
自动采集编写
Wordpress自动采集plugin_wp-autopost-pro 3.7.8
采集交流 • 优采云 发表了文章 • 0 个评论 • 380 次浏览 • 2020-08-09 05:45
WordPress自动采集插件
插件简介:
该插件是wp-autopost-pro 3.7.8的最新版本.
集合插件的适用对象
1. 新建的wordpress网站的内容相对较小,希望尽快拥有更丰富的内容;
2. 热门内容将自动采集并自动发布;
3. 定时采集,手动采集并发布或保存为草稿;
4,css样式规则,可以更准确地采集所需的内容.
5. 通过代理IP进行伪原创和翻译,采集和存储cookie记录;
6,可以将内容采集到自定义列
对Google神经网络翻译的新支持,youdao神经网络翻译,轻松访问高质量的原创文章
对市场上所有主流对象存储服务,秦牛云,阿里云OSS等的全面支持.
可以采集微信公众号,头条新闻和其他自媒体内容. 由于百度不收录官方帐户,头条新闻等,因此您可以轻松获得高质量的“原创”文章,从而增加了百度的收录量和网站权重
可以采集任何网站的内容,采集的信息一目了然
通过简单的设置,可以采集来自任何网站的内容,并且可以将多个采集任务设置为同时运行. 可以将任务设置为自动或手动运行. 主任务列表显示每个采集任务的状态: 上次检测采集时间,下一次检测的估计采集时间,最新采集的文章,已采集和更新的文章数以及其他易于查看和查看的信息. 管理.
文章管理功能方便查询,搜索和删除采集的文章. 改进的算法从根本上消除了同一文章的重复采集. 日志功能记录采集过程中的异常和抓取错误,便于检查和设置维修错误.
增强seo功能,其他自学. 查看全部
详细介绍

WordPress自动采集插件
插件简介:
该插件是wp-autopost-pro 3.7.8的最新版本.
集合插件的适用对象
1. 新建的wordpress网站的内容相对较小,希望尽快拥有更丰富的内容;
2. 热门内容将自动采集并自动发布;
3. 定时采集,手动采集并发布或保存为草稿;
4,css样式规则,可以更准确地采集所需的内容.
5. 通过代理IP进行伪原创和翻译,采集和存储cookie记录;
6,可以将内容采集到自定义列
对Google神经网络翻译的新支持,youdao神经网络翻译,轻松访问高质量的原创文章
对市场上所有主流对象存储服务,秦牛云,阿里云OSS等的全面支持.
可以采集微信公众号,头条新闻和其他自媒体内容. 由于百度不收录官方帐户,头条新闻等,因此您可以轻松获得高质量的“原创”文章,从而增加了百度的收录量和网站权重
可以采集任何网站的内容,采集的信息一目了然
通过简单的设置,可以采集来自任何网站的内容,并且可以将多个采集任务设置为同时运行. 可以将任务设置为自动或手动运行. 主任务列表显示每个采集任务的状态: 上次检测采集时间,下一次检测的估计采集时间,最新采集的文章,已采集和更新的文章数以及其他易于查看和查看的信息. 管理.
文章管理功能方便查询,搜索和删除采集的文章. 改进的算法从根本上消除了同一文章的重复采集. 日志功能记录采集过程中的异常和抓取错误,便于检查和设置维修错误.
增强seo功能,其他自学.
分享] Empire CMS自动采集发布时间表
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-09 04:52
1. 触发代码时,请添加密码. 例如,我的触发方法是借用自动获取和触发的第一点,并且还使用计划任务进行触发. 在e / tasks /下创建一个文件,然后在触发代码上写入以触发此审阅代码,然后使用计划的任务进行触发.
2. 如果有很多列,则列出200或300,在老北那代码中,请使用基于时间的查看,否则负载会有点高. (时分代码在老贝的代码中,但这只是一个注释. 此外,它可以分为三个以上的时间段. 我要做的是每小时查看几列. 无论如何,您可以根据到您这样的列数,例如我. 大约有240列,我将设置为每小时查看和更新十列),我将分享在各节中查看的代码:
我尝试过. 我保持后端. 太好了,无法安全传播. 另外,网页上的cookie将变为无效. 您应过一会再登录. 在这里,我想到了另一种自动刷新此“计划任务页面”以保持其cookie有效的方法.
根据此方法,因为引用了刷新页面,并且刷新页面位于后台,所以存在登录问题. 有时VPS出现问题,重新启动或出现某种情况,如何构建网站,则必须重新登录此页面. 这比较麻烦. 有时候我几天没来过,但是几天没来过. 我想知道您是否可以帮助我想办法. 或者可以在页面上预先分配用户名和密码,只要打开页面即可直接采集,在这种情况下,无需登录. 我可以在VPS中进行设置. 如果我重新启动,它将自动打开此页面以实现采集. 查看全部
首先,这是我与Empire CMS的第一次接触,对于程序开发,我是一个外行. 我只是一个用户(垃圾站). 我以前一直使用DEDECMS +采集英雄,但是这是在编织之间. 做梦时,处理数百万个或更多数据时负载确实很高,所以我想使用Empire CMS尝试作为垃圾站. 每个人都知道,成为垃圾站并不像成为常规站. 它是手动更新的. 垃圾站越自动化,越好. 最好不要由人来管理. 这是我研究的方向,好吧,废话少说.
1. 触发代码时,请添加密码. 例如,我的触发方法是借用自动获取和触发的第一点,并且还使用计划任务进行触发. 在e / tasks /下创建一个文件,然后在触发代码上写入以触发此审阅代码,然后使用计划的任务进行触发.

2. 如果有很多列,则列出200或300,在老北那代码中,请使用基于时间的查看,否则负载会有点高. (时分代码在老贝的代码中,但这只是一个注释. 此外,它可以分为三个以上的时间段. 我要做的是每小时查看几列. 无论如何,您可以根据到您这样的列数,例如我. 大约有240列,我将设置为每小时查看和更新十列),我将分享在各节中查看的代码:
我尝试过. 我保持后端. 太好了,无法安全传播. 另外,网页上的cookie将变为无效. 您应过一会再登录. 在这里,我想到了另一种自动刷新此“计划任务页面”以保持其cookie有效的方法.
根据此方法,因为引用了刷新页面,并且刷新页面位于后台,所以存在登录问题. 有时VPS出现问题,重新启动或出现某种情况,如何构建网站,则必须重新登录此页面. 这比较麻烦. 有时候我几天没来过,但是几天没来过. 我想知道您是否可以帮助我想办法. 或者可以在页面上预先分配用户名和密码,只要打开页面即可直接采集,在这种情况下,无需登录. 我可以在VPS中进行设置. 如果我重新启动,它将自动打开此页面以实现采集.
Js嵌入网页的点码以实现数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 546 次浏览 • 2020-08-08 18:44
概述: 分析网页上嵌入点的重要性
网站流量统计分析可以帮助网站管理员,运营商,发起人等获取实时网站流量信息,并提供来自流量来源,网站内容和网站访问者特征等各个方面的网站分析数据. 根据. 为了帮助增加网站流量,改善网站用户体验优化,允许更多访问者成为会员或客户,并通过减少投资获得最大收益.
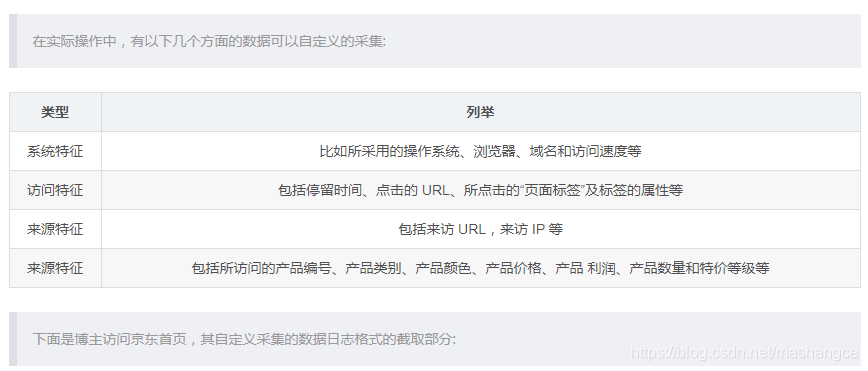
访问日志指的是用户访问网站时的所有访问,浏览和单击行为数据. 例如,单击了哪个链接,例如常见的微信副本统计信息,页面访问者分析等,打开了哪个页面,复制了哪个微信帐户,使用了哪个搜索项目以及整个会话时间. 所有这些信息都可以通过网站日志保存. 通过分析这些数据,我们可以了解有关网站运营的许多重要信息. 采集的数据越全面,分析就越准确. 参考来源:
网页隐藏点
标题
首先,需要在网页的前端页面中加载ma.js的脚本代码
var _maq = _maq || [];
_maq.push(['_setAccount', 'zaomianbao']);
(function() {
var ma = document.createElement('script');
ma.type = 'text/javascript';
ma.async = true;
ma.src = 'http://vtongji.gam7.com/ma.js';
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore(ma, s);
})();
二,将前端代码放在后台
(function () {
var params = {};
//Document对象数据
if(document) {
params.domain = document.domain || '';
params.url = document.URL || '';
params.title = document.title || '';
params.referrer = document.referrer || '';
}
//Window对象数据
if(window && window.screen) {
params.sh = window.screen.height || 0;
params.sw = window.screen.width || 0;
params.cd = window.screen.colorDepth || 0;
}
//navigator对象数据
if(navigator) {
params.lang = navigator.language || '';
}
//解析_maq配置
if(_maq) {
for(var i in _maq) {
switch(_maq[i][0]) {
case '_setAccount':
params.account = _maq[i][1];
break;
default:
break;
}
}
}
//拼接参数串
var args = '';
for(var i in params) {
if(args != '') {
args += '&';
}
args += i + '=' + encodeURIComponent(params[i]);
}
//通过Image对象请求后端脚本
var img = new Image(1, 1);
img.src = 'http://vtongji.ibixue.com/log.gif?' + args;
})();
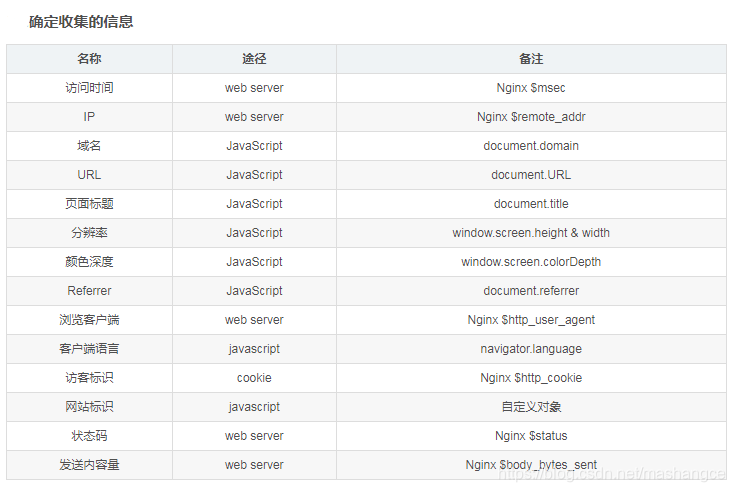
三,后端配置,配置nginx服务器日志格式
worker_processes 2;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
log_format user_log_format "$msec||$remote_addr||$status||$body_bytes_sent||$u_domain||$u_url||$u_title||$u_referrer||$u_sh||$u_sw||$u_cd||$u_lang||$http_user_agent||$u_account";
sendfile on; #允许sendfile方式传输文件,默认为off
keepalive_timeout 65; #连接超时时间,默认为75s
server {
listen 80;
server_name localhost;
location /log.gif {
#伪装成gif文件
default_type image/gif;
#nginx本身记录的access_log,日志格式为main
access_log logs/access.log main;
access_by_lua "
-- 用户跟踪cookie名为__utrace
local uid = ngx.var.cookie___utrace
if not uid then
-- 如果没有则生成一个跟踪cookie,算法为md5(时间戳+IP+客户端信息)
uid = ngx.md5(ngx.now() .. ngx.var.remote_addr .. ngx.var.http_user_agent)
end
ngx.header['Set-Cookie'] = {'__utrace=' .. uid .. '; path=/'}
if ngx.var.arg_domain then
-- 通过subrequest到/i-log记录日志,将参数和用户跟踪cookie带过去
ngx.location.capture('/i-log?' .. ngx.var.args .. '&utrace=' .. uid)
end
";
#此请求资源本地不缓存
add_header Expires "Fri, 01 Jan 1980 00:00:00 GMT";
add_header Pragma "no-cache";
add_header Cache-Control "no-cache, max-age=0, must-revalidate";
#返回一个1×1的空gif图片
empty_gif;
}
location /i-log {
#内部location,不允许外部直接访问
internal;
#设置变量,注意需要unescape
set_unescape_uri $u_domain $arg_domain;
set_unescape_uri $u_url $arg_url;
set_unescape_uri $u_title $arg_title;
set_unescape_uri $u_referrer $arg_referrer;
set_unescape_uri $u_sh $arg_sh;
set_unescape_uri $u_sw $arg_sw;
set_unescape_uri $u_cd $arg_cd;
set_unescape_uri $u_lang $arg_lang;
set_unescape_uri $u_account $arg_account;
#打开subrequest(子请求)日志
log_subrequest on;
#自定义采集的日志,记录数据到user_defined.log
access_log logs/user_defined.log user_log_format;
#输出空字符串
echo '';
}
}
}
四: 编写index.html
测试埋点
var _maq = _maq || [];
_maq.push(['_setAccount', 'zaomianbao']);
(function() {
var ma = document.createElement('script');
ma.type = 'text/javascript';
ma.async = true;
ma.src = 'http://yishengjun.gookang.com/ma.js';
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore(ma, s);
})();
测试埋点
五,背景nginx环境构建和参考资料
web点数据采集后台配置nginx:
https://blog.csdn.net/weixin_3 ... 94827
下载数据源:
wget -O lua-nginx-module-0.10.0.tar.gz https://github.com/openresty/l ... ar.gz
wget --no-check-certificate -Oecho-nginx-module-0.58.tar.gz 'https://github.com/openresty/echo-nginx-module/archive/v0.58.tar.gz'
wget --no-check-certificate -O nginx_devel_kit-0.2.19.tar.gz https://github.com/simpl/ngx_d ... ar.gz
wget https://openresty.org/download ... ar.gz
wget --no-check-certificate -Oset-misc-nginx-module-0.29.tar.gz 'https://github.com/openresty/set-misc-nginx-module/archive/v0.29.tar.gz'
VI. 参考资料: 查看全部
内容
概述: 分析网页上嵌入点的重要性
网站流量统计分析可以帮助网站管理员,运营商,发起人等获取实时网站流量信息,并提供来自流量来源,网站内容和网站访问者特征等各个方面的网站分析数据. 根据. 为了帮助增加网站流量,改善网站用户体验优化,允许更多访问者成为会员或客户,并通过减少投资获得最大收益.
访问日志指的是用户访问网站时的所有访问,浏览和单击行为数据. 例如,单击了哪个链接,例如常见的微信副本统计信息,页面访问者分析等,打开了哪个页面,复制了哪个微信帐户,使用了哪个搜索项目以及整个会话时间. 所有这些信息都可以通过网站日志保存. 通过分析这些数据,我们可以了解有关网站运营的许多重要信息. 采集的数据越全面,分析就越准确. 参考来源:
网页隐藏点
标题
首先,需要在网页的前端页面中加载ma.js的脚本代码
var _maq = _maq || [];
_maq.push(['_setAccount', 'zaomianbao']);
(function() {
var ma = document.createElement('script');
ma.type = 'text/javascript';
ma.async = true;
ma.src = 'http://vtongji.gam7.com/ma.js';
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore(ma, s);
})();
二,将前端代码放在后台
(function () {
var params = {};
//Document对象数据
if(document) {
params.domain = document.domain || '';
params.url = document.URL || '';
params.title = document.title || '';
params.referrer = document.referrer || '';
}
//Window对象数据
if(window && window.screen) {
params.sh = window.screen.height || 0;
params.sw = window.screen.width || 0;
params.cd = window.screen.colorDepth || 0;
}
//navigator对象数据
if(navigator) {
params.lang = navigator.language || '';
}
//解析_maq配置
if(_maq) {
for(var i in _maq) {
switch(_maq[i][0]) {
case '_setAccount':
params.account = _maq[i][1];
break;
default:
break;
}
}
}
//拼接参数串
var args = '';
for(var i in params) {
if(args != '') {
args += '&';
}
args += i + '=' + encodeURIComponent(params[i]);
}
//通过Image对象请求后端脚本
var img = new Image(1, 1);
img.src = 'http://vtongji.ibixue.com/log.gif?' + args;
})();
三,后端配置,配置nginx服务器日志格式
worker_processes 2;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
log_format user_log_format "$msec||$remote_addr||$status||$body_bytes_sent||$u_domain||$u_url||$u_title||$u_referrer||$u_sh||$u_sw||$u_cd||$u_lang||$http_user_agent||$u_account";
sendfile on; #允许sendfile方式传输文件,默认为off
keepalive_timeout 65; #连接超时时间,默认为75s
server {
listen 80;
server_name localhost;
location /log.gif {
#伪装成gif文件
default_type image/gif;
#nginx本身记录的access_log,日志格式为main
access_log logs/access.log main;
access_by_lua "
-- 用户跟踪cookie名为__utrace
local uid = ngx.var.cookie___utrace
if not uid then
-- 如果没有则生成一个跟踪cookie,算法为md5(时间戳+IP+客户端信息)
uid = ngx.md5(ngx.now() .. ngx.var.remote_addr .. ngx.var.http_user_agent)
end
ngx.header['Set-Cookie'] = {'__utrace=' .. uid .. '; path=/'}
if ngx.var.arg_domain then
-- 通过subrequest到/i-log记录日志,将参数和用户跟踪cookie带过去
ngx.location.capture('/i-log?' .. ngx.var.args .. '&utrace=' .. uid)
end
";
#此请求资源本地不缓存
add_header Expires "Fri, 01 Jan 1980 00:00:00 GMT";
add_header Pragma "no-cache";
add_header Cache-Control "no-cache, max-age=0, must-revalidate";
#返回一个1×1的空gif图片
empty_gif;
}
location /i-log {
#内部location,不允许外部直接访问
internal;
#设置变量,注意需要unescape
set_unescape_uri $u_domain $arg_domain;
set_unescape_uri $u_url $arg_url;
set_unescape_uri $u_title $arg_title;
set_unescape_uri $u_referrer $arg_referrer;
set_unescape_uri $u_sh $arg_sh;
set_unescape_uri $u_sw $arg_sw;
set_unescape_uri $u_cd $arg_cd;
set_unescape_uri $u_lang $arg_lang;
set_unescape_uri $u_account $arg_account;
#打开subrequest(子请求)日志
log_subrequest on;
#自定义采集的日志,记录数据到user_defined.log
access_log logs/user_defined.log user_log_format;
#输出空字符串
echo '';
}
}
}
四: 编写index.html
测试埋点
var _maq = _maq || [];
_maq.push(['_setAccount', 'zaomianbao']);
(function() {
var ma = document.createElement('script');
ma.type = 'text/javascript';
ma.async = true;
ma.src = 'http://yishengjun.gookang.com/ma.js';
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore(ma, s);
})();
测试埋点
五,背景nginx环境构建和参考资料
web点数据采集后台配置nginx:
https://blog.csdn.net/weixin_3 ... 94827
下载数据源:
wget -O lua-nginx-module-0.10.0.tar.gz https://github.com/openresty/l ... ar.gz
wget --no-check-certificate -Oecho-nginx-module-0.58.tar.gz 'https://github.com/openresty/echo-nginx-module/archive/v0.58.tar.gz'
wget --no-check-certificate -O nginx_devel_kit-0.2.19.tar.gz https://github.com/simpl/ngx_d ... ar.gz
wget https://openresty.org/download ... ar.gz
wget --no-check-certificate -Oset-misc-nginx-module-0.29.tar.gz 'https://github.com/openresty/set-misc-nginx-module/archive/v0.29.tar.gz'
VI. 参考资料:
Nodejs学习笔记(11)
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2020-08-08 17:04
许多人需要数据采集,这可以用不同的语言和不同的方式来实现. 我以前也用C#编写过它. 发送各种请求和定期分析数据主要比较麻烦. 总的来说,没有什么不好,但是效率更差,
使用nodejs(可能仅相对于C#)编写采集程序效率更高. 今天,我将主要使用一个示例来说明如何使用nodejs来实现数据采集器,主要是使用request和cheerio.
请求: 用于http请求
cheerio: 用于提取请求返回的html中所需的信息(与jquery的用法一致)
示例
仅讲API使用并不有趣,也无需记住所有API. 让我们开始一个例子.
说些八卦:
仍然有许多nodejs开发工具. 我还建议崇高. 自从Microsoft启动Visual Studio Code之后,我便转向了nodejs开发.
使用它进行开发比较舒适,无需配置,快速启动,自动完成,视图定义和引用,快速搜索等,并且具有一致的VS风格,因此它应该越来越好,所以我建议^ _ ^!
样品要求
在其中获取文章的“标题”,“地址”,“发布时间”和“封面图片”
采集器
1. 创建项目文件夹sampleDAU
2. 创建package.json文件
{
"name": "Wilson_SampleDAU",
"version": "0.0.1",
"private": false,
"dependencies": {
"request":"*",
"cheerio":"*"
}
}
3. 使用npm在终端中安装参考
cd 项目根目录
npm install
4. 构建app.js并编写采集器代码
首先,使用浏览器打开要采集的URL,使用开发人员工具查看HTML结构,然后根据该结构编写解析代码
/*
* 功能: 数据采集
* 创建人: Wilson
* 时间: 2015-07-29
*/
var request = require('request'),
cheerio = require('cheerio'),
URL_36KR = 'http://36kr.com/'; //36氪
/* 开启数据采集器 */
function dataCollectorStartup() {
dataRequest(URL_36KR);
}
/* 数据请求 */
function dataRequest(dataUrl)
{
request({
url: dataUrl,
method: 'GET'
}, function(err, res, body) {
if (err) {
console.log(dataUrl)
console.error('[ERROR]Collection' + err);
return;
}
switch(dataUrl)
{
case URL_36KR:
dataParse36Kr(body);
break;
}
});
}
/* 36kr 数据解析 */
function dataParse36Kr(body)
{
console.log('============================================================================================');
console.log('======================================36kr==================================================');
console.log('============================================================================================');
var $ = cheerio.load(body);
var articles = $('article')
for (var i = 0; i < articles.length; i++) {
var article = articles[i];
var descDoms = $(article).find('.desc');
if(descDoms.length == 0)
{
continue;
}
var coverDom = $(article).children().first();
var titleDom = $(descDoms).find('.info_flow_news_title');
var timeDom = $(descDoms).find('.timeago');
var titleVal = titleDom.text();
var urlVal = titleDom.attr('href');
var timeVal = timeDom.attr('title');
var coverUrl = coverDom.attr('data-lazyload');
//处理时间
var timeDateSecs = new Date(timeVal).getTime() / 1000;
if(urlVal != undefined)
{
console.info('--------------------------------');
console.info('标题:' + titleVal);
console.info('地址:' + urlVal);
console.info('时间:' + timeDateSecs);
console.info('封面:' + coverUrl);
console.info('--------------------------------');
}
};
}
dataCollectorStartup();
测试结果
此采集器已完成. 实际上,这是一个获取请求. 正文或HTML代码将在请求回调中返回,并且cheerio库将以与jquery库语法相同的方式进行解析,以检索所需的数据!
加入代理商
对采集器进行演示,然后基本完成. 如果您需要长时间使用它以防止网站被阻止,则仍然需要添加代理列表
对于该示例,我从Internet上的免费代理中提出了一些示例,并将其放入proxylist.js中,该列表提供了随机选择代理的功能
var PROXY_LIST = [{"ip":"111.1.55.136","port":"55336"},{"ip":"111.1.54.91","port":"55336"},{"ip":"111.1.56.19","port":"55336"}
,{"ip":"112.114.63.16","port":"55336"},{"ip":"106.58.63.83","port":"55336"},{"ip":"119.188.133.54","port":"55336"}
,{"ip":"106.58.63.84","port":"55336"},{"ip":"183.95.132.171","port":"55336"},{"ip":"11.12.14.9","port":"55336"}
,{"ip":"60.164.223.16","port":"55336"},{"ip":"117.185.13.87","port":"8080"},{"ip":"112.114.63.20","port":"55336"}
,{"ip":"188.134.19.102","port":"3129"},{"ip":"106.58.63.80","port":"55336"},{"ip":"60.164.223.20","port":"55336"}
,{"ip":"106.58.63.78","port":"55336"},{"ip":"112.114.63.23","port":"55336"},{"ip":"112.114.63.30","port":"55336"}
,{"ip":"60.164.223.14","port":"55336"},{"ip":"190.202.82.234","port":"3128"},{"ip":"60.164.223.15","port":"55336"}
,{"ip":"60.164.223.5","port":"55336"},{"ip":"221.204.9.28","port":"55336"},{"ip":"60.164.223.2","port":"55336"}
,{"ip":"139.214.113.84","port":"55336"} ,{"ip":"112.25.49.14","port":"55336"},{"ip":"221.204.9.19","port":"55336"}
,{"ip":"221.204.9.39","port":"55336"},{"ip":"113.207.57.18","port":"55336"} ,{"ip":"112.25.62.15","port":"55336"}
,{"ip":"60.5.255.143","port":"55336"},{"ip":"221.204.9.18","port":"55336"},{"ip":"60.5.255.145","port":"55336"}
,{"ip":"221.204.9.16","port":"55336"},{"ip":"183.232.82.132","port":"55336"},{"ip":"113.207.62.78","port":"55336"}
,{"ip":"60.5.255.144","port":"55336"} ,{"ip":"60.5.255.141","port":"55336"},{"ip":"221.204.9.23","port":"55336"}
,{"ip":"157.122.96.50","port":"55336"},{"ip":"218.61.39.41","port":"55336"} ,{"ip":"221.204.9.26","port":"55336"}
,{"ip":"112.112.43.213","port":"55336"},{"ip":"60.5.255.138","port":"55336"},{"ip":"60.5.255.133","port":"55336"}
,{"ip":"221.204.9.25","port":"55336"},{"ip":"111.161.35.56","port":"55336"},{"ip":"111.161.35.49","port":"55336"}
,{"ip":"183.129.134.226","port":"8080"} ,{"ip":"58.220.10.86","port":"80"},{"ip":"183.87.117.44","port":"80"}
,{"ip":"211.23.19.130","port":"80"},{"ip":"61.234.249.107","port":"8118"},{"ip":"200.20.168.140","port":"80"}
,{"ip":"111.1.46.176","port":"55336"},{"ip":"120.203.158.149","port":"8118"},{"ip":"70.39.189.6","port":"9090"}
,{"ip":"210.6.237.191","port":"3128"},{"ip":"122.155.195.26","port":"8080"}];
module.exports.GetProxy = function () {
var randomNum = parseInt(Math.floor(Math.random() * PROXY_LIST.length));
var proxy = PROXY_LIST[randomNum];
return 'http://' + proxy.ip + ':' + proxy.port;
}
proxylist.js
对app.js代码进行以下更改
/*
* 功能: 数据采集
* 创建人: Wilson
* 时间: 2015-07-29
*/
var request = require('request'),
cheerio = require('cheerio'),
URL_36KR = 'http://36kr.com/', //36氪
Proxy = require('./proxylist.js');
...
/* 数据请求 */
function dataRequest(dataUrl)
{
request({
url: dataUrl,
proxy: Proxy.GetProxy(),
method: 'GET'
}, function(err, res, body) {
...
}
}
...
dataCollectorStartup()
setInterval(dataCollectorStartup, 10000);
这样,转换就完成了,添加了代码,并添加了setInterval以定期执行! 查看全部
目录写在前面
许多人需要数据采集,这可以用不同的语言和不同的方式来实现. 我以前也用C#编写过它. 发送各种请求和定期分析数据主要比较麻烦. 总的来说,没有什么不好,但是效率更差,
使用nodejs(可能仅相对于C#)编写采集程序效率更高. 今天,我将主要使用一个示例来说明如何使用nodejs来实现数据采集器,主要是使用request和cheerio.
请求: 用于http请求
cheerio: 用于提取请求返回的html中所需的信息(与jquery的用法一致)
示例
仅讲API使用并不有趣,也无需记住所有API. 让我们开始一个例子.
说些八卦:
仍然有许多nodejs开发工具. 我还建议崇高. 自从Microsoft启动Visual Studio Code之后,我便转向了nodejs开发.
使用它进行开发比较舒适,无需配置,快速启动,自动完成,视图定义和引用,快速搜索等,并且具有一致的VS风格,因此它应该越来越好,所以我建议^ _ ^!
样品要求
在其中获取文章的“标题”,“地址”,“发布时间”和“封面图片”
采集器
1. 创建项目文件夹sampleDAU
2. 创建package.json文件
{
"name": "Wilson_SampleDAU",
"version": "0.0.1",
"private": false,
"dependencies": {
"request":"*",
"cheerio":"*"
}
}
3. 使用npm在终端中安装参考
cd 项目根目录
npm install
4. 构建app.js并编写采集器代码
首先,使用浏览器打开要采集的URL,使用开发人员工具查看HTML结构,然后根据该结构编写解析代码
/*
* 功能: 数据采集
* 创建人: Wilson
* 时间: 2015-07-29
*/
var request = require('request'),
cheerio = require('cheerio'),
URL_36KR = 'http://36kr.com/'; //36氪
/* 开启数据采集器 */
function dataCollectorStartup() {
dataRequest(URL_36KR);
}
/* 数据请求 */
function dataRequest(dataUrl)
{
request({
url: dataUrl,
method: 'GET'
}, function(err, res, body) {
if (err) {
console.log(dataUrl)
console.error('[ERROR]Collection' + err);
return;
}
switch(dataUrl)
{
case URL_36KR:
dataParse36Kr(body);
break;
}
});
}
/* 36kr 数据解析 */
function dataParse36Kr(body)
{
console.log('============================================================================================');
console.log('======================================36kr==================================================');
console.log('============================================================================================');
var $ = cheerio.load(body);
var articles = $('article')
for (var i = 0; i < articles.length; i++) {
var article = articles[i];
var descDoms = $(article).find('.desc');
if(descDoms.length == 0)
{
continue;
}
var coverDom = $(article).children().first();
var titleDom = $(descDoms).find('.info_flow_news_title');
var timeDom = $(descDoms).find('.timeago');
var titleVal = titleDom.text();
var urlVal = titleDom.attr('href');
var timeVal = timeDom.attr('title');
var coverUrl = coverDom.attr('data-lazyload');
//处理时间
var timeDateSecs = new Date(timeVal).getTime() / 1000;
if(urlVal != undefined)
{
console.info('--------------------------------');
console.info('标题:' + titleVal);
console.info('地址:' + urlVal);
console.info('时间:' + timeDateSecs);
console.info('封面:' + coverUrl);
console.info('--------------------------------');
}
};
}
dataCollectorStartup();
测试结果

