
输入关键字 抓取所有网页
输入关键字 抓取所有网页(利用Python网络爬虫微信朋友圈动态(上)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-19 09:12
阿里云 > 云栖社区 > 主题地图 > L > 用网络爬虫爬取关键词
推荐活动:
更多优惠>
当前主题: 使用网络爬虫进行爬网关键词添加到采集夹
相关话题:
使用网络爬虫爬取关键词相关博客查看更多博客
《Python爬虫开发与项目实践》——第3章Web爬虫入门3.1 Web爬虫概述
作者:华章电脑 3956人浏览评论:04年前
本章节选自华章计算机《Python爬虫开发与项目实战》一书第3章3.1节,作者:范传辉。更多章节请访问云栖社区“华章计算机”查看公众号第3章网络爬虫入门本章开始正式涉及Python爬虫的开发。本章主要分为两部分:一部分是网络
阅读全文
如何使用Python网络爬虫抓取微信好友数量和微信好友男女比例
作者:python进阶1453人查看评论:03年前
前几天给大家分享了使用Python网络爬虫爬取朋友圈的动态(上)和使用Python网络爬虫爬取朋友圈的动态——附代码(下),并对抓取的数据进行Python处理。词云和艺术字可视化,有兴趣的小伙伴可以戳这个文章:使用Python词云和艺术字
阅读全文
使用Python网络爬虫抓取微信好友签名并进行可视化展示
作者:python进阶1255人查看评论:03年前
前几天给大家分享了如何使用Python词云和wordart可视化工具对朋友圈数据进行可视化,使用Python网络爬虫抓取微信好友数量和微信男女比例好友,并使用Python网络爬虫抓取微信好友位置省市分布及其可视化,感兴趣的朋友可以点击查看
阅读全文
网络爬虫的实现
作者:xumaojun933 浏览评论:04年前
通过古普塔,P。乔哈里,K。印度 Linagay 大学 文章 发表于:工程技术新兴趋势 (ICETET),2009 年第 2 次实习生
阅读全文
网络爬虫的实现
作者:nothingfinal1246 浏览评论:23 年前
通过古普塔,P。乔哈里,K。Linagay's Univ., India 文章发表于:工程和技术的新兴趋势 (ICETET),2009 年第二届国际
阅读全文
网络爬虫的实现
作者:shapherd2738 浏览评论:05年前
摘要 - 万维网是通过HTML格式链接的数十亿文档的集合,那么如此海量的数据已经成为信息检索的障碍,用户可能不得不翻页才能找到他们想要的材料。网络爬虫是搜索引擎的核心部分,网络爬虫不断地爬取互联网,以查找任何添加到网络的新页面和已从网络中删除的页面。
阅读全文
网络爬虫的实现
作者:maojunxu558 浏览评论:04年前
作者:古普塔,P。乔哈里,K。Linagay 大学,印度文章发表于:工程技术新兴趋势 (ICETET),2009 年第二届实习生
阅读全文
【python爬虫】爬取图片打不开或损坏的简单探讨
作者:肖洛洛4401 浏览评论:06年前
本文主要针对python中使用urlretrieve或urlopen下载百度、搜狗、googto(谷歌镜像)等图片时出现“打不开图片或损坏”的问题。作者对此进行了简要讨论。同时作者会进一步帮你巩固 selenium 自动化和 urllib
阅读全文 查看全部
输入关键字 抓取所有网页(利用Python网络爬虫微信朋友圈动态(上)(组图))
阿里云 > 云栖社区 > 主题地图 > L > 用网络爬虫爬取关键词

推荐活动:
更多优惠>
当前主题: 使用网络爬虫进行爬网关键词添加到采集夹
相关话题:
使用网络爬虫爬取关键词相关博客查看更多博客
《Python爬虫开发与项目实践》——第3章Web爬虫入门3.1 Web爬虫概述

作者:华章电脑 3956人浏览评论:04年前
本章节选自华章计算机《Python爬虫开发与项目实战》一书第3章3.1节,作者:范传辉。更多章节请访问云栖社区“华章计算机”查看公众号第3章网络爬虫入门本章开始正式涉及Python爬虫的开发。本章主要分为两部分:一部分是网络
阅读全文
如何使用Python网络爬虫抓取微信好友数量和微信好友男女比例


作者:python进阶1453人查看评论:03年前
前几天给大家分享了使用Python网络爬虫爬取朋友圈的动态(上)和使用Python网络爬虫爬取朋友圈的动态——附代码(下),并对抓取的数据进行Python处理。词云和艺术字可视化,有兴趣的小伙伴可以戳这个文章:使用Python词云和艺术字
阅读全文
使用Python网络爬虫抓取微信好友签名并进行可视化展示

作者:python进阶1255人查看评论:03年前
前几天给大家分享了如何使用Python词云和wordart可视化工具对朋友圈数据进行可视化,使用Python网络爬虫抓取微信好友数量和微信男女比例好友,并使用Python网络爬虫抓取微信好友位置省市分布及其可视化,感兴趣的朋友可以点击查看
阅读全文
网络爬虫的实现


作者:xumaojun933 浏览评论:04年前
通过古普塔,P。乔哈里,K。印度 Linagay 大学 文章 发表于:工程技术新兴趋势 (ICETET),2009 年第 2 次实习生
阅读全文
网络爬虫的实现


作者:nothingfinal1246 浏览评论:23 年前
通过古普塔,P。乔哈里,K。Linagay's Univ., India 文章发表于:工程和技术的新兴趋势 (ICETET),2009 年第二届国际
阅读全文
网络爬虫的实现
作者:shapherd2738 浏览评论:05年前
摘要 - 万维网是通过HTML格式链接的数十亿文档的集合,那么如此海量的数据已经成为信息检索的障碍,用户可能不得不翻页才能找到他们想要的材料。网络爬虫是搜索引擎的核心部分,网络爬虫不断地爬取互联网,以查找任何添加到网络的新页面和已从网络中删除的页面。
阅读全文
网络爬虫的实现

作者:maojunxu558 浏览评论:04年前
作者:古普塔,P。乔哈里,K。Linagay 大学,印度文章发表于:工程技术新兴趋势 (ICETET),2009 年第二届实习生
阅读全文
【python爬虫】爬取图片打不开或损坏的简单探讨

作者:肖洛洛4401 浏览评论:06年前
本文主要针对python中使用urlretrieve或urlopen下载百度、搜狗、googto(谷歌镜像)等图片时出现“打不开图片或损坏”的问题。作者对此进行了简要讨论。同时作者会进一步帮你巩固 selenium 自动化和 urllib
阅读全文
输入关键字 抓取所有网页(项目招商找A5快速获取精准代理名单当选取了某个关键字)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-17 15:04
项目投资找A5快速获取精准代理商名单
选择某个关键字时,关键字需要将关键字集成到网页上,并通过此信息,可以告知搜索引擎与某个关键字密切相关。比如你的网站是一个与卖“炒股软件”相关的网站,所以你在网站首页设置要优化的关键词是“炒股软件”,但是在整个网页中,从头到尾从来没有出现过“炒股软件”这个词,所以无论网页再好,当你在搜索引擎中输入“炒股软件”这个关键词时,你也不会能够找到它,因为搜索引擎无法知道您的网页。它与关键字“股票交易软件”密切相关。
分布关键词,我们如何从以下几个方面来思考:
1)关键字密度
所谓关键词密度,是指关键词或关键字段在一个页面上所有页面的总文本中所占的比例。为了让大家更直观的理解“关键词密度”这个概念,这里我们举个例子:一句“诺基亚手机是世界知名品牌手机”,在这句话中,我们可以区分“诺基亚”“手机”手机”“是”、“世界”、“知名”和“手机”,其中“手机”在这句话中的关键词密度为2/6=1/3。
对于整个网页,我们检查这个网页的HTML代码,然后去掉代码中的HTML代码,剩下的就是网页的整个文本,然后按照上面的计算方法得到最终的关键词关键词密度。
当然,以上只是如何获取关键词密度的理论。在实践中,我们很少手动执行此操作。而是直接用站长工具检测,但是我们会发现每个站长工具检测的结果都不一样,所以这些数字只是给我们做个简单的参考,具体网上关键词密度可以输入关键词“搜索引擎中的关键字密度”和许多工具都会问世。
更合理的关键词密度范围是2%~8%,但我们不必太拘泥于这些数字,我们可以在网页中分配我们认为合理的内容。一般来说,一个网页大约分布6~10个关键词。不需要太多。
关键词的密度是搜索引擎排名的一个重要因素。不要累积关键字,否则会有触发关键字填充过滤器惩罚的后果。
2)关键字分布
关键字的分布原则如下:
a:整个网页均匀分布关键词,从左到上的结构分布
b:在title和meta中分布关键词
c:在网页中使用,,等为一两个关键字制作特殊标签
以上就是我们分配关键词的三个基本原则。首先,我们必须将它们均匀分布,并将它们分布在左侧和上方。在保证统一性的同时,还要保证左上角的关键词数量。二是关键词要分布在标题中,不仅对网站首页如此,对于写文章内容也是如此,如果你的一些网站文章 are 为了获取一个长尾关键字,使用这个长尾关键字来组织标题。最后是关于一些关键词的特殊处理。如果只是简单的关键词密度,可能无法强烈表达这个页面与这个关键词密切相关,但是如果对几个关键词做特殊处理,
关于 h1,h2.h3,h4,h5,h6 和强标签
其中,h4.h5.h6 用得比较少。如果按其功能排序,h1>h2>h3>strong>h4>h5>h6
用于标记内容,起到加强作用。除了强调这个标题在页面中的内容重要性外,如果有链接,也加强了对链接页面的推荐。这些标签可用于引导网页上的蜘蛛解释和跟踪网页。
h1——一个大标题,可以放在网站网页的顶部,告诉搜索引擎网站的作用。它应该收录 网站 主要关键字,但要避免关键字填充。最好出现在网页源代码body标签开头的第一个容器的第一行。并且保证在一个页面中只出现一次。
h2——副标题,每页出现的次数应该是1-3次。
比如阿里巴巴中文版的首页:
H1出现在LOGO的标签中,只有这一个,这里的源码是:
H2 出现在下栏
源代码在这里:
阿里巴巴服务
H3分布多次,这里有一个:
源代码在这里:
新:13,684
关键词的分布和其他标记的使用,不仅是关键词的分布和强化,也是控制蜘蛛爬取分布的重要作用。在蜘蛛无法关注的链接区域,如果你给这个区域的前面加上列名并标记,那么蜘蛛就会开始关注这个区域,这些链接也会被蜘蛛,在内部链接的构建中也起着重要的作用。
3)与关键字相关的相关术语
在关键词分布中,不仅目标关键词会影响这个网页的关键词排名,其他一些相关的词也会促进网页的关键词排名,比如“减肥”、“减肥”分布在您的网页中 相关词如“健身”、“优雅”、“苗条”,而相反的词如“胖”和“胖”也有助于您的网页排名,这些相关词将再次强化您的关键字,从而提升页面在搜索引擎排名中,这相当于告诉搜索引擎这个网页确实与关键词“减肥”息息相关。相反,如果你网页的关键词是“减肥”,但在你的网页中除了“减肥”之外,
4)标题和元信息的设置
在之前的关键词分布中,我们提到了title和meta信息的重要性,所以在第四点,我们将介绍title和meta信息的合理设置建议:
标题设置:
a:网站主页:网站名称 - 网站角色和使命
b:列表页(列页):列名-网站名称
c:内容页:标题-列名-网站名称
基本原理就是把当前网页的主要信息放在最上面,然后按照导航路径一步步到网站首页。一个简单的网站pass 收录三种类型的网页:主页、列表页和内容页。
元信息设置:
元信息主要是指关键词(keywords)和描述(description)信息。元信息对搜索引擎的作用逐渐减弱。搜索引擎可以在不使用这些元信息的情况下分发网页内容。设置元信息的建议:
关键字(keywords):你不需要设置它们。如果你设置它们,不要选择太多的关键字,也不要堆叠它们。
description(描述):用简单的语言描述网页信息,使每个网页的元信息都不同。如果做不到,最好不要设置。
这是一个网页,从中我们可以看到一些关于关键词分布的线索
这是一个农业特产信息网站的内页。猪流感时期,用文章的内页优化了关键词“山东猪流感”,虽然网站本身的权重还是很高的,但是内页的优化还是基于关键字的密度。首先,在TITLE(这里是文章的标题)中,“山东猪流感病例被确诊,回应是同一个人没有及时隔离的原因。“汽车”,收录关键词“山东猪流感”,标题使用标签,分布在正文内容中,第一段略多,三个关键词分布,第二段为一个。大体均匀,稍有分布,更重要的是自然。
超级站长网戴仁光原创文章 本文版权归戴仁光@超站科技所有。欢迎转载,并注明作者和出处。谢谢
申请创业报告,分享创业好点子。点击这里一起讨论新的商机! 查看全部
输入关键字 抓取所有网页(项目招商找A5快速获取精准代理名单当选取了某个关键字)
项目投资找A5快速获取精准代理商名单
选择某个关键字时,关键字需要将关键字集成到网页上,并通过此信息,可以告知搜索引擎与某个关键字密切相关。比如你的网站是一个与卖“炒股软件”相关的网站,所以你在网站首页设置要优化的关键词是“炒股软件”,但是在整个网页中,从头到尾从来没有出现过“炒股软件”这个词,所以无论网页再好,当你在搜索引擎中输入“炒股软件”这个关键词时,你也不会能够找到它,因为搜索引擎无法知道您的网页。它与关键字“股票交易软件”密切相关。
分布关键词,我们如何从以下几个方面来思考:
1)关键字密度
所谓关键词密度,是指关键词或关键字段在一个页面上所有页面的总文本中所占的比例。为了让大家更直观的理解“关键词密度”这个概念,这里我们举个例子:一句“诺基亚手机是世界知名品牌手机”,在这句话中,我们可以区分“诺基亚”“手机”手机”“是”、“世界”、“知名”和“手机”,其中“手机”在这句话中的关键词密度为2/6=1/3。
对于整个网页,我们检查这个网页的HTML代码,然后去掉代码中的HTML代码,剩下的就是网页的整个文本,然后按照上面的计算方法得到最终的关键词关键词密度。
当然,以上只是如何获取关键词密度的理论。在实践中,我们很少手动执行此操作。而是直接用站长工具检测,但是我们会发现每个站长工具检测的结果都不一样,所以这些数字只是给我们做个简单的参考,具体网上关键词密度可以输入关键词“搜索引擎中的关键字密度”和许多工具都会问世。
更合理的关键词密度范围是2%~8%,但我们不必太拘泥于这些数字,我们可以在网页中分配我们认为合理的内容。一般来说,一个网页大约分布6~10个关键词。不需要太多。
关键词的密度是搜索引擎排名的一个重要因素。不要累积关键字,否则会有触发关键字填充过滤器惩罚的后果。
2)关键字分布
关键字的分布原则如下:
a:整个网页均匀分布关键词,从左到上的结构分布
b:在title和meta中分布关键词
c:在网页中使用,,等为一两个关键字制作特殊标签
以上就是我们分配关键词的三个基本原则。首先,我们必须将它们均匀分布,并将它们分布在左侧和上方。在保证统一性的同时,还要保证左上角的关键词数量。二是关键词要分布在标题中,不仅对网站首页如此,对于写文章内容也是如此,如果你的一些网站文章 are 为了获取一个长尾关键字,使用这个长尾关键字来组织标题。最后是关于一些关键词的特殊处理。如果只是简单的关键词密度,可能无法强烈表达这个页面与这个关键词密切相关,但是如果对几个关键词做特殊处理,
关于 h1,h2.h3,h4,h5,h6 和强标签
其中,h4.h5.h6 用得比较少。如果按其功能排序,h1>h2>h3>strong>h4>h5>h6
用于标记内容,起到加强作用。除了强调这个标题在页面中的内容重要性外,如果有链接,也加强了对链接页面的推荐。这些标签可用于引导网页上的蜘蛛解释和跟踪网页。
h1——一个大标题,可以放在网站网页的顶部,告诉搜索引擎网站的作用。它应该收录 网站 主要关键字,但要避免关键字填充。最好出现在网页源代码body标签开头的第一个容器的第一行。并且保证在一个页面中只出现一次。
h2——副标题,每页出现的次数应该是1-3次。
比如阿里巴巴中文版的首页:
H1出现在LOGO的标签中,只有这一个,这里的源码是:
H2 出现在下栏
源代码在这里:
阿里巴巴服务
H3分布多次,这里有一个:
源代码在这里:
新:13,684
关键词的分布和其他标记的使用,不仅是关键词的分布和强化,也是控制蜘蛛爬取分布的重要作用。在蜘蛛无法关注的链接区域,如果你给这个区域的前面加上列名并标记,那么蜘蛛就会开始关注这个区域,这些链接也会被蜘蛛,在内部链接的构建中也起着重要的作用。
3)与关键字相关的相关术语
在关键词分布中,不仅目标关键词会影响这个网页的关键词排名,其他一些相关的词也会促进网页的关键词排名,比如“减肥”、“减肥”分布在您的网页中 相关词如“健身”、“优雅”、“苗条”,而相反的词如“胖”和“胖”也有助于您的网页排名,这些相关词将再次强化您的关键字,从而提升页面在搜索引擎排名中,这相当于告诉搜索引擎这个网页确实与关键词“减肥”息息相关。相反,如果你网页的关键词是“减肥”,但在你的网页中除了“减肥”之外,
4)标题和元信息的设置
在之前的关键词分布中,我们提到了title和meta信息的重要性,所以在第四点,我们将介绍title和meta信息的合理设置建议:
标题设置:
a:网站主页:网站名称 - 网站角色和使命
b:列表页(列页):列名-网站名称
c:内容页:标题-列名-网站名称
基本原理就是把当前网页的主要信息放在最上面,然后按照导航路径一步步到网站首页。一个简单的网站pass 收录三种类型的网页:主页、列表页和内容页。
元信息设置:
元信息主要是指关键词(keywords)和描述(description)信息。元信息对搜索引擎的作用逐渐减弱。搜索引擎可以在不使用这些元信息的情况下分发网页内容。设置元信息的建议:
关键字(keywords):你不需要设置它们。如果你设置它们,不要选择太多的关键字,也不要堆叠它们。
description(描述):用简单的语言描述网页信息,使每个网页的元信息都不同。如果做不到,最好不要设置。
这是一个网页,从中我们可以看到一些关于关键词分布的线索
这是一个农业特产信息网站的内页。猪流感时期,用文章的内页优化了关键词“山东猪流感”,虽然网站本身的权重还是很高的,但是内页的优化还是基于关键字的密度。首先,在TITLE(这里是文章的标题)中,“山东猪流感病例被确诊,回应是同一个人没有及时隔离的原因。“汽车”,收录关键词“山东猪流感”,标题使用标签,分布在正文内容中,第一段略多,三个关键词分布,第二段为一个。大体均匀,稍有分布,更重要的是自然。
超级站长网戴仁光原创文章 本文版权归戴仁光@超站科技所有。欢迎转载,并注明作者和出处。谢谢
申请创业报告,分享创业好点子。点击这里一起讨论新的商机!
输入关键字 抓取所有网页(利用Python网络爬虫微信朋友圈动态(上)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-13 21:10
阿里云 > 云栖社区 > 主题地图 > L > 用网络爬虫爬取关键词
推荐活动:
更多优惠>
当前主题: 使用网络爬虫进行爬网关键词添加到采集夹
相关话题:
使用网络爬虫爬取关键词相关博客查看更多博客
《Python爬虫开发与项目实践》——第3章Web爬虫入门3.1 Web爬虫概述
作者:华章电脑 3956人浏览评论:04年前
本章节选自华章计算机《Python爬虫开发与项目实战》一书第3章3.1节,作者:范传辉。更多章节请访问云栖社区“华章计算机”查看公众号第3章网络爬虫入门本章将正式涉及Python爬虫的开发。本章主要分为两部分:一部分是网络
阅读全文
如何使用Python网络爬虫抓取微信好友数量和微信好友男女比例
作者:python进阶1453人查看评论:03年前
前几天给大家分享了使用Python爬虫爬取朋友圈的动态(上)和使用Python爬虫爬取朋友圈的动态——附代码(下),并对抓取到的数据进行Python处理。词云和艺术字可视化,有兴趣的小伙伴可以戳这个文章:使用Python词云和艺术字
阅读全文
使用Python网络爬虫抓取微信好友签名并进行可视化展示
作者:python进阶1255人查看评论:03年前
前几天给大家分享了如何使用Python词云和wordart可视化工具对朋友圈数据进行可视化,使用Python网络爬虫抓取微信好友数量和微信男女比例好友,并使用Python网络爬虫抓取微信好友位置省市分布及其可视化,感兴趣的朋友可以点击查看
阅读全文
网络爬虫的实现
作者:xumaojun933 浏览评论:03年前
作者:古普塔,P。乔哈里,K。印度 Linagay 大学 文章 发表于:工程技术新兴趋势 (ICETET),2009 年第 2 次实习生
阅读全文
网络爬虫的实现
作者:nothingfinal1246 浏览评论:23 年前
通过古普塔,P。乔哈里,K。Linagay's Univ., India 文章发表于:工程和技术的新兴趋势 (ICETET),2009 年第二届国际
阅读全文
网络爬虫的实现
作者:shapherd2738 浏览评论:05年前
摘要 - 万维网是通过HTML格式链接的数十亿文档的集合,那么如此海量的数据已经成为信息检索的障碍,用户可能不得不翻页才能找到他们想要的材料。网络爬虫是搜索引擎的核心部分,网络爬虫不断地爬取互联网,以查找任何添加到网络的新页面和已从网络中删除的页面。
阅读全文
网络爬虫的实现
作者:maojunxu558 浏览评论:04年前
作者:古普塔,P。乔哈里,K。Linagay 大学,印度文章发表于:工程技术新兴趋势 (ICETET),2009 年第二届实习生
阅读全文
【python爬虫】爬取图片打不开或损坏的简单探讨
作者:肖洛洛4401 浏览评论:06年前
本文主要针对python中使用urlretrieve或urlopen下载百度、搜狗、googto(谷歌镜像)等图片时出现“打不开图片或损坏”的问题。作者对此进行了简要讨论。同时作者会进一步帮你巩固 selenium 自动化和 urllib
阅读全文 查看全部
输入关键字 抓取所有网页(利用Python网络爬虫微信朋友圈动态(上)(组图))
阿里云 > 云栖社区 > 主题地图 > L > 用网络爬虫爬取关键词
推荐活动:
更多优惠>
当前主题: 使用网络爬虫进行爬网关键词添加到采集夹
相关话题:
使用网络爬虫爬取关键词相关博客查看更多博客
《Python爬虫开发与项目实践》——第3章Web爬虫入门3.1 Web爬虫概述
作者:华章电脑 3956人浏览评论:04年前
本章节选自华章计算机《Python爬虫开发与项目实战》一书第3章3.1节,作者:范传辉。更多章节请访问云栖社区“华章计算机”查看公众号第3章网络爬虫入门本章将正式涉及Python爬虫的开发。本章主要分为两部分:一部分是网络
阅读全文
如何使用Python网络爬虫抓取微信好友数量和微信好友男女比例
作者:python进阶1453人查看评论:03年前
前几天给大家分享了使用Python爬虫爬取朋友圈的动态(上)和使用Python爬虫爬取朋友圈的动态——附代码(下),并对抓取到的数据进行Python处理。词云和艺术字可视化,有兴趣的小伙伴可以戳这个文章:使用Python词云和艺术字
阅读全文
使用Python网络爬虫抓取微信好友签名并进行可视化展示
作者:python进阶1255人查看评论:03年前
前几天给大家分享了如何使用Python词云和wordart可视化工具对朋友圈数据进行可视化,使用Python网络爬虫抓取微信好友数量和微信男女比例好友,并使用Python网络爬虫抓取微信好友位置省市分布及其可视化,感兴趣的朋友可以点击查看
阅读全文
网络爬虫的实现
作者:xumaojun933 浏览评论:03年前
作者:古普塔,P。乔哈里,K。印度 Linagay 大学 文章 发表于:工程技术新兴趋势 (ICETET),2009 年第 2 次实习生
阅读全文
网络爬虫的实现
作者:nothingfinal1246 浏览评论:23 年前
通过古普塔,P。乔哈里,K。Linagay's Univ., India 文章发表于:工程和技术的新兴趋势 (ICETET),2009 年第二届国际
阅读全文
网络爬虫的实现
作者:shapherd2738 浏览评论:05年前
摘要 - 万维网是通过HTML格式链接的数十亿文档的集合,那么如此海量的数据已经成为信息检索的障碍,用户可能不得不翻页才能找到他们想要的材料。网络爬虫是搜索引擎的核心部分,网络爬虫不断地爬取互联网,以查找任何添加到网络的新页面和已从网络中删除的页面。
阅读全文
网络爬虫的实现
作者:maojunxu558 浏览评论:04年前
作者:古普塔,P。乔哈里,K。Linagay 大学,印度文章发表于:工程技术新兴趋势 (ICETET),2009 年第二届实习生
阅读全文
【python爬虫】爬取图片打不开或损坏的简单探讨
作者:肖洛洛4401 浏览评论:06年前
本文主要针对python中使用urlretrieve或urlopen下载百度、搜狗、googto(谷歌镜像)等图片时出现“打不开图片或损坏”的问题。作者对此进行了简要讨论。同时作者会进一步帮你巩固 selenium 自动化和 urllib
阅读全文
输入关键字 抓取所有网页( 继续搜狗站长平台使用教程的分享,本文讲一下【站点信息】功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-13 04:19
继续搜狗站长平台使用教程的分享,本文讲一下【站点信息】功能)
继续分享搜狗站长平台使用教程。本文将讨论[站点信息]功能。当我们将网站添加到搜狗站长平台后,站点信息需要几天时间才能显示在这里。这部分内容以观看为主,没有太多可操作的东西。
我的网站
站点信息中的第一项是【我的站点】,显示了当前网站的具体数据。主要包括:收录指标体积、流量、关键词、抓压。
可能大部分公司网站的搜狗站数据都不是很好,这个不用太担心,只要你的网站建设不是专门针对搜狗SEO优化的,那么就看一看。
网站名片
站点信息中的第二项是[网站名片]。我记得这个功能是在2018年推出的,但是经过实际观察,这个功能可能对大多数网站都没有用。因为大多数 网站 没有这张名片。
我们来看看这张名片是什么网站,如上图所示!明白了,如果您的公司 网站 在业内知名度不高,一般不会出现在这里。另外,大家注意到上图下方有一条信息,即网站名片的信息由【安全联盟】提供。
点击【安全联盟】链接后,你会发现这个认证需要额外收费。如果你的企业觉得需要认证,那你可以自己付费,这里我就不多说了。
总结
站点信息功能仅用于展示网站的主要信息,可以让你知道网站在搜狗上的当前搜索数据,知道就知道了。 查看全部
输入关键字 抓取所有网页(
继续搜狗站长平台使用教程的分享,本文讲一下【站点信息】功能)
继续分享搜狗站长平台使用教程。本文将讨论[站点信息]功能。当我们将网站添加到搜狗站长平台后,站点信息需要几天时间才能显示在这里。这部分内容以观看为主,没有太多可操作的东西。
我的网站
站点信息中的第一项是【我的站点】,显示了当前网站的具体数据。主要包括:收录指标体积、流量、关键词、抓压。
可能大部分公司网站的搜狗站数据都不是很好,这个不用太担心,只要你的网站建设不是专门针对搜狗SEO优化的,那么就看一看。
网站名片
站点信息中的第二项是[网站名片]。我记得这个功能是在2018年推出的,但是经过实际观察,这个功能可能对大多数网站都没有用。因为大多数 网站 没有这张名片。
我们来看看这张名片是什么网站,如上图所示!明白了,如果您的公司 网站 在业内知名度不高,一般不会出现在这里。另外,大家注意到上图下方有一条信息,即网站名片的信息由【安全联盟】提供。
点击【安全联盟】链接后,你会发现这个认证需要额外收费。如果你的企业觉得需要认证,那你可以自己付费,这里我就不多说了。
总结
站点信息功能仅用于展示网站的主要信息,可以让你知道网站在搜狗上的当前搜索数据,知道就知道了。
输入关键字 抓取所有网页(java中操作数据库的基本使用方法--apachejavadriver数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-12 23:06
输入关键字抓取所有网页数据。
文件传输工具一般都可以直接将网页信息上传到服务器,比如webdav、ftp、apache等,可以和本地服务器通过sqlite(一种可以直接从数据库中取数据的数据库)进行对接,然后通过jdbc数据库驱动进行连接,在java中操作数据库是相对比较简单的。如果用java的话,可以考虑下apachejavadriver或者clouderajavadriver进行联接,以下是三种类型的apachejavadriver的基本使用方法:connector类:用来与apachejavadriver建立通信(可以直接通过apache的-x-dev来设置开关),分为几个属性,可以调用参数来对source和directory进行定义。
也可以通过构造方法自定义输入-->设置路径->数据库连接->sqlite(可以通过下面代码来自定义输入的数据库),如下:构造方法示例signal类:可以用来作为与服务器的通信,它的功能主要有两个,一个是notice,另一个是system,用于通知服务器两个重要信息:1)先要配置好网页源文件地址;2)必须对每个包含源文件的java文件进行读写权限控制,用于防止恶意上传文件。
百度就有了
百度就有。
怎么要,服务器服务器端自己处理的。国内还没有这种网站。国外最近的都是bs形式的apache+mysql这种。 查看全部
输入关键字 抓取所有网页(java中操作数据库的基本使用方法--apachejavadriver数据)
输入关键字抓取所有网页数据。
文件传输工具一般都可以直接将网页信息上传到服务器,比如webdav、ftp、apache等,可以和本地服务器通过sqlite(一种可以直接从数据库中取数据的数据库)进行对接,然后通过jdbc数据库驱动进行连接,在java中操作数据库是相对比较简单的。如果用java的话,可以考虑下apachejavadriver或者clouderajavadriver进行联接,以下是三种类型的apachejavadriver的基本使用方法:connector类:用来与apachejavadriver建立通信(可以直接通过apache的-x-dev来设置开关),分为几个属性,可以调用参数来对source和directory进行定义。
也可以通过构造方法自定义输入-->设置路径->数据库连接->sqlite(可以通过下面代码来自定义输入的数据库),如下:构造方法示例signal类:可以用来作为与服务器的通信,它的功能主要有两个,一个是notice,另一个是system,用于通知服务器两个重要信息:1)先要配置好网页源文件地址;2)必须对每个包含源文件的java文件进行读写权限控制,用于防止恶意上传文件。
百度就有了
百度就有。
怎么要,服务器服务器端自己处理的。国内还没有这种网站。国外最近的都是bs形式的apache+mysql这种。
输入关键字 抓取所有网页(功能介绍智能识别模式WebHarvy网页中出现的数据模式-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-12 06:19
特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
软件功能
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器浏览网络。您可以选择要单击的数据。这很容易!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面爬取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
变更日志
修复了可能导致页面启动时禁用连接的错误
您可以为页面模式配置专用的连接方法
可以自动搜索 HTML 上的可配置资源 查看全部
输入关键字 抓取所有网页(功能介绍智能识别模式WebHarvy网页中出现的数据模式-苏州安嘉)
特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。

软件功能
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器浏览网络。您可以选择要单击的数据。这很容易!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面爬取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
变更日志
修复了可能导致页面启动时禁用连接的错误
您可以为页面模式配置专用的连接方法
可以自动搜索 HTML 上的可配置资源
输入关键字 抓取所有网页(一下:新网站上线怎么才能被百度秒收录呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-09 15:22
百度收录一直是运营推广人员工作的重中之重,尤其是很多公司做网站网站没有被百度接受之后收录 , 导致优化的关键词 没有排名。上百度收录首页花了几个月的时间,导致运营上浪费了很多时间,所以今天我们来讲解一下:一个新的网站怎么能秒上百度网站 @收录?
1、添加搜索引擎条目
前提
收录就是内容可以被search和win抓取,所以我们发布的内容一定要输入好,而这些条目包括目录网站的提交,以及链接友情交流,以及外链的布局,让搜索引擎可以抓取我们的网站到其他的网站。同时我们也可以通过站长搜索平台的链接提交方式将内容提交给搜索引擎,让搜索引擎快速抓取我们的网站,提高收录的概率网站。
2、发布优质内容
网站上线前必须填写内容,内容必须结构合理,内容优质。因为网站上线后,搜索引擎会根据你的网站内容给你的网站内容评分。如果是优质内容,那么你的网站就是优质的网站,后续网站的收录和排名都会很好。如果搜索引擎把你的网站评价为质量差,那么收录的后续和审核周期也会很长,导致网站的排名很差,所以网站的质量@> 很好 不好的主要原因是 网站 上线的时候。
3、做网站的基础优化
网站的基础优化也是影响网站收录的重要因素,比如网站alt处理、h标签处理、网站301和404页面的设置,还有标题和栏目的设置,都需要做好。还有网站的访问速度。 网站的访问速度也会影响网站的评分,所以我们要选择访问速度快的空间和服务器。
把上面的内容做好,当搜索引擎爬取你的网站时,会判断你的网站内容质量高,基本会对你的网站秒收费。 ,后续网站的内容发布也将轻松收录,所以上线前一定要在建站时做好网站的基础优化和建设。不要急于上网。否则只会适得其反。 查看全部
输入关键字 抓取所有网页(一下:新网站上线怎么才能被百度秒收录呢?)
百度收录一直是运营推广人员工作的重中之重,尤其是很多公司做网站网站没有被百度接受之后收录 , 导致优化的关键词 没有排名。上百度收录首页花了几个月的时间,导致运营上浪费了很多时间,所以今天我们来讲解一下:一个新的网站怎么能秒上百度网站 @收录?
1、添加搜索引擎条目
前提
收录就是内容可以被search和win抓取,所以我们发布的内容一定要输入好,而这些条目包括目录网站的提交,以及链接友情交流,以及外链的布局,让搜索引擎可以抓取我们的网站到其他的网站。同时我们也可以通过站长搜索平台的链接提交方式将内容提交给搜索引擎,让搜索引擎快速抓取我们的网站,提高收录的概率网站。
2、发布优质内容
网站上线前必须填写内容,内容必须结构合理,内容优质。因为网站上线后,搜索引擎会根据你的网站内容给你的网站内容评分。如果是优质内容,那么你的网站就是优质的网站,后续网站的收录和排名都会很好。如果搜索引擎把你的网站评价为质量差,那么收录的后续和审核周期也会很长,导致网站的排名很差,所以网站的质量@> 很好 不好的主要原因是 网站 上线的时候。
3、做网站的基础优化
网站的基础优化也是影响网站收录的重要因素,比如网站alt处理、h标签处理、网站301和404页面的设置,还有标题和栏目的设置,都需要做好。还有网站的访问速度。 网站的访问速度也会影响网站的评分,所以我们要选择访问速度快的空间和服务器。
把上面的内容做好,当搜索引擎爬取你的网站时,会判断你的网站内容质量高,基本会对你的网站秒收费。 ,后续网站的内容发布也将轻松收录,所以上线前一定要在建站时做好网站的基础优化和建设。不要急于上网。否则只会适得其反。
输入关键字 抓取所有网页(自建站的“请输入关键字”搜索框怎么设置?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-09 15:05
“请输入查询关键字”的搜索框是大多数网站都会做的设置。这个搜索框可以帮助用户更快的找到自己想要的信息,对用户来说是正常的。但是对于SEO人员来说,这个搜索框的设置就没有那么简单了。自建网站的“请输入查询关键字”搜索框可能会直接影响产品的转化。
搜索框的作用
1.搜索框的作用是爬取页面。每个独立的搜索引擎都有自己的网页爬取过程(蜘蛛)。蜘蛛跟随网页中的超链接,不断地爬取网页。由于超链接在互联网中应用广泛,理论上,从一定大小的网页开始,可以采集到大部分网页。
2.在处理完网页后,搜索引擎需要做大量的预处理工作来提供检索服务。其中,最重要的是提取关键词并建立索引文件。其他还包括删除重复网页、分析超链接和计算网页的主要程度。
3.提供检索服务用户输入关键词进行检索,搜索引擎从索引库中找到与关键词匹配的网页。为方便用户,网页中除网页主题和网址外,还提供段落摘要等信息。
搜索框的重要性
大多数情况下,会使用搜索功能的用户,主要是产品的老用户,对产品的基本内容和服务有一定的了解,有非常明确的自身诉求。在这种情况下,如果用户可以检索到他们想要的内容或服务,那么肯定会出现高转化。
提高搜索的转化率,让用户直接让客户成功,即如何将粘性转化为结果,成功率高的购买转化才能带来利润和利润。
搜索框位置显眼,使用方便,会给客户留下更好的印象。这就需要网站组织清晰的访问路径,让用户可以流畅地浏览更深层次的内容,也可以帮助用户快速找到目标,也能到达目标页面。
如何设置“请输入关键字”搜索框
1、基于SEO优化
从SEO的角度来回顾“请输入搜索关键词”的问题,其实我们在说的是网站中的搜索框和搜索结果的反馈。我们需要从以下两个方面来理解:
①推荐和收录
利用站内搜索框“请输入关键词”的状态,产生大量长尾关键词,合理使用搜索结果列表,展示次数,适当增加关键词@的密度> 在 SERP 中,从而获得更高的排名。
②屏蔽和隐蔽
对于中小型企业,如果您的数据站点的检索量不大,通常建议使用 robots.txt 来屏蔽这个搜索结果 URL。尤其是当你的 SERP 页面没有标准化做 SEO 的时候,由于网站资源有限,真的没必要分配百度爬虫去爬这些页面。
2、基于用户体验
从用户体验的角度来看,网站搜索框中的“请输入内容设置”尤为重要。有利于推荐企业的核心产品,提高企业产品的转化率,提高UGC内容的输出,延缓用户的页面停留。时间,从而增加用户对网站品牌的粘性。
①详细的网站统计分析,了解用户画像、对方的爱好和喜好。
②控制行业更新热门话题,合理利用网站多个入口,分发优质内容,吸引他人参与讨论,提高当前热门话题栏目页面的热度,从而提高搜索引擎的可靠性。
3、输入的搜索词不准确
如果对方检索到的具体关键词没有搜索结果,90%以上的网站会返回一个空结果,或者一个标志“你的关键词输入不准确”会出现。但这是一个非常不明智的策略,您可以在此报告以下内容:
①网站逻辑构建图,类似于HTML版的sitemap。
②用户比较关注“请输入查询关键词”,推荐一些比较热的词进行搜索。
③ 站内热点文章,行业内比较热门的相关话题等。
由此可以推断,自建网站的“请输入查询关键词”搜索框其实是很重要的。 查看全部
输入关键字 抓取所有网页(自建站的“请输入关键字”搜索框怎么设置?(图))
“请输入查询关键字”的搜索框是大多数网站都会做的设置。这个搜索框可以帮助用户更快的找到自己想要的信息,对用户来说是正常的。但是对于SEO人员来说,这个搜索框的设置就没有那么简单了。自建网站的“请输入查询关键字”搜索框可能会直接影响产品的转化。

搜索框的作用
1.搜索框的作用是爬取页面。每个独立的搜索引擎都有自己的网页爬取过程(蜘蛛)。蜘蛛跟随网页中的超链接,不断地爬取网页。由于超链接在互联网中应用广泛,理论上,从一定大小的网页开始,可以采集到大部分网页。
2.在处理完网页后,搜索引擎需要做大量的预处理工作来提供检索服务。其中,最重要的是提取关键词并建立索引文件。其他还包括删除重复网页、分析超链接和计算网页的主要程度。
3.提供检索服务用户输入关键词进行检索,搜索引擎从索引库中找到与关键词匹配的网页。为方便用户,网页中除网页主题和网址外,还提供段落摘要等信息。
搜索框的重要性
大多数情况下,会使用搜索功能的用户,主要是产品的老用户,对产品的基本内容和服务有一定的了解,有非常明确的自身诉求。在这种情况下,如果用户可以检索到他们想要的内容或服务,那么肯定会出现高转化。
提高搜索的转化率,让用户直接让客户成功,即如何将粘性转化为结果,成功率高的购买转化才能带来利润和利润。
搜索框位置显眼,使用方便,会给客户留下更好的印象。这就需要网站组织清晰的访问路径,让用户可以流畅地浏览更深层次的内容,也可以帮助用户快速找到目标,也能到达目标页面。
如何设置“请输入关键字”搜索框
1、基于SEO优化
从SEO的角度来回顾“请输入搜索关键词”的问题,其实我们在说的是网站中的搜索框和搜索结果的反馈。我们需要从以下两个方面来理解:
①推荐和收录
利用站内搜索框“请输入关键词”的状态,产生大量长尾关键词,合理使用搜索结果列表,展示次数,适当增加关键词@的密度> 在 SERP 中,从而获得更高的排名。
②屏蔽和隐蔽
对于中小型企业,如果您的数据站点的检索量不大,通常建议使用 robots.txt 来屏蔽这个搜索结果 URL。尤其是当你的 SERP 页面没有标准化做 SEO 的时候,由于网站资源有限,真的没必要分配百度爬虫去爬这些页面。
2、基于用户体验
从用户体验的角度来看,网站搜索框中的“请输入内容设置”尤为重要。有利于推荐企业的核心产品,提高企业产品的转化率,提高UGC内容的输出,延缓用户的页面停留。时间,从而增加用户对网站品牌的粘性。
①详细的网站统计分析,了解用户画像、对方的爱好和喜好。
②控制行业更新热门话题,合理利用网站多个入口,分发优质内容,吸引他人参与讨论,提高当前热门话题栏目页面的热度,从而提高搜索引擎的可靠性。
3、输入的搜索词不准确
如果对方检索到的具体关键词没有搜索结果,90%以上的网站会返回一个空结果,或者一个标志“你的关键词输入不准确”会出现。但这是一个非常不明智的策略,您可以在此报告以下内容:
①网站逻辑构建图,类似于HTML版的sitemap。
②用户比较关注“请输入查询关键词”,推荐一些比较热的词进行搜索。
③ 站内热点文章,行业内比较热门的相关话题等。
由此可以推断,自建网站的“请输入查询关键词”搜索框其实是很重要的。
输入关键字 抓取所有网页(“请输入关键词”基于站搜索框的设置值得多一些研究)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-09 15:02
请输入查询关键字,这是您在访问任何网站时经常会在搜索框中看到的一些常见设置,对于用户来说并不是一个引人注目的地方,但是对于SEO人员来说,“请输入 关键词" 基于站点搜索框值得更多研究。原因很简单,可能直接影响企业产品的转化。
那么,如何设置“请输入关键字”搜索框呢?
根据以往SEO网站优化的经验,蝙蝠侠IT将详细阐述以下内容:
1、基于SEO优化
我们将从SEO的角度来回顾一下“请输入搜索关键字”的问题。其实我们说的是网站上的搜索框和搜索结果的反馈。基于SEO,我们这里不讨论:请输入关键词,内容本身。
您可能需要从以下两个角度来理解:
① 推荐和收录
如果你有优化电商网站的经验,你会发现,类似于京东的电商网站,是一个非常小的细分策略,就是利用搜索框在网站上,请输入关键词位置,产生大量长尾关键词,并合理利用搜索结果列表、展示次数,并适当增加SERP中关键词的密度,从而获得更高的排名。
但值得注意的是,要能够完美地使用这个策略,你可能需要两个小前提:
一是对方有大量的搜索查询需求。
二是网站中的搜索框,输出的搜索结果页面必须符合搜索引擎友好的URL。
② 屏蔽和隐藏
对于相当于中小企业的网站,如果你的数据网站检索量不大,我们这里通常给出的建议是使用robots.txt来屏蔽搜索结果的URL。
尤其是当你的 SERP 页面没有标准化做 SEO 的时候,由于网站资源有限,真的没必要分配百度爬虫去爬这些页面。
2、基于用户体验
从用户体验的角度来看,在网站的搜索框中设置输入内容是非常重要的,比如:
①有利于推荐企业核心产品,提高企业产品转化率。
②有利于推荐网站核心话题,提高UGC内容的输出。
③有利于推荐站点内的核心话题,延缓用户在页面的停留时间,从而增加用户对站点品牌的粘性。
为此,在进行站点搜索推荐时,您可能需要:
① 对网站做详细的统计分析,了解用户的画像,对方的喜好和喜好。
②掌握行业最新热门话题,适当利用站点内多个入口,分发优质内容,引导对方参与讨论,增加当前热门话题栏目页面的热度,从而提高搜索引擎的信任。
3、您输入的搜索词不正确
当你在搜索框中输入一些关键词时,如果对方检索到的具体关键词没有搜索结果,通常90%以上的网站都会返回一个空结果,或者是“您输入了不正确的 关键词”符号。
事实上,这是一个非常不明智的策略,你可以在这个地方给出这样的反馈:
① 网站逻辑结构图,类似于HTML版的sitemap。
②“请输入查询关键词”,最近用户非常关注,推荐了一些比较热门的搜索词。
③ 网站热门文章,行业最热相关话题等。
总结:请输入搜索关键字,貌似是个琐碎的地方,具体怎么设置,还是可以起到相应的作用的,以上内容仅供参考!
蝙蝠侠IT转载需授权! 查看全部
输入关键字 抓取所有网页(“请输入关键词”基于站搜索框的设置值得多一些研究)
请输入查询关键字,这是您在访问任何网站时经常会在搜索框中看到的一些常见设置,对于用户来说并不是一个引人注目的地方,但是对于SEO人员来说,“请输入 关键词" 基于站点搜索框值得更多研究。原因很简单,可能直接影响企业产品的转化。

那么,如何设置“请输入关键字”搜索框呢?
根据以往SEO网站优化的经验,蝙蝠侠IT将详细阐述以下内容:
1、基于SEO优化
我们将从SEO的角度来回顾一下“请输入搜索关键字”的问题。其实我们说的是网站上的搜索框和搜索结果的反馈。基于SEO,我们这里不讨论:请输入关键词,内容本身。
您可能需要从以下两个角度来理解:
① 推荐和收录
如果你有优化电商网站的经验,你会发现,类似于京东的电商网站,是一个非常小的细分策略,就是利用搜索框在网站上,请输入关键词位置,产生大量长尾关键词,并合理利用搜索结果列表、展示次数,并适当增加SERP中关键词的密度,从而获得更高的排名。
但值得注意的是,要能够完美地使用这个策略,你可能需要两个小前提:
一是对方有大量的搜索查询需求。
二是网站中的搜索框,输出的搜索结果页面必须符合搜索引擎友好的URL。
② 屏蔽和隐藏
对于相当于中小企业的网站,如果你的数据网站检索量不大,我们这里通常给出的建议是使用robots.txt来屏蔽搜索结果的URL。
尤其是当你的 SERP 页面没有标准化做 SEO 的时候,由于网站资源有限,真的没必要分配百度爬虫去爬这些页面。
2、基于用户体验
从用户体验的角度来看,在网站的搜索框中设置输入内容是非常重要的,比如:
①有利于推荐企业核心产品,提高企业产品转化率。
②有利于推荐网站核心话题,提高UGC内容的输出。
③有利于推荐站点内的核心话题,延缓用户在页面的停留时间,从而增加用户对站点品牌的粘性。
为此,在进行站点搜索推荐时,您可能需要:
① 对网站做详细的统计分析,了解用户的画像,对方的喜好和喜好。
②掌握行业最新热门话题,适当利用站点内多个入口,分发优质内容,引导对方参与讨论,增加当前热门话题栏目页面的热度,从而提高搜索引擎的信任。
3、您输入的搜索词不正确
当你在搜索框中输入一些关键词时,如果对方检索到的具体关键词没有搜索结果,通常90%以上的网站都会返回一个空结果,或者是“您输入了不正确的 关键词”符号。
事实上,这是一个非常不明智的策略,你可以在这个地方给出这样的反馈:
① 网站逻辑结构图,类似于HTML版的sitemap。
②“请输入查询关键词”,最近用户非常关注,推荐了一些比较热门的搜索词。
③ 网站热门文章,行业最热相关话题等。
总结:请输入搜索关键字,貌似是个琐碎的地方,具体怎么设置,还是可以起到相应的作用的,以上内容仅供参考!
蝙蝠侠IT转载需授权!
输入关键字 抓取所有网页(做seo很大程度是做关键词的基本目标,才有更好的转化率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-08 23:16
很大程度上,做SEO就是做关键词排名。将关键词设为首页是SEO的基本目标。只有首页的排名,才能有更好的展示机会和更高的转化率。
一、搜索原理
网络蜘蛛是网络蜘蛛。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到所有 网站 网页都被爬取。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
1、抢
搜索引擎和普通访问者一样,会按照网页上的链接,一一下载我们的网页,为下一步的预处理做准备。
2、预处理
①。判断是否符合其收录规则,若符合收录规则则继续处理
②。对 文章 进行分词
将网页中的 文章 剪切成单个单词。测量文档之间的相关性并准备反向索引。并记录单词出现的位置。
③。创建倒排索引
在搜索引擎中,每个文件对应一个文件ID,文件内容表示为一系列关键词的集合
将文件 ID 到 关键词 的映射转换为 关键词 到文件 ID 的映射。
使用词索引网页的好处是搜索引擎的用户也输入了词,这样他们就可以很容易地找到相关的网页。
3、搜索
①。用户对关键词查询进行分段,取索引的交集
②.排序
重要性 - 网页静态质量得分。搜索引擎将网站的各种性能条件转化为分数,这些分数相加得到一个页面的质量分数,即所谓的权重。
一种。页面信噪比:
页面信噪比是指页面中文字与非文字的比例,页面信噪比至少要大于1。
湾。缺乏
C。链接控制:
链接控制子链接的数量和链接自然度。页面的权重是固定的,链接可以传递权重。链路越多,每条链路传输的权重越低。
d。页面浏览量
相关性——以上只能通过倒排索引来定性的知道网页和查询词是否相关,但是没有办法知道谁更相关,也就是定量的。百度处理方法:
一种。记录单词出现的位置,关键词在不同位置的权重不同。
湾。tf-idf算法,即一个词在一篇文章文章中出现次数最多,词的权重越高;一个词在整个互联网上出现的次数越多,(比如“我”、“这个词”不足以区分一个文章的话题,几乎每一个文章都会出现)越小这个词的重量。
4、常用的高级搜索命令:
site:最熟悉的SEO高级搜索命令,用于搜索一个域名下的所有文件。
inurl: 指令用于搜索查询词出现在 url 中的页面。
intitle:该命令返回页面标题中收录关键词的页面。
domain:其作用是查询域名下的反向链接(反向链接=外部链接+内部链接)。
二、指数排名
1、收录 和索引
收录:页面被百度蜘蛛发现并分析
索引:百度蜘蛛初步分析认为有意义,做建库
收录索引的关系是收录关系。可以先建一个索引收录,收录的数量大于索引的数量。
百度表示,第三方提供的所谓收录查询是不可靠的。
1-1、索引文章行列式:
可信度;
文章质量;
更新频率;
网站结构体;
熊掌号和站点地图对百度有推广作用收录;
网站的年龄和体重影响百度收录对网站的影响。
1-2、加速页面索引方法:
做好网站TDK,不要修改;
积累优质网站内容;
每日定期和定量更新;
提交百度等搜索引擎,包括站点地图、熊掌号等;
重点制作熊掌号。目前熊爪号的提交已经可以做到移动站收录的80%以上;
有针对性、定期发布优质外链。
2、文章质量判断(百度官方)
①。观众
受众的规模代表了用户检索需求的规模。
②。稀缺
稀缺性主要描述了互联网页面的独特性。
③.质量
a 不能是死链接,网站访问速度是否令人满意。
b 主要内容是否完整,版式和字体是否易于阅读,广告是否过多。
c 信息是否丰富,是否满足扩展的次要需求。
④。老化
3、原创识别判断
①。释放时间——蜘蛛抓到的日期
②.锚文本链接——网站页面有多少个外部链接
③.信息指纹——文章内容的相似度
4、标题优化方法
搜索引擎搜索到的内容的标题往往就是网页标题的内容,搜索引擎给标题赋予了很高的权重。
①。标题流畅、吸引人且文章现实。
②。标题必须为原创,收录核心关键词和长尾词,与内容关键词保持一致
③。写作要符合搜索引擎的习惯,少用标点符号
④。长度适当,控制在22个汉字以内
5、内容优化方法
主要分为两部分:一部分是原创/伪原创,另一部分是采集素材库回顾。
至少第一段需要纯原创,最好有可搜索的内容,整个段落要根据玩家的搜索需求来写。
正文最好有条不紊地分成小标题
基于内容的 伪原创 方法
寻找有价值的文章,最好当天发布,或者使用爬虫爬取的数据库重写
有价值的 文章 可读性强、目标明确且引人注目。
①。修改文章的开头和结尾部分:
重新总结第一段和最后一段,打乱文中的顺序,去掉一些不相关的。添加透视。
②。对原文进行拆分重组:找几个相关的文章合并成一个新的文章
③。相关内容的组合与组合
④。将 文章 翻译成其他语言
⑤。使用论坛、博客、新媒体等方式挖掘文章
6、图像优化方法
搜索引擎已经具备一定的能力来识别大多数图像的 原创 属性
图片的算法主要包括计算hash值、pHash算法和SIFT算法,对目标图像进行编码形成“指纹”并存储。
①。给图片添加水印;
②。改变原图的纵横比,或者直接截取图片的某一部分;
③。图片长宽比尽量接近121*75,接近百度搜索显示的缩略图大小;
④。缩略图内部链接,相比文字链接,更能吸引访问者点击,关注相关性。
⑤。添加alt描述可以增强页面的主题关键词,但是注意不要堆放关键词。
⑥。百度越来越喜欢原创的内容,其实图片也是页面的一部分。
7、关键词优化方法
关键词类别:核心关键词;相关关键词;长尾 关键词; 错误 关键词; 不常见 关键词
①。从用户的角度考虑,想想用户在搜索时使用了什么词
②,不超过5个,一般3个:主关键词,辅助关键词,潜在长尾关键词
③、关键词密度不超过2% - 8%(根据需要,不是绝对的) 查看全部
输入关键字 抓取所有网页(做seo很大程度是做关键词的基本目标,才有更好的转化率)
很大程度上,做SEO就是做关键词排名。将关键词设为首页是SEO的基本目标。只有首页的排名,才能有更好的展示机会和更高的转化率。
一、搜索原理
网络蜘蛛是网络蜘蛛。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到所有 网站 网页都被爬取。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
1、抢
搜索引擎和普通访问者一样,会按照网页上的链接,一一下载我们的网页,为下一步的预处理做准备。
2、预处理
①。判断是否符合其收录规则,若符合收录规则则继续处理
②。对 文章 进行分词
将网页中的 文章 剪切成单个单词。测量文档之间的相关性并准备反向索引。并记录单词出现的位置。
③。创建倒排索引
在搜索引擎中,每个文件对应一个文件ID,文件内容表示为一系列关键词的集合
将文件 ID 到 关键词 的映射转换为 关键词 到文件 ID 的映射。
使用词索引网页的好处是搜索引擎的用户也输入了词,这样他们就可以很容易地找到相关的网页。
3、搜索
①。用户对关键词查询进行分段,取索引的交集
②.排序
重要性 - 网页静态质量得分。搜索引擎将网站的各种性能条件转化为分数,这些分数相加得到一个页面的质量分数,即所谓的权重。
一种。页面信噪比:
页面信噪比是指页面中文字与非文字的比例,页面信噪比至少要大于1。
湾。缺乏
C。链接控制:
链接控制子链接的数量和链接自然度。页面的权重是固定的,链接可以传递权重。链路越多,每条链路传输的权重越低。
d。页面浏览量
相关性——以上只能通过倒排索引来定性的知道网页和查询词是否相关,但是没有办法知道谁更相关,也就是定量的。百度处理方法:
一种。记录单词出现的位置,关键词在不同位置的权重不同。
湾。tf-idf算法,即一个词在一篇文章文章中出现次数最多,词的权重越高;一个词在整个互联网上出现的次数越多,(比如“我”、“这个词”不足以区分一个文章的话题,几乎每一个文章都会出现)越小这个词的重量。
4、常用的高级搜索命令:
site:最熟悉的SEO高级搜索命令,用于搜索一个域名下的所有文件。
inurl: 指令用于搜索查询词出现在 url 中的页面。
intitle:该命令返回页面标题中收录关键词的页面。
domain:其作用是查询域名下的反向链接(反向链接=外部链接+内部链接)。
二、指数排名
1、收录 和索引
收录:页面被百度蜘蛛发现并分析
索引:百度蜘蛛初步分析认为有意义,做建库
收录索引的关系是收录关系。可以先建一个索引收录,收录的数量大于索引的数量。
百度表示,第三方提供的所谓收录查询是不可靠的。
1-1、索引文章行列式:
可信度;
文章质量;
更新频率;
网站结构体;
熊掌号和站点地图对百度有推广作用收录;
网站的年龄和体重影响百度收录对网站的影响。
1-2、加速页面索引方法:
做好网站TDK,不要修改;
积累优质网站内容;
每日定期和定量更新;
提交百度等搜索引擎,包括站点地图、熊掌号等;
重点制作熊掌号。目前熊爪号的提交已经可以做到移动站收录的80%以上;
有针对性、定期发布优质外链。
2、文章质量判断(百度官方)
①。观众
受众的规模代表了用户检索需求的规模。
②。稀缺
稀缺性主要描述了互联网页面的独特性。
③.质量
a 不能是死链接,网站访问速度是否令人满意。
b 主要内容是否完整,版式和字体是否易于阅读,广告是否过多。
c 信息是否丰富,是否满足扩展的次要需求。
④。老化
3、原创识别判断
①。释放时间——蜘蛛抓到的日期
②.锚文本链接——网站页面有多少个外部链接
③.信息指纹——文章内容的相似度
4、标题优化方法
搜索引擎搜索到的内容的标题往往就是网页标题的内容,搜索引擎给标题赋予了很高的权重。
①。标题流畅、吸引人且文章现实。
②。标题必须为原创,收录核心关键词和长尾词,与内容关键词保持一致
③。写作要符合搜索引擎的习惯,少用标点符号
④。长度适当,控制在22个汉字以内
5、内容优化方法
主要分为两部分:一部分是原创/伪原创,另一部分是采集素材库回顾。
至少第一段需要纯原创,最好有可搜索的内容,整个段落要根据玩家的搜索需求来写。
正文最好有条不紊地分成小标题
基于内容的 伪原创 方法
寻找有价值的文章,最好当天发布,或者使用爬虫爬取的数据库重写
有价值的 文章 可读性强、目标明确且引人注目。
①。修改文章的开头和结尾部分:
重新总结第一段和最后一段,打乱文中的顺序,去掉一些不相关的。添加透视。
②。对原文进行拆分重组:找几个相关的文章合并成一个新的文章
③。相关内容的组合与组合
④。将 文章 翻译成其他语言
⑤。使用论坛、博客、新媒体等方式挖掘文章
6、图像优化方法
搜索引擎已经具备一定的能力来识别大多数图像的 原创 属性
图片的算法主要包括计算hash值、pHash算法和SIFT算法,对目标图像进行编码形成“指纹”并存储。
①。给图片添加水印;
②。改变原图的纵横比,或者直接截取图片的某一部分;
③。图片长宽比尽量接近121*75,接近百度搜索显示的缩略图大小;
④。缩略图内部链接,相比文字链接,更能吸引访问者点击,关注相关性。
⑤。添加alt描述可以增强页面的主题关键词,但是注意不要堆放关键词。
⑥。百度越来越喜欢原创的内容,其实图片也是页面的一部分。
7、关键词优化方法
关键词类别:核心关键词;相关关键词;长尾 关键词; 错误 关键词; 不常见 关键词
①。从用户的角度考虑,想想用户在搜索时使用了什么词
②,不超过5个,一般3个:主关键词,辅助关键词,潜在长尾关键词
③、关键词密度不超过2% - 8%(根据需要,不是绝对的)
输入关键字 抓取所有网页(企赢搜网络,外链分析怎么解决信息的问题?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-08 23:14
惠农用心服务网站关键词推企价格赢搜网,分析外链。我们在发送外链时,要注意外链的质量,而不是追求数量;有利于爬取、收录、排名、点击的因素。比如sitemap的制作,nofollow的使用,内部链接的合理使用;不利于爬取、收录、排名、点击的因素。比如网站速度、内部链接覆盖率、URL长度、URL参数过多、URL中使用的特殊字符、TDK编写。
如果您刚刚重新设计了您的网站或搬到了一个新的cms,请保持页面的原创数据不变。如果在更改过程中丢失了原创数据,则可能会减少流量。解决方案是使用丢失的原创数据更新所有网页。原号码。
网站地图最初创建的时候,是网站的设计者为了方便游客浏览网站而创建的。该页面涵盖了整个网站(大网站 >)或页面(中小网站)的所有栏目,目的是让浏览者能够快速找到他们需要的信息。而这种效果在小网站中并不明显,但是在一些门户网站中却很明显,这些大网站由于页面信息量大,用户想要从首页时间 你需要的页面比较难,一般有很清晰的地图结构。这些是为了方便用户而构建的,而不仅仅是为了让搜索引擎抓取。而用户友好的网站更容易受到搜索引擎的欢迎。自然,< @网站 地图发挥了不可估量的作用。网站地图可以让访问者更容易浏览和增加用户体验。
whois 信息对于很多人来说可能不是很熟悉。事实上,Seoer 经常忽略它。但是从这些信息中我们可以看到很多内容,比如网站是公司注册还是个人网站是个人还是团队维护的,当然一些相关的备案信息可以也可以看到。whois 信息字段。
如果您已经开始构建电子商务 网站 并开始尝试使用 关键词,那么您将使用某种类型的 关键词 排名来确定 关键词 的位置在相关搜索中排名。通过将您的 网站 添加到 GoogleSearchConsole,您可以获得现成的免费数据。6 使用 关键词 排名跟踪工具成功。
有时我对一件事感到好奇,我喜欢去看看。为此,我两三年前找到了自己的手机,重新登录了微信,看到了和他的所有聊天记录,每次都问了一个不同的问题。网站,不一样的关键词,每次我们报价太低,他总说太贵,报价再低也贵,就这样,从一开始2017年初的咨询,之后的咨询几乎每隔一两年举行一次。近年来,我咨询过一次。
总结 根据我上面总结的方法,一个一个研究。虽然你更加努力,但回报一定会更加丰厚。上帝不会对待辛勤工作的。
而一个真正能“对产品负责”的运营,至少应该围绕一个产品的成长,去走遍每一个环节,通过自身对具体运营策略和手段的优化调整,不断获得良好的产出。甚至你负责的产品,其实也只是一个QQ群或者豆瓣群。 查看全部
输入关键字 抓取所有网页(企赢搜网络,外链分析怎么解决信息的问题?)
惠农用心服务网站关键词推企价格赢搜网,分析外链。我们在发送外链时,要注意外链的质量,而不是追求数量;有利于爬取、收录、排名、点击的因素。比如sitemap的制作,nofollow的使用,内部链接的合理使用;不利于爬取、收录、排名、点击的因素。比如网站速度、内部链接覆盖率、URL长度、URL参数过多、URL中使用的特殊字符、TDK编写。

如果您刚刚重新设计了您的网站或搬到了一个新的cms,请保持页面的原创数据不变。如果在更改过程中丢失了原创数据,则可能会减少流量。解决方案是使用丢失的原创数据更新所有网页。原号码。
网站地图最初创建的时候,是网站的设计者为了方便游客浏览网站而创建的。该页面涵盖了整个网站(大网站 >)或页面(中小网站)的所有栏目,目的是让浏览者能够快速找到他们需要的信息。而这种效果在小网站中并不明显,但是在一些门户网站中却很明显,这些大网站由于页面信息量大,用户想要从首页时间 你需要的页面比较难,一般有很清晰的地图结构。这些是为了方便用户而构建的,而不仅仅是为了让搜索引擎抓取。而用户友好的网站更容易受到搜索引擎的欢迎。自然,< @网站 地图发挥了不可估量的作用。网站地图可以让访问者更容易浏览和增加用户体验。
whois 信息对于很多人来说可能不是很熟悉。事实上,Seoer 经常忽略它。但是从这些信息中我们可以看到很多内容,比如网站是公司注册还是个人网站是个人还是团队维护的,当然一些相关的备案信息可以也可以看到。whois 信息字段。

如果您已经开始构建电子商务 网站 并开始尝试使用 关键词,那么您将使用某种类型的 关键词 排名来确定 关键词 的位置在相关搜索中排名。通过将您的 网站 添加到 GoogleSearchConsole,您可以获得现成的免费数据。6 使用 关键词 排名跟踪工具成功。
有时我对一件事感到好奇,我喜欢去看看。为此,我两三年前找到了自己的手机,重新登录了微信,看到了和他的所有聊天记录,每次都问了一个不同的问题。网站,不一样的关键词,每次我们报价太低,他总说太贵,报价再低也贵,就这样,从一开始2017年初的咨询,之后的咨询几乎每隔一两年举行一次。近年来,我咨询过一次。
总结 根据我上面总结的方法,一个一个研究。虽然你更加努力,但回报一定会更加丰厚。上帝不会对待辛勤工作的。
而一个真正能“对产品负责”的运营,至少应该围绕一个产品的成长,去走遍每一个环节,通过自身对具体运营策略和手段的优化调整,不断获得良好的产出。甚至你负责的产品,其实也只是一个QQ群或者豆瓣群。
输入关键字 抓取所有网页(一下请输入关键字的技巧分享网络搜索框的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-08 23:14
)
我们经常会遇到这样的情况:在浏览网站的时候,会发现一个百度搜索框,里面写着输入关键词或者请输入关键字,给我们的搜索带来了方便。当然,关键词的选择也是有一定技巧的,所以如何输入关键词也是一门学问。本页是站长整理的关于“请输入关键字”和“请输入关键词”的信息,旨在帮助刚接触互联网的朋友。让我们介绍一下分享的技巧,请输入关键字。
请输入关键字 VS 请输入 关键词
注:本站搜索结果来自百度,建议您使用百度采集关键词!
百度()是最大的中文搜索引擎,你想找的都可以,百度使用技巧:
在上方“请输入关键词”框内进行“美女搜索、视频搜索、数据搜索、图片搜索、音乐搜索”,即可搜索到最想要的信息!
搜索小Tips:
首先让我们了解什么是关键字?我们通常说的关键字是指一个主题,也称为Keyword。刚接触搜索引擎的网友会遇到这样一句话:“\请输入关键字\”或\“请输入关键词\”,这其实是搜索引擎引导用户使用的一种简单方式。在搜索框中输入您要查询的关键字。点击查询,立马就有结果,这就是搜索引擎的魅力所在。例如,如果我想学习交易股票,那么你只需要在搜索框中输入“股票”或“股票”这两个词,就会出现很多关于“股票”或“股票”的信息。
让我们总结一下。事实上,关键词就是所有收录被搜索词和句子的信息。这些单词和短语是关键字。它也是一个网络术语。如果你还有什么问题,我会推荐你一个很好的网站百度知道:他真的什么都知道。
这个页面中间的百度搜索框就有这样的功能。您可以尝试在中间的搜索框中输入一些您感兴趣的主题,看看有什么结果?惊讶!搜索引擎几乎可以让你搜索任何东西。美丽的图画,流行的小说……
目前比较有名的搜索引擎有百度、GOOGLE、雅虎。各大门户网站网站也开始研究自己的搜索引擎,比如新浪爱问、腾讯SOSO、搜狐SOGOU、网易SO163。尽管它们的算法不同,但用法相似。下面将贴出三大搜索引擎的使用技巧,其他搜索引擎的大家可以自己看看。
百度使用技巧:
谷歌提示:
雅虎提示:
很多人说,如果你搜索娱乐关键字,你可以在百度上找到它们。如果你搜索学术关键词,你可以在 GOOGLE 上找到它们。至于雅虎,它只是一个备用搜索引擎。事实上,三大搜索引擎各有千秋。无论如何,搜索引擎的目的是让用户更快、更准确地找到他们需要的信息。为达到这个目的,相信三大搜索引擎会不断完善用户。有经验的。
解释有关“请输入关键字”和“请输入 关键词”的问题?
一、
问:我看到很多地方出现'Enter 关键词'和'请输入关键字',这是什么意思?
答:意思是让你输入你知道要查找的单词或单词。假设你想找一本书。然后,您可以在“请输入 关键词”下方输入单词“关键字”。单击搜索,您将找到您要查找的内容。
示例:例如,您要查看化妆品的相关信息。然后,您可以在下面的“请输入关键字”字段中输入“化妆品”一词。单击搜索以查找您要查找的相关信息。让我们试试吧^_^!
二、
问:我也看到很多网站带有“请输入关键字”,这是什么意思?
答:顾名思义,和上面差不多,请输入关键词。它是您要查找的内容的核心词。为了使搜索系统容易找到你需要的东西,输入方便,就是用代词或句子,以这个词为中心,找到你需要的东西。
示例:假设您要查看视频教程的相关信息。您可以在下面的“请输入关键字”中输入“视频教程”一词。单击搜索以查找您要查找的相关信息。让我们再试一次^_^!
一般我们搜索信息的时候,都会去百度和谷歌找。百度是最大的中文搜索引擎,我们可以找到最新的资讯文章。谷歌是国外的搜索引擎,实力也很强。当然,我们可以找到很多好东西。此外,等等,我们还可以从上述两个搜索引擎中得到不同的结果。关于如何确定输入的关键字,比如你在找菜谱,可以输入菜谱、菜谱、食物等,你会发现一些很专业的网站。例如,如果您输入的关键字是菜,则可能没有您想要的结果。在这种情况下,您可以查看下面的相关 关键词 查询。当然,你也可以在关键词中找到你想要的信息,在“
查看全部
输入关键字 抓取所有网页(一下请输入关键字的技巧分享网络搜索框的方法
)
我们经常会遇到这样的情况:在浏览网站的时候,会发现一个百度搜索框,里面写着输入关键词或者请输入关键字,给我们的搜索带来了方便。当然,关键词的选择也是有一定技巧的,所以如何输入关键词也是一门学问。本页是站长整理的关于“请输入关键字”和“请输入关键词”的信息,旨在帮助刚接触互联网的朋友。让我们介绍一下分享的技巧,请输入关键字。
请输入关键字 VS 请输入 关键词
注:本站搜索结果来自百度,建议您使用百度采集关键词!
百度()是最大的中文搜索引擎,你想找的都可以,百度使用技巧:
在上方“请输入关键词”框内进行“美女搜索、视频搜索、数据搜索、图片搜索、音乐搜索”,即可搜索到最想要的信息!
搜索小Tips:
首先让我们了解什么是关键字?我们通常说的关键字是指一个主题,也称为Keyword。刚接触搜索引擎的网友会遇到这样一句话:“\请输入关键字\”或\“请输入关键词\”,这其实是搜索引擎引导用户使用的一种简单方式。在搜索框中输入您要查询的关键字。点击查询,立马就有结果,这就是搜索引擎的魅力所在。例如,如果我想学习交易股票,那么你只需要在搜索框中输入“股票”或“股票”这两个词,就会出现很多关于“股票”或“股票”的信息。
让我们总结一下。事实上,关键词就是所有收录被搜索词和句子的信息。这些单词和短语是关键字。它也是一个网络术语。如果你还有什么问题,我会推荐你一个很好的网站百度知道:他真的什么都知道。
这个页面中间的百度搜索框就有这样的功能。您可以尝试在中间的搜索框中输入一些您感兴趣的主题,看看有什么结果?惊讶!搜索引擎几乎可以让你搜索任何东西。美丽的图画,流行的小说……
目前比较有名的搜索引擎有百度、GOOGLE、雅虎。各大门户网站网站也开始研究自己的搜索引擎,比如新浪爱问、腾讯SOSO、搜狐SOGOU、网易SO163。尽管它们的算法不同,但用法相似。下面将贴出三大搜索引擎的使用技巧,其他搜索引擎的大家可以自己看看。
百度使用技巧:
谷歌提示:
雅虎提示:
很多人说,如果你搜索娱乐关键字,你可以在百度上找到它们。如果你搜索学术关键词,你可以在 GOOGLE 上找到它们。至于雅虎,它只是一个备用搜索引擎。事实上,三大搜索引擎各有千秋。无论如何,搜索引擎的目的是让用户更快、更准确地找到他们需要的信息。为达到这个目的,相信三大搜索引擎会不断完善用户。有经验的。
解释有关“请输入关键字”和“请输入 关键词”的问题?
一、
问:我看到很多地方出现'Enter 关键词'和'请输入关键字',这是什么意思?
答:意思是让你输入你知道要查找的单词或单词。假设你想找一本书。然后,您可以在“请输入 关键词”下方输入单词“关键字”。单击搜索,您将找到您要查找的内容。
示例:例如,您要查看化妆品的相关信息。然后,您可以在下面的“请输入关键字”字段中输入“化妆品”一词。单击搜索以查找您要查找的相关信息。让我们试试吧^_^!
二、
问:我也看到很多网站带有“请输入关键字”,这是什么意思?
答:顾名思义,和上面差不多,请输入关键词。它是您要查找的内容的核心词。为了使搜索系统容易找到你需要的东西,输入方便,就是用代词或句子,以这个词为中心,找到你需要的东西。
示例:假设您要查看视频教程的相关信息。您可以在下面的“请输入关键字”中输入“视频教程”一词。单击搜索以查找您要查找的相关信息。让我们再试一次^_^!
一般我们搜索信息的时候,都会去百度和谷歌找。百度是最大的中文搜索引擎,我们可以找到最新的资讯文章。谷歌是国外的搜索引擎,实力也很强。当然,我们可以找到很多好东西。此外,等等,我们还可以从上述两个搜索引擎中得到不同的结果。关于如何确定输入的关键字,比如你在找菜谱,可以输入菜谱、菜谱、食物等,你会发现一些很专业的网站。例如,如果您输入的关键字是菜,则可能没有您想要的结果。在这种情况下,您可以查看下面的相关 关键词 查询。当然,你也可以在关键词中找到你想要的信息,在“


