
输入关键字 抓取所有网页
输入关键字 抓取所有网页(爬取一下京东的商品列表,下拉一下才可以拿到60个 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-22 13:18
)
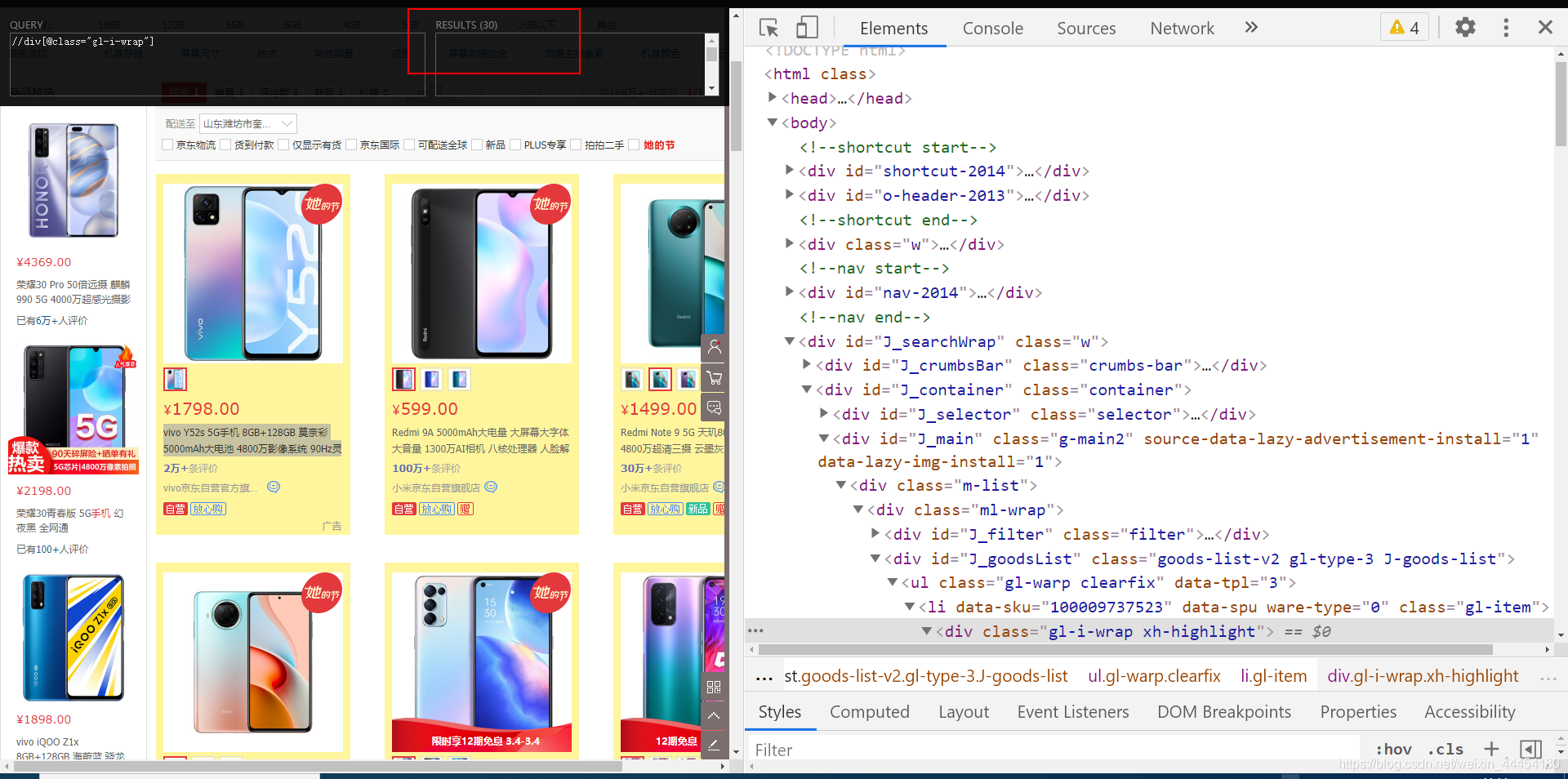
今天,我们将爬取京东产品列表。您无需为此 网站 保持登录状态,但列表中有 60 个项目。您必须下拉才能获得 60 件物品。今天,以京东手机为例,我们将涵盖所有这些。抓住
使用xpath获取并尝试一下,我们会看到30个加载并渲染,剩下的30个没有渲染。我们往下拉,会发现30变成了60,剩下的30是动态加载的
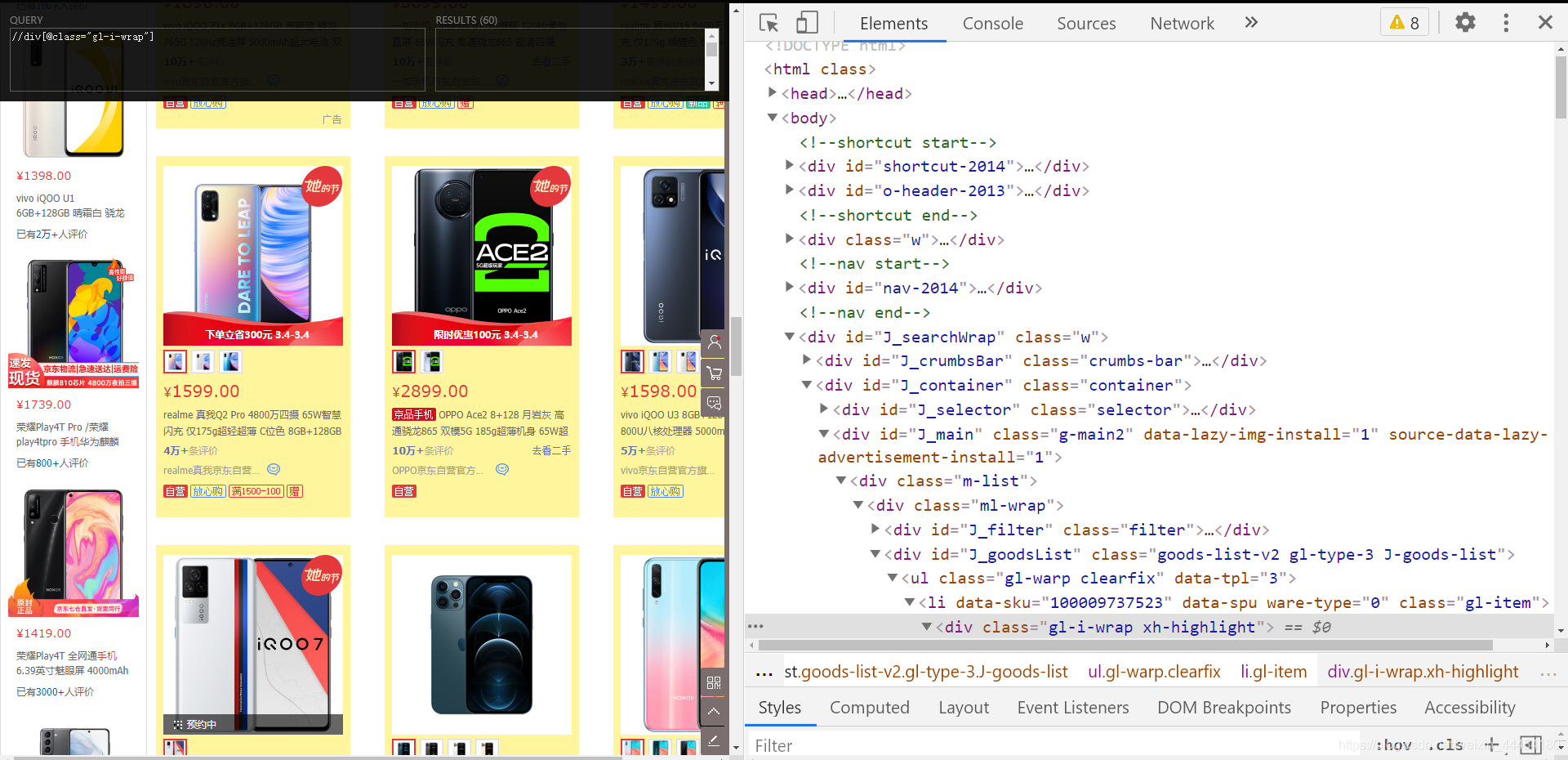
对于这个解决方案,我们选择使用 selenium 来下拉和加载它。我们使用scrapy来实现它。我们主要练习技术。有很多方法可以实现它。我们首先创建一个scrapy项目,scrapy startproject JD,cd到目录下,我们在创建一个spider文件,执行scrapy genspider dj,用pycharm打开,
先写item,确定我们要抓取的字段
import scrapy
class JdItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 手机名称
name = scrapy.Field()
# 链接
link = scrapy.Field()
# 价格
price = scrapy.Field()
# 评论数
comment_num = scrapy.Field()
# 店铺名称
shop_name = scrapy.Field()
# 店铺链接
shop_link = scrapy.Field()
让我们编写中间件,其中我们使用 selenium 下拉到底部并加载它们。我们必须在 MiddleWare.py 和 scrapy.http 中编写 HtmlResponse 模块。我们使用 HtmlResponse 将源代码返回给蜘蛛进行解析和渲染。记得自己配置webdriver。executable_path 写入路径后的值
import time
from selenium import webdriver
from scrapy.http import HtmlResponse
class SeleniumWare(object):
def process_request(self,spider,request):
self.option = webdriver.ChromeOptions()
self.option.add_argument("--headless")
self.driver = webdriver.Chrome(executable_path='C:\Program Files\Google\Chrome\Application\chromedriver.exe',options=self.option)
self.driver.get(request.url)
self.driver.implicitly_wait(10)
self.driver.execute_script('var p = document.documentElement.scrollTop=100000')
time.sleep(3)
data = self.driver.page_source
self.driver.close()
data = str(data)
res = HtmlResponse(body=data,encoding="utf-8",request=request,url=request.url)
return res
编写蜘蛛爬虫
<p># -*- coding: utf-8 -*-
import scrapy
from JD.items import JdItem
class JdSpider(scrapy.Spider):
name = 'jd'
allowed_domains = ['jd.com']
start_urls = ['https://search.jd.com/Search?keyword=手机']
page = 2
def parse(self, response):
# 获取节点
node_list = response.xpath('//div[@class="gl-i-wrap"]')
# 打印个数
print(len(node_list))
# 拿出节点每个信息
for node in node_list:
item = JdItem()
# 我们try一下,有些缺失的抛错,我们阻止异常,返回None
try:
item["name"] = node.xpath('./div[4]/a/em/text()').extract_first().strip()
except:
item["name"] = None
try:
item["link"] = response.urljoin(node.xpath('./div[4]/a/@href').extract_first())
except:
item["link"] = None
try:
item["price"] = node.xpath('./div[3]/strong/i/text()').extract_first() + '元'
except:
item["price"] = None
try:
item["comment_num"] = node.xpath('./div[5]/strong/a/text()').extract_first()
except:
item["comment_num"] = None
try:
item["shop_name"] = node.xpath('./div[7]/span/a/text()').extract_first().strip()
except:
item["shop_name"] = None
try:
item["shop_link"] = "https:" + node.xpath('./div[7]/span/a/@href').extract_first()
except:
item["shop_link"] = None
print(item)
# 返回item,交给pipline
yield item
# 采用拼接的方式获取下一页
if self.page 查看全部
输入关键字 抓取所有网页(爬取一下京东的商品列表,下拉一下才可以拿到60个
)
今天,我们将爬取京东产品列表。您无需为此 网站 保持登录状态,但列表中有 60 个项目。您必须下拉才能获得 60 件物品。今天,以京东手机为例,我们将涵盖所有这些。抓住
使用xpath获取并尝试一下,我们会看到30个加载并渲染,剩下的30个没有渲染。我们往下拉,会发现30变成了60,剩下的30是动态加载的
对于这个解决方案,我们选择使用 selenium 来下拉和加载它。我们使用scrapy来实现它。我们主要练习技术。有很多方法可以实现它。我们首先创建一个scrapy项目,scrapy startproject JD,cd到目录下,我们在创建一个spider文件,执行scrapy genspider dj,用pycharm打开,
先写item,确定我们要抓取的字段
import scrapy
class JdItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 手机名称
name = scrapy.Field()
# 链接
link = scrapy.Field()
# 价格
price = scrapy.Field()
# 评论数
comment_num = scrapy.Field()
# 店铺名称
shop_name = scrapy.Field()
# 店铺链接
shop_link = scrapy.Field()
让我们编写中间件,其中我们使用 selenium 下拉到底部并加载它们。我们必须在 MiddleWare.py 和 scrapy.http 中编写 HtmlResponse 模块。我们使用 HtmlResponse 将源代码返回给蜘蛛进行解析和渲染。记得自己配置webdriver。executable_path 写入路径后的值
import time
from selenium import webdriver
from scrapy.http import HtmlResponse
class SeleniumWare(object):
def process_request(self,spider,request):
self.option = webdriver.ChromeOptions()
self.option.add_argument("--headless")
self.driver = webdriver.Chrome(executable_path='C:\Program Files\Google\Chrome\Application\chromedriver.exe',options=self.option)
self.driver.get(request.url)
self.driver.implicitly_wait(10)
self.driver.execute_script('var p = document.documentElement.scrollTop=100000')
time.sleep(3)
data = self.driver.page_source
self.driver.close()
data = str(data)
res = HtmlResponse(body=data,encoding="utf-8",request=request,url=request.url)
return res
编写蜘蛛爬虫
<p># -*- coding: utf-8 -*-
import scrapy
from JD.items import JdItem
class JdSpider(scrapy.Spider):
name = 'jd'
allowed_domains = ['jd.com']
start_urls = ['https://search.jd.com/Search?keyword=手机']
page = 2
def parse(self, response):
# 获取节点
node_list = response.xpath('//div[@class="gl-i-wrap"]')
# 打印个数
print(len(node_list))
# 拿出节点每个信息
for node in node_list:
item = JdItem()
# 我们try一下,有些缺失的抛错,我们阻止异常,返回None
try:
item["name"] = node.xpath('./div[4]/a/em/text()').extract_first().strip()
except:
item["name"] = None
try:
item["link"] = response.urljoin(node.xpath('./div[4]/a/@href').extract_first())
except:
item["link"] = None
try:
item["price"] = node.xpath('./div[3]/strong/i/text()').extract_first() + '元'
except:
item["price"] = None
try:
item["comment_num"] = node.xpath('./div[5]/strong/a/text()').extract_first()
except:
item["comment_num"] = None
try:
item["shop_name"] = node.xpath('./div[7]/span/a/text()').extract_first().strip()
except:
item["shop_name"] = None
try:
item["shop_link"] = "https:" + node.xpath('./div[7]/span/a/@href').extract_first()
except:
item["shop_link"] = None
print(item)
# 返回item,交给pipline
yield item
# 采用拼接的方式获取下一页
if self.page
输入关键字 抓取所有网页(做seo很大程度是做关键词的基本目标,才有更好的转化率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-21 12:05
很大程度上,做SEO就是做关键词排名。将关键词设为首页是SEO的基本目标。只有首页的排名,才能有更好的展示机会和更高的转化率。
一、搜索原理
网络蜘蛛是网络蜘蛛。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到所有 网站 网页都被爬取。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
1、抢
搜索引擎和普通访问者一样,会按照网页上的链接,一一下载我们的网页,为下一步的预处理做准备。
2、预处理
①。判断是否符合其收录规则,若符合收录规则则继续处理
②。对 文章 进行分词
将网页中的 文章 剪切成单个单词。测量文档之间的相关性并准备反向索引。并记录单词出现的位置。
③。创建倒排索引
在搜索引擎中,每个文件对应一个文件ID,文件内容表示为一系列关键词的集合
将文件 ID 到 关键词 的映射转换为 关键词 到文件 ID 的映射。
使用词索引网页的好处是搜索引擎的用户也输入了词,这样他们就可以很容易地找到相关的网页。
3、搜索
①。用户对关键词查询进行分段,取索引的交集
②.排序
重要性 - 网页静态质量得分。搜索引擎将网站的各种性能条件转化为分数,这些分数相加得到一个页面的质量分数,即所谓的权重。
一种。页面信噪比:
页面信噪比是指页面中文字与非文字的比例,页面信噪比至少要大于1。
湾。缺乏
C。链接控制:
链接控制子链接的数量和链接自然度。页面的权重是固定的,链接可以传递权重。链路越多,每条链路传输的权重越低。
d。页面浏览量
相关性——以上只能通过倒排索引来定性的知道网页和查询词是否相关,但是没有办法知道谁更相关,也就是定量的。百度处理方法:
一种。记录单词出现的位置,关键词在不同位置的权重不同。
湾。tf-idf算法,即一个词在一篇文章文章中出现次数最多,词的权重越高;一个词在整个互联网上出现的次数越多,(比如“我”、“这个词”不足以区分一个文章的话题,几乎每一个文章都会出现)越小这个词的重量。
4、常用的高级搜索命令:
site:最熟悉的SEO高级搜索命令,用于搜索一个域名下的所有文件。
inurl: 指令用于搜索查询词出现在 url 中的页面。
intitle:该命令返回页面标题中收录关键词的页面。
domain:其作用是查询域名下的反向链接(反向链接=外部链接+内部链接)。
二、指数排名
1、收录 和索引
收录:页面被百度蜘蛛发现并分析
索引:百度蜘蛛初步分析认为有意义,做建库
收录索引的关系是收录关系。可以先建一个索引收录,收录的数量大于索引的数量。
百度表示,第三方提供的所谓收录查询是不可靠的。
1-1、索引文章行列式:
可信度;
文章质量;
更新频率;
网站结构体;
熊掌号和站点地图对百度有推广作用收录;
网站的年龄和体重影响百度收录对网站的影响。
1-2、加速页面索引方法:
做好网站TDK,不要修改;
积累优质网站内容;
每日定期和定量更新;
提交百度等搜索引擎,包括站点地图、熊掌号等;
重点制作熊掌号。目前熊爪号的提交已经可以做到移动站收录的80%以上;
有针对性、定期发布优质外链。
2、文章质量判断(百度官方)
①。观众
受众的规模代表了用户检索需求的规模。
②。稀缺
稀缺性主要描述了互联网页面的独特性。
③.质量
a 不能是死链接,网站访问速度是否令人满意。
b 主要内容是否完整,版式和字体是否易于阅读,广告是否过多。
c 信息是否丰富,是否满足扩展的次要需求。
④。老化
3、原创识别判断
①。释放时间——蜘蛛抓到的日期
②.锚文本链接——网站页面有多少个外部链接
③.信息指纹——文章内容的相似度
4、标题优化方法
搜索引擎搜索到的内容的标题往往就是网页标题的内容,搜索引擎给标题赋予了很高的权重。
①。标题流畅、吸引人且文章现实。
②。标题必须为原创,收录核心关键词和长尾词,与内容关键词保持一致
③。写作要符合搜索引擎的习惯,少用标点符号
④。长度适当,控制在22个汉字以内
5、内容优化方法
主要分为两部分:一部分是原创/伪原创,另一部分是采集素材库回顾。
至少第一段需要纯原创,最好有可搜索的内容,整个段落要根据玩家的搜索需求来写。
正文最好有条不紊地分成小标题
基于内容的 伪原创 方法
寻找有价值的文章,最好当天发布,或者使用爬虫爬取的数据库重写
有价值的 文章 可读性强、目标明确且引人注目。
①。修改文章的开头和结尾部分:
重新总结第一段和最后一段,打乱文中的顺序,去掉一些不相关的。添加透视。
②。对原文进行拆分重组:找几个相关的文章合并成一个新的文章
③。相关内容的组合与组合
④。将 文章 翻译成其他语言
⑤。使用论坛、博客、新媒体等方式挖掘文章
6、图像优化方法
搜索引擎已经具备一定的能力来识别大多数图像的 原创 属性
图片的算法主要包括计算hash值、pHash算法和SIFT算法,对目标图像进行编码形成“指纹”并存储。
①。给图片添加水印;
②。改变原图的纵横比,或者直接截取图片的某一部分;
③。图片长宽比尽量接近121*75,接近百度搜索显示的缩略图大小;
④。缩略图内部链接,相比文字链接,更能吸引访问者点击,关注相关性。
⑤。添加alt描述可以增强页面的主题关键词,但是注意不要堆放关键词。
⑥。百度越来越喜欢原创的内容,其实图片也是页面的一部分。
7、关键词优化方法
关键词类别:核心关键词;相关关键词;长尾 关键词; 错误 关键词; 不常见 关键词
①。从用户的角度考虑,想想用户在搜索时使用了什么词
②,不超过5个,一般3个:主关键词,辅助关键词,潜在长尾关键词
③、关键词密度不超过2% - 8%(根据需要,不是绝对的) 查看全部
输入关键字 抓取所有网页(做seo很大程度是做关键词的基本目标,才有更好的转化率)
很大程度上,做SEO就是做关键词排名。将关键词设为首页是SEO的基本目标。只有首页的排名,才能有更好的展示机会和更高的转化率。
一、搜索原理
网络蜘蛛是网络蜘蛛。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到所有 网站 网页都被爬取。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
1、抢
搜索引擎和普通访问者一样,会按照网页上的链接,一一下载我们的网页,为下一步的预处理做准备。
2、预处理
①。判断是否符合其收录规则,若符合收录规则则继续处理
②。对 文章 进行分词
将网页中的 文章 剪切成单个单词。测量文档之间的相关性并准备反向索引。并记录单词出现的位置。
③。创建倒排索引
在搜索引擎中,每个文件对应一个文件ID,文件内容表示为一系列关键词的集合
将文件 ID 到 关键词 的映射转换为 关键词 到文件 ID 的映射。
使用词索引网页的好处是搜索引擎的用户也输入了词,这样他们就可以很容易地找到相关的网页。
3、搜索
①。用户对关键词查询进行分段,取索引的交集
②.排序
重要性 - 网页静态质量得分。搜索引擎将网站的各种性能条件转化为分数,这些分数相加得到一个页面的质量分数,即所谓的权重。
一种。页面信噪比:
页面信噪比是指页面中文字与非文字的比例,页面信噪比至少要大于1。
湾。缺乏
C。链接控制:
链接控制子链接的数量和链接自然度。页面的权重是固定的,链接可以传递权重。链路越多,每条链路传输的权重越低。
d。页面浏览量
相关性——以上只能通过倒排索引来定性的知道网页和查询词是否相关,但是没有办法知道谁更相关,也就是定量的。百度处理方法:
一种。记录单词出现的位置,关键词在不同位置的权重不同。
湾。tf-idf算法,即一个词在一篇文章文章中出现次数最多,词的权重越高;一个词在整个互联网上出现的次数越多,(比如“我”、“这个词”不足以区分一个文章的话题,几乎每一个文章都会出现)越小这个词的重量。
4、常用的高级搜索命令:
site:最熟悉的SEO高级搜索命令,用于搜索一个域名下的所有文件。
inurl: 指令用于搜索查询词出现在 url 中的页面。
intitle:该命令返回页面标题中收录关键词的页面。
domain:其作用是查询域名下的反向链接(反向链接=外部链接+内部链接)。
二、指数排名
1、收录 和索引
收录:页面被百度蜘蛛发现并分析
索引:百度蜘蛛初步分析认为有意义,做建库
收录索引的关系是收录关系。可以先建一个索引收录,收录的数量大于索引的数量。
百度表示,第三方提供的所谓收录查询是不可靠的。
1-1、索引文章行列式:
可信度;
文章质量;
更新频率;
网站结构体;
熊掌号和站点地图对百度有推广作用收录;
网站的年龄和体重影响百度收录对网站的影响。
1-2、加速页面索引方法:
做好网站TDK,不要修改;
积累优质网站内容;
每日定期和定量更新;
提交百度等搜索引擎,包括站点地图、熊掌号等;
重点制作熊掌号。目前熊爪号的提交已经可以做到移动站收录的80%以上;
有针对性、定期发布优质外链。
2、文章质量判断(百度官方)
①。观众
受众的规模代表了用户检索需求的规模。
②。稀缺
稀缺性主要描述了互联网页面的独特性。
③.质量
a 不能是死链接,网站访问速度是否令人满意。
b 主要内容是否完整,版式和字体是否易于阅读,广告是否过多。
c 信息是否丰富,是否满足扩展的次要需求。
④。老化
3、原创识别判断
①。释放时间——蜘蛛抓到的日期
②.锚文本链接——网站页面有多少个外部链接
③.信息指纹——文章内容的相似度
4、标题优化方法
搜索引擎搜索到的内容的标题往往就是网页标题的内容,搜索引擎给标题赋予了很高的权重。
①。标题流畅、吸引人且文章现实。
②。标题必须为原创,收录核心关键词和长尾词,与内容关键词保持一致
③。写作要符合搜索引擎的习惯,少用标点符号
④。长度适当,控制在22个汉字以内
5、内容优化方法
主要分为两部分:一部分是原创/伪原创,另一部分是采集素材库回顾。
至少第一段需要纯原创,最好有可搜索的内容,整个段落要根据玩家的搜索需求来写。
正文最好有条不紊地分成小标题
基于内容的 伪原创 方法
寻找有价值的文章,最好当天发布,或者使用爬虫爬取的数据库重写
有价值的 文章 可读性强、目标明确且引人注目。
①。修改文章的开头和结尾部分:
重新总结第一段和最后一段,打乱文中的顺序,去掉一些不相关的。添加透视。
②。对原文进行拆分重组:找几个相关的文章合并成一个新的文章
③。相关内容的组合与组合
④。将 文章 翻译成其他语言
⑤。使用论坛、博客、新媒体等方式挖掘文章
6、图像优化方法
搜索引擎已经具备一定的能力来识别大多数图像的 原创 属性
图片的算法主要包括计算hash值、pHash算法和SIFT算法,对目标图像进行编码形成“指纹”并存储。
①。给图片添加水印;
②。改变原图的纵横比,或者直接截取图片的某一部分;
③。图片长宽比尽量接近121*75,接近百度搜索显示的缩略图大小;
④。缩略图内部链接,相比文字链接,更能吸引访问者点击,关注相关性。
⑤。添加alt描述可以增强页面的主题关键词,但是注意不要堆放关键词。
⑥。百度越来越喜欢原创的内容,其实图片也是页面的一部分。
7、关键词优化方法
关键词类别:核心关键词;相关关键词;长尾 关键词; 错误 关键词; 不常见 关键词
①。从用户的角度考虑,想想用户在搜索时使用了什么词
②,不超过5个,一般3个:主关键词,辅助关键词,潜在长尾关键词
③、关键词密度不超过2% - 8%(根据需要,不是绝对的)
输入关键字 抓取所有网页(做seo很大程度是做关键词的基本目标,才有更好的转化率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-02-21 12:04
很大程度上,做SEO就是做关键词排名。将关键词设为首页是SEO的基本目标。只有首页的排名,才能有更好的展示机会和更高的转化率。
一、搜索原理
网络蜘蛛是网络蜘蛛。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到所有 网站 网页都被爬取。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
1、抢
搜索引擎和普通访问者一样,会按照网页上的链接,一一下载我们的网页,为下一步的预处理做准备。
2、预处理
①。判断是否符合其收录规则,若符合收录规则则继续处理
②。对 文章 进行分词
将网页中的 文章 剪切成单个单词。测量文档之间的相关性并准备反向索引。并记录单词出现的位置。
③。创建倒排索引
在搜索引擎中,每个文件对应一个文件ID,文件内容表示为一系列关键词的集合
将文件 ID 到 关键词 的映射转换为 关键词 到文件 ID 的映射。
使用词索引网页的好处是搜索引擎的用户也输入了词,这样他们就可以很容易地找到相关的网页。
3、搜索
①。用户对关键词查询进行分段,取索引的交集
②.排序
重要性 - 网页静态质量得分。搜索引擎将网站的各种性能条件转化为分数,这些分数相加得到一个页面的质量分数,即所谓的权重。
一种。页面信噪比:
页面信噪比是指页面中文字与非文字的比例,页面信噪比至少要大于1。
湾。缺乏
C。链接控制:
链接控制子链接的数量和链接自然度。页面的权重是固定的,链接可以传递权重。链路越多,每条链路传输的权重越低。
d。页面浏览量
相关性——以上只能通过倒排索引来定性的知道网页和查询词是否相关,但是没有办法知道谁更相关,也就是定量的。百度处理方法:
一种。记录单词出现的位置,关键词在不同位置的权重不同。
湾。tf-idf算法,即一个词在一篇文章文章中出现次数最多,词的权重越高;一个词在整个互联网上出现的次数越多,(比如“我”、“这个词”不足以区分一个文章的话题,几乎每一个文章都会出现)越小这个词的重量。
4、常用的高级搜索命令:
site:最熟悉的SEO高级搜索命令,用于搜索一个域名下的所有文件。
inurl: 指令用于搜索查询词出现在 url 中的页面。
intitle:该命令返回页面标题中收录关键词的页面。
domain:其作用是查询域名下的反向链接(反向链接=外部链接+内部链接)。
二、指数排名
1、收录 和索引
收录:页面被百度蜘蛛发现并分析
索引:百度蜘蛛初步分析认为有意义,做建库
收录索引的关系是收录关系。可以先建一个索引收录,收录的数量大于索引的数量。
百度表示,第三方提供的所谓收录查询是不可靠的。
1-1、索引文章行列式:
可信度;
文章质量;
更新频率;
网站结构体;
熊掌号和站点地图对百度有推广作用收录;
网站的年龄和体重影响百度收录对网站的影响。
1-2、加速页面索引方法:
做好网站TDK,不要修改;
积累优质网站内容;
每日定期和定量更新;
提交百度等搜索引擎,包括站点地图、熊掌号等;
重点制作熊掌号。目前熊爪号的提交已经可以做到移动站收录的80%以上;
有针对性、定期发布优质外链。
2、文章质量判断(百度官方)
①。观众
受众的规模代表了用户检索需求的规模。
②。稀缺
稀缺性主要描述了互联网页面的独特性。
③.质量
a 不能是死链接,网站访问速度是否令人满意。
b 主要内容是否完整,版式和字体是否易于阅读,广告是否过多。
c 信息是否丰富,是否满足扩展的次要需求。
④。老化
3、原创识别判断
①。释放时间——蜘蛛抓到的日期
②.锚文本链接——网站页面有多少个外部链接
③.信息指纹——文章内容的相似度
4、标题优化方法
搜索引擎搜索到的内容的标题往往就是网页标题的内容,搜索引擎给标题赋予了很高的权重。
①。标题流畅、吸引人且文章现实。
②。标题必须为原创,收录核心关键词和长尾词,与内容关键词保持一致
③。写作要符合搜索引擎的习惯,少用标点符号
④。长度适当,控制在22个汉字以内
5、内容优化方法
主要分为两部分:一部分是原创/伪原创,另一部分是采集素材库回顾。
至少第一段需要纯原创,最好有可搜索的内容,整个段落要根据玩家的搜索需求来写。
正文最好有条不紊地分成小标题
基于内容的 伪原创 方法
寻找有价值的文章,最好当天发布,或者使用爬虫爬取的数据库重写
有价值的 文章 可读性强、目标明确且引人注目。
①。修改文章的开头和结尾部分:
重新总结第一段和最后一段,打乱文中的顺序,去掉一些不相关的。添加透视。
②。对原文进行拆分重组:找几个相关的文章合并成一个新的文章
③。相关内容的组合与组合
④。将 文章 翻译成其他语言
⑤。使用论坛、博客、新媒体等方式挖掘文章
6、图像优化方法
搜索引擎已经具备一定的能力来识别大多数图像的 原创 属性
图片的算法主要包括计算hash值、pHash算法和SIFT算法,对目标图像进行编码形成“指纹”并存储。
①。给图片添加水印;
②。改变原图的纵横比,或者直接截取图片的某一部分;
③。图片长宽比尽量接近121*75,接近百度搜索显示的缩略图大小;
④。缩略图内部链接,相比文字链接,更能吸引访问者点击,关注相关性。
⑤。添加alt描述可以增强页面的主题关键词,但是注意不要堆放关键词。
⑥。百度越来越喜欢原创的内容,其实图片也是页面的一部分。
7、关键词优化方法
关键词类别:核心关键词;相关关键词;长尾 关键词; 错误 关键词; 不常见 关键词
①。从用户的角度考虑,想想用户在搜索时使用了什么词
②,不超过5个,一般3个:主关键词,辅助关键词,潜在长尾关键词
③、关键词密度不超过2% - 8%(根据需要,不是绝对的) 查看全部
输入关键字 抓取所有网页(做seo很大程度是做关键词的基本目标,才有更好的转化率)
很大程度上,做SEO就是做关键词排名。将关键词设为首页是SEO的基本目标。只有首页的排名,才能有更好的展示机会和更高的转化率。
一、搜索原理
网络蜘蛛是网络蜘蛛。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到所有 网站 网页都被爬取。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
1、抢
搜索引擎和普通访问者一样,会按照网页上的链接,一一下载我们的网页,为下一步的预处理做准备。
2、预处理
①。判断是否符合其收录规则,若符合收录规则则继续处理
②。对 文章 进行分词
将网页中的 文章 剪切成单个单词。测量文档之间的相关性并准备反向索引。并记录单词出现的位置。
③。创建倒排索引
在搜索引擎中,每个文件对应一个文件ID,文件内容表示为一系列关键词的集合
将文件 ID 到 关键词 的映射转换为 关键词 到文件 ID 的映射。
使用词索引网页的好处是搜索引擎的用户也输入了词,这样他们就可以很容易地找到相关的网页。
3、搜索
①。用户对关键词查询进行分段,取索引的交集
②.排序
重要性 - 网页静态质量得分。搜索引擎将网站的各种性能条件转化为分数,这些分数相加得到一个页面的质量分数,即所谓的权重。
一种。页面信噪比:
页面信噪比是指页面中文字与非文字的比例,页面信噪比至少要大于1。
湾。缺乏
C。链接控制:
链接控制子链接的数量和链接自然度。页面的权重是固定的,链接可以传递权重。链路越多,每条链路传输的权重越低。
d。页面浏览量
相关性——以上只能通过倒排索引来定性的知道网页和查询词是否相关,但是没有办法知道谁更相关,也就是定量的。百度处理方法:
一种。记录单词出现的位置,关键词在不同位置的权重不同。
湾。tf-idf算法,即一个词在一篇文章文章中出现次数最多,词的权重越高;一个词在整个互联网上出现的次数越多,(比如“我”、“这个词”不足以区分一个文章的话题,几乎每一个文章都会出现)越小这个词的重量。
4、常用的高级搜索命令:
site:最熟悉的SEO高级搜索命令,用于搜索一个域名下的所有文件。
inurl: 指令用于搜索查询词出现在 url 中的页面。
intitle:该命令返回页面标题中收录关键词的页面。
domain:其作用是查询域名下的反向链接(反向链接=外部链接+内部链接)。
二、指数排名
1、收录 和索引
收录:页面被百度蜘蛛发现并分析
索引:百度蜘蛛初步分析认为有意义,做建库
收录索引的关系是收录关系。可以先建一个索引收录,收录的数量大于索引的数量。
百度表示,第三方提供的所谓收录查询是不可靠的。
1-1、索引文章行列式:
可信度;
文章质量;
更新频率;
网站结构体;
熊掌号和站点地图对百度有推广作用收录;
网站的年龄和体重影响百度收录对网站的影响。
1-2、加速页面索引方法:
做好网站TDK,不要修改;
积累优质网站内容;
每日定期和定量更新;
提交百度等搜索引擎,包括站点地图、熊掌号等;
重点制作熊掌号。目前熊爪号的提交已经可以做到移动站收录的80%以上;
有针对性、定期发布优质外链。
2、文章质量判断(百度官方)
①。观众
受众的规模代表了用户检索需求的规模。
②。稀缺
稀缺性主要描述了互联网页面的独特性。
③.质量
a 不能是死链接,网站访问速度是否令人满意。
b 主要内容是否完整,版式和字体是否易于阅读,广告是否过多。
c 信息是否丰富,是否满足扩展的次要需求。
④。老化
3、原创识别判断
①。释放时间——蜘蛛抓到的日期
②.锚文本链接——网站页面有多少个外部链接
③.信息指纹——文章内容的相似度
4、标题优化方法
搜索引擎搜索到的内容的标题往往就是网页标题的内容,搜索引擎给标题赋予了很高的权重。
①。标题流畅、吸引人且文章现实。
②。标题必须为原创,收录核心关键词和长尾词,与内容关键词保持一致
③。写作要符合搜索引擎的习惯,少用标点符号
④。长度适当,控制在22个汉字以内
5、内容优化方法
主要分为两部分:一部分是原创/伪原创,另一部分是采集素材库回顾。
至少第一段需要纯原创,最好有可搜索的内容,整个段落要根据玩家的搜索需求来写。
正文最好有条不紊地分成小标题
基于内容的 伪原创 方法
寻找有价值的文章,最好当天发布,或者使用爬虫爬取的数据库重写
有价值的 文章 可读性强、目标明确且引人注目。
①。修改文章的开头和结尾部分:
重新总结第一段和最后一段,打乱文中的顺序,去掉一些不相关的。添加透视。
②。对原文进行拆分重组:找几个相关的文章合并成一个新的文章
③。相关内容的组合与组合
④。将 文章 翻译成其他语言
⑤。使用论坛、博客、新媒体等方式挖掘文章
6、图像优化方法
搜索引擎已经具备一定的能力来识别大多数图像的 原创 属性
图片的算法主要包括计算hash值、pHash算法和SIFT算法,对目标图像进行编码形成“指纹”并存储。
①。给图片添加水印;
②。改变原图的纵横比,或者直接截取图片的某一部分;
③。图片长宽比尽量接近121*75,接近百度搜索显示的缩略图大小;
④。缩略图内部链接,相比文字链接,更能吸引访问者点击,关注相关性。
⑤。添加alt描述可以增强页面的主题关键词,但是注意不要堆放关键词。
⑥。百度越来越喜欢原创的内容,其实图片也是页面的一部分。
7、关键词优化方法
关键词类别:核心关键词;相关关键词;长尾 关键词; 错误 关键词; 不常见 关键词
①。从用户的角度考虑,想想用户在搜索时使用了什么词
②,不超过5个,一般3个:主关键词,辅助关键词,潜在长尾关键词
③、关键词密度不超过2% - 8%(根据需要,不是绝对的)
输入关键字 抓取所有网页(怎么用cloudflare为网站做cdn加速?哪些工具能查询PC端的网站流量?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-19 20:08
如何从网页中提取关键字?
您可以在此处输入域名以反映 网站 关键字。.
哪些工具可以查询PC端的网站流量?
如果是你自己的网站,你可以通过放置统计代码来准确统计你的网站上的流量。像这样的网站流量统计工具有很多,比如baidu、51LA、cnzz等。
如果想查询别人网站的流量,可以使用爱站、站长之家等工具查询。
如何使用cloudflare为网站做CDN加速?
1、开放注册
2、注册后点击login登录cloudflare。如图,输入自己的网站,然后点击添加网站按钮。然后等待 60 秒进行扫描。扫描结束后,单击继续继续。
3、进入DNS设置,请删除mx行,即点击删除。图片显示删除多余的行后。绿云代表驾驶和加速。灰色未启用。你可以自己检查。然后进行下一步。接下来,我们不需要任何修改,我们选择0元免费,点击继续。
4、不同的域名管理地址不同。比如在万网购买域名,可以登录万网修改域名的服务器。如下图所示,进行了相应的修改。
需要注意的是,更改域名的DNS服务器可能需要一段时间才能生效,最长可能需要48小时。但这并不影响您的访问。这一步完成,点击继续。
5、CDN 现已完全设置完毕。生效后,红色将变为下图中的绿色复选标记。当你查看自己的网站 ip时,你会发现显示的ip不再是服务器ip,而是cloudflare的ip。 查看全部
输入关键字 抓取所有网页(怎么用cloudflare为网站做cdn加速?哪些工具能查询PC端的网站流量?)
如何从网页中提取关键字?
您可以在此处输入域名以反映 网站 关键字。.
哪些工具可以查询PC端的网站流量?
如果是你自己的网站,你可以通过放置统计代码来准确统计你的网站上的流量。像这样的网站流量统计工具有很多,比如baidu、51LA、cnzz等。
如果想查询别人网站的流量,可以使用爱站、站长之家等工具查询。
如何使用cloudflare为网站做CDN加速?
1、开放注册
2、注册后点击login登录cloudflare。如图,输入自己的网站,然后点击添加网站按钮。然后等待 60 秒进行扫描。扫描结束后,单击继续继续。
3、进入DNS设置,请删除mx行,即点击删除。图片显示删除多余的行后。绿云代表驾驶和加速。灰色未启用。你可以自己检查。然后进行下一步。接下来,我们不需要任何修改,我们选择0元免费,点击继续。
4、不同的域名管理地址不同。比如在万网购买域名,可以登录万网修改域名的服务器。如下图所示,进行了相应的修改。
需要注意的是,更改域名的DNS服务器可能需要一段时间才能生效,最长可能需要48小时。但这并不影响您的访问。这一步完成,点击继续。
5、CDN 现已完全设置完毕。生效后,红色将变为下图中的绿色复选标记。当你查看自己的网站 ip时,你会发现显示的ip不再是服务器ip,而是cloudflare的ip。
输入关键字 抓取所有网页(Python爬取基金数据案例到的模块案例网址(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-02-19 07:19
)
使用搜索关键词爬取今日头条新闻评论信息案例爬虫4步:1.分析网页2.向网页发送请求,得到响应3.提取分析数据< @4.保存数据
本例中使用的模块
import requests
import time
import csv
案例网址:
一、分析网页
如果我们想通过关键字搜索和爬取新闻评论,我们需要找到他们的界面,但是如何找到这个界面其实并不难。我们在首页的搜索栏中输入关键字进行搜索。单词,点击搜索:
然后 URL 将跳转到搜索关键字的新闻页面:
找到这个页面,我们可以按F12进入开发者模式。经过分析,由于是动态加载的页面,我们很容易找到收录新闻数据的URL接口:
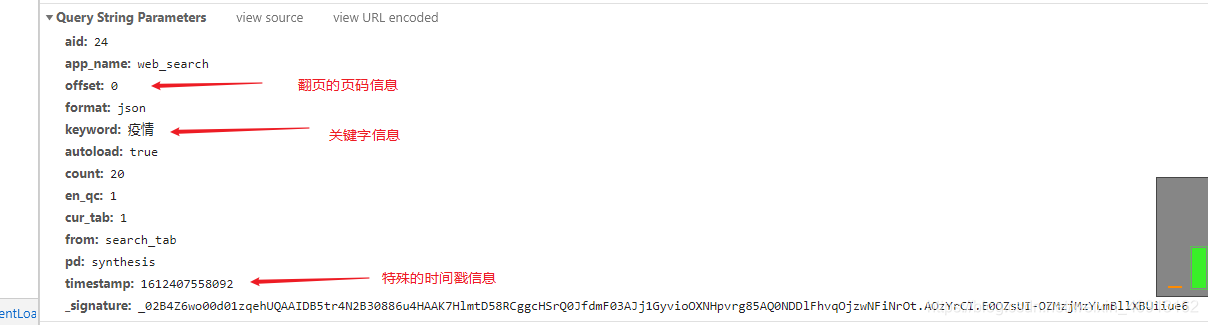
使用 URL 接口,需要分析这个 URL 的信息。可以看出这个URL很长,需要加载的参数很多。这个参数也就是我们常说的params参数:
图中标识的三个参数信息是我们必须使用的信息,offset是页码信息,我们可以用它来爬取数据进行翻页,keyword是关键字信息,这个一般理解,timestamp是一个时间戳,但是这个时间戳发生了一些变化。我在上一篇博文中也提到过,这里不再赘述。有兴趣的可以看我之前的博文:Python爬取基金数据案例
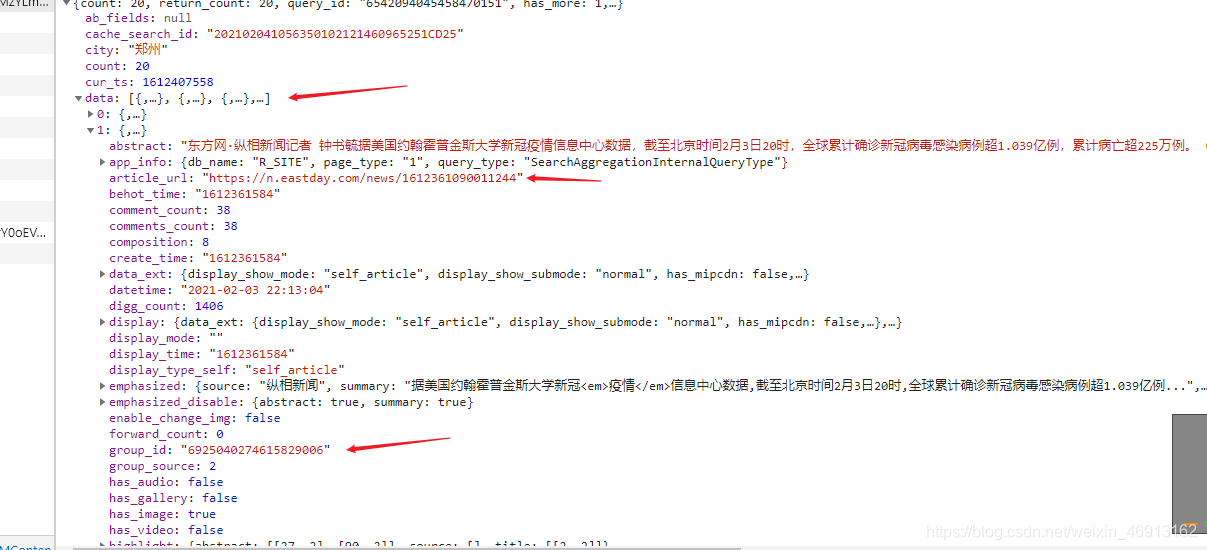
现在我们来看看这个接口URL中的信息是什么样的,如图:
可以看出,这个接口中的信息是json数据格式的信息。所有新闻数据信息都在数据列表中。每个列表收录一条新闻数据信息。我们需要提取每条信息数据的链接地址。以及该消息所属的ID信息。这个ID信息非常有用,提取评论信息时需要用到:
上图是收录评论信息的params参数。可以看到这个参数里面有两个关键参数,group_id和item_id。这个group_id对应上面接口信息中的group_id。item_id 与 group_id 相同。即使分析完成,我们也开始。现在让我们谈谈总体思路。通过搜索,我们得到所有收录新闻数据的界面URL,然后向该URL发送请求提取需要的数据,然后将需要的数据构建到收录每个信息数据的评论的界面中,向此发送请求再次界面,最后提取每条新闻数据的信息并保存。
二、构造params参数,发送请求,获取响应数据
代码显示如下:
def paramsData(self):
"""
构建params的方法
:return:
"""
params = {
"aid": "24",
"app_name": "web_search",
"offset": str(self.page),
"format": "json",
"keyword": self.search_name,
"autoload": "true",
"count": "20",
"en_qc": "1",
"cur_tab": "1",
"from": "search_tab",
"pd": "synthesis",
"timestamp": self.TIMESTRF,
}
return params
def parse_url(self, url, params):
"""
发送请求,获取响应的方法
:param url: self.API_URL
:param params:
:return:
"""
response = requests.get(url=url, headers=self.headers, params=params)
if response.status_code == 200:
return response
三、提取需要的数据
# 提取需要的信息的方法
def get_news_data(self, json_str):
"""
# 提取需要的信息的方法
:param json_str:
:return:
"""
news_dict = {
}
# 提取新闻的url
news_dict['news_url'] = json_str.get('article_url')
# 提取新闻的标题
news_dict['news_title'] = json_str.get('title')
# 提取新闻的ID
news_dict['group_id'] = json_str.get('group_id')
return news_dict
四、再次构建params参数,再次请求提取的URL
def paramsData2(self, news_dict):
"""
再次构建params的方法
:param news_dict:
:return:
"""
params2 = {
"aid": "24",
"app_name": "toutiao_web",
"offset": "0",
"count": "10",
"group_id": news_dict.get('group_id'),
"item_id": news_dict.get('group_id'),
}
return params2 查看全部
输入关键字 抓取所有网页(Python爬取基金数据案例到的模块案例网址(组图)
)
使用搜索关键词爬取今日头条新闻评论信息案例爬虫4步:1.分析网页2.向网页发送请求,得到响应3.提取分析数据< @4.保存数据
本例中使用的模块
import requests
import time
import csv
案例网址:
一、分析网页
如果我们想通过关键字搜索和爬取新闻评论,我们需要找到他们的界面,但是如何找到这个界面其实并不难。我们在首页的搜索栏中输入关键字进行搜索。单词,点击搜索:

然后 URL 将跳转到搜索关键字的新闻页面:

找到这个页面,我们可以按F12进入开发者模式。经过分析,由于是动态加载的页面,我们很容易找到收录新闻数据的URL接口:

使用 URL 接口,需要分析这个 URL 的信息。可以看出这个URL很长,需要加载的参数很多。这个参数也就是我们常说的params参数:
图中标识的三个参数信息是我们必须使用的信息,offset是页码信息,我们可以用它来爬取数据进行翻页,keyword是关键字信息,这个一般理解,timestamp是一个时间戳,但是这个时间戳发生了一些变化。我在上一篇博文中也提到过,这里不再赘述。有兴趣的可以看我之前的博文:Python爬取基金数据案例
现在我们来看看这个接口URL中的信息是什么样的,如图:
可以看出,这个接口中的信息是json数据格式的信息。所有新闻数据信息都在数据列表中。每个列表收录一条新闻数据信息。我们需要提取每条信息数据的链接地址。以及该消息所属的ID信息。这个ID信息非常有用,提取评论信息时需要用到:

上图是收录评论信息的params参数。可以看到这个参数里面有两个关键参数,group_id和item_id。这个group_id对应上面接口信息中的group_id。item_id 与 group_id 相同。即使分析完成,我们也开始。现在让我们谈谈总体思路。通过搜索,我们得到所有收录新闻数据的界面URL,然后向该URL发送请求提取需要的数据,然后将需要的数据构建到收录每个信息数据的评论的界面中,向此发送请求再次界面,最后提取每条新闻数据的信息并保存。
二、构造params参数,发送请求,获取响应数据
代码显示如下:
def paramsData(self):
"""
构建params的方法
:return:
"""
params = {
"aid": "24",
"app_name": "web_search",
"offset": str(self.page),
"format": "json",
"keyword": self.search_name,
"autoload": "true",
"count": "20",
"en_qc": "1",
"cur_tab": "1",
"from": "search_tab",
"pd": "synthesis",
"timestamp": self.TIMESTRF,
}
return params
def parse_url(self, url, params):
"""
发送请求,获取响应的方法
:param url: self.API_URL
:param params:
:return:
"""
response = requests.get(url=url, headers=self.headers, params=params)
if response.status_code == 200:
return response
三、提取需要的数据
# 提取需要的信息的方法
def get_news_data(self, json_str):
"""
# 提取需要的信息的方法
:param json_str:
:return:
"""
news_dict = {
}
# 提取新闻的url
news_dict['news_url'] = json_str.get('article_url')
# 提取新闻的标题
news_dict['news_title'] = json_str.get('title')
# 提取新闻的ID
news_dict['group_id'] = json_str.get('group_id')
return news_dict
四、再次构建params参数,再次请求提取的URL
def paramsData2(self, news_dict):
"""
再次构建params的方法
:param news_dict:
:return:
"""
params2 = {
"aid": "24",
"app_name": "toutiao_web",
"offset": "0",
"count": "10",
"group_id": news_dict.get('group_id'),
"item_id": news_dict.get('group_id'),
}
return params2
输入关键字 抓取所有网页(《BeautifulSoup库使用解析》库的使用方法与解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-02-18 20:21
BeautifulSoup 库使用解析
一、前言
BeautifulSoup 是一个 html 文档解析库,在爬虫解析数据时非常有用。接下来,记录它的使用情况。
二、准备导入库创建beautifulSoup对象
file = open("./Test.html",encoding="utf-8")
soup = BeautifulSoup(file,"html.parser")
content = '''
百度一下,你就知道
新闻
hao123
地图
视频
贴吧
更多产品
'''
soup = BeautifulSoup(content,"html.parser")
这个比较常用,但是在实际使用中,内容会被网页实时捕捉到的文本内容替换掉。
接下来,我们就以上面的文字作为数据源来说明,下面所有的方法都是基于这篇文字的分析
三、 类型 BeautifulSoup 类型
我们刚刚创建的汤对象是 BeautifulSoup 类型。可以打印
print(type(soup))
输出:
标签类型
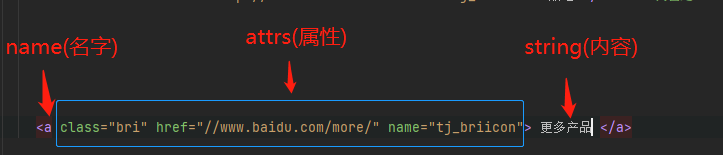
tag类型是一个很重要的类型,那么什么是Tag呢,它类似于xml中的一个标签,如下图
新闻
hao123
标签可以分为三个部分:名称、属性和字符串。结构如图
#获得找到的第一个名字为a的标签
print(soup.a)
#结果: 新闻
#打印名字
print(soup.a.name)
#结果:a
#打印属性
print(soup.a.attrs)
#结果:{'class': ['mnav'], 'href': 'http://news.baidu.com', 'name': 'tj_trnews'}
#打印内容
print(soup.a.string)
#结果:新闻
NavigableString 和 Comment 类型
这两个其实就是Tag的字符串内容。不同的是,如果内容是全注释的,则为 Comment 类型;否则,它是 NavigableString 类型
百度一下,你就知道
print(type(soup.title.string))
#结果:
print(type(soup.ha.string))
#结果:
print(soup.title.string)
#结果:百度一下,你就知道
print(soup.ha.string)
#结果:我是注释里的内容
#注意上面这里直接获得了注释里的内容
四、 遍历
我们可以通过名称获取标签。
遍历直接子节点内容
for item in soup.head.contents:
print(item.name)
'''
结果:
None
meta
None
meta
None
meta
None
link
None
title
None
ha
None
'''
可以看到子标签都打印出来了(里面会有一些none节点)
children 遍历所有子节点后代
前面的内容得到的直接子节点和children不能得到孙节点。并且后代可以获取所有子节点
for item in soup.body.descendants:
print(item.name)
遍历父节点 遍历兄弟节点 前后遍历
与兄弟节点的遍历不同,这里的前向和后向遍历都可以到达子节点。从根节点向后遍历,可以到达所有节点。
五、搜索 find_all() 指定名称
#查找 name=“a” 的所有标签
alla = soup.find_all(name="a")
for a in alla:
print(a)
结果
新闻
hao123
地图
视频
贴吧
更多产品
上面也可以写成soup.find_all("a"),如果没有指定关键字,默认使用name作为条件
指定文本
allItem = soup.find_all(text="新闻 ")
for item in allItem:
print(item)
结果
新闻
请注意,此处找到的所有字符串都是字符串,而不是标签
指定属性
除了name、text、attrs等关键词,其他代表属性。例如
allItem = soup.find_all(href="//www.baidu.com/more/")
for item in allItem:
print(item)
结果
更多产品
如果属性与python关键字重合,比如class,需要下划线_,比如
allItem = soup.find_all(class_="mnav")
for item in allItem:
print(item)
结果
新闻
hao123
地图
视频
贴吧
可以添加多个条件,例如
allItem = soup.find_all(class_="mnav",href="http://news.baidu.com",name="a")
for item in allItem:
print(item)
结果
新闻
指定名单
list = {"mnav","bri"}
allItem = soup.find_all(class_=list)
for item in allItem:
print(item)
结果
新闻
hao123
地图
视频
贴吧
更多产品
指定正则表达式
allItem = soup.find_all(href =re.compile("www."))
for item in allItem:
print(item)
结果
hao123
更多产品
指定方法
要指定一个方法,可以传入一个方法作为参数,但是这个方法需要一个Tag作为参数。例如:
def has_attr_name(tag):
return tag.has_attr('name')
allItem = soup.find_all(has_attr_name)
for item in allItem:
print(item)
结果
新闻
hao123
地图
视频
贴吧
更多产品
搜索()
BeautifulSoup 也可以使用 search() 进行搜索,但是因为我刚使用 BeautifulSoup 一段时间,所以大多使用 find_all() 来完成搜索,不是很熟悉。我不会写... 查看全部
输入关键字 抓取所有网页(《BeautifulSoup库使用解析》库的使用方法与解析)
BeautifulSoup 库使用解析
一、前言
BeautifulSoup 是一个 html 文档解析库,在爬虫解析数据时非常有用。接下来,记录它的使用情况。
二、准备导入库创建beautifulSoup对象
file = open("./Test.html",encoding="utf-8")
soup = BeautifulSoup(file,"html.parser")
content = '''
百度一下,你就知道
新闻
hao123
地图
视频
贴吧
更多产品
'''
soup = BeautifulSoup(content,"html.parser")
这个比较常用,但是在实际使用中,内容会被网页实时捕捉到的文本内容替换掉。
接下来,我们就以上面的文字作为数据源来说明,下面所有的方法都是基于这篇文字的分析
三、 类型 BeautifulSoup 类型
我们刚刚创建的汤对象是 BeautifulSoup 类型。可以打印
print(type(soup))
输出:
标签类型
tag类型是一个很重要的类型,那么什么是Tag呢,它类似于xml中的一个标签,如下图
新闻
hao123
标签可以分为三个部分:名称、属性和字符串。结构如图
#获得找到的第一个名字为a的标签
print(soup.a)
#结果: 新闻
#打印名字
print(soup.a.name)
#结果:a
#打印属性
print(soup.a.attrs)
#结果:{'class': ['mnav'], 'href': 'http://news.baidu.com', 'name': 'tj_trnews'}
#打印内容
print(soup.a.string)
#结果:新闻
NavigableString 和 Comment 类型
这两个其实就是Tag的字符串内容。不同的是,如果内容是全注释的,则为 Comment 类型;否则,它是 NavigableString 类型
百度一下,你就知道
print(type(soup.title.string))
#结果:
print(type(soup.ha.string))
#结果:
print(soup.title.string)
#结果:百度一下,你就知道
print(soup.ha.string)
#结果:我是注释里的内容
#注意上面这里直接获得了注释里的内容
四、 遍历
我们可以通过名称获取标签。
遍历直接子节点内容
for item in soup.head.contents:
print(item.name)
'''
结果:
None
meta
None
meta
None
meta
None
link
None
title
None
ha
None
'''
可以看到子标签都打印出来了(里面会有一些none节点)
children 遍历所有子节点后代
前面的内容得到的直接子节点和children不能得到孙节点。并且后代可以获取所有子节点
for item in soup.body.descendants:
print(item.name)
遍历父节点 遍历兄弟节点 前后遍历
与兄弟节点的遍历不同,这里的前向和后向遍历都可以到达子节点。从根节点向后遍历,可以到达所有节点。
五、搜索 find_all() 指定名称
#查找 name=“a” 的所有标签
alla = soup.find_all(name="a")
for a in alla:
print(a)
结果
新闻
hao123
地图
视频
贴吧
更多产品
上面也可以写成soup.find_all("a"),如果没有指定关键字,默认使用name作为条件
指定文本
allItem = soup.find_all(text="新闻 ")
for item in allItem:
print(item)
结果
新闻
请注意,此处找到的所有字符串都是字符串,而不是标签
指定属性
除了name、text、attrs等关键词,其他代表属性。例如
allItem = soup.find_all(href="//www.baidu.com/more/")
for item in allItem:
print(item)
结果
更多产品
如果属性与python关键字重合,比如class,需要下划线_,比如
allItem = soup.find_all(class_="mnav")
for item in allItem:
print(item)
结果
新闻
hao123
地图
视频
贴吧
可以添加多个条件,例如
allItem = soup.find_all(class_="mnav",href="http://news.baidu.com",name="a")
for item in allItem:
print(item)
结果
新闻
指定名单
list = {"mnav","bri"}
allItem = soup.find_all(class_=list)
for item in allItem:
print(item)
结果
新闻
hao123
地图
视频
贴吧
更多产品
指定正则表达式
allItem = soup.find_all(href =re.compile("www."))
for item in allItem:
print(item)
结果
hao123
更多产品
指定方法
要指定一个方法,可以传入一个方法作为参数,但是这个方法需要一个Tag作为参数。例如:
def has_attr_name(tag):
return tag.has_attr('name')
allItem = soup.find_all(has_attr_name)
for item in allItem:
print(item)
结果
新闻
hao123
地图
视频
贴吧
更多产品
搜索()
BeautifulSoup 也可以使用 search() 进行搜索,但是因为我刚使用 BeautifulSoup 一段时间,所以大多使用 find_all() 来完成搜索,不是很熟悉。我不会写...
输入关键字 抓取所有网页(网站关键词优化的四个方法有哪些?有什么作用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-02-17 20:10
4、二级目标关键词,在二级域名或二级栏目中做二级目标关键词。
5、长尾关键词在内容页,长尾关键词比音量好,音量是用来驱动目标的关键词。
就像一个金字塔一样,从下往上慢慢堆积,将目标关键词堆叠到顶部。
6、目标关键词围绕主要关键词工作。
7、我自己网站关键词,选择需要考虑很多。
8、如果你想做关键词,先百度看看关键词有多少页。
9、分析可以做多少负重能力关键词。
10、分析竞争对手:前3名需要分析其大小、收录体积和内容页面。
一般情况下,长尾关键词存在于内容页面中,我们需要看看这些文章是原创还是原创,甚至是转载。
如果是后两者,这些长尾关键词的权重不会太高。
11、采集对手数据后,创建一个态势表进行对手分析。
网站关键词四种优化方法[3]
一、网站域名
不知道大家有没有关注过这个英文网站,他们的域名非常规矩,这些网站非常关心他们的域名含义,他们的域名往往是由一个或几个字,不要在意你的域名的长度。
这正是谷歌所喜欢的。谷歌喜欢那些有特殊含义的域名,尤其是那些使用自己的网站的关键词作为域名的网站,即使他们的域名更长,但总比简短、无意义的域名。
对于国内的网站,域名一定要简单易记,让用户直接输入域名即可输入网站,访问者的转化率也会相应提高。
二、网站标题
<p>网站的标题、关键词标签和description标签一直是我们插入关键词的首选位置,但自从百搜更新算法后,将description与 查看全部
输入关键字 抓取所有网页(网站关键词优化的四个方法有哪些?有什么作用?)
4、二级目标关键词,在二级域名或二级栏目中做二级目标关键词。
5、长尾关键词在内容页,长尾关键词比音量好,音量是用来驱动目标的关键词。
就像一个金字塔一样,从下往上慢慢堆积,将目标关键词堆叠到顶部。
6、目标关键词围绕主要关键词工作。
7、我自己网站关键词,选择需要考虑很多。
8、如果你想做关键词,先百度看看关键词有多少页。
9、分析可以做多少负重能力关键词。
10、分析竞争对手:前3名需要分析其大小、收录体积和内容页面。
一般情况下,长尾关键词存在于内容页面中,我们需要看看这些文章是原创还是原创,甚至是转载。
如果是后两者,这些长尾关键词的权重不会太高。
11、采集对手数据后,创建一个态势表进行对手分析。
网站关键词四种优化方法[3]
一、网站域名
不知道大家有没有关注过这个英文网站,他们的域名非常规矩,这些网站非常关心他们的域名含义,他们的域名往往是由一个或几个字,不要在意你的域名的长度。
这正是谷歌所喜欢的。谷歌喜欢那些有特殊含义的域名,尤其是那些使用自己的网站的关键词作为域名的网站,即使他们的域名更长,但总比简短、无意义的域名。
对于国内的网站,域名一定要简单易记,让用户直接输入域名即可输入网站,访问者的转化率也会相应提高。
二、网站标题
<p>网站的标题、关键词标签和description标签一直是我们插入关键词的首选位置,但自从百搜更新算法后,将description与
输入关键字 抓取所有网页(如何在网站优化中有三到四个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-02-17 20:08
如果网站优化里面有三四个关键词,那么关注首页基本没问题。但是,如果关键字超过 10 个或 20 个或更多,则需要在整个 网站 中正确排列,而不是仅仅依靠主页。他们如何更好地联系?或者尝试在 网站 上对这些词进行排名。
通常的做法是将更重要的关键字放在头部。第二级中的附加关键字放置在每个列或频道页面上。如果尾部较长,属于三级关键词,可以使用内容页进行优化。
在首页,主关键词是优化的重点。从页面标题来看,粗体粗重的hx标签关键词比其他词更显眼。
次要关键字不能出现在主页上,相反,次要关键字应该出现在主页上,因为这些词加强了主要关键字。
搜索引擎也通过语义分析知道这一点。这种语义联系不是从字面上理解的,而是从大量统计数据中推导出来的,搜索引擎仍然具有这种智能。
至少这些次要关键词会出现在首页的导航链接中。其中一些出现在主页的主体中,并链接到相应的栏目和频道页面。
这样关键词就可以得到最优分配,整个网站就会有一个强大的逻辑语义关系体系,就像金字塔一样。主页是您想要排名的难词。整个 网站 突出了主页上的关键字分布,无论是语义上还是链接上。
这种多关键词优化方法的前提是,你更有可能拥有的关键词只有三四个更受欢迎。如果想要的二级关键词也很受欢迎,恐怕我们需要单独做一个网站,所有结果都在首页上实现。将它放在专栏页面上,因为您不太可能为所有专栏页面建立许多良好的链接,因此很难对热门词进行排名,除非您真的可以使该网站成为大型知名网站。
需求无处不在。有必要让陌生人见面并让无关的人合作。网站优化过程中如何满足需求?
1、从下拉框和相关搜索中查看需求
百度下拉框和相关搜索是分析用户需求的常用数据。百度下拉框是上周用户搜索最多的词,相关搜索是用户上月搜索最多的词。
(1)下拉框,下拉框中显示的关键词搜索越多,越重要。下拉框的关键词形成时间比较短,可以看到热点近期短期用户,如果行业更新快,爬取内容进行关键词排名。
(2)相关搜索。相关搜索是过去一个月的数据,从中我们可以得到用户最近一个月关心的内容。经验丰富的网站优化器结合下拉框数据,可以看到关键词搜索趋势,企业网站更应该关注相关搜索数据。
2、从搜索排名中发现隐藏需求
从 关键词 的主要搜索中,我们可以看到百度主页上的 网站 排名。从网站的排名,我们可以知道哪些网站用户更喜欢。比如图片、帖子、知识库、库等,比如搜索羊,无论是在下拉框、相关搜索还是首页排名中,都可以看到羊,说明用户对羊的需求强烈讨论的话,这个行业比较适合论坛类型网站。
(1)图片,百度首页图片展示,用户更关注图片,网站应该有更清晰的图片展示。比如装修
(2)海报栏,百度贴吧表示用户有讨论需求,网站可以是论坛栏,比如SEO论坛
(3)是的,首页好像知道用户有问答,网站可以设置一个常见的问答栏。比如医疗
(4)图书馆,图书馆首页显示用户有资料下载需求,网站可提供免费下载链接。 查看全部
输入关键字 抓取所有网页(如何在网站优化中有三到四个)
如果网站优化里面有三四个关键词,那么关注首页基本没问题。但是,如果关键字超过 10 个或 20 个或更多,则需要在整个 网站 中正确排列,而不是仅仅依靠主页。他们如何更好地联系?或者尝试在 网站 上对这些词进行排名。
通常的做法是将更重要的关键字放在头部。第二级中的附加关键字放置在每个列或频道页面上。如果尾部较长,属于三级关键词,可以使用内容页进行优化。
在首页,主关键词是优化的重点。从页面标题来看,粗体粗重的hx标签关键词比其他词更显眼。
次要关键字不能出现在主页上,相反,次要关键字应该出现在主页上,因为这些词加强了主要关键字。
搜索引擎也通过语义分析知道这一点。这种语义联系不是从字面上理解的,而是从大量统计数据中推导出来的,搜索引擎仍然具有这种智能。
至少这些次要关键词会出现在首页的导航链接中。其中一些出现在主页的主体中,并链接到相应的栏目和频道页面。
这样关键词就可以得到最优分配,整个网站就会有一个强大的逻辑语义关系体系,就像金字塔一样。主页是您想要排名的难词。整个 网站 突出了主页上的关键字分布,无论是语义上还是链接上。
这种多关键词优化方法的前提是,你更有可能拥有的关键词只有三四个更受欢迎。如果想要的二级关键词也很受欢迎,恐怕我们需要单独做一个网站,所有结果都在首页上实现。将它放在专栏页面上,因为您不太可能为所有专栏页面建立许多良好的链接,因此很难对热门词进行排名,除非您真的可以使该网站成为大型知名网站。

需求无处不在。有必要让陌生人见面并让无关的人合作。网站优化过程中如何满足需求?
1、从下拉框和相关搜索中查看需求
百度下拉框和相关搜索是分析用户需求的常用数据。百度下拉框是上周用户搜索最多的词,相关搜索是用户上月搜索最多的词。
(1)下拉框,下拉框中显示的关键词搜索越多,越重要。下拉框的关键词形成时间比较短,可以看到热点近期短期用户,如果行业更新快,爬取内容进行关键词排名。
(2)相关搜索。相关搜索是过去一个月的数据,从中我们可以得到用户最近一个月关心的内容。经验丰富的网站优化器结合下拉框数据,可以看到关键词搜索趋势,企业网站更应该关注相关搜索数据。
2、从搜索排名中发现隐藏需求
从 关键词 的主要搜索中,我们可以看到百度主页上的 网站 排名。从网站的排名,我们可以知道哪些网站用户更喜欢。比如图片、帖子、知识库、库等,比如搜索羊,无论是在下拉框、相关搜索还是首页排名中,都可以看到羊,说明用户对羊的需求强烈讨论的话,这个行业比较适合论坛类型网站。
(1)图片,百度首页图片展示,用户更关注图片,网站应该有更清晰的图片展示。比如装修
(2)海报栏,百度贴吧表示用户有讨论需求,网站可以是论坛栏,比如SEO论坛
(3)是的,首页好像知道用户有问答,网站可以设置一个常见的问答栏。比如医疗
(4)图书馆,图书馆首页显示用户有资料下载需求,网站可提供免费下载链接。
输入关键字 抓取所有网页(网络爬虫一般指的是百度搜索引擎谷歌搜索引擎、好搜)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-02-16 13:08
网络爬虫一般指百度搜索引擎、谷歌搜索引擎、好搜搜索引擎,每次都会从各大网站抓取内容更新。当然,至于内容要不要收录,主要还是要排名。基于以下标准:
1、网站保证访问速度,开服速度没有问题,让蜘蛛顺利爬行;
2、路径结构没有动态无限循环链接,最好有伪静态地址。将 文章Address 属性级别 3 添加到主域名列。
3、内容的主题关键词与内容一致,相关,不是头条党。
4、注意页面的元素,比如给图片添加alt属性等等。
5、网站应形成定期更新发布机制。
以上是保证收录的基础。如果要排名,页面必须达到搜索引擎的页面价值。如下:
来自百度工程师博客。
论互联网页面的价值
搜索引擎每天处理数以亿计的查询请求,每个查询请求都代表了用户对某种资源的特定需求。大多数时候,这些需求是通过查询返回的网页结果来满足的,我们可以认为结果中的某些页面对于特定用户的特定需求是有价值的。那么对于搜索引擎来说,一个页面的价值是什么,我们为什么要研究一个页面的价值,从技术上如何判断一个页面的价值呢?本文将一一解答这些问题。
一、什么页面值得
正如我们前面所说,如果一个页面满足了用户的特定需求,它就体现了该页面对用户的价值。那么搜索引擎的价值是什么?一个简单的推论是,所有可能为用户创造价值的页面对搜索引擎都是有价值的。将这些页面构建到搜索引擎的索引中,可以满足最终检索到的用户的需求。我们称之为价值检索。价值。只要能解决用户的信息需求,通过一些正常的检索需求可以达到,它就具有检索价值。
小学生张三喜欢在qzone上写日记,写前天吃了什么,今天玩了什么。这些内容很有价值。对于张三的父母、同学、老师等小学生,以及对小学生日记感兴趣的人来说,它们都很有价值。对于这个信息体,“张三”这个名字是检索的“钥匙”。
如果有一些信息单元只有“浏览”价值,而没有检索方式来达到该信息,则该资源可能是有价值的,但检索价值很低。比如百度大厦附近的地图,从浏览的角度来看是有价值的;但是如果没有周边文字描述(或者链接的锚文本),只有一张裸图,就没有检索价值。当然,如果图片的内容识别技术有朝一日可以自动识别这是一张“百度大厦附近的地图”,或者可以自动分析地图中各种建筑物、街道、餐厅等的名称,那么这张图片也将成为值被检索。所以一个页面是否有检索价值应该取决于两点:
1)是否解决特定需求(价值)
2)这个信息是否可以通过一些常规的搜索方法获得(检索)
那么,没有检索价值的页面对搜索引擎没有价值吗?仔细想想,答案是否定的。索引只是搜索引擎的一部分。对于其他部分,没有检索价值的页面可能对我们更好的具有高检索价值的收录页面有所帮助。例如,对于负责抓取互联网资源的蜘蛛来说,有一些页面是没有检索价值的,但是对这些页面的爬取和分析可以帮助我们更快地掌握这些页面没有检索价值的重要信息。这样可以节省更多流量以实现更有效的爬网。
考虑到这种值可以看作是一种“间接”的检索值,最终还是基于索引值,本文不再讨论。我们只关注“检索价值”这个根本问题。下面所说的“页面值”,特指页面的“检索值”。
二、为什么要研究页面价值
首先,互联网上的页面层出不穷,搜索引擎的硬件资源是有限的。如果我们想用有限的资源覆盖无尽的互联网,我们需要对页面的价值做出判断,而不是收录那些没有搜索价值的页面,更少收录搜索价值低的页面。这是页面值对收录控件的应用。
其次,搜索引擎蜘蛛的抓取能力有限。为了可访问性,网站或IP的爬取率需要有一个上限。在这个限制下,爬取或者页面更新需要有一个顺序,而这个排序的主要参考是页值,或者是页值的预测(不爬取的时候)。这是页面值在蜘蛛调度中的应用。
第三,对于某些页面,页面内容发生变化,导致其检索值由存在变为不存在,典型地成为“死链接”或“被黑”。对于这些页面,好的搜索引擎会在第一时间将其排除在索引之外,或者在检索时将其屏蔽,以确保返回给用户的结果是更多具有高检索价值的“好页面”。对于其他页面,不仅具有较高的检索价值,而且具有很强的“时效性”,可以让用户在第一时间检索到这些页面,从而极大地提升搜索体验。对于搜索引擎来说,更快的收录和索引页面意味着更多的额外资源开销,而收录的速度和索引更新的速度需要改变页面值。分析指导。
最后,一般意义上的页面价值高低对于搜索引擎返回给用户的结果排名也有指导意义。理想情况下,搜索引擎的结果会根据它们与查询请求的相关性进行排序。当相关性大致相等时,用户更倾向于浏览一般意义上页面价值高的网页。这就是页面价值在排名中的应用。
可以说,页面检索价值的研究是搜索引擎中一项比较基础的工作。对页面价值的理解和判断的准确性直接影响到搜索引擎覆盖率、死链接率、时效性等几大指标。.
三、如何判断页面价值
上一篇文章中提到过小学生张三的qzone日记的例子。我们认为这个页面对张三的同学、朋友和家人来说是有价值的和有价值的。同样,百度CEO李彦宏在i贴吧上发了一个十几字的i博,也很有价值,对李彦宏的千万粉丝来说是有价值的。虽然李彦宏的 i-post 的长度可能比张三的日记要小很多,但就这两页的价值而言,我们都有一个共识,那就是一般意义上的李彦宏的价值i-post 比张三的大很多。杂志。(当然,对于张三的妈妈来说,这个数值的关系很可能是相反的)
再比如,搜索一个人的手机号码,搜索引擎返回一个结果,这个结果是这个人在论坛上的回复。虽然关心这个手机号的人并不多,但是由于资源绝对稀缺,这个页面对于这个手机号的查询需求是完全不可替代的,所以具有极高的价值。
此外,页面检索值也受页面质量的影响。相似的页面往往在满足用户需求方面存在很大差异,比如资源下载速度、页面布局、广告数量等。这种差异,我们称之为页面质量。
最后,一些页面具有明显的公共话题性质,这些资源在刚创建时往往关注度非常高,随着时间的推移,热度下降明显,具有“新闻”的特点。典型如各种“门”事件、地震、火灾等大规模自然灾害。我们认为这些资源是“时间敏感的”。
因此,一个页面的检索值大致受以下四个要素影响:
1、感兴趣的观众人数
2、页面的稀缺性(可替代性)
3、页面质量
4、这个页面的时效性强弱
这四个要素,简称为受众、稀缺性、质量和及时性。
1. 观众
受众的规模代表了用户检索需求的规模。评价受众的规模主要基于两个方面:信息发布源的受众和信息内容本身的受众。具体因素包括但不限于:
网站忠实用户群规模
一般来说,知名的网站拥有自己的忠实用户群,他们的成功在于他们的内容和服务,比其他人更能吸引和满足用户。从这个角度来看,我们可以推断 网站 上拥有更多忠实用户群的内容将拥有更多的现有和潜在受众。这样,忠实用户群的规模就可以成为衡量网站内资源检索价值的指标。忠实用户群的好处在于它会发生变化。如果 网站 变得更糟,用户会用脚投票。超链有过期问题、作弊问题,假用户群很难作弊。一般来说,所谓的网站人气与忠实用户群的数量密切相关。
资源分配法
让我们考虑一下网站 内资源分布所反映的受众规模。比如新浪新闻首页的那些推荐内容。新浪编辑为什么要推送这些内容?因为他们认为这些才是用户最感兴趣的。所以从指数价值上看,相当于拥有庞大的编辑团队,已经将内容标记为“符合大众口味”。搜索引擎只需要享受他们的成就。这样,资源相对于某些结构性关键页面(主页、频道页面等)的链接深度也可以作为资源受众规模的指标。
访问人气
让我们从访问热度的角度来考虑受众规模。这是最直接的,当然它需要第三方工具来获取关键数据。这样不仅需要存储的页面,还有用户访问网站的访问方式。
超链
超链接在一定程度上也是受众规模的反映。一个资源的质量越高,它所覆盖的受众就越多,通常获得的正常链接的数量也就越多。
内容特点
A:我写了一篇博客:“传闻郭德纲要上春晚。”
B:我写博客:“我今天吃早餐了。”
从同一个来源来看,前者的受众肯定高于后者。即在发布来源相同的情况下,具有公共属性的内容得分会更高。
2. 稀缺
稀缺性主要描述了互联网页面的独特性。当谈到稀缺性时,人们经常会想到重复。稀缺性等于没有重复吗?我们应该如何解释这个概念?看一个例子:
有人发表了一篇关于新闻事件的原创 博客,然后被新浪转发到新闻频道。就所描述的而言,这是重复。但是,这种重复只是主要内容的重复。一方面,它的转载带来了访问速度和稳定性方面的收获,后续检索用户也可能会使用“新闻事件+新浪”来检索这条新闻。这可以称为站点增益。另一方面,它可能会在转载过程中更改页面标题,根据其受众,在转载页面上可能会有更多有价值的评论和回复,以及指向其他相关事件的新闻。关联。这些可以称为内容增益。因此,即使题材内容没有变化,新浪的转载也是有价值的,稀缺性很高。
同样,反之,如果重新发布的 网站 相当未知,则不会带来站点名称/稳定性/速度增益。更有什者,转载后在页面上添加大量广告妨碍阅读,或者只转载不完整的部分内容。这样的转载,或者说采集,是纯粹的重复,和采集一样,和出处相比,没有检索价值。
综上所述,对于主要内容重复的页面,我们应该评估它们是否具有站点增益和内容增益。只是对于大量没有任何收获的重复页面,我们应该认为它们的稀缺性很低。
3. 质量
页面的质量反映了它满足其需求的程度。判断页面质量的高低,应该从最基本的需求出发。
首先一定不能是死链接,网站要有一定的稳定性,访问速度要令人满意。
其次,主要内容是否完整,排版和字体是否易于阅读,广告是否过多。
最后,信息是否丰富,是否满足扩展的二次需求。
典型的低质量页面具有以下一些特征:
1、主要需求无效/未满足(分类广告/软件下载页面过期、下载链接无效等)
2、死链接
3、虚假信息/诈骗等。
4、点不稳定
5、影响主要需求的权限问题(下载/浏览需要注册会员/积分等)
6、资料不全(转载不全等)
7、浏览体验差(广告/字体/页面布局等)
典型的高质量页面具有以下一些特征:
1、快速访问(快速页面加载/快速资源下载)
2、页面整洁,主要内容突出。
3、页面信息齐全。 查看全部
输入关键字 抓取所有网页(网络爬虫一般指的是百度搜索引擎谷歌搜索引擎、好搜)
网络爬虫一般指百度搜索引擎、谷歌搜索引擎、好搜搜索引擎,每次都会从各大网站抓取内容更新。当然,至于内容要不要收录,主要还是要排名。基于以下标准:
1、网站保证访问速度,开服速度没有问题,让蜘蛛顺利爬行;
2、路径结构没有动态无限循环链接,最好有伪静态地址。将 文章Address 属性级别 3 添加到主域名列。
3、内容的主题关键词与内容一致,相关,不是头条党。
4、注意页面的元素,比如给图片添加alt属性等等。
5、网站应形成定期更新发布机制。
以上是保证收录的基础。如果要排名,页面必须达到搜索引擎的页面价值。如下:
来自百度工程师博客。
论互联网页面的价值
搜索引擎每天处理数以亿计的查询请求,每个查询请求都代表了用户对某种资源的特定需求。大多数时候,这些需求是通过查询返回的网页结果来满足的,我们可以认为结果中的某些页面对于特定用户的特定需求是有价值的。那么对于搜索引擎来说,一个页面的价值是什么,我们为什么要研究一个页面的价值,从技术上如何判断一个页面的价值呢?本文将一一解答这些问题。
一、什么页面值得
正如我们前面所说,如果一个页面满足了用户的特定需求,它就体现了该页面对用户的价值。那么搜索引擎的价值是什么?一个简单的推论是,所有可能为用户创造价值的页面对搜索引擎都是有价值的。将这些页面构建到搜索引擎的索引中,可以满足最终检索到的用户的需求。我们称之为价值检索。价值。只要能解决用户的信息需求,通过一些正常的检索需求可以达到,它就具有检索价值。
小学生张三喜欢在qzone上写日记,写前天吃了什么,今天玩了什么。这些内容很有价值。对于张三的父母、同学、老师等小学生,以及对小学生日记感兴趣的人来说,它们都很有价值。对于这个信息体,“张三”这个名字是检索的“钥匙”。
如果有一些信息单元只有“浏览”价值,而没有检索方式来达到该信息,则该资源可能是有价值的,但检索价值很低。比如百度大厦附近的地图,从浏览的角度来看是有价值的;但是如果没有周边文字描述(或者链接的锚文本),只有一张裸图,就没有检索价值。当然,如果图片的内容识别技术有朝一日可以自动识别这是一张“百度大厦附近的地图”,或者可以自动分析地图中各种建筑物、街道、餐厅等的名称,那么这张图片也将成为值被检索。所以一个页面是否有检索价值应该取决于两点:
1)是否解决特定需求(价值)
2)这个信息是否可以通过一些常规的搜索方法获得(检索)
那么,没有检索价值的页面对搜索引擎没有价值吗?仔细想想,答案是否定的。索引只是搜索引擎的一部分。对于其他部分,没有检索价值的页面可能对我们更好的具有高检索价值的收录页面有所帮助。例如,对于负责抓取互联网资源的蜘蛛来说,有一些页面是没有检索价值的,但是对这些页面的爬取和分析可以帮助我们更快地掌握这些页面没有检索价值的重要信息。这样可以节省更多流量以实现更有效的爬网。
考虑到这种值可以看作是一种“间接”的检索值,最终还是基于索引值,本文不再讨论。我们只关注“检索价值”这个根本问题。下面所说的“页面值”,特指页面的“检索值”。
二、为什么要研究页面价值
首先,互联网上的页面层出不穷,搜索引擎的硬件资源是有限的。如果我们想用有限的资源覆盖无尽的互联网,我们需要对页面的价值做出判断,而不是收录那些没有搜索价值的页面,更少收录搜索价值低的页面。这是页面值对收录控件的应用。
其次,搜索引擎蜘蛛的抓取能力有限。为了可访问性,网站或IP的爬取率需要有一个上限。在这个限制下,爬取或者页面更新需要有一个顺序,而这个排序的主要参考是页值,或者是页值的预测(不爬取的时候)。这是页面值在蜘蛛调度中的应用。
第三,对于某些页面,页面内容发生变化,导致其检索值由存在变为不存在,典型地成为“死链接”或“被黑”。对于这些页面,好的搜索引擎会在第一时间将其排除在索引之外,或者在检索时将其屏蔽,以确保返回给用户的结果是更多具有高检索价值的“好页面”。对于其他页面,不仅具有较高的检索价值,而且具有很强的“时效性”,可以让用户在第一时间检索到这些页面,从而极大地提升搜索体验。对于搜索引擎来说,更快的收录和索引页面意味着更多的额外资源开销,而收录的速度和索引更新的速度需要改变页面值。分析指导。
最后,一般意义上的页面价值高低对于搜索引擎返回给用户的结果排名也有指导意义。理想情况下,搜索引擎的结果会根据它们与查询请求的相关性进行排序。当相关性大致相等时,用户更倾向于浏览一般意义上页面价值高的网页。这就是页面价值在排名中的应用。
可以说,页面检索价值的研究是搜索引擎中一项比较基础的工作。对页面价值的理解和判断的准确性直接影响到搜索引擎覆盖率、死链接率、时效性等几大指标。.
三、如何判断页面价值
上一篇文章中提到过小学生张三的qzone日记的例子。我们认为这个页面对张三的同学、朋友和家人来说是有价值的和有价值的。同样,百度CEO李彦宏在i贴吧上发了一个十几字的i博,也很有价值,对李彦宏的千万粉丝来说是有价值的。虽然李彦宏的 i-post 的长度可能比张三的日记要小很多,但就这两页的价值而言,我们都有一个共识,那就是一般意义上的李彦宏的价值i-post 比张三的大很多。杂志。(当然,对于张三的妈妈来说,这个数值的关系很可能是相反的)
再比如,搜索一个人的手机号码,搜索引擎返回一个结果,这个结果是这个人在论坛上的回复。虽然关心这个手机号的人并不多,但是由于资源绝对稀缺,这个页面对于这个手机号的查询需求是完全不可替代的,所以具有极高的价值。
此外,页面检索值也受页面质量的影响。相似的页面往往在满足用户需求方面存在很大差异,比如资源下载速度、页面布局、广告数量等。这种差异,我们称之为页面质量。
最后,一些页面具有明显的公共话题性质,这些资源在刚创建时往往关注度非常高,随着时间的推移,热度下降明显,具有“新闻”的特点。典型如各种“门”事件、地震、火灾等大规模自然灾害。我们认为这些资源是“时间敏感的”。
因此,一个页面的检索值大致受以下四个要素影响:
1、感兴趣的观众人数
2、页面的稀缺性(可替代性)
3、页面质量
4、这个页面的时效性强弱
这四个要素,简称为受众、稀缺性、质量和及时性。
1. 观众
受众的规模代表了用户检索需求的规模。评价受众的规模主要基于两个方面:信息发布源的受众和信息内容本身的受众。具体因素包括但不限于:
网站忠实用户群规模
一般来说,知名的网站拥有自己的忠实用户群,他们的成功在于他们的内容和服务,比其他人更能吸引和满足用户。从这个角度来看,我们可以推断 网站 上拥有更多忠实用户群的内容将拥有更多的现有和潜在受众。这样,忠实用户群的规模就可以成为衡量网站内资源检索价值的指标。忠实用户群的好处在于它会发生变化。如果 网站 变得更糟,用户会用脚投票。超链有过期问题、作弊问题,假用户群很难作弊。一般来说,所谓的网站人气与忠实用户群的数量密切相关。
资源分配法
让我们考虑一下网站 内资源分布所反映的受众规模。比如新浪新闻首页的那些推荐内容。新浪编辑为什么要推送这些内容?因为他们认为这些才是用户最感兴趣的。所以从指数价值上看,相当于拥有庞大的编辑团队,已经将内容标记为“符合大众口味”。搜索引擎只需要享受他们的成就。这样,资源相对于某些结构性关键页面(主页、频道页面等)的链接深度也可以作为资源受众规模的指标。
访问人气
让我们从访问热度的角度来考虑受众规模。这是最直接的,当然它需要第三方工具来获取关键数据。这样不仅需要存储的页面,还有用户访问网站的访问方式。
超链
超链接在一定程度上也是受众规模的反映。一个资源的质量越高,它所覆盖的受众就越多,通常获得的正常链接的数量也就越多。
内容特点
A:我写了一篇博客:“传闻郭德纲要上春晚。”
B:我写博客:“我今天吃早餐了。”
从同一个来源来看,前者的受众肯定高于后者。即在发布来源相同的情况下,具有公共属性的内容得分会更高。
2. 稀缺
稀缺性主要描述了互联网页面的独特性。当谈到稀缺性时,人们经常会想到重复。稀缺性等于没有重复吗?我们应该如何解释这个概念?看一个例子:
有人发表了一篇关于新闻事件的原创 博客,然后被新浪转发到新闻频道。就所描述的而言,这是重复。但是,这种重复只是主要内容的重复。一方面,它的转载带来了访问速度和稳定性方面的收获,后续检索用户也可能会使用“新闻事件+新浪”来检索这条新闻。这可以称为站点增益。另一方面,它可能会在转载过程中更改页面标题,根据其受众,在转载页面上可能会有更多有价值的评论和回复,以及指向其他相关事件的新闻。关联。这些可以称为内容增益。因此,即使题材内容没有变化,新浪的转载也是有价值的,稀缺性很高。
同样,反之,如果重新发布的 网站 相当未知,则不会带来站点名称/稳定性/速度增益。更有什者,转载后在页面上添加大量广告妨碍阅读,或者只转载不完整的部分内容。这样的转载,或者说采集,是纯粹的重复,和采集一样,和出处相比,没有检索价值。
综上所述,对于主要内容重复的页面,我们应该评估它们是否具有站点增益和内容增益。只是对于大量没有任何收获的重复页面,我们应该认为它们的稀缺性很低。
3. 质量
页面的质量反映了它满足其需求的程度。判断页面质量的高低,应该从最基本的需求出发。
首先一定不能是死链接,网站要有一定的稳定性,访问速度要令人满意。
其次,主要内容是否完整,排版和字体是否易于阅读,广告是否过多。
最后,信息是否丰富,是否满足扩展的二次需求。
典型的低质量页面具有以下一些特征:
1、主要需求无效/未满足(分类广告/软件下载页面过期、下载链接无效等)
2、死链接
3、虚假信息/诈骗等。
4、点不稳定
5、影响主要需求的权限问题(下载/浏览需要注册会员/积分等)
6、资料不全(转载不全等)
7、浏览体验差(广告/字体/页面布局等)
典型的高质量页面具有以下一些特征:
1、快速访问(快速页面加载/快速资源下载)
2、页面整洁,主要内容突出。
3、页面信息齐全。
输入关键字 抓取所有网页(感觉代码有些复杂的一层网页直接上代码去了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-14 02:04
这是一款比较贴近现实生活的爬虫。根据用户输入的关键词,批量下载今日头条的相关图集。核心使用了urllib.request.urlretrieve()方法,然后百度看了一下进度条怎么玩,我直接加了代码,没问题,感觉代码有点复杂。其实理论上一层网页就可以把需要的图片全部爬下来,但是当时我担心会出现问题,所以就多加了一层网页url解析,主要用的还是json分析。这些都比较简单。关键是分析网页之间的url链接。写的时候听了,循环太多了。你自己写的吗),
这次下载的是fate相关的图片,因为是用ajax异步加载的,其实很容易控制,但是页面太多,加上有等待时间,所以加载的页面并没有太多,代码是直接加载的,(感觉注释挺清楚的)
import requests
from bs4 import BeautifulSoup
from skimage import io
import urllib
import re
import time
import json
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
,'Accept':'application/json, text/javascript'
,'Host':'www.toutiao.com'
,'Connection':'keep-alive'
,'Accept-Encoding':'gzip, deflate'
,'Accept-Language':'zh-CN,zh;q=0.8'
,'Upgrade-Insecure-Requests':'1'
,'Referer':'http://www.toutiao.com/search/'
}
url = 'http://www.toutiao.com/search_content/?offset={}&format=json&keyword={}&autoload=true&count=20&cur_tab=3'
#urltest = 'http://www.toutiao.com/search_ ... 39%3B
urllist = []#创建个列表用于存放每次异步加载所更新出来的20条网页url
name = input('请输入所要查找的图片关键词')
for i in range(0,2):#爬取前100条链接
urllist.append(url.format(i,name))
path = '/Users/loukun/Desktop/picture'
def Schedule(a,b,c):#显示下载进度
'''''
a:已经下载的数据块
b:数据块的大小
c:远程文件的大小
'''
per = 100.0 * a * b / c
if per > 100 :
per = 100
sys.stdout.write('\r%.2f%%' % per)
time.sleep(1)
if per == 100:
print('该图片加载完成')
urlname = []#存放每个图集的名称
urllist2 = []#存放每个图集的链接
def get_link(url):
session = requests.Session()
res = session.get(url)
soup = BeautifulSoup(res.text,'html.parser')
jd = json.loads(soup.text)
for articleurl in jd['data']:
name = articleurl['title']
urlimg = articleurl['url']
urlname.append(name)
urllist2.append(urlimg)
#print('图集名称:\n',name,'\n图集链接:\n',url)
return urllist2
#print(urllist)
for url in urllist:
#print('父URL',url)
get_link(url)
time.sleep(1)
def img_save(urllist3,urlname):
i2 = 1
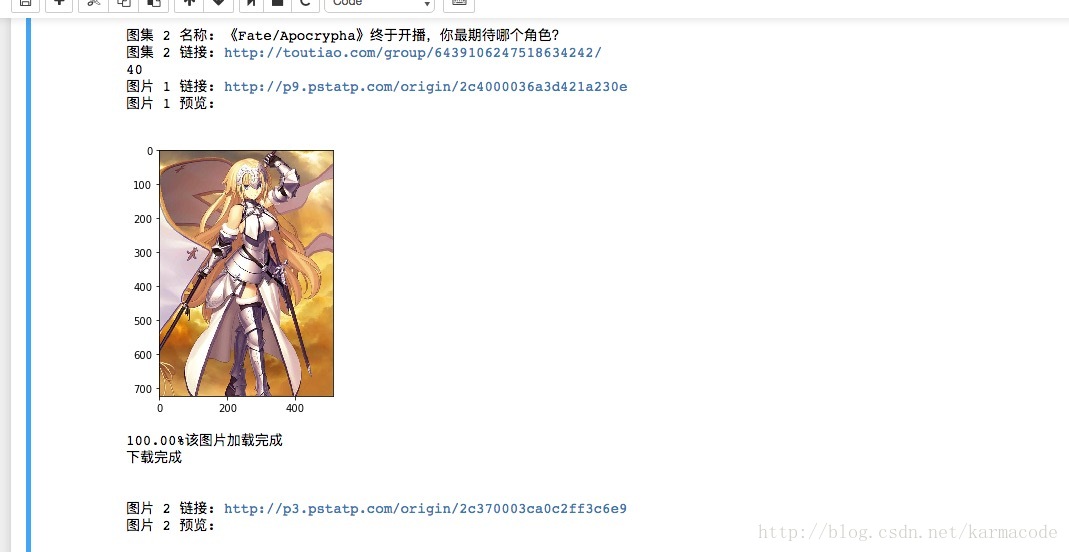
for imgurl,imgname in zip(urllist3,urlname):#将列表中所存放的图片url打印出来,通过skimage将图片打印到控制台上
print('图片',i2,'链接:',imgurl)
print('图片',i2,'预览:\n')
imgname2 = imgname.lstrip('origin/')
try:#查看图片
fateimg = io.imread(imgurl)
io.imshow(fateimg)
io.show()
except OSError:
print('图片打开失败!!')
try:#保存图片
if not os.path.exists(path):#若该路径下面的文件夹不存在则创建一个
os.mkdir(path)
urllib.request.urlretrieve(imgurl,path +'/'+ 'fate系列' + imgname2 + '%s.jpg' % i2,Schedule)
print('下载完成\n\n')
except Exception:
print('下载失败')
#time.sleep(1)
i2 += 1
#通过正则表达式以及json将每张图片的url爬取出来并打印并下载到本地文件夹
def get_jsonurl(url,urlnamecon):
urllist3 = []#该列表用于存放每张图片的url
urlname = []
res = session.get(url,headers = headers)
res.text
soup = BeautifulSoup(res.text,'html.parser')
message = re.findall('gallery: (.*?),\n',soup.text,re.S)#通过正则表达式将json文件提取出来
jd = json.loads(message[0])#通过loads方法将json文件转化为字典形式
url = jd['sub_images']#通过json在线解析器将解析出来的字典类型的网页元素通过键找出其所对应的值
for url1 in url:
urllist3.append(url1['url'])
urlname.append(url1['uri'])#将每张图片的名称保存到列表中
img_save(urllist3,urlname)
num = 1
for urlcontent,urlnamecon in zip(urllist2,urlname):
print('图集',num,'名称:',urlnamecon)#打印每个图集的名称
print('图集',num,'链接:',urlcontent)#打印每个图集的链接
print(len(urlname))
get_jsonurl(urlcontent,urlnamecon)
num += 1
当时文件名控制不好,一直覆盖原文件。久而久之,将原图片地址中的部分字符串作为文件名,避免了覆盖。
总之,马马虎虎,还有很多地方需要改进,欢迎大佬们测试(这段代码真的很实用#funny) 查看全部
输入关键字 抓取所有网页(感觉代码有些复杂的一层网页直接上代码去了)
这是一款比较贴近现实生活的爬虫。根据用户输入的关键词,批量下载今日头条的相关图集。核心使用了urllib.request.urlretrieve()方法,然后百度看了一下进度条怎么玩,我直接加了代码,没问题,感觉代码有点复杂。其实理论上一层网页就可以把需要的图片全部爬下来,但是当时我担心会出现问题,所以就多加了一层网页url解析,主要用的还是json分析。这些都比较简单。关键是分析网页之间的url链接。写的时候听了,循环太多了。你自己写的吗),
这次下载的是fate相关的图片,因为是用ajax异步加载的,其实很容易控制,但是页面太多,加上有等待时间,所以加载的页面并没有太多,代码是直接加载的,(感觉注释挺清楚的)
import requests
from bs4 import BeautifulSoup
from skimage import io
import urllib
import re
import time
import json
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
,'Accept':'application/json, text/javascript'
,'Host':'www.toutiao.com'
,'Connection':'keep-alive'
,'Accept-Encoding':'gzip, deflate'
,'Accept-Language':'zh-CN,zh;q=0.8'
,'Upgrade-Insecure-Requests':'1'
,'Referer':'http://www.toutiao.com/search/'
}
url = 'http://www.toutiao.com/search_content/?offset={}&format=json&keyword={}&autoload=true&count=20&cur_tab=3'
#urltest = 'http://www.toutiao.com/search_ ... 39%3B
urllist = []#创建个列表用于存放每次异步加载所更新出来的20条网页url
name = input('请输入所要查找的图片关键词')
for i in range(0,2):#爬取前100条链接
urllist.append(url.format(i,name))
path = '/Users/loukun/Desktop/picture'
def Schedule(a,b,c):#显示下载进度
'''''
a:已经下载的数据块
b:数据块的大小
c:远程文件的大小
'''
per = 100.0 * a * b / c
if per > 100 :
per = 100
sys.stdout.write('\r%.2f%%' % per)
time.sleep(1)
if per == 100:
print('该图片加载完成')
urlname = []#存放每个图集的名称
urllist2 = []#存放每个图集的链接
def get_link(url):
session = requests.Session()
res = session.get(url)
soup = BeautifulSoup(res.text,'html.parser')
jd = json.loads(soup.text)
for articleurl in jd['data']:
name = articleurl['title']
urlimg = articleurl['url']
urlname.append(name)
urllist2.append(urlimg)
#print('图集名称:\n',name,'\n图集链接:\n',url)
return urllist2
#print(urllist)
for url in urllist:
#print('父URL',url)
get_link(url)
time.sleep(1)
def img_save(urllist3,urlname):
i2 = 1
for imgurl,imgname in zip(urllist3,urlname):#将列表中所存放的图片url打印出来,通过skimage将图片打印到控制台上
print('图片',i2,'链接:',imgurl)
print('图片',i2,'预览:\n')
imgname2 = imgname.lstrip('origin/')
try:#查看图片
fateimg = io.imread(imgurl)
io.imshow(fateimg)
io.show()
except OSError:
print('图片打开失败!!')
try:#保存图片
if not os.path.exists(path):#若该路径下面的文件夹不存在则创建一个
os.mkdir(path)
urllib.request.urlretrieve(imgurl,path +'/'+ 'fate系列' + imgname2 + '%s.jpg' % i2,Schedule)
print('下载完成\n\n')
except Exception:
print('下载失败')
#time.sleep(1)
i2 += 1
#通过正则表达式以及json将每张图片的url爬取出来并打印并下载到本地文件夹
def get_jsonurl(url,urlnamecon):
urllist3 = []#该列表用于存放每张图片的url
urlname = []
res = session.get(url,headers = headers)
res.text
soup = BeautifulSoup(res.text,'html.parser')
message = re.findall('gallery: (.*?),\n',soup.text,re.S)#通过正则表达式将json文件提取出来
jd = json.loads(message[0])#通过loads方法将json文件转化为字典形式
url = jd['sub_images']#通过json在线解析器将解析出来的字典类型的网页元素通过键找出其所对应的值
for url1 in url:
urllist3.append(url1['url'])
urlname.append(url1['uri'])#将每张图片的名称保存到列表中
img_save(urllist3,urlname)
num = 1
for urlcontent,urlnamecon in zip(urllist2,urlname):
print('图集',num,'名称:',urlnamecon)#打印每个图集的名称
print('图集',num,'链接:',urlcontent)#打印每个图集的链接
print(len(urlname))
get_jsonurl(urlcontent,urlnamecon)
num += 1
当时文件名控制不好,一直覆盖原文件。久而久之,将原图片地址中的部分字符串作为文件名,避免了覆盖。
总之,马马虎虎,还有很多地方需要改进,欢迎大佬们测试(这段代码真的很实用#funny)
输入关键字 抓取所有网页(Java中实现标记引擎的无监督方法-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-13 12:25
问题描述
我目前正在尝试在 Java 中实现标签引擎并寻找从文本中提取关键字/标签的解决方案 (文章)。我在 stackoverflow 上找到了一些建议使用 Pointwise Mutual Information 的解决方案。
解决方案 1
我不能使用pyton和nltk,所以我必须自己实现。但我不知道如何计算概率。等式如下所示:
PMI(term, doc) = log [ P(term, doc) / (P(term)*P(doc)) ]
我想知道的是如何计算P(term, doc)
我已经有一个 Langer 文本语料库和一组 文章。这些 文章 不是语料库的一部分。语料库使用 lucene 进行索引。
请帮助我。最好的问候。
推荐答案
有很多算法可以做到这一点:
开源工具:
kea() 监督方法使用训练数据和受控词汇
maui indexer() 基本上是 kea 的扩展,提供了使用百科全书提取关键短语的便利。
carrot2() 用于关键短语提取的无监督方法。它支持多种输入、输出格式和关键短语提取参数。
槌主题建模模块()
斯坦福主题建模工具()
Mahout 聚类算法()
商业 API:
炼金术 API()
zemanta API()
yahoo 词条提取 api() 查看全部
输入关键字 抓取所有网页(Java中实现标记引擎的无监督方法-乐题库)
问题描述
我目前正在尝试在 Java 中实现标签引擎并寻找从文本中提取关键字/标签的解决方案 (文章)。我在 stackoverflow 上找到了一些建议使用 Pointwise Mutual Information 的解决方案。
解决方案 1
我不能使用pyton和nltk,所以我必须自己实现。但我不知道如何计算概率。等式如下所示:
PMI(term, doc) = log [ P(term, doc) / (P(term)*P(doc)) ]
我想知道的是如何计算P(term, doc)
我已经有一个 Langer 文本语料库和一组 文章。这些 文章 不是语料库的一部分。语料库使用 lucene 进行索引。
请帮助我。最好的问候。
推荐答案
有很多算法可以做到这一点:
开源工具:
kea() 监督方法使用训练数据和受控词汇
maui indexer() 基本上是 kea 的扩展,提供了使用百科全书提取关键短语的便利。
carrot2() 用于关键短语提取的无监督方法。它支持多种输入、输出格式和关键短语提取参数。
槌主题建模模块()
斯坦福主题建模工具()
Mahout 聚类算法()
商业 API:
炼金术 API()
zemanta API()
yahoo 词条提取 api()
输入关键字 抓取所有网页(关键词选好了,那么怎么才能让搜索引擎找到呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-13 03:13
关键词一旦被选中,如何被搜索引擎找到?
搜索引擎爬取信息的工作原理是当用户在搜索引擎中输入关键词时,它会通过分词等技术了解用户真实的搜索意图,然后搜索引擎蜘蛛会使用< @关键词 用户输入的信息。抓取网页内容,为用户提供搜索引擎认为相关且有价值的网页内容。
了解了它的工作原理后我们知道,为了让搜索引擎蜘蛛更好的抓取我们的文章内容并进行推荐,关键的一步就是让我们的文章尽可能的覆盖关键词@ >,只有被搜索引擎看到了,我们的目标用户才能看到。
一开始,似乎关键词只能放在像文章标题这样最明显的地方,如果这样做,我们也忽略了很多优化页面内容的空间.
关键词也可以放在文章页面的很多地方:文章标题、文章内容前100字、文章字幕、插入图片评论或者视频的文字描述,甚至URL都是我们可以放关键词的地方。
那么在每个位置,怎么操作呢?
文章标题:最好把你的目标关键词放在文章标题的前半部分,这样会让搜索引擎认为你关注标题开头的文字,并且搜索引擎会知道您的 文章 与您要关联的目标关键词 密切相关。
文章前100字:只在文章的前100字中谈论关键词相关内容,这样会让搜索引擎认为你的文章和关键词是高度相关的。
文章字幕:在写文章的时候,我们不会从头到尾写2000字,我们会加一些字幕,让我们的文章有清晰的逻辑结构。那么我们在设置字幕内容的时候,不要错过抓住关键词的好机会,同样的,尽量把关键词放在字幕的前半部分,吸引搜索引擎。
图片或视频的文字描述:在一些自媒体内容创作平台,如简书、百家号等,插入图片时,可以在图片下方描述关键词,在文字描述中您需要尽可能地添加您的目标 关键词 和相关的 关键词。
文章 标签:在一些内容管理平台中,该标签默认显示页面的标题。
网址:由乱码组成的网址很容易被搜索引擎判断为一组不稳定的网址,可以随时更改,所以当用户使用关键词进行搜索时,很难通过搜索引擎搜索到我们的网站. 网站。文章的SEO优化也是如此,在URL中加入关键词,方便搜索引擎检索到你的文章。但是,这种方法对于许多内容管理平台来说是非常有限的。比如百家号上发布的文章不能随意设置URL。通常,只有在它自己的 网站 中才能设置 URL。修改。
还有一个很重要的一点是这里提到的关键词不只是一个目标关键词,我们可以使用选题步骤中采集的关键词词库。充分利用它。充分利用您的 关键词 词库,该词库在 文章 的各个地方都精心布置。
比如我在编辑同学们的文章《从零开始向新媒体运营转型》的时候,除了放置《从零向新媒体运营转型》的关键词,我看到那在我的关键词库里有一个关键词在“新媒体运营前景如何”,而这个关键词和我的文章有关内容,我会从头开始介绍新媒体运营的时候,插入“新媒体运营前景如何”的相关内容。 查看全部
输入关键字 抓取所有网页(关键词选好了,那么怎么才能让搜索引擎找到呢?(图))
关键词一旦被选中,如何被搜索引擎找到?
搜索引擎爬取信息的工作原理是当用户在搜索引擎中输入关键词时,它会通过分词等技术了解用户真实的搜索意图,然后搜索引擎蜘蛛会使用< @关键词 用户输入的信息。抓取网页内容,为用户提供搜索引擎认为相关且有价值的网页内容。
了解了它的工作原理后我们知道,为了让搜索引擎蜘蛛更好的抓取我们的文章内容并进行推荐,关键的一步就是让我们的文章尽可能的覆盖关键词@ >,只有被搜索引擎看到了,我们的目标用户才能看到。

一开始,似乎关键词只能放在像文章标题这样最明显的地方,如果这样做,我们也忽略了很多优化页面内容的空间.
关键词也可以放在文章页面的很多地方:文章标题、文章内容前100字、文章字幕、插入图片评论或者视频的文字描述,甚至URL都是我们可以放关键词的地方。
那么在每个位置,怎么操作呢?
文章标题:最好把你的目标关键词放在文章标题的前半部分,这样会让搜索引擎认为你关注标题开头的文字,并且搜索引擎会知道您的 文章 与您要关联的目标关键词 密切相关。
文章前100字:只在文章的前100字中谈论关键词相关内容,这样会让搜索引擎认为你的文章和关键词是高度相关的。
文章字幕:在写文章的时候,我们不会从头到尾写2000字,我们会加一些字幕,让我们的文章有清晰的逻辑结构。那么我们在设置字幕内容的时候,不要错过抓住关键词的好机会,同样的,尽量把关键词放在字幕的前半部分,吸引搜索引擎。
图片或视频的文字描述:在一些自媒体内容创作平台,如简书、百家号等,插入图片时,可以在图片下方描述关键词,在文字描述中您需要尽可能地添加您的目标 关键词 和相关的 关键词。
文章 标签:在一些内容管理平台中,该标签默认显示页面的标题。
网址:由乱码组成的网址很容易被搜索引擎判断为一组不稳定的网址,可以随时更改,所以当用户使用关键词进行搜索时,很难通过搜索引擎搜索到我们的网站. 网站。文章的SEO优化也是如此,在URL中加入关键词,方便搜索引擎检索到你的文章。但是,这种方法对于许多内容管理平台来说是非常有限的。比如百家号上发布的文章不能随意设置URL。通常,只有在它自己的 网站 中才能设置 URL。修改。
还有一个很重要的一点是这里提到的关键词不只是一个目标关键词,我们可以使用选题步骤中采集的关键词词库。充分利用它。充分利用您的 关键词 词库,该词库在 文章 的各个地方都精心布置。
比如我在编辑同学们的文章《从零开始向新媒体运营转型》的时候,除了放置《从零向新媒体运营转型》的关键词,我看到那在我的关键词库里有一个关键词在“新媒体运营前景如何”,而这个关键词和我的文章有关内容,我会从头开始介绍新媒体运营的时候,插入“新媒体运营前景如何”的相关内容。
输入关键字 抓取所有网页(速卖通关键词的使用技巧及排序组合组合介绍!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-12 16:02
一、明确速卖通的目的关键词
写速卖通标题时,第一个明确的想法是标题是关键词的最直接体现。因此,一定要在标题中体现产品的核心和最准确的关键词。
运营服务v
标题中的 关键词 有两个目的:
1.启用搜索引擎抓取并输入搜索结果;
2.客户在浏览页面时可以准确了解Listing是什么产品。
二、如何使用速卖通关键词
关键词大致分为三类:大词、精准词、长尾词。
所谓大词,就是接近类词的意思。比如你卖服装,那么“服装/服装”就属于大词的范畴;至于确切的词,它指的是子类别。如果您销售的产品被分类到某个子类别中。比如韩版短裙,相比“服装/服饰”,“韩版短裙”更有针对性,同时这些词对于搜索的客户来说更精准对于这些 关键词; 长尾词是指不常用但恰好被某些特定群体搜索的词,例如某个明星的粉丝。
在使用速卖通标题关键词时,建议不要漏掉大词,精准词要高度相关,长尾词要适当匹配。
1. 大词覆盖的搜索量最大,所以在标题设置上,尽量多用,相关产品尽量用大词。
2. 用精确词搜索的买家很有目的性。他们为某种类型的产品甚至某种产品而来。因此,在匹配时,它们必须非常相关。不相关的产品使用精确的关键词,虽然可以吸引流量,但只能让买家飘过,不能产生实际购买。
3. 有了长尾词,并不是每个产品都有长尾词。因此,在长尾词的使用上,没有必要硬拉。
三、速卖通关键词排序组合
1、 完全匹配(与核心关键词,关键词在标题中出现完全一样,词序不打乱,词不分离)
2、中心匹配(收录核心关键词,由一两个其他单词分隔,但足够接近以形成与核心关键词的长尾关键词)
3、广泛匹配(还有其他与产品相关性较低的热搜词,核心关键词群没有长尾关键词)
注意力!钥匙关键词一定要放在前面并赋予更大的权重,既不会造成浪费,也不会造成关键词堆积。
四、速卖通标题优化注意事项
1、标题的描述是重中之重。对您的产品进行真实准确的总体描述符合海外买家的语法习惯。没有错别字和语法错误。请不要以同样的方式描述。买家也有审美疲劳。
2、切记避免关键词在标题中叠加,例如:“mp3、mp3 player, music mp3 player”这样的标题关键词叠加无助于提升排名,但会被搜索降级处罚。
3、记住要避免标题中的虚假描述。比如卖家销售的产品是MP3,但为了获得更多曝光,在标题中填写类似“MP4、MP5”的描述。有算法可以监控 此类假冒产品和虚假描述也会影响产品的转化,得不偿失。
4、标题除了商品名称外,还必须收录商品属性、尺寸等,但切记不要添加符号,尤其是引号、句号等。因为搜索商品的客户从不会在<之间插入此类符号@关键词,他们基本上使用空格。 查看全部
输入关键字 抓取所有网页(速卖通关键词的使用技巧及排序组合组合介绍!)
一、明确速卖通的目的关键词
写速卖通标题时,第一个明确的想法是标题是关键词的最直接体现。因此,一定要在标题中体现产品的核心和最准确的关键词。
运营服务v
标题中的 关键词 有两个目的:
1.启用搜索引擎抓取并输入搜索结果;
2.客户在浏览页面时可以准确了解Listing是什么产品。
二、如何使用速卖通关键词
关键词大致分为三类:大词、精准词、长尾词。
所谓大词,就是接近类词的意思。比如你卖服装,那么“服装/服装”就属于大词的范畴;至于确切的词,它指的是子类别。如果您销售的产品被分类到某个子类别中。比如韩版短裙,相比“服装/服饰”,“韩版短裙”更有针对性,同时这些词对于搜索的客户来说更精准对于这些 关键词; 长尾词是指不常用但恰好被某些特定群体搜索的词,例如某个明星的粉丝。
在使用速卖通标题关键词时,建议不要漏掉大词,精准词要高度相关,长尾词要适当匹配。
1. 大词覆盖的搜索量最大,所以在标题设置上,尽量多用,相关产品尽量用大词。
2. 用精确词搜索的买家很有目的性。他们为某种类型的产品甚至某种产品而来。因此,在匹配时,它们必须非常相关。不相关的产品使用精确的关键词,虽然可以吸引流量,但只能让买家飘过,不能产生实际购买。
3. 有了长尾词,并不是每个产品都有长尾词。因此,在长尾词的使用上,没有必要硬拉。
三、速卖通关键词排序组合
1、 完全匹配(与核心关键词,关键词在标题中出现完全一样,词序不打乱,词不分离)
2、中心匹配(收录核心关键词,由一两个其他单词分隔,但足够接近以形成与核心关键词的长尾关键词)
3、广泛匹配(还有其他与产品相关性较低的热搜词,核心关键词群没有长尾关键词)
注意力!钥匙关键词一定要放在前面并赋予更大的权重,既不会造成浪费,也不会造成关键词堆积。
四、速卖通标题优化注意事项
1、标题的描述是重中之重。对您的产品进行真实准确的总体描述符合海外买家的语法习惯。没有错别字和语法错误。请不要以同样的方式描述。买家也有审美疲劳。
2、切记避免关键词在标题中叠加,例如:“mp3、mp3 player, music mp3 player”这样的标题关键词叠加无助于提升排名,但会被搜索降级处罚。
3、记住要避免标题中的虚假描述。比如卖家销售的产品是MP3,但为了获得更多曝光,在标题中填写类似“MP4、MP5”的描述。有算法可以监控 此类假冒产品和虚假描述也会影响产品的转化,得不偿失。
4、标题除了商品名称外,还必须收录商品属性、尺寸等,但切记不要添加符号,尤其是引号、句号等。因为搜索商品的客户从不会在<之间插入此类符号@关键词,他们基本上使用空格。
输入关键字 抓取所有网页( 靠作弊手段增加访问量又有何用,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-12 04:04
靠作弊手段增加访问量又有何用,你知道吗?)
选择的 关键词 当然必须与您自己的产品或服务相关。不要听信靠不相关的点击关键词来拉动更多流量的宣传,这不仅不道德,而且毫无意义。想象一下,查找“Monica Lewinsky”的人会对您生产的酱油感兴趣。当然不是。必须承认,有时候这种做法确实可以增加网站的流量,但既然你的目的是卖产品,不是免费八卦,那么依靠这种作弊来增加流量有什么用呢?选择具体的关键词我们在选择关键词的时候还有一点要注意,就是避免以泛泛的词为主关键词,而是要根据你的类型业务或产品,选择尽可能具体的词。例如,一家销售木工工具的制造商,“CarpenterTools”不是正确的选择关键词,“ChainSaws”可能是一个明智的选择。有人会问,既然“CarpenterTools”是一个集合名词,涵盖了厂家的所有产品,不如我们把CarpenterTools拿去谷歌,你会发现搜索结果超过6位(实际数字是189,000),这意味着你有近 200,000 个竞争对手!要从众多竞争对手中脱颖而出几乎是“不可能完成的任务”。相反,“ChainSaws”下的搜索结果要少得多(69,800 个),你有有更多机会领先于竞争对手。选择更长的时间 关键词 查询信息时尽量用词 四词高中英语3500词表的原形式与原形式相反。在提交 网站 时,我们应该使用单词的较长形式。例如,当“游戏”可以使用时,尽量不要选择“游戏”。因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 在提交 网站 时,我们应该使用单词的较长形式。例如,当“游戏”可以使用时,尽量不要选择“游戏”。因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 在提交 网站 时,我们应该使用单词的较长形式。例如,当“游戏”可以使用时,尽量不要选择“游戏”。因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有
这些词经常被用户拼错,考虑到大多数人不会针对拼写错误关键词,所以如果你很聪明并且发现了这个技巧来优化你的网页拼错单词,一旦你遇到用户再次搜索那个错字,你会站在搜索结果的顶部!真的是这样吗?首先,我们来看看上面的例子有什么问题。“contemorary”其实就是“contemporary”,虽然是一个字母的区别,但是从关键词的角度来看,两者相差甚远。奇怪的是,根据关键词监控统计报告财务分析报告财务分析报告模板企业财务分析报告公司财务分析报告模板公司财务分析报告,” 并且那个错字被显着地加粗了多次?他会像发现金矿一样欣喜若狂,还是心中对这家公司的质量产生一点怀疑?他会认为一个连基本语法都没有掌握的厂商,真的是有问题的。所以,拼写错误的 关键词 是一个陷阱,我们必须三思而后行。此外,目前一些搜索引擎(如谷歌)已经增加了自动拼写检查功能。当用户输入错字时,系统会自动提供正确的单词选择。当用户意识到他们错了,大多数人倾向于通过正确的 关键词 提示进行搜索。所以到了这个阶段,优化拼写错误的网页已经基本失去了意义。寻找关键词技能作为网站的拥有者,您当然是最了解您的业务的人,因此您总能找到最能反映您业务的 关键词。但是靠自己的努力,难免会出现一些疏漏。这时候不妨去搜索引擎,找到你的竞争对手的网站,看看他们用什么
其中关键词,你可能会从中得到一些启发。另外,借助一些关键词自动分析软件,可以快速从你或你竞争对手的网页中提取出合适的关键词,你的工作效率可以成倍提升,我们可以通过这些软件找到很多< @关键词 之前没有考虑过,从而大大扩展了我们的关键词参与活动家名单。停用词/过滤词(StopWords/FilterWords)含义相同,指的是一些太常见而没有任何检索值的词,如“a”、“the”、“and”、“of”、“web” ”、“主页”等。搜索引擎遇到这些词一般都会过滤掉。因此,为了节省篇幅,应尽量避免使用此类词,尤其是在字数有严格限制的地方。(如果要验证上述规则,可以尝试在搜索引擎中搜索“staythenight”,会发现“the”这个词在结果中符合搜索条件,但没有以粗体显示,说明.) 重复 关键词 1000 次 既然 关键词 的出现频率是决定 网站 排名的重要因素,那为什么不重复 1000 次,是不是很简单并且有效?停下来。众所周知,这就是搜索引擎的“石器时代”做法,在当时确实奏效,但现在早已被搜索引擎抛弃。当时的典型做法是:“关键词, 关键词, 关键词...”。重复次数越多,网站 排名越高。所以登录搜索引擎变成了无休止的关键词重复竞赛。你重复500次不算太多,我会重复600次,而且重复关键词数千次的人很多。搜索引擎很快意识到了这种做法的危险性,终于在忍无可忍的时候站了起来,警告那些走得太远的人网站,如果他们继续执迷不悟,不仅达不到他们的目标,但他们也可能被判处死刑。- 永远不要让你的 网站 出来!所以不要刻意重复某个关键词,特别是不要在同一行连续使用某个关键词超过2次。使用关键词时,尽量做到自然流畅,符合基本语法规则。 查看全部
输入关键字 抓取所有网页(
靠作弊手段增加访问量又有何用,你知道吗?)

选择的 关键词 当然必须与您自己的产品或服务相关。不要听信靠不相关的点击关键词来拉动更多流量的宣传,这不仅不道德,而且毫无意义。想象一下,查找“Monica Lewinsky”的人会对您生产的酱油感兴趣。当然不是。必须承认,有时候这种做法确实可以增加网站的流量,但既然你的目的是卖产品,不是免费八卦,那么依靠这种作弊来增加流量有什么用呢?选择具体的关键词我们在选择关键词的时候还有一点要注意,就是避免以泛泛的词为主关键词,而是要根据你的类型业务或产品,选择尽可能具体的词。例如,一家销售木工工具的制造商,“CarpenterTools”不是正确的选择关键词,“ChainSaws”可能是一个明智的选择。有人会问,既然“CarpenterTools”是一个集合名词,涵盖了厂家的所有产品,不如我们把CarpenterTools拿去谷歌,你会发现搜索结果超过6位(实际数字是189,000),这意味着你有近 200,000 个竞争对手!要从众多竞争对手中脱颖而出几乎是“不可能完成的任务”。相反,“ChainSaws”下的搜索结果要少得多(69,800 个),你有有更多机会领先于竞争对手。选择更长的时间 关键词 查询信息时尽量用词 四词高中英语3500词表的原形式与原形式相反。在提交 网站 时,我们应该使用单词的较长形式。例如,当“游戏”可以使用时,尽量不要选择“游戏”。因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 在提交 网站 时,我们应该使用单词的较长形式。例如,当“游戏”可以使用时,尽量不要选择“游戏”。因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 在提交 网站 时,我们应该使用单词的较长形式。例如,当“游戏”可以使用时,尽量不要选择“游戏”。因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有

这些词经常被用户拼错,考虑到大多数人不会针对拼写错误关键词,所以如果你很聪明并且发现了这个技巧来优化你的网页拼错单词,一旦你遇到用户再次搜索那个错字,你会站在搜索结果的顶部!真的是这样吗?首先,我们来看看上面的例子有什么问题。“contemorary”其实就是“contemporary”,虽然是一个字母的区别,但是从关键词的角度来看,两者相差甚远。奇怪的是,根据关键词监控统计报告财务分析报告财务分析报告模板企业财务分析报告公司财务分析报告模板公司财务分析报告,” 并且那个错字被显着地加粗了多次?他会像发现金矿一样欣喜若狂,还是心中对这家公司的质量产生一点怀疑?他会认为一个连基本语法都没有掌握的厂商,真的是有问题的。所以,拼写错误的 关键词 是一个陷阱,我们必须三思而后行。此外,目前一些搜索引擎(如谷歌)已经增加了自动拼写检查功能。当用户输入错字时,系统会自动提供正确的单词选择。当用户意识到他们错了,大多数人倾向于通过正确的 关键词 提示进行搜索。所以到了这个阶段,优化拼写错误的网页已经基本失去了意义。寻找关键词技能作为网站的拥有者,您当然是最了解您的业务的人,因此您总能找到最能反映您业务的 关键词。但是靠自己的努力,难免会出现一些疏漏。这时候不妨去搜索引擎,找到你的竞争对手的网站,看看他们用什么

其中关键词,你可能会从中得到一些启发。另外,借助一些关键词自动分析软件,可以快速从你或你竞争对手的网页中提取出合适的关键词,你的工作效率可以成倍提升,我们可以通过这些软件找到很多< @关键词 之前没有考虑过,从而大大扩展了我们的关键词参与活动家名单。停用词/过滤词(StopWords/FilterWords)含义相同,指的是一些太常见而没有任何检索值的词,如“a”、“the”、“and”、“of”、“web” ”、“主页”等。搜索引擎遇到这些词一般都会过滤掉。因此,为了节省篇幅,应尽量避免使用此类词,尤其是在字数有严格限制的地方。(如果要验证上述规则,可以尝试在搜索引擎中搜索“staythenight”,会发现“the”这个词在结果中符合搜索条件,但没有以粗体显示,说明.) 重复 关键词 1000 次 既然 关键词 的出现频率是决定 网站 排名的重要因素,那为什么不重复 1000 次,是不是很简单并且有效?停下来。众所周知,这就是搜索引擎的“石器时代”做法,在当时确实奏效,但现在早已被搜索引擎抛弃。当时的典型做法是:“关键词, 关键词, 关键词...”。重复次数越多,网站 排名越高。所以登录搜索引擎变成了无休止的关键词重复竞赛。你重复500次不算太多,我会重复600次,而且重复关键词数千次的人很多。搜索引擎很快意识到了这种做法的危险性,终于在忍无可忍的时候站了起来,警告那些走得太远的人网站,如果他们继续执迷不悟,不仅达不到他们的目标,但他们也可能被判处死刑。- 永远不要让你的 网站 出来!所以不要刻意重复某个关键词,特别是不要在同一行连续使用某个关键词超过2次。使用关键词时,尽量做到自然流畅,符合基本语法规则。
输入关键字 抓取所有网页(如何选择有效关键字策略?优化项目中最重要的工作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-12 03:30
如何利用关键词获得良好的搜索引擎排名,选择有效的关键词策略,是SEO人在搜索引擎优化项目中最重要的工作。目前大部分搜索引擎都支持关键词索引,即根据注册网站提供的关键词记录网站,根据用户输入的关键词索引网站。因此,为您的促销活动的 网站 确定关键字
如何使用关键字获得良好的搜索引擎排名
选择有效的关键词策略是SEO家族认为的搜索引擎优化项目中最重要的工作。目前大部分搜索引擎都支持关键词索引,即根据注册网站提供的关键词记录网站,根据用户输入的关键词索引网站。因此,确定推广网站的关键词非常重要。正确的关键词可以让网站获得良好的搜索排名,从而赢得流量向量。错误的关键字会减少用户访问网站 @网站 的机会。
以下是一些选择关键字的策略:
①不断搜索关键词。尽可能多地写下你能想到的关键词,不断搜索不同的网站,找到最合适的关键词。
②拼写错误的使用。事实上,一些拼写错误的关键字被频繁使用,例如将Alta-sa(专业搜索引擎)拼写为“Alt Visa”或其他拼写。这增加了被用户找到的可能性。
③关键词的地域性。通常一个区域明显的关键词会比那些不太明显的关键词吸引更多的流量,因为人们一般按照区域范围进行搜索,这样更有利于检索的准确性。
④ 使用较长的关键词。有时一些初学者在使用搜索引擎输入关键词时,往往会更具体,输入更长的关键字。例如,如果用户想要查找他们的姓氏来源,他们通常需要在 关键词 中添加限定条件。比如“河北昌黎汉姓的由来”,就可以找到目标地址。
⑤关键词组合。用户使用关键字的另一个特点是他们经常使用组合关键字。如上例所述,关键字也可以输入为“汉姓源于河北昌黎”或“汉姓源于河北昌黎”。
⑥ 应避免的关键词。大多数搜索引擎会过滤掉某些词,例如:“a”、“the”、“and”、“of”、“that”、“it”、“too”、“web”和“homepage””等等on,即当搜索引擎找到这些词时。会忽略它们。因此,为确保正确的搜索排名,应避免使用这些 关键词。
⑦ 了解用户使用关键字的习惯。调查显示,用户有使用某些特定关键词的习惯,这就需要一些专业搜索引擎提供的实时检索状态,来了解一些人的搜索习惯和内容。
(2)选择关键字的步骤使用上述方法,可以选择可以使用的关键字,但是选择有效关键字的具体步骤如下:
第一步是明确关键词选择的方向。大多数搜索引擎在网站“标题”、“描述”、“关键字”、Web Content and Submission Center 中提取用于检索的关键字网站,并且会明确限制字词的使用或字符数. 因此,您应该选择至少 25 到 50 个关键字,具体取决于搜索引擎的一般限制。
第二步是总结尽可能多的关键词。无论是在网站的标题、描述还是网页内容中,关键词都会在网站的搜索排名中起到至关重要的作用。因此,尽可能多地总结关键词,而不用担心使用的关键词是否完全适合目标链接,只要关键词数量满足搜索引擎的要求即可。
第三步,进行关键词选择。总结出来的关键词中,网页中出现过的关键词被去掉,因为已经收录在网页中,剩下的会在后面用到。
第四步,关键词查询验证。在专业的搜索引擎(如百度)中对获取的关键词进行一一搜索,或者使用一些专业的分析软件(如“百度趋势”)进行分析。从而增加用户点击的可能性。
第五步,记录和分析搜索结果。在不同的搜索引擎中,会得到不同的搜索结果。仔细分析记录网站的总搜索次数和主要内容,对比自己的网站,大致可以得出三个结论:如果返回的结果很大,收录很多竞争对手' 网站,表示该关键字使用频率很高;如果返回的记录很少,并且收录很多竞争对手的网站,则表示该关键字被Less使用,如果返回的记录很少,并且带有网站的竞争对手,则该关键字可能没有被任何人使用。
第六步,关键词组合。单个关键字搜索完成后,即可进行验证。先将前两个关键词组合搜索,然后搜索所有其他组合(二乘二组合),分析并记录检索过程。
第七步,完成网站特征描述。完成以上关键词选择流程并选择正确关键词后,需要将其所有关键词组合成网站“title”、“description”、“keyword”、网页内容等网站特征描述。
第八步,重复第二步到第七步的过程,不断修正结果。 查看全部
输入关键字 抓取所有网页(如何选择有效关键字策略?优化项目中最重要的工作)
如何利用关键词获得良好的搜索引擎排名,选择有效的关键词策略,是SEO人在搜索引擎优化项目中最重要的工作。目前大部分搜索引擎都支持关键词索引,即根据注册网站提供的关键词记录网站,根据用户输入的关键词索引网站。因此,为您的促销活动的 网站 确定关键字
如何使用关键字获得良好的搜索引擎排名
选择有效的关键词策略是SEO家族认为的搜索引擎优化项目中最重要的工作。目前大部分搜索引擎都支持关键词索引,即根据注册网站提供的关键词记录网站,根据用户输入的关键词索引网站。因此,确定推广网站的关键词非常重要。正确的关键词可以让网站获得良好的搜索排名,从而赢得流量向量。错误的关键字会减少用户访问网站 @网站 的机会。
以下是一些选择关键字的策略:
①不断搜索关键词。尽可能多地写下你能想到的关键词,不断搜索不同的网站,找到最合适的关键词。
②拼写错误的使用。事实上,一些拼写错误的关键字被频繁使用,例如将Alta-sa(专业搜索引擎)拼写为“Alt Visa”或其他拼写。这增加了被用户找到的可能性。
③关键词的地域性。通常一个区域明显的关键词会比那些不太明显的关键词吸引更多的流量,因为人们一般按照区域范围进行搜索,这样更有利于检索的准确性。
④ 使用较长的关键词。有时一些初学者在使用搜索引擎输入关键词时,往往会更具体,输入更长的关键字。例如,如果用户想要查找他们的姓氏来源,他们通常需要在 关键词 中添加限定条件。比如“河北昌黎汉姓的由来”,就可以找到目标地址。
⑤关键词组合。用户使用关键字的另一个特点是他们经常使用组合关键字。如上例所述,关键字也可以输入为“汉姓源于河北昌黎”或“汉姓源于河北昌黎”。
⑥ 应避免的关键词。大多数搜索引擎会过滤掉某些词,例如:“a”、“the”、“and”、“of”、“that”、“it”、“too”、“web”和“homepage””等等on,即当搜索引擎找到这些词时。会忽略它们。因此,为确保正确的搜索排名,应避免使用这些 关键词。
⑦ 了解用户使用关键字的习惯。调查显示,用户有使用某些特定关键词的习惯,这就需要一些专业搜索引擎提供的实时检索状态,来了解一些人的搜索习惯和内容。
(2)选择关键字的步骤使用上述方法,可以选择可以使用的关键字,但是选择有效关键字的具体步骤如下:
第一步是明确关键词选择的方向。大多数搜索引擎在网站“标题”、“描述”、“关键字”、Web Content and Submission Center 中提取用于检索的关键字网站,并且会明确限制字词的使用或字符数. 因此,您应该选择至少 25 到 50 个关键字,具体取决于搜索引擎的一般限制。
第二步是总结尽可能多的关键词。无论是在网站的标题、描述还是网页内容中,关键词都会在网站的搜索排名中起到至关重要的作用。因此,尽可能多地总结关键词,而不用担心使用的关键词是否完全适合目标链接,只要关键词数量满足搜索引擎的要求即可。
第三步,进行关键词选择。总结出来的关键词中,网页中出现过的关键词被去掉,因为已经收录在网页中,剩下的会在后面用到。
第四步,关键词查询验证。在专业的搜索引擎(如百度)中对获取的关键词进行一一搜索,或者使用一些专业的分析软件(如“百度趋势”)进行分析。从而增加用户点击的可能性。
第五步,记录和分析搜索结果。在不同的搜索引擎中,会得到不同的搜索结果。仔细分析记录网站的总搜索次数和主要内容,对比自己的网站,大致可以得出三个结论:如果返回的结果很大,收录很多竞争对手' 网站,表示该关键字使用频率很高;如果返回的记录很少,并且收录很多竞争对手的网站,则表示该关键字被Less使用,如果返回的记录很少,并且带有网站的竞争对手,则该关键字可能没有被任何人使用。
第六步,关键词组合。单个关键字搜索完成后,即可进行验证。先将前两个关键词组合搜索,然后搜索所有其他组合(二乘二组合),分析并记录检索过程。
第七步,完成网站特征描述。完成以上关键词选择流程并选择正确关键词后,需要将其所有关键词组合成网站“title”、“description”、“keyword”、网页内容等网站特征描述。
第八步,重复第二步到第七步的过程,不断修正结果。
输入关键字 抓取所有网页(亲,我想做一个简单的360极速浏览器的插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-11 06:01
亲,想做一个简单的360极速浏览器插件,要求如下:
打开网页后,自动执行代码,自动搜索关键词(eg:公司)的链接,自动点进去!此代码每页仅执行一次。插件怎么写,每个文件的代码怎么编排!
背景,我对代码非常感兴趣。摸索了很多天,还是没有成功,但是个人觉得应该有以下两种方法:
1.使用正则表达式过滤出想要的URL,实现跳转
2.用js直接搜索你要的链接关键词实现跳转
认为后者应该更容易实现!我在网上搜索了一个例子,但仍然不会改变,请帮助!感激!
var kw = ['公司'];
var as = document.getElementsByTagName('a');
for (var i = 0; i < as.length; i++) {
for (var j = 0; j < kw.length; j++)
if (as[i].innerHTML.indexOf(kw[j]) != -1) {// 两者都被屏蔽
if (as[i].onclick) as[i].onclick();
否则 window.open(as[i].href);
}
} 查看全部
输入关键字 抓取所有网页(亲,我想做一个简单的360极速浏览器的插件)
亲,想做一个简单的360极速浏览器插件,要求如下:
打开网页后,自动执行代码,自动搜索关键词(eg:公司)的链接,自动点进去!此代码每页仅执行一次。插件怎么写,每个文件的代码怎么编排!
背景,我对代码非常感兴趣。摸索了很多天,还是没有成功,但是个人觉得应该有以下两种方法:
1.使用正则表达式过滤出想要的URL,实现跳转
2.用js直接搜索你要的链接关键词实现跳转
认为后者应该更容易实现!我在网上搜索了一个例子,但仍然不会改变,请帮助!感激!
var kw = ['公司'];
var as = document.getElementsByTagName('a');
for (var i = 0; i < as.length; i++) {
for (var j = 0; j < kw.length; j++)
if (as[i].innerHTML.indexOf(kw[j]) != -1) {// 两者都被屏蔽
if (as[i].onclick) as[i].onclick();
否则 window.open(as[i].href);
}
}
输入关键字 抓取所有网页(2个月前Gseeker的帖子:它将会革掉Google的命?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-09 05:10
转发 Gseeker 2 个月前的帖子
MyLiveSearch:它会杀死谷歌吗?
2007 年 5 月 29 日
<p>我们现在使用的大部分搜索引擎的工作原理都是类似的,就是搜索引擎发出爬虫,不断地跟踪互联网上的链接网站,并分析它们所经过的网页内容,然后把它们网站@收录进入搜索引擎的索引库;当用户输入关键词进行搜索时,搜索引擎会从已有的索引库中返回相关结果。全球四大搜索引擎Google、Yahoo!、Microsoft Live Search 和ASK 均采用此模式。谷歌更好,因为它的算法返回更相关和更准确的搜索结果。但可以想象,这种模式的缺点也很明显,即它提供的搜索结果不是实时的,而是基于索引数据库的。进一步来说,只有爬虫爬取的网页内容才会出现在索引库中,然后才能被用户搜索。也就是在这种模式下,用户得到的搜索结果不是最新的,因为网站新的内容要等待爬虫抓取,分析和 查看全部
输入关键字 抓取所有网页(2个月前Gseeker的帖子:它将会革掉Google的命?)
转发 Gseeker 2 个月前的帖子
MyLiveSearch:它会杀死谷歌吗?
2007 年 5 月 29 日

<p>我们现在使用的大部分搜索引擎的工作原理都是类似的,就是搜索引擎发出爬虫,不断地跟踪互联网上的链接网站,并分析它们所经过的网页内容,然后把它们网站@收录进入搜索引擎的索引库;当用户输入关键词进行搜索时,搜索引擎会从已有的索引库中返回相关结果。全球四大搜索引擎Google、Yahoo!、Microsoft Live Search 和ASK 均采用此模式。谷歌更好,因为它的算法返回更相关和更准确的搜索结果。但可以想象,这种模式的缺点也很明显,即它提供的搜索结果不是实时的,而是基于索引数据库的。进一步来说,只有爬虫爬取的网页内容才会出现在索引库中,然后才能被用户搜索。也就是在这种模式下,用户得到的搜索结果不是最新的,因为网站新的内容要等待爬虫抓取,分析和
输入关键字 抓取所有网页(关键词是什么意思?与搜索引擎的关系有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-09 05:09
只有通过关键字搜索,用户才能更好地找到他们需要的信息。关键词优化的好坏与SEO工作者最关心的排名有很大关系。所以,从SEO的角度来看,关键词是一个特别重要的概念,另一方面,关键词也是一个非常基础的概念。所以你知道 关键词 是什么吗?关键词 是什么意思?
1、关键词 是什么?
从百度百科可以看出,关键词是指用户在搜索引擎中输入的表达个人需求的词。从维基百科的定义来看,它意味着用户获取信息的简化词汇表。其实这两个定义表达的意思是一样的,假设你用的是百度,你想通过一个关键词获取信息,那么你输入的所有单词都可以称为关键词。
这里需要注意的是关键词是用户需求的载体,用户会使用简体字进行搜索,这样比较容易理解,因为用户通常不会输入大量的数字进行搜索for results,而是通过反映核心思想的词汇来搜索结果。
2、关键词与搜索引擎的关系
在进行 SEO 时,我们不仅向用户展示我们的网页,还向搜索引擎展示我们的网页。只有当当前网页被搜索引擎看到和索引时,该网页才能显示给用户。因此,有必要认真看待关键词与搜索引擎的关系。
搜索引擎的工作原理可以概括为爬取-索引构建-搜索词处理-排名。搜索引擎蜘蛛一直在爬行和爬行新鲜的网页。之后,他们将索引有价值的网页。当用户在搜索引擎中输入关键词时,通过分词等技术了解用户真实的搜索意图,并将最终结果以排序方式提供给用户。
如果我们了解搜索引擎的工作原理以及 关键词 是什么,我们就会知道关键字的重要性。在目前的技术情况下,百度等搜索引擎只能识别单词,单词是由单一的关键词词汇组成的。关键词是搜索引擎工作的前提条件,也是满足用户需求的必要条件。 查看全部
输入关键字 抓取所有网页(关键词是什么意思?与搜索引擎的关系有哪些?)
只有通过关键字搜索,用户才能更好地找到他们需要的信息。关键词优化的好坏与SEO工作者最关心的排名有很大关系。所以,从SEO的角度来看,关键词是一个特别重要的概念,另一方面,关键词也是一个非常基础的概念。所以你知道 关键词 是什么吗?关键词 是什么意思?

1、关键词 是什么?
从百度百科可以看出,关键词是指用户在搜索引擎中输入的表达个人需求的词。从维基百科的定义来看,它意味着用户获取信息的简化词汇表。其实这两个定义表达的意思是一样的,假设你用的是百度,你想通过一个关键词获取信息,那么你输入的所有单词都可以称为关键词。
这里需要注意的是关键词是用户需求的载体,用户会使用简体字进行搜索,这样比较容易理解,因为用户通常不会输入大量的数字进行搜索for results,而是通过反映核心思想的词汇来搜索结果。
2、关键词与搜索引擎的关系
在进行 SEO 时,我们不仅向用户展示我们的网页,还向搜索引擎展示我们的网页。只有当当前网页被搜索引擎看到和索引时,该网页才能显示给用户。因此,有必要认真看待关键词与搜索引擎的关系。
搜索引擎的工作原理可以概括为爬取-索引构建-搜索词处理-排名。搜索引擎蜘蛛一直在爬行和爬行新鲜的网页。之后,他们将索引有价值的网页。当用户在搜索引擎中输入关键词时,通过分词等技术了解用户真实的搜索意图,并将最终结果以排序方式提供给用户。
如果我们了解搜索引擎的工作原理以及 关键词 是什么,我们就会知道关键字的重要性。在目前的技术情况下,百度等搜索引擎只能识别单词,单词是由单一的关键词词汇组成的。关键词是搜索引擎工作的前提条件,也是满足用户需求的必要条件。
输入关键字 抓取所有网页(福建关键词优化哪家好,百诚互联选择我们你可以放心)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-08 13:02
福建关键词优化哪个更好,百诚互联网,选择我们,您可以少走弯路,选择我们,您可以放心。
福建关键词哪个更好优化,从小程序开发,到关键词排名优化,再到百度竞价账号结构搭建,外链资源发布,灵活选择各种相关配套服务,充分探索< @网站的营销功能。优化网站,你需要让更多的页面是收录,并尽量吸引蜘蛛爬取。如果它不能爬取所有的页面,蜘蛛所要做的就是尝试爬取重要的页面。
一个。关键词对应的网页快照必须有完全匹配或部分匹配;湾。关键词 和 网站 的主题必须相关;C。网站的结构必须便于百度掌握并更新;d。有些关键词是时间敏感的,比如大闸蟹、月饼、鞭炮等。网站快照更新一定要及时;网站修改频繁、TDK调整频繁、优化过度、内容采集、不符合gj策略的灰字、多域名绑定、经常被黑等,此类词排名靠前或搜索引擎排名无效;
福建关键词优化哪一个比较好,所以需要评估关键词的优化能否达到优化效果,评估关键词之后的优化效果。网站一般的施工流程是怎样的?网站 是一个相对复杂的系统。从一开始,您就需要考虑所需的功能。网站的规划也是构建所有网站需要做的。@网站 进行整体分析,明确网站的建设目标,确定网站的访问目标,网站提供的内容和服务,域名和标识网站、网站风格和网站目录分类,这一步也是网站成功搭建的前提 @网站,因为所有的施工步骤都是按照规划设计的。搭建正式的网站,需要到相关部门办理哪些手续,缴纳哪些费用?国家规定,通过互联网向网民提供信息,如购物网站,必须取得经营网站许可证,而不是网站备案,俗话说:有政策和对策。
网站通过实施百度优化,可以提升部分关键词排名。以前,如果您想通过这些 关键词 带来潜在客户,您需要不断地投放广告。这无疑为企业节省了一定的广告费用。即使公司不削减他们的广告预算,他们仍然可以将这些成本花在更多关键词上。随着搜索技术的发展,出现了越来越多的百度。但企业不可能针对所有相关内容在所有百度上投放广告,部分百度暂时不提供付费广告服务。
福建关键词哪个更好优化,快照视图:输入你的关键词,找到你的网站的位置。我们可以在域名后面看到灰色小字体的“搜索快照”。其次,搜索快照具有更新时间。从快照的更新时间可以看出搜索蜘蛛对网站的抓取频率。随着优化越来越好,日期越来越接近查询时间。更能体现搜索引擎对你的信任网站。可能会反映在出现阶段更新您 网站 的频率和情况。如果您的快照更接近,蜘蛛喜欢抓取您的内容。 查看全部
输入关键字 抓取所有网页(福建关键词优化哪家好,百诚互联选择我们你可以放心)
福建关键词优化哪个更好,百诚互联网,选择我们,您可以少走弯路,选择我们,您可以放心。
福建关键词哪个更好优化,从小程序开发,到关键词排名优化,再到百度竞价账号结构搭建,外链资源发布,灵活选择各种相关配套服务,充分探索< @网站的营销功能。优化网站,你需要让更多的页面是收录,并尽量吸引蜘蛛爬取。如果它不能爬取所有的页面,蜘蛛所要做的就是尝试爬取重要的页面。
一个。关键词对应的网页快照必须有完全匹配或部分匹配;湾。关键词 和 网站 的主题必须相关;C。网站的结构必须便于百度掌握并更新;d。有些关键词是时间敏感的,比如大闸蟹、月饼、鞭炮等。网站快照更新一定要及时;网站修改频繁、TDK调整频繁、优化过度、内容采集、不符合gj策略的灰字、多域名绑定、经常被黑等,此类词排名靠前或搜索引擎排名无效;
福建关键词优化哪一个比较好,所以需要评估关键词的优化能否达到优化效果,评估关键词之后的优化效果。网站一般的施工流程是怎样的?网站 是一个相对复杂的系统。从一开始,您就需要考虑所需的功能。网站的规划也是构建所有网站需要做的。@网站 进行整体分析,明确网站的建设目标,确定网站的访问目标,网站提供的内容和服务,域名和标识网站、网站风格和网站目录分类,这一步也是网站成功搭建的前提 @网站,因为所有的施工步骤都是按照规划设计的。搭建正式的网站,需要到相关部门办理哪些手续,缴纳哪些费用?国家规定,通过互联网向网民提供信息,如购物网站,必须取得经营网站许可证,而不是网站备案,俗话说:有政策和对策。
网站通过实施百度优化,可以提升部分关键词排名。以前,如果您想通过这些 关键词 带来潜在客户,您需要不断地投放广告。这无疑为企业节省了一定的广告费用。即使公司不削减他们的广告预算,他们仍然可以将这些成本花在更多关键词上。随着搜索技术的发展,出现了越来越多的百度。但企业不可能针对所有相关内容在所有百度上投放广告,部分百度暂时不提供付费广告服务。
福建关键词哪个更好优化,快照视图:输入你的关键词,找到你的网站的位置。我们可以在域名后面看到灰色小字体的“搜索快照”。其次,搜索快照具有更新时间。从快照的更新时间可以看出搜索蜘蛛对网站的抓取频率。随着优化越来越好,日期越来越接近查询时间。更能体现搜索引擎对你的信任网站。可能会反映在出现阶段更新您 网站 的频率和情况。如果您的快照更接近,蜘蛛喜欢抓取您的内容。
输入关键字 抓取所有网页( 中国少年先锋队基础知识100题管理基础知识真题及答案二级真题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-08 12:19
中国少年先锋队基础知识100题管理基础知识真题及答案二级真题)
百度搜索引擎基础知识 中国少先队基础知识 100题 管理基础知识 真实问答 管理基础知识 真实问答 出结果的过程往往在几毫秒内完成。百度是如何在网子资源互联的汪洋大海中,以如此快的速度将你的网站内容呈现给用户的?这背后有什么样的工作流程和计算?逻辑其实百度搜索引擎的工作并不像首页的搜索框那么简单。搜索引擎向用户展示的每一个搜索结果都对应于互联网上的一个页面。每一个搜索结果都需要经过搜索引擎从生成到展示给用户的过程。四进程爬网过滤,索引和输出结果爬取Baiduspider或Baidu Spider会通过搜索引擎系统的计算,以及爬取的内容和频率来决定爬取哪个网站搜索引擎的计算过程会参考性能你的网站历史记录,比如内容质量是否足够,是否有对用户不友好的设置,是否有过度的SEO行为等。当你的网站产生新内容时,百度蜘蛛吧将通过 Internet 上指向该页面的链接进行访问和爬取。如果您没有设置任何外部链接指向网站 中的新内容,Baiduspider 将无法抓取。搜索引擎的内容会记录爬取的页面、诚实谈话记录、退出采访记录、
某些页面对用户的重要性被安排为以不同的频率进行爬取和更新。您应该知道,一些爬虫软件会伪装成百度蜘蛛来爬取您的 网站 用于各种目的。这可能不会受到影响。当受控爬取行为严重时,会影响网站的正常运行。过滤 Internet 中并非所有网页对用户都有意义。例如,一些明显的欺骗用户的网页是死链接和空白内容页面。没有文字 zh201308 莆田安服 wwwanfufxcom 对百度来说已经足够有价值了,所以百度会自动过滤这些内容,避免给用户带来不必要的麻烦,你的网站建立索引百度会爬回内容,它会标记和识别一个一个并将这些标记存储为结构化数据,比如网页的tagtitlemetadescripton,网页的外部链接和描述,爬取记录。同时,网页中的关键词信息将被识别并存储,以供用户搜索。输出的内容匹配,用户输入的输出结果关键词百度会对其进行一系列复杂的分析,根据结论在索引库中搜索最匹配的系列网页分析。根据用户输入的关键词反映的需求和网页的优劣进行打分,根据最终打分显示给用户。网页中的信息将被识别并存储以供用户搜索。输出的内容匹配,用户输入的输出结果关键词百度会对其进行一系列复杂的分析,根据结论在索引库中搜索最匹配的系列网页分析。根据用户输入的关键词反映的需求和网页的优劣进行打分,根据最终打分显示给用户。网页中的信息将被识别并存储以供用户搜索。输出的内容匹配,用户输入的输出结果关键词百度会对其进行一系列复杂的分析,根据结论在索引库中搜索最匹配的系列网页分析。根据用户输入的关键词反映的需求和网页的优劣进行打分,根据最终打分显示给用户。 查看全部
输入关键字 抓取所有网页(
中国少年先锋队基础知识100题管理基础知识真题及答案二级真题)

百度搜索引擎基础知识 中国少先队基础知识 100题 管理基础知识 真实问答 管理基础知识 真实问答 出结果的过程往往在几毫秒内完成。百度是如何在网子资源互联的汪洋大海中,以如此快的速度将你的网站内容呈现给用户的?这背后有什么样的工作流程和计算?逻辑其实百度搜索引擎的工作并不像首页的搜索框那么简单。搜索引擎向用户展示的每一个搜索结果都对应于互联网上的一个页面。每一个搜索结果都需要经过搜索引擎从生成到展示给用户的过程。四进程爬网过滤,索引和输出结果爬取Baiduspider或Baidu Spider会通过搜索引擎系统的计算,以及爬取的内容和频率来决定爬取哪个网站搜索引擎的计算过程会参考性能你的网站历史记录,比如内容质量是否足够,是否有对用户不友好的设置,是否有过度的SEO行为等。当你的网站产生新内容时,百度蜘蛛吧将通过 Internet 上指向该页面的链接进行访问和爬取。如果您没有设置任何外部链接指向网站 中的新内容,Baiduspider 将无法抓取。搜索引擎的内容会记录爬取的页面、诚实谈话记录、退出采访记录、

某些页面对用户的重要性被安排为以不同的频率进行爬取和更新。您应该知道,一些爬虫软件会伪装成百度蜘蛛来爬取您的 网站 用于各种目的。这可能不会受到影响。当受控爬取行为严重时,会影响网站的正常运行。过滤 Internet 中并非所有网页对用户都有意义。例如,一些明显的欺骗用户的网页是死链接和空白内容页面。没有文字 zh201308 莆田安服 wwwanfufxcom 对百度来说已经足够有价值了,所以百度会自动过滤这些内容,避免给用户带来不必要的麻烦,你的网站建立索引百度会爬回内容,它会标记和识别一个一个并将这些标记存储为结构化数据,比如网页的tagtitlemetadescripton,网页的外部链接和描述,爬取记录。同时,网页中的关键词信息将被识别并存储,以供用户搜索。输出的内容匹配,用户输入的输出结果关键词百度会对其进行一系列复杂的分析,根据结论在索引库中搜索最匹配的系列网页分析。根据用户输入的关键词反映的需求和网页的优劣进行打分,根据最终打分显示给用户。网页中的信息将被识别并存储以供用户搜索。输出的内容匹配,用户输入的输出结果关键词百度会对其进行一系列复杂的分析,根据结论在索引库中搜索最匹配的系列网页分析。根据用户输入的关键词反映的需求和网页的优劣进行打分,根据最终打分显示给用户。网页中的信息将被识别并存储以供用户搜索。输出的内容匹配,用户输入的输出结果关键词百度会对其进行一系列复杂的分析,根据结论在索引库中搜索最匹配的系列网页分析。根据用户输入的关键词反映的需求和网页的优劣进行打分,根据最终打分显示给用户。
输入关键字 抓取所有网页(爬取一下京东的商品列表,下拉一下才可以拿到60个 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-22 13:18
)
今天,我们将爬取京东产品列表。您无需为此 网站 保持登录状态,但列表中有 60 个项目。您必须下拉才能获得 60 件物品。今天,以京东手机为例,我们将涵盖所有这些。抓住
使用xpath获取并尝试一下,我们会看到30个加载并渲染,剩下的30个没有渲染。我们往下拉,会发现30变成了60,剩下的30是动态加载的
对于这个解决方案,我们选择使用 selenium 来下拉和加载它。我们使用scrapy来实现它。我们主要练习技术。有很多方法可以实现它。我们首先创建一个scrapy项目,scrapy startproject JD,cd到目录下,我们在创建一个spider文件,执行scrapy genspider dj,用pycharm打开,
先写item,确定我们要抓取的字段
import scrapy
class JdItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 手机名称
name = scrapy.Field()
# 链接
link = scrapy.Field()
# 价格
price = scrapy.Field()
# 评论数
comment_num = scrapy.Field()
# 店铺名称
shop_name = scrapy.Field()
# 店铺链接
shop_link = scrapy.Field()
让我们编写中间件,其中我们使用 selenium 下拉到底部并加载它们。我们必须在 MiddleWare.py 和 scrapy.http 中编写 HtmlResponse 模块。我们使用 HtmlResponse 将源代码返回给蜘蛛进行解析和渲染。记得自己配置webdriver。executable_path 写入路径后的值
import time
from selenium import webdriver
from scrapy.http import HtmlResponse
class SeleniumWare(object):
def process_request(self,spider,request):
self.option = webdriver.ChromeOptions()
self.option.add_argument("--headless")
self.driver = webdriver.Chrome(executable_path='C:\Program Files\Google\Chrome\Application\chromedriver.exe',options=self.option)
self.driver.get(request.url)
self.driver.implicitly_wait(10)
self.driver.execute_script('var p = document.documentElement.scrollTop=100000')
time.sleep(3)
data = self.driver.page_source
self.driver.close()
data = str(data)
res = HtmlResponse(body=data,encoding="utf-8",request=request,url=request.url)
return res
编写蜘蛛爬虫
<p># -*- coding: utf-8 -*-
import scrapy
from JD.items import JdItem
class JdSpider(scrapy.Spider):
name = 'jd'
allowed_domains = ['jd.com']
start_urls = ['https://search.jd.com/Search?keyword=手机']
page = 2
def parse(self, response):
# 获取节点
node_list = response.xpath('//div[@class="gl-i-wrap"]')
# 打印个数
print(len(node_list))
# 拿出节点每个信息
for node in node_list:
item = JdItem()
# 我们try一下,有些缺失的抛错,我们阻止异常,返回None
try:
item["name"] = node.xpath('./div[4]/a/em/text()').extract_first().strip()
except:
item["name"] = None
try:
item["link"] = response.urljoin(node.xpath('./div[4]/a/@href').extract_first())
except:
item["link"] = None
try:
item["price"] = node.xpath('./div[3]/strong/i/text()').extract_first() + '元'
except:
item["price"] = None
try:
item["comment_num"] = node.xpath('./div[5]/strong/a/text()').extract_first()
except:
item["comment_num"] = None
try:
item["shop_name"] = node.xpath('./div[7]/span/a/text()').extract_first().strip()
except:
item["shop_name"] = None
try:
item["shop_link"] = "https:" + node.xpath('./div[7]/span/a/@href').extract_first()
except:
item["shop_link"] = None
print(item)
# 返回item,交给pipline
yield item
# 采用拼接的方式获取下一页
if self.page 查看全部
输入关键字 抓取所有网页(爬取一下京东的商品列表,下拉一下才可以拿到60个
)
今天,我们将爬取京东产品列表。您无需为此 网站 保持登录状态,但列表中有 60 个项目。您必须下拉才能获得 60 件物品。今天,以京东手机为例,我们将涵盖所有这些。抓住
使用xpath获取并尝试一下,我们会看到30个加载并渲染,剩下的30个没有渲染。我们往下拉,会发现30变成了60,剩下的30是动态加载的
对于这个解决方案,我们选择使用 selenium 来下拉和加载它。我们使用scrapy来实现它。我们主要练习技术。有很多方法可以实现它。我们首先创建一个scrapy项目,scrapy startproject JD,cd到目录下,我们在创建一个spider文件,执行scrapy genspider dj,用pycharm打开,
先写item,确定我们要抓取的字段
import scrapy
class JdItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 手机名称
name = scrapy.Field()
# 链接
link = scrapy.Field()
# 价格
price = scrapy.Field()
# 评论数
comment_num = scrapy.Field()
# 店铺名称
shop_name = scrapy.Field()
# 店铺链接
shop_link = scrapy.Field()
让我们编写中间件,其中我们使用 selenium 下拉到底部并加载它们。我们必须在 MiddleWare.py 和 scrapy.http 中编写 HtmlResponse 模块。我们使用 HtmlResponse 将源代码返回给蜘蛛进行解析和渲染。记得自己配置webdriver。executable_path 写入路径后的值
import time
from selenium import webdriver
from scrapy.http import HtmlResponse
class SeleniumWare(object):
def process_request(self,spider,request):
self.option = webdriver.ChromeOptions()
self.option.add_argument("--headless")
self.driver = webdriver.Chrome(executable_path='C:\Program Files\Google\Chrome\Application\chromedriver.exe',options=self.option)
self.driver.get(request.url)
self.driver.implicitly_wait(10)
self.driver.execute_script('var p = document.documentElement.scrollTop=100000')
time.sleep(3)
data = self.driver.page_source
self.driver.close()
data = str(data)
res = HtmlResponse(body=data,encoding="utf-8",request=request,url=request.url)
return res
编写蜘蛛爬虫
<p># -*- coding: utf-8 -*-
import scrapy
from JD.items import JdItem
class JdSpider(scrapy.Spider):
name = 'jd'
allowed_domains = ['jd.com']
start_urls = ['https://search.jd.com/Search?keyword=手机']
page = 2
def parse(self, response):
# 获取节点
node_list = response.xpath('//div[@class="gl-i-wrap"]')
# 打印个数
print(len(node_list))
# 拿出节点每个信息
for node in node_list:
item = JdItem()
# 我们try一下,有些缺失的抛错,我们阻止异常,返回None
try:
item["name"] = node.xpath('./div[4]/a/em/text()').extract_first().strip()
except:
item["name"] = None
try:
item["link"] = response.urljoin(node.xpath('./div[4]/a/@href').extract_first())
except:
item["link"] = None
try:
item["price"] = node.xpath('./div[3]/strong/i/text()').extract_first() + '元'
except:
item["price"] = None
try:
item["comment_num"] = node.xpath('./div[5]/strong/a/text()').extract_first()
except:
item["comment_num"] = None
try:
item["shop_name"] = node.xpath('./div[7]/span/a/text()').extract_first().strip()
except:
item["shop_name"] = None
try:
item["shop_link"] = "https:" + node.xpath('./div[7]/span/a/@href').extract_first()
except:
item["shop_link"] = None
print(item)
# 返回item,交给pipline
yield item
# 采用拼接的方式获取下一页
if self.page
输入关键字 抓取所有网页(做seo很大程度是做关键词的基本目标,才有更好的转化率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-21 12:05
很大程度上,做SEO就是做关键词排名。将关键词设为首页是SEO的基本目标。只有首页的排名,才能有更好的展示机会和更高的转化率。
一、搜索原理
网络蜘蛛是网络蜘蛛。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到所有 网站 网页都被爬取。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
1、抢
搜索引擎和普通访问者一样,会按照网页上的链接,一一下载我们的网页,为下一步的预处理做准备。
2、预处理
①。判断是否符合其收录规则,若符合收录规则则继续处理
②。对 文章 进行分词
将网页中的 文章 剪切成单个单词。测量文档之间的相关性并准备反向索引。并记录单词出现的位置。
③。创建倒排索引
在搜索引擎中,每个文件对应一个文件ID,文件内容表示为一系列关键词的集合
将文件 ID 到 关键词 的映射转换为 关键词 到文件 ID 的映射。
使用词索引网页的好处是搜索引擎的用户也输入了词,这样他们就可以很容易地找到相关的网页。
3、搜索
①。用户对关键词查询进行分段,取索引的交集
②.排序
重要性 - 网页静态质量得分。搜索引擎将网站的各种性能条件转化为分数,这些分数相加得到一个页面的质量分数,即所谓的权重。
一种。页面信噪比:
页面信噪比是指页面中文字与非文字的比例,页面信噪比至少要大于1。
湾。缺乏
C。链接控制:
链接控制子链接的数量和链接自然度。页面的权重是固定的,链接可以传递权重。链路越多,每条链路传输的权重越低。
d。页面浏览量
相关性——以上只能通过倒排索引来定性的知道网页和查询词是否相关,但是没有办法知道谁更相关,也就是定量的。百度处理方法:
一种。记录单词出现的位置,关键词在不同位置的权重不同。
湾。tf-idf算法,即一个词在一篇文章文章中出现次数最多,词的权重越高;一个词在整个互联网上出现的次数越多,(比如“我”、“这个词”不足以区分一个文章的话题,几乎每一个文章都会出现)越小这个词的重量。
4、常用的高级搜索命令:
site:最熟悉的SEO高级搜索命令,用于搜索一个域名下的所有文件。
inurl: 指令用于搜索查询词出现在 url 中的页面。
intitle:该命令返回页面标题中收录关键词的页面。
domain:其作用是查询域名下的反向链接(反向链接=外部链接+内部链接)。
二、指数排名
1、收录 和索引
收录:页面被百度蜘蛛发现并分析
索引:百度蜘蛛初步分析认为有意义,做建库
收录索引的关系是收录关系。可以先建一个索引收录,收录的数量大于索引的数量。
百度表示,第三方提供的所谓收录查询是不可靠的。
1-1、索引文章行列式:
可信度;
文章质量;
更新频率;
网站结构体;
熊掌号和站点地图对百度有推广作用收录;
网站的年龄和体重影响百度收录对网站的影响。
1-2、加速页面索引方法:
做好网站TDK,不要修改;
积累优质网站内容;
每日定期和定量更新;
提交百度等搜索引擎,包括站点地图、熊掌号等;
重点制作熊掌号。目前熊爪号的提交已经可以做到移动站收录的80%以上;
有针对性、定期发布优质外链。
2、文章质量判断(百度官方)
①。观众
受众的规模代表了用户检索需求的规模。
②。稀缺
稀缺性主要描述了互联网页面的独特性。
③.质量
a 不能是死链接,网站访问速度是否令人满意。
b 主要内容是否完整,版式和字体是否易于阅读,广告是否过多。
c 信息是否丰富,是否满足扩展的次要需求。
④。老化
3、原创识别判断
①。释放时间——蜘蛛抓到的日期
②.锚文本链接——网站页面有多少个外部链接
③.信息指纹——文章内容的相似度
4、标题优化方法
搜索引擎搜索到的内容的标题往往就是网页标题的内容,搜索引擎给标题赋予了很高的权重。
①。标题流畅、吸引人且文章现实。
②。标题必须为原创,收录核心关键词和长尾词,与内容关键词保持一致
③。写作要符合搜索引擎的习惯,少用标点符号
④。长度适当,控制在22个汉字以内
5、内容优化方法
主要分为两部分:一部分是原创/伪原创,另一部分是采集素材库回顾。
至少第一段需要纯原创,最好有可搜索的内容,整个段落要根据玩家的搜索需求来写。
正文最好有条不紊地分成小标题
基于内容的 伪原创 方法
寻找有价值的文章,最好当天发布,或者使用爬虫爬取的数据库重写
有价值的 文章 可读性强、目标明确且引人注目。
①。修改文章的开头和结尾部分:
重新总结第一段和最后一段,打乱文中的顺序,去掉一些不相关的。添加透视。
②。对原文进行拆分重组:找几个相关的文章合并成一个新的文章
③。相关内容的组合与组合
④。将 文章 翻译成其他语言
⑤。使用论坛、博客、新媒体等方式挖掘文章
6、图像优化方法
搜索引擎已经具备一定的能力来识别大多数图像的 原创 属性
图片的算法主要包括计算hash值、pHash算法和SIFT算法,对目标图像进行编码形成“指纹”并存储。
①。给图片添加水印;
②。改变原图的纵横比,或者直接截取图片的某一部分;
③。图片长宽比尽量接近121*75,接近百度搜索显示的缩略图大小;
④。缩略图内部链接,相比文字链接,更能吸引访问者点击,关注相关性。
⑤。添加alt描述可以增强页面的主题关键词,但是注意不要堆放关键词。
⑥。百度越来越喜欢原创的内容,其实图片也是页面的一部分。
7、关键词优化方法
关键词类别:核心关键词;相关关键词;长尾 关键词; 错误 关键词; 不常见 关键词
①。从用户的角度考虑,想想用户在搜索时使用了什么词
②,不超过5个,一般3个:主关键词,辅助关键词,潜在长尾关键词
③、关键词密度不超过2% - 8%(根据需要,不是绝对的) 查看全部
输入关键字 抓取所有网页(做seo很大程度是做关键词的基本目标,才有更好的转化率)
很大程度上,做SEO就是做关键词排名。将关键词设为首页是SEO的基本目标。只有首页的排名,才能有更好的展示机会和更高的转化率。
一、搜索原理
网络蜘蛛是网络蜘蛛。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到所有 网站 网页都被爬取。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
1、抢
搜索引擎和普通访问者一样,会按照网页上的链接,一一下载我们的网页,为下一步的预处理做准备。
2、预处理
①。判断是否符合其收录规则,若符合收录规则则继续处理
②。对 文章 进行分词
将网页中的 文章 剪切成单个单词。测量文档之间的相关性并准备反向索引。并记录单词出现的位置。
③。创建倒排索引
在搜索引擎中,每个文件对应一个文件ID,文件内容表示为一系列关键词的集合
将文件 ID 到 关键词 的映射转换为 关键词 到文件 ID 的映射。
使用词索引网页的好处是搜索引擎的用户也输入了词,这样他们就可以很容易地找到相关的网页。
3、搜索
①。用户对关键词查询进行分段,取索引的交集
②.排序
重要性 - 网页静态质量得分。搜索引擎将网站的各种性能条件转化为分数,这些分数相加得到一个页面的质量分数,即所谓的权重。
一种。页面信噪比:
页面信噪比是指页面中文字与非文字的比例,页面信噪比至少要大于1。
湾。缺乏
C。链接控制:
链接控制子链接的数量和链接自然度。页面的权重是固定的,链接可以传递权重。链路越多,每条链路传输的权重越低。
d。页面浏览量
相关性——以上只能通过倒排索引来定性的知道网页和查询词是否相关,但是没有办法知道谁更相关,也就是定量的。百度处理方法:
一种。记录单词出现的位置,关键词在不同位置的权重不同。
湾。tf-idf算法,即一个词在一篇文章文章中出现次数最多,词的权重越高;一个词在整个互联网上出现的次数越多,(比如“我”、“这个词”不足以区分一个文章的话题,几乎每一个文章都会出现)越小这个词的重量。
4、常用的高级搜索命令:
site:最熟悉的SEO高级搜索命令,用于搜索一个域名下的所有文件。
inurl: 指令用于搜索查询词出现在 url 中的页面。
intitle:该命令返回页面标题中收录关键词的页面。
domain:其作用是查询域名下的反向链接(反向链接=外部链接+内部链接)。
二、指数排名
1、收录 和索引
收录:页面被百度蜘蛛发现并分析
索引:百度蜘蛛初步分析认为有意义,做建库
收录索引的关系是收录关系。可以先建一个索引收录,收录的数量大于索引的数量。
百度表示,第三方提供的所谓收录查询是不可靠的。
1-1、索引文章行列式:
可信度;
文章质量;
更新频率;
网站结构体;
熊掌号和站点地图对百度有推广作用收录;
网站的年龄和体重影响百度收录对网站的影响。
1-2、加速页面索引方法:
做好网站TDK,不要修改;
积累优质网站内容;
每日定期和定量更新;
提交百度等搜索引擎,包括站点地图、熊掌号等;
重点制作熊掌号。目前熊爪号的提交已经可以做到移动站收录的80%以上;
有针对性、定期发布优质外链。
2、文章质量判断(百度官方)
①。观众
受众的规模代表了用户检索需求的规模。
②。稀缺
稀缺性主要描述了互联网页面的独特性。
③.质量
a 不能是死链接,网站访问速度是否令人满意。
b 主要内容是否完整,版式和字体是否易于阅读,广告是否过多。
c 信息是否丰富,是否满足扩展的次要需求。
④。老化
3、原创识别判断
①。释放时间——蜘蛛抓到的日期
②.锚文本链接——网站页面有多少个外部链接
③.信息指纹——文章内容的相似度
4、标题优化方法
搜索引擎搜索到的内容的标题往往就是网页标题的内容,搜索引擎给标题赋予了很高的权重。
①。标题流畅、吸引人且文章现实。
②。标题必须为原创,收录核心关键词和长尾词,与内容关键词保持一致
③。写作要符合搜索引擎的习惯,少用标点符号
④。长度适当,控制在22个汉字以内
5、内容优化方法
主要分为两部分:一部分是原创/伪原创,另一部分是采集素材库回顾。
至少第一段需要纯原创,最好有可搜索的内容,整个段落要根据玩家的搜索需求来写。
正文最好有条不紊地分成小标题
基于内容的 伪原创 方法
寻找有价值的文章,最好当天发布,或者使用爬虫爬取的数据库重写
有价值的 文章 可读性强、目标明确且引人注目。
①。修改文章的开头和结尾部分:
重新总结第一段和最后一段,打乱文中的顺序,去掉一些不相关的。添加透视。
②。对原文进行拆分重组:找几个相关的文章合并成一个新的文章
③。相关内容的组合与组合
④。将 文章 翻译成其他语言
⑤。使用论坛、博客、新媒体等方式挖掘文章
6、图像优化方法
搜索引擎已经具备一定的能力来识别大多数图像的 原创 属性
图片的算法主要包括计算hash值、pHash算法和SIFT算法,对目标图像进行编码形成“指纹”并存储。
①。给图片添加水印;
②。改变原图的纵横比,或者直接截取图片的某一部分;
③。图片长宽比尽量接近121*75,接近百度搜索显示的缩略图大小;
④。缩略图内部链接,相比文字链接,更能吸引访问者点击,关注相关性。
⑤。添加alt描述可以增强页面的主题关键词,但是注意不要堆放关键词。
⑥。百度越来越喜欢原创的内容,其实图片也是页面的一部分。
7、关键词优化方法
关键词类别:核心关键词;相关关键词;长尾 关键词; 错误 关键词; 不常见 关键词
①。从用户的角度考虑,想想用户在搜索时使用了什么词
②,不超过5个,一般3个:主关键词,辅助关键词,潜在长尾关键词
③、关键词密度不超过2% - 8%(根据需要,不是绝对的)
输入关键字 抓取所有网页(做seo很大程度是做关键词的基本目标,才有更好的转化率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-02-21 12:04
很大程度上,做SEO就是做关键词排名。将关键词设为首页是SEO的基本目标。只有首页的排名,才能有更好的展示机会和更高的转化率。
一、搜索原理
网络蜘蛛是网络蜘蛛。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到所有 网站 网页都被爬取。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
1、抢
搜索引擎和普通访问者一样,会按照网页上的链接,一一下载我们的网页,为下一步的预处理做准备。
2、预处理
①。判断是否符合其收录规则,若符合收录规则则继续处理
②。对 文章 进行分词
将网页中的 文章 剪切成单个单词。测量文档之间的相关性并准备反向索引。并记录单词出现的位置。
③。创建倒排索引
在搜索引擎中,每个文件对应一个文件ID,文件内容表示为一系列关键词的集合
将文件 ID 到 关键词 的映射转换为 关键词 到文件 ID 的映射。
使用词索引网页的好处是搜索引擎的用户也输入了词,这样他们就可以很容易地找到相关的网页。
3、搜索
①。用户对关键词查询进行分段,取索引的交集
②.排序
重要性 - 网页静态质量得分。搜索引擎将网站的各种性能条件转化为分数,这些分数相加得到一个页面的质量分数,即所谓的权重。
一种。页面信噪比:
页面信噪比是指页面中文字与非文字的比例,页面信噪比至少要大于1。
湾。缺乏
C。链接控制:
链接控制子链接的数量和链接自然度。页面的权重是固定的,链接可以传递权重。链路越多,每条链路传输的权重越低。
d。页面浏览量
相关性——以上只能通过倒排索引来定性的知道网页和查询词是否相关,但是没有办法知道谁更相关,也就是定量的。百度处理方法:
一种。记录单词出现的位置,关键词在不同位置的权重不同。
湾。tf-idf算法,即一个词在一篇文章文章中出现次数最多,词的权重越高;一个词在整个互联网上出现的次数越多,(比如“我”、“这个词”不足以区分一个文章的话题,几乎每一个文章都会出现)越小这个词的重量。
4、常用的高级搜索命令:
site:最熟悉的SEO高级搜索命令,用于搜索一个域名下的所有文件。
inurl: 指令用于搜索查询词出现在 url 中的页面。
intitle:该命令返回页面标题中收录关键词的页面。
domain:其作用是查询域名下的反向链接(反向链接=外部链接+内部链接)。
二、指数排名
1、收录 和索引
收录:页面被百度蜘蛛发现并分析
索引:百度蜘蛛初步分析认为有意义,做建库
收录索引的关系是收录关系。可以先建一个索引收录,收录的数量大于索引的数量。
百度表示,第三方提供的所谓收录查询是不可靠的。
1-1、索引文章行列式:
可信度;
文章质量;
更新频率;
网站结构体;
熊掌号和站点地图对百度有推广作用收录;
网站的年龄和体重影响百度收录对网站的影响。
1-2、加速页面索引方法:
做好网站TDK,不要修改;
积累优质网站内容;
每日定期和定量更新;
提交百度等搜索引擎,包括站点地图、熊掌号等;
重点制作熊掌号。目前熊爪号的提交已经可以做到移动站收录的80%以上;
有针对性、定期发布优质外链。
2、文章质量判断(百度官方)
①。观众
受众的规模代表了用户检索需求的规模。
②。稀缺
稀缺性主要描述了互联网页面的独特性。
③.质量
a 不能是死链接,网站访问速度是否令人满意。
b 主要内容是否完整,版式和字体是否易于阅读,广告是否过多。
c 信息是否丰富,是否满足扩展的次要需求。
④。老化
3、原创识别判断
①。释放时间——蜘蛛抓到的日期
②.锚文本链接——网站页面有多少个外部链接
③.信息指纹——文章内容的相似度
4、标题优化方法
搜索引擎搜索到的内容的标题往往就是网页标题的内容,搜索引擎给标题赋予了很高的权重。
①。标题流畅、吸引人且文章现实。
②。标题必须为原创,收录核心关键词和长尾词,与内容关键词保持一致
③。写作要符合搜索引擎的习惯,少用标点符号
④。长度适当,控制在22个汉字以内
5、内容优化方法
主要分为两部分:一部分是原创/伪原创,另一部分是采集素材库回顾。
至少第一段需要纯原创,最好有可搜索的内容,整个段落要根据玩家的搜索需求来写。
正文最好有条不紊地分成小标题
基于内容的 伪原创 方法
寻找有价值的文章,最好当天发布,或者使用爬虫爬取的数据库重写
有价值的 文章 可读性强、目标明确且引人注目。
①。修改文章的开头和结尾部分:
重新总结第一段和最后一段,打乱文中的顺序,去掉一些不相关的。添加透视。
②。对原文进行拆分重组:找几个相关的文章合并成一个新的文章
③。相关内容的组合与组合
④。将 文章 翻译成其他语言
⑤。使用论坛、博客、新媒体等方式挖掘文章
6、图像优化方法
搜索引擎已经具备一定的能力来识别大多数图像的 原创 属性
图片的算法主要包括计算hash值、pHash算法和SIFT算法,对目标图像进行编码形成“指纹”并存储。
①。给图片添加水印;
②。改变原图的纵横比,或者直接截取图片的某一部分;
③。图片长宽比尽量接近121*75,接近百度搜索显示的缩略图大小;
④。缩略图内部链接,相比文字链接,更能吸引访问者点击,关注相关性。
⑤。添加alt描述可以增强页面的主题关键词,但是注意不要堆放关键词。
⑥。百度越来越喜欢原创的内容,其实图片也是页面的一部分。
7、关键词优化方法
关键词类别:核心关键词;相关关键词;长尾 关键词; 错误 关键词; 不常见 关键词
①。从用户的角度考虑,想想用户在搜索时使用了什么词
②,不超过5个,一般3个:主关键词,辅助关键词,潜在长尾关键词
③、关键词密度不超过2% - 8%(根据需要,不是绝对的) 查看全部
输入关键字 抓取所有网页(做seo很大程度是做关键词的基本目标,才有更好的转化率)
很大程度上,做SEO就是做关键词排名。将关键词设为首页是SEO的基本目标。只有首页的排名,才能有更好的展示机会和更高的转化率。
一、搜索原理
网络蜘蛛是网络蜘蛛。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到所有 网站 网页都被爬取。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
1、抢
搜索引擎和普通访问者一样,会按照网页上的链接,一一下载我们的网页,为下一步的预处理做准备。
2、预处理
①。判断是否符合其收录规则,若符合收录规则则继续处理
②。对 文章 进行分词
将网页中的 文章 剪切成单个单词。测量文档之间的相关性并准备反向索引。并记录单词出现的位置。
③。创建倒排索引
在搜索引擎中,每个文件对应一个文件ID,文件内容表示为一系列关键词的集合
将文件 ID 到 关键词 的映射转换为 关键词 到文件 ID 的映射。
使用词索引网页的好处是搜索引擎的用户也输入了词,这样他们就可以很容易地找到相关的网页。
3、搜索
①。用户对关键词查询进行分段,取索引的交集
②.排序
重要性 - 网页静态质量得分。搜索引擎将网站的各种性能条件转化为分数,这些分数相加得到一个页面的质量分数,即所谓的权重。
一种。页面信噪比:
页面信噪比是指页面中文字与非文字的比例,页面信噪比至少要大于1。
湾。缺乏
C。链接控制:
链接控制子链接的数量和链接自然度。页面的权重是固定的,链接可以传递权重。链路越多,每条链路传输的权重越低。
d。页面浏览量
相关性——以上只能通过倒排索引来定性的知道网页和查询词是否相关,但是没有办法知道谁更相关,也就是定量的。百度处理方法:
一种。记录单词出现的位置,关键词在不同位置的权重不同。
湾。tf-idf算法,即一个词在一篇文章文章中出现次数最多,词的权重越高;一个词在整个互联网上出现的次数越多,(比如“我”、“这个词”不足以区分一个文章的话题,几乎每一个文章都会出现)越小这个词的重量。
4、常用的高级搜索命令:
site:最熟悉的SEO高级搜索命令,用于搜索一个域名下的所有文件。
inurl: 指令用于搜索查询词出现在 url 中的页面。
intitle:该命令返回页面标题中收录关键词的页面。
domain:其作用是查询域名下的反向链接(反向链接=外部链接+内部链接)。
二、指数排名
1、收录 和索引
收录:页面被百度蜘蛛发现并分析
索引:百度蜘蛛初步分析认为有意义,做建库
收录索引的关系是收录关系。可以先建一个索引收录,收录的数量大于索引的数量。
百度表示,第三方提供的所谓收录查询是不可靠的。
1-1、索引文章行列式:
可信度;
文章质量;
更新频率;
网站结构体;
熊掌号和站点地图对百度有推广作用收录;
网站的年龄和体重影响百度收录对网站的影响。
1-2、加速页面索引方法:
做好网站TDK,不要修改;
积累优质网站内容;
每日定期和定量更新;
提交百度等搜索引擎,包括站点地图、熊掌号等;
重点制作熊掌号。目前熊爪号的提交已经可以做到移动站收录的80%以上;
有针对性、定期发布优质外链。
2、文章质量判断(百度官方)
①。观众
受众的规模代表了用户检索需求的规模。
②。稀缺
稀缺性主要描述了互联网页面的独特性。
③.质量
a 不能是死链接,网站访问速度是否令人满意。
b 主要内容是否完整,版式和字体是否易于阅读,广告是否过多。
c 信息是否丰富,是否满足扩展的次要需求。
④。老化
3、原创识别判断
①。释放时间——蜘蛛抓到的日期
②.锚文本链接——网站页面有多少个外部链接
③.信息指纹——文章内容的相似度
4、标题优化方法
搜索引擎搜索到的内容的标题往往就是网页标题的内容,搜索引擎给标题赋予了很高的权重。
①。标题流畅、吸引人且文章现实。
②。标题必须为原创,收录核心关键词和长尾词,与内容关键词保持一致
③。写作要符合搜索引擎的习惯,少用标点符号
④。长度适当,控制在22个汉字以内
5、内容优化方法
主要分为两部分:一部分是原创/伪原创,另一部分是采集素材库回顾。
至少第一段需要纯原创,最好有可搜索的内容,整个段落要根据玩家的搜索需求来写。
正文最好有条不紊地分成小标题
基于内容的 伪原创 方法
寻找有价值的文章,最好当天发布,或者使用爬虫爬取的数据库重写
有价值的 文章 可读性强、目标明确且引人注目。
①。修改文章的开头和结尾部分:
重新总结第一段和最后一段,打乱文中的顺序,去掉一些不相关的。添加透视。
②。对原文进行拆分重组:找几个相关的文章合并成一个新的文章
③。相关内容的组合与组合
④。将 文章 翻译成其他语言
⑤。使用论坛、博客、新媒体等方式挖掘文章
6、图像优化方法
搜索引擎已经具备一定的能力来识别大多数图像的 原创 属性
图片的算法主要包括计算hash值、pHash算法和SIFT算法,对目标图像进行编码形成“指纹”并存储。
①。给图片添加水印;
②。改变原图的纵横比,或者直接截取图片的某一部分;
③。图片长宽比尽量接近121*75,接近百度搜索显示的缩略图大小;
④。缩略图内部链接,相比文字链接,更能吸引访问者点击,关注相关性。
⑤。添加alt描述可以增强页面的主题关键词,但是注意不要堆放关键词。
⑥。百度越来越喜欢原创的内容,其实图片也是页面的一部分。
7、关键词优化方法
关键词类别:核心关键词;相关关键词;长尾 关键词; 错误 关键词; 不常见 关键词
①。从用户的角度考虑,想想用户在搜索时使用了什么词
②,不超过5个,一般3个:主关键词,辅助关键词,潜在长尾关键词
③、关键词密度不超过2% - 8%(根据需要,不是绝对的)
输入关键字 抓取所有网页(怎么用cloudflare为网站做cdn加速?哪些工具能查询PC端的网站流量?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-19 20:08
如何从网页中提取关键字?
您可以在此处输入域名以反映 网站 关键字。.
哪些工具可以查询PC端的网站流量?
如果是你自己的网站,你可以通过放置统计代码来准确统计你的网站上的流量。像这样的网站流量统计工具有很多,比如baidu、51LA、cnzz等。
如果想查询别人网站的流量,可以使用爱站、站长之家等工具查询。
如何使用cloudflare为网站做CDN加速?
1、开放注册
2、注册后点击login登录cloudflare。如图,输入自己的网站,然后点击添加网站按钮。然后等待 60 秒进行扫描。扫描结束后,单击继续继续。
3、进入DNS设置,请删除mx行,即点击删除。图片显示删除多余的行后。绿云代表驾驶和加速。灰色未启用。你可以自己检查。然后进行下一步。接下来,我们不需要任何修改,我们选择0元免费,点击继续。
4、不同的域名管理地址不同。比如在万网购买域名,可以登录万网修改域名的服务器。如下图所示,进行了相应的修改。
需要注意的是,更改域名的DNS服务器可能需要一段时间才能生效,最长可能需要48小时。但这并不影响您的访问。这一步完成,点击继续。
5、CDN 现已完全设置完毕。生效后,红色将变为下图中的绿色复选标记。当你查看自己的网站 ip时,你会发现显示的ip不再是服务器ip,而是cloudflare的ip。 查看全部
输入关键字 抓取所有网页(怎么用cloudflare为网站做cdn加速?哪些工具能查询PC端的网站流量?)
如何从网页中提取关键字?
您可以在此处输入域名以反映 网站 关键字。.
哪些工具可以查询PC端的网站流量?
如果是你自己的网站,你可以通过放置统计代码来准确统计你的网站上的流量。像这样的网站流量统计工具有很多,比如baidu、51LA、cnzz等。
如果想查询别人网站的流量,可以使用爱站、站长之家等工具查询。
如何使用cloudflare为网站做CDN加速?
1、开放注册
2、注册后点击login登录cloudflare。如图,输入自己的网站,然后点击添加网站按钮。然后等待 60 秒进行扫描。扫描结束后,单击继续继续。
3、进入DNS设置,请删除mx行,即点击删除。图片显示删除多余的行后。绿云代表驾驶和加速。灰色未启用。你可以自己检查。然后进行下一步。接下来,我们不需要任何修改,我们选择0元免费,点击继续。
4、不同的域名管理地址不同。比如在万网购买域名,可以登录万网修改域名的服务器。如下图所示,进行了相应的修改。
需要注意的是,更改域名的DNS服务器可能需要一段时间才能生效,最长可能需要48小时。但这并不影响您的访问。这一步完成,点击继续。
5、CDN 现已完全设置完毕。生效后,红色将变为下图中的绿色复选标记。当你查看自己的网站 ip时,你会发现显示的ip不再是服务器ip,而是cloudflare的ip。
输入关键字 抓取所有网页(Python爬取基金数据案例到的模块案例网址(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-02-19 07:19
)
使用搜索关键词爬取今日头条新闻评论信息案例爬虫4步:1.分析网页2.向网页发送请求,得到响应3.提取分析数据< @4.保存数据
本例中使用的模块
import requests
import time
import csv
案例网址:
一、分析网页
如果我们想通过关键字搜索和爬取新闻评论,我们需要找到他们的界面,但是如何找到这个界面其实并不难。我们在首页的搜索栏中输入关键字进行搜索。单词,点击搜索:
然后 URL 将跳转到搜索关键字的新闻页面:
找到这个页面,我们可以按F12进入开发者模式。经过分析,由于是动态加载的页面,我们很容易找到收录新闻数据的URL接口:
使用 URL 接口,需要分析这个 URL 的信息。可以看出这个URL很长,需要加载的参数很多。这个参数也就是我们常说的params参数:
图中标识的三个参数信息是我们必须使用的信息,offset是页码信息,我们可以用它来爬取数据进行翻页,keyword是关键字信息,这个一般理解,timestamp是一个时间戳,但是这个时间戳发生了一些变化。我在上一篇博文中也提到过,这里不再赘述。有兴趣的可以看我之前的博文:Python爬取基金数据案例
现在我们来看看这个接口URL中的信息是什么样的,如图:
可以看出,这个接口中的信息是json数据格式的信息。所有新闻数据信息都在数据列表中。每个列表收录一条新闻数据信息。我们需要提取每条信息数据的链接地址。以及该消息所属的ID信息。这个ID信息非常有用,提取评论信息时需要用到:
上图是收录评论信息的params参数。可以看到这个参数里面有两个关键参数,group_id和item_id。这个group_id对应上面接口信息中的group_id。item_id 与 group_id 相同。即使分析完成,我们也开始。现在让我们谈谈总体思路。通过搜索,我们得到所有收录新闻数据的界面URL,然后向该URL发送请求提取需要的数据,然后将需要的数据构建到收录每个信息数据的评论的界面中,向此发送请求再次界面,最后提取每条新闻数据的信息并保存。
二、构造params参数,发送请求,获取响应数据
代码显示如下:
def paramsData(self):
"""
构建params的方法
:return:
"""
params = {
"aid": "24",
"app_name": "web_search",
"offset": str(self.page),
"format": "json",
"keyword": self.search_name,
"autoload": "true",
"count": "20",
"en_qc": "1",
"cur_tab": "1",
"from": "search_tab",
"pd": "synthesis",
"timestamp": self.TIMESTRF,
}
return params
def parse_url(self, url, params):
"""
发送请求,获取响应的方法
:param url: self.API_URL
:param params:
:return:
"""
response = requests.get(url=url, headers=self.headers, params=params)
if response.status_code == 200:
return response
三、提取需要的数据
# 提取需要的信息的方法
def get_news_data(self, json_str):
"""
# 提取需要的信息的方法
:param json_str:
:return:
"""
news_dict = {
}
# 提取新闻的url
news_dict['news_url'] = json_str.get('article_url')
# 提取新闻的标题
news_dict['news_title'] = json_str.get('title')
# 提取新闻的ID
news_dict['group_id'] = json_str.get('group_id')
return news_dict
四、再次构建params参数,再次请求提取的URL
def paramsData2(self, news_dict):
"""
再次构建params的方法
:param news_dict:
:return:
"""
params2 = {
"aid": "24",
"app_name": "toutiao_web",
"offset": "0",
"count": "10",
"group_id": news_dict.get('group_id'),
"item_id": news_dict.get('group_id'),
}
return params2 查看全部
输入关键字 抓取所有网页(Python爬取基金数据案例到的模块案例网址(组图)
)
使用搜索关键词爬取今日头条新闻评论信息案例爬虫4步:1.分析网页2.向网页发送请求,得到响应3.提取分析数据< @4.保存数据
本例中使用的模块
import requests
import time
import csv
案例网址:
一、分析网页
如果我们想通过关键字搜索和爬取新闻评论,我们需要找到他们的界面,但是如何找到这个界面其实并不难。我们在首页的搜索栏中输入关键字进行搜索。单词,点击搜索:
然后 URL 将跳转到搜索关键字的新闻页面:
找到这个页面,我们可以按F12进入开发者模式。经过分析,由于是动态加载的页面,我们很容易找到收录新闻数据的URL接口:
使用 URL 接口,需要分析这个 URL 的信息。可以看出这个URL很长,需要加载的参数很多。这个参数也就是我们常说的params参数:
图中标识的三个参数信息是我们必须使用的信息,offset是页码信息,我们可以用它来爬取数据进行翻页,keyword是关键字信息,这个一般理解,timestamp是一个时间戳,但是这个时间戳发生了一些变化。我在上一篇博文中也提到过,这里不再赘述。有兴趣的可以看我之前的博文:Python爬取基金数据案例
现在我们来看看这个接口URL中的信息是什么样的,如图:
可以看出,这个接口中的信息是json数据格式的信息。所有新闻数据信息都在数据列表中。每个列表收录一条新闻数据信息。我们需要提取每条信息数据的链接地址。以及该消息所属的ID信息。这个ID信息非常有用,提取评论信息时需要用到:
上图是收录评论信息的params参数。可以看到这个参数里面有两个关键参数,group_id和item_id。这个group_id对应上面接口信息中的group_id。item_id 与 group_id 相同。即使分析完成,我们也开始。现在让我们谈谈总体思路。通过搜索,我们得到所有收录新闻数据的界面URL,然后向该URL发送请求提取需要的数据,然后将需要的数据构建到收录每个信息数据的评论的界面中,向此发送请求再次界面,最后提取每条新闻数据的信息并保存。
二、构造params参数,发送请求,获取响应数据
代码显示如下:
def paramsData(self):
"""
构建params的方法
:return:
"""
params = {
"aid": "24",
"app_name": "web_search",
"offset": str(self.page),
"format": "json",
"keyword": self.search_name,
"autoload": "true",
"count": "20",
"en_qc": "1",
"cur_tab": "1",
"from": "search_tab",
"pd": "synthesis",
"timestamp": self.TIMESTRF,
}
return params
def parse_url(self, url, params):
"""
发送请求,获取响应的方法
:param url: self.API_URL
:param params:
:return:
"""
response = requests.get(url=url, headers=self.headers, params=params)
if response.status_code == 200:
return response
三、提取需要的数据
# 提取需要的信息的方法
def get_news_data(self, json_str):
"""
# 提取需要的信息的方法
:param json_str:
:return:
"""
news_dict = {
}
# 提取新闻的url
news_dict['news_url'] = json_str.get('article_url')
# 提取新闻的标题
news_dict['news_title'] = json_str.get('title')
# 提取新闻的ID
news_dict['group_id'] = json_str.get('group_id')
return news_dict
四、再次构建params参数,再次请求提取的URL
def paramsData2(self, news_dict):
"""
再次构建params的方法
:param news_dict:
:return:
"""
params2 = {
"aid": "24",
"app_name": "toutiao_web",
"offset": "0",
"count": "10",
"group_id": news_dict.get('group_id'),
"item_id": news_dict.get('group_id'),
}
return params2
输入关键字 抓取所有网页(《BeautifulSoup库使用解析》库的使用方法与解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-02-18 20:21
BeautifulSoup 库使用解析
一、前言
BeautifulSoup 是一个 html 文档解析库,在爬虫解析数据时非常有用。接下来,记录它的使用情况。
二、准备导入库创建beautifulSoup对象
file = open("./Test.html",encoding="utf-8")
soup = BeautifulSoup(file,"html.parser")
content = '''
百度一下,你就知道
新闻
hao123
地图
视频
贴吧
更多产品
'''
soup = BeautifulSoup(content,"html.parser")
这个比较常用,但是在实际使用中,内容会被网页实时捕捉到的文本内容替换掉。
接下来,我们就以上面的文字作为数据源来说明,下面所有的方法都是基于这篇文字的分析
三、 类型 BeautifulSoup 类型
我们刚刚创建的汤对象是 BeautifulSoup 类型。可以打印
print(type(soup))
输出:
标签类型
tag类型是一个很重要的类型,那么什么是Tag呢,它类似于xml中的一个标签,如下图
新闻
hao123
标签可以分为三个部分:名称、属性和字符串。结构如图
#获得找到的第一个名字为a的标签
print(soup.a)
#结果: 新闻
#打印名字
print(soup.a.name)
#结果:a
#打印属性
print(soup.a.attrs)
#结果:{'class': ['mnav'], 'href': 'http://news.baidu.com', 'name': 'tj_trnews'}
#打印内容
print(soup.a.string)
#结果:新闻
NavigableString 和 Comment 类型
这两个其实就是Tag的字符串内容。不同的是,如果内容是全注释的,则为 Comment 类型;否则,它是 NavigableString 类型
百度一下,你就知道
print(type(soup.title.string))
#结果:
print(type(soup.ha.string))
#结果:
print(soup.title.string)
#结果:百度一下,你就知道
print(soup.ha.string)
#结果:我是注释里的内容
#注意上面这里直接获得了注释里的内容
四、 遍历
我们可以通过名称获取标签。
遍历直接子节点内容
for item in soup.head.contents:
print(item.name)
'''
结果:
None
meta
None
meta
None
meta
None
link
None
title
None
ha
None
'''
可以看到子标签都打印出来了(里面会有一些none节点)
children 遍历所有子节点后代
前面的内容得到的直接子节点和children不能得到孙节点。并且后代可以获取所有子节点
for item in soup.body.descendants:
print(item.name)
遍历父节点 遍历兄弟节点 前后遍历
与兄弟节点的遍历不同,这里的前向和后向遍历都可以到达子节点。从根节点向后遍历,可以到达所有节点。
五、搜索 find_all() 指定名称
#查找 name=“a” 的所有标签
alla = soup.find_all(name="a")
for a in alla:
print(a)
结果
新闻
hao123
地图
视频
贴吧
更多产品
上面也可以写成soup.find_all("a"),如果没有指定关键字,默认使用name作为条件
指定文本
allItem = soup.find_all(text="新闻 ")
for item in allItem:
print(item)
结果
新闻
请注意,此处找到的所有字符串都是字符串,而不是标签
指定属性
除了name、text、attrs等关键词,其他代表属性。例如
allItem = soup.find_all(href="//www.baidu.com/more/")
for item in allItem:
print(item)
结果
更多产品
如果属性与python关键字重合,比如class,需要下划线_,比如
allItem = soup.find_all(class_="mnav")
for item in allItem:
print(item)
结果
新闻
hao123
地图
视频
贴吧
可以添加多个条件,例如
allItem = soup.find_all(class_="mnav",href="http://news.baidu.com",name="a")
for item in allItem:
print(item)
结果
新闻
指定名单
list = {"mnav","bri"}
allItem = soup.find_all(class_=list)
for item in allItem:
print(item)
结果
新闻
hao123
地图
视频
贴吧
更多产品
指定正则表达式
allItem = soup.find_all(href =re.compile("www."))
for item in allItem:
print(item)
结果
hao123
更多产品
指定方法
要指定一个方法,可以传入一个方法作为参数,但是这个方法需要一个Tag作为参数。例如:
def has_attr_name(tag):
return tag.has_attr('name')
allItem = soup.find_all(has_attr_name)
for item in allItem:
print(item)
结果
新闻
hao123
地图
视频
贴吧
更多产品
搜索()
BeautifulSoup 也可以使用 search() 进行搜索,但是因为我刚使用 BeautifulSoup 一段时间,所以大多使用 find_all() 来完成搜索,不是很熟悉。我不会写... 查看全部
输入关键字 抓取所有网页(《BeautifulSoup库使用解析》库的使用方法与解析)
BeautifulSoup 库使用解析
一、前言
BeautifulSoup 是一个 html 文档解析库,在爬虫解析数据时非常有用。接下来,记录它的使用情况。
二、准备导入库创建beautifulSoup对象
file = open("./Test.html",encoding="utf-8")
soup = BeautifulSoup(file,"html.parser")
content = '''
百度一下,你就知道
新闻
hao123
地图
视频
贴吧
更多产品
'''
soup = BeautifulSoup(content,"html.parser")
这个比较常用,但是在实际使用中,内容会被网页实时捕捉到的文本内容替换掉。
接下来,我们就以上面的文字作为数据源来说明,下面所有的方法都是基于这篇文字的分析
三、 类型 BeautifulSoup 类型
我们刚刚创建的汤对象是 BeautifulSoup 类型。可以打印
print(type(soup))
输出:
标签类型
tag类型是一个很重要的类型,那么什么是Tag呢,它类似于xml中的一个标签,如下图
新闻
hao123
标签可以分为三个部分:名称、属性和字符串。结构如图
#获得找到的第一个名字为a的标签
print(soup.a)
#结果: 新闻
#打印名字
print(soup.a.name)
#结果:a
#打印属性
print(soup.a.attrs)
#结果:{'class': ['mnav'], 'href': 'http://news.baidu.com', 'name': 'tj_trnews'}
#打印内容
print(soup.a.string)
#结果:新闻
NavigableString 和 Comment 类型
这两个其实就是Tag的字符串内容。不同的是,如果内容是全注释的,则为 Comment 类型;否则,它是 NavigableString 类型
百度一下,你就知道
print(type(soup.title.string))
#结果:
print(type(soup.ha.string))
#结果:
print(soup.title.string)
#结果:百度一下,你就知道
print(soup.ha.string)
#结果:我是注释里的内容
#注意上面这里直接获得了注释里的内容
四、 遍历
我们可以通过名称获取标签。
遍历直接子节点内容
for item in soup.head.contents:
print(item.name)
'''
结果:
None
meta
None
meta
None
meta
None
link
None
title
None
ha
None
'''
可以看到子标签都打印出来了(里面会有一些none节点)
children 遍历所有子节点后代
前面的内容得到的直接子节点和children不能得到孙节点。并且后代可以获取所有子节点
for item in soup.body.descendants:
print(item.name)
遍历父节点 遍历兄弟节点 前后遍历
与兄弟节点的遍历不同,这里的前向和后向遍历都可以到达子节点。从根节点向后遍历,可以到达所有节点。
五、搜索 find_all() 指定名称
#查找 name=“a” 的所有标签
alla = soup.find_all(name="a")
for a in alla:
print(a)
结果
新闻
hao123
地图
视频
贴吧
更多产品
上面也可以写成soup.find_all("a"),如果没有指定关键字,默认使用name作为条件
指定文本
allItem = soup.find_all(text="新闻 ")
for item in allItem:
print(item)
结果
新闻
请注意,此处找到的所有字符串都是字符串,而不是标签
指定属性
除了name、text、attrs等关键词,其他代表属性。例如
allItem = soup.find_all(href="//www.baidu.com/more/")
for item in allItem:
print(item)
结果
更多产品
如果属性与python关键字重合,比如class,需要下划线_,比如
allItem = soup.find_all(class_="mnav")
for item in allItem:
print(item)
结果
新闻
hao123
地图
视频
贴吧
可以添加多个条件,例如
allItem = soup.find_all(class_="mnav",href="http://news.baidu.com",name="a")
for item in allItem:
print(item)
结果
新闻
指定名单
list = {"mnav","bri"}
allItem = soup.find_all(class_=list)
for item in allItem:
print(item)
结果
新闻
hao123
地图
视频
贴吧
更多产品
指定正则表达式
allItem = soup.find_all(href =re.compile("www."))
for item in allItem:
print(item)
结果
hao123
更多产品
指定方法
要指定一个方法,可以传入一个方法作为参数,但是这个方法需要一个Tag作为参数。例如:
def has_attr_name(tag):
return tag.has_attr('name')
allItem = soup.find_all(has_attr_name)
for item in allItem:
print(item)
结果
新闻
hao123
地图
视频
贴吧
更多产品
搜索()
BeautifulSoup 也可以使用 search() 进行搜索,但是因为我刚使用 BeautifulSoup 一段时间,所以大多使用 find_all() 来完成搜索,不是很熟悉。我不会写...
输入关键字 抓取所有网页(网站关键词优化的四个方法有哪些?有什么作用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-02-17 20:10
4、二级目标关键词,在二级域名或二级栏目中做二级目标关键词。
5、长尾关键词在内容页,长尾关键词比音量好,音量是用来驱动目标的关键词。
就像一个金字塔一样,从下往上慢慢堆积,将目标关键词堆叠到顶部。
6、目标关键词围绕主要关键词工作。
7、我自己网站关键词,选择需要考虑很多。
8、如果你想做关键词,先百度看看关键词有多少页。
9、分析可以做多少负重能力关键词。
10、分析竞争对手:前3名需要分析其大小、收录体积和内容页面。
一般情况下,长尾关键词存在于内容页面中,我们需要看看这些文章是原创还是原创,甚至是转载。
如果是后两者,这些长尾关键词的权重不会太高。
11、采集对手数据后,创建一个态势表进行对手分析。
网站关键词四种优化方法[3]
一、网站域名
不知道大家有没有关注过这个英文网站,他们的域名非常规矩,这些网站非常关心他们的域名含义,他们的域名往往是由一个或几个字,不要在意你的域名的长度。
这正是谷歌所喜欢的。谷歌喜欢那些有特殊含义的域名,尤其是那些使用自己的网站的关键词作为域名的网站,即使他们的域名更长,但总比简短、无意义的域名。
对于国内的网站,域名一定要简单易记,让用户直接输入域名即可输入网站,访问者的转化率也会相应提高。
二、网站标题
<p>网站的标题、关键词标签和description标签一直是我们插入关键词的首选位置,但自从百搜更新算法后,将description与 查看全部
输入关键字 抓取所有网页(网站关键词优化的四个方法有哪些?有什么作用?)
4、二级目标关键词,在二级域名或二级栏目中做二级目标关键词。
5、长尾关键词在内容页,长尾关键词比音量好,音量是用来驱动目标的关键词。
就像一个金字塔一样,从下往上慢慢堆积,将目标关键词堆叠到顶部。
6、目标关键词围绕主要关键词工作。
7、我自己网站关键词,选择需要考虑很多。
8、如果你想做关键词,先百度看看关键词有多少页。
9、分析可以做多少负重能力关键词。
10、分析竞争对手:前3名需要分析其大小、收录体积和内容页面。
一般情况下,长尾关键词存在于内容页面中,我们需要看看这些文章是原创还是原创,甚至是转载。
如果是后两者,这些长尾关键词的权重不会太高。
11、采集对手数据后,创建一个态势表进行对手分析。
网站关键词四种优化方法[3]
一、网站域名
不知道大家有没有关注过这个英文网站,他们的域名非常规矩,这些网站非常关心他们的域名含义,他们的域名往往是由一个或几个字,不要在意你的域名的长度。
这正是谷歌所喜欢的。谷歌喜欢那些有特殊含义的域名,尤其是那些使用自己的网站的关键词作为域名的网站,即使他们的域名更长,但总比简短、无意义的域名。
对于国内的网站,域名一定要简单易记,让用户直接输入域名即可输入网站,访问者的转化率也会相应提高。
二、网站标题
<p>网站的标题、关键词标签和description标签一直是我们插入关键词的首选位置,但自从百搜更新算法后,将description与
输入关键字 抓取所有网页(如何在网站优化中有三到四个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-02-17 20:08
如果网站优化里面有三四个关键词,那么关注首页基本没问题。但是,如果关键字超过 10 个或 20 个或更多,则需要在整个 网站 中正确排列,而不是仅仅依靠主页。他们如何更好地联系?或者尝试在 网站 上对这些词进行排名。
通常的做法是将更重要的关键字放在头部。第二级中的附加关键字放置在每个列或频道页面上。如果尾部较长,属于三级关键词,可以使用内容页进行优化。
在首页,主关键词是优化的重点。从页面标题来看,粗体粗重的hx标签关键词比其他词更显眼。
次要关键字不能出现在主页上,相反,次要关键字应该出现在主页上,因为这些词加强了主要关键字。
搜索引擎也通过语义分析知道这一点。这种语义联系不是从字面上理解的,而是从大量统计数据中推导出来的,搜索引擎仍然具有这种智能。
至少这些次要关键词会出现在首页的导航链接中。其中一些出现在主页的主体中,并链接到相应的栏目和频道页面。
这样关键词就可以得到最优分配,整个网站就会有一个强大的逻辑语义关系体系,就像金字塔一样。主页是您想要排名的难词。整个 网站 突出了主页上的关键字分布,无论是语义上还是链接上。
这种多关键词优化方法的前提是,你更有可能拥有的关键词只有三四个更受欢迎。如果想要的二级关键词也很受欢迎,恐怕我们需要单独做一个网站,所有结果都在首页上实现。将它放在专栏页面上,因为您不太可能为所有专栏页面建立许多良好的链接,因此很难对热门词进行排名,除非您真的可以使该网站成为大型知名网站。
需求无处不在。有必要让陌生人见面并让无关的人合作。网站优化过程中如何满足需求?
1、从下拉框和相关搜索中查看需求
百度下拉框和相关搜索是分析用户需求的常用数据。百度下拉框是上周用户搜索最多的词,相关搜索是用户上月搜索最多的词。
(1)下拉框,下拉框中显示的关键词搜索越多,越重要。下拉框的关键词形成时间比较短,可以看到热点近期短期用户,如果行业更新快,爬取内容进行关键词排名。
(2)相关搜索。相关搜索是过去一个月的数据,从中我们可以得到用户最近一个月关心的内容。经验丰富的网站优化器结合下拉框数据,可以看到关键词搜索趋势,企业网站更应该关注相关搜索数据。
2、从搜索排名中发现隐藏需求
从 关键词 的主要搜索中,我们可以看到百度主页上的 网站 排名。从网站的排名,我们可以知道哪些网站用户更喜欢。比如图片、帖子、知识库、库等,比如搜索羊,无论是在下拉框、相关搜索还是首页排名中,都可以看到羊,说明用户对羊的需求强烈讨论的话,这个行业比较适合论坛类型网站。
(1)图片,百度首页图片展示,用户更关注图片,网站应该有更清晰的图片展示。比如装修
(2)海报栏,百度贴吧表示用户有讨论需求,网站可以是论坛栏,比如SEO论坛
(3)是的,首页好像知道用户有问答,网站可以设置一个常见的问答栏。比如医疗
(4)图书馆,图书馆首页显示用户有资料下载需求,网站可提供免费下载链接。 查看全部
输入关键字 抓取所有网页(如何在网站优化中有三到四个)
如果网站优化里面有三四个关键词,那么关注首页基本没问题。但是,如果关键字超过 10 个或 20 个或更多,则需要在整个 网站 中正确排列,而不是仅仅依靠主页。他们如何更好地联系?或者尝试在 网站 上对这些词进行排名。
通常的做法是将更重要的关键字放在头部。第二级中的附加关键字放置在每个列或频道页面上。如果尾部较长,属于三级关键词,可以使用内容页进行优化。
在首页,主关键词是优化的重点。从页面标题来看,粗体粗重的hx标签关键词比其他词更显眼。
次要关键字不能出现在主页上,相反,次要关键字应该出现在主页上,因为这些词加强了主要关键字。
搜索引擎也通过语义分析知道这一点。这种语义联系不是从字面上理解的,而是从大量统计数据中推导出来的,搜索引擎仍然具有这种智能。
至少这些次要关键词会出现在首页的导航链接中。其中一些出现在主页的主体中,并链接到相应的栏目和频道页面。
这样关键词就可以得到最优分配,整个网站就会有一个强大的逻辑语义关系体系,就像金字塔一样。主页是您想要排名的难词。整个 网站 突出了主页上的关键字分布,无论是语义上还是链接上。
这种多关键词优化方法的前提是,你更有可能拥有的关键词只有三四个更受欢迎。如果想要的二级关键词也很受欢迎,恐怕我们需要单独做一个网站,所有结果都在首页上实现。将它放在专栏页面上,因为您不太可能为所有专栏页面建立许多良好的链接,因此很难对热门词进行排名,除非您真的可以使该网站成为大型知名网站。
需求无处不在。有必要让陌生人见面并让无关的人合作。网站优化过程中如何满足需求?
1、从下拉框和相关搜索中查看需求
百度下拉框和相关搜索是分析用户需求的常用数据。百度下拉框是上周用户搜索最多的词,相关搜索是用户上月搜索最多的词。
(1)下拉框,下拉框中显示的关键词搜索越多,越重要。下拉框的关键词形成时间比较短,可以看到热点近期短期用户,如果行业更新快,爬取内容进行关键词排名。
(2)相关搜索。相关搜索是过去一个月的数据,从中我们可以得到用户最近一个月关心的内容。经验丰富的网站优化器结合下拉框数据,可以看到关键词搜索趋势,企业网站更应该关注相关搜索数据。
2、从搜索排名中发现隐藏需求
从 关键词 的主要搜索中,我们可以看到百度主页上的 网站 排名。从网站的排名,我们可以知道哪些网站用户更喜欢。比如图片、帖子、知识库、库等,比如搜索羊,无论是在下拉框、相关搜索还是首页排名中,都可以看到羊,说明用户对羊的需求强烈讨论的话,这个行业比较适合论坛类型网站。
(1)图片,百度首页图片展示,用户更关注图片,网站应该有更清晰的图片展示。比如装修
(2)海报栏,百度贴吧表示用户有讨论需求,网站可以是论坛栏,比如SEO论坛
(3)是的,首页好像知道用户有问答,网站可以设置一个常见的问答栏。比如医疗
(4)图书馆,图书馆首页显示用户有资料下载需求,网站可提供免费下载链接。
输入关键字 抓取所有网页(网络爬虫一般指的是百度搜索引擎谷歌搜索引擎、好搜)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-02-16 13:08
网络爬虫一般指百度搜索引擎、谷歌搜索引擎、好搜搜索引擎,每次都会从各大网站抓取内容更新。当然,至于内容要不要收录,主要还是要排名。基于以下标准:
1、网站保证访问速度,开服速度没有问题,让蜘蛛顺利爬行;
2、路径结构没有动态无限循环链接,最好有伪静态地址。将 文章Address 属性级别 3 添加到主域名列。
3、内容的主题关键词与内容一致,相关,不是头条党。
4、注意页面的元素,比如给图片添加alt属性等等。
5、网站应形成定期更新发布机制。
以上是保证收录的基础。如果要排名,页面必须达到搜索引擎的页面价值。如下:
来自百度工程师博客。
论互联网页面的价值
搜索引擎每天处理数以亿计的查询请求,每个查询请求都代表了用户对某种资源的特定需求。大多数时候,这些需求是通过查询返回的网页结果来满足的,我们可以认为结果中的某些页面对于特定用户的特定需求是有价值的。那么对于搜索引擎来说,一个页面的价值是什么,我们为什么要研究一个页面的价值,从技术上如何判断一个页面的价值呢?本文将一一解答这些问题。
一、什么页面值得
正如我们前面所说,如果一个页面满足了用户的特定需求,它就体现了该页面对用户的价值。那么搜索引擎的价值是什么?一个简单的推论是,所有可能为用户创造价值的页面对搜索引擎都是有价值的。将这些页面构建到搜索引擎的索引中,可以满足最终检索到的用户的需求。我们称之为价值检索。价值。只要能解决用户的信息需求,通过一些正常的检索需求可以达到,它就具有检索价值。
小学生张三喜欢在qzone上写日记,写前天吃了什么,今天玩了什么。这些内容很有价值。对于张三的父母、同学、老师等小学生,以及对小学生日记感兴趣的人来说,它们都很有价值。对于这个信息体,“张三”这个名字是检索的“钥匙”。
如果有一些信息单元只有“浏览”价值,而没有检索方式来达到该信息,则该资源可能是有价值的,但检索价值很低。比如百度大厦附近的地图,从浏览的角度来看是有价值的;但是如果没有周边文字描述(或者链接的锚文本),只有一张裸图,就没有检索价值。当然,如果图片的内容识别技术有朝一日可以自动识别这是一张“百度大厦附近的地图”,或者可以自动分析地图中各种建筑物、街道、餐厅等的名称,那么这张图片也将成为值被检索。所以一个页面是否有检索价值应该取决于两点:
1)是否解决特定需求(价值)
2)这个信息是否可以通过一些常规的搜索方法获得(检索)
那么,没有检索价值的页面对搜索引擎没有价值吗?仔细想想,答案是否定的。索引只是搜索引擎的一部分。对于其他部分,没有检索价值的页面可能对我们更好的具有高检索价值的收录页面有所帮助。例如,对于负责抓取互联网资源的蜘蛛来说,有一些页面是没有检索价值的,但是对这些页面的爬取和分析可以帮助我们更快地掌握这些页面没有检索价值的重要信息。这样可以节省更多流量以实现更有效的爬网。
考虑到这种值可以看作是一种“间接”的检索值,最终还是基于索引值,本文不再讨论。我们只关注“检索价值”这个根本问题。下面所说的“页面值”,特指页面的“检索值”。
二、为什么要研究页面价值
首先,互联网上的页面层出不穷,搜索引擎的硬件资源是有限的。如果我们想用有限的资源覆盖无尽的互联网,我们需要对页面的价值做出判断,而不是收录那些没有搜索价值的页面,更少收录搜索价值低的页面。这是页面值对收录控件的应用。
其次,搜索引擎蜘蛛的抓取能力有限。为了可访问性,网站或IP的爬取率需要有一个上限。在这个限制下,爬取或者页面更新需要有一个顺序,而这个排序的主要参考是页值,或者是页值的预测(不爬取的时候)。这是页面值在蜘蛛调度中的应用。
第三,对于某些页面,页面内容发生变化,导致其检索值由存在变为不存在,典型地成为“死链接”或“被黑”。对于这些页面,好的搜索引擎会在第一时间将其排除在索引之外,或者在检索时将其屏蔽,以确保返回给用户的结果是更多具有高检索价值的“好页面”。对于其他页面,不仅具有较高的检索价值,而且具有很强的“时效性”,可以让用户在第一时间检索到这些页面,从而极大地提升搜索体验。对于搜索引擎来说,更快的收录和索引页面意味着更多的额外资源开销,而收录的速度和索引更新的速度需要改变页面值。分析指导。
最后,一般意义上的页面价值高低对于搜索引擎返回给用户的结果排名也有指导意义。理想情况下,搜索引擎的结果会根据它们与查询请求的相关性进行排序。当相关性大致相等时,用户更倾向于浏览一般意义上页面价值高的网页。这就是页面价值在排名中的应用。
可以说,页面检索价值的研究是搜索引擎中一项比较基础的工作。对页面价值的理解和判断的准确性直接影响到搜索引擎覆盖率、死链接率、时效性等几大指标。.
三、如何判断页面价值
上一篇文章中提到过小学生张三的qzone日记的例子。我们认为这个页面对张三的同学、朋友和家人来说是有价值的和有价值的。同样,百度CEO李彦宏在i贴吧上发了一个十几字的i博,也很有价值,对李彦宏的千万粉丝来说是有价值的。虽然李彦宏的 i-post 的长度可能比张三的日记要小很多,但就这两页的价值而言,我们都有一个共识,那就是一般意义上的李彦宏的价值i-post 比张三的大很多。杂志。(当然,对于张三的妈妈来说,这个数值的关系很可能是相反的)
再比如,搜索一个人的手机号码,搜索引擎返回一个结果,这个结果是这个人在论坛上的回复。虽然关心这个手机号的人并不多,但是由于资源绝对稀缺,这个页面对于这个手机号的查询需求是完全不可替代的,所以具有极高的价值。
此外,页面检索值也受页面质量的影响。相似的页面往往在满足用户需求方面存在很大差异,比如资源下载速度、页面布局、广告数量等。这种差异,我们称之为页面质量。
最后,一些页面具有明显的公共话题性质,这些资源在刚创建时往往关注度非常高,随着时间的推移,热度下降明显,具有“新闻”的特点。典型如各种“门”事件、地震、火灾等大规模自然灾害。我们认为这些资源是“时间敏感的”。
因此,一个页面的检索值大致受以下四个要素影响:
1、感兴趣的观众人数
2、页面的稀缺性(可替代性)
3、页面质量
4、这个页面的时效性强弱
这四个要素,简称为受众、稀缺性、质量和及时性。
1. 观众
受众的规模代表了用户检索需求的规模。评价受众的规模主要基于两个方面:信息发布源的受众和信息内容本身的受众。具体因素包括但不限于:
网站忠实用户群规模
一般来说,知名的网站拥有自己的忠实用户群,他们的成功在于他们的内容和服务,比其他人更能吸引和满足用户。从这个角度来看,我们可以推断 网站 上拥有更多忠实用户群的内容将拥有更多的现有和潜在受众。这样,忠实用户群的规模就可以成为衡量网站内资源检索价值的指标。忠实用户群的好处在于它会发生变化。如果 网站 变得更糟,用户会用脚投票。超链有过期问题、作弊问题,假用户群很难作弊。一般来说,所谓的网站人气与忠实用户群的数量密切相关。
资源分配法
让我们考虑一下网站 内资源分布所反映的受众规模。比如新浪新闻首页的那些推荐内容。新浪编辑为什么要推送这些内容?因为他们认为这些才是用户最感兴趣的。所以从指数价值上看,相当于拥有庞大的编辑团队,已经将内容标记为“符合大众口味”。搜索引擎只需要享受他们的成就。这样,资源相对于某些结构性关键页面(主页、频道页面等)的链接深度也可以作为资源受众规模的指标。
访问人气
让我们从访问热度的角度来考虑受众规模。这是最直接的,当然它需要第三方工具来获取关键数据。这样不仅需要存储的页面,还有用户访问网站的访问方式。
超链
超链接在一定程度上也是受众规模的反映。一个资源的质量越高,它所覆盖的受众就越多,通常获得的正常链接的数量也就越多。
内容特点
A:我写了一篇博客:“传闻郭德纲要上春晚。”
B:我写博客:“我今天吃早餐了。”
从同一个来源来看,前者的受众肯定高于后者。即在发布来源相同的情况下,具有公共属性的内容得分会更高。
2. 稀缺
稀缺性主要描述了互联网页面的独特性。当谈到稀缺性时,人们经常会想到重复。稀缺性等于没有重复吗?我们应该如何解释这个概念?看一个例子:
有人发表了一篇关于新闻事件的原创 博客,然后被新浪转发到新闻频道。就所描述的而言,这是重复。但是,这种重复只是主要内容的重复。一方面,它的转载带来了访问速度和稳定性方面的收获,后续检索用户也可能会使用“新闻事件+新浪”来检索这条新闻。这可以称为站点增益。另一方面,它可能会在转载过程中更改页面标题,根据其受众,在转载页面上可能会有更多有价值的评论和回复,以及指向其他相关事件的新闻。关联。这些可以称为内容增益。因此,即使题材内容没有变化,新浪的转载也是有价值的,稀缺性很高。
同样,反之,如果重新发布的 网站 相当未知,则不会带来站点名称/稳定性/速度增益。更有什者,转载后在页面上添加大量广告妨碍阅读,或者只转载不完整的部分内容。这样的转载,或者说采集,是纯粹的重复,和采集一样,和出处相比,没有检索价值。
综上所述,对于主要内容重复的页面,我们应该评估它们是否具有站点增益和内容增益。只是对于大量没有任何收获的重复页面,我们应该认为它们的稀缺性很低。
3. 质量
页面的质量反映了它满足其需求的程度。判断页面质量的高低,应该从最基本的需求出发。
首先一定不能是死链接,网站要有一定的稳定性,访问速度要令人满意。
其次,主要内容是否完整,排版和字体是否易于阅读,广告是否过多。
最后,信息是否丰富,是否满足扩展的二次需求。
典型的低质量页面具有以下一些特征:
1、主要需求无效/未满足(分类广告/软件下载页面过期、下载链接无效等)
2、死链接
3、虚假信息/诈骗等。
4、点不稳定
5、影响主要需求的权限问题(下载/浏览需要注册会员/积分等)
6、资料不全(转载不全等)
7、浏览体验差(广告/字体/页面布局等)
典型的高质量页面具有以下一些特征:
1、快速访问(快速页面加载/快速资源下载)
2、页面整洁,主要内容突出。
3、页面信息齐全。 查看全部
输入关键字 抓取所有网页(网络爬虫一般指的是百度搜索引擎谷歌搜索引擎、好搜)
网络爬虫一般指百度搜索引擎、谷歌搜索引擎、好搜搜索引擎,每次都会从各大网站抓取内容更新。当然,至于内容要不要收录,主要还是要排名。基于以下标准:
1、网站保证访问速度,开服速度没有问题,让蜘蛛顺利爬行;
2、路径结构没有动态无限循环链接,最好有伪静态地址。将 文章Address 属性级别 3 添加到主域名列。
3、内容的主题关键词与内容一致,相关,不是头条党。
4、注意页面的元素,比如给图片添加alt属性等等。
5、网站应形成定期更新发布机制。
以上是保证收录的基础。如果要排名,页面必须达到搜索引擎的页面价值。如下:
来自百度工程师博客。
论互联网页面的价值
搜索引擎每天处理数以亿计的查询请求,每个查询请求都代表了用户对某种资源的特定需求。大多数时候,这些需求是通过查询返回的网页结果来满足的,我们可以认为结果中的某些页面对于特定用户的特定需求是有价值的。那么对于搜索引擎来说,一个页面的价值是什么,我们为什么要研究一个页面的价值,从技术上如何判断一个页面的价值呢?本文将一一解答这些问题。
一、什么页面值得
正如我们前面所说,如果一个页面满足了用户的特定需求,它就体现了该页面对用户的价值。那么搜索引擎的价值是什么?一个简单的推论是,所有可能为用户创造价值的页面对搜索引擎都是有价值的。将这些页面构建到搜索引擎的索引中,可以满足最终检索到的用户的需求。我们称之为价值检索。价值。只要能解决用户的信息需求,通过一些正常的检索需求可以达到,它就具有检索价值。
小学生张三喜欢在qzone上写日记,写前天吃了什么,今天玩了什么。这些内容很有价值。对于张三的父母、同学、老师等小学生,以及对小学生日记感兴趣的人来说,它们都很有价值。对于这个信息体,“张三”这个名字是检索的“钥匙”。
如果有一些信息单元只有“浏览”价值,而没有检索方式来达到该信息,则该资源可能是有价值的,但检索价值很低。比如百度大厦附近的地图,从浏览的角度来看是有价值的;但是如果没有周边文字描述(或者链接的锚文本),只有一张裸图,就没有检索价值。当然,如果图片的内容识别技术有朝一日可以自动识别这是一张“百度大厦附近的地图”,或者可以自动分析地图中各种建筑物、街道、餐厅等的名称,那么这张图片也将成为值被检索。所以一个页面是否有检索价值应该取决于两点:
1)是否解决特定需求(价值)
2)这个信息是否可以通过一些常规的搜索方法获得(检索)
那么,没有检索价值的页面对搜索引擎没有价值吗?仔细想想,答案是否定的。索引只是搜索引擎的一部分。对于其他部分,没有检索价值的页面可能对我们更好的具有高检索价值的收录页面有所帮助。例如,对于负责抓取互联网资源的蜘蛛来说,有一些页面是没有检索价值的,但是对这些页面的爬取和分析可以帮助我们更快地掌握这些页面没有检索价值的重要信息。这样可以节省更多流量以实现更有效的爬网。
考虑到这种值可以看作是一种“间接”的检索值,最终还是基于索引值,本文不再讨论。我们只关注“检索价值”这个根本问题。下面所说的“页面值”,特指页面的“检索值”。
二、为什么要研究页面价值
首先,互联网上的页面层出不穷,搜索引擎的硬件资源是有限的。如果我们想用有限的资源覆盖无尽的互联网,我们需要对页面的价值做出判断,而不是收录那些没有搜索价值的页面,更少收录搜索价值低的页面。这是页面值对收录控件的应用。
其次,搜索引擎蜘蛛的抓取能力有限。为了可访问性,网站或IP的爬取率需要有一个上限。在这个限制下,爬取或者页面更新需要有一个顺序,而这个排序的主要参考是页值,或者是页值的预测(不爬取的时候)。这是页面值在蜘蛛调度中的应用。
第三,对于某些页面,页面内容发生变化,导致其检索值由存在变为不存在,典型地成为“死链接”或“被黑”。对于这些页面,好的搜索引擎会在第一时间将其排除在索引之外,或者在检索时将其屏蔽,以确保返回给用户的结果是更多具有高检索价值的“好页面”。对于其他页面,不仅具有较高的检索价值,而且具有很强的“时效性”,可以让用户在第一时间检索到这些页面,从而极大地提升搜索体验。对于搜索引擎来说,更快的收录和索引页面意味着更多的额外资源开销,而收录的速度和索引更新的速度需要改变页面值。分析指导。
最后,一般意义上的页面价值高低对于搜索引擎返回给用户的结果排名也有指导意义。理想情况下,搜索引擎的结果会根据它们与查询请求的相关性进行排序。当相关性大致相等时,用户更倾向于浏览一般意义上页面价值高的网页。这就是页面价值在排名中的应用。
可以说,页面检索价值的研究是搜索引擎中一项比较基础的工作。对页面价值的理解和判断的准确性直接影响到搜索引擎覆盖率、死链接率、时效性等几大指标。.
三、如何判断页面价值
上一篇文章中提到过小学生张三的qzone日记的例子。我们认为这个页面对张三的同学、朋友和家人来说是有价值的和有价值的。同样,百度CEO李彦宏在i贴吧上发了一个十几字的i博,也很有价值,对李彦宏的千万粉丝来说是有价值的。虽然李彦宏的 i-post 的长度可能比张三的日记要小很多,但就这两页的价值而言,我们都有一个共识,那就是一般意义上的李彦宏的价值i-post 比张三的大很多。杂志。(当然,对于张三的妈妈来说,这个数值的关系很可能是相反的)
再比如,搜索一个人的手机号码,搜索引擎返回一个结果,这个结果是这个人在论坛上的回复。虽然关心这个手机号的人并不多,但是由于资源绝对稀缺,这个页面对于这个手机号的查询需求是完全不可替代的,所以具有极高的价值。
此外,页面检索值也受页面质量的影响。相似的页面往往在满足用户需求方面存在很大差异,比如资源下载速度、页面布局、广告数量等。这种差异,我们称之为页面质量。
最后,一些页面具有明显的公共话题性质,这些资源在刚创建时往往关注度非常高,随着时间的推移,热度下降明显,具有“新闻”的特点。典型如各种“门”事件、地震、火灾等大规模自然灾害。我们认为这些资源是“时间敏感的”。
因此,一个页面的检索值大致受以下四个要素影响:
1、感兴趣的观众人数
2、页面的稀缺性(可替代性)
3、页面质量
4、这个页面的时效性强弱
这四个要素,简称为受众、稀缺性、质量和及时性。
1. 观众
受众的规模代表了用户检索需求的规模。评价受众的规模主要基于两个方面:信息发布源的受众和信息内容本身的受众。具体因素包括但不限于:
网站忠实用户群规模
一般来说,知名的网站拥有自己的忠实用户群,他们的成功在于他们的内容和服务,比其他人更能吸引和满足用户。从这个角度来看,我们可以推断 网站 上拥有更多忠实用户群的内容将拥有更多的现有和潜在受众。这样,忠实用户群的规模就可以成为衡量网站内资源检索价值的指标。忠实用户群的好处在于它会发生变化。如果 网站 变得更糟,用户会用脚投票。超链有过期问题、作弊问题,假用户群很难作弊。一般来说,所谓的网站人气与忠实用户群的数量密切相关。
资源分配法
让我们考虑一下网站 内资源分布所反映的受众规模。比如新浪新闻首页的那些推荐内容。新浪编辑为什么要推送这些内容?因为他们认为这些才是用户最感兴趣的。所以从指数价值上看,相当于拥有庞大的编辑团队,已经将内容标记为“符合大众口味”。搜索引擎只需要享受他们的成就。这样,资源相对于某些结构性关键页面(主页、频道页面等)的链接深度也可以作为资源受众规模的指标。
访问人气
让我们从访问热度的角度来考虑受众规模。这是最直接的,当然它需要第三方工具来获取关键数据。这样不仅需要存储的页面,还有用户访问网站的访问方式。
超链
超链接在一定程度上也是受众规模的反映。一个资源的质量越高,它所覆盖的受众就越多,通常获得的正常链接的数量也就越多。
内容特点
A:我写了一篇博客:“传闻郭德纲要上春晚。”
B:我写博客:“我今天吃早餐了。”
从同一个来源来看,前者的受众肯定高于后者。即在发布来源相同的情况下,具有公共属性的内容得分会更高。
2. 稀缺
稀缺性主要描述了互联网页面的独特性。当谈到稀缺性时,人们经常会想到重复。稀缺性等于没有重复吗?我们应该如何解释这个概念?看一个例子:
有人发表了一篇关于新闻事件的原创 博客,然后被新浪转发到新闻频道。就所描述的而言,这是重复。但是,这种重复只是主要内容的重复。一方面,它的转载带来了访问速度和稳定性方面的收获,后续检索用户也可能会使用“新闻事件+新浪”来检索这条新闻。这可以称为站点增益。另一方面,它可能会在转载过程中更改页面标题,根据其受众,在转载页面上可能会有更多有价值的评论和回复,以及指向其他相关事件的新闻。关联。这些可以称为内容增益。因此,即使题材内容没有变化,新浪的转载也是有价值的,稀缺性很高。
同样,反之,如果重新发布的 网站 相当未知,则不会带来站点名称/稳定性/速度增益。更有什者,转载后在页面上添加大量广告妨碍阅读,或者只转载不完整的部分内容。这样的转载,或者说采集,是纯粹的重复,和采集一样,和出处相比,没有检索价值。
综上所述,对于主要内容重复的页面,我们应该评估它们是否具有站点增益和内容增益。只是对于大量没有任何收获的重复页面,我们应该认为它们的稀缺性很低。
3. 质量
页面的质量反映了它满足其需求的程度。判断页面质量的高低,应该从最基本的需求出发。
首先一定不能是死链接,网站要有一定的稳定性,访问速度要令人满意。
其次,主要内容是否完整,排版和字体是否易于阅读,广告是否过多。
最后,信息是否丰富,是否满足扩展的二次需求。
典型的低质量页面具有以下一些特征:
1、主要需求无效/未满足(分类广告/软件下载页面过期、下载链接无效等)
2、死链接
3、虚假信息/诈骗等。
4、点不稳定
5、影响主要需求的权限问题(下载/浏览需要注册会员/积分等)
6、资料不全(转载不全等)
7、浏览体验差(广告/字体/页面布局等)
典型的高质量页面具有以下一些特征:
1、快速访问(快速页面加载/快速资源下载)
2、页面整洁,主要内容突出。
3、页面信息齐全。
输入关键字 抓取所有网页(感觉代码有些复杂的一层网页直接上代码去了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-14 02:04
这是一款比较贴近现实生活的爬虫。根据用户输入的关键词,批量下载今日头条的相关图集。核心使用了urllib.request.urlretrieve()方法,然后百度看了一下进度条怎么玩,我直接加了代码,没问题,感觉代码有点复杂。其实理论上一层网页就可以把需要的图片全部爬下来,但是当时我担心会出现问题,所以就多加了一层网页url解析,主要用的还是json分析。这些都比较简单。关键是分析网页之间的url链接。写的时候听了,循环太多了。你自己写的吗),
这次下载的是fate相关的图片,因为是用ajax异步加载的,其实很容易控制,但是页面太多,加上有等待时间,所以加载的页面并没有太多,代码是直接加载的,(感觉注释挺清楚的)
import requests
from bs4 import BeautifulSoup
from skimage import io
import urllib
import re
import time
import json
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
,'Accept':'application/json, text/javascript'
,'Host':'www.toutiao.com'
,'Connection':'keep-alive'
,'Accept-Encoding':'gzip, deflate'
,'Accept-Language':'zh-CN,zh;q=0.8'
,'Upgrade-Insecure-Requests':'1'
,'Referer':'http://www.toutiao.com/search/'
}
url = 'http://www.toutiao.com/search_content/?offset={}&format=json&keyword={}&autoload=true&count=20&cur_tab=3'
#urltest = 'http://www.toutiao.com/search_ ... 39%3B
urllist = []#创建个列表用于存放每次异步加载所更新出来的20条网页url
name = input('请输入所要查找的图片关键词')
for i in range(0,2):#爬取前100条链接
urllist.append(url.format(i,name))
path = '/Users/loukun/Desktop/picture'
def Schedule(a,b,c):#显示下载进度
'''''
a:已经下载的数据块
b:数据块的大小
c:远程文件的大小
'''
per = 100.0 * a * b / c
if per > 100 :
per = 100
sys.stdout.write('\r%.2f%%' % per)
time.sleep(1)
if per == 100:
print('该图片加载完成')
urlname = []#存放每个图集的名称
urllist2 = []#存放每个图集的链接
def get_link(url):
session = requests.Session()
res = session.get(url)
soup = BeautifulSoup(res.text,'html.parser')
jd = json.loads(soup.text)
for articleurl in jd['data']:
name = articleurl['title']
urlimg = articleurl['url']
urlname.append(name)
urllist2.append(urlimg)
#print('图集名称:\n',name,'\n图集链接:\n',url)
return urllist2
#print(urllist)
for url in urllist:
#print('父URL',url)
get_link(url)
time.sleep(1)
def img_save(urllist3,urlname):
i2 = 1
for imgurl,imgname in zip(urllist3,urlname):#将列表中所存放的图片url打印出来,通过skimage将图片打印到控制台上
print('图片',i2,'链接:',imgurl)
print('图片',i2,'预览:\n')
imgname2 = imgname.lstrip('origin/')
try:#查看图片
fateimg = io.imread(imgurl)
io.imshow(fateimg)
io.show()
except OSError:
print('图片打开失败!!')
try:#保存图片
if not os.path.exists(path):#若该路径下面的文件夹不存在则创建一个
os.mkdir(path)
urllib.request.urlretrieve(imgurl,path +'/'+ 'fate系列' + imgname2 + '%s.jpg' % i2,Schedule)
print('下载完成\n\n')
except Exception:
print('下载失败')
#time.sleep(1)
i2 += 1
#通过正则表达式以及json将每张图片的url爬取出来并打印并下载到本地文件夹
def get_jsonurl(url,urlnamecon):
urllist3 = []#该列表用于存放每张图片的url
urlname = []
res = session.get(url,headers = headers)
res.text
soup = BeautifulSoup(res.text,'html.parser')
message = re.findall('gallery: (.*?),\n',soup.text,re.S)#通过正则表达式将json文件提取出来
jd = json.loads(message[0])#通过loads方法将json文件转化为字典形式
url = jd['sub_images']#通过json在线解析器将解析出来的字典类型的网页元素通过键找出其所对应的值
for url1 in url:
urllist3.append(url1['url'])
urlname.append(url1['uri'])#将每张图片的名称保存到列表中
img_save(urllist3,urlname)
num = 1
for urlcontent,urlnamecon in zip(urllist2,urlname):
print('图集',num,'名称:',urlnamecon)#打印每个图集的名称
print('图集',num,'链接:',urlcontent)#打印每个图集的链接
print(len(urlname))
get_jsonurl(urlcontent,urlnamecon)
num += 1
当时文件名控制不好,一直覆盖原文件。久而久之,将原图片地址中的部分字符串作为文件名,避免了覆盖。
总之,马马虎虎,还有很多地方需要改进,欢迎大佬们测试(这段代码真的很实用#funny) 查看全部
输入关键字 抓取所有网页(感觉代码有些复杂的一层网页直接上代码去了)
这是一款比较贴近现实生活的爬虫。根据用户输入的关键词,批量下载今日头条的相关图集。核心使用了urllib.request.urlretrieve()方法,然后百度看了一下进度条怎么玩,我直接加了代码,没问题,感觉代码有点复杂。其实理论上一层网页就可以把需要的图片全部爬下来,但是当时我担心会出现问题,所以就多加了一层网页url解析,主要用的还是json分析。这些都比较简单。关键是分析网页之间的url链接。写的时候听了,循环太多了。你自己写的吗),
这次下载的是fate相关的图片,因为是用ajax异步加载的,其实很容易控制,但是页面太多,加上有等待时间,所以加载的页面并没有太多,代码是直接加载的,(感觉注释挺清楚的)
import requests
from bs4 import BeautifulSoup
from skimage import io
import urllib
import re
import time
import json
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
,'Accept':'application/json, text/javascript'
,'Host':'www.toutiao.com'
,'Connection':'keep-alive'
,'Accept-Encoding':'gzip, deflate'
,'Accept-Language':'zh-CN,zh;q=0.8'
,'Upgrade-Insecure-Requests':'1'
,'Referer':'http://www.toutiao.com/search/'
}
url = 'http://www.toutiao.com/search_content/?offset={}&format=json&keyword={}&autoload=true&count=20&cur_tab=3'
#urltest = 'http://www.toutiao.com/search_ ... 39%3B
urllist = []#创建个列表用于存放每次异步加载所更新出来的20条网页url
name = input('请输入所要查找的图片关键词')
for i in range(0,2):#爬取前100条链接
urllist.append(url.format(i,name))
path = '/Users/loukun/Desktop/picture'
def Schedule(a,b,c):#显示下载进度
'''''
a:已经下载的数据块
b:数据块的大小
c:远程文件的大小
'''
per = 100.0 * a * b / c
if per > 100 :
per = 100
sys.stdout.write('\r%.2f%%' % per)
time.sleep(1)
if per == 100:
print('该图片加载完成')
urlname = []#存放每个图集的名称
urllist2 = []#存放每个图集的链接
def get_link(url):
session = requests.Session()
res = session.get(url)
soup = BeautifulSoup(res.text,'html.parser')
jd = json.loads(soup.text)
for articleurl in jd['data']:
name = articleurl['title']
urlimg = articleurl['url']
urlname.append(name)
urllist2.append(urlimg)
#print('图集名称:\n',name,'\n图集链接:\n',url)
return urllist2
#print(urllist)
for url in urllist:
#print('父URL',url)
get_link(url)
time.sleep(1)
def img_save(urllist3,urlname):
i2 = 1
for imgurl,imgname in zip(urllist3,urlname):#将列表中所存放的图片url打印出来,通过skimage将图片打印到控制台上
print('图片',i2,'链接:',imgurl)
print('图片',i2,'预览:\n')
imgname2 = imgname.lstrip('origin/')
try:#查看图片
fateimg = io.imread(imgurl)
io.imshow(fateimg)
io.show()
except OSError:
print('图片打开失败!!')
try:#保存图片
if not os.path.exists(path):#若该路径下面的文件夹不存在则创建一个
os.mkdir(path)
urllib.request.urlretrieve(imgurl,path +'/'+ 'fate系列' + imgname2 + '%s.jpg' % i2,Schedule)
print('下载完成\n\n')
except Exception:
print('下载失败')
#time.sleep(1)
i2 += 1
#通过正则表达式以及json将每张图片的url爬取出来并打印并下载到本地文件夹
def get_jsonurl(url,urlnamecon):
urllist3 = []#该列表用于存放每张图片的url
urlname = []
res = session.get(url,headers = headers)
res.text
soup = BeautifulSoup(res.text,'html.parser')
message = re.findall('gallery: (.*?),\n',soup.text,re.S)#通过正则表达式将json文件提取出来
jd = json.loads(message[0])#通过loads方法将json文件转化为字典形式
url = jd['sub_images']#通过json在线解析器将解析出来的字典类型的网页元素通过键找出其所对应的值
for url1 in url:
urllist3.append(url1['url'])
urlname.append(url1['uri'])#将每张图片的名称保存到列表中
img_save(urllist3,urlname)
num = 1
for urlcontent,urlnamecon in zip(urllist2,urlname):
print('图集',num,'名称:',urlnamecon)#打印每个图集的名称
print('图集',num,'链接:',urlcontent)#打印每个图集的链接
print(len(urlname))
get_jsonurl(urlcontent,urlnamecon)
num += 1
当时文件名控制不好,一直覆盖原文件。久而久之,将原图片地址中的部分字符串作为文件名,避免了覆盖。
总之,马马虎虎,还有很多地方需要改进,欢迎大佬们测试(这段代码真的很实用#funny)
输入关键字 抓取所有网页(Java中实现标记引擎的无监督方法-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-13 12:25
问题描述
我目前正在尝试在 Java 中实现标签引擎并寻找从文本中提取关键字/标签的解决方案 (文章)。我在 stackoverflow 上找到了一些建议使用 Pointwise Mutual Information 的解决方案。
解决方案 1
我不能使用pyton和nltk,所以我必须自己实现。但我不知道如何计算概率。等式如下所示:
PMI(term, doc) = log [ P(term, doc) / (P(term)*P(doc)) ]
我想知道的是如何计算P(term, doc)
我已经有一个 Langer 文本语料库和一组 文章。这些 文章 不是语料库的一部分。语料库使用 lucene 进行索引。
请帮助我。最好的问候。
推荐答案
有很多算法可以做到这一点:
开源工具:
kea() 监督方法使用训练数据和受控词汇
maui indexer() 基本上是 kea 的扩展,提供了使用百科全书提取关键短语的便利。
carrot2() 用于关键短语提取的无监督方法。它支持多种输入、输出格式和关键短语提取参数。
槌主题建模模块()
斯坦福主题建模工具()
Mahout 聚类算法()
商业 API:
炼金术 API()
zemanta API()
yahoo 词条提取 api() 查看全部
输入关键字 抓取所有网页(Java中实现标记引擎的无监督方法-乐题库)
问题描述
我目前正在尝试在 Java 中实现标签引擎并寻找从文本中提取关键字/标签的解决方案 (文章)。我在 stackoverflow 上找到了一些建议使用 Pointwise Mutual Information 的解决方案。
解决方案 1
我不能使用pyton和nltk,所以我必须自己实现。但我不知道如何计算概率。等式如下所示:
PMI(term, doc) = log [ P(term, doc) / (P(term)*P(doc)) ]
我想知道的是如何计算P(term, doc)
我已经有一个 Langer 文本语料库和一组 文章。这些 文章 不是语料库的一部分。语料库使用 lucene 进行索引。
请帮助我。最好的问候。
推荐答案
有很多算法可以做到这一点:
开源工具:
kea() 监督方法使用训练数据和受控词汇
maui indexer() 基本上是 kea 的扩展,提供了使用百科全书提取关键短语的便利。
carrot2() 用于关键短语提取的无监督方法。它支持多种输入、输出格式和关键短语提取参数。
槌主题建模模块()
斯坦福主题建模工具()
Mahout 聚类算法()
商业 API:
炼金术 API()
zemanta API()
yahoo 词条提取 api()
输入关键字 抓取所有网页(关键词选好了,那么怎么才能让搜索引擎找到呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-13 03:13
关键词一旦被选中,如何被搜索引擎找到?
搜索引擎爬取信息的工作原理是当用户在搜索引擎中输入关键词时,它会通过分词等技术了解用户真实的搜索意图,然后搜索引擎蜘蛛会使用< @关键词 用户输入的信息。抓取网页内容,为用户提供搜索引擎认为相关且有价值的网页内容。
了解了它的工作原理后我们知道,为了让搜索引擎蜘蛛更好的抓取我们的文章内容并进行推荐,关键的一步就是让我们的文章尽可能的覆盖关键词@ >,只有被搜索引擎看到了,我们的目标用户才能看到。
一开始,似乎关键词只能放在像文章标题这样最明显的地方,如果这样做,我们也忽略了很多优化页面内容的空间.
关键词也可以放在文章页面的很多地方:文章标题、文章内容前100字、文章字幕、插入图片评论或者视频的文字描述,甚至URL都是我们可以放关键词的地方。
那么在每个位置,怎么操作呢?
文章标题:最好把你的目标关键词放在文章标题的前半部分,这样会让搜索引擎认为你关注标题开头的文字,并且搜索引擎会知道您的 文章 与您要关联的目标关键词 密切相关。
文章前100字:只在文章的前100字中谈论关键词相关内容,这样会让搜索引擎认为你的文章和关键词是高度相关的。
文章字幕:在写文章的时候,我们不会从头到尾写2000字,我们会加一些字幕,让我们的文章有清晰的逻辑结构。那么我们在设置字幕内容的时候,不要错过抓住关键词的好机会,同样的,尽量把关键词放在字幕的前半部分,吸引搜索引擎。
图片或视频的文字描述:在一些自媒体内容创作平台,如简书、百家号等,插入图片时,可以在图片下方描述关键词,在文字描述中您需要尽可能地添加您的目标 关键词 和相关的 关键词。
文章 标签:在一些内容管理平台中,该标签默认显示页面的标题。
网址:由乱码组成的网址很容易被搜索引擎判断为一组不稳定的网址,可以随时更改,所以当用户使用关键词进行搜索时,很难通过搜索引擎搜索到我们的网站. 网站。文章的SEO优化也是如此,在URL中加入关键词,方便搜索引擎检索到你的文章。但是,这种方法对于许多内容管理平台来说是非常有限的。比如百家号上发布的文章不能随意设置URL。通常,只有在它自己的 网站 中才能设置 URL。修改。
还有一个很重要的一点是这里提到的关键词不只是一个目标关键词,我们可以使用选题步骤中采集的关键词词库。充分利用它。充分利用您的 关键词 词库,该词库在 文章 的各个地方都精心布置。
比如我在编辑同学们的文章《从零开始向新媒体运营转型》的时候,除了放置《从零向新媒体运营转型》的关键词,我看到那在我的关键词库里有一个关键词在“新媒体运营前景如何”,而这个关键词和我的文章有关内容,我会从头开始介绍新媒体运营的时候,插入“新媒体运营前景如何”的相关内容。 查看全部
输入关键字 抓取所有网页(关键词选好了,那么怎么才能让搜索引擎找到呢?(图))
关键词一旦被选中,如何被搜索引擎找到?
搜索引擎爬取信息的工作原理是当用户在搜索引擎中输入关键词时,它会通过分词等技术了解用户真实的搜索意图,然后搜索引擎蜘蛛会使用< @关键词 用户输入的信息。抓取网页内容,为用户提供搜索引擎认为相关且有价值的网页内容。
了解了它的工作原理后我们知道,为了让搜索引擎蜘蛛更好的抓取我们的文章内容并进行推荐,关键的一步就是让我们的文章尽可能的覆盖关键词@ >,只有被搜索引擎看到了,我们的目标用户才能看到。
一开始,似乎关键词只能放在像文章标题这样最明显的地方,如果这样做,我们也忽略了很多优化页面内容的空间.
关键词也可以放在文章页面的很多地方:文章标题、文章内容前100字、文章字幕、插入图片评论或者视频的文字描述,甚至URL都是我们可以放关键词的地方。
那么在每个位置,怎么操作呢?
文章标题:最好把你的目标关键词放在文章标题的前半部分,这样会让搜索引擎认为你关注标题开头的文字,并且搜索引擎会知道您的 文章 与您要关联的目标关键词 密切相关。
文章前100字:只在文章的前100字中谈论关键词相关内容,这样会让搜索引擎认为你的文章和关键词是高度相关的。
文章字幕:在写文章的时候,我们不会从头到尾写2000字,我们会加一些字幕,让我们的文章有清晰的逻辑结构。那么我们在设置字幕内容的时候,不要错过抓住关键词的好机会,同样的,尽量把关键词放在字幕的前半部分,吸引搜索引擎。
图片或视频的文字描述:在一些自媒体内容创作平台,如简书、百家号等,插入图片时,可以在图片下方描述关键词,在文字描述中您需要尽可能地添加您的目标 关键词 和相关的 关键词。
文章 标签:在一些内容管理平台中,该标签默认显示页面的标题。
网址:由乱码组成的网址很容易被搜索引擎判断为一组不稳定的网址,可以随时更改,所以当用户使用关键词进行搜索时,很难通过搜索引擎搜索到我们的网站. 网站。文章的SEO优化也是如此,在URL中加入关键词,方便搜索引擎检索到你的文章。但是,这种方法对于许多内容管理平台来说是非常有限的。比如百家号上发布的文章不能随意设置URL。通常,只有在它自己的 网站 中才能设置 URL。修改。
还有一个很重要的一点是这里提到的关键词不只是一个目标关键词,我们可以使用选题步骤中采集的关键词词库。充分利用它。充分利用您的 关键词 词库,该词库在 文章 的各个地方都精心布置。
比如我在编辑同学们的文章《从零开始向新媒体运营转型》的时候,除了放置《从零向新媒体运营转型》的关键词,我看到那在我的关键词库里有一个关键词在“新媒体运营前景如何”,而这个关键词和我的文章有关内容,我会从头开始介绍新媒体运营的时候,插入“新媒体运营前景如何”的相关内容。
输入关键字 抓取所有网页(速卖通关键词的使用技巧及排序组合组合介绍!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-12 16:02
一、明确速卖通的目的关键词
写速卖通标题时,第一个明确的想法是标题是关键词的最直接体现。因此,一定要在标题中体现产品的核心和最准确的关键词。
运营服务v
标题中的 关键词 有两个目的:
1.启用搜索引擎抓取并输入搜索结果;
2.客户在浏览页面时可以准确了解Listing是什么产品。
二、如何使用速卖通关键词
关键词大致分为三类:大词、精准词、长尾词。
所谓大词,就是接近类词的意思。比如你卖服装,那么“服装/服装”就属于大词的范畴;至于确切的词,它指的是子类别。如果您销售的产品被分类到某个子类别中。比如韩版短裙,相比“服装/服饰”,“韩版短裙”更有针对性,同时这些词对于搜索的客户来说更精准对于这些 关键词; 长尾词是指不常用但恰好被某些特定群体搜索的词,例如某个明星的粉丝。
在使用速卖通标题关键词时,建议不要漏掉大词,精准词要高度相关,长尾词要适当匹配。
1. 大词覆盖的搜索量最大,所以在标题设置上,尽量多用,相关产品尽量用大词。
2. 用精确词搜索的买家很有目的性。他们为某种类型的产品甚至某种产品而来。因此,在匹配时,它们必须非常相关。不相关的产品使用精确的关键词,虽然可以吸引流量,但只能让买家飘过,不能产生实际购买。
3. 有了长尾词,并不是每个产品都有长尾词。因此,在长尾词的使用上,没有必要硬拉。
三、速卖通关键词排序组合
1、 完全匹配(与核心关键词,关键词在标题中出现完全一样,词序不打乱,词不分离)
2、中心匹配(收录核心关键词,由一两个其他单词分隔,但足够接近以形成与核心关键词的长尾关键词)
3、广泛匹配(还有其他与产品相关性较低的热搜词,核心关键词群没有长尾关键词)
注意力!钥匙关键词一定要放在前面并赋予更大的权重,既不会造成浪费,也不会造成关键词堆积。
四、速卖通标题优化注意事项
1、标题的描述是重中之重。对您的产品进行真实准确的总体描述符合海外买家的语法习惯。没有错别字和语法错误。请不要以同样的方式描述。买家也有审美疲劳。
2、切记避免关键词在标题中叠加,例如:“mp3、mp3 player, music mp3 player”这样的标题关键词叠加无助于提升排名,但会被搜索降级处罚。
3、记住要避免标题中的虚假描述。比如卖家销售的产品是MP3,但为了获得更多曝光,在标题中填写类似“MP4、MP5”的描述。有算法可以监控 此类假冒产品和虚假描述也会影响产品的转化,得不偿失。
4、标题除了商品名称外,还必须收录商品属性、尺寸等,但切记不要添加符号,尤其是引号、句号等。因为搜索商品的客户从不会在<之间插入此类符号@关键词,他们基本上使用空格。 查看全部
输入关键字 抓取所有网页(速卖通关键词的使用技巧及排序组合组合介绍!)
一、明确速卖通的目的关键词
写速卖通标题时,第一个明确的想法是标题是关键词的最直接体现。因此,一定要在标题中体现产品的核心和最准确的关键词。
运营服务v
标题中的 关键词 有两个目的:
1.启用搜索引擎抓取并输入搜索结果;
2.客户在浏览页面时可以准确了解Listing是什么产品。
二、如何使用速卖通关键词
关键词大致分为三类:大词、精准词、长尾词。
所谓大词,就是接近类词的意思。比如你卖服装,那么“服装/服装”就属于大词的范畴;至于确切的词,它指的是子类别。如果您销售的产品被分类到某个子类别中。比如韩版短裙,相比“服装/服饰”,“韩版短裙”更有针对性,同时这些词对于搜索的客户来说更精准对于这些 关键词; 长尾词是指不常用但恰好被某些特定群体搜索的词,例如某个明星的粉丝。
在使用速卖通标题关键词时,建议不要漏掉大词,精准词要高度相关,长尾词要适当匹配。
1. 大词覆盖的搜索量最大,所以在标题设置上,尽量多用,相关产品尽量用大词。
2. 用精确词搜索的买家很有目的性。他们为某种类型的产品甚至某种产品而来。因此,在匹配时,它们必须非常相关。不相关的产品使用精确的关键词,虽然可以吸引流量,但只能让买家飘过,不能产生实际购买。
3. 有了长尾词,并不是每个产品都有长尾词。因此,在长尾词的使用上,没有必要硬拉。
三、速卖通关键词排序组合
1、 完全匹配(与核心关键词,关键词在标题中出现完全一样,词序不打乱,词不分离)
2、中心匹配(收录核心关键词,由一两个其他单词分隔,但足够接近以形成与核心关键词的长尾关键词)
3、广泛匹配(还有其他与产品相关性较低的热搜词,核心关键词群没有长尾关键词)
注意力!钥匙关键词一定要放在前面并赋予更大的权重,既不会造成浪费,也不会造成关键词堆积。
四、速卖通标题优化注意事项
1、标题的描述是重中之重。对您的产品进行真实准确的总体描述符合海外买家的语法习惯。没有错别字和语法错误。请不要以同样的方式描述。买家也有审美疲劳。
2、切记避免关键词在标题中叠加,例如:“mp3、mp3 player, music mp3 player”这样的标题关键词叠加无助于提升排名,但会被搜索降级处罚。
3、记住要避免标题中的虚假描述。比如卖家销售的产品是MP3,但为了获得更多曝光,在标题中填写类似“MP4、MP5”的描述。有算法可以监控 此类假冒产品和虚假描述也会影响产品的转化,得不偿失。
4、标题除了商品名称外,还必须收录商品属性、尺寸等,但切记不要添加符号,尤其是引号、句号等。因为搜索商品的客户从不会在<之间插入此类符号@关键词,他们基本上使用空格。
输入关键字 抓取所有网页( 靠作弊手段增加访问量又有何用,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-12 04:04
靠作弊手段增加访问量又有何用,你知道吗?)
选择的 关键词 当然必须与您自己的产品或服务相关。不要听信靠不相关的点击关键词来拉动更多流量的宣传,这不仅不道德,而且毫无意义。想象一下,查找“Monica Lewinsky”的人会对您生产的酱油感兴趣。当然不是。必须承认,有时候这种做法确实可以增加网站的流量,但既然你的目的是卖产品,不是免费八卦,那么依靠这种作弊来增加流量有什么用呢?选择具体的关键词我们在选择关键词的时候还有一点要注意,就是避免以泛泛的词为主关键词,而是要根据你的类型业务或产品,选择尽可能具体的词。例如,一家销售木工工具的制造商,“CarpenterTools”不是正确的选择关键词,“ChainSaws”可能是一个明智的选择。有人会问,既然“CarpenterTools”是一个集合名词,涵盖了厂家的所有产品,不如我们把CarpenterTools拿去谷歌,你会发现搜索结果超过6位(实际数字是189,000),这意味着你有近 200,000 个竞争对手!要从众多竞争对手中脱颖而出几乎是“不可能完成的任务”。相反,“ChainSaws”下的搜索结果要少得多(69,800 个),你有有更多机会领先于竞争对手。选择更长的时间 关键词 查询信息时尽量用词 四词高中英语3500词表的原形式与原形式相反。在提交 网站 时,我们应该使用单词的较长形式。例如,当“游戏”可以使用时,尽量不要选择“游戏”。因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 在提交 网站 时,我们应该使用单词的较长形式。例如,当“游戏”可以使用时,尽量不要选择“游戏”。因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 在提交 网站 时,我们应该使用单词的较长形式。例如,当“游戏”可以使用时,尽量不要选择“游戏”。因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有
这些词经常被用户拼错,考虑到大多数人不会针对拼写错误关键词,所以如果你很聪明并且发现了这个技巧来优化你的网页拼错单词,一旦你遇到用户再次搜索那个错字,你会站在搜索结果的顶部!真的是这样吗?首先,我们来看看上面的例子有什么问题。“contemorary”其实就是“contemporary”,虽然是一个字母的区别,但是从关键词的角度来看,两者相差甚远。奇怪的是,根据关键词监控统计报告财务分析报告财务分析报告模板企业财务分析报告公司财务分析报告模板公司财务分析报告,” 并且那个错字被显着地加粗了多次?他会像发现金矿一样欣喜若狂,还是心中对这家公司的质量产生一点怀疑?他会认为一个连基本语法都没有掌握的厂商,真的是有问题的。所以,拼写错误的 关键词 是一个陷阱,我们必须三思而后行。此外,目前一些搜索引擎(如谷歌)已经增加了自动拼写检查功能。当用户输入错字时,系统会自动提供正确的单词选择。当用户意识到他们错了,大多数人倾向于通过正确的 关键词 提示进行搜索。所以到了这个阶段,优化拼写错误的网页已经基本失去了意义。寻找关键词技能作为网站的拥有者,您当然是最了解您的业务的人,因此您总能找到最能反映您业务的 关键词。但是靠自己的努力,难免会出现一些疏漏。这时候不妨去搜索引擎,找到你的竞争对手的网站,看看他们用什么
其中关键词,你可能会从中得到一些启发。另外,借助一些关键词自动分析软件,可以快速从你或你竞争对手的网页中提取出合适的关键词,你的工作效率可以成倍提升,我们可以通过这些软件找到很多< @关键词 之前没有考虑过,从而大大扩展了我们的关键词参与活动家名单。停用词/过滤词(StopWords/FilterWords)含义相同,指的是一些太常见而没有任何检索值的词,如“a”、“the”、“and”、“of”、“web” ”、“主页”等。搜索引擎遇到这些词一般都会过滤掉。因此,为了节省篇幅,应尽量避免使用此类词,尤其是在字数有严格限制的地方。(如果要验证上述规则,可以尝试在搜索引擎中搜索“staythenight”,会发现“the”这个词在结果中符合搜索条件,但没有以粗体显示,说明.) 重复 关键词 1000 次 既然 关键词 的出现频率是决定 网站 排名的重要因素,那为什么不重复 1000 次,是不是很简单并且有效?停下来。众所周知,这就是搜索引擎的“石器时代”做法,在当时确实奏效,但现在早已被搜索引擎抛弃。当时的典型做法是:“关键词, 关键词, 关键词...”。重复次数越多,网站 排名越高。所以登录搜索引擎变成了无休止的关键词重复竞赛。你重复500次不算太多,我会重复600次,而且重复关键词数千次的人很多。搜索引擎很快意识到了这种做法的危险性,终于在忍无可忍的时候站了起来,警告那些走得太远的人网站,如果他们继续执迷不悟,不仅达不到他们的目标,但他们也可能被判处死刑。- 永远不要让你的 网站 出来!所以不要刻意重复某个关键词,特别是不要在同一行连续使用某个关键词超过2次。使用关键词时,尽量做到自然流畅,符合基本语法规则。 查看全部
输入关键字 抓取所有网页(
靠作弊手段增加访问量又有何用,你知道吗?)
选择的 关键词 当然必须与您自己的产品或服务相关。不要听信靠不相关的点击关键词来拉动更多流量的宣传,这不仅不道德,而且毫无意义。想象一下,查找“Monica Lewinsky”的人会对您生产的酱油感兴趣。当然不是。必须承认,有时候这种做法确实可以增加网站的流量,但既然你的目的是卖产品,不是免费八卦,那么依靠这种作弊来增加流量有什么用呢?选择具体的关键词我们在选择关键词的时候还有一点要注意,就是避免以泛泛的词为主关键词,而是要根据你的类型业务或产品,选择尽可能具体的词。例如,一家销售木工工具的制造商,“CarpenterTools”不是正确的选择关键词,“ChainSaws”可能是一个明智的选择。有人会问,既然“CarpenterTools”是一个集合名词,涵盖了厂家的所有产品,不如我们把CarpenterTools拿去谷歌,你会发现搜索结果超过6位(实际数字是189,000),这意味着你有近 200,000 个竞争对手!要从众多竞争对手中脱颖而出几乎是“不可能完成的任务”。相反,“ChainSaws”下的搜索结果要少得多(69,800 个),你有有更多机会领先于竞争对手。选择更长的时间 关键词 查询信息时尽量用词 四词高中英语3500词表的原形式与原形式相反。在提交 网站 时,我们应该使用单词的较长形式。例如,当“游戏”可以使用时,尽量不要选择“游戏”。因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 在提交 网站 时,我们应该使用单词的较长形式。例如,当“游戏”可以使用时,尽量不要选择“游戏”。因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 在提交 网站 时,我们应该使用单词的较长形式。例如,当“游戏”可以使用时,尽量不要选择“游戏”。因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 因为搜索引擎支持在多态或连字符查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。不要忘记有很多拼写错误的单词。选择 文章 of 关键词 两者都特别提到了“contemorarymoderncoffeetables”等单词的拼写错误,提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有 提醒我们不要忘记将它们收录在我们的 关键词 选项中。理论是有
这些词经常被用户拼错,考虑到大多数人不会针对拼写错误关键词,所以如果你很聪明并且发现了这个技巧来优化你的网页拼错单词,一旦你遇到用户再次搜索那个错字,你会站在搜索结果的顶部!真的是这样吗?首先,我们来看看上面的例子有什么问题。“contemorary”其实就是“contemporary”,虽然是一个字母的区别,但是从关键词的角度来看,两者相差甚远。奇怪的是,根据关键词监控统计报告财务分析报告财务分析报告模板企业财务分析报告公司财务分析报告模板公司财务分析报告,” 并且那个错字被显着地加粗了多次?他会像发现金矿一样欣喜若狂,还是心中对这家公司的质量产生一点怀疑?他会认为一个连基本语法都没有掌握的厂商,真的是有问题的。所以,拼写错误的 关键词 是一个陷阱,我们必须三思而后行。此外,目前一些搜索引擎(如谷歌)已经增加了自动拼写检查功能。当用户输入错字时,系统会自动提供正确的单词选择。当用户意识到他们错了,大多数人倾向于通过正确的 关键词 提示进行搜索。所以到了这个阶段,优化拼写错误的网页已经基本失去了意义。寻找关键词技能作为网站的拥有者,您当然是最了解您的业务的人,因此您总能找到最能反映您业务的 关键词。但是靠自己的努力,难免会出现一些疏漏。这时候不妨去搜索引擎,找到你的竞争对手的网站,看看他们用什么
其中关键词,你可能会从中得到一些启发。另外,借助一些关键词自动分析软件,可以快速从你或你竞争对手的网页中提取出合适的关键词,你的工作效率可以成倍提升,我们可以通过这些软件找到很多< @关键词 之前没有考虑过,从而大大扩展了我们的关键词参与活动家名单。停用词/过滤词(StopWords/FilterWords)含义相同,指的是一些太常见而没有任何检索值的词,如“a”、“the”、“and”、“of”、“web” ”、“主页”等。搜索引擎遇到这些词一般都会过滤掉。因此,为了节省篇幅,应尽量避免使用此类词,尤其是在字数有严格限制的地方。(如果要验证上述规则,可以尝试在搜索引擎中搜索“staythenight”,会发现“the”这个词在结果中符合搜索条件,但没有以粗体显示,说明.) 重复 关键词 1000 次 既然 关键词 的出现频率是决定 网站 排名的重要因素,那为什么不重复 1000 次,是不是很简单并且有效?停下来。众所周知,这就是搜索引擎的“石器时代”做法,在当时确实奏效,但现在早已被搜索引擎抛弃。当时的典型做法是:“关键词, 关键词, 关键词...”。重复次数越多,网站 排名越高。所以登录搜索引擎变成了无休止的关键词重复竞赛。你重复500次不算太多,我会重复600次,而且重复关键词数千次的人很多。搜索引擎很快意识到了这种做法的危险性,终于在忍无可忍的时候站了起来,警告那些走得太远的人网站,如果他们继续执迷不悟,不仅达不到他们的目标,但他们也可能被判处死刑。- 永远不要让你的 网站 出来!所以不要刻意重复某个关键词,特别是不要在同一行连续使用某个关键词超过2次。使用关键词时,尽量做到自然流畅,符合基本语法规则。
输入关键字 抓取所有网页(如何选择有效关键字策略?优化项目中最重要的工作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-12 03:30
如何利用关键词获得良好的搜索引擎排名,选择有效的关键词策略,是SEO人在搜索引擎优化项目中最重要的工作。目前大部分搜索引擎都支持关键词索引,即根据注册网站提供的关键词记录网站,根据用户输入的关键词索引网站。因此,为您的促销活动的 网站 确定关键字
如何使用关键字获得良好的搜索引擎排名
选择有效的关键词策略是SEO家族认为的搜索引擎优化项目中最重要的工作。目前大部分搜索引擎都支持关键词索引,即根据注册网站提供的关键词记录网站,根据用户输入的关键词索引网站。因此,确定推广网站的关键词非常重要。正确的关键词可以让网站获得良好的搜索排名,从而赢得流量向量。错误的关键字会减少用户访问网站 @网站 的机会。
以下是一些选择关键字的策略:
①不断搜索关键词。尽可能多地写下你能想到的关键词,不断搜索不同的网站,找到最合适的关键词。
②拼写错误的使用。事实上,一些拼写错误的关键字被频繁使用,例如将Alta-sa(专业搜索引擎)拼写为“Alt Visa”或其他拼写。这增加了被用户找到的可能性。
③关键词的地域性。通常一个区域明显的关键词会比那些不太明显的关键词吸引更多的流量,因为人们一般按照区域范围进行搜索,这样更有利于检索的准确性。
④ 使用较长的关键词。有时一些初学者在使用搜索引擎输入关键词时,往往会更具体,输入更长的关键字。例如,如果用户想要查找他们的姓氏来源,他们通常需要在 关键词 中添加限定条件。比如“河北昌黎汉姓的由来”,就可以找到目标地址。
⑤关键词组合。用户使用关键字的另一个特点是他们经常使用组合关键字。如上例所述,关键字也可以输入为“汉姓源于河北昌黎”或“汉姓源于河北昌黎”。
⑥ 应避免的关键词。大多数搜索引擎会过滤掉某些词,例如:“a”、“the”、“and”、“of”、“that”、“it”、“too”、“web”和“homepage””等等on,即当搜索引擎找到这些词时。会忽略它们。因此,为确保正确的搜索排名,应避免使用这些 关键词。
⑦ 了解用户使用关键字的习惯。调查显示,用户有使用某些特定关键词的习惯,这就需要一些专业搜索引擎提供的实时检索状态,来了解一些人的搜索习惯和内容。
(2)选择关键字的步骤使用上述方法,可以选择可以使用的关键字,但是选择有效关键字的具体步骤如下:
第一步是明确关键词选择的方向。大多数搜索引擎在网站“标题”、“描述”、“关键字”、Web Content and Submission Center 中提取用于检索的关键字网站,并且会明确限制字词的使用或字符数. 因此,您应该选择至少 25 到 50 个关键字,具体取决于搜索引擎的一般限制。
第二步是总结尽可能多的关键词。无论是在网站的标题、描述还是网页内容中,关键词都会在网站的搜索排名中起到至关重要的作用。因此,尽可能多地总结关键词,而不用担心使用的关键词是否完全适合目标链接,只要关键词数量满足搜索引擎的要求即可。
第三步,进行关键词选择。总结出来的关键词中,网页中出现过的关键词被去掉,因为已经收录在网页中,剩下的会在后面用到。
第四步,关键词查询验证。在专业的搜索引擎(如百度)中对获取的关键词进行一一搜索,或者使用一些专业的分析软件(如“百度趋势”)进行分析。从而增加用户点击的可能性。
第五步,记录和分析搜索结果。在不同的搜索引擎中,会得到不同的搜索结果。仔细分析记录网站的总搜索次数和主要内容,对比自己的网站,大致可以得出三个结论:如果返回的结果很大,收录很多竞争对手' 网站,表示该关键字使用频率很高;如果返回的记录很少,并且收录很多竞争对手的网站,则表示该关键字被Less使用,如果返回的记录很少,并且带有网站的竞争对手,则该关键字可能没有被任何人使用。
第六步,关键词组合。单个关键字搜索完成后,即可进行验证。先将前两个关键词组合搜索,然后搜索所有其他组合(二乘二组合),分析并记录检索过程。
第七步,完成网站特征描述。完成以上关键词选择流程并选择正确关键词后,需要将其所有关键词组合成网站“title”、“description”、“keyword”、网页内容等网站特征描述。
第八步,重复第二步到第七步的过程,不断修正结果。 查看全部
输入关键字 抓取所有网页(如何选择有效关键字策略?优化项目中最重要的工作)
如何利用关键词获得良好的搜索引擎排名,选择有效的关键词策略,是SEO人在搜索引擎优化项目中最重要的工作。目前大部分搜索引擎都支持关键词索引,即根据注册网站提供的关键词记录网站,根据用户输入的关键词索引网站。因此,为您的促销活动的 网站 确定关键字
如何使用关键字获得良好的搜索引擎排名
选择有效的关键词策略是SEO家族认为的搜索引擎优化项目中最重要的工作。目前大部分搜索引擎都支持关键词索引,即根据注册网站提供的关键词记录网站,根据用户输入的关键词索引网站。因此,确定推广网站的关键词非常重要。正确的关键词可以让网站获得良好的搜索排名,从而赢得流量向量。错误的关键字会减少用户访问网站 @网站 的机会。
以下是一些选择关键字的策略:
①不断搜索关键词。尽可能多地写下你能想到的关键词,不断搜索不同的网站,找到最合适的关键词。
②拼写错误的使用。事实上,一些拼写错误的关键字被频繁使用,例如将Alta-sa(专业搜索引擎)拼写为“Alt Visa”或其他拼写。这增加了被用户找到的可能性。
③关键词的地域性。通常一个区域明显的关键词会比那些不太明显的关键词吸引更多的流量,因为人们一般按照区域范围进行搜索,这样更有利于检索的准确性。
④ 使用较长的关键词。有时一些初学者在使用搜索引擎输入关键词时,往往会更具体,输入更长的关键字。例如,如果用户想要查找他们的姓氏来源,他们通常需要在 关键词 中添加限定条件。比如“河北昌黎汉姓的由来”,就可以找到目标地址。
⑤关键词组合。用户使用关键字的另一个特点是他们经常使用组合关键字。如上例所述,关键字也可以输入为“汉姓源于河北昌黎”或“汉姓源于河北昌黎”。
⑥ 应避免的关键词。大多数搜索引擎会过滤掉某些词,例如:“a”、“the”、“and”、“of”、“that”、“it”、“too”、“web”和“homepage””等等on,即当搜索引擎找到这些词时。会忽略它们。因此,为确保正确的搜索排名,应避免使用这些 关键词。
⑦ 了解用户使用关键字的习惯。调查显示,用户有使用某些特定关键词的习惯,这就需要一些专业搜索引擎提供的实时检索状态,来了解一些人的搜索习惯和内容。
(2)选择关键字的步骤使用上述方法,可以选择可以使用的关键字,但是选择有效关键字的具体步骤如下:
第一步是明确关键词选择的方向。大多数搜索引擎在网站“标题”、“描述”、“关键字”、Web Content and Submission Center 中提取用于检索的关键字网站,并且会明确限制字词的使用或字符数. 因此,您应该选择至少 25 到 50 个关键字,具体取决于搜索引擎的一般限制。
第二步是总结尽可能多的关键词。无论是在网站的标题、描述还是网页内容中,关键词都会在网站的搜索排名中起到至关重要的作用。因此,尽可能多地总结关键词,而不用担心使用的关键词是否完全适合目标链接,只要关键词数量满足搜索引擎的要求即可。
第三步,进行关键词选择。总结出来的关键词中,网页中出现过的关键词被去掉,因为已经收录在网页中,剩下的会在后面用到。
第四步,关键词查询验证。在专业的搜索引擎(如百度)中对获取的关键词进行一一搜索,或者使用一些专业的分析软件(如“百度趋势”)进行分析。从而增加用户点击的可能性。
第五步,记录和分析搜索结果。在不同的搜索引擎中,会得到不同的搜索结果。仔细分析记录网站的总搜索次数和主要内容,对比自己的网站,大致可以得出三个结论:如果返回的结果很大,收录很多竞争对手' 网站,表示该关键字使用频率很高;如果返回的记录很少,并且收录很多竞争对手的网站,则表示该关键字被Less使用,如果返回的记录很少,并且带有网站的竞争对手,则该关键字可能没有被任何人使用。
第六步,关键词组合。单个关键字搜索完成后,即可进行验证。先将前两个关键词组合搜索,然后搜索所有其他组合(二乘二组合),分析并记录检索过程。
第七步,完成网站特征描述。完成以上关键词选择流程并选择正确关键词后,需要将其所有关键词组合成网站“title”、“description”、“keyword”、网页内容等网站特征描述。
第八步,重复第二步到第七步的过程,不断修正结果。
输入关键字 抓取所有网页(亲,我想做一个简单的360极速浏览器的插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-11 06:01
亲,想做一个简单的360极速浏览器插件,要求如下:
打开网页后,自动执行代码,自动搜索关键词(eg:公司)的链接,自动点进去!此代码每页仅执行一次。插件怎么写,每个文件的代码怎么编排!
背景,我对代码非常感兴趣。摸索了很多天,还是没有成功,但是个人觉得应该有以下两种方法:
1.使用正则表达式过滤出想要的URL,实现跳转
2.用js直接搜索你要的链接关键词实现跳转
认为后者应该更容易实现!我在网上搜索了一个例子,但仍然不会改变,请帮助!感激!
var kw = ['公司'];
var as = document.getElementsByTagName('a');
for (var i = 0; i < as.length; i++) {
for (var j = 0; j < kw.length; j++)
if (as[i].innerHTML.indexOf(kw[j]) != -1) {// 两者都被屏蔽
if (as[i].onclick) as[i].onclick();
否则 window.open(as[i].href);
}
} 查看全部
输入关键字 抓取所有网页(亲,我想做一个简单的360极速浏览器的插件)
亲,想做一个简单的360极速浏览器插件,要求如下:
打开网页后,自动执行代码,自动搜索关键词(eg:公司)的链接,自动点进去!此代码每页仅执行一次。插件怎么写,每个文件的代码怎么编排!
背景,我对代码非常感兴趣。摸索了很多天,还是没有成功,但是个人觉得应该有以下两种方法:
1.使用正则表达式过滤出想要的URL,实现跳转
2.用js直接搜索你要的链接关键词实现跳转
认为后者应该更容易实现!我在网上搜索了一个例子,但仍然不会改变,请帮助!感激!
var kw = ['公司'];
var as = document.getElementsByTagName('a');
for (var i = 0; i < as.length; i++) {
for (var j = 0; j < kw.length; j++)
if (as[i].innerHTML.indexOf(kw[j]) != -1) {// 两者都被屏蔽
if (as[i].onclick) as[i].onclick();
否则 window.open(as[i].href);
}
}
输入关键字 抓取所有网页(2个月前Gseeker的帖子:它将会革掉Google的命?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-09 05:10
转发 Gseeker 2 个月前的帖子
MyLiveSearch:它会杀死谷歌吗?
2007 年 5 月 29 日
<p>我们现在使用的大部分搜索引擎的工作原理都是类似的,就是搜索引擎发出爬虫,不断地跟踪互联网上的链接网站,并分析它们所经过的网页内容,然后把它们网站@收录进入搜索引擎的索引库;当用户输入关键词进行搜索时,搜索引擎会从已有的索引库中返回相关结果。全球四大搜索引擎Google、Yahoo!、Microsoft Live Search 和ASK 均采用此模式。谷歌更好,因为它的算法返回更相关和更准确的搜索结果。但可以想象,这种模式的缺点也很明显,即它提供的搜索结果不是实时的,而是基于索引数据库的。进一步来说,只有爬虫爬取的网页内容才会出现在索引库中,然后才能被用户搜索。也就是在这种模式下,用户得到的搜索结果不是最新的,因为网站新的内容要等待爬虫抓取,分析和 查看全部
输入关键字 抓取所有网页(2个月前Gseeker的帖子:它将会革掉Google的命?)
转发 Gseeker 2 个月前的帖子
MyLiveSearch:它会杀死谷歌吗?
2007 年 5 月 29 日
<p>我们现在使用的大部分搜索引擎的工作原理都是类似的,就是搜索引擎发出爬虫,不断地跟踪互联网上的链接网站,并分析它们所经过的网页内容,然后把它们网站@收录进入搜索引擎的索引库;当用户输入关键词进行搜索时,搜索引擎会从已有的索引库中返回相关结果。全球四大搜索引擎Google、Yahoo!、Microsoft Live Search 和ASK 均采用此模式。谷歌更好,因为它的算法返回更相关和更准确的搜索结果。但可以想象,这种模式的缺点也很明显,即它提供的搜索结果不是实时的,而是基于索引数据库的。进一步来说,只有爬虫爬取的网页内容才会出现在索引库中,然后才能被用户搜索。也就是在这种模式下,用户得到的搜索结果不是最新的,因为网站新的内容要等待爬虫抓取,分析和
输入关键字 抓取所有网页(关键词是什么意思?与搜索引擎的关系有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-09 05:09
只有通过关键字搜索,用户才能更好地找到他们需要的信息。关键词优化的好坏与SEO工作者最关心的排名有很大关系。所以,从SEO的角度来看,关键词是一个特别重要的概念,另一方面,关键词也是一个非常基础的概念。所以你知道 关键词 是什么吗?关键词 是什么意思?
1、关键词 是什么?
从百度百科可以看出,关键词是指用户在搜索引擎中输入的表达个人需求的词。从维基百科的定义来看,它意味着用户获取信息的简化词汇表。其实这两个定义表达的意思是一样的,假设你用的是百度,你想通过一个关键词获取信息,那么你输入的所有单词都可以称为关键词。
这里需要注意的是关键词是用户需求的载体,用户会使用简体字进行搜索,这样比较容易理解,因为用户通常不会输入大量的数字进行搜索for results,而是通过反映核心思想的词汇来搜索结果。
2、关键词与搜索引擎的关系
在进行 SEO 时,我们不仅向用户展示我们的网页,还向搜索引擎展示我们的网页。只有当当前网页被搜索引擎看到和索引时,该网页才能显示给用户。因此,有必要认真看待关键词与搜索引擎的关系。
搜索引擎的工作原理可以概括为爬取-索引构建-搜索词处理-排名。搜索引擎蜘蛛一直在爬行和爬行新鲜的网页。之后,他们将索引有价值的网页。当用户在搜索引擎中输入关键词时,通过分词等技术了解用户真实的搜索意图,并将最终结果以排序方式提供给用户。
如果我们了解搜索引擎的工作原理以及 关键词 是什么,我们就会知道关键字的重要性。在目前的技术情况下,百度等搜索引擎只能识别单词,单词是由单一的关键词词汇组成的。关键词是搜索引擎工作的前提条件,也是满足用户需求的必要条件。 查看全部
输入关键字 抓取所有网页(关键词是什么意思?与搜索引擎的关系有哪些?)
只有通过关键字搜索,用户才能更好地找到他们需要的信息。关键词优化的好坏与SEO工作者最关心的排名有很大关系。所以,从SEO的角度来看,关键词是一个特别重要的概念,另一方面,关键词也是一个非常基础的概念。所以你知道 关键词 是什么吗?关键词 是什么意思?
1、关键词 是什么?
从百度百科可以看出,关键词是指用户在搜索引擎中输入的表达个人需求的词。从维基百科的定义来看,它意味着用户获取信息的简化词汇表。其实这两个定义表达的意思是一样的,假设你用的是百度,你想通过一个关键词获取信息,那么你输入的所有单词都可以称为关键词。
这里需要注意的是关键词是用户需求的载体,用户会使用简体字进行搜索,这样比较容易理解,因为用户通常不会输入大量的数字进行搜索for results,而是通过反映核心思想的词汇来搜索结果。
2、关键词与搜索引擎的关系
在进行 SEO 时,我们不仅向用户展示我们的网页,还向搜索引擎展示我们的网页。只有当当前网页被搜索引擎看到和索引时,该网页才能显示给用户。因此,有必要认真看待关键词与搜索引擎的关系。
搜索引擎的工作原理可以概括为爬取-索引构建-搜索词处理-排名。搜索引擎蜘蛛一直在爬行和爬行新鲜的网页。之后,他们将索引有价值的网页。当用户在搜索引擎中输入关键词时,通过分词等技术了解用户真实的搜索意图,并将最终结果以排序方式提供给用户。
如果我们了解搜索引擎的工作原理以及 关键词 是什么,我们就会知道关键字的重要性。在目前的技术情况下,百度等搜索引擎只能识别单词,单词是由单一的关键词词汇组成的。关键词是搜索引擎工作的前提条件,也是满足用户需求的必要条件。
输入关键字 抓取所有网页(福建关键词优化哪家好,百诚互联选择我们你可以放心)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-08 13:02
福建关键词优化哪个更好,百诚互联网,选择我们,您可以少走弯路,选择我们,您可以放心。
福建关键词哪个更好优化,从小程序开发,到关键词排名优化,再到百度竞价账号结构搭建,外链资源发布,灵活选择各种相关配套服务,充分探索< @网站的营销功能。优化网站,你需要让更多的页面是收录,并尽量吸引蜘蛛爬取。如果它不能爬取所有的页面,蜘蛛所要做的就是尝试爬取重要的页面。
一个。关键词对应的网页快照必须有完全匹配或部分匹配;湾。关键词 和 网站 的主题必须相关;C。网站的结构必须便于百度掌握并更新;d。有些关键词是时间敏感的,比如大闸蟹、月饼、鞭炮等。网站快照更新一定要及时;网站修改频繁、TDK调整频繁、优化过度、内容采集、不符合gj策略的灰字、多域名绑定、经常被黑等,此类词排名靠前或搜索引擎排名无效;
福建关键词优化哪一个比较好,所以需要评估关键词的优化能否达到优化效果,评估关键词之后的优化效果。网站一般的施工流程是怎样的?网站 是一个相对复杂的系统。从一开始,您就需要考虑所需的功能。网站的规划也是构建所有网站需要做的。@网站 进行整体分析,明确网站的建设目标,确定网站的访问目标,网站提供的内容和服务,域名和标识网站、网站风格和网站目录分类,这一步也是网站成功搭建的前提 @网站,因为所有的施工步骤都是按照规划设计的。搭建正式的网站,需要到相关部门办理哪些手续,缴纳哪些费用?国家规定,通过互联网向网民提供信息,如购物网站,必须取得经营网站许可证,而不是网站备案,俗话说:有政策和对策。
网站通过实施百度优化,可以提升部分关键词排名。以前,如果您想通过这些 关键词 带来潜在客户,您需要不断地投放广告。这无疑为企业节省了一定的广告费用。即使公司不削减他们的广告预算,他们仍然可以将这些成本花在更多关键词上。随着搜索技术的发展,出现了越来越多的百度。但企业不可能针对所有相关内容在所有百度上投放广告,部分百度暂时不提供付费广告服务。
福建关键词哪个更好优化,快照视图:输入你的关键词,找到你的网站的位置。我们可以在域名后面看到灰色小字体的“搜索快照”。其次,搜索快照具有更新时间。从快照的更新时间可以看出搜索蜘蛛对网站的抓取频率。随着优化越来越好,日期越来越接近查询时间。更能体现搜索引擎对你的信任网站。可能会反映在出现阶段更新您 网站 的频率和情况。如果您的快照更接近,蜘蛛喜欢抓取您的内容。 查看全部
输入关键字 抓取所有网页(福建关键词优化哪家好,百诚互联选择我们你可以放心)
福建关键词优化哪个更好,百诚互联网,选择我们,您可以少走弯路,选择我们,您可以放心。
福建关键词哪个更好优化,从小程序开发,到关键词排名优化,再到百度竞价账号结构搭建,外链资源发布,灵活选择各种相关配套服务,充分探索< @网站的营销功能。优化网站,你需要让更多的页面是收录,并尽量吸引蜘蛛爬取。如果它不能爬取所有的页面,蜘蛛所要做的就是尝试爬取重要的页面。
一个。关键词对应的网页快照必须有完全匹配或部分匹配;湾。关键词 和 网站 的主题必须相关;C。网站的结构必须便于百度掌握并更新;d。有些关键词是时间敏感的,比如大闸蟹、月饼、鞭炮等。网站快照更新一定要及时;网站修改频繁、TDK调整频繁、优化过度、内容采集、不符合gj策略的灰字、多域名绑定、经常被黑等,此类词排名靠前或搜索引擎排名无效;
福建关键词优化哪一个比较好,所以需要评估关键词的优化能否达到优化效果,评估关键词之后的优化效果。网站一般的施工流程是怎样的?网站 是一个相对复杂的系统。从一开始,您就需要考虑所需的功能。网站的规划也是构建所有网站需要做的。@网站 进行整体分析,明确网站的建设目标,确定网站的访问目标,网站提供的内容和服务,域名和标识网站、网站风格和网站目录分类,这一步也是网站成功搭建的前提 @网站,因为所有的施工步骤都是按照规划设计的。搭建正式的网站,需要到相关部门办理哪些手续,缴纳哪些费用?国家规定,通过互联网向网民提供信息,如购物网站,必须取得经营网站许可证,而不是网站备案,俗话说:有政策和对策。
网站通过实施百度优化,可以提升部分关键词排名。以前,如果您想通过这些 关键词 带来潜在客户,您需要不断地投放广告。这无疑为企业节省了一定的广告费用。即使公司不削减他们的广告预算,他们仍然可以将这些成本花在更多关键词上。随着搜索技术的发展,出现了越来越多的百度。但企业不可能针对所有相关内容在所有百度上投放广告,部分百度暂时不提供付费广告服务。
福建关键词哪个更好优化,快照视图:输入你的关键词,找到你的网站的位置。我们可以在域名后面看到灰色小字体的“搜索快照”。其次,搜索快照具有更新时间。从快照的更新时间可以看出搜索蜘蛛对网站的抓取频率。随着优化越来越好,日期越来越接近查询时间。更能体现搜索引擎对你的信任网站。可能会反映在出现阶段更新您 网站 的频率和情况。如果您的快照更接近,蜘蛛喜欢抓取您的内容。
输入关键字 抓取所有网页( 中国少年先锋队基础知识100题管理基础知识真题及答案二级真题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-08 12:19
中国少年先锋队基础知识100题管理基础知识真题及答案二级真题)
百度搜索引擎基础知识 中国少先队基础知识 100题 管理基础知识 真实问答 管理基础知识 真实问答 出结果的过程往往在几毫秒内完成。百度是如何在网子资源互联的汪洋大海中,以如此快的速度将你的网站内容呈现给用户的?这背后有什么样的工作流程和计算?逻辑其实百度搜索引擎的工作并不像首页的搜索框那么简单。搜索引擎向用户展示的每一个搜索结果都对应于互联网上的一个页面。每一个搜索结果都需要经过搜索引擎从生成到展示给用户的过程。四进程爬网过滤,索引和输出结果爬取Baiduspider或Baidu Spider会通过搜索引擎系统的计算,以及爬取的内容和频率来决定爬取哪个网站搜索引擎的计算过程会参考性能你的网站历史记录,比如内容质量是否足够,是否有对用户不友好的设置,是否有过度的SEO行为等。当你的网站产生新内容时,百度蜘蛛吧将通过 Internet 上指向该页面的链接进行访问和爬取。如果您没有设置任何外部链接指向网站 中的新内容,Baiduspider 将无法抓取。搜索引擎的内容会记录爬取的页面、诚实谈话记录、退出采访记录、
某些页面对用户的重要性被安排为以不同的频率进行爬取和更新。您应该知道,一些爬虫软件会伪装成百度蜘蛛来爬取您的 网站 用于各种目的。这可能不会受到影响。当受控爬取行为严重时,会影响网站的正常运行。过滤 Internet 中并非所有网页对用户都有意义。例如,一些明显的欺骗用户的网页是死链接和空白内容页面。没有文字 zh201308 莆田安服 wwwanfufxcom 对百度来说已经足够有价值了,所以百度会自动过滤这些内容,避免给用户带来不必要的麻烦,你的网站建立索引百度会爬回内容,它会标记和识别一个一个并将这些标记存储为结构化数据,比如网页的tagtitlemetadescripton,网页的外部链接和描述,爬取记录。同时,网页中的关键词信息将被识别并存储,以供用户搜索。输出的内容匹配,用户输入的输出结果关键词百度会对其进行一系列复杂的分析,根据结论在索引库中搜索最匹配的系列网页分析。根据用户输入的关键词反映的需求和网页的优劣进行打分,根据最终打分显示给用户。网页中的信息将被识别并存储以供用户搜索。输出的内容匹配,用户输入的输出结果关键词百度会对其进行一系列复杂的分析,根据结论在索引库中搜索最匹配的系列网页分析。根据用户输入的关键词反映的需求和网页的优劣进行打分,根据最终打分显示给用户。网页中的信息将被识别并存储以供用户搜索。输出的内容匹配,用户输入的输出结果关键词百度会对其进行一系列复杂的分析,根据结论在索引库中搜索最匹配的系列网页分析。根据用户输入的关键词反映的需求和网页的优劣进行打分,根据最终打分显示给用户。 查看全部
输入关键字 抓取所有网页(
中国少年先锋队基础知识100题管理基础知识真题及答案二级真题)
百度搜索引擎基础知识 中国少先队基础知识 100题 管理基础知识 真实问答 管理基础知识 真实问答 出结果的过程往往在几毫秒内完成。百度是如何在网子资源互联的汪洋大海中,以如此快的速度将你的网站内容呈现给用户的?这背后有什么样的工作流程和计算?逻辑其实百度搜索引擎的工作并不像首页的搜索框那么简单。搜索引擎向用户展示的每一个搜索结果都对应于互联网上的一个页面。每一个搜索结果都需要经过搜索引擎从生成到展示给用户的过程。四进程爬网过滤,索引和输出结果爬取Baiduspider或Baidu Spider会通过搜索引擎系统的计算,以及爬取的内容和频率来决定爬取哪个网站搜索引擎的计算过程会参考性能你的网站历史记录,比如内容质量是否足够,是否有对用户不友好的设置,是否有过度的SEO行为等。当你的网站产生新内容时,百度蜘蛛吧将通过 Internet 上指向该页面的链接进行访问和爬取。如果您没有设置任何外部链接指向网站 中的新内容,Baiduspider 将无法抓取。搜索引擎的内容会记录爬取的页面、诚实谈话记录、退出采访记录、
某些页面对用户的重要性被安排为以不同的频率进行爬取和更新。您应该知道,一些爬虫软件会伪装成百度蜘蛛来爬取您的 网站 用于各种目的。这可能不会受到影响。当受控爬取行为严重时,会影响网站的正常运行。过滤 Internet 中并非所有网页对用户都有意义。例如,一些明显的欺骗用户的网页是死链接和空白内容页面。没有文字 zh201308 莆田安服 wwwanfufxcom 对百度来说已经足够有价值了,所以百度会自动过滤这些内容,避免给用户带来不必要的麻烦,你的网站建立索引百度会爬回内容,它会标记和识别一个一个并将这些标记存储为结构化数据,比如网页的tagtitlemetadescripton,网页的外部链接和描述,爬取记录。同时,网页中的关键词信息将被识别并存储,以供用户搜索。输出的内容匹配,用户输入的输出结果关键词百度会对其进行一系列复杂的分析,根据结论在索引库中搜索最匹配的系列网页分析。根据用户输入的关键词反映的需求和网页的优劣进行打分,根据最终打分显示给用户。网页中的信息将被识别并存储以供用户搜索。输出的内容匹配,用户输入的输出结果关键词百度会对其进行一系列复杂的分析,根据结论在索引库中搜索最匹配的系列网页分析。根据用户输入的关键词反映的需求和网页的优劣进行打分,根据最终打分显示给用户。网页中的信息将被识别并存储以供用户搜索。输出的内容匹配,用户输入的输出结果关键词百度会对其进行一系列复杂的分析,根据结论在索引库中搜索最匹配的系列网页分析。根据用户输入的关键词反映的需求和网页的优劣进行打分,根据最终打分显示给用户。