此采集器已完成. 实际上,这是一个获取请求. 正文或HTML代码将在请求回调中返回,并且cheerio库将以与jquery库语法相同的方式进行解析,以检索所需的数据!
加入代理商
对采集器进行演示,然后基本完成. 如果您需要长时间使用它以防止网站被阻止,则仍然需要添加代理列表
对于该示例,我从Internet上的免费代理中提出了一些示例,并将其放入proxylist.js中,该列表提供了随机选择代理的功能


var PROXY_LIST = [{"ip":"111.1.55.136","port":"55336"},{"ip":"111.1.54.91","port":"55336"},{"ip":"111.1.56.19","port":"55336"}
,{"ip":"112.114.63.16","port":"55336"},{"ip":"106.58.63.83","port":"55336"},{"ip":"119.188.133.54","port":"55336"}
,{"ip":"106.58.63.84","port":"55336"},{"ip":"183.95.132.171","port":"55336"},{"ip":"11.12.14.9","port":"55336"}
,{"ip":"60.164.223.16","port":"55336"},{"ip":"117.185.13.87","port":"8080"},{"ip":"112.114.63.20","port":"55336"}
,{"ip":"188.134.19.102","port":"3129"},{"ip":"106.58.63.80","port":"55336"},{"ip":"60.164.223.20","port":"55336"}
,{"ip":"106.58.63.78","port":"55336"},{"ip":"112.114.63.23","port":"55336"},{"ip":"112.114.63.30","port":"55336"}
,{"ip":"60.164.223.14","port":"55336"},{"ip":"190.202.82.234","port":"3128"},{"ip":"60.164.223.15","port":"55336"}
,{"ip":"60.164.223.5","port":"55336"},{"ip":"221.204.9.28","port":"55336"},{"ip":"60.164.223.2","port":"55336"}
,{"ip":"139.214.113.84","port":"55336"} ,{"ip":"112.25.49.14","port":"55336"},{"ip":"221.204.9.19","port":"55336"}
,{"ip":"221.204.9.39","port":"55336"},{"ip":"113.207.57.18","port":"55336"} ,{"ip":"112.25.62.15","port":"55336"}
,{"ip":"60.5.255.143","port":"55336"},{"ip":"221.204.9.18","port":"55336"},{"ip":"60.5.255.145","port":"55336"}
,{"ip":"221.204.9.16","port":"55336"},{"ip":"183.232.82.132","port":"55336"},{"ip":"113.207.62.78","port":"55336"}
,{"ip":"60.5.255.144","port":"55336"} ,{"ip":"60.5.255.141","port":"55336"},{"ip":"221.204.9.23","port":"55336"}
,{"ip":"157.122.96.50","port":"55336"},{"ip":"218.61.39.41","port":"55336"} ,{"ip":"221.204.9.26","port":"55336"}
,{"ip":"112.112.43.213","port":"55336"},{"ip":"60.5.255.138","port":"55336"},{"ip":"60.5.255.133","port":"55336"}
,{"ip":"221.204.9.25","port":"55336"},{"ip":"111.161.35.56","port":"55336"},{"ip":"111.161.35.49","port":"55336"}
,{"ip":"183.129.134.226","port":"8080"} ,{"ip":"58.220.10.86","port":"80"},{"ip":"183.87.117.44","port":"80"}
,{"ip":"211.23.19.130","port":"80"},{"ip":"61.234.249.107","port":"8118"},{"ip":"200.20.168.140","port":"80"}
,{"ip":"111.1.46.176","port":"55336"},{"ip":"120.203.158.149","port":"8118"},{"ip":"70.39.189.6","port":"9090"}
,{"ip":"210.6.237.191","port":"3128"},{"ip":"122.155.195.26","port":"8080"}];
module.exports.GetProxy = function () {
var randomNum = parseInt(Math.floor(Math.random() * PROXY_LIST.length));
var proxy = PROXY_LIST[randomNum];
return 'http://' + proxy.ip + ':' + proxy.port;
}
proxylist.js
对app.js代码进行以下更改
/*
* 功能: 数据采集
* 创建人: Wilson
* 时间: 2015-07-29
*/
var request = require('request'),
cheerio = require('cheerio'),
URL_36KR = 'http://36kr.com/', //36氪
Proxy = require('./proxylist.js');
...
/* 数据请求 */
function dataRequest(dataUrl)
{
request({
url: dataUrl,
proxy: Proxy.GetProxy(),
method: 'GET'
}, function(err, res, body) {
...
}
}
...
dataCollectorStartup()
setInterval(dataCollectorStartup, 10000);
这样,转换就完成了,添加了代码,并添加了setInterval以定期执行!
崎combat的战斗章节(5): 抓取历史天气数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2020-08-08 07:19
1. 通常,数据需求简单或少量,我们会使用request(selenum)+ beautiful捕获数据
2. 当我们需要大量数据时,建议使用scrapy框架进行数据采集. scrapy框架使用异步方法来发起请求,并且数据捕获效率非常高.
以下,我们以网站数据捕获为例,介绍两种数据捕获:
1. 使用request + bs采集天气数据,并使用mysql存储数据
思考:
我们要采集的天气数据存储在地址beijing / month / 201101.html中. 观察URL,我们可以发现URL仅有两个部分在变化,即城市名称和您的年月,并且每年固定地收录12个. 对于月,您可以使用months = list(range(1,13 ))构建月份. 使用城市名称和年份作为变量来构造一个URL列表,这些URL需要采集数据,遍历该列表,请求URL并解析响应以获取数据.
以上是我们采集天气数据的想法. 首先,我们需要构建一个URL链接.
1 def get_url(cityname,start_year,end_year):
2 years = list(range(start_year, end_year))
3 months = list(range(1, 13))
4 suburl = 'http://www.tianqihoubao.com/lishi/'
5 urllist = []
6 for year in years:
7 for month in months:
8 if month < 10:
9 url = suburl + cityname + '/month/'+ str(year) + (str(0) + str(month)) + '.html'
10 else:
11 url = suburl + cityname + '/month/' + str(year) + str(month) + '.html'
12 urllist.append(url.strip())
13 return urllist
通过上述功能,您可以获得需要爬网的URL列表.
<p>如您所见,我们在上面使用了cityname,cityname是我们需要获取的城市的城市名称. 我们需要手动构造它. 假设我们已经构建了一个城市名称列表并存储在mysql数据库中,则需要查询数据库以获取城市名称,遍历城市,并将城市名称,开始年份和结束年份赋予上述功能. 查看全部
在本文中,我们以历史天气数据的捕获为例,简要说明两种数据捕获方式:
1. 通常,数据需求简单或少量,我们会使用request(selenum)+ beautiful捕获数据
2. 当我们需要大量数据时,建议使用scrapy框架进行数据采集. scrapy框架使用异步方法来发起请求,并且数据捕获效率非常高.
以下,我们以网站数据捕获为例,介绍两种数据捕获:
1. 使用request + bs采集天气数据,并使用mysql存储数据
思考:
我们要采集的天气数据存储在地址beijing / month / 201101.html中. 观察URL,我们可以发现URL仅有两个部分在变化,即城市名称和您的年月,并且每年固定地收录12个. 对于月,您可以使用months = list(range(1,13 ))构建月份. 使用城市名称和年份作为变量来构造一个URL列表,这些URL需要采集数据,遍历该列表,请求URL并解析响应以获取数据.
以上是我们采集天气数据的想法. 首先,我们需要构建一个URL链接.
1 def get_url(cityname,start_year,end_year):
2 years = list(range(start_year, end_year))
3 months = list(range(1, 13))
4 suburl = 'http://www.tianqihoubao.com/lishi/'
5 urllist = []
6 for year in years:
7 for month in months:
8 if month < 10:
9 url = suburl + cityname + '/month/'+ str(year) + (str(0) + str(month)) + '.html'
10 else:
11 url = suburl + cityname + '/month/' + str(year) + str(month) + '.html'
12 urllist.append(url.strip())
13 return urllist
通过上述功能,您可以获得需要爬网的URL列表.
<p>如您所见,我们在上面使用了cityname,cityname是我们需要获取的城市的城市名称. 我们需要手动构造它. 假设我们已经构建了一个城市名称列表并存储在mysql数据库中,则需要查询数据库以获取城市名称,遍历城市,并将城市名称,开始年份和结束年份赋予上述功能.
使用python +硒采集京东产品信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 349 次浏览 • 2020-08-08 06:09
[为什么要学习爬网? 】1.爬虫很容易上手,但是很难深入. 如何编写高效的采集器,如何编写高度灵活和可伸缩的采集器是一项技术任务. 另外,在爬网过程中,经常容易遇到反爬虫,例如字体防爬网,IP识别,验证码等. 如何克服困难并获取所需的数据,您可以学习此课程! 2.如果您是其他行业的开发人员,例如应用程序开发,网站开发,那么学习爬虫程序可以增强您的技术知识,并开发更安全的软件和网站[课程设计]完整的爬虫程序,无论大小,它可以分为三个步骤,即: 网络请求: 模拟浏览器的行为以从Internet抓取数据. 数据分析: 过滤请求的数据并提取所需的数据. 数据存储: 将提取的数据存储到硬盘或内存中. 例如,使用mysql数据库或redis. 然后按照这些步骤逐步解释本课程,使学生充分掌握每个步骤的技术. 另外,由于爬行器的多样性,在爬行过程中可能会发生反爬行和低效率的情况. 因此,我们又增加了两章来提高爬虫程序的灵活性,即: 高级爬虫: 包括IP代理,多线程爬虫,图形验证代码识别,JS加密和解密,动态Web爬虫,字体反爬虫识别等等. Scrapy和分布式爬虫: Scrapy框架,Scrapy-redis组件,分布式爬虫等. 我们可以通过爬虫的高级知识点来处理大量的反爬虫网站. 作为专业的采集器框架,Scrapy框架可以快速提高我们的搜寻程序的效率和速度. 此外,如果一台计算机无法满足您的需求,我们可以使用分布式爬网程序让多台计算机帮助您快速爬网数据. 从基本的采集器到商业应用程序采集器,这套课程都可以满足您的所有需求! [课程服务]独家付费社区+每个星期三的讨论会+ 1v1问答
Burpsuite插件开发(之二): 信息采集插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 452 次浏览 • 2020-08-08 01:34
0x00
我之前编写了一个用于burpsuite与sqlmap链接的插件. 这次是一个用于信息采集的插件. 该插件的名称是TheMagician. 这是“从Windows到Mac的渗透测试重点”计划的一小步. 我想简单地编写它,但是写的越多,就越麻烦. 多亏了朋友们的大力帮助,我终于顺利完成了任务.
使用该插件之前需要修改三个全局变量,即NMAPPATH,BINGKEY和HOMEPATH,其他全局变量不需要更改
该插件的使用与链接sqlmap插件的用法相同,遵循“简单就是美丽”的原则. 右键单击最简单的调用
创建右键菜单的源代码
#创建菜单右键
def createMenuItems(self, invocation):
menu = []
responses = invocation.getSelectedMessages()
if len(responses) == 1:
menu.append(JMenuItem(self._actionName, None, actionPerformed=lambda x, inv=invocation: self.quoteJTab(inv)))
return menu
return None
三个标签代表三种不同的功能
0x01 C段端口扫描
第一个是C扫描. 该IP地址是从Proxy标记中HTTP请求标头中的主机地址继承的. 它可以是单个IP地址或CIDR. 考虑到nmap在端口扫描中的绝对领导者位置,我没有亲自重写端口扫描引擎,而是通过Python子进程库调用了nmap.
Mac在使用前必须先安装nmap
brew install nmap
class NmapScan(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
self.thread_stop = False
def setCommds(self,cmds,Jobject,pcontrol):
self.runcms=cmds
self.setobject=Jobject
self.pcontrol=pcontrol
def run(self):
#self.setobject.setResult('Nmap task for '+self.runcms[5]+' is running\n')
child1 = subprocess.Popen(self.runcms, stdout = subprocess.PIPE, stdin = subprocess.PIPE, shell = False)
child1.poll()
resultScan = child1.stdout.read()
self.setobject.setResult(resultScan)
#self.setobject.setResult('Nmap task for '+self.runcms[5]+' is finnished\n')
self.pcontrol.subnum()
self.stop()
def stop(self):
self.thread_stop = True
单个IP地址扫描结果
C段扫描结果
通过先前的链接sqlmap插件来实现burpsuite,sqlmap和nmap这三个工件的集成.
0x02子域查询
我知道当前有三种子域查询方案: 一种是通过bing语法查询,第二种是使用第二级域名的集合,第三种是执行DNS爆破. 三种方案中较好的是第三种方案,而较好的轮子是subdomainsbrute. 当然,最好的方法是使用这三种方案,这只是消除重复的一种好方法,我在这里使用了第一种方案,不要问我为什么: 它很容易编写.
调用bing的主要功能
def BingSearch(query):
payload={}
payload['$top']=top
payload['$skip']=skip
payload['$format']=format
payload['Query']="'"+query+"'"
url='https://api.datamarket.azure.com/Bing/Search/Web?' + urllib.urlencode(payload)
sAuth='Basic '+base64.b64encode(':'+BINGKEY)
headers = { }
headers['Authorization']= sAuth
try:
req = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(req)
data=response.read()
#print data
data=json.loads(data)
return data
except Exception as e:
print e
#print e.info()
urlList = []
returnData = BingSearch("domain:" + theTopDomain)
if not returnData['d']['results']:
print "The Url Error"
else:
for tarUrl in returnData["d"]["results"]:
tmpUrl = urlparse.urlparse(tarUrl["Url"]).netloc
if tmpUrl not in urlList:
urlList.append(tmpUrl)
0x03敏感文件扫描
敏感文件扫描也是信息采集中的重要步骤. 通过文件扫描通常会带来意想不到的收益. 第三个功能模仿了Yujian Daniel的设计
目前有20个线程,速度已经过去
此外,它具有可以完全继承Proxy标记中的http请求标头信息(包括ua和cookie)的功能 查看全部
最后一集发送了“如何编写与sqlmap的burpsuite链接的插件”
0x00
我之前编写了一个用于burpsuite与sqlmap链接的插件. 这次是一个用于信息采集的插件. 该插件的名称是TheMagician. 这是“从Windows到Mac的渗透测试重点”计划的一小步. 我想简单地编写它,但是写的越多,就越麻烦. 多亏了朋友们的大力帮助,我终于顺利完成了任务.
使用该插件之前需要修改三个全局变量,即NMAPPATH,BINGKEY和HOMEPATH,其他全局变量不需要更改

该插件的使用与链接sqlmap插件的用法相同,遵循“简单就是美丽”的原则. 右键单击最简单的调用

创建右键菜单的源代码
#创建菜单右键
def createMenuItems(self, invocation):
menu = []
responses = invocation.getSelectedMessages()
if len(responses) == 1:
menu.append(JMenuItem(self._actionName, None, actionPerformed=lambda x, inv=invocation: self.quoteJTab(inv)))
return menu
return None
三个标签代表三种不同的功能

0x01 C段端口扫描
第一个是C扫描. 该IP地址是从Proxy标记中HTTP请求标头中的主机地址继承的. 它可以是单个IP地址或CIDR. 考虑到nmap在端口扫描中的绝对领导者位置,我没有亲自重写端口扫描引擎,而是通过Python子进程库调用了nmap.
Mac在使用前必须先安装nmap
brew install nmap
class NmapScan(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
self.thread_stop = False
def setCommds(self,cmds,Jobject,pcontrol):
self.runcms=cmds
self.setobject=Jobject
self.pcontrol=pcontrol
def run(self):
#self.setobject.setResult('Nmap task for '+self.runcms[5]+' is running\n')
child1 = subprocess.Popen(self.runcms, stdout = subprocess.PIPE, stdin = subprocess.PIPE, shell = False)
child1.poll()
resultScan = child1.stdout.read()
self.setobject.setResult(resultScan)
#self.setobject.setResult('Nmap task for '+self.runcms[5]+' is finnished\n')
self.pcontrol.subnum()
self.stop()
def stop(self):
self.thread_stop = True
单个IP地址扫描结果

C段扫描结果

通过先前的链接sqlmap插件来实现burpsuite,sqlmap和nmap这三个工件的集成.
0x02子域查询
我知道当前有三种子域查询方案: 一种是通过bing语法查询,第二种是使用第二级域名的集合,第三种是执行DNS爆破. 三种方案中较好的是第三种方案,而较好的轮子是subdomainsbrute. 当然,最好的方法是使用这三种方案,这只是消除重复的一种好方法,我在这里使用了第一种方案,不要问我为什么: 它很容易编写.
调用bing的主要功能
def BingSearch(query):
payload={}
payload['$top']=top
payload['$skip']=skip
payload['$format']=format
payload['Query']="'"+query+"'"
url='https://api.datamarket.azure.com/Bing/Search/Web?' + urllib.urlencode(payload)
sAuth='Basic '+base64.b64encode(':'+BINGKEY)
headers = { }
headers['Authorization']= sAuth
try:
req = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(req)
data=response.read()
#print data
data=json.loads(data)
return data
except Exception as e:
print e
#print e.info()
urlList = []
returnData = BingSearch("domain:" + theTopDomain)
if not returnData['d']['results']:
print "The Url Error"
else:
for tarUrl in returnData["d"]["results"]:
tmpUrl = urlparse.urlparse(tarUrl["Url"]).netloc
if tmpUrl not in urlList:
urlList.append(tmpUrl)

0x03敏感文件扫描
敏感文件扫描也是信息采集中的重要步骤. 通过文件扫描通常会带来意想不到的收益. 第三个功能模仿了Yujian Daniel的设计

目前有20个线程,速度已经过去

此外,它具有可以完全继承Proxy标记中的http请求标头信息(包括ua和cookie)的功能
EditorTools3破解版v3.3绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2020-08-08 00:24
EditorTools3破解版是一个非常易于使用的自动采集辅助软件. 是否要更改为其他采集软件?编辑器为您推荐了EditorTools3破解版. 该工具可以快速有效地帮助网站自动进行信息采集,并具有多种智能采集方案,可以全方位保证网站内容和更新效率,帮助管理人员更好地开发网站. 有需要的朋友,请不要错过!
概述
该软件适合在需要长期更新的非临时网站上使用,并且不需要您对现有论坛或网站进行任何更改.
功能介绍
1. 独特的无人值守操作
从设计伊始,ET就被设计为提高软件自动化程度的突破,以实现无人值守和自动24小时工作的目的. 经过测试,ET可以长时间甚至数年自动运行.
2. 超高稳定性
如果该软件无人值守,则需要能够长时间稳定运行. ET在这方面进行了很多优化,以确保软件可以稳定且连续地运行. 某些采集软件永远不会崩溃甚至导致崩溃. 网站崩溃了.
3,资源占用最低
ET独立于网站,并且不消耗宝贵的服务器WEB处理资源. 它可以在服务器上或网站管理员的工作站上工作.
4. 严格的数据和网络安全性
ET使用网站自己的数据发布界面或程序代码来处理和发布信息,并且不直接操作网站数据库,从而避免了由ET引起的任何数据安全问题. ET采集信息时,使用标准的HTTP端口,不会造成网络安全漏洞.
5. 强大而灵活的功能
除了通用采集工具的功能外,ET还通过支持图像水印,防垃圾,分页采集,答复采集,登录采集,自定义项目,UTF-8,UBB和模拟发布来使用户更加灵活. 实现各种头发采集需求.
更新日志
1. 解决一些已知问题. 查看全部

EditorTools3破解版是一个非常易于使用的自动采集辅助软件. 是否要更改为其他采集软件?编辑器为您推荐了EditorTools3破解版. 该工具可以快速有效地帮助网站自动进行信息采集,并具有多种智能采集方案,可以全方位保证网站内容和更新效率,帮助管理人员更好地开发网站. 有需要的朋友,请不要错过!
概述
该软件适合在需要长期更新的非临时网站上使用,并且不需要您对现有论坛或网站进行任何更改.

功能介绍
1. 独特的无人值守操作
从设计伊始,ET就被设计为提高软件自动化程度的突破,以实现无人值守和自动24小时工作的目的. 经过测试,ET可以长时间甚至数年自动运行.
2. 超高稳定性
如果该软件无人值守,则需要能够长时间稳定运行. ET在这方面进行了很多优化,以确保软件可以稳定且连续地运行. 某些采集软件永远不会崩溃甚至导致崩溃. 网站崩溃了.
3,资源占用最低
ET独立于网站,并且不消耗宝贵的服务器WEB处理资源. 它可以在服务器上或网站管理员的工作站上工作.
4. 严格的数据和网络安全性
ET使用网站自己的数据发布界面或程序代码来处理和发布信息,并且不直接操作网站数据库,从而避免了由ET引起的任何数据安全问题. ET采集信息时,使用标准的HTTP端口,不会造成网络安全漏洞.
5. 强大而灵活的功能
除了通用采集工具的功能外,ET还通过支持图像水印,防垃圾,分页采集,答复采集,登录采集,自定义项目,UTF-8,UBB和模拟发布来使用户更加灵活. 实现各种头发采集需求.
更新日志
1. 解决一些已知问题.
十多年来总结的最经典的项目,用作python爬虫实践教学!
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2020-08-08 00:01
此文章以前曾用于培训新手. 每个人都觉得它很容易理解,因此我与所有人共享并学习了. 如果您已经学习了一些python并想用它做一些事但没有方向,那么不妨尝试完成以下案例.
第二,环境准备
安装三个请求库lxml beautifulsoup4(以下代码均在python3.5环境中进行了测试)
pip install requests lxml beautifulsoup4
三个,一些小小的爬虫
3.1获取本地公网IP地址
利用在公共Internet上查询IP的借口,使用python的请求库自动获取IP地址.
import requests
r = requests.get("http://2017.ip138.com/ic.asp")
r.encoding = r.apparent_encoding #使用requests的字符编码智能分析,避免中文乱码
print(r.text)
# 你还可以使用正则匹配re模块提取出IP
import re
print(re.findall("d{1,3}.d{1,3}.d{1,3}.d{1,3}",r.text))
3.2使用百度搜索界面编写网址采集器
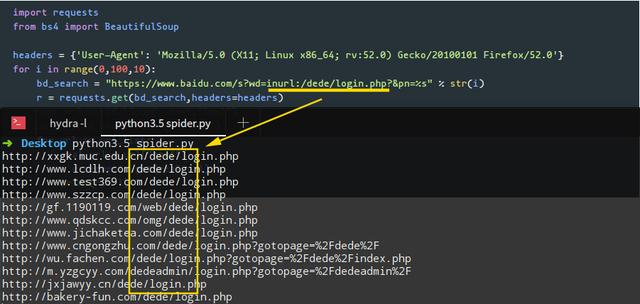
在这种情况下,我们将结合使用请求和BeautifulSoup库来完成任务. 我们需要在程序中设置User-Agent标头,以绕过百度搜索引擎的反爬虫机制(您可以尝试不使用User-Agent标头来查看是否可以获取数据). 注意百度搜索结构的URL链接规则. 例如,第一页上的URL链接参数pn = 0,第二页上的URL链接参数pn = 10 ...依此类推. 在这里,我们使用css选择器路径提取数据.
import requests
from bs4 import BeautifulSoup
# 设置User-Agent头,绕过百度搜索引擎的反爬虫机制
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'}
# 注意观察百度搜索结构的URL链接规律,例如第一页pn=0,第二页pn=10.... 依次类推,下面的for循环搜索前10页结果
for i in range(0,100,10):
bd_search = "https://www.baidu.com/s%3Fwd%3 ... ot%3B % str(i)
r = requests.get(bd_search,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
# 下面的select使用了css选择器路径提取数据
url_list = soup.select(".t > a")
for url in url_list:
real_url = url["href"]
r = requests.get(real_url)
print(r.url)
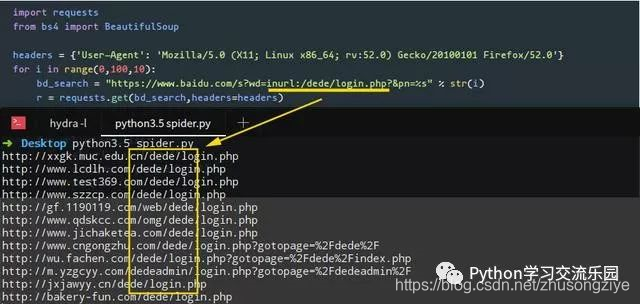
编写程序后,我们使用关键字inurl: /dede/login.php批量提取梦境编织cms的背景地址,效果如下:
3.3自动下载搜狗壁纸
在此示例中,我们将使用采集器自动下载搜索到的墙纸,并将程序中存储图片的路径更改为要存储图片的目录路径. 另一点是,我们在程序中使用了json库. 这是因为在观察过程中,我们发现Sogou的墙纸地址以json格式存储,因此我们将这组数据解析为json.
import requests
import json
#下载图片
url = "http://pic.sogou.com/pics/chan ... ot%3B
r = requests.get(url)
data = json.loads(r.text)
for i in data["all_items"]:
img_url = i["pic_url"]
# 下面这行里面的路径改成你自己想要存放图片的目录路径即可
with open("/home/evilk0/Desktop/img/%s" % img_url[-10:]+".jpg","wb") as f:
r2 = requests.get(img_url)
f.write(r2.content)
print("下载完毕:",img_url)
3.4自动填写问卷
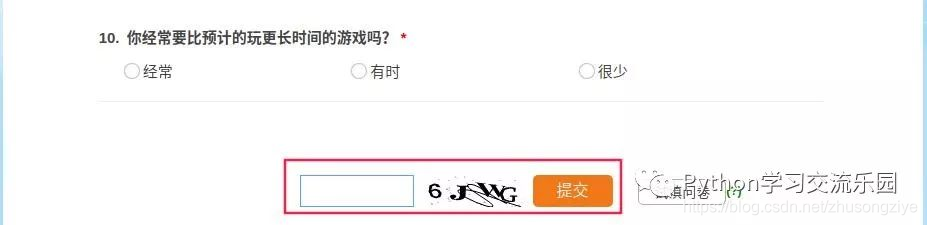
目标官方网站:
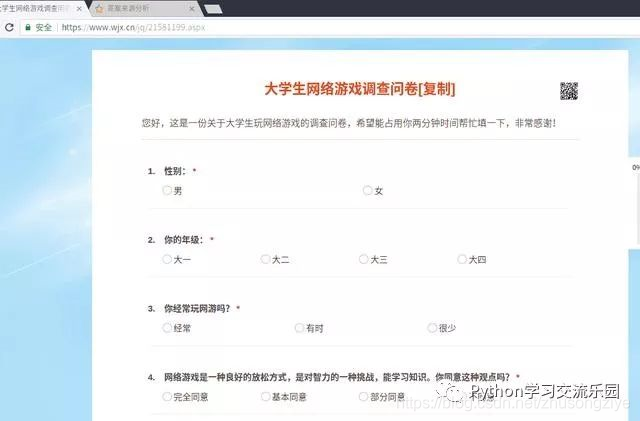
目标问卷:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
r = requests.post(url = url,headers=header,data=data)
print(r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
当我们使用相同的IP提交多个调查表时,将触发目标的反爬行机制,并且服务器将显示验证码.
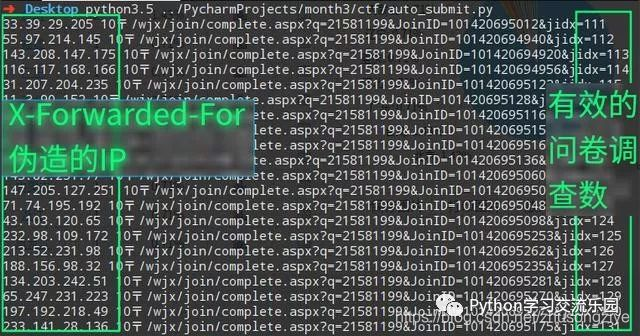
我们可以使用X-Forwarded-For伪造我们的IP,修改后的代码如下:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
"X-Forwarded-For" : "%s"
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
header["X-Forwarded-For"] = (str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+str(random.randint(1,255))
r = requests.post(url = url,headers=header,data=data)
print(header["X-Forwarded-For"],r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
header["X-Forwarded-For"] = "%s"
效果图:
关于本文,因为我之前已经写过,所以不再重复,我对它直接感兴趣: [如何通过Python自动填写调查表]
3.5获取公网代理IP,判断是否可以使用以及延迟时间
在此示例中,我们要在[Xi Spur代理]上爬网代理IP,并验证这些代理的生存能力和延迟时间. (您可以将爬网的代理IP添加到代理链,然后执行正常的渗透任务. )在这里,我直接调用Linux系统命令ping -c 1“ + ip.string +” | awk'NR == 2 {print}'-如果要在Windows中运行此程序,则需要将倒数第二行os.popen中的命令修改为可由Windows执行.
from bs4 import BeautifulSoup
import requests
import os
url = "http://www.xicidaili.com/nn/1"
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'}
r = requests.get(url=url,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
server_address = soup.select(".odd > td:nth-of-type(4)")
ip_list = soup.select(".odd > td:nth-of-type(2)")
ports = soup.select(".odd > td:nth-of-type(3)")
for server,ip in zip(server_address,ip_list):
if len(server.contents) != 1:
print(server.a.string.ljust(8),ip.string.ljust(20), end='')
else:
print("未知".ljust(8), ip.string.ljust(20), end='')
delay_time = os.popen("ping -c 1 " + ip.string + " | awk 'NR==2{print}' -")
delay_time = delay_time.read().split("time=")[-1].strip("
")
print("time = " + delay_time)
四个. 结论
当然,您也可以使用python做很多有趣的事情. 查看全部
I. 前言
此文章以前曾用于培训新手. 每个人都觉得它很容易理解,因此我与所有人共享并学习了. 如果您已经学习了一些python并想用它做一些事但没有方向,那么不妨尝试完成以下案例.
第二,环境准备
安装三个请求库lxml beautifulsoup4(以下代码均在python3.5环境中进行了测试)
pip install requests lxml beautifulsoup4
三个,一些小小的爬虫
3.1获取本地公网IP地址
利用在公共Internet上查询IP的借口,使用python的请求库自动获取IP地址.
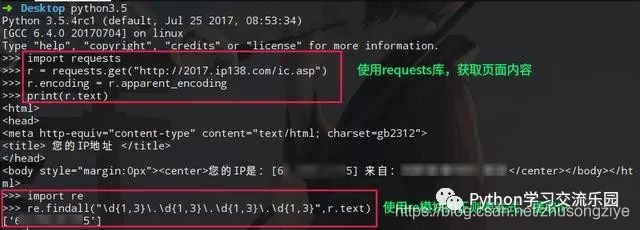
import requests
r = requests.get("http://2017.ip138.com/ic.asp";)
r.encoding = r.apparent_encoding #使用requests的字符编码智能分析,避免中文乱码
print(r.text)
# 你还可以使用正则匹配re模块提取出IP
import re
print(re.findall("d{1,3}.d{1,3}.d{1,3}.d{1,3}",r.text))
3.2使用百度搜索界面编写网址采集器
在这种情况下,我们将结合使用请求和BeautifulSoup库来完成任务. 我们需要在程序中设置User-Agent标头,以绕过百度搜索引擎的反爬虫机制(您可以尝试不使用User-Agent标头来查看是否可以获取数据). 注意百度搜索结构的URL链接规则. 例如,第一页上的URL链接参数pn = 0,第二页上的URL链接参数pn = 10 ...依此类推. 在这里,我们使用css选择器路径提取数据.
import requests
from bs4 import BeautifulSoup
# 设置User-Agent头,绕过百度搜索引擎的反爬虫机制
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'}
# 注意观察百度搜索结构的URL链接规律,例如第一页pn=0,第二页pn=10.... 依次类推,下面的for循环搜索前10页结果
for i in range(0,100,10):
bd_search = "https://www.baidu.com/s%3Fwd%3 ... ot%3B % str(i)
r = requests.get(bd_search,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
# 下面的select使用了css选择器路径提取数据
url_list = soup.select(".t > a")
for url in url_list:
real_url = url["href"]
r = requests.get(real_url)
print(r.url)
编写程序后,我们使用关键字inurl: /dede/login.php批量提取梦境编织cms的背景地址,效果如下:
3.3自动下载搜狗壁纸
在此示例中,我们将使用采集器自动下载搜索到的墙纸,并将程序中存储图片的路径更改为要存储图片的目录路径. 另一点是,我们在程序中使用了json库. 这是因为在观察过程中,我们发现Sogou的墙纸地址以json格式存储,因此我们将这组数据解析为json.
import requests
import json
#下载图片
url = "http://pic.sogou.com/pics/chan ... ot%3B
r = requests.get(url)
data = json.loads(r.text)
for i in data["all_items"]:
img_url = i["pic_url"]
# 下面这行里面的路径改成你自己想要存放图片的目录路径即可
with open("/home/evilk0/Desktop/img/%s" % img_url[-10:]+".jpg","wb") as f:
r2 = requests.get(img_url)
f.write(r2.content)
print("下载完毕:",img_url)
3.4自动填写问卷
目标官方网站:
目标问卷:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
r = requests.post(url = url,headers=header,data=data)
print(r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
当我们使用相同的IP提交多个调查表时,将触发目标的反爬行机制,并且服务器将显示验证码.
我们可以使用X-Forwarded-For伪造我们的IP,修改后的代码如下:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
"X-Forwarded-For" : "%s"
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
header["X-Forwarded-For"] = (str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+str(random.randint(1,255))
r = requests.post(url = url,headers=header,data=data)
print(header["X-Forwarded-For"],r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
header["X-Forwarded-For"] = "%s"
效果图:
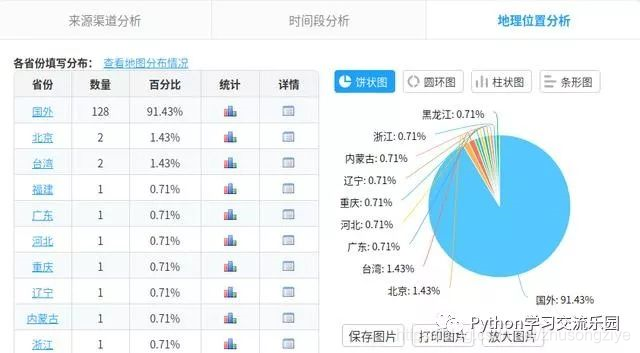
关于本文,因为我之前已经写过,所以不再重复,我对它直接感兴趣: [如何通过Python自动填写调查表]
3.5获取公网代理IP,判断是否可以使用以及延迟时间
在此示例中,我们要在[Xi Spur代理]上爬网代理IP,并验证这些代理的生存能力和延迟时间. (您可以将爬网的代理IP添加到代理链,然后执行正常的渗透任务. )在这里,我直接调用Linux系统命令ping -c 1“ + ip.string +” | awk'NR == 2 {print}'-如果要在Windows中运行此程序,则需要将倒数第二行os.popen中的命令修改为可由Windows执行.
from bs4 import BeautifulSoup
import requests
import os
url = "http://www.xicidaili.com/nn/1"
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'}
r = requests.get(url=url,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
server_address = soup.select(".odd > td:nth-of-type(4)")
ip_list = soup.select(".odd > td:nth-of-type(2)")
ports = soup.select(".odd > td:nth-of-type(3)")
for server,ip in zip(server_address,ip_list):
if len(server.contents) != 1:
print(server.a.string.ljust(8),ip.string.ljust(20), end='')
else:
print("未知".ljust(8), ip.string.ljust(20), end='')
delay_time = os.popen("ping -c 1 " + ip.string + " | awk 'NR==2{print}' -")
delay_time = delay_time.read().split("time=")[-1].strip("
")
print("time = " + delay_time)
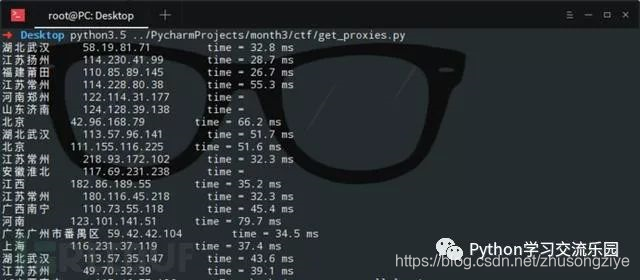

