
网页访客qq抓取
网页访客qq抓取(网站获取访客QQ系统是什么?如何使用访客统计助手)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-10-21 17:05
网站获取访客QQ系统
1、什么是访客统计助手?访客统计助手就是通过一段JS代码连接到本站独有的分析系统,获取你的网站实时访客QQ信息,通过这种有意的QQ访客,二次营销,可以挽回你流失的客户,让你的流量和竞价成本不再浪费!2、使用访客统计助手有什么好处?只需在您的网页中添加一段代码,即可准确获取客户QQ号。配置超级简单。快速准确分析来访目标客户,多一个网站 用户后台可管理,节省人力物力,最大化广告效果。使用我们的系统获取潜在客户QQ号后,您可以直接在系统后台与客户发起临时QQ对话,主动询问客户需求,了解客户需求,持续跟进,并最终产生销售。此外,本站还针对全网推出了独有的网页在线邮件群发功能,您还可以访问关键词分析潜在客户,发送个性化广告邮件。快捷方便!3、如何使用访客统计助手联系本站客服开户,登录网站后台,然后获取访客QQ统计码,插入你的网站底部或头部开始统计!1、
现在就下载 查看全部
网页访客qq抓取(网站获取访客QQ系统是什么?如何使用访客统计助手)
网站获取访客QQ系统
1、什么是访客统计助手?访客统计助手就是通过一段JS代码连接到本站独有的分析系统,获取你的网站实时访客QQ信息,通过这种有意的QQ访客,二次营销,可以挽回你流失的客户,让你的流量和竞价成本不再浪费!2、使用访客统计助手有什么好处?只需在您的网页中添加一段代码,即可准确获取客户QQ号。配置超级简单。快速准确分析来访目标客户,多一个网站 用户后台可管理,节省人力物力,最大化广告效果。使用我们的系统获取潜在客户QQ号后,您可以直接在系统后台与客户发起临时QQ对话,主动询问客户需求,了解客户需求,持续跟进,并最终产生销售。此外,本站还针对全网推出了独有的网页在线邮件群发功能,您还可以访问关键词分析潜在客户,发送个性化广告邮件。快捷方便!3、如何使用访客统计助手联系本站客服开户,登录网站后台,然后获取访客QQ统计码,插入你的网站底部或头部开始统计!1、
现在就下载
网页访客qq抓取(接到几次还是不能通过,搞得程序员、竞价员一直很头疼)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-17 16:23
最近收到了这么一个让人望而生畏的竞标问题,但是改了几次还是没通过。这让程序员和投标人头疼不已,互相抱怨。百度官方的回答是:只要百度宣传网站涉嫌恶意获取访客信息,就是恶意行为,类似于秘密获取访客信息:比如QQ号和手机号的代码就是恶意代码。, 百度推广的网址和里面的所有页面都需要测试。一经发现,原创无效,拒绝百度推广账号。
下面总结了几个可能的原因。
1、非法内容或链接
QQ强制弹出码、虚假百度搜索多结果、偷偷截取访客QQ码、手机网站获取访客联系信息码等均涉嫌“恶意代码”!对于这些我们很容易发现,一般都是存在于js文件中的部分,也是直接加载到页面上的,有的则是经过js混淆加密后加载到js文件中的,比较隐蔽。代码有注释,这里的提示最好删除。不要给百度的检查留下一句“有侥幸心理”。
还有一个是在Businesslink的track code中加载的。当用户打开会话时,会加载获取手机或QQ号码的代码。最好在Businesslink里面设置,去掉代码js。以下是Businesslink的公告:
这里提到cnzz企业qq。与百度官方的说法相比,cnzz也可以获得一定范围的用户信息,但不是主要的。如果使用企业QQ,可以看到当前登录的QQ用户正在浏览页面发起对话。建议先删除企业qq。
2.登陆页面登陆页面提示
提示部分关键词登陆页面有病毒木马,过一会还是一样。之前的恶意代码。现在这是第一次使用百度。我已经不玩了。新花样不断产生。我有点怀疑,是为了保证广大网友的隐私,只是为了宣传自己的产品。查了好几遍,发现确实删除了很多代码,甚至删除了QQ咨询,改变了业务通信。无需使用全套百度产品。这有点废话。
一般登陆页面的效果比较多,用到的jQuery也很多。它们都是经过加密和混淆的代码。这样的js最好通过正规渠道获得。不要从第三方或仿冒网站获取,因为您不知道。有多少混淆代码是后来添加的恶意代码。页面中还有一个带有php链接的页面,最容易判断为木马。程序员比我们更了解这一点。
3、对于“误杀”的情况
我个人认为肯定是有的,不管是百度审核的标准,还是有的客户发现有的客户之前表现不好,反复尝试隐藏恶意代码或者反技术识别。“恶意代码判断标准和整改标准暂不给出,不给不法方钻空子的机会。” 这句话让你很困惑
最后,百度的这次大整顿行动,将为百度商桥、百度统计等相关产品的推广带来新的高度。 查看全部
网页访客qq抓取(接到几次还是不能通过,搞得程序员、竞价员一直很头疼)
最近收到了这么一个让人望而生畏的竞标问题,但是改了几次还是没通过。这让程序员和投标人头疼不已,互相抱怨。百度官方的回答是:只要百度宣传网站涉嫌恶意获取访客信息,就是恶意行为,类似于秘密获取访客信息:比如QQ号和手机号的代码就是恶意代码。, 百度推广的网址和里面的所有页面都需要测试。一经发现,原创无效,拒绝百度推广账号。
下面总结了几个可能的原因。
1、非法内容或链接


QQ强制弹出码、虚假百度搜索多结果、偷偷截取访客QQ码、手机网站获取访客联系信息码等均涉嫌“恶意代码”!对于这些我们很容易发现,一般都是存在于js文件中的部分,也是直接加载到页面上的,有的则是经过js混淆加密后加载到js文件中的,比较隐蔽。代码有注释,这里的提示最好删除。不要给百度的检查留下一句“有侥幸心理”。
还有一个是在Businesslink的track code中加载的。当用户打开会话时,会加载获取手机或QQ号码的代码。最好在Businesslink里面设置,去掉代码js。以下是Businesslink的公告:

这里提到cnzz企业qq。与百度官方的说法相比,cnzz也可以获得一定范围的用户信息,但不是主要的。如果使用企业QQ,可以看到当前登录的QQ用户正在浏览页面发起对话。建议先删除企业qq。
2.登陆页面登陆页面提示

提示部分关键词登陆页面有病毒木马,过一会还是一样。之前的恶意代码。现在这是第一次使用百度。我已经不玩了。新花样不断产生。我有点怀疑,是为了保证广大网友的隐私,只是为了宣传自己的产品。查了好几遍,发现确实删除了很多代码,甚至删除了QQ咨询,改变了业务通信。无需使用全套百度产品。这有点废话。
一般登陆页面的效果比较多,用到的jQuery也很多。它们都是经过加密和混淆的代码。这样的js最好通过正规渠道获得。不要从第三方或仿冒网站获取,因为您不知道。有多少混淆代码是后来添加的恶意代码。页面中还有一个带有php链接的页面,最容易判断为木马。程序员比我们更了解这一点。
3、对于“误杀”的情况
我个人认为肯定是有的,不管是百度审核的标准,还是有的客户发现有的客户之前表现不好,反复尝试隐藏恶意代码或者反技术识别。“恶意代码判断标准和整改标准暂不给出,不给不法方钻空子的机会。” 这句话让你很困惑


最后,百度的这次大整顿行动,将为百度商桥、百度统计等相关产品的推广带来新的高度。
网页访客qq抓取(通过js,能获取到当前打开网站的人的QQ号码源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-10-12 12:31
通过js可以得到当前打开网站的人的QQ号的源码原理。获取登录QQ号源代码的功能介绍:QQ空间的快速登录方法可以检测到机器上登录的QQ号,并分析这个快速登录页面可以获取地址,然后加载页面通过WebBrowser控件,等待页面加载,分析html,提取当前登录的所有QQ号。 注:开发环境为VisualStudio 2010
其实这个对应的程序很久以前就已经存在了,当时并没有很好的使用。只是现在我们的投标行业导致了互联网的爆发。目前类似的统计系统可以在百度上查到一条大推文,但基本上是垃圾邮件程序。只有两三个做得好。比如闪电精灵和318访客QQ统计就做得最好。闪电收费非常昂贵。300一个月。318访客QQ统计一个月100个,性价比比较高。通过js,目前打开网站的人的QQ号源码将于5月发售。现在每个人看到的都不是 100% 可用的。只有刚才提到的源代码才能100%获得。因为现在还需要搭建一个平台,内部不断的测试。测试成功后才会上市销售,否则会带来很多困难。例如,用户体验中的错误等等。
大致原理就是这样一个过程,用户访问网站---默认打开QQ空间---快速登录功能(js代码程序)---php采集QQ号昵称--- 采集百度统计站长统计---反馈到数据库---用户页面调用数据库数据。如果您有能力编写这样的程序,那么您也可以自己开发一个软件并出售它。目前来看还是很有市场的。根据目前的市场调查。互联网上至少有80%的人不知道这个Q-grabbing系统。所以不要错过这个好机会。
如果您是新手,不会编写此程序,您可以联系我们318访客QQ统计客服讨论、共同学习,或者代理或购买我们的程序,我们提供技术支持,您出售源代码或销售会员,我们将不收一分钱。这是一个很好的创业机会。不知道大家有没有了解什么是暴利行业。暴利是市场竞争大、利润薄的项目。今天分享到这里。 查看全部
网页访客qq抓取(通过js,能获取到当前打开网站的人的QQ号码源码)
通过js可以得到当前打开网站的人的QQ号的源码原理。获取登录QQ号源代码的功能介绍:QQ空间的快速登录方法可以检测到机器上登录的QQ号,并分析这个快速登录页面可以获取地址,然后加载页面通过WebBrowser控件,等待页面加载,分析html,提取当前登录的所有QQ号。 注:开发环境为VisualStudio 2010
其实这个对应的程序很久以前就已经存在了,当时并没有很好的使用。只是现在我们的投标行业导致了互联网的爆发。目前类似的统计系统可以在百度上查到一条大推文,但基本上是垃圾邮件程序。只有两三个做得好。比如闪电精灵和318访客QQ统计就做得最好。闪电收费非常昂贵。300一个月。318访客QQ统计一个月100个,性价比比较高。通过js,目前打开网站的人的QQ号源码将于5月发售。现在每个人看到的都不是 100% 可用的。只有刚才提到的源代码才能100%获得。因为现在还需要搭建一个平台,内部不断的测试。测试成功后才会上市销售,否则会带来很多困难。例如,用户体验中的错误等等。
大致原理就是这样一个过程,用户访问网站---默认打开QQ空间---快速登录功能(js代码程序)---php采集QQ号昵称--- 采集百度统计站长统计---反馈到数据库---用户页面调用数据库数据。如果您有能力编写这样的程序,那么您也可以自己开发一个软件并出售它。目前来看还是很有市场的。根据目前的市场调查。互联网上至少有80%的人不知道这个Q-grabbing系统。所以不要错过这个好机会。
如果您是新手,不会编写此程序,您可以联系我们318访客QQ统计客服讨论、共同学习,或者代理或购买我们的程序,我们提供技术支持,您出售源代码或销售会员,我们将不收一分钱。这是一个很好的创业机会。不知道大家有没有了解什么是暴利行业。暴利是市场竞争大、利润薄的项目。今天分享到这里。
网页访客qq抓取(百度统计为帮助用户网站页面被搜索引擎发现提升抓取速度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-11 06:12
<p>百度统计升级,网页实时推送到搜索引擎,提高网页抓取速度!发布时间:2016-03-05 来源:百度统计是百度推出的一款免费的专业网站流量分析工具,可以告诉用户访问者如何找到和浏览用户网站,在 查看全部
网页访客qq抓取(百度统计为帮助用户网站页面被搜索引擎发现提升抓取速度)
<p>百度统计升级,网页实时推送到搜索引擎,提高网页抓取速度!发布时间:2016-03-05 来源:百度统计是百度推出的一款免费的专业网站流量分析工具,可以告诉用户访问者如何找到和浏览用户网站,在
网页访客qq抓取(如何让访客访问您网站时自动弹出QQ聊天的对话框)
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-10-08 07:34
伊恩今天不小心进入了一家公司的企业网站,QQ聊天窗口立马弹出窗口和那家公司的客服聊天。怀着好奇的心情,伊恩分析了公司网站的源代码,发现了网页弹出qq对话框的原理和实现方法。相信此时此刻,你的QQ已经打开了和伊恩的聊天窗口吧?!
伊恩在这里向各位企业朋友分享实现“网页自动弹出QQ对话框”的原理和方法网站。这些小方法可以通过“认证QQ空间首页同步展示网站”内容实现,对网站的推广也有更有用的效果。
自动弹出QQ对话框的方法可以实现大量的客户查询。相比“左一右一再中一”的客服组件,“打开网页自动弹出QQ对话框”的方式实现咨询量的增加,用户体验和效果要强得多。
好了,废话不多说了。下面我们进入正题,看看如何让访问者在访问你时自动弹出QQ聊天对话框网站。
一、网页上自动弹出QQ对话框的原理
1.在网页中插入iframe框架并设置src="tencent://message/?uin=你的QQ号&Site=&menu=yes";
2.当访问者打开你网站时,也会打开iframe框架中的链接;
3. 访问者的QQ窗口会弹出一个对话框,与您的QQ聊天。
二、验证打开网页会自动弹出QQ对话框
为了验证这个方法的实际可行性,相信你的QQ聊天窗口已经打开了和Ian对话的聊天窗口。你好奇吗?如果你对上面的原理分析没看懂,那么这里的验证结果应该能让你直观的理解!其实Ian也在这篇文章文章中加入了一段实现“打开网页时自动弹出QQ对话框”的代码。
打开网页自动弹出QQ对话框的代码在这里:【点右键查看源码,或者点这里捐给我】
三、设置多个QQ客服,然后随机弹出一个客服QQ对话框
针对企业存在多个客服的情况,直接合理分配接待客服。伊恩刚想出一个办法,就是预设多个客服QQ,然后随机弹出一个客服QQ对话框给访客!当然,这适用于企业,但对于个人站长来说不是必需的。
四、 延迟弹出对话框,让用户先看看
很多客户问我如何设置页面在访问者打开后10秒后弹出。伊恩再次研究并更新了弹出窗口,我确实找到了将其设置为 10 秒后弹出的方法!这样可以在一定程度上提升用户体验,同时让访问者首先看到网站的优质服务可以有效提升客户对产品的认可度,从而增加客户对产品的认知度。积极沟通!
五、手机QQ也有,手机用户不要错过
刚才有朋友问我这个能不能用在手机网页上,然后Ian测试了这个方法不行。然后研究了一会儿,终于找到了手机网页上手机QQ弹窗的突破点。经测试,在安卓和苹果手机上都可以正常弹出QQ对话框。
六、获取访客QQ,让客服主动掌握客户
通过上面的方法,有朋友说客户打开对话框后没有咨询就出去吃饭了,回来的时候忘记了。对此,伊恩还文章扩展想到了访问者访问网站时自动获取QQ号的方法,这种方法可以避免访问者的流失,即使访问者没有咨询也没有交易,没关系,你知道客户QQ号,以后可以随时给对方发消息。有需要的朋友可以在聊天窗口点击Qian。 查看全部
网页访客qq抓取(如何让访客访问您网站时自动弹出QQ聊天的对话框)
伊恩今天不小心进入了一家公司的企业网站,QQ聊天窗口立马弹出窗口和那家公司的客服聊天。怀着好奇的心情,伊恩分析了公司网站的源代码,发现了网页弹出qq对话框的原理和实现方法。相信此时此刻,你的QQ已经打开了和伊恩的聊天窗口吧?!
伊恩在这里向各位企业朋友分享实现“网页自动弹出QQ对话框”的原理和方法网站。这些小方法可以通过“认证QQ空间首页同步展示网站”内容实现,对网站的推广也有更有用的效果。
自动弹出QQ对话框的方法可以实现大量的客户查询。相比“左一右一再中一”的客服组件,“打开网页自动弹出QQ对话框”的方式实现咨询量的增加,用户体验和效果要强得多。
好了,废话不多说了。下面我们进入正题,看看如何让访问者在访问你时自动弹出QQ聊天对话框网站。
一、网页上自动弹出QQ对话框的原理
1.在网页中插入iframe框架并设置src="tencent://message/?uin=你的QQ号&Site=&menu=yes";
2.当访问者打开你网站时,也会打开iframe框架中的链接;
3. 访问者的QQ窗口会弹出一个对话框,与您的QQ聊天。
二、验证打开网页会自动弹出QQ对话框
为了验证这个方法的实际可行性,相信你的QQ聊天窗口已经打开了和Ian对话的聊天窗口。你好奇吗?如果你对上面的原理分析没看懂,那么这里的验证结果应该能让你直观的理解!其实Ian也在这篇文章文章中加入了一段实现“打开网页时自动弹出QQ对话框”的代码。
打开网页自动弹出QQ对话框的代码在这里:【点右键查看源码,或者点这里捐给我】
三、设置多个QQ客服,然后随机弹出一个客服QQ对话框
针对企业存在多个客服的情况,直接合理分配接待客服。伊恩刚想出一个办法,就是预设多个客服QQ,然后随机弹出一个客服QQ对话框给访客!当然,这适用于企业,但对于个人站长来说不是必需的。
四、 延迟弹出对话框,让用户先看看
很多客户问我如何设置页面在访问者打开后10秒后弹出。伊恩再次研究并更新了弹出窗口,我确实找到了将其设置为 10 秒后弹出的方法!这样可以在一定程度上提升用户体验,同时让访问者首先看到网站的优质服务可以有效提升客户对产品的认可度,从而增加客户对产品的认知度。积极沟通!
五、手机QQ也有,手机用户不要错过
刚才有朋友问我这个能不能用在手机网页上,然后Ian测试了这个方法不行。然后研究了一会儿,终于找到了手机网页上手机QQ弹窗的突破点。经测试,在安卓和苹果手机上都可以正常弹出QQ对话框。
六、获取访客QQ,让客服主动掌握客户
通过上面的方法,有朋友说客户打开对话框后没有咨询就出去吃饭了,回来的时候忘记了。对此,伊恩还文章扩展想到了访问者访问网站时自动获取QQ号的方法,这种方法可以避免访问者的流失,即使访问者没有咨询也没有交易,没关系,你知道客户QQ号,以后可以随时给对方发消息。有需要的朋友可以在聊天窗口点击Qian。
网页访客qq抓取(天眼获取网站访客QQ统计系统为你提升10倍业绩)
网站优化 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-10-01 02:06
天眼获取网站访客QQ,网站访客QQ统计系统是一款在线获取网站访客QQ的数据营销软件,让访客真正成为客户,不浪费任何意向客户,< @网站访客QQ统计系统让你的表现提高10倍。天眼访客统计是一款网络营销软件,可以有效捕捉访问网站的客户的QQ信息,让您的潜在客户轻松成为您的目标客户,后续系统可以有效地将访问者定位到有效客户,集成操作方便简单。
1、天眼QQ账号抓包系统是什么?
百度在医疗行业的竞价竞争越来越激烈。随着百度健康平台的出现,各种注册网站、健康网站、健康网站、医药网站,纷纷加入百度的大流量竞价中,目前竞价成本越来越高,流量相对减少;用户越来越排斥Businesslink 的弹出式用户体验,这导致越来越多的对话成本、预约成本和医院访问成本。高,所以作为一个行业,我们是不是也在思考如何从有限的日常竞价流量中最大化发展自己的客户?
天眼QQ抢号系统,只要您在您医院的竞价网站上添加系统提供的统计代码(类似于CNZZ的统计代码),您就可以在后台看到我们为您提供的访客QQ数量到您的投标网站。
2、天眼QQ账号抓包系统是如何工作的?
天眼QQ号抓取系统是一款基于Http、PC互联网协议的程序,用于分析当前用户QQ号。任何人通过PC(电脑)上网,访问医院竞价网站,都会默认抓取用户的QQ号。.
3、抓到的QQ号如何营销?
答:抓到的QQ号和商务沟通一样。一般咨询技能可以转换。如果可以加好友,可以直接加好友(需要及时通话,企业QQ或咨询个人QQ),不能发好友。发邮件,复印,准备一封类似医院介绍的邮件。
4、为什么要使用天眼QQ号抓取系统?
一方面,Businesslink类似广告的弹窗用户越来越反感,用户体验不好,导致竞价流量流失;另一方面,在Businesslink的对话中,最重要的咨询是用户的QQ号和手机号。天眼QQ号抓取系统可以帮助您直接抓取用户的QQ号进行顾问转换。
天眼网站访客QQ统计系统|获取访客QQ来源|网站QQ访客采集系统标题图片 查看全部
网页访客qq抓取(天眼获取网站访客QQ统计系统为你提升10倍业绩)
天眼获取网站访客QQ,网站访客QQ统计系统是一款在线获取网站访客QQ的数据营销软件,让访客真正成为客户,不浪费任何意向客户,< @网站访客QQ统计系统让你的表现提高10倍。天眼访客统计是一款网络营销软件,可以有效捕捉访问网站的客户的QQ信息,让您的潜在客户轻松成为您的目标客户,后续系统可以有效地将访问者定位到有效客户,集成操作方便简单。
1、天眼QQ账号抓包系统是什么?
百度在医疗行业的竞价竞争越来越激烈。随着百度健康平台的出现,各种注册网站、健康网站、健康网站、医药网站,纷纷加入百度的大流量竞价中,目前竞价成本越来越高,流量相对减少;用户越来越排斥Businesslink 的弹出式用户体验,这导致越来越多的对话成本、预约成本和医院访问成本。高,所以作为一个行业,我们是不是也在思考如何从有限的日常竞价流量中最大化发展自己的客户?
天眼QQ抢号系统,只要您在您医院的竞价网站上添加系统提供的统计代码(类似于CNZZ的统计代码),您就可以在后台看到我们为您提供的访客QQ数量到您的投标网站。
2、天眼QQ账号抓包系统是如何工作的?
天眼QQ号抓取系统是一款基于Http、PC互联网协议的程序,用于分析当前用户QQ号。任何人通过PC(电脑)上网,访问医院竞价网站,都会默认抓取用户的QQ号。.
3、抓到的QQ号如何营销?
答:抓到的QQ号和商务沟通一样。一般咨询技能可以转换。如果可以加好友,可以直接加好友(需要及时通话,企业QQ或咨询个人QQ),不能发好友。发邮件,复印,准备一封类似医院介绍的邮件。
4、为什么要使用天眼QQ号抓取系统?
一方面,Businesslink类似广告的弹窗用户越来越反感,用户体验不好,导致竞价流量流失;另一方面,在Businesslink的对话中,最重要的咨询是用户的QQ号和手机号。天眼QQ号抓取系统可以帮助您直接抓取用户的QQ号进行顾问转换。


天眼网站访客QQ统计系统|获取访客QQ来源|网站QQ访客采集系统标题图片
网页访客qq抓取(网站访客QQ获取系统怎么做?如何利用QQ号码展开二次营销)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-10-01 02:03
市场上有很多网站访客QQ获取系统,主要有网页版和客户端两种形式。各家公司的收购率和稳定性也参差不齐。我这里介绍的方法是使用QQ空间权限实现,而不是使用推测接口,所以成本更低,更稳定。获得QQ号后,即可使用QQ号进行二次营销,非常适合各种业务类型网站。
首先我们需要准备一个QQ小号来激活黄钻特权。这个费用大概是每月10元左右。打开黄色菱形后,进入QQ空间,选择空间设置->访问权限设置->只有你能看到,必须设置为只有你能看到。将以下代码复制到JS文件中,将代码中的“*”替换为你的小QQ号,命名为tongji.js,上传到网站FTP根目录。
document.writeln(_$[0]);
document.writeln(_$[1]);
然后将下面代码中的URL替换为你的URL,然后在网站中添加如下代码,即可添加到首页。如果你想得到尽可能多的,你可以将它添加到底部的模板文件中。这样每个页面都可以访问。
这样,访问者在访问网站的同时访问您的QQ空间。当然,他们在表面上是看不到的。由于QQ空间设置为自身可见,访问者无法成功访问QQ空间。这时候我们可以使用QQ黄钻查看被屏蔽访问者的权限,查看访问者的QQ号。
关于收购率的问题,所有声称收购率100%的软件商都是骗人的。如果网站访问者最近打开了QQ空间并且浏览器中保存了缓存,一般可以得到这种情况。如果网站访问者清除了cookies,那么他访问了网站多次@>,也无法获取QQ号。
此方法适用于少量游客。如果有多个网站,可以为每个网站准备一个QQ,这样可以更好的区分不同网站的访问者,针对不同的客户群做营销。如果需要大量获取访客QQ,可以找技术朋友或上威客网站,找人开发辅助工具,获取访客QQ号采集,解放双手。 查看全部
网页访客qq抓取(网站访客QQ获取系统怎么做?如何利用QQ号码展开二次营销)
市场上有很多网站访客QQ获取系统,主要有网页版和客户端两种形式。各家公司的收购率和稳定性也参差不齐。我这里介绍的方法是使用QQ空间权限实现,而不是使用推测接口,所以成本更低,更稳定。获得QQ号后,即可使用QQ号进行二次营销,非常适合各种业务类型网站。
首先我们需要准备一个QQ小号来激活黄钻特权。这个费用大概是每月10元左右。打开黄色菱形后,进入QQ空间,选择空间设置->访问权限设置->只有你能看到,必须设置为只有你能看到。将以下代码复制到JS文件中,将代码中的“*”替换为你的小QQ号,命名为tongji.js,上传到网站FTP根目录。
document.writeln(_$[0]);
document.writeln(_$[1]);
然后将下面代码中的URL替换为你的URL,然后在网站中添加如下代码,即可添加到首页。如果你想得到尽可能多的,你可以将它添加到底部的模板文件中。这样每个页面都可以访问。
这样,访问者在访问网站的同时访问您的QQ空间。当然,他们在表面上是看不到的。由于QQ空间设置为自身可见,访问者无法成功访问QQ空间。这时候我们可以使用QQ黄钻查看被屏蔽访问者的权限,查看访问者的QQ号。
关于收购率的问题,所有声称收购率100%的软件商都是骗人的。如果网站访问者最近打开了QQ空间并且浏览器中保存了缓存,一般可以得到这种情况。如果网站访问者清除了cookies,那么他访问了网站多次@>,也无法获取QQ号。
此方法适用于少量游客。如果有多个网站,可以为每个网站准备一个QQ,这样可以更好的区分不同网站的访问者,针对不同的客户群做营销。如果需要大量获取访客QQ,可以找技术朋友或上威客网站,找人开发辅助工具,获取访客QQ号采集,解放双手。
网页访客qq抓取(找到网站访客QQ号码的原理原理很简单,如何找到访问网站的用户)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-01 02:03
很多网站有流量却不懂营销。回想一下,目前对于所有网站来说,1%的转化率已经算是很好了网站,但是99%网站还达不到这个程度,主要问题是我们不能主动攻击,也找不到访问我们的用户网站。今天教大家如何找到访问网站的用户。这很简单。
查找网站访客QQ号的原理
原理很简单。当用户登录QQ时,打开你的网站,网站会自动弹出你的QQ空间页面,然后三秒左右自动关闭。这时,你打开你的QQ空间,查看你QQ空间的近期访客,这里的近期访客是你的网站访客。
这里提醒大家,最好申请一个新QQ,一个完全没有朋友的QQ,如果网站访问量大于300,最好激活黄钻。没有黄钻只能查看QQ空间。300以内的访客,300以内需要激活黄钻。
如何查找网站访客QQ号
道理看似简单,但并不是每个人都能做到。这涉及到JS弹窗、自动关闭、避免浏览器屏蔽弹窗等技术。别着急,这些代码我都整理好了,今天免费提供给大家。分享它。
第一步:首先下载本站的A.htm和b.html文件,保存到本地。然后把这两个文件上传到你的网站的根目录下,测试打开a.html文件,你会发现弹出一个窗口,这次弹出的窗口是我的QQ空间,不要别担心!
a.htm下载地址:点击直接
b.htm下载地址:点击直接
第二步:使用Dreamweaver打开b.htm文件,将里面的QQ空间链接修改为自己注册的新QQ空间地址,上传到服务器根目录。打开测试后,会弹出你的QQ空间。
第三步:进入QQ空间,将你的QQ空间设置为所有人都可以访问,点击右上角的设置-权限设置-设置谁可以访问我的空间,设置为所有人都可以访问你的QQ空间。否则弹窗无法计数。记得同时激活QQ黄钻。否则,将不会计算超过 300 名访客。
总结:不了解也不知道怎么做的朋友可以直接购买类似访客统计的软件,比如QQ云营销,价格一年1000元左右! 查看全部
网页访客qq抓取(找到网站访客QQ号码的原理原理很简单,如何找到访问网站的用户)
很多网站有流量却不懂营销。回想一下,目前对于所有网站来说,1%的转化率已经算是很好了网站,但是99%网站还达不到这个程度,主要问题是我们不能主动攻击,也找不到访问我们的用户网站。今天教大家如何找到访问网站的用户。这很简单。

查找网站访客QQ号的原理
原理很简单。当用户登录QQ时,打开你的网站,网站会自动弹出你的QQ空间页面,然后三秒左右自动关闭。这时,你打开你的QQ空间,查看你QQ空间的近期访客,这里的近期访客是你的网站访客。
这里提醒大家,最好申请一个新QQ,一个完全没有朋友的QQ,如果网站访问量大于300,最好激活黄钻。没有黄钻只能查看QQ空间。300以内的访客,300以内需要激活黄钻。
如何查找网站访客QQ号
道理看似简单,但并不是每个人都能做到。这涉及到JS弹窗、自动关闭、避免浏览器屏蔽弹窗等技术。别着急,这些代码我都整理好了,今天免费提供给大家。分享它。
第一步:首先下载本站的A.htm和b.html文件,保存到本地。然后把这两个文件上传到你的网站的根目录下,测试打开a.html文件,你会发现弹出一个窗口,这次弹出的窗口是我的QQ空间,不要别担心!
a.htm下载地址:点击直接
b.htm下载地址:点击直接
第二步:使用Dreamweaver打开b.htm文件,将里面的QQ空间链接修改为自己注册的新QQ空间地址,上传到服务器根目录。打开测试后,会弹出你的QQ空间。
第三步:进入QQ空间,将你的QQ空间设置为所有人都可以访问,点击右上角的设置-权限设置-设置谁可以访问我的空间,设置为所有人都可以访问你的QQ空间。否则弹窗无法计数。记得同时激活QQ黄钻。否则,将不会计算超过 300 名访客。
总结:不了解也不知道怎么做的朋友可以直接购买类似访客统计的软件,比如QQ云营销,价格一年1000元左右!
网页访客qq抓取(想要知道谁访问你的QQ空间吗,可以使用东方不败)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-09-30 11:37
想知道谁访问了你的QQ空间吗?您可以使用东方无敌QQ空间访客提取器帮助您整理详细的访问列表,并将其以TXT文本的形式保存在桌面上
版本特征:
顾名思义1、好友版只能提取QQ好友的QQ空间访客,而不能提取陌生人的QQ空间访客
2、此软件的优点是它可以实时访问采集访客,也就是说,无论访客在空间中访问哪个页面,他们都可以实时访问。即使他们只是进入该空间的首页,不点击任何内容,他们也可以采集
3、该软件的每个QQ空间最近都有20名访客采集。请仔细理解这个句子。最后20人并不意味着每个空间只能有20人。软件可以挂起采集。设置采集间隔。每指定一次,该软件都会自动进入该空间,查看是否有新访客,并且采集将返回。因此,每个空间的容量取决于该空间的流量
4、软件的访问者名单将不再重复。但是如果您清空列表,或者下次打开软件,它可能会重复上一个列表
5、为了解决这个问题,我们专门开发了重复过滤软件。点击这里下载QQ过滤复制软件
在6、软件采集的过程中采集可能没有结果。这是因为腾讯限制了IP。解决方案:① 关闭软件;② 更换IP;③ 重新打开软件登录采集
使用本教程:
东方无敌QQ空间访客提取器视频教程
更新日志:
于2015年7月22日更新至4.4
随着腾讯的变化而更新
于2015年1月13日更新至4.1
修正了一些用户登录QQ时软件闪回的错误 查看全部
网页访客qq抓取(想要知道谁访问你的QQ空间吗,可以使用东方不败)
想知道谁访问了你的QQ空间吗?您可以使用东方无敌QQ空间访客提取器帮助您整理详细的访问列表,并将其以TXT文本的形式保存在桌面上

版本特征:
顾名思义1、好友版只能提取QQ好友的QQ空间访客,而不能提取陌生人的QQ空间访客
2、此软件的优点是它可以实时访问采集访客,也就是说,无论访客在空间中访问哪个页面,他们都可以实时访问。即使他们只是进入该空间的首页,不点击任何内容,他们也可以采集
3、该软件的每个QQ空间最近都有20名访客采集。请仔细理解这个句子。最后20人并不意味着每个空间只能有20人。软件可以挂起采集。设置采集间隔。每指定一次,该软件都会自动进入该空间,查看是否有新访客,并且采集将返回。因此,每个空间的容量取决于该空间的流量
4、软件的访问者名单将不再重复。但是如果您清空列表,或者下次打开软件,它可能会重复上一个列表
5、为了解决这个问题,我们专门开发了重复过滤软件。点击这里下载QQ过滤复制软件
在6、软件采集的过程中采集可能没有结果。这是因为腾讯限制了IP。解决方案:① 关闭软件;② 更换IP;③ 重新打开软件登录采集
使用本教程:
东方无敌QQ空间访客提取器视频教程
更新日志:
于2015年7月22日更新至4.4
随着腾讯的变化而更新
于2015年1月13日更新至4.1
修正了一些用户登录QQ时软件闪回的错误
网页访客qq抓取(领跑者网站访客qq获取系统主要特性有哪些?怎么做)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-30 11:32
领跑者QQ自动获取系统是一个网站访问者QQ获取系统,主要用于统计网站访问用户的QQ信息,包括访问者QQ号、昵称和在线状态,也可以基于推送在访客智能信息上,支持QQ临时对话弹窗功能,可以更好地与访客交流,让网站有更好的推广和营销效果。
先行者QQ自动获取系统主要特点
1、访客QQ信息
信息包括:访客QQ号、QQ昵称、QQ状态...
领队系统可以准确方便的获取网站访客QQ号。系统采用先进的界面技术,抓取访问您网站的访客QQ号,让您有机会主动联系目标客户。
2、智能访客邮件推送
自动向访问者推送自定义电子邮件
领导系统,智能访客邮件推送功能,采用先进的WEB模拟人工发送技术,SMTP投诉方式,支持企业邮箱发送。系统支持添加无限发件箱,可随机选择发送,发送成功率高达99%,即向准客户发送邮件。
3、参观团跟进营销
功能:分组、营销、标记、给访客留言
领跑者系统支持在后台对抓取的访客信息进行分组,并支持用户主动一键联系访客并进行标记。同时,您可以对访客信息做笔记,以备日后跟进。更多营销功能等你体验。
4、智能QQ对话弹窗
功能:智能间隔时间QQ临时对话弹窗。
对于领跑者系统,智能QQ临时对话弹窗功能可以在访客访问网站时自动打开访客QQ临时对话弹窗。方便用户在临时QQ对话中直接联系网站在线服务人员。同时,当前系统后台允许用户调整设置弹窗的频率和延迟时间,从而更好的增加网站的访问体验。
5、,多会员管理账号
功能:用户可以开立员工管理账户。
在领跑者系统中,可以在后台设置员工账号,可以设置每个员工的管理和查看权限。为多个网站创建独立的管理和运行环境,让每个网站都可以由专人管理,不受干扰。
6、统计数据分析。
功能:统计报表、停留时间、访问深度
领导者系统后端提供每日抓取访客统计图表、访客网站停留时间和访问轨迹,让用户直观了解网站运营数据。 查看全部
网页访客qq抓取(领跑者网站访客qq获取系统主要特性有哪些?怎么做)
领跑者QQ自动获取系统是一个网站访问者QQ获取系统,主要用于统计网站访问用户的QQ信息,包括访问者QQ号、昵称和在线状态,也可以基于推送在访客智能信息上,支持QQ临时对话弹窗功能,可以更好地与访客交流,让网站有更好的推广和营销效果。
先行者QQ自动获取系统主要特点
1、访客QQ信息
信息包括:访客QQ号、QQ昵称、QQ状态...
领队系统可以准确方便的获取网站访客QQ号。系统采用先进的界面技术,抓取访问您网站的访客QQ号,让您有机会主动联系目标客户。
2、智能访客邮件推送
自动向访问者推送自定义电子邮件
领导系统,智能访客邮件推送功能,采用先进的WEB模拟人工发送技术,SMTP投诉方式,支持企业邮箱发送。系统支持添加无限发件箱,可随机选择发送,发送成功率高达99%,即向准客户发送邮件。
3、参观团跟进营销
功能:分组、营销、标记、给访客留言
领跑者系统支持在后台对抓取的访客信息进行分组,并支持用户主动一键联系访客并进行标记。同时,您可以对访客信息做笔记,以备日后跟进。更多营销功能等你体验。
4、智能QQ对话弹窗
功能:智能间隔时间QQ临时对话弹窗。
对于领跑者系统,智能QQ临时对话弹窗功能可以在访客访问网站时自动打开访客QQ临时对话弹窗。方便用户在临时QQ对话中直接联系网站在线服务人员。同时,当前系统后台允许用户调整设置弹窗的频率和延迟时间,从而更好的增加网站的访问体验。
5、,多会员管理账号
功能:用户可以开立员工管理账户。
在领跑者系统中,可以在后台设置员工账号,可以设置每个员工的管理和查看权限。为多个网站创建独立的管理和运行环境,让每个网站都可以由专人管理,不受干扰。
6、统计数据分析。
功能:统计报表、停留时间、访问深度
领导者系统后端提供每日抓取访客统计图表、访客网站停留时间和访问轨迹,让用户直观了解网站运营数据。
网页访客qq抓取(网站|网页页面|APP软件|访客手机号码获取抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 514 次浏览 • 2021-09-28 20:31
网站|网页|APP软件|访客手机号获取与抓取方法
让我从第一个开始。其实就是指网站或者APP软件的房地产开发商使用全新的网络爬虫来抓取访问者的手机号。关键是在网站的头部插入一段设计代码。没关系。当访问者访问网站网页时,会询问用户的手机号码,但这种抓取方式由于涉嫌侵犯隐私,速度很快,很容易被百度搜索和K站查到, 网站当然总流量,很多网站站长放弃了这种实际操作,
二是与可靠的互联网大数据运营商合作。基本原理是当访问者使用手机的3G总流量浏览网站或APP软件时,会产生一个特殊的属性。你自己的https报告,访问者的手机号,网站浏览了什么,停留了多久,都可以测出来,最终得出访问者需求的实物模型。运营商的座席再根据这种需求反馈给公司在这些方面的专业服务,并给他营销推广后台管理打电话处理客户的需求。由于皮肤过敏的个人信息保护了客户的隐私,第二客户在这些方面会有很高的转化率。
接下来主要介绍网站访客抢手机的第二种方法。利用运营商的大数据,精准定位人群画像和访客行为,依法合规定位用户需求,实现精准营销效果。下图是
手机号获取部分系统截图
实现原理
没有人,任何上网行为都离不开运营商
运营商存储每个人的上网行为、通话行为、短信互动、实时位置等行为
每一个行为都反映了客户的需求
您想要什么样的客户,对我们来说无非是搜索提取
【技术阅读免开卖家,服务商保证名称,直播保证违规退款商家商品加品牌热销安装源码原创拓展教育简单承诺案例参数崩溃三网北京精彩满意分享文档只能邮寄验证,一键正式查询工作招标网站,医疗视频通知频道,雇主权利精品店]
下载更详细的流程介绍文件 企业咨询资料
网站访客手机号抓取软件_抓取指定网站|Web和app手机号信息平台:所有平台|类别:系统工具|大小:2.39MB
点击下载
访客手机号抓取的具体流程,自主研发的系统自动获取手机号程序,推荐广告,支持小额付费测试交易。详细案例请参考以上文档
运营商存储每个用户的行为→根据您的要求对用户进行建模和过滤→准确提取符合您要求的客户
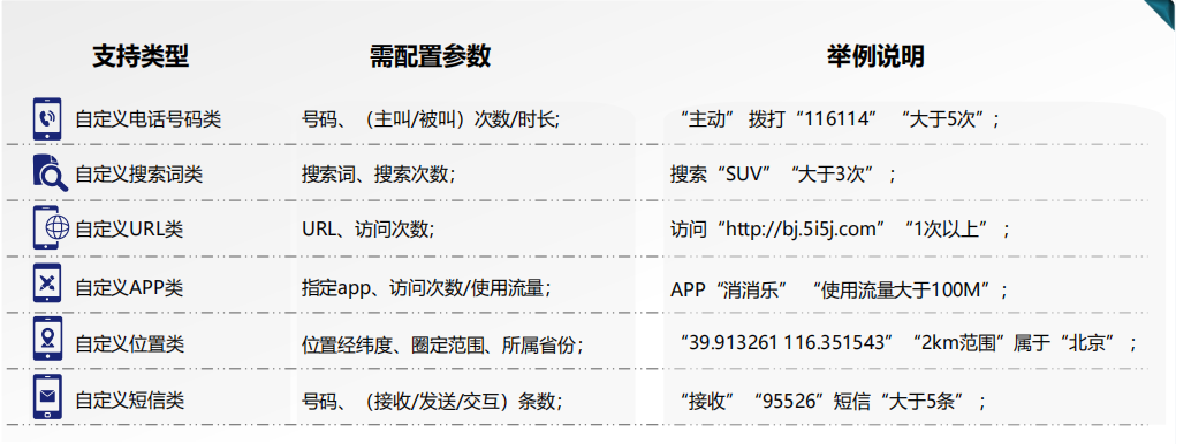
您可以根据上图中列出的类型提出您的需求。包括但不限于电话号码、搜索词、网址、APP、位置、短信,如果您需要其他维度,请联系站长微信,为您定制,过滤您的目标客户。
趣味快销-精准客源服务
低成本客源+高效率转化
解决获客难题
将利润提高十倍 查看全部
网页访客qq抓取(网站|网页页面|APP软件|访客手机号码获取抓取方法)
网站|网页|APP软件|访客手机号获取与抓取方法

让我从第一个开始。其实就是指网站或者APP软件的房地产开发商使用全新的网络爬虫来抓取访问者的手机号。关键是在网站的头部插入一段设计代码。没关系。当访问者访问网站网页时,会询问用户的手机号码,但这种抓取方式由于涉嫌侵犯隐私,速度很快,很容易被百度搜索和K站查到, 网站当然总流量,很多网站站长放弃了这种实际操作,

二是与可靠的互联网大数据运营商合作。基本原理是当访问者使用手机的3G总流量浏览网站或APP软件时,会产生一个特殊的属性。你自己的https报告,访问者的手机号,网站浏览了什么,停留了多久,都可以测出来,最终得出访问者需求的实物模型。运营商的座席再根据这种需求反馈给公司在这些方面的专业服务,并给他营销推广后台管理打电话处理客户的需求。由于皮肤过敏的个人信息保护了客户的隐私,第二客户在这些方面会有很高的转化率。
接下来主要介绍网站访客抢手机的第二种方法。利用运营商的大数据,精准定位人群画像和访客行为,依法合规定位用户需求,实现精准营销效果。下图是
手机号获取部分系统截图
实现原理
没有人,任何上网行为都离不开运营商
运营商存储每个人的上网行为、通话行为、短信互动、实时位置等行为
每一个行为都反映了客户的需求
您想要什么样的客户,对我们来说无非是搜索提取
【技术阅读免开卖家,服务商保证名称,直播保证违规退款商家商品加品牌热销安装源码原创拓展教育简单承诺案例参数崩溃三网北京精彩满意分享文档只能邮寄验证,一键正式查询工作招标网站,医疗视频通知频道,雇主权利精品店]
下载更详细的流程介绍文件 企业咨询资料
网站访客手机号抓取软件_抓取指定网站|Web和app手机号信息平台:所有平台|类别:系统工具|大小:2.39MB
点击下载
访客手机号抓取的具体流程,自主研发的系统自动获取手机号程序,推荐广告,支持小额付费测试交易。详细案例请参考以上文档

运营商存储每个用户的行为→根据您的要求对用户进行建模和过滤→准确提取符合您要求的客户
您可以根据上图中列出的类型提出您的需求。包括但不限于电话号码、搜索词、网址、APP、位置、短信,如果您需要其他维度,请联系站长微信,为您定制,过滤您的目标客户。
趣味快销-精准客源服务
低成本客源+高效率转化
解决获客难题
将利润提高十倍
网页访客qq抓取(有此一乐qq访客提取软件更新日志增加了大量时间)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-28 20:23
有这个快乐qq访客提取是一个实用的工具。使用这款易乐QQ访客提取软件,您可以提取访问您空间的朋友的QQ号码,让您随时了解哪些朋友访问了您的空间。该软件方便实用。感兴趣的用户快来当易下载体验吧!
QQ访客提取软件绿色版介绍
拥有这款易乐QQ好友提取工具是一款帮助您快速批量提取QQ好友号码的工具。专为QQ推广营销人员设计制作,帮助您提取自己的好友号码,支持保存为号码格式,或邮箱格式,提取速度快,效率高,为您省去繁琐的人工操作,节省不少时间,提高效率。即使你的电脑没有安装QQ也可以解压,非常方便。
有了QQ访客提取这个功能
1、可以批量提取。
2、 朋友也可以找回看不到的访客。
3、非好友可以看到访客找回。
4、 您可以设置只提取特定时间段的访问者。
5、可以保存为数字格式,也可以保存为邮箱格式,可以自由选择。
6、 系统不要挑,windows系统都可以用。WinXP、win2000、win2003、win7、win8都可以。
7、 可以隐身检索,检索过程中别人是看不到你的。这个单一的功能需要黄色菱形激活。未激活黄钻的用户不能使用此功能。
QQ访客提取软件绿色版更新日志
添加了可以试用的功能。您可以批量导入号码和批量采集访客。 查看全部
网页访客qq抓取(有此一乐qq访客提取软件更新日志增加了大量时间)
有这个快乐qq访客提取是一个实用的工具。使用这款易乐QQ访客提取软件,您可以提取访问您空间的朋友的QQ号码,让您随时了解哪些朋友访问了您的空间。该软件方便实用。感兴趣的用户快来当易下载体验吧!
QQ访客提取软件绿色版介绍
拥有这款易乐QQ好友提取工具是一款帮助您快速批量提取QQ好友号码的工具。专为QQ推广营销人员设计制作,帮助您提取自己的好友号码,支持保存为号码格式,或邮箱格式,提取速度快,效率高,为您省去繁琐的人工操作,节省不少时间,提高效率。即使你的电脑没有安装QQ也可以解压,非常方便。
有了QQ访客提取这个功能
1、可以批量提取。
2、 朋友也可以找回看不到的访客。
3、非好友可以看到访客找回。
4、 您可以设置只提取特定时间段的访问者。
5、可以保存为数字格式,也可以保存为邮箱格式,可以自由选择。
6、 系统不要挑,windows系统都可以用。WinXP、win2000、win2003、win7、win8都可以。
7、 可以隐身检索,检索过程中别人是看不到你的。这个单一的功能需要黄色菱形激活。未激活黄钻的用户不能使用此功能。
QQ访客提取软件绿色版更新日志
添加了可以试用的功能。您可以批量导入号码和批量采集访客。
网页访客qq抓取(海豹QQ访客QQ获取系统正式内测,每周可以有100个名额进行免费使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-09-27 07:10
经过几天的测试,封印QQ访客QQ获取系统正式测试通过。每周可免费使用100个名额。
功能亮点
1、安装方便,部署快速
本系统为PHP+MySQL开发,可轻松稳定运行于所有服务器环境,占用资源极少。安装完成后,只需要注册一个账号,添加网站,获取JS代码,放到前台网页就可以开始爬虫了。
2、35% 超高抓取率。由于访客未登录QQ或其他未知因素,本系统无法100%获取访客QQ。经测试,平均获得的用户QQ数占IP总访问量的35%!是目前最稳定、最高的采集算法。
3、海量客户存储管理我们的系统拥有最专业的海量客户信息存储管理功能,您可以按网站、时间、路线关键词、分组、停留时间等,为您查询和使用。当然,它还具有强大的导出功能,方便数据导出。
4、根据意向度的活跃对话,可以根据当天的访问时间对客户进行排序,也可以根据客户的路径判断客户的意向关键词和网站 停留时间,然后更新 有针对性地发起主动对话,直接与目标客户对话,提高转化率!
5、 除了在线直接主动对话外,系统的客户信息过滤导出功能可以帮助您导出客户群,更高效的导出,然后导入QQ营销工具批量群发,或者生成电子邮件地址,电子邮件营销。
6、账号,网站添加管理无论是大账号添加多个网站,还是网络营销团队按月单独销售系统功能,我们的系统自带灵活方便的账号和网站添加管理功能,方便您的各种需求。
封QQ官网:
配额申请群:208164697 查看全部
网页访客qq抓取(海豹QQ访客QQ获取系统正式内测,每周可以有100个名额进行免费使用)
经过几天的测试,封印QQ访客QQ获取系统正式测试通过。每周可免费使用100个名额。
功能亮点
1、安装方便,部署快速
本系统为PHP+MySQL开发,可轻松稳定运行于所有服务器环境,占用资源极少。安装完成后,只需要注册一个账号,添加网站,获取JS代码,放到前台网页就可以开始爬虫了。
2、35% 超高抓取率。由于访客未登录QQ或其他未知因素,本系统无法100%获取访客QQ。经测试,平均获得的用户QQ数占IP总访问量的35%!是目前最稳定、最高的采集算法。
3、海量客户存储管理我们的系统拥有最专业的海量客户信息存储管理功能,您可以按网站、时间、路线关键词、分组、停留时间等,为您查询和使用。当然,它还具有强大的导出功能,方便数据导出。
4、根据意向度的活跃对话,可以根据当天的访问时间对客户进行排序,也可以根据客户的路径判断客户的意向关键词和网站 停留时间,然后更新 有针对性地发起主动对话,直接与目标客户对话,提高转化率!
5、 除了在线直接主动对话外,系统的客户信息过滤导出功能可以帮助您导出客户群,更高效的导出,然后导入QQ营销工具批量群发,或者生成电子邮件地址,电子邮件营销。
6、账号,网站添加管理无论是大账号添加多个网站,还是网络营销团队按月单独销售系统功能,我们的系统自带灵活方便的账号和网站添加管理功能,方便您的各种需求。
封QQ官网:
配额申请群:208164697
网页访客qq抓取(网站访客QQ抓取系统,快速获取意向客户QQ信息,网页后台登陆统一管理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-26 13:19
>>>与此系统类似
>>>与此系统类似
>>>与此系统类似
网站访客QQ捕获系统是最快的QQ信息捕获系统,实时获取网站访客登录的QQ信息,快速获取目标客户的QQ,在网页背面登录,统一管理QQ,并在第一时间对访客QQ进行二次销售
网站访客QQ捕获系统是最快的QQ信息捕获系统,实时获取网站访客登录的QQ信息,快速获取目标客户的QQ,在网页背面登录,统一管理QQ,并在第一时间对访客QQ进行二次销售
监控网站访客QQ捕获和推送营销电子邮件
>>>与此系统类似
>>>与此系统类似
>>>与此系统类似 查看全部
网页访客qq抓取(网站访客QQ抓取系统,快速获取意向客户QQ信息,网页后台登陆统一管理)
>>>与此系统类似
>>>与此系统类似
>>>与此系统类似
网站访客QQ捕获系统是最快的QQ信息捕获系统,实时获取网站访客登录的QQ信息,快速获取目标客户的QQ,在网页背面登录,统一管理QQ,并在第一时间对访客QQ进行二次销售
网站访客QQ捕获系统是最快的QQ信息捕获系统,实时获取网站访客登录的QQ信息,快速获取目标客户的QQ,在网页背面登录,统一管理QQ,并在第一时间对访客QQ进行二次销售
监控网站访客QQ捕获和推送营销电子邮件
>>>与此系统类似
>>>与此系统类似
>>>与此系统类似
网页访客qq抓取(Grab指定网站访问者手机号:如何批量提取某网站手机号)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-09-26 02:05
在第一次测试中,无法获取非WiFi条件下的电话号码。手机号码获取率相当高。搜索手机,抢营销系统。网站 上也会有类似的。然后联系相关客服,直接在旁边的标签下方添加相关代码。
类似于下图中的代码:
网站访问者手机号的爬取效果如何?
部分客户安装后立即使用手机进行测试,发现无法获取手机号码。这是不科学的。有一定几率抢到,数量大的时候才能看到效果。比如一百个访客能抢到30个号和50个号是正常的。请记住,如果几个人访问它们,则无法抓取它们,这意味着该软件没有效果。
经测试,我们的软件爬网率超过60%,可以有效帮助中小企业建立潜在客户群,为公司带来真实的交易量。
抓取指定的网站访客手机号:如何批量提取网站的手机号
如何批量提取51个网站手机号批量提取母婴网站手机号。这是个人信息的暴露,这种行为是违法的。
如何获取访客的手机号码
获取访客手机号的方式一般有3种:
**种类是:获取你的网站访客手机号,抢同事的网站访客手机号。
第二种是:获取peer网站客户手机访问者手机号抓取js代码。
三是:获取app注册和下载信息。
火客_
这三种都是比较快速有效的方法。获取浏览网站的手机号码。
搜客宝网站访客手机抢系统有什么用??
简单来说,就是帮助网站有效抓取访问者的手机或QQ号,利用手机号和QQ号主动联系客户达成交易。一般来说,访问者网站的客户具有很强的目的性,他们可能会购买某些产品和服务。出于某种原因,他们在**时间内没有吸引相互访问者的咨询,90%的访问者关闭了页面并离开了。这样一来,90%的潜在客户都被浪费了。如果您有访客的手机或QQ号码,您可以主动帮助引导客户,交易的机会将大大增加。我希望它对你有用。
这就是无法获取用户数据的原因。首先,如果用户使用Wi-Fi上网,我们只能得到路由器的请求,无法将手机信息传输到我们的中转站。
所以如果用户的上网速度非常好,或者用户选择使用3GNET进行3G上网(这是一个非常昂贵的玩法),我们将无法获得。所以我们只能拿到4G模式下可以访问的手机。命中率只有30%-40%左右。几乎一个流量可以抢到20个号码。大数据捕获应用访问者的手机号码。
我已经稳定了好几年了。
PHP如何获取网页访问者的手机号?把源码发到g u_@.com,谢谢,满意的话给分
什么不现实,但难点在于需要与三大运营商合作。看看你有没有这个实力。这样的团队在技术上是稳定的。只要通过手机访问网站,在非WiFi条件下都可以获取。客户的手机号码。 查看全部
网页访客qq抓取(Grab指定网站访问者手机号:如何批量提取某网站手机号)
在第一次测试中,无法获取非WiFi条件下的电话号码。手机号码获取率相当高。搜索手机,抢营销系统。网站 上也会有类似的。然后联系相关客服,直接在旁边的标签下方添加相关代码。
类似于下图中的代码:
网站访问者手机号的爬取效果如何?
部分客户安装后立即使用手机进行测试,发现无法获取手机号码。这是不科学的。有一定几率抢到,数量大的时候才能看到效果。比如一百个访客能抢到30个号和50个号是正常的。请记住,如果几个人访问它们,则无法抓取它们,这意味着该软件没有效果。
经测试,我们的软件爬网率超过60%,可以有效帮助中小企业建立潜在客户群,为公司带来真实的交易量。

抓取指定的网站访客手机号:如何批量提取网站的手机号
如何批量提取51个网站手机号批量提取母婴网站手机号。这是个人信息的暴露,这种行为是违法的。
如何获取访客的手机号码
获取访客手机号的方式一般有3种:
**种类是:获取你的网站访客手机号,抢同事的网站访客手机号。
第二种是:获取peer网站客户手机访问者手机号抓取js代码。
三是:获取app注册和下载信息。
火客_
这三种都是比较快速有效的方法。获取浏览网站的手机号码。
搜客宝网站访客手机抢系统有什么用??
简单来说,就是帮助网站有效抓取访问者的手机或QQ号,利用手机号和QQ号主动联系客户达成交易。一般来说,访问者网站的客户具有很强的目的性,他们可能会购买某些产品和服务。出于某种原因,他们在**时间内没有吸引相互访问者的咨询,90%的访问者关闭了页面并离开了。这样一来,90%的潜在客户都被浪费了。如果您有访客的手机或QQ号码,您可以主动帮助引导客户,交易的机会将大大增加。我希望它对你有用。
这就是无法获取用户数据的原因。首先,如果用户使用Wi-Fi上网,我们只能得到路由器的请求,无法将手机信息传输到我们的中转站。
所以如果用户的上网速度非常好,或者用户选择使用3GNET进行3G上网(这是一个非常昂贵的玩法),我们将无法获得。所以我们只能拿到4G模式下可以访问的手机。命中率只有30%-40%左右。几乎一个流量可以抢到20个号码。大数据捕获应用访问者的手机号码。
我已经稳定了好几年了。
PHP如何获取网页访问者的手机号?把源码发到g u_@.com,谢谢,满意的话给分
什么不现实,但难点在于需要与三大运营商合作。看看你有没有这个实力。这样的团队在技术上是稳定的。只要通过手机访问网站,在非WiFi条件下都可以获取。客户的手机号码。
网页访客qq抓取(捕获移动QQ访客数访问Sookebao网站该系统有什么用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-09-26 02:04
部分客户安装后立即使用手机进行测试,发现手机号码无法抓取。这是不科学的。有爬虫的机会,当数量大的时候(比如一百个),真的可以看到效果。访客能抢到30个号码和50个号码是正常的。请记住,如果有几个人亲自访问,请不要抓住他们,这意味着软件**。
通过测试我们的软件爬取率超过60%,确实可以帮助中小企业建立潜在客户群,为企业带来真实的交易量。抓取指定网站和app的手机号。
捕获访问搜客宝网站的手机QQ访问量。这个系统有什么用?简而言之,这是为了帮助网站有效抓取访问者的手机或QQ号,利用手机和QQ号主动联系客户完成交易。一般来说,访问者网站的客户具有很强的目标性,他们可能会寻求某些产品和服务。由于某种原因,他们第一次没有吸引相互访问者咨询,然后90%的访问者关闭了页面并离开了。这样一来,90%的潜在客户就白白浪费了。如果您有访客的手机或QQ号码,您可以主动帮助引导客户,交易的可能性会大大增加。希望对你有用。
这就是无法获取用户数据的原因。首先,如果用户使用Wi-Fi上网,我们只能得到路由器的请求,手机信息无法传输到我们的中转站。
那么,如果用户上网速度好,或者用户选择使用3GNET进行3G上网(这是一种非常昂贵的播放方式),我们将无法获得。所以我们只能拿到4G模式下可以访问的手机。命中率只有30%-40%左右。流量可以捕获近 20 个号码。网站访客手机号码抓取软件。
我已经稳定了好几年了。**系统(同名Q)六六六五五一鹅酒抢同行网站访客手机号。
用于采集网站访客手机号的软件:QQ网站上获取手机号的软件还能用吗?
建议不要使用QQ抓取。很多人在卖QQ爬虫软件,或者它可以让网站访问者获取QQ,或者它可以。大部分都可以从微信购买。付款后,安装代码,稍后将关闭您的网站,威胁您增加资金,否则将破坏您的业务链接或业务桥梁。如果您将它们发送到 网站 与他们联系,他们将继续为您出价。
当有人访问我的网站时,什么样的软件可以及时详细地显示点击者的手机号码、姓名等信息。有谁可以帮忙,非常感谢!!
二楼的肯定回答是不可能的,除非他们主动给你填,你可以在二楼找到地址,因为我们可以看到他们的IP地址,这是全球统一的,我们可以知道是哪个IP地址对应哪个Address,所以可以找到如下
采集网站访问者手机号的软件:请求网页代码,可通过手机访问,获取对方手机号
**测试期间不可用。在非WiFi条件下,电话号码和手机号码的获取率非常高。搜索电话并获取营销系统。网站上也会有类似的内容。然后联系相关客服,在标签旁边添加相关代码。
类似于下图中的代码: 查看全部
网页访客qq抓取(捕获移动QQ访客数访问Sookebao网站该系统有什么用)
部分客户安装后立即使用手机进行测试,发现手机号码无法抓取。这是不科学的。有爬虫的机会,当数量大的时候(比如一百个),真的可以看到效果。访客能抢到30个号码和50个号码是正常的。请记住,如果有几个人亲自访问,请不要抓住他们,这意味着软件**。
通过测试我们的软件爬取率超过60%,确实可以帮助中小企业建立潜在客户群,为企业带来真实的交易量。抓取指定网站和app的手机号。
捕获访问搜客宝网站的手机QQ访问量。这个系统有什么用?简而言之,这是为了帮助网站有效抓取访问者的手机或QQ号,利用手机和QQ号主动联系客户完成交易。一般来说,访问者网站的客户具有很强的目标性,他们可能会寻求某些产品和服务。由于某种原因,他们第一次没有吸引相互访问者咨询,然后90%的访问者关闭了页面并离开了。这样一来,90%的潜在客户就白白浪费了。如果您有访客的手机或QQ号码,您可以主动帮助引导客户,交易的可能性会大大增加。希望对你有用。
这就是无法获取用户数据的原因。首先,如果用户使用Wi-Fi上网,我们只能得到路由器的请求,手机信息无法传输到我们的中转站。
那么,如果用户上网速度好,或者用户选择使用3GNET进行3G上网(这是一种非常昂贵的播放方式),我们将无法获得。所以我们只能拿到4G模式下可以访问的手机。命中率只有30%-40%左右。流量可以捕获近 20 个号码。网站访客手机号码抓取软件。
我已经稳定了好几年了。**系统(同名Q)六六六五五一鹅酒抢同行网站访客手机号。
用于采集网站访客手机号的软件:QQ网站上获取手机号的软件还能用吗?
建议不要使用QQ抓取。很多人在卖QQ爬虫软件,或者它可以让网站访问者获取QQ,或者它可以。大部分都可以从微信购买。付款后,安装代码,稍后将关闭您的网站,威胁您增加资金,否则将破坏您的业务链接或业务桥梁。如果您将它们发送到 网站 与他们联系,他们将继续为您出价。
当有人访问我的网站时,什么样的软件可以及时详细地显示点击者的手机号码、姓名等信息。有谁可以帮忙,非常感谢!!
二楼的肯定回答是不可能的,除非他们主动给你填,你可以在二楼找到地址,因为我们可以看到他们的IP地址,这是全球统一的,我们可以知道是哪个IP地址对应哪个Address,所以可以找到如下
采集网站访问者手机号的软件:请求网页代码,可通过手机访问,获取对方手机号
**测试期间不可用。在非WiFi条件下,电话号码和手机号码的获取率非常高。搜索电话并获取营销系统。网站上也会有类似的内容。然后联系相关客服,在标签旁边添加相关代码。
类似于下图中的代码:
网页访客qq抓取(如何在线获取访客qq号码的呢?他们用的是什么技术?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-25 20:35
文本:
近日,飘逸收到了大量网上获取网站访客QQ号的宣传邮件,不少商业网站也探索了这一需求,推出了一些商业项目。那么这些商业程序是如何获取访客QQ号的呢?他们使用什么技术?今天飘逸就跟大家分享一下如何在线获取访客QQ号。首先一句话,无论哪种方式,都需要精通js代码。目前市面上获取QQ号无非有以下几种方式:1、 打开QQ空间黄钻,在目标网页中嵌入隐藏的iframe框架,利用QQ空间屏蔽访客功能查看QQ号码;
2、本地软件开发,比如用c#嵌入一个webbrowser空间,然后分析html源码获取页面中的QQ号(这种方法没有实际意义,对网页登录没有价值) ,所以不讨论)
3、 通过js跨域,利用腾讯众多登录界面或功能页面读取用户QQ号;
4、使用PHPfile_get_contents获取腾讯某页面内容拦截QQ号。该方法在2013年之前可用,目前无效。以上方法均无法获取访问者的QQ号,前提是:
访问者在浏览器中登录了QQ空间、腾讯微博、QQ邮箱、朋友圈等腾讯产品,然后浏览器留下了他的cookies信息。只有在这个前提下才能获得访客QQ。先说一下使用QQ空间黄钻功能查看访客QQ空间的原理:
使用js或者iframe加载这个url:在目标网页上,其中12345678是QQ黄钻激活的QQ号。先打开QQ的黄砖,再关闭QQ空间的访问权限。当访问者访问网站时,在被屏蔽的访问者中可以看到该访问者的QQ。下面飘一重点介绍使用js跨域获取访客QQ的方法。一般情况下,我们无法跨域获取用户计算机上的cookie信息。例如,如果我的网页是,我可以获取用户 cookie 吗?答案当然是否定的,cookies不能跨域获取!那么,我们如何获取用户qq号呢?即找到该域名下的一些页面,以它们的页面为跳板,通过脚本调用远程QQ页面,然后使用回调函数提取QQ号。
红色的 URL 页面是域名本身下的页面。当然这个页面可以在QQ登录后获取cookie信息,所以很容易获取访问者的QQ。如果直接访问,返回的结果格式如下:
piaoyi({"result":1000005,"resultstr":"系统忙!","uin":123456})
uin 的值是访问者的 号。
和上面的红色网址一样,就是我们要找的页面,必须以它域名下的页面作为跳板。至于js跨域,我们也可以使用jQuery的jsonp来实现跨域,详见此链接。和上面的页面地址一样,有以下几个:
注:以上发布的网址已被腾讯屏蔽。今天的文章思路仅供参考。如果您有更多关于如何获取访客QQ号的信息,您可以在下方留言。 查看全部
网页访客qq抓取(如何在线获取访客qq号码的呢?他们用的是什么技术?)
文本:
近日,飘逸收到了大量网上获取网站访客QQ号的宣传邮件,不少商业网站也探索了这一需求,推出了一些商业项目。那么这些商业程序是如何获取访客QQ号的呢?他们使用什么技术?今天飘逸就跟大家分享一下如何在线获取访客QQ号。首先一句话,无论哪种方式,都需要精通js代码。目前市面上获取QQ号无非有以下几种方式:1、 打开QQ空间黄钻,在目标网页中嵌入隐藏的iframe框架,利用QQ空间屏蔽访客功能查看QQ号码;
2、本地软件开发,比如用c#嵌入一个webbrowser空间,然后分析html源码获取页面中的QQ号(这种方法没有实际意义,对网页登录没有价值) ,所以不讨论)
3、 通过js跨域,利用腾讯众多登录界面或功能页面读取用户QQ号;
4、使用PHPfile_get_contents获取腾讯某页面内容拦截QQ号。该方法在2013年之前可用,目前无效。以上方法均无法获取访问者的QQ号,前提是:
访问者在浏览器中登录了QQ空间、腾讯微博、QQ邮箱、朋友圈等腾讯产品,然后浏览器留下了他的cookies信息。只有在这个前提下才能获得访客QQ。先说一下使用QQ空间黄钻功能查看访客QQ空间的原理:
使用js或者iframe加载这个url:在目标网页上,其中12345678是QQ黄钻激活的QQ号。先打开QQ的黄砖,再关闭QQ空间的访问权限。当访问者访问网站时,在被屏蔽的访问者中可以看到该访问者的QQ。下面飘一重点介绍使用js跨域获取访客QQ的方法。一般情况下,我们无法跨域获取用户计算机上的cookie信息。例如,如果我的网页是,我可以获取用户 cookie 吗?答案当然是否定的,cookies不能跨域获取!那么,我们如何获取用户qq号呢?即找到该域名下的一些页面,以它们的页面为跳板,通过脚本调用远程QQ页面,然后使用回调函数提取QQ号。
红色的 URL 页面是域名本身下的页面。当然这个页面可以在QQ登录后获取cookie信息,所以很容易获取访问者的QQ。如果直接访问,返回的结果格式如下:
piaoyi({"result":1000005,"resultstr":"系统忙!","uin":123456})
uin 的值是访问者的 号。
和上面的红色网址一样,就是我们要找的页面,必须以它域名下的页面作为跳板。至于js跨域,我们也可以使用jQuery的jsonp来实现跨域,详见此链接。和上面的页面地址一样,有以下几个:
注:以上发布的网址已被腾讯屏蔽。今天的文章思路仅供参考。如果您有更多关于如何获取访客QQ号的信息,您可以在下方留言。
网页访客qq抓取( 解密如何获取网站访客QQ的方法及原理链接:免费开源使用地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-21 19:17
解密如何获取网站访客QQ的方法及原理链接:免费开源使用地址)
最新的开放访问网站visitor QQ开放源代码的成功率为90%,可以免费使用
最新的开放访问网站visitor QQ开放源代码的成功率为90%,可以免费使用
免费开源地址
之前,作者写了一个链接,链接到解密如何获得网站visitor QQ的方法和原理:
获得网站visitor QQ的方法有三种:
1、分析QQ登录空间非常困难,成功率高达90%(今天我们主要向大家展示这种开源的方法)
2、使用PHP文件获取内容获取腾讯页面内容并截取QQ号。这种方法在11月之前有效,现在不能再使用
3、打开QQ黄钻,用JS代码将QQ空间地址嵌入站内并做一些设置,你可以在QQ空间看到你的网站访客号。据估计,这种方法在很长一段时间内是有效的。有关详细信息,请打开此链接
今天,作者主要介绍和解释方法1。使用的代码未加密。如果您需要代码,请通过网站源代码复制
那么我们如何分析QQ登录空间并获得QQ号码呢?我相信很多人以前都为此付出过努力,但没有取得任何成果
要使用此地址,将使用Cookie,并且Cookie不能跨域。这里的每个人都很尴尬
那我该怎么做呢?代码中制作了一个小跳板来实现cookies的跨域幻觉!事实上,这不是跨域获得的信息。请看我的源代码
两天后自己使用织梦DEDEcmsdevelopment插件已经编写了一些源代码并制作了一套程序,这些程序是免费的,对每个人都是开放的。我不保证它可以使用多久,但如果有变化,我会及时升级算法。代码将不会被加密。请自己阅读代码
免费开源地址
文章from 查看全部
网页访客qq抓取(
解密如何获取网站访客QQ的方法及原理链接:免费开源使用地址)
最新的开放访问网站visitor QQ开放源代码的成功率为90%,可以免费使用
最新的开放访问网站visitor QQ开放源代码的成功率为90%,可以免费使用
免费开源地址
之前,作者写了一个链接,链接到解密如何获得网站visitor QQ的方法和原理:
获得网站visitor QQ的方法有三种:
1、分析QQ登录空间非常困难,成功率高达90%(今天我们主要向大家展示这种开源的方法)
2、使用PHP文件获取内容获取腾讯页面内容并截取QQ号。这种方法在11月之前有效,现在不能再使用
3、打开QQ黄钻,用JS代码将QQ空间地址嵌入站内并做一些设置,你可以在QQ空间看到你的网站访客号。据估计,这种方法在很长一段时间内是有效的。有关详细信息,请打开此链接
今天,作者主要介绍和解释方法1。使用的代码未加密。如果您需要代码,请通过网站源代码复制
那么我们如何分析QQ登录空间并获得QQ号码呢?我相信很多人以前都为此付出过努力,但没有取得任何成果
要使用此地址,将使用Cookie,并且Cookie不能跨域。这里的每个人都很尴尬
那我该怎么做呢?代码中制作了一个小跳板来实现cookies的跨域幻觉!事实上,这不是跨域获得的信息。请看我的源代码
两天后自己使用织梦DEDEcmsdevelopment插件已经编写了一些源代码并制作了一套程序,这些程序是免费的,对每个人都是开放的。我不保证它可以使用多久,但如果有变化,我会及时升级算法。代码将不会被加密。请自己阅读代码
免费开源地址
文章from
网页访客qq抓取(如何获得我们getContent函数中的那些需要使用的headers参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2021-09-21 12:14
urllib.error.HTTPError:HTTP错误403:禁止
从403禁止,我们可以发现程序访问被网站禁止,因为csdn网站已设置防爬虫机制。当检测到网站a爬虫时,访问将被拒绝,因此我们将得到上述结果
此时,我们需要模拟浏览器进行访问,以避免网站的反爬虫机制,顺利抓取我们想要的内容
接下来,我们将使用一个神奇的库urlib.request.request进行模拟工作。这一次,我们还将首先添加代码,然后对其进行解释。但是,这一次,我想提醒您,以下代码不能直接使用。我们需要在其中使用my\uHeader中的用户代理被它自己的替换。为了保密,我加了一个省略号,所以不能直接使用。更换方法见下图。这一次,为了方便起见,我们引入了以下功能:
#coding:utf - 8
from urllib.request import urlopen
from urllib.request import Request
import random
import re
def getContent(url,headers):
"""
此函数用于抓取返回403禁止访问的网页
"""
random_header = random.choice(headers)
"""
对于Request中的第二个参数headers,它是字典型参数,所以在传入时
也可以直接将个字典传入,字典中就是下面元组的键值对应
"""
req =Request(url)
req.add_header("User-Agent", random_header)
req.add_header("GET",url)
req.add_header("Host","blog.csdn.net")
req.add_header("Referer","http://www.csdn.net/")
content=urlopen(req).read().decode("utf-8")
return content
url="http://blog.csdn.net/beliefer/ ... ot%3B
#这里面的my_headers中的内容由于是个人主机的信息,所以我就用句号省略了一些,在使用时可以将自己主机的
my_headers = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/53 。。。Chrome/54.0.2840.99 Safari/537.36"]
print(getContent(url,my_headers))
使用上述代码,我们通常可以捕获此页面的信息。让我们介绍一下如何获取需要在getcontent函数中使用的标题中的参数
由于我们想要模拟浏览器进行web访问,这些参数自然需要我们在浏览器中查找
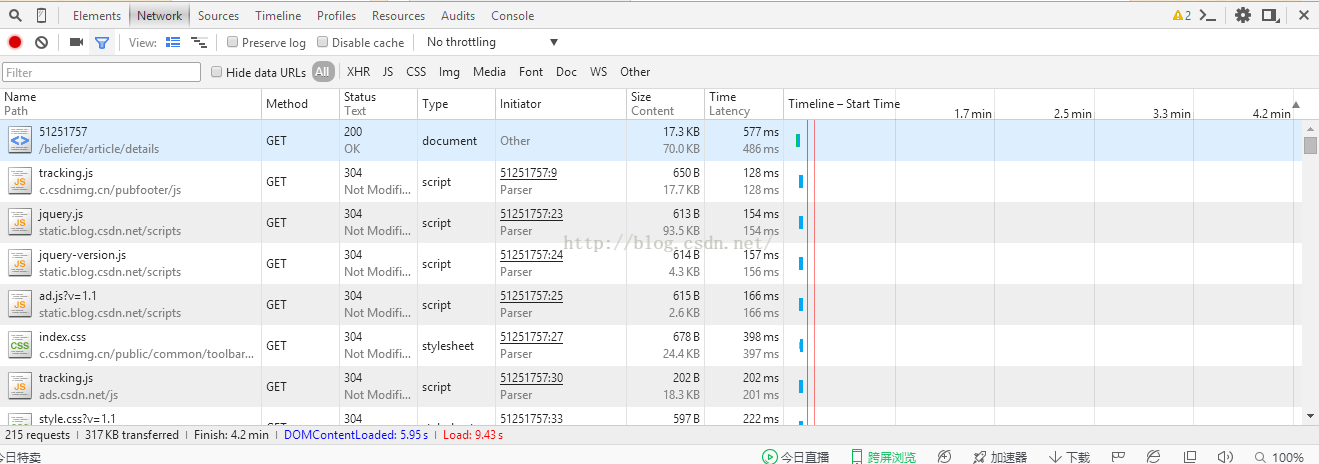
首先,我们单击进入要爬网的页面,然后右键单击该页面,单击review元素,将出现以下框架。然后我们点击网络,我们会发现我们页面上的信息没有出现。没关系。此时,我们刷新页面,将显示下图所示的信息
此时,我们将在第一行看到51251757,这是我们网站后面的标签。此时,当我们单击此标签时,将显示下图所示的内容:
以下是我直接访问本网站的截图:
对于前两个数字,我曾经编写版本2的Visite,现在我直接使用它们。当时,我在CSDN主页上点击了这个博客,所以在代码和前两个图中,我的标题中的referer被填充
,我用URL链接直接将这张图片输入浏览器,这样我们就可以从图片中看到引用者,这是我们的网站。在这里,我们发布了一张不同的图片,让每个人都更好地理解这个参考。在这张图片中,我用红线标出了要填写的四个内容。当您进行测试时,您不能使用我提供的用户代理,因为我用省略号替换了一些,您应该使用自己的
在这个时候,我们将发现头球是否有明亮的感觉。是的,你的直觉是对的。我们需要的信息在标题中
然后根据代码中需要的参数将信息复制回来,因为这里显示的信息只对应键值,所以复制和使用非常方便
现在让我们介绍一下urllib.request.request的用法(翻译自官方文档):
类urllib。要求请求(URL,data=none,headers={},origin\u req\u host=none,unverifiable=false,method=none)参数:URL:不用说,这是我们将访问的网站。它是一根绳子。数据:数据必须是字节对象,它指定向服务器发送附加数据,如果不需要,则不发送。目前,只有HTTP请求使用数据;当提供数据参数时,HTTP请求应该是post而不是get。数据应以标准的application/x-www-form-urlencoded格式进行缓冲。urllib的参数。作语法分析函数是一个映射或二进制序列,并返回此格式的ascii字符串。当用作数据参数时,应将其编码为字节。头:头是字典数据,当调用add\when header()并具有键和值参数时,此头将作为请求处理。此标头通常用于阻止爬虫访问服务器。浏览器使用头来标识自身,因为某些HTTP服务器只允许来自普通浏览器的请求,而不允许来自脚本(可以理解为爬虫)
例如,Mozilla Firefox浏览器可以将自己识别为“Mozilla/5(X11;u;Linuxi686)Gecko/2008070208 Firefox 20071127/2.0.0.11模块的默认用户代理字符串为“Python urlib/2.6 “ (Python2.6),也就是说,当访问网页时,对于带有反爬虫机制的网站来说,您可以使用此用户代理字符串“Python urlib/”2.6 “ (Python@k266)检查我们是爬虫程序,然后拒绝我们的访问,这就是为什么我们需要用户代理进行更正。在这方面,应该综合考虑网站的反爬虫机制有多严格,因为监视爬虫程序越严格,需要检查的内容就越多,这不可避免地会增加网站)@服务器的处理负担,即网站必须在爬虫检测和网站服务器的计算负担之间进行权衡。因此,爬虫检测机制越严格越好。还应考虑服务器的负担。Origin_req_host:Origin_req_host应该是t的请求主机原创事务,由RFC2965定义。它默认为http.coo kiejar.request\u host(self)
这是由用户发起的原创请求的主机名或IP地址。例如,如果请求的图像是HTML文档中的图像,则这应该是收录该图像的页面请求的主机。(我们通常不使用此名称,只知道此处)Unverifiable:Unverifiable应指示请求是否无法验证。它由RFC 2965定义,默认值为false。Unverifiable请求表示无法提交用户的网址。例如,当用户在网页的HTML文档中找到图像,但用户没有重试权限时e来自服务器的映像不可验证。值应为true。方法:方法应为指示将使用HTTP请求方法的字符串(如“header”)。如果提供,其值将存储在方法属性中,并通过方法get_Method()调用.子类可以通过在类中设置method属性来指示默认方法。(这很少使用)说了这么多无聊的定义,我无法忍受翻译。让我们回到我们的程序:对于我们的程序,只需要掌握几个要点。首先,我们需要构造请求:req=request(URL)此时,请求为空。我们需要向请求中添加信息。此信息供浏览器查看
Req.add_header(“user agent”,random_header)告诉网页服务器我是通过浏览器访问的,而我不是爬虫。Req.add_header(“get”,URL)告诉浏览器我们访问的网址。Req.add_header(“host”),是网站的信息,我们只是从网站.Req.add_标题(“引用者”、“引用者”)这句话非常重要。它告诉网站服务器我们在哪里找到了我们想要访问的页面。例如,如果你点击百度中的一个链接跳转到你当前访问的页面,那么这个引用就是百度中的链接,这是一种判断机制。你也可以对标题的构造方法这样做:
#coding:utf - 8
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.request import Request
import random
import re
def getContent(url,headers):
"""
此函数用于抓取返回403禁止访问的网页
"""
random_header = random.choice(headers)
"""
对于Request中的第二个参数headers,它是字典型参数,所以在传入时
也可以直接将个字典传入,字典中就是下面元组的键值对应
"""
# req =Request(url)
# req.add_header("User-Agent", random_header)
# req.add_header("GET",url)
# req.add_header("Host","blog.csdn.net")
# req.add_header("Referer","http://www.csdn.net/")
header = {"User-Agent": random_header, "GET": url, "Host": "blog.csdn.net", "Referer": "http://www.csdn.net/"}
req=Request(url,None,header)
content=urlopen(req).read().decode("utf-8")
return content
url="http://blog.csdn.net/beliefer/ ... ot%3B
#这里面的my_headers中的内容由于是个人主机的信息,所以我就用句号省略了一些,在使用时可以将自己主机的User-Agent放进去
my_headers = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/53。。。(KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"]
print(getContent(url,my_headers))
正如我们在上面的程序中所看到的,我们也可以直接构造头部,但这样做有一个缺陷,即头部的用户代理已经失效。事实上,我们可以发现,对于访问同一网页的不同计算机主机,我们的其他三个信息:get、host和referer可能是相同的,而此时,只有user-Agent被用来作为判断用户异同的标准,所以问题就来了"从我们周围的学生那里,如果使用一些用户代理,那么模拟多个用户的访问是否更好?事实上,这就是我刚刚开始编写代码的原因,因此有一个我的_头列表。事实上,可以在其中放置多个用户代理,然后通过随机函数随机选择一个进行组合,从而创建一个用户并实现多个-用户访问这种错觉其实很有用。你知道,对于网站,用户的IP访问太多时会被阻止。这并不有趣。因此,要长时间访问网站而不被阻止,还需要很多技能
当我们想要抓取多个网站的网页时,很容易被网站发现,因为一个主机经常访问,然后被阻止。如果我们在列表中放入更多不同的主机号并随机使用,就不容易被发现。当然,为了防止这种情况,更好的方法是使用IP代理,因为我们不知道它是e很容易获得大量主机信息,IP代理也很容易从互联网上搜索。我将在以后的博客中解释多次访问的相关问题,所以我在这里不多说 查看全部
网页访客qq抓取(如何获得我们getContent函数中的那些需要使用的headers参数)
urllib.error.HTTPError:HTTP错误403:禁止
从403禁止,我们可以发现程序访问被网站禁止,因为csdn网站已设置防爬虫机制。当检测到网站a爬虫时,访问将被拒绝,因此我们将得到上述结果
此时,我们需要模拟浏览器进行访问,以避免网站的反爬虫机制,顺利抓取我们想要的内容
接下来,我们将使用一个神奇的库urlib.request.request进行模拟工作。这一次,我们还将首先添加代码,然后对其进行解释。但是,这一次,我想提醒您,以下代码不能直接使用。我们需要在其中使用my\uHeader中的用户代理被它自己的替换。为了保密,我加了一个省略号,所以不能直接使用。更换方法见下图。这一次,为了方便起见,我们引入了以下功能:
#coding:utf - 8
from urllib.request import urlopen
from urllib.request import Request
import random
import re
def getContent(url,headers):
"""
此函数用于抓取返回403禁止访问的网页
"""
random_header = random.choice(headers)
"""
对于Request中的第二个参数headers,它是字典型参数,所以在传入时
也可以直接将个字典传入,字典中就是下面元组的键值对应
"""
req =Request(url)
req.add_header("User-Agent", random_header)
req.add_header("GET",url)
req.add_header("Host","blog.csdn.net")
req.add_header("Referer","http://www.csdn.net/";)
content=urlopen(req).read().decode("utf-8")
return content
url="http://blog.csdn.net/beliefer/ ... ot%3B
#这里面的my_headers中的内容由于是个人主机的信息,所以我就用句号省略了一些,在使用时可以将自己主机的
my_headers = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/53 。。。Chrome/54.0.2840.99 Safari/537.36"]
print(getContent(url,my_headers))
使用上述代码,我们通常可以捕获此页面的信息。让我们介绍一下如何获取需要在getcontent函数中使用的标题中的参数
由于我们想要模拟浏览器进行web访问,这些参数自然需要我们在浏览器中查找
首先,我们单击进入要爬网的页面,然后右键单击该页面,单击review元素,将出现以下框架。然后我们点击网络,我们会发现我们页面上的信息没有出现。没关系。此时,我们刷新页面,将显示下图所示的信息
此时,我们将在第一行看到51251757,这是我们网站后面的标签。此时,当我们单击此标签时,将显示下图所示的内容:
以下是我直接访问本网站的截图:
对于前两个数字,我曾经编写版本2的Visite,现在我直接使用它们。当时,我在CSDN主页上点击了这个博客,所以在代码和前两个图中,我的标题中的referer被填充
,我用URL链接直接将这张图片输入浏览器,这样我们就可以从图片中看到引用者,这是我们的网站。在这里,我们发布了一张不同的图片,让每个人都更好地理解这个参考。在这张图片中,我用红线标出了要填写的四个内容。当您进行测试时,您不能使用我提供的用户代理,因为我用省略号替换了一些,您应该使用自己的
在这个时候,我们将发现头球是否有明亮的感觉。是的,你的直觉是对的。我们需要的信息在标题中
然后根据代码中需要的参数将信息复制回来,因为这里显示的信息只对应键值,所以复制和使用非常方便
现在让我们介绍一下urllib.request.request的用法(翻译自官方文档):
类urllib。要求请求(URL,data=none,headers={},origin\u req\u host=none,unverifiable=false,method=none)参数:URL:不用说,这是我们将访问的网站。它是一根绳子。数据:数据必须是字节对象,它指定向服务器发送附加数据,如果不需要,则不发送。目前,只有HTTP请求使用数据;当提供数据参数时,HTTP请求应该是post而不是get。数据应以标准的application/x-www-form-urlencoded格式进行缓冲。urllib的参数。作语法分析函数是一个映射或二进制序列,并返回此格式的ascii字符串。当用作数据参数时,应将其编码为字节。头:头是字典数据,当调用add\when header()并具有键和值参数时,此头将作为请求处理。此标头通常用于阻止爬虫访问服务器。浏览器使用头来标识自身,因为某些HTTP服务器只允许来自普通浏览器的请求,而不允许来自脚本(可以理解为爬虫)
例如,Mozilla Firefox浏览器可以将自己识别为“Mozilla/5(X11;u;Linuxi686)Gecko/2008070208 Firefox 20071127/2.0.0.11模块的默认用户代理字符串为“Python urlib/2.6 “ (Python2.6),也就是说,当访问网页时,对于带有反爬虫机制的网站来说,您可以使用此用户代理字符串“Python urlib/”2.6 “ (Python@k266)检查我们是爬虫程序,然后拒绝我们的访问,这就是为什么我们需要用户代理进行更正。在这方面,应该综合考虑网站的反爬虫机制有多严格,因为监视爬虫程序越严格,需要检查的内容就越多,这不可避免地会增加网站)@服务器的处理负担,即网站必须在爬虫检测和网站服务器的计算负担之间进行权衡。因此,爬虫检测机制越严格越好。还应考虑服务器的负担。Origin_req_host:Origin_req_host应该是t的请求主机原创事务,由RFC2965定义。它默认为http.coo kiejar.request\u host(self)
这是由用户发起的原创请求的主机名或IP地址。例如,如果请求的图像是HTML文档中的图像,则这应该是收录该图像的页面请求的主机。(我们通常不使用此名称,只知道此处)Unverifiable:Unverifiable应指示请求是否无法验证。它由RFC 2965定义,默认值为false。Unverifiable请求表示无法提交用户的网址。例如,当用户在网页的HTML文档中找到图像,但用户没有重试权限时e来自服务器的映像不可验证。值应为true。方法:方法应为指示将使用HTTP请求方法的字符串(如“header”)。如果提供,其值将存储在方法属性中,并通过方法get_Method()调用.子类可以通过在类中设置method属性来指示默认方法。(这很少使用)说了这么多无聊的定义,我无法忍受翻译。让我们回到我们的程序:对于我们的程序,只需要掌握几个要点。首先,我们需要构造请求:req=request(URL)此时,请求为空。我们需要向请求中添加信息。此信息供浏览器查看
Req.add_header(“user agent”,random_header)告诉网页服务器我是通过浏览器访问的,而我不是爬虫。Req.add_header(“get”,URL)告诉浏览器我们访问的网址。Req.add_header(“host”),是网站的信息,我们只是从网站.Req.add_标题(“引用者”、“引用者”)这句话非常重要。它告诉网站服务器我们在哪里找到了我们想要访问的页面。例如,如果你点击百度中的一个链接跳转到你当前访问的页面,那么这个引用就是百度中的链接,这是一种判断机制。你也可以对标题的构造方法这样做:
#coding:utf - 8
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.request import Request
import random
import re
def getContent(url,headers):
"""
此函数用于抓取返回403禁止访问的网页
"""
random_header = random.choice(headers)
"""
对于Request中的第二个参数headers,它是字典型参数,所以在传入时
也可以直接将个字典传入,字典中就是下面元组的键值对应
"""
# req =Request(url)
# req.add_header("User-Agent", random_header)
# req.add_header("GET",url)
# req.add_header("Host","blog.csdn.net")
# req.add_header("Referer","http://www.csdn.net/";)
header = {"User-Agent": random_header, "GET": url, "Host": "blog.csdn.net", "Referer": "http://www.csdn.net/"}
req=Request(url,None,header)
content=urlopen(req).read().decode("utf-8")
return content
url="http://blog.csdn.net/beliefer/ ... ot%3B
#这里面的my_headers中的内容由于是个人主机的信息,所以我就用句号省略了一些,在使用时可以将自己主机的User-Agent放进去
my_headers = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/53。。。(KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"]
print(getContent(url,my_headers))
正如我们在上面的程序中所看到的,我们也可以直接构造头部,但这样做有一个缺陷,即头部的用户代理已经失效。事实上,我们可以发现,对于访问同一网页的不同计算机主机,我们的其他三个信息:get、host和referer可能是相同的,而此时,只有user-Agent被用来作为判断用户异同的标准,所以问题就来了"从我们周围的学生那里,如果使用一些用户代理,那么模拟多个用户的访问是否更好?事实上,这就是我刚刚开始编写代码的原因,因此有一个我的_头列表。事实上,可以在其中放置多个用户代理,然后通过随机函数随机选择一个进行组合,从而创建一个用户并实现多个-用户访问这种错觉其实很有用。你知道,对于网站,用户的IP访问太多时会被阻止。这并不有趣。因此,要长时间访问网站而不被阻止,还需要很多技能
当我们想要抓取多个网站的网页时,很容易被网站发现,因为一个主机经常访问,然后被阻止。如果我们在列表中放入更多不同的主机号并随机使用,就不容易被发现。当然,为了防止这种情况,更好的方法是使用IP代理,因为我们不知道它是e很容易获得大量主机信息,IP代理也很容易从互联网上搜索。我将在以后的博客中解释多次访问的相关问题,所以我在这里不多说
网页访客qq抓取(如何在当前网页里执行你想要的执行代码:通过浏览器抓包 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 560 次浏览 • 2021-09-12 09:07
)
在阅读本文之前,请参阅:Crazy Asylum:如何在当前网页中执行您要执行的代码。第一步,找出QQ访客界面:通过浏览器抓包:我们可以得到这个界面
在阅读本文之前,请阅读:
疯人院:如何在当前网页中执行你想执行的代码
第一步,找出QQ访客界面:
通过浏览器捕获数据包:
如何使用谷歌浏览器抓包:
我们可以得到这个接口
https://user.qzone.qq.com/prox ... %3DQQ号&mask=2&mod=2&fupdate=1&g_tk=121307362&qzonetoken=694e991fd4ee1f360edf1c18c63b2bd6fbb61be931b1a34b3c5b8ac5d27c372537f12f625db554f3&g_tk=121307362
关键参数为uin、g_tk、qzonetoken
第二步,找到上面三个参数值的来源
uin:您可以在 cookie 中获取它。
g_tk:QZONE.FP.getACSRFToken()
qzonetoken:在网页的源代码中。
window.g_qzonetoken = (function(){ try{return "694e991fd4ee1f360edf1c18c63b2bd6fbb61be931b1a34b3c5b8ac5d27c372537f12";} catch(e) {var xhr = new XMLHttpRequest();xhr.withCredentials = true;xhr.open('post', '//h5.qzone.qq.com/log/post/error/qzonetoken', true);xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');xhr.send(e);}})();
里面有这么一段
。我们只需要使用window.g_qzonetoken即可获取
第四步,让我们愉快的写程序。
首先我们尝试先在控制台写代码
最后整理成javascript:
var uinArray = /uin=o0*(\S+);/.exec(document.cookie || '');
var uin = uinArray[1];
var g_tk = QZONE.FP.getACSRFToken();
var qzone_token = window.g_qzonetoken;
var url = 'https://user.qzone.qq.com/prox ... en%3B
url 是获取数据的 URL。
最终代码:
包括回调方法和数据
<p>function _Callback(json){
var items = json.data.items;
var nicks = '';
for(var i=0;i 查看全部
网页访客qq抓取(如何在当前网页里执行你想要的执行代码:通过浏览器抓包
)
在阅读本文之前,请参阅:Crazy Asylum:如何在当前网页中执行您要执行的代码。第一步,找出QQ访客界面:通过浏览器抓包:我们可以得到这个界面
在阅读本文之前,请阅读:
疯人院:如何在当前网页中执行你想执行的代码
第一步,找出QQ访客界面:
通过浏览器捕获数据包:
如何使用谷歌浏览器抓包:

我们可以得到这个接口
https://user.qzone.qq.com/prox ... %3DQQ号&mask=2&mod=2&fupdate=1&g_tk=121307362&qzonetoken=694e991fd4ee1f360edf1c18c63b2bd6fbb61be931b1a34b3c5b8ac5d27c372537f12f625db554f3&g_tk=121307362
关键参数为uin、g_tk、qzonetoken
第二步,找到上面三个参数值的来源
uin:您可以在 cookie 中获取它。

g_tk:QZONE.FP.getACSRFToken()

qzonetoken:在网页的源代码中。
window.g_qzonetoken = (function(){ try{return "694e991fd4ee1f360edf1c18c63b2bd6fbb61be931b1a34b3c5b8ac5d27c372537f12";} catch(e) {var xhr = new XMLHttpRequest();xhr.withCredentials = true;xhr.open('post', '//h5.qzone.qq.com/log/post/error/qzonetoken', true);xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');xhr.send(e);}})();
里面有这么一段
。我们只需要使用window.g_qzonetoken即可获取

第四步,让我们愉快的写程序。
首先我们尝试先在控制台写代码

最后整理成javascript:
var uinArray = /uin=o0*(\S+);/.exec(document.cookie || '');
var uin = uinArray[1];
var g_tk = QZONE.FP.getACSRFToken();
var qzone_token = window.g_qzonetoken;
var url = 'https://user.qzone.qq.com/prox ... en%3B
url 是获取数据的 URL。
最终代码:
包括回调方法和数据
<p>function _Callback(json){
var items = json.data.items;
var nicks = '';
for(var i=0;i
网页访客qq抓取(网站获取访客QQ系统是什么?如何使用访客统计助手)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-10-21 17:05
网站获取访客QQ系统
1、什么是访客统计助手?访客统计助手就是通过一段JS代码连接到本站独有的分析系统,获取你的网站实时访客QQ信息,通过这种有意的QQ访客,二次营销,可以挽回你流失的客户,让你的流量和竞价成本不再浪费!2、使用访客统计助手有什么好处?只需在您的网页中添加一段代码,即可准确获取客户QQ号。配置超级简单。快速准确分析来访目标客户,多一个网站 用户后台可管理,节省人力物力,最大化广告效果。使用我们的系统获取潜在客户QQ号后,您可以直接在系统后台与客户发起临时QQ对话,主动询问客户需求,了解客户需求,持续跟进,并最终产生销售。此外,本站还针对全网推出了独有的网页在线邮件群发功能,您还可以访问关键词分析潜在客户,发送个性化广告邮件。快捷方便!3、如何使用访客统计助手联系本站客服开户,登录网站后台,然后获取访客QQ统计码,插入你的网站底部或头部开始统计!1、
现在就下载 查看全部
网页访客qq抓取(网站获取访客QQ系统是什么?如何使用访客统计助手)
网站获取访客QQ系统
1、什么是访客统计助手?访客统计助手就是通过一段JS代码连接到本站独有的分析系统,获取你的网站实时访客QQ信息,通过这种有意的QQ访客,二次营销,可以挽回你流失的客户,让你的流量和竞价成本不再浪费!2、使用访客统计助手有什么好处?只需在您的网页中添加一段代码,即可准确获取客户QQ号。配置超级简单。快速准确分析来访目标客户,多一个网站 用户后台可管理,节省人力物力,最大化广告效果。使用我们的系统获取潜在客户QQ号后,您可以直接在系统后台与客户发起临时QQ对话,主动询问客户需求,了解客户需求,持续跟进,并最终产生销售。此外,本站还针对全网推出了独有的网页在线邮件群发功能,您还可以访问关键词分析潜在客户,发送个性化广告邮件。快捷方便!3、如何使用访客统计助手联系本站客服开户,登录网站后台,然后获取访客QQ统计码,插入你的网站底部或头部开始统计!1、
现在就下载
网页访客qq抓取(接到几次还是不能通过,搞得程序员、竞价员一直很头疼)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-17 16:23
最近收到了这么一个让人望而生畏的竞标问题,但是改了几次还是没通过。这让程序员和投标人头疼不已,互相抱怨。百度官方的回答是:只要百度宣传网站涉嫌恶意获取访客信息,就是恶意行为,类似于秘密获取访客信息:比如QQ号和手机号的代码就是恶意代码。, 百度推广的网址和里面的所有页面都需要测试。一经发现,原创无效,拒绝百度推广账号。
下面总结了几个可能的原因。
1、非法内容或链接
QQ强制弹出码、虚假百度搜索多结果、偷偷截取访客QQ码、手机网站获取访客联系信息码等均涉嫌“恶意代码”!对于这些我们很容易发现,一般都是存在于js文件中的部分,也是直接加载到页面上的,有的则是经过js混淆加密后加载到js文件中的,比较隐蔽。代码有注释,这里的提示最好删除。不要给百度的检查留下一句“有侥幸心理”。
还有一个是在Businesslink的track code中加载的。当用户打开会话时,会加载获取手机或QQ号码的代码。最好在Businesslink里面设置,去掉代码js。以下是Businesslink的公告:
这里提到cnzz企业qq。与百度官方的说法相比,cnzz也可以获得一定范围的用户信息,但不是主要的。如果使用企业QQ,可以看到当前登录的QQ用户正在浏览页面发起对话。建议先删除企业qq。
2.登陆页面登陆页面提示
提示部分关键词登陆页面有病毒木马,过一会还是一样。之前的恶意代码。现在这是第一次使用百度。我已经不玩了。新花样不断产生。我有点怀疑,是为了保证广大网友的隐私,只是为了宣传自己的产品。查了好几遍,发现确实删除了很多代码,甚至删除了QQ咨询,改变了业务通信。无需使用全套百度产品。这有点废话。
一般登陆页面的效果比较多,用到的jQuery也很多。它们都是经过加密和混淆的代码。这样的js最好通过正规渠道获得。不要从第三方或仿冒网站获取,因为您不知道。有多少混淆代码是后来添加的恶意代码。页面中还有一个带有php链接的页面,最容易判断为木马。程序员比我们更了解这一点。
3、对于“误杀”的情况
我个人认为肯定是有的,不管是百度审核的标准,还是有的客户发现有的客户之前表现不好,反复尝试隐藏恶意代码或者反技术识别。“恶意代码判断标准和整改标准暂不给出,不给不法方钻空子的机会。” 这句话让你很困惑
最后,百度的这次大整顿行动,将为百度商桥、百度统计等相关产品的推广带来新的高度。 查看全部
网页访客qq抓取(接到几次还是不能通过,搞得程序员、竞价员一直很头疼)
最近收到了这么一个让人望而生畏的竞标问题,但是改了几次还是没通过。这让程序员和投标人头疼不已,互相抱怨。百度官方的回答是:只要百度宣传网站涉嫌恶意获取访客信息,就是恶意行为,类似于秘密获取访客信息:比如QQ号和手机号的代码就是恶意代码。, 百度推广的网址和里面的所有页面都需要测试。一经发现,原创无效,拒绝百度推广账号。
下面总结了几个可能的原因。
1、非法内容或链接
QQ强制弹出码、虚假百度搜索多结果、偷偷截取访客QQ码、手机网站获取访客联系信息码等均涉嫌“恶意代码”!对于这些我们很容易发现,一般都是存在于js文件中的部分,也是直接加载到页面上的,有的则是经过js混淆加密后加载到js文件中的,比较隐蔽。代码有注释,这里的提示最好删除。不要给百度的检查留下一句“有侥幸心理”。
还有一个是在Businesslink的track code中加载的。当用户打开会话时,会加载获取手机或QQ号码的代码。最好在Businesslink里面设置,去掉代码js。以下是Businesslink的公告:
这里提到cnzz企业qq。与百度官方的说法相比,cnzz也可以获得一定范围的用户信息,但不是主要的。如果使用企业QQ,可以看到当前登录的QQ用户正在浏览页面发起对话。建议先删除企业qq。
2.登陆页面登陆页面提示
提示部分关键词登陆页面有病毒木马,过一会还是一样。之前的恶意代码。现在这是第一次使用百度。我已经不玩了。新花样不断产生。我有点怀疑,是为了保证广大网友的隐私,只是为了宣传自己的产品。查了好几遍,发现确实删除了很多代码,甚至删除了QQ咨询,改变了业务通信。无需使用全套百度产品。这有点废话。
一般登陆页面的效果比较多,用到的jQuery也很多。它们都是经过加密和混淆的代码。这样的js最好通过正规渠道获得。不要从第三方或仿冒网站获取,因为您不知道。有多少混淆代码是后来添加的恶意代码。页面中还有一个带有php链接的页面,最容易判断为木马。程序员比我们更了解这一点。
3、对于“误杀”的情况
我个人认为肯定是有的,不管是百度审核的标准,还是有的客户发现有的客户之前表现不好,反复尝试隐藏恶意代码或者反技术识别。“恶意代码判断标准和整改标准暂不给出,不给不法方钻空子的机会。” 这句话让你很困惑
最后,百度的这次大整顿行动,将为百度商桥、百度统计等相关产品的推广带来新的高度。
网页访客qq抓取(通过js,能获取到当前打开网站的人的QQ号码源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-10-12 12:31
通过js可以得到当前打开网站的人的QQ号的源码原理。获取登录QQ号源代码的功能介绍:QQ空间的快速登录方法可以检测到机器上登录的QQ号,并分析这个快速登录页面可以获取地址,然后加载页面通过WebBrowser控件,等待页面加载,分析html,提取当前登录的所有QQ号。 注:开发环境为VisualStudio 2010
其实这个对应的程序很久以前就已经存在了,当时并没有很好的使用。只是现在我们的投标行业导致了互联网的爆发。目前类似的统计系统可以在百度上查到一条大推文,但基本上是垃圾邮件程序。只有两三个做得好。比如闪电精灵和318访客QQ统计就做得最好。闪电收费非常昂贵。300一个月。318访客QQ统计一个月100个,性价比比较高。通过js,目前打开网站的人的QQ号源码将于5月发售。现在每个人看到的都不是 100% 可用的。只有刚才提到的源代码才能100%获得。因为现在还需要搭建一个平台,内部不断的测试。测试成功后才会上市销售,否则会带来很多困难。例如,用户体验中的错误等等。
大致原理就是这样一个过程,用户访问网站---默认打开QQ空间---快速登录功能(js代码程序)---php采集QQ号昵称--- 采集百度统计站长统计---反馈到数据库---用户页面调用数据库数据。如果您有能力编写这样的程序,那么您也可以自己开发一个软件并出售它。目前来看还是很有市场的。根据目前的市场调查。互联网上至少有80%的人不知道这个Q-grabbing系统。所以不要错过这个好机会。
如果您是新手,不会编写此程序,您可以联系我们318访客QQ统计客服讨论、共同学习,或者代理或购买我们的程序,我们提供技术支持,您出售源代码或销售会员,我们将不收一分钱。这是一个很好的创业机会。不知道大家有没有了解什么是暴利行业。暴利是市场竞争大、利润薄的项目。今天分享到这里。 查看全部
网页访客qq抓取(通过js,能获取到当前打开网站的人的QQ号码源码)
通过js可以得到当前打开网站的人的QQ号的源码原理。获取登录QQ号源代码的功能介绍:QQ空间的快速登录方法可以检测到机器上登录的QQ号,并分析这个快速登录页面可以获取地址,然后加载页面通过WebBrowser控件,等待页面加载,分析html,提取当前登录的所有QQ号。 注:开发环境为VisualStudio 2010
其实这个对应的程序很久以前就已经存在了,当时并没有很好的使用。只是现在我们的投标行业导致了互联网的爆发。目前类似的统计系统可以在百度上查到一条大推文,但基本上是垃圾邮件程序。只有两三个做得好。比如闪电精灵和318访客QQ统计就做得最好。闪电收费非常昂贵。300一个月。318访客QQ统计一个月100个,性价比比较高。通过js,目前打开网站的人的QQ号源码将于5月发售。现在每个人看到的都不是 100% 可用的。只有刚才提到的源代码才能100%获得。因为现在还需要搭建一个平台,内部不断的测试。测试成功后才会上市销售,否则会带来很多困难。例如,用户体验中的错误等等。
大致原理就是这样一个过程,用户访问网站---默认打开QQ空间---快速登录功能(js代码程序)---php采集QQ号昵称--- 采集百度统计站长统计---反馈到数据库---用户页面调用数据库数据。如果您有能力编写这样的程序,那么您也可以自己开发一个软件并出售它。目前来看还是很有市场的。根据目前的市场调查。互联网上至少有80%的人不知道这个Q-grabbing系统。所以不要错过这个好机会。
如果您是新手,不会编写此程序,您可以联系我们318访客QQ统计客服讨论、共同学习,或者代理或购买我们的程序,我们提供技术支持,您出售源代码或销售会员,我们将不收一分钱。这是一个很好的创业机会。不知道大家有没有了解什么是暴利行业。暴利是市场竞争大、利润薄的项目。今天分享到这里。
网页访客qq抓取(百度统计为帮助用户网站页面被搜索引擎发现提升抓取速度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-11 06:12
<p>百度统计升级,网页实时推送到搜索引擎,提高网页抓取速度!发布时间:2016-03-05 来源:百度统计是百度推出的一款免费的专业网站流量分析工具,可以告诉用户访问者如何找到和浏览用户网站,在 查看全部
网页访客qq抓取(百度统计为帮助用户网站页面被搜索引擎发现提升抓取速度)
<p>百度统计升级,网页实时推送到搜索引擎,提高网页抓取速度!发布时间:2016-03-05 来源:百度统计是百度推出的一款免费的专业网站流量分析工具,可以告诉用户访问者如何找到和浏览用户网站,在
网页访客qq抓取(如何让访客访问您网站时自动弹出QQ聊天的对话框)
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-10-08 07:34
伊恩今天不小心进入了一家公司的企业网站,QQ聊天窗口立马弹出窗口和那家公司的客服聊天。怀着好奇的心情,伊恩分析了公司网站的源代码,发现了网页弹出qq对话框的原理和实现方法。相信此时此刻,你的QQ已经打开了和伊恩的聊天窗口吧?!
伊恩在这里向各位企业朋友分享实现“网页自动弹出QQ对话框”的原理和方法网站。这些小方法可以通过“认证QQ空间首页同步展示网站”内容实现,对网站的推广也有更有用的效果。
自动弹出QQ对话框的方法可以实现大量的客户查询。相比“左一右一再中一”的客服组件,“打开网页自动弹出QQ对话框”的方式实现咨询量的增加,用户体验和效果要强得多。
好了,废话不多说了。下面我们进入正题,看看如何让访问者在访问你时自动弹出QQ聊天对话框网站。
一、网页上自动弹出QQ对话框的原理
1.在网页中插入iframe框架并设置src="tencent://message/?uin=你的QQ号&Site=&menu=yes";
2.当访问者打开你网站时,也会打开iframe框架中的链接;
3. 访问者的QQ窗口会弹出一个对话框,与您的QQ聊天。
二、验证打开网页会自动弹出QQ对话框
为了验证这个方法的实际可行性,相信你的QQ聊天窗口已经打开了和Ian对话的聊天窗口。你好奇吗?如果你对上面的原理分析没看懂,那么这里的验证结果应该能让你直观的理解!其实Ian也在这篇文章文章中加入了一段实现“打开网页时自动弹出QQ对话框”的代码。
打开网页自动弹出QQ对话框的代码在这里:【点右键查看源码,或者点这里捐给我】
三、设置多个QQ客服,然后随机弹出一个客服QQ对话框
针对企业存在多个客服的情况,直接合理分配接待客服。伊恩刚想出一个办法,就是预设多个客服QQ,然后随机弹出一个客服QQ对话框给访客!当然,这适用于企业,但对于个人站长来说不是必需的。
四、 延迟弹出对话框,让用户先看看
很多客户问我如何设置页面在访问者打开后10秒后弹出。伊恩再次研究并更新了弹出窗口,我确实找到了将其设置为 10 秒后弹出的方法!这样可以在一定程度上提升用户体验,同时让访问者首先看到网站的优质服务可以有效提升客户对产品的认可度,从而增加客户对产品的认知度。积极沟通!
五、手机QQ也有,手机用户不要错过
刚才有朋友问我这个能不能用在手机网页上,然后Ian测试了这个方法不行。然后研究了一会儿,终于找到了手机网页上手机QQ弹窗的突破点。经测试,在安卓和苹果手机上都可以正常弹出QQ对话框。
六、获取访客QQ,让客服主动掌握客户
通过上面的方法,有朋友说客户打开对话框后没有咨询就出去吃饭了,回来的时候忘记了。对此,伊恩还文章扩展想到了访问者访问网站时自动获取QQ号的方法,这种方法可以避免访问者的流失,即使访问者没有咨询也没有交易,没关系,你知道客户QQ号,以后可以随时给对方发消息。有需要的朋友可以在聊天窗口点击Qian。 查看全部
网页访客qq抓取(如何让访客访问您网站时自动弹出QQ聊天的对话框)
伊恩今天不小心进入了一家公司的企业网站,QQ聊天窗口立马弹出窗口和那家公司的客服聊天。怀着好奇的心情,伊恩分析了公司网站的源代码,发现了网页弹出qq对话框的原理和实现方法。相信此时此刻,你的QQ已经打开了和伊恩的聊天窗口吧?!
伊恩在这里向各位企业朋友分享实现“网页自动弹出QQ对话框”的原理和方法网站。这些小方法可以通过“认证QQ空间首页同步展示网站”内容实现,对网站的推广也有更有用的效果。
自动弹出QQ对话框的方法可以实现大量的客户查询。相比“左一右一再中一”的客服组件,“打开网页自动弹出QQ对话框”的方式实现咨询量的增加,用户体验和效果要强得多。
好了,废话不多说了。下面我们进入正题,看看如何让访问者在访问你时自动弹出QQ聊天对话框网站。
一、网页上自动弹出QQ对话框的原理
1.在网页中插入iframe框架并设置src="tencent://message/?uin=你的QQ号&Site=&menu=yes";
2.当访问者打开你网站时,也会打开iframe框架中的链接;
3. 访问者的QQ窗口会弹出一个对话框,与您的QQ聊天。
二、验证打开网页会自动弹出QQ对话框
为了验证这个方法的实际可行性,相信你的QQ聊天窗口已经打开了和Ian对话的聊天窗口。你好奇吗?如果你对上面的原理分析没看懂,那么这里的验证结果应该能让你直观的理解!其实Ian也在这篇文章文章中加入了一段实现“打开网页时自动弹出QQ对话框”的代码。
打开网页自动弹出QQ对话框的代码在这里:【点右键查看源码,或者点这里捐给我】
三、设置多个QQ客服,然后随机弹出一个客服QQ对话框
针对企业存在多个客服的情况,直接合理分配接待客服。伊恩刚想出一个办法,就是预设多个客服QQ,然后随机弹出一个客服QQ对话框给访客!当然,这适用于企业,但对于个人站长来说不是必需的。
四、 延迟弹出对话框,让用户先看看
很多客户问我如何设置页面在访问者打开后10秒后弹出。伊恩再次研究并更新了弹出窗口,我确实找到了将其设置为 10 秒后弹出的方法!这样可以在一定程度上提升用户体验,同时让访问者首先看到网站的优质服务可以有效提升客户对产品的认可度,从而增加客户对产品的认知度。积极沟通!
五、手机QQ也有,手机用户不要错过
刚才有朋友问我这个能不能用在手机网页上,然后Ian测试了这个方法不行。然后研究了一会儿,终于找到了手机网页上手机QQ弹窗的突破点。经测试,在安卓和苹果手机上都可以正常弹出QQ对话框。
六、获取访客QQ,让客服主动掌握客户
通过上面的方法,有朋友说客户打开对话框后没有咨询就出去吃饭了,回来的时候忘记了。对此,伊恩还文章扩展想到了访问者访问网站时自动获取QQ号的方法,这种方法可以避免访问者的流失,即使访问者没有咨询也没有交易,没关系,你知道客户QQ号,以后可以随时给对方发消息。有需要的朋友可以在聊天窗口点击Qian。
网页访客qq抓取(天眼获取网站访客QQ统计系统为你提升10倍业绩)
网站优化 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-10-01 02:06
天眼获取网站访客QQ,网站访客QQ统计系统是一款在线获取网站访客QQ的数据营销软件,让访客真正成为客户,不浪费任何意向客户,< @网站访客QQ统计系统让你的表现提高10倍。天眼访客统计是一款网络营销软件,可以有效捕捉访问网站的客户的QQ信息,让您的潜在客户轻松成为您的目标客户,后续系统可以有效地将访问者定位到有效客户,集成操作方便简单。
1、天眼QQ账号抓包系统是什么?
百度在医疗行业的竞价竞争越来越激烈。随着百度健康平台的出现,各种注册网站、健康网站、健康网站、医药网站,纷纷加入百度的大流量竞价中,目前竞价成本越来越高,流量相对减少;用户越来越排斥Businesslink 的弹出式用户体验,这导致越来越多的对话成本、预约成本和医院访问成本。高,所以作为一个行业,我们是不是也在思考如何从有限的日常竞价流量中最大化发展自己的客户?
天眼QQ抢号系统,只要您在您医院的竞价网站上添加系统提供的统计代码(类似于CNZZ的统计代码),您就可以在后台看到我们为您提供的访客QQ数量到您的投标网站。
2、天眼QQ账号抓包系统是如何工作的?
天眼QQ号抓取系统是一款基于Http、PC互联网协议的程序,用于分析当前用户QQ号。任何人通过PC(电脑)上网,访问医院竞价网站,都会默认抓取用户的QQ号。.
3、抓到的QQ号如何营销?
答:抓到的QQ号和商务沟通一样。一般咨询技能可以转换。如果可以加好友,可以直接加好友(需要及时通话,企业QQ或咨询个人QQ),不能发好友。发邮件,复印,准备一封类似医院介绍的邮件。
4、为什么要使用天眼QQ号抓取系统?
一方面,Businesslink类似广告的弹窗用户越来越反感,用户体验不好,导致竞价流量流失;另一方面,在Businesslink的对话中,最重要的咨询是用户的QQ号和手机号。天眼QQ号抓取系统可以帮助您直接抓取用户的QQ号进行顾问转换。
天眼网站访客QQ统计系统|获取访客QQ来源|网站QQ访客采集系统标题图片 查看全部
网页访客qq抓取(天眼获取网站访客QQ统计系统为你提升10倍业绩)
天眼获取网站访客QQ,网站访客QQ统计系统是一款在线获取网站访客QQ的数据营销软件,让访客真正成为客户,不浪费任何意向客户,< @网站访客QQ统计系统让你的表现提高10倍。天眼访客统计是一款网络营销软件,可以有效捕捉访问网站的客户的QQ信息,让您的潜在客户轻松成为您的目标客户,后续系统可以有效地将访问者定位到有效客户,集成操作方便简单。
1、天眼QQ账号抓包系统是什么?
百度在医疗行业的竞价竞争越来越激烈。随着百度健康平台的出现,各种注册网站、健康网站、健康网站、医药网站,纷纷加入百度的大流量竞价中,目前竞价成本越来越高,流量相对减少;用户越来越排斥Businesslink 的弹出式用户体验,这导致越来越多的对话成本、预约成本和医院访问成本。高,所以作为一个行业,我们是不是也在思考如何从有限的日常竞价流量中最大化发展自己的客户?
天眼QQ抢号系统,只要您在您医院的竞价网站上添加系统提供的统计代码(类似于CNZZ的统计代码),您就可以在后台看到我们为您提供的访客QQ数量到您的投标网站。
2、天眼QQ账号抓包系统是如何工作的?
天眼QQ号抓取系统是一款基于Http、PC互联网协议的程序,用于分析当前用户QQ号。任何人通过PC(电脑)上网,访问医院竞价网站,都会默认抓取用户的QQ号。.
3、抓到的QQ号如何营销?
答:抓到的QQ号和商务沟通一样。一般咨询技能可以转换。如果可以加好友,可以直接加好友(需要及时通话,企业QQ或咨询个人QQ),不能发好友。发邮件,复印,准备一封类似医院介绍的邮件。
4、为什么要使用天眼QQ号抓取系统?
一方面,Businesslink类似广告的弹窗用户越来越反感,用户体验不好,导致竞价流量流失;另一方面,在Businesslink的对话中,最重要的咨询是用户的QQ号和手机号。天眼QQ号抓取系统可以帮助您直接抓取用户的QQ号进行顾问转换。
天眼网站访客QQ统计系统|获取访客QQ来源|网站QQ访客采集系统标题图片
网页访客qq抓取(网站访客QQ获取系统怎么做?如何利用QQ号码展开二次营销)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-10-01 02:03
市场上有很多网站访客QQ获取系统,主要有网页版和客户端两种形式。各家公司的收购率和稳定性也参差不齐。我这里介绍的方法是使用QQ空间权限实现,而不是使用推测接口,所以成本更低,更稳定。获得QQ号后,即可使用QQ号进行二次营销,非常适合各种业务类型网站。
首先我们需要准备一个QQ小号来激活黄钻特权。这个费用大概是每月10元左右。打开黄色菱形后,进入QQ空间,选择空间设置->访问权限设置->只有你能看到,必须设置为只有你能看到。将以下代码复制到JS文件中,将代码中的“*”替换为你的小QQ号,命名为tongji.js,上传到网站FTP根目录。
document.writeln(_$[0]);
document.writeln(_$[1]);
然后将下面代码中的URL替换为你的URL,然后在网站中添加如下代码,即可添加到首页。如果你想得到尽可能多的,你可以将它添加到底部的模板文件中。这样每个页面都可以访问。
这样,访问者在访问网站的同时访问您的QQ空间。当然,他们在表面上是看不到的。由于QQ空间设置为自身可见,访问者无法成功访问QQ空间。这时候我们可以使用QQ黄钻查看被屏蔽访问者的权限,查看访问者的QQ号。
关于收购率的问题,所有声称收购率100%的软件商都是骗人的。如果网站访问者最近打开了QQ空间并且浏览器中保存了缓存,一般可以得到这种情况。如果网站访问者清除了cookies,那么他访问了网站多次@>,也无法获取QQ号。
此方法适用于少量游客。如果有多个网站,可以为每个网站准备一个QQ,这样可以更好的区分不同网站的访问者,针对不同的客户群做营销。如果需要大量获取访客QQ,可以找技术朋友或上威客网站,找人开发辅助工具,获取访客QQ号采集,解放双手。 查看全部
网页访客qq抓取(网站访客QQ获取系统怎么做?如何利用QQ号码展开二次营销)
市场上有很多网站访客QQ获取系统,主要有网页版和客户端两种形式。各家公司的收购率和稳定性也参差不齐。我这里介绍的方法是使用QQ空间权限实现,而不是使用推测接口,所以成本更低,更稳定。获得QQ号后,即可使用QQ号进行二次营销,非常适合各种业务类型网站。
首先我们需要准备一个QQ小号来激活黄钻特权。这个费用大概是每月10元左右。打开黄色菱形后,进入QQ空间,选择空间设置->访问权限设置->只有你能看到,必须设置为只有你能看到。将以下代码复制到JS文件中,将代码中的“*”替换为你的小QQ号,命名为tongji.js,上传到网站FTP根目录。
document.writeln(_$[0]);
document.writeln(_$[1]);
然后将下面代码中的URL替换为你的URL,然后在网站中添加如下代码,即可添加到首页。如果你想得到尽可能多的,你可以将它添加到底部的模板文件中。这样每个页面都可以访问。
这样,访问者在访问网站的同时访问您的QQ空间。当然,他们在表面上是看不到的。由于QQ空间设置为自身可见,访问者无法成功访问QQ空间。这时候我们可以使用QQ黄钻查看被屏蔽访问者的权限,查看访问者的QQ号。
关于收购率的问题,所有声称收购率100%的软件商都是骗人的。如果网站访问者最近打开了QQ空间并且浏览器中保存了缓存,一般可以得到这种情况。如果网站访问者清除了cookies,那么他访问了网站多次@>,也无法获取QQ号。
此方法适用于少量游客。如果有多个网站,可以为每个网站准备一个QQ,这样可以更好的区分不同网站的访问者,针对不同的客户群做营销。如果需要大量获取访客QQ,可以找技术朋友或上威客网站,找人开发辅助工具,获取访客QQ号采集,解放双手。
网页访客qq抓取(找到网站访客QQ号码的原理原理很简单,如何找到访问网站的用户)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-01 02:03
很多网站有流量却不懂营销。回想一下,目前对于所有网站来说,1%的转化率已经算是很好了网站,但是99%网站还达不到这个程度,主要问题是我们不能主动攻击,也找不到访问我们的用户网站。今天教大家如何找到访问网站的用户。这很简单。
查找网站访客QQ号的原理
原理很简单。当用户登录QQ时,打开你的网站,网站会自动弹出你的QQ空间页面,然后三秒左右自动关闭。这时,你打开你的QQ空间,查看你QQ空间的近期访客,这里的近期访客是你的网站访客。
这里提醒大家,最好申请一个新QQ,一个完全没有朋友的QQ,如果网站访问量大于300,最好激活黄钻。没有黄钻只能查看QQ空间。300以内的访客,300以内需要激活黄钻。
如何查找网站访客QQ号
道理看似简单,但并不是每个人都能做到。这涉及到JS弹窗、自动关闭、避免浏览器屏蔽弹窗等技术。别着急,这些代码我都整理好了,今天免费提供给大家。分享它。
第一步:首先下载本站的A.htm和b.html文件,保存到本地。然后把这两个文件上传到你的网站的根目录下,测试打开a.html文件,你会发现弹出一个窗口,这次弹出的窗口是我的QQ空间,不要别担心!
a.htm下载地址:点击直接
b.htm下载地址:点击直接
第二步:使用Dreamweaver打开b.htm文件,将里面的QQ空间链接修改为自己注册的新QQ空间地址,上传到服务器根目录。打开测试后,会弹出你的QQ空间。
第三步:进入QQ空间,将你的QQ空间设置为所有人都可以访问,点击右上角的设置-权限设置-设置谁可以访问我的空间,设置为所有人都可以访问你的QQ空间。否则弹窗无法计数。记得同时激活QQ黄钻。否则,将不会计算超过 300 名访客。
总结:不了解也不知道怎么做的朋友可以直接购买类似访客统计的软件,比如QQ云营销,价格一年1000元左右! 查看全部
网页访客qq抓取(找到网站访客QQ号码的原理原理很简单,如何找到访问网站的用户)
很多网站有流量却不懂营销。回想一下,目前对于所有网站来说,1%的转化率已经算是很好了网站,但是99%网站还达不到这个程度,主要问题是我们不能主动攻击,也找不到访问我们的用户网站。今天教大家如何找到访问网站的用户。这很简单。
查找网站访客QQ号的原理
原理很简单。当用户登录QQ时,打开你的网站,网站会自动弹出你的QQ空间页面,然后三秒左右自动关闭。这时,你打开你的QQ空间,查看你QQ空间的近期访客,这里的近期访客是你的网站访客。
这里提醒大家,最好申请一个新QQ,一个完全没有朋友的QQ,如果网站访问量大于300,最好激活黄钻。没有黄钻只能查看QQ空间。300以内的访客,300以内需要激活黄钻。
如何查找网站访客QQ号
道理看似简单,但并不是每个人都能做到。这涉及到JS弹窗、自动关闭、避免浏览器屏蔽弹窗等技术。别着急,这些代码我都整理好了,今天免费提供给大家。分享它。
第一步:首先下载本站的A.htm和b.html文件,保存到本地。然后把这两个文件上传到你的网站的根目录下,测试打开a.html文件,你会发现弹出一个窗口,这次弹出的窗口是我的QQ空间,不要别担心!
a.htm下载地址:点击直接
b.htm下载地址:点击直接
第二步:使用Dreamweaver打开b.htm文件,将里面的QQ空间链接修改为自己注册的新QQ空间地址,上传到服务器根目录。打开测试后,会弹出你的QQ空间。
第三步:进入QQ空间,将你的QQ空间设置为所有人都可以访问,点击右上角的设置-权限设置-设置谁可以访问我的空间,设置为所有人都可以访问你的QQ空间。否则弹窗无法计数。记得同时激活QQ黄钻。否则,将不会计算超过 300 名访客。
总结:不了解也不知道怎么做的朋友可以直接购买类似访客统计的软件,比如QQ云营销,价格一年1000元左右!
网页访客qq抓取(想要知道谁访问你的QQ空间吗,可以使用东方不败)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-09-30 11:37
想知道谁访问了你的QQ空间吗?您可以使用东方无敌QQ空间访客提取器帮助您整理详细的访问列表,并将其以TXT文本的形式保存在桌面上
版本特征:
顾名思义1、好友版只能提取QQ好友的QQ空间访客,而不能提取陌生人的QQ空间访客
2、此软件的优点是它可以实时访问采集访客,也就是说,无论访客在空间中访问哪个页面,他们都可以实时访问。即使他们只是进入该空间的首页,不点击任何内容,他们也可以采集
3、该软件的每个QQ空间最近都有20名访客采集。请仔细理解这个句子。最后20人并不意味着每个空间只能有20人。软件可以挂起采集。设置采集间隔。每指定一次,该软件都会自动进入该空间,查看是否有新访客,并且采集将返回。因此,每个空间的容量取决于该空间的流量
4、软件的访问者名单将不再重复。但是如果您清空列表,或者下次打开软件,它可能会重复上一个列表
5、为了解决这个问题,我们专门开发了重复过滤软件。点击这里下载QQ过滤复制软件
在6、软件采集的过程中采集可能没有结果。这是因为腾讯限制了IP。解决方案:① 关闭软件;② 更换IP;③ 重新打开软件登录采集
使用本教程:
东方无敌QQ空间访客提取器视频教程
更新日志:
于2015年7月22日更新至4.4
随着腾讯的变化而更新
于2015年1月13日更新至4.1
修正了一些用户登录QQ时软件闪回的错误 查看全部
网页访客qq抓取(想要知道谁访问你的QQ空间吗,可以使用东方不败)
想知道谁访问了你的QQ空间吗?您可以使用东方无敌QQ空间访客提取器帮助您整理详细的访问列表,并将其以TXT文本的形式保存在桌面上
版本特征:
顾名思义1、好友版只能提取QQ好友的QQ空间访客,而不能提取陌生人的QQ空间访客
2、此软件的优点是它可以实时访问采集访客,也就是说,无论访客在空间中访问哪个页面,他们都可以实时访问。即使他们只是进入该空间的首页,不点击任何内容,他们也可以采集
3、该软件的每个QQ空间最近都有20名访客采集。请仔细理解这个句子。最后20人并不意味着每个空间只能有20人。软件可以挂起采集。设置采集间隔。每指定一次,该软件都会自动进入该空间,查看是否有新访客,并且采集将返回。因此,每个空间的容量取决于该空间的流量
4、软件的访问者名单将不再重复。但是如果您清空列表,或者下次打开软件,它可能会重复上一个列表
5、为了解决这个问题,我们专门开发了重复过滤软件。点击这里下载QQ过滤复制软件
在6、软件采集的过程中采集可能没有结果。这是因为腾讯限制了IP。解决方案:① 关闭软件;② 更换IP;③ 重新打开软件登录采集
使用本教程:
东方无敌QQ空间访客提取器视频教程
更新日志:
于2015年7月22日更新至4.4
随着腾讯的变化而更新
于2015年1月13日更新至4.1
修正了一些用户登录QQ时软件闪回的错误
网页访客qq抓取(领跑者网站访客qq获取系统主要特性有哪些?怎么做)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-30 11:32
领跑者QQ自动获取系统是一个网站访问者QQ获取系统,主要用于统计网站访问用户的QQ信息,包括访问者QQ号、昵称和在线状态,也可以基于推送在访客智能信息上,支持QQ临时对话弹窗功能,可以更好地与访客交流,让网站有更好的推广和营销效果。
先行者QQ自动获取系统主要特点
1、访客QQ信息
信息包括:访客QQ号、QQ昵称、QQ状态...
领队系统可以准确方便的获取网站访客QQ号。系统采用先进的界面技术,抓取访问您网站的访客QQ号,让您有机会主动联系目标客户。
2、智能访客邮件推送
自动向访问者推送自定义电子邮件
领导系统,智能访客邮件推送功能,采用先进的WEB模拟人工发送技术,SMTP投诉方式,支持企业邮箱发送。系统支持添加无限发件箱,可随机选择发送,发送成功率高达99%,即向准客户发送邮件。
3、参观团跟进营销
功能:分组、营销、标记、给访客留言
领跑者系统支持在后台对抓取的访客信息进行分组,并支持用户主动一键联系访客并进行标记。同时,您可以对访客信息做笔记,以备日后跟进。更多营销功能等你体验。
4、智能QQ对话弹窗
功能:智能间隔时间QQ临时对话弹窗。
对于领跑者系统,智能QQ临时对话弹窗功能可以在访客访问网站时自动打开访客QQ临时对话弹窗。方便用户在临时QQ对话中直接联系网站在线服务人员。同时,当前系统后台允许用户调整设置弹窗的频率和延迟时间,从而更好的增加网站的访问体验。
5、,多会员管理账号
功能:用户可以开立员工管理账户。
在领跑者系统中,可以在后台设置员工账号,可以设置每个员工的管理和查看权限。为多个网站创建独立的管理和运行环境,让每个网站都可以由专人管理,不受干扰。
6、统计数据分析。
功能:统计报表、停留时间、访问深度
领导者系统后端提供每日抓取访客统计图表、访客网站停留时间和访问轨迹,让用户直观了解网站运营数据。 查看全部
网页访客qq抓取(领跑者网站访客qq获取系统主要特性有哪些?怎么做)
领跑者QQ自动获取系统是一个网站访问者QQ获取系统,主要用于统计网站访问用户的QQ信息,包括访问者QQ号、昵称和在线状态,也可以基于推送在访客智能信息上,支持QQ临时对话弹窗功能,可以更好地与访客交流,让网站有更好的推广和营销效果。
先行者QQ自动获取系统主要特点
1、访客QQ信息
信息包括:访客QQ号、QQ昵称、QQ状态...
领队系统可以准确方便的获取网站访客QQ号。系统采用先进的界面技术,抓取访问您网站的访客QQ号,让您有机会主动联系目标客户。
2、智能访客邮件推送
自动向访问者推送自定义电子邮件
领导系统,智能访客邮件推送功能,采用先进的WEB模拟人工发送技术,SMTP投诉方式,支持企业邮箱发送。系统支持添加无限发件箱,可随机选择发送,发送成功率高达99%,即向准客户发送邮件。
3、参观团跟进营销
功能:分组、营销、标记、给访客留言
领跑者系统支持在后台对抓取的访客信息进行分组,并支持用户主动一键联系访客并进行标记。同时,您可以对访客信息做笔记,以备日后跟进。更多营销功能等你体验。
4、智能QQ对话弹窗
功能:智能间隔时间QQ临时对话弹窗。
对于领跑者系统,智能QQ临时对话弹窗功能可以在访客访问网站时自动打开访客QQ临时对话弹窗。方便用户在临时QQ对话中直接联系网站在线服务人员。同时,当前系统后台允许用户调整设置弹窗的频率和延迟时间,从而更好的增加网站的访问体验。
5、,多会员管理账号
功能:用户可以开立员工管理账户。
在领跑者系统中,可以在后台设置员工账号,可以设置每个员工的管理和查看权限。为多个网站创建独立的管理和运行环境,让每个网站都可以由专人管理,不受干扰。
6、统计数据分析。
功能:统计报表、停留时间、访问深度
领导者系统后端提供每日抓取访客统计图表、访客网站停留时间和访问轨迹,让用户直观了解网站运营数据。
网页访客qq抓取(网站|网页页面|APP软件|访客手机号码获取抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 514 次浏览 • 2021-09-28 20:31
网站|网页|APP软件|访客手机号获取与抓取方法
让我从第一个开始。其实就是指网站或者APP软件的房地产开发商使用全新的网络爬虫来抓取访问者的手机号。关键是在网站的头部插入一段设计代码。没关系。当访问者访问网站网页时,会询问用户的手机号码,但这种抓取方式由于涉嫌侵犯隐私,速度很快,很容易被百度搜索和K站查到, 网站当然总流量,很多网站站长放弃了这种实际操作,
二是与可靠的互联网大数据运营商合作。基本原理是当访问者使用手机的3G总流量浏览网站或APP软件时,会产生一个特殊的属性。你自己的https报告,访问者的手机号,网站浏览了什么,停留了多久,都可以测出来,最终得出访问者需求的实物模型。运营商的座席再根据这种需求反馈给公司在这些方面的专业服务,并给他营销推广后台管理打电话处理客户的需求。由于皮肤过敏的个人信息保护了客户的隐私,第二客户在这些方面会有很高的转化率。
接下来主要介绍网站访客抢手机的第二种方法。利用运营商的大数据,精准定位人群画像和访客行为,依法合规定位用户需求,实现精准营销效果。下图是
手机号获取部分系统截图
实现原理
没有人,任何上网行为都离不开运营商
运营商存储每个人的上网行为、通话行为、短信互动、实时位置等行为
每一个行为都反映了客户的需求
您想要什么样的客户,对我们来说无非是搜索提取
【技术阅读免开卖家,服务商保证名称,直播保证违规退款商家商品加品牌热销安装源码原创拓展教育简单承诺案例参数崩溃三网北京精彩满意分享文档只能邮寄验证,一键正式查询工作招标网站,医疗视频通知频道,雇主权利精品店]
下载更详细的流程介绍文件 企业咨询资料
网站访客手机号抓取软件_抓取指定网站|Web和app手机号信息平台:所有平台|类别:系统工具|大小:2.39MB
点击下载
访客手机号抓取的具体流程,自主研发的系统自动获取手机号程序,推荐广告,支持小额付费测试交易。详细案例请参考以上文档
运营商存储每个用户的行为→根据您的要求对用户进行建模和过滤→准确提取符合您要求的客户
您可以根据上图中列出的类型提出您的需求。包括但不限于电话号码、搜索词、网址、APP、位置、短信,如果您需要其他维度,请联系站长微信,为您定制,过滤您的目标客户。
趣味快销-精准客源服务
低成本客源+高效率转化
解决获客难题
将利润提高十倍 查看全部
网页访客qq抓取(网站|网页页面|APP软件|访客手机号码获取抓取方法)
网站|网页|APP软件|访客手机号获取与抓取方法
让我从第一个开始。其实就是指网站或者APP软件的房地产开发商使用全新的网络爬虫来抓取访问者的手机号。关键是在网站的头部插入一段设计代码。没关系。当访问者访问网站网页时,会询问用户的手机号码,但这种抓取方式由于涉嫌侵犯隐私,速度很快,很容易被百度搜索和K站查到, 网站当然总流量,很多网站站长放弃了这种实际操作,
二是与可靠的互联网大数据运营商合作。基本原理是当访问者使用手机的3G总流量浏览网站或APP软件时,会产生一个特殊的属性。你自己的https报告,访问者的手机号,网站浏览了什么,停留了多久,都可以测出来,最终得出访问者需求的实物模型。运营商的座席再根据这种需求反馈给公司在这些方面的专业服务,并给他营销推广后台管理打电话处理客户的需求。由于皮肤过敏的个人信息保护了客户的隐私,第二客户在这些方面会有很高的转化率。
接下来主要介绍网站访客抢手机的第二种方法。利用运营商的大数据,精准定位人群画像和访客行为,依法合规定位用户需求,实现精准营销效果。下图是
手机号获取部分系统截图
实现原理
没有人,任何上网行为都离不开运营商
运营商存储每个人的上网行为、通话行为、短信互动、实时位置等行为
每一个行为都反映了客户的需求
您想要什么样的客户,对我们来说无非是搜索提取
【技术阅读免开卖家,服务商保证名称,直播保证违规退款商家商品加品牌热销安装源码原创拓展教育简单承诺案例参数崩溃三网北京精彩满意分享文档只能邮寄验证,一键正式查询工作招标网站,医疗视频通知频道,雇主权利精品店]
下载更详细的流程介绍文件 企业咨询资料
网站访客手机号抓取软件_抓取指定网站|Web和app手机号信息平台:所有平台|类别:系统工具|大小:2.39MB
点击下载
访客手机号抓取的具体流程,自主研发的系统自动获取手机号程序,推荐广告,支持小额付费测试交易。详细案例请参考以上文档
运营商存储每个用户的行为→根据您的要求对用户进行建模和过滤→准确提取符合您要求的客户
您可以根据上图中列出的类型提出您的需求。包括但不限于电话号码、搜索词、网址、APP、位置、短信,如果您需要其他维度,请联系站长微信,为您定制,过滤您的目标客户。
趣味快销-精准客源服务
低成本客源+高效率转化
解决获客难题
将利润提高十倍
网页访客qq抓取(有此一乐qq访客提取软件更新日志增加了大量时间)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-28 20:23
有这个快乐qq访客提取是一个实用的工具。使用这款易乐QQ访客提取软件,您可以提取访问您空间的朋友的QQ号码,让您随时了解哪些朋友访问了您的空间。该软件方便实用。感兴趣的用户快来当易下载体验吧!
QQ访客提取软件绿色版介绍
拥有这款易乐QQ好友提取工具是一款帮助您快速批量提取QQ好友号码的工具。专为QQ推广营销人员设计制作,帮助您提取自己的好友号码,支持保存为号码格式,或邮箱格式,提取速度快,效率高,为您省去繁琐的人工操作,节省不少时间,提高效率。即使你的电脑没有安装QQ也可以解压,非常方便。
有了QQ访客提取这个功能
1、可以批量提取。
2、 朋友也可以找回看不到的访客。
3、非好友可以看到访客找回。
4、 您可以设置只提取特定时间段的访问者。
5、可以保存为数字格式,也可以保存为邮箱格式,可以自由选择。
6、 系统不要挑,windows系统都可以用。WinXP、win2000、win2003、win7、win8都可以。
7、 可以隐身检索,检索过程中别人是看不到你的。这个单一的功能需要黄色菱形激活。未激活黄钻的用户不能使用此功能。
QQ访客提取软件绿色版更新日志
添加了可以试用的功能。您可以批量导入号码和批量采集访客。 查看全部
网页访客qq抓取(有此一乐qq访客提取软件更新日志增加了大量时间)
有这个快乐qq访客提取是一个实用的工具。使用这款易乐QQ访客提取软件,您可以提取访问您空间的朋友的QQ号码,让您随时了解哪些朋友访问了您的空间。该软件方便实用。感兴趣的用户快来当易下载体验吧!
QQ访客提取软件绿色版介绍
拥有这款易乐QQ好友提取工具是一款帮助您快速批量提取QQ好友号码的工具。专为QQ推广营销人员设计制作,帮助您提取自己的好友号码,支持保存为号码格式,或邮箱格式,提取速度快,效率高,为您省去繁琐的人工操作,节省不少时间,提高效率。即使你的电脑没有安装QQ也可以解压,非常方便。
有了QQ访客提取这个功能
1、可以批量提取。
2、 朋友也可以找回看不到的访客。
3、非好友可以看到访客找回。
4、 您可以设置只提取特定时间段的访问者。
5、可以保存为数字格式,也可以保存为邮箱格式,可以自由选择。
6、 系统不要挑,windows系统都可以用。WinXP、win2000、win2003、win7、win8都可以。
7、 可以隐身检索,检索过程中别人是看不到你的。这个单一的功能需要黄色菱形激活。未激活黄钻的用户不能使用此功能。
QQ访客提取软件绿色版更新日志
添加了可以试用的功能。您可以批量导入号码和批量采集访客。
网页访客qq抓取(海豹QQ访客QQ获取系统正式内测,每周可以有100个名额进行免费使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-09-27 07:10
经过几天的测试,封印QQ访客QQ获取系统正式测试通过。每周可免费使用100个名额。
功能亮点
1、安装方便,部署快速
本系统为PHP+MySQL开发,可轻松稳定运行于所有服务器环境,占用资源极少。安装完成后,只需要注册一个账号,添加网站,获取JS代码,放到前台网页就可以开始爬虫了。
2、35% 超高抓取率。由于访客未登录QQ或其他未知因素,本系统无法100%获取访客QQ。经测试,平均获得的用户QQ数占IP总访问量的35%!是目前最稳定、最高的采集算法。
3、海量客户存储管理我们的系统拥有最专业的海量客户信息存储管理功能,您可以按网站、时间、路线关键词、分组、停留时间等,为您查询和使用。当然,它还具有强大的导出功能,方便数据导出。
4、根据意向度的活跃对话,可以根据当天的访问时间对客户进行排序,也可以根据客户的路径判断客户的意向关键词和网站 停留时间,然后更新 有针对性地发起主动对话,直接与目标客户对话,提高转化率!
5、 除了在线直接主动对话外,系统的客户信息过滤导出功能可以帮助您导出客户群,更高效的导出,然后导入QQ营销工具批量群发,或者生成电子邮件地址,电子邮件营销。
6、账号,网站添加管理无论是大账号添加多个网站,还是网络营销团队按月单独销售系统功能,我们的系统自带灵活方便的账号和网站添加管理功能,方便您的各种需求。
封QQ官网:
配额申请群:208164697 查看全部
网页访客qq抓取(海豹QQ访客QQ获取系统正式内测,每周可以有100个名额进行免费使用)
经过几天的测试,封印QQ访客QQ获取系统正式测试通过。每周可免费使用100个名额。
功能亮点
1、安装方便,部署快速
本系统为PHP+MySQL开发,可轻松稳定运行于所有服务器环境,占用资源极少。安装完成后,只需要注册一个账号,添加网站,获取JS代码,放到前台网页就可以开始爬虫了。
2、35% 超高抓取率。由于访客未登录QQ或其他未知因素,本系统无法100%获取访客QQ。经测试,平均获得的用户QQ数占IP总访问量的35%!是目前最稳定、最高的采集算法。
3、海量客户存储管理我们的系统拥有最专业的海量客户信息存储管理功能,您可以按网站、时间、路线关键词、分组、停留时间等,为您查询和使用。当然,它还具有强大的导出功能,方便数据导出。
4、根据意向度的活跃对话,可以根据当天的访问时间对客户进行排序,也可以根据客户的路径判断客户的意向关键词和网站 停留时间,然后更新 有针对性地发起主动对话,直接与目标客户对话,提高转化率!
5、 除了在线直接主动对话外,系统的客户信息过滤导出功能可以帮助您导出客户群,更高效的导出,然后导入QQ营销工具批量群发,或者生成电子邮件地址,电子邮件营销。
6、账号,网站添加管理无论是大账号添加多个网站,还是网络营销团队按月单独销售系统功能,我们的系统自带灵活方便的账号和网站添加管理功能,方便您的各种需求。
封QQ官网:
配额申请群:208164697
网页访客qq抓取(网站访客QQ抓取系统,快速获取意向客户QQ信息,网页后台登陆统一管理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-26 13:19
>>>与此系统类似
>>>与此系统类似
>>>与此系统类似
网站访客QQ捕获系统是最快的QQ信息捕获系统,实时获取网站访客登录的QQ信息,快速获取目标客户的QQ,在网页背面登录,统一管理QQ,并在第一时间对访客QQ进行二次销售
网站访客QQ捕获系统是最快的QQ信息捕获系统,实时获取网站访客登录的QQ信息,快速获取目标客户的QQ,在网页背面登录,统一管理QQ,并在第一时间对访客QQ进行二次销售
监控网站访客QQ捕获和推送营销电子邮件
>>>与此系统类似
>>>与此系统类似
>>>与此系统类似 查看全部
网页访客qq抓取(网站访客QQ抓取系统,快速获取意向客户QQ信息,网页后台登陆统一管理)
>>>与此系统类似
>>>与此系统类似
>>>与此系统类似
网站访客QQ捕获系统是最快的QQ信息捕获系统,实时获取网站访客登录的QQ信息,快速获取目标客户的QQ,在网页背面登录,统一管理QQ,并在第一时间对访客QQ进行二次销售
网站访客QQ捕获系统是最快的QQ信息捕获系统,实时获取网站访客登录的QQ信息,快速获取目标客户的QQ,在网页背面登录,统一管理QQ,并在第一时间对访客QQ进行二次销售
监控网站访客QQ捕获和推送营销电子邮件
>>>与此系统类似
>>>与此系统类似
>>>与此系统类似
网页访客qq抓取(Grab指定网站访问者手机号:如何批量提取某网站手机号)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-09-26 02:05
在第一次测试中,无法获取非WiFi条件下的电话号码。手机号码获取率相当高。搜索手机,抢营销系统。网站 上也会有类似的。然后联系相关客服,直接在旁边的标签下方添加相关代码。
类似于下图中的代码:
网站访问者手机号的爬取效果如何?
部分客户安装后立即使用手机进行测试,发现无法获取手机号码。这是不科学的。有一定几率抢到,数量大的时候才能看到效果。比如一百个访客能抢到30个号和50个号是正常的。请记住,如果几个人访问它们,则无法抓取它们,这意味着该软件没有效果。
经测试,我们的软件爬网率超过60%,可以有效帮助中小企业建立潜在客户群,为公司带来真实的交易量。
抓取指定的网站访客手机号:如何批量提取网站的手机号
如何批量提取51个网站手机号批量提取母婴网站手机号。这是个人信息的暴露,这种行为是违法的。
如何获取访客的手机号码
获取访客手机号的方式一般有3种:
**种类是:获取你的网站访客手机号,抢同事的网站访客手机号。
第二种是:获取peer网站客户手机访问者手机号抓取js代码。
三是:获取app注册和下载信息。
火客_
这三种都是比较快速有效的方法。获取浏览网站的手机号码。
搜客宝网站访客手机抢系统有什么用??
简单来说,就是帮助网站有效抓取访问者的手机或QQ号,利用手机号和QQ号主动联系客户达成交易。一般来说,访问者网站的客户具有很强的目的性,他们可能会购买某些产品和服务。出于某种原因,他们在**时间内没有吸引相互访问者的咨询,90%的访问者关闭了页面并离开了。这样一来,90%的潜在客户都被浪费了。如果您有访客的手机或QQ号码,您可以主动帮助引导客户,交易的机会将大大增加。我希望它对你有用。
这就是无法获取用户数据的原因。首先,如果用户使用Wi-Fi上网,我们只能得到路由器的请求,无法将手机信息传输到我们的中转站。
所以如果用户的上网速度非常好,或者用户选择使用3GNET进行3G上网(这是一个非常昂贵的玩法),我们将无法获得。所以我们只能拿到4G模式下可以访问的手机。命中率只有30%-40%左右。几乎一个流量可以抢到20个号码。大数据捕获应用访问者的手机号码。
我已经稳定了好几年了。
PHP如何获取网页访问者的手机号?把源码发到g u_@.com,谢谢,满意的话给分
什么不现实,但难点在于需要与三大运营商合作。看看你有没有这个实力。这样的团队在技术上是稳定的。只要通过手机访问网站,在非WiFi条件下都可以获取。客户的手机号码。 查看全部
网页访客qq抓取(Grab指定网站访问者手机号:如何批量提取某网站手机号)
在第一次测试中,无法获取非WiFi条件下的电话号码。手机号码获取率相当高。搜索手机,抢营销系统。网站 上也会有类似的。然后联系相关客服,直接在旁边的标签下方添加相关代码。
类似于下图中的代码:
网站访问者手机号的爬取效果如何?
部分客户安装后立即使用手机进行测试,发现无法获取手机号码。这是不科学的。有一定几率抢到,数量大的时候才能看到效果。比如一百个访客能抢到30个号和50个号是正常的。请记住,如果几个人访问它们,则无法抓取它们,这意味着该软件没有效果。
经测试,我们的软件爬网率超过60%,可以有效帮助中小企业建立潜在客户群,为公司带来真实的交易量。
抓取指定的网站访客手机号:如何批量提取网站的手机号
如何批量提取51个网站手机号批量提取母婴网站手机号。这是个人信息的暴露,这种行为是违法的。
如何获取访客的手机号码
获取访客手机号的方式一般有3种:
**种类是:获取你的网站访客手机号,抢同事的网站访客手机号。
第二种是:获取peer网站客户手机访问者手机号抓取js代码。
三是:获取app注册和下载信息。
火客_
这三种都是比较快速有效的方法。获取浏览网站的手机号码。
搜客宝网站访客手机抢系统有什么用??
简单来说,就是帮助网站有效抓取访问者的手机或QQ号,利用手机号和QQ号主动联系客户达成交易。一般来说,访问者网站的客户具有很强的目的性,他们可能会购买某些产品和服务。出于某种原因,他们在**时间内没有吸引相互访问者的咨询,90%的访问者关闭了页面并离开了。这样一来,90%的潜在客户都被浪费了。如果您有访客的手机或QQ号码,您可以主动帮助引导客户,交易的机会将大大增加。我希望它对你有用。
这就是无法获取用户数据的原因。首先,如果用户使用Wi-Fi上网,我们只能得到路由器的请求,无法将手机信息传输到我们的中转站。
所以如果用户的上网速度非常好,或者用户选择使用3GNET进行3G上网(这是一个非常昂贵的玩法),我们将无法获得。所以我们只能拿到4G模式下可以访问的手机。命中率只有30%-40%左右。几乎一个流量可以抢到20个号码。大数据捕获应用访问者的手机号码。
我已经稳定了好几年了。
PHP如何获取网页访问者的手机号?把源码发到g u_@.com,谢谢,满意的话给分
什么不现实,但难点在于需要与三大运营商合作。看看你有没有这个实力。这样的团队在技术上是稳定的。只要通过手机访问网站,在非WiFi条件下都可以获取。客户的手机号码。
网页访客qq抓取(捕获移动QQ访客数访问Sookebao网站该系统有什么用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-09-26 02:04
部分客户安装后立即使用手机进行测试,发现手机号码无法抓取。这是不科学的。有爬虫的机会,当数量大的时候(比如一百个),真的可以看到效果。访客能抢到30个号码和50个号码是正常的。请记住,如果有几个人亲自访问,请不要抓住他们,这意味着软件**。
通过测试我们的软件爬取率超过60%,确实可以帮助中小企业建立潜在客户群,为企业带来真实的交易量。抓取指定网站和app的手机号。
捕获访问搜客宝网站的手机QQ访问量。这个系统有什么用?简而言之,这是为了帮助网站有效抓取访问者的手机或QQ号,利用手机和QQ号主动联系客户完成交易。一般来说,访问者网站的客户具有很强的目标性,他们可能会寻求某些产品和服务。由于某种原因,他们第一次没有吸引相互访问者咨询,然后90%的访问者关闭了页面并离开了。这样一来,90%的潜在客户就白白浪费了。如果您有访客的手机或QQ号码,您可以主动帮助引导客户,交易的可能性会大大增加。希望对你有用。
这就是无法获取用户数据的原因。首先,如果用户使用Wi-Fi上网,我们只能得到路由器的请求,手机信息无法传输到我们的中转站。
那么,如果用户上网速度好,或者用户选择使用3GNET进行3G上网(这是一种非常昂贵的播放方式),我们将无法获得。所以我们只能拿到4G模式下可以访问的手机。命中率只有30%-40%左右。流量可以捕获近 20 个号码。网站访客手机号码抓取软件。
我已经稳定了好几年了。**系统(同名Q)六六六五五一鹅酒抢同行网站访客手机号。
用于采集网站访客手机号的软件:QQ网站上获取手机号的软件还能用吗?
建议不要使用QQ抓取。很多人在卖QQ爬虫软件,或者它可以让网站访问者获取QQ,或者它可以。大部分都可以从微信购买。付款后,安装代码,稍后将关闭您的网站,威胁您增加资金,否则将破坏您的业务链接或业务桥梁。如果您将它们发送到 网站 与他们联系,他们将继续为您出价。
当有人访问我的网站时,什么样的软件可以及时详细地显示点击者的手机号码、姓名等信息。有谁可以帮忙,非常感谢!!
二楼的肯定回答是不可能的,除非他们主动给你填,你可以在二楼找到地址,因为我们可以看到他们的IP地址,这是全球统一的,我们可以知道是哪个IP地址对应哪个Address,所以可以找到如下
采集网站访问者手机号的软件:请求网页代码,可通过手机访问,获取对方手机号
**测试期间不可用。在非WiFi条件下,电话号码和手机号码的获取率非常高。搜索电话并获取营销系统。网站上也会有类似的内容。然后联系相关客服,在标签旁边添加相关代码。
类似于下图中的代码: 查看全部
网页访客qq抓取(捕获移动QQ访客数访问Sookebao网站该系统有什么用)
部分客户安装后立即使用手机进行测试,发现手机号码无法抓取。这是不科学的。有爬虫的机会,当数量大的时候(比如一百个),真的可以看到效果。访客能抢到30个号码和50个号码是正常的。请记住,如果有几个人亲自访问,请不要抓住他们,这意味着软件**。
通过测试我们的软件爬取率超过60%,确实可以帮助中小企业建立潜在客户群,为企业带来真实的交易量。抓取指定网站和app的手机号。
捕获访问搜客宝网站的手机QQ访问量。这个系统有什么用?简而言之,这是为了帮助网站有效抓取访问者的手机或QQ号,利用手机和QQ号主动联系客户完成交易。一般来说,访问者网站的客户具有很强的目标性,他们可能会寻求某些产品和服务。由于某种原因,他们第一次没有吸引相互访问者咨询,然后90%的访问者关闭了页面并离开了。这样一来,90%的潜在客户就白白浪费了。如果您有访客的手机或QQ号码,您可以主动帮助引导客户,交易的可能性会大大增加。希望对你有用。
这就是无法获取用户数据的原因。首先,如果用户使用Wi-Fi上网,我们只能得到路由器的请求,手机信息无法传输到我们的中转站。
那么,如果用户上网速度好,或者用户选择使用3GNET进行3G上网(这是一种非常昂贵的播放方式),我们将无法获得。所以我们只能拿到4G模式下可以访问的手机。命中率只有30%-40%左右。流量可以捕获近 20 个号码。网站访客手机号码抓取软件。
我已经稳定了好几年了。**系统(同名Q)六六六五五一鹅酒抢同行网站访客手机号。
用于采集网站访客手机号的软件:QQ网站上获取手机号的软件还能用吗?
建议不要使用QQ抓取。很多人在卖QQ爬虫软件,或者它可以让网站访问者获取QQ,或者它可以。大部分都可以从微信购买。付款后,安装代码,稍后将关闭您的网站,威胁您增加资金,否则将破坏您的业务链接或业务桥梁。如果您将它们发送到 网站 与他们联系,他们将继续为您出价。
当有人访问我的网站时,什么样的软件可以及时详细地显示点击者的手机号码、姓名等信息。有谁可以帮忙,非常感谢!!
二楼的肯定回答是不可能的,除非他们主动给你填,你可以在二楼找到地址,因为我们可以看到他们的IP地址,这是全球统一的,我们可以知道是哪个IP地址对应哪个Address,所以可以找到如下
采集网站访问者手机号的软件:请求网页代码,可通过手机访问,获取对方手机号
**测试期间不可用。在非WiFi条件下,电话号码和手机号码的获取率非常高。搜索电话并获取营销系统。网站上也会有类似的内容。然后联系相关客服,在标签旁边添加相关代码。
类似于下图中的代码:
网页访客qq抓取(如何在线获取访客qq号码的呢?他们用的是什么技术?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-25 20:35
文本:
近日,飘逸收到了大量网上获取网站访客QQ号的宣传邮件,不少商业网站也探索了这一需求,推出了一些商业项目。那么这些商业程序是如何获取访客QQ号的呢?他们使用什么技术?今天飘逸就跟大家分享一下如何在线获取访客QQ号。首先一句话,无论哪种方式,都需要精通js代码。目前市面上获取QQ号无非有以下几种方式:1、 打开QQ空间黄钻,在目标网页中嵌入隐藏的iframe框架,利用QQ空间屏蔽访客功能查看QQ号码;
2、本地软件开发,比如用c#嵌入一个webbrowser空间,然后分析html源码获取页面中的QQ号(这种方法没有实际意义,对网页登录没有价值) ,所以不讨论)
3、 通过js跨域,利用腾讯众多登录界面或功能页面读取用户QQ号;
4、使用PHPfile_get_contents获取腾讯某页面内容拦截QQ号。该方法在2013年之前可用,目前无效。以上方法均无法获取访问者的QQ号,前提是:
访问者在浏览器中登录了QQ空间、腾讯微博、QQ邮箱、朋友圈等腾讯产品,然后浏览器留下了他的cookies信息。只有在这个前提下才能获得访客QQ。先说一下使用QQ空间黄钻功能查看访客QQ空间的原理:
使用js或者iframe加载这个url:在目标网页上,其中12345678是QQ黄钻激活的QQ号。先打开QQ的黄砖,再关闭QQ空间的访问权限。当访问者访问网站时,在被屏蔽的访问者中可以看到该访问者的QQ。下面飘一重点介绍使用js跨域获取访客QQ的方法。一般情况下,我们无法跨域获取用户计算机上的cookie信息。例如,如果我的网页是,我可以获取用户 cookie 吗?答案当然是否定的,cookies不能跨域获取!那么,我们如何获取用户qq号呢?即找到该域名下的一些页面,以它们的页面为跳板,通过脚本调用远程QQ页面,然后使用回调函数提取QQ号。
红色的 URL 页面是域名本身下的页面。当然这个页面可以在QQ登录后获取cookie信息,所以很容易获取访问者的QQ。如果直接访问,返回的结果格式如下:
piaoyi({"result":1000005,"resultstr":"系统忙!","uin":123456})
uin 的值是访问者的 号。
和上面的红色网址一样,就是我们要找的页面,必须以它域名下的页面作为跳板。至于js跨域,我们也可以使用jQuery的jsonp来实现跨域,详见此链接。和上面的页面地址一样,有以下几个:
注:以上发布的网址已被腾讯屏蔽。今天的文章思路仅供参考。如果您有更多关于如何获取访客QQ号的信息,您可以在下方留言。 查看全部
网页访客qq抓取(如何在线获取访客qq号码的呢?他们用的是什么技术?)
文本:
近日,飘逸收到了大量网上获取网站访客QQ号的宣传邮件,不少商业网站也探索了这一需求,推出了一些商业项目。那么这些商业程序是如何获取访客QQ号的呢?他们使用什么技术?今天飘逸就跟大家分享一下如何在线获取访客QQ号。首先一句话,无论哪种方式,都需要精通js代码。目前市面上获取QQ号无非有以下几种方式:1、 打开QQ空间黄钻,在目标网页中嵌入隐藏的iframe框架,利用QQ空间屏蔽访客功能查看QQ号码;
2、本地软件开发,比如用c#嵌入一个webbrowser空间,然后分析html源码获取页面中的QQ号(这种方法没有实际意义,对网页登录没有价值) ,所以不讨论)
3、 通过js跨域,利用腾讯众多登录界面或功能页面读取用户QQ号;
4、使用PHPfile_get_contents获取腾讯某页面内容拦截QQ号。该方法在2013年之前可用,目前无效。以上方法均无法获取访问者的QQ号,前提是:
访问者在浏览器中登录了QQ空间、腾讯微博、QQ邮箱、朋友圈等腾讯产品,然后浏览器留下了他的cookies信息。只有在这个前提下才能获得访客QQ。先说一下使用QQ空间黄钻功能查看访客QQ空间的原理:
使用js或者iframe加载这个url:在目标网页上,其中12345678是QQ黄钻激活的QQ号。先打开QQ的黄砖,再关闭QQ空间的访问权限。当访问者访问网站时,在被屏蔽的访问者中可以看到该访问者的QQ。下面飘一重点介绍使用js跨域获取访客QQ的方法。一般情况下,我们无法跨域获取用户计算机上的cookie信息。例如,如果我的网页是,我可以获取用户 cookie 吗?答案当然是否定的,cookies不能跨域获取!那么,我们如何获取用户qq号呢?即找到该域名下的一些页面,以它们的页面为跳板,通过脚本调用远程QQ页面,然后使用回调函数提取QQ号。
红色的 URL 页面是域名本身下的页面。当然这个页面可以在QQ登录后获取cookie信息,所以很容易获取访问者的QQ。如果直接访问,返回的结果格式如下:
piaoyi({"result":1000005,"resultstr":"系统忙!","uin":123456})
uin 的值是访问者的 号。
和上面的红色网址一样,就是我们要找的页面,必须以它域名下的页面作为跳板。至于js跨域,我们也可以使用jQuery的jsonp来实现跨域,详见此链接。和上面的页面地址一样,有以下几个:
注:以上发布的网址已被腾讯屏蔽。今天的文章思路仅供参考。如果您有更多关于如何获取访客QQ号的信息,您可以在下方留言。
网页访客qq抓取( 解密如何获取网站访客QQ的方法及原理链接:免费开源使用地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-21 19:17
解密如何获取网站访客QQ的方法及原理链接:免费开源使用地址)
最新的开放访问网站visitor QQ开放源代码的成功率为90%,可以免费使用
最新的开放访问网站visitor QQ开放源代码的成功率为90%,可以免费使用
免费开源地址
之前,作者写了一个链接,链接到解密如何获得网站visitor QQ的方法和原理:
获得网站visitor QQ的方法有三种:
1、分析QQ登录空间非常困难,成功率高达90%(今天我们主要向大家展示这种开源的方法)
2、使用PHP文件获取内容获取腾讯页面内容并截取QQ号。这种方法在11月之前有效,现在不能再使用
3、打开QQ黄钻,用JS代码将QQ空间地址嵌入站内并做一些设置,你可以在QQ空间看到你的网站访客号。据估计,这种方法在很长一段时间内是有效的。有关详细信息,请打开此链接
今天,作者主要介绍和解释方法1。使用的代码未加密。如果您需要代码,请通过网站源代码复制
那么我们如何分析QQ登录空间并获得QQ号码呢?我相信很多人以前都为此付出过努力,但没有取得任何成果
要使用此地址,将使用Cookie,并且Cookie不能跨域。这里的每个人都很尴尬
那我该怎么做呢?代码中制作了一个小跳板来实现cookies的跨域幻觉!事实上,这不是跨域获得的信息。请看我的源代码
两天后自己使用织梦DEDEcmsdevelopment插件已经编写了一些源代码并制作了一套程序,这些程序是免费的,对每个人都是开放的。我不保证它可以使用多久,但如果有变化,我会及时升级算法。代码将不会被加密。请自己阅读代码
免费开源地址
文章from 查看全部
网页访客qq抓取(
解密如何获取网站访客QQ的方法及原理链接:免费开源使用地址)
最新的开放访问网站visitor QQ开放源代码的成功率为90%,可以免费使用
最新的开放访问网站visitor QQ开放源代码的成功率为90%,可以免费使用
免费开源地址
之前,作者写了一个链接,链接到解密如何获得网站visitor QQ的方法和原理:
获得网站visitor QQ的方法有三种:
1、分析QQ登录空间非常困难,成功率高达90%(今天我们主要向大家展示这种开源的方法)
2、使用PHP文件获取内容获取腾讯页面内容并截取QQ号。这种方法在11月之前有效,现在不能再使用
3、打开QQ黄钻,用JS代码将QQ空间地址嵌入站内并做一些设置,你可以在QQ空间看到你的网站访客号。据估计,这种方法在很长一段时间内是有效的。有关详细信息,请打开此链接
今天,作者主要介绍和解释方法1。使用的代码未加密。如果您需要代码,请通过网站源代码复制
那么我们如何分析QQ登录空间并获得QQ号码呢?我相信很多人以前都为此付出过努力,但没有取得任何成果
要使用此地址,将使用Cookie,并且Cookie不能跨域。这里的每个人都很尴尬
那我该怎么做呢?代码中制作了一个小跳板来实现cookies的跨域幻觉!事实上,这不是跨域获得的信息。请看我的源代码
两天后自己使用织梦DEDEcmsdevelopment插件已经编写了一些源代码并制作了一套程序,这些程序是免费的,对每个人都是开放的。我不保证它可以使用多久,但如果有变化,我会及时升级算法。代码将不会被加密。请自己阅读代码
免费开源地址
文章from
网页访客qq抓取(如何获得我们getContent函数中的那些需要使用的headers参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2021-09-21 12:14
urllib.error.HTTPError:HTTP错误403:禁止
从403禁止,我们可以发现程序访问被网站禁止,因为csdn网站已设置防爬虫机制。当检测到网站a爬虫时,访问将被拒绝,因此我们将得到上述结果
此时,我们需要模拟浏览器进行访问,以避免网站的反爬虫机制,顺利抓取我们想要的内容
接下来,我们将使用一个神奇的库urlib.request.request进行模拟工作。这一次,我们还将首先添加代码,然后对其进行解释。但是,这一次,我想提醒您,以下代码不能直接使用。我们需要在其中使用my\uHeader中的用户代理被它自己的替换。为了保密,我加了一个省略号,所以不能直接使用。更换方法见下图。这一次,为了方便起见,我们引入了以下功能:
#coding:utf - 8
from urllib.request import urlopen
from urllib.request import Request
import random
import re
def getContent(url,headers):
"""
此函数用于抓取返回403禁止访问的网页
"""
random_header = random.choice(headers)
"""
对于Request中的第二个参数headers,它是字典型参数,所以在传入时
也可以直接将个字典传入,字典中就是下面元组的键值对应
"""
req =Request(url)
req.add_header("User-Agent", random_header)
req.add_header("GET",url)
req.add_header("Host","blog.csdn.net")
req.add_header("Referer","http://www.csdn.net/")
content=urlopen(req).read().decode("utf-8")
return content
url="http://blog.csdn.net/beliefer/ ... ot%3B
#这里面的my_headers中的内容由于是个人主机的信息,所以我就用句号省略了一些,在使用时可以将自己主机的
my_headers = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/53 。。。Chrome/54.0.2840.99 Safari/537.36"]
print(getContent(url,my_headers))
使用上述代码,我们通常可以捕获此页面的信息。让我们介绍一下如何获取需要在getcontent函数中使用的标题中的参数
由于我们想要模拟浏览器进行web访问,这些参数自然需要我们在浏览器中查找
首先,我们单击进入要爬网的页面,然后右键单击该页面,单击review元素,将出现以下框架。然后我们点击网络,我们会发现我们页面上的信息没有出现。没关系。此时,我们刷新页面,将显示下图所示的信息
此时,我们将在第一行看到51251757,这是我们网站后面的标签。此时,当我们单击此标签时,将显示下图所示的内容:
以下是我直接访问本网站的截图:
对于前两个数字,我曾经编写版本2的Visite,现在我直接使用它们。当时,我在CSDN主页上点击了这个博客,所以在代码和前两个图中,我的标题中的referer被填充
,我用URL链接直接将这张图片输入浏览器,这样我们就可以从图片中看到引用者,这是我们的网站。在这里,我们发布了一张不同的图片,让每个人都更好地理解这个参考。在这张图片中,我用红线标出了要填写的四个内容。当您进行测试时,您不能使用我提供的用户代理,因为我用省略号替换了一些,您应该使用自己的
在这个时候,我们将发现头球是否有明亮的感觉。是的,你的直觉是对的。我们需要的信息在标题中
然后根据代码中需要的参数将信息复制回来,因为这里显示的信息只对应键值,所以复制和使用非常方便
现在让我们介绍一下urllib.request.request的用法(翻译自官方文档):
类urllib。要求请求(URL,data=none,headers={},origin\u req\u host=none,unverifiable=false,method=none)参数:URL:不用说,这是我们将访问的网站。它是一根绳子。数据:数据必须是字节对象,它指定向服务器发送附加数据,如果不需要,则不发送。目前,只有HTTP请求使用数据;当提供数据参数时,HTTP请求应该是post而不是get。数据应以标准的application/x-www-form-urlencoded格式进行缓冲。urllib的参数。作语法分析函数是一个映射或二进制序列,并返回此格式的ascii字符串。当用作数据参数时,应将其编码为字节。头:头是字典数据,当调用add\when header()并具有键和值参数时,此头将作为请求处理。此标头通常用于阻止爬虫访问服务器。浏览器使用头来标识自身,因为某些HTTP服务器只允许来自普通浏览器的请求,而不允许来自脚本(可以理解为爬虫)
例如,Mozilla Firefox浏览器可以将自己识别为“Mozilla/5(X11;u;Linuxi686)Gecko/2008070208 Firefox 20071127/2.0.0.11模块的默认用户代理字符串为“Python urlib/2.6 “ (Python2.6),也就是说,当访问网页时,对于带有反爬虫机制的网站来说,您可以使用此用户代理字符串“Python urlib/”2.6 “ (Python@k266)检查我们是爬虫程序,然后拒绝我们的访问,这就是为什么我们需要用户代理进行更正。在这方面,应该综合考虑网站的反爬虫机制有多严格,因为监视爬虫程序越严格,需要检查的内容就越多,这不可避免地会增加网站)@服务器的处理负担,即网站必须在爬虫检测和网站服务器的计算负担之间进行权衡。因此,爬虫检测机制越严格越好。还应考虑服务器的负担。Origin_req_host:Origin_req_host应该是t的请求主机原创事务,由RFC2965定义。它默认为http.coo kiejar.request\u host(self)
这是由用户发起的原创请求的主机名或IP地址。例如,如果请求的图像是HTML文档中的图像,则这应该是收录该图像的页面请求的主机。(我们通常不使用此名称,只知道此处)Unverifiable:Unverifiable应指示请求是否无法验证。它由RFC 2965定义,默认值为false。Unverifiable请求表示无法提交用户的网址。例如,当用户在网页的HTML文档中找到图像,但用户没有重试权限时e来自服务器的映像不可验证。值应为true。方法:方法应为指示将使用HTTP请求方法的字符串(如“header”)。如果提供,其值将存储在方法属性中,并通过方法get_Method()调用.子类可以通过在类中设置method属性来指示默认方法。(这很少使用)说了这么多无聊的定义,我无法忍受翻译。让我们回到我们的程序:对于我们的程序,只需要掌握几个要点。首先,我们需要构造请求:req=request(URL)此时,请求为空。我们需要向请求中添加信息。此信息供浏览器查看
Req.add_header(“user agent”,random_header)告诉网页服务器我是通过浏览器访问的,而我不是爬虫。Req.add_header(“get”,URL)告诉浏览器我们访问的网址。Req.add_header(“host”),是网站的信息,我们只是从网站.Req.add_标题(“引用者”、“引用者”)这句话非常重要。它告诉网站服务器我们在哪里找到了我们想要访问的页面。例如,如果你点击百度中的一个链接跳转到你当前访问的页面,那么这个引用就是百度中的链接,这是一种判断机制。你也可以对标题的构造方法这样做:
#coding:utf - 8
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.request import Request
import random
import re
def getContent(url,headers):
"""
此函数用于抓取返回403禁止访问的网页
"""
random_header = random.choice(headers)
"""
对于Request中的第二个参数headers,它是字典型参数,所以在传入时
也可以直接将个字典传入,字典中就是下面元组的键值对应
"""
# req =Request(url)
# req.add_header("User-Agent", random_header)
# req.add_header("GET",url)
# req.add_header("Host","blog.csdn.net")
# req.add_header("Referer","http://www.csdn.net/")
header = {"User-Agent": random_header, "GET": url, "Host": "blog.csdn.net", "Referer": "http://www.csdn.net/"}
req=Request(url,None,header)
content=urlopen(req).read().decode("utf-8")
return content
url="http://blog.csdn.net/beliefer/ ... ot%3B
#这里面的my_headers中的内容由于是个人主机的信息,所以我就用句号省略了一些,在使用时可以将自己主机的User-Agent放进去
my_headers = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/53。。。(KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"]
print(getContent(url,my_headers))
正如我们在上面的程序中所看到的,我们也可以直接构造头部,但这样做有一个缺陷,即头部的用户代理已经失效。事实上,我们可以发现,对于访问同一网页的不同计算机主机,我们的其他三个信息:get、host和referer可能是相同的,而此时,只有user-Agent被用来作为判断用户异同的标准,所以问题就来了"从我们周围的学生那里,如果使用一些用户代理,那么模拟多个用户的访问是否更好?事实上,这就是我刚刚开始编写代码的原因,因此有一个我的_头列表。事实上,可以在其中放置多个用户代理,然后通过随机函数随机选择一个进行组合,从而创建一个用户并实现多个-用户访问这种错觉其实很有用。你知道,对于网站,用户的IP访问太多时会被阻止。这并不有趣。因此,要长时间访问网站而不被阻止,还需要很多技能
当我们想要抓取多个网站的网页时,很容易被网站发现,因为一个主机经常访问,然后被阻止。如果我们在列表中放入更多不同的主机号并随机使用,就不容易被发现。当然,为了防止这种情况,更好的方法是使用IP代理,因为我们不知道它是e很容易获得大量主机信息,IP代理也很容易从互联网上搜索。我将在以后的博客中解释多次访问的相关问题,所以我在这里不多说 查看全部
网页访客qq抓取(如何获得我们getContent函数中的那些需要使用的headers参数)
urllib.error.HTTPError:HTTP错误403:禁止
从403禁止,我们可以发现程序访问被网站禁止,因为csdn网站已设置防爬虫机制。当检测到网站a爬虫时,访问将被拒绝,因此我们将得到上述结果
此时,我们需要模拟浏览器进行访问,以避免网站的反爬虫机制,顺利抓取我们想要的内容
接下来,我们将使用一个神奇的库urlib.request.request进行模拟工作。这一次,我们还将首先添加代码,然后对其进行解释。但是,这一次,我想提醒您,以下代码不能直接使用。我们需要在其中使用my\uHeader中的用户代理被它自己的替换。为了保密,我加了一个省略号,所以不能直接使用。更换方法见下图。这一次,为了方便起见,我们引入了以下功能:
#coding:utf - 8
from urllib.request import urlopen
from urllib.request import Request
import random
import re
def getContent(url,headers):
"""
此函数用于抓取返回403禁止访问的网页
"""
random_header = random.choice(headers)
"""
对于Request中的第二个参数headers,它是字典型参数,所以在传入时
也可以直接将个字典传入,字典中就是下面元组的键值对应
"""
req =Request(url)
req.add_header("User-Agent", random_header)
req.add_header("GET",url)
req.add_header("Host","blog.csdn.net")
req.add_header("Referer","http://www.csdn.net/";)
content=urlopen(req).read().decode("utf-8")
return content
url="http://blog.csdn.net/beliefer/ ... ot%3B
#这里面的my_headers中的内容由于是个人主机的信息,所以我就用句号省略了一些,在使用时可以将自己主机的
my_headers = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/53 。。。Chrome/54.0.2840.99 Safari/537.36"]
print(getContent(url,my_headers))
使用上述代码,我们通常可以捕获此页面的信息。让我们介绍一下如何获取需要在getcontent函数中使用的标题中的参数
由于我们想要模拟浏览器进行web访问,这些参数自然需要我们在浏览器中查找
首先,我们单击进入要爬网的页面,然后右键单击该页面,单击review元素,将出现以下框架。然后我们点击网络,我们会发现我们页面上的信息没有出现。没关系。此时,我们刷新页面,将显示下图所示的信息
此时,我们将在第一行看到51251757,这是我们网站后面的标签。此时,当我们单击此标签时,将显示下图所示的内容:
以下是我直接访问本网站的截图:
对于前两个数字,我曾经编写版本2的Visite,现在我直接使用它们。当时,我在CSDN主页上点击了这个博客,所以在代码和前两个图中,我的标题中的referer被填充
,我用URL链接直接将这张图片输入浏览器,这样我们就可以从图片中看到引用者,这是我们的网站。在这里,我们发布了一张不同的图片,让每个人都更好地理解这个参考。在这张图片中,我用红线标出了要填写的四个内容。当您进行测试时,您不能使用我提供的用户代理,因为我用省略号替换了一些,您应该使用自己的
在这个时候,我们将发现头球是否有明亮的感觉。是的,你的直觉是对的。我们需要的信息在标题中
然后根据代码中需要的参数将信息复制回来,因为这里显示的信息只对应键值,所以复制和使用非常方便
现在让我们介绍一下urllib.request.request的用法(翻译自官方文档):
类urllib。要求请求(URL,data=none,headers={},origin\u req\u host=none,unverifiable=false,method=none)参数:URL:不用说,这是我们将访问的网站。它是一根绳子。数据:数据必须是字节对象,它指定向服务器发送附加数据,如果不需要,则不发送。目前,只有HTTP请求使用数据;当提供数据参数时,HTTP请求应该是post而不是get。数据应以标准的application/x-www-form-urlencoded格式进行缓冲。urllib的参数。作语法分析函数是一个映射或二进制序列,并返回此格式的ascii字符串。当用作数据参数时,应将其编码为字节。头:头是字典数据,当调用add\when header()并具有键和值参数时,此头将作为请求处理。此标头通常用于阻止爬虫访问服务器。浏览器使用头来标识自身,因为某些HTTP服务器只允许来自普通浏览器的请求,而不允许来自脚本(可以理解为爬虫)
例如,Mozilla Firefox浏览器可以将自己识别为“Mozilla/5(X11;u;Linuxi686)Gecko/2008070208 Firefox 20071127/2.0.0.11模块的默认用户代理字符串为“Python urlib/2.6 “ (Python2.6),也就是说,当访问网页时,对于带有反爬虫机制的网站来说,您可以使用此用户代理字符串“Python urlib/”2.6 “ (Python@k266)检查我们是爬虫程序,然后拒绝我们的访问,这就是为什么我们需要用户代理进行更正。在这方面,应该综合考虑网站的反爬虫机制有多严格,因为监视爬虫程序越严格,需要检查的内容就越多,这不可避免地会增加网站)@服务器的处理负担,即网站必须在爬虫检测和网站服务器的计算负担之间进行权衡。因此,爬虫检测机制越严格越好。还应考虑服务器的负担。Origin_req_host:Origin_req_host应该是t的请求主机原创事务,由RFC2965定义。它默认为http.coo kiejar.request\u host(self)
这是由用户发起的原创请求的主机名或IP地址。例如,如果请求的图像是HTML文档中的图像,则这应该是收录该图像的页面请求的主机。(我们通常不使用此名称,只知道此处)Unverifiable:Unverifiable应指示请求是否无法验证。它由RFC 2965定义,默认值为false。Unverifiable请求表示无法提交用户的网址。例如,当用户在网页的HTML文档中找到图像,但用户没有重试权限时e来自服务器的映像不可验证。值应为true。方法:方法应为指示将使用HTTP请求方法的字符串(如“header”)。如果提供,其值将存储在方法属性中,并通过方法get_Method()调用.子类可以通过在类中设置method属性来指示默认方法。(这很少使用)说了这么多无聊的定义,我无法忍受翻译。让我们回到我们的程序:对于我们的程序,只需要掌握几个要点。首先,我们需要构造请求:req=request(URL)此时,请求为空。我们需要向请求中添加信息。此信息供浏览器查看
Req.add_header(“user agent”,random_header)告诉网页服务器我是通过浏览器访问的,而我不是爬虫。Req.add_header(“get”,URL)告诉浏览器我们访问的网址。Req.add_header(“host”),是网站的信息,我们只是从网站.Req.add_标题(“引用者”、“引用者”)这句话非常重要。它告诉网站服务器我们在哪里找到了我们想要访问的页面。例如,如果你点击百度中的一个链接跳转到你当前访问的页面,那么这个引用就是百度中的链接,这是一种判断机制。你也可以对标题的构造方法这样做:
#coding:utf - 8
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.request import Request
import random
import re
def getContent(url,headers):
"""
此函数用于抓取返回403禁止访问的网页
"""
random_header = random.choice(headers)
"""
对于Request中的第二个参数headers,它是字典型参数,所以在传入时
也可以直接将个字典传入,字典中就是下面元组的键值对应
"""
# req =Request(url)
# req.add_header("User-Agent", random_header)
# req.add_header("GET",url)
# req.add_header("Host","blog.csdn.net")
# req.add_header("Referer","http://www.csdn.net/";)
header = {"User-Agent": random_header, "GET": url, "Host": "blog.csdn.net", "Referer": "http://www.csdn.net/"}
req=Request(url,None,header)
content=urlopen(req).read().decode("utf-8")
return content
url="http://blog.csdn.net/beliefer/ ... ot%3B
#这里面的my_headers中的内容由于是个人主机的信息,所以我就用句号省略了一些,在使用时可以将自己主机的User-Agent放进去
my_headers = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/53。。。(KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"]
print(getContent(url,my_headers))
正如我们在上面的程序中所看到的,我们也可以直接构造头部,但这样做有一个缺陷,即头部的用户代理已经失效。事实上,我们可以发现,对于访问同一网页的不同计算机主机,我们的其他三个信息:get、host和referer可能是相同的,而此时,只有user-Agent被用来作为判断用户异同的标准,所以问题就来了"从我们周围的学生那里,如果使用一些用户代理,那么模拟多个用户的访问是否更好?事实上,这就是我刚刚开始编写代码的原因,因此有一个我的_头列表。事实上,可以在其中放置多个用户代理,然后通过随机函数随机选择一个进行组合,从而创建一个用户并实现多个-用户访问这种错觉其实很有用。你知道,对于网站,用户的IP访问太多时会被阻止。这并不有趣。因此,要长时间访问网站而不被阻止,还需要很多技能
当我们想要抓取多个网站的网页时,很容易被网站发现,因为一个主机经常访问,然后被阻止。如果我们在列表中放入更多不同的主机号并随机使用,就不容易被发现。当然,为了防止这种情况,更好的方法是使用IP代理,因为我们不知道它是e很容易获得大量主机信息,IP代理也很容易从互联网上搜索。我将在以后的博客中解释多次访问的相关问题,所以我在这里不多说
网页访客qq抓取(如何在当前网页里执行你想要的执行代码:通过浏览器抓包 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 560 次浏览 • 2021-09-12 09:07
)
在阅读本文之前,请参阅:Crazy Asylum:如何在当前网页中执行您要执行的代码。第一步,找出QQ访客界面:通过浏览器抓包:我们可以得到这个界面
在阅读本文之前,请阅读:
疯人院:如何在当前网页中执行你想执行的代码
第一步,找出QQ访客界面:
通过浏览器捕获数据包:
如何使用谷歌浏览器抓包:
我们可以得到这个接口
https://user.qzone.qq.com/prox ... %3DQQ号&mask=2&mod=2&fupdate=1&g_tk=121307362&qzonetoken=694e991fd4ee1f360edf1c18c63b2bd6fbb61be931b1a34b3c5b8ac5d27c372537f12f625db554f3&g_tk=121307362
关键参数为uin、g_tk、qzonetoken
第二步,找到上面三个参数值的来源
uin:您可以在 cookie 中获取它。
g_tk:QZONE.FP.getACSRFToken()
qzonetoken:在网页的源代码中。
window.g_qzonetoken = (function(){ try{return "694e991fd4ee1f360edf1c18c63b2bd6fbb61be931b1a34b3c5b8ac5d27c372537f12";} catch(e) {var xhr = new XMLHttpRequest();xhr.withCredentials = true;xhr.open('post', '//h5.qzone.qq.com/log/post/error/qzonetoken', true);xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');xhr.send(e);}})();
里面有这么一段
。我们只需要使用window.g_qzonetoken即可获取
第四步,让我们愉快的写程序。
首先我们尝试先在控制台写代码
最后整理成javascript:
var uinArray = /uin=o0*(\S+);/.exec(document.cookie || '');
var uin = uinArray[1];
var g_tk = QZONE.FP.getACSRFToken();
var qzone_token = window.g_qzonetoken;
var url = 'https://user.qzone.qq.com/prox ... en%3B
url 是获取数据的 URL。
最终代码:
包括回调方法和数据
<p>function _Callback(json){
var items = json.data.items;
var nicks = '';
for(var i=0;i 查看全部
网页访客qq抓取(如何在当前网页里执行你想要的执行代码:通过浏览器抓包
)
在阅读本文之前,请参阅:Crazy Asylum:如何在当前网页中执行您要执行的代码。第一步,找出QQ访客界面:通过浏览器抓包:我们可以得到这个界面
在阅读本文之前,请阅读:
疯人院:如何在当前网页中执行你想执行的代码
第一步,找出QQ访客界面:
通过浏览器捕获数据包:
如何使用谷歌浏览器抓包:
我们可以得到这个接口
https://user.qzone.qq.com/prox ... %3DQQ号&mask=2&mod=2&fupdate=1&g_tk=121307362&qzonetoken=694e991fd4ee1f360edf1c18c63b2bd6fbb61be931b1a34b3c5b8ac5d27c372537f12f625db554f3&g_tk=121307362
关键参数为uin、g_tk、qzonetoken
第二步,找到上面三个参数值的来源
uin:您可以在 cookie 中获取它。
g_tk:QZONE.FP.getACSRFToken()
qzonetoken:在网页的源代码中。
window.g_qzonetoken = (function(){ try{return "694e991fd4ee1f360edf1c18c63b2bd6fbb61be931b1a34b3c5b8ac5d27c372537f12";} catch(e) {var xhr = new XMLHttpRequest();xhr.withCredentials = true;xhr.open('post', '//h5.qzone.qq.com/log/post/error/qzonetoken', true);xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');xhr.send(e);}})();
里面有这么一段
。我们只需要使用window.g_qzonetoken即可获取
第四步,让我们愉快的写程序。
首先我们尝试先在控制台写代码
最后整理成javascript:
var uinArray = /uin=o0*(\S+);/.exec(document.cookie || '');
var uin = uinArray[1];
var g_tk = QZONE.FP.getACSRFToken();
var qzone_token = window.g_qzonetoken;
var url = 'https://user.qzone.qq.com/prox ... en%3B
url 是获取数据的 URL。
最终代码:
包括回调方法和数据
<p>function _Callback(json){
var items = json.data.items;
var nicks = '';
for(var i=0;i

