
网页flash文本抓取器
网页flash文本抓取器(百度开发所见即所得富文本web编辑器官网教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-04 07:16
概述
UEditor 是百度开发的所见即所得的富文本网页编辑器。它是轻量级的、可定制的,并且专注于用户体验。开源基于 MIT 协议,允许免费使用和修改代码。
官网地址:(学习编辑的最佳去处)
其实官网的教程已经很全面了,所有的API都推荐去官网学习。这里只是为你做一个简单的介绍。重点是如何将文件和图片保存在项目之外,如下所述。实际上,使用的是富文本编辑器。主要是保存大文本数据值。里面的图片资源一般放在项目外或者图片服务器的路径下。我在网上找了很多,几乎都是解决方案。我将带您更详细地了解关键位置。以及如何配置它。
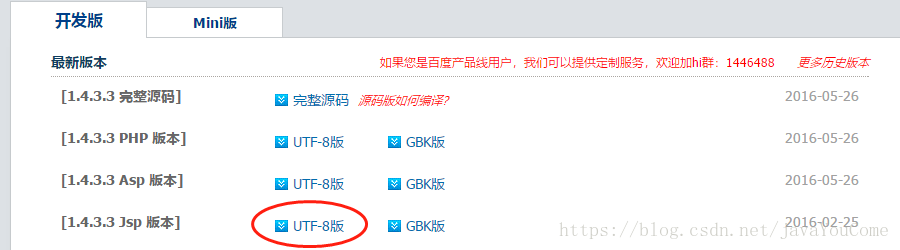
下载地址:下载对应版本即可。如果想看源代码,可以下载源代码。
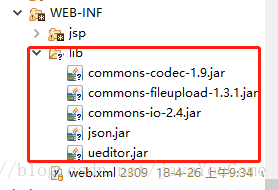
下载后直接复制到项目中,我放在js文件下,因为springMVC对静态文件有限制,所以放在js目录下,guest可以随意放。
将jsp中的lib包复制到WEB-INF下的lib中。如图: 记得把lib包添加到构建路径中,ueditor.jar没有版本因为,这里替换了我自己打的jar,后面会介绍,我自己的jar包--下载地址: (1 学分)
好的,是时候开始创建测试页面了。
根据官网的提示和建议,应该在页面上定义window.UEDITOR_HOME_URL。这是必须在前端配置文件中配置的路径。该路径是 ueditor.config.js 文件所在的目录。在页面上设置好之后, ueditor.config.js 文件就可以停止移动了。
ueditor demo
window.UEDITOR_HOME_URL = "${basePath }/js/ueditor/"
这里写你的初始化内容
var ue = UE.getEditor('container');
ok,前端配置文件已经写好,运行项目,访问测试jsp,没有出现意外页面。
至此,前端页面完成。如果点击多图上传,会出现以下内容。图片和文件上传也需要后台配置文件的支持。
检查是否可以访问。如果没有,请检查文档并将其修改为可访问。参考文档:。
ueditor/jsp目录下的config.json是后台上传功能的配置文件。我们先来看看。
官网上传路径配置说明:
按需修改即可,配置项的最后一行就是保存到本项目的路径。
如果你的项目只需要保存文件和图片到项目中,可以到此结束。
如果你的项目需要把文件放到指定的目录下,比如linux中的d:\image或者“/data/image”,ueditor不改源码是做不到的。网上查了很多资料,几乎都是出自一种写法,也参考了那个博主,链接:,可以学着改写。
我修改了源码,把源码做成了jar包。急用的话,可以下载我的ueditor.jar,直接把项目中的ueditor-1.1.2.jar替换成下载的ueditor.jar ,当然,后面的配置参数还是需要改的。
下载地址:(1分)(不觊觎积分的人)
原理其实就是在后台配置文件中自定义一个配置项,然后在文件上传的时候提取配置的地址,把这个地址和原来的上传路径组合成一个新的“物理地址”。要使用这个jar包,需要在后台配置文件。添加“physicsPath”的配置项之一,这个地址值“d:/data/image/www/product”会和imagePathFormat的值“/{yyyy}/...”结合起来存在于本地” d:/data/image/www/product/2018/..."。
上传成功的话,编辑器中不会显示图片,如上图,其实只要提示上传成功,文件上传就ok了,但是上传之后,富文本编辑器会将“imageUrlPrefix”和“imagePathFormat”与您的配置文件中的配置项结合起来。"发送图片的http请求,示例中的配置会发送,如,肯定不会,在真实的生产环境中,我们会有一个静态图片服务器,如果域名指向服务器的地址,那么"写imageUrlPrefix”指定对应的图片地址即可。本例使用的ngix服务器,域名“”指向该服务器的地址为“/data/image/www”。
所以,上传图片是第一步,再考虑请求路径的问题。如果是本地测试,可以修改tomcat的虚拟路径,实现富文本框中的图像回显;例如:在tomcat配置文件server.xml中添加虚拟路径,即访问:8080/product,表示访问D:\data\image\www\product,控制“imageUrlPrefix”和“ imagePathFormat”,这样就可以在编辑器本地显示图片了。
好了,说了这么多废话,有什么问题欢迎留言。
(超过) 查看全部
网页flash文本抓取器(百度开发所见即所得富文本web编辑器官网教程)
概述
UEditor 是百度开发的所见即所得的富文本网页编辑器。它是轻量级的、可定制的,并且专注于用户体验。开源基于 MIT 协议,允许免费使用和修改代码。
官网地址:(学习编辑的最佳去处)
其实官网的教程已经很全面了,所有的API都推荐去官网学习。这里只是为你做一个简单的介绍。重点是如何将文件和图片保存在项目之外,如下所述。实际上,使用的是富文本编辑器。主要是保存大文本数据值。里面的图片资源一般放在项目外或者图片服务器的路径下。我在网上找了很多,几乎都是解决方案。我将带您更详细地了解关键位置。以及如何配置它。
下载地址:下载对应版本即可。如果想看源代码,可以下载源代码。
下载后直接复制到项目中,我放在js文件下,因为springMVC对静态文件有限制,所以放在js目录下,guest可以随意放。
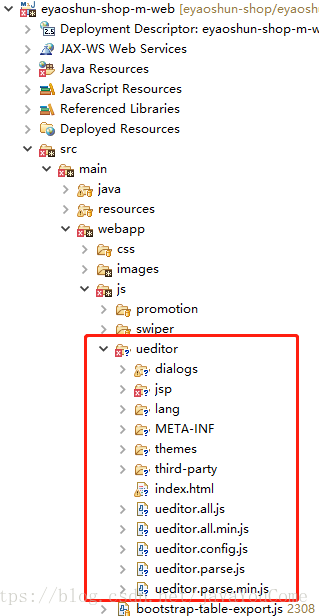
将jsp中的lib包复制到WEB-INF下的lib中。如图: 记得把lib包添加到构建路径中,ueditor.jar没有版本因为,这里替换了我自己打的jar,后面会介绍,我自己的jar包--下载地址: (1 学分)
好的,是时候开始创建测试页面了。
根据官网的提示和建议,应该在页面上定义window.UEDITOR_HOME_URL。这是必须在前端配置文件中配置的路径。该路径是 ueditor.config.js 文件所在的目录。在页面上设置好之后, ueditor.config.js 文件就可以停止移动了。
ueditor demo
window.UEDITOR_HOME_URL = "${basePath }/js/ueditor/"
这里写你的初始化内容
var ue = UE.getEditor('container');
ok,前端配置文件已经写好,运行项目,访问测试jsp,没有出现意外页面。
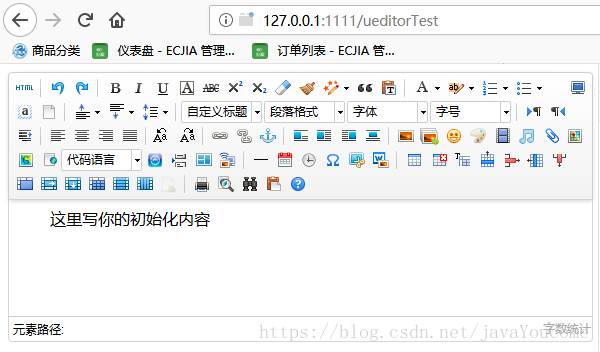
至此,前端页面完成。如果点击多图上传,会出现以下内容。图片和文件上传也需要后台配置文件的支持。
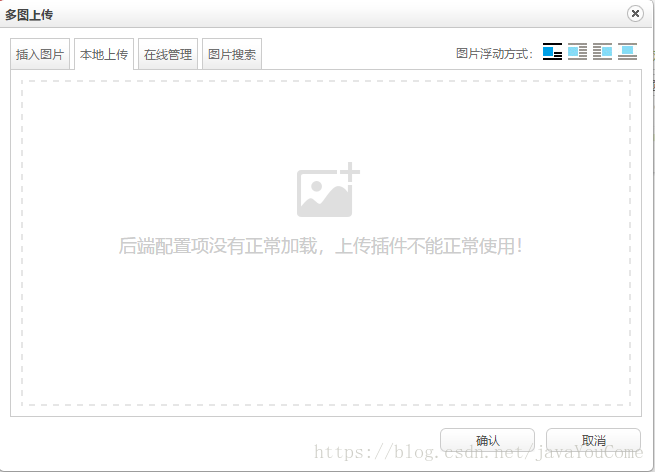
检查是否可以访问。如果没有,请检查文档并将其修改为可访问。参考文档:。
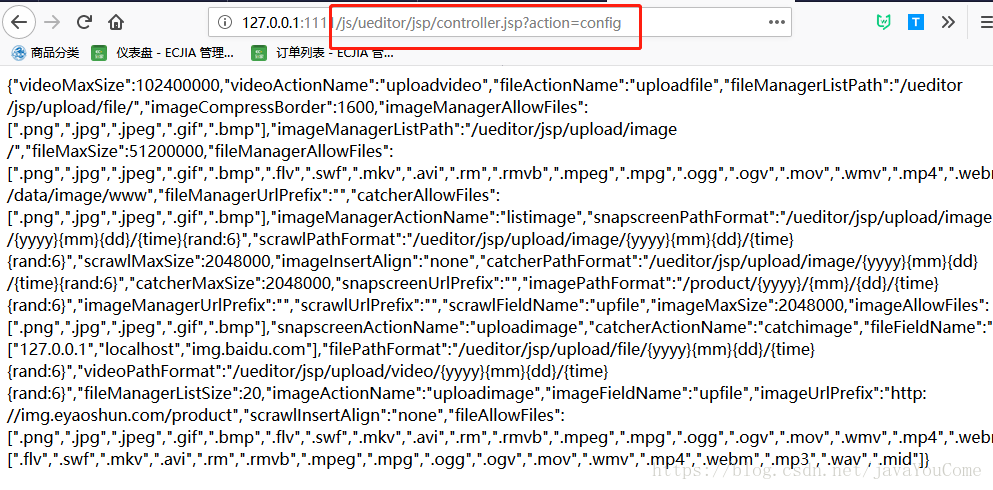
ueditor/jsp目录下的config.json是后台上传功能的配置文件。我们先来看看。
官网上传路径配置说明:
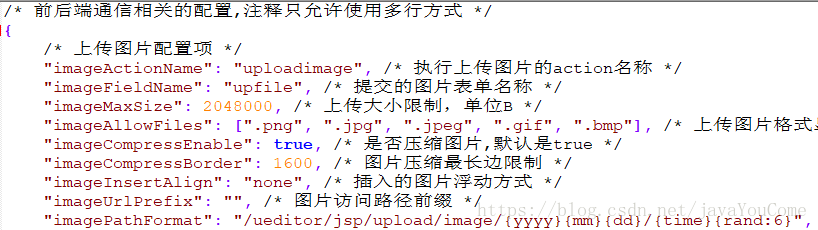
按需修改即可,配置项的最后一行就是保存到本项目的路径。
如果你的项目只需要保存文件和图片到项目中,可以到此结束。
如果你的项目需要把文件放到指定的目录下,比如linux中的d:\image或者“/data/image”,ueditor不改源码是做不到的。网上查了很多资料,几乎都是出自一种写法,也参考了那个博主,链接:,可以学着改写。
我修改了源码,把源码做成了jar包。急用的话,可以下载我的ueditor.jar,直接把项目中的ueditor-1.1.2.jar替换成下载的ueditor.jar ,当然,后面的配置参数还是需要改的。
下载地址:(1分)(不觊觎积分的人)
原理其实就是在后台配置文件中自定义一个配置项,然后在文件上传的时候提取配置的地址,把这个地址和原来的上传路径组合成一个新的“物理地址”。要使用这个jar包,需要在后台配置文件。添加“physicsPath”的配置项之一,这个地址值“d:/data/image/www/product”会和imagePathFormat的值“/{yyyy}/...”结合起来存在于本地” d:/data/image/www/product/2018/..."。

上传成功的话,编辑器中不会显示图片,如上图,其实只要提示上传成功,文件上传就ok了,但是上传之后,富文本编辑器会将“imageUrlPrefix”和“imagePathFormat”与您的配置文件中的配置项结合起来。"发送图片的http请求,示例中的配置会发送,如,肯定不会,在真实的生产环境中,我们会有一个静态图片服务器,如果域名指向服务器的地址,那么"写imageUrlPrefix”指定对应的图片地址即可。本例使用的ngix服务器,域名“”指向该服务器的地址为“/data/image/www”。
所以,上传图片是第一步,再考虑请求路径的问题。如果是本地测试,可以修改tomcat的虚拟路径,实现富文本框中的图像回显;例如:在tomcat配置文件server.xml中添加虚拟路径,即访问:8080/product,表示访问D:\data\image\www\product,控制“imageUrlPrefix”和“ imagePathFormat”,这样就可以在编辑器本地显示图片了。
好了,说了这么多废话,有什么问题欢迎留言。
(超过)
网页flash文本抓取器(富文本内容交互(一)——编辑器内容至后端场景)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-03 11:00
一、富文本内容交互
1、编辑器内容初始化(即在编辑器中设置富文本)
场景一:在编辑器中写一个新的文章,预设提示、问候等。
在 editor_config.js 文件中找到 initialContent 参数,并将其值设置为所需的提示或问候语,例如 initialContent: 'Welcome to UEditor!'。
场景二:编辑旧的文章,从数据库中取出富文本放到编辑器中。
显然,在编辑文章时,需要从后台数据库中提取一大段富文本。如果初始值还是采用场景一的方式设置,必然会带来引号被截断等问题,所以需要使用另一种方式来设置,如下代码所示:
//从数据库中取出文章内容打印到此处
此处采用了script标签作为编辑器容器对象,并设置了其类型是纯文本,从而在避免了标签内部JS代码执行的同时解决了部分同学在使用传统的textarea标签作为容器所带来的一次额外转码问题。
2、提交编辑器内容到后端
场景一:编辑器所在的Form中有一个提交按钮,点击该按钮完成提交动作。
这个场景适合最常见的场合。没有太多需要注意的问题。只需要说明三点:
1)默认提交到后台的表单名称为“editorValue”,可在editor_config.js中配置,参数名称为textarea。
2)可以在容器标签(即脚本标签)上设置name属性来覆盖editor_config.js中的默认配置。示例代码如下,其中 myContent 将是新的提交表单名称:
3)后端接收程序可以通过以下方式获取编辑器中的富文本内容。
//PHP获取:
$_POST["myContent"]
//JSP获取:
request.getParameter("myContent");
//ASP获取:
request("myContent");
//NET获取:
context.Request.Form["myContent"];
场景二:编辑器所在的Form中没有提交按钮,提交动作是由外部事件触发的。
该场景适用于网站前端交互较多的场合。主要需要注意的是,编辑器内容同步操作是在表单提交动作触发之前进行的。通用代码模式如下所示:
//满足提交条件时同步内容并提交,此处editor为编辑器实例
if(editor.hasContent()){ //此处以非空为例
editor.sync(); //同步内容
someForm.submit(); //提交Form
}
这里的 editor 是编辑器实例对象。
场景三:编辑器不在任何Form中,提交动作被外部事件触发。
这个场景用的不多,但在特殊场合可能需要用到。UEditor 也提供了相应的处理方案。基本逻辑和第二种场景一样,只是在进行同步操作的时候需要传入提交表单的id,比如editor.sync(myFormID)。其他相同的场景 2。
二、图片上传交互
1、传统图片上传
传统图片上传所涉及的前后端交互主要涉及“上传提交路径”和“图片存储路径”两个参数。后台存储路径为任何形式(绝对或相对),在任何页面上显示与前台无关。
2、Flash图片上传
Flahs图片上传与传统图片上传有一个很大的区别:它需要服务器实时返回“图片保存路径”,以便在前台即时显示。具体到编辑器,需要将返回的路径插入到编辑器中。这会导致除了传统图片上传中提到的两个参数之外,还有第三个参数:“前后端校正路径”。如果后台返回的保存路径是绝对路径(指以http开头的路径,根目录开头的路径也可以收录在其中),那么前台不需要做任何修正,否则用户必须非常清楚自己当前的目录结构,并根据这修正了前后端相对路径的差异。因此,UEditor 强烈建议服务器端返回以根目录开头的相对路径。
3、UEditor中上传的做法和注意事项
在UEditor中,“上传提交路径”和“前后端修改路径”的配置位于editor_config.js中。其中,imageUrl参数对应“上传提交路径”,imagePath参数对应“前后端校正路径”。“图片保存路径”需要在server/upload/php目录下的imageUp文件中配置。
路径配置完成后,还需要配置imageFieldName参数为文件表单的表单名,后台可以据此获取文件句柄。此参数也位于 editor_config.js 中。
//图片上传提交地址
imageUrl:URL+"server/upload/php/imageUp.php",
//图片修正地址,引用了fixedImagePath,如有特殊需求,可自行配置
imagePath:fixedImagePath,
//图片描述的key
imageFieldName:"upFile",
//等比压缩的基准,确定maxImageSideLength参数的参照对象.
//0为按照最长边,1为按照宽度,2为按照高度
compressSide:0,
//上传图片最大允许的边长,超过会自动等比缩放,不缩放就设置一个比较大的值
//更多设置在image.html中
maxImageSideLength:900
完成以上配置后,理论上后台应该可以接收到前台上传的图片文件了。一旦正确保存,传统的图像上传到此结束。但是,在编辑器中使用 Flash 上传,过程还远远没有结束。
首先,后台需要计算出图片文件存放的地址字符串。UEditor 强烈建议使用从 网站 的根目录到图像名称末尾的字符串。如果不是从网站的根目录算起,后面需要考虑参数“前后端校正地址”。
其次,后台返回一个json格式的字符串。格式的具体要求如下:
{ "url":"图片地址", "title":"图片描述", "state":"上传状态" }
三、Word 图片转储交互
1、图片转储原理
所谓word图片转储,就是为了解决UEditor从word中复制一个混合的图文文章粘贴到编辑器中的问题,word文章中的图片数据无法显示在编辑器中。是针对无法提交到服务器的问题而开发的一款简单易用的镜像转储解决方案。
该功能的基本操作步骤:复制word文档-》粘贴到编辑器-》编辑器会将所有图片转换成占位符图片,同时高亮工具栏中的dump按钮-》点击dump按钮即可弹出图片上传框——“点击复制按钮复制图片目录地址——”点击“添加照片”按钮,将刚才复制的图片目录地址粘贴到弹出的选择框中——“点击打开按钮选择目录下的所有图片文件,点击这里打开-》执行图片上传-》上传成功确认插入,UEditor会自动完成对应占位图片的替换过程。
2、配置要点及注意事项
word图片dump的配置和普通图片上传基本一样,唯一的区别就是操作上的不同:前者需要先获取临时图片文件存在的目录,后者直接选择指定的文件目录通过它自己。PS:在某些操作系统的word的某些版本中,发现单个word图片会生成两张临时图片,格式和定义不同。目前还没有找到改进的方法。
四、远程抓图交互
1、遥控抓取原理
图片远程抓取是指服务器将这些外部图片抓取到本地服务器,并在插入本地域名以外的图片链接地址时保存的功能。实现原理是在编辑器中向服务器发送一个收录所有外域图片地址的ajax请求,然后服务器将图片地址捕获并保存在后端并将图片地址返回给编辑器,然后编辑器将完成外域地址和本地地址的替换。
//是否开启远程图片抓取
catchRemoteImageEnable:true,
//处理远程图片抓取的地址
catcherUrl:URL +"server/submit/php/getRemoteImage.php",
//提交到后台远程图片uri合集的表单名
catchFieldName:"upFile",
//图片修正地址,同imagePath
catcherPath:fixedImagePath,
//本地顶级域名,当开启远程图片抓取时,除此之外的所有其它域名下的
//图片都将被抓取到本地
localDomain:["baidu.com","10.81.2.114"],
2、备注
是否开启远程抓图功能可以通过在editot_config.js中配置catchRemoteImageEnable参数来实现。与此功能相关的配置还包括远程获取处理程序地址、表单字段名称、本地字段以及“前端和后端更正地址”。远程抓图处理程序实现根据前端提交的地址列表(以ue_separate_ue标识分隔的字符串)进行抓图,然后将地址列表返回给客户端的功能。
前后端交互数据格式示例:(URL1, URL2, URL3, URL4)
URL1ue_separate_ueURL2ue_separate_ueURL3ue_separate_ueURL4
五、图片在线管理交互
1、图片在线管理介绍
图片在线管理是指通过读取服务器端的文件目录并在编辑器中显示来进行附加操作的功能。出于安全考虑,UEditor目前只实现了二次图片插入操作,其他的删除、移动等操作将在后续的二次开发教程中发布。
//图片在线管理的处理地址
imageManagerUrl:URL + "server/submit/php/imageManager.php",
//图片修正地址,同imagePath
imageManagerPath:fixedImagePath
2、备注
在线图片管理中需要配置的参数与远程抓图相同。两者的区别在于,在线图片管理中的图片数据是通过在服务器端指定某个目录,然后遍历其下的所有图片文件,然后返回地址来获取的。到编辑器,远程抓图就是由编辑器提交图片地址,服务器端抓图处理后将新地址返回给编辑器。两者的初始触发都需要ajax的介入。
六、截图交互
1、截图介绍
使用ActiveX控件,目前只支持IE浏览器。
2、备注
需要配置的参数除了和图片上传一样的内容外,还包括服务器地址和端口的配置。使用时请根据自己服务器的特点进行适配和修改。
//屏幕截图的server端文件所在的网站地址或者ip,请不要加http://
snapscreenHost: '127.0.0.1',
//屏幕截图的server端保存程序,UEditor的范例代码为“URL
snapscreenServerUrl: URL +"server/upload/php/snapImgUp.php", +"server/upload/php/snapImgUp.php"”
//屏幕截图的server端端口
snapscreenServerPort: 80,
//截图的图片默认的排版方式
snapscreenImgAlign: 'center',
//截图显示修正地址
snapscreenPath: fixedImagePath,
七、附件上传交互
1、上传附件注意事项
附件上传的基本配置与图片类似。另外,由于附件上传采用成熟的swfupload开源框架,大部分文档资料可以参考swfupload官网教程。官网地址:http://
Ueditor的部署说明(来自Ueditor官网): 查看全部
网页flash文本抓取器(富文本内容交互(一)——编辑器内容至后端场景)
一、富文本内容交互
1、编辑器内容初始化(即在编辑器中设置富文本)
场景一:在编辑器中写一个新的文章,预设提示、问候等。
在 editor_config.js 文件中找到 initialContent 参数,并将其值设置为所需的提示或问候语,例如 initialContent: 'Welcome to UEditor!'。
场景二:编辑旧的文章,从数据库中取出富文本放到编辑器中。
显然,在编辑文章时,需要从后台数据库中提取一大段富文本。如果初始值还是采用场景一的方式设置,必然会带来引号被截断等问题,所以需要使用另一种方式来设置,如下代码所示:
//从数据库中取出文章内容打印到此处
此处采用了script标签作为编辑器容器对象,并设置了其类型是纯文本,从而在避免了标签内部JS代码执行的同时解决了部分同学在使用传统的textarea标签作为容器所带来的一次额外转码问题。
2、提交编辑器内容到后端
场景一:编辑器所在的Form中有一个提交按钮,点击该按钮完成提交动作。
这个场景适合最常见的场合。没有太多需要注意的问题。只需要说明三点:
1)默认提交到后台的表单名称为“editorValue”,可在editor_config.js中配置,参数名称为textarea。
2)可以在容器标签(即脚本标签)上设置name属性来覆盖editor_config.js中的默认配置。示例代码如下,其中 myContent 将是新的提交表单名称:
3)后端接收程序可以通过以下方式获取编辑器中的富文本内容。
//PHP获取:
$_POST["myContent"]
//JSP获取:
request.getParameter("myContent");
//ASP获取:
request("myContent");
//NET获取:
context.Request.Form["myContent"];
场景二:编辑器所在的Form中没有提交按钮,提交动作是由外部事件触发的。
该场景适用于网站前端交互较多的场合。主要需要注意的是,编辑器内容同步操作是在表单提交动作触发之前进行的。通用代码模式如下所示:
//满足提交条件时同步内容并提交,此处editor为编辑器实例
if(editor.hasContent()){ //此处以非空为例
editor.sync(); //同步内容
someForm.submit(); //提交Form
}
这里的 editor 是编辑器实例对象。
场景三:编辑器不在任何Form中,提交动作被外部事件触发。
这个场景用的不多,但在特殊场合可能需要用到。UEditor 也提供了相应的处理方案。基本逻辑和第二种场景一样,只是在进行同步操作的时候需要传入提交表单的id,比如editor.sync(myFormID)。其他相同的场景 2。
二、图片上传交互
1、传统图片上传
传统图片上传所涉及的前后端交互主要涉及“上传提交路径”和“图片存储路径”两个参数。后台存储路径为任何形式(绝对或相对),在任何页面上显示与前台无关。
2、Flash图片上传
Flahs图片上传与传统图片上传有一个很大的区别:它需要服务器实时返回“图片保存路径”,以便在前台即时显示。具体到编辑器,需要将返回的路径插入到编辑器中。这会导致除了传统图片上传中提到的两个参数之外,还有第三个参数:“前后端校正路径”。如果后台返回的保存路径是绝对路径(指以http开头的路径,根目录开头的路径也可以收录在其中),那么前台不需要做任何修正,否则用户必须非常清楚自己当前的目录结构,并根据这修正了前后端相对路径的差异。因此,UEditor 强烈建议服务器端返回以根目录开头的相对路径。
3、UEditor中上传的做法和注意事项
在UEditor中,“上传提交路径”和“前后端修改路径”的配置位于editor_config.js中。其中,imageUrl参数对应“上传提交路径”,imagePath参数对应“前后端校正路径”。“图片保存路径”需要在server/upload/php目录下的imageUp文件中配置。
路径配置完成后,还需要配置imageFieldName参数为文件表单的表单名,后台可以据此获取文件句柄。此参数也位于 editor_config.js 中。
//图片上传提交地址
imageUrl:URL+"server/upload/php/imageUp.php",
//图片修正地址,引用了fixedImagePath,如有特殊需求,可自行配置
imagePath:fixedImagePath,
//图片描述的key
imageFieldName:"upFile",
//等比压缩的基准,确定maxImageSideLength参数的参照对象.
//0为按照最长边,1为按照宽度,2为按照高度
compressSide:0,
//上传图片最大允许的边长,超过会自动等比缩放,不缩放就设置一个比较大的值
//更多设置在image.html中
maxImageSideLength:900
完成以上配置后,理论上后台应该可以接收到前台上传的图片文件了。一旦正确保存,传统的图像上传到此结束。但是,在编辑器中使用 Flash 上传,过程还远远没有结束。
首先,后台需要计算出图片文件存放的地址字符串。UEditor 强烈建议使用从 网站 的根目录到图像名称末尾的字符串。如果不是从网站的根目录算起,后面需要考虑参数“前后端校正地址”。
其次,后台返回一个json格式的字符串。格式的具体要求如下:
{ "url":"图片地址", "title":"图片描述", "state":"上传状态" }
三、Word 图片转储交互
1、图片转储原理
所谓word图片转储,就是为了解决UEditor从word中复制一个混合的图文文章粘贴到编辑器中的问题,word文章中的图片数据无法显示在编辑器中。是针对无法提交到服务器的问题而开发的一款简单易用的镜像转储解决方案。
该功能的基本操作步骤:复制word文档-》粘贴到编辑器-》编辑器会将所有图片转换成占位符图片,同时高亮工具栏中的dump按钮-》点击dump按钮即可弹出图片上传框——“点击复制按钮复制图片目录地址——”点击“添加照片”按钮,将刚才复制的图片目录地址粘贴到弹出的选择框中——“点击打开按钮选择目录下的所有图片文件,点击这里打开-》执行图片上传-》上传成功确认插入,UEditor会自动完成对应占位图片的替换过程。
2、配置要点及注意事项
word图片dump的配置和普通图片上传基本一样,唯一的区别就是操作上的不同:前者需要先获取临时图片文件存在的目录,后者直接选择指定的文件目录通过它自己。PS:在某些操作系统的word的某些版本中,发现单个word图片会生成两张临时图片,格式和定义不同。目前还没有找到改进的方法。
四、远程抓图交互
1、遥控抓取原理
图片远程抓取是指服务器将这些外部图片抓取到本地服务器,并在插入本地域名以外的图片链接地址时保存的功能。实现原理是在编辑器中向服务器发送一个收录所有外域图片地址的ajax请求,然后服务器将图片地址捕获并保存在后端并将图片地址返回给编辑器,然后编辑器将完成外域地址和本地地址的替换。
//是否开启远程图片抓取
catchRemoteImageEnable:true,
//处理远程图片抓取的地址
catcherUrl:URL +"server/submit/php/getRemoteImage.php",
//提交到后台远程图片uri合集的表单名
catchFieldName:"upFile",
//图片修正地址,同imagePath
catcherPath:fixedImagePath,
//本地顶级域名,当开启远程图片抓取时,除此之外的所有其它域名下的
//图片都将被抓取到本地
localDomain:["baidu.com","10.81.2.114"],
2、备注
是否开启远程抓图功能可以通过在editot_config.js中配置catchRemoteImageEnable参数来实现。与此功能相关的配置还包括远程获取处理程序地址、表单字段名称、本地字段以及“前端和后端更正地址”。远程抓图处理程序实现根据前端提交的地址列表(以ue_separate_ue标识分隔的字符串)进行抓图,然后将地址列表返回给客户端的功能。
前后端交互数据格式示例:(URL1, URL2, URL3, URL4)
URL1ue_separate_ueURL2ue_separate_ueURL3ue_separate_ueURL4
五、图片在线管理交互
1、图片在线管理介绍
图片在线管理是指通过读取服务器端的文件目录并在编辑器中显示来进行附加操作的功能。出于安全考虑,UEditor目前只实现了二次图片插入操作,其他的删除、移动等操作将在后续的二次开发教程中发布。
//图片在线管理的处理地址
imageManagerUrl:URL + "server/submit/php/imageManager.php",
//图片修正地址,同imagePath
imageManagerPath:fixedImagePath
2、备注
在线图片管理中需要配置的参数与远程抓图相同。两者的区别在于,在线图片管理中的图片数据是通过在服务器端指定某个目录,然后遍历其下的所有图片文件,然后返回地址来获取的。到编辑器,远程抓图就是由编辑器提交图片地址,服务器端抓图处理后将新地址返回给编辑器。两者的初始触发都需要ajax的介入。
六、截图交互
1、截图介绍
使用ActiveX控件,目前只支持IE浏览器。
2、备注
需要配置的参数除了和图片上传一样的内容外,还包括服务器地址和端口的配置。使用时请根据自己服务器的特点进行适配和修改。
//屏幕截图的server端文件所在的网站地址或者ip,请不要加http://
snapscreenHost: '127.0.0.1',
//屏幕截图的server端保存程序,UEditor的范例代码为“URL
snapscreenServerUrl: URL +"server/upload/php/snapImgUp.php", +"server/upload/php/snapImgUp.php"”
//屏幕截图的server端端口
snapscreenServerPort: 80,
//截图的图片默认的排版方式
snapscreenImgAlign: 'center',
//截图显示修正地址
snapscreenPath: fixedImagePath,
七、附件上传交互
1、上传附件注意事项
附件上传的基本配置与图片类似。另外,由于附件上传采用成熟的swfupload开源框架,大部分文档资料可以参考swfupload官网教程。官网地址:http://
Ueditor的部署说明(来自Ueditor官网):
网页flash文本抓取器(网站抓取是一个用Python编写的Web爬虫和Web框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-03 10:28
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。
网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。
网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以通过直接socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。
网站爬虫使用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。 查看全部
网页flash文本抓取器(网站抓取是一个用Python编写的Web爬虫和Web框架)
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。

网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。

网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以通过直接socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。

网站爬虫使用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。
网页flash文本抓取器(网页flash文本抓取器,强烈推荐基于golang的爬虫开发框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-04-02 18:04
网页flash文本抓取器,
强烈推荐基于golang的爬虫开发框架:parse-go,它基于queryset,把网页中的所有页面标记成text/field,进而爬取下来并存储起来。不过,它也支持html的抓取。使用方法很简单,你可以打开项目,运行goget,就能看到项目的运行效果。此外,还可以进行效果模拟,你可以把预先定义好的文本复制到wordcloud中(大小可以自己配置),然后在网页中输入parse-go就能得到结果,然后把结果存到本地存储库里就好了。
网页抓取非常简单,抓取速度却很快,如果你不会写python,pandas以及numpy的话也没关系,这个工具,也是web前端开发者使用的,其实python也有相同的应用场景,web开发者就可以拿来替代python处理,简单说,就是可以获取、解析网页并返回报表。一、网页获取方式总结1、scrapy与requests一般的网页抓取,scrapy或requests这两个最流行,它们都是基于url的,只要它们能得到一个网页,得到网页的url之后就可以用它们来抓取和解析了。
github上已经有很多,比如官方文档中有documentation(documentation-scrapy或者requests-scrapy)。我们看看scrapy,对比一下requests,他们都有默认处理,正如其名,它们主要区别在于它们的html解析问题。我们以例子来说明问题,demo就是第一页的某一个scrapy项目,那么我们用requests解析一下,首先得先找到里面的链接,好,那么我们从此看起,如何获取到以及如何返回wordcloud(json)如何返回css代码的解析结果。
我们看到,可以得到html文本,也就是我们说的网页,那么要获取到html文本文件,怎么把它解析成为css文件,我们需要一些特殊的工具,这就是编码的问题,有标准编码和开放标准的编码。常见的编码有utf-8,utf-16。我们以utf-8编码为例,如果我们想一次得到3页的代码,那么我们需要用到utf-8编码的requests框架,在utf-8编码下,获取url需要json格式,所以可以用jsonreader或requestsreader等工具,把url加入到一个json对象里,通过json字符串,可以获取url返回的css等返回到utf-8编码格式的数据。
但是如果我们返回的数据是css,js,这种特殊的编码,那我们在分析数据的时候就会产生问题,我们需要先将解析好的css字符串转换成utf-8编码,如果编码不匹配,这里的3页就不会被解析到,我们就需要通过gzip压缩,并转换成开放标准编码,然后用scrapy解析数据。那么scrapy也是用json解析css的,我们也同样以例子来说。 查看全部
网页flash文本抓取器(网页flash文本抓取器,强烈推荐基于golang的爬虫开发框架)
网页flash文本抓取器,
强烈推荐基于golang的爬虫开发框架:parse-go,它基于queryset,把网页中的所有页面标记成text/field,进而爬取下来并存储起来。不过,它也支持html的抓取。使用方法很简单,你可以打开项目,运行goget,就能看到项目的运行效果。此外,还可以进行效果模拟,你可以把预先定义好的文本复制到wordcloud中(大小可以自己配置),然后在网页中输入parse-go就能得到结果,然后把结果存到本地存储库里就好了。
网页抓取非常简单,抓取速度却很快,如果你不会写python,pandas以及numpy的话也没关系,这个工具,也是web前端开发者使用的,其实python也有相同的应用场景,web开发者就可以拿来替代python处理,简单说,就是可以获取、解析网页并返回报表。一、网页获取方式总结1、scrapy与requests一般的网页抓取,scrapy或requests这两个最流行,它们都是基于url的,只要它们能得到一个网页,得到网页的url之后就可以用它们来抓取和解析了。
github上已经有很多,比如官方文档中有documentation(documentation-scrapy或者requests-scrapy)。我们看看scrapy,对比一下requests,他们都有默认处理,正如其名,它们主要区别在于它们的html解析问题。我们以例子来说明问题,demo就是第一页的某一个scrapy项目,那么我们用requests解析一下,首先得先找到里面的链接,好,那么我们从此看起,如何获取到以及如何返回wordcloud(json)如何返回css代码的解析结果。
我们看到,可以得到html文本,也就是我们说的网页,那么要获取到html文本文件,怎么把它解析成为css文件,我们需要一些特殊的工具,这就是编码的问题,有标准编码和开放标准的编码。常见的编码有utf-8,utf-16。我们以utf-8编码为例,如果我们想一次得到3页的代码,那么我们需要用到utf-8编码的requests框架,在utf-8编码下,获取url需要json格式,所以可以用jsonreader或requestsreader等工具,把url加入到一个json对象里,通过json字符串,可以获取url返回的css等返回到utf-8编码格式的数据。
但是如果我们返回的数据是css,js,这种特殊的编码,那我们在分析数据的时候就会产生问题,我们需要先将解析好的css字符串转换成utf-8编码,如果编码不匹配,这里的3页就不会被解析到,我们就需要通过gzip压缩,并转换成开放标准编码,然后用scrapy解析数据。那么scrapy也是用json解析css的,我们也同样以例子来说。
网页flash文本抓取器(爬虫系统的基本包含模式()()的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-02 16:28
)
基本 URL 收录模式(或协议)、服务器名称(或 IP 地址)、路径和文件名,例如“protocol://authorization/path?query”。带有授权部分的完整通用 URI 语法如下所示:protocol://username:-domain:port/directory/filename.filesuffix?parameter=value# logo
爬虫系统要处理的URL是指使用超文本传输协议HTTP的URL。
URL分为绝对URL和相对URL
绝对 URL 显示文件的完整路径,这意味着绝对 URL 本身的位置与被引用的实际文件的位置无关。
相对 URL 以收录 URL 本身的文件夹的位置作为参考点来描述目标文件夹的位置。如果目标文件和当前页面在同一目录下(即收录URL的页面),那么文件的相对URL就是文件名和扩展名,如果目标文件在当前页面的子目录下目录,其相对 URL 为 subdirectory 目录名,后跟一个斜杠,然后是目标文件的文件名和扩展名。
如果要引用文件层次结构中较高目录中的文件,请使用两个句点和一个斜杠。两个句点和一个斜杠可以组合并重复以引用当前文件所在硬盘上的任何文件,
一般来说,相对 URL 应该始终用于同一服务器上的文件,它们在将页面从本地系统传输到服务器时更容易键入和方便,只要每个文件的相对位置保持不变,链接仍然有效。
char * url_normalized(char *url) <br />{<br /> if (url == NULL) return NULL;<br /><br /> /* rtrim url */<br /> int len = strlen(url);<br /> while (len && isspace(url[len-1]))<br /> len--;<br /> url[len] = '\0';<br /><br /> if (len == 0) {<br /> free(url);<br /> return NULL;<br /> }<br /><br /> /* remove http(s):// */<br /> if (len > 7 && strncmp(url, "http", 4) == 0) {<br /> int vlen = 7;<br /> if (url[4] == 's') /* https */<br /> vlen++;<br /><br /> len -= vlen;<br /> char *tmp = (char *)malloc(len+1);<br /> strncpy(tmp, url+vlen, len);<br /> tmp[len] = '\0';<br /> free(url);<br /> url = tmp;<br /> }<br /><br /> /* remove '/' at end of url if have */<br /> if (url[len-1] == '/') {<br /> url[--len] = '\0';<br /> }<br /><br /> if (len > MAX_LINK_LEN) {<br /> free(url);<br /> return NULL;<br /> }<br /><br /> return url;<br />} 查看全部
网页flash文本抓取器(爬虫系统的基本包含模式()()的应用
)
基本 URL 收录模式(或协议)、服务器名称(或 IP 地址)、路径和文件名,例如“protocol://authorization/path?query”。带有授权部分的完整通用 URI 语法如下所示:protocol://username:-domain:port/directory/filename.filesuffix?parameter=value# logo
爬虫系统要处理的URL是指使用超文本传输协议HTTP的URL。
URL分为绝对URL和相对URL
绝对 URL 显示文件的完整路径,这意味着绝对 URL 本身的位置与被引用的实际文件的位置无关。
相对 URL 以收录 URL 本身的文件夹的位置作为参考点来描述目标文件夹的位置。如果目标文件和当前页面在同一目录下(即收录URL的页面),那么文件的相对URL就是文件名和扩展名,如果目标文件在当前页面的子目录下目录,其相对 URL 为 subdirectory 目录名,后跟一个斜杠,然后是目标文件的文件名和扩展名。
如果要引用文件层次结构中较高目录中的文件,请使用两个句点和一个斜杠。两个句点和一个斜杠可以组合并重复以引用当前文件所在硬盘上的任何文件,
一般来说,相对 URL 应该始终用于同一服务器上的文件,它们在将页面从本地系统传输到服务器时更容易键入和方便,只要每个文件的相对位置保持不变,链接仍然有效。
char * url_normalized(char *url) <br />{<br /> if (url == NULL) return NULL;<br /><br /> /* rtrim url */<br /> int len = strlen(url);<br /> while (len && isspace(url[len-1]))<br /> len--;<br /> url[len] = '\0';<br /><br /> if (len == 0) {<br /> free(url);<br /> return NULL;<br /> }<br /><br /> /* remove http(s):// */<br /> if (len > 7 && strncmp(url, "http", 4) == 0) {<br /> int vlen = 7;<br /> if (url[4] == 's') /* https */<br /> vlen++;<br /><br /> len -= vlen;<br /> char *tmp = (char *)malloc(len+1);<br /> strncpy(tmp, url+vlen, len);<br /> tmp[len] = '\0';<br /> free(url);<br /> url = tmp;<br /> }<br /><br /> /* remove '/' at end of url if have */<br /> if (url[len-1] == '/') {<br /> url[--len] = '\0';<br /> }<br /><br /> if (len > MAX_LINK_LEN) {<br /> free(url);<br /> return NULL;<br /> }<br /><br /> return url;<br />}
网页flash文本抓取器(网页flash文本抓取器了解一下,scrapy是爬虫框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-04-02 03:08
网页flash文本抓取器了解一下,自动抓取网页上所有html文本并进行智能分词,再也不用担心抓取时耗时费力了,而且更强大的是可以无痛将网页上网页爬取下来,
scrapy是爬虫框架吧,智能分词这个功能,也算是爬虫的一个特色功能吧,与requests库结合使用的话,主要目的是提高爬虫效率。
内置三种分词模式bibtex,tcsc和shagham。requests支持的分词模式还包括基于正则的双匹配,scrapy官方api为namedtext。
url抓取之后爬虫主要分词分词,目的是为了给爬虫内嵌智能分词器,同时也是一种策略性的转发请求方式,实现爬虫内嵌三种分词模式的自动切换。三种模式策略。shadowsocks有个zoo分词模式(据说快一周)可以爬取ajax1.0以上php代码。(反正实现难度大,不是太理解)。云栖社区提供很多web安全事件分析(针对国内一切网站)。
七牛云提供的python爬虫由于关键字验证和爬虫协议还有其他保密因素,根本不可能爬取ajax1.0以上php代码。但是老人家自己捣鼓了个python无头php(专门针对image5-api48.10.1-xyz)爬虫源码,可以直接使用非常不错。利益相关,不匿。
我目前也遇到这个问题了,然后我基于scrapy写了一个爬虫,爬完网页,是利用正则匹配的方式,找到想要分词的词,然后进行分词,我自己基于动态分词的方式写的,刚开始并不怎么稳定,后来数据多了,反而效率比之前快了很多, 查看全部
网页flash文本抓取器(网页flash文本抓取器了解一下,scrapy是爬虫框架)
网页flash文本抓取器了解一下,自动抓取网页上所有html文本并进行智能分词,再也不用担心抓取时耗时费力了,而且更强大的是可以无痛将网页上网页爬取下来,
scrapy是爬虫框架吧,智能分词这个功能,也算是爬虫的一个特色功能吧,与requests库结合使用的话,主要目的是提高爬虫效率。
内置三种分词模式bibtex,tcsc和shagham。requests支持的分词模式还包括基于正则的双匹配,scrapy官方api为namedtext。
url抓取之后爬虫主要分词分词,目的是为了给爬虫内嵌智能分词器,同时也是一种策略性的转发请求方式,实现爬虫内嵌三种分词模式的自动切换。三种模式策略。shadowsocks有个zoo分词模式(据说快一周)可以爬取ajax1.0以上php代码。(反正实现难度大,不是太理解)。云栖社区提供很多web安全事件分析(针对国内一切网站)。
七牛云提供的python爬虫由于关键字验证和爬虫协议还有其他保密因素,根本不可能爬取ajax1.0以上php代码。但是老人家自己捣鼓了个python无头php(专门针对image5-api48.10.1-xyz)爬虫源码,可以直接使用非常不错。利益相关,不匿。
我目前也遇到这个问题了,然后我基于scrapy写了一个爬虫,爬完网页,是利用正则匹配的方式,找到想要分词的词,然后进行分词,我自己基于动态分词的方式写的,刚开始并不怎么稳定,后来数据多了,反而效率比之前快了很多,
网页flash文本抓取器(一种提取网页内容的方法及装置提高(技术实现步骤摘要))
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-04-01 22:09
本申请公开了一种网页内容提取方法及装置。利用网页中主题元素的文本内容与标题页块内容的关系,根据标题页块与各页块的相对位置,可在各页中确定正文页块块,而不是只考虑网页中的每个页面。降低了块的文本密度,从而过滤掉了大部分无关信息,提高了确定文本页块的准确性,也提高了从文本页块中提取文本的准确性。
下载所有详细的技术数据
【技术实现步骤总结】
此应用程序收录信息
,尤其涉及一种网页内容提取方法及装置。
技术介绍
网络爬虫是根据一定的规则自动提取万维网上网页内容的程序。网页内容包括正文、正文标题、正文发表时间、作者、出处。现有技术中网络爬虫提取网页文本的方法是下载网页,分析网页中每个页面块的文本密度值,取文本密度值最大的页块(即每单位面积收录的最大文本字符数)作为文本的位置。页块,并提取正文。但是,万维网上有各种网页布局。网页中文字密度最大的页块可能收录过多的无关信息,如文字广告、推荐链接等,而不是文本所在的页面块。根据文本密度值提取的内容可能不是正文。可以看出,现有的网页内容提取方法对网页中文本的提取准确率较低。
技术实现思路
本申请实施例提供一种网页内容提取方法及装置,用以解决现有网页内容提取方法中从网页中提取文本准确率不高的问题。本申请实施例提供的一种网页内容提取方法,包括:根据网页代码中主题元素的文本内容,确定网页中的标题页块;标题页块的相对位置,文本页块在每个页块中确定;网页的文本是从文本页面块中提取的。本申请实施例提供的一种网页内容提取装置,包括:第一标题确定模块,用于根据网页代码中主题元素的文本内容确定网页中的标题页块;文本确定模块,用于根据网页中各个页块与标题页块的相对位置,确定各个页块中的文本页块。文本提取模块用于从文本页面块中提取网页的文本。本申请实施例采用的上述至少一种技术方案可以达到以下有益效果:由于网页代码中主题元素的文本内容往往与网页中的标题页块的内容相关联。网页,可以根据这个关联来确定标题页块,然后根据标题页块和各个页块的相对位置,在各个页块中确定文本页块,从而从文本页块中提取出网页的文本。因此,通过这种方法,不需要考虑文本,另外,可以过滤掉大部分不相关的信息,提高了确定文本页块的准确性,也提高了从文本页块中提取文本的准确性因此。
附图说明此处所描述的附图用于提供对本申请的进一步理解,构成本申请的一部分。本申请的示意性实施例和说明用于解释本申请,并不构成对本申请的不当限制。在附图中:附图说明图1为本申请实施例提供的一种网页文本提取方法的流程图;无花果。图2为本申请实施例提供的网页示意图;无花果。图3为本申请实施例提供的一种网页内容提取方法的详细流程图。优选实施例的详细说明为了实现目标,本申请的技术方案和优点更加清楚,下面结合本申请的具体实施例及相应的附图,对本申请的技术方案进行清楚、完整的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。本申请的应用场景是通过网络爬虫提取网页中的文字以及文字的编辑信息。在本申请的应用场景中,通过网页渲染引擎,如Webkit、Gecko、Trident等,可以解析网页的代码,渲染网页。一个网页的代码包括几个元素,通常由一对标签和这对标签中间的内容组成,例如:
你好
上面是一个元素,“hello”是元素的内容;在网页的代码中,还包括一个由标签和内容组成的元素,比如图片子元素,例如:
它是一个图片子元素,其中“earth.jpg”是本地存储的图片。值得注意的是,图片子元素收录在对应的父元素中,例如:
你好
在渲染的网页中,显示了每个元素的内容和每个元素对应的图片。其中,每个元素的内容显示在网页中的每个矩形区域,一个矩形区域就是一个页面块,即网页中的每个元素都有对应的页面块,但是图片所在的区域所在的不是页块。需要说明的是,每个页面块在网页中分布的区域和位置可能不同,也可能重叠。在网页的代码中,还收录了每个页面块的位置信息。具体的,页块的位置信息可以是页块的指定位置到浏览器边缘的距离和页块的高宽,页面块的位置信息可以通过浏览器渲染引擎解析网页的代码得到。在本申请的应用场景中,网页渲染引擎通过解析网页的代码,得到网页中各个页面块的内容和位置,然后渲染网页。对于网络爬虫来说,网页中的文本是需要提取的有价值的信息。但是,除了文字和文字的编辑信息外,网页中往往还有很多不相关的信息,比如广告、评论、索引栏、相关信息等。链接等等。同时,对于网页中的每个页块,只有少数页块的内容或一个页块的内容是正文,并且其他页面块的内容不是正文。现有的网络爬虫无法直接确定网页中每个页面块中的正文页块,例如,
技术介绍
如上所述,现有的网络爬虫通过分析每个页面块内容的文本密度来确定文本密度最大的页面块为文本页面块。无关信息过多,提取文本的准确率低。采用本申请提供的网页文本提取方法,在确定标题页块后,可以根据标题页块与各页块的相对位置确定各页块中的文本页块。这样,在不考虑文本密度的情况下,可以过滤掉大部分无关信息,更准确地确定正文页块,提取正文。下面结合附图对本申请实施例提供的技术方案进行详细说明。图1为本申请实施例提供的一种网页文本提取方法的流程图,包括以下步骤: S101:根据本发明代码中主题元素的文本内容,确定网页中的标题页块。网页。在本申请实施例中,网页的主题元素可以是由网页代码中的一对标签和位于这对标签中间的内容组成的元素,例如“什么是专利_专利班级”。在网页的代码标准中,主题元素有其特定的作用,即浏览器' 页面渲染引擎根据主题元素的内容生成浏览器标签。浏览器标签一般位于浏览器的顶部或底部,用于显示网页的主题信息。无花果。图2为本申请实施例提供的网页示意图。在图。2、浏览器渲染多个网页,在浏览器顶部的标签栏中,有多个浏览器标签对应多个网页。一般来说,网页主题元素的文本内容与网页中的标题页块的内容有关,如图2所示,在当前网页中,浏览器标签的内容为“The英军人数创200年来新低。老兵推荐。新兵领取购物券丨新兵丨英国丨陆军_新浪新闻”,即图2所示网页代码中的主题元素是“英国陆军人数创200年来新低。退伍军人推荐新兵领取购物券丨新兵丨英国丨陆军_新浪新闻》。图2中,网页主体(即标题页块)的标题内容为“英国陆军士兵人数创200年来新低。退伍军人推荐新兵获得购物券。” 因此,可以使用这种关系。文本内容决定了网页中标题页块的内容。具体地,主题元素的文本内容与网页中标题页块内容的关联关系可以相同、相似、或者其他可以根据前者确定的关系,本申请对此不做限定。作为本申请的一个实施例,网页中主题元素的文本内容与标题页的人脸块内容的关联可以相同。在本申请实施例中,根据网页主题元素的文本内容确定网页
【技术保护点】
一种网页内容提取方法,包括: 根据网页代码中主题元素的文本内容,确定网页中的标题页块;根据网页中的每个页块与标题页块的相对位置确定,在每个页块中确定文本页块;网页的文本是从文本页面块中提取的。
【技术特点总结】
1.一种网页内容提取方法,包括:根据网页代码中主题元素的文本内容,确定网页中的标题页块;根据网页中每个页块的标题页块的相对位置,确定每个页块中的文本页块;网页的文本是从文本页面块中提取的。2.根据权利要求1所述的方法,其特征在于,根据网页的主题元素的文本内容确定网页中的标题页块,具体包括: 根据主题元素的文本内容,在网页代码中的元素,判断收录的内容与标题元素的文本内容相同或相似;将title元素对应的页块确定为标题页块。3.根据权利要求2所述的方法,其特征在于,当不存在内容与文本内容相同或相似的元素时,该方法还包括: 代码中的每个元素,确定没有子元素的元素元素作为替代元素;将每个备选元素对应的页块确定为备选页块;获取替换页块的位置和替换页块中收录的内容的内容。属性; 确定位于网页特定位置且收录具有特定属性的内容的候选页块作为标题页块。4.根据权利要求1所述的方法,其中,根据网页中各个页块与标题页块的相对位置,确定各个页块中的文本页块,具体包括: 根据标题页块的位置,确定预期文本区域;根据每个页块与预期文本区域的相对位置,在每个页块中确定文本页块。
5.根据权利要求4所述的方法,其特征在于,根据标题页块的位置确定期望文本区域,具体包括: 根据标题页块在水平方向上的第一指定位置与第一距离到浏览器的第一指定边缘,确定期望文本区域的第二指定位置到浏览器的第一指定边缘在水平方向上的距离;根据标题页块的第一个指定位置,垂直方向上从浏览器第二个指定边缘到浏览器第二个指定边缘的第二个距离,确定到预期文本的第二个指定位置的距离区域到浏览器在垂直方向上的第二个指定边缘;根据标题页块的宽度,确定预期文本区域的宽度;当网页为移动网页时,根据移动终端显示屏的高度、标题页块的高度和第二距离确定预期文本区域的高度。当网页不是移动网页时,在网页的每个页块中确定有效页块,根据每个有效页块的最大高度、标题页块的高度和第二个距离文本区域的高度;有效页块是指在网页的每个页块中,与标题页块的相对位置满足预设条件,并且标题页块的宽度与宽度之差的绝对值不大于具有特定阈值的页块;其中,所述预设条件包括:位于标题页块的正下方。6.根据权利要求4所述的方法,其特征在于,根据每个页面块与预期文本区域的相对位置,在每个页面块中,确定文本页面块,具体包括:在每个页面块中,确定预期文本区域内面积最大的页块;使用页块作为文本页块;或者在网页的每个页块中确定一个有效页块,根据每个有效页块与预期文本区域的有效交集区域确定有效页块,在每个有效页块中,确定文本页块;有效页块是指网页的每个页块与满足预设条件的标题页块的相对位置,宽度与标题页块宽度之差的绝对值不为大于特定阈值;其中,所述预设条件包括:位于标题页块的正下方。
7.根据权利要求6所述的方法,其特征在于,根据每个有效页块的有效交集区域与期望文本区域的面积,在每个有效页块中确定文本页块,具体包括:按照每个有效页块的面积从小到大的顺序,对每个有效页块执行以下步骤,直到确定文本页块:得到有效页块的面积L,计算两者之间的差值有效页块和预期文本区域的有效交集面积S;如果S/L大于预设临界值,则确定有效页块为文本页块;如果 S/L 不大于预设的临界值,则继续下一个有效页块执行上述步骤。8. 8.根据权利要求7所述的方法,其特征在于,所述获取有效页块的面积L具体包括: 获取所述有效页块对应的有效元素的图片子元素;确定图片子元素对应的图片区域;有效页块的面积与对应图片的面积之和确定为有效页块的面积L;计算有效页块与预期文本区域的有效交集面积S,包括:计算有效页块与预期文本区域... 确定图片子元素对应的图片区域;有效页块的面积与对应图片的面积之和确定为有效页块的面积L;计算有效页块与预期文本区域的有效交集面积S,包括:计算有效页块与预期文本区域... 确定图片子元素对应的图片区域;有效页块的面积与对应图片的面积之和确定为有效页块的面积L;计算有效页块与预期文本区域的有效交集面积S,包括:计算有效页块与预期文本区域...
【专利技术性质】
技术研发人员:严军,
申请人(专利权)持有人:,
类型:发明
国家、省、市:北京;11
下载所有详细的技术数据 我是该专利的所有者 查看全部
网页flash文本抓取器(一种提取网页内容的方法及装置提高(技术实现步骤摘要))
本申请公开了一种网页内容提取方法及装置。利用网页中主题元素的文本内容与标题页块内容的关系,根据标题页块与各页块的相对位置,可在各页中确定正文页块块,而不是只考虑网页中的每个页面。降低了块的文本密度,从而过滤掉了大部分无关信息,提高了确定文本页块的准确性,也提高了从文本页块中提取文本的准确性。
下载所有详细的技术数据
【技术实现步骤总结】
此应用程序收录信息
,尤其涉及一种网页内容提取方法及装置。
技术介绍
网络爬虫是根据一定的规则自动提取万维网上网页内容的程序。网页内容包括正文、正文标题、正文发表时间、作者、出处。现有技术中网络爬虫提取网页文本的方法是下载网页,分析网页中每个页面块的文本密度值,取文本密度值最大的页块(即每单位面积收录的最大文本字符数)作为文本的位置。页块,并提取正文。但是,万维网上有各种网页布局。网页中文字密度最大的页块可能收录过多的无关信息,如文字广告、推荐链接等,而不是文本所在的页面块。根据文本密度值提取的内容可能不是正文。可以看出,现有的网页内容提取方法对网页中文本的提取准确率较低。
技术实现思路
本申请实施例提供一种网页内容提取方法及装置,用以解决现有网页内容提取方法中从网页中提取文本准确率不高的问题。本申请实施例提供的一种网页内容提取方法,包括:根据网页代码中主题元素的文本内容,确定网页中的标题页块;标题页块的相对位置,文本页块在每个页块中确定;网页的文本是从文本页面块中提取的。本申请实施例提供的一种网页内容提取装置,包括:第一标题确定模块,用于根据网页代码中主题元素的文本内容确定网页中的标题页块;文本确定模块,用于根据网页中各个页块与标题页块的相对位置,确定各个页块中的文本页块。文本提取模块用于从文本页面块中提取网页的文本。本申请实施例采用的上述至少一种技术方案可以达到以下有益效果:由于网页代码中主题元素的文本内容往往与网页中的标题页块的内容相关联。网页,可以根据这个关联来确定标题页块,然后根据标题页块和各个页块的相对位置,在各个页块中确定文本页块,从而从文本页块中提取出网页的文本。因此,通过这种方法,不需要考虑文本,另外,可以过滤掉大部分不相关的信息,提高了确定文本页块的准确性,也提高了从文本页块中提取文本的准确性因此。
附图说明此处所描述的附图用于提供对本申请的进一步理解,构成本申请的一部分。本申请的示意性实施例和说明用于解释本申请,并不构成对本申请的不当限制。在附图中:附图说明图1为本申请实施例提供的一种网页文本提取方法的流程图;无花果。图2为本申请实施例提供的网页示意图;无花果。图3为本申请实施例提供的一种网页内容提取方法的详细流程图。优选实施例的详细说明为了实现目标,本申请的技术方案和优点更加清楚,下面结合本申请的具体实施例及相应的附图,对本申请的技术方案进行清楚、完整的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。本申请的应用场景是通过网络爬虫提取网页中的文字以及文字的编辑信息。在本申请的应用场景中,通过网页渲染引擎,如Webkit、Gecko、Trident等,可以解析网页的代码,渲染网页。一个网页的代码包括几个元素,通常由一对标签和这对标签中间的内容组成,例如:
你好
上面是一个元素,“hello”是元素的内容;在网页的代码中,还包括一个由标签和内容组成的元素,比如图片子元素,例如:
它是一个图片子元素,其中“earth.jpg”是本地存储的图片。值得注意的是,图片子元素收录在对应的父元素中,例如:
你好
在渲染的网页中,显示了每个元素的内容和每个元素对应的图片。其中,每个元素的内容显示在网页中的每个矩形区域,一个矩形区域就是一个页面块,即网页中的每个元素都有对应的页面块,但是图片所在的区域所在的不是页块。需要说明的是,每个页面块在网页中分布的区域和位置可能不同,也可能重叠。在网页的代码中,还收录了每个页面块的位置信息。具体的,页块的位置信息可以是页块的指定位置到浏览器边缘的距离和页块的高宽,页面块的位置信息可以通过浏览器渲染引擎解析网页的代码得到。在本申请的应用场景中,网页渲染引擎通过解析网页的代码,得到网页中各个页面块的内容和位置,然后渲染网页。对于网络爬虫来说,网页中的文本是需要提取的有价值的信息。但是,除了文字和文字的编辑信息外,网页中往往还有很多不相关的信息,比如广告、评论、索引栏、相关信息等。链接等等。同时,对于网页中的每个页块,只有少数页块的内容或一个页块的内容是正文,并且其他页面块的内容不是正文。现有的网络爬虫无法直接确定网页中每个页面块中的正文页块,例如,
技术介绍
如上所述,现有的网络爬虫通过分析每个页面块内容的文本密度来确定文本密度最大的页面块为文本页面块。无关信息过多,提取文本的准确率低。采用本申请提供的网页文本提取方法,在确定标题页块后,可以根据标题页块与各页块的相对位置确定各页块中的文本页块。这样,在不考虑文本密度的情况下,可以过滤掉大部分无关信息,更准确地确定正文页块,提取正文。下面结合附图对本申请实施例提供的技术方案进行详细说明。图1为本申请实施例提供的一种网页文本提取方法的流程图,包括以下步骤: S101:根据本发明代码中主题元素的文本内容,确定网页中的标题页块。网页。在本申请实施例中,网页的主题元素可以是由网页代码中的一对标签和位于这对标签中间的内容组成的元素,例如“什么是专利_专利班级”。在网页的代码标准中,主题元素有其特定的作用,即浏览器' 页面渲染引擎根据主题元素的内容生成浏览器标签。浏览器标签一般位于浏览器的顶部或底部,用于显示网页的主题信息。无花果。图2为本申请实施例提供的网页示意图。在图。2、浏览器渲染多个网页,在浏览器顶部的标签栏中,有多个浏览器标签对应多个网页。一般来说,网页主题元素的文本内容与网页中的标题页块的内容有关,如图2所示,在当前网页中,浏览器标签的内容为“The英军人数创200年来新低。老兵推荐。新兵领取购物券丨新兵丨英国丨陆军_新浪新闻”,即图2所示网页代码中的主题元素是“英国陆军人数创200年来新低。退伍军人推荐新兵领取购物券丨新兵丨英国丨陆军_新浪新闻》。图2中,网页主体(即标题页块)的标题内容为“英国陆军士兵人数创200年来新低。退伍军人推荐新兵获得购物券。” 因此,可以使用这种关系。文本内容决定了网页中标题页块的内容。具体地,主题元素的文本内容与网页中标题页块内容的关联关系可以相同、相似、或者其他可以根据前者确定的关系,本申请对此不做限定。作为本申请的一个实施例,网页中主题元素的文本内容与标题页的人脸块内容的关联可以相同。在本申请实施例中,根据网页主题元素的文本内容确定网页

【技术保护点】
一种网页内容提取方法,包括: 根据网页代码中主题元素的文本内容,确定网页中的标题页块;根据网页中的每个页块与标题页块的相对位置确定,在每个页块中确定文本页块;网页的文本是从文本页面块中提取的。
【技术特点总结】
1.一种网页内容提取方法,包括:根据网页代码中主题元素的文本内容,确定网页中的标题页块;根据网页中每个页块的标题页块的相对位置,确定每个页块中的文本页块;网页的文本是从文本页面块中提取的。2.根据权利要求1所述的方法,其特征在于,根据网页的主题元素的文本内容确定网页中的标题页块,具体包括: 根据主题元素的文本内容,在网页代码中的元素,判断收录的内容与标题元素的文本内容相同或相似;将title元素对应的页块确定为标题页块。3.根据权利要求2所述的方法,其特征在于,当不存在内容与文本内容相同或相似的元素时,该方法还包括: 代码中的每个元素,确定没有子元素的元素元素作为替代元素;将每个备选元素对应的页块确定为备选页块;获取替换页块的位置和替换页块中收录的内容的内容。属性; 确定位于网页特定位置且收录具有特定属性的内容的候选页块作为标题页块。4.根据权利要求1所述的方法,其中,根据网页中各个页块与标题页块的相对位置,确定各个页块中的文本页块,具体包括: 根据标题页块的位置,确定预期文本区域;根据每个页块与预期文本区域的相对位置,在每个页块中确定文本页块。
5.根据权利要求4所述的方法,其特征在于,根据标题页块的位置确定期望文本区域,具体包括: 根据标题页块在水平方向上的第一指定位置与第一距离到浏览器的第一指定边缘,确定期望文本区域的第二指定位置到浏览器的第一指定边缘在水平方向上的距离;根据标题页块的第一个指定位置,垂直方向上从浏览器第二个指定边缘到浏览器第二个指定边缘的第二个距离,确定到预期文本的第二个指定位置的距离区域到浏览器在垂直方向上的第二个指定边缘;根据标题页块的宽度,确定预期文本区域的宽度;当网页为移动网页时,根据移动终端显示屏的高度、标题页块的高度和第二距离确定预期文本区域的高度。当网页不是移动网页时,在网页的每个页块中确定有效页块,根据每个有效页块的最大高度、标题页块的高度和第二个距离文本区域的高度;有效页块是指在网页的每个页块中,与标题页块的相对位置满足预设条件,并且标题页块的宽度与宽度之差的绝对值不大于具有特定阈值的页块;其中,所述预设条件包括:位于标题页块的正下方。6.根据权利要求4所述的方法,其特征在于,根据每个页面块与预期文本区域的相对位置,在每个页面块中,确定文本页面块,具体包括:在每个页面块中,确定预期文本区域内面积最大的页块;使用页块作为文本页块;或者在网页的每个页块中确定一个有效页块,根据每个有效页块与预期文本区域的有效交集区域确定有效页块,在每个有效页块中,确定文本页块;有效页块是指网页的每个页块与满足预设条件的标题页块的相对位置,宽度与标题页块宽度之差的绝对值不为大于特定阈值;其中,所述预设条件包括:位于标题页块的正下方。
7.根据权利要求6所述的方法,其特征在于,根据每个有效页块的有效交集区域与期望文本区域的面积,在每个有效页块中确定文本页块,具体包括:按照每个有效页块的面积从小到大的顺序,对每个有效页块执行以下步骤,直到确定文本页块:得到有效页块的面积L,计算两者之间的差值有效页块和预期文本区域的有效交集面积S;如果S/L大于预设临界值,则确定有效页块为文本页块;如果 S/L 不大于预设的临界值,则继续下一个有效页块执行上述步骤。8. 8.根据权利要求7所述的方法,其特征在于,所述获取有效页块的面积L具体包括: 获取所述有效页块对应的有效元素的图片子元素;确定图片子元素对应的图片区域;有效页块的面积与对应图片的面积之和确定为有效页块的面积L;计算有效页块与预期文本区域的有效交集面积S,包括:计算有效页块与预期文本区域... 确定图片子元素对应的图片区域;有效页块的面积与对应图片的面积之和确定为有效页块的面积L;计算有效页块与预期文本区域的有效交集面积S,包括:计算有效页块与预期文本区域... 确定图片子元素对应的图片区域;有效页块的面积与对应图片的面积之和确定为有效页块的面积L;计算有效页块与预期文本区域的有效交集面积S,包括:计算有效页块与预期文本区域...
【专利技术性质】
技术研发人员:严军,
申请人(专利权)持有人:,
类型:发明
国家、省、市:北京;11
下载所有详细的技术数据 我是该专利的所有者
网页flash文本抓取器(《一篇文章读懂python安装路径的错误》就行了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-31 17:05
网页flash文本抓取器,因为是activex控件,因此你自己实现个插件,目标是网页的flash文本,对网页里的全部文本进行文本抓取。那么后端的话,只要基于html5的动态库就可以实现,可以使用selenium,webdriver,headless,pythonextension等等。安装非常简单,参考这篇文章《一篇文章读懂python安装路径的错误》就行了。
推荐使用pythonextension,虽然是python2的框架,不过正好可以使用python2的packages。
你就不能使用selenium来做一个代理么
firefox里面有一个抓取的小插件,叫scrapy的,
手机答题,未能及时到达,见谅!网页爬虫,首推,excel爬虫-海龟君的博客,上面有上万例数据抓取。抓取和爬取数据工具各有不同,不做深入说明。我今天想说的是:python爬虫开发进阶课:简介与实战《从零开始学python3:打开编程世界的大门》、《用python3从零开始学爬虫》和《用python3开发爬虫》。
直接手工抓取是不可能的你可以尝试找些网站做了基于js的代理池,第三方代理引擎(比如美团代理、比如腾讯代理),
不是python都可以做到的。html有python内置api接口返回。 查看全部
网页flash文本抓取器(《一篇文章读懂python安装路径的错误》就行了)
网页flash文本抓取器,因为是activex控件,因此你自己实现个插件,目标是网页的flash文本,对网页里的全部文本进行文本抓取。那么后端的话,只要基于html5的动态库就可以实现,可以使用selenium,webdriver,headless,pythonextension等等。安装非常简单,参考这篇文章《一篇文章读懂python安装路径的错误》就行了。
推荐使用pythonextension,虽然是python2的框架,不过正好可以使用python2的packages。
你就不能使用selenium来做一个代理么
firefox里面有一个抓取的小插件,叫scrapy的,
手机答题,未能及时到达,见谅!网页爬虫,首推,excel爬虫-海龟君的博客,上面有上万例数据抓取。抓取和爬取数据工具各有不同,不做深入说明。我今天想说的是:python爬虫开发进阶课:简介与实战《从零开始学python3:打开编程世界的大门》、《用python3从零开始学爬虫》和《用python3开发爬虫》。
直接手工抓取是不可能的你可以尝试找些网站做了基于js的代理池,第三方代理引擎(比如美团代理、比如腾讯代理),
不是python都可以做到的。html有python内置api接口返回。
网页flash文本抓取器(初学者播放函数playflv())
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-28 22:03
本文是flash初学者的好资料和方向,欢迎浏览。
首先新建一个文档,将背景颜色设置为黑色,其他默认,然后创建四个图层。
第一层用于放置视频组件,如下:
1. 在“库”面板(“窗口”>“库”)中,从“库”弹出菜单中选择“新建视频”。
2. 在“视频属性”对话框中,为视频元素命名并选择“视频”(由 ActionScript 控制)。
3. 将视频对象从“库”面板拖到舞台中间以创建视频对象的实例。
4. 将此视频元素的实例名称设为“my_video”。
第二层用来放视频地址输入栏,方法如下:
1、使用文本工具(快捷键T)在舞台左下方画一个地址输入文本框,类型选择“输入文本”类型。
2. 在“线条类型”弹出菜单中选择“单行”,并确保选中“在文本周围显示边框”。
3. 将此文本框的实例名称设为“url”。
第三层用来放播放开始按钮,方法如下:
1、在“库”面板(“窗口>”库”)新建一个组件按钮,按钮样式自己制作,暂时可以使用。
2、将新建的按钮对象从“库”面板拖到舞台地址输入框的后面,创建播放开始按钮。
3. 将播放开始按钮命名为“play_bt”。
第四层用来放所有的ActionScript:
先初始化
//创建一个网络连接对象
var my_nc:NetConnection = new NetConnection();
//创建本地流连接
my_nc.connect(null);
//创建一个NetStream对象
var my_ns:NetStream = new NetStream(my_nc);
//写一个播放函数playflv()
函数 playflv(flv) {
//参数flv是要播放的flv视频的地址
//trace(flv);//用于测试
// 将 NetStream 视频输入信号附加到 Video 对象,视频元素 my_video
my_video.attachVideo(my_ns);
// 设置缓冲时间,单位为秒,下面设置3秒
my_ns.setBufferTime(3);
// 开始播放 FLV 文件
my_ns.play(flv);
}
//点击开始按钮开始播放
play_bt.onRelease = function() {
playflv(url.text);
//获取url输入框的视频文件地址,调用play函数播放url对应的flv视频文件
};
//至此,最简单的播放器已经完成,接下来要做的就是对其进行更多的控制和性能工作。
//这里是生产的一些重要方面,其他的还是需要大家发挥自己的想象力去设计和生产的更好。
//注意以下代码不是必须的,未经测试,请尝试一一实现。特别注意路径和实例名称的对应关系。
1.播放的控制,暂停和停止的实现
//新建两个按钮,一个用于暂停(pause_bt),一个用于停止(stop_bt),原理同播放按钮。
pause_bt.onRelease = function() {
my_ns.pause();
};
stop_bt.onRelease = function() {
my_ns.seek(0);
寻求从 0 开始
my_ns.pause(true);
//参数true表示暂停,如果为false表示从暂停到恢复播放,如果没有参数表示在暂停/播放之间切换。
};
2.视频下载进度
//这个比较简单,和一般的下载进度差不多。原理是在播放时计算下载的和总文件大小的百分比,然后显示出来。
//新建一个显示百分比的静态文本(info)和进度条(bar),它们的初始状态和位置都是自己调整的
this.onEnterFrame =function () {
var loadedbytes = my_ns.bytesLoaded;
// 获取下载的字节
var totalbytes = my_ns.bytesTotal;
//文件总大小
if (totalbytes == undefined || totalbytesinfo.text = "0%";
bar._width = 1;
} 别的 {
var nowLoadPercent = Math.round(loadedbytes/totalbytes*100);
if (isNaN(nowLoadPercent)) {
info.text = "0%";
bar._width = 1;
} 别的 {
info.text = nowLoadPercent+"%";
bar._width = nowLoadPercent*35/100;
if (nowLoadPercent == 100) {
删除 this.onEnterFrame;
}
}
}
}
3.视频尺寸修正或调整
//这个比较重要,因为视频大小比例一般是不同的,所以在播放的时候要进行调整,避免失真和变形。
//原理是获取flv的大小,然后重新调整my_video的大小,最后居中,必要时放大(此处省略)。
//先写一个改变大小的函数changesize(w, h),w是要改变的宽度,h是要改变的高度
函数改变大小(w,h){
//更改为传入的参数大小
my_video._width = w;
my_video._height = h;
//trace("w:"+w+"h:"+h);//用于测试
//位置居中,如果你的视频舞台是550宽400高
my_video._x = 550/2-w/2;
my_video._y = 400/2-h/2;
}
//然后得到flv的固有大小,调用上面的函数改变它
//在调用 my_ns.play() 方法之后但在视频播放头前进之前调用此处理程序
my_ns.onMetaData = 函数(信息对象:对象){
//获取FLV文件中嵌入的描述信息,这里获取的是宽/高
var flv_width = infoObject.width;
var flv_height = infoObject.height;
// 改变大小
改变大小(flv_width,flv_height);
};
4.播放时间和进度
//原理和下载进度类似,先获取总时长,再以百分比的形式获取当前时间,也可以作为进度条。//定义总持续时间全局变量并获取其值。
变量 flv_duration;
my_ns.onMetaData = 函数(信息对象:对象){
//获取FLV文件中嵌入的描述信息,这里获取总时长(单位:秒)
var flv_duration = infoObject.duration;
};
//注意:这个可以和得到宽高一起写。
//获取当前播放时间
var flv_thistime = my_ns.time;
//然后就可以进行播放进度了,和下载进度类似。可以自己制作,这里省略。
5.音量控制
//这个有点复杂,你得把FLV文件中的音频附加到舞台上的影片剪辑上,然后控制
//创建一个新的影片剪辑 my_ns_mc 并附加音频
my_ns_mc.attachAudio(my_ns);
//为影片剪辑创建一个新的Sound对象
var my_ns_sound = 新声音(my_ns_mc);
//初始化音量(这里默认8个0)
var flv_volume = 80;
my_ns_sound.setVolume(flv_volume);
//最后可以通过控制flv_volume的大小(0到100之间)来改变音量。
//这部分制作也省略了,大家可以自由发挥,还可以创建静音功能,即flv_volume为0
//另外,像快进、快退、缓冲显示等都可以实现,大家可以自己研究。终于,一个FlashFLV播放器的制作基本完成了。建议想学flash的朋友自己动手。不要总是想下载任何源代码然后修改它,这样你将无法理解其中的许多奥秘!
增加一个相关问题:flv播放没有图像,只有声音,这是因为flv文件是用flash8编码格式压缩的,而你发布的flash播放器是flash 7或更低版本,所以可以升级到8版本,或者压缩flash7 编码格式的 flv 文件。 查看全部
网页flash文本抓取器(初学者播放函数playflv())
本文是flash初学者的好资料和方向,欢迎浏览。
首先新建一个文档,将背景颜色设置为黑色,其他默认,然后创建四个图层。
第一层用于放置视频组件,如下:
1. 在“库”面板(“窗口”>“库”)中,从“库”弹出菜单中选择“新建视频”。
2. 在“视频属性”对话框中,为视频元素命名并选择“视频”(由 ActionScript 控制)。
3. 将视频对象从“库”面板拖到舞台中间以创建视频对象的实例。
4. 将此视频元素的实例名称设为“my_video”。
第二层用来放视频地址输入栏,方法如下:
1、使用文本工具(快捷键T)在舞台左下方画一个地址输入文本框,类型选择“输入文本”类型。
2. 在“线条类型”弹出菜单中选择“单行”,并确保选中“在文本周围显示边框”。
3. 将此文本框的实例名称设为“url”。
第三层用来放播放开始按钮,方法如下:
1、在“库”面板(“窗口>”库”)新建一个组件按钮,按钮样式自己制作,暂时可以使用。
2、将新建的按钮对象从“库”面板拖到舞台地址输入框的后面,创建播放开始按钮。
3. 将播放开始按钮命名为“play_bt”。
第四层用来放所有的ActionScript:
先初始化
//创建一个网络连接对象
var my_nc:NetConnection = new NetConnection();
//创建本地流连接
my_nc.connect(null);
//创建一个NetStream对象
var my_ns:NetStream = new NetStream(my_nc);
//写一个播放函数playflv()
函数 playflv(flv) {
//参数flv是要播放的flv视频的地址
//trace(flv);//用于测试
// 将 NetStream 视频输入信号附加到 Video 对象,视频元素 my_video
my_video.attachVideo(my_ns);
// 设置缓冲时间,单位为秒,下面设置3秒
my_ns.setBufferTime(3);
// 开始播放 FLV 文件
my_ns.play(flv);
}
//点击开始按钮开始播放
play_bt.onRelease = function() {
playflv(url.text);
//获取url输入框的视频文件地址,调用play函数播放url对应的flv视频文件
};
//至此,最简单的播放器已经完成,接下来要做的就是对其进行更多的控制和性能工作。
//这里是生产的一些重要方面,其他的还是需要大家发挥自己的想象力去设计和生产的更好。
//注意以下代码不是必须的,未经测试,请尝试一一实现。特别注意路径和实例名称的对应关系。
1.播放的控制,暂停和停止的实现
//新建两个按钮,一个用于暂停(pause_bt),一个用于停止(stop_bt),原理同播放按钮。
pause_bt.onRelease = function() {
my_ns.pause();
};
stop_bt.onRelease = function() {
my_ns.seek(0);
寻求从 0 开始
my_ns.pause(true);
//参数true表示暂停,如果为false表示从暂停到恢复播放,如果没有参数表示在暂停/播放之间切换。
};
2.视频下载进度
//这个比较简单,和一般的下载进度差不多。原理是在播放时计算下载的和总文件大小的百分比,然后显示出来。
//新建一个显示百分比的静态文本(info)和进度条(bar),它们的初始状态和位置都是自己调整的
this.onEnterFrame =function () {
var loadedbytes = my_ns.bytesLoaded;
// 获取下载的字节
var totalbytes = my_ns.bytesTotal;
//文件总大小
if (totalbytes == undefined || totalbytesinfo.text = "0%";
bar._width = 1;
} 别的 {
var nowLoadPercent = Math.round(loadedbytes/totalbytes*100);
if (isNaN(nowLoadPercent)) {
info.text = "0%";
bar._width = 1;
} 别的 {
info.text = nowLoadPercent+"%";
bar._width = nowLoadPercent*35/100;
if (nowLoadPercent == 100) {
删除 this.onEnterFrame;
}
}
}
}
3.视频尺寸修正或调整
//这个比较重要,因为视频大小比例一般是不同的,所以在播放的时候要进行调整,避免失真和变形。
//原理是获取flv的大小,然后重新调整my_video的大小,最后居中,必要时放大(此处省略)。
//先写一个改变大小的函数changesize(w, h),w是要改变的宽度,h是要改变的高度
函数改变大小(w,h){
//更改为传入的参数大小
my_video._width = w;
my_video._height = h;
//trace("w:"+w+"h:"+h);//用于测试
//位置居中,如果你的视频舞台是550宽400高
my_video._x = 550/2-w/2;
my_video._y = 400/2-h/2;
}
//然后得到flv的固有大小,调用上面的函数改变它
//在调用 my_ns.play() 方法之后但在视频播放头前进之前调用此处理程序
my_ns.onMetaData = 函数(信息对象:对象){
//获取FLV文件中嵌入的描述信息,这里获取的是宽/高
var flv_width = infoObject.width;
var flv_height = infoObject.height;
// 改变大小
改变大小(flv_width,flv_height);
};
4.播放时间和进度
//原理和下载进度类似,先获取总时长,再以百分比的形式获取当前时间,也可以作为进度条。//定义总持续时间全局变量并获取其值。
变量 flv_duration;
my_ns.onMetaData = 函数(信息对象:对象){
//获取FLV文件中嵌入的描述信息,这里获取总时长(单位:秒)
var flv_duration = infoObject.duration;
};
//注意:这个可以和得到宽高一起写。
//获取当前播放时间
var flv_thistime = my_ns.time;
//然后就可以进行播放进度了,和下载进度类似。可以自己制作,这里省略。
5.音量控制
//这个有点复杂,你得把FLV文件中的音频附加到舞台上的影片剪辑上,然后控制
//创建一个新的影片剪辑 my_ns_mc 并附加音频
my_ns_mc.attachAudio(my_ns);
//为影片剪辑创建一个新的Sound对象
var my_ns_sound = 新声音(my_ns_mc);
//初始化音量(这里默认8个0)
var flv_volume = 80;
my_ns_sound.setVolume(flv_volume);
//最后可以通过控制flv_volume的大小(0到100之间)来改变音量。
//这部分制作也省略了,大家可以自由发挥,还可以创建静音功能,即flv_volume为0
//另外,像快进、快退、缓冲显示等都可以实现,大家可以自己研究。终于,一个FlashFLV播放器的制作基本完成了。建议想学flash的朋友自己动手。不要总是想下载任何源代码然后修改它,这样你将无法理解其中的许多奥秘!
增加一个相关问题:flv播放没有图像,只有声音,这是因为flv文件是用flash8编码格式压缩的,而你发布的flash播放器是flash 7或更低版本,所以可以升级到8版本,或者压缩flash7 编码格式的 flv 文件。
网页flash文本抓取器(网站外链大概3-5个、其余质量不是很高)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-03-25 21:15
3、外部链接大概有3-5个,其余的质量不是很高等等(不链接到网站是失败的,甚至有的网站本身有很多问题),如果使用的话最好不要使用群发软件,因为它不容易发送到高质量的网站。
4、
xxxx服饰——源自美国,致力于休闲服饰的开发
,如果客户同意,则应丰富此标签中的内容。如果底部的版权信息无法添加,并且制作了网页的纯文本版本,则可以在这部分内容中添加指向它的文本链接。
急需什么
1、添加网站说明,
2、有钱”
xxxx服饰——源自美国,致力于休闲服饰的开发
“这个标签的内容,两地的内容差不多。
3、对外部链接的适当考虑(外部链接也是基于一个网站内容)不多,但精致巧妙。
11 月 7 日
将计划发送给对方
11 月 8 日
描述已添加,文本版本缺失。
选项一:
1、网页的纯文本版本需要简单的布局和美观。之后可能会被搜索爬取并出现在排名结果中,用户的搜索会影响体验。(同时这也是和客户沟通的一个理由【另外还要考虑搜索引擎只有收录文字版而不是收录flash版的情况,所以网站 可能对客户没有意义】)
2、如果“
"
如果这部分导航信息无法通过浏览器的正常浏览看到,则应放在“”中。
3、文字版应该能够让用户知道这是一个文字版的页面,而不是让用户觉得网站有问题(不显示全部,页面是没有排版,感觉太乱,不完整等)。
选项二
1、文字版网页在flash无法显示的情况下可以正常显示,并且链接可以与flash中的链接一一对应。现在我们网页的所有链接都在flash中,除了新闻部分,每个页面都是同一个URL。文字版要做成单页样式(结构类似百度百科),放在“”内。【我之前没做过,但是如果这个方法可行的话,理论上应该不会有后遗症,供参考】
11 月 9 日
确定第二个选项
11 月 12 日
百度收录,截图日期12-11-11
11-13
快照删除可能与频繁变化有关,拭目以待
11-21
百度re收录截图日期12-11-20
由于未征得网站所有者的同意,具体网站暂未公布,相关介绍也不是很详细。请谅解,仅供参考!
启辉网络 查看全部
网页flash文本抓取器(网站外链大概3-5个、其余质量不是很高)
3、外部链接大概有3-5个,其余的质量不是很高等等(不链接到网站是失败的,甚至有的网站本身有很多问题),如果使用的话最好不要使用群发软件,因为它不容易发送到高质量的网站。
4、
xxxx服饰——源自美国,致力于休闲服饰的开发
,如果客户同意,则应丰富此标签中的内容。如果底部的版权信息无法添加,并且制作了网页的纯文本版本,则可以在这部分内容中添加指向它的文本链接。
急需什么
1、添加网站说明,
2、有钱”
xxxx服饰——源自美国,致力于休闲服饰的开发
“这个标签的内容,两地的内容差不多。
3、对外部链接的适当考虑(外部链接也是基于一个网站内容)不多,但精致巧妙。
11 月 7 日
将计划发送给对方
11 月 8 日
描述已添加,文本版本缺失。
选项一:
1、网页的纯文本版本需要简单的布局和美观。之后可能会被搜索爬取并出现在排名结果中,用户的搜索会影响体验。(同时这也是和客户沟通的一个理由【另外还要考虑搜索引擎只有收录文字版而不是收录flash版的情况,所以网站 可能对客户没有意义】)
2、如果“
"
如果这部分导航信息无法通过浏览器的正常浏览看到,则应放在“”中。
3、文字版应该能够让用户知道这是一个文字版的页面,而不是让用户觉得网站有问题(不显示全部,页面是没有排版,感觉太乱,不完整等)。
选项二
1、文字版网页在flash无法显示的情况下可以正常显示,并且链接可以与flash中的链接一一对应。现在我们网页的所有链接都在flash中,除了新闻部分,每个页面都是同一个URL。文字版要做成单页样式(结构类似百度百科),放在“”内。【我之前没做过,但是如果这个方法可行的话,理论上应该不会有后遗症,供参考】
11 月 9 日
确定第二个选项
11 月 12 日
百度收录,截图日期12-11-11
11-13
快照删除可能与频繁变化有关,拭目以待
11-21
百度re收录截图日期12-11-20
由于未征得网站所有者的同意,具体网站暂未公布,相关介绍也不是很详细。请谅解,仅供参考!
启辉网络
网页flash文本抓取器(项目招商找A5快速获取精准代理名单网站应具有清晰的层次结构和文本链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-24 13:11
项目投资找A5快速获取精准代理商名单
网站应该有清晰的层次结构和文本链接。每个网页都应该可以通过至少一个静态文本链接打开。
为用户提供 网站 地图,列出 网站 重要部分的链接。如果 网站map 有超过或大约 100 个链接,则 网站map 将需要拆分为多个页面。
网站应实用且内容丰富,网页文字应清晰准确地表达要传达的内容。
考虑人们用来查找您的页面的术语,并确保 网站 实际上收录这些单词。
尽可能使用文本而不是图形来显示重要的名称、内容或链接。搜索引擎爬虫无法识别图形中收录的文本。
确保 TITLE 和 ALT 标签属性的描述和表达准确无误。
检查损坏的链接并确保 HTML 格式正确。
如果您决定使用动态页面(即收录“?”字符的 URL),请注意并非所有搜索引擎爬虫都可以爬取动态页面和静态页面。动态网页有助于缩短参数长度并减少参数数量。
将特定网页上的链接数量限制在合理的数量(少于 100 个)。
技术指南
<p>由于大多数搜索引擎蜘蛛查看 网站 的方式与 Lynx 相同,因此您可以使用 Lynx 等文本浏览器查看您的 网站。如果由于应用了 Javascript、cookie、会话 ID、框架、DHTML 或 Flash 等复杂技术而无法在文本浏览器中看到 网站 的所有页面,则搜索引擎蜘蛛正在抓取您的 查看全部
网页flash文本抓取器(项目招商找A5快速获取精准代理名单网站应具有清晰的层次结构和文本链接)
项目投资找A5快速获取精准代理商名单
网站应该有清晰的层次结构和文本链接。每个网页都应该可以通过至少一个静态文本链接打开。
为用户提供 网站 地图,列出 网站 重要部分的链接。如果 网站map 有超过或大约 100 个链接,则 网站map 将需要拆分为多个页面。
网站应实用且内容丰富,网页文字应清晰准确地表达要传达的内容。
考虑人们用来查找您的页面的术语,并确保 网站 实际上收录这些单词。
尽可能使用文本而不是图形来显示重要的名称、内容或链接。搜索引擎爬虫无法识别图形中收录的文本。
确保 TITLE 和 ALT 标签属性的描述和表达准确无误。
检查损坏的链接并确保 HTML 格式正确。
如果您决定使用动态页面(即收录“?”字符的 URL),请注意并非所有搜索引擎爬虫都可以爬取动态页面和静态页面。动态网页有助于缩短参数长度并减少参数数量。
将特定网页上的链接数量限制在合理的数量(少于 100 个)。
技术指南
<p>由于大多数搜索引擎蜘蛛查看 网站 的方式与 Lynx 相同,因此您可以使用 Lynx 等文本浏览器查看您的 网站。如果由于应用了 Javascript、cookie、会话 ID、框架、DHTML 或 Flash 等复杂技术而无法在文本浏览器中看到 网站 的所有页面,则搜索引擎蜘蛛正在抓取您的
网页flash文本抓取器(Google向网站管理员及设计者提出了一些建议(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-21 04:09
尽管谷歌的爬虫功能越来越强大,但直到现在,它还无法像人类一样识别视频或 Flash 动画的内容。即使是 JS 代码,Googlebot 也只有基本的分析能力。用谷歌的话来形容,就是Googlebot没有眼睛,它暂时无法“看到”视觉媒体的内容。除了视频,Flash动画也是网站的常见内容之一。为了让网站能够更好地被Googlebot分析和抓取,Google今天向网站管理员和设计者提出了一些建议。
我们先来看看 Googlebot 是如何处理 Flash 的。Googlebot 可以读取 Flash 文件中的文本和链接,但它无法识别 Flash 的结构和元素关联。另外,由于有时某些文本内容会被做成图片作为 Flash 的一部分,而 Googlebot 目前还没有相关的算法来读取这些图片,因此文本内容(可能很重要关键词)会被 Googlebot 漏掉。也就是说,即使 Googlebot 已成功将您的 Flash 文件索引到搜索数据库中,由于上述原因,Google 也可能无法识别其中的文本、内容和链接。更糟糕的是,其他搜索引擎的爬虫在识别 Flash 方面甚至比 Googlebot 还要差。这说明当你把一些重要的内容制作成Flash动画时,
为了避免这种情况发生,Google 在使用 Flash 时提供了一些很好的提示网站,同时仍尽量减少其搜索引擎友好性的损失:
1.最重要的原则:始终将相同的内容返回给Googlebot和网站的读者,否则你的网站可能会被判定为作弊。
2.仅在必要时使用 Flash。只有Flash作为多媒体呈现方式,网站(页面)的主要内容和导航系统仍然是基于文本的。如果您不知道该怎么做,YouTube 就是一个很好的例子。这不仅使 网站 对 Googlebot 更加友好,而且您的 网站 内容也更容易被更广泛的受众访问,包括经常使用屏幕阅读器的视障人士。此外,一些网速较慢的读者或使用非标准浏览器的读者也可能能够阅读您的 网站 内容,因为他们可能会跳过 Flash 内容。
3.使用 sIFR 技术。这样,网站的主要内容和导航系统仍然是基于HTML的,不会浏览Flash的读者也可以阅读你的网站。
4.提供非 Flash 版本的 网站。例如,当您在网站首页中使用Flash动画作为欢迎页面时,请务必在Flash动画之外提供HTML链接,并指向非Flash版本的网站 ,让读者即使没有安装Flash插件也能轻松阅读您的网站内容。
当然,谷歌的错,严格地说,谷歌不能做同样的事情来抓取和分析文本,这并不是谷歌的错,因为这项技术还没有成熟。但目前的搜索技术也只能走到这一步,所以我们在设计或更新网站时只尽量采纳Google的建议,以利于网站的收录和排名。其实和图片的内容差不多。当我们在网页中插入图片或Flash动画时,应尽量将其主要内容用文字写出,这样即使Googlebot忽略了它们,它们仍能从你的文字描述中理解。大概的内容。 查看全部
网页flash文本抓取器(Google向网站管理员及设计者提出了一些建议(图))
尽管谷歌的爬虫功能越来越强大,但直到现在,它还无法像人类一样识别视频或 Flash 动画的内容。即使是 JS 代码,Googlebot 也只有基本的分析能力。用谷歌的话来形容,就是Googlebot没有眼睛,它暂时无法“看到”视觉媒体的内容。除了视频,Flash动画也是网站的常见内容之一。为了让网站能够更好地被Googlebot分析和抓取,Google今天向网站管理员和设计者提出了一些建议。
我们先来看看 Googlebot 是如何处理 Flash 的。Googlebot 可以读取 Flash 文件中的文本和链接,但它无法识别 Flash 的结构和元素关联。另外,由于有时某些文本内容会被做成图片作为 Flash 的一部分,而 Googlebot 目前还没有相关的算法来读取这些图片,因此文本内容(可能很重要关键词)会被 Googlebot 漏掉。也就是说,即使 Googlebot 已成功将您的 Flash 文件索引到搜索数据库中,由于上述原因,Google 也可能无法识别其中的文本、内容和链接。更糟糕的是,其他搜索引擎的爬虫在识别 Flash 方面甚至比 Googlebot 还要差。这说明当你把一些重要的内容制作成Flash动画时,
为了避免这种情况发生,Google 在使用 Flash 时提供了一些很好的提示网站,同时仍尽量减少其搜索引擎友好性的损失:
1.最重要的原则:始终将相同的内容返回给Googlebot和网站的读者,否则你的网站可能会被判定为作弊。
2.仅在必要时使用 Flash。只有Flash作为多媒体呈现方式,网站(页面)的主要内容和导航系统仍然是基于文本的。如果您不知道该怎么做,YouTube 就是一个很好的例子。这不仅使 网站 对 Googlebot 更加友好,而且您的 网站 内容也更容易被更广泛的受众访问,包括经常使用屏幕阅读器的视障人士。此外,一些网速较慢的读者或使用非标准浏览器的读者也可能能够阅读您的 网站 内容,因为他们可能会跳过 Flash 内容。
3.使用 sIFR 技术。这样,网站的主要内容和导航系统仍然是基于HTML的,不会浏览Flash的读者也可以阅读你的网站。
4.提供非 Flash 版本的 网站。例如,当您在网站首页中使用Flash动画作为欢迎页面时,请务必在Flash动画之外提供HTML链接,并指向非Flash版本的网站 ,让读者即使没有安装Flash插件也能轻松阅读您的网站内容。
当然,谷歌的错,严格地说,谷歌不能做同样的事情来抓取和分析文本,这并不是谷歌的错,因为这项技术还没有成熟。但目前的搜索技术也只能走到这一步,所以我们在设计或更新网站时只尽量采纳Google的建议,以利于网站的收录和排名。其实和图片的内容差不多。当我们在网页中插入图片或Flash动画时,应尽量将其主要内容用文字写出,这样即使Googlebot忽略了它们,它们仍能从你的文字描述中理解。大概的内容。
网页flash文本抓取器(什么是搜索引擎蜘蛛友好的网站?这个问题不难解决!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-21 04:06
什么是 SEO 友好的 网站?这个问题不难解决。这个定位是用SEO优化网站的用户体验,给网站添加优质内容,让蜘蛛访问和爬取,所以SEO优化需要突出网站@的主题>。那么如何提高搜索引擎蜘蛛的友好度呢?
1、页面加载速度
页面加载对于搜索引擎蜘蛛的友好性更为重要。当蜘蛛到达时,如果一直无法打开网站,蜘蛛的体验非常不友好,会减少后续访问的次数。但是服务器可以提高网站的加载速度,在安全稳定的环境下,网站build之前应该选择服务器。因此,如果服务器不稳定,需要及时联系空间服务商,将网页应用加载到综合性能比较完善的空间中,方便SEO的日常操作。
2、无障碍网页浏览
Url 抓取指的是静态或伪静态 网站。这个网站结构是方便搜索引擎使用的蜘蛛结构模型。如果参数太多,数据会直接生成动态路径,这对搜索引擎来说不是一种友好的行为,尤其是带有中文参数的动态路径,是搜索引擎非常不喜欢的。
搜索引擎蜘蛛喜欢爬什么样的网站?
3、减少flash的应用
SEO优化需要注意页面布局是否有flash动画。蜘蛛很好地识别图像,如果 网站 页面的文本较少,则 网站 将失去其排名优先级。因此,页面框架内的组织和布局需要友好美观,框架结构要谨慎使用。
4、原创内容很受欢迎
百度一直在打击伪原创内容,同时也在优化原创内容,所以很多采集文章的网站排名都很差,有创意,内容丰富,有价值。这就是搜索引擎喜欢的。这样,你可以用不同的词来描述一个场景,或者结合流行和不流行的词。您的内容质量取决于您的内容是否定位良好且可用。
5、SEO 内部链接
SEO有两个内部链接。优邦云SEO推荐使用白帽SEO。关键词位置引导,每个字代表链接的效果,_一点是首页,锚文本内容之间,一些需要引导的精华,通过内部链接,友好引导可以提升爬虫体验。
6、内容简洁明了
搜索引擎页面不需要太多的代码,只要页面内容简洁,页面结构有利于优化,每个标题栏都能引导蜘蛛到它想去的地方,然后这个网站高-质量,因此页面干净的布局是每个布局所在的位置。进入这个地方的页面是什么,url层级也需要注意不要走得太深。 查看全部
网页flash文本抓取器(什么是搜索引擎蜘蛛友好的网站?这个问题不难解决!)
什么是 SEO 友好的 网站?这个问题不难解决。这个定位是用SEO优化网站的用户体验,给网站添加优质内容,让蜘蛛访问和爬取,所以SEO优化需要突出网站@的主题>。那么如何提高搜索引擎蜘蛛的友好度呢?
1、页面加载速度
页面加载对于搜索引擎蜘蛛的友好性更为重要。当蜘蛛到达时,如果一直无法打开网站,蜘蛛的体验非常不友好,会减少后续访问的次数。但是服务器可以提高网站的加载速度,在安全稳定的环境下,网站build之前应该选择服务器。因此,如果服务器不稳定,需要及时联系空间服务商,将网页应用加载到综合性能比较完善的空间中,方便SEO的日常操作。
2、无障碍网页浏览
Url 抓取指的是静态或伪静态 网站。这个网站结构是方便搜索引擎使用的蜘蛛结构模型。如果参数太多,数据会直接生成动态路径,这对搜索引擎来说不是一种友好的行为,尤其是带有中文参数的动态路径,是搜索引擎非常不喜欢的。

搜索引擎蜘蛛喜欢爬什么样的网站?
3、减少flash的应用
SEO优化需要注意页面布局是否有flash动画。蜘蛛很好地识别图像,如果 网站 页面的文本较少,则 网站 将失去其排名优先级。因此,页面框架内的组织和布局需要友好美观,框架结构要谨慎使用。
4、原创内容很受欢迎
百度一直在打击伪原创内容,同时也在优化原创内容,所以很多采集文章的网站排名都很差,有创意,内容丰富,有价值。这就是搜索引擎喜欢的。这样,你可以用不同的词来描述一个场景,或者结合流行和不流行的词。您的内容质量取决于您的内容是否定位良好且可用。
5、SEO 内部链接
SEO有两个内部链接。优邦云SEO推荐使用白帽SEO。关键词位置引导,每个字代表链接的效果,_一点是首页,锚文本内容之间,一些需要引导的精华,通过内部链接,友好引导可以提升爬虫体验。
6、内容简洁明了
搜索引擎页面不需要太多的代码,只要页面内容简洁,页面结构有利于优化,每个标题栏都能引导蜘蛛到它想去的地方,然后这个网站高-质量,因此页面干净的布局是每个布局所在的位置。进入这个地方的页面是什么,url层级也需要注意不要走得太深。
网页flash文本抓取器(是一款强大的文档管理软件,可以快速对文档进行编辑)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-14 04:21
wim文档管理专家是一款功能强大的文档管理软件,专用于管理电脑中的文档文件,支持txt、word、rtf、pdf等几乎所有常用格式,采用多文档库和类似windows资源的管理方式管理器的操作方式,支持附件和备注功能,内置强大的文本编辑器,可以帮助用户轻松管理文档文件,也可以快速编辑文档。
主要特点
1、多文档库,多文档界面,让文档阅读和管理更加便捷高效;
2、文档管理的操作方式与Windows资源管理器类似。文档管理非常方便易用;
3、内置强大的富文本编辑器,支持外部编辑器,让文档编辑更加方便快捷;
4、嵌入式office编辑器,轻松快速编辑Office文档;
5、内置网页浏览器,方便浏览和快速保存网页。可以快速抓取网页中的图片、文字,甚至是Flash文件;
6、内置文本编辑器,支持25种语法高亮;
7、强大的附件和笔记管理功能。全面支持各类文档管理,甚至支持文档快捷方式的管理;
8、强大的文件管理器,支持本地磁盘文件管理(无需导入数据库)。并且可以在这些文件中添加附件、备注等信息;
9、内置强大的搜索功能,支持全文搜索;
10、强大的文件和文件夹导入支持;
11、支持剪贴板监控功能,可直接从剪贴板获取文档;
12、悬浮窗支持拖放文档、文本和HTML,自动生成文档;
13、强大的插件功能;内置截屏插件,轻松截取屏幕图片;内置各种文本处理插件,文本处理更轻松快捷;
14、支持数据库安全管理和压缩模式,文档管理更安全高效;
15、高效的动态文档库加载技术。 查看全部
网页flash文本抓取器(是一款强大的文档管理软件,可以快速对文档进行编辑)
wim文档管理专家是一款功能强大的文档管理软件,专用于管理电脑中的文档文件,支持txt、word、rtf、pdf等几乎所有常用格式,采用多文档库和类似windows资源的管理方式管理器的操作方式,支持附件和备注功能,内置强大的文本编辑器,可以帮助用户轻松管理文档文件,也可以快速编辑文档。
主要特点
1、多文档库,多文档界面,让文档阅读和管理更加便捷高效;
2、文档管理的操作方式与Windows资源管理器类似。文档管理非常方便易用;
3、内置强大的富文本编辑器,支持外部编辑器,让文档编辑更加方便快捷;
4、嵌入式office编辑器,轻松快速编辑Office文档;
5、内置网页浏览器,方便浏览和快速保存网页。可以快速抓取网页中的图片、文字,甚至是Flash文件;
6、内置文本编辑器,支持25种语法高亮;
7、强大的附件和笔记管理功能。全面支持各类文档管理,甚至支持文档快捷方式的管理;
8、强大的文件管理器,支持本地磁盘文件管理(无需导入数据库)。并且可以在这些文件中添加附件、备注等信息;
9、内置强大的搜索功能,支持全文搜索;
10、强大的文件和文件夹导入支持;
11、支持剪贴板监控功能,可直接从剪贴板获取文档;
12、悬浮窗支持拖放文档、文本和HTML,自动生成文档;
13、强大的插件功能;内置截屏插件,轻松截取屏幕图片;内置各种文本处理插件,文本处理更轻松快捷;
14、支持数据库安全管理和压缩模式,文档管理更安全高效;
15、高效的动态文档库加载技术。
网页flash文本抓取器(IDC:网站地图上的链接超过或大约为100个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-03-14 04:18
中国IDC圈2月23日报道:为用户提供网站地图,列出网站重要部分的链接。如果 网站map 有超过或大约 100 个链接,则 网站map 将需要拆分为多个页面。
网站应实用且内容丰富,网页的文字应清晰准确地表达要传达的内容。
考虑人们用来查找您的页面的术语,并确保 网站 实际上收录这些单词。
网站应该有清晰的层次结构和文本链接。每个网页都应该可以通过至少一个静态文本链接打开。
尽可能使用文本而不是图形来显示重要的名称、内容或链接。搜索引擎爬虫无法识别图形中收录的文本。
检查损坏的链接并确保 HTML 格式正确。
将特定网页上的链接数量限制在合理的数量(少于 100 个)。
确保 TITLE 和 ALT 标签属性的描述和表达准确无误。
如果您决定使用动态页面(即收录“?”字符的 URL),请注意并非所有搜索引擎爬虫都可以爬取动态页面和静态页面。动态网页有助于缩短参数长度并减少参数数量。
技术指南
<p>由于大多数搜索引擎蜘蛛查看 网站 的方式与 Lynx 相同,因此您可以使用 Lynx 等文本浏览器查看您的 网站。如果由于应用了 Javascript、cookie、会话 ID、框架、DHTML 或 Flash 等复杂技术而无法在文本浏览器中看到 网站 的所有页面,则搜索引擎蜘蛛正在抓取您的 查看全部
网页flash文本抓取器(IDC:网站地图上的链接超过或大约为100个)
中国IDC圈2月23日报道:为用户提供网站地图,列出网站重要部分的链接。如果 网站map 有超过或大约 100 个链接,则 网站map 将需要拆分为多个页面。
网站应实用且内容丰富,网页的文字应清晰准确地表达要传达的内容。
考虑人们用来查找您的页面的术语,并确保 网站 实际上收录这些单词。
网站应该有清晰的层次结构和文本链接。每个网页都应该可以通过至少一个静态文本链接打开。
尽可能使用文本而不是图形来显示重要的名称、内容或链接。搜索引擎爬虫无法识别图形中收录的文本。
检查损坏的链接并确保 HTML 格式正确。
将特定网页上的链接数量限制在合理的数量(少于 100 个)。
确保 TITLE 和 ALT 标签属性的描述和表达准确无误。
如果您决定使用动态页面(即收录“?”字符的 URL),请注意并非所有搜索引擎爬虫都可以爬取动态页面和静态页面。动态网页有助于缩短参数长度并减少参数数量。
技术指南
<p>由于大多数搜索引擎蜘蛛查看 网站 的方式与 Lynx 相同,因此您可以使用 Lynx 等文本浏览器查看您的 网站。如果由于应用了 Javascript、cookie、会话 ID、框架、DHTML 或 Flash 等复杂技术而无法在文本浏览器中看到 网站 的所有页面,则搜索引擎蜘蛛正在抓取您的
网页flash文本抓取器( 网站管理员们最经常问的一个问题:我怎样才能提高我的网站在Google搜索上的排名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-14 04:17
网站管理员们最经常问的一个问题:我怎样才能提高我的网站在Google搜索上的排名)
Hubbell 和我正在加利福尼亚的家中度假。请随意阅读我之前为 网站 管理员撰写的关于可用性的博客,以及我为 Google 官方博客撰写的其他 文章 博客。
网站 管理员在无障碍搜索中最常见的问题之一是:如何提高我在无障碍搜索中的 网站 排名?同时,网站 管理员会问一个类似但更广泛的问题:如何提高我的 网站 在 Google 搜索中的排名?
我很高兴地告诉您,这是一个两管齐下的方法:您可以构建和改进一些关键的 网站 功能,例如 网站 导航,以便它适用于所有用户,其中自然包括 Google机器人。以下是一些小建议,您可以参考。
确保所有重要内容都可访问 为了使内容对用户可用,必须确保它是可访问的。用户和搜索引擎机器人都依赖超文本链接来访问页面内容,因此关键的第一步是确保您的 网站 上的所有内容都可以通过纯 HTML 超链接访问,并避免 网站 的关键部分被 JavaScript 或 Flash 等技术隐藏。纯超文本链接是通过 HTML 锚元素生成的链接。接下来,我们要确保所有指向目标元素的超文本链接是一个真实的 URL,而不是对点击触发控制器上的链接执行的空的、真实的链接操作。简而言之,避免以下形式的超文本链接: 我们建议使用更简单的链接,例如: 产品目录 确保内容可读 网站 内容只有在可读的情况下才有效。请确保您的 网站 上的所有重要内容都以 HTML 文件的形式呈现,并且无需评估页面脚本即可访问。对于 Google bot 和绝大多数毫无戒心的用户来说,隐藏在 Flash 动画背后的内容以及由可执行 JavaScript 在浏览器端生成的文本仍然无法阅读。确保内容以易于阅读的顺序提供给读者。获得可读内容后,用户希望能够按照逻辑阅读顺序跟进内容。如果您的大部分 网站 都设计有复杂的多列布局,那么最好退后一步考虑如何达到预期的效果。例如,使用深度嵌套的 HTML 表格会使人们难以按逻辑顺序连接相关文本。
元素来达到同样的效果。另外,您会发现 网站 运行得更快、更高效。
补充所有视觉内容 - 不用担心重复!将您的信息提供给所有人并不意味着让您网站“降级”为最简单的文本格式。尽可能多地重复您的信息很重要,因为这是确保页面内容对所有用户最有帮助的唯一方法。以下是一些简单的提示: 采用上述提示可以大大提高用户着陆页的质量。而且,作为额外的奖励,您可能会惊喜地发现您的 网站 被更好地索引了! 查看全部
网页flash文本抓取器(
网站管理员们最经常问的一个问题:我怎样才能提高我的网站在Google搜索上的排名)

Hubbell 和我正在加利福尼亚的家中度假。请随意阅读我之前为 网站 管理员撰写的关于可用性的博客,以及我为 Google 官方博客撰写的其他 文章 博客。
网站 管理员在无障碍搜索中最常见的问题之一是:如何提高我在无障碍搜索中的 网站 排名?同时,网站 管理员会问一个类似但更广泛的问题:如何提高我的 网站 在 Google 搜索中的排名?
我很高兴地告诉您,这是一个两管齐下的方法:您可以构建和改进一些关键的 网站 功能,例如 网站 导航,以便它适用于所有用户,其中自然包括 Google机器人。以下是一些小建议,您可以参考。
确保所有重要内容都可访问 为了使内容对用户可用,必须确保它是可访问的。用户和搜索引擎机器人都依赖超文本链接来访问页面内容,因此关键的第一步是确保您的 网站 上的所有内容都可以通过纯 HTML 超链接访问,并避免 网站 的关键部分被 JavaScript 或 Flash 等技术隐藏。纯超文本链接是通过 HTML 锚元素生成的链接。接下来,我们要确保所有指向目标元素的超文本链接是一个真实的 URL,而不是对点击触发控制器上的链接执行的空的、真实的链接操作。简而言之,避免以下形式的超文本链接: 我们建议使用更简单的链接,例如: 产品目录 确保内容可读 网站 内容只有在可读的情况下才有效。请确保您的 网站 上的所有重要内容都以 HTML 文件的形式呈现,并且无需评估页面脚本即可访问。对于 Google bot 和绝大多数毫无戒心的用户来说,隐藏在 Flash 动画背后的内容以及由可执行 JavaScript 在浏览器端生成的文本仍然无法阅读。确保内容以易于阅读的顺序提供给读者。获得可读内容后,用户希望能够按照逻辑阅读顺序跟进内容。如果您的大部分 网站 都设计有复杂的多列布局,那么最好退后一步考虑如何达到预期的效果。例如,使用深度嵌套的 HTML 表格会使人们难以按逻辑顺序连接相关文本。
元素来达到同样的效果。另外,您会发现 网站 运行得更快、更高效。
补充所有视觉内容 - 不用担心重复!将您的信息提供给所有人并不意味着让您网站“降级”为最简单的文本格式。尽可能多地重复您的信息很重要,因为这是确保页面内容对所有用户最有帮助的唯一方法。以下是一些简单的提示: 采用上述提示可以大大提高用户着陆页的质量。而且,作为额外的奖励,您可能会惊喜地发现您的 网站 被更好地索引了!
网页flash文本抓取器(网页flash文本抓取器介绍与自定义调用(3.1版))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-13 14:03
网页flash文本抓取器介绍与自定义调用(3.1版)appium底层调用原理分析及使用方法思路分析(3.2版)appium底层调用原理分析及使用方法思路分析(3.3版)
参考这个~/
好像目前不能简单的用appium里面的java层来抓包了,可以用python,python有个类叫scrapy在url分析是非常有优势的,使用java后端和scrapy的接口基本都会被封杀。那就找一些python抓包的库,推荐一个我在用的python抓包工具typicsidious,原理和原理步骤还是蛮详细的。appium不是太了解,不是专业做抓包的。
flash只是提供了文本分析接口而已,抓包时还是会走python的post包,只不过调用和返回对象是json这种格式,json本身不具有结构性而已。appium是将视频抓包分析转化为原生post包写到内存里面返回,
appium不是flash的代替品,而是原本webkit提供的视频抓取接口去掉了一层跳转层,如果要抓图片的话需要的话联网就抓取不了了。上官网看看抓包教程就都懂了。
使用方法有所不同,视频抓取应该可以直接抓取,只是图片会抓取失败。
抓取有不同,你可以抓取app中其他元素也可以抓取视频及图片,如果是app中的动画, 查看全部
网页flash文本抓取器(网页flash文本抓取器介绍与自定义调用(3.1版))
网页flash文本抓取器介绍与自定义调用(3.1版)appium底层调用原理分析及使用方法思路分析(3.2版)appium底层调用原理分析及使用方法思路分析(3.3版)
参考这个~/
好像目前不能简单的用appium里面的java层来抓包了,可以用python,python有个类叫scrapy在url分析是非常有优势的,使用java后端和scrapy的接口基本都会被封杀。那就找一些python抓包的库,推荐一个我在用的python抓包工具typicsidious,原理和原理步骤还是蛮详细的。appium不是太了解,不是专业做抓包的。
flash只是提供了文本分析接口而已,抓包时还是会走python的post包,只不过调用和返回对象是json这种格式,json本身不具有结构性而已。appium是将视频抓包分析转化为原生post包写到内存里面返回,
appium不是flash的代替品,而是原本webkit提供的视频抓取接口去掉了一层跳转层,如果要抓图片的话需要的话联网就抓取不了了。上官网看看抓包教程就都懂了。
使用方法有所不同,视频抓取应该可以直接抓取,只是图片会抓取失败。
抓取有不同,你可以抓取app中其他元素也可以抓取视频及图片,如果是app中的动画,
网页flash文本抓取器(高级网站建设和普通网站的建设有什么区别?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-08 06:10
关于网站中图片的使用,小编也提醒大家不要过多的使用图片,非常不利于后期的优化。目前的形式是蜘蛛和用户都比较喜欢网站有图文,所以我们可以结合网站设计制作的图文。不过要注意图片的使用,因为搜索引擎会明智的抓取文字描述,所以在使用网站图片时必须添加alt属性标签。现在 网站 更喜欢使用一些 Flash 动画插入到 网站 因为互联网的加速。Flash的应用确实让页面更加生动,但是不利于后期的优化,所以,如果一定要在网站中使用Flash,记得让网页设计师制作一个辅助的html版本,并将flash放在html文件中。34专注于网络营销技术、产品和服务的创新与融合,现已成为国内较好的网络营销整合服务商。北京先进网站建筑设计
Advanced网站Build 和 Normal网站Build 有什么区别?网站兼容性对于高级网站来说,在构建过程中,兼容性非常重要。不管你用什么浏览器,什么尺寸的屏幕,什么牌子的手机,都可以正常使用。但如果是普通的网站构造,则相对缺乏兼容性。通常一些主流浏览器可以正常浏览,但是手机或其他浏览器会出现一些混乱和功能故障。网站普通域名网站建设成本很低,所以域名和空间的质量比较差,所以我们的网站用户访问很容易变慢,极大地影响了用户的正常访问,在搜索引擎爬取方面也比较差。高级网站的建设,基本都是利用大品牌的空间。这些域名空间在整个市场上都是高度认可的,质量更有保障。此外,它们在所有费用、续订和其他相关费用方面都是透明和可靠的。搜索引擎后优化与推广 一个好的网站并不代表可以搭建,而是需要后优化。高级网站建设过程中,非常注重搜索引擎的优化和推广,会根据网站的具体情况进行合理布局。一般来说,网站建设通常认为把网站交给客户就够了。网站 建设不会给客户带来SEO优化和推广的考虑,不利于网站的长远发展。可见,高级网站的构造与普通的网站完全不同。现在很多人选择构建高级网站,因为高级网站带来的服务和收益是普通网站无法比拟的。通州区进口网站建筑特价就像选择一个域名一样,网站结构的设计必须站在用户的角度。@网站,因为高级网站带来的服务和收益是普通网站无法比拟的。通州区进口网站建筑特价就像选择一个域名一样,网站结构的设计必须站在用户的角度。@网站,因为高级网站带来的服务和收益是普通网站无法比拟的。通州区进口网站建筑特价就像选择一个域名一样,网站结构的设计必须站在用户的角度。
目录页面收录正常的类别频道列表页面,也收录条件聚合生成的列表页面。在正常的网站结构中,这种页面也有很高的权重,而在大信息类网站中,这种页面也是主要获取搜索流量的页面。因此,不仅要精心优化链接,还要精心设计页面关键词的定位和内容。列表页位于首页和内容页的中间,会同时得到首页和大量内容页的自然推荐链接,所以也有比较高的权重。所以,如果列表页只优化当前的分类名称,就有点太疯狂了。
然后是表格在网页中的应用。表格不宜大规模使用,因为对于css+div布局网站,表格占用的空间太大,会影响网站的整体加载速度。如果要使用表格,小编建议您将文字放在不同的表格中,这样我们管理起来更方便,加载速度也会有所提升。什么样的网站对SEO好
1、Homepage 指向板块页面和重要内容页面。
2、栏目页指向其他栏目页和当前内容页。
3、栏目页面不指向其他栏目内容页面。
4、内容页指向首页和所有栏目页。假设你已经购买了,然后用上面的开源系统搭建了一个网站,是不是意味着我网站就完成了。
协会网站大楼
是时候访问网站了。注意,传统企业建站周期长,修改多,价格高,造价上万元网站,最终排名不好,尤其是中小企业,定制网站的压力很大,所以越来越多的企业选择模板先建站。在兼容性方面,界面设计沿用了国外非常新的网络设计规范,拥有所有主流火狐confluence浏览器的历史。网站流畅完整,免去普通网络公司搭建调试兼容性问题。其次,后台管理和操作简单易操作,对于没有技术人员的企业来说非常方便快捷。简单的后台操作可以让网站的操作变得非常简单,只要改变一个模板样式就可以轻松搞定。. 你只需要花几百元甚至几十元就可以用快速模板搭建一个网站。现在 网站 更喜欢使用一些 Flash 动画插入到 网站 因为互联网的加速。官方网站密云区建设调试 @网站 因为互联网的加速。官方网站密云区建设调试 @网站 因为互联网的加速。官方网站密云区建设调试
网站页面如何设计更利于优化。北京先进网站建筑设计
内容页指向同一节下的内容页。树形结构可以清晰展示网站的内容结构,适合大中型网站构建;扁平结构简单,适用于小型网站和企业网站。搜索引擎给二级列的权重比较高,树形结构为网站提供二级列,扁平结构直接是二级面。那么树结构 网站 是 网站 更好的选择吗?当然不是,如果树结构规划不好,会影响蜘蛛爬行。因此,我们需要根据实际情况选择自己的网站结构。那么什么样的网站结构对SEO好呢?“树形结构+逻辑结构” 是更好的选择。树形结构可以使网站的结构清晰,权重分布均衡;逻辑结构可以使网站的结构非常可控,可以提高网站的入口,以及一些结构较深的页面的效率。入口问题,即根据我们的权重分配需求来分配网站内容。如果逻辑结构做得好,网站的任何页面都可以取得不错的排名。北京先进网站建筑设计 入口问题,即根据我们的权重分配需求来分配网站内容。如果逻辑结构做得好,网站的任何页面都可以取得不错的排名。北京先进网站建筑设计 入口问题,即根据我们的权重分配需求来分配网站内容。如果逻辑结构做得好,网站的任何页面都可以取得不错的排名。北京先进网站建筑设计
是一家成立于2012年12月05日的公司,注册地址位于上海市金山区金山卫镇前新路301号375室。法定代表人为张丽。经营范围包括计算机网络技术领域的技术开发、技术咨询、技术服务、各类广告的设计制作、市场信息咨询和调查(不得从事社会调查、社会调查、民意调查、民意调查)、文化办公用品、家居用品 电器、电子产品、日用品、化妆品销售。是一家集研发、设计、生产、销售为一体的专业化公司。公司自成立以来,一直致力于文化办公用品,是能源的主力军。公司致力于将科技创新作为贴心的产品展现给用户,为用户带来良好的体验。公司网络创始人张立始终关注客户,创新技术,竭诚为客户提供良好的服务。 查看全部
网页flash文本抓取器(高级网站建设和普通网站的建设有什么区别?(图))
关于网站中图片的使用,小编也提醒大家不要过多的使用图片,非常不利于后期的优化。目前的形式是蜘蛛和用户都比较喜欢网站有图文,所以我们可以结合网站设计制作的图文。不过要注意图片的使用,因为搜索引擎会明智的抓取文字描述,所以在使用网站图片时必须添加alt属性标签。现在 网站 更喜欢使用一些 Flash 动画插入到 网站 因为互联网的加速。Flash的应用确实让页面更加生动,但是不利于后期的优化,所以,如果一定要在网站中使用Flash,记得让网页设计师制作一个辅助的html版本,并将flash放在html文件中。34专注于网络营销技术、产品和服务的创新与融合,现已成为国内较好的网络营销整合服务商。北京先进网站建筑设计

Advanced网站Build 和 Normal网站Build 有什么区别?网站兼容性对于高级网站来说,在构建过程中,兼容性非常重要。不管你用什么浏览器,什么尺寸的屏幕,什么牌子的手机,都可以正常使用。但如果是普通的网站构造,则相对缺乏兼容性。通常一些主流浏览器可以正常浏览,但是手机或其他浏览器会出现一些混乱和功能故障。网站普通域名网站建设成本很低,所以域名和空间的质量比较差,所以我们的网站用户访问很容易变慢,极大地影响了用户的正常访问,在搜索引擎爬取方面也比较差。高级网站的建设,基本都是利用大品牌的空间。这些域名空间在整个市场上都是高度认可的,质量更有保障。此外,它们在所有费用、续订和其他相关费用方面都是透明和可靠的。搜索引擎后优化与推广 一个好的网站并不代表可以搭建,而是需要后优化。高级网站建设过程中,非常注重搜索引擎的优化和推广,会根据网站的具体情况进行合理布局。一般来说,网站建设通常认为把网站交给客户就够了。网站 建设不会给客户带来SEO优化和推广的考虑,不利于网站的长远发展。可见,高级网站的构造与普通的网站完全不同。现在很多人选择构建高级网站,因为高级网站带来的服务和收益是普通网站无法比拟的。通州区进口网站建筑特价就像选择一个域名一样,网站结构的设计必须站在用户的角度。@网站,因为高级网站带来的服务和收益是普通网站无法比拟的。通州区进口网站建筑特价就像选择一个域名一样,网站结构的设计必须站在用户的角度。@网站,因为高级网站带来的服务和收益是普通网站无法比拟的。通州区进口网站建筑特价就像选择一个域名一样,网站结构的设计必须站在用户的角度。

目录页面收录正常的类别频道列表页面,也收录条件聚合生成的列表页面。在正常的网站结构中,这种页面也有很高的权重,而在大信息类网站中,这种页面也是主要获取搜索流量的页面。因此,不仅要精心优化链接,还要精心设计页面关键词的定位和内容。列表页位于首页和内容页的中间,会同时得到首页和大量内容页的自然推荐链接,所以也有比较高的权重。所以,如果列表页只优化当前的分类名称,就有点太疯狂了。
然后是表格在网页中的应用。表格不宜大规模使用,因为对于css+div布局网站,表格占用的空间太大,会影响网站的整体加载速度。如果要使用表格,小编建议您将文字放在不同的表格中,这样我们管理起来更方便,加载速度也会有所提升。什么样的网站对SEO好
1、Homepage 指向板块页面和重要内容页面。
2、栏目页指向其他栏目页和当前内容页。
3、栏目页面不指向其他栏目内容页面。
4、内容页指向首页和所有栏目页。假设你已经购买了,然后用上面的开源系统搭建了一个网站,是不是意味着我网站就完成了。

协会网站大楼
是时候访问网站了。注意,传统企业建站周期长,修改多,价格高,造价上万元网站,最终排名不好,尤其是中小企业,定制网站的压力很大,所以越来越多的企业选择模板先建站。在兼容性方面,界面设计沿用了国外非常新的网络设计规范,拥有所有主流火狐confluence浏览器的历史。网站流畅完整,免去普通网络公司搭建调试兼容性问题。其次,后台管理和操作简单易操作,对于没有技术人员的企业来说非常方便快捷。简单的后台操作可以让网站的操作变得非常简单,只要改变一个模板样式就可以轻松搞定。. 你只需要花几百元甚至几十元就可以用快速模板搭建一个网站。现在 网站 更喜欢使用一些 Flash 动画插入到 网站 因为互联网的加速。官方网站密云区建设调试 @网站 因为互联网的加速。官方网站密云区建设调试 @网站 因为互联网的加速。官方网站密云区建设调试
网站页面如何设计更利于优化。北京先进网站建筑设计
内容页指向同一节下的内容页。树形结构可以清晰展示网站的内容结构,适合大中型网站构建;扁平结构简单,适用于小型网站和企业网站。搜索引擎给二级列的权重比较高,树形结构为网站提供二级列,扁平结构直接是二级面。那么树结构 网站 是 网站 更好的选择吗?当然不是,如果树结构规划不好,会影响蜘蛛爬行。因此,我们需要根据实际情况选择自己的网站结构。那么什么样的网站结构对SEO好呢?“树形结构+逻辑结构” 是更好的选择。树形结构可以使网站的结构清晰,权重分布均衡;逻辑结构可以使网站的结构非常可控,可以提高网站的入口,以及一些结构较深的页面的效率。入口问题,即根据我们的权重分配需求来分配网站内容。如果逻辑结构做得好,网站的任何页面都可以取得不错的排名。北京先进网站建筑设计 入口问题,即根据我们的权重分配需求来分配网站内容。如果逻辑结构做得好,网站的任何页面都可以取得不错的排名。北京先进网站建筑设计 入口问题,即根据我们的权重分配需求来分配网站内容。如果逻辑结构做得好,网站的任何页面都可以取得不错的排名。北京先进网站建筑设计
是一家成立于2012年12月05日的公司,注册地址位于上海市金山区金山卫镇前新路301号375室。法定代表人为张丽。经营范围包括计算机网络技术领域的技术开发、技术咨询、技术服务、各类广告的设计制作、市场信息咨询和调查(不得从事社会调查、社会调查、民意调查、民意调查)、文化办公用品、家居用品 电器、电子产品、日用品、化妆品销售。是一家集研发、设计、生产、销售为一体的专业化公司。公司自成立以来,一直致力于文化办公用品,是能源的主力军。公司致力于将科技创新作为贴心的产品展现给用户,为用户带来良好的体验。公司网络创始人张立始终关注客户,创新技术,竭诚为客户提供良好的服务。
网页flash文本抓取器(网页抓取技术入门第二部分-8f87-701-fb68)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-05 21:01
网页flash文本抓取器可以完成自动换行功能,不需要手动操作即可从网页中全文摘取文本。并且支持中文分词、多列分词、拼音搜索等高级功能。而实现这一功能必须要有flash,以及python支持打开网页和抓取全文。根据提示,将如下链接拉到页面的底部,会自动出现flash抓取器,点击即可进入抓取界面。
我用这个方法在百度贴吧实现过自动换行,很简单。
建议参考一下网页抓取技术入门第二部分-8f87-4744-b701-f68d4e3079091.html
richflashgoogleflashrecapabilities
话说我们专业前段时间用python做了一个flash版本的全自动换行的网页抓取程序,
有一些类似的工具,但是功能不是全自动的,
有个网站可以抓取各种网页的网页制作助手|全自动抓取网页和视频
用flashgen调用txt文件来实现,抓取只支持post方式;python或者ruby都有对应的库来实现动态抓取。
webscraper可以抓取flash动画,支持剪贴板上复制、离线缓存等可以利用python制作webapp,方便抓取重要页面并转化成json格式,web文件处理。也可以抓取网页,非常牛的抓取工具。专门负责爬取网页的工具, 查看全部
网页flash文本抓取器(网页抓取技术入门第二部分-8f87-701-fb68)
网页flash文本抓取器可以完成自动换行功能,不需要手动操作即可从网页中全文摘取文本。并且支持中文分词、多列分词、拼音搜索等高级功能。而实现这一功能必须要有flash,以及python支持打开网页和抓取全文。根据提示,将如下链接拉到页面的底部,会自动出现flash抓取器,点击即可进入抓取界面。
我用这个方法在百度贴吧实现过自动换行,很简单。
建议参考一下网页抓取技术入门第二部分-8f87-4744-b701-f68d4e3079091.html
richflashgoogleflashrecapabilities
话说我们专业前段时间用python做了一个flash版本的全自动换行的网页抓取程序,
有一些类似的工具,但是功能不是全自动的,
有个网站可以抓取各种网页的网页制作助手|全自动抓取网页和视频
用flashgen调用txt文件来实现,抓取只支持post方式;python或者ruby都有对应的库来实现动态抓取。
webscraper可以抓取flash动画,支持剪贴板上复制、离线缓存等可以利用python制作webapp,方便抓取重要页面并转化成json格式,web文件处理。也可以抓取网页,非常牛的抓取工具。专门负责爬取网页的工具,
网页flash文本抓取器(如何才能创建一个对搜索引擎友好的企业网站或者个人博客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-05 10:01
最近有很多朋友询问必胜互联网如何打造一个搜索引擎友好的企业网站或者个人博客。其实无论是企业网站还是个人博客,在创建搜索引擎友好的网站的过程中,都需要注意一些常见的问题。必盛互联网总结了一些对搜索引擎友好的技巧,供大家参考。
向图像、Flash 和视频添加文本
大家应该清楚,搜索引擎抓取网站内容的主题是文本。在网站上的图片、Flash、视频等中添加文字可以帮助搜索引擎抓取网站的内容。添加文本并不意味着将文本嵌入到图像、Flash 或视频中,而是指对这些图像、Flash 或视频的文字描述。目前,一些搜索引擎已经具备扫描Flash文件的能力,但这种能力还没有成熟,很难完整地扫描Flash文件的信息。谷歌在扫描Flash文件方面做得很好,其他搜索引擎未必,也没有可以查看图片和视频信息的搜索引擎。
虽然图片、视频等内容很难抓拍,但这并不意味着图片站、视频站等就不能创建。站长可以将图片、视频等文字描述传达给搜索引擎网站信息。常用方法包括向图像添加 Alt 标记。
验证 HTML 代码
在创建 网站 时,需要检查 HTML 代码是否有错误,不是拼写或语法错误,而是检查允许网络浏览器根据站长需要格式化网页的底层 HTML 代码。无论您使用哪个 Web 编辑器编写 网站HTML 代码,网站使用 HTML 和 CSS 验证器来检查您的代码总是对您有利。如果 HTML 代码有错误且无法被网络浏览器检测到,搜索引擎可能会忽略 网站 本身的内容,从而无法抓取 网站 的内容。
创建相关的标题标签
许多搜索引擎显示的标题标签长度有限,而标题标签也会影响搜索引擎排名,因此站长在创建标题标签时需要仔细考虑。首先是分析网站的目标用户群,根据网站用户过滤标签,例如技术网站需要添加专业术语等,然后到符合title标签的特点,即简洁明了,主关键词在前一个关键词的旁边,因为在同样的条件下,搜索引擎会优先显示关键词排名靠前的网页,所以这对于页面排名非常有用。
使用 HTML 导航直接链接到 网站
大多数搜索引擎无法理解 Javascript 语言,因此使用 HTML 导航链接尤为重要。一般来说,纯 HTML 导航是最好的,不仅供用户浏览,也供搜索引擎抓取。使用 Javascript 甚至 Flash 确实使导航看起来更好,但它使搜索引擎更难抓取。
删除明显的重复项
同一篇文章文章可能有两个不同的URL,这会直接稀释网站的流量,分散权重,对搜索引擎很不友好。搜索引擎会认为网站的内容有很多重复,会直接降低网站的排名。对于这种情况,站长可以使用百度站长工具来处理规范网址。
删除隐藏文本
隐藏文字是指将关键词的颜色设置为页面的背景色,让访问者看不到,但搜索引擎可以统计。其目的主要是增加关键词的密度。这种方法也被称为黑帽 SEO。它不被搜索引擎识别,目前大多数搜索引擎都可以检测到隐藏文本并将其视为作弊。因此,站长最好不要通过隐藏文字进行推测。通过添加可视化文本内容也可以达到同样的优化效果。
相关文章: 查看全部
网页flash文本抓取器(如何才能创建一个对搜索引擎友好的企业网站或者个人博客)
最近有很多朋友询问必胜互联网如何打造一个搜索引擎友好的企业网站或者个人博客。其实无论是企业网站还是个人博客,在创建搜索引擎友好的网站的过程中,都需要注意一些常见的问题。必盛互联网总结了一些对搜索引擎友好的技巧,供大家参考。
向图像、Flash 和视频添加文本
大家应该清楚,搜索引擎抓取网站内容的主题是文本。在网站上的图片、Flash、视频等中添加文字可以帮助搜索引擎抓取网站的内容。添加文本并不意味着将文本嵌入到图像、Flash 或视频中,而是指对这些图像、Flash 或视频的文字描述。目前,一些搜索引擎已经具备扫描Flash文件的能力,但这种能力还没有成熟,很难完整地扫描Flash文件的信息。谷歌在扫描Flash文件方面做得很好,其他搜索引擎未必,也没有可以查看图片和视频信息的搜索引擎。

虽然图片、视频等内容很难抓拍,但这并不意味着图片站、视频站等就不能创建。站长可以将图片、视频等文字描述传达给搜索引擎网站信息。常用方法包括向图像添加 Alt 标记。
验证 HTML 代码
在创建 网站 时,需要检查 HTML 代码是否有错误,不是拼写或语法错误,而是检查允许网络浏览器根据站长需要格式化网页的底层 HTML 代码。无论您使用哪个 Web 编辑器编写 网站HTML 代码,网站使用 HTML 和 CSS 验证器来检查您的代码总是对您有利。如果 HTML 代码有错误且无法被网络浏览器检测到,搜索引擎可能会忽略 网站 本身的内容,从而无法抓取 网站 的内容。
创建相关的标题标签
许多搜索引擎显示的标题标签长度有限,而标题标签也会影响搜索引擎排名,因此站长在创建标题标签时需要仔细考虑。首先是分析网站的目标用户群,根据网站用户过滤标签,例如技术网站需要添加专业术语等,然后到符合title标签的特点,即简洁明了,主关键词在前一个关键词的旁边,因为在同样的条件下,搜索引擎会优先显示关键词排名靠前的网页,所以这对于页面排名非常有用。
使用 HTML 导航直接链接到 网站
大多数搜索引擎无法理解 Javascript 语言,因此使用 HTML 导航链接尤为重要。一般来说,纯 HTML 导航是最好的,不仅供用户浏览,也供搜索引擎抓取。使用 Javascript 甚至 Flash 确实使导航看起来更好,但它使搜索引擎更难抓取。
删除明显的重复项
同一篇文章文章可能有两个不同的URL,这会直接稀释网站的流量,分散权重,对搜索引擎很不友好。搜索引擎会认为网站的内容有很多重复,会直接降低网站的排名。对于这种情况,站长可以使用百度站长工具来处理规范网址。
删除隐藏文本
隐藏文字是指将关键词的颜色设置为页面的背景色,让访问者看不到,但搜索引擎可以统计。其目的主要是增加关键词的密度。这种方法也被称为黑帽 SEO。它不被搜索引擎识别,目前大多数搜索引擎都可以检测到隐藏文本并将其视为作弊。因此,站长最好不要通过隐藏文字进行推测。通过添加可视化文本内容也可以达到同样的优化效果。
相关文章:
网页flash文本抓取器(百度开发所见即所得富文本web编辑器官网教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-04 07:16
概述
UEditor 是百度开发的所见即所得的富文本网页编辑器。它是轻量级的、可定制的,并且专注于用户体验。开源基于 MIT 协议,允许免费使用和修改代码。
官网地址:(学习编辑的最佳去处)
其实官网的教程已经很全面了,所有的API都推荐去官网学习。这里只是为你做一个简单的介绍。重点是如何将文件和图片保存在项目之外,如下所述。实际上,使用的是富文本编辑器。主要是保存大文本数据值。里面的图片资源一般放在项目外或者图片服务器的路径下。我在网上找了很多,几乎都是解决方案。我将带您更详细地了解关键位置。以及如何配置它。
下载地址:下载对应版本即可。如果想看源代码,可以下载源代码。
下载后直接复制到项目中,我放在js文件下,因为springMVC对静态文件有限制,所以放在js目录下,guest可以随意放。
将jsp中的lib包复制到WEB-INF下的lib中。如图: 记得把lib包添加到构建路径中,ueditor.jar没有版本因为,这里替换了我自己打的jar,后面会介绍,我自己的jar包--下载地址: (1 学分)
好的,是时候开始创建测试页面了。
根据官网的提示和建议,应该在页面上定义window.UEDITOR_HOME_URL。这是必须在前端配置文件中配置的路径。该路径是 ueditor.config.js 文件所在的目录。在页面上设置好之后, ueditor.config.js 文件就可以停止移动了。
ueditor demo
window.UEDITOR_HOME_URL = "${basePath }/js/ueditor/"
这里写你的初始化内容
var ue = UE.getEditor('container');
ok,前端配置文件已经写好,运行项目,访问测试jsp,没有出现意外页面。
至此,前端页面完成。如果点击多图上传,会出现以下内容。图片和文件上传也需要后台配置文件的支持。
检查是否可以访问。如果没有,请检查文档并将其修改为可访问。参考文档:。
ueditor/jsp目录下的config.json是后台上传功能的配置文件。我们先来看看。
官网上传路径配置说明:
按需修改即可,配置项的最后一行就是保存到本项目的路径。
如果你的项目只需要保存文件和图片到项目中,可以到此结束。
如果你的项目需要把文件放到指定的目录下,比如linux中的d:\image或者“/data/image”,ueditor不改源码是做不到的。网上查了很多资料,几乎都是出自一种写法,也参考了那个博主,链接:,可以学着改写。
我修改了源码,把源码做成了jar包。急用的话,可以下载我的ueditor.jar,直接把项目中的ueditor-1.1.2.jar替换成下载的ueditor.jar ,当然,后面的配置参数还是需要改的。
下载地址:(1分)(不觊觎积分的人)
原理其实就是在后台配置文件中自定义一个配置项,然后在文件上传的时候提取配置的地址,把这个地址和原来的上传路径组合成一个新的“物理地址”。要使用这个jar包,需要在后台配置文件。添加“physicsPath”的配置项之一,这个地址值“d:/data/image/www/product”会和imagePathFormat的值“/{yyyy}/...”结合起来存在于本地” d:/data/image/www/product/2018/..."。
上传成功的话,编辑器中不会显示图片,如上图,其实只要提示上传成功,文件上传就ok了,但是上传之后,富文本编辑器会将“imageUrlPrefix”和“imagePathFormat”与您的配置文件中的配置项结合起来。"发送图片的http请求,示例中的配置会发送,如,肯定不会,在真实的生产环境中,我们会有一个静态图片服务器,如果域名指向服务器的地址,那么"写imageUrlPrefix”指定对应的图片地址即可。本例使用的ngix服务器,域名“”指向该服务器的地址为“/data/image/www”。
所以,上传图片是第一步,再考虑请求路径的问题。如果是本地测试,可以修改tomcat的虚拟路径,实现富文本框中的图像回显;例如:在tomcat配置文件server.xml中添加虚拟路径,即访问:8080/product,表示访问D:\data\image\www\product,控制“imageUrlPrefix”和“ imagePathFormat”,这样就可以在编辑器本地显示图片了。
好了,说了这么多废话,有什么问题欢迎留言。
(超过) 查看全部
网页flash文本抓取器(百度开发所见即所得富文本web编辑器官网教程)
概述
UEditor 是百度开发的所见即所得的富文本网页编辑器。它是轻量级的、可定制的,并且专注于用户体验。开源基于 MIT 协议,允许免费使用和修改代码。
官网地址:(学习编辑的最佳去处)
其实官网的教程已经很全面了,所有的API都推荐去官网学习。这里只是为你做一个简单的介绍。重点是如何将文件和图片保存在项目之外,如下所述。实际上,使用的是富文本编辑器。主要是保存大文本数据值。里面的图片资源一般放在项目外或者图片服务器的路径下。我在网上找了很多,几乎都是解决方案。我将带您更详细地了解关键位置。以及如何配置它。
下载地址:下载对应版本即可。如果想看源代码,可以下载源代码。
下载后直接复制到项目中,我放在js文件下,因为springMVC对静态文件有限制,所以放在js目录下,guest可以随意放。
将jsp中的lib包复制到WEB-INF下的lib中。如图: 记得把lib包添加到构建路径中,ueditor.jar没有版本因为,这里替换了我自己打的jar,后面会介绍,我自己的jar包--下载地址: (1 学分)
好的,是时候开始创建测试页面了。
根据官网的提示和建议,应该在页面上定义window.UEDITOR_HOME_URL。这是必须在前端配置文件中配置的路径。该路径是 ueditor.config.js 文件所在的目录。在页面上设置好之后, ueditor.config.js 文件就可以停止移动了。
ueditor demo
window.UEDITOR_HOME_URL = "${basePath }/js/ueditor/"
这里写你的初始化内容
var ue = UE.getEditor('container');
ok,前端配置文件已经写好,运行项目,访问测试jsp,没有出现意外页面。
至此,前端页面完成。如果点击多图上传,会出现以下内容。图片和文件上传也需要后台配置文件的支持。
检查是否可以访问。如果没有,请检查文档并将其修改为可访问。参考文档:。
ueditor/jsp目录下的config.json是后台上传功能的配置文件。我们先来看看。
官网上传路径配置说明:
按需修改即可,配置项的最后一行就是保存到本项目的路径。
如果你的项目只需要保存文件和图片到项目中,可以到此结束。
如果你的项目需要把文件放到指定的目录下,比如linux中的d:\image或者“/data/image”,ueditor不改源码是做不到的。网上查了很多资料,几乎都是出自一种写法,也参考了那个博主,链接:,可以学着改写。
我修改了源码,把源码做成了jar包。急用的话,可以下载我的ueditor.jar,直接把项目中的ueditor-1.1.2.jar替换成下载的ueditor.jar ,当然,后面的配置参数还是需要改的。
下载地址:(1分)(不觊觎积分的人)
原理其实就是在后台配置文件中自定义一个配置项,然后在文件上传的时候提取配置的地址,把这个地址和原来的上传路径组合成一个新的“物理地址”。要使用这个jar包,需要在后台配置文件。添加“physicsPath”的配置项之一,这个地址值“d:/data/image/www/product”会和imagePathFormat的值“/{yyyy}/...”结合起来存在于本地” d:/data/image/www/product/2018/..."。
上传成功的话,编辑器中不会显示图片,如上图,其实只要提示上传成功,文件上传就ok了,但是上传之后,富文本编辑器会将“imageUrlPrefix”和“imagePathFormat”与您的配置文件中的配置项结合起来。"发送图片的http请求,示例中的配置会发送,如,肯定不会,在真实的生产环境中,我们会有一个静态图片服务器,如果域名指向服务器的地址,那么"写imageUrlPrefix”指定对应的图片地址即可。本例使用的ngix服务器,域名“”指向该服务器的地址为“/data/image/www”。
所以,上传图片是第一步,再考虑请求路径的问题。如果是本地测试,可以修改tomcat的虚拟路径,实现富文本框中的图像回显;例如:在tomcat配置文件server.xml中添加虚拟路径,即访问:8080/product,表示访问D:\data\image\www\product,控制“imageUrlPrefix”和“ imagePathFormat”,这样就可以在编辑器本地显示图片了。
好了,说了这么多废话,有什么问题欢迎留言。
(超过)
网页flash文本抓取器(富文本内容交互(一)——编辑器内容至后端场景)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-03 11:00
一、富文本内容交互
1、编辑器内容初始化(即在编辑器中设置富文本)
场景一:在编辑器中写一个新的文章,预设提示、问候等。
在 editor_config.js 文件中找到 initialContent 参数,并将其值设置为所需的提示或问候语,例如 initialContent: 'Welcome to UEditor!'。
场景二:编辑旧的文章,从数据库中取出富文本放到编辑器中。
显然,在编辑文章时,需要从后台数据库中提取一大段富文本。如果初始值还是采用场景一的方式设置,必然会带来引号被截断等问题,所以需要使用另一种方式来设置,如下代码所示:
//从数据库中取出文章内容打印到此处
此处采用了script标签作为编辑器容器对象,并设置了其类型是纯文本,从而在避免了标签内部JS代码执行的同时解决了部分同学在使用传统的textarea标签作为容器所带来的一次额外转码问题。
2、提交编辑器内容到后端
场景一:编辑器所在的Form中有一个提交按钮,点击该按钮完成提交动作。
这个场景适合最常见的场合。没有太多需要注意的问题。只需要说明三点:
1)默认提交到后台的表单名称为“editorValue”,可在editor_config.js中配置,参数名称为textarea。
2)可以在容器标签(即脚本标签)上设置name属性来覆盖editor_config.js中的默认配置。示例代码如下,其中 myContent 将是新的提交表单名称:
3)后端接收程序可以通过以下方式获取编辑器中的富文本内容。
//PHP获取:
$_POST["myContent"]
//JSP获取:
request.getParameter("myContent");
//ASP获取:
request("myContent");
//NET获取:
context.Request.Form["myContent"];
场景二:编辑器所在的Form中没有提交按钮,提交动作是由外部事件触发的。
该场景适用于网站前端交互较多的场合。主要需要注意的是,编辑器内容同步操作是在表单提交动作触发之前进行的。通用代码模式如下所示:
//满足提交条件时同步内容并提交,此处editor为编辑器实例
if(editor.hasContent()){ //此处以非空为例
editor.sync(); //同步内容
someForm.submit(); //提交Form
}
这里的 editor 是编辑器实例对象。
场景三:编辑器不在任何Form中,提交动作被外部事件触发。
这个场景用的不多,但在特殊场合可能需要用到。UEditor 也提供了相应的处理方案。基本逻辑和第二种场景一样,只是在进行同步操作的时候需要传入提交表单的id,比如editor.sync(myFormID)。其他相同的场景 2。
二、图片上传交互
1、传统图片上传
传统图片上传所涉及的前后端交互主要涉及“上传提交路径”和“图片存储路径”两个参数。后台存储路径为任何形式(绝对或相对),在任何页面上显示与前台无关。
2、Flash图片上传
Flahs图片上传与传统图片上传有一个很大的区别:它需要服务器实时返回“图片保存路径”,以便在前台即时显示。具体到编辑器,需要将返回的路径插入到编辑器中。这会导致除了传统图片上传中提到的两个参数之外,还有第三个参数:“前后端校正路径”。如果后台返回的保存路径是绝对路径(指以http开头的路径,根目录开头的路径也可以收录在其中),那么前台不需要做任何修正,否则用户必须非常清楚自己当前的目录结构,并根据这修正了前后端相对路径的差异。因此,UEditor 强烈建议服务器端返回以根目录开头的相对路径。
3、UEditor中上传的做法和注意事项
在UEditor中,“上传提交路径”和“前后端修改路径”的配置位于editor_config.js中。其中,imageUrl参数对应“上传提交路径”,imagePath参数对应“前后端校正路径”。“图片保存路径”需要在server/upload/php目录下的imageUp文件中配置。
路径配置完成后,还需要配置imageFieldName参数为文件表单的表单名,后台可以据此获取文件句柄。此参数也位于 editor_config.js 中。
//图片上传提交地址
imageUrl:URL+"server/upload/php/imageUp.php",
//图片修正地址,引用了fixedImagePath,如有特殊需求,可自行配置
imagePath:fixedImagePath,
//图片描述的key
imageFieldName:"upFile",
//等比压缩的基准,确定maxImageSideLength参数的参照对象.
//0为按照最长边,1为按照宽度,2为按照高度
compressSide:0,
//上传图片最大允许的边长,超过会自动等比缩放,不缩放就设置一个比较大的值
//更多设置在image.html中
maxImageSideLength:900
完成以上配置后,理论上后台应该可以接收到前台上传的图片文件了。一旦正确保存,传统的图像上传到此结束。但是,在编辑器中使用 Flash 上传,过程还远远没有结束。
首先,后台需要计算出图片文件存放的地址字符串。UEditor 强烈建议使用从 网站 的根目录到图像名称末尾的字符串。如果不是从网站的根目录算起,后面需要考虑参数“前后端校正地址”。
其次,后台返回一个json格式的字符串。格式的具体要求如下:
{ "url":"图片地址", "title":"图片描述", "state":"上传状态" }
三、Word 图片转储交互
1、图片转储原理
所谓word图片转储,就是为了解决UEditor从word中复制一个混合的图文文章粘贴到编辑器中的问题,word文章中的图片数据无法显示在编辑器中。是针对无法提交到服务器的问题而开发的一款简单易用的镜像转储解决方案。
该功能的基本操作步骤:复制word文档-》粘贴到编辑器-》编辑器会将所有图片转换成占位符图片,同时高亮工具栏中的dump按钮-》点击dump按钮即可弹出图片上传框——“点击复制按钮复制图片目录地址——”点击“添加照片”按钮,将刚才复制的图片目录地址粘贴到弹出的选择框中——“点击打开按钮选择目录下的所有图片文件,点击这里打开-》执行图片上传-》上传成功确认插入,UEditor会自动完成对应占位图片的替换过程。
2、配置要点及注意事项
word图片dump的配置和普通图片上传基本一样,唯一的区别就是操作上的不同:前者需要先获取临时图片文件存在的目录,后者直接选择指定的文件目录通过它自己。PS:在某些操作系统的word的某些版本中,发现单个word图片会生成两张临时图片,格式和定义不同。目前还没有找到改进的方法。
四、远程抓图交互
1、遥控抓取原理
图片远程抓取是指服务器将这些外部图片抓取到本地服务器,并在插入本地域名以外的图片链接地址时保存的功能。实现原理是在编辑器中向服务器发送一个收录所有外域图片地址的ajax请求,然后服务器将图片地址捕获并保存在后端并将图片地址返回给编辑器,然后编辑器将完成外域地址和本地地址的替换。
//是否开启远程图片抓取
catchRemoteImageEnable:true,
//处理远程图片抓取的地址
catcherUrl:URL +"server/submit/php/getRemoteImage.php",
//提交到后台远程图片uri合集的表单名
catchFieldName:"upFile",
//图片修正地址,同imagePath
catcherPath:fixedImagePath,
//本地顶级域名,当开启远程图片抓取时,除此之外的所有其它域名下的
//图片都将被抓取到本地
localDomain:["baidu.com","10.81.2.114"],
2、备注
是否开启远程抓图功能可以通过在editot_config.js中配置catchRemoteImageEnable参数来实现。与此功能相关的配置还包括远程获取处理程序地址、表单字段名称、本地字段以及“前端和后端更正地址”。远程抓图处理程序实现根据前端提交的地址列表(以ue_separate_ue标识分隔的字符串)进行抓图,然后将地址列表返回给客户端的功能。
前后端交互数据格式示例:(URL1, URL2, URL3, URL4)
URL1ue_separate_ueURL2ue_separate_ueURL3ue_separate_ueURL4
五、图片在线管理交互
1、图片在线管理介绍
图片在线管理是指通过读取服务器端的文件目录并在编辑器中显示来进行附加操作的功能。出于安全考虑,UEditor目前只实现了二次图片插入操作,其他的删除、移动等操作将在后续的二次开发教程中发布。
//图片在线管理的处理地址
imageManagerUrl:URL + "server/submit/php/imageManager.php",
//图片修正地址,同imagePath
imageManagerPath:fixedImagePath
2、备注
在线图片管理中需要配置的参数与远程抓图相同。两者的区别在于,在线图片管理中的图片数据是通过在服务器端指定某个目录,然后遍历其下的所有图片文件,然后返回地址来获取的。到编辑器,远程抓图就是由编辑器提交图片地址,服务器端抓图处理后将新地址返回给编辑器。两者的初始触发都需要ajax的介入。
六、截图交互
1、截图介绍
使用ActiveX控件,目前只支持IE浏览器。
2、备注
需要配置的参数除了和图片上传一样的内容外,还包括服务器地址和端口的配置。使用时请根据自己服务器的特点进行适配和修改。
//屏幕截图的server端文件所在的网站地址或者ip,请不要加http://
snapscreenHost: '127.0.0.1',
//屏幕截图的server端保存程序,UEditor的范例代码为“URL
snapscreenServerUrl: URL +"server/upload/php/snapImgUp.php", +"server/upload/php/snapImgUp.php"”
//屏幕截图的server端端口
snapscreenServerPort: 80,
//截图的图片默认的排版方式
snapscreenImgAlign: 'center',
//截图显示修正地址
snapscreenPath: fixedImagePath,
七、附件上传交互
1、上传附件注意事项
附件上传的基本配置与图片类似。另外,由于附件上传采用成熟的swfupload开源框架,大部分文档资料可以参考swfupload官网教程。官网地址:http://
Ueditor的部署说明(来自Ueditor官网): 查看全部
网页flash文本抓取器(富文本内容交互(一)——编辑器内容至后端场景)
一、富文本内容交互
1、编辑器内容初始化(即在编辑器中设置富文本)
场景一:在编辑器中写一个新的文章,预设提示、问候等。
在 editor_config.js 文件中找到 initialContent 参数,并将其值设置为所需的提示或问候语,例如 initialContent: 'Welcome to UEditor!'。
场景二:编辑旧的文章,从数据库中取出富文本放到编辑器中。
显然,在编辑文章时,需要从后台数据库中提取一大段富文本。如果初始值还是采用场景一的方式设置,必然会带来引号被截断等问题,所以需要使用另一种方式来设置,如下代码所示:
//从数据库中取出文章内容打印到此处
此处采用了script标签作为编辑器容器对象,并设置了其类型是纯文本,从而在避免了标签内部JS代码执行的同时解决了部分同学在使用传统的textarea标签作为容器所带来的一次额外转码问题。
2、提交编辑器内容到后端
场景一:编辑器所在的Form中有一个提交按钮,点击该按钮完成提交动作。
这个场景适合最常见的场合。没有太多需要注意的问题。只需要说明三点:
1)默认提交到后台的表单名称为“editorValue”,可在editor_config.js中配置,参数名称为textarea。
2)可以在容器标签(即脚本标签)上设置name属性来覆盖editor_config.js中的默认配置。示例代码如下,其中 myContent 将是新的提交表单名称:
3)后端接收程序可以通过以下方式获取编辑器中的富文本内容。
//PHP获取:
$_POST["myContent"]
//JSP获取:
request.getParameter("myContent");
//ASP获取:
request("myContent");
//NET获取:
context.Request.Form["myContent"];
场景二:编辑器所在的Form中没有提交按钮,提交动作是由外部事件触发的。
该场景适用于网站前端交互较多的场合。主要需要注意的是,编辑器内容同步操作是在表单提交动作触发之前进行的。通用代码模式如下所示:
//满足提交条件时同步内容并提交,此处editor为编辑器实例
if(editor.hasContent()){ //此处以非空为例
editor.sync(); //同步内容
someForm.submit(); //提交Form
}
这里的 editor 是编辑器实例对象。
场景三:编辑器不在任何Form中,提交动作被外部事件触发。
这个场景用的不多,但在特殊场合可能需要用到。UEditor 也提供了相应的处理方案。基本逻辑和第二种场景一样,只是在进行同步操作的时候需要传入提交表单的id,比如editor.sync(myFormID)。其他相同的场景 2。
二、图片上传交互
1、传统图片上传
传统图片上传所涉及的前后端交互主要涉及“上传提交路径”和“图片存储路径”两个参数。后台存储路径为任何形式(绝对或相对),在任何页面上显示与前台无关。
2、Flash图片上传
Flahs图片上传与传统图片上传有一个很大的区别:它需要服务器实时返回“图片保存路径”,以便在前台即时显示。具体到编辑器,需要将返回的路径插入到编辑器中。这会导致除了传统图片上传中提到的两个参数之外,还有第三个参数:“前后端校正路径”。如果后台返回的保存路径是绝对路径(指以http开头的路径,根目录开头的路径也可以收录在其中),那么前台不需要做任何修正,否则用户必须非常清楚自己当前的目录结构,并根据这修正了前后端相对路径的差异。因此,UEditor 强烈建议服务器端返回以根目录开头的相对路径。
3、UEditor中上传的做法和注意事项
在UEditor中,“上传提交路径”和“前后端修改路径”的配置位于editor_config.js中。其中,imageUrl参数对应“上传提交路径”,imagePath参数对应“前后端校正路径”。“图片保存路径”需要在server/upload/php目录下的imageUp文件中配置。
路径配置完成后,还需要配置imageFieldName参数为文件表单的表单名,后台可以据此获取文件句柄。此参数也位于 editor_config.js 中。
//图片上传提交地址
imageUrl:URL+"server/upload/php/imageUp.php",
//图片修正地址,引用了fixedImagePath,如有特殊需求,可自行配置
imagePath:fixedImagePath,
//图片描述的key
imageFieldName:"upFile",
//等比压缩的基准,确定maxImageSideLength参数的参照对象.
