楚实际用途,但这个api的目的是获取文章所有的url地址。我写过爬虫,一般是在需要的文章找的网站首页,多次跳转比较麻烦。只抓取某一小段内容是可以利用这个api实现的。另外,作为前端,定期更新自己的内容挺不错的,推荐个干货的网站/。
我有个大胆的想法,
同意楼上,有个webmagic提供免费接口用于抓取微信朋友圈所有文章。此前出现过新闻中介获取支付宝等等的付款信息。
用js抓取是主要办法。或者百度收录文章后,设定一些参数向服务器发送请求。现在也可以动态获取这些文章。但有些加密的文章,必须配合中间人软件才能解密出来。作为前端,还是为了通过不同渠道找到更多有用的文章才是正道。当然,如果你们有能力做微信或者其他网站的数据分析或者排名的数据分析的话,可以考虑做相关产品用来做网站竞价或者促销活动的分析。如果做某个内容网站而本身渠道不多的话,还是不要做文章抓取工具了。 查看全部
通过关键词采集文章采集api(如何通过关键词采集文章采集api后发送请求,获取指定文章)
通过关键词采集文章采集api后发送api请求,获取指定文章的apikey后请求获取文章链接就可以了。缺点:api用来采集的文章数量会比较少,如果需要的话自己采集。
开发者工具–spider.js–抓取代理–高级抓取,
作为前端,不清楚实际用途,但这个api的目的是获取文章所有的url地址。我写过爬虫,一般是在需要的文章找的网站首页,多次跳转比较麻烦。只抓取某一小段内容是可以利用这个api实现的。另外,作为前端,定期更新自己的内容挺不错的,推荐个干货的网站/。
我有个大胆的想法,
同意楼上,有个webmagic提供免费接口用于抓取微信朋友圈所有文章。此前出现过新闻中介获取支付宝等等的付款信息。
用js抓取是主要办法。或者百度收录文章后,设定一些参数向服务器发送请求。现在也可以动态获取这些文章。但有些加密的文章,必须配合中间人软件才能解密出来。作为前端,还是为了通过不同渠道找到更多有用的文章才是正道。当然,如果你们有能力做微信或者其他网站的数据分析或者排名的数据分析的话,可以考虑做相关产品用来做网站竞价或者促销活动的分析。如果做某个内容网站而本身渠道不多的话,还是不要做文章抓取工具了。
通过关键词采集文章采集api(采集思路HTML代码分析神器(HtmlAgilityPack)(HtmlAgilityPack)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-09-27 10:25
一开始就说
由于公司需要,为了降低工作成本,需要一些存储数据,需要插入到在线数据库中。
采集思考
HTML代码分析神器(HtmlAgilityPack),接下来分析阿里巴巴的店铺数据规则。我这里的想法是先在搜索栏中根据关键词和region进行搜索,然后根据结果分析店铺的URL。然后根据店铺的URL进入店铺,找到“所有分类页面”,解析所有分类,然后根据分类URL获取分类下的商品数据。找到产品网址后,进入产品页面,分析需要的产品信息。这是我个人的采集 想法。下面介绍每一步需要注意的关键点。
1、分析店铺网址
第一张图
URL 规则是:{search关键词}&province={location}&pageSize=30&sortType=pop&beginPage=1
关键字和省都是汉字,需要用GBK编码(阿里都是GBK编码),然后传入URL,beginPage是页码,这里必须是1,如果手动修改这个参数会触发阿里的安全验证。其实这一步是难点,关键是如何突破这个安全验证。在采集的开头,通过上面的URL下载并分析了HTML源代码,但是到了第二页,每次都启动阿里的安全验证。找了很多方法后,都没有突破。使用 webBrowser 模拟点击并跳转到下一页。
突破阿里的分页尝试(使用webBrowser之前):
1、 从 URL 开始,无论你如何获取都会触发此规则。
2、查看源码看看点击下一页会发生什么,这就是你会发现这样一段HTML
翻页时会触发此表单。请求中有两个验证参数,UA和TOKEN。这些加密字符是由下面的 UA.JS 动态生成的。更BT的是,UA参数中的字符会被鼠标操作(点击、移动等)动态修改,必须修改UA才能通过验证(不会研究这个东西稍后,只需改变您的想法)。才想到用webBrowser动态模拟鼠标移动,点击页面的下一页按钮。这就是为什么上图中会有webBrowser、模拟移动、模拟点击三个按钮的原因。
接下来,我们来谈谈如何模拟鼠标的移动和点击。这里我们调用WINDOWS API。如果您不确定,您可以查找信息。
其实就是模拟操作。自动处理完两个加密参数后,模拟页面下一页,点击,这样就不会有安全验证了。
完整的顺序是:首先通过第一页的URL加载webBrowser,然后在webBrowser的DocumentCompleted事件中使用WINDOWS API调用模拟鼠标移动。此时,验证参数已经开始发生变化。是的,这里它休眠了 500 毫秒。然后调用按钮点击下一页,这样第二页的数据就会在webBrowser中更新,然后取出来分析,剩下的就是重复上面的工作了。
需要说明的是,两个按钮都需要有自己的事件,当采集时,鼠标不能自行移动。
好了,这里你已经得到了公司的 URL,下一步就是分析每个商店并获取产品数据。
2、分析产品数据
这里没有安全验证。我没有使用 webBrowser,而是直接通过 URL 下载 HTML 代码字符分析。如果采集频繁,我可以动态设置代理。阿里的店铺网址都是很正规的{username}./,你可以拿到这个username,这是一个唯一的标识,以后可以用这个来判断店铺是否已经采集。
过程:
1、 通过店铺首页的URL分析,得到“公司简介”页面。规则是{username}./page/creditdetail.htm,在这里可以获取一些基本的公司信息(公司名称、联系人、电话、手机)、地址、介绍等)。
2、分析分类信息,规则是{username}./page/offerlist.htm,这里只需要获取店铺的所有分类ULR,并提供XPATH(//div[@class='wp-类别导航单元']/ul/li)。
3、分析分类号,在第二步的基础上,通过URL得到分类号。规则是 offerlist_{category number}.htm。在这里,有些店铺的品类有两层,到了第三层,我这里统一只取第一层。
4、获取规则{username}./page/offerlist_{category number}.htm?pageNum={page number}下的商品数据,取出HTML解析,提供XPATH(页码:/ /Em[@class='page-count'] 没有找到就只有一页;商品://ul[@class='offer-list-row']/li),商品网址映射。
5、获取商品详情,规则{商品编号}.html,通过上图中解析的URL获取商品编号,判断商品是否已经采集。下一步是通过 HTML 分析您需要什么。这里只有一点需要注意,就是产品描述是通过AJAX动态加载的。
找到data-tfs-url,下面的内容是产品说明。
最后一步是存储在数据库中。可以将 采集 的字段与您的数据库字段匹配。
好了,所有步骤都解释完了。如果想法还是不错的,请参考官方“推荐”!!! 查看全部
通过关键词采集文章采集api(采集思路HTML代码分析神器(HtmlAgilityPack)(HtmlAgilityPack)(组图))
一开始就说
由于公司需要,为了降低工作成本,需要一些存储数据,需要插入到在线数据库中。
采集思考
HTML代码分析神器(HtmlAgilityPack),接下来分析阿里巴巴的店铺数据规则。我这里的想法是先在搜索栏中根据关键词和region进行搜索,然后根据结果分析店铺的URL。然后根据店铺的URL进入店铺,找到“所有分类页面”,解析所有分类,然后根据分类URL获取分类下的商品数据。找到产品网址后,进入产品页面,分析需要的产品信息。这是我个人的采集 想法。下面介绍每一步需要注意的关键点。
1、分析店铺网址
第一张图
URL 规则是:{search关键词}&province={location}&pageSize=30&sortType=pop&beginPage=1
关键字和省都是汉字,需要用GBK编码(阿里都是GBK编码),然后传入URL,beginPage是页码,这里必须是1,如果手动修改这个参数会触发阿里的安全验证。其实这一步是难点,关键是如何突破这个安全验证。在采集的开头,通过上面的URL下载并分析了HTML源代码,但是到了第二页,每次都启动阿里的安全验证。找了很多方法后,都没有突破。使用 webBrowser 模拟点击并跳转到下一页。
突破阿里的分页尝试(使用webBrowser之前):
1、 从 URL 开始,无论你如何获取都会触发此规则。
2、查看源码看看点击下一页会发生什么,这就是你会发现这样一段HTML
翻页时会触发此表单。请求中有两个验证参数,UA和TOKEN。这些加密字符是由下面的 UA.JS 动态生成的。更BT的是,UA参数中的字符会被鼠标操作(点击、移动等)动态修改,必须修改UA才能通过验证(不会研究这个东西稍后,只需改变您的想法)。才想到用webBrowser动态模拟鼠标移动,点击页面的下一页按钮。这就是为什么上图中会有webBrowser、模拟移动、模拟点击三个按钮的原因。
接下来,我们来谈谈如何模拟鼠标的移动和点击。这里我们调用WINDOWS API。如果您不确定,您可以查找信息。
其实就是模拟操作。自动处理完两个加密参数后,模拟页面下一页,点击,这样就不会有安全验证了。
完整的顺序是:首先通过第一页的URL加载webBrowser,然后在webBrowser的DocumentCompleted事件中使用WINDOWS API调用模拟鼠标移动。此时,验证参数已经开始发生变化。是的,这里它休眠了 500 毫秒。然后调用按钮点击下一页,这样第二页的数据就会在webBrowser中更新,然后取出来分析,剩下的就是重复上面的工作了。
需要说明的是,两个按钮都需要有自己的事件,当采集时,鼠标不能自行移动。
好了,这里你已经得到了公司的 URL,下一步就是分析每个商店并获取产品数据。
2、分析产品数据
这里没有安全验证。我没有使用 webBrowser,而是直接通过 URL 下载 HTML 代码字符分析。如果采集频繁,我可以动态设置代理。阿里的店铺网址都是很正规的{username}./,你可以拿到这个username,这是一个唯一的标识,以后可以用这个来判断店铺是否已经采集。
过程:
1、 通过店铺首页的URL分析,得到“公司简介”页面。规则是{username}./page/creditdetail.htm,在这里可以获取一些基本的公司信息(公司名称、联系人、电话、手机)、地址、介绍等)。
2、分析分类信息,规则是{username}./page/offerlist.htm,这里只需要获取店铺的所有分类ULR,并提供XPATH(//div[@class='wp-类别导航单元']/ul/li)。
3、分析分类号,在第二步的基础上,通过URL得到分类号。规则是 offerlist_{category number}.htm。在这里,有些店铺的品类有两层,到了第三层,我这里统一只取第一层。
4、获取规则{username}./page/offerlist_{category number}.htm?pageNum={page number}下的商品数据,取出HTML解析,提供XPATH(页码:/ /Em[@class='page-count'] 没有找到就只有一页;商品://ul[@class='offer-list-row']/li),商品网址映射。
5、获取商品详情,规则{商品编号}.html,通过上图中解析的URL获取商品编号,判断商品是否已经采集。下一步是通过 HTML 分析您需要什么。这里只有一点需要注意,就是产品描述是通过AJAX动态加载的。
找到data-tfs-url,下面的内容是产品说明。
最后一步是存储在数据库中。可以将 采集 的字段与您的数据库字段匹配。
好了,所有步骤都解释完了。如果想法还是不错的,请参考官方“推荐”!!!
通过关键词采集文章采集api( WP英文垃圾站采集插件WPRobot_212破解版及使用教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 211 次浏览 • 2021-09-26 09:17
WP英文垃圾站采集插件WPRobot_212破解版及使用教程)
AllRightsReservedWordPress采集插件WPRobot_212破解版及使用教程 Wprobot312破解版下载合同下载合同模板下载红头文件模板免费下载简历免费下载模板求职简历模板免费下载地址httpdownqiannaocomspacefileliuzhilei121share20101126WPRobot31-63WPRobot31-63WP72078rbote一直想做WP英语垃圾站必备插件,特别适合我这种英语不好的人。它是 Wordpress 博客的 采集 插件。以上是WPRobot312最新破解版的下载地址。有需要的兄弟可以自行下载。这里会持续关注最新的破解版。当您开始使用 WPRobot 插件时,您就会意识到它是多么的智能。它是从多个来源生成的。您在自动驾驶仪上创建的 Wordpress 博客。在设计WPRobot时,负责人认为这是最好的分离方式。模块允许客户根据他们的特殊需要定制插件。例如,Amazon 和 Youtube 插件允许您添加主目录和备注。该系统的好处是可以通过智能生产的单个采购模块选择所有模块,以满足所有用户需求。WPRobot是一款自动博客你喜欢的超级插件认为所有主题都是乘法,口算,100题,七年级有理数,混合计算,100题,计算机一级题库,二元线性方程,单词题,真心话大冒险,它将让您发布目录而不是您的文本。努力根据您的选择自动更新您的博客。预设设置。有新帖子的热门网站。例如,关联目录可以是用于获取目录的巨大安排。WpRobot 是一个自动生成的 WordpressBlog文章 插件,可以根据设置进行设置。关键词自动采集yahoonewsyahooansweryoutubeflickramazonebayClickbankCj等网站视频、图片、产品信息等带有自动改写插件伪原创即日起,再也不用担心WpRobot建英文网站的特性了。创建你想要的任何内容文章并发布到你的WordPressBlog。只需要设置相关的关键字,在任意不同的分类下创建即可。文章比如不同的分类使用不同的关键词 自定义两篇文章文章 最小发布时间间隔为一小时。当然,你也可以设置一个或几天的间隔 精准控制文章内容生成,通过关键词搭配,打造不同的
文章 AllRightsReserved 自动出现。文章tagsTags 是 Wordpress 更好的功能之一。访问者可以通过一些标签检索具有相同标签的文章。自定义模板如果您对其内置模板不满意,可以修改模板。其实WpRobot肯定没有这些功能,只是我没有想到。您会发现它是如此强大且易于使用。有了它,就不再是建立英文博客的一种方式了。以下是WpRobot基础使用教程。第一步是上传WpRobot插件并在后台激活。第二步,设置关键词。进入WP后台,找到WpRobot3选项。一个是keywordcampaign by keyword Rsscampaign blog 文章RSSBrowseNodecampaign Amazon product node 第一个是by keyword < @采集点击右侧的Quicktemplatesetup可以快速创建模板。当然,你也可以选择Randomtemplate随机模板,看看两者有没有什么区别?在Nameyourcampaign填写你的关键词组名,比如IPad,在keywords下方的框内填写关键词每行一个关键词,在左边设置类别下方设置采集频率,例如每天一小时不推荐等待自动创建分类的权利,因为效果真的很差。以下是关键模板设置。总共有8个。请注意,单击 Quicktemplatesetup 将按顺序显示 8。CByoutube video ebay和Flickr建议不要全部使用,保留并添加每个模板采集如果比例不理想,点击相应模板下的removeTemplate,移除模板。下图基本不变。主要是替换关键字。删除关键字。设置翻译等。AllRightsReserved都设置好了。点击下方的 CreateCampaign 完成广告组的创建。三步WPRobotOptions选项设置LicenseOptions许可选项填写您购买的正版WpRobot插件贝宝邮箱破解版,随意输入邮箱
