
网页视频抓取软件 格式工厂
网页视频抓取软件 格式工厂(网站优化排名6大技巧,你知道几个?? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-04-12 04:38
)
网站优化排名的6个技巧
1、选择关键词:使用工具关键词planner来挖矿关键词;挖掘后,分析关键词的准确率、竞争力和搜索量。主要分析关键词的转化率和优化难度;后来确定关键词,首页大概5个字,栏目页关键词大概3个字。
2、设置关键词:在每个网页上设置确定的关键词。
首页和栏目页必须设置为关键词,首页为**关键词,栏目页为关键词与栏目内容相关。不要超过 80 个字符。
3、现场优化:URL结构优化:影响页面是否可以收录;影响页面排名关键词
站内链接结构:影响网站内部网页收录的搜索引擎效率,搜索引擎蜘蛛从一个网页链接到下一个网页。
制作网站的地图:xml格式,站点地图协议文件;html 格式,列出 网站 中的所有网页链接。提高搜索引擎对网站内容的抓取效率,网站的所有页面都存在网站地图链接。部分网站程序自带地图生成功能,如果没有,也可以使用第三方地图制作软件。
404错误页面是当用户输入错误的URL,无法找到页面时,可以根据404返回网站。
301重定向,即URL重定向。网站更换新域名时,通过301重定向将旧域名重定向到新域名,使旧域名的权重逐渐转移到新域名;网站通过将多个域名重定向到同一个域名,优化外包公司,实现权重集中在域名上。
robots.txt:存放在空间的根目录下,主要是告诉搜索引擎蜘蛛网站里面哪些内容可以抓取,哪些内容不能抓取。如果没有该文件,则说明网站的内容可以被爬取。常用函数有:User-agent蜘蛛名称,*表示所有蜘蛛;Disallow不允许抓取网页路径,省略域名,/表示根目录。添加 / 表示 网站 都不允许被捕获。
4、网站内容优化:跟上新内容,网站关键词优化公司,增加网站收录的数量;增加长尾关键词排名。
5、站外优化:友情链接、第三方平台。
6、站群seo:覆盖搜索引擎结果,使用第三方网站或自建多个网站。
强大的营销能力,覆盖多个平台
众所周知,网站在百度搜索中的排名位置越好,而影响排名的互联网系统的一个重要方面就是链接。不同类型的链接有不同的用途,但它们都有助于网站在搜索引擎中排名**。在科学家的共同努力下,犀牛云·网文战车通过6大人工智能机器人帮助用户定期发布文章内容,增强企业网站*照片的稳定性。
同时,英格拉姆是百度信息流、360信息流、搜狗信息流、微信广点通的广告合作伙伴,英格拉姆集团自身每年在这些平台上投入的广告费超过3000万,拥有较为丰富的第三-派对广告体验和资源渠道。Netwin Chariot通过结合AI算法机器人将这些经验和资源整合到产品中,帮助企业智能分析合适的投放渠道,为企业规划投放模式和内容,添加内链和外链,帮助企业在搜索引擎,免费广告联盟等平台带来精准流量,优化推广覆盖PC搜索、手机搜索、微信社区、QQ社区、微博社区等多个平台,
一、产品页面优化。同类型的产品很多,尤其是同一个产品,基本只是在几个参数上不同,所以在编辑内容的时候,会有很高的重复率和样板文字。这样的页面质量非常低,不利于收录,所以我们在编辑产品页面时可以根据不同的型号和代码来区分相似的产品。在内容编辑的过程中,关键词优化外包公司应该识别每个产品的特殊性,并将其与其他产品区分开来。这将使您能够区分相似的产品,这对 收录 更有利。当然,让'
二、案例页面优化。案例一般是用户购买产品后的反馈。我们可以将这些内容整理成文章,用图片说明,使用前后对比产品,展示产品的优势,从而促进用户转化。
三、问答页面优化。问答页面作为流量入口,是主要解决用户问题、满足用户需求的地方。因此,该栏目的内容必须有所区别。安徽网站优化公司,我没有人,人人有我优秀,提升页面附加值。请记住,这里的内容是关于最近的用户问题或关于产品的问题。不要填写公司内部新闻或行业咨询,只会让用户感到厌烦。
安徽卧龙网站宣传片(图)-网站关键词优化公司-安徽网站优化公司由提供。安徽卧龙网站促销(图)-网站关键词优化公司-安徽网站优化公司是今年推出的全新升级。以上图片仅供参考,您可以拨打本页或图片中的联系电话获取联系人:万少波。同时本公司()还从事合肥网络推广,合肥网络公司,安徽网络推广厂家,欢迎来电咨询。
查看全部
网页视频抓取软件 格式工厂(网站优化排名6大技巧,你知道几个??
)
网站优化排名的6个技巧
1、选择关键词:使用工具关键词planner来挖矿关键词;挖掘后,分析关键词的准确率、竞争力和搜索量。主要分析关键词的转化率和优化难度;后来确定关键词,首页大概5个字,栏目页关键词大概3个字。
2、设置关键词:在每个网页上设置确定的关键词。
首页和栏目页必须设置为关键词,首页为**关键词,栏目页为关键词与栏目内容相关。不要超过 80 个字符。
3、现场优化:URL结构优化:影响页面是否可以收录;影响页面排名关键词
站内链接结构:影响网站内部网页收录的搜索引擎效率,搜索引擎蜘蛛从一个网页链接到下一个网页。
制作网站的地图:xml格式,站点地图协议文件;html 格式,列出 网站 中的所有网页链接。提高搜索引擎对网站内容的抓取效率,网站的所有页面都存在网站地图链接。部分网站程序自带地图生成功能,如果没有,也可以使用第三方地图制作软件。
404错误页面是当用户输入错误的URL,无法找到页面时,可以根据404返回网站。
301重定向,即URL重定向。网站更换新域名时,通过301重定向将旧域名重定向到新域名,使旧域名的权重逐渐转移到新域名;网站通过将多个域名重定向到同一个域名,优化外包公司,实现权重集中在域名上。
robots.txt:存放在空间的根目录下,主要是告诉搜索引擎蜘蛛网站里面哪些内容可以抓取,哪些内容不能抓取。如果没有该文件,则说明网站的内容可以被爬取。常用函数有:User-agent蜘蛛名称,*表示所有蜘蛛;Disallow不允许抓取网页路径,省略域名,/表示根目录。添加 / 表示 网站 都不允许被捕获。
4、网站内容优化:跟上新内容,网站关键词优化公司,增加网站收录的数量;增加长尾关键词排名。
5、站外优化:友情链接、第三方平台。
6、站群seo:覆盖搜索引擎结果,使用第三方网站或自建多个网站。






强大的营销能力,覆盖多个平台
众所周知,网站在百度搜索中的排名位置越好,而影响排名的互联网系统的一个重要方面就是链接。不同类型的链接有不同的用途,但它们都有助于网站在搜索引擎中排名**。在科学家的共同努力下,犀牛云·网文战车通过6大人工智能机器人帮助用户定期发布文章内容,增强企业网站*照片的稳定性。
同时,英格拉姆是百度信息流、360信息流、搜狗信息流、微信广点通的广告合作伙伴,英格拉姆集团自身每年在这些平台上投入的广告费超过3000万,拥有较为丰富的第三-派对广告体验和资源渠道。Netwin Chariot通过结合AI算法机器人将这些经验和资源整合到产品中,帮助企业智能分析合适的投放渠道,为企业规划投放模式和内容,添加内链和外链,帮助企业在搜索引擎,免费广告联盟等平台带来精准流量,优化推广覆盖PC搜索、手机搜索、微信社区、QQ社区、微博社区等多个平台,



一、产品页面优化。同类型的产品很多,尤其是同一个产品,基本只是在几个参数上不同,所以在编辑内容的时候,会有很高的重复率和样板文字。这样的页面质量非常低,不利于收录,所以我们在编辑产品页面时可以根据不同的型号和代码来区分相似的产品。在内容编辑的过程中,关键词优化外包公司应该识别每个产品的特殊性,并将其与其他产品区分开来。这将使您能够区分相似的产品,这对 收录 更有利。当然,让'
二、案例页面优化。案例一般是用户购买产品后的反馈。我们可以将这些内容整理成文章,用图片说明,使用前后对比产品,展示产品的优势,从而促进用户转化。
三、问答页面优化。问答页面作为流量入口,是主要解决用户问题、满足用户需求的地方。因此,该栏目的内容必须有所区别。安徽网站优化公司,我没有人,人人有我优秀,提升页面附加值。请记住,这里的内容是关于最近的用户问题或关于产品的问题。不要填写公司内部新闻或行业咨询,只会让用户感到厌烦。

安徽卧龙网站宣传片(图)-网站关键词优化公司-安徽网站优化公司由提供。安徽卧龙网站促销(图)-网站关键词优化公司-安徽网站优化公司是今年推出的全新升级。以上图片仅供参考,您可以拨打本页或图片中的联系电话获取联系人:万少波。同时本公司()还从事合肥网络推广,合肥网络公司,安徽网络推广厂家,欢迎来电咨询。

网页视频抓取软件 格式工厂(格式工厂电脑版特色的视频文件转到MP4/3/)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-12 04:36
格式工厂PC版是一款免费的多功能多媒体处理工具,可以帮助您转换各种格式的文件,包括qsv\mkc\kux\qlv等多种文件格式。格式工厂PC版还提供了非常方便的批处理功能,界面非常简洁,使操作更简单。如果你喜欢它,请下载并尝试一下!
格式工厂 PC 功能
格式工厂支持将各种类型的视频文件转为 MP4/3GP/MPG/AVI/WMV/FLV/SWF。
支持所有类型的音频转换为 MP3/WMA/AMR/OGG/AAC/WAV。
格式工厂支持将所有类型的图像转换为 JPG/BMP/PNG/TIF/ICO/GIF/TGA。
可以将DVD翻录成视频文件,将音乐CD翻录成音频文件。
MP4 文件支持指定格式,例如 iPod/iPhone/PSP。
格式工厂支持RMVB、水印、音视频混合。
格式工厂 PC 功能
1、支持多种格式
格式工厂支持的视频格式非常广泛,从普通格式到iPhone/iPod/PSP等多媒体指定格式,几乎所有类型的多媒体格式都囊括在内;
2、修复函数
在转换过程中,格式工厂可以修复一些意外损坏的视频文件;
3、弹性提升
格式工厂允许多媒体文件灵活地“减肥”或“长大”(即提高或降低视频清晰度、帧率等);
4、图像转换
格式工厂可以转换图片,支持图片文件缩放、旋转、水印等功能;
5、DVD 翻录
格式工厂可以采集视频,用户可以通过此功能轻松将DVD备份到本地硬盘;
格式工厂 PC 质量保证
格式工厂软件转换 MP4 方法
1、首先,您在本站下载并安装格式工厂软件后,您可以在桌面上找到该软件的快捷方式。鼠标左键双击快捷方式打开软件,进入主界面。界面上有不同类型的转换格式。点击要转换的格式,进入详细转换界面。
2、编辑器以转换为MP4格式为例,点击上图中的MP4选项,然后进入转换界面,可以先点击添加文件或添加文件夹选项添加需要的文件转换成软件。添加后点击输出配置选项,设置文件类型、大小、质量等选项。设置完成后,需要点击界面下方的更改,选择合适的输出位置。设置完成后,我们可以点击界面上方的确定。选项,然后您可以耐心等待处理完成,然后您可以在设置的保存位置找到所需的文件。
格式工厂 PC 评论
操作简单,功能全面,使用非常方便! 查看全部
网页视频抓取软件 格式工厂(格式工厂电脑版特色的视频文件转到MP4/3/)
格式工厂PC版是一款免费的多功能多媒体处理工具,可以帮助您转换各种格式的文件,包括qsv\mkc\kux\qlv等多种文件格式。格式工厂PC版还提供了非常方便的批处理功能,界面非常简洁,使操作更简单。如果你喜欢它,请下载并尝试一下!
格式工厂 PC 功能
格式工厂支持将各种类型的视频文件转为 MP4/3GP/MPG/AVI/WMV/FLV/SWF。
支持所有类型的音频转换为 MP3/WMA/AMR/OGG/AAC/WAV。
格式工厂支持将所有类型的图像转换为 JPG/BMP/PNG/TIF/ICO/GIF/TGA。
可以将DVD翻录成视频文件,将音乐CD翻录成音频文件。
MP4 文件支持指定格式,例如 iPod/iPhone/PSP。
格式工厂支持RMVB、水印、音视频混合。
格式工厂 PC 功能
1、支持多种格式
格式工厂支持的视频格式非常广泛,从普通格式到iPhone/iPod/PSP等多媒体指定格式,几乎所有类型的多媒体格式都囊括在内;
2、修复函数
在转换过程中,格式工厂可以修复一些意外损坏的视频文件;
3、弹性提升
格式工厂允许多媒体文件灵活地“减肥”或“长大”(即提高或降低视频清晰度、帧率等);
4、图像转换
格式工厂可以转换图片,支持图片文件缩放、旋转、水印等功能;
5、DVD 翻录
格式工厂可以采集视频,用户可以通过此功能轻松将DVD备份到本地硬盘;
格式工厂 PC 质量保证
格式工厂软件转换 MP4 方法
1、首先,您在本站下载并安装格式工厂软件后,您可以在桌面上找到该软件的快捷方式。鼠标左键双击快捷方式打开软件,进入主界面。界面上有不同类型的转换格式。点击要转换的格式,进入详细转换界面。
2、编辑器以转换为MP4格式为例,点击上图中的MP4选项,然后进入转换界面,可以先点击添加文件或添加文件夹选项添加需要的文件转换成软件。添加后点击输出配置选项,设置文件类型、大小、质量等选项。设置完成后,需要点击界面下方的更改,选择合适的输出位置。设置完成后,我们可以点击界面上方的确定。选项,然后您可以耐心等待处理完成,然后您可以在设置的保存位置找到所需的文件。
格式工厂 PC 评论
操作简单,功能全面,使用非常方便!
网页视频抓取软件 格式工厂(格式工厂最新pc版特色版说明书下载地址下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-08 16:26
Format Factory PC版是一款非常好用的视频格式转换软件。用户可以在这里进行很多操作,帮助您轻松完成视频编辑、合成等操作。还是很不错的,可以轻松体验。格式工厂最新PC版的界面风格相当精致细腻。它似乎有不同的视觉效果。可以自由应用,相当不错。.
格式工厂最新 PC 版本的功能
1、多种功能集于一身,视频剪辑、合成等各种功能都可以在其中进行。是一款非常适合新手编辑的转换软件。
2、软件运行速度快,支持各类视频、音频、图片等格式,轻松转换成你想要的格式。
3、随心所欲地应用经验。在转换过程中,您可以修复损坏的文件,使转换质量不受损。
格式工厂最新PC版亮点
1、简单的操作是一个优势,它可以帮助你的文件“减肥”,让他们“瘦身”。两者都节省硬盘空间。
2、软件界面简洁,图片转换支持缩放、旋转、水印等常用功能,操作一气呵成。
3、这很有趣。它支持62种国家语言,易于访问,满足各种需求。
格式工厂最新pc版本说明
1、功能非常齐全,软件纯绿色,DVD视频采集功能,方便将DVD备份到本地硬盘。
2、体积小,占用空间小,性能强,支持iphone/ipod/psp等多媒体指定格式,你想要的,这里都有。
格式工厂最新PC版回顾
很好用,可以轻松体验,不受限制。 查看全部
网页视频抓取软件 格式工厂(格式工厂最新pc版特色版说明书下载地址下载)
Format Factory PC版是一款非常好用的视频格式转换软件。用户可以在这里进行很多操作,帮助您轻松完成视频编辑、合成等操作。还是很不错的,可以轻松体验。格式工厂最新PC版的界面风格相当精致细腻。它似乎有不同的视觉效果。可以自由应用,相当不错。.
格式工厂最新 PC 版本的功能
1、多种功能集于一身,视频剪辑、合成等各种功能都可以在其中进行。是一款非常适合新手编辑的转换软件。
2、软件运行速度快,支持各类视频、音频、图片等格式,轻松转换成你想要的格式。
3、随心所欲地应用经验。在转换过程中,您可以修复损坏的文件,使转换质量不受损。
格式工厂最新PC版亮点
1、简单的操作是一个优势,它可以帮助你的文件“减肥”,让他们“瘦身”。两者都节省硬盘空间。
2、软件界面简洁,图片转换支持缩放、旋转、水印等常用功能,操作一气呵成。
3、这很有趣。它支持62种国家语言,易于访问,满足各种需求。
格式工厂最新pc版本说明
1、功能非常齐全,软件纯绿色,DVD视频采集功能,方便将DVD备份到本地硬盘。
2、体积小,占用空间小,性能强,支持iphone/ipod/psp等多媒体指定格式,你想要的,这里都有。
格式工厂最新PC版回顾
很好用,可以轻松体验,不受限制。
网页视频抓取软件 格式工厂(网络爬虫21世纪数据的价值所在!(附案例) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-04-04 10:00
)
简介:随着大数据技术、分布式存储和分布式计算的发展,数据的价值不断被挖掘,特别是针对海量网络数据,爬取网站数据内容,分析数据背后隐藏的价值,人工智能的背后是需要海量数据支撑,这就是21世纪数据的价值!
1、网络爬虫的基本流程:
1.1、发起请求:客户端通过HTTP库向目标站点发起请求,等待服务器响应。
1.2、获取响应内容:服务器响应Response的内容为页面内容,类型有HTML、Json、二进制等。
1.3、解析内容:可以用正则表达式和网页解析库来解析HTML。json可以直接转化为json对象解析。二进制数据,可以进一步保存或处理。
1.4、保存数据:结构化存储,可以保存为文本、保存到数据库或保存为特定格式的文件。
2、请求和响应:
2.1、请求:
1)Request方法:主要有GET和POST两种,还有HEAD、PUT、DELETE、OPTIONS等。 2)Request URL:URL是Uniform Resource Locator,可用的URLs比如网页、图片、视频都是唯一确定的。
3)Request header:收录请求过程中的header信息,如User-Agent、Host、Cookies等信息。
4)请求体:请求中携带的附加数据,如表单提交时的表单数据。
2.2、回应:
1)响应状态:响应状态,如200表示成功,301表示跳转,404表示页面未找到,502服务器错误。
2)响应头:如内容类型、内容长度、服务器信息、设置cookies等。
3)响应体:最重要的部分,包括请求的资源内容,如HTML、图片和视频、二进制数据等。
3、爬虫可以抓取的数据:
3.1、网页文本:HTML文档、Json格式文本等。
3.2、Image:得到的二进制文件以图像格式保存。
3.3、视频:也是二进制文件,可以保存为视频格式。
3.4、其他:只要能请求数据,就能获取信息。
4、分析方法:
4.1、直接处理:适用于简单的网页。
4.2、Json解析:适用于Json字符串的网页。
4.3、正则表达式:适用于HTML解析。
4.4、库分析:BeautifulSoup库、PyQuery库、XPath库等。
5、请求的结果和浏览器看到的不一样:
5.1、原因:浏览器渲染。JavaScript 与后台的交互数据。
5.2、如何解决JavaScript渲染问题:分析Ajax请求(Json字符串)。Selenium/WebDriver 解决方案(pip 可以安装)。Splash 解决方案(安装可在 GitHub 中搜索)。PyV8、Ghost.py。
6、如何保存数据:
6.1、文本:纯文本、Json、Xml等。
6.2、关系型数据库:如MySQL、Oracle、SQLServer等,以结构化表的结构化形式存储。
6.3、非关系型数据库:如MongoDB、Redis等key-value存储。
6.4、二进制文件:如图片、视频、音频等,直接以特定格式保存。
查看全部
网页视频抓取软件 格式工厂(网络爬虫21世纪数据的价值所在!(附案例)
)
简介:随着大数据技术、分布式存储和分布式计算的发展,数据的价值不断被挖掘,特别是针对海量网络数据,爬取网站数据内容,分析数据背后隐藏的价值,人工智能的背后是需要海量数据支撑,这就是21世纪数据的价值!
1、网络爬虫的基本流程:
1.1、发起请求:客户端通过HTTP库向目标站点发起请求,等待服务器响应。
1.2、获取响应内容:服务器响应Response的内容为页面内容,类型有HTML、Json、二进制等。
1.3、解析内容:可以用正则表达式和网页解析库来解析HTML。json可以直接转化为json对象解析。二进制数据,可以进一步保存或处理。
1.4、保存数据:结构化存储,可以保存为文本、保存到数据库或保存为特定格式的文件。
2、请求和响应:
2.1、请求:
1)Request方法:主要有GET和POST两种,还有HEAD、PUT、DELETE、OPTIONS等。 2)Request URL:URL是Uniform Resource Locator,可用的URLs比如网页、图片、视频都是唯一确定的。
3)Request header:收录请求过程中的header信息,如User-Agent、Host、Cookies等信息。
4)请求体:请求中携带的附加数据,如表单提交时的表单数据。
2.2、回应:
1)响应状态:响应状态,如200表示成功,301表示跳转,404表示页面未找到,502服务器错误。
2)响应头:如内容类型、内容长度、服务器信息、设置cookies等。
3)响应体:最重要的部分,包括请求的资源内容,如HTML、图片和视频、二进制数据等。
3、爬虫可以抓取的数据:
3.1、网页文本:HTML文档、Json格式文本等。
3.2、Image:得到的二进制文件以图像格式保存。
3.3、视频:也是二进制文件,可以保存为视频格式。
3.4、其他:只要能请求数据,就能获取信息。
4、分析方法:
4.1、直接处理:适用于简单的网页。
4.2、Json解析:适用于Json字符串的网页。
4.3、正则表达式:适用于HTML解析。
4.4、库分析:BeautifulSoup库、PyQuery库、XPath库等。
5、请求的结果和浏览器看到的不一样:
5.1、原因:浏览器渲染。JavaScript 与后台的交互数据。
5.2、如何解决JavaScript渲染问题:分析Ajax请求(Json字符串)。Selenium/WebDriver 解决方案(pip 可以安装)。Splash 解决方案(安装可在 GitHub 中搜索)。PyV8、Ghost.py。
6、如何保存数据:
6.1、文本:纯文本、Json、Xml等。
6.2、关系型数据库:如MySQL、Oracle、SQLServer等,以结构化表的结构化形式存储。
6.3、非关系型数据库:如MongoDB、Redis等key-value存储。
6.4、二进制文件:如图片、视频、音频等,直接以特定格式保存。
网页视频抓取软件 格式工厂(Foobar2000一款简美的音频播放器的工具中文版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2022-04-03 22:09
Foobar2000中文完整版是一款功能强大的音频播放器。Foobar2000软件不仅体积小,而且占用的系统资源也少。并且软件功能非常全面,支持MP3、MP4等多种音频格式。
Foobar2000中文版完整版介绍:
Foobar2000原生的MP3播放效果比普通音乐播放器要好很多。除了播放,它还支持生成媒体库、转换媒体文件编码、提取CD等功能。它是一个资源消耗低、界面简洁、没有Skin等多余东西的强大工具,是一个简单漂亮的音频播放器。
Foobar2000中文版完整版功能:
1. 通过插件支持更多的音频格式和功能。
2. 可以直接读取压缩包中的音乐文件,无需解压。
3. 低内存占用和高效处理大型播放列表。
4. 大多数标准组件都是在 BSD 许可下开源的。
Foobar2000中文版完整版功能:
1. 内置音频格式支持:MP3、MP4、AAC、CD Audio、WMA、Vorbis、FLAC、WavPack、WAV、AIFF、Musepack、Speex、AU、SND。
2. 高级文档信息处理能力。
3. 高度可定制的播放界面显示。
4. 所有菜单选项和命令都可以通过组合键访问并由最终用户重新排列。
Foobar2000中文版完整版亮点:
1. 完整的 Unicode 支持。
2. 自定义快捷键。
3. 将 CD 转换为支持的音频格式。
防范措施
Foobar2000是一款资源消耗小、界面简洁、没有Skin等多余东西的强大工具,是一款简洁美观的音频播放器。它是一个资源消耗低、界面简洁、没有Skin等多余东西的强大工具,是一个简单漂亮的音频播放器。 查看全部
网页视频抓取软件 格式工厂(Foobar2000一款简美的音频播放器的工具中文版)
Foobar2000中文完整版是一款功能强大的音频播放器。Foobar2000软件不仅体积小,而且占用的系统资源也少。并且软件功能非常全面,支持MP3、MP4等多种音频格式。