输入关键字 抓取所有网页(获取Excel高手都在用的“插件合集+插件使用小技巧”!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-03-08 02:10
获取Excel高手正在使用的“加载项集合+加载项使用技巧”!
一时兴起,在知乎中搜索了Excel,想学习一些好评文章的写作方法。
看到这些标题,完结了,顿时激起了下载采集的欲望!
如何捕获所有 文章 高度喜欢的?
当我开始时,我考虑过使用 Python。
想了想,好像可以用Power query来实现,于是做了如下效果。
在表单中输入搜索词,然后右键刷新,即可得到搜索结果。
你明白我必须拿表格吗?
因为Excel可以直接按照“点赞数”排序!
那种感觉就像在排队。无论我在哪里排队,我都会是第一个并选择最好的!
好了,废话不多说,我们来看看这个表格是怎么做出来的。
大致可以分为4个步骤:
❶ 获取 JSON 数据连接;
❷ 电源查询处理数据;
❸ 配置搜索地址;
❹ 添加超链接。
01 操作步骤
❶ 获取 JSON 数据连接
通常在浏览网页时,它是一个简单的网址。
网页中看到的数据其实有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链接对应的是JSON格式的数据,如下所示。
找到方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制此链接,这是 Power 查询将获取数据的链接。
❷ 电量查询处理
你可能不知道,除了在 Excel 中捕获数据,Power Query 还可以
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站Data 也是其中之一:
将我们之前获取的链接粘贴到PQ中,链接就可以抓取数据了。
然后得到网页的数据格式。如何获取具体的 文章 数据?
Power Query的强大之处在于它可以自动识别json数据格式,并解析提取具体内容。
整个过程,我们不需要做任何操作,只需点击鼠标即可完成。
这时候我们获取的数据会有一些不必要的冗余数据。
例如:thumbnail_info(缩略图信息)、relationship、question、id.1等。
只需删除它们并仅保留所需的 文章 标题、作者、超链接等。
数据处理完成后,在开始选项卡中,点击“关闭并上传”即可完成数据抓取,非常简单。
❸ 配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词没有更新。
所以在这一步中,我们需要配置这个数据链接,实现基于搜索词的动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词,以变量的形式放入搜索地址中,完成搜索地址的配置。
修改后的地址码如下:
getdata = (page)=>
let
keywords = 搜索词[ 搜索词]{0},
源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random()))),
data = 源[data],
jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, ExtraValues.Error)
in
jsondata,
转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
▲ 左右滑动查看
❹ 添加超链接
至此所有数据都已经处理完毕,但是如果要查看原创的知乎页面,需要复制这个超链接并在浏览器中打开。
每次点击几次鼠标很麻烦;
这里我们使用 HYPERLINK 函数来生成一个可点击的超链接,这使得访问变得更加容易。
❺ 最终效果
最后的效果是:
❶ 输入搜索词;
❷ 右键刷新;
❸ 找到点赞最多的;
❹点击【点击查看】,享受跳线的感觉!
02总结
知道在表格中搜索的好处吗?
❶ 按“赞”和“评论”排序;
❷ 看过文章的可以加个栏目写笔记;
❸您可以过滤您喜欢的“作者”等。
明白为什么,精英都是Excel控制的吧?
大多数电子表格用户仍然使用 Excel 作为报告工具、绘制表格和编写公式。
请记住以下 Excel 新功能。这些功能让Excel成为了一个强大的数据统计和数据分析软件,不再只是你印象中的报表。
❶ 强力查询:数据整理清理工具,搭载M强大的M语言,可以实现多表合并,也是本文的主要技术。
❷ Power Pivot:数据统计工具,可以自定义统计方式,实现数据透视表多字段计算,自定义DAX数据计算方式。
❸ Power BI:强大易用的可视化工具,实现交互式数据呈现,是企业业务数据报表的优质解决方案。
欢迎在留言区聊天:
您还知道 Excel 的其他哪些神奇用途?
您最想在 Excel 中拥有什么功能?
... 查看全部
输入关键字 抓取所有网页(获取Excel高手都在用的“插件合集+插件使用小技巧”!)
获取Excel高手正在使用的“加载项集合+加载项使用技巧”!
一时兴起,在知乎中搜索了Excel,想学习一些好评文章的写作方法。
看到这些标题,完结了,顿时激起了下载采集的欲望!
如何捕获所有 文章 高度喜欢的?
当我开始时,我考虑过使用 Python。
想了想,好像可以用Power query来实现,于是做了如下效果。
在表单中输入搜索词,然后右键刷新,即可得到搜索结果。
你明白我必须拿表格吗?
因为Excel可以直接按照“点赞数”排序!
那种感觉就像在排队。无论我在哪里排队,我都会是第一个并选择最好的!
好了,废话不多说,我们来看看这个表格是怎么做出来的。
大致可以分为4个步骤:
❶ 获取 JSON 数据连接;
❷ 电源查询处理数据;
❸ 配置搜索地址;
❹ 添加超链接。
01 操作步骤
❶ 获取 JSON 数据连接
通常在浏览网页时,它是一个简单的网址。
网页中看到的数据其实有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链接对应的是JSON格式的数据,如下所示。
找到方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制此链接,这是 Power 查询将获取数据的链接。
❷ 电量查询处理
你可能不知道,除了在 Excel 中捕获数据,Power Query 还可以
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站Data 也是其中之一:
将我们之前获取的链接粘贴到PQ中,链接就可以抓取数据了。
然后得到网页的数据格式。如何获取具体的 文章 数据?
Power Query的强大之处在于它可以自动识别json数据格式,并解析提取具体内容。
整个过程,我们不需要做任何操作,只需点击鼠标即可完成。
这时候我们获取的数据会有一些不必要的冗余数据。
例如:thumbnail_info(缩略图信息)、relationship、question、id.1等。
只需删除它们并仅保留所需的 文章 标题、作者、超链接等。
数据处理完成后,在开始选项卡中,点击“关闭并上传”即可完成数据抓取,非常简单。
❸ 配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词没有更新。
所以在这一步中,我们需要配置这个数据链接,实现基于搜索词的动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词,以变量的形式放入搜索地址中,完成搜索地址的配置。
修改后的地址码如下:
getdata = (page)=>
let
keywords = 搜索词[ 搜索词]{0},
源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random()))),
data = 源[data],
jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, ExtraValues.Error)
in
jsondata,
转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
▲ 左右滑动查看
❹ 添加超链接
至此所有数据都已经处理完毕,但是如果要查看原创的知乎页面,需要复制这个超链接并在浏览器中打开。
每次点击几次鼠标很麻烦;
这里我们使用 HYPERLINK 函数来生成一个可点击的超链接,这使得访问变得更加容易。
❺ 最终效果
最后的效果是:
❶ 输入搜索词;
❷ 右键刷新;
❸ 找到点赞最多的;
❹点击【点击查看】,享受跳线的感觉!
02总结
知道在表格中搜索的好处吗?
❶ 按“赞”和“评论”排序;
❷ 看过文章的可以加个栏目写笔记;
❸您可以过滤您喜欢的“作者”等。
明白为什么,精英都是Excel控制的吧?
大多数电子表格用户仍然使用 Excel 作为报告工具、绘制表格和编写公式。
请记住以下 Excel 新功能。这些功能让Excel成为了一个强大的数据统计和数据分析软件,不再只是你印象中的报表。
❶ 强力查询:数据整理清理工具,搭载M强大的M语言,可以实现多表合并,也是本文的主要技术。
❷ Power Pivot:数据统计工具,可以自定义统计方式,实现数据透视表多字段计算,自定义DAX数据计算方式。
❸ Power BI:强大易用的可视化工具,实现交互式数据呈现,是企业业务数据报表的优质解决方案。
欢迎在留言区聊天:
您还知道 Excel 的其他哪些神奇用途?
您最想在 Excel 中拥有什么功能?
...
输入关键字 抓取所有网页(搜索引擎的工作的过程,而简单的讲搜索引擎工作过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-07 17:11
搜索引擎的工作过程非常复杂,简单来说,搜索引擎的工作过程大致可以分为三个阶段。
爬取爬取:搜索引擎蜘蛛通过以下链接访问页面,获取页面的 HTML 代码并将其存储在数据库中。
预处理:搜索引擎对抓取的页面数据进行文本提取、中文分词、索引等,为排名程序调用做准备。
排名:用户输入关键词后,排名调用索引数据库数据,计算相关度,然后生成一定格式的搜索结果页面。
爬行和爬行
爬取和爬取是搜索引擎工作的第一步,完成数据采集的任务。
蜘蛛
搜索引擎用来抓取和访问页面的程序称为蜘蛛,也称为机器人。
蜘蛛代理名称:
百度蜘蛛:百度蜘蛛+(+)·
雅虎!Slurp 中国:Mozilla/5.0(兼容;Yahoo! Slurp 中国;)·
英语雅虎蜘蛛:Mozilla/5.0(兼容;Yahoo! Slurp/3.0;)
谷歌蜘蛛:Mozilla/5.0(兼容;Googlebot/2.1;+)·
微软必应蜘蛛:msnbot/1.1 (+)·
搜狗蜘蛛:搜狗+网络+机器人+(+#07)·
搜搜蜘蛛:搜搜蜘蛛+(+) ·
有道蜘蛛:Mozilla/5.0(兼容;YodaoBot/1.0;;)
跟随链接
为了在网络上抓取尽可能多的页面,搜索引擎蜘蛛会跟随页面上的链接,从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样,这就是搜索引擎蜘蛛这个名字的由来. 最简单的爬行遍历策略分为两种,一种是深度优先,一种是广度优先。
深度优先搜索
深度优先搜索是在搜索树的每一层只展开一个子节点,继续往深处前进,直到不能再前进(到达叶子节点或被深度限制),然后从当前节点返回到上一个节点,继续另一个方向。这种方法的搜索树是从根开始逐个分支逐渐形成的。
深度优先搜索也称为垂直搜索。由于已解决的问题树可能收录无限分支,如果深度优先搜索误入无限分支(即深度是无限的),则无法找到目标节点。因此,深度优先搜索策略是不完整的。而且,应用这种策略得到的解不一定是最好的解(最短路径)。
广度优先搜索
在深度优先搜索算法中,首先扩展深度较大的节点。如果将算法改为按照搜索中节点的层级进行搜索,当该层的节点还没有被搜索和处理过时,下层节点无法处理,即先扩展深度较小的节点,即就是说先生成的节点先展开,这种搜索算法称为广度优先搜索。
在深度优先搜索算法中,首先扩展深度较大的节点。如果将算法改为按照搜索中节点的层级进行搜索,当该层的节点还没有被搜索和处理过时,下层节点无法处理,即先扩展深度较小的节点,即就是说先生成的节点先展开,这种搜索算法称为广度优先搜索。
吸引蜘蛛
哪些页面被认为更重要?有几个因素:
· 网站 和页面权重。优质和旧的网站被认为权重更高,在这个网站上的页面会被爬得更高的深度,所以更多的内页会是收录。
· 页面更新。蜘蛛每次抓取时都会存储页面数据。如果第二次爬取发现页面和第一次收录一模一样,说明页面没有更新,蜘蛛不需要频繁爬取。如果页面内容更新频繁,蜘蛛会更频繁地访问该页面,页面上出现的新链接自然会被蜘蛛更快地跟踪并抓取新页面。
· 导入链接。不管是外部链接还是同一个网站的内部链接,为了被蜘蛛爬取,必须有传入链接才能进入页面,否则蜘蛛没有机会知道这页纸。高质量的入站链接通常还会增加页面上出站链接的抓取深度。一般来说,首页在网站上的权重最高,大部分外部链接指向首页,首页也是蜘蛛访问频率最高的。离首页越近的点击距离,页面权重越高,被蜘蛛爬取的机会就越大。
地址库
为了避免重复爬取和爬取网址,搜索引擎会建立一个地址数据库来记录已找到但未爬取的页面,以及已爬取的页面。地址存储库中有几个 url 来源:
(1)手动输入种子网站。
(2)蜘蛛爬取页面后,从html中解析出新的链接url,并与地址库中的数据进行比较,如果是不在地址库中的url,则将其存储在要访问的地址库中。
(3)站长通过搜索引擎网页提交表单提交的网址。
蜘蛛根据重要性从要访问的地址库中提取url,访问并爬取页面,然后将要访问的地址库中的url删除,放入被访问地址的地址库中。
大多数主要搜索引擎都为网站管理员提供了提交 URL 的表单。但是,这些提交的 URL 只存储在地址数据库中。是否 收录 取决于页面的重要性。搜索引擎的绝大多数页面 收录 都是由蜘蛛自己通过链接获得的。可以说,提交页面基本没用,搜索引擎更喜欢跟随链接发现新页面。
文件存储 搜索引擎蜘蛛爬取的数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。每个 uRI 都有一个唯一的文件编号。
爬行时重复内容检测
检测和删除重复项通常在下面描述的预处理过程中完成,但是现代蜘蛛在爬取和爬取文件时也会进行一定程度的重复项检测。当你在网站上遇到大量转载或抄袭、权重极低的内容时,很可能会停止爬取。这就是为什么一些网站管理员在日志文件中发现蜘蛛,但该页面从未真正被 收录 访问过。
预处理
在一些 SEO 资料中,“预处理”也简称为“索引”,因为索引是预处理中最重要的步骤。
搜索引擎蜘蛛爬取的原创页面不能直接用于查询排名处理。搜索引擎数据库的页数在万亿级别。用户输入搜索词后,排名程序会实时分析这么多页面的相关性。计算量太大,不可能在一两秒内返回排名结果。因此,必须对爬取的页面进行预处理,为最终的查询排名做准备。
和爬虫一样,预处理是在后台提前完成的,用户在搜索的时候感受不到这个过程。
1.提取文本
今天的搜索引擎仍然基于文本内容。蜘蛛抓取到的页面中的HTML代码,除了用户在浏览器上可以看到的可见文本外,还收录大量的HTML格式标签、程序等不能用于排名的内容。搜索引擎预处理首先要做的就是去除HTML文件中的标签和程序,提取网页中可用于排名处理的文本内容。
今天是愚人节
去掉 HTML 代码后,剩下的用于排名的文字就是这一行:
今天是愚人节
除了可见文本,搜索引擎还会提取一些收录文本信息的特殊代码,例如 Meta 标签中的文本、图片 alt 文本、Flash 文件 alt 文本、链接锚文本等。
2.中文分词
分词是中文搜索引擎特有的一个步骤。搜索引擎基于单词存储和处理页面和用户搜索。英语等语言用空格隔开,搜索引擎索引程序可以直接把句子分成词组。但是,中文单词和单词之间没有分隔符,一个句子中的所有单词和单词都是连接在一起的。搜索引擎必须首先区分哪些词组成一个词,哪些词本身就是一个词。例如,“减肥法”将分为“减肥”和“方法”两个词。
中文分词基本上有两种方法,一种是基于字典匹配的,一种是基于统计的。
基于字典匹配的方法是指将一段待分析的汉字与预先制作的字典中的词条进行匹配,从待分析的字符串中扫描字典中已有的词条。分离出一个词。
根据扫描方向,基于字典的匹配方法可以分为正向匹配和反向匹配。根据匹配长度优先级的不同,可以分为最大匹配和最小匹配。优先混合扫描方向和长度可以产生不同的方法,例如正向最大匹配和反向最大匹配。
字典匹配方法计算简单,其准确性很大程度上取决于字典的完整性和更新。
基于统计的分词方法是指分析大量文本样本,计算相邻词的统计概率。出现的相邻单词越多,形成单词的可能性就越大。基于统计的方法的优点是对新出现的词更敏感,也有利于消歧。
基于字典匹配和统计的分词方法各有优缺点。实际使用的分词系统混合使用了这两种方法,快速高效,可以识别新词和新词,消除歧义。
中文分词的准确性往往会影响搜索引擎排名的相关性。比如你在百度上搜索“搜索引擎优化”,从截图中可以看出百度把“搜索引擎优化”这六个词当成一个词。
在 Google 上搜索相同的词时,快照显示 Google 将其拆分为“搜索引擎”和“优化”两个词。显然,百度有更合理的细分,搜索引擎优化是一个完整的概念。谷歌的分词往往更细化。
分词的这种差异可能是某些 关键词 排名在不同搜索引擎上表现不同的原因之一。例如,百度更喜欢匹配搜索词以显示在页面上。也就是说,在搜索“够玩博客”的时候,如果这四个词连续出现,在百度中更容易获得好的排名。另一方面,谷歌实际上并不需要完全匹配。有些页面出现了“足够的戏剧”和“博客”这两个词,但不一定完全匹配,“足够的戏剧”出现在页面的前面,“博客”在页面的其他位置,这样的页面出现在谷歌搜索“足够剧博客“”,也可以获得不错的排名。
搜索引擎对页面的分词取决于词库的大小、准确度和分词算法的质量,而不是页面本身,因此SEO人员对分词的作用很小。唯一能做的就是在页面上使用某种形式来提示搜索引擎某些词应该被当作一个词处理,尤其是当它可能有歧义的时候,比如页面标题中的关键词@,h1标签和黑体字>。如果页面是关于“和服”的内容,那么“和服”这个词可以特别用粗体标出。如果页面是关于“化妆和服装”的,你可以把“服装”这个词加粗。这样,当搜索引擎分析页面时,它就知道粗体字应该是一个词。
3.去停用词
无论是英文还是中文,都会出现一些在页面内容中出现频率高但对内容没有影响的词,比如“的”、“地”、“de”、“ah”等辅助词, “ha”、“ya”等感叹词、“therefore”、“with”、“but”等副词或介词。这些词被称为停用词,因为它们对页面的主要含义几乎没有影响。英语中常见的停用词有 the、a、an、to、of 等。
搜索引擎会在索引页面之前去除这些停用词,使索引数据的主题更加突出,减少不必要的计算量。
4.去除噪音
大部分页面也存在一些对页面主题没有贡献的内容,如版权声明文字、导航栏、广告等。以常见的博客导航为例,导航内容如文章categories几乎每个博客页面都会出现历史档案,但这些页面本身与“类别”和“历史”这两个词无关。用户搜索“历史”、“类别”并返回博客文章只是因为这些词出现在页面上是没有意义的,完全无关紧要的。因此,这些块都是噪音,只能对页面的主题起到分散作用。
搜索引擎需要在不使用嘈杂内容的情况下识别和消除这种噪音并进行排名。去噪的基本方法是根据HTML标签将页面分成块,区分页眉、导航、文本、页脚、广告等区域。网站 上重复出现的块通常是噪音。页面去噪后,剩下的就是页面的主要内容。
5.移除
搜索引擎还需要对页面进行重复数据删除。
同一个文章经常在不同的网站和同一个网站的不同URL上重复出现,搜索引擎不喜欢这种重复的内容。用户搜索时,如果在前两页看到来自不同网站的同一篇文章文章,用户体验太差了,尽管都是内容相关的。搜索引擎希望只返回一个相同的文章,所以在索引之前需要识别并删除重复的内容。此过程称为“重复数据删除”。
去重的基本方法是计算页面特征的指纹关键词,也就是从页面的主要内容中选择最有代表性的部分关键词(经常是出现频率最高的关键词) ,然后计算这些 关键词 的数字指纹。这里的关键词的选择是在分词、去停用词、降噪之后。实验表明,通常选择10个特征关键词可以达到比较高的计算精度,选择更多的词对去重精度的提升贡献不大。
典型的指纹计算方法如MD5算法(Information Digest Algorithm Fifth Edition)。这类指纹算法的特点是输入(feature关键词)的任何微小变化都会导致计算出的指纹出现很大的差距。
了解了搜索引擎的去重算法后,SEO人员应该知道,简单地加上“de”、“地”、“de”,改变段落的顺序,所谓伪原创,是逃不过去重的。搜索引擎。算法,因为这样的操作不能改变文章关键词的特性。此外,搜索引擎的重复数据删除算法可能不仅在页面级别,而且在段落级别。混用不同的文章,互换段落的顺序,不能让转载、抄袭变成原创。
6.正向索引
远期指数也可以简称为指数。
经过文本提取、分词、去噪和去重后,搜索引擎获得了能够反映页面主要内容的独特的、基于词的内容。接下来,搜索引擎索引程序可以提取关键词,按照分词程序对单词进行划分,将页面转换为关键词的集合,并将每个关键词的内容记录在这页纸。出现频率、出现次数、格式(如在标题标签、粗体、H标签、锚文本等)、位置(如页面第一段等)。这样,每一页就可以记录为一组关键词,其中还记录了每个关键词的词频、格式、位置等权重信息。
搜索引擎索引程序将页面和关键词 存储到索引数据库中以形成词汇结构。索引词汇表的简化形式如表2-1所示。
每个文件对应一个文件ID,文件内容表示为关键词的集合。事实上,在搜索引擎索引库中,关键词也已经转换为关键词ID。这样的数据结构称为前向索引。
7.倒排索引
前向索引还不能直接用于排名。假设用户搜索关键词2,如果只有前向索引,排序程序需要扫描索引库中的所有文件,找到收录关键词2的文件,然后执行相关性计算。这个计算量不能满足实时返回排名结果的要求。
因此,搜索引擎会将正向索引数据库重构为倒排索引,并将文件对应到关键词的映射转换为关键词到文件的映射,如表2-2所示.
在倒排索引中,关键词是主键,每一个关键词都对应着这个关键词出现的一系列文件。这样,当用户搜索某个关键词时,排序程序在倒排索引中定位到这个关键词,可以立即找到所有收录这个关键词的文件。
关键词0@>链接关系计算
链接关系计算也是预处理的重要组成部分。页面之间的链接流信息现在收录在所有主要的搜索引擎排名因素中。搜索引擎爬取页面内容后,必须提前计算:页面上的哪些链接指向了其他哪些页面,每个页面上有哪些传入链接,链接使用了哪些锚文本。这些复杂的链接指向关系形成了 网站 和页面的链接权重。
谷歌PR值是这种链接关系最重要的体现之一。其他搜索引擎做类似的计算,虽然它们不被称为 PR。
由于页面和链接的数量巨大,而且互联网上的链接关系不断更新,计算链接关系和PR需要很长时间。关于PR和链接分析,后面有专门的章节。
关键词1@>特殊文件处理
除了 HTML 文件,搜索引擎通常可以抓取和索引多种基于文本的文件类型,例如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们还经常在搜索结果中看到这些文件类型。但是,目前的搜索引擎无法处理图片、视频、Flash等非文本内容,也无法执行脚本和程序。
虽然搜索引擎在识别图片和从 Flash 中提取文本内容方面取得了一些进展,但距离通过读取图片、视频和 Flash 内容直接返回结果的目标还差得很远。图片和视频内容的排名往往基于相关的文字内容。有关详细信息,请参阅下面的集成搜索部分。
排行
搜索引擎程序通过搜索引擎蜘蛛爬取的接口计算出倒排索引后,搜索引擎就可以随时处理用户搜索。用户在搜索框中填写关键词后,排名程序调用索引数据库数据,计算排名并展示给客户。排名过程直接与客户互动。 查看全部
输入关键字 抓取所有网页(搜索引擎的工作的过程,而简单的讲搜索引擎工作过程)
搜索引擎的工作过程非常复杂,简单来说,搜索引擎的工作过程大致可以分为三个阶段。
爬取爬取:搜索引擎蜘蛛通过以下链接访问页面,获取页面的 HTML 代码并将其存储在数据库中。
预处理:搜索引擎对抓取的页面数据进行文本提取、中文分词、索引等,为排名程序调用做准备。
排名:用户输入关键词后,排名调用索引数据库数据,计算相关度,然后生成一定格式的搜索结果页面。
爬行和爬行
爬取和爬取是搜索引擎工作的第一步,完成数据采集的任务。
蜘蛛
搜索引擎用来抓取和访问页面的程序称为蜘蛛,也称为机器人。
蜘蛛代理名称:
百度蜘蛛:百度蜘蛛+(+)·
雅虎!Slurp 中国:Mozilla/5.0(兼容;Yahoo! Slurp 中国;)·
英语雅虎蜘蛛:Mozilla/5.0(兼容;Yahoo! Slurp/3.0;)
谷歌蜘蛛:Mozilla/5.0(兼容;Googlebot/2.1;+)·
微软必应蜘蛛:msnbot/1.1 (+)·
搜狗蜘蛛:搜狗+网络+机器人+(+#07)·
搜搜蜘蛛:搜搜蜘蛛+(+) ·
有道蜘蛛:Mozilla/5.0(兼容;YodaoBot/1.0;;)
跟随链接
为了在网络上抓取尽可能多的页面,搜索引擎蜘蛛会跟随页面上的链接,从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样,这就是搜索引擎蜘蛛这个名字的由来. 最简单的爬行遍历策略分为两种,一种是深度优先,一种是广度优先。
深度优先搜索
深度优先搜索是在搜索树的每一层只展开一个子节点,继续往深处前进,直到不能再前进(到达叶子节点或被深度限制),然后从当前节点返回到上一个节点,继续另一个方向。这种方法的搜索树是从根开始逐个分支逐渐形成的。
深度优先搜索也称为垂直搜索。由于已解决的问题树可能收录无限分支,如果深度优先搜索误入无限分支(即深度是无限的),则无法找到目标节点。因此,深度优先搜索策略是不完整的。而且,应用这种策略得到的解不一定是最好的解(最短路径)。
广度优先搜索
在深度优先搜索算法中,首先扩展深度较大的节点。如果将算法改为按照搜索中节点的层级进行搜索,当该层的节点还没有被搜索和处理过时,下层节点无法处理,即先扩展深度较小的节点,即就是说先生成的节点先展开,这种搜索算法称为广度优先搜索。
在深度优先搜索算法中,首先扩展深度较大的节点。如果将算法改为按照搜索中节点的层级进行搜索,当该层的节点还没有被搜索和处理过时,下层节点无法处理,即先扩展深度较小的节点,即就是说先生成的节点先展开,这种搜索算法称为广度优先搜索。
吸引蜘蛛
哪些页面被认为更重要?有几个因素:
· 网站 和页面权重。优质和旧的网站被认为权重更高,在这个网站上的页面会被爬得更高的深度,所以更多的内页会是收录。
· 页面更新。蜘蛛每次抓取时都会存储页面数据。如果第二次爬取发现页面和第一次收录一模一样,说明页面没有更新,蜘蛛不需要频繁爬取。如果页面内容更新频繁,蜘蛛会更频繁地访问该页面,页面上出现的新链接自然会被蜘蛛更快地跟踪并抓取新页面。
· 导入链接。不管是外部链接还是同一个网站的内部链接,为了被蜘蛛爬取,必须有传入链接才能进入页面,否则蜘蛛没有机会知道这页纸。高质量的入站链接通常还会增加页面上出站链接的抓取深度。一般来说,首页在网站上的权重最高,大部分外部链接指向首页,首页也是蜘蛛访问频率最高的。离首页越近的点击距离,页面权重越高,被蜘蛛爬取的机会就越大。
地址库
为了避免重复爬取和爬取网址,搜索引擎会建立一个地址数据库来记录已找到但未爬取的页面,以及已爬取的页面。地址存储库中有几个 url 来源:
(1)手动输入种子网站。
(2)蜘蛛爬取页面后,从html中解析出新的链接url,并与地址库中的数据进行比较,如果是不在地址库中的url,则将其存储在要访问的地址库中。
(3)站长通过搜索引擎网页提交表单提交的网址。
蜘蛛根据重要性从要访问的地址库中提取url,访问并爬取页面,然后将要访问的地址库中的url删除,放入被访问地址的地址库中。
大多数主要搜索引擎都为网站管理员提供了提交 URL 的表单。但是,这些提交的 URL 只存储在地址数据库中。是否 收录 取决于页面的重要性。搜索引擎的绝大多数页面 收录 都是由蜘蛛自己通过链接获得的。可以说,提交页面基本没用,搜索引擎更喜欢跟随链接发现新页面。
文件存储 搜索引擎蜘蛛爬取的数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。每个 uRI 都有一个唯一的文件编号。
爬行时重复内容检测
检测和删除重复项通常在下面描述的预处理过程中完成,但是现代蜘蛛在爬取和爬取文件时也会进行一定程度的重复项检测。当你在网站上遇到大量转载或抄袭、权重极低的内容时,很可能会停止爬取。这就是为什么一些网站管理员在日志文件中发现蜘蛛,但该页面从未真正被 收录 访问过。
预处理
在一些 SEO 资料中,“预处理”也简称为“索引”,因为索引是预处理中最重要的步骤。
搜索引擎蜘蛛爬取的原创页面不能直接用于查询排名处理。搜索引擎数据库的页数在万亿级别。用户输入搜索词后,排名程序会实时分析这么多页面的相关性。计算量太大,不可能在一两秒内返回排名结果。因此,必须对爬取的页面进行预处理,为最终的查询排名做准备。
和爬虫一样,预处理是在后台提前完成的,用户在搜索的时候感受不到这个过程。
1.提取文本
今天的搜索引擎仍然基于文本内容。蜘蛛抓取到的页面中的HTML代码,除了用户在浏览器上可以看到的可见文本外,还收录大量的HTML格式标签、程序等不能用于排名的内容。搜索引擎预处理首先要做的就是去除HTML文件中的标签和程序,提取网页中可用于排名处理的文本内容。
今天是愚人节
去掉 HTML 代码后,剩下的用于排名的文字就是这一行:
今天是愚人节
除了可见文本,搜索引擎还会提取一些收录文本信息的特殊代码,例如 Meta 标签中的文本、图片 alt 文本、Flash 文件 alt 文本、链接锚文本等。
2.中文分词
分词是中文搜索引擎特有的一个步骤。搜索引擎基于单词存储和处理页面和用户搜索。英语等语言用空格隔开,搜索引擎索引程序可以直接把句子分成词组。但是,中文单词和单词之间没有分隔符,一个句子中的所有单词和单词都是连接在一起的。搜索引擎必须首先区分哪些词组成一个词,哪些词本身就是一个词。例如,“减肥法”将分为“减肥”和“方法”两个词。
中文分词基本上有两种方法,一种是基于字典匹配的,一种是基于统计的。
基于字典匹配的方法是指将一段待分析的汉字与预先制作的字典中的词条进行匹配,从待分析的字符串中扫描字典中已有的词条。分离出一个词。
根据扫描方向,基于字典的匹配方法可以分为正向匹配和反向匹配。根据匹配长度优先级的不同,可以分为最大匹配和最小匹配。优先混合扫描方向和长度可以产生不同的方法,例如正向最大匹配和反向最大匹配。
字典匹配方法计算简单,其准确性很大程度上取决于字典的完整性和更新。
基于统计的分词方法是指分析大量文本样本,计算相邻词的统计概率。出现的相邻单词越多,形成单词的可能性就越大。基于统计的方法的优点是对新出现的词更敏感,也有利于消歧。
基于字典匹配和统计的分词方法各有优缺点。实际使用的分词系统混合使用了这两种方法,快速高效,可以识别新词和新词,消除歧义。
中文分词的准确性往往会影响搜索引擎排名的相关性。比如你在百度上搜索“搜索引擎优化”,从截图中可以看出百度把“搜索引擎优化”这六个词当成一个词。
在 Google 上搜索相同的词时,快照显示 Google 将其拆分为“搜索引擎”和“优化”两个词。显然,百度有更合理的细分,搜索引擎优化是一个完整的概念。谷歌的分词往往更细化。
分词的这种差异可能是某些 关键词 排名在不同搜索引擎上表现不同的原因之一。例如,百度更喜欢匹配搜索词以显示在页面上。也就是说,在搜索“够玩博客”的时候,如果这四个词连续出现,在百度中更容易获得好的排名。另一方面,谷歌实际上并不需要完全匹配。有些页面出现了“足够的戏剧”和“博客”这两个词,但不一定完全匹配,“足够的戏剧”出现在页面的前面,“博客”在页面的其他位置,这样的页面出现在谷歌搜索“足够剧博客“”,也可以获得不错的排名。
搜索引擎对页面的分词取决于词库的大小、准确度和分词算法的质量,而不是页面本身,因此SEO人员对分词的作用很小。唯一能做的就是在页面上使用某种形式来提示搜索引擎某些词应该被当作一个词处理,尤其是当它可能有歧义的时候,比如页面标题中的关键词@,h1标签和黑体字>。如果页面是关于“和服”的内容,那么“和服”这个词可以特别用粗体标出。如果页面是关于“化妆和服装”的,你可以把“服装”这个词加粗。这样,当搜索引擎分析页面时,它就知道粗体字应该是一个词。
3.去停用词
无论是英文还是中文,都会出现一些在页面内容中出现频率高但对内容没有影响的词,比如“的”、“地”、“de”、“ah”等辅助词, “ha”、“ya”等感叹词、“therefore”、“with”、“but”等副词或介词。这些词被称为停用词,因为它们对页面的主要含义几乎没有影响。英语中常见的停用词有 the、a、an、to、of 等。
搜索引擎会在索引页面之前去除这些停用词,使索引数据的主题更加突出,减少不必要的计算量。
4.去除噪音
大部分页面也存在一些对页面主题没有贡献的内容,如版权声明文字、导航栏、广告等。以常见的博客导航为例,导航内容如文章categories几乎每个博客页面都会出现历史档案,但这些页面本身与“类别”和“历史”这两个词无关。用户搜索“历史”、“类别”并返回博客文章只是因为这些词出现在页面上是没有意义的,完全无关紧要的。因此,这些块都是噪音,只能对页面的主题起到分散作用。
搜索引擎需要在不使用嘈杂内容的情况下识别和消除这种噪音并进行排名。去噪的基本方法是根据HTML标签将页面分成块,区分页眉、导航、文本、页脚、广告等区域。网站 上重复出现的块通常是噪音。页面去噪后,剩下的就是页面的主要内容。
5.移除
搜索引擎还需要对页面进行重复数据删除。
同一个文章经常在不同的网站和同一个网站的不同URL上重复出现,搜索引擎不喜欢这种重复的内容。用户搜索时,如果在前两页看到来自不同网站的同一篇文章文章,用户体验太差了,尽管都是内容相关的。搜索引擎希望只返回一个相同的文章,所以在索引之前需要识别并删除重复的内容。此过程称为“重复数据删除”。
去重的基本方法是计算页面特征的指纹关键词,也就是从页面的主要内容中选择最有代表性的部分关键词(经常是出现频率最高的关键词) ,然后计算这些 关键词 的数字指纹。这里的关键词的选择是在分词、去停用词、降噪之后。实验表明,通常选择10个特征关键词可以达到比较高的计算精度,选择更多的词对去重精度的提升贡献不大。
典型的指纹计算方法如MD5算法(Information Digest Algorithm Fifth Edition)。这类指纹算法的特点是输入(feature关键词)的任何微小变化都会导致计算出的指纹出现很大的差距。
了解了搜索引擎的去重算法后,SEO人员应该知道,简单地加上“de”、“地”、“de”,改变段落的顺序,所谓伪原创,是逃不过去重的。搜索引擎。算法,因为这样的操作不能改变文章关键词的特性。此外,搜索引擎的重复数据删除算法可能不仅在页面级别,而且在段落级别。混用不同的文章,互换段落的顺序,不能让转载、抄袭变成原创。
6.正向索引
远期指数也可以简称为指数。
经过文本提取、分词、去噪和去重后,搜索引擎获得了能够反映页面主要内容的独特的、基于词的内容。接下来,搜索引擎索引程序可以提取关键词,按照分词程序对单词进行划分,将页面转换为关键词的集合,并将每个关键词的内容记录在这页纸。出现频率、出现次数、格式(如在标题标签、粗体、H标签、锚文本等)、位置(如页面第一段等)。这样,每一页就可以记录为一组关键词,其中还记录了每个关键词的词频、格式、位置等权重信息。
搜索引擎索引程序将页面和关键词 存储到索引数据库中以形成词汇结构。索引词汇表的简化形式如表2-1所示。
每个文件对应一个文件ID,文件内容表示为关键词的集合。事实上,在搜索引擎索引库中,关键词也已经转换为关键词ID。这样的数据结构称为前向索引。
7.倒排索引
前向索引还不能直接用于排名。假设用户搜索关键词2,如果只有前向索引,排序程序需要扫描索引库中的所有文件,找到收录关键词2的文件,然后执行相关性计算。这个计算量不能满足实时返回排名结果的要求。
因此,搜索引擎会将正向索引数据库重构为倒排索引,并将文件对应到关键词的映射转换为关键词到文件的映射,如表2-2所示.
在倒排索引中,关键词是主键,每一个关键词都对应着这个关键词出现的一系列文件。这样,当用户搜索某个关键词时,排序程序在倒排索引中定位到这个关键词,可以立即找到所有收录这个关键词的文件。
关键词0@>链接关系计算
链接关系计算也是预处理的重要组成部分。页面之间的链接流信息现在收录在所有主要的搜索引擎排名因素中。搜索引擎爬取页面内容后,必须提前计算:页面上的哪些链接指向了其他哪些页面,每个页面上有哪些传入链接,链接使用了哪些锚文本。这些复杂的链接指向关系形成了 网站 和页面的链接权重。
谷歌PR值是这种链接关系最重要的体现之一。其他搜索引擎做类似的计算,虽然它们不被称为 PR。
由于页面和链接的数量巨大,而且互联网上的链接关系不断更新,计算链接关系和PR需要很长时间。关于PR和链接分析,后面有专门的章节。
关键词1@>特殊文件处理
除了 HTML 文件,搜索引擎通常可以抓取和索引多种基于文本的文件类型,例如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们还经常在搜索结果中看到这些文件类型。但是,目前的搜索引擎无法处理图片、视频、Flash等非文本内容,也无法执行脚本和程序。
虽然搜索引擎在识别图片和从 Flash 中提取文本内容方面取得了一些进展,但距离通过读取图片、视频和 Flash 内容直接返回结果的目标还差得很远。图片和视频内容的排名往往基于相关的文字内容。有关详细信息,请参阅下面的集成搜索部分。
排行
搜索引擎程序通过搜索引擎蜘蛛爬取的接口计算出倒排索引后,搜索引擎就可以随时处理用户搜索。用户在搜索框中填写关键词后,排名程序调用索引数据库数据,计算排名并展示给客户。排名过程直接与客户互动。
输入关键字 抓取所有网页(网站内容原创度不够高蜘蛛到网站上抓取时的原因)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-07 05:22
一:网站内容原创不够高
当蜘蛛在网站上爬行时,发现内容是原创有价值的信息,认为你对它很友好,赢得了搜索引擎的好感,给网站一个高排名. 石榴算法命中低质量页面后,站长不敢完全采集别人的内容。大部分站长改变 采集 的 文章 的头部和尾部,中间的内容保持不变。蜘蛛根据深度优先或广度优先的策略爬取页面,将爬取的页面放入数据库,进行索引工作,将那些“所谓的”原创内容删除。网站页面被取消收录的现象很明显。
二:内容更新次数变化较大
大网站或传送门网站,更新不多。网站每天有200多条更新,搜索引擎会特别关注你的网站,如果原创的度数不够高会认为你作弊,更新内容将不被接受。收录也正常。另一方面,更新次数变化太大。最初,每天有 200 篇 文章 文章。百度算法调整后,网站的数量也相应调整。人们开始注重质量而不是数量,下降到60篇。别说你的质量有多好,更新的次数和频率波动太大,很容易被百度惩罚,把你的网站 在观察期内。网站收录 的页面不被 收录 视为次要警告。
三:用户体验低
用户在搜索引擎中输入关键词,显示的网页都是匹配这个关键词的。我很高兴进入你的网站,以为我能找到满足我需求的内容。用户想知道的是XX化妆品怎么样,但是点击锚文链接就可以进入美容保健页面。用户会感到受骗并立即关闭网站。关键词堆叠也是降低用户体验的因素之一。站长优化应该是合适的。过度优化很容易降低用户体验,增加网站的跳出率,更不用说能带来多少转化。
四:度娘自身原因
近日,百度绿萝算法2.0更新,过滤去除了推广软文的外链,另一方面也对目标站点进行了适当的处罚。很多网站已经被降级,被降级的网站需要进入百度考核期。更新后的文章内容是收录然后删除是正常的。. 网站只要不违法,没有过激行为,过了考核期,删除的内容依然是收录。
收录数量在某种程度上是判断网站质量的因素之一。交换好友链时,对方会看你的网站的收录的数量,收录的数量少,或者网站被修改了重建 收录; 或者是网站内容不受搜索引擎青睐,而不是收录。即使你的网站权重比他高,他也不一定会和你交换,因为这样的网站不稳定,随时可能被降级。 查看全部
输入关键字 抓取所有网页(网站内容原创度不够高蜘蛛到网站上抓取时的原因)
一:网站内容原创不够高
当蜘蛛在网站上爬行时,发现内容是原创有价值的信息,认为你对它很友好,赢得了搜索引擎的好感,给网站一个高排名. 石榴算法命中低质量页面后,站长不敢完全采集别人的内容。大部分站长改变 采集 的 文章 的头部和尾部,中间的内容保持不变。蜘蛛根据深度优先或广度优先的策略爬取页面,将爬取的页面放入数据库,进行索引工作,将那些“所谓的”原创内容删除。网站页面被取消收录的现象很明显。
二:内容更新次数变化较大
大网站或传送门网站,更新不多。网站每天有200多条更新,搜索引擎会特别关注你的网站,如果原创的度数不够高会认为你作弊,更新内容将不被接受。收录也正常。另一方面,更新次数变化太大。最初,每天有 200 篇 文章 文章。百度算法调整后,网站的数量也相应调整。人们开始注重质量而不是数量,下降到60篇。别说你的质量有多好,更新的次数和频率波动太大,很容易被百度惩罚,把你的网站 在观察期内。网站收录 的页面不被 收录 视为次要警告。
三:用户体验低
用户在搜索引擎中输入关键词,显示的网页都是匹配这个关键词的。我很高兴进入你的网站,以为我能找到满足我需求的内容。用户想知道的是XX化妆品怎么样,但是点击锚文链接就可以进入美容保健页面。用户会感到受骗并立即关闭网站。关键词堆叠也是降低用户体验的因素之一。站长优化应该是合适的。过度优化很容易降低用户体验,增加网站的跳出率,更不用说能带来多少转化。
四:度娘自身原因
近日,百度绿萝算法2.0更新,过滤去除了推广软文的外链,另一方面也对目标站点进行了适当的处罚。很多网站已经被降级,被降级的网站需要进入百度考核期。更新后的文章内容是收录然后删除是正常的。. 网站只要不违法,没有过激行为,过了考核期,删除的内容依然是收录。
收录数量在某种程度上是判断网站质量的因素之一。交换好友链时,对方会看你的网站的收录的数量,收录的数量少,或者网站被修改了重建 收录; 或者是网站内容不受搜索引擎青睐,而不是收录。即使你的网站权重比他高,他也不一定会和你交换,因为这样的网站不稳定,随时可能被降级。
输入关键字 抓取所有网页(您意思是要在您的网站上用别人的数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-03 12:10
你的意思是自己使用别人的数据网站?如果是这样,你可以:网站输入关键字请求到自己的服务器,然后在服务器上使用HttpClient模拟向别人的网站发送请求获取数据,然后返回给自己网站 请求。
当然,你需要先弄清楚别人服务器请求的链接(使用一楼提到的方法),并分析请求的其他参数,以便模拟请求的图像。前提是他们对请求的安全限制不那么严格。
您还可以将捕获的数据保存在自己的数据库中。下次可以自己找数据库找。如果找不到,可以模拟一个请求来捕获它。这允许积累下一个数据量。
但是,这些数据毕竟可能是别人根据用户行为分析的结果,可能与你自己的站点情况不一致。
收获的菜豆:10
李奇鹏||远斗:1160|2015-07-01 13:18
好吧,我只需要计算他的表现,不管他的分析是否准确。
如果使用F12可以看到相关信息,但是不知道是哪个JS方法在处理这些请求。HTTPWatch 也是如此。你有什么好的方法可以定位到这样的请求方法吗?
给个思路,非常感谢。
我要成仙,在天上快乐|元豆:17|2015-07-01 13:38
@OmJJWang:了解如何使用 Google Chrome 的开发工具。我现在用手机,不太方便。简单的说。打开那个页面,使用谷歌浏览器,按F12,看到Network一栏,有一个清除按钮,找一下,先清除已有的请求信息,然后在搜索框中输入,应该可以看到刚才网络有东西,这是发送的请求,看链接。自己找出来。
李奇鹏|元豆:1160|2015-07-01 14:12
上传图片
Ctrl+Enter 快速提交 查看全部
输入关键字 抓取所有网页(您意思是要在您的网站上用别人的数据?)
你的意思是自己使用别人的数据网站?如果是这样,你可以:网站输入关键字请求到自己的服务器,然后在服务器上使用HttpClient模拟向别人的网站发送请求获取数据,然后返回给自己网站 请求。
当然,你需要先弄清楚别人服务器请求的链接(使用一楼提到的方法),并分析请求的其他参数,以便模拟请求的图像。前提是他们对请求的安全限制不那么严格。
您还可以将捕获的数据保存在自己的数据库中。下次可以自己找数据库找。如果找不到,可以模拟一个请求来捕获它。这允许积累下一个数据量。
但是,这些数据毕竟可能是别人根据用户行为分析的结果,可能与你自己的站点情况不一致。
收获的菜豆:10
李奇鹏||远斗:1160|2015-07-01 13:18
好吧,我只需要计算他的表现,不管他的分析是否准确。
如果使用F12可以看到相关信息,但是不知道是哪个JS方法在处理这些请求。HTTPWatch 也是如此。你有什么好的方法可以定位到这样的请求方法吗?
给个思路,非常感谢。
我要成仙,在天上快乐|元豆:17|2015-07-01 13:38
@OmJJWang:了解如何使用 Google Chrome 的开发工具。我现在用手机,不太方便。简单的说。打开那个页面,使用谷歌浏览器,按F12,看到Network一栏,有一个清除按钮,找一下,先清除已有的请求信息,然后在搜索框中输入,应该可以看到刚才网络有东西,这是发送的请求,看链接。自己找出来。
李奇鹏|元豆:1160|2015-07-01 14:12
上传图片
Ctrl+Enter 快速提交
输入关键字 抓取所有网页(谷歌分析代码,具体的文本,或代码等(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-25 18:28
AJAX 的 SEO AJAX 蜘蛛遵循 Google 的计划。
Inlinks - 所有页面都链接到一个 URI。
Outlinks - 所有页面都链接到 URI。
锚文本,链接文本。替代文字图片链接。
Follow & Nofollow - 在页面和链接上(真/假)。
图片 - 所有带有图片的 uris 和来自给定页面的所有图片都已链接。图片大小超过 100kb,缺少替代文字,替代文字超过 100 个字符。
User-Agent Switcher - 抓取 Googlebot、Bingbot、Yahoo!声音、移动用户代理或您自己的自定义 UA。
重定向链,查找重定向链和循环。
自定义源代码搜索 - 搜索引擎蜘蛛可以在 网站 中找到您想要的任何源代码!无论是 Google Analytics 代码、特定文本还是代码等(请注意,这不是数据提取或抓取功能。)
XML网站Map Generator - 您可以使用 SEO Spider 创建 XML 站点地图和图像地图。
如何使用 ScreamingFrogSEOSpider
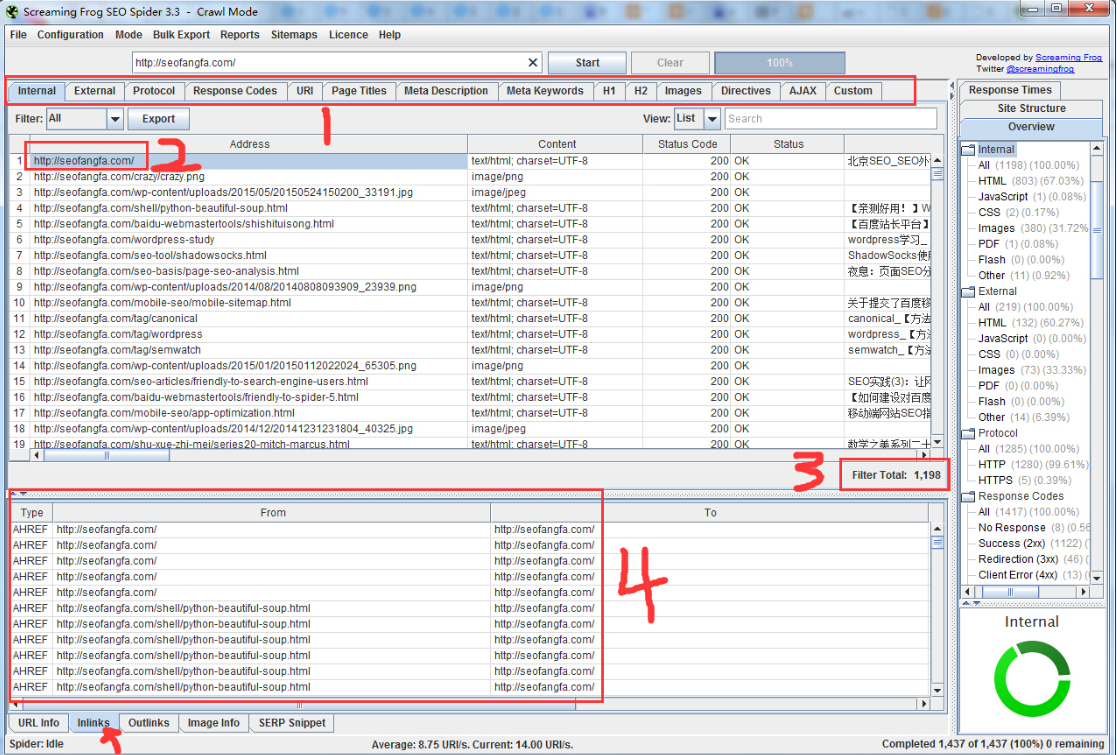
ScreamingFrogSEOSpider 使用起来非常方便,只需输入你的网站主页的URL,然后点击开始,等待爬取完成,就可以看到各种详细的数据了。
下图以提取我博客的整个站点URL为例,给大家展示一下效果:
红框1中的这些标签会依次为你翻译:内部链接、外部链接、HTTP协议(HTTP或HTTPS)、HTTP状态码(200、3XX、4XX、5XX)、URI(注意不是URL,URI是Uniform Resource Identifier,统一资源标识符;URL:Uniform Resource Locator,统一资源定位器;想了解更多请去百度),页面标题标签,页面描述标签,页面关键字标签,页面H1标签、页面H2标签、现场图片、页面链接、使用AJAX技术的链接、自定义过滤规则。
红框2:点击后会在我们的首页看到一些信息,比如红框4,首页的导入链接是什么,红框3,ScreamingFrogSEOSpider提取的整个站点的链接数,结合站点说明,您可以了解我们网站站点收录的大概情况。
通过以上的讲解,相信你已经了解了这个工具的强大之处!那么接下来你可能关心的是这个工具是付费的还是免费的?
通过官网的介绍,我们知道可以免费下载和使用该软件,但免费版只能抓取全站500个网址。如果是小型企业网站,就足够了。如果是大网站,可以考虑。一年99英镑起买一个,约合人民币972元(感谢seolabs指正:)),对于玩大站的朋友来说简直太便宜了,哈哈!
你认为文章 的写作应该到此结束吗?如果你这么想,那你就错了!方法博客只为分享有价值的文章而生,所以今天送上价值694元的礼物送给有幸看到这个文章的朋友!那就是:(睁大眼睛!)
ScreamingFrogSEOSpider 下载
由于官网在英国,打开速度极慢,这里是官网的直接下载链接:
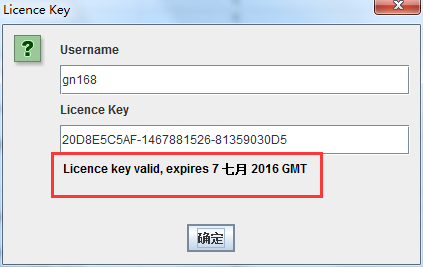
ScreamingFrogSEOSpider注册码!可以使用一年!
为了方便大家COPY,我贴在这里:
用户名:gn168
许可证密钥:20D8E5C5AF-1467881526-81359030D5
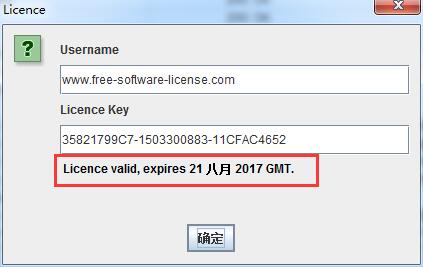
2016.9.28更新:上面的注册码已经过期,下面是新发现的,大家可以试试。我注册了第一个。
用户名:
序列号:35821799C7-1503300883-11CFAC4652
用户名:
序列号:180A8B33F9-1503300970-5859C71542
用户名:
序列号:99A43BF96D-1503300995-9F3AB42B03
以上注册码由广年论坛热心朋友提供。你可以访问这位朋友的网站:为他的无私奉献贡献一个IP!:)
如果要下载一个完整的网站到本地,会有更好的模拟搜索引擎爬虫工具,那就是国屏曾经分享的Httrack模拟搜索引擎爬虫工具,继续写文章与大家分享Httrack的使用方法!
文章写到这里,真的是该结束了,该说的也说完了。为了和大家分享这个好工具,我已经把它编码到凌晨1:00。看到我为人民付出的努力,你既然都看到了,下面的留言区不给我点个赞,你会不会不好意思?:):):):):) 查看全部
输入关键字 抓取所有网页(谷歌分析代码,具体的文本,或代码等(组图))
AJAX 的 SEO AJAX 蜘蛛遵循 Google 的计划。
Inlinks - 所有页面都链接到一个 URI。
Outlinks - 所有页面都链接到 URI。
锚文本,链接文本。替代文字图片链接。
Follow & Nofollow - 在页面和链接上(真/假)。
图片 - 所有带有图片的 uris 和来自给定页面的所有图片都已链接。图片大小超过 100kb,缺少替代文字,替代文字超过 100 个字符。
User-Agent Switcher - 抓取 Googlebot、Bingbot、Yahoo!声音、移动用户代理或您自己的自定义 UA。
重定向链,查找重定向链和循环。
自定义源代码搜索 - 搜索引擎蜘蛛可以在 网站 中找到您想要的任何源代码!无论是 Google Analytics 代码、特定文本还是代码等(请注意,这不是数据提取或抓取功能。)
XML网站Map Generator - 您可以使用 SEO Spider 创建 XML 站点地图和图像地图。
如何使用 ScreamingFrogSEOSpider
ScreamingFrogSEOSpider 使用起来非常方便,只需输入你的网站主页的URL,然后点击开始,等待爬取完成,就可以看到各种详细的数据了。
下图以提取我博客的整个站点URL为例,给大家展示一下效果:
红框1中的这些标签会依次为你翻译:内部链接、外部链接、HTTP协议(HTTP或HTTPS)、HTTP状态码(200、3XX、4XX、5XX)、URI(注意不是URL,URI是Uniform Resource Identifier,统一资源标识符;URL:Uniform Resource Locator,统一资源定位器;想了解更多请去百度),页面标题标签,页面描述标签,页面关键字标签,页面H1标签、页面H2标签、现场图片、页面链接、使用AJAX技术的链接、自定义过滤规则。
红框2:点击后会在我们的首页看到一些信息,比如红框4,首页的导入链接是什么,红框3,ScreamingFrogSEOSpider提取的整个站点的链接数,结合站点说明,您可以了解我们网站站点收录的大概情况。
通过以上的讲解,相信你已经了解了这个工具的强大之处!那么接下来你可能关心的是这个工具是付费的还是免费的?
通过官网的介绍,我们知道可以免费下载和使用该软件,但免费版只能抓取全站500个网址。如果是小型企业网站,就足够了。如果是大网站,可以考虑。一年99英镑起买一个,约合人民币972元(感谢seolabs指正:)),对于玩大站的朋友来说简直太便宜了,哈哈!
你认为文章 的写作应该到此结束吗?如果你这么想,那你就错了!方法博客只为分享有价值的文章而生,所以今天送上价值694元的礼物送给有幸看到这个文章的朋友!那就是:(睁大眼睛!)
ScreamingFrogSEOSpider 下载
由于官网在英国,打开速度极慢,这里是官网的直接下载链接:
ScreamingFrogSEOSpider注册码!可以使用一年!
为了方便大家COPY,我贴在这里:
用户名:gn168
许可证密钥:20D8E5C5AF-1467881526-81359030D5
2016.9.28更新:上面的注册码已经过期,下面是新发现的,大家可以试试。我注册了第一个。
用户名:
序列号:35821799C7-1503300883-11CFAC4652
用户名:
序列号:180A8B33F9-1503300970-5859C71542
用户名:
序列号:99A43BF96D-1503300995-9F3AB42B03
以上注册码由广年论坛热心朋友提供。你可以访问这位朋友的网站:为他的无私奉献贡献一个IP!:)

