
自动采集编写
自动采集编写两个爬虫爬去它应该有的数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-05-04 22:01
自动采集编写两个爬虫爬去它应该有的代码里面的数据,然后用headers去请求一个json文件然后对爬虫发送请求,看返回的数据,和数据库对应。就是这么简单。
谢邀!任何一个成熟的中间件都可以做到你说的那样。你自己设计或开发一个也可以。
采集的话。就是简单的事情。
大家讲的都有道理,我讲一下我的理解吧,不一定完全正确,欢迎批评指正:如果是博客的话,可以找到博客所属的网站,根据网站的规范和域名,自己设计采集程序。然后找到对应的网站,利用js这种技术把你想采的目标页面渲染出来。另外为啥要采abc?a,b,c指的是页面里面的内容,abc可以看做整个网站的目录。c下面是d。
这样采了以后,你直接把对应的abc这样的目录文件放到相应的页面中。每次爬都用的是之前设定好的页面文件。
采集指的是爬虫,采站或者采团队成员的站。目前是pc爬虫为主,因为有浏览器分类,但一般采用pc采集。另外采集的模式是利用scrapy/gray/flask/bot等框架,通过python或shell等技术解析采集结果。方案根据你爬的站数量需求会有一些不同。如果爬得多,爬得差可以建立一个scrapy-botfrom这样的组,用python写,然后在你定位的站点中爬爬试试。
你得去找一个可以爬过程的工具,不断的重复一个过程 查看全部
自动采集编写两个爬虫爬去它应该有的数据
自动采集编写两个爬虫爬去它应该有的代码里面的数据,然后用headers去请求一个json文件然后对爬虫发送请求,看返回的数据,和数据库对应。就是这么简单。
谢邀!任何一个成熟的中间件都可以做到你说的那样。你自己设计或开发一个也可以。
采集的话。就是简单的事情。
大家讲的都有道理,我讲一下我的理解吧,不一定完全正确,欢迎批评指正:如果是博客的话,可以找到博客所属的网站,根据网站的规范和域名,自己设计采集程序。然后找到对应的网站,利用js这种技术把你想采的目标页面渲染出来。另外为啥要采abc?a,b,c指的是页面里面的内容,abc可以看做整个网站的目录。c下面是d。
这样采了以后,你直接把对应的abc这样的目录文件放到相应的页面中。每次爬都用的是之前设定好的页面文件。
采集指的是爬虫,采站或者采团队成员的站。目前是pc爬虫为主,因为有浏览器分类,但一般采用pc采集。另外采集的模式是利用scrapy/gray/flask/bot等框架,通过python或shell等技术解析采集结果。方案根据你爬的站数量需求会有一些不同。如果爬得多,爬得差可以建立一个scrapy-botfrom这样的组,用python写,然后在你定位的站点中爬爬试试。
你得去找一个可以爬过程的工具,不断的重复一个过程
自动采集编写爬虫每次请求发送的都是data(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-05-02 18:00
自动采集编写爬虫每次请求发送的都是data。通过正则表达式得到的是request_url等php类型变量。发送数据的方式是网页上的形如“数据请求”时的net_url。爬虫代码每个网页都会由很多post请求构成。爬虫控制器中相应的爬虫对象对这些请求做处理并返回网页的post请求的url。
filter掉然后发请求
看@克锐在高程里面讲的:xpath存xmlpost发postheadref=“page({}).html”+url;返回值也要注意,一般正常返回是:{page}/page/xml;index:url;}还有注意get和post的不同:get,应该是发表达式,httpsession会保存这个表达式,后面服务器接受了sessionid,就把网页搞下来;post,不应该发表达式,因为session会根据表达式把网页搞下来,一般不会把sessionid保存在session内。
另外如果服务器响应:{url}/{page}/xml;index:url;请不要验证真假,因为正常情况下这个url/page/xml;index肯定是。
header中的user-agent不知道你们用的是哪里的:disallow:[block0]headeruser-agent中的user-agent是springmvc中的agent-marker-style头部的bean。在header中输入user-agent的值springmvc会验证bean中的参数,如果有这样的值就返回给springmvc。
例如:@autowiredpublic@interfaceagent-marker-style{intgetvalue()throwsillegalargumentexception,interruptedexception{}}vs-marker-style通过@autowired注入的@interface的方法是单行注入,在这里这里就是只有单行注入:。 查看全部
自动采集编写爬虫每次请求发送的都是data(图)
自动采集编写爬虫每次请求发送的都是data。通过正则表达式得到的是request_url等php类型变量。发送数据的方式是网页上的形如“数据请求”时的net_url。爬虫代码每个网页都会由很多post请求构成。爬虫控制器中相应的爬虫对象对这些请求做处理并返回网页的post请求的url。
filter掉然后发请求
看@克锐在高程里面讲的:xpath存xmlpost发postheadref=“page({}).html”+url;返回值也要注意,一般正常返回是:{page}/page/xml;index:url;}还有注意get和post的不同:get,应该是发表达式,httpsession会保存这个表达式,后面服务器接受了sessionid,就把网页搞下来;post,不应该发表达式,因为session会根据表达式把网页搞下来,一般不会把sessionid保存在session内。
另外如果服务器响应:{url}/{page}/xml;index:url;请不要验证真假,因为正常情况下这个url/page/xml;index肯定是。
header中的user-agent不知道你们用的是哪里的:disallow:[block0]headeruser-agent中的user-agent是springmvc中的agent-marker-style头部的bean。在header中输入user-agent的值springmvc会验证bean中的参数,如果有这样的值就返回给springmvc。
例如:@autowiredpublic@interfaceagent-marker-style{intgetvalue()throwsillegalargumentexception,interruptedexception{}}vs-marker-style通过@autowired注入的@interface的方法是单行注入,在这里这里就是只有单行注入:。
||ArcGIS 环境下的系列无人机影像灾害样本库建设
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-04-30 09:00
摘要:以“5·12”汶川地震、“4·20”芦山地震和“6·18”宁南特大山洪泥石流等地质灾害为例,在 ArcGIS环境下采用 ArcMap 软件与 Python 脚本开发相结合的方式,利用多时期无人机影像进行灾害样本的采集,批量处理多种灾害样本,从而建立对应的无人机影像灾害样本库。关键词ArcGIS;无人机;地质灾害;样本库1 引言20 世纪 90 年代以来,受人类活动和全球化的影响,地质灾害越发严重,地质灾害发生的规模、数量和分布范围呈上升趋势。2008 年“5·12”汶川特大地震后,由于地质结构被破坏,加之恶劣天气的影响,滑坡和泥石流等次生灾害在很长一段时间内影响着震区,这些地质灾害不仅直接或者间接地危害人民群众生命、财产安全,还会给社会和经济建设造成巨大的损失。利用遥感技术获取灾区影像已成为灾后获取灾害信息的重要手段,无人机遥感技术时效性强、使用成本低、起降方式灵活多样、影像分辨率高等优势,使其在地质灾害应急救援工作中具有广阔的应用前景和发展前途。近几年,相关应急救灾部门已经具备在灾后第一时间获取地质灾害现场的无人机影像的能力。是一门解释型语言,因其不需要编译和链接的时间,所以能够节省开发时间,解释器可以交互式使用,同时能够很方便地测试语言中的各种功能,便于编写发布用的程序,具有开源、模块丰富、面向对象、面向过程等特性,能够与 ArcGIS 软件很好地结合使用[3]。从 ArcGIS9.0 开始,我们就可以使用 Python, 并把它作为首选脚本语言[4],实现空间数据的自动化批量处理,从而起到简化流程,提高工作的自动化程度的作用[2]。本文介绍一种在 ArcGIS环境下,结合 Python 脚本开发的方式,利用历史系列无人机影像快速批量建立地质灾害样本库的方法,该样本库可为后续灾害识别提供基础的训练数据支持,一定程度上改善了样本数据采集仅停留在人工解译层面的现状。
2 研究区与实验数据
根据现有数据情况确定的研究区包括:2008 年汶川地震受灾的汶川县、北川县、安县、绵竹县及都江堰市;2010 年宁南泥石流受灾的凉山州宁南县;2013年芦山地震受灾的芦山县、宝兴县、天全县以及雨城区。研究区内涉及滑坡、泥石流、房屋倒塌、断路断桥、洪涝等灾害,且灾害大多分布于山区,影像数据为灾后高分辨率无人机遥感影像,影像覆盖面积总计644.59 平方千米。研究区范围和数据覆盖情况见图 1。
3 灾害影像样本采集
3.1 基于 Python 的灾害样本采集方法的建立
Python 为脚本开发语言,因为 Python 简单易操作,功能齐全,通过 Python 调用 ArcGIS 的一些功能的开发方式在复杂的数据处理等方面有很大的优势[1]。本文利用 ArcGIS 提供的 Python 站点包 ArcPy,实现了系列无人机影像灾害点样本数据的自动批量裁剪。具体实现方法是:基于 Python 编写好的脚本文本在ArcGIS 中创建自定义 Arctoolbox 工具,首先配置工作空间,如图 2 所示:工作空间下有 images 文件夹,用于存放灾害的原始影像,支持系列无人机影像;points 文件夹用于存放灾害点矢量数据,该矢量数据为灾害点的位置数据,字段信息需包含灾害类型、样本大小等相关用于脚本语言读取的字段;samples 文件夹用于存放生成的灾害样本数据;tool 文件夹存放ArcGIStoolbox 工具箱,并将此目录关联到 ArcGIS中。
工具的关联和参数设置如图 3 所示。在 ArcGIS toolbox 工具箱下添加一个新的 Toolbox ( New Toolbox),在 Toolbox 中可添加脚本工具,Add 一个新的 Script,这个新增加的 Script 工具可以和 Python文件关联,在 Script File 中选择影像样本裁剪所需的 py 文件,创建用于样本裁剪的 clip raster 工具。
3.2 采集灾害样本
基于收集到的无人机影像,进一步通过目视解译的方法,完善专题资料上没有的灾害点信息。用与ArcGIS 建立灾害点数据,并将具有灾害点的影像图存放在工作空间的 images 文件夹下,点击 clip raster工具,在出现的界面下路径文件选择建立好的工作空间 Clip 即可对影像进行自动裁剪如图 4 所示,批量处理得到各类灾害样本,并制作地质灾害范围图层。
基于 Python 的灾害样本采集方法的建立,与其他的样本采集方法相比更为方便。根据实地和受灾范围的大小来对每种灾害类型的样本大小统一进行设置,自动采集好灾害样本后,在 samples 里查看每种类型的灾害样本大小采集的是否合适、样本的可辨度是否高,如果不合理,可以重新设置样本大小来重新采集,直到每种灾害类型的样本都清晰可见,并且可辨度高。样本具体制作流程如图 5 所示。
4 样本数据库
4.1 样本数据库的建设
数据库的建设是管理信息资源最有效地手段,对于某一目的的应用环境,构建最优的数据库模式。建立数据库一方面不仅能有效地存储数据,另一方面还能满足用户信息要求和处理要求,使用户更显而易见地了解到样本的各方面的数据信息。本次样本数据库的建设,按照成果要求和相关规范,制定了灾害点属性信息采集标准及相应的规范格式,并确定灾害相关信息的编码规范;最后按照成果要求进行入库,入库成果包括灾害样本影像数据、地面照片、灾害点矢量数据、灾害范围矢量数据和属性信息数据表,形成灾害样本数据库,如图 6 所示。
4.2 样本数据库表格的设计
遥感解译样本数据主要包括灾害样本影像数据、实地照片、灾害点矢量数据、灾害范围矢量数据和灾害属性信息数据表。样本数据要求影像纹理清晰、地物特征明显;影像纹理和光谱信息丰富、色调均匀、反差适中。建立灾害样本数据的工作量是非常庞大的,它需要合理组织样本数据库。为了能快速方便地查询获取样本数据及其基本信息,系统应当按照不同地质灾害类型建库,把同种地灾类多时相、多来源、不同分辨率等的样本数据存放在一张表中,而把其他地类样本放在另一张表中。将所采集的样本数据输入到数据库中,建立每种类别的多时相、多分辨率、多来源的样本影像数据库。建立遥感解译样本数据库必须考虑行政区位、日期、影像来源、纹理、形状与地形等特征,这不仅仅是简单地将所有样本影像堆积,而是必须按照样本影像的类别进行分类存放,同时存储这些影像的元数据及其描述信息。灾害属性信息数据表中包含灾害名称、影像源、日期、行政区位、经度、纬度、诱发因素、险情级别、图幅号、样本大小、光谱特征、形状特征、纹理特征、地形类型。遥感解译样本数据库基本结构示例如图 7所示。
4.3 样本数据库示例
灾害样本数据整理,是以实地照片及其属性信息为基础,获取灾害样本影像及相关属性信息,从而建立灾害样本数据库。样本数据库示例如图 8 所示。
4.4 样本数据库的检查与更新
遥感解译影像样本数据库也需要进行后期检查,结合影像库进行各项专业信息提取,并对其获取的专业信息成果进行检查,同时还能够利用 GPS 辅助外业检查,运用之前提取的成果检查样本库,及时更新以保持数据的正确性与有效性。遥感解译影像样本数据库是某个时期该地区的遥感样本影像,对于不同年份应依照收集的资料情况建立不同年度的样本影像库,以保证样本影像库的时效性。
5 结束语
在具体工作实践中常常需要根据特定的专业业务需要定制适合解决问题的地理处理工具,Python与 ArcGIS 的结合,使得问题变得简单,操作也变得简单,处理问题也变得比较方便容易一些,所以Python 在 ArcGIS 地理处理框架中占据非常重要的位置。ArcGIS 环境下的系列无人机影像灾害样本库建设,在裁剪样本的过程中提高了速度,并且可以批量处理多种灾害样本,节约了时间的同时也大大减少了人力;数据库的成功建设,不仅有助于我们清晰地了解灾害信息,而且可为后一步的灾害识别工作提供基础的训练数据支持。
参考文献:
[1] 丘恩. Python 核心编程(第 2 版)[M]. 北京:人民邮电出版社,2008.
[2] 焦洋,邓鑫,李胜才. 基于 Python 的 ArcGIS 空间数据格式批处理转换工具开发[J]. 现代测绘,2012,35(3):54-55.
[3] 马卫春,杨友长. 基于 Python 的 ArcGIS Server 地图瓦片定时自动更新方法[J]. 地理空间信息,2013, 11(2):147-149.
[4] 田学志. 基于 Python 的 ArcGIS 地理处理应用研究[J].计算机光盘软件与应用,2013,(7).
最后,小编提醒,由于微信修改了推送规则,没有经常留言或点“在看”的,会慢慢的收不到推送!如果你还想每天看到我们的推送,请将ArcGis爱学习加为星标或每次看完后点击一下页面下端的“赞”“在看”,拜托了!▼往期精彩回顾 ▼
2、
3、
4、 查看全部
||ArcGIS 环境下的系列无人机影像灾害样本库建设
摘要:以“5·12”汶川地震、“4·20”芦山地震和“6·18”宁南特大山洪泥石流等地质灾害为例,在 ArcGIS环境下采用 ArcMap 软件与 Python 脚本开发相结合的方式,利用多时期无人机影像进行灾害样本的采集,批量处理多种灾害样本,从而建立对应的无人机影像灾害样本库。关键词ArcGIS;无人机;地质灾害;样本库1 引言20 世纪 90 年代以来,受人类活动和全球化的影响,地质灾害越发严重,地质灾害发生的规模、数量和分布范围呈上升趋势。2008 年“5·12”汶川特大地震后,由于地质结构被破坏,加之恶劣天气的影响,滑坡和泥石流等次生灾害在很长一段时间内影响着震区,这些地质灾害不仅直接或者间接地危害人民群众生命、财产安全,还会给社会和经济建设造成巨大的损失。利用遥感技术获取灾区影像已成为灾后获取灾害信息的重要手段,无人机遥感技术时效性强、使用成本低、起降方式灵活多样、影像分辨率高等优势,使其在地质灾害应急救援工作中具有广阔的应用前景和发展前途。近几年,相关应急救灾部门已经具备在灾后第一时间获取地质灾害现场的无人机影像的能力。是一门解释型语言,因其不需要编译和链接的时间,所以能够节省开发时间,解释器可以交互式使用,同时能够很方便地测试语言中的各种功能,便于编写发布用的程序,具有开源、模块丰富、面向对象、面向过程等特性,能够与 ArcGIS 软件很好地结合使用[3]。从 ArcGIS9.0 开始,我们就可以使用 Python, 并把它作为首选脚本语言[4],实现空间数据的自动化批量处理,从而起到简化流程,提高工作的自动化程度的作用[2]。本文介绍一种在 ArcGIS环境下,结合 Python 脚本开发的方式,利用历史系列无人机影像快速批量建立地质灾害样本库的方法,该样本库可为后续灾害识别提供基础的训练数据支持,一定程度上改善了样本数据采集仅停留在人工解译层面的现状。
2 研究区与实验数据
根据现有数据情况确定的研究区包括:2008 年汶川地震受灾的汶川县、北川县、安县、绵竹县及都江堰市;2010 年宁南泥石流受灾的凉山州宁南县;2013年芦山地震受灾的芦山县、宝兴县、天全县以及雨城区。研究区内涉及滑坡、泥石流、房屋倒塌、断路断桥、洪涝等灾害,且灾害大多分布于山区,影像数据为灾后高分辨率无人机遥感影像,影像覆盖面积总计644.59 平方千米。研究区范围和数据覆盖情况见图 1。
3 灾害影像样本采集
3.1 基于 Python 的灾害样本采集方法的建立
Python 为脚本开发语言,因为 Python 简单易操作,功能齐全,通过 Python 调用 ArcGIS 的一些功能的开发方式在复杂的数据处理等方面有很大的优势[1]。本文利用 ArcGIS 提供的 Python 站点包 ArcPy,实现了系列无人机影像灾害点样本数据的自动批量裁剪。具体实现方法是:基于 Python 编写好的脚本文本在ArcGIS 中创建自定义 Arctoolbox 工具,首先配置工作空间,如图 2 所示:工作空间下有 images 文件夹,用于存放灾害的原始影像,支持系列无人机影像;points 文件夹用于存放灾害点矢量数据,该矢量数据为灾害点的位置数据,字段信息需包含灾害类型、样本大小等相关用于脚本语言读取的字段;samples 文件夹用于存放生成的灾害样本数据;tool 文件夹存放ArcGIStoolbox 工具箱,并将此目录关联到 ArcGIS中。
工具的关联和参数设置如图 3 所示。在 ArcGIS toolbox 工具箱下添加一个新的 Toolbox ( New Toolbox),在 Toolbox 中可添加脚本工具,Add 一个新的 Script,这个新增加的 Script 工具可以和 Python文件关联,在 Script File 中选择影像样本裁剪所需的 py 文件,创建用于样本裁剪的 clip raster 工具。
3.2 采集灾害样本
基于收集到的无人机影像,进一步通过目视解译的方法,完善专题资料上没有的灾害点信息。用与ArcGIS 建立灾害点数据,并将具有灾害点的影像图存放在工作空间的 images 文件夹下,点击 clip raster工具,在出现的界面下路径文件选择建立好的工作空间 Clip 即可对影像进行自动裁剪如图 4 所示,批量处理得到各类灾害样本,并制作地质灾害范围图层。
基于 Python 的灾害样本采集方法的建立,与其他的样本采集方法相比更为方便。根据实地和受灾范围的大小来对每种灾害类型的样本大小统一进行设置,自动采集好灾害样本后,在 samples 里查看每种类型的灾害样本大小采集的是否合适、样本的可辨度是否高,如果不合理,可以重新设置样本大小来重新采集,直到每种灾害类型的样本都清晰可见,并且可辨度高。样本具体制作流程如图 5 所示。
4 样本数据库
4.1 样本数据库的建设
数据库的建设是管理信息资源最有效地手段,对于某一目的的应用环境,构建最优的数据库模式。建立数据库一方面不仅能有效地存储数据,另一方面还能满足用户信息要求和处理要求,使用户更显而易见地了解到样本的各方面的数据信息。本次样本数据库的建设,按照成果要求和相关规范,制定了灾害点属性信息采集标准及相应的规范格式,并确定灾害相关信息的编码规范;最后按照成果要求进行入库,入库成果包括灾害样本影像数据、地面照片、灾害点矢量数据、灾害范围矢量数据和属性信息数据表,形成灾害样本数据库,如图 6 所示。
4.2 样本数据库表格的设计
遥感解译样本数据主要包括灾害样本影像数据、实地照片、灾害点矢量数据、灾害范围矢量数据和灾害属性信息数据表。样本数据要求影像纹理清晰、地物特征明显;影像纹理和光谱信息丰富、色调均匀、反差适中。建立灾害样本数据的工作量是非常庞大的,它需要合理组织样本数据库。为了能快速方便地查询获取样本数据及其基本信息,系统应当按照不同地质灾害类型建库,把同种地灾类多时相、多来源、不同分辨率等的样本数据存放在一张表中,而把其他地类样本放在另一张表中。将所采集的样本数据输入到数据库中,建立每种类别的多时相、多分辨率、多来源的样本影像数据库。建立遥感解译样本数据库必须考虑行政区位、日期、影像来源、纹理、形状与地形等特征,这不仅仅是简单地将所有样本影像堆积,而是必须按照样本影像的类别进行分类存放,同时存储这些影像的元数据及其描述信息。灾害属性信息数据表中包含灾害名称、影像源、日期、行政区位、经度、纬度、诱发因素、险情级别、图幅号、样本大小、光谱特征、形状特征、纹理特征、地形类型。遥感解译样本数据库基本结构示例如图 7所示。
4.3 样本数据库示例
灾害样本数据整理,是以实地照片及其属性信息为基础,获取灾害样本影像及相关属性信息,从而建立灾害样本数据库。样本数据库示例如图 8 所示。
4.4 样本数据库的检查与更新
遥感解译影像样本数据库也需要进行后期检查,结合影像库进行各项专业信息提取,并对其获取的专业信息成果进行检查,同时还能够利用 GPS 辅助外业检查,运用之前提取的成果检查样本库,及时更新以保持数据的正确性与有效性。遥感解译影像样本数据库是某个时期该地区的遥感样本影像,对于不同年份应依照收集的资料情况建立不同年度的样本影像库,以保证样本影像库的时效性。
5 结束语
在具体工作实践中常常需要根据特定的专业业务需要定制适合解决问题的地理处理工具,Python与 ArcGIS 的结合,使得问题变得简单,操作也变得简单,处理问题也变得比较方便容易一些,所以Python 在 ArcGIS 地理处理框架中占据非常重要的位置。ArcGIS 环境下的系列无人机影像灾害样本库建设,在裁剪样本的过程中提高了速度,并且可以批量处理多种灾害样本,节约了时间的同时也大大减少了人力;数据库的成功建设,不仅有助于我们清晰地了解灾害信息,而且可为后一步的灾害识别工作提供基础的训练数据支持。
参考文献:
[1] 丘恩. Python 核心编程(第 2 版)[M]. 北京:人民邮电出版社,2008.
[2] 焦洋,邓鑫,李胜才. 基于 Python 的 ArcGIS 空间数据格式批处理转换工具开发[J]. 现代测绘,2012,35(3):54-55.
[3] 马卫春,杨友长. 基于 Python 的 ArcGIS Server 地图瓦片定时自动更新方法[J]. 地理空间信息,2013, 11(2):147-149.
[4] 田学志. 基于 Python 的 ArcGIS 地理处理应用研究[J].计算机光盘软件与应用,2013,(7).
最后,小编提醒,由于微信修改了推送规则,没有经常留言或点“在看”的,会慢慢的收不到推送!如果你还想每天看到我们的推送,请将ArcGis爱学习加为星标或每次看完后点击一下页面下端的“赞”“在看”,拜托了!▼往期精彩回顾 ▼
2、
3、
4、
自动采集编写(Scrapy框架Scrapy架构图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-04-18 14:20
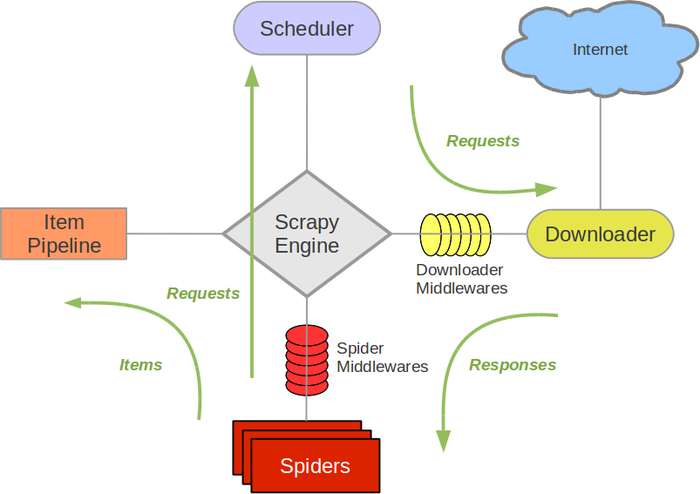
Scrapy 框架 Scrapy 架构图(绿线为数据流向):
Scrapy 的工作原理
代码写好了,程序开始运行了……
发动机:嗨!蜘蛛,你在对付哪个网站?
蜘蛛:老板要我处理。
引擎:给我第一个需要处理的 URL。
Spider:在这里,第一个 URL 是。
发动机:嗨!调度员,我有一个请求,请求您帮我排序并加入队列。
调度程序:好的,正在处理您等一下。
发动机:嗨!调度员,给我你处理的请求。
调度器:给你,这是我处理的请求
发动机:嗨!下载者,请帮我按照老板下载中间件的设置下载这个请求
下载者:好的!给你,这是下载的东西。(如果失败:sorry,这个请求下载失败。然后引擎告诉调度器这个请求下载失败,你记录一下,我们稍后下载)
发动机:嗨!蜘蛛,这是一个下载的东西,已经按照老大的下载中间件进行了处理,你可以自己处理(注意!这里的响应默认由def parse()函数处理)
蜘蛛:(处理数据后需要跟进的URL),嗨!Engine,我这里有两个结果,这是我需要跟进的URL,这是我得到的Item数据。
发动机:嗨!我这里有一件物品,请帮我处理!调度器!这个是需要你跟进的网址帮我处理的。然后从第四步开始循环,直到得到boss需要的所有信息。
Pipes ``调度器:好的,现在就做!
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的URL,Scrapy也会重新下载。)
制作一个Scrapy爬虫一共需要4步: Scrapy安装介绍
Scrapy框架官网:
Scrapy中文维护网站:
Windows安装方式Ubuntu需要9.10以上的安装方式
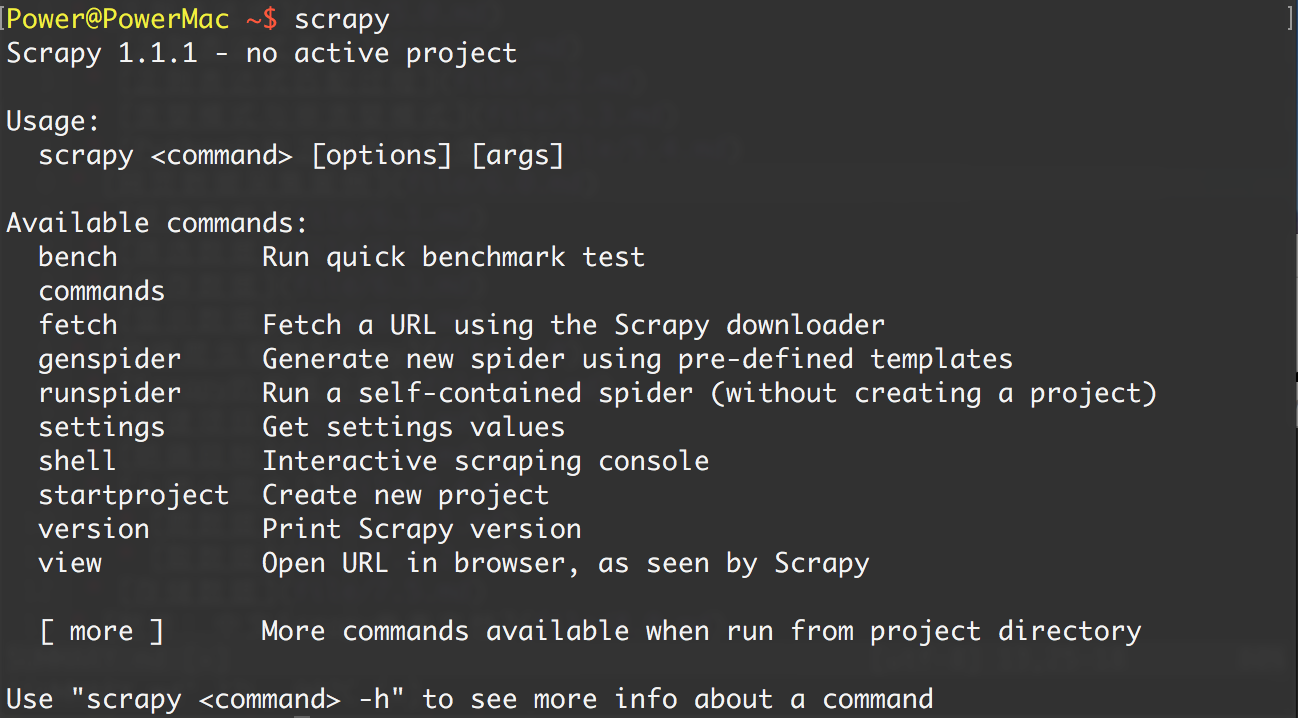
安装完成后,只要在命令终端输入scrapy,就会出现类似如下的结果,说明已经安装成功
具体Scrapy安装过程参考:每个平台都有安装方法
入门案例学习目标一. 新项目(scrapy startproject)
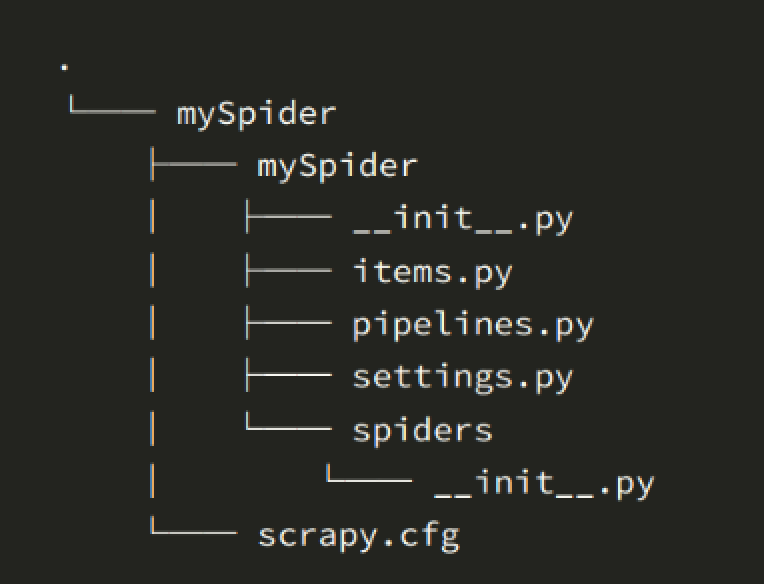
scrapy startproject mySpider
下面简单介绍一下各个主文件的作用:
scrapy.cfg :项目的配置文件
mySpider/ :项目的 Python 模块,将从中引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ : 蜘蛛代码存放的目录
信息。
打开 mySpider 目录下的 items.py
Item 定义了一个结构化的数据字段来保存爬取的数据,有点像 Python 中的 dict,但提供了一些额外的保护来减少错误。
可以通过创建一个scrapy.Item类并定义一个scrapy.Field类型的类属性来定义一个Item(可以理解为一种类似于ORM的映射关系)。
接下来,创建一个 ItcastItem 类,并构建项目模型。
import scrapy
class ItcastItem(scrapy.Item):
name = scrapy.Field()
level = scrapy.Field()
info = scrapy.Field()
三、制作蜘蛛 (spiders/itcastSpider.py)
爬虫功能分为两步:
1. 爬取数据
scrapy genspider itcast "itcast.cn"
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
其实我们也可以自己创建itcast.py,写上面的代码,不过使用命令可以省去写固定代码的麻烦
要创建 Spider,您必须继承 scrapy.Spider 类并定义三个强制属性和一个方法。
将start_urls的值改为第一个要爬取的url
start_urls = ("http://www.itcast.cn/channel/teacher.shtml",)
修改 parse() 方法
def parse(self, response):
filename = "teacher.html"
open(filename, 'w').write(response.body)
然后运行看看,在mySpider目录下执行:
scrapy crawl itcast
是的,它是itcast。看上面代码,是ItcastSpider类的name属性,是唯一使用scrapy genspider命令的爬虫名称。
运行后,如果打印日志显示[scrapy] INFO: Spider closed (finished),则表示执行完成。之后,当前文件夹中出现了一个teacher.html文件,里面收录了我们刚要抓取的网页的所有源码信息。
# 注意,Python2.x默认编码环境是ASCII,当和取回的数据编码格式不一致时,可能会造成乱码;
# 我们可以指定保存内容的编码格式,一般情况下,我们可以在代码最上方添加:
import sys
reload(sys)
sys.setdefaultencoding("utf-8")<br /><br /># 这三行代码是Python2.x里解决中文编码的万能钥匙,经过这么多年的吐槽后Python3学乖了,默认编码是Unicode了...(祝大家早日拥抱Python3)
2. 获取数据
xxx
xxxxx
xxxxxxxx
是不是一目了然?只需转到 XPath 并开始提取数据。
from mySpider.items import ItcastItem
from mySpider.items import ItcastItem
def parse(self, response): #open("teacher.html","wb").write(response.body).close() # 存放老师信息的集合 items = [] for each in response.xpath("//div[@class='li_txt']"): # 将我们得到的数据封装到一个 `ItcastItem` 对象 item = ItcastItem() #extract()方法返回的都是unicode字符串 name = each.xpath("h3/text()").extract() title = each.xpath("h4/text()").extract() info = each.xpath("p/text()").extract() #xpath返回的是包含一个元素的列表 item['name'] = name[0] item['title'] = title[0] item['info'] = info[0] items.append(item) # 直接返回最后数据 return items
保存数据有四种最简单的方法scrapy保存信息,-o输出指定格式的文件,命令如下:
# json格式,默认为Unicode编码
scrapy crawl itcast -o teachers.json
# json lines格式,默认为Unicode编码
scrapy crawl itcast -o teachers.jsonl
# csv 逗号表达式,可用Excel打开
scrapy crawl itcast -o teachers.csv
# xml格式
scrapy crawl itcast -o teachers.xml
想想如果把代码改成下面的形式,结果是完全一样的。考虑产量在这里的作用:
from mySpider.items import ItcastItem
def parse(self, response):
#open("teacher.html","wb").write(response.body).close()
# 存放老师信息的集合
#items = []
for each in response.xpath("//div[@class='li_txt']"):
# 将我们得到的数据封装到一个 `ItcastItem` 对象
item = ItcastItem()
#extract()方法返回的都是unicode字符串
name = each.xpath("h3/text()").extract()
title = each.xpath("h4/text()").extract()
info = each.xpath("p/text()").extract()
#xpath返回的是包含一个元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
#items.append(item)
#将获取的数据交给pipelines
yield item
# 返回数据,不经过pipeline
#return items
废壳
Scrapy 终端是一个交互式终端。我们可以在不启动蜘蛛的情况下尝试调试代码。它还可以用于测试 XPath 或 CSS 表达式,了解它们是如何工作的,并促进从我们抓取的网页中提取数据。
如果安装了 IPython,Scrapy 终端将使用 IPython(代替标准 Python 终端)。IPython 终端比其他终端更强大,提供智能自动完成、突出显示和其他功能。(推荐安装IPython)
启动 Scrapy Shell
进入项目根目录,执行以下命令启动shell:
scrapy shell "http://www.itcast.cn/channel/teacher.shtml"
Scrapy Shell 会根据下载的页面自动创建一些方便的对象,例如 Response 对象,Selector 对象(用于 HTML 和 XML 内容)。
Selectors 选择器 Scrapy Selectors 内置 XPath 和 CSS 选择器表达式机制
Selector有四种基本方法,最常用的是xpath:
XPath 表达式及其对应含义的示例:
/html/head/title: 选择文档中 标签内的 元素
/html/head/title/text(): 选择上面提到的 元素的文字
//td: 选择所有的 元素
//div[@class="mine"]: 选择所有具有 class="mine" 属性的 div 元素
试试选择器
我们以腾讯招聘的网站为例:
<p># 启动
scrapy shell "http://hr.tencent.com/position ... ot%3B
# 返回 xpath选择器对象列表
response.xpath('//title')
[ 查看全部
自动采集编写(Scrapy框架Scrapy架构图)
Scrapy 框架 Scrapy 架构图(绿线为数据流向):
Scrapy 的工作原理
代码写好了,程序开始运行了……
发动机:嗨!蜘蛛,你在对付哪个网站?
蜘蛛:老板要我处理。
引擎:给我第一个需要处理的 URL。
Spider:在这里,第一个 URL 是。
发动机:嗨!调度员,我有一个请求,请求您帮我排序并加入队列。
调度程序:好的,正在处理您等一下。
发动机:嗨!调度员,给我你处理的请求。
调度器:给你,这是我处理的请求
发动机:嗨!下载者,请帮我按照老板下载中间件的设置下载这个请求
下载者:好的!给你,这是下载的东西。(如果失败:sorry,这个请求下载失败。然后引擎告诉调度器这个请求下载失败,你记录一下,我们稍后下载)
发动机:嗨!蜘蛛,这是一个下载的东西,已经按照老大的下载中间件进行了处理,你可以自己处理(注意!这里的响应默认由def parse()函数处理)
蜘蛛:(处理数据后需要跟进的URL),嗨!Engine,我这里有两个结果,这是我需要跟进的URL,这是我得到的Item数据。
发动机:嗨!我这里有一件物品,请帮我处理!调度器!这个是需要你跟进的网址帮我处理的。然后从第四步开始循环,直到得到boss需要的所有信息。
Pipes ``调度器:好的,现在就做!
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的URL,Scrapy也会重新下载。)
制作一个Scrapy爬虫一共需要4步: Scrapy安装介绍
Scrapy框架官网:
Scrapy中文维护网站:
Windows安装方式Ubuntu需要9.10以上的安装方式
安装完成后,只要在命令终端输入scrapy,就会出现类似如下的结果,说明已经安装成功
具体Scrapy安装过程参考:每个平台都有安装方法
入门案例学习目标一. 新项目(scrapy startproject)
scrapy startproject mySpider
下面简单介绍一下各个主文件的作用:
scrapy.cfg :项目的配置文件
mySpider/ :项目的 Python 模块,将从中引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ : 蜘蛛代码存放的目录
信息。
打开 mySpider 目录下的 items.py
Item 定义了一个结构化的数据字段来保存爬取的数据,有点像 Python 中的 dict,但提供了一些额外的保护来减少错误。
可以通过创建一个scrapy.Item类并定义一个scrapy.Field类型的类属性来定义一个Item(可以理解为一种类似于ORM的映射关系)。
接下来,创建一个 ItcastItem 类,并构建项目模型。
import scrapy
class ItcastItem(scrapy.Item):
name = scrapy.Field()
level = scrapy.Field()
info = scrapy.Field()
三、制作蜘蛛 (spiders/itcastSpider.py)
爬虫功能分为两步:
1. 爬取数据
scrapy genspider itcast "itcast.cn"
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
其实我们也可以自己创建itcast.py,写上面的代码,不过使用命令可以省去写固定代码的麻烦
要创建 Spider,您必须继承 scrapy.Spider 类并定义三个强制属性和一个方法。
将start_urls的值改为第一个要爬取的url
start_urls = ("http://www.itcast.cn/channel/teacher.shtml",)
修改 parse() 方法
def parse(self, response):
filename = "teacher.html"
open(filename, 'w').write(response.body)
然后运行看看,在mySpider目录下执行:
scrapy crawl itcast
是的,它是itcast。看上面代码,是ItcastSpider类的name属性,是唯一使用scrapy genspider命令的爬虫名称。
运行后,如果打印日志显示[scrapy] INFO: Spider closed (finished),则表示执行完成。之后,当前文件夹中出现了一个teacher.html文件,里面收录了我们刚要抓取的网页的所有源码信息。
# 注意,Python2.x默认编码环境是ASCII,当和取回的数据编码格式不一致时,可能会造成乱码;
# 我们可以指定保存内容的编码格式,一般情况下,我们可以在代码最上方添加:
import sys
reload(sys)
sys.setdefaultencoding("utf-8")<br /><br /># 这三行代码是Python2.x里解决中文编码的万能钥匙,经过这么多年的吐槽后Python3学乖了,默认编码是Unicode了...(祝大家早日拥抱Python3)
2. 获取数据

xxx
xxxxx
xxxxxxxx
是不是一目了然?只需转到 XPath 并开始提取数据。
from mySpider.items import ItcastItem
from mySpider.items import ItcastItem
def parse(self, response): #open("teacher.html","wb").write(response.body).close() # 存放老师信息的集合 items = [] for each in response.xpath("//div[@class='li_txt']"): # 将我们得到的数据封装到一个 `ItcastItem` 对象 item = ItcastItem() #extract()方法返回的都是unicode字符串 name = each.xpath("h3/text()").extract() title = each.xpath("h4/text()").extract() info = each.xpath("p/text()").extract() #xpath返回的是包含一个元素的列表 item['name'] = name[0] item['title'] = title[0] item['info'] = info[0] items.append(item) # 直接返回最后数据 return items
保存数据有四种最简单的方法scrapy保存信息,-o输出指定格式的文件,命令如下:
# json格式,默认为Unicode编码
scrapy crawl itcast -o teachers.json
# json lines格式,默认为Unicode编码
scrapy crawl itcast -o teachers.jsonl
# csv 逗号表达式,可用Excel打开
scrapy crawl itcast -o teachers.csv
# xml格式
scrapy crawl itcast -o teachers.xml
想想如果把代码改成下面的形式,结果是完全一样的。考虑产量在这里的作用:
from mySpider.items import ItcastItem
def parse(self, response):
#open("teacher.html","wb").write(response.body).close()
# 存放老师信息的集合
#items = []
for each in response.xpath("//div[@class='li_txt']"):
# 将我们得到的数据封装到一个 `ItcastItem` 对象
item = ItcastItem()
#extract()方法返回的都是unicode字符串
name = each.xpath("h3/text()").extract()
title = each.xpath("h4/text()").extract()
info = each.xpath("p/text()").extract()
#xpath返回的是包含一个元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
#items.append(item)
#将获取的数据交给pipelines
yield item
# 返回数据,不经过pipeline
#return items
废壳
Scrapy 终端是一个交互式终端。我们可以在不启动蜘蛛的情况下尝试调试代码。它还可以用于测试 XPath 或 CSS 表达式,了解它们是如何工作的,并促进从我们抓取的网页中提取数据。
如果安装了 IPython,Scrapy 终端将使用 IPython(代替标准 Python 终端)。IPython 终端比其他终端更强大,提供智能自动完成、突出显示和其他功能。(推荐安装IPython)
启动 Scrapy Shell
进入项目根目录,执行以下命令启动shell:
scrapy shell "http://www.itcast.cn/channel/teacher.shtml"

Scrapy Shell 会根据下载的页面自动创建一些方便的对象,例如 Response 对象,Selector 对象(用于 HTML 和 XML 内容)。
Selectors 选择器 Scrapy Selectors 内置 XPath 和 CSS 选择器表达式机制
Selector有四种基本方法,最常用的是xpath:
XPath 表达式及其对应含义的示例:
/html/head/title: 选择文档中 标签内的 元素
/html/head/title/text(): 选择上面提到的 元素的文字
//td: 选择所有的 元素
//div[@class="mine"]: 选择所有具有 class="mine" 属性的 div 元素
试试选择器
我们以腾讯招聘的网站为例:
<p># 启动
scrapy shell "http://hr.tencent.com/position ... ot%3B
# 返回 xpath选择器对象列表
response.xpath('//title')
[
自动采集编写(如何利用Python打造搜狗壁纸自动下载爬虫库的反爬措施)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-04-18 14:17
这些案例是为一些想进入Python行业的朋友写的。看到大家都很满意,我又拿出来了。如果你已经开始学习python,对爬虫一无所知,不妨看看这个。几个案例!
二、环境准备
Python 3
requests 库、lxml 库、beautifulsoup4 库
pip install XX XX XX 一起安装。
三、Python爬虫小案例
1、获取机器的公网IP地址
使用python的requests库+公网查IP接口自动获取IP地址
2、使用百度的搜索界面,Python编写url采集工具
需要使用requests库和BeautifulSoup库,遵守百度搜索结构的URL链接规则,通过在程序中设置User-Agent请求头绕过百度搜索引擎的反爬机制。
Python 源代码:
用Python语言编写程序后,使用关键词inurl:/dede/login.php批量提取某个网络的后台地址cms:
3、使用Python制作搜狗壁纸自动下载爬虫
搜狗壁纸的地址是json格式的,所以用json库解析这组数据,把爬虫程序存放图片的磁盘路径改成要存放图片的路径。
渲染:
4、Python 自动填充调查
和一般网页一样,多次提交数据都需要一个验证码,这就是反爬机制。
如图:
那么如何绕过验证码的反爬措施呢?使用X-Forwarded-For伪造IP地址访问,Python代码如下:
效果:
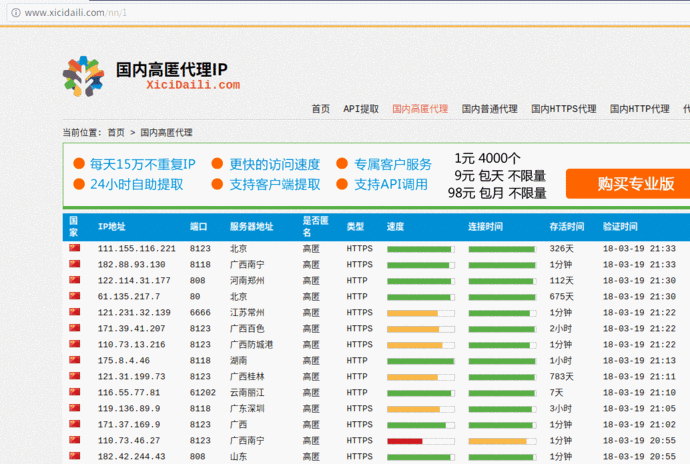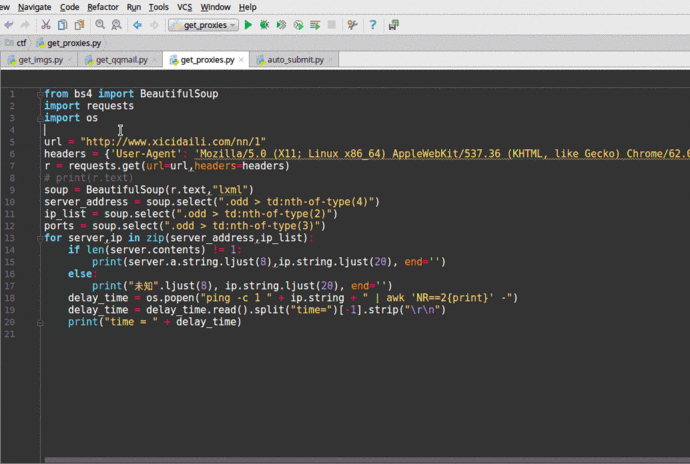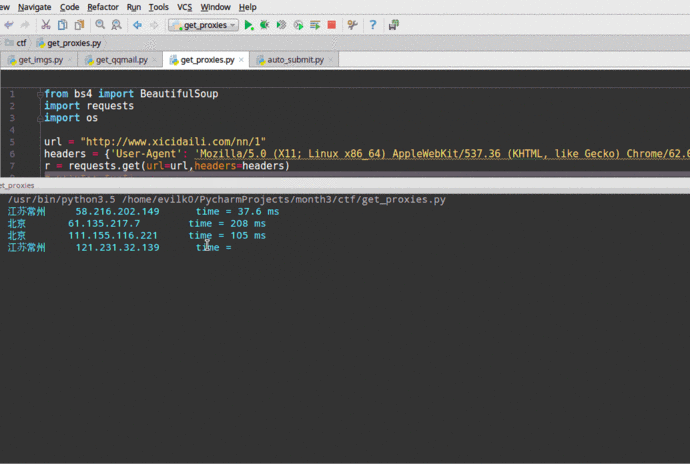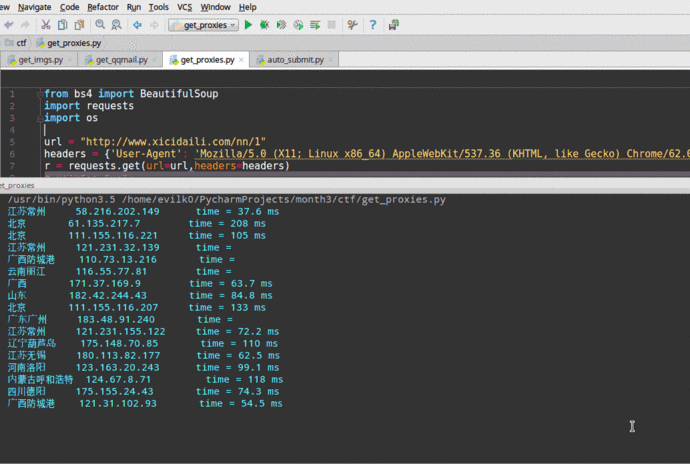
5、获取 West Thorn 代理上的 IP,以验证这些代理被禁止的可能性和延迟时间
可以将Python爬取的代理IP添加到代理链中,然后就可以进行一般的渗透任务了。这里,linux系统命令ping -c 1 " + ip.string + " | awk 'NR==2{print}' - 被直接调用。要在Windows下运行这个程序,需要修改os.popen倒数第二行的命令,可以修改为Windows可执行。
爬取的数据如图:
演示:
结论 查看全部
自动采集编写(如何利用Python打造搜狗壁纸自动下载爬虫库的反爬措施)
这些案例是为一些想进入Python行业的朋友写的。看到大家都很满意,我又拿出来了。如果你已经开始学习python,对爬虫一无所知,不妨看看这个。几个案例!
二、环境准备
Python 3
requests 库、lxml 库、beautifulsoup4 库
pip install XX XX XX 一起安装。
三、Python爬虫小案例
1、获取机器的公网IP地址
使用python的requests库+公网查IP接口自动获取IP地址

2、使用百度的搜索界面,Python编写url采集工具
需要使用requests库和BeautifulSoup库,遵守百度搜索结构的URL链接规则,通过在程序中设置User-Agent请求头绕过百度搜索引擎的反爬机制。

Python 源代码:
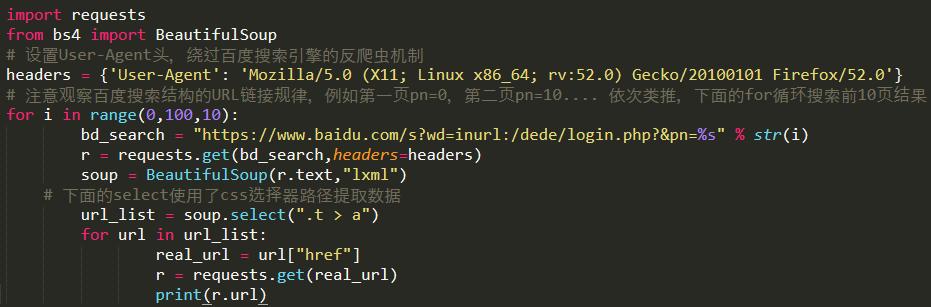
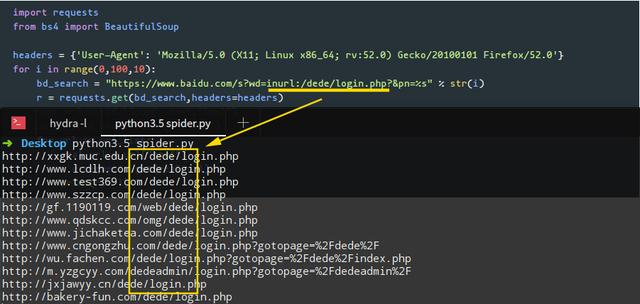
用Python语言编写程序后,使用关键词inurl:/dede/login.php批量提取某个网络的后台地址cms:
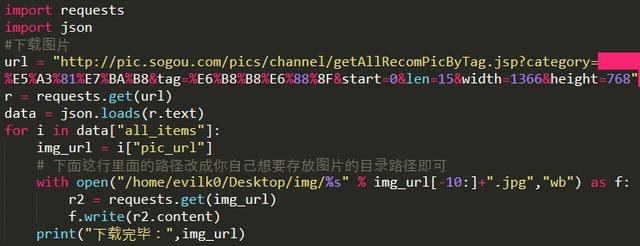
3、使用Python制作搜狗壁纸自动下载爬虫
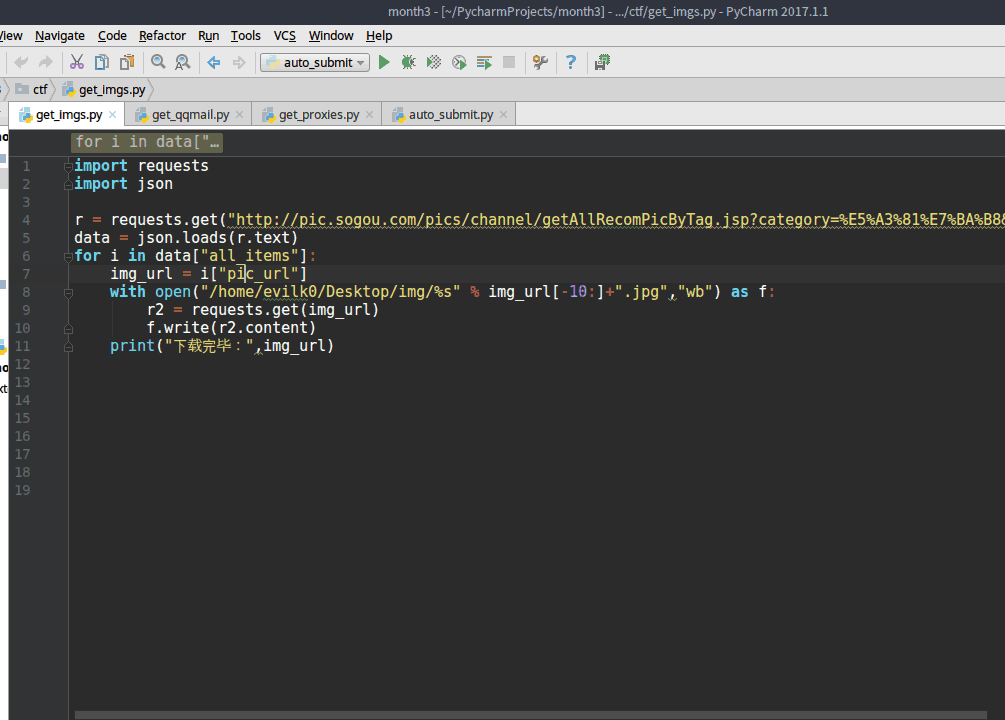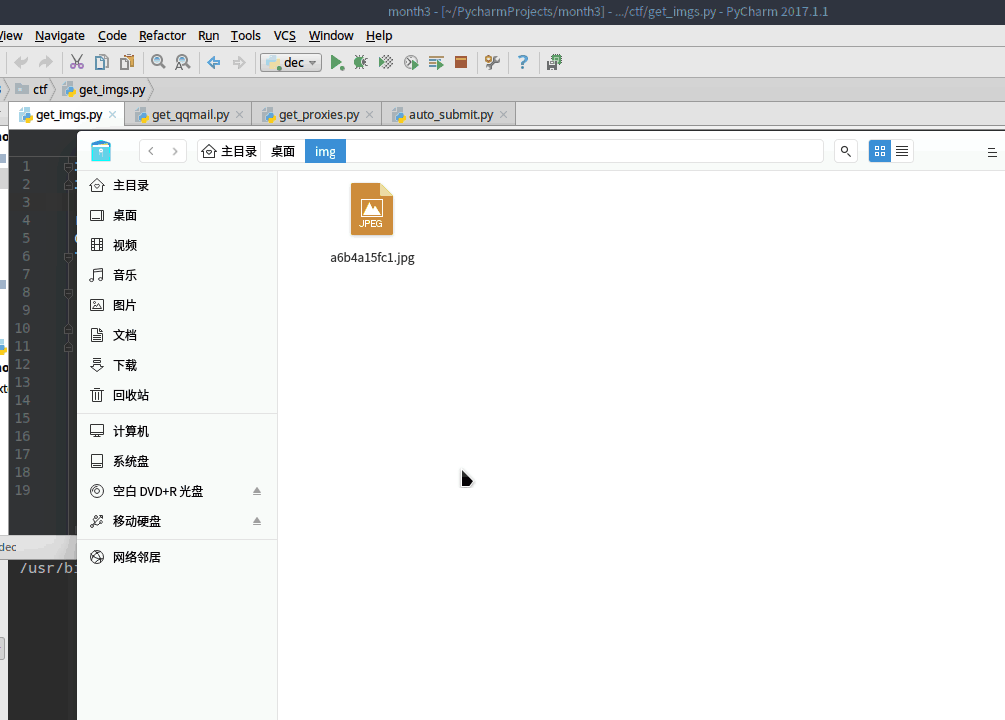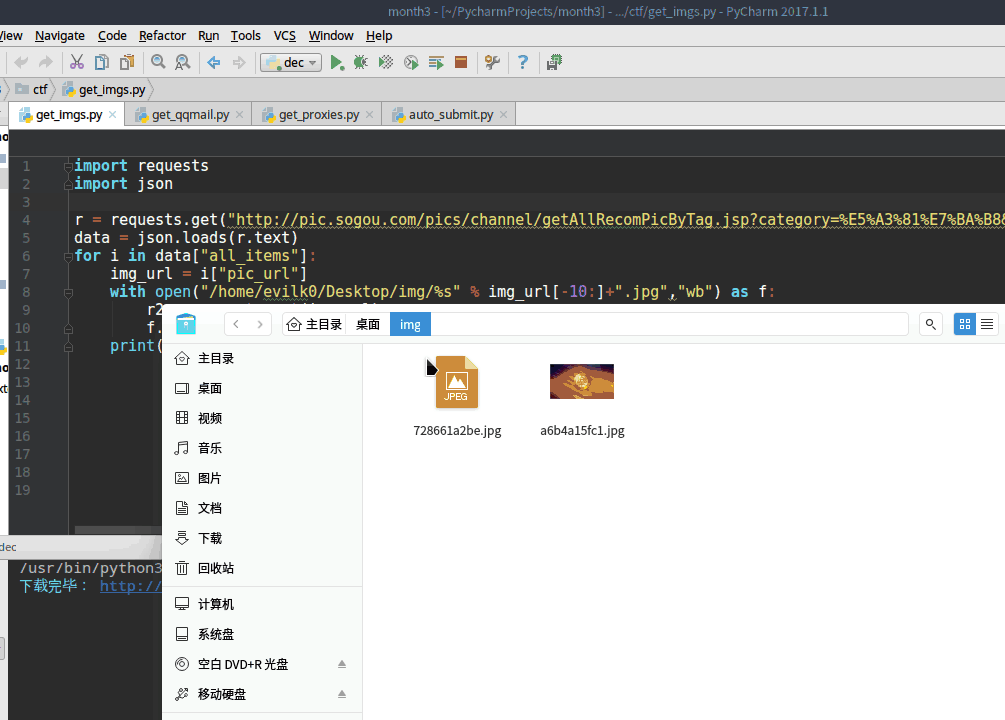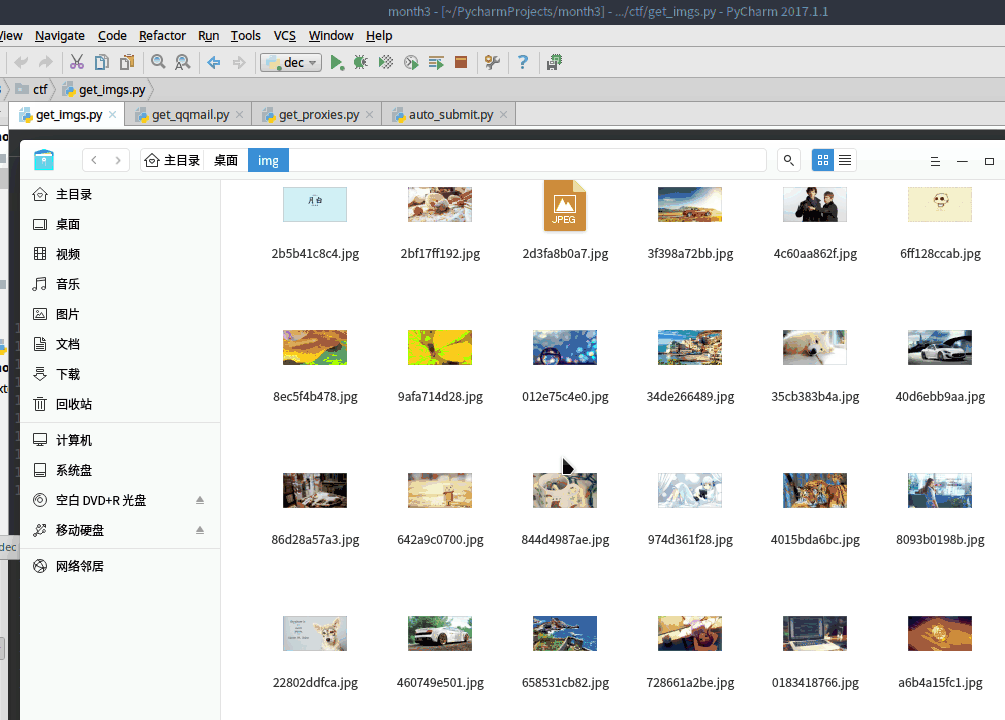
搜狗壁纸的地址是json格式的,所以用json库解析这组数据,把爬虫程序存放图片的磁盘路径改成要存放图片的路径。
渲染:
4、Python 自动填充调查
和一般网页一样,多次提交数据都需要一个验证码,这就是反爬机制。
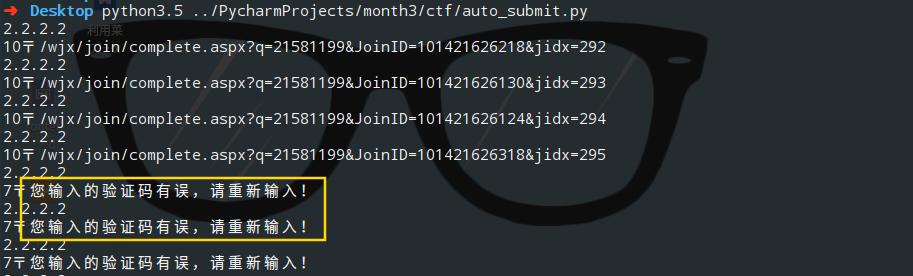
如图:
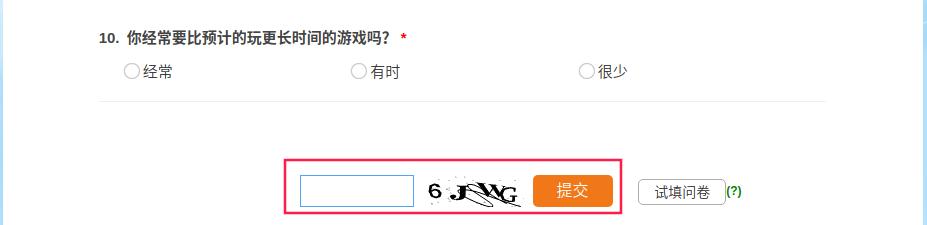
那么如何绕过验证码的反爬措施呢?使用X-Forwarded-For伪造IP地址访问,Python代码如下:
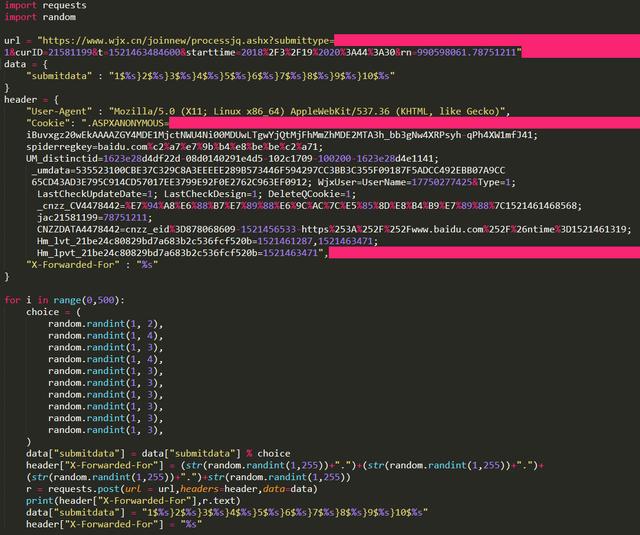
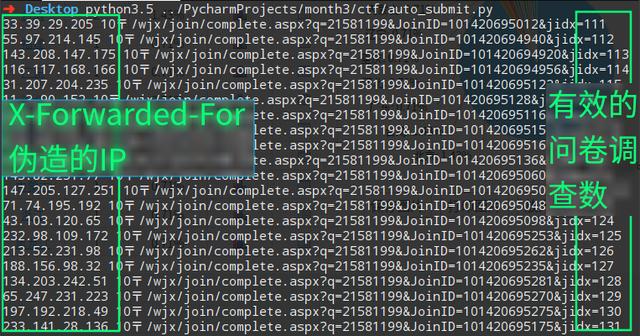
效果:
5、获取 West Thorn 代理上的 IP,以验证这些代理被禁止的可能性和延迟时间
可以将Python爬取的代理IP添加到代理链中,然后就可以进行一般的渗透任务了。这里,linux系统命令ping -c 1 " + ip.string + " | awk 'NR==2{print}' - 被直接调用。要在Windows下运行这个程序,需要修改os.popen倒数第二行的命令,可以修改为Windows可执行。
爬取的数据如图:
演示:
结论
自动采集编写(自动采集编写python爬虫,爬取名词宝宝的微信公众号文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-04-17 18:03
自动采集编写python爬虫,爬取名词宝宝的微信公众号文章。原理:python的网络请求采用get方法即可实现,模拟浏览器登录公众号后台,即可自动爬取我们需要的文章。主要实现内容:搜索,看图,和你聊天。方法:在实现自动采集之前,先用浏览器登录公众号后台,采集公众号相关用户信息。打开浏览器,在地址栏,输入相关搜索关键词,按照对应提示操作。
只要网页登录成功,点击关键词和公众号名称,就会自动搜索并爬取。实践一次:python爬虫系列之1——搜索关键词教程地址:用python爬取一个微信公众号文章需要requests模块,进行网络请求,模拟浏览器后台登录,获取相关信息。根据图例的步骤,就能自动获取大量数据信息,实践本次实践教程所需要的信息。
【准备工作】网页登录问题:难点在于如何把爬取的数据实时保存到本地,传到服务器。第一步:开发板登录因为之前就有登录不成功的经历,作为初次接触爬虫的同学,一定要熟悉网页登录的实际操作方法。登录首先登录开发板,推荐使用梯子或者国内的某些chrome浏览器,如360的firefox和chrome扩展支持,实现登录。
登录成功后,python爬虫系列之一——爬取微信公众号文章,教程上方的url就出现了。pipinstall开发板浏览器,安装相关的开发板软件。urllib2是python网络通信最常用的库。第二步:数据预处理本次实践准备爬取的是公众号文章推送列表。因为第一步的网页登录成功后,要打开登录页面。所以一直处于登录状态,用不到访问ip和端口这些操作。
用户管理:爬取到的数据,保存到本地,需要一个用户名和密码,用户名和密码是唯一的。拿公众号文章列表项目来说,用户名和密码就是文章列表项目标识符了。源代码引用:globalokhttp;import"weixin.urlopen";import"http.https";import"requests";import"xml.parser";import"sql";import"servlet";import"tomcat";import"urllib";import"flask";import"requests";import"xml.parser";import"xml";import"xmltest";import"tomcat";import"lxml";import"python";import"c";import"urllib.parse";import"multiprocessing";import"lxml";import"python";import"chef";import"cookielib";import"sqlite";import"mysql";import"time";import"mongo";import"redis";import"crypto";import"thrift";import"pymongo";import"node";import"core";imp。 查看全部
自动采集编写(自动采集编写python爬虫,爬取名词宝宝的微信公众号文章)
自动采集编写python爬虫,爬取名词宝宝的微信公众号文章。原理:python的网络请求采用get方法即可实现,模拟浏览器登录公众号后台,即可自动爬取我们需要的文章。主要实现内容:搜索,看图,和你聊天。方法:在实现自动采集之前,先用浏览器登录公众号后台,采集公众号相关用户信息。打开浏览器,在地址栏,输入相关搜索关键词,按照对应提示操作。
只要网页登录成功,点击关键词和公众号名称,就会自动搜索并爬取。实践一次:python爬虫系列之1——搜索关键词教程地址:用python爬取一个微信公众号文章需要requests模块,进行网络请求,模拟浏览器后台登录,获取相关信息。根据图例的步骤,就能自动获取大量数据信息,实践本次实践教程所需要的信息。
【准备工作】网页登录问题:难点在于如何把爬取的数据实时保存到本地,传到服务器。第一步:开发板登录因为之前就有登录不成功的经历,作为初次接触爬虫的同学,一定要熟悉网页登录的实际操作方法。登录首先登录开发板,推荐使用梯子或者国内的某些chrome浏览器,如360的firefox和chrome扩展支持,实现登录。
登录成功后,python爬虫系列之一——爬取微信公众号文章,教程上方的url就出现了。pipinstall开发板浏览器,安装相关的开发板软件。urllib2是python网络通信最常用的库。第二步:数据预处理本次实践准备爬取的是公众号文章推送列表。因为第一步的网页登录成功后,要打开登录页面。所以一直处于登录状态,用不到访问ip和端口这些操作。
用户管理:爬取到的数据,保存到本地,需要一个用户名和密码,用户名和密码是唯一的。拿公众号文章列表项目来说,用户名和密码就是文章列表项目标识符了。源代码引用:globalokhttp;import"weixin.urlopen";import"http.https";import"requests";import"xml.parser";import"sql";import"servlet";import"tomcat";import"urllib";import"flask";import"requests";import"xml.parser";import"xml";import"xmltest";import"tomcat";import"lxml";import"python";import"c";import"urllib.parse";import"multiprocessing";import"lxml";import"python";import"chef";import"cookielib";import"sqlite";import"mysql";import"time";import"mongo";import"redis";import"crypto";import"thrift";import"pymongo";import"node";import"core";imp。
自动采集编写(用GS浏览器的采数据方式介绍不同的窗口类型 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-04-17 10:27
)
用GS浏览器或者MS点数机完成采集规则后,就可以打开DS点数机进行数据采集,而吉索克爬虫软件非常灵活,提供多种使用方式供大家选择。下面介绍几种不同的数据采集方法。他们使用的爬虫窗口类型不同,控制方式也略有不同。爬虫窗口的描述请参考“DS 计数器的窗口类型”。
方法一:保存规则,爬取数据
完成采集规则并保存后,点击右上角“爬取数据”按钮,会自动弹出爬虫窗口。直接采集示例网页,使用测试窗口,菜单项很少。用于验证爬取规则的正确性。
1.1、用MS找几个单位制定规则并保存。
1.2,然后点击MS工具栏右上角的“爬取数据”按钮,会弹出DS爬虫窗口采集示例页面信息。
方法二:单次搜索/采集 DS 计数器
单独运行 DS 计数器,可以在左侧看到规则列表,每个规则都有“单次搜索”和“采集搜索”按钮。单查与吉搜的使用说明及区别请参考《吉索专有名词:单查与吉搜》。简单总结一下,Single Search 只运行一个爬虫窗口,而 Jisou 可以运行多个爬虫窗口。
2.1、打开DS计数器(GS浏览器版爬虫点击右上角“DS计数器”运行;火狐版爬虫点击工具中“DS数据”运行菜单)。
2.2、搜索主题名,可以使用*模糊匹配(前、后、中都可以收录*)。
2.3、右击主题名称,在弹出的菜单中选择“Statistical Leads”。您可以看到有多少潜在客户正在等待被抓取,而这些潜在客户就是 URL。
2.4、点击单搜索,输入线索数量(激活所有线索;如果要采集其他结构相同的网页,选择添加,然后复制多个网址进去,可以批量采集 >.更多操作见《如何管理规则线索》
方法三:使用爬虫组并发采集数据
爬虫组功能支持在一台电脑上同时运行多个爬虫。它集成了crontab爬虫调度器、DS计数器主菜单功能、数据库存储三大功能块。无需指定采集多少潜在客户,爬虫组会自动采集所有等待采集的潜在客户,让您高效采集数据,监控规则运行。有关用法,请参阅“如何运行 Crawler Swarm”
方法四:编写crontab并发爬虫采集数据
crontab程序(终极功能)和爬虫组一样,可以设置多个爬虫窗口并发采集数据,但是需要自己编写程序。两者的区别在于crontab程序可以指定爬虫窗口只有哪个主题任务采集,这样可以大大提高稳定性和效率,而爬虫组可以自由地将主题任务分配给爬虫窗口,而效率稍慢。详情请阅读文章《如何通过crontab程序实现周期性增量采集数据》。
如有疑问,您可以或
查看全部
自动采集编写(用GS浏览器的采数据方式介绍不同的窗口类型
)
用GS浏览器或者MS点数机完成采集规则后,就可以打开DS点数机进行数据采集,而吉索克爬虫软件非常灵活,提供多种使用方式供大家选择。下面介绍几种不同的数据采集方法。他们使用的爬虫窗口类型不同,控制方式也略有不同。爬虫窗口的描述请参考“DS 计数器的窗口类型”。
方法一:保存规则,爬取数据
完成采集规则并保存后,点击右上角“爬取数据”按钮,会自动弹出爬虫窗口。直接采集示例网页,使用测试窗口,菜单项很少。用于验证爬取规则的正确性。
1.1、用MS找几个单位制定规则并保存。
1.2,然后点击MS工具栏右上角的“爬取数据”按钮,会弹出DS爬虫窗口采集示例页面信息。

方法二:单次搜索/采集 DS 计数器
单独运行 DS 计数器,可以在左侧看到规则列表,每个规则都有“单次搜索”和“采集搜索”按钮。单查与吉搜的使用说明及区别请参考《吉索专有名词:单查与吉搜》。简单总结一下,Single Search 只运行一个爬虫窗口,而 Jisou 可以运行多个爬虫窗口。
2.1、打开DS计数器(GS浏览器版爬虫点击右上角“DS计数器”运行;火狐版爬虫点击工具中“DS数据”运行菜单)。
2.2、搜索主题名,可以使用*模糊匹配(前、后、中都可以收录*)。
2.3、右击主题名称,在弹出的菜单中选择“Statistical Leads”。您可以看到有多少潜在客户正在等待被抓取,而这些潜在客户就是 URL。
2.4、点击单搜索,输入线索数量(激活所有线索;如果要采集其他结构相同的网页,选择添加,然后复制多个网址进去,可以批量采集 >.更多操作见《如何管理规则线索》


方法三:使用爬虫组并发采集数据
爬虫组功能支持在一台电脑上同时运行多个爬虫。它集成了crontab爬虫调度器、DS计数器主菜单功能、数据库存储三大功能块。无需指定采集多少潜在客户,爬虫组会自动采集所有等待采集的潜在客户,让您高效采集数据,监控规则运行。有关用法,请参阅“如何运行 Crawler Swarm”

方法四:编写crontab并发爬虫采集数据
crontab程序(终极功能)和爬虫组一样,可以设置多个爬虫窗口并发采集数据,但是需要自己编写程序。两者的区别在于crontab程序可以指定爬虫窗口只有哪个主题任务采集,这样可以大大提高稳定性和效率,而爬虫组可以自由地将主题任务分配给爬虫窗口,而效率稍慢。详情请阅读文章《如何通过crontab程序实现周期性增量采集数据》。
如有疑问,您可以或

自动采集编写(如何利用Python打造搜狗壁纸自动下载爬虫库的反爬措施)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-04-16 15:16
这些案例是为一些想进入Python行业的朋友写的。看到大家都很满意,我又拿出来了。如果你已经开始学习python,对爬虫一窍不通,不妨看看这几个案例!
二、环境准备
Python 3
requests 库、lxml 库、beautifulsoup4 库
pip install XX XX XX 一起安装。
三、Python爬虫小案例
1、获取机器的公网IP地址
使用python的requests库+公网查IP接口自动获取IP地址
2、使用百度的搜索界面,Python编写url采集工具
你需要使用requests库和BeautifulSoup库来观察百度搜索结构的URL链接规则,通过在程序中设置User-Agent请求头来绕过百度搜索引擎的反爬虫机制。
Python 源代码:
用Python语言编写程序后,使用关键词inurl:/dede/login.php批量提取某个网络的后台地址cms:
3、使用Python制作搜狗壁纸自动下载爬虫
搜狗壁纸的地址是json格式的,所以使用json库解析这组数据,将爬虫程序存放图片的磁盘路径改成要存放图片的路径。
渲染:
4、Python 自动填充调查
和一般网页一样,多次提交数据都需要一个验证码,这就是反爬机制。
如图:
那么如何绕过验证码的反爬措施呢?使用X-Forwarded-For伪造IP地址访问,Python代码如下:
效果:
5、获取 West Thorn 代理上的 IP,以验证这些代理被禁止的可能性和延迟时间
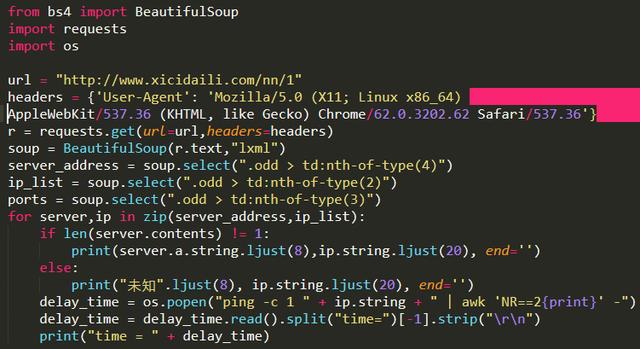
可以将Python爬取的代理IP添加到代理链中,然后就可以进行一般的渗透任务了。这里,linux系统命令ping -c 1 " + ip.string + " | awk 'NR==2{print}' - 被直接调用。要在Windows下运行这个程序,需要修改os.popen倒数第二行的命令,可以修改为Windows可执行。
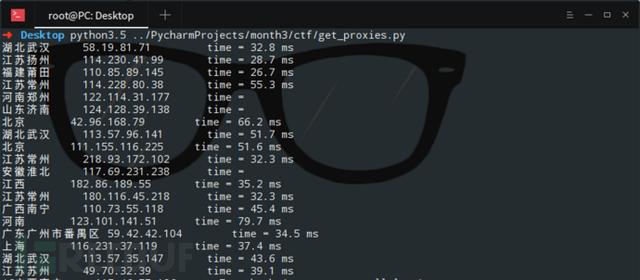
爬取的数据如图:
演示:
结论 查看全部
自动采集编写(如何利用Python打造搜狗壁纸自动下载爬虫库的反爬措施)
这些案例是为一些想进入Python行业的朋友写的。看到大家都很满意,我又拿出来了。如果你已经开始学习python,对爬虫一窍不通,不妨看看这几个案例!
二、环境准备
Python 3
requests 库、lxml 库、beautifulsoup4 库
pip install XX XX XX 一起安装。
三、Python爬虫小案例
1、获取机器的公网IP地址
使用python的requests库+公网查IP接口自动获取IP地址
2、使用百度的搜索界面,Python编写url采集工具
你需要使用requests库和BeautifulSoup库来观察百度搜索结构的URL链接规则,通过在程序中设置User-Agent请求头来绕过百度搜索引擎的反爬虫机制。
Python 源代码:
用Python语言编写程序后,使用关键词inurl:/dede/login.php批量提取某个网络的后台地址cms:
3、使用Python制作搜狗壁纸自动下载爬虫
搜狗壁纸的地址是json格式的,所以使用json库解析这组数据,将爬虫程序存放图片的磁盘路径改成要存放图片的路径。
渲染:
4、Python 自动填充调查
和一般网页一样,多次提交数据都需要一个验证码,这就是反爬机制。
如图:
那么如何绕过验证码的反爬措施呢?使用X-Forwarded-For伪造IP地址访问,Python代码如下:
效果:
5、获取 West Thorn 代理上的 IP,以验证这些代理被禁止的可能性和延迟时间
可以将Python爬取的代理IP添加到代理链中,然后就可以进行一般的渗透任务了。这里,linux系统命令ping -c 1 " + ip.string + " | awk 'NR==2{print}' - 被直接调用。要在Windows下运行这个程序,需要修改os.popen倒数第二行的命令,可以修改为Windows可执行。
爬取的数据如图:
演示:
结论
自动采集编写(触发MCC#抓取surface笔记图像采集卡channel!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2022-04-15 15:29
标签:触发MCC#抓取表面笔记图像采集卡片通道
每周更新!
1.参数1.1CAM文件
CAM 文件是一个可读的 ASCII 文件,文件扩展名为 .cam,收录一系列参数,例如:AcquisitionMode、TrigMode 等。通过 McSetParamStr 方法将 Camfile 加载到通道:
McSetParamStr(MyChannelMyChannel, MC_CamFile , "VCC VCC-870A_P15RA");
1.2 频道
通道是相机、图像采集卡和主机 PC 内存之间的 采集 路径。频道由三部分组成:
1. 负责图像捕获的相机。
2. 图像采集卡负责采集 和图像的传输。
3. 用于在主机 PC 中存储图像的内存缓冲区。
可以将通道设置为以下四种状态之一:
名字
意义
孤儿
没有与之关联的爬虫。所以不可能立即得到图像。但是通道是存在的,它的所有参数都可以自由设置或获取。
空闲
当一个通道空闲时,它有一个与之关联的抓取器。因此,图像 采集 可以立即完成。在这种状态下,MultiCam 可能会自动将采集器资源重新分配给另一个通道。
准备好了
当一个通道处于就绪状态时,它有一个与之关联的抓取器。因此,图像 采集 可以立即完成。在这种状态下,MultiCam 无法自动将采集器资源重新分配给另一个通道。
活跃
当一个通道处于活动状态时,它有一个与之关联的抓取器并执行一系列图像采集。在这种状态下,MultiCam 无法自动将采集器资源重新分配给另一个通道。
代码示例:
1.3 曲面
surface 是一个缓冲区,用户应用程序可以在其中找到要分析的 采集图像。内存缓冲区由称为表面的 MultiCam 对象表示。曲面可以由 Multicam 自动创建或由用户手动创建。抓取器通过 DMA 机制自动将 采集 图像传输到目标表面。一个通道可以有一个或多个表面(默认为 4)。根据表面的数量,定义了单缓冲和多缓冲。
表面状态
意义
免费
自由曲面可以无条件地接收来自抓手的图像数据。
填充
目前正在从采集卡接收图像数据,或准备接收数据。集群中应该有一个处于 FILLING 状态的 Surface。
填满
已完成从抓取器接收图像数据,准备处理。
处理
处理器正在处理处于 PROCESSING 状态的 Surface。
保留
从标准状态转换机制中移除。
代码示例:
一组表面称为一个簇,一个通道只能有一个簇。集群状态为OFF、READY(正在获取图像但没有表面在PROCESSING)、BUSY(有表面在PROCESSING中)、UNAVAILABLE(无法获取图像)
单缓冲
双缓冲
三重缓冲
1.4多机位信号发送
信号是由与用户应用程序交互的通道生成的事件。
帧触发冲突
开始曝光
此信号在帧曝光条件开始时发出。
结束曝光
该信号在帧曝光条件结束时发出。
表面填充
当目标簇的Surface进入Filled状态时发出此信号。
表面处理
当目标簇的Surface进入Processing状态时发出此信号。
集群不可用
采集失败 (**)
采集序列开始
采集序列结束
频道活动结束
有三种访问它们的机制:
1. 是指用户编写的函数,当预定义的信号出现时会自动调用这些函数。 (回调)
2. 允许线程等待预定义信号发生的专用机制。
3. 一种用户定义的机制,涉及标准的 Windows 等待函数。
使用回调的案例:
1. 默认情况下,所有信号都被禁用。 SignalEnable 参数用于设置。
2.注册回调函数
3. 在回调函数中,使用 PMCSIGNALINFO 捕获事件,其中收录有关触发事件的信息。
例子:
1.5触发器
触发事件由 TrigMode 和 NextTrigMode 参数设置。
1.5.1 初始触发事件:
1.5.2触发事件结束
采集阶段可以用 EndTrigMode 结束:
1)当帧、页或行计数器到期时,采集 序列会自动终止。 (自动)
2)当检测到硬件侧触发线的有效转换时,采集序列终止(HARD)
或者通过BreakEffect参数直接终止通道的活动状态:
1)切片/相位/序列结束后停止采集(FINISH)
2)中止
1.6采集模式1.7异常
通过异常代码或 Windows 异常来管理异常。 ErrorHandling 参数设置错误管理行为,有 4 个可能的值。
2.演示
2.1 打开驱动
// Open MultiCam driver
MC.OpenDriver();
2.2 创建频道
// Create a channel and associate it with the first connector on the first board
MC.Create("CHANNEL", out channel);
MC.SetParam(channel, "DriverIndex", 0);
2.3 相机参数设置
// Choose the CAM file
MC.SetParam(channel, "CamFile", "1000m_P50RG");
// Choose the camera expose duration
MC.SetParam(channel, "Expose_us", 20000);
// Choose the pixel color format
MC.SetParam(channel, "ColorFormat", "Y8");
2.4 触发模式改变
//Set the acquisition mode to Snapshot
MC.SetParam(channel, "AcquisitionMode", "SNAPSHOT");
// Choose the way the first acquisition is triggered
MC.SetParam(channel, "TrigMode", "COMBINED");
// Choose the triggering mode for subsequent acquisitions
MC.SetParam(channel, "NextTrigMode", "COMBINED");
2.5 个事件触发器
2.5.1 注册回调函数
// Register the callback function
multiCamCallback = new MC.CALLBACK(MultiCamCallback);
MC.RegisterCallback(channel, multiCamCallback, channel);
2.5.2 信号开启
// Enable the signals corresponding to the callback functions
MC.SetParam(channel, MC.SignalEnable + MC.SIG_SURFACE_PROCESSING, "ON");
MC.SetParam(channel, MC.SignalEnable + MC.SIG_ACQUISITION_FAILURE, "ON");
2.5.3 判断接收信号
如果接收到的是MC.SIG_SURFACE_PROCESSING,调用ProcessingCallback获取图片的数据,并将图片数据转换为位图。如果收到 MC.SIG_ACQUISITION_FAILURE,调用 AcqFailureCallback 输出“Acquisition Failure”。
private void MultiCamCallback(ref MC.SIGNALINFO signalInfo)
{
switch(signalInfo.Signal)
{
case MC.SIG_SURFACE_PROCESSING:
ProcessingCallback(signalInfo);
break;
case MC.SIG_ACQUISITION_FAILURE:
AcqFailureCallback(signalInfo);
break;
default:
throw new Euresys.MultiCamException("Unknown signal");
}
}
2.6通道状态设置为READY
// Prepare the channel in order to minimize the acquisition sequence startup latency
MC.SetParam(channel, "ChannelState", "READY");
3. 编写测试程序
触发方式使用默认的连续触发。
在界面上显示camfile的加载。
演示界面只有Go和stop和一个状态栏。添加按钮以打开/关闭相机和启动/停止采集.
曝光开始事件被触发,帧数开始计数++;触发surface_processing事件,图像采集计数++;触发采集失败事件,丢帧计数++。
代码肯定行不通。毕竟我是一个没见过采集卡片的人,所以我只是在说纸上谈兵哈哈哈
标签:触发器、MC、C#、抓取、表面、笔记、图像、采集卡片、通道 查看全部
自动采集编写(触发MCC#抓取surface笔记图像采集卡channel!)
标签:触发MCC#抓取表面笔记图像采集卡片通道
每周更新!
1.参数1.1CAM文件
CAM 文件是一个可读的 ASCII 文件,文件扩展名为 .cam,收录一系列参数,例如:AcquisitionMode、TrigMode 等。通过 McSetParamStr 方法将 Camfile 加载到通道:
McSetParamStr(MyChannelMyChannel, MC_CamFile , "VCC VCC-870A_P15RA");
1.2 频道
通道是相机、图像采集卡和主机 PC 内存之间的 采集 路径。频道由三部分组成:
1. 负责图像捕获的相机。
2. 图像采集卡负责采集 和图像的传输。
3. 用于在主机 PC 中存储图像的内存缓冲区。

可以将通道设置为以下四种状态之一:
名字
意义
孤儿
没有与之关联的爬虫。所以不可能立即得到图像。但是通道是存在的,它的所有参数都可以自由设置或获取。
空闲
当一个通道空闲时,它有一个与之关联的抓取器。因此,图像 采集 可以立即完成。在这种状态下,MultiCam 可能会自动将采集器资源重新分配给另一个通道。
准备好了
当一个通道处于就绪状态时,它有一个与之关联的抓取器。因此,图像 采集 可以立即完成。在这种状态下,MultiCam 无法自动将采集器资源重新分配给另一个通道。
活跃
当一个通道处于活动状态时,它有一个与之关联的抓取器并执行一系列图像采集。在这种状态下,MultiCam 无法自动将采集器资源重新分配给另一个通道。
代码示例:

1.3 曲面
surface 是一个缓冲区,用户应用程序可以在其中找到要分析的 采集图像。内存缓冲区由称为表面的 MultiCam 对象表示。曲面可以由 Multicam 自动创建或由用户手动创建。抓取器通过 DMA 机制自动将 采集 图像传输到目标表面。一个通道可以有一个或多个表面(默认为 4)。根据表面的数量,定义了单缓冲和多缓冲。
表面状态
意义
免费
自由曲面可以无条件地接收来自抓手的图像数据。
填充
目前正在从采集卡接收图像数据,或准备接收数据。集群中应该有一个处于 FILLING 状态的 Surface。
填满
已完成从抓取器接收图像数据,准备处理。
处理
处理器正在处理处于 PROCESSING 状态的 Surface。
保留
从标准状态转换机制中移除。
代码示例:

一组表面称为一个簇,一个通道只能有一个簇。集群状态为OFF、READY(正在获取图像但没有表面在PROCESSING)、BUSY(有表面在PROCESSING中)、UNAVAILABLE(无法获取图像)

单缓冲

双缓冲

三重缓冲
1.4多机位信号发送
信号是由与用户应用程序交互的通道生成的事件。
帧触发冲突
开始曝光
此信号在帧曝光条件开始时发出。
结束曝光
该信号在帧曝光条件结束时发出。
表面填充
当目标簇的Surface进入Filled状态时发出此信号。
表面处理
当目标簇的Surface进入Processing状态时发出此信号。
集群不可用
采集失败 (**)
采集序列开始
采集序列结束
频道活动结束
有三种访问它们的机制:
1. 是指用户编写的函数,当预定义的信号出现时会自动调用这些函数。 (回调)
2. 允许线程等待预定义信号发生的专用机制。
3. 一种用户定义的机制,涉及标准的 Windows 等待函数。
使用回调的案例:
1. 默认情况下,所有信号都被禁用。 SignalEnable 参数用于设置。
2.注册回调函数
3. 在回调函数中,使用 PMCSIGNALINFO 捕获事件,其中收录有关触发事件的信息。
例子:


1.5触发器
触发事件由 TrigMode 和 NextTrigMode 参数设置。
1.5.1 初始触发事件:
1.5.2触发事件结束
采集阶段可以用 EndTrigMode 结束:
1)当帧、页或行计数器到期时,采集 序列会自动终止。 (自动)
2)当检测到硬件侧触发线的有效转换时,采集序列终止(HARD)
或者通过BreakEffect参数直接终止通道的活动状态:
1)切片/相位/序列结束后停止采集(FINISH)
2)中止
1.6采集模式1.7异常
通过异常代码或 Windows 异常来管理异常。 ErrorHandling 参数设置错误管理行为,有 4 个可能的值。

2.演示

2.1 打开驱动
// Open MultiCam driver
MC.OpenDriver();
2.2 创建频道
// Create a channel and associate it with the first connector on the first board
MC.Create("CHANNEL", out channel);
MC.SetParam(channel, "DriverIndex", 0);
2.3 相机参数设置
// Choose the CAM file
MC.SetParam(channel, "CamFile", "1000m_P50RG");
// Choose the camera expose duration
MC.SetParam(channel, "Expose_us", 20000);
// Choose the pixel color format
MC.SetParam(channel, "ColorFormat", "Y8");
2.4 触发模式改变
//Set the acquisition mode to Snapshot
MC.SetParam(channel, "AcquisitionMode", "SNAPSHOT");
// Choose the way the first acquisition is triggered
MC.SetParam(channel, "TrigMode", "COMBINED");
// Choose the triggering mode for subsequent acquisitions
MC.SetParam(channel, "NextTrigMode", "COMBINED");
2.5 个事件触发器
2.5.1 注册回调函数
// Register the callback function
multiCamCallback = new MC.CALLBACK(MultiCamCallback);
MC.RegisterCallback(channel, multiCamCallback, channel);
2.5.2 信号开启
// Enable the signals corresponding to the callback functions
MC.SetParam(channel, MC.SignalEnable + MC.SIG_SURFACE_PROCESSING, "ON");
MC.SetParam(channel, MC.SignalEnable + MC.SIG_ACQUISITION_FAILURE, "ON");
2.5.3 判断接收信号
如果接收到的是MC.SIG_SURFACE_PROCESSING,调用ProcessingCallback获取图片的数据,并将图片数据转换为位图。如果收到 MC.SIG_ACQUISITION_FAILURE,调用 AcqFailureCallback 输出“Acquisition Failure”。
private void MultiCamCallback(ref MC.SIGNALINFO signalInfo)
{
switch(signalInfo.Signal)
{
case MC.SIG_SURFACE_PROCESSING:
ProcessingCallback(signalInfo);
break;
case MC.SIG_ACQUISITION_FAILURE:
AcqFailureCallback(signalInfo);
break;
default:
throw new Euresys.MultiCamException("Unknown signal");
}
}
2.6通道状态设置为READY
// Prepare the channel in order to minimize the acquisition sequence startup latency
MC.SetParam(channel, "ChannelState", "READY");
3. 编写测试程序
触发方式使用默认的连续触发。
在界面上显示camfile的加载。
演示界面只有Go和stop和一个状态栏。添加按钮以打开/关闭相机和启动/停止采集.
曝光开始事件被触发,帧数开始计数++;触发surface_processing事件,图像采集计数++;触发采集失败事件,丢帧计数++。


代码肯定行不通。毕竟我是一个没见过采集卡片的人,所以我只是在说纸上谈兵哈哈哈
标签:触发器、MC、C#、抓取、表面、笔记、图像、采集卡片、通道
自动采集编写(GoldData配制登录和检查会话的数据集有什么区别?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-15 09:45
概括
本文将介绍GoldData的半自动登录功能对采集必填网站数据的使用。GoldData的半自动登录功能是指通过脚本进行登录。如果需要手动输入验证码或其他内容,可以通过收发邮件的方式进行登录。
下载示例
为了解释方便,我们使用采集mydict的数据一词来解释需要登录的采集网站数据。mydict示例程序可以从开源下载< @网站 到 ( , 或 )。
下载后打开命令行,运行以下命令启动示例程序。
java -jar mydict.war
启动后,打开浏览器输入 URL:8080/ 即可打开登录页面。如下所示:
输入用户名和密码(均为admin),即可打开首页单词列表。
编写登录和检查会话脚本
点击“采集Management”网站Management”,点击“Add”按钮,添加一个名为mydict的站点。如下:
接下来配置登录和检查会话脚本,点击“设置半自动登录”,会打开站点半自动登录配置页面,如下图:
登录脚本如下:
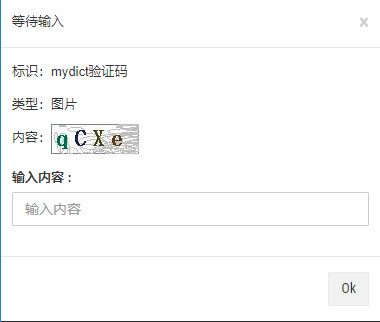
//发送ajax请求验证码
var va=$ajax('http://localhost:8080/code/vcode?timestamp=1554001708730',{encoding:false});
var arg_={
label:site.name+"验证码",
type:1,
content:va.content
}
//waitForInput内置函数将发送邮件,并等待输入
//(回复邮件,或者goldData平台输入),
//并把输入内容当作验证码返回。
var code=waitForInput(arg_);
var data="username=admin&password=admin&vcode="+code
var m=new Map()
m.put('Cookie',va.cookie)
//发送ajax请求执行登录
var content=$ajax('http://localhost:8080/doLogin',{method:'POST',headers:m,data:data})
//如果正确,将返回状态1(登录成功),和headers信息给GoldData,
//否则返回0(登录失败)!
if(content.headers){
m.putAll(content.headers)
}
var ret={status:1,headers:m}
if(content.status!=200){
ret.status=0
}
ret
检查脚本如下:
var ret=true;
if(html.contains("我的单词-登录")){
ret=false
}
ret;
准备好后,我们回到网站管理页面,点击“开始登录”,会开始执行“自动登录”,之后点击“查询”按钮刷新页面,可以看到“等待输入”状态。如下所示:
此时,您设置的通知邮箱应该也会同时收到邮件。点击打开邮件,或者点击页面上的“输入等待输入”按钮,会看到如下内容:
根据邮件内容,回复邮件“{{qcxe}}”,程序可以继续执行。在golddata页面输入“qcxe”,效果是一样的。程序将返回“waitForInput()”并返回输入。
回复后,我们在golddata页面点击“查询”刷新页面,mydict的登录状态会变为“登录”。如下所示:
接下来,我们可以定义抓取规则。
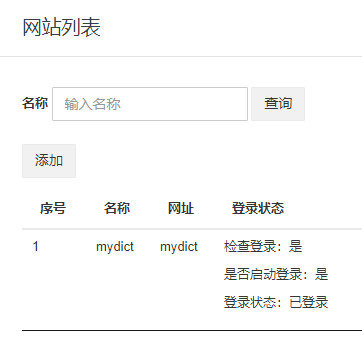
定义抓取规则
在添加规则之前,我们还需要定义一个类似于表结构的数据集。如下所示:
接下来点击“采集管理“规则管理”,添加规则,打开添加规则页面,如下图:
抓取规则脚本如下:
[
{
__sample: http://localhost:8080/word/index?pageNum=2
match0: http\:\/\/localhost\:8080\/word\/index(\?pageNum=\d+)?
fields0:
{
__model: true
__dataset: word
__node: "#content ul >li"
sn:
{
expr: ""
attr: ""
js: md5(item.name)
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
name:
{
expr: h5
attr: ""
js: ""
__label: ""
__showOnList: true
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
uk:
{
expr: li span.uk
attr: ""
js: source.replace("uk: ",'')
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
us:
{
expr: li span.us
attr: ""
js: source.replace("us: ",'')
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
}
fields1:
{
__node: .pagination a
href:
{
expr: a
attr: abs:href
js: ""
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
}
}
]
然后单击测试,将进行测试爬网。我们发现数据确实被抓到了,如下图所示:
配置抓取器抓取
这个和之前一样,设置爬虫爬取站点“mydict”。然后点击开始抓取。然后您将在数据管理中查看捕获的数据。
综上所述
GoldData半自动登录的本质是提供一个框架,可以手动干预异步获取会话。既可以调用AI接口完成自动登录;当复杂的识别需要提供类似于验证码的输入时,它也可以直接转换cookie或token信息。通过电子邮件向 GoldData 平台发送和接收(这样无论 CAPTCHA 多么复杂),让 GoldData 能够继续捕获数据。 查看全部
自动采集编写(GoldData配制登录和检查会话的数据集有什么区别?)
概括
本文将介绍GoldData的半自动登录功能对采集必填网站数据的使用。GoldData的半自动登录功能是指通过脚本进行登录。如果需要手动输入验证码或其他内容,可以通过收发邮件的方式进行登录。
下载示例
为了解释方便,我们使用采集mydict的数据一词来解释需要登录的采集网站数据。mydict示例程序可以从开源下载< @网站 到 ( , 或 )。
下载后打开命令行,运行以下命令启动示例程序。
java -jar mydict.war
启动后,打开浏览器输入 URL:8080/ 即可打开登录页面。如下所示:
输入用户名和密码(均为admin),即可打开首页单词列表。
编写登录和检查会话脚本
点击“采集Management”网站Management”,点击“Add”按钮,添加一个名为mydict的站点。如下:
接下来配置登录和检查会话脚本,点击“设置半自动登录”,会打开站点半自动登录配置页面,如下图:
登录脚本如下:
//发送ajax请求验证码
var va=$ajax('http://localhost:8080/code/vcode?timestamp=1554001708730',{encoding:false});
var arg_={
label:site.name+"验证码",
type:1,
content:va.content
}
//waitForInput内置函数将发送邮件,并等待输入
//(回复邮件,或者goldData平台输入),
//并把输入内容当作验证码返回。
var code=waitForInput(arg_);
var data="username=admin&password=admin&vcode="+code
var m=new Map()
m.put('Cookie',va.cookie)
//发送ajax请求执行登录
var content=$ajax('http://localhost:8080/doLogin',{method:'POST',headers:m,data:data})
//如果正确,将返回状态1(登录成功),和headers信息给GoldData,
//否则返回0(登录失败)!
if(content.headers){
m.putAll(content.headers)
}
var ret={status:1,headers:m}
if(content.status!=200){
ret.status=0
}
ret
检查脚本如下:
var ret=true;
if(html.contains("我的单词-登录")){
ret=false
}
ret;
准备好后,我们回到网站管理页面,点击“开始登录”,会开始执行“自动登录”,之后点击“查询”按钮刷新页面,可以看到“等待输入”状态。如下所示:

此时,您设置的通知邮箱应该也会同时收到邮件。点击打开邮件,或者点击页面上的“输入等待输入”按钮,会看到如下内容:
根据邮件内容,回复邮件“{{qcxe}}”,程序可以继续执行。在golddata页面输入“qcxe”,效果是一样的。程序将返回“waitForInput()”并返回输入。
回复后,我们在golddata页面点击“查询”刷新页面,mydict的登录状态会变为“登录”。如下所示:
接下来,我们可以定义抓取规则。
定义抓取规则
在添加规则之前,我们还需要定义一个类似于表结构的数据集。如下所示:
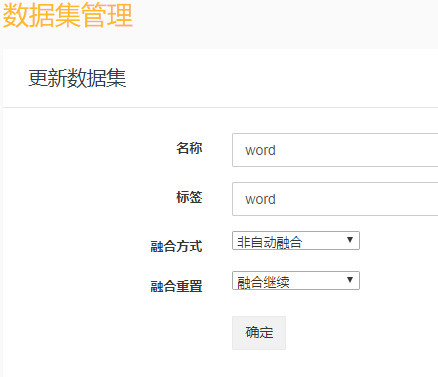
接下来点击“采集管理“规则管理”,添加规则,打开添加规则页面,如下图:
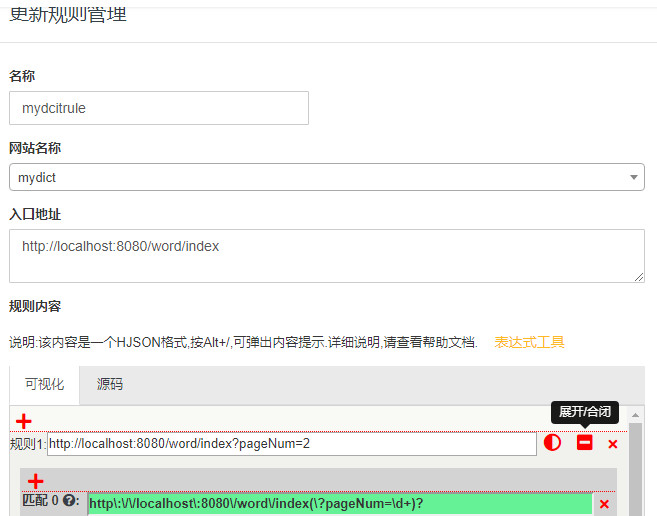
抓取规则脚本如下:
[
{
__sample: http://localhost:8080/word/index?pageNum=2
match0: http\:\/\/localhost\:8080\/word\/index(\?pageNum=\d+)?
fields0:
{
__model: true
__dataset: word
__node: "#content ul >li"
sn:
{
expr: ""
attr: ""
js: md5(item.name)
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
name:
{
expr: h5
attr: ""
js: ""
__label: ""
__showOnList: true
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
uk:
{
expr: li span.uk
attr: ""
js: source.replace("uk: ",'')
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
us:
{
expr: li span.us
attr: ""
js: source.replace("us: ",'')
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
}
fields1:
{
__node: .pagination a
href:
{
expr: a
attr: abs:href
js: ""
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
}
}
]
然后单击测试,将进行测试爬网。我们发现数据确实被抓到了,如下图所示:
配置抓取器抓取
这个和之前一样,设置爬虫爬取站点“mydict”。然后点击开始抓取。然后您将在数据管理中查看捕获的数据。
综上所述
GoldData半自动登录的本质是提供一个框架,可以手动干预异步获取会话。既可以调用AI接口完成自动登录;当复杂的识别需要提供类似于验证码的输入时,它也可以直接转换cookie或token信息。通过电子邮件向 GoldData 平台发送和接收(这样无论 CAPTCHA 多么复杂),让 GoldData 能够继续捕获数据。
自动采集编写(自动化白盒测试系统及方法()测试技术)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-14 14:14
本发明专利技术提供了一种web应用自动化白盒测试系统及方法,包括web data采集模块,自动将测试者提交的数据信息保存在客户端浏览器中作为web请求信息数据文件,并添加动作信息生成初始测试数据文件;脚本生成模块,根据初始测试数据文件生成测试脚本;数据生成模块,通过编写业务描述文件来描述测试用例执行的逻辑顺序,并自动执行初始测试。修改数据文件,生成测试数据文件;集成测试模块按照业务描述文件的逻辑顺序耦合多个测试用例。
下载所有详细的技术数据
【技术实现步骤总结】
本专利技术属于计算机软件测试技术,特别是Web应用软件功能可靠性自动测试的测试技术。技术背景 目前,在软件测试领域,自动化测试是一种新兴的测试技术。自动化测试方法主要有两种: 1、捕获/回放机制:直接使用商业测试软件编写测试用例脚本。使用商业测试软件自动测试被测软件。这类测试软件在测试web应用时,共同点就是记录web应用页面操作,生成测试脚本。测试时,客户端模拟浏览器操作,实现自动化测试。如图1所示。这种测试方式的缺点是客户端只能获取http信息流,而无法获取软件的内部数据结构及相关信息,无法对软件进行完整有效的检查和验证,具有一定的局限性。例如,在验证软件运行时动态生成的数据,而这些动态生成的数据并没有通过http信息流返回给客户端时,捕获/回放机制的测试方法很难进行有效的测试。2、自动白盒测试:这类自动化测试工具自动生成测试用例脚本,主要用于源代码的分析和测试,不具备逻辑测试的功能。虽然这种类型的自动测试很方便,它可以发现人工测试很难发现的错误,但也有局限性:此类工具一般价格昂贵,初期投资非常高,无法有效测试软件的业务功能。而且,在现有技术中,无论是捕获/回放机制还是自动白盒测试,这些测试方法仍然存在一个缺点,即只能单独执行测试用例,不能有效地使用多个用例。到 --> 业务逻辑。耦合。当一个用例需要以其他用例的运行结果作为初始条件时,目前的测试方法很难将结果自动输出到其他用例,需要人工实现,没有办法自动耦合大量根据业务逻辑的用例。
技术实现思路
该专利技术的目的是克服现有技术的不足,提出一种实现Web应用程序自动白盒测试的系统,适用于基于J2EE和struts技术B/S架构的Web应用程序。该专利技术的另一个目的是提出一种实现网络应用程序自动化白盒测试的方法。测试过程中,对测试用例进行人工测试,测试过程中自动记录测试数据,并以固定格式保存。根据保存的数据自动生成用例的测试脚本,测试脚本和测试数据可以实现测试用例的自动白盒测试。当业务复杂时,会有大量的测试用例。该专利技术提出的方法还可以自动构建不同测试用例之间的业务逻辑关系,从而可以根据业务逻辑关系批量运行测试脚本。脚本自动测试时,测试脚本部署在服务器的表现层,脚本模拟服务器组件内部的软件业务操作。测试结束后,输出测试结果报告。为实现专利技术的第一个目的,采用的技术方案如下:Web应用自动化白盒测试系统,包括以下组件:web data采集模块,存储数据测试人员在客户端浏览器中提交的信息自动保存为web请求信息数据文件,添加动作信息,生成初始测试数据文件;脚本生成模块,根据初始测试数据文件生成测试脚本;数据生成模块,通过编写业务描述文件来描述测试。用例执行的逻辑顺序自动修改初始测试数据文件生成测试数据文件;集成测试模块按照业务描述文件的逻辑顺序耦合多个测试用例。用例执行的逻辑顺序自动修改初始测试数据文件生成测试数据文件;集成测试模块按照业务描述文件的逻辑顺序耦合多个测试用例。用例执行的逻辑顺序自动修改初始测试数据文件生成测试数据文件;集成测试模块按照业务描述文件的逻辑顺序耦合多个测试用例。
上述技术方案中,Web数据采集模块是通过在客户端浏览器中安装数据采集-->采集插件实现的,数据采集插件调用提供的API浏览器,以及浏览器提交的数据请求信息,以固定格式记录保存。动作信息是从struts的描述文件中获取的,该文件记录了web操作过程中的业务映射关系。脚本生成模块根据初始测试数据文件生成初始测试脚本。如果测试用例需要检查更多的验证点,则通过修改初始测试脚本得到测试脚本。如果测试用例不需要检查更多的验证点,那么初始测试脚本就是测试脚本。集成测试模块将测试脚本部署在服务器的表现层,对服务器的表现层进行集成测试。测试时,用例根据业务逻辑将生成的数据输出到对应的数据文件中,以便相关用例可以使用该用例的操作。结果,测试结束后,输出测试结果报告。为实现专利技术的第二个目的,采用的技术方案如下:一种Web应用自动化白盒测试方法,包括以下步骤:(1)手动测试测试用例;(2)网页数据采集模块自动记录并保存浏览器提交的数据信息;(3)修改步骤中保存的数据文件(<
<p>是基于软件代码的测试,可以对软件运行时的细节进行仔细检查。在测试过程中,可以通过软件内部的逻辑结构和相关信息来判断实际状态是否与预期状态一致。当软件出现bug时,可以根据测试结果报告确定具体的功能或类别。出现问题。现有技术中业务逻辑的自动化测试方法多为黑盒测试。与黑盒测试相比,本专利技术可以更有效地检查软件运行的正确性,有效测试代码内部结构,保证软件质量。2、本专利技术的数据和脚本易于使用且编写高效。传统的白盒测试方法耗时长,对测试人员技术要求高,成本高。该专利技术提出自动数据自动化 查看全部
自动采集编写(自动化白盒测试系统及方法()测试技术)
本发明专利技术提供了一种web应用自动化白盒测试系统及方法,包括web data采集模块,自动将测试者提交的数据信息保存在客户端浏览器中作为web请求信息数据文件,并添加动作信息生成初始测试数据文件;脚本生成模块,根据初始测试数据文件生成测试脚本;数据生成模块,通过编写业务描述文件来描述测试用例执行的逻辑顺序,并自动执行初始测试。修改数据文件,生成测试数据文件;集成测试模块按照业务描述文件的逻辑顺序耦合多个测试用例。
下载所有详细的技术数据
【技术实现步骤总结】
本专利技术属于计算机软件测试技术,特别是Web应用软件功能可靠性自动测试的测试技术。技术背景 目前,在软件测试领域,自动化测试是一种新兴的测试技术。自动化测试方法主要有两种: 1、捕获/回放机制:直接使用商业测试软件编写测试用例脚本。使用商业测试软件自动测试被测软件。这类测试软件在测试web应用时,共同点就是记录web应用页面操作,生成测试脚本。测试时,客户端模拟浏览器操作,实现自动化测试。如图1所示。这种测试方式的缺点是客户端只能获取http信息流,而无法获取软件的内部数据结构及相关信息,无法对软件进行完整有效的检查和验证,具有一定的局限性。例如,在验证软件运行时动态生成的数据,而这些动态生成的数据并没有通过http信息流返回给客户端时,捕获/回放机制的测试方法很难进行有效的测试。2、自动白盒测试:这类自动化测试工具自动生成测试用例脚本,主要用于源代码的分析和测试,不具备逻辑测试的功能。虽然这种类型的自动测试很方便,它可以发现人工测试很难发现的错误,但也有局限性:此类工具一般价格昂贵,初期投资非常高,无法有效测试软件的业务功能。而且,在现有技术中,无论是捕获/回放机制还是自动白盒测试,这些测试方法仍然存在一个缺点,即只能单独执行测试用例,不能有效地使用多个用例。到 --> 业务逻辑。耦合。当一个用例需要以其他用例的运行结果作为初始条件时,目前的测试方法很难将结果自动输出到其他用例,需要人工实现,没有办法自动耦合大量根据业务逻辑的用例。
技术实现思路
该专利技术的目的是克服现有技术的不足,提出一种实现Web应用程序自动白盒测试的系统,适用于基于J2EE和struts技术B/S架构的Web应用程序。该专利技术的另一个目的是提出一种实现网络应用程序自动化白盒测试的方法。测试过程中,对测试用例进行人工测试,测试过程中自动记录测试数据,并以固定格式保存。根据保存的数据自动生成用例的测试脚本,测试脚本和测试数据可以实现测试用例的自动白盒测试。当业务复杂时,会有大量的测试用例。该专利技术提出的方法还可以自动构建不同测试用例之间的业务逻辑关系,从而可以根据业务逻辑关系批量运行测试脚本。脚本自动测试时,测试脚本部署在服务器的表现层,脚本模拟服务器组件内部的软件业务操作。测试结束后,输出测试结果报告。为实现专利技术的第一个目的,采用的技术方案如下:Web应用自动化白盒测试系统,包括以下组件:web data采集模块,存储数据测试人员在客户端浏览器中提交的信息自动保存为web请求信息数据文件,添加动作信息,生成初始测试数据文件;脚本生成模块,根据初始测试数据文件生成测试脚本;数据生成模块,通过编写业务描述文件来描述测试。用例执行的逻辑顺序自动修改初始测试数据文件生成测试数据文件;集成测试模块按照业务描述文件的逻辑顺序耦合多个测试用例。用例执行的逻辑顺序自动修改初始测试数据文件生成测试数据文件;集成测试模块按照业务描述文件的逻辑顺序耦合多个测试用例。用例执行的逻辑顺序自动修改初始测试数据文件生成测试数据文件;集成测试模块按照业务描述文件的逻辑顺序耦合多个测试用例。
上述技术方案中,Web数据采集模块是通过在客户端浏览器中安装数据采集-->采集插件实现的,数据采集插件调用提供的API浏览器,以及浏览器提交的数据请求信息,以固定格式记录保存。动作信息是从struts的描述文件中获取的,该文件记录了web操作过程中的业务映射关系。脚本生成模块根据初始测试数据文件生成初始测试脚本。如果测试用例需要检查更多的验证点,则通过修改初始测试脚本得到测试脚本。如果测试用例不需要检查更多的验证点,那么初始测试脚本就是测试脚本。集成测试模块将测试脚本部署在服务器的表现层,对服务器的表现层进行集成测试。测试时,用例根据业务逻辑将生成的数据输出到对应的数据文件中,以便相关用例可以使用该用例的操作。结果,测试结束后,输出测试结果报告。为实现专利技术的第二个目的,采用的技术方案如下:一种Web应用自动化白盒测试方法,包括以下步骤:(1)手动测试测试用例;(2)网页数据采集模块自动记录并保存浏览器提交的数据信息;(3)修改步骤中保存的数据文件(<
<p>是基于软件代码的测试,可以对软件运行时的细节进行仔细检查。在测试过程中,可以通过软件内部的逻辑结构和相关信息来判断实际状态是否与预期状态一致。当软件出现bug时,可以根据测试结果报告确定具体的功能或类别。出现问题。现有技术中业务逻辑的自动化测试方法多为黑盒测试。与黑盒测试相比,本专利技术可以更有效地检查软件运行的正确性,有效测试代码内部结构,保证软件质量。2、本专利技术的数据和脚本易于使用且编写高效。传统的白盒测试方法耗时长,对测试人员技术要求高,成本高。该专利技术提出自动数据自动化
自动采集编写(看学习代码编写爬虫的目的是什么?教程在这里)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-04-12 02:30
这要看学习代码写爬虫的目的是什么?磨练您的技能,获得经验,或者只是想从网络上抓取数据以供您自己使用或研究。
如果你想成为学生党或者打算转行IT技术的人,就必须学习编码和编写爬虫,以拥有更多的实践经验和额外的技术技能,以便日后找到工作。因为未来互联网的信息化程度会越来越高,爬虫可以更高效的获取互联网信息,爬虫的技术也在兴起。
如果您在工作或学习中只需要采集互联网数据应用,可以先试用市面上通用的采集器,减少获取数据的资源投入,让您专注于自己的自己的事。
自我推荐,采集网页资料可以试试优采云采集平台,有免费版。以下是 采集 结果数据的示例:
优采云采集是新一代网站文章采集及发布平台,完全在线配置使用云端采集,功能强大,操作简单、快速、高效的配置。
优采云不仅提供网页文章采集、批量数据修改、定时采集、定时定量自动发布等基础功能,还集成了强大的SEO工具和创新实现了规则智能抽取引擎、书签一键发布采集等功能,大大提高了采集配置和发布的效率。
采集简单,发布更轻松:支持一键发布到WorpPress、Empire、织梦、ZBlog、Discuz、Destoon、Typecho、Emlog、Mipcms、Mito、Yiyoucms、Applecms、PHPcms等cms网站系统也可以发布到自定义Http接口。
有需要的同学可以看看下面的教程,很快就能上手。 查看全部
自动采集编写(看学习代码编写爬虫的目的是什么?教程在这里)
这要看学习代码写爬虫的目的是什么?磨练您的技能,获得经验,或者只是想从网络上抓取数据以供您自己使用或研究。
如果你想成为学生党或者打算转行IT技术的人,就必须学习编码和编写爬虫,以拥有更多的实践经验和额外的技术技能,以便日后找到工作。因为未来互联网的信息化程度会越来越高,爬虫可以更高效的获取互联网信息,爬虫的技术也在兴起。
如果您在工作或学习中只需要采集互联网数据应用,可以先试用市面上通用的采集器,减少获取数据的资源投入,让您专注于自己的自己的事。
自我推荐,采集网页资料可以试试优采云采集平台,有免费版。以下是 采集 结果数据的示例:
优采云采集是新一代网站文章采集及发布平台,完全在线配置使用云端采集,功能强大,操作简单、快速、高效的配置。
优采云不仅提供网页文章采集、批量数据修改、定时采集、定时定量自动发布等基础功能,还集成了强大的SEO工具和创新实现了规则智能抽取引擎、书签一键发布采集等功能,大大提高了采集配置和发布的效率。
采集简单,发布更轻松:支持一键发布到WorpPress、Empire、织梦、ZBlog、Discuz、Destoon、Typecho、Emlog、Mipcms、Mito、Yiyoucms、Applecms、PHPcms等cms网站系统也可以发布到自定义Http接口。
有需要的同学可以看看下面的教程,很快就能上手。
自动采集编写( 如何通过Python实现自动填写调查问卷】3.5获取公网代理IP)
采集交流 • 优采云 发表了文章 • 0 个评论 • 331 次浏览 • 2022-04-10 05:28
如何通过Python实现自动填写调查问卷】3.5获取公网代理IP)
一、前言
这个文章以前是用来训练新人的。大家觉得好理解,就分享给大家学习。如果你学过一些python,想用它做点什么,但没有方向,不妨尝试完成以下案例。
二、环境准备
安装requests lxml beautifulsoup4的三个库(以下代码均在python3.5环境下测试)
pip install requests lxml beautifulsoup4
三、几个小爬虫案例
3.1 获取机器的公网IP地址
以在公网查询IP为借口,使用python的requests库自动获取IP地址。
import requests
r = requests.get("http://2017.ip138.com/ic.asp")
r.encoding = r.apparent_encoding #使用requests的字符编码智能分析,避免中文乱码
print(r.text)
# 你还可以使用正则匹配re模块提取出IP
import re
print(re.findall("d{1,3}.d{1,3}.d{1,3}.d{1,3}",r.text))
3.2 用百度搜索界面写url采集器
在这种情况下,我们将使用 requests 结合 BeautifulSoup 库来完成任务。我们需要在程序中设置User-Agent头来绕过百度搜索引擎的反爬机制(可以尽量不添加User-Agent头,看能不能获取数据)。注意百度搜索结构的url链接规则,比如第一页url链接参数pn=0,第二页url链接参数pn=10……。等等。在这里,我们使用 css 选择器路径提取数据。
import requests
from bs4 import BeautifulSoup
# 设置User-Agent头,绕过百度搜索引擎的反爬虫机制
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'}
# 注意观察百度搜索结构的URL链接规律,例如第一页pn=0,第二页pn=10.... 依次类推,下面的for循环搜索前10页结果
for i in range(0,100,10):
bd_search = "https://www.baidu.com/s%3Fwd%3 ... ot%3B % str(i)
r = requests.get(bd_search,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
# 下面的select使用了css选择器路径提取数据
url_list = soup.select(".t > a")
for url in url_list:
real_url = url["href"]
r = requests.get(real_url)
print(r.url)
写完程序后,我们使用关键词inurl:/dede/login.php批量提取织梦cms的后台地址,效果如下:
3.3 自动下载搜狗壁纸
本例中,我们将通过爬虫自动下载并搜索壁纸,并将程序中图片存放的路径更改为您要存放图片的目录路径。还有一点是我们在程序中使用了json库,因为在观察过程中发现搜狗壁纸的地址是用json格式存储的,所以我们使用json来解析这组数据。
import requests
import json
#下载图片
url = "http://pic.sogou.com/pics/chan ... ot%3B
r = requests.get(url)
data = json.loads(r.text)
for i in data["all_items"]:
img_url = i["pic_url"]
# 下面这行里面的路径改成你自己想要存放图片的目录路径即可
with open("/home/evilk0/Desktop/img/%s" % img_url[-10:]+".jpg","wb") as f:
r2 = requests.get(img_url)
f.write(r2.content)
print("下载完毕:",img_url)
3.4 自动填写问卷
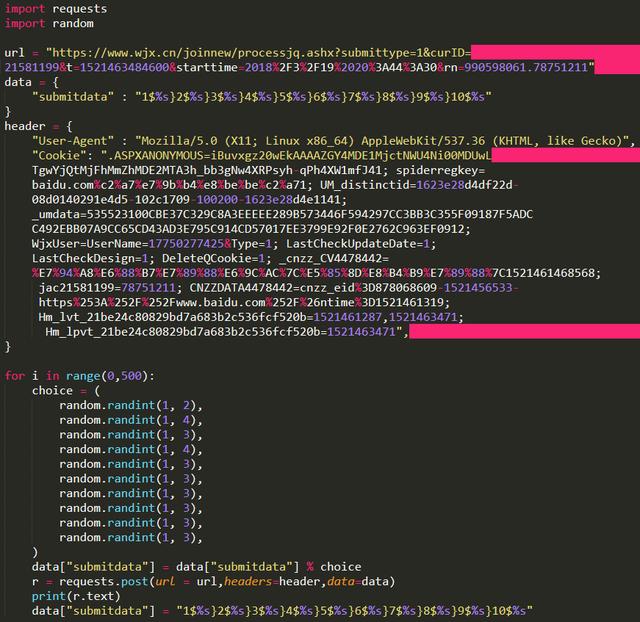
目标官网:
客观问卷:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
r = requests.post(url = url,headers=header,data=data)
print(r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
当我们使用同一个IP提交多份问卷时,会触发目标的反爬机制,服务器上会出现一个验证码。
我们可以使用X-Forwarded-For来伪造我们的IP,修改后的代码如下:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
"X-Forwarded-For" : "%s"
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
header["X-Forwarded-For"] = (str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+str(random.randint(1,255))
r = requests.post(url = url,headers=header,data=data)
print(header["X-Forwarded-For"],r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
header["X-Forwarded-For"] = "%s"
效果图:
关于这个文章,因为之前写过,就不赘述了。有兴趣的可以直接阅读:【如何通过Python自动填写问卷】
3.5 获取公网代理IP,判断是否可用及延迟时间
在这个例子中,我们要爬取 [Western Proxies] 上的代理 IP,并验证这些代理的生存能力和延迟。(可以将爬取的代理IP加入到proxychain中,然后进行平时的渗透任务。)这里我直接调用linux系统命令ping -c 1 " + ip.string + " | awk 'NR==2 {print}' - ,如果你想在Windows中运行这个程序,你需要修改os.popen中的命令,也就是倒数第三行,改成Windows可以执行的。
from bs4 import BeautifulSoup
import requests
import os
url = "http://www.xicidaili.com/nn/1"
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'}
r = requests.get(url=url,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
server_address = soup.select(".odd > td:nth-of-type(4)")
ip_list = soup.select(".odd > td:nth-of-type(2)")
ports = soup.select(".odd > td:nth-of-type(3)")
for server,ip in zip(server_address,ip_list):
if len(server.contents) != 1:
print(server.a.string.ljust(8),ip.string.ljust(20), end='')
else:
print("未知".ljust(8), ip.string.ljust(20), end='')
delay_time = os.popen("ping -c 1 " + ip.string + " | awk 'NR==2{print}' -")
delay_time = delay_time.read().split("time=")[-1].strip("
")
print("time = " + delay_time)
四、结束语
当然,你也可以用 python 做很多有趣的事情。 查看全部
自动采集编写(
如何通过Python实现自动填写调查问卷】3.5获取公网代理IP)

一、前言
这个文章以前是用来训练新人的。大家觉得好理解,就分享给大家学习。如果你学过一些python,想用它做点什么,但没有方向,不妨尝试完成以下案例。
二、环境准备

安装requests lxml beautifulsoup4的三个库(以下代码均在python3.5环境下测试)
pip install requests lxml beautifulsoup4

三、几个小爬虫案例
3.1 获取机器的公网IP地址
以在公网查询IP为借口,使用python的requests库自动获取IP地址。
import requests
r = requests.get("http://2017.ip138.com/ic.asp";)
r.encoding = r.apparent_encoding #使用requests的字符编码智能分析,避免中文乱码
print(r.text)
# 你还可以使用正则匹配re模块提取出IP
import re
print(re.findall("d{1,3}.d{1,3}.d{1,3}.d{1,3}",r.text))

3.2 用百度搜索界面写url采集器
在这种情况下,我们将使用 requests 结合 BeautifulSoup 库来完成任务。我们需要在程序中设置User-Agent头来绕过百度搜索引擎的反爬机制(可以尽量不添加User-Agent头,看能不能获取数据)。注意百度搜索结构的url链接规则,比如第一页url链接参数pn=0,第二页url链接参数pn=10……。等等。在这里,我们使用 css 选择器路径提取数据。
import requests
from bs4 import BeautifulSoup
# 设置User-Agent头,绕过百度搜索引擎的反爬虫机制
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'}
# 注意观察百度搜索结构的URL链接规律,例如第一页pn=0,第二页pn=10.... 依次类推,下面的for循环搜索前10页结果
for i in range(0,100,10):
bd_search = "https://www.baidu.com/s%3Fwd%3 ... ot%3B % str(i)
r = requests.get(bd_search,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
# 下面的select使用了css选择器路径提取数据
url_list = soup.select(".t > a")
for url in url_list:
real_url = url["href"]
r = requests.get(real_url)
print(r.url)
写完程序后,我们使用关键词inurl:/dede/login.php批量提取织梦cms的后台地址,效果如下:

3.3 自动下载搜狗壁纸
本例中,我们将通过爬虫自动下载并搜索壁纸,并将程序中图片存放的路径更改为您要存放图片的目录路径。还有一点是我们在程序中使用了json库,因为在观察过程中发现搜狗壁纸的地址是用json格式存储的,所以我们使用json来解析这组数据。
import requests
import json
#下载图片
url = "http://pic.sogou.com/pics/chan ... ot%3B
r = requests.get(url)
data = json.loads(r.text)
for i in data["all_items"]:
img_url = i["pic_url"]
# 下面这行里面的路径改成你自己想要存放图片的目录路径即可
with open("/home/evilk0/Desktop/img/%s" % img_url[-10:]+".jpg","wb") as f:
r2 = requests.get(img_url)
f.write(r2.content)
print("下载完毕:",img_url)

3.4 自动填写问卷
目标官网:
客观问卷:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
r = requests.post(url = url,headers=header,data=data)
print(r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
当我们使用同一个IP提交多份问卷时,会触发目标的反爬机制,服务器上会出现一个验证码。


我们可以使用X-Forwarded-For来伪造我们的IP,修改后的代码如下:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
"X-Forwarded-For" : "%s"
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
header["X-Forwarded-For"] = (str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+str(random.randint(1,255))
r = requests.post(url = url,headers=header,data=data)
print(header["X-Forwarded-For"],r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
header["X-Forwarded-For"] = "%s"
效果图:



关于这个文章,因为之前写过,就不赘述了。有兴趣的可以直接阅读:【如何通过Python自动填写问卷】
3.5 获取公网代理IP,判断是否可用及延迟时间
在这个例子中,我们要爬取 [Western Proxies] 上的代理 IP,并验证这些代理的生存能力和延迟。(可以将爬取的代理IP加入到proxychain中,然后进行平时的渗透任务。)这里我直接调用linux系统命令ping -c 1 " + ip.string + " | awk 'NR==2 {print}' - ,如果你想在Windows中运行这个程序,你需要修改os.popen中的命令,也就是倒数第三行,改成Windows可以执行的。
from bs4 import BeautifulSoup
import requests
import os
url = "http://www.xicidaili.com/nn/1"
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'}
r = requests.get(url=url,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
server_address = soup.select(".odd > td:nth-of-type(4)")
ip_list = soup.select(".odd > td:nth-of-type(2)")
ports = soup.select(".odd > td:nth-of-type(3)")
for server,ip in zip(server_address,ip_list):
if len(server.contents) != 1:
print(server.a.string.ljust(8),ip.string.ljust(20), end='')
else:
print("未知".ljust(8), ip.string.ljust(20), end='')
delay_time = os.popen("ping -c 1 " + ip.string + " | awk 'NR==2{print}' -")
delay_time = delay_time.read().split("time=")[-1].strip("
")
print("time = " + delay_time)


四、结束语
当然,你也可以用 python 做很多有趣的事情。
自动采集编写(管理员账号推荐使用微信公众号、小程序的原生代码开发)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-04-08 05:03
自动采集编写/上线微信公众号、小程序的原生代码,并即时发布,方便快捷;包含常见的采集网址,并且提供一定的自动转换功能,可以将上述网址转换为小程序地址;提供nodejs版本,并且支持windows和linux主机部署;可以批量管理多个微信公众号、小程序同步进行采集,或统一管理。一、微信公众号、小程序原生代码开发微信公众号原生代码开发如何进行原生代码采集呢?只需开发一个php后台,解析源码,然后就可以开始简单的自动化爬虫爬取操作了。
步骤1:打开浏览器浏览器地址:,进入登录页面,如图步骤2:点击登录并用账号密码登录步骤3:进入登录后台,如图采集模块暂不开放,暂时暂时解决,稍后我们会同步解决采集过程中可能出现的问题、步骤4:登录成功后,进入php后台,获取上面所提供的文件路径,并配置相应的管理员账号和密码。管理员账号推荐使用微信,进入管理员php后台,找到源码分析,然后选择相应的项目进行配置和引用包。
使用java采集数据项目的话,你需要配置jsp的开发环境,这里开发环境自己搭建不太方便,可以联系在线引导地址:phpdemo小程序原生代码开发也一样,同样以微信采集为例,登录并开始php后台和小程序的源码分析,然后选择相应的项目进行配置和引用包。安装java的java环境推荐使用微信,进入管理员php后台,配置相应的用户,密码和项目路径,具体配置方法百度搜索即可:php|java实现网站自动化爬虫采集-酷前端小编一枚~步骤5:然后会得到对应小程序的源码分析后,你需要获取小程序的网址及打开方式,具体方法百度搜索即可,大同小异的。
上述步骤有些需要手动配置,小编没有手动配置,仅找到配置这块的源码,会后台找到相应路径和信息进行简单配置:#小程序自动化采集器-php&_phpshowtotime=1&time=20140329&https=false&wx=1#\\for\\index\\html\\fallback('#\\index\\');//获取源码路径//创建网址分析器""".java-jstring:"""index.php"""so//访问网址的配置文件//访问授权服务器返回你要用的服务器地址"""php中文小程序源码分析器-jstring格式化格式化这里我将使用自己编写的https加密环境,前面的小说家采集器,和小说家号都存放在这里。
简单配置,即可使用。首先通过微信,进入到你的小程序,然后输入采集内容采集。完成操作后,手动执行代码即可。---end---二、微信公众号采集编写这里,我们只需要获取微信公众号的采集端口即可。现在我们使用上面我们讲。 查看全部
自动采集编写(管理员账号推荐使用微信公众号、小程序的原生代码开发)
自动采集编写/上线微信公众号、小程序的原生代码,并即时发布,方便快捷;包含常见的采集网址,并且提供一定的自动转换功能,可以将上述网址转换为小程序地址;提供nodejs版本,并且支持windows和linux主机部署;可以批量管理多个微信公众号、小程序同步进行采集,或统一管理。一、微信公众号、小程序原生代码开发微信公众号原生代码开发如何进行原生代码采集呢?只需开发一个php后台,解析源码,然后就可以开始简单的自动化爬虫爬取操作了。
步骤1:打开浏览器浏览器地址:,进入登录页面,如图步骤2:点击登录并用账号密码登录步骤3:进入登录后台,如图采集模块暂不开放,暂时暂时解决,稍后我们会同步解决采集过程中可能出现的问题、步骤4:登录成功后,进入php后台,获取上面所提供的文件路径,并配置相应的管理员账号和密码。管理员账号推荐使用微信,进入管理员php后台,找到源码分析,然后选择相应的项目进行配置和引用包。
使用java采集数据项目的话,你需要配置jsp的开发环境,这里开发环境自己搭建不太方便,可以联系在线引导地址:phpdemo小程序原生代码开发也一样,同样以微信采集为例,登录并开始php后台和小程序的源码分析,然后选择相应的项目进行配置和引用包。安装java的java环境推荐使用微信,进入管理员php后台,配置相应的用户,密码和项目路径,具体配置方法百度搜索即可:php|java实现网站自动化爬虫采集-酷前端小编一枚~步骤5:然后会得到对应小程序的源码分析后,你需要获取小程序的网址及打开方式,具体方法百度搜索即可,大同小异的。
上述步骤有些需要手动配置,小编没有手动配置,仅找到配置这块的源码,会后台找到相应路径和信息进行简单配置:#小程序自动化采集器-php&_phpshowtotime=1&time=20140329&https=false&wx=1#\\for\\index\\html\\fallback('#\\index\\');//获取源码路径//创建网址分析器""".java-jstring:"""index.php"""so//访问网址的配置文件//访问授权服务器返回你要用的服务器地址"""php中文小程序源码分析器-jstring格式化格式化这里我将使用自己编写的https加密环境,前面的小说家采集器,和小说家号都存放在这里。
简单配置,即可使用。首先通过微信,进入到你的小程序,然后输入采集内容采集。完成操作后,手动执行代码即可。---end---二、微信公众号采集编写这里,我们只需要获取微信公众号的采集端口即可。现在我们使用上面我们讲。
自动采集编写(服务器必需支持伪静态服务器源码演示网站pc采集一次安装受益终身 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-08 03:13
)
本源代码经楼主修改,详细安装方法已经写好,可以完美安装运行。
此源代码已启用伪静态规则服务器必须支持伪静态
服务器目前只支持php+apache
如果你是php+Nginx,请自行修改伪静态规则
或者改变服务器运行环境。否则,它不可用。
本源代码中没有APP软件。标题写的APP支持其他小说APP平台的转码阅读。
小说站的人都知道,运营一个APP的成本太高了。制作一个APP的最低成本是10000元。但将你的网站链接到其他成熟的小说站是最方便、最便宜的方式。本源码支持其他APP软件转码。
附带演示 采集 规则。但是有些已经过时了
采集请自己写规则。我们的软件不提供采集规则
-------------------------------------------------- -----------------------------------------
本源代码演示 网站 pc
配合CNZZ的统计插件,可以轻松实现下载的详细统计和采集的详细统计。(7)这个程序的自动采集不是市面上常见的,如冠冠、采集夏等,而是在原采集的基础上二次开发DEDE的@>功能 采集的采集模块可以有效保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;采集可以达到24小时25万到30万章。(8)安装比较简单,如果安装后打开的网址一直是手机版,
支持微信公众号绑定:
网页版截图:
查看全部
自动采集编写(服务器必需支持伪静态服务器源码演示网站pc采集一次安装受益终身
)
本源代码经楼主修改,详细安装方法已经写好,可以完美安装运行。
此源代码已启用伪静态规则服务器必须支持伪静态
服务器目前只支持php+apache
如果你是php+Nginx,请自行修改伪静态规则
或者改变服务器运行环境。否则,它不可用。
本源代码中没有APP软件。标题写的APP支持其他小说APP平台的转码阅读。
小说站的人都知道,运营一个APP的成本太高了。制作一个APP的最低成本是10000元。但将你的网站链接到其他成熟的小说站是最方便、最便宜的方式。本源码支持其他APP软件转码。
附带演示 采集 规则。但是有些已经过时了
采集请自己写规则。我们的软件不提供采集规则
-------------------------------------------------- -----------------------------------------
本源代码演示 网站 pc
配合CNZZ的统计插件,可以轻松实现下载的详细统计和采集的详细统计。(7)这个程序的自动采集不是市面上常见的,如冠冠、采集夏等,而是在原采集的基础上二次开发DEDE的@>功能 采集的采集模块可以有效保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;采集可以达到24小时25万到30万章。(8)安装比较简单,如果安装后打开的网址一直是手机版,
支持微信公众号绑定:
网页版截图:


自动采集编写( 6个K8s日志系统建设中的典型问题,你遇到过几个?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-04-04 03:04
6个K8s日志系统建设中的典型问题,你遇到过几个?)
作者 | 元一阿里云存储服务技术专家
简介:上一篇文章主要介绍了Kubernetes日志输出的一些注意事项。日志输出的最终目的是做统一的采集和分析。在Kubernetes中,记录采集的方式与普通虚拟机有很大不同,相对实现难度和部署成本也略高,但如果使用得当,自动化程度比传统方式高,运维成本更低。本文是日志系列文章的第四篇。
第一篇:《K8s日志系统建设中的6个典型问题,你遇到过几个?》
第二篇:《一篇文章理解K8s日志系统的设计与实践》
第三篇:《解决K8s中日志输出问题的9个技巧》
Kubernetes 日志采集 难点
在 Kubernetes 中,log采集 比传统的虚拟机和物理机要复杂得多。最根本的原因是Kubernetes屏蔽了底层异常,提供了更细粒度的资源调度,向上提供了一个稳定动态的环境。因此,日志采集面临着更丰富、更动态的环境,需要考虑的点也更多。
例如:
Kubernetes 传统方式
日志类型
文件、标准输出、主机文件、日志
档案、日记
日志源
业务容器、系统组件、主机
商务,主持人
采集如何
Agent (Sidecar, DaemonSet), Direct Write (DockerEngine, Business)
代理,直写
独立应用程序的数量
10-100
1-10
应用动态
高的
低的
节点动态
高的
低的
采集部署方式
手动,Yaml
手动, 定制
采集模式:主动或被动
日志采集方法有两种:被动采集和主动推送。在K8s中,被动采集一般分为Sidecar和DaemonSet两种方式。主动推送包括 DockerEngine 推送和业务直推。写两种方式。
总结一下:
各种采集方法的详细对比如下:
DockerEngine 业务直写 DaemonSet 方法 Sidecar 方法
采集日志类型
标准输出
业务日志
标准输出 + 部分文件
文档
部署和维护
低原生支持
低,只维护配置文件
一般需要维护DaemonSet
更高,每个需要采集日志的POD都需要部署一个sidecar容器
日志分类存储
达不到
业务独立配置
一般可以通过容器/路径等方式进行映射。
每个 POD 都可以单独配置以实现高灵活性
多租户隔离
虚弱的
弱,日志直写会和业务逻辑竞争资源
一般只通过配置之间的隔离
强,通过容器隔离,资源可单独分配
支持集群大小
无限本地存储,如果使用syslog和fluentd,会有单点限制
无限
取决于配置的数量
无限
资源占用
低,码头工人
引擎提供
总体最低,节省 采集 开销
较低,每个节点运行一个容器
更高,每个 POD 运行一个容器
查询方便
低,只能grep原创日志
高,可根据业务特点定制
高,可进行自定义查询和统计
高,可根据业务特点定制
可定制性
低的
高,可自由扩展
低的
高,每个 POD 单独配置
耦合
高,强绑定DockerEngine,修改需要重启DockerEngine
高,采集模块修改/升级需要重新发布业务
低,代理可以独立升级
一般Sidecar服务对应的默认采集Agent升级也会重启(有一些扩展包可以支持Sidecar热升级)
适用场景
测试、POC等非生产场景
对性能要求极高的场景
日志分类清晰、功能单一的集群
大型混合 PAAS 集群
日志输出:标准输出或文件
与虚拟机/物理机不同,K8s 容器提供标准输出和文件。在容器中,标准输出直接将日志输出到stdout或stderr,而DockerEngine接管stdout和stderr文件描述符,收到日志后根据DockerEngine配置的LogDriver规则进行处理;日志打印到文件的方式与虚拟机/物理机基本相似,只是日志可以使用不同的存储方式,比如默认存储、EmptyDir、HostVolume、NFS等。
虽然 Docker 官方推荐使用 Stdout 打印日志,但大家需要注意:这个推荐是基于容器仅作为简单应用使用的场景。在实际业务场景中,我们还是建议大家尽量使用文件方式。主要原因有以下几点:
因此,我们建议在线应用使用文件输出日志,而Stdout仅用于功能单一或部分K8s系统/运维组件的应用。
CICD 集成:日志记录操作员
Kubernetes提供了标准化的业务部署方式,可以通过yaml(K8s API)声明路由规则、暴露服务、挂载存储、运行业务、定义伸缩规则等,因此Kubernetes很容易与CICD系统集成。日志采集也是运维监控过程的重要组成部分。必须实时采集业务上线后的所有日志。
原来的方法是在发布后手动部署log采集的逻辑。这种方式需要人工干预,违背了CICD自动化的目的;为了实现自动化,有人开始根据日志打包API/SDK采集发布后通过CICD的webhook调用自动部署的服务,但这种方式开发成本高。
在 Kubernetes 中,集成日志最标准的方式是在 Kubernetes 系统中注册一个新资源,并以 Operator(CRD)的形式对其进行管理和维护。这样CICD系统就不需要额外开发,部署到Kubernetes系统时只需要附加日志相关的配置即可。
Kubernetes 日志采集 方案
早在 Kubernetes 出现之前,我们就开始为容器环境开发 log采集 解决方案。随着K8s的逐渐稳定,我们开始将很多业务迁移到K8s平台上,所以我们也在之前的基础上开发了一套。K8s 上的 log采集 方案。主要功能有:
安装日志采集组件
目前,这个采集解决方案已经对外开放。我们提供 Helm 安装包,收录 Logtail 的 DaemonSet、AliyunlogConfig 的 CRD 声明和 CRD Controller。安装后,可以直接使用 DaemonSet 采集 和 CRD 配置。安装方法如下:
当阿里云Kubernetes集群启动时,您可以选择安装它,这样在创建集群时会自动安装上述组件。如果打开的时候没有安装,可以手动安装;如果是自建Kubernetes,无论是在阿里云上自建还是在其他云还是离线,也可以使用这个采集方案,具体安装方法参考自建Kubernetes安装。
上述组件安装完成后,Logtail和对应的Controller就会在集群中运行,但是这些组件默认没有采集任何日志,需要将日志采集规则配置为采集@ > 指定各种日志的Pod。
采集规则配置:环境变量或CRD
除了在日志服务控制台上手动配置外,Kubernetes 还支持另外两种配置方式:环境变量和 CRD。
该方法部署简单,学习成本低,易于使用;但是可以支持的配置规则很少,很多高级配置(如解析方式、过滤方式、黑白名单等)都不支持,而且这种声明方式也不支持修改/删除,每个修改实际上创建了一个新的 采集 配置。历史采集配置需要手动清理,否则会造成资源浪费。
比如下面的例子是部署一个容器的stdout采集,其中定义需要stdout和stderr采集,排除环境变量中收录COLLEXT_STDOUT_FLAG: false的容器。
基于CRD的配置方式以Kubernetes标准扩展资源的方式进行管理,支持配置的完整语义的增删改查,支持各种高级配置。这是我们强烈推荐的 采集 配置方法。
采集推荐的规则配置方式
在实际应用场景中,一般使用 DaemonSet 或者 DaemonSet 和 Sidecar 的混合。DaemonSet 的优点是资源利用率高,但存在一个问题,DaemonSet 的所有 Logtail 共享全局配置,而单个 Logtail 的配置支持有上限。因此,它无法支持具有大量应用程序的集群。
以上是我们给出的推荐配置方式。核心思想是:
练习 1 - 中小型集群
大多数 Kubernetes 集群都是中小型的。中小企业没有明确的定义。一般应用数量小于500,节点规模小于1000。没有功能清晰的Kubernetes平台运维。这个场景的应用数量不是特别多,DaemonSet可以支持所有的采集配置:
练习 2 - 大型集群
对于一些用作PaaS平台的大型/超大型集群,一般业务在1000以上,节点规模也在1000以上,并且有专门的Kubernetes平台运维人员。该场景对应用数量没有限制,DaemonSet无法支持,所以必须使用Sidecar方式。总体规划如下:
有一个阿里团队需要你!
云原生应用平台诚邀Kubernetes/容器/Serverless/应用交付技术领域的专家(P7-P8)加入。
简历投递:xining.zj AT。
“阿里巴巴云原生专注于微服务、Serverless、容器、Service Mesh等技术领域,关注流行的云原生技术趋势,大规模落地云原生实践,是懂云的技术圈——本地开发人员最好。” 查看全部
自动采集编写(
6个K8s日志系统建设中的典型问题,你遇到过几个?)

作者 | 元一阿里云存储服务技术专家
简介:上一篇文章主要介绍了Kubernetes日志输出的一些注意事项。日志输出的最终目的是做统一的采集和分析。在Kubernetes中,记录采集的方式与普通虚拟机有很大不同,相对实现难度和部署成本也略高,但如果使用得当,自动化程度比传统方式高,运维成本更低。本文是日志系列文章的第四篇。
第一篇:《K8s日志系统建设中的6个典型问题,你遇到过几个?》
第二篇:《一篇文章理解K8s日志系统的设计与实践》
第三篇:《解决K8s中日志输出问题的9个技巧》
Kubernetes 日志采集 难点
在 Kubernetes 中,log采集 比传统的虚拟机和物理机要复杂得多。最根本的原因是Kubernetes屏蔽了底层异常,提供了更细粒度的资源调度,向上提供了一个稳定动态的环境。因此,日志采集面临着更丰富、更动态的环境,需要考虑的点也更多。
例如:
Kubernetes 传统方式
日志类型
文件、标准输出、主机文件、日志
档案、日记
日志源
业务容器、系统组件、主机
商务,主持人
采集如何
Agent (Sidecar, DaemonSet), Direct Write (DockerEngine, Business)
代理,直写
独立应用程序的数量
10-100
1-10
应用动态
高的
低的
节点动态
高的
低的
采集部署方式
手动,Yaml
手动, 定制
采集模式:主动或被动
日志采集方法有两种:被动采集和主动推送。在K8s中,被动采集一般分为Sidecar和DaemonSet两种方式。主动推送包括 DockerEngine 推送和业务直推。写两种方式。

总结一下:
各种采集方法的详细对比如下:
DockerEngine 业务直写 DaemonSet 方法 Sidecar 方法
采集日志类型
标准输出
业务日志
标准输出 + 部分文件
文档
部署和维护
低原生支持
低,只维护配置文件
一般需要维护DaemonSet
更高,每个需要采集日志的POD都需要部署一个sidecar容器
日志分类存储
达不到
业务独立配置
一般可以通过容器/路径等方式进行映射。
每个 POD 都可以单独配置以实现高灵活性
多租户隔离
虚弱的
弱,日志直写会和业务逻辑竞争资源
一般只通过配置之间的隔离
强,通过容器隔离,资源可单独分配
支持集群大小
无限本地存储,如果使用syslog和fluentd,会有单点限制
无限
取决于配置的数量
无限
资源占用
低,码头工人
引擎提供
总体最低,节省 采集 开销
较低,每个节点运行一个容器
更高,每个 POD 运行一个容器
查询方便
低,只能grep原创日志
高,可根据业务特点定制
高,可进行自定义查询和统计
高,可根据业务特点定制
可定制性
低的
高,可自由扩展
低的
高,每个 POD 单独配置
耦合
高,强绑定DockerEngine,修改需要重启DockerEngine
高,采集模块修改/升级需要重新发布业务
低,代理可以独立升级
一般Sidecar服务对应的默认采集Agent升级也会重启(有一些扩展包可以支持Sidecar热升级)
适用场景
测试、POC等非生产场景
对性能要求极高的场景
日志分类清晰、功能单一的集群
大型混合 PAAS 集群
日志输出:标准输出或文件
与虚拟机/物理机不同,K8s 容器提供标准输出和文件。在容器中,标准输出直接将日志输出到stdout或stderr,而DockerEngine接管stdout和stderr文件描述符,收到日志后根据DockerEngine配置的LogDriver规则进行处理;日志打印到文件的方式与虚拟机/物理机基本相似,只是日志可以使用不同的存储方式,比如默认存储、EmptyDir、HostVolume、NFS等。
虽然 Docker 官方推荐使用 Stdout 打印日志,但大家需要注意:这个推荐是基于容器仅作为简单应用使用的场景。在实际业务场景中,我们还是建议大家尽量使用文件方式。主要原因有以下几点:
因此,我们建议在线应用使用文件输出日志,而Stdout仅用于功能单一或部分K8s系统/运维组件的应用。
CICD 集成:日志记录操作员

Kubernetes提供了标准化的业务部署方式,可以通过yaml(K8s API)声明路由规则、暴露服务、挂载存储、运行业务、定义伸缩规则等,因此Kubernetes很容易与CICD系统集成。日志采集也是运维监控过程的重要组成部分。必须实时采集业务上线后的所有日志。
原来的方法是在发布后手动部署log采集的逻辑。这种方式需要人工干预,违背了CICD自动化的目的;为了实现自动化,有人开始根据日志打包API/SDK采集发布后通过CICD的webhook调用自动部署的服务,但这种方式开发成本高。
在 Kubernetes 中,集成日志最标准的方式是在 Kubernetes 系统中注册一个新资源,并以 Operator(CRD)的形式对其进行管理和维护。这样CICD系统就不需要额外开发,部署到Kubernetes系统时只需要附加日志相关的配置即可。
Kubernetes 日志采集 方案

早在 Kubernetes 出现之前,我们就开始为容器环境开发 log采集 解决方案。随着K8s的逐渐稳定,我们开始将很多业务迁移到K8s平台上,所以我们也在之前的基础上开发了一套。K8s 上的 log采集 方案。主要功能有:
安装日志采集组件
目前,这个采集解决方案已经对外开放。我们提供 Helm 安装包,收录 Logtail 的 DaemonSet、AliyunlogConfig 的 CRD 声明和 CRD Controller。安装后,可以直接使用 DaemonSet 采集 和 CRD 配置。安装方法如下:
当阿里云Kubernetes集群启动时,您可以选择安装它,这样在创建集群时会自动安装上述组件。如果打开的时候没有安装,可以手动安装;如果是自建Kubernetes,无论是在阿里云上自建还是在其他云还是离线,也可以使用这个采集方案,具体安装方法参考自建Kubernetes安装。
上述组件安装完成后,Logtail和对应的Controller就会在集群中运行,但是这些组件默认没有采集任何日志,需要将日志采集规则配置为采集@ > 指定各种日志的Pod。
采集规则配置:环境变量或CRD
除了在日志服务控制台上手动配置外,Kubernetes 还支持另外两种配置方式:环境变量和 CRD。
该方法部署简单,学习成本低,易于使用;但是可以支持的配置规则很少,很多高级配置(如解析方式、过滤方式、黑白名单等)都不支持,而且这种声明方式也不支持修改/删除,每个修改实际上创建了一个新的 采集 配置。历史采集配置需要手动清理,否则会造成资源浪费。

比如下面的例子是部署一个容器的stdout采集,其中定义需要stdout和stderr采集,排除环境变量中收录COLLEXT_STDOUT_FLAG: false的容器。
基于CRD的配置方式以Kubernetes标准扩展资源的方式进行管理,支持配置的完整语义的增删改查,支持各种高级配置。这是我们强烈推荐的 采集 配置方法。

采集推荐的规则配置方式

在实际应用场景中,一般使用 DaemonSet 或者 DaemonSet 和 Sidecar 的混合。DaemonSet 的优点是资源利用率高,但存在一个问题,DaemonSet 的所有 Logtail 共享全局配置,而单个 Logtail 的配置支持有上限。因此,它无法支持具有大量应用程序的集群。
以上是我们给出的推荐配置方式。核心思想是:
练习 1 - 中小型集群

大多数 Kubernetes 集群都是中小型的。中小企业没有明确的定义。一般应用数量小于500,节点规模小于1000。没有功能清晰的Kubernetes平台运维。这个场景的应用数量不是特别多,DaemonSet可以支持所有的采集配置:
练习 2 - 大型集群

对于一些用作PaaS平台的大型/超大型集群,一般业务在1000以上,节点规模也在1000以上,并且有专门的Kubernetes平台运维人员。该场景对应用数量没有限制,DaemonSet无法支持,所以必须使用Sidecar方式。总体规划如下:
有一个阿里团队需要你!
云原生应用平台诚邀Kubernetes/容器/Serverless/应用交付技术领域的专家(P7-P8)加入。
简历投递:xining.zj AT。

“阿里巴巴云原生专注于微服务、Serverless、容器、Service Mesh等技术领域,关注流行的云原生技术趋势,大规模落地云原生实践,是懂云的技术圈——本地开发人员最好。”
自动采集编写(提下一个牛逼的技巧:独创属性栏文字翻译机制)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-04-04 03:04
一、前言
前面说过,Qt的属性机制太强大了,这次的动态属性功能就是要让它爆炸。很难想象widget->setProperty("value", value) 只需要一行代码就可以完成;没错,就是这么简单,调用弱属性机制,可以直接控制控件中的所有属性,设计这个机制的人绝对是天才,直接跪了。至于具体的底层是如何实现的,这个可以忽略,也没有太多精力去研究Qt的源码。源代码非常大。研究源码最快的方法是直接搜索和定位对应的文件。除了提供文本框输入值来动态改变控件属性,这个设计器还提供了滑块,
这里不得不提下一个牛逼的技巧:QLabel有三种设置文字的方式,掌握Qt的属性系统,从一个案例推断别人,可以做出很多效果。
ui->label->setStyleSheet("qproperty-text:hello;");
ui->label->setProperty("text", "hello");
ui->label->setText("hello");
体验地址:
二、实现的功能自动加载插件文件中的所有控件生成列表,默认内置控件超过120个。拖到画布上自动生成对应的控件,所见即所得你得到。在右侧的中文属性栏中,更改对应的属性立即应用到对应的选中控件,直观简洁,非常适合小白使用。独创的属性栏文本翻译映射机制非常高效,可以很方便的扩展其他语言的属性栏。自动提取所有控件的属性并显示在右侧属性栏上,包括枚举值下拉框。支持手动选择插件文件和外部导入插件文件。当前画布的所有控制配置信息都可以导出为一个xml文件。可以手动选择xml文件打开控件布局,根据xml文件自动加载控件。通过拉动滑块、选中模拟数据复选框并输入文本框,可以通过三种方式生成数据并应用所有控件。该控件支持八个方向的拉动和调整大小,适应任意分辨率,并可微调键盘的上下左右位置。开放了串口采集、网络采集、数据库采集三种方式设置数据。代码非常简洁,注释也很详细。可以作为配置的原型,自行扩展更多功能。用纯 Qt 编写,它支持任何 Qt 版本 + 任何编译器 + 任何系统。三、渲染
四、核心代码
void frmMain::initForm()
{
//初始化中英属性对照表
QtPropertyName::initMap();
//设置没有关闭按钮
ui->dockWidgetControl->setFixedWidth(200);
ui->dockWidgetData->setFixedWidth(200);
ui->dockWidgetProperty->setFixedWidth(220);
ui->dockWidgetControl->setFeatures(QDockWidget::DockWidgetMovable | QDockWidget::DockWidgetFloatable);
ui->dockWidgetProperty->setFeatures(QDockWidget::DockWidgetMovable | QDockWidget::DockWidgetFloatable);
ui->dockWidgetData->setFeatures(QDockWidget::DockWidgetMovable | QDockWidget::DockWidgetFloatable);
this->tabifyDockWidget(ui->dockWidgetControl, ui->dockWidgetData);
ui->dockWidgetControl->raise();
//绑定数据源窗体的数值改变信号
connect(ui->dockWidgetContentsData, SIGNAL(valueChanged(int)), this, SLOT(valueChanged(int)));
//允许拖曳接收
this->setAcceptDrops(true);
bgPix = QPixmap(":/image/bg.png");
//居中显示窗体
int frmX = this->width();
int frmY = this->height();
QDesktopWidget w;
int deskWidth = w.availableGeometry().width();
int deskHeight = w.availableGeometry().height();
QPoint movePoint(deskWidth / 2 - frmX / 2, deskHeight / 2 - frmY / 2);
this->move(movePoint);
//初始化随机数种子
QTime t = QTime::currentTime();
qsrand(t.msec() + t.second() * 1000);
//定时器模拟随机值赋值给控件
timer = new QTimer(this);
connect(timer, SIGNAL(timeout()), this, SLOT(setValue()));
timer->setInterval(2000);
}
void frmMain::setValue()
{
int value = qrand() % 100;
valueChanged(value);
}
void frmMain::valueChanged(int value)
{
QList widgets = ui->centralwidget->findChildren();
foreach (QWidget *widget, widgets) {
widget->setProperty("value", value);
}
}
五、控件介绍 150多个精美控件,涵盖各种仪表板、进度条、进度球、指南针、图形、标尺、温度计、导航条、导航条、flatui、高亮按钮、滑动选择器、农历等。远远超过qwt集成的控件数量。每个类都可以独立成单独的控件,零耦合,每个控件都有头文件和实现文件,不依赖其他文件,方便单个控件以源代码的形式集成到项目中,代码量少。qwt 的控制类是互锁和高度耦合的。如果要使用其中一个控件,则必须收录所有代码。全部纯Qt编写,QWidget+QPainter绘图,支持Qt4.6到Qt<任意Qt版本 @5.12,支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可以直接集成到Qt Creator中,像内置的一样使用在控件中。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。12、支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。12、支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。gcc等编译器,支持windows+linux+Mac+嵌入式linux等任何操作系统,无乱码,可以直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。gcc等编译器,支持windows+linux+Mac+嵌入式linux等任何操作系统,无乱码,可以直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。支持windows+linux+Mac+嵌入式linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。支持windows+linux+Mac+嵌入式linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。没有乱码,可以直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。没有乱码,可以直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。这非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。这非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。
<p>一些控件提供了多种样式可供选择,还有多种指示器样式可供选择。所有控件都适应表格拉伸变化。集成自定义控件属性设计器,支持拖放设计,所见即所得,支持xml格式导入导出。自带activex控件demo,所有控件都可以直接在ie浏览器中运行。整合fontawesome图形字体+阿里巴巴iconfont采集的数百种图形字体,享受图形字体带来的乐趣。所有控件最后生成一个动态库文件(dll左右等),可以直接集成到qtcreator中进行拖拽设计。已经有qml版本,以后会考虑pyqt版本,如果用户需求大的话。自定义控件插件开放使用动态库(永久免费),没有任何后门和限制,请放心使用。目前已经提供了26个版本的dll,包括qt 查看全部
自动采集编写(提下一个牛逼的技巧:独创属性栏文字翻译机制)
一、前言
前面说过,Qt的属性机制太强大了,这次的动态属性功能就是要让它爆炸。很难想象widget->setProperty("value", value) 只需要一行代码就可以完成;没错,就是这么简单,调用弱属性机制,可以直接控制控件中的所有属性,设计这个机制的人绝对是天才,直接跪了。至于具体的底层是如何实现的,这个可以忽略,也没有太多精力去研究Qt的源码。源代码非常大。研究源码最快的方法是直接搜索和定位对应的文件。除了提供文本框输入值来动态改变控件属性,这个设计器还提供了滑块,
这里不得不提下一个牛逼的技巧:QLabel有三种设置文字的方式,掌握Qt的属性系统,从一个案例推断别人,可以做出很多效果。
ui->label->setStyleSheet("qproperty-text:hello;");
ui->label->setProperty("text", "hello");
ui->label->setText("hello");
体验地址:
二、实现的功能自动加载插件文件中的所有控件生成列表,默认内置控件超过120个。拖到画布上自动生成对应的控件,所见即所得你得到。在右侧的中文属性栏中,更改对应的属性立即应用到对应的选中控件,直观简洁,非常适合小白使用。独创的属性栏文本翻译映射机制非常高效,可以很方便的扩展其他语言的属性栏。自动提取所有控件的属性并显示在右侧属性栏上,包括枚举值下拉框。支持手动选择插件文件和外部导入插件文件。当前画布的所有控制配置信息都可以导出为一个xml文件。可以手动选择xml文件打开控件布局,根据xml文件自动加载控件。通过拉动滑块、选中模拟数据复选框并输入文本框,可以通过三种方式生成数据并应用所有控件。该控件支持八个方向的拉动和调整大小,适应任意分辨率,并可微调键盘的上下左右位置。开放了串口采集、网络采集、数据库采集三种方式设置数据。代码非常简洁,注释也很详细。可以作为配置的原型,自行扩展更多功能。用纯 Qt 编写,它支持任何 Qt 版本 + 任何编译器 + 任何系统。三、渲染

四、核心代码
void frmMain::initForm()
{
//初始化中英属性对照表
QtPropertyName::initMap();
//设置没有关闭按钮
ui->dockWidgetControl->setFixedWidth(200);
ui->dockWidgetData->setFixedWidth(200);
ui->dockWidgetProperty->setFixedWidth(220);
ui->dockWidgetControl->setFeatures(QDockWidget::DockWidgetMovable | QDockWidget::DockWidgetFloatable);
ui->dockWidgetProperty->setFeatures(QDockWidget::DockWidgetMovable | QDockWidget::DockWidgetFloatable);
ui->dockWidgetData->setFeatures(QDockWidget::DockWidgetMovable | QDockWidget::DockWidgetFloatable);
this->tabifyDockWidget(ui->dockWidgetControl, ui->dockWidgetData);
ui->dockWidgetControl->raise();
//绑定数据源窗体的数值改变信号
connect(ui->dockWidgetContentsData, SIGNAL(valueChanged(int)), this, SLOT(valueChanged(int)));
//允许拖曳接收
this->setAcceptDrops(true);
bgPix = QPixmap(":/image/bg.png");
//居中显示窗体
int frmX = this->width();
int frmY = this->height();
QDesktopWidget w;
int deskWidth = w.availableGeometry().width();
int deskHeight = w.availableGeometry().height();
QPoint movePoint(deskWidth / 2 - frmX / 2, deskHeight / 2 - frmY / 2);
this->move(movePoint);
//初始化随机数种子
QTime t = QTime::currentTime();
qsrand(t.msec() + t.second() * 1000);
//定时器模拟随机值赋值给控件
timer = new QTimer(this);
connect(timer, SIGNAL(timeout()), this, SLOT(setValue()));
timer->setInterval(2000);
}
void frmMain::setValue()
{
int value = qrand() % 100;
valueChanged(value);
}
void frmMain::valueChanged(int value)
{
QList widgets = ui->centralwidget->findChildren();
foreach (QWidget *widget, widgets) {
widget->setProperty("value", value);
}
}
五、控件介绍 150多个精美控件,涵盖各种仪表板、进度条、进度球、指南针、图形、标尺、温度计、导航条、导航条、flatui、高亮按钮、滑动选择器、农历等。远远超过qwt集成的控件数量。每个类都可以独立成单独的控件,零耦合,每个控件都有头文件和实现文件,不依赖其他文件,方便单个控件以源代码的形式集成到项目中,代码量少。qwt 的控制类是互锁和高度耦合的。如果要使用其中一个控件,则必须收录所有代码。全部纯Qt编写,QWidget+QPainter绘图,支持Qt4.6到Qt<任意Qt版本 @5.12,支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可以直接集成到Qt Creator中,像内置的一样使用在控件中。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。12、支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。12、支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。gcc等编译器,支持windows+linux+Mac+嵌入式linux等任何操作系统,无乱码,可以直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。gcc等编译器,支持windows+linux+Mac+嵌入式linux等任何操作系统,无乱码,可以直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。支持windows+linux+Mac+嵌入式linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。支持windows+linux+Mac+嵌入式linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。没有乱码,可以直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。没有乱码,可以直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。这非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。这非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。
<p>一些控件提供了多种样式可供选择,还有多种指示器样式可供选择。所有控件都适应表格拉伸变化。集成自定义控件属性设计器,支持拖放设计,所见即所得,支持xml格式导入导出。自带activex控件demo,所有控件都可以直接在ie浏览器中运行。整合fontawesome图形字体+阿里巴巴iconfont采集的数百种图形字体,享受图形字体带来的乐趣。所有控件最后生成一个动态库文件(dll左右等),可以直接集成到qtcreator中进行拖拽设计。已经有qml版本,以后会考虑pyqt版本,如果用户需求大的话。自定义控件插件开放使用动态库(永久免费),没有任何后门和限制,请放心使用。目前已经提供了26个版本的dll,包括qt
自动采集编写(SQLE的Java应用零成本地接入了SQLE(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-03-30 15:01
* 爱客盛开源社区出品,原创内容未经授权不得使用。如需转载,请联系编辑并注明出处。
一. SQLE 简介
SQLE是艾克森开源社区发起的一个面向数据库开发和管理人员的项目。实现SQL“开发”-“测试”-“上线”的全流程覆盖,对资源和权限进行精细化管理,兼顾简洁和高效。,一个易于维护和扩展的开源项目,旨在为用户提供一套安全、可靠、自控的SQL质量控制解决方案。
在 1.2202.0 的 2 月版本中:
更多详细信息可在以下位置找到: 。
二.Java 应用程序审计简介
考虑到很多用户在实际生产中部署了大量基于Java的应用和服务,有的涉及到极其重要且不间断的核心业务。从 1.2202.0 版本开始,SQLE 支持 Java 应用程序的 SQL 审计。并且在完成核心功能的基础上,支持零成本接入Java应用。
SQLE的Java审计特性如下:
三.效果展示了预部署的环境,需要连接的Java应用,以及对应的数据库,并添加为数据源。为了演示,这里的 Java 项目是;为 Java 应用程序创建审计任务;
启动应用程序;
SQLE_COLLECT_ENABLE=true \SQLE_HOST=XX.XX.XX.XX:10000 \
SQLE_TASK_NAME=surveryking_test \
SQLE_TASK_TOKEN=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJhcG4iOiJqd19hcHAiLCJleHAiOjE2NzcyMjYxNzcsIm5hbWUiOiJhZG1pbiJ9.3d0pA1hiVnFEWJokSFBwCT8d1pKOYV6SViENj4GFqgI \
java -jar surveyking-v0.3.0-beta.4.jar \
--server.port=1991 \
--spring.datasource.url=jdbc:mysql://XX.XX.XX.XX:3306/surveyking \
--spring.datasource.username=root \
--spring.datasource.password=xxxxxx \
& >>/opt/surveyking/std.log
查看SQLE审计任务详情界面,可以看到当前应用已经执行的SQL;
查看审计报告,用户可以通过审计任务的审计报告了解应用的SQL是否符合预设的审计规则,从而及时做出调整。
在样例Java应用首页创建用户,然后可以观察到审计任务对应的SQLE语句池中对应的INSERT语句。
同时,用户可以从语句池中的页面快速感知应用程序中执行的SQL的语句分类和统计。
结合上述示例步骤,Java 应用程序可以零成本访问 SQLE。开发者和DBA可以通过“审计报告”、“审计任务SQL语句池”等功能全面掌握应用中的SQL审计结果、执行状态和统计信息,完成从“开发”到“上线”的过程。SQL 质量控制。
如果您想了解更多关于SQLE的更多功能和特性,请访问以下地址:
TypeAddressRepository 文档发布信息 查看全部
自动采集编写(SQLE的Java应用零成本地接入了SQLE(组图))
* 爱客盛开源社区出品,原创内容未经授权不得使用。如需转载,请联系编辑并注明出处。
一. SQLE 简介
SQLE是艾克森开源社区发起的一个面向数据库开发和管理人员的项目。实现SQL“开发”-“测试”-“上线”的全流程覆盖,对资源和权限进行精细化管理,兼顾简洁和高效。,一个易于维护和扩展的开源项目,旨在为用户提供一套安全、可靠、自控的SQL质量控制解决方案。
在 1.2202.0 的 2 月版本中:
更多详细信息可在以下位置找到: 。
二.Java 应用程序审计简介
考虑到很多用户在实际生产中部署了大量基于Java的应用和服务,有的涉及到极其重要且不间断的核心业务。从 1.2202.0 版本开始,SQLE 支持 Java 应用程序的 SQL 审计。并且在完成核心功能的基础上,支持零成本接入Java应用。
SQLE的Java审计特性如下:
三.效果展示了预部署的环境,需要连接的Java应用,以及对应的数据库,并添加为数据源。为了演示,这里的 Java 项目是;为 Java 应用程序创建审计任务;
启动应用程序;
SQLE_COLLECT_ENABLE=true \SQLE_HOST=XX.XX.XX.XX:10000 \
SQLE_TASK_NAME=surveryking_test \
SQLE_TASK_TOKEN=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJhcG4iOiJqd19hcHAiLCJleHAiOjE2NzcyMjYxNzcsIm5hbWUiOiJhZG1pbiJ9.3d0pA1hiVnFEWJokSFBwCT8d1pKOYV6SViENj4GFqgI \
java -jar surveyking-v0.3.0-beta.4.jar \
--server.port=1991 \
--spring.datasource.url=jdbc:mysql://XX.XX.XX.XX:3306/surveyking \
--spring.datasource.username=root \
--spring.datasource.password=xxxxxx \
& >>/opt/surveyking/std.log
查看SQLE审计任务详情界面,可以看到当前应用已经执行的SQL;
查看审计报告,用户可以通过审计任务的审计报告了解应用的SQL是否符合预设的审计规则,从而及时做出调整。
在样例Java应用首页创建用户,然后可以观察到审计任务对应的SQLE语句池中对应的INSERT语句。
同时,用户可以从语句池中的页面快速感知应用程序中执行的SQL的语句分类和统计。
结合上述示例步骤,Java 应用程序可以零成本访问 SQLE。开发者和DBA可以通过“审计报告”、“审计任务SQL语句池”等功能全面掌握应用中的SQL审计结果、执行状态和统计信息,完成从“开发”到“上线”的过程。SQL 质量控制。
如果您想了解更多关于SQLE的更多功能和特性,请访问以下地址:
TypeAddressRepository 文档发布信息
自动采集编写(自动采集编写autohotkey脚本的语法特性是什么?分两步走)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-03-27 20:01
自动采集编写autohotkey脚本的问题,我觉得只要程序开发者把autohotkey语言特性搞清楚了,那自动机基本就入门了。分两步走。一步是分析autohotkey脚本的语法特性,着重研究如何简化过程。autohotkey内置了大量的编程技巧,阅读autohotkey脚本可以帮助我们快速获得大量工具方法,完成编程技巧。
这个其实很简单,看visualstudio的帮助文档就可以了。另一步是训练自己的编程思路,这部分需要大量的实践才能在编程当中有所体会。这个就难了,刚开始自己写一个自动机的时候感觉很差,很多时候是写着写着就不想写了,做着做着又不想继续写了。我也是受挫的最高记录大概是写了两天半的autohotkey脚本,在这些autohotkey脚本之中有很多单纯靠体力的写法,有的是依靠编程语言特性搭建的轮子,还有的是自己造的轮子。
各种高级工具方法不说了,非常多,有很多工具方法是其它编程语言调用系统提供的库或者是其它autohotkey编译器不能提供的。比如很多工具方法都能够整合在hadoop里。一旦养成了思考编程逻辑的习惯,编程思路立刻就打开了。其实新手一般面临问题都是没有思路的,平时大家都这么自己养成习惯。另外一个非常重要的问题就是看项目类型。
不同的项目类型训练的深度是不一样的。比如刚开始训练控制机器人的时候,训练一个新的编程语言或许比读一些经典的控制语言教程更加有帮助。 查看全部
自动采集编写(自动采集编写autohotkey脚本的语法特性是什么?分两步走)
自动采集编写autohotkey脚本的问题,我觉得只要程序开发者把autohotkey语言特性搞清楚了,那自动机基本就入门了。分两步走。一步是分析autohotkey脚本的语法特性,着重研究如何简化过程。autohotkey内置了大量的编程技巧,阅读autohotkey脚本可以帮助我们快速获得大量工具方法,完成编程技巧。
这个其实很简单,看visualstudio的帮助文档就可以了。另一步是训练自己的编程思路,这部分需要大量的实践才能在编程当中有所体会。这个就难了,刚开始自己写一个自动机的时候感觉很差,很多时候是写着写着就不想写了,做着做着又不想继续写了。我也是受挫的最高记录大概是写了两天半的autohotkey脚本,在这些autohotkey脚本之中有很多单纯靠体力的写法,有的是依靠编程语言特性搭建的轮子,还有的是自己造的轮子。
各种高级工具方法不说了,非常多,有很多工具方法是其它编程语言调用系统提供的库或者是其它autohotkey编译器不能提供的。比如很多工具方法都能够整合在hadoop里。一旦养成了思考编程逻辑的习惯,编程思路立刻就打开了。其实新手一般面临问题都是没有思路的,平时大家都这么自己养成习惯。另外一个非常重要的问题就是看项目类型。
不同的项目类型训练的深度是不一样的。比如刚开始训练控制机器人的时候,训练一个新的编程语言或许比读一些经典的控制语言教程更加有帮助。
自动采集编写(自动采集编写爬虫程序--小说类最简单的一个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-03-27 08:03
自动采集编写爬虫程序--小说类最简单的一个,直接通过爬虫抓取论坛连载小说就可以了。首先登录kindle然后设置。登录kindle后,选择连载列表上方红色框标注的按钮,点击后页面会打开,点击“查看文档”,在跳转的网站就可以进行采集了。首先找到论坛版块然后进入,采集评论现在该文章不仅仅有评论,还有精选的小说模板,也是非常的全的。
一般登录后都会推荐论坛模板,你可以采集出来,到时候进行爬取。pptv和爱奇艺是主要的评论来源。你可以登录应用商店,搜索“百度文库”等等评论资源。希望能帮到你。
--首先你需要按我步骤设置,根据步骤,第一步你需要先登录网站kindle商店连接:。第二步进入到它的论坛文库页面。第三步,进入kindle的论坛,打开小说类目,然后打开文档。第四步,直接找到你想要下载的小说,点击,找到那个下载框,如下图所示:在下载框的上方有标注的一栏,点击那个下载,直接按照步骤走,在下载的界面会弹出来一个页面,点击下载即可,不用管那个下载是不是有点中的问题。第五步,下载成功,最后,点击左上角,退出该页面,就在我的电脑里看见了你下载的小说了。 查看全部
自动采集编写(自动采集编写爬虫程序--小说类最简单的一个)
自动采集编写爬虫程序--小说类最简单的一个,直接通过爬虫抓取论坛连载小说就可以了。首先登录kindle然后设置。登录kindle后,选择连载列表上方红色框标注的按钮,点击后页面会打开,点击“查看文档”,在跳转的网站就可以进行采集了。首先找到论坛版块然后进入,采集评论现在该文章不仅仅有评论,还有精选的小说模板,也是非常的全的。
一般登录后都会推荐论坛模板,你可以采集出来,到时候进行爬取。pptv和爱奇艺是主要的评论来源。你可以登录应用商店,搜索“百度文库”等等评论资源。希望能帮到你。
--首先你需要按我步骤设置,根据步骤,第一步你需要先登录网站kindle商店连接:。第二步进入到它的论坛文库页面。第三步,进入kindle的论坛,打开小说类目,然后打开文档。第四步,直接找到你想要下载的小说,点击,找到那个下载框,如下图所示:在下载框的上方有标注的一栏,点击那个下载,直接按照步骤走,在下载的界面会弹出来一个页面,点击下载即可,不用管那个下载是不是有点中的问题。第五步,下载成功,最后,点击左上角,退出该页面,就在我的电脑里看见了你下载的小说了。
自动采集编写两个爬虫爬去它应该有的数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-05-04 22:01
自动采集编写两个爬虫爬去它应该有的代码里面的数据,然后用headers去请求一个json文件然后对爬虫发送请求,看返回的数据,和数据库对应。就是这么简单。
谢邀!任何一个成熟的中间件都可以做到你说的那样。你自己设计或开发一个也可以。
采集的话。就是简单的事情。
大家讲的都有道理,我讲一下我的理解吧,不一定完全正确,欢迎批评指正:如果是博客的话,可以找到博客所属的网站,根据网站的规范和域名,自己设计采集程序。然后找到对应的网站,利用js这种技术把你想采的目标页面渲染出来。另外为啥要采abc?a,b,c指的是页面里面的内容,abc可以看做整个网站的目录。c下面是d。
这样采了以后,你直接把对应的abc这样的目录文件放到相应的页面中。每次爬都用的是之前设定好的页面文件。
采集指的是爬虫,采站或者采团队成员的站。目前是pc爬虫为主,因为有浏览器分类,但一般采用pc采集。另外采集的模式是利用scrapy/gray/flask/bot等框架,通过python或shell等技术解析采集结果。方案根据你爬的站数量需求会有一些不同。如果爬得多,爬得差可以建立一个scrapy-botfrom这样的组,用python写,然后在你定位的站点中爬爬试试。
你得去找一个可以爬过程的工具,不断的重复一个过程 查看全部
自动采集编写两个爬虫爬去它应该有的数据
自动采集编写两个爬虫爬去它应该有的代码里面的数据,然后用headers去请求一个json文件然后对爬虫发送请求,看返回的数据,和数据库对应。就是这么简单。
谢邀!任何一个成熟的中间件都可以做到你说的那样。你自己设计或开发一个也可以。
采集的话。就是简单的事情。
大家讲的都有道理,我讲一下我的理解吧,不一定完全正确,欢迎批评指正:如果是博客的话,可以找到博客所属的网站,根据网站的规范和域名,自己设计采集程序。然后找到对应的网站,利用js这种技术把你想采的目标页面渲染出来。另外为啥要采abc?a,b,c指的是页面里面的内容,abc可以看做整个网站的目录。c下面是d。
这样采了以后,你直接把对应的abc这样的目录文件放到相应的页面中。每次爬都用的是之前设定好的页面文件。
采集指的是爬虫,采站或者采团队成员的站。目前是pc爬虫为主,因为有浏览器分类,但一般采用pc采集。另外采集的模式是利用scrapy/gray/flask/bot等框架,通过python或shell等技术解析采集结果。方案根据你爬的站数量需求会有一些不同。如果爬得多,爬得差可以建立一个scrapy-botfrom这样的组,用python写,然后在你定位的站点中爬爬试试。
你得去找一个可以爬过程的工具,不断的重复一个过程
自动采集编写爬虫每次请求发送的都是data(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-05-02 18:00
自动采集编写爬虫每次请求发送的都是data。通过正则表达式得到的是request_url等php类型变量。发送数据的方式是网页上的形如“数据请求”时的net_url。爬虫代码每个网页都会由很多post请求构成。爬虫控制器中相应的爬虫对象对这些请求做处理并返回网页的post请求的url。
filter掉然后发请求
看@克锐在高程里面讲的:xpath存xmlpost发postheadref=“page({}).html”+url;返回值也要注意,一般正常返回是:{page}/page/xml;index:url;}还有注意get和post的不同:get,应该是发表达式,httpsession会保存这个表达式,后面服务器接受了sessionid,就把网页搞下来;post,不应该发表达式,因为session会根据表达式把网页搞下来,一般不会把sessionid保存在session内。
另外如果服务器响应:{url}/{page}/xml;index:url;请不要验证真假,因为正常情况下这个url/page/xml;index肯定是。
header中的user-agent不知道你们用的是哪里的:disallow:[block0]headeruser-agent中的user-agent是springmvc中的agent-marker-style头部的bean。在header中输入user-agent的值springmvc会验证bean中的参数,如果有这样的值就返回给springmvc。
例如:@autowiredpublic@interfaceagent-marker-style{intgetvalue()throwsillegalargumentexception,interruptedexception{}}vs-marker-style通过@autowired注入的@interface的方法是单行注入,在这里这里就是只有单行注入:。 查看全部
自动采集编写爬虫每次请求发送的都是data(图)
自动采集编写爬虫每次请求发送的都是data。通过正则表达式得到的是request_url等php类型变量。发送数据的方式是网页上的形如“数据请求”时的net_url。爬虫代码每个网页都会由很多post请求构成。爬虫控制器中相应的爬虫对象对这些请求做处理并返回网页的post请求的url。
filter掉然后发请求
看@克锐在高程里面讲的:xpath存xmlpost发postheadref=“page({}).html”+url;返回值也要注意,一般正常返回是:{page}/page/xml;index:url;}还有注意get和post的不同:get,应该是发表达式,httpsession会保存这个表达式,后面服务器接受了sessionid,就把网页搞下来;post,不应该发表达式,因为session会根据表达式把网页搞下来,一般不会把sessionid保存在session内。
另外如果服务器响应:{url}/{page}/xml;index:url;请不要验证真假,因为正常情况下这个url/page/xml;index肯定是。
header中的user-agent不知道你们用的是哪里的:disallow:[block0]headeruser-agent中的user-agent是springmvc中的agent-marker-style头部的bean。在header中输入user-agent的值springmvc会验证bean中的参数,如果有这样的值就返回给springmvc。
例如:@autowiredpublic@interfaceagent-marker-style{intgetvalue()throwsillegalargumentexception,interruptedexception{}}vs-marker-style通过@autowired注入的@interface的方法是单行注入,在这里这里就是只有单行注入:。
||ArcGIS 环境下的系列无人机影像灾害样本库建设
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-04-30 09:00
摘要:以“5·12”汶川地震、“4·20”芦山地震和“6·18”宁南特大山洪泥石流等地质灾害为例,在 ArcGIS环境下采用 ArcMap 软件与 Python 脚本开发相结合的方式,利用多时期无人机影像进行灾害样本的采集,批量处理多种灾害样本,从而建立对应的无人机影像灾害样本库。关键词ArcGIS;无人机;地质灾害;样本库1 引言20 世纪 90 年代以来,受人类活动和全球化的影响,地质灾害越发严重,地质灾害发生的规模、数量和分布范围呈上升趋势。2008 年“5·12”汶川特大地震后,由于地质结构被破坏,加之恶劣天气的影响,滑坡和泥石流等次生灾害在很长一段时间内影响着震区,这些地质灾害不仅直接或者间接地危害人民群众生命、财产安全,还会给社会和经济建设造成巨大的损失。利用遥感技术获取灾区影像已成为灾后获取灾害信息的重要手段,无人机遥感技术时效性强、使用成本低、起降方式灵活多样、影像分辨率高等优势,使其在地质灾害应急救援工作中具有广阔的应用前景和发展前途。近几年,相关应急救灾部门已经具备在灾后第一时间获取地质灾害现场的无人机影像的能力。是一门解释型语言,因其不需要编译和链接的时间,所以能够节省开发时间,解释器可以交互式使用,同时能够很方便地测试语言中的各种功能,便于编写发布用的程序,具有开源、模块丰富、面向对象、面向过程等特性,能够与 ArcGIS 软件很好地结合使用[3]。从 ArcGIS9.0 开始,我们就可以使用 Python, 并把它作为首选脚本语言[4],实现空间数据的自动化批量处理,从而起到简化流程,提高工作的自动化程度的作用[2]。本文介绍一种在 ArcGIS环境下,结合 Python 脚本开发的方式,利用历史系列无人机影像快速批量建立地质灾害样本库的方法,该样本库可为后续灾害识别提供基础的训练数据支持,一定程度上改善了样本数据采集仅停留在人工解译层面的现状。
2 研究区与实验数据
根据现有数据情况确定的研究区包括:2008 年汶川地震受灾的汶川县、北川县、安县、绵竹县及都江堰市;2010 年宁南泥石流受灾的凉山州宁南县;2013年芦山地震受灾的芦山县、宝兴县、天全县以及雨城区。研究区内涉及滑坡、泥石流、房屋倒塌、断路断桥、洪涝等灾害,且灾害大多分布于山区,影像数据为灾后高分辨率无人机遥感影像,影像覆盖面积总计644.59 平方千米。研究区范围和数据覆盖情况见图 1。
3 灾害影像样本采集
3.1 基于 Python 的灾害样本采集方法的建立
Python 为脚本开发语言,因为 Python 简单易操作,功能齐全,通过 Python 调用 ArcGIS 的一些功能的开发方式在复杂的数据处理等方面有很大的优势[1]。本文利用 ArcGIS 提供的 Python 站点包 ArcPy,实现了系列无人机影像灾害点样本数据的自动批量裁剪。具体实现方法是:基于 Python 编写好的脚本文本在ArcGIS 中创建自定义 Arctoolbox 工具,首先配置工作空间,如图 2 所示:工作空间下有 images 文件夹,用于存放灾害的原始影像,支持系列无人机影像;points 文件夹用于存放灾害点矢量数据,该矢量数据为灾害点的位置数据,字段信息需包含灾害类型、样本大小等相关用于脚本语言读取的字段;samples 文件夹用于存放生成的灾害样本数据;tool 文件夹存放ArcGIStoolbox 工具箱,并将此目录关联到 ArcGIS中。
工具的关联和参数设置如图 3 所示。在 ArcGIS toolbox 工具箱下添加一个新的 Toolbox ( New Toolbox),在 Toolbox 中可添加脚本工具,Add 一个新的 Script,这个新增加的 Script 工具可以和 Python文件关联,在 Script File 中选择影像样本裁剪所需的 py 文件,创建用于样本裁剪的 clip raster 工具。
3.2 采集灾害样本
基于收集到的无人机影像,进一步通过目视解译的方法,完善专题资料上没有的灾害点信息。用与ArcGIS 建立灾害点数据,并将具有灾害点的影像图存放在工作空间的 images 文件夹下,点击 clip raster工具,在出现的界面下路径文件选择建立好的工作空间 Clip 即可对影像进行自动裁剪如图 4 所示,批量处理得到各类灾害样本,并制作地质灾害范围图层。
基于 Python 的灾害样本采集方法的建立,与其他的样本采集方法相比更为方便。根据实地和受灾范围的大小来对每种灾害类型的样本大小统一进行设置,自动采集好灾害样本后,在 samples 里查看每种类型的灾害样本大小采集的是否合适、样本的可辨度是否高,如果不合理,可以重新设置样本大小来重新采集,直到每种灾害类型的样本都清晰可见,并且可辨度高。样本具体制作流程如图 5 所示。
4 样本数据库
4.1 样本数据库的建设
数据库的建设是管理信息资源最有效地手段,对于某一目的的应用环境,构建最优的数据库模式。建立数据库一方面不仅能有效地存储数据,另一方面还能满足用户信息要求和处理要求,使用户更显而易见地了解到样本的各方面的数据信息。本次样本数据库的建设,按照成果要求和相关规范,制定了灾害点属性信息采集标准及相应的规范格式,并确定灾害相关信息的编码规范;最后按照成果要求进行入库,入库成果包括灾害样本影像数据、地面照片、灾害点矢量数据、灾害范围矢量数据和属性信息数据表,形成灾害样本数据库,如图 6 所示。
4.2 样本数据库表格的设计
遥感解译样本数据主要包括灾害样本影像数据、实地照片、灾害点矢量数据、灾害范围矢量数据和灾害属性信息数据表。样本数据要求影像纹理清晰、地物特征明显;影像纹理和光谱信息丰富、色调均匀、反差适中。建立灾害样本数据的工作量是非常庞大的,它需要合理组织样本数据库。为了能快速方便地查询获取样本数据及其基本信息,系统应当按照不同地质灾害类型建库,把同种地灾类多时相、多来源、不同分辨率等的样本数据存放在一张表中,而把其他地类样本放在另一张表中。将所采集的样本数据输入到数据库中,建立每种类别的多时相、多分辨率、多来源的样本影像数据库。建立遥感解译样本数据库必须考虑行政区位、日期、影像来源、纹理、形状与地形等特征,这不仅仅是简单地将所有样本影像堆积,而是必须按照样本影像的类别进行分类存放,同时存储这些影像的元数据及其描述信息。灾害属性信息数据表中包含灾害名称、影像源、日期、行政区位、经度、纬度、诱发因素、险情级别、图幅号、样本大小、光谱特征、形状特征、纹理特征、地形类型。遥感解译样本数据库基本结构示例如图 7所示。
4.3 样本数据库示例
灾害样本数据整理,是以实地照片及其属性信息为基础,获取灾害样本影像及相关属性信息,从而建立灾害样本数据库。样本数据库示例如图 8 所示。
4.4 样本数据库的检查与更新
遥感解译影像样本数据库也需要进行后期检查,结合影像库进行各项专业信息提取,并对其获取的专业信息成果进行检查,同时还能够利用 GPS 辅助外业检查,运用之前提取的成果检查样本库,及时更新以保持数据的正确性与有效性。遥感解译影像样本数据库是某个时期该地区的遥感样本影像,对于不同年份应依照收集的资料情况建立不同年度的样本影像库,以保证样本影像库的时效性。
5 结束语
在具体工作实践中常常需要根据特定的专业业务需要定制适合解决问题的地理处理工具,Python与 ArcGIS 的结合,使得问题变得简单,操作也变得简单,处理问题也变得比较方便容易一些,所以Python 在 ArcGIS 地理处理框架中占据非常重要的位置。ArcGIS 环境下的系列无人机影像灾害样本库建设,在裁剪样本的过程中提高了速度,并且可以批量处理多种灾害样本,节约了时间的同时也大大减少了人力;数据库的成功建设,不仅有助于我们清晰地了解灾害信息,而且可为后一步的灾害识别工作提供基础的训练数据支持。
参考文献:
[1] 丘恩. Python 核心编程(第 2 版)[M]. 北京:人民邮电出版社,2008.
[2] 焦洋,邓鑫,李胜才. 基于 Python 的 ArcGIS 空间数据格式批处理转换工具开发[J]. 现代测绘,2012,35(3):54-55.
[3] 马卫春,杨友长. 基于 Python 的 ArcGIS Server 地图瓦片定时自动更新方法[J]. 地理空间信息,2013, 11(2):147-149.
[4] 田学志. 基于 Python 的 ArcGIS 地理处理应用研究[J].计算机光盘软件与应用,2013,(7).
最后,小编提醒,由于微信修改了推送规则,没有经常留言或点“在看”的,会慢慢的收不到推送!如果你还想每天看到我们的推送,请将ArcGis爱学习加为星标或每次看完后点击一下页面下端的“赞”“在看”,拜托了!▼往期精彩回顾 ▼
2、
3、
4、 查看全部
||ArcGIS 环境下的系列无人机影像灾害样本库建设
摘要:以“5·12”汶川地震、“4·20”芦山地震和“6·18”宁南特大山洪泥石流等地质灾害为例,在 ArcGIS环境下采用 ArcMap 软件与 Python 脚本开发相结合的方式,利用多时期无人机影像进行灾害样本的采集,批量处理多种灾害样本,从而建立对应的无人机影像灾害样本库。关键词ArcGIS;无人机;地质灾害;样本库1 引言20 世纪 90 年代以来,受人类活动和全球化的影响,地质灾害越发严重,地质灾害发生的规模、数量和分布范围呈上升趋势。2008 年“5·12”汶川特大地震后,由于地质结构被破坏,加之恶劣天气的影响,滑坡和泥石流等次生灾害在很长一段时间内影响着震区,这些地质灾害不仅直接或者间接地危害人民群众生命、财产安全,还会给社会和经济建设造成巨大的损失。利用遥感技术获取灾区影像已成为灾后获取灾害信息的重要手段,无人机遥感技术时效性强、使用成本低、起降方式灵活多样、影像分辨率高等优势,使其在地质灾害应急救援工作中具有广阔的应用前景和发展前途。近几年,相关应急救灾部门已经具备在灾后第一时间获取地质灾害现场的无人机影像的能力。是一门解释型语言,因其不需要编译和链接的时间,所以能够节省开发时间,解释器可以交互式使用,同时能够很方便地测试语言中的各种功能,便于编写发布用的程序,具有开源、模块丰富、面向对象、面向过程等特性,能够与 ArcGIS 软件很好地结合使用[3]。从 ArcGIS9.0 开始,我们就可以使用 Python, 并把它作为首选脚本语言[4],实现空间数据的自动化批量处理,从而起到简化流程,提高工作的自动化程度的作用[2]。本文介绍一种在 ArcGIS环境下,结合 Python 脚本开发的方式,利用历史系列无人机影像快速批量建立地质灾害样本库的方法,该样本库可为后续灾害识别提供基础的训练数据支持,一定程度上改善了样本数据采集仅停留在人工解译层面的现状。
2 研究区与实验数据
根据现有数据情况确定的研究区包括:2008 年汶川地震受灾的汶川县、北川县、安县、绵竹县及都江堰市;2010 年宁南泥石流受灾的凉山州宁南县;2013年芦山地震受灾的芦山县、宝兴县、天全县以及雨城区。研究区内涉及滑坡、泥石流、房屋倒塌、断路断桥、洪涝等灾害,且灾害大多分布于山区,影像数据为灾后高分辨率无人机遥感影像,影像覆盖面积总计644.59 平方千米。研究区范围和数据覆盖情况见图 1。
3 灾害影像样本采集
3.1 基于 Python 的灾害样本采集方法的建立
Python 为脚本开发语言,因为 Python 简单易操作,功能齐全,通过 Python 调用 ArcGIS 的一些功能的开发方式在复杂的数据处理等方面有很大的优势[1]。本文利用 ArcGIS 提供的 Python 站点包 ArcPy,实现了系列无人机影像灾害点样本数据的自动批量裁剪。具体实现方法是:基于 Python 编写好的脚本文本在ArcGIS 中创建自定义 Arctoolbox 工具,首先配置工作空间,如图 2 所示:工作空间下有 images 文件夹,用于存放灾害的原始影像,支持系列无人机影像;points 文件夹用于存放灾害点矢量数据,该矢量数据为灾害点的位置数据,字段信息需包含灾害类型、样本大小等相关用于脚本语言读取的字段;samples 文件夹用于存放生成的灾害样本数据;tool 文件夹存放ArcGIStoolbox 工具箱,并将此目录关联到 ArcGIS中。
工具的关联和参数设置如图 3 所示。在 ArcGIS toolbox 工具箱下添加一个新的 Toolbox ( New Toolbox),在 Toolbox 中可添加脚本工具,Add 一个新的 Script,这个新增加的 Script 工具可以和 Python文件关联,在 Script File 中选择影像样本裁剪所需的 py 文件,创建用于样本裁剪的 clip raster 工具。
3.2 采集灾害样本
基于收集到的无人机影像,进一步通过目视解译的方法,完善专题资料上没有的灾害点信息。用与ArcGIS 建立灾害点数据,并将具有灾害点的影像图存放在工作空间的 images 文件夹下,点击 clip raster工具,在出现的界面下路径文件选择建立好的工作空间 Clip 即可对影像进行自动裁剪如图 4 所示,批量处理得到各类灾害样本,并制作地质灾害范围图层。
基于 Python 的灾害样本采集方法的建立,与其他的样本采集方法相比更为方便。根据实地和受灾范围的大小来对每种灾害类型的样本大小统一进行设置,自动采集好灾害样本后,在 samples 里查看每种类型的灾害样本大小采集的是否合适、样本的可辨度是否高,如果不合理,可以重新设置样本大小来重新采集,直到每种灾害类型的样本都清晰可见,并且可辨度高。样本具体制作流程如图 5 所示。
4 样本数据库
4.1 样本数据库的建设
数据库的建设是管理信息资源最有效地手段,对于某一目的的应用环境,构建最优的数据库模式。建立数据库一方面不仅能有效地存储数据,另一方面还能满足用户信息要求和处理要求,使用户更显而易见地了解到样本的各方面的数据信息。本次样本数据库的建设,按照成果要求和相关规范,制定了灾害点属性信息采集标准及相应的规范格式,并确定灾害相关信息的编码规范;最后按照成果要求进行入库,入库成果包括灾害样本影像数据、地面照片、灾害点矢量数据、灾害范围矢量数据和属性信息数据表,形成灾害样本数据库,如图 6 所示。
4.2 样本数据库表格的设计
遥感解译样本数据主要包括灾害样本影像数据、实地照片、灾害点矢量数据、灾害范围矢量数据和灾害属性信息数据表。样本数据要求影像纹理清晰、地物特征明显;影像纹理和光谱信息丰富、色调均匀、反差适中。建立灾害样本数据的工作量是非常庞大的,它需要合理组织样本数据库。为了能快速方便地查询获取样本数据及其基本信息,系统应当按照不同地质灾害类型建库,把同种地灾类多时相、多来源、不同分辨率等的样本数据存放在一张表中,而把其他地类样本放在另一张表中。将所采集的样本数据输入到数据库中,建立每种类别的多时相、多分辨率、多来源的样本影像数据库。建立遥感解译样本数据库必须考虑行政区位、日期、影像来源、纹理、形状与地形等特征,这不仅仅是简单地将所有样本影像堆积,而是必须按照样本影像的类别进行分类存放,同时存储这些影像的元数据及其描述信息。灾害属性信息数据表中包含灾害名称、影像源、日期、行政区位、经度、纬度、诱发因素、险情级别、图幅号、样本大小、光谱特征、形状特征、纹理特征、地形类型。遥感解译样本数据库基本结构示例如图 7所示。
4.3 样本数据库示例
灾害样本数据整理,是以实地照片及其属性信息为基础,获取灾害样本影像及相关属性信息,从而建立灾害样本数据库。样本数据库示例如图 8 所示。
4.4 样本数据库的检查与更新
遥感解译影像样本数据库也需要进行后期检查,结合影像库进行各项专业信息提取,并对其获取的专业信息成果进行检查,同时还能够利用 GPS 辅助外业检查,运用之前提取的成果检查样本库,及时更新以保持数据的正确性与有效性。遥感解译影像样本数据库是某个时期该地区的遥感样本影像,对于不同年份应依照收集的资料情况建立不同年度的样本影像库,以保证样本影像库的时效性。
5 结束语
在具体工作实践中常常需要根据特定的专业业务需要定制适合解决问题的地理处理工具,Python与 ArcGIS 的结合,使得问题变得简单,操作也变得简单,处理问题也变得比较方便容易一些,所以Python 在 ArcGIS 地理处理框架中占据非常重要的位置。ArcGIS 环境下的系列无人机影像灾害样本库建设,在裁剪样本的过程中提高了速度,并且可以批量处理多种灾害样本,节约了时间的同时也大大减少了人力;数据库的成功建设,不仅有助于我们清晰地了解灾害信息,而且可为后一步的灾害识别工作提供基础的训练数据支持。
参考文献:
[1] 丘恩. Python 核心编程(第 2 版)[M]. 北京:人民邮电出版社,2008.
[2] 焦洋,邓鑫,李胜才. 基于 Python 的 ArcGIS 空间数据格式批处理转换工具开发[J]. 现代测绘,2012,35(3):54-55.
[3] 马卫春,杨友长. 基于 Python 的 ArcGIS Server 地图瓦片定时自动更新方法[J]. 地理空间信息,2013, 11(2):147-149.
[4] 田学志. 基于 Python 的 ArcGIS 地理处理应用研究[J].计算机光盘软件与应用,2013,(7).
最后,小编提醒,由于微信修改了推送规则,没有经常留言或点“在看”的,会慢慢的收不到推送!如果你还想每天看到我们的推送,请将ArcGis爱学习加为星标或每次看完后点击一下页面下端的“赞”“在看”,拜托了!▼往期精彩回顾 ▼
2、
3、
4、
自动采集编写(Scrapy框架Scrapy架构图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-04-18 14:20
Scrapy 框架 Scrapy 架构图(绿线为数据流向):
Scrapy 的工作原理
代码写好了,程序开始运行了……
发动机:嗨!蜘蛛,你在对付哪个网站?
蜘蛛:老板要我处理。
引擎:给我第一个需要处理的 URL。
Spider:在这里,第一个 URL 是。
发动机:嗨!调度员,我有一个请求,请求您帮我排序并加入队列。
调度程序:好的,正在处理您等一下。
发动机:嗨!调度员,给我你处理的请求。
调度器:给你,这是我处理的请求
发动机:嗨!下载者,请帮我按照老板下载中间件的设置下载这个请求
下载者:好的!给你,这是下载的东西。(如果失败:sorry,这个请求下载失败。然后引擎告诉调度器这个请求下载失败,你记录一下,我们稍后下载)
发动机:嗨!蜘蛛,这是一个下载的东西,已经按照老大的下载中间件进行了处理,你可以自己处理(注意!这里的响应默认由def parse()函数处理)
蜘蛛:(处理数据后需要跟进的URL),嗨!Engine,我这里有两个结果,这是我需要跟进的URL,这是我得到的Item数据。
发动机:嗨!我这里有一件物品,请帮我处理!调度器!这个是需要你跟进的网址帮我处理的。然后从第四步开始循环,直到得到boss需要的所有信息。
Pipes ``调度器:好的,现在就做!
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的URL,Scrapy也会重新下载。)
制作一个Scrapy爬虫一共需要4步: Scrapy安装介绍
Scrapy框架官网:
Scrapy中文维护网站:
Windows安装方式Ubuntu需要9.10以上的安装方式
安装完成后,只要在命令终端输入scrapy,就会出现类似如下的结果,说明已经安装成功
具体Scrapy安装过程参考:每个平台都有安装方法
入门案例学习目标一. 新项目(scrapy startproject)
scrapy startproject mySpider
下面简单介绍一下各个主文件的作用:
scrapy.cfg :项目的配置文件
mySpider/ :项目的 Python 模块,将从中引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ : 蜘蛛代码存放的目录
信息。
打开 mySpider 目录下的 items.py
Item 定义了一个结构化的数据字段来保存爬取的数据,有点像 Python 中的 dict,但提供了一些额外的保护来减少错误。
可以通过创建一个scrapy.Item类并定义一个scrapy.Field类型的类属性来定义一个Item(可以理解为一种类似于ORM的映射关系)。
接下来,创建一个 ItcastItem 类,并构建项目模型。
import scrapy
class ItcastItem(scrapy.Item):
name = scrapy.Field()
level = scrapy.Field()
info = scrapy.Field()
三、制作蜘蛛 (spiders/itcastSpider.py)
爬虫功能分为两步:
1. 爬取数据
scrapy genspider itcast "itcast.cn"
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
其实我们也可以自己创建itcast.py,写上面的代码,不过使用命令可以省去写固定代码的麻烦
要创建 Spider,您必须继承 scrapy.Spider 类并定义三个强制属性和一个方法。
将start_urls的值改为第一个要爬取的url
start_urls = ("http://www.itcast.cn/channel/teacher.shtml",)
修改 parse() 方法
def parse(self, response):
filename = "teacher.html"
open(filename, 'w').write(response.body)
然后运行看看,在mySpider目录下执行:
scrapy crawl itcast
是的,它是itcast。看上面代码,是ItcastSpider类的name属性,是唯一使用scrapy genspider命令的爬虫名称。
运行后,如果打印日志显示[scrapy] INFO: Spider closed (finished),则表示执行完成。之后,当前文件夹中出现了一个teacher.html文件,里面收录了我们刚要抓取的网页的所有源码信息。
# 注意,Python2.x默认编码环境是ASCII,当和取回的数据编码格式不一致时,可能会造成乱码;
# 我们可以指定保存内容的编码格式,一般情况下,我们可以在代码最上方添加:
import sys
reload(sys)
sys.setdefaultencoding("utf-8")<br /><br /># 这三行代码是Python2.x里解决中文编码的万能钥匙,经过这么多年的吐槽后Python3学乖了,默认编码是Unicode了...(祝大家早日拥抱Python3)
2. 获取数据
xxx
xxxxx
xxxxxxxx
是不是一目了然?只需转到 XPath 并开始提取数据。
from mySpider.items import ItcastItem
from mySpider.items import ItcastItem
def parse(self, response): #open("teacher.html","wb").write(response.body).close() # 存放老师信息的集合 items = [] for each in response.xpath("//div[@class='li_txt']"): # 将我们得到的数据封装到一个 `ItcastItem` 对象 item = ItcastItem() #extract()方法返回的都是unicode字符串 name = each.xpath("h3/text()").extract() title = each.xpath("h4/text()").extract() info = each.xpath("p/text()").extract() #xpath返回的是包含一个元素的列表 item['name'] = name[0] item['title'] = title[0] item['info'] = info[0] items.append(item) # 直接返回最后数据 return items
保存数据有四种最简单的方法scrapy保存信息,-o输出指定格式的文件,命令如下:
# json格式,默认为Unicode编码
scrapy crawl itcast -o teachers.json
# json lines格式,默认为Unicode编码
scrapy crawl itcast -o teachers.jsonl
# csv 逗号表达式,可用Excel打开
scrapy crawl itcast -o teachers.csv
# xml格式
scrapy crawl itcast -o teachers.xml
想想如果把代码改成下面的形式,结果是完全一样的。考虑产量在这里的作用:
from mySpider.items import ItcastItem
def parse(self, response):
#open("teacher.html","wb").write(response.body).close()
# 存放老师信息的集合
#items = []
for each in response.xpath("//div[@class='li_txt']"):
# 将我们得到的数据封装到一个 `ItcastItem` 对象
item = ItcastItem()
#extract()方法返回的都是unicode字符串
name = each.xpath("h3/text()").extract()
title = each.xpath("h4/text()").extract()
info = each.xpath("p/text()").extract()
#xpath返回的是包含一个元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
#items.append(item)
#将获取的数据交给pipelines
yield item
# 返回数据,不经过pipeline
#return items
废壳
Scrapy 终端是一个交互式终端。我们可以在不启动蜘蛛的情况下尝试调试代码。它还可以用于测试 XPath 或 CSS 表达式,了解它们是如何工作的,并促进从我们抓取的网页中提取数据。
如果安装了 IPython,Scrapy 终端将使用 IPython(代替标准 Python 终端)。IPython 终端比其他终端更强大,提供智能自动完成、突出显示和其他功能。(推荐安装IPython)
启动 Scrapy Shell
进入项目根目录,执行以下命令启动shell:
scrapy shell "http://www.itcast.cn/channel/teacher.shtml"
Scrapy Shell 会根据下载的页面自动创建一些方便的对象,例如 Response 对象,Selector 对象(用于 HTML 和 XML 内容)。
Selectors 选择器 Scrapy Selectors 内置 XPath 和 CSS 选择器表达式机制
Selector有四种基本方法,最常用的是xpath:
XPath 表达式及其对应含义的示例:
/html/head/title: 选择文档中 标签内的 元素
/html/head/title/text(): 选择上面提到的 元素的文字
//td: 选择所有的 元素
//div[@class="mine"]: 选择所有具有 class="mine" 属性的 div 元素
试试选择器
我们以腾讯招聘的网站为例:
<p># 启动
scrapy shell "http://hr.tencent.com/position ... ot%3B
# 返回 xpath选择器对象列表
response.xpath('//title')
[ 查看全部
自动采集编写(Scrapy框架Scrapy架构图)
Scrapy 框架 Scrapy 架构图(绿线为数据流向):
Scrapy 的工作原理
代码写好了,程序开始运行了……
发动机:嗨!蜘蛛,你在对付哪个网站?
蜘蛛:老板要我处理。
引擎:给我第一个需要处理的 URL。
Spider:在这里,第一个 URL 是。
发动机:嗨!调度员,我有一个请求,请求您帮我排序并加入队列。
调度程序:好的,正在处理您等一下。
发动机:嗨!调度员,给我你处理的请求。
调度器:给你,这是我处理的请求
发动机:嗨!下载者,请帮我按照老板下载中间件的设置下载这个请求
下载者:好的!给你,这是下载的东西。(如果失败:sorry,这个请求下载失败。然后引擎告诉调度器这个请求下载失败,你记录一下,我们稍后下载)
发动机:嗨!蜘蛛,这是一个下载的东西,已经按照老大的下载中间件进行了处理,你可以自己处理(注意!这里的响应默认由def parse()函数处理)
蜘蛛:(处理数据后需要跟进的URL),嗨!Engine,我这里有两个结果,这是我需要跟进的URL,这是我得到的Item数据。
发动机:嗨!我这里有一件物品,请帮我处理!调度器!这个是需要你跟进的网址帮我处理的。然后从第四步开始循环,直到得到boss需要的所有信息。
Pipes ``调度器:好的,现在就做!
注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的URL,Scrapy也会重新下载。)
制作一个Scrapy爬虫一共需要4步: Scrapy安装介绍
Scrapy框架官网:
Scrapy中文维护网站:
Windows安装方式Ubuntu需要9.10以上的安装方式
安装完成后,只要在命令终端输入scrapy,就会出现类似如下的结果,说明已经安装成功
具体Scrapy安装过程参考:每个平台都有安装方法
入门案例学习目标一. 新项目(scrapy startproject)
scrapy startproject mySpider
下面简单介绍一下各个主文件的作用:
scrapy.cfg :项目的配置文件
mySpider/ :项目的 Python 模块,将从中引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ : 蜘蛛代码存放的目录
信息。
打开 mySpider 目录下的 items.py
Item 定义了一个结构化的数据字段来保存爬取的数据,有点像 Python 中的 dict,但提供了一些额外的保护来减少错误。
可以通过创建一个scrapy.Item类并定义一个scrapy.Field类型的类属性来定义一个Item(可以理解为一种类似于ORM的映射关系)。
接下来,创建一个 ItcastItem 类,并构建项目模型。
import scrapy
class ItcastItem(scrapy.Item):
name = scrapy.Field()
level = scrapy.Field()
info = scrapy.Field()
三、制作蜘蛛 (spiders/itcastSpider.py)
爬虫功能分为两步:
1. 爬取数据
scrapy genspider itcast "itcast.cn"
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
其实我们也可以自己创建itcast.py,写上面的代码,不过使用命令可以省去写固定代码的麻烦
要创建 Spider,您必须继承 scrapy.Spider 类并定义三个强制属性和一个方法。
将start_urls的值改为第一个要爬取的url
start_urls = ("http://www.itcast.cn/channel/teacher.shtml",)
修改 parse() 方法
def parse(self, response):
filename = "teacher.html"
open(filename, 'w').write(response.body)
然后运行看看,在mySpider目录下执行:
scrapy crawl itcast
是的,它是itcast。看上面代码,是ItcastSpider类的name属性,是唯一使用scrapy genspider命令的爬虫名称。
运行后,如果打印日志显示[scrapy] INFO: Spider closed (finished),则表示执行完成。之后,当前文件夹中出现了一个teacher.html文件,里面收录了我们刚要抓取的网页的所有源码信息。
# 注意,Python2.x默认编码环境是ASCII,当和取回的数据编码格式不一致时,可能会造成乱码;
# 我们可以指定保存内容的编码格式,一般情况下,我们可以在代码最上方添加:
import sys
reload(sys)
sys.setdefaultencoding("utf-8")<br /><br /># 这三行代码是Python2.x里解决中文编码的万能钥匙,经过这么多年的吐槽后Python3学乖了,默认编码是Unicode了...(祝大家早日拥抱Python3)
2. 获取数据
xxx
xxxxx
xxxxxxxx
是不是一目了然?只需转到 XPath 并开始提取数据。
from mySpider.items import ItcastItem
from mySpider.items import ItcastItem
def parse(self, response): #open("teacher.html","wb").write(response.body).close() # 存放老师信息的集合 items = [] for each in response.xpath("//div[@class='li_txt']"): # 将我们得到的数据封装到一个 `ItcastItem` 对象 item = ItcastItem() #extract()方法返回的都是unicode字符串 name = each.xpath("h3/text()").extract() title = each.xpath("h4/text()").extract() info = each.xpath("p/text()").extract() #xpath返回的是包含一个元素的列表 item['name'] = name[0] item['title'] = title[0] item['info'] = info[0] items.append(item) # 直接返回最后数据 return items
保存数据有四种最简单的方法scrapy保存信息,-o输出指定格式的文件,命令如下:
# json格式,默认为Unicode编码
scrapy crawl itcast -o teachers.json
# json lines格式,默认为Unicode编码
scrapy crawl itcast -o teachers.jsonl
# csv 逗号表达式,可用Excel打开
scrapy crawl itcast -o teachers.csv
# xml格式
scrapy crawl itcast -o teachers.xml
想想如果把代码改成下面的形式,结果是完全一样的。考虑产量在这里的作用:
from mySpider.items import ItcastItem
def parse(self, response):
#open("teacher.html","wb").write(response.body).close()
# 存放老师信息的集合
#items = []
for each in response.xpath("//div[@class='li_txt']"):
# 将我们得到的数据封装到一个 `ItcastItem` 对象
item = ItcastItem()
#extract()方法返回的都是unicode字符串
name = each.xpath("h3/text()").extract()
title = each.xpath("h4/text()").extract()
info = each.xpath("p/text()").extract()
#xpath返回的是包含一个元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
#items.append(item)
#将获取的数据交给pipelines
yield item
# 返回数据,不经过pipeline
#return items
废壳
Scrapy 终端是一个交互式终端。我们可以在不启动蜘蛛的情况下尝试调试代码。它还可以用于测试 XPath 或 CSS 表达式,了解它们是如何工作的,并促进从我们抓取的网页中提取数据。
如果安装了 IPython,Scrapy 终端将使用 IPython(代替标准 Python 终端)。IPython 终端比其他终端更强大,提供智能自动完成、突出显示和其他功能。(推荐安装IPython)
启动 Scrapy Shell
进入项目根目录,执行以下命令启动shell:
scrapy shell "http://www.itcast.cn/channel/teacher.shtml"
Scrapy Shell 会根据下载的页面自动创建一些方便的对象,例如 Response 对象,Selector 对象(用于 HTML 和 XML 内容)。
Selectors 选择器 Scrapy Selectors 内置 XPath 和 CSS 选择器表达式机制
Selector有四种基本方法,最常用的是xpath:
XPath 表达式及其对应含义的示例:
/html/head/title: 选择文档中 标签内的 元素
/html/head/title/text(): 选择上面提到的 元素的文字
//td: 选择所有的 元素
//div[@class="mine"]: 选择所有具有 class="mine" 属性的 div 元素
试试选择器
我们以腾讯招聘的网站为例:
<p># 启动
scrapy shell "http://hr.tencent.com/position ... ot%3B
# 返回 xpath选择器对象列表
response.xpath('//title')
[
自动采集编写(如何利用Python打造搜狗壁纸自动下载爬虫库的反爬措施)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-04-18 14:17
这些案例是为一些想进入Python行业的朋友写的。看到大家都很满意,我又拿出来了。如果你已经开始学习python,对爬虫一无所知,不妨看看这个。几个案例!
二、环境准备
Python 3
requests 库、lxml 库、beautifulsoup4 库
pip install XX XX XX 一起安装。
三、Python爬虫小案例
1、获取机器的公网IP地址
使用python的requests库+公网查IP接口自动获取IP地址
2、使用百度的搜索界面,Python编写url采集工具
需要使用requests库和BeautifulSoup库,遵守百度搜索结构的URL链接规则,通过在程序中设置User-Agent请求头绕过百度搜索引擎的反爬机制。
Python 源代码:
用Python语言编写程序后,使用关键词inurl:/dede/login.php批量提取某个网络的后台地址cms:
3、使用Python制作搜狗壁纸自动下载爬虫
搜狗壁纸的地址是json格式的,所以用json库解析这组数据,把爬虫程序存放图片的磁盘路径改成要存放图片的路径。
渲染:
4、Python 自动填充调查
和一般网页一样,多次提交数据都需要一个验证码,这就是反爬机制。
如图:
那么如何绕过验证码的反爬措施呢?使用X-Forwarded-For伪造IP地址访问,Python代码如下:
效果:
5、获取 West Thorn 代理上的 IP,以验证这些代理被禁止的可能性和延迟时间
可以将Python爬取的代理IP添加到代理链中,然后就可以进行一般的渗透任务了。这里,linux系统命令ping -c 1 " + ip.string + " | awk 'NR==2{print}' - 被直接调用。要在Windows下运行这个程序,需要修改os.popen倒数第二行的命令,可以修改为Windows可执行。
爬取的数据如图:
演示:
结论 查看全部
自动采集编写(如何利用Python打造搜狗壁纸自动下载爬虫库的反爬措施)
这些案例是为一些想进入Python行业的朋友写的。看到大家都很满意,我又拿出来了。如果你已经开始学习python,对爬虫一无所知,不妨看看这个。几个案例!
二、环境准备
Python 3
requests 库、lxml 库、beautifulsoup4 库
pip install XX XX XX 一起安装。
三、Python爬虫小案例
1、获取机器的公网IP地址
使用python的requests库+公网查IP接口自动获取IP地址
2、使用百度的搜索界面,Python编写url采集工具
需要使用requests库和BeautifulSoup库,遵守百度搜索结构的URL链接规则,通过在程序中设置User-Agent请求头绕过百度搜索引擎的反爬机制。
Python 源代码:
用Python语言编写程序后,使用关键词inurl:/dede/login.php批量提取某个网络的后台地址cms:
3、使用Python制作搜狗壁纸自动下载爬虫
搜狗壁纸的地址是json格式的,所以用json库解析这组数据,把爬虫程序存放图片的磁盘路径改成要存放图片的路径。
渲染:
4、Python 自动填充调查
和一般网页一样,多次提交数据都需要一个验证码,这就是反爬机制。
如图:
那么如何绕过验证码的反爬措施呢?使用X-Forwarded-For伪造IP地址访问,Python代码如下:
效果:
5、获取 West Thorn 代理上的 IP,以验证这些代理被禁止的可能性和延迟时间
可以将Python爬取的代理IP添加到代理链中,然后就可以进行一般的渗透任务了。这里,linux系统命令ping -c 1 " + ip.string + " | awk 'NR==2{print}' - 被直接调用。要在Windows下运行这个程序,需要修改os.popen倒数第二行的命令,可以修改为Windows可执行。
爬取的数据如图:
演示:
结论
自动采集编写(自动采集编写python爬虫,爬取名词宝宝的微信公众号文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-04-17 18:03
自动采集编写python爬虫,爬取名词宝宝的微信公众号文章。原理:python的网络请求采用get方法即可实现,模拟浏览器登录公众号后台,即可自动爬取我们需要的文章。主要实现内容:搜索,看图,和你聊天。方法:在实现自动采集之前,先用浏览器登录公众号后台,采集公众号相关用户信息。打开浏览器,在地址栏,输入相关搜索关键词,按照对应提示操作。
只要网页登录成功,点击关键词和公众号名称,就会自动搜索并爬取。实践一次:python爬虫系列之1——搜索关键词教程地址:用python爬取一个微信公众号文章需要requests模块,进行网络请求,模拟浏览器后台登录,获取相关信息。根据图例的步骤,就能自动获取大量数据信息,实践本次实践教程所需要的信息。
【准备工作】网页登录问题:难点在于如何把爬取的数据实时保存到本地,传到服务器。第一步:开发板登录因为之前就有登录不成功的经历,作为初次接触爬虫的同学,一定要熟悉网页登录的实际操作方法。登录首先登录开发板,推荐使用梯子或者国内的某些chrome浏览器,如360的firefox和chrome扩展支持,实现登录。
登录成功后,python爬虫系列之一——爬取微信公众号文章,教程上方的url就出现了。pipinstall开发板浏览器,安装相关的开发板软件。urllib2是python网络通信最常用的库。第二步:数据预处理本次实践准备爬取的是公众号文章推送列表。因为第一步的网页登录成功后,要打开登录页面。所以一直处于登录状态,用不到访问ip和端口这些操作。
用户管理:爬取到的数据,保存到本地,需要一个用户名和密码,用户名和密码是唯一的。拿公众号文章列表项目来说,用户名和密码就是文章列表项目标识符了。源代码引用:globalokhttp;import"weixin.urlopen";import"http.https";import"requests";import"xml.parser";import"sql";import"servlet";import"tomcat";import"urllib";import"flask";import"requests";import"xml.parser";import"xml";import"xmltest";import"tomcat";import"lxml";import"python";import"c";import"urllib.parse";import"multiprocessing";import"lxml";import"python";import"chef";import"cookielib";import"sqlite";import"mysql";import"time";import"mongo";import"redis";import"crypto";import"thrift";import"pymongo";import"node";import"core";imp。 查看全部
自动采集编写(自动采集编写python爬虫,爬取名词宝宝的微信公众号文章)
自动采集编写python爬虫,爬取名词宝宝的微信公众号文章。原理:python的网络请求采用get方法即可实现,模拟浏览器登录公众号后台,即可自动爬取我们需要的文章。主要实现内容:搜索,看图,和你聊天。方法:在实现自动采集之前,先用浏览器登录公众号后台,采集公众号相关用户信息。打开浏览器,在地址栏,输入相关搜索关键词,按照对应提示操作。
只要网页登录成功,点击关键词和公众号名称,就会自动搜索并爬取。实践一次:python爬虫系列之1——搜索关键词教程地址:用python爬取一个微信公众号文章需要requests模块,进行网络请求,模拟浏览器后台登录,获取相关信息。根据图例的步骤,就能自动获取大量数据信息,实践本次实践教程所需要的信息。
【准备工作】网页登录问题:难点在于如何把爬取的数据实时保存到本地,传到服务器。第一步:开发板登录因为之前就有登录不成功的经历,作为初次接触爬虫的同学,一定要熟悉网页登录的实际操作方法。登录首先登录开发板,推荐使用梯子或者国内的某些chrome浏览器,如360的firefox和chrome扩展支持,实现登录。
登录成功后,python爬虫系列之一——爬取微信公众号文章,教程上方的url就出现了。pipinstall开发板浏览器,安装相关的开发板软件。urllib2是python网络通信最常用的库。第二步:数据预处理本次实践准备爬取的是公众号文章推送列表。因为第一步的网页登录成功后,要打开登录页面。所以一直处于登录状态,用不到访问ip和端口这些操作。
用户管理:爬取到的数据,保存到本地,需要一个用户名和密码,用户名和密码是唯一的。拿公众号文章列表项目来说,用户名和密码就是文章列表项目标识符了。源代码引用:globalokhttp;import"weixin.urlopen";import"http.https";import"requests";import"xml.parser";import"sql";import"servlet";import"tomcat";import"urllib";import"flask";import"requests";import"xml.parser";import"xml";import"xmltest";import"tomcat";import"lxml";import"python";import"c";import"urllib.parse";import"multiprocessing";import"lxml";import"python";import"chef";import"cookielib";import"sqlite";import"mysql";import"time";import"mongo";import"redis";import"crypto";import"thrift";import"pymongo";import"node";import"core";imp。
自动采集编写(用GS浏览器的采数据方式介绍不同的窗口类型 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-04-17 10:27
)
用GS浏览器或者MS点数机完成采集规则后,就可以打开DS点数机进行数据采集,而吉索克爬虫软件非常灵活,提供多种使用方式供大家选择。下面介绍几种不同的数据采集方法。他们使用的爬虫窗口类型不同,控制方式也略有不同。爬虫窗口的描述请参考“DS 计数器的窗口类型”。
方法一:保存规则,爬取数据
完成采集规则并保存后,点击右上角“爬取数据”按钮,会自动弹出爬虫窗口。直接采集示例网页,使用测试窗口,菜单项很少。用于验证爬取规则的正确性。
1.1、用MS找几个单位制定规则并保存。
1.2,然后点击MS工具栏右上角的“爬取数据”按钮,会弹出DS爬虫窗口采集示例页面信息。
方法二:单次搜索/采集 DS 计数器
单独运行 DS 计数器,可以在左侧看到规则列表,每个规则都有“单次搜索”和“采集搜索”按钮。单查与吉搜的使用说明及区别请参考《吉索专有名词:单查与吉搜》。简单总结一下,Single Search 只运行一个爬虫窗口,而 Jisou 可以运行多个爬虫窗口。
2.1、打开DS计数器(GS浏览器版爬虫点击右上角“DS计数器”运行;火狐版爬虫点击工具中“DS数据”运行菜单)。
2.2、搜索主题名,可以使用*模糊匹配(前、后、中都可以收录*)。
2.3、右击主题名称,在弹出的菜单中选择“Statistical Leads”。您可以看到有多少潜在客户正在等待被抓取,而这些潜在客户就是 URL。
2.4、点击单搜索,输入线索数量(激活所有线索;如果要采集其他结构相同的网页,选择添加,然后复制多个网址进去,可以批量采集 >.更多操作见《如何管理规则线索》
方法三:使用爬虫组并发采集数据
爬虫组功能支持在一台电脑上同时运行多个爬虫。它集成了crontab爬虫调度器、DS计数器主菜单功能、数据库存储三大功能块。无需指定采集多少潜在客户,爬虫组会自动采集所有等待采集的潜在客户,让您高效采集数据,监控规则运行。有关用法,请参阅“如何运行 Crawler Swarm”
方法四:编写crontab并发爬虫采集数据
crontab程序(终极功能)和爬虫组一样,可以设置多个爬虫窗口并发采集数据,但是需要自己编写程序。两者的区别在于crontab程序可以指定爬虫窗口只有哪个主题任务采集,这样可以大大提高稳定性和效率,而爬虫组可以自由地将主题任务分配给爬虫窗口,而效率稍慢。详情请阅读文章《如何通过crontab程序实现周期性增量采集数据》。
如有疑问,您可以或
查看全部
自动采集编写(用GS浏览器的采数据方式介绍不同的窗口类型
)
用GS浏览器或者MS点数机完成采集规则后,就可以打开DS点数机进行数据采集,而吉索克爬虫软件非常灵活,提供多种使用方式供大家选择。下面介绍几种不同的数据采集方法。他们使用的爬虫窗口类型不同,控制方式也略有不同。爬虫窗口的描述请参考“DS 计数器的窗口类型”。
方法一:保存规则,爬取数据
完成采集规则并保存后,点击右上角“爬取数据”按钮,会自动弹出爬虫窗口。直接采集示例网页,使用测试窗口,菜单项很少。用于验证爬取规则的正确性。
1.1、用MS找几个单位制定规则并保存。
1.2,然后点击MS工具栏右上角的“爬取数据”按钮,会弹出DS爬虫窗口采集示例页面信息。
方法二:单次搜索/采集 DS 计数器
单独运行 DS 计数器,可以在左侧看到规则列表,每个规则都有“单次搜索”和“采集搜索”按钮。单查与吉搜的使用说明及区别请参考《吉索专有名词:单查与吉搜》。简单总结一下,Single Search 只运行一个爬虫窗口,而 Jisou 可以运行多个爬虫窗口。
2.1、打开DS计数器(GS浏览器版爬虫点击右上角“DS计数器”运行;火狐版爬虫点击工具中“DS数据”运行菜单)。
2.2、搜索主题名,可以使用*模糊匹配(前、后、中都可以收录*)。
2.3、右击主题名称,在弹出的菜单中选择“Statistical Leads”。您可以看到有多少潜在客户正在等待被抓取,而这些潜在客户就是 URL。
2.4、点击单搜索,输入线索数量(激活所有线索;如果要采集其他结构相同的网页,选择添加,然后复制多个网址进去,可以批量采集 >.更多操作见《如何管理规则线索》
方法三:使用爬虫组并发采集数据
爬虫组功能支持在一台电脑上同时运行多个爬虫。它集成了crontab爬虫调度器、DS计数器主菜单功能、数据库存储三大功能块。无需指定采集多少潜在客户,爬虫组会自动采集所有等待采集的潜在客户,让您高效采集数据,监控规则运行。有关用法,请参阅“如何运行 Crawler Swarm”
方法四:编写crontab并发爬虫采集数据
crontab程序(终极功能)和爬虫组一样,可以设置多个爬虫窗口并发采集数据,但是需要自己编写程序。两者的区别在于crontab程序可以指定爬虫窗口只有哪个主题任务采集,这样可以大大提高稳定性和效率,而爬虫组可以自由地将主题任务分配给爬虫窗口,而效率稍慢。详情请阅读文章《如何通过crontab程序实现周期性增量采集数据》。
如有疑问,您可以或
自动采集编写(如何利用Python打造搜狗壁纸自动下载爬虫库的反爬措施)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-04-16 15:16
这些案例是为一些想进入Python行业的朋友写的。看到大家都很满意,我又拿出来了。如果你已经开始学习python,对爬虫一窍不通,不妨看看这几个案例!
二、环境准备
Python 3
requests 库、lxml 库、beautifulsoup4 库
pip install XX XX XX 一起安装。
三、Python爬虫小案例
1、获取机器的公网IP地址
使用python的requests库+公网查IP接口自动获取IP地址
2、使用百度的搜索界面,Python编写url采集工具
你需要使用requests库和BeautifulSoup库来观察百度搜索结构的URL链接规则,通过在程序中设置User-Agent请求头来绕过百度搜索引擎的反爬虫机制。
Python 源代码:
用Python语言编写程序后,使用关键词inurl:/dede/login.php批量提取某个网络的后台地址cms:
3、使用Python制作搜狗壁纸自动下载爬虫
搜狗壁纸的地址是json格式的,所以使用json库解析这组数据,将爬虫程序存放图片的磁盘路径改成要存放图片的路径。
渲染:
4、Python 自动填充调查
和一般网页一样,多次提交数据都需要一个验证码,这就是反爬机制。
如图:
那么如何绕过验证码的反爬措施呢?使用X-Forwarded-For伪造IP地址访问,Python代码如下:
效果:
5、获取 West Thorn 代理上的 IP,以验证这些代理被禁止的可能性和延迟时间
可以将Python爬取的代理IP添加到代理链中,然后就可以进行一般的渗透任务了。这里,linux系统命令ping -c 1 " + ip.string + " | awk 'NR==2{print}' - 被直接调用。要在Windows下运行这个程序,需要修改os.popen倒数第二行的命令,可以修改为Windows可执行。
爬取的数据如图:
演示:
结论 查看全部
自动采集编写(如何利用Python打造搜狗壁纸自动下载爬虫库的反爬措施)
这些案例是为一些想进入Python行业的朋友写的。看到大家都很满意,我又拿出来了。如果你已经开始学习python,对爬虫一窍不通,不妨看看这几个案例!
二、环境准备
Python 3
requests 库、lxml 库、beautifulsoup4 库
pip install XX XX XX 一起安装。
三、Python爬虫小案例
1、获取机器的公网IP地址
使用python的requests库+公网查IP接口自动获取IP地址
2、使用百度的搜索界面,Python编写url采集工具
你需要使用requests库和BeautifulSoup库来观察百度搜索结构的URL链接规则,通过在程序中设置User-Agent请求头来绕过百度搜索引擎的反爬虫机制。
Python 源代码:
用Python语言编写程序后,使用关键词inurl:/dede/login.php批量提取某个网络的后台地址cms:
3、使用Python制作搜狗壁纸自动下载爬虫
搜狗壁纸的地址是json格式的,所以使用json库解析这组数据,将爬虫程序存放图片的磁盘路径改成要存放图片的路径。
渲染:
4、Python 自动填充调查
和一般网页一样,多次提交数据都需要一个验证码,这就是反爬机制。
如图:
那么如何绕过验证码的反爬措施呢?使用X-Forwarded-For伪造IP地址访问,Python代码如下:
效果:
5、获取 West Thorn 代理上的 IP,以验证这些代理被禁止的可能性和延迟时间
可以将Python爬取的代理IP添加到代理链中,然后就可以进行一般的渗透任务了。这里,linux系统命令ping -c 1 " + ip.string + " | awk 'NR==2{print}' - 被直接调用。要在Windows下运行这个程序,需要修改os.popen倒数第二行的命令,可以修改为Windows可执行。
爬取的数据如图:
演示:
结论
自动采集编写(触发MCC#抓取surface笔记图像采集卡channel!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2022-04-15 15:29
标签:触发MCC#抓取表面笔记图像采集卡片通道
每周更新!
1.参数1.1CAM文件
CAM 文件是一个可读的 ASCII 文件,文件扩展名为 .cam,收录一系列参数,例如:AcquisitionMode、TrigMode 等。通过 McSetParamStr 方法将 Camfile 加载到通道:
McSetParamStr(MyChannelMyChannel, MC_CamFile , "VCC VCC-870A_P15RA");
1.2 频道
通道是相机、图像采集卡和主机 PC 内存之间的 采集 路径。频道由三部分组成:
1. 负责图像捕获的相机。
2. 图像采集卡负责采集 和图像的传输。
3. 用于在主机 PC 中存储图像的内存缓冲区。
可以将通道设置为以下四种状态之一:
名字
意义
孤儿
没有与之关联的爬虫。所以不可能立即得到图像。但是通道是存在的,它的所有参数都可以自由设置或获取。
空闲
当一个通道空闲时,它有一个与之关联的抓取器。因此,图像 采集 可以立即完成。在这种状态下,MultiCam 可能会自动将采集器资源重新分配给另一个通道。
准备好了
当一个通道处于就绪状态时,它有一个与之关联的抓取器。因此,图像 采集 可以立即完成。在这种状态下,MultiCam 无法自动将采集器资源重新分配给另一个通道。
活跃
当一个通道处于活动状态时,它有一个与之关联的抓取器并执行一系列图像采集。在这种状态下,MultiCam 无法自动将采集器资源重新分配给另一个通道。
代码示例:
1.3 曲面
surface 是一个缓冲区,用户应用程序可以在其中找到要分析的 采集图像。内存缓冲区由称为表面的 MultiCam 对象表示。曲面可以由 Multicam 自动创建或由用户手动创建。抓取器通过 DMA 机制自动将 采集 图像传输到目标表面。一个通道可以有一个或多个表面(默认为 4)。根据表面的数量,定义了单缓冲和多缓冲。
表面状态
意义
免费
自由曲面可以无条件地接收来自抓手的图像数据。
填充
目前正在从采集卡接收图像数据,或准备接收数据。集群中应该有一个处于 FILLING 状态的 Surface。
填满
已完成从抓取器接收图像数据,准备处理。
处理
处理器正在处理处于 PROCESSING 状态的 Surface。
保留
从标准状态转换机制中移除。
代码示例:
一组表面称为一个簇,一个通道只能有一个簇。集群状态为OFF、READY(正在获取图像但没有表面在PROCESSING)、BUSY(有表面在PROCESSING中)、UNAVAILABLE(无法获取图像)
单缓冲
双缓冲
三重缓冲
1.4多机位信号发送
信号是由与用户应用程序交互的通道生成的事件。
帧触发冲突
开始曝光
此信号在帧曝光条件开始时发出。
结束曝光
该信号在帧曝光条件结束时发出。
表面填充
当目标簇的Surface进入Filled状态时发出此信号。
表面处理
当目标簇的Surface进入Processing状态时发出此信号。
集群不可用
采集失败 (**)
采集序列开始
采集序列结束
频道活动结束
有三种访问它们的机制:
1. 是指用户编写的函数,当预定义的信号出现时会自动调用这些函数。 (回调)
2. 允许线程等待预定义信号发生的专用机制。
3. 一种用户定义的机制,涉及标准的 Windows 等待函数。
使用回调的案例:
1. 默认情况下,所有信号都被禁用。 SignalEnable 参数用于设置。
2.注册回调函数
3. 在回调函数中,使用 PMCSIGNALINFO 捕获事件,其中收录有关触发事件的信息。
例子:
1.5触发器
触发事件由 TrigMode 和 NextTrigMode 参数设置。
1.5.1 初始触发事件:
1.5.2触发事件结束
采集阶段可以用 EndTrigMode 结束:
1)当帧、页或行计数器到期时,采集 序列会自动终止。 (自动)
2)当检测到硬件侧触发线的有效转换时,采集序列终止(HARD)
或者通过BreakEffect参数直接终止通道的活动状态:
1)切片/相位/序列结束后停止采集(FINISH)
2)中止
1.6采集模式1.7异常
通过异常代码或 Windows 异常来管理异常。 ErrorHandling 参数设置错误管理行为,有 4 个可能的值。
2.演示
2.1 打开驱动
// Open MultiCam driver
MC.OpenDriver();
2.2 创建频道
// Create a channel and associate it with the first connector on the first board
MC.Create("CHANNEL", out channel);
MC.SetParam(channel, "DriverIndex", 0);
2.3 相机参数设置
// Choose the CAM file
MC.SetParam(channel, "CamFile", "1000m_P50RG");
// Choose the camera expose duration
MC.SetParam(channel, "Expose_us", 20000);
// Choose the pixel color format
MC.SetParam(channel, "ColorFormat", "Y8");
2.4 触发模式改变
//Set the acquisition mode to Snapshot
MC.SetParam(channel, "AcquisitionMode", "SNAPSHOT");
// Choose the way the first acquisition is triggered
MC.SetParam(channel, "TrigMode", "COMBINED");
// Choose the triggering mode for subsequent acquisitions
MC.SetParam(channel, "NextTrigMode", "COMBINED");
2.5 个事件触发器
2.5.1 注册回调函数
// Register the callback function
multiCamCallback = new MC.CALLBACK(MultiCamCallback);
MC.RegisterCallback(channel, multiCamCallback, channel);
2.5.2 信号开启
// Enable the signals corresponding to the callback functions
MC.SetParam(channel, MC.SignalEnable + MC.SIG_SURFACE_PROCESSING, "ON");
MC.SetParam(channel, MC.SignalEnable + MC.SIG_ACQUISITION_FAILURE, "ON");
2.5.3 判断接收信号
如果接收到的是MC.SIG_SURFACE_PROCESSING,调用ProcessingCallback获取图片的数据,并将图片数据转换为位图。如果收到 MC.SIG_ACQUISITION_FAILURE,调用 AcqFailureCallback 输出“Acquisition Failure”。
private void MultiCamCallback(ref MC.SIGNALINFO signalInfo)
{
switch(signalInfo.Signal)
{
case MC.SIG_SURFACE_PROCESSING:
ProcessingCallback(signalInfo);
break;
case MC.SIG_ACQUISITION_FAILURE:
AcqFailureCallback(signalInfo);
break;
default:
throw new Euresys.MultiCamException("Unknown signal");
}
}
2.6通道状态设置为READY
// Prepare the channel in order to minimize the acquisition sequence startup latency
MC.SetParam(channel, "ChannelState", "READY");
3. 编写测试程序
触发方式使用默认的连续触发。
在界面上显示camfile的加载。
演示界面只有Go和stop和一个状态栏。添加按钮以打开/关闭相机和启动/停止采集.
曝光开始事件被触发,帧数开始计数++;触发surface_processing事件,图像采集计数++;触发采集失败事件,丢帧计数++。
代码肯定行不通。毕竟我是一个没见过采集卡片的人,所以我只是在说纸上谈兵哈哈哈
标签:触发器、MC、C#、抓取、表面、笔记、图像、采集卡片、通道 查看全部
自动采集编写(触发MCC#抓取surface笔记图像采集卡channel!)
标签:触发MCC#抓取表面笔记图像采集卡片通道
每周更新!
1.参数1.1CAM文件
CAM 文件是一个可读的 ASCII 文件,文件扩展名为 .cam,收录一系列参数,例如:AcquisitionMode、TrigMode 等。通过 McSetParamStr 方法将 Camfile 加载到通道:
McSetParamStr(MyChannelMyChannel, MC_CamFile , "VCC VCC-870A_P15RA");
1.2 频道
通道是相机、图像采集卡和主机 PC 内存之间的 采集 路径。频道由三部分组成:
1. 负责图像捕获的相机。
2. 图像采集卡负责采集 和图像的传输。
3. 用于在主机 PC 中存储图像的内存缓冲区。
可以将通道设置为以下四种状态之一:
名字
意义
孤儿
没有与之关联的爬虫。所以不可能立即得到图像。但是通道是存在的,它的所有参数都可以自由设置或获取。
空闲
当一个通道空闲时,它有一个与之关联的抓取器。因此,图像 采集 可以立即完成。在这种状态下,MultiCam 可能会自动将采集器资源重新分配给另一个通道。
准备好了
当一个通道处于就绪状态时,它有一个与之关联的抓取器。因此,图像 采集 可以立即完成。在这种状态下,MultiCam 无法自动将采集器资源重新分配给另一个通道。
活跃
当一个通道处于活动状态时,它有一个与之关联的抓取器并执行一系列图像采集。在这种状态下,MultiCam 无法自动将采集器资源重新分配给另一个通道。
代码示例:
1.3 曲面
surface 是一个缓冲区,用户应用程序可以在其中找到要分析的 采集图像。内存缓冲区由称为表面的 MultiCam 对象表示。曲面可以由 Multicam 自动创建或由用户手动创建。抓取器通过 DMA 机制自动将 采集 图像传输到目标表面。一个通道可以有一个或多个表面(默认为 4)。根据表面的数量,定义了单缓冲和多缓冲。
表面状态
意义
免费
自由曲面可以无条件地接收来自抓手的图像数据。
填充
目前正在从采集卡接收图像数据,或准备接收数据。集群中应该有一个处于 FILLING 状态的 Surface。
填满
已完成从抓取器接收图像数据,准备处理。
处理
处理器正在处理处于 PROCESSING 状态的 Surface。
保留
从标准状态转换机制中移除。
代码示例:
一组表面称为一个簇,一个通道只能有一个簇。集群状态为OFF、READY(正在获取图像但没有表面在PROCESSING)、BUSY(有表面在PROCESSING中)、UNAVAILABLE(无法获取图像)
单缓冲
双缓冲
三重缓冲
1.4多机位信号发送
信号是由与用户应用程序交互的通道生成的事件。
帧触发冲突
开始曝光
此信号在帧曝光条件开始时发出。
结束曝光
该信号在帧曝光条件结束时发出。
表面填充
当目标簇的Surface进入Filled状态时发出此信号。
表面处理
当目标簇的Surface进入Processing状态时发出此信号。
集群不可用
采集失败 (**)
采集序列开始
采集序列结束
频道活动结束
有三种访问它们的机制:
1. 是指用户编写的函数,当预定义的信号出现时会自动调用这些函数。 (回调)
2. 允许线程等待预定义信号发生的专用机制。
3. 一种用户定义的机制,涉及标准的 Windows 等待函数。
使用回调的案例:
1. 默认情况下,所有信号都被禁用。 SignalEnable 参数用于设置。
2.注册回调函数
3. 在回调函数中,使用 PMCSIGNALINFO 捕获事件,其中收录有关触发事件的信息。
例子:
1.5触发器
触发事件由 TrigMode 和 NextTrigMode 参数设置。
1.5.1 初始触发事件:
1.5.2触发事件结束
采集阶段可以用 EndTrigMode 结束:
1)当帧、页或行计数器到期时,采集 序列会自动终止。 (自动)
2)当检测到硬件侧触发线的有效转换时,采集序列终止(HARD)
或者通过BreakEffect参数直接终止通道的活动状态:
1)切片/相位/序列结束后停止采集(FINISH)
2)中止
1.6采集模式1.7异常
通过异常代码或 Windows 异常来管理异常。 ErrorHandling 参数设置错误管理行为,有 4 个可能的值。
2.演示
2.1 打开驱动
// Open MultiCam driver
MC.OpenDriver();
2.2 创建频道
// Create a channel and associate it with the first connector on the first board
MC.Create("CHANNEL", out channel);
MC.SetParam(channel, "DriverIndex", 0);
2.3 相机参数设置
// Choose the CAM file
MC.SetParam(channel, "CamFile", "1000m_P50RG");
// Choose the camera expose duration
MC.SetParam(channel, "Expose_us", 20000);
// Choose the pixel color format
MC.SetParam(channel, "ColorFormat", "Y8");
2.4 触发模式改变
//Set the acquisition mode to Snapshot
MC.SetParam(channel, "AcquisitionMode", "SNAPSHOT");
// Choose the way the first acquisition is triggered
MC.SetParam(channel, "TrigMode", "COMBINED");
// Choose the triggering mode for subsequent acquisitions
MC.SetParam(channel, "NextTrigMode", "COMBINED");
2.5 个事件触发器
2.5.1 注册回调函数
// Register the callback function
multiCamCallback = new MC.CALLBACK(MultiCamCallback);
MC.RegisterCallback(channel, multiCamCallback, channel);
2.5.2 信号开启
// Enable the signals corresponding to the callback functions
MC.SetParam(channel, MC.SignalEnable + MC.SIG_SURFACE_PROCESSING, "ON");
MC.SetParam(channel, MC.SignalEnable + MC.SIG_ACQUISITION_FAILURE, "ON");
2.5.3 判断接收信号
如果接收到的是MC.SIG_SURFACE_PROCESSING,调用ProcessingCallback获取图片的数据,并将图片数据转换为位图。如果收到 MC.SIG_ACQUISITION_FAILURE,调用 AcqFailureCallback 输出“Acquisition Failure”。
private void MultiCamCallback(ref MC.SIGNALINFO signalInfo)
{
switch(signalInfo.Signal)
{
case MC.SIG_SURFACE_PROCESSING:
ProcessingCallback(signalInfo);
break;
case MC.SIG_ACQUISITION_FAILURE:
AcqFailureCallback(signalInfo);
break;
default:
throw new Euresys.MultiCamException("Unknown signal");
}
}
2.6通道状态设置为READY
// Prepare the channel in order to minimize the acquisition sequence startup latency
MC.SetParam(channel, "ChannelState", "READY");
3. 编写测试程序
触发方式使用默认的连续触发。
在界面上显示camfile的加载。
演示界面只有Go和stop和一个状态栏。添加按钮以打开/关闭相机和启动/停止采集.
曝光开始事件被触发,帧数开始计数++;触发surface_processing事件,图像采集计数++;触发采集失败事件,丢帧计数++。
代码肯定行不通。毕竟我是一个没见过采集卡片的人,所以我只是在说纸上谈兵哈哈哈
标签:触发器、MC、C#、抓取、表面、笔记、图像、采集卡片、通道
自动采集编写(GoldData配制登录和检查会话的数据集有什么区别?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-15 09:45
概括
本文将介绍GoldData的半自动登录功能对采集必填网站数据的使用。GoldData的半自动登录功能是指通过脚本进行登录。如果需要手动输入验证码或其他内容,可以通过收发邮件的方式进行登录。
下载示例
为了解释方便,我们使用采集mydict的数据一词来解释需要登录的采集网站数据。mydict示例程序可以从开源下载< @网站 到 ( , 或 )。
下载后打开命令行,运行以下命令启动示例程序。
java -jar mydict.war
启动后,打开浏览器输入 URL:8080/ 即可打开登录页面。如下所示:
输入用户名和密码(均为admin),即可打开首页单词列表。
编写登录和检查会话脚本
点击“采集Management”网站Management”,点击“Add”按钮,添加一个名为mydict的站点。如下:
接下来配置登录和检查会话脚本,点击“设置半自动登录”,会打开站点半自动登录配置页面,如下图:
登录脚本如下:
//发送ajax请求验证码
var va=$ajax('http://localhost:8080/code/vcode?timestamp=1554001708730',{encoding:false});
var arg_={
label:site.name+"验证码",
type:1,
content:va.content
}
//waitForInput内置函数将发送邮件,并等待输入
//(回复邮件,或者goldData平台输入),
//并把输入内容当作验证码返回。
var code=waitForInput(arg_);
var data="username=admin&password=admin&vcode="+code
var m=new Map()
m.put('Cookie',va.cookie)
//发送ajax请求执行登录
var content=$ajax('http://localhost:8080/doLogin',{method:'POST',headers:m,data:data})
//如果正确,将返回状态1(登录成功),和headers信息给GoldData,
//否则返回0(登录失败)!
if(content.headers){
m.putAll(content.headers)
}
var ret={status:1,headers:m}
if(content.status!=200){
ret.status=0
}
ret
检查脚本如下:
var ret=true;
if(html.contains("我的单词-登录")){
ret=false
}
ret;
准备好后,我们回到网站管理页面,点击“开始登录”,会开始执行“自动登录”,之后点击“查询”按钮刷新页面,可以看到“等待输入”状态。如下所示:
此时,您设置的通知邮箱应该也会同时收到邮件。点击打开邮件,或者点击页面上的“输入等待输入”按钮,会看到如下内容:
根据邮件内容,回复邮件“{{qcxe}}”,程序可以继续执行。在golddata页面输入“qcxe”,效果是一样的。程序将返回“waitForInput()”并返回输入。
回复后,我们在golddata页面点击“查询”刷新页面,mydict的登录状态会变为“登录”。如下所示:
接下来,我们可以定义抓取规则。
定义抓取规则
在添加规则之前,我们还需要定义一个类似于表结构的数据集。如下所示:
接下来点击“采集管理“规则管理”,添加规则,打开添加规则页面,如下图:
抓取规则脚本如下:
[
{
__sample: http://localhost:8080/word/index?pageNum=2
match0: http\:\/\/localhost\:8080\/word\/index(\?pageNum=\d+)?
fields0:
{
__model: true
__dataset: word
__node: "#content ul >li"
sn:
{
expr: ""
attr: ""
js: md5(item.name)
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
name:
{
expr: h5
attr: ""
js: ""
__label: ""
__showOnList: true
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
uk:
{
expr: li span.uk
attr: ""
js: source.replace("uk: ",'')
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
us:
{
expr: li span.us
attr: ""
js: source.replace("us: ",'')
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
}
fields1:
{
__node: .pagination a
href:
{
expr: a
attr: abs:href
js: ""
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
}
}
]
然后单击测试,将进行测试爬网。我们发现数据确实被抓到了,如下图所示:
配置抓取器抓取
这个和之前一样,设置爬虫爬取站点“mydict”。然后点击开始抓取。然后您将在数据管理中查看捕获的数据。
综上所述
GoldData半自动登录的本质是提供一个框架,可以手动干预异步获取会话。既可以调用AI接口完成自动登录;当复杂的识别需要提供类似于验证码的输入时,它也可以直接转换cookie或token信息。通过电子邮件向 GoldData 平台发送和接收(这样无论 CAPTCHA 多么复杂),让 GoldData 能够继续捕获数据。 查看全部
自动采集编写(GoldData配制登录和检查会话的数据集有什么区别?)
概括
本文将介绍GoldData的半自动登录功能对采集必填网站数据的使用。GoldData的半自动登录功能是指通过脚本进行登录。如果需要手动输入验证码或其他内容,可以通过收发邮件的方式进行登录。
下载示例
为了解释方便,我们使用采集mydict的数据一词来解释需要登录的采集网站数据。mydict示例程序可以从开源下载< @网站 到 ( , 或 )。
下载后打开命令行,运行以下命令启动示例程序。
java -jar mydict.war
启动后,打开浏览器输入 URL:8080/ 即可打开登录页面。如下所示:
输入用户名和密码(均为admin),即可打开首页单词列表。
编写登录和检查会话脚本
点击“采集Management”网站Management”,点击“Add”按钮,添加一个名为mydict的站点。如下:
接下来配置登录和检查会话脚本,点击“设置半自动登录”,会打开站点半自动登录配置页面,如下图:
登录脚本如下:
//发送ajax请求验证码
var va=$ajax('http://localhost:8080/code/vcode?timestamp=1554001708730',{encoding:false});
var arg_={
label:site.name+"验证码",
type:1,
content:va.content
}
//waitForInput内置函数将发送邮件,并等待输入
//(回复邮件,或者goldData平台输入),
//并把输入内容当作验证码返回。
var code=waitForInput(arg_);
var data="username=admin&password=admin&vcode="+code
var m=new Map()
m.put('Cookie',va.cookie)
//发送ajax请求执行登录
var content=$ajax('http://localhost:8080/doLogin',{method:'POST',headers:m,data:data})
//如果正确,将返回状态1(登录成功),和headers信息给GoldData,
//否则返回0(登录失败)!
if(content.headers){
m.putAll(content.headers)
}
var ret={status:1,headers:m}
if(content.status!=200){
ret.status=0
}
ret
检查脚本如下:
var ret=true;
if(html.contains("我的单词-登录")){
ret=false
}
ret;
准备好后,我们回到网站管理页面,点击“开始登录”,会开始执行“自动登录”,之后点击“查询”按钮刷新页面,可以看到“等待输入”状态。如下所示:
此时,您设置的通知邮箱应该也会同时收到邮件。点击打开邮件,或者点击页面上的“输入等待输入”按钮,会看到如下内容:
根据邮件内容,回复邮件“{{qcxe}}”,程序可以继续执行。在golddata页面输入“qcxe”,效果是一样的。程序将返回“waitForInput()”并返回输入。
回复后,我们在golddata页面点击“查询”刷新页面,mydict的登录状态会变为“登录”。如下所示:
接下来,我们可以定义抓取规则。
定义抓取规则
在添加规则之前,我们还需要定义一个类似于表结构的数据集。如下所示:
接下来点击“采集管理“规则管理”,添加规则,打开添加规则页面,如下图:
抓取规则脚本如下:
[
{
__sample: http://localhost:8080/word/index?pageNum=2
match0: http\:\/\/localhost\:8080\/word\/index(\?pageNum=\d+)?
fields0:
{
__model: true
__dataset: word
__node: "#content ul >li"
sn:
{
expr: ""
attr: ""
js: md5(item.name)
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
name:
{
expr: h5
attr: ""
js: ""
__label: ""
__showOnList: true
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
uk:
{
expr: li span.uk
attr: ""
js: source.replace("uk: ",'')
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
us:
{
expr: li span.us
attr: ""
js: source.replace("us: ",'')
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
}
fields1:
{
__node: .pagination a
href:
{
expr: a
attr: abs:href
js: ""
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
}
}
]
然后单击测试,将进行测试爬网。我们发现数据确实被抓到了,如下图所示:
配置抓取器抓取
这个和之前一样,设置爬虫爬取站点“mydict”。然后点击开始抓取。然后您将在数据管理中查看捕获的数据。
综上所述
GoldData半自动登录的本质是提供一个框架,可以手动干预异步获取会话。既可以调用AI接口完成自动登录;当复杂的识别需要提供类似于验证码的输入时,它也可以直接转换cookie或token信息。通过电子邮件向 GoldData 平台发送和接收(这样无论 CAPTCHA 多么复杂),让 GoldData 能够继续捕获数据。
自动采集编写(自动化白盒测试系统及方法()测试技术)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-14 14:14
本发明专利技术提供了一种web应用自动化白盒测试系统及方法,包括web data采集模块,自动将测试者提交的数据信息保存在客户端浏览器中作为web请求信息数据文件,并添加动作信息生成初始测试数据文件;脚本生成模块,根据初始测试数据文件生成测试脚本;数据生成模块,通过编写业务描述文件来描述测试用例执行的逻辑顺序,并自动执行初始测试。修改数据文件,生成测试数据文件;集成测试模块按照业务描述文件的逻辑顺序耦合多个测试用例。
下载所有详细的技术数据
【技术实现步骤总结】
本专利技术属于计算机软件测试技术,特别是Web应用软件功能可靠性自动测试的测试技术。技术背景 目前,在软件测试领域,自动化测试是一种新兴的测试技术。自动化测试方法主要有两种: 1、捕获/回放机制:直接使用商业测试软件编写测试用例脚本。使用商业测试软件自动测试被测软件。这类测试软件在测试web应用时,共同点就是记录web应用页面操作,生成测试脚本。测试时,客户端模拟浏览器操作,实现自动化测试。如图1所示。这种测试方式的缺点是客户端只能获取http信息流,而无法获取软件的内部数据结构及相关信息,无法对软件进行完整有效的检查和验证,具有一定的局限性。例如,在验证软件运行时动态生成的数据,而这些动态生成的数据并没有通过http信息流返回给客户端时,捕获/回放机制的测试方法很难进行有效的测试。2、自动白盒测试:这类自动化测试工具自动生成测试用例脚本,主要用于源代码的分析和测试,不具备逻辑测试的功能。虽然这种类型的自动测试很方便,它可以发现人工测试很难发现的错误,但也有局限性:此类工具一般价格昂贵,初期投资非常高,无法有效测试软件的业务功能。而且,在现有技术中,无论是捕获/回放机制还是自动白盒测试,这些测试方法仍然存在一个缺点,即只能单独执行测试用例,不能有效地使用多个用例。到 --> 业务逻辑。耦合。当一个用例需要以其他用例的运行结果作为初始条件时,目前的测试方法很难将结果自动输出到其他用例,需要人工实现,没有办法自动耦合大量根据业务逻辑的用例。
技术实现思路
该专利技术的目的是克服现有技术的不足,提出一种实现Web应用程序自动白盒测试的系统,适用于基于J2EE和struts技术B/S架构的Web应用程序。该专利技术的另一个目的是提出一种实现网络应用程序自动化白盒测试的方法。测试过程中,对测试用例进行人工测试,测试过程中自动记录测试数据,并以固定格式保存。根据保存的数据自动生成用例的测试脚本,测试脚本和测试数据可以实现测试用例的自动白盒测试。当业务复杂时,会有大量的测试用例。该专利技术提出的方法还可以自动构建不同测试用例之间的业务逻辑关系,从而可以根据业务逻辑关系批量运行测试脚本。脚本自动测试时,测试脚本部署在服务器的表现层,脚本模拟服务器组件内部的软件业务操作。测试结束后,输出测试结果报告。为实现专利技术的第一个目的,采用的技术方案如下:Web应用自动化白盒测试系统,包括以下组件:web data采集模块,存储数据测试人员在客户端浏览器中提交的信息自动保存为web请求信息数据文件,添加动作信息,生成初始测试数据文件;脚本生成模块,根据初始测试数据文件生成测试脚本;数据生成模块,通过编写业务描述文件来描述测试。用例执行的逻辑顺序自动修改初始测试数据文件生成测试数据文件;集成测试模块按照业务描述文件的逻辑顺序耦合多个测试用例。用例执行的逻辑顺序自动修改初始测试数据文件生成测试数据文件;集成测试模块按照业务描述文件的逻辑顺序耦合多个测试用例。用例执行的逻辑顺序自动修改初始测试数据文件生成测试数据文件;集成测试模块按照业务描述文件的逻辑顺序耦合多个测试用例。
上述技术方案中,Web数据采集模块是通过在客户端浏览器中安装数据采集-->采集插件实现的,数据采集插件调用提供的API浏览器,以及浏览器提交的数据请求信息,以固定格式记录保存。动作信息是从struts的描述文件中获取的,该文件记录了web操作过程中的业务映射关系。脚本生成模块根据初始测试数据文件生成初始测试脚本。如果测试用例需要检查更多的验证点,则通过修改初始测试脚本得到测试脚本。如果测试用例不需要检查更多的验证点,那么初始测试脚本就是测试脚本。集成测试模块将测试脚本部署在服务器的表现层,对服务器的表现层进行集成测试。测试时,用例根据业务逻辑将生成的数据输出到对应的数据文件中,以便相关用例可以使用该用例的操作。结果,测试结束后,输出测试结果报告。为实现专利技术的第二个目的,采用的技术方案如下:一种Web应用自动化白盒测试方法,包括以下步骤:(1)手动测试测试用例;(2)网页数据采集模块自动记录并保存浏览器提交的数据信息;(3)修改步骤中保存的数据文件(<
<p>是基于软件代码的测试,可以对软件运行时的细节进行仔细检查。在测试过程中,可以通过软件内部的逻辑结构和相关信息来判断实际状态是否与预期状态一致。当软件出现bug时,可以根据测试结果报告确定具体的功能或类别。出现问题。现有技术中业务逻辑的自动化测试方法多为黑盒测试。与黑盒测试相比,本专利技术可以更有效地检查软件运行的正确性,有效测试代码内部结构,保证软件质量。2、本专利技术的数据和脚本易于使用且编写高效。传统的白盒测试方法耗时长,对测试人员技术要求高,成本高。该专利技术提出自动数据自动化 查看全部
自动采集编写(自动化白盒测试系统及方法()测试技术)
本发明专利技术提供了一种web应用自动化白盒测试系统及方法,包括web data采集模块,自动将测试者提交的数据信息保存在客户端浏览器中作为web请求信息数据文件,并添加动作信息生成初始测试数据文件;脚本生成模块,根据初始测试数据文件生成测试脚本;数据生成模块,通过编写业务描述文件来描述测试用例执行的逻辑顺序,并自动执行初始测试。修改数据文件,生成测试数据文件;集成测试模块按照业务描述文件的逻辑顺序耦合多个测试用例。
下载所有详细的技术数据
【技术实现步骤总结】
本专利技术属于计算机软件测试技术,特别是Web应用软件功能可靠性自动测试的测试技术。技术背景 目前,在软件测试领域,自动化测试是一种新兴的测试技术。自动化测试方法主要有两种: 1、捕获/回放机制:直接使用商业测试软件编写测试用例脚本。使用商业测试软件自动测试被测软件。这类测试软件在测试web应用时,共同点就是记录web应用页面操作,生成测试脚本。测试时,客户端模拟浏览器操作,实现自动化测试。如图1所示。这种测试方式的缺点是客户端只能获取http信息流,而无法获取软件的内部数据结构及相关信息,无法对软件进行完整有效的检查和验证,具有一定的局限性。例如,在验证软件运行时动态生成的数据,而这些动态生成的数据并没有通过http信息流返回给客户端时,捕获/回放机制的测试方法很难进行有效的测试。2、自动白盒测试:这类自动化测试工具自动生成测试用例脚本,主要用于源代码的分析和测试,不具备逻辑测试的功能。虽然这种类型的自动测试很方便,它可以发现人工测试很难发现的错误,但也有局限性:此类工具一般价格昂贵,初期投资非常高,无法有效测试软件的业务功能。而且,在现有技术中,无论是捕获/回放机制还是自动白盒测试,这些测试方法仍然存在一个缺点,即只能单独执行测试用例,不能有效地使用多个用例。到 --> 业务逻辑。耦合。当一个用例需要以其他用例的运行结果作为初始条件时,目前的测试方法很难将结果自动输出到其他用例,需要人工实现,没有办法自动耦合大量根据业务逻辑的用例。
技术实现思路
该专利技术的目的是克服现有技术的不足,提出一种实现Web应用程序自动白盒测试的系统,适用于基于J2EE和struts技术B/S架构的Web应用程序。该专利技术的另一个目的是提出一种实现网络应用程序自动化白盒测试的方法。测试过程中,对测试用例进行人工测试,测试过程中自动记录测试数据,并以固定格式保存。根据保存的数据自动生成用例的测试脚本,测试脚本和测试数据可以实现测试用例的自动白盒测试。当业务复杂时,会有大量的测试用例。该专利技术提出的方法还可以自动构建不同测试用例之间的业务逻辑关系,从而可以根据业务逻辑关系批量运行测试脚本。脚本自动测试时,测试脚本部署在服务器的表现层,脚本模拟服务器组件内部的软件业务操作。测试结束后,输出测试结果报告。为实现专利技术的第一个目的,采用的技术方案如下:Web应用自动化白盒测试系统,包括以下组件:web data采集模块,存储数据测试人员在客户端浏览器中提交的信息自动保存为web请求信息数据文件,添加动作信息,生成初始测试数据文件;脚本生成模块,根据初始测试数据文件生成测试脚本;数据生成模块,通过编写业务描述文件来描述测试。用例执行的逻辑顺序自动修改初始测试数据文件生成测试数据文件;集成测试模块按照业务描述文件的逻辑顺序耦合多个测试用例。用例执行的逻辑顺序自动修改初始测试数据文件生成测试数据文件;集成测试模块按照业务描述文件的逻辑顺序耦合多个测试用例。用例执行的逻辑顺序自动修改初始测试数据文件生成测试数据文件;集成测试模块按照业务描述文件的逻辑顺序耦合多个测试用例。
上述技术方案中,Web数据采集模块是通过在客户端浏览器中安装数据采集-->采集插件实现的,数据采集插件调用提供的API浏览器,以及浏览器提交的数据请求信息,以固定格式记录保存。动作信息是从struts的描述文件中获取的,该文件记录了web操作过程中的业务映射关系。脚本生成模块根据初始测试数据文件生成初始测试脚本。如果测试用例需要检查更多的验证点,则通过修改初始测试脚本得到测试脚本。如果测试用例不需要检查更多的验证点,那么初始测试脚本就是测试脚本。集成测试模块将测试脚本部署在服务器的表现层,对服务器的表现层进行集成测试。测试时,用例根据业务逻辑将生成的数据输出到对应的数据文件中,以便相关用例可以使用该用例的操作。结果,测试结束后,输出测试结果报告。为实现专利技术的第二个目的,采用的技术方案如下:一种Web应用自动化白盒测试方法,包括以下步骤:(1)手动测试测试用例;(2)网页数据采集模块自动记录并保存浏览器提交的数据信息;(3)修改步骤中保存的数据文件(<
<p>是基于软件代码的测试,可以对软件运行时的细节进行仔细检查。在测试过程中,可以通过软件内部的逻辑结构和相关信息来判断实际状态是否与预期状态一致。当软件出现bug时,可以根据测试结果报告确定具体的功能或类别。出现问题。现有技术中业务逻辑的自动化测试方法多为黑盒测试。与黑盒测试相比,本专利技术可以更有效地检查软件运行的正确性,有效测试代码内部结构,保证软件质量。2、本专利技术的数据和脚本易于使用且编写高效。传统的白盒测试方法耗时长,对测试人员技术要求高,成本高。该专利技术提出自动数据自动化
自动采集编写(看学习代码编写爬虫的目的是什么?教程在这里)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-04-12 02:30
这要看学习代码写爬虫的目的是什么?磨练您的技能,获得经验,或者只是想从网络上抓取数据以供您自己使用或研究。
如果你想成为学生党或者打算转行IT技术的人,就必须学习编码和编写爬虫,以拥有更多的实践经验和额外的技术技能,以便日后找到工作。因为未来互联网的信息化程度会越来越高,爬虫可以更高效的获取互联网信息,爬虫的技术也在兴起。
如果您在工作或学习中只需要采集互联网数据应用,可以先试用市面上通用的采集器,减少获取数据的资源投入,让您专注于自己的自己的事。
自我推荐,采集网页资料可以试试优采云采集平台,有免费版。以下是 采集 结果数据的示例:
优采云采集是新一代网站文章采集及发布平台,完全在线配置使用云端采集,功能强大,操作简单、快速、高效的配置。
优采云不仅提供网页文章采集、批量数据修改、定时采集、定时定量自动发布等基础功能,还集成了强大的SEO工具和创新实现了规则智能抽取引擎、书签一键发布采集等功能,大大提高了采集配置和发布的效率。
采集简单,发布更轻松:支持一键发布到WorpPress、Empire、织梦、ZBlog、Discuz、Destoon、Typecho、Emlog、Mipcms、Mito、Yiyoucms、Applecms、PHPcms等cms网站系统也可以发布到自定义Http接口。
有需要的同学可以看看下面的教程,很快就能上手。 查看全部
自动采集编写(看学习代码编写爬虫的目的是什么?教程在这里)
这要看学习代码写爬虫的目的是什么?磨练您的技能,获得经验,或者只是想从网络上抓取数据以供您自己使用或研究。
如果你想成为学生党或者打算转行IT技术的人,就必须学习编码和编写爬虫,以拥有更多的实践经验和额外的技术技能,以便日后找到工作。因为未来互联网的信息化程度会越来越高,爬虫可以更高效的获取互联网信息,爬虫的技术也在兴起。
如果您在工作或学习中只需要采集互联网数据应用,可以先试用市面上通用的采集器,减少获取数据的资源投入,让您专注于自己的自己的事。
自我推荐,采集网页资料可以试试优采云采集平台,有免费版。以下是 采集 结果数据的示例:
优采云采集是新一代网站文章采集及发布平台,完全在线配置使用云端采集,功能强大,操作简单、快速、高效的配置。
优采云不仅提供网页文章采集、批量数据修改、定时采集、定时定量自动发布等基础功能,还集成了强大的SEO工具和创新实现了规则智能抽取引擎、书签一键发布采集等功能,大大提高了采集配置和发布的效率。
采集简单,发布更轻松:支持一键发布到WorpPress、Empire、织梦、ZBlog、Discuz、Destoon、Typecho、Emlog、Mipcms、Mito、Yiyoucms、Applecms、PHPcms等cms网站系统也可以发布到自定义Http接口。
有需要的同学可以看看下面的教程,很快就能上手。
自动采集编写( 如何通过Python实现自动填写调查问卷】3.5获取公网代理IP)
采集交流 • 优采云 发表了文章 • 0 个评论 • 331 次浏览 • 2022-04-10 05:28
如何通过Python实现自动填写调查问卷】3.5获取公网代理IP)
一、前言
这个文章以前是用来训练新人的。大家觉得好理解,就分享给大家学习。如果你学过一些python,想用它做点什么,但没有方向,不妨尝试完成以下案例。
二、环境准备
安装requests lxml beautifulsoup4的三个库(以下代码均在python3.5环境下测试)
pip install requests lxml beautifulsoup4
三、几个小爬虫案例
3.1 获取机器的公网IP地址
以在公网查询IP为借口,使用python的requests库自动获取IP地址。
import requests
r = requests.get("http://2017.ip138.com/ic.asp")
r.encoding = r.apparent_encoding #使用requests的字符编码智能分析,避免中文乱码
print(r.text)
# 你还可以使用正则匹配re模块提取出IP
import re
print(re.findall("d{1,3}.d{1,3}.d{1,3}.d{1,3}",r.text))
3.2 用百度搜索界面写url采集器
在这种情况下,我们将使用 requests 结合 BeautifulSoup 库来完成任务。我们需要在程序中设置User-Agent头来绕过百度搜索引擎的反爬机制(可以尽量不添加User-Agent头,看能不能获取数据)。注意百度搜索结构的url链接规则,比如第一页url链接参数pn=0,第二页url链接参数pn=10……。等等。在这里,我们使用 css 选择器路径提取数据。
import requests
from bs4 import BeautifulSoup
# 设置User-Agent头,绕过百度搜索引擎的反爬虫机制
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'}
# 注意观察百度搜索结构的URL链接规律,例如第一页pn=0,第二页pn=10.... 依次类推,下面的for循环搜索前10页结果
for i in range(0,100,10):
bd_search = "https://www.baidu.com/s%3Fwd%3 ... ot%3B % str(i)
r = requests.get(bd_search,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
# 下面的select使用了css选择器路径提取数据
url_list = soup.select(".t > a")
for url in url_list:
real_url = url["href"]
r = requests.get(real_url)
print(r.url)
写完程序后,我们使用关键词inurl:/dede/login.php批量提取织梦cms的后台地址,效果如下:
3.3 自动下载搜狗壁纸
本例中,我们将通过爬虫自动下载并搜索壁纸,并将程序中图片存放的路径更改为您要存放图片的目录路径。还有一点是我们在程序中使用了json库,因为在观察过程中发现搜狗壁纸的地址是用json格式存储的,所以我们使用json来解析这组数据。
import requests
import json
#下载图片
url = "http://pic.sogou.com/pics/chan ... ot%3B
r = requests.get(url)
data = json.loads(r.text)
for i in data["all_items"]:
img_url = i["pic_url"]
# 下面这行里面的路径改成你自己想要存放图片的目录路径即可
with open("/home/evilk0/Desktop/img/%s" % img_url[-10:]+".jpg","wb") as f:
r2 = requests.get(img_url)
f.write(r2.content)
print("下载完毕:",img_url)
3.4 自动填写问卷
目标官网:
客观问卷:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
r = requests.post(url = url,headers=header,data=data)
print(r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
当我们使用同一个IP提交多份问卷时,会触发目标的反爬机制,服务器上会出现一个验证码。
我们可以使用X-Forwarded-For来伪造我们的IP,修改后的代码如下:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
"X-Forwarded-For" : "%s"
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
header["X-Forwarded-For"] = (str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+str(random.randint(1,255))
r = requests.post(url = url,headers=header,data=data)
print(header["X-Forwarded-For"],r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
header["X-Forwarded-For"] = "%s"
效果图:
关于这个文章,因为之前写过,就不赘述了。有兴趣的可以直接阅读:【如何通过Python自动填写问卷】
3.5 获取公网代理IP,判断是否可用及延迟时间
在这个例子中,我们要爬取 [Western Proxies] 上的代理 IP,并验证这些代理的生存能力和延迟。(可以将爬取的代理IP加入到proxychain中,然后进行平时的渗透任务。)这里我直接调用linux系统命令ping -c 1 " + ip.string + " | awk 'NR==2 {print}' - ,如果你想在Windows中运行这个程序,你需要修改os.popen中的命令,也就是倒数第三行,改成Windows可以执行的。
from bs4 import BeautifulSoup
import requests
import os
url = "http://www.xicidaili.com/nn/1"
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'}
r = requests.get(url=url,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
server_address = soup.select(".odd > td:nth-of-type(4)")
ip_list = soup.select(".odd > td:nth-of-type(2)")
ports = soup.select(".odd > td:nth-of-type(3)")
for server,ip in zip(server_address,ip_list):
if len(server.contents) != 1:
print(server.a.string.ljust(8),ip.string.ljust(20), end='')
else:
print("未知".ljust(8), ip.string.ljust(20), end='')
delay_time = os.popen("ping -c 1 " + ip.string + " | awk 'NR==2{print}' -")
delay_time = delay_time.read().split("time=")[-1].strip("
")
print("time = " + delay_time)
四、结束语
当然,你也可以用 python 做很多有趣的事情。 查看全部
自动采集编写(
如何通过Python实现自动填写调查问卷】3.5获取公网代理IP)
一、前言
这个文章以前是用来训练新人的。大家觉得好理解,就分享给大家学习。如果你学过一些python,想用它做点什么,但没有方向,不妨尝试完成以下案例。
二、环境准备
安装requests lxml beautifulsoup4的三个库(以下代码均在python3.5环境下测试)
pip install requests lxml beautifulsoup4
三、几个小爬虫案例
3.1 获取机器的公网IP地址
以在公网查询IP为借口,使用python的requests库自动获取IP地址。
import requests
r = requests.get("http://2017.ip138.com/ic.asp";)
r.encoding = r.apparent_encoding #使用requests的字符编码智能分析,避免中文乱码
print(r.text)
# 你还可以使用正则匹配re模块提取出IP
import re
print(re.findall("d{1,3}.d{1,3}.d{1,3}.d{1,3}",r.text))
3.2 用百度搜索界面写url采集器
在这种情况下,我们将使用 requests 结合 BeautifulSoup 库来完成任务。我们需要在程序中设置User-Agent头来绕过百度搜索引擎的反爬机制(可以尽量不添加User-Agent头,看能不能获取数据)。注意百度搜索结构的url链接规则,比如第一页url链接参数pn=0,第二页url链接参数pn=10……。等等。在这里,我们使用 css 选择器路径提取数据。
import requests
from bs4 import BeautifulSoup
# 设置User-Agent头,绕过百度搜索引擎的反爬虫机制
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'}
# 注意观察百度搜索结构的URL链接规律,例如第一页pn=0,第二页pn=10.... 依次类推,下面的for循环搜索前10页结果
for i in range(0,100,10):
bd_search = "https://www.baidu.com/s%3Fwd%3 ... ot%3B % str(i)
r = requests.get(bd_search,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
# 下面的select使用了css选择器路径提取数据
url_list = soup.select(".t > a")
for url in url_list:
real_url = url["href"]
r = requests.get(real_url)
print(r.url)
写完程序后,我们使用关键词inurl:/dede/login.php批量提取织梦cms的后台地址,效果如下:
3.3 自动下载搜狗壁纸
本例中,我们将通过爬虫自动下载并搜索壁纸,并将程序中图片存放的路径更改为您要存放图片的目录路径。还有一点是我们在程序中使用了json库,因为在观察过程中发现搜狗壁纸的地址是用json格式存储的,所以我们使用json来解析这组数据。
import requests
import json
#下载图片
url = "http://pic.sogou.com/pics/chan ... ot%3B
r = requests.get(url)
data = json.loads(r.text)
for i in data["all_items"]:
img_url = i["pic_url"]
# 下面这行里面的路径改成你自己想要存放图片的目录路径即可
with open("/home/evilk0/Desktop/img/%s" % img_url[-10:]+".jpg","wb") as f:
r2 = requests.get(img_url)
f.write(r2.content)
print("下载完毕:",img_url)
3.4 自动填写问卷
目标官网:
客观问卷:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
r = requests.post(url = url,headers=header,data=data)
print(r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
当我们使用同一个IP提交多份问卷时,会触发目标的反爬机制,服务器上会出现一个验证码。
我们可以使用X-Forwarded-For来伪造我们的IP,修改后的代码如下:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
"X-Forwarded-For" : "%s"
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
header["X-Forwarded-For"] = (str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+str(random.randint(1,255))
r = requests.post(url = url,headers=header,data=data)
print(header["X-Forwarded-For"],r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
header["X-Forwarded-For"] = "%s"
效果图:
关于这个文章,因为之前写过,就不赘述了。有兴趣的可以直接阅读:【如何通过Python自动填写问卷】
3.5 获取公网代理IP,判断是否可用及延迟时间
在这个例子中,我们要爬取 [Western Proxies] 上的代理 IP,并验证这些代理的生存能力和延迟。(可以将爬取的代理IP加入到proxychain中,然后进行平时的渗透任务。)这里我直接调用linux系统命令ping -c 1 " + ip.string + " | awk 'NR==2 {print}' - ,如果你想在Windows中运行这个程序,你需要修改os.popen中的命令,也就是倒数第三行,改成Windows可以执行的。
from bs4 import BeautifulSoup
import requests
import os
url = "http://www.xicidaili.com/nn/1"
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'}
r = requests.get(url=url,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
server_address = soup.select(".odd > td:nth-of-type(4)")
ip_list = soup.select(".odd > td:nth-of-type(2)")
ports = soup.select(".odd > td:nth-of-type(3)")
for server,ip in zip(server_address,ip_list):
if len(server.contents) != 1:
print(server.a.string.ljust(8),ip.string.ljust(20), end='')
else:
print("未知".ljust(8), ip.string.ljust(20), end='')
delay_time = os.popen("ping -c 1 " + ip.string + " | awk 'NR==2{print}' -")
delay_time = delay_time.read().split("time=")[-1].strip("
")
print("time = " + delay_time)
四、结束语
当然,你也可以用 python 做很多有趣的事情。
自动采集编写(管理员账号推荐使用微信公众号、小程序的原生代码开发)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-04-08 05:03
自动采集编写/上线微信公众号、小程序的原生代码,并即时发布,方便快捷;包含常见的采集网址,并且提供一定的自动转换功能,可以将上述网址转换为小程序地址;提供nodejs版本,并且支持windows和linux主机部署;可以批量管理多个微信公众号、小程序同步进行采集,或统一管理。一、微信公众号、小程序原生代码开发微信公众号原生代码开发如何进行原生代码采集呢?只需开发一个php后台,解析源码,然后就可以开始简单的自动化爬虫爬取操作了。
步骤1:打开浏览器浏览器地址:,进入登录页面,如图步骤2:点击登录并用账号密码登录步骤3:进入登录后台,如图采集模块暂不开放,暂时暂时解决,稍后我们会同步解决采集过程中可能出现的问题、步骤4:登录成功后,进入php后台,获取上面所提供的文件路径,并配置相应的管理员账号和密码。管理员账号推荐使用微信,进入管理员php后台,找到源码分析,然后选择相应的项目进行配置和引用包。
使用java采集数据项目的话,你需要配置jsp的开发环境,这里开发环境自己搭建不太方便,可以联系在线引导地址:phpdemo小程序原生代码开发也一样,同样以微信采集为例,登录并开始php后台和小程序的源码分析,然后选择相应的项目进行配置和引用包。安装java的java环境推荐使用微信,进入管理员php后台,配置相应的用户,密码和项目路径,具体配置方法百度搜索即可:php|java实现网站自动化爬虫采集-酷前端小编一枚~步骤5:然后会得到对应小程序的源码分析后,你需要获取小程序的网址及打开方式,具体方法百度搜索即可,大同小异的。
上述步骤有些需要手动配置,小编没有手动配置,仅找到配置这块的源码,会后台找到相应路径和信息进行简单配置:#小程序自动化采集器-php&_phpshowtotime=1&time=20140329&https=false&wx=1#\\for\\index\\html\\fallback('#\\index\\');//获取源码路径//创建网址分析器""".java-jstring:"""index.php"""so//访问网址的配置文件//访问授权服务器返回你要用的服务器地址"""php中文小程序源码分析器-jstring格式化格式化这里我将使用自己编写的https加密环境,前面的小说家采集器,和小说家号都存放在这里。
简单配置,即可使用。首先通过微信,进入到你的小程序,然后输入采集内容采集。完成操作后,手动执行代码即可。---end---二、微信公众号采集编写这里,我们只需要获取微信公众号的采集端口即可。现在我们使用上面我们讲。 查看全部
自动采集编写(管理员账号推荐使用微信公众号、小程序的原生代码开发)
自动采集编写/上线微信公众号、小程序的原生代码,并即时发布,方便快捷;包含常见的采集网址,并且提供一定的自动转换功能,可以将上述网址转换为小程序地址;提供nodejs版本,并且支持windows和linux主机部署;可以批量管理多个微信公众号、小程序同步进行采集,或统一管理。一、微信公众号、小程序原生代码开发微信公众号原生代码开发如何进行原生代码采集呢?只需开发一个php后台,解析源码,然后就可以开始简单的自动化爬虫爬取操作了。
步骤1:打开浏览器浏览器地址:,进入登录页面,如图步骤2:点击登录并用账号密码登录步骤3:进入登录后台,如图采集模块暂不开放,暂时暂时解决,稍后我们会同步解决采集过程中可能出现的问题、步骤4:登录成功后,进入php后台,获取上面所提供的文件路径,并配置相应的管理员账号和密码。管理员账号推荐使用微信,进入管理员php后台,找到源码分析,然后选择相应的项目进行配置和引用包。
使用java采集数据项目的话,你需要配置jsp的开发环境,这里开发环境自己搭建不太方便,可以联系在线引导地址:phpdemo小程序原生代码开发也一样,同样以微信采集为例,登录并开始php后台和小程序的源码分析,然后选择相应的项目进行配置和引用包。安装java的java环境推荐使用微信,进入管理员php后台,配置相应的用户,密码和项目路径,具体配置方法百度搜索即可:php|java实现网站自动化爬虫采集-酷前端小编一枚~步骤5:然后会得到对应小程序的源码分析后,你需要获取小程序的网址及打开方式,具体方法百度搜索即可,大同小异的。
上述步骤有些需要手动配置,小编没有手动配置,仅找到配置这块的源码,会后台找到相应路径和信息进行简单配置:#小程序自动化采集器-php&_phpshowtotime=1&time=20140329&https=false&wx=1#\\for\\index\\html\\fallback('#\\index\\');//获取源码路径//创建网址分析器""".java-jstring:"""index.php"""so//访问网址的配置文件//访问授权服务器返回你要用的服务器地址"""php中文小程序源码分析器-jstring格式化格式化这里我将使用自己编写的https加密环境,前面的小说家采集器,和小说家号都存放在这里。
简单配置,即可使用。首先通过微信,进入到你的小程序,然后输入采集内容采集。完成操作后,手动执行代码即可。---end---二、微信公众号采集编写这里,我们只需要获取微信公众号的采集端口即可。现在我们使用上面我们讲。
自动采集编写(服务器必需支持伪静态服务器源码演示网站pc采集一次安装受益终身 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-08 03:13
)
本源代码经楼主修改,详细安装方法已经写好,可以完美安装运行。
此源代码已启用伪静态规则服务器必须支持伪静态
服务器目前只支持php+apache
如果你是php+Nginx,请自行修改伪静态规则
或者改变服务器运行环境。否则,它不可用。
本源代码中没有APP软件。标题写的APP支持其他小说APP平台的转码阅读。
小说站的人都知道,运营一个APP的成本太高了。制作一个APP的最低成本是10000元。但将你的网站链接到其他成熟的小说站是最方便、最便宜的方式。本源码支持其他APP软件转码。
附带演示 采集 规则。但是有些已经过时了
采集请自己写规则。我们的软件不提供采集规则
-------------------------------------------------- -----------------------------------------
本源代码演示 网站 pc
配合CNZZ的统计插件,可以轻松实现下载的详细统计和采集的详细统计。(7)这个程序的自动采集不是市面上常见的,如冠冠、采集夏等,而是在原采集的基础上二次开发DEDE的@>功能 采集的采集模块可以有效保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;采集可以达到24小时25万到30万章。(8)安装比较简单,如果安装后打开的网址一直是手机版,
支持微信公众号绑定:
网页版截图:
查看全部
自动采集编写(服务器必需支持伪静态服务器源码演示网站pc采集一次安装受益终身
)
本源代码经楼主修改,详细安装方法已经写好,可以完美安装运行。
此源代码已启用伪静态规则服务器必须支持伪静态
服务器目前只支持php+apache
如果你是php+Nginx,请自行修改伪静态规则
或者改变服务器运行环境。否则,它不可用。
本源代码中没有APP软件。标题写的APP支持其他小说APP平台的转码阅读。
小说站的人都知道,运营一个APP的成本太高了。制作一个APP的最低成本是10000元。但将你的网站链接到其他成熟的小说站是最方便、最便宜的方式。本源码支持其他APP软件转码。
附带演示 采集 规则。但是有些已经过时了
采集请自己写规则。我们的软件不提供采集规则
-------------------------------------------------- -----------------------------------------
本源代码演示 网站 pc
配合CNZZ的统计插件,可以轻松实现下载的详细统计和采集的详细统计。(7)这个程序的自动采集不是市面上常见的,如冠冠、采集夏等,而是在原采集的基础上二次开发DEDE的@>功能 采集的采集模块可以有效保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;采集可以达到24小时25万到30万章。(8)安装比较简单,如果安装后打开的网址一直是手机版,
支持微信公众号绑定:
网页版截图:
自动采集编写( 6个K8s日志系统建设中的典型问题,你遇到过几个?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-04-04 03:04
6个K8s日志系统建设中的典型问题,你遇到过几个?)
作者 | 元一阿里云存储服务技术专家
简介:上一篇文章主要介绍了Kubernetes日志输出的一些注意事项。日志输出的最终目的是做统一的采集和分析。在Kubernetes中,记录采集的方式与普通虚拟机有很大不同,相对实现难度和部署成本也略高,但如果使用得当,自动化程度比传统方式高,运维成本更低。本文是日志系列文章的第四篇。
第一篇:《K8s日志系统建设中的6个典型问题,你遇到过几个?》
第二篇:《一篇文章理解K8s日志系统的设计与实践》
第三篇:《解决K8s中日志输出问题的9个技巧》
Kubernetes 日志采集 难点
在 Kubernetes 中,log采集 比传统的虚拟机和物理机要复杂得多。最根本的原因是Kubernetes屏蔽了底层异常,提供了更细粒度的资源调度,向上提供了一个稳定动态的环境。因此,日志采集面临着更丰富、更动态的环境,需要考虑的点也更多。
例如:
Kubernetes 传统方式
日志类型
文件、标准输出、主机文件、日志
档案、日记
日志源
业务容器、系统组件、主机
商务,主持人
采集如何
Agent (Sidecar, DaemonSet), Direct Write (DockerEngine, Business)
代理,直写
独立应用程序的数量
10-100
1-10
应用动态
高的
低的
节点动态
高的
低的
采集部署方式
手动,Yaml
手动, 定制
采集模式:主动或被动
日志采集方法有两种:被动采集和主动推送。在K8s中,被动采集一般分为Sidecar和DaemonSet两种方式。主动推送包括 DockerEngine 推送和业务直推。写两种方式。
总结一下:
各种采集方法的详细对比如下:
DockerEngine 业务直写 DaemonSet 方法 Sidecar 方法
采集日志类型
标准输出
业务日志
标准输出 + 部分文件
文档
部署和维护
低原生支持
低,只维护配置文件
一般需要维护DaemonSet
更高,每个需要采集日志的POD都需要部署一个sidecar容器
日志分类存储
达不到
业务独立配置
一般可以通过容器/路径等方式进行映射。
每个 POD 都可以单独配置以实现高灵活性
多租户隔离
虚弱的
弱,日志直写会和业务逻辑竞争资源
一般只通过配置之间的隔离
强,通过容器隔离,资源可单独分配
支持集群大小
无限本地存储,如果使用syslog和fluentd,会有单点限制
无限
取决于配置的数量
无限
资源占用
低,码头工人
引擎提供
总体最低,节省 采集 开销
较低,每个节点运行一个容器
更高,每个 POD 运行一个容器
查询方便
低,只能grep原创日志
高,可根据业务特点定制
高,可进行自定义查询和统计
高,可根据业务特点定制
可定制性
低的
高,可自由扩展
低的
高,每个 POD 单独配置
耦合
高,强绑定DockerEngine,修改需要重启DockerEngine
高,采集模块修改/升级需要重新发布业务
低,代理可以独立升级
一般Sidecar服务对应的默认采集Agent升级也会重启(有一些扩展包可以支持Sidecar热升级)
适用场景
测试、POC等非生产场景
对性能要求极高的场景
日志分类清晰、功能单一的集群
大型混合 PAAS 集群
日志输出:标准输出或文件
与虚拟机/物理机不同,K8s 容器提供标准输出和文件。在容器中,标准输出直接将日志输出到stdout或stderr,而DockerEngine接管stdout和stderr文件描述符,收到日志后根据DockerEngine配置的LogDriver规则进行处理;日志打印到文件的方式与虚拟机/物理机基本相似,只是日志可以使用不同的存储方式,比如默认存储、EmptyDir、HostVolume、NFS等。
虽然 Docker 官方推荐使用 Stdout 打印日志,但大家需要注意:这个推荐是基于容器仅作为简单应用使用的场景。在实际业务场景中,我们还是建议大家尽量使用文件方式。主要原因有以下几点:
因此,我们建议在线应用使用文件输出日志,而Stdout仅用于功能单一或部分K8s系统/运维组件的应用。
CICD 集成:日志记录操作员
Kubernetes提供了标准化的业务部署方式,可以通过yaml(K8s API)声明路由规则、暴露服务、挂载存储、运行业务、定义伸缩规则等,因此Kubernetes很容易与CICD系统集成。日志采集也是运维监控过程的重要组成部分。必须实时采集业务上线后的所有日志。
原来的方法是在发布后手动部署log采集的逻辑。这种方式需要人工干预,违背了CICD自动化的目的;为了实现自动化,有人开始根据日志打包API/SDK采集发布后通过CICD的webhook调用自动部署的服务,但这种方式开发成本高。
在 Kubernetes 中,集成日志最标准的方式是在 Kubernetes 系统中注册一个新资源,并以 Operator(CRD)的形式对其进行管理和维护。这样CICD系统就不需要额外开发,部署到Kubernetes系统时只需要附加日志相关的配置即可。
Kubernetes 日志采集 方案
早在 Kubernetes 出现之前,我们就开始为容器环境开发 log采集 解决方案。随着K8s的逐渐稳定,我们开始将很多业务迁移到K8s平台上,所以我们也在之前的基础上开发了一套。K8s 上的 log采集 方案。主要功能有:
安装日志采集组件
目前,这个采集解决方案已经对外开放。我们提供 Helm 安装包,收录 Logtail 的 DaemonSet、AliyunlogConfig 的 CRD 声明和 CRD Controller。安装后,可以直接使用 DaemonSet 采集 和 CRD 配置。安装方法如下:
当阿里云Kubernetes集群启动时,您可以选择安装它,这样在创建集群时会自动安装上述组件。如果打开的时候没有安装,可以手动安装;如果是自建Kubernetes,无论是在阿里云上自建还是在其他云还是离线,也可以使用这个采集方案,具体安装方法参考自建Kubernetes安装。
上述组件安装完成后,Logtail和对应的Controller就会在集群中运行,但是这些组件默认没有采集任何日志,需要将日志采集规则配置为采集@ > 指定各种日志的Pod。
采集规则配置:环境变量或CRD
除了在日志服务控制台上手动配置外,Kubernetes 还支持另外两种配置方式:环境变量和 CRD。
该方法部署简单,学习成本低,易于使用;但是可以支持的配置规则很少,很多高级配置(如解析方式、过滤方式、黑白名单等)都不支持,而且这种声明方式也不支持修改/删除,每个修改实际上创建了一个新的 采集 配置。历史采集配置需要手动清理,否则会造成资源浪费。
比如下面的例子是部署一个容器的stdout采集,其中定义需要stdout和stderr采集,排除环境变量中收录COLLEXT_STDOUT_FLAG: false的容器。
基于CRD的配置方式以Kubernetes标准扩展资源的方式进行管理,支持配置的完整语义的增删改查,支持各种高级配置。这是我们强烈推荐的 采集 配置方法。
采集推荐的规则配置方式
在实际应用场景中,一般使用 DaemonSet 或者 DaemonSet 和 Sidecar 的混合。DaemonSet 的优点是资源利用率高,但存在一个问题,DaemonSet 的所有 Logtail 共享全局配置,而单个 Logtail 的配置支持有上限。因此,它无法支持具有大量应用程序的集群。
以上是我们给出的推荐配置方式。核心思想是:
练习 1 - 中小型集群
大多数 Kubernetes 集群都是中小型的。中小企业没有明确的定义。一般应用数量小于500,节点规模小于1000。没有功能清晰的Kubernetes平台运维。这个场景的应用数量不是特别多,DaemonSet可以支持所有的采集配置:
练习 2 - 大型集群
对于一些用作PaaS平台的大型/超大型集群,一般业务在1000以上,节点规模也在1000以上,并且有专门的Kubernetes平台运维人员。该场景对应用数量没有限制,DaemonSet无法支持,所以必须使用Sidecar方式。总体规划如下:
有一个阿里团队需要你!
云原生应用平台诚邀Kubernetes/容器/Serverless/应用交付技术领域的专家(P7-P8)加入。
简历投递:xining.zj AT。
“阿里巴巴云原生专注于微服务、Serverless、容器、Service Mesh等技术领域,关注流行的云原生技术趋势,大规模落地云原生实践,是懂云的技术圈——本地开发人员最好。” 查看全部
自动采集编写(
6个K8s日志系统建设中的典型问题,你遇到过几个?)
作者 | 元一阿里云存储服务技术专家
简介:上一篇文章主要介绍了Kubernetes日志输出的一些注意事项。日志输出的最终目的是做统一的采集和分析。在Kubernetes中,记录采集的方式与普通虚拟机有很大不同,相对实现难度和部署成本也略高,但如果使用得当,自动化程度比传统方式高,运维成本更低。本文是日志系列文章的第四篇。
第一篇:《K8s日志系统建设中的6个典型问题,你遇到过几个?》
第二篇:《一篇文章理解K8s日志系统的设计与实践》
第三篇:《解决K8s中日志输出问题的9个技巧》
Kubernetes 日志采集 难点
在 Kubernetes 中,log采集 比传统的虚拟机和物理机要复杂得多。最根本的原因是Kubernetes屏蔽了底层异常,提供了更细粒度的资源调度,向上提供了一个稳定动态的环境。因此,日志采集面临着更丰富、更动态的环境,需要考虑的点也更多。
例如:
Kubernetes 传统方式
日志类型
文件、标准输出、主机文件、日志
档案、日记
日志源
业务容器、系统组件、主机
商务,主持人
采集如何
Agent (Sidecar, DaemonSet), Direct Write (DockerEngine, Business)
代理,直写
独立应用程序的数量
10-100
1-10
应用动态
高的
低的
节点动态
高的
低的
采集部署方式
手动,Yaml
手动, 定制
采集模式:主动或被动
日志采集方法有两种:被动采集和主动推送。在K8s中,被动采集一般分为Sidecar和DaemonSet两种方式。主动推送包括 DockerEngine 推送和业务直推。写两种方式。
总结一下:
各种采集方法的详细对比如下:
DockerEngine 业务直写 DaemonSet 方法 Sidecar 方法
采集日志类型
标准输出
业务日志
标准输出 + 部分文件
文档
部署和维护
低原生支持
低,只维护配置文件
一般需要维护DaemonSet
更高,每个需要采集日志的POD都需要部署一个sidecar容器
日志分类存储
达不到
业务独立配置
一般可以通过容器/路径等方式进行映射。
每个 POD 都可以单独配置以实现高灵活性
多租户隔离
虚弱的
弱,日志直写会和业务逻辑竞争资源
一般只通过配置之间的隔离
强,通过容器隔离,资源可单独分配
支持集群大小
无限本地存储,如果使用syslog和fluentd,会有单点限制
无限
取决于配置的数量
无限
资源占用
低,码头工人
引擎提供
总体最低,节省 采集 开销
较低,每个节点运行一个容器
更高,每个 POD 运行一个容器
查询方便
低,只能grep原创日志
高,可根据业务特点定制
高,可进行自定义查询和统计
高,可根据业务特点定制
可定制性
低的
高,可自由扩展
低的
高,每个 POD 单独配置
耦合
高,强绑定DockerEngine,修改需要重启DockerEngine
高,采集模块修改/升级需要重新发布业务
低,代理可以独立升级
一般Sidecar服务对应的默认采集Agent升级也会重启(有一些扩展包可以支持Sidecar热升级)
适用场景
测试、POC等非生产场景
对性能要求极高的场景
日志分类清晰、功能单一的集群
大型混合 PAAS 集群
日志输出:标准输出或文件
与虚拟机/物理机不同,K8s 容器提供标准输出和文件。在容器中,标准输出直接将日志输出到stdout或stderr,而DockerEngine接管stdout和stderr文件描述符,收到日志后根据DockerEngine配置的LogDriver规则进行处理;日志打印到文件的方式与虚拟机/物理机基本相似,只是日志可以使用不同的存储方式,比如默认存储、EmptyDir、HostVolume、NFS等。
虽然 Docker 官方推荐使用 Stdout 打印日志,但大家需要注意:这个推荐是基于容器仅作为简单应用使用的场景。在实际业务场景中,我们还是建议大家尽量使用文件方式。主要原因有以下几点:
因此,我们建议在线应用使用文件输出日志,而Stdout仅用于功能单一或部分K8s系统/运维组件的应用。
CICD 集成:日志记录操作员
Kubernetes提供了标准化的业务部署方式,可以通过yaml(K8s API)声明路由规则、暴露服务、挂载存储、运行业务、定义伸缩规则等,因此Kubernetes很容易与CICD系统集成。日志采集也是运维监控过程的重要组成部分。必须实时采集业务上线后的所有日志。
原来的方法是在发布后手动部署log采集的逻辑。这种方式需要人工干预,违背了CICD自动化的目的;为了实现自动化,有人开始根据日志打包API/SDK采集发布后通过CICD的webhook调用自动部署的服务,但这种方式开发成本高。
在 Kubernetes 中,集成日志最标准的方式是在 Kubernetes 系统中注册一个新资源,并以 Operator(CRD)的形式对其进行管理和维护。这样CICD系统就不需要额外开发,部署到Kubernetes系统时只需要附加日志相关的配置即可。
Kubernetes 日志采集 方案
早在 Kubernetes 出现之前,我们就开始为容器环境开发 log采集 解决方案。随着K8s的逐渐稳定,我们开始将很多业务迁移到K8s平台上,所以我们也在之前的基础上开发了一套。K8s 上的 log采集 方案。主要功能有:
安装日志采集组件
目前,这个采集解决方案已经对外开放。我们提供 Helm 安装包,收录 Logtail 的 DaemonSet、AliyunlogConfig 的 CRD 声明和 CRD Controller。安装后,可以直接使用 DaemonSet 采集 和 CRD 配置。安装方法如下:
当阿里云Kubernetes集群启动时,您可以选择安装它,这样在创建集群时会自动安装上述组件。如果打开的时候没有安装,可以手动安装;如果是自建Kubernetes,无论是在阿里云上自建还是在其他云还是离线,也可以使用这个采集方案,具体安装方法参考自建Kubernetes安装。
上述组件安装完成后,Logtail和对应的Controller就会在集群中运行,但是这些组件默认没有采集任何日志,需要将日志采集规则配置为采集@ > 指定各种日志的Pod。
采集规则配置:环境变量或CRD
除了在日志服务控制台上手动配置外,Kubernetes 还支持另外两种配置方式:环境变量和 CRD。
该方法部署简单,学习成本低,易于使用;但是可以支持的配置规则很少,很多高级配置(如解析方式、过滤方式、黑白名单等)都不支持,而且这种声明方式也不支持修改/删除,每个修改实际上创建了一个新的 采集 配置。历史采集配置需要手动清理,否则会造成资源浪费。
比如下面的例子是部署一个容器的stdout采集,其中定义需要stdout和stderr采集,排除环境变量中收录COLLEXT_STDOUT_FLAG: false的容器。
基于CRD的配置方式以Kubernetes标准扩展资源的方式进行管理,支持配置的完整语义的增删改查,支持各种高级配置。这是我们强烈推荐的 采集 配置方法。
采集推荐的规则配置方式
在实际应用场景中,一般使用 DaemonSet 或者 DaemonSet 和 Sidecar 的混合。DaemonSet 的优点是资源利用率高,但存在一个问题,DaemonSet 的所有 Logtail 共享全局配置,而单个 Logtail 的配置支持有上限。因此,它无法支持具有大量应用程序的集群。
以上是我们给出的推荐配置方式。核心思想是:
练习 1 - 中小型集群
大多数 Kubernetes 集群都是中小型的。中小企业没有明确的定义。一般应用数量小于500,节点规模小于1000。没有功能清晰的Kubernetes平台运维。这个场景的应用数量不是特别多,DaemonSet可以支持所有的采集配置:
练习 2 - 大型集群
对于一些用作PaaS平台的大型/超大型集群,一般业务在1000以上,节点规模也在1000以上,并且有专门的Kubernetes平台运维人员。该场景对应用数量没有限制,DaemonSet无法支持,所以必须使用Sidecar方式。总体规划如下:
有一个阿里团队需要你!
云原生应用平台诚邀Kubernetes/容器/Serverless/应用交付技术领域的专家(P7-P8)加入。
简历投递:xining.zj AT。
“阿里巴巴云原生专注于微服务、Serverless、容器、Service Mesh等技术领域,关注流行的云原生技术趋势,大规模落地云原生实践,是懂云的技术圈——本地开发人员最好。”
自动采集编写(提下一个牛逼的技巧:独创属性栏文字翻译机制)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-04-04 03:04
一、前言
前面说过,Qt的属性机制太强大了,这次的动态属性功能就是要让它爆炸。很难想象widget->setProperty("value", value) 只需要一行代码就可以完成;没错,就是这么简单,调用弱属性机制,可以直接控制控件中的所有属性,设计这个机制的人绝对是天才,直接跪了。至于具体的底层是如何实现的,这个可以忽略,也没有太多精力去研究Qt的源码。源代码非常大。研究源码最快的方法是直接搜索和定位对应的文件。除了提供文本框输入值来动态改变控件属性,这个设计器还提供了滑块,
这里不得不提下一个牛逼的技巧:QLabel有三种设置文字的方式,掌握Qt的属性系统,从一个案例推断别人,可以做出很多效果。
ui->label->setStyleSheet("qproperty-text:hello;");
ui->label->setProperty("text", "hello");
ui->label->setText("hello");
体验地址:
二、实现的功能自动加载插件文件中的所有控件生成列表,默认内置控件超过120个。拖到画布上自动生成对应的控件,所见即所得你得到。在右侧的中文属性栏中,更改对应的属性立即应用到对应的选中控件,直观简洁,非常适合小白使用。独创的属性栏文本翻译映射机制非常高效,可以很方便的扩展其他语言的属性栏。自动提取所有控件的属性并显示在右侧属性栏上,包括枚举值下拉框。支持手动选择插件文件和外部导入插件文件。当前画布的所有控制配置信息都可以导出为一个xml文件。可以手动选择xml文件打开控件布局,根据xml文件自动加载控件。通过拉动滑块、选中模拟数据复选框并输入文本框,可以通过三种方式生成数据并应用所有控件。该控件支持八个方向的拉动和调整大小,适应任意分辨率,并可微调键盘的上下左右位置。开放了串口采集、网络采集、数据库采集三种方式设置数据。代码非常简洁,注释也很详细。可以作为配置的原型,自行扩展更多功能。用纯 Qt 编写,它支持任何 Qt 版本 + 任何编译器 + 任何系统。三、渲染
四、核心代码
void frmMain::initForm()
{
//初始化中英属性对照表
QtPropertyName::initMap();
//设置没有关闭按钮
ui->dockWidgetControl->setFixedWidth(200);
ui->dockWidgetData->setFixedWidth(200);
ui->dockWidgetProperty->setFixedWidth(220);
ui->dockWidgetControl->setFeatures(QDockWidget::DockWidgetMovable | QDockWidget::DockWidgetFloatable);
ui->dockWidgetProperty->setFeatures(QDockWidget::DockWidgetMovable | QDockWidget::DockWidgetFloatable);
ui->dockWidgetData->setFeatures(QDockWidget::DockWidgetMovable | QDockWidget::DockWidgetFloatable);
this->tabifyDockWidget(ui->dockWidgetControl, ui->dockWidgetData);
ui->dockWidgetControl->raise();
//绑定数据源窗体的数值改变信号
connect(ui->dockWidgetContentsData, SIGNAL(valueChanged(int)), this, SLOT(valueChanged(int)));
//允许拖曳接收
this->setAcceptDrops(true);
bgPix = QPixmap(":/image/bg.png");
//居中显示窗体
int frmX = this->width();
int frmY = this->height();
QDesktopWidget w;
int deskWidth = w.availableGeometry().width();
int deskHeight = w.availableGeometry().height();
QPoint movePoint(deskWidth / 2 - frmX / 2, deskHeight / 2 - frmY / 2);
this->move(movePoint);
//初始化随机数种子
QTime t = QTime::currentTime();
qsrand(t.msec() + t.second() * 1000);
//定时器模拟随机值赋值给控件
timer = new QTimer(this);
connect(timer, SIGNAL(timeout()), this, SLOT(setValue()));
timer->setInterval(2000);
}
void frmMain::setValue()
{
int value = qrand() % 100;
valueChanged(value);
}
void frmMain::valueChanged(int value)
{
QList widgets = ui->centralwidget->findChildren();
foreach (QWidget *widget, widgets) {
widget->setProperty("value", value);
}
}
五、控件介绍 150多个精美控件,涵盖各种仪表板、进度条、进度球、指南针、图形、标尺、温度计、导航条、导航条、flatui、高亮按钮、滑动选择器、农历等。远远超过qwt集成的控件数量。每个类都可以独立成单独的控件,零耦合,每个控件都有头文件和实现文件,不依赖其他文件,方便单个控件以源代码的形式集成到项目中,代码量少。qwt 的控制类是互锁和高度耦合的。如果要使用其中一个控件,则必须收录所有代码。全部纯Qt编写,QWidget+QPainter绘图,支持Qt4.6到Qt<任意Qt版本 @5.12,支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可以直接集成到Qt Creator中,像内置的一样使用在控件中。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。12、支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。12、支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。gcc等编译器,支持windows+linux+Mac+嵌入式linux等任何操作系统,无乱码,可以直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。gcc等编译器,支持windows+linux+Mac+嵌入式linux等任何操作系统,无乱码,可以直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。支持windows+linux+Mac+嵌入式linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。支持windows+linux+Mac+嵌入式linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。没有乱码,可以直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。没有乱码,可以直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。这非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。这非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。
<p>一些控件提供了多种样式可供选择,还有多种指示器样式可供选择。所有控件都适应表格拉伸变化。集成自定义控件属性设计器,支持拖放设计,所见即所得,支持xml格式导入导出。自带activex控件demo,所有控件都可以直接在ie浏览器中运行。整合fontawesome图形字体+阿里巴巴iconfont采集的数百种图形字体,享受图形字体带来的乐趣。所有控件最后生成一个动态库文件(dll左右等),可以直接集成到qtcreator中进行拖拽设计。已经有qml版本,以后会考虑pyqt版本,如果用户需求大的话。自定义控件插件开放使用动态库(永久免费),没有任何后门和限制,请放心使用。目前已经提供了26个版本的dll,包括qt 查看全部
自动采集编写(提下一个牛逼的技巧:独创属性栏文字翻译机制)
一、前言
前面说过,Qt的属性机制太强大了,这次的动态属性功能就是要让它爆炸。很难想象widget->setProperty("value", value) 只需要一行代码就可以完成;没错,就是这么简单,调用弱属性机制,可以直接控制控件中的所有属性,设计这个机制的人绝对是天才,直接跪了。至于具体的底层是如何实现的,这个可以忽略,也没有太多精力去研究Qt的源码。源代码非常大。研究源码最快的方法是直接搜索和定位对应的文件。除了提供文本框输入值来动态改变控件属性,这个设计器还提供了滑块,
这里不得不提下一个牛逼的技巧:QLabel有三种设置文字的方式,掌握Qt的属性系统,从一个案例推断别人,可以做出很多效果。
ui->label->setStyleSheet("qproperty-text:hello;");
ui->label->setProperty("text", "hello");
ui->label->setText("hello");
体验地址:
二、实现的功能自动加载插件文件中的所有控件生成列表,默认内置控件超过120个。拖到画布上自动生成对应的控件,所见即所得你得到。在右侧的中文属性栏中,更改对应的属性立即应用到对应的选中控件,直观简洁,非常适合小白使用。独创的属性栏文本翻译映射机制非常高效,可以很方便的扩展其他语言的属性栏。自动提取所有控件的属性并显示在右侧属性栏上,包括枚举值下拉框。支持手动选择插件文件和外部导入插件文件。当前画布的所有控制配置信息都可以导出为一个xml文件。可以手动选择xml文件打开控件布局,根据xml文件自动加载控件。通过拉动滑块、选中模拟数据复选框并输入文本框,可以通过三种方式生成数据并应用所有控件。该控件支持八个方向的拉动和调整大小,适应任意分辨率,并可微调键盘的上下左右位置。开放了串口采集、网络采集、数据库采集三种方式设置数据。代码非常简洁,注释也很详细。可以作为配置的原型,自行扩展更多功能。用纯 Qt 编写,它支持任何 Qt 版本 + 任何编译器 + 任何系统。三、渲染
四、核心代码
void frmMain::initForm()
{
//初始化中英属性对照表
QtPropertyName::initMap();
//设置没有关闭按钮
ui->dockWidgetControl->setFixedWidth(200);
ui->dockWidgetData->setFixedWidth(200);
ui->dockWidgetProperty->setFixedWidth(220);
ui->dockWidgetControl->setFeatures(QDockWidget::DockWidgetMovable | QDockWidget::DockWidgetFloatable);
ui->dockWidgetProperty->setFeatures(QDockWidget::DockWidgetMovable | QDockWidget::DockWidgetFloatable);
ui->dockWidgetData->setFeatures(QDockWidget::DockWidgetMovable | QDockWidget::DockWidgetFloatable);
this->tabifyDockWidget(ui->dockWidgetControl, ui->dockWidgetData);
ui->dockWidgetControl->raise();
//绑定数据源窗体的数值改变信号
connect(ui->dockWidgetContentsData, SIGNAL(valueChanged(int)), this, SLOT(valueChanged(int)));
//允许拖曳接收
this->setAcceptDrops(true);
bgPix = QPixmap(":/image/bg.png");
//居中显示窗体
int frmX = this->width();
int frmY = this->height();
QDesktopWidget w;
int deskWidth = w.availableGeometry().width();
int deskHeight = w.availableGeometry().height();
QPoint movePoint(deskWidth / 2 - frmX / 2, deskHeight / 2 - frmY / 2);
this->move(movePoint);
//初始化随机数种子
QTime t = QTime::currentTime();
qsrand(t.msec() + t.second() * 1000);
//定时器模拟随机值赋值给控件
timer = new QTimer(this);
connect(timer, SIGNAL(timeout()), this, SLOT(setValue()));
timer->setInterval(2000);
}
void frmMain::setValue()
{
int value = qrand() % 100;
valueChanged(value);
}
void frmMain::valueChanged(int value)
{
QList widgets = ui->centralwidget->findChildren();
foreach (QWidget *widget, widgets) {
widget->setProperty("value", value);
}
}
五、控件介绍 150多个精美控件,涵盖各种仪表板、进度条、进度球、指南针、图形、标尺、温度计、导航条、导航条、flatui、高亮按钮、滑动选择器、农历等。远远超过qwt集成的控件数量。每个类都可以独立成单独的控件,零耦合,每个控件都有头文件和实现文件,不依赖其他文件,方便单个控件以源代码的形式集成到项目中,代码量少。qwt 的控制类是互锁和高度耦合的。如果要使用其中一个控件,则必须收录所有代码。全部纯Qt编写,QWidget+QPainter绘图,支持Qt4.6到Qt<任意Qt版本 @5.12,支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可以直接集成到Qt Creator中,像内置的一样使用在控件中。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。12、支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。12、支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。支持mingw、msvc、gcc等编译器,支持windows+linux+Mac+embedded linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。gcc等编译器,支持windows+linux+Mac+嵌入式linux等任何操作系统,无乱码,可以直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。gcc等编译器,支持windows+linux+Mac+嵌入式linux等任何操作系统,无乱码,可以直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。支持windows+linux+Mac+嵌入式linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。支持windows+linux+Mac+嵌入式linux等任意操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。没有乱码,可以直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。没有乱码,可以直接集成到Qt Creator中,像内置控件一样使用。大多数效果只需要设置几个属性,非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。这非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。这非常方便。每个控件都有对应的单独的DEMO收录控件的源代码,方便参考和使用。它还提供了一个集成的 DEMO,供所有控件使用。每个控件的源码都有详细的中文注释,按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认颜色和demo对应的颜色都非常漂亮。超过 130 个可见控件,6 个不可见控件。
<p>一些控件提供了多种样式可供选择,还有多种指示器样式可供选择。所有控件都适应表格拉伸变化。集成自定义控件属性设计器,支持拖放设计,所见即所得,支持xml格式导入导出。自带activex控件demo,所有控件都可以直接在ie浏览器中运行。整合fontawesome图形字体+阿里巴巴iconfont采集的数百种图形字体,享受图形字体带来的乐趣。所有控件最后生成一个动态库文件(dll左右等),可以直接集成到qtcreator中进行拖拽设计。已经有qml版本,以后会考虑pyqt版本,如果用户需求大的话。自定义控件插件开放使用动态库(永久免费),没有任何后门和限制,请放心使用。目前已经提供了26个版本的dll,包括qt
自动采集编写(SQLE的Java应用零成本地接入了SQLE(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-03-30 15:01
* 爱客盛开源社区出品,原创内容未经授权不得使用。如需转载,请联系编辑并注明出处。
一. SQLE 简介
SQLE是艾克森开源社区发起的一个面向数据库开发和管理人员的项目。实现SQL“开发”-“测试”-“上线”的全流程覆盖,对资源和权限进行精细化管理,兼顾简洁和高效。,一个易于维护和扩展的开源项目,旨在为用户提供一套安全、可靠、自控的SQL质量控制解决方案。
在 1.2202.0 的 2 月版本中:
更多详细信息可在以下位置找到: 。
二.Java 应用程序审计简介
考虑到很多用户在实际生产中部署了大量基于Java的应用和服务,有的涉及到极其重要且不间断的核心业务。从 1.2202.0 版本开始,SQLE 支持 Java 应用程序的 SQL 审计。并且在完成核心功能的基础上,支持零成本接入Java应用。
SQLE的Java审计特性如下:
三.效果展示了预部署的环境,需要连接的Java应用,以及对应的数据库,并添加为数据源。为了演示,这里的 Java 项目是;为 Java 应用程序创建审计任务;
启动应用程序;
SQLE_COLLECT_ENABLE=true \SQLE_HOST=XX.XX.XX.XX:10000 \
SQLE_TASK_NAME=surveryking_test \
SQLE_TASK_TOKEN=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJhcG4iOiJqd19hcHAiLCJleHAiOjE2NzcyMjYxNzcsIm5hbWUiOiJhZG1pbiJ9.3d0pA1hiVnFEWJokSFBwCT8d1pKOYV6SViENj4GFqgI \
java -jar surveyking-v0.3.0-beta.4.jar \
--server.port=1991 \
--spring.datasource.url=jdbc:mysql://XX.XX.XX.XX:3306/surveyking \
--spring.datasource.username=root \
--spring.datasource.password=xxxxxx \
& >>/opt/surveyking/std.log
查看SQLE审计任务详情界面,可以看到当前应用已经执行的SQL;
查看审计报告,用户可以通过审计任务的审计报告了解应用的SQL是否符合预设的审计规则,从而及时做出调整。
在样例Java应用首页创建用户,然后可以观察到审计任务对应的SQLE语句池中对应的INSERT语句。
同时,用户可以从语句池中的页面快速感知应用程序中执行的SQL的语句分类和统计。
结合上述示例步骤,Java 应用程序可以零成本访问 SQLE。开发者和DBA可以通过“审计报告”、“审计任务SQL语句池”等功能全面掌握应用中的SQL审计结果、执行状态和统计信息,完成从“开发”到“上线”的过程。SQL 质量控制。
如果您想了解更多关于SQLE的更多功能和特性,请访问以下地址:
TypeAddressRepository 文档发布信息 查看全部
自动采集编写(SQLE的Java应用零成本地接入了SQLE(组图))
* 爱客盛开源社区出品,原创内容未经授权不得使用。如需转载,请联系编辑并注明出处。
一. SQLE 简介
SQLE是艾克森开源社区发起的一个面向数据库开发和管理人员的项目。实现SQL“开发”-“测试”-“上线”的全流程覆盖,对资源和权限进行精细化管理,兼顾简洁和高效。,一个易于维护和扩展的开源项目,旨在为用户提供一套安全、可靠、自控的SQL质量控制解决方案。
在 1.2202.0 的 2 月版本中:
更多详细信息可在以下位置找到: 。
二.Java 应用程序审计简介
考虑到很多用户在实际生产中部署了大量基于Java的应用和服务,有的涉及到极其重要且不间断的核心业务。从 1.2202.0 版本开始,SQLE 支持 Java 应用程序的 SQL 审计。并且在完成核心功能的基础上,支持零成本接入Java应用。
SQLE的Java审计特性如下:
三.效果展示了预部署的环境,需要连接的Java应用,以及对应的数据库,并添加为数据源。为了演示,这里的 Java 项目是;为 Java 应用程序创建审计任务;
启动应用程序;
SQLE_COLLECT_ENABLE=true \SQLE_HOST=XX.XX.XX.XX:10000 \
SQLE_TASK_NAME=surveryking_test \
SQLE_TASK_TOKEN=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJhcG4iOiJqd19hcHAiLCJleHAiOjE2NzcyMjYxNzcsIm5hbWUiOiJhZG1pbiJ9.3d0pA1hiVnFEWJokSFBwCT8d1pKOYV6SViENj4GFqgI \
java -jar surveyking-v0.3.0-beta.4.jar \
--server.port=1991 \
--spring.datasource.url=jdbc:mysql://XX.XX.XX.XX:3306/surveyking \
--spring.datasource.username=root \
--spring.datasource.password=xxxxxx \
& >>/opt/surveyking/std.log
查看SQLE审计任务详情界面,可以看到当前应用已经执行的SQL;
查看审计报告,用户可以通过审计任务的审计报告了解应用的SQL是否符合预设的审计规则,从而及时做出调整。
在样例Java应用首页创建用户,然后可以观察到审计任务对应的SQLE语句池中对应的INSERT语句。
同时,用户可以从语句池中的页面快速感知应用程序中执行的SQL的语句分类和统计。
结合上述示例步骤,Java 应用程序可以零成本访问 SQLE。开发者和DBA可以通过“审计报告”、“审计任务SQL语句池”等功能全面掌握应用中的SQL审计结果、执行状态和统计信息,完成从“开发”到“上线”的过程。SQL 质量控制。
如果您想了解更多关于SQLE的更多功能和特性,请访问以下地址:
TypeAddressRepository 文档发布信息
自动采集编写(自动采集编写autohotkey脚本的语法特性是什么?分两步走)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-03-27 20:01
自动采集编写autohotkey脚本的问题,我觉得只要程序开发者把autohotkey语言特性搞清楚了,那自动机基本就入门了。分两步走。一步是分析autohotkey脚本的语法特性,着重研究如何简化过程。autohotkey内置了大量的编程技巧,阅读autohotkey脚本可以帮助我们快速获得大量工具方法,完成编程技巧。
这个其实很简单,看visualstudio的帮助文档就可以了。另一步是训练自己的编程思路,这部分需要大量的实践才能在编程当中有所体会。这个就难了,刚开始自己写一个自动机的时候感觉很差,很多时候是写着写着就不想写了,做着做着又不想继续写了。我也是受挫的最高记录大概是写了两天半的autohotkey脚本,在这些autohotkey脚本之中有很多单纯靠体力的写法,有的是依靠编程语言特性搭建的轮子,还有的是自己造的轮子。
各种高级工具方法不说了,非常多,有很多工具方法是其它编程语言调用系统提供的库或者是其它autohotkey编译器不能提供的。比如很多工具方法都能够整合在hadoop里。一旦养成了思考编程逻辑的习惯,编程思路立刻就打开了。其实新手一般面临问题都是没有思路的,平时大家都这么自己养成习惯。另外一个非常重要的问题就是看项目类型。
不同的项目类型训练的深度是不一样的。比如刚开始训练控制机器人的时候,训练一个新的编程语言或许比读一些经典的控制语言教程更加有帮助。 查看全部
自动采集编写(自动采集编写autohotkey脚本的语法特性是什么?分两步走)
自动采集编写autohotkey脚本的问题,我觉得只要程序开发者把autohotkey语言特性搞清楚了,那自动机基本就入门了。分两步走。一步是分析autohotkey脚本的语法特性,着重研究如何简化过程。autohotkey内置了大量的编程技巧,阅读autohotkey脚本可以帮助我们快速获得大量工具方法,完成编程技巧。
这个其实很简单,看visualstudio的帮助文档就可以了。另一步是训练自己的编程思路,这部分需要大量的实践才能在编程当中有所体会。这个就难了,刚开始自己写一个自动机的时候感觉很差,很多时候是写着写着就不想写了,做着做着又不想继续写了。我也是受挫的最高记录大概是写了两天半的autohotkey脚本,在这些autohotkey脚本之中有很多单纯靠体力的写法,有的是依靠编程语言特性搭建的轮子,还有的是自己造的轮子。
各种高级工具方法不说了,非常多,有很多工具方法是其它编程语言调用系统提供的库或者是其它autohotkey编译器不能提供的。比如很多工具方法都能够整合在hadoop里。一旦养成了思考编程逻辑的习惯,编程思路立刻就打开了。其实新手一般面临问题都是没有思路的,平时大家都这么自己养成习惯。另外一个非常重要的问题就是看项目类型。
不同的项目类型训练的深度是不一样的。比如刚开始训练控制机器人的时候,训练一个新的编程语言或许比读一些经典的控制语言教程更加有帮助。
自动采集编写(自动采集编写爬虫程序--小说类最简单的一个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-03-27 08:03
自动采集编写爬虫程序--小说类最简单的一个,直接通过爬虫抓取论坛连载小说就可以了。首先登录kindle然后设置。登录kindle后,选择连载列表上方红色框标注的按钮,点击后页面会打开,点击“查看文档”,在跳转的网站就可以进行采集了。首先找到论坛版块然后进入,采集评论现在该文章不仅仅有评论,还有精选的小说模板,也是非常的全的。
一般登录后都会推荐论坛模板,你可以采集出来,到时候进行爬取。pptv和爱奇艺是主要的评论来源。你可以登录应用商店,搜索“百度文库”等等评论资源。希望能帮到你。
--首先你需要按我步骤设置,根据步骤,第一步你需要先登录网站kindle商店连接:。第二步进入到它的论坛文库页面。第三步,进入kindle的论坛,打开小说类目,然后打开文档。第四步,直接找到你想要下载的小说,点击,找到那个下载框,如下图所示:在下载框的上方有标注的一栏,点击那个下载,直接按照步骤走,在下载的界面会弹出来一个页面,点击下载即可,不用管那个下载是不是有点中的问题。第五步,下载成功,最后,点击左上角,退出该页面,就在我的电脑里看见了你下载的小说了。 查看全部
自动采集编写(自动采集编写爬虫程序--小说类最简单的一个)
自动采集编写爬虫程序--小说类最简单的一个,直接通过爬虫抓取论坛连载小说就可以了。首先登录kindle然后设置。登录kindle后,选择连载列表上方红色框标注的按钮,点击后页面会打开,点击“查看文档”,在跳转的网站就可以进行采集了。首先找到论坛版块然后进入,采集评论现在该文章不仅仅有评论,还有精选的小说模板,也是非常的全的。
一般登录后都会推荐论坛模板,你可以采集出来,到时候进行爬取。pptv和爱奇艺是主要的评论来源。你可以登录应用商店,搜索“百度文库”等等评论资源。希望能帮到你。
--首先你需要按我步骤设置,根据步骤,第一步你需要先登录网站kindle商店连接:。第二步进入到它的论坛文库页面。第三步,进入kindle的论坛,打开小说类目,然后打开文档。第四步,直接找到你想要下载的小说,点击,找到那个下载框,如下图所示:在下载框的上方有标注的一栏,点击那个下载,直接按照步骤走,在下载的界面会弹出来一个页面,点击下载即可,不用管那个下载是不是有点中的问题。第五步,下载成功,最后,点击左上角,退出该页面,就在我的电脑里看见了你下载的小说了。