//0为按照最长边,1为按照宽度,2为按照高度
compressSide:0,
//上传图片最大允许的边长,超过会自动等比缩放,不缩放就设置一个比较大的值
//更多设置在image.html中
maxImageSideLength:900
完成以上配置后,理论上后台应该可以接收到前台上传的图片文件了。一旦正确保存,传统的图像上传到此结束。但是,在编辑器中使用 Flash 上传,过程还远远没有结束。
首先,后台需要计算出图片文件存放的地址字符串。UEditor 强烈建议使用从 网站 的根目录到图像名称末尾的字符串。如果不是从网站的根目录算起,后面需要考虑参数“前后端校正地址”。
其次,后台返回一个json格式的字符串。格式的具体要求如下:
{ "url":"图片地址", "title":"图片描述", "state":"上传状态" }
三、Word 图片转储交互
1、图片转储原理
所谓word图片转储,就是为了解决UEditor从word中复制一个混合的图文文章粘贴到编辑器中的问题,word文章中的图片数据无法显示在编辑器中。是针对无法提交到服务器的问题而开发的一款简单易用的镜像转储解决方案。
该功能的基本操作步骤:复制word文档-》粘贴到编辑器-》编辑器会将所有图片转换成占位符图片,同时高亮工具栏中的dump按钮-》点击dump按钮即可弹出图片上传框——“点击复制按钮复制图片目录地址——”点击“添加照片”按钮,将刚才复制的图片目录地址粘贴到弹出的选择框中——“点击打开按钮选择目录下的所有图片文件,点击这里打开-》执行图片上传-》上传成功确认插入,UEditor会自动完成对应占位图片的替换过程。
2、配置要点及注意事项
word图片dump的配置和普通图片上传基本一样,唯一的区别就是操作上的不同:前者需要先获取临时图片文件存在的目录,后者直接选择指定的文件目录通过它自己。PS:在某些操作系统的word的某些版本中,发现单个word图片会生成两张临时图片,格式和定义不同。目前还没有找到改进的方法。
四、远程抓图交互
1、遥控抓取原理
图片远程抓取是指服务器将这些外部图片抓取到本地服务器,并在插入本地域名以外的图片链接地址时保存的功能。实现原理是在编辑器中向服务器发送一个收录所有外域图片地址的ajax请求,然后服务器将图片地址捕获并保存在后端并将图片地址返回给编辑器,然后编辑器将完成外域地址和本地地址的替换。
//是否开启远程图片抓取
catchRemoteImageEnable:true,
//处理远程图片抓取的地址
catcherUrl:URL +"server/submit/php/getRemoteImage.php",
//提交到后台远程图片uri合集的表单名
catchFieldName:"upFile",
//图片修正地址,同imagePath
catcherPath:fixedImagePath,
//本地顶级域名,当开启远程图片抓取时,除此之外的所有其它域名下的
//图片都将被抓取到本地
localDomain:["baidu.com","10.81.2.114"],
2、备注
是否开启远程抓图功能可以通过在editot_config.js中配置catchRemoteImageEnable参数来实现。与此功能相关的配置还包括远程获取处理程序地址、表单字段名称、本地字段以及“前端和后端更正地址”。远程抓图处理程序实现根据前端提交的地址列表(以ue_separate_ue标识分隔的字符串)进行抓图,然后将地址列表返回给客户端的功能。
前后端交互数据格式示例:(URL1, URL2, URL3, URL4)
URL1ue_separate_ueURL2ue_separate_ueURL3ue_separate_ueURL4
五、图片在线管理交互
1、图片在线管理介绍
图片在线管理是指通过读取服务器端的文件目录并在编辑器中显示来进行附加操作的功能。出于安全考虑,UEditor目前只实现了二次图片插入操作,其他的删除、移动等操作将在后续的二次开发教程中发布。
//图片在线管理的处理地址
imageManagerUrl:URL + "server/submit/php/imageManager.php",
//图片修正地址,同imagePath
imageManagerPath:fixedImagePath
2、备注
在线图片管理中需要配置的参数与远程抓图相同。两者的区别在于,在线图片管理中的图片数据是通过在服务器端指定某个目录,然后遍历其下的所有图片文件,然后返回地址来获取的。到编辑器,远程抓图就是由编辑器提交图片地址,服务器端抓图处理后将新地址返回给编辑器。两者的初始触发都需要ajax的介入。
六、截图交互
1、截图介绍
使用ActiveX控件,目前只支持IE浏览器。
2、备注
需要配置的参数除了和图片上传一样的内容外,还包括服务器地址和端口的配置。使用时请根据自己服务器的特点进行适配和修改。
//屏幕截图的server端文件所在的网站地址或者ip,请不要加http://
snapscreenHost: '127.0.0.1',
//屏幕截图的server端保存程序,UEditor的范例代码为“URL
snapscreenServerUrl: URL +"server/upload/php/snapImgUp.php", +"server/upload/php/snapImgUp.php"”
//屏幕截图的server端端口
snapscreenServerPort: 80,
//截图的图片默认的排版方式
snapscreenImgAlign: 'center',
//截图显示修正地址
snapscreenPath: fixedImagePath,
七、附件上传交互
1、上传附件注意事项
附件上传的基本配置与图片类似。另外,由于附件上传采用成熟的swfupload开源框架,大部分文档资料可以参考swfupload官网教程。官网地址:http://
Ueditor的部署说明(来自Ueditor官网):
网页flash文本抓取器(网站抓取是一个用Python编写的Web爬虫和Web框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-03 10:28
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。
网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。
网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以通过直接socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。
网站爬虫使用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。 查看全部
网页flash文本抓取器(网站抓取是一个用Python编写的Web爬虫和Web框架)
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。
网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。
网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以通过直接socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。
网站爬虫使用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。
网页flash文本抓取器(网页flash文本抓取器,强烈推荐基于golang的爬虫开发框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-04-02 18:04
网页flash文本抓取器,
强烈推荐基于golang的爬虫开发框架:parse-go,它基于queryset,把网页中的所有页面标记成text/field,进而爬取下来并存储起来。不过,它也支持html的抓取。使用方法很简单,你可以打开项目,运行goget,就能看到项目的运行效果。此外,还可以进行效果模拟,你可以把预先定义好的文本复制到wordcloud中(大小可以自己配置),然后在网页中输入parse-go就能得到结果,然后把结果存到本地存储库里就好了。
网页抓取非常简单,抓取速度却很快,如果你不会写python,pandas以及numpy的话也没关系,这个工具,也是web前端开发者使用的,其实python也有相同的应用场景,web开发者就可以拿来替代python处理,简单说,就是可以获取、解析网页并返回报表。一、网页获取方式总结1、scrapy与requests一般的网页抓取,scrapy或requests这两个最流行,它们都是基于url的,只要它们能得到一个网页,得到网页的url之后就可以用它们来抓取和解析了。
github上已经有很多,比如官方文档中有documentation(documentation-scrapy或者requests-scrapy)。我们看看scrapy,对比一下requests,他们都有默认处理,正如其名,它们主要区别在于它们的html解析问题。我们以例子来说明问题,demo就是第一页的某一个scrapy项目,那么我们用requests解析一下,首先得先找到里面的链接,好,那么我们从此看起,如何获取到以及如何返回wordcloud(json)如何返回css代码的解析结果。
我们看到,可以得到html文本,也就是我们说的网页,那么要获取到html文本文件,怎么把它解析成为css文件,我们需要一些特殊的工具,这就是编码的问题,有标准编码和开放标准的编码。常见的编码有utf-8,utf-16。我们以utf-8编码为例,如果我们想一次得到3页的代码,那么我们需要用到utf-8编码的requests框架,在utf-8编码下,获取url需要json格式,所以可以用jsonreader或requestsreader等工具,把url加入到一个json对象里,通过json字符串,可以获取url返回的css等返回到utf-8编码格式的数据。
但是如果我们返回的数据是css,js,这种特殊的编码,那我们在分析数据的时候就会产生问题,我们需要先将解析好的css字符串转换成utf-8编码,如果编码不匹配,这里的3页就不会被解析到,我们就需要通过gzip压缩,并转换成开放标准编码,然后用scrapy解析数据。那么scrapy也是用json解析css的,我们也同样以例子来说。 查看全部
网页flash文本抓取器(网页flash文本抓取器,强烈推荐基于golang的爬虫开发框架)
网页flash文本抓取器,
强烈推荐基于golang的爬虫开发框架:parse-go,它基于queryset,把网页中的所有页面标记成text/field,进而爬取下来并存储起来。不过,它也支持html的抓取。使用方法很简单,你可以打开项目,运行goget,就能看到项目的运行效果。此外,还可以进行效果模拟,你可以把预先定义好的文本复制到wordcloud中(大小可以自己配置),然后在网页中输入parse-go就能得到结果,然后把结果存到本地存储库里就好了。
网页抓取非常简单,抓取速度却很快,如果你不会写python,pandas以及numpy的话也没关系,这个工具,也是web前端开发者使用的,其实python也有相同的应用场景,web开发者就可以拿来替代python处理,简单说,就是可以获取、解析网页并返回报表。一、网页获取方式总结1、scrapy与requests一般的网页抓取,scrapy或requests这两个最流行,它们都是基于url的,只要它们能得到一个网页,得到网页的url之后就可以用它们来抓取和解析了。
github上已经有很多,比如官方文档中有documentation(documentation-scrapy或者requests-scrapy)。我们看看scrapy,对比一下requests,他们都有默认处理,正如其名,它们主要区别在于它们的html解析问题。我们以例子来说明问题,demo就是第一页的某一个scrapy项目,那么我们用requests解析一下,首先得先找到里面的链接,好,那么我们从此看起,如何获取到以及如何返回wordcloud(json)如何返回css代码的解析结果。
我们看到,可以得到html文本,也就是我们说的网页,那么要获取到html文本文件,怎么把它解析成为css文件,我们需要一些特殊的工具,这就是编码的问题,有标准编码和开放标准的编码。常见的编码有utf-8,utf-16。我们以utf-8编码为例,如果我们想一次得到3页的代码,那么我们需要用到utf-8编码的requests框架,在utf-8编码下,获取url需要json格式,所以可以用jsonreader或requestsreader等工具,把url加入到一个json对象里,通过json字符串,可以获取url返回的css等返回到utf-8编码格式的数据。
但是如果我们返回的数据是css,js,这种特殊的编码,那我们在分析数据的时候就会产生问题,我们需要先将解析好的css字符串转换成utf-8编码,如果编码不匹配,这里的3页就不会被解析到,我们就需要通过gzip压缩,并转换成开放标准编码,然后用scrapy解析数据。那么scrapy也是用json解析css的,我们也同样以例子来说。
网页flash文本抓取器(爬虫系统的基本包含模式()()的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-02 16:28
)
基本 URL 收录模式(或协议)、服务器名称(或 IP 地址)、路径和文件名,例如“protocol://authorization/path?query”。带有授权部分的完整通用 URI 语法如下所示:protocol://username:-domain:port/directory/filename.filesuffix?parameter=value# logo
爬虫系统要处理的URL是指使用超文本传输协议HTTP的URL。
URL分为绝对URL和相对URL
绝对 URL 显示文件的完整路径,这意味着绝对 URL 本身的位置与被引用的实际文件的位置无关。
相对 URL 以收录 URL 本身的文件夹的位置作为参考点来描述目标文件夹的位置。如果目标文件和当前页面在同一目录下(即收录URL的页面),那么文件的相对URL就是文件名和扩展名,如果目标文件在当前页面的子目录下目录,其相对 URL 为 subdirectory 目录名,后跟一个斜杠,然后是目标文件的文件名和扩展名。
如果要引用文件层次结构中较高目录中的文件,请使用两个句点和一个斜杠。两个句点和一个斜杠可以组合并重复以引用当前文件所在硬盘上的任何文件,
一般来说,相对 URL 应该始终用于同一服务器上的文件,它们在将页面从本地系统传输到服务器时更容易键入和方便,只要每个文件的相对位置保持不变,链接仍然有效。
char * url_normalized(char *url) <br />{<br /> if (url == NULL) return NULL;<br /><br /> /* rtrim url */<br /> int len = strlen(url);<br /> while (len && isspace(url[len-1]))<br /> len--;<br /> url[len] = '\0';<br /><br /> if (len == 0) {<br /> free(url);<br /> return NULL;<br /> }<br /><br /> /* remove http(s):// */<br /> if (len > 7 && strncmp(url, "http", 4) == 0) {<br /> int vlen = 7;<br /> if (url[4] == 's') /* https */<br /> vlen++;<br /><br /> len -= vlen;<br /> char *tmp = (char *)malloc(len+1);<br /> strncpy(tmp, url+vlen, len);<br /> tmp[len] = '\0';<br /> free(url);<br /> url = tmp;<br /> }<br /><br /> /* remove '/' at end of url if have */<br /> if (url[len-1] == '/') {<br /> url[--len] = '\0';<br /> }<br /><br /> if (len > MAX_LINK_LEN) {<br /> free(url);<br /> return NULL;<br /> }<br /><br /> return url;<br />} 查看全部
网页flash文本抓取器(爬虫系统的基本包含模式()()的应用
)
基本 URL 收录模式(或协议)、服务器名称(或 IP 地址)、路径和文件名,例如“protocol://authorization/path?query”。带有授权部分的完整通用 URI 语法如下所示:protocol://username:-domain:port/directory/filename.filesuffix?parameter=value# logo
爬虫系统要处理的URL是指使用超文本传输协议HTTP的URL。
URL分为绝对URL和相对URL
绝对 URL 显示文件的完整路径,这意味着绝对 URL 本身的位置与被引用的实际文件的位置无关。
相对 URL 以收录 URL 本身的文件夹的位置作为参考点来描述目标文件夹的位置。如果目标文件和当前页面在同一目录下(即收录URL的页面),那么文件的相对URL就是文件名和扩展名,如果目标文件在当前页面的子目录下目录,其相对 URL 为 subdirectory 目录名,后跟一个斜杠,然后是目标文件的文件名和扩展名。
如果要引用文件层次结构中较高目录中的文件,请使用两个句点和一个斜杠。两个句点和一个斜杠可以组合并重复以引用当前文件所在硬盘上的任何文件,
一般来说,相对 URL 应该始终用于同一服务器上的文件,它们在将页面从本地系统传输到服务器时更容易键入和方便,只要每个文件的相对位置保持不变,链接仍然有效。
char * url_normalized(char *url) <br />{<br /> if (url == NULL) return NULL;<br /><br /> /* rtrim url */<br /> int len = strlen(url);<br /> while (len && isspace(url[len-1]))<br /> len--;<br /> url[len] = '\0';<br /><br /> if (len == 0) {<br /> free(url);<br /> return NULL;<br /> }<br /><br /> /* remove http(s):// */<br /> if (len > 7 && strncmp(url, "http", 4) == 0) {<br /> int vlen = 7;<br /> if (url[4] == 's') /* https */<br /> vlen++;<br /><br /> len -= vlen;<br /> char *tmp = (char *)malloc(len+1);<br /> strncpy(tmp, url+vlen, len);<br /> tmp[len] = '\0';<br /> free(url);<br /> url = tmp;<br /> }<br /><br /> /* remove '/' at end of url if have */<br /> if (url[len-1] == '/') {<br /> url[--len] = '\0';<br /> }<br /><br /> if (len > MAX_LINK_LEN) {<br /> free(url);<br /> return NULL;<br /> }<br /><br /> return url;<br />}
网页flash文本抓取器(网页flash文本抓取器了解一下,scrapy是爬虫框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-04-02 03:08
网页flash文本抓取器了解一下,自动抓取网页上所有html文本并进行智能分词,再也不用担心抓取时耗时费力了,而且更强大的是可以无痛将网页上网页爬取下来,
scrapy是爬虫框架吧,智能分词这个功能,也算是爬虫的一个特色功能吧,与requests库结合使用的话,主要目的是提高爬虫效率。
内置三种分词模式bibtex,tcsc和shagham。requests支持的分词模式还包括基于正则的双匹配,scrapy官方api为namedtext。
url抓取之后爬虫主要分词分词,目的是为了给爬虫内嵌智能分词器,同时也是一种策略性的转发请求方式,实现爬虫内嵌三种分词模式的自动切换。三种模式策略。shadowsocks有个zoo分词模式(据说快一周)可以爬取ajax1.0以上php代码。(反正实现难度大,不是太理解)。云栖社区提供很多web安全事件分析(针对国内一切网站)。
七牛云提供的python爬虫由于关键字验证和爬虫协议还有其他保密因素,根本不可能爬取ajax1.0以上php代码。但是老人家自己捣鼓了个python无头php(专门针对image5-api48.10.1-xyz)爬虫源码,可以直接使用非常不错。利益相关,不匿。
我目前也遇到这个问题了,然后我基于scrapy写了一个爬虫,爬完网页,是利用正则匹配的方式,找到想要分词的词,然后进行分词,我自己基于动态分词的方式写的,刚开始并不怎么稳定,后来数据多了,反而效率比之前快了很多, 查看全部
网页flash文本抓取器(网页flash文本抓取器了解一下,scrapy是爬虫框架)
网页flash文本抓取器了解一下,自动抓取网页上所有html文本并进行智能分词,再也不用担心抓取时耗时费力了,而且更强大的是可以无痛将网页上网页爬取下来,
scrapy是爬虫框架吧,智能分词这个功能,也算是爬虫的一个特色功能吧,与requests库结合使用的话,主要目的是提高爬虫效率。
内置三种分词模式bibtex,tcsc和shagham。requests支持的分词模式还包括基于正则的双匹配,scrapy官方api为namedtext。
url抓取之后爬虫主要分词分词,目的是为了给爬虫内嵌智能分词器,同时也是一种策略性的转发请求方式,实现爬虫内嵌三种分词模式的自动切换。三种模式策略。shadowsocks有个zoo分词模式(据说快一周)可以爬取ajax1.0以上php代码。(反正实现难度大,不是太理解)。云栖社区提供很多web安全事件分析(针对国内一切网站)。
七牛云提供的python爬虫由于关键字验证和爬虫协议还有其他保密因素,根本不可能爬取ajax1.0以上php代码。但是老人家自己捣鼓了个python无头php(专门针对image5-api48.10.1-xyz)爬虫源码,可以直接使用非常不错。利益相关,不匿。
我目前也遇到这个问题了,然后我基于scrapy写了一个爬虫,爬完网页,是利用正则匹配的方式,找到想要分词的词,然后进行分词,我自己基于动态分词的方式写的,刚开始并不怎么稳定,后来数据多了,反而效率比之前快了很多,
网页flash文本抓取器(一种提取网页内容的方法及装置提高(技术实现步骤摘要))
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-04-01 22:09
本申请公开了一种网页内容提取方法及装置。利用网页中主题元素的文本内容与标题页块内容的关系,根据标题页块与各页块的相对位置,可在各页中确定正文页块块,而不是只考虑网页中的每个页面。降低了块的文本密度,从而过滤掉了大部分无关信息,提高了确定文本页块的准确性,也提高了从文本页块中提取文本的准确性。
下载所有详细的技术数据
【技术实现步骤总结】
此应用程序收录信息
,尤其涉及一种网页内容提取方法及装置。
技术介绍
网络爬虫是根据一定的规则自动提取万维网上网页内容的程序。网页内容包括正文、正文标题、正文发表时间、作者、出处。现有技术中网络爬虫提取网页文本的方法是下载网页,分析网页中每个页面块的文本密度值,取文本密度值最大的页块(即每单位面积收录的最大文本字符数)作为文本的位置。页块,并提取正文。但是,万维网上有各种网页布局。网页中文字密度最大的页块可能收录过多的无关信息,如文字广告、推荐链接等,而不是文本所在的页面块。根据文本密度值提取的内容可能不是正文。可以看出,现有的网页内容提取方法对网页中文本的提取准确率较低。
技术实现思路
本申请实施例提供一种网页内容提取方法及装置,用以解决现有网页内容提取方法中从网页中提取文本准确率不高的问题。本申请实施例提供的一种网页内容提取方法,包括:根据网页代码中主题元素的文本内容,确定网页中的标题页块;标题页块的相对位置,文本页块在每个页块中确定;网页的文本是从文本页面块中提取的。本申请实施例提供的一种网页内容提取装置,包括:第一标题确定模块,用于根据网页代码中主题元素的文本内容确定网页中的标题页块;文本确定模块,用于根据网页中各个页块与标题页块的相对位置,确定各个页块中的文本页块。文本提取模块用于从文本页面块中提取网页的文本。本申请实施例采用的上述至少一种技术方案可以达到以下有益效果:由于网页代码中主题元素的文本内容往往与网页中的标题页块的内容相关联。网页,可以根据这个关联来确定标题页块,然后根据标题页块和各个页块的相对位置,在各个页块中确定文本页块,从而从文本页块中提取出网页的文本。因此,通过这种方法,不需要考虑文本,另外,可以过滤掉大部分不相关的信息,提高了确定文本页块的准确性,也提高了从文本页块中提取文本的准确性因此。
附图说明此处所描述的附图用于提供对本申请的进一步理解,构成本申请的一部分。本申请的示意性实施例和说明用于解释本申请,并不构成对本申请的不当限制。在附图中:附图说明图1为本申请实施例提供的一种网页文本提取方法的流程图;无花果。图2为本申请实施例提供的网页示意图;无花果。图3为本申请实施例提供的一种网页内容提取方法的详细流程图。优选实施例的详细说明为了实现目标,本申请的技术方案和优点更加清楚,下面结合本申请的具体实施例及相应的附图,对本申请的技术方案进行清楚、完整的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。本申请的应用场景是通过网络爬虫提取网页中的文字以及文字的编辑信息。在本申请的应用场景中,通过网页渲染引擎,如Webkit、Gecko、Trident等,可以解析网页的代码,渲染网页。一个网页的代码包括几个元素,通常由一对标签和这对标签中间的内容组成,例如:
你好
上面是一个元素,“hello”是元素的内容;在网页的代码中,还包括一个由标签和内容组成的元素,比如图片子元素,例如:
它是一个图片子元素,其中“earth.jpg”是本地存储的图片。值得注意的是,图片子元素收录在对应的父元素中,例如:
你好
在渲染的网页中,显示了每个元素的内容和每个元素对应的图片。其中,每个元素的内容显示在网页中的每个矩形区域,一个矩形区域就是一个页面块,即网页中的每个元素都有对应的页面块,但是图片所在的区域所在的不是页块。需要说明的是,每个页面块在网页中分布的区域和位置可能不同,也可能重叠。在网页的代码中,还收录了每个页面块的位置信息。具体的,页块的位置信息可以是页块的指定位置到浏览器边缘的距离和页块的高宽,页面块的位置信息可以通过浏览器渲染引擎解析网页的代码得到。在本申请的应用场景中,网页渲染引擎通过解析网页的代码,得到网页中各个页面块的内容和位置,然后渲染网页。对于网络爬虫来说,网页中的文本是需要提取的有价值的信息。但是,除了文字和文字的编辑信息外,网页中往往还有很多不相关的信息,比如广告、评论、索引栏、相关信息等。链接等等。同时,对于网页中的每个页块,只有少数页块的内容或一个页块的内容是正文,并且其他页面块的内容不是正文。现有的网络爬虫无法直接确定网页中每个页面块中的正文页块,例如,
技术介绍
如上所述,现有的网络爬虫通过分析每个页面块内容的文本密度来确定文本密度最大的页面块为文本页面块。无关信息过多,提取文本的准确率低。采用本申请提供的网页文本提取方法,在确定标题页块后,可以根据标题页块与各页块的相对位置确定各页块中的文本页块。这样,在不考虑文本密度的情况下,可以过滤掉大部分无关信息,更准确地确定正文页块,提取正文。下面结合附图对本申请实施例提供的技术方案进行详细说明。图1为本申请实施例提供的一种网页文本提取方法的流程图,包括以下步骤: S101:根据本发明代码中主题元素的文本内容,确定网页中的标题页块。网页。在本申请实施例中,网页的主题元素可以是由网页代码中的一对标签和位于这对标签中间的内容组成的元素,例如“什么是专利_专利班级”。在网页的代码标准中,主题元素有其特定的作用,即浏览器' 页面渲染引擎根据主题元素的内容生成浏览器标签。浏览器标签一般位于浏览器的顶部或底部,用于显示网页的主题信息。无花果。图2为本申请实施例提供的网页示意图。在图。2、浏览器渲染多个网页,在浏览器顶部的标签栏中,有多个浏览器标签对应多个网页。一般来说,网页主题元素的文本内容与网页中的标题页块的内容有关,如图2所示,在当前网页中,浏览器标签的内容为“The英军人数创200年来新低。老兵推荐。新兵领取购物券丨新兵丨英国丨陆军_新浪新闻”,即图2所示网页代码中的主题元素是“英国陆军人数创200年来新低。退伍军人推荐新兵领取购物券丨新兵丨英国丨陆军_新浪新闻》。图2中,网页主体(即标题页块)的标题内容为“英国陆军士兵人数创200年来新低。退伍军人推荐新兵获得购物券。” 因此,可以使用这种关系。文本内容决定了网页中标题页块的内容。具体地,主题元素的文本内容与网页中标题页块内容的关联关系可以相同、相似、或者其他可以根据前者确定的关系,本申请对此不做限定。作为本申请的一个实施例,网页中主题元素的文本内容与标题页的人脸块内容的关联可以相同。在本申请实施例中,根据网页主题元素的文本内容确定网页
【技术保护点】
一种网页内容提取方法,包括: 根据网页代码中主题元素的文本内容,确定网页中的标题页块;根据网页中的每个页块与标题页块的相对位置确定,在每个页块中确定文本页块;网页的文本是从文本页面块中提取的。
【技术特点总结】
1.一种网页内容提取方法,包括:根据网页代码中主题元素的文本内容,确定网页中的标题页块;根据网页中每个页块的标题页块的相对位置,确定每个页块中的文本页块;网页的文本是从文本页面块中提取的。2.根据权利要求1所述的方法,其特征在于,根据网页的主题元素的文本内容确定网页中的标题页块,具体包括: 根据主题元素的文本内容,在网页代码中的元素,判断收录的内容与标题元素的文本内容相同或相似;将title元素对应的页块确定为标题页块。3.根据权利要求2所述的方法,其特征在于,当不存在内容与文本内容相同或相似的元素时,该方法还包括: 代码中的每个元素,确定没有子元素的元素元素作为替代元素;将每个备选元素对应的页块确定为备选页块;获取替换页块的位置和替换页块中收录的内容的内容。属性; 确定位于网页特定位置且收录具有特定属性的内容的候选页块作为标题页块。4.根据权利要求1所述的方法,其中,根据网页中各个页块与标题页块的相对位置,确定各个页块中的文本页块,具体包括: 根据标题页块的位置,确定预期文本区域;根据每个页块与预期文本区域的相对位置,在每个页块中确定文本页块。
5.根据权利要求4所述的方法,其特征在于,根据标题页块的位置确定期望文本区域,具体包括: 根据标题页块在水平方向上的第一指定位置与第一距离到浏览器的第一指定边缘,确定期望文本区域的第二指定位置到浏览器的第一指定边缘在水平方向上的距离;根据标题页块的第一个指定位置,垂直方向上从浏览器第二个指定边缘到浏览器第二个指定边缘的第二个距离,确定到预期文本的第二个指定位置的距离区域到浏览器在垂直方向上的第二个指定边缘;根据标题页块的宽度,确定预期文本区域的宽度;当网页为移动网页时,根据移动终端显示屏的高度、标题页块的高度和第二距离确定预期文本区域的高度。当网页不是移动网页时,在网页的每个页块中确定有效页块,根据每个有效页块的最大高度、标题页块的高度和第二个距离文本区域的高度;有效页块是指在网页的每个页块中,与标题页块的相对位置满足预设条件,并且标题页块的宽度与宽度之差的绝对值不大于具有特定阈值的页块;其中,所述预设条件包括:位于标题页块的正下方。6.根据权利要求4所述的方法,其特征在于,根据每个页面块与预期文本区域的相对位置,在每个页面块中,确定文本页面块,具体包括:在每个页面块中,确定预期文本区域内面积最大的页块;使用页块作为文本页块;或者在网页的每个页块中确定一个有效页块,根据每个有效页块与预期文本区域的有效交集区域确定有效页块,在每个有效页块中,确定文本页块;有效页块是指网页的每个页块与满足预设条件的标题页块的相对位置,宽度与标题页块宽度之差的绝对值不为大于特定阈值;其中,所述预设条件包括:位于标题页块的正下方。
7.根据权利要求6所述的方法,其特征在于,根据每个有效页块的有效交集区域与期望文本区域的面积,在每个有效页块中确定文本页块,具体包括:按照每个有效页块的面积从小到大的顺序,对每个有效页块执行以下步骤,直到确定文本页块:得到有效页块的面积L,计算两者之间的差值有效页块和预期文本区域的有效交集面积S;如果S/L大于预设临界值,则确定有效页块为文本页块;如果 S/L 不大于预设的临界值,则继续下一个有效页块执行上述步骤。8. 8.根据权利要求7所述的方法,其特征在于,所述获取有效页块的面积L具体包括: 获取所述有效页块对应的有效元素的图片子元素;确定图片子元素对应的图片区域;有效页块的面积与对应图片的面积之和确定为有效页块的面积L;计算有效页块与预期文本区域的有效交集面积S,包括:计算有效页块与预期文本区域... 确定图片子元素对应的图片区域;有效页块的面积与对应图片的面积之和确定为有效页块的面积L;计算有效页块与预期文本区域的有效交集面积S,包括:计算有效页块与预期文本区域... 确定图片子元素对应的图片区域;有效页块的面积与对应图片的面积之和确定为有效页块的面积L;计算有效页块与预期文本区域的有效交集面积S,包括:计算有效页块与预期文本区域...
【专利技术性质】
技术研发人员:严军,
申请人(专利权)持有人:,
类型:发明
国家、省、市:北京;11
下载所有详细的技术数据 我是该专利的所有者 查看全部
网页flash文本抓取器(一种提取网页内容的方法及装置提高(技术实现步骤摘要))
本申请公开了一种网页内容提取方法及装置。利用网页中主题元素的文本内容与标题页块内容的关系,根据标题页块与各页块的相对位置,可在各页中确定正文页块块,而不是只考虑网页中的每个页面。降低了块的文本密度,从而过滤掉了大部分无关信息,提高了确定文本页块的准确性,也提高了从文本页块中提取文本的准确性。
下载所有详细的技术数据
【技术实现步骤总结】
此应用程序收录信息
,尤其涉及一种网页内容提取方法及装置。
技术介绍
网络爬虫是根据一定的规则自动提取万维网上网页内容的程序。网页内容包括正文、正文标题、正文发表时间、作者、出处。现有技术中网络爬虫提取网页文本的方法是下载网页,分析网页中每个页面块的文本密度值,取文本密度值最大的页块(即每单位面积收录的最大文本字符数)作为文本的位置。页块,并提取正文。但是,万维网上有各种网页布局。网页中文字密度最大的页块可能收录过多的无关信息,如文字广告、推荐链接等,而不是文本所在的页面块。根据文本密度值提取的内容可能不是正文。可以看出,现有的网页内容提取方法对网页中文本的提取准确率较低。
技术实现思路
本申请实施例提供一种网页内容提取方法及装置,用以解决现有网页内容提取方法中从网页中提取文本准确率不高的问题。本申请实施例提供的一种网页内容提取方法,包括:根据网页代码中主题元素的文本内容,确定网页中的标题页块;标题页块的相对位置,文本页块在每个页块中确定;网页的文本是从文本页面块中提取的。本申请实施例提供的一种网页内容提取装置,包括:第一标题确定模块,用于根据网页代码中主题元素的文本内容确定网页中的标题页块;文本确定模块,用于根据网页中各个页块与标题页块的相对位置,确定各个页块中的文本页块。文本提取模块用于从文本页面块中提取网页的文本。本申请实施例采用的上述至少一种技术方案可以达到以下有益效果:由于网页代码中主题元素的文本内容往往与网页中的标题页块的内容相关联。网页,可以根据这个关联来确定标题页块,然后根据标题页块和各个页块的相对位置,在各个页块中确定文本页块,从而从文本页块中提取出网页的文本。因此,通过这种方法,不需要考虑文本,另外,可以过滤掉大部分不相关的信息,提高了确定文本页块的准确性,也提高了从文本页块中提取文本的准确性因此。
附图说明此处所描述的附图用于提供对本申请的进一步理解,构成本申请的一部分。本申请的示意性实施例和说明用于解释本申请,并不构成对本申请的不当限制。在附图中:附图说明图1为本申请实施例提供的一种网页文本提取方法的流程图;无花果。图2为本申请实施例提供的网页示意图;无花果。图3为本申请实施例提供的一种网页内容提取方法的详细流程图。优选实施例的详细说明为了实现目标,本申请的技术方案和优点更加清楚,下面结合本申请的具体实施例及相应的附图,对本申请的技术方案进行清楚、完整的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。本申请的应用场景是通过网络爬虫提取网页中的文字以及文字的编辑信息。在本申请的应用场景中,通过网页渲染引擎,如Webkit、Gecko、Trident等,可以解析网页的代码,渲染网页。一个网页的代码包括几个元素,通常由一对标签和这对标签中间的内容组成,例如:
你好
上面是一个元素,“hello”是元素的内容;在网页的代码中,还包括一个由标签和内容组成的元素,比如图片子元素,例如:
它是一个图片子元素,其中“earth.jpg”是本地存储的图片。值得注意的是,图片子元素收录在对应的父元素中,例如:
你好
在渲染的网页中,显示了每个元素的内容和每个元素对应的图片。其中,每个元素的内容显示在网页中的每个矩形区域,一个矩形区域就是一个页面块,即网页中的每个元素都有对应的页面块,但是图片所在的区域所在的不是页块。需要说明的是,每个页面块在网页中分布的区域和位置可能不同,也可能重叠。在网页的代码中,还收录了每个页面块的位置信息。具体的,页块的位置信息可以是页块的指定位置到浏览器边缘的距离和页块的高宽,页面块的位置信息可以通过浏览器渲染引擎解析网页的代码得到。在本申请的应用场景中,网页渲染引擎通过解析网页的代码,得到网页中各个页面块的内容和位置,然后渲染网页。对于网络爬虫来说,网页中的文本是需要提取的有价值的信息。但是,除了文字和文字的编辑信息外,网页中往往还有很多不相关的信息,比如广告、评论、索引栏、相关信息等。链接等等。同时,对于网页中的每个页块,只有少数页块的内容或一个页块的内容是正文,并且其他页面块的内容不是正文。现有的网络爬虫无法直接确定网页中每个页面块中的正文页块,例如,
技术介绍
如上所述,现有的网络爬虫通过分析每个页面块内容的文本密度来确定文本密度最大的页面块为文本页面块。无关信息过多,提取文本的准确率低。采用本申请提供的网页文本提取方法,在确定标题页块后,可以根据标题页块与各页块的相对位置确定各页块中的文本页块。这样,在不考虑文本密度的情况下,可以过滤掉大部分无关信息,更准确地确定正文页块,提取正文。下面结合附图对本申请实施例提供的技术方案进行详细说明。图1为本申请实施例提供的一种网页文本提取方法的流程图,包括以下步骤: S101:根据本发明代码中主题元素的文本内容,确定网页中的标题页块。网页。在本申请实施例中,网页的主题元素可以是由网页代码中的一对标签和位于这对标签中间的内容组成的元素,例如“什么是专利_专利班级”。在网页的代码标准中,主题元素有其特定的作用,即浏览器' 页面渲染引擎根据主题元素的内容生成浏览器标签。浏览器标签一般位于浏览器的顶部或底部,用于显示网页的主题信息。无花果。图2为本申请实施例提供的网页示意图。在图。2、浏览器渲染多个网页,在浏览器顶部的标签栏中,有多个浏览器标签对应多个网页。一般来说,网页主题元素的文本内容与网页中的标题页块的内容有关,如图2所示,在当前网页中,浏览器标签的内容为“The英军人数创200年来新低。老兵推荐。新兵领取购物券丨新兵丨英国丨陆军_新浪新闻”,即图2所示网页代码中的主题元素是“英国陆军人数创200年来新低。退伍军人推荐新兵领取购物券丨新兵丨英国丨陆军_新浪新闻》。图2中,网页主体(即标题页块)的标题内容为“英国陆军士兵人数创200年来新低。退伍军人推荐新兵获得购物券。” 因此,可以使用这种关系。文本内容决定了网页中标题页块的内容。具体地,主题元素的文本内容与网页中标题页块内容的关联关系可以相同、相似、或者其他可以根据前者确定的关系,本申请对此不做限定。作为本申请的一个实施例,网页中主题元素的文本内容与标题页的人脸块内容的关联可以相同。在本申请实施例中,根据网页主题元素的文本内容确定网页
【技术保护点】
一种网页内容提取方法,包括: 根据网页代码中主题元素的文本内容,确定网页中的标题页块;根据网页中的每个页块与标题页块的相对位置确定,在每个页块中确定文本页块;网页的文本是从文本页面块中提取的。
【技术特点总结】
1.一种网页内容提取方法,包括:根据网页代码中主题元素的文本内容,确定网页中的标题页块;根据网页中每个页块的标题页块的相对位置,确定每个页块中的文本页块;网页的文本是从文本页面块中提取的。2.根据权利要求1所述的方法,其特征在于,根据网页的主题元素的文本内容确定网页中的标题页块,具体包括: 根据主题元素的文本内容,在网页代码中的元素,判断收录的内容与标题元素的文本内容相同或相似;将title元素对应的页块确定为标题页块。3.根据权利要求2所述的方法,其特征在于,当不存在内容与文本内容相同或相似的元素时,该方法还包括: 代码中的每个元素,确定没有子元素的元素元素作为替代元素;将每个备选元素对应的页块确定为备选页块;获取替换页块的位置和替换页块中收录的内容的内容。属性; 确定位于网页特定位置且收录具有特定属性的内容的候选页块作为标题页块。4.根据权利要求1所述的方法,其中,根据网页中各个页块与标题页块的相对位置,确定各个页块中的文本页块,具体包括: 根据标题页块的位置,确定预期文本区域;根据每个页块与预期文本区域的相对位置,在每个页块中确定文本页块。
5.根据权利要求4所述的方法,其特征在于,根据标题页块的位置确定期望文本区域,具体包括: 根据标题页块在水平方向上的第一指定位置与第一距离到浏览器的第一指定边缘,确定期望文本区域的第二指定位置到浏览器的第一指定边缘在水平方向上的距离;根据标题页块的第一个指定位置,垂直方向上从浏览器第二个指定边缘到浏览器第二个指定边缘的第二个距离,确定到预期文本的第二个指定位置的距离区域到浏览器在垂直方向上的第二个指定边缘;根据标题页块的宽度,确定预期文本区域的宽度;当网页为移动网页时,根据移动终端显示屏的高度、标题页块的高度和第二距离确定预期文本区域的高度。当网页不是移动网页时,在网页的每个页块中确定有效页块,根据每个有效页块的最大高度、标题页块的高度和第二个距离文本区域的高度;有效页块是指在网页的每个页块中,与标题页块的相对位置满足预设条件,并且标题页块的宽度与宽度之差的绝对值不大于具有特定阈值的页块;其中,所述预设条件包括:位于标题页块的正下方。6.根据权利要求4所述的方法,其特征在于,根据每个页面块与预期文本区域的相对位置,在每个页面块中,确定文本页面块,具体包括:在每个页面块中,确定预期文本区域内面积最大的页块;使用页块作为文本页块;或者在网页的每个页块中确定一个有效页块,根据每个有效页块与预期文本区域的有效交集区域确定有效页块,在每个有效页块中,确定文本页块;有效页块是指网页的每个页块与满足预设条件的标题页块的相对位置,宽度与标题页块宽度之差的绝对值不为大于特定阈值;其中,所述预设条件包括:位于标题页块的正下方。
7.根据权利要求6所述的方法,其特征在于,根据每个有效页块的有效交集区域与期望文本区域的面积,在每个有效页块中确定文本页块,具体包括:按照每个有效页块的面积从小到大的顺序,对每个有效页块执行以下步骤,直到确定文本页块:得到有效页块的面积L,计算两者之间的差值有效页块和预期文本区域的有效交集面积S;如果S/L大于预设临界值,则确定有效页块为文本页块;如果 S/L 不大于预设的临界值,则继续下一个有效页块执行上述步骤。8. 8.根据权利要求7所述的方法,其特征在于,所述获取有效页块的面积L具体包括: 获取所述有效页块对应的有效元素的图片子元素;确定图片子元素对应的图片区域;有效页块的面积与对应图片的面积之和确定为有效页块的面积L;计算有效页块与预期文本区域的有效交集面积S,包括:计算有效页块与预期文本区域... 确定图片子元素对应的图片区域;有效页块的面积与对应图片的面积之和确定为有效页块的面积L;计算有效页块与预期文本区域的有效交集面积S,包括:计算有效页块与预期文本区域... 确定图片子元素对应的图片区域;有效页块的面积与对应图片的面积之和确定为有效页块的面积L;计算有效页块与预期文本区域的有效交集面积S,包括:计算有效页块与预期文本区域...
【专利技术性质】
技术研发人员:严军,
申请人(专利权)持有人:,
类型:发明
国家、省、市:北京;11
下载所有详细的技术数据 我是该专利的所有者
网页flash文本抓取器(《一篇文章读懂python安装路径的错误》就行了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-31 17:05
网页flash文本抓取器,因为是activex控件,因此你自己实现个插件,目标是网页的flash文本,对网页里的全部文本进行文本抓取。那么后端的话,只要基于html5的动态库就可以实现,可以使用selenium,webdriver,headless,pythonextension等等。安装非常简单,参考这篇文章《一篇文章读懂python安装路径的错误》就行了。
推荐使用pythonextension,虽然是python2的框架,不过正好可以使用python2的packages。
你就不能使用selenium来做一个代理么
firefox里面有一个抓取的小插件,叫scrapy的,
手机答题,未能及时到达,见谅!网页爬虫,首推,excel爬虫-海龟君的博客,上面有上万例数据抓取。抓取和爬取数据工具各有不同,不做深入说明。我今天想说的是:python爬虫开发进阶课:简介与实战《从零开始学python3:打开编程世界的大门》、《用python3从零开始学爬虫》和《用python3开发爬虫》。
直接手工抓取是不可能的你可以尝试找些网站做了基于js的代理池,第三方代理引擎(比如美团代理、比如腾讯代理),
不是python都可以做到的。html有python内置api接口返回。 查看全部
网页flash文本抓取器(《一篇文章读懂python安装路径的错误》就行了)
网页flash文本抓取器,因为是activex控件,因此你自己实现个插件,目标是网页的flash文本,对网页里的全部文本进行文本抓取。那么后端的话,只要基于html5的动态库就可以实现,可以使用selenium,webdriver,headless,pythonextension等等。安装非常简单,参考这篇文章《一篇文章读懂python安装路径的错误》就行了。
推荐使用pythonextension,虽然是python2的框架,不过正好可以使用python2的packages。
你就不能使用selenium来做一个代理么
firefox里面有一个抓取的小插件,叫scrapy的,
手机答题,未能及时到达,见谅!网页爬虫,首推,excel爬虫-海龟君的博客,上面有上万例数据抓取。抓取和爬取数据工具各有不同,不做深入说明。我今天想说的是:python爬虫开发进阶课:简介与实战《从零开始学python3:打开编程世界的大门》、《用python3从零开始学爬虫》和《用python3开发爬虫》。
直接手工抓取是不可能的你可以尝试找些网站做了基于js的代理池,第三方代理引擎(比如美团代理、比如腾讯代理),
不是python都可以做到的。html有python内置api接口返回。
网页flash文本抓取器(初学者播放函数playflv())
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-28 22:03
本文是flash初学者的好资料和方向,欢迎浏览。
首先新建一个文档,将背景颜色设置为黑色,其他默认,然后创建四个图层。
第一层用于放置视频组件,如下:
1. 在“库”面板(“窗口”>“库”)中,从“库”弹出菜单中选择“新建视频”。
2. 在“视频属性”对话框中,为视频元素命名并选择“视频”(由 ActionScript 控制)。
3. 将视频对象从“库”面板拖到舞台中间以创建视频对象的实例。
4. 将此视频元素的实例名称设为“my_video”。
第二层用来放视频地址输入栏,方法如下:
1、使用文本工具(快捷键T)在舞台左下方画一个地址输入文本框,类型选择“输入文本”类型。
2. 在“线条类型”弹出菜单中选择“单行”,并确保选中“在文本周围显示边框”。
3. 将此文本框的实例名称设为“url”。
第三层用来放播放开始按钮,方法如下:
1、在“库”面板(“窗口>”库”)新建一个组件按钮,按钮样式自己制作,暂时可以使用。
2、将新建的按钮对象从“库”面板拖到舞台地址输入框的后面,创建播放开始按钮。
3. 将播放开始按钮命名为“play_bt”。
第四层用来放所有的ActionScript:
先初始化
//创建一个网络连接对象
var my_nc:NetConnection = new NetConnection();
//创建本地流连接
my_nc.connect(null);
//创建一个NetStream对象
var my_ns:NetStream = new NetStream(my_nc);
//写一个播放函数playflv()
函数 playflv(flv) {
//参数flv是要播放的flv视频的地址
//trace(flv);//用于测试
// 将 NetStream 视频输入信号附加到 Video 对象,视频元素 my_video
my_video.attachVideo(my_ns);
// 设置缓冲时间,单位为秒,下面设置3秒
my_ns.setBufferTime(3);
// 开始播放 FLV 文件
my_ns.play(flv);
}
//点击开始按钮开始播放
play_bt.onRelease = function() {
playflv(url.text);
//获取url输入框的视频文件地址,调用play函数播放url对应的flv视频文件
};
//至此,最简单的播放器已经完成,接下来要做的就是对其进行更多的控制和性能工作。
//这里是生产的一些重要方面,其他的还是需要大家发挥自己的想象力去设计和生产的更好。
//注意以下代码不是必须的,未经测试,请尝试一一实现。特别注意路径和实例名称的对应关系。
1.播放的控制,暂停和停止的实现
//新建两个按钮,一个用于暂停(pause_bt),一个用于停止(stop_bt),原理同播放按钮。
pause_bt.onRelease = function() {
my_ns.pause();
};
stop_bt.onRelease = function() {
my_ns.seek(0);
寻求从 0 开始
my_ns.pause(true);
//参数true表示暂停,如果为false表示从暂停到恢复播放,如果没有参数表示在暂停/播放之间切换。
};
2.视频下载进度
//这个比较简单,和一般的下载进度差不多。原理是在播放时计算下载的和总文件大小的百分比,然后显示出来。
//新建一个显示百分比的静态文本(info)和进度条(bar),它们的初始状态和位置都是自己调整的
this.onEnterFrame =function () {
var loadedbytes = my_ns.bytesLoaded;
// 获取下载的字节
var totalbytes = my_ns.bytesTotal;
//文件总大小
if (totalbytes == undefined || totalbytesinfo.text = "0%";
bar._width = 1;
} 别的 {
var nowLoadPercent = Math.round(loadedbytes/totalbytes*100);
if (isNaN(nowLoadPercent)) {
info.text = "0%";
bar._width = 1;
} 别的 {
info.text = nowLoadPercent+"%";
bar._width = nowLoadPercent*35/100;
if (nowLoadPercent == 100) {
删除 this.onEnterFrame;
}
}
}
}
3.视频尺寸修正或调整
//这个比较重要,因为视频大小比例一般是不同的,所以在播放的时候要进行调整,避免失真和变形。
//原理是获取flv的大小,然后重新调整my_video的大小,最后居中,必要时放大(此处省略)。
//先写一个改变大小的函数changesize(w, h),w是要改变的宽度,h是要改变的高度
函数改变大小(w,h){
//更改为传入的参数大小
my_video._width = w;
my_video._height = h;
//trace("w:"+w+"h:"+h);//用于测试
//位置居中,如果你的视频舞台是550宽400高
my_video._x = 550/2-w/2;
my_video._y = 400/2-h/2;
}
//然后得到flv的固有大小,调用上面的函数改变它
//在调用 my_ns.play() 方法之后但在视频播放头前进之前调用此处理程序
my_ns.onMetaData = 函数(信息对象:对象){
//获取FLV文件中嵌入的描述信息,这里获取的是宽/高
var flv_width = infoObject.width;
var flv_height = infoObject.height;
// 改变大小
改变大小(flv_width,flv_height);
};
4.播放时间和进度
//原理和下载进度类似,先获取总时长,再以百分比的形式获取当前时间,也可以作为进度条。//定义总持续时间全局变量并获取其值。
变量 flv_duration;
my_ns.onMetaData = 函数(信息对象:对象){
//获取FLV文件中嵌入的描述信息,这里获取总时长(单位:秒)
var flv_duration = infoObject.duration;
};
//注意:这个可以和得到宽高一起写。
//获取当前播放时间
var flv_thistime = my_ns.time;
//然后就可以进行播放进度了,和下载进度类似。可以自己制作,这里省略。
5.音量控制
//这个有点复杂,你得把FLV文件中的音频附加到舞台上的影片剪辑上,然后控制
//创建一个新的影片剪辑 my_ns_mc 并附加音频
my_ns_mc.attachAudio(my_ns);
//为影片剪辑创建一个新的Sound对象
var my_ns_sound = 新声音(my_ns_mc);
//初始化音量(这里默认8个0)
var flv_volume = 80;
my_ns_sound.setVolume(flv_volume);
//最后可以通过控制flv_volume的大小(0到100之间)来改变音量。
//这部分制作也省略了,大家可以自由发挥,还可以创建静音功能,即flv_volume为0
//另外,像快进、快退、缓冲显示等都可以实现,大家可以自己研究。终于,一个FlashFLV播放器的制作基本完成了。建议想学flash的朋友自己动手。不要总是想下载任何源代码然后修改它,这样你将无法理解其中的许多奥秘!
增加一个相关问题:flv播放没有图像,只有声音,这是因为flv文件是用flash8编码格式压缩的,而你发布的flash播放器是flash 7或更低版本,所以可以升级到8版本,或者压缩flash7 编码格式的 flv 文件。 查看全部
网页flash文本抓取器(初学者播放函数playflv())
本文是flash初学者的好资料和方向,欢迎浏览。
首先新建一个文档,将背景颜色设置为黑色,其他默认,然后创建四个图层。
第一层用于放置视频组件,如下:
1. 在“库”面板(“窗口”>“库”)中,从“库”弹出菜单中选择“新建视频”。
2. 在“视频属性”对话框中,为视频元素命名并选择“视频”(由 ActionScript 控制)。
3. 将视频对象从“库”面板拖到舞台中间以创建视频对象的实例。
4. 将此视频元素的实例名称设为“my_video”。
第二层用来放视频地址输入栏,方法如下:
1、使用文本工具(快捷键T)在舞台左下方画一个地址输入文本框,类型选择“输入文本”类型。
2. 在“线条类型”弹出菜单中选择“单行”,并确保选中“在文本周围显示边框”。
3. 将此文本框的实例名称设为“url”。
第三层用来放播放开始按钮,方法如下:
1、在“库”面板(“窗口>”库”)新建一个组件按钮,按钮样式自己制作,暂时可以使用。
2、将新建的按钮对象从“库”面板拖到舞台地址输入框的后面,创建播放开始按钮。
3. 将播放开始按钮命名为“play_bt”。
第四层用来放所有的ActionScript:
先初始化
//创建一个网络连接对象
var my_nc:NetConnection = new NetConnection();
//创建本地流连接
my_nc.connect(null);
//创建一个NetStream对象
var my_ns:NetStream = new NetStream(my_nc);
//写一个播放函数playflv()
函数 playflv(flv) {
//参数flv是要播放的flv视频的地址
//trace(flv);//用于测试
// 将 NetStream 视频输入信号附加到 Video 对象,视频元素 my_video
my_video.attachVideo(my_ns);
// 设置缓冲时间,单位为秒,下面设置3秒
my_ns.setBufferTime(3);
// 开始播放 FLV 文件
my_ns.play(flv);
}
//点击开始按钮开始播放
play_bt.onRelease = function() {
playflv(url.text);
//获取url输入框的视频文件地址,调用play函数播放url对应的flv视频文件
};
//至此,最简单的播放器已经完成,接下来要做的就是对其进行更多的控制和性能工作。
//这里是生产的一些重要方面,其他的还是需要大家发挥自己的想象力去设计和生产的更好。
//注意以下代码不是必须的,未经测试,请尝试一一实现。特别注意路径和实例名称的对应关系。
1.播放的控制,暂停和停止的实现
//新建两个按钮,一个用于暂停(pause_bt),一个用于停止(stop_bt),原理同播放按钮。
pause_bt.onRelease = function() {
my_ns.pause();
};
stop_bt.onRelease = function() {
my_ns.seek(0);
寻求从 0 开始
my_ns.pause(true);
//参数true表示暂停,如果为false表示从暂停到恢复播放,如果没有参数表示在暂停/播放之间切换。
};
2.视频下载进度
//这个比较简单,和一般的下载进度差不多。原理是在播放时计算下载的和总文件大小的百分比,然后显示出来。
//新建一个显示百分比的静态文本(info)和进度条(bar),它们的初始状态和位置都是自己调整的
this.onEnterFrame =function () {
var loadedbytes = my_ns.bytesLoaded;
// 获取下载的字节
var totalbytes = my_ns.bytesTotal;
//文件总大小
if (totalbytes == undefined || totalbytesinfo.text = "0%";
bar._width = 1;
} 别的 {
var nowLoadPercent = Math.round(loadedbytes/totalbytes*100);
if (isNaN(nowLoadPercent)) {
info.text = "0%";
bar._width = 1;
} 别的 {
info.text = nowLoadPercent+"%";
bar._width = nowLoadPercent*35/100;
if (nowLoadPercent == 100) {
删除 this.onEnterFrame;
}
}
}
}
3.视频尺寸修正或调整
//这个比较重要,因为视频大小比例一般是不同的,所以在播放的时候要进行调整,避免失真和变形。
//原理是获取flv的大小,然后重新调整my_video的大小,最后居中,必要时放大(此处省略)。
//先写一个改变大小的函数changesize(w, h),w是要改变的宽度,h是要改变的高度
函数改变大小(w,h){
//更改为传入的参数大小
my_video._width = w;
my_video._height = h;
//trace("w:"+w+"h:"+h);//用于测试
//位置居中,如果你的视频舞台是550宽400高
my_video._x = 550/2-w/2;
my_video._y = 400/2-h/2;
}
//然后得到flv的固有大小,调用上面的函数改变它
//在调用 my_ns.play() 方法之后但在视频播放头前进之前调用此处理程序
my_ns.onMetaData = 函数(信息对象:对象){
//获取FLV文件中嵌入的描述信息,这里获取的是宽/高
var flv_width = infoObject.width;
var flv_height = infoObject.height;
// 改变大小
改变大小(flv_width,flv_height);
};
4.播放时间和进度
//原理和下载进度类似,先获取总时长,再以百分比的形式获取当前时间,也可以作为进度条。//定义总持续时间全局变量并获取其值。
变量 flv_duration;
my_ns.onMetaData = 函数(信息对象:对象){
//获取FLV文件中嵌入的描述信息,这里获取总时长(单位:秒)
var flv_duration = infoObject.duration;
};
//注意:这个可以和得到宽高一起写。
//获取当前播放时间
var flv_thistime = my_ns.time;
//然后就可以进行播放进度了,和下载进度类似。可以自己制作,这里省略。
5.音量控制
//这个有点复杂,你得把FLV文件中的音频附加到舞台上的影片剪辑上,然后控制
//创建一个新的影片剪辑 my_ns_mc 并附加音频
my_ns_mc.attachAudio(my_ns);
//为影片剪辑创建一个新的Sound对象
var my_ns_sound = 新声音(my_ns_mc);
//初始化音量(这里默认8个0)
var flv_volume = 80;
my_ns_sound.setVolume(flv_volume);
//最后可以通过控制flv_volume的大小(0到100之间)来改变音量。
//这部分制作也省略了,大家可以自由发挥,还可以创建静音功能,即flv_volume为0
//另外,像快进、快退、缓冲显示等都可以实现,大家可以自己研究。终于,一个FlashFLV播放器的制作基本完成了。建议想学flash的朋友自己动手。不要总是想下载任何源代码然后修改它,这样你将无法理解其中的许多奥秘!
增加一个相关问题:flv播放没有图像,只有声音,这是因为flv文件是用flash8编码格式压缩的,而你发布的flash播放器是flash 7或更低版本,所以可以升级到8版本,或者压缩flash7 编码格式的 flv 文件。
网页flash文本抓取器(网站外链大概3-5个、其余质量不是很高)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-03-25 21:15
3、外部链接大概有3-5个,其余的质量不是很高等等(不链接到网站是失败的,甚至有的网站本身有很多问题),如果使用的话最好不要使用群发软件,因为它不容易发送到高质量的网站。
4、
xxxx服饰——源自美国,致力于休闲服饰的开发
,如果客户同意,则应丰富此标签中的内容。如果底部的版权信息无法添加,并且制作了网页的纯文本版本,则可以在这部分内容中添加指向它的文本链接。
急需什么
1、添加网站说明,
2、有钱”
xxxx服饰——源自美国,致力于休闲服饰的开发
“这个标签的内容,两地的内容差不多。
3、对外部链接的适当考虑(外部链接也是基于一个网站内容)不多,但精致巧妙。
11 月 7 日
将计划发送给对方
11 月 8 日
描述已添加,文本版本缺失。
选项一:
1、网页的纯文本版本需要简单的布局和美观。之后可能会被搜索爬取并出现在排名结果中,用户的搜索会影响体验。(同时这也是和客户沟通的一个理由【另外还要考虑搜索引擎只有收录文字版而不是收录flash版的情况,所以网站 可能对客户没有意义】)
2、如果“
"
如果这部分导航信息无法通过浏览器的正常浏览看到,则应放在“”中。
3、文字版应该能够让用户知道这是一个文字版的页面,而不是让用户觉得网站有问题(不显示全部,页面是没有排版,感觉太乱,不完整等)。
选项二
1、文字版网页在flash无法显示的情况下可以正常显示,并且链接可以与flash中的链接一一对应。现在我们网页的所有链接都在flash中,除了新闻部分,每个页面都是同一个URL。文字版要做成单页样式(结构类似百度百科),放在“”内。【我之前没做过,但是如果这个方法可行的话,理论上应该不会有后遗症,供参考】
11 月 9 日
确定第二个选项
11 月 12 日
百度收录,截图日期12-11-11
11-13
快照删除可能与频繁变化有关,拭目以待
11-21
百度re收录截图日期12-11-20
由于未征得网站所有者的同意,具体网站暂未公布,相关介绍也不是很详细。请谅解,仅供参考!
启辉网络 查看全部
网页flash文本抓取器(网站外链大概3-5个、其余质量不是很高)
3、外部链接大概有3-5个,其余的质量不是很高等等(不链接到网站是失败的,甚至有的网站本身有很多问题),如果使用的话最好不要使用群发软件,因为它不容易发送到高质量的网站。
4、
xxxx服饰——源自美国,致力于休闲服饰的开发
,如果客户同意,则应丰富此标签中的内容。如果底部的版权信息无法添加,并且制作了网页的纯文本版本,则可以在这部分内容中添加指向它的文本链接。
急需什么
1、添加网站说明,
2、有钱”
xxxx服饰——源自美国,致力于休闲服饰的开发
“这个标签的内容,两地的内容差不多。
3、对外部链接的适当考虑(外部链接也是基于一个网站内容)不多,但精致巧妙。
11 月 7 日
将计划发送给对方
11 月 8 日
描述已添加,文本版本缺失。
选项一:
1、网页的纯文本版本需要简单的布局和美观。之后可能会被搜索爬取并出现在排名结果中,用户的搜索会影响体验。(同时这也是和客户沟通的一个理由【另外还要考虑搜索引擎只有收录文字版而不是收录flash版的情况,所以网站 可能对客户没有意义】)
2、如果“
"
如果这部分导航信息无法通过浏览器的正常浏览看到,则应放在“”中。
3、文字版应该能够让用户知道这是一个文字版的页面,而不是让用户觉得网站有问题(不显示全部,页面是没有排版,感觉太乱,不完整等)。
选项二
1、文字版网页在flash无法显示的情况下可以正常显示,并且链接可以与flash中的链接一一对应。现在我们网页的所有链接都在flash中,除了新闻部分,每个页面都是同一个URL。文字版要做成单页样式(结构类似百度百科),放在“”内。【我之前没做过,但是如果这个方法可行的话,理论上应该不会有后遗症,供参考】
11 月 9 日
确定第二个选项
11 月 12 日
百度收录,截图日期12-11-11
11-13
快照删除可能与频繁变化有关,拭目以待
11-21
百度re收录截图日期12-11-20
由于未征得网站所有者的同意,具体网站暂未公布,相关介绍也不是很详细。请谅解,仅供参考!
启辉网络
网页flash文本抓取器(项目招商找A5快速获取精准代理名单网站应具有清晰的层次结构和文本链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-24 13:11
项目投资找A5快速获取精准代理商名单
网站应该有清晰的层次结构和文本链接。每个网页都应该可以通过至少一个静态文本链接打开。
为用户提供 网站 地图,列出 网站 重要部分的链接。如果 网站map 有超过或大约 100 个链接,则 网站map 将需要拆分为多个页面。
网站应实用且内容丰富,网页文字应清晰准确地表达要传达的内容。
考虑人们用来查找您的页面的术语,并确保 网站 实际上收录这些单词。
尽可能使用文本而不是图形来显示重要的名称、内容或链接。搜索引擎爬虫无法识别图形中收录的文本。
确保 TITLE 和 ALT 标签属性的描述和表达准确无误。
检查损坏的链接并确保 HTML 格式正确。
如果您决定使用动态页面(即收录“?”字符的 URL),请注意并非所有搜索引擎爬虫都可以爬取动态页面和静态页面。动态网页有助于缩短参数长度并减少参数数量。
将特定网页上的链接数量限制在合理的数量(少于 100 个)。
技术指南
<p>由于大多数搜索引擎蜘蛛查看 网站 的方式与 Lynx 相同,因此您可以使用 Lynx 等文本浏览器查看您的 网站。如果由于应用了 Javascript、cookie、会话 ID、框架、DHTML 或 Flash 等复杂技术而无法在文本浏览器中看到 网站 的所有页面,则搜索引擎蜘蛛正在抓取您的 查看全部
网页flash文本抓取器(项目招商找A5快速获取精准代理名单网站应具有清晰的层次结构和文本链接)
项目投资找A5快速获取精准代理商名单
网站应该有清晰的层次结构和文本链接。每个网页都应该可以通过至少一个静态文本链接打开。
为用户提供 网站 地图,列出 网站 重要部分的链接。如果 网站map 有超过或大约 100 个链接,则 网站map 将需要拆分为多个页面。
网站应实用且内容丰富,网页文字应清晰准确地表达要传达的内容。
考虑人们用来查找您的页面的术语,并确保 网站 实际上收录这些单词。
尽可能使用文本而不是图形来显示重要的名称、内容或链接。搜索引擎爬虫无法识别图形中收录的文本。
确保 TITLE 和 ALT 标签属性的描述和表达准确无误。
检查损坏的链接并确保 HTML 格式正确。
如果您决定使用动态页面(即收录“?”字符的 URL),请注意并非所有搜索引擎爬虫都可以爬取动态页面和静态页面。动态网页有助于缩短参数长度并减少参数数量。
将特定网页上的链接数量限制在合理的数量(少于 100 个)。
技术指南
<p>由于大多数搜索引擎蜘蛛查看 网站 的方式与 Lynx 相同,因此您可以使用 Lynx 等文本浏览器查看您的 网站。如果由于应用了 Javascript、cookie、会话 ID、框架、DHTML 或 Flash 等复杂技术而无法在文本浏览器中看到 网站 的所有页面,则搜索引擎蜘蛛正在抓取您的
网页flash文本抓取器(Google向网站管理员及设计者提出了一些建议(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-21 04:09
尽管谷歌的爬虫功能越来越强大,但直到现在,它还无法像人类一样识别视频或 Flash 动画的内容。即使是 JS 代码,Googlebot 也只有基本的分析能力。用谷歌的话来形容,就是Googlebot没有眼睛,它暂时无法“看到”视觉媒体的内容。除了视频,Flash动画也是网站的常见内容之一。为了让网站能够更好地被Googlebot分析和抓取,Google今天向网站管理员和设计者提出了一些建议。
我们先来看看 Googlebot 是如何处理 Flash 的。Googlebot 可以读取 Flash 文件中的文本和链接,但它无法识别 Flash 的结构和元素关联。另外,由于有时某些文本内容会被做成图片作为 Flash 的一部分,而 Googlebot 目前还没有相关的算法来读取这些图片,因此文本内容(可能很重要关键词)会被 Googlebot 漏掉。也就是说,即使 Googlebot 已成功将您的 Flash 文件索引到搜索数据库中,由于上述原因,Google 也可能无法识别其中的文本、内容和链接。更糟糕的是,其他搜索引擎的爬虫在识别 Flash 方面甚至比 Googlebot 还要差。这说明当你把一些重要的内容制作成Flash动画时,
为了避免这种情况发生,Google 在使用 Flash 时提供了一些很好的提示网站,同时仍尽量减少其搜索引擎友好性的损失:
1.最重要的原则:始终将相同的内容返回给Googlebot和网站的读者,否则你的网站可能会被判定为作弊。
2.仅在必要时使用 Flash。只有Flash作为多媒体呈现方式,网站(页面)的主要内容和导航系统仍然是基于文本的。如果您不知道该怎么做,YouTube 就是一个很好的例子。这不仅使 网站 对 Googlebot 更加友好,而且您的 网站 内容也更容易被更广泛的受众访问,包括经常使用屏幕阅读器的视障人士。此外,一些网速较慢的读者或使用非标准浏览器的读者也可能能够阅读您的 网站 内容,因为他们可能会跳过 Flash 内容。
3.使用 sIFR 技术。这样,网站的主要内容和导航系统仍然是基于HTML的,不会浏览Flash的读者也可以阅读你的网站。
4.提供非 Flash 版本的 网站。例如,当您在网站首页中使用Flash动画作为欢迎页面时,请务必在Flash动画之外提供HTML链接,并指向非Flash版本的网站 ,让读者即使没有安装Flash插件也能轻松阅读您的网站内容。
当然,谷歌的错,严格地说,谷歌不能做同样的事情来抓取和分析文本,这并不是谷歌的错,因为这项技术还没有成熟。但目前的搜索技术也只能走到这一步,所以我们在设计或更新网站时只尽量采纳Google的建议,以利于网站的收录和排名。其实和图片的内容差不多。当我们在网页中插入图片或Flash动画时,应尽量将其主要内容用文字写出,这样即使Googlebot忽略了它们,它们仍能从你的文字描述中理解。大概的内容。 查看全部
网页flash文本抓取器(Google向网站管理员及设计者提出了一些建议(图))
尽管谷歌的爬虫功能越来越强大,但直到现在,它还无法像人类一样识别视频或 Flash 动画的内容。即使是 JS 代码,Googlebot 也只有基本的分析能力。用谷歌的话来形容,就是Googlebot没有眼睛,它暂时无法“看到”视觉媒体的内容。除了视频,Flash动画也是网站的常见内容之一。为了让网站能够更好地被Googlebot分析和抓取,Google今天向网站管理员和设计者提出了一些建议。
我们先来看看 Googlebot 是如何处理 Flash 的。Googlebot 可以读取 Flash 文件中的文本和链接,但它无法识别 Flash 的结构和元素关联。另外,由于有时某些文本内容会被做成图片作为 Flash 的一部分,而 Googlebot 目前还没有相关的算法来读取这些图片,因此文本内容(可能很重要关键词)会被 Googlebot 漏掉。也就是说,即使 Googlebot 已成功将您的 Flash 文件索引到搜索数据库中,由于上述原因,Google 也可能无法识别其中的文本、内容和链接。更糟糕的是,其他搜索引擎的爬虫在识别 Flash 方面甚至比 Googlebot 还要差。这说明当你把一些重要的内容制作成Flash动画时,
为了避免这种情况发生,Google 在使用 Flash 时提供了一些很好的提示网站,同时仍尽量减少其搜索引擎友好性的损失:
1.最重要的原则:始终将相同的内容返回给Googlebot和网站的读者,否则你的网站可能会被判定为作弊。
2.仅在必要时使用 Flash。只有Flash作为多媒体呈现方式,网站(页面)的主要内容和导航系统仍然是基于文本的。如果您不知道该怎么做,YouTube 就是一个很好的例子。这不仅使 网站 对 Googlebot 更加友好,而且您的 网站 内容也更容易被更广泛的受众访问,包括经常使用屏幕阅读器的视障人士。此外,一些网速较慢的读者或使用非标准浏览器的读者也可能能够阅读您的 网站 内容,因为他们可能会跳过 Flash 内容。
3.使用 sIFR 技术。这样,网站的主要内容和导航系统仍然是基于HTML的,不会浏览Flash的读者也可以阅读你的网站。
4.提供非 Flash 版本的 网站。例如,当您在网站首页中使用Flash动画作为欢迎页面时,请务必在Flash动画之外提供HTML链接,并指向非Flash版本的网站 ,让读者即使没有安装Flash插件也能轻松阅读您的网站内容。
当然,谷歌的错,严格地说,谷歌不能做同样的事情来抓取和分析文本,这并不是谷歌的错,因为这项技术还没有成熟。但目前的搜索技术也只能走到这一步,所以我们在设计或更新网站时只尽量采纳Google的建议,以利于网站的收录和排名。其实和图片的内容差不多。当我们在网页中插入图片或Flash动画时,应尽量将其主要内容用文字写出,这样即使Googlebot忽略了它们,它们仍能从你的文字描述中理解。大概的内容。
网页flash文本抓取器(什么是搜索引擎蜘蛛友好的网站?这个问题不难解决!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-21 04:06
什么是 SEO 友好的 网站?这个问题不难解决。这个定位是用SEO优化网站的用户体验,给网站添加优质内容,让蜘蛛访问和爬取,所以SEO优化需要突出网站@的主题>。那么如何提高搜索引擎蜘蛛的友好度呢?
1、页面加载速度
页面加载对于搜索引擎蜘蛛的友好性更为重要。当蜘蛛到达时,如果一直无法打开网站,蜘蛛的体验非常不友好,会减少后续访问的次数。但是服务器可以提高网站的加载速度,在安全稳定的环境下,网站build之前应该选择服务器。因此,如果服务器不稳定,需要及时联系空间服务商,将网页应用加载到综合性能比较完善的空间中,方便SEO的日常操作。
2、无障碍网页浏览
Url 抓取指的是静态或伪静态 网站。这个网站结构是方便搜索引擎使用的蜘蛛结构模型。如果参数太多,数据会直接生成动态路径,这对搜索引擎来说不是一种友好的行为,尤其是带有中文参数的动态路径,是搜索引擎非常不喜欢的。
搜索引擎蜘蛛喜欢爬什么样的网站?
3、减少flash的应用
SEO优化需要注意页面布局是否有flash动画。蜘蛛很好地识别图像,如果 网站 页面的文本较少,则 网站 将失去其排名优先级。因此,页面框架内的组织和布局需要友好美观,框架结构要谨慎使用。
4、原创内容很受欢迎
百度一直在打击伪原创内容,同时也在优化原创内容,所以很多采集文章的网站排名都很差,有创意,内容丰富,有价值。这就是搜索引擎喜欢的。这样,你可以用不同的词来描述一个场景,或者结合流行和不流行的词。您的内容质量取决于您的内容是否定位良好且可用。
5、SEO 内部链接
SEO有两个内部链接。优邦云SEO推荐使用白帽SEO。关键词位置引导,每个字代表链接的效果,_一点是首页,锚文本内容之间,一些需要引导的精华,通过内部链接,友好引导可以提升爬虫体验。
6、内容简洁明了
搜索引擎页面不需要太多的代码,只要页面内容简洁,页面结构有利于优化,每个标题栏都能引导蜘蛛到它想去的地方,然后这个网站高-质量,因此页面干净的布局是每个布局所在的位置。进入这个地方的页面是什么,url层级也需要注意不要走得太深。 查看全部
网页flash文本抓取器(什么是搜索引擎蜘蛛友好的网站?这个问题不难解决!)
什么是 SEO 友好的 网站?这个问题不难解决。这个定位是用SEO优化网站的用户体验,给网站添加优质内容,让蜘蛛访问和爬取,所以SEO优化需要突出网站@的主题>。那么如何提高搜索引擎蜘蛛的友好度呢?
1、页面加载速度
页面加载对于搜索引擎蜘蛛的友好性更为重要。当蜘蛛到达时,如果一直无法打开网站,蜘蛛的体验非常不友好,会减少后续访问的次数。但是服务器可以提高网站的加载速度,在安全稳定的环境下,网站build之前应该选择服务器。因此,如果服务器不稳定,需要及时联系空间服务商,将网页应用加载到综合性能比较完善的空间中,方便SEO的日常操作。
2、无障碍网页浏览
Url 抓取指的是静态或伪静态 网站。这个网站结构是方便搜索引擎使用的蜘蛛结构模型。如果参数太多,数据会直接生成动态路径,这对搜索引擎来说不是一种友好的行为,尤其是带有中文参数的动态路径,是搜索引擎非常不喜欢的。
搜索引擎蜘蛛喜欢爬什么样的网站?
3、减少flash的应用
SEO优化需要注意页面布局是否有flash动画。蜘蛛很好地识别图像,如果 网站 页面的文本较少,则 网站 将失去其排名优先级。因此,页面框架内的组织和布局需要友好美观,框架结构要谨慎使用。
4、原创内容很受欢迎
百度一直在打击伪原创内容,同时也在优化原创内容,所以很多采集文章的网站排名都很差,有创意,内容丰富,有价值。这就是搜索引擎喜欢的。这样,你可以用不同的词来描述一个场景,或者结合流行和不流行的词。您的内容质量取决于您的内容是否定位良好且可用。
5、SEO 内部链接
SEO有两个内部链接。优邦云SEO推荐使用白帽SEO。关键词位置引导,每个字代表链接的效果,_一点是首页,锚文本内容之间,一些需要引导的精华,通过内部链接,友好引导可以提升爬虫体验。
6、内容简洁明了
搜索引擎页面不需要太多的代码,只要页面内容简洁,页面结构有利于优化,每个标题栏都能引导蜘蛛到它想去的地方,然后这个网站高-质量,因此页面干净的布局是每个布局所在的位置。进入这个地方的页面是什么,url层级也需要注意不要走得太深。
网页flash文本抓取器(是一款强大的文档管理软件,可以快速对文档进行编辑)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-14 04:21
wim文档管理专家是一款功能强大的文档管理软件,专用于管理电脑中的文档文件,支持txt、word、rtf、pdf等几乎所有常用格式,采用多文档库和类似windows资源的管理方式管理器的操作方式,支持附件和备注功能,内置强大的文本编辑器,可以帮助用户轻松管理文档文件,也可以快速编辑文档。
主要特点
1、多文档库,多文档界面,让文档阅读和管理更加便捷高效;
2、文档管理的操作方式与Windows资源管理器类似。文档管理非常方便易用;
3、内置强大的富文本编辑器,支持外部编辑器,让文档编辑更加方便快捷;
4、嵌入式office编辑器,轻松快速编辑Office文档;
5、内置网页浏览器,方便浏览和快速保存网页。可以快速抓取网页中的图片、文字,甚至是Flash文件;
6、内置文本编辑器,支持25种语法高亮;
7、强大的附件和笔记管理功能。全面支持各类文档管理,甚至支持文档快捷方式的管理;
8、强大的文件管理器,支持本地磁盘文件管理(无需导入数据库)。并且可以在这些文件中添加附件、备注等信息;
9、内置强大的搜索功能,支持全文搜索;
10、强大的文件和文件夹导入支持;
11、支持剪贴板监控功能,可直接从剪贴板获取文档;
12、悬浮窗支持拖放文档、文本和HTML,自动生成文档;
13、强大的插件功能;内置截屏插件,轻松截取屏幕图片;内置各种文本处理插件,文本处理更轻松快捷;
14、支持数据库安全管理和压缩模式,文档管理更安全高效;
15、高效的动态文档库加载技术。 查看全部
网页flash文本抓取器(是一款强大的文档管理软件,可以快速对文档进行编辑)
wim文档管理专家是一款功能强大的文档管理软件,专用于管理电脑中的文档文件,支持txt、word、rtf、pdf等几乎所有常用格式,采用多文档库和类似windows资源的管理方式管理器的操作方式,支持附件和备注功能,内置强大的文本编辑器,可以帮助用户轻松管理文档文件,也可以快速编辑文档。
主要特点
1、多文档库,多文档界面,让文档阅读和管理更加便捷高效;
2、文档管理的操作方式与Windows资源管理器类似。文档管理非常方便易用;
3、内置强大的富文本编辑器,支持外部编辑器,让文档编辑更加方便快捷;
4、嵌入式office编辑器,轻松快速编辑Office文档;
5、内置网页浏览器,方便浏览和快速保存网页。可以快速抓取网页中的图片、文字,甚至是Flash文件;
6、内置文本编辑器,支持25种语法高亮;
7、强大的附件和笔记管理功能。全面支持各类文档管理,甚至支持文档快捷方式的管理;
8、强大的文件管理器,支持本地磁盘文件管理(无需导入数据库)。并且可以在这些文件中添加附件、备注等信息;
9、内置强大的搜索功能,支持全文搜索;
10、强大的文件和文件夹导入支持;
11、支持剪贴板监控功能,可直接从剪贴板获取文档;
12、悬浮窗支持拖放文档、文本和HTML,自动生成文档;
13、强大的插件功能;内置截屏插件,轻松截取屏幕图片;内置各种文本处理插件,文本处理更轻松快捷;
14、支持数据库安全管理和压缩模式,文档管理更安全高效;
15、高效的动态文档库加载技术。
网页flash文本抓取器(IDC:网站地图上的链接超过或大约为100个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-03-14 04:18
中国IDC圈2月23日报道:为用户提供网站地图,列出网站重要部分的链接。如果 网站map 有超过或大约 100 个链接,则 网站map 将需要拆分为多个页面。
网站应实用且内容丰富,网页的文字应清晰准确地表达要传达的内容。
考虑人们用来查找您的页面的术语,并确保 网站 实际上收录这些单词。
网站应该有清晰的层次结构和文本链接。每个网页都应该可以通过至少一个静态文本链接打开。
尽可能使用文本而不是图形来显示重要的名称、内容或链接。搜索引擎爬虫无法识别图形中收录的文本。
检查损坏的链接并确保 HTML 格式正确。
将特定网页上的链接数量限制在合理的数量(少于 100 个)。
确保 TITLE 和 ALT 标签属性的描述和表达准确无误。
如果您决定使用动态页面(即收录“?”字符的 URL),请注意并非所有搜索引擎爬虫都可以爬取动态页面和静态页面。动态网页有助于缩短参数长度并减少参数数量。
技术指南
<p>由于大多数搜索引擎蜘蛛查看 网站 的方式与 Lynx 相同,因此您可以使用 Lynx 等文本浏览器查看您的 网站。如果由于应用了 Javascript、cookie、会话 ID、框架、DHTML 或 Flash 等复杂技术而无法在文本浏览器中看到 网站 的所有页面,则搜索引擎蜘蛛正在抓取您的 查看全部
网页flash文本抓取器(IDC:网站地图上的链接超过或大约为100个)
中国IDC圈2月23日报道:为用户提供网站地图,列出网站重要部分的链接。如果 网站map 有超过或大约 100 个链接,则 网站map 将需要拆分为多个页面。
网站应实用且内容丰富,网页的文字应清晰准确地表达要传达的内容。
考虑人们用来查找您的页面的术语,并确保 网站 实际上收录这些单词。
网站应该有清晰的层次结构和文本链接。每个网页都应该可以通过至少一个静态文本链接打开。
尽可能使用文本而不是图形来显示重要的名称、内容或链接。搜索引擎爬虫无法识别图形中收录的文本。
检查损坏的链接并确保 HTML 格式正确。
将特定网页上的链接数量限制在合理的数量(少于 100 个)。
确保 TITLE 和 ALT 标签属性的描述和表达准确无误。
如果您决定使用动态页面(即收录“?”字符的 URL),请注意并非所有搜索引擎爬虫都可以爬取动态页面和静态页面。动态网页有助于缩短参数长度并减少参数数量。
技术指南
<p>由于大多数搜索引擎蜘蛛查看 网站 的方式与 Lynx 相同,因此您可以使用 Lynx 等文本浏览器查看您的 网站。如果由于应用了 Javascript、cookie、会话 ID、框架、DHTML 或 Flash 等复杂技术而无法在文本浏览器中看到 网站 的所有页面,则搜索引擎蜘蛛正在抓取您的
网页flash文本抓取器( 网站管理员们最经常问的一个问题:我怎样才能提高我的网站在Google搜索上的排名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-14 04:17
网站管理员们最经常问的一个问题:我怎样才能提高我的网站在Google搜索上的排名)
Hubbell 和我正在加利福尼亚的家中度假。请随意阅读我之前为 网站 管理员撰写的关于可用性的博客,以及我为 Google 官方博客撰写的其他 文章 博客。
网站 管理员在无障碍搜索中最常见的问题之一是:如何提高我在无障碍搜索中的 网站 排名?同时,网站 管理员会问一个类似但更广泛的问题:如何提高我的 网站 在 Google 搜索中的排名?
我很高兴地告诉您,这是一个两管齐下的方法:您可以构建和改进一些关键的 网站 功能,例如 网站 导航,以便它适用于所有用户,其中自然包括 Google机器人。以下是一些小建议,您可以参考。
确保所有重要内容都可访问 为了使内容对用户可用,必须确保它是可访问的。用户和搜索引擎机器人都依赖超文本链接来访问页面内容,因此关键的第一步是确保您的 网站 上的所有内容都可以通过纯 HTML 超链接访问,并避免 网站 的关键部分被 JavaScript 或 Flash 等技术隐藏。纯超文本链接是通过 HTML 锚元素生成的链接。接下来,我们要确保所有指向目标元素的超文本链接是一个真实的 URL,而不是对点击触发控制器上的链接执行的空的、真实的链接操作。简而言之,避免以下形式的超文本链接: 我们建议使用更简单的链接,例如: 产品目录 确保内容可读 网站 内容只有在可读的情况下才有效。请确保您的 网站 上的所有重要内容都以 HTML 文件的形式呈现,并且无需评估页面脚本即可访问。对于 Google bot 和绝大多数毫无戒心的用户来说,隐藏在 Flash 动画背后的内容以及由可执行 JavaScript 在浏览器端生成的文本仍然无法阅读。确保内容以易于阅读的顺序提供给读者。获得可读内容后,用户希望能够按照逻辑阅读顺序跟进内容。如果您的大部分 网站 都设计有复杂的多列布局,那么最好退后一步考虑如何达到预期的效果。例如,使用深度嵌套的 HTML 表格会使人们难以按逻辑顺序连接相关文本。
元素来达到同样的效果。另外,您会发现 网站 运行得更快、更高效。
补充所有视觉内容 - 不用担心重复!将您的信息提供给所有人并不意味着让您网站“降级”为最简单的文本格式。尽可能多地重复您的信息很重要,因为这是确保页面内容对所有用户最有帮助的唯一方法。以下是一些简单的提示: 采用上述提示可以大大提高用户着陆页的质量。而且,作为额外的奖励,您可能会惊喜地发现您的 网站 被更好地索引了! 查看全部
网页flash文本抓取器(
网站管理员们最经常问的一个问题:我怎样才能提高我的网站在Google搜索上的排名)
Hubbell 和我正在加利福尼亚的家中度假。请随意阅读我之前为 网站 管理员撰写的关于可用性的博客,以及我为 Google 官方博客撰写的其他 文章 博客。
网站 管理员在无障碍搜索中最常见的问题之一是:如何提高我在无障碍搜索中的 网站 排名?同时,网站 管理员会问一个类似但更广泛的问题:如何提高我的 网站 在 Google 搜索中的排名?
我很高兴地告诉您,这是一个两管齐下的方法:您可以构建和改进一些关键的 网站 功能,例如 网站 导航,以便它适用于所有用户,其中自然包括 Google机器人。以下是一些小建议,您可以参考。
确保所有重要内容都可访问 为了使内容对用户可用,必须确保它是可访问的。用户和搜索引擎机器人都依赖超文本链接来访问页面内容,因此关键的第一步是确保您的 网站 上的所有内容都可以通过纯 HTML 超链接访问,并避免 网站 的关键部分被 JavaScript 或 Flash 等技术隐藏。纯超文本链接是通过 HTML 锚元素生成的链接。接下来,我们要确保所有指向目标元素的超文本链接是一个真实的 URL,而不是对点击触发控制器上的链接执行的空的、真实的链接操作。简而言之,避免以下形式的超文本链接: 我们建议使用更简单的链接,例如: 产品目录 确保内容可读 网站 内容只有在可读的情况下才有效。请确保您的 网站 上的所有重要内容都以 HTML 文件的形式呈现,并且无需评估页面脚本即可访问。对于 Google bot 和绝大多数毫无戒心的用户来说,隐藏在 Flash 动画背后的内容以及由可执行 JavaScript 在浏览器端生成的文本仍然无法阅读。确保内容以易于阅读的顺序提供给读者。获得可读内容后,用户希望能够按照逻辑阅读顺序跟进内容。如果您的大部分 网站 都设计有复杂的多列布局,那么最好退后一步考虑如何达到预期的效果。例如,使用深度嵌套的 HTML 表格会使人们难以按逻辑顺序连接相关文本。
元素来达到同样的效果。另外,您会发现 网站 运行得更快、更高效。
补充所有视觉内容 - 不用担心重复!将您的信息提供给所有人并不意味着让您网站“降级”为最简单的文本格式。尽可能多地重复您的信息很重要,因为这是确保页面内容对所有用户最有帮助的唯一方法。以下是一些简单的提示: 采用上述提示可以大大提高用户着陆页的质量。而且,作为额外的奖励,您可能会惊喜地发现您的 网站 被更好地索引了!
网页flash文本抓取器(网页flash文本抓取器介绍与自定义调用(3.1版))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-13 14:03
网页flash文本抓取器介绍与自定义调用(3.1版)appium底层调用原理分析及使用方法思路分析(3.2版)appium底层调用原理分析及使用方法思路分析(3.3版)
参考这个~/
好像目前不能简单的用appium里面的java层来抓包了,可以用python,python有个类叫scrapy在url分析是非常有优势的,使用java后端和scrapy的接口基本都会被封杀。那就找一些python抓包的库,推荐一个我在用的python抓包工具typicsidious,原理和原理步骤还是蛮详细的。appium不是太了解,不是专业做抓包的。
flash只是提供了文本分析接口而已,抓包时还是会走python的post包,只不过调用和返回对象是json这种格式,json本身不具有结构性而已。appium是将视频抓包分析转化为原生post包写到内存里面返回,
appium不是flash的代替品,而是原本webkit提供的视频抓取接口去掉了一层跳转层,如果要抓图片的话需要的话联网就抓取不了了。上官网看看抓包教程就都懂了。
使用方法有所不同,视频抓取应该可以直接抓取,只是图片会抓取失败。
抓取有不同,你可以抓取app中其他元素也可以抓取视频及图片,如果是app中的动画, 查看全部
网页flash文本抓取器(网页flash文本抓取器介绍与自定义调用(3.1版))
网页flash文本抓取器介绍与自定义调用(3.1版)appium底层调用原理分析及使用方法思路分析(3.2版)appium底层调用原理分析及使用方法思路分析(3.3版)
参考这个~/
好像目前不能简单的用appium里面的java层来抓包了,可以用python,python有个类叫scrapy在url分析是非常有优势的,使用java后端和scrapy的接口基本都会被封杀。那就找一些python抓包的库,推荐一个我在用的python抓包工具typicsidious,原理和原理步骤还是蛮详细的。appium不是太了解,不是专业做抓包的。
flash只是提供了文本分析接口而已,抓包时还是会走python的post包,只不过调用和返回对象是json这种格式,json本身不具有结构性而已。appium是将视频抓包分析转化为原生post包写到内存里面返回,
appium不是flash的代替品,而是原本webkit提供的视频抓取接口去掉了一层跳转层,如果要抓图片的话需要的话联网就抓取不了了。上官网看看抓包教程就都懂了。
使用方法有所不同,视频抓取应该可以直接抓取,只是图片会抓取失败。
抓取有不同,你可以抓取app中其他元素也可以抓取视频及图片,如果是app中的动画,
网页flash文本抓取器(高级网站建设和普通网站的建设有什么区别?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-08 06:10
关于网站中图片的使用,小编也提醒大家不要过多的使用图片,非常不利于后期的优化。目前的形式是蜘蛛和用户都比较喜欢网站有图文,所以我们可以结合网站设计制作的图文。不过要注意图片的使用,因为搜索引擎会明智的抓取文字描述,所以在使用网站图片时必须添加alt属性标签。现在 网站 更喜欢使用一些 Flash 动画插入到 网站 因为互联网的加速。Flash的应用确实让页面更加生动,但是不利于后期的优化,所以,如果一定要在网站中使用Flash,记得让网页设计师制作一个辅助的html版本,并将flash放在html文件中。34专注于网络营销技术、产品和服务的创新与融合,现已成为国内较好的网络营销整合服务商。北京先进网站建筑设计
Advanced网站Build 和 Normal网站Build 有什么区别?网站兼容性对于高级网站来说,在构建过程中,兼容性非常重要。不管你用什么浏览器,什么尺寸的屏幕,什么牌子的手机,都可以正常使用。但如果是普通的网站构造,则相对缺乏兼容性。通常一些主流浏览器可以正常浏览,但是手机或其他浏览器会出现一些混乱和功能故障。网站普通域名网站建设成本很低,所以域名和空间的质量比较差,所以我们的网站用户访问很容易变慢,极大地影响了用户的正常访问,在搜索引擎爬取方面也比较差。高级网站的建设,基本都是利用大品牌的空间。这些域名空间在整个市场上都是高度认可的,质量更有保障。此外,它们在所有费用、续订和其他相关费用方面都是透明和可靠的。搜索引擎后优化与推广 一个好的网站并不代表可以搭建,而是需要后优化。高级网站建设过程中,非常注重搜索引擎的优化和推广,会根据网站的具体情况进行合理布局。一般来说,网站建设通常认为把网站交给客户就够了。网站 建设不会给客户带来SEO优化和推广的考虑,不利于网站的长远发展。可见,高级网站的构造与普通的网站完全不同。现在很多人选择构建高级网站,因为高级网站带来的服务和收益是普通网站无法比拟的。通州区进口网站建筑特价就像选择一个域名一样,网站结构的设计必须站在用户的角度。@网站,因为高级网站带来的服务和收益是普通网站无法比拟的。通州区进口网站建筑特价就像选择一个域名一样,网站结构的设计必须站在用户的角度。@网站,因为高级网站带来的服务和收益是普通网站无法比拟的。通州区进口网站建筑特价就像选择一个域名一样,网站结构的设计必须站在用户的角度。
目录页面收录正常的类别频道列表页面,也收录条件聚合生成的列表页面。在正常的网站结构中,这种页面也有很高的权重,而在大信息类网站中,这种页面也是主要获取搜索流量的页面。因此,不仅要精心优化链接,还要精心设计页面关键词的定位和内容。列表页位于首页和内容页的中间,会同时得到首页和大量内容页的自然推荐链接,所以也有比较高的权重。所以,如果列表页只优化当前的分类名称,就有点太疯狂了。
然后是表格在网页中的应用。表格不宜大规模使用,因为对于css+div布局网站,表格占用的空间太大,会影响网站的整体加载速度。如果要使用表格,小编建议您将文字放在不同的表格中,这样我们管理起来更方便,加载速度也会有所提升。什么样的网站对SEO好
1、Homepage 指向板块页面和重要内容页面。
2、栏目页指向其他栏目页和当前内容页。
3、栏目页面不指向其他栏目内容页面。
4、内容页指向首页和所有栏目页。假设你已经购买了,然后用上面的开源系统搭建了一个网站,是不是意味着我网站就完成了。
协会网站大楼
是时候访问网站了。注意,传统企业建站周期长,修改多,价格高,造价上万元网站,最终排名不好,尤其是中小企业,定制网站的压力很大,所以越来越多的企业选择模板先建站。在兼容性方面,界面设计沿用了国外非常新的网络设计规范,拥有所有主流火狐confluence浏览器的历史。网站流畅完整,免去普通网络公司搭建调试兼容性问题。其次,后台管理和操作简单易操作,对于没有技术人员的企业来说非常方便快捷。简单的后台操作可以让网站的操作变得非常简单,只要改变一个模板样式就可以轻松搞定。. 你只需要花几百元甚至几十元就可以用快速模板搭建一个网站。现在 网站 更喜欢使用一些 Flash 动画插入到 网站 因为互联网的加速。官方网站密云区建设调试 @网站 因为互联网的加速。官方网站密云区建设调试 @网站 因为互联网的加速。官方网站密云区建设调试
网站页面如何设计更利于优化。北京先进网站建筑设计
内容页指向同一节下的内容页。树形结构可以清晰展示网站的内容结构,适合大中型网站构建;扁平结构简单,适用于小型网站和企业网站。搜索引擎给二级列的权重比较高,树形结构为网站提供二级列,扁平结构直接是二级面。那么树结构 网站 是 网站 更好的选择吗?当然不是,如果树结构规划不好,会影响蜘蛛爬行。因此,我们需要根据实际情况选择自己的网站结构。那么什么样的网站结构对SEO好呢?“树形结构+逻辑结构” 是更好的选择。树形结构可以使网站的结构清晰,权重分布均衡;逻辑结构可以使网站的结构非常可控,可以提高网站的入口,以及一些结构较深的页面的效率。入口问题,即根据我们的权重分配需求来分配网站内容。如果逻辑结构做得好,网站的任何页面都可以取得不错的排名。北京先进网站建筑设计 入口问题,即根据我们的权重分配需求来分配网站内容。如果逻辑结构做得好,网站的任何页面都可以取得不错的排名。北京先进网站建筑设计 入口问题,即根据我们的权重分配需求来分配网站内容。如果逻辑结构做得好,网站的任何页面都可以取得不错的排名。北京先进网站建筑设计
是一家成立于2012年12月05日的公司,注册地址位于上海市金山区金山卫镇前新路301号375室。法定代表人为张丽。经营范围包括计算机网络技术领域的技术开发、技术咨询、技术服务、各类广告的设计制作、市场信息咨询和调查(不得从事社会调查、社会调查、民意调查、民意调查)、文化办公用品、家居用品 电器、电子产品、日用品、化妆品销售。是一家集研发、设计、生产、销售为一体的专业化公司。公司自成立以来,一直致力于文化办公用品,是能源的主力军。公司致力于将科技创新作为贴心的产品展现给用户,为用户带来良好的体验。公司网络创始人张立始终关注客户,创新技术,竭诚为客户提供良好的服务。 查看全部
网页flash文本抓取器(高级网站建设和普通网站的建设有什么区别?(图))
关于网站中图片的使用,小编也提醒大家不要过多的使用图片,非常不利于后期的优化。目前的形式是蜘蛛和用户都比较喜欢网站有图文,所以我们可以结合网站设计制作的图文。不过要注意图片的使用,因为搜索引擎会明智的抓取文字描述,所以在使用网站图片时必须添加alt属性标签。现在 网站 更喜欢使用一些 Flash 动画插入到 网站 因为互联网的加速。Flash的应用确实让页面更加生动,但是不利于后期的优化,所以,如果一定要在网站中使用Flash,记得让网页设计师制作一个辅助的html版本,并将flash放在html文件中。34专注于网络营销技术、产品和服务的创新与融合,现已成为国内较好的网络营销整合服务商。北京先进网站建筑设计
Advanced网站Build 和 Normal网站Build 有什么区别?网站兼容性对于高级网站来说,在构建过程中,兼容性非常重要。不管你用什么浏览器,什么尺寸的屏幕,什么牌子的手机,都可以正常使用。但如果是普通的网站构造,则相对缺乏兼容性。通常一些主流浏览器可以正常浏览,但是手机或其他浏览器会出现一些混乱和功能故障。网站普通域名网站建设成本很低,所以域名和空间的质量比较差,所以我们的网站用户访问很容易变慢,极大地影响了用户的正常访问,在搜索引擎爬取方面也比较差。高级网站的建设,基本都是利用大品牌的空间。这些域名空间在整个市场上都是高度认可的,质量更有保障。此外,它们在所有费用、续订和其他相关费用方面都是透明和可靠的。搜索引擎后优化与推广 一个好的网站并不代表可以搭建,而是需要后优化。高级网站建设过程中,非常注重搜索引擎的优化和推广,会根据网站的具体情况进行合理布局。一般来说,网站建设通常认为把网站交给客户就够了。网站 建设不会给客户带来SEO优化和推广的考虑,不利于网站的长远发展。可见,高级网站的构造与普通的网站完全不同。现在很多人选择构建高级网站,因为高级网站带来的服务和收益是普通网站无法比拟的。通州区进口网站建筑特价就像选择一个域名一样,网站结构的设计必须站在用户的角度。@网站,因为高级网站带来的服务和收益是普通网站无法比拟的。通州区进口网站建筑特价就像选择一个域名一样,网站结构的设计必须站在用户的角度。@网站,因为高级网站带来的服务和收益是普通网站无法比拟的。通州区进口网站建筑特价就像选择一个域名一样,网站结构的设计必须站在用户的角度。
目录页面收录正常的类别频道列表页面,也收录条件聚合生成的列表页面。在正常的网站结构中,这种页面也有很高的权重,而在大信息类网站中,这种页面也是主要获取搜索流量的页面。因此,不仅要精心优化链接,还要精心设计页面关键词的定位和内容。列表页位于首页和内容页的中间,会同时得到首页和大量内容页的自然推荐链接,所以也有比较高的权重。所以,如果列表页只优化当前的分类名称,就有点太疯狂了。
然后是表格在网页中的应用。表格不宜大规模使用,因为对于css+div布局网站,表格占用的空间太大,会影响网站的整体加载速度。如果要使用表格,小编建议您将文字放在不同的表格中,这样我们管理起来更方便,加载速度也会有所提升。什么样的网站对SEO好
1、Homepage 指向板块页面和重要内容页面。
2、栏目页指向其他栏目页和当前内容页。
3、栏目页面不指向其他栏目内容页面。
4、内容页指向首页和所有栏目页。假设你已经购买了,然后用上面的开源系统搭建了一个网站,是不是意味着我网站就完成了。
协会网站大楼
是时候访问网站了。注意,传统企业建站周期长,修改多,价格高,造价上万元网站,最终排名不好,尤其是中小企业,定制网站的压力很大,所以越来越多的企业选择模板先建站。在兼容性方面,界面设计沿用了国外非常新的网络设计规范,拥有所有主流火狐confluence浏览器的历史。网站流畅完整,免去普通网络公司搭建调试兼容性问题。其次,后台管理和操作简单易操作,对于没有技术人员的企业来说非常方便快捷。简单的后台操作可以让网站的操作变得非常简单,只要改变一个模板样式就可以轻松搞定。. 你只需要花几百元甚至几十元就可以用快速模板搭建一个网站。现在 网站 更喜欢使用一些 Flash 动画插入到 网站 因为互联网的加速。官方网站密云区建设调试 @网站 因为互联网的加速。官方网站密云区建设调试 @网站 因为互联网的加速。官方网站密云区建设调试
网站页面如何设计更利于优化。北京先进网站建筑设计
内容页指向同一节下的内容页。树形结构可以清晰展示网站的内容结构,适合大中型网站构建;扁平结构简单,适用于小型网站和企业网站。搜索引擎给二级列的权重比较高,树形结构为网站提供二级列,扁平结构直接是二级面。那么树结构 网站 是 网站 更好的选择吗?当然不是,如果树结构规划不好,会影响蜘蛛爬行。因此,我们需要根据实际情况选择自己的网站结构。那么什么样的网站结构对SEO好呢?“树形结构+逻辑结构” 是更好的选择。树形结构可以使网站的结构清晰,权重分布均衡;逻辑结构可以使网站的结构非常可控,可以提高网站的入口,以及一些结构较深的页面的效率。入口问题,即根据我们的权重分配需求来分配网站内容。如果逻辑结构做得好,网站的任何页面都可以取得不错的排名。北京先进网站建筑设计 入口问题,即根据我们的权重分配需求来分配网站内容。如果逻辑结构做得好,网站的任何页面都可以取得不错的排名。北京先进网站建筑设计 入口问题,即根据我们的权重分配需求来分配网站内容。如果逻辑结构做得好,网站的任何页面都可以取得不错的排名。北京先进网站建筑设计
是一家成立于2012年12月05日的公司,注册地址位于上海市金山区金山卫镇前新路301号375室。法定代表人为张丽。经营范围包括计算机网络技术领域的技术开发、技术咨询、技术服务、各类广告的设计制作、市场信息咨询和调查(不得从事社会调查、社会调查、民意调查、民意调查)、文化办公用品、家居用品 电器、电子产品、日用品、化妆品销售。是一家集研发、设计、生产、销售为一体的专业化公司。公司自成立以来,一直致力于文化办公用品,是能源的主力军。公司致力于将科技创新作为贴心的产品展现给用户,为用户带来良好的体验。公司网络创始人张立始终关注客户,创新技术,竭诚为客户提供良好的服务。
网页flash文本抓取器(网页抓取技术入门第二部分-8f87-701-fb68)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-05 21:01
网页flash文本抓取器可以完成自动换行功能,不需要手动操作即可从网页中全文摘取文本。并且支持中文分词、多列分词、拼音搜索等高级功能。而实现这一功能必须要有flash,以及python支持打开网页和抓取全文。根据提示,将如下链接拉到页面的底部,会自动出现flash抓取器,点击即可进入抓取界面。
我用这个方法在百度贴吧实现过自动换行,很简单。
建议参考一下网页抓取技术入门第二部分-8f87-4744-b701-f68d4e3079091.html
richflashgoogleflashrecapabilities
话说我们专业前段时间用python做了一个flash版本的全自动换行的网页抓取程序,
有一些类似的工具,但是功能不是全自动的,
有个网站可以抓取各种网页的网页制作助手|全自动抓取网页和视频
用flashgen调用txt文件来实现,抓取只支持post方式;python或者ruby都有对应的库来实现动态抓取。
webscraper可以抓取flash动画,支持剪贴板上复制、离线缓存等可以利用python制作webapp,方便抓取重要页面并转化成json格式,web文件处理。也可以抓取网页,非常牛的抓取工具。专门负责爬取网页的工具, 查看全部
网页flash文本抓取器(网页抓取技术入门第二部分-8f87-701-fb68)
网页flash文本抓取器可以完成自动换行功能,不需要手动操作即可从网页中全文摘取文本。并且支持中文分词、多列分词、拼音搜索等高级功能。而实现这一功能必须要有flash,以及python支持打开网页和抓取全文。根据提示,将如下链接拉到页面的底部,会自动出现flash抓取器,点击即可进入抓取界面。
我用这个方法在百度贴吧实现过自动换行,很简单。
建议参考一下网页抓取技术入门第二部分-8f87-4744-b701-f68d4e3079091.html
richflashgoogleflashrecapabilities
话说我们专业前段时间用python做了一个flash版本的全自动换行的网页抓取程序,
有一些类似的工具,但是功能不是全自动的,
有个网站可以抓取各种网页的网页制作助手|全自动抓取网页和视频
用flashgen调用txt文件来实现,抓取只支持post方式;python或者ruby都有对应的库来实现动态抓取。
webscraper可以抓取flash动画,支持剪贴板上复制、离线缓存等可以利用python制作webapp,方便抓取重要页面并转化成json格式,web文件处理。也可以抓取网页,非常牛的抓取工具。专门负责爬取网页的工具,
网页flash文本抓取器(如何才能创建一个对搜索引擎友好的企业网站或者个人博客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-05 10:01
最近有很多朋友询问必胜互联网如何打造一个搜索引擎友好的企业网站或者个人博客。其实无论是企业网站还是个人博客,在创建搜索引擎友好的网站的过程中,都需要注意一些常见的问题。必盛互联网总结了一些对搜索引擎友好的技巧,供大家参考。
向图像、Flash 和视频添加文本
大家应该清楚,搜索引擎抓取网站内容的主题是文本。在网站上的图片、Flash、视频等中添加文字可以帮助搜索引擎抓取网站的内容。添加文本并不意味着将文本嵌入到图像、Flash 或视频中,而是指对这些图像、Flash 或视频的文字描述。目前,一些搜索引擎已经具备扫描Flash文件的能力,但这种能力还没有成熟,很难完整地扫描Flash文件的信息。谷歌在扫描Flash文件方面做得很好,其他搜索引擎未必,也没有可以查看图片和视频信息的搜索引擎。
虽然图片、视频等内容很难抓拍,但这并不意味着图片站、视频站等就不能创建。站长可以将图片、视频等文字描述传达给搜索引擎网站信息。常用方法包括向图像添加 Alt 标记。
验证 HTML 代码
在创建 网站 时,需要检查 HTML 代码是否有错误,不是拼写或语法错误,而是检查允许网络浏览器根据站长需要格式化网页的底层 HTML 代码。无论您使用哪个 Web 编辑器编写 网站HTML 代码,网站使用 HTML 和 CSS 验证器来检查您的代码总是对您有利。如果 HTML 代码有错误且无法被网络浏览器检测到,搜索引擎可能会忽略 网站 本身的内容,从而无法抓取 网站 的内容。
创建相关的标题标签
许多搜索引擎显示的标题标签长度有限,而标题标签也会影响搜索引擎排名,因此站长在创建标题标签时需要仔细考虑。首先是分析网站的目标用户群,根据网站用户过滤标签,例如技术网站需要添加专业术语等,然后到符合title标签的特点,即简洁明了,主关键词在前一个关键词的旁边,因为在同样的条件下,搜索引擎会优先显示关键词排名靠前的网页,所以这对于页面排名非常有用。
使用 HTML 导航直接链接到 网站
大多数搜索引擎无法理解 Javascript 语言,因此使用 HTML 导航链接尤为重要。一般来说,纯 HTML 导航是最好的,不仅供用户浏览,也供搜索引擎抓取。使用 Javascript 甚至 Flash 确实使导航看起来更好,但它使搜索引擎更难抓取。
删除明显的重复项
同一篇文章文章可能有两个不同的URL,这会直接稀释网站的流量,分散权重,对搜索引擎很不友好。搜索引擎会认为网站的内容有很多重复,会直接降低网站的排名。对于这种情况,站长可以使用百度站长工具来处理规范网址。
删除隐藏文本
隐藏文字是指将关键词的颜色设置为页面的背景色,让访问者看不到,但搜索引擎可以统计。其目的主要是增加关键词的密度。这种方法也被称为黑帽 SEO。它不被搜索引擎识别,目前大多数搜索引擎都可以检测到隐藏文本并将其视为作弊。因此,站长最好不要通过隐藏文字进行推测。通过添加可视化文本内容也可以达到同样的优化效果。
相关文章: 查看全部
网页flash文本抓取器(如何才能创建一个对搜索引擎友好的企业网站或者个人博客)
最近有很多朋友询问必胜互联网如何打造一个搜索引擎友好的企业网站或者个人博客。其实无论是企业网站还是个人博客,在创建搜索引擎友好的网站的过程中,都需要注意一些常见的问题。必盛互联网总结了一些对搜索引擎友好的技巧,供大家参考。
向图像、Flash 和视频添加文本
大家应该清楚,搜索引擎抓取网站内容的主题是文本。在网站上的图片、Flash、视频等中添加文字可以帮助搜索引擎抓取网站的内容。添加文本并不意味着将文本嵌入到图像、Flash 或视频中,而是指对这些图像、Flash 或视频的文字描述。目前,一些搜索引擎已经具备扫描Flash文件的能力,但这种能力还没有成熟,很难完整地扫描Flash文件的信息。谷歌在扫描Flash文件方面做得很好,其他搜索引擎未必,也没有可以查看图片和视频信息的搜索引擎。
虽然图片、视频等内容很难抓拍,但这并不意味着图片站、视频站等就不能创建。站长可以将图片、视频等文字描述传达给搜索引擎网站信息。常用方法包括向图像添加 Alt 标记。
验证 HTML 代码
在创建 网站 时,需要检查 HTML 代码是否有错误,不是拼写或语法错误,而是检查允许网络浏览器根据站长需要格式化网页的底层 HTML 代码。无论您使用哪个 Web 编辑器编写 网站HTML 代码,网站使用 HTML 和 CSS 验证器来检查您的代码总是对您有利。如果 HTML 代码有错误且无法被网络浏览器检测到,搜索引擎可能会忽略 网站 本身的内容,从而无法抓取 网站 的内容。
创建相关的标题标签
许多搜索引擎显示的标题标签长度有限,而标题标签也会影响搜索引擎排名,因此站长在创建标题标签时需要仔细考虑。首先是分析网站的目标用户群,根据网站用户过滤标签,例如技术网站需要添加专业术语等,然后到符合title标签的特点,即简洁明了,主关键词在前一个关键词的旁边,因为在同样的条件下,搜索引擎会优先显示关键词排名靠前的网页,所以这对于页面排名非常有用。
使用 HTML 导航直接链接到 网站
大多数搜索引擎无法理解 Javascript 语言,因此使用 HTML 导航链接尤为重要。一般来说,纯 HTML 导航是最好的,不仅供用户浏览,也供搜索引擎抓取。使用 Javascript 甚至 Flash 确实使导航看起来更好,但它使搜索引擎更难抓取。
删除明显的重复项
同一篇文章文章可能有两个不同的URL,这会直接稀释网站的流量,分散权重,对搜索引擎很不友好。搜索引擎会认为网站的内容有很多重复,会直接降低网站的排名。对于这种情况,站长可以使用百度站长工具来处理规范网址。
删除隐藏文本
隐藏文字是指将关键词的颜色设置为页面的背景色,让访问者看不到,但搜索引擎可以统计。其目的主要是增加关键词的密度。这种方法也被称为黑帽 SEO。它不被搜索引擎识别,目前大多数搜索引擎都可以检测到隐藏文本并将其视为作弊。因此,站长最好不要通过隐藏文字进行推测。通过添加可视化文本内容也可以达到同样的优化效果。
相关文章:

