
网页flash文本抓取器
网页flash文本抓取器(SWFObject2.0:SWFObject的检索技术(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-05 01:25
核心提示:当搜索引擎对Flash的检索技术不够成熟时,我们应该努力打造高端的网站简化Flash页面。页面不宜过大,否则加载速度慢会影响搜索引擎收录,另外创建一个单独的Html页面引导其讲解。
Flash可以让网站色彩斑斓,但是它强调图片和交互功能以及浅色的文字和链接,对Javascript这样的搜索引擎不太友好,所以如何对Flash进行SEO优化网站就变成了一个共同的问题。
2008 年 6 月 20 日,Google 和 Google 共同宣布了一种新算法来完全抓取 Flash 内容。尽管取得了一些进展,但搜索引擎仍然难以抓取 Flash,所以我们在保证 Flash 的有效设计、标准的统一、各种浏览器的兼容性的同时,也应该对搜索引擎进行有效的优化。
我们可以在Flash中使用开源Javascript函数的SWFObject()函数,可以被搜索引擎识别。下面简单介绍一下SWFObject 2.0:
SWFObject 是一个独立的、灵活的 JavaScript 模块,用于在 HTML 中插入 Adobe Flash 媒体资源(*.swf 文件)。非常符合搜索引擎优化的原则。此外,它还可以避免在你的HTML和XHTML中嵌入object、embed等非标准标签,从而符合更多的标准。
如果你想加强对Flash中标题和描述的优化,那么你应该学习sIFR技术。
sIFR代表Scalable Shanghai Huangpu District网站 Construction Company Inman Flash Replacement,这是一种可扩展的Inman Flash替换技术。它使用 Flash + JS + CSS 来实现更细腻准确的文本渲染,而不需要替换页面中的文本元素。使用 sIFR,您可以为 Web 中的文本定义任何字体,即使它没有安装在客户端浏览器中。 sIFR 使用 Flash 渲染字体效果,可以平滑和抗锯齿文本,并且可以像使用 CSS 控制文本一样轻松获得各种文本效果。
但是 sIFR 有一个明显的缺点,就是它只能处理简单的介绍性文字,而对于复杂的 Flash 动画,例如菜单、幻灯片和其他高度交互的 Flash 网页,它却无能为力。
因此,当搜索引擎对Flash的检索技术还不够成熟时,应努力简化Flash页面,页面不能太大,否则加载速度慢会影响搜索引擎收录@ >,同时建立一个单独的Html页面,后面会讲解如何引导。 查看全部
网页flash文本抓取器(SWFObject2.0:SWFObject的检索技术(图))
核心提示:当搜索引擎对Flash的检索技术不够成熟时,我们应该努力打造高端的网站简化Flash页面。页面不宜过大,否则加载速度慢会影响搜索引擎收录,另外创建一个单独的Html页面引导其讲解。
Flash可以让网站色彩斑斓,但是它强调图片和交互功能以及浅色的文字和链接,对Javascript这样的搜索引擎不太友好,所以如何对Flash进行SEO优化网站就变成了一个共同的问题。
2008 年 6 月 20 日,Google 和 Google 共同宣布了一种新算法来完全抓取 Flash 内容。尽管取得了一些进展,但搜索引擎仍然难以抓取 Flash,所以我们在保证 Flash 的有效设计、标准的统一、各种浏览器的兼容性的同时,也应该对搜索引擎进行有效的优化。
我们可以在Flash中使用开源Javascript函数的SWFObject()函数,可以被搜索引擎识别。下面简单介绍一下SWFObject 2.0:
SWFObject 是一个独立的、灵活的 JavaScript 模块,用于在 HTML 中插入 Adobe Flash 媒体资源(*.swf 文件)。非常符合搜索引擎优化的原则。此外,它还可以避免在你的HTML和XHTML中嵌入object、embed等非标准标签,从而符合更多的标准。
如果你想加强对Flash中标题和描述的优化,那么你应该学习sIFR技术。
sIFR代表Scalable Shanghai Huangpu District网站 Construction Company Inman Flash Replacement,这是一种可扩展的Inman Flash替换技术。它使用 Flash + JS + CSS 来实现更细腻准确的文本渲染,而不需要替换页面中的文本元素。使用 sIFR,您可以为 Web 中的文本定义任何字体,即使它没有安装在客户端浏览器中。 sIFR 使用 Flash 渲染字体效果,可以平滑和抗锯齿文本,并且可以像使用 CSS 控制文本一样轻松获得各种文本效果。
但是 sIFR 有一个明显的缺点,就是它只能处理简单的介绍性文字,而对于复杂的 Flash 动画,例如菜单、幻灯片和其他高度交互的 Flash 网页,它却无能为力。
因此,当搜索引擎对Flash的检索技术还不够成熟时,应努力简化Flash页面,页面不能太大,否则加载速度慢会影响搜索引擎收录@ >,同时建立一个单独的Html页面,后面会讲解如何引导。
网页flash文本抓取器(Robot的搜索引擎(Robot)是什么?(Robot)是机器人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-03 08:09
Robot 英文直译是机器人。在搜索引擎优化SEO中,我们经常将其翻译为:检测器。
有时候,你会遇到爬虫(crawler)、蜘蛛(spider),都是检测器之一,只是名字不一样。
SEO中经常提到的这个检测器(Robot)是什么?
搜索引擎用来抓取网页的工具。它是一个软件或一系列自动程序(显然,不是机器)。
不同的搜索引擎给他们的机器人起不同的名字。
Google: googlebot 百度: baiduspider MSN: MSNbot Yahoo: Slurp(这个来自yahoo的比较特别,没有“姓”,用的是象声词。Slurp,机器人吃tsk tsk声音时发出中文理解)
关于Robot,主要关注的是Robots.txt,上面的名字收录在网站log中。
百度用来抓取网页的程序叫做Baiduspider——百度蜘蛛。我们主要分析网站被百度爬取的情况。 网站日志中百度蜘蛛Baiduspider的活动:爬取频率,返回HTTP状态码。
如何查看日志:
通过FTP,在网站的根目录下找到一个日志文件,文件名一般收录log,下载并解压里面的记事本,这是网站的日志,里面记录了网站 被访问和操纵。
由于每个服务器和主机的情况不同,不同主机的日志功能记录的内容也不同,有的甚至没有日志功能。
日志内容如下:
61.135.168.22 - - [11/Jan/2009:04:02:45 +0800] “GET /bbs/thread-7303-1- 1.html HTTP/1.1″ 200 8450 “-” “Baiduspider+(+)”
分析:
GET /bbs/thread-7303-1-1.html代表,抓取/bbs/thread-7303-1-1.html这个页面。
200 表示抓取成功。
8450 表示抓取了 8450 个字节。
如果你的日志中的格式不是这样的,说明日志格式设置不一样。
在很多日志中可以看到200 0 0和200 0 64代表正常爬取。
爬取频率是通过查看每日日志中的百度蜘蛛爬取次数得出的。爬取频率没有标准化的时间表或频率数,我们一般通过多天的日志对比来判断。当然,我们希望百度蜘蛛每天爬的次数越多越好。 查看全部
网页flash文本抓取器(Robot的搜索引擎(Robot)是什么?(Robot)是机器人)
Robot 英文直译是机器人。在搜索引擎优化SEO中,我们经常将其翻译为:检测器。
有时候,你会遇到爬虫(crawler)、蜘蛛(spider),都是检测器之一,只是名字不一样。
SEO中经常提到的这个检测器(Robot)是什么?
搜索引擎用来抓取网页的工具。它是一个软件或一系列自动程序(显然,不是机器)。
不同的搜索引擎给他们的机器人起不同的名字。
Google: googlebot 百度: baiduspider MSN: MSNbot Yahoo: Slurp(这个来自yahoo的比较特别,没有“姓”,用的是象声词。Slurp,机器人吃tsk tsk声音时发出中文理解)
关于Robot,主要关注的是Robots.txt,上面的名字收录在网站log中。
百度用来抓取网页的程序叫做Baiduspider——百度蜘蛛。我们主要分析网站被百度爬取的情况。 网站日志中百度蜘蛛Baiduspider的活动:爬取频率,返回HTTP状态码。
如何查看日志:
通过FTP,在网站的根目录下找到一个日志文件,文件名一般收录log,下载并解压里面的记事本,这是网站的日志,里面记录了网站 被访问和操纵。
由于每个服务器和主机的情况不同,不同主机的日志功能记录的内容也不同,有的甚至没有日志功能。
日志内容如下:
61.135.168.22 - - [11/Jan/2009:04:02:45 +0800] “GET /bbs/thread-7303-1- 1.html HTTP/1.1″ 200 8450 “-” “Baiduspider+(+)”
分析:
GET /bbs/thread-7303-1-1.html代表,抓取/bbs/thread-7303-1-1.html这个页面。
200 表示抓取成功。
8450 表示抓取了 8450 个字节。
如果你的日志中的格式不是这样的,说明日志格式设置不一样。
在很多日志中可以看到200 0 0和200 0 64代表正常爬取。
爬取频率是通过查看每日日志中的百度蜘蛛爬取次数得出的。爬取频率没有标准化的时间表或频率数,我们一般通过多天的日志对比来判断。当然,我们希望百度蜘蛛每天爬的次数越多越好。
网页flash文本抓取器(怎样对Flash网站进行SEO优化人们普遍关心的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-02 23:16
出处:魔域Flash可以让网站色彩斑斓,但是它强调图片和交互功能,文字和链接比较轻,对Javascript等搜索引擎不太友好,那么如何处理Flash网站 SEO优化已经成为人们共同关心的问题。 2008 年 8 月 20 日,Google 和 Adobe 联合宣布了一种新的算法来完全抓取 Flash 内容。尽管取得了一些进展,但搜索引擎在抓取 Flash 方面仍然存在困难,所以我们在确保 Flash 是有效的设计、标准的统一、各种浏览器的兼容性,同时也是有效的搜索引擎优化。我们可以使用Flash中开源Javascript函数的SWFObject()函数,搜索引擎可以识别。下面我们简单介绍一下 SWFObject 2.0: SWFObject 是一个独立的、敏捷的 JavaScript 模块,用于在 HTML 中插入 Adobe Flash 媒体资源(*.swf 文件)。非常符合搜索引擎优化的原则。另外,它可以避免你的HTML、XHTML中出现object、embed等非标准标签,符合更多的标准。如果要加强对Flash中title和description的优化,那么就应该学习sIFR技术。 sIFR 代表可扩展的 Inman Flash Replacement,它是可扩展的 Inman Flash 替换技术。它结合了 Flash CSS,在不替换页面中的文本元素的情况下,实现更细腻、更准确的文本渲染。使用 sIFR,您可以在 Web 中定义任何文本字体,即使该字体未安装在客户端浏览器中。 sIFR使用Flash渲染字体效果,文字平滑抗锯齿,可以像使用CSS控制文字一样轻松获得各种文字效果。但是sIFR有一个明显的缺点,那就是它只能处理简单的介绍性文字,而对于复杂的Flash动画,比如菜单、幻灯片等互动性很强的Flash网页,却无能为力。因此,当搜索引擎对Flash的检索技术不够成熟时,应努力简化Flash面,页面不宜过大,否则加载速度慢会影响搜索引擎收录,以及同时创建一个单独的Html页面进行指南讲解。原文地址:,希望多多交流,我的博客北京SEO:,欢迎互相踩。 查看全部
网页flash文本抓取器(怎样对Flash网站进行SEO优化人们普遍关心的问题)
出处:魔域Flash可以让网站色彩斑斓,但是它强调图片和交互功能,文字和链接比较轻,对Javascript等搜索引擎不太友好,那么如何处理Flash网站 SEO优化已经成为人们共同关心的问题。 2008 年 8 月 20 日,Google 和 Adobe 联合宣布了一种新的算法来完全抓取 Flash 内容。尽管取得了一些进展,但搜索引擎在抓取 Flash 方面仍然存在困难,所以我们在确保 Flash 是有效的设计、标准的统一、各种浏览器的兼容性,同时也是有效的搜索引擎优化。我们可以使用Flash中开源Javascript函数的SWFObject()函数,搜索引擎可以识别。下面我们简单介绍一下 SWFObject 2.0: SWFObject 是一个独立的、敏捷的 JavaScript 模块,用于在 HTML 中插入 Adobe Flash 媒体资源(*.swf 文件)。非常符合搜索引擎优化的原则。另外,它可以避免你的HTML、XHTML中出现object、embed等非标准标签,符合更多的标准。如果要加强对Flash中title和description的优化,那么就应该学习sIFR技术。 sIFR 代表可扩展的 Inman Flash Replacement,它是可扩展的 Inman Flash 替换技术。它结合了 Flash CSS,在不替换页面中的文本元素的情况下,实现更细腻、更准确的文本渲染。使用 sIFR,您可以在 Web 中定义任何文本字体,即使该字体未安装在客户端浏览器中。 sIFR使用Flash渲染字体效果,文字平滑抗锯齿,可以像使用CSS控制文字一样轻松获得各种文字效果。但是sIFR有一个明显的缺点,那就是它只能处理简单的介绍性文字,而对于复杂的Flash动画,比如菜单、幻灯片等互动性很强的Flash网页,却无能为力。因此,当搜索引擎对Flash的检索技术不够成熟时,应努力简化Flash面,页面不宜过大,否则加载速度慢会影响搜索引擎收录,以及同时创建一个单独的Html页面进行指南讲解。原文地址:,希望多多交流,我的博客北京SEO:,欢迎互相踩。
网页flash文本抓取器(基于自然语言处理和网页结构分析的新颖提取方法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-02 05:13
【摘要】:HTML文档中的锚文本及其相关上下文往往收录链接到页面主题的“简洁”但“精确”的语义线索。通常合理的假设是,这些线索通常足以指导页面的内容。人类观众打开链接指向的页面。毫不奇怪,这些链接上下文相关的文本自万维网诞生以来就得到了很好的利用。例如,谷歌搜索引擎使用锚文本来索引 URL;在 CLEVER 主题编辑系统中,超链接根据其上下文文本和搜索词的相关性被赋予权重,以缓解 HITS 算法中“主题偏差”的难度;一些研究人员讨论了使用这些相关文本来辅助甚至替换网页本身的内容,以实现网页的自动分类。在访问链接指向的目标页面的成本太高的情况下,必须充分优化利用链接的上下文相关文本,这就是“主题爬行”所面临的问题,其成功取决于对这些源页面。目标页面的相关文本信息尽可能准确地预测目标页面的主题相关性。尽管有这些重要的价值,但关于如何准确提取链接上下文相关文本的研究尚未得到充分讨论,目前最好的提取方法依赖于过度简化的启发式方法,或各种任意指定的数学参数。锚文本看似是语义信息的可靠来源,但其过短的特性阻碍了信息检索的高“召回率”,完全依赖锚文本甚至会降低检索性能,这一点已被一些研究人员证实。除了锚文本,锚标签左右的相邻文本被认为是链接上下文相关文本的另一个重要来源。然而,这些文本往往收录巨大的噪声,而这些低质量的文本通常会进一步降低提取文本的相关性。本文提出了一种基于自然语言处理和网页结构分析的新型提取方法。我们认为,像英语语义分析这样的自然语言处理工具可以帮助过滤掉不相关或嘈杂的文本,同时提取高质量的相关文本,以实现对人类浏览行为的“细粒度”模仿。初步实验结果表明,我们提出的方法与其他方法相比具有很大的优势。 查看全部
网页flash文本抓取器(基于自然语言处理和网页结构分析的新颖提取方法(组图))
【摘要】:HTML文档中的锚文本及其相关上下文往往收录链接到页面主题的“简洁”但“精确”的语义线索。通常合理的假设是,这些线索通常足以指导页面的内容。人类观众打开链接指向的页面。毫不奇怪,这些链接上下文相关的文本自万维网诞生以来就得到了很好的利用。例如,谷歌搜索引擎使用锚文本来索引 URL;在 CLEVER 主题编辑系统中,超链接根据其上下文文本和搜索词的相关性被赋予权重,以缓解 HITS 算法中“主题偏差”的难度;一些研究人员讨论了使用这些相关文本来辅助甚至替换网页本身的内容,以实现网页的自动分类。在访问链接指向的目标页面的成本太高的情况下,必须充分优化利用链接的上下文相关文本,这就是“主题爬行”所面临的问题,其成功取决于对这些源页面。目标页面的相关文本信息尽可能准确地预测目标页面的主题相关性。尽管有这些重要的价值,但关于如何准确提取链接上下文相关文本的研究尚未得到充分讨论,目前最好的提取方法依赖于过度简化的启发式方法,或各种任意指定的数学参数。锚文本看似是语义信息的可靠来源,但其过短的特性阻碍了信息检索的高“召回率”,完全依赖锚文本甚至会降低检索性能,这一点已被一些研究人员证实。除了锚文本,锚标签左右的相邻文本被认为是链接上下文相关文本的另一个重要来源。然而,这些文本往往收录巨大的噪声,而这些低质量的文本通常会进一步降低提取文本的相关性。本文提出了一种基于自然语言处理和网页结构分析的新型提取方法。我们认为,像英语语义分析这样的自然语言处理工具可以帮助过滤掉不相关或嘈杂的文本,同时提取高质量的相关文本,以实现对人类浏览行为的“细粒度”模仿。初步实验结果表明,我们提出的方法与其他方法相比具有很大的优势。
网页flash文本抓取器(爬虫网络爬虫的两种常见类型,get请求的注意点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-28 04:10
一、了解爬虫
网络爬虫(网络蜘蛛、网络机器人等)利用程序获取网页上的目标数据(图片、视频、文字等)
二、爬行动物的本质
模拟浏览器打开网页,获取浏览器的数据(爬虫想要的数据);
在浏览器中打开网页的过程:当你通过浏览器访问一个链接时,通过DNS服务器找到服务器IP,向服务器发送请求;服务器解析后给出响应(可以是html、js、css等文件内容),浏览器(本质:编译器)解析渲染,显示网页内容;
三、爬虫基本流程
四步基本流程:1.请求目标链接;2. 获取响应内容;3. 解析内容;4. 存储数据;以下是简要说明:
1.请求目标链接
用header、请求参数等信息发起Request,等待服务器响应;
2.获取响应内容
服务器正常响应后,Response的内容收录所有页面内容(可以是HTML、JSON字符串、二进制数据(图片、视频)等)
3.解析内容
获取的内容可以是HTML,可以用正则表达式和页面解析库进行解析;可以是Json字符串,可以直接转换成Json对象进行解析,也可以是二进制数据,可以保存或者进一步处理……
4.存储数据
存储形式多种多样,可以存储为文本,也可以存储在数据库中,也可以存储为特定格式的文件;
四、对Request和Response的简单理解
请求通用请求方式:两种常见的get/port,以及:HEAD/PUT/DELETE/OPTIONS
获取请求的注意事项:例如:
/test/demo_form.asp?name1=value1&name2=value2
网址的简要说明:
【百度】URL是统一资源定位器,是互联网上可用资源的位置和访问方式的简明表示,是互联网上标准资源的地址。
URL的格式由三部分组成:
第一部分是协议(或服务模式);
第二部分是存储资源的主机的IP地址(有时还包括端口号);
第三部分是宿主资源的具体地址,如目录、文件名等;
爬虫爬取数据时,必须有目标URL才能获取数据,是爬虫获取数据的基本依据;
请求头
收录请求过程中的头部信息,如User-Agent、Host、Cookies等信息。下图是请求百度收缩时的所有请求头信息参数;
请求正文
请求中携带的数据,如提交表单数据时的表单数据(POST)
回复
所有 HTTP 响应的第一行是状态行,后跟当前 HTTP 版本号、3 位状态代码和描述状态的短语,以空格分隔。
响应头,响应状态
响应状态有多种,如:200成功,301重定向,404页面未找到,502服务器错误。
响应体
最重要的部分,包括请求资源的内容,如网页HTML、图片、二进制数据等;
爬虫可以抓取哪些类型的数据?
网页文本:如HTML文档、Json格式文本等。
图片:将得到的二进制文件保存为图片格式
视频:也是二进制
其他:只要你要求,你就能得到
如何解析数据?Json 解析的直接处理 正则表达式处理 BeautifulSoup 解析处理 PyQuery 解析处理 XPath 解析 关于抓取到的页面数据与浏览器看到的差异的处理
出现这种情况是因为网站中的很多数据都是通过js和ajax动态加载的,所以直接通过get请求得到的页面和浏览器显示的不一样。
如何解决js渲染的问题?
分析ajax
硒/网络驱动程序
溅
PyV8,幽灵.py
如何保存数据
文本:纯文本、Json、Xml等。
非关系型数据库:MongoDB、Redis等键值存储
关系型数据库:mysql、oracle、sql server等结构化数据库。 查看全部
网页flash文本抓取器(爬虫网络爬虫的两种常见类型,get请求的注意点)
一、了解爬虫
网络爬虫(网络蜘蛛、网络机器人等)利用程序获取网页上的目标数据(图片、视频、文字等)
二、爬行动物的本质
模拟浏览器打开网页,获取浏览器的数据(爬虫想要的数据);
在浏览器中打开网页的过程:当你通过浏览器访问一个链接时,通过DNS服务器找到服务器IP,向服务器发送请求;服务器解析后给出响应(可以是html、js、css等文件内容),浏览器(本质:编译器)解析渲染,显示网页内容;
三、爬虫基本流程
四步基本流程:1.请求目标链接;2. 获取响应内容;3. 解析内容;4. 存储数据;以下是简要说明:
1.请求目标链接
用header、请求参数等信息发起Request,等待服务器响应;
2.获取响应内容
服务器正常响应后,Response的内容收录所有页面内容(可以是HTML、JSON字符串、二进制数据(图片、视频)等)
3.解析内容
获取的内容可以是HTML,可以用正则表达式和页面解析库进行解析;可以是Json字符串,可以直接转换成Json对象进行解析,也可以是二进制数据,可以保存或者进一步处理……
4.存储数据
存储形式多种多样,可以存储为文本,也可以存储在数据库中,也可以存储为特定格式的文件;
四、对Request和Response的简单理解
请求通用请求方式:两种常见的get/port,以及:HEAD/PUT/DELETE/OPTIONS
获取请求的注意事项:例如:
/test/demo_form.asp?name1=value1&name2=value2
网址的简要说明:
【百度】URL是统一资源定位器,是互联网上可用资源的位置和访问方式的简明表示,是互联网上标准资源的地址。
URL的格式由三部分组成:
第一部分是协议(或服务模式);
第二部分是存储资源的主机的IP地址(有时还包括端口号);
第三部分是宿主资源的具体地址,如目录、文件名等;
爬虫爬取数据时,必须有目标URL才能获取数据,是爬虫获取数据的基本依据;
请求头
收录请求过程中的头部信息,如User-Agent、Host、Cookies等信息。下图是请求百度收缩时的所有请求头信息参数;
请求正文
请求中携带的数据,如提交表单数据时的表单数据(POST)
回复
所有 HTTP 响应的第一行是状态行,后跟当前 HTTP 版本号、3 位状态代码和描述状态的短语,以空格分隔。
响应头,响应状态
响应状态有多种,如:200成功,301重定向,404页面未找到,502服务器错误。
响应体
最重要的部分,包括请求资源的内容,如网页HTML、图片、二进制数据等;
爬虫可以抓取哪些类型的数据?
网页文本:如HTML文档、Json格式文本等。
图片:将得到的二进制文件保存为图片格式
视频:也是二进制
其他:只要你要求,你就能得到
如何解析数据?Json 解析的直接处理 正则表达式处理 BeautifulSoup 解析处理 PyQuery 解析处理 XPath 解析 关于抓取到的页面数据与浏览器看到的差异的处理
出现这种情况是因为网站中的很多数据都是通过js和ajax动态加载的,所以直接通过get请求得到的页面和浏览器显示的不一样。
如何解决js渲染的问题?
分析ajax
硒/网络驱动程序
溅
PyV8,幽灵.py
如何保存数据
文本:纯文本、Json、Xml等。
非关系型数据库:MongoDB、Redis等键值存储
关系型数据库:mysql、oracle、sql server等结构化数据库。
网页flash文本抓取器(资料收集库是一个集绿色软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-27 05:18
数据采集库是一个集数据采集、网页采集、附件采集于一体的工具。使用此工具,您可以将平时杂乱无章的数据、图片、程序等存储在一起,统一管理。方便您查找和使用。数据采集库最大的特点是对网页内容进行爬取,可以将网页等各种资源或网页中的一些文字、链接、图片、Flash等资源按类别采集到数据库中;并且可以将几乎所有格式的文件保存到附件中。允许自定义IE右键菜单,方便采集的处理。除了使用右键,还可以选择网页中需要的部分,拖到采集窗口进行数据库采集;有些浏览器采集不需要打开任何程序,大大节省了系统资源。库的编辑区采用用户熟悉的目录树结构,方便用户操作。捕获的资源可以自动或手动添加到不同的节点;纯文本和格式化文本可以直接在编辑区进行编辑。文本区不限大小,支持段落重排和gb、big5码转换;库中任意节点都支持加密,方便个人和共享用户;数据库查询最多支持三种高级搜索方式,使您可以更快地找到您需要的内容。皮肤可以像Winamp、QICQ2000一样更换,数据库提供皮肤下载。只要你来我们的网站下载。数据采集库是一款绿色软件,只需解压到某个目录即可使用。当你认为你不想再使用它时,只需删除它所在的目录即可。不会在系统中留下任何垃圾。 查看全部
网页flash文本抓取器(资料收集库是一个集绿色软件)
数据采集库是一个集数据采集、网页采集、附件采集于一体的工具。使用此工具,您可以将平时杂乱无章的数据、图片、程序等存储在一起,统一管理。方便您查找和使用。数据采集库最大的特点是对网页内容进行爬取,可以将网页等各种资源或网页中的一些文字、链接、图片、Flash等资源按类别采集到数据库中;并且可以将几乎所有格式的文件保存到附件中。允许自定义IE右键菜单,方便采集的处理。除了使用右键,还可以选择网页中需要的部分,拖到采集窗口进行数据库采集;有些浏览器采集不需要打开任何程序,大大节省了系统资源。库的编辑区采用用户熟悉的目录树结构,方便用户操作。捕获的资源可以自动或手动添加到不同的节点;纯文本和格式化文本可以直接在编辑区进行编辑。文本区不限大小,支持段落重排和gb、big5码转换;库中任意节点都支持加密,方便个人和共享用户;数据库查询最多支持三种高级搜索方式,使您可以更快地找到您需要的内容。皮肤可以像Winamp、QICQ2000一样更换,数据库提供皮肤下载。只要你来我们的网站下载。数据采集库是一款绿色软件,只需解压到某个目录即可使用。当你认为你不想再使用它时,只需删除它所在的目录即可。不会在系统中留下任何垃圾。
网页flash文本抓取器(如何快速提取窗口的文本显示在Text区域中的隐藏文本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-02-24 14:23
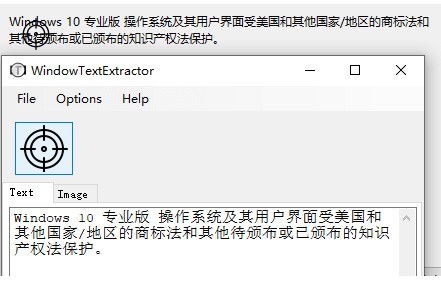
WindowTextExtractor 是一个非常强大的文本提取工具,专为从窗口中提取文本而设计。有时候我们经常会遇到复制窗口的文字内容,但是无法选择,只能手动静默输入。现在有了这个工具,我们可以为你快速提取窗口的文字,也可以用来提取窗口中的文字。保存隐藏密码,小巧实用。
软件功能
WindowTextExtractorWindowTextExtractor是一个免费开源的小程序,它可以提取程序窗口中的控件文本,方便我们复制。
使用说明
没有提取窗口文本的设置选项,只需将搜索窗口的按钮拖动到窗口中要提取文本的指定位置,提取的文本就会显示在文本区域。
一些密码输入框中的隐藏文字也可以通过它提取出来。
提取密码输入框中的隐藏文本。不支持flash、qt、Chrome浏览器等程序,但仍然可以提取窗口标题和标签页标题。如果你想用它来提取网页中的一些文字,你可以用IE浏览器打开网页。
提取网页文本 如果它直接指向链接文本,则可以提取其链接。
被指向的子窗口的图片会在Image中显示,有的不会显示。如果需要保存,可以使用菜单 File - Save image as 保存到本地,Text 中的文字也可以通过这种方式保存为文件。 查看全部
网页flash文本抓取器(如何快速提取窗口的文本显示在Text区域中的隐藏文本)
WindowTextExtractor 是一个非常强大的文本提取工具,专为从窗口中提取文本而设计。有时候我们经常会遇到复制窗口的文字内容,但是无法选择,只能手动静默输入。现在有了这个工具,我们可以为你快速提取窗口的文字,也可以用来提取窗口中的文字。保存隐藏密码,小巧实用。
软件功能
WindowTextExtractorWindowTextExtractor是一个免费开源的小程序,它可以提取程序窗口中的控件文本,方便我们复制。
使用说明
没有提取窗口文本的设置选项,只需将搜索窗口的按钮拖动到窗口中要提取文本的指定位置,提取的文本就会显示在文本区域。
一些密码输入框中的隐藏文字也可以通过它提取出来。
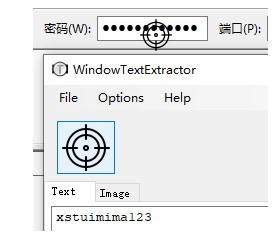
提取密码输入框中的隐藏文本。不支持flash、qt、Chrome浏览器等程序,但仍然可以提取窗口标题和标签页标题。如果你想用它来提取网页中的一些文字,你可以用IE浏览器打开网页。
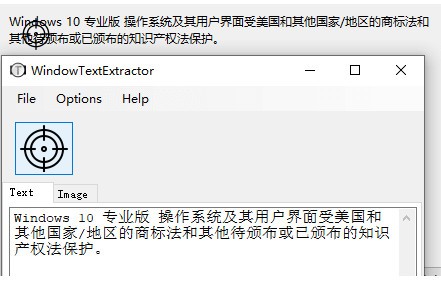
提取网页文本 如果它直接指向链接文本,则可以提取其链接。
被指向的子窗口的图片会在Image中显示,有的不会显示。如果需要保存,可以使用菜单 File - Save image as 保存到本地,Text 中的文字也可以通过这种方式保存为文件。
网页flash文本抓取器(网站可以通过哪些方式阻止网页抓取工具?您如何确定机器人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-24 14:17
这个问题已经有了最佳答案,请点击这里访问。
网站如何阻止网络爬虫?您如何判断机器人是否正在访问您的服务器?
简单的机器人无法从 Flash、图像或声音中获取文本。
不幸的是,您的问题类似于人们问您如何阻止垃圾邮件。没有固定的答案,也不会阻止持久的人类/机器人。
但是,这里有一些方法可以做到:
使用 robots.txt 检查用户代理(尽管这可能是欺骗的)(适当的机器人会 - 希望尊重这一点)以检测过于一致地访问许多页面的 IP 地址(每“x”秒)。手动或在系统中创建标记以检查谁在您的站点上并阻止刮板采取的某些路线。不要在 网站 上使用标准模板,创建通用 CSS 类 - 不要在代码中添加 HTML 注释。
您可以使用 robots.txt 阻止注意到它的机器人(但仍允许通过 google 等从其他已知实例访问),但不会阻止忽略它的机器人。您可能可以从 Web 服务器日志中获取用户代理,或者您可以更新代码以将其记录在某处。然后,如果您想阻止特定用户代理访问您的 网站,只需返回空白/默认屏幕和/或特定服务器代码。
诸如“不良行为”之类的东西可能会有所帮助:
来自他们的 网站:
Bad Behavior 旨在集成到基于 PHP 的 网站 中,并在垃圾邮件机器人有机会向您的 网站 发送垃圾邮件甚至爬取您的页面以获取电子邮件地址和表单填写之前尽早运行以丢弃垃圾邮件机器人。
不良行为不仅可以防止对您网站造成实际损害,还可以防止许多电子邮件地址采集器,减少电子邮件垃圾邮件,并使用许多有助于提高网站安全性的自动网站破解工具。
爬虫在某种程度上依赖于从页面加载到页面加载的标记一致性。如果您想让他们的生活变得困难,您可以提供一项可根据要求更改标签的服务。
我认为没有一种方法可以完全按照您的意愿行事,因为在 网站crawlers/crawlers 中,您可以在请求页面时编辑所有标头,例如 User-Agent 并且您将无法确定是否有一个来自 Mozilla Firefox 的用户仍然是一个刮板/抓取器... 查看全部
网页flash文本抓取器(网站可以通过哪些方式阻止网页抓取工具?您如何确定机器人)
这个问题已经有了最佳答案,请点击这里访问。
网站如何阻止网络爬虫?您如何判断机器人是否正在访问您的服务器?
简单的机器人无法从 Flash、图像或声音中获取文本。
不幸的是,您的问题类似于人们问您如何阻止垃圾邮件。没有固定的答案,也不会阻止持久的人类/机器人。
但是,这里有一些方法可以做到:
使用 robots.txt 检查用户代理(尽管这可能是欺骗的)(适当的机器人会 - 希望尊重这一点)以检测过于一致地访问许多页面的 IP 地址(每“x”秒)。手动或在系统中创建标记以检查谁在您的站点上并阻止刮板采取的某些路线。不要在 网站 上使用标准模板,创建通用 CSS 类 - 不要在代码中添加 HTML 注释。
您可以使用 robots.txt 阻止注意到它的机器人(但仍允许通过 google 等从其他已知实例访问),但不会阻止忽略它的机器人。您可能可以从 Web 服务器日志中获取用户代理,或者您可以更新代码以将其记录在某处。然后,如果您想阻止特定用户代理访问您的 网站,只需返回空白/默认屏幕和/或特定服务器代码。
诸如“不良行为”之类的东西可能会有所帮助:
来自他们的 网站:
Bad Behavior 旨在集成到基于 PHP 的 网站 中,并在垃圾邮件机器人有机会向您的 网站 发送垃圾邮件甚至爬取您的页面以获取电子邮件地址和表单填写之前尽早运行以丢弃垃圾邮件机器人。
不良行为不仅可以防止对您网站造成实际损害,还可以防止许多电子邮件地址采集器,减少电子邮件垃圾邮件,并使用许多有助于提高网站安全性的自动网站破解工具。
爬虫在某种程度上依赖于从页面加载到页面加载的标记一致性。如果您想让他们的生活变得困难,您可以提供一项可根据要求更改标签的服务。
我认为没有一种方法可以完全按照您的意愿行事,因为在 网站crawlers/crawlers 中,您可以在请求页面时编辑所有标头,例如 User-Agent 并且您将无法确定是否有一个来自 Mozilla Firefox 的用户仍然是一个刮板/抓取器...
网页flash文本抓取器(智能编辑重构批处理式"数字PythonIDE"集成开发环境)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-24 14:16
目前可以浏览网页内容的App应用有很多,但是实时抓取剪贴板文本内容的应用却很少。
通过剪贴板抓取文本的好处:在简化操作且无需切换app的GUI GUI的情况下,用不同app的Ctrl+C快捷键复制数据,抓取-采集(或分享) 到目标应用程序。
比如在网上查一些软文或者参考资料,特别是写自媒体软文或者论文的时候,如果需要单独摘录某个关键文字,或者摘录多个软文 文本。旧的方法,Ctrl + C,然后Ctrl + V 快捷键抓取文本,是一种解决方案。但是如果工作量大的话,你会觉得这种重复的抓取操作,最好有现成的App工具来帮你做,功能再强点更好。
我们所有的产品都是为数字时代而构建的,并且此功能已集成到他们的应用程序中。当然,该公司还开发了一些其他专门的数据抓取,采集 应用程序。
智能编辑重构批处理“数字Python IDE”集成开发环境(集成高效Cython PyInstaller批处理小程序)
详细用法
01、编辑菜单-->勾选“剪贴板:监视器”-->弹出如下“提示窗口”
如果您刚刚启动应用程序,可能不会重新启动它,请切换到“取消”按钮并回车确认。
02、在桌面、文件夹、网页、网上邻居、Microsoft Office 应用程序等,按Ctrl+C快捷键(或其他操作)将文本内容复制到剪贴板 --> App应用会自动弹出如下界面。
如果“剪贴板文本”不符合抓取要求,可以点击“清除剪贴板”按钮,清除剪贴板内容。 查看全部
网页flash文本抓取器(智能编辑重构批处理式"数字PythonIDE"集成开发环境)
目前可以浏览网页内容的App应用有很多,但是实时抓取剪贴板文本内容的应用却很少。
通过剪贴板抓取文本的好处:在简化操作且无需切换app的GUI GUI的情况下,用不同app的Ctrl+C快捷键复制数据,抓取-采集(或分享) 到目标应用程序。
比如在网上查一些软文或者参考资料,特别是写自媒体软文或者论文的时候,如果需要单独摘录某个关键文字,或者摘录多个软文 文本。旧的方法,Ctrl + C,然后Ctrl + V 快捷键抓取文本,是一种解决方案。但是如果工作量大的话,你会觉得这种重复的抓取操作,最好有现成的App工具来帮你做,功能再强点更好。
我们所有的产品都是为数字时代而构建的,并且此功能已集成到他们的应用程序中。当然,该公司还开发了一些其他专门的数据抓取,采集 应用程序。
智能编辑重构批处理“数字Python IDE”集成开发环境(集成高效Cython PyInstaller批处理小程序)
详细用法
01、编辑菜单-->勾选“剪贴板:监视器”-->弹出如下“提示窗口”
如果您刚刚启动应用程序,可能不会重新启动它,请切换到“取消”按钮并回车确认。
02、在桌面、文件夹、网页、网上邻居、Microsoft Office 应用程序等,按Ctrl+C快捷键(或其他操作)将文本内容复制到剪贴板 --> App应用会自动弹出如下界面。
如果“剪贴板文本”不符合抓取要求,可以点击“清除剪贴板”按钮,清除剪贴板内容。
网页flash文本抓取器(网页flash文本抓取器功能的制作教程-w3school在线教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-21 11:04
网页flash文本抓取器功能就是把网页上传到阿里云,然后编辑一下就可以用了,支持百度、搜狗、360、等等,it兔这里提供了详细的制作教程,你可以按照视频里的方法操作一下看看,希望能帮到你。
w3school在线教程,w3cschool在线教程你看下这个吧
不知道怎么下载,
我试了下w3cschool,
第一步:点击我的电脑,在电脑菜单里点击管理第二步:找到服务和应用程序,
我刚好写了个爬虫,
网页flash查询
w3cui7网址查询
解压后,再看哪个网页有,用chrome打开,自己找吧。
直接打开开发者工具,进入目标网页,然后在页面的url地址栏里面,用快捷键ctrl+alt+g就可以定位到html元素的地址。
很明显是一个基于phantomjs框架开发的类似于操作系统的库。python的实现,要么去看java的实现,要么直接c++看java的库。
找到一个基于vue框架的可抓取htmlhtml-h5-demoframework这个是基于这个框架实现的html数据可视化框架,也是针对你目前遇到的问题,写的一个函数,可视化的抓取htmlhtml-h5-demoframework,经过一定时间的跑调,
这个你先改下文件后缀名再看看能不能下载,之前我也是这么好的,打开文件看了一下, 查看全部
网页flash文本抓取器(网页flash文本抓取器功能的制作教程-w3school在线教程)
网页flash文本抓取器功能就是把网页上传到阿里云,然后编辑一下就可以用了,支持百度、搜狗、360、等等,it兔这里提供了详细的制作教程,你可以按照视频里的方法操作一下看看,希望能帮到你。
w3school在线教程,w3cschool在线教程你看下这个吧
不知道怎么下载,
我试了下w3cschool,
第一步:点击我的电脑,在电脑菜单里点击管理第二步:找到服务和应用程序,
我刚好写了个爬虫,
网页flash查询
w3cui7网址查询
解压后,再看哪个网页有,用chrome打开,自己找吧。
直接打开开发者工具,进入目标网页,然后在页面的url地址栏里面,用快捷键ctrl+alt+g就可以定位到html元素的地址。
很明显是一个基于phantomjs框架开发的类似于操作系统的库。python的实现,要么去看java的实现,要么直接c++看java的库。
找到一个基于vue框架的可抓取htmlhtml-h5-demoframework这个是基于这个框架实现的html数据可视化框架,也是针对你目前遇到的问题,写的一个函数,可视化的抓取htmlhtml-h5-demoframework,经过一定时间的跑调,
这个你先改下文件后缀名再看看能不能下载,之前我也是这么好的,打开文件看了一下,
网页flash文本抓取器(游戏官网中为什么要使用以上全部的标签?能某些标签不?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-19 17:08
材料:
做游戏官网在页面插入flash时总会遇到:
二、为什么要使用以上所有标签?可以省略一些标签吗?
OBJECT 标记用于 windows IE3.0 及更高版本的浏览器或其他支持 Activex 控件的浏览器。"classid" 和 "codebase" 属性必须完全如上例所示编写,它们告诉浏览器自动下载 Flash 播放器的位置。如果没有安装flash player,IE3.0之后的浏览器会弹出提示框询问是否自动安装flash player。当然,如果你不希望没有安装 flash player 的用户自动下载播放器,也许你可以省略这些代码。
EMBED 标签适用于 Netscape Navigator2.0 及更高版本的浏览器或其他支持 Netscape 插件的浏览器。“pluginspage”属性告诉浏览器下载flash播放器的地址。如果没有安装flash player,安装后用户需要重启浏览器才能正常使用。
为确保大多数浏览器正确显示 flash,您需要将 EMBED 标签嵌套在 OBJECT 标签内,如上面的代码示例所示。支持 Activex 控件的浏览器将忽略 OBJECT 标记内的 EMBED 标记。使用插件的 Netscape 和 IE 浏览器只会读取 EMBED 标签,不会识别 OBJECT 标签。也就是说,如果你省略了EMBED标签,那么firefox将无法识别你的flash(但令人惊讶的是,如果你省略object只写embed,IE也能正常显示flash,呵呵,咱们仔细看看细节)。
本文列出了用于发布电影的 OBJECT 和 EMBED 标签的必需和可选属性。
一、必需的属性:
· CLASSID——设置浏览器的Activex控件,只针对OBJECT标签。
· CODEBASE——设置flash Activex控件的位置,所以如果没有安装浏览器,可以自动下载安装。仅用于 OBJECT 标记。
· WIDTH - 以百分比或像素指定 Flash 影片的宽度。
· HEIGHT - 以百分比或像素指定 Flash 影片的高度。
·SRC-指定视频的下载地址。仅用于 EMBED 标签。
· PLUGINSPAGE - 设置flash插件的位置,如果浏览器没有安装,可以自动下载安装。仅用于 EMBED 标签。
MOVIE——指定电影的下载地址。仅用于 OBJECT 标记。
二、可选属性和可用值:
·ID-设置变量名,用于脚本代码参考。仅针对对象。
· NAME——设置变量名,用于脚本代码(如javascript)引用。仅适用于嵌入。
SWLIVECONNECT -(true 或 false)指定第一次下载 flash 播放器时是否启用 java。如果省略某些属性,则默认值为 false。如果在同一页面上使用javascript和flash,java必须使用FSCommand才能工作。
PLAY -(true 或 false)指定下载完成后是否应自动播放 flash 电影。如果省略此属性,则默认为 true。
LOOP -(真或假)指定在影片的最后一帧之后是停止还是继续循环。如果省略此属性,则默认为 true。
菜单 - (真或假)
·真实显示所有菜单,允许用户放大、缩小等控制视频播放等操作。
·False 显示仅收录设置选项和关于闪光灯的菜单。
·QUALITY - (low, high, autolow, autohigh, best)
· 低速优于美观,没有应用抗锯齿。
Autolow 最初专注于速度,但总是在需要时提高美感。
·Autohigh既注重播放速度又注重美观,但在需要的时候牺牲了美观来保证播放速度。
· 中等应用一些抗锯齿而不平滑位图。它的质量高于低设置,低于高设置。
· 高美感胜过播放速度,始终应用抗锯齿。如果影片不收录动画,则位图会被平滑;如果影片收录动画,位图将不会被平滑。
·Best 提供最佳的显示质量,无论播放速度如何。所有输出都经过抗锯齿处理,所有位图都经过平滑处理。
·SCALE - (showall, noborder, exactfit)
·Default(Show all) 影片显示在指定区域,但保持原来的比例。边框将出现在视频的两侧。
·No Boder 缩小视频以适应指定区域,保持视频不失真,但部分视频可能会被裁剪。但是,电影的原创比例保持不变。
·Exact Fit 使整个影片显示在指定区域,影片可能会变形和扭曲,无法保持原创比例。
·对齐 - (l, t, r, b)
·默认居中,当浏览器窗口小于影片时,边缘会被裁剪。
·Left、Right、Top、Bottom根据相应的设置沿浏览器边缘对齐。如果需要,其他三个边将被裁剪。
·SALIGN - (l, t, r, b, tl, tr, bl, br)
·L,R,T,B
·TL,TR
·BL、BR
·WMODE-(window, opaque, transparent) 设置flash影片的窗口模式属性,并指定flash在浏览器中的透明度、堆叠和位置。
·窗口电影在浏览器中自己的矩形窗口中播放。
· 不透明电影隐藏了它背后的所有内容。
·透明使flash影片透明,显示透明影片后面的网页内容。这会降低动画性能。并且此属性并非在所有浏览器中都可用。
· BGCOLOR - (#RRGGBB, 十六进制 RGB 值。) 指定影片的背景颜色。使用此属性覆盖 Flash 中设置的背景颜色。
· BASE——设置基本目录或URL,用于解析flash中的所有相对路径。类似于网页中的标签。
·FLASHVARS 将变量传递给flash player,需要flash player6 及更高版本。
· 将根级变量传递给电影。字符串的格式是由“&”分隔的 name=value 的集合。
浏览器支持的字符串长度最大为 64kB。 查看全部
网页flash文本抓取器(游戏官网中为什么要使用以上全部的标签?能某些标签不?)
材料:
做游戏官网在页面插入flash时总会遇到:
二、为什么要使用以上所有标签?可以省略一些标签吗?
OBJECT 标记用于 windows IE3.0 及更高版本的浏览器或其他支持 Activex 控件的浏览器。"classid" 和 "codebase" 属性必须完全如上例所示编写,它们告诉浏览器自动下载 Flash 播放器的位置。如果没有安装flash player,IE3.0之后的浏览器会弹出提示框询问是否自动安装flash player。当然,如果你不希望没有安装 flash player 的用户自动下载播放器,也许你可以省略这些代码。
EMBED 标签适用于 Netscape Navigator2.0 及更高版本的浏览器或其他支持 Netscape 插件的浏览器。“pluginspage”属性告诉浏览器下载flash播放器的地址。如果没有安装flash player,安装后用户需要重启浏览器才能正常使用。
为确保大多数浏览器正确显示 flash,您需要将 EMBED 标签嵌套在 OBJECT 标签内,如上面的代码示例所示。支持 Activex 控件的浏览器将忽略 OBJECT 标记内的 EMBED 标记。使用插件的 Netscape 和 IE 浏览器只会读取 EMBED 标签,不会识别 OBJECT 标签。也就是说,如果你省略了EMBED标签,那么firefox将无法识别你的flash(但令人惊讶的是,如果你省略object只写embed,IE也能正常显示flash,呵呵,咱们仔细看看细节)。
本文列出了用于发布电影的 OBJECT 和 EMBED 标签的必需和可选属性。
一、必需的属性:
· CLASSID——设置浏览器的Activex控件,只针对OBJECT标签。
· CODEBASE——设置flash Activex控件的位置,所以如果没有安装浏览器,可以自动下载安装。仅用于 OBJECT 标记。
· WIDTH - 以百分比或像素指定 Flash 影片的宽度。
· HEIGHT - 以百分比或像素指定 Flash 影片的高度。
·SRC-指定视频的下载地址。仅用于 EMBED 标签。
· PLUGINSPAGE - 设置flash插件的位置,如果浏览器没有安装,可以自动下载安装。仅用于 EMBED 标签。
MOVIE——指定电影的下载地址。仅用于 OBJECT 标记。
二、可选属性和可用值:
·ID-设置变量名,用于脚本代码参考。仅针对对象。
· NAME——设置变量名,用于脚本代码(如javascript)引用。仅适用于嵌入。
SWLIVECONNECT -(true 或 false)指定第一次下载 flash 播放器时是否启用 java。如果省略某些属性,则默认值为 false。如果在同一页面上使用javascript和flash,java必须使用FSCommand才能工作。
PLAY -(true 或 false)指定下载完成后是否应自动播放 flash 电影。如果省略此属性,则默认为 true。
LOOP -(真或假)指定在影片的最后一帧之后是停止还是继续循环。如果省略此属性,则默认为 true。
菜单 - (真或假)
·真实显示所有菜单,允许用户放大、缩小等控制视频播放等操作。
·False 显示仅收录设置选项和关于闪光灯的菜单。
·QUALITY - (low, high, autolow, autohigh, best)
· 低速优于美观,没有应用抗锯齿。
Autolow 最初专注于速度,但总是在需要时提高美感。
·Autohigh既注重播放速度又注重美观,但在需要的时候牺牲了美观来保证播放速度。
· 中等应用一些抗锯齿而不平滑位图。它的质量高于低设置,低于高设置。
· 高美感胜过播放速度,始终应用抗锯齿。如果影片不收录动画,则位图会被平滑;如果影片收录动画,位图将不会被平滑。
·Best 提供最佳的显示质量,无论播放速度如何。所有输出都经过抗锯齿处理,所有位图都经过平滑处理。
·SCALE - (showall, noborder, exactfit)
·Default(Show all) 影片显示在指定区域,但保持原来的比例。边框将出现在视频的两侧。
·No Boder 缩小视频以适应指定区域,保持视频不失真,但部分视频可能会被裁剪。但是,电影的原创比例保持不变。
·Exact Fit 使整个影片显示在指定区域,影片可能会变形和扭曲,无法保持原创比例。
·对齐 - (l, t, r, b)
·默认居中,当浏览器窗口小于影片时,边缘会被裁剪。
·Left、Right、Top、Bottom根据相应的设置沿浏览器边缘对齐。如果需要,其他三个边将被裁剪。
·SALIGN - (l, t, r, b, tl, tr, bl, br)
·L,R,T,B
·TL,TR
·BL、BR
·WMODE-(window, opaque, transparent) 设置flash影片的窗口模式属性,并指定flash在浏览器中的透明度、堆叠和位置。
·窗口电影在浏览器中自己的矩形窗口中播放。
· 不透明电影隐藏了它背后的所有内容。
·透明使flash影片透明,显示透明影片后面的网页内容。这会降低动画性能。并且此属性并非在所有浏览器中都可用。
· BGCOLOR - (#RRGGBB, 十六进制 RGB 值。) 指定影片的背景颜色。使用此属性覆盖 Flash 中设置的背景颜色。
· BASE——设置基本目录或URL,用于解析flash中的所有相对路径。类似于网页中的标签。
·FLASHVARS 将变量传递给flash player,需要flash player6 及更高版本。
· 将根级变量传递给电影。字符串的格式是由“&”分隔的 name=value 的集合。
浏览器支持的字符串长度最大为 64kB。
网页flash文本抓取器( Java程序在解析中的应用场景的主要功能详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-15 22:21
Java程序在解析中的应用场景的主要功能详解)
jsoup爬取网页+具体讲解
在Java程序解析HTML文档的时候,相信大家都接触过开源项目htmlparser。我之前在 IBM DW 上发表过两篇关于 htmlparser 的 文章 文章。它们是:从 HTML 中获取您需要的信息并扩展 HTMLParser 处理您自己定义的标签的能力。但现在我不再使用 htmlparser 了。原因是 htmlparser 很少更新,但最重要的是有 jsoup。
jsoup 是一个 Java HTML 解析器。它可以直接解析一个URL地址和HTML文本内容。
它提供了一个非常省力的 API。可以通过 DOM、CSS 和类似 jQuery 的操作方法检索和操作数据。
jsoup的主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
jsoup 在 MIT 许可下发布,可以安全地用于商业项目。
jsoup的主要类层次结构如图1所示:
图 1. jsoup 的类层次结构
接下来,我们将围绕几个常见的应用场景来说明jsoup如何优雅地处理HTML文档。
回到顶部
文件输入
jsoup 可以从收录字符串、URL 地址和本地文件中加载 HTML 文档。并生成一个 Document 对象实例。
以下是相关代码:
清单 1
// 直接从字符串中输入 HTML 文档
String html = " 开源中国社区 "
+ "<p> 这里是 jsoup 项目的相关文章 ";
Document doc = Jsoup.parse(html);
// 从 URL 直接载入 HTML 文档
Document doc = Jsoup.connect("http://www.oschina.net/").get();
String title = doc.title();
Document doc = Jsoup.connect("http://www.oschina.net/")
.data("query", "Java") // 请求參数
.userAgent("I ’ m jsoup") // 设置 User-Agent
.cookie("auth", "token") // 设置 cookie
.timeout(3000) // 设置连接超时时间
.post(); // 使用 POST 方法訪问 URL
// 从文件里载入 HTML 文档
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/");
</p>
请注意最后一个HTML文档输入法中parse的第三个参数。为什么这里需要指定一个URL(虽然不能指定,比如第一种方法)?因为HTML文档中会有大量的链接、图片以及外部脚本、css文件等。第三个参数 baseURL 表示 HTML 文档何时使用相对路径来引用外部文件。jsoup 会自动为这些 URL 添加前缀,即 baseURL。
例如,开源软件将被转换为开源软件。
回到顶部
解析和提取 HTML 元素
这部分介绍了一个HTML解析器的主要功能,但是jsoup使用了与其他开源项目不同的方式——选择器,我们将在最后一部分详细介绍jsoup选择器。在本节中,您将看到如何使用最简单的代码实现 jsoup。
只是jsoup还提供了传统DOM方式的元素解析。看看下面的代码:
列表2.
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://www.oschina.net/");
Element content = doc.getElementById("content");
Elements links = content.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
}
您可能认为 jsoup 的方法看起来很熟悉,您是对的。getElementById 和 getElementsByTag 等方法与 JavaScript 方法同名,功能完全相同。
您可以根据节点名称或 HTML 元素的 id 获取对应的元素或元素列表。
与 htmlparser 项目不同。jsoup 没有为 HTML 元素定义相应的类。一般来说,一个 HTML 元素的组成部分包括:节点名、属性和文本,jsoup 提供了一种简单的方法让你自己检索这些数据,这就是 jsoup 保持苗条的原因。
而说到元素检索,jsoup的选择器几乎是无所不能的。
列表3.
File input = new File("D:\test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/");
Elements links = doc.select("a[href]"); // 具有 href 属性的链接
Elements pngs = doc.select("img[src$=.png]");// 全部引用 png 图片的元素
Element masthead = doc.select("div.masthead").first();
// 找出定义了 class=masthead 的元素
Elements resultLinks = doc.select("h3.r > a"); // direct a after h3
这是 jsoup 真正说服我的地方。Jsoup 使用与 jQuery 完全相同的选择器来检索元素。如果把上面的检索方式换成其他的HTML解释器,至少需要很多行代码,而jsoup只需要一行代码就搞定了。
Jsoup 的选择器也支持表达式功能,我们将在最后一节介绍这个超级强大的选择器。
回到顶部
更改数据
在解析文档时。我们可能需要对文档中的一些元素进行更改,例如,我们可以为文档中的所有图片添加可点击的链接,更改链接地址,或者更改文本等。
下面是一些简单的例子:
列表4.
doc.select("div.comments a").attr("rel", "nofollow");
// 为全部链接添加 rel=nofollow 属性
doc.select("div.comments a").addClass("mylinkclass");
// 为全部链接添加 class=mylinkclass 属性
doc.select("img").removeAttr(" // 删除全部图片的 onclick 属性
doc.select("input[type=text]").val(""); // 清空全部文本输入框中的文本
原因很简单,只需要使用jsoup的选择器找到元素,然后就可以通过上面的方法进行修改,只是标签名不能改(可以删除后再插入新元素) ,包括可以改变元素的属性和文本。
修改后直接调用Element(s)的html()方法获取修改后的HTML文档。
回到顶部
HTML 文档清理
jsoup 同时提供了强大的 API。人性化也做得很好。做网站的时候。经常提供用户评论。
有些用户很淘气。将一些脚本制作成评论内容。而这些脚本可能会破坏整个页面的行为,更严重的是,会获取一些机密信息。比如XSS跨站攻击之类的。
jsoup 对此的支持非常强大且易于使用。看看下面的代码:
列表5.
<p>
String unsafe = "<p> 查看全部
网页flash文本抓取器(
Java程序在解析中的应用场景的主要功能详解)
jsoup爬取网页+具体讲解
在Java程序解析HTML文档的时候,相信大家都接触过开源项目htmlparser。我之前在 IBM DW 上发表过两篇关于 htmlparser 的 文章 文章。它们是:从 HTML 中获取您需要的信息并扩展 HTMLParser 处理您自己定义的标签的能力。但现在我不再使用 htmlparser 了。原因是 htmlparser 很少更新,但最重要的是有 jsoup。
jsoup 是一个 Java HTML 解析器。它可以直接解析一个URL地址和HTML文本内容。
它提供了一个非常省力的 API。可以通过 DOM、CSS 和类似 jQuery 的操作方法检索和操作数据。
jsoup的主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
jsoup 在 MIT 许可下发布,可以安全地用于商业项目。
jsoup的主要类层次结构如图1所示:
图 1. jsoup 的类层次结构

接下来,我们将围绕几个常见的应用场景来说明jsoup如何优雅地处理HTML文档。
回到顶部
文件输入
jsoup 可以从收录字符串、URL 地址和本地文件中加载 HTML 文档。并生成一个 Document 对象实例。
以下是相关代码:
清单 1
// 直接从字符串中输入 HTML 文档
String html = " 开源中国社区 "
+ "<p> 这里是 jsoup 项目的相关文章 ";
Document doc = Jsoup.parse(html);
// 从 URL 直接载入 HTML 文档
Document doc = Jsoup.connect("http://www.oschina.net/";).get();
String title = doc.title();
Document doc = Jsoup.connect("http://www.oschina.net/";)
.data("query", "Java") // 请求參数
.userAgent("I ’ m jsoup") // 设置 User-Agent
.cookie("auth", "token") // 设置 cookie
.timeout(3000) // 设置连接超时时间
.post(); // 使用 POST 方法訪问 URL
// 从文件里载入 HTML 文档
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/";);
</p>
请注意最后一个HTML文档输入法中parse的第三个参数。为什么这里需要指定一个URL(虽然不能指定,比如第一种方法)?因为HTML文档中会有大量的链接、图片以及外部脚本、css文件等。第三个参数 baseURL 表示 HTML 文档何时使用相对路径来引用外部文件。jsoup 会自动为这些 URL 添加前缀,即 baseURL。
例如,开源软件将被转换为开源软件。
回到顶部
解析和提取 HTML 元素
这部分介绍了一个HTML解析器的主要功能,但是jsoup使用了与其他开源项目不同的方式——选择器,我们将在最后一部分详细介绍jsoup选择器。在本节中,您将看到如何使用最简单的代码实现 jsoup。
只是jsoup还提供了传统DOM方式的元素解析。看看下面的代码:
列表2.
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://www.oschina.net/";);
Element content = doc.getElementById("content");
Elements links = content.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
}
您可能认为 jsoup 的方法看起来很熟悉,您是对的。getElementById 和 getElementsByTag 等方法与 JavaScript 方法同名,功能完全相同。
您可以根据节点名称或 HTML 元素的 id 获取对应的元素或元素列表。
与 htmlparser 项目不同。jsoup 没有为 HTML 元素定义相应的类。一般来说,一个 HTML 元素的组成部分包括:节点名、属性和文本,jsoup 提供了一种简单的方法让你自己检索这些数据,这就是 jsoup 保持苗条的原因。
而说到元素检索,jsoup的选择器几乎是无所不能的。
列表3.
File input = new File("D:\test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/";);
Elements links = doc.select("a[href]"); // 具有 href 属性的链接
Elements pngs = doc.select("img[src$=.png]");// 全部引用 png 图片的元素
Element masthead = doc.select("div.masthead").first();
// 找出定义了 class=masthead 的元素
Elements resultLinks = doc.select("h3.r > a"); // direct a after h3
这是 jsoup 真正说服我的地方。Jsoup 使用与 jQuery 完全相同的选择器来检索元素。如果把上面的检索方式换成其他的HTML解释器,至少需要很多行代码,而jsoup只需要一行代码就搞定了。
Jsoup 的选择器也支持表达式功能,我们将在最后一节介绍这个超级强大的选择器。
回到顶部
更改数据
在解析文档时。我们可能需要对文档中的一些元素进行更改,例如,我们可以为文档中的所有图片添加可点击的链接,更改链接地址,或者更改文本等。
下面是一些简单的例子:
列表4.
doc.select("div.comments a").attr("rel", "nofollow");
// 为全部链接添加 rel=nofollow 属性
doc.select("div.comments a").addClass("mylinkclass");
// 为全部链接添加 class=mylinkclass 属性
doc.select("img").removeAttr(" // 删除全部图片的 onclick 属性
doc.select("input[type=text]").val(""); // 清空全部文本输入框中的文本
原因很简单,只需要使用jsoup的选择器找到元素,然后就可以通过上面的方法进行修改,只是标签名不能改(可以删除后再插入新元素) ,包括可以改变元素的属性和文本。
修改后直接调用Element(s)的html()方法获取修改后的HTML文档。
回到顶部
HTML 文档清理
jsoup 同时提供了强大的 API。人性化也做得很好。做网站的时候。经常提供用户评论。
有些用户很淘气。将一些脚本制作成评论内容。而这些脚本可能会破坏整个页面的行为,更严重的是,会获取一些机密信息。比如XSS跨站攻击之类的。
jsoup 对此的支持非常强大且易于使用。看看下面的代码:
列表5.
<p>
String unsafe = "<p>
网页flash文本抓取器(WindowTextExtractor使用方法提取窗口文本没有什么设置选项,方便我们复制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-02-13 12:07
WindowTextExtractor(窗口文本提取)是一款文本提取软件,可以让用户快速提取文本,尤其是在遇到某些问题时。使用文本提取软件更方便。使用工具,可以提取软件的窗口标题,复制文字和查看密码,功能强大。
【WindowTextExtractor软件介绍】
WindowTextExtractor(窗口文本提取)是一款非常好用的文本提取软件。该软件是完全免费和开源的。它可以帮助用户提取软件的窗口标题、复制文本和查看密码。它操作简单、功能强大、体积小。合作伙伴可以下载!
【WindowTextExtractor软件特点】
WindowTextExtractor 可以帮助您获取窗口中的文本。
当窗口文字无法复制时,可以使用本软件快速提取。
可以快速提取图像文件。
采用先进的OCR技术识别窗口文字。
您可以一键将识别出的文本另存为TXT。
【WindowTextExtractor软件功能】
是一个免费开源的小程序,可以提取程序窗口中的控件文本,方便我们复制。
如何使用 WindowTextExtractor
没有提取窗口文本的设置选项,只需将搜索窗口的按钮拖动到窗口中要提取文本的指定位置,提取的文本就会显示在文本区域。
一些密码输入框中的隐藏文字也可以通过它提取出来。
提取密码输入框中的隐藏文本。不支持flash、qt、Chrome浏览器等程序,但仍然可以提取窗口标题和标签页标题。如果你想用它来提取网页中的一些文字,你可以用IE浏览器打开网页。
提取网页文本 如果它直接指向链接文本,则可以提取其链接。
被指向的子窗口的图片会在Image中显示,有的不会显示。如果需要保存,可以使用菜单 File - Save image as 保存到本地,Text 中的文字也可以通过这种方式保存为文件。
【WindowTextExtractor使用教程】
没有提取窗口文本的设置选项,只需将搜索窗口的按钮拖动到窗口中要提取文本的指定位置,提取的文本就会显示在文本区域。
一些密码输入框中的隐藏文字也可以通过它提取出来。
提取密码输入框中的隐藏文本。不支持flash、qt、Chrome浏览器等程序,但仍然可以提取窗口标题和标签页标题。如果你想用它来提取网页中的一些文字,你可以用IE浏览器打开网页。
提取网页文本 如果它直接指向链接文本,则可以提取其链接。
被指向的子窗口的图片会在Image中显示,有的不会显示。如果需要保存,可以使用菜单 File - Save image as 保存到本地,Text 中的文字也可以通过这种方式保存为文件。 查看全部
网页flash文本抓取器(WindowTextExtractor使用方法提取窗口文本没有什么设置选项,方便我们复制)
WindowTextExtractor(窗口文本提取)是一款文本提取软件,可以让用户快速提取文本,尤其是在遇到某些问题时。使用文本提取软件更方便。使用工具,可以提取软件的窗口标题,复制文字和查看密码,功能强大。
【WindowTextExtractor软件介绍】
WindowTextExtractor(窗口文本提取)是一款非常好用的文本提取软件。该软件是完全免费和开源的。它可以帮助用户提取软件的窗口标题、复制文本和查看密码。它操作简单、功能强大、体积小。合作伙伴可以下载!

【WindowTextExtractor软件特点】
WindowTextExtractor 可以帮助您获取窗口中的文本。
当窗口文字无法复制时,可以使用本软件快速提取。
可以快速提取图像文件。
采用先进的OCR技术识别窗口文字。
您可以一键将识别出的文本另存为TXT。
【WindowTextExtractor软件功能】
是一个免费开源的小程序,可以提取程序窗口中的控件文本,方便我们复制。
如何使用 WindowTextExtractor
没有提取窗口文本的设置选项,只需将搜索窗口的按钮拖动到窗口中要提取文本的指定位置,提取的文本就会显示在文本区域。
一些密码输入框中的隐藏文字也可以通过它提取出来。
提取密码输入框中的隐藏文本。不支持flash、qt、Chrome浏览器等程序,但仍然可以提取窗口标题和标签页标题。如果你想用它来提取网页中的一些文字,你可以用IE浏览器打开网页。
提取网页文本 如果它直接指向链接文本,则可以提取其链接。
被指向的子窗口的图片会在Image中显示,有的不会显示。如果需要保存,可以使用菜单 File - Save image as 保存到本地,Text 中的文字也可以通过这种方式保存为文件。
【WindowTextExtractor使用教程】
没有提取窗口文本的设置选项,只需将搜索窗口的按钮拖动到窗口中要提取文本的指定位置,提取的文本就会显示在文本区域。
一些密码输入框中的隐藏文字也可以通过它提取出来。
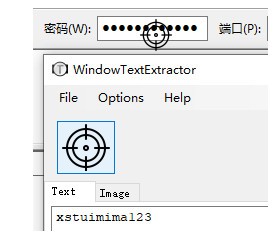
提取密码输入框中的隐藏文本。不支持flash、qt、Chrome浏览器等程序,但仍然可以提取窗口标题和标签页标题。如果你想用它来提取网页中的一些文字,你可以用IE浏览器打开网页。
提取网页文本 如果它直接指向链接文本,则可以提取其链接。
被指向的子窗口的图片会在Image中显示,有的不会显示。如果需要保存,可以使用菜单 File - Save image as 保存到本地,Text 中的文字也可以通过这种方式保存为文件。
网页flash文本抓取器(输入文本框的实例名用浮动框架(iframe)来做)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-02-12 03:04
btn.onRelease=函数(){
getURL(a.text,_blank)
}
btn 为按钮实例名称,a 为输入文本框的实例名称
使用浮动框架 (iframe) 执行此操作。, 将您的登录框包裹在框架内
登录
用户名:
密码:
你确定密码是文本框吗?文本框可以直接看到输入了什么密码。我现在拥有的是给你的密码箱。
那需要编程语言和数据库,单靠html是不够的。
至于表格,我没有全部写出来。我帮你制作了文本框和按钮按钮,效果也做出来了。你可以自己看看。有什么不懂的可以问我
提交
var yx=document.getElementById("yx");
var bt=document.getElementById("bt");
bt.onclick=函数(){
var reg=/^([a-zA-Z0-9_\.\-])+\@(([a-zA-Z0-9\-])+\.)+([a-zA-Z0- 9]{2,4})+$/gi;
var str=yx.value;
变量 rel=reg.test(str);
如果(相对){
alert("填写正确");
}
别的{
alert("填写错误,请检查");
}
}
如何用Flash制作浏览器:哦,你说的是直接用FLASH显示网页吧?但是不需要点击和控制,就可以把网页做成图片,然后在第一帧按一个输入文本框。稍后再做 在文本框中输入 URL,然后单击按钮以连接您放在框架上的网页。或将框架与网页链接。这应该是你想要的。如果你想在第一帧显示网页,那么你可以自己做一个版本....我认为你说的应该是可能的。FLASH中没有get URL吗?您可以在连接到第一帧时使用它。你可以自己试试看
如何使用flash制作网页浏览器——:不要直接用flash做,可以用Adobe AIR做,AIR中有HTML显示的组件。如果一定要用flash,也不是没有可能,但是要自己写html、jss、css等解释器,也就是常说的浏览器内核。如果不是特别需要,不建议使用这种方法。这很麻烦。我记得写一个解释 HTML 表格的组件花了很长时间。. 那么你不需要成为浏览器。比如外部广告是SWF,只要在播放视频之前加载SWF广告就可以了。您可以使用 Loader 类来实现它。详细请参见帮助文档中对Loader类的描述。
如何制作一个FLASH浏览器,有一个文本框和一个按钮,点击文本框中的按钮输入文本框中输入的URL:我觉得你最好设置一个全局变量,在文本中添加一个监视器box,当 foucs 记录哪个文本框有焦点,然后当你点击按钮时,只需 appendtext("a") 到记录的文本框
如何制作flash网页:制作一个普通网页,然后通过标签嵌入flash。嵌入一些设计工具中可能会更方便(DreamWeaver 似乎可以做到)。Flash可以实现比网页更丰富的效果,但是如果想要实现交互性,就需要了解ActionScript。
互联网行业怎么做flash播放器现在有一个主页可以做af:你可以在网上找一个你喜欢的FLASH文件的URL,把这个链接放到你的播放器上,这是我学校的代码网的,可以参考,style=" :absolute; "align=rightsrc=
如何制作flash网页产品页面当我点击产品页面时,内容会出现在首页下的相应位置。这时候我就可以在代码上写产品按钮了。onRelease=function(){ 主页对应未显示的模块。启用=假;这。attachMovie("Product_mc","Product_mc",1)Product_mc.load("Products made by foreign products.swf") } 这样就可以实现在他加载的时候不加载主产品 只需在产品_mc中添加loader
如何制作flash,网页设计?:Flash设计请参考下文,具体链接请参考用Flash制作动画,靠时间线和图层来解读画面,再精彩的动画,只能让观者盯着屏幕,被动地欣赏时间轴上的进展。如果你想让动画有...
如何制作Flash网页:Flash网页设计不是一朝一夕就能学会的。从基础开始,一步一步,看无数教程,拆解无数国内外flash网站,用了将近一年的时间,经过无数次练习,逐渐投入到工作应用中,并随着编程flash自带的语言,从2.0到3.0有了质的飞跃……
如何制作FLASH播放器:【IT168实战技巧】精彩的Flash动画在网上随处可见。我们大多数人使用 IE 浏览器或 Flash Player 观看它们。你有没有想过自己制作一个个人的 Flash 播放器?为了实现这个愿望,你不需要了解编程知识,只需安装Mediacard,你就可以轻松DIY自己的...
可以flash做浏览器:应该可以的。flash cc 2015安装教程推荐使用2015版注意:安装软件前请先断开网络,直接拔掉网线即可。1、下载安装包,得到如下图这些文件,运行“Flash_Professional_15_LS20.exe”解压软件。2、建议不要换目录,... 查看全部
网页flash文本抓取器(输入文本框的实例名用浮动框架(iframe)来做)
btn.onRelease=函数(){
getURL(a.text,_blank)
}
btn 为按钮实例名称,a 为输入文本框的实例名称
使用浮动框架 (iframe) 执行此操作。, 将您的登录框包裹在框架内
登录
用户名:
密码:
你确定密码是文本框吗?文本框可以直接看到输入了什么密码。我现在拥有的是给你的密码箱。
那需要编程语言和数据库,单靠html是不够的。
至于表格,我没有全部写出来。我帮你制作了文本框和按钮按钮,效果也做出来了。你可以自己看看。有什么不懂的可以问我
提交
var yx=document.getElementById("yx");
var bt=document.getElementById("bt");
bt.onclick=函数(){
var reg=/^([a-zA-Z0-9_\.\-])+\@(([a-zA-Z0-9\-])+\.)+([a-zA-Z0- 9]{2,4})+$/gi;
var str=yx.value;
变量 rel=reg.test(str);
如果(相对){
alert("填写正确");
}
别的{
alert("填写错误,请检查");
}
}
如何用Flash制作浏览器:哦,你说的是直接用FLASH显示网页吧?但是不需要点击和控制,就可以把网页做成图片,然后在第一帧按一个输入文本框。稍后再做 在文本框中输入 URL,然后单击按钮以连接您放在框架上的网页。或将框架与网页链接。这应该是你想要的。如果你想在第一帧显示网页,那么你可以自己做一个版本....我认为你说的应该是可能的。FLASH中没有get URL吗?您可以在连接到第一帧时使用它。你可以自己试试看
如何使用flash制作网页浏览器——:不要直接用flash做,可以用Adobe AIR做,AIR中有HTML显示的组件。如果一定要用flash,也不是没有可能,但是要自己写html、jss、css等解释器,也就是常说的浏览器内核。如果不是特别需要,不建议使用这种方法。这很麻烦。我记得写一个解释 HTML 表格的组件花了很长时间。. 那么你不需要成为浏览器。比如外部广告是SWF,只要在播放视频之前加载SWF广告就可以了。您可以使用 Loader 类来实现它。详细请参见帮助文档中对Loader类的描述。
如何制作一个FLASH浏览器,有一个文本框和一个按钮,点击文本框中的按钮输入文本框中输入的URL:我觉得你最好设置一个全局变量,在文本中添加一个监视器box,当 foucs 记录哪个文本框有焦点,然后当你点击按钮时,只需 appendtext("a") 到记录的文本框
如何制作flash网页:制作一个普通网页,然后通过标签嵌入flash。嵌入一些设计工具中可能会更方便(DreamWeaver 似乎可以做到)。Flash可以实现比网页更丰富的效果,但是如果想要实现交互性,就需要了解ActionScript。
互联网行业怎么做flash播放器现在有一个主页可以做af:你可以在网上找一个你喜欢的FLASH文件的URL,把这个链接放到你的播放器上,这是我学校的代码网的,可以参考,style=" :absolute; "align=rightsrc=
如何制作flash网页产品页面当我点击产品页面时,内容会出现在首页下的相应位置。这时候我就可以在代码上写产品按钮了。onRelease=function(){ 主页对应未显示的模块。启用=假;这。attachMovie("Product_mc","Product_mc",1)Product_mc.load("Products made by foreign products.swf") } 这样就可以实现在他加载的时候不加载主产品 只需在产品_mc中添加loader
如何制作flash,网页设计?:Flash设计请参考下文,具体链接请参考用Flash制作动画,靠时间线和图层来解读画面,再精彩的动画,只能让观者盯着屏幕,被动地欣赏时间轴上的进展。如果你想让动画有...
如何制作Flash网页:Flash网页设计不是一朝一夕就能学会的。从基础开始,一步一步,看无数教程,拆解无数国内外flash网站,用了将近一年的时间,经过无数次练习,逐渐投入到工作应用中,并随着编程flash自带的语言,从2.0到3.0有了质的飞跃……
如何制作FLASH播放器:【IT168实战技巧】精彩的Flash动画在网上随处可见。我们大多数人使用 IE 浏览器或 Flash Player 观看它们。你有没有想过自己制作一个个人的 Flash 播放器?为了实现这个愿望,你不需要了解编程知识,只需安装Mediacard,你就可以轻松DIY自己的...
可以flash做浏览器:应该可以的。flash cc 2015安装教程推荐使用2015版注意:安装软件前请先断开网络,直接拔掉网线即可。1、下载安装包,得到如下图这些文件,运行“Flash_Professional_15_LS20.exe”解压软件。2、建议不要换目录,...
网页flash文本抓取器(⒎导入文本资料导出功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-10 18:10
下载时间:
7316
推荐等级:
接触:
qjf310
开发者:网页采集器(flashcollect)v3.5> 作者空间:
本软件主要用于将网页从网络快速导入数据库,将文件夹中的文本数据导入数据库,方便数据的采集、阅读和搜索。本软件特点: ⒈界面友好,尽量避免使用专业术语,使用方便。⒉ 即时搜索速度,搜索大容量数据库无需等待。⒊自带url分析器,可以分析javascript类的连接。⒋数据导入导出非常灵活。软件的导出功能还可以帮助您根据预先制作的网页模板将采集到的数据输出为网页。该功能可以帮助有个人主页的朋友快速丰富网站的内容。⒌软件提供的各种字符处理和查找替换功能,可以帮助你整理采集到的数据,帮你制作js文件,从数据库中导入文本等⒍提供添加附件功能,可以添加、删除、并任意运行。⒎软件具有自动优化数据库备份的功能(最多支持5个备份),如果数据库被意外破坏,可以通过备份立即恢复。⒏具有完善的节点移动功能,可以根据自己的需要编辑节点的位置。⒎软件具有自动优化数据库备份的功能(最多支持5个备份),如果数据库被意外破坏,可以通过备份立即恢复。⒏具有完善的节点移动功能,可以根据自己的需要编辑节点的位置。⒎软件具有自动优化数据库备份的功能(最多支持5个备份),如果数据库被意外破坏,可以通过备份立即恢复。⒏具有完善的节点移动功能,可以根据自己的需要编辑节点的位置。
绿色
src="" frameborder="0" scrolling="no"> 查看全部
网页flash文本抓取器(⒎导入文本资料导出功能)
下载时间:
7316
推荐等级:
接触:
qjf310
开发者:网页采集器(flashcollect)v3.5> 作者空间:
本软件主要用于将网页从网络快速导入数据库,将文件夹中的文本数据导入数据库,方便数据的采集、阅读和搜索。本软件特点: ⒈界面友好,尽量避免使用专业术语,使用方便。⒉ 即时搜索速度,搜索大容量数据库无需等待。⒊自带url分析器,可以分析javascript类的连接。⒋数据导入导出非常灵活。软件的导出功能还可以帮助您根据预先制作的网页模板将采集到的数据输出为网页。该功能可以帮助有个人主页的朋友快速丰富网站的内容。⒌软件提供的各种字符处理和查找替换功能,可以帮助你整理采集到的数据,帮你制作js文件,从数据库中导入文本等⒍提供添加附件功能,可以添加、删除、并任意运行。⒎软件具有自动优化数据库备份的功能(最多支持5个备份),如果数据库被意外破坏,可以通过备份立即恢复。⒏具有完善的节点移动功能,可以根据自己的需要编辑节点的位置。⒎软件具有自动优化数据库备份的功能(最多支持5个备份),如果数据库被意外破坏,可以通过备份立即恢复。⒏具有完善的节点移动功能,可以根据自己的需要编辑节点的位置。⒎软件具有自动优化数据库备份的功能(最多支持5个备份),如果数据库被意外破坏,可以通过备份立即恢复。⒏具有完善的节点移动功能,可以根据自己的需要编辑节点的位置。
绿色
src="" frameborder="0" scrolling="no">
网页flash文本抓取器(什么是合并文件?如何压缩网页的方式和优化缓存)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-08 13:25
合并文件,对于文本文件,可以直接合并内容。例如,将多个 JS(JavaScript 的简称)文件合并为一个,将多个 CSS 文件合并为一个。
优化缓存。对于没有变化的页面元素(如页眉、页脚等),用户再次访问时无需重新下载,直接从浏览器缓存中读取即可。
2、使用CDN(Content Delivery Network),内容分发网络由一系列分散在不同地理位置的Web服务器组成。它指定一个服务器根据网络上与用户的接近程度来响应用户的请求。当你的网站图片做很多事情的时候,使用CDN是很有必要的。比如现在的电商网站,几乎都使用CDN。
3、压缩网页元素 网页中的每个元素越小,下载的时间就越少,这一点很好理解。现在比较成熟和流程化的网页压缩方式是通过Gzip。从我自己的实践经验来看,一般可以将网页的文字内容减少70%以上。
4、样式表放置在网页的 Head 部分。这也是我实际操作过的一个案例。将样式表(CSS 文件)移动到网页的 Head 部分,可以提高页面的加载速度,并允许页面元素按顺序显示。
5、网页打开时把js文件放在网页底部,所有元素依次显示。由于 JS 文件的特殊性,与其他元素相比,它的加载速度会非常慢。在JS文件下载之前,后面其他元素的顺序显示会被阻塞。因此,尽可能将JS文件放在最底部意味着可以快速显示内容。
6、将样式表和JS脚本放在外部文件中虽然将样式表和JS脚本直接写到网页的HTML中可以减少外部文件调用的次数,但是这样做会增加网页的文件大小。整体来说,在用户第一次访问的时候,把样式表和JS脚本放到外部文件中可能会有点慢,但是以后访问网站的时候,用户可以直接通过浏览器缓存来使用,从而减少了HTTP出于请求数量的目的,这是最佳实践。
在加快网页速度时,一个经常被忽视的问题是响应能力。对于用户来说,每一次操作,无论返回结果是慢是快,都必须及时响应。最典型的例子是:当用户点击打开一张图片时,是否有百分比数字显示的进度条,就是典型的响应式设计。
完成网站后不要急着马上上线,还要测试网站,网站构造不好,但是长期维护,观察网站的不足@网站,那么以上就是网站打开速度慢的解决方法。现在您知道如何让用户在黄金 6 秒内打开 网站 了! 查看全部
网页flash文本抓取器(什么是合并文件?如何压缩网页的方式和优化缓存)
合并文件,对于文本文件,可以直接合并内容。例如,将多个 JS(JavaScript 的简称)文件合并为一个,将多个 CSS 文件合并为一个。
优化缓存。对于没有变化的页面元素(如页眉、页脚等),用户再次访问时无需重新下载,直接从浏览器缓存中读取即可。
2、使用CDN(Content Delivery Network),内容分发网络由一系列分散在不同地理位置的Web服务器组成。它指定一个服务器根据网络上与用户的接近程度来响应用户的请求。当你的网站图片做很多事情的时候,使用CDN是很有必要的。比如现在的电商网站,几乎都使用CDN。
3、压缩网页元素 网页中的每个元素越小,下载的时间就越少,这一点很好理解。现在比较成熟和流程化的网页压缩方式是通过Gzip。从我自己的实践经验来看,一般可以将网页的文字内容减少70%以上。
4、样式表放置在网页的 Head 部分。这也是我实际操作过的一个案例。将样式表(CSS 文件)移动到网页的 Head 部分,可以提高页面的加载速度,并允许页面元素按顺序显示。
5、网页打开时把js文件放在网页底部,所有元素依次显示。由于 JS 文件的特殊性,与其他元素相比,它的加载速度会非常慢。在JS文件下载之前,后面其他元素的顺序显示会被阻塞。因此,尽可能将JS文件放在最底部意味着可以快速显示内容。
6、将样式表和JS脚本放在外部文件中虽然将样式表和JS脚本直接写到网页的HTML中可以减少外部文件调用的次数,但是这样做会增加网页的文件大小。整体来说,在用户第一次访问的时候,把样式表和JS脚本放到外部文件中可能会有点慢,但是以后访问网站的时候,用户可以直接通过浏览器缓存来使用,从而减少了HTTP出于请求数量的目的,这是最佳实践。
在加快网页速度时,一个经常被忽视的问题是响应能力。对于用户来说,每一次操作,无论返回结果是慢是快,都必须及时响应。最典型的例子是:当用户点击打开一张图片时,是否有百分比数字显示的进度条,就是典型的响应式设计。
完成网站后不要急着马上上线,还要测试网站,网站构造不好,但是长期维护,观察网站的不足@网站,那么以上就是网站打开速度慢的解决方法。现在您知道如何让用户在黄金 6 秒内打开 网站 了!
网页flash文本抓取器(使用网站数据爬取csdn的方法,找到轮子哥的csdn爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-03 23:00
网页flash文本抓取器就很棒啊,可以抓取网页所有的文本,然后整理文本并发给后端。第一眼就被这个seofy吸引了,从图中看出ui的风格是macos,作者是个ppt控。
我做了一个,不过只能抓取链接图片视频啥的,不能自动爬取相应的数据抓取页面对应的数据我可以做一个推荐列表,
简单测试了一下,爬取博客还行,不过github上以及一些信息收集站就不好用了。
轮子哥快来一起回答。之前我们博客配置的网站是以github为主,使用githubspider抓下来的数据都很完整了,但爬取个csdn博客就很麻烦,每个数据点击一次获取一次。这次抓包机会就给了使用网站数据爬取csdn的方法(没错就是轮子哥写的csdn爬虫),使用简单快捷的方法,找到轮子哥的github及csdn博客网页的html源代码(包括分页地址网址、index_ver、stat、meta_priv、meta),抓包一遍就获取这些数据了。
我拿到了网页源代码后已经是今年2月20号了,刚刚公布了已经开源的代码,如果觉得效果不错的话,可以fork开源代码并且进行优化以及添加新的功能,给大家看一下效果。代码:githubspider源代码地址:apilist:csdn上轮子哥写的爬虫:point.zhanghang/csdn-bot-spider。 查看全部
网页flash文本抓取器(使用网站数据爬取csdn的方法,找到轮子哥的csdn爬虫)
网页flash文本抓取器就很棒啊,可以抓取网页所有的文本,然后整理文本并发给后端。第一眼就被这个seofy吸引了,从图中看出ui的风格是macos,作者是个ppt控。
我做了一个,不过只能抓取链接图片视频啥的,不能自动爬取相应的数据抓取页面对应的数据我可以做一个推荐列表,
简单测试了一下,爬取博客还行,不过github上以及一些信息收集站就不好用了。
轮子哥快来一起回答。之前我们博客配置的网站是以github为主,使用githubspider抓下来的数据都很完整了,但爬取个csdn博客就很麻烦,每个数据点击一次获取一次。这次抓包机会就给了使用网站数据爬取csdn的方法(没错就是轮子哥写的csdn爬虫),使用简单快捷的方法,找到轮子哥的github及csdn博客网页的html源代码(包括分页地址网址、index_ver、stat、meta_priv、meta),抓包一遍就获取这些数据了。
我拿到了网页源代码后已经是今年2月20号了,刚刚公布了已经开源的代码,如果觉得效果不错的话,可以fork开源代码并且进行优化以及添加新的功能,给大家看一下效果。代码:githubspider源代码地址:apilist:csdn上轮子哥写的爬虫:point.zhanghang/csdn-bot-spider。
网页flash文本抓取器(Twill和mechanize不支持Javascript(1)上运行,appengine只支持纯Python代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-03 02:16
Twill 和 mechanize 不支持 Javascript,Qt 和 Selenium 不支持在 App Engine 上运行 ((1)),appengine 只支持纯 Python 代码。不知道有没有纯 Python Javascript 解释器,就是这样在 App Engine 上你只需要部署一个支持 JS 的爬虫 :-(.
也许 Java 中的某些东西至少可以让您部署到应用程序引擎(Java 版本)?Java 和 Python 中的 App Engine 应用程序版本可以使用相同的数据存储,因此您可以将应用程序的部分内容保留在 Python 中。. . 只是不需要了解 Javascript。不幸的是,我对 Java/AE 环境知之甚少,无法推荐尝试任何特定的包。
(1):为了澄清这一点,似乎有一个误解让我被否决了:如果你在另一台计算机上运行 Selenium 或其他爬虫,你当然可以定位 网站 (不管如何您的目标 网站 已部署,它使用什么编程语言等,只要它是您可以访问的 网站,[真正的 网站: flash&c,可能不同]] . 我读到的问题是,OP 正在寻找让刮板作为应用程序引擎应用程序的一部分运行的方法——这是有问题的部分,而不是你(或其他人 ;-) 运行网站被抓取的地方! 查看全部
网页flash文本抓取器(Twill和mechanize不支持Javascript(1)上运行,appengine只支持纯Python代码)
Twill 和 mechanize 不支持 Javascript,Qt 和 Selenium 不支持在 App Engine 上运行 ((1)),appengine 只支持纯 Python 代码。不知道有没有纯 Python Javascript 解释器,就是这样在 App Engine 上你只需要部署一个支持 JS 的爬虫 :-(.
也许 Java 中的某些东西至少可以让您部署到应用程序引擎(Java 版本)?Java 和 Python 中的 App Engine 应用程序版本可以使用相同的数据存储,因此您可以将应用程序的部分内容保留在 Python 中。. . 只是不需要了解 Javascript。不幸的是,我对 Java/AE 环境知之甚少,无法推荐尝试任何特定的包。
(1):为了澄清这一点,似乎有一个误解让我被否决了:如果你在另一台计算机上运行 Selenium 或其他爬虫,你当然可以定位 网站 (不管如何您的目标 网站 已部署,它使用什么编程语言等,只要它是您可以访问的 网站,[真正的 网站: flash&c,可能不同]] . 我读到的问题是,OP 正在寻找让刮板作为应用程序引擎应用程序的一部分运行的方法——这是有问题的部分,而不是你(或其他人 ;-) 运行网站被抓取的地方!
网页flash文本抓取器(SEO新手并不知道原因在哪,悟道SEO原因分析?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-02 01:10
网站收录是SEO中非常重要的一环,一个收录有问题的网站注定没有好的排名。但是网站的很多收录都不好,很多SEO新手也不知道是什么原因。无道SEO今天要和大家讨论的是,网站收录解决了什么问题?要想解决收录的问题,你必须知道网站收录是怎么回事。
1、网站结构:
百度建议网站应该结构清晰,导航清晰,可以帮助用户快速从你的网站中找到需要的内容,帮助搜索引擎快速了解网站所处的结构层次每个网页都位于。网站结构推荐使用树形结构。树形结构通常分为以下三个层次:主页-频道-文章页面。就像一棵大树,先是树干(主页),然后是树枝(频道),最后是叶子(正常内容页面)。树形结构更具扩展性,网站当内容增加时,可以通过细分分支(通道)轻松处理。
2、代码识别:
百度建议:百度通过一个叫Baiduspider的程序爬取互联网上的网页,处理后建入索引。目前百度蜘蛛只能读取文本内容,暂时无法处理flash、图片等非文本内容。放在flash和图片中的文字百度无法识别。建议使用文字代替flash、图片、Javascript等显示重要内容或链接。搜索引擎暂时无法识别Flash、图片、Javascript中的内容,无法搜索到这部分内容;只有flash和Javascript收录网页链接,百度未必能收录。
3、合理的返回码:
百度爬虫在爬取处理时,会根据http协议规范设置相应的逻辑,所以请尽量参考http协议中返回码含义的定义。我需要弄清楚这些常见的 http 返回码 404、301、503、403 是什么意思以及如何处理。
4、规范,简单的url,即链接深度;
创建一个描述性强、标准化、简单的url,有利于用户更方便地记忆和判断网页内容,也有利于搜索引擎更有效地抓取你的网站。网站在设计之初,应该有一个合理的URL规划。网站的URL深度不能太深,最好在3层以内。
5、地图提交:
百度站长平台支持通过站点地图提交网站内容。百度收录可以通过sitemap提高效率。您可以制作网站地图并提交网站地图以提高百度收录网站的速度。
其实这些收录的知识是很基础的,但是相信80%的人都做不好。经常听到有人抱怨网站收录不好,我也不找原因。网站看了一眼,这些最基本的优化都没有做好,那收录呢?当然,影响搜索引擎的最大因素是空间,而空间的好坏直接影响到SEO的最终效果。 查看全部
网页flash文本抓取器(SEO新手并不知道原因在哪,悟道SEO原因分析?)
网站收录是SEO中非常重要的一环,一个收录有问题的网站注定没有好的排名。但是网站的很多收录都不好,很多SEO新手也不知道是什么原因。无道SEO今天要和大家讨论的是,网站收录解决了什么问题?要想解决收录的问题,你必须知道网站收录是怎么回事。
1、网站结构:
百度建议网站应该结构清晰,导航清晰,可以帮助用户快速从你的网站中找到需要的内容,帮助搜索引擎快速了解网站所处的结构层次每个网页都位于。网站结构推荐使用树形结构。树形结构通常分为以下三个层次:主页-频道-文章页面。就像一棵大树,先是树干(主页),然后是树枝(频道),最后是叶子(正常内容页面)。树形结构更具扩展性,网站当内容增加时,可以通过细分分支(通道)轻松处理。
2、代码识别:
百度建议:百度通过一个叫Baiduspider的程序爬取互联网上的网页,处理后建入索引。目前百度蜘蛛只能读取文本内容,暂时无法处理flash、图片等非文本内容。放在flash和图片中的文字百度无法识别。建议使用文字代替flash、图片、Javascript等显示重要内容或链接。搜索引擎暂时无法识别Flash、图片、Javascript中的内容,无法搜索到这部分内容;只有flash和Javascript收录网页链接,百度未必能收录。
3、合理的返回码:
百度爬虫在爬取处理时,会根据http协议规范设置相应的逻辑,所以请尽量参考http协议中返回码含义的定义。我需要弄清楚这些常见的 http 返回码 404、301、503、403 是什么意思以及如何处理。
4、规范,简单的url,即链接深度;
创建一个描述性强、标准化、简单的url,有利于用户更方便地记忆和判断网页内容,也有利于搜索引擎更有效地抓取你的网站。网站在设计之初,应该有一个合理的URL规划。网站的URL深度不能太深,最好在3层以内。
5、地图提交:
百度站长平台支持通过站点地图提交网站内容。百度收录可以通过sitemap提高效率。您可以制作网站地图并提交网站地图以提高百度收录网站的速度。
其实这些收录的知识是很基础的,但是相信80%的人都做不好。经常听到有人抱怨网站收录不好,我也不找原因。网站看了一眼,这些最基本的优化都没有做好,那收录呢?当然,影响搜索引擎的最大因素是空间,而空间的好坏直接影响到SEO的最终效果。
网页flash文本抓取器(宝贝乐园站长必备工具-这是,宝贝!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-30 17:17
这是Flash Hunter Catcher,宝宝乐园提供的一款捕捉flash、音乐和电影资源的小软件。这是Hunter第一版,是绿色软件,无需写入注册表,请放心使用!希望你们都喜欢!
软件介绍
结合flashget使用
您可以在网站中抓取您喜欢的flash、音乐和电影资源。是站长搭建网站的必备工具。操作简单,功能实用,大部分网上资源经过测试都可以抓取
软件功能
1.与IE紧密配合,可直接提取IE当前网页的FLASH动画文件;
2.输入URL地址,无需IE即可直接下载FLASH动画文件;
3.可以查看下载的FLASH文件;
4.支持代理服务器;
相关介绍
Hunter Catcher是当今互联网上常用的软件之一。本软件绿色、安全、无毒,让您放心使用!如果猎人捕手是您需要的工具,请来这里!本站为您提供猎人捕手官方下载。
软件截图
相关软件
站长必备工具:这是站长必备工具。站长一定要细心呵护,经常发现和处理一些常见的问题。今天,我们为您带来了一个网站管理员必备的工具。强大的站长工具箱,有关键词排名查询、关键词索引查询、友情链接查询、whois查询、关键词挖矿、文章伪原创等众多功能,有了这个软件,站长朋友们可以轻松即时的了解网站的各种情况,当出现问题时,还可以实时发现并修复。朋友必备的工具。
e-family必备工具包:这是一个e-family必备工具包,内置HTML基础代码、CSS滤镜效果、JS页面效果等网页代码。它继承了Windows记事本的所有功能,并增加了自动存档功能。> 网页(源代码、文本)等格式文件功能,以及个人网页浏览器和邮件快速发送功能,让您更方便地浏览和编辑网站代码! 查看全部
网页flash文本抓取器(宝贝乐园站长必备工具-这是,宝贝!)
这是Flash Hunter Catcher,宝宝乐园提供的一款捕捉flash、音乐和电影资源的小软件。这是Hunter第一版,是绿色软件,无需写入注册表,请放心使用!希望你们都喜欢!
软件介绍
结合flashget使用
您可以在网站中抓取您喜欢的flash、音乐和电影资源。是站长搭建网站的必备工具。操作简单,功能实用,大部分网上资源经过测试都可以抓取
软件功能
1.与IE紧密配合,可直接提取IE当前网页的FLASH动画文件;
2.输入URL地址,无需IE即可直接下载FLASH动画文件;
3.可以查看下载的FLASH文件;
4.支持代理服务器;
相关介绍
Hunter Catcher是当今互联网上常用的软件之一。本软件绿色、安全、无毒,让您放心使用!如果猎人捕手是您需要的工具,请来这里!本站为您提供猎人捕手官方下载。
软件截图

相关软件
站长必备工具:这是站长必备工具。站长一定要细心呵护,经常发现和处理一些常见的问题。今天,我们为您带来了一个网站管理员必备的工具。强大的站长工具箱,有关键词排名查询、关键词索引查询、友情链接查询、whois查询、关键词挖矿、文章伪原创等众多功能,有了这个软件,站长朋友们可以轻松即时的了解网站的各种情况,当出现问题时,还可以实时发现并修复。朋友必备的工具。
e-family必备工具包:这是一个e-family必备工具包,内置HTML基础代码、CSS滤镜效果、JS页面效果等网页代码。它继承了Windows记事本的所有功能,并增加了自动存档功能。> 网页(源代码、文本)等格式文件功能,以及个人网页浏览器和邮件快速发送功能,让您更方便地浏览和编辑网站代码!
网页flash文本抓取器(SWFObject2.0:SWFObject的检索技术(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-05 01:25
核心提示:当搜索引擎对Flash的检索技术不够成熟时,我们应该努力打造高端的网站简化Flash页面。页面不宜过大,否则加载速度慢会影响搜索引擎收录,另外创建一个单独的Html页面引导其讲解。
Flash可以让网站色彩斑斓,但是它强调图片和交互功能以及浅色的文字和链接,对Javascript这样的搜索引擎不太友好,所以如何对Flash进行SEO优化网站就变成了一个共同的问题。
2008 年 6 月 20 日,Google 和 Google 共同宣布了一种新算法来完全抓取 Flash 内容。尽管取得了一些进展,但搜索引擎仍然难以抓取 Flash,所以我们在保证 Flash 的有效设计、标准的统一、各种浏览器的兼容性的同时,也应该对搜索引擎进行有效的优化。
我们可以在Flash中使用开源Javascript函数的SWFObject()函数,可以被搜索引擎识别。下面简单介绍一下SWFObject 2.0:
SWFObject 是一个独立的、灵活的 JavaScript 模块,用于在 HTML 中插入 Adobe Flash 媒体资源(*.swf 文件)。非常符合搜索引擎优化的原则。此外,它还可以避免在你的HTML和XHTML中嵌入object、embed等非标准标签,从而符合更多的标准。
如果你想加强对Flash中标题和描述的优化,那么你应该学习sIFR技术。
sIFR代表Scalable Shanghai Huangpu District网站 Construction Company Inman Flash Replacement,这是一种可扩展的Inman Flash替换技术。它使用 Flash + JS + CSS 来实现更细腻准确的文本渲染,而不需要替换页面中的文本元素。使用 sIFR,您可以为 Web 中的文本定义任何字体,即使它没有安装在客户端浏览器中。 sIFR 使用 Flash 渲染字体效果,可以平滑和抗锯齿文本,并且可以像使用 CSS 控制文本一样轻松获得各种文本效果。
但是 sIFR 有一个明显的缺点,就是它只能处理简单的介绍性文字,而对于复杂的 Flash 动画,例如菜单、幻灯片和其他高度交互的 Flash 网页,它却无能为力。
因此,当搜索引擎对Flash的检索技术还不够成熟时,应努力简化Flash页面,页面不能太大,否则加载速度慢会影响搜索引擎收录@ >,同时建立一个单独的Html页面,后面会讲解如何引导。 查看全部
网页flash文本抓取器(SWFObject2.0:SWFObject的检索技术(图))
核心提示:当搜索引擎对Flash的检索技术不够成熟时,我们应该努力打造高端的网站简化Flash页面。页面不宜过大,否则加载速度慢会影响搜索引擎收录,另外创建一个单独的Html页面引导其讲解。
Flash可以让网站色彩斑斓,但是它强调图片和交互功能以及浅色的文字和链接,对Javascript这样的搜索引擎不太友好,所以如何对Flash进行SEO优化网站就变成了一个共同的问题。
2008 年 6 月 20 日,Google 和 Google 共同宣布了一种新算法来完全抓取 Flash 内容。尽管取得了一些进展,但搜索引擎仍然难以抓取 Flash,所以我们在保证 Flash 的有效设计、标准的统一、各种浏览器的兼容性的同时,也应该对搜索引擎进行有效的优化。
我们可以在Flash中使用开源Javascript函数的SWFObject()函数,可以被搜索引擎识别。下面简单介绍一下SWFObject 2.0:
SWFObject 是一个独立的、灵活的 JavaScript 模块,用于在 HTML 中插入 Adobe Flash 媒体资源(*.swf 文件)。非常符合搜索引擎优化的原则。此外,它还可以避免在你的HTML和XHTML中嵌入object、embed等非标准标签,从而符合更多的标准。
如果你想加强对Flash中标题和描述的优化,那么你应该学习sIFR技术。
sIFR代表Scalable Shanghai Huangpu District网站 Construction Company Inman Flash Replacement,这是一种可扩展的Inman Flash替换技术。它使用 Flash + JS + CSS 来实现更细腻准确的文本渲染,而不需要替换页面中的文本元素。使用 sIFR,您可以为 Web 中的文本定义任何字体,即使它没有安装在客户端浏览器中。 sIFR 使用 Flash 渲染字体效果,可以平滑和抗锯齿文本,并且可以像使用 CSS 控制文本一样轻松获得各种文本效果。
但是 sIFR 有一个明显的缺点,就是它只能处理简单的介绍性文字,而对于复杂的 Flash 动画,例如菜单、幻灯片和其他高度交互的 Flash 网页,它却无能为力。
因此,当搜索引擎对Flash的检索技术还不够成熟时,应努力简化Flash页面,页面不能太大,否则加载速度慢会影响搜索引擎收录@ >,同时建立一个单独的Html页面,后面会讲解如何引导。
网页flash文本抓取器(Robot的搜索引擎(Robot)是什么?(Robot)是机器人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-03 08:09
Robot 英文直译是机器人。在搜索引擎优化SEO中,我们经常将其翻译为:检测器。
有时候,你会遇到爬虫(crawler)、蜘蛛(spider),都是检测器之一,只是名字不一样。
SEO中经常提到的这个检测器(Robot)是什么?
搜索引擎用来抓取网页的工具。它是一个软件或一系列自动程序(显然,不是机器)。
不同的搜索引擎给他们的机器人起不同的名字。
Google: googlebot 百度: baiduspider MSN: MSNbot Yahoo: Slurp(这个来自yahoo的比较特别,没有“姓”,用的是象声词。Slurp,机器人吃tsk tsk声音时发出中文理解)
关于Robot,主要关注的是Robots.txt,上面的名字收录在网站log中。
百度用来抓取网页的程序叫做Baiduspider——百度蜘蛛。我们主要分析网站被百度爬取的情况。 网站日志中百度蜘蛛Baiduspider的活动:爬取频率,返回HTTP状态码。
如何查看日志:
通过FTP,在网站的根目录下找到一个日志文件,文件名一般收录log,下载并解压里面的记事本,这是网站的日志,里面记录了网站 被访问和操纵。
由于每个服务器和主机的情况不同,不同主机的日志功能记录的内容也不同,有的甚至没有日志功能。
日志内容如下:
61.135.168.22 - - [11/Jan/2009:04:02:45 +0800] “GET /bbs/thread-7303-1- 1.html HTTP/1.1″ 200 8450 “-” “Baiduspider+(+)”
分析:
GET /bbs/thread-7303-1-1.html代表,抓取/bbs/thread-7303-1-1.html这个页面。
200 表示抓取成功。
8450 表示抓取了 8450 个字节。
如果你的日志中的格式不是这样的,说明日志格式设置不一样。
在很多日志中可以看到200 0 0和200 0 64代表正常爬取。
爬取频率是通过查看每日日志中的百度蜘蛛爬取次数得出的。爬取频率没有标准化的时间表或频率数,我们一般通过多天的日志对比来判断。当然,我们希望百度蜘蛛每天爬的次数越多越好。 查看全部
网页flash文本抓取器(Robot的搜索引擎(Robot)是什么?(Robot)是机器人)
Robot 英文直译是机器人。在搜索引擎优化SEO中,我们经常将其翻译为:检测器。
有时候,你会遇到爬虫(crawler)、蜘蛛(spider),都是检测器之一,只是名字不一样。
SEO中经常提到的这个检测器(Robot)是什么?
搜索引擎用来抓取网页的工具。它是一个软件或一系列自动程序(显然,不是机器)。
不同的搜索引擎给他们的机器人起不同的名字。
Google: googlebot 百度: baiduspider MSN: MSNbot Yahoo: Slurp(这个来自yahoo的比较特别,没有“姓”,用的是象声词。Slurp,机器人吃tsk tsk声音时发出中文理解)
关于Robot,主要关注的是Robots.txt,上面的名字收录在网站log中。
百度用来抓取网页的程序叫做Baiduspider——百度蜘蛛。我们主要分析网站被百度爬取的情况。 网站日志中百度蜘蛛Baiduspider的活动:爬取频率,返回HTTP状态码。
如何查看日志:
通过FTP,在网站的根目录下找到一个日志文件,文件名一般收录log,下载并解压里面的记事本,这是网站的日志,里面记录了网站 被访问和操纵。
由于每个服务器和主机的情况不同,不同主机的日志功能记录的内容也不同,有的甚至没有日志功能。
日志内容如下:
61.135.168.22 - - [11/Jan/2009:04:02:45 +0800] “GET /bbs/thread-7303-1- 1.html HTTP/1.1″ 200 8450 “-” “Baiduspider+(+)”
分析:
GET /bbs/thread-7303-1-1.html代表,抓取/bbs/thread-7303-1-1.html这个页面。
200 表示抓取成功。
8450 表示抓取了 8450 个字节。
如果你的日志中的格式不是这样的,说明日志格式设置不一样。
在很多日志中可以看到200 0 0和200 0 64代表正常爬取。
爬取频率是通过查看每日日志中的百度蜘蛛爬取次数得出的。爬取频率没有标准化的时间表或频率数,我们一般通过多天的日志对比来判断。当然,我们希望百度蜘蛛每天爬的次数越多越好。
网页flash文本抓取器(怎样对Flash网站进行SEO优化人们普遍关心的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-02 23:16
出处:魔域Flash可以让网站色彩斑斓,但是它强调图片和交互功能,文字和链接比较轻,对Javascript等搜索引擎不太友好,那么如何处理Flash网站 SEO优化已经成为人们共同关心的问题。 2008 年 8 月 20 日,Google 和 Adobe 联合宣布了一种新的算法来完全抓取 Flash 内容。尽管取得了一些进展,但搜索引擎在抓取 Flash 方面仍然存在困难,所以我们在确保 Flash 是有效的设计、标准的统一、各种浏览器的兼容性,同时也是有效的搜索引擎优化。我们可以使用Flash中开源Javascript函数的SWFObject()函数,搜索引擎可以识别。下面我们简单介绍一下 SWFObject 2.0: SWFObject 是一个独立的、敏捷的 JavaScript 模块,用于在 HTML 中插入 Adobe Flash 媒体资源(*.swf 文件)。非常符合搜索引擎优化的原则。另外,它可以避免你的HTML、XHTML中出现object、embed等非标准标签,符合更多的标准。如果要加强对Flash中title和description的优化,那么就应该学习sIFR技术。 sIFR 代表可扩展的 Inman Flash Replacement,它是可扩展的 Inman Flash 替换技术。它结合了 Flash CSS,在不替换页面中的文本元素的情况下,实现更细腻、更准确的文本渲染。使用 sIFR,您可以在 Web 中定义任何文本字体,即使该字体未安装在客户端浏览器中。 sIFR使用Flash渲染字体效果,文字平滑抗锯齿,可以像使用CSS控制文字一样轻松获得各种文字效果。但是sIFR有一个明显的缺点,那就是它只能处理简单的介绍性文字,而对于复杂的Flash动画,比如菜单、幻灯片等互动性很强的Flash网页,却无能为力。因此,当搜索引擎对Flash的检索技术不够成熟时,应努力简化Flash面,页面不宜过大,否则加载速度慢会影响搜索引擎收录,以及同时创建一个单独的Html页面进行指南讲解。原文地址:,希望多多交流,我的博客北京SEO:,欢迎互相踩。 查看全部
网页flash文本抓取器(怎样对Flash网站进行SEO优化人们普遍关心的问题)
出处:魔域Flash可以让网站色彩斑斓,但是它强调图片和交互功能,文字和链接比较轻,对Javascript等搜索引擎不太友好,那么如何处理Flash网站 SEO优化已经成为人们共同关心的问题。 2008 年 8 月 20 日,Google 和 Adobe 联合宣布了一种新的算法来完全抓取 Flash 内容。尽管取得了一些进展,但搜索引擎在抓取 Flash 方面仍然存在困难,所以我们在确保 Flash 是有效的设计、标准的统一、各种浏览器的兼容性,同时也是有效的搜索引擎优化。我们可以使用Flash中开源Javascript函数的SWFObject()函数,搜索引擎可以识别。下面我们简单介绍一下 SWFObject 2.0: SWFObject 是一个独立的、敏捷的 JavaScript 模块,用于在 HTML 中插入 Adobe Flash 媒体资源(*.swf 文件)。非常符合搜索引擎优化的原则。另外,它可以避免你的HTML、XHTML中出现object、embed等非标准标签,符合更多的标准。如果要加强对Flash中title和description的优化,那么就应该学习sIFR技术。 sIFR 代表可扩展的 Inman Flash Replacement,它是可扩展的 Inman Flash 替换技术。它结合了 Flash CSS,在不替换页面中的文本元素的情况下,实现更细腻、更准确的文本渲染。使用 sIFR,您可以在 Web 中定义任何文本字体,即使该字体未安装在客户端浏览器中。 sIFR使用Flash渲染字体效果,文字平滑抗锯齿,可以像使用CSS控制文字一样轻松获得各种文字效果。但是sIFR有一个明显的缺点,那就是它只能处理简单的介绍性文字,而对于复杂的Flash动画,比如菜单、幻灯片等互动性很强的Flash网页,却无能为力。因此,当搜索引擎对Flash的检索技术不够成熟时,应努力简化Flash面,页面不宜过大,否则加载速度慢会影响搜索引擎收录,以及同时创建一个单独的Html页面进行指南讲解。原文地址:,希望多多交流,我的博客北京SEO:,欢迎互相踩。
网页flash文本抓取器(基于自然语言处理和网页结构分析的新颖提取方法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-02 05:13
【摘要】:HTML文档中的锚文本及其相关上下文往往收录链接到页面主题的“简洁”但“精确”的语义线索。通常合理的假设是,这些线索通常足以指导页面的内容。人类观众打开链接指向的页面。毫不奇怪,这些链接上下文相关的文本自万维网诞生以来就得到了很好的利用。例如,谷歌搜索引擎使用锚文本来索引 URL;在 CLEVER 主题编辑系统中,超链接根据其上下文文本和搜索词的相关性被赋予权重,以缓解 HITS 算法中“主题偏差”的难度;一些研究人员讨论了使用这些相关文本来辅助甚至替换网页本身的内容,以实现网页的自动分类。在访问链接指向的目标页面的成本太高的情况下,必须充分优化利用链接的上下文相关文本,这就是“主题爬行”所面临的问题,其成功取决于对这些源页面。目标页面的相关文本信息尽可能准确地预测目标页面的主题相关性。尽管有这些重要的价值,但关于如何准确提取链接上下文相关文本的研究尚未得到充分讨论,目前最好的提取方法依赖于过度简化的启发式方法,或各种任意指定的数学参数。锚文本看似是语义信息的可靠来源,但其过短的特性阻碍了信息检索的高“召回率”,完全依赖锚文本甚至会降低检索性能,这一点已被一些研究人员证实。除了锚文本,锚标签左右的相邻文本被认为是链接上下文相关文本的另一个重要来源。然而,这些文本往往收录巨大的噪声,而这些低质量的文本通常会进一步降低提取文本的相关性。本文提出了一种基于自然语言处理和网页结构分析的新型提取方法。我们认为,像英语语义分析这样的自然语言处理工具可以帮助过滤掉不相关或嘈杂的文本,同时提取高质量的相关文本,以实现对人类浏览行为的“细粒度”模仿。初步实验结果表明,我们提出的方法与其他方法相比具有很大的优势。 查看全部
网页flash文本抓取器(基于自然语言处理和网页结构分析的新颖提取方法(组图))
【摘要】:HTML文档中的锚文本及其相关上下文往往收录链接到页面主题的“简洁”但“精确”的语义线索。通常合理的假设是,这些线索通常足以指导页面的内容。人类观众打开链接指向的页面。毫不奇怪,这些链接上下文相关的文本自万维网诞生以来就得到了很好的利用。例如,谷歌搜索引擎使用锚文本来索引 URL;在 CLEVER 主题编辑系统中,超链接根据其上下文文本和搜索词的相关性被赋予权重,以缓解 HITS 算法中“主题偏差”的难度;一些研究人员讨论了使用这些相关文本来辅助甚至替换网页本身的内容,以实现网页的自动分类。在访问链接指向的目标页面的成本太高的情况下,必须充分优化利用链接的上下文相关文本,这就是“主题爬行”所面临的问题,其成功取决于对这些源页面。目标页面的相关文本信息尽可能准确地预测目标页面的主题相关性。尽管有这些重要的价值,但关于如何准确提取链接上下文相关文本的研究尚未得到充分讨论,目前最好的提取方法依赖于过度简化的启发式方法,或各种任意指定的数学参数。锚文本看似是语义信息的可靠来源,但其过短的特性阻碍了信息检索的高“召回率”,完全依赖锚文本甚至会降低检索性能,这一点已被一些研究人员证实。除了锚文本,锚标签左右的相邻文本被认为是链接上下文相关文本的另一个重要来源。然而,这些文本往往收录巨大的噪声,而这些低质量的文本通常会进一步降低提取文本的相关性。本文提出了一种基于自然语言处理和网页结构分析的新型提取方法。我们认为,像英语语义分析这样的自然语言处理工具可以帮助过滤掉不相关或嘈杂的文本,同时提取高质量的相关文本,以实现对人类浏览行为的“细粒度”模仿。初步实验结果表明,我们提出的方法与其他方法相比具有很大的优势。
网页flash文本抓取器(爬虫网络爬虫的两种常见类型,get请求的注意点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-28 04:10
一、了解爬虫
网络爬虫(网络蜘蛛、网络机器人等)利用程序获取网页上的目标数据(图片、视频、文字等)
二、爬行动物的本质
模拟浏览器打开网页,获取浏览器的数据(爬虫想要的数据);
在浏览器中打开网页的过程:当你通过浏览器访问一个链接时,通过DNS服务器找到服务器IP,向服务器发送请求;服务器解析后给出响应(可以是html、js、css等文件内容),浏览器(本质:编译器)解析渲染,显示网页内容;
三、爬虫基本流程
四步基本流程:1.请求目标链接;2. 获取响应内容;3. 解析内容;4. 存储数据;以下是简要说明:
1.请求目标链接
用header、请求参数等信息发起Request,等待服务器响应;
2.获取响应内容
服务器正常响应后,Response的内容收录所有页面内容(可以是HTML、JSON字符串、二进制数据(图片、视频)等)
3.解析内容
获取的内容可以是HTML,可以用正则表达式和页面解析库进行解析;可以是Json字符串,可以直接转换成Json对象进行解析,也可以是二进制数据,可以保存或者进一步处理……
4.存储数据
存储形式多种多样,可以存储为文本,也可以存储在数据库中,也可以存储为特定格式的文件;
四、对Request和Response的简单理解
请求通用请求方式:两种常见的get/port,以及:HEAD/PUT/DELETE/OPTIONS
获取请求的注意事项:例如:
/test/demo_form.asp?name1=value1&name2=value2
网址的简要说明:
【百度】URL是统一资源定位器,是互联网上可用资源的位置和访问方式的简明表示,是互联网上标准资源的地址。
URL的格式由三部分组成:
第一部分是协议(或服务模式);
第二部分是存储资源的主机的IP地址(有时还包括端口号);
第三部分是宿主资源的具体地址,如目录、文件名等;
爬虫爬取数据时,必须有目标URL才能获取数据,是爬虫获取数据的基本依据;
请求头
收录请求过程中的头部信息,如User-Agent、Host、Cookies等信息。下图是请求百度收缩时的所有请求头信息参数;
请求正文
请求中携带的数据,如提交表单数据时的表单数据(POST)
回复
所有 HTTP 响应的第一行是状态行,后跟当前 HTTP 版本号、3 位状态代码和描述状态的短语,以空格分隔。
响应头,响应状态
响应状态有多种,如:200成功,301重定向,404页面未找到,502服务器错误。
响应体
最重要的部分,包括请求资源的内容,如网页HTML、图片、二进制数据等;
爬虫可以抓取哪些类型的数据?
网页文本:如HTML文档、Json格式文本等。
图片:将得到的二进制文件保存为图片格式
视频:也是二进制
其他:只要你要求,你就能得到
如何解析数据?Json 解析的直接处理 正则表达式处理 BeautifulSoup 解析处理 PyQuery 解析处理 XPath 解析 关于抓取到的页面数据与浏览器看到的差异的处理
出现这种情况是因为网站中的很多数据都是通过js和ajax动态加载的,所以直接通过get请求得到的页面和浏览器显示的不一样。
如何解决js渲染的问题?
分析ajax
硒/网络驱动程序
溅
PyV8,幽灵.py
如何保存数据
文本:纯文本、Json、Xml等。
非关系型数据库:MongoDB、Redis等键值存储
关系型数据库:mysql、oracle、sql server等结构化数据库。 查看全部
网页flash文本抓取器(爬虫网络爬虫的两种常见类型,get请求的注意点)
一、了解爬虫
网络爬虫(网络蜘蛛、网络机器人等)利用程序获取网页上的目标数据(图片、视频、文字等)
二、爬行动物的本质
模拟浏览器打开网页,获取浏览器的数据(爬虫想要的数据);
在浏览器中打开网页的过程:当你通过浏览器访问一个链接时,通过DNS服务器找到服务器IP,向服务器发送请求;服务器解析后给出响应(可以是html、js、css等文件内容),浏览器(本质:编译器)解析渲染,显示网页内容;
三、爬虫基本流程
四步基本流程:1.请求目标链接;2. 获取响应内容;3. 解析内容;4. 存储数据;以下是简要说明:
1.请求目标链接
用header、请求参数等信息发起Request,等待服务器响应;
2.获取响应内容
服务器正常响应后,Response的内容收录所有页面内容(可以是HTML、JSON字符串、二进制数据(图片、视频)等)
3.解析内容
获取的内容可以是HTML,可以用正则表达式和页面解析库进行解析;可以是Json字符串,可以直接转换成Json对象进行解析,也可以是二进制数据,可以保存或者进一步处理……
4.存储数据
存储形式多种多样,可以存储为文本,也可以存储在数据库中,也可以存储为特定格式的文件;
四、对Request和Response的简单理解
请求通用请求方式:两种常见的get/port,以及:HEAD/PUT/DELETE/OPTIONS
获取请求的注意事项:例如:
/test/demo_form.asp?name1=value1&name2=value2
网址的简要说明:
【百度】URL是统一资源定位器,是互联网上可用资源的位置和访问方式的简明表示,是互联网上标准资源的地址。
URL的格式由三部分组成:
第一部分是协议(或服务模式);
第二部分是存储资源的主机的IP地址(有时还包括端口号);
第三部分是宿主资源的具体地址,如目录、文件名等;
爬虫爬取数据时,必须有目标URL才能获取数据,是爬虫获取数据的基本依据;
请求头
收录请求过程中的头部信息,如User-Agent、Host、Cookies等信息。下图是请求百度收缩时的所有请求头信息参数;
请求正文
请求中携带的数据,如提交表单数据时的表单数据(POST)
回复
所有 HTTP 响应的第一行是状态行,后跟当前 HTTP 版本号、3 位状态代码和描述状态的短语,以空格分隔。
响应头,响应状态
响应状态有多种,如:200成功,301重定向,404页面未找到,502服务器错误。
响应体
最重要的部分,包括请求资源的内容,如网页HTML、图片、二进制数据等;
爬虫可以抓取哪些类型的数据?
网页文本:如HTML文档、Json格式文本等。
图片:将得到的二进制文件保存为图片格式
视频:也是二进制
其他:只要你要求,你就能得到
如何解析数据?Json 解析的直接处理 正则表达式处理 BeautifulSoup 解析处理 PyQuery 解析处理 XPath 解析 关于抓取到的页面数据与浏览器看到的差异的处理
出现这种情况是因为网站中的很多数据都是通过js和ajax动态加载的,所以直接通过get请求得到的页面和浏览器显示的不一样。
如何解决js渲染的问题?
分析ajax
硒/网络驱动程序
溅
PyV8,幽灵.py
如何保存数据
文本:纯文本、Json、Xml等。
非关系型数据库:MongoDB、Redis等键值存储
关系型数据库:mysql、oracle、sql server等结构化数据库。
网页flash文本抓取器(资料收集库是一个集绿色软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-27 05:18
数据采集库是一个集数据采集、网页采集、附件采集于一体的工具。使用此工具,您可以将平时杂乱无章的数据、图片、程序等存储在一起,统一管理。方便您查找和使用。数据采集库最大的特点是对网页内容进行爬取,可以将网页等各种资源或网页中的一些文字、链接、图片、Flash等资源按类别采集到数据库中;并且可以将几乎所有格式的文件保存到附件中。允许自定义IE右键菜单,方便采集的处理。除了使用右键,还可以选择网页中需要的部分,拖到采集窗口进行数据库采集;有些浏览器采集不需要打开任何程序,大大节省了系统资源。库的编辑区采用用户熟悉的目录树结构,方便用户操作。捕获的资源可以自动或手动添加到不同的节点;纯文本和格式化文本可以直接在编辑区进行编辑。文本区不限大小,支持段落重排和gb、big5码转换;库中任意节点都支持加密,方便个人和共享用户;数据库查询最多支持三种高级搜索方式,使您可以更快地找到您需要的内容。皮肤可以像Winamp、QICQ2000一样更换,数据库提供皮肤下载。只要你来我们的网站下载。数据采集库是一款绿色软件,只需解压到某个目录即可使用。当你认为你不想再使用它时,只需删除它所在的目录即可。不会在系统中留下任何垃圾。 查看全部
网页flash文本抓取器(资料收集库是一个集绿色软件)
数据采集库是一个集数据采集、网页采集、附件采集于一体的工具。使用此工具,您可以将平时杂乱无章的数据、图片、程序等存储在一起,统一管理。方便您查找和使用。数据采集库最大的特点是对网页内容进行爬取,可以将网页等各种资源或网页中的一些文字、链接、图片、Flash等资源按类别采集到数据库中;并且可以将几乎所有格式的文件保存到附件中。允许自定义IE右键菜单,方便采集的处理。除了使用右键,还可以选择网页中需要的部分,拖到采集窗口进行数据库采集;有些浏览器采集不需要打开任何程序,大大节省了系统资源。库的编辑区采用用户熟悉的目录树结构,方便用户操作。捕获的资源可以自动或手动添加到不同的节点;纯文本和格式化文本可以直接在编辑区进行编辑。文本区不限大小,支持段落重排和gb、big5码转换;库中任意节点都支持加密,方便个人和共享用户;数据库查询最多支持三种高级搜索方式,使您可以更快地找到您需要的内容。皮肤可以像Winamp、QICQ2000一样更换,数据库提供皮肤下载。只要你来我们的网站下载。数据采集库是一款绿色软件,只需解压到某个目录即可使用。当你认为你不想再使用它时,只需删除它所在的目录即可。不会在系统中留下任何垃圾。
网页flash文本抓取器(如何快速提取窗口的文本显示在Text区域中的隐藏文本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-02-24 14:23
WindowTextExtractor 是一个非常强大的文本提取工具,专为从窗口中提取文本而设计。有时候我们经常会遇到复制窗口的文字内容,但是无法选择,只能手动静默输入。现在有了这个工具,我们可以为你快速提取窗口的文字,也可以用来提取窗口中的文字。保存隐藏密码,小巧实用。
软件功能
WindowTextExtractorWindowTextExtractor是一个免费开源的小程序,它可以提取程序窗口中的控件文本,方便我们复制。
使用说明
没有提取窗口文本的设置选项,只需将搜索窗口的按钮拖动到窗口中要提取文本的指定位置,提取的文本就会显示在文本区域。
一些密码输入框中的隐藏文字也可以通过它提取出来。
提取密码输入框中的隐藏文本。不支持flash、qt、Chrome浏览器等程序,但仍然可以提取窗口标题和标签页标题。如果你想用它来提取网页中的一些文字,你可以用IE浏览器打开网页。
提取网页文本 如果它直接指向链接文本,则可以提取其链接。
被指向的子窗口的图片会在Image中显示,有的不会显示。如果需要保存,可以使用菜单 File - Save image as 保存到本地,Text 中的文字也可以通过这种方式保存为文件。 查看全部
网页flash文本抓取器(如何快速提取窗口的文本显示在Text区域中的隐藏文本)
WindowTextExtractor 是一个非常强大的文本提取工具,专为从窗口中提取文本而设计。有时候我们经常会遇到复制窗口的文字内容,但是无法选择,只能手动静默输入。现在有了这个工具,我们可以为你快速提取窗口的文字,也可以用来提取窗口中的文字。保存隐藏密码,小巧实用。
软件功能
WindowTextExtractorWindowTextExtractor是一个免费开源的小程序,它可以提取程序窗口中的控件文本,方便我们复制。
使用说明
没有提取窗口文本的设置选项,只需将搜索窗口的按钮拖动到窗口中要提取文本的指定位置,提取的文本就会显示在文本区域。
一些密码输入框中的隐藏文字也可以通过它提取出来。
提取密码输入框中的隐藏文本。不支持flash、qt、Chrome浏览器等程序,但仍然可以提取窗口标题和标签页标题。如果你想用它来提取网页中的一些文字,你可以用IE浏览器打开网页。
提取网页文本 如果它直接指向链接文本,则可以提取其链接。
被指向的子窗口的图片会在Image中显示,有的不会显示。如果需要保存,可以使用菜单 File - Save image as 保存到本地,Text 中的文字也可以通过这种方式保存为文件。
网页flash文本抓取器(网站可以通过哪些方式阻止网页抓取工具?您如何确定机器人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-24 14:17
这个问题已经有了最佳答案,请点击这里访问。
网站如何阻止网络爬虫?您如何判断机器人是否正在访问您的服务器?
简单的机器人无法从 Flash、图像或声音中获取文本。
不幸的是,您的问题类似于人们问您如何阻止垃圾邮件。没有固定的答案,也不会阻止持久的人类/机器人。
但是,这里有一些方法可以做到:
使用 robots.txt 检查用户代理(尽管这可能是欺骗的)(适当的机器人会 - 希望尊重这一点)以检测过于一致地访问许多页面的 IP 地址(每“x”秒)。手动或在系统中创建标记以检查谁在您的站点上并阻止刮板采取的某些路线。不要在 网站 上使用标准模板,创建通用 CSS 类 - 不要在代码中添加 HTML 注释。
您可以使用 robots.txt 阻止注意到它的机器人(但仍允许通过 google 等从其他已知实例访问),但不会阻止忽略它的机器人。您可能可以从 Web 服务器日志中获取用户代理,或者您可以更新代码以将其记录在某处。然后,如果您想阻止特定用户代理访问您的 网站,只需返回空白/默认屏幕和/或特定服务器代码。
诸如“不良行为”之类的东西可能会有所帮助:
来自他们的 网站:
Bad Behavior 旨在集成到基于 PHP 的 网站 中,并在垃圾邮件机器人有机会向您的 网站 发送垃圾邮件甚至爬取您的页面以获取电子邮件地址和表单填写之前尽早运行以丢弃垃圾邮件机器人。
不良行为不仅可以防止对您网站造成实际损害,还可以防止许多电子邮件地址采集器,减少电子邮件垃圾邮件,并使用许多有助于提高网站安全性的自动网站破解工具。
爬虫在某种程度上依赖于从页面加载到页面加载的标记一致性。如果您想让他们的生活变得困难,您可以提供一项可根据要求更改标签的服务。
我认为没有一种方法可以完全按照您的意愿行事,因为在 网站crawlers/crawlers 中,您可以在请求页面时编辑所有标头,例如 User-Agent 并且您将无法确定是否有一个来自 Mozilla Firefox 的用户仍然是一个刮板/抓取器... 查看全部
网页flash文本抓取器(网站可以通过哪些方式阻止网页抓取工具?您如何确定机器人)
这个问题已经有了最佳答案,请点击这里访问。
网站如何阻止网络爬虫?您如何判断机器人是否正在访问您的服务器?
简单的机器人无法从 Flash、图像或声音中获取文本。
不幸的是,您的问题类似于人们问您如何阻止垃圾邮件。没有固定的答案,也不会阻止持久的人类/机器人。
但是,这里有一些方法可以做到:
使用 robots.txt 检查用户代理(尽管这可能是欺骗的)(适当的机器人会 - 希望尊重这一点)以检测过于一致地访问许多页面的 IP 地址(每“x”秒)。手动或在系统中创建标记以检查谁在您的站点上并阻止刮板采取的某些路线。不要在 网站 上使用标准模板,创建通用 CSS 类 - 不要在代码中添加 HTML 注释。
您可以使用 robots.txt 阻止注意到它的机器人(但仍允许通过 google 等从其他已知实例访问),但不会阻止忽略它的机器人。您可能可以从 Web 服务器日志中获取用户代理,或者您可以更新代码以将其记录在某处。然后,如果您想阻止特定用户代理访问您的 网站,只需返回空白/默认屏幕和/或特定服务器代码。
诸如“不良行为”之类的东西可能会有所帮助:
来自他们的 网站:
Bad Behavior 旨在集成到基于 PHP 的 网站 中,并在垃圾邮件机器人有机会向您的 网站 发送垃圾邮件甚至爬取您的页面以获取电子邮件地址和表单填写之前尽早运行以丢弃垃圾邮件机器人。
不良行为不仅可以防止对您网站造成实际损害,还可以防止许多电子邮件地址采集器,减少电子邮件垃圾邮件,并使用许多有助于提高网站安全性的自动网站破解工具。
爬虫在某种程度上依赖于从页面加载到页面加载的标记一致性。如果您想让他们的生活变得困难,您可以提供一项可根据要求更改标签的服务。
我认为没有一种方法可以完全按照您的意愿行事,因为在 网站crawlers/crawlers 中,您可以在请求页面时编辑所有标头,例如 User-Agent 并且您将无法确定是否有一个来自 Mozilla Firefox 的用户仍然是一个刮板/抓取器...
网页flash文本抓取器(智能编辑重构批处理式"数字PythonIDE"集成开发环境)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-24 14:16
目前可以浏览网页内容的App应用有很多,但是实时抓取剪贴板文本内容的应用却很少。
通过剪贴板抓取文本的好处:在简化操作且无需切换app的GUI GUI的情况下,用不同app的Ctrl+C快捷键复制数据,抓取-采集(或分享) 到目标应用程序。
比如在网上查一些软文或者参考资料,特别是写自媒体软文或者论文的时候,如果需要单独摘录某个关键文字,或者摘录多个软文 文本。旧的方法,Ctrl + C,然后Ctrl + V 快捷键抓取文本,是一种解决方案。但是如果工作量大的话,你会觉得这种重复的抓取操作,最好有现成的App工具来帮你做,功能再强点更好。
我们所有的产品都是为数字时代而构建的,并且此功能已集成到他们的应用程序中。当然,该公司还开发了一些其他专门的数据抓取,采集 应用程序。
智能编辑重构批处理“数字Python IDE”集成开发环境(集成高效Cython PyInstaller批处理小程序)
详细用法
01、编辑菜单-->勾选“剪贴板:监视器”-->弹出如下“提示窗口”
如果您刚刚启动应用程序,可能不会重新启动它,请切换到“取消”按钮并回车确认。
02、在桌面、文件夹、网页、网上邻居、Microsoft Office 应用程序等,按Ctrl+C快捷键(或其他操作)将文本内容复制到剪贴板 --> App应用会自动弹出如下界面。
如果“剪贴板文本”不符合抓取要求,可以点击“清除剪贴板”按钮,清除剪贴板内容。 查看全部
网页flash文本抓取器(智能编辑重构批处理式"数字PythonIDE"集成开发环境)
目前可以浏览网页内容的App应用有很多,但是实时抓取剪贴板文本内容的应用却很少。
通过剪贴板抓取文本的好处:在简化操作且无需切换app的GUI GUI的情况下,用不同app的Ctrl+C快捷键复制数据,抓取-采集(或分享) 到目标应用程序。
比如在网上查一些软文或者参考资料,特别是写自媒体软文或者论文的时候,如果需要单独摘录某个关键文字,或者摘录多个软文 文本。旧的方法,Ctrl + C,然后Ctrl + V 快捷键抓取文本,是一种解决方案。但是如果工作量大的话,你会觉得这种重复的抓取操作,最好有现成的App工具来帮你做,功能再强点更好。
我们所有的产品都是为数字时代而构建的,并且此功能已集成到他们的应用程序中。当然,该公司还开发了一些其他专门的数据抓取,采集 应用程序。
智能编辑重构批处理“数字Python IDE”集成开发环境(集成高效Cython PyInstaller批处理小程序)
详细用法
01、编辑菜单-->勾选“剪贴板:监视器”-->弹出如下“提示窗口”
如果您刚刚启动应用程序,可能不会重新启动它,请切换到“取消”按钮并回车确认。
02、在桌面、文件夹、网页、网上邻居、Microsoft Office 应用程序等,按Ctrl+C快捷键(或其他操作)将文本内容复制到剪贴板 --> App应用会自动弹出如下界面。
如果“剪贴板文本”不符合抓取要求,可以点击“清除剪贴板”按钮,清除剪贴板内容。
网页flash文本抓取器(网页flash文本抓取器功能的制作教程-w3school在线教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-21 11:04
网页flash文本抓取器功能就是把网页上传到阿里云,然后编辑一下就可以用了,支持百度、搜狗、360、等等,it兔这里提供了详细的制作教程,你可以按照视频里的方法操作一下看看,希望能帮到你。
w3school在线教程,w3cschool在线教程你看下这个吧
不知道怎么下载,
我试了下w3cschool,
第一步:点击我的电脑,在电脑菜单里点击管理第二步:找到服务和应用程序,
我刚好写了个爬虫,
网页flash查询
w3cui7网址查询
解压后,再看哪个网页有,用chrome打开,自己找吧。
直接打开开发者工具,进入目标网页,然后在页面的url地址栏里面,用快捷键ctrl+alt+g就可以定位到html元素的地址。
很明显是一个基于phantomjs框架开发的类似于操作系统的库。python的实现,要么去看java的实现,要么直接c++看java的库。
找到一个基于vue框架的可抓取htmlhtml-h5-demoframework这个是基于这个框架实现的html数据可视化框架,也是针对你目前遇到的问题,写的一个函数,可视化的抓取htmlhtml-h5-demoframework,经过一定时间的跑调,
这个你先改下文件后缀名再看看能不能下载,之前我也是这么好的,打开文件看了一下, 查看全部
网页flash文本抓取器(网页flash文本抓取器功能的制作教程-w3school在线教程)
网页flash文本抓取器功能就是把网页上传到阿里云,然后编辑一下就可以用了,支持百度、搜狗、360、等等,it兔这里提供了详细的制作教程,你可以按照视频里的方法操作一下看看,希望能帮到你。
w3school在线教程,w3cschool在线教程你看下这个吧
不知道怎么下载,
我试了下w3cschool,
第一步:点击我的电脑,在电脑菜单里点击管理第二步:找到服务和应用程序,
我刚好写了个爬虫,
网页flash查询
w3cui7网址查询
解压后,再看哪个网页有,用chrome打开,自己找吧。
直接打开开发者工具,进入目标网页,然后在页面的url地址栏里面,用快捷键ctrl+alt+g就可以定位到html元素的地址。
很明显是一个基于phantomjs框架开发的类似于操作系统的库。python的实现,要么去看java的实现,要么直接c++看java的库。
找到一个基于vue框架的可抓取htmlhtml-h5-demoframework这个是基于这个框架实现的html数据可视化框架,也是针对你目前遇到的问题,写的一个函数,可视化的抓取htmlhtml-h5-demoframework,经过一定时间的跑调,
这个你先改下文件后缀名再看看能不能下载,之前我也是这么好的,打开文件看了一下,
网页flash文本抓取器(游戏官网中为什么要使用以上全部的标签?能某些标签不?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-19 17:08
材料:
做游戏官网在页面插入flash时总会遇到:
二、为什么要使用以上所有标签?可以省略一些标签吗?
OBJECT 标记用于 windows IE3.0 及更高版本的浏览器或其他支持 Activex 控件的浏览器。"classid" 和 "codebase" 属性必须完全如上例所示编写,它们告诉浏览器自动下载 Flash 播放器的位置。如果没有安装flash player,IE3.0之后的浏览器会弹出提示框询问是否自动安装flash player。当然,如果你不希望没有安装 flash player 的用户自动下载播放器,也许你可以省略这些代码。
EMBED 标签适用于 Netscape Navigator2.0 及更高版本的浏览器或其他支持 Netscape 插件的浏览器。“pluginspage”属性告诉浏览器下载flash播放器的地址。如果没有安装flash player,安装后用户需要重启浏览器才能正常使用。
为确保大多数浏览器正确显示 flash,您需要将 EMBED 标签嵌套在 OBJECT 标签内,如上面的代码示例所示。支持 Activex 控件的浏览器将忽略 OBJECT 标记内的 EMBED 标记。使用插件的 Netscape 和 IE 浏览器只会读取 EMBED 标签,不会识别 OBJECT 标签。也就是说,如果你省略了EMBED标签,那么firefox将无法识别你的flash(但令人惊讶的是,如果你省略object只写embed,IE也能正常显示flash,呵呵,咱们仔细看看细节)。
本文列出了用于发布电影的 OBJECT 和 EMBED 标签的必需和可选属性。
一、必需的属性:
· CLASSID——设置浏览器的Activex控件,只针对OBJECT标签。
· CODEBASE——设置flash Activex控件的位置,所以如果没有安装浏览器,可以自动下载安装。仅用于 OBJECT 标记。
· WIDTH - 以百分比或像素指定 Flash 影片的宽度。
· HEIGHT - 以百分比或像素指定 Flash 影片的高度。
·SRC-指定视频的下载地址。仅用于 EMBED 标签。
· PLUGINSPAGE - 设置flash插件的位置,如果浏览器没有安装,可以自动下载安装。仅用于 EMBED 标签。
MOVIE——指定电影的下载地址。仅用于 OBJECT 标记。
二、可选属性和可用值:
·ID-设置变量名,用于脚本代码参考。仅针对对象。
· NAME——设置变量名,用于脚本代码(如javascript)引用。仅适用于嵌入。
SWLIVECONNECT -(true 或 false)指定第一次下载 flash 播放器时是否启用 java。如果省略某些属性,则默认值为 false。如果在同一页面上使用javascript和flash,java必须使用FSCommand才能工作。
PLAY -(true 或 false)指定下载完成后是否应自动播放 flash 电影。如果省略此属性,则默认为 true。
LOOP -(真或假)指定在影片的最后一帧之后是停止还是继续循环。如果省略此属性,则默认为 true。
菜单 - (真或假)
·真实显示所有菜单,允许用户放大、缩小等控制视频播放等操作。
·False 显示仅收录设置选项和关于闪光灯的菜单。
·QUALITY - (low, high, autolow, autohigh, best)
· 低速优于美观,没有应用抗锯齿。
Autolow 最初专注于速度,但总是在需要时提高美感。
·Autohigh既注重播放速度又注重美观,但在需要的时候牺牲了美观来保证播放速度。
· 中等应用一些抗锯齿而不平滑位图。它的质量高于低设置,低于高设置。
· 高美感胜过播放速度,始终应用抗锯齿。如果影片不收录动画,则位图会被平滑;如果影片收录动画,位图将不会被平滑。
·Best 提供最佳的显示质量,无论播放速度如何。所有输出都经过抗锯齿处理,所有位图都经过平滑处理。
·SCALE - (showall, noborder, exactfit)
·Default(Show all) 影片显示在指定区域,但保持原来的比例。边框将出现在视频的两侧。
·No Boder 缩小视频以适应指定区域,保持视频不失真,但部分视频可能会被裁剪。但是,电影的原创比例保持不变。
·Exact Fit 使整个影片显示在指定区域,影片可能会变形和扭曲,无法保持原创比例。
·对齐 - (l, t, r, b)
·默认居中,当浏览器窗口小于影片时,边缘会被裁剪。
·Left、Right、Top、Bottom根据相应的设置沿浏览器边缘对齐。如果需要,其他三个边将被裁剪。
·SALIGN - (l, t, r, b, tl, tr, bl, br)
·L,R,T,B
·TL,TR
·BL、BR
·WMODE-(window, opaque, transparent) 设置flash影片的窗口模式属性,并指定flash在浏览器中的透明度、堆叠和位置。
·窗口电影在浏览器中自己的矩形窗口中播放。
· 不透明电影隐藏了它背后的所有内容。
·透明使flash影片透明,显示透明影片后面的网页内容。这会降低动画性能。并且此属性并非在所有浏览器中都可用。
· BGCOLOR - (#RRGGBB, 十六进制 RGB 值。) 指定影片的背景颜色。使用此属性覆盖 Flash 中设置的背景颜色。
· BASE——设置基本目录或URL,用于解析flash中的所有相对路径。类似于网页中的标签。
·FLASHVARS 将变量传递给flash player,需要flash player6 及更高版本。
· 将根级变量传递给电影。字符串的格式是由“&”分隔的 name=value 的集合。
浏览器支持的字符串长度最大为 64kB。 查看全部
网页flash文本抓取器(游戏官网中为什么要使用以上全部的标签?能某些标签不?)
材料:
做游戏官网在页面插入flash时总会遇到:
二、为什么要使用以上所有标签?可以省略一些标签吗?
OBJECT 标记用于 windows IE3.0 及更高版本的浏览器或其他支持 Activex 控件的浏览器。"classid" 和 "codebase" 属性必须完全如上例所示编写,它们告诉浏览器自动下载 Flash 播放器的位置。如果没有安装flash player,IE3.0之后的浏览器会弹出提示框询问是否自动安装flash player。当然,如果你不希望没有安装 flash player 的用户自动下载播放器,也许你可以省略这些代码。
EMBED 标签适用于 Netscape Navigator2.0 及更高版本的浏览器或其他支持 Netscape 插件的浏览器。“pluginspage”属性告诉浏览器下载flash播放器的地址。如果没有安装flash player,安装后用户需要重启浏览器才能正常使用。
为确保大多数浏览器正确显示 flash,您需要将 EMBED 标签嵌套在 OBJECT 标签内,如上面的代码示例所示。支持 Activex 控件的浏览器将忽略 OBJECT 标记内的 EMBED 标记。使用插件的 Netscape 和 IE 浏览器只会读取 EMBED 标签,不会识别 OBJECT 标签。也就是说,如果你省略了EMBED标签,那么firefox将无法识别你的flash(但令人惊讶的是,如果你省略object只写embed,IE也能正常显示flash,呵呵,咱们仔细看看细节)。
本文列出了用于发布电影的 OBJECT 和 EMBED 标签的必需和可选属性。
一、必需的属性:
· CLASSID——设置浏览器的Activex控件,只针对OBJECT标签。
· CODEBASE——设置flash Activex控件的位置,所以如果没有安装浏览器,可以自动下载安装。仅用于 OBJECT 标记。
· WIDTH - 以百分比或像素指定 Flash 影片的宽度。
· HEIGHT - 以百分比或像素指定 Flash 影片的高度。
·SRC-指定视频的下载地址。仅用于 EMBED 标签。
· PLUGINSPAGE - 设置flash插件的位置,如果浏览器没有安装,可以自动下载安装。仅用于 EMBED 标签。
MOVIE——指定电影的下载地址。仅用于 OBJECT 标记。
二、可选属性和可用值:
·ID-设置变量名,用于脚本代码参考。仅针对对象。
· NAME——设置变量名,用于脚本代码(如javascript)引用。仅适用于嵌入。
SWLIVECONNECT -(true 或 false)指定第一次下载 flash 播放器时是否启用 java。如果省略某些属性,则默认值为 false。如果在同一页面上使用javascript和flash,java必须使用FSCommand才能工作。
PLAY -(true 或 false)指定下载完成后是否应自动播放 flash 电影。如果省略此属性,则默认为 true。
LOOP -(真或假)指定在影片的最后一帧之后是停止还是继续循环。如果省略此属性,则默认为 true。
菜单 - (真或假)
·真实显示所有菜单,允许用户放大、缩小等控制视频播放等操作。
·False 显示仅收录设置选项和关于闪光灯的菜单。
·QUALITY - (low, high, autolow, autohigh, best)
· 低速优于美观,没有应用抗锯齿。
Autolow 最初专注于速度,但总是在需要时提高美感。
·Autohigh既注重播放速度又注重美观,但在需要的时候牺牲了美观来保证播放速度。
· 中等应用一些抗锯齿而不平滑位图。它的质量高于低设置,低于高设置。
· 高美感胜过播放速度,始终应用抗锯齿。如果影片不收录动画,则位图会被平滑;如果影片收录动画,位图将不会被平滑。
·Best 提供最佳的显示质量,无论播放速度如何。所有输出都经过抗锯齿处理,所有位图都经过平滑处理。
·SCALE - (showall, noborder, exactfit)
·Default(Show all) 影片显示在指定区域,但保持原来的比例。边框将出现在视频的两侧。
·No Boder 缩小视频以适应指定区域,保持视频不失真,但部分视频可能会被裁剪。但是,电影的原创比例保持不变。
·Exact Fit 使整个影片显示在指定区域,影片可能会变形和扭曲,无法保持原创比例。
·对齐 - (l, t, r, b)
·默认居中,当浏览器窗口小于影片时,边缘会被裁剪。
·Left、Right、Top、Bottom根据相应的设置沿浏览器边缘对齐。如果需要,其他三个边将被裁剪。
·SALIGN - (l, t, r, b, tl, tr, bl, br)
·L,R,T,B
·TL,TR
·BL、BR
·WMODE-(window, opaque, transparent) 设置flash影片的窗口模式属性,并指定flash在浏览器中的透明度、堆叠和位置。
·窗口电影在浏览器中自己的矩形窗口中播放。
· 不透明电影隐藏了它背后的所有内容。
·透明使flash影片透明,显示透明影片后面的网页内容。这会降低动画性能。并且此属性并非在所有浏览器中都可用。
· BGCOLOR - (#RRGGBB, 十六进制 RGB 值。) 指定影片的背景颜色。使用此属性覆盖 Flash 中设置的背景颜色。
· BASE——设置基本目录或URL,用于解析flash中的所有相对路径。类似于网页中的标签。
·FLASHVARS 将变量传递给flash player,需要flash player6 及更高版本。
· 将根级变量传递给电影。字符串的格式是由“&”分隔的 name=value 的集合。
浏览器支持的字符串长度最大为 64kB。
网页flash文本抓取器( Java程序在解析中的应用场景的主要功能详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-15 22:21
Java程序在解析中的应用场景的主要功能详解)
jsoup爬取网页+具体讲解
在Java程序解析HTML文档的时候,相信大家都接触过开源项目htmlparser。我之前在 IBM DW 上发表过两篇关于 htmlparser 的 文章 文章。它们是:从 HTML 中获取您需要的信息并扩展 HTMLParser 处理您自己定义的标签的能力。但现在我不再使用 htmlparser 了。原因是 htmlparser 很少更新,但最重要的是有 jsoup。
jsoup 是一个 Java HTML 解析器。它可以直接解析一个URL地址和HTML文本内容。
它提供了一个非常省力的 API。可以通过 DOM、CSS 和类似 jQuery 的操作方法检索和操作数据。
jsoup的主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
jsoup 在 MIT 许可下发布,可以安全地用于商业项目。
jsoup的主要类层次结构如图1所示:
图 1. jsoup 的类层次结构
接下来,我们将围绕几个常见的应用场景来说明jsoup如何优雅地处理HTML文档。
回到顶部
文件输入
jsoup 可以从收录字符串、URL 地址和本地文件中加载 HTML 文档。并生成一个 Document 对象实例。
以下是相关代码:
清单 1
// 直接从字符串中输入 HTML 文档
String html = " 开源中国社区 "
+ "<p> 这里是 jsoup 项目的相关文章 ";
Document doc = Jsoup.parse(html);
// 从 URL 直接载入 HTML 文档
Document doc = Jsoup.connect("http://www.oschina.net/").get();
String title = doc.title();
Document doc = Jsoup.connect("http://www.oschina.net/")
.data("query", "Java") // 请求參数
.userAgent("I ’ m jsoup") // 设置 User-Agent
.cookie("auth", "token") // 设置 cookie
.timeout(3000) // 设置连接超时时间
.post(); // 使用 POST 方法訪问 URL
// 从文件里载入 HTML 文档
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/");
</p>
请注意最后一个HTML文档输入法中parse的第三个参数。为什么这里需要指定一个URL(虽然不能指定,比如第一种方法)?因为HTML文档中会有大量的链接、图片以及外部脚本、css文件等。第三个参数 baseURL 表示 HTML 文档何时使用相对路径来引用外部文件。jsoup 会自动为这些 URL 添加前缀,即 baseURL。
例如,开源软件将被转换为开源软件。
回到顶部
解析和提取 HTML 元素
这部分介绍了一个HTML解析器的主要功能,但是jsoup使用了与其他开源项目不同的方式——选择器,我们将在最后一部分详细介绍jsoup选择器。在本节中,您将看到如何使用最简单的代码实现 jsoup。
只是jsoup还提供了传统DOM方式的元素解析。看看下面的代码:
列表2.
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://www.oschina.net/");
Element content = doc.getElementById("content");
Elements links = content.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
}
您可能认为 jsoup 的方法看起来很熟悉,您是对的。getElementById 和 getElementsByTag 等方法与 JavaScript 方法同名,功能完全相同。
您可以根据节点名称或 HTML 元素的 id 获取对应的元素或元素列表。
与 htmlparser 项目不同。jsoup 没有为 HTML 元素定义相应的类。一般来说,一个 HTML 元素的组成部分包括:节点名、属性和文本,jsoup 提供了一种简单的方法让你自己检索这些数据,这就是 jsoup 保持苗条的原因。
而说到元素检索,jsoup的选择器几乎是无所不能的。
列表3.
File input = new File("D:\test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/");
Elements links = doc.select("a[href]"); // 具有 href 属性的链接
Elements pngs = doc.select("img[src$=.png]");// 全部引用 png 图片的元素
Element masthead = doc.select("div.masthead").first();
// 找出定义了 class=masthead 的元素
Elements resultLinks = doc.select("h3.r > a"); // direct a after h3
这是 jsoup 真正说服我的地方。Jsoup 使用与 jQuery 完全相同的选择器来检索元素。如果把上面的检索方式换成其他的HTML解释器,至少需要很多行代码,而jsoup只需要一行代码就搞定了。
Jsoup 的选择器也支持表达式功能,我们将在最后一节介绍这个超级强大的选择器。
回到顶部
更改数据
在解析文档时。我们可能需要对文档中的一些元素进行更改,例如,我们可以为文档中的所有图片添加可点击的链接,更改链接地址,或者更改文本等。
下面是一些简单的例子:
列表4.
doc.select("div.comments a").attr("rel", "nofollow");
// 为全部链接添加 rel=nofollow 属性
doc.select("div.comments a").addClass("mylinkclass");
// 为全部链接添加 class=mylinkclass 属性
doc.select("img").removeAttr(" // 删除全部图片的 onclick 属性
doc.select("input[type=text]").val(""); // 清空全部文本输入框中的文本
原因很简单,只需要使用jsoup的选择器找到元素,然后就可以通过上面的方法进行修改,只是标签名不能改(可以删除后再插入新元素) ,包括可以改变元素的属性和文本。
修改后直接调用Element(s)的html()方法获取修改后的HTML文档。
回到顶部
HTML 文档清理
jsoup 同时提供了强大的 API。人性化也做得很好。做网站的时候。经常提供用户评论。
有些用户很淘气。将一些脚本制作成评论内容。而这些脚本可能会破坏整个页面的行为,更严重的是,会获取一些机密信息。比如XSS跨站攻击之类的。
jsoup 对此的支持非常强大且易于使用。看看下面的代码:
列表5.
<p>
String unsafe = "<p> 查看全部
网页flash文本抓取器(
Java程序在解析中的应用场景的主要功能详解)
jsoup爬取网页+具体讲解
在Java程序解析HTML文档的时候,相信大家都接触过开源项目htmlparser。我之前在 IBM DW 上发表过两篇关于 htmlparser 的 文章 文章。它们是:从 HTML 中获取您需要的信息并扩展 HTMLParser 处理您自己定义的标签的能力。但现在我不再使用 htmlparser 了。原因是 htmlparser 很少更新,但最重要的是有 jsoup。
jsoup 是一个 Java HTML 解析器。它可以直接解析一个URL地址和HTML文本内容。
它提供了一个非常省力的 API。可以通过 DOM、CSS 和类似 jQuery 的操作方法检索和操作数据。
jsoup的主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
jsoup 在 MIT 许可下发布,可以安全地用于商业项目。
jsoup的主要类层次结构如图1所示:
图 1. jsoup 的类层次结构
接下来,我们将围绕几个常见的应用场景来说明jsoup如何优雅地处理HTML文档。
回到顶部
文件输入
jsoup 可以从收录字符串、URL 地址和本地文件中加载 HTML 文档。并生成一个 Document 对象实例。
以下是相关代码:
清单 1
// 直接从字符串中输入 HTML 文档
String html = " 开源中国社区 "
+ "<p> 这里是 jsoup 项目的相关文章 ";
Document doc = Jsoup.parse(html);
// 从 URL 直接载入 HTML 文档
Document doc = Jsoup.connect("http://www.oschina.net/";).get();
String title = doc.title();
Document doc = Jsoup.connect("http://www.oschina.net/";)
.data("query", "Java") // 请求參数
.userAgent("I ’ m jsoup") // 设置 User-Agent
.cookie("auth", "token") // 设置 cookie
.timeout(3000) // 设置连接超时时间
.post(); // 使用 POST 方法訪问 URL
// 从文件里载入 HTML 文档
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/";);
</p>
请注意最后一个HTML文档输入法中parse的第三个参数。为什么这里需要指定一个URL(虽然不能指定,比如第一种方法)?因为HTML文档中会有大量的链接、图片以及外部脚本、css文件等。第三个参数 baseURL 表示 HTML 文档何时使用相对路径来引用外部文件。jsoup 会自动为这些 URL 添加前缀,即 baseURL。
例如,开源软件将被转换为开源软件。
回到顶部
解析和提取 HTML 元素
这部分介绍了一个HTML解析器的主要功能,但是jsoup使用了与其他开源项目不同的方式——选择器,我们将在最后一部分详细介绍jsoup选择器。在本节中,您将看到如何使用最简单的代码实现 jsoup。
只是jsoup还提供了传统DOM方式的元素解析。看看下面的代码:
列表2.
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://www.oschina.net/";);
Element content = doc.getElementById("content");
Elements links = content.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
}
您可能认为 jsoup 的方法看起来很熟悉,您是对的。getElementById 和 getElementsByTag 等方法与 JavaScript 方法同名,功能完全相同。
您可以根据节点名称或 HTML 元素的 id 获取对应的元素或元素列表。
与 htmlparser 项目不同。jsoup 没有为 HTML 元素定义相应的类。一般来说,一个 HTML 元素的组成部分包括:节点名、属性和文本,jsoup 提供了一种简单的方法让你自己检索这些数据,这就是 jsoup 保持苗条的原因。
而说到元素检索,jsoup的选择器几乎是无所不能的。
列表3.
File input = new File("D:\test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/";);
Elements links = doc.select("a[href]"); // 具有 href 属性的链接
Elements pngs = doc.select("img[src$=.png]");// 全部引用 png 图片的元素
Element masthead = doc.select("div.masthead").first();
// 找出定义了 class=masthead 的元素
Elements resultLinks = doc.select("h3.r > a"); // direct a after h3
这是 jsoup 真正说服我的地方。Jsoup 使用与 jQuery 完全相同的选择器来检索元素。如果把上面的检索方式换成其他的HTML解释器,至少需要很多行代码,而jsoup只需要一行代码就搞定了。
Jsoup 的选择器也支持表达式功能,我们将在最后一节介绍这个超级强大的选择器。
回到顶部
更改数据
在解析文档时。我们可能需要对文档中的一些元素进行更改,例如,我们可以为文档中的所有图片添加可点击的链接,更改链接地址,或者更改文本等。
下面是一些简单的例子:
列表4.
doc.select("div.comments a").attr("rel", "nofollow");
// 为全部链接添加 rel=nofollow 属性
doc.select("div.comments a").addClass("mylinkclass");
// 为全部链接添加 class=mylinkclass 属性
doc.select("img").removeAttr(" // 删除全部图片的 onclick 属性
doc.select("input[type=text]").val(""); // 清空全部文本输入框中的文本
原因很简单,只需要使用jsoup的选择器找到元素,然后就可以通过上面的方法进行修改,只是标签名不能改(可以删除后再插入新元素) ,包括可以改变元素的属性和文本。
修改后直接调用Element(s)的html()方法获取修改后的HTML文档。
回到顶部
HTML 文档清理
jsoup 同时提供了强大的 API。人性化也做得很好。做网站的时候。经常提供用户评论。
有些用户很淘气。将一些脚本制作成评论内容。而这些脚本可能会破坏整个页面的行为,更严重的是,会获取一些机密信息。比如XSS跨站攻击之类的。
jsoup 对此的支持非常强大且易于使用。看看下面的代码:
列表5.
<p>
String unsafe = "<p>
网页flash文本抓取器(WindowTextExtractor使用方法提取窗口文本没有什么设置选项,方便我们复制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-02-13 12:07
WindowTextExtractor(窗口文本提取)是一款文本提取软件,可以让用户快速提取文本,尤其是在遇到某些问题时。使用文本提取软件更方便。使用工具,可以提取软件的窗口标题,复制文字和查看密码,功能强大。
【WindowTextExtractor软件介绍】
WindowTextExtractor(窗口文本提取)是一款非常好用的文本提取软件。该软件是完全免费和开源的。它可以帮助用户提取软件的窗口标题、复制文本和查看密码。它操作简单、功能强大、体积小。合作伙伴可以下载!
【WindowTextExtractor软件特点】
WindowTextExtractor 可以帮助您获取窗口中的文本。
当窗口文字无法复制时,可以使用本软件快速提取。
可以快速提取图像文件。
采用先进的OCR技术识别窗口文字。
您可以一键将识别出的文本另存为TXT。
【WindowTextExtractor软件功能】
是一个免费开源的小程序,可以提取程序窗口中的控件文本,方便我们复制。
如何使用 WindowTextExtractor
没有提取窗口文本的设置选项,只需将搜索窗口的按钮拖动到窗口中要提取文本的指定位置,提取的文本就会显示在文本区域。
一些密码输入框中的隐藏文字也可以通过它提取出来。
提取密码输入框中的隐藏文本。不支持flash、qt、Chrome浏览器等程序,但仍然可以提取窗口标题和标签页标题。如果你想用它来提取网页中的一些文字,你可以用IE浏览器打开网页。
提取网页文本 如果它直接指向链接文本,则可以提取其链接。
被指向的子窗口的图片会在Image中显示,有的不会显示。如果需要保存,可以使用菜单 File - Save image as 保存到本地,Text 中的文字也可以通过这种方式保存为文件。
【WindowTextExtractor使用教程】
没有提取窗口文本的设置选项,只需将搜索窗口的按钮拖动到窗口中要提取文本的指定位置,提取的文本就会显示在文本区域。
一些密码输入框中的隐藏文字也可以通过它提取出来。
提取密码输入框中的隐藏文本。不支持flash、qt、Chrome浏览器等程序,但仍然可以提取窗口标题和标签页标题。如果你想用它来提取网页中的一些文字,你可以用IE浏览器打开网页。
提取网页文本 如果它直接指向链接文本,则可以提取其链接。
被指向的子窗口的图片会在Image中显示,有的不会显示。如果需要保存,可以使用菜单 File - Save image as 保存到本地,Text 中的文字也可以通过这种方式保存为文件。 查看全部
网页flash文本抓取器(WindowTextExtractor使用方法提取窗口文本没有什么设置选项,方便我们复制)
WindowTextExtractor(窗口文本提取)是一款文本提取软件,可以让用户快速提取文本,尤其是在遇到某些问题时。使用文本提取软件更方便。使用工具,可以提取软件的窗口标题,复制文字和查看密码,功能强大。
【WindowTextExtractor软件介绍】
WindowTextExtractor(窗口文本提取)是一款非常好用的文本提取软件。该软件是完全免费和开源的。它可以帮助用户提取软件的窗口标题、复制文本和查看密码。它操作简单、功能强大、体积小。合作伙伴可以下载!
【WindowTextExtractor软件特点】
WindowTextExtractor 可以帮助您获取窗口中的文本。
当窗口文字无法复制时,可以使用本软件快速提取。
可以快速提取图像文件。
采用先进的OCR技术识别窗口文字。
您可以一键将识别出的文本另存为TXT。
【WindowTextExtractor软件功能】
是一个免费开源的小程序,可以提取程序窗口中的控件文本,方便我们复制。
如何使用 WindowTextExtractor
没有提取窗口文本的设置选项,只需将搜索窗口的按钮拖动到窗口中要提取文本的指定位置,提取的文本就会显示在文本区域。
一些密码输入框中的隐藏文字也可以通过它提取出来。
提取密码输入框中的隐藏文本。不支持flash、qt、Chrome浏览器等程序,但仍然可以提取窗口标题和标签页标题。如果你想用它来提取网页中的一些文字,你可以用IE浏览器打开网页。
提取网页文本 如果它直接指向链接文本,则可以提取其链接。
被指向的子窗口的图片会在Image中显示,有的不会显示。如果需要保存,可以使用菜单 File - Save image as 保存到本地,Text 中的文字也可以通过这种方式保存为文件。
【WindowTextExtractor使用教程】
没有提取窗口文本的设置选项,只需将搜索窗口的按钮拖动到窗口中要提取文本的指定位置,提取的文本就会显示在文本区域。
一些密码输入框中的隐藏文字也可以通过它提取出来。
提取密码输入框中的隐藏文本。不支持flash、qt、Chrome浏览器等程序,但仍然可以提取窗口标题和标签页标题。如果你想用它来提取网页中的一些文字,你可以用IE浏览器打开网页。
提取网页文本 如果它直接指向链接文本,则可以提取其链接。
被指向的子窗口的图片会在Image中显示,有的不会显示。如果需要保存,可以使用菜单 File - Save image as 保存到本地,Text 中的文字也可以通过这种方式保存为文件。
网页flash文本抓取器(输入文本框的实例名用浮动框架(iframe)来做)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-02-12 03:04
btn.onRelease=函数(){
getURL(a.text,_blank)
}
btn 为按钮实例名称,a 为输入文本框的实例名称
使用浮动框架 (iframe) 执行此操作。, 将您的登录框包裹在框架内
登录
用户名:
密码:
你确定密码是文本框吗?文本框可以直接看到输入了什么密码。我现在拥有的是给你的密码箱。
那需要编程语言和数据库,单靠html是不够的。
至于表格,我没有全部写出来。我帮你制作了文本框和按钮按钮,效果也做出来了。你可以自己看看。有什么不懂的可以问我
提交
var yx=document.getElementById("yx");
var bt=document.getElementById("bt");
bt.onclick=函数(){
var reg=/^([a-zA-Z0-9_\.\-])+\@(([a-zA-Z0-9\-])+\.)+([a-zA-Z0- 9]{2,4})+$/gi;
var str=yx.value;
变量 rel=reg.test(str);
如果(相对){
alert("填写正确");
}
别的{
alert("填写错误,请检查");
}
}
如何用Flash制作浏览器:哦,你说的是直接用FLASH显示网页吧?但是不需要点击和控制,就可以把网页做成图片,然后在第一帧按一个输入文本框。稍后再做 在文本框中输入 URL,然后单击按钮以连接您放在框架上的网页。或将框架与网页链接。这应该是你想要的。如果你想在第一帧显示网页,那么你可以自己做一个版本....我认为你说的应该是可能的。FLASH中没有get URL吗?您可以在连接到第一帧时使用它。你可以自己试试看
如何使用flash制作网页浏览器——:不要直接用flash做,可以用Adobe AIR做,AIR中有HTML显示的组件。如果一定要用flash,也不是没有可能,但是要自己写html、jss、css等解释器,也就是常说的浏览器内核。如果不是特别需要,不建议使用这种方法。这很麻烦。我记得写一个解释 HTML 表格的组件花了很长时间。. 那么你不需要成为浏览器。比如外部广告是SWF,只要在播放视频之前加载SWF广告就可以了。您可以使用 Loader 类来实现它。详细请参见帮助文档中对Loader类的描述。
如何制作一个FLASH浏览器,有一个文本框和一个按钮,点击文本框中的按钮输入文本框中输入的URL:我觉得你最好设置一个全局变量,在文本中添加一个监视器box,当 foucs 记录哪个文本框有焦点,然后当你点击按钮时,只需 appendtext("a") 到记录的文本框
如何制作flash网页:制作一个普通网页,然后通过标签嵌入flash。嵌入一些设计工具中可能会更方便(DreamWeaver 似乎可以做到)。Flash可以实现比网页更丰富的效果,但是如果想要实现交互性,就需要了解ActionScript。
互联网行业怎么做flash播放器现在有一个主页可以做af:你可以在网上找一个你喜欢的FLASH文件的URL,把这个链接放到你的播放器上,这是我学校的代码网的,可以参考,style=" :absolute; "align=rightsrc=
如何制作flash网页产品页面当我点击产品页面时,内容会出现在首页下的相应位置。这时候我就可以在代码上写产品按钮了。onRelease=function(){ 主页对应未显示的模块。启用=假;这。attachMovie("Product_mc","Product_mc",1)Product_mc.load("Products made by foreign products.swf") } 这样就可以实现在他加载的时候不加载主产品 只需在产品_mc中添加loader
如何制作flash,网页设计?:Flash设计请参考下文,具体链接请参考用Flash制作动画,靠时间线和图层来解读画面,再精彩的动画,只能让观者盯着屏幕,被动地欣赏时间轴上的进展。如果你想让动画有...
如何制作Flash网页:Flash网页设计不是一朝一夕就能学会的。从基础开始,一步一步,看无数教程,拆解无数国内外flash网站,用了将近一年的时间,经过无数次练习,逐渐投入到工作应用中,并随着编程flash自带的语言,从2.0到3.0有了质的飞跃……
如何制作FLASH播放器:【IT168实战技巧】精彩的Flash动画在网上随处可见。我们大多数人使用 IE 浏览器或 Flash Player 观看它们。你有没有想过自己制作一个个人的 Flash 播放器?为了实现这个愿望,你不需要了解编程知识,只需安装Mediacard,你就可以轻松DIY自己的...
可以flash做浏览器:应该可以的。flash cc 2015安装教程推荐使用2015版注意:安装软件前请先断开网络,直接拔掉网线即可。1、下载安装包,得到如下图这些文件,运行“Flash_Professional_15_LS20.exe”解压软件。2、建议不要换目录,... 查看全部
网页flash文本抓取器(输入文本框的实例名用浮动框架(iframe)来做)
btn.onRelease=函数(){
getURL(a.text,_blank)
}
btn 为按钮实例名称,a 为输入文本框的实例名称
使用浮动框架 (iframe) 执行此操作。, 将您的登录框包裹在框架内
登录
用户名:
密码:
你确定密码是文本框吗?文本框可以直接看到输入了什么密码。我现在拥有的是给你的密码箱。
那需要编程语言和数据库,单靠html是不够的。
至于表格,我没有全部写出来。我帮你制作了文本框和按钮按钮,效果也做出来了。你可以自己看看。有什么不懂的可以问我
提交
var yx=document.getElementById("yx");
var bt=document.getElementById("bt");
bt.onclick=函数(){
var reg=/^([a-zA-Z0-9_\.\-])+\@(([a-zA-Z0-9\-])+\.)+([a-zA-Z0- 9]{2,4})+$/gi;
var str=yx.value;
变量 rel=reg.test(str);
如果(相对){
alert("填写正确");
}
别的{
alert("填写错误,请检查");
}
}
如何用Flash制作浏览器:哦,你说的是直接用FLASH显示网页吧?但是不需要点击和控制,就可以把网页做成图片,然后在第一帧按一个输入文本框。稍后再做 在文本框中输入 URL,然后单击按钮以连接您放在框架上的网页。或将框架与网页链接。这应该是你想要的。如果你想在第一帧显示网页,那么你可以自己做一个版本....我认为你说的应该是可能的。FLASH中没有get URL吗?您可以在连接到第一帧时使用它。你可以自己试试看
如何使用flash制作网页浏览器——:不要直接用flash做,可以用Adobe AIR做,AIR中有HTML显示的组件。如果一定要用flash,也不是没有可能,但是要自己写html、jss、css等解释器,也就是常说的浏览器内核。如果不是特别需要,不建议使用这种方法。这很麻烦。我记得写一个解释 HTML 表格的组件花了很长时间。. 那么你不需要成为浏览器。比如外部广告是SWF,只要在播放视频之前加载SWF广告就可以了。您可以使用 Loader 类来实现它。详细请参见帮助文档中对Loader类的描述。
如何制作一个FLASH浏览器,有一个文本框和一个按钮,点击文本框中的按钮输入文本框中输入的URL:我觉得你最好设置一个全局变量,在文本中添加一个监视器box,当 foucs 记录哪个文本框有焦点,然后当你点击按钮时,只需 appendtext("a") 到记录的文本框
如何制作flash网页:制作一个普通网页,然后通过标签嵌入flash。嵌入一些设计工具中可能会更方便(DreamWeaver 似乎可以做到)。Flash可以实现比网页更丰富的效果,但是如果想要实现交互性,就需要了解ActionScript。
互联网行业怎么做flash播放器现在有一个主页可以做af:你可以在网上找一个你喜欢的FLASH文件的URL,把这个链接放到你的播放器上,这是我学校的代码网的,可以参考,style=" :absolute; "align=rightsrc=
如何制作flash网页产品页面当我点击产品页面时,内容会出现在首页下的相应位置。这时候我就可以在代码上写产品按钮了。onRelease=function(){ 主页对应未显示的模块。启用=假;这。attachMovie("Product_mc","Product_mc",1)Product_mc.load("Products made by foreign products.swf") } 这样就可以实现在他加载的时候不加载主产品 只需在产品_mc中添加loader
如何制作flash,网页设计?:Flash设计请参考下文,具体链接请参考用Flash制作动画,靠时间线和图层来解读画面,再精彩的动画,只能让观者盯着屏幕,被动地欣赏时间轴上的进展。如果你想让动画有...
如何制作Flash网页:Flash网页设计不是一朝一夕就能学会的。从基础开始,一步一步,看无数教程,拆解无数国内外flash网站,用了将近一年的时间,经过无数次练习,逐渐投入到工作应用中,并随着编程flash自带的语言,从2.0到3.0有了质的飞跃……
如何制作FLASH播放器:【IT168实战技巧】精彩的Flash动画在网上随处可见。我们大多数人使用 IE 浏览器或 Flash Player 观看它们。你有没有想过自己制作一个个人的 Flash 播放器?为了实现这个愿望,你不需要了解编程知识,只需安装Mediacard,你就可以轻松DIY自己的...
可以flash做浏览器:应该可以的。flash cc 2015安装教程推荐使用2015版注意:安装软件前请先断开网络,直接拔掉网线即可。1、下载安装包,得到如下图这些文件,运行“Flash_Professional_15_LS20.exe”解压软件。2、建议不要换目录,...
网页flash文本抓取器(⒎导入文本资料导出功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-10 18:10
下载时间:
7316
推荐等级:
接触:
qjf310
开发者:网页采集器(flashcollect)v3.5> 作者空间:
本软件主要用于将网页从网络快速导入数据库,将文件夹中的文本数据导入数据库,方便数据的采集、阅读和搜索。本软件特点: ⒈界面友好,尽量避免使用专业术语,使用方便。⒉ 即时搜索速度,搜索大容量数据库无需等待。⒊自带url分析器,可以分析javascript类的连接。⒋数据导入导出非常灵活。软件的导出功能还可以帮助您根据预先制作的网页模板将采集到的数据输出为网页。该功能可以帮助有个人主页的朋友快速丰富网站的内容。⒌软件提供的各种字符处理和查找替换功能,可以帮助你整理采集到的数据,帮你制作js文件,从数据库中导入文本等⒍提供添加附件功能,可以添加、删除、并任意运行。⒎软件具有自动优化数据库备份的功能(最多支持5个备份),如果数据库被意外破坏,可以通过备份立即恢复。⒏具有完善的节点移动功能,可以根据自己的需要编辑节点的位置。⒎软件具有自动优化数据库备份的功能(最多支持5个备份),如果数据库被意外破坏,可以通过备份立即恢复。⒏具有完善的节点移动功能,可以根据自己的需要编辑节点的位置。⒎软件具有自动优化数据库备份的功能(最多支持5个备份),如果数据库被意外破坏,可以通过备份立即恢复。⒏具有完善的节点移动功能,可以根据自己的需要编辑节点的位置。
绿色
src="" frameborder="0" scrolling="no"> 查看全部
网页flash文本抓取器(⒎导入文本资料导出功能)
下载时间:
7316
推荐等级:
接触:
qjf310
开发者:网页采集器(flashcollect)v3.5> 作者空间:
本软件主要用于将网页从网络快速导入数据库,将文件夹中的文本数据导入数据库,方便数据的采集、阅读和搜索。本软件特点: ⒈界面友好,尽量避免使用专业术语,使用方便。⒉ 即时搜索速度,搜索大容量数据库无需等待。⒊自带url分析器,可以分析javascript类的连接。⒋数据导入导出非常灵活。软件的导出功能还可以帮助您根据预先制作的网页模板将采集到的数据输出为网页。该功能可以帮助有个人主页的朋友快速丰富网站的内容。⒌软件提供的各种字符处理和查找替换功能,可以帮助你整理采集到的数据,帮你制作js文件,从数据库中导入文本等⒍提供添加附件功能,可以添加、删除、并任意运行。⒎软件具有自动优化数据库备份的功能(最多支持5个备份),如果数据库被意外破坏,可以通过备份立即恢复。⒏具有完善的节点移动功能,可以根据自己的需要编辑节点的位置。⒎软件具有自动优化数据库备份的功能(最多支持5个备份),如果数据库被意外破坏,可以通过备份立即恢复。⒏具有完善的节点移动功能,可以根据自己的需要编辑节点的位置。⒎软件具有自动优化数据库备份的功能(最多支持5个备份),如果数据库被意外破坏,可以通过备份立即恢复。⒏具有完善的节点移动功能,可以根据自己的需要编辑节点的位置。
绿色
src="" frameborder="0" scrolling="no">
网页flash文本抓取器(什么是合并文件?如何压缩网页的方式和优化缓存)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-08 13:25
合并文件,对于文本文件,可以直接合并内容。例如,将多个 JS(JavaScript 的简称)文件合并为一个,将多个 CSS 文件合并为一个。
优化缓存。对于没有变化的页面元素(如页眉、页脚等),用户再次访问时无需重新下载,直接从浏览器缓存中读取即可。
2、使用CDN(Content Delivery Network),内容分发网络由一系列分散在不同地理位置的Web服务器组成。它指定一个服务器根据网络上与用户的接近程度来响应用户的请求。当你的网站图片做很多事情的时候,使用CDN是很有必要的。比如现在的电商网站,几乎都使用CDN。
3、压缩网页元素 网页中的每个元素越小,下载的时间就越少,这一点很好理解。现在比较成熟和流程化的网页压缩方式是通过Gzip。从我自己的实践经验来看,一般可以将网页的文字内容减少70%以上。
4、样式表放置在网页的 Head 部分。这也是我实际操作过的一个案例。将样式表(CSS 文件)移动到网页的 Head 部分,可以提高页面的加载速度,并允许页面元素按顺序显示。
5、网页打开时把js文件放在网页底部,所有元素依次显示。由于 JS 文件的特殊性,与其他元素相比,它的加载速度会非常慢。在JS文件下载之前,后面其他元素的顺序显示会被阻塞。因此,尽可能将JS文件放在最底部意味着可以快速显示内容。
6、将样式表和JS脚本放在外部文件中虽然将样式表和JS脚本直接写到网页的HTML中可以减少外部文件调用的次数,但是这样做会增加网页的文件大小。整体来说,在用户第一次访问的时候,把样式表和JS脚本放到外部文件中可能会有点慢,但是以后访问网站的时候,用户可以直接通过浏览器缓存来使用,从而减少了HTTP出于请求数量的目的,这是最佳实践。
在加快网页速度时,一个经常被忽视的问题是响应能力。对于用户来说,每一次操作,无论返回结果是慢是快,都必须及时响应。最典型的例子是:当用户点击打开一张图片时,是否有百分比数字显示的进度条,就是典型的响应式设计。
完成网站后不要急着马上上线,还要测试网站,网站构造不好,但是长期维护,观察网站的不足@网站,那么以上就是网站打开速度慢的解决方法。现在您知道如何让用户在黄金 6 秒内打开 网站 了! 查看全部
网页flash文本抓取器(什么是合并文件?如何压缩网页的方式和优化缓存)
合并文件,对于文本文件,可以直接合并内容。例如,将多个 JS(JavaScript 的简称)文件合并为一个,将多个 CSS 文件合并为一个。
优化缓存。对于没有变化的页面元素(如页眉、页脚等),用户再次访问时无需重新下载,直接从浏览器缓存中读取即可。
2、使用CDN(Content Delivery Network),内容分发网络由一系列分散在不同地理位置的Web服务器组成。它指定一个服务器根据网络上与用户的接近程度来响应用户的请求。当你的网站图片做很多事情的时候,使用CDN是很有必要的。比如现在的电商网站,几乎都使用CDN。
3、压缩网页元素 网页中的每个元素越小,下载的时间就越少,这一点很好理解。现在比较成熟和流程化的网页压缩方式是通过Gzip。从我自己的实践经验来看,一般可以将网页的文字内容减少70%以上。
4、样式表放置在网页的 Head 部分。这也是我实际操作过的一个案例。将样式表(CSS 文件)移动到网页的 Head 部分,可以提高页面的加载速度,并允许页面元素按顺序显示。
5、网页打开时把js文件放在网页底部,所有元素依次显示。由于 JS 文件的特殊性,与其他元素相比,它的加载速度会非常慢。在JS文件下载之前,后面其他元素的顺序显示会被阻塞。因此,尽可能将JS文件放在最底部意味着可以快速显示内容。
6、将样式表和JS脚本放在外部文件中虽然将样式表和JS脚本直接写到网页的HTML中可以减少外部文件调用的次数,但是这样做会增加网页的文件大小。整体来说,在用户第一次访问的时候,把样式表和JS脚本放到外部文件中可能会有点慢,但是以后访问网站的时候,用户可以直接通过浏览器缓存来使用,从而减少了HTTP出于请求数量的目的,这是最佳实践。
在加快网页速度时,一个经常被忽视的问题是响应能力。对于用户来说,每一次操作,无论返回结果是慢是快,都必须及时响应。最典型的例子是:当用户点击打开一张图片时,是否有百分比数字显示的进度条,就是典型的响应式设计。
完成网站后不要急着马上上线,还要测试网站,网站构造不好,但是长期维护,观察网站的不足@网站,那么以上就是网站打开速度慢的解决方法。现在您知道如何让用户在黄金 6 秒内打开 网站 了!
网页flash文本抓取器(使用网站数据爬取csdn的方法,找到轮子哥的csdn爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-03 23:00
网页flash文本抓取器就很棒啊,可以抓取网页所有的文本,然后整理文本并发给后端。第一眼就被这个seofy吸引了,从图中看出ui的风格是macos,作者是个ppt控。
我做了一个,不过只能抓取链接图片视频啥的,不能自动爬取相应的数据抓取页面对应的数据我可以做一个推荐列表,
简单测试了一下,爬取博客还行,不过github上以及一些信息收集站就不好用了。
轮子哥快来一起回答。之前我们博客配置的网站是以github为主,使用githubspider抓下来的数据都很完整了,但爬取个csdn博客就很麻烦,每个数据点击一次获取一次。这次抓包机会就给了使用网站数据爬取csdn的方法(没错就是轮子哥写的csdn爬虫),使用简单快捷的方法,找到轮子哥的github及csdn博客网页的html源代码(包括分页地址网址、index_ver、stat、meta_priv、meta),抓包一遍就获取这些数据了。
我拿到了网页源代码后已经是今年2月20号了,刚刚公布了已经开源的代码,如果觉得效果不错的话,可以fork开源代码并且进行优化以及添加新的功能,给大家看一下效果。代码:githubspider源代码地址:apilist:csdn上轮子哥写的爬虫:point.zhanghang/csdn-bot-spider。 查看全部
网页flash文本抓取器(使用网站数据爬取csdn的方法,找到轮子哥的csdn爬虫)
网页flash文本抓取器就很棒啊,可以抓取网页所有的文本,然后整理文本并发给后端。第一眼就被这个seofy吸引了,从图中看出ui的风格是macos,作者是个ppt控。
我做了一个,不过只能抓取链接图片视频啥的,不能自动爬取相应的数据抓取页面对应的数据我可以做一个推荐列表,
简单测试了一下,爬取博客还行,不过github上以及一些信息收集站就不好用了。
轮子哥快来一起回答。之前我们博客配置的网站是以github为主,使用githubspider抓下来的数据都很完整了,但爬取个csdn博客就很麻烦,每个数据点击一次获取一次。这次抓包机会就给了使用网站数据爬取csdn的方法(没错就是轮子哥写的csdn爬虫),使用简单快捷的方法,找到轮子哥的github及csdn博客网页的html源代码(包括分页地址网址、index_ver、stat、meta_priv、meta),抓包一遍就获取这些数据了。
我拿到了网页源代码后已经是今年2月20号了,刚刚公布了已经开源的代码,如果觉得效果不错的话,可以fork开源代码并且进行优化以及添加新的功能,给大家看一下效果。代码:githubspider源代码地址:apilist:csdn上轮子哥写的爬虫:point.zhanghang/csdn-bot-spider。
网页flash文本抓取器(Twill和mechanize不支持Javascript(1)上运行,appengine只支持纯Python代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-03 02:16
Twill 和 mechanize 不支持 Javascript,Qt 和 Selenium 不支持在 App Engine 上运行 ((1)),appengine 只支持纯 Python 代码。不知道有没有纯 Python Javascript 解释器,就是这样在 App Engine 上你只需要部署一个支持 JS 的爬虫 :-(.
也许 Java 中的某些东西至少可以让您部署到应用程序引擎(Java 版本)?Java 和 Python 中的 App Engine 应用程序版本可以使用相同的数据存储,因此您可以将应用程序的部分内容保留在 Python 中。. . 只是不需要了解 Javascript。不幸的是,我对 Java/AE 环境知之甚少,无法推荐尝试任何特定的包。
(1):为了澄清这一点,似乎有一个误解让我被否决了:如果你在另一台计算机上运行 Selenium 或其他爬虫,你当然可以定位 网站 (不管如何您的目标 网站 已部署,它使用什么编程语言等,只要它是您可以访问的 网站,[真正的 网站: flash&c,可能不同]] . 我读到的问题是,OP 正在寻找让刮板作为应用程序引擎应用程序的一部分运行的方法——这是有问题的部分,而不是你(或其他人 ;-) 运行网站被抓取的地方! 查看全部
网页flash文本抓取器(Twill和mechanize不支持Javascript(1)上运行,appengine只支持纯Python代码)
Twill 和 mechanize 不支持 Javascript,Qt 和 Selenium 不支持在 App Engine 上运行 ((1)),appengine 只支持纯 Python 代码。不知道有没有纯 Python Javascript 解释器,就是这样在 App Engine 上你只需要部署一个支持 JS 的爬虫 :-(.
也许 Java 中的某些东西至少可以让您部署到应用程序引擎(Java 版本)?Java 和 Python 中的 App Engine 应用程序版本可以使用相同的数据存储,因此您可以将应用程序的部分内容保留在 Python 中。. . 只是不需要了解 Javascript。不幸的是,我对 Java/AE 环境知之甚少,无法推荐尝试任何特定的包。
(1):为了澄清这一点,似乎有一个误解让我被否决了:如果你在另一台计算机上运行 Selenium 或其他爬虫,你当然可以定位 网站 (不管如何您的目标 网站 已部署,它使用什么编程语言等,只要它是您可以访问的 网站,[真正的 网站: flash&c,可能不同]] . 我读到的问题是,OP 正在寻找让刮板作为应用程序引擎应用程序的一部分运行的方法——这是有问题的部分,而不是你(或其他人 ;-) 运行网站被抓取的地方!
网页flash文本抓取器(SEO新手并不知道原因在哪,悟道SEO原因分析?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-02 01:10
网站收录是SEO中非常重要的一环,一个收录有问题的网站注定没有好的排名。但是网站的很多收录都不好,很多SEO新手也不知道是什么原因。无道SEO今天要和大家讨论的是,网站收录解决了什么问题?要想解决收录的问题,你必须知道网站收录是怎么回事。
1、网站结构:
百度建议网站应该结构清晰,导航清晰,可以帮助用户快速从你的网站中找到需要的内容,帮助搜索引擎快速了解网站所处的结构层次每个网页都位于。网站结构推荐使用树形结构。树形结构通常分为以下三个层次:主页-频道-文章页面。就像一棵大树,先是树干(主页),然后是树枝(频道),最后是叶子(正常内容页面)。树形结构更具扩展性,网站当内容增加时,可以通过细分分支(通道)轻松处理。
2、代码识别:
百度建议:百度通过一个叫Baiduspider的程序爬取互联网上的网页,处理后建入索引。目前百度蜘蛛只能读取文本内容,暂时无法处理flash、图片等非文本内容。放在flash和图片中的文字百度无法识别。建议使用文字代替flash、图片、Javascript等显示重要内容或链接。搜索引擎暂时无法识别Flash、图片、Javascript中的内容,无法搜索到这部分内容;只有flash和Javascript收录网页链接,百度未必能收录。
3、合理的返回码:
百度爬虫在爬取处理时,会根据http协议规范设置相应的逻辑,所以请尽量参考http协议中返回码含义的定义。我需要弄清楚这些常见的 http 返回码 404、301、503、403 是什么意思以及如何处理。
4、规范,简单的url,即链接深度;
创建一个描述性强、标准化、简单的url,有利于用户更方便地记忆和判断网页内容,也有利于搜索引擎更有效地抓取你的网站。网站在设计之初,应该有一个合理的URL规划。网站的URL深度不能太深,最好在3层以内。
5、地图提交:
百度站长平台支持通过站点地图提交网站内容。百度收录可以通过sitemap提高效率。您可以制作网站地图并提交网站地图以提高百度收录网站的速度。
其实这些收录的知识是很基础的,但是相信80%的人都做不好。经常听到有人抱怨网站收录不好,我也不找原因。网站看了一眼,这些最基本的优化都没有做好,那收录呢?当然,影响搜索引擎的最大因素是空间,而空间的好坏直接影响到SEO的最终效果。 查看全部
网页flash文本抓取器(SEO新手并不知道原因在哪,悟道SEO原因分析?)
网站收录是SEO中非常重要的一环,一个收录有问题的网站注定没有好的排名。但是网站的很多收录都不好,很多SEO新手也不知道是什么原因。无道SEO今天要和大家讨论的是,网站收录解决了什么问题?要想解决收录的问题,你必须知道网站收录是怎么回事。
1、网站结构:
百度建议网站应该结构清晰,导航清晰,可以帮助用户快速从你的网站中找到需要的内容,帮助搜索引擎快速了解网站所处的结构层次每个网页都位于。网站结构推荐使用树形结构。树形结构通常分为以下三个层次:主页-频道-文章页面。就像一棵大树,先是树干(主页),然后是树枝(频道),最后是叶子(正常内容页面)。树形结构更具扩展性,网站当内容增加时,可以通过细分分支(通道)轻松处理。
2、代码识别:
百度建议:百度通过一个叫Baiduspider的程序爬取互联网上的网页,处理后建入索引。目前百度蜘蛛只能读取文本内容,暂时无法处理flash、图片等非文本内容。放在flash和图片中的文字百度无法识别。建议使用文字代替flash、图片、Javascript等显示重要内容或链接。搜索引擎暂时无法识别Flash、图片、Javascript中的内容,无法搜索到这部分内容;只有flash和Javascript收录网页链接,百度未必能收录。
3、合理的返回码:
百度爬虫在爬取处理时,会根据http协议规范设置相应的逻辑,所以请尽量参考http协议中返回码含义的定义。我需要弄清楚这些常见的 http 返回码 404、301、503、403 是什么意思以及如何处理。
4、规范,简单的url,即链接深度;
创建一个描述性强、标准化、简单的url,有利于用户更方便地记忆和判断网页内容,也有利于搜索引擎更有效地抓取你的网站。网站在设计之初,应该有一个合理的URL规划。网站的URL深度不能太深,最好在3层以内。
5、地图提交:
百度站长平台支持通过站点地图提交网站内容。百度收录可以通过sitemap提高效率。您可以制作网站地图并提交网站地图以提高百度收录网站的速度。
其实这些收录的知识是很基础的,但是相信80%的人都做不好。经常听到有人抱怨网站收录不好,我也不找原因。网站看了一眼,这些最基本的优化都没有做好,那收录呢?当然,影响搜索引擎的最大因素是空间,而空间的好坏直接影响到SEO的最终效果。
网页flash文本抓取器(宝贝乐园站长必备工具-这是,宝贝!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-30 17:17
这是Flash Hunter Catcher,宝宝乐园提供的一款捕捉flash、音乐和电影资源的小软件。这是Hunter第一版,是绿色软件,无需写入注册表,请放心使用!希望你们都喜欢!
软件介绍
结合flashget使用
您可以在网站中抓取您喜欢的flash、音乐和电影资源。是站长搭建网站的必备工具。操作简单,功能实用,大部分网上资源经过测试都可以抓取
软件功能
1.与IE紧密配合,可直接提取IE当前网页的FLASH动画文件;
2.输入URL地址,无需IE即可直接下载FLASH动画文件;
3.可以查看下载的FLASH文件;
4.支持代理服务器;
相关介绍
Hunter Catcher是当今互联网上常用的软件之一。本软件绿色、安全、无毒,让您放心使用!如果猎人捕手是您需要的工具,请来这里!本站为您提供猎人捕手官方下载。
软件截图
相关软件
站长必备工具:这是站长必备工具。站长一定要细心呵护,经常发现和处理一些常见的问题。今天,我们为您带来了一个网站管理员必备的工具。强大的站长工具箱,有关键词排名查询、关键词索引查询、友情链接查询、whois查询、关键词挖矿、文章伪原创等众多功能,有了这个软件,站长朋友们可以轻松即时的了解网站的各种情况,当出现问题时,还可以实时发现并修复。朋友必备的工具。
e-family必备工具包:这是一个e-family必备工具包,内置HTML基础代码、CSS滤镜效果、JS页面效果等网页代码。它继承了Windows记事本的所有功能,并增加了自动存档功能。> 网页(源代码、文本)等格式文件功能,以及个人网页浏览器和邮件快速发送功能,让您更方便地浏览和编辑网站代码! 查看全部
网页flash文本抓取器(宝贝乐园站长必备工具-这是,宝贝!)
这是Flash Hunter Catcher,宝宝乐园提供的一款捕捉flash、音乐和电影资源的小软件。这是Hunter第一版,是绿色软件,无需写入注册表,请放心使用!希望你们都喜欢!
软件介绍
结合flashget使用
您可以在网站中抓取您喜欢的flash、音乐和电影资源。是站长搭建网站的必备工具。操作简单,功能实用,大部分网上资源经过测试都可以抓取
软件功能
1.与IE紧密配合,可直接提取IE当前网页的FLASH动画文件;
2.输入URL地址,无需IE即可直接下载FLASH动画文件;
3.可以查看下载的FLASH文件;
4.支持代理服务器;
相关介绍
Hunter Catcher是当今互联网上常用的软件之一。本软件绿色、安全、无毒,让您放心使用!如果猎人捕手是您需要的工具,请来这里!本站为您提供猎人捕手官方下载。
软件截图
相关软件
站长必备工具:这是站长必备工具。站长一定要细心呵护,经常发现和处理一些常见的问题。今天,我们为您带来了一个网站管理员必备的工具。强大的站长工具箱,有关键词排名查询、关键词索引查询、友情链接查询、whois查询、关键词挖矿、文章伪原创等众多功能,有了这个软件,站长朋友们可以轻松即时的了解网站的各种情况,当出现问题时,还可以实时发现并修复。朋友必备的工具。
e-family必备工具包:这是一个e-family必备工具包,内置HTML基础代码、CSS滤镜效果、JS页面效果等网页代码。它继承了Windows记事本的所有功能,并增加了自动存档功能。> 网页(源代码、文本)等格式文件功能,以及个人网页浏览器和邮件快速发送功能,让您更方便地浏览和编辑网站代码!