盒子没问题。此选项会自动显示。当您启用 WpRobot 时,系统会要求您输入此电子邮件。常规选项。常规选项。设置启用简单模式。是否允许简单模式。请勾选 NewPostStatus。选中并发布 ResetPostCounter文章 将统计数量重置为零 No 或 YesEnableHelpTooltips 是否启用帮助工具提示 EnableOldDuplicateCheck 是否启用旧版本重复检查 RandomizePostTimes 随机文章 发布活动人数入党和毫米对照表教师职称等级表员工考核评分表一般年金现值系数表时间这里还有一些其他选项,我就不一一解释了,翻译过来你就知道什么意思了用翻译工具。API 会给你这个 SearchMethod 搜索方法 ExactMatch 严格匹配 BroadMatch 广泛匹配 SkipProducts 如果 Dontskip 没有被跳过或者 Nodescriptionfound 没有描述或者 Nothumbnailimagefound 没有缩略图或者 NodescriptionORnothumbnail 没有描述或缩略图,跳过这个产品 AmazonDescriptionLength 描述长度 AmazonWebsite select amazoncomStripbracketsfromtitlesYes 默认, PostReviewsasComments 可以选择 YesPostTemplatepost 模板。默认或修改后的烟台SEOhttpwwwliuzhileicom 整理转载。注明来源。谢谢 AllRightsReservedArticleOptions文章Option SettingsArticleLanguage文章如果选择EnglishPages作为语言,会将很长的文章分割成N个字符的几页,并删除StripAllLinksfrom
请Yes 随机选择以下Iftranslationfails,如果翻译失败,则创建未翻译的文章 或跳过文章AllRightsReservedTwitterOptions 设置CommissionJunctionOptions 设置。如果您有做过 CJ 的朋友,如果您以前没有做过 CJ,这些设置应该很容易修复。继续并省略一些设置。这些是最不常用的默认值。最后,按 SaveOptions 保存设置。第四步是修改模板。修改模板也是比较关键的一步。如果对现成的模板不满意,可以自行修改。有时它运作良好。比如一些伟人采集ebay的信息,把标题改成了产品名称和拍卖的组合模板。效果明显提升。发售的第五步发布。文章release文章是最后一步添加关键词然后点击WpRobot的第一个选项Campaigns,你会发现你刚才填写的采集关键字是这里。将鼠标移到某个关键字上,就会出现一堆链接。单击立即发布。
惊讶地发现WpRobot开始采集并发布文章 AllRightsReserved。当然,还有更强大的可以同时发布N篇文章。在NuberofPosts中填写文章数,如50篇,并在Backdate前面打勾。文章发布日期从2008-09-24开始。两篇文章文章的发表时间相隔1到2天,然后点击PostNowWpRobot启动采集文章采集到达的50篇文章文章 2008年9月24日发布。这两篇文章文章将相隔一到两天。WP自动外链插件 这里我要推荐WP自动外链插件AutomaticBacklinkCreator插件。我用过的软件很好,今天推荐到这里,希望能省去大家外链的时间和精力。AutomaticBacklinkCreator主要是为wordpress程序搭建的。网站热衷WP的站长朋友,尤其是做外贸的。GoogleYahoo 搜索引擎 SEO 应该是一个很好的消息,这应该是一个很好的消息。这个软件类似于WP插件。是WP网站外链建设的完美解决方案。施工方案、施工方案示例、结构施工方案、营销方案方案模板、施工组织设计(施工方案),只需要在网站后台轻松安装,就可以用好方法搜索引擎自动增加WP网站高度 近日,官方网站 该软件的 AutomaticBacklinkCreator 仅需 37 美元。您可以使用信用卡或贝宝支付。它在国外销售,非常受欢迎。它还带有一个 MetaSnatcher 插件。这个插件可以自动跟踪谷歌排名。著名竞争对手网站核心键并自动返回软件,为关键词分析节省大量时间。SpinMasterPro插件 这个插件相当于WP离线伪原创安装这个插件后,可以在自己的电脑上发布内容伪原创,离线发布可以节省大量时间。同时,本软件提供60天不满意退款保证。点击查看这个软件的开发者是一群SEO高手。谷歌和雅虎的外链算法开发了这款强大而优秀的外链软件, 查看全部
通过关键词采集文章采集api(
WP英文垃圾站采集插件WPRobot_212破解版及使用教程)
AllRightsReservedWordPress采集插件WPRobot_212破解版及使用教程 Wprobot312破解版下载合同下载合同模板下载红头文件模板免费下载简历免费下载模板求职简历模板免费下载地址httpdownqiannaocomspacefileliuzhilei121share20101126WPRobot31-63WPRobot31-63WP72078rbote一直想做WP英语垃圾站必备插件,特别适合我这种英语不好的人。它是 Wordpress 博客的 采集 插件。以上是WPRobot312最新破解版的下载地址。有需要的兄弟可以自行下载。这里会持续关注最新的破解版。当您开始使用 WPRobot 插件时,您就会意识到它是多么的智能。它是从多个来源生成的。您在自动驾驶仪上创建的 Wordpress 博客。在设计WPRobot时,负责人认为这是最好的分离方式。模块允许客户根据他们的特殊需要定制插件。例如,Amazon 和 Youtube 插件允许您添加主目录和备注。该系统的好处是可以通过智能生产的单个采购模块选择所有模块,以满足所有用户需求。WPRobot是一款自动博客你喜欢的超级插件认为所有主题都是乘法,口算,100题,七年级有理数,混合计算,100题,计算机一级题库,二元线性方程,单词题,真心话大冒险,它将让您发布目录而不是您的文本。努力根据您的选择自动更新您的博客。预设设置。有新帖子的热门网站。例如,关联目录可以是用于获取目录的巨大安排。WpRobot 是一个自动生成的 WordpressBlog文章 插件,可以根据设置进行设置。关键词自动采集yahoonewsyahooansweryoutubeflickramazonebayClickbankCj等网站视频、图片、产品信息等带有自动改写插件伪原创即日起,再也不用担心WpRobot建英文网站的特性了。创建你想要的任何内容文章并发布到你的WordPressBlog。只需要设置相关的关键字,在任意不同的分类下创建即可。文章比如不同的分类使用不同的关键词 自定义两篇文章文章 最小发布时间间隔为一小时。当然,你也可以设置一个或几天的间隔 精准控制文章内容生成,通过关键词搭配,打造不同的
文章 AllRightsReserved 自动出现。文章tagsTags 是 Wordpress 更好的功能之一。访问者可以通过一些标签检索具有相同标签的文章。自定义模板如果您对其内置模板不满意,可以修改模板。其实WpRobot肯定没有这些功能,只是我没有想到。您会发现它是如此强大且易于使用。有了它,就不再是建立英文博客的一种方式了。以下是WpRobot基础使用教程。第一步是上传WpRobot插件并在后台激活。第二步,设置关键词。进入WP后台,找到WpRobot3选项。一个是keywordcampaign by keyword Rsscampaign blog 文章RSSBrowseNodecampaign Amazon product node 第一个是by keyword < @采集点击右侧的Quicktemplatesetup可以快速创建模板。当然,你也可以选择Randomtemplate随机模板,看看两者有没有什么区别?在Nameyourcampaign填写你的关键词组名,比如IPad,在keywords下方的框内填写关键词每行一个关键词,在左边设置类别下方设置采集频率,例如每天一小时不推荐等待自动创建分类的权利,因为效果真的很差。以下是关键模板设置。总共有8个。请注意,单击 Quicktemplatesetup 将按顺序显示 8。CByoutube video ebay和Flickr建议不要全部使用,保留并添加每个模板采集如果比例不理想,点击相应模板下的removeTemplate,移除模板。下图基本不变。主要是替换关键字。删除关键字。设置翻译等。AllRightsReserved都设置好了。点击下方的 CreateCampaign 完成广告组的创建。三步WPRobotOptions选项设置LicenseOptions许可选项填写您购买的正版WpRobot插件贝宝邮箱破解版,随意输入邮箱
