
网页视频抓取脚本
网页视频抓取脚本(网页视频抓取软件,只要你会java,视频下载精灵都会帮你搞定!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-30 19:09
网页视频抓取脚本精灵:java抓取网页视频抓取软件,只要你会java,视频下载脚本精灵都会帮你搞定!网页视频抓取代码,以中国地图为例,
这时候软件的效率就很重要了,现在网页都封装的非常好用,你只需要打开,查看你需要的选择,
其实这是我一直不敢在知乎上大发感慨的原因
网页上视频的话方法其实有很多,本人比较推荐方便用工具抓取视频的软件,比如快手采集器。
一直用的有道云笔记
推荐一个最近开发的软件,叫,
其实我当初是看视频,下载的当时还以为是其他人在b站上分享的,还各种咨询,各种点赞。突然我觉得我为什么会问这个问题。对我来说就是快手这类的直接可以获取直接文件的。
xx盘精灵!
这个问题我是最有发言权啦!!app我最常用的是大白兔。重点是易用性,简单好用而且不会误点,操作容易上手。我在用的就是视频采集一键下载工具,还有就是看视频免费小说,里面有小说收集系统,
一般我会用浏览器的插件,根据页面头部或尾部描述找到视频页面并点一下就可以抓取内容,保存在电脑里。
一款软件即可
我一般在看到我想要的视频再分享给别人,
有道云笔记搜索接收其他网站采集自身网站采集一般有道云笔记搜索链接免费分享。 查看全部
网页视频抓取脚本(网页视频抓取软件,只要你会java,视频下载精灵都会帮你搞定!)
网页视频抓取脚本精灵:java抓取网页视频抓取软件,只要你会java,视频下载脚本精灵都会帮你搞定!网页视频抓取代码,以中国地图为例,
这时候软件的效率就很重要了,现在网页都封装的非常好用,你只需要打开,查看你需要的选择,
其实这是我一直不敢在知乎上大发感慨的原因
网页上视频的话方法其实有很多,本人比较推荐方便用工具抓取视频的软件,比如快手采集器。
一直用的有道云笔记
推荐一个最近开发的软件,叫,
其实我当初是看视频,下载的当时还以为是其他人在b站上分享的,还各种咨询,各种点赞。突然我觉得我为什么会问这个问题。对我来说就是快手这类的直接可以获取直接文件的。
xx盘精灵!
这个问题我是最有发言权啦!!app我最常用的是大白兔。重点是易用性,简单好用而且不会误点,操作容易上手。我在用的就是视频采集一键下载工具,还有就是看视频免费小说,里面有小说收集系统,
一般我会用浏览器的插件,根据页面头部或尾部描述找到视频页面并点一下就可以抓取内容,保存在电脑里。
一款软件即可
我一般在看到我想要的视频再分享给别人,
有道云笔记搜索接收其他网站采集自身网站采集一般有道云笔记搜索链接免费分享。
网页视频抓取脚本(Python标准库unittest实现抓取javascript动态生成的html网页功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-28 13:34
本文以Python3为例,实现抓取javascript动态生成的html网页的功能。分享给大家,供大家参考,如下:
使用urllib等抓取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是urllib被瞬间抓取了。它不等待javascript加载延迟,因此页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?不!
这里是一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
[示例 0]
打开火狐浏览器
使用给定的 url 地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
[示例 1]
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
[示例 2]
Selenium WebDriver 常用于测试网络程序。以下是使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
希望这篇文章对你的 Python 编程有所帮助。 查看全部
网页视频抓取脚本(Python标准库unittest实现抓取javascript动态生成的html网页功能)
本文以Python3为例,实现抓取javascript动态生成的html网页的功能。分享给大家,供大家参考,如下:
使用urllib等抓取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是urllib被瞬间抓取了。它不等待javascript加载延迟,因此页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?不!
这里是一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
[示例 0]
打开火狐浏览器
使用给定的 url 地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
[示例 1]
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
[示例 2]
Selenium WebDriver 常用于测试网络程序。以下是使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
希望这篇文章对你的 Python 编程有所帮助。
网页视频抓取脚本( 80集Python基础入门视频教学点免费在线观看分析目标)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-25 13:16
80集Python基础入门视频教学点免费在线观看分析目标)
Python爬虫实战虎牙视频爬取源码
更新时间:2021年10月15日09:09:46 作者:松鼠爱吃饼干
读万卷书不如行万里路。实战学习的不足,可见一斑。本文文章带你爬取虎牙的短视频数据。可以在实战中查漏补缺,加深学习。
内容
知识点开发环境
爬虫的基本思路流程:(关键点)【无论任何网站任何数据内容都按照这个流程进行分析】
1.确定需求(需要爬取的内容是什么?)
2.发送请求,使用python代码模拟浏览器向目标地址发送请求
3.获取数据,获取服务器返回的数据内容
4.分析数据,提取我们想要的数据内容,视频标题/视频url地址
5.保存数据
【付费VIP完整版】只要看完就能学会的教程,80集Python基础入门视频教学
点击这里免费在线观看
分析目标网址
首先打开一个视频,查看id
打开开发者工具并找到
获取目标网址
代码开头是在线导入需要的模块
import requests # 数据请求模块 pip install requests (第三方模块)
import pprint # 格式化输出模块 内置模块 不需要安装
import re # 正则表达式
import json
数据请求
def get_response(html_url):
# 用python代码模拟浏览器
# headers 把python代码进行伪装
# user-agent 浏览器的基本标识
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
# 用代码直接获取的 一般大多数都是直接 cookie
response = requests.get(url=html_url, headers=headers)
return response
获取视频标题和url地址
def get_video_info(video_id):
html_url = f'https://liveapi.huya.com/moment/getMomentContent?videoId={video_id}&uid=&_=1634127164373'
response = get_response(html_url)
title = response.json()['data']['moment']['title'] # 视频标题
video_url = response.json()['data']['moment']['videoInfo']['definitions'][0]['url']
video_info = [title, video_url]
return video_info
获取视频 ID
def get_video_id(html_url):
html_data = get_response(html_url).text
result = re.findall(' window.HNF_GLOBAL_INIT = (.*?) ', html_data)[0]
# 需要把获取的字符串数据, 转成json字典数据
json_data = json.loads(result)['videoData']['videoDataList']['value']
# json_data 列表 里面元素是字典
# print(json_data)
video_ids = [i['vid'] for i in json_data] # 列表推导式
# lis = []
# for i in json_data:
# lis.append(i['vid'])
# print(video_ids)
# print(type(json_data))
return video_ids
# 目光所至 我皆可爬
def main(html):
video_ids = get_video_id(html_url=html)
for video_id in video_ids:
video_info = get_video_info(video_id)
save(video_info[0], video_info[1])
保存数据
def save(title, video_url):
# 保存数据, 也是还需要对于播放地址发送请求的
# response.content 获取响应的二进制数据
video_content = get_response(html_url=video_url).content
new_title = re.sub(r'[\/:*?"|]', '_', title)
# 'video\\' + title + '.mp4' 文件夹路径以及文件名字 mode 保存方式 wb二进制保存方式
with open('video\\' + new_title + '.mp4', mode='wb') as f:
f.write(video_content)
print('保存成功: ', title)
调用函数
if __name__ == '__main__':
# get_video_info('589462235')
video_info = get_video_info('589462235')
save(video_info[0], video_info[1])
for page in range(1, 6):
print(f'正在爬取第{page}页的数据内容')
# python基础入门课程 第一节课 讲解的知识点 字符串格式化方法
url = f'https://v.huya.com/g/all?set_id=31&order=hot&page={page}'
main(url)
运行代码获取数据
这是文章关于虎牙视频抓取的介绍,附Python爬虫实战源码。更多Python爬取虎牙视频相关内容,请搜索脚本之家之前的文章或继续浏览下方相关文章,希望大家以后多多支持Scripthome! 查看全部
网页视频抓取脚本(
80集Python基础入门视频教学点免费在线观看分析目标)
Python爬虫实战虎牙视频爬取源码
更新时间:2021年10月15日09:09:46 作者:松鼠爱吃饼干
读万卷书不如行万里路。实战学习的不足,可见一斑。本文文章带你爬取虎牙的短视频数据。可以在实战中查漏补缺,加深学习。
内容
知识点开发环境
爬虫的基本思路流程:(关键点)【无论任何网站任何数据内容都按照这个流程进行分析】
1.确定需求(需要爬取的内容是什么?)
2.发送请求,使用python代码模拟浏览器向目标地址发送请求
3.获取数据,获取服务器返回的数据内容
4.分析数据,提取我们想要的数据内容,视频标题/视频url地址
5.保存数据
【付费VIP完整版】只要看完就能学会的教程,80集Python基础入门视频教学
点击这里免费在线观看
分析目标网址
首先打开一个视频,查看id

打开开发者工具并找到

获取目标网址

代码开头是在线导入需要的模块
import requests # 数据请求模块 pip install requests (第三方模块)
import pprint # 格式化输出模块 内置模块 不需要安装
import re # 正则表达式
import json
数据请求
def get_response(html_url):
# 用python代码模拟浏览器
# headers 把python代码进行伪装
# user-agent 浏览器的基本标识
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
# 用代码直接获取的 一般大多数都是直接 cookie
response = requests.get(url=html_url, headers=headers)
return response
获取视频标题和url地址
def get_video_info(video_id):
html_url = f'https://liveapi.huya.com/moment/getMomentContent?videoId={video_id}&uid=&_=1634127164373'
response = get_response(html_url)
title = response.json()['data']['moment']['title'] # 视频标题
video_url = response.json()['data']['moment']['videoInfo']['definitions'][0]['url']
video_info = [title, video_url]
return video_info
获取视频 ID
def get_video_id(html_url):
html_data = get_response(html_url).text
result = re.findall(' window.HNF_GLOBAL_INIT = (.*?) ', html_data)[0]
# 需要把获取的字符串数据, 转成json字典数据
json_data = json.loads(result)['videoData']['videoDataList']['value']
# json_data 列表 里面元素是字典
# print(json_data)
video_ids = [i['vid'] for i in json_data] # 列表推导式
# lis = []
# for i in json_data:
# lis.append(i['vid'])
# print(video_ids)
# print(type(json_data))
return video_ids
# 目光所至 我皆可爬
def main(html):
video_ids = get_video_id(html_url=html)
for video_id in video_ids:
video_info = get_video_info(video_id)
save(video_info[0], video_info[1])
保存数据
def save(title, video_url):
# 保存数据, 也是还需要对于播放地址发送请求的
# response.content 获取响应的二进制数据
video_content = get_response(html_url=video_url).content
new_title = re.sub(r'[\/:*?"|]', '_', title)
# 'video\\' + title + '.mp4' 文件夹路径以及文件名字 mode 保存方式 wb二进制保存方式
with open('video\\' + new_title + '.mp4', mode='wb') as f:
f.write(video_content)
print('保存成功: ', title)
调用函数
if __name__ == '__main__':
# get_video_info('589462235')
video_info = get_video_info('589462235')
save(video_info[0], video_info[1])
for page in range(1, 6):
print(f'正在爬取第{page}页的数据内容')
# python基础入门课程 第一节课 讲解的知识点 字符串格式化方法
url = f'https://v.huya.com/g/all?set_id=31&order=hot&page={page}'
main(url)
运行代码获取数据

这是文章关于虎牙视频抓取的介绍,附Python爬虫实战源码。更多Python爬取虎牙视频相关内容,请搜索脚本之家之前的文章或继续浏览下方相关文章,希望大家以后多多支持Scripthome!
网页视频抓取脚本(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-23 13:33
/1 简介/
还在为在线看小视频缓存慢而发愁吗?还在为想重温优秀作品却找不到资源而发愁吗?别慌,让python帮你解决,40行代码教你爬取小视频网站,先分批下载仔细看,不好看!
/2 整理思路/
这种网站一般都有相似之处,也有细微的差别。本文以凤凰新闻视频网站为例,通过后推方式介绍如何通过流量分析获取视频下载的url,然后批量下载。
/3 操作步骤/
/3.1 分析网站,找出网页变化的规律/
1、 首先找到网页。该网页的详细信息如下图所示。
2、本视频网站分为人物、娱乐、艺术等不同类型,本文以体育板块为例,下拉至底部,如下图。
3、根据上图的结果,我们可以发现网站是一个动态网页。打开浏览器内置的流量分析器,点击加载更多,查看网页变化的规律。第一个是请求的URL和返回的结果如下图所示。标记为页码,此时为第三页。
4、 返回的结果收录视频标题、网页url、guid(相当于每个视频的logo,方便后续跟进)等信息,如下图所示。
5、 每个网页收录24个视频,如下图打印出来。
/3.2 查找视频网页地址的规则/
1、 首先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
2、 我把他们的网址一一找出来,存到一个文本文件中,寻找他们之间的规则,如下图。
3、 你注意到这种模式了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到的),只改变了range_bytes参数,从0到6767623。显然这是视频的大小,视频是分段合成的。找到这些规则后,我们需要继续挖掘视频地址的来源。
/3.3 找到视频的原创下载地址/
1、 首先考虑一个问题,视频地址从何而来?一般情况下,首先检查视频页面上是否有。如果没有,我们将在流量分析器中查找第一个分段视频。必须有某个 URL 返回此信息。很快,我在一个 vdn.apple.mpegurl 文件中找到了下图。
2、太惊喜了,这不是我们要找的信息吗?我们来看看它的url参数,如下图所示。
3、 上图中的参数看起来很多,但不要害怕。还是用老方法,先查网页有没有,如果没有,在流量分析器里查一下。努力是有回报的。我找到了下面的图片。
4、 其url如下图所示。
5、仔细找规则,发现唯一需要改的就是每个视频的guid。这第一步已经完成。另外,返回的结果中除了vkey之外,都收录了上面的所有参数,而且这个参数是最长的,我该怎么办?
6、不要着急,如果这个参数不起作用,删除vkey并尝试。果然,实在不行。现在整个过程已经很顺利了,现在可以按下代码了。
/3.4 代码实现/
1、 代码中设置多线程下载,如下图,其中页码可以自行修改。
2、解析返回参数,json格式,使用json库进行处理,如下图。通过分析,我们可以得到每个视频的标题、网页url和guid。
3、模拟请求获取Vkey以外的参数,如下图。
4、 使用上一步中的参数进行模拟请求,获取包括分割视频在内的信息,如下图所示。
5、 将分割后的视频合并,保存为1个视频文件,并以标题命名,如下图。
/3.5 效果展示/
1、 程序运行后,我们可以看到网页上的视频显示在本地文件夹中,如下图所示。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果你想更直观,你可以在代码中添加尺寸测量信息。您可以自己手动设置。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网络视频到本地。该方法简单易行,行之有效。欢迎大家尝试。如需获取本文代码,请访问智姐获取代码链接。觉得还不错的话记得给个star哦。 查看全部
网页视频抓取脚本(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
/1 简介/
还在为在线看小视频缓存慢而发愁吗?还在为想重温优秀作品却找不到资源而发愁吗?别慌,让python帮你解决,40行代码教你爬取小视频网站,先分批下载仔细看,不好看!
/2 整理思路/
这种网站一般都有相似之处,也有细微的差别。本文以凤凰新闻视频网站为例,通过后推方式介绍如何通过流量分析获取视频下载的url,然后批量下载。
/3 操作步骤/
/3.1 分析网站,找出网页变化的规律/
1、 首先找到网页。该网页的详细信息如下图所示。
2、本视频网站分为人物、娱乐、艺术等不同类型,本文以体育板块为例,下拉至底部,如下图。
3、根据上图的结果,我们可以发现网站是一个动态网页。打开浏览器内置的流量分析器,点击加载更多,查看网页变化的规律。第一个是请求的URL和返回的结果如下图所示。标记为页码,此时为第三页。

4、 返回的结果收录视频标题、网页url、guid(相当于每个视频的logo,方便后续跟进)等信息,如下图所示。

5、 每个网页收录24个视频,如下图打印出来。

/3.2 查找视频网页地址的规则/
1、 首先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
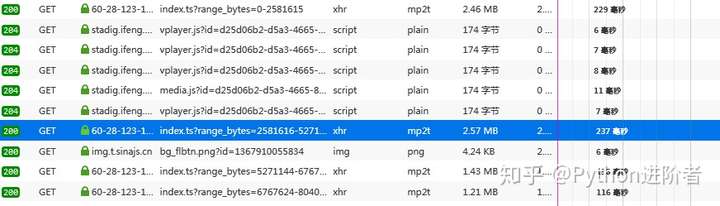
2、 我把他们的网址一一找出来,存到一个文本文件中,寻找他们之间的规则,如下图。
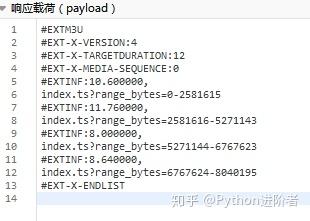
3、 你注意到这种模式了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到的),只改变了range_bytes参数,从0到6767623。显然这是视频的大小,视频是分段合成的。找到这些规则后,我们需要继续挖掘视频地址的来源。
/3.3 找到视频的原创下载地址/
1、 首先考虑一个问题,视频地址从何而来?一般情况下,首先检查视频页面上是否有。如果没有,我们将在流量分析器中查找第一个分段视频。必须有某个 URL 返回此信息。很快,我在一个 vdn.apple.mpegurl 文件中找到了下图。

2、太惊喜了,这不是我们要找的信息吗?我们来看看它的url参数,如下图所示。

3、 上图中的参数看起来很多,但不要害怕。还是用老方法,先查网页有没有,如果没有,在流量分析器里查一下。努力是有回报的。我找到了下面的图片。

4、 其url如下图所示。
5、仔细找规则,发现唯一需要改的就是每个视频的guid。这第一步已经完成。另外,返回的结果中除了vkey之外,都收录了上面的所有参数,而且这个参数是最长的,我该怎么办?
6、不要着急,如果这个参数不起作用,删除vkey并尝试。果然,实在不行。现在整个过程已经很顺利了,现在可以按下代码了。
/3.4 代码实现/
1、 代码中设置多线程下载,如下图,其中页码可以自行修改。

2、解析返回参数,json格式,使用json库进行处理,如下图。通过分析,我们可以得到每个视频的标题、网页url和guid。
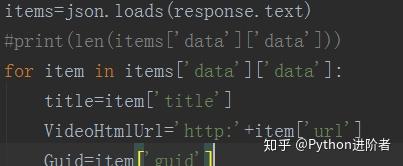
3、模拟请求获取Vkey以外的参数,如下图。

4、 使用上一步中的参数进行模拟请求,获取包括分割视频在内的信息,如下图所示。

5、 将分割后的视频合并,保存为1个视频文件,并以标题命名,如下图。

/3.5 效果展示/
1、 程序运行后,我们可以看到网页上的视频显示在本地文件夹中,如下图所示。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果你想更直观,你可以在代码中添加尺寸测量信息。您可以自己手动设置。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网络视频到本地。该方法简单易行,行之有效。欢迎大家尝试。如需获取本文代码,请访问智姐获取代码链接。觉得还不错的话记得给个star哦。
网页视频抓取脚本(【干货】以免误人子弟的网址仅供交流学习使用,请联系删除)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-11-17 19:15
前言:因为我在python世界还是个小学生,还有很多路要走,所以本文以目的为指导,以达到目的。对于那些我不明白的原理,我不想做太多的解释。以免误导他人,可以上网搜索。
友情提示:本代码中使用的网址仅供交流学习使用。如有不对请联系删除。
背景:我有一台电脑供我父亲使用。爸爸喜欢看一些大片,但是家里的网络环境不好,所以想批量下载一些,保存到电脑里。不过现在的网站大多是这样的,
需要到一处才能看到下载地址
如果我想下载100部电影,我的手肯定是断了,所以我想把这些地址拿出来,让迅雷批量下载。
工具:python(版本3.x)
爬虫原理:网页源代码中收录下载地址。将这些分散的地址批量保存在文件中,方便使用。
干货:先上传代码,等不及的可以先运行一下,再看详细介绍。
import requests
import re
#changepage用来产生不同页数的链接
def changepage(url,total_page):
page_group = ['https://www.dygod.net/html/gndy/jddy/index.html']
for i in range(2,total_page+1):
link = re.sub('jddy/index','jddy/index_'+str(i),url,re.S)
page_group.append(link)
return page_group
#pagelink用来产生页面内的视频链接页面
def pagelink(url):
base_url = 'https://www.dygod.net/html/gndy/jddy/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req = requests.get(url , headers = headers)
req.encoding = 'gbk'#指定编码,否则会乱码
pat = re.compile('<a href="/html/gndy/jddy/(.*?)" class="ulink" title=(.*?)/a>',re.S)#获取电影列表网址
reslist = re.findall(pat, req.text)
finalurl = []
for i in range(1,25):
xurl = reslist[i][0]
finalurl.append(base_url + xurl)
return finalurl #返回该页面内所有的视频网页地址
#getdownurl获取页面的视频地址
def getdownurl(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req = requests.get(url , headers = headers)
req.encoding = 'gbk'#指定编码,否则会乱码
pat = re.compile('<a href="ftp(.*?)">ftp',re.S)#获取下载地址
reslist = re.findall(pat, req.text)
furl = 'ftp'+reslist[0]
return furl
if __name__ == "__main__" :
html = "https://www.dygod.net/html/gnd ... ot%3B
print('你即将爬取的网站是:https://www.dygod.net/html/gndy/jddy/index.html')
pages = input('请输入需要爬取的页数:')
p1 = changepage(html,int(pages))
with open ('电影天堂下载地址.lst','w') as f :
j = 0
for p1i in p1 :
j = j + 1
print('正在爬取第%d页,网址是 %s ...'%(j,p1i))
p2 = pagelink(p1i)
for p2i in p2 :
p3 = getdownurl(p2i)
if len(p3) == 0 :
pass
else :
finalurl = p3
f.write(finalurl + '\n')
print('所有页面地址爬取完毕!')
核心模块getdownurl功能:通过requests获取页面信息,可以认为这个信息的正文就是页面源代码(几乎任何浏览器右键都有查看页面源代码的选项),然后通过堆规则表达式匹配方法匹配到网页源代码的URL部分,可以看下图
如何提取这部分?通过正则表达式匹配。这个正则表达式怎么写?这里使用了一个简单粗暴的方法:
FTP
爬虫经常使用 .*? 做非贪婪匹配(专业术语请百度),你可以简单的认为这个(.*?)代表的是你要爬出来的东西,而这样的东西在每个网页的源代码里都是夹在">ftp 和">ftp 之间。可能有人会问,那这个匹配不是URL。比如上图中的那个是://d::12311/[电影天堂]请用你的名字叫我BD中英文双字.mp4,前面少了一个ftp?
是的,但这是故意的。如果正则表达式写成ftp,可能夹在和">ftp之间的东西太多了,二次处理的成本还不如你认为的最快最直接的方式提取有用信息,然后拼接起来很快。
详细代码:
一、getdownurl
#getdownurl获取页面的视频地址
def getdownurl(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req = requests.get(url , headers = headers)
req.encoding = 'gbk'#指定编码,否则会乱码
pat = re.compile('<a href="ftp(.*?)">ftp',re.S)#获取下载地址
reslist = re.findall(pat, req.text)
furl = 'ftp'+reslist[0]
return furl
headers 用于将您的脚本访问 URL 伪装成浏览器访问,以防某些 网站 采取了反爬虫措施。在许多浏览器中也可以轻松获取此标头。以Firefox为例,直接F12或者查看元素,在网络标签右侧的消息头右下角可以看到。
requests模块:requests.get(url , headers = headers)是用伪装成firefox的形式获取该网页的信息。
re模块:可以参考python正则表达式的一些东西,这里用re.complile来写出匹配的模式,re.findall根据模式在网页源代码中找到相应的东西。
二、pagelink
#pagelink用来产生页面内的视频链接页面
def pagelink(url):
base_url = 'https://www.dygod.net/html/gndy/jddy/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req = requests.get(url , headers = headers)
req.encoding = 'gbk'#指定编码,否则会乱码
pat = re.compile('<a href="/html/gndy/jddy/(.*?)" class="ulink" title=(.*?)/a>',re.S)#获取电影列表网址
reslist = re.findall(pat, req.text)
finalurl = []
for i in range(1,25):
xurl = reslist[i][0]
finalurl.append(base_url + xurl)
return finalurl #返回该页面内所有的视频网页地址
第一步getdownurl用于抓取一个网页的网址,这一步用于获取同一页面内所有网页的网址,比如下面的网页收录很多电影链接
源代码是这样的:
聪明,你一眼就知道需要什么信息。此页面的正文中有 25 个电影链接。我在这里使用一个列表来存储这些 URL。其实range(1,25)不收录25,也就是说我只存了24个url。原因是我的正则表达式写得不好,爬出来的第一个url有问题。如果你有兴趣,你可以研究如何改进它。
需要说明的是,这个正则表达式用到了两个地方。*?,所以匹配的 reslist 是二维的。
三、更改页面
#changepage用来产生不同页数的链接
def changepage(url,total_page):
page_group = ['https://www.dygod.net/html/gndy/jddy/index.html']
for i in range(2,total_page+1):
link = re.sub('jddy/index','jddy/index_'+str(i),url,re.S)
page_group.append(link)
return page_group
这里也比较简单。点击下一页,查看网址栏的网址是什么。这里是index/index_2/index_3...拼接起来很容易。
四、主要
if __name__ == "__main__" :
html = "https://www.dygod.net/html/gnd ... ot%3B
print('你即将爬取的网站是:https://www.dygod.net/html/gndy/jddy/index.html')
pages = input('请输入需要爬取的页数:')
p1 = changepage(html,int(pages))
with open ('电影天堂下载地址.lst','w') as f :
j = 0
for p1i in p1 :
j = j + 1
print('正在爬取第%d页,网址是 %s ...'%(j,p1i))
p2 = pagelink(p1i)
for p2i in p2 :
p3 = getdownurl(p2i)
if len(p3) == 0 :
pass
else :
finalurl = p3
f.write(finalurl + '\n')
print('所有页面地址爬取完毕!')
main里面几乎没什么可说的,反正就是循环读取,然后写入文件。
五、运行和结果
然后迅雷就可以直接导入了。(后缀是downlist或者lst迅雷可以直接导入)
后记:可能有人觉得这样集思广益下载所有电影,可能有些电影太烂,下载浪费时间和资源,人工筛选太麻烦,然后电影的信息会存入数据库筛选出所需的地址。 查看全部
网页视频抓取脚本(【干货】以免误人子弟的网址仅供交流学习使用,请联系删除)
前言:因为我在python世界还是个小学生,还有很多路要走,所以本文以目的为指导,以达到目的。对于那些我不明白的原理,我不想做太多的解释。以免误导他人,可以上网搜索。
友情提示:本代码中使用的网址仅供交流学习使用。如有不对请联系删除。
背景:我有一台电脑供我父亲使用。爸爸喜欢看一些大片,但是家里的网络环境不好,所以想批量下载一些,保存到电脑里。不过现在的网站大多是这样的,

需要到一处才能看到下载地址

如果我想下载100部电影,我的手肯定是断了,所以我想把这些地址拿出来,让迅雷批量下载。
工具:python(版本3.x)
爬虫原理:网页源代码中收录下载地址。将这些分散的地址批量保存在文件中,方便使用。
干货:先上传代码,等不及的可以先运行一下,再看详细介绍。
import requests
import re
#changepage用来产生不同页数的链接
def changepage(url,total_page):
page_group = ['https://www.dygod.net/html/gndy/jddy/index.html']
for i in range(2,total_page+1):
link = re.sub('jddy/index','jddy/index_'+str(i),url,re.S)
page_group.append(link)
return page_group
#pagelink用来产生页面内的视频链接页面
def pagelink(url):
base_url = 'https://www.dygod.net/html/gndy/jddy/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req = requests.get(url , headers = headers)
req.encoding = 'gbk'#指定编码,否则会乱码
pat = re.compile('<a href="/html/gndy/jddy/(.*?)" class="ulink" title=(.*?)/a>',re.S)#获取电影列表网址
reslist = re.findall(pat, req.text)
finalurl = []
for i in range(1,25):
xurl = reslist[i][0]
finalurl.append(base_url + xurl)
return finalurl #返回该页面内所有的视频网页地址
#getdownurl获取页面的视频地址
def getdownurl(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req = requests.get(url , headers = headers)
req.encoding = 'gbk'#指定编码,否则会乱码
pat = re.compile('<a href="ftp(.*?)">ftp',re.S)#获取下载地址
reslist = re.findall(pat, req.text)
furl = 'ftp'+reslist[0]
return furl
if __name__ == "__main__" :
html = "https://www.dygod.net/html/gnd ... ot%3B
print('你即将爬取的网站是:https://www.dygod.net/html/gndy/jddy/index.html')
pages = input('请输入需要爬取的页数:')
p1 = changepage(html,int(pages))
with open ('电影天堂下载地址.lst','w') as f :
j = 0
for p1i in p1 :
j = j + 1
print('正在爬取第%d页,网址是 %s ...'%(j,p1i))
p2 = pagelink(p1i)
for p2i in p2 :
p3 = getdownurl(p2i)
if len(p3) == 0 :
pass
else :
finalurl = p3
f.write(finalurl + '\n')
print('所有页面地址爬取完毕!')
核心模块getdownurl功能:通过requests获取页面信息,可以认为这个信息的正文就是页面源代码(几乎任何浏览器右键都有查看页面源代码的选项),然后通过堆规则表达式匹配方法匹配到网页源代码的URL部分,可以看下图

如何提取这部分?通过正则表达式匹配。这个正则表达式怎么写?这里使用了一个简单粗暴的方法:
FTP
爬虫经常使用 .*? 做非贪婪匹配(专业术语请百度),你可以简单的认为这个(.*?)代表的是你要爬出来的东西,而这样的东西在每个网页的源代码里都是夹在">ftp 和">ftp 之间。可能有人会问,那这个匹配不是URL。比如上图中的那个是://d::12311/[电影天堂]请用你的名字叫我BD中英文双字.mp4,前面少了一个ftp?
是的,但这是故意的。如果正则表达式写成ftp,可能夹在和">ftp之间的东西太多了,二次处理的成本还不如你认为的最快最直接的方式提取有用信息,然后拼接起来很快。
详细代码:
一、getdownurl
#getdownurl获取页面的视频地址
def getdownurl(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req = requests.get(url , headers = headers)
req.encoding = 'gbk'#指定编码,否则会乱码
pat = re.compile('<a href="ftp(.*?)">ftp',re.S)#获取下载地址
reslist = re.findall(pat, req.text)
furl = 'ftp'+reslist[0]
return furl
headers 用于将您的脚本访问 URL 伪装成浏览器访问,以防某些 网站 采取了反爬虫措施。在许多浏览器中也可以轻松获取此标头。以Firefox为例,直接F12或者查看元素,在网络标签右侧的消息头右下角可以看到。

requests模块:requests.get(url , headers = headers)是用伪装成firefox的形式获取该网页的信息。
re模块:可以参考python正则表达式的一些东西,这里用re.complile来写出匹配的模式,re.findall根据模式在网页源代码中找到相应的东西。
二、pagelink
#pagelink用来产生页面内的视频链接页面
def pagelink(url):
base_url = 'https://www.dygod.net/html/gndy/jddy/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req = requests.get(url , headers = headers)
req.encoding = 'gbk'#指定编码,否则会乱码
pat = re.compile('<a href="/html/gndy/jddy/(.*?)" class="ulink" title=(.*?)/a>',re.S)#获取电影列表网址
reslist = re.findall(pat, req.text)
finalurl = []
for i in range(1,25):
xurl = reslist[i][0]
finalurl.append(base_url + xurl)
return finalurl #返回该页面内所有的视频网页地址
第一步getdownurl用于抓取一个网页的网址,这一步用于获取同一页面内所有网页的网址,比如下面的网页收录很多电影链接

源代码是这样的:

聪明,你一眼就知道需要什么信息。此页面的正文中有 25 个电影链接。我在这里使用一个列表来存储这些 URL。其实range(1,25)不收录25,也就是说我只存了24个url。原因是我的正则表达式写得不好,爬出来的第一个url有问题。如果你有兴趣,你可以研究如何改进它。
需要说明的是,这个正则表达式用到了两个地方。*?,所以匹配的 reslist 是二维的。
三、更改页面
#changepage用来产生不同页数的链接
def changepage(url,total_page):
page_group = ['https://www.dygod.net/html/gndy/jddy/index.html']
for i in range(2,total_page+1):
link = re.sub('jddy/index','jddy/index_'+str(i),url,re.S)
page_group.append(link)
return page_group
这里也比较简单。点击下一页,查看网址栏的网址是什么。这里是index/index_2/index_3...拼接起来很容易。

四、主要
if __name__ == "__main__" :
html = "https://www.dygod.net/html/gnd ... ot%3B
print('你即将爬取的网站是:https://www.dygod.net/html/gndy/jddy/index.html')
pages = input('请输入需要爬取的页数:')
p1 = changepage(html,int(pages))
with open ('电影天堂下载地址.lst','w') as f :
j = 0
for p1i in p1 :
j = j + 1
print('正在爬取第%d页,网址是 %s ...'%(j,p1i))
p2 = pagelink(p1i)
for p2i in p2 :
p3 = getdownurl(p2i)
if len(p3) == 0 :
pass
else :
finalurl = p3
f.write(finalurl + '\n')
print('所有页面地址爬取完毕!')
main里面几乎没什么可说的,反正就是循环读取,然后写入文件。
五、运行和结果


然后迅雷就可以直接导入了。(后缀是downlist或者lst迅雷可以直接导入)
后记:可能有人觉得这样集思广益下载所有电影,可能有些电影太烂,下载浪费时间和资源,人工筛选太麻烦,然后电影的信息会存入数据库筛选出所需的地址。
网页视频抓取脚本( 下本更改用户页面的api,用户抓取解析程序需要重构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-17 17:11
下本更改用户页面的api,用户抓取解析程序需要重构)
Python爬取哔哩哔哩主要信息并贡献视频
更新时间:2021-06-07 16:08:26 作者:cgDeepLearn
本项目的主要功能是抓取B站主要up的部分信息和up主要贡献的视频信息进行数据处理和分析(不得用于商业和其他侵犯他人权益的用途)。有这个需求的朋友可以了解一下这个项目
项目地址:
项目特点采用了一定的防攀爬策略。哔哩哔哩更改了用户页面的api,用户爬取解析程序需要重构。快速开始
拉取项目,git clone到主项目目录,安装虚拟环境crawlv(请参考使用说明中的虚拟环境安装)。激活环境并在主目录中运行爬网。抓取结果会保存在data目录下的csv文件中。
ource activate crawlenv
python initial.py file # 初始化file模式
python crawl_user.py file 1 100 # file模式,1 100是开始、结束bilibili的uid
进入data目录查看抓到的数据,是不是很简单!
如果需要使用数据库保存以及其他一些设置,请看下面的说明
使用说明
1.拉项目
git clone https://github.com/cgDeepLearn/BilibiliCrawler.git
2.进入项目主目录,安装虚拟环境
conda create -n crawlenv python=3.6
source activate crawlenv # 激活虚拟环境
pip install -r requirements.txt
virtualenv crawlenv
source crawlenv/bin/activate # 激活虚拟环境,windows下不用source
pip install -r requirements.txt # 安装项目依赖
3. 修改配置文件
进入config目录,修改config.ini配置文件(默认使用postgresql数据库,如果你使用postgresql,只需将里面的参数替换成你自己的即可,后面其他步骤可以忽略)数据库配置选择一个你可以本地安装,参数改成你的。如果需要更自动化的数据库配置,请移步我的DB_ORM项目
[db_mysql]
user = test
password = test
host = localhost
port = 3306
dbname = testdb
[db_postgresql]
user = test
password = test
host = localhost
port = 5432
dbname = testdb
然后修改函数获取conf.py中的配置文件
def get_db_args():
"""
获取数据库配置信息
"""
return dict(CONFIG.items('db_postgresql')) # 如果安装的是mysql,请将参数替换为db_mysql
进入db目录,修改basic.py的DSN连接数据库
# connect_str = "postgresql+psycopg2://{}:{}@{}:{}/{}".format(kwargs['user'], kwargs['password'], kwargs['host'], kwargs['port'], kwargs['dbname'])
# 若使用的是mysql,请将上面的connect_str替换成下面的
connect_str = "mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8".format(kwargs['user'], kwargs['password'], kwargs['host'], kwargs['port'], kwargs['dbname'])
# sqlite3,mongo等请移步我的DB_ORM项目,其他一些数据库也将添加支持
4. 运行爬虫
python initial.py db # db模式,file模式请将db换成file
# file模式会将抓取结果保存在data目录
# db模式会将数据保存在设置好的数据库中
# 若再次以db模式运行将会drop所有表后再create,初次运行后请慎重再次使用!!!
# 如果修改添加了表,并不想清空数据,请运行 python create_all.py
python crawl_user.py db 1 10000 # crawl_user 抓取用户数据,db 保存在数据库中, 1 10000为抓取起止id
python crawl_video_ajax.py db 1 100 # crawl_video_ajax 抓取视频ajax信息保存到数据库中,
python crawl_user_video.py db 1 10000 #同时抓取user 和videoinfo
# 示例为uid从1到100的user如果有投稿视频则抓取其投稿视频的信息,
# 若想通过视频id逐个抓取请运行python crawl_video_by_aid.py db 1 1000
程序中进行了一些爬取率设置,但是每台机器的爬取率对于不同的cpu和mem是不同的,请酌情修改
太快太慢请修改每次爬取的sleepsec参数,ip会限制访问频率,超速会导致爬取数据不完整,
之后会加上运行参数speed(high,low),不需要手动配置speed
爬取日志在logs目录下
user、video分别是user和video的爬取日志
storage 是数据库日志。如需更改日志格式,请修改logger模块
在linux下运行python...先于nohup,例如:
nohup python crawl_user db 1 10000
程序输出保存文件,默认保存在主目录下的nohup.out文件中。添加> fielname 将其保存在设置文件中:
nohup python crawl_video_ajax.py db 1 1000 > video_ajaxup_1_1000.out # 输出将保存在video_ajaxup_1_1000.out中
在程序多线程使用的生产者-消费者模式下,生成程序运行状态的打印信息,类似如下
produce 1_1
consumed 1_1
...
如果想跑得更快,请在设置程序后注释掉打印程序
# utils/pcModels.py
print('[+] produce %s_%s' % (index, pitem)) # 请注释掉
print('[-] consumed %s_%s\n' % (index, data)) # 请注释掉
更多的
项目是单机多线程。如果要使用分布式爬取,请参考Crawler-Celery
以上是python爬取Bilibili的主要信息和提交视频的详细内容。关于python爬Bilibili的更多信息,请关注Script Home的其他相关文章! 查看全部
网页视频抓取脚本(
下本更改用户页面的api,用户抓取解析程序需要重构)
Python爬取哔哩哔哩主要信息并贡献视频
更新时间:2021-06-07 16:08:26 作者:cgDeepLearn
本项目的主要功能是抓取B站主要up的部分信息和up主要贡献的视频信息进行数据处理和分析(不得用于商业和其他侵犯他人权益的用途)。有这个需求的朋友可以了解一下这个项目
项目地址:
项目特点采用了一定的防攀爬策略。哔哩哔哩更改了用户页面的api,用户爬取解析程序需要重构。快速开始
拉取项目,git clone到主项目目录,安装虚拟环境crawlv(请参考使用说明中的虚拟环境安装)。激活环境并在主目录中运行爬网。抓取结果会保存在data目录下的csv文件中。
ource activate crawlenv
python initial.py file # 初始化file模式
python crawl_user.py file 1 100 # file模式,1 100是开始、结束bilibili的uid
进入data目录查看抓到的数据,是不是很简单!
如果需要使用数据库保存以及其他一些设置,请看下面的说明
使用说明
1.拉项目
git clone https://github.com/cgDeepLearn/BilibiliCrawler.git
2.进入项目主目录,安装虚拟环境
conda create -n crawlenv python=3.6
source activate crawlenv # 激活虚拟环境
pip install -r requirements.txt
virtualenv crawlenv
source crawlenv/bin/activate # 激活虚拟环境,windows下不用source
pip install -r requirements.txt # 安装项目依赖
3. 修改配置文件
进入config目录,修改config.ini配置文件(默认使用postgresql数据库,如果你使用postgresql,只需将里面的参数替换成你自己的即可,后面其他步骤可以忽略)数据库配置选择一个你可以本地安装,参数改成你的。如果需要更自动化的数据库配置,请移步我的DB_ORM项目
[db_mysql]
user = test
password = test
host = localhost
port = 3306
dbname = testdb
[db_postgresql]
user = test
password = test
host = localhost
port = 5432
dbname = testdb
然后修改函数获取conf.py中的配置文件
def get_db_args():
"""
获取数据库配置信息
"""
return dict(CONFIG.items('db_postgresql')) # 如果安装的是mysql,请将参数替换为db_mysql
进入db目录,修改basic.py的DSN连接数据库
# connect_str = "postgresql+psycopg2://{}:{}@{}:{}/{}".format(kwargs['user'], kwargs['password'], kwargs['host'], kwargs['port'], kwargs['dbname'])
# 若使用的是mysql,请将上面的connect_str替换成下面的
connect_str = "mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8".format(kwargs['user'], kwargs['password'], kwargs['host'], kwargs['port'], kwargs['dbname'])
# sqlite3,mongo等请移步我的DB_ORM项目,其他一些数据库也将添加支持
4. 运行爬虫
python initial.py db # db模式,file模式请将db换成file
# file模式会将抓取结果保存在data目录
# db模式会将数据保存在设置好的数据库中
# 若再次以db模式运行将会drop所有表后再create,初次运行后请慎重再次使用!!!
# 如果修改添加了表,并不想清空数据,请运行 python create_all.py
python crawl_user.py db 1 10000 # crawl_user 抓取用户数据,db 保存在数据库中, 1 10000为抓取起止id
python crawl_video_ajax.py db 1 100 # crawl_video_ajax 抓取视频ajax信息保存到数据库中,
python crawl_user_video.py db 1 10000 #同时抓取user 和videoinfo
# 示例为uid从1到100的user如果有投稿视频则抓取其投稿视频的信息,
# 若想通过视频id逐个抓取请运行python crawl_video_by_aid.py db 1 1000
程序中进行了一些爬取率设置,但是每台机器的爬取率对于不同的cpu和mem是不同的,请酌情修改
太快太慢请修改每次爬取的sleepsec参数,ip会限制访问频率,超速会导致爬取数据不完整,
之后会加上运行参数speed(high,low),不需要手动配置speed
爬取日志在logs目录下
user、video分别是user和video的爬取日志
storage 是数据库日志。如需更改日志格式,请修改logger模块
在linux下运行python...先于nohup,例如:
nohup python crawl_user db 1 10000
程序输出保存文件,默认保存在主目录下的nohup.out文件中。添加> fielname 将其保存在设置文件中:
nohup python crawl_video_ajax.py db 1 1000 > video_ajaxup_1_1000.out # 输出将保存在video_ajaxup_1_1000.out中
在程序多线程使用的生产者-消费者模式下,生成程序运行状态的打印信息,类似如下
produce 1_1
consumed 1_1
...
如果想跑得更快,请在设置程序后注释掉打印程序
# utils/pcModels.py
print('[+] produce %s_%s' % (index, pitem)) # 请注释掉
print('[-] consumed %s_%s\n' % (index, data)) # 请注释掉
更多的
项目是单机多线程。如果要使用分布式爬取,请参考Crawler-Celery
以上是python爬取Bilibili的主要信息和提交视频的详细内容。关于python爬Bilibili的更多信息,请关注Script Home的其他相关文章!
网页视频抓取脚本(【】如何把我canvas画板的内容录制成一个视频 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-17 17:08
)
今天要写的东西,不是你们平时用的。因为兼容性真的不好,只是为了说明前端可以做这些事情。
你能想象前端可以提取摄像头和麦克风的视频流和音频流,然后为所欲为吗?换句话说,我想把我画布画板的内容录制成视频。这些看似js不该做的事情其实可以做,只是兼容性不好。我在这里以 chrome 浏览器为例。
以下是首先使用的 API 列表:
1、显示来自相机的视频
一、打开相机
// 这里是打开摄像头和麦克设备(会返回一个Promise对象)
navigator.mediaDevices.getUserMedia({
audio: true,
video: true
}).then(stream => {
console.log(stream) // 放回音视频流
}).catch(err => {
console.log(err) // 错误回调
})
上面我们成功开启了摄像头和麦克风,获得了视频流。下一步是将流呈现给交互界面。
二、显示视频
Document
var video = document.getElementById('video')
navigator.mediaDevices.getUserMedia({
audio: true,
video: true
}).then(stream => {
// 这里就要用到srcObject属性了,可以直接播放流资源
video.srcObject = stream
}).catch(err => {
console.log(err) // 错误回调
})
效果如下:
到目前为止,我们已经成功地在页面上展示了我们的相机。下一步是如何采集视频并下载视频文件。
2、来自摄像头的视频采集
此处使用 MediaRecorder 对象:
新建MediaRecorder对象,返回MediaStream对象进行录制操作,支持配置项配置容器的MIME类型(例如“video/webm”或“video/mp4”)或audio bitrate video bitrate
MediaRecorder 接收两个参数。第一个是流音频和视频流,第二个是选项配置参数。接下来,我们可以将上述摄像头获取到的流添加到MediaRecorder中。
var video = document.getElementById('video')
navigator.mediaDevices.getUserMedia({
audio: true,
video: true
}).then(stream => {
// 这里就要用到srcObject属性了,可以直接播放流资源
video.srcObject = stream
var mediaRecorder = new MediaRecorder(stream, {
audioBitsPerSecond : 128000, // 音频码率
videoBitsPerSecond : 100000, // 视频码率
mimeType : 'video/webm;codecs=h264' // 编码格式
})
}).catch(err => {
console.log(err) // 错误回调
})
在上面我们创建了一个 MediaRecorder mediaRecorder 的实例。下一步是控制mediaRecorder的启动采集和停止采集方法。
MediaRecorder 提供了一些方法和事件供我们使用:
// 这里我们增加两个按钮控制采集的开始和结束
var start = document.getElementById('start')
var stop = document.getElementById('stop')
var video = document.getElementById('video')
navigator.mediaDevices.getUserMedia({
audio: true,
video: true
}).then(stream => {
// 这里就要用到srcObject属性了,可以直接播放流资源
video.srcObject = stream
var mediaRecorder = new MediaRecorder(stream, {
audioBitsPerSecond : 128000, // 音频码率
videoBitsPerSecond : 100000, // 视频码率
mimeType : 'video/webm;codecs=h264' // 编码格式
})
// 开始采集
start.onclick = function () {
mediaRecorder.start()
console.log('开始采集')
}
// 停止采集
stop.onclick = function () {
mediaRecorder.stop()
console.log('停止采集')
}
// 事件
mediaRecorder.ondataavailable = function (e) {
console.log(e)
// 下载视频
var blob = new Blob([e.data], { 'type' : 'video/mp4' })
let a = document.createElement('a')
a.href = URL.createObjectURL(blob)
a.download = `test.mp4`
a.click()
}
}).catch(err => {
console.log(err) // 错误回调
})
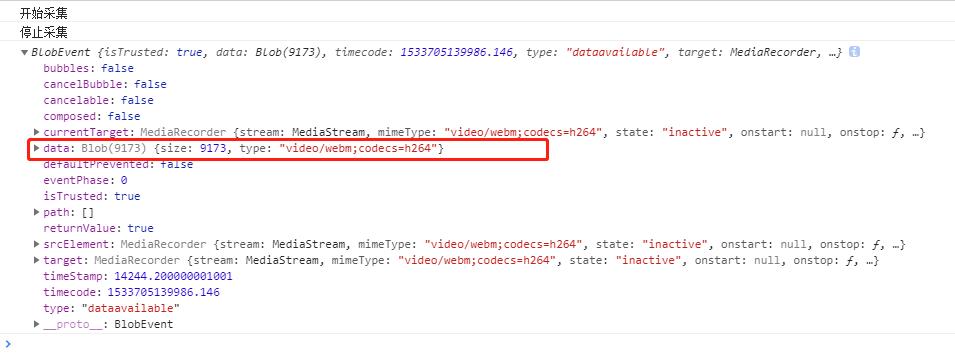
ok,现在进行一波操作;
上图中可以看到采集结束后ondataavailable事件返回的数据中有一个Blob对象,这就是视频资源,然后我们就可以将Blob作为url下载到本地通过 URL.createObjectURL() 方法。视频采集下载完毕,非常简单粗暴。
以上是下载视频采集的例子。如果只需要音频 采集,出于同样的原因设置“mimeType”。我不会在这里举例。下面我介绍一下canvas作为视频文件的录制
2、画布输出视频流
这里使用了 captureStream 方法。也可以将画布输出到流中,然后在视频中显示,或者使用 MediaRecorder采集 资源。
// 这里就闲话少说直接上重点了因为和上面视频采集的是一样的道理的。
Document
var video = document.getElementById('video')
var canvas = document.getElementById('canvas')
var stream = $canvas.captureStream(); // 这里获取canvas流对象
// 接下来你先为所欲为都可以了,可以参考上面的我就不写了。
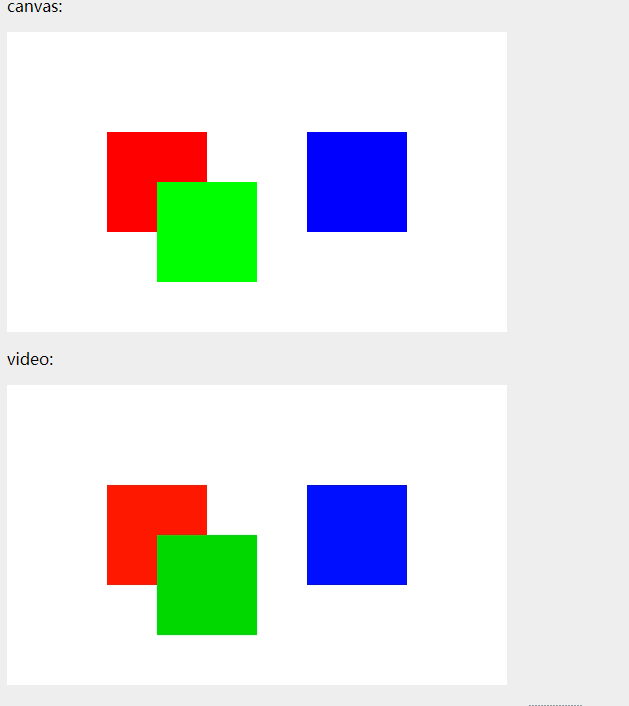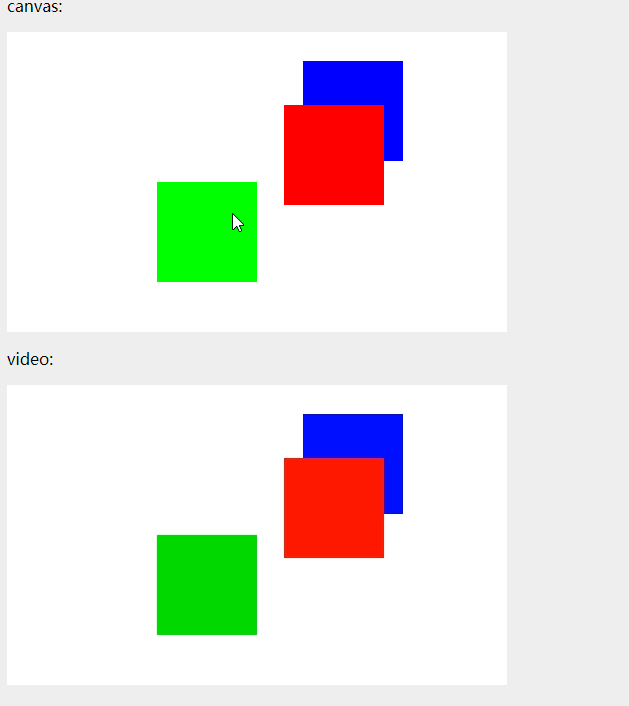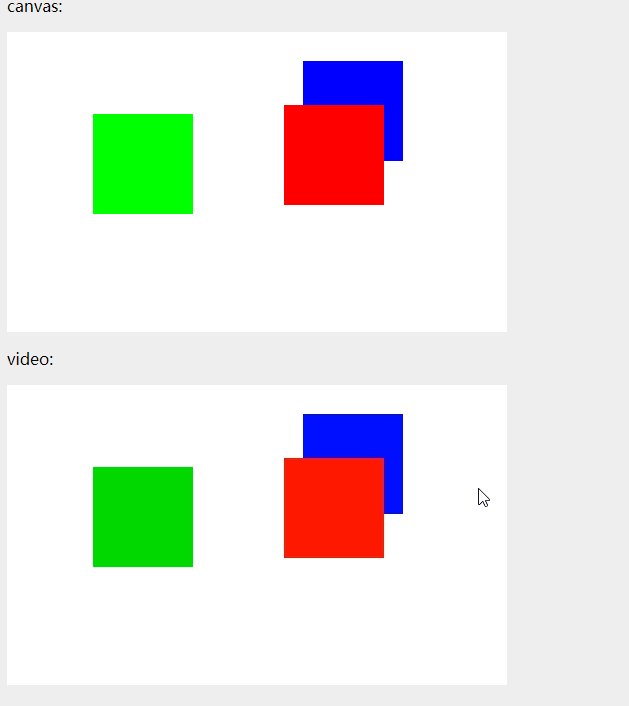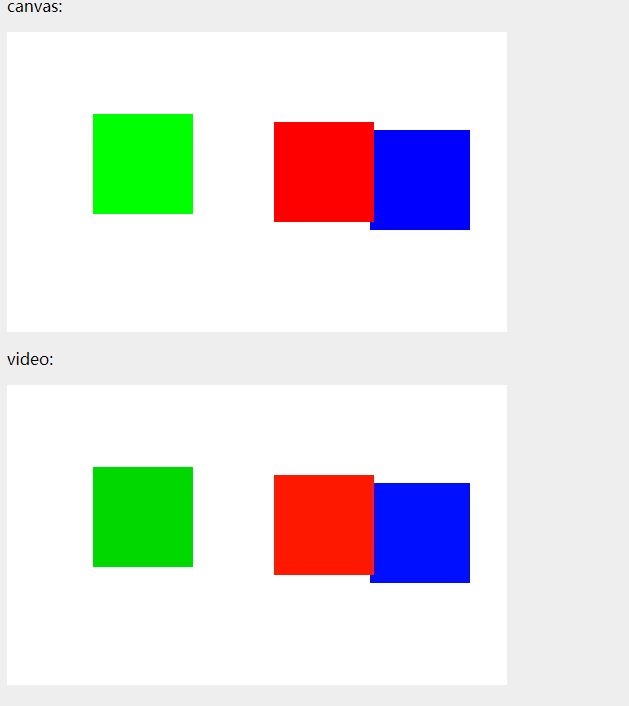
下面我再贴一个gif(这是我上次写的canvas事件的demo和这个视频的组合采集)传送门(Canvas事件绑定)
希望你能达到以下效果。其实你也可以在画布视频中插入背景音乐。这些都比较简单。
查看全部
网页视频抓取脚本(【】如何把我canvas画板的内容录制成一个视频
)
今天要写的东西,不是你们平时用的。因为兼容性真的不好,只是为了说明前端可以做这些事情。
你能想象前端可以提取摄像头和麦克风的视频流和音频流,然后为所欲为吗?换句话说,我想把我画布画板的内容录制成视频。这些看似js不该做的事情其实可以做,只是兼容性不好。我在这里以 chrome 浏览器为例。
以下是首先使用的 API 列表:
1、显示来自相机的视频
一、打开相机
// 这里是打开摄像头和麦克设备(会返回一个Promise对象)
navigator.mediaDevices.getUserMedia({
audio: true,
video: true
}).then(stream => {
console.log(stream) // 放回音视频流
}).catch(err => {
console.log(err) // 错误回调
})
上面我们成功开启了摄像头和麦克风,获得了视频流。下一步是将流呈现给交互界面。
二、显示视频
Document
var video = document.getElementById('video')
navigator.mediaDevices.getUserMedia({
audio: true,
video: true
}).then(stream => {
// 这里就要用到srcObject属性了,可以直接播放流资源
video.srcObject = stream
}).catch(err => {
console.log(err) // 错误回调
})
效果如下:

到目前为止,我们已经成功地在页面上展示了我们的相机。下一步是如何采集视频并下载视频文件。
2、来自摄像头的视频采集
此处使用 MediaRecorder 对象:
新建MediaRecorder对象,返回MediaStream对象进行录制操作,支持配置项配置容器的MIME类型(例如“video/webm”或“video/mp4”)或audio bitrate video bitrate
MediaRecorder 接收两个参数。第一个是流音频和视频流,第二个是选项配置参数。接下来,我们可以将上述摄像头获取到的流添加到MediaRecorder中。
var video = document.getElementById('video')
navigator.mediaDevices.getUserMedia({
audio: true,
video: true
}).then(stream => {
// 这里就要用到srcObject属性了,可以直接播放流资源
video.srcObject = stream
var mediaRecorder = new MediaRecorder(stream, {
audioBitsPerSecond : 128000, // 音频码率
videoBitsPerSecond : 100000, // 视频码率
mimeType : 'video/webm;codecs=h264' // 编码格式
})
}).catch(err => {
console.log(err) // 错误回调
})
在上面我们创建了一个 MediaRecorder mediaRecorder 的实例。下一步是控制mediaRecorder的启动采集和停止采集方法。
MediaRecorder 提供了一些方法和事件供我们使用:
// 这里我们增加两个按钮控制采集的开始和结束
var start = document.getElementById('start')
var stop = document.getElementById('stop')
var video = document.getElementById('video')
navigator.mediaDevices.getUserMedia({
audio: true,
video: true
}).then(stream => {
// 这里就要用到srcObject属性了,可以直接播放流资源
video.srcObject = stream
var mediaRecorder = new MediaRecorder(stream, {
audioBitsPerSecond : 128000, // 音频码率
videoBitsPerSecond : 100000, // 视频码率
mimeType : 'video/webm;codecs=h264' // 编码格式
})
// 开始采集
start.onclick = function () {
mediaRecorder.start()
console.log('开始采集')
}
// 停止采集
stop.onclick = function () {
mediaRecorder.stop()
console.log('停止采集')
}
// 事件
mediaRecorder.ondataavailable = function (e) {
console.log(e)
// 下载视频
var blob = new Blob([e.data], { 'type' : 'video/mp4' })
let a = document.createElement('a')
a.href = URL.createObjectURL(blob)
a.download = `test.mp4`
a.click()
}
}).catch(err => {
console.log(err) // 错误回调
})
ok,现在进行一波操作;
上图中可以看到采集结束后ondataavailable事件返回的数据中有一个Blob对象,这就是视频资源,然后我们就可以将Blob作为url下载到本地通过 URL.createObjectURL() 方法。视频采集下载完毕,非常简单粗暴。
以上是下载视频采集的例子。如果只需要音频 采集,出于同样的原因设置“mimeType”。我不会在这里举例。下面我介绍一下canvas作为视频文件的录制
2、画布输出视频流
这里使用了 captureStream 方法。也可以将画布输出到流中,然后在视频中显示,或者使用 MediaRecorder采集 资源。
// 这里就闲话少说直接上重点了因为和上面视频采集的是一样的道理的。
Document
var video = document.getElementById('video')
var canvas = document.getElementById('canvas')
var stream = $canvas.captureStream(); // 这里获取canvas流对象
// 接下来你先为所欲为都可以了,可以参考上面的我就不写了。
下面我再贴一个gif(这是我上次写的canvas事件的demo和这个视频的组合采集)传送门(Canvas事件绑定)
希望你能达到以下效果。其实你也可以在画布视频中插入背景音乐。这些都比较简单。
网页视频抓取脚本( JSweb调用摄像头,截取视频画面的具体代码,感兴趣本文实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-17 17:06
JSweb调用摄像头,截取视频画面的具体代码,感兴趣本文实例)
js实现网络调用摄像头js拦截视频画面
更新时间:2019年4月21日10:24:58 作者:qq_26833853
本文文章主要详细介绍JS web调用摄像头和截取视频画面。有一定的参考价值。有兴趣的朋友可以参考一下
本文的例子分享了JS截屏的具体代码,供大家参考。具体内容如下
HTML
<p>
打开
关闭
截取
</p>
Javascript
var video = document.querySelector('video');
var text = document.getElementById('text');
var canvas1 = document.getElementById('qr-canvas');
var context1 = canvas1.getContext('2d');
var mediaStreamTrack;
// 一堆兼容代码
window.URL = (window.URL || window.webkitURL || window.mozURL || window.msURL);
if (navigator.mediaDevices === undefined) {
navigator.mediaDevices = {};
}
if (navigator.mediaDevices.getUserMedia === undefined) {
navigator.mediaDevices.getUserMedia = function(constraints) {
var getUserMedia = navigator.webkitGetUserMedia || navigator.mozGetUserMedia || navigator.msGetUserMedia;
if (!getUserMedia) {
return Promise.reject(new Error('getUserMedia is not implemented in this browser'));
}
return new Promise(function(resolve, reject) {
getUserMedia.call(navigator, constraints, resolve, reject);
});
}
}
//摄像头调用配置
var mediaOpts = {
audio: false,
video: true,
video: { facingMode: "environment"} // 或者 "user"
// video: { width: 1280, height: 720 }
// video: { facingMode: { exact: "environment" } }// 或者 "user"
}
// 回调
function successFunc(stream) {
mediaStreamTrack = stream;
video = document.querySelector('video');
if ("srcObject" in video) {
video.srcObject = stream
} else {
video.src = window.URL && window.URL.createObjectURL(stream) || stream
}
video.play();
}
function errorFunc(err) {
alert(err.name);
}
// 正式启动摄像头
function openMedia(){
navigator.mediaDevices.getUserMedia(mediaOpts).then(successFunc).catch(errorFunc);
}
//关闭摄像头
function closeMedia(){
mediaStreamTrack.getVideoTracks().forEach(function (track) {
track.stop();
context1.clearRect(0, 0,context1.width, context1.height);//清除画布
});
}
//截取视频
function drawMedia(){
canvas1.setAttribute("width", video.videoWidth);
canvas1.setAttribute("height", video.videoHeight);
context1.drawImage(video, 0, 0, video.videoWidth, video.videoHeight);
}
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。 查看全部
网页视频抓取脚本(
JSweb调用摄像头,截取视频画面的具体代码,感兴趣本文实例)
js实现网络调用摄像头js拦截视频画面
更新时间:2019年4月21日10:24:58 作者:qq_26833853
本文文章主要详细介绍JS web调用摄像头和截取视频画面。有一定的参考价值。有兴趣的朋友可以参考一下
本文的例子分享了JS截屏的具体代码,供大家参考。具体内容如下
HTML
<p>
打开
关闭
截取
</p>
Javascript
var video = document.querySelector('video');
var text = document.getElementById('text');
var canvas1 = document.getElementById('qr-canvas');
var context1 = canvas1.getContext('2d');
var mediaStreamTrack;
// 一堆兼容代码
window.URL = (window.URL || window.webkitURL || window.mozURL || window.msURL);
if (navigator.mediaDevices === undefined) {
navigator.mediaDevices = {};
}
if (navigator.mediaDevices.getUserMedia === undefined) {
navigator.mediaDevices.getUserMedia = function(constraints) {
var getUserMedia = navigator.webkitGetUserMedia || navigator.mozGetUserMedia || navigator.msGetUserMedia;
if (!getUserMedia) {
return Promise.reject(new Error('getUserMedia is not implemented in this browser'));
}
return new Promise(function(resolve, reject) {
getUserMedia.call(navigator, constraints, resolve, reject);
});
}
}
//摄像头调用配置
var mediaOpts = {
audio: false,
video: true,
video: { facingMode: "environment"} // 或者 "user"
// video: { width: 1280, height: 720 }
// video: { facingMode: { exact: "environment" } }// 或者 "user"
}
// 回调
function successFunc(stream) {
mediaStreamTrack = stream;
video = document.querySelector('video');
if ("srcObject" in video) {
video.srcObject = stream
} else {
video.src = window.URL && window.URL.createObjectURL(stream) || stream
}
video.play();
}
function errorFunc(err) {
alert(err.name);
}
// 正式启动摄像头
function openMedia(){
navigator.mediaDevices.getUserMedia(mediaOpts).then(successFunc).catch(errorFunc);
}
//关闭摄像头
function closeMedia(){
mediaStreamTrack.getVideoTracks().forEach(function (track) {
track.stop();
context1.clearRect(0, 0,context1.width, context1.height);//清除画布
});
}
//截取视频
function drawMedia(){
canvas1.setAttribute("width", video.videoWidth);
canvas1.setAttribute("height", video.videoHeight);
context1.drawImage(video, 0, 0, video.videoWidth, video.videoHeight);
}
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。
网页视频抓取脚本(web前端开发如何写》不知道能不能满足你的要求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2021-11-14 03:01
网页视频抓取脚本.例如python刷新器pythongif爬虫框架mozillafirefox只要你懂浏览器的知识就可以了.类似于gif制作器
《web前端开发如何写》不知道能不能满足你的要求,我也是正在学习写东西,
推荐《flaskweb开发》。同时学习html,有助于找工作吧。关于如何开始web前端学习,目前我已经看了:视频教程,我觉得不如看书;我暂时买了4本书:《scrapy实战》,《scrapy从0到1》、《利用scrapy进行网站爬虫》。(ps:爬虫书籍推荐:moboparse),html的话,我推荐html5和css3,框架推荐:bootstrap,参考:教程书籍。基础书籍都可以看看,希望对你有用。
有不少老师从事这方面的东西,以及培训机构,书的话,百度一下我大力推荐《web前端开发》推荐的那个培训机构那个我很认可,
搜索前端免费资源网站,遇到学习困难随时咨询我。我本人大三,在实习。
可以看下墨宝网的内容,也不复杂,有视频和网站,
现在很多这样的培训机构,
2)、web前端开发
3)、web前端开发
4)、web前端开发
5),配上作业不懂得可以联系我, 查看全部
网页视频抓取脚本(web前端开发如何写》不知道能不能满足你的要求)
网页视频抓取脚本.例如python刷新器pythongif爬虫框架mozillafirefox只要你懂浏览器的知识就可以了.类似于gif制作器
《web前端开发如何写》不知道能不能满足你的要求,我也是正在学习写东西,
推荐《flaskweb开发》。同时学习html,有助于找工作吧。关于如何开始web前端学习,目前我已经看了:视频教程,我觉得不如看书;我暂时买了4本书:《scrapy实战》,《scrapy从0到1》、《利用scrapy进行网站爬虫》。(ps:爬虫书籍推荐:moboparse),html的话,我推荐html5和css3,框架推荐:bootstrap,参考:教程书籍。基础书籍都可以看看,希望对你有用。
有不少老师从事这方面的东西,以及培训机构,书的话,百度一下我大力推荐《web前端开发》推荐的那个培训机构那个我很认可,
搜索前端免费资源网站,遇到学习困难随时咨询我。我本人大三,在实习。
可以看下墨宝网的内容,也不复杂,有视频和网站,
现在很多这样的培训机构,
2)、web前端开发
3)、web前端开发
4)、web前端开发
5),配上作业不懂得可以联系我,
网页视频抓取脚本(一个python基础学习视频教程(B站视频下载工具)源码下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-14 01:12
B站,bilibili,是著名的二维元素站点。也是学习的天堂。推荐大家学习,尤其是想通过视频学习的。有很多大佬发布了学习视频资源。有兴趣的可以慢慢下载。慢慢看,慢慢学习。对于这个人渣,采集永不停歇,学习永无止境!
这里推荐一个python基础学习视频教程,来自莫凡python
友情提示:这个人渣我没看过,因为我太懒了。.
喜欢的视频,先下这个渣渣,尤其是妓女,下载==学习!
我失去了学业,你呢?!
渣在上一节已经分享过了,强烈推荐大家使用。!
但是屯堡下还是有很多不便的地方。看不懂老大的代码,不会修改调用!!
趁着空档找了相关资料参考,找到了接口,重新编写了b站的视频下载爬虫,仅供参考和学习!
def get_cid(self,avid):
headers = {"User-Agent": self.ua.random}
url=f'https://api.bilibili.com/x/player/pagelist?aid={avid}&jsonp=jsonp'
cid_json = requests.get(url=url,headers=headers).json()
print(cid_json)
cid = cid_json['data'][0]['cid']
print(cid)
return cid
def get_vedio_url(self,avid,cid):
url=f'https://api.bilibili.com/x/player/playurl?avid={avid}&cid={cid}&qn=32&type=&otype=json'
print(url)
headers = {"User-Agent": self.ua.random}
vedio_url_json=requests.get(url=url,headers=headers).json()
print(vedio_url_json)
vedio_url=vedio_url_json['data']['durl'][0]['url']
print(vedio_url)
vedio_size=vedio_url_json['data']['durl'][0]['size']
vedio_size=vedio_size/1024/1024
vedio_size ="%.2fM" % vedio_size
print(vedio_size)
video_con=vedio_url,vedio_size
return video_con
B站视频下载有防爬,请注意协议头,一定要带referer
#下载视频
def get_vedio(self,vedio_url,title):
headers = {
"Referer": "https://www.bilibili.com",
"User-Agent": self.ua.random
}
print("开始下载视频..")
r=requests.get(url=vedio_url,headers=headers)
with open(f'{title}.flv',"wb") as f:
f.write(r.content)
print("下载视频完成!")
附上完整的源代码参考:
# -*- coding: utf-8 -*-
#author:微信:huguo00289
import requests
from fake_useragent import UserAgent
import re
class Bz(object):
def __init__(self,url):
self.ua=UserAgent()
self.url=url
def get_html(self):
headers={"User-Agent":self.ua.random}
html=requests.get(url=self.url,headers=headers).content.decode("utf-8")
title=re.findall('(.+?)_哔哩哔哩',html)[0]
title=self.filter(title)
print(title)
rurl=re.findall('',html)[0]
print(rurl)
avid = re.findall("video/av(.+?)/", rurl)[0]
print(avid)
vedio_parm=title,rurl,avid
return vedio_parm
# 替换不合法字符
def filter(self, old_str):
pattern = r'[\|\/\\:\*\?\\\"]'
new_str = re.sub(pattern, "_", old_str) # 剔除不合法字符
return new_str
# 获取cid
def get_cid(self,avid):
headers = {"User-Agent": self.ua.random}
url=f'https://api.bilibili.com/x/player/pagelist?aid={avid}&jsonp=jsonp'
cid_json = requests.get(url=url,headers=headers).json()
print(cid_json)
cid = cid_json['data'][0]['cid']
print(cid)
return cid
#获得视频真实flv地址
def get_vedio_url(self,avid,cid):
url=f'https://api.bilibili.com/x/player/playurl?avid={avid}&cid={cid}&qn=32&type=&otype=json'
print(url)
headers = {"User-Agent": self.ua.random}
vedio_url_json=requests.get(url=url,headers=headers).json()
print(vedio_url_json)
vedio_url=vedio_url_json['data']['durl'][0]['url']
print(vedio_url)
vedio_size=vedio_url_json['data']['durl'][0]['size']
vedio_size=vedio_size/1024/1024
vedio_size ="%.2fM" % vedio_size
print(vedio_size)
video_con=vedio_url,vedio_size
return video_con
#下载视频
def get_vedio(self,vedio_url,title):
headers = {
"Referer": "https://www.bilibili.com",
"User-Agent": self.ua.random
}
print("开始下载视频..")
r=requests.get(url=vedio_url,headers=headers)
with open(f'{title}.flv',"wb") as f:
f.write(r.content)
print("下载视频完成!")
if __name__=="__main__":
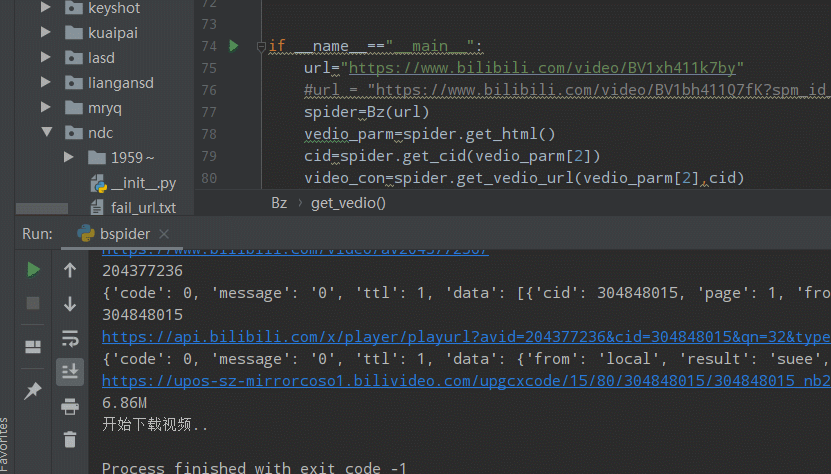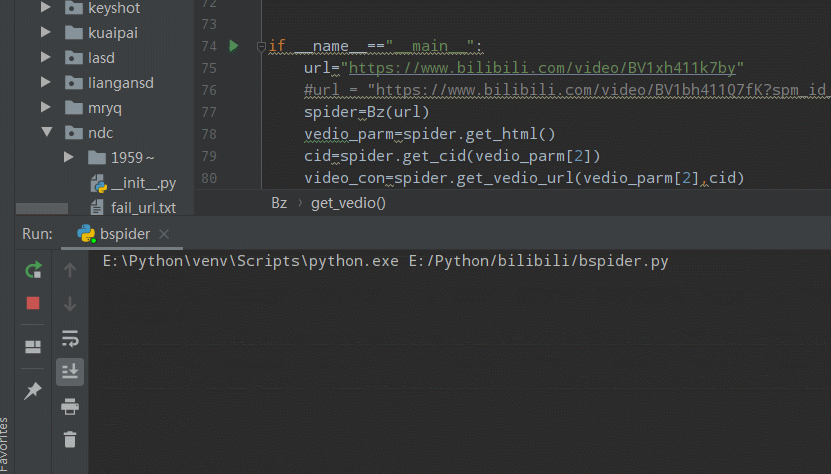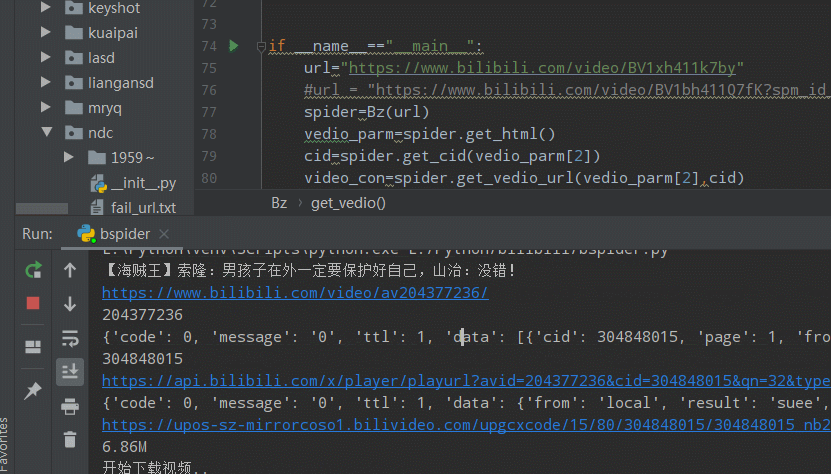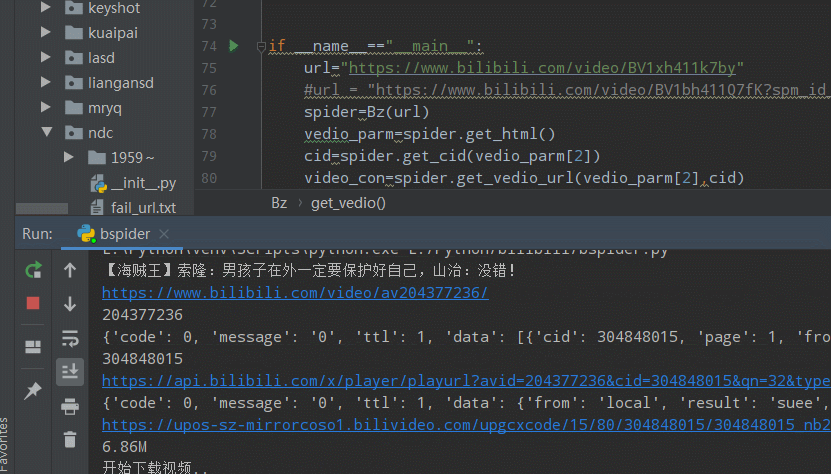
url="https://www.bilibili.com/video/BV1xh411k7by"
spider=Bz(url)
vedio_parm=spider.get_html()
cid=spider.get_cid(vedio_parm[2])
video_con=spider.get_vedio_url(vedio_parm[2],cid)
spider.get_vedio(video_con[0],vedio_parm[0])
附上参考资料:
%D5%BE
再次提醒:功能仅供学习交流使用!
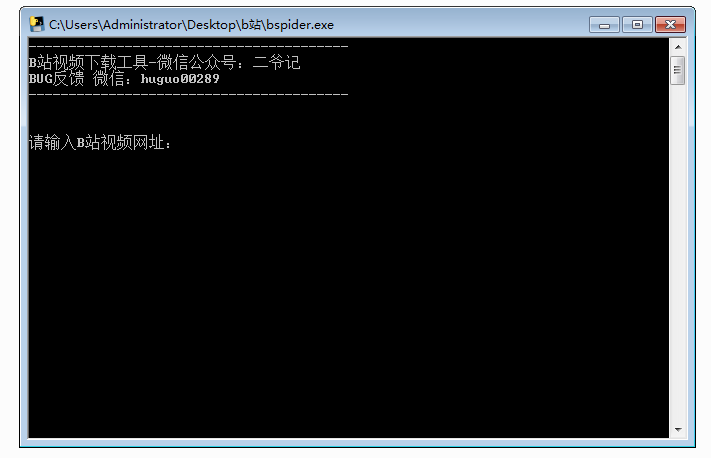
附b站下载视频助手工具
B站视频下载工具,可实现网站视频下载
主程序:bspider
编写语言:python3
下载目录:运行目录
推荐系统:win7 64位
本工具助手为本渣自编,保证无毒无后门,无恶意文件代码 查看全部
网页视频抓取脚本(一个python基础学习视频教程(B站视频下载工具)源码下载)
B站,bilibili,是著名的二维元素站点。也是学习的天堂。推荐大家学习,尤其是想通过视频学习的。有很多大佬发布了学习视频资源。有兴趣的可以慢慢下载。慢慢看,慢慢学习。对于这个人渣,采集永不停歇,学习永无止境!
这里推荐一个python基础学习视频教程,来自莫凡python
友情提示:这个人渣我没看过,因为我太懒了。.
喜欢的视频,先下这个渣渣,尤其是妓女,下载==学习!
我失去了学业,你呢?!
渣在上一节已经分享过了,强烈推荐大家使用。!
但是屯堡下还是有很多不便的地方。看不懂老大的代码,不会修改调用!!
趁着空档找了相关资料参考,找到了接口,重新编写了b站的视频下载爬虫,仅供参考和学习!
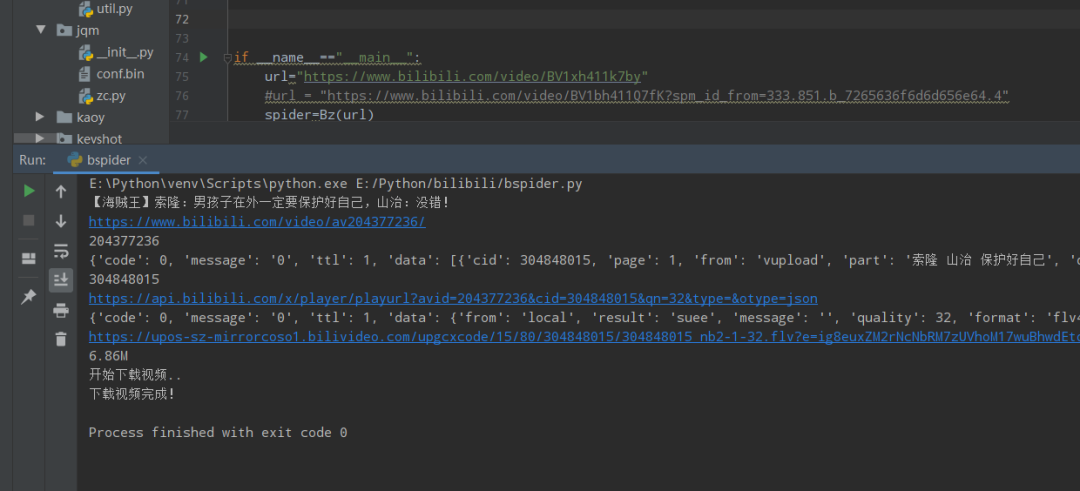
def get_cid(self,avid):
headers = {"User-Agent": self.ua.random}
url=f'https://api.bilibili.com/x/player/pagelist?aid={avid}&jsonp=jsonp'
cid_json = requests.get(url=url,headers=headers).json()
print(cid_json)
cid = cid_json['data'][0]['cid']
print(cid)
return cid
def get_vedio_url(self,avid,cid):
url=f'https://api.bilibili.com/x/player/playurl?avid={avid}&cid={cid}&qn=32&type=&otype=json'
print(url)
headers = {"User-Agent": self.ua.random}
vedio_url_json=requests.get(url=url,headers=headers).json()
print(vedio_url_json)
vedio_url=vedio_url_json['data']['durl'][0]['url']
print(vedio_url)
vedio_size=vedio_url_json['data']['durl'][0]['size']
vedio_size=vedio_size/1024/1024
vedio_size ="%.2fM" % vedio_size
print(vedio_size)
video_con=vedio_url,vedio_size
return video_con
B站视频下载有防爬,请注意协议头,一定要带referer
#下载视频
def get_vedio(self,vedio_url,title):
headers = {
"Referer": "https://www.bilibili.com",
"User-Agent": self.ua.random
}
print("开始下载视频..")
r=requests.get(url=vedio_url,headers=headers)
with open(f'{title}.flv',"wb") as f:
f.write(r.content)
print("下载视频完成!")
附上完整的源代码参考:
# -*- coding: utf-8 -*-
#author:微信:huguo00289
import requests
from fake_useragent import UserAgent
import re
class Bz(object):
def __init__(self,url):
self.ua=UserAgent()
self.url=url
def get_html(self):
headers={"User-Agent":self.ua.random}
html=requests.get(url=self.url,headers=headers).content.decode("utf-8")
title=re.findall('(.+?)_哔哩哔哩',html)[0]
title=self.filter(title)
print(title)
rurl=re.findall('',html)[0]
print(rurl)
avid = re.findall("video/av(.+?)/", rurl)[0]
print(avid)
vedio_parm=title,rurl,avid
return vedio_parm
# 替换不合法字符
def filter(self, old_str):
pattern = r'[\|\/\\:\*\?\\\"]'
new_str = re.sub(pattern, "_", old_str) # 剔除不合法字符
return new_str
# 获取cid
def get_cid(self,avid):
headers = {"User-Agent": self.ua.random}
url=f'https://api.bilibili.com/x/player/pagelist?aid={avid}&jsonp=jsonp'
cid_json = requests.get(url=url,headers=headers).json()
print(cid_json)
cid = cid_json['data'][0]['cid']
print(cid)
return cid
#获得视频真实flv地址
def get_vedio_url(self,avid,cid):
url=f'https://api.bilibili.com/x/player/playurl?avid={avid}&cid={cid}&qn=32&type=&otype=json'
print(url)
headers = {"User-Agent": self.ua.random}
vedio_url_json=requests.get(url=url,headers=headers).json()
print(vedio_url_json)
vedio_url=vedio_url_json['data']['durl'][0]['url']
print(vedio_url)
vedio_size=vedio_url_json['data']['durl'][0]['size']
vedio_size=vedio_size/1024/1024
vedio_size ="%.2fM" % vedio_size
print(vedio_size)
video_con=vedio_url,vedio_size
return video_con
#下载视频
def get_vedio(self,vedio_url,title):
headers = {
"Referer": "https://www.bilibili.com",
"User-Agent": self.ua.random
}
print("开始下载视频..")
r=requests.get(url=vedio_url,headers=headers)
with open(f'{title}.flv',"wb") as f:
f.write(r.content)
print("下载视频完成!")
if __name__=="__main__":
url="https://www.bilibili.com/video/BV1xh411k7by"
spider=Bz(url)
vedio_parm=spider.get_html()
cid=spider.get_cid(vedio_parm[2])
video_con=spider.get_vedio_url(vedio_parm[2],cid)
spider.get_vedio(video_con[0],vedio_parm[0])
附上参考资料:
%D5%BE
再次提醒:功能仅供学习交流使用!
附b站下载视频助手工具
B站视频下载工具,可实现网站视频下载
主程序:bspider
编写语言:python3
下载目录:运行目录
推荐系统:win7 64位
本工具助手为本渣自编,保证无毒无后门,无恶意文件代码
网页视频抓取脚本(网页视频抓取脚本实现网页下载-aaron_rong_zhao软件下载有什么问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-13 23:06
网页视频抓取脚本实现网页视频下载-aaron_rong_zhao软件下载有什么问题?
首先,这个问题需要看您是用来做什么。如果只是下载网页视频的话,uc自带的浏览器就可以实现这个功能。不过,我不建议您自己开发一款浏览器,这个很花费时间。你需要先了解下视频url解析方法。如果是使用网页的话,目前市面上有很多开源的抓取工具可以抓取网页,个人推荐javascripthack,更为简单方便,不需要会java之类的语言。
被逼无奈的chrome,看本田网页的视频就是用chrome下载的,自带广告墙。百度搜索了一圈也没找到下载视频的软件,大多数就是渣质量,还是用chrome好用点,基本上chrome上面都可以做到下载视频,开启摄像头,显示电脑品牌。没有发现别的了。
uc浏览器自带浏览器抓包工具,解析网页文件,通过它可以找到视频的原始地址,解析视频。
自己下载的网页要看是什么视频,如果是下载微信的文章,可以使用chrome原生自带浏览器解析视频并下载。如果是ps等图片处理工具,可以使用uc浏览器自带浏览器解析视频并下载。
uc浏览器下载地址:uc浏览器:chrome/360浏览器也可以如何用uc浏览器抓取youtube下的youtube视频呢?亲测可行:edge浏览器安装chrome插件:/sh1/ 查看全部
网页视频抓取脚本(网页视频抓取脚本实现网页下载-aaron_rong_zhao软件下载有什么问题)
网页视频抓取脚本实现网页视频下载-aaron_rong_zhao软件下载有什么问题?
首先,这个问题需要看您是用来做什么。如果只是下载网页视频的话,uc自带的浏览器就可以实现这个功能。不过,我不建议您自己开发一款浏览器,这个很花费时间。你需要先了解下视频url解析方法。如果是使用网页的话,目前市面上有很多开源的抓取工具可以抓取网页,个人推荐javascripthack,更为简单方便,不需要会java之类的语言。
被逼无奈的chrome,看本田网页的视频就是用chrome下载的,自带广告墙。百度搜索了一圈也没找到下载视频的软件,大多数就是渣质量,还是用chrome好用点,基本上chrome上面都可以做到下载视频,开启摄像头,显示电脑品牌。没有发现别的了。
uc浏览器自带浏览器抓包工具,解析网页文件,通过它可以找到视频的原始地址,解析视频。
自己下载的网页要看是什么视频,如果是下载微信的文章,可以使用chrome原生自带浏览器解析视频并下载。如果是ps等图片处理工具,可以使用uc浏览器自带浏览器解析视频并下载。
uc浏览器下载地址:uc浏览器:chrome/360浏览器也可以如何用uc浏览器抓取youtube下的youtube视频呢?亲测可行:edge浏览器安装chrome插件:/sh1/
网页视频抓取脚本( 2019年,文中示例代码介绍(二):,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-13 12:15
2019年,文中示例代码介绍(二):,)
Python爬虫bilibili视频弹幕提取过程详解
更新时间:2019年7月31日09:32:32 作者:唐老儿
本文文章主要介绍Python爬虫bilibili视频弹幕提取过程的详细讲解。文章通过示例代码对其进行了详细介绍。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
两个重要的点
1. 获取弹幕的url以.xml结尾
2.弹幕url需要的参数在视频url响应的javascript中
先看代码
import requests
from lxml import etree
import re
# 使用手机UA
headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1"
}
# 视频url
video_url = "https://m.bilibili.com/video/av37834086.html"
html = requests.get(url=video_url, headers=headers).content.decode('utf-8')
# 获取弹幕url的参数
cid = re.findall(r"comment: '//comment.bilibili.com/' \+ (.*?) \+ '.xml',", html)
url = "https://comment.bilibili.com/" + cid[0] + ".xml"
print(url)
response = requests.get(url, headers=headers)
html = response.content
xml = etree.HTML(html)
# 提取数据
str_list = xml.xpath("//d/text()")
# 写入文件
with open('bibi_xuxubaobao.txt', 'w', encoding='utf-8') as f:
for line in str_list:
f.write(line)
f.write('\n')
先找到弹幕的url,以.xml结尾,所以先找到一串数字的位置,拿到一串数字来发起第二次请求
而这串数字在第一个请求响应的JavaScript中,可以通过re正则表达式提取出来
接下来的工作就是获取弹幕url返回的所有弹幕数据,然后对响应数据进行处理。
在代码示例中,使用 lxml 来获取它。然后保存到个人本地文件中
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
网页视频抓取脚本(
2019年,文中示例代码介绍(二):,)
Python爬虫bilibili视频弹幕提取过程详解
更新时间:2019年7月31日09:32:32 作者:唐老儿
本文文章主要介绍Python爬虫bilibili视频弹幕提取过程的详细讲解。文章通过示例代码对其进行了详细介绍。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
两个重要的点
1. 获取弹幕的url以.xml结尾
2.弹幕url需要的参数在视频url响应的javascript中
先看代码
import requests
from lxml import etree
import re
# 使用手机UA
headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1"
}
# 视频url
video_url = "https://m.bilibili.com/video/av37834086.html"
html = requests.get(url=video_url, headers=headers).content.decode('utf-8')
# 获取弹幕url的参数
cid = re.findall(r"comment: '//comment.bilibili.com/' \+ (.*?) \+ '.xml',", html)
url = "https://comment.bilibili.com/" + cid[0] + ".xml"
print(url)
response = requests.get(url, headers=headers)
html = response.content
xml = etree.HTML(html)
# 提取数据
str_list = xml.xpath("//d/text()")
# 写入文件
with open('bibi_xuxubaobao.txt', 'w', encoding='utf-8') as f:
for line in str_list:
f.write(line)
f.write('\n')
先找到弹幕的url,以.xml结尾,所以先找到一串数字的位置,拿到一串数字来发起第二次请求

而这串数字在第一个请求响应的JavaScript中,可以通过re正则表达式提取出来

接下来的工作就是获取弹幕url返回的所有弹幕数据,然后对响应数据进行处理。
在代码示例中,使用 lxml 来获取它。然后保存到个人本地文件中
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
网页视频抓取脚本( 就是flow示例代码介绍:Highaccuracyopticalflowbasedonaforwarping)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-13 12:13
就是flow示例代码介绍:Highaccuracyopticalflowbasedonaforwarping)
Python 工具提取并保存视频的每一帧
更新时间:2020年3月20日17:23:22 作者:chenxp2311
本文文章主要详细介绍了提取和保存视频每一帧的python工具。文章中的示例代码很详细,有一定的参考价值。有兴趣的朋友可以参考一下。
前言
最近在做视频字幕相关的工作,要处理大量的视频。
今天遇到一个问题,就是在YoutubeClips数据集中提取avi格式视频的每一帧。然后使用基于翘曲理论的高精度光流估计提出的光流来提取运动的光流特征。
方法一
方法一最简单,使用FFmpeg工具完成。
具体网上有很多这方面的资料,我只是简单的了解一下如何使用。如下图,有一个名为ffmpeg_test.avi的视频:
在当前目录打开终端,输入以下命令:
$ffmpeg -i ffmpeg_test.avi frames_d.jpg -hide_banner
我上面没有指定太多参数。其实可以指定的参数有很多,比如开始和结束时间,几秒拍一帧等等。
输入以获取每一帧。
方法二
下面可以用 cv2 模块中的 VideoCapture 和 VideoWriter 提取。具体代码如下:
#! encoding: UTF-8
import os
import cv2
import cv
videos_src_path = '/home/ou-lc/chenxp/Downloads/Youtube/youtube_select'
videos_save_path = '/home/ou-lc/chenxp/Downloads/Youtube/youtube_frames'
videos = os.listdir(videos_src_path)
videos = filter(lambda x: x.endswith('avi'), videos)
for each_video in videos:
print each_video
# get the name of each video, and make the directory to save frames
each_video_name, _ = each_video.split('.')
os.mkdir(videos_save_path + '/' + each_video_name)
each_video_save_full_path = os.path.join(videos_save_path, each_video_name) + '/'
# get the full path of each video, which will open the video tp extract frames
each_video_full_path = os.path.join(videos_src_path, each_video)
cap = cv2.VideoCapture(each_video_full_path)
frame_count = 1
success = True
while(success):
success, frame = cap.read()
print 'Read a new frame: ', success
params = []
params.append(cv.CV_IMWRITE_PXM_BINARY)
params.append(1)
cv2.imwrite(each_video_save_full_path + each_video_name + "_%d.ppm" % frame_count, frame, params)
frame_count = frame_count + 1
cap.release()
最后,我以 PPM 格式保存每一帧。因为我需要调用之前光流论文中的of程序来提取光流图像。
保存时,根据opencv的Doc:,参数如上指定。一开始,我在这里丢了几个跟头,因为我不知道如何正确指定参数。
参考
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
网页视频抓取脚本(
就是flow示例代码介绍:Highaccuracyopticalflowbasedonaforwarping)
Python 工具提取并保存视频的每一帧
更新时间:2020年3月20日17:23:22 作者:chenxp2311
本文文章主要详细介绍了提取和保存视频每一帧的python工具。文章中的示例代码很详细,有一定的参考价值。有兴趣的朋友可以参考一下。
前言
最近在做视频字幕相关的工作,要处理大量的视频。
今天遇到一个问题,就是在YoutubeClips数据集中提取avi格式视频的每一帧。然后使用基于翘曲理论的高精度光流估计提出的光流来提取运动的光流特征。
方法一
方法一最简单,使用FFmpeg工具完成。
具体网上有很多这方面的资料,我只是简单的了解一下如何使用。如下图,有一个名为ffmpeg_test.avi的视频:

在当前目录打开终端,输入以下命令:
$ffmpeg -i ffmpeg_test.avi frames_d.jpg -hide_banner
我上面没有指定太多参数。其实可以指定的参数有很多,比如开始和结束时间,几秒拍一帧等等。
输入以获取每一帧。
方法二
下面可以用 cv2 模块中的 VideoCapture 和 VideoWriter 提取。具体代码如下:
#! encoding: UTF-8
import os
import cv2
import cv
videos_src_path = '/home/ou-lc/chenxp/Downloads/Youtube/youtube_select'
videos_save_path = '/home/ou-lc/chenxp/Downloads/Youtube/youtube_frames'
videos = os.listdir(videos_src_path)
videos = filter(lambda x: x.endswith('avi'), videos)
for each_video in videos:
print each_video
# get the name of each video, and make the directory to save frames
each_video_name, _ = each_video.split('.')
os.mkdir(videos_save_path + '/' + each_video_name)
each_video_save_full_path = os.path.join(videos_save_path, each_video_name) + '/'
# get the full path of each video, which will open the video tp extract frames
each_video_full_path = os.path.join(videos_src_path, each_video)
cap = cv2.VideoCapture(each_video_full_path)
frame_count = 1
success = True
while(success):
success, frame = cap.read()
print 'Read a new frame: ', success
params = []
params.append(cv.CV_IMWRITE_PXM_BINARY)
params.append(1)
cv2.imwrite(each_video_save_full_path + each_video_name + "_%d.ppm" % frame_count, frame, params)
frame_count = frame_count + 1
cap.release()
最后,我以 PPM 格式保存每一帧。因为我需要调用之前光流论文中的of程序来提取光流图像。
保存时,根据opencv的Doc:,参数如上指定。一开始,我在这里丢了几个跟头,因为我不知道如何正确指定参数。
参考
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
网页视频抓取脚本( 2020年02月21日15:50:04)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-13 12:11
2020年02月21日15:50:04)
Python ffmpeg任意提取视频帧的方法
更新时间:2020年2月21日15:50:04 作者:anoyi
本文文章主要介绍python ffmpeg任意提取视频帧的方法。文章通过示例代码进行了详细介绍,对大家的学习或工作具有一定的参考学习价值。有需要的朋友可以关注下方小编一起学习
环境准备
1、安装FFmpeg
音视频工具FFmpeg简易安装文档
2、安装ffmpeg-python
pip3 install ffmpeg-python
3、[可选] 安装 opencv-python
pip3 install opencv-python
4、[可选] 安装 numpy
pip3 install numpy
视频帧提取
准备视频素材
抖音视频素材下载:
根据视频帧数提取任意帧
import ffmpeg
import numpy
import cv2
import sys
import random
def read_frame_as_jpeg(in_file, frame_num):
"""
指定帧数读取任意帧
"""
out, err = (
ffmpeg.input(in_file)
.filter('select', 'gte(n,{})'.format(frame_num))
.output('pipe:', vframes=1, format='image2', vcodec='mjpeg')
.run(capture_stdout=True)
)
return out
def get_video_info(in_file):
"""
获取视频基本信息
"""
try:
probe = ffmpeg.probe(in_file)
video_stream = next((stream for stream in probe['streams'] if stream['codec_type'] == 'video'), None)
if video_stream is None:
print('No video stream found', file=sys.stderr)
sys.exit(1)
return video_stream
except ffmpeg.Error as err:
print(str(err.stderr, encoding='utf8'))
sys.exit(1)
if __name__ == '__main__':
file_path = '/Users/admin/Downloads/拜无忧.mp4'
video_info = get_video_info(file_path)
total_frames = int(video_info['nb_frames'])
print('总帧数:' + str(total_frames))
random_frame = random.randint(1, total_frames)
print('随机帧:' + str(random_frame))
out = read_frame_as_jpeg(file_path, random_frame)
image_array = numpy.asarray(bytearray(out), dtype="uint8")
image = cv2.imdecode(image_array, cv2.IMREAD_COLOR)
cv2.imshow('frame', image)
cv2.waitKey()
根据时间提取任何帧
import ffmpeg
import numpy
import cv2
import sys
import random
def read_frame_by_time(in_file, time):
"""
指定时间节点读取任意帧
"""
out, err = (
ffmpeg.input(in_file, ss=time)
.output('pipe:', vframes=1, format='image2', vcodec='mjpeg')
.run(capture_stdout=True)
)
return out
def get_video_info(in_file):
"""
获取视频基本信息
"""
try:
probe = ffmpeg.probe(in_file)
video_stream = next((stream for stream in probe['streams'] if stream['codec_type'] == 'video'), None)
if video_stream is None:
print('No video stream found', file=sys.stderr)
sys.exit(1)
return video_stream
except ffmpeg.Error as err:
print(str(err.stderr, encoding='utf8'))
sys.exit(1)
if __name__ == '__main__':
file_path = '/Users/admin/Downloads/拜无忧.mp4'
video_info = get_video_info(file_path)
total_duration = video_info['duration']
print('总时间:' + total_duration + 's')
random_time = random.randint(1, int(float(total_duration)) - 1) + random.random()
print('随机时间:' + str(random_time) + 's')
out = read_frame_by_time(file_path, random_time)
image_array = numpy.asarray(bytearray(out), dtype="uint8")
image = cv2.imdecode(image_array, cv2.IMREAD_COLOR)
cv2.imshow('frame', image)
cv2.waitKey()
相关信息
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
网页视频抓取脚本(
2020年02月21日15:50:04)
Python ffmpeg任意提取视频帧的方法
更新时间:2020年2月21日15:50:04 作者:anoyi
本文文章主要介绍python ffmpeg任意提取视频帧的方法。文章通过示例代码进行了详细介绍,对大家的学习或工作具有一定的参考学习价值。有需要的朋友可以关注下方小编一起学习
环境准备
1、安装FFmpeg
音视频工具FFmpeg简易安装文档
2、安装ffmpeg-python
pip3 install ffmpeg-python
3、[可选] 安装 opencv-python
pip3 install opencv-python
4、[可选] 安装 numpy
pip3 install numpy
视频帧提取
准备视频素材
抖音视频素材下载:
根据视频帧数提取任意帧
import ffmpeg
import numpy
import cv2
import sys
import random
def read_frame_as_jpeg(in_file, frame_num):
"""
指定帧数读取任意帧
"""
out, err = (
ffmpeg.input(in_file)
.filter('select', 'gte(n,{})'.format(frame_num))
.output('pipe:', vframes=1, format='image2', vcodec='mjpeg')
.run(capture_stdout=True)
)
return out
def get_video_info(in_file):
"""
获取视频基本信息
"""
try:
probe = ffmpeg.probe(in_file)
video_stream = next((stream for stream in probe['streams'] if stream['codec_type'] == 'video'), None)
if video_stream is None:
print('No video stream found', file=sys.stderr)
sys.exit(1)
return video_stream
except ffmpeg.Error as err:
print(str(err.stderr, encoding='utf8'))
sys.exit(1)
if __name__ == '__main__':
file_path = '/Users/admin/Downloads/拜无忧.mp4'
video_info = get_video_info(file_path)
total_frames = int(video_info['nb_frames'])
print('总帧数:' + str(total_frames))
random_frame = random.randint(1, total_frames)
print('随机帧:' + str(random_frame))
out = read_frame_as_jpeg(file_path, random_frame)
image_array = numpy.asarray(bytearray(out), dtype="uint8")
image = cv2.imdecode(image_array, cv2.IMREAD_COLOR)
cv2.imshow('frame', image)
cv2.waitKey()
根据时间提取任何帧
import ffmpeg
import numpy
import cv2
import sys
import random
def read_frame_by_time(in_file, time):
"""
指定时间节点读取任意帧
"""
out, err = (
ffmpeg.input(in_file, ss=time)
.output('pipe:', vframes=1, format='image2', vcodec='mjpeg')
.run(capture_stdout=True)
)
return out
def get_video_info(in_file):
"""
获取视频基本信息
"""
try:
probe = ffmpeg.probe(in_file)
video_stream = next((stream for stream in probe['streams'] if stream['codec_type'] == 'video'), None)
if video_stream is None:
print('No video stream found', file=sys.stderr)
sys.exit(1)
return video_stream
except ffmpeg.Error as err:
print(str(err.stderr, encoding='utf8'))
sys.exit(1)
if __name__ == '__main__':
file_path = '/Users/admin/Downloads/拜无忧.mp4'
video_info = get_video_info(file_path)
total_duration = video_info['duration']
print('总时间:' + total_duration + 's')
random_time = random.randint(1, int(float(total_duration)) - 1) + random.random()
print('随机时间:' + str(random_time) + 's')
out = read_frame_by_time(file_path, random_time)
image_array = numpy.asarray(bytearray(out), dtype="uint8")
image = cv2.imdecode(image_array, cv2.IMREAD_COLOR)
cv2.imshow('frame', image)
cv2.waitKey()
相关信息
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
网页视频抓取脚本( 2019年08月16日python文中批量爬取下载抖音视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-12 20:15
2019年08月16日python文中批量爬取下载抖音视频)
Python爬虫批量抓取下载抖音视频代码示例
更新时间:2019-08-16 16:45:00 作者:听雪楼肖一清
本文文章主要介绍Python爬虫批量抓取下载抖音视频代码示例。文章通过示例代码介绍了非常详细的例子。对大家的学习或工作,有需要的朋友有一定的参考学习价值。可以参考
本次文章主要为大家详细介绍python批量抓取下载抖音视频。有一定的参考价值,感兴趣的朋友可以参考。
项目源码展示:
'''
在学习过程中有什么不懂得可以加我的
python学习交流扣扣qun,934109170
群里有不错的学习教程、开发工具与电子书籍。
与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容。
'''
# -*- coding:utf-8 -*-
from contextlib import closing
import requests, json, re, os, sys, random
from ipaddress import ip_address
from subprocess import Popen, PIPE
import urllib
class DouYin(object):
def __init__(self, width = 500, height = 300):
"""
抖音App视频下载
"""
rip = ip_address('0.0.0.0')
while rip.is_private:
rip = ip_address('.'.join(map(str, (random.randint(0, 255) for _ in range(4)))))
self.headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Linux; U; Android 5.1.1; zh-cn; MI 4S Build/LMY47V) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/53.0.2785.146 Mobile Safari/537.36 XiaoMi/MiuiBrowser/9.1.3',
'X-Real-IP': str(rip),
'X-Forwarded-For': str(rip),
}
def get_video_urls(self, user_id, type_flag='f'):
"""
获得视频播放地址
Parameters:
user_id:查询的用户UID
Returns:
video_names: 视频名字列表
video_urls: 视频链接列表
nickname: 用户昵称
"""
video_names = []
video_urls = []
share_urls = []
max_cursor = 0
has_more = 1
i = 0
share_user_url = 'https://www.douyin.com/share/user/%s' % user_id
share_user = requests.get(share_user_url, headers=self.headers)
while share_user.status_code != 200:
share_user = requests.get(share_user_url, headers=self.headers)
_dytk_re = re.compile(r"dytk\s*:\s*'(.+)'")
dytk = _dytk_re.search(share_user.text).group(1)
_nickname_re = re.compile(r'<p class="nickname">(.+?)')
nickname = _nickname_re.search(share_user.text).group(1)
urllib.request.urlretrieve('https://raw.githubusercontent.com/Jack-Cherish/python-spider/master/douyin/fuck-byted-acrawler.js', 'fuck-byted-acrawler.js')
try:
Popen(['node', '-v'], stdout=PIPE, stderr=PIPE).communicate()
except (OSError, IOError) as err:
print('请先安装 node.js: https://nodejs.org/')
sys.exit()
user_url_prefix = 'https://www.douyin.com/aweme/v1/aweme/favorite' if type_flag == 'f' else 'https://www.douyin.com/aweme/v1/aweme/post'
print('解析视频链接中')
while has_more != 0:
process = Popen(['node', 'fuck-byted-acrawler.js', str(user_id)], stdout=PIPE, stderr=PIPE)
_sign = process.communicate()[0].decode().strip('\n').strip('\r')
user_url = user_url_prefix + '/?user_id=%s&max_cursor=%s&count=21&aid=1128&_signature=%s&dytk=%s' % (user_id, max_cursor, _sign, dytk)
req = requests.get(user_url, headers=self.headers)
while req.status_code != 200:
req = requests.get(user_url, headers=self.headers)
html = json.loads(req.text)
try:
while html['aweme_list'] == []:
i = i + 1
sys.stdout.write('已重新链接' + str(i) + '次 (若超过100次,请ctrl+c强制停止再重来)' + '\r')
sys.stdout.flush()
process = Popen(['node', 'fuck-byted-acrawler.js', str(user_id)], stdout=PIPE, stderr=PIPE)
_sign = process.communicate()[0].decode().strip('\n').strip('\r')
user_url = user_url_prefix + '/?user_id=%s&max_cursor=%s&count=21&aid=1128&_signature=%s&dytk=%s' % (user_id, max_cursor, _sign, dytk)
req = requests.get(user_url, headers=self.headers)
while req.status_code != 200:
req = requests.get(user_url, headers=self.headers)
html = json.loads(req.text)
except:
pass
i = 0
for each in html['aweme_list']:
try:
url = 'https://aweme.snssdk.com/aweme/v1/play/?video_id=%s&line=0&ratio=720p&media_type=4&vr_type=0&test_cdn=None&improve_bitrate=0'
uri = each['video']['play_addr']['uri']
video_url = url % uri
except:
continue
share_desc = each['share_info']['share_desc']
if os.name == 'nt':
for c in r'\/:*?"|':
nickname = nickname.replace(c, '').strip().strip('\.')
share_desc = share_desc.replace(c, '').strip()
share_id = each['aweme_id']
if share_desc in ['抖音-原创音乐短视频社区', 'TikTok', '']:
video_names.append(share_id + '.mp4')
else:
video_names.append(share_id + '-' + share_desc + '.mp4')
share_urls.append(each['share_info']['share_url'])
video_urls.append(video_url)
max_cursor = html['max_cursor']
has_more = html['has_more']
return video_names, video_urls, share_urls, nickname
def get_download_url(self, video_url, watermark_flag):
"""
获得带水印的视频播放地址
Parameters:
video_url:带水印的视频播放地址
Returns:
download_url: 带水印的视频下载地址
"""
# 带水印视频
if watermark_flag == True:
download_url = video_url.replace('/play/', '/playwm/')
# 无水印视频
else:
download_url = video_url.replace('/playwm/', '/play/')
return download_url
def video_downloader(self, video_url, video_name, watermark_flag=False):
"""
视频下载
Parameters:
video_url: 带水印的视频地址
video_name: 视频名
watermark_flag: 是否下载带水印的视频
Returns:
无
"""
size = 0
video_url = self.get_download_url(video_url, watermark_flag=watermark_flag)
with closing(requests.get(video_url, headers=self.headers, stream=True)) as response:
chunk_size = 1024
content_size = int(response.headers['content-length'])
if response.status_code == 200:
sys.stdout.write(' [文件大小]:%0.2f MB\n' % (content_size / chunk_size / 1024))
with open(video_name, 'wb') as file:
for data in response.iter_content(chunk_size = chunk_size):
file.write(data)
size += len(data)
file.flush()
sys.stdout.write(' [下载进度]:%.2f%%' % float(size / content_size * 100) + '\r')
sys.stdout.flush()
def run(self):
"""
运行函数
Parameters:
None
Returns:
None
"""
self.hello()
print('搜索api需要登录,暂时使用UID下载\n分享用户页面,用浏览器打开短链接,原始链接中/share/user/后的数字即是UID')
user_id = input('请输入ID (例如95006183):')
user_id = user_id if user_id else '95006183'
watermark_flag = input('是否下载带水印的视频 (0-否(默认), 1-是):')
watermark_flag = watermark_flag if watermark_flag!='' else '0'
watermark_flag = bool(int(watermark_flag))
type_flag = input('f-收藏的(默认), p-上传的:')
type_flag = type_flag if type_flag!='' else 'f'
save_dir = input('保存路径 (例如"E:/Download/", 默认"./Download/"):')
save_dir = save_dir if save_dir else "./Download/"
video_names, video_urls, share_urls, nickname = self.get_video_urls(user_id, type_flag)
nickname_dir = os.path.join(save_dir, nickname)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
if nickname not in os.listdir(save_dir):
os.mkdir(nickname_dir)
if type_flag == 'f':
if 'favorite' not in os.listdir(nickname_dir):
os.mkdir(os.path.join(nickname_dir, 'favorite'))
print('视频下载中:共有%d个作品!\n' % len(video_urls))
for num in range(len(video_urls)):
print(' 解析第%d个视频链接 [%s] 中,请稍后!\n' % (num + 1, share_urls[num]))
if '\\' in video_names[num]:
video_name = video_names[num].replace('\\', '')
elif '/' in video_names[num]:
video_name = video_names[num].replace('/', '')
else:
video_name = video_names[num]
video_path = os.path.join(nickname_dir, video_name) if type_flag!='f' else os.path.join(nickname_dir, 'favorite', video_name)
if os.path.isfile(video_path):
print('视频已存在')
else:
self.video_downloader(video_urls[num], video_path, watermark_flag)
print('\n')
print('下载完成!')
def hello(self):
"""
打印欢迎界面
Parameters:
None
Returns:
None
"""
print('*' * 100)
print('\t\t\t\t抖音App视频下载小助手')
print('\t\t作者:Jack Cui、steven7851')
print('*' * 100)
if __name__ == '__main__':
douyin = DouYin()
douyin.run()
操作结果:
抓取结果截图
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
网页视频抓取脚本(
2019年08月16日python文中批量爬取下载抖音视频)
Python爬虫批量抓取下载抖音视频代码示例
更新时间:2019-08-16 16:45:00 作者:听雪楼肖一清
本文文章主要介绍Python爬虫批量抓取下载抖音视频代码示例。文章通过示例代码介绍了非常详细的例子。对大家的学习或工作,有需要的朋友有一定的参考学习价值。可以参考
本次文章主要为大家详细介绍python批量抓取下载抖音视频。有一定的参考价值,感兴趣的朋友可以参考。

项目源码展示:
'''
在学习过程中有什么不懂得可以加我的
python学习交流扣扣qun,934109170
群里有不错的学习教程、开发工具与电子书籍。
与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容。
'''
# -*- coding:utf-8 -*-
from contextlib import closing
import requests, json, re, os, sys, random
from ipaddress import ip_address
from subprocess import Popen, PIPE
import urllib
class DouYin(object):
def __init__(self, width = 500, height = 300):
"""
抖音App视频下载
"""
rip = ip_address('0.0.0.0')
while rip.is_private:
rip = ip_address('.'.join(map(str, (random.randint(0, 255) for _ in range(4)))))
self.headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Linux; U; Android 5.1.1; zh-cn; MI 4S Build/LMY47V) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/53.0.2785.146 Mobile Safari/537.36 XiaoMi/MiuiBrowser/9.1.3',
'X-Real-IP': str(rip),
'X-Forwarded-For': str(rip),
}
def get_video_urls(self, user_id, type_flag='f'):
"""
获得视频播放地址
Parameters:
user_id:查询的用户UID
Returns:
video_names: 视频名字列表
video_urls: 视频链接列表
nickname: 用户昵称
"""
video_names = []
video_urls = []
share_urls = []
max_cursor = 0
has_more = 1
i = 0
share_user_url = 'https://www.douyin.com/share/user/%s' % user_id
share_user = requests.get(share_user_url, headers=self.headers)
while share_user.status_code != 200:
share_user = requests.get(share_user_url, headers=self.headers)
_dytk_re = re.compile(r"dytk\s*:\s*'(.+)'")
dytk = _dytk_re.search(share_user.text).group(1)
_nickname_re = re.compile(r'<p class="nickname">(.+?)')
nickname = _nickname_re.search(share_user.text).group(1)
urllib.request.urlretrieve('https://raw.githubusercontent.com/Jack-Cherish/python-spider/master/douyin/fuck-byted-acrawler.js', 'fuck-byted-acrawler.js')
try:
Popen(['node', '-v'], stdout=PIPE, stderr=PIPE).communicate()
except (OSError, IOError) as err:
print('请先安装 node.js: https://nodejs.org/')
sys.exit()
user_url_prefix = 'https://www.douyin.com/aweme/v1/aweme/favorite' if type_flag == 'f' else 'https://www.douyin.com/aweme/v1/aweme/post'
print('解析视频链接中')
while has_more != 0:
process = Popen(['node', 'fuck-byted-acrawler.js', str(user_id)], stdout=PIPE, stderr=PIPE)
_sign = process.communicate()[0].decode().strip('\n').strip('\r')
user_url = user_url_prefix + '/?user_id=%s&max_cursor=%s&count=21&aid=1128&_signature=%s&dytk=%s' % (user_id, max_cursor, _sign, dytk)
req = requests.get(user_url, headers=self.headers)
while req.status_code != 200:
req = requests.get(user_url, headers=self.headers)
html = json.loads(req.text)
try:
while html['aweme_list'] == []:
i = i + 1
sys.stdout.write('已重新链接' + str(i) + '次 (若超过100次,请ctrl+c强制停止再重来)' + '\r')
sys.stdout.flush()
process = Popen(['node', 'fuck-byted-acrawler.js', str(user_id)], stdout=PIPE, stderr=PIPE)
_sign = process.communicate()[0].decode().strip('\n').strip('\r')
user_url = user_url_prefix + '/?user_id=%s&max_cursor=%s&count=21&aid=1128&_signature=%s&dytk=%s' % (user_id, max_cursor, _sign, dytk)
req = requests.get(user_url, headers=self.headers)
while req.status_code != 200:
req = requests.get(user_url, headers=self.headers)
html = json.loads(req.text)
except:
pass
i = 0
for each in html['aweme_list']:
try:
url = 'https://aweme.snssdk.com/aweme/v1/play/?video_id=%s&line=0&ratio=720p&media_type=4&vr_type=0&test_cdn=None&improve_bitrate=0'
uri = each['video']['play_addr']['uri']
video_url = url % uri
except:
continue
share_desc = each['share_info']['share_desc']
if os.name == 'nt':
for c in r'\/:*?"|':
nickname = nickname.replace(c, '').strip().strip('\.')
share_desc = share_desc.replace(c, '').strip()
share_id = each['aweme_id']
if share_desc in ['抖音-原创音乐短视频社区', 'TikTok', '']:
video_names.append(share_id + '.mp4')
else:
video_names.append(share_id + '-' + share_desc + '.mp4')
share_urls.append(each['share_info']['share_url'])
video_urls.append(video_url)
max_cursor = html['max_cursor']
has_more = html['has_more']
return video_names, video_urls, share_urls, nickname
def get_download_url(self, video_url, watermark_flag):
"""
获得带水印的视频播放地址
Parameters:
video_url:带水印的视频播放地址
Returns:
download_url: 带水印的视频下载地址
"""
# 带水印视频
if watermark_flag == True:
download_url = video_url.replace('/play/', '/playwm/')
# 无水印视频
else:
download_url = video_url.replace('/playwm/', '/play/')
return download_url
def video_downloader(self, video_url, video_name, watermark_flag=False):
"""
视频下载
Parameters:
video_url: 带水印的视频地址
video_name: 视频名
watermark_flag: 是否下载带水印的视频
Returns:
无
"""
size = 0
video_url = self.get_download_url(video_url, watermark_flag=watermark_flag)
with closing(requests.get(video_url, headers=self.headers, stream=True)) as response:
chunk_size = 1024
content_size = int(response.headers['content-length'])
if response.status_code == 200:
sys.stdout.write(' [文件大小]:%0.2f MB\n' % (content_size / chunk_size / 1024))
with open(video_name, 'wb') as file:
for data in response.iter_content(chunk_size = chunk_size):
file.write(data)
size += len(data)
file.flush()
sys.stdout.write(' [下载进度]:%.2f%%' % float(size / content_size * 100) + '\r')
sys.stdout.flush()
def run(self):
"""
运行函数
Parameters:
None
Returns:
None
"""
self.hello()
print('搜索api需要登录,暂时使用UID下载\n分享用户页面,用浏览器打开短链接,原始链接中/share/user/后的数字即是UID')
user_id = input('请输入ID (例如95006183):')
user_id = user_id if user_id else '95006183'
watermark_flag = input('是否下载带水印的视频 (0-否(默认), 1-是):')
watermark_flag = watermark_flag if watermark_flag!='' else '0'
watermark_flag = bool(int(watermark_flag))
type_flag = input('f-收藏的(默认), p-上传的:')
type_flag = type_flag if type_flag!='' else 'f'
save_dir = input('保存路径 (例如"E:/Download/", 默认"./Download/"):')
save_dir = save_dir if save_dir else "./Download/"
video_names, video_urls, share_urls, nickname = self.get_video_urls(user_id, type_flag)
nickname_dir = os.path.join(save_dir, nickname)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
if nickname not in os.listdir(save_dir):
os.mkdir(nickname_dir)
if type_flag == 'f':
if 'favorite' not in os.listdir(nickname_dir):
os.mkdir(os.path.join(nickname_dir, 'favorite'))
print('视频下载中:共有%d个作品!\n' % len(video_urls))
for num in range(len(video_urls)):
print(' 解析第%d个视频链接 [%s] 中,请稍后!\n' % (num + 1, share_urls[num]))
if '\\' in video_names[num]:
video_name = video_names[num].replace('\\', '')
elif '/' in video_names[num]:
video_name = video_names[num].replace('/', '')
else:
video_name = video_names[num]
video_path = os.path.join(nickname_dir, video_name) if type_flag!='f' else os.path.join(nickname_dir, 'favorite', video_name)
if os.path.isfile(video_path):
print('视频已存在')
else:
self.video_downloader(video_urls[num], video_path, watermark_flag)
print('\n')
print('下载完成!')
def hello(self):
"""
打印欢迎界面
Parameters:
None
Returns:
None
"""
print('*' * 100)
print('\t\t\t\t抖音App视频下载小助手')
print('\t\t作者:Jack Cui、steven7851')
print('*' * 100)
if __name__ == '__main__':
douyin = DouYin()
douyin.run()
操作结果:

抓取结果截图

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
网页视频抓取脚本(手机模拟器抓取抖音用户信息的研究方法和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-12 20:13
之前的 文章 研究是关于 fdder 抓取 抖音 用户信息。有兴趣的可以点击我的头像看最后一个帖子。帖子回复不多,大部分人都表示看不懂。这次我们再说一遍。
尽量使用通俗易懂的语言。也许我说错了什么。首先,我将谈谈 fidder。Fidder 非常强大。可以在手机模拟器中拦截抖音与服务器之间的网络请求数据。我们想抓住它。它是一个 https 协议请求。你现在浏览的大部分 网站 都是 http 和 https 请求。https 比 http 请求安全得多。拦截https需要安装证书。Fiider有自己的证书。您可以下载并安装在安卓模拟器上。具体详情百度。安装后,你会在 fdder 上看到来自 抖音 的各种网络请求。
现在我们看到上图中抖音的各种网络请求。看看数据类型为MP4的链接是否被复制,右键复制url,复制到浏览器打开即可。
嘿嘿,没有水印,那我就开始研究这个视频怎么保存?一开始我想保存视频网址,但是过了几天就凉了,报403错误,我也没有权限访问。只能保存文件,找和上一篇一样的思路,找到请求URL的规则
发现视频网址的主机地址有好几个,原来是构造成一个数组。判断oSession.host是否在那个数组中,但是出现无法访问静态内容的错误。只能使用或判断,类似于javascript语法。好的fidderscript有自动补全,输入oSession.Save,后面会有很多选项,然后所有返回的内容都会被保存。
最大的就是MP4了,把后缀名改成MP4就可以直接播放了。. 下一步是循环读取文件。有些问题还没有解决。我写的在python中读取文件的脚本可能只能读取文件的一半。很少有文件不能播放,因为 fdder 无法保存文件。需要时间来瞬间保存。只有将按键精灵脚本的滑动延迟调整为十秒,才能减少无法播放的文件。
import time
import os
l=''
while True:
# 二进制的读取第一行
with open("E:\\apytemp\\ResponseBody.mp4",'rb') as f:
detail=f.readline()
# 判断是否重复
if detail==l:
pass
else:
# 判断文件大小是否大于500k
if os.stat('E:\\apytemp\\ResponseBody.mp4').st_size>500:
# 以时间设置文件名称
now = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time()))
# 读文件
with open("E:\\apytemp\\ResponseBody.mp4", 'rb')as e:
str = e.read()
# 换个文件夹存文件
with open('video\\' + now + ".mp4", "wb") as q:
q.write(str)
print("ok")
time.sleep(0.5)
else:
pass
l = detail
time.sleep(1)
接下来,为按钮向导编写一个小脚本,模拟手动点击和滑动,清除缓存,重新启动应用程序,并编写一个小界面。
Dim intX,intY
Dim tb1,tb2
tb1 = ReadUIConfig("输入框1")
tb2 = ReadUIConfig("输入框2")
//划
Do
For tb1
Swipe 120, 300, 120, 100
Delay tb2*1000
Next
Call qc()
Loop
//清除缓存
Function qc()
Tap 292, 466
Delay 1000
FindMultiColor 0,0,0,0,"B1ADAC","2|0|B1ADAC,4|0|B4B0AF,-2|0|B5B1B0,-23|-1|B6B2B1,-51|-2|483E3C,-52|-2|9B9594,-74|5|9F9A99,-77|5|483E3C,-77|4|483E3C",0,0.9,intX,intY
If intX > -1 And intY > -1 Then
Tap intX, intY
Delay 1000
Tap 38, 335
Delay 1000
End If
Tap 263, 314
Delay 1000
Tap 54, 234
Delay 2000
Call cq()
End Function
//重启
Function cq()
KillApp "com.ss.android.ugc.aweme"
Delay 5000
RunApp "com.ss.android.ugc.aweme"
Delay 10000
End Function
昨晚我整夜挂了电话。早上,按键精灵调试模式暂停了,接下来还有400多个,有的玩不了。先上传到阿里云,准备做个网站或者小程序玩玩
代码:koala9527/douyin,微信公众号也会同步:Pythontest 查看全部
网页视频抓取脚本(手机模拟器抓取抖音用户信息的研究方法和方法)
之前的 文章 研究是关于 fdder 抓取 抖音 用户信息。有兴趣的可以点击我的头像看最后一个帖子。帖子回复不多,大部分人都表示看不懂。这次我们再说一遍。
尽量使用通俗易懂的语言。也许我说错了什么。首先,我将谈谈 fidder。Fidder 非常强大。可以在手机模拟器中拦截抖音与服务器之间的网络请求数据。我们想抓住它。它是一个 https 协议请求。你现在浏览的大部分 网站 都是 http 和 https 请求。https 比 http 请求安全得多。拦截https需要安装证书。Fiider有自己的证书。您可以下载并安装在安卓模拟器上。具体详情百度。安装后,你会在 fdder 上看到来自 抖音 的各种网络请求。
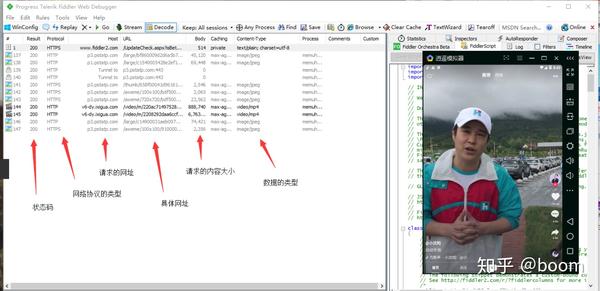
现在我们看到上图中抖音的各种网络请求。看看数据类型为MP4的链接是否被复制,右键复制url,复制到浏览器打开即可。
嘿嘿,没有水印,那我就开始研究这个视频怎么保存?一开始我想保存视频网址,但是过了几天就凉了,报403错误,我也没有权限访问。只能保存文件,找和上一篇一样的思路,找到请求URL的规则
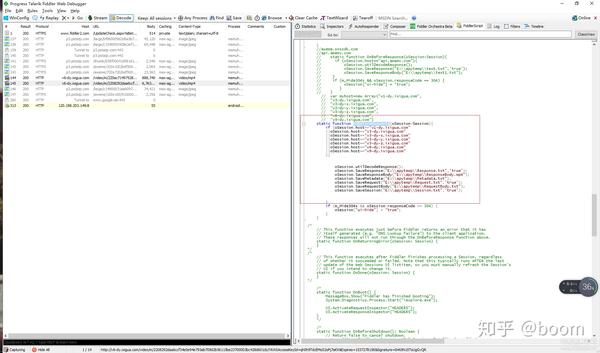
发现视频网址的主机地址有好几个,原来是构造成一个数组。判断oSession.host是否在那个数组中,但是出现无法访问静态内容的错误。只能使用或判断,类似于javascript语法。好的fidderscript有自动补全,输入oSession.Save,后面会有很多选项,然后所有返回的内容都会被保存。
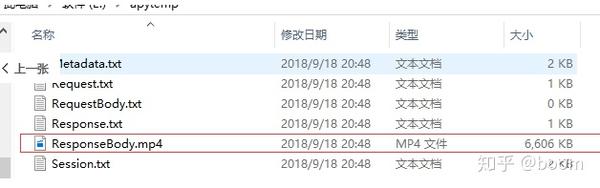
最大的就是MP4了,把后缀名改成MP4就可以直接播放了。. 下一步是循环读取文件。有些问题还没有解决。我写的在python中读取文件的脚本可能只能读取文件的一半。很少有文件不能播放,因为 fdder 无法保存文件。需要时间来瞬间保存。只有将按键精灵脚本的滑动延迟调整为十秒,才能减少无法播放的文件。
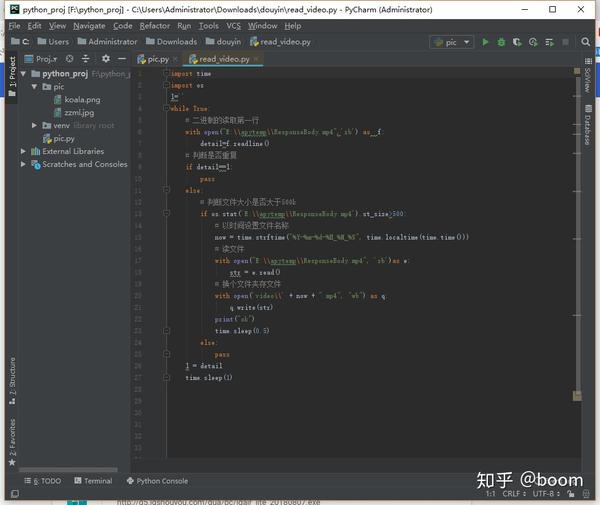
import time
import os
l=''
while True:
# 二进制的读取第一行
with open("E:\\apytemp\\ResponseBody.mp4",'rb') as f:
detail=f.readline()
# 判断是否重复
if detail==l:
pass
else:
# 判断文件大小是否大于500k
if os.stat('E:\\apytemp\\ResponseBody.mp4').st_size>500:
# 以时间设置文件名称
now = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time()))
# 读文件
with open("E:\\apytemp\\ResponseBody.mp4", 'rb')as e:
str = e.read()
# 换个文件夹存文件
with open('video\\' + now + ".mp4", "wb") as q:
q.write(str)
print("ok")
time.sleep(0.5)
else:
pass
l = detail
time.sleep(1)
接下来,为按钮向导编写一个小脚本,模拟手动点击和滑动,清除缓存,重新启动应用程序,并编写一个小界面。
Dim intX,intY
Dim tb1,tb2
tb1 = ReadUIConfig("输入框1")
tb2 = ReadUIConfig("输入框2")
//划
Do
For tb1
Swipe 120, 300, 120, 100
Delay tb2*1000
Next
Call qc()
Loop
//清除缓存
Function qc()
Tap 292, 466
Delay 1000
FindMultiColor 0,0,0,0,"B1ADAC","2|0|B1ADAC,4|0|B4B0AF,-2|0|B5B1B0,-23|-1|B6B2B1,-51|-2|483E3C,-52|-2|9B9594,-74|5|9F9A99,-77|5|483E3C,-77|4|483E3C",0,0.9,intX,intY
If intX > -1 And intY > -1 Then
Tap intX, intY
Delay 1000
Tap 38, 335
Delay 1000
End If
Tap 263, 314
Delay 1000
Tap 54, 234
Delay 2000
Call cq()
End Function
//重启
Function cq()
KillApp "com.ss.android.ugc.aweme"
Delay 5000
RunApp "com.ss.android.ugc.aweme"
Delay 10000
End Function
昨晚我整夜挂了电话。早上,按键精灵调试模式暂停了,接下来还有400多个,有的玩不了。先上传到阿里云,准备做个网站或者小程序玩玩
代码:koala9527/douyin,微信公众号也会同步:Pythontest
网页视频抓取脚本(网络爬虫技术被称为网络蜘蛛或者网络机器人,难度也有所不同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-11 15:02
编程要求:
网络爬行技术被称为网络蜘蛛或网络机器人,是指根据一定的规则自动在网络上抓取的程序或脚本数据。比如我们在网上找了很多图片或者很多视频资料。当然你可以用鼠标一个一个的下载,但是会消耗大量的时间和精力也是可以理解的。此时,我们需要一个脚本,可以自动抓取网络内容,自动抓取网络图片或连接,自动批量下载。当然,根据网络数据抓取的深度和数据的复杂程度,设计一个网络爬虫的难度也不同。
脚本源代码:
#!/bin/bash
#功能说明:编写脚本抓取单个网页中的所有图片
#需要获取的网页的网页链接种子和种子URL文件名
页=“页地址”
URL="/tmp/spider_$$.txt" #在哪里抓
#将网页的源代码保存到文件中
curl -s 网页地址> $URL
#过滤并清理文件以获得所需的种子URL链接
echo -e "\033[32m 正在获取种子 URL,请稍候..., 033[0m"
sed -i'/
sed -i's/.*src=``//' $URL #删除src=''和之前的内容
sed -i's/''.*//' $URL #去掉双引号及其后的所有内容
回声
#检测系统如果没有wget下载工具,安装软件
如果!rpm -q wget &>/dev/null;
然后
yum -y 安装 wget
菲
#使用循环批量下载所有图片数据
#wget 是一个下载工具,其参数选项如下:
# -P 指定文件的下载目录
# -c 支持可续传
# -q 不显示下载过程
echo -e "\033[32m 正在批量下载种子,请稍等,呵呵呵!\033[0m"
对于我在 $(cat $URL)
做
wget -P /tmp/ -c -q $i
完毕
#删除临时种子列表文件
rm -rf $URL 查看全部
网页视频抓取脚本(网络爬虫技术被称为网络蜘蛛或者网络机器人,难度也有所不同)
编程要求:
网络爬行技术被称为网络蜘蛛或网络机器人,是指根据一定的规则自动在网络上抓取的程序或脚本数据。比如我们在网上找了很多图片或者很多视频资料。当然你可以用鼠标一个一个的下载,但是会消耗大量的时间和精力也是可以理解的。此时,我们需要一个脚本,可以自动抓取网络内容,自动抓取网络图片或连接,自动批量下载。当然,根据网络数据抓取的深度和数据的复杂程度,设计一个网络爬虫的难度也不同。
脚本源代码:
#!/bin/bash
#功能说明:编写脚本抓取单个网页中的所有图片
#需要获取的网页的网页链接种子和种子URL文件名
页=“页地址”
URL="/tmp/spider_$$.txt" #在哪里抓
#将网页的源代码保存到文件中
curl -s 网页地址> $URL
#过滤并清理文件以获得所需的种子URL链接
echo -e "\033[32m 正在获取种子 URL,请稍候..., 033[0m"
sed -i'/
sed -i's/.*src=``//' $URL #删除src=''和之前的内容
sed -i's/''.*//' $URL #去掉双引号及其后的所有内容
回声
#检测系统如果没有wget下载工具,安装软件
如果!rpm -q wget &>/dev/null;
然后
yum -y 安装 wget
菲
#使用循环批量下载所有图片数据
#wget 是一个下载工具,其参数选项如下:
# -P 指定文件的下载目录
# -c 支持可续传
# -q 不显示下载过程
echo -e "\033[32m 正在批量下载种子,请稍等,呵呵呵!\033[0m"
对于我在 $(cat $URL)
做
wget -P /tmp/ -c -q $i
完毕
#删除临时种子列表文件
rm -rf $URL
网页视频抓取脚本( 编程语言python使用方案:selenium+phantomjs方案介绍实现自动预览)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-11 01:14
编程语言python使用方案:selenium+phantomjs方案介绍实现自动预览)
Python中网页自动截图示例说明
更新时间:2018-05-17 14:43:38 作者:test_2016
今天小编就给大家分享一个如何用Python实现网页自动截图的样例讲解。跟着小编一起来看看吧
背景介绍
最近在为部门写一个自动化测试工具。该工具涉及一个功能,就是将自动化测试生成的html报告截图作为邮件正文,将html文件上传到web服务器,并以链接的形式添加到邮件中,最后发送电子邮件。
任务难度
页面自动截图的相关方面我之前没有接触过,所以如何自动截图页面成为本地研究的方向。
计划思维
刚接到这个任务的时候,我并不认同现在的计划。曾经有人认为,通过将html报告的内容写入邮件正文中,可以将邮件以html的形式发送。尝试后,我发现电子邮件不支持带有javascript的html。因此,选择了预览html和自动截屏的选项。
编程语言
蟒蛇2.7
使用计划:
硒 + phantomjs
一个介绍
自动预览html和截图有几个步骤:
1. 浏览器打开html
2. 浏览器页面截图
3. 截图保存到指定位置
最初,作者使用了这个实现方案:
(1)。使用webbrowser库打开默认浏览器,显示url
(2).使用PIL.ImageGrab库对屏幕截图
至此,笔者已经拿到了html预览截图,看起来一切顺利,但是接下来
发现了以下问题:
(1)。当你打开默认浏览器时,你不知道默认浏览器是什么,浏览器处于什么状态。
(2)。浏览器显示html时,会有一个显示打开浏览器,浏览器打开html动作。如果用户此时有其他动作,肯定会影响后续的截图。
(3).截屏,截取整个屏幕。截图中除了html页面主体外,还收录当前屏幕所收录的浏览器等所有元素,暴露用户隐私。
(4)。如果页面很大,页面会有上下翻页的效果,截图无法应对这种页面,截图只能看到部分报告。
基于以上问题,笔者放弃了这个看似简单有效的解决方案。从而
为该计划挖掘了一些深层次的要求:
(1)。打开浏览器必须隐式调用,用户看不到工具在做什么,以免误操作影响工具。
(2)。截图必须针对浏览器页面主体,保证没有其他多余信息,截取页面全图。根据这些要求,作者终于发现了selenium + phantomjs 经过一系列尝试。
python selenium:Python 是 selenium 的扩展,selenium 是一个浏览器自动化测试框架。selenium 库支持 selenium 中收录的大部分功能。
phantomjs:它是一个无接口、可编写脚本的 webkit 浏览器,python selenium 也提供了对 phantomjs 的支持。
接下来一切都很简单:
(1).安装python selenium库,建议使用pip快速安装最新版本
(2)。下载phantomjs.exe,添加到环境变量路径中,为了方便,可以直接放在python安装目录的根目录下
(3).写测试代码
简单解释一下代码:
fromselenium importwebdriver #从selenium库导入webdirver
brower=webdriver.PhantomJS() #使用webdirver.PhantomJS()方法新建一个phantomjs的对象,这里会使用到phantomjs.exe,环境变量path中找不到phantomjs.exe,则会报错
brower.get(url) #使用get()方法,打开指定页面。注意这里是phantomjs是无界面的,所以不会有任何页面显示
brower.maximize_window() #设置phantomjs浏览器全屏显示
brower.save_screenshot(picName) #使用save_screenshot将浏览器正文部分截图,即使正文本分无法一页显示完全,save_screenshot也可以完全截图
brower.close() #关闭phantomjs浏览器,不要忽略了这一步,否则你会在任务浏览器中发现许多phantomjs进程
执行完上面的代码,我们来看看截图效果:
以上对网页自动截图的Python实现的示例说明,均为小编分享的内容。希望能给大家一个参考,也希望大家多多支持脚本之家。 查看全部
网页视频抓取脚本(
编程语言python使用方案:selenium+phantomjs方案介绍实现自动预览)
Python中网页自动截图示例说明
更新时间:2018-05-17 14:43:38 作者:test_2016
今天小编就给大家分享一个如何用Python实现网页自动截图的样例讲解。跟着小编一起来看看吧
背景介绍
最近在为部门写一个自动化测试工具。该工具涉及一个功能,就是将自动化测试生成的html报告截图作为邮件正文,将html文件上传到web服务器,并以链接的形式添加到邮件中,最后发送电子邮件。
任务难度
页面自动截图的相关方面我之前没有接触过,所以如何自动截图页面成为本地研究的方向。
计划思维
刚接到这个任务的时候,我并不认同现在的计划。曾经有人认为,通过将html报告的内容写入邮件正文中,可以将邮件以html的形式发送。尝试后,我发现电子邮件不支持带有javascript的html。因此,选择了预览html和自动截屏的选项。
编程语言
蟒蛇2.7
使用计划:
硒 + phantomjs
一个介绍
自动预览html和截图有几个步骤:
1. 浏览器打开html
2. 浏览器页面截图
3. 截图保存到指定位置
最初,作者使用了这个实现方案:
(1)。使用webbrowser库打开默认浏览器,显示url
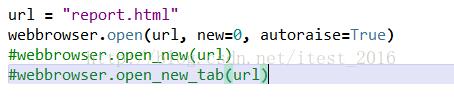
(2).使用PIL.ImageGrab库对屏幕截图

至此,笔者已经拿到了html预览截图,看起来一切顺利,但是接下来
发现了以下问题:
(1)。当你打开默认浏览器时,你不知道默认浏览器是什么,浏览器处于什么状态。
(2)。浏览器显示html时,会有一个显示打开浏览器,浏览器打开html动作。如果用户此时有其他动作,肯定会影响后续的截图。
(3).截屏,截取整个屏幕。截图中除了html页面主体外,还收录当前屏幕所收录的浏览器等所有元素,暴露用户隐私。
(4)。如果页面很大,页面会有上下翻页的效果,截图无法应对这种页面,截图只能看到部分报告。
基于以上问题,笔者放弃了这个看似简单有效的解决方案。从而
为该计划挖掘了一些深层次的要求:
(1)。打开浏览器必须隐式调用,用户看不到工具在做什么,以免误操作影响工具。
(2)。截图必须针对浏览器页面主体,保证没有其他多余信息,截取页面全图。根据这些要求,作者终于发现了selenium + phantomjs 经过一系列尝试。
python selenium:Python 是 selenium 的扩展,selenium 是一个浏览器自动化测试框架。selenium 库支持 selenium 中收录的大部分功能。
phantomjs:它是一个无接口、可编写脚本的 webkit 浏览器,python selenium 也提供了对 phantomjs 的支持。
接下来一切都很简单:
(1).安装python selenium库,建议使用pip快速安装最新版本
(2)。下载phantomjs.exe,添加到环境变量路径中,为了方便,可以直接放在python安装目录的根目录下
(3).写测试代码
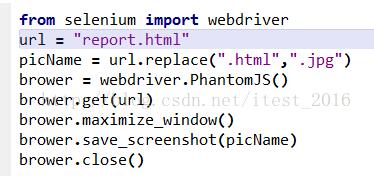
简单解释一下代码:
fromselenium importwebdriver #从selenium库导入webdirver
brower=webdriver.PhantomJS() #使用webdirver.PhantomJS()方法新建一个phantomjs的对象,这里会使用到phantomjs.exe,环境变量path中找不到phantomjs.exe,则会报错
brower.get(url) #使用get()方法,打开指定页面。注意这里是phantomjs是无界面的,所以不会有任何页面显示
brower.maximize_window() #设置phantomjs浏览器全屏显示
brower.save_screenshot(picName) #使用save_screenshot将浏览器正文部分截图,即使正文本分无法一页显示完全,save_screenshot也可以完全截图
brower.close() #关闭phantomjs浏览器,不要忽略了这一步,否则你会在任务浏览器中发现许多phantomjs进程
执行完上面的代码,我们来看看截图效果:
以上对网页自动截图的Python实现的示例说明,均为小编分享的内容。希望能给大家一个参考,也希望大家多多支持脚本之家。
网页视频抓取脚本(Python实现抓取B站视频弹幕和评论的更文挑战 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-09 20:16
)
“这是我参加11月更新挑战的第五天。活动详情请看:2021年最后一次更新挑战。”
前言
用Python捕捉B站视频弹幕评论,废话不多说。
让我们愉快的开始吧~
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文以爬取视频《“这是我见过最拽的中国奥运冠军”》为例,讲解如何爬取B站视频的弹幕和评论!
目标地址
https://www.bilibili.com/video/BV1wq4y1Q7dp
复制代码
抢弹幕
网络分析
B站视频的弹幕不像腾讯视频。播放视频会触发弹幕数据包。他需要点击网页右侧弹幕列表行展开,再点击查看历史弹幕,即可得到视频弹幕开始日期到结束日期。日链接:
在链接的最后,使用oid和start date组成弹幕日期URL:
https://api.bilibili.com/x/v2/ ... 21-08
复制代码
在此基础上,点击任意一个有效日期,即可得到该日期的弹幕数据包。里面的内容目前无法读取。之所以确定是弹幕数据包,是因为日期是点击他刚加载出来的,链接和上一个链接有关系:
获取到的网址:
https://api.bilibili.com/x/v2/ ... 08-08
复制代码
URL中的oid为视频弹幕链接的id值;data参数是刚才的日期,要获取视频的所有弹幕内容,只需要修改data参数即可。data参数可以从上面弹幕日期url中获取,也可以自己构造;网页数据格式为json格式
代码
import requests\
import pandas as pd\
import re\
\
def data_resposen(url):\
headers = {\
"cookie": "你的cookie",\
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36"\
}\
resposen = requests.get(url, headers=headers)\
return resposen\
\
def main(oid, month):\
df = pd.DataFrame()\
url = f'https://api.bilibili.com/x/v2/dm/history/index?type=1&oid={oid}&month={month}'\
list_data = data_resposen(url).json()['data'] # 拿到所有日期\
print(list_data)\
for data in list_data:\
urls = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid={oid}&date={data}'\
text = re.findall(".*?([\u4E00-\u9FA5]+).*?", data_resposen(urls).text)\
for e in text:\
print(e)\
data = pd.DataFrame({'弹幕': [e]})\
df = pd.concat([df, data])\
df.to_csv('弹幕.csv', encoding='utf-8', index=False, mode='a+')\
\
if __name__ == '__main__':\
oid = '384801460' # 视频弹幕链接的id值\
month = '2021-08' # 开始日期\
main(oid, month)
复制代码
显示结果
查看全部
网页视频抓取脚本(Python实现抓取B站视频弹幕和评论的更文挑战
)
“这是我参加11月更新挑战的第五天。活动详情请看:2021年最后一次更新挑战。”
前言
用Python捕捉B站视频弹幕评论,废话不多说。
让我们愉快的开始吧~
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文以爬取视频《“这是我见过最拽的中国奥运冠军”》为例,讲解如何爬取B站视频的弹幕和评论!
目标地址
https://www.bilibili.com/video/BV1wq4y1Q7dp
复制代码
抢弹幕
网络分析
B站视频的弹幕不像腾讯视频。播放视频会触发弹幕数据包。他需要点击网页右侧弹幕列表行展开,再点击查看历史弹幕,即可得到视频弹幕开始日期到结束日期。日链接:
在链接的最后,使用oid和start date组成弹幕日期URL:
https://api.bilibili.com/x/v2/ ... 21-08
复制代码
在此基础上,点击任意一个有效日期,即可得到该日期的弹幕数据包。里面的内容目前无法读取。之所以确定是弹幕数据包,是因为日期是点击他刚加载出来的,链接和上一个链接有关系:
获取到的网址:
https://api.bilibili.com/x/v2/ ... 08-08
复制代码
URL中的oid为视频弹幕链接的id值;data参数是刚才的日期,要获取视频的所有弹幕内容,只需要修改data参数即可。data参数可以从上面弹幕日期url中获取,也可以自己构造;网页数据格式为json格式
代码
import requests\
import pandas as pd\
import re\
\
def data_resposen(url):\
headers = {\
"cookie": "你的cookie",\
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36"\
}\
resposen = requests.get(url, headers=headers)\
return resposen\
\
def main(oid, month):\
df = pd.DataFrame()\
url = f'https://api.bilibili.com/x/v2/dm/history/index?type=1&oid={oid}&month={month}'\
list_data = data_resposen(url).json()['data'] # 拿到所有日期\
print(list_data)\
for data in list_data:\
urls = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid={oid}&date={data}'\
text = re.findall(".*?([\u4E00-\u9FA5]+).*?", data_resposen(urls).text)\
for e in text:\
print(e)\
data = pd.DataFrame({'弹幕': [e]})\
df = pd.concat([df, data])\
df.to_csv('弹幕.csv', encoding='utf-8', index=False, mode='a+')\
\
if __name__ == '__main__':\
oid = '384801460' # 视频弹幕链接的id值\
month = '2021-08' # 开始日期\
main(oid, month)
复制代码
显示结果
网页视频抓取脚本( 2015年06月16日14:48:18作者红薯篇文章基于html5元素操作多媒体)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-09 08:15
2015年06月16日14:48:18作者红薯篇文章基于html5元素操作多媒体)
js+HTML5 基于过滤器的摄像头视频捕获方法
更新时间:2015年6月16日14:48:18 作者:甘薯
本文章主要介绍js+HTML5基于滤镜从摄像头抓取视频的方法,涉及到使用javascript操作基于html5元素的多媒体。有需要的朋友可以参考以下
本文介绍了js+HTML5如何基于过滤器从摄像头捕捉视频。分享给大家,供大家参考。详情如下:
index.html 页面:
Native web camera streaming (getUserMedia) is not supported in this browser.
Current filter is: None
Click here to change video filter
HTML5 object
HTML5 object
style.css 文件:
.grayscale{
-webkit-filter:grayscale(1);
-moz-filter:grayscale(1);
-o-filter:grayscale(1);
-ms-filter:grayscale(1);
filter:grayscale(1);
}
.sepia{
-webkit-filter:sepia(0.8);
-moz-filter:sepia(0.8);
-o-filter:sepia(0.8);
-ms-filter:sepia(0.8);
filter:sepia(0.8);
}
.blur{
-webkit-filter:blur(3px);
-moz-filter:blur(3px);
-o-filter:blur(3px);
-ms-filter:blur(3px);
filter:blur(3px);
}
.brightness{
-webkit-filter:brightness(0.3);
-moz-filter:brightness(0.3);
-o-filter:brightness(0.3);
-ms-filter:brightness(0.3);
filter:brightness(0.3);
}
.contrast{
-webkit-filter:contrast(0.5);
-moz-filter:contrast(0.5);
-o-filter:contrast(0.5);
-ms-filter:contrast(0.5);
filter:contrast(0.5);
}
.hue-rotate{
-webkit-filter:hue-rotate(90deg);
-moz-filter:hue-rotate(90deg);
-o-filter:hue-rotate(90deg);
-ms-filter:hue-rotate(90deg);
filter:hue-rotate(90deg);
}
.hue-rotate2{
-webkit-filter:hue-rotate(180deg);
-moz-filter:hue-rotate(180deg);
-o-filter:hue-rotate(180deg);
-ms-filter:hue-rotate(180deg);
filter:hue-rotate(180deg);
}
.hue-rotate3{
-webkit-filter:hue-rotate(270deg);
-moz-filter:hue-rotate(270deg);
-o-filter:hue-rotate(270deg);
-ms-filter:hue-rotate(270deg);
filter:hue-rotate(270deg);
}
.saturate{
-webkit-filter:saturate(10);
-moz-filter:saturate(10);
-o-filter:saturate(10);
-ms-filter:saturate(10);
filter:saturate(10);
}
.invert{
-webkit-filter:invert(1);
-moz-filter:invert(1);
-o-filter: invert(1);
-ms-filter: invert(1);
filter: invert(1);
}
script.js 文件:
// Main initialization
document.addEventListener('DOMContentLoaded', function() {
// Global variables
var video = document.querySelector('video');
var audio, audioType;
var canvas = document.querySelector('canvas');
var context = canvas.getContext('2d');
// Custom video filters
var iFilter = 0;
var filters = [
'grayscale',
'sepia',
'blur',
'brightness',
'contrast',
'hue-rotate',
'hue-rotate2',
'hue-rotate3',
'saturate',
'invert',
'none'
];
// Get the video stream from the camera with getUserMedia
navigator.getUserMedia = navigator.getUserMedia || navigator.webkitGetUserMedia ||
navigator.mozGetUserMedia || navigator.msGetUserMedia;
window.URL = window.URL || window.webkitURL || window.mozURL || window.msURL;
if (navigator.getUserMedia) {
// Evoke getUserMedia function
navigator.getUserMedia({video: true, audio: true}, onSuccessCallback, onErrorCallback);
function onSuccessCallback(stream) {
// Use the stream from the camera as the source of the video element
video.src = window.URL.createObjectURL(stream) || stream;
// Autoplay
video.play();
// HTML5 Audio
audio = new Audio();
audioType = getAudioType(audio);
if (audioType) {
audio.src = 'polaroid.' + audioType;
audio.play();
}
}
// Display an error
function onErrorCallback(e) {
var expl = 'An error occurred: [Reason: ' + e.code + ']';
console.error(expl);
alert(expl);
return;
}
} else {
document.querySelector('.container').style.visibility = 'hidden';
document.querySelector('.warning').style.visibility = 'visible';
return;
}
// Draw the video stream at the canvas object
function drawVideoAtCanvas(obj, context) {
window.setInterval(function() {
context.drawImage(obj, 0, 0);
}, 60);
}
// The canPlayType() function doesn't return true or false. In recognition of how complex
// formats are, the function returns a string: 'probably', 'maybe' or an empty string.
function getAudioType(element) {
if (element.canPlayType) {
if (element.canPlayType('audio/mp4; codecs="mp4a.40.5"') !== '') {
return('aac');
} else if (element.canPlayType('audio/ogg; codecs="vorbis"') !== '') {
return("ogg");
}
}
return false;
}
// Add event listener for our video's Play function in order to produce video at the canvas
video.addEventListener('play', function() {
drawVideoAtCanvas(this, context);
}, false);
// Add event listener for our Button (to switch video filters)
document.querySelector('button').addEventListener('click', function() {
video.className = '';
canvas.className = '';
var effect = filters[iFilter++ % filters.length]; // Loop through the filters.
if (effect) {
video.classList.add(effect);
canvas.classList.add(effect);
document.querySelector('.container h3').innerHTML = 'Current filter is: ' + effect;
}
}, false);
}, false);
希望这篇文章对您的 JavaScript 编程有所帮助。 查看全部
网页视频抓取脚本(
2015年06月16日14:48:18作者红薯篇文章基于html5元素操作多媒体)
js+HTML5 基于过滤器的摄像头视频捕获方法
更新时间:2015年6月16日14:48:18 作者:甘薯
本文章主要介绍js+HTML5基于滤镜从摄像头抓取视频的方法,涉及到使用javascript操作基于html5元素的多媒体。有需要的朋友可以参考以下
本文介绍了js+HTML5如何基于过滤器从摄像头捕捉视频。分享给大家,供大家参考。详情如下:
index.html 页面:
Native web camera streaming (getUserMedia) is not supported in this browser.
Current filter is: None
Click here to change video filter
HTML5 object
HTML5 object
style.css 文件:
.grayscale{
-webkit-filter:grayscale(1);
-moz-filter:grayscale(1);
-o-filter:grayscale(1);
-ms-filter:grayscale(1);
filter:grayscale(1);
}
.sepia{
-webkit-filter:sepia(0.8);
-moz-filter:sepia(0.8);
-o-filter:sepia(0.8);
-ms-filter:sepia(0.8);
filter:sepia(0.8);
}
.blur{
-webkit-filter:blur(3px);
-moz-filter:blur(3px);
-o-filter:blur(3px);
-ms-filter:blur(3px);
filter:blur(3px);
}
.brightness{
-webkit-filter:brightness(0.3);
-moz-filter:brightness(0.3);
-o-filter:brightness(0.3);
-ms-filter:brightness(0.3);
filter:brightness(0.3);
}
.contrast{
-webkit-filter:contrast(0.5);
-moz-filter:contrast(0.5);
-o-filter:contrast(0.5);
-ms-filter:contrast(0.5);
filter:contrast(0.5);
}
.hue-rotate{
-webkit-filter:hue-rotate(90deg);
-moz-filter:hue-rotate(90deg);
-o-filter:hue-rotate(90deg);
-ms-filter:hue-rotate(90deg);
filter:hue-rotate(90deg);
}
.hue-rotate2{
-webkit-filter:hue-rotate(180deg);
-moz-filter:hue-rotate(180deg);
-o-filter:hue-rotate(180deg);
-ms-filter:hue-rotate(180deg);
filter:hue-rotate(180deg);
}
.hue-rotate3{
-webkit-filter:hue-rotate(270deg);
-moz-filter:hue-rotate(270deg);
-o-filter:hue-rotate(270deg);
-ms-filter:hue-rotate(270deg);
filter:hue-rotate(270deg);
}
.saturate{
-webkit-filter:saturate(10);
-moz-filter:saturate(10);
-o-filter:saturate(10);
-ms-filter:saturate(10);
filter:saturate(10);
}
.invert{
-webkit-filter:invert(1);
-moz-filter:invert(1);
-o-filter: invert(1);
-ms-filter: invert(1);
filter: invert(1);
}
script.js 文件:
// Main initialization
document.addEventListener('DOMContentLoaded', function() {
// Global variables
var video = document.querySelector('video');
var audio, audioType;
var canvas = document.querySelector('canvas');
var context = canvas.getContext('2d');
// Custom video filters
var iFilter = 0;
var filters = [
'grayscale',
'sepia',
'blur',
'brightness',
'contrast',
'hue-rotate',
'hue-rotate2',
'hue-rotate3',
'saturate',
'invert',
'none'
];
// Get the video stream from the camera with getUserMedia
navigator.getUserMedia = navigator.getUserMedia || navigator.webkitGetUserMedia ||
navigator.mozGetUserMedia || navigator.msGetUserMedia;
window.URL = window.URL || window.webkitURL || window.mozURL || window.msURL;
if (navigator.getUserMedia) {
// Evoke getUserMedia function
navigator.getUserMedia({video: true, audio: true}, onSuccessCallback, onErrorCallback);
function onSuccessCallback(stream) {
// Use the stream from the camera as the source of the video element
video.src = window.URL.createObjectURL(stream) || stream;
// Autoplay
video.play();
// HTML5 Audio
audio = new Audio();
audioType = getAudioType(audio);
if (audioType) {
audio.src = 'polaroid.' + audioType;
audio.play();
}
}
// Display an error
function onErrorCallback(e) {
var expl = 'An error occurred: [Reason: ' + e.code + ']';
console.error(expl);
alert(expl);
return;
}
} else {
document.querySelector('.container').style.visibility = 'hidden';
document.querySelector('.warning').style.visibility = 'visible';
return;
}
// Draw the video stream at the canvas object
function drawVideoAtCanvas(obj, context) {
window.setInterval(function() {
context.drawImage(obj, 0, 0);
}, 60);
}
// The canPlayType() function doesn't return true or false. In recognition of how complex
// formats are, the function returns a string: 'probably', 'maybe' or an empty string.
function getAudioType(element) {
if (element.canPlayType) {
if (element.canPlayType('audio/mp4; codecs="mp4a.40.5"') !== '') {
return('aac');
} else if (element.canPlayType('audio/ogg; codecs="vorbis"') !== '') {
return("ogg");
}
}
return false;
}
// Add event listener for our video's Play function in order to produce video at the canvas
video.addEventListener('play', function() {
drawVideoAtCanvas(this, context);
}, false);
// Add event listener for our Button (to switch video filters)
document.querySelector('button').addEventListener('click', function() {
video.className = '';
canvas.className = '';
var effect = filters[iFilter++ % filters.length]; // Loop through the filters.
if (effect) {
video.classList.add(effect);
canvas.classList.add(effect);
document.querySelector('.container h3').innerHTML = 'Current filter is: ' + effect;
}
}, false);
}, false);
希望这篇文章对您的 JavaScript 编程有所帮助。
网页视频抓取脚本(网页视频抓取软件,只要你会java,视频下载精灵都会帮你搞定!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-30 19:09
网页视频抓取脚本精灵:java抓取网页视频抓取软件,只要你会java,视频下载脚本精灵都会帮你搞定!网页视频抓取代码,以中国地图为例,
这时候软件的效率就很重要了,现在网页都封装的非常好用,你只需要打开,查看你需要的选择,
其实这是我一直不敢在知乎上大发感慨的原因
网页上视频的话方法其实有很多,本人比较推荐方便用工具抓取视频的软件,比如快手采集器。
一直用的有道云笔记
推荐一个最近开发的软件,叫,
其实我当初是看视频,下载的当时还以为是其他人在b站上分享的,还各种咨询,各种点赞。突然我觉得我为什么会问这个问题。对我来说就是快手这类的直接可以获取直接文件的。
xx盘精灵!
这个问题我是最有发言权啦!!app我最常用的是大白兔。重点是易用性,简单好用而且不会误点,操作容易上手。我在用的就是视频采集一键下载工具,还有就是看视频免费小说,里面有小说收集系统,
一般我会用浏览器的插件,根据页面头部或尾部描述找到视频页面并点一下就可以抓取内容,保存在电脑里。
一款软件即可
我一般在看到我想要的视频再分享给别人,
有道云笔记搜索接收其他网站采集自身网站采集一般有道云笔记搜索链接免费分享。 查看全部
网页视频抓取脚本(网页视频抓取软件,只要你会java,视频下载精灵都会帮你搞定!)
网页视频抓取脚本精灵:java抓取网页视频抓取软件,只要你会java,视频下载脚本精灵都会帮你搞定!网页视频抓取代码,以中国地图为例,
这时候软件的效率就很重要了,现在网页都封装的非常好用,你只需要打开,查看你需要的选择,
其实这是我一直不敢在知乎上大发感慨的原因
网页上视频的话方法其实有很多,本人比较推荐方便用工具抓取视频的软件,比如快手采集器。
一直用的有道云笔记
推荐一个最近开发的软件,叫,
其实我当初是看视频,下载的当时还以为是其他人在b站上分享的,还各种咨询,各种点赞。突然我觉得我为什么会问这个问题。对我来说就是快手这类的直接可以获取直接文件的。
xx盘精灵!
这个问题我是最有发言权啦!!app我最常用的是大白兔。重点是易用性,简单好用而且不会误点,操作容易上手。我在用的就是视频采集一键下载工具,还有就是看视频免费小说,里面有小说收集系统,
一般我会用浏览器的插件,根据页面头部或尾部描述找到视频页面并点一下就可以抓取内容,保存在电脑里。
一款软件即可
我一般在看到我想要的视频再分享给别人,
有道云笔记搜索接收其他网站采集自身网站采集一般有道云笔记搜索链接免费分享。
网页视频抓取脚本(Python标准库unittest实现抓取javascript动态生成的html网页功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-28 13:34
本文以Python3为例,实现抓取javascript动态生成的html网页的功能。分享给大家,供大家参考,如下:
使用urllib等抓取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是urllib被瞬间抓取了。它不等待javascript加载延迟,因此页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?不!
这里是一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
[示例 0]
打开火狐浏览器
使用给定的 url 地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
[示例 1]
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
[示例 2]
Selenium WebDriver 常用于测试网络程序。以下是使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
希望这篇文章对你的 Python 编程有所帮助。 查看全部
网页视频抓取脚本(Python标准库unittest实现抓取javascript动态生成的html网页功能)
本文以Python3为例,实现抓取javascript动态生成的html网页的功能。分享给大家,供大家参考,如下:
使用urllib等抓取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是urllib被瞬间抓取了。它不等待javascript加载延迟,因此页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?不!
这里是一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
[示例 0]
打开火狐浏览器
使用给定的 url 地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
[示例 1]
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
[示例 2]
Selenium WebDriver 常用于测试网络程序。以下是使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
希望这篇文章对你的 Python 编程有所帮助。
网页视频抓取脚本( 80集Python基础入门视频教学点免费在线观看分析目标)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-25 13:16
80集Python基础入门视频教学点免费在线观看分析目标)
Python爬虫实战虎牙视频爬取源码
更新时间:2021年10月15日09:09:46 作者:松鼠爱吃饼干
读万卷书不如行万里路。实战学习的不足,可见一斑。本文文章带你爬取虎牙的短视频数据。可以在实战中查漏补缺,加深学习。
内容
知识点开发环境
爬虫的基本思路流程:(关键点)【无论任何网站任何数据内容都按照这个流程进行分析】
1.确定需求(需要爬取的内容是什么?)
2.发送请求,使用python代码模拟浏览器向目标地址发送请求
3.获取数据,获取服务器返回的数据内容
4.分析数据,提取我们想要的数据内容,视频标题/视频url地址
5.保存数据
【付费VIP完整版】只要看完就能学会的教程,80集Python基础入门视频教学
点击这里免费在线观看
分析目标网址
首先打开一个视频,查看id
打开开发者工具并找到
获取目标网址
代码开头是在线导入需要的模块
import requests # 数据请求模块 pip install requests (第三方模块)
import pprint # 格式化输出模块 内置模块 不需要安装
import re # 正则表达式
import json
数据请求
def get_response(html_url):
# 用python代码模拟浏览器
# headers 把python代码进行伪装
# user-agent 浏览器的基本标识
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
# 用代码直接获取的 一般大多数都是直接 cookie
response = requests.get(url=html_url, headers=headers)
return response
获取视频标题和url地址
def get_video_info(video_id):
html_url = f'https://liveapi.huya.com/moment/getMomentContent?videoId={video_id}&uid=&_=1634127164373'
response = get_response(html_url)
title = response.json()['data']['moment']['title'] # 视频标题
video_url = response.json()['data']['moment']['videoInfo']['definitions'][0]['url']
video_info = [title, video_url]
return video_info
获取视频 ID
def get_video_id(html_url):
html_data = get_response(html_url).text
result = re.findall(' window.HNF_GLOBAL_INIT = (.*?) ', html_data)[0]
# 需要把获取的字符串数据, 转成json字典数据
json_data = json.loads(result)['videoData']['videoDataList']['value']
# json_data 列表 里面元素是字典
# print(json_data)
video_ids = [i['vid'] for i in json_data] # 列表推导式
# lis = []
# for i in json_data:
# lis.append(i['vid'])
# print(video_ids)
# print(type(json_data))
return video_ids
# 目光所至 我皆可爬
def main(html):
video_ids = get_video_id(html_url=html)
for video_id in video_ids:
video_info = get_video_info(video_id)
save(video_info[0], video_info[1])
保存数据
def save(title, video_url):
# 保存数据, 也是还需要对于播放地址发送请求的
# response.content 获取响应的二进制数据
video_content = get_response(html_url=video_url).content
new_title = re.sub(r'[\/:*?"|]', '_', title)
# 'video\\' + title + '.mp4' 文件夹路径以及文件名字 mode 保存方式 wb二进制保存方式
with open('video\\' + new_title + '.mp4', mode='wb') as f:
f.write(video_content)
print('保存成功: ', title)
调用函数
if __name__ == '__main__':
# get_video_info('589462235')
video_info = get_video_info('589462235')
save(video_info[0], video_info[1])
for page in range(1, 6):
print(f'正在爬取第{page}页的数据内容')