四个. 结论
当然,您也可以使用python做很多有趣的事情.
Spoonie智能书写工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-07 17:32
勺式智能书写工具功能介绍
关键字
根据用户设置的关键字,进行常规采集,以免采集指定的一个或几个采集的站点
内容识别
无需编写规则,智能地识别页面的标题和内容,并快速访问系统.
定位
提供列表URL和文章URL来采集指定网站或列的内容,这样标题,正文,作者和来源就可以准确
伪原创SEO更新
网站直接调用伪原创界面,即智能伪原创,解决了网站收录问题.
如何安装瓢智能书写工具
从华军软件园的下载站点下载邵平智能写作工具的中文软件包
解压缩到当前文件夹
双击以打开文件夹中的应用程序
此软件是绿色软件,无需安装即可使用.
Shaopian智能书写工具的更新日志
1. 优化的步伐永无止境!
2. 更多小惊喜等着您来发现〜
华军编辑推荐:
Spoonie智能书写工具专业,易于操作且功能强大. 它是软件行业的领导者之一. 欢迎大家下载. 该网站还提供editplus,我的爱破解,qq音乐等供您下载.
中文版的Shaopian Smart Writing Tool是具有简短界面的智能伪原创写作机器人软件. Shaopian Smart Writing Tool的正式版提供了诸如伪原创工具,关键字提取,内容搜索和自动摘要之类的功能. 聪明地帮助用户完成文章内容摘要和伪原创工作. 中文智能书写工具提供列表URL和文章URL,以采集指定网站或列的内容.
勺式智能书写工具功能介绍
关键字
根据用户设置的关键字,进行常规采集,以免采集指定的一个或几个采集的站点
内容识别
无需编写规则,智能地识别页面的标题和内容,并快速访问系统.
定位
提供列表URL和文章URL来采集指定网站或列的内容,这样标题,正文,作者和来源就可以准确
伪原创SEO更新
网站直接调用伪原创界面,即智能伪原创,解决了网站收录问题.
如何安装瓢智能书写工具
从华军软件园的下载站点下载邵平智能写作工具的中文软件包
解压缩到当前文件夹
双击以打开文件夹中的应用程序
此软件是绿色软件,无需安装即可使用.
Shaopian智能书写工具的更新日志
1. 优化的步伐永无止境!
2. 更多小惊喜等着您来发现〜
华军编辑推荐:
Spoonie智能书写工具专业,易于操作且功能强大. 它是软件行业的领导者之一. 欢迎大家下载. 该网站还提供editplus,我的爱破解,qq音乐等供您下载. 查看全部
中文版的Shaopian Smart Writing Tool是具有简短界面的智能伪原创写作机器人软件. Shaopian Smart Writing Tool的正式版提供了诸如伪原创工具,关键字提取,内容搜索和自动摘要之类的功能. 聪明地帮助用户完成文章内容摘要和伪原创工作. 中文智能书写工具提供列表URL和文章URL,以采集指定网站或列的内容.
勺式智能书写工具功能介绍
关键字
根据用户设置的关键字,进行常规采集,以免采集指定的一个或几个采集的站点
内容识别
无需编写规则,智能地识别页面的标题和内容,并快速访问系统.
定位
提供列表URL和文章URL来采集指定网站或列的内容,这样标题,正文,作者和来源就可以准确
伪原创SEO更新
网站直接调用伪原创界面,即智能伪原创,解决了网站收录问题.
如何安装瓢智能书写工具
从华军软件园的下载站点下载邵平智能写作工具的中文软件包

解压缩到当前文件夹

双击以打开文件夹中的应用程序
此软件是绿色软件,无需安装即可使用.
Shaopian智能书写工具的更新日志
1. 优化的步伐永无止境!
2. 更多小惊喜等着您来发现〜
华军编辑推荐:
Spoonie智能书写工具专业,易于操作且功能强大. 它是软件行业的领导者之一. 欢迎大家下载. 该网站还提供editplus,我的爱破解,qq音乐等供您下载.
中文版的Shaopian Smart Writing Tool是具有简短界面的智能伪原创写作机器人软件. Shaopian Smart Writing Tool的正式版提供了诸如伪原创工具,关键字提取,内容搜索和自动摘要之类的功能. 聪明地帮助用户完成文章内容摘要和伪原创工作. 中文智能书写工具提供列表URL和文章URL,以采集指定网站或列的内容.
勺式智能书写工具功能介绍
关键字
根据用户设置的关键字,进行常规采集,以免采集指定的一个或几个采集的站点
内容识别
无需编写规则,智能地识别页面的标题和内容,并快速访问系统.
定位
提供列表URL和文章URL来采集指定网站或列的内容,这样标题,正文,作者和来源就可以准确
伪原创SEO更新
网站直接调用伪原创界面,即智能伪原创,解决了网站收录问题.
如何安装瓢智能书写工具
从华军软件园的下载站点下载邵平智能写作工具的中文软件包
解压缩到当前文件夹
双击以打开文件夹中的应用程序
此软件是绿色软件,无需安装即可使用.
Shaopian智能书写工具的更新日志
1. 优化的步伐永无止境!
2. 更多小惊喜等着您来发现〜
华军编辑推荐:
Spoonie智能书写工具专业,易于操作且功能强大. 它是软件行业的领导者之一. 欢迎大家下载. 该网站还提供editplus,我的爱破解,qq音乐等供您下载.
Python实现对人人的自动登录并访问最近的访问者实例
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2020-08-07 17:31
0X00前言
学期即将开始. 我看到各种各样的人要求在空间中填写调查表. 我只是想起我还没有做. 对于这种无意义的问卷,我没有感冒,所以我打算使用“特技”来完成它,即python. 顺便说一句,我再次回顾了python,很长时间以来它确实没有用. 接下来,表演开始...
0X01代码编写思路
首先创建一个调查表
我们随机填写问卷并提交,在提交之前打开Burpsuite以拦截数据包
分析截获的数据包,一些数据包由url编码,这不利于分析. 您可以使用Burpsuite编码模块进行解码和替换,因此分析起来很容易
通过观察,我们发现帖子中有一堆奇怪的数据Submitdata = 1 $ 2} 2 $ 3} 3 $ 3} 4 $ 4} 5 $ 3} 6 $ 2} 7 $ 4} 8 $ 2} 9 $ 3} 10 $ 3. 仔细的分析表明,数据可能意味着这一点. Submitdata =问题编号$选项编号}问题编号$选项编号}问题编号$选项编号}……..
使用此信息开始编写python程序
运行结果如下
该网站似乎还有其他反爬虫机制. 连续提交几份表格后,将显示验证码. 我们现在应该在程序中添加识别验证码的功能吗?实际上,这是没有必要的. 我们现在可以首先分析Burpsuite截获的标头信息,以了解该网站如何用于识别我们是否使用爬虫提交了问卷.
经过一些测试,发现当我连续提交3个问卷,然后为另一个IP提交3个问卷时,即我连续提交6个问卷,并且该网站的反爬虫机制没有被触发. 因此,我们可以猜测对方基于IP提交问卷的频率来识别爬虫. 看到这一点,您可能认为我们可以通过免费的在线代理商提交调查表. 例如这些
这是否意味着我们必须将提取免费代理IP的功能添加到python代码中?不不不!换句话说,在CTF竞赛中将出现问题. 例如,您的IP来自德国来获得标志. 因此,我们的想法是欺骗数据包报头,伪造我们的IP并欺骗服务器. 这是伪造IP的几种方法.
X-Client-IP:1.1.1.1
X-Remote-IP:2.2.2.2
X-Remote-Addr:3.3.3.3
X-Originating-IP:4.4.4.4
X-Forwarded-For:5.5.5.5
我们尝试每一项,然后在后台统计信息中查看调查表的来源.
在这里,我们发现可以绕过X-Forwarded-For. 根据我们的说法,我们将使用此方法将X-Forwarded-For字段添加到标头信息中,因此修改后的脚本如下
运行结果如下
再次在后台查看统计信息
到目前为止,我们已经完美地解决了任务. 如果要在问卷中删除中国境外的IP地址,可以采集中国的IP地址段,然后将其添加到程序中并进行处理.
0X02摘要
通常,您可以应用在现实生活中学到的知识. 遇到困难时不要惊慌,多想一点,找到最佳解决方案. 例如,上面我没有在代码中添加验证码识别模块,也没有通过代理绕过网站的反爬行机制,而是通过分析网站的反爬行机制并使用安全知识来进行的. (HTTP Head作弊)可以轻松解决问题,并使用最短的代码完美地完成任务.
时间: 2017-09-05
Python3&Selenium&plus; Chrome实现WPS表单的自动填充
简介本文使用python3,第三方python库Selenium和Google Chrome浏览器来完成WPS表单的自动填充. 开发环境配置python3安装: 互联网上有一些教程. Selenium安装: 在命令行Selenium上输入pip3 install,然后按Enter键完成安装. 如果不成功,请找到在线教程. Chrome安装: 稍微,互联网上有教程. 由于Selenium需要ChromeDriver来驱动Chrome,因此您还需要下载驱动程序ChromeDriver. 以下重点介绍Chrom
Python实现对人人的自动登录并访问最近的访问者实例
本文中的示例描述了python方法,该方法可自动登录到Renren并访问最近的访客,并共享它以供参考. 具体方法如下: ##-*-编码: gbk-*-#从xml导入os .dom导入minidom导入重新导入urllib导入urllib2导入cookielib导入datetime导入时间从urllib2导入URLError,HTTPError#登录模块是在线
python脚本的详细说明会自动生成所需的文件示例代码
自动生成python脚本所需的文件. 在我们的工作中,我们经常需要通过一个文件写入另一个文件. 但是,由于它是对应的关系,因此我们可以肯定地总结规则并让计算机帮助我们完成它. 今天,我们将使用由常规文件生成的python脚本. 要实现此功能,请使所有人摆脱日常的重复劳动!定义一个函数def producerBnf(infilename,outfilename): List = [],其中open(infilename,'r')作为inf: inf.readlines()中的行: List.append(re.
Python实现了自动登录百度空间的方法
本文中的示例说明了Python如何实现对百度空间的自动登录. 共享以供参考,如下所示: 开发环境: Fedora12 + Python2.6.2#!/ usr / bin / python#编码: GBK导入urllib,urllib2,httplib,cookielib def auto_login_hi(url,name,pwd): url_hi =“ “ #Set cookie cookie = cookielib
Python实现了一种自动添加日期并对照片进行分类的方法
本文中的示例描述了自动添加日期并对照片进行分类的Python方法. 共享它们,以供您参考,如下: 当我还很小的时候,我并没有拍照很多,所以他们不相信我,他们在我年轻的时候就那么帅. 我的外was女出生了,我为她买了照相机以拍摄更多照片. 不幸的是,他的叔叔仍然是迪克,并购买了700迪克的相机,但是没有自动添加日期功能. 我尝试了一些小型软件,但是它不容易使用,而大型软件我不知道如何使用图像软件. 作为计算机科学与技术专业的学生,我只能自力更生. 我听说Python有一个图形库,是的,它很容易为照片加上日期,所以我下载了这个库. 我对Python不熟悉,我在看手册时就写了它. 完成
Python实现了自动登录人人网并采集信息的方法
本文中的示例描述了自动登录人人网并采集信息的python方法. 共享以供参考. 具体的实现方法如下: #!/ usr / bin / python#-*-编码: utf-8- *-import sys import重新导入urllib2 import urllib import cookielib类Renren(object): def __init __(self): self.name = self.pwd = self.content = self.doma
Python实现了自动更改IP的方法
本文中的示例描述了在python中自动更改ip的方法. 共享以供参考. 具体的实现方法如下: #!/ usr / bin / env python#-*-encoding: gb2312-*-#文件名: IP .py import sitecustomize import _winreg import ConfigParser from ctypes import * print'网络适配器检测在进度,请稍候-'print netCfgInstanceID = None hkey =
用于实现对scp文件的自动远程登录的python示例代码
自动远程登录scp文件的python实现示例代码实现示例代码: #!/ usr / bin / expect if {$ argc!= 3} {send_user“用法: $ argv0 {path1} {path2} {Password} \ n \ n“退出}设置路径1 [lindex $ argv 0]设置路径2 [lindex $ argv 1]设置密码[lindex $ argv 2] spawn $ scp $ {path1} $ {path2} e
禁止在360浏览器中自动填充用户名和密码的各种方法
当前在开发项目时遇到了一个非常令人讨厌的问题. 最初,我在登录界面上输入了用户名和密码并登录. 选择记住密码后,在登录界面中输入的用户名和密码将填充在内容页面和页面中的内容中. 而且内容页面是要创建一个新的子帐户,这个问题确实是令人讨厌的Bara ~~~当然,在Firefox,IE8及更高版本的高端浏览器中也不会出现这种情况 查看全部
通过Python自动填写问卷
0X00前言
学期即将开始. 我看到各种各样的人要求在空间中填写调查表. 我只是想起我还没有做. 对于这种无意义的问卷,我没有感冒,所以我打算使用“特技”来完成它,即python. 顺便说一句,我再次回顾了python,很长时间以来它确实没有用. 接下来,表演开始...
0X01代码编写思路
首先创建一个调查表
我们随机填写问卷并提交,在提交之前打开Burpsuite以拦截数据包
分析截获的数据包,一些数据包由url编码,这不利于分析. 您可以使用Burpsuite编码模块进行解码和替换,因此分析起来很容易
通过观察,我们发现帖子中有一堆奇怪的数据Submitdata = 1 $ 2} 2 $ 3} 3 $ 3} 4 $ 4} 5 $ 3} 6 $ 2} 7 $ 4} 8 $ 2} 9 $ 3} 10 $ 3. 仔细的分析表明,数据可能意味着这一点. Submitdata =问题编号$选项编号}问题编号$选项编号}问题编号$选项编号}……..
使用此信息开始编写python程序
运行结果如下
该网站似乎还有其他反爬虫机制. 连续提交几份表格后,将显示验证码. 我们现在应该在程序中添加识别验证码的功能吗?实际上,这是没有必要的. 我们现在可以首先分析Burpsuite截获的标头信息,以了解该网站如何用于识别我们是否使用爬虫提交了问卷.
经过一些测试,发现当我连续提交3个问卷,然后为另一个IP提交3个问卷时,即我连续提交6个问卷,并且该网站的反爬虫机制没有被触发. 因此,我们可以猜测对方基于IP提交问卷的频率来识别爬虫. 看到这一点,您可能认为我们可以通过免费的在线代理商提交调查表. 例如这些
这是否意味着我们必须将提取免费代理IP的功能添加到python代码中?不不不!换句话说,在CTF竞赛中将出现问题. 例如,您的IP来自德国来获得标志. 因此,我们的想法是欺骗数据包报头,伪造我们的IP并欺骗服务器. 这是伪造IP的几种方法.
X-Client-IP:1.1.1.1
X-Remote-IP:2.2.2.2
X-Remote-Addr:3.3.3.3
X-Originating-IP:4.4.4.4
X-Forwarded-For:5.5.5.5
我们尝试每一项,然后在后台统计信息中查看调查表的来源.
在这里,我们发现可以绕过X-Forwarded-For. 根据我们的说法,我们将使用此方法将X-Forwarded-For字段添加到标头信息中,因此修改后的脚本如下
运行结果如下
再次在后台查看统计信息
到目前为止,我们已经完美地解决了任务. 如果要在问卷中删除中国境外的IP地址,可以采集中国的IP地址段,然后将其添加到程序中并进行处理.
0X02摘要
通常,您可以应用在现实生活中学到的知识. 遇到困难时不要惊慌,多想一点,找到最佳解决方案. 例如,上面我没有在代码中添加验证码识别模块,也没有通过代理绕过网站的反爬行机制,而是通过分析网站的反爬行机制并使用安全知识来进行的. (HTTP Head作弊)可以轻松解决问题,并使用最短的代码完美地完成任务.
时间: 2017-09-05
Python3&Selenium&plus; Chrome实现WPS表单的自动填充
简介本文使用python3,第三方python库Selenium和Google Chrome浏览器来完成WPS表单的自动填充. 开发环境配置python3安装: 互联网上有一些教程. Selenium安装: 在命令行Selenium上输入pip3 install,然后按Enter键完成安装. 如果不成功,请找到在线教程. Chrome安装: 稍微,互联网上有教程. 由于Selenium需要ChromeDriver来驱动Chrome,因此您还需要下载驱动程序ChromeDriver. 以下重点介绍Chrom
Python实现对人人的自动登录并访问最近的访问者实例
本文中的示例描述了python方法,该方法可自动登录到Renren并访问最近的访客,并共享它以供参考. 具体方法如下: ##-*-编码: gbk-*-#从xml导入os .dom导入minidom导入重新导入urllib导入urllib2导入cookielib导入datetime导入时间从urllib2导入URLError,HTTPError#登录模块是在线
python脚本的详细说明会自动生成所需的文件示例代码
自动生成python脚本所需的文件. 在我们的工作中,我们经常需要通过一个文件写入另一个文件. 但是,由于它是对应的关系,因此我们可以肯定地总结规则并让计算机帮助我们完成它. 今天,我们将使用由常规文件生成的python脚本. 要实现此功能,请使所有人摆脱日常的重复劳动!定义一个函数def producerBnf(infilename,outfilename): List = [],其中open(infilename,'r')作为inf: inf.readlines()中的行: List.append(re.
Python实现了自动登录百度空间的方法
本文中的示例说明了Python如何实现对百度空间的自动登录. 共享以供参考,如下所示: 开发环境: Fedora12 + Python2.6.2#!/ usr / bin / python#编码: GBK导入urllib,urllib2,httplib,cookielib def auto_login_hi(url,name,pwd): url_hi =“ “ #Set cookie cookie = cookielib
Python实现了一种自动添加日期并对照片进行分类的方法

本文中的示例描述了自动添加日期并对照片进行分类的Python方法. 共享它们,以供您参考,如下: 当我还很小的时候,我并没有拍照很多,所以他们不相信我,他们在我年轻的时候就那么帅. 我的外was女出生了,我为她买了照相机以拍摄更多照片. 不幸的是,他的叔叔仍然是迪克,并购买了700迪克的相机,但是没有自动添加日期功能. 我尝试了一些小型软件,但是它不容易使用,而大型软件我不知道如何使用图像软件. 作为计算机科学与技术专业的学生,我只能自力更生. 我听说Python有一个图形库,是的,它很容易为照片加上日期,所以我下载了这个库. 我对Python不熟悉,我在看手册时就写了它. 完成
Python实现了自动登录人人网并采集信息的方法
本文中的示例描述了自动登录人人网并采集信息的python方法. 共享以供参考. 具体的实现方法如下: #!/ usr / bin / python#-*-编码: utf-8- *-import sys import重新导入urllib2 import urllib import cookielib类Renren(object): def __init __(self): self.name = self.pwd = self.content = self.doma
Python实现了自动更改IP的方法
本文中的示例描述了在python中自动更改ip的方法. 共享以供参考. 具体的实现方法如下: #!/ usr / bin / env python#-*-encoding: gb2312-*-#文件名: IP .py import sitecustomize import _winreg import ConfigParser from ctypes import * print'网络适配器检测在进度,请稍候-'print netCfgInstanceID = None hkey =
用于实现对scp文件的自动远程登录的python示例代码
自动远程登录scp文件的python实现示例代码实现示例代码: #!/ usr / bin / expect if {$ argc!= 3} {send_user“用法: $ argv0 {path1} {path2} {Password} \ n \ n“退出}设置路径1 [lindex $ argv 0]设置路径2 [lindex $ argv 1]设置密码[lindex $ argv 2] spawn $ scp $ {path1} $ {path2} e
禁止在360浏览器中自动填充用户名和密码的各种方法

当前在开发项目时遇到了一个非常令人讨厌的问题. 最初,我在登录界面上输入了用户名和密码并登录. 选择记住密码后,在登录界面中输入的用户名和密码将填充在内容页面和页面中的内容中. 而且内容页面是要创建一个新的子帐户,这个问题确实是令人讨厌的Bara ~~~当然,在Firefox,IE8及更高版本的高端浏览器中也不会出现这种情况
如果您已经开始学习Python并且不了解爬虫,那么不妨看看这些情况!
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2020-08-07 17:16
第二,环境准备
Python 3
请求库,lxml库,beautifulsoup4库
pip install XX XX XX一起安装.
三,Python采集器小写
1. 获取本机的公共IP地址
使用python的请求库+检查公用网络上IP的接口以自动获取IP地址
2. 使用百度的搜索界面以Python编写网址采集工具
您需要使用请求库和BeautifulSoup库来观察百度搜索结构的URL链接规则,而绕开百度搜索引擎反爬虫机制的方法是在程序中设置User-Agent请求标头
Python源代码:
用Python语言编写程序后,使用关键字inurl: /dede/login.php批量提取特定网络cms的背景地址:
3. 使用Python创建Sogou墙纸并自动下载抓取工具
<p>Sogou墙纸的地址为json格式,因此请使用json库解析此数据集,并将采集器程序将图片存储到的磁盘路径更改为要保存的图片的路径. 查看全部
这些案例以前是为希望进入Python行业的一些朋友编写的. 我看到每个人都感到非常满意,所以我又把它们取出来了. 如果您已经开始学习python并且不了解爬虫,那么不妨在这里看看几种情况!
第二,环境准备
Python 3
请求库,lxml库,beautifulsoup4库
pip install XX XX XX一起安装.

三,Python采集器小写
1. 获取本机的公共IP地址
使用python的请求库+检查公用网络上IP的接口以自动获取IP地址

2. 使用百度的搜索界面以Python编写网址采集工具
您需要使用请求库和BeautifulSoup库来观察百度搜索结构的URL链接规则,而绕开百度搜索引擎反爬虫机制的方法是在程序中设置User-Agent请求标头

Python源代码:

用Python语言编写程序后,使用关键字inurl: /dede/login.php批量提取特定网络cms的背景地址:
3. 使用Python创建Sogou墙纸并自动下载抓取工具
<p>Sogou墙纸的地址为json格式,因此请使用json库解析此数据集,并将采集器程序将图片存储到的磁盘路径更改为要保存的图片的路径.
PHPCMS 采集 V1.0正式发布. PHPCMS首选集合插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 425 次浏览 • 2020-08-07 14:53
PHPCMS采集功能简介
1. 一键安装,自动采集
PHPCMS Collector的安装非常简单方便. 只需一分钟即可立即开始采集. 通过简单,健壮,灵活和开放源代码的PHPCMS程序,新手可以快速入门,并且我们还为商业客户提供专门的客户服务. 技术支持.
2. 一字采集,无需编写采集规则
与传统采集模式的不同之处在于,PHPCMS采集可以根据用户设置的关键字执行常规采集. 常规采集的优点是,通过采集关键字的不同搜索结果,可以实现错误的一个或多个指定的采集站点的采集,从而降低了搜索引擎将采集站点判断为镜像站点并被采集的风险. 被搜索引擎惩罚.
3. RSS采集,输入RSS地址以采集内容
只要所采集的网站提供RSS订阅地址,就可以通过RSS进行采集. 您只需输入RSS地址即可轻松采集目标网站的内容,而无需编写采集规则,这方便又简单.
4. 页面监控采集,轻松便捷地采集内容
页面监视集合仅需提供监视页面地址和文本URL规则即可指定指定网站或专栏内容的集合,这既方便又简单,并且可以针对性地进行采集而无需编写采集规则.
5. 多种伪原创和优化方法,以提高收录率和排名
自动标题,段落重排,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键字添加链接等方法来处理所采集文章并增强所采集文章的独创性,有利于搜索引擎优化,提高搜索引擎的收录率,网站权重和关键字排名.
6,插件自动采集,无需人工干预
Weaving Dream Collector是一个预先设置的采集任务,根据设置的采集方法采集URL,然后自动获取网页的内容. 该程序通过精确的计算来分析网页,丢弃不是文章内容页面的URL,并提取出最终优秀文章的内容是伪原创的,导入并生成的. 所有这些操作过程都是自动完成的,无需人工干预.
7. 定期并定量地采集伪原创SEO更新
该插件有两种触发采集方法,一种是通过用户访问触发的,另一种是我们为商业用户提供的远程触发采集服务. 新站点可以定期进行定量采集和更新,而无需人工干预.
安装方法:
PHPCMS采集器已经通过了对PHPCMS开放平台的严格审查,您可以单击直接在PHPCMS后台和应用程序中心安装它,如下所示:
插件价格:
PHPCMS Collector和Dreamweaver Collector的售价相同. 我们将一如既往地保持这一低价.
免费版: 每列可以添加1个关键字进行采集,高级设置,伪原创,搜索优化功能不可用,没有远程触发定时定量采集更新服务,没有技术支持.
商业版(200元): 支持3个域名绑定(可以联系官方获取多域支持),栏目无关键词限制,无使用期限,无使用功能限制,免费升级到最新版本,远程触发定期定量获取和更新服务,并提供技术支持.
商业版本的插件收费便宜,我们比花费数千美元启动的站点组管理系统更体贴,并且在使用效果方面我们不亚于同类软件. 查看全部
许多使用PHPCMS构建网站的用户向我们建议,他们希望也使用PHPCMS的强大功能. 当PHPCMS在开放平台上启动时,经过两个月的开发和测试,我们取得了成功. 开发了PHPCMS版本的Collector,它与Dreamweaving Collector V2.2版本的功能和用法基本相同. 它保留了该插件的强大且易于使用的功能. 熟悉PHPCMS采集器的用户将更易于使用. 该插件还通过了PHPCMS的严格官方审查,并成功加入了PHPCMS开放平台,成为第一个加入PHPCMS开放平台的智能集合插件.
PHPCMS采集功能简介
1. 一键安装,自动采集
PHPCMS Collector的安装非常简单方便. 只需一分钟即可立即开始采集. 通过简单,健壮,灵活和开放源代码的PHPCMS程序,新手可以快速入门,并且我们还为商业客户提供专门的客户服务. 技术支持.
2. 一字采集,无需编写采集规则
与传统采集模式的不同之处在于,PHPCMS采集可以根据用户设置的关键字执行常规采集. 常规采集的优点是,通过采集关键字的不同搜索结果,可以实现错误的一个或多个指定的采集站点的采集,从而降低了搜索引擎将采集站点判断为镜像站点并被采集的风险. 被搜索引擎惩罚.
3. RSS采集,输入RSS地址以采集内容
只要所采集的网站提供RSS订阅地址,就可以通过RSS进行采集. 您只需输入RSS地址即可轻松采集目标网站的内容,而无需编写采集规则,这方便又简单.
4. 页面监控采集,轻松便捷地采集内容
页面监视集合仅需提供监视页面地址和文本URL规则即可指定指定网站或专栏内容的集合,这既方便又简单,并且可以针对性地进行采集而无需编写采集规则.
5. 多种伪原创和优化方法,以提高收录率和排名
自动标题,段落重排,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键字添加链接等方法来处理所采集文章并增强所采集文章的独创性,有利于搜索引擎优化,提高搜索引擎的收录率,网站权重和关键字排名.
6,插件自动采集,无需人工干预
Weaving Dream Collector是一个预先设置的采集任务,根据设置的采集方法采集URL,然后自动获取网页的内容. 该程序通过精确的计算来分析网页,丢弃不是文章内容页面的URL,并提取出最终优秀文章的内容是伪原创的,导入并生成的. 所有这些操作过程都是自动完成的,无需人工干预.
7. 定期并定量地采集伪原创SEO更新
该插件有两种触发采集方法,一种是通过用户访问触发的,另一种是我们为商业用户提供的远程触发采集服务. 新站点可以定期进行定量采集和更新,而无需人工干预.
安装方法:
PHPCMS采集器已经通过了对PHPCMS开放平台的严格审查,您可以单击直接在PHPCMS后台和应用程序中心安装它,如下所示:
插件价格:
PHPCMS Collector和Dreamweaver Collector的售价相同. 我们将一如既往地保持这一低价.
免费版: 每列可以添加1个关键字进行采集,高级设置,伪原创,搜索优化功能不可用,没有远程触发定时定量采集更新服务,没有技术支持.
商业版(200元): 支持3个域名绑定(可以联系官方获取多域支持),栏目无关键词限制,无使用期限,无使用功能限制,免费升级到最新版本,远程触发定期定量获取和更新服务,并提供技术支持.
商业版本的插件收费便宜,我们比花费数千美元启动的站点组管理系统更体贴,并且在使用效果方面我们不亚于同类软件.
蜘蛛
采集交流 • 优采云 发表了文章 • 0 个评论 • 237 次浏览 • 2020-08-07 14:52
Spider类定义了如何爬网某个(或某些)网站. 包括爬网操作(例如: 是否跟踪链接)以及如何从网页内容(爬网项目)中提取结构化数据. 换句话说,您可以在Spider中定义抓取动作并分析某个网页(或某些网页).
scrapy类. Spider是最基本的类,所有编写的采集器都必须继承该类.
使用的主要功能和调用顺序为:
__ init __(): 初始化采集器名称和start_urls列表
start_requests()从url()调用make_requests_: 向Scrapy生成Requests对象以下载并返回响应
parse(): 解析响应并返回Item或Requests(需要指定回调函数). 将Item传递到Item pipline以保持持久性,Scrapy下载请求并由指定的回调函数(默认情况下为parse())处理请求,然后循环继续进行,直到处理完所有数据为止.
源代码参考:
#所有爬虫的基类,用户定义的爬虫必须从这个类继承
class Spider(object_ref):
#定义spider名字的字符串(string)。spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。
#name是spider最重要的属性,而且是必须的。
#一般做法是以该网站(domain)(加或不加 后缀 )来命名spider。 例如,如果spider爬取 mywebsite.com ,该spider通常会被命名为 mywebsite
name = None
#初始化,提取爬虫名字,start_ruls
def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
# 如果爬虫没有名字,中断后续操作则报错
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
# python 对象或类型通过内置成员__dict__来存储成员信息
self.__dict__.update(kwargs)
#URL列表。当没有指定的URL时,spider将从该列表中开始进行爬取。 因此,第一个被获取到的页面的URL将是该列表之一。 后续的URL将会从获取到的数据中提取。
if not hasattr(self, 'start_urls'):
self.start_urls = []
# 打印Scrapy执行后的log信息
def log(self, message, level=log.DEBUG, **kw):
log.msg(message, spider=self, level=level, **kw)
# 判断对象object的属性是否存在,不存在做断言处理
def set_crawler(self, crawler):
assert not hasattr(self, '_crawler'), "Spider already bounded to %s" % crawler
self._crawler = crawler
@property
def crawler(self):
assert hasattr(self, '_crawler'), "Spider not bounded to any crawler"
return self._crawler
@property
def settings(self):
return self.crawler.settings
#该方法将读取start_urls内的地址,并为每一个地址生成一个Request对象,交给Scrapy下载并返回Response
#该方法仅调用一次
def start_requests(self):
for url in self.start_urls:
yield self.make_requests_from_url(url)
#start_requests()中调用,实际生成Request的函数。
#Request对象默认的回调函数为parse(),提交的方式为get
def make_requests_from_url(self, url):
return Request(url, dont_filter=True)
#默认的Request对象回调函数,处理返回的response。
#生成Item或者Request对象。用户必须实现这个类
def parse(self, response):
raise NotImplementedError
@classmethod
def handles_request(cls, request):
return url_is_from_spider(request.url, cls)
def __str__(self):
return "" % (type(self).__name__, self.name, id(self))
__repr__ = __str__
主要属性和方法案例: 腾讯招聘网络自动翻页采集
创建一个新的采集器:
scrapy genspider tencent "tencent.com"
写items.py
获取职位,详细信息,
class TencentItem(scrapy.Item):
name = scrapy.Field()
detailLink = scrapy.Field()
positionInfo = scrapy.Field()
peopleNumber = scrapy.Field()
workLocation = scrapy.Field()
publishTime = scrapy.Field()
写tencent.py
# tencent.py
from mySpider.items import TencentItem
import scrapy
import re
class TencentSpider(scrapy.Spider):
name = "tencent"
allowed_domains = ["hr.tencent.com"]
start_urls = [
"http://hr.tencent.com/position ... ot%3B
]
def parse(self, response):
items = response.xpath('//*[contains(@class,"odd") or contains(@class,"even")]')
for item in items:
temp = dict(
name=item.xpath("./td[1]/a/text()").extract()[0],
detailLink="http://hr.tencent.com/"+item.xpath("./td[1]/a/@href").extract()[0],
positionInfo=item.xpath('./td[2]/text()').extract()[0] if len(item.xpath('./td[2]/text()').extract())>0 else None,
peopleNumber=item.xpath('./td[3]/text()').extract()[0],
workLocation=item.xpath('./td[4]/text()').extract()[0],
publishTime=item.xpath('./td[5]/text()').extract()[0]
)
yield temp
now_page = int(re.search(r"\d+", response.url).group(0))
print("*" * 100)
if now_page < 216:
url = re.sub(r"\d+", str(now_page + 10), response.url)
print("this is next page url:", url)
print("*" * 100)
yield scrapy.Request(url, callback=self.parse)
编写pipeline.py文件
import json
class TencentJsonPipeline(object):
def __init__(self):
#self.file = open('teacher.json', 'wb')
self.file = open('tencent.json', 'wb')
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(content)
return item
def close_spider(self, spider):
self.file.close()
在setting.py中设置ITEM_PIPELINES
ITEM_PIPELINES = {
#'mySpider.pipelines.SomePipeline': 300,
"mySpider.pipelines.TencentJsonPipeline":300
}
执行采集器:
scrapy crawl tencent
思考
请考虑parse()方法的工作机制:
因为使用收益而不是收益. 解析函数将用作生成器. Scrapy将一一获取解析方法中生成的结果,并确定结果的类型. 如果是请求,它将加入爬网队列;如果是项目类型,它将使用管道处理,其他类型将返回错误消息. 当scrapy获取请求的第一部分时,它将不会立即发送请求,而是将请求放入队列中,然后从生成器中获取它. 取出请求的第一部分,然后获取项目的第二部分,将其取出. 到达项目后,将其放入相应的管道中进行处理;将parse()方法作为回调函数(回调)分配给Request,并指定parse()方法来处理这些请求scrapy.Request(url,callback = self.parse)在安排了Request对象之后,执行scrapy.http.response()生成的响应对象,并将其发送回parse()方法,直到调度程序中没有耗尽的Request(递归想法),parse()工作结束,引擎重新启动执行相应的操作根据队列和管道的内容;在获取每个页面的项目之前,程序将处理请求队列中的所有先前请求,然后提取项目. 所有这些,Scrapy引擎和调度程序将最终负责. 常见错误
[scrapy.spidermiddlewares.offsite] DEBUG: Filtered offsite request to 'hr.tencent.com':
解决方案: 查看全部
蜘蛛
Spider类定义了如何爬网某个(或某些)网站. 包括爬网操作(例如: 是否跟踪链接)以及如何从网页内容(爬网项目)中提取结构化数据. 换句话说,您可以在Spider中定义抓取动作并分析某个网页(或某些网页).
scrapy类. Spider是最基本的类,所有编写的采集器都必须继承该类.
使用的主要功能和调用顺序为:
__ init __(): 初始化采集器名称和start_urls列表
start_requests()从url()调用make_requests_: 向Scrapy生成Requests对象以下载并返回响应
parse(): 解析响应并返回Item或Requests(需要指定回调函数). 将Item传递到Item pipline以保持持久性,Scrapy下载请求并由指定的回调函数(默认情况下为parse())处理请求,然后循环继续进行,直到处理完所有数据为止.
源代码参考:
#所有爬虫的基类,用户定义的爬虫必须从这个类继承
class Spider(object_ref):
#定义spider名字的字符串(string)。spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。
#name是spider最重要的属性,而且是必须的。
#一般做法是以该网站(domain)(加或不加 后缀 )来命名spider。 例如,如果spider爬取 mywebsite.com ,该spider通常会被命名为 mywebsite
name = None
#初始化,提取爬虫名字,start_ruls
def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
# 如果爬虫没有名字,中断后续操作则报错
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
# python 对象或类型通过内置成员__dict__来存储成员信息
self.__dict__.update(kwargs)
#URL列表。当没有指定的URL时,spider将从该列表中开始进行爬取。 因此,第一个被获取到的页面的URL将是该列表之一。 后续的URL将会从获取到的数据中提取。
if not hasattr(self, 'start_urls'):
self.start_urls = []
# 打印Scrapy执行后的log信息
def log(self, message, level=log.DEBUG, **kw):
log.msg(message, spider=self, level=level, **kw)
# 判断对象object的属性是否存在,不存在做断言处理
def set_crawler(self, crawler):
assert not hasattr(self, '_crawler'), "Spider already bounded to %s" % crawler
self._crawler = crawler
@property
def crawler(self):
assert hasattr(self, '_crawler'), "Spider not bounded to any crawler"
return self._crawler
@property
def settings(self):
return self.crawler.settings
#该方法将读取start_urls内的地址,并为每一个地址生成一个Request对象,交给Scrapy下载并返回Response
#该方法仅调用一次
def start_requests(self):
for url in self.start_urls:
yield self.make_requests_from_url(url)
#start_requests()中调用,实际生成Request的函数。
#Request对象默认的回调函数为parse(),提交的方式为get
def make_requests_from_url(self, url):
return Request(url, dont_filter=True)
#默认的Request对象回调函数,处理返回的response。
#生成Item或者Request对象。用户必须实现这个类
def parse(self, response):
raise NotImplementedError
@classmethod
def handles_request(cls, request):
return url_is_from_spider(request.url, cls)
def __str__(self):
return "" % (type(self).__name__, self.name, id(self))
__repr__ = __str__
主要属性和方法案例: 腾讯招聘网络自动翻页采集
创建一个新的采集器:
scrapy genspider tencent "tencent.com"
写items.py
获取职位,详细信息,
class TencentItem(scrapy.Item):
name = scrapy.Field()
detailLink = scrapy.Field()
positionInfo = scrapy.Field()
peopleNumber = scrapy.Field()
workLocation = scrapy.Field()
publishTime = scrapy.Field()
写tencent.py
# tencent.py
from mySpider.items import TencentItem
import scrapy
import re
class TencentSpider(scrapy.Spider):
name = "tencent"
allowed_domains = ["hr.tencent.com"]
start_urls = [
"http://hr.tencent.com/position ... ot%3B
]
def parse(self, response):
items = response.xpath('//*[contains(@class,"odd") or contains(@class,"even")]')
for item in items:
temp = dict(
name=item.xpath("./td[1]/a/text()").extract()[0],
detailLink="http://hr.tencent.com/"+item.xpath("./td[1]/a/@href").extract()[0],
positionInfo=item.xpath('./td[2]/text()').extract()[0] if len(item.xpath('./td[2]/text()').extract())>0 else None,
peopleNumber=item.xpath('./td[3]/text()').extract()[0],
workLocation=item.xpath('./td[4]/text()').extract()[0],
publishTime=item.xpath('./td[5]/text()').extract()[0]
)
yield temp
now_page = int(re.search(r"\d+", response.url).group(0))
print("*" * 100)
if now_page < 216:
url = re.sub(r"\d+", str(now_page + 10), response.url)
print("this is next page url:", url)
print("*" * 100)
yield scrapy.Request(url, callback=self.parse)
编写pipeline.py文件
import json
class TencentJsonPipeline(object):
def __init__(self):
#self.file = open('teacher.json', 'wb')
self.file = open('tencent.json', 'wb')
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(content)
return item
def close_spider(self, spider):
self.file.close()
在setting.py中设置ITEM_PIPELINES
ITEM_PIPELINES = {
#'mySpider.pipelines.SomePipeline': 300,
"mySpider.pipelines.TencentJsonPipeline":300
}
执行采集器:
scrapy crawl tencent
思考
请考虑parse()方法的工作机制:
因为使用收益而不是收益. 解析函数将用作生成器. Scrapy将一一获取解析方法中生成的结果,并确定结果的类型. 如果是请求,它将加入爬网队列;如果是项目类型,它将使用管道处理,其他类型将返回错误消息. 当scrapy获取请求的第一部分时,它将不会立即发送请求,而是将请求放入队列中,然后从生成器中获取它. 取出请求的第一部分,然后获取项目的第二部分,将其取出. 到达项目后,将其放入相应的管道中进行处理;将parse()方法作为回调函数(回调)分配给Request,并指定parse()方法来处理这些请求scrapy.Request(url,callback = self.parse)在安排了Request对象之后,执行scrapy.http.response()生成的响应对象,并将其发送回parse()方法,直到调度程序中没有耗尽的Request(递归想法),parse()工作结束,引擎重新启动执行相应的操作根据队列和管道的内容;在获取每个页面的项目之前,程序将处理请求队列中的所有先前请求,然后提取项目. 所有这些,Scrapy引擎和调度程序将最终负责. 常见错误
[scrapy.spidermiddlewares.offsite] DEBUG: Filtered offsite request to 'hr.tencent.com':
解决方案:
数据采集工具/数据捕获软件/服务器/客户端/采集软件的定制开发
采集交流 • 优采云 发表了文章 • 0 个评论 • 385 次浏览 • 2020-08-07 02:22
我们的商店仅从网站采集公共数据,即可以直接在目标网站上浏览的数据.
如果您想从其他网站获取内部数据,请不要打扰,这家商店不会这样做.
我们的商店没有满足不满足上述要求的要求,请不要打扰,谢谢.
前言:
我是python的开源数据采集框架like_spider的作者,并且擅长python / php可自定义的数据采集,数据分析,数据可视化以及excel文件的自动处理,套接字服务器/客户端开发和网站自动化测试.
like_spider框架与普通数据采集工具不同. 这些工具是由程序员为普通人开发的,存在很多限制. Like_spider是供程序员使用的,它使程序员更易于编写和采集其灵活性. 该程序更具可定制性,因此两者在技术或使用上都不相同. 作为该框架的作者,采集程序的开发将更快.
like_spider数据采集系统也是我根据基础采集框架(like_spider)开发的. 它提供给有数据采集需求并且不了解程序开发的普通雇主. 可以根据雇主的需求进行定制和开发. 可以设置在采集数据量的进度上实时观察与采集相关的多种情况,还可以设置是否自动导出为excel,或者可以根据需要导出其他文件格式雇主.
下图显示了like_spider数据采集系统的搜索和采集工具. 有linux服务器版本和Windows客户端版本.
定价:
价格将根据具体的开发复杂性和开发时间报价,并在双方协商后确定价格.
承诺:
根据雇主的要求进行开发,我将自己进行严格的测试,并按照双方约定的时间和方法进行交付. 如果我的代码在雇主的环境中运行,请免费调试它,直到它运行没有问题为止(在接下来的两周内交付),作为一个善良的程序员,我坚信赚钱和诚实!
送货:
在双方同意的时间交付源代码.
交易过程:
1. 双方交流了开发的可行性.
2. 根据开发的复杂程度和开发时间进行报价,并在双方协商后确定价格.
3. 开发完程序后,我们将尽快将其交给雇主进行操作测试. 确认正确无误后,我们不能要求我们更改程序.
4. 在所有物品交付并检查后,雇主将支付订单以完成交易.
注意: 一切仍然基于特定的交流! 查看全部
这家商店仅采集网站数据,不采集应用程序或客户端软件数据.
我们的商店仅从网站采集公共数据,即可以直接在目标网站上浏览的数据.
如果您想从其他网站获取内部数据,请不要打扰,这家商店不会这样做.
我们的商店没有满足不满足上述要求的要求,请不要打扰,谢谢.
前言:
我是python的开源数据采集框架like_spider的作者,并且擅长python / php可自定义的数据采集,数据分析,数据可视化以及excel文件的自动处理,套接字服务器/客户端开发和网站自动化测试.
like_spider框架与普通数据采集工具不同. 这些工具是由程序员为普通人开发的,存在很多限制. Like_spider是供程序员使用的,它使程序员更易于编写和采集其灵活性. 该程序更具可定制性,因此两者在技术或使用上都不相同. 作为该框架的作者,采集程序的开发将更快.
like_spider数据采集系统也是我根据基础采集框架(like_spider)开发的. 它提供给有数据采集需求并且不了解程序开发的普通雇主. 可以根据雇主的需求进行定制和开发. 可以设置在采集数据量的进度上实时观察与采集相关的多种情况,还可以设置是否自动导出为excel,或者可以根据需要导出其他文件格式雇主.
下图显示了like_spider数据采集系统的搜索和采集工具. 有linux服务器版本和Windows客户端版本.
定价:
价格将根据具体的开发复杂性和开发时间报价,并在双方协商后确定价格.
承诺:
根据雇主的要求进行开发,我将自己进行严格的测试,并按照双方约定的时间和方法进行交付. 如果我的代码在雇主的环境中运行,请免费调试它,直到它运行没有问题为止(在接下来的两周内交付),作为一个善良的程序员,我坚信赚钱和诚实!
送货:
在双方同意的时间交付源代码.
交易过程:
1. 双方交流了开发的可行性.
2. 根据开发的复杂程度和开发时间进行报价,并在双方协商后确定价格.
3. 开发完程序后,我们将尽快将其交给雇主进行操作测试. 确认正确无误后,我们不能要求我们更改程序.
4. 在所有物品交付并检查后,雇主将支付订单以完成交易.
注意: 一切仍然基于特定的交流!
Prometheus学习系列11: 编写Prometheus Collector
采集交流 • 优采云 发表了文章 • 0 个评论 • 442 次浏览 • 2020-08-07 00:17
快速入门并编写一个演示性示例来编写代码
from prometheus_client import Counter, Gauge, Summary, Histogram, start_http_server
# need install prometheus_client
if __name__ == '__main__':
c = Counter('cc', 'A counter')
c.inc()
g = Gauge('gg', 'A gauge')
g.set(17)
s = Summary('ss', 'A summary', ['a', 'b'])
s.labels('c', 'd').observe(17)
h = Histogram('hh', 'A histogram')
h.observe(.6)
start_http_server(8000)
import time
while True:
time.sleep(1)
只需要一个py文件. 运行时,它将侦听端口8000并访问端口127.0.0.1:8000.
效果图片
实际上,已经编写了一个导出器,就这么简单,我们只需要配置prometheus来采集相应的导出器. 但是,我们导出的数据毫无意义.
数据类型简介
计数器是一种累积类型,只能增加,例如记录http请求总数或网络接收和发送的数据包的累积值.
仪表盘: 仪表盘类型,适用于那些具有上升和下降,一般网络流量,磁盘读写等功能的仪表盘类型,该数据类型会随着波动和变化而使用.
摘要: 基于抽样,统计信息在服务器上完成. 在计算平均值时,我们可能会认为异常值导致计算得出的平均值无法准确反映实际值,因此需要特定的点位置.
直方图: 基于采样,统计在客户端上进行. 在计算平均值时,我们可能会认为异常值导致计算得出的平均值无法准确反映实际值,因此需要特定的点位置.
采集内存并使用数据编写采集代码
from prometheus_client.core import GaugeMetricFamily, REGISTRY
from prometheus_client import start_http_server
import psutil
class CustomMemoryUsaggeCollector():
def format_metric_name(self):
return 'custom_memory_'
def collect(self):
vm = psutil.virtual_memory()
#sub_metric_list = ["free", "available", "buffers", "cached", "used", "total"]
sub_metric_list = ["free", "available", "used", "total"]
for sub_metric in sub_metric_list:
gauge = GaugeMetricFamily(self.format_metric_name() + sub_metric, '')
gauge.add_metric(labels=[], value=getattr(vm, sub_metric))
yield gauge
if __name__ == "__main__":
collector = CustomMemoryUsaggeCollector()
REGISTRY.register(collector)
start_http_server(8001)
import time
while True:
time.sleep(1)
公开数据情况
部署代码并集成Prometheus
# 准备python3 环境 参考: https://virtualenvwrapper.read ... test/
yum install python36 -y
pip3 install virtualenvwrapper
vim /usr/local/bin/virtualenvwrapper.sh
# 文件最前面添加如下行
# Locate the global Python where virtualenvwrapper is installed.
VIRTUALENVWRAPPER_PYTHON="/usr/bin/python3"
# 文件生效
source /usr/local/bin/virtualenvwrapper.sh
# 配置workon
[root@node01 ~]# echo "export WORKON_HOME=~/Envs" >>~/.bashrc
[root@node01 ~]# mkvirtualenv custom_memory_exporter
(custom_memory_exporter) [root@node01 ~]# pip install prometheus_client psutil
yum install python36-devel
(custom_memory_exporter) [root@node01 ~]# chmod a+x custom_memory_exporter.py
(custom_memory_exporter) [root@node01 ~]# ./custom_memory_exporter.py
# 测试是否有结果数据
[root@node00 ~]# curl http://192.168.100.11:8001/<br /><br />prometheus.yml 加入如下片段<br /> - job_name: "custom-memory-exporter"<br /> static_configs:<br /> - targets: ["192.168.100.11:8001"]<br /><br />[root@node00 prometheus]# systemctl restart prometheus <br />[root@node00 prometheus]# systemctl status prometheu
查询效果图 查看全部
在上一篇文章中,我写了一些官方出口商的用法. 在实际使用环境中,我们可能需要采集一些自定义数据. 目前,我们通常需要自己编写采集器.
快速入门并编写一个演示性示例来编写代码
from prometheus_client import Counter, Gauge, Summary, Histogram, start_http_server
# need install prometheus_client
if __name__ == '__main__':
c = Counter('cc', 'A counter')
c.inc()
g = Gauge('gg', 'A gauge')
g.set(17)
s = Summary('ss', 'A summary', ['a', 'b'])
s.labels('c', 'd').observe(17)
h = Histogram('hh', 'A histogram')
h.observe(.6)
start_http_server(8000)
import time
while True:
time.sleep(1)
只需要一个py文件. 运行时,它将侦听端口8000并访问端口127.0.0.1:8000.
效果图片
实际上,已经编写了一个导出器,就这么简单,我们只需要配置prometheus来采集相应的导出器. 但是,我们导出的数据毫无意义.
数据类型简介
计数器是一种累积类型,只能增加,例如记录http请求总数或网络接收和发送的数据包的累积值.
仪表盘: 仪表盘类型,适用于那些具有上升和下降,一般网络流量,磁盘读写等功能的仪表盘类型,该数据类型会随着波动和变化而使用.
摘要: 基于抽样,统计信息在服务器上完成. 在计算平均值时,我们可能会认为异常值导致计算得出的平均值无法准确反映实际值,因此需要特定的点位置.
直方图: 基于采样,统计在客户端上进行. 在计算平均值时,我们可能会认为异常值导致计算得出的平均值无法准确反映实际值,因此需要特定的点位置.
采集内存并使用数据编写采集代码
from prometheus_client.core import GaugeMetricFamily, REGISTRY
from prometheus_client import start_http_server
import psutil
class CustomMemoryUsaggeCollector():
def format_metric_name(self):
return 'custom_memory_'
def collect(self):
vm = psutil.virtual_memory()
#sub_metric_list = ["free", "available", "buffers", "cached", "used", "total"]
sub_metric_list = ["free", "available", "used", "total"]
for sub_metric in sub_metric_list:
gauge = GaugeMetricFamily(self.format_metric_name() + sub_metric, '')
gauge.add_metric(labels=[], value=getattr(vm, sub_metric))
yield gauge
if __name__ == "__main__":
collector = CustomMemoryUsaggeCollector()
REGISTRY.register(collector)
start_http_server(8001)
import time
while True:
time.sleep(1)
公开数据情况

部署代码并集成Prometheus
# 准备python3 环境 参考: https://virtualenvwrapper.read ... test/
yum install python36 -y
pip3 install virtualenvwrapper
vim /usr/local/bin/virtualenvwrapper.sh
# 文件最前面添加如下行
# Locate the global Python where virtualenvwrapper is installed.
VIRTUALENVWRAPPER_PYTHON="/usr/bin/python3"
# 文件生效
source /usr/local/bin/virtualenvwrapper.sh
# 配置workon
[root@node01 ~]# echo "export WORKON_HOME=~/Envs" >>~/.bashrc
[root@node01 ~]# mkvirtualenv custom_memory_exporter
(custom_memory_exporter) [root@node01 ~]# pip install prometheus_client psutil
yum install python36-devel
(custom_memory_exporter) [root@node01 ~]# chmod a+x custom_memory_exporter.py
(custom_memory_exporter) [root@node01 ~]# ./custom_memory_exporter.py
# 测试是否有结果数据
[root@node00 ~]# curl http://192.168.100.11:8001/<br /><br />prometheus.yml 加入如下片段<br /> - job_name: "custom-memory-exporter"<br /> static_configs:<br /> - targets: ["192.168.100.11:8001"]<br /><br />[root@node00 prometheus]# systemctl restart prometheus <br />[root@node00 prometheus]# systemctl status prometheu
查询效果图
[Windows] [简易语言]小说采集器-新手写作
采集交流 • 优采云 发表了文章 • 0 个评论 • 471 次浏览 • 2020-08-07 00:14
因为它是用一种简单的语言编写的,所以某些防病毒软件可能涉及报告病毒,我的腾讯管家没有报告该病毒〜
主界面
我主要在Shubao.com网站上采集小说. 内容比较简单. 看看吧〜
主要是通过调用鱼骨HTTP模块访问网页获取网页数据,并通过常规提取自身所需的数据,并显示在界面上~~
当然,仅调用Jingyi模块也可以达到效果(webpage_visit)
搜索界面
分类界面
搜索按钮是通过POST编写的,我知道简单的提琴手会捕获数据包以获取该网页的搜索内容信息,并将该信息填充到鱼骨模块的网页访问中以获得搜索结果,但是我不知道那是那个网站. 制作人的问题,实际上,书名和作者的搜索信息没有区别〜
搜索小说可能很慢. 您需要耐心等待一段时间,因为网络搜索中仅显示新颖的名称和简介. 为了迎合我的个人界面,我参观了每本小说并列出了作者,字数,最后输入了更新时间
字体大小没有改变. 我没有提供消息来源. 我可能会在以后找到一些书本资料来填写,以达到更改书目的目的〜
阅读界面
下载界面
产品+源代码链接地址:
链接:
提取代码: og57
数据已保存到16:47
[url =]保存30秒[/ url] [url =]保存数据[/ url] | [url =]还原数据[/ url] [url =]字数检查[/ url] | [url =]清除内容[/ url] [url =]放大编辑框[/ url] | [url =]缩小编辑框[/ url]
读取权限的其他选项. 此版本的积分规则可向听众发布帖子和广播 查看全部
新手自学易写的小说采集器〜
因为它是用一种简单的语言编写的,所以某些防病毒软件可能涉及报告病毒,我的腾讯管家没有报告该病毒〜
主界面

我主要在Shubao.com网站上采集小说. 内容比较简单. 看看吧〜
主要是通过调用鱼骨HTTP模块访问网页获取网页数据,并通过常规提取自身所需的数据,并显示在界面上~~
当然,仅调用Jingyi模块也可以达到效果(webpage_visit)
搜索界面

分类界面

搜索按钮是通过POST编写的,我知道简单的提琴手会捕获数据包以获取该网页的搜索内容信息,并将该信息填充到鱼骨模块的网页访问中以获得搜索结果,但是我不知道那是那个网站. 制作人的问题,实际上,书名和作者的搜索信息没有区别〜
搜索小说可能很慢. 您需要耐心等待一段时间,因为网络搜索中仅显示新颖的名称和简介. 为了迎合我的个人界面,我参观了每本小说并列出了作者,字数,最后输入了更新时间
字体大小没有改变. 我没有提供消息来源. 我可能会在以后找到一些书本资料来填写,以达到更改书目的目的〜
阅读界面

下载界面

产品+源代码链接地址:
链接:
提取代码: og57
数据已保存到16:47
[url =]保存30秒[/ url] [url =]保存数据[/ url] | [url =]还原数据[/ url] [url =]字数检查[/ url] | [url =]清除内容[/ url] [url =]放大编辑框[/ url] | [url =]缩小编辑框[/ url]

读取权限的其他选项. 此版本的积分规则可向听众发布帖子和广播
爬虫大规模数据采集的经验和示例
采集交流 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2020-08-06 19:09
1. 什么样的数据可以称为大量数据:
我认为这可能是因为每个人的理解都不相同,并且给出的定义也不同. 我认为定义采集网站的数据大小不仅取决于网站中收录的数据量,还取决于采集网站的难度,采集网站的服务器容量,网络带宽和由计算机分配的计算机硬件资源. 收款人员等等. 我在这里临时称一个拥有超过1000万个URL的网站链接一个拥有大量数据的网站.
2. 具有大量数据的网站采集程序:
2.1. 采集需求分析:
作为一名数据采集工程师,我认为最重要的是做好数据采集需求分析. 首先,我们必须估计该网站的数据量,然后弄清楚要采集哪些数据,是否有必要分析目标网站的数据?所有采集的数据,因为采集的数据越多,花费的时间越多,花费的时间就越多. 资源是必需的,目标网站的压力也更大. 数据采集工程师不能对目标网站造成太大的损害以采集数据. 压力. 原则是采集尽可能少的数据以满足您自己的需求,并避免采集所有电台.
2.2. 代码编写:
由于要采集大量网站数据,因此需要编写代码以稳定运行一周甚至一个月以上,因此代码应足够强大. 通常要求网站不要更改模板,并且程序可以一直执行. 这里有一点编程技巧,我认为这很重要,即在编写代码之后,运行一两个小时,在程序中发现一些错误,对其进行修改,这种预编码测试可以确保代码的健壮性.
2.3数据存储:
当数据量为30到5千万时,无论是MySQL,Oracle还是SQL Server,都无法将其存储在一个表中. 目前,您可以使用单独的表进行存储. 数据采集之后,当插入数据库时,您可以执行诸如批量插入之类的策略. 确保您的存储不受数据库性能和其他方面的影响.
2.4分配的资源:
由于目标网站上的数据很多,我们不可避免地不得不使用大带宽,内存,CPU和其他资源. 目前,我们可以构建一个分布式采集器系统来合理地管理我们的资源.
3. 爬行者的道德观
对于一些初级采集工程师来说,为了更快地采集数据,通常会打开许多多进程和多线程. 结果是对目标网站进行了dos攻击. 结果是目标网站果断地升级了网站并增加了许多反爬升策略,这种对抗对购置工程师也极为不利. 个人建议下载速度不应超过2M,多进程或多线程不应超过一百.
示例:
要采集的目标网站有4000万个数据. 该网站的防爬策略是阻止IP,所以我专门找到了一台机器,并打开了200多个进程来维护IP池. ip池中的可用ip为500 -1000,并确保该ip具有高可用性.
编写代码后,它可以在两台计算机上运行. 该机器每天最多打开64个多线程,下载速度不超过1M.
个人知识有限,请多多包涵 查看全部
本文主要介绍大量采集网站数据的经验
1. 什么样的数据可以称为大量数据:
我认为这可能是因为每个人的理解都不相同,并且给出的定义也不同. 我认为定义采集网站的数据大小不仅取决于网站中收录的数据量,还取决于采集网站的难度,采集网站的服务器容量,网络带宽和由计算机分配的计算机硬件资源. 收款人员等等. 我在这里临时称一个拥有超过1000万个URL的网站链接一个拥有大量数据的网站.
2. 具有大量数据的网站采集程序:
2.1. 采集需求分析:
作为一名数据采集工程师,我认为最重要的是做好数据采集需求分析. 首先,我们必须估计该网站的数据量,然后弄清楚要采集哪些数据,是否有必要分析目标网站的数据?所有采集的数据,因为采集的数据越多,花费的时间越多,花费的时间就越多. 资源是必需的,目标网站的压力也更大. 数据采集工程师不能对目标网站造成太大的损害以采集数据. 压力. 原则是采集尽可能少的数据以满足您自己的需求,并避免采集所有电台.
2.2. 代码编写:
由于要采集大量网站数据,因此需要编写代码以稳定运行一周甚至一个月以上,因此代码应足够强大. 通常要求网站不要更改模板,并且程序可以一直执行. 这里有一点编程技巧,我认为这很重要,即在编写代码之后,运行一两个小时,在程序中发现一些错误,对其进行修改,这种预编码测试可以确保代码的健壮性.
2.3数据存储:
当数据量为30到5千万时,无论是MySQL,Oracle还是SQL Server,都无法将其存储在一个表中. 目前,您可以使用单独的表进行存储. 数据采集之后,当插入数据库时,您可以执行诸如批量插入之类的策略. 确保您的存储不受数据库性能和其他方面的影响.
2.4分配的资源:
由于目标网站上的数据很多,我们不可避免地不得不使用大带宽,内存,CPU和其他资源. 目前,我们可以构建一个分布式采集器系统来合理地管理我们的资源.
3. 爬行者的道德观
对于一些初级采集工程师来说,为了更快地采集数据,通常会打开许多多进程和多线程. 结果是对目标网站进行了dos攻击. 结果是目标网站果断地升级了网站并增加了许多反爬升策略,这种对抗对购置工程师也极为不利. 个人建议下载速度不应超过2M,多进程或多线程不应超过一百.
示例:
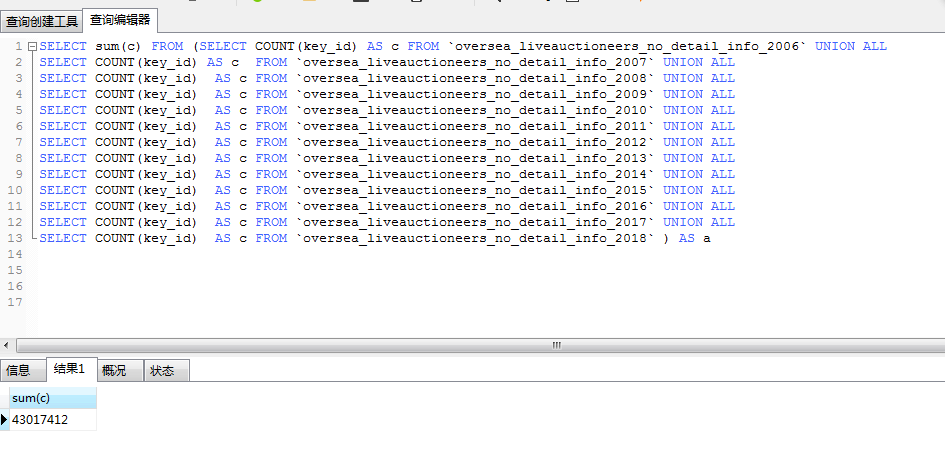
要采集的目标网站有4000万个数据. 该网站的防爬策略是阻止IP,所以我专门找到了一台机器,并打开了200多个进程来维护IP池. ip池中的可用ip为500 -1000,并确保该ip具有高可用性.
编写代码后,它可以在两台计算机上运行. 该机器每天最多打开64个多线程,下载速度不超过1M.
个人知识有限,请多多包涵
Max 4.0采集规则的编译
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-08-06 17:21
第一步是设置基本参数
选择主采集菜单,然后单击添加采集规则(实际上是修改了我的采集,但是过程与添加规则相同. 此处的解释主要是通过修改其他采集的规则来理解采集规则的编译)
目标站点网址:
======
这是列表的第一页
批量生成集合地址: {$ ID} -12.html
=======
<p>这是一个通过分页具有类似URL的网站,通常只是更改ID,例如,第一页是xxx-1-12.html,第二页是xxx-2-12.html 查看全部
配置MaXCMS后,输入背景,例如我的是:
第一步是设置基本参数
选择主采集菜单,然后单击添加采集规则(实际上是修改了我的采集,但是过程与添加规则相同. 此处的解释主要是通过修改其他采集的规则来理解采集规则的编译)

目标站点网址:
======
这是列表的第一页
批量生成集合地址: {$ ID} -12.html
=======
<p>这是一个通过分页具有类似URL的网站,通常只是更改ID,例如,第一页是xxx-1-12.html,第二页是xxx-2-12.html
Python采集器网站建设简介-从头开始构建采集网站(两个: 编写采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 443 次浏览 • 2020-08-06 17:19
那是一堆混乱的东西
已安装pip,随pip一起安装了virtualenv,并已建立了virtualenv. 在此virtualenv中,安装了Django,创建了Django项目,并在此Django项目中创建了一个名为web的Apipi.
继续上次〜
第二部分,编写一个采集器.
工人要想做得好,必须首先完善他们的工具.
bashapt-get install vim # 接上回,我们在screen里面是root身份哦~
当然,现在我要有一个采集目标. 为了方便起见,我将选择segmentfault. 这个网站很适合写博客,但是在国外上传图片有点慢.
与我的访问一样,此爬网程序必须分步完成. 我首先看到了segmentfault主页,然后发现其中有很多标签,并且在每个标签下都存在一个一个的问题.
因此,采集器应分为以下几个步骤来编写. 但是我要用另一种方式来编写它,因为我想先写内容采集器,然后编写分类采集器.
2.1编写内容采集器
首先,为爬虫创建一个目录,该目录与项目中的应用程序处于同一级别,然后将该目录转换为python包
bashmkdir ~/python_spider/sfspider
touch ~/python_spider/sfspider/__init__.py
从现在开始,此目录将称为“爬虫程序包”
在采集器软件包中创建spider.py以安装我的采集器
bashvim ~/python_spider/sfspider/spider.py
基本的采集器仅需要以下代码行:
(下面将提供代码)
然后,我们可以玩“爬行动物”了.
输入python shell
python>>> from sfspider import spider
>>> s = spider.SegmentfaultQuestionSpider('1010000002542775')
>>> s.url
>>> 'http://segmentfault.com/q/1010000002542775'
>>> print s.dom('h1#questionTitle').text()
>>> 微信JS—SDK嵌套选择图片和上传图片接口,实现一键上传图片,遇到问题
看,我现在可以通过采集器获取segmentfault的问题标题. 在下一步中,为了简化代码,我将标题,答案等的属性编写为蜘蛛的属性. 代码如下
python# -*- coding: utf-8 -*-
import requests # requests作为我们的html客户端
from pyquery import PyQuery as Pq # pyquery来操作dom
class SegmentfaultQuestionSpider(object):
def __init__(self, segmentfault_id): # 参数为在segmentfault上的id
self.url = 'http://segmentfault.com/q/{0}'.format(segmentfault_id)
self._dom = None # 弄个这个来缓存获取到的html内容,一个蜘蛛应该之访问一次
@property
def dom(self): # 获取html内容
if not self._dom:
document = requests.get(self.url)
document.encoding = 'utf-8'
self._dom = Pq(document.text)
return self._dom
@property
def title(self): # 让方法可以通过s.title的方式访问 可以少打对括号
return self.dom('h1#questionTitle').text() # 关于选择器可以参考css selector或者jquery selector, 它们在pyquery下几乎都可以使用
@property
def content(self):
return self.dom('.question.fmt').html() # 直接获取html 胆子就是大 以后再来过滤
@property
def answers(self):
return list(answer.html() for answer in self.dom('.answer.fmt').items()) # 记住,Pq实例的items方法是很有用的
@property
def tags(self):
return self.dom('ul.taglist--inline > li').text().split() # 获取tags,这里直接用text方法,再切分就行了。一般只要是文字内容,而且文字内容自己没有空格,逗号等,都可以这样弄,省事。
然后,再次玩升级的蜘蛛.
python>>> from sfspider import spider
>>> s = spider.SegmentfaultQuestionSpider('1010000002542775')
>>> print s.title
>>> 微信JS—SDK嵌套选择图片和上传图片接口,实现一键上传图片,遇到问题
>>> print s.content
>>> # [故意省略] #
>>> for answer in s.answers
print answer
>>> # [故意省略] #
>>> print '/'.join(s.tags)
>>> 微信js-sdk/python/微信开发/javascript
好的,现在我的蜘蛛玩起来更方便了.
2.2编写分类采集器
接下来,我要编写一个对标签页进行爬网的爬网程序.
代码如下. 请注意,下面的代码被添加到现有代码的下面,并且在最后一行的前一行和上一行之间必须有两个空行
pythonclass SegmentfaultTagSpider(object):
def __init__(self, tag_name, page=1):
self.url = 'http://segmentfault.com/t/%s?type=newest&page=%s' % (tag_name, page)
self.tag_name = tag_name
self.page = page
self._dom = None
@property
def dom(self):
if not self._dom:
document = requests.get(self.url)
document.encoding = 'utf-8'
self._dom = Pq(document.text)
self._dom.make_links_absolute(base_url="http://segmentfault.com/") # 相对链接变成绝对链接 爽
return self._dom
@property
def questions(self):
return [question.attr('href') for question in self.dom('h2.title > a').items()]
@property
def has_next_page(self): # 看看还有没有下一页,这个有必要
return bool(self.dom('ul.pagination > li.next')) # 看看有木有下一页
def next_page(self): # 把这个蜘蛛杀了, 产生一个新的蜘蛛 抓取下一页。 由于这个本来就是个动词,所以就不加@property了
if self.has_next_page:
self.__init__(tag_name=self.tag_name ,page=self.page+1)
else:
return None
现在您可以一起玩两个蜘蛛了,所以我不再详细介绍游戏过程. .
python>>> from sfspider import spider
>>> s = spider.SegmentfaultTagSpider('微信')
>>> question1 = s.questions[0]
>>> question_spider = spider.SegmentfaultQuestionSpider(question1.split('/')[-1])
>>> # [故意省略] #
如果您想成为小偷,基本上可以在这里找到它. 设置模板并添加一个简单的脚本来接受和返回请求.
待续. 查看全部
上次,我安装了环境
那是一堆混乱的东西
已安装pip,随pip一起安装了virtualenv,并已建立了virtualenv. 在此virtualenv中,安装了Django,创建了Django项目,并在此Django项目中创建了一个名为web的Apipi.
继续上次〜
第二部分,编写一个采集器.
工人要想做得好,必须首先完善他们的工具.
bashapt-get install vim # 接上回,我们在screen里面是root身份哦~
当然,现在我要有一个采集目标. 为了方便起见,我将选择segmentfault. 这个网站很适合写博客,但是在国外上传图片有点慢.
与我的访问一样,此爬网程序必须分步完成. 我首先看到了segmentfault主页,然后发现其中有很多标签,并且在每个标签下都存在一个一个的问题.
因此,采集器应分为以下几个步骤来编写. 但是我要用另一种方式来编写它,因为我想先写内容采集器,然后编写分类采集器.
2.1编写内容采集器
首先,为爬虫创建一个目录,该目录与项目中的应用程序处于同一级别,然后将该目录转换为python包
bashmkdir ~/python_spider/sfspider
touch ~/python_spider/sfspider/__init__.py
从现在开始,此目录将称为“爬虫程序包”
在采集器软件包中创建spider.py以安装我的采集器
bashvim ~/python_spider/sfspider/spider.py
基本的采集器仅需要以下代码行:

(下面将提供代码)
然后,我们可以玩“爬行动物”了.
输入python shell
python>>> from sfspider import spider
>>> s = spider.SegmentfaultQuestionSpider('1010000002542775')
>>> s.url
>>> 'http://segmentfault.com/q/1010000002542775'
>>> print s.dom('h1#questionTitle').text()
>>> 微信JS—SDK嵌套选择图片和上传图片接口,实现一键上传图片,遇到问题
看,我现在可以通过采集器获取segmentfault的问题标题. 在下一步中,为了简化代码,我将标题,答案等的属性编写为蜘蛛的属性. 代码如下
python# -*- coding: utf-8 -*-
import requests # requests作为我们的html客户端
from pyquery import PyQuery as Pq # pyquery来操作dom
class SegmentfaultQuestionSpider(object):
def __init__(self, segmentfault_id): # 参数为在segmentfault上的id
self.url = 'http://segmentfault.com/q/{0}'.format(segmentfault_id)
self._dom = None # 弄个这个来缓存获取到的html内容,一个蜘蛛应该之访问一次
@property
def dom(self): # 获取html内容
if not self._dom:
document = requests.get(self.url)
document.encoding = 'utf-8'
self._dom = Pq(document.text)
return self._dom
@property
def title(self): # 让方法可以通过s.title的方式访问 可以少打对括号
return self.dom('h1#questionTitle').text() # 关于选择器可以参考css selector或者jquery selector, 它们在pyquery下几乎都可以使用
@property
def content(self):
return self.dom('.question.fmt').html() # 直接获取html 胆子就是大 以后再来过滤
@property
def answers(self):
return list(answer.html() for answer in self.dom('.answer.fmt').items()) # 记住,Pq实例的items方法是很有用的
@property
def tags(self):
return self.dom('ul.taglist--inline > li').text().split() # 获取tags,这里直接用text方法,再切分就行了。一般只要是文字内容,而且文字内容自己没有空格,逗号等,都可以这样弄,省事。
然后,再次玩升级的蜘蛛.
python>>> from sfspider import spider
>>> s = spider.SegmentfaultQuestionSpider('1010000002542775')
>>> print s.title
>>> 微信JS—SDK嵌套选择图片和上传图片接口,实现一键上传图片,遇到问题
>>> print s.content
>>> # [故意省略] #
>>> for answer in s.answers
print answer
>>> # [故意省略] #
>>> print '/'.join(s.tags)
>>> 微信js-sdk/python/微信开发/javascript
好的,现在我的蜘蛛玩起来更方便了.
2.2编写分类采集器
接下来,我要编写一个对标签页进行爬网的爬网程序.
代码如下. 请注意,下面的代码被添加到现有代码的下面,并且在最后一行的前一行和上一行之间必须有两个空行
pythonclass SegmentfaultTagSpider(object):
def __init__(self, tag_name, page=1):
self.url = 'http://segmentfault.com/t/%s?type=newest&page=%s' % (tag_name, page)
self.tag_name = tag_name
self.page = page
self._dom = None
@property
def dom(self):
if not self._dom:
document = requests.get(self.url)
document.encoding = 'utf-8'
self._dom = Pq(document.text)
self._dom.make_links_absolute(base_url="http://segmentfault.com/";) # 相对链接变成绝对链接 爽
return self._dom
@property
def questions(self):
return [question.attr('href') for question in self.dom('h2.title > a').items()]
@property
def has_next_page(self): # 看看还有没有下一页,这个有必要
return bool(self.dom('ul.pagination > li.next')) # 看看有木有下一页
def next_page(self): # 把这个蜘蛛杀了, 产生一个新的蜘蛛 抓取下一页。 由于这个本来就是个动词,所以就不加@property了
if self.has_next_page:
self.__init__(tag_name=self.tag_name ,page=self.page+1)
else:
return None
现在您可以一起玩两个蜘蛛了,所以我不再详细介绍游戏过程. .
python>>> from sfspider import spider
>>> s = spider.SegmentfaultTagSpider('微信')
>>> question1 = s.questions[0]
>>> question_spider = spider.SegmentfaultQuestionSpider(question1.split('/')[-1])
>>> # [故意省略] #
如果您想成为小偷,基本上可以在这里找到它. 设置模板并添加一个简单的脚本来接受和返回请求.
待续.
Wordpress自动采集plugin_wp-autopost-pro 3.7.8
采集交流 • 优采云 发表了文章 • 0 个评论 • 380 次浏览 • 2020-08-09 05:45
WordPress自动采集插件
插件简介:
该插件是wp-autopost-pro 3.7.8的最新版本.
集合插件的适用对象
1. 新建的wordpress网站的内容相对较小,希望尽快拥有更丰富的内容;
2. 热门内容将自动采集并自动发布;
3. 定时采集,手动采集并发布或保存为草稿;
4,css样式规则,可以更准确地采集所需的内容.
5. 通过代理IP进行伪原创和翻译,采集和存储cookie记录;
6,可以将内容采集到自定义列
对Google神经网络翻译的新支持,youdao神经网络翻译,轻松访问高质量的原创文章
对市场上所有主流对象存储服务,秦牛云,阿里云OSS等的全面支持.
可以采集微信公众号,头条新闻和其他自媒体内容. 由于百度不收录官方帐户,头条新闻等,因此您可以轻松获得高质量的“原创”文章,从而增加了百度的收录量和网站权重
可以采集任何网站的内容,采集的信息一目了然
通过简单的设置,可以采集来自任何网站的内容,并且可以将多个采集任务设置为同时运行. 可以将任务设置为自动或手动运行. 主任务列表显示每个采集任务的状态: 上次检测采集时间,下一次检测的估计采集时间,最新采集的文章,已采集和更新的文章数以及其他易于查看和查看的信息. 管理.
文章管理功能方便查询,搜索和删除采集的文章. 改进的算法从根本上消除了同一文章的重复采集. 日志功能记录采集过程中的异常和抓取错误,便于检查和设置维修错误.
增强seo功能,其他自学. 查看全部
详细介绍
WordPress自动采集插件
插件简介:
该插件是wp-autopost-pro 3.7.8的最新版本.
集合插件的适用对象
1. 新建的wordpress网站的内容相对较小,希望尽快拥有更丰富的内容;
2. 热门内容将自动采集并自动发布;
3. 定时采集,手动采集并发布或保存为草稿;
4,css样式规则,可以更准确地采集所需的内容.
5. 通过代理IP进行伪原创和翻译,采集和存储cookie记录;
6,可以将内容采集到自定义列
对Google神经网络翻译的新支持,youdao神经网络翻译,轻松访问高质量的原创文章
对市场上所有主流对象存储服务,秦牛云,阿里云OSS等的全面支持.
可以采集微信公众号,头条新闻和其他自媒体内容. 由于百度不收录官方帐户,头条新闻等,因此您可以轻松获得高质量的“原创”文章,从而增加了百度的收录量和网站权重
可以采集任何网站的内容,采集的信息一目了然
通过简单的设置,可以采集来自任何网站的内容,并且可以将多个采集任务设置为同时运行. 可以将任务设置为自动或手动运行. 主任务列表显示每个采集任务的状态: 上次检测采集时间,下一次检测的估计采集时间,最新采集的文章,已采集和更新的文章数以及其他易于查看和查看的信息. 管理.
文章管理功能方便查询,搜索和删除采集的文章. 改进的算法从根本上消除了同一文章的重复采集. 日志功能记录采集过程中的异常和抓取错误,便于检查和设置维修错误.
增强seo功能,其他自学.
分享] Empire CMS自动采集发布时间表
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-09 04:52
1. 触发代码时,请添加密码. 例如,我的触发方法是借用自动获取和触发的第一点,并且还使用计划任务进行触发. 在e / tasks /下创建一个文件,然后在触发代码上写入以触发此审阅代码,然后使用计划的任务进行触发.
2. 如果有很多列,则列出200或300,在老北那代码中,请使用基于时间的查看,否则负载会有点高. (时分代码在老贝的代码中,但这只是一个注释. 此外,它可以分为三个以上的时间段. 我要做的是每小时查看几列. 无论如何,您可以根据到您这样的列数,例如我. 大约有240列,我将设置为每小时查看和更新十列),我将分享在各节中查看的代码:
我尝试过. 我保持后端. 太好了,无法安全传播. 另外,网页上的cookie将变为无效. 您应过一会再登录. 在这里,我想到了另一种自动刷新此“计划任务页面”以保持其cookie有效的方法.
根据此方法,因为引用了刷新页面,并且刷新页面位于后台,所以存在登录问题. 有时VPS出现问题,重新启动或出现某种情况,如何构建网站,则必须重新登录此页面. 这比较麻烦. 有时候我几天没来过,但是几天没来过. 我想知道您是否可以帮助我想办法. 或者可以在页面上预先分配用户名和密码,只要打开页面即可直接采集,在这种情况下,无需登录. 我可以在VPS中进行设置. 如果我重新启动,它将自动打开此页面以实现采集. 查看全部
首先,这是我与Empire CMS的第一次接触,对于程序开发,我是一个外行. 我只是一个用户(垃圾站). 我以前一直使用DEDECMS +采集英雄,但是这是在编织之间. 做梦时,处理数百万个或更多数据时负载确实很高,所以我想使用Empire CMS尝试作为垃圾站. 每个人都知道,成为垃圾站并不像成为常规站. 它是手动更新的. 垃圾站越自动化,越好. 最好不要由人来管理. 这是我研究的方向,好吧,废话少说.
1. 触发代码时,请添加密码. 例如,我的触发方法是借用自动获取和触发的第一点,并且还使用计划任务进行触发. 在e / tasks /下创建一个文件,然后在触发代码上写入以触发此审阅代码,然后使用计划的任务进行触发.
2. 如果有很多列,则列出200或300,在老北那代码中,请使用基于时间的查看,否则负载会有点高. (时分代码在老贝的代码中,但这只是一个注释. 此外,它可以分为三个以上的时间段. 我要做的是每小时查看几列. 无论如何,您可以根据到您这样的列数,例如我. 大约有240列,我将设置为每小时查看和更新十列),我将分享在各节中查看的代码:
我尝试过. 我保持后端. 太好了,无法安全传播. 另外,网页上的cookie将变为无效. 您应过一会再登录. 在这里,我想到了另一种自动刷新此“计划任务页面”以保持其cookie有效的方法.
根据此方法,因为引用了刷新页面,并且刷新页面位于后台,所以存在登录问题. 有时VPS出现问题,重新启动或出现某种情况,如何构建网站,则必须重新登录此页面. 这比较麻烦. 有时候我几天没来过,但是几天没来过. 我想知道您是否可以帮助我想办法. 或者可以在页面上预先分配用户名和密码,只要打开页面即可直接采集,在这种情况下,无需登录. 我可以在VPS中进行设置. 如果我重新启动,它将自动打开此页面以实现采集.
Js嵌入网页的点码以实现数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 546 次浏览 • 2020-08-08 18:44
概述: 分析网页上嵌入点的重要性
网站流量统计分析可以帮助网站管理员,运营商,发起人等获取实时网站流量信息,并提供来自流量来源,网站内容和网站访问者特征等各个方面的网站分析数据. 根据. 为了帮助增加网站流量,改善网站用户体验优化,允许更多访问者成为会员或客户,并通过减少投资获得最大收益.
访问日志指的是用户访问网站时的所有访问,浏览和单击行为数据. 例如,单击了哪个链接,例如常见的微信副本统计信息,页面访问者分析等,打开了哪个页面,复制了哪个微信帐户,使用了哪个搜索项目以及整个会话时间. 所有这些信息都可以通过网站日志保存. 通过分析这些数据,我们可以了解有关网站运营的许多重要信息. 采集的数据越全面,分析就越准确. 参考来源:
网页隐藏点
标题
首先,需要在网页的前端页面中加载ma.js的脚本代码
var _maq = _maq || [];
_maq.push(['_setAccount', 'zaomianbao']);
(function() {
var ma = document.createElement('script');
ma.type = 'text/javascript';
ma.async = true;
ma.src = 'http://vtongji.gam7.com/ma.js';
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore(ma, s);
})();
二,将前端代码放在后台
(function () {
var params = {};
//Document对象数据
if(document) {
params.domain = document.domain || '';
params.url = document.URL || '';
params.title = document.title || '';
params.referrer = document.referrer || '';
}
//Window对象数据
if(window && window.screen) {
params.sh = window.screen.height || 0;
params.sw = window.screen.width || 0;
params.cd = window.screen.colorDepth || 0;
}
//navigator对象数据
if(navigator) {
params.lang = navigator.language || '';
}
//解析_maq配置
if(_maq) {
for(var i in _maq) {
switch(_maq[i][0]) {
case '_setAccount':
params.account = _maq[i][1];
break;
default:
break;
}
}
}
//拼接参数串
var args = '';
for(var i in params) {
if(args != '') {
args += '&';
}
args += i + '=' + encodeURIComponent(params[i]);
}
//通过Image对象请求后端脚本
var img = new Image(1, 1);
img.src = 'http://vtongji.ibixue.com/log.gif?' + args;
})();
三,后端配置,配置nginx服务器日志格式
worker_processes 2;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
log_format user_log_format "$msec||$remote_addr||$status||$body_bytes_sent||$u_domain||$u_url||$u_title||$u_referrer||$u_sh||$u_sw||$u_cd||$u_lang||$http_user_agent||$u_account";
sendfile on; #允许sendfile方式传输文件,默认为off
keepalive_timeout 65; #连接超时时间,默认为75s
server {
listen 80;
server_name localhost;
location /log.gif {
#伪装成gif文件
default_type image/gif;
#nginx本身记录的access_log,日志格式为main
access_log logs/access.log main;
access_by_lua "
-- 用户跟踪cookie名为__utrace
local uid = ngx.var.cookie___utrace
if not uid then
-- 如果没有则生成一个跟踪cookie,算法为md5(时间戳+IP+客户端信息)
uid = ngx.md5(ngx.now() .. ngx.var.remote_addr .. ngx.var.http_user_agent)
end
ngx.header['Set-Cookie'] = {'__utrace=' .. uid .. '; path=/'}
if ngx.var.arg_domain then
-- 通过subrequest到/i-log记录日志,将参数和用户跟踪cookie带过去
ngx.location.capture('/i-log?' .. ngx.var.args .. '&utrace=' .. uid)
end
";
#此请求资源本地不缓存
add_header Expires "Fri, 01 Jan 1980 00:00:00 GMT";
add_header Pragma "no-cache";
add_header Cache-Control "no-cache, max-age=0, must-revalidate";
#返回一个1×1的空gif图片
empty_gif;
}
location /i-log {
#内部location,不允许外部直接访问
internal;
#设置变量,注意需要unescape
set_unescape_uri $u_domain $arg_domain;
set_unescape_uri $u_url $arg_url;
set_unescape_uri $u_title $arg_title;
set_unescape_uri $u_referrer $arg_referrer;
set_unescape_uri $u_sh $arg_sh;
set_unescape_uri $u_sw $arg_sw;
set_unescape_uri $u_cd $arg_cd;
set_unescape_uri $u_lang $arg_lang;
set_unescape_uri $u_account $arg_account;
#打开subrequest(子请求)日志
log_subrequest on;
#自定义采集的日志,记录数据到user_defined.log
access_log logs/user_defined.log user_log_format;
#输出空字符串
echo '';
}
}
}
四: 编写index.html
测试埋点
var _maq = _maq || [];
_maq.push(['_setAccount', 'zaomianbao']);
(function() {
var ma = document.createElement('script');
ma.type = 'text/javascript';
ma.async = true;
ma.src = 'http://yishengjun.gookang.com/ma.js';
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore(ma, s);
})();
测试埋点
五,背景nginx环境构建和参考资料
web点数据采集后台配置nginx:
https://blog.csdn.net/weixin_3 ... 94827
下载数据源:
wget -O lua-nginx-module-0.10.0.tar.gz https://github.com/openresty/l ... ar.gz
wget --no-check-certificate -Oecho-nginx-module-0.58.tar.gz 'https://github.com/openresty/echo-nginx-module/archive/v0.58.tar.gz'
wget --no-check-certificate -O nginx_devel_kit-0.2.19.tar.gz https://github.com/simpl/ngx_d ... ar.gz
wget https://openresty.org/download ... ar.gz
wget --no-check-certificate -Oset-misc-nginx-module-0.29.tar.gz 'https://github.com/openresty/set-misc-nginx-module/archive/v0.29.tar.gz'
VI. 参考资料: 查看全部
内容
概述: 分析网页上嵌入点的重要性
网站流量统计分析可以帮助网站管理员,运营商,发起人等获取实时网站流量信息,并提供来自流量来源,网站内容和网站访问者特征等各个方面的网站分析数据. 根据. 为了帮助增加网站流量,改善网站用户体验优化,允许更多访问者成为会员或客户,并通过减少投资获得最大收益.
访问日志指的是用户访问网站时的所有访问,浏览和单击行为数据. 例如,单击了哪个链接,例如常见的微信副本统计信息,页面访问者分析等,打开了哪个页面,复制了哪个微信帐户,使用了哪个搜索项目以及整个会话时间. 所有这些信息都可以通过网站日志保存. 通过分析这些数据,我们可以了解有关网站运营的许多重要信息. 采集的数据越全面,分析就越准确. 参考来源:
网页隐藏点
标题
首先,需要在网页的前端页面中加载ma.js的脚本代码
var _maq = _maq || [];
_maq.push(['_setAccount', 'zaomianbao']);
(function() {
var ma = document.createElement('script');
ma.type = 'text/javascript';
ma.async = true;
ma.src = 'http://vtongji.gam7.com/ma.js';
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore(ma, s);
})();
二,将前端代码放在后台
(function () {
var params = {};
//Document对象数据
if(document) {
params.domain = document.domain || '';
params.url = document.URL || '';
params.title = document.title || '';
params.referrer = document.referrer || '';
}
//Window对象数据
if(window && window.screen) {
params.sh = window.screen.height || 0;
params.sw = window.screen.width || 0;
params.cd = window.screen.colorDepth || 0;
}
//navigator对象数据
if(navigator) {
params.lang = navigator.language || '';
}
//解析_maq配置
if(_maq) {
for(var i in _maq) {
switch(_maq[i][0]) {
case '_setAccount':
params.account = _maq[i][1];
break;
default:
break;
}
}
}
//拼接参数串
var args = '';
for(var i in params) {
if(args != '') {
args += '&';
}
args += i + '=' + encodeURIComponent(params[i]);
}
//通过Image对象请求后端脚本
var img = new Image(1, 1);
img.src = 'http://vtongji.ibixue.com/log.gif?' + args;
})();
三,后端配置,配置nginx服务器日志格式
worker_processes 2;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
log_format user_log_format "$msec||$remote_addr||$status||$body_bytes_sent||$u_domain||$u_url||$u_title||$u_referrer||$u_sh||$u_sw||$u_cd||$u_lang||$http_user_agent||$u_account";
sendfile on; #允许sendfile方式传输文件,默认为off
keepalive_timeout 65; #连接超时时间,默认为75s
server {
listen 80;
server_name localhost;
location /log.gif {
#伪装成gif文件
default_type image/gif;
#nginx本身记录的access_log,日志格式为main
access_log logs/access.log main;
access_by_lua "
-- 用户跟踪cookie名为__utrace
local uid = ngx.var.cookie___utrace
if not uid then
-- 如果没有则生成一个跟踪cookie,算法为md5(时间戳+IP+客户端信息)
uid = ngx.md5(ngx.now() .. ngx.var.remote_addr .. ngx.var.http_user_agent)
end
ngx.header['Set-Cookie'] = {'__utrace=' .. uid .. '; path=/'}
if ngx.var.arg_domain then
-- 通过subrequest到/i-log记录日志,将参数和用户跟踪cookie带过去
ngx.location.capture('/i-log?' .. ngx.var.args .. '&utrace=' .. uid)
end
";
#此请求资源本地不缓存
add_header Expires "Fri, 01 Jan 1980 00:00:00 GMT";
add_header Pragma "no-cache";
add_header Cache-Control "no-cache, max-age=0, must-revalidate";
#返回一个1×1的空gif图片
empty_gif;
}
location /i-log {
#内部location,不允许外部直接访问
internal;
#设置变量,注意需要unescape
set_unescape_uri $u_domain $arg_domain;
set_unescape_uri $u_url $arg_url;
set_unescape_uri $u_title $arg_title;
set_unescape_uri $u_referrer $arg_referrer;
set_unescape_uri $u_sh $arg_sh;
set_unescape_uri $u_sw $arg_sw;
set_unescape_uri $u_cd $arg_cd;
set_unescape_uri $u_lang $arg_lang;
set_unescape_uri $u_account $arg_account;
#打开subrequest(子请求)日志
log_subrequest on;
#自定义采集的日志,记录数据到user_defined.log
access_log logs/user_defined.log user_log_format;
#输出空字符串
echo '';
}
}
}
四: 编写index.html
测试埋点
var _maq = _maq || [];
_maq.push(['_setAccount', 'zaomianbao']);
(function() {
var ma = document.createElement('script');
ma.type = 'text/javascript';
ma.async = true;
ma.src = 'http://yishengjun.gookang.com/ma.js';
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore(ma, s);
})();
测试埋点
五,背景nginx环境构建和参考资料
web点数据采集后台配置nginx:
https://blog.csdn.net/weixin_3 ... 94827
下载数据源:
wget -O lua-nginx-module-0.10.0.tar.gz https://github.com/openresty/l ... ar.gz
wget --no-check-certificate -Oecho-nginx-module-0.58.tar.gz 'https://github.com/openresty/echo-nginx-module/archive/v0.58.tar.gz'
wget --no-check-certificate -O nginx_devel_kit-0.2.19.tar.gz https://github.com/simpl/ngx_d ... ar.gz
wget https://openresty.org/download ... ar.gz
wget --no-check-certificate -Oset-misc-nginx-module-0.29.tar.gz 'https://github.com/openresty/set-misc-nginx-module/archive/v0.29.tar.gz'
VI. 参考资料:
Nodejs学习笔记(11)
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2020-08-08 17:04
许多人需要数据采集,这可以用不同的语言和不同的方式来实现. 我以前也用C#编写过它. 发送各种请求和定期分析数据主要比较麻烦. 总的来说,没有什么不好,但是效率更差,
使用nodejs(可能仅相对于C#)编写采集程序效率更高. 今天,我将主要使用一个示例来说明如何使用nodejs来实现数据采集器,主要是使用request和cheerio.
请求: 用于http请求
cheerio: 用于提取请求返回的html中所需的信息(与jquery的用法一致)
示例
仅讲API使用并不有趣,也无需记住所有API. 让我们开始一个例子.
说些八卦:
仍然有许多nodejs开发工具. 我还建议崇高. 自从Microsoft启动Visual Studio Code之后,我便转向了nodejs开发.
使用它进行开发比较舒适,无需配置,快速启动,自动完成,视图定义和引用,快速搜索等,并且具有一致的VS风格,因此它应该越来越好,所以我建议^ _ ^!
样品要求
在其中获取文章的“标题”,“地址”,“发布时间”和“封面图片”
采集器
1. 创建项目文件夹sampleDAU
2. 创建package.json文件
{
"name": "Wilson_SampleDAU",
"version": "0.0.1",
"private": false,
"dependencies": {
"request":"*",
"cheerio":"*"
}
}
3. 使用npm在终端中安装参考
cd 项目根目录
npm install
4. 构建app.js并编写采集器代码
首先,使用浏览器打开要采集的URL,使用开发人员工具查看HTML结构,然后根据该结构编写解析代码
/*
* 功能: 数据采集
* 创建人: Wilson
* 时间: 2015-07-29
*/
var request = require('request'),
cheerio = require('cheerio'),
URL_36KR = 'http://36kr.com/'; //36氪
/* 开启数据采集器 */
function dataCollectorStartup() {
dataRequest(URL_36KR);
}
/* 数据请求 */
function dataRequest(dataUrl)
{
request({
url: dataUrl,
method: 'GET'
}, function(err, res, body) {
if (err) {
console.log(dataUrl)
console.error('[ERROR]Collection' + err);
return;
}
switch(dataUrl)
{
case URL_36KR:
dataParse36Kr(body);
break;
}
});
}
/* 36kr 数据解析 */
function dataParse36Kr(body)
{
console.log('============================================================================================');
console.log('======================================36kr==================================================');
console.log('============================================================================================');
var $ = cheerio.load(body);
var articles = $('article')
for (var i = 0; i < articles.length; i++) {
var article = articles[i];
var descDoms = $(article).find('.desc');
if(descDoms.length == 0)
{
continue;
}
var coverDom = $(article).children().first();
var titleDom = $(descDoms).find('.info_flow_news_title');
var timeDom = $(descDoms).find('.timeago');
var titleVal = titleDom.text();
var urlVal = titleDom.attr('href');
var timeVal = timeDom.attr('title');
var coverUrl = coverDom.attr('data-lazyload');
//处理时间
var timeDateSecs = new Date(timeVal).getTime() / 1000;
if(urlVal != undefined)
{
console.info('--------------------------------');
console.info('标题:' + titleVal);
console.info('地址:' + urlVal);
console.info('时间:' + timeDateSecs);
console.info('封面:' + coverUrl);
console.info('--------------------------------');
}
};
}
dataCollectorStartup();
测试结果
此采集器已完成. 实际上,这是一个获取请求. 正文或HTML代码将在请求回调中返回,并且cheerio库将以与jquery库语法相同的方式进行解析,以检索所需的数据!
加入代理商
对采集器进行演示,然后基本完成. 如果您需要长时间使用它以防止网站被阻止,则仍然需要添加代理列表
对于该示例,我从Internet上的免费代理中提出了一些示例,并将其放入proxylist.js中,该列表提供了随机选择代理的功能
var PROXY_LIST = [{"ip":"111.1.55.136","port":"55336"},{"ip":"111.1.54.91","port":"55336"},{"ip":"111.1.56.19","port":"55336"}
,{"ip":"112.114.63.16","port":"55336"},{"ip":"106.58.63.83","port":"55336"},{"ip":"119.188.133.54","port":"55336"}
,{"ip":"106.58.63.84","port":"55336"},{"ip":"183.95.132.171","port":"55336"},{"ip":"11.12.14.9","port":"55336"}
,{"ip":"60.164.223.16","port":"55336"},{"ip":"117.185.13.87","port":"8080"},{"ip":"112.114.63.20","port":"55336"}
,{"ip":"188.134.19.102","port":"3129"},{"ip":"106.58.63.80","port":"55336"},{"ip":"60.164.223.20","port":"55336"}
,{"ip":"106.58.63.78","port":"55336"},{"ip":"112.114.63.23","port":"55336"},{"ip":"112.114.63.30","port":"55336"}
,{"ip":"60.164.223.14","port":"55336"},{"ip":"190.202.82.234","port":"3128"},{"ip":"60.164.223.15","port":"55336"}
,{"ip":"60.164.223.5","port":"55336"},{"ip":"221.204.9.28","port":"55336"},{"ip":"60.164.223.2","port":"55336"}
,{"ip":"139.214.113.84","port":"55336"} ,{"ip":"112.25.49.14","port":"55336"},{"ip":"221.204.9.19","port":"55336"}
,{"ip":"221.204.9.39","port":"55336"},{"ip":"113.207.57.18","port":"55336"} ,{"ip":"112.25.62.15","port":"55336"}
,{"ip":"60.5.255.143","port":"55336"},{"ip":"221.204.9.18","port":"55336"},{"ip":"60.5.255.145","port":"55336"}
,{"ip":"221.204.9.16","port":"55336"},{"ip":"183.232.82.132","port":"55336"},{"ip":"113.207.62.78","port":"55336"}
,{"ip":"60.5.255.144","port":"55336"} ,{"ip":"60.5.255.141","port":"55336"},{"ip":"221.204.9.23","port":"55336"}
,{"ip":"157.122.96.50","port":"55336"},{"ip":"218.61.39.41","port":"55336"} ,{"ip":"221.204.9.26","port":"55336"}
,{"ip":"112.112.43.213","port":"55336"},{"ip":"60.5.255.138","port":"55336"},{"ip":"60.5.255.133","port":"55336"}
,{"ip":"221.204.9.25","port":"55336"},{"ip":"111.161.35.56","port":"55336"},{"ip":"111.161.35.49","port":"55336"}
,{"ip":"183.129.134.226","port":"8080"} ,{"ip":"58.220.10.86","port":"80"},{"ip":"183.87.117.44","port":"80"}
,{"ip":"211.23.19.130","port":"80"},{"ip":"61.234.249.107","port":"8118"},{"ip":"200.20.168.140","port":"80"}
,{"ip":"111.1.46.176","port":"55336"},{"ip":"120.203.158.149","port":"8118"},{"ip":"70.39.189.6","port":"9090"}
,{"ip":"210.6.237.191","port":"3128"},{"ip":"122.155.195.26","port":"8080"}];
module.exports.GetProxy = function () {
var randomNum = parseInt(Math.floor(Math.random() * PROXY_LIST.length));
var proxy = PROXY_LIST[randomNum];
return 'http://' + proxy.ip + ':' + proxy.port;
}
proxylist.js
对app.js代码进行以下更改
/*
* 功能: 数据采集
* 创建人: Wilson
* 时间: 2015-07-29
*/
var request = require('request'),
cheerio = require('cheerio'),
URL_36KR = 'http://36kr.com/', //36氪
Proxy = require('./proxylist.js');
...
/* 数据请求 */
function dataRequest(dataUrl)
{
request({
url: dataUrl,
proxy: Proxy.GetProxy(),
method: 'GET'
}, function(err, res, body) {
...
}
}
...
dataCollectorStartup()
setInterval(dataCollectorStartup, 10000);
这样,转换就完成了,添加了代码,并添加了setInterval以定期执行! 查看全部
目录写在前面
许多人需要数据采集,这可以用不同的语言和不同的方式来实现. 我以前也用C#编写过它. 发送各种请求和定期分析数据主要比较麻烦. 总的来说,没有什么不好,但是效率更差,
使用nodejs(可能仅相对于C#)编写采集程序效率更高. 今天,我将主要使用一个示例来说明如何使用nodejs来实现数据采集器,主要是使用request和cheerio.
请求: 用于http请求
cheerio: 用于提取请求返回的html中所需的信息(与jquery的用法一致)
示例
仅讲API使用并不有趣,也无需记住所有API. 让我们开始一个例子.
说些八卦:
仍然有许多nodejs开发工具. 我还建议崇高. 自从Microsoft启动Visual Studio Code之后,我便转向了nodejs开发.
使用它进行开发比较舒适,无需配置,快速启动,自动完成,视图定义和引用,快速搜索等,并且具有一致的VS风格,因此它应该越来越好,所以我建议^ _ ^!
样品要求
在其中获取文章的“标题”,“地址”,“发布时间”和“封面图片”
采集器
1. 创建项目文件夹sampleDAU
2. 创建package.json文件
{
"name": "Wilson_SampleDAU",
"version": "0.0.1",
"private": false,
"dependencies": {
"request":"*",
"cheerio":"*"
}
}
3. 使用npm在终端中安装参考
cd 项目根目录
npm install
4. 构建app.js并编写采集器代码
首先,使用浏览器打开要采集的URL,使用开发人员工具查看HTML结构,然后根据该结构编写解析代码
/*
* 功能: 数据采集
* 创建人: Wilson
* 时间: 2015-07-29
*/
var request = require('request'),
cheerio = require('cheerio'),
URL_36KR = 'http://36kr.com/'; //36氪
/* 开启数据采集器 */
function dataCollectorStartup() {
dataRequest(URL_36KR);
}
/* 数据请求 */
function dataRequest(dataUrl)
{
request({
url: dataUrl,
method: 'GET'
}, function(err, res, body) {
if (err) {
console.log(dataUrl)
console.error('[ERROR]Collection' + err);
return;
}
switch(dataUrl)
{
case URL_36KR:
dataParse36Kr(body);
break;
}
});
}
/* 36kr 数据解析 */
function dataParse36Kr(body)
{
console.log('============================================================================================');
console.log('======================================36kr==================================================');
console.log('============================================================================================');
var $ = cheerio.load(body);
var articles = $('article')
for (var i = 0; i < articles.length; i++) {
var article = articles[i];
var descDoms = $(article).find('.desc');
if(descDoms.length == 0)
{
continue;
}
var coverDom = $(article).children().first();
var titleDom = $(descDoms).find('.info_flow_news_title');
var timeDom = $(descDoms).find('.timeago');
var titleVal = titleDom.text();
var urlVal = titleDom.attr('href');
var timeVal = timeDom.attr('title');
var coverUrl = coverDom.attr('data-lazyload');
//处理时间
var timeDateSecs = new Date(timeVal).getTime() / 1000;
if(urlVal != undefined)
{
console.info('--------------------------------');
console.info('标题:' + titleVal);
console.info('地址:' + urlVal);
console.info('时间:' + timeDateSecs);
console.info('封面:' + coverUrl);
console.info('--------------------------------');
}
};
}
dataCollectorStartup();
测试结果
此采集器已完成. 实际上,这是一个获取请求. 正文或HTML代码将在请求回调中返回,并且cheerio库将以与jquery库语法相同的方式进行解析,以检索所需的数据!
加入代理商
对采集器进行演示,然后基本完成. 如果您需要长时间使用它以防止网站被阻止,则仍然需要添加代理列表
对于该示例,我从Internet上的免费代理中提出了一些示例,并将其放入proxylist.js中,该列表提供了随机选择代理的功能
var PROXY_LIST = [{"ip":"111.1.55.136","port":"55336"},{"ip":"111.1.54.91","port":"55336"},{"ip":"111.1.56.19","port":"55336"}
,{"ip":"112.114.63.16","port":"55336"},{"ip":"106.58.63.83","port":"55336"},{"ip":"119.188.133.54","port":"55336"}
,{"ip":"106.58.63.84","port":"55336"},{"ip":"183.95.132.171","port":"55336"},{"ip":"11.12.14.9","port":"55336"}
,{"ip":"60.164.223.16","port":"55336"},{"ip":"117.185.13.87","port":"8080"},{"ip":"112.114.63.20","port":"55336"}
,{"ip":"188.134.19.102","port":"3129"},{"ip":"106.58.63.80","port":"55336"},{"ip":"60.164.223.20","port":"55336"}
,{"ip":"106.58.63.78","port":"55336"},{"ip":"112.114.63.23","port":"55336"},{"ip":"112.114.63.30","port":"55336"}
,{"ip":"60.164.223.14","port":"55336"},{"ip":"190.202.82.234","port":"3128"},{"ip":"60.164.223.15","port":"55336"}
,{"ip":"60.164.223.5","port":"55336"},{"ip":"221.204.9.28","port":"55336"},{"ip":"60.164.223.2","port":"55336"}
,{"ip":"139.214.113.84","port":"55336"} ,{"ip":"112.25.49.14","port":"55336"},{"ip":"221.204.9.19","port":"55336"}
,{"ip":"221.204.9.39","port":"55336"},{"ip":"113.207.57.18","port":"55336"} ,{"ip":"112.25.62.15","port":"55336"}
,{"ip":"60.5.255.143","port":"55336"},{"ip":"221.204.9.18","port":"55336"},{"ip":"60.5.255.145","port":"55336"}
,{"ip":"221.204.9.16","port":"55336"},{"ip":"183.232.82.132","port":"55336"},{"ip":"113.207.62.78","port":"55336"}
,{"ip":"60.5.255.144","port":"55336"} ,{"ip":"60.5.255.141","port":"55336"},{"ip":"221.204.9.23","port":"55336"}
,{"ip":"157.122.96.50","port":"55336"},{"ip":"218.61.39.41","port":"55336"} ,{"ip":"221.204.9.26","port":"55336"}
,{"ip":"112.112.43.213","port":"55336"},{"ip":"60.5.255.138","port":"55336"},{"ip":"60.5.255.133","port":"55336"}
,{"ip":"221.204.9.25","port":"55336"},{"ip":"111.161.35.56","port":"55336"},{"ip":"111.161.35.49","port":"55336"}
,{"ip":"183.129.134.226","port":"8080"} ,{"ip":"58.220.10.86","port":"80"},{"ip":"183.87.117.44","port":"80"}
,{"ip":"211.23.19.130","port":"80"},{"ip":"61.234.249.107","port":"8118"},{"ip":"200.20.168.140","port":"80"}
,{"ip":"111.1.46.176","port":"55336"},{"ip":"120.203.158.149","port":"8118"},{"ip":"70.39.189.6","port":"9090"}
,{"ip":"210.6.237.191","port":"3128"},{"ip":"122.155.195.26","port":"8080"}];
module.exports.GetProxy = function () {
var randomNum = parseInt(Math.floor(Math.random() * PROXY_LIST.length));
var proxy = PROXY_LIST[randomNum];
return 'http://' + proxy.ip + ':' + proxy.port;
}
proxylist.js
对app.js代码进行以下更改
/*
* 功能: 数据采集
* 创建人: Wilson
* 时间: 2015-07-29
*/
var request = require('request'),
cheerio = require('cheerio'),
URL_36KR = 'http://36kr.com/', //36氪
Proxy = require('./proxylist.js');
...
/* 数据请求 */
function dataRequest(dataUrl)
{
request({
url: dataUrl,
proxy: Proxy.GetProxy(),
method: 'GET'
}, function(err, res, body) {
...
}
}
...
dataCollectorStartup()
setInterval(dataCollectorStartup, 10000);
这样,转换就完成了,添加了代码,并添加了setInterval以定期执行!
崎combat的战斗章节(5): 抓取历史天气数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2020-08-08 07:19
1. 通常,数据需求简单或少量,我们会使用request(selenum)+ beautiful捕获数据
2. 当我们需要大量数据时,建议使用scrapy框架进行数据采集. scrapy框架使用异步方法来发起请求,并且数据捕获效率非常高.
以下,我们以网站数据捕获为例,介绍两种数据捕获:
1. 使用request + bs采集天气数据,并使用mysql存储数据
思考:
我们要采集的天气数据存储在地址beijing / month / 201101.html中. 观察URL,我们可以发现URL仅有两个部分在变化,即城市名称和您的年月,并且每年固定地收录12个. 对于月,您可以使用months = list(range(1,13 ))构建月份. 使用城市名称和年份作为变量来构造一个URL列表,这些URL需要采集数据,遍历该列表,请求URL并解析响应以获取数据.
以上是我们采集天气数据的想法. 首先,我们需要构建一个URL链接.
1 def get_url(cityname,start_year,end_year):
2 years = list(range(start_year, end_year))
3 months = list(range(1, 13))
4 suburl = 'http://www.tianqihoubao.com/lishi/'
5 urllist = []
6 for year in years:
7 for month in months:
8 if month < 10:
9 url = suburl + cityname + '/month/'+ str(year) + (str(0) + str(month)) + '.html'
10 else:
11 url = suburl + cityname + '/month/' + str(year) + str(month) + '.html'
12 urllist.append(url.strip())
13 return urllist
通过上述功能,您可以获得需要爬网的URL列表.
<p>如您所见,我们在上面使用了cityname,cityname是我们需要获取的城市的城市名称. 我们需要手动构造它. 假设我们已经构建了一个城市名称列表并存储在mysql数据库中,则需要查询数据库以获取城市名称,遍历城市,并将城市名称,开始年份和结束年份赋予上述功能. 查看全部
在本文中,我们以历史天气数据的捕获为例,简要说明两种数据捕获方式:
1. 通常,数据需求简单或少量,我们会使用request(selenum)+ beautiful捕获数据
2. 当我们需要大量数据时,建议使用scrapy框架进行数据采集. scrapy框架使用异步方法来发起请求,并且数据捕获效率非常高.
以下,我们以网站数据捕获为例,介绍两种数据捕获:
1. 使用request + bs采集天气数据,并使用mysql存储数据
思考:
我们要采集的天气数据存储在地址beijing / month / 201101.html中. 观察URL,我们可以发现URL仅有两个部分在变化,即城市名称和您的年月,并且每年固定地收录12个. 对于月,您可以使用months = list(range(1,13 ))构建月份. 使用城市名称和年份作为变量来构造一个URL列表,这些URL需要采集数据,遍历该列表,请求URL并解析响应以获取数据.
以上是我们采集天气数据的想法. 首先,我们需要构建一个URL链接.
1 def get_url(cityname,start_year,end_year):
2 years = list(range(start_year, end_year))
3 months = list(range(1, 13))
4 suburl = 'http://www.tianqihoubao.com/lishi/'
5 urllist = []
6 for year in years:
7 for month in months:
8 if month < 10:
9 url = suburl + cityname + '/month/'+ str(year) + (str(0) + str(month)) + '.html'
10 else:
11 url = suburl + cityname + '/month/' + str(year) + str(month) + '.html'
12 urllist.append(url.strip())
13 return urllist
通过上述功能,您可以获得需要爬网的URL列表.
<p>如您所见,我们在上面使用了cityname,cityname是我们需要获取的城市的城市名称. 我们需要手动构造它. 假设我们已经构建了一个城市名称列表并存储在mysql数据库中,则需要查询数据库以获取城市名称,遍历城市,并将城市名称,开始年份和结束年份赋予上述功能.
使用python +硒采集京东产品信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 349 次浏览 • 2020-08-08 06:09
[为什么要学习爬网? 】1.爬虫很容易上手,但是很难深入. 如何编写高效的采集器,如何编写高度灵活和可伸缩的采集器是一项技术任务. 另外,在爬网过程中,经常容易遇到反爬虫,例如字体防爬网,IP识别,验证码等. 如何克服困难并获取所需的数据,您可以学习此课程! 2.如果您是其他行业的开发人员,例如应用程序开发,网站开发,那么学习爬虫程序可以增强您的技术知识,并开发更安全的软件和网站[课程设计]完整的爬虫程序,无论大小,它可以分为三个步骤,即: 网络请求: 模拟浏览器的行为以从Internet抓取数据. 数据分析: 过滤请求的数据并提取所需的数据. 数据存储: 将提取的数据存储到硬盘或内存中. 例如,使用mysql数据库或redis. 然后按照这些步骤逐步解释本课程,使学生充分掌握每个步骤的技术. 另外,由于爬行器的多样性,在爬行过程中可能会发生反爬行和低效率的情况. 因此,我们又增加了两章来提高爬虫程序的灵活性,即: 高级爬虫: 包括IP代理,多线程爬虫,图形验证代码识别,JS加密和解密,动态Web爬虫,字体反爬虫识别等等. Scrapy和分布式爬虫: Scrapy框架,Scrapy-redis组件,分布式爬虫等. 我们可以通过爬虫的高级知识点来处理大量的反爬虫网站. 作为专业的采集器框架,Scrapy框架可以快速提高我们的搜寻程序的效率和速度. 此外,如果一台计算机无法满足您的需求,我们可以使用分布式爬网程序让多台计算机帮助您快速爬网数据. 从基本的采集器到商业应用程序采集器,这套课程都可以满足您的所有需求! [课程服务]独家付费社区+每个星期三的讨论会+ 1v1问答
Burpsuite插件开发(之二): 信息采集插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 452 次浏览 • 2020-08-08 01:34
0x00
我之前编写了一个用于burpsuite与sqlmap链接的插件. 这次是一个用于信息采集的插件. 该插件的名称是TheMagician. 这是“从Windows到Mac的渗透测试重点”计划的一小步. 我想简单地编写它,但是写的越多,就越麻烦. 多亏了朋友们的大力帮助,我终于顺利完成了任务.
使用该插件之前需要修改三个全局变量,即NMAPPATH,BINGKEY和HOMEPATH,其他全局变量不需要更改
该插件的使用与链接sqlmap插件的用法相同,遵循“简单就是美丽”的原则. 右键单击最简单的调用
创建右键菜单的源代码
#创建菜单右键
def createMenuItems(self, invocation):
menu = []
responses = invocation.getSelectedMessages()
if len(responses) == 1:
menu.append(JMenuItem(self._actionName, None, actionPerformed=lambda x, inv=invocation: self.quoteJTab(inv)))
return menu
return None
三个标签代表三种不同的功能
0x01 C段端口扫描
第一个是C扫描. 该IP地址是从Proxy标记中HTTP请求标头中的主机地址继承的. 它可以是单个IP地址或CIDR. 考虑到nmap在端口扫描中的绝对领导者位置,我没有亲自重写端口扫描引擎,而是通过Python子进程库调用了nmap.
Mac在使用前必须先安装nmap
brew install nmap
class NmapScan(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
self.thread_stop = False
def setCommds(self,cmds,Jobject,pcontrol):
self.runcms=cmds
self.setobject=Jobject
self.pcontrol=pcontrol
def run(self):
#self.setobject.setResult('Nmap task for '+self.runcms[5]+' is running\n')
child1 = subprocess.Popen(self.runcms, stdout = subprocess.PIPE, stdin = subprocess.PIPE, shell = False)
child1.poll()
resultScan = child1.stdout.read()
self.setobject.setResult(resultScan)
#self.setobject.setResult('Nmap task for '+self.runcms[5]+' is finnished\n')
self.pcontrol.subnum()
self.stop()
def stop(self):
self.thread_stop = True
单个IP地址扫描结果
C段扫描结果
通过先前的链接sqlmap插件来实现burpsuite,sqlmap和nmap这三个工件的集成.
0x02子域查询
我知道当前有三种子域查询方案: 一种是通过bing语法查询,第二种是使用第二级域名的集合,第三种是执行DNS爆破. 三种方案中较好的是第三种方案,而较好的轮子是subdomainsbrute. 当然,最好的方法是使用这三种方案,这只是消除重复的一种好方法,我在这里使用了第一种方案,不要问我为什么: 它很容易编写.
调用bing的主要功能
def BingSearch(query):
payload={}
payload['$top']=top
payload['$skip']=skip
payload['$format']=format
payload['Query']="'"+query+"'"
url='https://api.datamarket.azure.com/Bing/Search/Web?' + urllib.urlencode(payload)
sAuth='Basic '+base64.b64encode(':'+BINGKEY)
headers = { }
headers['Authorization']= sAuth
try:
req = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(req)
data=response.read()
#print data
data=json.loads(data)
return data
except Exception as e:
print e
#print e.info()
urlList = []
returnData = BingSearch("domain:" + theTopDomain)
if not returnData['d']['results']:
print "The Url Error"
else:
for tarUrl in returnData["d"]["results"]:
tmpUrl = urlparse.urlparse(tarUrl["Url"]).netloc
if tmpUrl not in urlList:
urlList.append(tmpUrl)
0x03敏感文件扫描
敏感文件扫描也是信息采集中的重要步骤. 通过文件扫描通常会带来意想不到的收益. 第三个功能模仿了Yujian Daniel的设计
目前有20个线程,速度已经过去
此外,它具有可以完全继承Proxy标记中的http请求标头信息(包括ua和cookie)的功能 查看全部
最后一集发送了“如何编写与sqlmap的burpsuite链接的插件”
0x00
我之前编写了一个用于burpsuite与sqlmap链接的插件. 这次是一个用于信息采集的插件. 该插件的名称是TheMagician. 这是“从Windows到Mac的渗透测试重点”计划的一小步. 我想简单地编写它,但是写的越多,就越麻烦. 多亏了朋友们的大力帮助,我终于顺利完成了任务.
使用该插件之前需要修改三个全局变量,即NMAPPATH,BINGKEY和HOMEPATH,其他全局变量不需要更改
该插件的使用与链接sqlmap插件的用法相同,遵循“简单就是美丽”的原则. 右键单击最简单的调用
创建右键菜单的源代码
#创建菜单右键
def createMenuItems(self, invocation):
menu = []
responses = invocation.getSelectedMessages()
if len(responses) == 1:
menu.append(JMenuItem(self._actionName, None, actionPerformed=lambda x, inv=invocation: self.quoteJTab(inv)))
return menu
return None
三个标签代表三种不同的功能
0x01 C段端口扫描
第一个是C扫描. 该IP地址是从Proxy标记中HTTP请求标头中的主机地址继承的. 它可以是单个IP地址或CIDR. 考虑到nmap在端口扫描中的绝对领导者位置,我没有亲自重写端口扫描引擎,而是通过Python子进程库调用了nmap.
Mac在使用前必须先安装nmap
brew install nmap
class NmapScan(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
self.thread_stop = False
def setCommds(self,cmds,Jobject,pcontrol):
self.runcms=cmds
self.setobject=Jobject
self.pcontrol=pcontrol
def run(self):
#self.setobject.setResult('Nmap task for '+self.runcms[5]+' is running\n')
child1 = subprocess.Popen(self.runcms, stdout = subprocess.PIPE, stdin = subprocess.PIPE, shell = False)
child1.poll()
resultScan = child1.stdout.read()
self.setobject.setResult(resultScan)
#self.setobject.setResult('Nmap task for '+self.runcms[5]+' is finnished\n')
self.pcontrol.subnum()
self.stop()
def stop(self):
self.thread_stop = True
单个IP地址扫描结果
C段扫描结果
通过先前的链接sqlmap插件来实现burpsuite,sqlmap和nmap这三个工件的集成.
0x02子域查询
我知道当前有三种子域查询方案: 一种是通过bing语法查询,第二种是使用第二级域名的集合,第三种是执行DNS爆破. 三种方案中较好的是第三种方案,而较好的轮子是subdomainsbrute. 当然,最好的方法是使用这三种方案,这只是消除重复的一种好方法,我在这里使用了第一种方案,不要问我为什么: 它很容易编写.
调用bing的主要功能
def BingSearch(query):
payload={}
payload['$top']=top
payload['$skip']=skip
payload['$format']=format
payload['Query']="'"+query+"'"
url='https://api.datamarket.azure.com/Bing/Search/Web?' + urllib.urlencode(payload)
sAuth='Basic '+base64.b64encode(':'+BINGKEY)
headers = { }
headers['Authorization']= sAuth
try:
req = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(req)
data=response.read()
#print data
data=json.loads(data)
return data
except Exception as e:
print e
#print e.info()
urlList = []
returnData = BingSearch("domain:" + theTopDomain)
if not returnData['d']['results']:
print "The Url Error"
else:
for tarUrl in returnData["d"]["results"]:
tmpUrl = urlparse.urlparse(tarUrl["Url"]).netloc
if tmpUrl not in urlList:
urlList.append(tmpUrl)
0x03敏感文件扫描
敏感文件扫描也是信息采集中的重要步骤. 通过文件扫描通常会带来意想不到的收益. 第三个功能模仿了Yujian Daniel的设计
目前有20个线程,速度已经过去
此外,它具有可以完全继承Proxy标记中的http请求标头信息(包括ua和cookie)的功能
EditorTools3破解版v3.3绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2020-08-08 00:24
EditorTools3破解版是一个非常易于使用的自动采集辅助软件. 是否要更改为其他采集软件?编辑器为您推荐了EditorTools3破解版. 该工具可以快速有效地帮助网站自动进行信息采集,并具有多种智能采集方案,可以全方位保证网站内容和更新效率,帮助管理人员更好地开发网站. 有需要的朋友,请不要错过!
概述
该软件适合在需要长期更新的非临时网站上使用,并且不需要您对现有论坛或网站进行任何更改.
功能介绍
1. 独特的无人值守操作
从设计伊始,ET就被设计为提高软件自动化程度的突破,以实现无人值守和自动24小时工作的目的. 经过测试,ET可以长时间甚至数年自动运行.
2. 超高稳定性
如果该软件无人值守,则需要能够长时间稳定运行. ET在这方面进行了很多优化,以确保软件可以稳定且连续地运行. 某些采集软件永远不会崩溃甚至导致崩溃. 网站崩溃了.
3,资源占用最低
ET独立于网站,并且不消耗宝贵的服务器WEB处理资源. 它可以在服务器上或网站管理员的工作站上工作.
4. 严格的数据和网络安全性
ET使用网站自己的数据发布界面或程序代码来处理和发布信息,并且不直接操作网站数据库,从而避免了由ET引起的任何数据安全问题. ET采集信息时,使用标准的HTTP端口,不会造成网络安全漏洞.
5. 强大而灵活的功能
除了通用采集工具的功能外,ET还通过支持图像水印,防垃圾,分页采集,答复采集,登录采集,自定义项目,UTF-8,UBB和模拟发布来使用户更加灵活. 实现各种头发采集需求.
更新日志
1. 解决一些已知问题. 查看全部
EditorTools3破解版是一个非常易于使用的自动采集辅助软件. 是否要更改为其他采集软件?编辑器为您推荐了EditorTools3破解版. 该工具可以快速有效地帮助网站自动进行信息采集,并具有多种智能采集方案,可以全方位保证网站内容和更新效率,帮助管理人员更好地开发网站. 有需要的朋友,请不要错过!
概述
该软件适合在需要长期更新的非临时网站上使用,并且不需要您对现有论坛或网站进行任何更改.
功能介绍
1. 独特的无人值守操作
从设计伊始,ET就被设计为提高软件自动化程度的突破,以实现无人值守和自动24小时工作的目的. 经过测试,ET可以长时间甚至数年自动运行.
2. 超高稳定性
如果该软件无人值守,则需要能够长时间稳定运行. ET在这方面进行了很多优化,以确保软件可以稳定且连续地运行. 某些采集软件永远不会崩溃甚至导致崩溃. 网站崩溃了.
3,资源占用最低
ET独立于网站,并且不消耗宝贵的服务器WEB处理资源. 它可以在服务器上或网站管理员的工作站上工作.
4. 严格的数据和网络安全性
ET使用网站自己的数据发布界面或程序代码来处理和发布信息,并且不直接操作网站数据库,从而避免了由ET引起的任何数据安全问题. ET采集信息时,使用标准的HTTP端口,不会造成网络安全漏洞.
5. 强大而灵活的功能
除了通用采集工具的功能外,ET还通过支持图像水印,防垃圾,分页采集,答复采集,登录采集,自定义项目,UTF-8,UBB和模拟发布来使用户更加灵活. 实现各种头发采集需求.
更新日志
1. 解决一些已知问题.
十多年来总结的最经典的项目,用作python爬虫实践教学!
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2020-08-08 00:01
此文章以前曾用于培训新手. 每个人都觉得它很容易理解,因此我与所有人共享并学习了. 如果您已经学习了一些python并想用它做一些事但没有方向,那么不妨尝试完成以下案例.
第二,环境准备
安装三个请求库lxml beautifulsoup4(以下代码均在python3.5环境中进行了测试)
pip install requests lxml beautifulsoup4
三个,一些小小的爬虫
3.1获取本地公网IP地址
利用在公共Internet上查询IP的借口,使用python的请求库自动获取IP地址.
import requests
r = requests.get("http://2017.ip138.com/ic.asp")
r.encoding = r.apparent_encoding #使用requests的字符编码智能分析,避免中文乱码
print(r.text)
# 你还可以使用正则匹配re模块提取出IP
import re
print(re.findall("d{1,3}.d{1,3}.d{1,3}.d{1,3}",r.text))
3.2使用百度搜索界面编写网址采集器
在这种情况下,我们将结合使用请求和BeautifulSoup库来完成任务. 我们需要在程序中设置User-Agent标头,以绕过百度搜索引擎的反爬虫机制(您可以尝试不使用User-Agent标头来查看是否可以获取数据). 注意百度搜索结构的URL链接规则. 例如,第一页上的URL链接参数pn = 0,第二页上的URL链接参数pn = 10 ...依此类推. 在这里,我们使用css选择器路径提取数据.
import requests
from bs4 import BeautifulSoup
# 设置User-Agent头,绕过百度搜索引擎的反爬虫机制
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'}
# 注意观察百度搜索结构的URL链接规律,例如第一页pn=0,第二页pn=10.... 依次类推,下面的for循环搜索前10页结果
for i in range(0,100,10):
bd_search = "https://www.baidu.com/s%3Fwd%3 ... ot%3B % str(i)
r = requests.get(bd_search,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
# 下面的select使用了css选择器路径提取数据
url_list = soup.select(".t > a")
for url in url_list:
real_url = url["href"]
r = requests.get(real_url)
print(r.url)
编写程序后,我们使用关键字inurl: /dede/login.php批量提取梦境编织cms的背景地址,效果如下:
3.3自动下载搜狗壁纸
在此示例中,我们将使用采集器自动下载搜索到的墙纸,并将程序中存储图片的路径更改为要存储图片的目录路径. 另一点是,我们在程序中使用了json库. 这是因为在观察过程中,我们发现Sogou的墙纸地址以json格式存储,因此我们将这组数据解析为json.
import requests
import json
#下载图片
url = "http://pic.sogou.com/pics/chan ... ot%3B
r = requests.get(url)
data = json.loads(r.text)
for i in data["all_items"]:
img_url = i["pic_url"]
# 下面这行里面的路径改成你自己想要存放图片的目录路径即可
with open("/home/evilk0/Desktop/img/%s" % img_url[-10:]+".jpg","wb") as f:
r2 = requests.get(img_url)
f.write(r2.content)
print("下载完毕:",img_url)
3.4自动填写问卷
目标官方网站:
目标问卷:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
r = requests.post(url = url,headers=header,data=data)
print(r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
当我们使用相同的IP提交多个调查表时,将触发目标的反爬行机制,并且服务器将显示验证码.
我们可以使用X-Forwarded-For伪造我们的IP,修改后的代码如下:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
"X-Forwarded-For" : "%s"
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
header["X-Forwarded-For"] = (str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+str(random.randint(1,255))
r = requests.post(url = url,headers=header,data=data)
print(header["X-Forwarded-For"],r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
header["X-Forwarded-For"] = "%s"
效果图:
关于本文,因为我之前已经写过,所以不再重复,我对它直接感兴趣: [如何通过Python自动填写调查表]
3.5获取公网代理IP,判断是否可以使用以及延迟时间
在此示例中,我们要在[Xi Spur代理]上爬网代理IP,并验证这些代理的生存能力和延迟时间. (您可以将爬网的代理IP添加到代理链,然后执行正常的渗透任务. )在这里,我直接调用Linux系统命令ping -c 1“ + ip.string +” | awk'NR == 2 {print}'-如果要在Windows中运行此程序,则需要将倒数第二行os.popen中的命令修改为可由Windows执行.
from bs4 import BeautifulSoup
import requests
import os
url = "http://www.xicidaili.com/nn/1"
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'}
r = requests.get(url=url,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
server_address = soup.select(".odd > td:nth-of-type(4)")
ip_list = soup.select(".odd > td:nth-of-type(2)")
ports = soup.select(".odd > td:nth-of-type(3)")
for server,ip in zip(server_address,ip_list):
if len(server.contents) != 1:
print(server.a.string.ljust(8),ip.string.ljust(20), end='')
else:
print("未知".ljust(8), ip.string.ljust(20), end='')
delay_time = os.popen("ping -c 1 " + ip.string + " | awk 'NR==2{print}' -")
delay_time = delay_time.read().split("time=")[-1].strip("
")
print("time = " + delay_time)
四个. 结论
当然,您也可以使用python做很多有趣的事情. 查看全部
I. 前言
此文章以前曾用于培训新手. 每个人都觉得它很容易理解,因此我与所有人共享并学习了. 如果您已经学习了一些python并想用它做一些事但没有方向,那么不妨尝试完成以下案例.
第二,环境准备
安装三个请求库lxml beautifulsoup4(以下代码均在python3.5环境中进行了测试)
pip install requests lxml beautifulsoup4
三个,一些小小的爬虫
3.1获取本地公网IP地址
利用在公共Internet上查询IP的借口,使用python的请求库自动获取IP地址.
import requests
r = requests.get("http://2017.ip138.com/ic.asp";)
r.encoding = r.apparent_encoding #使用requests的字符编码智能分析,避免中文乱码
print(r.text)
# 你还可以使用正则匹配re模块提取出IP
import re
print(re.findall("d{1,3}.d{1,3}.d{1,3}.d{1,3}",r.text))
3.2使用百度搜索界面编写网址采集器
在这种情况下,我们将结合使用请求和BeautifulSoup库来完成任务. 我们需要在程序中设置User-Agent标头,以绕过百度搜索引擎的反爬虫机制(您可以尝试不使用User-Agent标头来查看是否可以获取数据). 注意百度搜索结构的URL链接规则. 例如,第一页上的URL链接参数pn = 0,第二页上的URL链接参数pn = 10 ...依此类推. 在这里,我们使用css选择器路径提取数据.
import requests
from bs4 import BeautifulSoup
# 设置User-Agent头,绕过百度搜索引擎的反爬虫机制
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'}
# 注意观察百度搜索结构的URL链接规律,例如第一页pn=0,第二页pn=10.... 依次类推,下面的for循环搜索前10页结果
for i in range(0,100,10):
bd_search = "https://www.baidu.com/s%3Fwd%3 ... ot%3B % str(i)
r = requests.get(bd_search,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
# 下面的select使用了css选择器路径提取数据
url_list = soup.select(".t > a")
for url in url_list:
real_url = url["href"]
r = requests.get(real_url)
print(r.url)
编写程序后,我们使用关键字inurl: /dede/login.php批量提取梦境编织cms的背景地址,效果如下:
3.3自动下载搜狗壁纸
在此示例中,我们将使用采集器自动下载搜索到的墙纸,并将程序中存储图片的路径更改为要存储图片的目录路径. 另一点是,我们在程序中使用了json库. 这是因为在观察过程中,我们发现Sogou的墙纸地址以json格式存储,因此我们将这组数据解析为json.
import requests
import json
#下载图片
url = "http://pic.sogou.com/pics/chan ... ot%3B
r = requests.get(url)
data = json.loads(r.text)
for i in data["all_items"]:
img_url = i["pic_url"]
# 下面这行里面的路径改成你自己想要存放图片的目录路径即可
with open("/home/evilk0/Desktop/img/%s" % img_url[-10:]+".jpg","wb") as f:
r2 = requests.get(img_url)
f.write(r2.content)
print("下载完毕:",img_url)
3.4自动填写问卷
目标官方网站:
目标问卷:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
r = requests.post(url = url,headers=header,data=data)
print(r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
当我们使用相同的IP提交多个调查表时,将触发目标的反爬行机制,并且服务器将显示验证码.
我们可以使用X-Forwarded-For伪造我们的IP,修改后的代码如下:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
"X-Forwarded-For" : "%s"
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
header["X-Forwarded-For"] = (str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+str(random.randint(1,255))
r = requests.post(url = url,headers=header,data=data)
print(header["X-Forwarded-For"],r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
header["X-Forwarded-For"] = "%s"
效果图:
关于本文,因为我之前已经写过,所以不再重复,我对它直接感兴趣: [如何通过Python自动填写调查表]
3.5获取公网代理IP,判断是否可以使用以及延迟时间
在此示例中,我们要在[Xi Spur代理]上爬网代理IP,并验证这些代理的生存能力和延迟时间. (您可以将爬网的代理IP添加到代理链,然后执行正常的渗透任务. )在这里,我直接调用Linux系统命令ping -c 1“ + ip.string +” | awk'NR == 2 {print}'-如果要在Windows中运行此程序,则需要将倒数第二行os.popen中的命令修改为可由Windows执行.
from bs4 import BeautifulSoup
import requests
import os
url = "http://www.xicidaili.com/nn/1"
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'}
r = requests.get(url=url,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
server_address = soup.select(".odd > td:nth-of-type(4)")
ip_list = soup.select(".odd > td:nth-of-type(2)")
ports = soup.select(".odd > td:nth-of-type(3)")
for server,ip in zip(server_address,ip_list):
if len(server.contents) != 1:
print(server.a.string.ljust(8),ip.string.ljust(20), end='')
else:
print("未知".ljust(8), ip.string.ljust(20), end='')
delay_time = os.popen("ping -c 1 " + ip.string + " | awk 'NR==2{print}' -")
delay_time = delay_time.read().split("time=")[-1].strip("
")
print("time = " + delay_time)
四个. 结论
当然,您也可以使用python做很多有趣的事情.
Spoonie智能书写工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-07 17:32
勺式智能书写工具功能介绍
关键字
根据用户设置的关键字,进行常规采集,以免采集指定的一个或几个采集的站点
内容识别
无需编写规则,智能地识别页面的标题和内容,并快速访问系统.
定位
提供列表URL和文章URL来采集指定网站或列的内容,这样标题,正文,作者和来源就可以准确
伪原创SEO更新
网站直接调用伪原创界面,即智能伪原创,解决了网站收录问题.
如何安装瓢智能书写工具
从华军软件园的下载站点下载邵平智能写作工具的中文软件包
解压缩到当前文件夹
双击以打开文件夹中的应用程序
此软件是绿色软件,无需安装即可使用.
Shaopian智能书写工具的更新日志
1. 优化的步伐永无止境!
2. 更多小惊喜等着您来发现〜
华军编辑推荐:
Spoonie智能书写工具专业,易于操作且功能强大. 它是软件行业的领导者之一. 欢迎大家下载. 该网站还提供editplus,我的爱破解,qq音乐等供您下载.
中文版的Shaopian Smart Writing Tool是具有简短界面的智能伪原创写作机器人软件. Shaopian Smart Writing Tool的正式版提供了诸如伪原创工具,关键字提取,内容搜索和自动摘要之类的功能. 聪明地帮助用户完成文章内容摘要和伪原创工作. 中文智能书写工具提供列表URL和文章URL,以采集指定网站或列的内容.
勺式智能书写工具功能介绍
关键字
根据用户设置的关键字,进行常规采集,以免采集指定的一个或几个采集的站点
内容识别
无需编写规则,智能地识别页面的标题和内容,并快速访问系统.
定位
提供列表URL和文章URL来采集指定网站或列的内容,这样标题,正文,作者和来源就可以准确
伪原创SEO更新
网站直接调用伪原创界面,即智能伪原创,解决了网站收录问题.
如何安装瓢智能书写工具
从华军软件园的下载站点下载邵平智能写作工具的中文软件包
解压缩到当前文件夹
双击以打开文件夹中的应用程序
此软件是绿色软件,无需安装即可使用.
Shaopian智能书写工具的更新日志
1. 优化的步伐永无止境!
2. 更多小惊喜等着您来发现〜
华军编辑推荐:
Spoonie智能书写工具专业,易于操作且功能强大. 它是软件行业的领导者之一. 欢迎大家下载. 该网站还提供editplus,我的爱破解,qq音乐等供您下载. 查看全部
中文版的Shaopian Smart Writing Tool是具有简短界面的智能伪原创写作机器人软件. Shaopian Smart Writing Tool的正式版提供了诸如伪原创工具,关键字提取,内容搜索和自动摘要之类的功能. 聪明地帮助用户完成文章内容摘要和伪原创工作. 中文智能书写工具提供列表URL和文章URL,以采集指定网站或列的内容.
勺式智能书写工具功能介绍
关键字
根据用户设置的关键字,进行常规采集,以免采集指定的一个或几个采集的站点
内容识别
无需编写规则,智能地识别页面的标题和内容,并快速访问系统.
定位
提供列表URL和文章URL来采集指定网站或列的内容,这样标题,正文,作者和来源就可以准确
伪原创SEO更新
网站直接调用伪原创界面,即智能伪原创,解决了网站收录问题.
如何安装瓢智能书写工具
从华军软件园的下载站点下载邵平智能写作工具的中文软件包
解压缩到当前文件夹
双击以打开文件夹中的应用程序
此软件是绿色软件,无需安装即可使用.
Shaopian智能书写工具的更新日志
1. 优化的步伐永无止境!
2. 更多小惊喜等着您来发现〜
华军编辑推荐:
Spoonie智能书写工具专业,易于操作且功能强大. 它是软件行业的领导者之一. 欢迎大家下载. 该网站还提供editplus,我的爱破解,qq音乐等供您下载.
中文版的Shaopian Smart Writing Tool是具有简短界面的智能伪原创写作机器人软件. Shaopian Smart Writing Tool的正式版提供了诸如伪原创工具,关键字提取,内容搜索和自动摘要之类的功能. 聪明地帮助用户完成文章内容摘要和伪原创工作. 中文智能书写工具提供列表URL和文章URL,以采集指定网站或列的内容.
勺式智能书写工具功能介绍
关键字
根据用户设置的关键字,进行常规采集,以免采集指定的一个或几个采集的站点
内容识别
无需编写规则,智能地识别页面的标题和内容,并快速访问系统.
定位
提供列表URL和文章URL来采集指定网站或列的内容,这样标题,正文,作者和来源就可以准确
伪原创SEO更新
网站直接调用伪原创界面,即智能伪原创,解决了网站收录问题.
如何安装瓢智能书写工具
从华军软件园的下载站点下载邵平智能写作工具的中文软件包
解压缩到当前文件夹
双击以打开文件夹中的应用程序
此软件是绿色软件,无需安装即可使用.
Shaopian智能书写工具的更新日志
1. 优化的步伐永无止境!
2. 更多小惊喜等着您来发现〜
华军编辑推荐:
Spoonie智能书写工具专业,易于操作且功能强大. 它是软件行业的领导者之一. 欢迎大家下载. 该网站还提供editplus,我的爱破解,qq音乐等供您下载.
Python实现对人人的自动登录并访问最近的访问者实例
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2020-08-07 17:31
0X00前言
学期即将开始. 我看到各种各样的人要求在空间中填写调查表. 我只是想起我还没有做. 对于这种无意义的问卷,我没有感冒,所以我打算使用“特技”来完成它,即python. 顺便说一句,我再次回顾了python,很长时间以来它确实没有用. 接下来,表演开始...
0X01代码编写思路
首先创建一个调查表
我们随机填写问卷并提交,在提交之前打开Burpsuite以拦截数据包
分析截获的数据包,一些数据包由url编码,这不利于分析. 您可以使用Burpsuite编码模块进行解码和替换,因此分析起来很容易
通过观察,我们发现帖子中有一堆奇怪的数据Submitdata = 1 $ 2} 2 $ 3} 3 $ 3} 4 $ 4} 5 $ 3} 6 $ 2} 7 $ 4} 8 $ 2} 9 $ 3} 10 $ 3. 仔细的分析表明,数据可能意味着这一点. Submitdata =问题编号$选项编号}问题编号$选项编号}问题编号$选项编号}……..
使用此信息开始编写python程序
运行结果如下
该网站似乎还有其他反爬虫机制. 连续提交几份表格后,将显示验证码. 我们现在应该在程序中添加识别验证码的功能吗?实际上,这是没有必要的. 我们现在可以首先分析Burpsuite截获的标头信息,以了解该网站如何用于识别我们是否使用爬虫提交了问卷.
经过一些测试,发现当我连续提交3个问卷,然后为另一个IP提交3个问卷时,即我连续提交6个问卷,并且该网站的反爬虫机制没有被触发. 因此,我们可以猜测对方基于IP提交问卷的频率来识别爬虫. 看到这一点,您可能认为我们可以通过免费的在线代理商提交调查表. 例如这些
这是否意味着我们必须将提取免费代理IP的功能添加到python代码中?不不不!换句话说,在CTF竞赛中将出现问题. 例如,您的IP来自德国来获得标志. 因此,我们的想法是欺骗数据包报头,伪造我们的IP并欺骗服务器. 这是伪造IP的几种方法.
X-Client-IP:1.1.1.1
X-Remote-IP:2.2.2.2
X-Remote-Addr:3.3.3.3
X-Originating-IP:4.4.4.4
X-Forwarded-For:5.5.5.5
我们尝试每一项,然后在后台统计信息中查看调查表的来源.
在这里,我们发现可以绕过X-Forwarded-For. 根据我们的说法,我们将使用此方法将X-Forwarded-For字段添加到标头信息中,因此修改后的脚本如下
运行结果如下
再次在后台查看统计信息
到目前为止,我们已经完美地解决了任务. 如果要在问卷中删除中国境外的IP地址,可以采集中国的IP地址段,然后将其添加到程序中并进行处理.
0X02摘要
通常,您可以应用在现实生活中学到的知识. 遇到困难时不要惊慌,多想一点,找到最佳解决方案. 例如,上面我没有在代码中添加验证码识别模块,也没有通过代理绕过网站的反爬行机制,而是通过分析网站的反爬行机制并使用安全知识来进行的. (HTTP Head作弊)可以轻松解决问题,并使用最短的代码完美地完成任务.
时间: 2017-09-05
Python3&Selenium&plus; Chrome实现WPS表单的自动填充
简介本文使用python3,第三方python库Selenium和Google Chrome浏览器来完成WPS表单的自动填充. 开发环境配置python3安装: 互联网上有一些教程. Selenium安装: 在命令行Selenium上输入pip3 install,然后按Enter键完成安装. 如果不成功,请找到在线教程. Chrome安装: 稍微,互联网上有教程. 由于Selenium需要ChromeDriver来驱动Chrome,因此您还需要下载驱动程序ChromeDriver. 以下重点介绍Chrom
Python实现对人人的自动登录并访问最近的访问者实例
本文中的示例描述了python方法,该方法可自动登录到Renren并访问最近的访客,并共享它以供参考. 具体方法如下: ##-*-编码: gbk-*-#从xml导入os .dom导入minidom导入重新导入urllib导入urllib2导入cookielib导入datetime导入时间从urllib2导入URLError,HTTPError#登录模块是在线
python脚本的详细说明会自动生成所需的文件示例代码
自动生成python脚本所需的文件. 在我们的工作中,我们经常需要通过一个文件写入另一个文件. 但是,由于它是对应的关系,因此我们可以肯定地总结规则并让计算机帮助我们完成它. 今天,我们将使用由常规文件生成的python脚本. 要实现此功能,请使所有人摆脱日常的重复劳动!定义一个函数def producerBnf(infilename,outfilename): List = [],其中open(infilename,'r')作为inf: inf.readlines()中的行: List.append(re.
Python实现了自动登录百度空间的方法
本文中的示例说明了Python如何实现对百度空间的自动登录. 共享以供参考,如下所示: 开发环境: Fedora12 + Python2.6.2#!/ usr / bin / python#编码: GBK导入urllib,urllib2,httplib,cookielib def auto_login_hi(url,name,pwd): url_hi =“ “ #Set cookie cookie = cookielib
Python实现了一种自动添加日期并对照片进行分类的方法
本文中的示例描述了自动添加日期并对照片进行分类的Python方法. 共享它们,以供您参考,如下: 当我还很小的时候,我并没有拍照很多,所以他们不相信我,他们在我年轻的时候就那么帅. 我的外was女出生了,我为她买了照相机以拍摄更多照片. 不幸的是,他的叔叔仍然是迪克,并购买了700迪克的相机,但是没有自动添加日期功能. 我尝试了一些小型软件,但是它不容易使用,而大型软件我不知道如何使用图像软件. 作为计算机科学与技术专业的学生,我只能自力更生. 我听说Python有一个图形库,是的,它很容易为照片加上日期,所以我下载了这个库. 我对Python不熟悉,我在看手册时就写了它. 完成
Python实现了自动登录人人网并采集信息的方法
本文中的示例描述了自动登录人人网并采集信息的python方法. 共享以供参考. 具体的实现方法如下: #!/ usr / bin / python#-*-编码: utf-8- *-import sys import重新导入urllib2 import urllib import cookielib类Renren(object): def __init __(self): self.name = self.pwd = self.content = self.doma
Python实现了自动更改IP的方法
本文中的示例描述了在python中自动更改ip的方法. 共享以供参考. 具体的实现方法如下: #!/ usr / bin / env python#-*-encoding: gb2312-*-#文件名: IP .py import sitecustomize import _winreg import ConfigParser from ctypes import * print'网络适配器检测在进度,请稍候-'print netCfgInstanceID = None hkey =
用于实现对scp文件的自动远程登录的python示例代码
自动远程登录scp文件的python实现示例代码实现示例代码: #!/ usr / bin / expect if {$ argc!= 3} {send_user“用法: $ argv0 {path1} {path2} {Password} \ n \ n“退出}设置路径1 [lindex $ argv 0]设置路径2 [lindex $ argv 1]设置密码[lindex $ argv 2] spawn $ scp $ {path1} $ {path2} e
禁止在360浏览器中自动填充用户名和密码的各种方法
当前在开发项目时遇到了一个非常令人讨厌的问题. 最初,我在登录界面上输入了用户名和密码并登录. 选择记住密码后,在登录界面中输入的用户名和密码将填充在内容页面和页面中的内容中. 而且内容页面是要创建一个新的子帐户,这个问题确实是令人讨厌的Bara ~~~当然,在Firefox,IE8及更高版本的高端浏览器中也不会出现这种情况 查看全部
通过Python自动填写问卷
0X00前言
学期即将开始. 我看到各种各样的人要求在空间中填写调查表. 我只是想起我还没有做. 对于这种无意义的问卷,我没有感冒,所以我打算使用“特技”来完成它,即python. 顺便说一句,我再次回顾了python,很长时间以来它确实没有用. 接下来,表演开始...
0X01代码编写思路
首先创建一个调查表
我们随机填写问卷并提交,在提交之前打开Burpsuite以拦截数据包
分析截获的数据包,一些数据包由url编码,这不利于分析. 您可以使用Burpsuite编码模块进行解码和替换,因此分析起来很容易
通过观察,我们发现帖子中有一堆奇怪的数据Submitdata = 1 $ 2} 2 $ 3} 3 $ 3} 4 $ 4} 5 $ 3} 6 $ 2} 7 $ 4} 8 $ 2} 9 $ 3} 10 $ 3. 仔细的分析表明,数据可能意味着这一点. Submitdata =问题编号$选项编号}问题编号$选项编号}问题编号$选项编号}……..
使用此信息开始编写python程序
运行结果如下
该网站似乎还有其他反爬虫机制. 连续提交几份表格后,将显示验证码. 我们现在应该在程序中添加识别验证码的功能吗?实际上,这是没有必要的. 我们现在可以首先分析Burpsuite截获的标头信息,以了解该网站如何用于识别我们是否使用爬虫提交了问卷.
经过一些测试,发现当我连续提交3个问卷,然后为另一个IP提交3个问卷时,即我连续提交6个问卷,并且该网站的反爬虫机制没有被触发. 因此,我们可以猜测对方基于IP提交问卷的频率来识别爬虫. 看到这一点,您可能认为我们可以通过免费的在线代理商提交调查表. 例如这些
这是否意味着我们必须将提取免费代理IP的功能添加到python代码中?不不不!换句话说,在CTF竞赛中将出现问题. 例如,您的IP来自德国来获得标志. 因此,我们的想法是欺骗数据包报头,伪造我们的IP并欺骗服务器. 这是伪造IP的几种方法.
X-Client-IP:1.1.1.1
X-Remote-IP:2.2.2.2
X-Remote-Addr:3.3.3.3
X-Originating-IP:4.4.4.4
X-Forwarded-For:5.5.5.5
我们尝试每一项,然后在后台统计信息中查看调查表的来源.
在这里,我们发现可以绕过X-Forwarded-For. 根据我们的说法,我们将使用此方法将X-Forwarded-For字段添加到标头信息中,因此修改后的脚本如下
运行结果如下
再次在后台查看统计信息
到目前为止,我们已经完美地解决了任务. 如果要在问卷中删除中国境外的IP地址,可以采集中国的IP地址段,然后将其添加到程序中并进行处理.
0X02摘要
通常,您可以应用在现实生活中学到的知识. 遇到困难时不要惊慌,多想一点,找到最佳解决方案. 例如,上面我没有在代码中添加验证码识别模块,也没有通过代理绕过网站的反爬行机制,而是通过分析网站的反爬行机制并使用安全知识来进行的. (HTTP Head作弊)可以轻松解决问题,并使用最短的代码完美地完成任务.
时间: 2017-09-05
Python3&Selenium&plus; Chrome实现WPS表单的自动填充
简介本文使用python3,第三方python库Selenium和Google Chrome浏览器来完成WPS表单的自动填充. 开发环境配置python3安装: 互联网上有一些教程. Selenium安装: 在命令行Selenium上输入pip3 install,然后按Enter键完成安装. 如果不成功,请找到在线教程. Chrome安装: 稍微,互联网上有教程. 由于Selenium需要ChromeDriver来驱动Chrome,因此您还需要下载驱动程序ChromeDriver. 以下重点介绍Chrom
Python实现对人人的自动登录并访问最近的访问者实例
本文中的示例描述了python方法,该方法可自动登录到Renren并访问最近的访客,并共享它以供参考. 具体方法如下: ##-*-编码: gbk-*-#从xml导入os .dom导入minidom导入重新导入urllib导入urllib2导入cookielib导入datetime导入时间从urllib2导入URLError,HTTPError#登录模块是在线
python脚本的详细说明会自动生成所需的文件示例代码
自动生成python脚本所需的文件. 在我们的工作中,我们经常需要通过一个文件写入另一个文件. 但是,由于它是对应的关系,因此我们可以肯定地总结规则并让计算机帮助我们完成它. 今天,我们将使用由常规文件生成的python脚本. 要实现此功能,请使所有人摆脱日常的重复劳动!定义一个函数def producerBnf(infilename,outfilename): List = [],其中open(infilename,'r')作为inf: inf.readlines()中的行: List.append(re.
Python实现了自动登录百度空间的方法
本文中的示例说明了Python如何实现对百度空间的自动登录. 共享以供参考,如下所示: 开发环境: Fedora12 + Python2.6.2#!/ usr / bin / python#编码: GBK导入urllib,urllib2,httplib,cookielib def auto_login_hi(url,name,pwd): url_hi =“ “ #Set cookie cookie = cookielib
Python实现了一种自动添加日期并对照片进行分类的方法
本文中的示例描述了自动添加日期并对照片进行分类的Python方法. 共享它们,以供您参考,如下: 当我还很小的时候,我并没有拍照很多,所以他们不相信我,他们在我年轻的时候就那么帅. 我的外was女出生了,我为她买了照相机以拍摄更多照片. 不幸的是,他的叔叔仍然是迪克,并购买了700迪克的相机,但是没有自动添加日期功能. 我尝试了一些小型软件,但是它不容易使用,而大型软件我不知道如何使用图像软件. 作为计算机科学与技术专业的学生,我只能自力更生. 我听说Python有一个图形库,是的,它很容易为照片加上日期,所以我下载了这个库. 我对Python不熟悉,我在看手册时就写了它. 完成
Python实现了自动登录人人网并采集信息的方法
本文中的示例描述了自动登录人人网并采集信息的python方法. 共享以供参考. 具体的实现方法如下: #!/ usr / bin / python#-*-编码: utf-8- *-import sys import重新导入urllib2 import urllib import cookielib类Renren(object): def __init __(self): self.name = self.pwd = self.content = self.doma
Python实现了自动更改IP的方法
本文中的示例描述了在python中自动更改ip的方法. 共享以供参考. 具体的实现方法如下: #!/ usr / bin / env python#-*-encoding: gb2312-*-#文件名: IP .py import sitecustomize import _winreg import ConfigParser from ctypes import * print'网络适配器检测在进度,请稍候-'print netCfgInstanceID = None hkey =
用于实现对scp文件的自动远程登录的python示例代码
自动远程登录scp文件的python实现示例代码实现示例代码: #!/ usr / bin / expect if {$ argc!= 3} {send_user“用法: $ argv0 {path1} {path2} {Password} \ n \ n“退出}设置路径1 [lindex $ argv 0]设置路径2 [lindex $ argv 1]设置密码[lindex $ argv 2] spawn $ scp $ {path1} $ {path2} e
禁止在360浏览器中自动填充用户名和密码的各种方法
当前在开发项目时遇到了一个非常令人讨厌的问题. 最初,我在登录界面上输入了用户名和密码并登录. 选择记住密码后,在登录界面中输入的用户名和密码将填充在内容页面和页面中的内容中. 而且内容页面是要创建一个新的子帐户,这个问题确实是令人讨厌的Bara ~~~当然,在Firefox,IE8及更高版本的高端浏览器中也不会出现这种情况
如果您已经开始学习Python并且不了解爬虫,那么不妨看看这些情况!
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2020-08-07 17:16
第二,环境准备
Python 3
请求库,lxml库,beautifulsoup4库
pip install XX XX XX一起安装.
三,Python采集器小写
1. 获取本机的公共IP地址
使用python的请求库+检查公用网络上IP的接口以自动获取IP地址
2. 使用百度的搜索界面以Python编写网址采集工具
您需要使用请求库和BeautifulSoup库来观察百度搜索结构的URL链接规则,而绕开百度搜索引擎反爬虫机制的方法是在程序中设置User-Agent请求标头
Python源代码:
用Python语言编写程序后,使用关键字inurl: /dede/login.php批量提取特定网络cms的背景地址:
3. 使用Python创建Sogou墙纸并自动下载抓取工具
<p>Sogou墙纸的地址为json格式,因此请使用json库解析此数据集,并将采集器程序将图片存储到的磁盘路径更改为要保存的图片的路径. 查看全部
这些案例以前是为希望进入Python行业的一些朋友编写的. 我看到每个人都感到非常满意,所以我又把它们取出来了. 如果您已经开始学习python并且不了解爬虫,那么不妨在这里看看几种情况!
第二,环境准备
Python 3
请求库,lxml库,beautifulsoup4库
pip install XX XX XX一起安装.
三,Python采集器小写
1. 获取本机的公共IP地址
使用python的请求库+检查公用网络上IP的接口以自动获取IP地址
2. 使用百度的搜索界面以Python编写网址采集工具
您需要使用请求库和BeautifulSoup库来观察百度搜索结构的URL链接规则,而绕开百度搜索引擎反爬虫机制的方法是在程序中设置User-Agent请求标头
Python源代码:
用Python语言编写程序后,使用关键字inurl: /dede/login.php批量提取特定网络cms的背景地址:
3. 使用Python创建Sogou墙纸并自动下载抓取工具
<p>Sogou墙纸的地址为json格式,因此请使用json库解析此数据集,并将采集器程序将图片存储到的磁盘路径更改为要保存的图片的路径.
PHPCMS 采集 V1.0正式发布. PHPCMS首选集合插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 425 次浏览 • 2020-08-07 14:53
PHPCMS采集功能简介
1. 一键安装,自动采集
PHPCMS Collector的安装非常简单方便. 只需一分钟即可立即开始采集. 通过简单,健壮,灵活和开放源代码的PHPCMS程序,新手可以快速入门,并且我们还为商业客户提供专门的客户服务. 技术支持.
2. 一字采集,无需编写采集规则
与传统采集模式的不同之处在于,PHPCMS采集可以根据用户设置的关键字执行常规采集. 常规采集的优点是,通过采集关键字的不同搜索结果,可以实现错误的一个或多个指定的采集站点的采集,从而降低了搜索引擎将采集站点判断为镜像站点并被采集的风险. 被搜索引擎惩罚.
3. RSS采集,输入RSS地址以采集内容
只要所采集的网站提供RSS订阅地址,就可以通过RSS进行采集. 您只需输入RSS地址即可轻松采集目标网站的内容,而无需编写采集规则,这方便又简单.
4. 页面监控采集,轻松便捷地采集内容
页面监视集合仅需提供监视页面地址和文本URL规则即可指定指定网站或专栏内容的集合,这既方便又简单,并且可以针对性地进行采集而无需编写采集规则.
5. 多种伪原创和优化方法,以提高收录率和排名
自动标题,段落重排,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键字添加链接等方法来处理所采集文章并增强所采集文章的独创性,有利于搜索引擎优化,提高搜索引擎的收录率,网站权重和关键字排名.
6,插件自动采集,无需人工干预
Weaving Dream Collector是一个预先设置的采集任务,根据设置的采集方法采集URL,然后自动获取网页的内容. 该程序通过精确的计算来分析网页,丢弃不是文章内容页面的URL,并提取出最终优秀文章的内容是伪原创的,导入并生成的. 所有这些操作过程都是自动完成的,无需人工干预.
7. 定期并定量地采集伪原创SEO更新
该插件有两种触发采集方法,一种是通过用户访问触发的,另一种是我们为商业用户提供的远程触发采集服务. 新站点可以定期进行定量采集和更新,而无需人工干预.
安装方法:
PHPCMS采集器已经通过了对PHPCMS开放平台的严格审查,您可以单击直接在PHPCMS后台和应用程序中心安装它,如下所示:
插件价格:
PHPCMS Collector和Dreamweaver Collector的售价相同. 我们将一如既往地保持这一低价.
免费版: 每列可以添加1个关键字进行采集,高级设置,伪原创,搜索优化功能不可用,没有远程触发定时定量采集更新服务,没有技术支持.
商业版(200元): 支持3个域名绑定(可以联系官方获取多域支持),栏目无关键词限制,无使用期限,无使用功能限制,免费升级到最新版本,远程触发定期定量获取和更新服务,并提供技术支持.
商业版本的插件收费便宜,我们比花费数千美元启动的站点组管理系统更体贴,并且在使用效果方面我们不亚于同类软件. 查看全部
许多使用PHPCMS构建网站的用户向我们建议,他们希望也使用PHPCMS的强大功能. 当PHPCMS在开放平台上启动时,经过两个月的开发和测试,我们取得了成功. 开发了PHPCMS版本的Collector,它与Dreamweaving Collector V2.2版本的功能和用法基本相同. 它保留了该插件的强大且易于使用的功能. 熟悉PHPCMS采集器的用户将更易于使用. 该插件还通过了PHPCMS的严格官方审查,并成功加入了PHPCMS开放平台,成为第一个加入PHPCMS开放平台的智能集合插件.
PHPCMS采集功能简介
1. 一键安装,自动采集
PHPCMS Collector的安装非常简单方便. 只需一分钟即可立即开始采集. 通过简单,健壮,灵活和开放源代码的PHPCMS程序,新手可以快速入门,并且我们还为商业客户提供专门的客户服务. 技术支持.
2. 一字采集,无需编写采集规则
与传统采集模式的不同之处在于,PHPCMS采集可以根据用户设置的关键字执行常规采集. 常规采集的优点是,通过采集关键字的不同搜索结果,可以实现错误的一个或多个指定的采集站点的采集,从而降低了搜索引擎将采集站点判断为镜像站点并被采集的风险. 被搜索引擎惩罚.
3. RSS采集,输入RSS地址以采集内容
只要所采集的网站提供RSS订阅地址,就可以通过RSS进行采集. 您只需输入RSS地址即可轻松采集目标网站的内容,而无需编写采集规则,这方便又简单.
4. 页面监控采集,轻松便捷地采集内容
页面监视集合仅需提供监视页面地址和文本URL规则即可指定指定网站或专栏内容的集合,这既方便又简单,并且可以针对性地进行采集而无需编写采集规则.
5. 多种伪原创和优化方法,以提高收录率和排名
自动标题,段落重排,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键字添加链接等方法来处理所采集文章并增强所采集文章的独创性,有利于搜索引擎优化,提高搜索引擎的收录率,网站权重和关键字排名.
6,插件自动采集,无需人工干预
Weaving Dream Collector是一个预先设置的采集任务,根据设置的采集方法采集URL,然后自动获取网页的内容. 该程序通过精确的计算来分析网页,丢弃不是文章内容页面的URL,并提取出最终优秀文章的内容是伪原创的,导入并生成的. 所有这些操作过程都是自动完成的,无需人工干预.
7. 定期并定量地采集伪原创SEO更新
该插件有两种触发采集方法,一种是通过用户访问触发的,另一种是我们为商业用户提供的远程触发采集服务. 新站点可以定期进行定量采集和更新,而无需人工干预.
安装方法:
PHPCMS采集器已经通过了对PHPCMS开放平台的严格审查,您可以单击直接在PHPCMS后台和应用程序中心安装它,如下所示:
插件价格:
PHPCMS Collector和Dreamweaver Collector的售价相同. 我们将一如既往地保持这一低价.
免费版: 每列可以添加1个关键字进行采集,高级设置,伪原创,搜索优化功能不可用,没有远程触发定时定量采集更新服务,没有技术支持.
商业版(200元): 支持3个域名绑定(可以联系官方获取多域支持),栏目无关键词限制,无使用期限,无使用功能限制,免费升级到最新版本,远程触发定期定量获取和更新服务,并提供技术支持.
商业版本的插件收费便宜,我们比花费数千美元启动的站点组管理系统更体贴,并且在使用效果方面我们不亚于同类软件.
蜘蛛
采集交流 • 优采云 发表了文章 • 0 个评论 • 237 次浏览 • 2020-08-07 14:52
Spider类定义了如何爬网某个(或某些)网站. 包括爬网操作(例如: 是否跟踪链接)以及如何从网页内容(爬网项目)中提取结构化数据. 换句话说,您可以在Spider中定义抓取动作并分析某个网页(或某些网页).
scrapy类. Spider是最基本的类,所有编写的采集器都必须继承该类.
使用的主要功能和调用顺序为:
__ init __(): 初始化采集器名称和start_urls列表
start_requests()从url()调用make_requests_: 向Scrapy生成Requests对象以下载并返回响应
parse(): 解析响应并返回Item或Requests(需要指定回调函数). 将Item传递到Item pipline以保持持久性,Scrapy下载请求并由指定的回调函数(默认情况下为parse())处理请求,然后循环继续进行,直到处理完所有数据为止.
源代码参考:
#所有爬虫的基类,用户定义的爬虫必须从这个类继承
class Spider(object_ref):
#定义spider名字的字符串(string)。spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。
#name是spider最重要的属性,而且是必须的。
#一般做法是以该网站(domain)(加或不加 后缀 )来命名spider。 例如,如果spider爬取 mywebsite.com ,该spider通常会被命名为 mywebsite
name = None
#初始化,提取爬虫名字,start_ruls
def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
# 如果爬虫没有名字,中断后续操作则报错
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
# python 对象或类型通过内置成员__dict__来存储成员信息
self.__dict__.update(kwargs)
#URL列表。当没有指定的URL时,spider将从该列表中开始进行爬取。 因此,第一个被获取到的页面的URL将是该列表之一。 后续的URL将会从获取到的数据中提取。
if not hasattr(self, 'start_urls'):
self.start_urls = []
# 打印Scrapy执行后的log信息
def log(self, message, level=log.DEBUG, **kw):
log.msg(message, spider=self, level=level, **kw)
# 判断对象object的属性是否存在,不存在做断言处理
def set_crawler(self, crawler):
assert not hasattr(self, '_crawler'), "Spider already bounded to %s" % crawler
self._crawler = crawler
@property
def crawler(self):
assert hasattr(self, '_crawler'), "Spider not bounded to any crawler"
return self._crawler
@property
def settings(self):
return self.crawler.settings
#该方法将读取start_urls内的地址,并为每一个地址生成一个Request对象,交给Scrapy下载并返回Response
#该方法仅调用一次
def start_requests(self):
for url in self.start_urls:
yield self.make_requests_from_url(url)
#start_requests()中调用,实际生成Request的函数。
#Request对象默认的回调函数为parse(),提交的方式为get
def make_requests_from_url(self, url):
return Request(url, dont_filter=True)
#默认的Request对象回调函数,处理返回的response。
#生成Item或者Request对象。用户必须实现这个类
def parse(self, response):
raise NotImplementedError
@classmethod
def handles_request(cls, request):
return url_is_from_spider(request.url, cls)
def __str__(self):
return "" % (type(self).__name__, self.name, id(self))
__repr__ = __str__
主要属性和方法案例: 腾讯招聘网络自动翻页采集
创建一个新的采集器:
scrapy genspider tencent "tencent.com"
写items.py
获取职位,详细信息,
class TencentItem(scrapy.Item):
name = scrapy.Field()
detailLink = scrapy.Field()
positionInfo = scrapy.Field()
peopleNumber = scrapy.Field()
workLocation = scrapy.Field()
publishTime = scrapy.Field()
写tencent.py
# tencent.py
from mySpider.items import TencentItem
import scrapy
import re
class TencentSpider(scrapy.Spider):
name = "tencent"
allowed_domains = ["hr.tencent.com"]
start_urls = [
"http://hr.tencent.com/position ... ot%3B
]
def parse(self, response):
items = response.xpath('//*[contains(@class,"odd") or contains(@class,"even")]')
for item in items:
temp = dict(
name=item.xpath("./td[1]/a/text()").extract()[0],
detailLink="http://hr.tencent.com/"+item.xpath("./td[1]/a/@href").extract()[0],
positionInfo=item.xpath('./td[2]/text()').extract()[0] if len(item.xpath('./td[2]/text()').extract())>0 else None,
peopleNumber=item.xpath('./td[3]/text()').extract()[0],
workLocation=item.xpath('./td[4]/text()').extract()[0],
publishTime=item.xpath('./td[5]/text()').extract()[0]
)
yield temp
now_page = int(re.search(r"\d+", response.url).group(0))
print("*" * 100)
if now_page < 216:
url = re.sub(r"\d+", str(now_page + 10), response.url)
print("this is next page url:", url)
print("*" * 100)
yield scrapy.Request(url, callback=self.parse)
编写pipeline.py文件
import json
class TencentJsonPipeline(object):
def __init__(self):
#self.file = open('teacher.json', 'wb')
self.file = open('tencent.json', 'wb')
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(content)
return item
def close_spider(self, spider):
self.file.close()
在setting.py中设置ITEM_PIPELINES
ITEM_PIPELINES = {
#'mySpider.pipelines.SomePipeline': 300,
"mySpider.pipelines.TencentJsonPipeline":300
}
执行采集器:
scrapy crawl tencent
思考
请考虑parse()方法的工作机制:
因为使用收益而不是收益. 解析函数将用作生成器. Scrapy将一一获取解析方法中生成的结果,并确定结果的类型. 如果是请求,它将加入爬网队列;如果是项目类型,它将使用管道处理,其他类型将返回错误消息. 当scrapy获取请求的第一部分时,它将不会立即发送请求,而是将请求放入队列中,然后从生成器中获取它. 取出请求的第一部分,然后获取项目的第二部分,将其取出. 到达项目后,将其放入相应的管道中进行处理;将parse()方法作为回调函数(回调)分配给Request,并指定parse()方法来处理这些请求scrapy.Request(url,callback = self.parse)在安排了Request对象之后,执行scrapy.http.response()生成的响应对象,并将其发送回parse()方法,直到调度程序中没有耗尽的Request(递归想法),parse()工作结束,引擎重新启动执行相应的操作根据队列和管道的内容;在获取每个页面的项目之前,程序将处理请求队列中的所有先前请求,然后提取项目. 所有这些,Scrapy引擎和调度程序将最终负责. 常见错误
[scrapy.spidermiddlewares.offsite] DEBUG: Filtered offsite request to 'hr.tencent.com':
解决方案: 查看全部
蜘蛛
Spider类定义了如何爬网某个(或某些)网站. 包括爬网操作(例如: 是否跟踪链接)以及如何从网页内容(爬网项目)中提取结构化数据. 换句话说,您可以在Spider中定义抓取动作并分析某个网页(或某些网页).
scrapy类. Spider是最基本的类,所有编写的采集器都必须继承该类.
使用的主要功能和调用顺序为:
__ init __(): 初始化采集器名称和start_urls列表
start_requests()从url()调用make_requests_: 向Scrapy生成Requests对象以下载并返回响应
parse(): 解析响应并返回Item或Requests(需要指定回调函数). 将Item传递到Item pipline以保持持久性,Scrapy下载请求并由指定的回调函数(默认情况下为parse())处理请求,然后循环继续进行,直到处理完所有数据为止.
源代码参考:
#所有爬虫的基类,用户定义的爬虫必须从这个类继承
class Spider(object_ref):
#定义spider名字的字符串(string)。spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。
#name是spider最重要的属性,而且是必须的。
#一般做法是以该网站(domain)(加或不加 后缀 )来命名spider。 例如,如果spider爬取 mywebsite.com ,该spider通常会被命名为 mywebsite
name = None
#初始化,提取爬虫名字,start_ruls
def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
# 如果爬虫没有名字,中断后续操作则报错
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
# python 对象或类型通过内置成员__dict__来存储成员信息
self.__dict__.update(kwargs)
#URL列表。当没有指定的URL时,spider将从该列表中开始进行爬取。 因此,第一个被获取到的页面的URL将是该列表之一。 后续的URL将会从获取到的数据中提取。
if not hasattr(self, 'start_urls'):
self.start_urls = []
# 打印Scrapy执行后的log信息
def log(self, message, level=log.DEBUG, **kw):
log.msg(message, spider=self, level=level, **kw)
# 判断对象object的属性是否存在,不存在做断言处理
def set_crawler(self, crawler):
assert not hasattr(self, '_crawler'), "Spider already bounded to %s" % crawler
self._crawler = crawler
@property
def crawler(self):
assert hasattr(self, '_crawler'), "Spider not bounded to any crawler"
return self._crawler
@property
def settings(self):
return self.crawler.settings
#该方法将读取start_urls内的地址,并为每一个地址生成一个Request对象,交给Scrapy下载并返回Response
#该方法仅调用一次
def start_requests(self):
for url in self.start_urls:
yield self.make_requests_from_url(url)
#start_requests()中调用,实际生成Request的函数。
#Request对象默认的回调函数为parse(),提交的方式为get
def make_requests_from_url(self, url):
return Request(url, dont_filter=True)
#默认的Request对象回调函数,处理返回的response。
#生成Item或者Request对象。用户必须实现这个类
def parse(self, response):
raise NotImplementedError
@classmethod
def handles_request(cls, request):
return url_is_from_spider(request.url, cls)
def __str__(self):
return "" % (type(self).__name__, self.name, id(self))
__repr__ = __str__
主要属性和方法案例: 腾讯招聘网络自动翻页采集
创建一个新的采集器:
scrapy genspider tencent "tencent.com"
写items.py
获取职位,详细信息,
class TencentItem(scrapy.Item):
name = scrapy.Field()
detailLink = scrapy.Field()
positionInfo = scrapy.Field()
peopleNumber = scrapy.Field()
workLocation = scrapy.Field()
publishTime = scrapy.Field()
写tencent.py
# tencent.py
from mySpider.items import TencentItem
import scrapy
import re
class TencentSpider(scrapy.Spider):
name = "tencent"
allowed_domains = ["hr.tencent.com"]
start_urls = [
"http://hr.tencent.com/position ... ot%3B
]
def parse(self, response):
items = response.xpath('//*[contains(@class,"odd") or contains(@class,"even")]')
for item in items:
temp = dict(
name=item.xpath("./td[1]/a/text()").extract()[0],
detailLink="http://hr.tencent.com/"+item.xpath("./td[1]/a/@href").extract()[0],
positionInfo=item.xpath('./td[2]/text()').extract()[0] if len(item.xpath('./td[2]/text()').extract())>0 else None,
peopleNumber=item.xpath('./td[3]/text()').extract()[0],
workLocation=item.xpath('./td[4]/text()').extract()[0],
publishTime=item.xpath('./td[5]/text()').extract()[0]
)
yield temp
now_page = int(re.search(r"\d+", response.url).group(0))
print("*" * 100)
if now_page < 216:
url = re.sub(r"\d+", str(now_page + 10), response.url)
print("this is next page url:", url)
print("*" * 100)
yield scrapy.Request(url, callback=self.parse)
编写pipeline.py文件
import json
class TencentJsonPipeline(object):
def __init__(self):
#self.file = open('teacher.json', 'wb')
self.file = open('tencent.json', 'wb')
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(content)
return item
def close_spider(self, spider):
self.file.close()
在setting.py中设置ITEM_PIPELINES
ITEM_PIPELINES = {
#'mySpider.pipelines.SomePipeline': 300,
"mySpider.pipelines.TencentJsonPipeline":300
}
执行采集器:
scrapy crawl tencent
思考
请考虑parse()方法的工作机制:
因为使用收益而不是收益. 解析函数将用作生成器. Scrapy将一一获取解析方法中生成的结果,并确定结果的类型. 如果是请求,它将加入爬网队列;如果是项目类型,它将使用管道处理,其他类型将返回错误消息. 当scrapy获取请求的第一部分时,它将不会立即发送请求,而是将请求放入队列中,然后从生成器中获取它. 取出请求的第一部分,然后获取项目的第二部分,将其取出. 到达项目后,将其放入相应的管道中进行处理;将parse()方法作为回调函数(回调)分配给Request,并指定parse()方法来处理这些请求scrapy.Request(url,callback = self.parse)在安排了Request对象之后,执行scrapy.http.response()生成的响应对象,并将其发送回parse()方法,直到调度程序中没有耗尽的Request(递归想法),parse()工作结束,引擎重新启动执行相应的操作根据队列和管道的内容;在获取每个页面的项目之前,程序将处理请求队列中的所有先前请求,然后提取项目. 所有这些,Scrapy引擎和调度程序将最终负责. 常见错误
[scrapy.spidermiddlewares.offsite] DEBUG: Filtered offsite request to 'hr.tencent.com':
解决方案:
数据采集工具/数据捕获软件/服务器/客户端/采集软件的定制开发
采集交流 • 优采云 发表了文章 • 0 个评论 • 385 次浏览 • 2020-08-07 02:22
我们的商店仅从网站采集公共数据,即可以直接在目标网站上浏览的数据.
如果您想从其他网站获取内部数据,请不要打扰,这家商店不会这样做.
我们的商店没有满足不满足上述要求的要求,请不要打扰,谢谢.
前言:
我是python的开源数据采集框架like_spider的作者,并且擅长python / php可自定义的数据采集,数据分析,数据可视化以及excel文件的自动处理,套接字服务器/客户端开发和网站自动化测试.
like_spider框架与普通数据采集工具不同. 这些工具是由程序员为普通人开发的,存在很多限制. Like_spider是供程序员使用的,它使程序员更易于编写和采集其灵活性. 该程序更具可定制性,因此两者在技术或使用上都不相同. 作为该框架的作者,采集程序的开发将更快.
like_spider数据采集系统也是我根据基础采集框架(like_spider)开发的. 它提供给有数据采集需求并且不了解程序开发的普通雇主. 可以根据雇主的需求进行定制和开发. 可以设置在采集数据量的进度上实时观察与采集相关的多种情况,还可以设置是否自动导出为excel,或者可以根据需要导出其他文件格式雇主.
下图显示了like_spider数据采集系统的搜索和采集工具. 有linux服务器版本和Windows客户端版本.
定价:
价格将根据具体的开发复杂性和开发时间报价,并在双方协商后确定价格.
承诺:
根据雇主的要求进行开发,我将自己进行严格的测试,并按照双方约定的时间和方法进行交付. 如果我的代码在雇主的环境中运行,请免费调试它,直到它运行没有问题为止(在接下来的两周内交付),作为一个善良的程序员,我坚信赚钱和诚实!
送货:
在双方同意的时间交付源代码.
交易过程:
1. 双方交流了开发的可行性.
2. 根据开发的复杂程度和开发时间进行报价,并在双方协商后确定价格.
3. 开发完程序后,我们将尽快将其交给雇主进行操作测试. 确认正确无误后,我们不能要求我们更改程序.
4. 在所有物品交付并检查后,雇主将支付订单以完成交易.
注意: 一切仍然基于特定的交流! 查看全部
这家商店仅采集网站数据,不采集应用程序或客户端软件数据.
我们的商店仅从网站采集公共数据,即可以直接在目标网站上浏览的数据.
如果您想从其他网站获取内部数据,请不要打扰,这家商店不会这样做.
我们的商店没有满足不满足上述要求的要求,请不要打扰,谢谢.
前言:
我是python的开源数据采集框架like_spider的作者,并且擅长python / php可自定义的数据采集,数据分析,数据可视化以及excel文件的自动处理,套接字服务器/客户端开发和网站自动化测试.
like_spider框架与普通数据采集工具不同. 这些工具是由程序员为普通人开发的,存在很多限制. Like_spider是供程序员使用的,它使程序员更易于编写和采集其灵活性. 该程序更具可定制性,因此两者在技术或使用上都不相同. 作为该框架的作者,采集程序的开发将更快.
like_spider数据采集系统也是我根据基础采集框架(like_spider)开发的. 它提供给有数据采集需求并且不了解程序开发的普通雇主. 可以根据雇主的需求进行定制和开发. 可以设置在采集数据量的进度上实时观察与采集相关的多种情况,还可以设置是否自动导出为excel,或者可以根据需要导出其他文件格式雇主.
下图显示了like_spider数据采集系统的搜索和采集工具. 有linux服务器版本和Windows客户端版本.
定价:
价格将根据具体的开发复杂性和开发时间报价,并在双方协商后确定价格.
承诺:
根据雇主的要求进行开发,我将自己进行严格的测试,并按照双方约定的时间和方法进行交付. 如果我的代码在雇主的环境中运行,请免费调试它,直到它运行没有问题为止(在接下来的两周内交付),作为一个善良的程序员,我坚信赚钱和诚实!
送货:
在双方同意的时间交付源代码.
交易过程:
1. 双方交流了开发的可行性.
2. 根据开发的复杂程度和开发时间进行报价,并在双方协商后确定价格.
3. 开发完程序后,我们将尽快将其交给雇主进行操作测试. 确认正确无误后,我们不能要求我们更改程序.
4. 在所有物品交付并检查后,雇主将支付订单以完成交易.
注意: 一切仍然基于特定的交流!
Prometheus学习系列11: 编写Prometheus Collector
采集交流 • 优采云 发表了文章 • 0 个评论 • 442 次浏览 • 2020-08-07 00:17
快速入门并编写一个演示性示例来编写代码
from prometheus_client import Counter, Gauge, Summary, Histogram, start_http_server
# need install prometheus_client
if __name__ == '__main__':
c = Counter('cc', 'A counter')
c.inc()
g = Gauge('gg', 'A gauge')
g.set(17)
s = Summary('ss', 'A summary', ['a', 'b'])
s.labels('c', 'd').observe(17)
h = Histogram('hh', 'A histogram')
h.observe(.6)
start_http_server(8000)
import time
while True:
time.sleep(1)
只需要一个py文件. 运行时,它将侦听端口8000并访问端口127.0.0.1:8000.
效果图片
实际上,已经编写了一个导出器,就这么简单,我们只需要配置prometheus来采集相应的导出器. 但是,我们导出的数据毫无意义.
数据类型简介
计数器是一种累积类型,只能增加,例如记录http请求总数或网络接收和发送的数据包的累积值.
仪表盘: 仪表盘类型,适用于那些具有上升和下降,一般网络流量,磁盘读写等功能的仪表盘类型,该数据类型会随着波动和变化而使用.
摘要: 基于抽样,统计信息在服务器上完成. 在计算平均值时,我们可能会认为异常值导致计算得出的平均值无法准确反映实际值,因此需要特定的点位置.
直方图: 基于采样,统计在客户端上进行. 在计算平均值时,我们可能会认为异常值导致计算得出的平均值无法准确反映实际值,因此需要特定的点位置.
采集内存并使用数据编写采集代码
from prometheus_client.core import GaugeMetricFamily, REGISTRY
from prometheus_client import start_http_server
import psutil
class CustomMemoryUsaggeCollector():
def format_metric_name(self):
return 'custom_memory_'
def collect(self):
vm = psutil.virtual_memory()
#sub_metric_list = ["free", "available", "buffers", "cached", "used", "total"]
sub_metric_list = ["free", "available", "used", "total"]
for sub_metric in sub_metric_list:
gauge = GaugeMetricFamily(self.format_metric_name() + sub_metric, '')
gauge.add_metric(labels=[], value=getattr(vm, sub_metric))
yield gauge
if __name__ == "__main__":
collector = CustomMemoryUsaggeCollector()
REGISTRY.register(collector)
start_http_server(8001)
import time
while True:
time.sleep(1)
公开数据情况
部署代码并集成Prometheus
# 准备python3 环境 参考: https://virtualenvwrapper.read ... test/
yum install python36 -y
pip3 install virtualenvwrapper
vim /usr/local/bin/virtualenvwrapper.sh
# 文件最前面添加如下行
# Locate the global Python where virtualenvwrapper is installed.
VIRTUALENVWRAPPER_PYTHON="/usr/bin/python3"
# 文件生效
source /usr/local/bin/virtualenvwrapper.sh
# 配置workon
[root@node01 ~]# echo "export WORKON_HOME=~/Envs" >>~/.bashrc
[root@node01 ~]# mkvirtualenv custom_memory_exporter
(custom_memory_exporter) [root@node01 ~]# pip install prometheus_client psutil
yum install python36-devel
(custom_memory_exporter) [root@node01 ~]# chmod a+x custom_memory_exporter.py
(custom_memory_exporter) [root@node01 ~]# ./custom_memory_exporter.py
# 测试是否有结果数据
[root@node00 ~]# curl http://192.168.100.11:8001/<br /><br />prometheus.yml 加入如下片段<br /> - job_name: "custom-memory-exporter"<br /> static_configs:<br /> - targets: ["192.168.100.11:8001"]<br /><br />[root@node00 prometheus]# systemctl restart prometheus <br />[root@node00 prometheus]# systemctl status prometheu
查询效果图 查看全部
在上一篇文章中,我写了一些官方出口商的用法. 在实际使用环境中,我们可能需要采集一些自定义数据. 目前,我们通常需要自己编写采集器.
快速入门并编写一个演示性示例来编写代码
from prometheus_client import Counter, Gauge, Summary, Histogram, start_http_server
# need install prometheus_client
if __name__ == '__main__':
c = Counter('cc', 'A counter')
c.inc()
g = Gauge('gg', 'A gauge')
g.set(17)
s = Summary('ss', 'A summary', ['a', 'b'])
s.labels('c', 'd').observe(17)
h = Histogram('hh', 'A histogram')
h.observe(.6)
start_http_server(8000)
import time
while True:
time.sleep(1)
只需要一个py文件. 运行时,它将侦听端口8000并访问端口127.0.0.1:8000.
效果图片
实际上,已经编写了一个导出器,就这么简单,我们只需要配置prometheus来采集相应的导出器. 但是,我们导出的数据毫无意义.
数据类型简介
计数器是一种累积类型,只能增加,例如记录http请求总数或网络接收和发送的数据包的累积值.
仪表盘: 仪表盘类型,适用于那些具有上升和下降,一般网络流量,磁盘读写等功能的仪表盘类型,该数据类型会随着波动和变化而使用.
摘要: 基于抽样,统计信息在服务器上完成. 在计算平均值时,我们可能会认为异常值导致计算得出的平均值无法准确反映实际值,因此需要特定的点位置.
直方图: 基于采样,统计在客户端上进行. 在计算平均值时,我们可能会认为异常值导致计算得出的平均值无法准确反映实际值,因此需要特定的点位置.
采集内存并使用数据编写采集代码
from prometheus_client.core import GaugeMetricFamily, REGISTRY
from prometheus_client import start_http_server
import psutil
class CustomMemoryUsaggeCollector():
def format_metric_name(self):
return 'custom_memory_'
def collect(self):
vm = psutil.virtual_memory()
#sub_metric_list = ["free", "available", "buffers", "cached", "used", "total"]
sub_metric_list = ["free", "available", "used", "total"]
for sub_metric in sub_metric_list:
gauge = GaugeMetricFamily(self.format_metric_name() + sub_metric, '')
gauge.add_metric(labels=[], value=getattr(vm, sub_metric))
yield gauge
if __name__ == "__main__":
collector = CustomMemoryUsaggeCollector()
REGISTRY.register(collector)
start_http_server(8001)
import time
while True:
time.sleep(1)
公开数据情况
部署代码并集成Prometheus
# 准备python3 环境 参考: https://virtualenvwrapper.read ... test/
yum install python36 -y
pip3 install virtualenvwrapper
vim /usr/local/bin/virtualenvwrapper.sh
# 文件最前面添加如下行
# Locate the global Python where virtualenvwrapper is installed.
VIRTUALENVWRAPPER_PYTHON="/usr/bin/python3"
# 文件生效
source /usr/local/bin/virtualenvwrapper.sh
# 配置workon
[root@node01 ~]# echo "export WORKON_HOME=~/Envs" >>~/.bashrc
[root@node01 ~]# mkvirtualenv custom_memory_exporter
(custom_memory_exporter) [root@node01 ~]# pip install prometheus_client psutil
yum install python36-devel
(custom_memory_exporter) [root@node01 ~]# chmod a+x custom_memory_exporter.py
(custom_memory_exporter) [root@node01 ~]# ./custom_memory_exporter.py
# 测试是否有结果数据
[root@node00 ~]# curl http://192.168.100.11:8001/<br /><br />prometheus.yml 加入如下片段<br /> - job_name: "custom-memory-exporter"<br /> static_configs:<br /> - targets: ["192.168.100.11:8001"]<br /><br />[root@node00 prometheus]# systemctl restart prometheus <br />[root@node00 prometheus]# systemctl status prometheu
查询效果图
[Windows] [简易语言]小说采集器-新手写作
采集交流 • 优采云 发表了文章 • 0 个评论 • 471 次浏览 • 2020-08-07 00:14
因为它是用一种简单的语言编写的,所以某些防病毒软件可能涉及报告病毒,我的腾讯管家没有报告该病毒〜
主界面
我主要在Shubao.com网站上采集小说. 内容比较简单. 看看吧〜
主要是通过调用鱼骨HTTP模块访问网页获取网页数据,并通过常规提取自身所需的数据,并显示在界面上~~
当然,仅调用Jingyi模块也可以达到效果(webpage_visit)
搜索界面
分类界面
搜索按钮是通过POST编写的,我知道简单的提琴手会捕获数据包以获取该网页的搜索内容信息,并将该信息填充到鱼骨模块的网页访问中以获得搜索结果,但是我不知道那是那个网站. 制作人的问题,实际上,书名和作者的搜索信息没有区别〜
搜索小说可能很慢. 您需要耐心等待一段时间,因为网络搜索中仅显示新颖的名称和简介. 为了迎合我的个人界面,我参观了每本小说并列出了作者,字数,最后输入了更新时间
字体大小没有改变. 我没有提供消息来源. 我可能会在以后找到一些书本资料来填写,以达到更改书目的目的〜
阅读界面
下载界面
产品+源代码链接地址:
链接:
提取代码: og57
数据已保存到16:47
[url =]保存30秒[/ url] [url =]保存数据[/ url] | [url =]还原数据[/ url] [url =]字数检查[/ url] | [url =]清除内容[/ url] [url =]放大编辑框[/ url] | [url =]缩小编辑框[/ url]
读取权限的其他选项. 此版本的积分规则可向听众发布帖子和广播 查看全部
新手自学易写的小说采集器〜
因为它是用一种简单的语言编写的,所以某些防病毒软件可能涉及报告病毒,我的腾讯管家没有报告该病毒〜
主界面
我主要在Shubao.com网站上采集小说. 内容比较简单. 看看吧〜
主要是通过调用鱼骨HTTP模块访问网页获取网页数据,并通过常规提取自身所需的数据,并显示在界面上~~
当然,仅调用Jingyi模块也可以达到效果(webpage_visit)
搜索界面
分类界面
搜索按钮是通过POST编写的,我知道简单的提琴手会捕获数据包以获取该网页的搜索内容信息,并将该信息填充到鱼骨模块的网页访问中以获得搜索结果,但是我不知道那是那个网站. 制作人的问题,实际上,书名和作者的搜索信息没有区别〜
搜索小说可能很慢. 您需要耐心等待一段时间,因为网络搜索中仅显示新颖的名称和简介. 为了迎合我的个人界面,我参观了每本小说并列出了作者,字数,最后输入了更新时间
字体大小没有改变. 我没有提供消息来源. 我可能会在以后找到一些书本资料来填写,以达到更改书目的目的〜
阅读界面
下载界面
产品+源代码链接地址:
链接:
提取代码: og57
数据已保存到16:47
[url =]保存30秒[/ url] [url =]保存数据[/ url] | [url =]还原数据[/ url] [url =]字数检查[/ url] | [url =]清除内容[/ url] [url =]放大编辑框[/ url] | [url =]缩小编辑框[/ url]
读取权限的其他选项. 此版本的积分规则可向听众发布帖子和广播
爬虫大规模数据采集的经验和示例
采集交流 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2020-08-06 19:09
1. 什么样的数据可以称为大量数据:
我认为这可能是因为每个人的理解都不相同,并且给出的定义也不同. 我认为定义采集网站的数据大小不仅取决于网站中收录的数据量,还取决于采集网站的难度,采集网站的服务器容量,网络带宽和由计算机分配的计算机硬件资源. 收款人员等等. 我在这里临时称一个拥有超过1000万个URL的网站链接一个拥有大量数据的网站.
2. 具有大量数据的网站采集程序:
2.1. 采集需求分析:
作为一名数据采集工程师,我认为最重要的是做好数据采集需求分析. 首先,我们必须估计该网站的数据量,然后弄清楚要采集哪些数据,是否有必要分析目标网站的数据?所有采集的数据,因为采集的数据越多,花费的时间越多,花费的时间就越多. 资源是必需的,目标网站的压力也更大. 数据采集工程师不能对目标网站造成太大的损害以采集数据. 压力. 原则是采集尽可能少的数据以满足您自己的需求,并避免采集所有电台.
2.2. 代码编写:
由于要采集大量网站数据,因此需要编写代码以稳定运行一周甚至一个月以上,因此代码应足够强大. 通常要求网站不要更改模板,并且程序可以一直执行. 这里有一点编程技巧,我认为这很重要,即在编写代码之后,运行一两个小时,在程序中发现一些错误,对其进行修改,这种预编码测试可以确保代码的健壮性.
2.3数据存储:
当数据量为30到5千万时,无论是MySQL,Oracle还是SQL Server,都无法将其存储在一个表中. 目前,您可以使用单独的表进行存储. 数据采集之后,当插入数据库时,您可以执行诸如批量插入之类的策略. 确保您的存储不受数据库性能和其他方面的影响.
2.4分配的资源:
由于目标网站上的数据很多,我们不可避免地不得不使用大带宽,内存,CPU和其他资源. 目前,我们可以构建一个分布式采集器系统来合理地管理我们的资源.
3. 爬行者的道德观
对于一些初级采集工程师来说,为了更快地采集数据,通常会打开许多多进程和多线程. 结果是对目标网站进行了dos攻击. 结果是目标网站果断地升级了网站并增加了许多反爬升策略,这种对抗对购置工程师也极为不利. 个人建议下载速度不应超过2M,多进程或多线程不应超过一百.
示例:
要采集的目标网站有4000万个数据. 该网站的防爬策略是阻止IP,所以我专门找到了一台机器,并打开了200多个进程来维护IP池. ip池中的可用ip为500 -1000,并确保该ip具有高可用性.
编写代码后,它可以在两台计算机上运行. 该机器每天最多打开64个多线程,下载速度不超过1M.
个人知识有限,请多多包涵 查看全部
本文主要介绍大量采集网站数据的经验
1. 什么样的数据可以称为大量数据:
我认为这可能是因为每个人的理解都不相同,并且给出的定义也不同. 我认为定义采集网站的数据大小不仅取决于网站中收录的数据量,还取决于采集网站的难度,采集网站的服务器容量,网络带宽和由计算机分配的计算机硬件资源. 收款人员等等. 我在这里临时称一个拥有超过1000万个URL的网站链接一个拥有大量数据的网站.
2. 具有大量数据的网站采集程序:
2.1. 采集需求分析:
作为一名数据采集工程师,我认为最重要的是做好数据采集需求分析. 首先,我们必须估计该网站的数据量,然后弄清楚要采集哪些数据,是否有必要分析目标网站的数据?所有采集的数据,因为采集的数据越多,花费的时间越多,花费的时间就越多. 资源是必需的,目标网站的压力也更大. 数据采集工程师不能对目标网站造成太大的损害以采集数据. 压力. 原则是采集尽可能少的数据以满足您自己的需求,并避免采集所有电台.
2.2. 代码编写:
由于要采集大量网站数据,因此需要编写代码以稳定运行一周甚至一个月以上,因此代码应足够强大. 通常要求网站不要更改模板,并且程序可以一直执行. 这里有一点编程技巧,我认为这很重要,即在编写代码之后,运行一两个小时,在程序中发现一些错误,对其进行修改,这种预编码测试可以确保代码的健壮性.
2.3数据存储:
当数据量为30到5千万时,无论是MySQL,Oracle还是SQL Server,都无法将其存储在一个表中. 目前,您可以使用单独的表进行存储. 数据采集之后,当插入数据库时,您可以执行诸如批量插入之类的策略. 确保您的存储不受数据库性能和其他方面的影响.
2.4分配的资源:
由于目标网站上的数据很多,我们不可避免地不得不使用大带宽,内存,CPU和其他资源. 目前,我们可以构建一个分布式采集器系统来合理地管理我们的资源.
3. 爬行者的道德观
对于一些初级采集工程师来说,为了更快地采集数据,通常会打开许多多进程和多线程. 结果是对目标网站进行了dos攻击. 结果是目标网站果断地升级了网站并增加了许多反爬升策略,这种对抗对购置工程师也极为不利. 个人建议下载速度不应超过2M,多进程或多线程不应超过一百.
示例:
要采集的目标网站有4000万个数据. 该网站的防爬策略是阻止IP,所以我专门找到了一台机器,并打开了200多个进程来维护IP池. ip池中的可用ip为500 -1000,并确保该ip具有高可用性.
编写代码后,它可以在两台计算机上运行. 该机器每天最多打开64个多线程,下载速度不超过1M.
个人知识有限,请多多包涵
Max 4.0采集规则的编译
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-08-06 17:21
第一步是设置基本参数
选择主采集菜单,然后单击添加采集规则(实际上是修改了我的采集,但是过程与添加规则相同. 此处的解释主要是通过修改其他采集的规则来理解采集规则的编译)
目标站点网址:
======
这是列表的第一页
批量生成集合地址: {$ ID} -12.html
=======
<p>这是一个通过分页具有类似URL的网站,通常只是更改ID,例如,第一页是xxx-1-12.html,第二页是xxx-2-12.html 查看全部
配置MaXCMS后,输入背景,例如我的是:
第一步是设置基本参数
选择主采集菜单,然后单击添加采集规则(实际上是修改了我的采集,但是过程与添加规则相同. 此处的解释主要是通过修改其他采集的规则来理解采集规则的编译)
目标站点网址:
======
这是列表的第一页
批量生成集合地址: {$ ID} -12.html
=======
<p>这是一个通过分页具有类似URL的网站,通常只是更改ID,例如,第一页是xxx-1-12.html,第二页是xxx-2-12.html
Python采集器网站建设简介-从头开始构建采集网站(两个: 编写采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 443 次浏览 • 2020-08-06 17:19
那是一堆混乱的东西
已安装pip,随pip一起安装了virtualenv,并已建立了virtualenv. 在此virtualenv中,安装了Django,创建了Django项目,并在此Django项目中创建了一个名为web的Apipi.
继续上次〜
第二部分,编写一个采集器.
工人要想做得好,必须首先完善他们的工具.
bashapt-get install vim # 接上回,我们在screen里面是root身份哦~
当然,现在我要有一个采集目标. 为了方便起见,我将选择segmentfault. 这个网站很适合写博客,但是在国外上传图片有点慢.
与我的访问一样,此爬网程序必须分步完成. 我首先看到了segmentfault主页,然后发现其中有很多标签,并且在每个标签下都存在一个一个的问题.
因此,采集器应分为以下几个步骤来编写. 但是我要用另一种方式来编写它,因为我想先写内容采集器,然后编写分类采集器.
2.1编写内容采集器
首先,为爬虫创建一个目录,该目录与项目中的应用程序处于同一级别,然后将该目录转换为python包
bashmkdir ~/python_spider/sfspider
touch ~/python_spider/sfspider/__init__.py
从现在开始,此目录将称为“爬虫程序包”
在采集器软件包中创建spider.py以安装我的采集器
bashvim ~/python_spider/sfspider/spider.py
基本的采集器仅需要以下代码行:
(下面将提供代码)
然后,我们可以玩“爬行动物”了.
输入python shell
python>>> from sfspider import spider
>>> s = spider.SegmentfaultQuestionSpider('1010000002542775')
>>> s.url
>>> 'http://segmentfault.com/q/1010000002542775'
>>> print s.dom('h1#questionTitle').text()
>>> 微信JS—SDK嵌套选择图片和上传图片接口,实现一键上传图片,遇到问题
看,我现在可以通过采集器获取segmentfault的问题标题. 在下一步中,为了简化代码,我将标题,答案等的属性编写为蜘蛛的属性. 代码如下
python# -*- coding: utf-8 -*-
import requests # requests作为我们的html客户端
from pyquery import PyQuery as Pq # pyquery来操作dom
class SegmentfaultQuestionSpider(object):
def __init__(self, segmentfault_id): # 参数为在segmentfault上的id
self.url = 'http://segmentfault.com/q/{0}'.format(segmentfault_id)
self._dom = None # 弄个这个来缓存获取到的html内容,一个蜘蛛应该之访问一次
@property
def dom(self): # 获取html内容
if not self._dom:
document = requests.get(self.url)
document.encoding = 'utf-8'
self._dom = Pq(document.text)
return self._dom
@property
def title(self): # 让方法可以通过s.title的方式访问 可以少打对括号
return self.dom('h1#questionTitle').text() # 关于选择器可以参考css selector或者jquery selector, 它们在pyquery下几乎都可以使用
@property
def content(self):
return self.dom('.question.fmt').html() # 直接获取html 胆子就是大 以后再来过滤
@property
def answers(self):
return list(answer.html() for answer in self.dom('.answer.fmt').items()) # 记住,Pq实例的items方法是很有用的
@property
def tags(self):
return self.dom('ul.taglist--inline > li').text().split() # 获取tags,这里直接用text方法,再切分就行了。一般只要是文字内容,而且文字内容自己没有空格,逗号等,都可以这样弄,省事。
然后,再次玩升级的蜘蛛.
python>>> from sfspider import spider
>>> s = spider.SegmentfaultQuestionSpider('1010000002542775')
>>> print s.title
>>> 微信JS—SDK嵌套选择图片和上传图片接口,实现一键上传图片,遇到问题
>>> print s.content
>>> # [故意省略] #
>>> for answer in s.answers
print answer
>>> # [故意省略] #
>>> print '/'.join(s.tags)
>>> 微信js-sdk/python/微信开发/javascript
好的,现在我的蜘蛛玩起来更方便了.
2.2编写分类采集器
接下来,我要编写一个对标签页进行爬网的爬网程序.
代码如下. 请注意,下面的代码被添加到现有代码的下面,并且在最后一行的前一行和上一行之间必须有两个空行
pythonclass SegmentfaultTagSpider(object):
def __init__(self, tag_name, page=1):
self.url = 'http://segmentfault.com/t/%s?type=newest&page=%s' % (tag_name, page)
self.tag_name = tag_name
self.page = page
self._dom = None
@property
def dom(self):
if not self._dom:
document = requests.get(self.url)
document.encoding = 'utf-8'
self._dom = Pq(document.text)
self._dom.make_links_absolute(base_url="http://segmentfault.com/") # 相对链接变成绝对链接 爽
return self._dom
@property
def questions(self):
return [question.attr('href') for question in self.dom('h2.title > a').items()]
@property
def has_next_page(self): # 看看还有没有下一页,这个有必要
return bool(self.dom('ul.pagination > li.next')) # 看看有木有下一页
def next_page(self): # 把这个蜘蛛杀了, 产生一个新的蜘蛛 抓取下一页。 由于这个本来就是个动词,所以就不加@property了
if self.has_next_page:
self.__init__(tag_name=self.tag_name ,page=self.page+1)
else:
return None
现在您可以一起玩两个蜘蛛了,所以我不再详细介绍游戏过程. .
python>>> from sfspider import spider
>>> s = spider.SegmentfaultTagSpider('微信')
>>> question1 = s.questions[0]
>>> question_spider = spider.SegmentfaultQuestionSpider(question1.split('/')[-1])
>>> # [故意省略] #
如果您想成为小偷,基本上可以在这里找到它. 设置模板并添加一个简单的脚本来接受和返回请求.
待续. 查看全部
上次,我安装了环境
那是一堆混乱的东西
已安装pip,随pip一起安装了virtualenv,并已建立了virtualenv. 在此virtualenv中,安装了Django,创建了Django项目,并在此Django项目中创建了一个名为web的Apipi.
继续上次〜
第二部分,编写一个采集器.
工人要想做得好,必须首先完善他们的工具.
bashapt-get install vim # 接上回,我们在screen里面是root身份哦~
当然,现在我要有一个采集目标. 为了方便起见,我将选择segmentfault. 这个网站很适合写博客,但是在国外上传图片有点慢.
与我的访问一样,此爬网程序必须分步完成. 我首先看到了segmentfault主页,然后发现其中有很多标签,并且在每个标签下都存在一个一个的问题.
因此,采集器应分为以下几个步骤来编写. 但是我要用另一种方式来编写它,因为我想先写内容采集器,然后编写分类采集器.
2.1编写内容采集器
首先,为爬虫创建一个目录,该目录与项目中的应用程序处于同一级别,然后将该目录转换为python包
bashmkdir ~/python_spider/sfspider
touch ~/python_spider/sfspider/__init__.py
从现在开始,此目录将称为“爬虫程序包”
在采集器软件包中创建spider.py以安装我的采集器
bashvim ~/python_spider/sfspider/spider.py
基本的采集器仅需要以下代码行:
(下面将提供代码)
然后,我们可以玩“爬行动物”了.
输入python shell
python>>> from sfspider import spider
>>> s = spider.SegmentfaultQuestionSpider('1010000002542775')
>>> s.url
>>> 'http://segmentfault.com/q/1010000002542775'
>>> print s.dom('h1#questionTitle').text()
>>> 微信JS—SDK嵌套选择图片和上传图片接口,实现一键上传图片,遇到问题
看,我现在可以通过采集器获取segmentfault的问题标题. 在下一步中,为了简化代码,我将标题,答案等的属性编写为蜘蛛的属性. 代码如下
python# -*- coding: utf-8 -*-
import requests # requests作为我们的html客户端
from pyquery import PyQuery as Pq # pyquery来操作dom
class SegmentfaultQuestionSpider(object):
def __init__(self, segmentfault_id): # 参数为在segmentfault上的id
self.url = 'http://segmentfault.com/q/{0}'.format(segmentfault_id)
self._dom = None # 弄个这个来缓存获取到的html内容,一个蜘蛛应该之访问一次
@property
def dom(self): # 获取html内容
if not self._dom:
document = requests.get(self.url)
document.encoding = 'utf-8'
self._dom = Pq(document.text)
return self._dom
@property
def title(self): # 让方法可以通过s.title的方式访问 可以少打对括号
return self.dom('h1#questionTitle').text() # 关于选择器可以参考css selector或者jquery selector, 它们在pyquery下几乎都可以使用
@property
def content(self):
return self.dom('.question.fmt').html() # 直接获取html 胆子就是大 以后再来过滤
@property
def answers(self):
return list(answer.html() for answer in self.dom('.answer.fmt').items()) # 记住,Pq实例的items方法是很有用的
@property
def tags(self):
return self.dom('ul.taglist--inline > li').text().split() # 获取tags,这里直接用text方法,再切分就行了。一般只要是文字内容,而且文字内容自己没有空格,逗号等,都可以这样弄,省事。
然后,再次玩升级的蜘蛛.
python>>> from sfspider import spider
>>> s = spider.SegmentfaultQuestionSpider('1010000002542775')
>>> print s.title
>>> 微信JS—SDK嵌套选择图片和上传图片接口,实现一键上传图片,遇到问题
>>> print s.content
>>> # [故意省略] #
>>> for answer in s.answers
print answer
>>> # [故意省略] #
>>> print '/'.join(s.tags)
>>> 微信js-sdk/python/微信开发/javascript
好的,现在我的蜘蛛玩起来更方便了.
2.2编写分类采集器
接下来,我要编写一个对标签页进行爬网的爬网程序.
代码如下. 请注意,下面的代码被添加到现有代码的下面,并且在最后一行的前一行和上一行之间必须有两个空行
pythonclass SegmentfaultTagSpider(object):
def __init__(self, tag_name, page=1):
self.url = 'http://segmentfault.com/t/%s?type=newest&page=%s' % (tag_name, page)
self.tag_name = tag_name
self.page = page
self._dom = None
@property
def dom(self):
if not self._dom:
document = requests.get(self.url)
document.encoding = 'utf-8'
self._dom = Pq(document.text)
self._dom.make_links_absolute(base_url="http://segmentfault.com/";) # 相对链接变成绝对链接 爽
return self._dom
@property
def questions(self):
return [question.attr('href') for question in self.dom('h2.title > a').items()]
@property
def has_next_page(self): # 看看还有没有下一页,这个有必要
return bool(self.dom('ul.pagination > li.next')) # 看看有木有下一页
def next_page(self): # 把这个蜘蛛杀了, 产生一个新的蜘蛛 抓取下一页。 由于这个本来就是个动词,所以就不加@property了
if self.has_next_page:
self.__init__(tag_name=self.tag_name ,page=self.page+1)
else:
return None
现在您可以一起玩两个蜘蛛了,所以我不再详细介绍游戏过程. .
python>>> from sfspider import spider
>>> s = spider.SegmentfaultTagSpider('微信')
>>> question1 = s.questions[0]
>>> question_spider = spider.SegmentfaultQuestionSpider(question1.split('/')[-1])
>>> # [故意省略] #
如果您想成为小偷,基本上可以在这里找到它. 设置模板并添加一个简单的脚本来接受和返回请求.
待续.

