
网页视频抓取软件 格式工厂
网页视频抓取软件 格式工厂(网页视频抓取软件格式工厂-格式转换工具-免费、免签水印)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-15 12:02
网页视频抓取软件格式工厂-格式转换工具-免费、免签水印编辑|【视频抓取工具网站+短视频脚本制作工具】-格式工厂如果需要公众号素材,
网页视频搬运,有一个叫做格式工厂的工具。
在百度里搜“电视剧各种网盘及资源网站”吧,会有很多,建议在百度里搜“电视剧”。还有就是在网上搜“各种网盘”或者“电视剧下载”,会有很多,建议在百度里搜“电视剧”。
百度搜“电视剧资源”,然后从相关贴吧找。小说资源请百度“网盘”。
有个app叫“盘多多”,可以满足你的各种需求。
把下载好的电视剧的文件夹下载下来,再移动到电视机上,在的电视机上一般都是有crt电视机有个专门的电视软件叫“bilibili电视”只要有充电功能的电视机,
最快的还是自己想办法联系了,
网页上找自己需要的视频,
格式工厂
我回答一下,我用什么都可以下载视频,有个软件可以。
下一个app,
百度网盘,
现在就连电视剧网站上也都是下载不了,他们是联盟到网站本身,然后挂了商业广告联盟,或者广告商花钱联盟的话,他们又为了下载点击率,才能挣钱。建议用格式工厂,或者转换器, 查看全部
网页视频抓取软件 格式工厂(网页视频抓取软件格式工厂-格式转换工具-免费、免签水印)
网页视频抓取软件格式工厂-格式转换工具-免费、免签水印编辑|【视频抓取工具网站+短视频脚本制作工具】-格式工厂如果需要公众号素材,
网页视频搬运,有一个叫做格式工厂的工具。
在百度里搜“电视剧各种网盘及资源网站”吧,会有很多,建议在百度里搜“电视剧”。还有就是在网上搜“各种网盘”或者“电视剧下载”,会有很多,建议在百度里搜“电视剧”。
百度搜“电视剧资源”,然后从相关贴吧找。小说资源请百度“网盘”。
有个app叫“盘多多”,可以满足你的各种需求。
把下载好的电视剧的文件夹下载下来,再移动到电视机上,在的电视机上一般都是有crt电视机有个专门的电视软件叫“bilibili电视”只要有充电功能的电视机,
最快的还是自己想办法联系了,
网页上找自己需要的视频,
格式工厂
我回答一下,我用什么都可以下载视频,有个软件可以。
下一个app,
百度网盘,
现在就连电视剧网站上也都是下载不了,他们是联盟到网站本身,然后挂了商业广告联盟,或者广告商花钱联盟的话,他们又为了下载点击率,才能挣钱。建议用格式工厂,或者转换器,
网页视频抓取软件 格式工厂(格式工厂转换视频时转换失败的解决方法着解决)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-01-10 21:20
图片和视频文件在我们的日常工作和生活中占据着非常重要的位置。而当我们制作视频发给朋友的时候,我们知道朋友的电脑无法打开这种格式的视频,此时为了让朋友能够流畅的查看视频的内容,我们需要转换视频的内容。要转换的格式。
格式工厂软件是一款支持多种视频格式转换的软件。使用这个软件,我们不仅可以转换视频格式,还可以转换音频格式。音频提取等
有的朋友在使用格式工厂转换视频的格式时遇到这样的问题,也就是格式工厂转换失败的问题,请问这个问题是什么原因呢?我们如何解决这个问题?下面小编将为大家总结和介绍解决这个问题的方法,希望对大家有所帮助。
格式工厂转换视频时转换失败的解决方法一:
打开格式工厂软件,选择要转换的视频格式,然后在添加文件界面点击界面右上角的【输出配置】按钮。
然后在弹出的【视频设置】窗口中,调整转换后视频的视频编码、二次编码等参数。全部设置完成后,点击窗口右下角的【确定】按钮。然后尝试再次转换视频。
格式工厂转换视频时转换失败的解决方法二:
如果你安装的格式工厂软件版本太低,软件会有很多bug,所以我们需要将电脑上的格式工厂升级到最新版本,这样我们才能进行正常的音视频格式。转换。
好了,这就是解决格式工厂无法转换视频的问题了。如果大家在使用本软件进行格式转换的时候经常会遇到这样的问题,那么不妨试试小编为大家整理的解决方法,让我们的转换工作变得更加轻松。 查看全部
网页视频抓取软件 格式工厂(格式工厂转换视频时转换失败的解决方法着解决)
图片和视频文件在我们的日常工作和生活中占据着非常重要的位置。而当我们制作视频发给朋友的时候,我们知道朋友的电脑无法打开这种格式的视频,此时为了让朋友能够流畅的查看视频的内容,我们需要转换视频的内容。要转换的格式。
格式工厂软件是一款支持多种视频格式转换的软件。使用这个软件,我们不仅可以转换视频格式,还可以转换音频格式。音频提取等

有的朋友在使用格式工厂转换视频的格式时遇到这样的问题,也就是格式工厂转换失败的问题,请问这个问题是什么原因呢?我们如何解决这个问题?下面小编将为大家总结和介绍解决这个问题的方法,希望对大家有所帮助。
格式工厂转换视频时转换失败的解决方法一:
打开格式工厂软件,选择要转换的视频格式,然后在添加文件界面点击界面右上角的【输出配置】按钮。

然后在弹出的【视频设置】窗口中,调整转换后视频的视频编码、二次编码等参数。全部设置完成后,点击窗口右下角的【确定】按钮。然后尝试再次转换视频。

格式工厂转换视频时转换失败的解决方法二:
如果你安装的格式工厂软件版本太低,软件会有很多bug,所以我们需要将电脑上的格式工厂升级到最新版本,这样我们才能进行正常的音视频格式。转换。
好了,这就是解决格式工厂无法转换视频的问题了。如果大家在使用本软件进行格式转换的时候经常会遇到这样的问题,那么不妨试试小编为大家整理的解决方法,让我们的转换工作变得更加轻松。
网页视频抓取软件 格式工厂(VideoDownloadHelper火狐插件,建议你下载一个新东方在线的手机app)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-10 09:08
我只能制作你已经购买的课程的视频,你也可以下载,但是视频是加密的PCF。没有视频ID就无法下载。Video DownloadHelper 火狐插件
呃,建议你下载一个新的东方在线手机app,然后缓存到你的手机里,就这样。
可以提取总部
你去下载就是用傲游。然后去插件下载并下载一个网络嗅探器。首先清除网络临时文件夹。然后打开那个视频。用嗅探器下载
总裁网(chinaceot_com)为您解答:
总统网是一所现代化的新型在线自助商学院。在线视频学习集数上万,学习视频还在不断增加中。还有海量资料可供免费下载。庄网互联网商学院分为:企业商学院和个人商学院。如果满足于出门在外,只能安排时间在家学习和充电。展网商学院还分为:“企业商学院”和“个人商学院”,不仅提供在线学习,还提供自学,在线评估你的学习成绩,会根据你的分数为你颁发展网商学院证书。
总裁网络
如何捕获在线视频- : 1、使用在线提供的URLsnooper 软件,有使用说明,可以跟踪大多数文件地址。2、如果方法一无效,右击正在播放的视频选择属性,可以在详细信息中找到实际播放地址3、如果以上方法都不行,还有一个开始播放时立即停止视频的方法...
在线视频抓拍有什么好用的软件:camtasia studio 6.0.0【中文绿色版】:
关于网络视频抓拍的问题:别想了……因为视频分为两段。您只捕获了前一个段的地址。无需软件即可下载视频。您可以直接观看视频。将视频复制到临时文件夹
使用什么工具?怎么剪视频??- : 最简单的方法就是使用“英雄解霸”...
QQ视频和视频可以采集在线视频吗?如果没有,能否推荐一些可以捕捉在线视频的软件?:QQ视频和视频可以在线播放视频吗?这里是我推荐给你的软件1、项目 URL Snooper 下载地址: URL Snooper 实现流媒体抓包的步骤比较重要,先打开软件开始检测,再打开需要抓包流媒体。 ..
有没有可以免费拍视频的软件?- : PhotoImpression 5 和 VideoImpression 2
如何抓取网络视频的真实地址:可以在百度和雅虎上搜索音乐,或者使用网络大师软件分析流量找出地址。
如何截取网页上的视频?- : 1. Red Dragonfly Snap 2005 V1.23 build 0430 Red Dragonfly Snap 2005 是一个完全免费的专业屏幕2. Red Dragonfly Capture Wizard 2005 1.23 build 0430 Red Dragonfly捕获向导 (R...
手机视频抓拍软件-:录屏大师,但是录制这种视频需要root权限才能使用本软件,否则下载后将无法使用,可以先在应用中下载一个root大师宝,这种情况下你可以一键root,然后在app宝里下载这个录屏大师,就可以录屏了。应用宝中的软件下载方便,删除方便。以后用起来很方便,希望采纳。
正在寻找一个软件来从 网站 中获取整个视频!- :首先,你的网站是什么样的网站?和优酷一样吗?如果是这样,这并不难。可以用相应的软件来完成。推荐两个软件:①正版网站,正版视频,可以使用微堂或者说书下载器。②那种网站(你懂的),可以在视频缓冲的时候用VideoCacheView软件找到缓冲目录,然后转移到电脑的其他磁盘上。总之,以上两个软件对你来说已经足够了,但是还需要具体情况具体分析。. 查看全部
网页视频抓取软件 格式工厂(VideoDownloadHelper火狐插件,建议你下载一个新东方在线的手机app)
我只能制作你已经购买的课程的视频,你也可以下载,但是视频是加密的PCF。没有视频ID就无法下载。Video DownloadHelper 火狐插件
呃,建议你下载一个新的东方在线手机app,然后缓存到你的手机里,就这样。
可以提取总部
你去下载就是用傲游。然后去插件下载并下载一个网络嗅探器。首先清除网络临时文件夹。然后打开那个视频。用嗅探器下载
总裁网(chinaceot_com)为您解答:
总统网是一所现代化的新型在线自助商学院。在线视频学习集数上万,学习视频还在不断增加中。还有海量资料可供免费下载。庄网互联网商学院分为:企业商学院和个人商学院。如果满足于出门在外,只能安排时间在家学习和充电。展网商学院还分为:“企业商学院”和“个人商学院”,不仅提供在线学习,还提供自学,在线评估你的学习成绩,会根据你的分数为你颁发展网商学院证书。
总裁网络
如何捕获在线视频- : 1、使用在线提供的URLsnooper 软件,有使用说明,可以跟踪大多数文件地址。2、如果方法一无效,右击正在播放的视频选择属性,可以在详细信息中找到实际播放地址3、如果以上方法都不行,还有一个开始播放时立即停止视频的方法...
在线视频抓拍有什么好用的软件:camtasia studio 6.0.0【中文绿色版】:
关于网络视频抓拍的问题:别想了……因为视频分为两段。您只捕获了前一个段的地址。无需软件即可下载视频。您可以直接观看视频。将视频复制到临时文件夹
使用什么工具?怎么剪视频??- : 最简单的方法就是使用“英雄解霸”...
QQ视频和视频可以采集在线视频吗?如果没有,能否推荐一些可以捕捉在线视频的软件?:QQ视频和视频可以在线播放视频吗?这里是我推荐给你的软件1、项目 URL Snooper 下载地址: URL Snooper 实现流媒体抓包的步骤比较重要,先打开软件开始检测,再打开需要抓包流媒体。 ..
有没有可以免费拍视频的软件?- : PhotoImpression 5 和 VideoImpression 2
如何抓取网络视频的真实地址:可以在百度和雅虎上搜索音乐,或者使用网络大师软件分析流量找出地址。
如何截取网页上的视频?- : 1. Red Dragonfly Snap 2005 V1.23 build 0430 Red Dragonfly Snap 2005 是一个完全免费的专业屏幕2. Red Dragonfly Capture Wizard 2005 1.23 build 0430 Red Dragonfly捕获向导 (R...
手机视频抓拍软件-:录屏大师,但是录制这种视频需要root权限才能使用本软件,否则下载后将无法使用,可以先在应用中下载一个root大师宝,这种情况下你可以一键root,然后在app宝里下载这个录屏大师,就可以录屏了。应用宝中的软件下载方便,删除方便。以后用起来很方便,希望采纳。
正在寻找一个软件来从 网站 中获取整个视频!- :首先,你的网站是什么样的网站?和优酷一样吗?如果是这样,这并不难。可以用相应的软件来完成。推荐两个软件:①正版网站,正版视频,可以使用微堂或者说书下载器。②那种网站(你懂的),可以在视频缓冲的时候用VideoCacheView软件找到缓冲目录,然后转移到电脑的其他磁盘上。总之,以上两个软件对你来说已经足够了,但是还需要具体情况具体分析。.
网页视频抓取软件 格式工厂(提取介绍格式工厂(英文名FormatFactory)版本提取出来)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-09 16:06
格式工厂播放器提取版是一款可以自动识别多种音频格式的播放器工具。它可以帮助您在转换过程中修复视频质量,支持多种格式的转换,并且还具有智能捕获功能。为用户备份,使用非常方便,无需安装,下载使用即可。
介绍
Format Factory(英文名称Format Factory)提供音视频文件的编辑、合并、分割、视频文件混合、裁剪和去水印。软件还包括视频播放、录屏和视频网站下载功能,无需额外安装几个软件
指示
双击鼠标左键2次全屏视频
空格键暂停/播放
完全控制栏
内置设置和其他功能
格式工厂播放器的优势
支持iphone/ipod/psp等多媒体指定格式。支持图片常用功能
支持各类视频、音频、图片等格式,轻松转换为您想要的格式。修复损坏的视频文件
DVD视频翻录功能,轻松备份DVD到本地硬盘。支持多种语言
转换图片支持缩放、旋转、加水印等常用功能,操作一气呵成。备份很简单
它支持62种国家语言,易于访问,满足各种需求。
支持几乎所有类型的多媒体格式
在转换过程中,可以修复损坏的文件,使转换质量不受损。用于减肥的多媒体文件
它可以帮助你的文件“减肥”,让它们“变瘦”。不仅节省硬盘空间,而且易于保存和备份。可以指定格式
软件功能
能有效解决视频播放器无法播放的问题;
视频压缩后,可快速传输给好友或保存到云盘;
音频提取非常好用,一键提取视音频,将mp4转为mp3,播放更方便。
软件操作简单,一键导入需要转换的视频;
支持多种视频格式,转换成功后播放过程不会卡顿;
萃取简介
本软件提取自格式工厂5.7.1版本
可以播放大多数视频格式
我测试了,播放正常,但是播放NAS或者本地视频可能有点卡 查看全部
网页视频抓取软件 格式工厂(提取介绍格式工厂(英文名FormatFactory)版本提取出来)
格式工厂播放器提取版是一款可以自动识别多种音频格式的播放器工具。它可以帮助您在转换过程中修复视频质量,支持多种格式的转换,并且还具有智能捕获功能。为用户备份,使用非常方便,无需安装,下载使用即可。
介绍
Format Factory(英文名称Format Factory)提供音视频文件的编辑、合并、分割、视频文件混合、裁剪和去水印。软件还包括视频播放、录屏和视频网站下载功能,无需额外安装几个软件
指示
双击鼠标左键2次全屏视频
空格键暂停/播放
完全控制栏
内置设置和其他功能

格式工厂播放器的优势
支持iphone/ipod/psp等多媒体指定格式。支持图片常用功能
支持各类视频、音频、图片等格式,轻松转换为您想要的格式。修复损坏的视频文件
DVD视频翻录功能,轻松备份DVD到本地硬盘。支持多种语言
转换图片支持缩放、旋转、加水印等常用功能,操作一气呵成。备份很简单
它支持62种国家语言,易于访问,满足各种需求。
支持几乎所有类型的多媒体格式
在转换过程中,可以修复损坏的文件,使转换质量不受损。用于减肥的多媒体文件
它可以帮助你的文件“减肥”,让它们“变瘦”。不仅节省硬盘空间,而且易于保存和备份。可以指定格式
软件功能
能有效解决视频播放器无法播放的问题;
视频压缩后,可快速传输给好友或保存到云盘;
音频提取非常好用,一键提取视音频,将mp4转为mp3,播放更方便。
软件操作简单,一键导入需要转换的视频;
支持多种视频格式,转换成功后播放过程不会卡顿;
萃取简介
本软件提取自格式工厂5.7.1版本
可以播放大多数视频格式
我测试了,播放正常,但是播放NAS或者本地视频可能有点卡
网页视频抓取软件 格式工厂(【手游坊评测】2017年11月8日前端开发扒视频辛酸历程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-09 01:15
时间:2017 年 11 月 8 日
说到前端开发,在网页上放视频是不可避免的。如果你放视频,有时你会不可避免地拿起视频。以下是我视频的辛酸历程。让我们关注并珍惜它们。
一、直接刷代码
和 pandakill 的视频一样,直接拿代码就可以了。
至于什么格式,自行下载后,直接用格式工厂转换即可。
二、查看网络
比如触手的视频,看网络就可以找到。起初,我还在慢慢寻找。后来有网友建议可以先按大小排序,因为视频会比一般文件大很多==,这样就很容易了,哈哈哈。
三、更改域名
本视频适用于B站(bilibili)。
例如,网站 地址是
怎么接视频,把bilibili改成kanbilibili就行了
打开后,页面顶部是这样的:
点击“下载地址”后,
分为下载地址和弹幕下载地址两部分,我们只需要选择下载地址(第一部分)即可。
在下载地址部分,有3种下载方式,P2、P3和P4。一般可以下载P3。我已经下载了P4,但是中间会有几块下载失败。P3可以下载。下载完成,很多ts文件都下载下来了,然后我们就可以使用B站提供的代码合并工具,将多个ts文件合并为一个ts文件。合并地址:.
首先添加多个已下载的文件。如果需要排序,可以点击“自动排序”,然后输入合并后的文件名,点击“开始合并”,稍等片刻,合并后下载就ok啦。
但是这个时候可能有人会问,我需要mp4格式的视频,不知道ts文件是什么。这这,还有一个特别简单粗暴的方法,就是直接把视频的后缀名改成mp4。可以在本地完全播放,但是我们绝对不局限于本地播放,还可以放在我们的代码中,那么其他人访问这个页面就可以播放这个页面了。那么这个方法就行不通了。我们都知道视频编码格式有很多种,不同的浏览器支持的编码格式也不一样。比如ts的编码格式是MPEG,谷歌、火狐等浏览器支持的编码格式是FLV。所以~~主角来了:格式工厂,它不仅可以转换视频格式,还可以转换视频格式,原来如此简单~~
四、使用 Chrome 和迅雷下载视频
推荐使用此方法。虽然很复杂,但是非常有效。
适用网站:斗鱼、MOOC、网易云课堂、B站等。
我们都知道视频网站为了保护版权,防止盗链下载,一般都是分段加载的。一般的.flv格式,视频源最多有十几个,而.ts格式一般每段几兆,一个小时左右的视频基本有几百个段。手动下载太累了。接下来分享一个无痛的方法,只需要使用系统的常用软件即可。
1、获取原创视频
以一个视频为例,用Chrome访问并打开开发者工具切换到Netword面板,点击视频开始和结束的位置,我们可以发现视频源是一个普通地址,从001 至 344 。
只关注我用红色标记的地方。
2、批量下载 .ts 视频
你只需要注意我圈子里的3个部分。
第一部分:选择要更改的数字的位置,用一对括号和通配符替换,即(*),但是这里有几点需要注意,我们注意到我写了6个0和一个通配符这里,然后在下面那一栏中,对应的写法是0到9(一位数)。当ts文件为10到99时,必须写成5个0加通配符,以此类推,ts文件是100到999.,这里要写成4个0加通配符。简而言之,ts文件的总位数是7位,也就是说虽然我们是分批下载的,但还是分批,0到9批,10到99批,100到999批等,这没关系,如果你注意的话。
第二部分:前两个输入框的第一部分已经讲完了。现在主要的是通配符的长度。这里默认写1就够了。那为什么不写2和3呢?你可以看到结果。
第三部分:这相当于检查部分。前两部分填好后,可以在第三部分查看ts文件的范围,我们可以检查一下前面的配置是否正确。
点击“确定”后,会弹出如下弹窗:
为此,我们只需要注意“合并到一个任务组”即可。这是什么意思?意思是把这个ts文件归入你先写的任务组,方便管理。
其实这个比较简单,使用一行DOS命令就可以实现。
copy/b D:\video\*.ts D:\video-all\all.ts
执行上述命令后,D:\video\目录下的所有.ts文件都会合并到all.ts中,all.ts文件会放在video-all文件夹下。
命令说明:copy用于合并文件。如果没有 /b 参数,它将被合并为一个普通的文本文件。添加这个参数意味着它将被合并为一个二进制文件;此外,文件顺序按文件名排序。文件名也很规整,基本不用自己重命名和排序。(注意:路径中不能有空格)
五、使用下载工具下载视频
适用于:斗鱼等
我这次测试失败了,你可以自己试试,哈哈哈。
步骤1、打开火狐浏览器插件页面,安装视频下载器插件
安装插件后,您会在浏览器的右上角看到一个下载图标。
2、配置插件
单击插件下载图标旁边的向下箭头 ↓ 并选择 Preferences,其中:
注意:因为这个插件不能满足我们所有的需求,所以这里的视频文件夹保存在哪里都没有关系,也不一定所有的视频都保存在这里。
3、打开斗鱼视频详情页获取视频真实地址
打开要下载的视频详情页面,如:
页面加载完成后,可以看到视频插件的下载图标是动画的。单击下载以查看当前可下载视频的列表。
由于斗鱼的视频是分段的,一个视频会被分割成多个ts格式的视频,所以在视频列表中可以看到多个文件。
左键单击列表中的倒数第二个开始下载。(此文件是完整视频的第一段)
下载完成后,可以在浏览器右上角找到下载的文件。右键单击刚刚下载的文件,然后选择复制下载链接。
复制下载链接后,可以回到上面介绍的方法,用迅雷批量下载。
至此,我们先来说说这5种方法。其实还有其他方法,大家可以自己摸索~~~
我的博客将同步到腾讯云+社区,诚邀大家加入: 查看全部
网页视频抓取软件 格式工厂(【手游坊评测】2017年11月8日前端开发扒视频辛酸历程)
时间:2017 年 11 月 8 日
说到前端开发,在网页上放视频是不可避免的。如果你放视频,有时你会不可避免地拿起视频。以下是我视频的辛酸历程。让我们关注并珍惜它们。
一、直接刷代码
和 pandakill 的视频一样,直接拿代码就可以了。
至于什么格式,自行下载后,直接用格式工厂转换即可。
二、查看网络
比如触手的视频,看网络就可以找到。起初,我还在慢慢寻找。后来有网友建议可以先按大小排序,因为视频会比一般文件大很多==,这样就很容易了,哈哈哈。
三、更改域名
本视频适用于B站(bilibili)。
例如,网站 地址是
怎么接视频,把bilibili改成kanbilibili就行了
打开后,页面顶部是这样的:
点击“下载地址”后,
分为下载地址和弹幕下载地址两部分,我们只需要选择下载地址(第一部分)即可。
在下载地址部分,有3种下载方式,P2、P3和P4。一般可以下载P3。我已经下载了P4,但是中间会有几块下载失败。P3可以下载。下载完成,很多ts文件都下载下来了,然后我们就可以使用B站提供的代码合并工具,将多个ts文件合并为一个ts文件。合并地址:.
首先添加多个已下载的文件。如果需要排序,可以点击“自动排序”,然后输入合并后的文件名,点击“开始合并”,稍等片刻,合并后下载就ok啦。
但是这个时候可能有人会问,我需要mp4格式的视频,不知道ts文件是什么。这这,还有一个特别简单粗暴的方法,就是直接把视频的后缀名改成mp4。可以在本地完全播放,但是我们绝对不局限于本地播放,还可以放在我们的代码中,那么其他人访问这个页面就可以播放这个页面了。那么这个方法就行不通了。我们都知道视频编码格式有很多种,不同的浏览器支持的编码格式也不一样。比如ts的编码格式是MPEG,谷歌、火狐等浏览器支持的编码格式是FLV。所以~~主角来了:格式工厂,它不仅可以转换视频格式,还可以转换视频格式,原来如此简单~~
四、使用 Chrome 和迅雷下载视频
推荐使用此方法。虽然很复杂,但是非常有效。
适用网站:斗鱼、MOOC、网易云课堂、B站等。
我们都知道视频网站为了保护版权,防止盗链下载,一般都是分段加载的。一般的.flv格式,视频源最多有十几个,而.ts格式一般每段几兆,一个小时左右的视频基本有几百个段。手动下载太累了。接下来分享一个无痛的方法,只需要使用系统的常用软件即可。
1、获取原创视频
以一个视频为例,用Chrome访问并打开开发者工具切换到Netword面板,点击视频开始和结束的位置,我们可以发现视频源是一个普通地址,从001 至 344 。
只关注我用红色标记的地方。
2、批量下载 .ts 视频
你只需要注意我圈子里的3个部分。
第一部分:选择要更改的数字的位置,用一对括号和通配符替换,即(*),但是这里有几点需要注意,我们注意到我写了6个0和一个通配符这里,然后在下面那一栏中,对应的写法是0到9(一位数)。当ts文件为10到99时,必须写成5个0加通配符,以此类推,ts文件是100到999.,这里要写成4个0加通配符。简而言之,ts文件的总位数是7位,也就是说虽然我们是分批下载的,但还是分批,0到9批,10到99批,100到999批等,这没关系,如果你注意的话。
第二部分:前两个输入框的第一部分已经讲完了。现在主要的是通配符的长度。这里默认写1就够了。那为什么不写2和3呢?你可以看到结果。
第三部分:这相当于检查部分。前两部分填好后,可以在第三部分查看ts文件的范围,我们可以检查一下前面的配置是否正确。
点击“确定”后,会弹出如下弹窗:
为此,我们只需要注意“合并到一个任务组”即可。这是什么意思?意思是把这个ts文件归入你先写的任务组,方便管理。
其实这个比较简单,使用一行DOS命令就可以实现。
copy/b D:\video\*.ts D:\video-all\all.ts
执行上述命令后,D:\video\目录下的所有.ts文件都会合并到all.ts中,all.ts文件会放在video-all文件夹下。
命令说明:copy用于合并文件。如果没有 /b 参数,它将被合并为一个普通的文本文件。添加这个参数意味着它将被合并为一个二进制文件;此外,文件顺序按文件名排序。文件名也很规整,基本不用自己重命名和排序。(注意:路径中不能有空格)
五、使用下载工具下载视频
适用于:斗鱼等
我这次测试失败了,你可以自己试试,哈哈哈。
步骤1、打开火狐浏览器插件页面,安装视频下载器插件
安装插件后,您会在浏览器的右上角看到一个下载图标。
2、配置插件
单击插件下载图标旁边的向下箭头 ↓ 并选择 Preferences,其中:
注意:因为这个插件不能满足我们所有的需求,所以这里的视频文件夹保存在哪里都没有关系,也不一定所有的视频都保存在这里。
3、打开斗鱼视频详情页获取视频真实地址
打开要下载的视频详情页面,如:
页面加载完成后,可以看到视频插件的下载图标是动画的。单击下载以查看当前可下载视频的列表。
由于斗鱼的视频是分段的,一个视频会被分割成多个ts格式的视频,所以在视频列表中可以看到多个文件。
左键单击列表中的倒数第二个开始下载。(此文件是完整视频的第一段)
下载完成后,可以在浏览器右上角找到下载的文件。右键单击刚刚下载的文件,然后选择复制下载链接。
复制下载链接后,可以回到上面介绍的方法,用迅雷批量下载。
至此,我们先来说说这5种方法。其实还有其他方法,大家可以自己摸索~~~
我的博客将同步到腾讯云+社区,诚邀大家加入:
网页视频抓取软件 格式工厂(格式工厂是套万能的多媒体格式转换软件-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-03 18:13
格式工厂是一款多功能的多媒体格式转换软件。
提供以下功能:
所有类型的视频都传输到 MP4/3GP/MPG/AVI/WMV/FLV/SWF。
所有类型的音频都传输到 MP3/WMA/AMR/OGG/AAC/WAV。
所有类型的图片都转为JPG/BMP/PNG/TIF/ICO/GIF/TGA。
将 DVD 翻录为视频文件,将音乐 CD 抓取为音频文件。
MP4 文件支持 iPod/iPhone/PSP/Black Mold 等指定格式。
支持RMVB、水印、音视频混合。
格式工厂的专长:
1 支持几乎所有类型的多媒体格式到几种常用格式。
2 在转换过程中可以修复一些损坏的视频文件。
3 个多媒体文件来减肥。
4 支持 iPhone/iPod/PSP 等指定多媒体格式。
5 转换后的图片文件支持缩放、旋转、水印等功能。
6 DVD视频采集功能,轻松备份DVD到本地硬盘。
7 支持 60 种国家语言
配置要求:所有windows系统
注意:
软件包内含百度搜索工具栏,免费软件赞助商。
如果您不想安装它们,请在安装过程中取消它们。
部分杀毒软件可能会误报,开发者保证格式工厂安装包不收录任何恶意程序。
格式工厂 v4.0 更新日志:
1、添加最新的HEVC(H265)编码、MP4、MKV压缩比大幅提升
2、优化默认码率算法
3、添加编码 CRF 支持
4、更新了一些编码器版本 查看全部
网页视频抓取软件 格式工厂(格式工厂是套万能的多媒体格式转换软件-上海怡健医学)
格式工厂是一款多功能的多媒体格式转换软件。
提供以下功能:
所有类型的视频都传输到 MP4/3GP/MPG/AVI/WMV/FLV/SWF。
所有类型的音频都传输到 MP3/WMA/AMR/OGG/AAC/WAV。
所有类型的图片都转为JPG/BMP/PNG/TIF/ICO/GIF/TGA。
将 DVD 翻录为视频文件,将音乐 CD 抓取为音频文件。
MP4 文件支持 iPod/iPhone/PSP/Black Mold 等指定格式。
支持RMVB、水印、音视频混合。
格式工厂的专长:
1 支持几乎所有类型的多媒体格式到几种常用格式。
2 在转换过程中可以修复一些损坏的视频文件。
3 个多媒体文件来减肥。
4 支持 iPhone/iPod/PSP 等指定多媒体格式。
5 转换后的图片文件支持缩放、旋转、水印等功能。
6 DVD视频采集功能,轻松备份DVD到本地硬盘。
7 支持 60 种国家语言
配置要求:所有windows系统
注意:
软件包内含百度搜索工具栏,免费软件赞助商。
如果您不想安装它们,请在安装过程中取消它们。
部分杀毒软件可能会误报,开发者保证格式工厂安装包不收录任何恶意程序。
格式工厂 v4.0 更新日志:
1、添加最新的HEVC(H265)编码、MP4、MKV压缩比大幅提升
2、优化默认码率算法
3、添加编码 CRF 支持
4、更新了一些编码器版本
网页视频抓取软件 格式工厂(一个百度文库的下载神器,冰点文库,支持多个平台)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-01-02 20:02
下载豆丁文档
有段时间,我推荐了百度文库的一个下载神器,冰点文库。相信很多朋友都用过,一定也感受到了它的强大功能。无需担心下载、不使用或看不到它。这条推文里的小虾还给了温暖的友情链接:
点库:[windows]百度库免费下载,功能强大,支持多平台
不过,滇文库也有一个缺点,就是对百度文库的支持很好,但是对豆丁和阿里巴巴的支持就没有那么多了。发现有些资源无法下载,而且冰点文库下载的文件都是pdf,不管原文件是什么格式,如果下载后要编辑,就得重新转换格式,也就是稍微麻烦一些。
接下来虾米推荐一种下载豆丁文件的方法。这是一个网站,无需下载软件,简单方便,不限制系统,就是只要有浏览器,随时随地都可以下载,不管是电脑或手机。另外,网站工具是豆丁的文档复制和抓取工具。导出的文档为word格式,不是源文件,但文本可以编辑,收录图片。尽量保持原创文档的格式。支持原文档为WORD、PDF、TXT的文档,暂不支持PPT、Excel文档。
使用方法:
到豆丁图书馆你需要的文档,复制文档的URL地址;将文档链接粘贴到本站输入框中,点击下载,等待下载完成;打开下载的文档,进行一些内容格式化的详细调整优化处理。
另外还有很多老哥私信给我,说我不会下载,我这里再解释一下:
首先关注我的微信公众号私信回复关键词。当然,它们必须是正确的关键字。它们是我推文中的关键词。不要只是猜测每个人的链接。有官方网站。我已经推过他们了。另外,还有我上传的兰邹云。建议安卓用户使用蓝藻云下载。苹果用户只能到官网正常下载安装。某些手机将受到限制。请在手机设置中允许。未知源文件安装,打开浏览器等软件安装权限部分破解软件,手机会提示病毒,这是从非官方应用市场安装的,或者破解软件有反广告机制被检测到由手机厂商所有软件小虾米都测试过了,请放心使用。当然,如果你介意的话,你不应该安装它。有些软件对时间敏感,可以在我发布推文时使用。过一会,可能无法下载或暂停服务(如麻花影视),或开始收费等,请关注我的推文,切换到其他软件即可。重要提示 查看全部
网页视频抓取软件 格式工厂(一个百度文库的下载神器,冰点文库,支持多个平台)
下载豆丁文档
有段时间,我推荐了百度文库的一个下载神器,冰点文库。相信很多朋友都用过,一定也感受到了它的强大功能。无需担心下载、不使用或看不到它。这条推文里的小虾还给了温暖的友情链接:
点库:[windows]百度库免费下载,功能强大,支持多平台
不过,滇文库也有一个缺点,就是对百度文库的支持很好,但是对豆丁和阿里巴巴的支持就没有那么多了。发现有些资源无法下载,而且冰点文库下载的文件都是pdf,不管原文件是什么格式,如果下载后要编辑,就得重新转换格式,也就是稍微麻烦一些。
接下来虾米推荐一种下载豆丁文件的方法。这是一个网站,无需下载软件,简单方便,不限制系统,就是只要有浏览器,随时随地都可以下载,不管是电脑或手机。另外,网站工具是豆丁的文档复制和抓取工具。导出的文档为word格式,不是源文件,但文本可以编辑,收录图片。尽量保持原创文档的格式。支持原文档为WORD、PDF、TXT的文档,暂不支持PPT、Excel文档。
使用方法:
到豆丁图书馆你需要的文档,复制文档的URL地址;将文档链接粘贴到本站输入框中,点击下载,等待下载完成;打开下载的文档,进行一些内容格式化的详细调整优化处理。
另外还有很多老哥私信给我,说我不会下载,我这里再解释一下:
首先关注我的微信公众号私信回复关键词。当然,它们必须是正确的关键字。它们是我推文中的关键词。不要只是猜测每个人的链接。有官方网站。我已经推过他们了。另外,还有我上传的兰邹云。建议安卓用户使用蓝藻云下载。苹果用户只能到官网正常下载安装。某些手机将受到限制。请在手机设置中允许。未知源文件安装,打开浏览器等软件安装权限部分破解软件,手机会提示病毒,这是从非官方应用市场安装的,或者破解软件有反广告机制被检测到由手机厂商所有软件小虾米都测试过了,请放心使用。当然,如果你介意的话,你不应该安装它。有些软件对时间敏感,可以在我发布推文时使用。过一会,可能无法下载或暂停服务(如麻花影视),或开始收费等,请关注我的推文,切换到其他软件即可。重要提示
网页视频抓取软件 格式工厂( 网上摘录的一段介绍框架的文字,大过年的懒癌高发期)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-02 20:01
网上摘录的一段介绍框架的文字,大过年的懒癌高发期)
Scrapy 是一个用 Python 编写的爬虫框架,简单、轻量、非常方便。 Scrapy 使用异步网络库 Twisted 来处理网络通信。架构清晰,收录各种中间件接口,可以灵活满足各种需求。
以上摘自网上,介绍了scrapy框架。是懒癌高发期...
安装scrapy,pip可以解决你的问题:pip install scrapy。
这里插一句,如果运行代码后看到这个错误:
ImportError: No module named win32api
出现一个深坑,需要安装pywin32。如果已经安装了pywin32出现错误,还是需要手动将你的python安装目录放到\Lib\site-packages\pywin32_system32下:pythoncom27.dll,复制pywintypes27.这两个文件dll 到 c:\windows\system32!当然,如果不是windows系统,请无视!
话不多说,开始我们的爬虫吧!
首先分析网页结构:
1、url:打开旅行者的主页,这里我用的是火狐,见下图
点击精彩游记,然后跳出游记页面,
然后点击所有游记,就会出现我们的目标,拖到最下方,共3993页,1页20篇
一个非常简单的网站
2、我们开始分析每个页面的数据,直接打开F12抓包,然后刷新网页或者点击其他页面看看服务器返回的请求是什么!
找到一个get请求,里面有json格式的内容,里面有游记的作者、标题、缩略图等,ok,可以开始写代码了!
Ps:这里我们只是做一个简单的页面目录爬虫,不会一一抓取文章的内容(需要的可以自行添加相关内容)。
3、 打开cmd新建一个scrapy框架,命令是:scrapy startproject autohome,然后系统会自动帮我们创建相关目录和py文件,我们还是需要手动创建一个spider。 py(文件名可以取自Take)放入我们的爬虫
首先打开item.py,这里是我们的目标,告诉爬虫我们要爬取什么!代码如下:
然后打开setting.py(如果没有必要,不要修改这里的内容),把ROBOTSTXT_OBEY的值改成False(如果不改,有些内容是爬不出来的,这里是选择是否跟随robots协议),然后改变你的UA写在下面的header信息中!
别担心其他的一切。最后,打开spider文件夹,我们就要开始写爬虫了!
4、打开新建的py文件,先导入用到的模块
(如果导入模块后有错误提示,可以忽略),编写如下代码:
第6行的名字是唯一的,你可以自己命名
第7幕定义了爬虫的作用域,即允许执行的URL的作用域是:,注意这里是列表的形式
9.10.11 是抓取的内容所在的url,通过yield Request返回。上图没有截断,全部分为:
yield Request('https://you.autohome.com.cn/summary/getsearchresultlist?ps=20&pg={}&type=3&tagCode=&tagName=&sortType=3'.format(pg),self.parse)
因为只有3993页,所以可以直接在for循环中检索所有页码。定义start_requests函数后,可以省略start_urls列表,即起始列表。
第14行开始定义爬取方法
第15行,将json格式的内容赋值给一个变量
第16行,初始化导入的Items文件中定义的类
第17-24行,循环json格式的内容,给item赋值,其中item为字典格式,然后返回items文件
我已经在这里写完了这个爬虫。为了使用方便,我们直接把结果写成json格式
打开cmd,命令:scrapy crawl autohome -o autohome.json -t json
因为我们抓取的内容很少,所以速度还是很快的
大约十分钟,数据就会被抓到!来看看结果吧,因为是json格式,可以截个短片,找到一个可以在线解析的网页。
验证:
太简单了!
喜欢就关注吧(;°○°)! 查看全部
网页视频抓取软件 格式工厂(
网上摘录的一段介绍框架的文字,大过年的懒癌高发期)
Scrapy 是一个用 Python 编写的爬虫框架,简单、轻量、非常方便。 Scrapy 使用异步网络库 Twisted 来处理网络通信。架构清晰,收录各种中间件接口,可以灵活满足各种需求。
以上摘自网上,介绍了scrapy框架。是懒癌高发期...
安装scrapy,pip可以解决你的问题:pip install scrapy。
这里插一句,如果运行代码后看到这个错误:
ImportError: No module named win32api
出现一个深坑,需要安装pywin32。如果已经安装了pywin32出现错误,还是需要手动将你的python安装目录放到\Lib\site-packages\pywin32_system32下:pythoncom27.dll,复制pywintypes27.这两个文件dll 到 c:\windows\system32!当然,如果不是windows系统,请无视!
话不多说,开始我们的爬虫吧!
首先分析网页结构:
1、url:打开旅行者的主页,这里我用的是火狐,见下图
点击精彩游记,然后跳出游记页面,
然后点击所有游记,就会出现我们的目标,拖到最下方,共3993页,1页20篇
一个非常简单的网站
2、我们开始分析每个页面的数据,直接打开F12抓包,然后刷新网页或者点击其他页面看看服务器返回的请求是什么!
找到一个get请求,里面有json格式的内容,里面有游记的作者、标题、缩略图等,ok,可以开始写代码了!
Ps:这里我们只是做一个简单的页面目录爬虫,不会一一抓取文章的内容(需要的可以自行添加相关内容)。
3、 打开cmd新建一个scrapy框架,命令是:scrapy startproject autohome,然后系统会自动帮我们创建相关目录和py文件,我们还是需要手动创建一个spider。 py(文件名可以取自Take)放入我们的爬虫
首先打开item.py,这里是我们的目标,告诉爬虫我们要爬取什么!代码如下:
然后打开setting.py(如果没有必要,不要修改这里的内容),把ROBOTSTXT_OBEY的值改成False(如果不改,有些内容是爬不出来的,这里是选择是否跟随robots协议),然后改变你的UA写在下面的header信息中!
别担心其他的一切。最后,打开spider文件夹,我们就要开始写爬虫了!
4、打开新建的py文件,先导入用到的模块
(如果导入模块后有错误提示,可以忽略),编写如下代码:
第6行的名字是唯一的,你可以自己命名
第7幕定义了爬虫的作用域,即允许执行的URL的作用域是:,注意这里是列表的形式
9.10.11 是抓取的内容所在的url,通过yield Request返回。上图没有截断,全部分为:
yield Request('https://you.autohome.com.cn/summary/getsearchresultlist?ps=20&pg={}&type=3&tagCode=&tagName=&sortType=3'.format(pg),self.parse)
因为只有3993页,所以可以直接在for循环中检索所有页码。定义start_requests函数后,可以省略start_urls列表,即起始列表。
第14行开始定义爬取方法
第15行,将json格式的内容赋值给一个变量
第16行,初始化导入的Items文件中定义的类
第17-24行,循环json格式的内容,给item赋值,其中item为字典格式,然后返回items文件
我已经在这里写完了这个爬虫。为了使用方便,我们直接把结果写成json格式
打开cmd,命令:scrapy crawl autohome -o autohome.json -t json
因为我们抓取的内容很少,所以速度还是很快的
大约十分钟,数据就会被抓到!来看看结果吧,因为是json格式,可以截个短片,找到一个可以在线解析的网页。
验证:
太简单了!
喜欢就关注吧(;°○°)!
网页视频抓取软件 格式工厂(数据爬取爬取拉勾网求职信息,废话不多说。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-02 06:18
前言
利用requests抓取拉勾求职信息,废话不多说。
让我们快乐开始吧~
开发工具
**Python 版本:**3.6.4
相关模块:
请求模块;
重新模块;
操作系统模块
结巴模块;
熊猫模块
numpy 模块
pyecharts 模块;
还有一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
数据爬虫爬取拉勾网的求职信息1.requests request,获取单个页面
# 我们最常用的流程:网页上复制url->发送get请求—>打印页面内容->分析抓取数据
# 1.获取拉钩网url
req_url = 'https://www.lagou.com/jobs/lis ... 39%3B
# 2.发送get请求
req_result = requests.get(req_url)
# 3.打印请求结果
print(req_result.text)
复制代码
输出结果如下
HZRxWevI();é?μé?¢?? è????-...
复制代码
我们可以看到,上面的结果和我们想象的还是有很大的不同。为什么会出现上述情况?其实很简单,因为它不是一个简单的静态页面。我们知道请求方法有两个基本区别:get 和 post 请求。
(1)Get 是向服务器请求数据;Post 是向服务器提交数据的请求。要提交的数据位于消息头后面的实体中。GET 和 POST 只是发送的机制不同,取一个也不是一回事。(2)GET请求时,发送的信息是以url明文形式发送的,其参数会保存在浏览器历史或web服务器中,而帖子不会(这也是后来翻页的时候发现拉勾网翻页时浏览器url栏地址没有变化的原因。)
2.分析页面加载并找到数据
1.请求分析
在拉勾网首页,按F12进入开发者模式,然后在查询框中输入python,点击搜索,经过我的搜索,终于找到了页面上职位信息所在的页面,它确实是post请求,页面返回的内容是json格式的字典。
2.返回数据内容分析。页面上:我们主要获取7个数据(公司|城市|职位|薪资|学历要求|工作经验|职位优势)
json数据中:我整理了爬下来的json数据,如下图
我们会发现我们需要的所有数据都在req_info['content']['positionResult']['result']中,它是一个列表,收录了很多其他的信息。这次我们不关心其他数据。 我们需要的数据在下图
3.添加headers信息模仿浏览器请求
通过上面的请求分析,我们可以找到post请求的URL:...
{'success': False, 'msg': '您操作太频繁,请稍后再访问', 'clientIp': '122.xxx.xxx.xxx'}
复制代码
出现这个提示的原因是我们直接post访问网址,服务器会误认为我们是“机器人”。这也是反爬虫。解决方法很简单。添加请求头,完全模拟浏览器请求。 , 获取请求头如下图
4.分析页面实现翻页抓取
分析发现如下规律:在post请求中,有一个请求参数->表单数据,首先包括三个参数,kd,pn,通过动画演示,不难猜出其含义
data = {
'first':'true', # 是不是第一页,false表示不是,true 表示是 'kd':'Python', # 搜索关键字
'pn':1 # 页码
}
复制代码
代码
import requests\
# 1. post 请求的 url\
req_url = 'https://www.lagou.com/jobs/pos ... 39%3B\
# 2. 请求头 headers\
headers = {'你的请求头'}\
# 3. for 循环请求\
for i in range(1,31):\
data = { 'first':'false','kd':'Python','pn':i} \
# 3.1 requests 发送请求\
req_result = requests.post(req_url,headers = headers,data = data) req_result.encoding = 'utf-8'\
# 3.2 获取数据\
req_info = req_result.json() \
# 打印出获取到的数据\
print(req_info)
复制代码
5.将抓取到的数据保存成csv文件
def file_do(list_info): # 获取文件大小 file_size = os.path.getsize(r'G:\lagou_test.csv') \
if file_size == 0: \
# 表头 name = ['公司','城市','职位','薪资','学历要求','工作经验','职位优点'] \
# 建立DataFrame对象 file_test = pd.DataFrame(columns=name, data=list_info) \
# 数据写入 file_test.to_csv(r'G:\lagou_test.csv', encoding='gbk',index=False) \
else: \
with open(r'G:\lagou_test.csv','a+',newline='') as file_test : # 追加到文件后面 writer = csv.writer(file_test) \
# 写入文件 writer.writerows(list_info)
复制代码
显示抓取的数据
数据可视化数据分析+pyechart数据可视化
薪酬分配分析
我们可以看到python的工资基本都是10k起的,大部分公司给的工资在10k-40k之间,所以不用怕学python不够。
2.工作地点分析
通过图表我们不难看出,大部分需要python程序员的公司都位于北京、上海、深圳,而广州则落后。所以学python的同学千万不要走错城市。
3.岗位教育要求
从图表来看,python程序员的学历要求不高,主要是本科。虽然学历要求不高,但要有思考能力。
4.工作经验要求
主要是需要3-5年工作经验的学生,不老不幼,成熟稳重,能学新东西的年纪,招聘公司真聪明。
5.岗位研究方向分析
6.工作福利的好处分析
# 福利关键词分析
content = ''
# 连接所有公司福利介绍
for x in positionAdvantage:
content = content + x
# 去除多余字符
content = re.sub('[,、(),1234567890;;&%$#@!~_=+]', '', content)
# jieba 切词,pandas、numpy计数
segment = jieba.lcut(content)
words_df = pd.DataFrame({'segment': segment})
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数": numpy.size})
words_stat = words_stat.reset_index().sort_values(by=["计数"], ascending=False) test = words_stat.head(1000).values
# 制作词云图\
codes = [test[i][0] for i in range(0,len(test))]
counts = [test[i][1] for i in range(0,len(test))]
wordcloud = WordCloud(width=1300, height=620,page_title='福利关键词') wordcloud.add("福利关键词", codes, counts, word_size_range=[20, 100]) wordcloud.render()
复制代码
终于
感谢您的支持和厚爱。小编每天都会和大家分享更多Python学习知识,记得关注小编哦。 查看全部
网页视频抓取软件 格式工厂(数据爬取爬取拉勾网求职信息,废话不多说。)
前言
利用requests抓取拉勾求职信息,废话不多说。
让我们快乐开始吧~
开发工具
**Python 版本:**3.6.4
相关模块:
请求模块;
重新模块;
操作系统模块
结巴模块;
熊猫模块
numpy 模块
pyecharts 模块;
还有一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
数据爬虫爬取拉勾网的求职信息1.requests request,获取单个页面
# 我们最常用的流程:网页上复制url->发送get请求—>打印页面内容->分析抓取数据
# 1.获取拉钩网url
req_url = 'https://www.lagou.com/jobs/lis ... 39%3B
# 2.发送get请求
req_result = requests.get(req_url)
# 3.打印请求结果
print(req_result.text)
复制代码
输出结果如下
HZRxWevI();é?μé?¢?? è????-...
复制代码
我们可以看到,上面的结果和我们想象的还是有很大的不同。为什么会出现上述情况?其实很简单,因为它不是一个简单的静态页面。我们知道请求方法有两个基本区别:get 和 post 请求。
(1)Get 是向服务器请求数据;Post 是向服务器提交数据的请求。要提交的数据位于消息头后面的实体中。GET 和 POST 只是发送的机制不同,取一个也不是一回事。(2)GET请求时,发送的信息是以url明文形式发送的,其参数会保存在浏览器历史或web服务器中,而帖子不会(这也是后来翻页的时候发现拉勾网翻页时浏览器url栏地址没有变化的原因。)
2.分析页面加载并找到数据
1.请求分析
在拉勾网首页,按F12进入开发者模式,然后在查询框中输入python,点击搜索,经过我的搜索,终于找到了页面上职位信息所在的页面,它确实是post请求,页面返回的内容是json格式的字典。
2.返回数据内容分析。页面上:我们主要获取7个数据(公司|城市|职位|薪资|学历要求|工作经验|职位优势)

json数据中:我整理了爬下来的json数据,如下图

我们会发现我们需要的所有数据都在req_info['content']['positionResult']['result']中,它是一个列表,收录了很多其他的信息。这次我们不关心其他数据。 我们需要的数据在下图

3.添加headers信息模仿浏览器请求
通过上面的请求分析,我们可以找到post请求的URL:...
{'success': False, 'msg': '您操作太频繁,请稍后再访问', 'clientIp': '122.xxx.xxx.xxx'}
复制代码
出现这个提示的原因是我们直接post访问网址,服务器会误认为我们是“机器人”。这也是反爬虫。解决方法很简单。添加请求头,完全模拟浏览器请求。 , 获取请求头如下图

4.分析页面实现翻页抓取
分析发现如下规律:在post请求中,有一个请求参数->表单数据,首先包括三个参数,kd,pn,通过动画演示,不难猜出其含义
data = {
'first':'true', # 是不是第一页,false表示不是,true 表示是 'kd':'Python', # 搜索关键字
'pn':1 # 页码
}
复制代码
代码
import requests\
# 1. post 请求的 url\
req_url = 'https://www.lagou.com/jobs/pos ... 39%3B\
# 2. 请求头 headers\
headers = {'你的请求头'}\
# 3. for 循环请求\
for i in range(1,31):\
data = { 'first':'false','kd':'Python','pn':i} \
# 3.1 requests 发送请求\
req_result = requests.post(req_url,headers = headers,data = data) req_result.encoding = 'utf-8'\
# 3.2 获取数据\
req_info = req_result.json() \
# 打印出获取到的数据\
print(req_info)
复制代码
5.将抓取到的数据保存成csv文件
def file_do(list_info): # 获取文件大小 file_size = os.path.getsize(r'G:\lagou_test.csv') \
if file_size == 0: \
# 表头 name = ['公司','城市','职位','薪资','学历要求','工作经验','职位优点'] \
# 建立DataFrame对象 file_test = pd.DataFrame(columns=name, data=list_info) \
# 数据写入 file_test.to_csv(r'G:\lagou_test.csv', encoding='gbk',index=False) \
else: \
with open(r'G:\lagou_test.csv','a+',newline='') as file_test : # 追加到文件后面 writer = csv.writer(file_test) \
# 写入文件 writer.writerows(list_info)
复制代码
显示抓取的数据

数据可视化数据分析+pyechart数据可视化
薪酬分配分析

我们可以看到python的工资基本都是10k起的,大部分公司给的工资在10k-40k之间,所以不用怕学python不够。
2.工作地点分析

通过图表我们不难看出,大部分需要python程序员的公司都位于北京、上海、深圳,而广州则落后。所以学python的同学千万不要走错城市。
3.岗位教育要求

从图表来看,python程序员的学历要求不高,主要是本科。虽然学历要求不高,但要有思考能力。
4.工作经验要求

主要是需要3-5年工作经验的学生,不老不幼,成熟稳重,能学新东西的年纪,招聘公司真聪明。
5.岗位研究方向分析

6.工作福利的好处分析
# 福利关键词分析
content = ''
# 连接所有公司福利介绍
for x in positionAdvantage:
content = content + x
# 去除多余字符
content = re.sub('[,、(),1234567890;;&%$#@!~_=+]', '', content)
# jieba 切词,pandas、numpy计数
segment = jieba.lcut(content)
words_df = pd.DataFrame({'segment': segment})
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数": numpy.size})
words_stat = words_stat.reset_index().sort_values(by=["计数"], ascending=False) test = words_stat.head(1000).values
# 制作词云图\
codes = [test[i][0] for i in range(0,len(test))]
counts = [test[i][1] for i in range(0,len(test))]
wordcloud = WordCloud(width=1300, height=620,page_title='福利关键词') wordcloud.add("福利关键词", codes, counts, word_size_range=[20, 100]) wordcloud.render()
复制代码

终于
感谢您的支持和厚爱。小编每天都会和大家分享更多Python学习知识,记得关注小编哦。
网页视频抓取软件 格式工厂(一个.get(网页地址)第三步和requests哪个好?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-01 05:14
通过前面几节课的学习,我们大概已经学会了如何通过urllib模块获取数据,解析数据,保存数据,得到我们想要的数据。今天给大家介绍一个Python爬虫获取数据。方法请求库。那么哪个更好,urllib 或请求? urllib 和请求有什么区别?
1.如何安装requests库
我们已经讲解了Python内置的urllib模块,用于访问网络资源。但是使用起来比较麻烦,缺少很多实用的高级功能。
更好的解决方案是使用请求。是一个Python第三方库,特别方便处理URL资源。
requests库的安装和安装其他第三方应用一样(如下图):
2.如何使用请求库。
我们以简单抓取百度网页()为例进行操作:
第一步是导入requests库
第二步是发起请求。
首先我们需要确定请求的类型。最常见的请求方法是 GET 和 POST。我们可以通过右键查看-network-headers-Request Method,看到这个页面的请求方法是get
所以我们的请求格式是:
requests.get(网址)
第三步,获取网页内容。
首先,我们需要确定我们获取的是什么类型的网页。也可以右击-network-headers-Content-Type查看网页内容为文本类型
所以我们得到的网页的基本格式是:
响应文本
可以输出如下图所示的网页内容:
第四步是存储网页信息。
基本格式为:
以打开(保存文件名,读写模式,编码=“utf-8”)为变量:
Variables.write(网页内容)
以上是关于requests的用法,大家可以结合之前学过的内容,想想urllib和requests哪个更方便,反爬虫机制如何使用requests获取内容信息网站,下一课,urllib和requests有什么区别? urllib 和请求哪个更好。 查看全部
网页视频抓取软件 格式工厂(一个.get(网页地址)第三步和requests哪个好?)
通过前面几节课的学习,我们大概已经学会了如何通过urllib模块获取数据,解析数据,保存数据,得到我们想要的数据。今天给大家介绍一个Python爬虫获取数据。方法请求库。那么哪个更好,urllib 或请求? urllib 和请求有什么区别?
1.如何安装requests库
我们已经讲解了Python内置的urllib模块,用于访问网络资源。但是使用起来比较麻烦,缺少很多实用的高级功能。
更好的解决方案是使用请求。是一个Python第三方库,特别方便处理URL资源。
requests库的安装和安装其他第三方应用一样(如下图):
2.如何使用请求库。
我们以简单抓取百度网页()为例进行操作:
第一步是导入requests库
第二步是发起请求。
首先我们需要确定请求的类型。最常见的请求方法是 GET 和 POST。我们可以通过右键查看-network-headers-Request Method,看到这个页面的请求方法是get
所以我们的请求格式是:
requests.get(网址)
第三步,获取网页内容。
首先,我们需要确定我们获取的是什么类型的网页。也可以右击-network-headers-Content-Type查看网页内容为文本类型
所以我们得到的网页的基本格式是:
响应文本
可以输出如下图所示的网页内容:
第四步是存储网页信息。
基本格式为:
以打开(保存文件名,读写模式,编码=“utf-8”)为变量:
Variables.write(网页内容)
以上是关于requests的用法,大家可以结合之前学过的内容,想想urllib和requests哪个更方便,反爬虫机制如何使用requests获取内容信息网站,下一课,urllib和requests有什么区别? urllib 和请求哪个更好。
网页视频抓取软件 格式工厂(通常我们要在自己做的网站上放视频方法将自己的视频先上)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-01 04:18
通常我们想把视频放在我们自己制作的网站上。方法是把我们的视频上传到优酷、土豆等大视频网站,然后再上传优酷和土豆上的视频。通过共享代码将其嵌入您自己的 网站。 (相关教程:如何给网页添加视频动画)
这种方式可以节省网站空间,但是这些视频上有大量的优酷广告,尤其是60秒的长时间,用户体验不是很好。使用去除优酷广告的方法也很困难。
那么如何在自己的网站中嵌入视频播放器,直接播放自己的视频?
方法/步骤
1、 将自己的视频格式转换为 MP4 格式;
一般来说,AVI格式的视频都非常大,所以我们需要做的第一步就是转换视频格式,以节省空间资源,更快地打开视频。视频格式的转换,我们经常用到的一个软件——格式工厂,这个软件是免费的,大家可以从网上下载,也可以在帖子底部找到该软件的下载地址,使用这个软件将 AVI 等视频转换为 MP4 和其他网络视频格式。
2、将转换后的视频上传到你的网站空间,(通常你可以在你的空间根目录新建一个文件夹video来存放视频);
3、上传完成后,可以通过以下代码直接在文章Edit(文本编辑模式)中插入调用代码;
4、 提示:由于流量限制,虚拟主机将不支持很多视频的播放。建议使用服务器或上传视频到大视频网站,然后引用。 查看全部
网页视频抓取软件 格式工厂(通常我们要在自己做的网站上放视频方法将自己的视频先上)
通常我们想把视频放在我们自己制作的网站上。方法是把我们的视频上传到优酷、土豆等大视频网站,然后再上传优酷和土豆上的视频。通过共享代码将其嵌入您自己的 网站。 (相关教程:如何给网页添加视频动画)
这种方式可以节省网站空间,但是这些视频上有大量的优酷广告,尤其是60秒的长时间,用户体验不是很好。使用去除优酷广告的方法也很困难。
那么如何在自己的网站中嵌入视频播放器,直接播放自己的视频?
方法/步骤
1、 将自己的视频格式转换为 MP4 格式;
一般来说,AVI格式的视频都非常大,所以我们需要做的第一步就是转换视频格式,以节省空间资源,更快地打开视频。视频格式的转换,我们经常用到的一个软件——格式工厂,这个软件是免费的,大家可以从网上下载,也可以在帖子底部找到该软件的下载地址,使用这个软件将 AVI 等视频转换为 MP4 和其他网络视频格式。
2、将转换后的视频上传到你的网站空间,(通常你可以在你的空间根目录新建一个文件夹video来存放视频);
3、上传完成后,可以通过以下代码直接在文章Edit(文本编辑模式)中插入调用代码;
4、 提示:由于流量限制,虚拟主机将不支持很多视频的播放。建议使用服务器或上传视频到大视频网站,然后引用。
网页视频抓取软件 格式工厂(格式工厂免费软件中文版如何设置输出文件地址?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-12-31 22:27
格式工厂免费软件中文版是一款永久免费的多媒体转换工具。格式工厂免费软件中文版可以帮助用户将视频、图片等转换成多种视频文件格式。软件的操作非常简单易上手,界面设计简洁明了,一站式操作,方便快捷,并且可以支持多种格式的转换,可以抓取DVD到视频文件,抓取音乐CD到音频文件,这个软件也可以转换音频,功能多多,是一款非常流行的转换工具。
格式工厂免费软件中文版特点:
1.支持多种格式
格式工厂支持广泛的视频格式,从常用格式到iPhone/iPod/PSP等指定多媒体格式,几乎涵盖所有类型的多媒体格式。
2.修复功能
在转换过程中,格式工厂可以修复一些意外损坏的视频文件。
3.灵活性改进
格式工厂可以让多媒体文件弹性“减肥”或“脂肪化”(即增加或减少视频的清晰度、帧率等)。
格式工厂免费软件中文版的优点:
1.图片转换
格式工厂可以进行图片转换,支持图片文件缩放、旋转、水印等功能。
2.DVD 翻录
格式工厂可以采集视频,用户可以通过该功能轻松备份DVD到本地硬盘。
格式工厂免费软件中文版的优点:
1.支持音频、视频、图片等多种格式,轻松转换所需格式。
2.可以帮助文件减肥,节省硬盘空间,方便存储和备份。
3. 支持图片缩放、旋转和水印功能,所有操作一次完成。
4.支持多种语言,完全无障碍满足各种需求。
5.可以保质保量修复损坏的文件。
6.可指定格式,同时支持iPhone等格式。
如何使用格式工厂免费软件中文版?
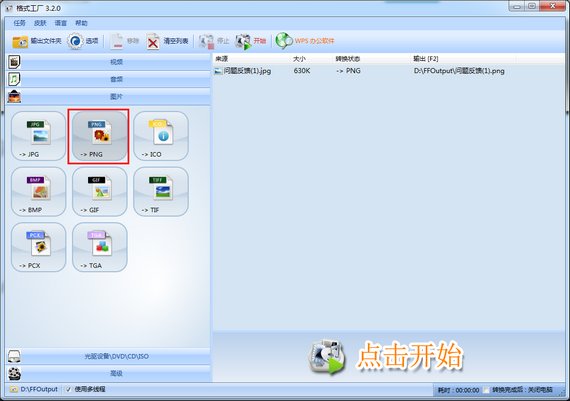
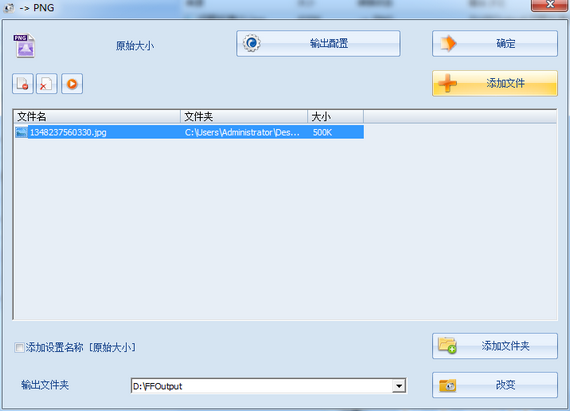
1.第一步:选择要转换的格式。以转换成“PNG”格式为例,打开软件后点击“PNG”:
2.第2步:添加文件/文件夹,然后点击“确定”。
3.第三步:“点击开始。”
4.第 4 步:完成。
格式工厂免费软件中文版如何在此处设置输出文件地址?
可以根据需要单独设置输出文件,以图片“GIF”为例:
1.第一步:点击“输出配置”:
2.第 2 步:根据需要进行编辑。 查看全部
网页视频抓取软件 格式工厂(格式工厂免费软件中文版如何设置输出文件地址?(组图))
格式工厂免费软件中文版是一款永久免费的多媒体转换工具。格式工厂免费软件中文版可以帮助用户将视频、图片等转换成多种视频文件格式。软件的操作非常简单易上手,界面设计简洁明了,一站式操作,方便快捷,并且可以支持多种格式的转换,可以抓取DVD到视频文件,抓取音乐CD到音频文件,这个软件也可以转换音频,功能多多,是一款非常流行的转换工具。
格式工厂免费软件中文版特点:
1.支持多种格式
格式工厂支持广泛的视频格式,从常用格式到iPhone/iPod/PSP等指定多媒体格式,几乎涵盖所有类型的多媒体格式。
2.修复功能
在转换过程中,格式工厂可以修复一些意外损坏的视频文件。
3.灵活性改进
格式工厂可以让多媒体文件弹性“减肥”或“脂肪化”(即增加或减少视频的清晰度、帧率等)。
格式工厂免费软件中文版的优点:
1.图片转换
格式工厂可以进行图片转换,支持图片文件缩放、旋转、水印等功能。
2.DVD 翻录
格式工厂可以采集视频,用户可以通过该功能轻松备份DVD到本地硬盘。
格式工厂免费软件中文版的优点:
1.支持音频、视频、图片等多种格式,轻松转换所需格式。
2.可以帮助文件减肥,节省硬盘空间,方便存储和备份。
3. 支持图片缩放、旋转和水印功能,所有操作一次完成。
4.支持多种语言,完全无障碍满足各种需求。
5.可以保质保量修复损坏的文件。
6.可指定格式,同时支持iPhone等格式。
如何使用格式工厂免费软件中文版?
1.第一步:选择要转换的格式。以转换成“PNG”格式为例,打开软件后点击“PNG”:
2.第2步:添加文件/文件夹,然后点击“确定”。
3.第三步:“点击开始。”
4.第 4 步:完成。
格式工厂免费软件中文版如何在此处设置输出文件地址?
可以根据需要单独设置输出文件,以图片“GIF”为例:
1.第一步:点击“输出配置”:
2.第 2 步:根据需要进行编辑。
网页视频抓取软件 格式工厂(迅捷CAD转换器常见问题为何编辑保存文件后无法将其打开)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-30 06:18
Fast CAD Converter是一款专业的CAD版本转换器和PDF转CAD软件。它兼容 DWG、DXF、DWT 和其他绘图格式。可以实现各种CAD版本的相互转换,以及PDF到CAD、CAD到PDF、CAD到CAD的相互转换。JPG等操作,并支持批量转换文件,自定义文件输出效果,转换后的文件可以正常编辑使用。软件操作简单,功能强大,所有转换一键完成!该站点提供免费下载。
Swift CAD 转换器软件的特点
功能全面:软件集成多种格式转换,可实现CAD版本转换、CAD转PDF、PDF转CAD、CAD转JPG。
完全兼容:软件基本支持所有格式的CAD图纸文件,包括DWG、DXF、DWT格式的常用CAD图纸文件。
分析准确:软件采用新开发的图纸文件格式分析、处理和转换核心技术,转换后的文件可以正常编辑和使用。
超级输出:软件可实现批量转换,并可自定义文件输出效果,操作简单,一键转换。
快速CAD转换器安装说明
1、从51下载站下载快速cad编辑器,双击运行应用
2、进入安装界面,点击立即安装。
3、 安装完成后,点击立即体验,即可使用软件。
快速CAD转换器教程
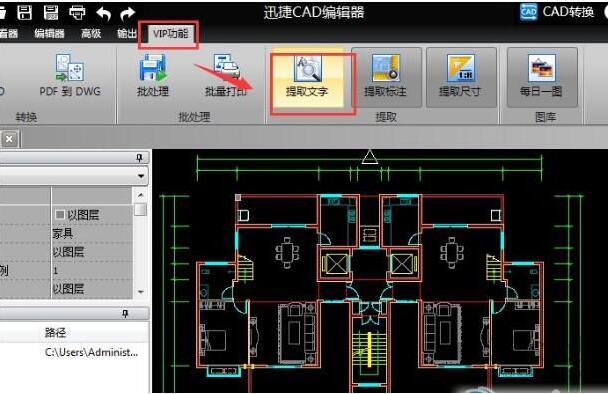
1、 运行 Swift CAD 编辑器。软件打开后,点击界面中的“文件”-“打开”选项,打开需要编辑的CAD文件。
2、打开CAD文件后,如果想一键提取文字,可以点击“VIP功能”,然后点击里面的“提取文字”选项。
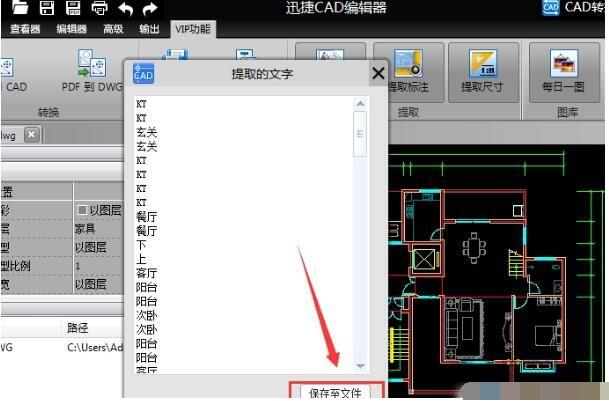
3、 点击后,软件会自动提取CAD文件中的文字,然后点击“保存到文件”按钮保存。
4、在另存为界面选择要保存的位置,最后点击“保存”按钮保存提取的文本。
Swift CAD Converter 常见问题
1、为什么快速CAD编辑器编辑后打不开文件?
答:用户编辑文件损坏或用户未从正规渠道下载软件,导致软件中病毒。
2、我可以使用 Swift CAD 编辑器创建一个新文件吗?
回答:是的。用户可以在软件上新建一个空白编辑页面,编辑完成后保存。
3、快速CAD编辑器免费试用版和软件注册版有什么区别?
答:软件免费试用版只能编辑2M以内的CAD文件,软件注册版没有文件大小限制。
格式工厂和 Swift CAD 转换器的比较
一、 格式工厂是一款免费的多功能多媒体文件转换工具,可以轻松转换所有你想要的格式。格式工厂支持几乎所有主流多媒体文件格式的转换,格式工厂支持多种语言。安装界面显示英文,启动后显示中文。格式工厂支持各种视频、音频和图片格式之间的转换。格式工厂还支持各种手机视频格式的转换。而且格式工厂是免费的,任何人都可以随意下载、使用和传播。51下载站提供格式工厂官方下载!
二、Quick CAD Converter是一款专业的CAD版本转换器和PDF转CAD软件。软件兼容DWG、DXF、DWT等绘图格式,可实现各种CAD版本的相互转换,以及PDF转CAD、CAD转PDF、CAD转JPG等操作,支持批量文件的转换,文件输出效果的自定义设置,转换后的文件可以正常编辑使用。软件操作简单,功能强大,所有转换一键完成!
小编总结:都是格式转换软件,各有千秋,大家可以根据自己的需要选择下载。
Swift CAD 转换器更新日志
1.优化内容
2. 细节更出众,bug 消失得无影无踪
免责声明:因版权及厂商要求,51下载站提供Swift CAD转换软件官方下载包
51下载编辑器推荐:
Fast CAD Converter 是一款非常实用且简单的工具。有兴趣的用户可以在{展店}下载使用。另外还有很多类似的软件可以下载,比如:{recommendWords}等。 查看全部
网页视频抓取软件 格式工厂(迅捷CAD转换器常见问题为何编辑保存文件后无法将其打开)
Fast CAD Converter是一款专业的CAD版本转换器和PDF转CAD软件。它兼容 DWG、DXF、DWT 和其他绘图格式。可以实现各种CAD版本的相互转换,以及PDF到CAD、CAD到PDF、CAD到CAD的相互转换。JPG等操作,并支持批量转换文件,自定义文件输出效果,转换后的文件可以正常编辑使用。软件操作简单,功能强大,所有转换一键完成!该站点提供免费下载。
Swift CAD 转换器软件的特点
功能全面:软件集成多种格式转换,可实现CAD版本转换、CAD转PDF、PDF转CAD、CAD转JPG。
完全兼容:软件基本支持所有格式的CAD图纸文件,包括DWG、DXF、DWT格式的常用CAD图纸文件。
分析准确:软件采用新开发的图纸文件格式分析、处理和转换核心技术,转换后的文件可以正常编辑和使用。
超级输出:软件可实现批量转换,并可自定义文件输出效果,操作简单,一键转换。
快速CAD转换器安装说明
1、从51下载站下载快速cad编辑器,双击运行应用
2、进入安装界面,点击立即安装。

3、 安装完成后,点击立即体验,即可使用软件。

快速CAD转换器教程
1、 运行 Swift CAD 编辑器。软件打开后,点击界面中的“文件”-“打开”选项,打开需要编辑的CAD文件。
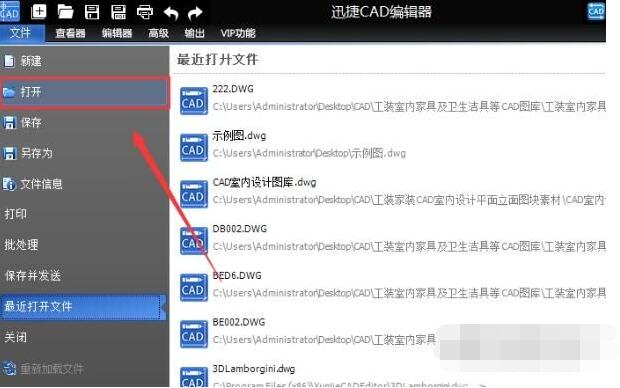
2、打开CAD文件后,如果想一键提取文字,可以点击“VIP功能”,然后点击里面的“提取文字”选项。
3、 点击后,软件会自动提取CAD文件中的文字,然后点击“保存到文件”按钮保存。
4、在另存为界面选择要保存的位置,最后点击“保存”按钮保存提取的文本。
Swift CAD Converter 常见问题
1、为什么快速CAD编辑器编辑后打不开文件?
答:用户编辑文件损坏或用户未从正规渠道下载软件,导致软件中病毒。
2、我可以使用 Swift CAD 编辑器创建一个新文件吗?
回答:是的。用户可以在软件上新建一个空白编辑页面,编辑完成后保存。
3、快速CAD编辑器免费试用版和软件注册版有什么区别?
答:软件免费试用版只能编辑2M以内的CAD文件,软件注册版没有文件大小限制。
格式工厂和 Swift CAD 转换器的比较
一、 格式工厂是一款免费的多功能多媒体文件转换工具,可以轻松转换所有你想要的格式。格式工厂支持几乎所有主流多媒体文件格式的转换,格式工厂支持多种语言。安装界面显示英文,启动后显示中文。格式工厂支持各种视频、音频和图片格式之间的转换。格式工厂还支持各种手机视频格式的转换。而且格式工厂是免费的,任何人都可以随意下载、使用和传播。51下载站提供格式工厂官方下载!
二、Quick CAD Converter是一款专业的CAD版本转换器和PDF转CAD软件。软件兼容DWG、DXF、DWT等绘图格式,可实现各种CAD版本的相互转换,以及PDF转CAD、CAD转PDF、CAD转JPG等操作,支持批量文件的转换,文件输出效果的自定义设置,转换后的文件可以正常编辑使用。软件操作简单,功能强大,所有转换一键完成!
小编总结:都是格式转换软件,各有千秋,大家可以根据自己的需要选择下载。
Swift CAD 转换器更新日志
1.优化内容
2. 细节更出众,bug 消失得无影无踪
免责声明:因版权及厂商要求,51下载站提供Swift CAD转换软件官方下载包
51下载编辑器推荐:
Fast CAD Converter 是一款非常实用且简单的工具。有兴趣的用户可以在{展店}下载使用。另外还有很多类似的软件可以下载,比如:{recommendWords}等。
网页视频抓取软件 格式工厂(如何打造符合搜索引擎抓取的网站?我个人的理解应该从以下四个方面去考虑)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-29 08:15
摘要:在我上一篇文章《如何提高企业网络曝光率》中,我曾经说过一个解决企业网络曝光的方法:要有一个适合搜索引擎的网站,那么如何搭建一个满足搜索引擎爬取的网站呢?个人理解应从以下四个方面考虑:
就像我上一篇文章《如何提高企业网络曝光度》,我曾经说过一个解决企业网络曝光度的方法:要有一个适合搜索引擎的网站,那么如何搭建一个满足搜索引擎抓取的网站呢?我个人的理解应该从以下四个方面来考虑:
一、网站程序
1. 从网站的栏目来看,首页的内容是搜索引擎抓取非常重要的一步。一些公司的网站为了追求美观和氛围,采用全Flash主页。搜索引擎技术再先进,毕竟也是机器实现的。所以它的爬取根本不认Flash,推荐大家使用Pushba网徐强博客中的旋转样式。通过旋转图,网站可以达到高端大气和高档效果,也有利于爬虫的效果。增加用户的视觉体验。
所以,从网站程序的角度来说,首页的设置很重要,尽量不要使用完整的Flash首页!
2. 代码太冗余了。举个简单的例子,如果一个搜索用户在同一个服务器网站、同一个宽带带宽的前提下,打开两个同行业的企业网站,一个打开一秒,另一个缓冲时间长。. 搜索用户会看哪个网站?
答案应该是显而易见的。那么,为什么在上述场景中会出现网站缓冲的情况呢?这主要是由于选择了网站程序中的代码。
现在,相对来说,DIV+CSS布局减少了页面代码,大大提高了加载速度。同时,对于搜索引擎的抓取也是非常有利的。页面代码过多可能导致抓取超时,搜索引擎会认为该页面无法访问,从而影响收录和权重。
3.网站的结构,扁平的树状网站结构在爬取深度和广度上都有优势。但是这里提醒一下,一个清晰的网站结构一定要“分清楚”,交接点也一定要有关联。对于一些比较大的网站,使用二级域名时一定要慎重。不要大量开放无意义的二级域名来增加网站的繁琐页面。此类垃圾邮件页面对搜索引擎不友好,同时也是如此。会影响网站的友好度。4.URL 是伪静态的。URL静态的目的是帮助网站排名。虽然搜索引擎现在可以收录
动态地址,但静态页面比动态排名更有优势。所以,
一个好的网站程序不是重点。关键是我们需要有这样的想法,这些网站适合搜索引擎。
二、网站的标题和描述
三、网站内容
四、网站其他通知
当然,本文只从网站本身考虑如何搭建一个满足搜索引擎爬取的网站,并没有考虑域名、服务器等问题。 查看全部
网页视频抓取软件 格式工厂(如何打造符合搜索引擎抓取的网站?我个人的理解应该从以下四个方面去考虑)
摘要:在我上一篇文章《如何提高企业网络曝光率》中,我曾经说过一个解决企业网络曝光的方法:要有一个适合搜索引擎的网站,那么如何搭建一个满足搜索引擎爬取的网站呢?个人理解应从以下四个方面考虑:
就像我上一篇文章《如何提高企业网络曝光度》,我曾经说过一个解决企业网络曝光度的方法:要有一个适合搜索引擎的网站,那么如何搭建一个满足搜索引擎抓取的网站呢?我个人的理解应该从以下四个方面来考虑:
一、网站程序
1. 从网站的栏目来看,首页的内容是搜索引擎抓取非常重要的一步。一些公司的网站为了追求美观和氛围,采用全Flash主页。搜索引擎技术再先进,毕竟也是机器实现的。所以它的爬取根本不认Flash,推荐大家使用Pushba网徐强博客中的旋转样式。通过旋转图,网站可以达到高端大气和高档效果,也有利于爬虫的效果。增加用户的视觉体验。
所以,从网站程序的角度来说,首页的设置很重要,尽量不要使用完整的Flash首页!
2. 代码太冗余了。举个简单的例子,如果一个搜索用户在同一个服务器网站、同一个宽带带宽的前提下,打开两个同行业的企业网站,一个打开一秒,另一个缓冲时间长。. 搜索用户会看哪个网站?
答案应该是显而易见的。那么,为什么在上述场景中会出现网站缓冲的情况呢?这主要是由于选择了网站程序中的代码。
现在,相对来说,DIV+CSS布局减少了页面代码,大大提高了加载速度。同时,对于搜索引擎的抓取也是非常有利的。页面代码过多可能导致抓取超时,搜索引擎会认为该页面无法访问,从而影响收录和权重。
3.网站的结构,扁平的树状网站结构在爬取深度和广度上都有优势。但是这里提醒一下,一个清晰的网站结构一定要“分清楚”,交接点也一定要有关联。对于一些比较大的网站,使用二级域名时一定要慎重。不要大量开放无意义的二级域名来增加网站的繁琐页面。此类垃圾邮件页面对搜索引擎不友好,同时也是如此。会影响网站的友好度。4.URL 是伪静态的。URL静态的目的是帮助网站排名。虽然搜索引擎现在可以收录
动态地址,但静态页面比动态排名更有优势。所以,
一个好的网站程序不是重点。关键是我们需要有这样的想法,这些网站适合搜索引擎。
二、网站的标题和描述
三、网站内容
四、网站其他通知
当然,本文只从网站本身考虑如何搭建一个满足搜索引擎爬取的网站,并没有考虑域名、服务器等问题。
网页视频抓取软件 格式工厂( 如何将网页中的数据刮到Excel中?(组图) )
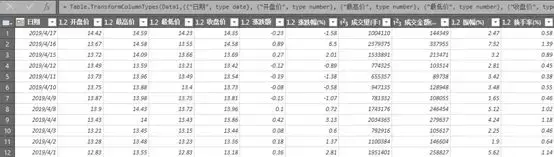
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-12-27 18:03
如何将网页中的数据刮到Excel中?(组图)
)
有一个问题经常被讨论;“如何将网页中的数据抓取到 Excel 中?”
通过 POWER QUERY 从 Web 获取数据
使用 Power Query 从 Web 获取数据的能力非常方便。Power Query在不懂VBA的时候可以这样用,但是如果懂VBA其实还是很方便的,主要看你的选择和喜好了。
从互联网上抓取的数据也可以实时更新。在这种情况下,如果你有一些从网上抓取的数据集,那么添加经验公式来计算一些从抓取的数据中得出的最终结果,这种方式的想法是非常好的。我经常这样做。
目前Power Query的限制是只能以HTML格式的网表格式查询。某些网页使用 JavaScript 生成表格,本教程不涉及这些内容。
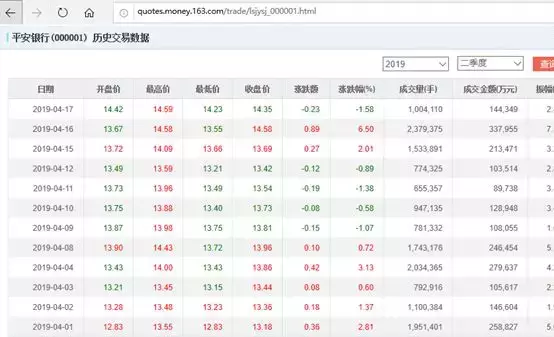
我们以网易的股票为例:
当然,如果你打开这个网页,你也会发现右上角会出现文件下载。你也选择下载文件文件,然后保存进行数据分析,但是这样会显得有点麻烦,我们直接把这个网络数据表和我们的EXCEL建立链接。如果您有每天看股票的习惯,点击下方的更新按钮,即可更新最新的股价情况。
注意:在撰写本文时,上面的 URL 提供了本示例中使用的数据,但此页面的布局和内容超出了我的控制范围。链接后我们可以做一些格式调整。
如何通过 Power Query 从 Web 获取数据
步骤 1:复制收录
该表的网页的 URL。我在用
第 2 步:Excel 2016-“数据”选项卡>来自网络
Excel 2013及更早版本-“Power Query”选项卡>从网页导入,因为我目前用的是2016,所以如果你用的是以前的版本,自己找吧。
注意:如果在 excel 2010 或 2013 中看不到“Power Query”选项卡,可以从相关网站下载。
第 3 步:将 URL 粘贴到“来自网络”对话框中,然后单击“确定”:
第 4 步:在“导航器”对话框(如下图)中,左窗格提供了网页上可用的表格列表。
第一项“文档”收录
页面的 HTML 代码,因此对我们没有用,但其余的表收录
您可以通过 Power Query 获取的数据表。请记住,它只会显示使用 HTML 表格标签生成的表格。
选择你想要的表,类似下图,我们需要表1
也可以进入WEB视图,看看下面的对比。下表是您需要查找的内容吗?
技能:
1.点击对话框右上角的全屏图标,可以全屏查看“导航”对话框。
2.如果要导入多个表,请在左侧窗格中选中“选择多个项目”框。
第五步:选择好要导入的表格后,点击“转换数据”按钮。这将打开 Power Query 编辑器窗口,让您有机会在将数据加载到 Excel 或 Power Pivot 数据模型之前对其进行组织。
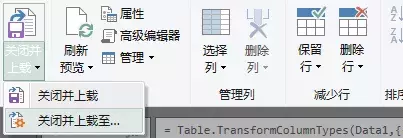
数据清理完毕后,可以将其加载到 Excel 或 Power Pivot 数据模型中。
第 6 步:“开始”选项卡>“关闭并加载到”:
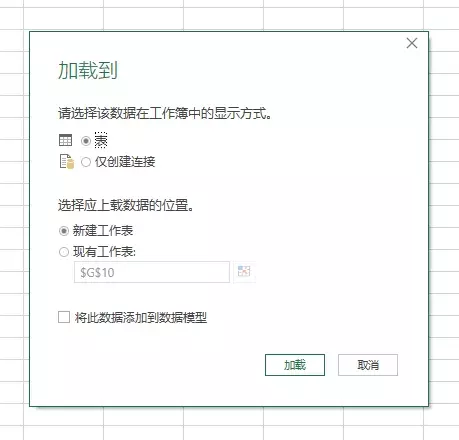
“导入数据”对话框将打开:
提示:如果加载到数据模型中,一定要选择“仅创建连接”,这样文件中的数据就不会被复制,直接在数据透视表这样的地方建立名称连接。
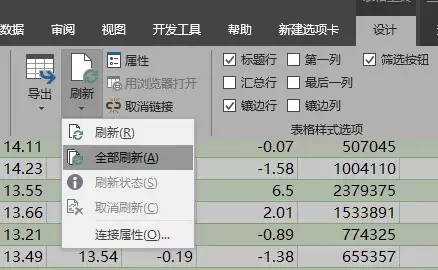
第七步:刷新数据。要从网页获取更新,只需转到功能区的“外部数据”选项卡,然后单击“全部刷新”:
或者,如果您有多个查询,您可以打开查询和连接窗格:
Power Query 网站限制
正如我之前提到的,PowerQuery 非常擅长从 Web 获取数据。在 Web 中,它被格式化为 HTML 表格,而不是由 JavaScript 生成的表格。您可以通过检查网页的源代码并查找 HTML 表格标签来轻松确定表格是 HTML 还是 JavaScript。
为此,请在网页部分空白处右击>查看页面源代码(或类似,取决于您使用的浏览器,我使用的WIN10系统自带的浏览器不是以前版本的Internet Explorer ):
CTRL + F 打开“查找”对话框。进入”
如果找到HTML table标签,那么确认power Query可以从页面中获取一个表,但是不能保证就是你实际需要的表,因为页面上可能还有其他的表,所以可以使用我之前提到的表 进行选择。
查看全部
网页视频抓取软件 格式工厂(
如何将网页中的数据刮到Excel中?(组图)
)
有一个问题经常被讨论;“如何将网页中的数据抓取到 Excel 中?”
通过 POWER QUERY 从 Web 获取数据
使用 Power Query 从 Web 获取数据的能力非常方便。Power Query在不懂VBA的时候可以这样用,但是如果懂VBA其实还是很方便的,主要看你的选择和喜好了。
从互联网上抓取的数据也可以实时更新。在这种情况下,如果你有一些从网上抓取的数据集,那么添加经验公式来计算一些从抓取的数据中得出的最终结果,这种方式的想法是非常好的。我经常这样做。
目前Power Query的限制是只能以HTML格式的网表格式查询。某些网页使用 JavaScript 生成表格,本教程不涉及这些内容。
我们以网易的股票为例:
当然,如果你打开这个网页,你也会发现右上角会出现文件下载。你也选择下载文件文件,然后保存进行数据分析,但是这样会显得有点麻烦,我们直接把这个网络数据表和我们的EXCEL建立链接。如果您有每天看股票的习惯,点击下方的更新按钮,即可更新最新的股价情况。
注意:在撰写本文时,上面的 URL 提供了本示例中使用的数据,但此页面的布局和内容超出了我的控制范围。链接后我们可以做一些格式调整。
如何通过 Power Query 从 Web 获取数据
步骤 1:复制收录
该表的网页的 URL。我在用
第 2 步:Excel 2016-“数据”选项卡>来自网络
Excel 2013及更早版本-“Power Query”选项卡>从网页导入,因为我目前用的是2016,所以如果你用的是以前的版本,自己找吧。
注意:如果在 excel 2010 或 2013 中看不到“Power Query”选项卡,可以从相关网站下载。
第 3 步:将 URL 粘贴到“来自网络”对话框中,然后单击“确定”:
第 4 步:在“导航器”对话框(如下图)中,左窗格提供了网页上可用的表格列表。
第一项“文档”收录
页面的 HTML 代码,因此对我们没有用,但其余的表收录
您可以通过 Power Query 获取的数据表。请记住,它只会显示使用 HTML 表格标签生成的表格。
选择你想要的表,类似下图,我们需要表1
也可以进入WEB视图,看看下面的对比。下表是您需要查找的内容吗?
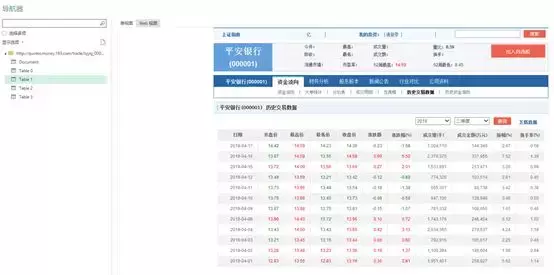
技能:
1.点击对话框右上角的全屏图标,可以全屏查看“导航”对话框。
2.如果要导入多个表,请在左侧窗格中选中“选择多个项目”框。
第五步:选择好要导入的表格后,点击“转换数据”按钮。这将打开 Power Query 编辑器窗口,让您有机会在将数据加载到 Excel 或 Power Pivot 数据模型之前对其进行组织。
数据清理完毕后,可以将其加载到 Excel 或 Power Pivot 数据模型中。
第 6 步:“开始”选项卡>“关闭并加载到”:
“导入数据”对话框将打开:
提示:如果加载到数据模型中,一定要选择“仅创建连接”,这样文件中的数据就不会被复制,直接在数据透视表这样的地方建立名称连接。
第七步:刷新数据。要从网页获取更新,只需转到功能区的“外部数据”选项卡,然后单击“全部刷新”:
或者,如果您有多个查询,您可以打开查询和连接窗格:

Power Query 网站限制
正如我之前提到的,PowerQuery 非常擅长从 Web 获取数据。在 Web 中,它被格式化为 HTML 表格,而不是由 JavaScript 生成的表格。您可以通过检查网页的源代码并查找 HTML 表格标签来轻松确定表格是 HTML 还是 JavaScript。
为此,请在网页部分空白处右击>查看页面源代码(或类似,取决于您使用的浏览器,我使用的WIN10系统自带的浏览器不是以前版本的Internet Explorer ):
CTRL + F 打开“查找”对话框。进入”
如果找到HTML table标签,那么确认power Query可以从页面中获取一个表,但是不能保证就是你实际需要的表,因为页面上可能还有其他的表,所以可以使用我之前提到的表 进行选择。
网页视频抓取软件 格式工厂(格式工厂怎么压缩视频大小/转换/压缩/多媒体/psp)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-24 00:12
格式工厂官网版是一款非常实用的格式转换工具。它可以轻松转换您想要的所有格式。格式工厂支持几乎所有主流多媒体文件格式的转换。同时格式工厂支持多种语言,功能非常强大。, 有需要的赶紧下载体验吧!
格式工厂官网版软件介绍
格式工厂是一款免费的多功能多媒体文件转换工具,可以轻松转换您想要的所有格式。格式工厂支持几乎所有主流多媒体文件格式的转换。同时格式工厂支持多国语言,安装界面显示英文。开机后显示中文。格式工厂支持各种视频、音频和图片格式之间的转换。格式工厂还支持各种手机视频格式的转换。
格式工厂是如何压缩视频大小的
1、格式工厂支持几乎所有类型的多媒体格式。支持各类视频、音频、图片等格式,轻松转换成你想要的格式。
2、 修复损坏的视频文件。在转换过程中,可以修复损坏的文件,从而不损坏转换质量。
3、多媒体文件减肥。它可以帮助您的文件“减肥”,使它们“小巧纤薄”。它不仅节省了硬盘空间,而且便于存储和备份。
4、 可以指定格式。支持iphone/ipod/psp等多媒体指定格式。
5、 支持图片常用功能。转换后的图片支持缩放、旋转、水印等常用功能,操作简单。
6、备份很简单。DVD视频采集功能,轻松备份DVD到本地硬盘。
7、支持多种语言。支持62国语言,使用无障碍,满足多种需求。
如何在格式工厂中转换 MP4
1.支持几乎所有类型的多媒体格式
支持各类视频、音频、图片等格式,轻松转换成你想要的格式。
2.修复损坏的视频文件
在转换过程中,可以修复损坏的文件,从而不损坏转换质量。
3.多媒体文件减肥
它可以帮助您的文件“减肥”,使它们“小巧纤薄”。它不仅节省了硬盘空间,而且便于存储和备份。
4. 可以指定格式
支持iphone/ipod/psp等多媒体指定格式。
5.支持图片常用功能
转换后的图片支持缩放、旋转、水印等常用功能,操作简单。
6. 简单备份
DVD视频采集功能,轻松备份DVD到本地硬盘。
7.支持多种语言
支持62国语言,使用无障碍,满足多种需求。
格式工厂官网版安装步骤
在本站下载安装包,点击一键安装,等待安装完成。
格式工厂官网版本更新日志
格式工厂5.7.5.0:
添加可调整的最大任务线程数的选项;
增加了对没有 OpenGL 的 Win7 机器的支持;
PDF密码支持批量输入;
修改了窗口大小和位置的保存;
修复了混流时无法翻转和旋转的问题。
格式工厂5.7.1.0:
修复部分win7系统无法使用的问题
去除水印和添加多个区域的操作
改进输出配置界面,页面显示更多选项
添加 MP4/MKV 以维护多源音频字幕流
修复了快速编辑中的不同步问题
更新NVIDIA Video Codec SDK至最新版本10.0.26,支持更多图形加速
格式工厂官网评测
非常好用的格式转换工具,功能非常强大。
细节 查看全部
网页视频抓取软件 格式工厂(格式工厂怎么压缩视频大小/转换/压缩/多媒体/psp)
格式工厂官网版是一款非常实用的格式转换工具。它可以轻松转换您想要的所有格式。格式工厂支持几乎所有主流多媒体文件格式的转换。同时格式工厂支持多种语言,功能非常强大。, 有需要的赶紧下载体验吧!

格式工厂官网版软件介绍
格式工厂是一款免费的多功能多媒体文件转换工具,可以轻松转换您想要的所有格式。格式工厂支持几乎所有主流多媒体文件格式的转换。同时格式工厂支持多国语言,安装界面显示英文。开机后显示中文。格式工厂支持各种视频、音频和图片格式之间的转换。格式工厂还支持各种手机视频格式的转换。
格式工厂是如何压缩视频大小的
1、格式工厂支持几乎所有类型的多媒体格式。支持各类视频、音频、图片等格式,轻松转换成你想要的格式。
2、 修复损坏的视频文件。在转换过程中,可以修复损坏的文件,从而不损坏转换质量。
3、多媒体文件减肥。它可以帮助您的文件“减肥”,使它们“小巧纤薄”。它不仅节省了硬盘空间,而且便于存储和备份。
4、 可以指定格式。支持iphone/ipod/psp等多媒体指定格式。
5、 支持图片常用功能。转换后的图片支持缩放、旋转、水印等常用功能,操作简单。
6、备份很简单。DVD视频采集功能,轻松备份DVD到本地硬盘。
7、支持多种语言。支持62国语言,使用无障碍,满足多种需求。

如何在格式工厂中转换 MP4
1.支持几乎所有类型的多媒体格式
支持各类视频、音频、图片等格式,轻松转换成你想要的格式。
2.修复损坏的视频文件
在转换过程中,可以修复损坏的文件,从而不损坏转换质量。
3.多媒体文件减肥
它可以帮助您的文件“减肥”,使它们“小巧纤薄”。它不仅节省了硬盘空间,而且便于存储和备份。
4. 可以指定格式
支持iphone/ipod/psp等多媒体指定格式。
5.支持图片常用功能
转换后的图片支持缩放、旋转、水印等常用功能,操作简单。
6. 简单备份
DVD视频采集功能,轻松备份DVD到本地硬盘。
7.支持多种语言
支持62国语言,使用无障碍,满足多种需求。
格式工厂官网版安装步骤
在本站下载安装包,点击一键安装,等待安装完成。

格式工厂官网版本更新日志
格式工厂5.7.5.0:
添加可调整的最大任务线程数的选项;
增加了对没有 OpenGL 的 Win7 机器的支持;
PDF密码支持批量输入;
修改了窗口大小和位置的保存;
修复了混流时无法翻转和旋转的问题。
格式工厂5.7.1.0:
修复部分win7系统无法使用的问题
去除水印和添加多个区域的操作
改进输出配置界面,页面显示更多选项
添加 MP4/MKV 以维护多源音频字幕流
修复了快速编辑中的不同步问题
更新NVIDIA Video Codec SDK至最新版本10.0.26,支持更多图形加速
格式工厂官网评测
非常好用的格式转换工具,功能非常强大。
细节
网页视频抓取软件 格式工厂(如何下载下来过程定位视频链接?软件的详细介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-22 15:06
背景
吉友给了一个在线视频网址,想问问有没有推荐的录屏软件。我首先想到的是如何下载它
过程定位视频链接
因为之前做过爬虫,有的网站直接在网页源码上显示视频链接。因此,您可以直接查看网页源代码的元素。
坑要填。. .
1、使用文件连接命令(windows为type,linux为cat)将所有段合并为一个m4s文件。
2、使用ffmpeg进行音视频合成和格式转换
3、我用过invidownloader,了解到windows下的文件连接命令是type
4、 试过用ffmpeg直接合成所有的分割文件,视频会有问题(绿屏)
5、 段文件需要有头文件(包括段信息等),是网上搜到的mpd文件。但是,这个 网站 没有。后来上了一招(也是从invidownloader找到的),从segment-0.m4s开始下载,发现用ffmpeg可以合成成功
6、这个网站有一个陷阱。/video/segment-1.m4s 的链接和其他的不一样。直接使用其他seqs的链接就可以了。
后记
写这个文章的时候,突然想:像“blob:”这样的地址能不能转换成实际的视频地址?
这次搜索发现真的很好(我去看看,上面好多都是折腾了……)
已搜索 文章
开发者工具会自动定位这个视频对应页面源码的位置
然后将iframe中src的内容复制到视频的src中
PS:如果真的没有变化,再做一次 查看全部
网页视频抓取软件 格式工厂(如何下载下来过程定位视频链接?软件的详细介绍)
背景
吉友给了一个在线视频网址,想问问有没有推荐的录屏软件。我首先想到的是如何下载它
过程定位视频链接
因为之前做过爬虫,有的网站直接在网页源码上显示视频链接。因此,您可以直接查看网页源代码的元素。
坑要填。. .
1、使用文件连接命令(windows为type,linux为cat)将所有段合并为一个m4s文件。
2、使用ffmpeg进行音视频合成和格式转换
3、我用过invidownloader,了解到windows下的文件连接命令是type
4、 试过用ffmpeg直接合成所有的分割文件,视频会有问题(绿屏)
5、 段文件需要有头文件(包括段信息等),是网上搜到的mpd文件。但是,这个 网站 没有。后来上了一招(也是从invidownloader找到的),从segment-0.m4s开始下载,发现用ffmpeg可以合成成功
6、这个网站有一个陷阱。/video/segment-1.m4s 的链接和其他的不一样。直接使用其他seqs的链接就可以了。
后记
写这个文章的时候,突然想:像“blob:”这样的地址能不能转换成实际的视频地址?
这次搜索发现真的很好(我去看看,上面好多都是折腾了……)
已搜索 文章

开发者工具会自动定位这个视频对应页面源码的位置


然后将iframe中src的内容复制到视频的src中

PS:如果真的没有变化,再做一次
网页视频抓取软件 格式工厂(2种下载B站超清视频的方法(图下载))
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-12-21 07:08
这个问题一点也不难。这里有两种从B站下载超清视频的方法。
一、直接下载方式也是最简单的下载方式(仅限Win10系统)
操作步骤如下:
①打开Win10系统自带的应用商店,搜索Bilibili,就会出现Bilibili相关内容,然后选择-Bilibili动画,点击安装。
②找到您需要下载的视频,点击直接下载
③注意:此方法仅适用于Win10系统,点击下载前需要设置下载路径,以便快速找到下载视频的位置。下载格式默认为Flv,您可以通过其他方式转换MP4。
二、插件下载方式,需要安装插件+脚本
操作步骤如下:
①安装Tampermonkey插件。这里就不介绍了。安装方法非常简单。回复2获取微信对话框中的插件。点击浏览器右上角的三个点>>更多工具>>扩展>>拖入添加插件。能。
②安装脚本程序,在脚本网站:/zh-CN中,搜索并找到一个以bilibili开头的脚本并安装。如下所示
③测试:打开哔哩哔哩官方网站,这里我随意点击一个视频进入播放页面,此时我们会在播放器的左上角看到一个原生MP4和超清FLV按钮。
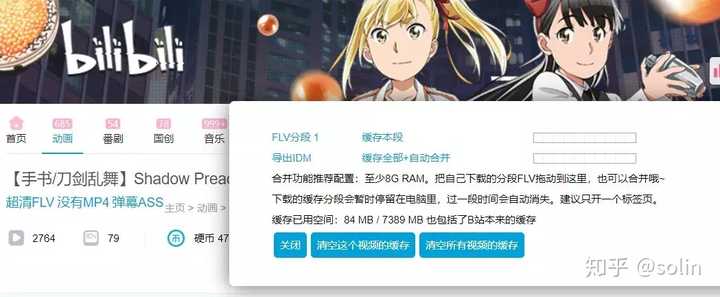
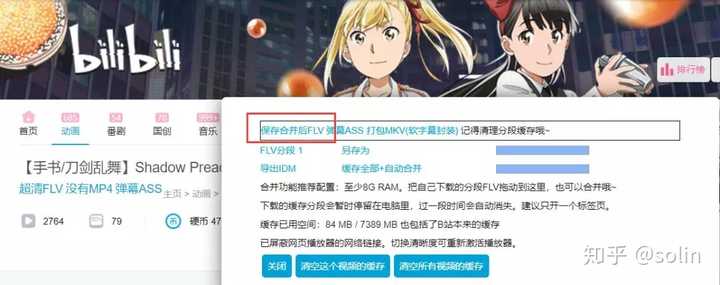
④下载方式:部分视频没有原生MP4,只能点击Super Clear FLV,然后点击Cache All+Auto Merge,如下图
⑤ 下载完成后,点击 保存合并后的FLV,大功告成。
三、注意事项:
强烈建议使用 Potplayer 播放器进行播放。功能真的很强大(在回复17中获取)。如果需要转换成MP4格式,可以通过格式工厂进行转换,操作简单。 查看全部
网页视频抓取软件 格式工厂(2种下载B站超清视频的方法(图下载))
这个问题一点也不难。这里有两种从B站下载超清视频的方法。
一、直接下载方式也是最简单的下载方式(仅限Win10系统)
操作步骤如下:
①打开Win10系统自带的应用商店,搜索Bilibili,就会出现Bilibili相关内容,然后选择-Bilibili动画,点击安装。
②找到您需要下载的视频,点击直接下载
③注意:此方法仅适用于Win10系统,点击下载前需要设置下载路径,以便快速找到下载视频的位置。下载格式默认为Flv,您可以通过其他方式转换MP4。
二、插件下载方式,需要安装插件+脚本
操作步骤如下:
①安装Tampermonkey插件。这里就不介绍了。安装方法非常简单。回复2获取微信对话框中的插件。点击浏览器右上角的三个点>>更多工具>>扩展>>拖入添加插件。能。
②安装脚本程序,在脚本网站:/zh-CN中,搜索并找到一个以bilibili开头的脚本并安装。如下所示
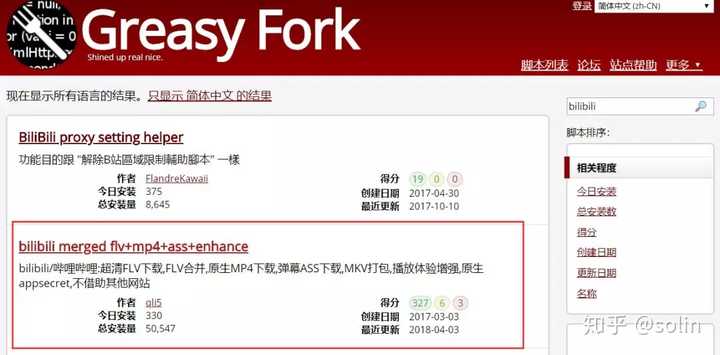
③测试:打开哔哩哔哩官方网站,这里我随意点击一个视频进入播放页面,此时我们会在播放器的左上角看到一个原生MP4和超清FLV按钮。

④下载方式:部分视频没有原生MP4,只能点击Super Clear FLV,然后点击Cache All+Auto Merge,如下图
⑤ 下载完成后,点击 保存合并后的FLV,大功告成。
三、注意事项:
强烈建议使用 Potplayer 播放器进行播放。功能真的很强大(在回复17中获取)。如果需要转换成MP4格式,可以通过格式工厂进行转换,操作简单。
网页视频抓取软件 格式工厂(网页视频抓取软件格式工厂,可抓取各大视频网站的所有视频,支持源码下载,下载视频效果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 393 次浏览 • 2021-12-18 16:01
网页视频抓取软件格式工厂,可抓取各大视频网站的所有视频,更可以批量抓取抖音/快手/优酷/b站/n站/土豆的视频,支持源码下载,下载视频效果如下:randomwalk视频抓取软件-非常简单的视频抓取器,可以批量抓取抖音/快手/优酷/b站/n站/uc等国内主流视频网站的视频.
土豆bt站估计没几个人知道,国内比较早的电影站。
为什么这么没人回答???我来给你推荐个,我不怎么用网页端的,都是直接保存视频,
我就知道有种东西叫迅雷保存
可以下载网站的视频的工具,找到一个很不错的工具,一键搞定多种视频格式转换,还有视频保存,
我就看动漫,看新番,看电影都是下载的网盘,想看有的是资源的,
里面有直接下载视频,或者后期加视频的方法,
下载一些图片啊,电子书啊,
微鱼,一款在线网页视频下载工具;支持手机和电脑端:。
可以去知乎找一下“如何从atm上取走钱”,
:;c=aa&d=song&e=ajax&wd=%e7%ad%b0%e4%bc%80%e4%b8%84%e4%bb%83%e6%96%b0%e5%a4%a8%e5%ad%a3%e8%a5%b7 查看全部
网页视频抓取软件 格式工厂(网页视频抓取软件格式工厂,可抓取各大视频网站的所有视频,支持源码下载,下载视频效果)
网页视频抓取软件格式工厂,可抓取各大视频网站的所有视频,更可以批量抓取抖音/快手/优酷/b站/n站/土豆的视频,支持源码下载,下载视频效果如下:randomwalk视频抓取软件-非常简单的视频抓取器,可以批量抓取抖音/快手/优酷/b站/n站/uc等国内主流视频网站的视频.
土豆bt站估计没几个人知道,国内比较早的电影站。
为什么这么没人回答???我来给你推荐个,我不怎么用网页端的,都是直接保存视频,
我就知道有种东西叫迅雷保存
可以下载网站的视频的工具,找到一个很不错的工具,一键搞定多种视频格式转换,还有视频保存,
我就看动漫,看新番,看电影都是下载的网盘,想看有的是资源的,
里面有直接下载视频,或者后期加视频的方法,
下载一些图片啊,电子书啊,
微鱼,一款在线网页视频下载工具;支持手机和电脑端:。
可以去知乎找一下“如何从atm上取走钱”,
:;c=aa&d=song&e=ajax&wd=%e7%ad%b0%e4%bc%80%e4%b8%84%e4%bb%83%e6%96%b0%e5%a4%a8%e5%ad%a3%e8%a5%b7
网页视频抓取软件 格式工厂(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-16 15:21
/1 简介/
还在为在线看小视频缓存慢而发愁吗?您是否还在为想重温优秀作品却找不到资源而苦恼?别慌,让python帮你解决,40行代码教你爬取小视频网站,先分批下载仔细看,不好看!
/2 整理思路/
这种网站一般都是一样的。本文以凤凰新闻视频网站为例,通过后推方式向大家展示如何通过流量分析获取视频下载的url,然后批量下载。
/3 操作步骤/
/3.1 分析网站,找出网页变化的规律/
1、 首先找到网页。该网页的详细信息如下图所示。
2、这个视频网站分为人物、娱乐、艺术等不同类型。本文以体育板块为例,下拉至底部,如下图所示。
3、根据上图的结果,我们可以发现网站是一个动态网页。打开浏览器内置的流量分析器,点击加载更多,查看网页变化的规律。第一个是请求的 URL 和返回的结果如下图所示。标记为页码,此时为第三页。
4、 返回的结果收录视频标题、网页url、guid(相当于每个视频的logo,方便后续跟进)等信息,如下图所示。
5、 每个网页收录24个视频,如下图打印出来。
/3.2 查找视频网页地址的规则/
1、 首先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
2、 我一一找到了它们的网址,并存入一个文本文件中,以查找它们之间的规则,如下图所示。
3、 你注意到这种模式了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到的),只有range_bytes参数变化,从0到6767623。显然这是视频的大小,视频是分段合成。找到这些规则后,我们需要继续挖掘视频地址的来源。
/3.3 找到视频的原创下载地址/
1、 首先考虑一个问题,视频地址从何而来?一般情况下,首先检查视频页面上是否有。如果没有,我们将在流量分析器中查找第一个分段视频。必须有某个 URL 返回此信息。很快,我在一个 vdn.apple.mpegurl 文件中找到了下图。
2、 太惊喜了,这不是我们要找的信息吗?我们来看看它的url参数,如下图所示。
3、上图中的参数看起来很多,但不要害怕。还是用老办法,先查网页有没有,如果没有就在流量分析器里找。努力是有回报的。我找到了下面的图片。
4、 其url如下图所示。
5、仔细找规则,发现唯一需要改的就是每个视频的guid。这第一步已经完成。另外,返回的结果中除了vkey之外,都收录了上面的所有参数,而且这个参数是最长的,我该怎么办?
6、不要着急,如果这个参数不起作用,删除vkey并尝试。果然,实在不行。现在整个过程已经很顺利了,现在可以按下代码了。
/3.4 代码实现/
1、 代码中设置多线程下载,如下图,其中页码可以自行修改。
2、 解析返回参数,为json格式,使用json库进行处理,如下图。通过分析,我们可以得到每个视频的标题、网页url和guid。
3、模拟请求获取Vkey以外的参数,如下图。
4、 使用上一步中的参数进行模拟请求,获取收录分段视频的信息,如下图所示。
5、 将分割后的视频合并,保存为1个视频文件,并以标题命名,如下图。
/3.5 效果展示/
1、 程序运行后,我们可以在本地文件夹中看到网页上的视频飞溅,如下图。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果你想更直观,你可以在代码中添加尺寸测量信息。您可以自己手动设置。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网络视频到本地。该方法简单易行,行之有效。欢迎您试用。如需获取本文代码,请访问/cassieeric/python_crawler/tree/master/little_video_crawler获取代码链接。觉得还不错的话记得给个star哦。 查看全部
网页视频抓取软件 格式工厂(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
/1 简介/
还在为在线看小视频缓存慢而发愁吗?您是否还在为想重温优秀作品却找不到资源而苦恼?别慌,让python帮你解决,40行代码教你爬取小视频网站,先分批下载仔细看,不好看!
/2 整理思路/
这种网站一般都是一样的。本文以凤凰新闻视频网站为例,通过后推方式向大家展示如何通过流量分析获取视频下载的url,然后批量下载。
/3 操作步骤/
/3.1 分析网站,找出网页变化的规律/
1、 首先找到网页。该网页的详细信息如下图所示。
2、这个视频网站分为人物、娱乐、艺术等不同类型。本文以体育板块为例,下拉至底部,如下图所示。
3、根据上图的结果,我们可以发现网站是一个动态网页。打开浏览器内置的流量分析器,点击加载更多,查看网页变化的规律。第一个是请求的 URL 和返回的结果如下图所示。标记为页码,此时为第三页。

4、 返回的结果收录视频标题、网页url、guid(相当于每个视频的logo,方便后续跟进)等信息,如下图所示。

5、 每个网页收录24个视频,如下图打印出来。

/3.2 查找视频网页地址的规则/
1、 首先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
2、 我一一找到了它们的网址,并存入一个文本文件中,以查找它们之间的规则,如下图所示。
3、 你注意到这种模式了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到的),只有range_bytes参数变化,从0到6767623。显然这是视频的大小,视频是分段合成。找到这些规则后,我们需要继续挖掘视频地址的来源。
/3.3 找到视频的原创下载地址/
1、 首先考虑一个问题,视频地址从何而来?一般情况下,首先检查视频页面上是否有。如果没有,我们将在流量分析器中查找第一个分段视频。必须有某个 URL 返回此信息。很快,我在一个 vdn.apple.mpegurl 文件中找到了下图。

2、 太惊喜了,这不是我们要找的信息吗?我们来看看它的url参数,如下图所示。

3、上图中的参数看起来很多,但不要害怕。还是用老办法,先查网页有没有,如果没有就在流量分析器里找。努力是有回报的。我找到了下面的图片。

4、 其url如下图所示。

5、仔细找规则,发现唯一需要改的就是每个视频的guid。这第一步已经完成。另外,返回的结果中除了vkey之外,都收录了上面的所有参数,而且这个参数是最长的,我该怎么办?
6、不要着急,如果这个参数不起作用,删除vkey并尝试。果然,实在不行。现在整个过程已经很顺利了,现在可以按下代码了。
/3.4 代码实现/
1、 代码中设置多线程下载,如下图,其中页码可以自行修改。

2、 解析返回参数,为json格式,使用json库进行处理,如下图。通过分析,我们可以得到每个视频的标题、网页url和guid。
3、模拟请求获取Vkey以外的参数,如下图。

4、 使用上一步中的参数进行模拟请求,获取收录分段视频的信息,如下图所示。

5、 将分割后的视频合并,保存为1个视频文件,并以标题命名,如下图。

/3.5 效果展示/
1、 程序运行后,我们可以在本地文件夹中看到网页上的视频飞溅,如下图。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果你想更直观,你可以在代码中添加尺寸测量信息。您可以自己手动设置。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网络视频到本地。该方法简单易行,行之有效。欢迎您试用。如需获取本文代码,请访问/cassieeric/python_crawler/tree/master/little_video_crawler获取代码链接。觉得还不错的话记得给个star哦。
网页视频抓取软件 格式工厂(网页视频抓取软件格式工厂-格式转换工具-免费、免签水印)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-15 12:02
网页视频抓取软件格式工厂-格式转换工具-免费、免签水印编辑|【视频抓取工具网站+短视频脚本制作工具】-格式工厂如果需要公众号素材,
网页视频搬运,有一个叫做格式工厂的工具。
在百度里搜“电视剧各种网盘及资源网站”吧,会有很多,建议在百度里搜“电视剧”。还有就是在网上搜“各种网盘”或者“电视剧下载”,会有很多,建议在百度里搜“电视剧”。
百度搜“电视剧资源”,然后从相关贴吧找。小说资源请百度“网盘”。
有个app叫“盘多多”,可以满足你的各种需求。
把下载好的电视剧的文件夹下载下来,再移动到电视机上,在的电视机上一般都是有crt电视机有个专门的电视软件叫“bilibili电视”只要有充电功能的电视机,
最快的还是自己想办法联系了,
网页上找自己需要的视频,
格式工厂
我回答一下,我用什么都可以下载视频,有个软件可以。
下一个app,
百度网盘,
现在就连电视剧网站上也都是下载不了,他们是联盟到网站本身,然后挂了商业广告联盟,或者广告商花钱联盟的话,他们又为了下载点击率,才能挣钱。建议用格式工厂,或者转换器, 查看全部
网页视频抓取软件 格式工厂(网页视频抓取软件格式工厂-格式转换工具-免费、免签水印)
网页视频抓取软件格式工厂-格式转换工具-免费、免签水印编辑|【视频抓取工具网站+短视频脚本制作工具】-格式工厂如果需要公众号素材,
网页视频搬运,有一个叫做格式工厂的工具。
在百度里搜“电视剧各种网盘及资源网站”吧,会有很多,建议在百度里搜“电视剧”。还有就是在网上搜“各种网盘”或者“电视剧下载”,会有很多,建议在百度里搜“电视剧”。
百度搜“电视剧资源”,然后从相关贴吧找。小说资源请百度“网盘”。
有个app叫“盘多多”,可以满足你的各种需求。
把下载好的电视剧的文件夹下载下来,再移动到电视机上,在的电视机上一般都是有crt电视机有个专门的电视软件叫“bilibili电视”只要有充电功能的电视机,
最快的还是自己想办法联系了,
网页上找自己需要的视频,
格式工厂
我回答一下,我用什么都可以下载视频,有个软件可以。
下一个app,
百度网盘,
现在就连电视剧网站上也都是下载不了,他们是联盟到网站本身,然后挂了商业广告联盟,或者广告商花钱联盟的话,他们又为了下载点击率,才能挣钱。建议用格式工厂,或者转换器,
网页视频抓取软件 格式工厂(格式工厂转换视频时转换失败的解决方法着解决)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-01-10 21:20
图片和视频文件在我们的日常工作和生活中占据着非常重要的位置。而当我们制作视频发给朋友的时候,我们知道朋友的电脑无法打开这种格式的视频,此时为了让朋友能够流畅的查看视频的内容,我们需要转换视频的内容。要转换的格式。
格式工厂软件是一款支持多种视频格式转换的软件。使用这个软件,我们不仅可以转换视频格式,还可以转换音频格式。音频提取等
有的朋友在使用格式工厂转换视频的格式时遇到这样的问题,也就是格式工厂转换失败的问题,请问这个问题是什么原因呢?我们如何解决这个问题?下面小编将为大家总结和介绍解决这个问题的方法,希望对大家有所帮助。
格式工厂转换视频时转换失败的解决方法一:
打开格式工厂软件,选择要转换的视频格式,然后在添加文件界面点击界面右上角的【输出配置】按钮。
然后在弹出的【视频设置】窗口中,调整转换后视频的视频编码、二次编码等参数。全部设置完成后,点击窗口右下角的【确定】按钮。然后尝试再次转换视频。
格式工厂转换视频时转换失败的解决方法二:
如果你安装的格式工厂软件版本太低,软件会有很多bug,所以我们需要将电脑上的格式工厂升级到最新版本,这样我们才能进行正常的音视频格式。转换。
好了,这就是解决格式工厂无法转换视频的问题了。如果大家在使用本软件进行格式转换的时候经常会遇到这样的问题,那么不妨试试小编为大家整理的解决方法,让我们的转换工作变得更加轻松。 查看全部
网页视频抓取软件 格式工厂(格式工厂转换视频时转换失败的解决方法着解决)
图片和视频文件在我们的日常工作和生活中占据着非常重要的位置。而当我们制作视频发给朋友的时候,我们知道朋友的电脑无法打开这种格式的视频,此时为了让朋友能够流畅的查看视频的内容,我们需要转换视频的内容。要转换的格式。
格式工厂软件是一款支持多种视频格式转换的软件。使用这个软件,我们不仅可以转换视频格式,还可以转换音频格式。音频提取等
有的朋友在使用格式工厂转换视频的格式时遇到这样的问题,也就是格式工厂转换失败的问题,请问这个问题是什么原因呢?我们如何解决这个问题?下面小编将为大家总结和介绍解决这个问题的方法,希望对大家有所帮助。
格式工厂转换视频时转换失败的解决方法一:
打开格式工厂软件,选择要转换的视频格式,然后在添加文件界面点击界面右上角的【输出配置】按钮。
然后在弹出的【视频设置】窗口中,调整转换后视频的视频编码、二次编码等参数。全部设置完成后,点击窗口右下角的【确定】按钮。然后尝试再次转换视频。
格式工厂转换视频时转换失败的解决方法二:
如果你安装的格式工厂软件版本太低,软件会有很多bug,所以我们需要将电脑上的格式工厂升级到最新版本,这样我们才能进行正常的音视频格式。转换。
好了,这就是解决格式工厂无法转换视频的问题了。如果大家在使用本软件进行格式转换的时候经常会遇到这样的问题,那么不妨试试小编为大家整理的解决方法,让我们的转换工作变得更加轻松。
网页视频抓取软件 格式工厂(VideoDownloadHelper火狐插件,建议你下载一个新东方在线的手机app)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-10 09:08
我只能制作你已经购买的课程的视频,你也可以下载,但是视频是加密的PCF。没有视频ID就无法下载。Video DownloadHelper 火狐插件
呃,建议你下载一个新的东方在线手机app,然后缓存到你的手机里,就这样。
可以提取总部
你去下载就是用傲游。然后去插件下载并下载一个网络嗅探器。首先清除网络临时文件夹。然后打开那个视频。用嗅探器下载
总裁网(chinaceot_com)为您解答:
总统网是一所现代化的新型在线自助商学院。在线视频学习集数上万,学习视频还在不断增加中。还有海量资料可供免费下载。庄网互联网商学院分为:企业商学院和个人商学院。如果满足于出门在外,只能安排时间在家学习和充电。展网商学院还分为:“企业商学院”和“个人商学院”,不仅提供在线学习,还提供自学,在线评估你的学习成绩,会根据你的分数为你颁发展网商学院证书。
总裁网络
如何捕获在线视频- : 1、使用在线提供的URLsnooper 软件,有使用说明,可以跟踪大多数文件地址。2、如果方法一无效,右击正在播放的视频选择属性,可以在详细信息中找到实际播放地址3、如果以上方法都不行,还有一个开始播放时立即停止视频的方法...
在线视频抓拍有什么好用的软件:camtasia studio 6.0.0【中文绿色版】:
关于网络视频抓拍的问题:别想了……因为视频分为两段。您只捕获了前一个段的地址。无需软件即可下载视频。您可以直接观看视频。将视频复制到临时文件夹
使用什么工具?怎么剪视频??- : 最简单的方法就是使用“英雄解霸”...
QQ视频和视频可以采集在线视频吗?如果没有,能否推荐一些可以捕捉在线视频的软件?:QQ视频和视频可以在线播放视频吗?这里是我推荐给你的软件1、项目 URL Snooper 下载地址: URL Snooper 实现流媒体抓包的步骤比较重要,先打开软件开始检测,再打开需要抓包流媒体。 ..
有没有可以免费拍视频的软件?- : PhotoImpression 5 和 VideoImpression 2
如何抓取网络视频的真实地址:可以在百度和雅虎上搜索音乐,或者使用网络大师软件分析流量找出地址。
如何截取网页上的视频?- : 1. Red Dragonfly Snap 2005 V1.23 build 0430 Red Dragonfly Snap 2005 是一个完全免费的专业屏幕2. Red Dragonfly Capture Wizard 2005 1.23 build 0430 Red Dragonfly捕获向导 (R...
手机视频抓拍软件-:录屏大师,但是录制这种视频需要root权限才能使用本软件,否则下载后将无法使用,可以先在应用中下载一个root大师宝,这种情况下你可以一键root,然后在app宝里下载这个录屏大师,就可以录屏了。应用宝中的软件下载方便,删除方便。以后用起来很方便,希望采纳。
正在寻找一个软件来从 网站 中获取整个视频!- :首先,你的网站是什么样的网站?和优酷一样吗?如果是这样,这并不难。可以用相应的软件来完成。推荐两个软件:①正版网站,正版视频,可以使用微堂或者说书下载器。②那种网站(你懂的),可以在视频缓冲的时候用VideoCacheView软件找到缓冲目录,然后转移到电脑的其他磁盘上。总之,以上两个软件对你来说已经足够了,但是还需要具体情况具体分析。. 查看全部
网页视频抓取软件 格式工厂(VideoDownloadHelper火狐插件,建议你下载一个新东方在线的手机app)
我只能制作你已经购买的课程的视频,你也可以下载,但是视频是加密的PCF。没有视频ID就无法下载。Video DownloadHelper 火狐插件
呃,建议你下载一个新的东方在线手机app,然后缓存到你的手机里,就这样。
可以提取总部
你去下载就是用傲游。然后去插件下载并下载一个网络嗅探器。首先清除网络临时文件夹。然后打开那个视频。用嗅探器下载
总裁网(chinaceot_com)为您解答:
总统网是一所现代化的新型在线自助商学院。在线视频学习集数上万,学习视频还在不断增加中。还有海量资料可供免费下载。庄网互联网商学院分为:企业商学院和个人商学院。如果满足于出门在外,只能安排时间在家学习和充电。展网商学院还分为:“企业商学院”和“个人商学院”,不仅提供在线学习,还提供自学,在线评估你的学习成绩,会根据你的分数为你颁发展网商学院证书。
总裁网络
如何捕获在线视频- : 1、使用在线提供的URLsnooper 软件,有使用说明,可以跟踪大多数文件地址。2、如果方法一无效,右击正在播放的视频选择属性,可以在详细信息中找到实际播放地址3、如果以上方法都不行,还有一个开始播放时立即停止视频的方法...
在线视频抓拍有什么好用的软件:camtasia studio 6.0.0【中文绿色版】:
关于网络视频抓拍的问题:别想了……因为视频分为两段。您只捕获了前一个段的地址。无需软件即可下载视频。您可以直接观看视频。将视频复制到临时文件夹
使用什么工具?怎么剪视频??- : 最简单的方法就是使用“英雄解霸”...
QQ视频和视频可以采集在线视频吗?如果没有,能否推荐一些可以捕捉在线视频的软件?:QQ视频和视频可以在线播放视频吗?这里是我推荐给你的软件1、项目 URL Snooper 下载地址: URL Snooper 实现流媒体抓包的步骤比较重要,先打开软件开始检测,再打开需要抓包流媒体。 ..
有没有可以免费拍视频的软件?- : PhotoImpression 5 和 VideoImpression 2
如何抓取网络视频的真实地址:可以在百度和雅虎上搜索音乐,或者使用网络大师软件分析流量找出地址。
如何截取网页上的视频?- : 1. Red Dragonfly Snap 2005 V1.23 build 0430 Red Dragonfly Snap 2005 是一个完全免费的专业屏幕2. Red Dragonfly Capture Wizard 2005 1.23 build 0430 Red Dragonfly捕获向导 (R...
手机视频抓拍软件-:录屏大师,但是录制这种视频需要root权限才能使用本软件,否则下载后将无法使用,可以先在应用中下载一个root大师宝,这种情况下你可以一键root,然后在app宝里下载这个录屏大师,就可以录屏了。应用宝中的软件下载方便,删除方便。以后用起来很方便,希望采纳。
正在寻找一个软件来从 网站 中获取整个视频!- :首先,你的网站是什么样的网站?和优酷一样吗?如果是这样,这并不难。可以用相应的软件来完成。推荐两个软件:①正版网站,正版视频,可以使用微堂或者说书下载器。②那种网站(你懂的),可以在视频缓冲的时候用VideoCacheView软件找到缓冲目录,然后转移到电脑的其他磁盘上。总之,以上两个软件对你来说已经足够了,但是还需要具体情况具体分析。.
网页视频抓取软件 格式工厂(提取介绍格式工厂(英文名FormatFactory)版本提取出来)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-09 16:06
格式工厂播放器提取版是一款可以自动识别多种音频格式的播放器工具。它可以帮助您在转换过程中修复视频质量,支持多种格式的转换,并且还具有智能捕获功能。为用户备份,使用非常方便,无需安装,下载使用即可。
介绍
Format Factory(英文名称Format Factory)提供音视频文件的编辑、合并、分割、视频文件混合、裁剪和去水印。软件还包括视频播放、录屏和视频网站下载功能,无需额外安装几个软件
指示
双击鼠标左键2次全屏视频
空格键暂停/播放
完全控制栏
内置设置和其他功能
格式工厂播放器的优势
支持iphone/ipod/psp等多媒体指定格式。支持图片常用功能
支持各类视频、音频、图片等格式,轻松转换为您想要的格式。修复损坏的视频文件
DVD视频翻录功能,轻松备份DVD到本地硬盘。支持多种语言
转换图片支持缩放、旋转、加水印等常用功能,操作一气呵成。备份很简单
它支持62种国家语言,易于访问,满足各种需求。
支持几乎所有类型的多媒体格式
在转换过程中,可以修复损坏的文件,使转换质量不受损。用于减肥的多媒体文件
它可以帮助你的文件“减肥”,让它们“变瘦”。不仅节省硬盘空间,而且易于保存和备份。可以指定格式
软件功能
能有效解决视频播放器无法播放的问题;
视频压缩后,可快速传输给好友或保存到云盘;
音频提取非常好用,一键提取视音频,将mp4转为mp3,播放更方便。
软件操作简单,一键导入需要转换的视频;
支持多种视频格式,转换成功后播放过程不会卡顿;
萃取简介
本软件提取自格式工厂5.7.1版本
可以播放大多数视频格式
我测试了,播放正常,但是播放NAS或者本地视频可能有点卡 查看全部
网页视频抓取软件 格式工厂(提取介绍格式工厂(英文名FormatFactory)版本提取出来)
格式工厂播放器提取版是一款可以自动识别多种音频格式的播放器工具。它可以帮助您在转换过程中修复视频质量,支持多种格式的转换,并且还具有智能捕获功能。为用户备份,使用非常方便,无需安装,下载使用即可。
介绍
Format Factory(英文名称Format Factory)提供音视频文件的编辑、合并、分割、视频文件混合、裁剪和去水印。软件还包括视频播放、录屏和视频网站下载功能,无需额外安装几个软件
指示
双击鼠标左键2次全屏视频
空格键暂停/播放
完全控制栏
内置设置和其他功能
格式工厂播放器的优势
支持iphone/ipod/psp等多媒体指定格式。支持图片常用功能
支持各类视频、音频、图片等格式,轻松转换为您想要的格式。修复损坏的视频文件
DVD视频翻录功能,轻松备份DVD到本地硬盘。支持多种语言
转换图片支持缩放、旋转、加水印等常用功能,操作一气呵成。备份很简单
它支持62种国家语言,易于访问,满足各种需求。
支持几乎所有类型的多媒体格式
在转换过程中,可以修复损坏的文件,使转换质量不受损。用于减肥的多媒体文件
它可以帮助你的文件“减肥”,让它们“变瘦”。不仅节省硬盘空间,而且易于保存和备份。可以指定格式
软件功能
能有效解决视频播放器无法播放的问题;
视频压缩后,可快速传输给好友或保存到云盘;
音频提取非常好用,一键提取视音频,将mp4转为mp3,播放更方便。
软件操作简单,一键导入需要转换的视频;
支持多种视频格式,转换成功后播放过程不会卡顿;
萃取简介
本软件提取自格式工厂5.7.1版本
可以播放大多数视频格式
我测试了,播放正常,但是播放NAS或者本地视频可能有点卡
网页视频抓取软件 格式工厂(【手游坊评测】2017年11月8日前端开发扒视频辛酸历程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-09 01:15
时间:2017 年 11 月 8 日
说到前端开发,在网页上放视频是不可避免的。如果你放视频,有时你会不可避免地拿起视频。以下是我视频的辛酸历程。让我们关注并珍惜它们。
一、直接刷代码
和 pandakill 的视频一样,直接拿代码就可以了。
至于什么格式,自行下载后,直接用格式工厂转换即可。
二、查看网络
比如触手的视频,看网络就可以找到。起初,我还在慢慢寻找。后来有网友建议可以先按大小排序,因为视频会比一般文件大很多==,这样就很容易了,哈哈哈。
三、更改域名
本视频适用于B站(bilibili)。
例如,网站 地址是
怎么接视频,把bilibili改成kanbilibili就行了
打开后,页面顶部是这样的:
点击“下载地址”后,
分为下载地址和弹幕下载地址两部分,我们只需要选择下载地址(第一部分)即可。
在下载地址部分,有3种下载方式,P2、P3和P4。一般可以下载P3。我已经下载了P4,但是中间会有几块下载失败。P3可以下载。下载完成,很多ts文件都下载下来了,然后我们就可以使用B站提供的代码合并工具,将多个ts文件合并为一个ts文件。合并地址:.
首先添加多个已下载的文件。如果需要排序,可以点击“自动排序”,然后输入合并后的文件名,点击“开始合并”,稍等片刻,合并后下载就ok啦。
但是这个时候可能有人会问,我需要mp4格式的视频,不知道ts文件是什么。这这,还有一个特别简单粗暴的方法,就是直接把视频的后缀名改成mp4。可以在本地完全播放,但是我们绝对不局限于本地播放,还可以放在我们的代码中,那么其他人访问这个页面就可以播放这个页面了。那么这个方法就行不通了。我们都知道视频编码格式有很多种,不同的浏览器支持的编码格式也不一样。比如ts的编码格式是MPEG,谷歌、火狐等浏览器支持的编码格式是FLV。所以~~主角来了:格式工厂,它不仅可以转换视频格式,还可以转换视频格式,原来如此简单~~
四、使用 Chrome 和迅雷下载视频
推荐使用此方法。虽然很复杂,但是非常有效。
适用网站:斗鱼、MOOC、网易云课堂、B站等。
我们都知道视频网站为了保护版权,防止盗链下载,一般都是分段加载的。一般的.flv格式,视频源最多有十几个,而.ts格式一般每段几兆,一个小时左右的视频基本有几百个段。手动下载太累了。接下来分享一个无痛的方法,只需要使用系统的常用软件即可。
1、获取原创视频
以一个视频为例,用Chrome访问并打开开发者工具切换到Netword面板,点击视频开始和结束的位置,我们可以发现视频源是一个普通地址,从001 至 344 。
只关注我用红色标记的地方。
2、批量下载 .ts 视频
你只需要注意我圈子里的3个部分。
第一部分:选择要更改的数字的位置,用一对括号和通配符替换,即(*),但是这里有几点需要注意,我们注意到我写了6个0和一个通配符这里,然后在下面那一栏中,对应的写法是0到9(一位数)。当ts文件为10到99时,必须写成5个0加通配符,以此类推,ts文件是100到999.,这里要写成4个0加通配符。简而言之,ts文件的总位数是7位,也就是说虽然我们是分批下载的,但还是分批,0到9批,10到99批,100到999批等,这没关系,如果你注意的话。
第二部分:前两个输入框的第一部分已经讲完了。现在主要的是通配符的长度。这里默认写1就够了。那为什么不写2和3呢?你可以看到结果。
第三部分:这相当于检查部分。前两部分填好后,可以在第三部分查看ts文件的范围,我们可以检查一下前面的配置是否正确。
点击“确定”后,会弹出如下弹窗:
为此,我们只需要注意“合并到一个任务组”即可。这是什么意思?意思是把这个ts文件归入你先写的任务组,方便管理。
其实这个比较简单,使用一行DOS命令就可以实现。
copy/b D:\video\*.ts D:\video-all\all.ts
执行上述命令后,D:\video\目录下的所有.ts文件都会合并到all.ts中,all.ts文件会放在video-all文件夹下。
命令说明:copy用于合并文件。如果没有 /b 参数,它将被合并为一个普通的文本文件。添加这个参数意味着它将被合并为一个二进制文件;此外,文件顺序按文件名排序。文件名也很规整,基本不用自己重命名和排序。(注意:路径中不能有空格)
五、使用下载工具下载视频
适用于:斗鱼等
我这次测试失败了,你可以自己试试,哈哈哈。
步骤1、打开火狐浏览器插件页面,安装视频下载器插件
安装插件后,您会在浏览器的右上角看到一个下载图标。
2、配置插件
单击插件下载图标旁边的向下箭头 ↓ 并选择 Preferences,其中:
注意:因为这个插件不能满足我们所有的需求,所以这里的视频文件夹保存在哪里都没有关系,也不一定所有的视频都保存在这里。
3、打开斗鱼视频详情页获取视频真实地址
打开要下载的视频详情页面,如:
页面加载完成后,可以看到视频插件的下载图标是动画的。单击下载以查看当前可下载视频的列表。
由于斗鱼的视频是分段的,一个视频会被分割成多个ts格式的视频,所以在视频列表中可以看到多个文件。
左键单击列表中的倒数第二个开始下载。(此文件是完整视频的第一段)
下载完成后,可以在浏览器右上角找到下载的文件。右键单击刚刚下载的文件,然后选择复制下载链接。
复制下载链接后,可以回到上面介绍的方法,用迅雷批量下载。
至此,我们先来说说这5种方法。其实还有其他方法,大家可以自己摸索~~~
我的博客将同步到腾讯云+社区,诚邀大家加入: 查看全部
网页视频抓取软件 格式工厂(【手游坊评测】2017年11月8日前端开发扒视频辛酸历程)
时间:2017 年 11 月 8 日
说到前端开发,在网页上放视频是不可避免的。如果你放视频,有时你会不可避免地拿起视频。以下是我视频的辛酸历程。让我们关注并珍惜它们。
一、直接刷代码
和 pandakill 的视频一样,直接拿代码就可以了。
至于什么格式,自行下载后,直接用格式工厂转换即可。
二、查看网络
比如触手的视频,看网络就可以找到。起初,我还在慢慢寻找。后来有网友建议可以先按大小排序,因为视频会比一般文件大很多==,这样就很容易了,哈哈哈。
三、更改域名
本视频适用于B站(bilibili)。
例如,网站 地址是
怎么接视频,把bilibili改成kanbilibili就行了
打开后,页面顶部是这样的:
点击“下载地址”后,
分为下载地址和弹幕下载地址两部分,我们只需要选择下载地址(第一部分)即可。
在下载地址部分,有3种下载方式,P2、P3和P4。一般可以下载P3。我已经下载了P4,但是中间会有几块下载失败。P3可以下载。下载完成,很多ts文件都下载下来了,然后我们就可以使用B站提供的代码合并工具,将多个ts文件合并为一个ts文件。合并地址:.
首先添加多个已下载的文件。如果需要排序,可以点击“自动排序”,然后输入合并后的文件名,点击“开始合并”,稍等片刻,合并后下载就ok啦。
但是这个时候可能有人会问,我需要mp4格式的视频,不知道ts文件是什么。这这,还有一个特别简单粗暴的方法,就是直接把视频的后缀名改成mp4。可以在本地完全播放,但是我们绝对不局限于本地播放,还可以放在我们的代码中,那么其他人访问这个页面就可以播放这个页面了。那么这个方法就行不通了。我们都知道视频编码格式有很多种,不同的浏览器支持的编码格式也不一样。比如ts的编码格式是MPEG,谷歌、火狐等浏览器支持的编码格式是FLV。所以~~主角来了:格式工厂,它不仅可以转换视频格式,还可以转换视频格式,原来如此简单~~
四、使用 Chrome 和迅雷下载视频
推荐使用此方法。虽然很复杂,但是非常有效。
适用网站:斗鱼、MOOC、网易云课堂、B站等。
我们都知道视频网站为了保护版权,防止盗链下载,一般都是分段加载的。一般的.flv格式,视频源最多有十几个,而.ts格式一般每段几兆,一个小时左右的视频基本有几百个段。手动下载太累了。接下来分享一个无痛的方法,只需要使用系统的常用软件即可。
1、获取原创视频
以一个视频为例,用Chrome访问并打开开发者工具切换到Netword面板,点击视频开始和结束的位置,我们可以发现视频源是一个普通地址,从001 至 344 。
只关注我用红色标记的地方。
2、批量下载 .ts 视频
你只需要注意我圈子里的3个部分。
第一部分:选择要更改的数字的位置,用一对括号和通配符替换,即(*),但是这里有几点需要注意,我们注意到我写了6个0和一个通配符这里,然后在下面那一栏中,对应的写法是0到9(一位数)。当ts文件为10到99时,必须写成5个0加通配符,以此类推,ts文件是100到999.,这里要写成4个0加通配符。简而言之,ts文件的总位数是7位,也就是说虽然我们是分批下载的,但还是分批,0到9批,10到99批,100到999批等,这没关系,如果你注意的话。
第二部分:前两个输入框的第一部分已经讲完了。现在主要的是通配符的长度。这里默认写1就够了。那为什么不写2和3呢?你可以看到结果。
第三部分:这相当于检查部分。前两部分填好后,可以在第三部分查看ts文件的范围,我们可以检查一下前面的配置是否正确。
点击“确定”后,会弹出如下弹窗:
为此,我们只需要注意“合并到一个任务组”即可。这是什么意思?意思是把这个ts文件归入你先写的任务组,方便管理。
其实这个比较简单,使用一行DOS命令就可以实现。
copy/b D:\video\*.ts D:\video-all\all.ts
执行上述命令后,D:\video\目录下的所有.ts文件都会合并到all.ts中,all.ts文件会放在video-all文件夹下。
命令说明:copy用于合并文件。如果没有 /b 参数,它将被合并为一个普通的文本文件。添加这个参数意味着它将被合并为一个二进制文件;此外,文件顺序按文件名排序。文件名也很规整,基本不用自己重命名和排序。(注意:路径中不能有空格)
五、使用下载工具下载视频
适用于:斗鱼等
我这次测试失败了,你可以自己试试,哈哈哈。
步骤1、打开火狐浏览器插件页面,安装视频下载器插件
安装插件后,您会在浏览器的右上角看到一个下载图标。
2、配置插件
单击插件下载图标旁边的向下箭头 ↓ 并选择 Preferences,其中:
注意:因为这个插件不能满足我们所有的需求,所以这里的视频文件夹保存在哪里都没有关系,也不一定所有的视频都保存在这里。
3、打开斗鱼视频详情页获取视频真实地址
打开要下载的视频详情页面,如:
页面加载完成后,可以看到视频插件的下载图标是动画的。单击下载以查看当前可下载视频的列表。
由于斗鱼的视频是分段的,一个视频会被分割成多个ts格式的视频,所以在视频列表中可以看到多个文件。
左键单击列表中的倒数第二个开始下载。(此文件是完整视频的第一段)
下载完成后,可以在浏览器右上角找到下载的文件。右键单击刚刚下载的文件,然后选择复制下载链接。
复制下载链接后,可以回到上面介绍的方法,用迅雷批量下载。
至此,我们先来说说这5种方法。其实还有其他方法,大家可以自己摸索~~~
我的博客将同步到腾讯云+社区,诚邀大家加入:
网页视频抓取软件 格式工厂(格式工厂是套万能的多媒体格式转换软件-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-03 18:13
格式工厂是一款多功能的多媒体格式转换软件。
提供以下功能:
所有类型的视频都传输到 MP4/3GP/MPG/AVI/WMV/FLV/SWF。
所有类型的音频都传输到 MP3/WMA/AMR/OGG/AAC/WAV。
所有类型的图片都转为JPG/BMP/PNG/TIF/ICO/GIF/TGA。
将 DVD 翻录为视频文件,将音乐 CD 抓取为音频文件。
MP4 文件支持 iPod/iPhone/PSP/Black Mold 等指定格式。
支持RMVB、水印、音视频混合。
格式工厂的专长:
1 支持几乎所有类型的多媒体格式到几种常用格式。
2 在转换过程中可以修复一些损坏的视频文件。
3 个多媒体文件来减肥。
4 支持 iPhone/iPod/PSP 等指定多媒体格式。
5 转换后的图片文件支持缩放、旋转、水印等功能。
6 DVD视频采集功能,轻松备份DVD到本地硬盘。
7 支持 60 种国家语言
配置要求:所有windows系统
注意:
软件包内含百度搜索工具栏,免费软件赞助商。
如果您不想安装它们,请在安装过程中取消它们。
部分杀毒软件可能会误报,开发者保证格式工厂安装包不收录任何恶意程序。
格式工厂 v4.0 更新日志:
1、添加最新的HEVC(H265)编码、MP4、MKV压缩比大幅提升
2、优化默认码率算法
3、添加编码 CRF 支持
4、更新了一些编码器版本 查看全部
网页视频抓取软件 格式工厂(格式工厂是套万能的多媒体格式转换软件-上海怡健医学)
格式工厂是一款多功能的多媒体格式转换软件。
提供以下功能:
所有类型的视频都传输到 MP4/3GP/MPG/AVI/WMV/FLV/SWF。
所有类型的音频都传输到 MP3/WMA/AMR/OGG/AAC/WAV。
所有类型的图片都转为JPG/BMP/PNG/TIF/ICO/GIF/TGA。
将 DVD 翻录为视频文件,将音乐 CD 抓取为音频文件。
MP4 文件支持 iPod/iPhone/PSP/Black Mold 等指定格式。
支持RMVB、水印、音视频混合。
格式工厂的专长:
1 支持几乎所有类型的多媒体格式到几种常用格式。
2 在转换过程中可以修复一些损坏的视频文件。
3 个多媒体文件来减肥。
4 支持 iPhone/iPod/PSP 等指定多媒体格式。
5 转换后的图片文件支持缩放、旋转、水印等功能。
6 DVD视频采集功能,轻松备份DVD到本地硬盘。
7 支持 60 种国家语言
配置要求:所有windows系统
注意:
软件包内含百度搜索工具栏,免费软件赞助商。
如果您不想安装它们,请在安装过程中取消它们。
部分杀毒软件可能会误报,开发者保证格式工厂安装包不收录任何恶意程序。
格式工厂 v4.0 更新日志:
1、添加最新的HEVC(H265)编码、MP4、MKV压缩比大幅提升
2、优化默认码率算法
3、添加编码 CRF 支持
4、更新了一些编码器版本
网页视频抓取软件 格式工厂(一个百度文库的下载神器,冰点文库,支持多个平台)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-01-02 20:02
下载豆丁文档
有段时间,我推荐了百度文库的一个下载神器,冰点文库。相信很多朋友都用过,一定也感受到了它的强大功能。无需担心下载、不使用或看不到它。这条推文里的小虾还给了温暖的友情链接:
点库:[windows]百度库免费下载,功能强大,支持多平台
不过,滇文库也有一个缺点,就是对百度文库的支持很好,但是对豆丁和阿里巴巴的支持就没有那么多了。发现有些资源无法下载,而且冰点文库下载的文件都是pdf,不管原文件是什么格式,如果下载后要编辑,就得重新转换格式,也就是稍微麻烦一些。
接下来虾米推荐一种下载豆丁文件的方法。这是一个网站,无需下载软件,简单方便,不限制系统,就是只要有浏览器,随时随地都可以下载,不管是电脑或手机。另外,网站工具是豆丁的文档复制和抓取工具。导出的文档为word格式,不是源文件,但文本可以编辑,收录图片。尽量保持原创文档的格式。支持原文档为WORD、PDF、TXT的文档,暂不支持PPT、Excel文档。
使用方法:
到豆丁图书馆你需要的文档,复制文档的URL地址;将文档链接粘贴到本站输入框中,点击下载,等待下载完成;打开下载的文档,进行一些内容格式化的详细调整优化处理。
另外还有很多老哥私信给我,说我不会下载,我这里再解释一下:
首先关注我的微信公众号私信回复关键词。当然,它们必须是正确的关键字。它们是我推文中的关键词。不要只是猜测每个人的链接。有官方网站。我已经推过他们了。另外,还有我上传的兰邹云。建议安卓用户使用蓝藻云下载。苹果用户只能到官网正常下载安装。某些手机将受到限制。请在手机设置中允许。未知源文件安装,打开浏览器等软件安装权限部分破解软件,手机会提示病毒,这是从非官方应用市场安装的,或者破解软件有反广告机制被检测到由手机厂商所有软件小虾米都测试过了,请放心使用。当然,如果你介意的话,你不应该安装它。有些软件对时间敏感,可以在我发布推文时使用。过一会,可能无法下载或暂停服务(如麻花影视),或开始收费等,请关注我的推文,切换到其他软件即可。重要提示 查看全部
网页视频抓取软件 格式工厂(一个百度文库的下载神器,冰点文库,支持多个平台)
下载豆丁文档
有段时间,我推荐了百度文库的一个下载神器,冰点文库。相信很多朋友都用过,一定也感受到了它的强大功能。无需担心下载、不使用或看不到它。这条推文里的小虾还给了温暖的友情链接:
点库:[windows]百度库免费下载,功能强大,支持多平台
不过,滇文库也有一个缺点,就是对百度文库的支持很好,但是对豆丁和阿里巴巴的支持就没有那么多了。发现有些资源无法下载,而且冰点文库下载的文件都是pdf,不管原文件是什么格式,如果下载后要编辑,就得重新转换格式,也就是稍微麻烦一些。
接下来虾米推荐一种下载豆丁文件的方法。这是一个网站,无需下载软件,简单方便,不限制系统,就是只要有浏览器,随时随地都可以下载,不管是电脑或手机。另外,网站工具是豆丁的文档复制和抓取工具。导出的文档为word格式,不是源文件,但文本可以编辑,收录图片。尽量保持原创文档的格式。支持原文档为WORD、PDF、TXT的文档,暂不支持PPT、Excel文档。
使用方法:
到豆丁图书馆你需要的文档,复制文档的URL地址;将文档链接粘贴到本站输入框中,点击下载,等待下载完成;打开下载的文档,进行一些内容格式化的详细调整优化处理。
另外还有很多老哥私信给我,说我不会下载,我这里再解释一下:
首先关注我的微信公众号私信回复关键词。当然,它们必须是正确的关键字。它们是我推文中的关键词。不要只是猜测每个人的链接。有官方网站。我已经推过他们了。另外,还有我上传的兰邹云。建议安卓用户使用蓝藻云下载。苹果用户只能到官网正常下载安装。某些手机将受到限制。请在手机设置中允许。未知源文件安装,打开浏览器等软件安装权限部分破解软件,手机会提示病毒,这是从非官方应用市场安装的,或者破解软件有反广告机制被检测到由手机厂商所有软件小虾米都测试过了,请放心使用。当然,如果你介意的话,你不应该安装它。有些软件对时间敏感,可以在我发布推文时使用。过一会,可能无法下载或暂停服务(如麻花影视),或开始收费等,请关注我的推文,切换到其他软件即可。重要提示
网页视频抓取软件 格式工厂( 网上摘录的一段介绍框架的文字,大过年的懒癌高发期)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-02 20:01
网上摘录的一段介绍框架的文字,大过年的懒癌高发期)
Scrapy 是一个用 Python 编写的爬虫框架,简单、轻量、非常方便。 Scrapy 使用异步网络库 Twisted 来处理网络通信。架构清晰,收录各种中间件接口,可以灵活满足各种需求。
以上摘自网上,介绍了scrapy框架。是懒癌高发期...
安装scrapy,pip可以解决你的问题:pip install scrapy。
这里插一句,如果运行代码后看到这个错误:
ImportError: No module named win32api
出现一个深坑,需要安装pywin32。如果已经安装了pywin32出现错误,还是需要手动将你的python安装目录放到\Lib\site-packages\pywin32_system32下:pythoncom27.dll,复制pywintypes27.这两个文件dll 到 c:\windows\system32!当然,如果不是windows系统,请无视!
话不多说,开始我们的爬虫吧!
首先分析网页结构:
1、url:打开旅行者的主页,这里我用的是火狐,见下图
点击精彩游记,然后跳出游记页面,
然后点击所有游记,就会出现我们的目标,拖到最下方,共3993页,1页20篇
一个非常简单的网站
2、我们开始分析每个页面的数据,直接打开F12抓包,然后刷新网页或者点击其他页面看看服务器返回的请求是什么!
找到一个get请求,里面有json格式的内容,里面有游记的作者、标题、缩略图等,ok,可以开始写代码了!
Ps:这里我们只是做一个简单的页面目录爬虫,不会一一抓取文章的内容(需要的可以自行添加相关内容)。
3、 打开cmd新建一个scrapy框架,命令是:scrapy startproject autohome,然后系统会自动帮我们创建相关目录和py文件,我们还是需要手动创建一个spider。 py(文件名可以取自Take)放入我们的爬虫
首先打开item.py,这里是我们的目标,告诉爬虫我们要爬取什么!代码如下:
然后打开setting.py(如果没有必要,不要修改这里的内容),把ROBOTSTXT_OBEY的值改成False(如果不改,有些内容是爬不出来的,这里是选择是否跟随robots协议),然后改变你的UA写在下面的header信息中!
别担心其他的一切。最后,打开spider文件夹,我们就要开始写爬虫了!
4、打开新建的py文件,先导入用到的模块
(如果导入模块后有错误提示,可以忽略),编写如下代码:
第6行的名字是唯一的,你可以自己命名
第7幕定义了爬虫的作用域,即允许执行的URL的作用域是:,注意这里是列表的形式
9.10.11 是抓取的内容所在的url,通过yield Request返回。上图没有截断,全部分为:
yield Request('https://you.autohome.com.cn/summary/getsearchresultlist?ps=20&pg={}&type=3&tagCode=&tagName=&sortType=3'.format(pg),self.parse)
因为只有3993页,所以可以直接在for循环中检索所有页码。定义start_requests函数后,可以省略start_urls列表,即起始列表。
第14行开始定义爬取方法
第15行,将json格式的内容赋值给一个变量
第16行,初始化导入的Items文件中定义的类
第17-24行,循环json格式的内容,给item赋值,其中item为字典格式,然后返回items文件
我已经在这里写完了这个爬虫。为了使用方便,我们直接把结果写成json格式
打开cmd,命令:scrapy crawl autohome -o autohome.json -t json
因为我们抓取的内容很少,所以速度还是很快的
大约十分钟,数据就会被抓到!来看看结果吧,因为是json格式,可以截个短片,找到一个可以在线解析的网页。
验证:
太简单了!
喜欢就关注吧(;°○°)! 查看全部
网页视频抓取软件 格式工厂(
网上摘录的一段介绍框架的文字,大过年的懒癌高发期)
Scrapy 是一个用 Python 编写的爬虫框架,简单、轻量、非常方便。 Scrapy 使用异步网络库 Twisted 来处理网络通信。架构清晰,收录各种中间件接口,可以灵活满足各种需求。
以上摘自网上,介绍了scrapy框架。是懒癌高发期...
安装scrapy,pip可以解决你的问题:pip install scrapy。
这里插一句,如果运行代码后看到这个错误:
ImportError: No module named win32api
出现一个深坑,需要安装pywin32。如果已经安装了pywin32出现错误,还是需要手动将你的python安装目录放到\Lib\site-packages\pywin32_system32下:pythoncom27.dll,复制pywintypes27.这两个文件dll 到 c:\windows\system32!当然,如果不是windows系统,请无视!
话不多说,开始我们的爬虫吧!
首先分析网页结构:
1、url:打开旅行者的主页,这里我用的是火狐,见下图
点击精彩游记,然后跳出游记页面,
然后点击所有游记,就会出现我们的目标,拖到最下方,共3993页,1页20篇
一个非常简单的网站
2、我们开始分析每个页面的数据,直接打开F12抓包,然后刷新网页或者点击其他页面看看服务器返回的请求是什么!
找到一个get请求,里面有json格式的内容,里面有游记的作者、标题、缩略图等,ok,可以开始写代码了!
Ps:这里我们只是做一个简单的页面目录爬虫,不会一一抓取文章的内容(需要的可以自行添加相关内容)。
3、 打开cmd新建一个scrapy框架,命令是:scrapy startproject autohome,然后系统会自动帮我们创建相关目录和py文件,我们还是需要手动创建一个spider。 py(文件名可以取自Take)放入我们的爬虫
首先打开item.py,这里是我们的目标,告诉爬虫我们要爬取什么!代码如下:
然后打开setting.py(如果没有必要,不要修改这里的内容),把ROBOTSTXT_OBEY的值改成False(如果不改,有些内容是爬不出来的,这里是选择是否跟随robots协议),然后改变你的UA写在下面的header信息中!
别担心其他的一切。最后,打开spider文件夹,我们就要开始写爬虫了!
4、打开新建的py文件,先导入用到的模块
(如果导入模块后有错误提示,可以忽略),编写如下代码:
第6行的名字是唯一的,你可以自己命名
第7幕定义了爬虫的作用域,即允许执行的URL的作用域是:,注意这里是列表的形式
9.10.11 是抓取的内容所在的url,通过yield Request返回。上图没有截断,全部分为:
yield Request('https://you.autohome.com.cn/summary/getsearchresultlist?ps=20&pg={}&type=3&tagCode=&tagName=&sortType=3'.format(pg),self.parse)
因为只有3993页,所以可以直接在for循环中检索所有页码。定义start_requests函数后,可以省略start_urls列表,即起始列表。
第14行开始定义爬取方法
第15行,将json格式的内容赋值给一个变量
第16行,初始化导入的Items文件中定义的类
第17-24行,循环json格式的内容,给item赋值,其中item为字典格式,然后返回items文件
我已经在这里写完了这个爬虫。为了使用方便,我们直接把结果写成json格式
打开cmd,命令:scrapy crawl autohome -o autohome.json -t json
因为我们抓取的内容很少,所以速度还是很快的
大约十分钟,数据就会被抓到!来看看结果吧,因为是json格式,可以截个短片,找到一个可以在线解析的网页。
验证:
太简单了!
喜欢就关注吧(;°○°)!
网页视频抓取软件 格式工厂(数据爬取爬取拉勾网求职信息,废话不多说。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-02 06:18
前言
利用requests抓取拉勾求职信息,废话不多说。
让我们快乐开始吧~
开发工具
**Python 版本:**3.6.4
相关模块:
请求模块;
重新模块;
操作系统模块
结巴模块;
熊猫模块
numpy 模块
pyecharts 模块;
还有一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
数据爬虫爬取拉勾网的求职信息1.requests request,获取单个页面
# 我们最常用的流程:网页上复制url->发送get请求—>打印页面内容->分析抓取数据
# 1.获取拉钩网url
req_url = 'https://www.lagou.com/jobs/lis ... 39%3B
# 2.发送get请求
req_result = requests.get(req_url)
# 3.打印请求结果
print(req_result.text)
复制代码
输出结果如下
HZRxWevI();é?μé?¢?? è????-...
复制代码
我们可以看到,上面的结果和我们想象的还是有很大的不同。为什么会出现上述情况?其实很简单,因为它不是一个简单的静态页面。我们知道请求方法有两个基本区别:get 和 post 请求。
(1)Get 是向服务器请求数据;Post 是向服务器提交数据的请求。要提交的数据位于消息头后面的实体中。GET 和 POST 只是发送的机制不同,取一个也不是一回事。(2)GET请求时,发送的信息是以url明文形式发送的,其参数会保存在浏览器历史或web服务器中,而帖子不会(这也是后来翻页的时候发现拉勾网翻页时浏览器url栏地址没有变化的原因。)
2.分析页面加载并找到数据
1.请求分析
在拉勾网首页,按F12进入开发者模式,然后在查询框中输入python,点击搜索,经过我的搜索,终于找到了页面上职位信息所在的页面,它确实是post请求,页面返回的内容是json格式的字典。
2.返回数据内容分析。页面上:我们主要获取7个数据(公司|城市|职位|薪资|学历要求|工作经验|职位优势)
json数据中:我整理了爬下来的json数据,如下图
我们会发现我们需要的所有数据都在req_info['content']['positionResult']['result']中,它是一个列表,收录了很多其他的信息。这次我们不关心其他数据。 我们需要的数据在下图
3.添加headers信息模仿浏览器请求
通过上面的请求分析,我们可以找到post请求的URL:...
{'success': False, 'msg': '您操作太频繁,请稍后再访问', 'clientIp': '122.xxx.xxx.xxx'}
复制代码
出现这个提示的原因是我们直接post访问网址,服务器会误认为我们是“机器人”。这也是反爬虫。解决方法很简单。添加请求头,完全模拟浏览器请求。 , 获取请求头如下图
4.分析页面实现翻页抓取
分析发现如下规律:在post请求中,有一个请求参数->表单数据,首先包括三个参数,kd,pn,通过动画演示,不难猜出其含义
data = {
'first':'true', # 是不是第一页,false表示不是,true 表示是 'kd':'Python', # 搜索关键字
'pn':1 # 页码
}
复制代码
代码
import requests\
# 1. post 请求的 url\
req_url = 'https://www.lagou.com/jobs/pos ... 39%3B\
# 2. 请求头 headers\
headers = {'你的请求头'}\
# 3. for 循环请求\
for i in range(1,31):\
data = { 'first':'false','kd':'Python','pn':i} \
# 3.1 requests 发送请求\
req_result = requests.post(req_url,headers = headers,data = data) req_result.encoding = 'utf-8'\
# 3.2 获取数据\
req_info = req_result.json() \
# 打印出获取到的数据\
print(req_info)
复制代码
5.将抓取到的数据保存成csv文件
def file_do(list_info): # 获取文件大小 file_size = os.path.getsize(r'G:\lagou_test.csv') \
if file_size == 0: \
# 表头 name = ['公司','城市','职位','薪资','学历要求','工作经验','职位优点'] \
# 建立DataFrame对象 file_test = pd.DataFrame(columns=name, data=list_info) \
# 数据写入 file_test.to_csv(r'G:\lagou_test.csv', encoding='gbk',index=False) \
else: \
with open(r'G:\lagou_test.csv','a+',newline='') as file_test : # 追加到文件后面 writer = csv.writer(file_test) \
# 写入文件 writer.writerows(list_info)
复制代码
显示抓取的数据
数据可视化数据分析+pyechart数据可视化
薪酬分配分析
我们可以看到python的工资基本都是10k起的,大部分公司给的工资在10k-40k之间,所以不用怕学python不够。
2.工作地点分析
通过图表我们不难看出,大部分需要python程序员的公司都位于北京、上海、深圳,而广州则落后。所以学python的同学千万不要走错城市。
3.岗位教育要求
从图表来看,python程序员的学历要求不高,主要是本科。虽然学历要求不高,但要有思考能力。
4.工作经验要求
主要是需要3-5年工作经验的学生,不老不幼,成熟稳重,能学新东西的年纪,招聘公司真聪明。
5.岗位研究方向分析
6.工作福利的好处分析
# 福利关键词分析
content = ''
# 连接所有公司福利介绍
for x in positionAdvantage:
content = content + x
# 去除多余字符
content = re.sub('[,、(),1234567890;;&%$#@!~_=+]', '', content)
# jieba 切词,pandas、numpy计数
segment = jieba.lcut(content)
words_df = pd.DataFrame({'segment': segment})
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数": numpy.size})
words_stat = words_stat.reset_index().sort_values(by=["计数"], ascending=False) test = words_stat.head(1000).values
# 制作词云图\
codes = [test[i][0] for i in range(0,len(test))]
counts = [test[i][1] for i in range(0,len(test))]
wordcloud = WordCloud(width=1300, height=620,page_title='福利关键词') wordcloud.add("福利关键词", codes, counts, word_size_range=[20, 100]) wordcloud.render()
复制代码
终于
感谢您的支持和厚爱。小编每天都会和大家分享更多Python学习知识,记得关注小编哦。 查看全部
网页视频抓取软件 格式工厂(数据爬取爬取拉勾网求职信息,废话不多说。)
前言
利用requests抓取拉勾求职信息,废话不多说。
让我们快乐开始吧~
开发工具
**Python 版本:**3.6.4
相关模块:
请求模块;
重新模块;
操作系统模块
结巴模块;
熊猫模块
numpy 模块
pyecharts 模块;
还有一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
数据爬虫爬取拉勾网的求职信息1.requests request,获取单个页面
# 我们最常用的流程:网页上复制url->发送get请求—>打印页面内容->分析抓取数据
# 1.获取拉钩网url
req_url = 'https://www.lagou.com/jobs/lis ... 39%3B
# 2.发送get请求
req_result = requests.get(req_url)
# 3.打印请求结果
print(req_result.text)
复制代码
输出结果如下
HZRxWevI();é?μé?¢?? è????-...
复制代码
我们可以看到,上面的结果和我们想象的还是有很大的不同。为什么会出现上述情况?其实很简单,因为它不是一个简单的静态页面。我们知道请求方法有两个基本区别:get 和 post 请求。
(1)Get 是向服务器请求数据;Post 是向服务器提交数据的请求。要提交的数据位于消息头后面的实体中。GET 和 POST 只是发送的机制不同,取一个也不是一回事。(2)GET请求时,发送的信息是以url明文形式发送的,其参数会保存在浏览器历史或web服务器中,而帖子不会(这也是后来翻页的时候发现拉勾网翻页时浏览器url栏地址没有变化的原因。)
2.分析页面加载并找到数据
1.请求分析
在拉勾网首页,按F12进入开发者模式,然后在查询框中输入python,点击搜索,经过我的搜索,终于找到了页面上职位信息所在的页面,它确实是post请求,页面返回的内容是json格式的字典。
2.返回数据内容分析。页面上:我们主要获取7个数据(公司|城市|职位|薪资|学历要求|工作经验|职位优势)
json数据中:我整理了爬下来的json数据,如下图
我们会发现我们需要的所有数据都在req_info['content']['positionResult']['result']中,它是一个列表,收录了很多其他的信息。这次我们不关心其他数据。 我们需要的数据在下图
3.添加headers信息模仿浏览器请求
通过上面的请求分析,我们可以找到post请求的URL:...
{'success': False, 'msg': '您操作太频繁,请稍后再访问', 'clientIp': '122.xxx.xxx.xxx'}
复制代码
出现这个提示的原因是我们直接post访问网址,服务器会误认为我们是“机器人”。这也是反爬虫。解决方法很简单。添加请求头,完全模拟浏览器请求。 , 获取请求头如下图
4.分析页面实现翻页抓取
分析发现如下规律:在post请求中,有一个请求参数->表单数据,首先包括三个参数,kd,pn,通过动画演示,不难猜出其含义
data = {
'first':'true', # 是不是第一页,false表示不是,true 表示是 'kd':'Python', # 搜索关键字
'pn':1 # 页码
}
复制代码
代码
import requests\
# 1. post 请求的 url\
req_url = 'https://www.lagou.com/jobs/pos ... 39%3B\
# 2. 请求头 headers\
headers = {'你的请求头'}\
# 3. for 循环请求\
for i in range(1,31):\
data = { 'first':'false','kd':'Python','pn':i} \
# 3.1 requests 发送请求\
req_result = requests.post(req_url,headers = headers,data = data) req_result.encoding = 'utf-8'\
# 3.2 获取数据\
req_info = req_result.json() \
# 打印出获取到的数据\
print(req_info)
复制代码
5.将抓取到的数据保存成csv文件
def file_do(list_info): # 获取文件大小 file_size = os.path.getsize(r'G:\lagou_test.csv') \
if file_size == 0: \
# 表头 name = ['公司','城市','职位','薪资','学历要求','工作经验','职位优点'] \
# 建立DataFrame对象 file_test = pd.DataFrame(columns=name, data=list_info) \
# 数据写入 file_test.to_csv(r'G:\lagou_test.csv', encoding='gbk',index=False) \
else: \
with open(r'G:\lagou_test.csv','a+',newline='') as file_test : # 追加到文件后面 writer = csv.writer(file_test) \
# 写入文件 writer.writerows(list_info)
复制代码
显示抓取的数据
数据可视化数据分析+pyechart数据可视化
薪酬分配分析
我们可以看到python的工资基本都是10k起的,大部分公司给的工资在10k-40k之间,所以不用怕学python不够。
2.工作地点分析
通过图表我们不难看出,大部分需要python程序员的公司都位于北京、上海、深圳,而广州则落后。所以学python的同学千万不要走错城市。
3.岗位教育要求
从图表来看,python程序员的学历要求不高,主要是本科。虽然学历要求不高,但要有思考能力。
4.工作经验要求
主要是需要3-5年工作经验的学生,不老不幼,成熟稳重,能学新东西的年纪,招聘公司真聪明。
5.岗位研究方向分析
6.工作福利的好处分析
# 福利关键词分析
content = ''
# 连接所有公司福利介绍
for x in positionAdvantage:
content = content + x
# 去除多余字符
content = re.sub('[,、(),1234567890;;&%$#@!~_=+]', '', content)
# jieba 切词,pandas、numpy计数
segment = jieba.lcut(content)
words_df = pd.DataFrame({'segment': segment})
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数": numpy.size})
words_stat = words_stat.reset_index().sort_values(by=["计数"], ascending=False) test = words_stat.head(1000).values
# 制作词云图\
codes = [test[i][0] for i in range(0,len(test))]
counts = [test[i][1] for i in range(0,len(test))]
wordcloud = WordCloud(width=1300, height=620,page_title='福利关键词') wordcloud.add("福利关键词", codes, counts, word_size_range=[20, 100]) wordcloud.render()
复制代码
终于
感谢您的支持和厚爱。小编每天都会和大家分享更多Python学习知识,记得关注小编哦。
网页视频抓取软件 格式工厂(一个.get(网页地址)第三步和requests哪个好?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-01 05:14
通过前面几节课的学习,我们大概已经学会了如何通过urllib模块获取数据,解析数据,保存数据,得到我们想要的数据。今天给大家介绍一个Python爬虫获取数据。方法请求库。那么哪个更好,urllib 或请求? urllib 和请求有什么区别?
1.如何安装requests库
我们已经讲解了Python内置的urllib模块,用于访问网络资源。但是使用起来比较麻烦,缺少很多实用的高级功能。
更好的解决方案是使用请求。是一个Python第三方库,特别方便处理URL资源。
requests库的安装和安装其他第三方应用一样(如下图):
2.如何使用请求库。
我们以简单抓取百度网页()为例进行操作:
第一步是导入requests库
第二步是发起请求。
首先我们需要确定请求的类型。最常见的请求方法是 GET 和 POST。我们可以通过右键查看-network-headers-Request Method,看到这个页面的请求方法是get
所以我们的请求格式是:
requests.get(网址)
第三步,获取网页内容。
首先,我们需要确定我们获取的是什么类型的网页。也可以右击-network-headers-Content-Type查看网页内容为文本类型
所以我们得到的网页的基本格式是:
响应文本
可以输出如下图所示的网页内容:
第四步是存储网页信息。
基本格式为:
以打开(保存文件名,读写模式,编码=“utf-8”)为变量:
Variables.write(网页内容)
以上是关于requests的用法,大家可以结合之前学过的内容,想想urllib和requests哪个更方便,反爬虫机制如何使用requests获取内容信息网站,下一课,urllib和requests有什么区别? urllib 和请求哪个更好。 查看全部
网页视频抓取软件 格式工厂(一个.get(网页地址)第三步和requests哪个好?)
通过前面几节课的学习,我们大概已经学会了如何通过urllib模块获取数据,解析数据,保存数据,得到我们想要的数据。今天给大家介绍一个Python爬虫获取数据。方法请求库。那么哪个更好,urllib 或请求? urllib 和请求有什么区别?
1.如何安装requests库
我们已经讲解了Python内置的urllib模块,用于访问网络资源。但是使用起来比较麻烦,缺少很多实用的高级功能。
更好的解决方案是使用请求。是一个Python第三方库,特别方便处理URL资源。
requests库的安装和安装其他第三方应用一样(如下图):
2.如何使用请求库。
我们以简单抓取百度网页()为例进行操作:
第一步是导入requests库
第二步是发起请求。
首先我们需要确定请求的类型。最常见的请求方法是 GET 和 POST。我们可以通过右键查看-network-headers-Request Method,看到这个页面的请求方法是get
所以我们的请求格式是:
requests.get(网址)
第三步,获取网页内容。
首先,我们需要确定我们获取的是什么类型的网页。也可以右击-network-headers-Content-Type查看网页内容为文本类型
所以我们得到的网页的基本格式是:
响应文本
可以输出如下图所示的网页内容:
第四步是存储网页信息。
基本格式为:
以打开(保存文件名,读写模式,编码=“utf-8”)为变量:
Variables.write(网页内容)
以上是关于requests的用法,大家可以结合之前学过的内容,想想urllib和requests哪个更方便,反爬虫机制如何使用requests获取内容信息网站,下一课,urllib和requests有什么区别? urllib 和请求哪个更好。
网页视频抓取软件 格式工厂(通常我们要在自己做的网站上放视频方法将自己的视频先上)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-01 04:18
通常我们想把视频放在我们自己制作的网站上。方法是把我们的视频上传到优酷、土豆等大视频网站,然后再上传优酷和土豆上的视频。通过共享代码将其嵌入您自己的 网站。 (相关教程:如何给网页添加视频动画)
这种方式可以节省网站空间,但是这些视频上有大量的优酷广告,尤其是60秒的长时间,用户体验不是很好。使用去除优酷广告的方法也很困难。
那么如何在自己的网站中嵌入视频播放器,直接播放自己的视频?
方法/步骤
1、 将自己的视频格式转换为 MP4 格式;
一般来说,AVI格式的视频都非常大,所以我们需要做的第一步就是转换视频格式,以节省空间资源,更快地打开视频。视频格式的转换,我们经常用到的一个软件——格式工厂,这个软件是免费的,大家可以从网上下载,也可以在帖子底部找到该软件的下载地址,使用这个软件将 AVI 等视频转换为 MP4 和其他网络视频格式。
2、将转换后的视频上传到你的网站空间,(通常你可以在你的空间根目录新建一个文件夹video来存放视频);
3、上传完成后,可以通过以下代码直接在文章Edit(文本编辑模式)中插入调用代码;
4、 提示:由于流量限制,虚拟主机将不支持很多视频的播放。建议使用服务器或上传视频到大视频网站,然后引用。 查看全部
网页视频抓取软件 格式工厂(通常我们要在自己做的网站上放视频方法将自己的视频先上)
通常我们想把视频放在我们自己制作的网站上。方法是把我们的视频上传到优酷、土豆等大视频网站,然后再上传优酷和土豆上的视频。通过共享代码将其嵌入您自己的 网站。 (相关教程:如何给网页添加视频动画)
这种方式可以节省网站空间,但是这些视频上有大量的优酷广告,尤其是60秒的长时间,用户体验不是很好。使用去除优酷广告的方法也很困难。
那么如何在自己的网站中嵌入视频播放器,直接播放自己的视频?
方法/步骤
1、 将自己的视频格式转换为 MP4 格式;
一般来说,AVI格式的视频都非常大,所以我们需要做的第一步就是转换视频格式,以节省空间资源,更快地打开视频。视频格式的转换,我们经常用到的一个软件——格式工厂,这个软件是免费的,大家可以从网上下载,也可以在帖子底部找到该软件的下载地址,使用这个软件将 AVI 等视频转换为 MP4 和其他网络视频格式。
2、将转换后的视频上传到你的网站空间,(通常你可以在你的空间根目录新建一个文件夹video来存放视频);
3、上传完成后,可以通过以下代码直接在文章Edit(文本编辑模式)中插入调用代码;
4、 提示:由于流量限制,虚拟主机将不支持很多视频的播放。建议使用服务器或上传视频到大视频网站,然后引用。
网页视频抓取软件 格式工厂(格式工厂免费软件中文版如何设置输出文件地址?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-12-31 22:27
格式工厂免费软件中文版是一款永久免费的多媒体转换工具。格式工厂免费软件中文版可以帮助用户将视频、图片等转换成多种视频文件格式。软件的操作非常简单易上手,界面设计简洁明了,一站式操作,方便快捷,并且可以支持多种格式的转换,可以抓取DVD到视频文件,抓取音乐CD到音频文件,这个软件也可以转换音频,功能多多,是一款非常流行的转换工具。
格式工厂免费软件中文版特点:
1.支持多种格式
格式工厂支持广泛的视频格式,从常用格式到iPhone/iPod/PSP等指定多媒体格式,几乎涵盖所有类型的多媒体格式。
2.修复功能
在转换过程中,格式工厂可以修复一些意外损坏的视频文件。
3.灵活性改进
格式工厂可以让多媒体文件弹性“减肥”或“脂肪化”(即增加或减少视频的清晰度、帧率等)。
格式工厂免费软件中文版的优点:
1.图片转换
格式工厂可以进行图片转换,支持图片文件缩放、旋转、水印等功能。
2.DVD 翻录
格式工厂可以采集视频,用户可以通过该功能轻松备份DVD到本地硬盘。
格式工厂免费软件中文版的优点:
1.支持音频、视频、图片等多种格式,轻松转换所需格式。
2.可以帮助文件减肥,节省硬盘空间,方便存储和备份。
3. 支持图片缩放、旋转和水印功能,所有操作一次完成。
4.支持多种语言,完全无障碍满足各种需求。
5.可以保质保量修复损坏的文件。
6.可指定格式,同时支持iPhone等格式。
如何使用格式工厂免费软件中文版?
1.第一步:选择要转换的格式。以转换成“PNG”格式为例,打开软件后点击“PNG”:
2.第2步:添加文件/文件夹,然后点击“确定”。
3.第三步:“点击开始。”
4.第 4 步:完成。
格式工厂免费软件中文版如何在此处设置输出文件地址?
可以根据需要单独设置输出文件,以图片“GIF”为例:
1.第一步:点击“输出配置”:
2.第 2 步:根据需要进行编辑。 查看全部
网页视频抓取软件 格式工厂(格式工厂免费软件中文版如何设置输出文件地址?(组图))
格式工厂免费软件中文版是一款永久免费的多媒体转换工具。格式工厂免费软件中文版可以帮助用户将视频、图片等转换成多种视频文件格式。软件的操作非常简单易上手,界面设计简洁明了,一站式操作,方便快捷,并且可以支持多种格式的转换,可以抓取DVD到视频文件,抓取音乐CD到音频文件,这个软件也可以转换音频,功能多多,是一款非常流行的转换工具。
格式工厂免费软件中文版特点:
1.支持多种格式
格式工厂支持广泛的视频格式,从常用格式到iPhone/iPod/PSP等指定多媒体格式,几乎涵盖所有类型的多媒体格式。
2.修复功能
在转换过程中,格式工厂可以修复一些意外损坏的视频文件。
3.灵活性改进
格式工厂可以让多媒体文件弹性“减肥”或“脂肪化”(即增加或减少视频的清晰度、帧率等)。
格式工厂免费软件中文版的优点:
1.图片转换
格式工厂可以进行图片转换,支持图片文件缩放、旋转、水印等功能。
2.DVD 翻录
格式工厂可以采集视频,用户可以通过该功能轻松备份DVD到本地硬盘。
格式工厂免费软件中文版的优点:
1.支持音频、视频、图片等多种格式,轻松转换所需格式。
2.可以帮助文件减肥,节省硬盘空间,方便存储和备份。
3. 支持图片缩放、旋转和水印功能,所有操作一次完成。
4.支持多种语言,完全无障碍满足各种需求。
5.可以保质保量修复损坏的文件。
6.可指定格式,同时支持iPhone等格式。
如何使用格式工厂免费软件中文版?
1.第一步:选择要转换的格式。以转换成“PNG”格式为例,打开软件后点击“PNG”:
2.第2步:添加文件/文件夹,然后点击“确定”。
3.第三步:“点击开始。”
4.第 4 步:完成。
格式工厂免费软件中文版如何在此处设置输出文件地址?
可以根据需要单独设置输出文件,以图片“GIF”为例:
1.第一步:点击“输出配置”:
2.第 2 步:根据需要进行编辑。
网页视频抓取软件 格式工厂(迅捷CAD转换器常见问题为何编辑保存文件后无法将其打开)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-30 06:18
Fast CAD Converter是一款专业的CAD版本转换器和PDF转CAD软件。它兼容 DWG、DXF、DWT 和其他绘图格式。可以实现各种CAD版本的相互转换,以及PDF到CAD、CAD到PDF、CAD到CAD的相互转换。JPG等操作,并支持批量转换文件,自定义文件输出效果,转换后的文件可以正常编辑使用。软件操作简单,功能强大,所有转换一键完成!该站点提供免费下载。
Swift CAD 转换器软件的特点
功能全面:软件集成多种格式转换,可实现CAD版本转换、CAD转PDF、PDF转CAD、CAD转JPG。
完全兼容:软件基本支持所有格式的CAD图纸文件,包括DWG、DXF、DWT格式的常用CAD图纸文件。
分析准确:软件采用新开发的图纸文件格式分析、处理和转换核心技术,转换后的文件可以正常编辑和使用。
超级输出:软件可实现批量转换,并可自定义文件输出效果,操作简单,一键转换。
快速CAD转换器安装说明
1、从51下载站下载快速cad编辑器,双击运行应用
2、进入安装界面,点击立即安装。
3、 安装完成后,点击立即体验,即可使用软件。
快速CAD转换器教程
1、 运行 Swift CAD 编辑器。软件打开后,点击界面中的“文件”-“打开”选项,打开需要编辑的CAD文件。
2、打开CAD文件后,如果想一键提取文字,可以点击“VIP功能”,然后点击里面的“提取文字”选项。
3、 点击后,软件会自动提取CAD文件中的文字,然后点击“保存到文件”按钮保存。
4、在另存为界面选择要保存的位置,最后点击“保存”按钮保存提取的文本。
Swift CAD Converter 常见问题
1、为什么快速CAD编辑器编辑后打不开文件?
答:用户编辑文件损坏或用户未从正规渠道下载软件,导致软件中病毒。
2、我可以使用 Swift CAD 编辑器创建一个新文件吗?
回答:是的。用户可以在软件上新建一个空白编辑页面,编辑完成后保存。
3、快速CAD编辑器免费试用版和软件注册版有什么区别?
答:软件免费试用版只能编辑2M以内的CAD文件,软件注册版没有文件大小限制。
格式工厂和 Swift CAD 转换器的比较
一、 格式工厂是一款免费的多功能多媒体文件转换工具,可以轻松转换所有你想要的格式。格式工厂支持几乎所有主流多媒体文件格式的转换,格式工厂支持多种语言。安装界面显示英文,启动后显示中文。格式工厂支持各种视频、音频和图片格式之间的转换。格式工厂还支持各种手机视频格式的转换。而且格式工厂是免费的,任何人都可以随意下载、使用和传播。51下载站提供格式工厂官方下载!
二、Quick CAD Converter是一款专业的CAD版本转换器和PDF转CAD软件。软件兼容DWG、DXF、DWT等绘图格式,可实现各种CAD版本的相互转换,以及PDF转CAD、CAD转PDF、CAD转JPG等操作,支持批量文件的转换,文件输出效果的自定义设置,转换后的文件可以正常编辑使用。软件操作简单,功能强大,所有转换一键完成!
小编总结:都是格式转换软件,各有千秋,大家可以根据自己的需要选择下载。
Swift CAD 转换器更新日志
1.优化内容
2. 细节更出众,bug 消失得无影无踪
免责声明:因版权及厂商要求,51下载站提供Swift CAD转换软件官方下载包
51下载编辑器推荐:
Fast CAD Converter 是一款非常实用且简单的工具。有兴趣的用户可以在{展店}下载使用。另外还有很多类似的软件可以下载,比如:{recommendWords}等。 查看全部
网页视频抓取软件 格式工厂(迅捷CAD转换器常见问题为何编辑保存文件后无法将其打开)
Fast CAD Converter是一款专业的CAD版本转换器和PDF转CAD软件。它兼容 DWG、DXF、DWT 和其他绘图格式。可以实现各种CAD版本的相互转换,以及PDF到CAD、CAD到PDF、CAD到CAD的相互转换。JPG等操作,并支持批量转换文件,自定义文件输出效果,转换后的文件可以正常编辑使用。软件操作简单,功能强大,所有转换一键完成!该站点提供免费下载。
Swift CAD 转换器软件的特点
功能全面:软件集成多种格式转换,可实现CAD版本转换、CAD转PDF、PDF转CAD、CAD转JPG。
完全兼容:软件基本支持所有格式的CAD图纸文件,包括DWG、DXF、DWT格式的常用CAD图纸文件。
分析准确:软件采用新开发的图纸文件格式分析、处理和转换核心技术,转换后的文件可以正常编辑和使用。
超级输出:软件可实现批量转换,并可自定义文件输出效果,操作简单,一键转换。
快速CAD转换器安装说明
1、从51下载站下载快速cad编辑器,双击运行应用
2、进入安装界面,点击立即安装。
3、 安装完成后,点击立即体验,即可使用软件。
快速CAD转换器教程
1、 运行 Swift CAD 编辑器。软件打开后,点击界面中的“文件”-“打开”选项,打开需要编辑的CAD文件。
2、打开CAD文件后,如果想一键提取文字,可以点击“VIP功能”,然后点击里面的“提取文字”选项。
3、 点击后,软件会自动提取CAD文件中的文字,然后点击“保存到文件”按钮保存。
4、在另存为界面选择要保存的位置,最后点击“保存”按钮保存提取的文本。
Swift CAD Converter 常见问题
1、为什么快速CAD编辑器编辑后打不开文件?
答:用户编辑文件损坏或用户未从正规渠道下载软件,导致软件中病毒。
2、我可以使用 Swift CAD 编辑器创建一个新文件吗?
回答:是的。用户可以在软件上新建一个空白编辑页面,编辑完成后保存。
3、快速CAD编辑器免费试用版和软件注册版有什么区别?
答:软件免费试用版只能编辑2M以内的CAD文件,软件注册版没有文件大小限制。
格式工厂和 Swift CAD 转换器的比较
一、 格式工厂是一款免费的多功能多媒体文件转换工具,可以轻松转换所有你想要的格式。格式工厂支持几乎所有主流多媒体文件格式的转换,格式工厂支持多种语言。安装界面显示英文,启动后显示中文。格式工厂支持各种视频、音频和图片格式之间的转换。格式工厂还支持各种手机视频格式的转换。而且格式工厂是免费的,任何人都可以随意下载、使用和传播。51下载站提供格式工厂官方下载!
二、Quick CAD Converter是一款专业的CAD版本转换器和PDF转CAD软件。软件兼容DWG、DXF、DWT等绘图格式,可实现各种CAD版本的相互转换,以及PDF转CAD、CAD转PDF、CAD转JPG等操作,支持批量文件的转换,文件输出效果的自定义设置,转换后的文件可以正常编辑使用。软件操作简单,功能强大,所有转换一键完成!
小编总结:都是格式转换软件,各有千秋,大家可以根据自己的需要选择下载。
Swift CAD 转换器更新日志
1.优化内容
2. 细节更出众,bug 消失得无影无踪
免责声明:因版权及厂商要求,51下载站提供Swift CAD转换软件官方下载包
51下载编辑器推荐:
Fast CAD Converter 是一款非常实用且简单的工具。有兴趣的用户可以在{展店}下载使用。另外还有很多类似的软件可以下载,比如:{recommendWords}等。
网页视频抓取软件 格式工厂(如何打造符合搜索引擎抓取的网站?我个人的理解应该从以下四个方面去考虑)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-29 08:15
摘要:在我上一篇文章《如何提高企业网络曝光率》中,我曾经说过一个解决企业网络曝光的方法:要有一个适合搜索引擎的网站,那么如何搭建一个满足搜索引擎爬取的网站呢?个人理解应从以下四个方面考虑:
就像我上一篇文章《如何提高企业网络曝光度》,我曾经说过一个解决企业网络曝光度的方法:要有一个适合搜索引擎的网站,那么如何搭建一个满足搜索引擎抓取的网站呢?我个人的理解应该从以下四个方面来考虑:
一、网站程序
1. 从网站的栏目来看,首页的内容是搜索引擎抓取非常重要的一步。一些公司的网站为了追求美观和氛围,采用全Flash主页。搜索引擎技术再先进,毕竟也是机器实现的。所以它的爬取根本不认Flash,推荐大家使用Pushba网徐强博客中的旋转样式。通过旋转图,网站可以达到高端大气和高档效果,也有利于爬虫的效果。增加用户的视觉体验。
所以,从网站程序的角度来说,首页的设置很重要,尽量不要使用完整的Flash首页!
2. 代码太冗余了。举个简单的例子,如果一个搜索用户在同一个服务器网站、同一个宽带带宽的前提下,打开两个同行业的企业网站,一个打开一秒,另一个缓冲时间长。. 搜索用户会看哪个网站?
答案应该是显而易见的。那么,为什么在上述场景中会出现网站缓冲的情况呢?这主要是由于选择了网站程序中的代码。
现在,相对来说,DIV+CSS布局减少了页面代码,大大提高了加载速度。同时,对于搜索引擎的抓取也是非常有利的。页面代码过多可能导致抓取超时,搜索引擎会认为该页面无法访问,从而影响收录和权重。
3.网站的结构,扁平的树状网站结构在爬取深度和广度上都有优势。但是这里提醒一下,一个清晰的网站结构一定要“分清楚”,交接点也一定要有关联。对于一些比较大的网站,使用二级域名时一定要慎重。不要大量开放无意义的二级域名来增加网站的繁琐页面。此类垃圾邮件页面对搜索引擎不友好,同时也是如此。会影响网站的友好度。4.URL 是伪静态的。URL静态的目的是帮助网站排名。虽然搜索引擎现在可以收录
动态地址,但静态页面比动态排名更有优势。所以,
一个好的网站程序不是重点。关键是我们需要有这样的想法,这些网站适合搜索引擎。
二、网站的标题和描述
三、网站内容
四、网站其他通知
当然,本文只从网站本身考虑如何搭建一个满足搜索引擎爬取的网站,并没有考虑域名、服务器等问题。 查看全部
网页视频抓取软件 格式工厂(如何打造符合搜索引擎抓取的网站?我个人的理解应该从以下四个方面去考虑)
摘要:在我上一篇文章《如何提高企业网络曝光率》中,我曾经说过一个解决企业网络曝光的方法:要有一个适合搜索引擎的网站,那么如何搭建一个满足搜索引擎爬取的网站呢?个人理解应从以下四个方面考虑:
就像我上一篇文章《如何提高企业网络曝光度》,我曾经说过一个解决企业网络曝光度的方法:要有一个适合搜索引擎的网站,那么如何搭建一个满足搜索引擎抓取的网站呢?我个人的理解应该从以下四个方面来考虑:
一、网站程序
1. 从网站的栏目来看,首页的内容是搜索引擎抓取非常重要的一步。一些公司的网站为了追求美观和氛围,采用全Flash主页。搜索引擎技术再先进,毕竟也是机器实现的。所以它的爬取根本不认Flash,推荐大家使用Pushba网徐强博客中的旋转样式。通过旋转图,网站可以达到高端大气和高档效果,也有利于爬虫的效果。增加用户的视觉体验。
所以,从网站程序的角度来说,首页的设置很重要,尽量不要使用完整的Flash首页!
2. 代码太冗余了。举个简单的例子,如果一个搜索用户在同一个服务器网站、同一个宽带带宽的前提下,打开两个同行业的企业网站,一个打开一秒,另一个缓冲时间长。. 搜索用户会看哪个网站?
答案应该是显而易见的。那么,为什么在上述场景中会出现网站缓冲的情况呢?这主要是由于选择了网站程序中的代码。
现在,相对来说,DIV+CSS布局减少了页面代码,大大提高了加载速度。同时,对于搜索引擎的抓取也是非常有利的。页面代码过多可能导致抓取超时,搜索引擎会认为该页面无法访问,从而影响收录和权重。
3.网站的结构,扁平的树状网站结构在爬取深度和广度上都有优势。但是这里提醒一下,一个清晰的网站结构一定要“分清楚”,交接点也一定要有关联。对于一些比较大的网站,使用二级域名时一定要慎重。不要大量开放无意义的二级域名来增加网站的繁琐页面。此类垃圾邮件页面对搜索引擎不友好,同时也是如此。会影响网站的友好度。4.URL 是伪静态的。URL静态的目的是帮助网站排名。虽然搜索引擎现在可以收录
动态地址,但静态页面比动态排名更有优势。所以,
一个好的网站程序不是重点。关键是我们需要有这样的想法,这些网站适合搜索引擎。
二、网站的标题和描述
三、网站内容
四、网站其他通知
当然,本文只从网站本身考虑如何搭建一个满足搜索引擎爬取的网站,并没有考虑域名、服务器等问题。
网页视频抓取软件 格式工厂( 如何将网页中的数据刮到Excel中?(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-12-27 18:03
如何将网页中的数据刮到Excel中?(组图)
)
有一个问题经常被讨论;“如何将网页中的数据抓取到 Excel 中?”
通过 POWER QUERY 从 Web 获取数据
使用 Power Query 从 Web 获取数据的能力非常方便。Power Query在不懂VBA的时候可以这样用,但是如果懂VBA其实还是很方便的,主要看你的选择和喜好了。
从互联网上抓取的数据也可以实时更新。在这种情况下,如果你有一些从网上抓取的数据集,那么添加经验公式来计算一些从抓取的数据中得出的最终结果,这种方式的想法是非常好的。我经常这样做。
目前Power Query的限制是只能以HTML格式的网表格式查询。某些网页使用 JavaScript 生成表格,本教程不涉及这些内容。
我们以网易的股票为例:
当然,如果你打开这个网页,你也会发现右上角会出现文件下载。你也选择下载文件文件,然后保存进行数据分析,但是这样会显得有点麻烦,我们直接把这个网络数据表和我们的EXCEL建立链接。如果您有每天看股票的习惯,点击下方的更新按钮,即可更新最新的股价情况。
注意:在撰写本文时,上面的 URL 提供了本示例中使用的数据,但此页面的布局和内容超出了我的控制范围。链接后我们可以做一些格式调整。
如何通过 Power Query 从 Web 获取数据
步骤 1:复制收录
该表的网页的 URL。我在用
第 2 步:Excel 2016-“数据”选项卡>来自网络
Excel 2013及更早版本-“Power Query”选项卡>从网页导入,因为我目前用的是2016,所以如果你用的是以前的版本,自己找吧。
注意:如果在 excel 2010 或 2013 中看不到“Power Query”选项卡,可以从相关网站下载。
第 3 步:将 URL 粘贴到“来自网络”对话框中,然后单击“确定”:
第 4 步:在“导航器”对话框(如下图)中,左窗格提供了网页上可用的表格列表。
第一项“文档”收录
页面的 HTML 代码,因此对我们没有用,但其余的表收录
您可以通过 Power Query 获取的数据表。请记住,它只会显示使用 HTML 表格标签生成的表格。
选择你想要的表,类似下图,我们需要表1
也可以进入WEB视图,看看下面的对比。下表是您需要查找的内容吗?
技能:
1.点击对话框右上角的全屏图标,可以全屏查看“导航”对话框。
2.如果要导入多个表,请在左侧窗格中选中“选择多个项目”框。
第五步:选择好要导入的表格后,点击“转换数据”按钮。这将打开 Power Query 编辑器窗口,让您有机会在将数据加载到 Excel 或 Power Pivot 数据模型之前对其进行组织。
数据清理完毕后,可以将其加载到 Excel 或 Power Pivot 数据模型中。
第 6 步:“开始”选项卡>“关闭并加载到”:
“导入数据”对话框将打开:
提示:如果加载到数据模型中,一定要选择“仅创建连接”,这样文件中的数据就不会被复制,直接在数据透视表这样的地方建立名称连接。
第七步:刷新数据。要从网页获取更新,只需转到功能区的“外部数据”选项卡,然后单击“全部刷新”:
或者,如果您有多个查询,您可以打开查询和连接窗格:
Power Query 网站限制
正如我之前提到的,PowerQuery 非常擅长从 Web 获取数据。在 Web 中,它被格式化为 HTML 表格,而不是由 JavaScript 生成的表格。您可以通过检查网页的源代码并查找 HTML 表格标签来轻松确定表格是 HTML 还是 JavaScript。
为此,请在网页部分空白处右击>查看页面源代码(或类似,取决于您使用的浏览器,我使用的WIN10系统自带的浏览器不是以前版本的Internet Explorer ):
CTRL + F 打开“查找”对话框。进入”
如果找到HTML table标签,那么确认power Query可以从页面中获取一个表,但是不能保证就是你实际需要的表,因为页面上可能还有其他的表,所以可以使用我之前提到的表 进行选择。
查看全部
网页视频抓取软件 格式工厂(
如何将网页中的数据刮到Excel中?(组图)
)
有一个问题经常被讨论;“如何将网页中的数据抓取到 Excel 中?”
通过 POWER QUERY 从 Web 获取数据
使用 Power Query 从 Web 获取数据的能力非常方便。Power Query在不懂VBA的时候可以这样用,但是如果懂VBA其实还是很方便的,主要看你的选择和喜好了。
从互联网上抓取的数据也可以实时更新。在这种情况下,如果你有一些从网上抓取的数据集,那么添加经验公式来计算一些从抓取的数据中得出的最终结果,这种方式的想法是非常好的。我经常这样做。
目前Power Query的限制是只能以HTML格式的网表格式查询。某些网页使用 JavaScript 生成表格,本教程不涉及这些内容。
我们以网易的股票为例:
当然,如果你打开这个网页,你也会发现右上角会出现文件下载。你也选择下载文件文件,然后保存进行数据分析,但是这样会显得有点麻烦,我们直接把这个网络数据表和我们的EXCEL建立链接。如果您有每天看股票的习惯,点击下方的更新按钮,即可更新最新的股价情况。
注意:在撰写本文时,上面的 URL 提供了本示例中使用的数据,但此页面的布局和内容超出了我的控制范围。链接后我们可以做一些格式调整。
如何通过 Power Query 从 Web 获取数据
步骤 1:复制收录
该表的网页的 URL。我在用
第 2 步:Excel 2016-“数据”选项卡>来自网络
Excel 2013及更早版本-“Power Query”选项卡>从网页导入,因为我目前用的是2016,所以如果你用的是以前的版本,自己找吧。
注意:如果在 excel 2010 或 2013 中看不到“Power Query”选项卡,可以从相关网站下载。
第 3 步:将 URL 粘贴到“来自网络”对话框中,然后单击“确定”:
第 4 步:在“导航器”对话框(如下图)中,左窗格提供了网页上可用的表格列表。
第一项“文档”收录
页面的 HTML 代码,因此对我们没有用,但其余的表收录
您可以通过 Power Query 获取的数据表。请记住,它只会显示使用 HTML 表格标签生成的表格。
选择你想要的表,类似下图,我们需要表1
也可以进入WEB视图,看看下面的对比。下表是您需要查找的内容吗?
技能:
1.点击对话框右上角的全屏图标,可以全屏查看“导航”对话框。
2.如果要导入多个表,请在左侧窗格中选中“选择多个项目”框。
第五步:选择好要导入的表格后,点击“转换数据”按钮。这将打开 Power Query 编辑器窗口,让您有机会在将数据加载到 Excel 或 Power Pivot 数据模型之前对其进行组织。
数据清理完毕后,可以将其加载到 Excel 或 Power Pivot 数据模型中。
第 6 步:“开始”选项卡>“关闭并加载到”:
“导入数据”对话框将打开:
提示:如果加载到数据模型中,一定要选择“仅创建连接”,这样文件中的数据就不会被复制,直接在数据透视表这样的地方建立名称连接。
第七步:刷新数据。要从网页获取更新,只需转到功能区的“外部数据”选项卡,然后单击“全部刷新”:
或者,如果您有多个查询,您可以打开查询和连接窗格:
Power Query 网站限制
正如我之前提到的,PowerQuery 非常擅长从 Web 获取数据。在 Web 中,它被格式化为 HTML 表格,而不是由 JavaScript 生成的表格。您可以通过检查网页的源代码并查找 HTML 表格标签来轻松确定表格是 HTML 还是 JavaScript。
为此,请在网页部分空白处右击>查看页面源代码(或类似,取决于您使用的浏览器,我使用的WIN10系统自带的浏览器不是以前版本的Internet Explorer ):
CTRL + F 打开“查找”对话框。进入”
如果找到HTML table标签,那么确认power Query可以从页面中获取一个表,但是不能保证就是你实际需要的表,因为页面上可能还有其他的表,所以可以使用我之前提到的表 进行选择。
网页视频抓取软件 格式工厂(格式工厂怎么压缩视频大小/转换/压缩/多媒体/psp)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-24 00:12
格式工厂官网版是一款非常实用的格式转换工具。它可以轻松转换您想要的所有格式。格式工厂支持几乎所有主流多媒体文件格式的转换。同时格式工厂支持多种语言,功能非常强大。, 有需要的赶紧下载体验吧!
格式工厂官网版软件介绍
格式工厂是一款免费的多功能多媒体文件转换工具,可以轻松转换您想要的所有格式。格式工厂支持几乎所有主流多媒体文件格式的转换。同时格式工厂支持多国语言,安装界面显示英文。开机后显示中文。格式工厂支持各种视频、音频和图片格式之间的转换。格式工厂还支持各种手机视频格式的转换。
格式工厂是如何压缩视频大小的
1、格式工厂支持几乎所有类型的多媒体格式。支持各类视频、音频、图片等格式,轻松转换成你想要的格式。
2、 修复损坏的视频文件。在转换过程中,可以修复损坏的文件,从而不损坏转换质量。
3、多媒体文件减肥。它可以帮助您的文件“减肥”,使它们“小巧纤薄”。它不仅节省了硬盘空间,而且便于存储和备份。
4、 可以指定格式。支持iphone/ipod/psp等多媒体指定格式。
5、 支持图片常用功能。转换后的图片支持缩放、旋转、水印等常用功能,操作简单。
6、备份很简单。DVD视频采集功能,轻松备份DVD到本地硬盘。
7、支持多种语言。支持62国语言,使用无障碍,满足多种需求。
如何在格式工厂中转换 MP4
1.支持几乎所有类型的多媒体格式
支持各类视频、音频、图片等格式,轻松转换成你想要的格式。
2.修复损坏的视频文件
在转换过程中,可以修复损坏的文件,从而不损坏转换质量。
3.多媒体文件减肥
它可以帮助您的文件“减肥”,使它们“小巧纤薄”。它不仅节省了硬盘空间,而且便于存储和备份。
4. 可以指定格式
支持iphone/ipod/psp等多媒体指定格式。
5.支持图片常用功能
转换后的图片支持缩放、旋转、水印等常用功能,操作简单。
6. 简单备份
DVD视频采集功能,轻松备份DVD到本地硬盘。
7.支持多种语言
支持62国语言,使用无障碍,满足多种需求。
格式工厂官网版安装步骤
在本站下载安装包,点击一键安装,等待安装完成。
格式工厂官网版本更新日志
格式工厂5.7.5.0:
添加可调整的最大任务线程数的选项;
增加了对没有 OpenGL 的 Win7 机器的支持;
PDF密码支持批量输入;
修改了窗口大小和位置的保存;
修复了混流时无法翻转和旋转的问题。
格式工厂5.7.1.0:
修复部分win7系统无法使用的问题
去除水印和添加多个区域的操作
改进输出配置界面,页面显示更多选项
添加 MP4/MKV 以维护多源音频字幕流
修复了快速编辑中的不同步问题
更新NVIDIA Video Codec SDK至最新版本10.0.26,支持更多图形加速
格式工厂官网评测
非常好用的格式转换工具,功能非常强大。
细节 查看全部
网页视频抓取软件 格式工厂(格式工厂怎么压缩视频大小/转换/压缩/多媒体/psp)
格式工厂官网版是一款非常实用的格式转换工具。它可以轻松转换您想要的所有格式。格式工厂支持几乎所有主流多媒体文件格式的转换。同时格式工厂支持多种语言,功能非常强大。, 有需要的赶紧下载体验吧!
格式工厂官网版软件介绍
格式工厂是一款免费的多功能多媒体文件转换工具,可以轻松转换您想要的所有格式。格式工厂支持几乎所有主流多媒体文件格式的转换。同时格式工厂支持多国语言,安装界面显示英文。开机后显示中文。格式工厂支持各种视频、音频和图片格式之间的转换。格式工厂还支持各种手机视频格式的转换。
格式工厂是如何压缩视频大小的
1、格式工厂支持几乎所有类型的多媒体格式。支持各类视频、音频、图片等格式,轻松转换成你想要的格式。
2、 修复损坏的视频文件。在转换过程中,可以修复损坏的文件,从而不损坏转换质量。
3、多媒体文件减肥。它可以帮助您的文件“减肥”,使它们“小巧纤薄”。它不仅节省了硬盘空间,而且便于存储和备份。
4、 可以指定格式。支持iphone/ipod/psp等多媒体指定格式。
5、 支持图片常用功能。转换后的图片支持缩放、旋转、水印等常用功能,操作简单。
6、备份很简单。DVD视频采集功能,轻松备份DVD到本地硬盘。
7、支持多种语言。支持62国语言,使用无障碍,满足多种需求。
如何在格式工厂中转换 MP4
1.支持几乎所有类型的多媒体格式
支持各类视频、音频、图片等格式,轻松转换成你想要的格式。
2.修复损坏的视频文件
在转换过程中,可以修复损坏的文件,从而不损坏转换质量。
3.多媒体文件减肥
它可以帮助您的文件“减肥”,使它们“小巧纤薄”。它不仅节省了硬盘空间,而且便于存储和备份。
4. 可以指定格式
支持iphone/ipod/psp等多媒体指定格式。
5.支持图片常用功能
转换后的图片支持缩放、旋转、水印等常用功能,操作简单。
6. 简单备份
DVD视频采集功能,轻松备份DVD到本地硬盘。
7.支持多种语言
支持62国语言,使用无障碍,满足多种需求。
格式工厂官网版安装步骤
在本站下载安装包,点击一键安装,等待安装完成。
格式工厂官网版本更新日志
格式工厂5.7.5.0:
添加可调整的最大任务线程数的选项;
增加了对没有 OpenGL 的 Win7 机器的支持;
PDF密码支持批量输入;
修改了窗口大小和位置的保存;
修复了混流时无法翻转和旋转的问题。
格式工厂5.7.1.0:
修复部分win7系统无法使用的问题
去除水印和添加多个区域的操作
改进输出配置界面,页面显示更多选项
添加 MP4/MKV 以维护多源音频字幕流
修复了快速编辑中的不同步问题
更新NVIDIA Video Codec SDK至最新版本10.0.26,支持更多图形加速
格式工厂官网评测
非常好用的格式转换工具,功能非常强大。
细节
网页视频抓取软件 格式工厂(如何下载下来过程定位视频链接?软件的详细介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-22 15:06
背景
吉友给了一个在线视频网址,想问问有没有推荐的录屏软件。我首先想到的是如何下载它
过程定位视频链接
因为之前做过爬虫,有的网站直接在网页源码上显示视频链接。因此,您可以直接查看网页源代码的元素。
坑要填。. .
1、使用文件连接命令(windows为type,linux为cat)将所有段合并为一个m4s文件。
2、使用ffmpeg进行音视频合成和格式转换
3、我用过invidownloader,了解到windows下的文件连接命令是type
4、 试过用ffmpeg直接合成所有的分割文件,视频会有问题(绿屏)
5、 段文件需要有头文件(包括段信息等),是网上搜到的mpd文件。但是,这个 网站 没有。后来上了一招(也是从invidownloader找到的),从segment-0.m4s开始下载,发现用ffmpeg可以合成成功
6、这个网站有一个陷阱。/video/segment-1.m4s 的链接和其他的不一样。直接使用其他seqs的链接就可以了。
后记
写这个文章的时候,突然想:像“blob:”这样的地址能不能转换成实际的视频地址?
这次搜索发现真的很好(我去看看,上面好多都是折腾了……)
已搜索 文章
开发者工具会自动定位这个视频对应页面源码的位置
然后将iframe中src的内容复制到视频的src中
PS:如果真的没有变化,再做一次 查看全部
网页视频抓取软件 格式工厂(如何下载下来过程定位视频链接?软件的详细介绍)
背景
吉友给了一个在线视频网址,想问问有没有推荐的录屏软件。我首先想到的是如何下载它
过程定位视频链接
因为之前做过爬虫,有的网站直接在网页源码上显示视频链接。因此,您可以直接查看网页源代码的元素。
坑要填。. .
1、使用文件连接命令(windows为type,linux为cat)将所有段合并为一个m4s文件。
2、使用ffmpeg进行音视频合成和格式转换
3、我用过invidownloader,了解到windows下的文件连接命令是type
4、 试过用ffmpeg直接合成所有的分割文件,视频会有问题(绿屏)
5、 段文件需要有头文件(包括段信息等),是网上搜到的mpd文件。但是,这个 网站 没有。后来上了一招(也是从invidownloader找到的),从segment-0.m4s开始下载,发现用ffmpeg可以合成成功
6、这个网站有一个陷阱。/video/segment-1.m4s 的链接和其他的不一样。直接使用其他seqs的链接就可以了。
后记
写这个文章的时候,突然想:像“blob:”这样的地址能不能转换成实际的视频地址?
这次搜索发现真的很好(我去看看,上面好多都是折腾了……)
已搜索 文章
开发者工具会自动定位这个视频对应页面源码的位置
然后将iframe中src的内容复制到视频的src中
PS:如果真的没有变化,再做一次
网页视频抓取软件 格式工厂(2种下载B站超清视频的方法(图下载))
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-12-21 07:08
这个问题一点也不难。这里有两种从B站下载超清视频的方法。
一、直接下载方式也是最简单的下载方式(仅限Win10系统)
操作步骤如下:
①打开Win10系统自带的应用商店,搜索Bilibili,就会出现Bilibili相关内容,然后选择-Bilibili动画,点击安装。
②找到您需要下载的视频,点击直接下载
③注意:此方法仅适用于Win10系统,点击下载前需要设置下载路径,以便快速找到下载视频的位置。下载格式默认为Flv,您可以通过其他方式转换MP4。
二、插件下载方式,需要安装插件+脚本
操作步骤如下:
①安装Tampermonkey插件。这里就不介绍了。安装方法非常简单。回复2获取微信对话框中的插件。点击浏览器右上角的三个点>>更多工具>>扩展>>拖入添加插件。能。
②安装脚本程序,在脚本网站:/zh-CN中,搜索并找到一个以bilibili开头的脚本并安装。如下所示
③测试:打开哔哩哔哩官方网站,这里我随意点击一个视频进入播放页面,此时我们会在播放器的左上角看到一个原生MP4和超清FLV按钮。
④下载方式:部分视频没有原生MP4,只能点击Super Clear FLV,然后点击Cache All+Auto Merge,如下图
⑤ 下载完成后,点击 保存合并后的FLV,大功告成。
三、注意事项:
强烈建议使用 Potplayer 播放器进行播放。功能真的很强大(在回复17中获取)。如果需要转换成MP4格式,可以通过格式工厂进行转换,操作简单。 查看全部
网页视频抓取软件 格式工厂(2种下载B站超清视频的方法(图下载))
这个问题一点也不难。这里有两种从B站下载超清视频的方法。
一、直接下载方式也是最简单的下载方式(仅限Win10系统)
操作步骤如下:
①打开Win10系统自带的应用商店,搜索Bilibili,就会出现Bilibili相关内容,然后选择-Bilibili动画,点击安装。
②找到您需要下载的视频,点击直接下载
③注意:此方法仅适用于Win10系统,点击下载前需要设置下载路径,以便快速找到下载视频的位置。下载格式默认为Flv,您可以通过其他方式转换MP4。
二、插件下载方式,需要安装插件+脚本
操作步骤如下:
①安装Tampermonkey插件。这里就不介绍了。安装方法非常简单。回复2获取微信对话框中的插件。点击浏览器右上角的三个点>>更多工具>>扩展>>拖入添加插件。能。
②安装脚本程序,在脚本网站:/zh-CN中,搜索并找到一个以bilibili开头的脚本并安装。如下所示
③测试:打开哔哩哔哩官方网站,这里我随意点击一个视频进入播放页面,此时我们会在播放器的左上角看到一个原生MP4和超清FLV按钮。
④下载方式:部分视频没有原生MP4,只能点击Super Clear FLV,然后点击Cache All+Auto Merge,如下图
⑤ 下载完成后,点击 保存合并后的FLV,大功告成。
三、注意事项:
强烈建议使用 Potplayer 播放器进行播放。功能真的很强大(在回复17中获取)。如果需要转换成MP4格式,可以通过格式工厂进行转换,操作简单。
网页视频抓取软件 格式工厂(网页视频抓取软件格式工厂,可抓取各大视频网站的所有视频,支持源码下载,下载视频效果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 393 次浏览 • 2021-12-18 16:01
网页视频抓取软件格式工厂,可抓取各大视频网站的所有视频,更可以批量抓取抖音/快手/优酷/b站/n站/土豆的视频,支持源码下载,下载视频效果如下:randomwalk视频抓取软件-非常简单的视频抓取器,可以批量抓取抖音/快手/优酷/b站/n站/uc等国内主流视频网站的视频.
土豆bt站估计没几个人知道,国内比较早的电影站。
为什么这么没人回答???我来给你推荐个,我不怎么用网页端的,都是直接保存视频,
我就知道有种东西叫迅雷保存
可以下载网站的视频的工具,找到一个很不错的工具,一键搞定多种视频格式转换,还有视频保存,
我就看动漫,看新番,看电影都是下载的网盘,想看有的是资源的,
里面有直接下载视频,或者后期加视频的方法,
下载一些图片啊,电子书啊,
微鱼,一款在线网页视频下载工具;支持手机和电脑端:。
可以去知乎找一下“如何从atm上取走钱”,
:;c=aa&d=song&e=ajax&wd=%e7%ad%b0%e4%bc%80%e4%b8%84%e4%bb%83%e6%96%b0%e5%a4%a8%e5%ad%a3%e8%a5%b7 查看全部
网页视频抓取软件 格式工厂(网页视频抓取软件格式工厂,可抓取各大视频网站的所有视频,支持源码下载,下载视频效果)
网页视频抓取软件格式工厂,可抓取各大视频网站的所有视频,更可以批量抓取抖音/快手/优酷/b站/n站/土豆的视频,支持源码下载,下载视频效果如下:randomwalk视频抓取软件-非常简单的视频抓取器,可以批量抓取抖音/快手/优酷/b站/n站/uc等国内主流视频网站的视频.
土豆bt站估计没几个人知道,国内比较早的电影站。
为什么这么没人回答???我来给你推荐个,我不怎么用网页端的,都是直接保存视频,
我就知道有种东西叫迅雷保存
可以下载网站的视频的工具,找到一个很不错的工具,一键搞定多种视频格式转换,还有视频保存,
我就看动漫,看新番,看电影都是下载的网盘,想看有的是资源的,
里面有直接下载视频,或者后期加视频的方法,
下载一些图片啊,电子书啊,
微鱼,一款在线网页视频下载工具;支持手机和电脑端:。
可以去知乎找一下“如何从atm上取走钱”,
:;c=aa&d=song&e=ajax&wd=%e7%ad%b0%e4%bc%80%e4%b8%84%e4%bb%83%e6%96%b0%e5%a4%a8%e5%ad%a3%e8%a5%b7
网页视频抓取软件 格式工厂(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-16 15:21
/1 简介/
还在为在线看小视频缓存慢而发愁吗?您是否还在为想重温优秀作品却找不到资源而苦恼?别慌,让python帮你解决,40行代码教你爬取小视频网站,先分批下载仔细看,不好看!
/2 整理思路/
这种网站一般都是一样的。本文以凤凰新闻视频网站为例,通过后推方式向大家展示如何通过流量分析获取视频下载的url,然后批量下载。
/3 操作步骤/
/3.1 分析网站,找出网页变化的规律/
1、 首先找到网页。该网页的详细信息如下图所示。
2、这个视频网站分为人物、娱乐、艺术等不同类型。本文以体育板块为例,下拉至底部,如下图所示。
3、根据上图的结果,我们可以发现网站是一个动态网页。打开浏览器内置的流量分析器,点击加载更多,查看网页变化的规律。第一个是请求的 URL 和返回的结果如下图所示。标记为页码,此时为第三页。
4、 返回的结果收录视频标题、网页url、guid(相当于每个视频的logo,方便后续跟进)等信息,如下图所示。
5、 每个网页收录24个视频,如下图打印出来。
/3.2 查找视频网页地址的规则/
1、 首先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
2、 我一一找到了它们的网址,并存入一个文本文件中,以查找它们之间的规则,如下图所示。
3、 你注意到这种模式了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到的),只有range_bytes参数变化,从0到6767623。显然这是视频的大小,视频是分段合成。找到这些规则后,我们需要继续挖掘视频地址的来源。
/3.3 找到视频的原创下载地址/
1、 首先考虑一个问题,视频地址从何而来?一般情况下,首先检查视频页面上是否有。如果没有,我们将在流量分析器中查找第一个分段视频。必须有某个 URL 返回此信息。很快,我在一个 vdn.apple.mpegurl 文件中找到了下图。
2、 太惊喜了,这不是我们要找的信息吗?我们来看看它的url参数,如下图所示。
3、上图中的参数看起来很多,但不要害怕。还是用老办法,先查网页有没有,如果没有就在流量分析器里找。努力是有回报的。我找到了下面的图片。
4、 其url如下图所示。
5、仔细找规则,发现唯一需要改的就是每个视频的guid。这第一步已经完成。另外,返回的结果中除了vkey之外,都收录了上面的所有参数,而且这个参数是最长的,我该怎么办?
6、不要着急,如果这个参数不起作用,删除vkey并尝试。果然,实在不行。现在整个过程已经很顺利了,现在可以按下代码了。
/3.4 代码实现/
1、 代码中设置多线程下载,如下图,其中页码可以自行修改。
2、 解析返回参数,为json格式,使用json库进行处理,如下图。通过分析,我们可以得到每个视频的标题、网页url和guid。
3、模拟请求获取Vkey以外的参数,如下图。
4、 使用上一步中的参数进行模拟请求,获取收录分段视频的信息,如下图所示。
5、 将分割后的视频合并,保存为1个视频文件,并以标题命名,如下图。
/3.5 效果展示/
1、 程序运行后,我们可以在本地文件夹中看到网页上的视频飞溅,如下图。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果你想更直观,你可以在代码中添加尺寸测量信息。您可以自己手动设置。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网络视频到本地。该方法简单易行,行之有效。欢迎您试用。如需获取本文代码,请访问/cassieeric/python_crawler/tree/master/little_video_crawler获取代码链接。觉得还不错的话记得给个star哦。 查看全部
网页视频抓取软件 格式工厂(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
/1 简介/
还在为在线看小视频缓存慢而发愁吗?您是否还在为想重温优秀作品却找不到资源而苦恼?别慌,让python帮你解决,40行代码教你爬取小视频网站,先分批下载仔细看,不好看!
/2 整理思路/
这种网站一般都是一样的。本文以凤凰新闻视频网站为例,通过后推方式向大家展示如何通过流量分析获取视频下载的url,然后批量下载。
/3 操作步骤/
/3.1 分析网站,找出网页变化的规律/
1、 首先找到网页。该网页的详细信息如下图所示。
2、这个视频网站分为人物、娱乐、艺术等不同类型。本文以体育板块为例,下拉至底部,如下图所示。
3、根据上图的结果,我们可以发现网站是一个动态网页。打开浏览器内置的流量分析器,点击加载更多,查看网页变化的规律。第一个是请求的 URL 和返回的结果如下图所示。标记为页码,此时为第三页。
4、 返回的结果收录视频标题、网页url、guid(相当于每个视频的logo,方便后续跟进)等信息,如下图所示。
5、 每个网页收录24个视频,如下图打印出来。
/3.2 查找视频网页地址的规则/
1、 首先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
2、 我一一找到了它们的网址,并存入一个文本文件中,以查找它们之间的规则,如下图所示。
3、 你注意到这种模式了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到的),只有range_bytes参数变化,从0到6767623。显然这是视频的大小,视频是分段合成。找到这些规则后,我们需要继续挖掘视频地址的来源。
/3.3 找到视频的原创下载地址/
1、 首先考虑一个问题,视频地址从何而来?一般情况下,首先检查视频页面上是否有。如果没有,我们将在流量分析器中查找第一个分段视频。必须有某个 URL 返回此信息。很快,我在一个 vdn.apple.mpegurl 文件中找到了下图。
2、 太惊喜了,这不是我们要找的信息吗?我们来看看它的url参数,如下图所示。
3、上图中的参数看起来很多,但不要害怕。还是用老办法,先查网页有没有,如果没有就在流量分析器里找。努力是有回报的。我找到了下面的图片。
4、 其url如下图所示。
5、仔细找规则,发现唯一需要改的就是每个视频的guid。这第一步已经完成。另外,返回的结果中除了vkey之外,都收录了上面的所有参数,而且这个参数是最长的,我该怎么办?
6、不要着急,如果这个参数不起作用,删除vkey并尝试。果然,实在不行。现在整个过程已经很顺利了,现在可以按下代码了。
/3.4 代码实现/
1、 代码中设置多线程下载,如下图,其中页码可以自行修改。
2、 解析返回参数,为json格式,使用json库进行处理,如下图。通过分析,我们可以得到每个视频的标题、网页url和guid。
3、模拟请求获取Vkey以外的参数,如下图。
4、 使用上一步中的参数进行模拟请求,获取收录分段视频的信息,如下图所示。
5、 将分割后的视频合并,保存为1个视频文件,并以标题命名,如下图。
/3.5 效果展示/
1、 程序运行后,我们可以在本地文件夹中看到网页上的视频飞溅,如下图。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果你想更直观,你可以在代码中添加尺寸测量信息。您可以自己手动设置。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网络视频到本地。该方法简单易行,行之有效。欢迎您试用。如需获取本文代码,请访问/cassieeric/python_crawler/tree/master/little_video_crawler获取代码链接。觉得还不错的话记得给个star哦。