盒子没问题。此选项会自动显示。当您启用 WpRobot 时,系统会要求您输入此电子邮件。常规选项。常规选项。设置启用简单模式。是否允许简单模式。请勾选 NewPostStatus。选中并发布 ResetPostCounter文章 将统计数量重置为零 No 或 YesEnableHelpTooltips 是否启用帮助工具提示 EnableOldDuplicateCheck 是否启用旧版本重复检查 RandomizePostTimes 随机文章 发布活动人数入党和毫米对照表教师职称等级表员工考核评分表一般年金现值系数表时间这里还有一些其他选项,我就不一一解释了,翻译过来你就知道什么意思了用翻译工具。API 会给你这个 SearchMethod 搜索方法 ExactMatch 严格匹配 BroadMatch 广泛匹配 SkipProducts 如果 Dontskip 没有被跳过或者 Nodescriptionfound 没有描述或者 Nothumbnailimagefound 没有缩略图或者 NodescriptionORnothumbnail 没有描述或缩略图,跳过这个产品 AmazonDescriptionLength 描述长度 AmazonWebsite select amazoncomStripbracketsfromtitlesYes 默认, PostReviewsasComments 可以选择 YesPostTemplatepost 模板。默认或修改后的烟台SEOhttpwwwliuzhileicom 整理转载。注明来源。谢谢 AllRightsReservedArticleOptions文章Option SettingsArticleLanguage文章如果选择EnglishPages作为语言,会将很长的文章分割成N个字符的几页,并删除StripAllLinksfrom
请Yes 随机选择以下Iftranslationfails,如果翻译失败,则创建未翻译的文章 或跳过文章AllRightsReservedTwitterOptions 设置CommissionJunctionOptions 设置。如果您有做过 CJ 的朋友,如果您以前没有做过 CJ,这些设置应该很容易修复。继续并省略一些设置。这些是最不常用的默认值。最后,按 SaveOptions 保存设置。第四步是修改模板。修改模板也是比较关键的一步。如果对现成的模板不满意,可以自行修改。有时它运作良好。比如一些伟人采集ebay的信息,把标题改成了产品名称和拍卖的组合模板。效果明显提升。发售的第五步发布。文章release文章是最后一步添加关键词然后点击WpRobot的第一个选项Campaigns,你会发现你刚才填写的采集关键字是这里。将鼠标移到某个关键字上,就会出现一堆链接。单击立即发布。
惊讶地发现WpRobot开始采集并发布文章 AllRightsReserved。当然,还有更强大的可以同时发布N篇文章。在NuberofPosts中填写文章数,如50篇,并在Backdate前面打勾。文章发布日期从2008-09-24开始。两篇文章文章的发表时间相隔1到2天,然后点击PostNowWpRobot启动采集文章采集到达的50篇文章文章 2008年9月24日发布。这两篇文章文章将相隔一到两天。WP自动外链插件 这里我要推荐WP自动外链插件AutomaticBacklinkCreator插件。我用过的软件很好,今天推荐到这里,希望能省去大家外链的时间和精力。AutomaticBacklinkCreator主要是为wordpress程序搭建的。网站热衷WP的站长朋友,尤其是做外贸的。GoogleYahoo 搜索引擎 SEO 应该是一个很好的消息,这应该是一个很好的消息。这个软件类似于WP插件。是WP网站外链建设的完美解决方案。施工方案、施工方案示例、结构施工方案、营销方案方案模板、施工组织设计(施工方案),只需要在网站后台轻松安装,就可以用好方法搜索引擎自动增加WP网站高度 近日,官方网站 该软件的 AutomaticBacklinkCreator 仅需 37 美元。您可以使用信用卡或贝宝支付。它在国外销售,非常受欢迎。它还带有一个 MetaSnatcher 插件。这个插件可以自动跟踪谷歌排名。著名竞争对手网站核心键并自动返回软件,为关键词分析节省大量时间。SpinMasterPro插件 这个插件相当于WP离线伪原创安装这个插件后,可以在自己的电脑上发布内容伪原创,离线发布可以节省大量时间。同时,本软件提供60天不满意退款保证。点击查看这个软件的开发者是一群SEO高手。谷歌和雅虎的外链算法开发了这款强大而优秀的外链软件,
通过关键词采集文章采集api(做SEO的人多少会用到各种查询工具,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-25 12:07
有多少SEO人会使用各种查询工具,
今天给大家分享一些常用的SEO工具包:
1、URL 批处理采集:
一分钟多线程IP变更采集3000,速度超快【突破百度验证码】
实测效率:
电脑配置(四核8G,win10系统,线程:50)
采集一分钟3218个网址,挂断后24小时内采集百万条数据,
可以说,只要你的关键词数量足够,你就用不完采集的URL。
Spike 市场上唯一的单线程、非抗阻塞工具
2、搜索索引批量查询:
多线程IP变更查询【突破百度验证码】
众所周知,百度的限制越来越严,无法破解的验证码层出不穷。
而这个工具就应运而生了,可以通过验证码进行批量校验
支持宽带拨号和代理API更改IP,
直接导入关键词点击开始,
右侧输出查询结果,
格式:关键词——PC Index/Mobile Index
3、下拉框关联词采集:
百度、搜狗、神马PC、手机搜索下拉框采集是SEO人获取大量长尾词的重要途径。
4、权重批量查询
站群人必备的权重批量查询工具,包括电脑权重和手机权重。海量网站无需手动一一查询
5、网站收录 批量查询:
也是站群人的最爱,批量查询收录量,实时监控网站爬取效果
6、AI人工智能文章批量伪原创
伪原创中独创的AI云人工智能文章,句子流畅(非同义词转换),就像网上请人改写,原创率达80%以上,以及秒变奶盘等同义词伪原创类工具
注:百度、搜狗、神马、360,还有很多SEO工具包,这里就不一一列举了
………… 查看全部
通过关键词采集文章采集api(做SEO的人多少会用到各种查询工具,你知道吗?)
有多少SEO人会使用各种查询工具,
今天给大家分享一些常用的SEO工具包:
1、URL 批处理采集:
一分钟多线程IP变更采集3000,速度超快【突破百度验证码】
实测效率:
电脑配置(四核8G,win10系统,线程:50)
采集一分钟3218个网址,挂断后24小时内采集百万条数据,
可以说,只要你的关键词数量足够,你就用不完采集的URL。
Spike 市场上唯一的单线程、非抗阻塞工具
2、搜索索引批量查询:
多线程IP变更查询【突破百度验证码】
众所周知,百度的限制越来越严,无法破解的验证码层出不穷。
而这个工具就应运而生了,可以通过验证码进行批量校验
支持宽带拨号和代理API更改IP,
直接导入关键词点击开始,
右侧输出查询结果,
格式:关键词——PC Index/Mobile Index
3、下拉框关联词采集:
百度、搜狗、神马PC、手机搜索下拉框采集是SEO人获取大量长尾词的重要途径。
4、权重批量查询
站群人必备的权重批量查询工具,包括电脑权重和手机权重。海量网站无需手动一一查询
5、网站收录 批量查询:
也是站群人的最爱,批量查询收录量,实时监控网站爬取效果
6、AI人工智能文章批量伪原创
伪原创中独创的AI云人工智能文章,句子流畅(非同义词转换),就像网上请人改写,原创率达80%以上,以及秒变奶盘等同义词伪原创类工具
注:百度、搜狗、神马、360,还有很多SEO工具包,这里就不一一列举了
…………