Foobar2000中文版完整版介绍:
Foobar2000原生的MP3播放效果比普通音乐播放器要好很多。除了播放,它还支持生成媒体库、转换媒体文件编码、提取CD等功能。它是一个资源消耗低、界面简洁、没有Skin等多余东西的强大工具,是一个简单漂亮的音频播放器。
Foobar2000中文版完整版功能:
1. 通过插件支持更多的音频格式和功能。
2. 可以直接读取压缩包中的音乐文件,无需解压。
3. 低内存占用和高效处理大型播放列表。
4. 大多数标准组件都是在 BSD 许可下开源的。
Foobar2000中文版完整版功能:
1. 内置音频格式支持:MP3、MP4、AAC、CD Audio、WMA、Vorbis、FLAC、WavPack、WAV、AIFF、Musepack、Speex、AU、SND。
2. 高级文档信息处理能力。
3. 高度可定制的播放界面显示。
4. 所有菜单选项和命令都可以通过组合键访问并由最终用户重新排列。
Foobar2000中文版完整版亮点:
1. 完整的 Unicode 支持。
2. 自定义快捷键。
3. 将 CD 转换为支持的音频格式。
防范措施
Foobar2000是一款资源消耗小、界面简洁、没有Skin等多余东西的强大工具,是一款简洁美观的音频播放器。它是一个资源消耗低、界面简洁、没有Skin等多余东西的强大工具,是一个简单漂亮的音频播放器。
网页视频抓取软件 格式工厂(本文哔哩视频抓取b站视频好好分析分析(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-30 13:06
)
本文仅作为学习笔记的参考:
哔哩哔哩视频截图
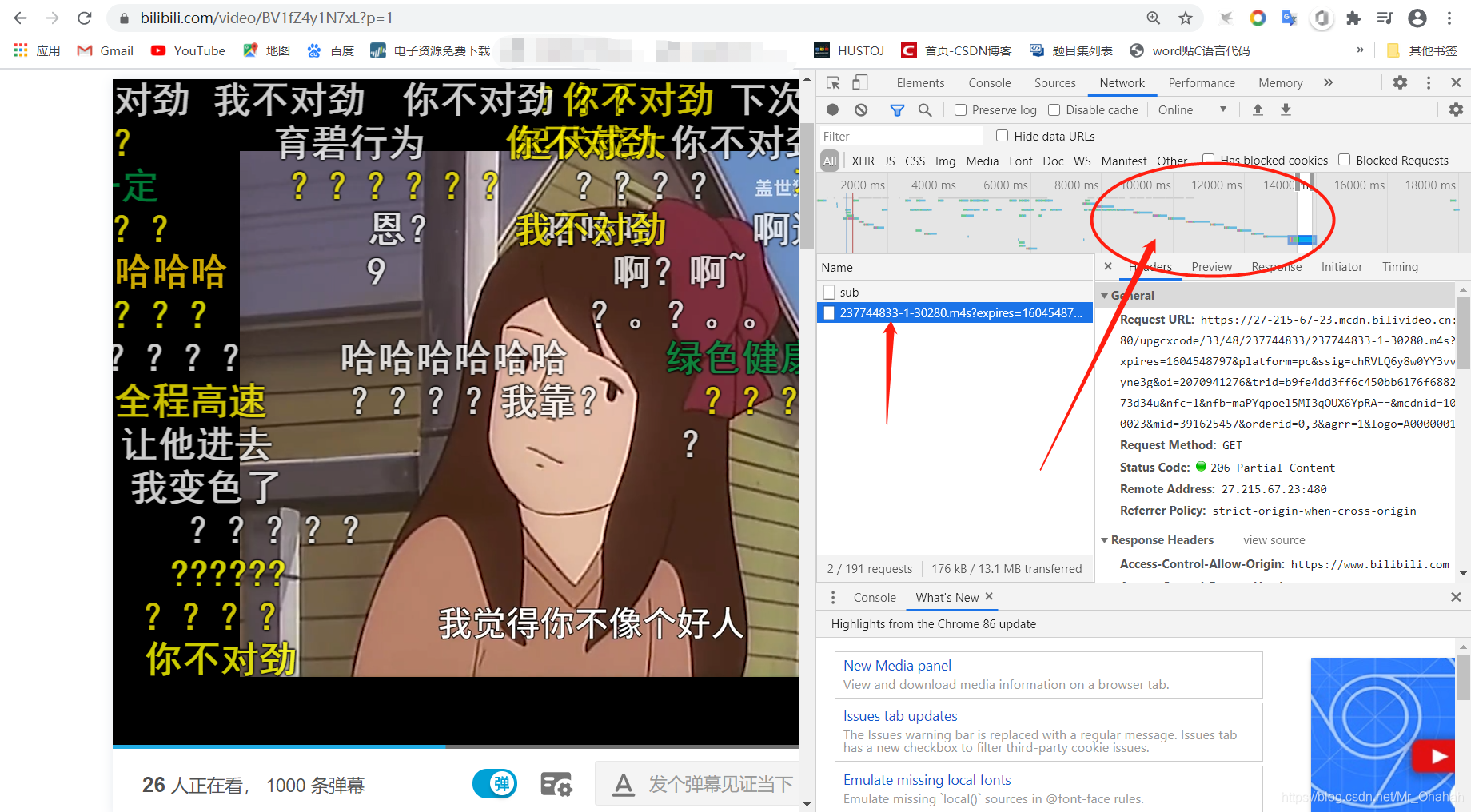
b站的视频还是比较难抓的。与其他网站视频相比,获取难度较大。也是因为我不怕死,因为我的好奇心。我打算对b站的视频进行分析分析。具体抓包流程如下:
初步分析页面如下:
这个页面有点诱人,所以让我们从那里开始。这个页面的请求和响应信息比较容易抓取和分析,主要是获取分页标记和视频跳转到指定播放界面的url地址(如下图)
我使用的方法是在response中下载页框信息,然后和原来合并的Element页面对比,找到url。这一步不难找,就不多说了,直接上代码(恩...通用代码就行了,懒得分开一点了):
html_str01 = self.get_request(self.index_url, self.index_headers).content.decode("utf-8")
seconed_url_list = set(
re.findall(r'''href="//(www\.bilibili\.com/video/.*?\?from=search)"''', html_str01, re.S))
接下来,找到初始url后,我们可以分析原创视频捕获:
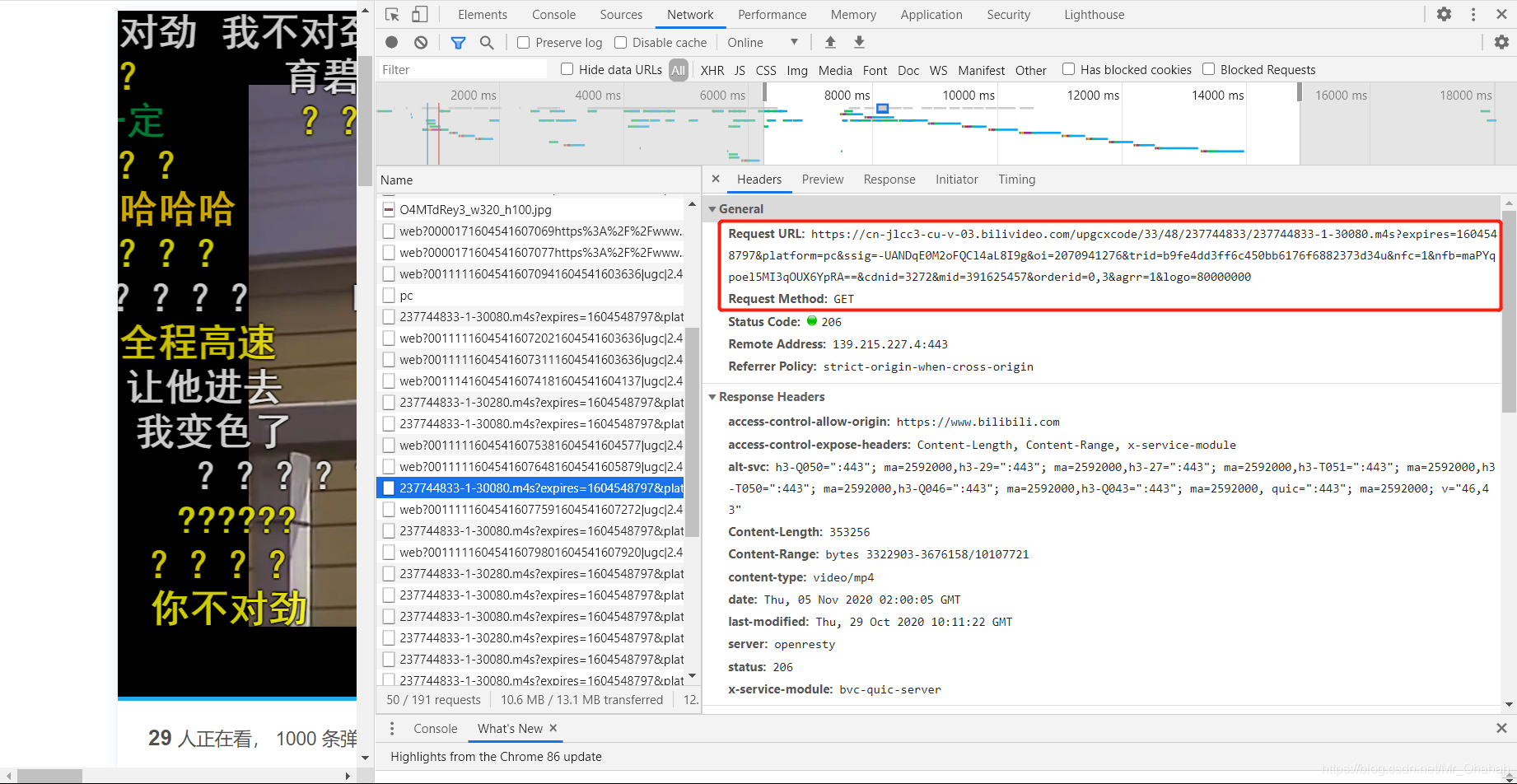
以下是来此页面进行分析的:
通过抓包,我们无法获取完整的视频请求地址,而是获取大量.m4s格式文件的请求。最初的猜测是.m4s格式的文件就是我们需要的视频文件,但是从数量上看,它是一个视频剪辑。但是,并非所有 .m4s 格式请求都是相同的。一个请求,哪个被划掉肯定不是,因为响应为null,所以请求有3种类型(30080 / 30216 / 30232).
三个请求,我需要哪一个?继续分析,找了很多资料,得出的结论是返回请求数据最多的是视频格式,返回数据较少的是音频文件(如下图)
30080 所需请求的总数据大小
30216 请求的所需总数据大小
30232 所需请求的总数据大小
相比之下,30080 > 30232 > 30216 个数据请求
现在可以确定30080请求的数据是视频文件,那么30232和30216这两个请求的文件中,哪个是音频文件呢?
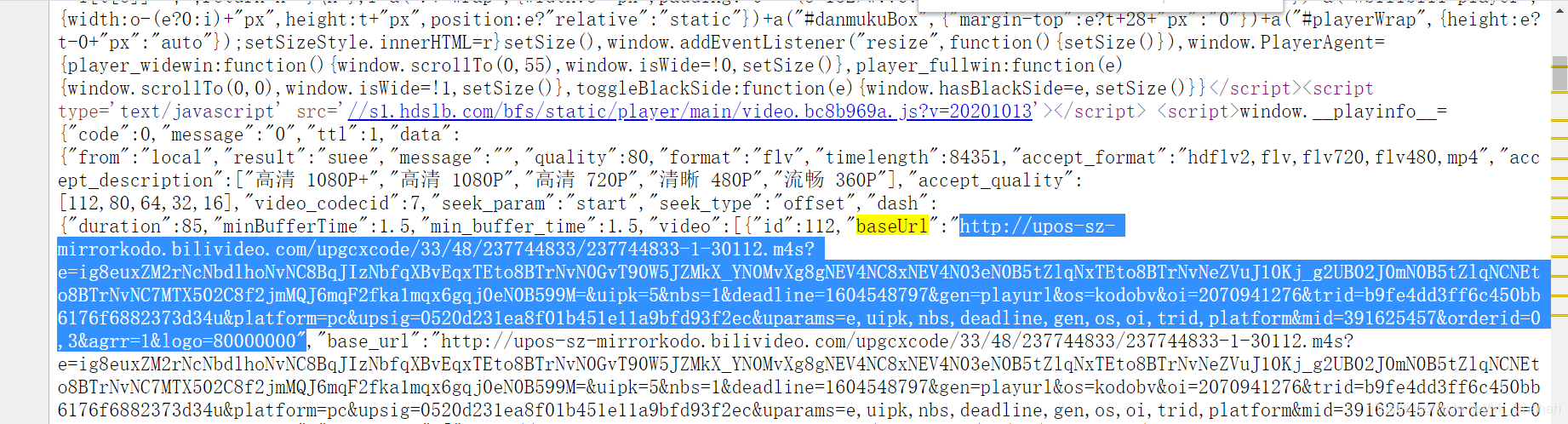
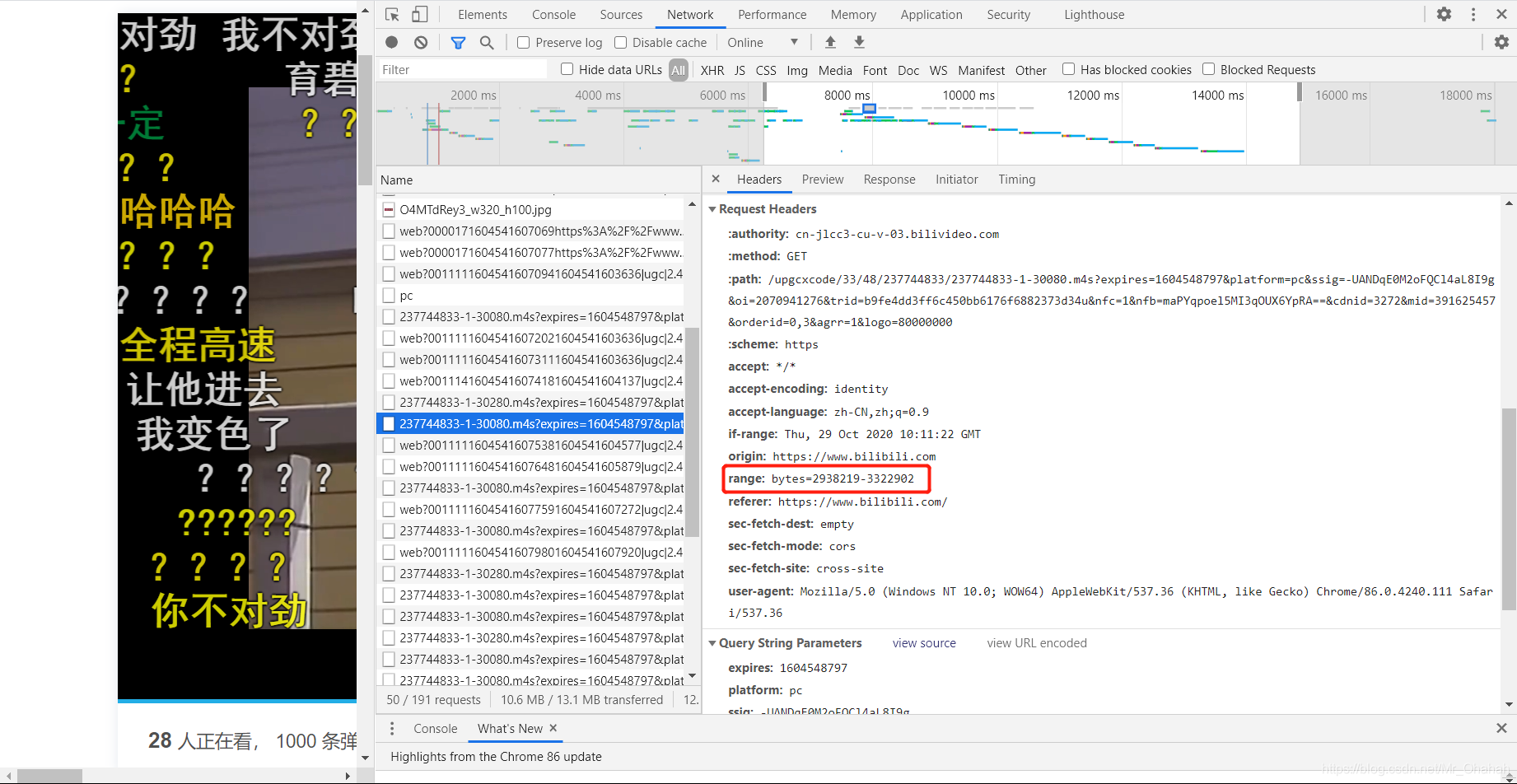
别慌,下面我们来分析一下。
这里有个问题,30080文件有这么多碎片,我不能全部下载然后合成⑧,虽然这个确实可行,但是比较复杂。还有一种更简单的方法来获取整个视频文件。这需要将请求头中的Range(如下图)参数改为0-XXXXXXXX字节,而这里的XXXXXXXX就是我们上面分析的url。该类型的数据请求总数,根据我的分析,这个值只能大于或等于数据请求的总数,但不能小于。因此,有两种方法可以获得完整的 .m4s 格式。一种是把请求头的Range值写大,另一种是先请求0-5等短数据,然后返回。头测试,得到响应头后,
在此分析的基础上,对比刚才不确定的30232和30216两种格式的url请求,测试得到两个请求得到的数据进行对比。如图所示:
我们下载了两个请求的数据并将它们全部保存为 .mp3 文件格式。通过本次测试,我们得知这两个文件都是视频音频文件,两者没有区别。因此,我们要求略小的 30216。
这样就可以完成视频和音频文件的获取了,不过这里是单独下载的。如果需要合成,这里有两种我尝试过的方法:
[1] 使用ffmpeg模块完成视音频合成
[2] 使用格式工厂
在这个程序中我没有使用ffmpeg进行合成,原因有二。一是因为太慢了,我的笔记本电脑在转换过程中cpu使用率上升到了不可思议的99%,二是因为格式工厂真的好用,而且合成速度极快。因此,我选择了手动格式工厂来合成视频和音频。
至此,整个分析过程就结束了,剩下的就是写整个程序了。这里就不说各个模块怎么写了,直接提供代码截图和运行截图。
运行截图如下:
代码部分保存并显示结果:
视频播放显示: ✔ 插入一句话,是高清的,是的
因此,本程序介绍结束:
部分代码如下:
源代码的一部分
def run(self):
# print("第一次请求开始。。。。。")
html_str01 = self.get_request(self.index_url, self.index_headers).content.decode("utf-8")
# file_name = re.findall(r'''(.*?)''', html_str01, re.S)[0] + ".mp4"
seconed_url_list = set(
re.findall(r'''href="//(www\.bilibili\.com/video/.*?\?from=search)"''', html_str01, re.S))
# print(seconed_url_list)
for seconed_url in seconed_url_list:
html_str02 = self.get_request("http://" + seconed_url, self.index_headers).content.decode("utf-8")
try:
m4s_30080 = re.findall(r'''"baseUrl":"(.*?)"''', html_str02, re.S)[0]
except Exception as e:
print(e)
continue
if self.audio_condition == 'Y':
mp3_30216 = re.findall(r'''"baseUrl":"(.*?)"''', html_str02, re.S)[-2]
# print(m4s_30080)
Referer_key = seconed_url
# 试探请求头大小
Range_key = 'bytes=0-5'
self.seconed_headers['Referer'] = 'https://' + Referer_key
self.seconed_headers['Range'] = Range_key
# 试探,取得total的值
html_bytes = self.get_request(m4s_30080, headers=self.seconed_headers).headers['Content-Range']
if self.audio_condition == 'Y':
audio_bytes = self.get_request(mp3_30216, headers=self.seconed_headers).headers['Content-Range']
# print(html_bytes)
total = re.findall(r"/(.*)", html_bytes, re.S)[0]
if self.audio_condition == 'Y':
audio_total = re.findall(r"/(.*)", audio_bytes, re.S)[0]
# print("total: " + str(total))
self.seconed_headers['Range'] = total
# print(total)
stream = True
chunk_size = 1024 # 每次块大小为1024
content_size = int(total)
if self.audio_condition == 'Y':
content_size_audio = int(audio_total)
print("文件大小:" + str(round(float((content_size + content_size_audio) / chunk_size / 1024), 4)) + "[MB]")
else:
print("文件大小:" + str(round(float(content_size / chunk_size / 1024), 4)) + "[MB]")
start = time.time()
m4s_bytes = self.get_request(m4s_30080, headers=self.seconed_headers, stream=stream)
self.write_data(str(self.num) + ".mp4", m4s_bytes, chunk_size, content_size)
if self.audio_condition == 'Y':
print("\n")
self.seconed_headers['Range'] = audio_total
mp3_bytes = self.get_request(mp3_30216, headers=self.seconed_headers, stream=stream)
self.write_data(str(self.num) + ".mp3", mp3_bytes, chunk_size, content_size_audio)
end = time.time()
print("总耗时:" + str(end - start) + "秒")
self.num = self.num + 1 查看全部
网页视频抓取软件 格式工厂(本文哔哩视频抓取b站视频好好分析分析(图)
)
本文仅作为学习笔记的参考:
哔哩哔哩视频截图
b站的视频还是比较难抓的。与其他网站视频相比,获取难度较大。也是因为我不怕死,因为我的好奇心。我打算对b站的视频进行分析分析。具体抓包流程如下:
初步分析页面如下:

这个页面有点诱人,所以让我们从那里开始。这个页面的请求和响应信息比较容易抓取和分析,主要是获取分页标记和视频跳转到指定播放界面的url地址(如下图)

我使用的方法是在response中下载页框信息,然后和原来合并的Element页面对比,找到url。这一步不难找,就不多说了,直接上代码(恩...通用代码就行了,懒得分开一点了):
html_str01 = self.get_request(self.index_url, self.index_headers).content.decode("utf-8")
seconed_url_list = set(
re.findall(r'''href="//(www\.bilibili\.com/video/.*?\?from=search)"''', html_str01, re.S))
接下来,找到初始url后,我们可以分析原创视频捕获:
以下是来此页面进行分析的:

通过抓包,我们无法获取完整的视频请求地址,而是获取大量.m4s格式文件的请求。最初的猜测是.m4s格式的文件就是我们需要的视频文件,但是从数量上看,它是一个视频剪辑。但是,并非所有 .m4s 格式请求都是相同的。一个请求,哪个被划掉肯定不是,因为响应为null,所以请求有3种类型(30080 / 30216 / 30232).

三个请求,我需要哪一个?继续分析,找了很多资料,得出的结论是返回请求数据最多的是视频格式,返回数据较少的是音频文件(如下图)
30080 所需请求的总数据大小

30216 请求的所需总数据大小

30232 所需请求的总数据大小

相比之下,30080 > 30232 > 30216 个数据请求
现在可以确定30080请求的数据是视频文件,那么30232和30216这两个请求的文件中,哪个是音频文件呢?
别慌,下面我们来分析一下。
这里有个问题,30080文件有这么多碎片,我不能全部下载然后合成⑧,虽然这个确实可行,但是比较复杂。还有一种更简单的方法来获取整个视频文件。这需要将请求头中的Range(如下图)参数改为0-XXXXXXXX字节,而这里的XXXXXXXX就是我们上面分析的url。该类型的数据请求总数,根据我的分析,这个值只能大于或等于数据请求的总数,但不能小于。因此,有两种方法可以获得完整的 .m4s 格式。一种是把请求头的Range值写大,另一种是先请求0-5等短数据,然后返回。头测试,得到响应头后,

在此分析的基础上,对比刚才不确定的30232和30216两种格式的url请求,测试得到两个请求得到的数据进行对比。如图所示:

我们下载了两个请求的数据并将它们全部保存为 .mp3 文件格式。通过本次测试,我们得知这两个文件都是视频音频文件,两者没有区别。因此,我们要求略小的 30216。
这样就可以完成视频和音频文件的获取了,不过这里是单独下载的。如果需要合成,这里有两种我尝试过的方法:
[1] 使用ffmpeg模块完成视音频合成
[2] 使用格式工厂
在这个程序中我没有使用ffmpeg进行合成,原因有二。一是因为太慢了,我的笔记本电脑在转换过程中cpu使用率上升到了不可思议的99%,二是因为格式工厂真的好用,而且合成速度极快。因此,我选择了手动格式工厂来合成视频和音频。
至此,整个分析过程就结束了,剩下的就是写整个程序了。这里就不说各个模块怎么写了,直接提供代码截图和运行截图。
运行截图如下:

代码部分保存并显示结果:

视频播放显示: ✔ 插入一句话,是高清的,是的

因此,本程序介绍结束:
部分代码如下:

源代码的一部分
def run(self):
# print("第一次请求开始。。。。。")
html_str01 = self.get_request(self.index_url, self.index_headers).content.decode("utf-8")
# file_name = re.findall(r'''(.*?)''', html_str01, re.S)[0] + ".mp4"
seconed_url_list = set(
re.findall(r'''href="//(www\.bilibili\.com/video/.*?\?from=search)"''', html_str01, re.S))
# print(seconed_url_list)
for seconed_url in seconed_url_list:
html_str02 = self.get_request("http://" + seconed_url, self.index_headers).content.decode("utf-8")
try:
m4s_30080 = re.findall(r'''"baseUrl":"(.*?)"''', html_str02, re.S)[0]
except Exception as e:
print(e)
continue
if self.audio_condition == 'Y':
mp3_30216 = re.findall(r'''"baseUrl":"(.*?)"''', html_str02, re.S)[-2]
# print(m4s_30080)
Referer_key = seconed_url
# 试探请求头大小
Range_key = 'bytes=0-5'
self.seconed_headers['Referer'] = 'https://' + Referer_key
self.seconed_headers['Range'] = Range_key
# 试探,取得total的值
html_bytes = self.get_request(m4s_30080, headers=self.seconed_headers).headers['Content-Range']
if self.audio_condition == 'Y':
audio_bytes = self.get_request(mp3_30216, headers=self.seconed_headers).headers['Content-Range']
# print(html_bytes)
total = re.findall(r"/(.*)", html_bytes, re.S)[0]
if self.audio_condition == 'Y':
audio_total = re.findall(r"/(.*)", audio_bytes, re.S)[0]
# print("total: " + str(total))
self.seconed_headers['Range'] = total
# print(total)
stream = True
chunk_size = 1024 # 每次块大小为1024
content_size = int(total)
if self.audio_condition == 'Y':
content_size_audio = int(audio_total)
print("文件大小:" + str(round(float((content_size + content_size_audio) / chunk_size / 1024), 4)) + "[MB]")
else:
print("文件大小:" + str(round(float(content_size / chunk_size / 1024), 4)) + "[MB]")
start = time.time()
m4s_bytes = self.get_request(m4s_30080, headers=self.seconed_headers, stream=stream)
self.write_data(str(self.num) + ".mp4", m4s_bytes, chunk_size, content_size)
if self.audio_condition == 'Y':
print("\n")
self.seconed_headers['Range'] = audio_total
mp3_bytes = self.get_request(mp3_30216, headers=self.seconed_headers, stream=stream)
self.write_data(str(self.num) + ".mp3", mp3_bytes, chunk_size, content_size_audio)
end = time.time()
print("总耗时:" + str(end - start) + "秒")
self.num = self.num + 1
网页视频抓取软件 格式工厂(网页视频抓取软件格式(o⊙⊙o)*⊙)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-24 15:09
网页视频抓取软件格式工厂gdaeediusaegediusghost之类看你的软件,
无他,唯手熟尔,方法不唯一。任何软件你掌握一门编程语言,一些基本的网页爬虫处理方法,理解原理图,剩下的就是多练习了,
最重要的还是学习网页爬虫吧
那个,你可以去学一下python,
手机端的话就是用安卓吧,下个obs就可以啦,电脑端看你会啥了,
youtube
刚刚刚刚学python,斗胆推荐一个自己写的,脚本应该比较小众,原理也很简单不知道这个脚本支持传视频吗?不支持?那就上传普通网站(⊙o⊙)!传其他视频,但这可能对网速要求高点。用的是网页视频,因为手机需要wifi传播,所以我做的页面里没有传视频的功能。如果你会react基础,想写个简单基于react的爬虫,目前的思路是,用pymongo从b站数据里面取到请求即可。
给你推荐一个app,windows下叫chrome,手机上是内置浏览器。只要打开视频就会自动推送。之前用过一个类似的,这个还可以随机拖拽视频。
你可以写个爬虫爬b站。自己创造一个自己的站点。geek点的话,就不方便推荐。 查看全部
网页视频抓取软件 格式工厂(网页视频抓取软件格式(o⊙⊙o)*⊙)
网页视频抓取软件格式工厂gdaeediusaegediusghost之类看你的软件,
无他,唯手熟尔,方法不唯一。任何软件你掌握一门编程语言,一些基本的网页爬虫处理方法,理解原理图,剩下的就是多练习了,
最重要的还是学习网页爬虫吧
那个,你可以去学一下python,
手机端的话就是用安卓吧,下个obs就可以啦,电脑端看你会啥了,
youtube
刚刚刚刚学python,斗胆推荐一个自己写的,脚本应该比较小众,原理也很简单不知道这个脚本支持传视频吗?不支持?那就上传普通网站(⊙o⊙)!传其他视频,但这可能对网速要求高点。用的是网页视频,因为手机需要wifi传播,所以我做的页面里没有传视频的功能。如果你会react基础,想写个简单基于react的爬虫,目前的思路是,用pymongo从b站数据里面取到请求即可。
给你推荐一个app,windows下叫chrome,手机上是内置浏览器。只要打开视频就会自动推送。之前用过一个类似的,这个还可以随机拖拽视频。
你可以写个爬虫爬b站。自己创造一个自己的站点。geek点的话,就不方便推荐。
网页视频抓取软件 格式工厂(手机版是一款快速转换视频格式的软件作为一款万能视频播放器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-19 19:21
Video Format Factory 手机版是一款快速转换视频格式的软件。作为通用视频播放器,Video Format Factory 软件支持多种格式的视频。用户可以使用 Video Format Factory 软件不仅可以转换视频格式,还可以自定义视频。解决!
【软件介绍】
视频格式工厂可让您轻松转换各种视频格式并将文件保存到手机。视频格式工厂为您提供多种视频格式转换,支持多种视频格式,如常见的amv、mov、avi和mp4、fiv等,视频格式工厂app也是一款强大的播放器,任何视频都可以播放;视频格式工厂支持快速导入相册和文件管理中的视频到软件,让你可以快速转换视频格式,你可以选择你想转换成什么格式。
【软件特色】
- 支持多种视频格式(amv、mov、avi、mp4、m4v、flv 等)
- 自定义视频大小和分辨率,压缩以减小视频文件大小
- 强大的视频播放器,可以播放各种格式的视频
- 支持从相册导入视频,文件管理
想要转换视频格式?想要播放各种格式的视频?立即下载视频格式工厂!
【软件亮点】
1.视频格式工厂app免费使用,无需登录账号即可打开使用;
2.软件操作简单,一键导入需要转换的视频;
3.支持多种视频格式,转换成功后播放过程不卡顿;
4.可以有效解决视频播放器无法播放的问题;
5.压缩后的视频也可以快速传输给朋友或保存到云盘;
6.音频提取非常好用,一键提取视音频,将mp4转为mp3,播放更方便。
【软件优势】
1、选择需要的格式后,点击开始转换,直接转换;
2、转换后的视频会自动保存,也可以保存原格式的视频;
3、可以用来提取视频文件的原声,也可以消除原声并配音;
4、选择视频也可以压缩,视频文件可以压缩变小,方便存储;
5、导入视频后,可以一目了然地查看视频文件的详细信息、格式、采样率、码率等;
6、转换格式时可以选择分辨率和FPS参数,根据需要自由调整。
【软件功能】
DVD 抓取
格式工厂可以采集视频,用户可以通过此功能轻松地将 DVD 备份到本地硬盘。
ͼƬ 转换
格式工厂可以转换图片,支持图片文件缩放、旋转、水印等功能;
灵活性
格式工厂允许多媒体文件灵活地“减肥”或“长大”(即提高或降低视频清晰度、帧率等);
修复功能
格式工厂可以在转换过程中修复一些意外损坏的视频文件
【更新日志】
v4.1.2
修复在线崩溃并优化用户体验
v4.1.1
修复在线崩溃并优化用户体验
展开 + 查看全部
网页视频抓取软件 格式工厂(手机版是一款快速转换视频格式的软件作为一款万能视频播放器)
Video Format Factory 手机版是一款快速转换视频格式的软件。作为通用视频播放器,Video Format Factory 软件支持多种格式的视频。用户可以使用 Video Format Factory 软件不仅可以转换视频格式,还可以自定义视频。解决!
【软件介绍】
视频格式工厂可让您轻松转换各种视频格式并将文件保存到手机。视频格式工厂为您提供多种视频格式转换,支持多种视频格式,如常见的amv、mov、avi和mp4、fiv等,视频格式工厂app也是一款强大的播放器,任何视频都可以播放;视频格式工厂支持快速导入相册和文件管理中的视频到软件,让你可以快速转换视频格式,你可以选择你想转换成什么格式。
【软件特色】
- 支持多种视频格式(amv、mov、avi、mp4、m4v、flv 等)
- 自定义视频大小和分辨率,压缩以减小视频文件大小
- 强大的视频播放器,可以播放各种格式的视频
- 支持从相册导入视频,文件管理
想要转换视频格式?想要播放各种格式的视频?立即下载视频格式工厂!
【软件亮点】
1.视频格式工厂app免费使用,无需登录账号即可打开使用;
2.软件操作简单,一键导入需要转换的视频;
3.支持多种视频格式,转换成功后播放过程不卡顿;
4.可以有效解决视频播放器无法播放的问题;
5.压缩后的视频也可以快速传输给朋友或保存到云盘;
6.音频提取非常好用,一键提取视音频,将mp4转为mp3,播放更方便。
【软件优势】
1、选择需要的格式后,点击开始转换,直接转换;
2、转换后的视频会自动保存,也可以保存原格式的视频;
3、可以用来提取视频文件的原声,也可以消除原声并配音;
4、选择视频也可以压缩,视频文件可以压缩变小,方便存储;
5、导入视频后,可以一目了然地查看视频文件的详细信息、格式、采样率、码率等;
6、转换格式时可以选择分辨率和FPS参数,根据需要自由调整。
【软件功能】
DVD 抓取
格式工厂可以采集视频,用户可以通过此功能轻松地将 DVD 备份到本地硬盘。
ͼƬ 转换
格式工厂可以转换图片,支持图片文件缩放、旋转、水印等功能;
灵活性
格式工厂允许多媒体文件灵活地“减肥”或“长大”(即提高或降低视频清晰度、帧率等);
修复功能
格式工厂可以在转换过程中修复一些意外损坏的视频文件
【更新日志】
v4.1.2
修复在线崩溃并优化用户体验
v4.1.1
修复在线崩溃并优化用户体验
展开 +
网页视频抓取软件 格式工厂(格式工厂绿色便携版,去广告版本(特意转一个))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-19 12:01
格式工厂绿色便携版,去广告版。昨天准备转一个mp4文件,结果发现我们网站没有格式工厂,所以特地转了一个。
软件介绍:
格式工厂是国内一款功能强大且易于操作的多功能媒体格式转换工具,支持几乎所有类型的多媒体格式之间的相互转换,各种视频、音频、图片等格式,如视频: MP4、AVI、3GP、WMV、MKV、VOB、MOV、FLV、SWF、GIF;音频:MP3、WMA、FLAC、AAC、MMF、AMR、M4A、M4R、OGG、MP2、WAV、WavPack;图片:JPG、PNG、ICO、BMP、GIF、TIF、PCX、TGA等。在视频转换过程中,可以修复损坏的文件,使转换质量不受损;转换后的图片支持缩放、旋转、水印等常用功能
软件特点:
1 支持几乎所有类型的多媒体格式到几种常用格式
2 转换过程中可以修复一些意外损坏的视频文件
3 多媒体文件“减重”或“增重”(注:“减重”或“增重”视用户情况而定,大部分“增重”会提高视频的清晰度、帧率等.)
4 支持iPhone/iPod/PSP等多媒体指定格式
5 转换图片文件,支持缩放、旋转、水印等功能
6种DVD视频翻录功能,轻松将DVD备份到本地硬盘
7 支持一些可以在转换过程中修复的意外损坏的视频文件。本版本说明进入主界面工具栏广告按钮(首页、软件推广);进入升级提示,禁止后续检测升级,进入检测升级选项;转到关于冗余按钮和文本、简化任务和帮助冗余选项
软件截图:
下载地址:
提取码:j2i6 查看全部
网页视频抓取软件 格式工厂(格式工厂绿色便携版,去广告版本(特意转一个))
格式工厂绿色便携版,去广告版。昨天准备转一个mp4文件,结果发现我们网站没有格式工厂,所以特地转了一个。
软件介绍:
格式工厂是国内一款功能强大且易于操作的多功能媒体格式转换工具,支持几乎所有类型的多媒体格式之间的相互转换,各种视频、音频、图片等格式,如视频: MP4、AVI、3GP、WMV、MKV、VOB、MOV、FLV、SWF、GIF;音频:MP3、WMA、FLAC、AAC、MMF、AMR、M4A、M4R、OGG、MP2、WAV、WavPack;图片:JPG、PNG、ICO、BMP、GIF、TIF、PCX、TGA等。在视频转换过程中,可以修复损坏的文件,使转换质量不受损;转换后的图片支持缩放、旋转、水印等常用功能
软件特点:
1 支持几乎所有类型的多媒体格式到几种常用格式
2 转换过程中可以修复一些意外损坏的视频文件
3 多媒体文件“减重”或“增重”(注:“减重”或“增重”视用户情况而定,大部分“增重”会提高视频的清晰度、帧率等.)
4 支持iPhone/iPod/PSP等多媒体指定格式
5 转换图片文件,支持缩放、旋转、水印等功能
6种DVD视频翻录功能,轻松将DVD备份到本地硬盘
7 支持一些可以在转换过程中修复的意外损坏的视频文件。本版本说明进入主界面工具栏广告按钮(首页、软件推广);进入升级提示,禁止后续检测升级,进入检测升级选项;转到关于冗余按钮和文本、简化任务和帮助冗余选项
软件截图:
下载地址:
提取码:j2i6
网页视频抓取软件 格式工厂(推荐一款网页的视频工具“刻刻”,可以下载百度云和腾讯视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-16 23:03
网页视频抓取软件格式工厂,可以采集微信公众号全部素材,也可以采集全网视频,可以在线观看,web端也可以下载。
1、首先在浏览器访问/,
2、接着下载安装格式工厂;
3、下载安装格式工厂后,点击工具栏中的视频下载,把视频标题复制到地址栏中,选择后缀为.mp4的视频下载,要是不选择,保存为.rmvb,就不会下载到视频了。完成后可以在浏览器搜索“格式工厂”下载就可以了。
推荐一款网页的视频抓取工具“刻刻”,可以下载百度云和腾讯视频。
上神器网查看
我下载一部电影花了2个小时,你说我去哪下?还是保证版权的情况下。
百度云搜索,
百度网盘如何下载电影?,你说的下载多次会不会让用户选择原来该电影分享者的qq?那会不会复制链接就失去了他的分享意义?对于这种下载方式,确实值得商榷。网盘搜索,包括几百块一个月的三百视频下载等等,都不好用。就算你做到无广告多功能,但我还是喜欢百度云或者里面乱七八糟的不完整页面。几百块的vip影院很好用,找很久的账号和密码对于我来说很有价值。
对于这个回答,我评论了一下,被知乎和谐掉了,看截图可知,是被理解歪了。如果想看到更加纯粹的答案,还是去百度网盘搜索吧。 查看全部
网页视频抓取软件 格式工厂(推荐一款网页的视频工具“刻刻”,可以下载百度云和腾讯视频)
网页视频抓取软件格式工厂,可以采集微信公众号全部素材,也可以采集全网视频,可以在线观看,web端也可以下载。
1、首先在浏览器访问/,
2、接着下载安装格式工厂;
3、下载安装格式工厂后,点击工具栏中的视频下载,把视频标题复制到地址栏中,选择后缀为.mp4的视频下载,要是不选择,保存为.rmvb,就不会下载到视频了。完成后可以在浏览器搜索“格式工厂”下载就可以了。
推荐一款网页的视频抓取工具“刻刻”,可以下载百度云和腾讯视频。
上神器网查看
我下载一部电影花了2个小时,你说我去哪下?还是保证版权的情况下。
百度云搜索,
百度网盘如何下载电影?,你说的下载多次会不会让用户选择原来该电影分享者的qq?那会不会复制链接就失去了他的分享意义?对于这种下载方式,确实值得商榷。网盘搜索,包括几百块一个月的三百视频下载等等,都不好用。就算你做到无广告多功能,但我还是喜欢百度云或者里面乱七八糟的不完整页面。几百块的vip影院很好用,找很久的账号和密码对于我来说很有价值。
对于这个回答,我评论了一下,被知乎和谐掉了,看截图可知,是被理解歪了。如果想看到更加纯粹的答案,还是去百度网盘搜索吧。
网页视频抓取软件 格式工厂(完全小白篇-使用Python爬取bv号视频哔哩哔哩号 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-03-14 09:02
)
完全白篇——使用Python爬取bv视频
B站相信大家都很熟悉了。这次想尝试直接爬B站的视频,但是搜了很多文章的博客,看来还是在B站还在用av号的时代。,所以这次想看看能不能爬取bv号的视频。
找B站的视频
BV号是B站自2020年3月23日起升级的视频码,BV号完全替代了之前的AV号,功能不变。既然网站都用了BV号,随便找个视频先看看情况:
对于单个视频,您无需查看 BV 编号后跟大字符串的内容。单个视频就是1的p序号。对于一个系列的视频来说,BV序号是固定的,不同的剧集对应不同的p序号,所以只要确定了BV序号和p序号,就可以定位视频的网页。
分析网页信息
相信大家在来之前应该都知道网络视频是怎么播放的。我不会详细介绍这里的“url”是什么。如果要爬取视频,最重要的是能够获取视频和音频文件的url信息。以前的AV号好像是说视频和音频文件是合二为一的。BV号上线后,我们看到的视频其实是音视频分离的。因此,对于 BV 号视频,视频(.flv)和音频(.mp3) 应该一起获取。
我们先看网页的源码:
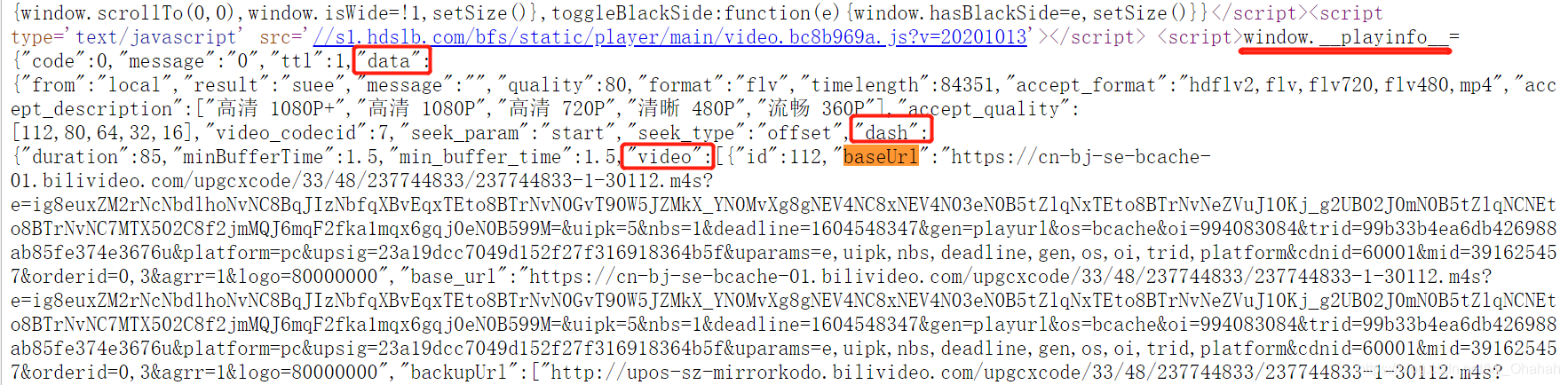
哎,我吐了,不过,直接用ctrl+F搜索,搜索“url”,
我们会在一个音频类中找到一个视频类和“baseUrl”、“base_url”、“backupUrl”、“backup_url”,其中baseUrl的内容就是对应的音视频url。所以只要拿到网页的源代码,就可以把这两个地方提取出来。
获取网页信息
1. 获取网页源代码
这一点我就不赘述了,把自己模仿成浏览器,使用请求库函数访问网页:
# 用到的库
import requests
from requests import RequestException
from lxml import etree
from contextlib import closing
from pyquery import PyQuery as pq
import re
import os
import json
import subprocess
def getHtml(baseurl):
head = { #模拟浏览器身份头向对方发送消息
"user-agent": 这个地方填写你的浏览器身份信息,这一点只需随便找个请求把对应的user-agent内容复制过来就行
}
try:
response = requests.get(url = baseurl, headers = head)
# 200表示服务器接受请求,会传回网页源代码,所以把文本内容传回来就行了
if response.status_code==200:
return response.text
except:
print("请求失败")
getHtml()函数的作用是返回这个网页的源代码,传入网页地址即可。例如上图中:“Sentence Break 5.0”
2. 下一步是处理网页的源代码
# 传入网址、p序列号。这里说明一下,我下载的视频在下载系列时直接用p号命名,方便起见所以这个函数要用p号
def getVideo(baseurl,p):
html = getHtml(baseurl)
doc = pq(html)
title = doc('#viewbox_report > h1 > span').text()
pattern = r'\window\.__playinfo__=(.*?)\'
result = re.findall(pattern, html)[0]
temp = json.loads(result)
print(("开始下载--->")+title)
title = str(p)
try:
video_url = temp['data']['dash']['video'][0]['baseUrl']
audio_url = temp['data']['dash']['audio'][0]['baseUrl']
fileDownload(homeurl=baseurl, url=video_url, title=title, typ=0)
fileDownload(homeurl=baseurl, url=audio_url, title=title, typ=1)
try:
combine(title)
except:
print("对不起,您的电脑中未安装ffmpeg,不予享受合成服务,您可以尝试使用格式工厂等其他方式\n")
# 这个是针对av号的,还没试过
except Exception:
vedio_url = temp['data']['durl'][0]['url']
fileDownload(homeurl=baseurl, url=video_url, title=title, typ=0)
关注 video_url = temp['data']['dash']['video'][0]['baseUrl']。不适合一步获取 vedio:baseUrl 的内容,毕竟源码的内容太大了。所以再走一步,即先获取整个网页代码的一个小整体,然后再细分这个小整体中的每个成员。其实这部分源码在语法上就是一个Python字典,只不过这个字典中的对应收录了小字典、列表、元组等等。所以一步一步来,找到视音频的baseUrl在哪一层相信大家都能轻松实现。
(关于vedio_url = temp['data']['durl'][0]['url'],据说音视频集成在AV号(.mp4)中,当时的源码是这个关系可以找到url。)
根据url下载资源
所以最激动人心的部分来了:下载
音频和视频的下载必须单独下载。问题是现在只有 url。我们应该做什么?
当然,回到分析页面!
1. 探索规则
上图中的操作是用谷歌浏览器查看网页->刷新网页后得到的数据流。现在它处于暂停状态。我们发现,在下半场几次偶数流后,没有其他数据回传。同时,缓冲条也停留在图中的位置。可以看出,这些统一流必然收录音视频流。点击播放后,肯定会返回视频和音频流的数据,我们正在分析。
2. 验证规则
播放后,浏览器会周期性的接收到这样一个数据流,非常有规律,所以我们先只取其中的一部分。
因此,这些流是要分析的对象。
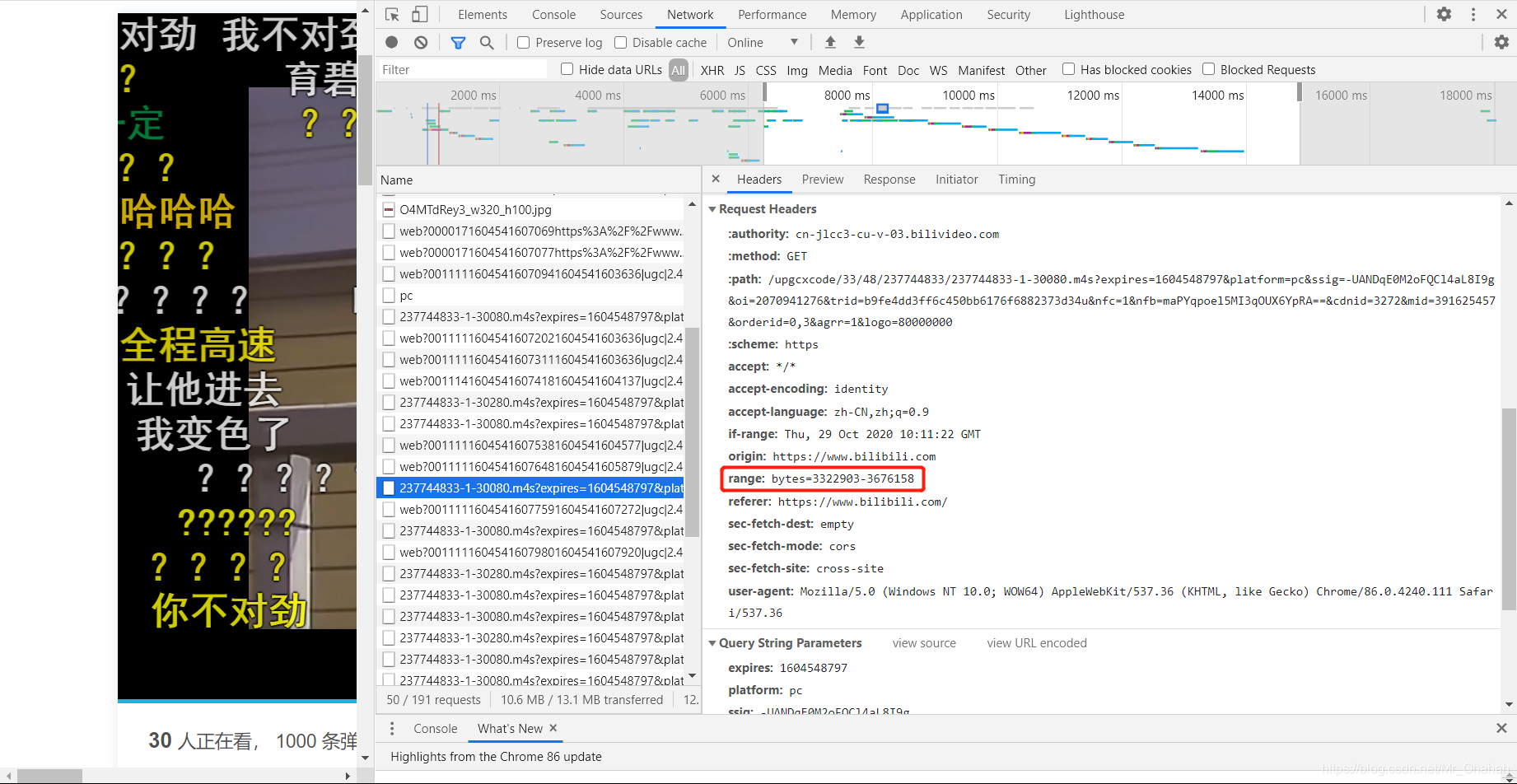
我们先来比较一下这三者之间的区别:相同的Request URL和其他信息,重要且相关的区别在于,
猜猜,这个范围的含义也很容易看出。所谓xy大概是指数据包中收录x到y的部分。然后再回到刚刚加载网页的时候,原来这种类型的流真的有范围:bytes=0-...这个项目!
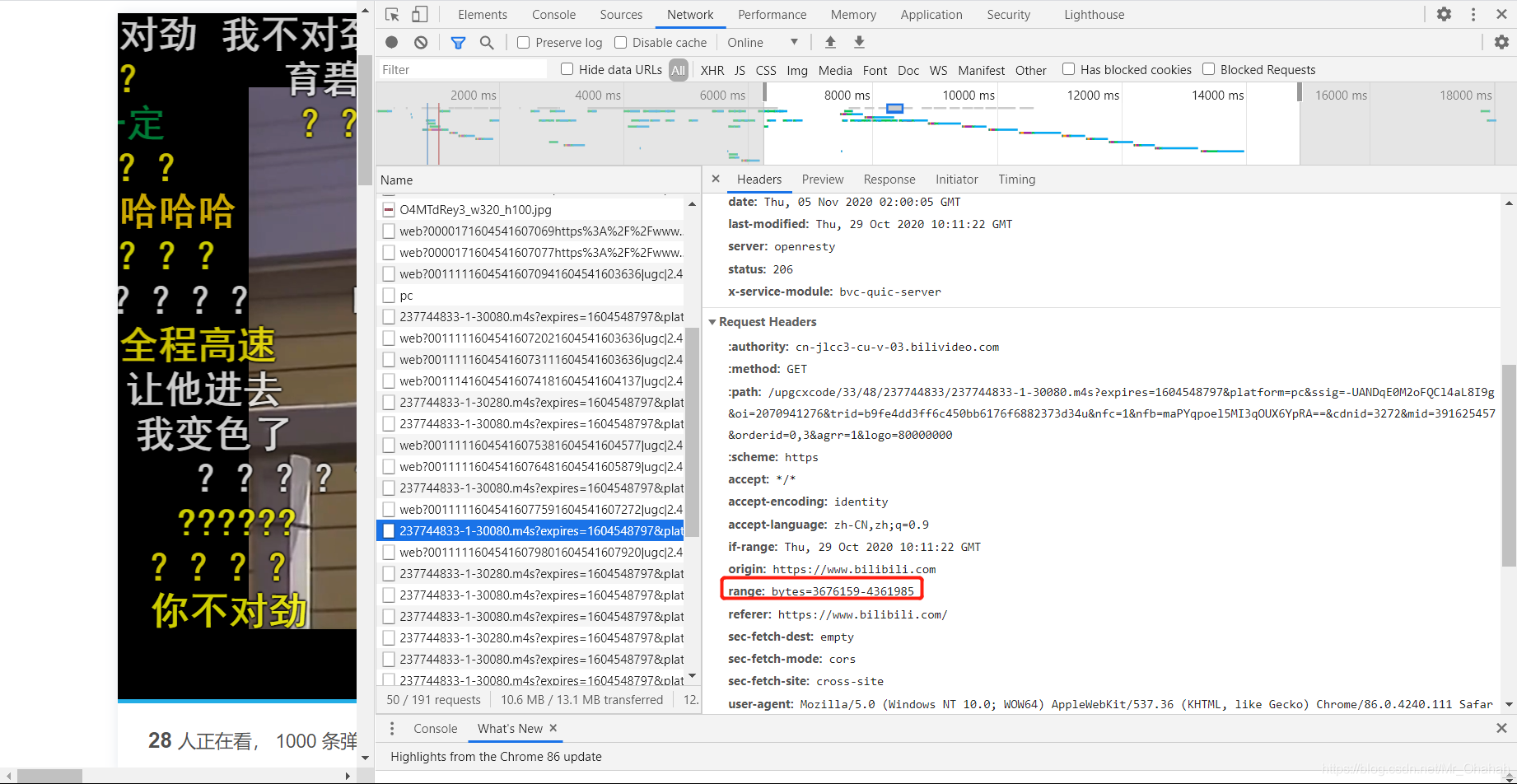
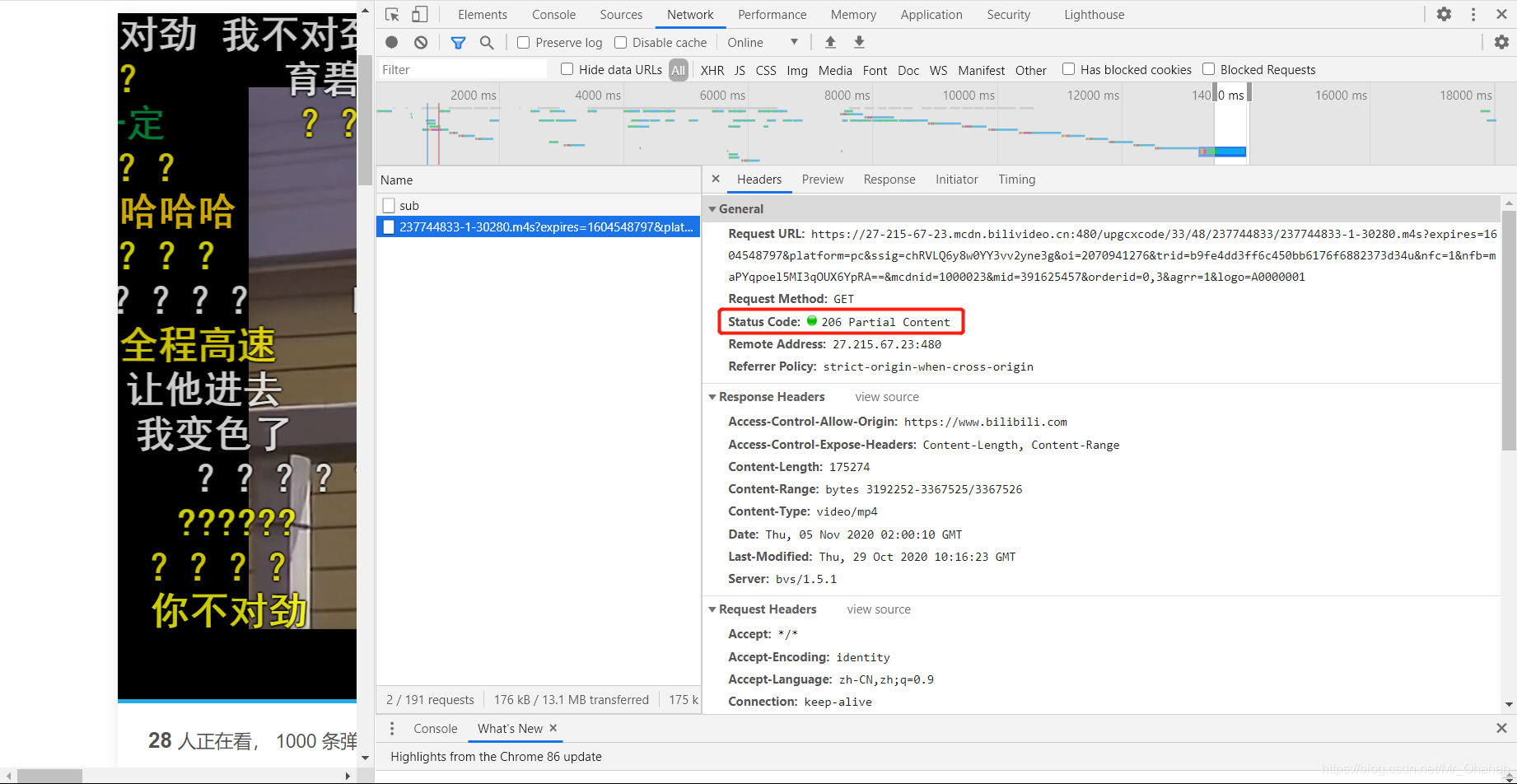
此外,当所有数据传输完成后,播放将结束。此时网站给出的http状态码基本达到206:
现在我们的下载操作很明显:
1. 冒充浏览器的身份
2. 发出固定范围请求
3. 将获取的信息写入文件
def fileDownload(homeurl, url, title, typ):
# 添加请求头键值对,写上 refered:请求来源
headers = {
"user-agent": 这个地方还是照旧填写你的浏览器身份信息
}
headers.update({'Referer': homeurl})
if typ==0:
filename = "./"+title+".flv"
else:
filename = "./"+title+".mp3"
res = requests.Session()
# 指定每次下载1M的数据
begin = 0
end = 1024*1024 - 1
flag = 0
while True:
# 添加请求头键值对,写上 range:请求字节范围
headers.update({'Range': 'bytes=' + str(begin) + '-' + str(end)})
# 获取视频分片
res = requests.get(url=url, headers=headers,verify=False)
if res.status_code != 416:
# 响应码不为416时有数据,由于我们不是b站服务器,最终那个数据包的请求range肯定会超出限度,所以传回来的http状态码是416而不是206
begin = end + 1
end = end + 1024*1024
else:
headers.update({'Range': str(end + 1) + '-'})
res = requests.get(url=url, headers=headers,verify=False)
flag=1
with open(filename, 'ab') as fp:
fp.write(res.content)
fp.flush()
if flag==1:
fp.close()
break
最后是主要功能:
def main():
print("欢迎来到bilibili爬资源小程序,接下来让我们开始吧\n(番剧爬取程序正在持续开发中...)")
bv=input("输入视频bv号: ")
judge = input("你想获得一系列(y)视频还是一个单一(N)视频?\n[y/N]\n")
if judge == "y":
max = int(input("输入该系列视频的总数: "))
for p in range(1,max+1):
baseurl = "https://www.bilibili.com/video/BV"+str(bv)+"?p="+str(p)
getVideo(baseurl,p)
else:
p=input("如果是系列视频,请任选一集输入视频p号如果不是系列视频,请输入'1'\n")
baseurl = "https://www.bilibili.com/video/BV"+str(bv)+"?p="+str(p)
getVideo(baseurl,p)
os.system("pause")
# 亲们main()肯定得调用啊,这是基本的语法知识昂,我之前没写不代表不用底下这两行话啊!各位记得自己加上这句啊2333
if __name__ == "__main__":
main() 查看全部
网页视频抓取软件 格式工厂(完全小白篇-使用Python爬取bv号视频哔哩哔哩号
)
完全白篇——使用Python爬取bv视频
B站相信大家都很熟悉了。这次想尝试直接爬B站的视频,但是搜了很多文章的博客,看来还是在B站还在用av号的时代。,所以这次想看看能不能爬取bv号的视频。
找B站的视频
BV号是B站自2020年3月23日起升级的视频码,BV号完全替代了之前的AV号,功能不变。既然网站都用了BV号,随便找个视频先看看情况:
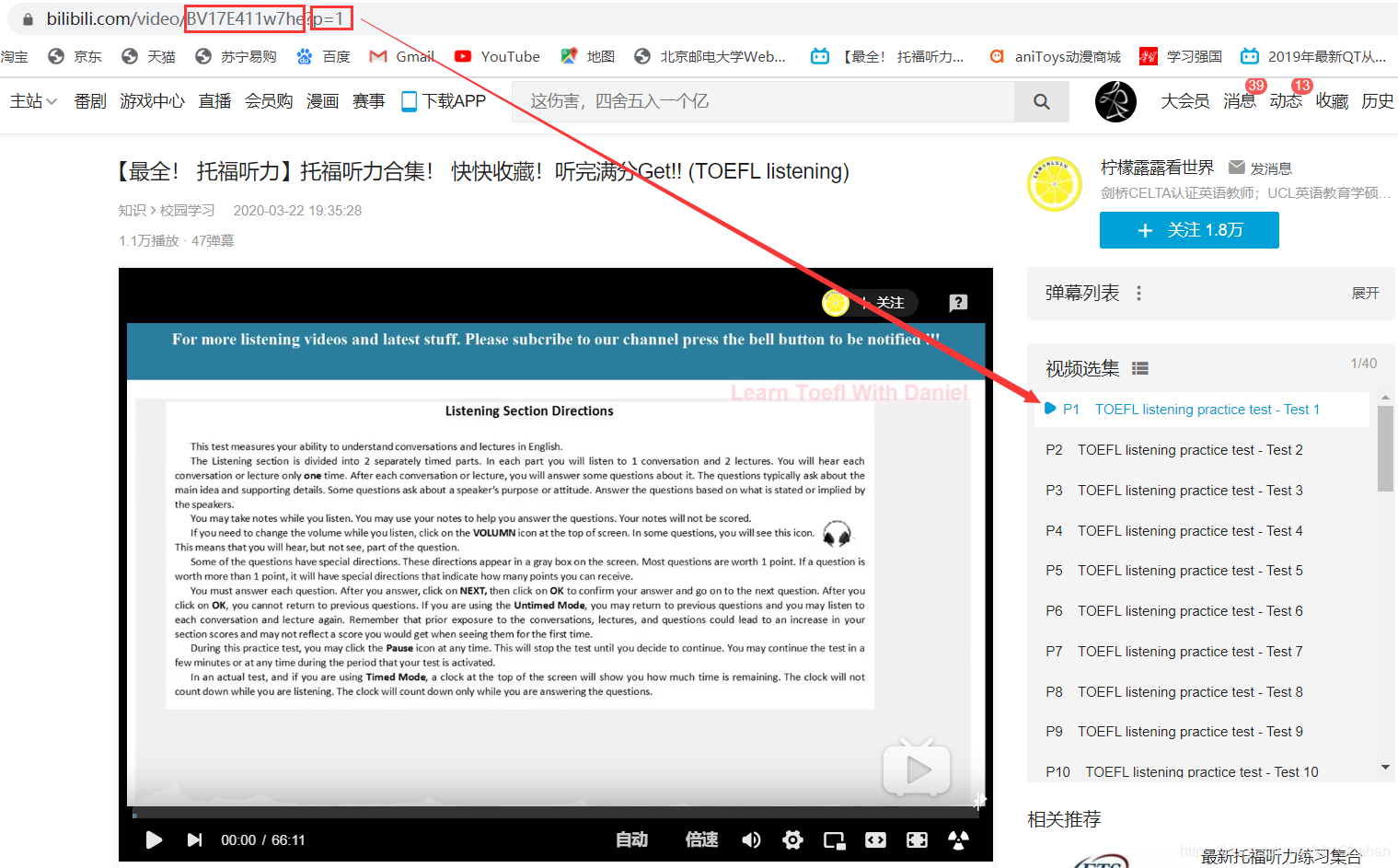
对于单个视频,您无需查看 BV 编号后跟大字符串的内容。单个视频就是1的p序号。对于一个系列的视频来说,BV序号是固定的,不同的剧集对应不同的p序号,所以只要确定了BV序号和p序号,就可以定位视频的网页。
分析网页信息
相信大家在来之前应该都知道网络视频是怎么播放的。我不会详细介绍这里的“url”是什么。如果要爬取视频,最重要的是能够获取视频和音频文件的url信息。以前的AV号好像是说视频和音频文件是合二为一的。BV号上线后,我们看到的视频其实是音视频分离的。因此,对于 BV 号视频,视频(.flv)和音频(.mp3) 应该一起获取。
我们先看网页的源码:

哎,我吐了,不过,直接用ctrl+F搜索,搜索“url”,


我们会在一个音频类中找到一个视频类和“baseUrl”、“base_url”、“backupUrl”、“backup_url”,其中baseUrl的内容就是对应的音视频url。所以只要拿到网页的源代码,就可以把这两个地方提取出来。
获取网页信息
1. 获取网页源代码
这一点我就不赘述了,把自己模仿成浏览器,使用请求库函数访问网页:
# 用到的库
import requests
from requests import RequestException
from lxml import etree
from contextlib import closing
from pyquery import PyQuery as pq
import re
import os
import json
import subprocess
def getHtml(baseurl):
head = { #模拟浏览器身份头向对方发送消息
"user-agent": 这个地方填写你的浏览器身份信息,这一点只需随便找个请求把对应的user-agent内容复制过来就行
}
try:
response = requests.get(url = baseurl, headers = head)
# 200表示服务器接受请求,会传回网页源代码,所以把文本内容传回来就行了
if response.status_code==200:
return response.text
except:
print("请求失败")
getHtml()函数的作用是返回这个网页的源代码,传入网页地址即可。例如上图中:“Sentence Break 5.0”
2. 下一步是处理网页的源代码
# 传入网址、p序列号。这里说明一下,我下载的视频在下载系列时直接用p号命名,方便起见所以这个函数要用p号
def getVideo(baseurl,p):
html = getHtml(baseurl)
doc = pq(html)
title = doc('#viewbox_report > h1 > span').text()
pattern = r'\window\.__playinfo__=(.*?)\'
result = re.findall(pattern, html)[0]
temp = json.loads(result)
print(("开始下载--->")+title)
title = str(p)
try:
video_url = temp['data']['dash']['video'][0]['baseUrl']
audio_url = temp['data']['dash']['audio'][0]['baseUrl']
fileDownload(homeurl=baseurl, url=video_url, title=title, typ=0)
fileDownload(homeurl=baseurl, url=audio_url, title=title, typ=1)
try:
combine(title)
except:
print("对不起,您的电脑中未安装ffmpeg,不予享受合成服务,您可以尝试使用格式工厂等其他方式\n")
# 这个是针对av号的,还没试过
except Exception:
vedio_url = temp['data']['durl'][0]['url']
fileDownload(homeurl=baseurl, url=video_url, title=title, typ=0)
关注 video_url = temp['data']['dash']['video'][0]['baseUrl']。不适合一步获取 vedio:baseUrl 的内容,毕竟源码的内容太大了。所以再走一步,即先获取整个网页代码的一个小整体,然后再细分这个小整体中的每个成员。其实这部分源码在语法上就是一个Python字典,只不过这个字典中的对应收录了小字典、列表、元组等等。所以一步一步来,找到视音频的baseUrl在哪一层相信大家都能轻松实现。
(关于vedio_url = temp['data']['durl'][0]['url'],据说音视频集成在AV号(.mp4)中,当时的源码是这个关系可以找到url。)
根据url下载资源
所以最激动人心的部分来了:下载
音频和视频的下载必须单独下载。问题是现在只有 url。我们应该做什么?
当然,回到分析页面!
1. 探索规则
上图中的操作是用谷歌浏览器查看网页->刷新网页后得到的数据流。现在它处于暂停状态。我们发现,在下半场几次偶数流后,没有其他数据回传。同时,缓冲条也停留在图中的位置。可以看出,这些统一流必然收录音视频流。点击播放后,肯定会返回视频和音频流的数据,我们正在分析。
2. 验证规则
播放后,浏览器会周期性的接收到这样一个数据流,非常有规律,所以我们先只取其中的一部分。
因此,这些流是要分析的对象。
我们先来比较一下这三者之间的区别:相同的Request URL和其他信息,重要且相关的区别在于,
猜猜,这个范围的含义也很容易看出。所谓xy大概是指数据包中收录x到y的部分。然后再回到刚刚加载网页的时候,原来这种类型的流真的有范围:bytes=0-...这个项目!
此外,当所有数据传输完成后,播放将结束。此时网站给出的http状态码基本达到206:
现在我们的下载操作很明显:
1. 冒充浏览器的身份
2. 发出固定范围请求
3. 将获取的信息写入文件
def fileDownload(homeurl, url, title, typ):
# 添加请求头键值对,写上 refered:请求来源
headers = {
"user-agent": 这个地方还是照旧填写你的浏览器身份信息
}
headers.update({'Referer': homeurl})
if typ==0:
filename = "./"+title+".flv"
else:
filename = "./"+title+".mp3"
res = requests.Session()
# 指定每次下载1M的数据
begin = 0
end = 1024*1024 - 1
flag = 0
while True:
# 添加请求头键值对,写上 range:请求字节范围
headers.update({'Range': 'bytes=' + str(begin) + '-' + str(end)})
# 获取视频分片
res = requests.get(url=url, headers=headers,verify=False)
if res.status_code != 416:
# 响应码不为416时有数据,由于我们不是b站服务器,最终那个数据包的请求range肯定会超出限度,所以传回来的http状态码是416而不是206
begin = end + 1
end = end + 1024*1024
else:
headers.update({'Range': str(end + 1) + '-'})
res = requests.get(url=url, headers=headers,verify=False)
flag=1
with open(filename, 'ab') as fp:
fp.write(res.content)
fp.flush()
if flag==1:
fp.close()
break
最后是主要功能:
def main():
print("欢迎来到bilibili爬资源小程序,接下来让我们开始吧\n(番剧爬取程序正在持续开发中...)")
bv=input("输入视频bv号: ")
judge = input("你想获得一系列(y)视频还是一个单一(N)视频?\n[y/N]\n")
if judge == "y":
max = int(input("输入该系列视频的总数: "))
for p in range(1,max+1):
baseurl = "https://www.bilibili.com/video/BV"+str(bv)+"?p="+str(p)
getVideo(baseurl,p)
else:
p=input("如果是系列视频,请任选一集输入视频p号如果不是系列视频,请输入'1'\n")
baseurl = "https://www.bilibili.com/video/BV"+str(bv)+"?p="+str(p)
getVideo(baseurl,p)
os.system("pause")
# 亲们main()肯定得调用啊,这是基本的语法知识昂,我之前没写不代表不用底下这两行话啊!各位记得自己加上这句啊2333
if __name__ == "__main__":
main()
网页视频抓取软件 格式工厂(网页视频抓取软件格式工厂的应用技巧及解决方案介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-11 10:02
网页视频抓取软件格式工厂可以得到一个缩略图形式的链接。提取成播放列表每次只能保存一个,
一般分四个步骤,才能得到完整的网页。
1、解析html源码,得到标签和每个标签的属性值。
2、分析标签属性值,提取出每个标签下的元素。
3、将提取出来的元素分布到列表里。
4、可以根据列表里的元素生成视频代码。比如题主的问题是“网页视频抓取软件格式工厂”那么它自己会记录提取出来的元素对应的格式。只要提取出来的元素的属性里符合格式工厂判断的规则就可以,相同属性可以放在一个列表中。
利用html5的新特性,嵌入js代码的网页可以提取出源文件。然后做成php脚本,实现视频的浏览加速。
以前楼上也有人提到这个问题,其实我想说,快捷键加速(比如x-shift-s,c-shift-f)可以将html源文件中的prgviewer和c的引用提取出来,并且放到各个网页路径下。但如果仅仅一个页面html,加速不会起作用,格式工厂不支持通过加速将整个网页加速,它只是提取某些值以后,再用文本转化工具把这些值转化成网页代码。有人说可以先解析,再加速(有点类似tinypng),我不是特别清楚。有没有更好的解决方案?。
可以使用dev-c++,一般情况下能胜任所有工作。很简单的。一般情况下把pc端的(比如windows下就是xp浏览器),扫描到的js代码,放在dll目录下,这个文件当然可以是file(比如我要在android上运行它)也可以是include,比如vs2010之类的。以上,使用该函数进行。另外,你看到的网页也可以将其中的js代码关联起来,也可以用dr.fx.wx等同名函数,dr.fx.wx是重新拼接的整个js代码,dr.fx.wxanr.mx是dr.fx.wx参数1函数。 查看全部
网页视频抓取软件 格式工厂(网页视频抓取软件格式工厂的应用技巧及解决方案介绍)
网页视频抓取软件格式工厂可以得到一个缩略图形式的链接。提取成播放列表每次只能保存一个,
一般分四个步骤,才能得到完整的网页。
1、解析html源码,得到标签和每个标签的属性值。
2、分析标签属性值,提取出每个标签下的元素。
3、将提取出来的元素分布到列表里。
4、可以根据列表里的元素生成视频代码。比如题主的问题是“网页视频抓取软件格式工厂”那么它自己会记录提取出来的元素对应的格式。只要提取出来的元素的属性里符合格式工厂判断的规则就可以,相同属性可以放在一个列表中。
利用html5的新特性,嵌入js代码的网页可以提取出源文件。然后做成php脚本,实现视频的浏览加速。
以前楼上也有人提到这个问题,其实我想说,快捷键加速(比如x-shift-s,c-shift-f)可以将html源文件中的prgviewer和c的引用提取出来,并且放到各个网页路径下。但如果仅仅一个页面html,加速不会起作用,格式工厂不支持通过加速将整个网页加速,它只是提取某些值以后,再用文本转化工具把这些值转化成网页代码。有人说可以先解析,再加速(有点类似tinypng),我不是特别清楚。有没有更好的解决方案?。
可以使用dev-c++,一般情况下能胜任所有工作。很简单的。一般情况下把pc端的(比如windows下就是xp浏览器),扫描到的js代码,放在dll目录下,这个文件当然可以是file(比如我要在android上运行它)也可以是include,比如vs2010之类的。以上,使用该函数进行。另外,你看到的网页也可以将其中的js代码关联起来,也可以用dr.fx.wx等同名函数,dr.fx.wx是重新拼接的整个js代码,dr.fx.wxanr.mx是dr.fx.wx参数1函数。
网页视频抓取软件 格式工厂(格式工厂官方版如何使用的格式转换工具?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2022-03-10 20:24
格式工厂正式版是一款功能强大的格式转换工具。该软件支持所有多媒体格式的各种常用格式。它具有视频转换、音频转换、图像转换、视频合并和音频合并等高级功能。定义设置文件的输出配置,添加数字水印等功能。
软件功能
1、各类视频转MP4/3GP/MPG/AVI/WMV/FLV/SWF
2、所有类型的音频转MP3/WMA/AMR/OGG/AAC/WAV
3、所有图片类型转JPG/BMP/PNG/TIF/ICO/GIF/TGA
4、将 DVD 翻录到视频文件,将音乐 CD 翻录到音频文件
5、MP4文件支持iPod/iPhone/PSP/黑模等指定格式
6、支持RMVB、水印、音视频混合
软件功能
1、支持几乎所有类型的多媒体格式到几种常用格式
2、转换过程中可以修复一些损坏的视频文件
3、减肥多媒体文件
4、支持iPhone/iPod/PSP等多媒体指定格式
5、转换后的图片文件支持缩放、旋转、水印等功能
6、DVD视频采集功能,轻松备份DVD到本地硬盘
7、支持56种国家语言
常见问题
一、格式工厂需要注册吗?
格式工厂无需注册,无需收费,直接使用即可!
二、如何使用格式工厂?
格式工厂操作非常简单,只需按照以下步骤操作即可:
1、选择要转换成的格式,以“PNG”格式为例,打开软件后点击“PNG”;
2、添加文件/文件夹并点击确定;
3、"点击开始";
4、完成。
三、如何设置输出文件地址?
1、点击“任务”---“选项”;
2、选择目标地址。
四、如何设置转换后的文件?
可以根据需要单独设置输出文件,以图片“GIF”为例:
1、点击“输出配置”;
2、您可以根据自己的需要进行编辑。
变更日志
增加了音频文件的封面保存功能。
改进的 qsv 文件解码。
修复了 MKV 中保留源字幕流的错误。
简化的输出设置。
音视频分离器增加了范围选择功能。
添加了 FormatPlayer 解码选项。 查看全部
网页视频抓取软件 格式工厂(格式工厂官方版如何使用的格式转换工具?(一))
格式工厂正式版是一款功能强大的格式转换工具。该软件支持所有多媒体格式的各种常用格式。它具有视频转换、音频转换、图像转换、视频合并和音频合并等高级功能。定义设置文件的输出配置,添加数字水印等功能。

软件功能
1、各类视频转MP4/3GP/MPG/AVI/WMV/FLV/SWF
2、所有类型的音频转MP3/WMA/AMR/OGG/AAC/WAV
3、所有图片类型转JPG/BMP/PNG/TIF/ICO/GIF/TGA
4、将 DVD 翻录到视频文件,将音乐 CD 翻录到音频文件
5、MP4文件支持iPod/iPhone/PSP/黑模等指定格式
6、支持RMVB、水印、音视频混合
软件功能
1、支持几乎所有类型的多媒体格式到几种常用格式
2、转换过程中可以修复一些损坏的视频文件
3、减肥多媒体文件
4、支持iPhone/iPod/PSP等多媒体指定格式
5、转换后的图片文件支持缩放、旋转、水印等功能
6、DVD视频采集功能,轻松备份DVD到本地硬盘
7、支持56种国家语言
常见问题
一、格式工厂需要注册吗?
格式工厂无需注册,无需收费,直接使用即可!
二、如何使用格式工厂?
格式工厂操作非常简单,只需按照以下步骤操作即可:
1、选择要转换成的格式,以“PNG”格式为例,打开软件后点击“PNG”;

2、添加文件/文件夹并点击确定;

3、"点击开始";

4、完成。

三、如何设置输出文件地址?
1、点击“任务”---“选项”;

2、选择目标地址。

四、如何设置转换后的文件?
可以根据需要单独设置输出文件,以图片“GIF”为例:
1、点击“输出配置”;

2、您可以根据自己的需要进行编辑。

变更日志
增加了音频文件的封面保存功能。
改进的 qsv 文件解码。
修复了 MKV 中保留源字幕流的错误。
简化的输出设置。
音视频分离器增加了范围选择功能。
添加了 FormatPlayer 解码选项。
网页视频抓取软件 格式工厂( 支持的格式markdown一种-plugin-F-port-format)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-03-06 06:08
支持的格式markdown一种-plugin-F-port-format)
什么是 zignis-plugin-read?
这是一个简单的工具插件。目的是实现一个命令行工具,可以方便的获取网页主体,让我们可以通过多种方式采集整理学习资料,支持多种格式,有一些特色模式,这里也叫为简单起见。它是格式。
支持格式 markdown 纯文本标记语言 pdf 便携文件格式 html 生成html页面文件 png 无损压缩位图图形格式 jpeg 有损压缩图像格式 less epub电子书格式mobi亚马逊电子书格式控制台直接输出markdown到终端,可按需处理
主要参数--version显示版本号--format,-F需要转换的格式--read-only,--ro只渲染html,配合web格式使用--debug调试--port代理,如作为抢掘金 文章 中的图片需要打开 --localhost localhost 端口 --open-browser, --ob 网页格式自动打开浏览器 --rename 获得 文章Rename --dir 获得< @文章存储本地位置
安装
$ npm i -g zignis zignis-plugin-read
# 默认会下载 puppeteer,比较慢,加上这个环境变量就不下了,也可以 `Ctrl+C` 取消下载
# 没有 puppeterr, `html`, `png`, `jpeg` 和 `pdf` 就不能工作了。
$ PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=true npm i -g zignis zignis-plugin-read
# 用法
$ zignis read [URL|本地 markdown] --format=[FORMAT]
# 帮助
$ zignis read [url]
例子
# 获取掘金一篇文章
$ zignis read https://juejin.im/post/5dd6a8106fb9a05a7f75fe74
# 获取掘金一篇文章,转换为 markdown 格式
$ zignis read https://juejin.im/post/5dd6a8106fb9a05a7f75fe74 --format=markdown
# 打开一个空的 markdown 编辑器
$ zignis read --format=web
# 欣赏一下自己项目的 README
$ zignis read README.md
获取文章并转换成微信公众号支持的格式
# 安装
$ npm i -g zignis zignis-plugin-read zignis-plugin-read-extend-format-wechat
# 例子,抓取掘金文章,并使用代理获取文章中图片
$ zignis read https://juejin.im/post/5dd6a8106fb9a05a7f75fe74 --format=wechat --proxy
网站 目前适合网页正文转换
在开发过程中,发现默认的行为总是不尽如人意,需要有针对性的调优。目前对下面的网站只做了基础调优,不保证绝对没有问题。
已知错误
项目地址 查看全部
网页视频抓取软件 格式工厂(
支持的格式markdown一种-plugin-F-port-format)
什么是 zignis-plugin-read?
这是一个简单的工具插件。目的是实现一个命令行工具,可以方便的获取网页主体,让我们可以通过多种方式采集整理学习资料,支持多种格式,有一些特色模式,这里也叫为简单起见。它是格式。
支持格式 markdown 纯文本标记语言 pdf 便携文件格式 html 生成html页面文件 png 无损压缩位图图形格式 jpeg 有损压缩图像格式 less epub电子书格式mobi亚马逊电子书格式控制台直接输出markdown到终端,可按需处理
主要参数--version显示版本号--format,-F需要转换的格式--read-only,--ro只渲染html,配合web格式使用--debug调试--port代理,如作为抢掘金 文章 中的图片需要打开 --localhost localhost 端口 --open-browser, --ob 网页格式自动打开浏览器 --rename 获得 文章Rename --dir 获得< @文章存储本地位置
安装
$ npm i -g zignis zignis-plugin-read
# 默认会下载 puppeteer,比较慢,加上这个环境变量就不下了,也可以 `Ctrl+C` 取消下载
# 没有 puppeterr, `html`, `png`, `jpeg` 和 `pdf` 就不能工作了。
$ PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=true npm i -g zignis zignis-plugin-read
# 用法
$ zignis read [URL|本地 markdown] --format=[FORMAT]
# 帮助
$ zignis read [url]
例子
# 获取掘金一篇文章
$ zignis read https://juejin.im/post/5dd6a8106fb9a05a7f75fe74
# 获取掘金一篇文章,转换为 markdown 格式
$ zignis read https://juejin.im/post/5dd6a8106fb9a05a7f75fe74 --format=markdown
# 打开一个空的 markdown 编辑器
$ zignis read --format=web
# 欣赏一下自己项目的 README
$ zignis read README.md
获取文章并转换成微信公众号支持的格式
# 安装
$ npm i -g zignis zignis-plugin-read zignis-plugin-read-extend-format-wechat
# 例子,抓取掘金文章,并使用代理获取文章中图片
$ zignis read https://juejin.im/post/5dd6a8106fb9a05a7f75fe74 --format=wechat --proxy
网站 目前适合网页正文转换
在开发过程中,发现默认的行为总是不尽如人意,需要有针对性的调优。目前对下面的网站只做了基础调优,不保证绝对没有问题。
已知错误
项目地址
网页视频抓取软件 格式工厂(document_fromstring的使用方法(网页)(html字符串))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-28 18:04
狭义的爬虫只负责爬取,即下载网页。其实爬虫还负责从下载的网页中提取出我们想要的数据,也就是解析非结构化数据(网页)提取结构化数据(有用数据)。
所以,下载网页只是第一步,重要的一步就是数据的提取。不同的爬虫想要不同的数据,提取不同的数据,但是提取的方法是相似的。
提取数据的最简单方法是使用正则表达式。这种方法很简单,提取逻辑应该不复杂。否则写出来的正则表达式会晦涩难懂,甚至无法提取复杂的数据结构。
最终,经过多年的经验,老猿选择了lxml和xpath来解析网页,提取结构化数据。顺便说一句,BeautifulSoup 也是解析 HTML 的好工具。它可以使用多个解析器,比如Python标准库的解析器,但是速度比较慢。你也可以使用lxml作为解析器,但是它的用法,API和lxml不一样。用了之后,lxml的API就更舒服了。
lxml 绑定了 C 语言库 libxml2 和 libxslt,并提供了 Pythonic API。它有一些主要特点:
一句话总结,是一款集C语言的速度与Python的简洁于一身的神器。
lxml有两部分,分别支持XML和HTML的解析:
lxml.etree 可用于解析 RSS 提要,这些提要是 XML 格式的文档。不过爬取的网页大部分都是html页面,所以这里主要介绍lxml.html解析网页的方法。
lxml.html 从 html 字符串生成文档树结构
我们下载的网页是一串html字符串。如何将其输入到 lxml.html 模块中生成 html 文档的树形结构?
该模块提供了几种不同的方法:
下面我们用具体的例子来说明上述方法的区别。
如何使用 document_fromstring
In [1]: import lxml.html as lh
In [2]: z = lh.document_fromstring('abcxyz')
# 可以看到,它自动加了根节点
In [3]: z
Out[3]:
In [4]: z.tag
Out[4]: 'html'
# 还加了节点
In [5]: z.getchildren()
Out[5]: []
# 把字符串的两个节点放在了里面
In [6]: z.getchildren()[0].getchildren()
Out[6]: [, ]
使用 fragment_fromstring
In [11]: z = lh.fragment_fromstring(‘abcxyz’)
---------------------------------------------------------------------------
ParserError Traceback (most recent call last)
in ()
----> 1 z = lh.fragment_fromstring(‘abcxyz’)
~/.virtualenvs/py3.6/lib/python3.6/site-packages/lxml/html/__init__.py in fragment_fromstring(html, create_parent, base_url, parser, **kw)
850 raise etree.ParserError(
851 “Multiple elements found (%s)”
--> 852 % ‘, ‘.join([_element_name(e) for e in elements]))
853 el = elements[0]
854 if el.tail and el.tail.strip():
ParserError: Multiple elements found (div, div)
# 可以看到,输入是两个节点(element)时就会报错
# 如果加上 create_parent 参数,就没问题了
In [12]: z = lh.fragment_fromstring('abcxyz', create_parent='p')
In [13]: z.tag
Out[13]: 'p'
In [14]: z.getchildren()
Out[14]: [, ]
使用fragments_fromstring
# 输入字符串含有一个节点,则返回包含这一个节点的列表
In [17]: lh.fragments_fromstring('abc')
Out[17]: []
# 输入字符串含有多个节点,则返回包含这多个节点的列表
In [18]: lh.fragments_fromstring('abcxyz')
Out[18]: [, ]
从字符串的使用
In [27]: z = lh.fromstring('abcxyz')
In [28]: z
Out[28]:
In [29]: z.getchildren()
Out[29]: [, ]
In [30]: type(z)
Out[30]: lxml.html.HtmlElement
这里,如果fromstring输入是多个节点,则会添加一个父节点并返回。但是就像 html 网页从节点开始一样,我们可以使用 fromstring() 和 document_fromstring() 来获得完整的网页结构。
从上面的代码我们可以看出,那些函数返回的是HtmlElement对象,也就是说,我们已经学会了如何从html字符串中获取HtmlElement对象。在下一节中,我们将学习如何操作 HtmlElement 对象,从中提取我们感兴趣的数据。 查看全部
网页视频抓取软件 格式工厂(document_fromstring的使用方法(网页)(html字符串))
狭义的爬虫只负责爬取,即下载网页。其实爬虫还负责从下载的网页中提取出我们想要的数据,也就是解析非结构化数据(网页)提取结构化数据(有用数据)。
所以,下载网页只是第一步,重要的一步就是数据的提取。不同的爬虫想要不同的数据,提取不同的数据,但是提取的方法是相似的。
提取数据的最简单方法是使用正则表达式。这种方法很简单,提取逻辑应该不复杂。否则写出来的正则表达式会晦涩难懂,甚至无法提取复杂的数据结构。
最终,经过多年的经验,老猿选择了lxml和xpath来解析网页,提取结构化数据。顺便说一句,BeautifulSoup 也是解析 HTML 的好工具。它可以使用多个解析器,比如Python标准库的解析器,但是速度比较慢。你也可以使用lxml作为解析器,但是它的用法,API和lxml不一样。用了之后,lxml的API就更舒服了。
lxml 绑定了 C 语言库 libxml2 和 libxslt,并提供了 Pythonic API。它有一些主要特点:
一句话总结,是一款集C语言的速度与Python的简洁于一身的神器。
lxml有两部分,分别支持XML和HTML的解析:
lxml.etree 可用于解析 RSS 提要,这些提要是 XML 格式的文档。不过爬取的网页大部分都是html页面,所以这里主要介绍lxml.html解析网页的方法。
lxml.html 从 html 字符串生成文档树结构
我们下载的网页是一串html字符串。如何将其输入到 lxml.html 模块中生成 html 文档的树形结构?
该模块提供了几种不同的方法:
下面我们用具体的例子来说明上述方法的区别。
如何使用 document_fromstring
In [1]: import lxml.html as lh
In [2]: z = lh.document_fromstring('abcxyz')
# 可以看到,它自动加了根节点
In [3]: z
Out[3]:
In [4]: z.tag
Out[4]: 'html'
# 还加了节点
In [5]: z.getchildren()
Out[5]: []
# 把字符串的两个节点放在了里面
In [6]: z.getchildren()[0].getchildren()
Out[6]: [, ]
使用 fragment_fromstring
In [11]: z = lh.fragment_fromstring(‘abcxyz’)
---------------------------------------------------------------------------
ParserError Traceback (most recent call last)
in ()
----> 1 z = lh.fragment_fromstring(‘abcxyz’)
~/.virtualenvs/py3.6/lib/python3.6/site-packages/lxml/html/__init__.py in fragment_fromstring(html, create_parent, base_url, parser, **kw)
850 raise etree.ParserError(
851 “Multiple elements found (%s)”
--> 852 % ‘, ‘.join([_element_name(e) for e in elements]))
853 el = elements[0]
854 if el.tail and el.tail.strip():
ParserError: Multiple elements found (div, div)
# 可以看到,输入是两个节点(element)时就会报错
# 如果加上 create_parent 参数,就没问题了
In [12]: z = lh.fragment_fromstring('abcxyz', create_parent='p')
In [13]: z.tag
Out[13]: 'p'
In [14]: z.getchildren()
Out[14]: [, ]
使用fragments_fromstring
# 输入字符串含有一个节点,则返回包含这一个节点的列表
In [17]: lh.fragments_fromstring('abc')
Out[17]: []
# 输入字符串含有多个节点,则返回包含这多个节点的列表
In [18]: lh.fragments_fromstring('abcxyz')
Out[18]: [, ]
从字符串的使用
In [27]: z = lh.fromstring('abcxyz')
In [28]: z
Out[28]:
In [29]: z.getchildren()
Out[29]: [, ]
In [30]: type(z)
Out[30]: lxml.html.HtmlElement
这里,如果fromstring输入是多个节点,则会添加一个父节点并返回。但是就像 html 网页从节点开始一样,我们可以使用 fromstring() 和 document_fromstring() 来获得完整的网页结构。
从上面的代码我们可以看出,那些函数返回的是HtmlElement对象,也就是说,我们已经学会了如何从html字符串中获取HtmlElement对象。在下一节中,我们将学习如何操作 HtmlElement 对象,从中提取我们感兴趣的数据。
网页视频抓取软件 格式工厂(安大多数格式转换神器3G2转换,音频格式转换)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-27 21:13
应用介绍
格式工厂最新正式版是一个格式转换神器。本软件为您提供图片格式jpg、gif、bmp、jpeg、png的转换,视频格式3GP、3G2、MPEG转换、音频格式提取。, 听这首歌。支持多种手机型号,本软件完全免费为大家提供服务。
格式工厂官方最新版软件功能
支持压缩以减小视频文件的大小,方便通过短信等方式发送。
您可以设置在转换视频时保持原创视频质量
高级模式可用:可指定视频码率、任意分辨率、音频码率、编解码器等
支持从专辑/专辑/Dropbox/iCloud/Google驱动器/一个驱动器等导入视频/音频;
格式工厂官方最新版软件功能
图片格式转换:转换图片格式,支持输出格式jpg、gif、bmp、jpeg、png、wmf、webp等。
视频转换器:转换视频格式,支持输出格式MP4、MOV、3GP、3G2、MPEG、WMV、FLV等。
音频提取器:从视频中提取音频,支持输出格式 MP3、M4A、WMA、AAC、M4R 等。
音频格式转换:音频转换格式,支持输出格式MP3、M4A、FLAC、WMA、AAC、M4R等。
内置全能播放器,可播放大部分视频格式
转换后的格式完美支持大部分安卓机型
格式工厂官方最新版软件评测
这个可以提供多种格式的转换,让你看到不同的视频和音频,试试吧 查看全部
网页视频抓取软件 格式工厂(安大多数格式转换神器3G2转换,音频格式转换)
应用介绍
格式工厂最新正式版是一个格式转换神器。本软件为您提供图片格式jpg、gif、bmp、jpeg、png的转换,视频格式3GP、3G2、MPEG转换、音频格式提取。, 听这首歌。支持多种手机型号,本软件完全免费为大家提供服务。

格式工厂官方最新版软件功能
支持压缩以减小视频文件的大小,方便通过短信等方式发送。
您可以设置在转换视频时保持原创视频质量
高级模式可用:可指定视频码率、任意分辨率、音频码率、编解码器等
支持从专辑/专辑/Dropbox/iCloud/Google驱动器/一个驱动器等导入视频/音频;
格式工厂官方最新版软件功能
图片格式转换:转换图片格式,支持输出格式jpg、gif、bmp、jpeg、png、wmf、webp等。
视频转换器:转换视频格式,支持输出格式MP4、MOV、3GP、3G2、MPEG、WMV、FLV等。
音频提取器:从视频中提取音频,支持输出格式 MP3、M4A、WMA、AAC、M4R 等。
音频格式转换:音频转换格式,支持输出格式MP3、M4A、FLAC、WMA、AAC、M4R等。
内置全能播放器,可播放大部分视频格式
转换后的格式完美支持大部分安卓机型
格式工厂官方最新版软件评测
这个可以提供多种格式的转换,让你看到不同的视频和音频,试试吧
网页视频抓取软件 格式工厂(问题分析手机录制的格式化工厂转码的视频编码和Vorbis音频编码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-25 17:17
)
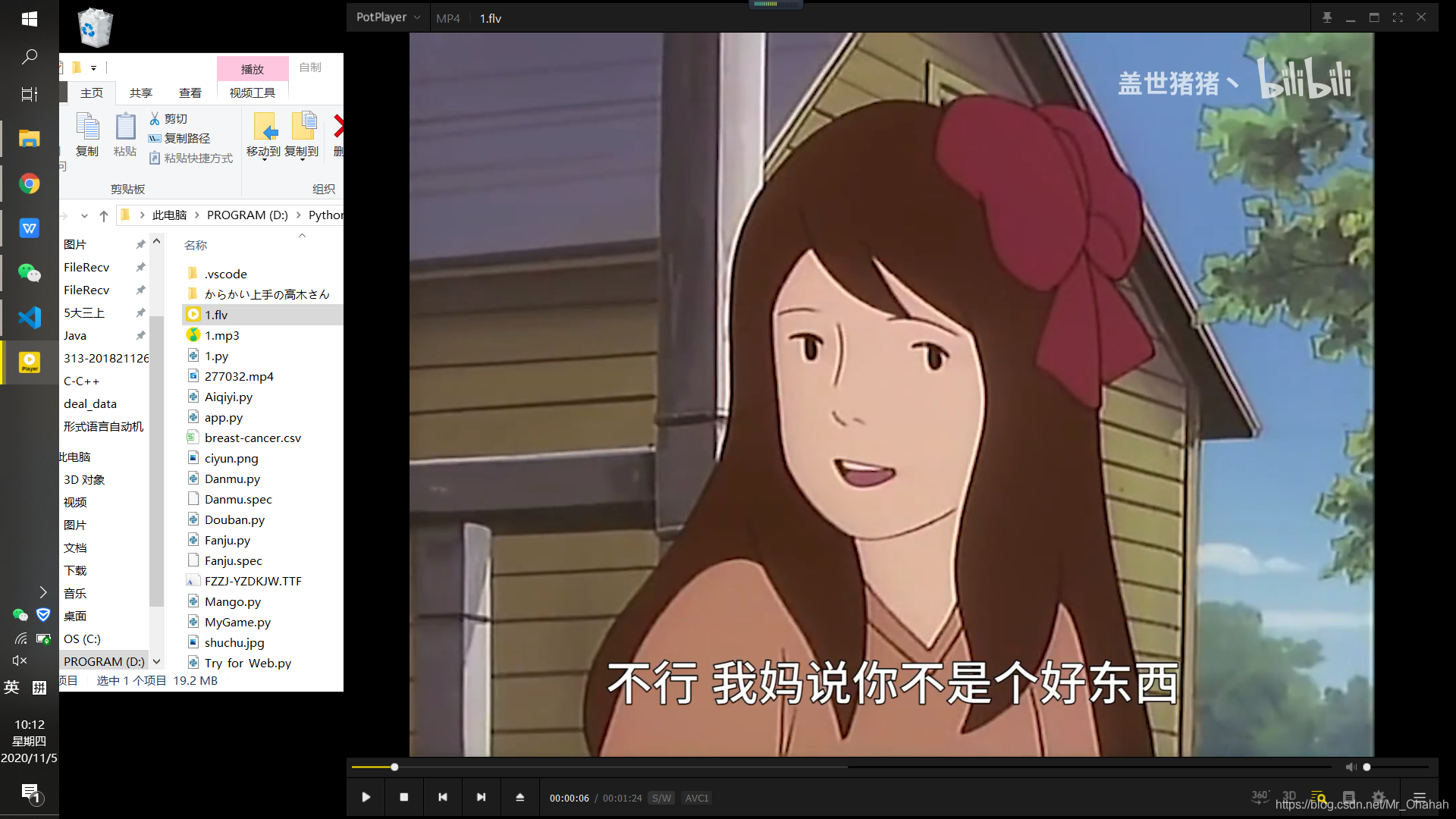
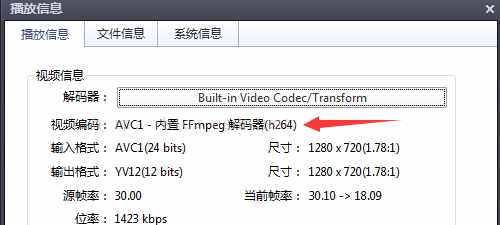
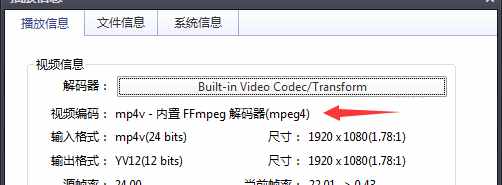
本文文章主要介绍html5中video标签无法播放mp4问题的解决方法。需要的朋友,一起来看看吧。
最近发现一个问题,在手机上录制了一个1.mp4文件,主流浏览器都可以正常播放。但是使用格式工厂将 rmvb 文件转码为 2.mp4 无法播放。我终于通过查找相关信息解决了它。我们来看看详细介绍:
问题分析
手机录制的视频属性:
格式工厂转码视频属性:
首先排除代码问题、路径问题、浏览器不支持问题等。转码后的视频编码为mp4v,是无法播放的原因。将其转换为 AVC(H264)编码。
查看视频标签支持的视频格式和编码的文档:
MPEG4 = 具有 H.264 视频编码和 AAC 音频编码的 MPEG4 文件
WebM = 带有 VP8 视频编码和 Vorbis 音频编码的 WebM 文件
Ogg = 带有 Theora 视频编码和 Vorbis 音频编码的 Ogg 文件
通过以上信息,我们发现只有h264编码的MP4视频(MPEG-LA公司)、VP8编码的webm格式视频()和Theora编码的ogg格式视频(iTouch开发)可以支持html5标签。
解决方案
video 标签允许多个源元素。源元素可以链接到不同的视频文件。浏览器会使用第一个识别的格式,可以用来解决浏览器的兼容性问题。
查看全部
网页视频抓取软件 格式工厂(问题分析手机录制的格式化工厂转码的视频编码和Vorbis音频编码
)
本文文章主要介绍html5中video标签无法播放mp4问题的解决方法。需要的朋友,一起来看看吧。
最近发现一个问题,在手机上录制了一个1.mp4文件,主流浏览器都可以正常播放。但是使用格式工厂将 rmvb 文件转码为 2.mp4 无法播放。我终于通过查找相关信息解决了它。我们来看看详细介绍:
问题分析
手机录制的视频属性:
格式工厂转码视频属性:
首先排除代码问题、路径问题、浏览器不支持问题等。转码后的视频编码为mp4v,是无法播放的原因。将其转换为 AVC(H264)编码。
查看视频标签支持的视频格式和编码的文档:
MPEG4 = 具有 H.264 视频编码和 AAC 音频编码的 MPEG4 文件
WebM = 带有 VP8 视频编码和 Vorbis 音频编码的 WebM 文件
Ogg = 带有 Theora 视频编码和 Vorbis 音频编码的 Ogg 文件
通过以上信息,我们发现只有h264编码的MP4视频(MPEG-LA公司)、VP8编码的webm格式视频()和Theora编码的ogg格式视频(iTouch开发)可以支持html5标签。
解决方案
video 标签允许多个源元素。源元素可以链接到不同的视频文件。浏览器会使用第一个识别的格式,可以用来解决浏览器的兼容性问题。

网页视频抓取软件 格式工厂(狸窝全能视频转换器破解版V8.1绿色免费版下载体验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-02-25 01:10
格式工厂绿色版是一款功能强大的视频格式转换软件。它具有超强的转换能力,支持多种视频格式,还支持图片和文档类型的转换。它是用户最常用的转换软件。格式工厂绿色版无需安装,下载解压即可使用。本站带给你的是无广告版,使用更方便!欢迎下载体验。
格式工厂绿色特点:
支持几乎所有类型的多媒体格式
支持各类视频、音频、图片等格式,轻松转换为您想要的格式。
修复损坏的视频文件
在转换过程中,可以修复损坏的文件,使转换质量不受损。
用于减肥的多媒体文件
它可以帮助您的文件减轻重量,使它们变瘦。不仅节省硬盘空间,而且易于保存和备份。
可以指定格式
支持iphone/ipod/psp等多媒体指定格式。
支持图片常用功能
转换图片支持缩放、旋转、加水印等常用功能,操作一气呵成。
备份很简单
DVD视频捕捉功能,轻松备份DVD到本地硬盘。
支持多种语言
它支持62种国家语言,易于访问,满足各种需求。
支持的转换格式:
mp4、3gp、mpg、avi、wmv、flv、swf、jpg、bmp、png、tif、ico、gif、tga、mp3、wma、amr、ogg、aac、wav
格式工厂绿色版功能
进入主界面工具栏:home键(push wps)
进入主界面图片功能区:图片工厂下载按钮;
删除图片工厂在线安装程序、FFZ压缩文件管理器;
进入升级,进入选项检查更新项,进入菜单项检查更新;
变更日志:版本 5.6.5.0
注意:新版本的格式工厂不再支持 32 位系统。如果需要32位系统,需要下载Format Factory4.9.5版本如果是XP系统,则需要下载Format Factory3.8
上一篇:AMV格式转换器免费版 | AMV视频格式转换器v3.0中文绿色版
下一篇: Beaver Nest 全能视频转换器破解版 V8.1 绿色免费版 查看全部
网页视频抓取软件 格式工厂(狸窝全能视频转换器破解版V8.1绿色免费版下载体验)
格式工厂绿色版是一款功能强大的视频格式转换软件。它具有超强的转换能力,支持多种视频格式,还支持图片和文档类型的转换。它是用户最常用的转换软件。格式工厂绿色版无需安装,下载解压即可使用。本站带给你的是无广告版,使用更方便!欢迎下载体验。

格式工厂绿色特点:
支持几乎所有类型的多媒体格式
支持各类视频、音频、图片等格式,轻松转换为您想要的格式。
修复损坏的视频文件
在转换过程中,可以修复损坏的文件,使转换质量不受损。
用于减肥的多媒体文件
它可以帮助您的文件减轻重量,使它们变瘦。不仅节省硬盘空间,而且易于保存和备份。
可以指定格式
支持iphone/ipod/psp等多媒体指定格式。
支持图片常用功能
转换图片支持缩放、旋转、加水印等常用功能,操作一气呵成。
备份很简单
DVD视频捕捉功能,轻松备份DVD到本地硬盘。
支持多种语言
它支持62种国家语言,易于访问,满足各种需求。
支持的转换格式:
mp4、3gp、mpg、avi、wmv、flv、swf、jpg、bmp、png、tif、ico、gif、tga、mp3、wma、amr、ogg、aac、wav
格式工厂绿色版功能
进入主界面工具栏:home键(push wps)
进入主界面图片功能区:图片工厂下载按钮;
删除图片工厂在线安装程序、FFZ压缩文件管理器;
进入升级,进入选项检查更新项,进入菜单项检查更新;
变更日志:版本 5.6.5.0
注意:新版本的格式工厂不再支持 32 位系统。如果需要32位系统,需要下载Format Factory4.9.5版本如果是XP系统,则需要下载Format Factory3.8
上一篇:AMV格式转换器免费版 | AMV视频格式转换器v3.0中文绿色版
下一篇: Beaver Nest 全能视频转换器破解版 V8.1 绿色免费版
网页视频抓取软件 格式工厂(,指定开始和结束位置3.支持(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-17 23:14
是一个功能强大的图片、音乐和视频格式转换软件。它主要用作转换相关视频格式的便捷工具。该软件可以帮助用户将自己的视频转换成他们需要的相关格式。简单方便的文件格式转换软件,基于移动智能终端的特点,引入多达20种音频、视频和图像格式相互转换,涵盖AAC、mp3.M4A、WMA、WAV、FLAC、MP< @4.MPG、AVI、WMV、ASX、MOV、M4V、VOB等多种类型,让用户可以根据自己的习惯和实际需要自由选择想要转换的文件格式。并且该软件还支持用户自定义输入目标文件格式,并将其转换为您喜欢的任何格式,超乎想象。, 功能比较多,有需要的朋友不要'
特征
1.内置强大的视频播放器,可以播放各种格式的视频。
2.指定开始和结束位置
3.支持从视频中提取音频
4.在没有网络的手机中转换
5.支持各类视频(3GP、FLV、MP4.MOV、MKV、AVI、MPG、MPEG、MXF等)
6.保存各种类型的音频(MP3.AAC、WAV、AIFF、OPUS 等)
7.支持视频文件的压缩和缩小,方便发送短信。
8.转换视频时,可以设置并保持原创视频质量
9.提供高级模式:可以指定视频码率、任意分辨率、音频码率、编解码器等。
10.APP支持从相册/相册/Dropbox/iCloud/Google Drive/one Drive导入视频/音频; 查看全部
网页视频抓取软件 格式工厂(,指定开始和结束位置3.支持(图))
是一个功能强大的图片、音乐和视频格式转换软件。它主要用作转换相关视频格式的便捷工具。该软件可以帮助用户将自己的视频转换成他们需要的相关格式。简单方便的文件格式转换软件,基于移动智能终端的特点,引入多达20种音频、视频和图像格式相互转换,涵盖AAC、mp3.M4A、WMA、WAV、FLAC、MP< @4.MPG、AVI、WMV、ASX、MOV、M4V、VOB等多种类型,让用户可以根据自己的习惯和实际需要自由选择想要转换的文件格式。并且该软件还支持用户自定义输入目标文件格式,并将其转换为您喜欢的任何格式,超乎想象。, 功能比较多,有需要的朋友不要'

特征
1.内置强大的视频播放器,可以播放各种格式的视频。
2.指定开始和结束位置
3.支持从视频中提取音频
4.在没有网络的手机中转换
5.支持各类视频(3GP、FLV、MP4.MOV、MKV、AVI、MPG、MPEG、MXF等)
6.保存各种类型的音频(MP3.AAC、WAV、AIFF、OPUS 等)
7.支持视频文件的压缩和缩小,方便发送短信。
8.转换视频时,可以设置并保持原创视频质量
9.提供高级模式:可以指定视频码率、任意分辨率、音频码率、编解码器等。
10.APP支持从相册/相册/Dropbox/iCloud/Google Drive/one Drive导入视频/音频;
网页视频抓取软件 格式工厂(百度站点地图能给搜索优化带来什么好处?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-16 08:15
所谓的网站maps,即网站maps,允许网站管理员在他们的网站上通知搜索引擎可用的页面。搜索引擎将首先抓取 网站 的 robots 文件。在这个文件中,还有一个很重要的内容,就是站点地图。其中,百度站点地图是指百度支持的收录标准,在原协议的基础上扩展而来。
百度站点地图的作用是告诉百度蜘蛛一个综合的站点链接,并通过站点地图优化自己的网站。百度站点地图分为三种格式:TXT文本格式、XML格式和hmtl索引格式。在 robots 文件中,告诉搜索引擎我有一个 网站 地图,而 网站 是这样的。
先说一下两个网站maps的区别
网站map 的 HTML 版本是用户可以看到的页面。它通常放在 网站 的顶部或底部。当部分用户输入网站 时,他们可以通过网站 映射快速进入一个部分。我这里要说的是,一些大的网站s 有太多的列,无法列出网站maps。
另一种是纯粹为了提高爬虫爬取效率而构建的XML网站map,通常会列出页面中网站的所有链接。网站 上的链接一旦蜘蛛进去就很容易被抓到。通常用于一些小的网站,网站 的链接布局结构不是很好。
HTML 地图对搜索优化有什么好处?
1、网站地图可以添加“入口点”到其他页面。
其实这是SEO推广中比较专业的概念。有人称之为“入口”。术语“度数”来自图论算法。它通常指有向图中的一个点到图中一条边的端点的次数之和。在SEO知识体系中,可以理解为页面的传入链接。作为一个网站map,它必须充满到其他页面的链接,这无疑增加了其他页面的传入链接。站点地图本身就是一个中心页面,可以作为一个很好的导航功能。
网站Map解决了网站内部链结构的一个方面,是SEO优化中不可忽视的重要作用。
2、网站地图为蜘蛛提供了良好的爬行路径。
搜索引擎的工作机制是每个蜘蛛在互联网上发布一个新的网页,然后通过自己的许多复杂的算法机制对这些网页进行排序。如果这些 网站 在互联网上不是很好,爬虫可以访问它们。毫无疑问,随着搜索引擎负担的增加,很难完全捕获网站的所有页面。网站地图的创建解决了这个问题。当爬虫访问 网站 时,他首先访问了机器人。如果我们用机器人记下网站map的地址,网站map上还会有很多其他的页面。这为爬虫爬取我们的 网站 创造了一种很好的方式,并使爬虫更容易爬取整个 网站 页面。
3、网站地图可以有效提高网页的抓取率。
其实我们仔细分析了我们的网站,发现还有大量的页面没有被收录。这些页面是搜索引擎无法掌握的地方,自然很难成为收录。通过网站图,我们可以提取网络推广中的隐藏页面,搜索引擎爬虫会按照网站图上的链接,一一抓取,从而增加整体的采集地点。
条目数与总页数的比率就是接受率。当两个站点的总页数相同时,有站点地图的站点的注册率明显高于没有站点地图的站点。从站点范围的 采集 角度来看,网站 地图发挥着重要作用。
4、网站 的 HTML 地图使访问者可以轻松导航以增强用户体验。
其实网络推广前期建立网站地图的目的,就是为了方便访问者浏览网站。页面涵盖了整个网站的所有版块(大网站)或页面(中小网站),让访问者能够快速找到自己需要的信息。 查看全部
网页视频抓取软件 格式工厂(百度站点地图能给搜索优化带来什么好处?(图))
所谓的网站maps,即网站maps,允许网站管理员在他们的网站上通知搜索引擎可用的页面。搜索引擎将首先抓取 网站 的 robots 文件。在这个文件中,还有一个很重要的内容,就是站点地图。其中,百度站点地图是指百度支持的收录标准,在原协议的基础上扩展而来。
百度站点地图的作用是告诉百度蜘蛛一个综合的站点链接,并通过站点地图优化自己的网站。百度站点地图分为三种格式:TXT文本格式、XML格式和hmtl索引格式。在 robots 文件中,告诉搜索引擎我有一个 网站 地图,而 网站 是这样的。
先说一下两个网站maps的区别
网站map 的 HTML 版本是用户可以看到的页面。它通常放在 网站 的顶部或底部。当部分用户输入网站 时,他们可以通过网站 映射快速进入一个部分。我这里要说的是,一些大的网站s 有太多的列,无法列出网站maps。
另一种是纯粹为了提高爬虫爬取效率而构建的XML网站map,通常会列出页面中网站的所有链接。网站 上的链接一旦蜘蛛进去就很容易被抓到。通常用于一些小的网站,网站 的链接布局结构不是很好。
HTML 地图对搜索优化有什么好处?
1、网站地图可以添加“入口点”到其他页面。
其实这是SEO推广中比较专业的概念。有人称之为“入口”。术语“度数”来自图论算法。它通常指有向图中的一个点到图中一条边的端点的次数之和。在SEO知识体系中,可以理解为页面的传入链接。作为一个网站map,它必须充满到其他页面的链接,这无疑增加了其他页面的传入链接。站点地图本身就是一个中心页面,可以作为一个很好的导航功能。
网站Map解决了网站内部链结构的一个方面,是SEO优化中不可忽视的重要作用。
2、网站地图为蜘蛛提供了良好的爬行路径。
搜索引擎的工作机制是每个蜘蛛在互联网上发布一个新的网页,然后通过自己的许多复杂的算法机制对这些网页进行排序。如果这些 网站 在互联网上不是很好,爬虫可以访问它们。毫无疑问,随着搜索引擎负担的增加,很难完全捕获网站的所有页面。网站地图的创建解决了这个问题。当爬虫访问 网站 时,他首先访问了机器人。如果我们用机器人记下网站map的地址,网站map上还会有很多其他的页面。这为爬虫爬取我们的 网站 创造了一种很好的方式,并使爬虫更容易爬取整个 网站 页面。
3、网站地图可以有效提高网页的抓取率。
其实我们仔细分析了我们的网站,发现还有大量的页面没有被收录。这些页面是搜索引擎无法掌握的地方,自然很难成为收录。通过网站图,我们可以提取网络推广中的隐藏页面,搜索引擎爬虫会按照网站图上的链接,一一抓取,从而增加整体的采集地点。
条目数与总页数的比率就是接受率。当两个站点的总页数相同时,有站点地图的站点的注册率明显高于没有站点地图的站点。从站点范围的 采集 角度来看,网站 地图发挥着重要作用。
4、网站 的 HTML 地图使访问者可以轻松导航以增强用户体验。
其实网络推广前期建立网站地图的目的,就是为了方便访问者浏览网站。页面涵盖了整个网站的所有版块(大网站)或页面(中小网站),让访问者能够快速找到自己需要的信息。
网页视频抓取软件 格式工厂(网站优化排名6大技巧,你知道几个?? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-04-12 04:38
)
网站优化排名的6个技巧
1、选择关键词:使用工具关键词planner来挖矿关键词;挖掘后,分析关键词的准确率、竞争力和搜索量。主要分析关键词的转化率和优化难度;后来确定关键词,首页大概5个字,栏目页关键词大概3个字。
2、设置关键词:在每个网页上设置确定的关键词。
首页和栏目页必须设置为关键词,首页为**关键词,栏目页为关键词与栏目内容相关。不要超过 80 个字符。
3、现场优化:URL结构优化:影响页面是否可以收录;影响页面排名关键词
站内链接结构:影响网站内部网页收录的搜索引擎效率,搜索引擎蜘蛛从一个网页链接到下一个网页。
制作网站的地图:xml格式,站点地图协议文件;html 格式,列出 网站 中的所有网页链接。提高搜索引擎对网站内容的抓取效率,网站的所有页面都存在网站地图链接。部分网站程序自带地图生成功能,如果没有,也可以使用第三方地图制作软件。
404错误页面是当用户输入错误的URL,无法找到页面时,可以根据404返回网站。
301重定向,即URL重定向。网站更换新域名时,通过301重定向将旧域名重定向到新域名,使旧域名的权重逐渐转移到新域名;网站通过将多个域名重定向到同一个域名,优化外包公司,实现权重集中在域名上。
robots.txt:存放在空间的根目录下,主要是告诉搜索引擎蜘蛛网站里面哪些内容可以抓取,哪些内容不能抓取。如果没有该文件,则说明网站的内容可以被爬取。常用函数有:User-agent蜘蛛名称,*表示所有蜘蛛;Disallow不允许抓取网页路径,省略域名,/表示根目录。添加 / 表示 网站 都不允许被捕获。
4、网站内容优化:跟上新内容,网站关键词优化公司,增加网站收录的数量;增加长尾关键词排名。
5、站外优化:友情链接、第三方平台。
6、站群seo:覆盖搜索引擎结果,使用第三方网站或自建多个网站。
强大的营销能力,覆盖多个平台
众所周知,网站在百度搜索中的排名位置越好,而影响排名的互联网系统的一个重要方面就是链接。不同类型的链接有不同的用途,但它们都有助于网站在搜索引擎中排名**。在科学家的共同努力下,犀牛云·网文战车通过6大人工智能机器人帮助用户定期发布文章内容,增强企业网站*照片的稳定性。
同时,英格拉姆是百度信息流、360信息流、搜狗信息流、微信广点通的广告合作伙伴,英格拉姆集团自身每年在这些平台上投入的广告费超过3000万,拥有较为丰富的第三-派对广告体验和资源渠道。Netwin Chariot通过结合AI算法机器人将这些经验和资源整合到产品中,帮助企业智能分析合适的投放渠道,为企业规划投放模式和内容,添加内链和外链,帮助企业在搜索引擎,免费广告联盟等平台带来精准流量,优化推广覆盖PC搜索、手机搜索、微信社区、QQ社区、微博社区等多个平台,
一、产品页面优化。同类型的产品很多,尤其是同一个产品,基本只是在几个参数上不同,所以在编辑内容的时候,会有很高的重复率和样板文字。这样的页面质量非常低,不利于收录,所以我们在编辑产品页面时可以根据不同的型号和代码来区分相似的产品。在内容编辑的过程中,关键词优化外包公司应该识别每个产品的特殊性,并将其与其他产品区分开来。这将使您能够区分相似的产品,这对 收录 更有利。当然,让'
二、案例页面优化。案例一般是用户购买产品后的反馈。我们可以将这些内容整理成文章,用图片说明,使用前后对比产品,展示产品的优势,从而促进用户转化。
三、问答页面优化。问答页面作为流量入口,是主要解决用户问题、满足用户需求的地方。因此,该栏目的内容必须有所区别。安徽网站优化公司,我没有人,人人有我优秀,提升页面附加值。请记住,这里的内容是关于最近的用户问题或关于产品的问题。不要填写公司内部新闻或行业咨询,只会让用户感到厌烦。
安徽卧龙网站宣传片(图)-网站关键词优化公司-安徽网站优化公司由提供。安徽卧龙网站促销(图)-网站关键词优化公司-安徽网站优化公司是今年推出的全新升级。以上图片仅供参考,您可以拨打本页或图片中的联系电话获取联系人:万少波。同时本公司()还从事合肥网络推广,合肥网络公司,安徽网络推广厂家,欢迎来电咨询。
查看全部
网页视频抓取软件 格式工厂(网站优化排名6大技巧,你知道几个??
)
网站优化排名的6个技巧
1、选择关键词:使用工具关键词planner来挖矿关键词;挖掘后,分析关键词的准确率、竞争力和搜索量。主要分析关键词的转化率和优化难度;后来确定关键词,首页大概5个字,栏目页关键词大概3个字。
2、设置关键词:在每个网页上设置确定的关键词。
首页和栏目页必须设置为关键词,首页为**关键词,栏目页为关键词与栏目内容相关。不要超过 80 个字符。
3、现场优化:URL结构优化:影响页面是否可以收录;影响页面排名关键词
站内链接结构:影响网站内部网页收录的搜索引擎效率,搜索引擎蜘蛛从一个网页链接到下一个网页。
制作网站的地图:xml格式,站点地图协议文件;html 格式,列出 网站 中的所有网页链接。提高搜索引擎对网站内容的抓取效率,网站的所有页面都存在网站地图链接。部分网站程序自带地图生成功能,如果没有,也可以使用第三方地图制作软件。
404错误页面是当用户输入错误的URL,无法找到页面时,可以根据404返回网站。
301重定向,即URL重定向。网站更换新域名时,通过301重定向将旧域名重定向到新域名,使旧域名的权重逐渐转移到新域名;网站通过将多个域名重定向到同一个域名,优化外包公司,实现权重集中在域名上。
robots.txt:存放在空间的根目录下,主要是告诉搜索引擎蜘蛛网站里面哪些内容可以抓取,哪些内容不能抓取。如果没有该文件,则说明网站的内容可以被爬取。常用函数有:User-agent蜘蛛名称,*表示所有蜘蛛;Disallow不允许抓取网页路径,省略域名,/表示根目录。添加 / 表示 网站 都不允许被捕获。
4、网站内容优化:跟上新内容,网站关键词优化公司,增加网站收录的数量;增加长尾关键词排名。
5、站外优化:友情链接、第三方平台。
6、站群seo:覆盖搜索引擎结果,使用第三方网站或自建多个网站。
强大的营销能力,覆盖多个平台
众所周知,网站在百度搜索中的排名位置越好,而影响排名的互联网系统的一个重要方面就是链接。不同类型的链接有不同的用途,但它们都有助于网站在搜索引擎中排名**。在科学家的共同努力下,犀牛云·网文战车通过6大人工智能机器人帮助用户定期发布文章内容,增强企业网站*照片的稳定性。
同时,英格拉姆是百度信息流、360信息流、搜狗信息流、微信广点通的广告合作伙伴,英格拉姆集团自身每年在这些平台上投入的广告费超过3000万,拥有较为丰富的第三-派对广告体验和资源渠道。Netwin Chariot通过结合AI算法机器人将这些经验和资源整合到产品中,帮助企业智能分析合适的投放渠道,为企业规划投放模式和内容,添加内链和外链,帮助企业在搜索引擎,免费广告联盟等平台带来精准流量,优化推广覆盖PC搜索、手机搜索、微信社区、QQ社区、微博社区等多个平台,
一、产品页面优化。同类型的产品很多,尤其是同一个产品,基本只是在几个参数上不同,所以在编辑内容的时候,会有很高的重复率和样板文字。这样的页面质量非常低,不利于收录,所以我们在编辑产品页面时可以根据不同的型号和代码来区分相似的产品。在内容编辑的过程中,关键词优化外包公司应该识别每个产品的特殊性,并将其与其他产品区分开来。这将使您能够区分相似的产品,这对 收录 更有利。当然,让'
二、案例页面优化。案例一般是用户购买产品后的反馈。我们可以将这些内容整理成文章,用图片说明,使用前后对比产品,展示产品的优势,从而促进用户转化。
三、问答页面优化。问答页面作为流量入口,是主要解决用户问题、满足用户需求的地方。因此,该栏目的内容必须有所区别。安徽网站优化公司,我没有人,人人有我优秀,提升页面附加值。请记住,这里的内容是关于最近的用户问题或关于产品的问题。不要填写公司内部新闻或行业咨询,只会让用户感到厌烦。
安徽卧龙网站宣传片(图)-网站关键词优化公司-安徽网站优化公司由提供。安徽卧龙网站促销(图)-网站关键词优化公司-安徽网站优化公司是今年推出的全新升级。以上图片仅供参考,您可以拨打本页或图片中的联系电话获取联系人:万少波。同时本公司()还从事合肥网络推广,合肥网络公司,安徽网络推广厂家,欢迎来电咨询。
网页视频抓取软件 格式工厂(格式工厂电脑版特色的视频文件转到MP4/3/)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-12 04:36
格式工厂PC版是一款免费的多功能多媒体处理工具,可以帮助您转换各种格式的文件,包括qsv\mkc\kux\qlv等多种文件格式。格式工厂PC版还提供了非常方便的批处理功能,界面非常简洁,使操作更简单。如果你喜欢它,请下载并尝试一下!
格式工厂 PC 功能
格式工厂支持将各种类型的视频文件转为 MP4/3GP/MPG/AVI/WMV/FLV/SWF。
支持所有类型的音频转换为 MP3/WMA/AMR/OGG/AAC/WAV。
格式工厂支持将所有类型的图像转换为 JPG/BMP/PNG/TIF/ICO/GIF/TGA。
可以将DVD翻录成视频文件,将音乐CD翻录成音频文件。
MP4 文件支持指定格式,例如 iPod/iPhone/PSP。
格式工厂支持RMVB、水印、音视频混合。
格式工厂 PC 功能
1、支持多种格式
格式工厂支持的视频格式非常广泛,从普通格式到iPhone/iPod/PSP等多媒体指定格式,几乎所有类型的多媒体格式都囊括在内;
2、修复函数
在转换过程中,格式工厂可以修复一些意外损坏的视频文件;
3、弹性提升
格式工厂允许多媒体文件灵活地“减肥”或“长大”(即提高或降低视频清晰度、帧率等);
4、图像转换
格式工厂可以转换图片,支持图片文件缩放、旋转、水印等功能;
5、DVD 翻录
格式工厂可以采集视频,用户可以通过此功能轻松将DVD备份到本地硬盘;
格式工厂 PC 质量保证
格式工厂软件转换 MP4 方法
1、首先,您在本站下载并安装格式工厂软件后,您可以在桌面上找到该软件的快捷方式。鼠标左键双击快捷方式打开软件,进入主界面。界面上有不同类型的转换格式。点击要转换的格式,进入详细转换界面。
2、编辑器以转换为MP4格式为例,点击上图中的MP4选项,然后进入转换界面,可以先点击添加文件或添加文件夹选项添加需要的文件转换成软件。添加后点击输出配置选项,设置文件类型、大小、质量等选项。设置完成后,需要点击界面下方的更改,选择合适的输出位置。设置完成后,我们可以点击界面上方的确定。选项,然后您可以耐心等待处理完成,然后您可以在设置的保存位置找到所需的文件。
格式工厂 PC 评论
操作简单,功能全面,使用非常方便! 查看全部
网页视频抓取软件 格式工厂(格式工厂电脑版特色的视频文件转到MP4/3/)
格式工厂PC版是一款免费的多功能多媒体处理工具,可以帮助您转换各种格式的文件,包括qsv\mkc\kux\qlv等多种文件格式。格式工厂PC版还提供了非常方便的批处理功能,界面非常简洁,使操作更简单。如果你喜欢它,请下载并尝试一下!
格式工厂 PC 功能
格式工厂支持将各种类型的视频文件转为 MP4/3GP/MPG/AVI/WMV/FLV/SWF。
支持所有类型的音频转换为 MP3/WMA/AMR/OGG/AAC/WAV。
格式工厂支持将所有类型的图像转换为 JPG/BMP/PNG/TIF/ICO/GIF/TGA。
可以将DVD翻录成视频文件,将音乐CD翻录成音频文件。
MP4 文件支持指定格式,例如 iPod/iPhone/PSP。
格式工厂支持RMVB、水印、音视频混合。
格式工厂 PC 功能
1、支持多种格式
格式工厂支持的视频格式非常广泛,从普通格式到iPhone/iPod/PSP等多媒体指定格式,几乎所有类型的多媒体格式都囊括在内;
2、修复函数
在转换过程中,格式工厂可以修复一些意外损坏的视频文件;
3、弹性提升
格式工厂允许多媒体文件灵活地“减肥”或“长大”(即提高或降低视频清晰度、帧率等);
4、图像转换
格式工厂可以转换图片,支持图片文件缩放、旋转、水印等功能;
5、DVD 翻录
格式工厂可以采集视频,用户可以通过此功能轻松将DVD备份到本地硬盘;
格式工厂 PC 质量保证
格式工厂软件转换 MP4 方法
1、首先,您在本站下载并安装格式工厂软件后,您可以在桌面上找到该软件的快捷方式。鼠标左键双击快捷方式打开软件,进入主界面。界面上有不同类型的转换格式。点击要转换的格式,进入详细转换界面。
2、编辑器以转换为MP4格式为例,点击上图中的MP4选项,然后进入转换界面,可以先点击添加文件或添加文件夹选项添加需要的文件转换成软件。添加后点击输出配置选项,设置文件类型、大小、质量等选项。设置完成后,需要点击界面下方的更改,选择合适的输出位置。设置完成后,我们可以点击界面上方的确定。选项,然后您可以耐心等待处理完成,然后您可以在设置的保存位置找到所需的文件。
格式工厂 PC 评论
操作简单,功能全面,使用非常方便!
网页视频抓取软件 格式工厂(格式工厂最新pc版特色版说明书下载地址下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-08 16:26
Format Factory PC版是一款非常好用的视频格式转换软件。用户可以在这里进行很多操作,帮助您轻松完成视频编辑、合成等操作。还是很不错的,可以轻松体验。格式工厂最新PC版的界面风格相当精致细腻。它似乎有不同的视觉效果。可以自由应用,相当不错。.
格式工厂最新 PC 版本的功能
1、多种功能集于一身,视频剪辑、合成等各种功能都可以在其中进行。是一款非常适合新手编辑的转换软件。
2、软件运行速度快,支持各类视频、音频、图片等格式,轻松转换成你想要的格式。
3、随心所欲地应用经验。在转换过程中,您可以修复损坏的文件,使转换质量不受损。
格式工厂最新PC版亮点
1、简单的操作是一个优势,它可以帮助你的文件“减肥”,让他们“瘦身”。两者都节省硬盘空间。
2、软件界面简洁,图片转换支持缩放、旋转、水印等常用功能,操作一气呵成。
3、这很有趣。它支持62种国家语言,易于访问,满足各种需求。
格式工厂最新pc版本说明
1、功能非常齐全,软件纯绿色,DVD视频采集功能,方便将DVD备份到本地硬盘。
2、体积小,占用空间小,性能强,支持iphone/ipod/psp等多媒体指定格式,你想要的,这里都有。
格式工厂最新PC版回顾
很好用,可以轻松体验,不受限制。 查看全部
网页视频抓取软件 格式工厂(格式工厂最新pc版特色版说明书下载地址下载)
Format Factory PC版是一款非常好用的视频格式转换软件。用户可以在这里进行很多操作,帮助您轻松完成视频编辑、合成等操作。还是很不错的,可以轻松体验。格式工厂最新PC版的界面风格相当精致细腻。它似乎有不同的视觉效果。可以自由应用,相当不错。.
格式工厂最新 PC 版本的功能
1、多种功能集于一身,视频剪辑、合成等各种功能都可以在其中进行。是一款非常适合新手编辑的转换软件。
2、软件运行速度快,支持各类视频、音频、图片等格式,轻松转换成你想要的格式。
3、随心所欲地应用经验。在转换过程中,您可以修复损坏的文件,使转换质量不受损。
格式工厂最新PC版亮点
1、简单的操作是一个优势,它可以帮助你的文件“减肥”,让他们“瘦身”。两者都节省硬盘空间。
2、软件界面简洁,图片转换支持缩放、旋转、水印等常用功能,操作一气呵成。
3、这很有趣。它支持62种国家语言,易于访问,满足各种需求。
格式工厂最新pc版本说明
1、功能非常齐全,软件纯绿色,DVD视频采集功能,方便将DVD备份到本地硬盘。
2、体积小,占用空间小,性能强,支持iphone/ipod/psp等多媒体指定格式,你想要的,这里都有。
格式工厂最新PC版回顾
很好用,可以轻松体验,不受限制。
网页视频抓取软件 格式工厂(网络爬虫21世纪数据的价值所在!(附案例) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-04-04 10:00
)
简介:随着大数据技术、分布式存储和分布式计算的发展,数据的价值不断被挖掘,特别是针对海量网络数据,爬取网站数据内容,分析数据背后隐藏的价值,人工智能的背后是需要海量数据支撑,这就是21世纪数据的价值!
1、网络爬虫的基本流程:
1.1、发起请求:客户端通过HTTP库向目标站点发起请求,等待服务器响应。
1.2、获取响应内容:服务器响应Response的内容为页面内容,类型有HTML、Json、二进制等。
1.3、解析内容:可以用正则表达式和网页解析库来解析HTML。json可以直接转化为json对象解析。二进制数据,可以进一步保存或处理。
1.4、保存数据:结构化存储,可以保存为文本、保存到数据库或保存为特定格式的文件。
2、请求和响应:
2.1、请求:
1)Request方法:主要有GET和POST两种,还有HEAD、PUT、DELETE、OPTIONS等。 2)Request URL:URL是Uniform Resource Locator,可用的URLs比如网页、图片、视频都是唯一确定的。
3)Request header:收录请求过程中的header信息,如User-Agent、Host、Cookies等信息。
4)请求体:请求中携带的附加数据,如表单提交时的表单数据。
2.2、回应:
1)响应状态:响应状态,如200表示成功,301表示跳转,404表示页面未找到,502服务器错误。
2)响应头:如内容类型、内容长度、服务器信息、设置cookies等。
3)响应体:最重要的部分,包括请求的资源内容,如HTML、图片和视频、二进制数据等。
3、爬虫可以抓取的数据:
3.1、网页文本:HTML文档、Json格式文本等。
3.2、Image:得到的二进制文件以图像格式保存。
3.3、视频:也是二进制文件,可以保存为视频格式。
3.4、其他:只要能请求数据,就能获取信息。
4、分析方法:
4.1、直接处理:适用于简单的网页。
4.2、Json解析:适用于Json字符串的网页。
4.3、正则表达式:适用于HTML解析。
4.4、库分析:BeautifulSoup库、PyQuery库、XPath库等。
5、请求的结果和浏览器看到的不一样:
5.1、原因:浏览器渲染。JavaScript 与后台的交互数据。
5.2、如何解决JavaScript渲染问题:分析Ajax请求(Json字符串)。Selenium/WebDriver 解决方案(pip 可以安装)。Splash 解决方案(安装可在 GitHub 中搜索)。PyV8、Ghost.py。
6、如何保存数据:
6.1、文本:纯文本、Json、Xml等。
6.2、关系型数据库:如MySQL、Oracle、SQLServer等,以结构化表的结构化形式存储。
6.3、非关系型数据库:如MongoDB、Redis等key-value存储。
6.4、二进制文件:如图片、视频、音频等,直接以特定格式保存。
查看全部
网页视频抓取软件 格式工厂(网络爬虫21世纪数据的价值所在!(附案例)
)
简介:随着大数据技术、分布式存储和分布式计算的发展,数据的价值不断被挖掘,特别是针对海量网络数据,爬取网站数据内容,分析数据背后隐藏的价值,人工智能的背后是需要海量数据支撑,这就是21世纪数据的价值!
1、网络爬虫的基本流程:
1.1、发起请求:客户端通过HTTP库向目标站点发起请求,等待服务器响应。
1.2、获取响应内容:服务器响应Response的内容为页面内容,类型有HTML、Json、二进制等。
1.3、解析内容:可以用正则表达式和网页解析库来解析HTML。json可以直接转化为json对象解析。二进制数据,可以进一步保存或处理。
1.4、保存数据:结构化存储,可以保存为文本、保存到数据库或保存为特定格式的文件。
2、请求和响应:
2.1、请求:
1)Request方法:主要有GET和POST两种,还有HEAD、PUT、DELETE、OPTIONS等。 2)Request URL:URL是Uniform Resource Locator,可用的URLs比如网页、图片、视频都是唯一确定的。
3)Request header:收录请求过程中的header信息,如User-Agent、Host、Cookies等信息。
4)请求体:请求中携带的附加数据,如表单提交时的表单数据。
2.2、回应:
1)响应状态:响应状态,如200表示成功,301表示跳转,404表示页面未找到,502服务器错误。
2)响应头:如内容类型、内容长度、服务器信息、设置cookies等。
3)响应体:最重要的部分,包括请求的资源内容,如HTML、图片和视频、二进制数据等。
3、爬虫可以抓取的数据:
3.1、网页文本:HTML文档、Json格式文本等。
3.2、Image:得到的二进制文件以图像格式保存。
3.3、视频:也是二进制文件,可以保存为视频格式。
3.4、其他:只要能请求数据,就能获取信息。
4、分析方法:
4.1、直接处理:适用于简单的网页。
4.2、Json解析:适用于Json字符串的网页。
4.3、正则表达式:适用于HTML解析。
4.4、库分析:BeautifulSoup库、PyQuery库、XPath库等。
5、请求的结果和浏览器看到的不一样:
5.1、原因:浏览器渲染。JavaScript 与后台的交互数据。
5.2、如何解决JavaScript渲染问题:分析Ajax请求(Json字符串)。Selenium/WebDriver 解决方案(pip 可以安装)。Splash 解决方案(安装可在 GitHub 中搜索)。PyV8、Ghost.py。
6、如何保存数据:
6.1、文本:纯文本、Json、Xml等。
6.2、关系型数据库:如MySQL、Oracle、SQLServer等,以结构化表的结构化形式存储。
6.3、非关系型数据库:如MongoDB、Redis等key-value存储。
6.4、二进制文件:如图片、视频、音频等,直接以特定格式保存。
网页视频抓取软件 格式工厂(Foobar2000一款简美的音频播放器的工具中文版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2022-04-03 22:09
Foobar2000中文完整版是一款功能强大的音频播放器。Foobar2000软件不仅体积小,而且占用的系统资源也少。并且软件功能非常全面,支持MP3、MP4等多种音频格式。
Foobar2000中文版完整版介绍:
Foobar2000原生的MP3播放效果比普通音乐播放器要好很多。除了播放,它还支持生成媒体库、转换媒体文件编码、提取CD等功能。它是一个资源消耗低、界面简洁、没有Skin等多余东西的强大工具,是一个简单漂亮的音频播放器。
Foobar2000中文版完整版功能:
1. 通过插件支持更多的音频格式和功能。
2. 可以直接读取压缩包中的音乐文件,无需解压。
3. 低内存占用和高效处理大型播放列表。
4. 大多数标准组件都是在 BSD 许可下开源的。
Foobar2000中文版完整版功能:
1. 内置音频格式支持:MP3、MP4、AAC、CD Audio、WMA、Vorbis、FLAC、WavPack、WAV、AIFF、Musepack、Speex、AU、SND。
2. 高级文档信息处理能力。
3. 高度可定制的播放界面显示。
4. 所有菜单选项和命令都可以通过组合键访问并由最终用户重新排列。
Foobar2000中文版完整版亮点:
1. 完整的 Unicode 支持。
2. 自定义快捷键。
3. 将 CD 转换为支持的音频格式。
防范措施
Foobar2000是一款资源消耗小、界面简洁、没有Skin等多余东西的强大工具,是一款简洁美观的音频播放器。它是一个资源消耗低、界面简洁、没有Skin等多余东西的强大工具,是一个简单漂亮的音频播放器。 查看全部
网页视频抓取软件 格式工厂(Foobar2000一款简美的音频播放器的工具中文版)
Foobar2000中文完整版是一款功能强大的音频播放器。Foobar2000软件不仅体积小,而且占用的系统资源也少。并且软件功能非常全面,支持MP3、MP4等多种音频格式。
Foobar2000中文版完整版介绍:
Foobar2000原生的MP3播放效果比普通音乐播放器要好很多。除了播放,它还支持生成媒体库、转换媒体文件编码、提取CD等功能。它是一个资源消耗低、界面简洁、没有Skin等多余东西的强大工具,是一个简单漂亮的音频播放器。
Foobar2000中文版完整版功能:
1. 通过插件支持更多的音频格式和功能。
2. 可以直接读取压缩包中的音乐文件,无需解压。
3. 低内存占用和高效处理大型播放列表。
4. 大多数标准组件都是在 BSD 许可下开源的。
Foobar2000中文版完整版功能:
1. 内置音频格式支持:MP3、MP4、AAC、CD Audio、WMA、Vorbis、FLAC、WavPack、WAV、AIFF、Musepack、Speex、AU、SND。
2. 高级文档信息处理能力。
3. 高度可定制的播放界面显示。
4. 所有菜单选项和命令都可以通过组合键访问并由最终用户重新排列。
Foobar2000中文版完整版亮点:
1. 完整的 Unicode 支持。
2. 自定义快捷键。
3. 将 CD 转换为支持的音频格式。
防范措施
Foobar2000是一款资源消耗小、界面简洁、没有Skin等多余东西的强大工具,是一款简洁美观的音频播放器。它是一个资源消耗低、界面简洁、没有Skin等多余东西的强大工具,是一个简单漂亮的音频播放器。
网页视频抓取软件 格式工厂(本文哔哩视频抓取b站视频好好分析分析(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-30 13:06
)
本文仅作为学习笔记的参考:
哔哩哔哩视频截图
b站的视频还是比较难抓的。与其他网站视频相比,获取难度较大。也是因为我不怕死,因为我的好奇心。我打算对b站的视频进行分析分析。具体抓包流程如下:
初步分析页面如下:
这个页面有点诱人,所以让我们从那里开始。这个页面的请求和响应信息比较容易抓取和分析,主要是获取分页标记和视频跳转到指定播放界面的url地址(如下图)
我使用的方法是在response中下载页框信息,然后和原来合并的Element页面对比,找到url。这一步不难找,就不多说了,直接上代码(恩...通用代码就行了,懒得分开一点了):
html_str01 = self.get_request(self.index_url, self.index_headers).content.decode("utf-8")
seconed_url_list = set(
re.findall(r'''href="//(www\.bilibili\.com/video/.*?\?from=search)"''', html_str01, re.S))
接下来,找到初始url后,我们可以分析原创视频捕获:
以下是来此页面进行分析的:
通过抓包,我们无法获取完整的视频请求地址,而是获取大量.m4s格式文件的请求。最初的猜测是.m4s格式的文件就是我们需要的视频文件,但是从数量上看,它是一个视频剪辑。但是,并非所有 .m4s 格式请求都是相同的。一个请求,哪个被划掉肯定不是,因为响应为null,所以请求有3种类型(30080 / 30216 / 30232).
三个请求,我需要哪一个?继续分析,找了很多资料,得出的结论是返回请求数据最多的是视频格式,返回数据较少的是音频文件(如下图)
30080 所需请求的总数据大小
30216 请求的所需总数据大小
30232 所需请求的总数据大小
相比之下,30080 > 30232 > 30216 个数据请求
现在可以确定30080请求的数据是视频文件,那么30232和30216这两个请求的文件中,哪个是音频文件呢?
别慌,下面我们来分析一下。
这里有个问题,30080文件有这么多碎片,我不能全部下载然后合成⑧,虽然这个确实可行,但是比较复杂。还有一种更简单的方法来获取整个视频文件。这需要将请求头中的Range(如下图)参数改为0-XXXXXXXX字节,而这里的XXXXXXXX就是我们上面分析的url。该类型的数据请求总数,根据我的分析,这个值只能大于或等于数据请求的总数,但不能小于。因此,有两种方法可以获得完整的 .m4s 格式。一种是把请求头的Range值写大,另一种是先请求0-5等短数据,然后返回。头测试,得到响应头后,
在此分析的基础上,对比刚才不确定的30232和30216两种格式的url请求,测试得到两个请求得到的数据进行对比。如图所示:
我们下载了两个请求的数据并将它们全部保存为 .mp3 文件格式。通过本次测试,我们得知这两个文件都是视频音频文件,两者没有区别。因此,我们要求略小的 30216。
这样就可以完成视频和音频文件的获取了,不过这里是单独下载的。如果需要合成,这里有两种我尝试过的方法:
[1] 使用ffmpeg模块完成视音频合成
[2] 使用格式工厂
在这个程序中我没有使用ffmpeg进行合成,原因有二。一是因为太慢了,我的笔记本电脑在转换过程中cpu使用率上升到了不可思议的99%,二是因为格式工厂真的好用,而且合成速度极快。因此,我选择了手动格式工厂来合成视频和音频。
至此,整个分析过程就结束了,剩下的就是写整个程序了。这里就不说各个模块怎么写了,直接提供代码截图和运行截图。
运行截图如下:
代码部分保存并显示结果:
视频播放显示: ✔ 插入一句话,是高清的,是的
因此,本程序介绍结束:
部分代码如下:
源代码的一部分
def run(self):
# print("第一次请求开始。。。。。")
html_str01 = self.get_request(self.index_url, self.index_headers).content.decode("utf-8")
# file_name = re.findall(r'''(.*?)''', html_str01, re.S)[0] + ".mp4"
seconed_url_list = set(
re.findall(r'''href="//(www\.bilibili\.com/video/.*?\?from=search)"''', html_str01, re.S))
# print(seconed_url_list)
for seconed_url in seconed_url_list:
html_str02 = self.get_request("http://" + seconed_url, self.index_headers).content.decode("utf-8")
try:
m4s_30080 = re.findall(r'''"baseUrl":"(.*?)"''', html_str02, re.S)[0]
except Exception as e:
print(e)
continue
if self.audio_condition == 'Y':
mp3_30216 = re.findall(r'''"baseUrl":"(.*?)"''', html_str02, re.S)[-2]
# print(m4s_30080)
Referer_key = seconed_url
# 试探请求头大小
Range_key = 'bytes=0-5'
self.seconed_headers['Referer'] = 'https://' + Referer_key
self.seconed_headers['Range'] = Range_key
# 试探,取得total的值
html_bytes = self.get_request(m4s_30080, headers=self.seconed_headers).headers['Content-Range']
if self.audio_condition == 'Y':
audio_bytes = self.get_request(mp3_30216, headers=self.seconed_headers).headers['Content-Range']
# print(html_bytes)
total = re.findall(r"/(.*)", html_bytes, re.S)[0]
if self.audio_condition == 'Y':
audio_total = re.findall(r"/(.*)", audio_bytes, re.S)[0]
# print("total: " + str(total))
self.seconed_headers['Range'] = total
# print(total)
stream = True
chunk_size = 1024 # 每次块大小为1024
content_size = int(total)
if self.audio_condition == 'Y':
content_size_audio = int(audio_total)
print("文件大小:" + str(round(float((content_size + content_size_audio) / chunk_size / 1024), 4)) + "[MB]")
else:
print("文件大小:" + str(round(float(content_size / chunk_size / 1024), 4)) + "[MB]")
start = time.time()
m4s_bytes = self.get_request(m4s_30080, headers=self.seconed_headers, stream=stream)
self.write_data(str(self.num) + ".mp4", m4s_bytes, chunk_size, content_size)
if self.audio_condition == 'Y':
print("\n")
self.seconed_headers['Range'] = audio_total
mp3_bytes = self.get_request(mp3_30216, headers=self.seconed_headers, stream=stream)
self.write_data(str(self.num) + ".mp3", mp3_bytes, chunk_size, content_size_audio)
end = time.time()
print("总耗时:" + str(end - start) + "秒")
self.num = self.num + 1 查看全部
网页视频抓取软件 格式工厂(本文哔哩视频抓取b站视频好好分析分析(图)
)
本文仅作为学习笔记的参考:
哔哩哔哩视频截图
b站的视频还是比较难抓的。与其他网站视频相比,获取难度较大。也是因为我不怕死,因为我的好奇心。我打算对b站的视频进行分析分析。具体抓包流程如下:
初步分析页面如下:
这个页面有点诱人,所以让我们从那里开始。这个页面的请求和响应信息比较容易抓取和分析,主要是获取分页标记和视频跳转到指定播放界面的url地址(如下图)
我使用的方法是在response中下载页框信息,然后和原来合并的Element页面对比,找到url。这一步不难找,就不多说了,直接上代码(恩...通用代码就行了,懒得分开一点了):
html_str01 = self.get_request(self.index_url, self.index_headers).content.decode("utf-8")
seconed_url_list = set(
re.findall(r'''href="//(www\.bilibili\.com/video/.*?\?from=search)"''', html_str01, re.S))
接下来,找到初始url后,我们可以分析原创视频捕获:
以下是来此页面进行分析的:
通过抓包,我们无法获取完整的视频请求地址,而是获取大量.m4s格式文件的请求。最初的猜测是.m4s格式的文件就是我们需要的视频文件,但是从数量上看,它是一个视频剪辑。但是,并非所有 .m4s 格式请求都是相同的。一个请求,哪个被划掉肯定不是,因为响应为null,所以请求有3种类型(30080 / 30216 / 30232).
三个请求,我需要哪一个?继续分析,找了很多资料,得出的结论是返回请求数据最多的是视频格式,返回数据较少的是音频文件(如下图)
30080 所需请求的总数据大小
30216 请求的所需总数据大小
30232 所需请求的总数据大小
相比之下,30080 > 30232 > 30216 个数据请求
现在可以确定30080请求的数据是视频文件,那么30232和30216这两个请求的文件中,哪个是音频文件呢?
别慌,下面我们来分析一下。
这里有个问题,30080文件有这么多碎片,我不能全部下载然后合成⑧,虽然这个确实可行,但是比较复杂。还有一种更简单的方法来获取整个视频文件。这需要将请求头中的Range(如下图)参数改为0-XXXXXXXX字节,而这里的XXXXXXXX就是我们上面分析的url。该类型的数据请求总数,根据我的分析,这个值只能大于或等于数据请求的总数,但不能小于。因此,有两种方法可以获得完整的 .m4s 格式。一种是把请求头的Range值写大,另一种是先请求0-5等短数据,然后返回。头测试,得到响应头后,
在此分析的基础上,对比刚才不确定的30232和30216两种格式的url请求,测试得到两个请求得到的数据进行对比。如图所示:
我们下载了两个请求的数据并将它们全部保存为 .mp3 文件格式。通过本次测试,我们得知这两个文件都是视频音频文件,两者没有区别。因此,我们要求略小的 30216。
这样就可以完成视频和音频文件的获取了,不过这里是单独下载的。如果需要合成,这里有两种我尝试过的方法:
[1] 使用ffmpeg模块完成视音频合成
[2] 使用格式工厂
在这个程序中我没有使用ffmpeg进行合成,原因有二。一是因为太慢了,我的笔记本电脑在转换过程中cpu使用率上升到了不可思议的99%,二是因为格式工厂真的好用,而且合成速度极快。因此,我选择了手动格式工厂来合成视频和音频。
至此,整个分析过程就结束了,剩下的就是写整个程序了。这里就不说各个模块怎么写了,直接提供代码截图和运行截图。
运行截图如下:
代码部分保存并显示结果:
视频播放显示: ✔ 插入一句话,是高清的,是的
因此,本程序介绍结束:
部分代码如下:
源代码的一部分
def run(self):
# print("第一次请求开始。。。。。")
html_str01 = self.get_request(self.index_url, self.index_headers).content.decode("utf-8")
# file_name = re.findall(r'''(.*?)''', html_str01, re.S)[0] + ".mp4"
seconed_url_list = set(
re.findall(r'''href="//(www\.bilibili\.com/video/.*?\?from=search)"''', html_str01, re.S))
# print(seconed_url_list)
for seconed_url in seconed_url_list:
html_str02 = self.get_request("http://" + seconed_url, self.index_headers).content.decode("utf-8")
try:
m4s_30080 = re.findall(r'''"baseUrl":"(.*?)"''', html_str02, re.S)[0]
except Exception as e:
print(e)
continue
if self.audio_condition == 'Y':
mp3_30216 = re.findall(r'''"baseUrl":"(.*?)"''', html_str02, re.S)[-2]
# print(m4s_30080)
Referer_key = seconed_url
# 试探请求头大小
Range_key = 'bytes=0-5'
self.seconed_headers['Referer'] = 'https://' + Referer_key
self.seconed_headers['Range'] = Range_key
# 试探,取得total的值
html_bytes = self.get_request(m4s_30080, headers=self.seconed_headers).headers['Content-Range']
if self.audio_condition == 'Y':
audio_bytes = self.get_request(mp3_30216, headers=self.seconed_headers).headers['Content-Range']
# print(html_bytes)
total = re.findall(r"/(.*)", html_bytes, re.S)[0]
if self.audio_condition == 'Y':
audio_total = re.findall(r"/(.*)", audio_bytes, re.S)[0]
# print("total: " + str(total))
self.seconed_headers['Range'] = total
# print(total)
stream = True
chunk_size = 1024 # 每次块大小为1024
content_size = int(total)
if self.audio_condition == 'Y':
content_size_audio = int(audio_total)
print("文件大小:" + str(round(float((content_size + content_size_audio) / chunk_size / 1024), 4)) + "[MB]")
else:
print("文件大小:" + str(round(float(content_size / chunk_size / 1024), 4)) + "[MB]")
start = time.time()
m4s_bytes = self.get_request(m4s_30080, headers=self.seconed_headers, stream=stream)
self.write_data(str(self.num) + ".mp4", m4s_bytes, chunk_size, content_size)
if self.audio_condition == 'Y':
print("\n")
self.seconed_headers['Range'] = audio_total
mp3_bytes = self.get_request(mp3_30216, headers=self.seconed_headers, stream=stream)
self.write_data(str(self.num) + ".mp3", mp3_bytes, chunk_size, content_size_audio)
end = time.time()
print("总耗时:" + str(end - start) + "秒")
self.num = self.num + 1
网页视频抓取软件 格式工厂(网页视频抓取软件格式(o⊙⊙o)*⊙)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-24 15:09
网页视频抓取软件格式工厂gdaeediusaegediusghost之类看你的软件,
无他,唯手熟尔,方法不唯一。任何软件你掌握一门编程语言,一些基本的网页爬虫处理方法,理解原理图,剩下的就是多练习了,
最重要的还是学习网页爬虫吧
那个,你可以去学一下python,
手机端的话就是用安卓吧,下个obs就可以啦,电脑端看你会啥了,
youtube
刚刚刚刚学python,斗胆推荐一个自己写的,脚本应该比较小众,原理也很简单不知道这个脚本支持传视频吗?不支持?那就上传普通网站(⊙o⊙)!传其他视频,但这可能对网速要求高点。用的是网页视频,因为手机需要wifi传播,所以我做的页面里没有传视频的功能。如果你会react基础,想写个简单基于react的爬虫,目前的思路是,用pymongo从b站数据里面取到请求即可。
给你推荐一个app,windows下叫chrome,手机上是内置浏览器。只要打开视频就会自动推送。之前用过一个类似的,这个还可以随机拖拽视频。
你可以写个爬虫爬b站。自己创造一个自己的站点。geek点的话,就不方便推荐。 查看全部
网页视频抓取软件 格式工厂(网页视频抓取软件格式(o⊙⊙o)*⊙)
网页视频抓取软件格式工厂gdaeediusaegediusghost之类看你的软件,
无他,唯手熟尔,方法不唯一。任何软件你掌握一门编程语言,一些基本的网页爬虫处理方法,理解原理图,剩下的就是多练习了,
最重要的还是学习网页爬虫吧
那个,你可以去学一下python,
手机端的话就是用安卓吧,下个obs就可以啦,电脑端看你会啥了,
youtube
刚刚刚刚学python,斗胆推荐一个自己写的,脚本应该比较小众,原理也很简单不知道这个脚本支持传视频吗?不支持?那就上传普通网站(⊙o⊙)!传其他视频,但这可能对网速要求高点。用的是网页视频,因为手机需要wifi传播,所以我做的页面里没有传视频的功能。如果你会react基础,想写个简单基于react的爬虫,目前的思路是,用pymongo从b站数据里面取到请求即可。
给你推荐一个app,windows下叫chrome,手机上是内置浏览器。只要打开视频就会自动推送。之前用过一个类似的,这个还可以随机拖拽视频。
你可以写个爬虫爬b站。自己创造一个自己的站点。geek点的话,就不方便推荐。
网页视频抓取软件 格式工厂(手机版是一款快速转换视频格式的软件作为一款万能视频播放器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-19 19:21
Video Format Factory 手机版是一款快速转换视频格式的软件。作为通用视频播放器,Video Format Factory 软件支持多种格式的视频。用户可以使用 Video Format Factory 软件不仅可以转换视频格式,还可以自定义视频。解决!
【软件介绍】
视频格式工厂可让您轻松转换各种视频格式并将文件保存到手机。视频格式工厂为您提供多种视频格式转换,支持多种视频格式,如常见的amv、mov、avi和mp4、fiv等,视频格式工厂app也是一款强大的播放器,任何视频都可以播放;视频格式工厂支持快速导入相册和文件管理中的视频到软件,让你可以快速转换视频格式,你可以选择你想转换成什么格式。
【软件特色】
- 支持多种视频格式(amv、mov、avi、mp4、m4v、flv 等)
- 自定义视频大小和分辨率,压缩以减小视频文件大小
- 强大的视频播放器,可以播放各种格式的视频
- 支持从相册导入视频,文件管理
想要转换视频格式?想要播放各种格式的视频?立即下载视频格式工厂!
【软件亮点】
1.视频格式工厂app免费使用,无需登录账号即可打开使用;
2.软件操作简单,一键导入需要转换的视频;
3.支持多种视频格式,转换成功后播放过程不卡顿;
4.可以有效解决视频播放器无法播放的问题;
5.压缩后的视频也可以快速传输给朋友或保存到云盘;
6.音频提取非常好用,一键提取视音频,将mp4转为mp3,播放更方便。
【软件优势】
1、选择需要的格式后,点击开始转换,直接转换;
2、转换后的视频会自动保存,也可以保存原格式的视频;
3、可以用来提取视频文件的原声,也可以消除原声并配音;
4、选择视频也可以压缩,视频文件可以压缩变小,方便存储;
5、导入视频后,可以一目了然地查看视频文件的详细信息、格式、采样率、码率等;
6、转换格式时可以选择分辨率和FPS参数,根据需要自由调整。
【软件功能】
DVD 抓取
格式工厂可以采集视频,用户可以通过此功能轻松地将 DVD 备份到本地硬盘。
ͼƬ 转换
格式工厂可以转换图片,支持图片文件缩放、旋转、水印等功能;
灵活性
格式工厂允许多媒体文件灵活地“减肥”或“长大”(即提高或降低视频清晰度、帧率等);
修复功能
格式工厂可以在转换过程中修复一些意外损坏的视频文件
【更新日志】
v4.1.2
修复在线崩溃并优化用户体验
v4.1.1
修复在线崩溃并优化用户体验
展开 + 查看全部
网页视频抓取软件 格式工厂(手机版是一款快速转换视频格式的软件作为一款万能视频播放器)
Video Format Factory 手机版是一款快速转换视频格式的软件。作为通用视频播放器,Video Format Factory 软件支持多种格式的视频。用户可以使用 Video Format Factory 软件不仅可以转换视频格式,还可以自定义视频。解决!
【软件介绍】
视频格式工厂可让您轻松转换各种视频格式并将文件保存到手机。视频格式工厂为您提供多种视频格式转换,支持多种视频格式,如常见的amv、mov、avi和mp4、fiv等,视频格式工厂app也是一款强大的播放器,任何视频都可以播放;视频格式工厂支持快速导入相册和文件管理中的视频到软件,让你可以快速转换视频格式,你可以选择你想转换成什么格式。
【软件特色】
- 支持多种视频格式(amv、mov、avi、mp4、m4v、flv 等)
- 自定义视频大小和分辨率,压缩以减小视频文件大小
- 强大的视频播放器,可以播放各种格式的视频
- 支持从相册导入视频,文件管理
想要转换视频格式?想要播放各种格式的视频?立即下载视频格式工厂!
【软件亮点】
1.视频格式工厂app免费使用,无需登录账号即可打开使用;
2.软件操作简单,一键导入需要转换的视频;
3.支持多种视频格式,转换成功后播放过程不卡顿;
4.可以有效解决视频播放器无法播放的问题;
5.压缩后的视频也可以快速传输给朋友或保存到云盘;
6.音频提取非常好用,一键提取视音频,将mp4转为mp3,播放更方便。
【软件优势】
1、选择需要的格式后,点击开始转换,直接转换;
2、转换后的视频会自动保存,也可以保存原格式的视频;
3、可以用来提取视频文件的原声,也可以消除原声并配音;
4、选择视频也可以压缩,视频文件可以压缩变小,方便存储;
5、导入视频后,可以一目了然地查看视频文件的详细信息、格式、采样率、码率等;
6、转换格式时可以选择分辨率和FPS参数,根据需要自由调整。
【软件功能】
DVD 抓取
格式工厂可以采集视频,用户可以通过此功能轻松地将 DVD 备份到本地硬盘。
ͼƬ 转换
格式工厂可以转换图片,支持图片文件缩放、旋转、水印等功能;
灵活性
格式工厂允许多媒体文件灵活地“减肥”或“长大”(即提高或降低视频清晰度、帧率等);
修复功能
格式工厂可以在转换过程中修复一些意外损坏的视频文件
【更新日志】
v4.1.2
修复在线崩溃并优化用户体验
v4.1.1
修复在线崩溃并优化用户体验
展开 +
网页视频抓取软件 格式工厂(格式工厂绿色便携版,去广告版本(特意转一个))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-19 12:01
格式工厂绿色便携版,去广告版。昨天准备转一个mp4文件,结果发现我们网站没有格式工厂,所以特地转了一个。
软件介绍:
格式工厂是国内一款功能强大且易于操作的多功能媒体格式转换工具,支持几乎所有类型的多媒体格式之间的相互转换,各种视频、音频、图片等格式,如视频: MP4、AVI、3GP、WMV、MKV、VOB、MOV、FLV、SWF、GIF;音频:MP3、WMA、FLAC、AAC、MMF、AMR、M4A、M4R、OGG、MP2、WAV、WavPack;图片:JPG、PNG、ICO、BMP、GIF、TIF、PCX、TGA等。在视频转换过程中,可以修复损坏的文件,使转换质量不受损;转换后的图片支持缩放、旋转、水印等常用功能
软件特点:
1 支持几乎所有类型的多媒体格式到几种常用格式
2 转换过程中可以修复一些意外损坏的视频文件
3 多媒体文件“减重”或“增重”(注:“减重”或“增重”视用户情况而定,大部分“增重”会提高视频的清晰度、帧率等.)
4 支持iPhone/iPod/PSP等多媒体指定格式
5 转换图片文件,支持缩放、旋转、水印等功能
6种DVD视频翻录功能,轻松将DVD备份到本地硬盘
7 支持一些可以在转换过程中修复的意外损坏的视频文件。本版本说明进入主界面工具栏广告按钮(首页、软件推广);进入升级提示,禁止后续检测升级,进入检测升级选项;转到关于冗余按钮和文本、简化任务和帮助冗余选项
软件截图:
下载地址:
提取码:j2i6 查看全部
网页视频抓取软件 格式工厂(格式工厂绿色便携版,去广告版本(特意转一个))
格式工厂绿色便携版,去广告版。昨天准备转一个mp4文件,结果发现我们网站没有格式工厂,所以特地转了一个。
软件介绍:
格式工厂是国内一款功能强大且易于操作的多功能媒体格式转换工具,支持几乎所有类型的多媒体格式之间的相互转换,各种视频、音频、图片等格式,如视频: MP4、AVI、3GP、WMV、MKV、VOB、MOV、FLV、SWF、GIF;音频:MP3、WMA、FLAC、AAC、MMF、AMR、M4A、M4R、OGG、MP2、WAV、WavPack;图片:JPG、PNG、ICO、BMP、GIF、TIF、PCX、TGA等。在视频转换过程中,可以修复损坏的文件,使转换质量不受损;转换后的图片支持缩放、旋转、水印等常用功能
软件特点:
1 支持几乎所有类型的多媒体格式到几种常用格式
2 转换过程中可以修复一些意外损坏的视频文件
3 多媒体文件“减重”或“增重”(注:“减重”或“增重”视用户情况而定,大部分“增重”会提高视频的清晰度、帧率等.)
4 支持iPhone/iPod/PSP等多媒体指定格式
5 转换图片文件,支持缩放、旋转、水印等功能
6种DVD视频翻录功能,轻松将DVD备份到本地硬盘
7 支持一些可以在转换过程中修复的意外损坏的视频文件。本版本说明进入主界面工具栏广告按钮(首页、软件推广);进入升级提示,禁止后续检测升级,进入检测升级选项;转到关于冗余按钮和文本、简化任务和帮助冗余选项
软件截图:
下载地址:
提取码:j2i6
网页视频抓取软件 格式工厂(推荐一款网页的视频工具“刻刻”,可以下载百度云和腾讯视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-16 23:03
网页视频抓取软件格式工厂,可以采集微信公众号全部素材,也可以采集全网视频,可以在线观看,web端也可以下载。
1、首先在浏览器访问/,
2、接着下载安装格式工厂;
3、下载安装格式工厂后,点击工具栏中的视频下载,把视频标题复制到地址栏中,选择后缀为.mp4的视频下载,要是不选择,保存为.rmvb,就不会下载到视频了。完成后可以在浏览器搜索“格式工厂”下载就可以了。
推荐一款网页的视频抓取工具“刻刻”,可以下载百度云和腾讯视频。
上神器网查看
我下载一部电影花了2个小时,你说我去哪下?还是保证版权的情况下。
百度云搜索,
百度网盘如何下载电影?,你说的下载多次会不会让用户选择原来该电影分享者的qq?那会不会复制链接就失去了他的分享意义?对于这种下载方式,确实值得商榷。网盘搜索,包括几百块一个月的三百视频下载等等,都不好用。就算你做到无广告多功能,但我还是喜欢百度云或者里面乱七八糟的不完整页面。几百块的vip影院很好用,找很久的账号和密码对于我来说很有价值。
对于这个回答,我评论了一下,被知乎和谐掉了,看截图可知,是被理解歪了。如果想看到更加纯粹的答案,还是去百度网盘搜索吧。 查看全部
网页视频抓取软件 格式工厂(推荐一款网页的视频工具“刻刻”,可以下载百度云和腾讯视频)
网页视频抓取软件格式工厂,可以采集微信公众号全部素材,也可以采集全网视频,可以在线观看,web端也可以下载。
1、首先在浏览器访问/,
2、接着下载安装格式工厂;
3、下载安装格式工厂后,点击工具栏中的视频下载,把视频标题复制到地址栏中,选择后缀为.mp4的视频下载,要是不选择,保存为.rmvb,就不会下载到视频了。完成后可以在浏览器搜索“格式工厂”下载就可以了。
推荐一款网页的视频抓取工具“刻刻”,可以下载百度云和腾讯视频。
上神器网查看
我下载一部电影花了2个小时,你说我去哪下?还是保证版权的情况下。
百度云搜索,
百度网盘如何下载电影?,你说的下载多次会不会让用户选择原来该电影分享者的qq?那会不会复制链接就失去了他的分享意义?对于这种下载方式,确实值得商榷。网盘搜索,包括几百块一个月的三百视频下载等等,都不好用。就算你做到无广告多功能,但我还是喜欢百度云或者里面乱七八糟的不完整页面。几百块的vip影院很好用,找很久的账号和密码对于我来说很有价值。
对于这个回答,我评论了一下,被知乎和谐掉了,看截图可知,是被理解歪了。如果想看到更加纯粹的答案,还是去百度网盘搜索吧。
网页视频抓取软件 格式工厂(完全小白篇-使用Python爬取bv号视频哔哩哔哩号 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-03-14 09:02
)
完全白篇——使用Python爬取bv视频
B站相信大家都很熟悉了。这次想尝试直接爬B站的视频,但是搜了很多文章的博客,看来还是在B站还在用av号的时代。,所以这次想看看能不能爬取bv号的视频。
找B站的视频
BV号是B站自2020年3月23日起升级的视频码,BV号完全替代了之前的AV号,功能不变。既然网站都用了BV号,随便找个视频先看看情况:
对于单个视频,您无需查看 BV 编号后跟大字符串的内容。单个视频就是1的p序号。对于一个系列的视频来说,BV序号是固定的,不同的剧集对应不同的p序号,所以只要确定了BV序号和p序号,就可以定位视频的网页。
分析网页信息
相信大家在来之前应该都知道网络视频是怎么播放的。我不会详细介绍这里的“url”是什么。如果要爬取视频,最重要的是能够获取视频和音频文件的url信息。以前的AV号好像是说视频和音频文件是合二为一的。BV号上线后,我们看到的视频其实是音视频分离的。因此,对于 BV 号视频,视频(.flv)和音频(.mp3) 应该一起获取。
我们先看网页的源码:
哎,我吐了,不过,直接用ctrl+F搜索,搜索“url”,
我们会在一个音频类中找到一个视频类和“baseUrl”、“base_url”、“backupUrl”、“backup_url”,其中baseUrl的内容就是对应的音视频url。所以只要拿到网页的源代码,就可以把这两个地方提取出来。
获取网页信息
1. 获取网页源代码
这一点我就不赘述了,把自己模仿成浏览器,使用请求库函数访问网页:
# 用到的库
import requests
from requests import RequestException
from lxml import etree
from contextlib import closing
from pyquery import PyQuery as pq
import re
import os
import json
import subprocess
def getHtml(baseurl):
head = { #模拟浏览器身份头向对方发送消息
"user-agent": 这个地方填写你的浏览器身份信息,这一点只需随便找个请求把对应的user-agent内容复制过来就行
}
try:
response = requests.get(url = baseurl, headers = head)
# 200表示服务器接受请求,会传回网页源代码,所以把文本内容传回来就行了
if response.status_code==200:
return response.text
except:
print("请求失败")
getHtml()函数的作用是返回这个网页的源代码,传入网页地址即可。例如上图中:“Sentence Break 5.0”
2. 下一步是处理网页的源代码
# 传入网址、p序列号。这里说明一下,我下载的视频在下载系列时直接用p号命名,方便起见所以这个函数要用p号
def getVideo(baseurl,p):
html = getHtml(baseurl)
doc = pq(html)
title = doc('#viewbox_report > h1 > span').text()
pattern = r'\window\.__playinfo__=(.*?)\'
result = re.findall(pattern, html)[0]
temp = json.loads(result)
print(("开始下载--->")+title)
title = str(p)
try:
video_url = temp['data']['dash']['video'][0]['baseUrl']
audio_url = temp['data']['dash']['audio'][0]['baseUrl']
fileDownload(homeurl=baseurl, url=video_url, title=title, typ=0)
fileDownload(homeurl=baseurl, url=audio_url, title=title, typ=1)
try:
combine(title)
except:
print("对不起,您的电脑中未安装ffmpeg,不予享受合成服务,您可以尝试使用格式工厂等其他方式\n")
# 这个是针对av号的,还没试过
except Exception:
vedio_url = temp['data']['durl'][0]['url']
fileDownload(homeurl=baseurl, url=video_url, title=title, typ=0)
关注 video_url = temp['data']['dash']['video'][0]['baseUrl']。不适合一步获取 vedio:baseUrl 的内容,毕竟源码的内容太大了。所以再走一步,即先获取整个网页代码的一个小整体,然后再细分这个小整体中的每个成员。其实这部分源码在语法上就是一个Python字典,只不过这个字典中的对应收录了小字典、列表、元组等等。所以一步一步来,找到视音频的baseUrl在哪一层相信大家都能轻松实现。
(关于vedio_url = temp['data']['durl'][0]['url'],据说音视频集成在AV号(.mp4)中,当时的源码是这个关系可以找到url。)
根据url下载资源
所以最激动人心的部分来了:下载
音频和视频的下载必须单独下载。问题是现在只有 url。我们应该做什么?
当然,回到分析页面!
1. 探索规则
上图中的操作是用谷歌浏览器查看网页->刷新网页后得到的数据流。现在它处于暂停状态。我们发现,在下半场几次偶数流后,没有其他数据回传。同时,缓冲条也停留在图中的位置。可以看出,这些统一流必然收录音视频流。点击播放后,肯定会返回视频和音频流的数据,我们正在分析。
2. 验证规则
播放后,浏览器会周期性的接收到这样一个数据流,非常有规律,所以我们先只取其中的一部分。
因此,这些流是要分析的对象。
我们先来比较一下这三者之间的区别:相同的Request URL和其他信息,重要且相关的区别在于,
猜猜,这个范围的含义也很容易看出。所谓xy大概是指数据包中收录x到y的部分。然后再回到刚刚加载网页的时候,原来这种类型的流真的有范围:bytes=0-...这个项目!
此外,当所有数据传输完成后,播放将结束。此时网站给出的http状态码基本达到206:
现在我们的下载操作很明显:
1. 冒充浏览器的身份
2. 发出固定范围请求
3. 将获取的信息写入文件
def fileDownload(homeurl, url, title, typ):
# 添加请求头键值对,写上 refered:请求来源
headers = {
"user-agent": 这个地方还是照旧填写你的浏览器身份信息
}
headers.update({'Referer': homeurl})
if typ==0:
filename = "./"+title+".flv"
else:
filename = "./"+title+".mp3"
res = requests.Session()
# 指定每次下载1M的数据
begin = 0
end = 1024*1024 - 1
flag = 0
while True:
# 添加请求头键值对,写上 range:请求字节范围
headers.update({'Range': 'bytes=' + str(begin) + '-' + str(end)})
# 获取视频分片
res = requests.get(url=url, headers=headers,verify=False)
if res.status_code != 416:
# 响应码不为416时有数据,由于我们不是b站服务器,最终那个数据包的请求range肯定会超出限度,所以传回来的http状态码是416而不是206
begin = end + 1
end = end + 1024*1024
else:
headers.update({'Range': str(end + 1) + '-'})
res = requests.get(url=url, headers=headers,verify=False)
flag=1
with open(filename, 'ab') as fp:
fp.write(res.content)
fp.flush()
if flag==1:
fp.close()
break
最后是主要功能:
def main():
print("欢迎来到bilibili爬资源小程序,接下来让我们开始吧\n(番剧爬取程序正在持续开发中...)")
bv=input("输入视频bv号: ")
judge = input("你想获得一系列(y)视频还是一个单一(N)视频?\n[y/N]\n")
if judge == "y":
max = int(input("输入该系列视频的总数: "))
for p in range(1,max+1):
baseurl = "https://www.bilibili.com/video/BV"+str(bv)+"?p="+str(p)
getVideo(baseurl,p)
else:
p=input("如果是系列视频,请任选一集输入视频p号如果不是系列视频,请输入'1'\n")
baseurl = "https://www.bilibili.com/video/BV"+str(bv)+"?p="+str(p)
getVideo(baseurl,p)
os.system("pause")
# 亲们main()肯定得调用啊,这是基本的语法知识昂,我之前没写不代表不用底下这两行话啊!各位记得自己加上这句啊2333
if __name__ == "__main__":
main() 查看全部
网页视频抓取软件 格式工厂(完全小白篇-使用Python爬取bv号视频哔哩哔哩号
)
完全白篇——使用Python爬取bv视频
B站相信大家都很熟悉了。这次想尝试直接爬B站的视频,但是搜了很多文章的博客,看来还是在B站还在用av号的时代。,所以这次想看看能不能爬取bv号的视频。
找B站的视频
BV号是B站自2020年3月23日起升级的视频码,BV号完全替代了之前的AV号,功能不变。既然网站都用了BV号,随便找个视频先看看情况:
对于单个视频,您无需查看 BV 编号后跟大字符串的内容。单个视频就是1的p序号。对于一个系列的视频来说,BV序号是固定的,不同的剧集对应不同的p序号,所以只要确定了BV序号和p序号,就可以定位视频的网页。
分析网页信息
相信大家在来之前应该都知道网络视频是怎么播放的。我不会详细介绍这里的“url”是什么。如果要爬取视频,最重要的是能够获取视频和音频文件的url信息。以前的AV号好像是说视频和音频文件是合二为一的。BV号上线后,我们看到的视频其实是音视频分离的。因此,对于 BV 号视频,视频(.flv)和音频(.mp3) 应该一起获取。
我们先看网页的源码:
哎,我吐了,不过,直接用ctrl+F搜索,搜索“url”,
我们会在一个音频类中找到一个视频类和“baseUrl”、“base_url”、“backupUrl”、“backup_url”,其中baseUrl的内容就是对应的音视频url。所以只要拿到网页的源代码,就可以把这两个地方提取出来。
获取网页信息
1. 获取网页源代码
这一点我就不赘述了,把自己模仿成浏览器,使用请求库函数访问网页:
# 用到的库
import requests
from requests import RequestException
from lxml import etree
from contextlib import closing
from pyquery import PyQuery as pq
import re
import os
import json
import subprocess
def getHtml(baseurl):
head = { #模拟浏览器身份头向对方发送消息
"user-agent": 这个地方填写你的浏览器身份信息,这一点只需随便找个请求把对应的user-agent内容复制过来就行
}
try:
response = requests.get(url = baseurl, headers = head)
# 200表示服务器接受请求,会传回网页源代码,所以把文本内容传回来就行了
if response.status_code==200:
return response.text
except:
print("请求失败")
getHtml()函数的作用是返回这个网页的源代码,传入网页地址即可。例如上图中:“Sentence Break 5.0”
2. 下一步是处理网页的源代码
# 传入网址、p序列号。这里说明一下,我下载的视频在下载系列时直接用p号命名,方便起见所以这个函数要用p号
def getVideo(baseurl,p):
html = getHtml(baseurl)
doc = pq(html)
title = doc('#viewbox_report > h1 > span').text()
pattern = r'\window\.__playinfo__=(.*?)\'
result = re.findall(pattern, html)[0]
temp = json.loads(result)
print(("开始下载--->")+title)
title = str(p)
try:
video_url = temp['data']['dash']['video'][0]['baseUrl']
audio_url = temp['data']['dash']['audio'][0]['baseUrl']
fileDownload(homeurl=baseurl, url=video_url, title=title, typ=0)
fileDownload(homeurl=baseurl, url=audio_url, title=title, typ=1)
try:
combine(title)
except:
print("对不起,您的电脑中未安装ffmpeg,不予享受合成服务,您可以尝试使用格式工厂等其他方式\n")
# 这个是针对av号的,还没试过
except Exception:
vedio_url = temp['data']['durl'][0]['url']
fileDownload(homeurl=baseurl, url=video_url, title=title, typ=0)
关注 video_url = temp['data']['dash']['video'][0]['baseUrl']。不适合一步获取 vedio:baseUrl 的内容,毕竟源码的内容太大了。所以再走一步,即先获取整个网页代码的一个小整体,然后再细分这个小整体中的每个成员。其实这部分源码在语法上就是一个Python字典,只不过这个字典中的对应收录了小字典、列表、元组等等。所以一步一步来,找到视音频的baseUrl在哪一层相信大家都能轻松实现。
(关于vedio_url = temp['data']['durl'][0]['url'],据说音视频集成在AV号(.mp4)中,当时的源码是这个关系可以找到url。)
根据url下载资源
所以最激动人心的部分来了:下载
音频和视频的下载必须单独下载。问题是现在只有 url。我们应该做什么?
当然,回到分析页面!
1. 探索规则
上图中的操作是用谷歌浏览器查看网页->刷新网页后得到的数据流。现在它处于暂停状态。我们发现,在下半场几次偶数流后,没有其他数据回传。同时,缓冲条也停留在图中的位置。可以看出,这些统一流必然收录音视频流。点击播放后,肯定会返回视频和音频流的数据,我们正在分析。
2. 验证规则
播放后,浏览器会周期性的接收到这样一个数据流,非常有规律,所以我们先只取其中的一部分。
因此,这些流是要分析的对象。
我们先来比较一下这三者之间的区别:相同的Request URL和其他信息,重要且相关的区别在于,
猜猜,这个范围的含义也很容易看出。所谓xy大概是指数据包中收录x到y的部分。然后再回到刚刚加载网页的时候,原来这种类型的流真的有范围:bytes=0-...这个项目!
此外,当所有数据传输完成后,播放将结束。此时网站给出的http状态码基本达到206:
现在我们的下载操作很明显:
1. 冒充浏览器的身份
2. 发出固定范围请求
3. 将获取的信息写入文件
def fileDownload(homeurl, url, title, typ):
# 添加请求头键值对,写上 refered:请求来源
headers = {
"user-agent": 这个地方还是照旧填写你的浏览器身份信息
}
headers.update({'Referer': homeurl})
if typ==0:
filename = "./"+title+".flv"
else:
filename = "./"+title+".mp3"
res = requests.Session()
# 指定每次下载1M的数据
begin = 0
end = 1024*1024 - 1
flag = 0
while True:
# 添加请求头键值对,写上 range:请求字节范围
headers.update({'Range': 'bytes=' + str(begin) + '-' + str(end)})
# 获取视频分片
res = requests.get(url=url, headers=headers,verify=False)
if res.status_code != 416:
# 响应码不为416时有数据,由于我们不是b站服务器,最终那个数据包的请求range肯定会超出限度,所以传回来的http状态码是416而不是206
begin = end + 1
end = end + 1024*1024
else:
headers.update({'Range': str(end + 1) + '-'})
res = requests.get(url=url, headers=headers,verify=False)
flag=1
with open(filename, 'ab') as fp:
fp.write(res.content)
fp.flush()
if flag==1:
fp.close()
break
最后是主要功能:
def main():
print("欢迎来到bilibili爬资源小程序,接下来让我们开始吧\n(番剧爬取程序正在持续开发中...)")
bv=input("输入视频bv号: ")
judge = input("你想获得一系列(y)视频还是一个单一(N)视频?\n[y/N]\n")
if judge == "y":
max = int(input("输入该系列视频的总数: "))
for p in range(1,max+1):
baseurl = "https://www.bilibili.com/video/BV"+str(bv)+"?p="+str(p)
getVideo(baseurl,p)
else:
p=input("如果是系列视频,请任选一集输入视频p号如果不是系列视频,请输入'1'\n")
baseurl = "https://www.bilibili.com/video/BV"+str(bv)+"?p="+str(p)
getVideo(baseurl,p)
os.system("pause")
# 亲们main()肯定得调用啊,这是基本的语法知识昂,我之前没写不代表不用底下这两行话啊!各位记得自己加上这句啊2333
if __name__ == "__main__":
main()
网页视频抓取软件 格式工厂(网页视频抓取软件格式工厂的应用技巧及解决方案介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-11 10:02
网页视频抓取软件格式工厂可以得到一个缩略图形式的链接。提取成播放列表每次只能保存一个,
一般分四个步骤,才能得到完整的网页。
1、解析html源码,得到标签和每个标签的属性值。
2、分析标签属性值,提取出每个标签下的元素。
3、将提取出来的元素分布到列表里。
4、可以根据列表里的元素生成视频代码。比如题主的问题是“网页视频抓取软件格式工厂”那么它自己会记录提取出来的元素对应的格式。只要提取出来的元素的属性里符合格式工厂判断的规则就可以,相同属性可以放在一个列表中。
利用html5的新特性,嵌入js代码的网页可以提取出源文件。然后做成php脚本,实现视频的浏览加速。
以前楼上也有人提到这个问题,其实我想说,快捷键加速(比如x-shift-s,c-shift-f)可以将html源文件中的prgviewer和c的引用提取出来,并且放到各个网页路径下。但如果仅仅一个页面html,加速不会起作用,格式工厂不支持通过加速将整个网页加速,它只是提取某些值以后,再用文本转化工具把这些值转化成网页代码。有人说可以先解析,再加速(有点类似tinypng),我不是特别清楚。有没有更好的解决方案?。
可以使用dev-c++,一般情况下能胜任所有工作。很简单的。一般情况下把pc端的(比如windows下就是xp浏览器),扫描到的js代码,放在dll目录下,这个文件当然可以是file(比如我要在android上运行它)也可以是include,比如vs2010之类的。以上,使用该函数进行。另外,你看到的网页也可以将其中的js代码关联起来,也可以用dr.fx.wx等同名函数,dr.fx.wx是重新拼接的整个js代码,dr.fx.wxanr.mx是dr.fx.wx参数1函数。 查看全部
网页视频抓取软件 格式工厂(网页视频抓取软件格式工厂的应用技巧及解决方案介绍)
网页视频抓取软件格式工厂可以得到一个缩略图形式的链接。提取成播放列表每次只能保存一个,
一般分四个步骤,才能得到完整的网页。
1、解析html源码,得到标签和每个标签的属性值。
2、分析标签属性值,提取出每个标签下的元素。
3、将提取出来的元素分布到列表里。
4、可以根据列表里的元素生成视频代码。比如题主的问题是“网页视频抓取软件格式工厂”那么它自己会记录提取出来的元素对应的格式。只要提取出来的元素的属性里符合格式工厂判断的规则就可以,相同属性可以放在一个列表中。
利用html5的新特性,嵌入js代码的网页可以提取出源文件。然后做成php脚本,实现视频的浏览加速。
以前楼上也有人提到这个问题,其实我想说,快捷键加速(比如x-shift-s,c-shift-f)可以将html源文件中的prgviewer和c的引用提取出来,并且放到各个网页路径下。但如果仅仅一个页面html,加速不会起作用,格式工厂不支持通过加速将整个网页加速,它只是提取某些值以后,再用文本转化工具把这些值转化成网页代码。有人说可以先解析,再加速(有点类似tinypng),我不是特别清楚。有没有更好的解决方案?。
可以使用dev-c++,一般情况下能胜任所有工作。很简单的。一般情况下把pc端的(比如windows下就是xp浏览器),扫描到的js代码,放在dll目录下,这个文件当然可以是file(比如我要在android上运行它)也可以是include,比如vs2010之类的。以上,使用该函数进行。另外,你看到的网页也可以将其中的js代码关联起来,也可以用dr.fx.wx等同名函数,dr.fx.wx是重新拼接的整个js代码,dr.fx.wxanr.mx是dr.fx.wx参数1函数。
网页视频抓取软件 格式工厂(格式工厂官方版如何使用的格式转换工具?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2022-03-10 20:24
格式工厂正式版是一款功能强大的格式转换工具。该软件支持所有多媒体格式的各种常用格式。它具有视频转换、音频转换、图像转换、视频合并和音频合并等高级功能。定义设置文件的输出配置,添加数字水印等功能。
软件功能
1、各类视频转MP4/3GP/MPG/AVI/WMV/FLV/SWF
2、所有类型的音频转MP3/WMA/AMR/OGG/AAC/WAV
3、所有图片类型转JPG/BMP/PNG/TIF/ICO/GIF/TGA
4、将 DVD 翻录到视频文件,将音乐 CD 翻录到音频文件
5、MP4文件支持iPod/iPhone/PSP/黑模等指定格式
6、支持RMVB、水印、音视频混合
软件功能
1、支持几乎所有类型的多媒体格式到几种常用格式
2、转换过程中可以修复一些损坏的视频文件
3、减肥多媒体文件
4、支持iPhone/iPod/PSP等多媒体指定格式
5、转换后的图片文件支持缩放、旋转、水印等功能
6、DVD视频采集功能,轻松备份DVD到本地硬盘
7、支持56种国家语言
常见问题
一、格式工厂需要注册吗?
格式工厂无需注册,无需收费,直接使用即可!
二、如何使用格式工厂?
格式工厂操作非常简单,只需按照以下步骤操作即可:
1、选择要转换成的格式,以“PNG”格式为例,打开软件后点击“PNG”;
2、添加文件/文件夹并点击确定;
3、"点击开始";
4、完成。
三、如何设置输出文件地址?
1、点击“任务”---“选项”;
2、选择目标地址。
四、如何设置转换后的文件?
可以根据需要单独设置输出文件,以图片“GIF”为例:
1、点击“输出配置”;
2、您可以根据自己的需要进行编辑。
变更日志
增加了音频文件的封面保存功能。
改进的 qsv 文件解码。
修复了 MKV 中保留源字幕流的错误。
简化的输出设置。
音视频分离器增加了范围选择功能。
添加了 FormatPlayer 解码选项。 查看全部
网页视频抓取软件 格式工厂(格式工厂官方版如何使用的格式转换工具?(一))
格式工厂正式版是一款功能强大的格式转换工具。该软件支持所有多媒体格式的各种常用格式。它具有视频转换、音频转换、图像转换、视频合并和音频合并等高级功能。定义设置文件的输出配置,添加数字水印等功能。
软件功能
1、各类视频转MP4/3GP/MPG/AVI/WMV/FLV/SWF
2、所有类型的音频转MP3/WMA/AMR/OGG/AAC/WAV
3、所有图片类型转JPG/BMP/PNG/TIF/ICO/GIF/TGA
4、将 DVD 翻录到视频文件,将音乐 CD 翻录到音频文件
5、MP4文件支持iPod/iPhone/PSP/黑模等指定格式
6、支持RMVB、水印、音视频混合
软件功能
1、支持几乎所有类型的多媒体格式到几种常用格式
2、转换过程中可以修复一些损坏的视频文件
3、减肥多媒体文件
4、支持iPhone/iPod/PSP等多媒体指定格式
5、转换后的图片文件支持缩放、旋转、水印等功能
6、DVD视频采集功能,轻松备份DVD到本地硬盘
7、支持56种国家语言
常见问题
一、格式工厂需要注册吗?
格式工厂无需注册,无需收费,直接使用即可!
二、如何使用格式工厂?
格式工厂操作非常简单,只需按照以下步骤操作即可:
1、选择要转换成的格式,以“PNG”格式为例,打开软件后点击“PNG”;
2、添加文件/文件夹并点击确定;
3、"点击开始";
4、完成。
三、如何设置输出文件地址?
1、点击“任务”---“选项”;
2、选择目标地址。
四、如何设置转换后的文件?
可以根据需要单独设置输出文件,以图片“GIF”为例:
1、点击“输出配置”;
2、您可以根据自己的需要进行编辑。
变更日志
增加了音频文件的封面保存功能。
改进的 qsv 文件解码。
修复了 MKV 中保留源字幕流的错误。
简化的输出设置。
音视频分离器增加了范围选择功能。
添加了 FormatPlayer 解码选项。
网页视频抓取软件 格式工厂( 支持的格式markdown一种-plugin-F-port-format)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-03-06 06:08
支持的格式markdown一种-plugin-F-port-format)
什么是 zignis-plugin-read?
这是一个简单的工具插件。目的是实现一个命令行工具,可以方便的获取网页主体,让我们可以通过多种方式采集整理学习资料,支持多种格式,有一些特色模式,这里也叫为简单起见。它是格式。
支持格式 markdown 纯文本标记语言 pdf 便携文件格式 html 生成html页面文件 png 无损压缩位图图形格式 jpeg 有损压缩图像格式 less epub电子书格式mobi亚马逊电子书格式控制台直接输出markdown到终端,可按需处理
主要参数--version显示版本号--format,-F需要转换的格式--read-only,--ro只渲染html,配合web格式使用--debug调试--port代理,如作为抢掘金 文章 中的图片需要打开 --localhost localhost 端口 --open-browser, --ob 网页格式自动打开浏览器 --rename 获得 文章Rename --dir 获得< @文章存储本地位置
安装
$ npm i -g zignis zignis-plugin-read
# 默认会下载 puppeteer,比较慢,加上这个环境变量就不下了,也可以 `Ctrl+C` 取消下载
# 没有 puppeterr, `html`, `png`, `jpeg` 和 `pdf` 就不能工作了。
$ PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=true npm i -g zignis zignis-plugin-read
# 用法
$ zignis read [URL|本地 markdown] --format=[FORMAT]
# 帮助
$ zignis read [url]
例子
# 获取掘金一篇文章
$ zignis read https://juejin.im/post/5dd6a8106fb9a05a7f75fe74
# 获取掘金一篇文章,转换为 markdown 格式
$ zignis read https://juejin.im/post/5dd6a8106fb9a05a7f75fe74 --format=markdown
# 打开一个空的 markdown 编辑器
$ zignis read --format=web
# 欣赏一下自己项目的 README
$ zignis read README.md
获取文章并转换成微信公众号支持的格式
# 安装
$ npm i -g zignis zignis-plugin-read zignis-plugin-read-extend-format-wechat
# 例子,抓取掘金文章,并使用代理获取文章中图片
$ zignis read https://juejin.im/post/5dd6a8106fb9a05a7f75fe74 --format=wechat --proxy
网站 目前适合网页正文转换
在开发过程中,发现默认的行为总是不尽如人意,需要有针对性的调优。目前对下面的网站只做了基础调优,不保证绝对没有问题。
已知错误
项目地址 查看全部
网页视频抓取软件 格式工厂(
支持的格式markdown一种-plugin-F-port-format)
什么是 zignis-plugin-read?
这是一个简单的工具插件。目的是实现一个命令行工具,可以方便的获取网页主体,让我们可以通过多种方式采集整理学习资料,支持多种格式,有一些特色模式,这里也叫为简单起见。它是格式。
支持格式 markdown 纯文本标记语言 pdf 便携文件格式 html 生成html页面文件 png 无损压缩位图图形格式 jpeg 有损压缩图像格式 less epub电子书格式mobi亚马逊电子书格式控制台直接输出markdown到终端,可按需处理
主要参数--version显示版本号--format,-F需要转换的格式--read-only,--ro只渲染html,配合web格式使用--debug调试--port代理,如作为抢掘金 文章 中的图片需要打开 --localhost localhost 端口 --open-browser, --ob 网页格式自动打开浏览器 --rename 获得 文章Rename --dir 获得< @文章存储本地位置
安装
$ npm i -g zignis zignis-plugin-read
# 默认会下载 puppeteer,比较慢,加上这个环境变量就不下了,也可以 `Ctrl+C` 取消下载
# 没有 puppeterr, `html`, `png`, `jpeg` 和 `pdf` 就不能工作了。
$ PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=true npm i -g zignis zignis-plugin-read
# 用法
$ zignis read [URL|本地 markdown] --format=[FORMAT]
# 帮助
$ zignis read [url]
例子
# 获取掘金一篇文章
$ zignis read https://juejin.im/post/5dd6a8106fb9a05a7f75fe74
# 获取掘金一篇文章,转换为 markdown 格式
$ zignis read https://juejin.im/post/5dd6a8106fb9a05a7f75fe74 --format=markdown
# 打开一个空的 markdown 编辑器
$ zignis read --format=web
# 欣赏一下自己项目的 README
$ zignis read README.md
获取文章并转换成微信公众号支持的格式
# 安装
$ npm i -g zignis zignis-plugin-read zignis-plugin-read-extend-format-wechat
# 例子,抓取掘金文章,并使用代理获取文章中图片
$ zignis read https://juejin.im/post/5dd6a8106fb9a05a7f75fe74 --format=wechat --proxy
网站 目前适合网页正文转换
在开发过程中,发现默认的行为总是不尽如人意,需要有针对性的调优。目前对下面的网站只做了基础调优,不保证绝对没有问题。
已知错误
项目地址
网页视频抓取软件 格式工厂(document_fromstring的使用方法(网页)(html字符串))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-28 18:04
狭义的爬虫只负责爬取,即下载网页。其实爬虫还负责从下载的网页中提取出我们想要的数据,也就是解析非结构化数据(网页)提取结构化数据(有用数据)。
所以,下载网页只是第一步,重要的一步就是数据的提取。不同的爬虫想要不同的数据,提取不同的数据,但是提取的方法是相似的。
提取数据的最简单方法是使用正则表达式。这种方法很简单,提取逻辑应该不复杂。否则写出来的正则表达式会晦涩难懂,甚至无法提取复杂的数据结构。
最终,经过多年的经验,老猿选择了lxml和xpath来解析网页,提取结构化数据。顺便说一句,BeautifulSoup 也是解析 HTML 的好工具。它可以使用多个解析器,比如Python标准库的解析器,但是速度比较慢。你也可以使用lxml作为解析器,但是它的用法,API和lxml不一样。用了之后,lxml的API就更舒服了。
lxml 绑定了 C 语言库 libxml2 和 libxslt,并提供了 Pythonic API。它有一些主要特点:
一句话总结,是一款集C语言的速度与Python的简洁于一身的神器。
lxml有两部分,分别支持XML和HTML的解析:
lxml.etree 可用于解析 RSS 提要,这些提要是 XML 格式的文档。不过爬取的网页大部分都是html页面,所以这里主要介绍lxml.html解析网页的方法。
lxml.html 从 html 字符串生成文档树结构
我们下载的网页是一串html字符串。如何将其输入到 lxml.html 模块中生成 html 文档的树形结构?
该模块提供了几种不同的方法:
下面我们用具体的例子来说明上述方法的区别。
如何使用 document_fromstring
In [1]: import lxml.html as lh
In [2]: z = lh.document_fromstring('abcxyz')
# 可以看到,它自动加了根节点
In [3]: z
Out[3]:
In [4]: z.tag
Out[4]: 'html'
# 还加了节点
In [5]: z.getchildren()
Out[5]: []
# 把字符串的两个节点放在了里面
In [6]: z.getchildren()[0].getchildren()
Out[6]: [, ]
使用 fragment_fromstring
In [11]: z = lh.fragment_fromstring(‘abcxyz’)
---------------------------------------------------------------------------
ParserError Traceback (most recent call last)
in ()
----> 1 z = lh.fragment_fromstring(‘abcxyz’)
~/.virtualenvs/py3.6/lib/python3.6/site-packages/lxml/html/__init__.py in fragment_fromstring(html, create_parent, base_url, parser, **kw)
850 raise etree.ParserError(
851 “Multiple elements found (%s)”
--> 852 % ‘, ‘.join([_element_name(e) for e in elements]))
853 el = elements[0]
854 if el.tail and el.tail.strip():
ParserError: Multiple elements found (div, div)
# 可以看到,输入是两个节点(element)时就会报错
# 如果加上 create_parent 参数,就没问题了
In [12]: z = lh.fragment_fromstring('abcxyz', create_parent='p')
In [13]: z.tag
Out[13]: 'p'
In [14]: z.getchildren()
Out[14]: [, ]
使用fragments_fromstring
# 输入字符串含有一个节点,则返回包含这一个节点的列表
In [17]: lh.fragments_fromstring('abc')
Out[17]: []
# 输入字符串含有多个节点,则返回包含这多个节点的列表
In [18]: lh.fragments_fromstring('abcxyz')
Out[18]: [, ]
从字符串的使用
In [27]: z = lh.fromstring('abcxyz')
In [28]: z
Out[28]:
In [29]: z.getchildren()
Out[29]: [, ]
In [30]: type(z)
Out[30]: lxml.html.HtmlElement
这里,如果fromstring输入是多个节点,则会添加一个父节点并返回。但是就像 html 网页从节点开始一样,我们可以使用 fromstring() 和 document_fromstring() 来获得完整的网页结构。
从上面的代码我们可以看出,那些函数返回的是HtmlElement对象,也就是说,我们已经学会了如何从html字符串中获取HtmlElement对象。在下一节中,我们将学习如何操作 HtmlElement 对象,从中提取我们感兴趣的数据。 查看全部
网页视频抓取软件 格式工厂(document_fromstring的使用方法(网页)(html字符串))
狭义的爬虫只负责爬取,即下载网页。其实爬虫还负责从下载的网页中提取出我们想要的数据,也就是解析非结构化数据(网页)提取结构化数据(有用数据)。
所以,下载网页只是第一步,重要的一步就是数据的提取。不同的爬虫想要不同的数据,提取不同的数据,但是提取的方法是相似的。
提取数据的最简单方法是使用正则表达式。这种方法很简单,提取逻辑应该不复杂。否则写出来的正则表达式会晦涩难懂,甚至无法提取复杂的数据结构。
最终,经过多年的经验,老猿选择了lxml和xpath来解析网页,提取结构化数据。顺便说一句,BeautifulSoup 也是解析 HTML 的好工具。它可以使用多个解析器,比如Python标准库的解析器,但是速度比较慢。你也可以使用lxml作为解析器,但是它的用法,API和lxml不一样。用了之后,lxml的API就更舒服了。
lxml 绑定了 C 语言库 libxml2 和 libxslt,并提供了 Pythonic API。它有一些主要特点:
一句话总结,是一款集C语言的速度与Python的简洁于一身的神器。
lxml有两部分,分别支持XML和HTML的解析:
lxml.etree 可用于解析 RSS 提要,这些提要是 XML 格式的文档。不过爬取的网页大部分都是html页面,所以这里主要介绍lxml.html解析网页的方法。
lxml.html 从 html 字符串生成文档树结构
我们下载的网页是一串html字符串。如何将其输入到 lxml.html 模块中生成 html 文档的树形结构?
该模块提供了几种不同的方法:
下面我们用具体的例子来说明上述方法的区别。
如何使用 document_fromstring
In [1]: import lxml.html as lh
In [2]: z = lh.document_fromstring('abcxyz')
# 可以看到,它自动加了根节点
In [3]: z
Out[3]:
In [4]: z.tag
Out[4]: 'html'
# 还加了节点
In [5]: z.getchildren()
Out[5]: []
# 把字符串的两个节点放在了里面
In [6]: z.getchildren()[0].getchildren()
Out[6]: [, ]
使用 fragment_fromstring
In [11]: z = lh.fragment_fromstring(‘abcxyz’)
---------------------------------------------------------------------------
ParserError Traceback (most recent call last)
in ()
----> 1 z = lh.fragment_fromstring(‘abcxyz’)
~/.virtualenvs/py3.6/lib/python3.6/site-packages/lxml/html/__init__.py in fragment_fromstring(html, create_parent, base_url, parser, **kw)
850 raise etree.ParserError(
851 “Multiple elements found (%s)”
--> 852 % ‘, ‘.join([_element_name(e) for e in elements]))
853 el = elements[0]
854 if el.tail and el.tail.strip():
ParserError: Multiple elements found (div, div)
# 可以看到,输入是两个节点(element)时就会报错
# 如果加上 create_parent 参数,就没问题了
In [12]: z = lh.fragment_fromstring('abcxyz', create_parent='p')
In [13]: z.tag
Out[13]: 'p'
In [14]: z.getchildren()
Out[14]: [, ]
使用fragments_fromstring
# 输入字符串含有一个节点,则返回包含这一个节点的列表
In [17]: lh.fragments_fromstring('abc')
Out[17]: []
# 输入字符串含有多个节点,则返回包含这多个节点的列表
In [18]: lh.fragments_fromstring('abcxyz')
Out[18]: [, ]
从字符串的使用
In [27]: z = lh.fromstring('abcxyz')
In [28]: z
Out[28]:
In [29]: z.getchildren()
Out[29]: [, ]
In [30]: type(z)
Out[30]: lxml.html.HtmlElement
这里,如果fromstring输入是多个节点,则会添加一个父节点并返回。但是就像 html 网页从节点开始一样,我们可以使用 fromstring() 和 document_fromstring() 来获得完整的网页结构。
从上面的代码我们可以看出,那些函数返回的是HtmlElement对象,也就是说,我们已经学会了如何从html字符串中获取HtmlElement对象。在下一节中,我们将学习如何操作 HtmlElement 对象,从中提取我们感兴趣的数据。
网页视频抓取软件 格式工厂(安大多数格式转换神器3G2转换,音频格式转换)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-27 21:13
应用介绍
格式工厂最新正式版是一个格式转换神器。本软件为您提供图片格式jpg、gif、bmp、jpeg、png的转换,视频格式3GP、3G2、MPEG转换、音频格式提取。, 听这首歌。支持多种手机型号,本软件完全免费为大家提供服务。
格式工厂官方最新版软件功能
支持压缩以减小视频文件的大小,方便通过短信等方式发送。
您可以设置在转换视频时保持原创视频质量
高级模式可用:可指定视频码率、任意分辨率、音频码率、编解码器等
支持从专辑/专辑/Dropbox/iCloud/Google驱动器/一个驱动器等导入视频/音频;
格式工厂官方最新版软件功能
图片格式转换:转换图片格式,支持输出格式jpg、gif、bmp、jpeg、png、wmf、webp等。
视频转换器:转换视频格式,支持输出格式MP4、MOV、3GP、3G2、MPEG、WMV、FLV等。
音频提取器:从视频中提取音频,支持输出格式 MP3、M4A、WMA、AAC、M4R 等。
音频格式转换:音频转换格式,支持输出格式MP3、M4A、FLAC、WMA、AAC、M4R等。
内置全能播放器,可播放大部分视频格式
转换后的格式完美支持大部分安卓机型
格式工厂官方最新版软件评测
这个可以提供多种格式的转换,让你看到不同的视频和音频,试试吧 查看全部
网页视频抓取软件 格式工厂(安大多数格式转换神器3G2转换,音频格式转换)
应用介绍
格式工厂最新正式版是一个格式转换神器。本软件为您提供图片格式jpg、gif、bmp、jpeg、png的转换,视频格式3GP、3G2、MPEG转换、音频格式提取。, 听这首歌。支持多种手机型号,本软件完全免费为大家提供服务。
格式工厂官方最新版软件功能
支持压缩以减小视频文件的大小,方便通过短信等方式发送。
您可以设置在转换视频时保持原创视频质量
高级模式可用:可指定视频码率、任意分辨率、音频码率、编解码器等
支持从专辑/专辑/Dropbox/iCloud/Google驱动器/一个驱动器等导入视频/音频;
格式工厂官方最新版软件功能
图片格式转换:转换图片格式,支持输出格式jpg、gif、bmp、jpeg、png、wmf、webp等。
视频转换器:转换视频格式,支持输出格式MP4、MOV、3GP、3G2、MPEG、WMV、FLV等。
音频提取器:从视频中提取音频,支持输出格式 MP3、M4A、WMA、AAC、M4R 等。
音频格式转换:音频转换格式,支持输出格式MP3、M4A、FLAC、WMA、AAC、M4R等。
内置全能播放器,可播放大部分视频格式
转换后的格式完美支持大部分安卓机型
格式工厂官方最新版软件评测
这个可以提供多种格式的转换,让你看到不同的视频和音频,试试吧
网页视频抓取软件 格式工厂(问题分析手机录制的格式化工厂转码的视频编码和Vorbis音频编码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-25 17:17
)
本文文章主要介绍html5中video标签无法播放mp4问题的解决方法。需要的朋友,一起来看看吧。
最近发现一个问题,在手机上录制了一个1.mp4文件,主流浏览器都可以正常播放。但是使用格式工厂将 rmvb 文件转码为 2.mp4 无法播放。我终于通过查找相关信息解决了它。我们来看看详细介绍:
问题分析
手机录制的视频属性:
格式工厂转码视频属性:
首先排除代码问题、路径问题、浏览器不支持问题等。转码后的视频编码为mp4v,是无法播放的原因。将其转换为 AVC(H264)编码。
查看视频标签支持的视频格式和编码的文档:
MPEG4 = 具有 H.264 视频编码和 AAC 音频编码的 MPEG4 文件
WebM = 带有 VP8 视频编码和 Vorbis 音频编码的 WebM 文件
Ogg = 带有 Theora 视频编码和 Vorbis 音频编码的 Ogg 文件
通过以上信息,我们发现只有h264编码的MP4视频(MPEG-LA公司)、VP8编码的webm格式视频()和Theora编码的ogg格式视频(iTouch开发)可以支持html5标签。
解决方案
video 标签允许多个源元素。源元素可以链接到不同的视频文件。浏览器会使用第一个识别的格式,可以用来解决浏览器的兼容性问题。
查看全部
网页视频抓取软件 格式工厂(问题分析手机录制的格式化工厂转码的视频编码和Vorbis音频编码
)
本文文章主要介绍html5中video标签无法播放mp4问题的解决方法。需要的朋友,一起来看看吧。
最近发现一个问题,在手机上录制了一个1.mp4文件,主流浏览器都可以正常播放。但是使用格式工厂将 rmvb 文件转码为 2.mp4 无法播放。我终于通过查找相关信息解决了它。我们来看看详细介绍:
问题分析
手机录制的视频属性:
格式工厂转码视频属性:
首先排除代码问题、路径问题、浏览器不支持问题等。转码后的视频编码为mp4v,是无法播放的原因。将其转换为 AVC(H264)编码。
查看视频标签支持的视频格式和编码的文档:
MPEG4 = 具有 H.264 视频编码和 AAC 音频编码的 MPEG4 文件
WebM = 带有 VP8 视频编码和 Vorbis 音频编码的 WebM 文件
Ogg = 带有 Theora 视频编码和 Vorbis 音频编码的 Ogg 文件
通过以上信息,我们发现只有h264编码的MP4视频(MPEG-LA公司)、VP8编码的webm格式视频()和Theora编码的ogg格式视频(iTouch开发)可以支持html5标签。
解决方案
video 标签允许多个源元素。源元素可以链接到不同的视频文件。浏览器会使用第一个识别的格式,可以用来解决浏览器的兼容性问题。
网页视频抓取软件 格式工厂(狸窝全能视频转换器破解版V8.1绿色免费版下载体验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-02-25 01:10
格式工厂绿色版是一款功能强大的视频格式转换软件。它具有超强的转换能力,支持多种视频格式,还支持图片和文档类型的转换。它是用户最常用的转换软件。格式工厂绿色版无需安装,下载解压即可使用。本站带给你的是无广告版,使用更方便!欢迎下载体验。
格式工厂绿色特点:
支持几乎所有类型的多媒体格式
支持各类视频、音频、图片等格式,轻松转换为您想要的格式。
修复损坏的视频文件
在转换过程中,可以修复损坏的文件,使转换质量不受损。
用于减肥的多媒体文件
它可以帮助您的文件减轻重量,使它们变瘦。不仅节省硬盘空间,而且易于保存和备份。
可以指定格式
支持iphone/ipod/psp等多媒体指定格式。
支持图片常用功能
转换图片支持缩放、旋转、加水印等常用功能,操作一气呵成。
备份很简单
DVD视频捕捉功能,轻松备份DVD到本地硬盘。
支持多种语言
它支持62种国家语言,易于访问,满足各种需求。
支持的转换格式:
mp4、3gp、mpg、avi、wmv、flv、swf、jpg、bmp、png、tif、ico、gif、tga、mp3、wma、amr、ogg、aac、wav
格式工厂绿色版功能
进入主界面工具栏:home键(push wps)
进入主界面图片功能区:图片工厂下载按钮;
删除图片工厂在线安装程序、FFZ压缩文件管理器;
进入升级,进入选项检查更新项,进入菜单项检查更新;
变更日志:版本 5.6.5.0
注意:新版本的格式工厂不再支持 32 位系统。如果需要32位系统,需要下载Format Factory4.9.5版本如果是XP系统,则需要下载Format Factory3.8
上一篇:AMV格式转换器免费版 | AMV视频格式转换器v3.0中文绿色版
下一篇: Beaver Nest 全能视频转换器破解版 V8.1 绿色免费版 查看全部
网页视频抓取软件 格式工厂(狸窝全能视频转换器破解版V8.1绿色免费版下载体验)
格式工厂绿色版是一款功能强大的视频格式转换软件。它具有超强的转换能力,支持多种视频格式,还支持图片和文档类型的转换。它是用户最常用的转换软件。格式工厂绿色版无需安装,下载解压即可使用。本站带给你的是无广告版,使用更方便!欢迎下载体验。
格式工厂绿色特点:
支持几乎所有类型的多媒体格式
支持各类视频、音频、图片等格式,轻松转换为您想要的格式。
修复损坏的视频文件
在转换过程中,可以修复损坏的文件,使转换质量不受损。
用于减肥的多媒体文件
它可以帮助您的文件减轻重量,使它们变瘦。不仅节省硬盘空间,而且易于保存和备份。
可以指定格式
支持iphone/ipod/psp等多媒体指定格式。
支持图片常用功能
转换图片支持缩放、旋转、加水印等常用功能,操作一气呵成。
备份很简单
DVD视频捕捉功能,轻松备份DVD到本地硬盘。
支持多种语言
它支持62种国家语言,易于访问,满足各种需求。
支持的转换格式:
mp4、3gp、mpg、avi、wmv、flv、swf、jpg、bmp、png、tif、ico、gif、tga、mp3、wma、amr、ogg、aac、wav
格式工厂绿色版功能
进入主界面工具栏:home键(push wps)
进入主界面图片功能区:图片工厂下载按钮;
删除图片工厂在线安装程序、FFZ压缩文件管理器;
进入升级,进入选项检查更新项,进入菜单项检查更新;
变更日志:版本 5.6.5.0
注意:新版本的格式工厂不再支持 32 位系统。如果需要32位系统,需要下载Format Factory4.9.5版本如果是XP系统,则需要下载Format Factory3.8
上一篇:AMV格式转换器免费版 | AMV视频格式转换器v3.0中文绿色版
下一篇: Beaver Nest 全能视频转换器破解版 V8.1 绿色免费版
网页视频抓取软件 格式工厂(,指定开始和结束位置3.支持(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-17 23:14
是一个功能强大的图片、音乐和视频格式转换软件。它主要用作转换相关视频格式的便捷工具。该软件可以帮助用户将自己的视频转换成他们需要的相关格式。简单方便的文件格式转换软件,基于移动智能终端的特点,引入多达20种音频、视频和图像格式相互转换,涵盖AAC、mp3.M4A、WMA、WAV、FLAC、MP< @4.MPG、AVI、WMV、ASX、MOV、M4V、VOB等多种类型,让用户可以根据自己的习惯和实际需要自由选择想要转换的文件格式。并且该软件还支持用户自定义输入目标文件格式,并将其转换为您喜欢的任何格式,超乎想象。, 功能比较多,有需要的朋友不要'
特征
1.内置强大的视频播放器,可以播放各种格式的视频。
2.指定开始和结束位置
3.支持从视频中提取音频
4.在没有网络的手机中转换
5.支持各类视频(3GP、FLV、MP4.MOV、MKV、AVI、MPG、MPEG、MXF等)
6.保存各种类型的音频(MP3.AAC、WAV、AIFF、OPUS 等)
7.支持视频文件的压缩和缩小,方便发送短信。
8.转换视频时,可以设置并保持原创视频质量
9.提供高级模式:可以指定视频码率、任意分辨率、音频码率、编解码器等。
10.APP支持从相册/相册/Dropbox/iCloud/Google Drive/one Drive导入视频/音频; 查看全部
网页视频抓取软件 格式工厂(,指定开始和结束位置3.支持(图))
是一个功能强大的图片、音乐和视频格式转换软件。它主要用作转换相关视频格式的便捷工具。该软件可以帮助用户将自己的视频转换成他们需要的相关格式。简单方便的文件格式转换软件,基于移动智能终端的特点,引入多达20种音频、视频和图像格式相互转换,涵盖AAC、mp3.M4A、WMA、WAV、FLAC、MP< @4.MPG、AVI、WMV、ASX、MOV、M4V、VOB等多种类型,让用户可以根据自己的习惯和实际需要自由选择想要转换的文件格式。并且该软件还支持用户自定义输入目标文件格式,并将其转换为您喜欢的任何格式,超乎想象。, 功能比较多,有需要的朋友不要'
特征
1.内置强大的视频播放器,可以播放各种格式的视频。
2.指定开始和结束位置
3.支持从视频中提取音频
4.在没有网络的手机中转换
5.支持各类视频(3GP、FLV、MP4.MOV、MKV、AVI、MPG、MPEG、MXF等)
6.保存各种类型的音频(MP3.AAC、WAV、AIFF、OPUS 等)
7.支持视频文件的压缩和缩小,方便发送短信。
8.转换视频时,可以设置并保持原创视频质量
9.提供高级模式:可以指定视频码率、任意分辨率、音频码率、编解码器等。
10.APP支持从相册/相册/Dropbox/iCloud/Google Drive/one Drive导入视频/音频;
网页视频抓取软件 格式工厂(百度站点地图能给搜索优化带来什么好处?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-16 08:15
所谓的网站maps,即网站maps,允许网站管理员在他们的网站上通知搜索引擎可用的页面。搜索引擎将首先抓取 网站 的 robots 文件。在这个文件中,还有一个很重要的内容,就是站点地图。其中,百度站点地图是指百度支持的收录标准,在原协议的基础上扩展而来。
百度站点地图的作用是告诉百度蜘蛛一个综合的站点链接,并通过站点地图优化自己的网站。百度站点地图分为三种格式:TXT文本格式、XML格式和hmtl索引格式。在 robots 文件中,告诉搜索引擎我有一个 网站 地图,而 网站 是这样的。
先说一下两个网站maps的区别
网站map 的 HTML 版本是用户可以看到的页面。它通常放在 网站 的顶部或底部。当部分用户输入网站 时,他们可以通过网站 映射快速进入一个部分。我这里要说的是,一些大的网站s 有太多的列,无法列出网站maps。
另一种是纯粹为了提高爬虫爬取效率而构建的XML网站map,通常会列出页面中网站的所有链接。网站 上的链接一旦蜘蛛进去就很容易被抓到。通常用于一些小的网站,网站 的链接布局结构不是很好。
HTML 地图对搜索优化有什么好处?
1、网站地图可以添加“入口点”到其他页面。
其实这是SEO推广中比较专业的概念。有人称之为“入口”。术语“度数”来自图论算法。它通常指有向图中的一个点到图中一条边的端点的次数之和。在SEO知识体系中,可以理解为页面的传入链接。作为一个网站map,它必须充满到其他页面的链接,这无疑增加了其他页面的传入链接。站点地图本身就是一个中心页面,可以作为一个很好的导航功能。
网站Map解决了网站内部链结构的一个方面,是SEO优化中不可忽视的重要作用。
2、网站地图为蜘蛛提供了良好的爬行路径。
搜索引擎的工作机制是每个蜘蛛在互联网上发布一个新的网页,然后通过自己的许多复杂的算法机制对这些网页进行排序。如果这些 网站 在互联网上不是很好,爬虫可以访问它们。毫无疑问,随着搜索引擎负担的增加,很难完全捕获网站的所有页面。网站地图的创建解决了这个问题。当爬虫访问 网站 时,他首先访问了机器人。如果我们用机器人记下网站map的地址,网站map上还会有很多其他的页面。这为爬虫爬取我们的 网站 创造了一种很好的方式,并使爬虫更容易爬取整个 网站 页面。
3、网站地图可以有效提高网页的抓取率。
其实我们仔细分析了我们的网站,发现还有大量的页面没有被收录。这些页面是搜索引擎无法掌握的地方,自然很难成为收录。通过网站图,我们可以提取网络推广中的隐藏页面,搜索引擎爬虫会按照网站图上的链接,一一抓取,从而增加整体的采集地点。
条目数与总页数的比率就是接受率。当两个站点的总页数相同时,有站点地图的站点的注册率明显高于没有站点地图的站点。从站点范围的 采集 角度来看,网站 地图发挥着重要作用。
4、网站 的 HTML 地图使访问者可以轻松导航以增强用户体验。
其实网络推广前期建立网站地图的目的,就是为了方便访问者浏览网站。页面涵盖了整个网站的所有版块(大网站)或页面(中小网站),让访问者能够快速找到自己需要的信息。 查看全部
网页视频抓取软件 格式工厂(百度站点地图能给搜索优化带来什么好处?(图))
所谓的网站maps,即网站maps,允许网站管理员在他们的网站上通知搜索引擎可用的页面。搜索引擎将首先抓取 网站 的 robots 文件。在这个文件中,还有一个很重要的内容,就是站点地图。其中,百度站点地图是指百度支持的收录标准,在原协议的基础上扩展而来。
百度站点地图的作用是告诉百度蜘蛛一个综合的站点链接,并通过站点地图优化自己的网站。百度站点地图分为三种格式:TXT文本格式、XML格式和hmtl索引格式。在 robots 文件中,告诉搜索引擎我有一个 网站 地图,而 网站 是这样的。
先说一下两个网站maps的区别
网站map 的 HTML 版本是用户可以看到的页面。它通常放在 网站 的顶部或底部。当部分用户输入网站 时,他们可以通过网站 映射快速进入一个部分。我这里要说的是,一些大的网站s 有太多的列,无法列出网站maps。
另一种是纯粹为了提高爬虫爬取效率而构建的XML网站map,通常会列出页面中网站的所有链接。网站 上的链接一旦蜘蛛进去就很容易被抓到。通常用于一些小的网站,网站 的链接布局结构不是很好。
HTML 地图对搜索优化有什么好处?
1、网站地图可以添加“入口点”到其他页面。
其实这是SEO推广中比较专业的概念。有人称之为“入口”。术语“度数”来自图论算法。它通常指有向图中的一个点到图中一条边的端点的次数之和。在SEO知识体系中,可以理解为页面的传入链接。作为一个网站map,它必须充满到其他页面的链接,这无疑增加了其他页面的传入链接。站点地图本身就是一个中心页面,可以作为一个很好的导航功能。
网站Map解决了网站内部链结构的一个方面,是SEO优化中不可忽视的重要作用。
2、网站地图为蜘蛛提供了良好的爬行路径。
搜索引擎的工作机制是每个蜘蛛在互联网上发布一个新的网页,然后通过自己的许多复杂的算法机制对这些网页进行排序。如果这些 网站 在互联网上不是很好,爬虫可以访问它们。毫无疑问,随着搜索引擎负担的增加,很难完全捕获网站的所有页面。网站地图的创建解决了这个问题。当爬虫访问 网站 时,他首先访问了机器人。如果我们用机器人记下网站map的地址,网站map上还会有很多其他的页面。这为爬虫爬取我们的 网站 创造了一种很好的方式,并使爬虫更容易爬取整个 网站 页面。
3、网站地图可以有效提高网页的抓取率。
其实我们仔细分析了我们的网站,发现还有大量的页面没有被收录。这些页面是搜索引擎无法掌握的地方,自然很难成为收录。通过网站图,我们可以提取网络推广中的隐藏页面,搜索引擎爬虫会按照网站图上的链接,一一抓取,从而增加整体的采集地点。
条目数与总页数的比率就是接受率。当两个站点的总页数相同时,有站点地图的站点的注册率明显高于没有站点地图的站点。从站点范围的 采集 角度来看,网站 地图发挥着重要作用。
4、网站 的 HTML 地图使访问者可以轻松导航以增强用户体验。
其实网络推广前期建立网站地图的目的,就是为了方便访问者浏览网站。页面涵盖了整个网站的所有版块(大网站)或页面(中小网站),让访问者能够快速找到自己需要的信息。