如果要下载一个完整的网站到本地,会有更好的模拟搜索引擎爬虫工具,那就是国屏曾经分享的Httrack模拟搜索引擎爬虫工具,继续写文章与大家分享Httrack的使用方法!
文章写到这里,真的是该结束了,该说的也说完了。为了和大家分享这个好工具,我已经把它编码到凌晨1:00。看到我为人民付出的努力,你既然都看到了,下面的留言区不给我点个赞,你会不会不好意思?:):):):):)
输入关键字 抓取所有网页(如何在网站优化中有三到四个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-24 23:17
如果网站优化里面有三四个关键词,那么关注首页基本没问题。但是,如果关键字超过 10 个或 20 个或更多,则需要在整个 网站 中正确排列,而不是仅仅依靠主页。他们如何更好地联系?或者尝试在 网站 上对这些词进行排名。
通常的做法是将更重要的关键字放在头部。第二级中的附加关键字放置在每个列或频道页面上。如果尾部较长,属于三级关键词,可以使用内容页进行优化。
在首页,主关键词是优化的重点。从页面标题来看,粗体粗重的hx标签关键词比其他词更显眼。
次要关键字不能出现在主页上,相反,次要关键字应该出现在主页上,因为这些词加强了主要关键字。
搜索引擎也通过语义分析知道这一点。这种语义联系不是从字面上理解的,而是从大量统计数据中推导出来的,搜索引擎仍然具有这种智能。
至少这些次要关键词会出现在首页的导航链接中。其中一些出现在主页的主体中,并链接到相应的栏目和频道页面。
这样关键词就可以得到最优的分配,整个网站就会有一个强大的逻辑和语义关系体系,就像一个金字塔。主页是您想要排名的最难的词。整个 网站 突出了主页上的关键字分布,无论是语义上还是链接上。
这种多关键词优化方式的前提是你比较感兴趣的关键词最多只能有三四个热门词。如果想要的二级关键词也很受欢迎,恐怕我们需要单独做一个网站,所有结果都在首页上实现。把它放在一个专栏页面上,因为你不太可能为所有专栏页面建立很多好的链接,所以很难对热门词进行排名,除非你真的可以让这个网站成为一个大的、权威的网站。
需求无处不在。有必要让陌生人见面并让无关的人合作。网站优化过程中如何满足需求?
1、从下拉框和相关搜索中查看需求
百度下拉框和相关搜索是分析用户需求的常用数据。百度下拉框是上周用户搜索最多的词,相关搜索是用户上月搜索最多的词。
(1)下拉框,下拉框中显示的关键词搜索越多,越重要。下拉框的关键词形成时间比较短,可以看到热点近期短期用户,如果行业更新快,爬取内容进行关键词排名。
(2)相关搜索。相关搜索是上个月的数据,从中我们可以得到用户最近一个月关心的内容。经验丰富的网站优化器结合drop中的数据-down 框可以看到关键词的搜索趋势,企业网站要多关注相关搜索数据。
2、从搜索排名中发现隐藏需求
从 关键词 的主要搜索中,我们可以看到百度主页上的 网站 排名。从排名第一的网站,我们可以知道用户喜欢哪个网站。比如图片、帖子、知识库、库等,比如搜索羊,无论是在下拉框、相关搜索还是首页排名中,都可以看到羊,说明用户对羊的需求强烈讨论的话,这个行业比较适合论坛类型网站。
(1)图片,百度首页图片展示,用户更关注图片,网站应该有更清晰的图片展示。比如装修
(2)海报栏,百度贴吧表示用户有讨论需求,网站可以是论坛栏,比如SEO论坛
(3)是的,首页好像知道用户有问答,网站可以设置一个常见的问答栏。比如医疗
(4)图书馆,图书馆首页显示用户有资料下载需求,网站可提供免费下载链接。 查看全部
输入关键字 抓取所有网页(如何在网站优化中有三到四个)
如果网站优化里面有三四个关键词,那么关注首页基本没问题。但是,如果关键字超过 10 个或 20 个或更多,则需要在整个 网站 中正确排列,而不是仅仅依靠主页。他们如何更好地联系?或者尝试在 网站 上对这些词进行排名。
通常的做法是将更重要的关键字放在头部。第二级中的附加关键字放置在每个列或频道页面上。如果尾部较长,属于三级关键词,可以使用内容页进行优化。
在首页,主关键词是优化的重点。从页面标题来看,粗体粗重的hx标签关键词比其他词更显眼。
次要关键字不能出现在主页上,相反,次要关键字应该出现在主页上,因为这些词加强了主要关键字。
搜索引擎也通过语义分析知道这一点。这种语义联系不是从字面上理解的,而是从大量统计数据中推导出来的,搜索引擎仍然具有这种智能。
至少这些次要关键词会出现在首页的导航链接中。其中一些出现在主页的主体中,并链接到相应的栏目和频道页面。
这样关键词就可以得到最优的分配,整个网站就会有一个强大的逻辑和语义关系体系,就像一个金字塔。主页是您想要排名的最难的词。整个 网站 突出了主页上的关键字分布,无论是语义上还是链接上。
这种多关键词优化方式的前提是你比较感兴趣的关键词最多只能有三四个热门词。如果想要的二级关键词也很受欢迎,恐怕我们需要单独做一个网站,所有结果都在首页上实现。把它放在一个专栏页面上,因为你不太可能为所有专栏页面建立很多好的链接,所以很难对热门词进行排名,除非你真的可以让这个网站成为一个大的、权威的网站。
需求无处不在。有必要让陌生人见面并让无关的人合作。网站优化过程中如何满足需求?
1、从下拉框和相关搜索中查看需求
百度下拉框和相关搜索是分析用户需求的常用数据。百度下拉框是上周用户搜索最多的词,相关搜索是用户上月搜索最多的词。
(1)下拉框,下拉框中显示的关键词搜索越多,越重要。下拉框的关键词形成时间比较短,可以看到热点近期短期用户,如果行业更新快,爬取内容进行关键词排名。
(2)相关搜索。相关搜索是上个月的数据,从中我们可以得到用户最近一个月关心的内容。经验丰富的网站优化器结合drop中的数据-down 框可以看到关键词的搜索趋势,企业网站要多关注相关搜索数据。
2、从搜索排名中发现隐藏需求
从 关键词 的主要搜索中,我们可以看到百度主页上的 网站 排名。从排名第一的网站,我们可以知道用户喜欢哪个网站。比如图片、帖子、知识库、库等,比如搜索羊,无论是在下拉框、相关搜索还是首页排名中,都可以看到羊,说明用户对羊的需求强烈讨论的话,这个行业比较适合论坛类型网站。
(1)图片,百度首页图片展示,用户更关注图片,网站应该有更清晰的图片展示。比如装修
(2)海报栏,百度贴吧表示用户有讨论需求,网站可以是论坛栏,比如SEO论坛
(3)是的,首页好像知道用户有问答,网站可以设置一个常见的问答栏。比如医疗
(4)图书馆,图书馆首页显示用户有资料下载需求,网站可提供免费下载链接。
输入关键字 抓取所有网页(百度、360两种搜索引擎介绍关键字的提交爬取信息优化方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-23 12:21
)
文章目录
写在前面
本文介绍了百度和360搜索引擎的关键词提交和爬取信息,并在引用示例的基础上进行了优化。可以独立输入关键字,提交关键词后打印出搜索内容的字符串长度和关联的URL。
一.爬取原创页面
以 关键词 for python 为例。
1.百度页面如下
2.360页如下
Whisper BB:通过上面的对比,发现他们也在卖课程。看来这些机构给的钱不一样。一定程度上还是把自己的平台放在了首位。
二.爬取原理解析
首先,我以python为例,给大家展示一下百度和360搜索页面的url结果。
1.百度
2.360
通过上面的实践,我们可以发现搜索引擎有它的关键词提交接口。
百度的关键词接口:
360的关键词界面:
关键字就是我们输入的关键字,所以我们只要替换掉关键字就可以提交关键词给搜索引擎,也就是只要构造好URL链接就可以提取出关键词,最后使用 len() 函数显示提交后搜索内容的字符串长度关键词。
3.使用的库
import requests
三.完整代码
import requests
#百度搜索
def baiDu():
key = input("请输入百度搜索关键词:")
url = "https://www.baidu.com/s?wd="+key
try:
r = requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(len(r.text))
print(r.request.url)
except:
print("爬取异常")
#360搜索
def threeSZ():
key = input("请输入360搜索关键词:")
url = "https://www.so.com/s?q="+key
try:
r = requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(len(r.text))
print(r.request.url)
except:
print("爬取异常")
#调用函数
baiDu()
threeSZ()
本文结束后,如有错误请指出~
引用自
中国大学MOOC Python网络爬虫与信息提取
https://www.icourse163.org/course/BIT-1001870001 查看全部
输入关键字 抓取所有网页(百度、360两种搜索引擎介绍关键字的提交爬取信息优化方法
)
文章目录
写在前面
本文介绍了百度和360搜索引擎的关键词提交和爬取信息,并在引用示例的基础上进行了优化。可以独立输入关键字,提交关键词后打印出搜索内容的字符串长度和关联的URL。
一.爬取原创页面
以 关键词 for python 为例。
1.百度页面如下

2.360页如下

Whisper BB:通过上面的对比,发现他们也在卖课程。看来这些机构给的钱不一样。一定程度上还是把自己的平台放在了首位。
二.爬取原理解析
首先,我以python为例,给大家展示一下百度和360搜索页面的url结果。
1.百度

2.360

通过上面的实践,我们可以发现搜索引擎有它的关键词提交接口。
百度的关键词接口:
360的关键词界面:
关键字就是我们输入的关键字,所以我们只要替换掉关键字就可以提交关键词给搜索引擎,也就是只要构造好URL链接就可以提取出关键词,最后使用 len() 函数显示提交后搜索内容的字符串长度关键词。
3.使用的库
import requests
三.完整代码
import requests
#百度搜索
def baiDu():
key = input("请输入百度搜索关键词:")
url = "https://www.baidu.com/s?wd="+key
try:
r = requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(len(r.text))
print(r.request.url)
except:
print("爬取异常")
#360搜索
def threeSZ():
key = input("请输入360搜索关键词:")
url = "https://www.so.com/s?q="+key
try:
r = requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(len(r.text))
print(r.request.url)
except:
print("爬取异常")
#调用函数
baiDu()
threeSZ()
本文结束后,如有错误请指出~
引用自
中国大学MOOC Python网络爬虫与信息提取
https://www.icourse163.org/course/BIT-1001870001
输入关键字 抓取所有网页(windows环境下的操作版本为3urllib库介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-22 14:08
(以下是windows环境下的操作,python版本为3)
1.urllib库介绍
官方文档上的解释是:
urllib 是一个包,它采集了几个用于处理 URL 的模块
简单来说就是用来处理url的,它收录以下模块:
urllib.request 模块定义了有助于在复杂世界中打开 URL(主要是 HTTP)的函数和类——基本和摘要式身份验证、重定向、cookie 等等。
在这里,只需使用 urllib.request 模块。请求模块收录一些处理打开的url的函数。
urlopen()
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
这个函数的主要参数是url,可以是字符串,也可以是请求对象。
该函数返回一个可用作文本管理器的对象,方法如下:
要查看这些函数的作用,我们运行以下 python 代码:
import urllib.request
url = "http://www.baidu.com"
a = urllib.request.urlopen(url)
print('----------type of a----------')
print(type(a))
print('----------geturl()----------')
print(a.geturl())
print('----------info()----------')
print(a.info())
print('----------getcode()----------')
print(a.getcode())
运行结果:
3.在百度上抓取关键词的搜索结果
首先我们要知道百度搜索的url,打开百度搜索一个词,地址栏就可以看到url了
拿到url后,剩下的就是爬取url了,代码如下:
# coding=utf-8
# Created by dockerchen
import urllib.request
data = {}
data['word'] = '网络安全'
url_values = urllib.parse.urlencode(data)
url = 'http://www.baidu.com/s?wd='
full_url = url + url_values
data = urllib.request.urlopen(full_url).read()
data = data.decode('utf-8')
print(data)
urllib.parse.urlencode() 可以将字符串转换为url格式的字符串,在转换数据的地方,我们可以得到wd=%E7%BD%91%E7%BB%9C%E5%AE%一个字符串89%E5%85%A8。
如果只想对字符串进行urlencode,可以使用urllib.parse.quote(),例如:
>>> import urllib.parse
>>> urllib.parse.quote('网络安全')
'%E7%BD%91%E7%BB%9C%E5%AE%89%E5%85%A8'
上面代码的输出结果其实就是爬取的百度页面搜索结果的源码。接下来要做的就是对爬取的东西进行处理,得到我们想要的数据
参考:
转载于: 查看全部
输入关键字 抓取所有网页(windows环境下的操作版本为3urllib库介绍)
(以下是windows环境下的操作,python版本为3)
1.urllib库介绍
官方文档上的解释是:
urllib 是一个包,它采集了几个用于处理 URL 的模块
简单来说就是用来处理url的,它收录以下模块:
urllib.request 模块定义了有助于在复杂世界中打开 URL(主要是 HTTP)的函数和类——基本和摘要式身份验证、重定向、cookie 等等。
在这里,只需使用 urllib.request 模块。请求模块收录一些处理打开的url的函数。
urlopen()
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
这个函数的主要参数是url,可以是字符串,也可以是请求对象。
该函数返回一个可用作文本管理器的对象,方法如下:
要查看这些函数的作用,我们运行以下 python 代码:
import urllib.request
url = "http://www.baidu.com"
a = urllib.request.urlopen(url)
print('----------type of a----------')
print(type(a))
print('----------geturl()----------')
print(a.geturl())
print('----------info()----------')
print(a.info())
print('----------getcode()----------')
print(a.getcode())
运行结果:

3.在百度上抓取关键词的搜索结果
首先我们要知道百度搜索的url,打开百度搜索一个词,地址栏就可以看到url了

拿到url后,剩下的就是爬取url了,代码如下:
# coding=utf-8
# Created by dockerchen
import urllib.request
data = {}
data['word'] = '网络安全'
url_values = urllib.parse.urlencode(data)
url = 'http://www.baidu.com/s?wd='
full_url = url + url_values
data = urllib.request.urlopen(full_url).read()
data = data.decode('utf-8')
print(data)
urllib.parse.urlencode() 可以将字符串转换为url格式的字符串,在转换数据的地方,我们可以得到wd=%E7%BD%91%E7%BB%9C%E5%AE%一个字符串89%E5%85%A8。
如果只想对字符串进行urlencode,可以使用urllib.parse.quote(),例如:
>>> import urllib.parse
>>> urllib.parse.quote('网络安全')
'%E7%BD%91%E7%BB%9C%E5%AE%89%E5%85%A8'
上面代码的输出结果其实就是爬取的百度页面搜索结果的源码。接下来要做的就是对爬取的东西进行处理,得到我们想要的数据
参考:
转载于:
输入关键字 抓取所有网页(利用Python网络爬虫微信朋友圈动态(上)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-19 09:12
阿里云 > 云栖社区 > 主题地图 > L > 用网络爬虫爬取关键词
推荐活动:
更多优惠>
当前主题: 使用网络爬虫进行爬网关键词添加到采集夹
相关话题:
使用网络爬虫爬取关键词相关博客查看更多博客
《Python爬虫开发与项目实践》——第3章Web爬虫入门3.1 Web爬虫概述
作者:华章电脑 3956人浏览评论:04年前
本章节选自华章计算机《Python爬虫开发与项目实战》一书第3章3.1节,作者:范传辉。更多章节请访问云栖社区“华章计算机”查看公众号第3章网络爬虫入门本章开始正式涉及Python爬虫的开发。本章主要分为两部分:一部分是网络
阅读全文
如何使用Python网络爬虫抓取微信好友数量和微信好友男女比例
作者:python进阶1453人查看评论:03年前
前几天给大家分享了使用Python网络爬虫爬取朋友圈的动态(上)和使用Python网络爬虫爬取朋友圈的动态——附代码(下),并对抓取的数据进行Python处理。词云和艺术字可视化,有兴趣的小伙伴可以戳这个文章:使用Python词云和艺术字
阅读全文
使用Python网络爬虫抓取微信好友签名并进行可视化展示
作者:python进阶1255人查看评论:03年前
前几天给大家分享了如何使用Python词云和wordart可视化工具对朋友圈数据进行可视化,使用Python网络爬虫抓取微信好友数量和微信男女比例好友,并使用Python网络爬虫抓取微信好友位置省市分布及其可视化,感兴趣的朋友可以点击查看
阅读全文
网络爬虫的实现
作者:xumaojun933 浏览评论:04年前
通过古普塔,P。乔哈里,K。印度 Linagay 大学 文章 发表于:工程技术新兴趋势 (ICETET),2009 年第 2 次实习生
阅读全文
网络爬虫的实现
作者:nothingfinal1246 浏览评论:23 年前
通过古普塔,P。乔哈里,K。Linagay's Univ., India 文章发表于:工程和技术的新兴趋势 (ICETET),2009 年第二届国际
阅读全文
网络爬虫的实现
作者:shapherd2738 浏览评论:05年前
摘要 - 万维网是通过HTML格式链接的数十亿文档的集合,那么如此海量的数据已经成为信息检索的障碍,用户可能不得不翻页才能找到他们想要的材料。网络爬虫是搜索引擎的核心部分,网络爬虫不断地爬取互联网,以查找任何添加到网络的新页面和已从网络中删除的页面。
阅读全文
网络爬虫的实现
作者:maojunxu558 浏览评论:04年前
作者:古普塔,P。乔哈里,K。Linagay 大学,印度文章发表于:工程技术新兴趋势 (ICETET),2009 年第二届实习生
阅读全文
【python爬虫】爬取图片打不开或损坏的简单探讨
作者:肖洛洛4401 浏览评论:06年前
本文主要针对python中使用urlretrieve或urlopen下载百度、搜狗、googto(谷歌镜像)等图片时出现“打不开图片或损坏”的问题。作者对此进行了简要讨论。同时作者会进一步帮你巩固 selenium 自动化和 urllib
阅读全文 查看全部
输入关键字 抓取所有网页(利用Python网络爬虫微信朋友圈动态(上)(组图))
阿里云 > 云栖社区 > 主题地图 > L > 用网络爬虫爬取关键词
推荐活动:
更多优惠>
当前主题: 使用网络爬虫进行爬网关键词添加到采集夹
相关话题:
使用网络爬虫爬取关键词相关博客查看更多博客
《Python爬虫开发与项目实践》——第3章Web爬虫入门3.1 Web爬虫概述
作者:华章电脑 3956人浏览评论:04年前
本章节选自华章计算机《Python爬虫开发与项目实战》一书第3章3.1节,作者:范传辉。更多章节请访问云栖社区“华章计算机”查看公众号第3章网络爬虫入门本章开始正式涉及Python爬虫的开发。本章主要分为两部分:一部分是网络
阅读全文
如何使用Python网络爬虫抓取微信好友数量和微信好友男女比例
作者:python进阶1453人查看评论:03年前
前几天给大家分享了使用Python网络爬虫爬取朋友圈的动态(上)和使用Python网络爬虫爬取朋友圈的动态——附代码(下),并对抓取的数据进行Python处理。词云和艺术字可视化,有兴趣的小伙伴可以戳这个文章:使用Python词云和艺术字
阅读全文
使用Python网络爬虫抓取微信好友签名并进行可视化展示
作者:python进阶1255人查看评论:03年前
前几天给大家分享了如何使用Python词云和wordart可视化工具对朋友圈数据进行可视化,使用Python网络爬虫抓取微信好友数量和微信男女比例好友,并使用Python网络爬虫抓取微信好友位置省市分布及其可视化,感兴趣的朋友可以点击查看
阅读全文
网络爬虫的实现
作者:xumaojun933 浏览评论:04年前
通过古普塔,P。乔哈里,K。印度 Linagay 大学 文章 发表于:工程技术新兴趋势 (ICETET),2009 年第 2 次实习生
阅读全文
网络爬虫的实现
作者:nothingfinal1246 浏览评论:23 年前
通过古普塔,P。乔哈里,K。Linagay's Univ., India 文章发表于:工程和技术的新兴趋势 (ICETET),2009 年第二届国际
阅读全文
网络爬虫的实现
作者:shapherd2738 浏览评论:05年前
摘要 - 万维网是通过HTML格式链接的数十亿文档的集合,那么如此海量的数据已经成为信息检索的障碍,用户可能不得不翻页才能找到他们想要的材料。网络爬虫是搜索引擎的核心部分,网络爬虫不断地爬取互联网,以查找任何添加到网络的新页面和已从网络中删除的页面。
阅读全文
网络爬虫的实现
作者:maojunxu558 浏览评论:04年前
作者:古普塔,P。乔哈里,K。Linagay 大学,印度文章发表于:工程技术新兴趋势 (ICETET),2009 年第二届实习生
阅读全文
【python爬虫】爬取图片打不开或损坏的简单探讨
作者:肖洛洛4401 浏览评论:06年前
本文主要针对python中使用urlretrieve或urlopen下载百度、搜狗、googto(谷歌镜像)等图片时出现“打不开图片或损坏”的问题。作者对此进行了简要讨论。同时作者会进一步帮你巩固 selenium 自动化和 urllib
阅读全文
输入关键字 抓取所有网页(项目招商找A5快速获取精准代理名单当选取了某个关键字)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-17 15:04
项目投资找A5快速获取精准代理商名单
选择某个关键字时,关键字需要将关键字集成到网页上,并通过此信息,可以告知搜索引擎与某个关键字密切相关。比如你的网站是一个与卖“炒股软件”相关的网站,所以你在网站首页设置要优化的关键词是“炒股软件”,但是在整个网页中,从头到尾从来没有出现过“炒股软件”这个词,所以无论网页再好,当你在搜索引擎中输入“炒股软件”这个关键词时,你也不会能够找到它,因为搜索引擎无法知道您的网页。它与关键字“股票交易软件”密切相关。
分布关键词,我们如何从以下几个方面来思考:
1)关键字密度
所谓关键词密度,是指关键词或关键字段在一个页面上所有页面的总文本中所占的比例。为了让大家更直观的理解“关键词密度”这个概念,这里我们举个例子:一句“诺基亚手机是世界知名品牌手机”,在这句话中,我们可以区分“诺基亚”“手机”手机”“是”、“世界”、“知名”和“手机”,其中“手机”在这句话中的关键词密度为2/6=1/3。
对于整个网页,我们检查这个网页的HTML代码,然后去掉代码中的HTML代码,剩下的就是网页的整个文本,然后按照上面的计算方法得到最终的关键词关键词密度。
当然,以上只是如何获取关键词密度的理论。在实践中,我们很少手动执行此操作。而是直接用站长工具检测,但是我们会发现每个站长工具检测的结果都不一样,所以这些数字只是给我们做个简单的参考,具体网上关键词密度可以输入关键词“搜索引擎中的关键字密度”和许多工具都会问世。
更合理的关键词密度范围是2%~8%,但我们不必太拘泥于这些数字,我们可以在网页中分配我们认为合理的内容。一般来说,一个网页大约分布6~10个关键词。不需要太多。
关键词的密度是搜索引擎排名的一个重要因素。不要累积关键字,否则会有触发关键字填充过滤器惩罚的后果。
2)关键字分布
关键字的分布原则如下:
a:整个网页均匀分布关键词,从左到上的结构分布
b:在title和meta中分布关键词
c:在网页中使用,,等为一两个关键字制作特殊标签
以上就是我们分配关键词的三个基本原则。首先,我们必须将它们均匀分布,并将它们分布在左侧和上方。在保证统一性的同时,还要保证左上角的关键词数量。二是关键词要分布在标题中,不仅对网站首页如此,对于写文章内容也是如此,如果你的一些网站文章 are 为了获取一个长尾关键字,使用这个长尾关键字来组织标题。最后是关于一些关键词的特殊处理。如果只是简单的关键词密度,可能无法强烈表达这个页面与这个关键词密切相关,但是如果对几个关键词做特殊处理,
关于 h1,h2.h3,h4,h5,h6 和强标签
其中,h4.h5.h6 用得比较少。如果按其功能排序,h1>h2>h3>strong>h4>h5>h6
用于标记内容,起到加强作用。除了强调这个标题在页面中的内容重要性外,如果有链接,也加强了对链接页面的推荐。这些标签可用于引导网页上的蜘蛛解释和跟踪网页。
h1——一个大标题,可以放在网站网页的顶部,告诉搜索引擎网站的作用。它应该收录 网站 主要关键字,但要避免关键字填充。最好出现在网页源代码body标签开头的第一个容器的第一行。并且保证在一个页面中只出现一次。
h2——副标题,每页出现的次数应该是1-3次。
比如阿里巴巴中文版的首页:
H1出现在LOGO的标签中,只有这一个,这里的源码是:
H2 出现在下栏
源代码在这里:
阿里巴巴服务
H3分布多次,这里有一个:
源代码在这里:
新:13,684
关键词的分布和其他标记的使用,不仅是关键词的分布和强化,也是控制蜘蛛爬取分布的重要作用。在蜘蛛无法关注的链接区域,如果你给这个区域的前面加上列名并标记,那么蜘蛛就会开始关注这个区域,这些链接也会被蜘蛛,在内部链接的构建中也起着重要的作用。
3)与关键字相关的相关术语
在关键词分布中,不仅目标关键词会影响这个网页的关键词排名,其他一些相关的词也会促进网页的关键词排名,比如“减肥”、“减肥”分布在您的网页中 相关词如“健身”、“优雅”、“苗条”,而相反的词如“胖”和“胖”也有助于您的网页排名,这些相关词将再次强化您的关键字,从而提升页面在搜索引擎排名中,这相当于告诉搜索引擎这个网页确实与关键词“减肥”息息相关。相反,如果你网页的关键词是“减肥”,但在你的网页中除了“减肥”之外,
4)标题和元信息的设置
在之前的关键词分布中,我们提到了title和meta信息的重要性,所以在第四点,我们将介绍title和meta信息的合理设置建议:
标题设置:
a:网站主页:网站名称 - 网站角色和使命
b:列表页(列页):列名-网站名称
c:内容页:标题-列名-网站名称
基本原理就是把当前网页的主要信息放在最上面,然后按照导航路径一步步到网站首页。一个简单的网站pass 收录三种类型的网页:主页、列表页和内容页。
元信息设置:
元信息主要是指关键词(keywords)和描述(description)信息。元信息对搜索引擎的作用逐渐减弱。搜索引擎可以在不使用这些元信息的情况下分发网页内容。设置元信息的建议:
关键字(keywords):你不需要设置它们。如果你设置它们,不要选择太多的关键字,也不要堆叠它们。
description(描述):用简单的语言描述网页信息,使每个网页的元信息都不同。如果做不到,最好不要设置。
这是一个网页,从中我们可以看到一些关于关键词分布的线索
这是一个农业特产信息网站的内页。猪流感时期,用文章的内页优化了关键词“山东猪流感”,虽然网站本身的权重还是很高的,但是内页的优化还是基于关键字的密度。首先,在TITLE(这里是文章的标题)中,“山东猪流感病例被确诊,回应是同一个人没有及时隔离的原因。“汽车”,收录关键词“山东猪流感”,标题使用标签,分布在正文内容中,第一段略多,三个关键词分布,第二段为一个。大体均匀,稍有分布,更重要的是自然。
超级站长网戴仁光原创文章 本文版权归戴仁光@超站科技所有。欢迎转载,并注明作者和出处。谢谢
申请创业报告,分享创业好点子。点击这里一起讨论新的商机! 查看全部
输入关键字 抓取所有网页(项目招商找A5快速获取精准代理名单当选取了某个关键字)
项目投资找A5快速获取精准代理商名单
选择某个关键字时,关键字需要将关键字集成到网页上,并通过此信息,可以告知搜索引擎与某个关键字密切相关。比如你的网站是一个与卖“炒股软件”相关的网站,所以你在网站首页设置要优化的关键词是“炒股软件”,但是在整个网页中,从头到尾从来没有出现过“炒股软件”这个词,所以无论网页再好,当你在搜索引擎中输入“炒股软件”这个关键词时,你也不会能够找到它,因为搜索引擎无法知道您的网页。它与关键字“股票交易软件”密切相关。
分布关键词,我们如何从以下几个方面来思考:
1)关键字密度
所谓关键词密度,是指关键词或关键字段在一个页面上所有页面的总文本中所占的比例。为了让大家更直观的理解“关键词密度”这个概念,这里我们举个例子:一句“诺基亚手机是世界知名品牌手机”,在这句话中,我们可以区分“诺基亚”“手机”手机”“是”、“世界”、“知名”和“手机”,其中“手机”在这句话中的关键词密度为2/6=1/3。
对于整个网页,我们检查这个网页的HTML代码,然后去掉代码中的HTML代码,剩下的就是网页的整个文本,然后按照上面的计算方法得到最终的关键词关键词密度。
当然,以上只是如何获取关键词密度的理论。在实践中,我们很少手动执行此操作。而是直接用站长工具检测,但是我们会发现每个站长工具检测的结果都不一样,所以这些数字只是给我们做个简单的参考,具体网上关键词密度可以输入关键词“搜索引擎中的关键字密度”和许多工具都会问世。
更合理的关键词密度范围是2%~8%,但我们不必太拘泥于这些数字,我们可以在网页中分配我们认为合理的内容。一般来说,一个网页大约分布6~10个关键词。不需要太多。
关键词的密度是搜索引擎排名的一个重要因素。不要累积关键字,否则会有触发关键字填充过滤器惩罚的后果。
2)关键字分布
关键字的分布原则如下:
a:整个网页均匀分布关键词,从左到上的结构分布
b:在title和meta中分布关键词
c:在网页中使用,,等为一两个关键字制作特殊标签
以上就是我们分配关键词的三个基本原则。首先,我们必须将它们均匀分布,并将它们分布在左侧和上方。在保证统一性的同时,还要保证左上角的关键词数量。二是关键词要分布在标题中,不仅对网站首页如此,对于写文章内容也是如此,如果你的一些网站文章 are 为了获取一个长尾关键字,使用这个长尾关键字来组织标题。最后是关于一些关键词的特殊处理。如果只是简单的关键词密度,可能无法强烈表达这个页面与这个关键词密切相关,但是如果对几个关键词做特殊处理,
关于 h1,h2.h3,h4,h5,h6 和强标签
其中,h4.h5.h6 用得比较少。如果按其功能排序,h1>h2>h3>strong>h4>h5>h6
用于标记内容,起到加强作用。除了强调这个标题在页面中的内容重要性外,如果有链接,也加强了对链接页面的推荐。这些标签可用于引导网页上的蜘蛛解释和跟踪网页。
h1——一个大标题,可以放在网站网页的顶部,告诉搜索引擎网站的作用。它应该收录 网站 主要关键字,但要避免关键字填充。最好出现在网页源代码body标签开头的第一个容器的第一行。并且保证在一个页面中只出现一次。
h2——副标题,每页出现的次数应该是1-3次。
比如阿里巴巴中文版的首页:
H1出现在LOGO的标签中,只有这一个,这里的源码是:
H2 出现在下栏
源代码在这里:
阿里巴巴服务
H3分布多次,这里有一个:
源代码在这里:
新:13,684
关键词的分布和其他标记的使用,不仅是关键词的分布和强化,也是控制蜘蛛爬取分布的重要作用。在蜘蛛无法关注的链接区域,如果你给这个区域的前面加上列名并标记,那么蜘蛛就会开始关注这个区域,这些链接也会被蜘蛛,在内部链接的构建中也起着重要的作用。
3)与关键字相关的相关术语
在关键词分布中,不仅目标关键词会影响这个网页的关键词排名,其他一些相关的词也会促进网页的关键词排名,比如“减肥”、“减肥”分布在您的网页中 相关词如“健身”、“优雅”、“苗条”,而相反的词如“胖”和“胖”也有助于您的网页排名,这些相关词将再次强化您的关键字,从而提升页面在搜索引擎排名中,这相当于告诉搜索引擎这个网页确实与关键词“减肥”息息相关。相反,如果你网页的关键词是“减肥”,但在你的网页中除了“减肥”之外,
4)标题和元信息的设置
在之前的关键词分布中,我们提到了title和meta信息的重要性,所以在第四点,我们将介绍title和meta信息的合理设置建议:
标题设置:
a:网站主页:网站名称 - 网站角色和使命
b:列表页(列页):列名-网站名称
c:内容页:标题-列名-网站名称
基本原理就是把当前网页的主要信息放在最上面,然后按照导航路径一步步到网站首页。一个简单的网站pass 收录三种类型的网页:主页、列表页和内容页。
元信息设置:
元信息主要是指关键词(keywords)和描述(description)信息。元信息对搜索引擎的作用逐渐减弱。搜索引擎可以在不使用这些元信息的情况下分发网页内容。设置元信息的建议:
关键字(keywords):你不需要设置它们。如果你设置它们,不要选择太多的关键字,也不要堆叠它们。
description(描述):用简单的语言描述网页信息,使每个网页的元信息都不同。如果做不到,最好不要设置。
这是一个网页,从中我们可以看到一些关于关键词分布的线索
这是一个农业特产信息网站的内页。猪流感时期,用文章的内页优化了关键词“山东猪流感”,虽然网站本身的权重还是很高的,但是内页的优化还是基于关键字的密度。首先,在TITLE(这里是文章的标题)中,“山东猪流感病例被确诊,回应是同一个人没有及时隔离的原因。“汽车”,收录关键词“山东猪流感”,标题使用标签,分布在正文内容中,第一段略多,三个关键词分布,第二段为一个。大体均匀,稍有分布,更重要的是自然。
超级站长网戴仁光原创文章 本文版权归戴仁光@超站科技所有。欢迎转载,并注明作者和出处。谢谢
申请创业报告,分享创业好点子。点击这里一起讨论新的商机!
输入关键字 抓取所有网页(利用Python网络爬虫微信朋友圈动态(上)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-13 21:10
阿里云 > 云栖社区 > 主题地图 > L > 用网络爬虫爬取关键词
推荐活动:
更多优惠>
当前主题: 使用网络爬虫进行爬网关键词添加到采集夹
相关话题:
使用网络爬虫爬取关键词相关博客查看更多博客
《Python爬虫开发与项目实践》——第3章Web爬虫入门3.1 Web爬虫概述
作者:华章电脑 3956人浏览评论:04年前
本章节选自华章计算机《Python爬虫开发与项目实战》一书第3章3.1节,作者:范传辉。更多章节请访问云栖社区“华章计算机”查看公众号第3章网络爬虫入门本章将正式涉及Python爬虫的开发。本章主要分为两部分:一部分是网络
阅读全文
如何使用Python网络爬虫抓取微信好友数量和微信好友男女比例
作者:python进阶1453人查看评论:03年前
前几天给大家分享了使用Python爬虫爬取朋友圈的动态(上)和使用Python爬虫爬取朋友圈的动态——附代码(下),并对抓取到的数据进行Python处理。词云和艺术字可视化,有兴趣的小伙伴可以戳这个文章:使用Python词云和艺术字
阅读全文
使用Python网络爬虫抓取微信好友签名并进行可视化展示
作者:python进阶1255人查看评论:03年前
前几天给大家分享了如何使用Python词云和wordart可视化工具对朋友圈数据进行可视化,使用Python网络爬虫抓取微信好友数量和微信男女比例好友,并使用Python网络爬虫抓取微信好友位置省市分布及其可视化,感兴趣的朋友可以点击查看
阅读全文
网络爬虫的实现
作者:xumaojun933 浏览评论:03年前
作者:古普塔,P。乔哈里,K。印度 Linagay 大学 文章 发表于:工程技术新兴趋势 (ICETET),2009 年第 2 次实习生
阅读全文
网络爬虫的实现
作者:nothingfinal1246 浏览评论:23 年前
通过古普塔,P。乔哈里,K。Linagay's Univ., India 文章发表于:工程和技术的新兴趋势 (ICETET),2009 年第二届国际
阅读全文
网络爬虫的实现
作者:shapherd2738 浏览评论:05年前
摘要 - 万维网是通过HTML格式链接的数十亿文档的集合,那么如此海量的数据已经成为信息检索的障碍,用户可能不得不翻页才能找到他们想要的材料。网络爬虫是搜索引擎的核心部分,网络爬虫不断地爬取互联网,以查找任何添加到网络的新页面和已从网络中删除的页面。
阅读全文
网络爬虫的实现
作者:maojunxu558 浏览评论:04年前
作者:古普塔,P。乔哈里,K。Linagay 大学,印度文章发表于:工程技术新兴趋势 (ICETET),2009 年第二届实习生
阅读全文
【python爬虫】爬取图片打不开或损坏的简单探讨
作者:肖洛洛4401 浏览评论:06年前
本文主要针对python中使用urlretrieve或urlopen下载百度、搜狗、googto(谷歌镜像)等图片时出现“打不开图片或损坏”的问题。作者对此进行了简要讨论。同时作者会进一步帮你巩固 selenium 自动化和 urllib
阅读全文 查看全部
输入关键字 抓取所有网页(利用Python网络爬虫微信朋友圈动态(上)(组图))
阿里云 > 云栖社区 > 主题地图 > L > 用网络爬虫爬取关键词
推荐活动:
更多优惠>
当前主题: 使用网络爬虫进行爬网关键词添加到采集夹
相关话题:
使用网络爬虫爬取关键词相关博客查看更多博客
《Python爬虫开发与项目实践》——第3章Web爬虫入门3.1 Web爬虫概述
作者:华章电脑 3956人浏览评论:04年前
本章节选自华章计算机《Python爬虫开发与项目实战》一书第3章3.1节,作者:范传辉。更多章节请访问云栖社区“华章计算机”查看公众号第3章网络爬虫入门本章将正式涉及Python爬虫的开发。本章主要分为两部分:一部分是网络
阅读全文
如何使用Python网络爬虫抓取微信好友数量和微信好友男女比例
作者:python进阶1453人查看评论:03年前
前几天给大家分享了使用Python爬虫爬取朋友圈的动态(上)和使用Python爬虫爬取朋友圈的动态——附代码(下),并对抓取到的数据进行Python处理。词云和艺术字可视化,有兴趣的小伙伴可以戳这个文章:使用Python词云和艺术字
阅读全文
使用Python网络爬虫抓取微信好友签名并进行可视化展示
作者:python进阶1255人查看评论:03年前
前几天给大家分享了如何使用Python词云和wordart可视化工具对朋友圈数据进行可视化,使用Python网络爬虫抓取微信好友数量和微信男女比例好友,并使用Python网络爬虫抓取微信好友位置省市分布及其可视化,感兴趣的朋友可以点击查看
阅读全文
网络爬虫的实现
作者:xumaojun933 浏览评论:03年前
作者:古普塔,P。乔哈里,K。印度 Linagay 大学 文章 发表于:工程技术新兴趋势 (ICETET),2009 年第 2 次实习生
阅读全文
网络爬虫的实现
作者:nothingfinal1246 浏览评论:23 年前
通过古普塔,P。乔哈里,K。Linagay's Univ., India 文章发表于:工程和技术的新兴趋势 (ICETET),2009 年第二届国际
阅读全文
网络爬虫的实现
作者:shapherd2738 浏览评论:05年前
摘要 - 万维网是通过HTML格式链接的数十亿文档的集合,那么如此海量的数据已经成为信息检索的障碍,用户可能不得不翻页才能找到他们想要的材料。网络爬虫是搜索引擎的核心部分,网络爬虫不断地爬取互联网,以查找任何添加到网络的新页面和已从网络中删除的页面。
阅读全文
网络爬虫的实现
作者:maojunxu558 浏览评论:04年前
作者:古普塔,P。乔哈里,K。Linagay 大学,印度文章发表于:工程技术新兴趋势 (ICETET),2009 年第二届实习生
阅读全文
【python爬虫】爬取图片打不开或损坏的简单探讨
作者:肖洛洛4401 浏览评论:06年前
本文主要针对python中使用urlretrieve或urlopen下载百度、搜狗、googto(谷歌镜像)等图片时出现“打不开图片或损坏”的问题。作者对此进行了简要讨论。同时作者会进一步帮你巩固 selenium 自动化和 urllib
阅读全文
输入关键字 抓取所有网页( 继续搜狗站长平台使用教程的分享,本文讲一下【站点信息】功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-13 04:19
继续搜狗站长平台使用教程的分享,本文讲一下【站点信息】功能)
继续分享搜狗站长平台使用教程。本文将讨论[站点信息]功能。当我们将网站添加到搜狗站长平台后,站点信息需要几天时间才能显示在这里。这部分内容以观看为主,没有太多可操作的东西。
我的网站
站点信息中的第一项是【我的站点】,显示了当前网站的具体数据。主要包括:收录指标体积、流量、关键词、抓压。
可能大部分公司网站的搜狗站数据都不是很好,这个不用太担心,只要你的网站建设不是专门针对搜狗SEO优化的,那么就看一看。
网站名片
站点信息中的第二项是[网站名片]。我记得这个功能是在2018年推出的,但是经过实际观察,这个功能可能对大多数网站都没有用。因为大多数 网站 没有这张名片。
我们来看看这张名片是什么网站,如上图所示!明白了,如果您的公司 网站 在业内知名度不高,一般不会出现在这里。另外,大家注意到上图下方有一条信息,即网站名片的信息由【安全联盟】提供。
点击【安全联盟】链接后,你会发现这个认证需要额外收费。如果你的企业觉得需要认证,那你可以自己付费,这里我就不多说了。
总结
站点信息功能仅用于展示网站的主要信息,可以让你知道网站在搜狗上的当前搜索数据,知道就知道了。 查看全部
输入关键字 抓取所有网页(
继续搜狗站长平台使用教程的分享,本文讲一下【站点信息】功能)
继续分享搜狗站长平台使用教程。本文将讨论[站点信息]功能。当我们将网站添加到搜狗站长平台后,站点信息需要几天时间才能显示在这里。这部分内容以观看为主,没有太多可操作的东西。
我的网站
站点信息中的第一项是【我的站点】,显示了当前网站的具体数据。主要包括:收录指标体积、流量、关键词、抓压。
可能大部分公司网站的搜狗站数据都不是很好,这个不用太担心,只要你的网站建设不是专门针对搜狗SEO优化的,那么就看一看。
网站名片
站点信息中的第二项是[网站名片]。我记得这个功能是在2018年推出的,但是经过实际观察,这个功能可能对大多数网站都没有用。因为大多数 网站 没有这张名片。
我们来看看这张名片是什么网站,如上图所示!明白了,如果您的公司 网站 在业内知名度不高,一般不会出现在这里。另外,大家注意到上图下方有一条信息,即网站名片的信息由【安全联盟】提供。
点击【安全联盟】链接后,你会发现这个认证需要额外收费。如果你的企业觉得需要认证,那你可以自己付费,这里我就不多说了。
总结
站点信息功能仅用于展示网站的主要信息,可以让你知道网站在搜狗上的当前搜索数据,知道就知道了。
输入关键字 抓取所有网页(java中操作数据库的基本使用方法--apachejavadriver数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-12 23:06
输入关键字抓取所有网页数据。
文件传输工具一般都可以直接将网页信息上传到服务器,比如webdav、ftp、apache等,可以和本地服务器通过sqlite(一种可以直接从数据库中取数据的数据库)进行对接,然后通过jdbc数据库驱动进行连接,在java中操作数据库是相对比较简单的。如果用java的话,可以考虑下apachejavadriver或者clouderajavadriver进行联接,以下是三种类型的apachejavadriver的基本使用方法:connector类:用来与apachejavadriver建立通信(可以直接通过apache的-x-dev来设置开关),分为几个属性,可以调用参数来对source和directory进行定义。
也可以通过构造方法自定义输入-->设置路径->数据库连接->sqlite(可以通过下面代码来自定义输入的数据库),如下:构造方法示例signal类:可以用来作为与服务器的通信,它的功能主要有两个,一个是notice,另一个是system,用于通知服务器两个重要信息:1)先要配置好网页源文件地址;2)必须对每个包含源文件的java文件进行读写权限控制,用于防止恶意上传文件。
百度就有了
百度就有。
怎么要,服务器服务器端自己处理的。国内还没有这种网站。国外最近的都是bs形式的apache+mysql这种。 查看全部
输入关键字 抓取所有网页(java中操作数据库的基本使用方法--apachejavadriver数据)
输入关键字抓取所有网页数据。
文件传输工具一般都可以直接将网页信息上传到服务器,比如webdav、ftp、apache等,可以和本地服务器通过sqlite(一种可以直接从数据库中取数据的数据库)进行对接,然后通过jdbc数据库驱动进行连接,在java中操作数据库是相对比较简单的。如果用java的话,可以考虑下apachejavadriver或者clouderajavadriver进行联接,以下是三种类型的apachejavadriver的基本使用方法:connector类:用来与apachejavadriver建立通信(可以直接通过apache的-x-dev来设置开关),分为几个属性,可以调用参数来对source和directory进行定义。
也可以通过构造方法自定义输入-->设置路径->数据库连接->sqlite(可以通过下面代码来自定义输入的数据库),如下:构造方法示例signal类:可以用来作为与服务器的通信,它的功能主要有两个,一个是notice,另一个是system,用于通知服务器两个重要信息:1)先要配置好网页源文件地址;2)必须对每个包含源文件的java文件进行读写权限控制,用于防止恶意上传文件。
百度就有了
百度就有。
怎么要,服务器服务器端自己处理的。国内还没有这种网站。国外最近的都是bs形式的apache+mysql这种。
输入关键字 抓取所有网页(功能介绍智能识别模式WebHarvy网页中出现的数据模式-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-12 06:19
特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
软件功能
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器浏览网络。您可以选择要单击的数据。这很容易!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面爬取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
变更日志
修复了可能导致页面启动时禁用连接的错误
您可以为页面模式配置专用的连接方法
可以自动搜索 HTML 上的可配置资源 查看全部
输入关键字 抓取所有网页(功能介绍智能识别模式WebHarvy网页中出现的数据模式-苏州安嘉)
特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
软件功能
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器浏览网络。您可以选择要单击的数据。这很容易!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面爬取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
变更日志
修复了可能导致页面启动时禁用连接的错误
您可以为页面模式配置专用的连接方法
可以自动搜索 HTML 上的可配置资源
输入关键字 抓取所有网页(一下:新网站上线怎么才能被百度秒收录呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-09 15:22
百度收录一直是运营推广人员工作的重中之重,尤其是很多公司做网站网站没有被百度接受之后收录 , 导致优化的关键词 没有排名。上百度收录首页花了几个月的时间,导致运营上浪费了很多时间,所以今天我们来讲解一下:一个新的网站怎么能秒上百度网站 @收录?
1、添加搜索引擎条目
前提
收录就是内容可以被search和win抓取,所以我们发布的内容一定要输入好,而这些条目包括目录网站的提交,以及链接友情交流,以及外链的布局,让搜索引擎可以抓取我们的网站到其他的网站。同时我们也可以通过站长搜索平台的链接提交方式将内容提交给搜索引擎,让搜索引擎快速抓取我们的网站,提高收录的概率网站。
2、发布优质内容
网站上线前必须填写内容,内容必须结构合理,内容优质。因为网站上线后,搜索引擎会根据你的网站内容给你的网站内容评分。如果是优质内容,那么你的网站就是优质的网站,后续网站的收录和排名都会很好。如果搜索引擎把你的网站评价为质量差,那么收录的后续和审核周期也会很长,导致网站的排名很差,所以网站的质量@> 很好 不好的主要原因是 网站 上线的时候。
3、做网站的基础优化
网站的基础优化也是影响网站收录的重要因素,比如网站alt处理、h标签处理、网站301和404页面的设置,还有标题和栏目的设置,都需要做好。还有网站的访问速度。 网站的访问速度也会影响网站的评分,所以我们要选择访问速度快的空间和服务器。
把上面的内容做好,当搜索引擎爬取你的网站时,会判断你的网站内容质量高,基本会对你的网站秒收费。 ,后续网站的内容发布也将轻松收录,所以上线前一定要在建站时做好网站的基础优化和建设。不要急于上网。否则只会适得其反。 查看全部
输入关键字 抓取所有网页(一下:新网站上线怎么才能被百度秒收录呢?)
百度收录一直是运营推广人员工作的重中之重,尤其是很多公司做网站网站没有被百度接受之后收录 , 导致优化的关键词 没有排名。上百度收录首页花了几个月的时间,导致运营上浪费了很多时间,所以今天我们来讲解一下:一个新的网站怎么能秒上百度网站 @收录?
1、添加搜索引擎条目
前提
收录就是内容可以被search和win抓取,所以我们发布的内容一定要输入好,而这些条目包括目录网站的提交,以及链接友情交流,以及外链的布局,让搜索引擎可以抓取我们的网站到其他的网站。同时我们也可以通过站长搜索平台的链接提交方式将内容提交给搜索引擎,让搜索引擎快速抓取我们的网站,提高收录的概率网站。
2、发布优质内容
网站上线前必须填写内容,内容必须结构合理,内容优质。因为网站上线后,搜索引擎会根据你的网站内容给你的网站内容评分。如果是优质内容,那么你的网站就是优质的网站,后续网站的收录和排名都会很好。如果搜索引擎把你的网站评价为质量差,那么收录的后续和审核周期也会很长,导致网站的排名很差,所以网站的质量@> 很好 不好的主要原因是 网站 上线的时候。
3、做网站的基础优化
网站的基础优化也是影响网站收录的重要因素,比如网站alt处理、h标签处理、网站301和404页面的设置,还有标题和栏目的设置,都需要做好。还有网站的访问速度。 网站的访问速度也会影响网站的评分,所以我们要选择访问速度快的空间和服务器。
把上面的内容做好,当搜索引擎爬取你的网站时,会判断你的网站内容质量高,基本会对你的网站秒收费。 ,后续网站的内容发布也将轻松收录,所以上线前一定要在建站时做好网站的基础优化和建设。不要急于上网。否则只会适得其反。
输入关键字 抓取所有网页(自建站的“请输入关键字”搜索框怎么设置?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-09 15:05
“请输入查询关键字”的搜索框是大多数网站都会做的设置。这个搜索框可以帮助用户更快的找到自己想要的信息,对用户来说是正常的。但是对于SEO人员来说,这个搜索框的设置就没有那么简单了。自建网站的“请输入查询关键字”搜索框可能会直接影响产品的转化。
搜索框的作用
1.搜索框的作用是爬取页面。每个独立的搜索引擎都有自己的网页爬取过程(蜘蛛)。蜘蛛跟随网页中的超链接,不断地爬取网页。由于超链接在互联网中应用广泛,理论上,从一定大小的网页开始,可以采集到大部分网页。
2.在处理完网页后,搜索引擎需要做大量的预处理工作来提供检索服务。其中,最重要的是提取关键词并建立索引文件。其他还包括删除重复网页、分析超链接和计算网页的主要程度。
3.提供检索服务用户输入关键词进行检索,搜索引擎从索引库中找到与关键词匹配的网页。为方便用户,网页中除网页主题和网址外,还提供段落摘要等信息。
搜索框的重要性
大多数情况下,会使用搜索功能的用户,主要是产品的老用户,对产品的基本内容和服务有一定的了解,有非常明确的自身诉求。在这种情况下,如果用户可以检索到他们想要的内容或服务,那么肯定会出现高转化。
提高搜索的转化率,让用户直接让客户成功,即如何将粘性转化为结果,成功率高的购买转化才能带来利润和利润。
搜索框位置显眼,使用方便,会给客户留下更好的印象。这就需要网站组织清晰的访问路径,让用户可以流畅地浏览更深层次的内容,也可以帮助用户快速找到目标,也能到达目标页面。
如何设置“请输入关键字”搜索框
1、基于SEO优化
从SEO的角度来回顾“请输入搜索关键词”的问题,其实我们在说的是网站中的搜索框和搜索结果的反馈。我们需要从以下两个方面来理解:
①推荐和收录
利用站内搜索框“请输入关键词”的状态,产生大量长尾关键词,合理使用搜索结果列表,展示次数,适当增加关键词@的密度> 在 SERP 中,从而获得更高的排名。
②屏蔽和隐蔽
对于中小型企业,如果您的数据站点的检索量不大,通常建议使用 robots.txt 来屏蔽这个搜索结果 URL。尤其是当你的 SERP 页面没有标准化做 SEO 的时候,由于网站资源有限,真的没必要分配百度爬虫去爬这些页面。
2、基于用户体验
从用户体验的角度来看,网站搜索框中的“请输入内容设置”尤为重要。有利于推荐企业的核心产品,提高企业产品的转化率,提高UGC内容的输出,延缓用户的页面停留。时间,从而增加用户对网站品牌的粘性。
①详细的网站统计分析,了解用户画像、对方的爱好和喜好。
②控制行业更新热门话题,合理利用网站多个入口,分发优质内容,吸引他人参与讨论,提高当前热门话题栏目页面的热度,从而提高搜索引擎的可靠性。
3、输入的搜索词不准确
如果对方检索到的具体关键词没有搜索结果,90%以上的网站会返回一个空结果,或者一个标志“你的关键词输入不准确”会出现。但这是一个非常不明智的策略,您可以在此报告以下内容:
①网站逻辑构建图,类似于HTML版的sitemap。
②用户比较关注“请输入查询关键词”,推荐一些比较热的词进行搜索。
③ 站内热点文章,行业内比较热门的相关话题等。
由此可以推断,自建网站的“请输入查询关键词”搜索框其实是很重要的。 查看全部
输入关键字 抓取所有网页(自建站的“请输入关键字”搜索框怎么设置?(图))
“请输入查询关键字”的搜索框是大多数网站都会做的设置。这个搜索框可以帮助用户更快的找到自己想要的信息,对用户来说是正常的。但是对于SEO人员来说,这个搜索框的设置就没有那么简单了。自建网站的“请输入查询关键字”搜索框可能会直接影响产品的转化。
搜索框的作用
1.搜索框的作用是爬取页面。每个独立的搜索引擎都有自己的网页爬取过程(蜘蛛)。蜘蛛跟随网页中的超链接,不断地爬取网页。由于超链接在互联网中应用广泛,理论上,从一定大小的网页开始,可以采集到大部分网页。
2.在处理完网页后,搜索引擎需要做大量的预处理工作来提供检索服务。其中,最重要的是提取关键词并建立索引文件。其他还包括删除重复网页、分析超链接和计算网页的主要程度。
3.提供检索服务用户输入关键词进行检索,搜索引擎从索引库中找到与关键词匹配的网页。为方便用户,网页中除网页主题和网址外,还提供段落摘要等信息。
搜索框的重要性
大多数情况下,会使用搜索功能的用户,主要是产品的老用户,对产品的基本内容和服务有一定的了解,有非常明确的自身诉求。在这种情况下,如果用户可以检索到他们想要的内容或服务,那么肯定会出现高转化。
提高搜索的转化率,让用户直接让客户成功,即如何将粘性转化为结果,成功率高的购买转化才能带来利润和利润。
搜索框位置显眼,使用方便,会给客户留下更好的印象。这就需要网站组织清晰的访问路径,让用户可以流畅地浏览更深层次的内容,也可以帮助用户快速找到目标,也能到达目标页面。
如何设置“请输入关键字”搜索框
1、基于SEO优化
从SEO的角度来回顾“请输入搜索关键词”的问题,其实我们在说的是网站中的搜索框和搜索结果的反馈。我们需要从以下两个方面来理解:
①推荐和收录
利用站内搜索框“请输入关键词”的状态,产生大量长尾关键词,合理使用搜索结果列表,展示次数,适当增加关键词@的密度> 在 SERP 中,从而获得更高的排名。
②屏蔽和隐蔽
对于中小型企业,如果您的数据站点的检索量不大,通常建议使用 robots.txt 来屏蔽这个搜索结果 URL。尤其是当你的 SERP 页面没有标准化做 SEO 的时候,由于网站资源有限,真的没必要分配百度爬虫去爬这些页面。
2、基于用户体验
从用户体验的角度来看,网站搜索框中的“请输入内容设置”尤为重要。有利于推荐企业的核心产品,提高企业产品的转化率,提高UGC内容的输出,延缓用户的页面停留。时间,从而增加用户对网站品牌的粘性。
①详细的网站统计分析,了解用户画像、对方的爱好和喜好。
②控制行业更新热门话题,合理利用网站多个入口,分发优质内容,吸引他人参与讨论,提高当前热门话题栏目页面的热度,从而提高搜索引擎的可靠性。
3、输入的搜索词不准确
如果对方检索到的具体关键词没有搜索结果,90%以上的网站会返回一个空结果,或者一个标志“你的关键词输入不准确”会出现。但这是一个非常不明智的策略,您可以在此报告以下内容:
①网站逻辑构建图,类似于HTML版的sitemap。
②用户比较关注“请输入查询关键词”,推荐一些比较热的词进行搜索。
③ 站内热点文章,行业内比较热门的相关话题等。
由此可以推断,自建网站的“请输入查询关键词”搜索框其实是很重要的。
输入关键字 抓取所有网页(“请输入关键词”基于站搜索框的设置值得多一些研究)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-09 15:02
请输入查询关键字,这是您在访问任何网站时经常会在搜索框中看到的一些常见设置,对于用户来说并不是一个引人注目的地方,但是对于SEO人员来说,“请输入 关键词" 基于站点搜索框值得更多研究。原因很简单,可能直接影响企业产品的转化。
那么,如何设置“请输入关键字”搜索框呢?
根据以往SEO网站优化的经验,蝙蝠侠IT将详细阐述以下内容:
1、基于SEO优化
我们将从SEO的角度来回顾一下“请输入搜索关键字”的问题。其实我们说的是网站上的搜索框和搜索结果的反馈。基于SEO,我们这里不讨论:请输入关键词,内容本身。
您可能需要从以下两个角度来理解:
① 推荐和收录
如果你有优化电商网站的经验,你会发现,类似于京东的电商网站,是一个非常小的细分策略,就是利用搜索框在网站上,请输入关键词位置,产生大量长尾关键词,并合理利用搜索结果列表、展示次数,并适当增加SERP中关键词的密度,从而获得更高的排名。
但值得注意的是,要能够完美地使用这个策略,你可能需要两个小前提:
一是对方有大量的搜索查询需求。
二是网站中的搜索框,输出的搜索结果页面必须符合搜索引擎友好的URL。
② 屏蔽和隐藏
对于相当于中小企业的网站,如果你的数据网站检索量不大,我们这里通常给出的建议是使用robots.txt来屏蔽搜索结果的URL。
尤其是当你的 SERP 页面没有标准化做 SEO 的时候,由于网站资源有限,真的没必要分配百度爬虫去爬这些页面。
2、基于用户体验
从用户体验的角度来看,在网站的搜索框中设置输入内容是非常重要的,比如:
①有利于推荐企业核心产品,提高企业产品转化率。
②有利于推荐网站核心话题,提高UGC内容的输出。
③有利于推荐站点内的核心话题,延缓用户在页面的停留时间,从而增加用户对站点品牌的粘性。
为此,在进行站点搜索推荐时,您可能需要:
① 对网站做详细的统计分析,了解用户的画像,对方的喜好和喜好。
②掌握行业最新热门话题,适当利用站点内多个入口,分发优质内容,引导对方参与讨论,增加当前热门话题栏目页面的热度,从而提高搜索引擎的信任。
3、您输入的搜索词不正确
当你在搜索框中输入一些关键词时,如果对方检索到的具体关键词没有搜索结果,通常90%以上的网站都会返回一个空结果,或者是“您输入了不正确的 关键词”符号。
事实上,这是一个非常不明智的策略,你可以在这个地方给出这样的反馈:
① 网站逻辑结构图,类似于HTML版的sitemap。
②“请输入查询关键词”,最近用户非常关注,推荐了一些比较热门的搜索词。
③ 网站热门文章,行业最热相关话题等。
总结:请输入搜索关键字,貌似是个琐碎的地方,具体怎么设置,还是可以起到相应的作用的,以上内容仅供参考!
蝙蝠侠IT转载需授权! 查看全部
输入关键字 抓取所有网页(“请输入关键词”基于站搜索框的设置值得多一些研究)
请输入查询关键字,这是您在访问任何网站时经常会在搜索框中看到的一些常见设置,对于用户来说并不是一个引人注目的地方,但是对于SEO人员来说,“请输入 关键词" 基于站点搜索框值得更多研究。原因很简单,可能直接影响企业产品的转化。
那么,如何设置“请输入关键字”搜索框呢?
根据以往SEO网站优化的经验,蝙蝠侠IT将详细阐述以下内容:
1、基于SEO优化
我们将从SEO的角度来回顾一下“请输入搜索关键字”的问题。其实我们说的是网站上的搜索框和搜索结果的反馈。基于SEO,我们这里不讨论:请输入关键词,内容本身。
您可能需要从以下两个角度来理解:
① 推荐和收录
如果你有优化电商网站的经验,你会发现,类似于京东的电商网站,是一个非常小的细分策略,就是利用搜索框在网站上,请输入关键词位置,产生大量长尾关键词,并合理利用搜索结果列表、展示次数,并适当增加SERP中关键词的密度,从而获得更高的排名。
但值得注意的是,要能够完美地使用这个策略,你可能需要两个小前提:
一是对方有大量的搜索查询需求。
二是网站中的搜索框,输出的搜索结果页面必须符合搜索引擎友好的URL。
② 屏蔽和隐藏
对于相当于中小企业的网站,如果你的数据网站检索量不大,我们这里通常给出的建议是使用robots.txt来屏蔽搜索结果的URL。
尤其是当你的 SERP 页面没有标准化做 SEO 的时候,由于网站资源有限,真的没必要分配百度爬虫去爬这些页面。
2、基于用户体验
从用户体验的角度来看,在网站的搜索框中设置输入内容是非常重要的,比如:
①有利于推荐企业核心产品,提高企业产品转化率。
②有利于推荐网站核心话题,提高UGC内容的输出。
③有利于推荐站点内的核心话题,延缓用户在页面的停留时间,从而增加用户对站点品牌的粘性。
为此,在进行站点搜索推荐时,您可能需要:
① 对网站做详细的统计分析,了解用户的画像,对方的喜好和喜好。
②掌握行业最新热门话题,适当利用站点内多个入口,分发优质内容,引导对方参与讨论,增加当前热门话题栏目页面的热度,从而提高搜索引擎的信任。
3、您输入的搜索词不正确
当你在搜索框中输入一些关键词时,如果对方检索到的具体关键词没有搜索结果,通常90%以上的网站都会返回一个空结果,或者是“您输入了不正确的 关键词”符号。
事实上,这是一个非常不明智的策略,你可以在这个地方给出这样的反馈:
① 网站逻辑结构图,类似于HTML版的sitemap。
②“请输入查询关键词”,最近用户非常关注,推荐了一些比较热门的搜索词。
③ 网站热门文章,行业最热相关话题等。
总结:请输入搜索关键字,貌似是个琐碎的地方,具体怎么设置,还是可以起到相应的作用的,以上内容仅供参考!
蝙蝠侠IT转载需授权!
输入关键字 抓取所有网页(做seo很大程度是做关键词的基本目标,才有更好的转化率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-08 23:16
很大程度上,做SEO就是做关键词排名。将关键词设为首页是SEO的基本目标。只有首页的排名,才能有更好的展示机会和更高的转化率。
一、搜索原理
网络蜘蛛是网络蜘蛛。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到所有 网站 网页都被爬取。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
1、抢
搜索引擎和普通访问者一样,会按照网页上的链接,一一下载我们的网页,为下一步的预处理做准备。
2、预处理
①。判断是否符合其收录规则,若符合收录规则则继续处理
②。对 文章 进行分词
将网页中的 文章 剪切成单个单词。测量文档之间的相关性并准备反向索引。并记录单词出现的位置。
③。创建倒排索引
在搜索引擎中,每个文件对应一个文件ID,文件内容表示为一系列关键词的集合
将文件 ID 到 关键词 的映射转换为 关键词 到文件 ID 的映射。
使用词索引网页的好处是搜索引擎的用户也输入了词,这样他们就可以很容易地找到相关的网页。
3、搜索
①。用户对关键词查询进行分段,取索引的交集
②.排序
重要性 - 网页静态质量得分。搜索引擎将网站的各种性能条件转化为分数,这些分数相加得到一个页面的质量分数,即所谓的权重。
一种。页面信噪比:
页面信噪比是指页面中文字与非文字的比例,页面信噪比至少要大于1。
湾。缺乏
C。链接控制:
链接控制子链接的数量和链接自然度。页面的权重是固定的,链接可以传递权重。链路越多,每条链路传输的权重越低。
d。页面浏览量
相关性——以上只能通过倒排索引来定性的知道网页和查询词是否相关,但是没有办法知道谁更相关,也就是定量的。百度处理方法:
一种。记录单词出现的位置,关键词在不同位置的权重不同。
湾。tf-idf算法,即一个词在一篇文章文章中出现次数最多,词的权重越高;一个词在整个互联网上出现的次数越多,(比如“我”、“这个词”不足以区分一个文章的话题,几乎每一个文章都会出现)越小这个词的重量。
4、常用的高级搜索命令:
site:最熟悉的SEO高级搜索命令,用于搜索一个域名下的所有文件。
inurl: 指令用于搜索查询词出现在 url 中的页面。
intitle:该命令返回页面标题中收录关键词的页面。
domain:其作用是查询域名下的反向链接(反向链接=外部链接+内部链接)。
二、指数排名
1、收录 和索引
收录:页面被百度蜘蛛发现并分析
索引:百度蜘蛛初步分析认为有意义,做建库
收录索引的关系是收录关系。可以先建一个索引收录,收录的数量大于索引的数量。
百度表示,第三方提供的所谓收录查询是不可靠的。
1-1、索引文章行列式:
可信度;
文章质量;
更新频率;
网站结构体;
熊掌号和站点地图对百度有推广作用收录;
网站的年龄和体重影响百度收录对网站的影响。
1-2、加速页面索引方法:
做好网站TDK,不要修改;
积累优质网站内容;
每日定期和定量更新;
提交百度等搜索引擎,包括站点地图、熊掌号等;
重点制作熊掌号。目前熊爪号的提交已经可以做到移动站收录的80%以上;
有针对性、定期发布优质外链。
2、文章质量判断(百度官方)
①。观众
受众的规模代表了用户检索需求的规模。
②。稀缺
稀缺性主要描述了互联网页面的独特性。
③.质量
a 不能是死链接,网站访问速度是否令人满意。
b 主要内容是否完整,版式和字体是否易于阅读,广告是否过多。
c 信息是否丰富,是否满足扩展的次要需求。
④。老化
3、原创识别判断
①。释放时间——蜘蛛抓到的日期
②.锚文本链接——网站页面有多少个外部链接
③.信息指纹——文章内容的相似度
4、标题优化方法
搜索引擎搜索到的内容的标题往往就是网页标题的内容,搜索引擎给标题赋予了很高的权重。
①。标题流畅、吸引人且文章现实。
②。标题必须为原创,收录核心关键词和长尾词,与内容关键词保持一致
③。写作要符合搜索引擎的习惯,少用标点符号
④。长度适当,控制在22个汉字以内
5、内容优化方法
主要分为两部分:一部分是原创/伪原创,另一部分是采集素材库回顾。
至少第一段需要纯原创,最好有可搜索的内容,整个段落要根据玩家的搜索需求来写。
正文最好有条不紊地分成小标题
基于内容的 伪原创 方法
寻找有价值的文章,最好当天发布,或者使用爬虫爬取的数据库重写
有价值的 文章 可读性强、目标明确且引人注目。
①。修改文章的开头和结尾部分:
重新总结第一段和最后一段,打乱文中的顺序,去掉一些不相关的。添加透视。
②。对原文进行拆分重组:找几个相关的文章合并成一个新的文章
③。相关内容的组合与组合
④。将 文章 翻译成其他语言
⑤。使用论坛、博客、新媒体等方式挖掘文章
6、图像优化方法
搜索引擎已经具备一定的能力来识别大多数图像的 原创 属性
图片的算法主要包括计算hash值、pHash算法和SIFT算法,对目标图像进行编码形成“指纹”并存储。
①。给图片添加水印;
②。改变原图的纵横比,或者直接截取图片的某一部分;
③。图片长宽比尽量接近121*75,接近百度搜索显示的缩略图大小;
④。缩略图内部链接,相比文字链接,更能吸引访问者点击,关注相关性。
⑤。添加alt描述可以增强页面的主题关键词,但是注意不要堆放关键词。
⑥。百度越来越喜欢原创的内容,其实图片也是页面的一部分。
7、关键词优化方法
关键词类别:核心关键词;相关关键词;长尾 关键词; 错误 关键词; 不常见 关键词
①。从用户的角度考虑,想想用户在搜索时使用了什么词
②,不超过5个,一般3个:主关键词,辅助关键词,潜在长尾关键词
③、关键词密度不超过2% - 8%(根据需要,不是绝对的) 查看全部
输入关键字 抓取所有网页(做seo很大程度是做关键词的基本目标,才有更好的转化率)
很大程度上,做SEO就是做关键词排名。将关键词设为首页是SEO的基本目标。只有首页的排名,才能有更好的展示机会和更高的转化率。
一、搜索原理
网络蜘蛛是网络蜘蛛。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到所有 网站 网页都被爬取。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
1、抢
搜索引擎和普通访问者一样,会按照网页上的链接,一一下载我们的网页,为下一步的预处理做准备。
2、预处理
①。判断是否符合其收录规则,若符合收录规则则继续处理
②。对 文章 进行分词
将网页中的 文章 剪切成单个单词。测量文档之间的相关性并准备反向索引。并记录单词出现的位置。
③。创建倒排索引
在搜索引擎中,每个文件对应一个文件ID,文件内容表示为一系列关键词的集合
将文件 ID 到 关键词 的映射转换为 关键词 到文件 ID 的映射。
使用词索引网页的好处是搜索引擎的用户也输入了词,这样他们就可以很容易地找到相关的网页。
3、搜索
①。用户对关键词查询进行分段,取索引的交集
②.排序
重要性 - 网页静态质量得分。搜索引擎将网站的各种性能条件转化为分数,这些分数相加得到一个页面的质量分数,即所谓的权重。
一种。页面信噪比:
页面信噪比是指页面中文字与非文字的比例,页面信噪比至少要大于1。
湾。缺乏
C。链接控制:
链接控制子链接的数量和链接自然度。页面的权重是固定的,链接可以传递权重。链路越多,每条链路传输的权重越低。
d。页面浏览量
相关性——以上只能通过倒排索引来定性的知道网页和查询词是否相关,但是没有办法知道谁更相关,也就是定量的。百度处理方法:
一种。记录单词出现的位置,关键词在不同位置的权重不同。
湾。tf-idf算法,即一个词在一篇文章文章中出现次数最多,词的权重越高;一个词在整个互联网上出现的次数越多,(比如“我”、“这个词”不足以区分一个文章的话题,几乎每一个文章都会出现)越小这个词的重量。
4、常用的高级搜索命令:
site:最熟悉的SEO高级搜索命令,用于搜索一个域名下的所有文件。
inurl: 指令用于搜索查询词出现在 url 中的页面。
intitle:该命令返回页面标题中收录关键词的页面。
domain:其作用是查询域名下的反向链接(反向链接=外部链接+内部链接)。
二、指数排名
1、收录 和索引
收录:页面被百度蜘蛛发现并分析
索引:百度蜘蛛初步分析认为有意义,做建库
收录索引的关系是收录关系。可以先建一个索引收录,收录的数量大于索引的数量。
百度表示,第三方提供的所谓收录查询是不可靠的。
1-1、索引文章行列式:
可信度;
文章质量;
更新频率;
网站结构体;
熊掌号和站点地图对百度有推广作用收录;
网站的年龄和体重影响百度收录对网站的影响。
1-2、加速页面索引方法:
做好网站TDK,不要修改;
积累优质网站内容;
每日定期和定量更新;
提交百度等搜索引擎,包括站点地图、熊掌号等;
重点制作熊掌号。目前熊爪号的提交已经可以做到移动站收录的80%以上;
有针对性、定期发布优质外链。
2、文章质量判断(百度官方)
①。观众
受众的规模代表了用户检索需求的规模。
②。稀缺
稀缺性主要描述了互联网页面的独特性。
③.质量
a 不能是死链接,网站访问速度是否令人满意。
b 主要内容是否完整,版式和字体是否易于阅读,广告是否过多。
c 信息是否丰富,是否满足扩展的次要需求。
④。老化
3、原创识别判断
①。释放时间——蜘蛛抓到的日期
②.锚文本链接——网站页面有多少个外部链接
③.信息指纹——文章内容的相似度
4、标题优化方法
搜索引擎搜索到的内容的标题往往就是网页标题的内容,搜索引擎给标题赋予了很高的权重。
①。标题流畅、吸引人且文章现实。
②。标题必须为原创,收录核心关键词和长尾词,与内容关键词保持一致
③。写作要符合搜索引擎的习惯,少用标点符号
④。长度适当,控制在22个汉字以内
5、内容优化方法
主要分为两部分:一部分是原创/伪原创,另一部分是采集素材库回顾。
至少第一段需要纯原创,最好有可搜索的内容,整个段落要根据玩家的搜索需求来写。
正文最好有条不紊地分成小标题
基于内容的 伪原创 方法
寻找有价值的文章,最好当天发布,或者使用爬虫爬取的数据库重写
有价值的 文章 可读性强、目标明确且引人注目。
①。修改文章的开头和结尾部分:
重新总结第一段和最后一段,打乱文中的顺序,去掉一些不相关的。添加透视。
②。对原文进行拆分重组:找几个相关的文章合并成一个新的文章
③。相关内容的组合与组合
④。将 文章 翻译成其他语言
⑤。使用论坛、博客、新媒体等方式挖掘文章
6、图像优化方法
搜索引擎已经具备一定的能力来识别大多数图像的 原创 属性
图片的算法主要包括计算hash值、pHash算法和SIFT算法,对目标图像进行编码形成“指纹”并存储。
①。给图片添加水印;
②。改变原图的纵横比,或者直接截取图片的某一部分;
③。图片长宽比尽量接近121*75,接近百度搜索显示的缩略图大小;
④。缩略图内部链接,相比文字链接,更能吸引访问者点击,关注相关性。
⑤。添加alt描述可以增强页面的主题关键词,但是注意不要堆放关键词。
⑥。百度越来越喜欢原创的内容,其实图片也是页面的一部分。
7、关键词优化方法
关键词类别:核心关键词;相关关键词;长尾 关键词; 错误 关键词; 不常见 关键词
①。从用户的角度考虑,想想用户在搜索时使用了什么词
②,不超过5个,一般3个:主关键词,辅助关键词,潜在长尾关键词
③、关键词密度不超过2% - 8%(根据需要,不是绝对的)
输入关键字 抓取所有网页(企赢搜网络,外链分析怎么解决信息的问题?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-08 23:14
惠农用心服务网站关键词推企价格赢搜网,分析外链。我们在发送外链时,要注意外链的质量,而不是追求数量;有利于爬取、收录、排名、点击的因素。比如sitemap的制作,nofollow的使用,内部链接的合理使用;不利于爬取、收录、排名、点击的因素。比如网站速度、内部链接覆盖率、URL长度、URL参数过多、URL中使用的特殊字符、TDK编写。
如果您刚刚重新设计了您的网站或搬到了一个新的cms,请保持页面的原创数据不变。如果在更改过程中丢失了原创数据,则可能会减少流量。解决方案是使用丢失的原创数据更新所有网页。原号码。
网站地图最初创建的时候,是网站的设计者为了方便游客浏览网站而创建的。该页面涵盖了整个网站(大网站 >)或页面(中小网站)的所有栏目,目的是让浏览者能够快速找到他们需要的信息。而这种效果在小网站中并不明显,但是在一些门户网站中却很明显,这些大网站由于页面信息量大,用户想要从首页时间 你需要的页面比较难,一般有很清晰的地图结构。这些是为了方便用户而构建的,而不仅仅是为了让搜索引擎抓取。而用户友好的网站更容易受到搜索引擎的欢迎。自然,< @网站 地图发挥了不可估量的作用。网站地图可以让访问者更容易浏览和增加用户体验。
whois 信息对于很多人来说可能不是很熟悉。事实上,Seoer 经常忽略它。但是从这些信息中我们可以看到很多内容,比如网站是公司注册还是个人网站是个人还是团队维护的,当然一些相关的备案信息可以也可以看到。whois 信息字段。
如果您已经开始构建电子商务 网站 并开始尝试使用 关键词,那么您将使用某种类型的 关键词 排名来确定 关键词 的位置在相关搜索中排名。通过将您的 网站 添加到 GoogleSearchConsole,您可以获得现成的免费数据。6 使用 关键词 排名跟踪工具成功。
有时我对一件事感到好奇,我喜欢去看看。为此,我两三年前找到了自己的手机,重新登录了微信,看到了和他的所有聊天记录,每次都问了一个不同的问题。网站,不一样的关键词,每次我们报价太低,他总说太贵,报价再低也贵,就这样,从一开始2017年初的咨询,之后的咨询几乎每隔一两年举行一次。近年来,我咨询过一次。
总结 根据我上面总结的方法,一个一个研究。虽然你更加努力,但回报一定会更加丰厚。上帝不会对待辛勤工作的。
而一个真正能“对产品负责”的运营,至少应该围绕一个产品的成长,去走遍每一个环节,通过自身对具体运营策略和手段的优化调整,不断获得良好的产出。甚至你负责的产品,其实也只是一个QQ群或者豆瓣群。 查看全部
输入关键字 抓取所有网页(企赢搜网络,外链分析怎么解决信息的问题?)
惠农用心服务网站关键词推企价格赢搜网,分析外链。我们在发送外链时,要注意外链的质量,而不是追求数量;有利于爬取、收录、排名、点击的因素。比如sitemap的制作,nofollow的使用,内部链接的合理使用;不利于爬取、收录、排名、点击的因素。比如网站速度、内部链接覆盖率、URL长度、URL参数过多、URL中使用的特殊字符、TDK编写。
如果您刚刚重新设计了您的网站或搬到了一个新的cms,请保持页面的原创数据不变。如果在更改过程中丢失了原创数据,则可能会减少流量。解决方案是使用丢失的原创数据更新所有网页。原号码。
网站地图最初创建的时候,是网站的设计者为了方便游客浏览网站而创建的。该页面涵盖了整个网站(大网站 >)或页面(中小网站)的所有栏目,目的是让浏览者能够快速找到他们需要的信息。而这种效果在小网站中并不明显,但是在一些门户网站中却很明显,这些大网站由于页面信息量大,用户想要从首页时间 你需要的页面比较难,一般有很清晰的地图结构。这些是为了方便用户而构建的,而不仅仅是为了让搜索引擎抓取。而用户友好的网站更容易受到搜索引擎的欢迎。自然,< @网站 地图发挥了不可估量的作用。网站地图可以让访问者更容易浏览和增加用户体验。
whois 信息对于很多人来说可能不是很熟悉。事实上,Seoer 经常忽略它。但是从这些信息中我们可以看到很多内容,比如网站是公司注册还是个人网站是个人还是团队维护的,当然一些相关的备案信息可以也可以看到。whois 信息字段。
如果您已经开始构建电子商务 网站 并开始尝试使用 关键词,那么您将使用某种类型的 关键词 排名来确定 关键词 的位置在相关搜索中排名。通过将您的 网站 添加到 GoogleSearchConsole,您可以获得现成的免费数据。6 使用 关键词 排名跟踪工具成功。
有时我对一件事感到好奇,我喜欢去看看。为此,我两三年前找到了自己的手机,重新登录了微信,看到了和他的所有聊天记录,每次都问了一个不同的问题。网站,不一样的关键词,每次我们报价太低,他总说太贵,报价再低也贵,就这样,从一开始2017年初的咨询,之后的咨询几乎每隔一两年举行一次。近年来,我咨询过一次。
总结 根据我上面总结的方法,一个一个研究。虽然你更加努力,但回报一定会更加丰厚。上帝不会对待辛勤工作的。
而一个真正能“对产品负责”的运营,至少应该围绕一个产品的成长,去走遍每一个环节,通过自身对具体运营策略和手段的优化调整,不断获得良好的产出。甚至你负责的产品,其实也只是一个QQ群或者豆瓣群。
输入关键字 抓取所有网页(一下请输入关键字的技巧分享网络搜索框的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-08 23:14
)
我们经常会遇到这样的情况:在浏览网站的时候,会发现一个百度搜索框,里面写着输入关键词或者请输入关键字,给我们的搜索带来了方便。当然,关键词的选择也是有一定技巧的,所以如何输入关键词也是一门学问。本页是站长整理的关于“请输入关键字”和“请输入关键词”的信息,旨在帮助刚接触互联网的朋友。让我们介绍一下分享的技巧,请输入关键字。
请输入关键字 VS 请输入 关键词
注:本站搜索结果来自百度,建议您使用百度采集关键词!
百度()是最大的中文搜索引擎,你想找的都可以,百度使用技巧:
在上方“请输入关键词”框内进行“美女搜索、视频搜索、数据搜索、图片搜索、音乐搜索”,即可搜索到最想要的信息!
搜索小Tips:
首先让我们了解什么是关键字?我们通常说的关键字是指一个主题,也称为Keyword。刚接触搜索引擎的网友会遇到这样一句话:“\请输入关键字\”或\“请输入关键词\”,这其实是搜索引擎引导用户使用的一种简单方式。在搜索框中输入您要查询的关键字。点击查询,立马就有结果,这就是搜索引擎的魅力所在。例如,如果我想学习交易股票,那么你只需要在搜索框中输入“股票”或“股票”这两个词,就会出现很多关于“股票”或“股票”的信息。
让我们总结一下。事实上,关键词就是所有收录被搜索词和句子的信息。这些单词和短语是关键字。它也是一个网络术语。如果你还有什么问题,我会推荐你一个很好的网站百度知道:他真的什么都知道。
这个页面中间的百度搜索框就有这样的功能。您可以尝试在中间的搜索框中输入一些您感兴趣的主题,看看有什么结果?惊讶!搜索引擎几乎可以让你搜索任何东西。美丽的图画,流行的小说……
目前比较有名的搜索引擎有百度、GOOGLE、雅虎。各大门户网站网站也开始研究自己的搜索引擎,比如新浪爱问、腾讯SOSO、搜狐SOGOU、网易SO163。尽管它们的算法不同,但用法相似。下面将贴出三大搜索引擎的使用技巧,其他搜索引擎的大家可以自己看看。
百度使用技巧:
谷歌提示:
雅虎提示:
很多人说,如果你搜索娱乐关键字,你可以在百度上找到它们。如果你搜索学术关键词,你可以在 GOOGLE 上找到它们。至于雅虎,它只是一个备用搜索引擎。事实上,三大搜索引擎各有千秋。无论如何,搜索引擎的目的是让用户更快、更准确地找到他们需要的信息。为达到这个目的,相信三大搜索引擎会不断完善用户。有经验的。
解释有关“请输入关键字”和“请输入 关键词”的问题?
一、
问:我看到很多地方出现'Enter 关键词'和'请输入关键字',这是什么意思?
答:意思是让你输入你知道要查找的单词或单词。假设你想找一本书。然后,您可以在“请输入 关键词”下方输入单词“关键字”。单击搜索,您将找到您要查找的内容。
示例:例如,您要查看化妆品的相关信息。然后,您可以在下面的“请输入关键字”字段中输入“化妆品”一词。单击搜索以查找您要查找的相关信息。让我们试试吧^_^!
二、
问:我也看到很多网站带有“请输入关键字”,这是什么意思?
答:顾名思义,和上面差不多,请输入关键词。它是您要查找的内容的核心词。为了使搜索系统容易找到你需要的东西,输入方便,就是用代词或句子,以这个词为中心,找到你需要的东西。
示例:假设您要查看视频教程的相关信息。您可以在下面的“请输入关键字”中输入“视频教程”一词。单击搜索以查找您要查找的相关信息。让我们再试一次^_^!
一般我们搜索信息的时候,都会去百度和谷歌找。百度是最大的中文搜索引擎,我们可以找到最新的资讯文章。谷歌是国外的搜索引擎,实力也很强。当然,我们可以找到很多好东西。此外,等等,我们还可以从上述两个搜索引擎中得到不同的结果。关于如何确定输入的关键字,比如你在找菜谱,可以输入菜谱、菜谱、食物等,你会发现一些很专业的网站。例如,如果您输入的关键字是菜,则可能没有您想要的结果。在这种情况下,您可以查看下面的相关 关键词 查询。当然,你也可以在关键词中找到你想要的信息,在“
查看全部
输入关键字 抓取所有网页(一下请输入关键字的技巧分享网络搜索框的方法
)
我们经常会遇到这样的情况:在浏览网站的时候,会发现一个百度搜索框,里面写着输入关键词或者请输入关键字,给我们的搜索带来了方便。当然,关键词的选择也是有一定技巧的,所以如何输入关键词也是一门学问。本页是站长整理的关于“请输入关键字”和“请输入关键词”的信息,旨在帮助刚接触互联网的朋友。让我们介绍一下分享的技巧,请输入关键字。
请输入关键字 VS 请输入 关键词
注:本站搜索结果来自百度,建议您使用百度采集关键词!
百度()是最大的中文搜索引擎,你想找的都可以,百度使用技巧:
在上方“请输入关键词”框内进行“美女搜索、视频搜索、数据搜索、图片搜索、音乐搜索”,即可搜索到最想要的信息!
搜索小Tips:
首先让我们了解什么是关键字?我们通常说的关键字是指一个主题,也称为Keyword。刚接触搜索引擎的网友会遇到这样一句话:“\请输入关键字\”或\“请输入关键词\”,这其实是搜索引擎引导用户使用的一种简单方式。在搜索框中输入您要查询的关键字。点击查询,立马就有结果,这就是搜索引擎的魅力所在。例如,如果我想学习交易股票,那么你只需要在搜索框中输入“股票”或“股票”这两个词,就会出现很多关于“股票”或“股票”的信息。
让我们总结一下。事实上,关键词就是所有收录被搜索词和句子的信息。这些单词和短语是关键字。它也是一个网络术语。如果你还有什么问题,我会推荐你一个很好的网站百度知道:他真的什么都知道。
这个页面中间的百度搜索框就有这样的功能。您可以尝试在中间的搜索框中输入一些您感兴趣的主题,看看有什么结果?惊讶!搜索引擎几乎可以让你搜索任何东西。美丽的图画,流行的小说……
目前比较有名的搜索引擎有百度、GOOGLE、雅虎。各大门户网站网站也开始研究自己的搜索引擎,比如新浪爱问、腾讯SOSO、搜狐SOGOU、网易SO163。尽管它们的算法不同,但用法相似。下面将贴出三大搜索引擎的使用技巧,其他搜索引擎的大家可以自己看看。
百度使用技巧:
谷歌提示:
雅虎提示:
很多人说,如果你搜索娱乐关键字,你可以在百度上找到它们。如果你搜索学术关键词,你可以在 GOOGLE 上找到它们。至于雅虎,它只是一个备用搜索引擎。事实上,三大搜索引擎各有千秋。无论如何,搜索引擎的目的是让用户更快、更准确地找到他们需要的信息。为达到这个目的,相信三大搜索引擎会不断完善用户。有经验的。
解释有关“请输入关键字”和“请输入 关键词”的问题?
一、
问:我看到很多地方出现'Enter 关键词'和'请输入关键字',这是什么意思?
答:意思是让你输入你知道要查找的单词或单词。假设你想找一本书。然后,您可以在“请输入 关键词”下方输入单词“关键字”。单击搜索,您将找到您要查找的内容。
示例:例如,您要查看化妆品的相关信息。然后,您可以在下面的“请输入关键字”字段中输入“化妆品”一词。单击搜索以查找您要查找的相关信息。让我们试试吧^_^!
二、
问:我也看到很多网站带有“请输入关键字”,这是什么意思?
答:顾名思义,和上面差不多,请输入关键词。它是您要查找的内容的核心词。为了使搜索系统容易找到你需要的东西,输入方便,就是用代词或句子,以这个词为中心,找到你需要的东西。
示例:假设您要查看视频教程的相关信息。您可以在下面的“请输入关键字”中输入“视频教程”一词。单击搜索以查找您要查找的相关信息。让我们再试一次^_^!
一般我们搜索信息的时候,都会去百度和谷歌找。百度是最大的中文搜索引擎,我们可以找到最新的资讯文章。谷歌是国外的搜索引擎,实力也很强。当然,我们可以找到很多好东西。此外,等等,我们还可以从上述两个搜索引擎中得到不同的结果。关于如何确定输入的关键字,比如你在找菜谱,可以输入菜谱、菜谱、食物等,你会发现一些很专业的网站。例如,如果您输入的关键字是菜,则可能没有您想要的结果。在这种情况下,您可以查看下面的相关 关键词 查询。当然,你也可以在关键词中找到你想要的信息,在“
输入关键字 抓取所有网页(获取Excel高手都在用的“插件合集+插件使用小技巧”!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-03-08 02:10
获取Excel高手正在使用的“加载项集合+加载项使用技巧”!
一时兴起,在知乎中搜索了Excel,想学习一些好评文章的写作方法。
看到这些标题,完结了,顿时激起了下载采集的欲望!
如何捕获所有 文章 高度喜欢的?
当我开始时,我考虑过使用 Python。
想了想,好像可以用Power query来实现,于是做了如下效果。
在表单中输入搜索词,然后右键刷新,即可得到搜索结果。
你明白我必须拿表格吗?
因为Excel可以直接按照“点赞数”排序!
那种感觉就像在排队。无论我在哪里排队,我都会是第一个并选择最好的!
好了,废话不多说,我们来看看这个表格是怎么做出来的。
大致可以分为4个步骤:
❶ 获取 JSON 数据连接;
❷ 电源查询处理数据;
❸ 配置搜索地址;
❹ 添加超链接。
01 操作步骤
❶ 获取 JSON 数据连接
通常在浏览网页时,它是一个简单的网址。
网页中看到的数据其实有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链接对应的是JSON格式的数据,如下所示。
找到方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制此链接,这是 Power 查询将获取数据的链接。
❷ 电量查询处理
你可能不知道,除了在 Excel 中捕获数据,Power Query 还可以
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站Data 也是其中之一:
将我们之前获取的链接粘贴到PQ中,链接就可以抓取数据了。
然后得到网页的数据格式。如何获取具体的 文章 数据?
Power Query的强大之处在于它可以自动识别json数据格式,并解析提取具体内容。
整个过程,我们不需要做任何操作,只需点击鼠标即可完成。
这时候我们获取的数据会有一些不必要的冗余数据。
例如:thumbnail_info(缩略图信息)、relationship、question、id.1等。
只需删除它们并仅保留所需的 文章 标题、作者、超链接等。
数据处理完成后,在开始选项卡中,点击“关闭并上传”即可完成数据抓取,非常简单。
❸ 配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词没有更新。
所以在这一步中,我们需要配置这个数据链接,实现基于搜索词的动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词,以变量的形式放入搜索地址中,完成搜索地址的配置。
修改后的地址码如下:
getdata = (page)=>
let
keywords = 搜索词[ 搜索词]{0},
源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random()))),
data = 源[data],
jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, ExtraValues.Error)
in
jsondata,
转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
▲ 左右滑动查看
❹ 添加超链接
至此所有数据都已经处理完毕,但是如果要查看原创的知乎页面,需要复制这个超链接并在浏览器中打开。
每次点击几次鼠标很麻烦;
这里我们使用 HYPERLINK 函数来生成一个可点击的超链接,这使得访问变得更加容易。
❺ 最终效果
最后的效果是:
❶ 输入搜索词;
❷ 右键刷新;
❸ 找到点赞最多的;
❹点击【点击查看】,享受跳线的感觉!
02总结
知道在表格中搜索的好处吗?
❶ 按“赞”和“评论”排序;
❷ 看过文章的可以加个栏目写笔记;
❸您可以过滤您喜欢的“作者”等。
明白为什么,精英都是Excel控制的吧?
大多数电子表格用户仍然使用 Excel 作为报告工具、绘制表格和编写公式。
请记住以下 Excel 新功能。这些功能让Excel成为了一个强大的数据统计和数据分析软件,不再只是你印象中的报表。
❶ 强力查询:数据整理清理工具,搭载M强大的M语言,可以实现多表合并,也是本文的主要技术。
❷ Power Pivot:数据统计工具,可以自定义统计方式,实现数据透视表多字段计算,自定义DAX数据计算方式。
❸ Power BI:强大易用的可视化工具,实现交互式数据呈现,是企业业务数据报表的优质解决方案。
欢迎在留言区聊天:
您还知道 Excel 的其他哪些神奇用途?
您最想在 Excel 中拥有什么功能?
... 查看全部
输入关键字 抓取所有网页(获取Excel高手都在用的“插件合集+插件使用小技巧”!)
获取Excel高手正在使用的“加载项集合+加载项使用技巧”!
一时兴起,在知乎中搜索了Excel,想学习一些好评文章的写作方法。
看到这些标题,完结了,顿时激起了下载采集的欲望!
如何捕获所有 文章 高度喜欢的?
当我开始时,我考虑过使用 Python。
想了想,好像可以用Power query来实现,于是做了如下效果。
在表单中输入搜索词,然后右键刷新,即可得到搜索结果。
你明白我必须拿表格吗?
因为Excel可以直接按照“点赞数”排序!
那种感觉就像在排队。无论我在哪里排队,我都会是第一个并选择最好的!
好了,废话不多说,我们来看看这个表格是怎么做出来的。
大致可以分为4个步骤:
❶ 获取 JSON 数据连接;
❷ 电源查询处理数据;
❸ 配置搜索地址;
❹ 添加超链接。
01 操作步骤
❶ 获取 JSON 数据连接
通常在浏览网页时,它是一个简单的网址。
网页中看到的数据其实有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链接对应的是JSON格式的数据,如下所示。
找到方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制此链接,这是 Power 查询将获取数据的链接。
❷ 电量查询处理
你可能不知道,除了在 Excel 中捕获数据,Power Query 还可以
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站Data 也是其中之一:
将我们之前获取的链接粘贴到PQ中,链接就可以抓取数据了。
然后得到网页的数据格式。如何获取具体的 文章 数据?
Power Query的强大之处在于它可以自动识别json数据格式,并解析提取具体内容。
整个过程,我们不需要做任何操作,只需点击鼠标即可完成。
这时候我们获取的数据会有一些不必要的冗余数据。
例如:thumbnail_info(缩略图信息)、relationship、question、id.1等。
只需删除它们并仅保留所需的 文章 标题、作者、超链接等。
数据处理完成后,在开始选项卡中,点击“关闭并上传”即可完成数据抓取,非常简单。
❸ 配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词没有更新。
所以在这一步中,我们需要配置这个数据链接,实现基于搜索词的动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词,以变量的形式放入搜索地址中,完成搜索地址的配置。
修改后的地址码如下:
getdata = (page)=>
let
keywords = 搜索词[ 搜索词]{0},
源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random()))),
data = 源[data],
jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, ExtraValues.Error)
in
jsondata,
转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
▲ 左右滑动查看
❹ 添加超链接
至此所有数据都已经处理完毕,但是如果要查看原创的知乎页面,需要复制这个超链接并在浏览器中打开。
每次点击几次鼠标很麻烦;
这里我们使用 HYPERLINK 函数来生成一个可点击的超链接,这使得访问变得更加容易。
❺ 最终效果
最后的效果是:
❶ 输入搜索词;
❷ 右键刷新;
❸ 找到点赞最多的;
❹点击【点击查看】,享受跳线的感觉!
02总结
知道在表格中搜索的好处吗?
❶ 按“赞”和“评论”排序;
❷ 看过文章的可以加个栏目写笔记;
❸您可以过滤您喜欢的“作者”等。
明白为什么,精英都是Excel控制的吧?
大多数电子表格用户仍然使用 Excel 作为报告工具、绘制表格和编写公式。
请记住以下 Excel 新功能。这些功能让Excel成为了一个强大的数据统计和数据分析软件,不再只是你印象中的报表。
❶ 强力查询:数据整理清理工具,搭载M强大的M语言,可以实现多表合并,也是本文的主要技术。
❷ Power Pivot:数据统计工具,可以自定义统计方式,实现数据透视表多字段计算,自定义DAX数据计算方式。
❸ Power BI:强大易用的可视化工具,实现交互式数据呈现,是企业业务数据报表的优质解决方案。
欢迎在留言区聊天:
您还知道 Excel 的其他哪些神奇用途?
您最想在 Excel 中拥有什么功能?
...
输入关键字 抓取所有网页(搜索引擎的工作的过程,而简单的讲搜索引擎工作过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-07 17:11
搜索引擎的工作过程非常复杂,简单来说,搜索引擎的工作过程大致可以分为三个阶段。
爬取爬取:搜索引擎蜘蛛通过以下链接访问页面,获取页面的 HTML 代码并将其存储在数据库中。
预处理:搜索引擎对抓取的页面数据进行文本提取、中文分词、索引等,为排名程序调用做准备。
排名:用户输入关键词后,排名调用索引数据库数据,计算相关度,然后生成一定格式的搜索结果页面。
爬行和爬行
爬取和爬取是搜索引擎工作的第一步,完成数据采集的任务。
蜘蛛
搜索引擎用来抓取和访问页面的程序称为蜘蛛,也称为机器人。
蜘蛛代理名称:
百度蜘蛛:百度蜘蛛+(+)·
雅虎!Slurp 中国:Mozilla/5.0(兼容;Yahoo! Slurp 中国;)·
英语雅虎蜘蛛:Mozilla/5.0(兼容;Yahoo! Slurp/3.0;)
谷歌蜘蛛:Mozilla/5.0(兼容;Googlebot/2.1;+)·
微软必应蜘蛛:msnbot/1.1 (+)·
搜狗蜘蛛:搜狗+网络+机器人+(+#07)·
搜搜蜘蛛:搜搜蜘蛛+(+) ·
有道蜘蛛:Mozilla/5.0(兼容;YodaoBot/1.0;;)
跟随链接
为了在网络上抓取尽可能多的页面,搜索引擎蜘蛛会跟随页面上的链接,从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样,这就是搜索引擎蜘蛛这个名字的由来. 最简单的爬行遍历策略分为两种,一种是深度优先,一种是广度优先。
深度优先搜索
深度优先搜索是在搜索树的每一层只展开一个子节点,继续往深处前进,直到不能再前进(到达叶子节点或被深度限制),然后从当前节点返回到上一个节点,继续另一个方向。这种方法的搜索树是从根开始逐个分支逐渐形成的。
深度优先搜索也称为垂直搜索。由于已解决的问题树可能收录无限分支,如果深度优先搜索误入无限分支(即深度是无限的),则无法找到目标节点。因此,深度优先搜索策略是不完整的。而且,应用这种策略得到的解不一定是最好的解(最短路径)。
广度优先搜索
在深度优先搜索算法中,首先扩展深度较大的节点。如果将算法改为按照搜索中节点的层级进行搜索,当该层的节点还没有被搜索和处理过时,下层节点无法处理,即先扩展深度较小的节点,即就是说先生成的节点先展开,这种搜索算法称为广度优先搜索。
在深度优先搜索算法中,首先扩展深度较大的节点。如果将算法改为按照搜索中节点的层级进行搜索,当该层的节点还没有被搜索和处理过时,下层节点无法处理,即先扩展深度较小的节点,即就是说先生成的节点先展开,这种搜索算法称为广度优先搜索。
吸引蜘蛛
哪些页面被认为更重要?有几个因素:
· 网站 和页面权重。优质和旧的网站被认为权重更高,在这个网站上的页面会被爬得更高的深度,所以更多的内页会是收录。
· 页面更新。蜘蛛每次抓取时都会存储页面数据。如果第二次爬取发现页面和第一次收录一模一样,说明页面没有更新,蜘蛛不需要频繁爬取。如果页面内容更新频繁,蜘蛛会更频繁地访问该页面,页面上出现的新链接自然会被蜘蛛更快地跟踪并抓取新页面。
· 导入链接。不管是外部链接还是同一个网站的内部链接,为了被蜘蛛爬取,必须有传入链接才能进入页面,否则蜘蛛没有机会知道这页纸。高质量的入站链接通常还会增加页面上出站链接的抓取深度。一般来说,首页在网站上的权重最高,大部分外部链接指向首页,首页也是蜘蛛访问频率最高的。离首页越近的点击距离,页面权重越高,被蜘蛛爬取的机会就越大。
地址库
为了避免重复爬取和爬取网址,搜索引擎会建立一个地址数据库来记录已找到但未爬取的页面,以及已爬取的页面。地址存储库中有几个 url 来源:
(1)手动输入种子网站。
(2)蜘蛛爬取页面后,从html中解析出新的链接url,并与地址库中的数据进行比较,如果是不在地址库中的url,则将其存储在要访问的地址库中。
(3)站长通过搜索引擎网页提交表单提交的网址。
蜘蛛根据重要性从要访问的地址库中提取url,访问并爬取页面,然后将要访问的地址库中的url删除,放入被访问地址的地址库中。
大多数主要搜索引擎都为网站管理员提供了提交 URL 的表单。但是,这些提交的 URL 只存储在地址数据库中。是否 收录 取决于页面的重要性。搜索引擎的绝大多数页面 收录 都是由蜘蛛自己通过链接获得的。可以说,提交页面基本没用,搜索引擎更喜欢跟随链接发现新页面。
文件存储 搜索引擎蜘蛛爬取的数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。每个 uRI 都有一个唯一的文件编号。
爬行时重复内容检测
检测和删除重复项通常在下面描述的预处理过程中完成,但是现代蜘蛛在爬取和爬取文件时也会进行一定程度的重复项检测。当你在网站上遇到大量转载或抄袭、权重极低的内容时,很可能会停止爬取。这就是为什么一些网站管理员在日志文件中发现蜘蛛,但该页面从未真正被 收录 访问过。
预处理
在一些 SEO 资料中,“预处理”也简称为“索引”,因为索引是预处理中最重要的步骤。
搜索引擎蜘蛛爬取的原创页面不能直接用于查询排名处理。搜索引擎数据库的页数在万亿级别。用户输入搜索词后,排名程序会实时分析这么多页面的相关性。计算量太大,不可能在一两秒内返回排名结果。因此,必须对爬取的页面进行预处理,为最终的查询排名做准备。
和爬虫一样,预处理是在后台提前完成的,用户在搜索的时候感受不到这个过程。
1.提取文本
今天的搜索引擎仍然基于文本内容。蜘蛛抓取到的页面中的HTML代码,除了用户在浏览器上可以看到的可见文本外,还收录大量的HTML格式标签、程序等不能用于排名的内容。搜索引擎预处理首先要做的就是去除HTML文件中的标签和程序,提取网页中可用于排名处理的文本内容。
今天是愚人节
去掉 HTML 代码后,剩下的用于排名的文字就是这一行:
今天是愚人节
除了可见文本,搜索引擎还会提取一些收录文本信息的特殊代码,例如 Meta 标签中的文本、图片 alt 文本、Flash 文件 alt 文本、链接锚文本等。
2.中文分词
分词是中文搜索引擎特有的一个步骤。搜索引擎基于单词存储和处理页面和用户搜索。英语等语言用空格隔开,搜索引擎索引程序可以直接把句子分成词组。但是,中文单词和单词之间没有分隔符,一个句子中的所有单词和单词都是连接在一起的。搜索引擎必须首先区分哪些词组成一个词,哪些词本身就是一个词。例如,“减肥法”将分为“减肥”和“方法”两个词。
中文分词基本上有两种方法,一种是基于字典匹配的,一种是基于统计的。
基于字典匹配的方法是指将一段待分析的汉字与预先制作的字典中的词条进行匹配,从待分析的字符串中扫描字典中已有的词条。分离出一个词。
根据扫描方向,基于字典的匹配方法可以分为正向匹配和反向匹配。根据匹配长度优先级的不同,可以分为最大匹配和最小匹配。优先混合扫描方向和长度可以产生不同的方法,例如正向最大匹配和反向最大匹配。
字典匹配方法计算简单,其准确性很大程度上取决于字典的完整性和更新。
基于统计的分词方法是指分析大量文本样本,计算相邻词的统计概率。出现的相邻单词越多,形成单词的可能性就越大。基于统计的方法的优点是对新出现的词更敏感,也有利于消歧。
基于字典匹配和统计的分词方法各有优缺点。实际使用的分词系统混合使用了这两种方法,快速高效,可以识别新词和新词,消除歧义。
中文分词的准确性往往会影响搜索引擎排名的相关性。比如你在百度上搜索“搜索引擎优化”,从截图中可以看出百度把“搜索引擎优化”这六个词当成一个词。
在 Google 上搜索相同的词时,快照显示 Google 将其拆分为“搜索引擎”和“优化”两个词。显然,百度有更合理的细分,搜索引擎优化是一个完整的概念。谷歌的分词往往更细化。
分词的这种差异可能是某些 关键词 排名在不同搜索引擎上表现不同的原因之一。例如,百度更喜欢匹配搜索词以显示在页面上。也就是说,在搜索“够玩博客”的时候,如果这四个词连续出现,在百度中更容易获得好的排名。另一方面,谷歌实际上并不需要完全匹配。有些页面出现了“足够的戏剧”和“博客”这两个词,但不一定完全匹配,“足够的戏剧”出现在页面的前面,“博客”在页面的其他位置,这样的页面出现在谷歌搜索“足够剧博客“”,也可以获得不错的排名。
搜索引擎对页面的分词取决于词库的大小、准确度和分词算法的质量,而不是页面本身,因此SEO人员对分词的作用很小。唯一能做的就是在页面上使用某种形式来提示搜索引擎某些词应该被当作一个词处理,尤其是当它可能有歧义的时候,比如页面标题中的关键词@,h1标签和黑体字>。如果页面是关于“和服”的内容,那么“和服”这个词可以特别用粗体标出。如果页面是关于“化妆和服装”的,你可以把“服装”这个词加粗。这样,当搜索引擎分析页面时,它就知道粗体字应该是一个词。
3.去停用词
无论是英文还是中文,都会出现一些在页面内容中出现频率高但对内容没有影响的词,比如“的”、“地”、“de”、“ah”等辅助词, “ha”、“ya”等感叹词、“therefore”、“with”、“but”等副词或介词。这些词被称为停用词,因为它们对页面的主要含义几乎没有影响。英语中常见的停用词有 the、a、an、to、of 等。
搜索引擎会在索引页面之前去除这些停用词,使索引数据的主题更加突出,减少不必要的计算量。
4.去除噪音
大部分页面也存在一些对页面主题没有贡献的内容,如版权声明文字、导航栏、广告等。以常见的博客导航为例,导航内容如文章categories几乎每个博客页面都会出现历史档案,但这些页面本身与“类别”和“历史”这两个词无关。用户搜索“历史”、“类别”并返回博客文章只是因为这些词出现在页面上是没有意义的,完全无关紧要的。因此,这些块都是噪音,只能对页面的主题起到分散作用。
搜索引擎需要在不使用嘈杂内容的情况下识别和消除这种噪音并进行排名。去噪的基本方法是根据HTML标签将页面分成块,区分页眉、导航、文本、页脚、广告等区域。网站 上重复出现的块通常是噪音。页面去噪后,剩下的就是页面的主要内容。
5.移除
搜索引擎还需要对页面进行重复数据删除。
同一个文章经常在不同的网站和同一个网站的不同URL上重复出现,搜索引擎不喜欢这种重复的内容。用户搜索时,如果在前两页看到来自不同网站的同一篇文章文章,用户体验太差了,尽管都是内容相关的。搜索引擎希望只返回一个相同的文章,所以在索引之前需要识别并删除重复的内容。此过程称为“重复数据删除”。
去重的基本方法是计算页面特征的指纹关键词,也就是从页面的主要内容中选择最有代表性的部分关键词(经常是出现频率最高的关键词) ,然后计算这些 关键词 的数字指纹。这里的关键词的选择是在分词、去停用词、降噪之后。实验表明,通常选择10个特征关键词可以达到比较高的计算精度,选择更多的词对去重精度的提升贡献不大。
典型的指纹计算方法如MD5算法(Information Digest Algorithm Fifth Edition)。这类指纹算法的特点是输入(feature关键词)的任何微小变化都会导致计算出的指纹出现很大的差距。
了解了搜索引擎的去重算法后,SEO人员应该知道,简单地加上“de”、“地”、“de”,改变段落的顺序,所谓伪原创,是逃不过去重的。搜索引擎。算法,因为这样的操作不能改变文章关键词的特性。此外,搜索引擎的重复数据删除算法可能不仅在页面级别,而且在段落级别。混用不同的文章,互换段落的顺序,不能让转载、抄袭变成原创。
6.正向索引
远期指数也可以简称为指数。
经过文本提取、分词、去噪和去重后,搜索引擎获得了能够反映页面主要内容的独特的、基于词的内容。接下来,搜索引擎索引程序可以提取关键词,按照分词程序对单词进行划分,将页面转换为关键词的集合,并将每个关键词的内容记录在这页纸。出现频率、出现次数、格式(如在标题标签、粗体、H标签、锚文本等)、位置(如页面第一段等)。这样,每一页就可以记录为一组关键词,其中还记录了每个关键词的词频、格式、位置等权重信息。
搜索引擎索引程序将页面和关键词 存储到索引数据库中以形成词汇结构。索引词汇表的简化形式如表2-1所示。
每个文件对应一个文件ID,文件内容表示为关键词的集合。事实上,在搜索引擎索引库中,关键词也已经转换为关键词ID。这样的数据结构称为前向索引。
7.倒排索引
前向索引还不能直接用于排名。假设用户搜索关键词2,如果只有前向索引,排序程序需要扫描索引库中的所有文件,找到收录关键词2的文件,然后执行相关性计算。这个计算量不能满足实时返回排名结果的要求。
因此,搜索引擎会将正向索引数据库重构为倒排索引,并将文件对应到关键词的映射转换为关键词到文件的映射,如表2-2所示.
在倒排索引中,关键词是主键,每一个关键词都对应着这个关键词出现的一系列文件。这样,当用户搜索某个关键词时,排序程序在倒排索引中定位到这个关键词,可以立即找到所有收录这个关键词的文件。
关键词0@>链接关系计算
链接关系计算也是预处理的重要组成部分。页面之间的链接流信息现在收录在所有主要的搜索引擎排名因素中。搜索引擎爬取页面内容后,必须提前计算:页面上的哪些链接指向了其他哪些页面,每个页面上有哪些传入链接,链接使用了哪些锚文本。这些复杂的链接指向关系形成了 网站 和页面的链接权重。
谷歌PR值是这种链接关系最重要的体现之一。其他搜索引擎做类似的计算,虽然它们不被称为 PR。
由于页面和链接的数量巨大,而且互联网上的链接关系不断更新,计算链接关系和PR需要很长时间。关于PR和链接分析,后面有专门的章节。
关键词1@>特殊文件处理
除了 HTML 文件,搜索引擎通常可以抓取和索引多种基于文本的文件类型,例如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们还经常在搜索结果中看到这些文件类型。但是,目前的搜索引擎无法处理图片、视频、Flash等非文本内容,也无法执行脚本和程序。
虽然搜索引擎在识别图片和从 Flash 中提取文本内容方面取得了一些进展,但距离通过读取图片、视频和 Flash 内容直接返回结果的目标还差得很远。图片和视频内容的排名往往基于相关的文字内容。有关详细信息,请参阅下面的集成搜索部分。
排行
搜索引擎程序通过搜索引擎蜘蛛爬取的接口计算出倒排索引后,搜索引擎就可以随时处理用户搜索。用户在搜索框中填写关键词后,排名程序调用索引数据库数据,计算排名并展示给客户。排名过程直接与客户互动。 查看全部
输入关键字 抓取所有网页(搜索引擎的工作的过程,而简单的讲搜索引擎工作过程)
搜索引擎的工作过程非常复杂,简单来说,搜索引擎的工作过程大致可以分为三个阶段。
爬取爬取:搜索引擎蜘蛛通过以下链接访问页面,获取页面的 HTML 代码并将其存储在数据库中。
预处理:搜索引擎对抓取的页面数据进行文本提取、中文分词、索引等,为排名程序调用做准备。
排名:用户输入关键词后,排名调用索引数据库数据,计算相关度,然后生成一定格式的搜索结果页面。
爬行和爬行
爬取和爬取是搜索引擎工作的第一步,完成数据采集的任务。
蜘蛛
搜索引擎用来抓取和访问页面的程序称为蜘蛛,也称为机器人。
蜘蛛代理名称:
百度蜘蛛:百度蜘蛛+(+)·
雅虎!Slurp 中国:Mozilla/5.0(兼容;Yahoo! Slurp 中国;)·
英语雅虎蜘蛛:Mozilla/5.0(兼容;Yahoo! Slurp/3.0;)
谷歌蜘蛛:Mozilla/5.0(兼容;Googlebot/2.1;+)·
微软必应蜘蛛:msnbot/1.1 (+)·
搜狗蜘蛛:搜狗+网络+机器人+(+#07)·
搜搜蜘蛛:搜搜蜘蛛+(+) ·
有道蜘蛛:Mozilla/5.0(兼容;YodaoBot/1.0;;)
跟随链接
为了在网络上抓取尽可能多的页面,搜索引擎蜘蛛会跟随页面上的链接,从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样,这就是搜索引擎蜘蛛这个名字的由来. 最简单的爬行遍历策略分为两种,一种是深度优先,一种是广度优先。
深度优先搜索
深度优先搜索是在搜索树的每一层只展开一个子节点,继续往深处前进,直到不能再前进(到达叶子节点或被深度限制),然后从当前节点返回到上一个节点,继续另一个方向。这种方法的搜索树是从根开始逐个分支逐渐形成的。
深度优先搜索也称为垂直搜索。由于已解决的问题树可能收录无限分支,如果深度优先搜索误入无限分支(即深度是无限的),则无法找到目标节点。因此,深度优先搜索策略是不完整的。而且,应用这种策略得到的解不一定是最好的解(最短路径)。
广度优先搜索
在深度优先搜索算法中,首先扩展深度较大的节点。如果将算法改为按照搜索中节点的层级进行搜索,当该层的节点还没有被搜索和处理过时,下层节点无法处理,即先扩展深度较小的节点,即就是说先生成的节点先展开,这种搜索算法称为广度优先搜索。
在深度优先搜索算法中,首先扩展深度较大的节点。如果将算法改为按照搜索中节点的层级进行搜索,当该层的节点还没有被搜索和处理过时,下层节点无法处理,即先扩展深度较小的节点,即就是说先生成的节点先展开,这种搜索算法称为广度优先搜索。
吸引蜘蛛
哪些页面被认为更重要?有几个因素:
· 网站 和页面权重。优质和旧的网站被认为权重更高,在这个网站上的页面会被爬得更高的深度,所以更多的内页会是收录。
· 页面更新。蜘蛛每次抓取时都会存储页面数据。如果第二次爬取发现页面和第一次收录一模一样,说明页面没有更新,蜘蛛不需要频繁爬取。如果页面内容更新频繁,蜘蛛会更频繁地访问该页面,页面上出现的新链接自然会被蜘蛛更快地跟踪并抓取新页面。
· 导入链接。不管是外部链接还是同一个网站的内部链接,为了被蜘蛛爬取,必须有传入链接才能进入页面,否则蜘蛛没有机会知道这页纸。高质量的入站链接通常还会增加页面上出站链接的抓取深度。一般来说,首页在网站上的权重最高,大部分外部链接指向首页,首页也是蜘蛛访问频率最高的。离首页越近的点击距离,页面权重越高,被蜘蛛爬取的机会就越大。
地址库
为了避免重复爬取和爬取网址,搜索引擎会建立一个地址数据库来记录已找到但未爬取的页面,以及已爬取的页面。地址存储库中有几个 url 来源:
(1)手动输入种子网站。
(2)蜘蛛爬取页面后,从html中解析出新的链接url,并与地址库中的数据进行比较,如果是不在地址库中的url,则将其存储在要访问的地址库中。
(3)站长通过搜索引擎网页提交表单提交的网址。
蜘蛛根据重要性从要访问的地址库中提取url,访问并爬取页面,然后将要访问的地址库中的url删除,放入被访问地址的地址库中。
大多数主要搜索引擎都为网站管理员提供了提交 URL 的表单。但是,这些提交的 URL 只存储在地址数据库中。是否 收录 取决于页面的重要性。搜索引擎的绝大多数页面 收录 都是由蜘蛛自己通过链接获得的。可以说,提交页面基本没用,搜索引擎更喜欢跟随链接发现新页面。
文件存储 搜索引擎蜘蛛爬取的数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。每个 uRI 都有一个唯一的文件编号。
爬行时重复内容检测
检测和删除重复项通常在下面描述的预处理过程中完成,但是现代蜘蛛在爬取和爬取文件时也会进行一定程度的重复项检测。当你在网站上遇到大量转载或抄袭、权重极低的内容时,很可能会停止爬取。这就是为什么一些网站管理员在日志文件中发现蜘蛛,但该页面从未真正被 收录 访问过。
预处理
在一些 SEO 资料中,“预处理”也简称为“索引”,因为索引是预处理中最重要的步骤。
搜索引擎蜘蛛爬取的原创页面不能直接用于查询排名处理。搜索引擎数据库的页数在万亿级别。用户输入搜索词后,排名程序会实时分析这么多页面的相关性。计算量太大,不可能在一两秒内返回排名结果。因此,必须对爬取的页面进行预处理,为最终的查询排名做准备。
和爬虫一样,预处理是在后台提前完成的,用户在搜索的时候感受不到这个过程。
1.提取文本
今天的搜索引擎仍然基于文本内容。蜘蛛抓取到的页面中的HTML代码,除了用户在浏览器上可以看到的可见文本外,还收录大量的HTML格式标签、程序等不能用于排名的内容。搜索引擎预处理首先要做的就是去除HTML文件中的标签和程序,提取网页中可用于排名处理的文本内容。
今天是愚人节
去掉 HTML 代码后,剩下的用于排名的文字就是这一行:
今天是愚人节
除了可见文本,搜索引擎还会提取一些收录文本信息的特殊代码,例如 Meta 标签中的文本、图片 alt 文本、Flash 文件 alt 文本、链接锚文本等。
2.中文分词
分词是中文搜索引擎特有的一个步骤。搜索引擎基于单词存储和处理页面和用户搜索。英语等语言用空格隔开,搜索引擎索引程序可以直接把句子分成词组。但是,中文单词和单词之间没有分隔符,一个句子中的所有单词和单词都是连接在一起的。搜索引擎必须首先区分哪些词组成一个词,哪些词本身就是一个词。例如,“减肥法”将分为“减肥”和“方法”两个词。
中文分词基本上有两种方法,一种是基于字典匹配的,一种是基于统计的。
基于字典匹配的方法是指将一段待分析的汉字与预先制作的字典中的词条进行匹配,从待分析的字符串中扫描字典中已有的词条。分离出一个词。
根据扫描方向,基于字典的匹配方法可以分为正向匹配和反向匹配。根据匹配长度优先级的不同,可以分为最大匹配和最小匹配。优先混合扫描方向和长度可以产生不同的方法,例如正向最大匹配和反向最大匹配。
字典匹配方法计算简单,其准确性很大程度上取决于字典的完整性和更新。
基于统计的分词方法是指分析大量文本样本,计算相邻词的统计概率。出现的相邻单词越多,形成单词的可能性就越大。基于统计的方法的优点是对新出现的词更敏感,也有利于消歧。
基于字典匹配和统计的分词方法各有优缺点。实际使用的分词系统混合使用了这两种方法,快速高效,可以识别新词和新词,消除歧义。
中文分词的准确性往往会影响搜索引擎排名的相关性。比如你在百度上搜索“搜索引擎优化”,从截图中可以看出百度把“搜索引擎优化”这六个词当成一个词。
在 Google 上搜索相同的词时,快照显示 Google 将其拆分为“搜索引擎”和“优化”两个词。显然,百度有更合理的细分,搜索引擎优化是一个完整的概念。谷歌的分词往往更细化。
分词的这种差异可能是某些 关键词 排名在不同搜索引擎上表现不同的原因之一。例如,百度更喜欢匹配搜索词以显示在页面上。也就是说,在搜索“够玩博客”的时候,如果这四个词连续出现,在百度中更容易获得好的排名。另一方面,谷歌实际上并不需要完全匹配。有些页面出现了“足够的戏剧”和“博客”这两个词,但不一定完全匹配,“足够的戏剧”出现在页面的前面,“博客”在页面的其他位置,这样的页面出现在谷歌搜索“足够剧博客“”,也可以获得不错的排名。
搜索引擎对页面的分词取决于词库的大小、准确度和分词算法的质量,而不是页面本身,因此SEO人员对分词的作用很小。唯一能做的就是在页面上使用某种形式来提示搜索引擎某些词应该被当作一个词处理,尤其是当它可能有歧义的时候,比如页面标题中的关键词@,h1标签和黑体字>。如果页面是关于“和服”的内容,那么“和服”这个词可以特别用粗体标出。如果页面是关于“化妆和服装”的,你可以把“服装”这个词加粗。这样,当搜索引擎分析页面时,它就知道粗体字应该是一个词。
3.去停用词
无论是英文还是中文,都会出现一些在页面内容中出现频率高但对内容没有影响的词,比如“的”、“地”、“de”、“ah”等辅助词, “ha”、“ya”等感叹词、“therefore”、“with”、“but”等副词或介词。这些词被称为停用词,因为它们对页面的主要含义几乎没有影响。英语中常见的停用词有 the、a、an、to、of 等。
搜索引擎会在索引页面之前去除这些停用词,使索引数据的主题更加突出,减少不必要的计算量。
4.去除噪音
大部分页面也存在一些对页面主题没有贡献的内容,如版权声明文字、导航栏、广告等。以常见的博客导航为例,导航内容如文章categories几乎每个博客页面都会出现历史档案,但这些页面本身与“类别”和“历史”这两个词无关。用户搜索“历史”、“类别”并返回博客文章只是因为这些词出现在页面上是没有意义的,完全无关紧要的。因此,这些块都是噪音,只能对页面的主题起到分散作用。
搜索引擎需要在不使用嘈杂内容的情况下识别和消除这种噪音并进行排名。去噪的基本方法是根据HTML标签将页面分成块,区分页眉、导航、文本、页脚、广告等区域。网站 上重复出现的块通常是噪音。页面去噪后,剩下的就是页面的主要内容。
5.移除
搜索引擎还需要对页面进行重复数据删除。
同一个文章经常在不同的网站和同一个网站的不同URL上重复出现,搜索引擎不喜欢这种重复的内容。用户搜索时,如果在前两页看到来自不同网站的同一篇文章文章,用户体验太差了,尽管都是内容相关的。搜索引擎希望只返回一个相同的文章,所以在索引之前需要识别并删除重复的内容。此过程称为“重复数据删除”。
去重的基本方法是计算页面特征的指纹关键词,也就是从页面的主要内容中选择最有代表性的部分关键词(经常是出现频率最高的关键词) ,然后计算这些 关键词 的数字指纹。这里的关键词的选择是在分词、去停用词、降噪之后。实验表明,通常选择10个特征关键词可以达到比较高的计算精度,选择更多的词对去重精度的提升贡献不大。
典型的指纹计算方法如MD5算法(Information Digest Algorithm Fifth Edition)。这类指纹算法的特点是输入(feature关键词)的任何微小变化都会导致计算出的指纹出现很大的差距。
了解了搜索引擎的去重算法后,SEO人员应该知道,简单地加上“de”、“地”、“de”,改变段落的顺序,所谓伪原创,是逃不过去重的。搜索引擎。算法,因为这样的操作不能改变文章关键词的特性。此外,搜索引擎的重复数据删除算法可能不仅在页面级别,而且在段落级别。混用不同的文章,互换段落的顺序,不能让转载、抄袭变成原创。
6.正向索引
远期指数也可以简称为指数。
经过文本提取、分词、去噪和去重后,搜索引擎获得了能够反映页面主要内容的独特的、基于词的内容。接下来,搜索引擎索引程序可以提取关键词,按照分词程序对单词进行划分,将页面转换为关键词的集合,并将每个关键词的内容记录在这页纸。出现频率、出现次数、格式(如在标题标签、粗体、H标签、锚文本等)、位置(如页面第一段等)。这样,每一页就可以记录为一组关键词,其中还记录了每个关键词的词频、格式、位置等权重信息。
搜索引擎索引程序将页面和关键词 存储到索引数据库中以形成词汇结构。索引词汇表的简化形式如表2-1所示。
每个文件对应一个文件ID,文件内容表示为关键词的集合。事实上,在搜索引擎索引库中,关键词也已经转换为关键词ID。这样的数据结构称为前向索引。
7.倒排索引
前向索引还不能直接用于排名。假设用户搜索关键词2,如果只有前向索引,排序程序需要扫描索引库中的所有文件,找到收录关键词2的文件,然后执行相关性计算。这个计算量不能满足实时返回排名结果的要求。
因此,搜索引擎会将正向索引数据库重构为倒排索引,并将文件对应到关键词的映射转换为关键词到文件的映射,如表2-2所示.
在倒排索引中,关键词是主键,每一个关键词都对应着这个关键词出现的一系列文件。这样,当用户搜索某个关键词时,排序程序在倒排索引中定位到这个关键词,可以立即找到所有收录这个关键词的文件。
关键词0@>链接关系计算
链接关系计算也是预处理的重要组成部分。页面之间的链接流信息现在收录在所有主要的搜索引擎排名因素中。搜索引擎爬取页面内容后,必须提前计算:页面上的哪些链接指向了其他哪些页面,每个页面上有哪些传入链接,链接使用了哪些锚文本。这些复杂的链接指向关系形成了 网站 和页面的链接权重。
谷歌PR值是这种链接关系最重要的体现之一。其他搜索引擎做类似的计算,虽然它们不被称为 PR。
由于页面和链接的数量巨大,而且互联网上的链接关系不断更新,计算链接关系和PR需要很长时间。关于PR和链接分析,后面有专门的章节。
关键词1@>特殊文件处理
除了 HTML 文件,搜索引擎通常可以抓取和索引多种基于文本的文件类型,例如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们还经常在搜索结果中看到这些文件类型。但是,目前的搜索引擎无法处理图片、视频、Flash等非文本内容,也无法执行脚本和程序。
虽然搜索引擎在识别图片和从 Flash 中提取文本内容方面取得了一些进展,但距离通过读取图片、视频和 Flash 内容直接返回结果的目标还差得很远。图片和视频内容的排名往往基于相关的文字内容。有关详细信息,请参阅下面的集成搜索部分。
排行
搜索引擎程序通过搜索引擎蜘蛛爬取的接口计算出倒排索引后,搜索引擎就可以随时处理用户搜索。用户在搜索框中填写关键词后,排名程序调用索引数据库数据,计算排名并展示给客户。排名过程直接与客户互动。
输入关键字 抓取所有网页(网站内容原创度不够高蜘蛛到网站上抓取时的原因)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-07 05:22
一:网站内容原创不够高
当蜘蛛在网站上爬行时,发现内容是原创有价值的信息,认为你对它很友好,赢得了搜索引擎的好感,给网站一个高排名. 石榴算法命中低质量页面后,站长不敢完全采集别人的内容。大部分站长改变 采集 的 文章 的头部和尾部,中间的内容保持不变。蜘蛛根据深度优先或广度优先的策略爬取页面,将爬取的页面放入数据库,进行索引工作,将那些“所谓的”原创内容删除。网站页面被取消收录的现象很明显。
二:内容更新次数变化较大
大网站或传送门网站,更新不多。网站每天有200多条更新,搜索引擎会特别关注你的网站,如果原创的度数不够高会认为你作弊,更新内容将不被接受。收录也正常。另一方面,更新次数变化太大。最初,每天有 200 篇 文章 文章。百度算法调整后,网站的数量也相应调整。人们开始注重质量而不是数量,下降到60篇。别说你的质量有多好,更新的次数和频率波动太大,很容易被百度惩罚,把你的网站 在观察期内。网站收录 的页面不被 收录 视为次要警告。
三:用户体验低
用户在搜索引擎中输入关键词,显示的网页都是匹配这个关键词的。我很高兴进入你的网站,以为我能找到满足我需求的内容。用户想知道的是XX化妆品怎么样,但是点击锚文链接就可以进入美容保健页面。用户会感到受骗并立即关闭网站。关键词堆叠也是降低用户体验的因素之一。站长优化应该是合适的。过度优化很容易降低用户体验,增加网站的跳出率,更不用说能带来多少转化。
四:度娘自身原因
近日,百度绿萝算法2.0更新,过滤去除了推广软文的外链,另一方面也对目标站点进行了适当的处罚。很多网站已经被降级,被降级的网站需要进入百度考核期。更新后的文章内容是收录然后删除是正常的。. 网站只要不违法,没有过激行为,过了考核期,删除的内容依然是收录。
收录数量在某种程度上是判断网站质量的因素之一。交换好友链时,对方会看你的网站的收录的数量,收录的数量少,或者网站被修改了重建 收录; 或者是网站内容不受搜索引擎青睐,而不是收录。即使你的网站权重比他高,他也不一定会和你交换,因为这样的网站不稳定,随时可能被降级。 查看全部
输入关键字 抓取所有网页(网站内容原创度不够高蜘蛛到网站上抓取时的原因)
一:网站内容原创不够高
当蜘蛛在网站上爬行时,发现内容是原创有价值的信息,认为你对它很友好,赢得了搜索引擎的好感,给网站一个高排名. 石榴算法命中低质量页面后,站长不敢完全采集别人的内容。大部分站长改变 采集 的 文章 的头部和尾部,中间的内容保持不变。蜘蛛根据深度优先或广度优先的策略爬取页面,将爬取的页面放入数据库,进行索引工作,将那些“所谓的”原创内容删除。网站页面被取消收录的现象很明显。
二:内容更新次数变化较大
大网站或传送门网站,更新不多。网站每天有200多条更新,搜索引擎会特别关注你的网站,如果原创的度数不够高会认为你作弊,更新内容将不被接受。收录也正常。另一方面,更新次数变化太大。最初,每天有 200 篇 文章 文章。百度算法调整后,网站的数量也相应调整。人们开始注重质量而不是数量,下降到60篇。别说你的质量有多好,更新的次数和频率波动太大,很容易被百度惩罚,把你的网站 在观察期内。网站收录 的页面不被 收录 视为次要警告。
三:用户体验低
用户在搜索引擎中输入关键词,显示的网页都是匹配这个关键词的。我很高兴进入你的网站,以为我能找到满足我需求的内容。用户想知道的是XX化妆品怎么样,但是点击锚文链接就可以进入美容保健页面。用户会感到受骗并立即关闭网站。关键词堆叠也是降低用户体验的因素之一。站长优化应该是合适的。过度优化很容易降低用户体验,增加网站的跳出率,更不用说能带来多少转化。
四:度娘自身原因
近日,百度绿萝算法2.0更新,过滤去除了推广软文的外链,另一方面也对目标站点进行了适当的处罚。很多网站已经被降级,被降级的网站需要进入百度考核期。更新后的文章内容是收录然后删除是正常的。. 网站只要不违法,没有过激行为,过了考核期,删除的内容依然是收录。
收录数量在某种程度上是判断网站质量的因素之一。交换好友链时,对方会看你的网站的收录的数量,收录的数量少,或者网站被修改了重建 收录; 或者是网站内容不受搜索引擎青睐,而不是收录。即使你的网站权重比他高,他也不一定会和你交换,因为这样的网站不稳定,随时可能被降级。
输入关键字 抓取所有网页(您意思是要在您的网站上用别人的数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-03 12:10
你的意思是自己使用别人的数据网站?如果是这样,你可以:网站输入关键字请求到自己的服务器,然后在服务器上使用HttpClient模拟向别人的网站发送请求获取数据,然后返回给自己网站 请求。
当然,你需要先弄清楚别人服务器请求的链接(使用一楼提到的方法),并分析请求的其他参数,以便模拟请求的图像。前提是他们对请求的安全限制不那么严格。
您还可以将捕获的数据保存在自己的数据库中。下次可以自己找数据库找。如果找不到,可以模拟一个请求来捕获它。这允许积累下一个数据量。
但是,这些数据毕竟可能是别人根据用户行为分析的结果,可能与你自己的站点情况不一致。
收获的菜豆:10
李奇鹏||远斗:1160|2015-07-01 13:18
好吧,我只需要计算他的表现,不管他的分析是否准确。
如果使用F12可以看到相关信息,但是不知道是哪个JS方法在处理这些请求。HTTPWatch 也是如此。你有什么好的方法可以定位到这样的请求方法吗?
给个思路,非常感谢。
我要成仙,在天上快乐|元豆:17|2015-07-01 13:38
@OmJJWang:了解如何使用 Google Chrome 的开发工具。我现在用手机,不太方便。简单的说。打开那个页面,使用谷歌浏览器,按F12,看到Network一栏,有一个清除按钮,找一下,先清除已有的请求信息,然后在搜索框中输入,应该可以看到刚才网络有东西,这是发送的请求,看链接。自己找出来。
李奇鹏|元豆:1160|2015-07-01 14:12
上传图片
Ctrl+Enter 快速提交 查看全部
输入关键字 抓取所有网页(您意思是要在您的网站上用别人的数据?)
你的意思是自己使用别人的数据网站?如果是这样,你可以:网站输入关键字请求到自己的服务器,然后在服务器上使用HttpClient模拟向别人的网站发送请求获取数据,然后返回给自己网站 请求。
当然,你需要先弄清楚别人服务器请求的链接(使用一楼提到的方法),并分析请求的其他参数,以便模拟请求的图像。前提是他们对请求的安全限制不那么严格。
您还可以将捕获的数据保存在自己的数据库中。下次可以自己找数据库找。如果找不到,可以模拟一个请求来捕获它。这允许积累下一个数据量。
但是,这些数据毕竟可能是别人根据用户行为分析的结果,可能与你自己的站点情况不一致。
收获的菜豆:10
李奇鹏||远斗:1160|2015-07-01 13:18
好吧,我只需要计算他的表现,不管他的分析是否准确。
如果使用F12可以看到相关信息,但是不知道是哪个JS方法在处理这些请求。HTTPWatch 也是如此。你有什么好的方法可以定位到这样的请求方法吗?
给个思路,非常感谢。
我要成仙,在天上快乐|元豆:17|2015-07-01 13:38
@OmJJWang:了解如何使用 Google Chrome 的开发工具。我现在用手机,不太方便。简单的说。打开那个页面,使用谷歌浏览器,按F12,看到Network一栏,有一个清除按钮,找一下,先清除已有的请求信息,然后在搜索框中输入,应该可以看到刚才网络有东西,这是发送的请求,看链接。自己找出来。
李奇鹏|元豆:1160|2015-07-01 14:12
上传图片
Ctrl+Enter 快速提交
输入关键字 抓取所有网页(谷歌分析代码,具体的文本,或代码等(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-25 18:28
AJAX 的 SEO AJAX 蜘蛛遵循 Google 的计划。
Inlinks - 所有页面都链接到一个 URI。
Outlinks - 所有页面都链接到 URI。
锚文本,链接文本。替代文字图片链接。
Follow & Nofollow - 在页面和链接上(真/假)。
图片 - 所有带有图片的 uris 和来自给定页面的所有图片都已链接。图片大小超过 100kb,缺少替代文字,替代文字超过 100 个字符。
User-Agent Switcher - 抓取 Googlebot、Bingbot、Yahoo!声音、移动用户代理或您自己的自定义 UA。
重定向链,查找重定向链和循环。
自定义源代码搜索 - 搜索引擎蜘蛛可以在 网站 中找到您想要的任何源代码!无论是 Google Analytics 代码、特定文本还是代码等(请注意,这不是数据提取或抓取功能。)
XML网站Map Generator - 您可以使用 SEO Spider 创建 XML 站点地图和图像地图。
如何使用 ScreamingFrogSEOSpider
ScreamingFrogSEOSpider 使用起来非常方便,只需输入你的网站主页的URL,然后点击开始,等待爬取完成,就可以看到各种详细的数据了。
下图以提取我博客的整个站点URL为例,给大家展示一下效果:
红框1中的这些标签会依次为你翻译:内部链接、外部链接、HTTP协议(HTTP或HTTPS)、HTTP状态码(200、3XX、4XX、5XX)、URI(注意不是URL,URI是Uniform Resource Identifier,统一资源标识符;URL:Uniform Resource Locator,统一资源定位器;想了解更多请去百度),页面标题标签,页面描述标签,页面关键字标签,页面H1标签、页面H2标签、现场图片、页面链接、使用AJAX技术的链接、自定义过滤规则。
红框2:点击后会在我们的首页看到一些信息,比如红框4,首页的导入链接是什么,红框3,ScreamingFrogSEOSpider提取的整个站点的链接数,结合站点说明,您可以了解我们网站站点收录的大概情况。
通过以上的讲解,相信你已经了解了这个工具的强大之处!那么接下来你可能关心的是这个工具是付费的还是免费的?
通过官网的介绍,我们知道可以免费下载和使用该软件,但免费版只能抓取全站500个网址。如果是小型企业网站,就足够了。如果是大网站,可以考虑。一年99英镑起买一个,约合人民币972元(感谢seolabs指正:)),对于玩大站的朋友来说简直太便宜了,哈哈!
你认为文章 的写作应该到此结束吗?如果你这么想,那你就错了!方法博客只为分享有价值的文章而生,所以今天送上价值694元的礼物送给有幸看到这个文章的朋友!那就是:(睁大眼睛!)
ScreamingFrogSEOSpider 下载
由于官网在英国,打开速度极慢,这里是官网的直接下载链接:
ScreamingFrogSEOSpider注册码!可以使用一年!
为了方便大家COPY,我贴在这里:
用户名:gn168
许可证密钥:20D8E5C5AF-1467881526-81359030D5
2016.9.28更新:上面的注册码已经过期,下面是新发现的,大家可以试试。我注册了第一个。
用户名:
序列号:35821799C7-1503300883-11CFAC4652
用户名:
序列号:180A8B33F9-1503300970-5859C71542
用户名:
序列号:99A43BF96D-1503300995-9F3AB42B03
以上注册码由广年论坛热心朋友提供。你可以访问这位朋友的网站:为他的无私奉献贡献一个IP!:)
如果要下载一个完整的网站到本地,会有更好的模拟搜索引擎爬虫工具,那就是国屏曾经分享的Httrack模拟搜索引擎爬虫工具,继续写文章与大家分享Httrack的使用方法!
文章写到这里,真的是该结束了,该说的也说完了。为了和大家分享这个好工具,我已经把它编码到凌晨1:00。看到我为人民付出的努力,你既然都看到了,下面的留言区不给我点个赞,你会不会不好意思?:):):):):) 查看全部
输入关键字 抓取所有网页(谷歌分析代码,具体的文本,或代码等(组图))
AJAX 的 SEO AJAX 蜘蛛遵循 Google 的计划。
Inlinks - 所有页面都链接到一个 URI。
Outlinks - 所有页面都链接到 URI。
锚文本,链接文本。替代文字图片链接。
Follow & Nofollow - 在页面和链接上(真/假)。
图片 - 所有带有图片的 uris 和来自给定页面的所有图片都已链接。图片大小超过 100kb,缺少替代文字,替代文字超过 100 个字符。
User-Agent Switcher - 抓取 Googlebot、Bingbot、Yahoo!声音、移动用户代理或您自己的自定义 UA。
重定向链,查找重定向链和循环。
自定义源代码搜索 - 搜索引擎蜘蛛可以在 网站 中找到您想要的任何源代码!无论是 Google Analytics 代码、特定文本还是代码等(请注意,这不是数据提取或抓取功能。)
XML网站Map Generator - 您可以使用 SEO Spider 创建 XML 站点地图和图像地图。
如何使用 ScreamingFrogSEOSpider
ScreamingFrogSEOSpider 使用起来非常方便,只需输入你的网站主页的URL,然后点击开始,等待爬取完成,就可以看到各种详细的数据了。
下图以提取我博客的整个站点URL为例,给大家展示一下效果:
红框1中的这些标签会依次为你翻译:内部链接、外部链接、HTTP协议(HTTP或HTTPS)、HTTP状态码(200、3XX、4XX、5XX)、URI(注意不是URL,URI是Uniform Resource Identifier,统一资源标识符;URL:Uniform Resource Locator,统一资源定位器;想了解更多请去百度),页面标题标签,页面描述标签,页面关键字标签,页面H1标签、页面H2标签、现场图片、页面链接、使用AJAX技术的链接、自定义过滤规则。
红框2:点击后会在我们的首页看到一些信息,比如红框4,首页的导入链接是什么,红框3,ScreamingFrogSEOSpider提取的整个站点的链接数,结合站点说明,您可以了解我们网站站点收录的大概情况。
通过以上的讲解,相信你已经了解了这个工具的强大之处!那么接下来你可能关心的是这个工具是付费的还是免费的?
通过官网的介绍,我们知道可以免费下载和使用该软件,但免费版只能抓取全站500个网址。如果是小型企业网站,就足够了。如果是大网站,可以考虑。一年99英镑起买一个,约合人民币972元(感谢seolabs指正:)),对于玩大站的朋友来说简直太便宜了,哈哈!
你认为文章 的写作应该到此结束吗?如果你这么想,那你就错了!方法博客只为分享有价值的文章而生,所以今天送上价值694元的礼物送给有幸看到这个文章的朋友!那就是:(睁大眼睛!)
ScreamingFrogSEOSpider 下载
由于官网在英国,打开速度极慢,这里是官网的直接下载链接:
ScreamingFrogSEOSpider注册码!可以使用一年!
为了方便大家COPY,我贴在这里:
用户名:gn168
许可证密钥:20D8E5C5AF-1467881526-81359030D5
2016.9.28更新:上面的注册码已经过期,下面是新发现的,大家可以试试。我注册了第一个。
用户名:
序列号:35821799C7-1503300883-11CFAC4652
用户名:
序列号:180A8B33F9-1503300970-5859C71542
用户名:
序列号:99A43BF96D-1503300995-9F3AB42B03
以上注册码由广年论坛热心朋友提供。你可以访问这位朋友的网站:为他的无私奉献贡献一个IP!:)
如果要下载一个完整的网站到本地,会有更好的模拟搜索引擎爬虫工具,那就是国屏曾经分享的Httrack模拟搜索引擎爬虫工具,继续写文章与大家分享Httrack的使用方法!
文章写到这里,真的是该结束了,该说的也说完了。为了和大家分享这个好工具,我已经把它编码到凌晨1:00。看到我为人民付出的努力,你既然都看到了,下面的留言区不给我点个赞,你会不会不好意思?:):):):):)
输入关键字 抓取所有网页(如何在网站优化中有三到四个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-24 23:17
如果网站优化里面有三四个关键词,那么关注首页基本没问题。但是,如果关键字超过 10 个或 20 个或更多,则需要在整个 网站 中正确排列,而不是仅仅依靠主页。他们如何更好地联系?或者尝试在 网站 上对这些词进行排名。
通常的做法是将更重要的关键字放在头部。第二级中的附加关键字放置在每个列或频道页面上。如果尾部较长,属于三级关键词,可以使用内容页进行优化。
在首页,主关键词是优化的重点。从页面标题来看,粗体粗重的hx标签关键词比其他词更显眼。
次要关键字不能出现在主页上,相反,次要关键字应该出现在主页上,因为这些词加强了主要关键字。
搜索引擎也通过语义分析知道这一点。这种语义联系不是从字面上理解的,而是从大量统计数据中推导出来的,搜索引擎仍然具有这种智能。
至少这些次要关键词会出现在首页的导航链接中。其中一些出现在主页的主体中,并链接到相应的栏目和频道页面。
这样关键词就可以得到最优的分配,整个网站就会有一个强大的逻辑和语义关系体系,就像一个金字塔。主页是您想要排名的最难的词。整个 网站 突出了主页上的关键字分布,无论是语义上还是链接上。
这种多关键词优化方式的前提是你比较感兴趣的关键词最多只能有三四个热门词。如果想要的二级关键词也很受欢迎,恐怕我们需要单独做一个网站,所有结果都在首页上实现。把它放在一个专栏页面上,因为你不太可能为所有专栏页面建立很多好的链接,所以很难对热门词进行排名,除非你真的可以让这个网站成为一个大的、权威的网站。
需求无处不在。有必要让陌生人见面并让无关的人合作。网站优化过程中如何满足需求?
1、从下拉框和相关搜索中查看需求
百度下拉框和相关搜索是分析用户需求的常用数据。百度下拉框是上周用户搜索最多的词,相关搜索是用户上月搜索最多的词。
(1)下拉框,下拉框中显示的关键词搜索越多,越重要。下拉框的关键词形成时间比较短,可以看到热点近期短期用户,如果行业更新快,爬取内容进行关键词排名。
(2)相关搜索。相关搜索是上个月的数据,从中我们可以得到用户最近一个月关心的内容。经验丰富的网站优化器结合drop中的数据-down 框可以看到关键词的搜索趋势,企业网站要多关注相关搜索数据。
2、从搜索排名中发现隐藏需求
从 关键词 的主要搜索中,我们可以看到百度主页上的 网站 排名。从排名第一的网站,我们可以知道用户喜欢哪个网站。比如图片、帖子、知识库、库等,比如搜索羊,无论是在下拉框、相关搜索还是首页排名中,都可以看到羊,说明用户对羊的需求强烈讨论的话,这个行业比较适合论坛类型网站。
(1)图片,百度首页图片展示,用户更关注图片,网站应该有更清晰的图片展示。比如装修
(2)海报栏,百度贴吧表示用户有讨论需求,网站可以是论坛栏,比如SEO论坛
(3)是的,首页好像知道用户有问答,网站可以设置一个常见的问答栏。比如医疗
(4)图书馆,图书馆首页显示用户有资料下载需求,网站可提供免费下载链接。 查看全部
输入关键字 抓取所有网页(如何在网站优化中有三到四个)
如果网站优化里面有三四个关键词,那么关注首页基本没问题。但是,如果关键字超过 10 个或 20 个或更多,则需要在整个 网站 中正确排列,而不是仅仅依靠主页。他们如何更好地联系?或者尝试在 网站 上对这些词进行排名。
通常的做法是将更重要的关键字放在头部。第二级中的附加关键字放置在每个列或频道页面上。如果尾部较长,属于三级关键词,可以使用内容页进行优化。
在首页,主关键词是优化的重点。从页面标题来看,粗体粗重的hx标签关键词比其他词更显眼。
次要关键字不能出现在主页上,相反,次要关键字应该出现在主页上,因为这些词加强了主要关键字。
搜索引擎也通过语义分析知道这一点。这种语义联系不是从字面上理解的,而是从大量统计数据中推导出来的,搜索引擎仍然具有这种智能。
至少这些次要关键词会出现在首页的导航链接中。其中一些出现在主页的主体中,并链接到相应的栏目和频道页面。
这样关键词就可以得到最优的分配,整个网站就会有一个强大的逻辑和语义关系体系,就像一个金字塔。主页是您想要排名的最难的词。整个 网站 突出了主页上的关键字分布,无论是语义上还是链接上。
这种多关键词优化方式的前提是你比较感兴趣的关键词最多只能有三四个热门词。如果想要的二级关键词也很受欢迎,恐怕我们需要单独做一个网站,所有结果都在首页上实现。把它放在一个专栏页面上,因为你不太可能为所有专栏页面建立很多好的链接,所以很难对热门词进行排名,除非你真的可以让这个网站成为一个大的、权威的网站。
需求无处不在。有必要让陌生人见面并让无关的人合作。网站优化过程中如何满足需求?
1、从下拉框和相关搜索中查看需求
百度下拉框和相关搜索是分析用户需求的常用数据。百度下拉框是上周用户搜索最多的词,相关搜索是用户上月搜索最多的词。
(1)下拉框,下拉框中显示的关键词搜索越多,越重要。下拉框的关键词形成时间比较短,可以看到热点近期短期用户,如果行业更新快,爬取内容进行关键词排名。
(2)相关搜索。相关搜索是上个月的数据,从中我们可以得到用户最近一个月关心的内容。经验丰富的网站优化器结合drop中的数据-down 框可以看到关键词的搜索趋势,企业网站要多关注相关搜索数据。
2、从搜索排名中发现隐藏需求
从 关键词 的主要搜索中,我们可以看到百度主页上的 网站 排名。从排名第一的网站,我们可以知道用户喜欢哪个网站。比如图片、帖子、知识库、库等,比如搜索羊,无论是在下拉框、相关搜索还是首页排名中,都可以看到羊,说明用户对羊的需求强烈讨论的话,这个行业比较适合论坛类型网站。
(1)图片,百度首页图片展示,用户更关注图片,网站应该有更清晰的图片展示。比如装修
(2)海报栏,百度贴吧表示用户有讨论需求,网站可以是论坛栏,比如SEO论坛
(3)是的,首页好像知道用户有问答,网站可以设置一个常见的问答栏。比如医疗
(4)图书馆,图书馆首页显示用户有资料下载需求,网站可提供免费下载链接。
输入关键字 抓取所有网页(百度、360两种搜索引擎介绍关键字的提交爬取信息优化方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-23 12:21
)
文章目录
写在前面
本文介绍了百度和360搜索引擎的关键词提交和爬取信息,并在引用示例的基础上进行了优化。可以独立输入关键字,提交关键词后打印出搜索内容的字符串长度和关联的URL。
一.爬取原创页面
以 关键词 for python 为例。
1.百度页面如下
2.360页如下
Whisper BB:通过上面的对比,发现他们也在卖课程。看来这些机构给的钱不一样。一定程度上还是把自己的平台放在了首位。
二.爬取原理解析
首先,我以python为例,给大家展示一下百度和360搜索页面的url结果。
1.百度
2.360
通过上面的实践,我们可以发现搜索引擎有它的关键词提交接口。
百度的关键词接口:
360的关键词界面:
关键字就是我们输入的关键字,所以我们只要替换掉关键字就可以提交关键词给搜索引擎,也就是只要构造好URL链接就可以提取出关键词,最后使用 len() 函数显示提交后搜索内容的字符串长度关键词。
3.使用的库
import requests
三.完整代码
import requests
#百度搜索
def baiDu():
key = input("请输入百度搜索关键词:")
url = "https://www.baidu.com/s?wd="+key
try:
r = requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(len(r.text))
print(r.request.url)
except:
print("爬取异常")
#360搜索
def threeSZ():
key = input("请输入360搜索关键词:")
url = "https://www.so.com/s?q="+key
try:
r = requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(len(r.text))
print(r.request.url)
except:
print("爬取异常")
#调用函数
baiDu()
threeSZ()
本文结束后,如有错误请指出~
引用自
中国大学MOOC Python网络爬虫与信息提取
https://www.icourse163.org/course/BIT-1001870001 查看全部
输入关键字 抓取所有网页(百度、360两种搜索引擎介绍关键字的提交爬取信息优化方法
)
文章目录
写在前面
本文介绍了百度和360搜索引擎的关键词提交和爬取信息,并在引用示例的基础上进行了优化。可以独立输入关键字,提交关键词后打印出搜索内容的字符串长度和关联的URL。
一.爬取原创页面
以 关键词 for python 为例。
1.百度页面如下
2.360页如下
Whisper BB:通过上面的对比,发现他们也在卖课程。看来这些机构给的钱不一样。一定程度上还是把自己的平台放在了首位。
二.爬取原理解析
首先,我以python为例,给大家展示一下百度和360搜索页面的url结果。
1.百度
2.360
通过上面的实践,我们可以发现搜索引擎有它的关键词提交接口。
百度的关键词接口:
360的关键词界面:
关键字就是我们输入的关键字,所以我们只要替换掉关键字就可以提交关键词给搜索引擎,也就是只要构造好URL链接就可以提取出关键词,最后使用 len() 函数显示提交后搜索内容的字符串长度关键词。
3.使用的库
import requests
三.完整代码
import requests
#百度搜索
def baiDu():
key = input("请输入百度搜索关键词:")
url = "https://www.baidu.com/s?wd="+key
try:
r = requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(len(r.text))
print(r.request.url)
except:
print("爬取异常")
#360搜索
def threeSZ():
key = input("请输入360搜索关键词:")
url = "https://www.so.com/s?q="+key
try:
r = requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(len(r.text))
print(r.request.url)
except:
print("爬取异常")
#调用函数
baiDu()
threeSZ()
本文结束后,如有错误请指出~
引用自
中国大学MOOC Python网络爬虫与信息提取
https://www.icourse163.org/course/BIT-1001870001
输入关键字 抓取所有网页(windows环境下的操作版本为3urllib库介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-22 14:08
(以下是windows环境下的操作,python版本为3)
1.urllib库介绍
官方文档上的解释是:
urllib 是一个包,它采集了几个用于处理 URL 的模块
简单来说就是用来处理url的,它收录以下模块:
urllib.request 模块定义了有助于在复杂世界中打开 URL(主要是 HTTP)的函数和类——基本和摘要式身份验证、重定向、cookie 等等。
在这里,只需使用 urllib.request 模块。请求模块收录一些处理打开的url的函数。
urlopen()
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
这个函数的主要参数是url,可以是字符串,也可以是请求对象。
该函数返回一个可用作文本管理器的对象,方法如下:
要查看这些函数的作用,我们运行以下 python 代码:
import urllib.request
url = "http://www.baidu.com"
a = urllib.request.urlopen(url)
print('----------type of a----------')
print(type(a))
print('----------geturl()----------')
print(a.geturl())
print('----------info()----------')
print(a.info())
print('----------getcode()----------')
print(a.getcode())
运行结果:
3.在百度上抓取关键词的搜索结果
首先我们要知道百度搜索的url,打开百度搜索一个词,地址栏就可以看到url了
拿到url后,剩下的就是爬取url了,代码如下:
# coding=utf-8
# Created by dockerchen
import urllib.request
data = {}
data['word'] = '网络安全'
url_values = urllib.parse.urlencode(data)
url = 'http://www.baidu.com/s?wd='
full_url = url + url_values
data = urllib.request.urlopen(full_url).read()
data = data.decode('utf-8')
print(data)
urllib.parse.urlencode() 可以将字符串转换为url格式的字符串,在转换数据的地方,我们可以得到wd=%E7%BD%91%E7%BB%9C%E5%AE%一个字符串89%E5%85%A8。
如果只想对字符串进行urlencode,可以使用urllib.parse.quote(),例如:
>>> import urllib.parse
>>> urllib.parse.quote('网络安全')
'%E7%BD%91%E7%BB%9C%E5%AE%89%E5%85%A8'
上面代码的输出结果其实就是爬取的百度页面搜索结果的源码。接下来要做的就是对爬取的东西进行处理,得到我们想要的数据
参考:
转载于: 查看全部
输入关键字 抓取所有网页(windows环境下的操作版本为3urllib库介绍)
(以下是windows环境下的操作,python版本为3)
1.urllib库介绍
官方文档上的解释是:
urllib 是一个包,它采集了几个用于处理 URL 的模块
简单来说就是用来处理url的,它收录以下模块:
urllib.request 模块定义了有助于在复杂世界中打开 URL(主要是 HTTP)的函数和类——基本和摘要式身份验证、重定向、cookie 等等。
在这里,只需使用 urllib.request 模块。请求模块收录一些处理打开的url的函数。
urlopen()
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
这个函数的主要参数是url,可以是字符串,也可以是请求对象。
该函数返回一个可用作文本管理器的对象,方法如下:
要查看这些函数的作用,我们运行以下 python 代码:
import urllib.request
url = "http://www.baidu.com"
a = urllib.request.urlopen(url)
print('----------type of a----------')
print(type(a))
print('----------geturl()----------')
print(a.geturl())
print('----------info()----------')
print(a.info())
print('----------getcode()----------')
print(a.getcode())
运行结果:
3.在百度上抓取关键词的搜索结果
首先我们要知道百度搜索的url,打开百度搜索一个词,地址栏就可以看到url了
拿到url后,剩下的就是爬取url了,代码如下:
# coding=utf-8
# Created by dockerchen
import urllib.request
data = {}
data['word'] = '网络安全'
url_values = urllib.parse.urlencode(data)
url = 'http://www.baidu.com/s?wd='
full_url = url + url_values
data = urllib.request.urlopen(full_url).read()
data = data.decode('utf-8')
print(data)
urllib.parse.urlencode() 可以将字符串转换为url格式的字符串,在转换数据的地方,我们可以得到wd=%E7%BD%91%E7%BB%9C%E5%AE%一个字符串89%E5%85%A8。
如果只想对字符串进行urlencode,可以使用urllib.parse.quote(),例如:
>>> import urllib.parse
>>> urllib.parse.quote('网络安全')
'%E7%BD%91%E7%BB%9C%E5%AE%89%E5%85%A8'
上面代码的输出结果其实就是爬取的百度页面搜索结果的源码。接下来要做的就是对爬取的东西进行处理,得到我们想要的数据
参考:
转载于:

