技巧:初学指南| 用Python进行网页抓取
优采云 发布时间: 2022-09-21 14:12技巧:初学指南| 用Python进行网页抓取
关于转载授权
大数据抽象作品,欢迎个人转发朋友圈。 自媒体,媒体和机构转载需申请授权,并在后台留言“机构名称+转载”。可以,但是大数据摘要二维码必须放在文末。
编译|丁学黄年程序笔记|奚雄芬校对|姚嘉玲
简介
从网页中提取信息的需求和重要性呈指数级增长。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。这是一个问题或产品,其有效性更多地取决于网络抓取和信息提取(数据集)技术,而不是我们过去使用的数据聚合技术。
如何从网页中提取信息
有几种方法可以从网页中提取信息。使用 API 可能被认为是从 网站 中提取信息的最佳方式。几乎所有大型 网站 像 Twitter、Facebook、Google、Twitter、StackOverflow 都提供 API 以更结构化的方式访问这些 网站 数据。如果可以直接通过 API 获取所需信息,这种方法几乎总是比网络抓取更好。因为如果可以从数据提供者那里获取结构化数据,为什么还要构建自己的引擎来提取相同的数据?
很遗憾,并不是所有的网站都提供API。有的网站不愿意让读者以结构化的方式捕捉大量信息,而有的网站由于缺乏相关的技术知识而无法提供API。在这样的情况下,应该怎么办?那么,我们需要通过网络抓取来获取数据。
当然还有其他方式,比如 RSS 提要等,但由于使用限制,我不会在这里讨论。
什么是网页抓取?
网页抓取是一种用于从 网站 获取信息的计算机软件技术。该技术主要侧重于将网络上的非结构化数据(HTML格式)转化为结构化数据(数据库或电子表格)。
网络抓取可以通过不同的方式实现,从 Google Docs 到几乎任何编程语言。我会选择使用 Python,因为它的易用性和丰富的生态系统。 Python 中的 BeautifulSoup 库可以协助完成这项任务。在本文中,我将向您展示使用 Python 编程语言学习网络抓取的最简单方法。
对于需要以非编程方式从网页中提取数据的读者,请访问 import.io。有基于GUI的驱动来运行网页抓取的基本操作,电脑爱好者可以继续阅读这篇文章!
网页抓取所需的库
我们都知道 Python 是一种开源编程语言。您也许可以找到许多库来实现一个功能。因此,找出最好的库是非常有必要的。我倾向于使用 BeautifulSoup(一个 Python 库),因为它易于使用且直观。准确地说,我使用了两个 Python 模块来抓取数据:
•Urllib2:它是一个用于获取 URL 的 Python 模块。它定义了实现 URL 操作(基本、摘要式身份验证、重定向、cookie 等)的函数和类。有关详细信息,请参阅文档页面。
•BeautifulSoup:它是从网页中提取信息的绝佳工具。您可以使用它从网页中提取表格、列表、段落,还可以添加过滤器。在本文中,我们将使用最新版本 BeautifulSoup 4。安装说明可以在其文档页面上找到。
BeautifulSoup 不能帮助我们获取网页,这就是我使用 urllib2 和 BeautifulSoup 库的原因。除了 BeautifulSoup,Python 还有其他抓取 HTML 的方法。例如:
•机械化
•刮痕
•scrapy
基本 - 熟悉 HTML(标签)
在进行网页抓取时,我们需要处理 html 标签。因此,我们首先要搞清楚标签。如果您已经了解 HTML 的基础知识,则可以跳过本节。以下是 HTML 的基本语法:
该语法的各种标签解释如下:
1.:html 文档必须以类型声明开头
2.html文档写在和标签之间
3.html文档的可见部分写在和标签之间
4.html header 用于标记定义
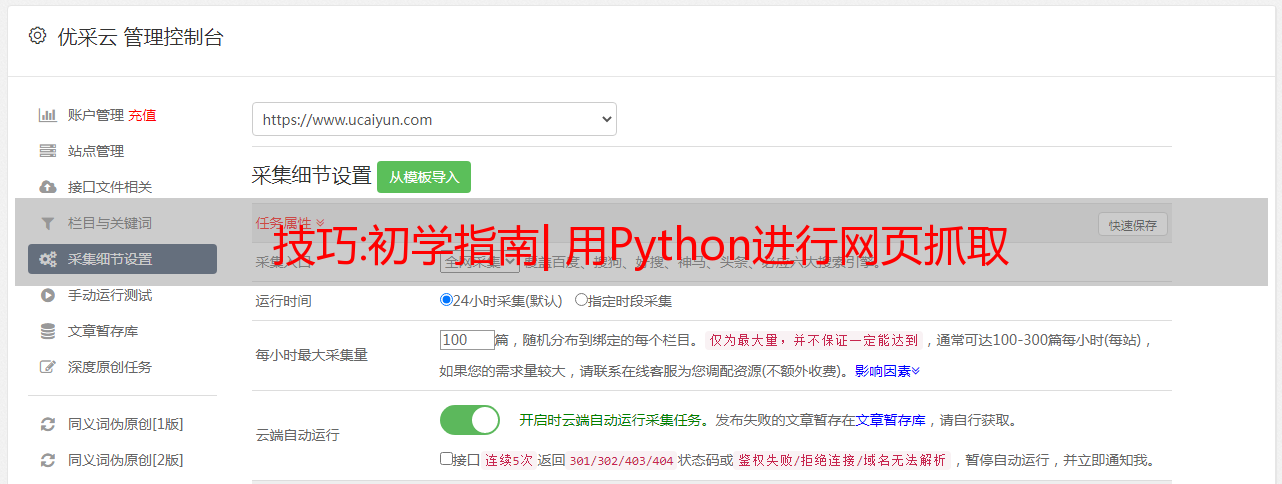
5.html段落用法
标签定义
其他有用的 HTML 标签有:
1.html 链接是使用标签定义的,“This is a test ”
2.html表格用定义,行用来表示,行分数据
3.html列表以(无序)和(有序)开头,列表中的每个元素都以
如果您不熟悉这些 HTML 标签,我建议您在 W3schools 学习 HTML 教程。这将使您对 HTML 标记有一个清晰的了解。
使用 BeautifulSoup 抓取网页
在这里,我将从 Wikipedia 页面中抓取数据。我们的最终目标是获取印度各州、联邦首都以及一些基本细节的列表,例如创建信息、前首都以及构成此 Wikipedia 页面的其他信息。让我们一步步做这个项目来学习:
1.导入必要的库
2.使用“美化”功能查看HTML页面的嵌套结构
如上图,可以看到HTML标签的结构。这将帮助您了解可用的不同标签以及如何使用它们来抓取信息。
3.处理 HTML 标签
a.soup.:返回开始和结束标签之间的内容,包括标签。
b.soup..string:返回给定标签内的字符串
c。在标签中查找链接:我们知道我们可以用标签来标记链接。因此,我们应该利用soup.a 选项,它应该返回网页中可用的链接。让我们去做吧。
如上图,可以看到只有一个结果。现在,我们将使用“find_all()”来抓取所有的链接。
上面显示了所有链接,包括标题、链接和其他信息。现在,为了只显示链接,我们需要使用get的“href”属性:遍历每个标签,然后返回链接。
4.找表:当我们在找表来抓取州首府信息时,首先要找到合适的表。让我们编写指令来获取所有表格标签中的信息。
现在为了找出正确的表,我们将使用表的属性“类”,并用它来过滤出正确的表。在chrome浏览器中,可以通过右键单击所需的web表->检查元素->复制类名来查询其类名,或者通过上述命令的输出找到正确表的类名。
5.将信息提取到DataFrame中:在这里,我们遍历每一行(tr),然后将tr(td)的每个元素分配给一个变量,将其添加到一个列表中。我们先看一下表格的html结构(我不想抓取表格头信息)
如上所示,您会注意到第二个元素在 标签内,而不是在标签内。所以我们需要注意这一点。现在要访问每个元素的值,我们将为每个元素使用“find(text=True)”选项。我们来看代码:
最后我们dataframe中的数据如下:
同样,BeautifulSoup 可以执行各种其他类型的网页抓取。这将简化从网页手动采集数据的工作。另请参阅其他属性,例如 .parent、.contents、.descendants 和 .next_sibling、.prev_sibling 以及标签名称浏览的各种属性。这些将帮助您有效地抓取网络。
但为什么我不能只使用正则表达式?
现在,如果您知道一个正则表达式,您可能会认为您可以使用它来编写代码来做同样的事情。当然,我也遇到过这个问题。我使用 BeautifulSoup 和正则表达式来做同样的事情,发现:
BeautifulSoup 中的代码比正则表达式更强大。使用正则表达式编写的代码必须随着页面的变化而变化。虽然 BeautifulSoup 在某些情况下需要调整,但相对来说,BeautifulSoup 更好。
正则表达式比 BeautifulSoup 快得多,在相同结果下比 BeautifulSoup 快 100 倍。
所以它归结为代码的速度和健壮性之间的比较,这里没有一刀切的赢家。如果您要查找的信息可以通过简单的正则表达式语句获取,那么您应该选择使用它们。对于几乎所有复杂的工作,我通常比正则表达式更推荐 BeautifulSoup。
结论
在本文中,我们使用了两个 Python 库,BeautifulSoup 和 urllib2。我们还学习了 HTML 的基础知识,并通过解决一个问题逐步实现了网页抓取。我建议您练习并使用它从网页中采集数据。
译者简介 丁雪华,华中师范大学信息科学硕士,从事用户行为与个性化服务研究。关注大数据的发展,希望从事互联网和咨询行业的相关工作。黄念是上海长海医院的硕士生。他对生物医学大数据的挖掘及其应用非常感兴趣。他愿意通过这个平台结识更多的朋友。奚雄芬,北京邮电大学无线信号处理专业在读*敏*感*词*。主要研究图信号处理,对基于社交网络的图数据挖掘感兴趣。他希望通过这个平台结识更多从事大数据的人,结交更多志同道合的人。 家庭主妇姚嘉玲对数据分析处理非常感兴趣。她正在努力学习,希望能和你多交流。
【限时干货下载】
2015/11/30 之前
2015年10月干货文件打包下载,请点击大数据文摘底部菜单:下载等--10月下载
精彩的大数据文摘文章:
回复【财经】见【财经】专栏历史期刊文章
回复【可视化】感受科技与艺术的完美结合
回复【安全】关于泄密、黑客、攻防的新鲜案例
回复【算法】既博学又有趣的人和事
回复 [Google] 了解其在大数据领域的举措
回复【院士】看看有多少院士谈大数据
回复【隐私】看看大数据时代有多少隐私
回复【医学】查看文章医学领域6篇文章
Google 优化怎么做 - 谷歌搜索引擎优化初学者指南- 外贸先生
欢迎来到谷歌搜索引擎优化初学者指南。
很多外贸人都想做好Google SEO(谷歌搜索引擎优化),很多人对Google SEO到底怎么做的很感兴趣,接下里,我们会把《谷歌官方的谷歌搜索引擎优化初学者指南》,以文字的方式给大家做陈述。
初学者指南起初只是在谷歌内部使用 , 但是我们考虑到 , 也许它对那些刚刚接触搜索引擎优化、 并且希望提高网站与用户和搜索引擎交互性的网站站长们也一样会有帮助 , 所以我们对其进行进一步整理完善 , 发表出来供大家参考。 尽管这个指南不会告诉您怎样做才能使自己的网站排在谷歌搜索结果的第一位 , 但是遵循下文介绍的 一些推荐做法会使搜索引擎更容易抓取和索引您网站的内容。
搜索引擎优化(也就是Google SEO )通常是指对您网站的某些部分做一些小的改进。如果个别来看 , 这些改进的效果可能并不那么明显。 但是当和其他的优化结合起来看时 , 它们将对您网站的用户体验以及在搜索结果中的表现有显著的影响。您可能对此指南中的相当一部分话题已 经比较熟悉了 , 因为它们都是构成网页的基本元素 , 但是您可能并没有非常充分地利用这些基本元素。
从这里开始,外贸先生会从各个方面来介绍搜索引擎优化(SEO)!我们会从以下六个方面来做介绍。为了更好的把每个点完整的表达,我们把每个点都单独做成了独立的内容,点击相应链接,即可了解具体内容。
1.搜索引擎优化基础
1.1 创建独特、 准确的页面标题
1.2 更好地使用描述元标签
2.优化网站结构
2.1 优化 URL 的结构
2.2 让您的网站更易于检索和浏览
3.优化内容
3.1 提供高质量的内容和服务
3.2 写好链接锚文本
3.3 优化图片的使用
3.4 正确使用 heading 标签
4.处理页面的抓取
4.1更加有效地使用 robots.txt 文件
4.2谨慎使用 rel=“nofollow”
5.移动网站的搜索引擎优化
5.1 将移动网站告知 Google
5.2 正确引导手机用户
6.网站的推广和分析
6.1 用正确的手段推广您的网站
6.2 充分利用免费的网站站长工具
把这6条全部了解,您就对Google SEO有个入门级的了解了。
当然,尽管这个指南的标题含有 “ 搜索引擎 ” 这个词 , 但是我们想说的是 您应该将您优化的重心和出发点主要放在用户体验上 , 因为用户才是您网站内容的主要受众 , 是他们通过搜索引擎找到了您的网站。 过度专注于用特定的技巧获取搜索引擎自然搜索结果的排名不一 定能够达到您想要的结果。 通俗地讲 , 搜索引擎优化就是让您的网站以最理想的姿态出现在搜索引擎的结果中 , 但是您的最终的服务对象是您的用户而不是搜索引擎。
Google 的建议推崇白帽SEO,关于白帽SEO,点击访问:为什么外贸先生坚持白帽SEO ?
您的网站可能比我们作为例子的网站大也可能比它小 , 网站的内容 也可能有很大不同 , 但是我们下面讨论的优化主题将适用于所有不同大小和类型的网站。 我们希望我们的指南能够给您在如何改进 您的网站方面提供一些启发。
●Google SEO服务内容
●Google SEO相关问题

