
自动采集编写
使用Python3编撰一个爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 224 次浏览 • 2020-08-23 07:12
使用Python3编撰一个爬虫需求简介
最近厂里有一个新闻采集类的需求,细节大体如下:
模拟登陆一个外网网站(SSO)抓取新闻(支持代理服务器的形式访问)加工内容款式,以适配手机屏幕将正文中的图片转存到自已的服务器,并替换img标签中的url图片储存服务器须要复用已有的FastDFS分布式文件系统采集结果导出生产库支持日志复印
初学Python3,正好用这个需求练练手,最后太吃惊的是只用200多行代码就实现了,如果换成Java的话大约须要1200行吧。果然应了那句俗话:人生苦短,我用Python
登录页面抓包
第一步其实是抓包,然后再按照抓到的内容,模拟进行HTTP恳求。
常用的抓包工具,有Mac下的Charles和Windows下的Fiddler。
它们的原理都是在本机开一个HTTP或SOCKS代理服务器端口,然后将浏览器的代理服务器设置成这个端口,这样浏览器中所有的HTTP恳求就会先经过抓包工具记录出来了。
这里推荐尽量使用Fiddler,原因是Charles对于cookie的展示是有bug的,举个事例,真实情况:请求A返回了LtpaToken这个cookie,请求B中返回了sid这个cookie。但在Charles中的展示是:请求A中早已同时返回了LtpaToken和sid两个cookie,这就很容易欺骗人了。
另外Fiddler如今早已有了Linux的Beta版本,貌似是用类似wine的形式实现的。
如果网站使用了单点登录,可能会涉及到手工生成cookie。所以除了须要剖析每一条HTTP请求的request和response,以及带回去的cookie,还要对页面中的javascript进行剖析,看一下是怎样生成cookie的。
模拟登陆
将页面剖析完毕以后,就可以进行模拟HTTP恳求了。
这里有两个非常好用的第三方库, request 和 BeautifulSoup
requests 库是拿来替代urllib的,可以十分人性化的的生成HTTP请求,模拟session以及伪造cookie更是便捷。
BeautifulSoup 用来取代re模块,进行HTML内容解析,可以用tag, class, id来定位想要提取的内容,也支持正则表达式等。
具体的使用方法直接看官方文档就可以了,写的特别详尽,这里直接给出地址:
requests官方文档
BeautifulSoup官方文档
通过pip3来安装这两个模块:
sudo apt-get install python3-pip
sudo pip3 install requests
sudo pip3 install beautifulsoup4
导入模块:
import requests
from bs4 import BeautifulSoup
模拟登陆:
def sso_login():
# 调用单点登录工号认证页面
response = session.post(const.SSO_URL,
data={'login': const.LOGIN_USERNAME, 'password': const.LOGIN_PASSWORD, 'appid': 'np000'})
# 分析页面,取token及ltpa
soup = BeautifulSoup(response.text, 'html.parser')
token = soup.form.input.get('value')
ltpa = soup.form.input.input.input.get('value')
ltpa_value = ltpa.split(';')[0].split('=', 1)[1]
# 手工设置Cookie
session.cookies.set('LtpaToken', ltpa_value, domain='unicom.local', path='/')
# 调用云门户登录页面(2次)
payload = {'token': token}
session.post(const.LOGIN_URL, data=payload, proxies=const.PROXIES)
response = session.post(const.LOGIN_URL, data=payload, proxies=const.PROXIES)
if response.text == "success":
logging.info("登录成功")
return True
else:
logging.info("登录失败")
return False
这里用到了BeautifulSoup进行HTML解析,取出页面中的token、ltpa等数组。
然后使用session.cookies.set伪造了一个cookie,注意其中的domain参数,设置成1级域名。
然后用这个session,去调用网站页面,换回sid这个token。并可以依据页面的返回信息,来简单判定一下成功还是失败。
列表页面抓取
登录成功以后,接下来的列表页面抓取就要简单的多了,不考虑分页的话,直接取一个list下来遍历即可。
def capture_list(list_url):
response = session.get(list_url, proxies=const.PROXIES)
response.encoding = "UTF-8"
soup = BeautifulSoup(response.text, 'html.parser')
news_list = soup.find('div', 'xinwen_list').find_all('a')
news_list.reverse()
logging.info("开始采集")
for news_archor in news_list:
news_cid = news_archor.attrs['href'].split('=')[1]
capture_content(news_cid)
logging.info("结束采集")
这里使用了response.encoding = "UTF-8"来手工解决乱码问题。
新闻页面抓取
新闻页面抓取,涉及到插临时表,这里没有使用每三方库,直接用SQL形式插入。
其中涉及到款式处理与图片转存,另写一个模块pconvert来实现。
def capture_content(news_cid):
# 建立DB连接
conn = mysql.connector.connect(user=const.DB_USERNAME, password=const.DB_PASSWORD, host=const.DB_HOST,
port=const.DB_PORT, database=const.DB_DATABASE)
cursor = conn.cursor()
# 判断是否已存在
cursor.execute('select count(*) from material_prepare where news_cid = %s', (news_cid,))
news_count = cursor.fetchone()[0]
if news_count > 0:
logging.info("采集" + news_cid + ':已存在')
else:
logging.info("采集" + news_cid + ':新增')
news_url = const.NEWS_BASE_URL + news_cid
response = session.post(news_url, proxies=const.PROXIES)
response.encoding = "UTF-8"
soup = BeautifulSoup(response.text, 'html.parser')
# logging.info(soup)
news_title = soup.h3.text.strip()[:64]
news_brief = soup.find('div', 'brief').p.text.strip()[:100]
news_author = soup.h5.span.a.text.strip()[:100]
news_content = soup.find('table', 'unis_detail_content').tr.td.prettify()[66:-7].strip()
# 样式处理
news_content = pconvert.convert_style(news_content)
# 将图片转存至DFS并替换URL
news_content = pconvert.convert_img(news_content)
# 入表
cursor.execute(
'INSERT INTO material_prepare (news_cid, title, author, summary, content, add_time, status) VALUES (%s, %s, %s, %s, %s, now(), "0")'
, [news_cid, news_title, news_author, news_brief, news_content])
# 提交
conn.commit()
cursor.close()
样式处理
文本式样处理,还是要用到BeautifulSoup,因为原创站点上的新闻内容款式是五花八门的,根据实际情况,一边写一个test函数来生成文本,一边在浏览器上渐渐调试。
def convert_style(rawtext):
newtext = '' \
+ rawtext + ''
newtext = newtext.replace(' align="center"', '')
soup = BeautifulSoup(newtext, 'html.parser')
img_tags = soup.find_all("img")
for img_tag in img_tags:
del img_tag.parent['style']
return soup.prettify()
图片转存至DFS
因为原创站点是在外网中的,采集下来的HTML中,
标签的地址是外网地址,所以在网段中是诠释不下来的,需要将图片转存,并用新的URL替换原有的URL。
def convert_img(rawtext):
soup = BeautifulSoup(rawtext, 'html.parser')
img_tags = soup.find_all("img")
for img_tag in img_tags:
raw_img_url = img_tag['src']
dfs_img_url = convert_url(raw_img_url)
img_tag['src'] = dfs_img_url
del img_tag['style']
return soup.prettify()
图片转存最简单的形式是保存成本地的文件,然后再通过nginx或httpd服务将图片开放出去:
pic_name = raw_img_url.split('/')[-1]
pic_path = TMP_PATH + '/' + pic_name
with open(pic_path, 'wb') as pic_file:
pic_file.write(pic_content)
但这儿我们须要复用已有的FastDFS分布式文件系统,要用到它的一个客户端的库fdfs_client-py
fdfs_client-py不能直接使用pip3安装,需要直接使用一个python3版的源码,并手工更改其中代码。操作过程如下:
git clone https://github.com/jefforeilly/fdfs_client-py.git
cd dfs_client-py
vi ./fdfs_client/storage_client.py
将第12行 from fdfs_client.sendfile import * 注释掉
python3 setup.py install
sudo pip3 install mutagen
客户端的使用上没有哪些非常的,直接调用upload_by_buffer,传一个图片的buffer进去就可以了,成功后会返回手动生成的文件名。
from fdfs_client.client import *
dfs_client = Fdfs_client('conf/dfs.conf')
def convert_url(raw_img_url):
response = requests.get(raw_img_url, proxies=const.PROXIES)
pic_buffer = response.content
pic_ext = raw_img_url.split('.')[-1]
response = dfs_client.upload_by_buffer(pic_buffer, pic_ext)
dfs_img_url = const.DFS_BASE_URL + '/' + response['Remote file_id']
return dfs_img_url
其中dfs.conf文件中,主要就是配置一下 tracker_server
日志处理
这里使用配置文件的形式处理日志,类似JAVA中的log4j吧,首先新建一个log.conf:
[loggers]
keys=root
[handlers]
keys=stream_handler,file_handler
[formatters]
keys=formatter
[logger_root]
level=DEBUG
handlers=stream_handler,file_handler
[handler_stream_handler]
class=StreamHandler
level=DEBUG
formatter=formatter
args=(sys.stderr,)
[handler_file_handler]
class=FileHandler
level=DEBUG
formatter=formatter
args=('logs/pspider.log','a','utf8')
[formatter_formatter]
format=%(asctime)s %(name)-12s %(levelname)-8s %(message)s
这里通过配置handlers,可以同时将日志复印到stderr和文件。
注意args=('logs/pspider.log','a','utf8') 这一行,用来解决文本文件中的英文乱码问题。
日志初始化:
import logging
from logging.config import fileConfig
fileConfig('conf/log.conf')
日志复印:
logging.info("test")
完整源码
到此为止,就是怎样用Python3写一个爬虫的全部过程了。
采集不同的站点,肯定是要有不同的处理,但方式都是大同小异。 查看全部
使用Python3编撰一个爬虫
使用Python3编撰一个爬虫需求简介
最近厂里有一个新闻采集类的需求,细节大体如下:
模拟登陆一个外网网站(SSO)抓取新闻(支持代理服务器的形式访问)加工内容款式,以适配手机屏幕将正文中的图片转存到自已的服务器,并替换img标签中的url图片储存服务器须要复用已有的FastDFS分布式文件系统采集结果导出生产库支持日志复印
初学Python3,正好用这个需求练练手,最后太吃惊的是只用200多行代码就实现了,如果换成Java的话大约须要1200行吧。果然应了那句俗话:人生苦短,我用Python
登录页面抓包
第一步其实是抓包,然后再按照抓到的内容,模拟进行HTTP恳求。
常用的抓包工具,有Mac下的Charles和Windows下的Fiddler。
它们的原理都是在本机开一个HTTP或SOCKS代理服务器端口,然后将浏览器的代理服务器设置成这个端口,这样浏览器中所有的HTTP恳求就会先经过抓包工具记录出来了。
这里推荐尽量使用Fiddler,原因是Charles对于cookie的展示是有bug的,举个事例,真实情况:请求A返回了LtpaToken这个cookie,请求B中返回了sid这个cookie。但在Charles中的展示是:请求A中早已同时返回了LtpaToken和sid两个cookie,这就很容易欺骗人了。
另外Fiddler如今早已有了Linux的Beta版本,貌似是用类似wine的形式实现的。
如果网站使用了单点登录,可能会涉及到手工生成cookie。所以除了须要剖析每一条HTTP请求的request和response,以及带回去的cookie,还要对页面中的javascript进行剖析,看一下是怎样生成cookie的。
模拟登陆
将页面剖析完毕以后,就可以进行模拟HTTP恳求了。
这里有两个非常好用的第三方库, request 和 BeautifulSoup
requests 库是拿来替代urllib的,可以十分人性化的的生成HTTP请求,模拟session以及伪造cookie更是便捷。
BeautifulSoup 用来取代re模块,进行HTML内容解析,可以用tag, class, id来定位想要提取的内容,也支持正则表达式等。
具体的使用方法直接看官方文档就可以了,写的特别详尽,这里直接给出地址:
requests官方文档
BeautifulSoup官方文档
通过pip3来安装这两个模块:
sudo apt-get install python3-pip
sudo pip3 install requests
sudo pip3 install beautifulsoup4
导入模块:
import requests
from bs4 import BeautifulSoup
模拟登陆:
def sso_login():
# 调用单点登录工号认证页面
response = session.post(const.SSO_URL,
data={'login': const.LOGIN_USERNAME, 'password': const.LOGIN_PASSWORD, 'appid': 'np000'})
# 分析页面,取token及ltpa
soup = BeautifulSoup(response.text, 'html.parser')
token = soup.form.input.get('value')
ltpa = soup.form.input.input.input.get('value')
ltpa_value = ltpa.split(';')[0].split('=', 1)[1]
# 手工设置Cookie
session.cookies.set('LtpaToken', ltpa_value, domain='unicom.local', path='/')
# 调用云门户登录页面(2次)
payload = {'token': token}
session.post(const.LOGIN_URL, data=payload, proxies=const.PROXIES)
response = session.post(const.LOGIN_URL, data=payload, proxies=const.PROXIES)
if response.text == "success":
logging.info("登录成功")
return True
else:
logging.info("登录失败")
return False
这里用到了BeautifulSoup进行HTML解析,取出页面中的token、ltpa等数组。
然后使用session.cookies.set伪造了一个cookie,注意其中的domain参数,设置成1级域名。
然后用这个session,去调用网站页面,换回sid这个token。并可以依据页面的返回信息,来简单判定一下成功还是失败。
列表页面抓取
登录成功以后,接下来的列表页面抓取就要简单的多了,不考虑分页的话,直接取一个list下来遍历即可。
def capture_list(list_url):
response = session.get(list_url, proxies=const.PROXIES)
response.encoding = "UTF-8"
soup = BeautifulSoup(response.text, 'html.parser')
news_list = soup.find('div', 'xinwen_list').find_all('a')
news_list.reverse()
logging.info("开始采集")
for news_archor in news_list:
news_cid = news_archor.attrs['href'].split('=')[1]
capture_content(news_cid)
logging.info("结束采集")
这里使用了response.encoding = "UTF-8"来手工解决乱码问题。
新闻页面抓取
新闻页面抓取,涉及到插临时表,这里没有使用每三方库,直接用SQL形式插入。
其中涉及到款式处理与图片转存,另写一个模块pconvert来实现。
def capture_content(news_cid):
# 建立DB连接
conn = mysql.connector.connect(user=const.DB_USERNAME, password=const.DB_PASSWORD, host=const.DB_HOST,
port=const.DB_PORT, database=const.DB_DATABASE)
cursor = conn.cursor()
# 判断是否已存在
cursor.execute('select count(*) from material_prepare where news_cid = %s', (news_cid,))
news_count = cursor.fetchone()[0]
if news_count > 0:
logging.info("采集" + news_cid + ':已存在')
else:
logging.info("采集" + news_cid + ':新增')
news_url = const.NEWS_BASE_URL + news_cid
response = session.post(news_url, proxies=const.PROXIES)
response.encoding = "UTF-8"
soup = BeautifulSoup(response.text, 'html.parser')
# logging.info(soup)
news_title = soup.h3.text.strip()[:64]
news_brief = soup.find('div', 'brief').p.text.strip()[:100]
news_author = soup.h5.span.a.text.strip()[:100]
news_content = soup.find('table', 'unis_detail_content').tr.td.prettify()[66:-7].strip()
# 样式处理
news_content = pconvert.convert_style(news_content)
# 将图片转存至DFS并替换URL
news_content = pconvert.convert_img(news_content)
# 入表
cursor.execute(
'INSERT INTO material_prepare (news_cid, title, author, summary, content, add_time, status) VALUES (%s, %s, %s, %s, %s, now(), "0")'
, [news_cid, news_title, news_author, news_brief, news_content])
# 提交
conn.commit()
cursor.close()
样式处理
文本式样处理,还是要用到BeautifulSoup,因为原创站点上的新闻内容款式是五花八门的,根据实际情况,一边写一个test函数来生成文本,一边在浏览器上渐渐调试。
def convert_style(rawtext):
newtext = '' \
+ rawtext + ''
newtext = newtext.replace(' align="center"', '')
soup = BeautifulSoup(newtext, 'html.parser')
img_tags = soup.find_all("img")
for img_tag in img_tags:
del img_tag.parent['style']
return soup.prettify()
图片转存至DFS
因为原创站点是在外网中的,采集下来的HTML中,
标签的地址是外网地址,所以在网段中是诠释不下来的,需要将图片转存,并用新的URL替换原有的URL。
def convert_img(rawtext):
soup = BeautifulSoup(rawtext, 'html.parser')
img_tags = soup.find_all("img")
for img_tag in img_tags:
raw_img_url = img_tag['src']
dfs_img_url = convert_url(raw_img_url)
img_tag['src'] = dfs_img_url
del img_tag['style']
return soup.prettify()
图片转存最简单的形式是保存成本地的文件,然后再通过nginx或httpd服务将图片开放出去:
pic_name = raw_img_url.split('/')[-1]
pic_path = TMP_PATH + '/' + pic_name
with open(pic_path, 'wb') as pic_file:
pic_file.write(pic_content)
但这儿我们须要复用已有的FastDFS分布式文件系统,要用到它的一个客户端的库fdfs_client-py
fdfs_client-py不能直接使用pip3安装,需要直接使用一个python3版的源码,并手工更改其中代码。操作过程如下:
git clone https://github.com/jefforeilly/fdfs_client-py.git
cd dfs_client-py
vi ./fdfs_client/storage_client.py
将第12行 from fdfs_client.sendfile import * 注释掉
python3 setup.py install
sudo pip3 install mutagen
客户端的使用上没有哪些非常的,直接调用upload_by_buffer,传一个图片的buffer进去就可以了,成功后会返回手动生成的文件名。
from fdfs_client.client import *
dfs_client = Fdfs_client('conf/dfs.conf')
def convert_url(raw_img_url):
response = requests.get(raw_img_url, proxies=const.PROXIES)
pic_buffer = response.content
pic_ext = raw_img_url.split('.')[-1]
response = dfs_client.upload_by_buffer(pic_buffer, pic_ext)
dfs_img_url = const.DFS_BASE_URL + '/' + response['Remote file_id']
return dfs_img_url
其中dfs.conf文件中,主要就是配置一下 tracker_server
日志处理
这里使用配置文件的形式处理日志,类似JAVA中的log4j吧,首先新建一个log.conf:
[loggers]
keys=root
[handlers]
keys=stream_handler,file_handler
[formatters]
keys=formatter
[logger_root]
level=DEBUG
handlers=stream_handler,file_handler
[handler_stream_handler]
class=StreamHandler
level=DEBUG
formatter=formatter
args=(sys.stderr,)
[handler_file_handler]
class=FileHandler
level=DEBUG
formatter=formatter
args=('logs/pspider.log','a','utf8')
[formatter_formatter]
format=%(asctime)s %(name)-12s %(levelname)-8s %(message)s
这里通过配置handlers,可以同时将日志复印到stderr和文件。
注意args=('logs/pspider.log','a','utf8') 这一行,用来解决文本文件中的英文乱码问题。
日志初始化:
import logging
from logging.config import fileConfig
fileConfig('conf/log.conf')
日志复印:
logging.info("test")
完整源码
到此为止,就是怎样用Python3写一个爬虫的全部过程了。
采集不同的站点,肯定是要有不同的处理,但方式都是大同小异。
Python爬虫建站入门杂记——从零开始构建采集站点(二:编写爬虫)
采集交流 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2020-08-23 06:51
上回,我装了环境
也就是一对乱七八糟的东西
装了pip,用pip装了virtualenv,建立了一个virtualenv,在这个virtualenv上面,装了Django,创建了一个Django项目,在这个Django项目上面创建了一个称作web的阿皮皮。
接上回~
第二部份,编写爬虫。
工欲善其事,必先利其器。
bashapt-get install vim # 接上回,我们在screen里面是root身份哦~
当然了,现在我要想一个采集的目标,为了便捷,我就选择segmentfault吧,这网站写博客不错,就是在海外上传图片有点慢。
这个爬虫,就像我访问一样,要分步骤来。 我先听到segmentfault首页,然后发觉上面有很多tags,每个tags下边,才是一个一个的问题的内容。
所以,爬虫也要分为这几个步骤来写。 但是我要反着写,先写内容爬虫,再写分类爬虫, 因为我想。
2.1 编写内容爬虫
首先,给爬虫构建个目录,在项目上面和app同级,然后把这个目录弄成一个python的package
bashmkdir ~/python_spider/sfspider
touch ~/python_spider/sfspider/__init__.py
以后,这个目录就叫爬虫包了
在爬虫包上面构建一个spider.py拿来装我的爬虫们
bashvim ~/python_spider/sfspider/spider.py
一个基本的爬虫,只须要下边几行代码:
(代码下边会提供)
然后呢,就可以玩儿我们的“爬虫”了。
进入python shell
python>>> from sfspider import spider
>>> s = spider.SegmentfaultQuestionSpider('1010000002542775')
>>> s.url
>>> 'http://segmentfault.com/q/1010000002542775'
>>> print s.dom('h1#questionTitle').text()
>>> 微信JS—SDK嵌套选择图片和上传图片接口,实现一键上传图片,遇到问题
看吧,我如今早已可以通过爬虫获取segmentfault的提问标题了。下一步,为了简化代码,我把标题,回答等等的属性都写为这个蜘蛛的属性。代码如下
python# -*- coding: utf-8 -*-
import requests # requests作为我们的html客户端
from pyquery import PyQuery as Pq # pyquery来操作dom
class SegmentfaultQuestionSpider(object):
def __init__(self, segmentfault_id): # 参数为在segmentfault上的id
self.url = 'http://segmentfault.com/q/{0}'.format(segmentfault_id)
self._dom = None # 弄个这个来缓存获取到的html内容,一个蜘蛛应该之访问一次
@property
def dom(self): # 获取html内容
if not self._dom:
document = requests.get(self.url)
document.encoding = 'utf-8'
self._dom = Pq(document.text)
return self._dom
@property
def title(self): # 让方法可以通过s.title的方式访问 可以少打对括号
return self.dom('h1#questionTitle').text() # 关于选择器可以参考css selector或者jquery selector, 它们在pyquery下几乎都可以使用
@property
def content(self):
return self.dom('.question.fmt').html() # 直接获取html 胆子就是大 以后再来过滤
@property
def answers(self):
return list(answer.html() for answer in self.dom('.answer.fmt').items()) # 记住,Pq实例的items方法是很有用的
@property
def tags(self):
return self.dom('ul.taglist--inline > li').text().split() # 获取tags,这里直接用text方法,再切分就行了。一般只要是文字内容,而且文字内容自己没有空格,逗号等,都可以这样弄,省事。
然后,再把玩一下升级后的蜘蛛。
python>>> from sfspider import spider
>>> s = spider.SegmentfaultQuestionSpider('1010000002542775')
>>> print s.title
>>> 微信JS—SDK嵌套选择图片和上传图片接口,实现一键上传图片,遇到问题
>>> print s.content
>>> # [故意省略] #
>>> for answer in s.answers
print answer
>>> # [故意省略] #
>>> print '/'.join(s.tags)
>>> 微信js-sdk/python/微信开发/javascript
OK,现在我的蜘蛛玩上去更方便了。
2.2 编写分类爬虫
下面,我要写一个抓取标签页面的问题的爬虫。
代码如下, 注意下边的代码是添加在已有代码下边的, 和之前的最后一行之间 要有两个空行
pythonclass SegmentfaultTagSpider(object):
def __init__(self, tag_name, page=1):
self.url = 'http://segmentfault.com/t/%s?type=newest&page=%s' % (tag_name, page)
self.tag_name = tag_name
self.page = page
self._dom = None
@property
def dom(self):
if not self._dom:
document = requests.get(self.url)
document.encoding = 'utf-8'
self._dom = Pq(document.text)
self._dom.make_links_absolute(base_url="http://segmentfault.com/") # 相对链接变成绝对链接 爽
return self._dom
@property
def questions(self):
return [question.attr('href') for question in self.dom('h2.title > a').items()]
@property
def has_next_page(self): # 看看还有没有下一页,这个有必要
return bool(self.dom('ul.pagination > li.next')) # 看看有木有下一页
def next_page(self): # 把这个蜘蛛杀了, 产生一个新的蜘蛛 抓取下一页。 由于这个本来就是个动词,所以就不加@property了
if self.has_next_page:
self.__init__(tag_name=self.tag_name ,page=self.page+1)
else:
return None
现在可以两个蜘蛛一起把玩了,就不贴出详尽把玩过程了。。。
python>>> from sfspider import spider
>>> s = spider.SegmentfaultTagSpider('微信')
>>> question1 = s.questions[0]
>>> question_spider = spider.SegmentfaultQuestionSpider(question1.split('/')[-1])
>>> # [故意省略] #
想做窃贼站的,看到这儿基本上能够搞下来了。 套个模板 加一个简单的脚本来接受和返回恳求就行了。
未完待续。 查看全部
Python爬虫建站入门杂记——从零开始构建采集站点(二:编写爬虫)
上回,我装了环境
也就是一对乱七八糟的东西
装了pip,用pip装了virtualenv,建立了一个virtualenv,在这个virtualenv上面,装了Django,创建了一个Django项目,在这个Django项目上面创建了一个称作web的阿皮皮。
接上回~
第二部份,编写爬虫。
工欲善其事,必先利其器。
bashapt-get install vim # 接上回,我们在screen里面是root身份哦~
当然了,现在我要想一个采集的目标,为了便捷,我就选择segmentfault吧,这网站写博客不错,就是在海外上传图片有点慢。
这个爬虫,就像我访问一样,要分步骤来。 我先听到segmentfault首页,然后发觉上面有很多tags,每个tags下边,才是一个一个的问题的内容。
所以,爬虫也要分为这几个步骤来写。 但是我要反着写,先写内容爬虫,再写分类爬虫, 因为我想。
2.1 编写内容爬虫
首先,给爬虫构建个目录,在项目上面和app同级,然后把这个目录弄成一个python的package
bashmkdir ~/python_spider/sfspider
touch ~/python_spider/sfspider/__init__.py
以后,这个目录就叫爬虫包了
在爬虫包上面构建一个spider.py拿来装我的爬虫们
bashvim ~/python_spider/sfspider/spider.py
一个基本的爬虫,只须要下边几行代码:

(代码下边会提供)
然后呢,就可以玩儿我们的“爬虫”了。
进入python shell
python>>> from sfspider import spider
>>> s = spider.SegmentfaultQuestionSpider('1010000002542775')
>>> s.url
>>> 'http://segmentfault.com/q/1010000002542775'
>>> print s.dom('h1#questionTitle').text()
>>> 微信JS—SDK嵌套选择图片和上传图片接口,实现一键上传图片,遇到问题
看吧,我如今早已可以通过爬虫获取segmentfault的提问标题了。下一步,为了简化代码,我把标题,回答等等的属性都写为这个蜘蛛的属性。代码如下
python# -*- coding: utf-8 -*-
import requests # requests作为我们的html客户端
from pyquery import PyQuery as Pq # pyquery来操作dom
class SegmentfaultQuestionSpider(object):
def __init__(self, segmentfault_id): # 参数为在segmentfault上的id
self.url = 'http://segmentfault.com/q/{0}'.format(segmentfault_id)
self._dom = None # 弄个这个来缓存获取到的html内容,一个蜘蛛应该之访问一次
@property
def dom(self): # 获取html内容
if not self._dom:
document = requests.get(self.url)
document.encoding = 'utf-8'
self._dom = Pq(document.text)
return self._dom
@property
def title(self): # 让方法可以通过s.title的方式访问 可以少打对括号
return self.dom('h1#questionTitle').text() # 关于选择器可以参考css selector或者jquery selector, 它们在pyquery下几乎都可以使用
@property
def content(self):
return self.dom('.question.fmt').html() # 直接获取html 胆子就是大 以后再来过滤
@property
def answers(self):
return list(answer.html() for answer in self.dom('.answer.fmt').items()) # 记住,Pq实例的items方法是很有用的
@property
def tags(self):
return self.dom('ul.taglist--inline > li').text().split() # 获取tags,这里直接用text方法,再切分就行了。一般只要是文字内容,而且文字内容自己没有空格,逗号等,都可以这样弄,省事。
然后,再把玩一下升级后的蜘蛛。
python>>> from sfspider import spider
>>> s = spider.SegmentfaultQuestionSpider('1010000002542775')
>>> print s.title
>>> 微信JS—SDK嵌套选择图片和上传图片接口,实现一键上传图片,遇到问题
>>> print s.content
>>> # [故意省略] #
>>> for answer in s.answers
print answer
>>> # [故意省略] #
>>> print '/'.join(s.tags)
>>> 微信js-sdk/python/微信开发/javascript
OK,现在我的蜘蛛玩上去更方便了。
2.2 编写分类爬虫
下面,我要写一个抓取标签页面的问题的爬虫。
代码如下, 注意下边的代码是添加在已有代码下边的, 和之前的最后一行之间 要有两个空行
pythonclass SegmentfaultTagSpider(object):
def __init__(self, tag_name, page=1):
self.url = 'http://segmentfault.com/t/%s?type=newest&page=%s' % (tag_name, page)
self.tag_name = tag_name
self.page = page
self._dom = None
@property
def dom(self):
if not self._dom:
document = requests.get(self.url)
document.encoding = 'utf-8'
self._dom = Pq(document.text)
self._dom.make_links_absolute(base_url="http://segmentfault.com/";) # 相对链接变成绝对链接 爽
return self._dom
@property
def questions(self):
return [question.attr('href') for question in self.dom('h2.title > a').items()]
@property
def has_next_page(self): # 看看还有没有下一页,这个有必要
return bool(self.dom('ul.pagination > li.next')) # 看看有木有下一页
def next_page(self): # 把这个蜘蛛杀了, 产生一个新的蜘蛛 抓取下一页。 由于这个本来就是个动词,所以就不加@property了
if self.has_next_page:
self.__init__(tag_name=self.tag_name ,page=self.page+1)
else:
return None
现在可以两个蜘蛛一起把玩了,就不贴出详尽把玩过程了。。。
python>>> from sfspider import spider
>>> s = spider.SegmentfaultTagSpider('微信')
>>> question1 = s.questions[0]
>>> question_spider = spider.SegmentfaultQuestionSpider(question1.split('/')[-1])
>>> # [故意省略] #
想做窃贼站的,看到这儿基本上能够搞下来了。 套个模板 加一个简单的脚本来接受和返回恳求就行了。
未完待续。
爬虫 大规模数据 采集心得和示例
采集交流 • 优采云 发表了文章 • 0 个评论 • 387 次浏览 • 2020-08-23 04:03
本篇主要介绍网站数据特别大的采集心得
1. 什么样的数据能够称为数据量大:
我认为这个可能会由于每位人的理解不太一样,给出的定义 也不相同。我觉得定义一个采集网站的数据大小,不仅仅要看这个网站包括的数据量的大小,还应当包括这个网址的采集难度,采集网站的服务器承受能力,采集人员所调配的网路带宽和计算机硬件资源等。这里我暂且把一个网站超过一千万个URL链接的称作数据量大的网站。
2. 数据量大的网站采集方案:
2.1 . 采集需求剖析:
作为数据采集工程师,我觉得最重要的是要做好数据采集的需求剖析,首先要预估这个网址的数据量大小,然后去明晰采集哪些数据,有没有必要去把目标网站的数据都采集下来,因为采集的数据量越多,耗费的时间就越多,需要的资源就越多,对目标网站造成的压力就越大,数据采集工程师不能为了采集数据,对目标网站造成很大的压力。原则是尽量少采集数据来满足自己的需求,避免全站采集。
2.2. 代码编撰:
因为要采集的网站数据好多,所以要求编撰的代码做到稳定运行一周甚至一个月以上,所以代码要足够的强壮,足够的强大。一般要求做到网站不变更模板,程序能始终执行出来。这里有个编程的小技巧,我觉得很重要,就是代码编撰好之后,先去跑一两个小时,发现程序的一些报错的地方,修改掉,这样的前期代码测试,能保证代码的健壮性。
2.3 数据储存:
当数据量有三五千万的时侯,无论是MySQL还是Oracle还是SQL Server,想在一个表上面储存,已经不太可能了,这个时侯可以采用分表来储存。数据采集完毕,往数据库插入的时侯,可以执行批量插入等策略。保证自己的储存不受数据库性能等方面的影响。
2.4 调配的资源:
由于目标网站数据好多,我们免不了要去使用大的房贷,内存,CPU等资源,这个时侯我们可以搞一个分布式爬虫系统,来合理的管理我们的资源。
3. 爬虫的道德
对于一些中级的采集工程师,为了更快的采集到数据,往往开了好多的多进程和多线程,后果就是对目标网站造成了dos攻击,结果是目标网站果断的升级网站,加入更多的反爬策略,这种对抗对采集工程师也是非常不利的。个人建议下载速率不要超过2M,多进程或则多线程不要过百。
示例:
要采集的目标网站有四千万数据,网站的反爬策略是封ip,于是专门找了一台机器,开了二百多个进程去维护ip池,ip池可用的ip在500-1000个,并且保证ip是高度可用的。
代码编撰完毕后,同是在两台机器上运行,每天机器开启的多线程不超过64个,下载速率不超过1M.
个人知识有限,请大牛多多包涵 查看全部
爬虫 大规模数据 采集心得和示例
本篇主要介绍网站数据特别大的采集心得
1. 什么样的数据能够称为数据量大:
我认为这个可能会由于每位人的理解不太一样,给出的定义 也不相同。我觉得定义一个采集网站的数据大小,不仅仅要看这个网站包括的数据量的大小,还应当包括这个网址的采集难度,采集网站的服务器承受能力,采集人员所调配的网路带宽和计算机硬件资源等。这里我暂且把一个网站超过一千万个URL链接的称作数据量大的网站。
2. 数据量大的网站采集方案:
2.1 . 采集需求剖析:
作为数据采集工程师,我觉得最重要的是要做好数据采集的需求剖析,首先要预估这个网址的数据量大小,然后去明晰采集哪些数据,有没有必要去把目标网站的数据都采集下来,因为采集的数据量越多,耗费的时间就越多,需要的资源就越多,对目标网站造成的压力就越大,数据采集工程师不能为了采集数据,对目标网站造成很大的压力。原则是尽量少采集数据来满足自己的需求,避免全站采集。
2.2. 代码编撰:
因为要采集的网站数据好多,所以要求编撰的代码做到稳定运行一周甚至一个月以上,所以代码要足够的强壮,足够的强大。一般要求做到网站不变更模板,程序能始终执行出来。这里有个编程的小技巧,我觉得很重要,就是代码编撰好之后,先去跑一两个小时,发现程序的一些报错的地方,修改掉,这样的前期代码测试,能保证代码的健壮性。
2.3 数据储存:
当数据量有三五千万的时侯,无论是MySQL还是Oracle还是SQL Server,想在一个表上面储存,已经不太可能了,这个时侯可以采用分表来储存。数据采集完毕,往数据库插入的时侯,可以执行批量插入等策略。保证自己的储存不受数据库性能等方面的影响。
2.4 调配的资源:
由于目标网站数据好多,我们免不了要去使用大的房贷,内存,CPU等资源,这个时侯我们可以搞一个分布式爬虫系统,来合理的管理我们的资源。
3. 爬虫的道德
对于一些中级的采集工程师,为了更快的采集到数据,往往开了好多的多进程和多线程,后果就是对目标网站造成了dos攻击,结果是目标网站果断的升级网站,加入更多的反爬策略,这种对抗对采集工程师也是非常不利的。个人建议下载速率不要超过2M,多进程或则多线程不要过百。
示例:
要采集的目标网站有四千万数据,网站的反爬策略是封ip,于是专门找了一台机器,开了二百多个进程去维护ip池,ip池可用的ip在500-1000个,并且保证ip是高度可用的。
代码编撰完毕后,同是在两台机器上运行,每天机器开启的多线程不超过64个,下载速率不超过1M.
个人知识有限,请大牛多多包涵
[Android]橘子视频。e4a源码+成品。采集360可看全网vip影片
采集交流 • 优采云 发表了文章 • 0 个评论 • 800 次浏览 • 2020-08-22 18:54
源码我更改成黑色的了。改动比较大。但源码只发布原版。需要自己改。数据手动采集360影视,解析插口自己找。论坛不知道能不能发布插口。这次先不发,后期单独发一贴.各大平台影片基本都能解下来
安装须要虚拟空间安装网站,注册用户。和对接APP验证。
类库齐全
蓝奏云下载地址
*********源码在最下边*************
这个程序修补了好多个BUG目前是没有BUG的,而且都是可以看的,用的是内置浏览器播放器可以无视广告,带充值卡,充值卡后台自己设置,自己定价,自己决定充值卡的名子,带一键分享功能和用户中心功能,完全仿造原生主流APP而做,界面完美无错!
(可挣钱)影视app源码可注册登录带后台,批量生成卡密在线授权可设置试看时间
(可挣钱)影视app源码带后台,批量生成卡密在线授权可设置试看时间,试看时间可以随时修改,很方便,后台可以直接管理用户
支持批量生成卡密,用户使用卡密可以直接授权
卡密的时间由你设定,收不收费你说了算
可以设置绑定IP或则绑定机器码,就是说换了手机之前的帐号不能使用,防止一号多用
***************************************************
查看全部
[Android]橘子视频。e4a源码+成品。采集360可看全网vip影片
源码我更改成黑色的了。改动比较大。但源码只发布原版。需要自己改。数据手动采集360影视,解析插口自己找。论坛不知道能不能发布插口。这次先不发,后期单独发一贴.各大平台影片基本都能解下来
安装须要虚拟空间安装网站,注册用户。和对接APP验证。
类库齐全
蓝奏云下载地址
*********源码在最下边*************
这个程序修补了好多个BUG目前是没有BUG的,而且都是可以看的,用的是内置浏览器播放器可以无视广告,带充值卡,充值卡后台自己设置,自己定价,自己决定充值卡的名子,带一键分享功能和用户中心功能,完全仿造原生主流APP而做,界面完美无错!
(可挣钱)影视app源码可注册登录带后台,批量生成卡密在线授权可设置试看时间
(可挣钱)影视app源码带后台,批量生成卡密在线授权可设置试看时间,试看时间可以随时修改,很方便,后台可以直接管理用户
支持批量生成卡密,用户使用卡密可以直接授权
卡密的时间由你设定,收不收费你说了算
可以设置绑定IP或则绑定机器码,就是说换了手机之前的帐号不能使用,防止一号多用
***************************************************


[杂谈]关于报刀机器人是手动搜集刀数吗?(不做了,被团扇乱杀)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2020-08-22 15:21
2020-07-01 19:42
[杂谈]关于报刀机器人是手动搜集刀数吗?(不做了,被团扇乱杀)
就是会里打了boss,机器人就手动记录谁谁出了第几刀,伤害多少。 还是须要会员自己去群里报刀?[s:ac:晕]
如果是自己去报刀,那捉鱼的不捉鱼的不是就全靠自觉了嘛。[s:ac:呆]
现在可以做到爬取游戏里的实时数据吗?最近想试试自己搭个机器人。主要是为了那个但求每晚出满三刀帮会用的。[s:ac:哭笑]
补充:主要啊[s:ac:擦汗]咸鱼帮会只有每晚出满三刀这个要求,1w开外那个,昨天9点多了还有7个人没出刀,大家出没出满3刀也不清楚,作为会长我就只有自己用纸笔逐个记录对比,看看谁谁没打,没出刀,怪累的,才想问问的,看来实现上去还是有点困难[s:a2:不活了]
不过我还是先试试吧,明天再改改
好吧,基本做出来了[s:ac:擦汗]不过还是有很多麻烦,等会我发图瞧瞧疗效
2020.7.3更新目前实现了对截图的数据进行剖析,俗话说小数据剖析[s:ac:哭笑]
分离提纯我们须要的信息,然后写入数据库筛选,最后再输出
这个是截图保存位置,目前实现了手动截图,也就是说只要号仍然在线视奸,然后定时或则主动截图,程序都会辨识读取
这个是输出,就详尽的筛选了玩家名子和对应的出刀次数
其实数据库的话,是记录了boss和伤害的,但是俺们休闲帮会用不上,就没必要输出了[s:ac:哭笑](休闲帮会伤害是真的不能看)
功能的话基本上实现了,只是要正常运作的话难度还是很大了,首先得保证有号仍然在线而且在工会战页面,就这一个条件就太严苛了
只要这个条件能达成的话,其他都不是事了,配合QQ机器人,定时截图或则发送QQ信息截图,然后统计信息就很简单了
只能说有看法,但不成熟啊[s:ac:冷]附件
附件改动 查看全部
[杂谈]关于报刀机器人是手动搜集刀数吗?(不做了,被团扇乱杀)
2020-07-01 19:42
[杂谈]关于报刀机器人是手动搜集刀数吗?(不做了,被团扇乱杀)
就是会里打了boss,机器人就手动记录谁谁出了第几刀,伤害多少。 还是须要会员自己去群里报刀?[s:ac:晕]
如果是自己去报刀,那捉鱼的不捉鱼的不是就全靠自觉了嘛。[s:ac:呆]
现在可以做到爬取游戏里的实时数据吗?最近想试试自己搭个机器人。主要是为了那个但求每晚出满三刀帮会用的。[s:ac:哭笑]
补充:主要啊[s:ac:擦汗]咸鱼帮会只有每晚出满三刀这个要求,1w开外那个,昨天9点多了还有7个人没出刀,大家出没出满3刀也不清楚,作为会长我就只有自己用纸笔逐个记录对比,看看谁谁没打,没出刀,怪累的,才想问问的,看来实现上去还是有点困难[s:a2:不活了]
不过我还是先试试吧,明天再改改
好吧,基本做出来了[s:ac:擦汗]不过还是有很多麻烦,等会我发图瞧瞧疗效
2020.7.3更新目前实现了对截图的数据进行剖析,俗话说小数据剖析[s:ac:哭笑]
分离提纯我们须要的信息,然后写入数据库筛选,最后再输出

这个是截图保存位置,目前实现了手动截图,也就是说只要号仍然在线视奸,然后定时或则主动截图,程序都会辨识读取
这个是输出,就详尽的筛选了玩家名子和对应的出刀次数

其实数据库的话,是记录了boss和伤害的,但是俺们休闲帮会用不上,就没必要输出了[s:ac:哭笑](休闲帮会伤害是真的不能看)
功能的话基本上实现了,只是要正常运作的话难度还是很大了,首先得保证有号仍然在线而且在工会战页面,就这一个条件就太严苛了
只要这个条件能达成的话,其他都不是事了,配合QQ机器人,定时截图或则发送QQ信息截图,然后统计信息就很简单了
只能说有看法,但不成熟啊[s:ac:冷]附件

附件改动
【web系统UI自动化】关于UI自动化的总结
采集交流 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2020-08-22 12:44
实施过了web系统的UI自动化,回顾梳理下,想到哪些写哪些,随时补充。
首先,自动化测试不是自动测试的替代品,是比较好的补充,而且不是占大比重的补充。
70%的测试工作集中在底层接口测试和单元测试,20%的测试工作为集成测试,其他10%的测试即为界面测试。
开发方向:尽可能的相通的模块,通用的封装开发约定好,便于定位适用兼容测试无界面运行快速定位问题:报错信息、错误截图多环境利润点脚本开发时间和复用次数快速验证,第一时间响应问题还可以做什么?兼容性多环境以便快速定位提炼更多通用模块。调研更优解决方案,比如:cypress等case依赖优化深度校准什么样的项目适宜web自动化系统稳定,太多的制止程序或修改。准备之前,先手工测试,确认手动测试可以囊括的系统功能。需要多系统,多浏览器兼容性测试什么样的功能点须要web自动化主业务流程便于实现自动化的web元素、页面重复量大的功能web自动化常见的验证点页面元素验证页面列表数据验证页面元素属性?UI的文本,图片显示正确性UI的交互逻辑正确性测试UI上的用户行为正确性测试对于web自动化框架常见的需求点分布式执行,可以多机器,多浏览器同步执行脚本适用于不同环境运行分层设计,方便维护生成测试报告模块的复用必要的日志采集UI自动化利润点的采集回归测试须要定期运行,在自动化时,它们可以节约测试人员的时间,我们可以更专注于其他场景和探索性测试。脚本开发时间和复用次数误报频度UI自动化缺点or局限不能快速反馈(相对于单元测试和API测试)只会对于case已确定的内容进行校准运行的稳定性发觉的错误不多,大多数错误其实是通过“意外”或进行探索性测试而发觉的。这可能是因为在每位探索性测试会话期间,我们可能以不同的方法测试应用程序,从而通过应用程序找到新的漏洞。编写优秀且稳定的XPath / CSS定位器所耗费的时间,并在底层HTML标记发生变化时更新它们。UI本身的变化性,要想达到和手工测试相同的覆盖率,投入比较大。如何进行CI(Continuous Integration),也就是持续集成
● 持续提交代码 (Check-in)
○ 一天之中多次提交
● 持续构建代码 (Build)
○ 保证在任何时刻代码是可以继续开发的
● 持续部署代码 (Deploy)
○ 保证始终有一个可以部署的版本
● 持续测试代码 (Test)
○ 每次提交均执行单元测试
○ 每天一次或数次集成测试
○ 每天一次或数次系统测试
不过,高频的集成,还是用插口愈发合适,后面的工作会把系统的交互插口自动化,届时分享。 查看全部
【web系统UI自动化】关于UI自动化的总结

实施过了web系统的UI自动化,回顾梳理下,想到哪些写哪些,随时补充。
首先,自动化测试不是自动测试的替代品,是比较好的补充,而且不是占大比重的补充。
70%的测试工作集中在底层接口测试和单元测试,20%的测试工作为集成测试,其他10%的测试即为界面测试。
开发方向:尽可能的相通的模块,通用的封装开发约定好,便于定位适用兼容测试无界面运行快速定位问题:报错信息、错误截图多环境利润点脚本开发时间和复用次数快速验证,第一时间响应问题还可以做什么?兼容性多环境以便快速定位提炼更多通用模块。调研更优解决方案,比如:cypress等case依赖优化深度校准什么样的项目适宜web自动化系统稳定,太多的制止程序或修改。准备之前,先手工测试,确认手动测试可以囊括的系统功能。需要多系统,多浏览器兼容性测试什么样的功能点须要web自动化主业务流程便于实现自动化的web元素、页面重复量大的功能web自动化常见的验证点页面元素验证页面列表数据验证页面元素属性?UI的文本,图片显示正确性UI的交互逻辑正确性测试UI上的用户行为正确性测试对于web自动化框架常见的需求点分布式执行,可以多机器,多浏览器同步执行脚本适用于不同环境运行分层设计,方便维护生成测试报告模块的复用必要的日志采集UI自动化利润点的采集回归测试须要定期运行,在自动化时,它们可以节约测试人员的时间,我们可以更专注于其他场景和探索性测试。脚本开发时间和复用次数误报频度UI自动化缺点or局限不能快速反馈(相对于单元测试和API测试)只会对于case已确定的内容进行校准运行的稳定性发觉的错误不多,大多数错误其实是通过“意外”或进行探索性测试而发觉的。这可能是因为在每位探索性测试会话期间,我们可能以不同的方法测试应用程序,从而通过应用程序找到新的漏洞。编写优秀且稳定的XPath / CSS定位器所耗费的时间,并在底层HTML标记发生变化时更新它们。UI本身的变化性,要想达到和手工测试相同的覆盖率,投入比较大。如何进行CI(Continuous Integration),也就是持续集成
● 持续提交代码 (Check-in)
○ 一天之中多次提交
● 持续构建代码 (Build)
○ 保证在任何时刻代码是可以继续开发的
● 持续部署代码 (Deploy)
○ 保证始终有一个可以部署的版本
● 持续测试代码 (Test)
○ 每次提交均执行单元测试
○ 每天一次或数次集成测试
○ 每天一次或数次系统测试
不过,高频的集成,还是用插口愈发合适,后面的工作会把系统的交互插口自动化,届时分享。
用Python爬虫实现图片手动下载的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 227 次浏览 • 2020-08-21 18:12
爬虫的出现,可以乘以许多重复性的工作,在须要大量采集数据时,爬虫可以实现手动下载,极大的提升了工作效率。那么python如何实现图片手动下载的呢?如何借助python写爬虫?本文为你们介绍了用Python爬虫实现图片手动下载的方式。
1.分析需求
比如上百度找图片,可以通过搜索功能,查找图片后,选中其中一个查看源代码,找到图片对应的源代码,如果图片多地址,比如有thumbURL,middleURL,hoverURL,objURL,分别打开看那个图片符合需求。如果objURL符合需求,格式为.jpg。
2.选择python库
选择2个包,一个是正则,一个是requests包。
3.编写代码
复制百度图片搜索的链接,传入requests,然后把正则表达式写好。
因为有很多张图片,所以要循环,我们复印出结果来瞧瞧,然后用requests获取网址,由于有些图片可能存在网址打不开的情况,所以加了10秒超时控制。
4.图片保存
建立好一个images目录,把图片都放进去,命名的时侯,以数字命名。
python如何实现图片手动下载?仅须要进行四步,即可编撰好python爬虫并实现图片手动下载。学习爬虫简单吧,即使是菜鸟,也能特别快的上手呢。
能够成功实现手动下载也千万不大意,说不定就遇上了反爬虫机制,记得使用IP池突破限制,比如使用黑洞代理。 查看全部
用Python爬虫实现图片手动下载的方式
爬虫的出现,可以乘以许多重复性的工作,在须要大量采集数据时,爬虫可以实现手动下载,极大的提升了工作效率。那么python如何实现图片手动下载的呢?如何借助python写爬虫?本文为你们介绍了用Python爬虫实现图片手动下载的方式。
1.分析需求
比如上百度找图片,可以通过搜索功能,查找图片后,选中其中一个查看源代码,找到图片对应的源代码,如果图片多地址,比如有thumbURL,middleURL,hoverURL,objURL,分别打开看那个图片符合需求。如果objURL符合需求,格式为.jpg。
2.选择python库
选择2个包,一个是正则,一个是requests包。
3.编写代码
复制百度图片搜索的链接,传入requests,然后把正则表达式写好。
因为有很多张图片,所以要循环,我们复印出结果来瞧瞧,然后用requests获取网址,由于有些图片可能存在网址打不开的情况,所以加了10秒超时控制。

4.图片保存
建立好一个images目录,把图片都放进去,命名的时侯,以数字命名。


python如何实现图片手动下载?仅须要进行四步,即可编撰好python爬虫并实现图片手动下载。学习爬虫简单吧,即使是菜鸟,也能特别快的上手呢。
能够成功实现手动下载也千万不大意,说不定就遇上了反爬虫机制,记得使用IP池突破限制,比如使用黑洞代理。
详解基于Android的Appium+Python自动化脚本编撰
采集交流 • 优采云 发表了文章 • 0 个评论 • 383 次浏览 • 2020-08-21 05:06
详解基于Android的Appium+Python自动化脚本编撰
更新时间:2020年08月20日 10:31:19 转载投稿:zx
这篇文章主要介绍了解读基于Android的Appium+Python自动化脚本编撰,文中通过示例代码介绍的十分详尽,对你们的学习或则工作具有一定的参考学习价值,需要的朋友们下边随着小编来一起学习学习吧
1.Appium
Appium是一个开源测试自动化框架,可用于原生,混合和联通Web应用程序测试, 它使用WebDriver合同驱动iOS,Android和Windows应用程序。
通过Appium,我们可以模拟点击和屏幕的滑动,可以获取元素的id和classname,还可以依照操作生成相关的脚本代码。
下面开始Appium的配置。
appPackage和APPActivity的获取
任意下载一个app
解压
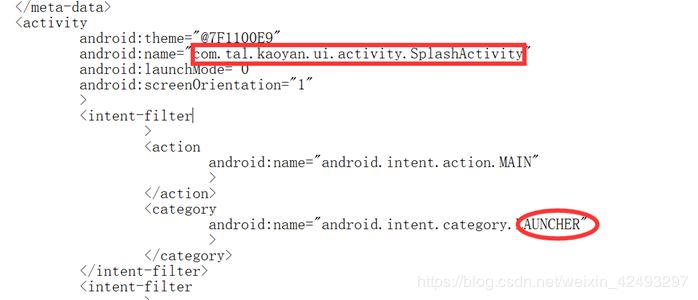
但是解压下来的xml文件可能是乱码,所以我们须要反编译文件。
逆向AndroidManifest.xml
下载AXMLPrinter2.jar文件,逆向xml文件:命令行输入以下命令:
java -jar AXMLPrinter2.jar AndroidManifest.xml ->AndroidManifest.txt
获得以下可以查看的TXT文件
寻找带有launcher 的Activity
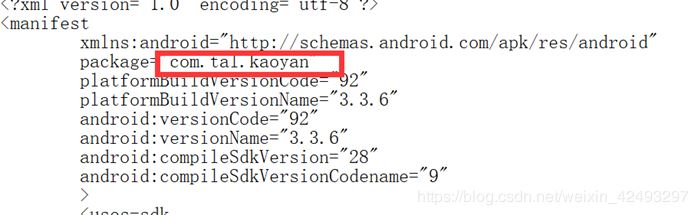
寻找manifest上面的package
Devicename的获取
通过命令行输入 adb devices:
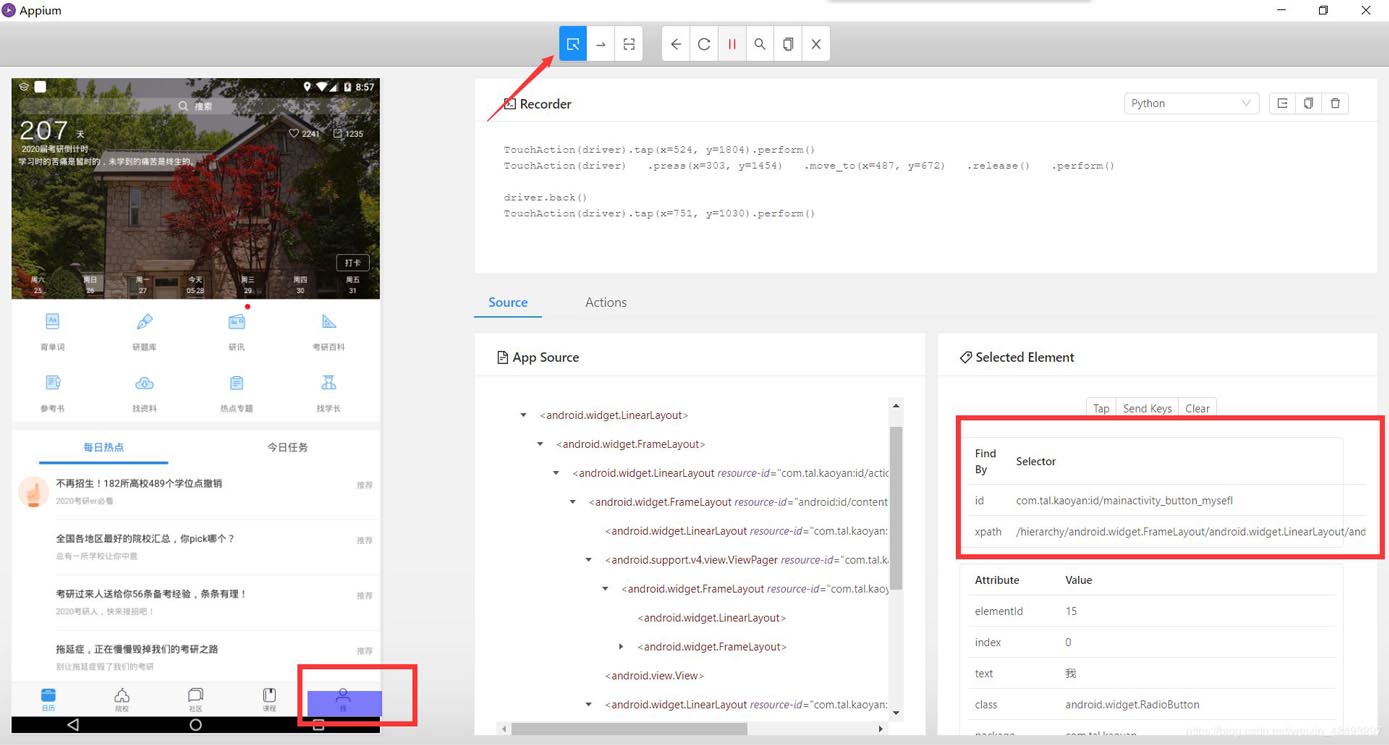
appium的功能介绍
下面将按照上图序号一一介绍功能:
选中界面元素,显示元素相关信息
模拟滑动屏幕,先点击一下代表触摸起始位置,在点击一下代表触摸结束为止
模拟点击屏幕
模拟手机的返回按键
刷新一侧的页面,使之与手机同步
记录模拟操作,生成相关脚本
根据元素的id或则其他相关信息查找元素
复制当前界面的xml布局
文件退出
2.Python的脚本
元素定位的使用
(1).xpath定位
xpath定位是一种路径定位方法,主要是依赖于元素绝对路径或则相关属性来定位,但是绝对路径xpath执行效率比较低(特别是元素路径比较深的时侯),一般使用比较少。
通常使用xpath相对路径和属性定位。
by_xpath.py
from find_element.capability import driver
driver.find_element_by_xpath('//android.widget.EditText[@text="请输入用户名"]').send_keys('123456')
driver.find_element_by_xpath('//*[@class="android.widget.EditText" and @index="3"]').send_keys('123456')
driver.find_element_by_xpath('//android.widget.Button').click()
driver.find_element_by_xpath('//[@class="android.widget.Button"]').click()
(2).classname定位
classname定位是依据元素类型来进行定位,但是实际情况中好多元素的classname都是相同的,
如用户名和密码都是clasName属性值都是:“android.widget.EditText” 因此只能定位第一个元素也就是用户名,而密码输入框就须要使用其他方法来定位,这样也许太鸡肋.一般情况下假如有id就毋须使用classname定位。
by_classname.py
from find_element.capability import driver
driver.find_element_by_class_name('android.widget.EditText').send_keys('123565')
driver.find_element_by_class_name('android.widget.EditText').send_keys('456879')
driver.find_element_by_class_name('android.widget.Button').click()
(3).id定位
日常生活中身边可能存在相同名子的人,但是每位人的身份证号码是惟一的,在app界面元素中也可以使用id值来分辨不同的元素,然后进行定位操作。
Appium中可以使用 find_element_by_id() 方法来进行id定位。
driver.find_element_by_id('android:id/button2').click()
driver.find_element_by_id('com.tal.kaoyan:id/tv_skip').click()
3.示例:模拟软件的手动注册
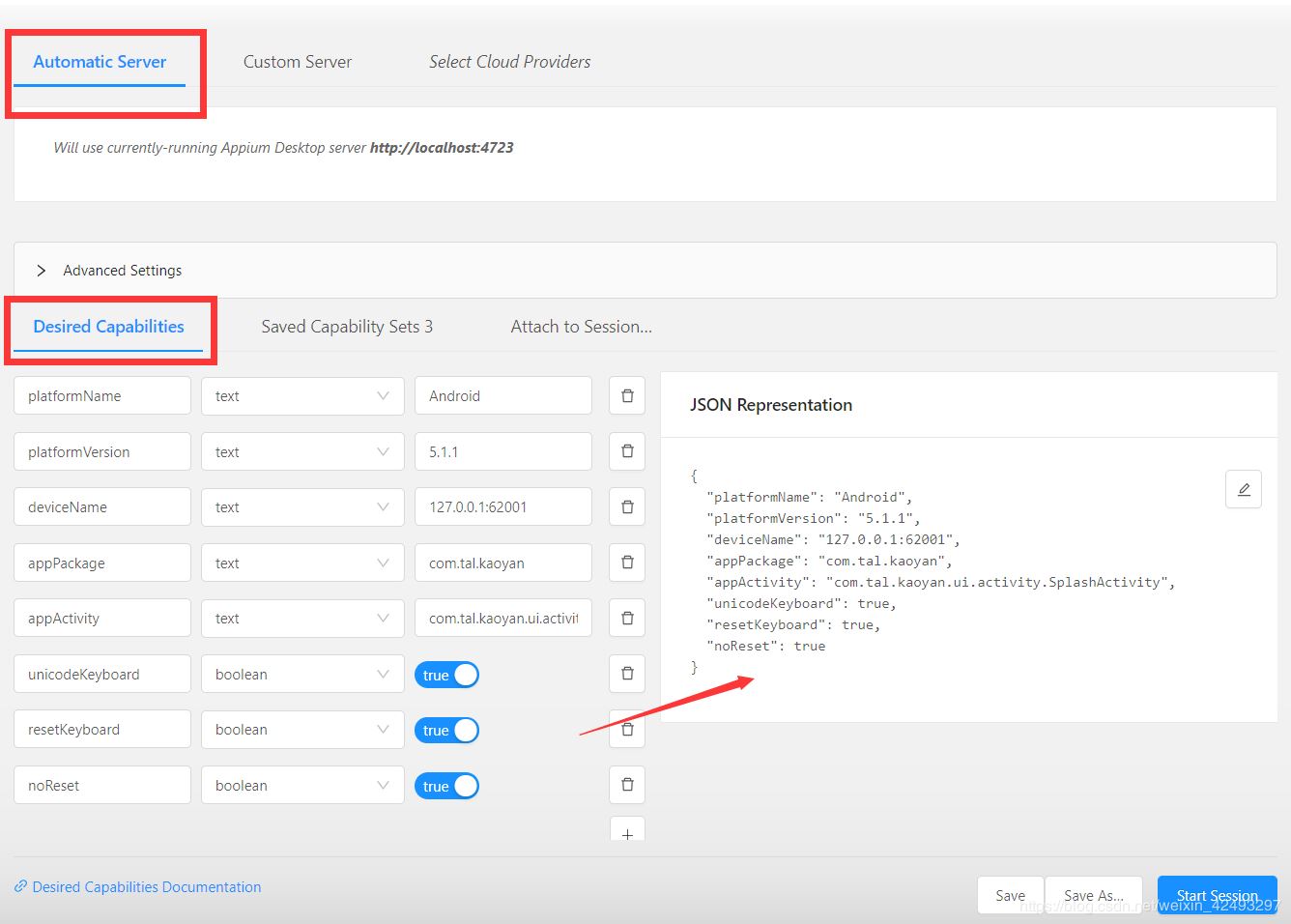
首先配置联接属性
desired_caps={}
# 所使用的平台
desired_caps['platformName']='Android'
# 所使用的手机的名字 可以通过 adb devices 获得
desired_caps['deviceName']='127.0.0.1:62001'
# ANDROID 的版本
desired_caps['platforVersion']='5.1.1'
# app 的路径
desired_caps['app']=r'D:\extend\kaoyanbang.apk'
# app的包名
desired_caps['appPackage']='com.tal.kaoyan'
# app 加载页面
desired_caps['appActivity']='com.tal.kaoyan.ui.activity.SplashActivity'
# 设置每次是否清除数据
desired_caps['noReset']='False'
# 是否使用unicode键盘输入,在输入中文字符和unicode字符时设置为true
desired_caps['unicodeKeyboard']="True"
# 是否将键盘重置为初始状态,设置了unicodeKeyboard时,在测试完成后,设置为true,将键盘重置
desired_caps['resetKeyboard']="True"
# appium服务器的连接地址
driver=webdriver.Remote('http://localhost:4723/wd/hub',desired_caps)
driver.implicitly_wait(2)
编写操作脚本
import random
import time
driver.find_element_by_id('com.tal.kaoyan:id/login_register_text').click()
username='zx2019'+'F2LY'+str(random.randint(1000,9000))
print('username: %s' %username)
driver.find_element_by_id('com.tal.kaoyan:id/activity_register_username_edittext').send_keys(username)
password='zxw2018'+str(random.randint(1000,9000))
print('password: %s' %password)
driver.find_element_by_id('com.tal.kaoyan:id/activity_register_password_edittext').send_keys(password)
email='51zxw'+str(random.randint(1000,9000))+'@163.com'
print('email: %s' %email)
driver.find_element_by_id('com.tal.kaoyan:id/activity_register_email_edittext').send_keys(email)
#点击进入考研帮
driver.find_element_by_id('com.tal.kaoyan:id/activity_register_register_btn').click()
#专业选择
driver.find_element_by_id('com.tal.kaoyan:id/activity_perfectinfomation_major').click()
driver.find_elements_by_id('com.tal.kaoyan:id/major_subject_title')[1].click()
driver.find_elements_by_id('com.tal.kaoyan:id/major_group_title')[2].click()
driver.find_elements_by_id('com.tal.kaoyan:id/major_search_item_name')[1].click()
#院校选择
driver.find_element_by_id('com.tal.kaoyan:id/activity_perfectinfomation_school').click()
driver.tap([(182,1557),])
driver.find_element_by_xpath('/hierarchy/android.widget.FrameLayout/'
'android.widget.LinearLayout/android.widget.FrameLayout/'
'android.widget.LinearLayout/android.widget.FrameLayout/android.widget.'
'RelativeLayout/android.widget.ExpandableListView/android.widget.'
'LinearLayout[1]/android.widget.TextView[1]').click()
driver.find_element_by_xpath('/hierarchy/android.widget.FrameLayout/'
'android.widget.LinearLayout/android.widget.FrameLayout/'
'android.widget.LinearLayout/android.widget.FrameLayout/'
'android.widget.RelativeLayout/android.widget.ExpandableListView/'
'android.widget.LinearLayout[4]/android.widget.TextView').click()
time.sleep(2)
driver.tap([(983,1354),])
# driver.find_elements_by_id('com.tal.kaoyan:id/more_forum_title')[1].click()
# driver.find_elements_by_id('com.tal.kaoyan:id/university_search_item_name')[1].click()
driver.find_element_by_id('com.tal.kaoyan:id/activity_perfectinfomation_goBtn').click()
print('注册成功')
到此这篇关于解读基于Android的Appium+Python自动化脚本编撰的文章就介绍到这了,更多相关Android的Appium+Python自动化脚本内容请搜索脚本之家先前的文章或继续浏览下边的相关文章希望你们之后多多支持脚本之家! 查看全部
详解基于Android的Appium+Python自动化脚本编撰
详解基于Android的Appium+Python自动化脚本编撰
更新时间:2020年08月20日 10:31:19 转载投稿:zx
这篇文章主要介绍了解读基于Android的Appium+Python自动化脚本编撰,文中通过示例代码介绍的十分详尽,对你们的学习或则工作具有一定的参考学习价值,需要的朋友们下边随着小编来一起学习学习吧
1.Appium
Appium是一个开源测试自动化框架,可用于原生,混合和联通Web应用程序测试, 它使用WebDriver合同驱动iOS,Android和Windows应用程序。
通过Appium,我们可以模拟点击和屏幕的滑动,可以获取元素的id和classname,还可以依照操作生成相关的脚本代码。
下面开始Appium的配置。
appPackage和APPActivity的获取
任意下载一个app
解压

但是解压下来的xml文件可能是乱码,所以我们须要反编译文件。
逆向AndroidManifest.xml
下载AXMLPrinter2.jar文件,逆向xml文件:命令行输入以下命令:
java -jar AXMLPrinter2.jar AndroidManifest.xml ->AndroidManifest.txt
获得以下可以查看的TXT文件

寻找带有launcher 的Activity
寻找manifest上面的package
Devicename的获取
通过命令行输入 adb devices:

appium的功能介绍

下面将按照上图序号一一介绍功能:
选中界面元素,显示元素相关信息

模拟滑动屏幕,先点击一下代表触摸起始位置,在点击一下代表触摸结束为止
模拟点击屏幕
模拟手机的返回按键
刷新一侧的页面,使之与手机同步
记录模拟操作,生成相关脚本

根据元素的id或则其他相关信息查找元素

复制当前界面的xml布局
文件退出
2.Python的脚本
元素定位的使用
(1).xpath定位
xpath定位是一种路径定位方法,主要是依赖于元素绝对路径或则相关属性来定位,但是绝对路径xpath执行效率比较低(特别是元素路径比较深的时侯),一般使用比较少。
通常使用xpath相对路径和属性定位。
by_xpath.py
from find_element.capability import driver
driver.find_element_by_xpath('//android.widget.EditText[@text="请输入用户名"]').send_keys('123456')
driver.find_element_by_xpath('//*[@class="android.widget.EditText" and @index="3"]').send_keys('123456')
driver.find_element_by_xpath('//android.widget.Button').click()
driver.find_element_by_xpath('//[@class="android.widget.Button"]').click()
(2).classname定位
classname定位是依据元素类型来进行定位,但是实际情况中好多元素的classname都是相同的,
如用户名和密码都是clasName属性值都是:“android.widget.EditText” 因此只能定位第一个元素也就是用户名,而密码输入框就须要使用其他方法来定位,这样也许太鸡肋.一般情况下假如有id就毋须使用classname定位。
by_classname.py
from find_element.capability import driver
driver.find_element_by_class_name('android.widget.EditText').send_keys('123565')
driver.find_element_by_class_name('android.widget.EditText').send_keys('456879')
driver.find_element_by_class_name('android.widget.Button').click()
(3).id定位
日常生活中身边可能存在相同名子的人,但是每位人的身份证号码是惟一的,在app界面元素中也可以使用id值来分辨不同的元素,然后进行定位操作。
Appium中可以使用 find_element_by_id() 方法来进行id定位。
driver.find_element_by_id('android:id/button2').click()
driver.find_element_by_id('com.tal.kaoyan:id/tv_skip').click()
3.示例:模拟软件的手动注册
首先配置联接属性
desired_caps={}
# 所使用的平台
desired_caps['platformName']='Android'
# 所使用的手机的名字 可以通过 adb devices 获得
desired_caps['deviceName']='127.0.0.1:62001'
# ANDROID 的版本
desired_caps['platforVersion']='5.1.1'
# app 的路径
desired_caps['app']=r'D:\extend\kaoyanbang.apk'
# app的包名
desired_caps['appPackage']='com.tal.kaoyan'
# app 加载页面
desired_caps['appActivity']='com.tal.kaoyan.ui.activity.SplashActivity'
# 设置每次是否清除数据
desired_caps['noReset']='False'
# 是否使用unicode键盘输入,在输入中文字符和unicode字符时设置为true
desired_caps['unicodeKeyboard']="True"
# 是否将键盘重置为初始状态,设置了unicodeKeyboard时,在测试完成后,设置为true,将键盘重置
desired_caps['resetKeyboard']="True"
# appium服务器的连接地址
driver=webdriver.Remote('http://localhost:4723/wd/hub',desired_caps)
driver.implicitly_wait(2)
编写操作脚本
import random
import time
driver.find_element_by_id('com.tal.kaoyan:id/login_register_text').click()
username='zx2019'+'F2LY'+str(random.randint(1000,9000))
print('username: %s' %username)
driver.find_element_by_id('com.tal.kaoyan:id/activity_register_username_edittext').send_keys(username)
password='zxw2018'+str(random.randint(1000,9000))
print('password: %s' %password)
driver.find_element_by_id('com.tal.kaoyan:id/activity_register_password_edittext').send_keys(password)
email='51zxw'+str(random.randint(1000,9000))+'@163.com'
print('email: %s' %email)
driver.find_element_by_id('com.tal.kaoyan:id/activity_register_email_edittext').send_keys(email)
#点击进入考研帮
driver.find_element_by_id('com.tal.kaoyan:id/activity_register_register_btn').click()
#专业选择
driver.find_element_by_id('com.tal.kaoyan:id/activity_perfectinfomation_major').click()
driver.find_elements_by_id('com.tal.kaoyan:id/major_subject_title')[1].click()
driver.find_elements_by_id('com.tal.kaoyan:id/major_group_title')[2].click()
driver.find_elements_by_id('com.tal.kaoyan:id/major_search_item_name')[1].click()
#院校选择
driver.find_element_by_id('com.tal.kaoyan:id/activity_perfectinfomation_school').click()
driver.tap([(182,1557),])
driver.find_element_by_xpath('/hierarchy/android.widget.FrameLayout/'
'android.widget.LinearLayout/android.widget.FrameLayout/'
'android.widget.LinearLayout/android.widget.FrameLayout/android.widget.'
'RelativeLayout/android.widget.ExpandableListView/android.widget.'
'LinearLayout[1]/android.widget.TextView[1]').click()
driver.find_element_by_xpath('/hierarchy/android.widget.FrameLayout/'
'android.widget.LinearLayout/android.widget.FrameLayout/'
'android.widget.LinearLayout/android.widget.FrameLayout/'
'android.widget.RelativeLayout/android.widget.ExpandableListView/'
'android.widget.LinearLayout[4]/android.widget.TextView').click()
time.sleep(2)
driver.tap([(983,1354),])
# driver.find_elements_by_id('com.tal.kaoyan:id/more_forum_title')[1].click()
# driver.find_elements_by_id('com.tal.kaoyan:id/university_search_item_name')[1].click()
driver.find_element_by_id('com.tal.kaoyan:id/activity_perfectinfomation_goBtn').click()
print('注册成功')
到此这篇关于解读基于Android的Appium+Python自动化脚本编撰的文章就介绍到这了,更多相关Android的Appium+Python自动化脚本内容请搜索脚本之家先前的文章或继续浏览下边的相关文章希望你们之后多多支持脚本之家!
使用Shell编撰定时向指定API获取数据的脚本
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2020-08-20 18:32
场景:这个在服务器上写定时脚本的情况十分多,比如每晚向定时往用户推送相关信息,定时清除相关数据,定时短信提醒等等。
本文的场景是采用shell定时向指定开放API获取数据。
本文使用的是crontab,可以先在终端查看是开启此服务,命令如下:
yang@master:~$ sudo service cron status
[sudo] password for yang:
● cron.service - Regular background program processing daemon
Loaded: loaded (/lib/systemd/system/cron.service; enabled; vendor preset: ena
Active: active (running) since Sat 2016-08-13 08:29:16 CST; 30min ago
Docs: man:cron(8)
Main PID: 831 (cron)
CGroup: /system.slice/cron.service
└─831 /usr/sbin/cron -f
Aug 13 08:29:16 master systemd[1]: Started Regular background program processing
Aug 13 08:29:16 master cron[831]: (CRON) INFO (pidfile fd = 3)
Aug 13 08:29:16 master cron[831]: (CRON) INFO (Running @reboot jobs)
编写定时脚本
这个脚本是我们要定时器定时执行的任务,即我们要定时做什么,在这里,我是要使脚本手动采集数据,脚本如下:
#!/usr/bin/env bash
path_log="fetch_data.log"
path_stuTenSch="http://www.google.com"
code_success="200"
#get http response code
http_code=$(curl -s -o /dev/null -I -w "%{http_code}" $path_stuTenSch)
#echo "$http_code" >> $path_log
if [ "$http_code"==$code_success ]; then
echo "Status Code:$http_code, success, Resquest URL: $path_stuTenSch" >> $path_log
echo "starting..........." >> $path_log
curl $path_stuTenSch > /home/hadoop/tmp_data/users.json
echo "end----------------" >> $path_log
else
echo "Status Code:$http_code, fail, Resquest URL: $path_stuTenSch" >> $path_log
fi
编辑crontab
编辑crontab是用crontab -e执行,crontab -l来显示有什么定时器。每个定时器用一行来表示。通常情况下,有6个参数,分别为分钟,小时,天,月,周,要执行的命令,*表示任意时间,/n表示每隔n的时间进行重复。
yang@master:~$ crontab -e
*/1 * * * * /home/yang/shell/fetch_data.sh
在这里,我是每隔一分钟执行一次sh脚本。 查看全部
使用Shell编撰定时向指定API获取数据的脚本
场景:这个在服务器上写定时脚本的情况十分多,比如每晚向定时往用户推送相关信息,定时清除相关数据,定时短信提醒等等。
本文的场景是采用shell定时向指定开放API获取数据。
本文使用的是crontab,可以先在终端查看是开启此服务,命令如下:
yang@master:~$ sudo service cron status
[sudo] password for yang:
● cron.service - Regular background program processing daemon
Loaded: loaded (/lib/systemd/system/cron.service; enabled; vendor preset: ena
Active: active (running) since Sat 2016-08-13 08:29:16 CST; 30min ago
Docs: man:cron(8)
Main PID: 831 (cron)
CGroup: /system.slice/cron.service
└─831 /usr/sbin/cron -f
Aug 13 08:29:16 master systemd[1]: Started Regular background program processing
Aug 13 08:29:16 master cron[831]: (CRON) INFO (pidfile fd = 3)
Aug 13 08:29:16 master cron[831]: (CRON) INFO (Running @reboot jobs)
编写定时脚本
这个脚本是我们要定时器定时执行的任务,即我们要定时做什么,在这里,我是要使脚本手动采集数据,脚本如下:
#!/usr/bin/env bash
path_log="fetch_data.log"
path_stuTenSch="http://www.google.com"
code_success="200"
#get http response code
http_code=$(curl -s -o /dev/null -I -w "%{http_code}" $path_stuTenSch)
#echo "$http_code" >> $path_log
if [ "$http_code"==$code_success ]; then
echo "Status Code:$http_code, success, Resquest URL: $path_stuTenSch" >> $path_log
echo "starting..........." >> $path_log
curl $path_stuTenSch > /home/hadoop/tmp_data/users.json
echo "end----------------" >> $path_log
else
echo "Status Code:$http_code, fail, Resquest URL: $path_stuTenSch" >> $path_log
fi
编辑crontab
编辑crontab是用crontab -e执行,crontab -l来显示有什么定时器。每个定时器用一行来表示。通常情况下,有6个参数,分别为分钟,小时,天,月,周,要执行的命令,*表示任意时间,/n表示每隔n的时间进行重复。
yang@master:~$ crontab -e
*/1 * * * * /home/yang/shell/fetch_data.sh
在这里,我是每隔一分钟执行一次sh脚本。
自己编撰网站防采集程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2020-08-20 18:15
对于我们这些数据量很大的网站,面临的一个麻烦是总有人来采集,以前多使用过人工检测、屏蔽的办法,这种办法有疗效但很费精力,前段时间也找了插件来自动限制最大连接数,但存在误屏蔽搜索引擎的问题,最近老朽下决定亲自操刀写程序,把那些采集器都斩草除根,虽然编程麻烦但效果好。
思路是在Drupal的模板文件中嵌入PHP程序代码,读取$_SERVER参数并记录到数据库中,通过对参数及访问频度的判定来决定是否要访问者递交验证码,如果验证码错误或则不填写的次数过多则屏蔽,可以通过host反向dns查找来判断常见搜索引擎。
这个程序还稍稍有点复杂,以前更改开源PHP程序都是直接上手,这个程序还编撰了流程图,数据库表结构也是自己规划的,为了防止拉慢速率,MySQL中采用了Memory引擎,对于多是临时访问记录早已够用了。程序写得太烂,就不放到博客中了。
这个程序anti-scraping.php上周调试了几天,本周刚才投入试用,已经可以从日志中见到疗效,还须要不断改进,例如降低黑名单、白名单、尝试改用Drupal标准第三方模块的形式等。因为完成采用自己编程实现,所以可以对判断标准、屏蔽方法做各类更改尝试,应对各类采集器。
版本历史:
To Do List: 查看全部
自己编撰网站防采集程序
对于我们这些数据量很大的网站,面临的一个麻烦是总有人来采集,以前多使用过人工检测、屏蔽的办法,这种办法有疗效但很费精力,前段时间也找了插件来自动限制最大连接数,但存在误屏蔽搜索引擎的问题,最近老朽下决定亲自操刀写程序,把那些采集器都斩草除根,虽然编程麻烦但效果好。
思路是在Drupal的模板文件中嵌入PHP程序代码,读取$_SERVER参数并记录到数据库中,通过对参数及访问频度的判定来决定是否要访问者递交验证码,如果验证码错误或则不填写的次数过多则屏蔽,可以通过host反向dns查找来判断常见搜索引擎。
这个程序还稍稍有点复杂,以前更改开源PHP程序都是直接上手,这个程序还编撰了流程图,数据库表结构也是自己规划的,为了防止拉慢速率,MySQL中采用了Memory引擎,对于多是临时访问记录早已够用了。程序写得太烂,就不放到博客中了。
这个程序anti-scraping.php上周调试了几天,本周刚才投入试用,已经可以从日志中见到疗效,还须要不断改进,例如降低黑名单、白名单、尝试改用Drupal标准第三方模块的形式等。因为完成采用自己编程实现,所以可以对判断标准、屏蔽方法做各类更改尝试,应对各类采集器。
版本历史:
To Do List:
自动采集编写 聊一聊爬虫那点事儿(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 486 次浏览 • 2020-08-20 02:08
爬虫学习入门篇
作为一名程序员,大家对于爬虫这个词的理解都有不同,我曾经的理解就是一只spider在网路上爬取东西,不过我们能控制这只spider去爬取须要内容并存取到数据库中。后来才发觉爬虫有点重要!!!
网络爬虫的介绍
在大数据时代,信息的采集是一项重要的工作,而互联网中的数据是海量的,如果单纯靠人力进行信息采集,不仅低效繁杂,搜集的成本也会增强。如何手动高效地获取互联网中我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这种问题而生的。
网络爬虫(Web crawler)也称作网路机器人,可以取代人们手动地在互联网中进行数据信息的采集与整理。它是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本,可以手动采集所有其才能访问到的页面内容,以获取相关数据。
从功能上来讲,爬虫通常分为数据采集,处理,储存三个部份。爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。
为什么要学爬虫可以实现搜索引擎。我们学会了爬虫编撰以后,就可以借助爬虫手动地采集互联网中的信息,采集回来后进行相应的储存或处理,在须要检索个别信息的时侯,只需在采集回来的信息中进行检索,即实现了私人的搜索引擎。大数据时代,可以使我们获取更多的数据源。在进行大数据剖析或则进行数据挖掘的时侯,需要有数据源进行剖析。我们可以从个别提供数据统计的网站获得,也可以从个别文献或内部资料中获得,但是这种获得数据的方法,有时很难满足我们对数据的需求,而自动从互联网中去找寻那些数据,则花费的精力过大。此时就可以借助爬虫技术,自动地从互联网中获取我们感兴趣的数据内容,并将这种数据内容爬取回去,作为我们的数据源,再进行更深层次的数据剖析,并获得更多有价值的信息。可以更好地进行搜索引擎优化(SEO)。对于好多SEO从业者来说,为了更好的完成工作,那么就必须要对搜索引擎的工作原理十分清楚,同时也须要把握搜索引擎爬虫的工作原理。而学习爬虫,可以更深层次地理解搜索引擎爬虫的工作原理,这样在进行搜索引擎优化时,才能知己知彼,百战不殆。有利于就业。从就业来说,爬虫工程师方向是不错的选择之一,因为目前爬虫工程师的需求越来越大,而能否胜任这方面岗位的人员较少,所以属于一个比较短缺的职业方向,并且随着大数据时代和人工智能的将至,爬虫技术的应用将越来越广泛,在未来会拥有挺好的发展空间。
爬虫入门程序1.环境打算
编译环境打算:
l JDK1.8l IntelliJ IDEAlIDEA自带的Maven
IDEA操作步骤:
1.创建Maven工程itcast-crawler-first并给pom.xml加入依赖
org.apache.httpcomponents
httpclient
4.5.3
org.slf4j
slf4j-log4j12
1.7.25
2.加入log4j.properties
log4j.rootLogger=DEBUG,A1
log4j.logger.cn.itcast = DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
2.编写代码 查看全部
自动采集编写 聊一聊爬虫那点事儿(一)
爬虫学习入门篇

作为一名程序员,大家对于爬虫这个词的理解都有不同,我曾经的理解就是一只spider在网路上爬取东西,不过我们能控制这只spider去爬取须要内容并存取到数据库中。后来才发觉爬虫有点重要!!!
网络爬虫的介绍
在大数据时代,信息的采集是一项重要的工作,而互联网中的数据是海量的,如果单纯靠人力进行信息采集,不仅低效繁杂,搜集的成本也会增强。如何手动高效地获取互联网中我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这种问题而生的。
网络爬虫(Web crawler)也称作网路机器人,可以取代人们手动地在互联网中进行数据信息的采集与整理。它是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本,可以手动采集所有其才能访问到的页面内容,以获取相关数据。
从功能上来讲,爬虫通常分为数据采集,处理,储存三个部份。爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。
为什么要学爬虫可以实现搜索引擎。我们学会了爬虫编撰以后,就可以借助爬虫手动地采集互联网中的信息,采集回来后进行相应的储存或处理,在须要检索个别信息的时侯,只需在采集回来的信息中进行检索,即实现了私人的搜索引擎。大数据时代,可以使我们获取更多的数据源。在进行大数据剖析或则进行数据挖掘的时侯,需要有数据源进行剖析。我们可以从个别提供数据统计的网站获得,也可以从个别文献或内部资料中获得,但是这种获得数据的方法,有时很难满足我们对数据的需求,而自动从互联网中去找寻那些数据,则花费的精力过大。此时就可以借助爬虫技术,自动地从互联网中获取我们感兴趣的数据内容,并将这种数据内容爬取回去,作为我们的数据源,再进行更深层次的数据剖析,并获得更多有价值的信息。可以更好地进行搜索引擎优化(SEO)。对于好多SEO从业者来说,为了更好的完成工作,那么就必须要对搜索引擎的工作原理十分清楚,同时也须要把握搜索引擎爬虫的工作原理。而学习爬虫,可以更深层次地理解搜索引擎爬虫的工作原理,这样在进行搜索引擎优化时,才能知己知彼,百战不殆。有利于就业。从就业来说,爬虫工程师方向是不错的选择之一,因为目前爬虫工程师的需求越来越大,而能否胜任这方面岗位的人员较少,所以属于一个比较短缺的职业方向,并且随着大数据时代和人工智能的将至,爬虫技术的应用将越来越广泛,在未来会拥有挺好的发展空间。

爬虫入门程序1.环境打算
编译环境打算:
l JDK1.8l IntelliJ IDEAlIDEA自带的Maven
IDEA操作步骤:
1.创建Maven工程itcast-crawler-first并给pom.xml加入依赖

org.apache.httpcomponents
httpclient
4.5.3
org.slf4j
slf4j-log4j12
1.7.25
2.加入log4j.properties
log4j.rootLogger=DEBUG,A1
log4j.logger.cn.itcast = DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
2.编写代码
自动采集编写 scrapy爬取新浪微博分享(2)
采集交流 • 优采云 发表了文章 • 0 个评论 • 376 次浏览 • 2020-08-18 23:34
内容概要:
最近自己学习了一些爬虫,学习之余,写了一个新浪微博的爬虫。大规模爬数据没有试过,但是爬取几十万应当没有哪些问题。爬虫爬取的站点是新浪移动端站点。github地址为:
第一次写文章,难免有疏漏,大家共同交流,共同进步。也请喜欢的同学,在github上打个star
内容分为三章,第一张介绍scrapy,第二张剖析爬取网站,第三章剖析代码。
Fiddler工具
Fiddler是坐落客户端和服务器端的HTTP代理,也是目前最常用的http抓包工具之一。它才能记录客户端和服务器之间的所有HTTP请求,可以针对特定的HTTP请求,分析恳求数据、设置断点、调试Web应用、请求更改数据、甚至可以更改服务器返回的数据,功能十分强悍,是WEB调试的神器。
既然是代理,也就是说:客户端的所有恳求都要先经过Fiddler,然后转发到相应的服务器,反之,服务器端的所有相应,也就会先经过Fiddler之后发送到客户端。
分析新浪微博数据结构
首先我们登陆微博可以看见Fiddler抓取的包:
其中点击 /api/container/getIndex?type=uid&value=6311254871&containerid=54871 HTTP/1.1我们可以看见微博获取个人信息的API接口,里面储存着json数据。
简单剖析下JSON,我们可以晓得上面储存着爱称、个性签名、微博数、关注数、粉丝数等个人信息。我们可以记录下我们须要的信息。
同理,我们通过不断剖析Fiddler抓取的包可以得到微博内容的API,粉丝列表的API,关注者列表的API。里面依然是JSON格式,我们从中记录下我们须要的信息。
编写Model层
刚刚我们记录下了各个API中我们须要抓取的信息,然后就可以在程序中编撰我们的数据层了。scrapy是用Django编撰的,他们的数据层基本是一样的,是由Django的ARM框架封装的。
类似于右图,我们把带抓取的数据格式写好:
把数据库配置好:
完成以上步骤就可以打算编撰我们的爬虫代码了。
参考:
1、《Python网路数据采集》
2、 查看全部
自动采集编写 scrapy爬取新浪微博分享(2)
内容概要:
最近自己学习了一些爬虫,学习之余,写了一个新浪微博的爬虫。大规模爬数据没有试过,但是爬取几十万应当没有哪些问题。爬虫爬取的站点是新浪移动端站点。github地址为:
第一次写文章,难免有疏漏,大家共同交流,共同进步。也请喜欢的同学,在github上打个star
内容分为三章,第一张介绍scrapy,第二张剖析爬取网站,第三章剖析代码。
Fiddler工具
Fiddler是坐落客户端和服务器端的HTTP代理,也是目前最常用的http抓包工具之一。它才能记录客户端和服务器之间的所有HTTP请求,可以针对特定的HTTP请求,分析恳求数据、设置断点、调试Web应用、请求更改数据、甚至可以更改服务器返回的数据,功能十分强悍,是WEB调试的神器。
既然是代理,也就是说:客户端的所有恳求都要先经过Fiddler,然后转发到相应的服务器,反之,服务器端的所有相应,也就会先经过Fiddler之后发送到客户端。
分析新浪微博数据结构
首先我们登陆微博可以看见Fiddler抓取的包:

其中点击 /api/container/getIndex?type=uid&value=6311254871&containerid=54871 HTTP/1.1我们可以看见微博获取个人信息的API接口,里面储存着json数据。
简单剖析下JSON,我们可以晓得上面储存着爱称、个性签名、微博数、关注数、粉丝数等个人信息。我们可以记录下我们须要的信息。
同理,我们通过不断剖析Fiddler抓取的包可以得到微博内容的API,粉丝列表的API,关注者列表的API。里面依然是JSON格式,我们从中记录下我们须要的信息。
编写Model层
刚刚我们记录下了各个API中我们须要抓取的信息,然后就可以在程序中编撰我们的数据层了。scrapy是用Django编撰的,他们的数据层基本是一样的,是由Django的ARM框架封装的。
类似于右图,我们把带抓取的数据格式写好:

把数据库配置好:

完成以上步骤就可以打算编撰我们的爬虫代码了。
参考:
1、《Python网路数据采集》
2、
全手动采集版小说网站不用管理
采集交流 • 优采云 发表了文章 • 0 个评论 • 386 次浏览 • 2020-08-18 16:03
商品属性
安装环境
商品介绍
您能找到这个小说源码,说明您准备用心建一个小说网站,做站最重要的就是稳定更新和程序的不断升级,你会选择仍然不升级的源码吗?该小说源码程序,定期更新,请放心使用建站。为什么选择dedecms做的这个程序做小说网,那是因为现今杰奇小说程序和模板猖獗,您假如想从几百万个一样的网站中脱引而出这么就选择这套dedecms开发的源码来建设您的网站吗?大家都晓得国外SEO好友的程序源码就是这个dedecms。还在迟疑哪些呢,赶快下手吧,建站和更新内容一样,越早越好。
全网仅此一家为正版域名授权,如果有其他店面销售,那肯定是二手或则山寨的了!
近期发觉有同行盗卖本店的程序,并且十分不厚道的说是他自己开发的,真是无语。
全新升级20151107版,支持:
百度主动推送
百度站内搜索
后台采集规则在线更新(目前预留)
多种章节内容储存方法
微信小说公众号验证平台(支持微信公众号自定义顶部菜单)
支持缓存功能等等,程序更快,负载更大!
重大更新,本程序被百度收录后,主页会手动显示logo,小说目录会手动小说模版适配:
还有好多功能是这些盗卖的难以提供的。
另外,本程序实行后台在线更新后,其他盗卖的就难以继续升级了,之前的更新都是直接提供更新包,而这些盗卖的就直接从群里拿了更新包说是自己提供的更新包。 我们故意拖延了半年没更新,结果就可想而知了......
我们的后台还提供了更新历史,可以查看每次更新了什么功能,并提供了新功能的使用说明......
1、源码类型:整站源码
2-1、环境要求:PHP5.2/5.3/5.4/5.5+MYSQL5(URLrewrite)
2-2、服务器要求:建议用40G数据盘以上的VPS或则独立服务器,系统建议用Windows而不建议用Linux,99%的小说站服务器是用Windows系统,方便文件管理以及备份等(目前演示站空间使用情况:6.5G数据库+5G网页空间,经群内站友网站证实:4核CPU+4G显存的xen构架VPS能承受日5万IP、50万PV流量毫无压力,每天收入700元以上)
3、原创程序:织梦DEDECMS 5.7SP1
4、编码类型:GBK
5、可否采集:全手动采集,赠送规则,好评后还可以免费订制一条
6、演示站点: ,自带手机版:(可提供免费友情链接)
7、安装升级:包安装、附带详尽使用说明,免费升级
8、其他特征:
(1)自动生成首页、分类、目录、作者、排行榜、sitemap页面静态html。
(2)全站拼音目录化(可自定义URL格式),章节页面伪静态。
(3)支持下载功能,可以手动生成对应文本文件,可在文件中设置广告。
(4)自动生成关键词及关键词手动内链。
(5)自动伪原创成语替换(采集、输出时都可以替换)。
(6)配合CNZZ的统计插件,能便捷实现下载明细统计和被采集的明细统计等。
(7)本程序的手动采集并非市面上常见的、关关、采集侠等,而是在DEDE原有采集功能的基础上二次开发的采集模块,可以有效的保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;一天24小时采集量能达到25~30万章节。
20140623更新后全面提高了本源码程序的采集功能,使采集速度更快、更稳定,后台可以单独优先采集某本小说,可以对无关紧要的章节手动进行过滤……
20140806更新后新增了【无缝换站采集功能】,当原先的采集目标站不能采集时,可切换到其他目标站进行采集,采集永不间断,章节永远;新增【自定义小说封面页URL】、【自定义作者页URL】;任何对章节的操作(新增、修改、删除、移动、合并等)执行后均手动更新小说封面的功能……
20141110本支持自动换站采集、自动换站,半自动添加单本采集,无采集规则或规则失效时手动提醒功能……
采集模式降低为3种,增加目标站章节正序采集功能,能采集市面上99%的小说站
20141205更新陌陌小说模块,可以在陌陌上看小说……
20150306更新后台全新的小说管理面板,功能更强大,操作更简单。增加单本自定义换站采集功能,增加小说百度指数查询,方便删掉没有指数的小说。增加批量删掉小说、批量更新小说简介页面的功能。优化全手动采集功能,不需要任何采集工具,不需要打开任何采集页面,只要网站有流量,就能时间更新书友最喜欢看的小说,与源站更新时间差保持在5秒以内……
20151020全新升级20多项功能,支持后台直接更新程序....
本程序本为20160414版,低于些版本都为盗卖。
给诸位新站长的友情提示:
不要相信这些所谓“有访客下载时才手动生成txt电子书”的外行说法,因为提出这些概念的人可以肯定他不是站长出生,没有服务器资源需求的概念!这里说明一下,txt电子书在生成的时侯是比较占用服务器资源的,同时生成1本小说的txt电子书大约会占用5%~8%左右的CPU以及部份硬碟I/O,但是假如须要同时生成20本小说的电子书的话,你的服务器都会吃不消,如果同时须要生成更多的电子书,那你的服务器就立刻奔溃了,整个网站都难以访问!如果使用须要下载的时侯再生成电子书的办法,你就要考虑一下当你的网站同时有几十个人在下载的时侯会是什么样的情况了。 查看全部
全手动采集版小说网站不用管理
商品属性
安装环境
商品介绍
您能找到这个小说源码,说明您准备用心建一个小说网站,做站最重要的就是稳定更新和程序的不断升级,你会选择仍然不升级的源码吗?该小说源码程序,定期更新,请放心使用建站。为什么选择dedecms做的这个程序做小说网,那是因为现今杰奇小说程序和模板猖獗,您假如想从几百万个一样的网站中脱引而出这么就选择这套dedecms开发的源码来建设您的网站吗?大家都晓得国外SEO好友的程序源码就是这个dedecms。还在迟疑哪些呢,赶快下手吧,建站和更新内容一样,越早越好。
全网仅此一家为正版域名授权,如果有其他店面销售,那肯定是二手或则山寨的了!
近期发觉有同行盗卖本店的程序,并且十分不厚道的说是他自己开发的,真是无语。
全新升级20151107版,支持:
百度主动推送
百度站内搜索
后台采集规则在线更新(目前预留)
多种章节内容储存方法
微信小说公众号验证平台(支持微信公众号自定义顶部菜单)
支持缓存功能等等,程序更快,负载更大!
重大更新,本程序被百度收录后,主页会手动显示logo,小说目录会手动小说模版适配:
还有好多功能是这些盗卖的难以提供的。
另外,本程序实行后台在线更新后,其他盗卖的就难以继续升级了,之前的更新都是直接提供更新包,而这些盗卖的就直接从群里拿了更新包说是自己提供的更新包。 我们故意拖延了半年没更新,结果就可想而知了......
我们的后台还提供了更新历史,可以查看每次更新了什么功能,并提供了新功能的使用说明......
1、源码类型:整站源码
2-1、环境要求:PHP5.2/5.3/5.4/5.5+MYSQL5(URLrewrite)
2-2、服务器要求:建议用40G数据盘以上的VPS或则独立服务器,系统建议用Windows而不建议用Linux,99%的小说站服务器是用Windows系统,方便文件管理以及备份等(目前演示站空间使用情况:6.5G数据库+5G网页空间,经群内站友网站证实:4核CPU+4G显存的xen构架VPS能承受日5万IP、50万PV流量毫无压力,每天收入700元以上)
3、原创程序:织梦DEDECMS 5.7SP1
4、编码类型:GBK
5、可否采集:全手动采集,赠送规则,好评后还可以免费订制一条
6、演示站点: ,自带手机版:(可提供免费友情链接)
7、安装升级:包安装、附带详尽使用说明,免费升级
8、其他特征:
(1)自动生成首页、分类、目录、作者、排行榜、sitemap页面静态html。
(2)全站拼音目录化(可自定义URL格式),章节页面伪静态。
(3)支持下载功能,可以手动生成对应文本文件,可在文件中设置广告。
(4)自动生成关键词及关键词手动内链。
(5)自动伪原创成语替换(采集、输出时都可以替换)。
(6)配合CNZZ的统计插件,能便捷实现下载明细统计和被采集的明细统计等。
(7)本程序的手动采集并非市面上常见的、关关、采集侠等,而是在DEDE原有采集功能的基础上二次开发的采集模块,可以有效的保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;一天24小时采集量能达到25~30万章节。
20140623更新后全面提高了本源码程序的采集功能,使采集速度更快、更稳定,后台可以单独优先采集某本小说,可以对无关紧要的章节手动进行过滤……
20140806更新后新增了【无缝换站采集功能】,当原先的采集目标站不能采集时,可切换到其他目标站进行采集,采集永不间断,章节永远;新增【自定义小说封面页URL】、【自定义作者页URL】;任何对章节的操作(新增、修改、删除、移动、合并等)执行后均手动更新小说封面的功能……
20141110本支持自动换站采集、自动换站,半自动添加单本采集,无采集规则或规则失效时手动提醒功能……
采集模式降低为3种,增加目标站章节正序采集功能,能采集市面上99%的小说站
20141205更新陌陌小说模块,可以在陌陌上看小说……
20150306更新后台全新的小说管理面板,功能更强大,操作更简单。增加单本自定义换站采集功能,增加小说百度指数查询,方便删掉没有指数的小说。增加批量删掉小说、批量更新小说简介页面的功能。优化全手动采集功能,不需要任何采集工具,不需要打开任何采集页面,只要网站有流量,就能时间更新书友最喜欢看的小说,与源站更新时间差保持在5秒以内……
20151020全新升级20多项功能,支持后台直接更新程序....
本程序本为20160414版,低于些版本都为盗卖。
给诸位新站长的友情提示:
不要相信这些所谓“有访客下载时才手动生成txt电子书”的外行说法,因为提出这些概念的人可以肯定他不是站长出生,没有服务器资源需求的概念!这里说明一下,txt电子书在生成的时侯是比较占用服务器资源的,同时生成1本小说的txt电子书大约会占用5%~8%左右的CPU以及部份硬碟I/O,但是假如须要同时生成20本小说的电子书的话,你的服务器都会吃不消,如果同时须要生成更多的电子书,那你的服务器就立刻奔溃了,整个网站都难以访问!如果使用须要下载的时侯再生成电子书的办法,你就要考虑一下当你的网站同时有几十个人在下载的时侯会是什么样的情况了。
web网路漏洞扫描器编撰
采集交流 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2020-08-18 00:36
这三天看了好多web漏洞扫描器编撰的文章,比如W12scan以及其前身W8scan,还有猪猪侠的自动化功击背景下的过去、现在与未来,以及网上好多优秀的扫描器和博客,除了之前写了一部分的静湖ABC段扫描器,接下来有空的大部分时间就会用于编撰这个扫描器,相当于是对自己的一个阶段性挑战吧,也算是为了建立自己的技术栈。
因为想把扫描器弄成web应用,像W12scan,bugscan,AWVS那样的,部署好了以后登录,添加须要扫描的url,自动化进行漏洞扫描,首先须要将扫描器的web界面完成,也就是前前端弄好,漏洞扫描作为前面添加进去的功能,在原基础上进行更改。
因为时间不是太充裕,所以选择Flask框架进行web的开发,学习的视频是:
找了许久的视频,要么就是太紧了,对于好多地方没有讲透彻,要么就是几百集的教程丢过来,过于冗长。
文档可以看官方文档,或者是这个:
当然遇见不会的问题还须要微软搜索一下,发挥自己的主观能动性。
接下来渐渐更新这一篇博客,先学Flask,哪里不会点技能树的那里吧。当然也不能舍弃代码审计,CTF和网课的学习
2020/4/2更新
框架快搭建好了,先做了登陆界面
然后扫描器的基础功能也在readme上面写好了,侧重的功能模块是信息采集和FUZZ模块
碎遮 Web漏洞扫描器
环境要求:
python版本要求:3.x,python运行需要的类库在requirements.txt中,执行
pip3 install -r requirements.txt
进行类库的下载
主要功能:
一,输入源采集:
1,基于流量清洗
2,基于日志提取
3,基于爬虫提取
二,输入源信息搜集(+)
1,被动信息搜集:(公开渠道可获得信息,与目标系统不产生直接交互)
1,whois 信息 获取关键注册人的信息 chinaz
2,在线子域名挖掘(这里不会ban掉自身IP,放进被动信息搜集中)
3,绕过CDN查找真实IP
4,DNS信息搜集
5,旁站查询
6,云悉指纹
7,备案信息
8,搜索引擎搜索
9,备案查询
2,主动信息搜集:
1,旁站C段服务简单扫描
2,子域名爆破
3,CMS指纹识别
4,敏感目录,文件扫描
5,端口及运行服务
6,服务器及中间件信息
7,WAF检测
8,敏感信息泄露 .svn,.git 等等
9,登录界面发现
三,SQL注入漏洞
四,XSS漏洞检测
五,命令执行类漏洞
六,文件包含类漏洞
七,登录弱密码爆破
八,FUZZ模块
可视化界面:
使用flask+javascript+html+css编写
启动index.py,在浏览器中访问127.0.0.1:5000访问
准备开始模块的编撰,加油趴
整个项目如今完成了1/3的样子,因为自己缺少构架的经验,所以暂时只能走一步看一步,最开始使用MySQL数据库打算换成redis非关系型数据库推动读写速率,扫描器在写的过程中丰富了自己对于各方面知识的把握
贴上W12scan的代码构架乡楼
从构架图上面跟自己扫描器的看法进行了一些验证和补充。自己写的时侯应当不会用到elastic,可以考虑使用redis和MySQL数据库两个互相进行配合储存数据。
另外在扫描范围上要进行合法范围的扩大化。 查看全部
web网路漏洞扫描器编撰
这三天看了好多web漏洞扫描器编撰的文章,比如W12scan以及其前身W8scan,还有猪猪侠的自动化功击背景下的过去、现在与未来,以及网上好多优秀的扫描器和博客,除了之前写了一部分的静湖ABC段扫描器,接下来有空的大部分时间就会用于编撰这个扫描器,相当于是对自己的一个阶段性挑战吧,也算是为了建立自己的技术栈。
因为想把扫描器弄成web应用,像W12scan,bugscan,AWVS那样的,部署好了以后登录,添加须要扫描的url,自动化进行漏洞扫描,首先须要将扫描器的web界面完成,也就是前前端弄好,漏洞扫描作为前面添加进去的功能,在原基础上进行更改。
因为时间不是太充裕,所以选择Flask框架进行web的开发,学习的视频是:
找了许久的视频,要么就是太紧了,对于好多地方没有讲透彻,要么就是几百集的教程丢过来,过于冗长。
文档可以看官方文档,或者是这个:
当然遇见不会的问题还须要微软搜索一下,发挥自己的主观能动性。
接下来渐渐更新这一篇博客,先学Flask,哪里不会点技能树的那里吧。当然也不能舍弃代码审计,CTF和网课的学习
2020/4/2更新
框架快搭建好了,先做了登陆界面
然后扫描器的基础功能也在readme上面写好了,侧重的功能模块是信息采集和FUZZ模块
碎遮 Web漏洞扫描器
环境要求:
python版本要求:3.x,python运行需要的类库在requirements.txt中,执行
pip3 install -r requirements.txt
进行类库的下载
主要功能:
一,输入源采集:
1,基于流量清洗
2,基于日志提取
3,基于爬虫提取
二,输入源信息搜集(+)
1,被动信息搜集:(公开渠道可获得信息,与目标系统不产生直接交互)
1,whois 信息 获取关键注册人的信息 chinaz
2,在线子域名挖掘(这里不会ban掉自身IP,放进被动信息搜集中)
3,绕过CDN查找真实IP
4,DNS信息搜集
5,旁站查询
6,云悉指纹
7,备案信息
8,搜索引擎搜索
9,备案查询
2,主动信息搜集:
1,旁站C段服务简单扫描
2,子域名爆破
3,CMS指纹识别
4,敏感目录,文件扫描
5,端口及运行服务
6,服务器及中间件信息
7,WAF检测
8,敏感信息泄露 .svn,.git 等等
9,登录界面发现
三,SQL注入漏洞
四,XSS漏洞检测
五,命令执行类漏洞
六,文件包含类漏洞
七,登录弱密码爆破
八,FUZZ模块
可视化界面:
使用flask+javascript+html+css编写
启动index.py,在浏览器中访问127.0.0.1:5000访问
准备开始模块的编撰,加油趴
整个项目如今完成了1/3的样子,因为自己缺少构架的经验,所以暂时只能走一步看一步,最开始使用MySQL数据库打算换成redis非关系型数据库推动读写速率,扫描器在写的过程中丰富了自己对于各方面知识的把握
贴上W12scan的代码构架乡楼
从构架图上面跟自己扫描器的看法进行了一些验证和补充。自己写的时侯应当不会用到elastic,可以考虑使用redis和MySQL数据库两个互相进行配合储存数据。
另外在扫描范围上要进行合法范围的扩大化。
第04期:Prometheus 数据采集(三)
采集交流 • 优采云 发表了文章 • 0 个评论 • 433 次浏览 • 2020-08-17 22:27
本期作者:罗韦
爱可生上海研发中心成员,研发工程师,主要负责 DMP 平台监控告警功能的相关工作。
Prometheus 的监控对象各式各样,没有统一标准。为了解决这个问题,Prometheus 制定了一套监控规范,符合这个规范的样本数据可以被 Prometheus 采集并解析样本数据。Exporter 在 Prometheus 监控系统中是一个采集监控数据并通过 Prometheus 监控规范对外提供数据的组件,针对不同的监控对象可以实现不同的 Exporter,这样就解决了监控对象标准不一的问题。从广义上说,所有可以向 Prometheus 提供监控样本数据的程序都可以称为 Exporter,Exporter 的实例也就是我们上期所说的"target"。
Exporter 的运行方法Exporter 有两种运行方法Exporter 接口数据规范
Exporter 通过 HTTP 接口以文本方式向 Prometheus 暴露样本数据,格式简单,没有嵌套,可读性强。每个监控指标对应的数据文本格式如下:
# HELP
# TYPE
{ =,=...}
{ =,=...}
...
# HELP x balabala
# TYPE x summary
x{quantile="0.5"} value1
x{quantile="0.9"} value2
x{quantile="0.99"} value3
x_sum sum(values)
x_count count(values)
# HELP x The temperature of cpu
# TYPE x histogram
x_bucket{le="20"} value1
x_bucket{le="50"} value2
x_bucket{le="70"} value3
x_bucket{le="+Inf"} count(values)
x_sum sum(values)
x_count count(values)
这样的文本格式也有不足之处:
1. 文本内容可能过分繁琐;
2. Prometheus 在解析时不能校准 HELP 和 TYPE 字段是否缺位,如果缺位 HELP 字段,这条样本数据的来源可能就无法判定;如果缺位 TYPE 字段,Prometheus 对这条样本数据的类型就无从得悉;
3. 相比于 protobuf,Prometheus 使用的文本格式没有做任何压缩处理,解析成本较高。
MySQL Server Exporter
针对被广泛使用的关系型数据库 MySQL,Prometheus 官方提供了 MySQL Server Exporter,支持 MySQL 5.6 及以上版本,对于 5.6 以下的版本,部分监控指标可能不支持。
MySQL Server Exporter 监控的信息包括了常用的 global status/variables 信息、schema/table 的统计信息、user 统计信息、innodb 的信息以及主从复制、组复制的信息,监控指标比较全面。但是因为它提供的监控指标中缺乏对 MySQL 实例的标示,所以当一台主机上存在多个 MySQL 实例,需要运行多个 MySQL Server Exporter 进行监控时,就会无法分辨实例信息。具体使用方法可参考:
Node Exporter
Prometheus 官方的 Node Exporter 提供对 *NIX 系统、硬件信息的监控,监控指标包括 CPU 使用率/配置、系统平均负载、内存信息、网络状况、文件系统信息统计、磁盘使用情况统计等。对于不同的系统,监控指标会有所差别,如 diskstats 支持 Darwin, Linux, OpenBSD 系统;loadavg 支持 Darwin, Dragonfly, FreeBSD, Linux, NetBSD, OpenBSD, Solaris 系统。Node Exporter 的监控指标没有对主机身分的标示,可以通过 relabel 功能在 Prometheus Server 端降低一些标示标签。具体使用方法可参考:
如何实现一个 Exporter编撰一个简单的 Exporter
使用 prometheus/client_golang 包,我们来编撰一个简单的 Exporter,包括 Prometheus 支持的四种监控指标类型
package main
import (
"log"
"net/http"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var (
//使用GaugeVec类型可以为监控指标设置标签,这里为监控指标增加一个标签"device"
speed = prometheus.NewGaugeVec(prometheus.GaugeOpts{
Name: "disk_available_bytes",
Help: "Disk space available in bytes",
}, []string{"device"})
tasksTotal = prometheus.NewCounter(prometheus.CounterOpts{
Name: "test_tasks_total",
Help: "Total number of test tasks",
})
taskDuration = prometheus.NewSummary(prometheus.SummaryOpts{
Name: "task_duration_seconds",
Help: "Duration of task in seconds",
//Summary类型的监控指标需要提供分位点
Objectives: map[float64]float64{0.5: 0.05, 0.9: 0.01, 0.99: 0.001},
})
cpuTemperature = prometheus.NewHistogram(prometheus.HistogramOpts{
Name: "cpu_temperature",
Help: "The temperature of cpu",
//Histogram类型的监控指标需要提供Bucket
Buckets: []float64{20, 50, 70, 80},
})
)
func init() {
//注册监控指标
prometheus.MustRegister(speed)
prometheus.MustRegister(tasksTotal)
prometheus.MustRegister(taskDuration)
prometheus.MustRegister(cpuTemperature)
}
func main() {
//模拟采集监控数据
fakeData()
//使用prometheus提供的promhttp.Handler()暴露监控样本数据
//prometheus默认从"/metrics"接口拉取监控样本数据
http.Handle("/metrics", promhttp.Handler())
log.Fatal(http.ListenAndServe(":10000", nil))
}
func fakeData() {
tasksTotal.Inc()
//设置该条样本数据的"device"标签值为"/dev/sda"
speed.With(prometheus.Labels{"device": "/dev/sda"}).Set(82115880)
taskDuration.Observe(10)
taskDuration.Observe(20)
taskDuration.Observe(30)
taskDuration.Observe(45)
taskDuration.Observe(56)
taskDuration.Observe(80)
cpuTemperature.Observe(30)
cpuTemperature.Observe(43)
cpuTemperature.Observe(56)
cpuTemperature.Observe(58)
cpuTemperature.Observe(65)
cpuTemperature.Observe(70)
}
接下来编译、运行我们的 Exporter
GOOS=linux GOARCH=amd64 go build -o my_exporter main.go
./my_exporter &
Exporter 运行上去以后,还要在 Prometheus 的配置文件中加入 Exporter 信息,Prometheus 才能从 Exporter 拉取数据。
static_configs:
- targets: ['localhost:9090','172.17.0.3:10000']
在 Prometheus 的 targets 页面可以看见刚刚新增的 Exporter 了
untitled.png
访问"/metrics"接口可以找到如下数据:
Gauge
因为我们使用了 GaugeVec,所以形成了带标签的样本数据
# HELP disk_available_bytes disk space available in bytes
# TYPE disk_available_bytes gauge
disk_available_bytes{device="/dev/sda"} 8.211588e+07
Counter
# HELP test_tasks_total total number of test tasks
# TYPE test_tasks_total counter
test_tasks_total 1
Summary
# HELP task_duration_seconds Duration of task in seconds
# TYPE task_duration_seconds summary
task_duration_seconds{quantile="0.5"} 30
task_duration_seconds{quantile="0.9"} 80
task_duration_seconds{quantile="0.99"} 80
task_duration_seconds_sum 241
task_duration_seconds_count 6
Histogram
# HELP cpu_temperature The temperature of cpu
# TYPE cpu_temperature histogram
cpu_temperature_bucket{le="20"} 0
cpu_temperature_bucket{le="50"} 2
cpu_temperature_bucket{le="70"} 6
cpu_temperature_bucket{le="80"} 6
cpu_temperature_bucket{le="+Inf"} 6
cpu_temperature_sum 322
cpu_temperature_count 6
Exporter实现方法的审视
上面的板栗中,我们在程序一开始就初始化所有的监控指标,这种方案一般接下来会开启一个取样解释器去定期采集、更新监控指标的样本数据,最新的样本数据将仍然保留在显存中,在接到 Prometheus Server 的恳求时,返回显存里的样本数据。这个方案的优点在于,易于控制取样频度;不用害怕并发取样可能带来的资源占据问题。不足之处有:
1. 由于样本数据不会被手动清除,当某个已被取样的采集对象失效了,Prometheus Server 依然能拉取到它的样本数据,只是这个数据从监控对象失效时就早已不会再被更新。这就须要 Exporter 自己提供一个对无效监控对象的数据清除机制;
2. 由于响应 Prometheus Server 的恳求是从显存里取数据,如果 Exporter 的取样解释器异常卡住,Prometheus Server 也难以感知,拉取到的数据可能是过期数据;
3. Prometheus Server 拉取的数据不是即时取样的,对于某时间点的数据一致性不能保证。
另一种方案是 MySQL Server Exporter 和 Node Exporter 采用的,也是 Prometheus 官方推荐的方案。该方案是在每次接到 Prometheus Server 的恳求时,初始化新的监控指标,开启一个取样解释器。和方案一不同的是,这些监控指标只在恳求期间存活。然后取样解释器会去采集所有样本数据并返回给 Prometheus Server。相比于方案一,方案二的数据是即时拉取的,可以保证时间点的数据一致性;因为监控指标会在每次恳求时重新初始化,所以也不会存在失效的样本数据。不过方案二同样有不足之处:
1. 当多个拉取恳求同时发生时,需要控制并发采集样本的资源消耗;
2. 当多个拉取恳求同时发生时,在短时间内须要对同一个监控指标读取多次,对于一个变化频度较低的监控指标来说,多次读取意义不大,却降低了对资源的占用。
相关内容方面的知识,大家还有哪些疑惑或则想知道的吗?赶紧留言告诉小编吧! 查看全部
第04期:Prometheus 数据采集(三)

本期作者:罗韦
爱可生上海研发中心成员,研发工程师,主要负责 DMP 平台监控告警功能的相关工作。
Prometheus 的监控对象各式各样,没有统一标准。为了解决这个问题,Prometheus 制定了一套监控规范,符合这个规范的样本数据可以被 Prometheus 采集并解析样本数据。Exporter 在 Prometheus 监控系统中是一个采集监控数据并通过 Prometheus 监控规范对外提供数据的组件,针对不同的监控对象可以实现不同的 Exporter,这样就解决了监控对象标准不一的问题。从广义上说,所有可以向 Prometheus 提供监控样本数据的程序都可以称为 Exporter,Exporter 的实例也就是我们上期所说的"target"。
Exporter 的运行方法Exporter 有两种运行方法Exporter 接口数据规范
Exporter 通过 HTTP 接口以文本方式向 Prometheus 暴露样本数据,格式简单,没有嵌套,可读性强。每个监控指标对应的数据文本格式如下:
# HELP
# TYPE
{ =,=...}
{ =,=...}
...
# HELP x balabala
# TYPE x summary
x{quantile="0.5"} value1
x{quantile="0.9"} value2
x{quantile="0.99"} value3
x_sum sum(values)
x_count count(values)
# HELP x The temperature of cpu
# TYPE x histogram
x_bucket{le="20"} value1
x_bucket{le="50"} value2
x_bucket{le="70"} value3
x_bucket{le="+Inf"} count(values)
x_sum sum(values)
x_count count(values)
这样的文本格式也有不足之处:
1. 文本内容可能过分繁琐;
2. Prometheus 在解析时不能校准 HELP 和 TYPE 字段是否缺位,如果缺位 HELP 字段,这条样本数据的来源可能就无法判定;如果缺位 TYPE 字段,Prometheus 对这条样本数据的类型就无从得悉;
3. 相比于 protobuf,Prometheus 使用的文本格式没有做任何压缩处理,解析成本较高。
MySQL Server Exporter
针对被广泛使用的关系型数据库 MySQL,Prometheus 官方提供了 MySQL Server Exporter,支持 MySQL 5.6 及以上版本,对于 5.6 以下的版本,部分监控指标可能不支持。
MySQL Server Exporter 监控的信息包括了常用的 global status/variables 信息、schema/table 的统计信息、user 统计信息、innodb 的信息以及主从复制、组复制的信息,监控指标比较全面。但是因为它提供的监控指标中缺乏对 MySQL 实例的标示,所以当一台主机上存在多个 MySQL 实例,需要运行多个 MySQL Server Exporter 进行监控时,就会无法分辨实例信息。具体使用方法可参考:
Node Exporter
Prometheus 官方的 Node Exporter 提供对 *NIX 系统、硬件信息的监控,监控指标包括 CPU 使用率/配置、系统平均负载、内存信息、网络状况、文件系统信息统计、磁盘使用情况统计等。对于不同的系统,监控指标会有所差别,如 diskstats 支持 Darwin, Linux, OpenBSD 系统;loadavg 支持 Darwin, Dragonfly, FreeBSD, Linux, NetBSD, OpenBSD, Solaris 系统。Node Exporter 的监控指标没有对主机身分的标示,可以通过 relabel 功能在 Prometheus Server 端降低一些标示标签。具体使用方法可参考:
如何实现一个 Exporter编撰一个简单的 Exporter
使用 prometheus/client_golang 包,我们来编撰一个简单的 Exporter,包括 Prometheus 支持的四种监控指标类型
package main
import (
"log"
"net/http"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var (
//使用GaugeVec类型可以为监控指标设置标签,这里为监控指标增加一个标签"device"
speed = prometheus.NewGaugeVec(prometheus.GaugeOpts{
Name: "disk_available_bytes",
Help: "Disk space available in bytes",
}, []string{"device"})
tasksTotal = prometheus.NewCounter(prometheus.CounterOpts{
Name: "test_tasks_total",
Help: "Total number of test tasks",
})
taskDuration = prometheus.NewSummary(prometheus.SummaryOpts{
Name: "task_duration_seconds",
Help: "Duration of task in seconds",
//Summary类型的监控指标需要提供分位点
Objectives: map[float64]float64{0.5: 0.05, 0.9: 0.01, 0.99: 0.001},
})
cpuTemperature = prometheus.NewHistogram(prometheus.HistogramOpts{
Name: "cpu_temperature",
Help: "The temperature of cpu",
//Histogram类型的监控指标需要提供Bucket
Buckets: []float64{20, 50, 70, 80},
})
)
func init() {
//注册监控指标
prometheus.MustRegister(speed)
prometheus.MustRegister(tasksTotal)
prometheus.MustRegister(taskDuration)
prometheus.MustRegister(cpuTemperature)
}
func main() {
//模拟采集监控数据
fakeData()
//使用prometheus提供的promhttp.Handler()暴露监控样本数据
//prometheus默认从"/metrics"接口拉取监控样本数据
http.Handle("/metrics", promhttp.Handler())
log.Fatal(http.ListenAndServe(":10000", nil))
}
func fakeData() {
tasksTotal.Inc()
//设置该条样本数据的"device"标签值为"/dev/sda"
speed.With(prometheus.Labels{"device": "/dev/sda"}).Set(82115880)
taskDuration.Observe(10)
taskDuration.Observe(20)
taskDuration.Observe(30)
taskDuration.Observe(45)
taskDuration.Observe(56)
taskDuration.Observe(80)
cpuTemperature.Observe(30)
cpuTemperature.Observe(43)
cpuTemperature.Observe(56)
cpuTemperature.Observe(58)
cpuTemperature.Observe(65)
cpuTemperature.Observe(70)
}
接下来编译、运行我们的 Exporter
GOOS=linux GOARCH=amd64 go build -o my_exporter main.go
./my_exporter &
Exporter 运行上去以后,还要在 Prometheus 的配置文件中加入 Exporter 信息,Prometheus 才能从 Exporter 拉取数据。
static_configs:
- targets: ['localhost:9090','172.17.0.3:10000']
在 Prometheus 的 targets 页面可以看见刚刚新增的 Exporter 了

untitled.png
访问"/metrics"接口可以找到如下数据:
Gauge
因为我们使用了 GaugeVec,所以形成了带标签的样本数据
# HELP disk_available_bytes disk space available in bytes
# TYPE disk_available_bytes gauge
disk_available_bytes{device="/dev/sda"} 8.211588e+07
Counter
# HELP test_tasks_total total number of test tasks
# TYPE test_tasks_total counter
test_tasks_total 1
Summary
# HELP task_duration_seconds Duration of task in seconds
# TYPE task_duration_seconds summary
task_duration_seconds{quantile="0.5"} 30
task_duration_seconds{quantile="0.9"} 80
task_duration_seconds{quantile="0.99"} 80
task_duration_seconds_sum 241
task_duration_seconds_count 6
Histogram
# HELP cpu_temperature The temperature of cpu
# TYPE cpu_temperature histogram
cpu_temperature_bucket{le="20"} 0
cpu_temperature_bucket{le="50"} 2
cpu_temperature_bucket{le="70"} 6
cpu_temperature_bucket{le="80"} 6
cpu_temperature_bucket{le="+Inf"} 6
cpu_temperature_sum 322
cpu_temperature_count 6
Exporter实现方法的审视
上面的板栗中,我们在程序一开始就初始化所有的监控指标,这种方案一般接下来会开启一个取样解释器去定期采集、更新监控指标的样本数据,最新的样本数据将仍然保留在显存中,在接到 Prometheus Server 的恳求时,返回显存里的样本数据。这个方案的优点在于,易于控制取样频度;不用害怕并发取样可能带来的资源占据问题。不足之处有:
1. 由于样本数据不会被手动清除,当某个已被取样的采集对象失效了,Prometheus Server 依然能拉取到它的样本数据,只是这个数据从监控对象失效时就早已不会再被更新。这就须要 Exporter 自己提供一个对无效监控对象的数据清除机制;
2. 由于响应 Prometheus Server 的恳求是从显存里取数据,如果 Exporter 的取样解释器异常卡住,Prometheus Server 也难以感知,拉取到的数据可能是过期数据;
3. Prometheus Server 拉取的数据不是即时取样的,对于某时间点的数据一致性不能保证。
另一种方案是 MySQL Server Exporter 和 Node Exporter 采用的,也是 Prometheus 官方推荐的方案。该方案是在每次接到 Prometheus Server 的恳求时,初始化新的监控指标,开启一个取样解释器。和方案一不同的是,这些监控指标只在恳求期间存活。然后取样解释器会去采集所有样本数据并返回给 Prometheus Server。相比于方案一,方案二的数据是即时拉取的,可以保证时间点的数据一致性;因为监控指标会在每次恳求时重新初始化,所以也不会存在失效的样本数据。不过方案二同样有不足之处:
1. 当多个拉取恳求同时发生时,需要控制并发采集样本的资源消耗;
2. 当多个拉取恳求同时发生时,在短时间内须要对同一个监控指标读取多次,对于一个变化频度较低的监控指标来说,多次读取意义不大,却降低了对资源的占用。
相关内容方面的知识,大家还有哪些疑惑或则想知道的吗?赶紧留言告诉小编吧!
Golddata怎么采集需要登入/会话的数据?
采集交流 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2020-08-14 14:05
点击“采集管理》网站管理”,点击“添加”按扭,添加名为mydict的站点。如下所示:
接下来配制登陆和检测会话脚本,点击“设置半自动登陆”,会打开站点半自动登陆配制页面,如下图所示:
登录脚本如下:
//发送ajax请求验证码
var va=$ajax('http://localhost:8080/code/vcode?timestamp=1554001708730',{encoding:false});
var arg_={
label:site.name+"验证码",
type:1,
content:va.content
}
//waitForInput内置函数将发送邮件,并等待输入
//(回复邮件,或者goldData平台输入),
//并把输入内容当作验证码返回。
var code=waitForInput(arg_);
var data="username=admin&password=admin&vcode="+code
var m=new Map()
m.put('Cookie',va.cookie)
//发送ajax请求执行登录
var content=$ajax('http://localhost:8080/doLogin',{method:'POST',headers:m,data:data})
//如果正确,将返回状态1(登录成功),和headers信息给GoldData,
//否则返回0(登录失败)!
if(content.headers){
m.putAll(content.headers)
}
var ret={status:1,headers:m}
if(content.status!=200){
ret.status=0
}
ret
检查脚本如下:
var ret=true;
if(html.contains("我的单词-登录")){
ret=false
}
ret;
配制好以后,我们回到网站管理页面,点击“启动登陆”,则会开始执行“自动登入”,这以后,点击“查询”按扭来刷新页面,可以见到“等待输入”的状态。如下图所示:
此时,您设置的通知邮箱,也应当同时收到了电邮。点开电邮,或者点击页面上的“录入等待输入”按扭,将会听到如下内容:
依据电邮内容,回复电邮“{{qcxe}}”,就可以使程序继续执行。在golddata页面里输入"qcxe",效果是一样的。程序将会回到“waitForInput()”,并且返回输入的内容。
回复以后,我们将在golddata页面里,点击“查询”刷新页面,mydict的登陆状态会变为“已登陆”。如下图所示:
接下来,我们可以定义抓取规则。
定义抓取规则
在添加规则之前,我们还须要定义类似于表结构的数据集。如下图所示:
接下来,点击“采集管理》规则管理”,添加规则,打开添加规则页面,如下图所示:
抓取规则脚本如下:
[
{
__sample: http://localhost:8080/word/index?pageNum=2
match0: http\:\/\/localhost\:8080\/word\/index(\?pageNum=\d+)?
fields0:
{
__model: true
__dataset: word
__node: "#content ul >li"
sn:
{
expr: ""
attr: ""
js: md5(item.name)
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
name:
{
expr: h5
attr: ""
js: ""
__label: ""
__showOnList: true
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
uk:
{
expr: li span.uk
attr: ""
js: source.replace("uk: ",'')
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
us:
{
expr: li span.us
attr: ""
js: source.replace("us: ",'')
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
}
fields1:
{
__node: .pagination a
href:
{
expr: a
attr: abs:href
js: ""
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
}
}
]
然后点击测试,将会进行测试抓取。我们发觉数据的确被抓取到了,如下图所示:
配制抓取器抓取
这和之前是一样的,将抓取器设置抓取站点“mydict”.然后点击开始抓取。然后会在数据管理上面查看抓取的数据。
结论
GoldData半自动登陆实质是提供了一个可以人工介入来异步获取会话的框架,既可以调用AI插口做到完全手动登入;也可以将类似于验证码须要复杂辨识须要提供输入时,直接将cookie或则token信息通过短信收发到GoldData平台(这样可以不管CAPTCHA多复杂 ),都可以使GoldData抓取数据的动作持续进行下去。 查看全部
编写登陆和检测会话脚本
点击“采集管理》网站管理”,点击“添加”按扭,添加名为mydict的站点。如下所示:
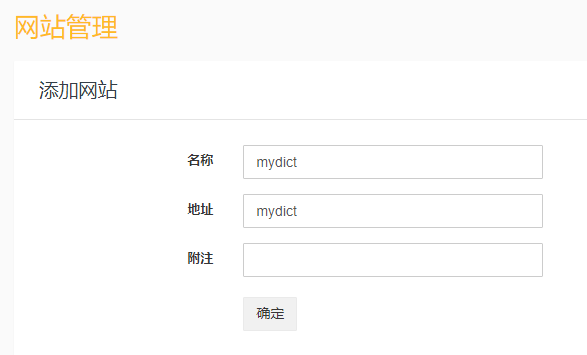
接下来配制登陆和检测会话脚本,点击“设置半自动登陆”,会打开站点半自动登陆配制页面,如下图所示:
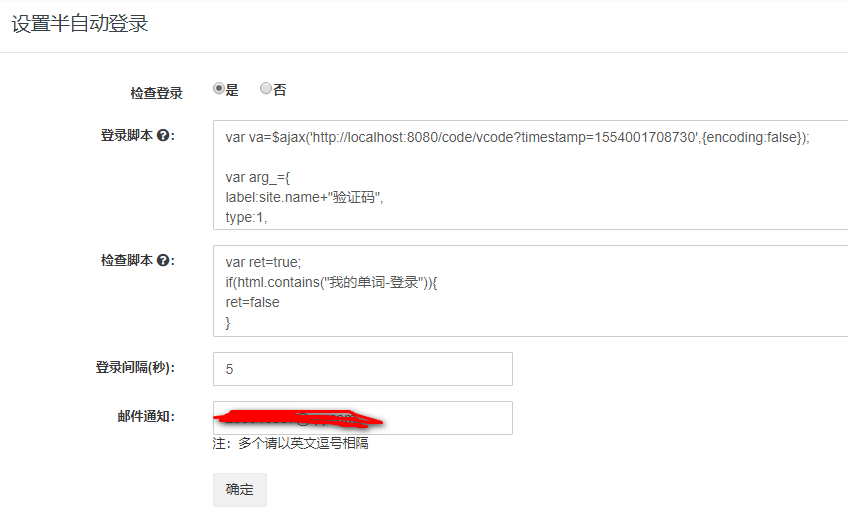
登录脚本如下:
//发送ajax请求验证码
var va=$ajax('http://localhost:8080/code/vcode?timestamp=1554001708730',{encoding:false});
var arg_={
label:site.name+"验证码",
type:1,
content:va.content
}
//waitForInput内置函数将发送邮件,并等待输入
//(回复邮件,或者goldData平台输入),
//并把输入内容当作验证码返回。
var code=waitForInput(arg_);
var data="username=admin&password=admin&vcode="+code
var m=new Map()
m.put('Cookie',va.cookie)
//发送ajax请求执行登录
var content=$ajax('http://localhost:8080/doLogin',{method:'POST',headers:m,data:data})
//如果正确,将返回状态1(登录成功),和headers信息给GoldData,
//否则返回0(登录失败)!
if(content.headers){
m.putAll(content.headers)
}
var ret={status:1,headers:m}
if(content.status!=200){
ret.status=0
}
ret
检查脚本如下:
var ret=true;
if(html.contains("我的单词-登录")){
ret=false
}
ret;
配制好以后,我们回到网站管理页面,点击“启动登陆”,则会开始执行“自动登入”,这以后,点击“查询”按扭来刷新页面,可以见到“等待输入”的状态。如下图所示:

此时,您设置的通知邮箱,也应当同时收到了电邮。点开电邮,或者点击页面上的“录入等待输入”按扭,将会听到如下内容:
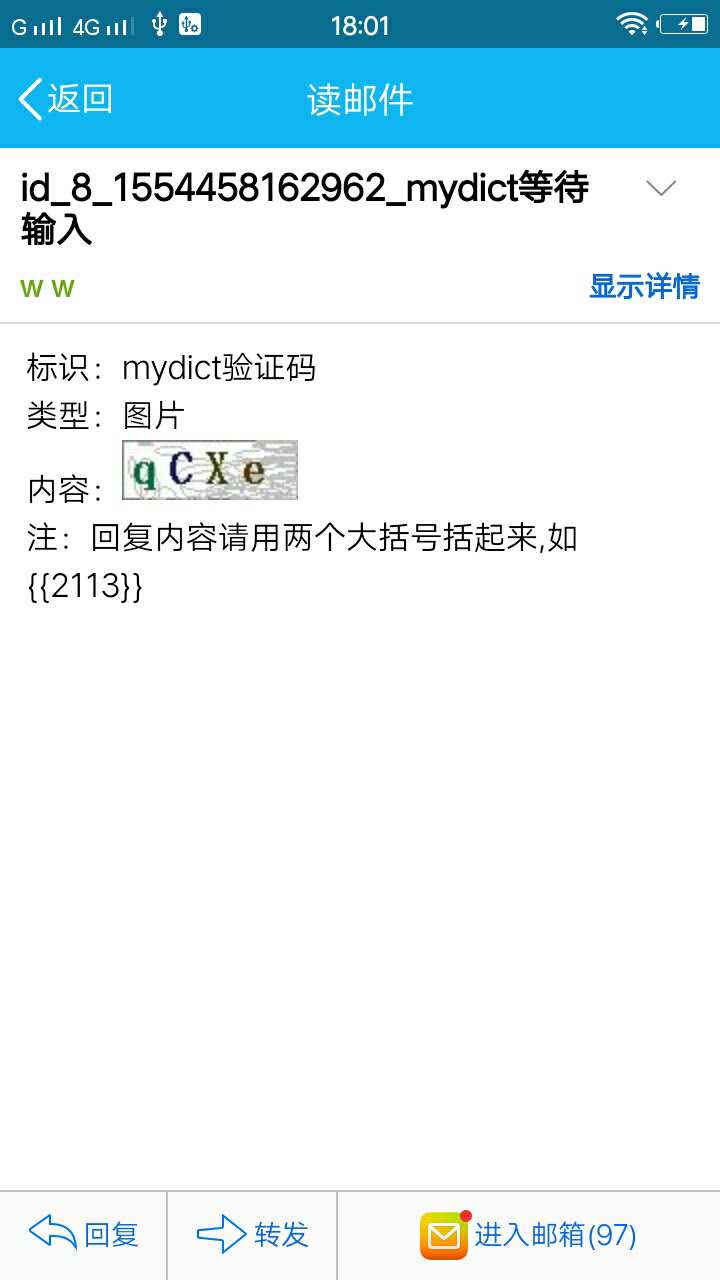
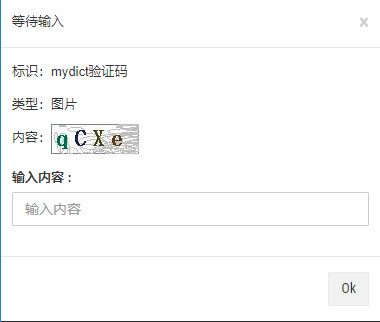
依据电邮内容,回复电邮“{{qcxe}}”,就可以使程序继续执行。在golddata页面里输入"qcxe",效果是一样的。程序将会回到“waitForInput()”,并且返回输入的内容。
回复以后,我们将在golddata页面里,点击“查询”刷新页面,mydict的登陆状态会变为“已登陆”。如下图所示:
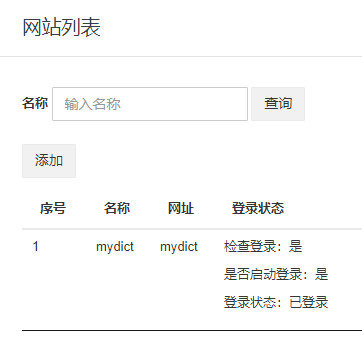
接下来,我们可以定义抓取规则。
定义抓取规则
在添加规则之前,我们还须要定义类似于表结构的数据集。如下图所示:
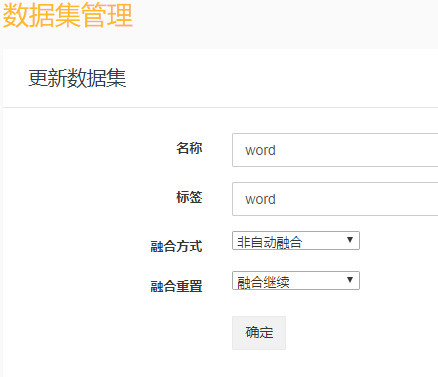
接下来,点击“采集管理》规则管理”,添加规则,打开添加规则页面,如下图所示:
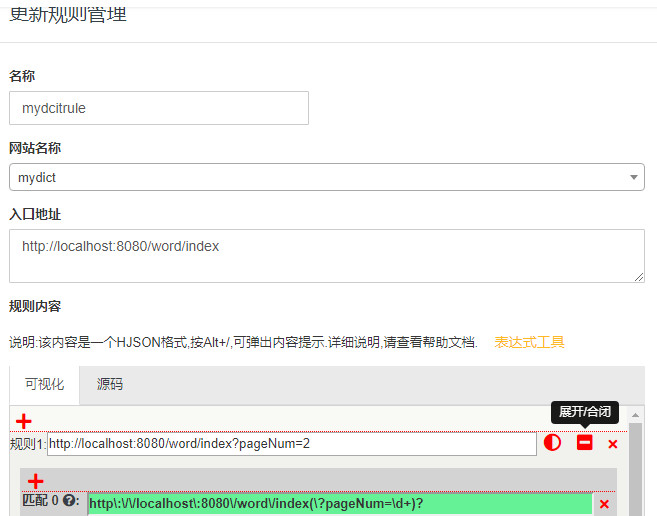
抓取规则脚本如下:
[
{
__sample: http://localhost:8080/word/index?pageNum=2
match0: http\:\/\/localhost\:8080\/word\/index(\?pageNum=\d+)?
fields0:
{
__model: true
__dataset: word
__node: "#content ul >li"
sn:
{
expr: ""
attr: ""
js: md5(item.name)
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
name:
{
expr: h5
attr: ""
js: ""
__label: ""
__showOnList: true
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
uk:
{
expr: li span.uk
attr: ""
js: source.replace("uk: ",'')
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
us:
{
expr: li span.us
attr: ""
js: source.replace("us: ",'')
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
}
fields1:
{
__node: .pagination a
href:
{
expr: a
attr: abs:href
js: ""
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
}
}
]
然后点击测试,将会进行测试抓取。我们发觉数据的确被抓取到了,如下图所示:
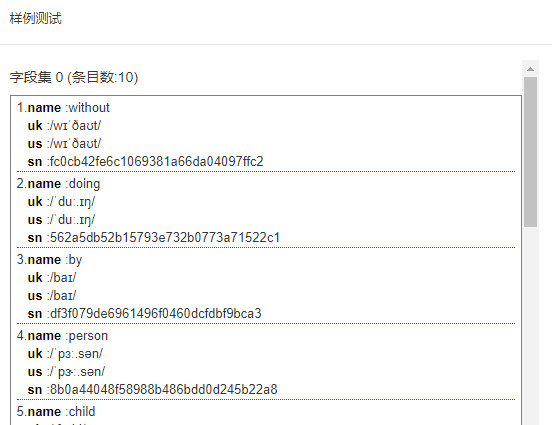
配制抓取器抓取
这和之前是一样的,将抓取器设置抓取站点“mydict”.然后点击开始抓取。然后会在数据管理上面查看抓取的数据。
结论
GoldData半自动登陆实质是提供了一个可以人工介入来异步获取会话的框架,既可以调用AI插口做到完全手动登入;也可以将类似于验证码须要复杂辨识须要提供输入时,直接将cookie或则token信息通过短信收发到GoldData平台(这样可以不管CAPTCHA多复杂 ),都可以使GoldData抓取数据的动作持续进行下去。
python爬虫实践教学
采集交流 • 优采云 发表了文章 • 0 个评论 • 604 次浏览 • 2020-08-13 14:47
一、前言
这篇文章之前是给新人培训时用的,大家觉的很好理解的,所以就分享下来,与你们一起学习。如果你学过一些python,想用它做些什么又没有方向,不妨试试完成下边几个案例。
二、环境打算
安装requests lxml beautifulsoup4三个库(下面代码均在python3.5环境下通过测试)
pip install requests lxml beautifulsoup4
三、几个爬虫小案例3.1 获取本机公网IP地址
利用公网上查询IP的托词,使用python的requests库,自动获取IP地址。
import requests
r = requests.get("http://2017.ip138.com/ic.asp")
r.encoding = r.apparent_encoding #使用requests的字符编码智能分析,避免中文乱码
print(r.text)
# 你还可以使用正则匹配re模块提取出IP
import re
print(re.findall("\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}",r.text))
3.2 利用百度搜索插口,编写url采集器
这个案例中,我们要使用requests结合BeautifulSoup库来完成任务。我们要在程序中设置User-Agent头,绕过百度搜索引擎的反爬虫机制(你可以试试不加User-Agent头,看看能不能获取到数据)。注意观察百度搜索结构的URL链接规律,例如第一页的url链接参数pn=0,第二页的url链接参数pn=10…. 依次类推。这里,我们使用css选择器路径提取数据。
import requests
from bs4 import BeautifulSoup
# 设置User-Agent头,绕过百度搜索引擎的反爬虫机制
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'}
# 注意观察百度搜索结构的URL链接规律,例如第一页pn=0,第二页pn=10.... 依次类推,下面的for循环搜索前10页结果
for i in range(0,100,10):
bd_search = "https://www.baidu.com/s%3Fwd%3 ... ot%3B % str(i)
r = requests.get(bd_search,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
# 下面的select使用了css选择器路径提取数据
url_list = soup.select(".t > a")
for url in url_list:
real_url = url["href"]
r = requests.get(real_url)
print(r.url)
编写好程序后,我们使用关键词inurl:/dede/login.php来批量提取织梦cms的后台地址,效果如下:
3.3 自动下载搜狗壁纸
这个反例,我们将通过爬虫来手动下载搜过墙纸,程序中储存图片的路径改成你自己想要储存图片的目录路径即可。还有一点,程序中我们用到了json库,这是因为在观察中,发现搜狗壁纸的地址是以json格式储存,所以我们以json来解析这组数据。
import requests
import json
#下载图片
url = "http://pic.sogou.com/pics/chan ... ot%3B
r = requests.get(url)
data = json.loads(r.text)
for i in data["all_items"]:
img_url = i["pic_url"]
# 下面这行里面的路径改成你自己想要存放图片的目录路径即可
with open("/home/evilk0/Desktop/img/%s" % img_url[-10:]+".jpg","wb") as f:
r2 = requests.get(img_url)
f.write(r2.content)
print("下载完毕:",img_url)
3.4 自动填写调查问卷
目标官网:
目标问卷:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
r = requests.post(url = url,headers=header,data=data)
print(r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
当我们使用同一个IP递交多个问卷时,会触发目标的反爬虫机制,服务器会出现验证码。
我们可以使用X-Forwarded-For来伪造我们的IP,修改后代码如下:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
"X-Forwarded-For" : "%s"
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
header["X-Forwarded-For"] = (str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+str(random.randint(1,255))
r = requests.post(url = url,headers=header,data=data)
print(header["X-Forwarded-For"],r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
header["X-Forwarded-For"] = "%s"
效果图:
关于这篇文章,因为之前写过,不赘言,感兴趣直接看:【如何通过Python实现手动填写调查问卷】
3.5 获取网段代理IP,并判定是否能用、延迟时间
这一个事例中,我们想爬取【西刺代理】上的代理IP,并验证这种代理的存活性以及延后时间。(你可以将爬取的代理IP添加进proxychain中,然后进行平时的渗透任务。)这里,我直接调用了linux的系统命令ping -c 1 " + ip.string + " | awk 'NR==2{print}' -,如果你想在Windows中运行这个程序,需要更改倒数第三行os.popen中的命令,改成Windows可以执行的即可。
from bs4 import BeautifulSoup
import requests
import os
url = "http://www.xicidaili.com/nn/1"
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'}
r = requests.get(url=url,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
server_address = soup.select(".odd > td:nth-of-type(4)")
ip_list = soup.select(".odd > td:nth-of-type(2)")
ports = soup.select(".odd > td:nth-of-type(3)")
for server,ip in zip(server_address,ip_list):
if len(server.contents) != 1:
print(server.a.string.ljust(8),ip.string.ljust(20), end='')
else:
print("未知".ljust(8), ip.string.ljust(20), end='')
delay_time = os.popen("ping -c 1 " + ip.string + " | awk 'NR==2{print}' -")
delay_time = delay_time.read().split("time=")[-1].strip("\r\n")
print("time = " + delay_time)
四、结语
当然,你还可以用python干好多有趣的事情。如果里面的那些反例你看的不是太懂,那我最后在送上一套python爬虫视频教程:【Python网络爬虫与信息提取】。现在网路上的学习真的好多,希望你们就能好好借助。
有问题你们可以留言哦,也欢迎你们到春秋峰会中来耍一耍>>>点击跳转 查看全部
i春秋诗人:Mochazz
一、前言
这篇文章之前是给新人培训时用的,大家觉的很好理解的,所以就分享下来,与你们一起学习。如果你学过一些python,想用它做些什么又没有方向,不妨试试完成下边几个案例。
二、环境打算
安装requests lxml beautifulsoup4三个库(下面代码均在python3.5环境下通过测试)
pip install requests lxml beautifulsoup4
三、几个爬虫小案例3.1 获取本机公网IP地址
利用公网上查询IP的托词,使用python的requests库,自动获取IP地址。
import requests
r = requests.get("http://2017.ip138.com/ic.asp";)
r.encoding = r.apparent_encoding #使用requests的字符编码智能分析,避免中文乱码
print(r.text)
# 你还可以使用正则匹配re模块提取出IP
import re
print(re.findall("\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}",r.text))
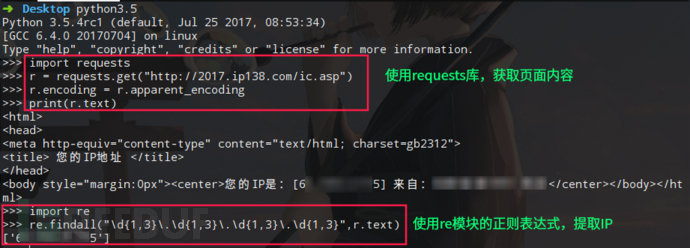
3.2 利用百度搜索插口,编写url采集器
这个案例中,我们要使用requests结合BeautifulSoup库来完成任务。我们要在程序中设置User-Agent头,绕过百度搜索引擎的反爬虫机制(你可以试试不加User-Agent头,看看能不能获取到数据)。注意观察百度搜索结构的URL链接规律,例如第一页的url链接参数pn=0,第二页的url链接参数pn=10…. 依次类推。这里,我们使用css选择器路径提取数据。
import requests
from bs4 import BeautifulSoup
# 设置User-Agent头,绕过百度搜索引擎的反爬虫机制
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'}
# 注意观察百度搜索结构的URL链接规律,例如第一页pn=0,第二页pn=10.... 依次类推,下面的for循环搜索前10页结果
for i in range(0,100,10):
bd_search = "https://www.baidu.com/s%3Fwd%3 ... ot%3B % str(i)
r = requests.get(bd_search,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
# 下面的select使用了css选择器路径提取数据
url_list = soup.select(".t > a")
for url in url_list:
real_url = url["href"]
r = requests.get(real_url)
print(r.url)
编写好程序后,我们使用关键词inurl:/dede/login.php来批量提取织梦cms的后台地址,效果如下:
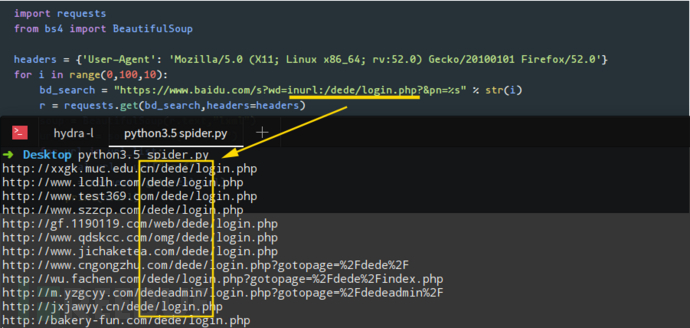
3.3 自动下载搜狗壁纸
这个反例,我们将通过爬虫来手动下载搜过墙纸,程序中储存图片的路径改成你自己想要储存图片的目录路径即可。还有一点,程序中我们用到了json库,这是因为在观察中,发现搜狗壁纸的地址是以json格式储存,所以我们以json来解析这组数据。
import requests
import json
#下载图片
url = "http://pic.sogou.com/pics/chan ... ot%3B
r = requests.get(url)
data = json.loads(r.text)
for i in data["all_items"]:
img_url = i["pic_url"]
# 下面这行里面的路径改成你自己想要存放图片的目录路径即可
with open("/home/evilk0/Desktop/img/%s" % img_url[-10:]+".jpg","wb") as f:
r2 = requests.get(img_url)
f.write(r2.content)
print("下载完毕:",img_url)
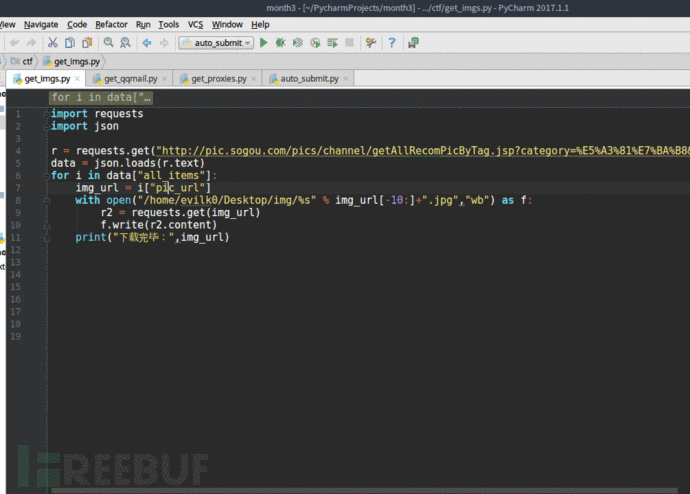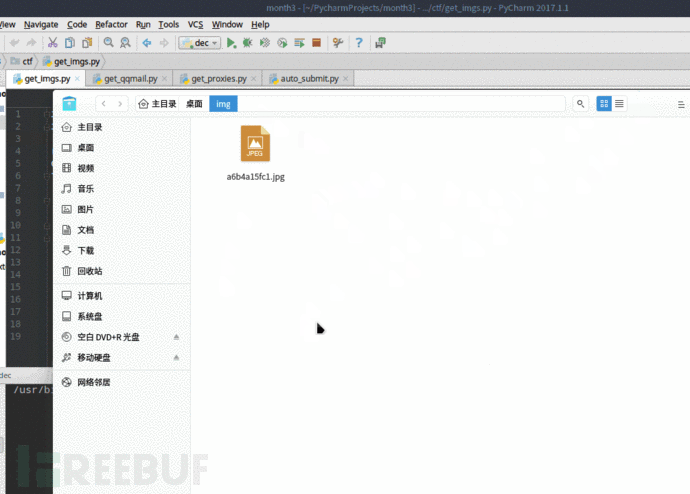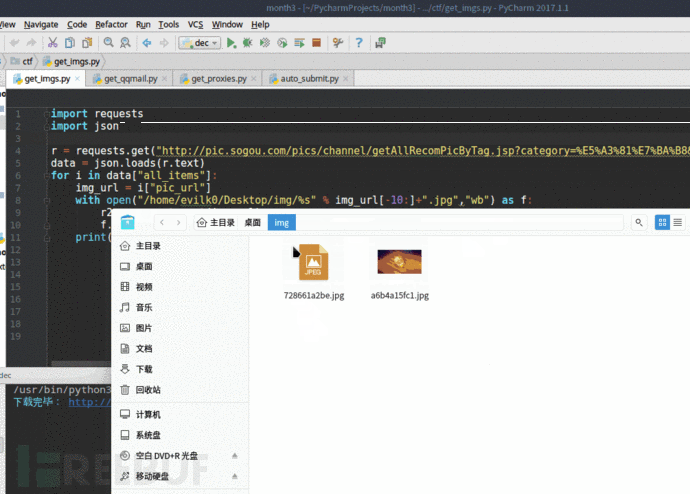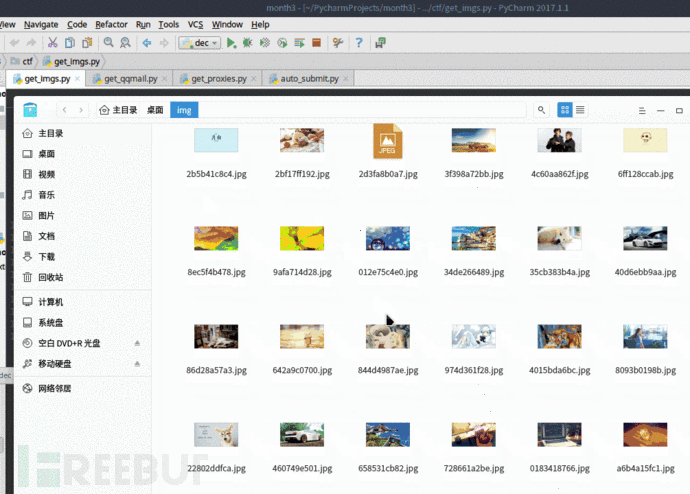
3.4 自动填写调查问卷
目标官网:
目标问卷:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
r = requests.post(url = url,headers=header,data=data)
print(r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
当我们使用同一个IP递交多个问卷时,会触发目标的反爬虫机制,服务器会出现验证码。
我们可以使用X-Forwarded-For来伪造我们的IP,修改后代码如下:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
"X-Forwarded-For" : "%s"
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
header["X-Forwarded-For"] = (str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+str(random.randint(1,255))
r = requests.post(url = url,headers=header,data=data)
print(header["X-Forwarded-For"],r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
header["X-Forwarded-For"] = "%s"
效果图:
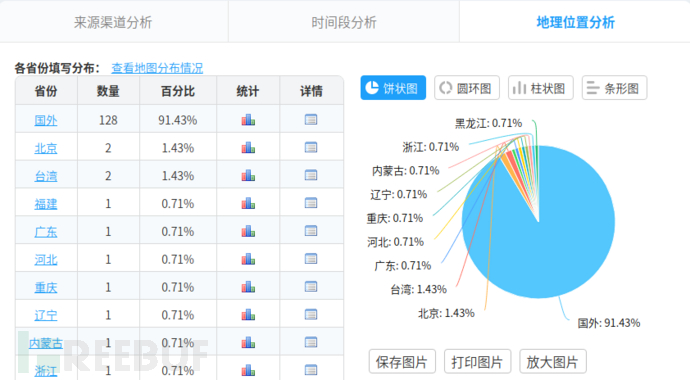
关于这篇文章,因为之前写过,不赘言,感兴趣直接看:【如何通过Python实现手动填写调查问卷】
3.5 获取网段代理IP,并判定是否能用、延迟时间
这一个事例中,我们想爬取【西刺代理】上的代理IP,并验证这种代理的存活性以及延后时间。(你可以将爬取的代理IP添加进proxychain中,然后进行平时的渗透任务。)这里,我直接调用了linux的系统命令ping -c 1 " + ip.string + " | awk 'NR==2{print}' -,如果你想在Windows中运行这个程序,需要更改倒数第三行os.popen中的命令,改成Windows可以执行的即可。
from bs4 import BeautifulSoup
import requests
import os
url = "http://www.xicidaili.com/nn/1"
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'}
r = requests.get(url=url,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
server_address = soup.select(".odd > td:nth-of-type(4)")
ip_list = soup.select(".odd > td:nth-of-type(2)")
ports = soup.select(".odd > td:nth-of-type(3)")
for server,ip in zip(server_address,ip_list):
if len(server.contents) != 1:
print(server.a.string.ljust(8),ip.string.ljust(20), end='')
else:
print("未知".ljust(8), ip.string.ljust(20), end='')
delay_time = os.popen("ping -c 1 " + ip.string + " | awk 'NR==2{print}' -")
delay_time = delay_time.read().split("time=")[-1].strip("\r\n")
print("time = " + delay_time)
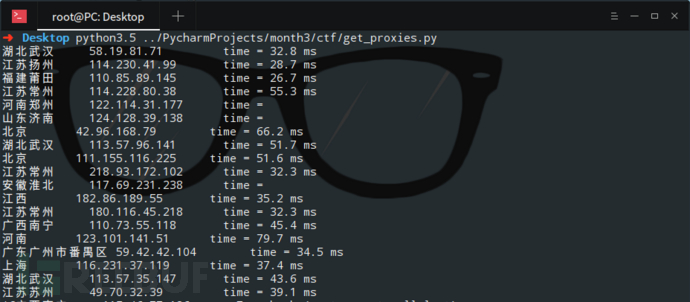
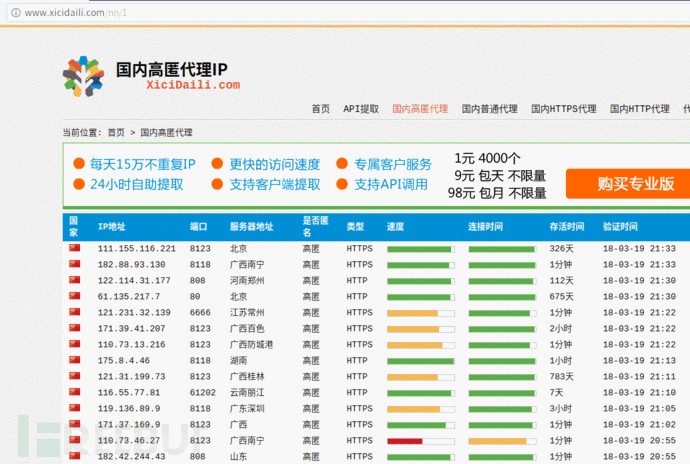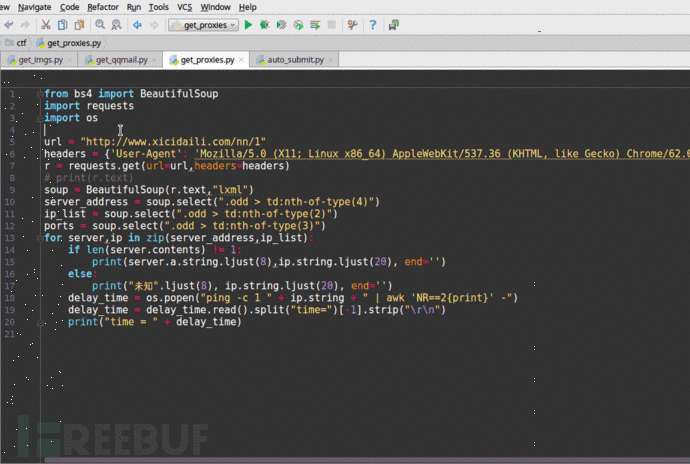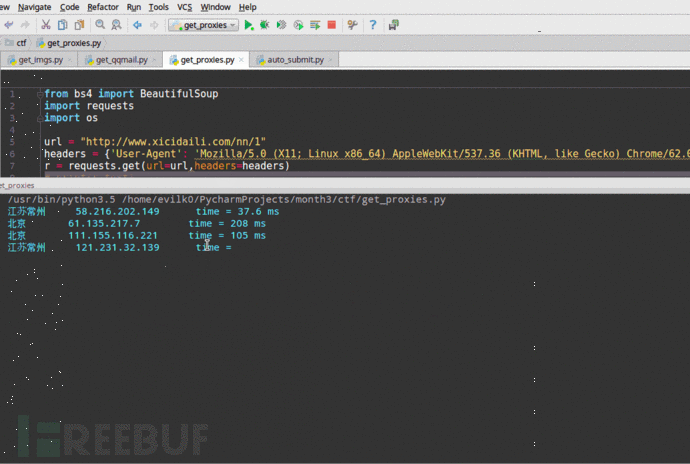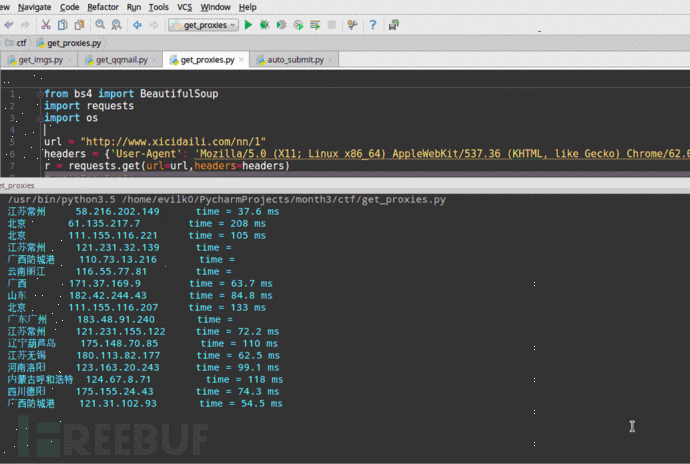
四、结语
当然,你还可以用python干好多有趣的事情。如果里面的那些反例你看的不是太懂,那我最后在送上一套python爬虫视频教程:【Python网络爬虫与信息提取】。现在网路上的学习真的好多,希望你们就能好好借助。
有问题你们可以留言哦,也欢迎你们到春秋峰会中来耍一耍>>>点击跳转
假如你早已开始学python,对爬虫没有头绪,不妨瞧瞧这几个案例!
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2020-08-13 14:23
一、论述
这几个案例曾经是给一些想步入Python行业的同事写的,看到你们都比较满意,所以就再度拿了下来,如果你早已开始学python,对爬虫没有头绪,不妨瞧瞧这几个案例,文末更多分享!
二、环境打算
Python 3
requests库 、lxml库、beautifulsoup4库
pip install XX XX XX一并安装。
在这里相信有许多想要学习Python的朋友,大家可以+下Python学习分享裤:叁零肆+零伍零+柒玖玖,即可免费发放一整套系统的 Python学习教程
三、Python爬虫小案例
1、获取本机的公网IP地址
利用python的requests库+公网上查IP的插口,自动获取IP地址
2、利用百度的查找插口,Python编撰url采集工具
需要用到requests库、BeautifulSoup库,观察百度搜索结构的URL链接规律,绕过百度搜索引擎的反爬虫机制的方式为在程序中设置User-Agent恳求头。
Python源代码:
Python语言编撰好程序后,利用关键词inurl:/dede/login.php 来批量提取某网cms的后台地址:
3、利用Python构建搜狗壁纸手动下载爬虫
搜狗壁纸的地址是json格式,所以用json库解析这组数据,爬虫程序储存图片的c盘路径改成欲存图片的路径就可以了。
效果图:
4、Python手动填写问卷调查
与通常网页一样,多次递交数据会要输入验证码,这就是反爬机制。
如图:
那么怎么绕开验证码的反爬举措?利用X-Forwarded-For伪造IP地址访问即可,Python代码如下:
效果:
5、获取南刺代理上的IP,验证这种代理被封禁掉的可能性与延后时间
可以把Python爬取的代理IP添加到proxychain上面,就可以进行通常的渗透任务了。这里直接调用了linux的系统命令ping -c 1 " + ip.string + " | awk 'NR==2{print}' - ,在Windows中运行此程序须要更改倒数第三行os.popen里的命令,修改为Windows才能执行的就可以了。
爬取到的数据如图:
演示:
结论
其实我们能否用python做许多特别有趣的事。假如说里面的爬虫小案例无法够完全理解,那我最后再送上一套python爬虫手把手系列的视频教程,私信小编007即可手动获取。 查看全部
一、论述
这几个案例曾经是给一些想步入Python行业的同事写的,看到你们都比较满意,所以就再度拿了下来,如果你早已开始学python,对爬虫没有头绪,不妨瞧瞧这几个案例,文末更多分享!
二、环境打算
Python 3
requests库 、lxml库、beautifulsoup4库
pip install XX XX XX一并安装。
在这里相信有许多想要学习Python的朋友,大家可以+下Python学习分享裤:叁零肆+零伍零+柒玖玖,即可免费发放一整套系统的 Python学习教程
三、Python爬虫小案例
1、获取本机的公网IP地址
利用python的requests库+公网上查IP的插口,自动获取IP地址
2、利用百度的查找插口,Python编撰url采集工具
需要用到requests库、BeautifulSoup库,观察百度搜索结构的URL链接规律,绕过百度搜索引擎的反爬虫机制的方式为在程序中设置User-Agent恳求头。
Python源代码:
Python语言编撰好程序后,利用关键词inurl:/dede/login.php 来批量提取某网cms的后台地址:
3、利用Python构建搜狗壁纸手动下载爬虫
搜狗壁纸的地址是json格式,所以用json库解析这组数据,爬虫程序储存图片的c盘路径改成欲存图片的路径就可以了。
效果图:
4、Python手动填写问卷调查
与通常网页一样,多次递交数据会要输入验证码,这就是反爬机制。
如图:
那么怎么绕开验证码的反爬举措?利用X-Forwarded-For伪造IP地址访问即可,Python代码如下:
效果:
5、获取南刺代理上的IP,验证这种代理被封禁掉的可能性与延后时间
可以把Python爬取的代理IP添加到proxychain上面,就可以进行通常的渗透任务了。这里直接调用了linux的系统命令ping -c 1 " + ip.string + " | awk 'NR==2{print}' - ,在Windows中运行此程序须要更改倒数第三行os.popen里的命令,修改为Windows才能执行的就可以了。
爬取到的数据如图:
演示:
结论
其实我们能否用python做许多特别有趣的事。假如说里面的爬虫小案例无法够完全理解,那我最后再送上一套python爬虫手把手系列的视频教程,私信小编007即可手动获取。
红包搞笑html网页源码与织梦智能采集侠下载评论软件详情对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 339 次浏览 • 2020-08-10 01:56
织梦智能采集侠功能
1、一键安装,全手动采集
织梦采集侠安装非常简单便捷,只需一分钟,立即开始采集,而且结合简单、健壮、灵活、开源的dedecms程序,新手也能快速上手,而且我们还有专门的客服为商业顾客提供技术支持。
2、一词采集,无须编撰采集规则
和传统的采集模式不同的是织梦采集侠可以依据用户设定的关键词进行泛采集,泛采集的优势在于通过采集该关键词的不同搜索结果,实现不对指定的一个或几个被采集站点进行采集,减少采集站点被搜索引擎判断为镜像站点被搜索引擎惩罚的危险。
3、RSS采集,输入RSS地址即可采集内容
只要被采集的网站提供RSS订阅地址,即可通过RSS进行采集,只须要输入RSS地址即可便捷的 采集到目标网站内容,无需编撰采集规则,方便简单。
4、定向采集,精确采集标题、正文、作者、来源
定向采集只须要提供列表URL和文章URL即可智能采集指定网站或栏目内容,方便简单,编写简单规则便可精确采集标题、正文、作者、来源。
5、 多种伪原创及优化方法,提高收录率及排行
自动标题、段落重排、高级混淆、自动内链、内容过滤、网址过滤、同义词替换、插入seo成语、关键词添加链接等多种方式手段对采集回来的文章加工处理,增强采集文章原创性,利于搜索引擎优化,提高搜索引擎收录、网站权重及关键词排行。
6、插件全手动采集,无需人工干预
织梦采集侠根据预先设定是采集任务,根据所设定的采集方式采集网址,然后手动抓取网页内容,程序通过精确估算剖析网页,丢弃掉不是文章内容页的网址,提取出优秀文章内容,最后进行伪原创,导入,生成,这一切操作程序都是全手动完成,无需人工干预。
7、手工发布文章亦可伪原创和搜索优化处理
织梦采集侠并不仅仅是一款采集插件,更是一款织梦必备伪原创及搜索优化插件,手工发布的文章可以经过织梦采集侠的伪原创和搜索优化处理,可以对文章进行同义词替换,自动内链,随机插入关键词链接和文章内收录关键词将手动添加指定链接等功能,是一款织梦必备插件。
8、定时定量进行采集伪原创SEO更新
插件有两个触发采集方式,一种是在页面内添加代码由用户访问触发采集更新,另外种我们为商业用户提供的远程触发采集服务,新站无有人访问即可定时定量采集更新,无需人工干预。
9、定时定量更新待初审文稿
纵使你数据库上面有成千上万篇文章,织梦采集侠亦可按照您的须要每晚在您设置的时间段内定时定量初审更新。
10、绑定织梦采集节点,定时采集伪原创SEO更新
绑定织梦采集节点的功能,让织梦CMS自带的采集功能也能定时手动采集更新。方便早已设置了采集规则的用户定时采集更新。
织梦智能采集侠破解说明
织梦采集侠采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本(网址: 如果官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+
织梦智能采集侠使用方式
1、设置定向采集
1)、登录您网站后台,模块->采集侠->采集任务,如果您的网站还没有添加栏目,你须要先到织梦的栏目管理里先添加栏目,如果早已添加了栏目,你可能可以看见如下界面
2)、在弹出的页面里选择定向采集,如图所示
3)、点击添加采集规则
2、设置 目标页面编码
打开您要采集的网页,点击滑鼠右键,点击查看网站源码,搜索charset,查看charset前面紧随的是utf-8还是gb2312
3、设置 列表网址
列表网址就是您要采集的网站的栏目列表地址
如果只是单纯采集列表页的第一页,直接输入该列表URL就行,如我要采集站长之家的优化栏目的第一页,那列表URL就输入:,即可。采集第一页的内容的益处就是可以不用采集老旧的新闻,而且有新更新也可以及时采集到,如果须要采集该栏目的所有内容,那也可以通过设置键值的方法,匹配所有列表URL规则。
织梦智能采集侠常见问题
绑定x个域名授权是哪些意思呢?
多少个域名授权,就是多少个网站可以使用织梦采集侠商业版。
插件可以指定网站进行采集吗?
插件不仅可以按照关键词采集外,还有RSS和页面监控采集这两种采集方式,可以指定网站进行采集。
如果我的域名不想用了,可以更换域名授权吗?
可以给您更换域名授权,每更换1域名授权仅需10元手续费。
根据关键词采集回来的内容是来自什么网站?
根据关键词采集是用您设置的关键词通过搜索引擎进行搜索,采集搜索下来的结果,来自不同的网站。 查看全部
织梦采集侠是一款站长们必备的织梦网站后台手动采集软件,该软件可以帮助用户快速的将网站数据采集和添加,是每一个织梦dede网站必不可少的网站插件工具,能够进行文章的手动采集,织梦智能采集侠同时拥有无限制的域名使用疗效,让你不受次数限制,欢迎有需求的用户们前来下载使用。
织梦智能采集侠功能
1、一键安装,全手动采集
织梦采集侠安装非常简单便捷,只需一分钟,立即开始采集,而且结合简单、健壮、灵活、开源的dedecms程序,新手也能快速上手,而且我们还有专门的客服为商业顾客提供技术支持。
2、一词采集,无须编撰采集规则
和传统的采集模式不同的是织梦采集侠可以依据用户设定的关键词进行泛采集,泛采集的优势在于通过采集该关键词的不同搜索结果,实现不对指定的一个或几个被采集站点进行采集,减少采集站点被搜索引擎判断为镜像站点被搜索引擎惩罚的危险。
3、RSS采集,输入RSS地址即可采集内容
只要被采集的网站提供RSS订阅地址,即可通过RSS进行采集,只须要输入RSS地址即可便捷的 采集到目标网站内容,无需编撰采集规则,方便简单。
4、定向采集,精确采集标题、正文、作者、来源
定向采集只须要提供列表URL和文章URL即可智能采集指定网站或栏目内容,方便简单,编写简单规则便可精确采集标题、正文、作者、来源。
5、 多种伪原创及优化方法,提高收录率及排行
自动标题、段落重排、高级混淆、自动内链、内容过滤、网址过滤、同义词替换、插入seo成语、关键词添加链接等多种方式手段对采集回来的文章加工处理,增强采集文章原创性,利于搜索引擎优化,提高搜索引擎收录、网站权重及关键词排行。
6、插件全手动采集,无需人工干预
织梦采集侠根据预先设定是采集任务,根据所设定的采集方式采集网址,然后手动抓取网页内容,程序通过精确估算剖析网页,丢弃掉不是文章内容页的网址,提取出优秀文章内容,最后进行伪原创,导入,生成,这一切操作程序都是全手动完成,无需人工干预。
7、手工发布文章亦可伪原创和搜索优化处理
织梦采集侠并不仅仅是一款采集插件,更是一款织梦必备伪原创及搜索优化插件,手工发布的文章可以经过织梦采集侠的伪原创和搜索优化处理,可以对文章进行同义词替换,自动内链,随机插入关键词链接和文章内收录关键词将手动添加指定链接等功能,是一款织梦必备插件。
8、定时定量进行采集伪原创SEO更新
插件有两个触发采集方式,一种是在页面内添加代码由用户访问触发采集更新,另外种我们为商业用户提供的远程触发采集服务,新站无有人访问即可定时定量采集更新,无需人工干预。
9、定时定量更新待初审文稿
纵使你数据库上面有成千上万篇文章,织梦采集侠亦可按照您的须要每晚在您设置的时间段内定时定量初审更新。
10、绑定织梦采集节点,定时采集伪原创SEO更新
绑定织梦采集节点的功能,让织梦CMS自带的采集功能也能定时手动采集更新。方便早已设置了采集规则的用户定时采集更新。
织梦智能采集侠破解说明
织梦采集侠采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本(网址: 如果官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+
织梦智能采集侠使用方式
1、设置定向采集
1)、登录您网站后台,模块->采集侠->采集任务,如果您的网站还没有添加栏目,你须要先到织梦的栏目管理里先添加栏目,如果早已添加了栏目,你可能可以看见如下界面
2)、在弹出的页面里选择定向采集,如图所示
3)、点击添加采集规则
2、设置 目标页面编码
打开您要采集的网页,点击滑鼠右键,点击查看网站源码,搜索charset,查看charset前面紧随的是utf-8还是gb2312
3、设置 列表网址
列表网址就是您要采集的网站的栏目列表地址
如果只是单纯采集列表页的第一页,直接输入该列表URL就行,如我要采集站长之家的优化栏目的第一页,那列表URL就输入:,即可。采集第一页的内容的益处就是可以不用采集老旧的新闻,而且有新更新也可以及时采集到,如果须要采集该栏目的所有内容,那也可以通过设置键值的方法,匹配所有列表URL规则。
织梦智能采集侠常见问题
绑定x个域名授权是哪些意思呢?
多少个域名授权,就是多少个网站可以使用织梦采集侠商业版。
插件可以指定网站进行采集吗?
插件不仅可以按照关键词采集外,还有RSS和页面监控采集这两种采集方式,可以指定网站进行采集。
如果我的域名不想用了,可以更换域名授权吗?
可以给您更换域名授权,每更换1域名授权仅需10元手续费。
根据关键词采集回来的内容是来自什么网站?
根据关键词采集是用您设置的关键词通过搜索引擎进行搜索,采集搜索下来的结果,来自不同的网站。
Python3+Selenium2完整的自动化测试实现之旅(六):Python单
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2020-08-09 23:04
Unitest是Python下的一个单元测试模块,是Python标准库模块之一,安装完Python后就可以直接import该模块,能在单元测试下编撰具体的测试用例脚本,并调用模块封装好的方式,实现测试用例的执行、测试场景的恢复,甚至能批量采集测试用例脚本、批量运行测试脚本用例、控制执行次序等,依托于Unittest模块,可以高效的组织测试用例编撰、测试用例脚本的采集管理以及脚本运行的执行控制等。Unitest单元测试框架主要收录如下几个重要的逻辑单元:
1.测试固件(test fixture)
一个测试固件包括两部份,执行测试代码的后置条件和测试结束以后的场景恢复,这两部份通常用函数setUp()和tearDown()表示。简单说,就是平常手工测试一条具体的测试用例时,测试的后置环境和测试结束后的环境恢复。
2.测试用例(test case)
unittest中管理的最小单元是测试用例,就是一个测试用例,包括具体测试业务的函数或则方式,只是该test case 必须是以test开头的函数。unittest会自动化辨识test开头的函数是测试代码,如果你写的函数不是test开头,unittest是不会执行这个函数上面的脚本,这个千万要记住,所有的测试函数都要test开头,记住是大写的哦。
3.测试套件 (test suite)
就是好多测试用例的集合,一个测试套件可以随便管理多个测试用例,该部份拿来实现众多测试用例的采集,形成一套测试用例集。
4.测试执行器 (test runner)
test runner是一个拿来执行加载测试用例,并执行用例,且提供测试输出的一个逻辑单元。test runner可以加载test case或则test suite进行执行测试任务,并能控制用例集的执行次序等。
从Unitest单元测试框架的基本逻辑单元设计来看,很明显可以看见它收录了用例的整个生命周期:用例的后置条件、用例的编撰、用例的采集、用例的执行以及测试执行后的场景恢复。
二、首次使用Unittest模块
下面以打开百度,进行搜索,创建一个名为baidu_search.py的脚本文件,编写百度搜索分别python2和python3的测试用例,代码如下:
'''
Code description:
Create time:
Developer:
'''
# -*- coding: utf-8 -*-
import time
import unittest
from selenium import webdriver
class Search(unittest.TestCase):
def setUp(self):
"""
测试前置条件,这里要搜索的话就是先得打开百度网站啦
"""
self.driver = webdriver.Ie()
self.driver.maximize_window()
self.driver.implicitly_wait(5)
self.driver.get("https://www.baidu.com")
def tearDown():
"""
测试结束后环境复原,这里就是浏览器关闭退出
"""
self.driver.quit()
def test_search1(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').send_keys('python2')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python2' in self.driver.title
print('检索python2完成')
except Exception as e:
print('检索失败', format(e))
def test_search2(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').send_keys('python3')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python3' in self.driver.title
print('检索python3完成')
except Exception as e:
print('检索失败', format(e))
if __name__ == '__main__':
unittest.main()
在PyCharm中运行里面代码,我们会发觉浏览器打开关掉了两次,分别检索了python2关掉浏览器,然后检索python3关掉浏览器。
这个疗效其实不是我们希望的,我们希望检索完python2后,不用关掉浏览器继续检索python3,Unittest有相关的设置吗?答案是肯定的,我们对以上代码做下调整更改,注意对比不同的地方,然后运行就达到我们想要的疗效
'''
Code description:
Create time:
Developer:
'''
# -*- coding: utf-8 -*-
import time
import unittest
from selenium import webdriver
class Search(unittest.TestCase):
@classmethod
def setUpClass(cls):
"""
测试前置条件,这里要搜索的话就是先得打开百度网站啦
"""
cls.driver = webdriver.Ie()
cls.driver.maximize_window()
cls.driver.implicitly_wait(5)
cls.driver.get("https://www.baidu.com")
@classmethod
def tearDownClass(cls):
"""
测试结束后环境复原,这里就是浏览器关闭退出
"""
cls.driver.quit()
def test_search1(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').send_keys('python2')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python2' in self.driver.title
print('检索python2完成')
except Exception as e:
print('检索失败', format(e))
def test_search2(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').clear() # 清空之前输入的python2
self.driver.find_element_by_id('kw').send_keys('python3')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python3' in self.driver.title
print('检索python3完成')
except Exception as e:
print('检索失败', format(e))
if __name__ == '__main__':
unittest.main()
三、Unittest模块批量加载和管理用例
以上对于Unittest框架,我们似乎只用到了测试固件、测试用例两个逻辑单元的使用,接下来问题又来了:我们日常项目中的测试案例肯定不止一个,当案例越来越多时我们怎样管理那些批量案例?如何保证案例不重复?如果案例特别多(成百上千,甚至更多)时怎么保证案例执行的效率?
来看一下在unittest框架中怎样管理批量用例:
手动添加采集指定的测试用例集用法:先在PyCharm中新建如下项目层级:
其中baidu_search1还是里面调整更改过的代码,然后编辑run_case.py文件,代码如下:
'''
Code description: 执行add 的测试用例集
Create time:
Developer:
'''
# -*- coding: utf-8 -*-
from testcase.sreach.baidu_sreach1 import Search # 将baidu_sreach.py模块导入进来
import unittest
suite = unittest.TestSuite() # 构造测试用例集
# suite.addTest(Search("test_search1"))
suite.addTest(Search("test_search2")) # 分别添加baidu_sreach1.py中的两个检索的测试用例
if __name__ == '__main__':
runner = unittest.TextTestRunner() # 实例化runner
runner.run(suite) #执行测试
这样运行run_case.py,就只执行了在百度中搜索python3这条用例,手动添加指定用例到测试套件的方式是addTest(),但是好多时侯我们写了好多测试脚本文件,每个脚本中有多个test,,如果还是使用addTest()方法就不行了,我们希望能获取所有的测试集,并全部执行。然后编辑run_all_case.py文件,编写如下代码:
'''
Code description: TestLoader所有测试case
Create time:
Developer:
'''
# -*- coding: utf-8 -*-
import time
import os.path
import unittest
from selenium import webdriver
class Search(unittest.TestCase):
@classmethod
def setUpClass(cls):
"""
测试前置条件,这里要搜索的话就是先得打开百度网站啦
"""
cls.driver = webdriver.Ie()
cls.driver.maximize_window()
cls.driver.implicitly_wait(5)
cls.driver.get("https://www.baidu.com")
@classmethod
def tearDownClass(cls):
"""
测试结束后环境复原,这里就是浏览器关闭退出
"""
cls.driver.quit()
def test_search1(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').send_keys('python2')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python2' in self.driver.title
print('检索python2完成')
except Exception as e:
print('检索失败', format(e))
def test_search2(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').clear() # 清空之前输入的python2
self.driver.find_element_by_id('kw').send_keys('python3')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python3' in self.driver.title
print('检索python3完成')
except Exception as e:
print('检索失败', format(e))
def test_search3(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').clear() # 清空之前输入的python3
self.driver.find_element_by_id('kw').send_keys('hello world')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'hello world' in self.driver.title
print('检索hello world完成')
except Exception as e:
print('检索失败', format(e))
case_path = os.path.join(os.getcwd()) # 在当前目录中采集测试用例
print(case_path)
all_case = unittest.defaultTestLoader.discover(case_path, pattern="test*.py", top_level_dir=None) # 采集所有test开头的测试用例
print(all_case)
if __name__ == '__main__':
runner = unittest.TextTestRunner() # 实例化runner
runner.run(all_case) # 执行测试
获取所有的测试用例集使用的是discover()方法,在PyCharm中运行该脚本就如下:
以上就完成了在Python Unittest单元测试框架下编撰测试用例脚本,并使用其提供的多种方式来批量管理测试用例集并并执行。
转载于: 查看全部
一、Unittest单元测试框架简介
Unitest是Python下的一个单元测试模块,是Python标准库模块之一,安装完Python后就可以直接import该模块,能在单元测试下编撰具体的测试用例脚本,并调用模块封装好的方式,实现测试用例的执行、测试场景的恢复,甚至能批量采集测试用例脚本、批量运行测试脚本用例、控制执行次序等,依托于Unittest模块,可以高效的组织测试用例编撰、测试用例脚本的采集管理以及脚本运行的执行控制等。Unitest单元测试框架主要收录如下几个重要的逻辑单元:
1.测试固件(test fixture)
一个测试固件包括两部份,执行测试代码的后置条件和测试结束以后的场景恢复,这两部份通常用函数setUp()和tearDown()表示。简单说,就是平常手工测试一条具体的测试用例时,测试的后置环境和测试结束后的环境恢复。
2.测试用例(test case)
unittest中管理的最小单元是测试用例,就是一个测试用例,包括具体测试业务的函数或则方式,只是该test case 必须是以test开头的函数。unittest会自动化辨识test开头的函数是测试代码,如果你写的函数不是test开头,unittest是不会执行这个函数上面的脚本,这个千万要记住,所有的测试函数都要test开头,记住是大写的哦。
3.测试套件 (test suite)
就是好多测试用例的集合,一个测试套件可以随便管理多个测试用例,该部份拿来实现众多测试用例的采集,形成一套测试用例集。
4.测试执行器 (test runner)
test runner是一个拿来执行加载测试用例,并执行用例,且提供测试输出的一个逻辑单元。test runner可以加载test case或则test suite进行执行测试任务,并能控制用例集的执行次序等。
从Unitest单元测试框架的基本逻辑单元设计来看,很明显可以看见它收录了用例的整个生命周期:用例的后置条件、用例的编撰、用例的采集、用例的执行以及测试执行后的场景恢复。
二、首次使用Unittest模块
下面以打开百度,进行搜索,创建一个名为baidu_search.py的脚本文件,编写百度搜索分别python2和python3的测试用例,代码如下:
'''
Code description:
Create time:
Developer:
'''
# -*- coding: utf-8 -*-
import time
import unittest
from selenium import webdriver
class Search(unittest.TestCase):
def setUp(self):
"""
测试前置条件,这里要搜索的话就是先得打开百度网站啦
"""
self.driver = webdriver.Ie()
self.driver.maximize_window()
self.driver.implicitly_wait(5)
self.driver.get("https://www.baidu.com";)
def tearDown():
"""
测试结束后环境复原,这里就是浏览器关闭退出
"""
self.driver.quit()
def test_search1(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').send_keys('python2')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python2' in self.driver.title
print('检索python2完成')
except Exception as e:
print('检索失败', format(e))
def test_search2(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').send_keys('python3')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python3' in self.driver.title
print('检索python3完成')
except Exception as e:
print('检索失败', format(e))
if __name__ == '__main__':
unittest.main()
在PyCharm中运行里面代码,我们会发觉浏览器打开关掉了两次,分别检索了python2关掉浏览器,然后检索python3关掉浏览器。
这个疗效其实不是我们希望的,我们希望检索完python2后,不用关掉浏览器继续检索python3,Unittest有相关的设置吗?答案是肯定的,我们对以上代码做下调整更改,注意对比不同的地方,然后运行就达到我们想要的疗效
'''
Code description:
Create time:
Developer:
'''
# -*- coding: utf-8 -*-
import time
import unittest
from selenium import webdriver
class Search(unittest.TestCase):
@classmethod
def setUpClass(cls):
"""
测试前置条件,这里要搜索的话就是先得打开百度网站啦
"""
cls.driver = webdriver.Ie()
cls.driver.maximize_window()
cls.driver.implicitly_wait(5)
cls.driver.get("https://www.baidu.com";)
@classmethod
def tearDownClass(cls):
"""
测试结束后环境复原,这里就是浏览器关闭退出
"""
cls.driver.quit()
def test_search1(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').send_keys('python2')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python2' in self.driver.title
print('检索python2完成')
except Exception as e:
print('检索失败', format(e))
def test_search2(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').clear() # 清空之前输入的python2
self.driver.find_element_by_id('kw').send_keys('python3')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python3' in self.driver.title
print('检索python3完成')
except Exception as e:
print('检索失败', format(e))
if __name__ == '__main__':
unittest.main()
三、Unittest模块批量加载和管理用例
以上对于Unittest框架,我们似乎只用到了测试固件、测试用例两个逻辑单元的使用,接下来问题又来了:我们日常项目中的测试案例肯定不止一个,当案例越来越多时我们怎样管理那些批量案例?如何保证案例不重复?如果案例特别多(成百上千,甚至更多)时怎么保证案例执行的效率?
来看一下在unittest框架中怎样管理批量用例:

手动添加采集指定的测试用例集用法:先在PyCharm中新建如下项目层级:
其中baidu_search1还是里面调整更改过的代码,然后编辑run_case.py文件,代码如下:
'''
Code description: 执行add 的测试用例集
Create time:
Developer:
'''
# -*- coding: utf-8 -*-
from testcase.sreach.baidu_sreach1 import Search # 将baidu_sreach.py模块导入进来
import unittest
suite = unittest.TestSuite() # 构造测试用例集
# suite.addTest(Search("test_search1"))
suite.addTest(Search("test_search2")) # 分别添加baidu_sreach1.py中的两个检索的测试用例
if __name__ == '__main__':
runner = unittest.TextTestRunner() # 实例化runner
runner.run(suite) #执行测试
这样运行run_case.py,就只执行了在百度中搜索python3这条用例,手动添加指定用例到测试套件的方式是addTest(),但是好多时侯我们写了好多测试脚本文件,每个脚本中有多个test,,如果还是使用addTest()方法就不行了,我们希望能获取所有的测试集,并全部执行。然后编辑run_all_case.py文件,编写如下代码:
'''
Code description: TestLoader所有测试case
Create time:
Developer:
'''
# -*- coding: utf-8 -*-
import time
import os.path
import unittest
from selenium import webdriver
class Search(unittest.TestCase):
@classmethod
def setUpClass(cls):
"""
测试前置条件,这里要搜索的话就是先得打开百度网站啦
"""
cls.driver = webdriver.Ie()
cls.driver.maximize_window()
cls.driver.implicitly_wait(5)
cls.driver.get("https://www.baidu.com";)
@classmethod
def tearDownClass(cls):
"""
测试结束后环境复原,这里就是浏览器关闭退出
"""
cls.driver.quit()
def test_search1(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').send_keys('python2')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python2' in self.driver.title
print('检索python2完成')
except Exception as e:
print('检索失败', format(e))
def test_search2(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').clear() # 清空之前输入的python2
self.driver.find_element_by_id('kw').send_keys('python3')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python3' in self.driver.title
print('检索python3完成')
except Exception as e:
print('检索失败', format(e))
def test_search3(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').clear() # 清空之前输入的python3
self.driver.find_element_by_id('kw').send_keys('hello world')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'hello world' in self.driver.title
print('检索hello world完成')
except Exception as e:
print('检索失败', format(e))
case_path = os.path.join(os.getcwd()) # 在当前目录中采集测试用例
print(case_path)
all_case = unittest.defaultTestLoader.discover(case_path, pattern="test*.py", top_level_dir=None) # 采集所有test开头的测试用例
print(all_case)
if __name__ == '__main__':
runner = unittest.TextTestRunner() # 实例化runner
runner.run(all_case) # 执行测试
获取所有的测试用例集使用的是discover()方法,在PyCharm中运行该脚本就如下:
以上就完成了在Python Unittest单元测试框架下编撰测试用例脚本,并使用其提供的多种方式来批量管理测试用例集并并执行。
转载于:
使用Python3编撰一个爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 224 次浏览 • 2020-08-23 07:12
使用Python3编撰一个爬虫需求简介
最近厂里有一个新闻采集类的需求,细节大体如下:
模拟登陆一个外网网站(SSO)抓取新闻(支持代理服务器的形式访问)加工内容款式,以适配手机屏幕将正文中的图片转存到自已的服务器,并替换img标签中的url图片储存服务器须要复用已有的FastDFS分布式文件系统采集结果导出生产库支持日志复印
初学Python3,正好用这个需求练练手,最后太吃惊的是只用200多行代码就实现了,如果换成Java的话大约须要1200行吧。果然应了那句俗话:人生苦短,我用Python
登录页面抓包
第一步其实是抓包,然后再按照抓到的内容,模拟进行HTTP恳求。
常用的抓包工具,有Mac下的Charles和Windows下的Fiddler。
它们的原理都是在本机开一个HTTP或SOCKS代理服务器端口,然后将浏览器的代理服务器设置成这个端口,这样浏览器中所有的HTTP恳求就会先经过抓包工具记录出来了。
这里推荐尽量使用Fiddler,原因是Charles对于cookie的展示是有bug的,举个事例,真实情况:请求A返回了LtpaToken这个cookie,请求B中返回了sid这个cookie。但在Charles中的展示是:请求A中早已同时返回了LtpaToken和sid两个cookie,这就很容易欺骗人了。
另外Fiddler如今早已有了Linux的Beta版本,貌似是用类似wine的形式实现的。
如果网站使用了单点登录,可能会涉及到手工生成cookie。所以除了须要剖析每一条HTTP请求的request和response,以及带回去的cookie,还要对页面中的javascript进行剖析,看一下是怎样生成cookie的。
模拟登陆
将页面剖析完毕以后,就可以进行模拟HTTP恳求了。
这里有两个非常好用的第三方库, request 和 BeautifulSoup
requests 库是拿来替代urllib的,可以十分人性化的的生成HTTP请求,模拟session以及伪造cookie更是便捷。
BeautifulSoup 用来取代re模块,进行HTML内容解析,可以用tag, class, id来定位想要提取的内容,也支持正则表达式等。
具体的使用方法直接看官方文档就可以了,写的特别详尽,这里直接给出地址:
requests官方文档
BeautifulSoup官方文档
通过pip3来安装这两个模块:
sudo apt-get install python3-pip
sudo pip3 install requests
sudo pip3 install beautifulsoup4
导入模块:
import requests
from bs4 import BeautifulSoup
模拟登陆:
def sso_login():
# 调用单点登录工号认证页面
response = session.post(const.SSO_URL,
data={'login': const.LOGIN_USERNAME, 'password': const.LOGIN_PASSWORD, 'appid': 'np000'})
# 分析页面,取token及ltpa
soup = BeautifulSoup(response.text, 'html.parser')
token = soup.form.input.get('value')
ltpa = soup.form.input.input.input.get('value')
ltpa_value = ltpa.split(';')[0].split('=', 1)[1]
# 手工设置Cookie
session.cookies.set('LtpaToken', ltpa_value, domain='unicom.local', path='/')
# 调用云门户登录页面(2次)
payload = {'token': token}
session.post(const.LOGIN_URL, data=payload, proxies=const.PROXIES)
response = session.post(const.LOGIN_URL, data=payload, proxies=const.PROXIES)
if response.text == "success":
logging.info("登录成功")
return True
else:
logging.info("登录失败")
return False
这里用到了BeautifulSoup进行HTML解析,取出页面中的token、ltpa等数组。
然后使用session.cookies.set伪造了一个cookie,注意其中的domain参数,设置成1级域名。
然后用这个session,去调用网站页面,换回sid这个token。并可以依据页面的返回信息,来简单判定一下成功还是失败。
列表页面抓取
登录成功以后,接下来的列表页面抓取就要简单的多了,不考虑分页的话,直接取一个list下来遍历即可。
def capture_list(list_url):
response = session.get(list_url, proxies=const.PROXIES)
response.encoding = "UTF-8"
soup = BeautifulSoup(response.text, 'html.parser')
news_list = soup.find('div', 'xinwen_list').find_all('a')
news_list.reverse()
logging.info("开始采集")
for news_archor in news_list:
news_cid = news_archor.attrs['href'].split('=')[1]
capture_content(news_cid)
logging.info("结束采集")
这里使用了response.encoding = "UTF-8"来手工解决乱码问题。
新闻页面抓取
新闻页面抓取,涉及到插临时表,这里没有使用每三方库,直接用SQL形式插入。
其中涉及到款式处理与图片转存,另写一个模块pconvert来实现。
def capture_content(news_cid):
# 建立DB连接
conn = mysql.connector.connect(user=const.DB_USERNAME, password=const.DB_PASSWORD, host=const.DB_HOST,
port=const.DB_PORT, database=const.DB_DATABASE)
cursor = conn.cursor()
# 判断是否已存在
cursor.execute('select count(*) from material_prepare where news_cid = %s', (news_cid,))
news_count = cursor.fetchone()[0]
if news_count > 0:
logging.info("采集" + news_cid + ':已存在')
else:
logging.info("采集" + news_cid + ':新增')
news_url = const.NEWS_BASE_URL + news_cid
response = session.post(news_url, proxies=const.PROXIES)
response.encoding = "UTF-8"
soup = BeautifulSoup(response.text, 'html.parser')
# logging.info(soup)
news_title = soup.h3.text.strip()[:64]
news_brief = soup.find('div', 'brief').p.text.strip()[:100]
news_author = soup.h5.span.a.text.strip()[:100]
news_content = soup.find('table', 'unis_detail_content').tr.td.prettify()[66:-7].strip()
# 样式处理
news_content = pconvert.convert_style(news_content)
# 将图片转存至DFS并替换URL
news_content = pconvert.convert_img(news_content)
# 入表
cursor.execute(
'INSERT INTO material_prepare (news_cid, title, author, summary, content, add_time, status) VALUES (%s, %s, %s, %s, %s, now(), "0")'
, [news_cid, news_title, news_author, news_brief, news_content])
# 提交
conn.commit()
cursor.close()
样式处理
文本式样处理,还是要用到BeautifulSoup,因为原创站点上的新闻内容款式是五花八门的,根据实际情况,一边写一个test函数来生成文本,一边在浏览器上渐渐调试。
def convert_style(rawtext):
newtext = '' \
+ rawtext + ''
newtext = newtext.replace(' align="center"', '')
soup = BeautifulSoup(newtext, 'html.parser')
img_tags = soup.find_all("img")
for img_tag in img_tags:
del img_tag.parent['style']
return soup.prettify()
图片转存至DFS
因为原创站点是在外网中的,采集下来的HTML中,
标签的地址是外网地址,所以在网段中是诠释不下来的,需要将图片转存,并用新的URL替换原有的URL。
def convert_img(rawtext):
soup = BeautifulSoup(rawtext, 'html.parser')
img_tags = soup.find_all("img")
for img_tag in img_tags:
raw_img_url = img_tag['src']
dfs_img_url = convert_url(raw_img_url)
img_tag['src'] = dfs_img_url
del img_tag['style']
return soup.prettify()
图片转存最简单的形式是保存成本地的文件,然后再通过nginx或httpd服务将图片开放出去:
pic_name = raw_img_url.split('/')[-1]
pic_path = TMP_PATH + '/' + pic_name
with open(pic_path, 'wb') as pic_file:
pic_file.write(pic_content)
但这儿我们须要复用已有的FastDFS分布式文件系统,要用到它的一个客户端的库fdfs_client-py
fdfs_client-py不能直接使用pip3安装,需要直接使用一个python3版的源码,并手工更改其中代码。操作过程如下:
git clone https://github.com/jefforeilly/fdfs_client-py.git
cd dfs_client-py
vi ./fdfs_client/storage_client.py
将第12行 from fdfs_client.sendfile import * 注释掉
python3 setup.py install
sudo pip3 install mutagen
客户端的使用上没有哪些非常的,直接调用upload_by_buffer,传一个图片的buffer进去就可以了,成功后会返回手动生成的文件名。
from fdfs_client.client import *
dfs_client = Fdfs_client('conf/dfs.conf')
def convert_url(raw_img_url):
response = requests.get(raw_img_url, proxies=const.PROXIES)
pic_buffer = response.content
pic_ext = raw_img_url.split('.')[-1]
response = dfs_client.upload_by_buffer(pic_buffer, pic_ext)
dfs_img_url = const.DFS_BASE_URL + '/' + response['Remote file_id']
return dfs_img_url
其中dfs.conf文件中,主要就是配置一下 tracker_server
日志处理
这里使用配置文件的形式处理日志,类似JAVA中的log4j吧,首先新建一个log.conf:
[loggers]
keys=root
[handlers]
keys=stream_handler,file_handler
[formatters]
keys=formatter
[logger_root]
level=DEBUG
handlers=stream_handler,file_handler
[handler_stream_handler]
class=StreamHandler
level=DEBUG
formatter=formatter
args=(sys.stderr,)
[handler_file_handler]
class=FileHandler
level=DEBUG
formatter=formatter
args=('logs/pspider.log','a','utf8')
[formatter_formatter]
format=%(asctime)s %(name)-12s %(levelname)-8s %(message)s
这里通过配置handlers,可以同时将日志复印到stderr和文件。
注意args=('logs/pspider.log','a','utf8') 这一行,用来解决文本文件中的英文乱码问题。
日志初始化:
import logging
from logging.config import fileConfig
fileConfig('conf/log.conf')
日志复印:
logging.info("test")
完整源码
到此为止,就是怎样用Python3写一个爬虫的全部过程了。
采集不同的站点,肯定是要有不同的处理,但方式都是大同小异。 查看全部
使用Python3编撰一个爬虫
使用Python3编撰一个爬虫需求简介
最近厂里有一个新闻采集类的需求,细节大体如下:
模拟登陆一个外网网站(SSO)抓取新闻(支持代理服务器的形式访问)加工内容款式,以适配手机屏幕将正文中的图片转存到自已的服务器,并替换img标签中的url图片储存服务器须要复用已有的FastDFS分布式文件系统采集结果导出生产库支持日志复印
初学Python3,正好用这个需求练练手,最后太吃惊的是只用200多行代码就实现了,如果换成Java的话大约须要1200行吧。果然应了那句俗话:人生苦短,我用Python
登录页面抓包
第一步其实是抓包,然后再按照抓到的内容,模拟进行HTTP恳求。
常用的抓包工具,有Mac下的Charles和Windows下的Fiddler。
它们的原理都是在本机开一个HTTP或SOCKS代理服务器端口,然后将浏览器的代理服务器设置成这个端口,这样浏览器中所有的HTTP恳求就会先经过抓包工具记录出来了。
这里推荐尽量使用Fiddler,原因是Charles对于cookie的展示是有bug的,举个事例,真实情况:请求A返回了LtpaToken这个cookie,请求B中返回了sid这个cookie。但在Charles中的展示是:请求A中早已同时返回了LtpaToken和sid两个cookie,这就很容易欺骗人了。
另外Fiddler如今早已有了Linux的Beta版本,貌似是用类似wine的形式实现的。
如果网站使用了单点登录,可能会涉及到手工生成cookie。所以除了须要剖析每一条HTTP请求的request和response,以及带回去的cookie,还要对页面中的javascript进行剖析,看一下是怎样生成cookie的。
模拟登陆
将页面剖析完毕以后,就可以进行模拟HTTP恳求了。
这里有两个非常好用的第三方库, request 和 BeautifulSoup
requests 库是拿来替代urllib的,可以十分人性化的的生成HTTP请求,模拟session以及伪造cookie更是便捷。
BeautifulSoup 用来取代re模块,进行HTML内容解析,可以用tag, class, id来定位想要提取的内容,也支持正则表达式等。
具体的使用方法直接看官方文档就可以了,写的特别详尽,这里直接给出地址:
requests官方文档
BeautifulSoup官方文档
通过pip3来安装这两个模块:
sudo apt-get install python3-pip
sudo pip3 install requests
sudo pip3 install beautifulsoup4
导入模块:
import requests
from bs4 import BeautifulSoup
模拟登陆:
def sso_login():
# 调用单点登录工号认证页面
response = session.post(const.SSO_URL,
data={'login': const.LOGIN_USERNAME, 'password': const.LOGIN_PASSWORD, 'appid': 'np000'})
# 分析页面,取token及ltpa
soup = BeautifulSoup(response.text, 'html.parser')
token = soup.form.input.get('value')
ltpa = soup.form.input.input.input.get('value')
ltpa_value = ltpa.split(';')[0].split('=', 1)[1]
# 手工设置Cookie
session.cookies.set('LtpaToken', ltpa_value, domain='unicom.local', path='/')
# 调用云门户登录页面(2次)
payload = {'token': token}
session.post(const.LOGIN_URL, data=payload, proxies=const.PROXIES)
response = session.post(const.LOGIN_URL, data=payload, proxies=const.PROXIES)
if response.text == "success":
logging.info("登录成功")
return True
else:
logging.info("登录失败")
return False
这里用到了BeautifulSoup进行HTML解析,取出页面中的token、ltpa等数组。
然后使用session.cookies.set伪造了一个cookie,注意其中的domain参数,设置成1级域名。
然后用这个session,去调用网站页面,换回sid这个token。并可以依据页面的返回信息,来简单判定一下成功还是失败。
列表页面抓取
登录成功以后,接下来的列表页面抓取就要简单的多了,不考虑分页的话,直接取一个list下来遍历即可。
def capture_list(list_url):
response = session.get(list_url, proxies=const.PROXIES)
response.encoding = "UTF-8"
soup = BeautifulSoup(response.text, 'html.parser')
news_list = soup.find('div', 'xinwen_list').find_all('a')
news_list.reverse()
logging.info("开始采集")
for news_archor in news_list:
news_cid = news_archor.attrs['href'].split('=')[1]
capture_content(news_cid)
logging.info("结束采集")
这里使用了response.encoding = "UTF-8"来手工解决乱码问题。
新闻页面抓取
新闻页面抓取,涉及到插临时表,这里没有使用每三方库,直接用SQL形式插入。
其中涉及到款式处理与图片转存,另写一个模块pconvert来实现。
def capture_content(news_cid):
# 建立DB连接
conn = mysql.connector.connect(user=const.DB_USERNAME, password=const.DB_PASSWORD, host=const.DB_HOST,
port=const.DB_PORT, database=const.DB_DATABASE)
cursor = conn.cursor()
# 判断是否已存在
cursor.execute('select count(*) from material_prepare where news_cid = %s', (news_cid,))
news_count = cursor.fetchone()[0]
if news_count > 0:
logging.info("采集" + news_cid + ':已存在')
else:
logging.info("采集" + news_cid + ':新增')
news_url = const.NEWS_BASE_URL + news_cid
response = session.post(news_url, proxies=const.PROXIES)
response.encoding = "UTF-8"
soup = BeautifulSoup(response.text, 'html.parser')
# logging.info(soup)
news_title = soup.h3.text.strip()[:64]
news_brief = soup.find('div', 'brief').p.text.strip()[:100]
news_author = soup.h5.span.a.text.strip()[:100]
news_content = soup.find('table', 'unis_detail_content').tr.td.prettify()[66:-7].strip()
# 样式处理
news_content = pconvert.convert_style(news_content)
# 将图片转存至DFS并替换URL
news_content = pconvert.convert_img(news_content)
# 入表
cursor.execute(
'INSERT INTO material_prepare (news_cid, title, author, summary, content, add_time, status) VALUES (%s, %s, %s, %s, %s, now(), "0")'
, [news_cid, news_title, news_author, news_brief, news_content])
# 提交
conn.commit()
cursor.close()
样式处理
文本式样处理,还是要用到BeautifulSoup,因为原创站点上的新闻内容款式是五花八门的,根据实际情况,一边写一个test函数来生成文本,一边在浏览器上渐渐调试。
def convert_style(rawtext):
newtext = '' \
+ rawtext + ''
newtext = newtext.replace(' align="center"', '')
soup = BeautifulSoup(newtext, 'html.parser')
img_tags = soup.find_all("img")
for img_tag in img_tags:
del img_tag.parent['style']
return soup.prettify()
图片转存至DFS
因为原创站点是在外网中的,采集下来的HTML中,
标签的地址是外网地址,所以在网段中是诠释不下来的,需要将图片转存,并用新的URL替换原有的URL。
def convert_img(rawtext):
soup = BeautifulSoup(rawtext, 'html.parser')
img_tags = soup.find_all("img")
for img_tag in img_tags:
raw_img_url = img_tag['src']
dfs_img_url = convert_url(raw_img_url)
img_tag['src'] = dfs_img_url
del img_tag['style']
return soup.prettify()
图片转存最简单的形式是保存成本地的文件,然后再通过nginx或httpd服务将图片开放出去:
pic_name = raw_img_url.split('/')[-1]
pic_path = TMP_PATH + '/' + pic_name
with open(pic_path, 'wb') as pic_file:
pic_file.write(pic_content)
但这儿我们须要复用已有的FastDFS分布式文件系统,要用到它的一个客户端的库fdfs_client-py
fdfs_client-py不能直接使用pip3安装,需要直接使用一个python3版的源码,并手工更改其中代码。操作过程如下:
git clone https://github.com/jefforeilly/fdfs_client-py.git
cd dfs_client-py
vi ./fdfs_client/storage_client.py
将第12行 from fdfs_client.sendfile import * 注释掉
python3 setup.py install
sudo pip3 install mutagen
客户端的使用上没有哪些非常的,直接调用upload_by_buffer,传一个图片的buffer进去就可以了,成功后会返回手动生成的文件名。
from fdfs_client.client import *
dfs_client = Fdfs_client('conf/dfs.conf')
def convert_url(raw_img_url):
response = requests.get(raw_img_url, proxies=const.PROXIES)
pic_buffer = response.content
pic_ext = raw_img_url.split('.')[-1]
response = dfs_client.upload_by_buffer(pic_buffer, pic_ext)
dfs_img_url = const.DFS_BASE_URL + '/' + response['Remote file_id']
return dfs_img_url
其中dfs.conf文件中,主要就是配置一下 tracker_server
日志处理
这里使用配置文件的形式处理日志,类似JAVA中的log4j吧,首先新建一个log.conf:
[loggers]
keys=root
[handlers]
keys=stream_handler,file_handler
[formatters]
keys=formatter
[logger_root]
level=DEBUG
handlers=stream_handler,file_handler
[handler_stream_handler]
class=StreamHandler
level=DEBUG
formatter=formatter
args=(sys.stderr,)
[handler_file_handler]
class=FileHandler
level=DEBUG
formatter=formatter
args=('logs/pspider.log','a','utf8')
[formatter_formatter]
format=%(asctime)s %(name)-12s %(levelname)-8s %(message)s
这里通过配置handlers,可以同时将日志复印到stderr和文件。
注意args=('logs/pspider.log','a','utf8') 这一行,用来解决文本文件中的英文乱码问题。
日志初始化:
import logging
from logging.config import fileConfig
fileConfig('conf/log.conf')
日志复印:
logging.info("test")
完整源码
到此为止,就是怎样用Python3写一个爬虫的全部过程了。
采集不同的站点,肯定是要有不同的处理,但方式都是大同小异。
Python爬虫建站入门杂记——从零开始构建采集站点(二:编写爬虫)
采集交流 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2020-08-23 06:51
上回,我装了环境
也就是一对乱七八糟的东西
装了pip,用pip装了virtualenv,建立了一个virtualenv,在这个virtualenv上面,装了Django,创建了一个Django项目,在这个Django项目上面创建了一个称作web的阿皮皮。
接上回~
第二部份,编写爬虫。
工欲善其事,必先利其器。
bashapt-get install vim # 接上回,我们在screen里面是root身份哦~
当然了,现在我要想一个采集的目标,为了便捷,我就选择segmentfault吧,这网站写博客不错,就是在海外上传图片有点慢。
这个爬虫,就像我访问一样,要分步骤来。 我先听到segmentfault首页,然后发觉上面有很多tags,每个tags下边,才是一个一个的问题的内容。
所以,爬虫也要分为这几个步骤来写。 但是我要反着写,先写内容爬虫,再写分类爬虫, 因为我想。
2.1 编写内容爬虫
首先,给爬虫构建个目录,在项目上面和app同级,然后把这个目录弄成一个python的package
bashmkdir ~/python_spider/sfspider
touch ~/python_spider/sfspider/__init__.py
以后,这个目录就叫爬虫包了
在爬虫包上面构建一个spider.py拿来装我的爬虫们
bashvim ~/python_spider/sfspider/spider.py
一个基本的爬虫,只须要下边几行代码:
(代码下边会提供)
然后呢,就可以玩儿我们的“爬虫”了。
进入python shell
python>>> from sfspider import spider
>>> s = spider.SegmentfaultQuestionSpider('1010000002542775')
>>> s.url
>>> 'http://segmentfault.com/q/1010000002542775'
>>> print s.dom('h1#questionTitle').text()
>>> 微信JS—SDK嵌套选择图片和上传图片接口,实现一键上传图片,遇到问题
看吧,我如今早已可以通过爬虫获取segmentfault的提问标题了。下一步,为了简化代码,我把标题,回答等等的属性都写为这个蜘蛛的属性。代码如下
python# -*- coding: utf-8 -*-
import requests # requests作为我们的html客户端
from pyquery import PyQuery as Pq # pyquery来操作dom
class SegmentfaultQuestionSpider(object):
def __init__(self, segmentfault_id): # 参数为在segmentfault上的id
self.url = 'http://segmentfault.com/q/{0}'.format(segmentfault_id)
self._dom = None # 弄个这个来缓存获取到的html内容,一个蜘蛛应该之访问一次
@property
def dom(self): # 获取html内容
if not self._dom:
document = requests.get(self.url)
document.encoding = 'utf-8'
self._dom = Pq(document.text)
return self._dom
@property
def title(self): # 让方法可以通过s.title的方式访问 可以少打对括号
return self.dom('h1#questionTitle').text() # 关于选择器可以参考css selector或者jquery selector, 它们在pyquery下几乎都可以使用
@property
def content(self):
return self.dom('.question.fmt').html() # 直接获取html 胆子就是大 以后再来过滤
@property
def answers(self):
return list(answer.html() for answer in self.dom('.answer.fmt').items()) # 记住,Pq实例的items方法是很有用的
@property
def tags(self):
return self.dom('ul.taglist--inline > li').text().split() # 获取tags,这里直接用text方法,再切分就行了。一般只要是文字内容,而且文字内容自己没有空格,逗号等,都可以这样弄,省事。
然后,再把玩一下升级后的蜘蛛。
python>>> from sfspider import spider
>>> s = spider.SegmentfaultQuestionSpider('1010000002542775')
>>> print s.title
>>> 微信JS—SDK嵌套选择图片和上传图片接口,实现一键上传图片,遇到问题
>>> print s.content
>>> # [故意省略] #
>>> for answer in s.answers
print answer
>>> # [故意省略] #
>>> print '/'.join(s.tags)
>>> 微信js-sdk/python/微信开发/javascript
OK,现在我的蜘蛛玩上去更方便了。
2.2 编写分类爬虫
下面,我要写一个抓取标签页面的问题的爬虫。
代码如下, 注意下边的代码是添加在已有代码下边的, 和之前的最后一行之间 要有两个空行
pythonclass SegmentfaultTagSpider(object):
def __init__(self, tag_name, page=1):
self.url = 'http://segmentfault.com/t/%s?type=newest&page=%s' % (tag_name, page)
self.tag_name = tag_name
self.page = page
self._dom = None
@property
def dom(self):
if not self._dom:
document = requests.get(self.url)
document.encoding = 'utf-8'
self._dom = Pq(document.text)
self._dom.make_links_absolute(base_url="http://segmentfault.com/") # 相对链接变成绝对链接 爽
return self._dom
@property
def questions(self):
return [question.attr('href') for question in self.dom('h2.title > a').items()]
@property
def has_next_page(self): # 看看还有没有下一页,这个有必要
return bool(self.dom('ul.pagination > li.next')) # 看看有木有下一页
def next_page(self): # 把这个蜘蛛杀了, 产生一个新的蜘蛛 抓取下一页。 由于这个本来就是个动词,所以就不加@property了
if self.has_next_page:
self.__init__(tag_name=self.tag_name ,page=self.page+1)
else:
return None
现在可以两个蜘蛛一起把玩了,就不贴出详尽把玩过程了。。。
python>>> from sfspider import spider
>>> s = spider.SegmentfaultTagSpider('微信')
>>> question1 = s.questions[0]
>>> question_spider = spider.SegmentfaultQuestionSpider(question1.split('/')[-1])
>>> # [故意省略] #
想做窃贼站的,看到这儿基本上能够搞下来了。 套个模板 加一个简单的脚本来接受和返回恳求就行了。
未完待续。 查看全部
Python爬虫建站入门杂记——从零开始构建采集站点(二:编写爬虫)
上回,我装了环境
也就是一对乱七八糟的东西
装了pip,用pip装了virtualenv,建立了一个virtualenv,在这个virtualenv上面,装了Django,创建了一个Django项目,在这个Django项目上面创建了一个称作web的阿皮皮。
接上回~
第二部份,编写爬虫。
工欲善其事,必先利其器。
bashapt-get install vim # 接上回,我们在screen里面是root身份哦~
当然了,现在我要想一个采集的目标,为了便捷,我就选择segmentfault吧,这网站写博客不错,就是在海外上传图片有点慢。
这个爬虫,就像我访问一样,要分步骤来。 我先听到segmentfault首页,然后发觉上面有很多tags,每个tags下边,才是一个一个的问题的内容。
所以,爬虫也要分为这几个步骤来写。 但是我要反着写,先写内容爬虫,再写分类爬虫, 因为我想。
2.1 编写内容爬虫
首先,给爬虫构建个目录,在项目上面和app同级,然后把这个目录弄成一个python的package
bashmkdir ~/python_spider/sfspider
touch ~/python_spider/sfspider/__init__.py
以后,这个目录就叫爬虫包了
在爬虫包上面构建一个spider.py拿来装我的爬虫们
bashvim ~/python_spider/sfspider/spider.py
一个基本的爬虫,只须要下边几行代码:
(代码下边会提供)
然后呢,就可以玩儿我们的“爬虫”了。
进入python shell
python>>> from sfspider import spider
>>> s = spider.SegmentfaultQuestionSpider('1010000002542775')
>>> s.url
>>> 'http://segmentfault.com/q/1010000002542775'
>>> print s.dom('h1#questionTitle').text()
>>> 微信JS—SDK嵌套选择图片和上传图片接口,实现一键上传图片,遇到问题
看吧,我如今早已可以通过爬虫获取segmentfault的提问标题了。下一步,为了简化代码,我把标题,回答等等的属性都写为这个蜘蛛的属性。代码如下
python# -*- coding: utf-8 -*-
import requests # requests作为我们的html客户端
from pyquery import PyQuery as Pq # pyquery来操作dom
class SegmentfaultQuestionSpider(object):
def __init__(self, segmentfault_id): # 参数为在segmentfault上的id
self.url = 'http://segmentfault.com/q/{0}'.format(segmentfault_id)
self._dom = None # 弄个这个来缓存获取到的html内容,一个蜘蛛应该之访问一次
@property
def dom(self): # 获取html内容
if not self._dom:
document = requests.get(self.url)
document.encoding = 'utf-8'
self._dom = Pq(document.text)
return self._dom
@property
def title(self): # 让方法可以通过s.title的方式访问 可以少打对括号
return self.dom('h1#questionTitle').text() # 关于选择器可以参考css selector或者jquery selector, 它们在pyquery下几乎都可以使用
@property
def content(self):
return self.dom('.question.fmt').html() # 直接获取html 胆子就是大 以后再来过滤
@property
def answers(self):
return list(answer.html() for answer in self.dom('.answer.fmt').items()) # 记住,Pq实例的items方法是很有用的
@property
def tags(self):
return self.dom('ul.taglist--inline > li').text().split() # 获取tags,这里直接用text方法,再切分就行了。一般只要是文字内容,而且文字内容自己没有空格,逗号等,都可以这样弄,省事。
然后,再把玩一下升级后的蜘蛛。
python>>> from sfspider import spider
>>> s = spider.SegmentfaultQuestionSpider('1010000002542775')
>>> print s.title
>>> 微信JS—SDK嵌套选择图片和上传图片接口,实现一键上传图片,遇到问题
>>> print s.content
>>> # [故意省略] #
>>> for answer in s.answers
print answer
>>> # [故意省略] #
>>> print '/'.join(s.tags)
>>> 微信js-sdk/python/微信开发/javascript
OK,现在我的蜘蛛玩上去更方便了。
2.2 编写分类爬虫
下面,我要写一个抓取标签页面的问题的爬虫。
代码如下, 注意下边的代码是添加在已有代码下边的, 和之前的最后一行之间 要有两个空行
pythonclass SegmentfaultTagSpider(object):
def __init__(self, tag_name, page=1):
self.url = 'http://segmentfault.com/t/%s?type=newest&page=%s' % (tag_name, page)
self.tag_name = tag_name
self.page = page
self._dom = None
@property
def dom(self):
if not self._dom:
document = requests.get(self.url)
document.encoding = 'utf-8'
self._dom = Pq(document.text)
self._dom.make_links_absolute(base_url="http://segmentfault.com/";) # 相对链接变成绝对链接 爽
return self._dom
@property
def questions(self):
return [question.attr('href') for question in self.dom('h2.title > a').items()]
@property
def has_next_page(self): # 看看还有没有下一页,这个有必要
return bool(self.dom('ul.pagination > li.next')) # 看看有木有下一页
def next_page(self): # 把这个蜘蛛杀了, 产生一个新的蜘蛛 抓取下一页。 由于这个本来就是个动词,所以就不加@property了
if self.has_next_page:
self.__init__(tag_name=self.tag_name ,page=self.page+1)
else:
return None
现在可以两个蜘蛛一起把玩了,就不贴出详尽把玩过程了。。。
python>>> from sfspider import spider
>>> s = spider.SegmentfaultTagSpider('微信')
>>> question1 = s.questions[0]
>>> question_spider = spider.SegmentfaultQuestionSpider(question1.split('/')[-1])
>>> # [故意省略] #
想做窃贼站的,看到这儿基本上能够搞下来了。 套个模板 加一个简单的脚本来接受和返回恳求就行了。
未完待续。
爬虫 大规模数据 采集心得和示例
采集交流 • 优采云 发表了文章 • 0 个评论 • 387 次浏览 • 2020-08-23 04:03
本篇主要介绍网站数据特别大的采集心得
1. 什么样的数据能够称为数据量大:
我认为这个可能会由于每位人的理解不太一样,给出的定义 也不相同。我觉得定义一个采集网站的数据大小,不仅仅要看这个网站包括的数据量的大小,还应当包括这个网址的采集难度,采集网站的服务器承受能力,采集人员所调配的网路带宽和计算机硬件资源等。这里我暂且把一个网站超过一千万个URL链接的称作数据量大的网站。
2. 数据量大的网站采集方案:
2.1 . 采集需求剖析:
作为数据采集工程师,我觉得最重要的是要做好数据采集的需求剖析,首先要预估这个网址的数据量大小,然后去明晰采集哪些数据,有没有必要去把目标网站的数据都采集下来,因为采集的数据量越多,耗费的时间就越多,需要的资源就越多,对目标网站造成的压力就越大,数据采集工程师不能为了采集数据,对目标网站造成很大的压力。原则是尽量少采集数据来满足自己的需求,避免全站采集。
2.2. 代码编撰:
因为要采集的网站数据好多,所以要求编撰的代码做到稳定运行一周甚至一个月以上,所以代码要足够的强壮,足够的强大。一般要求做到网站不变更模板,程序能始终执行出来。这里有个编程的小技巧,我觉得很重要,就是代码编撰好之后,先去跑一两个小时,发现程序的一些报错的地方,修改掉,这样的前期代码测试,能保证代码的健壮性。
2.3 数据储存:
当数据量有三五千万的时侯,无论是MySQL还是Oracle还是SQL Server,想在一个表上面储存,已经不太可能了,这个时侯可以采用分表来储存。数据采集完毕,往数据库插入的时侯,可以执行批量插入等策略。保证自己的储存不受数据库性能等方面的影响。
2.4 调配的资源:
由于目标网站数据好多,我们免不了要去使用大的房贷,内存,CPU等资源,这个时侯我们可以搞一个分布式爬虫系统,来合理的管理我们的资源。
3. 爬虫的道德
对于一些中级的采集工程师,为了更快的采集到数据,往往开了好多的多进程和多线程,后果就是对目标网站造成了dos攻击,结果是目标网站果断的升级网站,加入更多的反爬策略,这种对抗对采集工程师也是非常不利的。个人建议下载速率不要超过2M,多进程或则多线程不要过百。
示例:
要采集的目标网站有四千万数据,网站的反爬策略是封ip,于是专门找了一台机器,开了二百多个进程去维护ip池,ip池可用的ip在500-1000个,并且保证ip是高度可用的。
代码编撰完毕后,同是在两台机器上运行,每天机器开启的多线程不超过64个,下载速率不超过1M.
个人知识有限,请大牛多多包涵 查看全部
爬虫 大规模数据 采集心得和示例
本篇主要介绍网站数据特别大的采集心得
1. 什么样的数据能够称为数据量大:
我认为这个可能会由于每位人的理解不太一样,给出的定义 也不相同。我觉得定义一个采集网站的数据大小,不仅仅要看这个网站包括的数据量的大小,还应当包括这个网址的采集难度,采集网站的服务器承受能力,采集人员所调配的网路带宽和计算机硬件资源等。这里我暂且把一个网站超过一千万个URL链接的称作数据量大的网站。
2. 数据量大的网站采集方案:
2.1 . 采集需求剖析:
作为数据采集工程师,我觉得最重要的是要做好数据采集的需求剖析,首先要预估这个网址的数据量大小,然后去明晰采集哪些数据,有没有必要去把目标网站的数据都采集下来,因为采集的数据量越多,耗费的时间就越多,需要的资源就越多,对目标网站造成的压力就越大,数据采集工程师不能为了采集数据,对目标网站造成很大的压力。原则是尽量少采集数据来满足自己的需求,避免全站采集。
2.2. 代码编撰:
因为要采集的网站数据好多,所以要求编撰的代码做到稳定运行一周甚至一个月以上,所以代码要足够的强壮,足够的强大。一般要求做到网站不变更模板,程序能始终执行出来。这里有个编程的小技巧,我觉得很重要,就是代码编撰好之后,先去跑一两个小时,发现程序的一些报错的地方,修改掉,这样的前期代码测试,能保证代码的健壮性。
2.3 数据储存:
当数据量有三五千万的时侯,无论是MySQL还是Oracle还是SQL Server,想在一个表上面储存,已经不太可能了,这个时侯可以采用分表来储存。数据采集完毕,往数据库插入的时侯,可以执行批量插入等策略。保证自己的储存不受数据库性能等方面的影响。
2.4 调配的资源:
由于目标网站数据好多,我们免不了要去使用大的房贷,内存,CPU等资源,这个时侯我们可以搞一个分布式爬虫系统,来合理的管理我们的资源。
3. 爬虫的道德
对于一些中级的采集工程师,为了更快的采集到数据,往往开了好多的多进程和多线程,后果就是对目标网站造成了dos攻击,结果是目标网站果断的升级网站,加入更多的反爬策略,这种对抗对采集工程师也是非常不利的。个人建议下载速率不要超过2M,多进程或则多线程不要过百。
示例:
要采集的目标网站有四千万数据,网站的反爬策略是封ip,于是专门找了一台机器,开了二百多个进程去维护ip池,ip池可用的ip在500-1000个,并且保证ip是高度可用的。
代码编撰完毕后,同是在两台机器上运行,每天机器开启的多线程不超过64个,下载速率不超过1M.
个人知识有限,请大牛多多包涵
[Android]橘子视频。e4a源码+成品。采集360可看全网vip影片
采集交流 • 优采云 发表了文章 • 0 个评论 • 800 次浏览 • 2020-08-22 18:54
源码我更改成黑色的了。改动比较大。但源码只发布原版。需要自己改。数据手动采集360影视,解析插口自己找。论坛不知道能不能发布插口。这次先不发,后期单独发一贴.各大平台影片基本都能解下来
安装须要虚拟空间安装网站,注册用户。和对接APP验证。
类库齐全
蓝奏云下载地址
*********源码在最下边*************
这个程序修补了好多个BUG目前是没有BUG的,而且都是可以看的,用的是内置浏览器播放器可以无视广告,带充值卡,充值卡后台自己设置,自己定价,自己决定充值卡的名子,带一键分享功能和用户中心功能,完全仿造原生主流APP而做,界面完美无错!
(可挣钱)影视app源码可注册登录带后台,批量生成卡密在线授权可设置试看时间
(可挣钱)影视app源码带后台,批量生成卡密在线授权可设置试看时间,试看时间可以随时修改,很方便,后台可以直接管理用户
支持批量生成卡密,用户使用卡密可以直接授权
卡密的时间由你设定,收不收费你说了算
可以设置绑定IP或则绑定机器码,就是说换了手机之前的帐号不能使用,防止一号多用
***************************************************
查看全部
[Android]橘子视频。e4a源码+成品。采集360可看全网vip影片
源码我更改成黑色的了。改动比较大。但源码只发布原版。需要自己改。数据手动采集360影视,解析插口自己找。论坛不知道能不能发布插口。这次先不发,后期单独发一贴.各大平台影片基本都能解下来
安装须要虚拟空间安装网站,注册用户。和对接APP验证。
类库齐全
蓝奏云下载地址
*********源码在最下边*************
这个程序修补了好多个BUG目前是没有BUG的,而且都是可以看的,用的是内置浏览器播放器可以无视广告,带充值卡,充值卡后台自己设置,自己定价,自己决定充值卡的名子,带一键分享功能和用户中心功能,完全仿造原生主流APP而做,界面完美无错!
(可挣钱)影视app源码可注册登录带后台,批量生成卡密在线授权可设置试看时间
(可挣钱)影视app源码带后台,批量生成卡密在线授权可设置试看时间,试看时间可以随时修改,很方便,后台可以直接管理用户
支持批量生成卡密,用户使用卡密可以直接授权
卡密的时间由你设定,收不收费你说了算
可以设置绑定IP或则绑定机器码,就是说换了手机之前的帐号不能使用,防止一号多用
***************************************************
[杂谈]关于报刀机器人是手动搜集刀数吗?(不做了,被团扇乱杀)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2020-08-22 15:21
2020-07-01 19:42
[杂谈]关于报刀机器人是手动搜集刀数吗?(不做了,被团扇乱杀)
就是会里打了boss,机器人就手动记录谁谁出了第几刀,伤害多少。 还是须要会员自己去群里报刀?[s:ac:晕]
如果是自己去报刀,那捉鱼的不捉鱼的不是就全靠自觉了嘛。[s:ac:呆]
现在可以做到爬取游戏里的实时数据吗?最近想试试自己搭个机器人。主要是为了那个但求每晚出满三刀帮会用的。[s:ac:哭笑]
补充:主要啊[s:ac:擦汗]咸鱼帮会只有每晚出满三刀这个要求,1w开外那个,昨天9点多了还有7个人没出刀,大家出没出满3刀也不清楚,作为会长我就只有自己用纸笔逐个记录对比,看看谁谁没打,没出刀,怪累的,才想问问的,看来实现上去还是有点困难[s:a2:不活了]
不过我还是先试试吧,明天再改改
好吧,基本做出来了[s:ac:擦汗]不过还是有很多麻烦,等会我发图瞧瞧疗效
2020.7.3更新目前实现了对截图的数据进行剖析,俗话说小数据剖析[s:ac:哭笑]
分离提纯我们须要的信息,然后写入数据库筛选,最后再输出
这个是截图保存位置,目前实现了手动截图,也就是说只要号仍然在线视奸,然后定时或则主动截图,程序都会辨识读取
这个是输出,就详尽的筛选了玩家名子和对应的出刀次数
其实数据库的话,是记录了boss和伤害的,但是俺们休闲帮会用不上,就没必要输出了[s:ac:哭笑](休闲帮会伤害是真的不能看)
功能的话基本上实现了,只是要正常运作的话难度还是很大了,首先得保证有号仍然在线而且在工会战页面,就这一个条件就太严苛了
只要这个条件能达成的话,其他都不是事了,配合QQ机器人,定时截图或则发送QQ信息截图,然后统计信息就很简单了
只能说有看法,但不成熟啊[s:ac:冷]附件
附件改动 查看全部
[杂谈]关于报刀机器人是手动搜集刀数吗?(不做了,被团扇乱杀)
2020-07-01 19:42
[杂谈]关于报刀机器人是手动搜集刀数吗?(不做了,被团扇乱杀)
就是会里打了boss,机器人就手动记录谁谁出了第几刀,伤害多少。 还是须要会员自己去群里报刀?[s:ac:晕]
如果是自己去报刀,那捉鱼的不捉鱼的不是就全靠自觉了嘛。[s:ac:呆]
现在可以做到爬取游戏里的实时数据吗?最近想试试自己搭个机器人。主要是为了那个但求每晚出满三刀帮会用的。[s:ac:哭笑]
补充:主要啊[s:ac:擦汗]咸鱼帮会只有每晚出满三刀这个要求,1w开外那个,昨天9点多了还有7个人没出刀,大家出没出满3刀也不清楚,作为会长我就只有自己用纸笔逐个记录对比,看看谁谁没打,没出刀,怪累的,才想问问的,看来实现上去还是有点困难[s:a2:不活了]
不过我还是先试试吧,明天再改改
好吧,基本做出来了[s:ac:擦汗]不过还是有很多麻烦,等会我发图瞧瞧疗效
2020.7.3更新目前实现了对截图的数据进行剖析,俗话说小数据剖析[s:ac:哭笑]
分离提纯我们须要的信息,然后写入数据库筛选,最后再输出
这个是截图保存位置,目前实现了手动截图,也就是说只要号仍然在线视奸,然后定时或则主动截图,程序都会辨识读取
这个是输出,就详尽的筛选了玩家名子和对应的出刀次数
其实数据库的话,是记录了boss和伤害的,但是俺们休闲帮会用不上,就没必要输出了[s:ac:哭笑](休闲帮会伤害是真的不能看)
功能的话基本上实现了,只是要正常运作的话难度还是很大了,首先得保证有号仍然在线而且在工会战页面,就这一个条件就太严苛了
只要这个条件能达成的话,其他都不是事了,配合QQ机器人,定时截图或则发送QQ信息截图,然后统计信息就很简单了
只能说有看法,但不成熟啊[s:ac:冷]附件
附件改动
【web系统UI自动化】关于UI自动化的总结
采集交流 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2020-08-22 12:44
实施过了web系统的UI自动化,回顾梳理下,想到哪些写哪些,随时补充。
首先,自动化测试不是自动测试的替代品,是比较好的补充,而且不是占大比重的补充。
70%的测试工作集中在底层接口测试和单元测试,20%的测试工作为集成测试,其他10%的测试即为界面测试。
开发方向:尽可能的相通的模块,通用的封装开发约定好,便于定位适用兼容测试无界面运行快速定位问题:报错信息、错误截图多环境利润点脚本开发时间和复用次数快速验证,第一时间响应问题还可以做什么?兼容性多环境以便快速定位提炼更多通用模块。调研更优解决方案,比如:cypress等case依赖优化深度校准什么样的项目适宜web自动化系统稳定,太多的制止程序或修改。准备之前,先手工测试,确认手动测试可以囊括的系统功能。需要多系统,多浏览器兼容性测试什么样的功能点须要web自动化主业务流程便于实现自动化的web元素、页面重复量大的功能web自动化常见的验证点页面元素验证页面列表数据验证页面元素属性?UI的文本,图片显示正确性UI的交互逻辑正确性测试UI上的用户行为正确性测试对于web自动化框架常见的需求点分布式执行,可以多机器,多浏览器同步执行脚本适用于不同环境运行分层设计,方便维护生成测试报告模块的复用必要的日志采集UI自动化利润点的采集回归测试须要定期运行,在自动化时,它们可以节约测试人员的时间,我们可以更专注于其他场景和探索性测试。脚本开发时间和复用次数误报频度UI自动化缺点or局限不能快速反馈(相对于单元测试和API测试)只会对于case已确定的内容进行校准运行的稳定性发觉的错误不多,大多数错误其实是通过“意外”或进行探索性测试而发觉的。这可能是因为在每位探索性测试会话期间,我们可能以不同的方法测试应用程序,从而通过应用程序找到新的漏洞。编写优秀且稳定的XPath / CSS定位器所耗费的时间,并在底层HTML标记发生变化时更新它们。UI本身的变化性,要想达到和手工测试相同的覆盖率,投入比较大。如何进行CI(Continuous Integration),也就是持续集成
● 持续提交代码 (Check-in)
○ 一天之中多次提交
● 持续构建代码 (Build)
○ 保证在任何时刻代码是可以继续开发的
● 持续部署代码 (Deploy)
○ 保证始终有一个可以部署的版本
● 持续测试代码 (Test)
○ 每次提交均执行单元测试
○ 每天一次或数次集成测试
○ 每天一次或数次系统测试
不过,高频的集成,还是用插口愈发合适,后面的工作会把系统的交互插口自动化,届时分享。 查看全部
【web系统UI自动化】关于UI自动化的总结
实施过了web系统的UI自动化,回顾梳理下,想到哪些写哪些,随时补充。
首先,自动化测试不是自动测试的替代品,是比较好的补充,而且不是占大比重的补充。
70%的测试工作集中在底层接口测试和单元测试,20%的测试工作为集成测试,其他10%的测试即为界面测试。
开发方向:尽可能的相通的模块,通用的封装开发约定好,便于定位适用兼容测试无界面运行快速定位问题:报错信息、错误截图多环境利润点脚本开发时间和复用次数快速验证,第一时间响应问题还可以做什么?兼容性多环境以便快速定位提炼更多通用模块。调研更优解决方案,比如:cypress等case依赖优化深度校准什么样的项目适宜web自动化系统稳定,太多的制止程序或修改。准备之前,先手工测试,确认手动测试可以囊括的系统功能。需要多系统,多浏览器兼容性测试什么样的功能点须要web自动化主业务流程便于实现自动化的web元素、页面重复量大的功能web自动化常见的验证点页面元素验证页面列表数据验证页面元素属性?UI的文本,图片显示正确性UI的交互逻辑正确性测试UI上的用户行为正确性测试对于web自动化框架常见的需求点分布式执行,可以多机器,多浏览器同步执行脚本适用于不同环境运行分层设计,方便维护生成测试报告模块的复用必要的日志采集UI自动化利润点的采集回归测试须要定期运行,在自动化时,它们可以节约测试人员的时间,我们可以更专注于其他场景和探索性测试。脚本开发时间和复用次数误报频度UI自动化缺点or局限不能快速反馈(相对于单元测试和API测试)只会对于case已确定的内容进行校准运行的稳定性发觉的错误不多,大多数错误其实是通过“意外”或进行探索性测试而发觉的。这可能是因为在每位探索性测试会话期间,我们可能以不同的方法测试应用程序,从而通过应用程序找到新的漏洞。编写优秀且稳定的XPath / CSS定位器所耗费的时间,并在底层HTML标记发生变化时更新它们。UI本身的变化性,要想达到和手工测试相同的覆盖率,投入比较大。如何进行CI(Continuous Integration),也就是持续集成
● 持续提交代码 (Check-in)
○ 一天之中多次提交
● 持续构建代码 (Build)
○ 保证在任何时刻代码是可以继续开发的
● 持续部署代码 (Deploy)
○ 保证始终有一个可以部署的版本
● 持续测试代码 (Test)
○ 每次提交均执行单元测试
○ 每天一次或数次集成测试
○ 每天一次或数次系统测试
不过,高频的集成,还是用插口愈发合适,后面的工作会把系统的交互插口自动化,届时分享。
用Python爬虫实现图片手动下载的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 227 次浏览 • 2020-08-21 18:12
爬虫的出现,可以乘以许多重复性的工作,在须要大量采集数据时,爬虫可以实现手动下载,极大的提升了工作效率。那么python如何实现图片手动下载的呢?如何借助python写爬虫?本文为你们介绍了用Python爬虫实现图片手动下载的方式。
1.分析需求
比如上百度找图片,可以通过搜索功能,查找图片后,选中其中一个查看源代码,找到图片对应的源代码,如果图片多地址,比如有thumbURL,middleURL,hoverURL,objURL,分别打开看那个图片符合需求。如果objURL符合需求,格式为.jpg。
2.选择python库
选择2个包,一个是正则,一个是requests包。
3.编写代码
复制百度图片搜索的链接,传入requests,然后把正则表达式写好。
因为有很多张图片,所以要循环,我们复印出结果来瞧瞧,然后用requests获取网址,由于有些图片可能存在网址打不开的情况,所以加了10秒超时控制。
4.图片保存
建立好一个images目录,把图片都放进去,命名的时侯,以数字命名。
python如何实现图片手动下载?仅须要进行四步,即可编撰好python爬虫并实现图片手动下载。学习爬虫简单吧,即使是菜鸟,也能特别快的上手呢。
能够成功实现手动下载也千万不大意,说不定就遇上了反爬虫机制,记得使用IP池突破限制,比如使用黑洞代理。 查看全部
用Python爬虫实现图片手动下载的方式
爬虫的出现,可以乘以许多重复性的工作,在须要大量采集数据时,爬虫可以实现手动下载,极大的提升了工作效率。那么python如何实现图片手动下载的呢?如何借助python写爬虫?本文为你们介绍了用Python爬虫实现图片手动下载的方式。
1.分析需求
比如上百度找图片,可以通过搜索功能,查找图片后,选中其中一个查看源代码,找到图片对应的源代码,如果图片多地址,比如有thumbURL,middleURL,hoverURL,objURL,分别打开看那个图片符合需求。如果objURL符合需求,格式为.jpg。
2.选择python库
选择2个包,一个是正则,一个是requests包。
3.编写代码
复制百度图片搜索的链接,传入requests,然后把正则表达式写好。
因为有很多张图片,所以要循环,我们复印出结果来瞧瞧,然后用requests获取网址,由于有些图片可能存在网址打不开的情况,所以加了10秒超时控制。
4.图片保存
建立好一个images目录,把图片都放进去,命名的时侯,以数字命名。
python如何实现图片手动下载?仅须要进行四步,即可编撰好python爬虫并实现图片手动下载。学习爬虫简单吧,即使是菜鸟,也能特别快的上手呢。
能够成功实现手动下载也千万不大意,说不定就遇上了反爬虫机制,记得使用IP池突破限制,比如使用黑洞代理。
详解基于Android的Appium+Python自动化脚本编撰
采集交流 • 优采云 发表了文章 • 0 个评论 • 383 次浏览 • 2020-08-21 05:06
详解基于Android的Appium+Python自动化脚本编撰
更新时间:2020年08月20日 10:31:19 转载投稿:zx
这篇文章主要介绍了解读基于Android的Appium+Python自动化脚本编撰,文中通过示例代码介绍的十分详尽,对你们的学习或则工作具有一定的参考学习价值,需要的朋友们下边随着小编来一起学习学习吧
1.Appium
Appium是一个开源测试自动化框架,可用于原生,混合和联通Web应用程序测试, 它使用WebDriver合同驱动iOS,Android和Windows应用程序。
通过Appium,我们可以模拟点击和屏幕的滑动,可以获取元素的id和classname,还可以依照操作生成相关的脚本代码。
下面开始Appium的配置。
appPackage和APPActivity的获取
任意下载一个app
解压
但是解压下来的xml文件可能是乱码,所以我们须要反编译文件。
逆向AndroidManifest.xml
下载AXMLPrinter2.jar文件,逆向xml文件:命令行输入以下命令:
java -jar AXMLPrinter2.jar AndroidManifest.xml ->AndroidManifest.txt
获得以下可以查看的TXT文件
寻找带有launcher 的Activity
寻找manifest上面的package
Devicename的获取
通过命令行输入 adb devices:
appium的功能介绍
下面将按照上图序号一一介绍功能:
选中界面元素,显示元素相关信息
模拟滑动屏幕,先点击一下代表触摸起始位置,在点击一下代表触摸结束为止
模拟点击屏幕
模拟手机的返回按键
刷新一侧的页面,使之与手机同步
记录模拟操作,生成相关脚本
根据元素的id或则其他相关信息查找元素
复制当前界面的xml布局
文件退出
2.Python的脚本
元素定位的使用
(1).xpath定位
xpath定位是一种路径定位方法,主要是依赖于元素绝对路径或则相关属性来定位,但是绝对路径xpath执行效率比较低(特别是元素路径比较深的时侯),一般使用比较少。
通常使用xpath相对路径和属性定位。
by_xpath.py
from find_element.capability import driver
driver.find_element_by_xpath('//android.widget.EditText[@text="请输入用户名"]').send_keys('123456')
driver.find_element_by_xpath('//*[@class="android.widget.EditText" and @index="3"]').send_keys('123456')
driver.find_element_by_xpath('//android.widget.Button').click()
driver.find_element_by_xpath('//[@class="android.widget.Button"]').click()
(2).classname定位
classname定位是依据元素类型来进行定位,但是实际情况中好多元素的classname都是相同的,
如用户名和密码都是clasName属性值都是:“android.widget.EditText” 因此只能定位第一个元素也就是用户名,而密码输入框就须要使用其他方法来定位,这样也许太鸡肋.一般情况下假如有id就毋须使用classname定位。
by_classname.py
from find_element.capability import driver
driver.find_element_by_class_name('android.widget.EditText').send_keys('123565')
driver.find_element_by_class_name('android.widget.EditText').send_keys('456879')
driver.find_element_by_class_name('android.widget.Button').click()
(3).id定位
日常生活中身边可能存在相同名子的人,但是每位人的身份证号码是惟一的,在app界面元素中也可以使用id值来分辨不同的元素,然后进行定位操作。
Appium中可以使用 find_element_by_id() 方法来进行id定位。
driver.find_element_by_id('android:id/button2').click()
driver.find_element_by_id('com.tal.kaoyan:id/tv_skip').click()
3.示例:模拟软件的手动注册
首先配置联接属性
desired_caps={}
# 所使用的平台
desired_caps['platformName']='Android'
# 所使用的手机的名字 可以通过 adb devices 获得
desired_caps['deviceName']='127.0.0.1:62001'
# ANDROID 的版本
desired_caps['platforVersion']='5.1.1'
# app 的路径
desired_caps['app']=r'D:\extend\kaoyanbang.apk'
# app的包名
desired_caps['appPackage']='com.tal.kaoyan'
# app 加载页面
desired_caps['appActivity']='com.tal.kaoyan.ui.activity.SplashActivity'
# 设置每次是否清除数据
desired_caps['noReset']='False'
# 是否使用unicode键盘输入,在输入中文字符和unicode字符时设置为true
desired_caps['unicodeKeyboard']="True"
# 是否将键盘重置为初始状态,设置了unicodeKeyboard时,在测试完成后,设置为true,将键盘重置
desired_caps['resetKeyboard']="True"
# appium服务器的连接地址
driver=webdriver.Remote('http://localhost:4723/wd/hub',desired_caps)
driver.implicitly_wait(2)
编写操作脚本
import random
import time
driver.find_element_by_id('com.tal.kaoyan:id/login_register_text').click()
username='zx2019'+'F2LY'+str(random.randint(1000,9000))
print('username: %s' %username)
driver.find_element_by_id('com.tal.kaoyan:id/activity_register_username_edittext').send_keys(username)
password='zxw2018'+str(random.randint(1000,9000))
print('password: %s' %password)
driver.find_element_by_id('com.tal.kaoyan:id/activity_register_password_edittext').send_keys(password)
email='51zxw'+str(random.randint(1000,9000))+'@163.com'
print('email: %s' %email)
driver.find_element_by_id('com.tal.kaoyan:id/activity_register_email_edittext').send_keys(email)
#点击进入考研帮
driver.find_element_by_id('com.tal.kaoyan:id/activity_register_register_btn').click()
#专业选择
driver.find_element_by_id('com.tal.kaoyan:id/activity_perfectinfomation_major').click()
driver.find_elements_by_id('com.tal.kaoyan:id/major_subject_title')[1].click()
driver.find_elements_by_id('com.tal.kaoyan:id/major_group_title')[2].click()
driver.find_elements_by_id('com.tal.kaoyan:id/major_search_item_name')[1].click()
#院校选择
driver.find_element_by_id('com.tal.kaoyan:id/activity_perfectinfomation_school').click()
driver.tap([(182,1557),])
driver.find_element_by_xpath('/hierarchy/android.widget.FrameLayout/'
'android.widget.LinearLayout/android.widget.FrameLayout/'
'android.widget.LinearLayout/android.widget.FrameLayout/android.widget.'
'RelativeLayout/android.widget.ExpandableListView/android.widget.'
'LinearLayout[1]/android.widget.TextView[1]').click()
driver.find_element_by_xpath('/hierarchy/android.widget.FrameLayout/'
'android.widget.LinearLayout/android.widget.FrameLayout/'
'android.widget.LinearLayout/android.widget.FrameLayout/'
'android.widget.RelativeLayout/android.widget.ExpandableListView/'
'android.widget.LinearLayout[4]/android.widget.TextView').click()
time.sleep(2)
driver.tap([(983,1354),])
# driver.find_elements_by_id('com.tal.kaoyan:id/more_forum_title')[1].click()
# driver.find_elements_by_id('com.tal.kaoyan:id/university_search_item_name')[1].click()
driver.find_element_by_id('com.tal.kaoyan:id/activity_perfectinfomation_goBtn').click()
print('注册成功')
到此这篇关于解读基于Android的Appium+Python自动化脚本编撰的文章就介绍到这了,更多相关Android的Appium+Python自动化脚本内容请搜索脚本之家先前的文章或继续浏览下边的相关文章希望你们之后多多支持脚本之家! 查看全部
详解基于Android的Appium+Python自动化脚本编撰
详解基于Android的Appium+Python自动化脚本编撰
更新时间:2020年08月20日 10:31:19 转载投稿:zx
这篇文章主要介绍了解读基于Android的Appium+Python自动化脚本编撰,文中通过示例代码介绍的十分详尽,对你们的学习或则工作具有一定的参考学习价值,需要的朋友们下边随着小编来一起学习学习吧
1.Appium
Appium是一个开源测试自动化框架,可用于原生,混合和联通Web应用程序测试, 它使用WebDriver合同驱动iOS,Android和Windows应用程序。
通过Appium,我们可以模拟点击和屏幕的滑动,可以获取元素的id和classname,还可以依照操作生成相关的脚本代码。
下面开始Appium的配置。
appPackage和APPActivity的获取
任意下载一个app
解压
但是解压下来的xml文件可能是乱码,所以我们须要反编译文件。
逆向AndroidManifest.xml
下载AXMLPrinter2.jar文件,逆向xml文件:命令行输入以下命令:
java -jar AXMLPrinter2.jar AndroidManifest.xml ->AndroidManifest.txt
获得以下可以查看的TXT文件
寻找带有launcher 的Activity
寻找manifest上面的package
Devicename的获取
通过命令行输入 adb devices:
appium的功能介绍
下面将按照上图序号一一介绍功能:
选中界面元素,显示元素相关信息
模拟滑动屏幕,先点击一下代表触摸起始位置,在点击一下代表触摸结束为止
模拟点击屏幕
模拟手机的返回按键
刷新一侧的页面,使之与手机同步
记录模拟操作,生成相关脚本
根据元素的id或则其他相关信息查找元素
复制当前界面的xml布局
文件退出
2.Python的脚本
元素定位的使用
(1).xpath定位
xpath定位是一种路径定位方法,主要是依赖于元素绝对路径或则相关属性来定位,但是绝对路径xpath执行效率比较低(特别是元素路径比较深的时侯),一般使用比较少。
通常使用xpath相对路径和属性定位。
by_xpath.py
from find_element.capability import driver
driver.find_element_by_xpath('//android.widget.EditText[@text="请输入用户名"]').send_keys('123456')
driver.find_element_by_xpath('//*[@class="android.widget.EditText" and @index="3"]').send_keys('123456')
driver.find_element_by_xpath('//android.widget.Button').click()
driver.find_element_by_xpath('//[@class="android.widget.Button"]').click()
(2).classname定位
classname定位是依据元素类型来进行定位,但是实际情况中好多元素的classname都是相同的,
如用户名和密码都是clasName属性值都是:“android.widget.EditText” 因此只能定位第一个元素也就是用户名,而密码输入框就须要使用其他方法来定位,这样也许太鸡肋.一般情况下假如有id就毋须使用classname定位。
by_classname.py
from find_element.capability import driver
driver.find_element_by_class_name('android.widget.EditText').send_keys('123565')
driver.find_element_by_class_name('android.widget.EditText').send_keys('456879')
driver.find_element_by_class_name('android.widget.Button').click()
(3).id定位
日常生活中身边可能存在相同名子的人,但是每位人的身份证号码是惟一的,在app界面元素中也可以使用id值来分辨不同的元素,然后进行定位操作。
Appium中可以使用 find_element_by_id() 方法来进行id定位。
driver.find_element_by_id('android:id/button2').click()
driver.find_element_by_id('com.tal.kaoyan:id/tv_skip').click()
3.示例:模拟软件的手动注册
首先配置联接属性
desired_caps={}
# 所使用的平台
desired_caps['platformName']='Android'
# 所使用的手机的名字 可以通过 adb devices 获得
desired_caps['deviceName']='127.0.0.1:62001'
# ANDROID 的版本
desired_caps['platforVersion']='5.1.1'
# app 的路径
desired_caps['app']=r'D:\extend\kaoyanbang.apk'
# app的包名
desired_caps['appPackage']='com.tal.kaoyan'
# app 加载页面
desired_caps['appActivity']='com.tal.kaoyan.ui.activity.SplashActivity'
# 设置每次是否清除数据
desired_caps['noReset']='False'
# 是否使用unicode键盘输入,在输入中文字符和unicode字符时设置为true
desired_caps['unicodeKeyboard']="True"
# 是否将键盘重置为初始状态,设置了unicodeKeyboard时,在测试完成后,设置为true,将键盘重置
desired_caps['resetKeyboard']="True"
# appium服务器的连接地址
driver=webdriver.Remote('http://localhost:4723/wd/hub',desired_caps)
driver.implicitly_wait(2)
编写操作脚本
import random
import time
driver.find_element_by_id('com.tal.kaoyan:id/login_register_text').click()
username='zx2019'+'F2LY'+str(random.randint(1000,9000))
print('username: %s' %username)
driver.find_element_by_id('com.tal.kaoyan:id/activity_register_username_edittext').send_keys(username)
password='zxw2018'+str(random.randint(1000,9000))
print('password: %s' %password)
driver.find_element_by_id('com.tal.kaoyan:id/activity_register_password_edittext').send_keys(password)
email='51zxw'+str(random.randint(1000,9000))+'@163.com'
print('email: %s' %email)
driver.find_element_by_id('com.tal.kaoyan:id/activity_register_email_edittext').send_keys(email)
#点击进入考研帮
driver.find_element_by_id('com.tal.kaoyan:id/activity_register_register_btn').click()
#专业选择
driver.find_element_by_id('com.tal.kaoyan:id/activity_perfectinfomation_major').click()
driver.find_elements_by_id('com.tal.kaoyan:id/major_subject_title')[1].click()
driver.find_elements_by_id('com.tal.kaoyan:id/major_group_title')[2].click()
driver.find_elements_by_id('com.tal.kaoyan:id/major_search_item_name')[1].click()
#院校选择
driver.find_element_by_id('com.tal.kaoyan:id/activity_perfectinfomation_school').click()
driver.tap([(182,1557),])
driver.find_element_by_xpath('/hierarchy/android.widget.FrameLayout/'
'android.widget.LinearLayout/android.widget.FrameLayout/'
'android.widget.LinearLayout/android.widget.FrameLayout/android.widget.'
'RelativeLayout/android.widget.ExpandableListView/android.widget.'
'LinearLayout[1]/android.widget.TextView[1]').click()
driver.find_element_by_xpath('/hierarchy/android.widget.FrameLayout/'
'android.widget.LinearLayout/android.widget.FrameLayout/'
'android.widget.LinearLayout/android.widget.FrameLayout/'
'android.widget.RelativeLayout/android.widget.ExpandableListView/'
'android.widget.LinearLayout[4]/android.widget.TextView').click()
time.sleep(2)
driver.tap([(983,1354),])
# driver.find_elements_by_id('com.tal.kaoyan:id/more_forum_title')[1].click()
# driver.find_elements_by_id('com.tal.kaoyan:id/university_search_item_name')[1].click()
driver.find_element_by_id('com.tal.kaoyan:id/activity_perfectinfomation_goBtn').click()
print('注册成功')
到此这篇关于解读基于Android的Appium+Python自动化脚本编撰的文章就介绍到这了,更多相关Android的Appium+Python自动化脚本内容请搜索脚本之家先前的文章或继续浏览下边的相关文章希望你们之后多多支持脚本之家!
使用Shell编撰定时向指定API获取数据的脚本
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2020-08-20 18:32
场景:这个在服务器上写定时脚本的情况十分多,比如每晚向定时往用户推送相关信息,定时清除相关数据,定时短信提醒等等。
本文的场景是采用shell定时向指定开放API获取数据。
本文使用的是crontab,可以先在终端查看是开启此服务,命令如下:
yang@master:~$ sudo service cron status
[sudo] password for yang:
● cron.service - Regular background program processing daemon
Loaded: loaded (/lib/systemd/system/cron.service; enabled; vendor preset: ena
Active: active (running) since Sat 2016-08-13 08:29:16 CST; 30min ago
Docs: man:cron(8)
Main PID: 831 (cron)
CGroup: /system.slice/cron.service
└─831 /usr/sbin/cron -f
Aug 13 08:29:16 master systemd[1]: Started Regular background program processing
Aug 13 08:29:16 master cron[831]: (CRON) INFO (pidfile fd = 3)
Aug 13 08:29:16 master cron[831]: (CRON) INFO (Running @reboot jobs)
编写定时脚本
这个脚本是我们要定时器定时执行的任务,即我们要定时做什么,在这里,我是要使脚本手动采集数据,脚本如下:
#!/usr/bin/env bash
path_log="fetch_data.log"
path_stuTenSch="http://www.google.com"
code_success="200"
#get http response code
http_code=$(curl -s -o /dev/null -I -w "%{http_code}" $path_stuTenSch)
#echo "$http_code" >> $path_log
if [ "$http_code"==$code_success ]; then
echo "Status Code:$http_code, success, Resquest URL: $path_stuTenSch" >> $path_log
echo "starting..........." >> $path_log
curl $path_stuTenSch > /home/hadoop/tmp_data/users.json
echo "end----------------" >> $path_log
else
echo "Status Code:$http_code, fail, Resquest URL: $path_stuTenSch" >> $path_log
fi
编辑crontab
编辑crontab是用crontab -e执行,crontab -l来显示有什么定时器。每个定时器用一行来表示。通常情况下,有6个参数,分别为分钟,小时,天,月,周,要执行的命令,*表示任意时间,/n表示每隔n的时间进行重复。
yang@master:~$ crontab -e
*/1 * * * * /home/yang/shell/fetch_data.sh
在这里,我是每隔一分钟执行一次sh脚本。 查看全部
使用Shell编撰定时向指定API获取数据的脚本
场景:这个在服务器上写定时脚本的情况十分多,比如每晚向定时往用户推送相关信息,定时清除相关数据,定时短信提醒等等。
本文的场景是采用shell定时向指定开放API获取数据。
本文使用的是crontab,可以先在终端查看是开启此服务,命令如下:
yang@master:~$ sudo service cron status
[sudo] password for yang:
● cron.service - Regular background program processing daemon
Loaded: loaded (/lib/systemd/system/cron.service; enabled; vendor preset: ena
Active: active (running) since Sat 2016-08-13 08:29:16 CST; 30min ago
Docs: man:cron(8)
Main PID: 831 (cron)
CGroup: /system.slice/cron.service
└─831 /usr/sbin/cron -f
Aug 13 08:29:16 master systemd[1]: Started Regular background program processing
Aug 13 08:29:16 master cron[831]: (CRON) INFO (pidfile fd = 3)
Aug 13 08:29:16 master cron[831]: (CRON) INFO (Running @reboot jobs)
编写定时脚本
这个脚本是我们要定时器定时执行的任务,即我们要定时做什么,在这里,我是要使脚本手动采集数据,脚本如下:
#!/usr/bin/env bash
path_log="fetch_data.log"
path_stuTenSch="http://www.google.com"
code_success="200"
#get http response code
http_code=$(curl -s -o /dev/null -I -w "%{http_code}" $path_stuTenSch)
#echo "$http_code" >> $path_log
if [ "$http_code"==$code_success ]; then
echo "Status Code:$http_code, success, Resquest URL: $path_stuTenSch" >> $path_log
echo "starting..........." >> $path_log
curl $path_stuTenSch > /home/hadoop/tmp_data/users.json
echo "end----------------" >> $path_log
else
echo "Status Code:$http_code, fail, Resquest URL: $path_stuTenSch" >> $path_log
fi
编辑crontab
编辑crontab是用crontab -e执行,crontab -l来显示有什么定时器。每个定时器用一行来表示。通常情况下,有6个参数,分别为分钟,小时,天,月,周,要执行的命令,*表示任意时间,/n表示每隔n的时间进行重复。
yang@master:~$ crontab -e
*/1 * * * * /home/yang/shell/fetch_data.sh
在这里,我是每隔一分钟执行一次sh脚本。
自己编撰网站防采集程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2020-08-20 18:15
对于我们这些数据量很大的网站,面临的一个麻烦是总有人来采集,以前多使用过人工检测、屏蔽的办法,这种办法有疗效但很费精力,前段时间也找了插件来自动限制最大连接数,但存在误屏蔽搜索引擎的问题,最近老朽下决定亲自操刀写程序,把那些采集器都斩草除根,虽然编程麻烦但效果好。
思路是在Drupal的模板文件中嵌入PHP程序代码,读取$_SERVER参数并记录到数据库中,通过对参数及访问频度的判定来决定是否要访问者递交验证码,如果验证码错误或则不填写的次数过多则屏蔽,可以通过host反向dns查找来判断常见搜索引擎。
这个程序还稍稍有点复杂,以前更改开源PHP程序都是直接上手,这个程序还编撰了流程图,数据库表结构也是自己规划的,为了防止拉慢速率,MySQL中采用了Memory引擎,对于多是临时访问记录早已够用了。程序写得太烂,就不放到博客中了。
这个程序anti-scraping.php上周调试了几天,本周刚才投入试用,已经可以从日志中见到疗效,还须要不断改进,例如降低黑名单、白名单、尝试改用Drupal标准第三方模块的形式等。因为完成采用自己编程实现,所以可以对判断标准、屏蔽方法做各类更改尝试,应对各类采集器。
版本历史:
To Do List: 查看全部
自己编撰网站防采集程序
对于我们这些数据量很大的网站,面临的一个麻烦是总有人来采集,以前多使用过人工检测、屏蔽的办法,这种办法有疗效但很费精力,前段时间也找了插件来自动限制最大连接数,但存在误屏蔽搜索引擎的问题,最近老朽下决定亲自操刀写程序,把那些采集器都斩草除根,虽然编程麻烦但效果好。
思路是在Drupal的模板文件中嵌入PHP程序代码,读取$_SERVER参数并记录到数据库中,通过对参数及访问频度的判定来决定是否要访问者递交验证码,如果验证码错误或则不填写的次数过多则屏蔽,可以通过host反向dns查找来判断常见搜索引擎。
这个程序还稍稍有点复杂,以前更改开源PHP程序都是直接上手,这个程序还编撰了流程图,数据库表结构也是自己规划的,为了防止拉慢速率,MySQL中采用了Memory引擎,对于多是临时访问记录早已够用了。程序写得太烂,就不放到博客中了。
这个程序anti-scraping.php上周调试了几天,本周刚才投入试用,已经可以从日志中见到疗效,还须要不断改进,例如降低黑名单、白名单、尝试改用Drupal标准第三方模块的形式等。因为完成采用自己编程实现,所以可以对判断标准、屏蔽方法做各类更改尝试,应对各类采集器。
版本历史:
To Do List:
自动采集编写 聊一聊爬虫那点事儿(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 486 次浏览 • 2020-08-20 02:08
爬虫学习入门篇
作为一名程序员,大家对于爬虫这个词的理解都有不同,我曾经的理解就是一只spider在网路上爬取东西,不过我们能控制这只spider去爬取须要内容并存取到数据库中。后来才发觉爬虫有点重要!!!
网络爬虫的介绍
在大数据时代,信息的采集是一项重要的工作,而互联网中的数据是海量的,如果单纯靠人力进行信息采集,不仅低效繁杂,搜集的成本也会增强。如何手动高效地获取互联网中我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这种问题而生的。
网络爬虫(Web crawler)也称作网路机器人,可以取代人们手动地在互联网中进行数据信息的采集与整理。它是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本,可以手动采集所有其才能访问到的页面内容,以获取相关数据。
从功能上来讲,爬虫通常分为数据采集,处理,储存三个部份。爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。
为什么要学爬虫可以实现搜索引擎。我们学会了爬虫编撰以后,就可以借助爬虫手动地采集互联网中的信息,采集回来后进行相应的储存或处理,在须要检索个别信息的时侯,只需在采集回来的信息中进行检索,即实现了私人的搜索引擎。大数据时代,可以使我们获取更多的数据源。在进行大数据剖析或则进行数据挖掘的时侯,需要有数据源进行剖析。我们可以从个别提供数据统计的网站获得,也可以从个别文献或内部资料中获得,但是这种获得数据的方法,有时很难满足我们对数据的需求,而自动从互联网中去找寻那些数据,则花费的精力过大。此时就可以借助爬虫技术,自动地从互联网中获取我们感兴趣的数据内容,并将这种数据内容爬取回去,作为我们的数据源,再进行更深层次的数据剖析,并获得更多有价值的信息。可以更好地进行搜索引擎优化(SEO)。对于好多SEO从业者来说,为了更好的完成工作,那么就必须要对搜索引擎的工作原理十分清楚,同时也须要把握搜索引擎爬虫的工作原理。而学习爬虫,可以更深层次地理解搜索引擎爬虫的工作原理,这样在进行搜索引擎优化时,才能知己知彼,百战不殆。有利于就业。从就业来说,爬虫工程师方向是不错的选择之一,因为目前爬虫工程师的需求越来越大,而能否胜任这方面岗位的人员较少,所以属于一个比较短缺的职业方向,并且随着大数据时代和人工智能的将至,爬虫技术的应用将越来越广泛,在未来会拥有挺好的发展空间。
爬虫入门程序1.环境打算
编译环境打算:
l JDK1.8l IntelliJ IDEAlIDEA自带的Maven
IDEA操作步骤:
1.创建Maven工程itcast-crawler-first并给pom.xml加入依赖
org.apache.httpcomponents
httpclient
4.5.3
org.slf4j
slf4j-log4j12
1.7.25
2.加入log4j.properties
log4j.rootLogger=DEBUG,A1
log4j.logger.cn.itcast = DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
2.编写代码 查看全部
自动采集编写 聊一聊爬虫那点事儿(一)
爬虫学习入门篇
作为一名程序员,大家对于爬虫这个词的理解都有不同,我曾经的理解就是一只spider在网路上爬取东西,不过我们能控制这只spider去爬取须要内容并存取到数据库中。后来才发觉爬虫有点重要!!!
网络爬虫的介绍
在大数据时代,信息的采集是一项重要的工作,而互联网中的数据是海量的,如果单纯靠人力进行信息采集,不仅低效繁杂,搜集的成本也会增强。如何手动高效地获取互联网中我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这种问题而生的。
网络爬虫(Web crawler)也称作网路机器人,可以取代人们手动地在互联网中进行数据信息的采集与整理。它是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本,可以手动采集所有其才能访问到的页面内容,以获取相关数据。
从功能上来讲,爬虫通常分为数据采集,处理,储存三个部份。爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。
为什么要学爬虫可以实现搜索引擎。我们学会了爬虫编撰以后,就可以借助爬虫手动地采集互联网中的信息,采集回来后进行相应的储存或处理,在须要检索个别信息的时侯,只需在采集回来的信息中进行检索,即实现了私人的搜索引擎。大数据时代,可以使我们获取更多的数据源。在进行大数据剖析或则进行数据挖掘的时侯,需要有数据源进行剖析。我们可以从个别提供数据统计的网站获得,也可以从个别文献或内部资料中获得,但是这种获得数据的方法,有时很难满足我们对数据的需求,而自动从互联网中去找寻那些数据,则花费的精力过大。此时就可以借助爬虫技术,自动地从互联网中获取我们感兴趣的数据内容,并将这种数据内容爬取回去,作为我们的数据源,再进行更深层次的数据剖析,并获得更多有价值的信息。可以更好地进行搜索引擎优化(SEO)。对于好多SEO从业者来说,为了更好的完成工作,那么就必须要对搜索引擎的工作原理十分清楚,同时也须要把握搜索引擎爬虫的工作原理。而学习爬虫,可以更深层次地理解搜索引擎爬虫的工作原理,这样在进行搜索引擎优化时,才能知己知彼,百战不殆。有利于就业。从就业来说,爬虫工程师方向是不错的选择之一,因为目前爬虫工程师的需求越来越大,而能否胜任这方面岗位的人员较少,所以属于一个比较短缺的职业方向,并且随着大数据时代和人工智能的将至,爬虫技术的应用将越来越广泛,在未来会拥有挺好的发展空间。
爬虫入门程序1.环境打算
编译环境打算:
l JDK1.8l IntelliJ IDEAlIDEA自带的Maven
IDEA操作步骤:
1.创建Maven工程itcast-crawler-first并给pom.xml加入依赖
org.apache.httpcomponents
httpclient
4.5.3
org.slf4j
slf4j-log4j12
1.7.25
2.加入log4j.properties
log4j.rootLogger=DEBUG,A1
log4j.logger.cn.itcast = DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
2.编写代码
自动采集编写 scrapy爬取新浪微博分享(2)
采集交流 • 优采云 发表了文章 • 0 个评论 • 376 次浏览 • 2020-08-18 23:34
内容概要:
最近自己学习了一些爬虫,学习之余,写了一个新浪微博的爬虫。大规模爬数据没有试过,但是爬取几十万应当没有哪些问题。爬虫爬取的站点是新浪移动端站点。github地址为:
第一次写文章,难免有疏漏,大家共同交流,共同进步。也请喜欢的同学,在github上打个star
内容分为三章,第一张介绍scrapy,第二张剖析爬取网站,第三章剖析代码。
Fiddler工具
Fiddler是坐落客户端和服务器端的HTTP代理,也是目前最常用的http抓包工具之一。它才能记录客户端和服务器之间的所有HTTP请求,可以针对特定的HTTP请求,分析恳求数据、设置断点、调试Web应用、请求更改数据、甚至可以更改服务器返回的数据,功能十分强悍,是WEB调试的神器。
既然是代理,也就是说:客户端的所有恳求都要先经过Fiddler,然后转发到相应的服务器,反之,服务器端的所有相应,也就会先经过Fiddler之后发送到客户端。
分析新浪微博数据结构
首先我们登陆微博可以看见Fiddler抓取的包:
其中点击 /api/container/getIndex?type=uid&value=6311254871&containerid=54871 HTTP/1.1我们可以看见微博获取个人信息的API接口,里面储存着json数据。
简单剖析下JSON,我们可以晓得上面储存着爱称、个性签名、微博数、关注数、粉丝数等个人信息。我们可以记录下我们须要的信息。
同理,我们通过不断剖析Fiddler抓取的包可以得到微博内容的API,粉丝列表的API,关注者列表的API。里面依然是JSON格式,我们从中记录下我们须要的信息。
编写Model层
刚刚我们记录下了各个API中我们须要抓取的信息,然后就可以在程序中编撰我们的数据层了。scrapy是用Django编撰的,他们的数据层基本是一样的,是由Django的ARM框架封装的。
类似于右图,我们把带抓取的数据格式写好:
把数据库配置好:
完成以上步骤就可以打算编撰我们的爬虫代码了。
参考:
1、《Python网路数据采集》
2、 查看全部
自动采集编写 scrapy爬取新浪微博分享(2)
内容概要:
最近自己学习了一些爬虫,学习之余,写了一个新浪微博的爬虫。大规模爬数据没有试过,但是爬取几十万应当没有哪些问题。爬虫爬取的站点是新浪移动端站点。github地址为:
第一次写文章,难免有疏漏,大家共同交流,共同进步。也请喜欢的同学,在github上打个star
内容分为三章,第一张介绍scrapy,第二张剖析爬取网站,第三章剖析代码。
Fiddler工具
Fiddler是坐落客户端和服务器端的HTTP代理,也是目前最常用的http抓包工具之一。它才能记录客户端和服务器之间的所有HTTP请求,可以针对特定的HTTP请求,分析恳求数据、设置断点、调试Web应用、请求更改数据、甚至可以更改服务器返回的数据,功能十分强悍,是WEB调试的神器。
既然是代理,也就是说:客户端的所有恳求都要先经过Fiddler,然后转发到相应的服务器,反之,服务器端的所有相应,也就会先经过Fiddler之后发送到客户端。
分析新浪微博数据结构
首先我们登陆微博可以看见Fiddler抓取的包:
其中点击 /api/container/getIndex?type=uid&value=6311254871&containerid=54871 HTTP/1.1我们可以看见微博获取个人信息的API接口,里面储存着json数据。
简单剖析下JSON,我们可以晓得上面储存着爱称、个性签名、微博数、关注数、粉丝数等个人信息。我们可以记录下我们须要的信息。
同理,我们通过不断剖析Fiddler抓取的包可以得到微博内容的API,粉丝列表的API,关注者列表的API。里面依然是JSON格式,我们从中记录下我们须要的信息。
编写Model层
刚刚我们记录下了各个API中我们须要抓取的信息,然后就可以在程序中编撰我们的数据层了。scrapy是用Django编撰的,他们的数据层基本是一样的,是由Django的ARM框架封装的。
类似于右图,我们把带抓取的数据格式写好:
把数据库配置好:
完成以上步骤就可以打算编撰我们的爬虫代码了。
参考:
1、《Python网路数据采集》
2、
全手动采集版小说网站不用管理
采集交流 • 优采云 发表了文章 • 0 个评论 • 386 次浏览 • 2020-08-18 16:03
商品属性
安装环境
商品介绍
您能找到这个小说源码,说明您准备用心建一个小说网站,做站最重要的就是稳定更新和程序的不断升级,你会选择仍然不升级的源码吗?该小说源码程序,定期更新,请放心使用建站。为什么选择dedecms做的这个程序做小说网,那是因为现今杰奇小说程序和模板猖獗,您假如想从几百万个一样的网站中脱引而出这么就选择这套dedecms开发的源码来建设您的网站吗?大家都晓得国外SEO好友的程序源码就是这个dedecms。还在迟疑哪些呢,赶快下手吧,建站和更新内容一样,越早越好。
全网仅此一家为正版域名授权,如果有其他店面销售,那肯定是二手或则山寨的了!
近期发觉有同行盗卖本店的程序,并且十分不厚道的说是他自己开发的,真是无语。
全新升级20151107版,支持:
百度主动推送
百度站内搜索
后台采集规则在线更新(目前预留)
多种章节内容储存方法
微信小说公众号验证平台(支持微信公众号自定义顶部菜单)
支持缓存功能等等,程序更快,负载更大!
重大更新,本程序被百度收录后,主页会手动显示logo,小说目录会手动小说模版适配:
还有好多功能是这些盗卖的难以提供的。
另外,本程序实行后台在线更新后,其他盗卖的就难以继续升级了,之前的更新都是直接提供更新包,而这些盗卖的就直接从群里拿了更新包说是自己提供的更新包。 我们故意拖延了半年没更新,结果就可想而知了......
我们的后台还提供了更新历史,可以查看每次更新了什么功能,并提供了新功能的使用说明......
1、源码类型:整站源码
2-1、环境要求:PHP5.2/5.3/5.4/5.5+MYSQL5(URLrewrite)
2-2、服务器要求:建议用40G数据盘以上的VPS或则独立服务器,系统建议用Windows而不建议用Linux,99%的小说站服务器是用Windows系统,方便文件管理以及备份等(目前演示站空间使用情况:6.5G数据库+5G网页空间,经群内站友网站证实:4核CPU+4G显存的xen构架VPS能承受日5万IP、50万PV流量毫无压力,每天收入700元以上)
3、原创程序:织梦DEDECMS 5.7SP1
4、编码类型:GBK
5、可否采集:全手动采集,赠送规则,好评后还可以免费订制一条
6、演示站点: ,自带手机版:(可提供免费友情链接)
7、安装升级:包安装、附带详尽使用说明,免费升级
8、其他特征:
(1)自动生成首页、分类、目录、作者、排行榜、sitemap页面静态html。
(2)全站拼音目录化(可自定义URL格式),章节页面伪静态。
(3)支持下载功能,可以手动生成对应文本文件,可在文件中设置广告。
(4)自动生成关键词及关键词手动内链。
(5)自动伪原创成语替换(采集、输出时都可以替换)。
(6)配合CNZZ的统计插件,能便捷实现下载明细统计和被采集的明细统计等。
(7)本程序的手动采集并非市面上常见的、关关、采集侠等,而是在DEDE原有采集功能的基础上二次开发的采集模块,可以有效的保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;一天24小时采集量能达到25~30万章节。
20140623更新后全面提高了本源码程序的采集功能,使采集速度更快、更稳定,后台可以单独优先采集某本小说,可以对无关紧要的章节手动进行过滤……
20140806更新后新增了【无缝换站采集功能】,当原先的采集目标站不能采集时,可切换到其他目标站进行采集,采集永不间断,章节永远;新增【自定义小说封面页URL】、【自定义作者页URL】;任何对章节的操作(新增、修改、删除、移动、合并等)执行后均手动更新小说封面的功能……
20141110本支持自动换站采集、自动换站,半自动添加单本采集,无采集规则或规则失效时手动提醒功能……
采集模式降低为3种,增加目标站章节正序采集功能,能采集市面上99%的小说站
20141205更新陌陌小说模块,可以在陌陌上看小说……
20150306更新后台全新的小说管理面板,功能更强大,操作更简单。增加单本自定义换站采集功能,增加小说百度指数查询,方便删掉没有指数的小说。增加批量删掉小说、批量更新小说简介页面的功能。优化全手动采集功能,不需要任何采集工具,不需要打开任何采集页面,只要网站有流量,就能时间更新书友最喜欢看的小说,与源站更新时间差保持在5秒以内……
20151020全新升级20多项功能,支持后台直接更新程序....
本程序本为20160414版,低于些版本都为盗卖。
给诸位新站长的友情提示:
不要相信这些所谓“有访客下载时才手动生成txt电子书”的外行说法,因为提出这些概念的人可以肯定他不是站长出生,没有服务器资源需求的概念!这里说明一下,txt电子书在生成的时侯是比较占用服务器资源的,同时生成1本小说的txt电子书大约会占用5%~8%左右的CPU以及部份硬碟I/O,但是假如须要同时生成20本小说的电子书的话,你的服务器都会吃不消,如果同时须要生成更多的电子书,那你的服务器就立刻奔溃了,整个网站都难以访问!如果使用须要下载的时侯再生成电子书的办法,你就要考虑一下当你的网站同时有几十个人在下载的时侯会是什么样的情况了。 查看全部
全手动采集版小说网站不用管理
商品属性
安装环境
商品介绍
您能找到这个小说源码,说明您准备用心建一个小说网站,做站最重要的就是稳定更新和程序的不断升级,你会选择仍然不升级的源码吗?该小说源码程序,定期更新,请放心使用建站。为什么选择dedecms做的这个程序做小说网,那是因为现今杰奇小说程序和模板猖獗,您假如想从几百万个一样的网站中脱引而出这么就选择这套dedecms开发的源码来建设您的网站吗?大家都晓得国外SEO好友的程序源码就是这个dedecms。还在迟疑哪些呢,赶快下手吧,建站和更新内容一样,越早越好。
全网仅此一家为正版域名授权,如果有其他店面销售,那肯定是二手或则山寨的了!
近期发觉有同行盗卖本店的程序,并且十分不厚道的说是他自己开发的,真是无语。
全新升级20151107版,支持:
百度主动推送
百度站内搜索
后台采集规则在线更新(目前预留)
多种章节内容储存方法
微信小说公众号验证平台(支持微信公众号自定义顶部菜单)
支持缓存功能等等,程序更快,负载更大!
重大更新,本程序被百度收录后,主页会手动显示logo,小说目录会手动小说模版适配:
还有好多功能是这些盗卖的难以提供的。
另外,本程序实行后台在线更新后,其他盗卖的就难以继续升级了,之前的更新都是直接提供更新包,而这些盗卖的就直接从群里拿了更新包说是自己提供的更新包。 我们故意拖延了半年没更新,结果就可想而知了......
我们的后台还提供了更新历史,可以查看每次更新了什么功能,并提供了新功能的使用说明......
1、源码类型:整站源码
2-1、环境要求:PHP5.2/5.3/5.4/5.5+MYSQL5(URLrewrite)
2-2、服务器要求:建议用40G数据盘以上的VPS或则独立服务器,系统建议用Windows而不建议用Linux,99%的小说站服务器是用Windows系统,方便文件管理以及备份等(目前演示站空间使用情况:6.5G数据库+5G网页空间,经群内站友网站证实:4核CPU+4G显存的xen构架VPS能承受日5万IP、50万PV流量毫无压力,每天收入700元以上)
3、原创程序:织梦DEDECMS 5.7SP1
4、编码类型:GBK
5、可否采集:全手动采集,赠送规则,好评后还可以免费订制一条
6、演示站点: ,自带手机版:(可提供免费友情链接)
7、安装升级:包安装、附带详尽使用说明,免费升级
8、其他特征:
(1)自动生成首页、分类、目录、作者、排行榜、sitemap页面静态html。
(2)全站拼音目录化(可自定义URL格式),章节页面伪静态。
(3)支持下载功能,可以手动生成对应文本文件,可在文件中设置广告。
(4)自动生成关键词及关键词手动内链。
(5)自动伪原创成语替换(采集、输出时都可以替换)。
(6)配合CNZZ的统计插件,能便捷实现下载明细统计和被采集的明细统计等。
(7)本程序的手动采集并非市面上常见的、关关、采集侠等,而是在DEDE原有采集功能的基础上二次开发的采集模块,可以有效的保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;一天24小时采集量能达到25~30万章节。
20140623更新后全面提高了本源码程序的采集功能,使采集速度更快、更稳定,后台可以单独优先采集某本小说,可以对无关紧要的章节手动进行过滤……
20140806更新后新增了【无缝换站采集功能】,当原先的采集目标站不能采集时,可切换到其他目标站进行采集,采集永不间断,章节永远;新增【自定义小说封面页URL】、【自定义作者页URL】;任何对章节的操作(新增、修改、删除、移动、合并等)执行后均手动更新小说封面的功能……
20141110本支持自动换站采集、自动换站,半自动添加单本采集,无采集规则或规则失效时手动提醒功能……
采集模式降低为3种,增加目标站章节正序采集功能,能采集市面上99%的小说站
20141205更新陌陌小说模块,可以在陌陌上看小说……
20150306更新后台全新的小说管理面板,功能更强大,操作更简单。增加单本自定义换站采集功能,增加小说百度指数查询,方便删掉没有指数的小说。增加批量删掉小说、批量更新小说简介页面的功能。优化全手动采集功能,不需要任何采集工具,不需要打开任何采集页面,只要网站有流量,就能时间更新书友最喜欢看的小说,与源站更新时间差保持在5秒以内……
20151020全新升级20多项功能,支持后台直接更新程序....
本程序本为20160414版,低于些版本都为盗卖。
给诸位新站长的友情提示:
不要相信这些所谓“有访客下载时才手动生成txt电子书”的外行说法,因为提出这些概念的人可以肯定他不是站长出生,没有服务器资源需求的概念!这里说明一下,txt电子书在生成的时侯是比较占用服务器资源的,同时生成1本小说的txt电子书大约会占用5%~8%左右的CPU以及部份硬碟I/O,但是假如须要同时生成20本小说的电子书的话,你的服务器都会吃不消,如果同时须要生成更多的电子书,那你的服务器就立刻奔溃了,整个网站都难以访问!如果使用须要下载的时侯再生成电子书的办法,你就要考虑一下当你的网站同时有几十个人在下载的时侯会是什么样的情况了。
web网路漏洞扫描器编撰
采集交流 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2020-08-18 00:36
这三天看了好多web漏洞扫描器编撰的文章,比如W12scan以及其前身W8scan,还有猪猪侠的自动化功击背景下的过去、现在与未来,以及网上好多优秀的扫描器和博客,除了之前写了一部分的静湖ABC段扫描器,接下来有空的大部分时间就会用于编撰这个扫描器,相当于是对自己的一个阶段性挑战吧,也算是为了建立自己的技术栈。
因为想把扫描器弄成web应用,像W12scan,bugscan,AWVS那样的,部署好了以后登录,添加须要扫描的url,自动化进行漏洞扫描,首先须要将扫描器的web界面完成,也就是前前端弄好,漏洞扫描作为前面添加进去的功能,在原基础上进行更改。
因为时间不是太充裕,所以选择Flask框架进行web的开发,学习的视频是:
找了许久的视频,要么就是太紧了,对于好多地方没有讲透彻,要么就是几百集的教程丢过来,过于冗长。
文档可以看官方文档,或者是这个:
当然遇见不会的问题还须要微软搜索一下,发挥自己的主观能动性。
接下来渐渐更新这一篇博客,先学Flask,哪里不会点技能树的那里吧。当然也不能舍弃代码审计,CTF和网课的学习
2020/4/2更新
框架快搭建好了,先做了登陆界面
然后扫描器的基础功能也在readme上面写好了,侧重的功能模块是信息采集和FUZZ模块
碎遮 Web漏洞扫描器
环境要求:
python版本要求:3.x,python运行需要的类库在requirements.txt中,执行
pip3 install -r requirements.txt
进行类库的下载
主要功能:
一,输入源采集:
1,基于流量清洗
2,基于日志提取
3,基于爬虫提取
二,输入源信息搜集(+)
1,被动信息搜集:(公开渠道可获得信息,与目标系统不产生直接交互)
1,whois 信息 获取关键注册人的信息 chinaz
2,在线子域名挖掘(这里不会ban掉自身IP,放进被动信息搜集中)
3,绕过CDN查找真实IP
4,DNS信息搜集
5,旁站查询
6,云悉指纹
7,备案信息
8,搜索引擎搜索
9,备案查询
2,主动信息搜集:
1,旁站C段服务简单扫描
2,子域名爆破
3,CMS指纹识别
4,敏感目录,文件扫描
5,端口及运行服务
6,服务器及中间件信息
7,WAF检测
8,敏感信息泄露 .svn,.git 等等
9,登录界面发现
三,SQL注入漏洞
四,XSS漏洞检测
五,命令执行类漏洞
六,文件包含类漏洞
七,登录弱密码爆破
八,FUZZ模块
可视化界面:
使用flask+javascript+html+css编写
启动index.py,在浏览器中访问127.0.0.1:5000访问
准备开始模块的编撰,加油趴
整个项目如今完成了1/3的样子,因为自己缺少构架的经验,所以暂时只能走一步看一步,最开始使用MySQL数据库打算换成redis非关系型数据库推动读写速率,扫描器在写的过程中丰富了自己对于各方面知识的把握
贴上W12scan的代码构架乡楼
从构架图上面跟自己扫描器的看法进行了一些验证和补充。自己写的时侯应当不会用到elastic,可以考虑使用redis和MySQL数据库两个互相进行配合储存数据。
另外在扫描范围上要进行合法范围的扩大化。 查看全部
web网路漏洞扫描器编撰
这三天看了好多web漏洞扫描器编撰的文章,比如W12scan以及其前身W8scan,还有猪猪侠的自动化功击背景下的过去、现在与未来,以及网上好多优秀的扫描器和博客,除了之前写了一部分的静湖ABC段扫描器,接下来有空的大部分时间就会用于编撰这个扫描器,相当于是对自己的一个阶段性挑战吧,也算是为了建立自己的技术栈。
因为想把扫描器弄成web应用,像W12scan,bugscan,AWVS那样的,部署好了以后登录,添加须要扫描的url,自动化进行漏洞扫描,首先须要将扫描器的web界面完成,也就是前前端弄好,漏洞扫描作为前面添加进去的功能,在原基础上进行更改。
因为时间不是太充裕,所以选择Flask框架进行web的开发,学习的视频是:
找了许久的视频,要么就是太紧了,对于好多地方没有讲透彻,要么就是几百集的教程丢过来,过于冗长。
文档可以看官方文档,或者是这个:
当然遇见不会的问题还须要微软搜索一下,发挥自己的主观能动性。
接下来渐渐更新这一篇博客,先学Flask,哪里不会点技能树的那里吧。当然也不能舍弃代码审计,CTF和网课的学习
2020/4/2更新
框架快搭建好了,先做了登陆界面
然后扫描器的基础功能也在readme上面写好了,侧重的功能模块是信息采集和FUZZ模块
碎遮 Web漏洞扫描器
环境要求:
python版本要求:3.x,python运行需要的类库在requirements.txt中,执行
pip3 install -r requirements.txt
进行类库的下载
主要功能:
一,输入源采集:
1,基于流量清洗
2,基于日志提取
3,基于爬虫提取
二,输入源信息搜集(+)
1,被动信息搜集:(公开渠道可获得信息,与目标系统不产生直接交互)
1,whois 信息 获取关键注册人的信息 chinaz
2,在线子域名挖掘(这里不会ban掉自身IP,放进被动信息搜集中)
3,绕过CDN查找真实IP
4,DNS信息搜集
5,旁站查询
6,云悉指纹
7,备案信息
8,搜索引擎搜索
9,备案查询
2,主动信息搜集:
1,旁站C段服务简单扫描
2,子域名爆破
3,CMS指纹识别
4,敏感目录,文件扫描
5,端口及运行服务
6,服务器及中间件信息
7,WAF检测
8,敏感信息泄露 .svn,.git 等等
9,登录界面发现
三,SQL注入漏洞
四,XSS漏洞检测
五,命令执行类漏洞
六,文件包含类漏洞
七,登录弱密码爆破
八,FUZZ模块
可视化界面:
使用flask+javascript+html+css编写
启动index.py,在浏览器中访问127.0.0.1:5000访问
准备开始模块的编撰,加油趴
整个项目如今完成了1/3的样子,因为自己缺少构架的经验,所以暂时只能走一步看一步,最开始使用MySQL数据库打算换成redis非关系型数据库推动读写速率,扫描器在写的过程中丰富了自己对于各方面知识的把握
贴上W12scan的代码构架乡楼
从构架图上面跟自己扫描器的看法进行了一些验证和补充。自己写的时侯应当不会用到elastic,可以考虑使用redis和MySQL数据库两个互相进行配合储存数据。
另外在扫描范围上要进行合法范围的扩大化。
第04期:Prometheus 数据采集(三)
采集交流 • 优采云 发表了文章 • 0 个评论 • 433 次浏览 • 2020-08-17 22:27
本期作者:罗韦
爱可生上海研发中心成员,研发工程师,主要负责 DMP 平台监控告警功能的相关工作。
Prometheus 的监控对象各式各样,没有统一标准。为了解决这个问题,Prometheus 制定了一套监控规范,符合这个规范的样本数据可以被 Prometheus 采集并解析样本数据。Exporter 在 Prometheus 监控系统中是一个采集监控数据并通过 Prometheus 监控规范对外提供数据的组件,针对不同的监控对象可以实现不同的 Exporter,这样就解决了监控对象标准不一的问题。从广义上说,所有可以向 Prometheus 提供监控样本数据的程序都可以称为 Exporter,Exporter 的实例也就是我们上期所说的"target"。
Exporter 的运行方法Exporter 有两种运行方法Exporter 接口数据规范
Exporter 通过 HTTP 接口以文本方式向 Prometheus 暴露样本数据,格式简单,没有嵌套,可读性强。每个监控指标对应的数据文本格式如下:
# HELP
# TYPE
{ =,=...}
{ =,=...}
...
# HELP x balabala
# TYPE x summary
x{quantile="0.5"} value1
x{quantile="0.9"} value2
x{quantile="0.99"} value3
x_sum sum(values)
x_count count(values)
# HELP x The temperature of cpu
# TYPE x histogram
x_bucket{le="20"} value1
x_bucket{le="50"} value2
x_bucket{le="70"} value3
x_bucket{le="+Inf"} count(values)
x_sum sum(values)
x_count count(values)
这样的文本格式也有不足之处:
1. 文本内容可能过分繁琐;
2. Prometheus 在解析时不能校准 HELP 和 TYPE 字段是否缺位,如果缺位 HELP 字段,这条样本数据的来源可能就无法判定;如果缺位 TYPE 字段,Prometheus 对这条样本数据的类型就无从得悉;
3. 相比于 protobuf,Prometheus 使用的文本格式没有做任何压缩处理,解析成本较高。
MySQL Server Exporter
针对被广泛使用的关系型数据库 MySQL,Prometheus 官方提供了 MySQL Server Exporter,支持 MySQL 5.6 及以上版本,对于 5.6 以下的版本,部分监控指标可能不支持。
MySQL Server Exporter 监控的信息包括了常用的 global status/variables 信息、schema/table 的统计信息、user 统计信息、innodb 的信息以及主从复制、组复制的信息,监控指标比较全面。但是因为它提供的监控指标中缺乏对 MySQL 实例的标示,所以当一台主机上存在多个 MySQL 实例,需要运行多个 MySQL Server Exporter 进行监控时,就会无法分辨实例信息。具体使用方法可参考:
Node Exporter
Prometheus 官方的 Node Exporter 提供对 *NIX 系统、硬件信息的监控,监控指标包括 CPU 使用率/配置、系统平均负载、内存信息、网络状况、文件系统信息统计、磁盘使用情况统计等。对于不同的系统,监控指标会有所差别,如 diskstats 支持 Darwin, Linux, OpenBSD 系统;loadavg 支持 Darwin, Dragonfly, FreeBSD, Linux, NetBSD, OpenBSD, Solaris 系统。Node Exporter 的监控指标没有对主机身分的标示,可以通过 relabel 功能在 Prometheus Server 端降低一些标示标签。具体使用方法可参考:
如何实现一个 Exporter编撰一个简单的 Exporter
使用 prometheus/client_golang 包,我们来编撰一个简单的 Exporter,包括 Prometheus 支持的四种监控指标类型
package main
import (
"log"
"net/http"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var (
//使用GaugeVec类型可以为监控指标设置标签,这里为监控指标增加一个标签"device"
speed = prometheus.NewGaugeVec(prometheus.GaugeOpts{
Name: "disk_available_bytes",
Help: "Disk space available in bytes",
}, []string{"device"})
tasksTotal = prometheus.NewCounter(prometheus.CounterOpts{
Name: "test_tasks_total",
Help: "Total number of test tasks",
})
taskDuration = prometheus.NewSummary(prometheus.SummaryOpts{
Name: "task_duration_seconds",
Help: "Duration of task in seconds",
//Summary类型的监控指标需要提供分位点
Objectives: map[float64]float64{0.5: 0.05, 0.9: 0.01, 0.99: 0.001},
})
cpuTemperature = prometheus.NewHistogram(prometheus.HistogramOpts{
Name: "cpu_temperature",
Help: "The temperature of cpu",
//Histogram类型的监控指标需要提供Bucket
Buckets: []float64{20, 50, 70, 80},
})
)
func init() {
//注册监控指标
prometheus.MustRegister(speed)
prometheus.MustRegister(tasksTotal)
prometheus.MustRegister(taskDuration)
prometheus.MustRegister(cpuTemperature)
}
func main() {
//模拟采集监控数据
fakeData()
//使用prometheus提供的promhttp.Handler()暴露监控样本数据
//prometheus默认从"/metrics"接口拉取监控样本数据
http.Handle("/metrics", promhttp.Handler())
log.Fatal(http.ListenAndServe(":10000", nil))
}
func fakeData() {
tasksTotal.Inc()
//设置该条样本数据的"device"标签值为"/dev/sda"
speed.With(prometheus.Labels{"device": "/dev/sda"}).Set(82115880)
taskDuration.Observe(10)
taskDuration.Observe(20)
taskDuration.Observe(30)
taskDuration.Observe(45)
taskDuration.Observe(56)
taskDuration.Observe(80)
cpuTemperature.Observe(30)
cpuTemperature.Observe(43)
cpuTemperature.Observe(56)
cpuTemperature.Observe(58)
cpuTemperature.Observe(65)
cpuTemperature.Observe(70)
}
接下来编译、运行我们的 Exporter
GOOS=linux GOARCH=amd64 go build -o my_exporter main.go
./my_exporter &
Exporter 运行上去以后,还要在 Prometheus 的配置文件中加入 Exporter 信息,Prometheus 才能从 Exporter 拉取数据。
static_configs:
- targets: ['localhost:9090','172.17.0.3:10000']
在 Prometheus 的 targets 页面可以看见刚刚新增的 Exporter 了
untitled.png
访问"/metrics"接口可以找到如下数据:
Gauge
因为我们使用了 GaugeVec,所以形成了带标签的样本数据
# HELP disk_available_bytes disk space available in bytes
# TYPE disk_available_bytes gauge
disk_available_bytes{device="/dev/sda"} 8.211588e+07
Counter
# HELP test_tasks_total total number of test tasks
# TYPE test_tasks_total counter
test_tasks_total 1
Summary
# HELP task_duration_seconds Duration of task in seconds
# TYPE task_duration_seconds summary
task_duration_seconds{quantile="0.5"} 30
task_duration_seconds{quantile="0.9"} 80
task_duration_seconds{quantile="0.99"} 80
task_duration_seconds_sum 241
task_duration_seconds_count 6
Histogram
# HELP cpu_temperature The temperature of cpu
# TYPE cpu_temperature histogram
cpu_temperature_bucket{le="20"} 0
cpu_temperature_bucket{le="50"} 2
cpu_temperature_bucket{le="70"} 6
cpu_temperature_bucket{le="80"} 6
cpu_temperature_bucket{le="+Inf"} 6
cpu_temperature_sum 322
cpu_temperature_count 6
Exporter实现方法的审视
上面的板栗中,我们在程序一开始就初始化所有的监控指标,这种方案一般接下来会开启一个取样解释器去定期采集、更新监控指标的样本数据,最新的样本数据将仍然保留在显存中,在接到 Prometheus Server 的恳求时,返回显存里的样本数据。这个方案的优点在于,易于控制取样频度;不用害怕并发取样可能带来的资源占据问题。不足之处有:
1. 由于样本数据不会被手动清除,当某个已被取样的采集对象失效了,Prometheus Server 依然能拉取到它的样本数据,只是这个数据从监控对象失效时就早已不会再被更新。这就须要 Exporter 自己提供一个对无效监控对象的数据清除机制;
2. 由于响应 Prometheus Server 的恳求是从显存里取数据,如果 Exporter 的取样解释器异常卡住,Prometheus Server 也难以感知,拉取到的数据可能是过期数据;
3. Prometheus Server 拉取的数据不是即时取样的,对于某时间点的数据一致性不能保证。
另一种方案是 MySQL Server Exporter 和 Node Exporter 采用的,也是 Prometheus 官方推荐的方案。该方案是在每次接到 Prometheus Server 的恳求时,初始化新的监控指标,开启一个取样解释器。和方案一不同的是,这些监控指标只在恳求期间存活。然后取样解释器会去采集所有样本数据并返回给 Prometheus Server。相比于方案一,方案二的数据是即时拉取的,可以保证时间点的数据一致性;因为监控指标会在每次恳求时重新初始化,所以也不会存在失效的样本数据。不过方案二同样有不足之处:
1. 当多个拉取恳求同时发生时,需要控制并发采集样本的资源消耗;
2. 当多个拉取恳求同时发生时,在短时间内须要对同一个监控指标读取多次,对于一个变化频度较低的监控指标来说,多次读取意义不大,却降低了对资源的占用。
相关内容方面的知识,大家还有哪些疑惑或则想知道的吗?赶紧留言告诉小编吧! 查看全部
第04期:Prometheus 数据采集(三)
本期作者:罗韦
爱可生上海研发中心成员,研发工程师,主要负责 DMP 平台监控告警功能的相关工作。
Prometheus 的监控对象各式各样,没有统一标准。为了解决这个问题,Prometheus 制定了一套监控规范,符合这个规范的样本数据可以被 Prometheus 采集并解析样本数据。Exporter 在 Prometheus 监控系统中是一个采集监控数据并通过 Prometheus 监控规范对外提供数据的组件,针对不同的监控对象可以实现不同的 Exporter,这样就解决了监控对象标准不一的问题。从广义上说,所有可以向 Prometheus 提供监控样本数据的程序都可以称为 Exporter,Exporter 的实例也就是我们上期所说的"target"。
Exporter 的运行方法Exporter 有两种运行方法Exporter 接口数据规范
Exporter 通过 HTTP 接口以文本方式向 Prometheus 暴露样本数据,格式简单,没有嵌套,可读性强。每个监控指标对应的数据文本格式如下:
# HELP
# TYPE
{ =,=...}
{ =,=...}
...
# HELP x balabala
# TYPE x summary
x{quantile="0.5"} value1
x{quantile="0.9"} value2
x{quantile="0.99"} value3
x_sum sum(values)
x_count count(values)
# HELP x The temperature of cpu
# TYPE x histogram
x_bucket{le="20"} value1
x_bucket{le="50"} value2
x_bucket{le="70"} value3
x_bucket{le="+Inf"} count(values)
x_sum sum(values)
x_count count(values)
这样的文本格式也有不足之处:
1. 文本内容可能过分繁琐;
2. Prometheus 在解析时不能校准 HELP 和 TYPE 字段是否缺位,如果缺位 HELP 字段,这条样本数据的来源可能就无法判定;如果缺位 TYPE 字段,Prometheus 对这条样本数据的类型就无从得悉;
3. 相比于 protobuf,Prometheus 使用的文本格式没有做任何压缩处理,解析成本较高。
MySQL Server Exporter
针对被广泛使用的关系型数据库 MySQL,Prometheus 官方提供了 MySQL Server Exporter,支持 MySQL 5.6 及以上版本,对于 5.6 以下的版本,部分监控指标可能不支持。
MySQL Server Exporter 监控的信息包括了常用的 global status/variables 信息、schema/table 的统计信息、user 统计信息、innodb 的信息以及主从复制、组复制的信息,监控指标比较全面。但是因为它提供的监控指标中缺乏对 MySQL 实例的标示,所以当一台主机上存在多个 MySQL 实例,需要运行多个 MySQL Server Exporter 进行监控时,就会无法分辨实例信息。具体使用方法可参考:
Node Exporter
Prometheus 官方的 Node Exporter 提供对 *NIX 系统、硬件信息的监控,监控指标包括 CPU 使用率/配置、系统平均负载、内存信息、网络状况、文件系统信息统计、磁盘使用情况统计等。对于不同的系统,监控指标会有所差别,如 diskstats 支持 Darwin, Linux, OpenBSD 系统;loadavg 支持 Darwin, Dragonfly, FreeBSD, Linux, NetBSD, OpenBSD, Solaris 系统。Node Exporter 的监控指标没有对主机身分的标示,可以通过 relabel 功能在 Prometheus Server 端降低一些标示标签。具体使用方法可参考:
如何实现一个 Exporter编撰一个简单的 Exporter
使用 prometheus/client_golang 包,我们来编撰一个简单的 Exporter,包括 Prometheus 支持的四种监控指标类型
package main
import (
"log"
"net/http"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var (
//使用GaugeVec类型可以为监控指标设置标签,这里为监控指标增加一个标签"device"
speed = prometheus.NewGaugeVec(prometheus.GaugeOpts{
Name: "disk_available_bytes",
Help: "Disk space available in bytes",
}, []string{"device"})
tasksTotal = prometheus.NewCounter(prometheus.CounterOpts{
Name: "test_tasks_total",
Help: "Total number of test tasks",
})
taskDuration = prometheus.NewSummary(prometheus.SummaryOpts{
Name: "task_duration_seconds",
Help: "Duration of task in seconds",
//Summary类型的监控指标需要提供分位点
Objectives: map[float64]float64{0.5: 0.05, 0.9: 0.01, 0.99: 0.001},
})
cpuTemperature = prometheus.NewHistogram(prometheus.HistogramOpts{
Name: "cpu_temperature",
Help: "The temperature of cpu",
//Histogram类型的监控指标需要提供Bucket
Buckets: []float64{20, 50, 70, 80},
})
)
func init() {
//注册监控指标
prometheus.MustRegister(speed)
prometheus.MustRegister(tasksTotal)
prometheus.MustRegister(taskDuration)
prometheus.MustRegister(cpuTemperature)
}
func main() {
//模拟采集监控数据
fakeData()
//使用prometheus提供的promhttp.Handler()暴露监控样本数据
//prometheus默认从"/metrics"接口拉取监控样本数据
http.Handle("/metrics", promhttp.Handler())
log.Fatal(http.ListenAndServe(":10000", nil))
}
func fakeData() {
tasksTotal.Inc()
//设置该条样本数据的"device"标签值为"/dev/sda"
speed.With(prometheus.Labels{"device": "/dev/sda"}).Set(82115880)
taskDuration.Observe(10)
taskDuration.Observe(20)
taskDuration.Observe(30)
taskDuration.Observe(45)
taskDuration.Observe(56)
taskDuration.Observe(80)
cpuTemperature.Observe(30)
cpuTemperature.Observe(43)
cpuTemperature.Observe(56)
cpuTemperature.Observe(58)
cpuTemperature.Observe(65)
cpuTemperature.Observe(70)
}
接下来编译、运行我们的 Exporter
GOOS=linux GOARCH=amd64 go build -o my_exporter main.go
./my_exporter &
Exporter 运行上去以后,还要在 Prometheus 的配置文件中加入 Exporter 信息,Prometheus 才能从 Exporter 拉取数据。
static_configs:
- targets: ['localhost:9090','172.17.0.3:10000']
在 Prometheus 的 targets 页面可以看见刚刚新增的 Exporter 了
untitled.png
访问"/metrics"接口可以找到如下数据:
Gauge
因为我们使用了 GaugeVec,所以形成了带标签的样本数据
# HELP disk_available_bytes disk space available in bytes
# TYPE disk_available_bytes gauge
disk_available_bytes{device="/dev/sda"} 8.211588e+07
Counter
# HELP test_tasks_total total number of test tasks
# TYPE test_tasks_total counter
test_tasks_total 1
Summary
# HELP task_duration_seconds Duration of task in seconds
# TYPE task_duration_seconds summary
task_duration_seconds{quantile="0.5"} 30
task_duration_seconds{quantile="0.9"} 80
task_duration_seconds{quantile="0.99"} 80
task_duration_seconds_sum 241
task_duration_seconds_count 6
Histogram
# HELP cpu_temperature The temperature of cpu
# TYPE cpu_temperature histogram
cpu_temperature_bucket{le="20"} 0
cpu_temperature_bucket{le="50"} 2
cpu_temperature_bucket{le="70"} 6
cpu_temperature_bucket{le="80"} 6
cpu_temperature_bucket{le="+Inf"} 6
cpu_temperature_sum 322
cpu_temperature_count 6
Exporter实现方法的审视
上面的板栗中,我们在程序一开始就初始化所有的监控指标,这种方案一般接下来会开启一个取样解释器去定期采集、更新监控指标的样本数据,最新的样本数据将仍然保留在显存中,在接到 Prometheus Server 的恳求时,返回显存里的样本数据。这个方案的优点在于,易于控制取样频度;不用害怕并发取样可能带来的资源占据问题。不足之处有:
1. 由于样本数据不会被手动清除,当某个已被取样的采集对象失效了,Prometheus Server 依然能拉取到它的样本数据,只是这个数据从监控对象失效时就早已不会再被更新。这就须要 Exporter 自己提供一个对无效监控对象的数据清除机制;
2. 由于响应 Prometheus Server 的恳求是从显存里取数据,如果 Exporter 的取样解释器异常卡住,Prometheus Server 也难以感知,拉取到的数据可能是过期数据;
3. Prometheus Server 拉取的数据不是即时取样的,对于某时间点的数据一致性不能保证。
另一种方案是 MySQL Server Exporter 和 Node Exporter 采用的,也是 Prometheus 官方推荐的方案。该方案是在每次接到 Prometheus Server 的恳求时,初始化新的监控指标,开启一个取样解释器。和方案一不同的是,这些监控指标只在恳求期间存活。然后取样解释器会去采集所有样本数据并返回给 Prometheus Server。相比于方案一,方案二的数据是即时拉取的,可以保证时间点的数据一致性;因为监控指标会在每次恳求时重新初始化,所以也不会存在失效的样本数据。不过方案二同样有不足之处:
1. 当多个拉取恳求同时发生时,需要控制并发采集样本的资源消耗;
2. 当多个拉取恳求同时发生时,在短时间内须要对同一个监控指标读取多次,对于一个变化频度较低的监控指标来说,多次读取意义不大,却降低了对资源的占用。
相关内容方面的知识,大家还有哪些疑惑或则想知道的吗?赶紧留言告诉小编吧!
Golddata怎么采集需要登入/会话的数据?
采集交流 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2020-08-14 14:05
点击“采集管理》网站管理”,点击“添加”按扭,添加名为mydict的站点。如下所示:
接下来配制登陆和检测会话脚本,点击“设置半自动登陆”,会打开站点半自动登陆配制页面,如下图所示:
登录脚本如下:
//发送ajax请求验证码
var va=$ajax('http://localhost:8080/code/vcode?timestamp=1554001708730',{encoding:false});
var arg_={
label:site.name+"验证码",
type:1,
content:va.content
}
//waitForInput内置函数将发送邮件,并等待输入
//(回复邮件,或者goldData平台输入),
//并把输入内容当作验证码返回。
var code=waitForInput(arg_);
var data="username=admin&password=admin&vcode="+code
var m=new Map()
m.put('Cookie',va.cookie)
//发送ajax请求执行登录
var content=$ajax('http://localhost:8080/doLogin',{method:'POST',headers:m,data:data})
//如果正确,将返回状态1(登录成功),和headers信息给GoldData,
//否则返回0(登录失败)!
if(content.headers){
m.putAll(content.headers)
}
var ret={status:1,headers:m}
if(content.status!=200){
ret.status=0
}
ret
检查脚本如下:
var ret=true;
if(html.contains("我的单词-登录")){
ret=false
}
ret;
配制好以后,我们回到网站管理页面,点击“启动登陆”,则会开始执行“自动登入”,这以后,点击“查询”按扭来刷新页面,可以见到“等待输入”的状态。如下图所示:
此时,您设置的通知邮箱,也应当同时收到了电邮。点开电邮,或者点击页面上的“录入等待输入”按扭,将会听到如下内容:
依据电邮内容,回复电邮“{{qcxe}}”,就可以使程序继续执行。在golddata页面里输入"qcxe",效果是一样的。程序将会回到“waitForInput()”,并且返回输入的内容。
回复以后,我们将在golddata页面里,点击“查询”刷新页面,mydict的登陆状态会变为“已登陆”。如下图所示:
接下来,我们可以定义抓取规则。
定义抓取规则
在添加规则之前,我们还须要定义类似于表结构的数据集。如下图所示:
接下来,点击“采集管理》规则管理”,添加规则,打开添加规则页面,如下图所示:
抓取规则脚本如下:
[
{
__sample: http://localhost:8080/word/index?pageNum=2
match0: http\:\/\/localhost\:8080\/word\/index(\?pageNum=\d+)?
fields0:
{
__model: true
__dataset: word
__node: "#content ul >li"
sn:
{
expr: ""
attr: ""
js: md5(item.name)
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
name:
{
expr: h5
attr: ""
js: ""
__label: ""
__showOnList: true
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
uk:
{
expr: li span.uk
attr: ""
js: source.replace("uk: ",'')
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
us:
{
expr: li span.us
attr: ""
js: source.replace("us: ",'')
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
}
fields1:
{
__node: .pagination a
href:
{
expr: a
attr: abs:href
js: ""
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
}
}
]
然后点击测试,将会进行测试抓取。我们发觉数据的确被抓取到了,如下图所示:
配制抓取器抓取
这和之前是一样的,将抓取器设置抓取站点“mydict”.然后点击开始抓取。然后会在数据管理上面查看抓取的数据。
结论
GoldData半自动登陆实质是提供了一个可以人工介入来异步获取会话的框架,既可以调用AI插口做到完全手动登入;也可以将类似于验证码须要复杂辨识须要提供输入时,直接将cookie或则token信息通过短信收发到GoldData平台(这样可以不管CAPTCHA多复杂 ),都可以使GoldData抓取数据的动作持续进行下去。 查看全部
编写登陆和检测会话脚本
点击“采集管理》网站管理”,点击“添加”按扭,添加名为mydict的站点。如下所示:
接下来配制登陆和检测会话脚本,点击“设置半自动登陆”,会打开站点半自动登陆配制页面,如下图所示:
登录脚本如下:
//发送ajax请求验证码
var va=$ajax('http://localhost:8080/code/vcode?timestamp=1554001708730',{encoding:false});
var arg_={
label:site.name+"验证码",
type:1,
content:va.content
}
//waitForInput内置函数将发送邮件,并等待输入
//(回复邮件,或者goldData平台输入),
//并把输入内容当作验证码返回。
var code=waitForInput(arg_);
var data="username=admin&password=admin&vcode="+code
var m=new Map()
m.put('Cookie',va.cookie)
//发送ajax请求执行登录
var content=$ajax('http://localhost:8080/doLogin',{method:'POST',headers:m,data:data})
//如果正确,将返回状态1(登录成功),和headers信息给GoldData,
//否则返回0(登录失败)!
if(content.headers){
m.putAll(content.headers)
}
var ret={status:1,headers:m}
if(content.status!=200){
ret.status=0
}
ret
检查脚本如下:
var ret=true;
if(html.contains("我的单词-登录")){
ret=false
}
ret;
配制好以后,我们回到网站管理页面,点击“启动登陆”,则会开始执行“自动登入”,这以后,点击“查询”按扭来刷新页面,可以见到“等待输入”的状态。如下图所示:
此时,您设置的通知邮箱,也应当同时收到了电邮。点开电邮,或者点击页面上的“录入等待输入”按扭,将会听到如下内容:
依据电邮内容,回复电邮“{{qcxe}}”,就可以使程序继续执行。在golddata页面里输入"qcxe",效果是一样的。程序将会回到“waitForInput()”,并且返回输入的内容。
回复以后,我们将在golddata页面里,点击“查询”刷新页面,mydict的登陆状态会变为“已登陆”。如下图所示:
接下来,我们可以定义抓取规则。
定义抓取规则
在添加规则之前,我们还须要定义类似于表结构的数据集。如下图所示:
接下来,点击“采集管理》规则管理”,添加规则,打开添加规则页面,如下图所示:
抓取规则脚本如下:
[
{
__sample: http://localhost:8080/word/index?pageNum=2
match0: http\:\/\/localhost\:8080\/word\/index(\?pageNum=\d+)?
fields0:
{
__model: true
__dataset: word
__node: "#content ul >li"
sn:
{
expr: ""
attr: ""
js: md5(item.name)
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
name:
{
expr: h5
attr: ""
js: ""
__label: ""
__showOnList: true
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
uk:
{
expr: li span.uk
attr: ""
js: source.replace("uk: ",'')
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
us:
{
expr: li span.us
attr: ""
js: source.replace("us: ",'')
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
}
fields1:
{
__node: .pagination a
href:
{
expr: a
attr: abs:href
js: ""
__label: ""
__showOnList: false
__type: ""
down: "0"
accessPathJs: ""
uploadConf: s1
}
}
}
]
然后点击测试,将会进行测试抓取。我们发觉数据的确被抓取到了,如下图所示:
配制抓取器抓取
这和之前是一样的,将抓取器设置抓取站点“mydict”.然后点击开始抓取。然后会在数据管理上面查看抓取的数据。
结论
GoldData半自动登陆实质是提供了一个可以人工介入来异步获取会话的框架,既可以调用AI插口做到完全手动登入;也可以将类似于验证码须要复杂辨识须要提供输入时,直接将cookie或则token信息通过短信收发到GoldData平台(这样可以不管CAPTCHA多复杂 ),都可以使GoldData抓取数据的动作持续进行下去。
python爬虫实践教学
采集交流 • 优采云 发表了文章 • 0 个评论 • 604 次浏览 • 2020-08-13 14:47
一、前言
这篇文章之前是给新人培训时用的,大家觉的很好理解的,所以就分享下来,与你们一起学习。如果你学过一些python,想用它做些什么又没有方向,不妨试试完成下边几个案例。
二、环境打算
安装requests lxml beautifulsoup4三个库(下面代码均在python3.5环境下通过测试)
pip install requests lxml beautifulsoup4
三、几个爬虫小案例3.1 获取本机公网IP地址
利用公网上查询IP的托词,使用python的requests库,自动获取IP地址。
import requests
r = requests.get("http://2017.ip138.com/ic.asp")
r.encoding = r.apparent_encoding #使用requests的字符编码智能分析,避免中文乱码
print(r.text)
# 你还可以使用正则匹配re模块提取出IP
import re
print(re.findall("\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}",r.text))
3.2 利用百度搜索插口,编写url采集器
这个案例中,我们要使用requests结合BeautifulSoup库来完成任务。我们要在程序中设置User-Agent头,绕过百度搜索引擎的反爬虫机制(你可以试试不加User-Agent头,看看能不能获取到数据)。注意观察百度搜索结构的URL链接规律,例如第一页的url链接参数pn=0,第二页的url链接参数pn=10…. 依次类推。这里,我们使用css选择器路径提取数据。
import requests
from bs4 import BeautifulSoup
# 设置User-Agent头,绕过百度搜索引擎的反爬虫机制
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'}
# 注意观察百度搜索结构的URL链接规律,例如第一页pn=0,第二页pn=10.... 依次类推,下面的for循环搜索前10页结果
for i in range(0,100,10):
bd_search = "https://www.baidu.com/s%3Fwd%3 ... ot%3B % str(i)
r = requests.get(bd_search,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
# 下面的select使用了css选择器路径提取数据
url_list = soup.select(".t > a")
for url in url_list:
real_url = url["href"]
r = requests.get(real_url)
print(r.url)
编写好程序后,我们使用关键词inurl:/dede/login.php来批量提取织梦cms的后台地址,效果如下:
3.3 自动下载搜狗壁纸
这个反例,我们将通过爬虫来手动下载搜过墙纸,程序中储存图片的路径改成你自己想要储存图片的目录路径即可。还有一点,程序中我们用到了json库,这是因为在观察中,发现搜狗壁纸的地址是以json格式储存,所以我们以json来解析这组数据。
import requests
import json
#下载图片
url = "http://pic.sogou.com/pics/chan ... ot%3B
r = requests.get(url)
data = json.loads(r.text)
for i in data["all_items"]:
img_url = i["pic_url"]
# 下面这行里面的路径改成你自己想要存放图片的目录路径即可
with open("/home/evilk0/Desktop/img/%s" % img_url[-10:]+".jpg","wb") as f:
r2 = requests.get(img_url)
f.write(r2.content)
print("下载完毕:",img_url)
3.4 自动填写调查问卷
目标官网:
目标问卷:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
r = requests.post(url = url,headers=header,data=data)
print(r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
当我们使用同一个IP递交多个问卷时,会触发目标的反爬虫机制,服务器会出现验证码。
我们可以使用X-Forwarded-For来伪造我们的IP,修改后代码如下:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
"X-Forwarded-For" : "%s"
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
header["X-Forwarded-For"] = (str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+str(random.randint(1,255))
r = requests.post(url = url,headers=header,data=data)
print(header["X-Forwarded-For"],r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
header["X-Forwarded-For"] = "%s"
效果图:
关于这篇文章,因为之前写过,不赘言,感兴趣直接看:【如何通过Python实现手动填写调查问卷】
3.5 获取网段代理IP,并判定是否能用、延迟时间
这一个事例中,我们想爬取【西刺代理】上的代理IP,并验证这种代理的存活性以及延后时间。(你可以将爬取的代理IP添加进proxychain中,然后进行平时的渗透任务。)这里,我直接调用了linux的系统命令ping -c 1 " + ip.string + " | awk 'NR==2{print}' -,如果你想在Windows中运行这个程序,需要更改倒数第三行os.popen中的命令,改成Windows可以执行的即可。
from bs4 import BeautifulSoup
import requests
import os
url = "http://www.xicidaili.com/nn/1"
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'}
r = requests.get(url=url,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
server_address = soup.select(".odd > td:nth-of-type(4)")
ip_list = soup.select(".odd > td:nth-of-type(2)")
ports = soup.select(".odd > td:nth-of-type(3)")
for server,ip in zip(server_address,ip_list):
if len(server.contents) != 1:
print(server.a.string.ljust(8),ip.string.ljust(20), end='')
else:
print("未知".ljust(8), ip.string.ljust(20), end='')
delay_time = os.popen("ping -c 1 " + ip.string + " | awk 'NR==2{print}' -")
delay_time = delay_time.read().split("time=")[-1].strip("\r\n")
print("time = " + delay_time)
四、结语
当然,你还可以用python干好多有趣的事情。如果里面的那些反例你看的不是太懂,那我最后在送上一套python爬虫视频教程:【Python网络爬虫与信息提取】。现在网路上的学习真的好多,希望你们就能好好借助。
有问题你们可以留言哦,也欢迎你们到春秋峰会中来耍一耍>>>点击跳转 查看全部
i春秋诗人:Mochazz
一、前言
这篇文章之前是给新人培训时用的,大家觉的很好理解的,所以就分享下来,与你们一起学习。如果你学过一些python,想用它做些什么又没有方向,不妨试试完成下边几个案例。
二、环境打算
安装requests lxml beautifulsoup4三个库(下面代码均在python3.5环境下通过测试)
pip install requests lxml beautifulsoup4
三、几个爬虫小案例3.1 获取本机公网IP地址
利用公网上查询IP的托词,使用python的requests库,自动获取IP地址。
import requests
r = requests.get("http://2017.ip138.com/ic.asp";)
r.encoding = r.apparent_encoding #使用requests的字符编码智能分析,避免中文乱码
print(r.text)
# 你还可以使用正则匹配re模块提取出IP
import re
print(re.findall("\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}",r.text))
3.2 利用百度搜索插口,编写url采集器
这个案例中,我们要使用requests结合BeautifulSoup库来完成任务。我们要在程序中设置User-Agent头,绕过百度搜索引擎的反爬虫机制(你可以试试不加User-Agent头,看看能不能获取到数据)。注意观察百度搜索结构的URL链接规律,例如第一页的url链接参数pn=0,第二页的url链接参数pn=10…. 依次类推。这里,我们使用css选择器路径提取数据。
import requests
from bs4 import BeautifulSoup
# 设置User-Agent头,绕过百度搜索引擎的反爬虫机制
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'}
# 注意观察百度搜索结构的URL链接规律,例如第一页pn=0,第二页pn=10.... 依次类推,下面的for循环搜索前10页结果
for i in range(0,100,10):
bd_search = "https://www.baidu.com/s%3Fwd%3 ... ot%3B % str(i)
r = requests.get(bd_search,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
# 下面的select使用了css选择器路径提取数据
url_list = soup.select(".t > a")
for url in url_list:
real_url = url["href"]
r = requests.get(real_url)
print(r.url)
编写好程序后,我们使用关键词inurl:/dede/login.php来批量提取织梦cms的后台地址,效果如下:
3.3 自动下载搜狗壁纸
这个反例,我们将通过爬虫来手动下载搜过墙纸,程序中储存图片的路径改成你自己想要储存图片的目录路径即可。还有一点,程序中我们用到了json库,这是因为在观察中,发现搜狗壁纸的地址是以json格式储存,所以我们以json来解析这组数据。
import requests
import json
#下载图片
url = "http://pic.sogou.com/pics/chan ... ot%3B
r = requests.get(url)
data = json.loads(r.text)
for i in data["all_items"]:
img_url = i["pic_url"]
# 下面这行里面的路径改成你自己想要存放图片的目录路径即可
with open("/home/evilk0/Desktop/img/%s" % img_url[-10:]+".jpg","wb") as f:
r2 = requests.get(img_url)
f.write(r2.content)
print("下载完毕:",img_url)
3.4 自动填写调查问卷
目标官网:
目标问卷:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
r = requests.post(url = url,headers=header,data=data)
print(r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
当我们使用同一个IP递交多个问卷时,会触发目标的反爬虫机制,服务器会出现验证码。
我们可以使用X-Forwarded-For来伪造我们的IP,修改后代码如下:
import requests
import random
url = "https://www.wjx.cn/joinnew/pro ... ot%3B
data = {
"submitdata" : "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
}
header = {
"User-Agent" : "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)",
"Cookie": ".ASPXANONYMOUS=iBuvxgz20wEkAAAAZGY4MDE1MjctNWU4Ni00MDUwLTgwYjQtMjFhMmZhMDE2MTA3h_bb3gNw4XRPsyh-qPh4XW1mfJ41; spiderregkey=baidu.com%c2%a7%e7%9b%b4%e8%be%be%c2%a71; UM_distinctid=1623e28d4df22d-08d0140291e4d5-102c1709-100200-1623e28d4e1141; _umdata=535523100CBE37C329C8A3EEEEE289B573446F594297CC3BB3C355F09187F5ADCC492EBB07A9CC65CD43AD3E795C914CD57017EE3799E92F0E2762C963EF0912; WjxUser=UserName=17750277425&Type=1; LastCheckUpdateDate=1; LastCheckDesign=1; DeleteQCookie=1; _cnzz_CV4478442=%E7%94%A8%E6%88%B7%E7%89%88%E6%9C%AC%7C%E5%85%8D%E8%B4%B9%E7%89%88%7C1521461468568; jac21581199=78751211; CNZZDATA4478442=cnzz_eid%3D878068609-1521456533-https%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1521461319; Hm_lvt_21be24c80829bd7a683b2c536fcf520b=1521461287,1521463471; Hm_lpvt_21be24c80829bd7a683b2c536fcf520b=1521463471",
"X-Forwarded-For" : "%s"
}
for i in range(0,500):
choice = (
random.randint(1, 2),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 4),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
random.randint(1, 3),
)
data["submitdata"] = data["submitdata"] % choice
header["X-Forwarded-For"] = (str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+(str(random.randint(1,255))+".")+str(random.randint(1,255))
r = requests.post(url = url,headers=header,data=data)
print(header["X-Forwarded-For"],r.text)
data["submitdata"] = "1$%s}2$%s}3$%s}4$%s}5$%s}6$%s}7$%s}8$%s}9$%s}10$%s"
header["X-Forwarded-For"] = "%s"
效果图:
关于这篇文章,因为之前写过,不赘言,感兴趣直接看:【如何通过Python实现手动填写调查问卷】
3.5 获取网段代理IP,并判定是否能用、延迟时间
这一个事例中,我们想爬取【西刺代理】上的代理IP,并验证这种代理的存活性以及延后时间。(你可以将爬取的代理IP添加进proxychain中,然后进行平时的渗透任务。)这里,我直接调用了linux的系统命令ping -c 1 " + ip.string + " | awk 'NR==2{print}' -,如果你想在Windows中运行这个程序,需要更改倒数第三行os.popen中的命令,改成Windows可以执行的即可。
from bs4 import BeautifulSoup
import requests
import os
url = "http://www.xicidaili.com/nn/1"
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'}
r = requests.get(url=url,headers=headers)
soup = BeautifulSoup(r.text,"lxml")
server_address = soup.select(".odd > td:nth-of-type(4)")
ip_list = soup.select(".odd > td:nth-of-type(2)")
ports = soup.select(".odd > td:nth-of-type(3)")
for server,ip in zip(server_address,ip_list):
if len(server.contents) != 1:
print(server.a.string.ljust(8),ip.string.ljust(20), end='')
else:
print("未知".ljust(8), ip.string.ljust(20), end='')
delay_time = os.popen("ping -c 1 " + ip.string + " | awk 'NR==2{print}' -")
delay_time = delay_time.read().split("time=")[-1].strip("\r\n")
print("time = " + delay_time)
四、结语
当然,你还可以用python干好多有趣的事情。如果里面的那些反例你看的不是太懂,那我最后在送上一套python爬虫视频教程:【Python网络爬虫与信息提取】。现在网路上的学习真的好多,希望你们就能好好借助。
有问题你们可以留言哦,也欢迎你们到春秋峰会中来耍一耍>>>点击跳转
假如你早已开始学python,对爬虫没有头绪,不妨瞧瞧这几个案例!
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2020-08-13 14:23
一、论述
这几个案例曾经是给一些想步入Python行业的同事写的,看到你们都比较满意,所以就再度拿了下来,如果你早已开始学python,对爬虫没有头绪,不妨瞧瞧这几个案例,文末更多分享!
二、环境打算
Python 3
requests库 、lxml库、beautifulsoup4库
pip install XX XX XX一并安装。
在这里相信有许多想要学习Python的朋友,大家可以+下Python学习分享裤:叁零肆+零伍零+柒玖玖,即可免费发放一整套系统的 Python学习教程
三、Python爬虫小案例
1、获取本机的公网IP地址
利用python的requests库+公网上查IP的插口,自动获取IP地址
2、利用百度的查找插口,Python编撰url采集工具
需要用到requests库、BeautifulSoup库,观察百度搜索结构的URL链接规律,绕过百度搜索引擎的反爬虫机制的方式为在程序中设置User-Agent恳求头。
Python源代码:
Python语言编撰好程序后,利用关键词inurl:/dede/login.php 来批量提取某网cms的后台地址:
3、利用Python构建搜狗壁纸手动下载爬虫
搜狗壁纸的地址是json格式,所以用json库解析这组数据,爬虫程序储存图片的c盘路径改成欲存图片的路径就可以了。
效果图:
4、Python手动填写问卷调查
与通常网页一样,多次递交数据会要输入验证码,这就是反爬机制。
如图:
那么怎么绕开验证码的反爬举措?利用X-Forwarded-For伪造IP地址访问即可,Python代码如下:
效果:
5、获取南刺代理上的IP,验证这种代理被封禁掉的可能性与延后时间
可以把Python爬取的代理IP添加到proxychain上面,就可以进行通常的渗透任务了。这里直接调用了linux的系统命令ping -c 1 " + ip.string + " | awk 'NR==2{print}' - ,在Windows中运行此程序须要更改倒数第三行os.popen里的命令,修改为Windows才能执行的就可以了。
爬取到的数据如图:
演示:
结论
其实我们能否用python做许多特别有趣的事。假如说里面的爬虫小案例无法够完全理解,那我最后再送上一套python爬虫手把手系列的视频教程,私信小编007即可手动获取。 查看全部
一、论述
这几个案例曾经是给一些想步入Python行业的同事写的,看到你们都比较满意,所以就再度拿了下来,如果你早已开始学python,对爬虫没有头绪,不妨瞧瞧这几个案例,文末更多分享!
二、环境打算
Python 3
requests库 、lxml库、beautifulsoup4库
pip install XX XX XX一并安装。
在这里相信有许多想要学习Python的朋友,大家可以+下Python学习分享裤:叁零肆+零伍零+柒玖玖,即可免费发放一整套系统的 Python学习教程
三、Python爬虫小案例
1、获取本机的公网IP地址
利用python的requests库+公网上查IP的插口,自动获取IP地址
2、利用百度的查找插口,Python编撰url采集工具
需要用到requests库、BeautifulSoup库,观察百度搜索结构的URL链接规律,绕过百度搜索引擎的反爬虫机制的方式为在程序中设置User-Agent恳求头。
Python源代码:
Python语言编撰好程序后,利用关键词inurl:/dede/login.php 来批量提取某网cms的后台地址:
3、利用Python构建搜狗壁纸手动下载爬虫
搜狗壁纸的地址是json格式,所以用json库解析这组数据,爬虫程序储存图片的c盘路径改成欲存图片的路径就可以了。
效果图:
4、Python手动填写问卷调查
与通常网页一样,多次递交数据会要输入验证码,这就是反爬机制。
如图:
那么怎么绕开验证码的反爬举措?利用X-Forwarded-For伪造IP地址访问即可,Python代码如下:
效果:
5、获取南刺代理上的IP,验证这种代理被封禁掉的可能性与延后时间
可以把Python爬取的代理IP添加到proxychain上面,就可以进行通常的渗透任务了。这里直接调用了linux的系统命令ping -c 1 " + ip.string + " | awk 'NR==2{print}' - ,在Windows中运行此程序须要更改倒数第三行os.popen里的命令,修改为Windows才能执行的就可以了。
爬取到的数据如图:
演示:
结论
其实我们能否用python做许多特别有趣的事。假如说里面的爬虫小案例无法够完全理解,那我最后再送上一套python爬虫手把手系列的视频教程,私信小编007即可手动获取。
红包搞笑html网页源码与织梦智能采集侠下载评论软件详情对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 339 次浏览 • 2020-08-10 01:56
织梦智能采集侠功能
1、一键安装,全手动采集
织梦采集侠安装非常简单便捷,只需一分钟,立即开始采集,而且结合简单、健壮、灵活、开源的dedecms程序,新手也能快速上手,而且我们还有专门的客服为商业顾客提供技术支持。
2、一词采集,无须编撰采集规则
和传统的采集模式不同的是织梦采集侠可以依据用户设定的关键词进行泛采集,泛采集的优势在于通过采集该关键词的不同搜索结果,实现不对指定的一个或几个被采集站点进行采集,减少采集站点被搜索引擎判断为镜像站点被搜索引擎惩罚的危险。
3、RSS采集,输入RSS地址即可采集内容
只要被采集的网站提供RSS订阅地址,即可通过RSS进行采集,只须要输入RSS地址即可便捷的 采集到目标网站内容,无需编撰采集规则,方便简单。
4、定向采集,精确采集标题、正文、作者、来源
定向采集只须要提供列表URL和文章URL即可智能采集指定网站或栏目内容,方便简单,编写简单规则便可精确采集标题、正文、作者、来源。
5、 多种伪原创及优化方法,提高收录率及排行
自动标题、段落重排、高级混淆、自动内链、内容过滤、网址过滤、同义词替换、插入seo成语、关键词添加链接等多种方式手段对采集回来的文章加工处理,增强采集文章原创性,利于搜索引擎优化,提高搜索引擎收录、网站权重及关键词排行。
6、插件全手动采集,无需人工干预
织梦采集侠根据预先设定是采集任务,根据所设定的采集方式采集网址,然后手动抓取网页内容,程序通过精确估算剖析网页,丢弃掉不是文章内容页的网址,提取出优秀文章内容,最后进行伪原创,导入,生成,这一切操作程序都是全手动完成,无需人工干预。
7、手工发布文章亦可伪原创和搜索优化处理
织梦采集侠并不仅仅是一款采集插件,更是一款织梦必备伪原创及搜索优化插件,手工发布的文章可以经过织梦采集侠的伪原创和搜索优化处理,可以对文章进行同义词替换,自动内链,随机插入关键词链接和文章内收录关键词将手动添加指定链接等功能,是一款织梦必备插件。
8、定时定量进行采集伪原创SEO更新
插件有两个触发采集方式,一种是在页面内添加代码由用户访问触发采集更新,另外种我们为商业用户提供的远程触发采集服务,新站无有人访问即可定时定量采集更新,无需人工干预。
9、定时定量更新待初审文稿
纵使你数据库上面有成千上万篇文章,织梦采集侠亦可按照您的须要每晚在您设置的时间段内定时定量初审更新。
10、绑定织梦采集节点,定时采集伪原创SEO更新
绑定织梦采集节点的功能,让织梦CMS自带的采集功能也能定时手动采集更新。方便早已设置了采集规则的用户定时采集更新。
织梦智能采集侠破解说明
织梦采集侠采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本(网址: 如果官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+
织梦智能采集侠使用方式
1、设置定向采集
1)、登录您网站后台,模块->采集侠->采集任务,如果您的网站还没有添加栏目,你须要先到织梦的栏目管理里先添加栏目,如果早已添加了栏目,你可能可以看见如下界面
2)、在弹出的页面里选择定向采集,如图所示
3)、点击添加采集规则
2、设置 目标页面编码
打开您要采集的网页,点击滑鼠右键,点击查看网站源码,搜索charset,查看charset前面紧随的是utf-8还是gb2312
3、设置 列表网址
列表网址就是您要采集的网站的栏目列表地址
如果只是单纯采集列表页的第一页,直接输入该列表URL就行,如我要采集站长之家的优化栏目的第一页,那列表URL就输入:,即可。采集第一页的内容的益处就是可以不用采集老旧的新闻,而且有新更新也可以及时采集到,如果须要采集该栏目的所有内容,那也可以通过设置键值的方法,匹配所有列表URL规则。
织梦智能采集侠常见问题
绑定x个域名授权是哪些意思呢?
多少个域名授权,就是多少个网站可以使用织梦采集侠商业版。
插件可以指定网站进行采集吗?
插件不仅可以按照关键词采集外,还有RSS和页面监控采集这两种采集方式,可以指定网站进行采集。
如果我的域名不想用了,可以更换域名授权吗?
可以给您更换域名授权,每更换1域名授权仅需10元手续费。
根据关键词采集回来的内容是来自什么网站?
根据关键词采集是用您设置的关键词通过搜索引擎进行搜索,采集搜索下来的结果,来自不同的网站。 查看全部
织梦采集侠是一款站长们必备的织梦网站后台手动采集软件,该软件可以帮助用户快速的将网站数据采集和添加,是每一个织梦dede网站必不可少的网站插件工具,能够进行文章的手动采集,织梦智能采集侠同时拥有无限制的域名使用疗效,让你不受次数限制,欢迎有需求的用户们前来下载使用。
织梦智能采集侠功能
1、一键安装,全手动采集
织梦采集侠安装非常简单便捷,只需一分钟,立即开始采集,而且结合简单、健壮、灵活、开源的dedecms程序,新手也能快速上手,而且我们还有专门的客服为商业顾客提供技术支持。
2、一词采集,无须编撰采集规则
和传统的采集模式不同的是织梦采集侠可以依据用户设定的关键词进行泛采集,泛采集的优势在于通过采集该关键词的不同搜索结果,实现不对指定的一个或几个被采集站点进行采集,减少采集站点被搜索引擎判断为镜像站点被搜索引擎惩罚的危险。
3、RSS采集,输入RSS地址即可采集内容
只要被采集的网站提供RSS订阅地址,即可通过RSS进行采集,只须要输入RSS地址即可便捷的 采集到目标网站内容,无需编撰采集规则,方便简单。
4、定向采集,精确采集标题、正文、作者、来源
定向采集只须要提供列表URL和文章URL即可智能采集指定网站或栏目内容,方便简单,编写简单规则便可精确采集标题、正文、作者、来源。
5、 多种伪原创及优化方法,提高收录率及排行
自动标题、段落重排、高级混淆、自动内链、内容过滤、网址过滤、同义词替换、插入seo成语、关键词添加链接等多种方式手段对采集回来的文章加工处理,增强采集文章原创性,利于搜索引擎优化,提高搜索引擎收录、网站权重及关键词排行。
6、插件全手动采集,无需人工干预
织梦采集侠根据预先设定是采集任务,根据所设定的采集方式采集网址,然后手动抓取网页内容,程序通过精确估算剖析网页,丢弃掉不是文章内容页的网址,提取出优秀文章内容,最后进行伪原创,导入,生成,这一切操作程序都是全手动完成,无需人工干预。
7、手工发布文章亦可伪原创和搜索优化处理
织梦采集侠并不仅仅是一款采集插件,更是一款织梦必备伪原创及搜索优化插件,手工发布的文章可以经过织梦采集侠的伪原创和搜索优化处理,可以对文章进行同义词替换,自动内链,随机插入关键词链接和文章内收录关键词将手动添加指定链接等功能,是一款织梦必备插件。
8、定时定量进行采集伪原创SEO更新
插件有两个触发采集方式,一种是在页面内添加代码由用户访问触发采集更新,另外种我们为商业用户提供的远程触发采集服务,新站无有人访问即可定时定量采集更新,无需人工干预。
9、定时定量更新待初审文稿
纵使你数据库上面有成千上万篇文章,织梦采集侠亦可按照您的须要每晚在您设置的时间段内定时定量初审更新。
10、绑定织梦采集节点,定时采集伪原创SEO更新
绑定织梦采集节点的功能,让织梦CMS自带的采集功能也能定时手动采集更新。方便早已设置了采集规则的用户定时采集更新。
织梦智能采集侠破解说明
织梦采集侠采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本(网址: 如果官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+
织梦智能采集侠使用方式
1、设置定向采集
1)、登录您网站后台,模块->采集侠->采集任务,如果您的网站还没有添加栏目,你须要先到织梦的栏目管理里先添加栏目,如果早已添加了栏目,你可能可以看见如下界面
2)、在弹出的页面里选择定向采集,如图所示
3)、点击添加采集规则
2、设置 目标页面编码
打开您要采集的网页,点击滑鼠右键,点击查看网站源码,搜索charset,查看charset前面紧随的是utf-8还是gb2312
3、设置 列表网址
列表网址就是您要采集的网站的栏目列表地址
如果只是单纯采集列表页的第一页,直接输入该列表URL就行,如我要采集站长之家的优化栏目的第一页,那列表URL就输入:,即可。采集第一页的内容的益处就是可以不用采集老旧的新闻,而且有新更新也可以及时采集到,如果须要采集该栏目的所有内容,那也可以通过设置键值的方法,匹配所有列表URL规则。
织梦智能采集侠常见问题
绑定x个域名授权是哪些意思呢?
多少个域名授权,就是多少个网站可以使用织梦采集侠商业版。
插件可以指定网站进行采集吗?
插件不仅可以按照关键词采集外,还有RSS和页面监控采集这两种采集方式,可以指定网站进行采集。
如果我的域名不想用了,可以更换域名授权吗?
可以给您更换域名授权,每更换1域名授权仅需10元手续费。
根据关键词采集回来的内容是来自什么网站?
根据关键词采集是用您设置的关键词通过搜索引擎进行搜索,采集搜索下来的结果,来自不同的网站。
Python3+Selenium2完整的自动化测试实现之旅(六):Python单
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2020-08-09 23:04
Unitest是Python下的一个单元测试模块,是Python标准库模块之一,安装完Python后就可以直接import该模块,能在单元测试下编撰具体的测试用例脚本,并调用模块封装好的方式,实现测试用例的执行、测试场景的恢复,甚至能批量采集测试用例脚本、批量运行测试脚本用例、控制执行次序等,依托于Unittest模块,可以高效的组织测试用例编撰、测试用例脚本的采集管理以及脚本运行的执行控制等。Unitest单元测试框架主要收录如下几个重要的逻辑单元:
1.测试固件(test fixture)
一个测试固件包括两部份,执行测试代码的后置条件和测试结束以后的场景恢复,这两部份通常用函数setUp()和tearDown()表示。简单说,就是平常手工测试一条具体的测试用例时,测试的后置环境和测试结束后的环境恢复。
2.测试用例(test case)
unittest中管理的最小单元是测试用例,就是一个测试用例,包括具体测试业务的函数或则方式,只是该test case 必须是以test开头的函数。unittest会自动化辨识test开头的函数是测试代码,如果你写的函数不是test开头,unittest是不会执行这个函数上面的脚本,这个千万要记住,所有的测试函数都要test开头,记住是大写的哦。
3.测试套件 (test suite)
就是好多测试用例的集合,一个测试套件可以随便管理多个测试用例,该部份拿来实现众多测试用例的采集,形成一套测试用例集。
4.测试执行器 (test runner)
test runner是一个拿来执行加载测试用例,并执行用例,且提供测试输出的一个逻辑单元。test runner可以加载test case或则test suite进行执行测试任务,并能控制用例集的执行次序等。
从Unitest单元测试框架的基本逻辑单元设计来看,很明显可以看见它收录了用例的整个生命周期:用例的后置条件、用例的编撰、用例的采集、用例的执行以及测试执行后的场景恢复。
二、首次使用Unittest模块
下面以打开百度,进行搜索,创建一个名为baidu_search.py的脚本文件,编写百度搜索分别python2和python3的测试用例,代码如下:
'''
Code description:
Create time:
Developer:
'''
# -*- coding: utf-8 -*-
import time
import unittest
from selenium import webdriver
class Search(unittest.TestCase):
def setUp(self):
"""
测试前置条件,这里要搜索的话就是先得打开百度网站啦
"""
self.driver = webdriver.Ie()
self.driver.maximize_window()
self.driver.implicitly_wait(5)
self.driver.get("https://www.baidu.com")
def tearDown():
"""
测试结束后环境复原,这里就是浏览器关闭退出
"""
self.driver.quit()
def test_search1(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').send_keys('python2')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python2' in self.driver.title
print('检索python2完成')
except Exception as e:
print('检索失败', format(e))
def test_search2(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').send_keys('python3')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python3' in self.driver.title
print('检索python3完成')
except Exception as e:
print('检索失败', format(e))
if __name__ == '__main__':
unittest.main()
在PyCharm中运行里面代码,我们会发觉浏览器打开关掉了两次,分别检索了python2关掉浏览器,然后检索python3关掉浏览器。
这个疗效其实不是我们希望的,我们希望检索完python2后,不用关掉浏览器继续检索python3,Unittest有相关的设置吗?答案是肯定的,我们对以上代码做下调整更改,注意对比不同的地方,然后运行就达到我们想要的疗效
'''
Code description:
Create time:
Developer:
'''
# -*- coding: utf-8 -*-
import time
import unittest
from selenium import webdriver
class Search(unittest.TestCase):
@classmethod
def setUpClass(cls):
"""
测试前置条件,这里要搜索的话就是先得打开百度网站啦
"""
cls.driver = webdriver.Ie()
cls.driver.maximize_window()
cls.driver.implicitly_wait(5)
cls.driver.get("https://www.baidu.com")
@classmethod
def tearDownClass(cls):
"""
测试结束后环境复原,这里就是浏览器关闭退出
"""
cls.driver.quit()
def test_search1(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').send_keys('python2')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python2' in self.driver.title
print('检索python2完成')
except Exception as e:
print('检索失败', format(e))
def test_search2(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').clear() # 清空之前输入的python2
self.driver.find_element_by_id('kw').send_keys('python3')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python3' in self.driver.title
print('检索python3完成')
except Exception as e:
print('检索失败', format(e))
if __name__ == '__main__':
unittest.main()
三、Unittest模块批量加载和管理用例
以上对于Unittest框架,我们似乎只用到了测试固件、测试用例两个逻辑单元的使用,接下来问题又来了:我们日常项目中的测试案例肯定不止一个,当案例越来越多时我们怎样管理那些批量案例?如何保证案例不重复?如果案例特别多(成百上千,甚至更多)时怎么保证案例执行的效率?
来看一下在unittest框架中怎样管理批量用例:
手动添加采集指定的测试用例集用法:先在PyCharm中新建如下项目层级:
其中baidu_search1还是里面调整更改过的代码,然后编辑run_case.py文件,代码如下:
'''
Code description: 执行add 的测试用例集
Create time:
Developer:
'''
# -*- coding: utf-8 -*-
from testcase.sreach.baidu_sreach1 import Search # 将baidu_sreach.py模块导入进来
import unittest
suite = unittest.TestSuite() # 构造测试用例集
# suite.addTest(Search("test_search1"))
suite.addTest(Search("test_search2")) # 分别添加baidu_sreach1.py中的两个检索的测试用例
if __name__ == '__main__':
runner = unittest.TextTestRunner() # 实例化runner
runner.run(suite) #执行测试
这样运行run_case.py,就只执行了在百度中搜索python3这条用例,手动添加指定用例到测试套件的方式是addTest(),但是好多时侯我们写了好多测试脚本文件,每个脚本中有多个test,,如果还是使用addTest()方法就不行了,我们希望能获取所有的测试集,并全部执行。然后编辑run_all_case.py文件,编写如下代码:
'''
Code description: TestLoader所有测试case
Create time:
Developer:
'''
# -*- coding: utf-8 -*-
import time
import os.path
import unittest
from selenium import webdriver
class Search(unittest.TestCase):
@classmethod
def setUpClass(cls):
"""
测试前置条件,这里要搜索的话就是先得打开百度网站啦
"""
cls.driver = webdriver.Ie()
cls.driver.maximize_window()
cls.driver.implicitly_wait(5)
cls.driver.get("https://www.baidu.com")
@classmethod
def tearDownClass(cls):
"""
测试结束后环境复原,这里就是浏览器关闭退出
"""
cls.driver.quit()
def test_search1(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').send_keys('python2')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python2' in self.driver.title
print('检索python2完成')
except Exception as e:
print('检索失败', format(e))
def test_search2(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').clear() # 清空之前输入的python2
self.driver.find_element_by_id('kw').send_keys('python3')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python3' in self.driver.title
print('检索python3完成')
except Exception as e:
print('检索失败', format(e))
def test_search3(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').clear() # 清空之前输入的python3
self.driver.find_element_by_id('kw').send_keys('hello world')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'hello world' in self.driver.title
print('检索hello world完成')
except Exception as e:
print('检索失败', format(e))
case_path = os.path.join(os.getcwd()) # 在当前目录中采集测试用例
print(case_path)
all_case = unittest.defaultTestLoader.discover(case_path, pattern="test*.py", top_level_dir=None) # 采集所有test开头的测试用例
print(all_case)
if __name__ == '__main__':
runner = unittest.TextTestRunner() # 实例化runner
runner.run(all_case) # 执行测试
获取所有的测试用例集使用的是discover()方法,在PyCharm中运行该脚本就如下:
以上就完成了在Python Unittest单元测试框架下编撰测试用例脚本,并使用其提供的多种方式来批量管理测试用例集并并执行。
转载于: 查看全部
一、Unittest单元测试框架简介
Unitest是Python下的一个单元测试模块,是Python标准库模块之一,安装完Python后就可以直接import该模块,能在单元测试下编撰具体的测试用例脚本,并调用模块封装好的方式,实现测试用例的执行、测试场景的恢复,甚至能批量采集测试用例脚本、批量运行测试脚本用例、控制执行次序等,依托于Unittest模块,可以高效的组织测试用例编撰、测试用例脚本的采集管理以及脚本运行的执行控制等。Unitest单元测试框架主要收录如下几个重要的逻辑单元:
1.测试固件(test fixture)
一个测试固件包括两部份,执行测试代码的后置条件和测试结束以后的场景恢复,这两部份通常用函数setUp()和tearDown()表示。简单说,就是平常手工测试一条具体的测试用例时,测试的后置环境和测试结束后的环境恢复。
2.测试用例(test case)
unittest中管理的最小单元是测试用例,就是一个测试用例,包括具体测试业务的函数或则方式,只是该test case 必须是以test开头的函数。unittest会自动化辨识test开头的函数是测试代码,如果你写的函数不是test开头,unittest是不会执行这个函数上面的脚本,这个千万要记住,所有的测试函数都要test开头,记住是大写的哦。
3.测试套件 (test suite)
就是好多测试用例的集合,一个测试套件可以随便管理多个测试用例,该部份拿来实现众多测试用例的采集,形成一套测试用例集。
4.测试执行器 (test runner)
test runner是一个拿来执行加载测试用例,并执行用例,且提供测试输出的一个逻辑单元。test runner可以加载test case或则test suite进行执行测试任务,并能控制用例集的执行次序等。
从Unitest单元测试框架的基本逻辑单元设计来看,很明显可以看见它收录了用例的整个生命周期:用例的后置条件、用例的编撰、用例的采集、用例的执行以及测试执行后的场景恢复。
二、首次使用Unittest模块
下面以打开百度,进行搜索,创建一个名为baidu_search.py的脚本文件,编写百度搜索分别python2和python3的测试用例,代码如下:
'''
Code description:
Create time:
Developer:
'''
# -*- coding: utf-8 -*-
import time
import unittest
from selenium import webdriver
class Search(unittest.TestCase):
def setUp(self):
"""
测试前置条件,这里要搜索的话就是先得打开百度网站啦
"""
self.driver = webdriver.Ie()
self.driver.maximize_window()
self.driver.implicitly_wait(5)
self.driver.get("https://www.baidu.com";)
def tearDown():
"""
测试结束后环境复原,这里就是浏览器关闭退出
"""
self.driver.quit()
def test_search1(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').send_keys('python2')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python2' in self.driver.title
print('检索python2完成')
except Exception as e:
print('检索失败', format(e))
def test_search2(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').send_keys('python3')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python3' in self.driver.title
print('检索python3完成')
except Exception as e:
print('检索失败', format(e))
if __name__ == '__main__':
unittest.main()
在PyCharm中运行里面代码,我们会发觉浏览器打开关掉了两次,分别检索了python2关掉浏览器,然后检索python3关掉浏览器。
这个疗效其实不是我们希望的,我们希望检索完python2后,不用关掉浏览器继续检索python3,Unittest有相关的设置吗?答案是肯定的,我们对以上代码做下调整更改,注意对比不同的地方,然后运行就达到我们想要的疗效
'''
Code description:
Create time:
Developer:
'''
# -*- coding: utf-8 -*-
import time
import unittest
from selenium import webdriver
class Search(unittest.TestCase):
@classmethod
def setUpClass(cls):
"""
测试前置条件,这里要搜索的话就是先得打开百度网站啦
"""
cls.driver = webdriver.Ie()
cls.driver.maximize_window()
cls.driver.implicitly_wait(5)
cls.driver.get("https://www.baidu.com";)
@classmethod
def tearDownClass(cls):
"""
测试结束后环境复原,这里就是浏览器关闭退出
"""
cls.driver.quit()
def test_search1(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').send_keys('python2')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python2' in self.driver.title
print('检索python2完成')
except Exception as e:
print('检索失败', format(e))
def test_search2(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').clear() # 清空之前输入的python2
self.driver.find_element_by_id('kw').send_keys('python3')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python3' in self.driver.title
print('检索python3完成')
except Exception as e:
print('检索失败', format(e))
if __name__ == '__main__':
unittest.main()
三、Unittest模块批量加载和管理用例
以上对于Unittest框架,我们似乎只用到了测试固件、测试用例两个逻辑单元的使用,接下来问题又来了:我们日常项目中的测试案例肯定不止一个,当案例越来越多时我们怎样管理那些批量案例?如何保证案例不重复?如果案例特别多(成百上千,甚至更多)时怎么保证案例执行的效率?
来看一下在unittest框架中怎样管理批量用例:
手动添加采集指定的测试用例集用法:先在PyCharm中新建如下项目层级:
其中baidu_search1还是里面调整更改过的代码,然后编辑run_case.py文件,代码如下:
'''
Code description: 执行add 的测试用例集
Create time:
Developer:
'''
# -*- coding: utf-8 -*-
from testcase.sreach.baidu_sreach1 import Search # 将baidu_sreach.py模块导入进来
import unittest
suite = unittest.TestSuite() # 构造测试用例集
# suite.addTest(Search("test_search1"))
suite.addTest(Search("test_search2")) # 分别添加baidu_sreach1.py中的两个检索的测试用例
if __name__ == '__main__':
runner = unittest.TextTestRunner() # 实例化runner
runner.run(suite) #执行测试
这样运行run_case.py,就只执行了在百度中搜索python3这条用例,手动添加指定用例到测试套件的方式是addTest(),但是好多时侯我们写了好多测试脚本文件,每个脚本中有多个test,,如果还是使用addTest()方法就不行了,我们希望能获取所有的测试集,并全部执行。然后编辑run_all_case.py文件,编写如下代码:
'''
Code description: TestLoader所有测试case
Create time:
Developer:
'''
# -*- coding: utf-8 -*-
import time
import os.path
import unittest
from selenium import webdriver
class Search(unittest.TestCase):
@classmethod
def setUpClass(cls):
"""
测试前置条件,这里要搜索的话就是先得打开百度网站啦
"""
cls.driver = webdriver.Ie()
cls.driver.maximize_window()
cls.driver.implicitly_wait(5)
cls.driver.get("https://www.baidu.com";)
@classmethod
def tearDownClass(cls):
"""
测试结束后环境复原,这里就是浏览器关闭退出
"""
cls.driver.quit()
def test_search1(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').send_keys('python2')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python2' in self.driver.title
print('检索python2完成')
except Exception as e:
print('检索失败', format(e))
def test_search2(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').clear() # 清空之前输入的python2
self.driver.find_element_by_id('kw').send_keys('python3')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'python3' in self.driver.title
print('检索python3完成')
except Exception as e:
print('检索失败', format(e))
def test_search3(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
"""
self.driver.find_element_by_id('kw').clear() # 清空之前输入的python3
self.driver.find_element_by_id('kw').send_keys('hello world')
self.driver.find_element_by_id('su').click()
time.sleep(1)
try:
assert 'hello world' in self.driver.title
print('检索hello world完成')
except Exception as e:
print('检索失败', format(e))
case_path = os.path.join(os.getcwd()) # 在当前目录中采集测试用例
print(case_path)
all_case = unittest.defaultTestLoader.discover(case_path, pattern="test*.py", top_level_dir=None) # 采集所有test开头的测试用例
print(all_case)
if __name__ == '__main__':
runner = unittest.TextTestRunner() # 实例化runner
runner.run(all_case) # 执行测试
获取所有的测试用例集使用的是discover()方法,在PyCharm中运行该脚本就如下:
以上就完成了在Python Unittest单元测试框架下编撰测试用例脚本,并使用其提供的多种方式来批量管理测试用例集并并执行。
转载于:

