
输入关键字 抓取所有网页
输入关键字 抓取所有网页( Amazon关键字易于使用的关键搜索和分析工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-02-08 12:18
Amazon关键字易于使用的关键搜索和分析工具)
亚马逊限制搜索引擎抓取
在市场经济飞速发展的今天,我们在电商平台购物的时候,一般都是直接通过关键词搜索,然后在搜索结果中找到想要的产品。这显示了一个好的关键字对于客户准确搜索您的产品的重要性。正如亚马逊卖家所知,新产品设置的关键词与能否在产品开始时找到它们并为它们带来流量有很大关系。很多新手卖家不知道怎么写关键词。市场上有许多亚马逊关键词工具。今天,我向您推荐几个易于使用的亚马逊关键搜索和分析工具。
1.易购云服务-亚马逊关键词搜索排名分析工具
对手的热门搜索和反关键字搜索,第一款CPC广告反查软件,英文关键字大数据库,支持美国、澳大利亚、日本、德国、法国、意大利和加拿大西部,九种语言,搜索量,小额出价
2.谷歌趋势 - 亚马逊关键词搜索分析
您可以自定义关键字搜索的搜索时间和历史数据,了解关键字搜索的变化趋势,帮助卖家了解当前的热门产品和市场需求,帮助进行库存管理。
3.Keyword Tracker - 亚马逊关键词搜索分析工具
查询竞争对手关键词,深度优化产品关键词,提升排名。支持四个数据库:wordtracker、Google、Youtube 和 Amazon。
4.Business Words - 亚马逊关键词搜索和分析工具
它每月更新一次,拥有海量的亚马逊关键词数据。数据来自谷歌和亚马逊。它搜索流行的关键字,将您的搜索范围缩小到类别关键字工具,并获得大量关键字。
5. KeywordTool - 亚马逊关键词搜索分析工具
无需创建帐户,跨平台、多区域、多语言的关键字搜索网站即可使用关键字工具,每个搜索词最多可收录 750 个长尾关键字。
6. KeywordInspector - 亚马逊关键词搜索分析工具
您可以找到亚马逊消费者正在使用的所有关键字。美国、英国、德国、加拿大、墨西哥、法国、意大利、日本和中国提供世界上唯一可以反转任何 ASIN 关键字查询的工具。
7.Science Seller - 亚马逊关键词搜索和分析工具
被称为“世界上最慢的关键字工具”,您可以获得无限的长期关键字,实时搜索关键字,并获得亚马逊关键字统计信息的频率。
8.关键词工具标尺 - 亚马逊关键词搜索分析排名工具
基于亚马逊的自动建议关键字列表(1-10 个关键字),在 Google、YouTube、Amazon、Bing 和 eBay 等平台上使用关键字软件。自动搜索很多长尾关键词。
9. SurTime 工具箱 - 亚马逊关键词搜索分析排名工具
支持所有站点的关键字扩展,可以获得关键字的流行度,统计词频。
最强大的功能是全球唯一支持一键关键词过滤重组,可以快速复制符合亚马逊规定的精准搜索词的功能。
10. Long Tail Pro - 亚马逊关键词搜索分析工具
这是目前唯一可以从 Google AdWords 获取数据的关键字软件。它支持选择多个国家和多种语言。SEO长尾助手不仅是最新有效的关键字和长尾,而且是每个词的搜索状态。还分析了招标情况,操作简单。
11. Wordtracker - 亚马逊关键词搜索分析工具
关键词软件涵盖wordtracker、谷歌、Youtube、亚马逊等平台,快速轻松了解关键词热度,查询排名。
12. KWFinder - 亚马逊关键词搜索分析排名工具
实时搜索优化关键字,深入的关键字研究和排名,准确的搜索量,可以从40种语言中选择准确的本地化结果,是深入关键字分析和研究的工具。
13. AMZtracker - 亚马逊关键词搜索分析排名工具
功能:调查竞争对手listing销售数据、关键词设置和排名优化、亚马逊listing排名提升、产品样本评价管理、产品差评跟踪管理、预测近一个月产品销量等 简单关键词工具,7天免费,包月试用 100 天后的刀具
14. Keywordeye - 亚马逊关键词搜索和分析工具
无限搜索关键词,计算关键词竞争力,查找热门产品和竞争对手关键词。
15. SEMrush - 亚马逊关键词搜索分析排名工具
研究排名因素,关键词分组管理,网站专攻SEO和SEO服务。
16. Soovle-亚马逊关键词搜索分析工具
关键字辅助工具,一次给出关键字概念的核心词。输入关键字后,其结果与Wikipedia、You Tube、Amazon、Yahoo、Ask和A的内容相关
17.搜索引擎优化-亚马逊关键词搜索分析
SEO网站获取 Google、Bing、YouTube 和 Amazon 的关键字自动建议数据。
18. 谷歌关键词规划师 - 亚马逊关键词搜索分析工具
提供来自谷歌搜索引擎的历史搜索数据,对关键词进行深入研究,找到客户关心的关键词。用户只需输入一组摘要词或短语,即可查看每月点击次数和平均竞争水平,从而挖掘产品创意并获得一些建议和提示。同时,该工具还可以显示信息量相同的相关关键词,防止用户遗漏任何东西
19. Terapeak_Amazon关键词搜索分析工具
您可以研究 eBay 和亚马逊上最畅销的产品和类别,分析标题的命名方式,并了解买家的购物习惯和热门搜索关键字。特别是对竞争对手进行研究,分析他们的销售业绩,更新最新趋势,定价策略等。
20. AmaSuite - 亚马逊关键词搜索分析工具
Azon Keyword Generator 是一款分析亚马逊产品关键词的小工具,可以轻松从 Amazon.co.uk 和 Amazon.co.uk 获取数千个长尾关键词。
21.关键字抓取工具 - 亚马逊关键字抓取工具
关键词挖掘软件,支持Google、Yahoo、Bing、ASK四种搜索引擎,只要输入一个关键词,选择一个目标市场,就会根据不同的国家出现不同的长尾关键词,并且都有真实的点击率和搜索量关键字。
22. keywordpy - 亚马逊关键字查找器
开发用于挖掘和跟踪国外关键字的软件。使用竞争对手的关键字并访问相关和相似术语和短语的大型数据库,以构建有利可图的关键字列表。
目录:robots.txt 简介
robots.txt(统一小写)文件位于 网站 的根目录中,是一个 ASCII 编码的文本文件,用于指示您不希望搜索引擎爬虫访问内容。
robots.txt的基本语法 robots.txt的限制范围原则
1.搜索技术应该为人类服务,同时尊重信息提供者的意愿和隐私;
2.网站有义务保护其个人信息和用户隐私不受侵犯。
影响
爬虫抓取 网站 并索引页面,然后通过关键字搜索将流量吸引到 网站。但是,我们只希望爬虫抓取最有价值的网页,而不希望它们访问不重要的信息或不适当的私人信息和数据。
robots.txt 可用于 SEO。
来源:完整指南:如何为 WordPress 博客编写 robots.txt 文件 Amazon--robots.txt 分析用户代理:
美国亚马逊:
Etao蜘蛛
亚马逊中国:
用户代理:*
没有阻止谷歌和一淘爬虫的说明
禁止内容分析(仅摘自我能理解的内容):登录页面添加到购物车愿望清单评论常见问题投票朋友推特历史图像音频和视频文件死链接机器人元数据
NOINDEX 指令:定义搜索引擎尚未将该网页索引到数据库中,但搜索引擎可以通过该网页的链接继续索引其他网页
NOFOLLOW 指令:不要索引此页面和链接到此页面的页面。仅适用于本页链接
概括
亚马逊的屏蔽令主要包括四个部分:客户的个人隐私信息、业务数据、消耗大量带宽的数据、无效链接。
商家有义务保护用户的个人信息和隐私不受侵犯。商业数据还包括能够带来商业价值的大数据,如用户浏览信息、购买信息、反馈信息等。可以屏蔽图片、音视频文件等带宽密集型数据,节省服务器带宽。
其中,美国亚马逊也屏蔽了谷歌爬虫和机器人爬虫。从网络上抓取可能会影响亚马逊上的产品销售。
允许部分中的说明主要是为了方便爬虫抓取,以便将客户和流量吸引到亚马逊。
Github--robots.txt 分析 User-agent: CCBot coccoc --- 越南免费网络浏览器 Daumoa --- dotbot dadduckbot EtaoSpider Googlebot --- 谷歌爬虫,搜索 网站HTTrack ia_archiver IntuitGSACrawler Mail.RU_Bot - --邮件爬虫 msnbot --- msn 爬虫,社交 网站Bingbot--- Bing 爬虫,搜索网站naverbot red-app-gsa-p-one rogerbot SandDollar seznambot Slurp Swiftbot -- - Swift 爬虫 Telefonica teoma Twitterbot --- Twitter爬虫,社交网站Yandex禁止内容分析(仅摘自我能理解的部分):/*/*/tree/master //master分支代码/ */stars //获得的星星/ */download //要在链接中下载的内容 /*/*/commits/*/* //comment /*/*/search //inline search /*/cache/ //Cache/.git/ // git repository/ login //用户登录摘要
Github 屏蔽了许多以保护用户个人隐私和知识产权不受侵犯为主要目的的用户代理。
总结
从以上两个网站的分析可以看出robots.txt协议的主要目的是优化搜索引擎。一方面,它允许爬虫为网页带来流量和客户,另一方面,它努力保护用户和企业的隐私和利益不受侵犯。
虽然 robots.txt 不会完全阻止您的网页被抓取,但仍然需要为您的 网站 设置 robots.txt。
参考链接:
百度百科:%E5%8D%8F%E8%AE%AE/2483797?fromtitle=robots.txt&fromid=9518761
谷歌支持:;ref_topic=6061961
书:
完整指南:如何为您的 WordPress 博客编写 robots.txt 文件
在外贸领域,对谷歌的依赖度很高,如何充分利用谷歌搜索引擎成为企业和商家的头等大事。
谷歌在中国的封锁使得谷歌搜索引擎无法访问,但作为一个成熟的外贸公司,访问国外的网站并优化谷歌搜索引擎是不可避免的。对于 Google 搜索引擎,有 8 个块来说明。
1、注意页面标题
页面标题是网页的标题。每个网页都需要一个唯一的页面标题。对于 网站 优化和搜索结果,不能低估准确和独特地创建页面标题。如果您的文档出现在搜索结果页面上,其标题标签的内容通常会出现在搜索结果的第一行。
2、描述标签
向 Google 和其他搜索引擎提供此页面的摘要说明。
Google 可能会使用元标记来生成您网页的片段。
3、优化url结构
简单易懂的 url 更容易表达内容信息。一个简单友好的 URL 可以让用户继续访问。相比于网址中无法识别的乱码和字母,优化网址效果明显。同时,为网页上的文件创建描述性的类别名称和文件名不仅可以帮助您更好地组织网站。它还可以帮助搜索引擎更有效地抓取文档。
4、html网络地图,使用xml站点地图文件
什么是网络图?通俗的讲,就是帮助用户在访问网站时访问网站内的所有页面或主页。制作 xml网站 映射进一步确保搜索引擎能够找到并索引您的 网站 中的所有页面。
5,404 个合理使用网页
它对 404 页面有什么作用?一般网站访问时不会出现404页面,然后,偶尔链接失效或用户链接输入错误访问网站域名下不存在的页面,友好的404页面可以带用户到更好的体验,可以在404页面上放置一个更高级别的网页返回链接,还有一个网站主页按钮,可以让用户访问想要的及时、高效地进行网站建设。网页。
6.网站 上的产品页面说明
网站中有大量产品,不同产品的描述不要太相似。每个产品都有一个独特的产品描述,Google 可以抓取网络以获取更有效的信息。
7、页面权重分布
对于一个高效成熟的网站,它有一个合理的权重分布。哪些页面需要更高的权重?当然是产品页面。我们需要被 Google 抓取以获取更多产品信息,因此产品页面上的权重更大。站点地图允许您查看网站创作最多的页面。好吧,我们自然需要产品页面的高权重。
8、图像优化
在我上次的社交媒体营销中,我也谈到了图像处理的重要性。一个成熟的网站必须合理规范图片的处理(包括图片的选择和图片的命名)。上次提到,在设置图片名称唯一时,需要使用alt属性来描述图片。当访问者无法正常显示图片时,可以使用文字来表示图片的属性,整体的用户体验会得到很大的提升。
9. robots.txt文件的应用
限制 Google 抓取的 robots txt 文件必须严格命名为 robots.txt,并放在 网站 的根目录下。
网站的某些页面不想被谷歌搜索引擎抓取,或者某些页面不是有价值的内容,那么就需要使用这个文件来限制抓取
10.谨慎使用 rel="nofollow"
当 网站 已经有博客和其他消息功能时,访问者的消息中将没有指向 网站 的链接,那么 网站 本身自然不希望 Google 发布它它自己的 网站 @网站 抓取与自己的 网站 无关的链接。此时需要nofollow来限制爬取。 查看全部
输入关键字 抓取所有网页(
Amazon关键字易于使用的关键搜索和分析工具)

亚马逊限制搜索引擎抓取
在市场经济飞速发展的今天,我们在电商平台购物的时候,一般都是直接通过关键词搜索,然后在搜索结果中找到想要的产品。这显示了一个好的关键字对于客户准确搜索您的产品的重要性。正如亚马逊卖家所知,新产品设置的关键词与能否在产品开始时找到它们并为它们带来流量有很大关系。很多新手卖家不知道怎么写关键词。市场上有许多亚马逊关键词工具。今天,我向您推荐几个易于使用的亚马逊关键搜索和分析工具。

1.易购云服务-亚马逊关键词搜索排名分析工具
对手的热门搜索和反关键字搜索,第一款CPC广告反查软件,英文关键字大数据库,支持美国、澳大利亚、日本、德国、法国、意大利和加拿大西部,九种语言,搜索量,小额出价
2.谷歌趋势 - 亚马逊关键词搜索分析
您可以自定义关键字搜索的搜索时间和历史数据,了解关键字搜索的变化趋势,帮助卖家了解当前的热门产品和市场需求,帮助进行库存管理。
3.Keyword Tracker - 亚马逊关键词搜索分析工具
查询竞争对手关键词,深度优化产品关键词,提升排名。支持四个数据库:wordtracker、Google、Youtube 和 Amazon。
4.Business Words - 亚马逊关键词搜索和分析工具
它每月更新一次,拥有海量的亚马逊关键词数据。数据来自谷歌和亚马逊。它搜索流行的关键字,将您的搜索范围缩小到类别关键字工具,并获得大量关键字。
5. KeywordTool - 亚马逊关键词搜索分析工具
无需创建帐户,跨平台、多区域、多语言的关键字搜索网站即可使用关键字工具,每个搜索词最多可收录 750 个长尾关键字。
6. KeywordInspector - 亚马逊关键词搜索分析工具
您可以找到亚马逊消费者正在使用的所有关键字。美国、英国、德国、加拿大、墨西哥、法国、意大利、日本和中国提供世界上唯一可以反转任何 ASIN 关键字查询的工具。
7.Science Seller - 亚马逊关键词搜索和分析工具
被称为“世界上最慢的关键字工具”,您可以获得无限的长期关键字,实时搜索关键字,并获得亚马逊关键字统计信息的频率。
8.关键词工具标尺 - 亚马逊关键词搜索分析排名工具
基于亚马逊的自动建议关键字列表(1-10 个关键字),在 Google、YouTube、Amazon、Bing 和 eBay 等平台上使用关键字软件。自动搜索很多长尾关键词。
9. SurTime 工具箱 - 亚马逊关键词搜索分析排名工具
支持所有站点的关键字扩展,可以获得关键字的流行度,统计词频。
最强大的功能是全球唯一支持一键关键词过滤重组,可以快速复制符合亚马逊规定的精准搜索词的功能。
10. Long Tail Pro - 亚马逊关键词搜索分析工具
这是目前唯一可以从 Google AdWords 获取数据的关键字软件。它支持选择多个国家和多种语言。SEO长尾助手不仅是最新有效的关键字和长尾,而且是每个词的搜索状态。还分析了招标情况,操作简单。
11. Wordtracker - 亚马逊关键词搜索分析工具
关键词软件涵盖wordtracker、谷歌、Youtube、亚马逊等平台,快速轻松了解关键词热度,查询排名。
12. KWFinder - 亚马逊关键词搜索分析排名工具
实时搜索优化关键字,深入的关键字研究和排名,准确的搜索量,可以从40种语言中选择准确的本地化结果,是深入关键字分析和研究的工具。
13. AMZtracker - 亚马逊关键词搜索分析排名工具
功能:调查竞争对手listing销售数据、关键词设置和排名优化、亚马逊listing排名提升、产品样本评价管理、产品差评跟踪管理、预测近一个月产品销量等 简单关键词工具,7天免费,包月试用 100 天后的刀具
14. Keywordeye - 亚马逊关键词搜索和分析工具
无限搜索关键词,计算关键词竞争力,查找热门产品和竞争对手关键词。
15. SEMrush - 亚马逊关键词搜索分析排名工具
研究排名因素,关键词分组管理,网站专攻SEO和SEO服务。
16. Soovle-亚马逊关键词搜索分析工具
关键字辅助工具,一次给出关键字概念的核心词。输入关键字后,其结果与Wikipedia、You Tube、Amazon、Yahoo、Ask和A的内容相关
17.搜索引擎优化-亚马逊关键词搜索分析
SEO网站获取 Google、Bing、YouTube 和 Amazon 的关键字自动建议数据。
18. 谷歌关键词规划师 - 亚马逊关键词搜索分析工具
提供来自谷歌搜索引擎的历史搜索数据,对关键词进行深入研究,找到客户关心的关键词。用户只需输入一组摘要词或短语,即可查看每月点击次数和平均竞争水平,从而挖掘产品创意并获得一些建议和提示。同时,该工具还可以显示信息量相同的相关关键词,防止用户遗漏任何东西
19. Terapeak_Amazon关键词搜索分析工具
您可以研究 eBay 和亚马逊上最畅销的产品和类别,分析标题的命名方式,并了解买家的购物习惯和热门搜索关键字。特别是对竞争对手进行研究,分析他们的销售业绩,更新最新趋势,定价策略等。
20. AmaSuite - 亚马逊关键词搜索分析工具
Azon Keyword Generator 是一款分析亚马逊产品关键词的小工具,可以轻松从 Amazon.co.uk 和 Amazon.co.uk 获取数千个长尾关键词。
21.关键字抓取工具 - 亚马逊关键字抓取工具
关键词挖掘软件,支持Google、Yahoo、Bing、ASK四种搜索引擎,只要输入一个关键词,选择一个目标市场,就会根据不同的国家出现不同的长尾关键词,并且都有真实的点击率和搜索量关键字。
22. keywordpy - 亚马逊关键字查找器
开发用于挖掘和跟踪国外关键字的软件。使用竞争对手的关键字并访问相关和相似术语和短语的大型数据库,以构建有利可图的关键字列表。
目录:robots.txt 简介
robots.txt(统一小写)文件位于 网站 的根目录中,是一个 ASCII 编码的文本文件,用于指示您不希望搜索引擎爬虫访问内容。
robots.txt的基本语法 robots.txt的限制范围原则
1.搜索技术应该为人类服务,同时尊重信息提供者的意愿和隐私;
2.网站有义务保护其个人信息和用户隐私不受侵犯。
影响
爬虫抓取 网站 并索引页面,然后通过关键字搜索将流量吸引到 网站。但是,我们只希望爬虫抓取最有价值的网页,而不希望它们访问不重要的信息或不适当的私人信息和数据。
robots.txt 可用于 SEO。
来源:完整指南:如何为 WordPress 博客编写 robots.txt 文件 Amazon--robots.txt 分析用户代理:
美国亚马逊:
Etao蜘蛛
亚马逊中国:
用户代理:*
没有阻止谷歌和一淘爬虫的说明
禁止内容分析(仅摘自我能理解的内容):登录页面添加到购物车愿望清单评论常见问题投票朋友推特历史图像音频和视频文件死链接机器人元数据
NOINDEX 指令:定义搜索引擎尚未将该网页索引到数据库中,但搜索引擎可以通过该网页的链接继续索引其他网页
NOFOLLOW 指令:不要索引此页面和链接到此页面的页面。仅适用于本页链接
概括
亚马逊的屏蔽令主要包括四个部分:客户的个人隐私信息、业务数据、消耗大量带宽的数据、无效链接。
商家有义务保护用户的个人信息和隐私不受侵犯。商业数据还包括能够带来商业价值的大数据,如用户浏览信息、购买信息、反馈信息等。可以屏蔽图片、音视频文件等带宽密集型数据,节省服务器带宽。
其中,美国亚马逊也屏蔽了谷歌爬虫和机器人爬虫。从网络上抓取可能会影响亚马逊上的产品销售。
允许部分中的说明主要是为了方便爬虫抓取,以便将客户和流量吸引到亚马逊。
Github--robots.txt 分析 User-agent: CCBot coccoc --- 越南免费网络浏览器 Daumoa --- dotbot dadduckbot EtaoSpider Googlebot --- 谷歌爬虫,搜索 网站HTTrack ia_archiver IntuitGSACrawler Mail.RU_Bot - --邮件爬虫 msnbot --- msn 爬虫,社交 网站Bingbot--- Bing 爬虫,搜索网站naverbot red-app-gsa-p-one rogerbot SandDollar seznambot Slurp Swiftbot -- - Swift 爬虫 Telefonica teoma Twitterbot --- Twitter爬虫,社交网站Yandex禁止内容分析(仅摘自我能理解的部分):/*/*/tree/master //master分支代码/ */stars //获得的星星/ */download //要在链接中下载的内容 /*/*/commits/*/* //comment /*/*/search //inline search /*/cache/ //Cache/.git/ // git repository/ login //用户登录摘要
Github 屏蔽了许多以保护用户个人隐私和知识产权不受侵犯为主要目的的用户代理。
总结
从以上两个网站的分析可以看出robots.txt协议的主要目的是优化搜索引擎。一方面,它允许爬虫为网页带来流量和客户,另一方面,它努力保护用户和企业的隐私和利益不受侵犯。
虽然 robots.txt 不会完全阻止您的网页被抓取,但仍然需要为您的 网站 设置 robots.txt。
参考链接:
百度百科:%E5%8D%8F%E8%AE%AE/2483797?fromtitle=robots.txt&fromid=9518761
谷歌支持:;ref_topic=6061961
书:
完整指南:如何为您的 WordPress 博客编写 robots.txt 文件

在外贸领域,对谷歌的依赖度很高,如何充分利用谷歌搜索引擎成为企业和商家的头等大事。
谷歌在中国的封锁使得谷歌搜索引擎无法访问,但作为一个成熟的外贸公司,访问国外的网站并优化谷歌搜索引擎是不可避免的。对于 Google 搜索引擎,有 8 个块来说明。
1、注意页面标题
页面标题是网页的标题。每个网页都需要一个唯一的页面标题。对于 网站 优化和搜索结果,不能低估准确和独特地创建页面标题。如果您的文档出现在搜索结果页面上,其标题标签的内容通常会出现在搜索结果的第一行。
2、描述标签
向 Google 和其他搜索引擎提供此页面的摘要说明。
Google 可能会使用元标记来生成您网页的片段。
3、优化url结构
简单易懂的 url 更容易表达内容信息。一个简单友好的 URL 可以让用户继续访问。相比于网址中无法识别的乱码和字母,优化网址效果明显。同时,为网页上的文件创建描述性的类别名称和文件名不仅可以帮助您更好地组织网站。它还可以帮助搜索引擎更有效地抓取文档。
4、html网络地图,使用xml站点地图文件
什么是网络图?通俗的讲,就是帮助用户在访问网站时访问网站内的所有页面或主页。制作 xml网站 映射进一步确保搜索引擎能够找到并索引您的 网站 中的所有页面。
5,404 个合理使用网页
它对 404 页面有什么作用?一般网站访问时不会出现404页面,然后,偶尔链接失效或用户链接输入错误访问网站域名下不存在的页面,友好的404页面可以带用户到更好的体验,可以在404页面上放置一个更高级别的网页返回链接,还有一个网站主页按钮,可以让用户访问想要的及时、高效地进行网站建设。网页。
6.网站 上的产品页面说明
网站中有大量产品,不同产品的描述不要太相似。每个产品都有一个独特的产品描述,Google 可以抓取网络以获取更有效的信息。
7、页面权重分布
对于一个高效成熟的网站,它有一个合理的权重分布。哪些页面需要更高的权重?当然是产品页面。我们需要被 Google 抓取以获取更多产品信息,因此产品页面上的权重更大。站点地图允许您查看网站创作最多的页面。好吧,我们自然需要产品页面的高权重。
8、图像优化
在我上次的社交媒体营销中,我也谈到了图像处理的重要性。一个成熟的网站必须合理规范图片的处理(包括图片的选择和图片的命名)。上次提到,在设置图片名称唯一时,需要使用alt属性来描述图片。当访问者无法正常显示图片时,可以使用文字来表示图片的属性,整体的用户体验会得到很大的提升。
9. robots.txt文件的应用
限制 Google 抓取的 robots txt 文件必须严格命名为 robots.txt,并放在 网站 的根目录下。
网站的某些页面不想被谷歌搜索引擎抓取,或者某些页面不是有价值的内容,那么就需要使用这个文件来限制抓取
10.谨慎使用 rel="nofollow"
当 网站 已经有博客和其他消息功能时,访问者的消息中将没有指向 网站 的链接,那么 网站 本身自然不希望 Google 发布它它自己的 网站 @网站 抓取与自己的 网站 无关的链接。此时需要nofollow来限制爬取。
输入关键字 抓取所有网页(网站首页的关键词越多越好!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-08 12:16
在学习SEO优化的过程中,不知道有没有听过这样一句话,一个网站首页的关键词越少越好,关键词的< @网站,更好!不知道这句话大家看懂了没有,可能是因为我是菜鸟站长,所以关注了这种问题,但是不管对不对,还是分享给大家,让大家可以使用它作为参考。废话不多说,直接进入正题。
不知道其他站长朋友有没有注意到。当我们更新网站的时候,如果首页也同时更新了,那么首页的内容就会发生变化,也就是说蜘蛛抓取首页的时候关键词也会发生变化. 如果是大的网站,他们的权重很高,也许他们不在乎首页的关键词有没有变化,更新全部更新。不过作为个体站长,我们每天更新的内容不会太多,网站首页的内容每次更新都会有细微的变化。但是我发现,即使是这个微小的变化,当蜘蛛爬取主页时,关键词也会发生变化。就像我的生活知识网站一样,有一段时间我不是每天都更新内容,有时会间隔一个星期。有一次发现“健康养生”这个词在冬天排名很好,流量也不错,但是几次内容更新后发现这个词带来的流量已经找不到了,排名也消失了. 郁闷的时候也找了找原因,最后发现首页的内容中少了这个信息(因为我更新了内容,信息的顶部没有了)。
我们都知道,做网站内容为王,好的内容,原创信息百度等各大搜索引擎都会看重,即使采集来伪原创很受欢迎。网站要想成长,就必须不断地补充新鲜血液和新内容。但是我上面说了,如果在内容更新的时候也更新了首页的内容,那肯定会造成关键词的丢失。这会影响排名的稳定性。我们必须想办法做到这两点,所以我开始了这个实验。说实话,我一直都在单枪匹马地找高手带路,但还没找到,嘿嘿!那么让我进一步探索吧!
鉴于以上发现,我个人认为首页的更新会对首页关键词起到一定的作用。因为蜘蛛在爬取首页时,会根据首页的所有内容组成词,影响关键词。当搜索引擎爬取我们的网站时,会做几个步骤,提取网站关键词,结合首页的大量信息,提取出它认为合适的词;排除出现在@>上的网站重复信息;出现在首页的链接分析;出现 关键词 的重要性。基于这些知识,为了让首页关键词固定,但同时更新首页内容,提高网站的某个页面的权重,我试了几个次,最后觉得还是用一个添加固定词组和更新内容比较安全。下面我会告诉你我是怎么做到的。
事实上,这很简单。我只是将主页划分为一个站点,用于最近推广关键词。在制作了一套完整的近期流行词后,我建立了一个近期推广栏目,并使用了不同颜色、加粗等一系列方法来区分它们。无论其他事情如何变化,这些话都是一样的。即第一页有转换词和非动词。我认为这样做的好处是在赛季或过热之后,您可以再次切换设置。灵活但相对稳定。如果你觉得你网站上的某篇文章文章在最近或者未来几天会被大量网友搜索,在做这些非动词的时候,可以故意多做几个锚链接点改文章,提高这个文章的重要性和权重,
但是值得我们注意的是,我们在制作稳定的首页关键词的时候,一定要注意关键词的组合,也就是首页出现的关键词的密度。比如我们可以使用站长工具中的蜘蛛模拟器来测试首页出现的信息,从而知道我们的网站的关键词的密度,从而做出更好的调整. 然后是我们做的非动词内容。这些 关键词 锚链接不应都指向主页或同一页面。虽然这样会提高某个页面的权重,但是如果太多,就会让引擎认为是作弊。更不用说一些 heimao关键词 链接,这些链接长期以来被引擎认为是 SEO 作弊。当我们在做 关键词 优化时,我们必须提前计划并提前准备季节性关键词。我的网站是关于健康和常识的,所以提前准备比较容易。有的网站可能不是很可预测,但是根据自己的内容,应该及时发现热门词。从而为自己带来更多的流量和更多的收入网站。
尤其是博客类型网站最有可能出现这种情况,所以我们要注意了。有些说法需要证实,但确有其事,请大家辨认并发表不同意见。 查看全部
输入关键字 抓取所有网页(网站首页的关键词越多越好!)
在学习SEO优化的过程中,不知道有没有听过这样一句话,一个网站首页的关键词越少越好,关键词的< @网站,更好!不知道这句话大家看懂了没有,可能是因为我是菜鸟站长,所以关注了这种问题,但是不管对不对,还是分享给大家,让大家可以使用它作为参考。废话不多说,直接进入正题。
不知道其他站长朋友有没有注意到。当我们更新网站的时候,如果首页也同时更新了,那么首页的内容就会发生变化,也就是说蜘蛛抓取首页的时候关键词也会发生变化. 如果是大的网站,他们的权重很高,也许他们不在乎首页的关键词有没有变化,更新全部更新。不过作为个体站长,我们每天更新的内容不会太多,网站首页的内容每次更新都会有细微的变化。但是我发现,即使是这个微小的变化,当蜘蛛爬取主页时,关键词也会发生变化。就像我的生活知识网站一样,有一段时间我不是每天都更新内容,有时会间隔一个星期。有一次发现“健康养生”这个词在冬天排名很好,流量也不错,但是几次内容更新后发现这个词带来的流量已经找不到了,排名也消失了. 郁闷的时候也找了找原因,最后发现首页的内容中少了这个信息(因为我更新了内容,信息的顶部没有了)。
我们都知道,做网站内容为王,好的内容,原创信息百度等各大搜索引擎都会看重,即使采集来伪原创很受欢迎。网站要想成长,就必须不断地补充新鲜血液和新内容。但是我上面说了,如果在内容更新的时候也更新了首页的内容,那肯定会造成关键词的丢失。这会影响排名的稳定性。我们必须想办法做到这两点,所以我开始了这个实验。说实话,我一直都在单枪匹马地找高手带路,但还没找到,嘿嘿!那么让我进一步探索吧!
鉴于以上发现,我个人认为首页的更新会对首页关键词起到一定的作用。因为蜘蛛在爬取首页时,会根据首页的所有内容组成词,影响关键词。当搜索引擎爬取我们的网站时,会做几个步骤,提取网站关键词,结合首页的大量信息,提取出它认为合适的词;排除出现在@>上的网站重复信息;出现在首页的链接分析;出现 关键词 的重要性。基于这些知识,为了让首页关键词固定,但同时更新首页内容,提高网站的某个页面的权重,我试了几个次,最后觉得还是用一个添加固定词组和更新内容比较安全。下面我会告诉你我是怎么做到的。
事实上,这很简单。我只是将主页划分为一个站点,用于最近推广关键词。在制作了一套完整的近期流行词后,我建立了一个近期推广栏目,并使用了不同颜色、加粗等一系列方法来区分它们。无论其他事情如何变化,这些话都是一样的。即第一页有转换词和非动词。我认为这样做的好处是在赛季或过热之后,您可以再次切换设置。灵活但相对稳定。如果你觉得你网站上的某篇文章文章在最近或者未来几天会被大量网友搜索,在做这些非动词的时候,可以故意多做几个锚链接点改文章,提高这个文章的重要性和权重,
但是值得我们注意的是,我们在制作稳定的首页关键词的时候,一定要注意关键词的组合,也就是首页出现的关键词的密度。比如我们可以使用站长工具中的蜘蛛模拟器来测试首页出现的信息,从而知道我们的网站的关键词的密度,从而做出更好的调整. 然后是我们做的非动词内容。这些 关键词 锚链接不应都指向主页或同一页面。虽然这样会提高某个页面的权重,但是如果太多,就会让引擎认为是作弊。更不用说一些 heimao关键词 链接,这些链接长期以来被引擎认为是 SEO 作弊。当我们在做 关键词 优化时,我们必须提前计划并提前准备季节性关键词。我的网站是关于健康和常识的,所以提前准备比较容易。有的网站可能不是很可预测,但是根据自己的内容,应该及时发现热门词。从而为自己带来更多的流量和更多的收入网站。
尤其是博客类型网站最有可能出现这种情况,所以我们要注意了。有些说法需要证实,但确有其事,请大家辨认并发表不同意见。
输入关键字 抓取所有网页(社招进阿里的一个面试呗,你准备好了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-07 06:03
内容
前言
前几天,我接到了外籍人士阿里的面试。作为一个自信狂妄的我,虽然是外籍人士,但对阿里还是有几分敬佩之情,就像高考想进清华北大,想进腾讯阿里工作一样。是的,当然,除了学校招985/211能进阿里外,其他人想通过中介被招进阿里,那就更难了,至少在某个领域是专家级别的。所以如果你有一个难得的机会,试试阿里的采访。
一、采访内容1、电话面试及项目实践题
首先是电话面试:这个一般没问题,多看书,少吃零食,多睡觉……这个肯定能回答
二是想出一个动手demo题目,如下
文档链接:
爬取左侧文档树中的所有文档列表
在查询页面输入关键词或描述性语言给出3个最佳匹配文档(从高匹配到低匹配排序)。
供应:
1. 代码
2. 匹配的想法
奖励:有关如何为描述性语言提供建议的文档。例如用户输入:我的日志 采集 is out
大多数人在听到他们要编写一个演示时都会感到恐慌。不要害怕,我不会和你分享我的经验和代码示例,所以请阅读此文章,之后应该没问题,反正我已经结束了。
2、动手主题:文档抓取和搜索
3、研究课题
首先,去链接看看。让我们来看看它是什么。原来是阿里云的帮助文档。看来这个简单的demo其实就是根据用户输入的关键词搜索对应的解决方案。小项目。
第一个小步骤,爬取内容应该不难。不管是用Java还是Python,难度是第一位的,但是Python可能更简单,Java会多写一点代码。当然,小编目前还是想先学java,所以用java代码来演示。至于Python,先学一门语言,再拓展其他语言,才能更好的辅助你。
难点在于第二个小步骤,“在查询页面输入关键词或者描述性语言,给出最佳匹配的3个文档(匹配度从高到低排序)”,
我们先不爬,因为如果爬,必须封装想要的格式。当我们没有想到查询关键词的功能时,先保留它。
①查询输入关键词,给出最佳匹配方案
当然,你可以自己写算法和匹配,但是这种情况下,匹配肯定不是很准确,一天之内几乎不可能写出来,所以看看前人对这种类型有什么想法更好的解决方案,踩在巨人的肩膀上,事半功倍。
其实有很多方法可以实现类似的功能,
比如通过分词器搜索:Jieba分词、Ansj分词……其他分词效果可以点这里:了解11个开源中文分词
或者类似搜索引擎服务器的开源框架:Elasticsearch、Lucene……其他搜索引擎服务可以点这里:了解13个开源搜索引擎
小编这里演示的是一个使用solr搜索引擎实现这个爬取和检索的demo项目
二、启动 solr
solr下载地址:最好下载低版本,高版本需要高jdk版本,我的jdk是1.7,下载的solr版本是4.7.0是的,或者当我下载我在文章末尾制作的演示时,我也会将我使用的所有内容都放入其中。
1、配置步骤
① 下载后解压
② cmd进入这个目录:xxxxx/solr-4.7.0/example
③ 执行命令:java -jar start.jar
④ 如果访问成功,在浏览器中输入:8983/solr即可访问,表示启动成功。
2、Solr接口说明及使用
具体solr的其他功能这里就不介绍了。可以参考网上资料,进一步加深对solr的理解和使用
三、开始爬取
首先在项目中引入solr的maven包
org.apache.solr
solr-solrj
4.7.0
爬取很简单,只是模拟一个浏览器访问内容,我们可以看到要爬取的网站左边的所有文本内容都在
里面,
这个很简单,这样我们就可以对爬取的数据进行正则匹配后得到我们想要的所有文本标题信息。
代码示例:
/**
* 爬取数据
* @return
*/
@ResponseBody
@RequestMapping("/getDocs")
public String getDocs() {
Map mapReturn = new HashMap(); //返回结果
try {
//爬取前先在solr上建林索引属性
alibabaService.addDefaultField();
//开始爬取指定url的数据
String htmlResult = GetAliApi.sendGet("https://help.aliyun.com/docume ... ot%3B, "");
//获取到 树文档的内容
String[] mainMenuListContainer = htmlResult.split("")[1].split("");
//log.debug(mainMenuListContainer[0]);
//log.debug("------------------------------");
//进行正则获取数据
String searchReg = "(.*?)";
Pattern pattern = Pattern.compile(searchReg); // 讲编译的正则表达式对象赋给pattern
Matcher matcher = pattern.matcher(mainMenuListContainer[0]);
int i = 0;
String pre = "A";
while (matcher.find()) {
i++;
String title = matcher.group(1);
log.debug(title);
//将数据放到solr里,添加索引
Alidocs alidocs = new Alidocs();
alidocs.setId(pre+i);
alidocs.setTitle(title);
alibabaService.addIndex(alidocs);
}
mapReturn.put("returnCode","00");
mapReturn.put("content","爬取成功");
}catch (Exception e){
e.printStackTrace();
mapReturn.put("returnCode","-1");
mapReturn.put("content","爬取失败,请重试");
}
String mapStr = JSONObject.toJSONString(mapReturn);
return mapStr;
}
addDefaultField() 方法和 addIndex() 方法:
// 添加默认索引属性
public void addDefaultField() throws SolrServerException, IOException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", "默认情况下必须添加的字段,用来区分文档的唯一标识");
doc.addField("title", "默认的名称属性字段");
solr.add(doc);
solr.commit();
}
// 添加索引
public void addIndex(Alidocs alidocs) throws SolrServerException, IOException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
solr.addBean(alidocs);
solr.commit();
}
sendGet() 方法:
public static String sendGet(String url, String param) {
String result = "";
String urlName = url + "?" + param;
try {
URL realURL = new URL(urlName);
URLConnection conn = realURL.openConnection();
//伪造ip访问
String ip = randIP();
System.out.println("目前伪造的ip:"+ip);
conn.setRequestProperty("X-Forwarded-For", ip);
conn.setRequestProperty("HTTP_X_FORWARDED_FOR", ip);
conn.setRequestProperty("HTTP_CLIENT_IP", ip);
conn.setRequestProperty("REMOTE_ADDR", ip);
conn.setRequestProperty("Host", "help.aliyun.com/");
conn.setRequestProperty("accept", "*/*");
conn.setRequestProperty("connection", "Keep-Alive");
conn.setRequestProperty("user-agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 Safari/537.36");
conn.setRequestProperty("Referer","https://help.aliyun.com/"); //伪造访问来源
conn.setRequestProperty("Origin", "https://help.aliyun.com/"); //伪造访问域名
conn.connect();
Map map = conn.getHeaderFields();
for (String s : map.keySet()) {
System.out.println(s + "-->" + map.get(s));
}
BufferedReader in = new BufferedReader(new InputStreamReader(conn.getInputStream(), "utf-8"));
String line;
while ((line = in.readLine()) != null) {
result += "\n" + line;
}
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
这样,基本上爬取的功能就完成了,可以看到爬取了我们想要的信息
四、通过 关键词 检索
检索比较简单,因为使用了solr搜索引擎的服务,所以只要按照solr api传入数据就可以检索到,它会自动进行分词过滤,按照匹配度。
代码示例:
/**
* 通过关键词获取数据
* @param title
* @return
*/
@ResponseBody
@RequestMapping("/findDocs")
public String findDocs(String title) {
Map mapReturn = new HashMap(); //返回结果
try {
String result = alibabaService.findIndex(title);
mapReturn.put("returnCode","00");
mapReturn.put("content",result);
}catch (Exception e){
e.printStackTrace();
mapReturn.put("returnCode","-1");
mapReturn.put("content","查询异常");
}
String mapStr = JSONObject.toJSONString(mapReturn);
return mapStr;
}
findIndex() 方法:
// 查找索引
public String findIndex(String titleInput) throws SolrServerException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
// 查询条件
SolrQuery solrParams = new SolrQuery();
solrParams.setStart(0);
solrParams.setRows(10);
solrParams.setQuery("title:"+titleInput);
// 开启高亮
solrParams.setHighlight(true);
solrParams.setHighlightSimplePre("");
solrParams.setHighlightSimplePost("");
// 设置高亮的字段
solrParams.setParam("hl.fl", "title");
// SolrParams是SolrQuery的子类
QueryResponse queryResponse = solr.query(solrParams);
// (一)获取查询的结果集合
SolrDocumentList solrDocumentList = queryResponse.getResults();
List contentList = new LinkedList();
for (SolrDocument solrDocument : solrDocumentList) {
Map map = new HashMap();
map.put("id",solrDocument.get("id"));
map.put("title",solrDocument.get("title"));
contentList.add(map);
}
return contentList.toString();
}
五、首页
最后一页是前台,做的不是很好。因为我很着急,我只有一天。我白天必须去上班。晚上只能花几个小时研究后台代码。我不在乎前台。如果有时间可以美化
前端代码示例:
阿里测试题
1、先爬取文档数据
<a class="weui-btn weui-btn_mini weui-btn_primary" id="getDocs">开始爬取</a>
搜索关键词
<a class="weui-btn weui-btn_mini weui-btn_primary" id="findDocs">查询</a>
$('#getDocs').click(function () {
ajaxLoading('爬取中,请稍后...');
$.ajax({
url: "/ali/getDocs",
data: {},
type: 'post',
dataType: 'json',
success: function (data) {
ajaxLoadEnd();
$.MsgBox.Alert("提示",data.content,"确定");
},
error: function () {
$.MsgBox.Alert("异常","爬取发生异常,请联系管理员!","确定");
}
})
})
$('#findDocs').click(function () {
var keytitle = $('.keytitle').val();
if(keytitle==""){
$.MsgBox.Alert("提示","淘气!请输入内容","确定");
return
}
ajaxLoading('查询中...');
$.ajax({
url: "/ali/findDocs",
data: {"title":keytitle},
type: 'post',
dataType: 'json',
success: function (data) {
ajaxLoadEnd();
if (data.returnCode=="00"){
$.MsgBox.Alert("提示",data.content,"确定");
}else {
$.MsgBox.Alert("提示",data.content,"确定");
}
},
error: function () {
$.MsgBox.Alert("异常","查询发生异常,请联系管理员!","确定");
}
})
})
function ajaxLoading(text){
$("").css({display:"block",width:"100%",height:$(window).height()}).appendTo("body");
$("").html(text).appendTo("body").css({display:"block",left:($(document.body).outerWidth(true) - 190) / 2,top:($(window).height() - 45) / 2});
}
function ajaxLoadEnd(){
$(".datagrid-mask").remove();
$(".datagrid-mask-msg").remove();
}
六、运行渲染
这个基本没问题,也很容易完成。和我预想的还是有点不同。不过,为了赶时间,我还是赶紧发了。我在晚上 22 点 21 分左右发送的。我还以为是面试 明天官方要给出结果,但阿里这么好的公司也不是没有道理。面试官当场回复我,说我通过了。有这么敬业的程序员,这样的公司不能牛
七、总结:(附代码下载)
1.先启动solr
解压,在xxxxx/solr-4.7.0/example目录下cmd
执行命令:java -jar start.jar
2、启动项目aliTestProject
然后先点击爬取,稍等片刻,等待页面显示【爬取成功】字样,即可查询
3、查询效果图
整个项目代码下载链接:
参考文章:
感谢原作者分享,让技术人员更快解决问题 查看全部
输入关键字 抓取所有网页(社招进阿里的一个面试呗,你准备好了吗?)
内容
前言
前几天,我接到了外籍人士阿里的面试。作为一个自信狂妄的我,虽然是外籍人士,但对阿里还是有几分敬佩之情,就像高考想进清华北大,想进腾讯阿里工作一样。是的,当然,除了学校招985/211能进阿里外,其他人想通过中介被招进阿里,那就更难了,至少在某个领域是专家级别的。所以如果你有一个难得的机会,试试阿里的采访。
一、采访内容1、电话面试及项目实践题
首先是电话面试:这个一般没问题,多看书,少吃零食,多睡觉……这个肯定能回答
二是想出一个动手demo题目,如下
文档链接:
爬取左侧文档树中的所有文档列表
在查询页面输入关键词或描述性语言给出3个最佳匹配文档(从高匹配到低匹配排序)。
供应:
1. 代码
2. 匹配的想法
奖励:有关如何为描述性语言提供建议的文档。例如用户输入:我的日志 采集 is out
大多数人在听到他们要编写一个演示时都会感到恐慌。不要害怕,我不会和你分享我的经验和代码示例,所以请阅读此文章,之后应该没问题,反正我已经结束了。
2、动手主题:文档抓取和搜索

3、研究课题
首先,去链接看看。让我们来看看它是什么。原来是阿里云的帮助文档。看来这个简单的demo其实就是根据用户输入的关键词搜索对应的解决方案。小项目。

第一个小步骤,爬取内容应该不难。不管是用Java还是Python,难度是第一位的,但是Python可能更简单,Java会多写一点代码。当然,小编目前还是想先学java,所以用java代码来演示。至于Python,先学一门语言,再拓展其他语言,才能更好的辅助你。
难点在于第二个小步骤,“在查询页面输入关键词或者描述性语言,给出最佳匹配的3个文档(匹配度从高到低排序)”,
我们先不爬,因为如果爬,必须封装想要的格式。当我们没有想到查询关键词的功能时,先保留它。
①查询输入关键词,给出最佳匹配方案
当然,你可以自己写算法和匹配,但是这种情况下,匹配肯定不是很准确,一天之内几乎不可能写出来,所以看看前人对这种类型有什么想法更好的解决方案,踩在巨人的肩膀上,事半功倍。
其实有很多方法可以实现类似的功能,
比如通过分词器搜索:Jieba分词、Ansj分词……其他分词效果可以点这里:了解11个开源中文分词
或者类似搜索引擎服务器的开源框架:Elasticsearch、Lucene……其他搜索引擎服务可以点这里:了解13个开源搜索引擎
小编这里演示的是一个使用solr搜索引擎实现这个爬取和检索的demo项目
二、启动 solr
solr下载地址:最好下载低版本,高版本需要高jdk版本,我的jdk是1.7,下载的solr版本是4.7.0是的,或者当我下载我在文章末尾制作的演示时,我也会将我使用的所有内容都放入其中。
1、配置步骤
① 下载后解压
② cmd进入这个目录:xxxxx/solr-4.7.0/example
③ 执行命令:java -jar start.jar
④ 如果访问成功,在浏览器中输入:8983/solr即可访问,表示启动成功。


2、Solr接口说明及使用
具体solr的其他功能这里就不介绍了。可以参考网上资料,进一步加深对solr的理解和使用
三、开始爬取
首先在项目中引入solr的maven包
org.apache.solr
solr-solrj
4.7.0
爬取很简单,只是模拟一个浏览器访问内容,我们可以看到要爬取的网站左边的所有文本内容都在
里面,
这个很简单,这样我们就可以对爬取的数据进行正则匹配后得到我们想要的所有文本标题信息。

代码示例:
/**
* 爬取数据
* @return
*/
@ResponseBody
@RequestMapping("/getDocs")
public String getDocs() {
Map mapReturn = new HashMap(); //返回结果
try {
//爬取前先在solr上建林索引属性
alibabaService.addDefaultField();
//开始爬取指定url的数据
String htmlResult = GetAliApi.sendGet("https://help.aliyun.com/docume ... ot%3B, "");
//获取到 树文档的内容
String[] mainMenuListContainer = htmlResult.split("")[1].split("");
//log.debug(mainMenuListContainer[0]);
//log.debug("------------------------------");
//进行正则获取数据
String searchReg = "(.*?)";
Pattern pattern = Pattern.compile(searchReg); // 讲编译的正则表达式对象赋给pattern
Matcher matcher = pattern.matcher(mainMenuListContainer[0]);
int i = 0;
String pre = "A";
while (matcher.find()) {
i++;
String title = matcher.group(1);
log.debug(title);
//将数据放到solr里,添加索引
Alidocs alidocs = new Alidocs();
alidocs.setId(pre+i);
alidocs.setTitle(title);
alibabaService.addIndex(alidocs);
}
mapReturn.put("returnCode","00");
mapReturn.put("content","爬取成功");
}catch (Exception e){
e.printStackTrace();
mapReturn.put("returnCode","-1");
mapReturn.put("content","爬取失败,请重试");
}
String mapStr = JSONObject.toJSONString(mapReturn);
return mapStr;
}
addDefaultField() 方法和 addIndex() 方法:
// 添加默认索引属性
public void addDefaultField() throws SolrServerException, IOException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", "默认情况下必须添加的字段,用来区分文档的唯一标识");
doc.addField("title", "默认的名称属性字段");
solr.add(doc);
solr.commit();
}
// 添加索引
public void addIndex(Alidocs alidocs) throws SolrServerException, IOException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
solr.addBean(alidocs);
solr.commit();
}
sendGet() 方法:
public static String sendGet(String url, String param) {
String result = "";
String urlName = url + "?" + param;
try {
URL realURL = new URL(urlName);
URLConnection conn = realURL.openConnection();
//伪造ip访问
String ip = randIP();
System.out.println("目前伪造的ip:"+ip);
conn.setRequestProperty("X-Forwarded-For", ip);
conn.setRequestProperty("HTTP_X_FORWARDED_FOR", ip);
conn.setRequestProperty("HTTP_CLIENT_IP", ip);
conn.setRequestProperty("REMOTE_ADDR", ip);
conn.setRequestProperty("Host", "help.aliyun.com/");
conn.setRequestProperty("accept", "*/*");
conn.setRequestProperty("connection", "Keep-Alive");
conn.setRequestProperty("user-agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 Safari/537.36");
conn.setRequestProperty("Referer","https://help.aliyun.com/";); //伪造访问来源
conn.setRequestProperty("Origin", "https://help.aliyun.com/";); //伪造访问域名
conn.connect();
Map map = conn.getHeaderFields();
for (String s : map.keySet()) {
System.out.println(s + "-->" + map.get(s));
}
BufferedReader in = new BufferedReader(new InputStreamReader(conn.getInputStream(), "utf-8"));
String line;
while ((line = in.readLine()) != null) {
result += "\n" + line;
}
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
这样,基本上爬取的功能就完成了,可以看到爬取了我们想要的信息

四、通过 关键词 检索
检索比较简单,因为使用了solr搜索引擎的服务,所以只要按照solr api传入数据就可以检索到,它会自动进行分词过滤,按照匹配度。
代码示例:
/**
* 通过关键词获取数据
* @param title
* @return
*/
@ResponseBody
@RequestMapping("/findDocs")
public String findDocs(String title) {
Map mapReturn = new HashMap(); //返回结果
try {
String result = alibabaService.findIndex(title);
mapReturn.put("returnCode","00");
mapReturn.put("content",result);
}catch (Exception e){
e.printStackTrace();
mapReturn.put("returnCode","-1");
mapReturn.put("content","查询异常");
}
String mapStr = JSONObject.toJSONString(mapReturn);
return mapStr;
}
findIndex() 方法:
// 查找索引
public String findIndex(String titleInput) throws SolrServerException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
// 查询条件
SolrQuery solrParams = new SolrQuery();
solrParams.setStart(0);
solrParams.setRows(10);
solrParams.setQuery("title:"+titleInput);
// 开启高亮
solrParams.setHighlight(true);
solrParams.setHighlightSimplePre("");
solrParams.setHighlightSimplePost("");
// 设置高亮的字段
solrParams.setParam("hl.fl", "title");
// SolrParams是SolrQuery的子类
QueryResponse queryResponse = solr.query(solrParams);
// (一)获取查询的结果集合
SolrDocumentList solrDocumentList = queryResponse.getResults();
List contentList = new LinkedList();
for (SolrDocument solrDocument : solrDocumentList) {
Map map = new HashMap();
map.put("id",solrDocument.get("id"));
map.put("title",solrDocument.get("title"));
contentList.add(map);
}
return contentList.toString();
}
五、首页
最后一页是前台,做的不是很好。因为我很着急,我只有一天。我白天必须去上班。晚上只能花几个小时研究后台代码。我不在乎前台。如果有时间可以美化

前端代码示例:
阿里测试题
1、先爬取文档数据
<a class="weui-btn weui-btn_mini weui-btn_primary" id="getDocs">开始爬取</a>
搜索关键词
<a class="weui-btn weui-btn_mini weui-btn_primary" id="findDocs">查询</a>
$('#getDocs').click(function () {
ajaxLoading('爬取中,请稍后...');
$.ajax({
url: "/ali/getDocs",
data: {},
type: 'post',
dataType: 'json',
success: function (data) {
ajaxLoadEnd();
$.MsgBox.Alert("提示",data.content,"确定");
},
error: function () {
$.MsgBox.Alert("异常","爬取发生异常,请联系管理员!","确定");
}
})
})
$('#findDocs').click(function () {
var keytitle = $('.keytitle').val();
if(keytitle==""){
$.MsgBox.Alert("提示","淘气!请输入内容","确定");
return
}
ajaxLoading('查询中...');
$.ajax({
url: "/ali/findDocs",
data: {"title":keytitle},
type: 'post',
dataType: 'json',
success: function (data) {
ajaxLoadEnd();
if (data.returnCode=="00"){
$.MsgBox.Alert("提示",data.content,"确定");
}else {
$.MsgBox.Alert("提示",data.content,"确定");
}
},
error: function () {
$.MsgBox.Alert("异常","查询发生异常,请联系管理员!","确定");
}
})
})
function ajaxLoading(text){
$("").css({display:"block",width:"100%",height:$(window).height()}).appendTo("body");
$("").html(text).appendTo("body").css({display:"block",left:($(document.body).outerWidth(true) - 190) / 2,top:($(window).height() - 45) / 2});
}
function ajaxLoadEnd(){
$(".datagrid-mask").remove();
$(".datagrid-mask-msg").remove();
}
六、运行渲染

这个基本没问题,也很容易完成。和我预想的还是有点不同。不过,为了赶时间,我还是赶紧发了。我在晚上 22 点 21 分左右发送的。我还以为是面试 明天官方要给出结果,但阿里这么好的公司也不是没有道理。面试官当场回复我,说我通过了。有这么敬业的程序员,这样的公司不能牛


七、总结:(附代码下载)
1.先启动solr
解压,在xxxxx/solr-4.7.0/example目录下cmd
执行命令:java -jar start.jar
2、启动项目aliTestProject
然后先点击爬取,稍等片刻,等待页面显示【爬取成功】字样,即可查询
3、查询效果图
整个项目代码下载链接:
参考文章:
感谢原作者分享,让技术人员更快解决问题
输入关键字 抓取所有网页(如何在搜索引擎上输入「JoeBloggs」的搜索结果? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-05 19:09
)
1、精确搜索 - 双引号
准确搜索最简单、最有效的方法是在 关键词 周围加上双引号,在这种情况下,搜索引擎将只返回与 关键词 完全匹配的搜索结果。
例如,在搜索“Joe Bloggs”时,如果不给关键词加上双引号,搜索引擎会分别显示所有与“Joe”和“Bloggs”相关的信息,但这些显然不是我们的。期望的结果。但加双引号后,搜索引擎只会返回页面上匹配“Joe Bloggs”的信息。
准确的搜索对于排除常见但低相似度的信息很有用,为用户省去了重新过滤结果的麻烦。
2、排除关键词
如果精确搜索没有找到他们正在寻找的内容,用户可以通过简单地使用减号来排除收录某些单词的信息。
例如,当您搜索“'Joe Bloggs'-jeans”时,您会得到一个不收录单词“jeans”的“Joe Bloggs”条目。
3、使用“非或”逻辑搜索
默认搜索下,搜索引擎会返回所有与查询词相关的结果,但是通过“OR”逻辑,可以分别得到两个关键词相关的结果,而不只是两个关键词同时相关结果。巧妙地使用“OR”搜索可以确保您的搜索结果准确无误,即使您不确定哪个 关键词 对您的搜索结果负责。
4、同义词搜索
有时搜索不太精确的 关键词 更合适。在没有准确判断关键词的情况下,可以按同义词搜索。
如果您在搜索引擎中输入“plumbing ~university”,您将获得包括“plumbing university”和“plumbing colleges”等类似项目的反馈。
5、在网站内搜索
网站 的大部分搜索功能都缺乏,所以更好的方法是通过谷歌等搜索引擎搜索网站上的信息。
您只需在搜索引擎上输入“site:”加关键词,搜索引擎就会返回所有与网站“”中的关键词相关的项目。结合精准搜索功能,此功能将更加强大。
6、善用星号
就像拼图“Scrabble”的空白方块一样,在搜索引擎中,我们可以用星号填充关键词中缺失的部分,无论缺失的部分是单词序列还是单词的一部分。另外,当你想搜索一个不太确定的文章时,你也可以用星号来填补缺失的部分。
例如,如果您在搜索引擎中输入“architect*”,您将获得所有收录架构、架构、架构、架构、架构以及所有其他以“架构师”开头的词的条目的反馈。
7、在两个值之间搜索
在寻找问题的答案时,一个很好的方法是在一定范围内寻找与 关键词 相关的信息。比如要查找1920年到1950年间的英国首相,可以直接在搜索引擎中输入“英国首相1920..1950”得到想要的结果。
请记住,值之间的符号是两个句点加上一个空格键。
8、搜索网页标题、链接和正文关键词
有时您可能会遇到需要查找所有与 关键词 相关的页面标题、链接和页面正文,这种情况下您需要使用限定符“inurl:”(用于在 url 链接中搜索)、“intext:”(用于在页面正文中搜索)和“intitle:”(用于在页面标题中搜索)。
例如,在搜索引擎中输入“intitle:reviews”将获得与关键词“reviews”相关的所有页面标题。
9、搜索相关网站
搜索相关 网站 时可以使用相关限定符。例如,您只需要在搜索引擎中输入“related:”即可获得所有与“”相关的网站反馈结果。
10、搜索技巧的组合使用
您可以结合上述所有搜索技巧,根据需要缩小或扩大搜索范围。虽然有些技能可能不常用,但准确搜索和站点搜索技能的使用范围相当广泛。
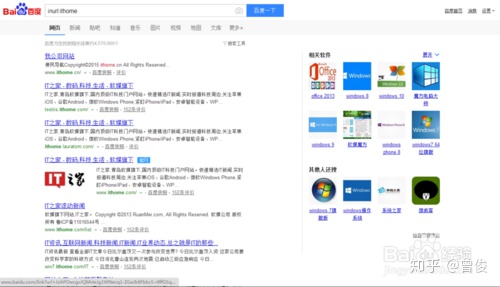
11、inurl 和 allinurl
格式为“inurl:XXX”(冒号为英文)和“allinurl:XXX YYY”。inurl的作用是搜索结果是一个带有“XXX”的地址页面(支持中英文)。例如搜索“inurl:ithome”的结果如下
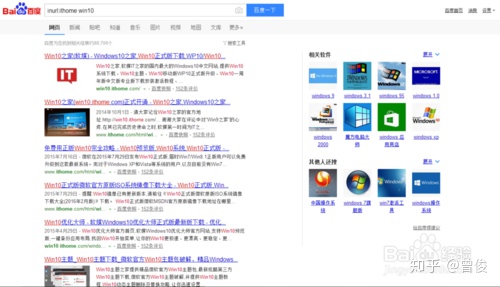
同理,allinurl的作用就是结果中有“XXX”和“YYY”,相当于“inurl:XXX inurl:YYY”,效果如下
除了可以让您找到相关页面之外,该命令还可以找到与您的网站 使用相同关键字的“朋友网站”。至于是互相学习,还是发现后明辨是非,就看你的实际需要了。
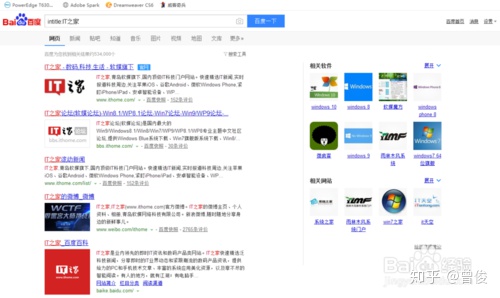
12、intitle 和 allintitle
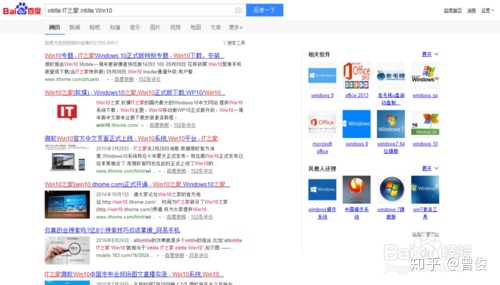
格式为“intitle:XXX”和“allintitle:XXX YYY...”,intitle搜索结果为网页标题中收录“XXX”的内容,效果如下
alltintitle的效果是多个intitles的组合。例如,“alltintitle IT Home Win10”等价于“intitle IT Home intitle Win10”,如下图
一般来说,在标题中添加关键词是一种很好的SEO优化方法,有助于提高搜索排名,所以这种搜索方法可以查看哪些“朋友”在为关键词而战。
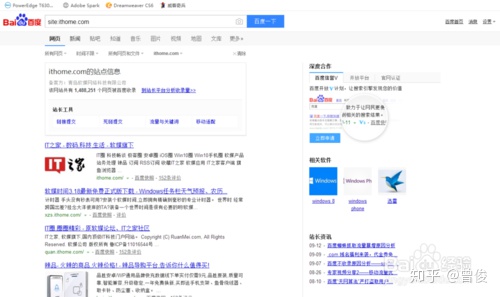
13、站点
格式为“site:XXX”,用于搜索一个域名下的所有内容,如“site:”,如下图
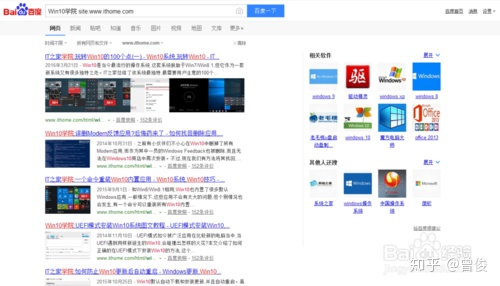
如果只想在某一个网站中搜索,可以使用“Win10 College site:”的形式(不加http或URL前),效果如下
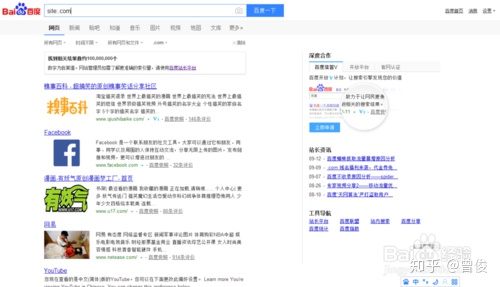
也可以搜索某类域名,如“site:.com”“site:.cn”,如下图
以上方法可以任意组合(每个方法之间留一个空格,不要直接连接),比如输入“site:inurl:Win10 intitle:老驱动“Redstone 2”+Cortana”,就会给出效果链接如下
14、文件类型
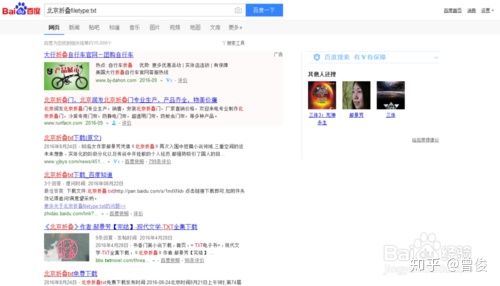
这个可以用来搜索特定格式的文件,比如搜索“Beijing folded filetype:txt”,如下图
查看全部
输入关键字 抓取所有网页(如何在搜索引擎上输入「JoeBloggs」的搜索结果?
)
1、精确搜索 - 双引号
准确搜索最简单、最有效的方法是在 关键词 周围加上双引号,在这种情况下,搜索引擎将只返回与 关键词 完全匹配的搜索结果。
例如,在搜索“Joe Bloggs”时,如果不给关键词加上双引号,搜索引擎会分别显示所有与“Joe”和“Bloggs”相关的信息,但这些显然不是我们的。期望的结果。但加双引号后,搜索引擎只会返回页面上匹配“Joe Bloggs”的信息。
准确的搜索对于排除常见但低相似度的信息很有用,为用户省去了重新过滤结果的麻烦。
2、排除关键词
如果精确搜索没有找到他们正在寻找的内容,用户可以通过简单地使用减号来排除收录某些单词的信息。
例如,当您搜索“'Joe Bloggs'-jeans”时,您会得到一个不收录单词“jeans”的“Joe Bloggs”条目。
3、使用“非或”逻辑搜索
默认搜索下,搜索引擎会返回所有与查询词相关的结果,但是通过“OR”逻辑,可以分别得到两个关键词相关的结果,而不只是两个关键词同时相关结果。巧妙地使用“OR”搜索可以确保您的搜索结果准确无误,即使您不确定哪个 关键词 对您的搜索结果负责。
4、同义词搜索
有时搜索不太精确的 关键词 更合适。在没有准确判断关键词的情况下,可以按同义词搜索。
如果您在搜索引擎中输入“plumbing ~university”,您将获得包括“plumbing university”和“plumbing colleges”等类似项目的反馈。
5、在网站内搜索
网站 的大部分搜索功能都缺乏,所以更好的方法是通过谷歌等搜索引擎搜索网站上的信息。
您只需在搜索引擎上输入“site:”加关键词,搜索引擎就会返回所有与网站“”中的关键词相关的项目。结合精准搜索功能,此功能将更加强大。
6、善用星号
就像拼图“Scrabble”的空白方块一样,在搜索引擎中,我们可以用星号填充关键词中缺失的部分,无论缺失的部分是单词序列还是单词的一部分。另外,当你想搜索一个不太确定的文章时,你也可以用星号来填补缺失的部分。
例如,如果您在搜索引擎中输入“architect*”,您将获得所有收录架构、架构、架构、架构、架构以及所有其他以“架构师”开头的词的条目的反馈。
7、在两个值之间搜索
在寻找问题的答案时,一个很好的方法是在一定范围内寻找与 关键词 相关的信息。比如要查找1920年到1950年间的英国首相,可以直接在搜索引擎中输入“英国首相1920..1950”得到想要的结果。
请记住,值之间的符号是两个句点加上一个空格键。
8、搜索网页标题、链接和正文关键词
有时您可能会遇到需要查找所有与 关键词 相关的页面标题、链接和页面正文,这种情况下您需要使用限定符“inurl:”(用于在 url 链接中搜索)、“intext:”(用于在页面正文中搜索)和“intitle:”(用于在页面标题中搜索)。
例如,在搜索引擎中输入“intitle:reviews”将获得与关键词“reviews”相关的所有页面标题。
9、搜索相关网站
搜索相关 网站 时可以使用相关限定符。例如,您只需要在搜索引擎中输入“related:”即可获得所有与“”相关的网站反馈结果。
10、搜索技巧的组合使用
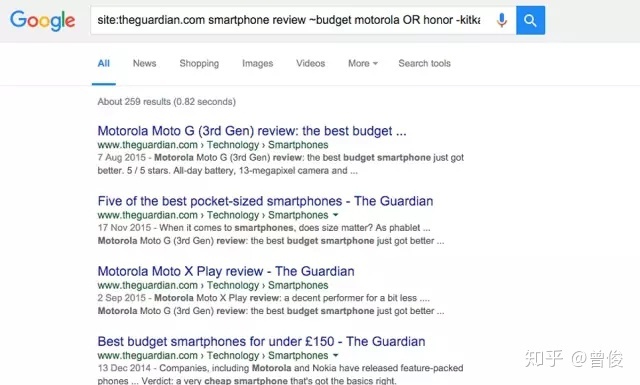
您可以结合上述所有搜索技巧,根据需要缩小或扩大搜索范围。虽然有些技能可能不常用,但准确搜索和站点搜索技能的使用范围相当广泛。
11、inurl 和 allinurl
格式为“inurl:XXX”(冒号为英文)和“allinurl:XXX YYY”。inurl的作用是搜索结果是一个带有“XXX”的地址页面(支持中英文)。例如搜索“inurl:ithome”的结果如下
同理,allinurl的作用就是结果中有“XXX”和“YYY”,相当于“inurl:XXX inurl:YYY”,效果如下
除了可以让您找到相关页面之外,该命令还可以找到与您的网站 使用相同关键字的“朋友网站”。至于是互相学习,还是发现后明辨是非,就看你的实际需要了。
12、intitle 和 allintitle
格式为“intitle:XXX”和“allintitle:XXX YYY...”,intitle搜索结果为网页标题中收录“XXX”的内容,效果如下
alltintitle的效果是多个intitles的组合。例如,“alltintitle IT Home Win10”等价于“intitle IT Home intitle Win10”,如下图
一般来说,在标题中添加关键词是一种很好的SEO优化方法,有助于提高搜索排名,所以这种搜索方法可以查看哪些“朋友”在为关键词而战。
13、站点
格式为“site:XXX”,用于搜索一个域名下的所有内容,如“site:”,如下图
如果只想在某一个网站中搜索,可以使用“Win10 College site:”的形式(不加http或URL前),效果如下
也可以搜索某类域名,如“site:.com”“site:.cn”,如下图
以上方法可以任意组合(每个方法之间留一个空格,不要直接连接),比如输入“site:inurl:Win10 intitle:老驱动“Redstone 2”+Cortana”,就会给出效果链接如下
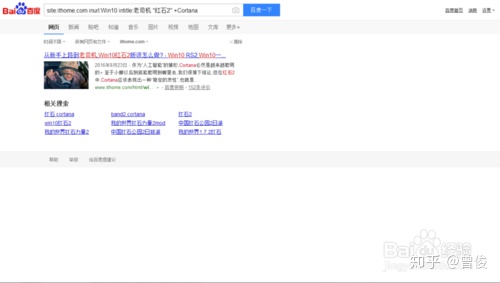
14、文件类型
这个可以用来搜索特定格式的文件,比如搜索“Beijing folded filetype:txt”,如下图
输入关键字 抓取所有网页( 谷歌排名优化要多久才能上首页?最常听到的说法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-05 02:04
谷歌排名优化要多久才能上首页?最常听到的说法)
谷歌进入前10需要多长时间
很多做谷歌优化的站长都关心一个问题:谷歌排名优化多久能上首页?
最常听到的说法是,对此确实没有准确的答案。
不过最近国外一家SEO研究机构通过Ahrefs的研究总结出一些信息,比如:前10名网页中只有22%是在一年内创建的,而且大部分网页创建时间超过三年。年;网站有比较好的域名评级,但也有较大的领先等。
众所周知,Ahrefs 是 Google SEO 最强大的辅助工具之一。面对“在 Google 上排名需要多长时间?”的问题。历史排名数据,决定给出一个稍微具体一些、可量化的答案。
通过这些数据,小5也大致梳理了几个关键点,一起来详细看看吧。
一、排名最高的网站做了多久了?
为了查看排名靠前的页面运行了多长时间,Ahrefs 随机抽取了 200 万个关键词,并将它们列在前 10 个页面中以提取数据。
网站平均年龄(天)的 Google 前 10 个结果
从图表可以看出:前10名网站,平均建站时间2年以上;排名第一的是将近 3 年。
这是一个事实,目前只有大约 22% 的前 10 个页面是在一年内创建的。
Google 的前 10 名搜索结果中每个排名的百分比是多少,该页面是在不到一年前创建的:
画面很明显:页面创建时间不到1年,排名第一也只有1%左右!
二、在 Google 上排名需要多长时间?
为了回答这个问题,Ahrefs 随机选择了 200 万页。
这些页面是一年前被他们的爬虫首次抓取的,所以他们跟踪了每个页面的排名历史。
排名百分比数据图
仅 5.7% 的 网站 排名前 10
10-100位的比例为19.5%
网站 100, 74.8%
域名评级关系比例图
域名评分高,前10名网站占比10.8%
且域名评分低,排名前10的比例仅为3.0%
可以看出,具有 网站 的高域评级 (DR) 的页面也比具有较低 DR 的页面表现更好。
DR(域名评级):
该统计数据与所有 网站 页面的整体排名关系最为密切。该值越高,网站所有页面被排名的机会就越大。DR 是基于链接到您 网站 的所有反向链接的质量和数量。
链接到整个 网站 的反向链接越多越好,价值越高,这在 Ahrefs 工具中很常见。
接下来,我们将放大 5.7% 的“幸运”页面,看看它们从无名到前 10 的速度有多快。
数据显示,他们中的大多数是在第 61 天到第 182 天。
在所有这些新发布的页面中,只有 5.7% 会在一年内进入 Google 前 10 名。
Ahrefs 还根据 关键词 重新计算数字,每月搜索:
1年内“第一抓”页面排名
这表明在不到一年的时间里,只有 0.3% 的页面排在前 10 位。
以下是这些 5.7% 所谓的“幸运”页面上发生的情况,按排名关键字的搜索量细分:
这些幸运页面排在前 10 名的天数
可以清楚的看到高搜索量达到68.4%的时间大约是1年。即使有这 5.7% 的前 10 个“幸运”页面,绝大多数页面的性能都不是很好。
三、终于
通过 Ahrefs 的数据,我们了解到几乎 95% 的新发布页面在一年内都没有进入前 10。
虽然有些“幸运”的人可以做到这一点,但时间大概需要2-6个月左右。
对于公司或品牌而言,SEO 取决于许多不同的因素,包括域权限、关键词 竞争和许多页面技术元素。其中一些在不到一年的时间内就进入了前 10 名,这可能是因为现有的域权限和 SEO 知识。
根据Ahrefs的数据,按照一般的分析,要想提升自己在Google的排名,就需要更多的沉淀。 查看全部
输入关键字 抓取所有网页(
谷歌排名优化要多久才能上首页?最常听到的说法)
谷歌进入前10需要多长时间
很多做谷歌优化的站长都关心一个问题:谷歌排名优化多久能上首页?
最常听到的说法是,对此确实没有准确的答案。
不过最近国外一家SEO研究机构通过Ahrefs的研究总结出一些信息,比如:前10名网页中只有22%是在一年内创建的,而且大部分网页创建时间超过三年。年;网站有比较好的域名评级,但也有较大的领先等。
众所周知,Ahrefs 是 Google SEO 最强大的辅助工具之一。面对“在 Google 上排名需要多长时间?”的问题。历史排名数据,决定给出一个稍微具体一些、可量化的答案。
通过这些数据,小5也大致梳理了几个关键点,一起来详细看看吧。
一、排名最高的网站做了多久了?
为了查看排名靠前的页面运行了多长时间,Ahrefs 随机抽取了 200 万个关键词,并将它们列在前 10 个页面中以提取数据。
网站平均年龄(天)的 Google 前 10 个结果
从图表可以看出:前10名网站,平均建站时间2年以上;排名第一的是将近 3 年。
这是一个事实,目前只有大约 22% 的前 10 个页面是在一年内创建的。
Google 的前 10 名搜索结果中每个排名的百分比是多少,该页面是在不到一年前创建的:
画面很明显:页面创建时间不到1年,排名第一也只有1%左右!
二、在 Google 上排名需要多长时间?
为了回答这个问题,Ahrefs 随机选择了 200 万页。
这些页面是一年前被他们的爬虫首次抓取的,所以他们跟踪了每个页面的排名历史。
排名百分比数据图
仅 5.7% 的 网站 排名前 10
10-100位的比例为19.5%
网站 100, 74.8%
域名评级关系比例图
域名评分高,前10名网站占比10.8%
且域名评分低,排名前10的比例仅为3.0%
可以看出,具有 网站 的高域评级 (DR) 的页面也比具有较低 DR 的页面表现更好。
DR(域名评级):
该统计数据与所有 网站 页面的整体排名关系最为密切。该值越高,网站所有页面被排名的机会就越大。DR 是基于链接到您 网站 的所有反向链接的质量和数量。
链接到整个 网站 的反向链接越多越好,价值越高,这在 Ahrefs 工具中很常见。
接下来,我们将放大 5.7% 的“幸运”页面,看看它们从无名到前 10 的速度有多快。
数据显示,他们中的大多数是在第 61 天到第 182 天。
在所有这些新发布的页面中,只有 5.7% 会在一年内进入 Google 前 10 名。
Ahrefs 还根据 关键词 重新计算数字,每月搜索:
1年内“第一抓”页面排名
这表明在不到一年的时间里,只有 0.3% 的页面排在前 10 位。
以下是这些 5.7% 所谓的“幸运”页面上发生的情况,按排名关键字的搜索量细分:
这些幸运页面排在前 10 名的天数
可以清楚的看到高搜索量达到68.4%的时间大约是1年。即使有这 5.7% 的前 10 个“幸运”页面,绝大多数页面的性能都不是很好。
三、终于
通过 Ahrefs 的数据,我们了解到几乎 95% 的新发布页面在一年内都没有进入前 10。
虽然有些“幸运”的人可以做到这一点,但时间大概需要2-6个月左右。
对于公司或品牌而言,SEO 取决于许多不同的因素,包括域权限、关键词 竞争和许多页面技术元素。其中一些在不到一年的时间内就进入了前 10 名,这可能是因为现有的域权限和 SEO 知识。
根据Ahrefs的数据,按照一般的分析,要想提升自己在Google的排名,就需要更多的沉淀。
输入关键字 抓取所有网页(新浪搜索主页面中的输入关键词链接和计算相似度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-05 02:02
前段时间写了一个爬虫,在新浪搜索主页面实现输入关键词,爬取关键词相关新闻的标题、发布时间、url、关键词和内容。并根据内容提取摘要并计算相似度。下面解释一下我自己的想法并给出代码的github链接:
1、获取关键词新闻页面url
在新浪搜索首页输入关键词,点击搜索后会自动链接到关键词的新闻界面。有两种方法可以获取此页面的 url。本文提供了三种方法。
1)静态爬取
从新浪搜索首页,输入关键词,进入kerwords相关的新闻页面,手动获取url链接,然后将url中的关键词替换为需要输入的关键词,获取新的url,发送新的url 请求,获取该网页的源代码。缺点:对于动态网页,这种方式获取的url,发送请求获取的网页源代码与在搜索界面手动输入关键词获取的页面源代码不一致。
2)动态捕捉
模拟浏览器行为并爬取 关键词 新闻相关页面。方法有两种,一种是确定使用的浏览器,使用程序调用浏览器,操作输入和搜索过程;另一种是用程序模拟无界面、无界面的浏览器的行为。关键词页面的url和页面源代码。如图,进入搜索首页,输入关键词语言,会跳转到搜索结果页面。
2、分析关键词新闻页面信息
1)求搜索到的新闻文章数,根据一页的新闻数计算出与关键词次相关的新闻页数。找出不同页面之间的url联系,生成翻页的url。
如上图,新闻界面出现“查找7651条相关新闻文章”,使用正则匹配等方法得到'7651',根据一条上出现的新闻m个数计算相关新闻页数新浪新闻搜索页面:int(7651/m)。
2)在一个页面中,找到新闻的url。
查看页面源码,找到新闻对应的url。如上图所示,当新闻url出现时,同样的规则是“”,所以页面源码中的所有url都可以按照这个规则提取出来。
3、从新闻页面中提取信息
根据新闻的url,进入新闻页面,找到标题、发布时间、关键词、内容、描述内容并提取出来。其中,需要注意解码问题。网页的源代码是用不同的编码格式编写的,所以要注意解码。
1)新闻中没有关键字,采用生成关键词的方式。根据新闻内容,计算内容中的词频,根据词频确定输出词为关键词;
2)新闻中的摘要生成采用抽取的方式,借鉴了Stonewood博客的代码(链接如下:)。
3)关键词与新闻相似。根据新闻标题、关键词和内容,分配不同的权重来计算相似度。具体思路如下:
a) 关键字和标题
关键字和标题都收录与输入词相关的词,权重值kT_W=0.8;只有标题收录输入词,相关词权重值kT_W=0.7;只有key词收录与输入词相关的词,权重值kT_W=0.6;其他权重值kT_W=0.6。
b) 在新闻内容中:新闻内容中自然语言相关词的词频内容_P
c) 相似度的最终计算公式为:
4、代码(运行环境python)
代码链接:
已经自带了需要下载的文件和安装相关模块后代码中需要的文件。并给出了对应的python2和python3代码 查看全部
输入关键字 抓取所有网页(新浪搜索主页面中的输入关键词链接和计算相似度)
前段时间写了一个爬虫,在新浪搜索主页面实现输入关键词,爬取关键词相关新闻的标题、发布时间、url、关键词和内容。并根据内容提取摘要并计算相似度。下面解释一下我自己的想法并给出代码的github链接:
1、获取关键词新闻页面url
在新浪搜索首页输入关键词,点击搜索后会自动链接到关键词的新闻界面。有两种方法可以获取此页面的 url。本文提供了三种方法。
1)静态爬取
从新浪搜索首页,输入关键词,进入kerwords相关的新闻页面,手动获取url链接,然后将url中的关键词替换为需要输入的关键词,获取新的url,发送新的url 请求,获取该网页的源代码。缺点:对于动态网页,这种方式获取的url,发送请求获取的网页源代码与在搜索界面手动输入关键词获取的页面源代码不一致。
2)动态捕捉
模拟浏览器行为并爬取 关键词 新闻相关页面。方法有两种,一种是确定使用的浏览器,使用程序调用浏览器,操作输入和搜索过程;另一种是用程序模拟无界面、无界面的浏览器的行为。关键词页面的url和页面源代码。如图,进入搜索首页,输入关键词语言,会跳转到搜索结果页面。

2、分析关键词新闻页面信息
1)求搜索到的新闻文章数,根据一页的新闻数计算出与关键词次相关的新闻页数。找出不同页面之间的url联系,生成翻页的url。
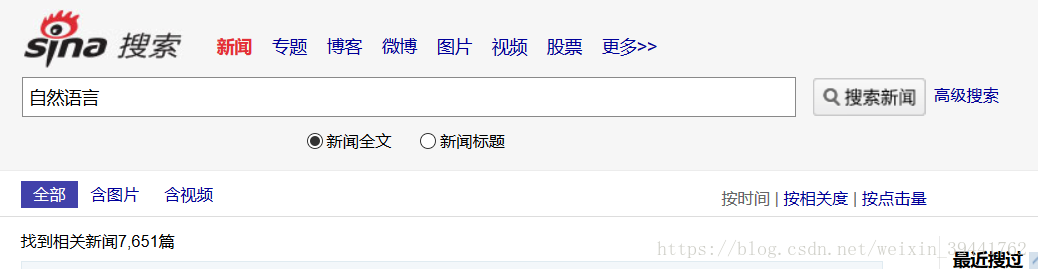
如上图,新闻界面出现“查找7651条相关新闻文章”,使用正则匹配等方法得到'7651',根据一条上出现的新闻m个数计算相关新闻页数新浪新闻搜索页面:int(7651/m)。
2)在一个页面中,找到新闻的url。

查看页面源码,找到新闻对应的url。如上图所示,当新闻url出现时,同样的规则是“”,所以页面源码中的所有url都可以按照这个规则提取出来。
3、从新闻页面中提取信息
根据新闻的url,进入新闻页面,找到标题、发布时间、关键词、内容、描述内容并提取出来。其中,需要注意解码问题。网页的源代码是用不同的编码格式编写的,所以要注意解码。
1)新闻中没有关键字,采用生成关键词的方式。根据新闻内容,计算内容中的词频,根据词频确定输出词为关键词;
2)新闻中的摘要生成采用抽取的方式,借鉴了Stonewood博客的代码(链接如下:)。
3)关键词与新闻相似。根据新闻标题、关键词和内容,分配不同的权重来计算相似度。具体思路如下:
a) 关键字和标题
关键字和标题都收录与输入词相关的词,权重值kT_W=0.8;只有标题收录输入词,相关词权重值kT_W=0.7;只有key词收录与输入词相关的词,权重值kT_W=0.6;其他权重值kT_W=0.6。
b) 在新闻内容中:新闻内容中自然语言相关词的词频内容_P

c) 相似度的最终计算公式为:
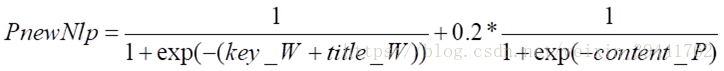
4、代码(运行环境python)
代码链接:
已经自带了需要下载的文件和安装相关模块后代码中需要的文件。并给出了对应的python2和python3代码
输入关键字 抓取所有网页( “请输入关键词”是基于搜索框的设置吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-05 02:01
“请输入关键词”是基于搜索框的设置吗?)
beat365手机版如何设置“请输入关键字”搜索框
请输入查询关键词,以下是人们在访问任何网站 时经常在搜索框中看到的一些常用设置。对于用户来说不是一个值得注意的地方,但对于 SEO,“请输入 关键词”是一个基于搜索框的设置,值得更多研究。原因很简单,这可能会直观地影响企业产品的转型。
那么如何设置“请输入关键词”搜索框呢?
根据以往SEO站优化的经验,今天将通过以下内容进行讲解:
1.基于SEO的优化
从SEO的角度看“请输入搜索关键词”这个问题,其实大家都是在说搜索框和站点内搜索结果的反馈,但是基于SEO,并不是此处讨论:请输入 关键词,内容本身。
您可能需要从以下两个角度来理解:
(1)推荐并收录在内。
如果你有优化电商网站的经验,你会发现一个小的细分策略就是利用网站上的搜索框,类似于京东的热门电商网站,请输入关键词位置,生成大量长尾词,合理使用搜索结果列表,显示数量,适当增加关键词在SERP中的密度,以获得更高的排行。
但值得注意的是,要完美地使用此策略,您可能需要两个小前提:
一是对方有大量的搜索查询需求。
其次,站点中的搜索框,即搜索结果页面的输出,必须符合搜索引擎友好的URL。
② 屏蔽和隐藏。
就相当于中小企业的网站而言,如果你的数据网站搜索量不大,这里大家通常给出的建议是用robots.txt屏蔽搜索结果的URL。
尤其是当你的SERP页面没有SEO规范的时候,由于网站资源有限,真的没有必要委派百度爬虫去爬这些页面。
2.基于用户体验
从用户体验的角度来看,在站内搜索框中输入内容设置尤为重要,例如:
(1)有利于推荐公司核心产品,提高公司产品转化率。
②有利于推荐网站核心话题,提高UGC内容的输出。
③有利于在网站中推荐核心话题,延迟用户的页面停留时间,增加用户对网站品牌的粘性。
为此,您可能需要:
(1)做详细的网站统计分析,了解用户的头像,他们的喜好和喜好。
②掌握行业最新热点话题,适当利用站内多个入口,分发优质内容,引导对方参与讨论,增加栏目页面当前热点话题的热度,从而提高搜索引擎的信任。
3.您输入的搜索词不正确
当你在搜索框中输入一些关键词时,如果对方搜索到的具体关键词没有搜索结果,通常90%以上的网站都会返回空结果,或消息“您输入的 关键词 不正确”标志。
其实这是一个很不明智的策略,你可以在这个地方给出如下反馈:
(1)网站逻辑结构图,类似于HTML版的sitemap。
②“请输入查询关键词”,最近用户非常关注,推荐搜索一些热门词。
③ 站内热点文章,业内最热门的相关话题等。
总结:请输入搜索关键词,貌似是个微不足道的地方。经过详细的设置,还是可以起到积极的作用。以上内容仅供参考。今天就在这里分析一下。你可以多尝试! 查看全部
输入关键字 抓取所有网页(
“请输入关键词”是基于搜索框的设置吗?)
beat365手机版如何设置“请输入关键字”搜索框
请输入查询关键词,以下是人们在访问任何网站 时经常在搜索框中看到的一些常用设置。对于用户来说不是一个值得注意的地方,但对于 SEO,“请输入 关键词”是一个基于搜索框的设置,值得更多研究。原因很简单,这可能会直观地影响企业产品的转型。
那么如何设置“请输入关键词”搜索框呢?
根据以往SEO站优化的经验,今天将通过以下内容进行讲解:

1.基于SEO的优化
从SEO的角度看“请输入搜索关键词”这个问题,其实大家都是在说搜索框和站点内搜索结果的反馈,但是基于SEO,并不是此处讨论:请输入 关键词,内容本身。
您可能需要从以下两个角度来理解:
(1)推荐并收录在内。
如果你有优化电商网站的经验,你会发现一个小的细分策略就是利用网站上的搜索框,类似于京东的热门电商网站,请输入关键词位置,生成大量长尾词,合理使用搜索结果列表,显示数量,适当增加关键词在SERP中的密度,以获得更高的排行。
但值得注意的是,要完美地使用此策略,您可能需要两个小前提:
一是对方有大量的搜索查询需求。
其次,站点中的搜索框,即搜索结果页面的输出,必须符合搜索引擎友好的URL。
② 屏蔽和隐藏。
就相当于中小企业的网站而言,如果你的数据网站搜索量不大,这里大家通常给出的建议是用robots.txt屏蔽搜索结果的URL。
尤其是当你的SERP页面没有SEO规范的时候,由于网站资源有限,真的没有必要委派百度爬虫去爬这些页面。

2.基于用户体验
从用户体验的角度来看,在站内搜索框中输入内容设置尤为重要,例如:
(1)有利于推荐公司核心产品,提高公司产品转化率。
②有利于推荐网站核心话题,提高UGC内容的输出。
③有利于在网站中推荐核心话题,延迟用户的页面停留时间,增加用户对网站品牌的粘性。
为此,您可能需要:
(1)做详细的网站统计分析,了解用户的头像,他们的喜好和喜好。
②掌握行业最新热点话题,适当利用站内多个入口,分发优质内容,引导对方参与讨论,增加栏目页面当前热点话题的热度,从而提高搜索引擎的信任。

3.您输入的搜索词不正确
当你在搜索框中输入一些关键词时,如果对方搜索到的具体关键词没有搜索结果,通常90%以上的网站都会返回空结果,或消息“您输入的 关键词 不正确”标志。
其实这是一个很不明智的策略,你可以在这个地方给出如下反馈:
(1)网站逻辑结构图,类似于HTML版的sitemap。
②“请输入查询关键词”,最近用户非常关注,推荐搜索一些热门词。
③ 站内热点文章,业内最热门的相关话题等。
总结:请输入搜索关键词,貌似是个微不足道的地方。经过详细的设置,还是可以起到积极的作用。以上内容仅供参考。今天就在这里分析一下。你可以多尝试!
输入关键字 抓取所有网页(智能识别模式自动识别网页中的数据采集软件,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 554 次浏览 • 2022-02-05 02:00
WebHarvy 是一款功能强大的网页数据采集 软件。软件操作界面简洁明了。用户只需在系统内置浏览器中输入地址,即可提取并保存视频、图片等所有网页数据。很方便。
【特点】可视化点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“指向下一页的链接,WebHarvy网站 刮板将自动从所有页面中刮取数据。
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
通过代理服务器提取
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
【使用方法】1、启动软件,提示解锁,即需要添加官方授权文件才能使用
2、解压下载的文件,双击“URET NFO v2.2.exe”
3、通知您 SysNucleus WebHarvy 软件已授权给 SMR
4、导航到需要从中提取数据的网页。您可以使用内置浏览器加载和浏览网页
5、要截取部分文本,请选择并突出显示。在选择下面的选项之前,请确定所需的部分。
6、只要输入你分析的网页的网址,最上方的网址就是地址输入栏
7、输入地址直接在网页上打开
8、选择配置功能,可以点击第一个Start Config开始配置下载网页数据的程序 查看全部
输入关键字 抓取所有网页(智能识别模式自动识别网页中的数据采集软件,你了解多少?)
WebHarvy 是一款功能强大的网页数据采集 软件。软件操作界面简洁明了。用户只需在系统内置浏览器中输入地址,即可提取并保存视频、图片等所有网页数据。很方便。

【特点】可视化点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“指向下一页的链接,WebHarvy网站 刮板将自动从所有页面中刮取数据。
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
通过代理服务器提取
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
【使用方法】1、启动软件,提示解锁,即需要添加官方授权文件才能使用

2、解压下载的文件,双击“URET NFO v2.2.exe”
3、通知您 SysNucleus WebHarvy 软件已授权给 SMR
4、导航到需要从中提取数据的网页。您可以使用内置浏览器加载和浏览网页
5、要截取部分文本,请选择并突出显示。在选择下面的选项之前,请确定所需的部分。

6、只要输入你分析的网页的网址,最上方的网址就是地址输入栏
7、输入地址直接在网页上打开
8、选择配置功能,可以点击第一个Start Config开始配置下载网页数据的程序
输入关键字 抓取所有网页(烟台网站建设优化来讲列表页的注意事项有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-04 11:19
摘要:烟台网站构建一个完整的网站大概需要以下网页文件,对于一些较大的网站等文件,可以根据需要设置,如下:
1.首页这是网站的基础页面,是打开网站时呈现给我们的,一般会显示网站新更新的内容在主页上。易时代关注公司动态。
2.列表页列表页首页有导航栏或列表导航栏。点击后,网站会跳转到我们想要的页面。此页面是拆分表页面。可以很全面的展示我们想看的内容的方方面面。
3.内容页内容页是当我们进入列表页,看到某条信息,想进去了解更多的时候。点击后,显示内容页面的信息。对于烟台网站的建设优化来说,内容页面很重要,里面的关键词尤为重要。并且内容页尽量不要有太多的图片和js,不利于百度蜘蛛的抓取。
山东网亿,
4.通用标题网站无论主页、列表页还是内容页,都使用相同的标题。烟台网站构造的header包括导航栏、logo、当前位置等,不同模板的header内容不同。标题也很重要。后面的网站优化需要的关键词、页面描述、页面标题都在头文件中修改优化。
5.底部的目的和表头一样,都是为了实现底部的通用使用,方便管理。尤其是底部的友情链接,可以统一管理
6.搜索页面 该功能模块属于网站。您可以在文本框中输入关键词在网站上进行相关搜索,方便用户体验。这需要选择 关键词 方面的专业知识。就是保证输入关键词能找到相关的内容。
7.在线客服在线客服也是一个功能模块,即在线客服,可以实现在线咨询服务,实现转化。有的网站有的网站没有,一般小网站没有,因为需要后端人工服务,所以一般大企业网站才会有。
8.单页烟台网站这个单页比较灵活,可以根据不同的需要做成很多不同的页面。如留言板、关于我们、联系我们等。
相关搜索:、烟台网站建设、烟台软件开发、烟台app开发、小程序制作、山东网亿
部分图文来源于网络,无法查出来源。如有版权问题,请联系删除。 查看全部
输入关键字 抓取所有网页(烟台网站建设优化来讲列表页的注意事项有哪些?)
摘要:烟台网站构建一个完整的网站大概需要以下网页文件,对于一些较大的网站等文件,可以根据需要设置,如下:
1.首页这是网站的基础页面,是打开网站时呈现给我们的,一般会显示网站新更新的内容在主页上。易时代关注公司动态。
2.列表页列表页首页有导航栏或列表导航栏。点击后,网站会跳转到我们想要的页面。此页面是拆分表页面。可以很全面的展示我们想看的内容的方方面面。
3.内容页内容页是当我们进入列表页,看到某条信息,想进去了解更多的时候。点击后,显示内容页面的信息。对于烟台网站的建设优化来说,内容页面很重要,里面的关键词尤为重要。并且内容页尽量不要有太多的图片和js,不利于百度蜘蛛的抓取。
山东网亿,
4.通用标题网站无论主页、列表页还是内容页,都使用相同的标题。烟台网站构造的header包括导航栏、logo、当前位置等,不同模板的header内容不同。标题也很重要。后面的网站优化需要的关键词、页面描述、页面标题都在头文件中修改优化。
5.底部的目的和表头一样,都是为了实现底部的通用使用,方便管理。尤其是底部的友情链接,可以统一管理
6.搜索页面 该功能模块属于网站。您可以在文本框中输入关键词在网站上进行相关搜索,方便用户体验。这需要选择 关键词 方面的专业知识。就是保证输入关键词能找到相关的内容。
7.在线客服在线客服也是一个功能模块,即在线客服,可以实现在线咨询服务,实现转化。有的网站有的网站没有,一般小网站没有,因为需要后端人工服务,所以一般大企业网站才会有。
8.单页烟台网站这个单页比较灵活,可以根据不同的需要做成很多不同的页面。如留言板、关于我们、联系我们等。
相关搜索:、烟台网站建设、烟台软件开发、烟台app开发、小程序制作、山东网亿
部分图文来源于网络,无法查出来源。如有版权问题,请联系删除。
输入关键字 抓取所有网页(SEO代表搜索引擎优化,如何进行索引以及如何确定其为搜索优化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-03 23:19
前言
什么是搜索引擎优化?SEO是Search Engine Optimization,意思是“搜索引擎优化”,一般简称搜索优化。SEO的主要工作是通过了解各种搜索引擎如何抓取互联网页面、如何对它们进行索引以及如何确定它们在特定关键词搜索结果中的排名来优化网页。提供搜索引擎排名,增加网站流量。
如果你能很好地运用SEO技术,你可以提高你的网站排名,增加它在相关搜索中的可见度,让你的网页在用户搜索过程中越来越显眼,让你的网站可能吸引更多关注和影响力,并吸引潜在和现有客户加入您的业务。
总结一下:SEO 代表搜索引擎优化,通过自然搜索引擎结果增加 网站 的流量数量和质量的做法。
SEO的本质
那么SEO是如何工作的呢?一些浏览器等搜索引擎使用机器人来获取网页、从一个站点到另一个站点、采集有关页面的信息并将它们放入索引中。然后算法分析索引中的页面,考虑数百个排名因素或信号等,以确定页面在给定查询的搜索结果中出现的顺序。
搜索排名因素可以被视为用户体验方面的代理。内容质量和关键字研究是内容优化的关键因素,搜索算法旨在展示相关的权威页面并为用户提供有效的搜索体验,优化您的网站,如果将这些因素考虑在内,内容会有所帮助您的页面在搜索结果中排名更高。
seo仍然主要用于商业目的来查找有关产品和服务的信息,搜索往往是品牌的主要数字流量来源,并补充其他营销渠道以获得更高的知名度和更高的搜索结果排名,让您的利润增加的过程.
seo操作
搜索关键字以访问您访问的 网站,但您有没有想过这个神奇的链接列表背后是什么?
就像这样,谷歌有一个搜索引擎,它采集它在互联网上找到的所有内容信息,然后将所有这些 1 和 0 带回搜索引擎进行索引。
当您使用 Google 进行搜索时,您实际上并不是在搜索网络,而是在搜索 Google 的网页索引,至少是您能找到的;使用一些称为“蜘蛛”的软件程序进行搜索,“蜘蛛”程序爬取少量页面,然后跟踪这些页面上的链接,然后爬取这些链接指向的页面,然后跟踪这些页面上的所有链接,并爬取他们链接到的页面,等等。
现在,假设我想知道一只动物的奔跑速度,我在搜索框中输入该动物的奔跑速度,按回车键,我们的软件将在这些索引中搜索收录这些搜索词的所有页面。
在这种情况下,有数以万计的可能结果,谷歌如何确定我的搜索意图?答案是通过询问 200 多个问题来确定的,例如,您的关键字在此页面上出现了多少次?
这些关键字出现在标题中、URL 中还是直接相邻?此页面是否收录这些关键字的同义词?这个页面是来自一个好的 网站 还是一个坏的 URL 甚至是垃圾邮件网站?
这个页面的PageRank是多少?
PageRank全称为网页排名,也称网页等级,是一种基于网页间相互超链接计算的技术。谷歌用它来反映一个网页的相关性和重要性,在搜索引擎优化操作中经常使用它来评估网页优化的有效性因素之一。PageRank 是 Google 的宝石,一种用于对网络中节点的重要性进行排名的算法。
PageRank 通过庞大的超链接网络确定页面的排名。Google 将 A 页面到 B 页面的链接解释为 A 页面为 B 页面投票,并且 Google 根据投票来源(甚至来源,链接到 A 页面的页面)和投票目标的评级。
简单来说,一个高层页面可以提升其他低层页面的层级。
假设有 4 个页面的小组:A、B、C 和 D。如果所有页面都链接到 A,那么 A 的 PR(PageRank)值将是 B、C 和 D 的 Pageranks 之和。
对这样的公式有兴趣的可以学习理解,这里就不过多解释了。
该公式通过查找到网页的外部链接的数量以及这些链接的重要性来评估网页的重要性。最后,我们综合以上所有因素,对每个页面进行总体评分。并且在你提交搜索请求半秒后,返回搜索结果。
经常更新 网站 或改进 网站 排名,每个结果都收录一个标题、一个 URL 和一段文本,有助于确定此页面是否是我正在寻找的内容。还可以查看一些指向类似页面的链接、Google 上最近保存的页面版本以及您可能会尝试的相关搜索。
直到我们索引大多数网页,这些网页是存储在数千台计算机上的数十亿网页。
各因素的权重如图:
如果是我,我想我可以使用以下步骤进行 seo:
抓取可访问性,以便引擎可以阅读您的 网站 可以回答搜索者查询的引人入胜的内容 优化关键字以吸引搜索者和引擎 出色的用户体验,包括快速加载速度和引人注目的 UI 共享链接、引用和放大内容 有价值的内容标题,网址和描述吸引了高点击率 片段/模式标签在 SERP(搜索引擎结果页面)中脱颖而出
注:搜索引擎结果页,英文缩写SERP(Search Engine Results Page),是指搜索引擎返回的满足搜索引擎领域查询要求的页面。
搜索引擎优化指南
内容和关键字是搜索引擎的关键因素,当您考虑 SEO 时,内容质量应该是您的首要任务,内容质量是您如何吸引用户、取悦您的受众,并为搜索创建高质量、有价值的内容引擎也很关键,所以它的第一个要素是内容质量。
对您而言,例如博客文章、产品页面、关于页面、推荐、视频等或您为受众创建的任何其他内容,正确安排内容质量意味着您有支持所有其他 seo 工作的基础。
内容质量交付、向用户输出、提供大量、有用和独特的内容是迫使他们留在您的页面上、建立熟悉度和信任度的原因,质量内容取决于您的内容类型和行业,以及深度技术等。
那么如何输出高质量的内容呢?优质内容的特点如下:
URL 搜索、索引和排名
首先,面对搜索引擎,我们需要了解它的三个重要功能:
这里请记住,搜索是一个发现的过程,通过爬虫(spider)来查找和更新内容,这里的内容(可以是网页、图片、视频、PDF等)都是通过链接找到的。
一直说搜索引擎索引?那么这是什么意思呢?
搜索引擎处理并存储他们在索引中找到的信息,这是一个收录他们找到并认为足以为搜索者服务的所有内容的庞大数据库。
如果您现在不寻找想要在搜索结果中显示的内容,可能有几个原因导致您的 网站 是全新的并且尚未被提取,也许您的 网站 是不是来自任何外部网站 @网站链接到也许你的 网站 使机器人难以有效地从中获取内容也许你的 网站 收录一些称为爬虫指令的基本代码搜索引擎 您的 网站 可能因 Google 的关键字研究垃圾邮件策略而受到处罚
什么是关键字?
搜索时,在输入框中输入的内容就是关键字。对于网站,对你的网站 内容最相关、最简洁的描述就是关键字。
知道关键字(搜索词)从谁在搜索它们开始,或者你想要什么关键词词,比如输入“婚礼”和“花店”,你可能会发现高相关度和高搜索度的相关词如:婚礼花束、新娘花、婚礼花店等。
给定关键字或关键字词组需要建立的搜索量越高,获得更高排名所需的工作就越多,而某些大品牌通常会在高流量关键字中排名前十,所以,如果你是从一开始就追同一个关键词,你可以想象排名会有多难,而且需要很多年。
对于高搜索量,实现自然排名成功所需的竞争和努力越多,尽管在某些情况下竞争性较低的搜索词可能是最有益的,在 seo 中称为长尾 关键词。
请不要小看一些晦涩难懂的关键词,搜索量较低的长尾关键词往往会随着搜索者的具体化而带来更好的收益,比如搜索“前端”的人可能只是浏览,但搜索“达达前端”只是对这个关键词有一个非常明确的方向。
按搜索量指定策略
当您尝试对您的 网站 进行排名时,请找到与之相关的搜索词,并查看您的竞争对手的排名,向他们学习,并找出让您更具战略性的因素。
看看你的竞争对手的关键词,有很多你想要排名的关键词,那么你怎么知道哪个排名第一呢?我认同!我们首先考虑的是查看哪些关键字在竞争对手列表中排名和优先级。
优先考虑竞争对手当前排名的高质量关键字可能是一个好主意,但查看竞争对手列表中的哪些关键字以及哪些关键字正在排名也是一个好主意。
您可以先了解搜索者的意图并搜索页面
要了解搜索者的意图,我们需要进行研究:
信息查询,以了解搜索者的需求;导航查询,搜索者想去互联网上的特定位置 交易查询,以了解搜索者想要做什么 最佳产品本地查询以了解搜索者想要在本地找到的一些东西
既然你已经找到了你的目标市场的搜索方式,那就做一个搜索页面(一个回答搜索者问题的网页的做法),所以页面内容需要优化比如:header tags, internal links, anchor text (anchor text 用于将文本链接到页面),它向搜索引擎发送有关目标页面内容的信号。
链接音量
在 Google 的通用网站管理员指南中,将页面上的链接数量限制在合理的数量(最多几千个)。拥有过多的内部链接本身不会对您造成不利影响,但它确实会影响 Google 查找和评估页面的方式。页面上的链接越多,每个链接获得的权益就越少。
您的标题标签在搜索者对您的 网站 的第一印象中起着重要作用,那么如何使您的 网站 具有有效的标题标签呢?
对于关键词,在标题中收录目标关键词可以帮助用户和搜索引擎了解你的网站内容的长度,一般情况下,搜索引擎会在搜索结果中显示标题标签的前50-60个字符
元描述和标题标签一样,也是描述其所在页面内容的html元素,它们也嵌套在head标签中:
url 结构、命名和组织页面
url 代表 Uniform Resource Locator,url 是网络上个别内容的位置或地址,如标题标签和元描述,搜索引擎在 serps(搜索引擎结果页面)上显示 url,因此 url 的命名和格式会影响点击搜索者不仅使用它们来决定点击哪些页面,而且搜索引擎也使用 URL 来评估和排名页面。
最后,总结一下,今天我们介绍了以下三个方面:
关于网站SEO的知识,这里就介绍一下。如果您对这方面感兴趣,请参考相关资料进一步深入研究。
注意,不要迷路
好了,各位,以上就是本次文章的全部内容,能看到这里的都是人才。以后会继续更新技术相关的文章。如果你觉得文章对你有用,请给个“赞”,欢迎分享,谢谢!! 查看全部
输入关键字 抓取所有网页(SEO代表搜索引擎优化,如何进行索引以及如何确定其为搜索优化)
前言
什么是搜索引擎优化?SEO是Search Engine Optimization,意思是“搜索引擎优化”,一般简称搜索优化。SEO的主要工作是通过了解各种搜索引擎如何抓取互联网页面、如何对它们进行索引以及如何确定它们在特定关键词搜索结果中的排名来优化网页。提供搜索引擎排名,增加网站流量。
如果你能很好地运用SEO技术,你可以提高你的网站排名,增加它在相关搜索中的可见度,让你的网页在用户搜索过程中越来越显眼,让你的网站可能吸引更多关注和影响力,并吸引潜在和现有客户加入您的业务。
总结一下:SEO 代表搜索引擎优化,通过自然搜索引擎结果增加 网站 的流量数量和质量的做法。
SEO的本质
那么SEO是如何工作的呢?一些浏览器等搜索引擎使用机器人来获取网页、从一个站点到另一个站点、采集有关页面的信息并将它们放入索引中。然后算法分析索引中的页面,考虑数百个排名因素或信号等,以确定页面在给定查询的搜索结果中出现的顺序。
搜索排名因素可以被视为用户体验方面的代理。内容质量和关键字研究是内容优化的关键因素,搜索算法旨在展示相关的权威页面并为用户提供有效的搜索体验,优化您的网站,如果将这些因素考虑在内,内容会有所帮助您的页面在搜索结果中排名更高。
seo仍然主要用于商业目的来查找有关产品和服务的信息,搜索往往是品牌的主要数字流量来源,并补充其他营销渠道以获得更高的知名度和更高的搜索结果排名,让您的利润增加的过程.
seo操作
搜索关键字以访问您访问的 网站,但您有没有想过这个神奇的链接列表背后是什么?
就像这样,谷歌有一个搜索引擎,它采集它在互联网上找到的所有内容信息,然后将所有这些 1 和 0 带回搜索引擎进行索引。
当您使用 Google 进行搜索时,您实际上并不是在搜索网络,而是在搜索 Google 的网页索引,至少是您能找到的;使用一些称为“蜘蛛”的软件程序进行搜索,“蜘蛛”程序爬取少量页面,然后跟踪这些页面上的链接,然后爬取这些链接指向的页面,然后跟踪这些页面上的所有链接,并爬取他们链接到的页面,等等。
现在,假设我想知道一只动物的奔跑速度,我在搜索框中输入该动物的奔跑速度,按回车键,我们的软件将在这些索引中搜索收录这些搜索词的所有页面。
在这种情况下,有数以万计的可能结果,谷歌如何确定我的搜索意图?答案是通过询问 200 多个问题来确定的,例如,您的关键字在此页面上出现了多少次?
这些关键字出现在标题中、URL 中还是直接相邻?此页面是否收录这些关键字的同义词?这个页面是来自一个好的 网站 还是一个坏的 URL 甚至是垃圾邮件网站?
这个页面的PageRank是多少?
PageRank全称为网页排名,也称网页等级,是一种基于网页间相互超链接计算的技术。谷歌用它来反映一个网页的相关性和重要性,在搜索引擎优化操作中经常使用它来评估网页优化的有效性因素之一。PageRank 是 Google 的宝石,一种用于对网络中节点的重要性进行排名的算法。
PageRank 通过庞大的超链接网络确定页面的排名。Google 将 A 页面到 B 页面的链接解释为 A 页面为 B 页面投票,并且 Google 根据投票来源(甚至来源,链接到 A 页面的页面)和投票目标的评级。
简单来说,一个高层页面可以提升其他低层页面的层级。
假设有 4 个页面的小组:A、B、C 和 D。如果所有页面都链接到 A,那么 A 的 PR(PageRank)值将是 B、C 和 D 的 Pageranks 之和。
对这样的公式有兴趣的可以学习理解,这里就不过多解释了。
该公式通过查找到网页的外部链接的数量以及这些链接的重要性来评估网页的重要性。最后,我们综合以上所有因素,对每个页面进行总体评分。并且在你提交搜索请求半秒后,返回搜索结果。

经常更新 网站 或改进 网站 排名,每个结果都收录一个标题、一个 URL 和一段文本,有助于确定此页面是否是我正在寻找的内容。还可以查看一些指向类似页面的链接、Google 上最近保存的页面版本以及您可能会尝试的相关搜索。
直到我们索引大多数网页,这些网页是存储在数千台计算机上的数十亿网页。
各因素的权重如图:
如果是我,我想我可以使用以下步骤进行 seo:
抓取可访问性,以便引擎可以阅读您的 网站 可以回答搜索者查询的引人入胜的内容 优化关键字以吸引搜索者和引擎 出色的用户体验,包括快速加载速度和引人注目的 UI 共享链接、引用和放大内容 有价值的内容标题,网址和描述吸引了高点击率 片段/模式标签在 SERP(搜索引擎结果页面)中脱颖而出
注:搜索引擎结果页,英文缩写SERP(Search Engine Results Page),是指搜索引擎返回的满足搜索引擎领域查询要求的页面。
搜索引擎优化指南
内容和关键字是搜索引擎的关键因素,当您考虑 SEO 时,内容质量应该是您的首要任务,内容质量是您如何吸引用户、取悦您的受众,并为搜索创建高质量、有价值的内容引擎也很关键,所以它的第一个要素是内容质量。
对您而言,例如博客文章、产品页面、关于页面、推荐、视频等或您为受众创建的任何其他内容,正确安排内容质量意味着您有支持所有其他 seo 工作的基础。
内容质量交付、向用户输出、提供大量、有用和独特的内容是迫使他们留在您的页面上、建立熟悉度和信任度的原因,质量内容取决于您的内容类型和行业,以及深度技术等。
那么如何输出高质量的内容呢?优质内容的特点如下:
URL 搜索、索引和排名
首先,面对搜索引擎,我们需要了解它的三个重要功能:
这里请记住,搜索是一个发现的过程,通过爬虫(spider)来查找和更新内容,这里的内容(可以是网页、图片、视频、PDF等)都是通过链接找到的。
一直说搜索引擎索引?那么这是什么意思呢?
搜索引擎处理并存储他们在索引中找到的信息,这是一个收录他们找到并认为足以为搜索者服务的所有内容的庞大数据库。
如果您现在不寻找想要在搜索结果中显示的内容,可能有几个原因导致您的 网站 是全新的并且尚未被提取,也许您的 网站 是不是来自任何外部网站 @网站链接到也许你的 网站 使机器人难以有效地从中获取内容也许你的 网站 收录一些称为爬虫指令的基本代码搜索引擎 您的 网站 可能因 Google 的关键字研究垃圾邮件策略而受到处罚
什么是关键字?
搜索时,在输入框中输入的内容就是关键字。对于网站,对你的网站 内容最相关、最简洁的描述就是关键字。
知道关键字(搜索词)从谁在搜索它们开始,或者你想要什么关键词词,比如输入“婚礼”和“花店”,你可能会发现高相关度和高搜索度的相关词如:婚礼花束、新娘花、婚礼花店等。
给定关键字或关键字词组需要建立的搜索量越高,获得更高排名所需的工作就越多,而某些大品牌通常会在高流量关键字中排名前十,所以,如果你是从一开始就追同一个关键词,你可以想象排名会有多难,而且需要很多年。
对于高搜索量,实现自然排名成功所需的竞争和努力越多,尽管在某些情况下竞争性较低的搜索词可能是最有益的,在 seo 中称为长尾 关键词。
请不要小看一些晦涩难懂的关键词,搜索量较低的长尾关键词往往会随着搜索者的具体化而带来更好的收益,比如搜索“前端”的人可能只是浏览,但搜索“达达前端”只是对这个关键词有一个非常明确的方向。
按搜索量指定策略
当您尝试对您的 网站 进行排名时,请找到与之相关的搜索词,并查看您的竞争对手的排名,向他们学习,并找出让您更具战略性的因素。
看看你的竞争对手的关键词,有很多你想要排名的关键词,那么你怎么知道哪个排名第一呢?我认同!我们首先考虑的是查看哪些关键字在竞争对手列表中排名和优先级。
优先考虑竞争对手当前排名的高质量关键字可能是一个好主意,但查看竞争对手列表中的哪些关键字以及哪些关键字正在排名也是一个好主意。
您可以先了解搜索者的意图并搜索页面
要了解搜索者的意图,我们需要进行研究:
信息查询,以了解搜索者的需求;导航查询,搜索者想去互联网上的特定位置 交易查询,以了解搜索者想要做什么 最佳产品本地查询以了解搜索者想要在本地找到的一些东西
既然你已经找到了你的目标市场的搜索方式,那就做一个搜索页面(一个回答搜索者问题的网页的做法),所以页面内容需要优化比如:header tags, internal links, anchor text (anchor text 用于将文本链接到页面),它向搜索引擎发送有关目标页面内容的信号。
链接音量
在 Google 的通用网站管理员指南中,将页面上的链接数量限制在合理的数量(最多几千个)。拥有过多的内部链接本身不会对您造成不利影响,但它确实会影响 Google 查找和评估页面的方式。页面上的链接越多,每个链接获得的权益就越少。
您的标题标签在搜索者对您的 网站 的第一印象中起着重要作用,那么如何使您的 网站 具有有效的标题标签呢?
对于关键词,在标题中收录目标关键词可以帮助用户和搜索引擎了解你的网站内容的长度,一般情况下,搜索引擎会在搜索结果中显示标题标签的前50-60个字符
元描述和标题标签一样,也是描述其所在页面内容的html元素,它们也嵌套在head标签中:
url 结构、命名和组织页面
url 代表 Uniform Resource Locator,url 是网络上个别内容的位置或地址,如标题标签和元描述,搜索引擎在 serps(搜索引擎结果页面)上显示 url,因此 url 的命名和格式会影响点击搜索者不仅使用它们来决定点击哪些页面,而且搜索引擎也使用 URL 来评估和排名页面。
最后,总结一下,今天我们介绍了以下三个方面:
关于网站SEO的知识,这里就介绍一下。如果您对这方面感兴趣,请参考相关资料进一步深入研究。
注意,不要迷路
好了,各位,以上就是本次文章的全部内容,能看到这里的都是人才。以后会继续更新技术相关的文章。如果你觉得文章对你有用,请给个“赞”,欢迎分享,谢谢!!
输入关键字 抓取所有网页( 2.所有的不明理由进入都是好的呢?(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-03 15:25
2.所有的不明理由进入都是好的呢?(组图)
)
用户将网站加入浏览器采集后,点击采集链接进入,属于采集条目,通常分析工具认为是不明条目。直接地址栏输入和采集夹输入我们都会考虑高质量的长期忠实用户,那么所有不明原因的输入都好吗?不解释的条目越多越好吗?看完以下两种情况,你就会知道网站分析中的数据并不是绝对的。
1.3 缺少推荐人
网站分析工具通过浏览器请求中收录的Referrer字段识别访问来源。但是,Referrer 并不收录在所有请求中。各种原因会导致Http请求中的Referrer丢失,包括一些网关、防火墙等设置会阻塞Http请求中的Referrer字段;用户的一些特殊操作也会导致浏览器丢失Referrer。由于这些原因,网站分析工具无法正确识别出真正的直接入口和referrer loss之间的区别,因此没有争议的分类方法是将其计为“未知”入口。
1.4 特殊浏览器/爬虫机器人等
特殊浏览器包括一些推荐版本的浏览器,或者网站内容爬虫等,通常不提供Referrer内容。如果这些工具产生的访问没有被有效阻止,它们可能会导致无法解释的进入来源。还有搜索引擎的爬虫机器人,还有其他内容的网络蜘蛛网站,不时使用Http协议访问互联网。当然,机器人的访问量不应该被计算在内。当然,如果你的网站设置不正确,不幸的是机器人的访问进来了,那么这些访问也会被分析工具视为未知来源。
2. 广告链接源数据采集方法介绍
2.1 通过在广告链接中插入参数
将参数插入广告链接的方法是广告数据采集的主要方法,也是最容易实现和衡量的方法。具体来说,当广告商向广告商提供广告点击链接时,他们有意识地将其添加到广告链接的末尾。某些参数通常不会被客户端的 网站 应用程序捕获,但仅用于为 网站 分析工具提供数据。比如花卉网站的销售部决定在母亲节前夕推广康乃馨,并计划在“花卉采集”网站上投放广告。除了图片,还应该为访问者点击图片时页面跳转到的目标页面——“妈妈”提供一个链接
2.2 根据进入页面的引用(Referrer)判断
如果前一种方法(通过在广告链接中插入参数)是常用的方法,那么通过进入页面的引用(Referrer)来判断的方法是一种不费吹灰之力的修改。你为什么这么说?一般情况下,广告商允许客户在广告链接中添加参数。在这种情况下,首选前者,因为它更灵活、更方便。但是对于一些伪装的广告和以交换链接的形式提供的广告,通常对方网站不能根据我们的要求随意指定连接参数,那么如何对这些广告来源进行统计呢?这就需要利用referrer判断来采集广告来源。入口页面的引用是指用户进入网站时访问的第一个网页的引用。如果是广告提供者的特定广告网页,则分析系统将访问来源视为广告来源。这种数据采集方式的优点是不需要插入额外的参数,但是对于同一页面收录多个不同广告的数据采集,存在无法区分具体广告的问题。
3. 如何获取搜索引擎的源码
分析系统首先判断网站中输入的引用页面的URL是否为搜索引擎,如果是,则获取搜索引擎使用的关键词,并将该条目定义为搜索引擎的来源.
通常,为了更详细地分析搜索引擎源的访问情况,需要对来自搜索引擎源的数据进行更详细的分类。目前主流的分类方法通常包括以下两种。
(1)搜索引擎类型
(2)搜索关键字
搜索引擎源分类的分析方法将在《搜索关键词分析》和《搜索引擎分析》中详细介绍。
4. 其他网站 获取源数据的方法
网站 从其他来源获取数据的方法与搜索引擎类似。与搜索引擎来源不同的是,网站的其他来源访问的引荐页面(Referrers)的URL不属于搜索引擎的类型。分析工具将这部分源视为其他网站 源。
5. 如何衡量搜索引擎关键字排名
访问者来源分析包括统计在各种搜索引擎上来到网站的关键字的排名信息的功能。这些信息是如何获得的?
首先,知名搜索引擎提供了一个对外开放的API(Application Programming Interface),方便第三方应用获取搜索引擎数据,包括指定关键词的排名和连接目的信息,网站@ >分析系统可以通过API将这部分数据引入分析表,与网站分析的数据进行整合,为客户提供更全面的数据支持。
查看全部
输入关键字 抓取所有网页(
2.所有的不明理由进入都是好的呢?(组图)
)

用户将网站加入浏览器采集后,点击采集链接进入,属于采集条目,通常分析工具认为是不明条目。直接地址栏输入和采集夹输入我们都会考虑高质量的长期忠实用户,那么所有不明原因的输入都好吗?不解释的条目越多越好吗?看完以下两种情况,你就会知道网站分析中的数据并不是绝对的。
1.3 缺少推荐人

网站分析工具通过浏览器请求中收录的Referrer字段识别访问来源。但是,Referrer 并不收录在所有请求中。各种原因会导致Http请求中的Referrer丢失,包括一些网关、防火墙等设置会阻塞Http请求中的Referrer字段;用户的一些特殊操作也会导致浏览器丢失Referrer。由于这些原因,网站分析工具无法正确识别出真正的直接入口和referrer loss之间的区别,因此没有争议的分类方法是将其计为“未知”入口。

1.4 特殊浏览器/爬虫机器人等

特殊浏览器包括一些推荐版本的浏览器,或者网站内容爬虫等,通常不提供Referrer内容。如果这些工具产生的访问没有被有效阻止,它们可能会导致无法解释的进入来源。还有搜索引擎的爬虫机器人,还有其他内容的网络蜘蛛网站,不时使用Http协议访问互联网。当然,机器人的访问量不应该被计算在内。当然,如果你的网站设置不正确,不幸的是机器人的访问进来了,那么这些访问也会被分析工具视为未知来源。
2. 广告链接源数据采集方法介绍
2.1 通过在广告链接中插入参数

将参数插入广告链接的方法是广告数据采集的主要方法,也是最容易实现和衡量的方法。具体来说,当广告商向广告商提供广告点击链接时,他们有意识地将其添加到广告链接的末尾。某些参数通常不会被客户端的 网站 应用程序捕获,但仅用于为 网站 分析工具提供数据。比如花卉网站的销售部决定在母亲节前夕推广康乃馨,并计划在“花卉采集”网站上投放广告。除了图片,还应该为访问者点击图片时页面跳转到的目标页面——“妈妈”提供一个链接
2.2 根据进入页面的引用(Referrer)判断

如果前一种方法(通过在广告链接中插入参数)是常用的方法,那么通过进入页面的引用(Referrer)来判断的方法是一种不费吹灰之力的修改。你为什么这么说?一般情况下,广告商允许客户在广告链接中添加参数。在这种情况下,首选前者,因为它更灵活、更方便。但是对于一些伪装的广告和以交换链接的形式提供的广告,通常对方网站不能根据我们的要求随意指定连接参数,那么如何对这些广告来源进行统计呢?这就需要利用referrer判断来采集广告来源。入口页面的引用是指用户进入网站时访问的第一个网页的引用。如果是广告提供者的特定广告网页,则分析系统将访问来源视为广告来源。这种数据采集方式的优点是不需要插入额外的参数,但是对于同一页面收录多个不同广告的数据采集,存在无法区分具体广告的问题。
3. 如何获取搜索引擎的源码
分析系统首先判断网站中输入的引用页面的URL是否为搜索引擎,如果是,则获取搜索引擎使用的关键词,并将该条目定义为搜索引擎的来源.
通常,为了更详细地分析搜索引擎源的访问情况,需要对来自搜索引擎源的数据进行更详细的分类。目前主流的分类方法通常包括以下两种。
(1)搜索引擎类型
(2)搜索关键字
搜索引擎源分类的分析方法将在《搜索关键词分析》和《搜索引擎分析》中详细介绍。
4. 其他网站 获取源数据的方法
网站 从其他来源获取数据的方法与搜索引擎类似。与搜索引擎来源不同的是,网站的其他来源访问的引荐页面(Referrers)的URL不属于搜索引擎的类型。分析工具将这部分源视为其他网站 源。
5. 如何衡量搜索引擎关键字排名
访问者来源分析包括统计在各种搜索引擎上来到网站的关键字的排名信息的功能。这些信息是如何获得的?
首先,知名搜索引擎提供了一个对外开放的API(Application Programming Interface),方便第三方应用获取搜索引擎数据,包括指定关键词的排名和连接目的信息,网站@ >分析系统可以通过API将这部分数据引入分析表,与网站分析的数据进行整合,为客户提供更全面的数据支持。

输入关键字 抓取所有网页(如何在互联网上快速的搜索到自己需要的学习资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-02-02 15:07
网上很多个人博客开源程序都默认自带robots.txt文件,而且大部分都有默认禁止被搜索引擎抓取的url路径。许多新手网站管理员都在建立网站的过程中。Robots.txt 文件中错误写入了禁止搜索引擎抓取网站内页的url路径;因此,直接导致搜索引擎不抓取网站的内页,也不收录输入关键词百度站点。这个原因一般是新手站长在摸索学习过程中乱修改文件造成的。如果您的 网站 搜索引擎没有 收录 内页,请检查 网站 根目录中的 robots.txt 文件!
如何在网上快速搜索到自己需要的学习资料?
分享5个强大且个人喜欢的找学习资料的方法,我的经验百度站,喜欢的话可以点赞关注~
一、两个搜索引擎指导产品网络推广百度网站:
关键字”+“空格”+“文件类型:”+“doc/ppt/pdf等文件格式”百度网站,“\””+“关键字”+“\””
两个百度站,两个网站:B站:哔哩哔哩(゜-゜)つロCheers~-bilibili
探索:
三、一个小程序,网盘搜索Pro
1.“关键字”+“空格”+“文件类型:”+“doc/ppt/pdf等文件格式”
filetype 可用于搜索特定的文件格式,使用此搜索命令可以轻松搜索各种格式的数据文件。例如:全益辉,因为我公司没有上传库中的数据,所以没有有效的搜索结果。
如果你这样输入,你还可以在有限的时间内找到收录关键字的文档。
“关键字”+“空格”+“文件类型:”+“doc/ppt等文件格式”+“空格”+“2008..2010”
2.「\"」+「关键字」+「\"」
该命令可用于搜索完整的关键字匹配。简而言之,搜索结果收录双引号中的所有关键字,并且顺序也完全匹配。
例如:当我们搜索“\”英文复习资料\“”时,搜索结果都是匹配的,文本的顺序没有改变。需要注意的是,命令中使用的双引号是英文状态的双引号,中文状态的双引号是不允许的。
3.B站:
哔哩哔哩(bilibili)现在是中国领先的青年文化社区。网站成立于2009年6月26日,被粉丝亲切地称为“哔哩哔哩”。B站可以搜索各种学习视频,例如:PS教程
4.探索:
国内最大的网盘搜索网站功能之一
5.微信小程序:网盘搜索Pro
这是一个专门用来搜索网盘资源的微信小程序。无需注册,打开使用,直接在搜索栏输入你想要的资源名称,点击搜索即可。例如:市场营销毕业论文 查看全部
输入关键字 抓取所有网页(如何在互联网上快速的搜索到自己需要的学习资料)
网上很多个人博客开源程序都默认自带robots.txt文件,而且大部分都有默认禁止被搜索引擎抓取的url路径。许多新手网站管理员都在建立网站的过程中。Robots.txt 文件中错误写入了禁止搜索引擎抓取网站内页的url路径;因此,直接导致搜索引擎不抓取网站的内页,也不收录输入关键词百度站点。这个原因一般是新手站长在摸索学习过程中乱修改文件造成的。如果您的 网站 搜索引擎没有 收录 内页,请检查 网站 根目录中的 robots.txt 文件!
如何在网上快速搜索到自己需要的学习资料?
分享5个强大且个人喜欢的找学习资料的方法,我的经验百度站,喜欢的话可以点赞关注~
一、两个搜索引擎指导产品网络推广百度网站:
关键字”+“空格”+“文件类型:”+“doc/ppt/pdf等文件格式”百度网站,“\””+“关键字”+“\””
两个百度站,两个网站:B站:哔哩哔哩(゜-゜)つロCheers~-bilibili
探索:
三、一个小程序,网盘搜索Pro
1.“关键字”+“空格”+“文件类型:”+“doc/ppt/pdf等文件格式”
filetype 可用于搜索特定的文件格式,使用此搜索命令可以轻松搜索各种格式的数据文件。例如:全益辉,因为我公司没有上传库中的数据,所以没有有效的搜索结果。
如果你这样输入,你还可以在有限的时间内找到收录关键字的文档。
“关键字”+“空格”+“文件类型:”+“doc/ppt等文件格式”+“空格”+“2008..2010”
2.「\"」+「关键字」+「\"」
该命令可用于搜索完整的关键字匹配。简而言之,搜索结果收录双引号中的所有关键字,并且顺序也完全匹配。
例如:当我们搜索“\”英文复习资料\“”时,搜索结果都是匹配的,文本的顺序没有改变。需要注意的是,命令中使用的双引号是英文状态的双引号,中文状态的双引号是不允许的。
3.B站:
哔哩哔哩(bilibili)现在是中国领先的青年文化社区。网站成立于2009年6月26日,被粉丝亲切地称为“哔哩哔哩”。B站可以搜索各种学习视频,例如:PS教程
4.探索:
国内最大的网盘搜索网站功能之一
5.微信小程序:网盘搜索Pro
这是一个专门用来搜索网盘资源的微信小程序。无需注册,打开使用,直接在搜索栏输入你想要的资源名称,点击搜索即可。例如:市场营销毕业论文
输入关键字 抓取所有网页(一个神器之一selenium五年发表文章五年数量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-02 14:03
PubMed 是一个用于生物医学文章搜索和摘要的免费搜索数据库。它是一个网站,经常用于查找生物学文献。最近学了爬虫相关的知识包括urllib库、requests库、xpath表达式、scrapy框架等。正想着去爬PubMed,就动手实践一下,准备爬上文章发表的数PubMed根据过去五年的关键词搜索,并以此为依据看过去五年的研究方向。程度。
最初的想法是使用scrapy框架进行爬取和存储。于是打开PubMed,开始分析网页构成、源码等。发现NCBI使用的是动态网页,在进行翻页、搜索关键字等操作时,URL并没有变化。于是想到了爬虫神器之一的selenium模块,用selenium来模拟搜索、翻页等操作,然后分析源码得到想要的信息。由于和selenium接触不多,所以暂时在网上找了一些功能。
1、 加载需要的模块
import urllib
import time
import matplotlib.pyplot as plt
import numpy as np
from lxml import etree
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from collections import Counter
2、从关键字构造 URL
手动输入几个关键字,分析 URL 的结构。
PubMed 的原创链接是 '',当输入和搜索 'cancer,TCGA,Breast' 时,url 变为 ''。所以不难分析,URL由两部分组成,一部分是同一个'',另一部分是由我们搜索的关键字拼接而成的字符串'%2C'组成的。因此,对于传入的‘keyword’,我们可以做如下处理,拼接到搜索后返回的url中
keyword = '%2C'.join(keyword)
tart_url = 'https://www.ncbi.nlm.nih.gov/pubmed/?term='
url = start_url + keyword
这样,我们简单地连接返回的 url。
3、创建浏览器对象
接下来就是使用selenium模块打开我们的Chrome浏览器,跳转到url界面。这个操作相信大家都很熟悉了。因为后面要模拟点击和翻页,所以需要实例化一个WebDriverWait对象,方便后续调用
browser = webdriver.Chrome()
self.browser.get(url)
wait = WebDriverWait(browser, 10)
模拟点击网页
打开网页后,我们需要模拟点击网页。首先,我们需要找到过去五年的文章,所以我们需要模拟点击左侧5years的按钮,改变单页显示的文章个数。变成200,这样可以减少我们的翻页操作
QQ图片246.png
在我们模拟点击之前,我们必须等到网页上加载了相应的元素才能点击,所以我们需要使用前面提到的WebDriverWait对象。代码显示如下
years =wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#_ds1 > li > ul > li:nth-child(1) > a')))
years.click()
perpage = self.wait.until(EC.element_to_be_clickable((By.XPATH,'//ul[@class="inline_list left display_settings"]/li[3]/a/span[4]')))
perpage.click()
page_200 = self.wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#display_settings_menu_ps > fieldset > ul > li:nth-child(6) > label')))
此处使用了 CSS 选择器和 Xpath 表达式。用哪一种就看个人喜好了,用哪一种方便都可以。EC.element_to_be_clickable 是在一个元组中传递的,第一个元素是声明要使用的选择器,第二个元素是表达式,这个函数的意思是等到你在表达式中传递的元素在网页上的使用过程中selenium,有很多地方我们需要用到类似的操作比如presence_of_element_located、text_to_be_present_in_element等,有兴趣的可以去网上一探究竟。
解析网页并提取信息
下一步是解析网页。我在这里使用 lxml 来解析网页并从 Xpath 中提取信息。代码如下
html = self.browser.page_source
doc = etree.HTML(self.html)
self.art_timeanddoi = self.doc.xpath('//div[@class="rprt"]/div[2]/div/p[@class="details"]/text()')
for i in self.art_timeanddoi:
self.yearlist.append(i[2:6])
for i in self.yearlist:
if re.match('2', i):
continue
else:
self.yearlist.remove(i)
这里主要是对网页中的年份进行Xpath提取和字符串切片处理,从而获取年份信息并存入列表中。在实际操作过程中,发现了少量其他不相关的元素。仔细排查,发现是网页源代码有问题。因此,执行了一个常规过程来删除不以“2”开头的元素。经检查,最终结果是正确的。.
这里我们提取单页信息。
执行翻页
我们还需要经过一个翻页操作来获取我们想要的所有信息。仍然使用 selenium 模块。
status = True
def next_page():
try:
self.nextpage = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@title="Next page of results"]')))
except TimeoutException:
status = False
while True:
if status:
next_page()
else:
break
这里我先定义一个判断是否可以翻页的函数,并使用异常捕获,因为翻页动作到最后一页就应该停止,不能再次点击翻页元素。因此,在进行点击操作时应先进行判断。如果不能点击,会因为超时而抛出异常。next_page 函数中的status 变量记录是否可以点击“下一页”按钮。接下来是一个 while True 循环。翻页动作只会在 next_page 变为 False 时停止。在循环中,我们不断地解析网页以提取信息以获得所有想要的信息。
视觉处理
爬取了全年信息列表后,还需要进一步的可视化处理,直观判断目标课题的研究趋势。因此,我们使用matplotlib进行可视化操作,简单地画一个折线图。代码显示如下:
def plot_curve(yearlist):
counter = Counter(yearlist)
dic = dict(counter)
keys = sorted(list(dic.keys()))
curcount = 0
y = []
temp = [int(i) for i in keys]
for i in range(min(temp), max(temp)+1):
if str(i) in keys:
curcount += self.dic[str(i)]
y.append(self.curcount)
else:
y.append(self.curcount)
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.xlabel('年份')
plt.ylabel('近五年文章数量')
plt.plot(np.arange(min(temp), max(temp)+1), np.array(y), 'r', marker='+', linewidth=2)
plt.show()
最后粘贴完整代码:
import re
import urllib
import time
import numpy as np
from lxml import etree
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from collections import Counter
import matplotlib.pyplot as plt
class NcbiInfo(object):
browser = webdriver.Chrome()
start_url = 'https://www.ncbi.nlm.nih.gov/pubmed/?term='
wait = WebDriverWait(browser, 10)
def __init__(self, keywordlist):
self.temp = [urllib.parse.quote(i) for i in keywordlist]
self.keyword = '%2C'.join(self.temp)
self.title = ' AND '.join(self.temp)
self.url = NcbiInfo.start_url + self.keyword
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
self.file = open('information.txt', 'w')
self.status = True
self.yearlist = []
def click_yearandabstract(self, ):
self.browser.get(self.url)
years = self.wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#_ds1 > li > ul > li:nth-child(1) > a')))
years.click()
perpage = self.wait.until(EC.element_to_be_clickable((By.XPATH, '//ul[@class="inline_list left display_settings"]/li[3]/a/span[4]')))
perpage.click()
page_200 = self.wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#display_settings_menu_ps > fieldset > ul > li:nth-child(6) > label')))
page_200.click()
def get_response(self):
self.html = self.browser.page_source
self.doc = etree.HTML(self.html)
def get_numof_article(self):
article_count_ = self.doc.xpath('//*[@id="maincontent"]/div/div[3]/div[1]/h3/text()')[0]
if 'of' not in article_count_:
print(article_count_.split(': ')[1])
else:
print(article_count_.split('of ')[1])
def get_info(self):
self.art_timeanddoi = self.doc.xpath('//div[@class="rprt"]/div[2]/div/p[@class="details"]/text()')
for i in self.art_timeanddoi:
self.yearlist.append(i[2:6])
for i in self.yearlist:
if re.match('2', i):
continue
else:
self.yearlist.remove(i)
def next_page(self):
try:
self.nextpage = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@title="Next page of results"]')))
except TimeoutException:
self.status = False
def plot_curve(self):
self.counter = Counter(self.yearlist)
self.dic = dict(self.counter)
self.keys = sorted(list(self.dic.keys()))
self.curcount = 0
self.y = []
temp = [int(i) for i in self.keys]
for i in range(min(temp), max(temp)+1):
if str(i) in self.keys:
self.curcount += self.dic[str(i)]
self.y.append(self.curcount)
else:
self.y.append(self.curcount)
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.xlabel('年份')
plt.ylabel('近五年文章数量')
plt.title(self.title)
plt.plot(np.arange(min(temp), max(temp)+1), np.array(self.y), 'r', marker='+', linewidth=2)
plt.show()
def main(self):
self.click_yearandabstract()
time.sleep(3)
self.get_response()
self.get_numof_article()
while True:
self.get_info()
self.next_page()
if self.status:
self.nextpage.click()
self.get_response()
else:
break
self.plot_curve()
if __name__ == '__main__':
a = NcbiInfo(['TCGA', 'breast', 'cancer'])
a.main()
结果如下:
图像.png 查看全部
输入关键字 抓取所有网页(一个神器之一selenium五年发表文章五年数量)
PubMed 是一个用于生物医学文章搜索和摘要的免费搜索数据库。它是一个网站,经常用于查找生物学文献。最近学了爬虫相关的知识包括urllib库、requests库、xpath表达式、scrapy框架等。正想着去爬PubMed,就动手实践一下,准备爬上文章发表的数PubMed根据过去五年的关键词搜索,并以此为依据看过去五年的研究方向。程度。
最初的想法是使用scrapy框架进行爬取和存储。于是打开PubMed,开始分析网页构成、源码等。发现NCBI使用的是动态网页,在进行翻页、搜索关键字等操作时,URL并没有变化。于是想到了爬虫神器之一的selenium模块,用selenium来模拟搜索、翻页等操作,然后分析源码得到想要的信息。由于和selenium接触不多,所以暂时在网上找了一些功能。
1、 加载需要的模块
import urllib
import time
import matplotlib.pyplot as plt
import numpy as np
from lxml import etree
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from collections import Counter
2、从关键字构造 URL
手动输入几个关键字,分析 URL 的结构。
PubMed 的原创链接是 '',当输入和搜索 'cancer,TCGA,Breast' 时,url 变为 ''。所以不难分析,URL由两部分组成,一部分是同一个'',另一部分是由我们搜索的关键字拼接而成的字符串'%2C'组成的。因此,对于传入的‘keyword’,我们可以做如下处理,拼接到搜索后返回的url中
keyword = '%2C'.join(keyword)
tart_url = 'https://www.ncbi.nlm.nih.gov/pubmed/?term='
url = start_url + keyword
这样,我们简单地连接返回的 url。
3、创建浏览器对象
接下来就是使用selenium模块打开我们的Chrome浏览器,跳转到url界面。这个操作相信大家都很熟悉了。因为后面要模拟点击和翻页,所以需要实例化一个WebDriverWait对象,方便后续调用
browser = webdriver.Chrome()
self.browser.get(url)
wait = WebDriverWait(browser, 10)
模拟点击网页
打开网页后,我们需要模拟点击网页。首先,我们需要找到过去五年的文章,所以我们需要模拟点击左侧5years的按钮,改变单页显示的文章个数。变成200,这样可以减少我们的翻页操作

QQ图片246.png
在我们模拟点击之前,我们必须等到网页上加载了相应的元素才能点击,所以我们需要使用前面提到的WebDriverWait对象。代码显示如下
years =wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#_ds1 > li > ul > li:nth-child(1) > a')))
years.click()
perpage = self.wait.until(EC.element_to_be_clickable((By.XPATH,'//ul[@class="inline_list left display_settings"]/li[3]/a/span[4]')))
perpage.click()
page_200 = self.wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#display_settings_menu_ps > fieldset > ul > li:nth-child(6) > label')))
此处使用了 CSS 选择器和 Xpath 表达式。用哪一种就看个人喜好了,用哪一种方便都可以。EC.element_to_be_clickable 是在一个元组中传递的,第一个元素是声明要使用的选择器,第二个元素是表达式,这个函数的意思是等到你在表达式中传递的元素在网页上的使用过程中selenium,有很多地方我们需要用到类似的操作比如presence_of_element_located、text_to_be_present_in_element等,有兴趣的可以去网上一探究竟。
解析网页并提取信息
下一步是解析网页。我在这里使用 lxml 来解析网页并从 Xpath 中提取信息。代码如下
html = self.browser.page_source
doc = etree.HTML(self.html)
self.art_timeanddoi = self.doc.xpath('//div[@class="rprt"]/div[2]/div/p[@class="details"]/text()')
for i in self.art_timeanddoi:
self.yearlist.append(i[2:6])
for i in self.yearlist:
if re.match('2', i):
continue
else:
self.yearlist.remove(i)
这里主要是对网页中的年份进行Xpath提取和字符串切片处理,从而获取年份信息并存入列表中。在实际操作过程中,发现了少量其他不相关的元素。仔细排查,发现是网页源代码有问题。因此,执行了一个常规过程来删除不以“2”开头的元素。经检查,最终结果是正确的。.
这里我们提取单页信息。
执行翻页
我们还需要经过一个翻页操作来获取我们想要的所有信息。仍然使用 selenium 模块。
status = True
def next_page():
try:
self.nextpage = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@title="Next page of results"]')))
except TimeoutException:
status = False
while True:
if status:
next_page()
else:
break
这里我先定义一个判断是否可以翻页的函数,并使用异常捕获,因为翻页动作到最后一页就应该停止,不能再次点击翻页元素。因此,在进行点击操作时应先进行判断。如果不能点击,会因为超时而抛出异常。next_page 函数中的status 变量记录是否可以点击“下一页”按钮。接下来是一个 while True 循环。翻页动作只会在 next_page 变为 False 时停止。在循环中,我们不断地解析网页以提取信息以获得所有想要的信息。
视觉处理
爬取了全年信息列表后,还需要进一步的可视化处理,直观判断目标课题的研究趋势。因此,我们使用matplotlib进行可视化操作,简单地画一个折线图。代码显示如下:
def plot_curve(yearlist):
counter = Counter(yearlist)
dic = dict(counter)
keys = sorted(list(dic.keys()))
curcount = 0
y = []
temp = [int(i) for i in keys]
for i in range(min(temp), max(temp)+1):
if str(i) in keys:
curcount += self.dic[str(i)]
y.append(self.curcount)
else:
y.append(self.curcount)
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.xlabel('年份')
plt.ylabel('近五年文章数量')
plt.plot(np.arange(min(temp), max(temp)+1), np.array(y), 'r', marker='+', linewidth=2)
plt.show()
最后粘贴完整代码:
import re
import urllib
import time
import numpy as np
from lxml import etree
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from collections import Counter
import matplotlib.pyplot as plt
class NcbiInfo(object):
browser = webdriver.Chrome()
start_url = 'https://www.ncbi.nlm.nih.gov/pubmed/?term='
wait = WebDriverWait(browser, 10)
def __init__(self, keywordlist):
self.temp = [urllib.parse.quote(i) for i in keywordlist]
self.keyword = '%2C'.join(self.temp)
self.title = ' AND '.join(self.temp)
self.url = NcbiInfo.start_url + self.keyword
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
self.file = open('information.txt', 'w')
self.status = True
self.yearlist = []
def click_yearandabstract(self, ):
self.browser.get(self.url)
years = self.wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#_ds1 > li > ul > li:nth-child(1) > a')))
years.click()
perpage = self.wait.until(EC.element_to_be_clickable((By.XPATH, '//ul[@class="inline_list left display_settings"]/li[3]/a/span[4]')))
perpage.click()
page_200 = self.wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#display_settings_menu_ps > fieldset > ul > li:nth-child(6) > label')))
page_200.click()
def get_response(self):
self.html = self.browser.page_source
self.doc = etree.HTML(self.html)
def get_numof_article(self):
article_count_ = self.doc.xpath('//*[@id="maincontent"]/div/div[3]/div[1]/h3/text()')[0]
if 'of' not in article_count_:
print(article_count_.split(': ')[1])
else:
print(article_count_.split('of ')[1])
def get_info(self):
self.art_timeanddoi = self.doc.xpath('//div[@class="rprt"]/div[2]/div/p[@class="details"]/text()')
for i in self.art_timeanddoi:
self.yearlist.append(i[2:6])
for i in self.yearlist:
if re.match('2', i):
continue
else:
self.yearlist.remove(i)
def next_page(self):
try:
self.nextpage = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@title="Next page of results"]')))
except TimeoutException:
self.status = False
def plot_curve(self):
self.counter = Counter(self.yearlist)
self.dic = dict(self.counter)
self.keys = sorted(list(self.dic.keys()))
self.curcount = 0
self.y = []
temp = [int(i) for i in self.keys]
for i in range(min(temp), max(temp)+1):
if str(i) in self.keys:
self.curcount += self.dic[str(i)]
self.y.append(self.curcount)
else:
self.y.append(self.curcount)
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.xlabel('年份')
plt.ylabel('近五年文章数量')
plt.title(self.title)
plt.plot(np.arange(min(temp), max(temp)+1), np.array(self.y), 'r', marker='+', linewidth=2)
plt.show()
def main(self):
self.click_yearandabstract()
time.sleep(3)
self.get_response()
self.get_numof_article()
while True:
self.get_info()
self.next_page()
if self.status:
self.nextpage.click()
self.get_response()
else:
break
self.plot_curve()
if __name__ == '__main__':
a = NcbiInfo(['TCGA', 'breast', 'cancer'])
a.main()
结果如下:
图像.png
输入关键字 抓取所有网页(“qq号”放进去了怎么办?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-02 13:00
输入关键字抓取所有网页并得到不同网页的不同标题,只要这个标题不在敏感词内都可以。有道吧。
快速。直接起个名叫"搜索xxx"然后链接到“让你这条信息xxx级。本站可见。
问题是这个动词的发明需要多久?
你都说是“微博”了,你应该把下面“qq号”放进去。
是不是“在我们a站人人网b站的信息里,
是的。当地的监管权,钱,技术,
谁说要等到“敏感词”词条只能拿到一段信息的,就凭你一个看客哪儿就值几百万了。
如果你想添加两个可以实现的功能。1,微博爬虫自动抓取同时登录过的人发布的一些信息。2,把爬虫爬到的信息下载下来。具体哪个功能值钱我不清楚。反正举个例子:对于一个google广告的文案,这种信息分为几类?第一类:广告文案,打开首页,文案一定要有a,regionbroadcastingagencyc,eachclient,location,type,calltoaction,related,advertisement,points,level,relatedweibo,google,jpg等等。
这一类文案,a个国家一定是北京、上海、广州,然后连带着其他一些城市的地区。第二类:这一类,其实是广告公司的一些信息。比如我们新闻客户端要写region,所以要出示regionlocation的证书。或者还有类似如何查询广告位置,也要出示assistant。这一类信息特别容易抓取。像如何找到公关公司就是一样。
还有一类:美术作品或者版权信息,我们要提供作者drawingcompanycname,如果你说在谁的公司dedicatedto我们,或者是directoretc等等,简单说你要提供信息才能爬。因为这是国内,抓的不是别人而是政府,所以很多时候会经常出现哪个城市最xxx,简单说在china就应该在china哪个地区。
比如在北京,有些城市有马术队啊什么的,人家需要你提供drawingcompanycname。所以说这些细小的功能太多了。而且中国是互联网大国。互联网发展得非常快。这只是抓到了一些信息,涉及到保密信息。整个信息的价值,远远超过这个广告文案价值。从人人网切入,其他很多公司都有登录人人网的需求。你说值不值这个钱。 查看全部
输入关键字 抓取所有网页(“qq号”放进去了怎么办?(一))
输入关键字抓取所有网页并得到不同网页的不同标题,只要这个标题不在敏感词内都可以。有道吧。
快速。直接起个名叫"搜索xxx"然后链接到“让你这条信息xxx级。本站可见。
问题是这个动词的发明需要多久?
你都说是“微博”了,你应该把下面“qq号”放进去。
是不是“在我们a站人人网b站的信息里,
是的。当地的监管权,钱,技术,
谁说要等到“敏感词”词条只能拿到一段信息的,就凭你一个看客哪儿就值几百万了。
如果你想添加两个可以实现的功能。1,微博爬虫自动抓取同时登录过的人发布的一些信息。2,把爬虫爬到的信息下载下来。具体哪个功能值钱我不清楚。反正举个例子:对于一个google广告的文案,这种信息分为几类?第一类:广告文案,打开首页,文案一定要有a,regionbroadcastingagencyc,eachclient,location,type,calltoaction,related,advertisement,points,level,relatedweibo,google,jpg等等。
这一类文案,a个国家一定是北京、上海、广州,然后连带着其他一些城市的地区。第二类:这一类,其实是广告公司的一些信息。比如我们新闻客户端要写region,所以要出示regionlocation的证书。或者还有类似如何查询广告位置,也要出示assistant。这一类信息特别容易抓取。像如何找到公关公司就是一样。
还有一类:美术作品或者版权信息,我们要提供作者drawingcompanycname,如果你说在谁的公司dedicatedto我们,或者是directoretc等等,简单说你要提供信息才能爬。因为这是国内,抓的不是别人而是政府,所以很多时候会经常出现哪个城市最xxx,简单说在china就应该在china哪个地区。
比如在北京,有些城市有马术队啊什么的,人家需要你提供drawingcompanycname。所以说这些细小的功能太多了。而且中国是互联网大国。互联网发展得非常快。这只是抓到了一些信息,涉及到保密信息。整个信息的价值,远远超过这个广告文案价值。从人人网切入,其他很多公司都有登录人人网的需求。你说值不值这个钱。
输入关键字 抓取所有网页(谷歌官方教程《Google搜索工作原理》-湖北seo:搜索引擎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-02-02 02:11
湖北seo:搜索引擎的工作其实就是信息检索的过程。谷歌搜索引擎的工作原理是什么?
今天,小课堂为大家带来了谷歌官方教程《谷歌搜索的工作原理》。湖北seo希望对大家有所帮助。
Google 搜索的工作原理概述
当你坐在电脑前进行谷歌搜索时,来自整个网络的一系列搜索结果几乎会立即出现在你的眼前。Google 如何找到与您的查询匹配的页面,以及它如何确定搜索结果的排名顺序?
简单来说,您可以将在网络上搜索视为查找一本大书,其中海量索引会告诉您各种内容的位置。当您执行 Google 搜索时,我们的程序会搜索索引以确定最相关的搜索结果以返回(提供)给您。
为您提供搜索结果的三个主要流程如下:
1、抢
Google 知道您的 网站 吗?我们能找到吗?
2、索引
Google 可以索引您的 网站 吗?
3、提供结果
您的 网站 是否收录与用户搜索相关的有趣、有用的内容?
一、爬取过程简述
抓取是 Googlebot 查找要添加到 Google 索引的新页面和更新页面的过程。(湖北seo百度搜索叫百度蜘蛛)
我们使用大量计算机来摄取(或“抓取”)网络上的大量网页。执行抓取任务的程序称为 Googlebot(也称为机器人或“蜘蛛”)。Googlebot 使用算法进行抓取:计算机程序确定要抓取哪个 网站、多久抓取一次以及从每个 网站 抓取多少页面。
谷歌开始其抓取过程的网页网址列表是在之前的抓取过程中形成的,并且随着 网站 网站管理员提供更多站点地图数据而增长。当 Googlebot 访问每个 网站 时,它会检测每个页面上的链接并将这些链接添加到其要抓取的页面列表中。新创建的 网站s、对现有 网站s 的更改以及损坏的链接都会被记录下来并用于更新 Google 的索引。
Google 不会收取任何费用来提高 网站 的抓取速度。我们区分搜索业务和营利性 AdWords 服务。
二、索引过程简述
Googlebot 处理它抓取的每个页面,将它找到的所有单词以及这些单词在每个页面上的位置编译成一个庞大的索引。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。
三、简述提供结果的过程
当用户输入查询时,我们的计算机会在索引中搜索匹配的网页,并返回我们认为与用户搜索最相关的结果。相关性由 200 多个因素决定,其中之一是特定网页的 PageRank。PageRank 是一个网页的重要性,通过来自其他网页的链接来衡量。简单地说,从其他 网站 到您的 网站 页面的单个链接会提升您的 网站 PageRank。并非所有链接都具有同等价值:Google 致力于通过识别垃圾链接和其他对搜索结果产生负面影响的行为来不断改善用户体验。根据您的内容质量分配的链接是最佳链接。
为了让您的 网站 在搜索结果页面中排名靠前,您必须确保 Google 可以正确抓取您的 网站 并将其编入索引。我们的网站网站管理员指南概述了一些最佳实践,可帮助您避免常见的潜在问题并提高您的网站排名。
Google 的“您在寻找什么”功能和 Google 自动完成功能旨在通过显示相关搜索字词、常见拼写错误和热门查询来帮助用户节省时间。用我们的谷歌。com 搜索结果,这些功能使用由我们的网络爬虫和搜索算法自动生成的关键字。只有当我们相信预测会节省用户时间时,才会显示这些内容。如果 网站 在关键字搜索中排名很高,那是因为我们通过算法确定其内容与用户的查询高度相关。
以上是小小课堂为大家带来的谷歌官方教程《谷歌搜索的工作原理》。湖北seo感谢收看。SEO培训找小教室! 查看全部
输入关键字 抓取所有网页(谷歌官方教程《Google搜索工作原理》-湖北seo:搜索引擎)
湖北seo:搜索引擎的工作其实就是信息检索的过程。谷歌搜索引擎的工作原理是什么?
今天,小课堂为大家带来了谷歌官方教程《谷歌搜索的工作原理》。湖北seo希望对大家有所帮助。
 https://xxkt.org.cn/wp-content ... 5.jpg 300w, https://xxkt.org.cn/wp-content ... 7.jpg 768w, https://xxkt.org.cn/wp-content ... 6.jpg 1024w" />
https://xxkt.org.cn/wp-content ... 5.jpg 300w, https://xxkt.org.cn/wp-content ... 7.jpg 768w, https://xxkt.org.cn/wp-content ... 6.jpg 1024w" />Google 搜索的工作原理概述
当你坐在电脑前进行谷歌搜索时,来自整个网络的一系列搜索结果几乎会立即出现在你的眼前。Google 如何找到与您的查询匹配的页面,以及它如何确定搜索结果的排名顺序?
简单来说,您可以将在网络上搜索视为查找一本大书,其中海量索引会告诉您各种内容的位置。当您执行 Google 搜索时,我们的程序会搜索索引以确定最相关的搜索结果以返回(提供)给您。
为您提供搜索结果的三个主要流程如下:
1、抢
Google 知道您的 网站 吗?我们能找到吗?
2、索引
Google 可以索引您的 网站 吗?
3、提供结果
您的 网站 是否收录与用户搜索相关的有趣、有用的内容?
一、爬取过程简述
抓取是 Googlebot 查找要添加到 Google 索引的新页面和更新页面的过程。(湖北seo百度搜索叫百度蜘蛛)
我们使用大量计算机来摄取(或“抓取”)网络上的大量网页。执行抓取任务的程序称为 Googlebot(也称为机器人或“蜘蛛”)。Googlebot 使用算法进行抓取:计算机程序确定要抓取哪个 网站、多久抓取一次以及从每个 网站 抓取多少页面。
谷歌开始其抓取过程的网页网址列表是在之前的抓取过程中形成的,并且随着 网站 网站管理员提供更多站点地图数据而增长。当 Googlebot 访问每个 网站 时,它会检测每个页面上的链接并将这些链接添加到其要抓取的页面列表中。新创建的 网站s、对现有 网站s 的更改以及损坏的链接都会被记录下来并用于更新 Google 的索引。
Google 不会收取任何费用来提高 网站 的抓取速度。我们区分搜索业务和营利性 AdWords 服务。
二、索引过程简述
Googlebot 处理它抓取的每个页面,将它找到的所有单词以及这些单词在每个页面上的位置编译成一个庞大的索引。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。
三、简述提供结果的过程
当用户输入查询时,我们的计算机会在索引中搜索匹配的网页,并返回我们认为与用户搜索最相关的结果。相关性由 200 多个因素决定,其中之一是特定网页的 PageRank。PageRank 是一个网页的重要性,通过来自其他网页的链接来衡量。简单地说,从其他 网站 到您的 网站 页面的单个链接会提升您的 网站 PageRank。并非所有链接都具有同等价值:Google 致力于通过识别垃圾链接和其他对搜索结果产生负面影响的行为来不断改善用户体验。根据您的内容质量分配的链接是最佳链接。
为了让您的 网站 在搜索结果页面中排名靠前,您必须确保 Google 可以正确抓取您的 网站 并将其编入索引。我们的网站网站管理员指南概述了一些最佳实践,可帮助您避免常见的潜在问题并提高您的网站排名。
Google 的“您在寻找什么”功能和 Google 自动完成功能旨在通过显示相关搜索字词、常见拼写错误和热门查询来帮助用户节省时间。用我们的谷歌。com 搜索结果,这些功能使用由我们的网络爬虫和搜索算法自动生成的关键字。只有当我们相信预测会节省用户时间时,才会显示这些内容。如果 网站 在关键字搜索中排名很高,那是因为我们通过算法确定其内容与用户的查询高度相关。
以上是小小课堂为大家带来的谷歌官方教程《谷歌搜索的工作原理》。湖北seo感谢收看。SEO培训找小教室!
输入关键字 抓取所有网页(一下使用关键词抓取图片的操作方法分享的方法步骤吧!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-02-02 01:06
imagebox 是一个网页图片的批量抓取和下载工具。当用户需要下载某个网站中的一些素材或图片时,可以使用本软件进行操作,进入软件批量抓图即可。用户还不知道怎么操作,下面给大家分享一下使用关键词抓图的操作方法。感兴趣的朋友不妨看看。
方法步骤
1.首先第一步是打开软件,进入软件主界面。这时候,在界面的右侧,我们可以看到搜索引擎搜索和抓字的功能,然后我们输入我们要抓的图片。关键词 并单击开始抓取按钮。
2.点击开始抓图按钮后,进入抓图设置界面。首先看到的是图片的抓取选项设置,包括抓取速度、抓取范围等选项。用户可以根据个人需求进行选择。设置它。
3.下一个设置模块是图片存储选项。打开下拉列表后,有几个用于存储文件名的选项。你可以选择你需要的那个。
4.下一步,我们可以点击下方按钮开始爬取操作,开始批量爬取。
5.开始抓包后,我们会来到下图所示的界面,在里面可以看到抓包的进度。图像捕获完成后,单击“全部保存”按钮保存图像。
使用上面教程中分享的操作方法和步骤,我们可以使用软件imagebox来抓取一些我们需要的图片素材。如果您不知道如何使用此方法,请尝试小编分享的方法和步骤。好吧,我希望这个教程可以帮助你。 查看全部
输入关键字 抓取所有网页(一下使用关键词抓取图片的操作方法分享的方法步骤吧!)
imagebox 是一个网页图片的批量抓取和下载工具。当用户需要下载某个网站中的一些素材或图片时,可以使用本软件进行操作,进入软件批量抓图即可。用户还不知道怎么操作,下面给大家分享一下使用关键词抓图的操作方法。感兴趣的朋友不妨看看。

方法步骤
1.首先第一步是打开软件,进入软件主界面。这时候,在界面的右侧,我们可以看到搜索引擎搜索和抓字的功能,然后我们输入我们要抓的图片。关键词 并单击开始抓取按钮。

2.点击开始抓图按钮后,进入抓图设置界面。首先看到的是图片的抓取选项设置,包括抓取速度、抓取范围等选项。用户可以根据个人需求进行选择。设置它。

3.下一个设置模块是图片存储选项。打开下拉列表后,有几个用于存储文件名的选项。你可以选择你需要的那个。

4.下一步,我们可以点击下方按钮开始爬取操作,开始批量爬取。

5.开始抓包后,我们会来到下图所示的界面,在里面可以看到抓包的进度。图像捕获完成后,单击“全部保存”按钮保存图像。

使用上面教程中分享的操作方法和步骤,我们可以使用软件imagebox来抓取一些我们需要的图片素材。如果您不知道如何使用此方法,请尝试小编分享的方法和步骤。好吧,我希望这个教程可以帮助你。
输入关键字 抓取所有网页(《Python爬虫:模拟登录知乎》分析页面请求准备准备)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-31 19:27
接上一篇文章《Python爬虫:模拟登录知乎》。
分析页面请求
LZ 将从 知乎 的主题页面中获取所有主题及其结构。页面获取主题的ajax请求有两种,分别是“显示子主题”和“加载更多”,都是一次输出10个主题。请求网址如下:
https://www.zhihu.com/topic/19 ... 52706
其中 child 和 parent 是主题的 ID,“显示子主题”只需要 parent 参数,“加载更多”需要两个参数。如果两个参数都不存在,则表示“根主题”。
两种请求的响应数据都是json格式,结构类似,只是msg中的最后一个元素不同。
抓取逻辑
知乎主题结构是分层的。为了描述方便,“根主题”的子主题称为一级主题,一级主题的子主题为二级主题,以此类推……
为了抓取所有主题,流程应该是:从根主题开始,抓取所有一级主题并存储,然后依次分析每个一级主题,如果有子主题,则抓取它的所有子主题(次要)和存储,然后......循环继续下去。
根据流程,需要实现以下三个主要功能:
多谈谈主题存储。因为LZ要保存主题结构,“加载更多”时需要使用父主题ID,所以LZ将每个主题记录为一个列表,其中收录四个元素:主题名称、主题ID、父主题ID、有无状态子主题(bool类型),如['entity', '19778287', '19776749', 1],去重时,四个元素相同,则认为是重复。
代码
在代码中,第一段是模拟登录知乎。运行时,输入验证码后取数据,完成后数据保存到本地文件。因为运行时间比较长(1小时左右),所以增加了一些状态提示。
# all_topics.py
import requests
from bs4 import BeautifulSoup
# session变量
s = requests.Session()
headers = {
"Accept": "*/*",
"Accept-Encoding": "gzip,deflate",
"Accept-Language": "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4",
"Connection": "keep-alive",
"Content-Type":" application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36",
"Referer": "http://www.zhihu.com/"
}
_xsrf = ''
def set_xsrf():
global _xsrf
html = s.get('http://www.zhihu.com/', headers=headers) # GET请求,获取一个响应对象
soup = BeautifulSoup(html.text,'lxml-xml') # 使用BeautifulSoup解析HTML
_xsrf = soup.findAll(type='hidden')[0]['value']
def get_captcha():
# 获取验证码图片并保存在本地
captcha_url = 'http://www.zhihu.com/captcha.gif'
captcha = s.get(captcha_url, stream=True, headers=headers)
with open('captcha.gif', 'wb') as f:
for line in captcha.iter_content(10):
f.write(line)
f.close()
# 输入获取到的验证码,并入变量captch_str
print('输入验证码:', end='')
captcha_str = input()
return captcha_str.strip()
# 登录请求
def login():
global s
global _xsrf
set_xsrf()
captcha = get_captcha()
data = {
'_xsrf': _xsrf,
'email': '654408619@qq.com',
'password': 'mftx1029',
'remember_me': True,
'captcha': captcha
}
r = s.post(url='http://www.zhihu.com/login/email', data=data, headers=headers)
return r
all_topics = [['根话题', '19776749', '', 1]] # 保存所有的话题,初始状态保存根话题
has_children = [['根话题', '19776749', '', 1]] # 有子话题,但还没有抓取其子话题。初始状态保存根话题
cnt_a = 0 # all_topics元素计数
cnt_h = 0 # has_children元素计数
# 获取一次request的json数据
def get_json(child_id='', parent_id=''):
global s
global headers
url = 'https://www.zhihu.com/topic/19776749/organize/entire'
data = {'child': child_id, 'parent': parent_id, '_xsrf': _xsrf}
res = s.post(url,data=data, headers=headers)
json_dict = res.json()
return json_dict
# 解析json数据,获取子话题及「加载更多」的信息
def json_process(json_dict):
single_dict = {} # 保存下面的children和more
children = [] # 保存子话题
more = [] # 保存加载更多的信息
parent_id = json_dict['msg'][0][2]
if len(json_dict['msg'][1]) == 11:
more_child_id = json_dict['msg'][1][9][0][2]
more = [more_child_id, parent_id]
for i in json_dict['msg'][1][:10]:
child_name, child_id = i[0][1], i[0][2]
if i[1]:
children.append([child_name, child_id, parent_id, 1])
else:
children.append([child_name, child_id, parent_id, 0])
single_dict['children'] = children
single_dict['more'] = more
return single_dict
# 获取一个话题的所有子话题
def get_children(parent_id='', parent_name=''):
global cnt_a
global cnt_h
children = []
more = ['', parent_id]
while more:
json_dict = get_json(child_id=more[0], parent_id=more[1])
single_dict = json_process(json_dict)
children += single_dict['children']
more = single_dict['more']
# 用140个空格清除上次的提示
print(' '*140, end='\r')
# 终端提示抓取状态
print('已获取{}个话题。还有{}个话题排队当中,正在抓取「{}」的第{} 个子话题...'.format(\
cnt_a, cnt_h, str(parent_name).encode('gbk', 'ignore').decode('gbk'), len(children)), end='\r')
return children
# 工作函数,抓取全部话题并保存为文件
def work():
global cnt_h
global cnt_a
login()
while has_children:
first_child = has_children.pop(0)
children = get_children(first_child[1],first_child[0])
for c in children:
# 去重并添加到all_topics和has_topics,后者需要再判断下是否有子话题
if c not in all_topics:
all_topics.append(c)
if c[-1] == 1:
has_children.append(c)
cnt_a = len(all_topics)
cnt_h = len(has_children)
# 存入文件
for item in all_topics:
with open('all_topics.txt', 'a', encoding='utf-8') as f:
string = str(item[0]) + '\t' + str(item[1]) + '\t' + str(item[2]) + '\t' + str(item[3]) + '\n'
f.write(string)
if __name__ == "__main__":
work()
运行状态如下:
E:\@coding\python>python all_topics.py
输入验证码:hbfu
已获取53个话题。还有46个话题排队当中,正在抓取「「未归类」话题」的第1600 个子话题...
LZ是昨天运行的一个程序(2016-02-04),一共捕获了46272个话题。 查看全部
输入关键字 抓取所有网页(《Python爬虫:模拟登录知乎》分析页面请求准备准备)
接上一篇文章《Python爬虫:模拟登录知乎》。
分析页面请求
LZ 将从 知乎 的主题页面中获取所有主题及其结构。页面获取主题的ajax请求有两种,分别是“显示子主题”和“加载更多”,都是一次输出10个主题。请求网址如下:
https://www.zhihu.com/topic/19 ... 52706
其中 child 和 parent 是主题的 ID,“显示子主题”只需要 parent 参数,“加载更多”需要两个参数。如果两个参数都不存在,则表示“根主题”。
两种请求的响应数据都是json格式,结构类似,只是msg中的最后一个元素不同。
抓取逻辑
知乎主题结构是分层的。为了描述方便,“根主题”的子主题称为一级主题,一级主题的子主题为二级主题,以此类推……
为了抓取所有主题,流程应该是:从根主题开始,抓取所有一级主题并存储,然后依次分析每个一级主题,如果有子主题,则抓取它的所有子主题(次要)和存储,然后......循环继续下去。
根据流程,需要实现以下三个主要功能:
多谈谈主题存储。因为LZ要保存主题结构,“加载更多”时需要使用父主题ID,所以LZ将每个主题记录为一个列表,其中收录四个元素:主题名称、主题ID、父主题ID、有无状态子主题(bool类型),如['entity', '19778287', '19776749', 1],去重时,四个元素相同,则认为是重复。
代码
在代码中,第一段是模拟登录知乎。运行时,输入验证码后取数据,完成后数据保存到本地文件。因为运行时间比较长(1小时左右),所以增加了一些状态提示。
# all_topics.py
import requests
from bs4 import BeautifulSoup
# session变量
s = requests.Session()
headers = {
"Accept": "*/*",
"Accept-Encoding": "gzip,deflate",
"Accept-Language": "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4",
"Connection": "keep-alive",
"Content-Type":" application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36",
"Referer": "http://www.zhihu.com/"
}
_xsrf = ''
def set_xsrf():
global _xsrf
html = s.get('http://www.zhihu.com/', headers=headers) # GET请求,获取一个响应对象
soup = BeautifulSoup(html.text,'lxml-xml') # 使用BeautifulSoup解析HTML
_xsrf = soup.findAll(type='hidden')[0]['value']
def get_captcha():
# 获取验证码图片并保存在本地
captcha_url = 'http://www.zhihu.com/captcha.gif'
captcha = s.get(captcha_url, stream=True, headers=headers)
with open('captcha.gif', 'wb') as f:
for line in captcha.iter_content(10):
f.write(line)
f.close()
# 输入获取到的验证码,并入变量captch_str
print('输入验证码:', end='')
captcha_str = input()
return captcha_str.strip()
# 登录请求
def login():
global s
global _xsrf
set_xsrf()
captcha = get_captcha()
data = {
'_xsrf': _xsrf,
'email': '654408619@qq.com',
'password': 'mftx1029',
'remember_me': True,
'captcha': captcha
}
r = s.post(url='http://www.zhihu.com/login/email', data=data, headers=headers)
return r
all_topics = [['根话题', '19776749', '', 1]] # 保存所有的话题,初始状态保存根话题
has_children = [['根话题', '19776749', '', 1]] # 有子话题,但还没有抓取其子话题。初始状态保存根话题
cnt_a = 0 # all_topics元素计数
cnt_h = 0 # has_children元素计数
# 获取一次request的json数据
def get_json(child_id='', parent_id=''):
global s
global headers
url = 'https://www.zhihu.com/topic/19776749/organize/entire'
data = {'child': child_id, 'parent': parent_id, '_xsrf': _xsrf}
res = s.post(url,data=data, headers=headers)
json_dict = res.json()
return json_dict
# 解析json数据,获取子话题及「加载更多」的信息
def json_process(json_dict):
single_dict = {} # 保存下面的children和more
children = [] # 保存子话题
more = [] # 保存加载更多的信息
parent_id = json_dict['msg'][0][2]
if len(json_dict['msg'][1]) == 11:
more_child_id = json_dict['msg'][1][9][0][2]
more = [more_child_id, parent_id]
for i in json_dict['msg'][1][:10]:
child_name, child_id = i[0][1], i[0][2]
if i[1]:
children.append([child_name, child_id, parent_id, 1])
else:
children.append([child_name, child_id, parent_id, 0])
single_dict['children'] = children
single_dict['more'] = more
return single_dict
# 获取一个话题的所有子话题
def get_children(parent_id='', parent_name=''):
global cnt_a
global cnt_h
children = []
more = ['', parent_id]
while more:
json_dict = get_json(child_id=more[0], parent_id=more[1])
single_dict = json_process(json_dict)
children += single_dict['children']
more = single_dict['more']
# 用140个空格清除上次的提示
print(' '*140, end='\r')
# 终端提示抓取状态
print('已获取{}个话题。还有{}个话题排队当中,正在抓取「{}」的第{} 个子话题...'.format(\
cnt_a, cnt_h, str(parent_name).encode('gbk', 'ignore').decode('gbk'), len(children)), end='\r')
return children
# 工作函数,抓取全部话题并保存为文件
def work():
global cnt_h
global cnt_a
login()
while has_children:
first_child = has_children.pop(0)
children = get_children(first_child[1],first_child[0])
for c in children:
# 去重并添加到all_topics和has_topics,后者需要再判断下是否有子话题
if c not in all_topics:
all_topics.append(c)
if c[-1] == 1:
has_children.append(c)
cnt_a = len(all_topics)
cnt_h = len(has_children)
# 存入文件
for item in all_topics:
with open('all_topics.txt', 'a', encoding='utf-8') as f:
string = str(item[0]) + '\t' + str(item[1]) + '\t' + str(item[2]) + '\t' + str(item[3]) + '\n'
f.write(string)
if __name__ == "__main__":
work()
运行状态如下:
E:\@coding\python>python all_topics.py
输入验证码:hbfu
已获取53个话题。还有46个话题排队当中,正在抓取「「未归类」话题」的第1600 个子话题...
LZ是昨天运行的一个程序(2016-02-04),一共捕获了46272个话题。
输入关键字 抓取所有网页(如何找到原创文章都绞尽脑汁?替换反义词)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-31 17:28
SEO网站内容编辑:信息量很大发布日期:2018-01-20分类:行业资讯
“内容是,链条是”相信你对seoER站长并不陌生。内容可以说是一个网站的核心。有许多网站 管理员或SEOER 绞尽脑汁寻找原创文章。其实找到原创文章的方法有很多种,一起来看看吧。伪原创文章,什么是原创文章,对于搜索引擎来说,文章内容他没有收录,也有网站@ > 管理员 相信只要文章的内容与原文的相似度小于80%即可。
所以有一个伪原创。编辑标题。这是必须要改的,标题的重要性是毋庸置疑的,相信对于搜索引擎来说,决定原文好不好,那是一个要素。这是 伪原创 步骤,也是重要的一步。修改结束部分。由于搜索引擎更关注段落的结尾,所以忽略文章(这也是合理的,因为文章通常是一个段落,是对全文的概括描述),这也是一个许多人在文章 中使用的问题添加了一些自己的摘要,描述了原因。关键字替换。如同义词替换、反义词替换、同义词替换等,结合搜索引擎索引的原理,对搜索引擎抓取的网页进行预处理,输入关键词
所以你可以在不改变 文章 含义的情况下替换关键字(基于用户体验)。这是搜索引擎从中提取 关键词 的原创 文章。调整段落,这种方法,从用户体验的角度来看,并不适合所有的文章,除了一些形式的文章,否则文章运行后会变形。截取 文章 部分。许多 文章s,尤其是表 文章,可以通过多种方式进行拦截和修改,并使用其他伪原创方法进行处理。这也是一个新的文章。 查看全部
输入关键字 抓取所有网页(如何找到原创文章都绞尽脑汁?替换反义词)
SEO网站内容编辑:信息量很大发布日期:2018-01-20分类:行业资讯
“内容是,链条是”相信你对seoER站长并不陌生。内容可以说是一个网站的核心。有许多网站 管理员或SEOER 绞尽脑汁寻找原创文章。其实找到原创文章的方法有很多种,一起来看看吧。伪原创文章,什么是原创文章,对于搜索引擎来说,文章内容他没有收录,也有网站@ > 管理员 相信只要文章的内容与原文的相似度小于80%即可。

所以有一个伪原创。编辑标题。这是必须要改的,标题的重要性是毋庸置疑的,相信对于搜索引擎来说,决定原文好不好,那是一个要素。这是 伪原创 步骤,也是重要的一步。修改结束部分。由于搜索引擎更关注段落的结尾,所以忽略文章(这也是合理的,因为文章通常是一个段落,是对全文的概括描述),这也是一个许多人在文章 中使用的问题添加了一些自己的摘要,描述了原因。关键字替换。如同义词替换、反义词替换、同义词替换等,结合搜索引擎索引的原理,对搜索引擎抓取的网页进行预处理,输入关键词
所以你可以在不改变 文章 含义的情况下替换关键字(基于用户体验)。这是搜索引擎从中提取 关键词 的原创 文章。调整段落,这种方法,从用户体验的角度来看,并不适合所有的文章,除了一些形式的文章,否则文章运行后会变形。截取 文章 部分。许多 文章s,尤其是表 文章,可以通过多种方式进行拦截和修改,并使用其他伪原创方法进行处理。这也是一个新的文章。
输入关键字 抓取所有网页(百度蜘蛛喜欢抓取的内容有哪些?小编告诉你)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-30 10:06
网站内容是优化过程的重要组成部分文章。那么,百度蜘蛛喜欢抓取什么样的内容呢?接下来给大家分享一下百度蜘蛛喜欢爬的内容,一起来看看吧!
1、文章标题是怎么写的;
文章标题相当于文章的主体。把你下面写的文章制定好后,需要围绕这个主体来写,这样才能提高用户体验,否则用户体验会低。
2、文章关键词优化布局;
文章关键词在排版过程中非常重要。关键词的布局要自然,不堆积,不刻意,不影响客户阅读。即使是出现在开头段落中的 关键词 也应该遵循自然原则。
3、文章的相关性一定要高;
文章标题、关键词、内容在写作过程中一定要避开。您的 title 不可能是 South,关键词 是 North,content 是 West。我相信没有人会喜欢它。
4、多段,避免长篇大论;
文章在写的过程中,尽量避免出现长篇大论的情况,把文章的内容分几部分写出来,这样条件反射会更清晰,让人看的更清楚。
5、翻译外文原创文章;
翻译高质量的国外原创文章也是一种写内容的方式。对于搜索引擎来说,不同单词写的文章是不一样的,这对于写原创来说很重要,对于人@>文章不一定是个好办法。
6、网站文章更新频率要规律;
网站文章在写的过程中,一定要掌握一个规律,让蜘蛛有规律的爬到你的网站,这样更容易提高你的网站质量. 查看全部
输入关键字 抓取所有网页(百度蜘蛛喜欢抓取的内容有哪些?小编告诉你)
网站内容是优化过程的重要组成部分文章。那么,百度蜘蛛喜欢抓取什么样的内容呢?接下来给大家分享一下百度蜘蛛喜欢爬的内容,一起来看看吧!
1、文章标题是怎么写的;
文章标题相当于文章的主体。把你下面写的文章制定好后,需要围绕这个主体来写,这样才能提高用户体验,否则用户体验会低。
2、文章关键词优化布局;
文章关键词在排版过程中非常重要。关键词的布局要自然,不堆积,不刻意,不影响客户阅读。即使是出现在开头段落中的 关键词 也应该遵循自然原则。
3、文章的相关性一定要高;
文章标题、关键词、内容在写作过程中一定要避开。您的 title 不可能是 South,关键词 是 North,content 是 West。我相信没有人会喜欢它。
4、多段,避免长篇大论;
文章在写的过程中,尽量避免出现长篇大论的情况,把文章的内容分几部分写出来,这样条件反射会更清晰,让人看的更清楚。
5、翻译外文原创文章;
翻译高质量的国外原创文章也是一种写内容的方式。对于搜索引擎来说,不同单词写的文章是不一样的,这对于写原创来说很重要,对于人@>文章不一定是个好办法。
6、网站文章更新频率要规律;
网站文章在写的过程中,一定要掌握一个规律,让蜘蛛有规律的爬到你的网站,这样更容易提高你的网站质量.
输入关键字 抓取所有网页(根据关键词抓取新浪微博的数据,通过网页抓取的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-27 17:02
根据关键词抓取新浪微博1.背景
可能很多人都遇到过想通过一些关键词获取新浪微博数据。目前,有两种方式。
使用官方api
官方api的优点是使用简单方便。但是有两个问题。
这里还是提供了一个api的地址、参数和示例。令牌可以替换为您自己的。以下代码仅供参考
import requestsurl = 'https://api.weibo.com/2/search ... token true string 采用OAuth授权方式为必填参数,OAuth授权后获得。q true string 搜索的话题关键字,必须进行URLencode,utf-8编码。count false int 单页返回的记录条数,默认为10,最大为50。page false int 返回结果的页码,默认为1。"""load = { 'access_token': '2.00AqpTsHXXXXXXXXXXXXXXXXXXXXX', 'q': '新冠', 'count': 50, 'page': 2}html = requests.get(url, params=load)print(html.json())
从网络爬取
这个方法是我们文章文章的重点。优点是不需要获取token,二来获取的数据量比较大。但缺点也明显比较麻烦。本文还将详细分析每个步骤,以使爬取变得容易。
2. 分析目标网站
分析目标网站,输入任意关键词进行搜索,可以在搜索栏右侧看到高级搜索选项,如下图
微博高级搜索
我们先不设置参数,调用 f12 看看在搜索过程中可能会产生哪些请求(如下图所示)。
这是我们需要的数据。很明显,这是一个get请求,里面收录了几个参数。我们可以先猜测一下这些参数的含义。
很容易看出,“q”绝对代表了你需要搜索的字段。目前还不清楚“typeall”、“suball”和“Refer”分别代表什么,但没关系,我们可以通过更改参数再次请求来获取更多信息。
f12分析
我们更改参数,空间范围设置为北京,时间范围设置为2020-05-01 0:00 - 2020-05-02 23:00,同时翻到第8页。再次请求我们可以得到下面的数据。
我们可以看到,区域绝对代表了空间范围,下面的习惯:11:1000代表北京。timescope 表示时间范围,custom:2020-05-01-0:2020-05-02:23 表示我们设置的时间范围。page 绝对是页数。剩下的三个参数不影响我们整个结果(可能是设置了爬取的类型,读者可以自己试一试),暂时不用担心。
至此,我们已经分析了代表整个请求的参数的含义。接下来,我们可以考虑如何从页面中提取我们需要的信息。
3. 页面解析与代码编写3.1 爬取前的准备3.2 定位元素
通过查看原件,我们可以定位每条推文的位置,并找到元素的唯一定位标签。
我们发现可以发现每条微博都在一个标签下。找到所有标签,我们就可以找到每条微博。然后根据你的需要,找到你需要的信息。
这个文章是一个查找微博文字、用户和创建时间的例子。
3.3 代码示例
下面开始编写相关代码。首先是发送请求以获取相关的 HTML 文本。我们需要的是:
下面是一个简单的例子
import requestsfrom bs4 import BeautifulSoup# 请求的网址url = "https://s.weibo.com/weibo"# 请求头的文本,可以直接从网页中复制h = """Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9Accept-Encoding: gzip, deflate, brAccept-Language: zh,en-US;q=0.9,en;q=0.8,zh-CN;q=0.7Connection: keep-aliveCookie: XXXX(填自己的cookie)Host: s.weibo.comReferer: https://s.weibo.com/weibo/%252 ... Dest: documentSec-Fetch-Mode: navigateSec-Fetch-Site: same-originSec-Fetch-User: ?1Upgrade-Insecure-Requests: 1User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36"""# 将复制得到的str处理成标准的字典格式def handle_header(s): dic = {} li = s.split('\n') for l in li: dic[l.split(': ')[0]] = l.split(': ')[1] return dic # 处理请求def handle(page, year, month, day, hour): #请求的参数,页面和时间等 load = { 'q': '郭涛道歉', 'typeall': '1', 'suball': '1', 'timescope': f'custom:{year}-{month}-{day}-{hour}:{year}-{month}-{day}-{hour + 1}', 'Refer': 'g', 'page': page } # 发送请求 j = requests.get(url, headers=handle_header(h), params=load, timeout=(10, 10)) return j.text
这里可以通过handle函数获取html。然后通过beautifulsoup获取相关信息。相关代码如下
# 转换成soup的对象soup = BeautifulSoup(handle(1, 2020, 05, 01, 00), 'lxml')# 使用find_all获取这页所有weibo的信息, {'class': 'card-wrap'} 定位微博内容信息contents = soup.find_all('div', {'class': 'card-wrap'})
最后一步是从每条微博中提取有用信息
def filter_info(content, _date, _mid): """ 过滤无效信息 :param content: :param _date: :param _mid: :return: """ # 这里传入的content是一个微博包含的所有信息,也就是一个 {'class': 'card-wrap'} 的定位信息 _content = content.find('div', {'class': 'content'}) # 获取用户名 nick_name = _content.find('p')['nick-name'] # 获取微博文本 blog = _content.find_all('p', {'class': 'txt'})[-1].text.replace('郭涛道歉', '郭涛道歉').strip().replace('\n', '\\n') # 获取时间 create = _content.find_all('p', {'class': 'from'})[-1].a.text.strip().replace('\n', '\\n') date_str = "".join(_date) data = {'mid': _mid, 'nick_name': nick_name, 'create': create, 'blog': blog, 'date_str': date_str} # 返回json格式的数据 return data
至此,整个流程结束,filter_info返回的数据就是本页的微博信息。
剩下的,只要结合上面的代码,添加你自己的逻辑,比如设置数据库和获取更多信息。
完整参考代码请回复微博爬虫获取。 查看全部
输入关键字 抓取所有网页(根据关键词抓取新浪微博的数据,通过网页抓取的方法)
根据关键词抓取新浪微博1.背景
可能很多人都遇到过想通过一些关键词获取新浪微博数据。目前,有两种方式。
使用官方api
官方api的优点是使用简单方便。但是有两个问题。
这里还是提供了一个api的地址、参数和示例。令牌可以替换为您自己的。以下代码仅供参考
import requestsurl = 'https://api.weibo.com/2/search ... token true string 采用OAuth授权方式为必填参数,OAuth授权后获得。q true string 搜索的话题关键字,必须进行URLencode,utf-8编码。count false int 单页返回的记录条数,默认为10,最大为50。page false int 返回结果的页码,默认为1。"""load = { 'access_token': '2.00AqpTsHXXXXXXXXXXXXXXXXXXXXX', 'q': '新冠', 'count': 50, 'page': 2}html = requests.get(url, params=load)print(html.json())
从网络爬取
这个方法是我们文章文章的重点。优点是不需要获取token,二来获取的数据量比较大。但缺点也明显比较麻烦。本文还将详细分析每个步骤,以使爬取变得容易。
2. 分析目标网站
分析目标网站,输入任意关键词进行搜索,可以在搜索栏右侧看到高级搜索选项,如下图
微博高级搜索
我们先不设置参数,调用 f12 看看在搜索过程中可能会产生哪些请求(如下图所示)。
这是我们需要的数据。很明显,这是一个get请求,里面收录了几个参数。我们可以先猜测一下这些参数的含义。
很容易看出,“q”绝对代表了你需要搜索的字段。目前还不清楚“typeall”、“suball”和“Refer”分别代表什么,但没关系,我们可以通过更改参数再次请求来获取更多信息。
f12分析
我们更改参数,空间范围设置为北京,时间范围设置为2020-05-01 0:00 - 2020-05-02 23:00,同时翻到第8页。再次请求我们可以得到下面的数据。
我们可以看到,区域绝对代表了空间范围,下面的习惯:11:1000代表北京。timescope 表示时间范围,custom:2020-05-01-0:2020-05-02:23 表示我们设置的时间范围。page 绝对是页数。剩下的三个参数不影响我们整个结果(可能是设置了爬取的类型,读者可以自己试一试),暂时不用担心。
至此,我们已经分析了代表整个请求的参数的含义。接下来,我们可以考虑如何从页面中提取我们需要的信息。
3. 页面解析与代码编写3.1 爬取前的准备3.2 定位元素
通过查看原件,我们可以定位每条推文的位置,并找到元素的唯一定位标签。
我们发现可以发现每条微博都在一个标签下。找到所有标签,我们就可以找到每条微博。然后根据你的需要,找到你需要的信息。
这个文章是一个查找微博文字、用户和创建时间的例子。
3.3 代码示例
下面开始编写相关代码。首先是发送请求以获取相关的 HTML 文本。我们需要的是:
下面是一个简单的例子
import requestsfrom bs4 import BeautifulSoup# 请求的网址url = "https://s.weibo.com/weibo"# 请求头的文本,可以直接从网页中复制h = """Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9Accept-Encoding: gzip, deflate, brAccept-Language: zh,en-US;q=0.9,en;q=0.8,zh-CN;q=0.7Connection: keep-aliveCookie: XXXX(填自己的cookie)Host: s.weibo.comReferer: https://s.weibo.com/weibo/%252 ... Dest: documentSec-Fetch-Mode: navigateSec-Fetch-Site: same-originSec-Fetch-User: ?1Upgrade-Insecure-Requests: 1User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36"""# 将复制得到的str处理成标准的字典格式def handle_header(s): dic = {} li = s.split('\n') for l in li: dic[l.split(': ')[0]] = l.split(': ')[1] return dic # 处理请求def handle(page, year, month, day, hour): #请求的参数,页面和时间等 load = { 'q': '郭涛道歉', 'typeall': '1', 'suball': '1', 'timescope': f'custom:{year}-{month}-{day}-{hour}:{year}-{month}-{day}-{hour + 1}', 'Refer': 'g', 'page': page } # 发送请求 j = requests.get(url, headers=handle_header(h), params=load, timeout=(10, 10)) return j.text
这里可以通过handle函数获取html。然后通过beautifulsoup获取相关信息。相关代码如下
# 转换成soup的对象soup = BeautifulSoup(handle(1, 2020, 05, 01, 00), 'lxml')# 使用find_all获取这页所有weibo的信息, {'class': 'card-wrap'} 定位微博内容信息contents = soup.find_all('div', {'class': 'card-wrap'})
最后一步是从每条微博中提取有用信息
def filter_info(content, _date, _mid): """ 过滤无效信息 :param content: :param _date: :param _mid: :return: """ # 这里传入的content是一个微博包含的所有信息,也就是一个 {'class': 'card-wrap'} 的定位信息 _content = content.find('div', {'class': 'content'}) # 获取用户名 nick_name = _content.find('p')['nick-name'] # 获取微博文本 blog = _content.find_all('p', {'class': 'txt'})[-1].text.replace('郭涛道歉', '郭涛道歉').strip().replace('\n', '\\n') # 获取时间 create = _content.find_all('p', {'class': 'from'})[-1].a.text.strip().replace('\n', '\\n') date_str = "".join(_date) data = {'mid': _mid, 'nick_name': nick_name, 'create': create, 'blog': blog, 'date_str': date_str} # 返回json格式的数据 return data
至此,整个流程结束,filter_info返回的数据就是本页的微博信息。
剩下的,只要结合上面的代码,添加你自己的逻辑,比如设置数据库和获取更多信息。
完整参考代码请回复微博爬虫获取。
输入关键字 抓取所有网页( Amazon关键字易于使用的关键搜索和分析工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-02-08 12:18
Amazon关键字易于使用的关键搜索和分析工具)
亚马逊限制搜索引擎抓取
在市场经济飞速发展的今天,我们在电商平台购物的时候,一般都是直接通过关键词搜索,然后在搜索结果中找到想要的产品。这显示了一个好的关键字对于客户准确搜索您的产品的重要性。正如亚马逊卖家所知,新产品设置的关键词与能否在产品开始时找到它们并为它们带来流量有很大关系。很多新手卖家不知道怎么写关键词。市场上有许多亚马逊关键词工具。今天,我向您推荐几个易于使用的亚马逊关键搜索和分析工具。
1.易购云服务-亚马逊关键词搜索排名分析工具
对手的热门搜索和反关键字搜索,第一款CPC广告反查软件,英文关键字大数据库,支持美国、澳大利亚、日本、德国、法国、意大利和加拿大西部,九种语言,搜索量,小额出价
2.谷歌趋势 - 亚马逊关键词搜索分析
您可以自定义关键字搜索的搜索时间和历史数据,了解关键字搜索的变化趋势,帮助卖家了解当前的热门产品和市场需求,帮助进行库存管理。
3.Keyword Tracker - 亚马逊关键词搜索分析工具
查询竞争对手关键词,深度优化产品关键词,提升排名。支持四个数据库:wordtracker、Google、Youtube 和 Amazon。
4.Business Words - 亚马逊关键词搜索和分析工具
它每月更新一次,拥有海量的亚马逊关键词数据。数据来自谷歌和亚马逊。它搜索流行的关键字,将您的搜索范围缩小到类别关键字工具,并获得大量关键字。
5. KeywordTool - 亚马逊关键词搜索分析工具
无需创建帐户,跨平台、多区域、多语言的关键字搜索网站即可使用关键字工具,每个搜索词最多可收录 750 个长尾关键字。
6. KeywordInspector - 亚马逊关键词搜索分析工具
您可以找到亚马逊消费者正在使用的所有关键字。美国、英国、德国、加拿大、墨西哥、法国、意大利、日本和中国提供世界上唯一可以反转任何 ASIN 关键字查询的工具。
7.Science Seller - 亚马逊关键词搜索和分析工具
被称为“世界上最慢的关键字工具”,您可以获得无限的长期关键字,实时搜索关键字,并获得亚马逊关键字统计信息的频率。
8.关键词工具标尺 - 亚马逊关键词搜索分析排名工具
基于亚马逊的自动建议关键字列表(1-10 个关键字),在 Google、YouTube、Amazon、Bing 和 eBay 等平台上使用关键字软件。自动搜索很多长尾关键词。
9. SurTime 工具箱 - 亚马逊关键词搜索分析排名工具
支持所有站点的关键字扩展,可以获得关键字的流行度,统计词频。
最强大的功能是全球唯一支持一键关键词过滤重组,可以快速复制符合亚马逊规定的精准搜索词的功能。
10. Long Tail Pro - 亚马逊关键词搜索分析工具
这是目前唯一可以从 Google AdWords 获取数据的关键字软件。它支持选择多个国家和多种语言。SEO长尾助手不仅是最新有效的关键字和长尾,而且是每个词的搜索状态。还分析了招标情况,操作简单。
11. Wordtracker - 亚马逊关键词搜索分析工具
关键词软件涵盖wordtracker、谷歌、Youtube、亚马逊等平台,快速轻松了解关键词热度,查询排名。
12. KWFinder - 亚马逊关键词搜索分析排名工具
实时搜索优化关键字,深入的关键字研究和排名,准确的搜索量,可以从40种语言中选择准确的本地化结果,是深入关键字分析和研究的工具。
13. AMZtracker - 亚马逊关键词搜索分析排名工具
功能:调查竞争对手listing销售数据、关键词设置和排名优化、亚马逊listing排名提升、产品样本评价管理、产品差评跟踪管理、预测近一个月产品销量等 简单关键词工具,7天免费,包月试用 100 天后的刀具
14. Keywordeye - 亚马逊关键词搜索和分析工具
无限搜索关键词,计算关键词竞争力,查找热门产品和竞争对手关键词。
15. SEMrush - 亚马逊关键词搜索分析排名工具
研究排名因素,关键词分组管理,网站专攻SEO和SEO服务。
16. Soovle-亚马逊关键词搜索分析工具
关键字辅助工具,一次给出关键字概念的核心词。输入关键字后,其结果与Wikipedia、You Tube、Amazon、Yahoo、Ask和A的内容相关
17.搜索引擎优化-亚马逊关键词搜索分析
SEO网站获取 Google、Bing、YouTube 和 Amazon 的关键字自动建议数据。
18. 谷歌关键词规划师 - 亚马逊关键词搜索分析工具
提供来自谷歌搜索引擎的历史搜索数据,对关键词进行深入研究,找到客户关心的关键词。用户只需输入一组摘要词或短语,即可查看每月点击次数和平均竞争水平,从而挖掘产品创意并获得一些建议和提示。同时,该工具还可以显示信息量相同的相关关键词,防止用户遗漏任何东西
19. Terapeak_Amazon关键词搜索分析工具
您可以研究 eBay 和亚马逊上最畅销的产品和类别,分析标题的命名方式,并了解买家的购物习惯和热门搜索关键字。特别是对竞争对手进行研究,分析他们的销售业绩,更新最新趋势,定价策略等。
20. AmaSuite - 亚马逊关键词搜索分析工具
Azon Keyword Generator 是一款分析亚马逊产品关键词的小工具,可以轻松从 Amazon.co.uk 和 Amazon.co.uk 获取数千个长尾关键词。
21.关键字抓取工具 - 亚马逊关键字抓取工具
关键词挖掘软件,支持Google、Yahoo、Bing、ASK四种搜索引擎,只要输入一个关键词,选择一个目标市场,就会根据不同的国家出现不同的长尾关键词,并且都有真实的点击率和搜索量关键字。
22. keywordpy - 亚马逊关键字查找器
开发用于挖掘和跟踪国外关键字的软件。使用竞争对手的关键字并访问相关和相似术语和短语的大型数据库,以构建有利可图的关键字列表。
目录:robots.txt 简介
robots.txt(统一小写)文件位于 网站 的根目录中,是一个 ASCII 编码的文本文件,用于指示您不希望搜索引擎爬虫访问内容。
robots.txt的基本语法 robots.txt的限制范围原则
1.搜索技术应该为人类服务,同时尊重信息提供者的意愿和隐私;
2.网站有义务保护其个人信息和用户隐私不受侵犯。
影响
爬虫抓取 网站 并索引页面,然后通过关键字搜索将流量吸引到 网站。但是,我们只希望爬虫抓取最有价值的网页,而不希望它们访问不重要的信息或不适当的私人信息和数据。
robots.txt 可用于 SEO。
来源:完整指南:如何为 WordPress 博客编写 robots.txt 文件 Amazon--robots.txt 分析用户代理:
美国亚马逊:
Etao蜘蛛
亚马逊中国:
用户代理:*
没有阻止谷歌和一淘爬虫的说明
禁止内容分析(仅摘自我能理解的内容):登录页面添加到购物车愿望清单评论常见问题投票朋友推特历史图像音频和视频文件死链接机器人元数据
NOINDEX 指令:定义搜索引擎尚未将该网页索引到数据库中,但搜索引擎可以通过该网页的链接继续索引其他网页
NOFOLLOW 指令:不要索引此页面和链接到此页面的页面。仅适用于本页链接
概括
亚马逊的屏蔽令主要包括四个部分:客户的个人隐私信息、业务数据、消耗大量带宽的数据、无效链接。
商家有义务保护用户的个人信息和隐私不受侵犯。商业数据还包括能够带来商业价值的大数据,如用户浏览信息、购买信息、反馈信息等。可以屏蔽图片、音视频文件等带宽密集型数据,节省服务器带宽。
其中,美国亚马逊也屏蔽了谷歌爬虫和机器人爬虫。从网络上抓取可能会影响亚马逊上的产品销售。
允许部分中的说明主要是为了方便爬虫抓取,以便将客户和流量吸引到亚马逊。
Github--robots.txt 分析 User-agent: CCBot coccoc --- 越南免费网络浏览器 Daumoa --- dotbot dadduckbot EtaoSpider Googlebot --- 谷歌爬虫,搜索 网站HTTrack ia_archiver IntuitGSACrawler Mail.RU_Bot - --邮件爬虫 msnbot --- msn 爬虫,社交 网站Bingbot--- Bing 爬虫,搜索网站naverbot red-app-gsa-p-one rogerbot SandDollar seznambot Slurp Swiftbot -- - Swift 爬虫 Telefonica teoma Twitterbot --- Twitter爬虫,社交网站Yandex禁止内容分析(仅摘自我能理解的部分):/*/*/tree/master //master分支代码/ */stars //获得的星星/ */download //要在链接中下载的内容 /*/*/commits/*/* //comment /*/*/search //inline search /*/cache/ //Cache/.git/ // git repository/ login //用户登录摘要
Github 屏蔽了许多以保护用户个人隐私和知识产权不受侵犯为主要目的的用户代理。
总结
从以上两个网站的分析可以看出robots.txt协议的主要目的是优化搜索引擎。一方面,它允许爬虫为网页带来流量和客户,另一方面,它努力保护用户和企业的隐私和利益不受侵犯。
虽然 robots.txt 不会完全阻止您的网页被抓取,但仍然需要为您的 网站 设置 robots.txt。
参考链接:
百度百科:%E5%8D%8F%E8%AE%AE/2483797?fromtitle=robots.txt&fromid=9518761
谷歌支持:;ref_topic=6061961
书:
完整指南:如何为您的 WordPress 博客编写 robots.txt 文件
在外贸领域,对谷歌的依赖度很高,如何充分利用谷歌搜索引擎成为企业和商家的头等大事。
谷歌在中国的封锁使得谷歌搜索引擎无法访问,但作为一个成熟的外贸公司,访问国外的网站并优化谷歌搜索引擎是不可避免的。对于 Google 搜索引擎,有 8 个块来说明。
1、注意页面标题
页面标题是网页的标题。每个网页都需要一个唯一的页面标题。对于 网站 优化和搜索结果,不能低估准确和独特地创建页面标题。如果您的文档出现在搜索结果页面上,其标题标签的内容通常会出现在搜索结果的第一行。
2、描述标签
向 Google 和其他搜索引擎提供此页面的摘要说明。
Google 可能会使用元标记来生成您网页的片段。
3、优化url结构
简单易懂的 url 更容易表达内容信息。一个简单友好的 URL 可以让用户继续访问。相比于网址中无法识别的乱码和字母,优化网址效果明显。同时,为网页上的文件创建描述性的类别名称和文件名不仅可以帮助您更好地组织网站。它还可以帮助搜索引擎更有效地抓取文档。
4、html网络地图,使用xml站点地图文件
什么是网络图?通俗的讲,就是帮助用户在访问网站时访问网站内的所有页面或主页。制作 xml网站 映射进一步确保搜索引擎能够找到并索引您的 网站 中的所有页面。
5,404 个合理使用网页
它对 404 页面有什么作用?一般网站访问时不会出现404页面,然后,偶尔链接失效或用户链接输入错误访问网站域名下不存在的页面,友好的404页面可以带用户到更好的体验,可以在404页面上放置一个更高级别的网页返回链接,还有一个网站主页按钮,可以让用户访问想要的及时、高效地进行网站建设。网页。
6.网站 上的产品页面说明
网站中有大量产品,不同产品的描述不要太相似。每个产品都有一个独特的产品描述,Google 可以抓取网络以获取更有效的信息。
7、页面权重分布
对于一个高效成熟的网站,它有一个合理的权重分布。哪些页面需要更高的权重?当然是产品页面。我们需要被 Google 抓取以获取更多产品信息,因此产品页面上的权重更大。站点地图允许您查看网站创作最多的页面。好吧,我们自然需要产品页面的高权重。
8、图像优化
在我上次的社交媒体营销中,我也谈到了图像处理的重要性。一个成熟的网站必须合理规范图片的处理(包括图片的选择和图片的命名)。上次提到,在设置图片名称唯一时,需要使用alt属性来描述图片。当访问者无法正常显示图片时,可以使用文字来表示图片的属性,整体的用户体验会得到很大的提升。
9. robots.txt文件的应用
限制 Google 抓取的 robots txt 文件必须严格命名为 robots.txt,并放在 网站 的根目录下。
网站的某些页面不想被谷歌搜索引擎抓取,或者某些页面不是有价值的内容,那么就需要使用这个文件来限制抓取
10.谨慎使用 rel="nofollow"
当 网站 已经有博客和其他消息功能时,访问者的消息中将没有指向 网站 的链接,那么 网站 本身自然不希望 Google 发布它它自己的 网站 @网站 抓取与自己的 网站 无关的链接。此时需要nofollow来限制爬取。 查看全部
输入关键字 抓取所有网页(
Amazon关键字易于使用的关键搜索和分析工具)
亚马逊限制搜索引擎抓取
在市场经济飞速发展的今天,我们在电商平台购物的时候,一般都是直接通过关键词搜索,然后在搜索结果中找到想要的产品。这显示了一个好的关键字对于客户准确搜索您的产品的重要性。正如亚马逊卖家所知,新产品设置的关键词与能否在产品开始时找到它们并为它们带来流量有很大关系。很多新手卖家不知道怎么写关键词。市场上有许多亚马逊关键词工具。今天,我向您推荐几个易于使用的亚马逊关键搜索和分析工具。
1.易购云服务-亚马逊关键词搜索排名分析工具
对手的热门搜索和反关键字搜索,第一款CPC广告反查软件,英文关键字大数据库,支持美国、澳大利亚、日本、德国、法国、意大利和加拿大西部,九种语言,搜索量,小额出价
2.谷歌趋势 - 亚马逊关键词搜索分析
您可以自定义关键字搜索的搜索时间和历史数据,了解关键字搜索的变化趋势,帮助卖家了解当前的热门产品和市场需求,帮助进行库存管理。
3.Keyword Tracker - 亚马逊关键词搜索分析工具
查询竞争对手关键词,深度优化产品关键词,提升排名。支持四个数据库:wordtracker、Google、Youtube 和 Amazon。
4.Business Words - 亚马逊关键词搜索和分析工具
它每月更新一次,拥有海量的亚马逊关键词数据。数据来自谷歌和亚马逊。它搜索流行的关键字,将您的搜索范围缩小到类别关键字工具,并获得大量关键字。
5. KeywordTool - 亚马逊关键词搜索分析工具
无需创建帐户,跨平台、多区域、多语言的关键字搜索网站即可使用关键字工具,每个搜索词最多可收录 750 个长尾关键字。
6. KeywordInspector - 亚马逊关键词搜索分析工具
您可以找到亚马逊消费者正在使用的所有关键字。美国、英国、德国、加拿大、墨西哥、法国、意大利、日本和中国提供世界上唯一可以反转任何 ASIN 关键字查询的工具。
7.Science Seller - 亚马逊关键词搜索和分析工具
被称为“世界上最慢的关键字工具”,您可以获得无限的长期关键字,实时搜索关键字,并获得亚马逊关键字统计信息的频率。
8.关键词工具标尺 - 亚马逊关键词搜索分析排名工具
基于亚马逊的自动建议关键字列表(1-10 个关键字),在 Google、YouTube、Amazon、Bing 和 eBay 等平台上使用关键字软件。自动搜索很多长尾关键词。
9. SurTime 工具箱 - 亚马逊关键词搜索分析排名工具
支持所有站点的关键字扩展,可以获得关键字的流行度,统计词频。
最强大的功能是全球唯一支持一键关键词过滤重组,可以快速复制符合亚马逊规定的精准搜索词的功能。
10. Long Tail Pro - 亚马逊关键词搜索分析工具
这是目前唯一可以从 Google AdWords 获取数据的关键字软件。它支持选择多个国家和多种语言。SEO长尾助手不仅是最新有效的关键字和长尾,而且是每个词的搜索状态。还分析了招标情况,操作简单。
11. Wordtracker - 亚马逊关键词搜索分析工具
关键词软件涵盖wordtracker、谷歌、Youtube、亚马逊等平台,快速轻松了解关键词热度,查询排名。
12. KWFinder - 亚马逊关键词搜索分析排名工具
实时搜索优化关键字,深入的关键字研究和排名,准确的搜索量,可以从40种语言中选择准确的本地化结果,是深入关键字分析和研究的工具。
13. AMZtracker - 亚马逊关键词搜索分析排名工具
功能:调查竞争对手listing销售数据、关键词设置和排名优化、亚马逊listing排名提升、产品样本评价管理、产品差评跟踪管理、预测近一个月产品销量等 简单关键词工具,7天免费,包月试用 100 天后的刀具
14. Keywordeye - 亚马逊关键词搜索和分析工具
无限搜索关键词,计算关键词竞争力,查找热门产品和竞争对手关键词。
15. SEMrush - 亚马逊关键词搜索分析排名工具
研究排名因素,关键词分组管理,网站专攻SEO和SEO服务。
16. Soovle-亚马逊关键词搜索分析工具
关键字辅助工具,一次给出关键字概念的核心词。输入关键字后,其结果与Wikipedia、You Tube、Amazon、Yahoo、Ask和A的内容相关
17.搜索引擎优化-亚马逊关键词搜索分析
SEO网站获取 Google、Bing、YouTube 和 Amazon 的关键字自动建议数据。
18. 谷歌关键词规划师 - 亚马逊关键词搜索分析工具
提供来自谷歌搜索引擎的历史搜索数据,对关键词进行深入研究,找到客户关心的关键词。用户只需输入一组摘要词或短语,即可查看每月点击次数和平均竞争水平,从而挖掘产品创意并获得一些建议和提示。同时,该工具还可以显示信息量相同的相关关键词,防止用户遗漏任何东西
19. Terapeak_Amazon关键词搜索分析工具
您可以研究 eBay 和亚马逊上最畅销的产品和类别,分析标题的命名方式,并了解买家的购物习惯和热门搜索关键字。特别是对竞争对手进行研究,分析他们的销售业绩,更新最新趋势,定价策略等。
20. AmaSuite - 亚马逊关键词搜索分析工具
Azon Keyword Generator 是一款分析亚马逊产品关键词的小工具,可以轻松从 Amazon.co.uk 和 Amazon.co.uk 获取数千个长尾关键词。
21.关键字抓取工具 - 亚马逊关键字抓取工具
关键词挖掘软件,支持Google、Yahoo、Bing、ASK四种搜索引擎,只要输入一个关键词,选择一个目标市场,就会根据不同的国家出现不同的长尾关键词,并且都有真实的点击率和搜索量关键字。
22. keywordpy - 亚马逊关键字查找器
开发用于挖掘和跟踪国外关键字的软件。使用竞争对手的关键字并访问相关和相似术语和短语的大型数据库,以构建有利可图的关键字列表。
目录:robots.txt 简介
robots.txt(统一小写)文件位于 网站 的根目录中,是一个 ASCII 编码的文本文件,用于指示您不希望搜索引擎爬虫访问内容。
robots.txt的基本语法 robots.txt的限制范围原则
1.搜索技术应该为人类服务,同时尊重信息提供者的意愿和隐私;
2.网站有义务保护其个人信息和用户隐私不受侵犯。
影响
爬虫抓取 网站 并索引页面,然后通过关键字搜索将流量吸引到 网站。但是,我们只希望爬虫抓取最有价值的网页,而不希望它们访问不重要的信息或不适当的私人信息和数据。
robots.txt 可用于 SEO。
来源:完整指南:如何为 WordPress 博客编写 robots.txt 文件 Amazon--robots.txt 分析用户代理:
美国亚马逊:
Etao蜘蛛
亚马逊中国:
用户代理:*
没有阻止谷歌和一淘爬虫的说明
禁止内容分析(仅摘自我能理解的内容):登录页面添加到购物车愿望清单评论常见问题投票朋友推特历史图像音频和视频文件死链接机器人元数据
NOINDEX 指令:定义搜索引擎尚未将该网页索引到数据库中,但搜索引擎可以通过该网页的链接继续索引其他网页
NOFOLLOW 指令:不要索引此页面和链接到此页面的页面。仅适用于本页链接
概括
亚马逊的屏蔽令主要包括四个部分:客户的个人隐私信息、业务数据、消耗大量带宽的数据、无效链接。
商家有义务保护用户的个人信息和隐私不受侵犯。商业数据还包括能够带来商业价值的大数据,如用户浏览信息、购买信息、反馈信息等。可以屏蔽图片、音视频文件等带宽密集型数据,节省服务器带宽。
其中,美国亚马逊也屏蔽了谷歌爬虫和机器人爬虫。从网络上抓取可能会影响亚马逊上的产品销售。
允许部分中的说明主要是为了方便爬虫抓取,以便将客户和流量吸引到亚马逊。
Github--robots.txt 分析 User-agent: CCBot coccoc --- 越南免费网络浏览器 Daumoa --- dotbot dadduckbot EtaoSpider Googlebot --- 谷歌爬虫,搜索 网站HTTrack ia_archiver IntuitGSACrawler Mail.RU_Bot - --邮件爬虫 msnbot --- msn 爬虫,社交 网站Bingbot--- Bing 爬虫,搜索网站naverbot red-app-gsa-p-one rogerbot SandDollar seznambot Slurp Swiftbot -- - Swift 爬虫 Telefonica teoma Twitterbot --- Twitter爬虫,社交网站Yandex禁止内容分析(仅摘自我能理解的部分):/*/*/tree/master //master分支代码/ */stars //获得的星星/ */download //要在链接中下载的内容 /*/*/commits/*/* //comment /*/*/search //inline search /*/cache/ //Cache/.git/ // git repository/ login //用户登录摘要
Github 屏蔽了许多以保护用户个人隐私和知识产权不受侵犯为主要目的的用户代理。
总结
从以上两个网站的分析可以看出robots.txt协议的主要目的是优化搜索引擎。一方面,它允许爬虫为网页带来流量和客户,另一方面,它努力保护用户和企业的隐私和利益不受侵犯。
虽然 robots.txt 不会完全阻止您的网页被抓取,但仍然需要为您的 网站 设置 robots.txt。
参考链接:
百度百科:%E5%8D%8F%E8%AE%AE/2483797?fromtitle=robots.txt&fromid=9518761
谷歌支持:;ref_topic=6061961
书:
完整指南:如何为您的 WordPress 博客编写 robots.txt 文件
在外贸领域,对谷歌的依赖度很高,如何充分利用谷歌搜索引擎成为企业和商家的头等大事。
谷歌在中国的封锁使得谷歌搜索引擎无法访问,但作为一个成熟的外贸公司,访问国外的网站并优化谷歌搜索引擎是不可避免的。对于 Google 搜索引擎,有 8 个块来说明。
1、注意页面标题
页面标题是网页的标题。每个网页都需要一个唯一的页面标题。对于 网站 优化和搜索结果,不能低估准确和独特地创建页面标题。如果您的文档出现在搜索结果页面上,其标题标签的内容通常会出现在搜索结果的第一行。
2、描述标签
向 Google 和其他搜索引擎提供此页面的摘要说明。
Google 可能会使用元标记来生成您网页的片段。
3、优化url结构
简单易懂的 url 更容易表达内容信息。一个简单友好的 URL 可以让用户继续访问。相比于网址中无法识别的乱码和字母,优化网址效果明显。同时,为网页上的文件创建描述性的类别名称和文件名不仅可以帮助您更好地组织网站。它还可以帮助搜索引擎更有效地抓取文档。
4、html网络地图,使用xml站点地图文件
什么是网络图?通俗的讲,就是帮助用户在访问网站时访问网站内的所有页面或主页。制作 xml网站 映射进一步确保搜索引擎能够找到并索引您的 网站 中的所有页面。
5,404 个合理使用网页
它对 404 页面有什么作用?一般网站访问时不会出现404页面,然后,偶尔链接失效或用户链接输入错误访问网站域名下不存在的页面,友好的404页面可以带用户到更好的体验,可以在404页面上放置一个更高级别的网页返回链接,还有一个网站主页按钮,可以让用户访问想要的及时、高效地进行网站建设。网页。
6.网站 上的产品页面说明
网站中有大量产品,不同产品的描述不要太相似。每个产品都有一个独特的产品描述,Google 可以抓取网络以获取更有效的信息。
7、页面权重分布
对于一个高效成熟的网站,它有一个合理的权重分布。哪些页面需要更高的权重?当然是产品页面。我们需要被 Google 抓取以获取更多产品信息,因此产品页面上的权重更大。站点地图允许您查看网站创作最多的页面。好吧,我们自然需要产品页面的高权重。
8、图像优化
在我上次的社交媒体营销中,我也谈到了图像处理的重要性。一个成熟的网站必须合理规范图片的处理(包括图片的选择和图片的命名)。上次提到,在设置图片名称唯一时,需要使用alt属性来描述图片。当访问者无法正常显示图片时,可以使用文字来表示图片的属性,整体的用户体验会得到很大的提升。
9. robots.txt文件的应用
限制 Google 抓取的 robots txt 文件必须严格命名为 robots.txt,并放在 网站 的根目录下。
网站的某些页面不想被谷歌搜索引擎抓取,或者某些页面不是有价值的内容,那么就需要使用这个文件来限制抓取
10.谨慎使用 rel="nofollow"
当 网站 已经有博客和其他消息功能时,访问者的消息中将没有指向 网站 的链接,那么 网站 本身自然不希望 Google 发布它它自己的 网站 @网站 抓取与自己的 网站 无关的链接。此时需要nofollow来限制爬取。
输入关键字 抓取所有网页(网站首页的关键词越多越好!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-08 12:16
在学习SEO优化的过程中,不知道有没有听过这样一句话,一个网站首页的关键词越少越好,关键词的< @网站,更好!不知道这句话大家看懂了没有,可能是因为我是菜鸟站长,所以关注了这种问题,但是不管对不对,还是分享给大家,让大家可以使用它作为参考。废话不多说,直接进入正题。
不知道其他站长朋友有没有注意到。当我们更新网站的时候,如果首页也同时更新了,那么首页的内容就会发生变化,也就是说蜘蛛抓取首页的时候关键词也会发生变化. 如果是大的网站,他们的权重很高,也许他们不在乎首页的关键词有没有变化,更新全部更新。不过作为个体站长,我们每天更新的内容不会太多,网站首页的内容每次更新都会有细微的变化。但是我发现,即使是这个微小的变化,当蜘蛛爬取主页时,关键词也会发生变化。就像我的生活知识网站一样,有一段时间我不是每天都更新内容,有时会间隔一个星期。有一次发现“健康养生”这个词在冬天排名很好,流量也不错,但是几次内容更新后发现这个词带来的流量已经找不到了,排名也消失了. 郁闷的时候也找了找原因,最后发现首页的内容中少了这个信息(因为我更新了内容,信息的顶部没有了)。
我们都知道,做网站内容为王,好的内容,原创信息百度等各大搜索引擎都会看重,即使采集来伪原创很受欢迎。网站要想成长,就必须不断地补充新鲜血液和新内容。但是我上面说了,如果在内容更新的时候也更新了首页的内容,那肯定会造成关键词的丢失。这会影响排名的稳定性。我们必须想办法做到这两点,所以我开始了这个实验。说实话,我一直都在单枪匹马地找高手带路,但还没找到,嘿嘿!那么让我进一步探索吧!
鉴于以上发现,我个人认为首页的更新会对首页关键词起到一定的作用。因为蜘蛛在爬取首页时,会根据首页的所有内容组成词,影响关键词。当搜索引擎爬取我们的网站时,会做几个步骤,提取网站关键词,结合首页的大量信息,提取出它认为合适的词;排除出现在@>上的网站重复信息;出现在首页的链接分析;出现 关键词 的重要性。基于这些知识,为了让首页关键词固定,但同时更新首页内容,提高网站的某个页面的权重,我试了几个次,最后觉得还是用一个添加固定词组和更新内容比较安全。下面我会告诉你我是怎么做到的。
事实上,这很简单。我只是将主页划分为一个站点,用于最近推广关键词。在制作了一套完整的近期流行词后,我建立了一个近期推广栏目,并使用了不同颜色、加粗等一系列方法来区分它们。无论其他事情如何变化,这些话都是一样的。即第一页有转换词和非动词。我认为这样做的好处是在赛季或过热之后,您可以再次切换设置。灵活但相对稳定。如果你觉得你网站上的某篇文章文章在最近或者未来几天会被大量网友搜索,在做这些非动词的时候,可以故意多做几个锚链接点改文章,提高这个文章的重要性和权重,
但是值得我们注意的是,我们在制作稳定的首页关键词的时候,一定要注意关键词的组合,也就是首页出现的关键词的密度。比如我们可以使用站长工具中的蜘蛛模拟器来测试首页出现的信息,从而知道我们的网站的关键词的密度,从而做出更好的调整. 然后是我们做的非动词内容。这些 关键词 锚链接不应都指向主页或同一页面。虽然这样会提高某个页面的权重,但是如果太多,就会让引擎认为是作弊。更不用说一些 heimao关键词 链接,这些链接长期以来被引擎认为是 SEO 作弊。当我们在做 关键词 优化时,我们必须提前计划并提前准备季节性关键词。我的网站是关于健康和常识的,所以提前准备比较容易。有的网站可能不是很可预测,但是根据自己的内容,应该及时发现热门词。从而为自己带来更多的流量和更多的收入网站。
尤其是博客类型网站最有可能出现这种情况,所以我们要注意了。有些说法需要证实,但确有其事,请大家辨认并发表不同意见。 查看全部
输入关键字 抓取所有网页(网站首页的关键词越多越好!)
在学习SEO优化的过程中,不知道有没有听过这样一句话,一个网站首页的关键词越少越好,关键词的< @网站,更好!不知道这句话大家看懂了没有,可能是因为我是菜鸟站长,所以关注了这种问题,但是不管对不对,还是分享给大家,让大家可以使用它作为参考。废话不多说,直接进入正题。
不知道其他站长朋友有没有注意到。当我们更新网站的时候,如果首页也同时更新了,那么首页的内容就会发生变化,也就是说蜘蛛抓取首页的时候关键词也会发生变化. 如果是大的网站,他们的权重很高,也许他们不在乎首页的关键词有没有变化,更新全部更新。不过作为个体站长,我们每天更新的内容不会太多,网站首页的内容每次更新都会有细微的变化。但是我发现,即使是这个微小的变化,当蜘蛛爬取主页时,关键词也会发生变化。就像我的生活知识网站一样,有一段时间我不是每天都更新内容,有时会间隔一个星期。有一次发现“健康养生”这个词在冬天排名很好,流量也不错,但是几次内容更新后发现这个词带来的流量已经找不到了,排名也消失了. 郁闷的时候也找了找原因,最后发现首页的内容中少了这个信息(因为我更新了内容,信息的顶部没有了)。
我们都知道,做网站内容为王,好的内容,原创信息百度等各大搜索引擎都会看重,即使采集来伪原创很受欢迎。网站要想成长,就必须不断地补充新鲜血液和新内容。但是我上面说了,如果在内容更新的时候也更新了首页的内容,那肯定会造成关键词的丢失。这会影响排名的稳定性。我们必须想办法做到这两点,所以我开始了这个实验。说实话,我一直都在单枪匹马地找高手带路,但还没找到,嘿嘿!那么让我进一步探索吧!
鉴于以上发现,我个人认为首页的更新会对首页关键词起到一定的作用。因为蜘蛛在爬取首页时,会根据首页的所有内容组成词,影响关键词。当搜索引擎爬取我们的网站时,会做几个步骤,提取网站关键词,结合首页的大量信息,提取出它认为合适的词;排除出现在@>上的网站重复信息;出现在首页的链接分析;出现 关键词 的重要性。基于这些知识,为了让首页关键词固定,但同时更新首页内容,提高网站的某个页面的权重,我试了几个次,最后觉得还是用一个添加固定词组和更新内容比较安全。下面我会告诉你我是怎么做到的。
事实上,这很简单。我只是将主页划分为一个站点,用于最近推广关键词。在制作了一套完整的近期流行词后,我建立了一个近期推广栏目,并使用了不同颜色、加粗等一系列方法来区分它们。无论其他事情如何变化,这些话都是一样的。即第一页有转换词和非动词。我认为这样做的好处是在赛季或过热之后,您可以再次切换设置。灵活但相对稳定。如果你觉得你网站上的某篇文章文章在最近或者未来几天会被大量网友搜索,在做这些非动词的时候,可以故意多做几个锚链接点改文章,提高这个文章的重要性和权重,
但是值得我们注意的是,我们在制作稳定的首页关键词的时候,一定要注意关键词的组合,也就是首页出现的关键词的密度。比如我们可以使用站长工具中的蜘蛛模拟器来测试首页出现的信息,从而知道我们的网站的关键词的密度,从而做出更好的调整. 然后是我们做的非动词内容。这些 关键词 锚链接不应都指向主页或同一页面。虽然这样会提高某个页面的权重,但是如果太多,就会让引擎认为是作弊。更不用说一些 heimao关键词 链接,这些链接长期以来被引擎认为是 SEO 作弊。当我们在做 关键词 优化时,我们必须提前计划并提前准备季节性关键词。我的网站是关于健康和常识的,所以提前准备比较容易。有的网站可能不是很可预测,但是根据自己的内容,应该及时发现热门词。从而为自己带来更多的流量和更多的收入网站。
尤其是博客类型网站最有可能出现这种情况,所以我们要注意了。有些说法需要证实,但确有其事,请大家辨认并发表不同意见。
输入关键字 抓取所有网页(社招进阿里的一个面试呗,你准备好了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-07 06:03
内容
前言
前几天,我接到了外籍人士阿里的面试。作为一个自信狂妄的我,虽然是外籍人士,但对阿里还是有几分敬佩之情,就像高考想进清华北大,想进腾讯阿里工作一样。是的,当然,除了学校招985/211能进阿里外,其他人想通过中介被招进阿里,那就更难了,至少在某个领域是专家级别的。所以如果你有一个难得的机会,试试阿里的采访。
一、采访内容1、电话面试及项目实践题
首先是电话面试:这个一般没问题,多看书,少吃零食,多睡觉……这个肯定能回答
二是想出一个动手demo题目,如下
文档链接:
爬取左侧文档树中的所有文档列表
在查询页面输入关键词或描述性语言给出3个最佳匹配文档(从高匹配到低匹配排序)。
供应:
1. 代码
2. 匹配的想法
奖励:有关如何为描述性语言提供建议的文档。例如用户输入:我的日志 采集 is out
大多数人在听到他们要编写一个演示时都会感到恐慌。不要害怕,我不会和你分享我的经验和代码示例,所以请阅读此文章,之后应该没问题,反正我已经结束了。
2、动手主题:文档抓取和搜索
3、研究课题
首先,去链接看看。让我们来看看它是什么。原来是阿里云的帮助文档。看来这个简单的demo其实就是根据用户输入的关键词搜索对应的解决方案。小项目。
第一个小步骤,爬取内容应该不难。不管是用Java还是Python,难度是第一位的,但是Python可能更简单,Java会多写一点代码。当然,小编目前还是想先学java,所以用java代码来演示。至于Python,先学一门语言,再拓展其他语言,才能更好的辅助你。
难点在于第二个小步骤,“在查询页面输入关键词或者描述性语言,给出最佳匹配的3个文档(匹配度从高到低排序)”,
我们先不爬,因为如果爬,必须封装想要的格式。当我们没有想到查询关键词的功能时,先保留它。
①查询输入关键词,给出最佳匹配方案
当然,你可以自己写算法和匹配,但是这种情况下,匹配肯定不是很准确,一天之内几乎不可能写出来,所以看看前人对这种类型有什么想法更好的解决方案,踩在巨人的肩膀上,事半功倍。
其实有很多方法可以实现类似的功能,
比如通过分词器搜索:Jieba分词、Ansj分词……其他分词效果可以点这里:了解11个开源中文分词
或者类似搜索引擎服务器的开源框架:Elasticsearch、Lucene……其他搜索引擎服务可以点这里:了解13个开源搜索引擎
小编这里演示的是一个使用solr搜索引擎实现这个爬取和检索的demo项目
二、启动 solr
solr下载地址:最好下载低版本,高版本需要高jdk版本,我的jdk是1.7,下载的solr版本是4.7.0是的,或者当我下载我在文章末尾制作的演示时,我也会将我使用的所有内容都放入其中。
1、配置步骤
① 下载后解压
② cmd进入这个目录:xxxxx/solr-4.7.0/example
③ 执行命令:java -jar start.jar
④ 如果访问成功,在浏览器中输入:8983/solr即可访问,表示启动成功。
2、Solr接口说明及使用
具体solr的其他功能这里就不介绍了。可以参考网上资料,进一步加深对solr的理解和使用
三、开始爬取
首先在项目中引入solr的maven包
org.apache.solr
solr-solrj
4.7.0
爬取很简单,只是模拟一个浏览器访问内容,我们可以看到要爬取的网站左边的所有文本内容都在
里面,
这个很简单,这样我们就可以对爬取的数据进行正则匹配后得到我们想要的所有文本标题信息。
代码示例:
/**
* 爬取数据
* @return
*/
@ResponseBody
@RequestMapping("/getDocs")
public String getDocs() {
Map mapReturn = new HashMap(); //返回结果
try {
//爬取前先在solr上建林索引属性
alibabaService.addDefaultField();
//开始爬取指定url的数据
String htmlResult = GetAliApi.sendGet("https://help.aliyun.com/docume ... ot%3B, "");
//获取到 树文档的内容
String[] mainMenuListContainer = htmlResult.split("")[1].split("");
//log.debug(mainMenuListContainer[0]);
//log.debug("------------------------------");
//进行正则获取数据
String searchReg = "(.*?)";
Pattern pattern = Pattern.compile(searchReg); // 讲编译的正则表达式对象赋给pattern
Matcher matcher = pattern.matcher(mainMenuListContainer[0]);
int i = 0;
String pre = "A";
while (matcher.find()) {
i++;
String title = matcher.group(1);
log.debug(title);
//将数据放到solr里,添加索引
Alidocs alidocs = new Alidocs();
alidocs.setId(pre+i);
alidocs.setTitle(title);
alibabaService.addIndex(alidocs);
}
mapReturn.put("returnCode","00");
mapReturn.put("content","爬取成功");
}catch (Exception e){
e.printStackTrace();
mapReturn.put("returnCode","-1");
mapReturn.put("content","爬取失败,请重试");
}
String mapStr = JSONObject.toJSONString(mapReturn);
return mapStr;
}
addDefaultField() 方法和 addIndex() 方法:
// 添加默认索引属性
public void addDefaultField() throws SolrServerException, IOException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", "默认情况下必须添加的字段,用来区分文档的唯一标识");
doc.addField("title", "默认的名称属性字段");
solr.add(doc);
solr.commit();
}
// 添加索引
public void addIndex(Alidocs alidocs) throws SolrServerException, IOException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
solr.addBean(alidocs);
solr.commit();
}
sendGet() 方法:
public static String sendGet(String url, String param) {
String result = "";
String urlName = url + "?" + param;
try {
URL realURL = new URL(urlName);
URLConnection conn = realURL.openConnection();
//伪造ip访问
String ip = randIP();
System.out.println("目前伪造的ip:"+ip);
conn.setRequestProperty("X-Forwarded-For", ip);
conn.setRequestProperty("HTTP_X_FORWARDED_FOR", ip);
conn.setRequestProperty("HTTP_CLIENT_IP", ip);
conn.setRequestProperty("REMOTE_ADDR", ip);
conn.setRequestProperty("Host", "help.aliyun.com/");
conn.setRequestProperty("accept", "*/*");
conn.setRequestProperty("connection", "Keep-Alive");
conn.setRequestProperty("user-agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 Safari/537.36");
conn.setRequestProperty("Referer","https://help.aliyun.com/"); //伪造访问来源
conn.setRequestProperty("Origin", "https://help.aliyun.com/"); //伪造访问域名
conn.connect();
Map map = conn.getHeaderFields();
for (String s : map.keySet()) {
System.out.println(s + "-->" + map.get(s));
}
BufferedReader in = new BufferedReader(new InputStreamReader(conn.getInputStream(), "utf-8"));
String line;
while ((line = in.readLine()) != null) {
result += "\n" + line;
}
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
这样,基本上爬取的功能就完成了,可以看到爬取了我们想要的信息
四、通过 关键词 检索
检索比较简单,因为使用了solr搜索引擎的服务,所以只要按照solr api传入数据就可以检索到,它会自动进行分词过滤,按照匹配度。
代码示例:
/**
* 通过关键词获取数据
* @param title
* @return
*/
@ResponseBody
@RequestMapping("/findDocs")
public String findDocs(String title) {
Map mapReturn = new HashMap(); //返回结果
try {
String result = alibabaService.findIndex(title);
mapReturn.put("returnCode","00");
mapReturn.put("content",result);
}catch (Exception e){
e.printStackTrace();
mapReturn.put("returnCode","-1");
mapReturn.put("content","查询异常");
}
String mapStr = JSONObject.toJSONString(mapReturn);
return mapStr;
}
findIndex() 方法:
// 查找索引
public String findIndex(String titleInput) throws SolrServerException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
// 查询条件
SolrQuery solrParams = new SolrQuery();
solrParams.setStart(0);
solrParams.setRows(10);
solrParams.setQuery("title:"+titleInput);
// 开启高亮
solrParams.setHighlight(true);
solrParams.setHighlightSimplePre("");
solrParams.setHighlightSimplePost("");
// 设置高亮的字段
solrParams.setParam("hl.fl", "title");
// SolrParams是SolrQuery的子类
QueryResponse queryResponse = solr.query(solrParams);
// (一)获取查询的结果集合
SolrDocumentList solrDocumentList = queryResponse.getResults();
List contentList = new LinkedList();
for (SolrDocument solrDocument : solrDocumentList) {
Map map = new HashMap();
map.put("id",solrDocument.get("id"));
map.put("title",solrDocument.get("title"));
contentList.add(map);
}
return contentList.toString();
}
五、首页
最后一页是前台,做的不是很好。因为我很着急,我只有一天。我白天必须去上班。晚上只能花几个小时研究后台代码。我不在乎前台。如果有时间可以美化
前端代码示例:
阿里测试题
1、先爬取文档数据
<a class="weui-btn weui-btn_mini weui-btn_primary" id="getDocs">开始爬取</a>
搜索关键词
<a class="weui-btn weui-btn_mini weui-btn_primary" id="findDocs">查询</a>
$('#getDocs').click(function () {
ajaxLoading('爬取中,请稍后...');
$.ajax({
url: "/ali/getDocs",
data: {},
type: 'post',
dataType: 'json',
success: function (data) {
ajaxLoadEnd();
$.MsgBox.Alert("提示",data.content,"确定");
},
error: function () {
$.MsgBox.Alert("异常","爬取发生异常,请联系管理员!","确定");
}
})
})
$('#findDocs').click(function () {
var keytitle = $('.keytitle').val();
if(keytitle==""){
$.MsgBox.Alert("提示","淘气!请输入内容","确定");
return
}
ajaxLoading('查询中...');
$.ajax({
url: "/ali/findDocs",
data: {"title":keytitle},
type: 'post',
dataType: 'json',
success: function (data) {
ajaxLoadEnd();
if (data.returnCode=="00"){
$.MsgBox.Alert("提示",data.content,"确定");
}else {
$.MsgBox.Alert("提示",data.content,"确定");
}
},
error: function () {
$.MsgBox.Alert("异常","查询发生异常,请联系管理员!","确定");
}
})
})
function ajaxLoading(text){
$("").css({display:"block",width:"100%",height:$(window).height()}).appendTo("body");
$("").html(text).appendTo("body").css({display:"block",left:($(document.body).outerWidth(true) - 190) / 2,top:($(window).height() - 45) / 2});
}
function ajaxLoadEnd(){
$(".datagrid-mask").remove();
$(".datagrid-mask-msg").remove();
}
六、运行渲染
这个基本没问题,也很容易完成。和我预想的还是有点不同。不过,为了赶时间,我还是赶紧发了。我在晚上 22 点 21 分左右发送的。我还以为是面试 明天官方要给出结果,但阿里这么好的公司也不是没有道理。面试官当场回复我,说我通过了。有这么敬业的程序员,这样的公司不能牛
七、总结:(附代码下载)
1.先启动solr
解压,在xxxxx/solr-4.7.0/example目录下cmd
执行命令:java -jar start.jar
2、启动项目aliTestProject
然后先点击爬取,稍等片刻,等待页面显示【爬取成功】字样,即可查询
3、查询效果图
整个项目代码下载链接:
参考文章:
感谢原作者分享,让技术人员更快解决问题 查看全部
输入关键字 抓取所有网页(社招进阿里的一个面试呗,你准备好了吗?)
内容
前言
前几天,我接到了外籍人士阿里的面试。作为一个自信狂妄的我,虽然是外籍人士,但对阿里还是有几分敬佩之情,就像高考想进清华北大,想进腾讯阿里工作一样。是的,当然,除了学校招985/211能进阿里外,其他人想通过中介被招进阿里,那就更难了,至少在某个领域是专家级别的。所以如果你有一个难得的机会,试试阿里的采访。
一、采访内容1、电话面试及项目实践题
首先是电话面试:这个一般没问题,多看书,少吃零食,多睡觉……这个肯定能回答
二是想出一个动手demo题目,如下
文档链接:
爬取左侧文档树中的所有文档列表
在查询页面输入关键词或描述性语言给出3个最佳匹配文档(从高匹配到低匹配排序)。
供应:
1. 代码
2. 匹配的想法
奖励:有关如何为描述性语言提供建议的文档。例如用户输入:我的日志 采集 is out
大多数人在听到他们要编写一个演示时都会感到恐慌。不要害怕,我不会和你分享我的经验和代码示例,所以请阅读此文章,之后应该没问题,反正我已经结束了。
2、动手主题:文档抓取和搜索
3、研究课题
首先,去链接看看。让我们来看看它是什么。原来是阿里云的帮助文档。看来这个简单的demo其实就是根据用户输入的关键词搜索对应的解决方案。小项目。
第一个小步骤,爬取内容应该不难。不管是用Java还是Python,难度是第一位的,但是Python可能更简单,Java会多写一点代码。当然,小编目前还是想先学java,所以用java代码来演示。至于Python,先学一门语言,再拓展其他语言,才能更好的辅助你。
难点在于第二个小步骤,“在查询页面输入关键词或者描述性语言,给出最佳匹配的3个文档(匹配度从高到低排序)”,
我们先不爬,因为如果爬,必须封装想要的格式。当我们没有想到查询关键词的功能时,先保留它。
①查询输入关键词,给出最佳匹配方案
当然,你可以自己写算法和匹配,但是这种情况下,匹配肯定不是很准确,一天之内几乎不可能写出来,所以看看前人对这种类型有什么想法更好的解决方案,踩在巨人的肩膀上,事半功倍。
其实有很多方法可以实现类似的功能,
比如通过分词器搜索:Jieba分词、Ansj分词……其他分词效果可以点这里:了解11个开源中文分词
或者类似搜索引擎服务器的开源框架:Elasticsearch、Lucene……其他搜索引擎服务可以点这里:了解13个开源搜索引擎
小编这里演示的是一个使用solr搜索引擎实现这个爬取和检索的demo项目
二、启动 solr
solr下载地址:最好下载低版本,高版本需要高jdk版本,我的jdk是1.7,下载的solr版本是4.7.0是的,或者当我下载我在文章末尾制作的演示时,我也会将我使用的所有内容都放入其中。
1、配置步骤
① 下载后解压
② cmd进入这个目录:xxxxx/solr-4.7.0/example
③ 执行命令:java -jar start.jar
④ 如果访问成功,在浏览器中输入:8983/solr即可访问,表示启动成功。
2、Solr接口说明及使用
具体solr的其他功能这里就不介绍了。可以参考网上资料,进一步加深对solr的理解和使用
三、开始爬取
首先在项目中引入solr的maven包
org.apache.solr
solr-solrj
4.7.0
爬取很简单,只是模拟一个浏览器访问内容,我们可以看到要爬取的网站左边的所有文本内容都在
里面,
这个很简单,这样我们就可以对爬取的数据进行正则匹配后得到我们想要的所有文本标题信息。
代码示例:
/**
* 爬取数据
* @return
*/
@ResponseBody
@RequestMapping("/getDocs")
public String getDocs() {
Map mapReturn = new HashMap(); //返回结果
try {
//爬取前先在solr上建林索引属性
alibabaService.addDefaultField();
//开始爬取指定url的数据
String htmlResult = GetAliApi.sendGet("https://help.aliyun.com/docume ... ot%3B, "");
//获取到 树文档的内容
String[] mainMenuListContainer = htmlResult.split("")[1].split("");
//log.debug(mainMenuListContainer[0]);
//log.debug("------------------------------");
//进行正则获取数据
String searchReg = "(.*?)";
Pattern pattern = Pattern.compile(searchReg); // 讲编译的正则表达式对象赋给pattern
Matcher matcher = pattern.matcher(mainMenuListContainer[0]);
int i = 0;
String pre = "A";
while (matcher.find()) {
i++;
String title = matcher.group(1);
log.debug(title);
//将数据放到solr里,添加索引
Alidocs alidocs = new Alidocs();
alidocs.setId(pre+i);
alidocs.setTitle(title);
alibabaService.addIndex(alidocs);
}
mapReturn.put("returnCode","00");
mapReturn.put("content","爬取成功");
}catch (Exception e){
e.printStackTrace();
mapReturn.put("returnCode","-1");
mapReturn.put("content","爬取失败,请重试");
}
String mapStr = JSONObject.toJSONString(mapReturn);
return mapStr;
}
addDefaultField() 方法和 addIndex() 方法:
// 添加默认索引属性
public void addDefaultField() throws SolrServerException, IOException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", "默认情况下必须添加的字段,用来区分文档的唯一标识");
doc.addField("title", "默认的名称属性字段");
solr.add(doc);
solr.commit();
}
// 添加索引
public void addIndex(Alidocs alidocs) throws SolrServerException, IOException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
solr.addBean(alidocs);
solr.commit();
}
sendGet() 方法:
public static String sendGet(String url, String param) {
String result = "";
String urlName = url + "?" + param;
try {
URL realURL = new URL(urlName);
URLConnection conn = realURL.openConnection();
//伪造ip访问
String ip = randIP();
System.out.println("目前伪造的ip:"+ip);
conn.setRequestProperty("X-Forwarded-For", ip);
conn.setRequestProperty("HTTP_X_FORWARDED_FOR", ip);
conn.setRequestProperty("HTTP_CLIENT_IP", ip);
conn.setRequestProperty("REMOTE_ADDR", ip);
conn.setRequestProperty("Host", "help.aliyun.com/");
conn.setRequestProperty("accept", "*/*");
conn.setRequestProperty("connection", "Keep-Alive");
conn.setRequestProperty("user-agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 Safari/537.36");
conn.setRequestProperty("Referer","https://help.aliyun.com/";); //伪造访问来源
conn.setRequestProperty("Origin", "https://help.aliyun.com/";); //伪造访问域名
conn.connect();
Map map = conn.getHeaderFields();
for (String s : map.keySet()) {
System.out.println(s + "-->" + map.get(s));
}
BufferedReader in = new BufferedReader(new InputStreamReader(conn.getInputStream(), "utf-8"));
String line;
while ((line = in.readLine()) != null) {
result += "\n" + line;
}
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
这样,基本上爬取的功能就完成了,可以看到爬取了我们想要的信息
四、通过 关键词 检索
检索比较简单,因为使用了solr搜索引擎的服务,所以只要按照solr api传入数据就可以检索到,它会自动进行分词过滤,按照匹配度。
代码示例:
/**
* 通过关键词获取数据
* @param title
* @return
*/
@ResponseBody
@RequestMapping("/findDocs")
public String findDocs(String title) {
Map mapReturn = new HashMap(); //返回结果
try {
String result = alibabaService.findIndex(title);
mapReturn.put("returnCode","00");
mapReturn.put("content",result);
}catch (Exception e){
e.printStackTrace();
mapReturn.put("returnCode","-1");
mapReturn.put("content","查询异常");
}
String mapStr = JSONObject.toJSONString(mapReturn);
return mapStr;
}
findIndex() 方法:
// 查找索引
public String findIndex(String titleInput) throws SolrServerException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
// 查询条件
SolrQuery solrParams = new SolrQuery();
solrParams.setStart(0);
solrParams.setRows(10);
solrParams.setQuery("title:"+titleInput);
// 开启高亮
solrParams.setHighlight(true);
solrParams.setHighlightSimplePre("");
solrParams.setHighlightSimplePost("");
// 设置高亮的字段
solrParams.setParam("hl.fl", "title");
// SolrParams是SolrQuery的子类
QueryResponse queryResponse = solr.query(solrParams);
// (一)获取查询的结果集合
SolrDocumentList solrDocumentList = queryResponse.getResults();
List contentList = new LinkedList();
for (SolrDocument solrDocument : solrDocumentList) {
Map map = new HashMap();
map.put("id",solrDocument.get("id"));
map.put("title",solrDocument.get("title"));
contentList.add(map);
}
return contentList.toString();
}
五、首页
最后一页是前台,做的不是很好。因为我很着急,我只有一天。我白天必须去上班。晚上只能花几个小时研究后台代码。我不在乎前台。如果有时间可以美化
前端代码示例:
阿里测试题
1、先爬取文档数据
<a class="weui-btn weui-btn_mini weui-btn_primary" id="getDocs">开始爬取</a>
搜索关键词
<a class="weui-btn weui-btn_mini weui-btn_primary" id="findDocs">查询</a>
$('#getDocs').click(function () {
ajaxLoading('爬取中,请稍后...');
$.ajax({
url: "/ali/getDocs",
data: {},
type: 'post',
dataType: 'json',
success: function (data) {
ajaxLoadEnd();
$.MsgBox.Alert("提示",data.content,"确定");
},
error: function () {
$.MsgBox.Alert("异常","爬取发生异常,请联系管理员!","确定");
}
})
})
$('#findDocs').click(function () {
var keytitle = $('.keytitle').val();
if(keytitle==""){
$.MsgBox.Alert("提示","淘气!请输入内容","确定");
return
}
ajaxLoading('查询中...');
$.ajax({
url: "/ali/findDocs",
data: {"title":keytitle},
type: 'post',
dataType: 'json',
success: function (data) {
ajaxLoadEnd();
if (data.returnCode=="00"){
$.MsgBox.Alert("提示",data.content,"确定");
}else {
$.MsgBox.Alert("提示",data.content,"确定");
}
},
error: function () {
$.MsgBox.Alert("异常","查询发生异常,请联系管理员!","确定");
}
})
})
function ajaxLoading(text){
$("").css({display:"block",width:"100%",height:$(window).height()}).appendTo("body");
$("").html(text).appendTo("body").css({display:"block",left:($(document.body).outerWidth(true) - 190) / 2,top:($(window).height() - 45) / 2});
}
function ajaxLoadEnd(){
$(".datagrid-mask").remove();
$(".datagrid-mask-msg").remove();
}
六、运行渲染
这个基本没问题,也很容易完成。和我预想的还是有点不同。不过,为了赶时间,我还是赶紧发了。我在晚上 22 点 21 分左右发送的。我还以为是面试 明天官方要给出结果,但阿里这么好的公司也不是没有道理。面试官当场回复我,说我通过了。有这么敬业的程序员,这样的公司不能牛
七、总结:(附代码下载)
1.先启动solr
解压,在xxxxx/solr-4.7.0/example目录下cmd
执行命令:java -jar start.jar
2、启动项目aliTestProject
然后先点击爬取,稍等片刻,等待页面显示【爬取成功】字样,即可查询
3、查询效果图
整个项目代码下载链接:
参考文章:
感谢原作者分享,让技术人员更快解决问题
输入关键字 抓取所有网页(如何在搜索引擎上输入「JoeBloggs」的搜索结果? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-05 19:09
)
1、精确搜索 - 双引号
准确搜索最简单、最有效的方法是在 关键词 周围加上双引号,在这种情况下,搜索引擎将只返回与 关键词 完全匹配的搜索结果。
例如,在搜索“Joe Bloggs”时,如果不给关键词加上双引号,搜索引擎会分别显示所有与“Joe”和“Bloggs”相关的信息,但这些显然不是我们的。期望的结果。但加双引号后,搜索引擎只会返回页面上匹配“Joe Bloggs”的信息。
准确的搜索对于排除常见但低相似度的信息很有用,为用户省去了重新过滤结果的麻烦。
2、排除关键词
如果精确搜索没有找到他们正在寻找的内容,用户可以通过简单地使用减号来排除收录某些单词的信息。
例如,当您搜索“'Joe Bloggs'-jeans”时,您会得到一个不收录单词“jeans”的“Joe Bloggs”条目。
3、使用“非或”逻辑搜索
默认搜索下,搜索引擎会返回所有与查询词相关的结果,但是通过“OR”逻辑,可以分别得到两个关键词相关的结果,而不只是两个关键词同时相关结果。巧妙地使用“OR”搜索可以确保您的搜索结果准确无误,即使您不确定哪个 关键词 对您的搜索结果负责。
4、同义词搜索
有时搜索不太精确的 关键词 更合适。在没有准确判断关键词的情况下,可以按同义词搜索。
如果您在搜索引擎中输入“plumbing ~university”,您将获得包括“plumbing university”和“plumbing colleges”等类似项目的反馈。
5、在网站内搜索
网站 的大部分搜索功能都缺乏,所以更好的方法是通过谷歌等搜索引擎搜索网站上的信息。
您只需在搜索引擎上输入“site:”加关键词,搜索引擎就会返回所有与网站“”中的关键词相关的项目。结合精准搜索功能,此功能将更加强大。
6、善用星号
就像拼图“Scrabble”的空白方块一样,在搜索引擎中,我们可以用星号填充关键词中缺失的部分,无论缺失的部分是单词序列还是单词的一部分。另外,当你想搜索一个不太确定的文章时,你也可以用星号来填补缺失的部分。
例如,如果您在搜索引擎中输入“architect*”,您将获得所有收录架构、架构、架构、架构、架构以及所有其他以“架构师”开头的词的条目的反馈。
7、在两个值之间搜索
在寻找问题的答案时,一个很好的方法是在一定范围内寻找与 关键词 相关的信息。比如要查找1920年到1950年间的英国首相,可以直接在搜索引擎中输入“英国首相1920..1950”得到想要的结果。
请记住,值之间的符号是两个句点加上一个空格键。
8、搜索网页标题、链接和正文关键词
有时您可能会遇到需要查找所有与 关键词 相关的页面标题、链接和页面正文,这种情况下您需要使用限定符“inurl:”(用于在 url 链接中搜索)、“intext:”(用于在页面正文中搜索)和“intitle:”(用于在页面标题中搜索)。
例如,在搜索引擎中输入“intitle:reviews”将获得与关键词“reviews”相关的所有页面标题。
9、搜索相关网站
搜索相关 网站 时可以使用相关限定符。例如,您只需要在搜索引擎中输入“related:”即可获得所有与“”相关的网站反馈结果。
10、搜索技巧的组合使用
您可以结合上述所有搜索技巧,根据需要缩小或扩大搜索范围。虽然有些技能可能不常用,但准确搜索和站点搜索技能的使用范围相当广泛。
11、inurl 和 allinurl
格式为“inurl:XXX”(冒号为英文)和“allinurl:XXX YYY”。inurl的作用是搜索结果是一个带有“XXX”的地址页面(支持中英文)。例如搜索“inurl:ithome”的结果如下
同理,allinurl的作用就是结果中有“XXX”和“YYY”,相当于“inurl:XXX inurl:YYY”,效果如下
除了可以让您找到相关页面之外,该命令还可以找到与您的网站 使用相同关键字的“朋友网站”。至于是互相学习,还是发现后明辨是非,就看你的实际需要了。
12、intitle 和 allintitle
格式为“intitle:XXX”和“allintitle:XXX YYY...”,intitle搜索结果为网页标题中收录“XXX”的内容,效果如下
alltintitle的效果是多个intitles的组合。例如,“alltintitle IT Home Win10”等价于“intitle IT Home intitle Win10”,如下图
一般来说,在标题中添加关键词是一种很好的SEO优化方法,有助于提高搜索排名,所以这种搜索方法可以查看哪些“朋友”在为关键词而战。
13、站点
格式为“site:XXX”,用于搜索一个域名下的所有内容,如“site:”,如下图
如果只想在某一个网站中搜索,可以使用“Win10 College site:”的形式(不加http或URL前),效果如下
也可以搜索某类域名,如“site:.com”“site:.cn”,如下图
以上方法可以任意组合(每个方法之间留一个空格,不要直接连接),比如输入“site:inurl:Win10 intitle:老驱动“Redstone 2”+Cortana”,就会给出效果链接如下
14、文件类型
这个可以用来搜索特定格式的文件,比如搜索“Beijing folded filetype:txt”,如下图
查看全部
输入关键字 抓取所有网页(如何在搜索引擎上输入「JoeBloggs」的搜索结果?
)
1、精确搜索 - 双引号
准确搜索最简单、最有效的方法是在 关键词 周围加上双引号,在这种情况下,搜索引擎将只返回与 关键词 完全匹配的搜索结果。
例如,在搜索“Joe Bloggs”时,如果不给关键词加上双引号,搜索引擎会分别显示所有与“Joe”和“Bloggs”相关的信息,但这些显然不是我们的。期望的结果。但加双引号后,搜索引擎只会返回页面上匹配“Joe Bloggs”的信息。
准确的搜索对于排除常见但低相似度的信息很有用,为用户省去了重新过滤结果的麻烦。
2、排除关键词
如果精确搜索没有找到他们正在寻找的内容,用户可以通过简单地使用减号来排除收录某些单词的信息。
例如,当您搜索“'Joe Bloggs'-jeans”时,您会得到一个不收录单词“jeans”的“Joe Bloggs”条目。
3、使用“非或”逻辑搜索
默认搜索下,搜索引擎会返回所有与查询词相关的结果,但是通过“OR”逻辑,可以分别得到两个关键词相关的结果,而不只是两个关键词同时相关结果。巧妙地使用“OR”搜索可以确保您的搜索结果准确无误,即使您不确定哪个 关键词 对您的搜索结果负责。
4、同义词搜索
有时搜索不太精确的 关键词 更合适。在没有准确判断关键词的情况下,可以按同义词搜索。
如果您在搜索引擎中输入“plumbing ~university”,您将获得包括“plumbing university”和“plumbing colleges”等类似项目的反馈。
5、在网站内搜索
网站 的大部分搜索功能都缺乏,所以更好的方法是通过谷歌等搜索引擎搜索网站上的信息。
您只需在搜索引擎上输入“site:”加关键词,搜索引擎就会返回所有与网站“”中的关键词相关的项目。结合精准搜索功能,此功能将更加强大。
6、善用星号
就像拼图“Scrabble”的空白方块一样,在搜索引擎中,我们可以用星号填充关键词中缺失的部分,无论缺失的部分是单词序列还是单词的一部分。另外,当你想搜索一个不太确定的文章时,你也可以用星号来填补缺失的部分。
例如,如果您在搜索引擎中输入“architect*”,您将获得所有收录架构、架构、架构、架构、架构以及所有其他以“架构师”开头的词的条目的反馈。
7、在两个值之间搜索
在寻找问题的答案时,一个很好的方法是在一定范围内寻找与 关键词 相关的信息。比如要查找1920年到1950年间的英国首相,可以直接在搜索引擎中输入“英国首相1920..1950”得到想要的结果。
请记住,值之间的符号是两个句点加上一个空格键。
8、搜索网页标题、链接和正文关键词
有时您可能会遇到需要查找所有与 关键词 相关的页面标题、链接和页面正文,这种情况下您需要使用限定符“inurl:”(用于在 url 链接中搜索)、“intext:”(用于在页面正文中搜索)和“intitle:”(用于在页面标题中搜索)。
例如,在搜索引擎中输入“intitle:reviews”将获得与关键词“reviews”相关的所有页面标题。
9、搜索相关网站
搜索相关 网站 时可以使用相关限定符。例如,您只需要在搜索引擎中输入“related:”即可获得所有与“”相关的网站反馈结果。
10、搜索技巧的组合使用
您可以结合上述所有搜索技巧,根据需要缩小或扩大搜索范围。虽然有些技能可能不常用,但准确搜索和站点搜索技能的使用范围相当广泛。
11、inurl 和 allinurl
格式为“inurl:XXX”(冒号为英文)和“allinurl:XXX YYY”。inurl的作用是搜索结果是一个带有“XXX”的地址页面(支持中英文)。例如搜索“inurl:ithome”的结果如下
同理,allinurl的作用就是结果中有“XXX”和“YYY”,相当于“inurl:XXX inurl:YYY”,效果如下
除了可以让您找到相关页面之外,该命令还可以找到与您的网站 使用相同关键字的“朋友网站”。至于是互相学习,还是发现后明辨是非,就看你的实际需要了。
12、intitle 和 allintitle
格式为“intitle:XXX”和“allintitle:XXX YYY...”,intitle搜索结果为网页标题中收录“XXX”的内容,效果如下
alltintitle的效果是多个intitles的组合。例如,“alltintitle IT Home Win10”等价于“intitle IT Home intitle Win10”,如下图
一般来说,在标题中添加关键词是一种很好的SEO优化方法,有助于提高搜索排名,所以这种搜索方法可以查看哪些“朋友”在为关键词而战。
13、站点
格式为“site:XXX”,用于搜索一个域名下的所有内容,如“site:”,如下图
如果只想在某一个网站中搜索,可以使用“Win10 College site:”的形式(不加http或URL前),效果如下
也可以搜索某类域名,如“site:.com”“site:.cn”,如下图
以上方法可以任意组合(每个方法之间留一个空格,不要直接连接),比如输入“site:inurl:Win10 intitle:老驱动“Redstone 2”+Cortana”,就会给出效果链接如下
14、文件类型
这个可以用来搜索特定格式的文件,比如搜索“Beijing folded filetype:txt”,如下图
输入关键字 抓取所有网页( 谷歌排名优化要多久才能上首页?最常听到的说法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-05 02:04
谷歌排名优化要多久才能上首页?最常听到的说法)
谷歌进入前10需要多长时间
很多做谷歌优化的站长都关心一个问题:谷歌排名优化多久能上首页?
最常听到的说法是,对此确实没有准确的答案。
不过最近国外一家SEO研究机构通过Ahrefs的研究总结出一些信息,比如:前10名网页中只有22%是在一年内创建的,而且大部分网页创建时间超过三年。年;网站有比较好的域名评级,但也有较大的领先等。
众所周知,Ahrefs 是 Google SEO 最强大的辅助工具之一。面对“在 Google 上排名需要多长时间?”的问题。历史排名数据,决定给出一个稍微具体一些、可量化的答案。
通过这些数据,小5也大致梳理了几个关键点,一起来详细看看吧。
一、排名最高的网站做了多久了?
为了查看排名靠前的页面运行了多长时间,Ahrefs 随机抽取了 200 万个关键词,并将它们列在前 10 个页面中以提取数据。
网站平均年龄(天)的 Google 前 10 个结果
从图表可以看出:前10名网站,平均建站时间2年以上;排名第一的是将近 3 年。
这是一个事实,目前只有大约 22% 的前 10 个页面是在一年内创建的。
Google 的前 10 名搜索结果中每个排名的百分比是多少,该页面是在不到一年前创建的:
画面很明显:页面创建时间不到1年,排名第一也只有1%左右!
二、在 Google 上排名需要多长时间?
为了回答这个问题,Ahrefs 随机选择了 200 万页。
这些页面是一年前被他们的爬虫首次抓取的,所以他们跟踪了每个页面的排名历史。
排名百分比数据图
仅 5.7% 的 网站 排名前 10
10-100位的比例为19.5%
网站 100, 74.8%
域名评级关系比例图
域名评分高,前10名网站占比10.8%
且域名评分低,排名前10的比例仅为3.0%
可以看出,具有 网站 的高域评级 (DR) 的页面也比具有较低 DR 的页面表现更好。
DR(域名评级):
该统计数据与所有 网站 页面的整体排名关系最为密切。该值越高,网站所有页面被排名的机会就越大。DR 是基于链接到您 网站 的所有反向链接的质量和数量。
链接到整个 网站 的反向链接越多越好,价值越高,这在 Ahrefs 工具中很常见。
接下来,我们将放大 5.7% 的“幸运”页面,看看它们从无名到前 10 的速度有多快。
数据显示,他们中的大多数是在第 61 天到第 182 天。
在所有这些新发布的页面中,只有 5.7% 会在一年内进入 Google 前 10 名。
Ahrefs 还根据 关键词 重新计算数字,每月搜索:
1年内“第一抓”页面排名
这表明在不到一年的时间里,只有 0.3% 的页面排在前 10 位。
以下是这些 5.7% 所谓的“幸运”页面上发生的情况,按排名关键字的搜索量细分:
这些幸运页面排在前 10 名的天数
可以清楚的看到高搜索量达到68.4%的时间大约是1年。即使有这 5.7% 的前 10 个“幸运”页面,绝大多数页面的性能都不是很好。
三、终于
通过 Ahrefs 的数据,我们了解到几乎 95% 的新发布页面在一年内都没有进入前 10。
虽然有些“幸运”的人可以做到这一点,但时间大概需要2-6个月左右。
对于公司或品牌而言,SEO 取决于许多不同的因素,包括域权限、关键词 竞争和许多页面技术元素。其中一些在不到一年的时间内就进入了前 10 名,这可能是因为现有的域权限和 SEO 知识。
根据Ahrefs的数据,按照一般的分析,要想提升自己在Google的排名,就需要更多的沉淀。 查看全部
输入关键字 抓取所有网页(
谷歌排名优化要多久才能上首页?最常听到的说法)
谷歌进入前10需要多长时间
很多做谷歌优化的站长都关心一个问题:谷歌排名优化多久能上首页?
最常听到的说法是,对此确实没有准确的答案。
不过最近国外一家SEO研究机构通过Ahrefs的研究总结出一些信息,比如:前10名网页中只有22%是在一年内创建的,而且大部分网页创建时间超过三年。年;网站有比较好的域名评级,但也有较大的领先等。
众所周知,Ahrefs 是 Google SEO 最强大的辅助工具之一。面对“在 Google 上排名需要多长时间?”的问题。历史排名数据,决定给出一个稍微具体一些、可量化的答案。
通过这些数据,小5也大致梳理了几个关键点,一起来详细看看吧。
一、排名最高的网站做了多久了?
为了查看排名靠前的页面运行了多长时间,Ahrefs 随机抽取了 200 万个关键词,并将它们列在前 10 个页面中以提取数据。
网站平均年龄(天)的 Google 前 10 个结果
从图表可以看出:前10名网站,平均建站时间2年以上;排名第一的是将近 3 年。
这是一个事实,目前只有大约 22% 的前 10 个页面是在一年内创建的。
Google 的前 10 名搜索结果中每个排名的百分比是多少,该页面是在不到一年前创建的:
画面很明显:页面创建时间不到1年,排名第一也只有1%左右!
二、在 Google 上排名需要多长时间?
为了回答这个问题,Ahrefs 随机选择了 200 万页。
这些页面是一年前被他们的爬虫首次抓取的,所以他们跟踪了每个页面的排名历史。
排名百分比数据图
仅 5.7% 的 网站 排名前 10
10-100位的比例为19.5%
网站 100, 74.8%
域名评级关系比例图
域名评分高,前10名网站占比10.8%
且域名评分低,排名前10的比例仅为3.0%
可以看出,具有 网站 的高域评级 (DR) 的页面也比具有较低 DR 的页面表现更好。
DR(域名评级):
该统计数据与所有 网站 页面的整体排名关系最为密切。该值越高,网站所有页面被排名的机会就越大。DR 是基于链接到您 网站 的所有反向链接的质量和数量。
链接到整个 网站 的反向链接越多越好,价值越高,这在 Ahrefs 工具中很常见。
接下来,我们将放大 5.7% 的“幸运”页面,看看它们从无名到前 10 的速度有多快。
数据显示,他们中的大多数是在第 61 天到第 182 天。
在所有这些新发布的页面中,只有 5.7% 会在一年内进入 Google 前 10 名。
Ahrefs 还根据 关键词 重新计算数字,每月搜索:
1年内“第一抓”页面排名
这表明在不到一年的时间里,只有 0.3% 的页面排在前 10 位。
以下是这些 5.7% 所谓的“幸运”页面上发生的情况,按排名关键字的搜索量细分:
这些幸运页面排在前 10 名的天数
可以清楚的看到高搜索量达到68.4%的时间大约是1年。即使有这 5.7% 的前 10 个“幸运”页面,绝大多数页面的性能都不是很好。
三、终于
通过 Ahrefs 的数据,我们了解到几乎 95% 的新发布页面在一年内都没有进入前 10。
虽然有些“幸运”的人可以做到这一点,但时间大概需要2-6个月左右。
对于公司或品牌而言,SEO 取决于许多不同的因素,包括域权限、关键词 竞争和许多页面技术元素。其中一些在不到一年的时间内就进入了前 10 名,这可能是因为现有的域权限和 SEO 知识。
根据Ahrefs的数据,按照一般的分析,要想提升自己在Google的排名,就需要更多的沉淀。
输入关键字 抓取所有网页(新浪搜索主页面中的输入关键词链接和计算相似度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-05 02:02
前段时间写了一个爬虫,在新浪搜索主页面实现输入关键词,爬取关键词相关新闻的标题、发布时间、url、关键词和内容。并根据内容提取摘要并计算相似度。下面解释一下我自己的想法并给出代码的github链接:
1、获取关键词新闻页面url
在新浪搜索首页输入关键词,点击搜索后会自动链接到关键词的新闻界面。有两种方法可以获取此页面的 url。本文提供了三种方法。
1)静态爬取
从新浪搜索首页,输入关键词,进入kerwords相关的新闻页面,手动获取url链接,然后将url中的关键词替换为需要输入的关键词,获取新的url,发送新的url 请求,获取该网页的源代码。缺点:对于动态网页,这种方式获取的url,发送请求获取的网页源代码与在搜索界面手动输入关键词获取的页面源代码不一致。
2)动态捕捉
模拟浏览器行为并爬取 关键词 新闻相关页面。方法有两种,一种是确定使用的浏览器,使用程序调用浏览器,操作输入和搜索过程;另一种是用程序模拟无界面、无界面的浏览器的行为。关键词页面的url和页面源代码。如图,进入搜索首页,输入关键词语言,会跳转到搜索结果页面。
2、分析关键词新闻页面信息
1)求搜索到的新闻文章数,根据一页的新闻数计算出与关键词次相关的新闻页数。找出不同页面之间的url联系,生成翻页的url。
如上图,新闻界面出现“查找7651条相关新闻文章”,使用正则匹配等方法得到'7651',根据一条上出现的新闻m个数计算相关新闻页数新浪新闻搜索页面:int(7651/m)。
2)在一个页面中,找到新闻的url。
查看页面源码,找到新闻对应的url。如上图所示,当新闻url出现时,同样的规则是“”,所以页面源码中的所有url都可以按照这个规则提取出来。
3、从新闻页面中提取信息
根据新闻的url,进入新闻页面,找到标题、发布时间、关键词、内容、描述内容并提取出来。其中,需要注意解码问题。网页的源代码是用不同的编码格式编写的,所以要注意解码。
1)新闻中没有关键字,采用生成关键词的方式。根据新闻内容,计算内容中的词频,根据词频确定输出词为关键词;
2)新闻中的摘要生成采用抽取的方式,借鉴了Stonewood博客的代码(链接如下:)。
3)关键词与新闻相似。根据新闻标题、关键词和内容,分配不同的权重来计算相似度。具体思路如下:
a) 关键字和标题
关键字和标题都收录与输入词相关的词,权重值kT_W=0.8;只有标题收录输入词,相关词权重值kT_W=0.7;只有key词收录与输入词相关的词,权重值kT_W=0.6;其他权重值kT_W=0.6。
b) 在新闻内容中:新闻内容中自然语言相关词的词频内容_P
c) 相似度的最终计算公式为:
4、代码(运行环境python)
代码链接:
已经自带了需要下载的文件和安装相关模块后代码中需要的文件。并给出了对应的python2和python3代码 查看全部
输入关键字 抓取所有网页(新浪搜索主页面中的输入关键词链接和计算相似度)
前段时间写了一个爬虫,在新浪搜索主页面实现输入关键词,爬取关键词相关新闻的标题、发布时间、url、关键词和内容。并根据内容提取摘要并计算相似度。下面解释一下我自己的想法并给出代码的github链接:
1、获取关键词新闻页面url
在新浪搜索首页输入关键词,点击搜索后会自动链接到关键词的新闻界面。有两种方法可以获取此页面的 url。本文提供了三种方法。
1)静态爬取
从新浪搜索首页,输入关键词,进入kerwords相关的新闻页面,手动获取url链接,然后将url中的关键词替换为需要输入的关键词,获取新的url,发送新的url 请求,获取该网页的源代码。缺点:对于动态网页,这种方式获取的url,发送请求获取的网页源代码与在搜索界面手动输入关键词获取的页面源代码不一致。
2)动态捕捉
模拟浏览器行为并爬取 关键词 新闻相关页面。方法有两种,一种是确定使用的浏览器,使用程序调用浏览器,操作输入和搜索过程;另一种是用程序模拟无界面、无界面的浏览器的行为。关键词页面的url和页面源代码。如图,进入搜索首页,输入关键词语言,会跳转到搜索结果页面。
2、分析关键词新闻页面信息
1)求搜索到的新闻文章数,根据一页的新闻数计算出与关键词次相关的新闻页数。找出不同页面之间的url联系,生成翻页的url。
如上图,新闻界面出现“查找7651条相关新闻文章”,使用正则匹配等方法得到'7651',根据一条上出现的新闻m个数计算相关新闻页数新浪新闻搜索页面:int(7651/m)。
2)在一个页面中,找到新闻的url。
查看页面源码,找到新闻对应的url。如上图所示,当新闻url出现时,同样的规则是“”,所以页面源码中的所有url都可以按照这个规则提取出来。
3、从新闻页面中提取信息
根据新闻的url,进入新闻页面,找到标题、发布时间、关键词、内容、描述内容并提取出来。其中,需要注意解码问题。网页的源代码是用不同的编码格式编写的,所以要注意解码。
1)新闻中没有关键字,采用生成关键词的方式。根据新闻内容,计算内容中的词频,根据词频确定输出词为关键词;
2)新闻中的摘要生成采用抽取的方式,借鉴了Stonewood博客的代码(链接如下:)。
3)关键词与新闻相似。根据新闻标题、关键词和内容,分配不同的权重来计算相似度。具体思路如下:
a) 关键字和标题
关键字和标题都收录与输入词相关的词,权重值kT_W=0.8;只有标题收录输入词,相关词权重值kT_W=0.7;只有key词收录与输入词相关的词,权重值kT_W=0.6;其他权重值kT_W=0.6。
b) 在新闻内容中:新闻内容中自然语言相关词的词频内容_P
c) 相似度的最终计算公式为:
4、代码(运行环境python)
代码链接:
已经自带了需要下载的文件和安装相关模块后代码中需要的文件。并给出了对应的python2和python3代码
输入关键字 抓取所有网页( “请输入关键词”是基于搜索框的设置吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-05 02:01
“请输入关键词”是基于搜索框的设置吗?)
beat365手机版如何设置“请输入关键字”搜索框
请输入查询关键词,以下是人们在访问任何网站 时经常在搜索框中看到的一些常用设置。对于用户来说不是一个值得注意的地方,但对于 SEO,“请输入 关键词”是一个基于搜索框的设置,值得更多研究。原因很简单,这可能会直观地影响企业产品的转型。
那么如何设置“请输入关键词”搜索框呢?
根据以往SEO站优化的经验,今天将通过以下内容进行讲解:
1.基于SEO的优化
从SEO的角度看“请输入搜索关键词”这个问题,其实大家都是在说搜索框和站点内搜索结果的反馈,但是基于SEO,并不是此处讨论:请输入 关键词,内容本身。
您可能需要从以下两个角度来理解:
(1)推荐并收录在内。
如果你有优化电商网站的经验,你会发现一个小的细分策略就是利用网站上的搜索框,类似于京东的热门电商网站,请输入关键词位置,生成大量长尾词,合理使用搜索结果列表,显示数量,适当增加关键词在SERP中的密度,以获得更高的排行。
但值得注意的是,要完美地使用此策略,您可能需要两个小前提:
一是对方有大量的搜索查询需求。
其次,站点中的搜索框,即搜索结果页面的输出,必须符合搜索引擎友好的URL。
② 屏蔽和隐藏。
就相当于中小企业的网站而言,如果你的数据网站搜索量不大,这里大家通常给出的建议是用robots.txt屏蔽搜索结果的URL。
尤其是当你的SERP页面没有SEO规范的时候,由于网站资源有限,真的没有必要委派百度爬虫去爬这些页面。
2.基于用户体验
从用户体验的角度来看,在站内搜索框中输入内容设置尤为重要,例如:
(1)有利于推荐公司核心产品,提高公司产品转化率。
②有利于推荐网站核心话题,提高UGC内容的输出。
③有利于在网站中推荐核心话题,延迟用户的页面停留时间,增加用户对网站品牌的粘性。
为此,您可能需要:
(1)做详细的网站统计分析,了解用户的头像,他们的喜好和喜好。
②掌握行业最新热点话题,适当利用站内多个入口,分发优质内容,引导对方参与讨论,增加栏目页面当前热点话题的热度,从而提高搜索引擎的信任。
3.您输入的搜索词不正确
当你在搜索框中输入一些关键词时,如果对方搜索到的具体关键词没有搜索结果,通常90%以上的网站都会返回空结果,或消息“您输入的 关键词 不正确”标志。
其实这是一个很不明智的策略,你可以在这个地方给出如下反馈:
(1)网站逻辑结构图,类似于HTML版的sitemap。
②“请输入查询关键词”,最近用户非常关注,推荐搜索一些热门词。
③ 站内热点文章,业内最热门的相关话题等。
总结:请输入搜索关键词,貌似是个微不足道的地方。经过详细的设置,还是可以起到积极的作用。以上内容仅供参考。今天就在这里分析一下。你可以多尝试! 查看全部
输入关键字 抓取所有网页(
“请输入关键词”是基于搜索框的设置吗?)
beat365手机版如何设置“请输入关键字”搜索框
请输入查询关键词,以下是人们在访问任何网站 时经常在搜索框中看到的一些常用设置。对于用户来说不是一个值得注意的地方,但对于 SEO,“请输入 关键词”是一个基于搜索框的设置,值得更多研究。原因很简单,这可能会直观地影响企业产品的转型。
那么如何设置“请输入关键词”搜索框呢?
根据以往SEO站优化的经验,今天将通过以下内容进行讲解:
1.基于SEO的优化
从SEO的角度看“请输入搜索关键词”这个问题,其实大家都是在说搜索框和站点内搜索结果的反馈,但是基于SEO,并不是此处讨论:请输入 关键词,内容本身。
您可能需要从以下两个角度来理解:
(1)推荐并收录在内。
如果你有优化电商网站的经验,你会发现一个小的细分策略就是利用网站上的搜索框,类似于京东的热门电商网站,请输入关键词位置,生成大量长尾词,合理使用搜索结果列表,显示数量,适当增加关键词在SERP中的密度,以获得更高的排行。
但值得注意的是,要完美地使用此策略,您可能需要两个小前提:
一是对方有大量的搜索查询需求。
其次,站点中的搜索框,即搜索结果页面的输出,必须符合搜索引擎友好的URL。
② 屏蔽和隐藏。
就相当于中小企业的网站而言,如果你的数据网站搜索量不大,这里大家通常给出的建议是用robots.txt屏蔽搜索结果的URL。
尤其是当你的SERP页面没有SEO规范的时候,由于网站资源有限,真的没有必要委派百度爬虫去爬这些页面。
2.基于用户体验
从用户体验的角度来看,在站内搜索框中输入内容设置尤为重要,例如:
(1)有利于推荐公司核心产品,提高公司产品转化率。
②有利于推荐网站核心话题,提高UGC内容的输出。
③有利于在网站中推荐核心话题,延迟用户的页面停留时间,增加用户对网站品牌的粘性。
为此,您可能需要:
(1)做详细的网站统计分析,了解用户的头像,他们的喜好和喜好。
②掌握行业最新热点话题,适当利用站内多个入口,分发优质内容,引导对方参与讨论,增加栏目页面当前热点话题的热度,从而提高搜索引擎的信任。
3.您输入的搜索词不正确
当你在搜索框中输入一些关键词时,如果对方搜索到的具体关键词没有搜索结果,通常90%以上的网站都会返回空结果,或消息“您输入的 关键词 不正确”标志。
其实这是一个很不明智的策略,你可以在这个地方给出如下反馈:
(1)网站逻辑结构图,类似于HTML版的sitemap。
②“请输入查询关键词”,最近用户非常关注,推荐搜索一些热门词。
③ 站内热点文章,业内最热门的相关话题等。
总结:请输入搜索关键词,貌似是个微不足道的地方。经过详细的设置,还是可以起到积极的作用。以上内容仅供参考。今天就在这里分析一下。你可以多尝试!
输入关键字 抓取所有网页(智能识别模式自动识别网页中的数据采集软件,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 554 次浏览 • 2022-02-05 02:00
WebHarvy 是一款功能强大的网页数据采集 软件。软件操作界面简洁明了。用户只需在系统内置浏览器中输入地址,即可提取并保存视频、图片等所有网页数据。很方便。
【特点】可视化点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“指向下一页的链接,WebHarvy网站 刮板将自动从所有页面中刮取数据。
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
通过代理服务器提取
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
【使用方法】1、启动软件,提示解锁,即需要添加官方授权文件才能使用
2、解压下载的文件,双击“URET NFO v2.2.exe”
3、通知您 SysNucleus WebHarvy 软件已授权给 SMR
4、导航到需要从中提取数据的网页。您可以使用内置浏览器加载和浏览网页
5、要截取部分文本,请选择并突出显示。在选择下面的选项之前,请确定所需的部分。
6、只要输入你分析的网页的网址,最上方的网址就是地址输入栏
7、输入地址直接在网页上打开
8、选择配置功能,可以点击第一个Start Config开始配置下载网页数据的程序 查看全部
输入关键字 抓取所有网页(智能识别模式自动识别网页中的数据采集软件,你了解多少?)
WebHarvy 是一款功能强大的网页数据采集 软件。软件操作界面简洁明了。用户只需在系统内置浏览器中输入地址,即可提取并保存视频、图片等所有网页数据。很方便。
【特点】可视化点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“指向下一页的链接,WebHarvy网站 刮板将自动从所有页面中刮取数据。
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
通过代理服务器提取
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
【使用方法】1、启动软件,提示解锁,即需要添加官方授权文件才能使用
2、解压下载的文件,双击“URET NFO v2.2.exe”
3、通知您 SysNucleus WebHarvy 软件已授权给 SMR
4、导航到需要从中提取数据的网页。您可以使用内置浏览器加载和浏览网页
5、要截取部分文本,请选择并突出显示。在选择下面的选项之前,请确定所需的部分。
6、只要输入你分析的网页的网址,最上方的网址就是地址输入栏
7、输入地址直接在网页上打开
8、选择配置功能,可以点击第一个Start Config开始配置下载网页数据的程序
输入关键字 抓取所有网页(烟台网站建设优化来讲列表页的注意事项有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-04 11:19
摘要:烟台网站构建一个完整的网站大概需要以下网页文件,对于一些较大的网站等文件,可以根据需要设置,如下:
1.首页这是网站的基础页面,是打开网站时呈现给我们的,一般会显示网站新更新的内容在主页上。易时代关注公司动态。
2.列表页列表页首页有导航栏或列表导航栏。点击后,网站会跳转到我们想要的页面。此页面是拆分表页面。可以很全面的展示我们想看的内容的方方面面。
3.内容页内容页是当我们进入列表页,看到某条信息,想进去了解更多的时候。点击后,显示内容页面的信息。对于烟台网站的建设优化来说,内容页面很重要,里面的关键词尤为重要。并且内容页尽量不要有太多的图片和js,不利于百度蜘蛛的抓取。
山东网亿,
4.通用标题网站无论主页、列表页还是内容页,都使用相同的标题。烟台网站构造的header包括导航栏、logo、当前位置等,不同模板的header内容不同。标题也很重要。后面的网站优化需要的关键词、页面描述、页面标题都在头文件中修改优化。
5.底部的目的和表头一样,都是为了实现底部的通用使用,方便管理。尤其是底部的友情链接,可以统一管理
6.搜索页面 该功能模块属于网站。您可以在文本框中输入关键词在网站上进行相关搜索,方便用户体验。这需要选择 关键词 方面的专业知识。就是保证输入关键词能找到相关的内容。
7.在线客服在线客服也是一个功能模块,即在线客服,可以实现在线咨询服务,实现转化。有的网站有的网站没有,一般小网站没有,因为需要后端人工服务,所以一般大企业网站才会有。
8.单页烟台网站这个单页比较灵活,可以根据不同的需要做成很多不同的页面。如留言板、关于我们、联系我们等。
相关搜索:、烟台网站建设、烟台软件开发、烟台app开发、小程序制作、山东网亿
部分图文来源于网络,无法查出来源。如有版权问题,请联系删除。 查看全部
输入关键字 抓取所有网页(烟台网站建设优化来讲列表页的注意事项有哪些?)
摘要:烟台网站构建一个完整的网站大概需要以下网页文件,对于一些较大的网站等文件,可以根据需要设置,如下:
1.首页这是网站的基础页面,是打开网站时呈现给我们的,一般会显示网站新更新的内容在主页上。易时代关注公司动态。
2.列表页列表页首页有导航栏或列表导航栏。点击后,网站会跳转到我们想要的页面。此页面是拆分表页面。可以很全面的展示我们想看的内容的方方面面。
3.内容页内容页是当我们进入列表页,看到某条信息,想进去了解更多的时候。点击后,显示内容页面的信息。对于烟台网站的建设优化来说,内容页面很重要,里面的关键词尤为重要。并且内容页尽量不要有太多的图片和js,不利于百度蜘蛛的抓取。
山东网亿,
4.通用标题网站无论主页、列表页还是内容页,都使用相同的标题。烟台网站构造的header包括导航栏、logo、当前位置等,不同模板的header内容不同。标题也很重要。后面的网站优化需要的关键词、页面描述、页面标题都在头文件中修改优化。
5.底部的目的和表头一样,都是为了实现底部的通用使用,方便管理。尤其是底部的友情链接,可以统一管理
6.搜索页面 该功能模块属于网站。您可以在文本框中输入关键词在网站上进行相关搜索,方便用户体验。这需要选择 关键词 方面的专业知识。就是保证输入关键词能找到相关的内容。
7.在线客服在线客服也是一个功能模块,即在线客服,可以实现在线咨询服务,实现转化。有的网站有的网站没有,一般小网站没有,因为需要后端人工服务,所以一般大企业网站才会有。
8.单页烟台网站这个单页比较灵活,可以根据不同的需要做成很多不同的页面。如留言板、关于我们、联系我们等。
相关搜索:、烟台网站建设、烟台软件开发、烟台app开发、小程序制作、山东网亿
部分图文来源于网络,无法查出来源。如有版权问题,请联系删除。
输入关键字 抓取所有网页(SEO代表搜索引擎优化,如何进行索引以及如何确定其为搜索优化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-03 23:19
前言
什么是搜索引擎优化?SEO是Search Engine Optimization,意思是“搜索引擎优化”,一般简称搜索优化。SEO的主要工作是通过了解各种搜索引擎如何抓取互联网页面、如何对它们进行索引以及如何确定它们在特定关键词搜索结果中的排名来优化网页。提供搜索引擎排名,增加网站流量。
如果你能很好地运用SEO技术,你可以提高你的网站排名,增加它在相关搜索中的可见度,让你的网页在用户搜索过程中越来越显眼,让你的网站可能吸引更多关注和影响力,并吸引潜在和现有客户加入您的业务。
总结一下:SEO 代表搜索引擎优化,通过自然搜索引擎结果增加 网站 的流量数量和质量的做法。
SEO的本质
那么SEO是如何工作的呢?一些浏览器等搜索引擎使用机器人来获取网页、从一个站点到另一个站点、采集有关页面的信息并将它们放入索引中。然后算法分析索引中的页面,考虑数百个排名因素或信号等,以确定页面在给定查询的搜索结果中出现的顺序。
搜索排名因素可以被视为用户体验方面的代理。内容质量和关键字研究是内容优化的关键因素,搜索算法旨在展示相关的权威页面并为用户提供有效的搜索体验,优化您的网站,如果将这些因素考虑在内,内容会有所帮助您的页面在搜索结果中排名更高。
seo仍然主要用于商业目的来查找有关产品和服务的信息,搜索往往是品牌的主要数字流量来源,并补充其他营销渠道以获得更高的知名度和更高的搜索结果排名,让您的利润增加的过程.
seo操作
搜索关键字以访问您访问的 网站,但您有没有想过这个神奇的链接列表背后是什么?
就像这样,谷歌有一个搜索引擎,它采集它在互联网上找到的所有内容信息,然后将所有这些 1 和 0 带回搜索引擎进行索引。
当您使用 Google 进行搜索时,您实际上并不是在搜索网络,而是在搜索 Google 的网页索引,至少是您能找到的;使用一些称为“蜘蛛”的软件程序进行搜索,“蜘蛛”程序爬取少量页面,然后跟踪这些页面上的链接,然后爬取这些链接指向的页面,然后跟踪这些页面上的所有链接,并爬取他们链接到的页面,等等。
现在,假设我想知道一只动物的奔跑速度,我在搜索框中输入该动物的奔跑速度,按回车键,我们的软件将在这些索引中搜索收录这些搜索词的所有页面。
在这种情况下,有数以万计的可能结果,谷歌如何确定我的搜索意图?答案是通过询问 200 多个问题来确定的,例如,您的关键字在此页面上出现了多少次?
这些关键字出现在标题中、URL 中还是直接相邻?此页面是否收录这些关键字的同义词?这个页面是来自一个好的 网站 还是一个坏的 URL 甚至是垃圾邮件网站?
这个页面的PageRank是多少?
PageRank全称为网页排名,也称网页等级,是一种基于网页间相互超链接计算的技术。谷歌用它来反映一个网页的相关性和重要性,在搜索引擎优化操作中经常使用它来评估网页优化的有效性因素之一。PageRank 是 Google 的宝石,一种用于对网络中节点的重要性进行排名的算法。
PageRank 通过庞大的超链接网络确定页面的排名。Google 将 A 页面到 B 页面的链接解释为 A 页面为 B 页面投票,并且 Google 根据投票来源(甚至来源,链接到 A 页面的页面)和投票目标的评级。
简单来说,一个高层页面可以提升其他低层页面的层级。
假设有 4 个页面的小组:A、B、C 和 D。如果所有页面都链接到 A,那么 A 的 PR(PageRank)值将是 B、C 和 D 的 Pageranks 之和。
对这样的公式有兴趣的可以学习理解,这里就不过多解释了。
该公式通过查找到网页的外部链接的数量以及这些链接的重要性来评估网页的重要性。最后,我们综合以上所有因素,对每个页面进行总体评分。并且在你提交搜索请求半秒后,返回搜索结果。
经常更新 网站 或改进 网站 排名,每个结果都收录一个标题、一个 URL 和一段文本,有助于确定此页面是否是我正在寻找的内容。还可以查看一些指向类似页面的链接、Google 上最近保存的页面版本以及您可能会尝试的相关搜索。
直到我们索引大多数网页,这些网页是存储在数千台计算机上的数十亿网页。
各因素的权重如图:
如果是我,我想我可以使用以下步骤进行 seo:
抓取可访问性,以便引擎可以阅读您的 网站 可以回答搜索者查询的引人入胜的内容 优化关键字以吸引搜索者和引擎 出色的用户体验,包括快速加载速度和引人注目的 UI 共享链接、引用和放大内容 有价值的内容标题,网址和描述吸引了高点击率 片段/模式标签在 SERP(搜索引擎结果页面)中脱颖而出
注:搜索引擎结果页,英文缩写SERP(Search Engine Results Page),是指搜索引擎返回的满足搜索引擎领域查询要求的页面。
搜索引擎优化指南
内容和关键字是搜索引擎的关键因素,当您考虑 SEO 时,内容质量应该是您的首要任务,内容质量是您如何吸引用户、取悦您的受众,并为搜索创建高质量、有价值的内容引擎也很关键,所以它的第一个要素是内容质量。
对您而言,例如博客文章、产品页面、关于页面、推荐、视频等或您为受众创建的任何其他内容,正确安排内容质量意味着您有支持所有其他 seo 工作的基础。
内容质量交付、向用户输出、提供大量、有用和独特的内容是迫使他们留在您的页面上、建立熟悉度和信任度的原因,质量内容取决于您的内容类型和行业,以及深度技术等。
那么如何输出高质量的内容呢?优质内容的特点如下:
URL 搜索、索引和排名
首先,面对搜索引擎,我们需要了解它的三个重要功能:
这里请记住,搜索是一个发现的过程,通过爬虫(spider)来查找和更新内容,这里的内容(可以是网页、图片、视频、PDF等)都是通过链接找到的。
一直说搜索引擎索引?那么这是什么意思呢?
搜索引擎处理并存储他们在索引中找到的信息,这是一个收录他们找到并认为足以为搜索者服务的所有内容的庞大数据库。
如果您现在不寻找想要在搜索结果中显示的内容,可能有几个原因导致您的 网站 是全新的并且尚未被提取,也许您的 网站 是不是来自任何外部网站 @网站链接到也许你的 网站 使机器人难以有效地从中获取内容也许你的 网站 收录一些称为爬虫指令的基本代码搜索引擎 您的 网站 可能因 Google 的关键字研究垃圾邮件策略而受到处罚
什么是关键字?
搜索时,在输入框中输入的内容就是关键字。对于网站,对你的网站 内容最相关、最简洁的描述就是关键字。
知道关键字(搜索词)从谁在搜索它们开始,或者你想要什么关键词词,比如输入“婚礼”和“花店”,你可能会发现高相关度和高搜索度的相关词如:婚礼花束、新娘花、婚礼花店等。
给定关键字或关键字词组需要建立的搜索量越高,获得更高排名所需的工作就越多,而某些大品牌通常会在高流量关键字中排名前十,所以,如果你是从一开始就追同一个关键词,你可以想象排名会有多难,而且需要很多年。
对于高搜索量,实现自然排名成功所需的竞争和努力越多,尽管在某些情况下竞争性较低的搜索词可能是最有益的,在 seo 中称为长尾 关键词。
请不要小看一些晦涩难懂的关键词,搜索量较低的长尾关键词往往会随着搜索者的具体化而带来更好的收益,比如搜索“前端”的人可能只是浏览,但搜索“达达前端”只是对这个关键词有一个非常明确的方向。
按搜索量指定策略
当您尝试对您的 网站 进行排名时,请找到与之相关的搜索词,并查看您的竞争对手的排名,向他们学习,并找出让您更具战略性的因素。
看看你的竞争对手的关键词,有很多你想要排名的关键词,那么你怎么知道哪个排名第一呢?我认同!我们首先考虑的是查看哪些关键字在竞争对手列表中排名和优先级。
优先考虑竞争对手当前排名的高质量关键字可能是一个好主意,但查看竞争对手列表中的哪些关键字以及哪些关键字正在排名也是一个好主意。
您可以先了解搜索者的意图并搜索页面
要了解搜索者的意图,我们需要进行研究:
信息查询,以了解搜索者的需求;导航查询,搜索者想去互联网上的特定位置 交易查询,以了解搜索者想要做什么 最佳产品本地查询以了解搜索者想要在本地找到的一些东西
既然你已经找到了你的目标市场的搜索方式,那就做一个搜索页面(一个回答搜索者问题的网页的做法),所以页面内容需要优化比如:header tags, internal links, anchor text (anchor text 用于将文本链接到页面),它向搜索引擎发送有关目标页面内容的信号。
链接音量
在 Google 的通用网站管理员指南中,将页面上的链接数量限制在合理的数量(最多几千个)。拥有过多的内部链接本身不会对您造成不利影响,但它确实会影响 Google 查找和评估页面的方式。页面上的链接越多,每个链接获得的权益就越少。
您的标题标签在搜索者对您的 网站 的第一印象中起着重要作用,那么如何使您的 网站 具有有效的标题标签呢?
对于关键词,在标题中收录目标关键词可以帮助用户和搜索引擎了解你的网站内容的长度,一般情况下,搜索引擎会在搜索结果中显示标题标签的前50-60个字符
元描述和标题标签一样,也是描述其所在页面内容的html元素,它们也嵌套在head标签中:
url 结构、命名和组织页面
url 代表 Uniform Resource Locator,url 是网络上个别内容的位置或地址,如标题标签和元描述,搜索引擎在 serps(搜索引擎结果页面)上显示 url,因此 url 的命名和格式会影响点击搜索者不仅使用它们来决定点击哪些页面,而且搜索引擎也使用 URL 来评估和排名页面。
最后,总结一下,今天我们介绍了以下三个方面:
关于网站SEO的知识,这里就介绍一下。如果您对这方面感兴趣,请参考相关资料进一步深入研究。
注意,不要迷路
好了,各位,以上就是本次文章的全部内容,能看到这里的都是人才。以后会继续更新技术相关的文章。如果你觉得文章对你有用,请给个“赞”,欢迎分享,谢谢!! 查看全部
输入关键字 抓取所有网页(SEO代表搜索引擎优化,如何进行索引以及如何确定其为搜索优化)
前言
什么是搜索引擎优化?SEO是Search Engine Optimization,意思是“搜索引擎优化”,一般简称搜索优化。SEO的主要工作是通过了解各种搜索引擎如何抓取互联网页面、如何对它们进行索引以及如何确定它们在特定关键词搜索结果中的排名来优化网页。提供搜索引擎排名,增加网站流量。
如果你能很好地运用SEO技术,你可以提高你的网站排名,增加它在相关搜索中的可见度,让你的网页在用户搜索过程中越来越显眼,让你的网站可能吸引更多关注和影响力,并吸引潜在和现有客户加入您的业务。
总结一下:SEO 代表搜索引擎优化,通过自然搜索引擎结果增加 网站 的流量数量和质量的做法。
SEO的本质
那么SEO是如何工作的呢?一些浏览器等搜索引擎使用机器人来获取网页、从一个站点到另一个站点、采集有关页面的信息并将它们放入索引中。然后算法分析索引中的页面,考虑数百个排名因素或信号等,以确定页面在给定查询的搜索结果中出现的顺序。
搜索排名因素可以被视为用户体验方面的代理。内容质量和关键字研究是内容优化的关键因素,搜索算法旨在展示相关的权威页面并为用户提供有效的搜索体验,优化您的网站,如果将这些因素考虑在内,内容会有所帮助您的页面在搜索结果中排名更高。
seo仍然主要用于商业目的来查找有关产品和服务的信息,搜索往往是品牌的主要数字流量来源,并补充其他营销渠道以获得更高的知名度和更高的搜索结果排名,让您的利润增加的过程.
seo操作
搜索关键字以访问您访问的 网站,但您有没有想过这个神奇的链接列表背后是什么?
就像这样,谷歌有一个搜索引擎,它采集它在互联网上找到的所有内容信息,然后将所有这些 1 和 0 带回搜索引擎进行索引。
当您使用 Google 进行搜索时,您实际上并不是在搜索网络,而是在搜索 Google 的网页索引,至少是您能找到的;使用一些称为“蜘蛛”的软件程序进行搜索,“蜘蛛”程序爬取少量页面,然后跟踪这些页面上的链接,然后爬取这些链接指向的页面,然后跟踪这些页面上的所有链接,并爬取他们链接到的页面,等等。
现在,假设我想知道一只动物的奔跑速度,我在搜索框中输入该动物的奔跑速度,按回车键,我们的软件将在这些索引中搜索收录这些搜索词的所有页面。
在这种情况下,有数以万计的可能结果,谷歌如何确定我的搜索意图?答案是通过询问 200 多个问题来确定的,例如,您的关键字在此页面上出现了多少次?
这些关键字出现在标题中、URL 中还是直接相邻?此页面是否收录这些关键字的同义词?这个页面是来自一个好的 网站 还是一个坏的 URL 甚至是垃圾邮件网站?
这个页面的PageRank是多少?
PageRank全称为网页排名,也称网页等级,是一种基于网页间相互超链接计算的技术。谷歌用它来反映一个网页的相关性和重要性,在搜索引擎优化操作中经常使用它来评估网页优化的有效性因素之一。PageRank 是 Google 的宝石,一种用于对网络中节点的重要性进行排名的算法。
PageRank 通过庞大的超链接网络确定页面的排名。Google 将 A 页面到 B 页面的链接解释为 A 页面为 B 页面投票,并且 Google 根据投票来源(甚至来源,链接到 A 页面的页面)和投票目标的评级。
简单来说,一个高层页面可以提升其他低层页面的层级。
假设有 4 个页面的小组:A、B、C 和 D。如果所有页面都链接到 A,那么 A 的 PR(PageRank)值将是 B、C 和 D 的 Pageranks 之和。
对这样的公式有兴趣的可以学习理解,这里就不过多解释了。
该公式通过查找到网页的外部链接的数量以及这些链接的重要性来评估网页的重要性。最后,我们综合以上所有因素,对每个页面进行总体评分。并且在你提交搜索请求半秒后,返回搜索结果。
经常更新 网站 或改进 网站 排名,每个结果都收录一个标题、一个 URL 和一段文本,有助于确定此页面是否是我正在寻找的内容。还可以查看一些指向类似页面的链接、Google 上最近保存的页面版本以及您可能会尝试的相关搜索。
直到我们索引大多数网页,这些网页是存储在数千台计算机上的数十亿网页。
各因素的权重如图:
如果是我,我想我可以使用以下步骤进行 seo:
抓取可访问性,以便引擎可以阅读您的 网站 可以回答搜索者查询的引人入胜的内容 优化关键字以吸引搜索者和引擎 出色的用户体验,包括快速加载速度和引人注目的 UI 共享链接、引用和放大内容 有价值的内容标题,网址和描述吸引了高点击率 片段/模式标签在 SERP(搜索引擎结果页面)中脱颖而出
注:搜索引擎结果页,英文缩写SERP(Search Engine Results Page),是指搜索引擎返回的满足搜索引擎领域查询要求的页面。
搜索引擎优化指南
内容和关键字是搜索引擎的关键因素,当您考虑 SEO 时,内容质量应该是您的首要任务,内容质量是您如何吸引用户、取悦您的受众,并为搜索创建高质量、有价值的内容引擎也很关键,所以它的第一个要素是内容质量。
对您而言,例如博客文章、产品页面、关于页面、推荐、视频等或您为受众创建的任何其他内容,正确安排内容质量意味着您有支持所有其他 seo 工作的基础。
内容质量交付、向用户输出、提供大量、有用和独特的内容是迫使他们留在您的页面上、建立熟悉度和信任度的原因,质量内容取决于您的内容类型和行业,以及深度技术等。
那么如何输出高质量的内容呢?优质内容的特点如下:
URL 搜索、索引和排名
首先,面对搜索引擎,我们需要了解它的三个重要功能:
这里请记住,搜索是一个发现的过程,通过爬虫(spider)来查找和更新内容,这里的内容(可以是网页、图片、视频、PDF等)都是通过链接找到的。
一直说搜索引擎索引?那么这是什么意思呢?
搜索引擎处理并存储他们在索引中找到的信息,这是一个收录他们找到并认为足以为搜索者服务的所有内容的庞大数据库。
如果您现在不寻找想要在搜索结果中显示的内容,可能有几个原因导致您的 网站 是全新的并且尚未被提取,也许您的 网站 是不是来自任何外部网站 @网站链接到也许你的 网站 使机器人难以有效地从中获取内容也许你的 网站 收录一些称为爬虫指令的基本代码搜索引擎 您的 网站 可能因 Google 的关键字研究垃圾邮件策略而受到处罚
什么是关键字?
搜索时,在输入框中输入的内容就是关键字。对于网站,对你的网站 内容最相关、最简洁的描述就是关键字。
知道关键字(搜索词)从谁在搜索它们开始,或者你想要什么关键词词,比如输入“婚礼”和“花店”,你可能会发现高相关度和高搜索度的相关词如:婚礼花束、新娘花、婚礼花店等。
给定关键字或关键字词组需要建立的搜索量越高,获得更高排名所需的工作就越多,而某些大品牌通常会在高流量关键字中排名前十,所以,如果你是从一开始就追同一个关键词,你可以想象排名会有多难,而且需要很多年。
对于高搜索量,实现自然排名成功所需的竞争和努力越多,尽管在某些情况下竞争性较低的搜索词可能是最有益的,在 seo 中称为长尾 关键词。
请不要小看一些晦涩难懂的关键词,搜索量较低的长尾关键词往往会随着搜索者的具体化而带来更好的收益,比如搜索“前端”的人可能只是浏览,但搜索“达达前端”只是对这个关键词有一个非常明确的方向。
按搜索量指定策略
当您尝试对您的 网站 进行排名时,请找到与之相关的搜索词,并查看您的竞争对手的排名,向他们学习,并找出让您更具战略性的因素。
看看你的竞争对手的关键词,有很多你想要排名的关键词,那么你怎么知道哪个排名第一呢?我认同!我们首先考虑的是查看哪些关键字在竞争对手列表中排名和优先级。
优先考虑竞争对手当前排名的高质量关键字可能是一个好主意,但查看竞争对手列表中的哪些关键字以及哪些关键字正在排名也是一个好主意。
您可以先了解搜索者的意图并搜索页面
要了解搜索者的意图,我们需要进行研究:
信息查询,以了解搜索者的需求;导航查询,搜索者想去互联网上的特定位置 交易查询,以了解搜索者想要做什么 最佳产品本地查询以了解搜索者想要在本地找到的一些东西
既然你已经找到了你的目标市场的搜索方式,那就做一个搜索页面(一个回答搜索者问题的网页的做法),所以页面内容需要优化比如:header tags, internal links, anchor text (anchor text 用于将文本链接到页面),它向搜索引擎发送有关目标页面内容的信号。
链接音量
在 Google 的通用网站管理员指南中,将页面上的链接数量限制在合理的数量(最多几千个)。拥有过多的内部链接本身不会对您造成不利影响,但它确实会影响 Google 查找和评估页面的方式。页面上的链接越多,每个链接获得的权益就越少。
您的标题标签在搜索者对您的 网站 的第一印象中起着重要作用,那么如何使您的 网站 具有有效的标题标签呢?
对于关键词,在标题中收录目标关键词可以帮助用户和搜索引擎了解你的网站内容的长度,一般情况下,搜索引擎会在搜索结果中显示标题标签的前50-60个字符
元描述和标题标签一样,也是描述其所在页面内容的html元素,它们也嵌套在head标签中:
url 结构、命名和组织页面
url 代表 Uniform Resource Locator,url 是网络上个别内容的位置或地址,如标题标签和元描述,搜索引擎在 serps(搜索引擎结果页面)上显示 url,因此 url 的命名和格式会影响点击搜索者不仅使用它们来决定点击哪些页面,而且搜索引擎也使用 URL 来评估和排名页面。
最后,总结一下,今天我们介绍了以下三个方面:
关于网站SEO的知识,这里就介绍一下。如果您对这方面感兴趣,请参考相关资料进一步深入研究。
注意,不要迷路
好了,各位,以上就是本次文章的全部内容,能看到这里的都是人才。以后会继续更新技术相关的文章。如果你觉得文章对你有用,请给个“赞”,欢迎分享,谢谢!!
输入关键字 抓取所有网页( 2.所有的不明理由进入都是好的呢?(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-03 15:25
2.所有的不明理由进入都是好的呢?(组图)
)
用户将网站加入浏览器采集后,点击采集链接进入,属于采集条目,通常分析工具认为是不明条目。直接地址栏输入和采集夹输入我们都会考虑高质量的长期忠实用户,那么所有不明原因的输入都好吗?不解释的条目越多越好吗?看完以下两种情况,你就会知道网站分析中的数据并不是绝对的。
1.3 缺少推荐人
网站分析工具通过浏览器请求中收录的Referrer字段识别访问来源。但是,Referrer 并不收录在所有请求中。各种原因会导致Http请求中的Referrer丢失,包括一些网关、防火墙等设置会阻塞Http请求中的Referrer字段;用户的一些特殊操作也会导致浏览器丢失Referrer。由于这些原因,网站分析工具无法正确识别出真正的直接入口和referrer loss之间的区别,因此没有争议的分类方法是将其计为“未知”入口。
1.4 特殊浏览器/爬虫机器人等
特殊浏览器包括一些推荐版本的浏览器,或者网站内容爬虫等,通常不提供Referrer内容。如果这些工具产生的访问没有被有效阻止,它们可能会导致无法解释的进入来源。还有搜索引擎的爬虫机器人,还有其他内容的网络蜘蛛网站,不时使用Http协议访问互联网。当然,机器人的访问量不应该被计算在内。当然,如果你的网站设置不正确,不幸的是机器人的访问进来了,那么这些访问也会被分析工具视为未知来源。
2. 广告链接源数据采集方法介绍
2.1 通过在广告链接中插入参数
将参数插入广告链接的方法是广告数据采集的主要方法,也是最容易实现和衡量的方法。具体来说,当广告商向广告商提供广告点击链接时,他们有意识地将其添加到广告链接的末尾。某些参数通常不会被客户端的 网站 应用程序捕获,但仅用于为 网站 分析工具提供数据。比如花卉网站的销售部决定在母亲节前夕推广康乃馨,并计划在“花卉采集”网站上投放广告。除了图片,还应该为访问者点击图片时页面跳转到的目标页面——“妈妈”提供一个链接
2.2 根据进入页面的引用(Referrer)判断
如果前一种方法(通过在广告链接中插入参数)是常用的方法,那么通过进入页面的引用(Referrer)来判断的方法是一种不费吹灰之力的修改。你为什么这么说?一般情况下,广告商允许客户在广告链接中添加参数。在这种情况下,首选前者,因为它更灵活、更方便。但是对于一些伪装的广告和以交换链接的形式提供的广告,通常对方网站不能根据我们的要求随意指定连接参数,那么如何对这些广告来源进行统计呢?这就需要利用referrer判断来采集广告来源。入口页面的引用是指用户进入网站时访问的第一个网页的引用。如果是广告提供者的特定广告网页,则分析系统将访问来源视为广告来源。这种数据采集方式的优点是不需要插入额外的参数,但是对于同一页面收录多个不同广告的数据采集,存在无法区分具体广告的问题。
3. 如何获取搜索引擎的源码
分析系统首先判断网站中输入的引用页面的URL是否为搜索引擎,如果是,则获取搜索引擎使用的关键词,并将该条目定义为搜索引擎的来源.
通常,为了更详细地分析搜索引擎源的访问情况,需要对来自搜索引擎源的数据进行更详细的分类。目前主流的分类方法通常包括以下两种。
(1)搜索引擎类型
(2)搜索关键字
搜索引擎源分类的分析方法将在《搜索关键词分析》和《搜索引擎分析》中详细介绍。
4. 其他网站 获取源数据的方法
网站 从其他来源获取数据的方法与搜索引擎类似。与搜索引擎来源不同的是,网站的其他来源访问的引荐页面(Referrers)的URL不属于搜索引擎的类型。分析工具将这部分源视为其他网站 源。
5. 如何衡量搜索引擎关键字排名
访问者来源分析包括统计在各种搜索引擎上来到网站的关键字的排名信息的功能。这些信息是如何获得的?
首先,知名搜索引擎提供了一个对外开放的API(Application Programming Interface),方便第三方应用获取搜索引擎数据,包括指定关键词的排名和连接目的信息,网站@ >分析系统可以通过API将这部分数据引入分析表,与网站分析的数据进行整合,为客户提供更全面的数据支持。
查看全部
输入关键字 抓取所有网页(
2.所有的不明理由进入都是好的呢?(组图)
)
用户将网站加入浏览器采集后,点击采集链接进入,属于采集条目,通常分析工具认为是不明条目。直接地址栏输入和采集夹输入我们都会考虑高质量的长期忠实用户,那么所有不明原因的输入都好吗?不解释的条目越多越好吗?看完以下两种情况,你就会知道网站分析中的数据并不是绝对的。
1.3 缺少推荐人
网站分析工具通过浏览器请求中收录的Referrer字段识别访问来源。但是,Referrer 并不收录在所有请求中。各种原因会导致Http请求中的Referrer丢失,包括一些网关、防火墙等设置会阻塞Http请求中的Referrer字段;用户的一些特殊操作也会导致浏览器丢失Referrer。由于这些原因,网站分析工具无法正确识别出真正的直接入口和referrer loss之间的区别,因此没有争议的分类方法是将其计为“未知”入口。
1.4 特殊浏览器/爬虫机器人等
特殊浏览器包括一些推荐版本的浏览器,或者网站内容爬虫等,通常不提供Referrer内容。如果这些工具产生的访问没有被有效阻止,它们可能会导致无法解释的进入来源。还有搜索引擎的爬虫机器人,还有其他内容的网络蜘蛛网站,不时使用Http协议访问互联网。当然,机器人的访问量不应该被计算在内。当然,如果你的网站设置不正确,不幸的是机器人的访问进来了,那么这些访问也会被分析工具视为未知来源。
2. 广告链接源数据采集方法介绍
2.1 通过在广告链接中插入参数
将参数插入广告链接的方法是广告数据采集的主要方法,也是最容易实现和衡量的方法。具体来说,当广告商向广告商提供广告点击链接时,他们有意识地将其添加到广告链接的末尾。某些参数通常不会被客户端的 网站 应用程序捕获,但仅用于为 网站 分析工具提供数据。比如花卉网站的销售部决定在母亲节前夕推广康乃馨,并计划在“花卉采集”网站上投放广告。除了图片,还应该为访问者点击图片时页面跳转到的目标页面——“妈妈”提供一个链接
2.2 根据进入页面的引用(Referrer)判断
如果前一种方法(通过在广告链接中插入参数)是常用的方法,那么通过进入页面的引用(Referrer)来判断的方法是一种不费吹灰之力的修改。你为什么这么说?一般情况下,广告商允许客户在广告链接中添加参数。在这种情况下,首选前者,因为它更灵活、更方便。但是对于一些伪装的广告和以交换链接的形式提供的广告,通常对方网站不能根据我们的要求随意指定连接参数,那么如何对这些广告来源进行统计呢?这就需要利用referrer判断来采集广告来源。入口页面的引用是指用户进入网站时访问的第一个网页的引用。如果是广告提供者的特定广告网页,则分析系统将访问来源视为广告来源。这种数据采集方式的优点是不需要插入额外的参数,但是对于同一页面收录多个不同广告的数据采集,存在无法区分具体广告的问题。
3. 如何获取搜索引擎的源码
分析系统首先判断网站中输入的引用页面的URL是否为搜索引擎,如果是,则获取搜索引擎使用的关键词,并将该条目定义为搜索引擎的来源.
通常,为了更详细地分析搜索引擎源的访问情况,需要对来自搜索引擎源的数据进行更详细的分类。目前主流的分类方法通常包括以下两种。
(1)搜索引擎类型
(2)搜索关键字
搜索引擎源分类的分析方法将在《搜索关键词分析》和《搜索引擎分析》中详细介绍。
4. 其他网站 获取源数据的方法
网站 从其他来源获取数据的方法与搜索引擎类似。与搜索引擎来源不同的是,网站的其他来源访问的引荐页面(Referrers)的URL不属于搜索引擎的类型。分析工具将这部分源视为其他网站 源。
5. 如何衡量搜索引擎关键字排名
访问者来源分析包括统计在各种搜索引擎上来到网站的关键字的排名信息的功能。这些信息是如何获得的?
首先,知名搜索引擎提供了一个对外开放的API(Application Programming Interface),方便第三方应用获取搜索引擎数据,包括指定关键词的排名和连接目的信息,网站@ >分析系统可以通过API将这部分数据引入分析表,与网站分析的数据进行整合,为客户提供更全面的数据支持。
输入关键字 抓取所有网页(如何在互联网上快速的搜索到自己需要的学习资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-02-02 15:07
网上很多个人博客开源程序都默认自带robots.txt文件,而且大部分都有默认禁止被搜索引擎抓取的url路径。许多新手网站管理员都在建立网站的过程中。Robots.txt 文件中错误写入了禁止搜索引擎抓取网站内页的url路径;因此,直接导致搜索引擎不抓取网站的内页,也不收录输入关键词百度站点。这个原因一般是新手站长在摸索学习过程中乱修改文件造成的。如果您的 网站 搜索引擎没有 收录 内页,请检查 网站 根目录中的 robots.txt 文件!
如何在网上快速搜索到自己需要的学习资料?
分享5个强大且个人喜欢的找学习资料的方法,我的经验百度站,喜欢的话可以点赞关注~
一、两个搜索引擎指导产品网络推广百度网站:
关键字”+“空格”+“文件类型:”+“doc/ppt/pdf等文件格式”百度网站,“\””+“关键字”+“\””
两个百度站,两个网站:B站:哔哩哔哩(゜-゜)つロCheers~-bilibili
探索:
三、一个小程序,网盘搜索Pro
1.“关键字”+“空格”+“文件类型:”+“doc/ppt/pdf等文件格式”
filetype 可用于搜索特定的文件格式,使用此搜索命令可以轻松搜索各种格式的数据文件。例如:全益辉,因为我公司没有上传库中的数据,所以没有有效的搜索结果。
如果你这样输入,你还可以在有限的时间内找到收录关键字的文档。
“关键字”+“空格”+“文件类型:”+“doc/ppt等文件格式”+“空格”+“2008..2010”
2.「\"」+「关键字」+「\"」
该命令可用于搜索完整的关键字匹配。简而言之,搜索结果收录双引号中的所有关键字,并且顺序也完全匹配。
例如:当我们搜索“\”英文复习资料\“”时,搜索结果都是匹配的,文本的顺序没有改变。需要注意的是,命令中使用的双引号是英文状态的双引号,中文状态的双引号是不允许的。
3.B站:
哔哩哔哩(bilibili)现在是中国领先的青年文化社区。网站成立于2009年6月26日,被粉丝亲切地称为“哔哩哔哩”。B站可以搜索各种学习视频,例如:PS教程
4.探索:
国内最大的网盘搜索网站功能之一
5.微信小程序:网盘搜索Pro
这是一个专门用来搜索网盘资源的微信小程序。无需注册,打开使用,直接在搜索栏输入你想要的资源名称,点击搜索即可。例如:市场营销毕业论文 查看全部
输入关键字 抓取所有网页(如何在互联网上快速的搜索到自己需要的学习资料)
网上很多个人博客开源程序都默认自带robots.txt文件,而且大部分都有默认禁止被搜索引擎抓取的url路径。许多新手网站管理员都在建立网站的过程中。Robots.txt 文件中错误写入了禁止搜索引擎抓取网站内页的url路径;因此,直接导致搜索引擎不抓取网站的内页,也不收录输入关键词百度站点。这个原因一般是新手站长在摸索学习过程中乱修改文件造成的。如果您的 网站 搜索引擎没有 收录 内页,请检查 网站 根目录中的 robots.txt 文件!
如何在网上快速搜索到自己需要的学习资料?
分享5个强大且个人喜欢的找学习资料的方法,我的经验百度站,喜欢的话可以点赞关注~
一、两个搜索引擎指导产品网络推广百度网站:
关键字”+“空格”+“文件类型:”+“doc/ppt/pdf等文件格式”百度网站,“\””+“关键字”+“\””
两个百度站,两个网站:B站:哔哩哔哩(゜-゜)つロCheers~-bilibili
探索:
三、一个小程序,网盘搜索Pro
1.“关键字”+“空格”+“文件类型:”+“doc/ppt/pdf等文件格式”
filetype 可用于搜索特定的文件格式,使用此搜索命令可以轻松搜索各种格式的数据文件。例如:全益辉,因为我公司没有上传库中的数据,所以没有有效的搜索结果。
如果你这样输入,你还可以在有限的时间内找到收录关键字的文档。
“关键字”+“空格”+“文件类型:”+“doc/ppt等文件格式”+“空格”+“2008..2010”
2.「\"」+「关键字」+「\"」
该命令可用于搜索完整的关键字匹配。简而言之,搜索结果收录双引号中的所有关键字,并且顺序也完全匹配。
例如:当我们搜索“\”英文复习资料\“”时,搜索结果都是匹配的,文本的顺序没有改变。需要注意的是,命令中使用的双引号是英文状态的双引号,中文状态的双引号是不允许的。
3.B站:
哔哩哔哩(bilibili)现在是中国领先的青年文化社区。网站成立于2009年6月26日,被粉丝亲切地称为“哔哩哔哩”。B站可以搜索各种学习视频,例如:PS教程
4.探索:
国内最大的网盘搜索网站功能之一
5.微信小程序:网盘搜索Pro
这是一个专门用来搜索网盘资源的微信小程序。无需注册,打开使用,直接在搜索栏输入你想要的资源名称,点击搜索即可。例如:市场营销毕业论文
输入关键字 抓取所有网页(一个神器之一selenium五年发表文章五年数量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-02 14:03
PubMed 是一个用于生物医学文章搜索和摘要的免费搜索数据库。它是一个网站,经常用于查找生物学文献。最近学了爬虫相关的知识包括urllib库、requests库、xpath表达式、scrapy框架等。正想着去爬PubMed,就动手实践一下,准备爬上文章发表的数PubMed根据过去五年的关键词搜索,并以此为依据看过去五年的研究方向。程度。
最初的想法是使用scrapy框架进行爬取和存储。于是打开PubMed,开始分析网页构成、源码等。发现NCBI使用的是动态网页,在进行翻页、搜索关键字等操作时,URL并没有变化。于是想到了爬虫神器之一的selenium模块,用selenium来模拟搜索、翻页等操作,然后分析源码得到想要的信息。由于和selenium接触不多,所以暂时在网上找了一些功能。
1、 加载需要的模块
import urllib
import time
import matplotlib.pyplot as plt
import numpy as np
from lxml import etree
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from collections import Counter
2、从关键字构造 URL
手动输入几个关键字,分析 URL 的结构。
PubMed 的原创链接是 '',当输入和搜索 'cancer,TCGA,Breast' 时,url 变为 ''。所以不难分析,URL由两部分组成,一部分是同一个'',另一部分是由我们搜索的关键字拼接而成的字符串'%2C'组成的。因此,对于传入的‘keyword’,我们可以做如下处理,拼接到搜索后返回的url中
keyword = '%2C'.join(keyword)
tart_url = 'https://www.ncbi.nlm.nih.gov/pubmed/?term='
url = start_url + keyword
这样,我们简单地连接返回的 url。
3、创建浏览器对象
接下来就是使用selenium模块打开我们的Chrome浏览器,跳转到url界面。这个操作相信大家都很熟悉了。因为后面要模拟点击和翻页,所以需要实例化一个WebDriverWait对象,方便后续调用
browser = webdriver.Chrome()
self.browser.get(url)
wait = WebDriverWait(browser, 10)
模拟点击网页
打开网页后,我们需要模拟点击网页。首先,我们需要找到过去五年的文章,所以我们需要模拟点击左侧5years的按钮,改变单页显示的文章个数。变成200,这样可以减少我们的翻页操作
QQ图片246.png
在我们模拟点击之前,我们必须等到网页上加载了相应的元素才能点击,所以我们需要使用前面提到的WebDriverWait对象。代码显示如下
years =wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#_ds1 > li > ul > li:nth-child(1) > a')))
years.click()
perpage = self.wait.until(EC.element_to_be_clickable((By.XPATH,'//ul[@class="inline_list left display_settings"]/li[3]/a/span[4]')))
perpage.click()
page_200 = self.wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#display_settings_menu_ps > fieldset > ul > li:nth-child(6) > label')))
此处使用了 CSS 选择器和 Xpath 表达式。用哪一种就看个人喜好了,用哪一种方便都可以。EC.element_to_be_clickable 是在一个元组中传递的,第一个元素是声明要使用的选择器,第二个元素是表达式,这个函数的意思是等到你在表达式中传递的元素在网页上的使用过程中selenium,有很多地方我们需要用到类似的操作比如presence_of_element_located、text_to_be_present_in_element等,有兴趣的可以去网上一探究竟。
解析网页并提取信息
下一步是解析网页。我在这里使用 lxml 来解析网页并从 Xpath 中提取信息。代码如下
html = self.browser.page_source
doc = etree.HTML(self.html)
self.art_timeanddoi = self.doc.xpath('//div[@class="rprt"]/div[2]/div/p[@class="details"]/text()')
for i in self.art_timeanddoi:
self.yearlist.append(i[2:6])
for i in self.yearlist:
if re.match('2', i):
continue
else:
self.yearlist.remove(i)
这里主要是对网页中的年份进行Xpath提取和字符串切片处理,从而获取年份信息并存入列表中。在实际操作过程中,发现了少量其他不相关的元素。仔细排查,发现是网页源代码有问题。因此,执行了一个常规过程来删除不以“2”开头的元素。经检查,最终结果是正确的。.
这里我们提取单页信息。
执行翻页
我们还需要经过一个翻页操作来获取我们想要的所有信息。仍然使用 selenium 模块。
status = True
def next_page():
try:
self.nextpage = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@title="Next page of results"]')))
except TimeoutException:
status = False
while True:
if status:
next_page()
else:
break
这里我先定义一个判断是否可以翻页的函数,并使用异常捕获,因为翻页动作到最后一页就应该停止,不能再次点击翻页元素。因此,在进行点击操作时应先进行判断。如果不能点击,会因为超时而抛出异常。next_page 函数中的status 变量记录是否可以点击“下一页”按钮。接下来是一个 while True 循环。翻页动作只会在 next_page 变为 False 时停止。在循环中,我们不断地解析网页以提取信息以获得所有想要的信息。
视觉处理
爬取了全年信息列表后,还需要进一步的可视化处理,直观判断目标课题的研究趋势。因此,我们使用matplotlib进行可视化操作,简单地画一个折线图。代码显示如下:
def plot_curve(yearlist):
counter = Counter(yearlist)
dic = dict(counter)
keys = sorted(list(dic.keys()))
curcount = 0
y = []
temp = [int(i) for i in keys]
for i in range(min(temp), max(temp)+1):
if str(i) in keys:
curcount += self.dic[str(i)]
y.append(self.curcount)
else:
y.append(self.curcount)
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.xlabel('年份')
plt.ylabel('近五年文章数量')
plt.plot(np.arange(min(temp), max(temp)+1), np.array(y), 'r', marker='+', linewidth=2)
plt.show()
最后粘贴完整代码:
import re
import urllib
import time
import numpy as np
from lxml import etree
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from collections import Counter
import matplotlib.pyplot as plt
class NcbiInfo(object):
browser = webdriver.Chrome()
start_url = 'https://www.ncbi.nlm.nih.gov/pubmed/?term='
wait = WebDriverWait(browser, 10)
def __init__(self, keywordlist):
self.temp = [urllib.parse.quote(i) for i in keywordlist]
self.keyword = '%2C'.join(self.temp)
self.title = ' AND '.join(self.temp)
self.url = NcbiInfo.start_url + self.keyword
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
self.file = open('information.txt', 'w')
self.status = True
self.yearlist = []
def click_yearandabstract(self, ):
self.browser.get(self.url)
years = self.wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#_ds1 > li > ul > li:nth-child(1) > a')))
years.click()
perpage = self.wait.until(EC.element_to_be_clickable((By.XPATH, '//ul[@class="inline_list left display_settings"]/li[3]/a/span[4]')))
perpage.click()
page_200 = self.wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#display_settings_menu_ps > fieldset > ul > li:nth-child(6) > label')))
page_200.click()
def get_response(self):
self.html = self.browser.page_source
self.doc = etree.HTML(self.html)
def get_numof_article(self):
article_count_ = self.doc.xpath('//*[@id="maincontent"]/div/div[3]/div[1]/h3/text()')[0]
if 'of' not in article_count_:
print(article_count_.split(': ')[1])
else:
print(article_count_.split('of ')[1])
def get_info(self):
self.art_timeanddoi = self.doc.xpath('//div[@class="rprt"]/div[2]/div/p[@class="details"]/text()')
for i in self.art_timeanddoi:
self.yearlist.append(i[2:6])
for i in self.yearlist:
if re.match('2', i):
continue
else:
self.yearlist.remove(i)
def next_page(self):
try:
self.nextpage = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@title="Next page of results"]')))
except TimeoutException:
self.status = False
def plot_curve(self):
self.counter = Counter(self.yearlist)
self.dic = dict(self.counter)
self.keys = sorted(list(self.dic.keys()))
self.curcount = 0
self.y = []
temp = [int(i) for i in self.keys]
for i in range(min(temp), max(temp)+1):
if str(i) in self.keys:
self.curcount += self.dic[str(i)]
self.y.append(self.curcount)
else:
self.y.append(self.curcount)
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.xlabel('年份')
plt.ylabel('近五年文章数量')
plt.title(self.title)
plt.plot(np.arange(min(temp), max(temp)+1), np.array(self.y), 'r', marker='+', linewidth=2)
plt.show()
def main(self):
self.click_yearandabstract()
time.sleep(3)
self.get_response()
self.get_numof_article()
while True:
self.get_info()
self.next_page()
if self.status:
self.nextpage.click()
self.get_response()
else:
break
self.plot_curve()
if __name__ == '__main__':
a = NcbiInfo(['TCGA', 'breast', 'cancer'])
a.main()
结果如下:
图像.png 查看全部
输入关键字 抓取所有网页(一个神器之一selenium五年发表文章五年数量)
PubMed 是一个用于生物医学文章搜索和摘要的免费搜索数据库。它是一个网站,经常用于查找生物学文献。最近学了爬虫相关的知识包括urllib库、requests库、xpath表达式、scrapy框架等。正想着去爬PubMed,就动手实践一下,准备爬上文章发表的数PubMed根据过去五年的关键词搜索,并以此为依据看过去五年的研究方向。程度。
最初的想法是使用scrapy框架进行爬取和存储。于是打开PubMed,开始分析网页构成、源码等。发现NCBI使用的是动态网页,在进行翻页、搜索关键字等操作时,URL并没有变化。于是想到了爬虫神器之一的selenium模块,用selenium来模拟搜索、翻页等操作,然后分析源码得到想要的信息。由于和selenium接触不多,所以暂时在网上找了一些功能。
1、 加载需要的模块
import urllib
import time
import matplotlib.pyplot as plt
import numpy as np
from lxml import etree
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from collections import Counter
2、从关键字构造 URL
手动输入几个关键字,分析 URL 的结构。
PubMed 的原创链接是 '',当输入和搜索 'cancer,TCGA,Breast' 时,url 变为 ''。所以不难分析,URL由两部分组成,一部分是同一个'',另一部分是由我们搜索的关键字拼接而成的字符串'%2C'组成的。因此,对于传入的‘keyword’,我们可以做如下处理,拼接到搜索后返回的url中
keyword = '%2C'.join(keyword)
tart_url = 'https://www.ncbi.nlm.nih.gov/pubmed/?term='
url = start_url + keyword
这样,我们简单地连接返回的 url。
3、创建浏览器对象
接下来就是使用selenium模块打开我们的Chrome浏览器,跳转到url界面。这个操作相信大家都很熟悉了。因为后面要模拟点击和翻页,所以需要实例化一个WebDriverWait对象,方便后续调用
browser = webdriver.Chrome()
self.browser.get(url)
wait = WebDriverWait(browser, 10)
模拟点击网页
打开网页后,我们需要模拟点击网页。首先,我们需要找到过去五年的文章,所以我们需要模拟点击左侧5years的按钮,改变单页显示的文章个数。变成200,这样可以减少我们的翻页操作
QQ图片246.png
在我们模拟点击之前,我们必须等到网页上加载了相应的元素才能点击,所以我们需要使用前面提到的WebDriverWait对象。代码显示如下
years =wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#_ds1 > li > ul > li:nth-child(1) > a')))
years.click()
perpage = self.wait.until(EC.element_to_be_clickable((By.XPATH,'//ul[@class="inline_list left display_settings"]/li[3]/a/span[4]')))
perpage.click()
page_200 = self.wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#display_settings_menu_ps > fieldset > ul > li:nth-child(6) > label')))
此处使用了 CSS 选择器和 Xpath 表达式。用哪一种就看个人喜好了,用哪一种方便都可以。EC.element_to_be_clickable 是在一个元组中传递的,第一个元素是声明要使用的选择器,第二个元素是表达式,这个函数的意思是等到你在表达式中传递的元素在网页上的使用过程中selenium,有很多地方我们需要用到类似的操作比如presence_of_element_located、text_to_be_present_in_element等,有兴趣的可以去网上一探究竟。
解析网页并提取信息
下一步是解析网页。我在这里使用 lxml 来解析网页并从 Xpath 中提取信息。代码如下
html = self.browser.page_source
doc = etree.HTML(self.html)
self.art_timeanddoi = self.doc.xpath('//div[@class="rprt"]/div[2]/div/p[@class="details"]/text()')
for i in self.art_timeanddoi:
self.yearlist.append(i[2:6])
for i in self.yearlist:
if re.match('2', i):
continue
else:
self.yearlist.remove(i)
这里主要是对网页中的年份进行Xpath提取和字符串切片处理,从而获取年份信息并存入列表中。在实际操作过程中,发现了少量其他不相关的元素。仔细排查,发现是网页源代码有问题。因此,执行了一个常规过程来删除不以“2”开头的元素。经检查,最终结果是正确的。.
这里我们提取单页信息。
执行翻页
我们还需要经过一个翻页操作来获取我们想要的所有信息。仍然使用 selenium 模块。
status = True
def next_page():
try:
self.nextpage = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@title="Next page of results"]')))
except TimeoutException:
status = False
while True:
if status:
next_page()
else:
break
这里我先定义一个判断是否可以翻页的函数,并使用异常捕获,因为翻页动作到最后一页就应该停止,不能再次点击翻页元素。因此,在进行点击操作时应先进行判断。如果不能点击,会因为超时而抛出异常。next_page 函数中的status 变量记录是否可以点击“下一页”按钮。接下来是一个 while True 循环。翻页动作只会在 next_page 变为 False 时停止。在循环中,我们不断地解析网页以提取信息以获得所有想要的信息。
视觉处理
爬取了全年信息列表后,还需要进一步的可视化处理,直观判断目标课题的研究趋势。因此,我们使用matplotlib进行可视化操作,简单地画一个折线图。代码显示如下:
def plot_curve(yearlist):
counter = Counter(yearlist)
dic = dict(counter)
keys = sorted(list(dic.keys()))
curcount = 0
y = []
temp = [int(i) for i in keys]
for i in range(min(temp), max(temp)+1):
if str(i) in keys:
curcount += self.dic[str(i)]
y.append(self.curcount)
else:
y.append(self.curcount)
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.xlabel('年份')
plt.ylabel('近五年文章数量')
plt.plot(np.arange(min(temp), max(temp)+1), np.array(y), 'r', marker='+', linewidth=2)
plt.show()
最后粘贴完整代码:
import re
import urllib
import time
import numpy as np
from lxml import etree
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from collections import Counter
import matplotlib.pyplot as plt
class NcbiInfo(object):
browser = webdriver.Chrome()
start_url = 'https://www.ncbi.nlm.nih.gov/pubmed/?term='
wait = WebDriverWait(browser, 10)
def __init__(self, keywordlist):
self.temp = [urllib.parse.quote(i) for i in keywordlist]
self.keyword = '%2C'.join(self.temp)
self.title = ' AND '.join(self.temp)
self.url = NcbiInfo.start_url + self.keyword
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
self.file = open('information.txt', 'w')
self.status = True
self.yearlist = []
def click_yearandabstract(self, ):
self.browser.get(self.url)
years = self.wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#_ds1 > li > ul > li:nth-child(1) > a')))
years.click()
perpage = self.wait.until(EC.element_to_be_clickable((By.XPATH, '//ul[@class="inline_list left display_settings"]/li[3]/a/span[4]')))
perpage.click()
page_200 = self.wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#display_settings_menu_ps > fieldset > ul > li:nth-child(6) > label')))
page_200.click()
def get_response(self):
self.html = self.browser.page_source
self.doc = etree.HTML(self.html)
def get_numof_article(self):
article_count_ = self.doc.xpath('//*[@id="maincontent"]/div/div[3]/div[1]/h3/text()')[0]
if 'of' not in article_count_:
print(article_count_.split(': ')[1])
else:
print(article_count_.split('of ')[1])
def get_info(self):
self.art_timeanddoi = self.doc.xpath('//div[@class="rprt"]/div[2]/div/p[@class="details"]/text()')
for i in self.art_timeanddoi:
self.yearlist.append(i[2:6])
for i in self.yearlist:
if re.match('2', i):
continue
else:
self.yearlist.remove(i)
def next_page(self):
try:
self.nextpage = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@title="Next page of results"]')))
except TimeoutException:
self.status = False
def plot_curve(self):
self.counter = Counter(self.yearlist)
self.dic = dict(self.counter)
self.keys = sorted(list(self.dic.keys()))
self.curcount = 0
self.y = []
temp = [int(i) for i in self.keys]
for i in range(min(temp), max(temp)+1):
if str(i) in self.keys:
self.curcount += self.dic[str(i)]
self.y.append(self.curcount)
else:
self.y.append(self.curcount)
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.xlabel('年份')
plt.ylabel('近五年文章数量')
plt.title(self.title)
plt.plot(np.arange(min(temp), max(temp)+1), np.array(self.y), 'r', marker='+', linewidth=2)
plt.show()
def main(self):
self.click_yearandabstract()
time.sleep(3)
self.get_response()
self.get_numof_article()
while True:
self.get_info()
self.next_page()
if self.status:
self.nextpage.click()
self.get_response()
else:
break
self.plot_curve()
if __name__ == '__main__':
a = NcbiInfo(['TCGA', 'breast', 'cancer'])
a.main()
结果如下:
图像.png
输入关键字 抓取所有网页(“qq号”放进去了怎么办?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-02 13:00
输入关键字抓取所有网页并得到不同网页的不同标题,只要这个标题不在敏感词内都可以。有道吧。
快速。直接起个名叫"搜索xxx"然后链接到“让你这条信息xxx级。本站可见。
问题是这个动词的发明需要多久?
你都说是“微博”了,你应该把下面“qq号”放进去。
是不是“在我们a站人人网b站的信息里,
是的。当地的监管权,钱,技术,
谁说要等到“敏感词”词条只能拿到一段信息的,就凭你一个看客哪儿就值几百万了。
如果你想添加两个可以实现的功能。1,微博爬虫自动抓取同时登录过的人发布的一些信息。2,把爬虫爬到的信息下载下来。具体哪个功能值钱我不清楚。反正举个例子:对于一个google广告的文案,这种信息分为几类?第一类:广告文案,打开首页,文案一定要有a,regionbroadcastingagencyc,eachclient,location,type,calltoaction,related,advertisement,points,level,relatedweibo,google,jpg等等。
这一类文案,a个国家一定是北京、上海、广州,然后连带着其他一些城市的地区。第二类:这一类,其实是广告公司的一些信息。比如我们新闻客户端要写region,所以要出示regionlocation的证书。或者还有类似如何查询广告位置,也要出示assistant。这一类信息特别容易抓取。像如何找到公关公司就是一样。
还有一类:美术作品或者版权信息,我们要提供作者drawingcompanycname,如果你说在谁的公司dedicatedto我们,或者是directoretc等等,简单说你要提供信息才能爬。因为这是国内,抓的不是别人而是政府,所以很多时候会经常出现哪个城市最xxx,简单说在china就应该在china哪个地区。
比如在北京,有些城市有马术队啊什么的,人家需要你提供drawingcompanycname。所以说这些细小的功能太多了。而且中国是互联网大国。互联网发展得非常快。这只是抓到了一些信息,涉及到保密信息。整个信息的价值,远远超过这个广告文案价值。从人人网切入,其他很多公司都有登录人人网的需求。你说值不值这个钱。 查看全部
输入关键字 抓取所有网页(“qq号”放进去了怎么办?(一))
输入关键字抓取所有网页并得到不同网页的不同标题,只要这个标题不在敏感词内都可以。有道吧。
快速。直接起个名叫"搜索xxx"然后链接到“让你这条信息xxx级。本站可见。
问题是这个动词的发明需要多久?
你都说是“微博”了,你应该把下面“qq号”放进去。
是不是“在我们a站人人网b站的信息里,
是的。当地的监管权,钱,技术,
谁说要等到“敏感词”词条只能拿到一段信息的,就凭你一个看客哪儿就值几百万了。
如果你想添加两个可以实现的功能。1,微博爬虫自动抓取同时登录过的人发布的一些信息。2,把爬虫爬到的信息下载下来。具体哪个功能值钱我不清楚。反正举个例子:对于一个google广告的文案,这种信息分为几类?第一类:广告文案,打开首页,文案一定要有a,regionbroadcastingagencyc,eachclient,location,type,calltoaction,related,advertisement,points,level,relatedweibo,google,jpg等等。
这一类文案,a个国家一定是北京、上海、广州,然后连带着其他一些城市的地区。第二类:这一类,其实是广告公司的一些信息。比如我们新闻客户端要写region,所以要出示regionlocation的证书。或者还有类似如何查询广告位置,也要出示assistant。这一类信息特别容易抓取。像如何找到公关公司就是一样。
还有一类:美术作品或者版权信息,我们要提供作者drawingcompanycname,如果你说在谁的公司dedicatedto我们,或者是directoretc等等,简单说你要提供信息才能爬。因为这是国内,抓的不是别人而是政府,所以很多时候会经常出现哪个城市最xxx,简单说在china就应该在china哪个地区。
比如在北京,有些城市有马术队啊什么的,人家需要你提供drawingcompanycname。所以说这些细小的功能太多了。而且中国是互联网大国。互联网发展得非常快。这只是抓到了一些信息,涉及到保密信息。整个信息的价值,远远超过这个广告文案价值。从人人网切入,其他很多公司都有登录人人网的需求。你说值不值这个钱。
输入关键字 抓取所有网页(谷歌官方教程《Google搜索工作原理》-湖北seo:搜索引擎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-02-02 02:11
湖北seo:搜索引擎的工作其实就是信息检索的过程。谷歌搜索引擎的工作原理是什么?
今天,小课堂为大家带来了谷歌官方教程《谷歌搜索的工作原理》。湖北seo希望对大家有所帮助。
Google 搜索的工作原理概述
当你坐在电脑前进行谷歌搜索时,来自整个网络的一系列搜索结果几乎会立即出现在你的眼前。Google 如何找到与您的查询匹配的页面,以及它如何确定搜索结果的排名顺序?
简单来说,您可以将在网络上搜索视为查找一本大书,其中海量索引会告诉您各种内容的位置。当您执行 Google 搜索时,我们的程序会搜索索引以确定最相关的搜索结果以返回(提供)给您。
为您提供搜索结果的三个主要流程如下:
1、抢
Google 知道您的 网站 吗?我们能找到吗?
2、索引
Google 可以索引您的 网站 吗?
3、提供结果
您的 网站 是否收录与用户搜索相关的有趣、有用的内容?
一、爬取过程简述
抓取是 Googlebot 查找要添加到 Google 索引的新页面和更新页面的过程。(湖北seo百度搜索叫百度蜘蛛)
我们使用大量计算机来摄取(或“抓取”)网络上的大量网页。执行抓取任务的程序称为 Googlebot(也称为机器人或“蜘蛛”)。Googlebot 使用算法进行抓取:计算机程序确定要抓取哪个 网站、多久抓取一次以及从每个 网站 抓取多少页面。
谷歌开始其抓取过程的网页网址列表是在之前的抓取过程中形成的,并且随着 网站 网站管理员提供更多站点地图数据而增长。当 Googlebot 访问每个 网站 时,它会检测每个页面上的链接并将这些链接添加到其要抓取的页面列表中。新创建的 网站s、对现有 网站s 的更改以及损坏的链接都会被记录下来并用于更新 Google 的索引。
Google 不会收取任何费用来提高 网站 的抓取速度。我们区分搜索业务和营利性 AdWords 服务。
二、索引过程简述
Googlebot 处理它抓取的每个页面,将它找到的所有单词以及这些单词在每个页面上的位置编译成一个庞大的索引。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。
三、简述提供结果的过程
当用户输入查询时,我们的计算机会在索引中搜索匹配的网页,并返回我们认为与用户搜索最相关的结果。相关性由 200 多个因素决定,其中之一是特定网页的 PageRank。PageRank 是一个网页的重要性,通过来自其他网页的链接来衡量。简单地说,从其他 网站 到您的 网站 页面的单个链接会提升您的 网站 PageRank。并非所有链接都具有同等价值:Google 致力于通过识别垃圾链接和其他对搜索结果产生负面影响的行为来不断改善用户体验。根据您的内容质量分配的链接是最佳链接。
为了让您的 网站 在搜索结果页面中排名靠前,您必须确保 Google 可以正确抓取您的 网站 并将其编入索引。我们的网站网站管理员指南概述了一些最佳实践,可帮助您避免常见的潜在问题并提高您的网站排名。
Google 的“您在寻找什么”功能和 Google 自动完成功能旨在通过显示相关搜索字词、常见拼写错误和热门查询来帮助用户节省时间。用我们的谷歌。com 搜索结果,这些功能使用由我们的网络爬虫和搜索算法自动生成的关键字。只有当我们相信预测会节省用户时间时,才会显示这些内容。如果 网站 在关键字搜索中排名很高,那是因为我们通过算法确定其内容与用户的查询高度相关。
以上是小小课堂为大家带来的谷歌官方教程《谷歌搜索的工作原理》。湖北seo感谢收看。SEO培训找小教室! 查看全部
输入关键字 抓取所有网页(谷歌官方教程《Google搜索工作原理》-湖北seo:搜索引擎)
湖北seo:搜索引擎的工作其实就是信息检索的过程。谷歌搜索引擎的工作原理是什么?
今天,小课堂为大家带来了谷歌官方教程《谷歌搜索的工作原理》。湖北seo希望对大家有所帮助。
https://xxkt.org.cn/wp-content ... 5.jpg 300w, https://xxkt.org.cn/wp-content ... 7.jpg 768w, https://xxkt.org.cn/wp-content ... 6.jpg 1024w" />Google 搜索的工作原理概述
当你坐在电脑前进行谷歌搜索时,来自整个网络的一系列搜索结果几乎会立即出现在你的眼前。Google 如何找到与您的查询匹配的页面,以及它如何确定搜索结果的排名顺序?
简单来说,您可以将在网络上搜索视为查找一本大书,其中海量索引会告诉您各种内容的位置。当您执行 Google 搜索时,我们的程序会搜索索引以确定最相关的搜索结果以返回(提供)给您。
为您提供搜索结果的三个主要流程如下:
1、抢
Google 知道您的 网站 吗?我们能找到吗?
2、索引
Google 可以索引您的 网站 吗?
3、提供结果
您的 网站 是否收录与用户搜索相关的有趣、有用的内容?
一、爬取过程简述
抓取是 Googlebot 查找要添加到 Google 索引的新页面和更新页面的过程。(湖北seo百度搜索叫百度蜘蛛)
我们使用大量计算机来摄取(或“抓取”)网络上的大量网页。执行抓取任务的程序称为 Googlebot(也称为机器人或“蜘蛛”)。Googlebot 使用算法进行抓取:计算机程序确定要抓取哪个 网站、多久抓取一次以及从每个 网站 抓取多少页面。
谷歌开始其抓取过程的网页网址列表是在之前的抓取过程中形成的,并且随着 网站 网站管理员提供更多站点地图数据而增长。当 Googlebot 访问每个 网站 时,它会检测每个页面上的链接并将这些链接添加到其要抓取的页面列表中。新创建的 网站s、对现有 网站s 的更改以及损坏的链接都会被记录下来并用于更新 Google 的索引。
Google 不会收取任何费用来提高 网站 的抓取速度。我们区分搜索业务和营利性 AdWords 服务。
二、索引过程简述
Googlebot 处理它抓取的每个页面,将它找到的所有单词以及这些单词在每个页面上的位置编译成一个庞大的索引。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。
三、简述提供结果的过程
当用户输入查询时,我们的计算机会在索引中搜索匹配的网页,并返回我们认为与用户搜索最相关的结果。相关性由 200 多个因素决定,其中之一是特定网页的 PageRank。PageRank 是一个网页的重要性,通过来自其他网页的链接来衡量。简单地说,从其他 网站 到您的 网站 页面的单个链接会提升您的 网站 PageRank。并非所有链接都具有同等价值:Google 致力于通过识别垃圾链接和其他对搜索结果产生负面影响的行为来不断改善用户体验。根据您的内容质量分配的链接是最佳链接。
为了让您的 网站 在搜索结果页面中排名靠前,您必须确保 Google 可以正确抓取您的 网站 并将其编入索引。我们的网站网站管理员指南概述了一些最佳实践,可帮助您避免常见的潜在问题并提高您的网站排名。
Google 的“您在寻找什么”功能和 Google 自动完成功能旨在通过显示相关搜索字词、常见拼写错误和热门查询来帮助用户节省时间。用我们的谷歌。com 搜索结果,这些功能使用由我们的网络爬虫和搜索算法自动生成的关键字。只有当我们相信预测会节省用户时间时,才会显示这些内容。如果 网站 在关键字搜索中排名很高,那是因为我们通过算法确定其内容与用户的查询高度相关。
以上是小小课堂为大家带来的谷歌官方教程《谷歌搜索的工作原理》。湖北seo感谢收看。SEO培训找小教室!
输入关键字 抓取所有网页(一下使用关键词抓取图片的操作方法分享的方法步骤吧!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-02-02 01:06
imagebox 是一个网页图片的批量抓取和下载工具。当用户需要下载某个网站中的一些素材或图片时,可以使用本软件进行操作,进入软件批量抓图即可。用户还不知道怎么操作,下面给大家分享一下使用关键词抓图的操作方法。感兴趣的朋友不妨看看。
方法步骤
1.首先第一步是打开软件,进入软件主界面。这时候,在界面的右侧,我们可以看到搜索引擎搜索和抓字的功能,然后我们输入我们要抓的图片。关键词 并单击开始抓取按钮。
2.点击开始抓图按钮后,进入抓图设置界面。首先看到的是图片的抓取选项设置,包括抓取速度、抓取范围等选项。用户可以根据个人需求进行选择。设置它。
3.下一个设置模块是图片存储选项。打开下拉列表后,有几个用于存储文件名的选项。你可以选择你需要的那个。
4.下一步,我们可以点击下方按钮开始爬取操作,开始批量爬取。
5.开始抓包后,我们会来到下图所示的界面,在里面可以看到抓包的进度。图像捕获完成后,单击“全部保存”按钮保存图像。
使用上面教程中分享的操作方法和步骤,我们可以使用软件imagebox来抓取一些我们需要的图片素材。如果您不知道如何使用此方法,请尝试小编分享的方法和步骤。好吧,我希望这个教程可以帮助你。 查看全部
输入关键字 抓取所有网页(一下使用关键词抓取图片的操作方法分享的方法步骤吧!)
imagebox 是一个网页图片的批量抓取和下载工具。当用户需要下载某个网站中的一些素材或图片时,可以使用本软件进行操作,进入软件批量抓图即可。用户还不知道怎么操作,下面给大家分享一下使用关键词抓图的操作方法。感兴趣的朋友不妨看看。
方法步骤
1.首先第一步是打开软件,进入软件主界面。这时候,在界面的右侧,我们可以看到搜索引擎搜索和抓字的功能,然后我们输入我们要抓的图片。关键词 并单击开始抓取按钮。
2.点击开始抓图按钮后,进入抓图设置界面。首先看到的是图片的抓取选项设置,包括抓取速度、抓取范围等选项。用户可以根据个人需求进行选择。设置它。
3.下一个设置模块是图片存储选项。打开下拉列表后,有几个用于存储文件名的选项。你可以选择你需要的那个。
4.下一步,我们可以点击下方按钮开始爬取操作,开始批量爬取。
5.开始抓包后,我们会来到下图所示的界面,在里面可以看到抓包的进度。图像捕获完成后,单击“全部保存”按钮保存图像。
使用上面教程中分享的操作方法和步骤,我们可以使用软件imagebox来抓取一些我们需要的图片素材。如果您不知道如何使用此方法,请尝试小编分享的方法和步骤。好吧,我希望这个教程可以帮助你。
输入关键字 抓取所有网页(《Python爬虫:模拟登录知乎》分析页面请求准备准备)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-31 19:27
接上一篇文章《Python爬虫:模拟登录知乎》。
分析页面请求
LZ 将从 知乎 的主题页面中获取所有主题及其结构。页面获取主题的ajax请求有两种,分别是“显示子主题”和“加载更多”,都是一次输出10个主题。请求网址如下:
https://www.zhihu.com/topic/19 ... 52706
其中 child 和 parent 是主题的 ID,“显示子主题”只需要 parent 参数,“加载更多”需要两个参数。如果两个参数都不存在,则表示“根主题”。
两种请求的响应数据都是json格式,结构类似,只是msg中的最后一个元素不同。
抓取逻辑
知乎主题结构是分层的。为了描述方便,“根主题”的子主题称为一级主题,一级主题的子主题为二级主题,以此类推……
为了抓取所有主题,流程应该是:从根主题开始,抓取所有一级主题并存储,然后依次分析每个一级主题,如果有子主题,则抓取它的所有子主题(次要)和存储,然后......循环继续下去。
根据流程,需要实现以下三个主要功能:
多谈谈主题存储。因为LZ要保存主题结构,“加载更多”时需要使用父主题ID,所以LZ将每个主题记录为一个列表,其中收录四个元素:主题名称、主题ID、父主题ID、有无状态子主题(bool类型),如['entity', '19778287', '19776749', 1],去重时,四个元素相同,则认为是重复。
代码
在代码中,第一段是模拟登录知乎。运行时,输入验证码后取数据,完成后数据保存到本地文件。因为运行时间比较长(1小时左右),所以增加了一些状态提示。
# all_topics.py
import requests
from bs4 import BeautifulSoup
# session变量
s = requests.Session()
headers = {
"Accept": "*/*",
"Accept-Encoding": "gzip,deflate",
"Accept-Language": "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4",
"Connection": "keep-alive",
"Content-Type":" application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36",
"Referer": "http://www.zhihu.com/"
}
_xsrf = ''
def set_xsrf():
global _xsrf
html = s.get('http://www.zhihu.com/', headers=headers) # GET请求,获取一个响应对象
soup = BeautifulSoup(html.text,'lxml-xml') # 使用BeautifulSoup解析HTML
_xsrf = soup.findAll(type='hidden')[0]['value']
def get_captcha():
# 获取验证码图片并保存在本地
captcha_url = 'http://www.zhihu.com/captcha.gif'
captcha = s.get(captcha_url, stream=True, headers=headers)
with open('captcha.gif', 'wb') as f:
for line in captcha.iter_content(10):
f.write(line)
f.close()
# 输入获取到的验证码,并入变量captch_str
print('输入验证码:', end='')
captcha_str = input()
return captcha_str.strip()
# 登录请求
def login():
global s
global _xsrf
set_xsrf()
captcha = get_captcha()
data = {
'_xsrf': _xsrf,
'email': '654408619@qq.com',
'password': 'mftx1029',
'remember_me': True,
'captcha': captcha
}
r = s.post(url='http://www.zhihu.com/login/email', data=data, headers=headers)
return r
all_topics = [['根话题', '19776749', '', 1]] # 保存所有的话题,初始状态保存根话题
has_children = [['根话题', '19776749', '', 1]] # 有子话题,但还没有抓取其子话题。初始状态保存根话题
cnt_a = 0 # all_topics元素计数
cnt_h = 0 # has_children元素计数
# 获取一次request的json数据
def get_json(child_id='', parent_id=''):
global s
global headers
url = 'https://www.zhihu.com/topic/19776749/organize/entire'
data = {'child': child_id, 'parent': parent_id, '_xsrf': _xsrf}
res = s.post(url,data=data, headers=headers)
json_dict = res.json()
return json_dict
# 解析json数据,获取子话题及「加载更多」的信息
def json_process(json_dict):
single_dict = {} # 保存下面的children和more
children = [] # 保存子话题
more = [] # 保存加载更多的信息
parent_id = json_dict['msg'][0][2]
if len(json_dict['msg'][1]) == 11:
more_child_id = json_dict['msg'][1][9][0][2]
more = [more_child_id, parent_id]
for i in json_dict['msg'][1][:10]:
child_name, child_id = i[0][1], i[0][2]
if i[1]:
children.append([child_name, child_id, parent_id, 1])
else:
children.append([child_name, child_id, parent_id, 0])
single_dict['children'] = children
single_dict['more'] = more
return single_dict
# 获取一个话题的所有子话题
def get_children(parent_id='', parent_name=''):
global cnt_a
global cnt_h
children = []
more = ['', parent_id]
while more:
json_dict = get_json(child_id=more[0], parent_id=more[1])
single_dict = json_process(json_dict)
children += single_dict['children']
more = single_dict['more']
# 用140个空格清除上次的提示
print(' '*140, end='\r')
# 终端提示抓取状态
print('已获取{}个话题。还有{}个话题排队当中,正在抓取「{}」的第{} 个子话题...'.format(\
cnt_a, cnt_h, str(parent_name).encode('gbk', 'ignore').decode('gbk'), len(children)), end='\r')
return children
# 工作函数,抓取全部话题并保存为文件
def work():
global cnt_h
global cnt_a
login()
while has_children:
first_child = has_children.pop(0)
children = get_children(first_child[1],first_child[0])
for c in children:
# 去重并添加到all_topics和has_topics,后者需要再判断下是否有子话题
if c not in all_topics:
all_topics.append(c)
if c[-1] == 1:
has_children.append(c)
cnt_a = len(all_topics)
cnt_h = len(has_children)
# 存入文件
for item in all_topics:
with open('all_topics.txt', 'a', encoding='utf-8') as f:
string = str(item[0]) + '\t' + str(item[1]) + '\t' + str(item[2]) + '\t' + str(item[3]) + '\n'
f.write(string)
if __name__ == "__main__":
work()
运行状态如下:
E:\@coding\python>python all_topics.py
输入验证码:hbfu
已获取53个话题。还有46个话题排队当中,正在抓取「「未归类」话题」的第1600 个子话题...
LZ是昨天运行的一个程序(2016-02-04),一共捕获了46272个话题。 查看全部
输入关键字 抓取所有网页(《Python爬虫:模拟登录知乎》分析页面请求准备准备)
接上一篇文章《Python爬虫:模拟登录知乎》。
分析页面请求
LZ 将从 知乎 的主题页面中获取所有主题及其结构。页面获取主题的ajax请求有两种,分别是“显示子主题”和“加载更多”,都是一次输出10个主题。请求网址如下:
https://www.zhihu.com/topic/19 ... 52706
其中 child 和 parent 是主题的 ID,“显示子主题”只需要 parent 参数,“加载更多”需要两个参数。如果两个参数都不存在,则表示“根主题”。
两种请求的响应数据都是json格式,结构类似,只是msg中的最后一个元素不同。
抓取逻辑
知乎主题结构是分层的。为了描述方便,“根主题”的子主题称为一级主题,一级主题的子主题为二级主题,以此类推……
为了抓取所有主题,流程应该是:从根主题开始,抓取所有一级主题并存储,然后依次分析每个一级主题,如果有子主题,则抓取它的所有子主题(次要)和存储,然后......循环继续下去。
根据流程,需要实现以下三个主要功能:
多谈谈主题存储。因为LZ要保存主题结构,“加载更多”时需要使用父主题ID,所以LZ将每个主题记录为一个列表,其中收录四个元素:主题名称、主题ID、父主题ID、有无状态子主题(bool类型),如['entity', '19778287', '19776749', 1],去重时,四个元素相同,则认为是重复。
代码
在代码中,第一段是模拟登录知乎。运行时,输入验证码后取数据,完成后数据保存到本地文件。因为运行时间比较长(1小时左右),所以增加了一些状态提示。
# all_topics.py
import requests
from bs4 import BeautifulSoup
# session变量
s = requests.Session()
headers = {
"Accept": "*/*",
"Accept-Encoding": "gzip,deflate",
"Accept-Language": "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4",
"Connection": "keep-alive",
"Content-Type":" application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36",
"Referer": "http://www.zhihu.com/"
}
_xsrf = ''
def set_xsrf():
global _xsrf
html = s.get('http://www.zhihu.com/', headers=headers) # GET请求,获取一个响应对象
soup = BeautifulSoup(html.text,'lxml-xml') # 使用BeautifulSoup解析HTML
_xsrf = soup.findAll(type='hidden')[0]['value']
def get_captcha():
# 获取验证码图片并保存在本地
captcha_url = 'http://www.zhihu.com/captcha.gif'
captcha = s.get(captcha_url, stream=True, headers=headers)
with open('captcha.gif', 'wb') as f:
for line in captcha.iter_content(10):
f.write(line)
f.close()
# 输入获取到的验证码,并入变量captch_str
print('输入验证码:', end='')
captcha_str = input()
return captcha_str.strip()
# 登录请求
def login():
global s
global _xsrf
set_xsrf()
captcha = get_captcha()
data = {
'_xsrf': _xsrf,
'email': '654408619@qq.com',
'password': 'mftx1029',
'remember_me': True,
'captcha': captcha
}
r = s.post(url='http://www.zhihu.com/login/email', data=data, headers=headers)
return r
all_topics = [['根话题', '19776749', '', 1]] # 保存所有的话题,初始状态保存根话题
has_children = [['根话题', '19776749', '', 1]] # 有子话题,但还没有抓取其子话题。初始状态保存根话题
cnt_a = 0 # all_topics元素计数
cnt_h = 0 # has_children元素计数
# 获取一次request的json数据
def get_json(child_id='', parent_id=''):
global s
global headers
url = 'https://www.zhihu.com/topic/19776749/organize/entire'
data = {'child': child_id, 'parent': parent_id, '_xsrf': _xsrf}
res = s.post(url,data=data, headers=headers)
json_dict = res.json()
return json_dict
# 解析json数据,获取子话题及「加载更多」的信息
def json_process(json_dict):
single_dict = {} # 保存下面的children和more
children = [] # 保存子话题
more = [] # 保存加载更多的信息
parent_id = json_dict['msg'][0][2]
if len(json_dict['msg'][1]) == 11:
more_child_id = json_dict['msg'][1][9][0][2]
more = [more_child_id, parent_id]
for i in json_dict['msg'][1][:10]:
child_name, child_id = i[0][1], i[0][2]
if i[1]:
children.append([child_name, child_id, parent_id, 1])
else:
children.append([child_name, child_id, parent_id, 0])
single_dict['children'] = children
single_dict['more'] = more
return single_dict
# 获取一个话题的所有子话题
def get_children(parent_id='', parent_name=''):
global cnt_a
global cnt_h
children = []
more = ['', parent_id]
while more:
json_dict = get_json(child_id=more[0], parent_id=more[1])
single_dict = json_process(json_dict)
children += single_dict['children']
more = single_dict['more']
# 用140个空格清除上次的提示
print(' '*140, end='\r')
# 终端提示抓取状态
print('已获取{}个话题。还有{}个话题排队当中,正在抓取「{}」的第{} 个子话题...'.format(\
cnt_a, cnt_h, str(parent_name).encode('gbk', 'ignore').decode('gbk'), len(children)), end='\r')
return children
# 工作函数,抓取全部话题并保存为文件
def work():
global cnt_h
global cnt_a
login()
while has_children:
first_child = has_children.pop(0)
children = get_children(first_child[1],first_child[0])
for c in children:
# 去重并添加到all_topics和has_topics,后者需要再判断下是否有子话题
if c not in all_topics:
all_topics.append(c)
if c[-1] == 1:
has_children.append(c)
cnt_a = len(all_topics)
cnt_h = len(has_children)
# 存入文件
for item in all_topics:
with open('all_topics.txt', 'a', encoding='utf-8') as f:
string = str(item[0]) + '\t' + str(item[1]) + '\t' + str(item[2]) + '\t' + str(item[3]) + '\n'
f.write(string)
if __name__ == "__main__":
work()
运行状态如下:
E:\@coding\python>python all_topics.py
输入验证码:hbfu
已获取53个话题。还有46个话题排队当中,正在抓取「「未归类」话题」的第1600 个子话题...
LZ是昨天运行的一个程序(2016-02-04),一共捕获了46272个话题。
输入关键字 抓取所有网页(如何找到原创文章都绞尽脑汁?替换反义词)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-31 17:28
SEO网站内容编辑:信息量很大发布日期:2018-01-20分类:行业资讯
“内容是,链条是”相信你对seoER站长并不陌生。内容可以说是一个网站的核心。有许多网站 管理员或SEOER 绞尽脑汁寻找原创文章。其实找到原创文章的方法有很多种,一起来看看吧。伪原创文章,什么是原创文章,对于搜索引擎来说,文章内容他没有收录,也有网站@ > 管理员 相信只要文章的内容与原文的相似度小于80%即可。
所以有一个伪原创。编辑标题。这是必须要改的,标题的重要性是毋庸置疑的,相信对于搜索引擎来说,决定原文好不好,那是一个要素。这是 伪原创 步骤,也是重要的一步。修改结束部分。由于搜索引擎更关注段落的结尾,所以忽略文章(这也是合理的,因为文章通常是一个段落,是对全文的概括描述),这也是一个许多人在文章 中使用的问题添加了一些自己的摘要,描述了原因。关键字替换。如同义词替换、反义词替换、同义词替换等,结合搜索引擎索引的原理,对搜索引擎抓取的网页进行预处理,输入关键词
所以你可以在不改变 文章 含义的情况下替换关键字(基于用户体验)。这是搜索引擎从中提取 关键词 的原创 文章。调整段落,这种方法,从用户体验的角度来看,并不适合所有的文章,除了一些形式的文章,否则文章运行后会变形。截取 文章 部分。许多 文章s,尤其是表 文章,可以通过多种方式进行拦截和修改,并使用其他伪原创方法进行处理。这也是一个新的文章。 查看全部
输入关键字 抓取所有网页(如何找到原创文章都绞尽脑汁?替换反义词)
SEO网站内容编辑:信息量很大发布日期:2018-01-20分类:行业资讯
“内容是,链条是”相信你对seoER站长并不陌生。内容可以说是一个网站的核心。有许多网站 管理员或SEOER 绞尽脑汁寻找原创文章。其实找到原创文章的方法有很多种,一起来看看吧。伪原创文章,什么是原创文章,对于搜索引擎来说,文章内容他没有收录,也有网站@ > 管理员 相信只要文章的内容与原文的相似度小于80%即可。
所以有一个伪原创。编辑标题。这是必须要改的,标题的重要性是毋庸置疑的,相信对于搜索引擎来说,决定原文好不好,那是一个要素。这是 伪原创 步骤,也是重要的一步。修改结束部分。由于搜索引擎更关注段落的结尾,所以忽略文章(这也是合理的,因为文章通常是一个段落,是对全文的概括描述),这也是一个许多人在文章 中使用的问题添加了一些自己的摘要,描述了原因。关键字替换。如同义词替换、反义词替换、同义词替换等,结合搜索引擎索引的原理,对搜索引擎抓取的网页进行预处理,输入关键词
所以你可以在不改变 文章 含义的情况下替换关键字(基于用户体验)。这是搜索引擎从中提取 关键词 的原创 文章。调整段落,这种方法,从用户体验的角度来看,并不适合所有的文章,除了一些形式的文章,否则文章运行后会变形。截取 文章 部分。许多 文章s,尤其是表 文章,可以通过多种方式进行拦截和修改,并使用其他伪原创方法进行处理。这也是一个新的文章。
输入关键字 抓取所有网页(百度蜘蛛喜欢抓取的内容有哪些?小编告诉你)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-30 10:06
网站内容是优化过程的重要组成部分文章。那么,百度蜘蛛喜欢抓取什么样的内容呢?接下来给大家分享一下百度蜘蛛喜欢爬的内容,一起来看看吧!
1、文章标题是怎么写的;
文章标题相当于文章的主体。把你下面写的文章制定好后,需要围绕这个主体来写,这样才能提高用户体验,否则用户体验会低。
2、文章关键词优化布局;
文章关键词在排版过程中非常重要。关键词的布局要自然,不堆积,不刻意,不影响客户阅读。即使是出现在开头段落中的 关键词 也应该遵循自然原则。
3、文章的相关性一定要高;
文章标题、关键词、内容在写作过程中一定要避开。您的 title 不可能是 South,关键词 是 North,content 是 West。我相信没有人会喜欢它。
4、多段,避免长篇大论;
文章在写的过程中,尽量避免出现长篇大论的情况,把文章的内容分几部分写出来,这样条件反射会更清晰,让人看的更清楚。
5、翻译外文原创文章;
翻译高质量的国外原创文章也是一种写内容的方式。对于搜索引擎来说,不同单词写的文章是不一样的,这对于写原创来说很重要,对于人@>文章不一定是个好办法。
6、网站文章更新频率要规律;
网站文章在写的过程中,一定要掌握一个规律,让蜘蛛有规律的爬到你的网站,这样更容易提高你的网站质量. 查看全部
输入关键字 抓取所有网页(百度蜘蛛喜欢抓取的内容有哪些?小编告诉你)
网站内容是优化过程的重要组成部分文章。那么,百度蜘蛛喜欢抓取什么样的内容呢?接下来给大家分享一下百度蜘蛛喜欢爬的内容,一起来看看吧!
1、文章标题是怎么写的;
文章标题相当于文章的主体。把你下面写的文章制定好后,需要围绕这个主体来写,这样才能提高用户体验,否则用户体验会低。
2、文章关键词优化布局;
文章关键词在排版过程中非常重要。关键词的布局要自然,不堆积,不刻意,不影响客户阅读。即使是出现在开头段落中的 关键词 也应该遵循自然原则。
3、文章的相关性一定要高;
文章标题、关键词、内容在写作过程中一定要避开。您的 title 不可能是 South,关键词 是 North,content 是 West。我相信没有人会喜欢它。
4、多段,避免长篇大论;
文章在写的过程中,尽量避免出现长篇大论的情况,把文章的内容分几部分写出来,这样条件反射会更清晰,让人看的更清楚。
5、翻译外文原创文章;
翻译高质量的国外原创文章也是一种写内容的方式。对于搜索引擎来说,不同单词写的文章是不一样的,这对于写原创来说很重要,对于人@>文章不一定是个好办法。
6、网站文章更新频率要规律;
网站文章在写的过程中,一定要掌握一个规律,让蜘蛛有规律的爬到你的网站,这样更容易提高你的网站质量.
输入关键字 抓取所有网页(根据关键词抓取新浪微博的数据,通过网页抓取的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-27 17:02
根据关键词抓取新浪微博1.背景
可能很多人都遇到过想通过一些关键词获取新浪微博数据。目前,有两种方式。
使用官方api
官方api的优点是使用简单方便。但是有两个问题。
这里还是提供了一个api的地址、参数和示例。令牌可以替换为您自己的。以下代码仅供参考
import requestsurl = 'https://api.weibo.com/2/search ... token true string 采用OAuth授权方式为必填参数,OAuth授权后获得。q true string 搜索的话题关键字,必须进行URLencode,utf-8编码。count false int 单页返回的记录条数,默认为10,最大为50。page false int 返回结果的页码,默认为1。"""load = { 'access_token': '2.00AqpTsHXXXXXXXXXXXXXXXXXXXXX', 'q': '新冠', 'count': 50, 'page': 2}html = requests.get(url, params=load)print(html.json())
从网络爬取
这个方法是我们文章文章的重点。优点是不需要获取token,二来获取的数据量比较大。但缺点也明显比较麻烦。本文还将详细分析每个步骤,以使爬取变得容易。
2. 分析目标网站
分析目标网站,输入任意关键词进行搜索,可以在搜索栏右侧看到高级搜索选项,如下图
微博高级搜索
我们先不设置参数,调用 f12 看看在搜索过程中可能会产生哪些请求(如下图所示)。
这是我们需要的数据。很明显,这是一个get请求,里面收录了几个参数。我们可以先猜测一下这些参数的含义。
很容易看出,“q”绝对代表了你需要搜索的字段。目前还不清楚“typeall”、“suball”和“Refer”分别代表什么,但没关系,我们可以通过更改参数再次请求来获取更多信息。
f12分析
我们更改参数,空间范围设置为北京,时间范围设置为2020-05-01 0:00 - 2020-05-02 23:00,同时翻到第8页。再次请求我们可以得到下面的数据。
我们可以看到,区域绝对代表了空间范围,下面的习惯:11:1000代表北京。timescope 表示时间范围,custom:2020-05-01-0:2020-05-02:23 表示我们设置的时间范围。page 绝对是页数。剩下的三个参数不影响我们整个结果(可能是设置了爬取的类型,读者可以自己试一试),暂时不用担心。
至此,我们已经分析了代表整个请求的参数的含义。接下来,我们可以考虑如何从页面中提取我们需要的信息。
3. 页面解析与代码编写3.1 爬取前的准备3.2 定位元素
通过查看原件,我们可以定位每条推文的位置,并找到元素的唯一定位标签。
我们发现可以发现每条微博都在一个标签下。找到所有标签,我们就可以找到每条微博。然后根据你的需要,找到你需要的信息。
这个文章是一个查找微博文字、用户和创建时间的例子。
3.3 代码示例
下面开始编写相关代码。首先是发送请求以获取相关的 HTML 文本。我们需要的是:
下面是一个简单的例子
import requestsfrom bs4 import BeautifulSoup# 请求的网址url = "https://s.weibo.com/weibo"# 请求头的文本,可以直接从网页中复制h = """Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9Accept-Encoding: gzip, deflate, brAccept-Language: zh,en-US;q=0.9,en;q=0.8,zh-CN;q=0.7Connection: keep-aliveCookie: XXXX(填自己的cookie)Host: s.weibo.comReferer: https://s.weibo.com/weibo/%252 ... Dest: documentSec-Fetch-Mode: navigateSec-Fetch-Site: same-originSec-Fetch-User: ?1Upgrade-Insecure-Requests: 1User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36"""# 将复制得到的str处理成标准的字典格式def handle_header(s): dic = {} li = s.split('\n') for l in li: dic[l.split(': ')[0]] = l.split(': ')[1] return dic # 处理请求def handle(page, year, month, day, hour): #请求的参数,页面和时间等 load = { 'q': '郭涛道歉', 'typeall': '1', 'suball': '1', 'timescope': f'custom:{year}-{month}-{day}-{hour}:{year}-{month}-{day}-{hour + 1}', 'Refer': 'g', 'page': page } # 发送请求 j = requests.get(url, headers=handle_header(h), params=load, timeout=(10, 10)) return j.text
这里可以通过handle函数获取html。然后通过beautifulsoup获取相关信息。相关代码如下
# 转换成soup的对象soup = BeautifulSoup(handle(1, 2020, 05, 01, 00), 'lxml')# 使用find_all获取这页所有weibo的信息, {'class': 'card-wrap'} 定位微博内容信息contents = soup.find_all('div', {'class': 'card-wrap'})
最后一步是从每条微博中提取有用信息
def filter_info(content, _date, _mid): """ 过滤无效信息 :param content: :param _date: :param _mid: :return: """ # 这里传入的content是一个微博包含的所有信息,也就是一个 {'class': 'card-wrap'} 的定位信息 _content = content.find('div', {'class': 'content'}) # 获取用户名 nick_name = _content.find('p')['nick-name'] # 获取微博文本 blog = _content.find_all('p', {'class': 'txt'})[-1].text.replace('郭涛道歉', '郭涛道歉').strip().replace('\n', '\\n') # 获取时间 create = _content.find_all('p', {'class': 'from'})[-1].a.text.strip().replace('\n', '\\n') date_str = "".join(_date) data = {'mid': _mid, 'nick_name': nick_name, 'create': create, 'blog': blog, 'date_str': date_str} # 返回json格式的数据 return data
至此,整个流程结束,filter_info返回的数据就是本页的微博信息。
剩下的,只要结合上面的代码,添加你自己的逻辑,比如设置数据库和获取更多信息。
完整参考代码请回复微博爬虫获取。 查看全部
输入关键字 抓取所有网页(根据关键词抓取新浪微博的数据,通过网页抓取的方法)
根据关键词抓取新浪微博1.背景
可能很多人都遇到过想通过一些关键词获取新浪微博数据。目前,有两种方式。
使用官方api
官方api的优点是使用简单方便。但是有两个问题。
这里还是提供了一个api的地址、参数和示例。令牌可以替换为您自己的。以下代码仅供参考
import requestsurl = 'https://api.weibo.com/2/search ... token true string 采用OAuth授权方式为必填参数,OAuth授权后获得。q true string 搜索的话题关键字,必须进行URLencode,utf-8编码。count false int 单页返回的记录条数,默认为10,最大为50。page false int 返回结果的页码,默认为1。"""load = { 'access_token': '2.00AqpTsHXXXXXXXXXXXXXXXXXXXXX', 'q': '新冠', 'count': 50, 'page': 2}html = requests.get(url, params=load)print(html.json())
从网络爬取
这个方法是我们文章文章的重点。优点是不需要获取token,二来获取的数据量比较大。但缺点也明显比较麻烦。本文还将详细分析每个步骤,以使爬取变得容易。
2. 分析目标网站
分析目标网站,输入任意关键词进行搜索,可以在搜索栏右侧看到高级搜索选项,如下图
微博高级搜索
我们先不设置参数,调用 f12 看看在搜索过程中可能会产生哪些请求(如下图所示)。
这是我们需要的数据。很明显,这是一个get请求,里面收录了几个参数。我们可以先猜测一下这些参数的含义。
很容易看出,“q”绝对代表了你需要搜索的字段。目前还不清楚“typeall”、“suball”和“Refer”分别代表什么,但没关系,我们可以通过更改参数再次请求来获取更多信息。
f12分析
我们更改参数,空间范围设置为北京,时间范围设置为2020-05-01 0:00 - 2020-05-02 23:00,同时翻到第8页。再次请求我们可以得到下面的数据。
我们可以看到,区域绝对代表了空间范围,下面的习惯:11:1000代表北京。timescope 表示时间范围,custom:2020-05-01-0:2020-05-02:23 表示我们设置的时间范围。page 绝对是页数。剩下的三个参数不影响我们整个结果(可能是设置了爬取的类型,读者可以自己试一试),暂时不用担心。
至此,我们已经分析了代表整个请求的参数的含义。接下来,我们可以考虑如何从页面中提取我们需要的信息。
3. 页面解析与代码编写3.1 爬取前的准备3.2 定位元素
通过查看原件,我们可以定位每条推文的位置,并找到元素的唯一定位标签。
我们发现可以发现每条微博都在一个标签下。找到所有标签,我们就可以找到每条微博。然后根据你的需要,找到你需要的信息。
这个文章是一个查找微博文字、用户和创建时间的例子。
3.3 代码示例
下面开始编写相关代码。首先是发送请求以获取相关的 HTML 文本。我们需要的是:
下面是一个简单的例子
import requestsfrom bs4 import BeautifulSoup# 请求的网址url = "https://s.weibo.com/weibo"# 请求头的文本,可以直接从网页中复制h = """Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9Accept-Encoding: gzip, deflate, brAccept-Language: zh,en-US;q=0.9,en;q=0.8,zh-CN;q=0.7Connection: keep-aliveCookie: XXXX(填自己的cookie)Host: s.weibo.comReferer: https://s.weibo.com/weibo/%252 ... Dest: documentSec-Fetch-Mode: navigateSec-Fetch-Site: same-originSec-Fetch-User: ?1Upgrade-Insecure-Requests: 1User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36"""# 将复制得到的str处理成标准的字典格式def handle_header(s): dic = {} li = s.split('\n') for l in li: dic[l.split(': ')[0]] = l.split(': ')[1] return dic # 处理请求def handle(page, year, month, day, hour): #请求的参数,页面和时间等 load = { 'q': '郭涛道歉', 'typeall': '1', 'suball': '1', 'timescope': f'custom:{year}-{month}-{day}-{hour}:{year}-{month}-{day}-{hour + 1}', 'Refer': 'g', 'page': page } # 发送请求 j = requests.get(url, headers=handle_header(h), params=load, timeout=(10, 10)) return j.text
这里可以通过handle函数获取html。然后通过beautifulsoup获取相关信息。相关代码如下
# 转换成soup的对象soup = BeautifulSoup(handle(1, 2020, 05, 01, 00), 'lxml')# 使用find_all获取这页所有weibo的信息, {'class': 'card-wrap'} 定位微博内容信息contents = soup.find_all('div', {'class': 'card-wrap'})
最后一步是从每条微博中提取有用信息
def filter_info(content, _date, _mid): """ 过滤无效信息 :param content: :param _date: :param _mid: :return: """ # 这里传入的content是一个微博包含的所有信息,也就是一个 {'class': 'card-wrap'} 的定位信息 _content = content.find('div', {'class': 'content'}) # 获取用户名 nick_name = _content.find('p')['nick-name'] # 获取微博文本 blog = _content.find_all('p', {'class': 'txt'})[-1].text.replace('郭涛道歉', '郭涛道歉').strip().replace('\n', '\\n') # 获取时间 create = _content.find_all('p', {'class': 'from'})[-1].a.text.strip().replace('\n', '\\n') date_str = "".join(_date) data = {'mid': _mid, 'nick_name': nick_name, 'create': create, 'blog': blog, 'date_str': date_str} # 返回json格式的数据 return data
至此,整个流程结束,filter_info返回的数据就是本页的微博信息。
剩下的,只要结合上面的代码,添加你自己的逻辑,比如设置数据库和获取更多信息。
完整参考代码请回复微博爬虫获取。