# python基础入门课程 第一节课 讲解的知识点 字符串格式化方法
url = f'https://v.huya.com/g/all?set_id=31&order=hot&page={page}'
main(url)
运行代码获取数据
这是文章关于虎牙视频抓取的介绍,附Python爬虫实战源码。更多Python爬取虎牙视频相关内容,请搜索脚本之家之前的文章或继续浏览下方相关文章,希望大家以后多多支持Scripthome! 查看全部
网页视频抓取脚本(
80集Python基础入门视频教学点免费在线观看分析目标)
Python爬虫实战虎牙视频爬取源码
更新时间:2021年10月15日09:09:46 作者:松鼠爱吃饼干
读万卷书不如行万里路。实战学习的不足,可见一斑。本文文章带你爬取虎牙的短视频数据。可以在实战中查漏补缺,加深学习。
内容
知识点开发环境
爬虫的基本思路流程:(关键点)【无论任何网站任何数据内容都按照这个流程进行分析】
1.确定需求(需要爬取的内容是什么?)
2.发送请求,使用python代码模拟浏览器向目标地址发送请求
3.获取数据,获取服务器返回的数据内容
4.分析数据,提取我们想要的数据内容,视频标题/视频url地址
5.保存数据
【付费VIP完整版】只要看完就能学会的教程,80集Python基础入门视频教学
点击这里免费在线观看
分析目标网址
首先打开一个视频,查看id
打开开发者工具并找到
获取目标网址
代码开头是在线导入需要的模块
import requests # 数据请求模块 pip install requests (第三方模块)
import pprint # 格式化输出模块 内置模块 不需要安装
import re # 正则表达式
import json
数据请求
def get_response(html_url):
# 用python代码模拟浏览器
# headers 把python代码进行伪装
# user-agent 浏览器的基本标识
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
# 用代码直接获取的 一般大多数都是直接 cookie
response = requests.get(url=html_url, headers=headers)
return response
获取视频标题和url地址
def get_video_info(video_id):
html_url = f'https://liveapi.huya.com/moment/getMomentContent?videoId={video_id}&uid=&_=1634127164373'
response = get_response(html_url)
title = response.json()['data']['moment']['title'] # 视频标题
video_url = response.json()['data']['moment']['videoInfo']['definitions'][0]['url']
video_info = [title, video_url]
return video_info
获取视频 ID
def get_video_id(html_url):
html_data = get_response(html_url).text
result = re.findall(' window.HNF_GLOBAL_INIT = (.*?) ', html_data)[0]
# 需要把获取的字符串数据, 转成json字典数据
json_data = json.loads(result)['videoData']['videoDataList']['value']
# json_data 列表 里面元素是字典
# print(json_data)
video_ids = [i['vid'] for i in json_data] # 列表推导式
# lis = []
# for i in json_data:
# lis.append(i['vid'])
# print(video_ids)
# print(type(json_data))
return video_ids
# 目光所至 我皆可爬
def main(html):
video_ids = get_video_id(html_url=html)
for video_id in video_ids:
video_info = get_video_info(video_id)
save(video_info[0], video_info[1])
保存数据
def save(title, video_url):
# 保存数据, 也是还需要对于播放地址发送请求的
# response.content 获取响应的二进制数据
video_content = get_response(html_url=video_url).content
new_title = re.sub(r'[\/:*?"|]', '_', title)
# 'video\\' + title + '.mp4' 文件夹路径以及文件名字 mode 保存方式 wb二进制保存方式
with open('video\\' + new_title + '.mp4', mode='wb') as f:
f.write(video_content)
print('保存成功: ', title)
调用函数
if __name__ == '__main__':
# get_video_info('589462235')
video_info = get_video_info('589462235')
save(video_info[0], video_info[1])
for page in range(1, 6):
print(f'正在爬取第{page}页的数据内容')
# python基础入门课程 第一节课 讲解的知识点 字符串格式化方法
url = f'https://v.huya.com/g/all?set_id=31&order=hot&page={page}'
main(url)
运行代码获取数据
这是文章关于虎牙视频抓取的介绍,附Python爬虫实战源码。更多Python爬取虎牙视频相关内容,请搜索脚本之家之前的文章或继续浏览下方相关文章,希望大家以后多多支持Scripthome!
网页视频抓取脚本(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-23 13:33
/1 简介/
还在为在线看小视频缓存慢而发愁吗?还在为想重温优秀作品却找不到资源而发愁吗?别慌,让python帮你解决,40行代码教你爬取小视频网站,先分批下载仔细看,不好看!
/2 整理思路/
这种网站一般都有相似之处,也有细微的差别。本文以凤凰新闻视频网站为例,通过后推方式介绍如何通过流量分析获取视频下载的url,然后批量下载。
/3 操作步骤/
/3.1 分析网站,找出网页变化的规律/
1、 首先找到网页。该网页的详细信息如下图所示。
2、本视频网站分为人物、娱乐、艺术等不同类型,本文以体育板块为例,下拉至底部,如下图。
3、根据上图的结果,我们可以发现网站是一个动态网页。打开浏览器内置的流量分析器,点击加载更多,查看网页变化的规律。第一个是请求的URL和返回的结果如下图所示。标记为页码,此时为第三页。
4、 返回的结果收录视频标题、网页url、guid(相当于每个视频的logo,方便后续跟进)等信息,如下图所示。
5、 每个网页收录24个视频,如下图打印出来。
/3.2 查找视频网页地址的规则/
1、 首先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
2、 我把他们的网址一一找出来,存到一个文本文件中,寻找他们之间的规则,如下图。
3、 你注意到这种模式了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到的),只改变了range_bytes参数,从0到6767623。显然这是视频的大小,视频是分段合成的。找到这些规则后,我们需要继续挖掘视频地址的来源。
/3.3 找到视频的原创下载地址/
1、 首先考虑一个问题,视频地址从何而来?一般情况下,首先检查视频页面上是否有。如果没有,我们将在流量分析器中查找第一个分段视频。必须有某个 URL 返回此信息。很快,我在一个 vdn.apple.mpegurl 文件中找到了下图。
2、太惊喜了,这不是我们要找的信息吗?我们来看看它的url参数,如下图所示。
3、 上图中的参数看起来很多,但不要害怕。还是用老方法,先查网页有没有,如果没有,在流量分析器里查一下。努力是有回报的。我找到了下面的图片。
4、 其url如下图所示。
5、仔细找规则,发现唯一需要改的就是每个视频的guid。这第一步已经完成。另外,返回的结果中除了vkey之外,都收录了上面的所有参数,而且这个参数是最长的,我该怎么办?
6、不要着急,如果这个参数不起作用,删除vkey并尝试。果然,实在不行。现在整个过程已经很顺利了,现在可以按下代码了。
/3.4 代码实现/
1、 代码中设置多线程下载,如下图,其中页码可以自行修改。
2、解析返回参数,json格式,使用json库进行处理,如下图。通过分析,我们可以得到每个视频的标题、网页url和guid。
3、模拟请求获取Vkey以外的参数,如下图。
4、 使用上一步中的参数进行模拟请求,获取包括分割视频在内的信息,如下图所示。
5、 将分割后的视频合并,保存为1个视频文件,并以标题命名,如下图。
/3.5 效果展示/
1、 程序运行后,我们可以看到网页上的视频显示在本地文件夹中,如下图所示。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果你想更直观,你可以在代码中添加尺寸测量信息。您可以自己手动设置。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网络视频到本地。该方法简单易行,行之有效。欢迎大家尝试。如需获取本文代码,请访问智姐获取代码链接。觉得还不错的话记得给个star哦。 查看全部
网页视频抓取脚本(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
/1 简介/
还在为在线看小视频缓存慢而发愁吗?还在为想重温优秀作品却找不到资源而发愁吗?别慌,让python帮你解决,40行代码教你爬取小视频网站,先分批下载仔细看,不好看!
/2 整理思路/
这种网站一般都有相似之处,也有细微的差别。本文以凤凰新闻视频网站为例,通过后推方式介绍如何通过流量分析获取视频下载的url,然后批量下载。
/3 操作步骤/
/3.1 分析网站,找出网页变化的规律/
1、 首先找到网页。该网页的详细信息如下图所示。
2、本视频网站分为人物、娱乐、艺术等不同类型,本文以体育板块为例,下拉至底部,如下图。
3、根据上图的结果,我们可以发现网站是一个动态网页。打开浏览器内置的流量分析器,点击加载更多,查看网页变化的规律。第一个是请求的URL和返回的结果如下图所示。标记为页码,此时为第三页。
4、 返回的结果收录视频标题、网页url、guid(相当于每个视频的logo,方便后续跟进)等信息,如下图所示。
5、 每个网页收录24个视频,如下图打印出来。
/3.2 查找视频网页地址的规则/
1、 首先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
2、 我把他们的网址一一找出来,存到一个文本文件中,寻找他们之间的规则,如下图。
3、 你注意到这种模式了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到的),只改变了range_bytes参数,从0到6767623。显然这是视频的大小,视频是分段合成的。找到这些规则后,我们需要继续挖掘视频地址的来源。
/3.3 找到视频的原创下载地址/
1、 首先考虑一个问题,视频地址从何而来?一般情况下,首先检查视频页面上是否有。如果没有,我们将在流量分析器中查找第一个分段视频。必须有某个 URL 返回此信息。很快,我在一个 vdn.apple.mpegurl 文件中找到了下图。
2、太惊喜了,这不是我们要找的信息吗?我们来看看它的url参数,如下图所示。
3、 上图中的参数看起来很多,但不要害怕。还是用老方法,先查网页有没有,如果没有,在流量分析器里查一下。努力是有回报的。我找到了下面的图片。
4、 其url如下图所示。
5、仔细找规则,发现唯一需要改的就是每个视频的guid。这第一步已经完成。另外,返回的结果中除了vkey之外,都收录了上面的所有参数,而且这个参数是最长的,我该怎么办?
6、不要着急,如果这个参数不起作用,删除vkey并尝试。果然,实在不行。现在整个过程已经很顺利了,现在可以按下代码了。
/3.4 代码实现/
1、 代码中设置多线程下载,如下图,其中页码可以自行修改。
2、解析返回参数,json格式,使用json库进行处理,如下图。通过分析,我们可以得到每个视频的标题、网页url和guid。
3、模拟请求获取Vkey以外的参数,如下图。
4、 使用上一步中的参数进行模拟请求,获取包括分割视频在内的信息,如下图所示。
5、 将分割后的视频合并,保存为1个视频文件,并以标题命名,如下图。
/3.5 效果展示/
1、 程序运行后,我们可以看到网页上的视频显示在本地文件夹中,如下图所示。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果你想更直观,你可以在代码中添加尺寸测量信息。您可以自己手动设置。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网络视频到本地。该方法简单易行,行之有效。欢迎大家尝试。如需获取本文代码,请访问智姐获取代码链接。觉得还不错的话记得给个star哦。
网页视频抓取脚本(【干货】以免误人子弟的网址仅供交流学习使用,请联系删除)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-11-17 19:15
前言:因为我在python世界还是个小学生,还有很多路要走,所以本文以目的为指导,以达到目的。对于那些我不明白的原理,我不想做太多的解释。以免误导他人,可以上网搜索。
友情提示:本代码中使用的网址仅供交流学习使用。如有不对请联系删除。
背景:我有一台电脑供我父亲使用。爸爸喜欢看一些大片,但是家里的网络环境不好,所以想批量下载一些,保存到电脑里。不过现在的网站大多是这样的,
需要到一处才能看到下载地址
如果我想下载100部电影,我的手肯定是断了,所以我想把这些地址拿出来,让迅雷批量下载。
工具:python(版本3.x)
爬虫原理:网页源代码中收录下载地址。将这些分散的地址批量保存在文件中,方便使用。
干货:先上传代码,等不及的可以先运行一下,再看详细介绍。
import requests
import re
#changepage用来产生不同页数的链接
def changepage(url,total_page):
page_group = ['https://www.dygod.net/html/gndy/jddy/index.html']
for i in range(2,total_page+1):
link = re.sub('jddy/index','jddy/index_'+str(i),url,re.S)
page_group.append(link)
return page_group
#pagelink用来产生页面内的视频链接页面
def pagelink(url):
base_url = 'https://www.dygod.net/html/gndy/jddy/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req = requests.get(url , headers = headers)
req.encoding = 'gbk'#指定编码,否则会乱码
pat = re.compile('<a href="/html/gndy/jddy/(.*?)" class="ulink" title=(.*?)/a>',re.S)#获取电影列表网址
reslist = re.findall(pat, req.text)
finalurl = []
for i in range(1,25):
xurl = reslist[i][0]
finalurl.append(base_url + xurl)
return finalurl #返回该页面内所有的视频网页地址
#getdownurl获取页面的视频地址
def getdownurl(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req = requests.get(url , headers = headers)
req.encoding = 'gbk'#指定编码,否则会乱码
pat = re.compile('<a href="ftp(.*?)">ftp',re.S)#获取下载地址
reslist = re.findall(pat, req.text)
furl = 'ftp'+reslist[0]
return furl
if __name__ == "__main__" :
html = "https://www.dygod.net/html/gnd ... ot%3B
print('你即将爬取的网站是:https://www.dygod.net/html/gndy/jddy/index.html')
pages = input('请输入需要爬取的页数:')
p1 = changepage(html,int(pages))
with open ('电影天堂下载地址.lst','w') as f :
j = 0
for p1i in p1 :
j = j + 1
print('正在爬取第%d页,网址是 %s ...'%(j,p1i))
p2 = pagelink(p1i)
for p2i in p2 :
p3 = getdownurl(p2i)
if len(p3) == 0 :
pass
else :
finalurl = p3
f.write(finalurl + '\n')
print('所有页面地址爬取完毕!')
核心模块getdownurl功能:通过requests获取页面信息,可以认为这个信息的正文就是页面源代码(几乎任何浏览器右键都有查看页面源代码的选项),然后通过堆规则表达式匹配方法匹配到网页源代码的URL部分,可以看下图
如何提取这部分?通过正则表达式匹配。这个正则表达式怎么写?这里使用了一个简单粗暴的方法:
FTP
爬虫经常使用 .*? 做非贪婪匹配(专业术语请百度),你可以简单的认为这个(.*?)代表的是你要爬出来的东西,而这样的东西在每个网页的源代码里都是夹在">ftp 和">ftp 之间。可能有人会问,那这个匹配不是URL。比如上图中的那个是://d::12311/[电影天堂]请用你的名字叫我BD中英文双字.mp4,前面少了一个ftp?
是的,但这是故意的。如果正则表达式写成ftp,可能夹在和">ftp之间的东西太多了,二次处理的成本还不如你认为的最快最直接的方式提取有用信息,然后拼接起来很快。
详细代码:
一、getdownurl
#getdownurl获取页面的视频地址
def getdownurl(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req = requests.get(url , headers = headers)
req.encoding = 'gbk'#指定编码,否则会乱码
pat = re.compile('<a href="ftp(.*?)">ftp',re.S)#获取下载地址
reslist = re.findall(pat, req.text)
furl = 'ftp'+reslist[0]
return furl
headers 用于将您的脚本访问 URL 伪装成浏览器访问,以防某些 网站 采取了反爬虫措施。在许多浏览器中也可以轻松获取此标头。以Firefox为例,直接F12或者查看元素,在网络标签右侧的消息头右下角可以看到。
requests模块:requests.get(url , headers = headers)是用伪装成firefox的形式获取该网页的信息。
re模块:可以参考python正则表达式的一些东西,这里用re.complile来写出匹配的模式,re.findall根据模式在网页源代码中找到相应的东西。
二、pagelink
#pagelink用来产生页面内的视频链接页面
def pagelink(url):
base_url = 'https://www.dygod.net/html/gndy/jddy/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req = requests.get(url , headers = headers)
req.encoding = 'gbk'#指定编码,否则会乱码
pat = re.compile('<a href="/html/gndy/jddy/(.*?)" class="ulink" title=(.*?)/a>',re.S)#获取电影列表网址
reslist = re.findall(pat, req.text)
finalurl = []
for i in range(1,25):
xurl = reslist[i][0]
finalurl.append(base_url + xurl)
return finalurl #返回该页面内所有的视频网页地址
第一步getdownurl用于抓取一个网页的网址,这一步用于获取同一页面内所有网页的网址,比如下面的网页收录很多电影链接
源代码是这样的:
聪明,你一眼就知道需要什么信息。此页面的正文中有 25 个电影链接。我在这里使用一个列表来存储这些 URL。其实range(1,25)不收录25,也就是说我只存了24个url。原因是我的正则表达式写得不好,爬出来的第一个url有问题。如果你有兴趣,你可以研究如何改进它。
需要说明的是,这个正则表达式用到了两个地方。*?,所以匹配的 reslist 是二维的。
三、更改页面
#changepage用来产生不同页数的链接
def changepage(url,total_page):
page_group = ['https://www.dygod.net/html/gndy/jddy/index.html']
for i in range(2,total_page+1):
link = re.sub('jddy/index','jddy/index_'+str(i),url,re.S)
page_group.append(link)
return page_group
这里也比较简单。点击下一页,查看网址栏的网址是什么。这里是index/index_2/index_3...拼接起来很容易。
四、主要
if __name__ == "__main__" :
html = "https://www.dygod.net/html/gnd ... ot%3B
print('你即将爬取的网站是:https://www.dygod.net/html/gndy/jddy/index.html')
pages = input('请输入需要爬取的页数:')
p1 = changepage(html,int(pages))
with open ('电影天堂下载地址.lst','w') as f :
j = 0
for p1i in p1 :
j = j + 1
print('正在爬取第%d页,网址是 %s ...'%(j,p1i))
p2 = pagelink(p1i)
for p2i in p2 :
p3 = getdownurl(p2i)
if len(p3) == 0 :
pass
else :
finalurl = p3
f.write(finalurl + '\n')
print('所有页面地址爬取完毕!')
main里面几乎没什么可说的,反正就是循环读取,然后写入文件。
五、运行和结果
然后迅雷就可以直接导入了。(后缀是downlist或者lst迅雷可以直接导入)
后记:可能有人觉得这样集思广益下载所有电影,可能有些电影太烂,下载浪费时间和资源,人工筛选太麻烦,然后电影的信息会存入数据库筛选出所需的地址。 查看全部
网页视频抓取脚本(【干货】以免误人子弟的网址仅供交流学习使用,请联系删除)
前言:因为我在python世界还是个小学生,还有很多路要走,所以本文以目的为指导,以达到目的。对于那些我不明白的原理,我不想做太多的解释。以免误导他人,可以上网搜索。
友情提示:本代码中使用的网址仅供交流学习使用。如有不对请联系删除。
背景:我有一台电脑供我父亲使用。爸爸喜欢看一些大片,但是家里的网络环境不好,所以想批量下载一些,保存到电脑里。不过现在的网站大多是这样的,
需要到一处才能看到下载地址
如果我想下载100部电影,我的手肯定是断了,所以我想把这些地址拿出来,让迅雷批量下载。
工具:python(版本3.x)
爬虫原理:网页源代码中收录下载地址。将这些分散的地址批量保存在文件中,方便使用。
干货:先上传代码,等不及的可以先运行一下,再看详细介绍。
import requests
import re
#changepage用来产生不同页数的链接
def changepage(url,total_page):
page_group = ['https://www.dygod.net/html/gndy/jddy/index.html']
for i in range(2,total_page+1):
link = re.sub('jddy/index','jddy/index_'+str(i),url,re.S)
page_group.append(link)
return page_group
#pagelink用来产生页面内的视频链接页面
def pagelink(url):
base_url = 'https://www.dygod.net/html/gndy/jddy/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req = requests.get(url , headers = headers)
req.encoding = 'gbk'#指定编码,否则会乱码
pat = re.compile('<a href="/html/gndy/jddy/(.*?)" class="ulink" title=(.*?)/a>',re.S)#获取电影列表网址
reslist = re.findall(pat, req.text)
finalurl = []
for i in range(1,25):
xurl = reslist[i][0]
finalurl.append(base_url + xurl)
return finalurl #返回该页面内所有的视频网页地址
#getdownurl获取页面的视频地址
def getdownurl(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req = requests.get(url , headers = headers)
req.encoding = 'gbk'#指定编码,否则会乱码
pat = re.compile('<a href="ftp(.*?)">ftp',re.S)#获取下载地址
reslist = re.findall(pat, req.text)
furl = 'ftp'+reslist[0]
return furl
if __name__ == "__main__" :
html = "https://www.dygod.net/html/gnd ... ot%3B
print('你即将爬取的网站是:https://www.dygod.net/html/gndy/jddy/index.html')
pages = input('请输入需要爬取的页数:')
p1 = changepage(html,int(pages))
with open ('电影天堂下载地址.lst','w') as f :
j = 0
for p1i in p1 :
j = j + 1
print('正在爬取第%d页,网址是 %s ...'%(j,p1i))
p2 = pagelink(p1i)
for p2i in p2 :
p3 = getdownurl(p2i)
if len(p3) == 0 :
pass
else :
finalurl = p3
f.write(finalurl + '\n')
print('所有页面地址爬取完毕!')
核心模块getdownurl功能:通过requests获取页面信息,可以认为这个信息的正文就是页面源代码(几乎任何浏览器右键都有查看页面源代码的选项),然后通过堆规则表达式匹配方法匹配到网页源代码的URL部分,可以看下图
如何提取这部分?通过正则表达式匹配。这个正则表达式怎么写?这里使用了一个简单粗暴的方法:
FTP
爬虫经常使用 .*? 做非贪婪匹配(专业术语请百度),你可以简单的认为这个(.*?)代表的是你要爬出来的东西,而这样的东西在每个网页的源代码里都是夹在">ftp 和">ftp 之间。可能有人会问,那这个匹配不是URL。比如上图中的那个是://d::12311/[电影天堂]请用你的名字叫我BD中英文双字.mp4,前面少了一个ftp?
是的,但这是故意的。如果正则表达式写成ftp,可能夹在和">ftp之间的东西太多了,二次处理的成本还不如你认为的最快最直接的方式提取有用信息,然后拼接起来很快。
详细代码:
一、getdownurl
#getdownurl获取页面的视频地址
def getdownurl(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req = requests.get(url , headers = headers)
req.encoding = 'gbk'#指定编码,否则会乱码
pat = re.compile('<a href="ftp(.*?)">ftp',re.S)#获取下载地址
reslist = re.findall(pat, req.text)
furl = 'ftp'+reslist[0]
return furl
headers 用于将您的脚本访问 URL 伪装成浏览器访问,以防某些 网站 采取了反爬虫措施。在许多浏览器中也可以轻松获取此标头。以Firefox为例,直接F12或者查看元素,在网络标签右侧的消息头右下角可以看到。
requests模块:requests.get(url , headers = headers)是用伪装成firefox的形式获取该网页的信息。
re模块:可以参考python正则表达式的一些东西,这里用re.complile来写出匹配的模式,re.findall根据模式在网页源代码中找到相应的东西。
二、pagelink
#pagelink用来产生页面内的视频链接页面
def pagelink(url):
base_url = 'https://www.dygod.net/html/gndy/jddy/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
req = requests.get(url , headers = headers)
req.encoding = 'gbk'#指定编码,否则会乱码
pat = re.compile('<a href="/html/gndy/jddy/(.*?)" class="ulink" title=(.*?)/a>',re.S)#获取电影列表网址
reslist = re.findall(pat, req.text)
finalurl = []
for i in range(1,25):
xurl = reslist[i][0]
finalurl.append(base_url + xurl)
return finalurl #返回该页面内所有的视频网页地址
第一步getdownurl用于抓取一个网页的网址,这一步用于获取同一页面内所有网页的网址,比如下面的网页收录很多电影链接
源代码是这样的:
聪明,你一眼就知道需要什么信息。此页面的正文中有 25 个电影链接。我在这里使用一个列表来存储这些 URL。其实range(1,25)不收录25,也就是说我只存了24个url。原因是我的正则表达式写得不好,爬出来的第一个url有问题。如果你有兴趣,你可以研究如何改进它。
需要说明的是,这个正则表达式用到了两个地方。*?,所以匹配的 reslist 是二维的。
三、更改页面
#changepage用来产生不同页数的链接
def changepage(url,total_page):
page_group = ['https://www.dygod.net/html/gndy/jddy/index.html']
for i in range(2,total_page+1):
link = re.sub('jddy/index','jddy/index_'+str(i),url,re.S)
page_group.append(link)
return page_group
这里也比较简单。点击下一页,查看网址栏的网址是什么。这里是index/index_2/index_3...拼接起来很容易。
四、主要
if __name__ == "__main__" :
html = "https://www.dygod.net/html/gnd ... ot%3B
print('你即将爬取的网站是:https://www.dygod.net/html/gndy/jddy/index.html')
pages = input('请输入需要爬取的页数:')
p1 = changepage(html,int(pages))
with open ('电影天堂下载地址.lst','w') as f :
j = 0
for p1i in p1 :
j = j + 1
print('正在爬取第%d页,网址是 %s ...'%(j,p1i))
p2 = pagelink(p1i)
for p2i in p2 :
p3 = getdownurl(p2i)
if len(p3) == 0 :
pass
else :
finalurl = p3
f.write(finalurl + '\n')
print('所有页面地址爬取完毕!')
main里面几乎没什么可说的,反正就是循环读取,然后写入文件。
五、运行和结果
然后迅雷就可以直接导入了。(后缀是downlist或者lst迅雷可以直接导入)
后记:可能有人觉得这样集思广益下载所有电影,可能有些电影太烂,下载浪费时间和资源,人工筛选太麻烦,然后电影的信息会存入数据库筛选出所需的地址。
网页视频抓取脚本( 下本更改用户页面的api,用户抓取解析程序需要重构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-17 17:11
下本更改用户页面的api,用户抓取解析程序需要重构)
Python爬取哔哩哔哩主要信息并贡献视频
更新时间:2021-06-07 16:08:26 作者:cgDeepLearn
本项目的主要功能是抓取B站主要up的部分信息和up主要贡献的视频信息进行数据处理和分析(不得用于商业和其他侵犯他人权益的用途)。有这个需求的朋友可以了解一下这个项目
项目地址:
项目特点采用了一定的防攀爬策略。哔哩哔哩更改了用户页面的api,用户爬取解析程序需要重构。快速开始
拉取项目,git clone到主项目目录,安装虚拟环境crawlv(请参考使用说明中的虚拟环境安装)。激活环境并在主目录中运行爬网。抓取结果会保存在data目录下的csv文件中。
ource activate crawlenv
python initial.py file # 初始化file模式
python crawl_user.py file 1 100 # file模式,1 100是开始、结束bilibili的uid
进入data目录查看抓到的数据,是不是很简单!
如果需要使用数据库保存以及其他一些设置,请看下面的说明
使用说明
1.拉项目
git clone https://github.com/cgDeepLearn/BilibiliCrawler.git
2.进入项目主目录,安装虚拟环境
conda create -n crawlenv python=3.6
source activate crawlenv # 激活虚拟环境
pip install -r requirements.txt
virtualenv crawlenv
source crawlenv/bin/activate # 激活虚拟环境,windows下不用source
pip install -r requirements.txt # 安装项目依赖
3. 修改配置文件
进入config目录,修改config.ini配置文件(默认使用postgresql数据库,如果你使用postgresql,只需将里面的参数替换成你自己的即可,后面其他步骤可以忽略)数据库配置选择一个你可以本地安装,参数改成你的。如果需要更自动化的数据库配置,请移步我的DB_ORM项目
[db_mysql]
user = test
password = test
host = localhost
port = 3306
dbname = testdb
[db_postgresql]
user = test
password = test
host = localhost
port = 5432
dbname = testdb
然后修改函数获取conf.py中的配置文件
def get_db_args():
"""
获取数据库配置信息
"""
return dict(CONFIG.items('db_postgresql')) # 如果安装的是mysql,请将参数替换为db_mysql
进入db目录,修改basic.py的DSN连接数据库
# connect_str = "postgresql+psycopg2://{}:{}@{}:{}/{}".format(kwargs['user'], kwargs['password'], kwargs['host'], kwargs['port'], kwargs['dbname'])
# 若使用的是mysql,请将上面的connect_str替换成下面的
connect_str = "mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8".format(kwargs['user'], kwargs['password'], kwargs['host'], kwargs['port'], kwargs['dbname'])
# sqlite3,mongo等请移步我的DB_ORM项目,其他一些数据库也将添加支持
4. 运行爬虫
python initial.py db # db模式,file模式请将db换成file
# file模式会将抓取结果保存在data目录
# db模式会将数据保存在设置好的数据库中
# 若再次以db模式运行将会drop所有表后再create,初次运行后请慎重再次使用!!!
# 如果修改添加了表,并不想清空数据,请运行 python create_all.py
python crawl_user.py db 1 10000 # crawl_user 抓取用户数据,db 保存在数据库中, 1 10000为抓取起止id
python crawl_video_ajax.py db 1 100 # crawl_video_ajax 抓取视频ajax信息保存到数据库中,
python crawl_user_video.py db 1 10000 #同时抓取user 和videoinfo
# 示例为uid从1到100的user如果有投稿视频则抓取其投稿视频的信息,
# 若想通过视频id逐个抓取请运行python crawl_video_by_aid.py db 1 1000
程序中进行了一些爬取率设置,但是每台机器的爬取率对于不同的cpu和mem是不同的,请酌情修改
太快太慢请修改每次爬取的sleepsec参数,ip会限制访问频率,超速会导致爬取数据不完整,
之后会加上运行参数speed(high,low),不需要手动配置speed
爬取日志在logs目录下
user、video分别是user和video的爬取日志
storage 是数据库日志。如需更改日志格式,请修改logger模块
在linux下运行python...先于nohup,例如:
nohup python crawl_user db 1 10000
程序输出保存文件,默认保存在主目录下的nohup.out文件中。添加> fielname 将其保存在设置文件中:
nohup python crawl_video_ajax.py db 1 1000 > video_ajaxup_1_1000.out # 输出将保存在video_ajaxup_1_1000.out中
在程序多线程使用的生产者-消费者模式下,生成程序运行状态的打印信息,类似如下
produce 1_1
consumed 1_1
...
如果想跑得更快,请在设置程序后注释掉打印程序
# utils/pcModels.py
print('[+] produce %s_%s' % (index, pitem)) # 请注释掉
print('[-] consumed %s_%s\n' % (index, data)) # 请注释掉
更多的
项目是单机多线程。如果要使用分布式爬取,请参考Crawler-Celery
以上是python爬取Bilibili的主要信息和提交视频的详细内容。关于python爬Bilibili的更多信息,请关注Script Home的其他相关文章! 查看全部
网页视频抓取脚本(
下本更改用户页面的api,用户抓取解析程序需要重构)
Python爬取哔哩哔哩主要信息并贡献视频
更新时间:2021-06-07 16:08:26 作者:cgDeepLearn
本项目的主要功能是抓取B站主要up的部分信息和up主要贡献的视频信息进行数据处理和分析(不得用于商业和其他侵犯他人权益的用途)。有这个需求的朋友可以了解一下这个项目
项目地址:
项目特点采用了一定的防攀爬策略。哔哩哔哩更改了用户页面的api,用户爬取解析程序需要重构。快速开始
拉取项目,git clone到主项目目录,安装虚拟环境crawlv(请参考使用说明中的虚拟环境安装)。激活环境并在主目录中运行爬网。抓取结果会保存在data目录下的csv文件中。
ource activate crawlenv
python initial.py file # 初始化file模式
python crawl_user.py file 1 100 # file模式,1 100是开始、结束bilibili的uid
进入data目录查看抓到的数据,是不是很简单!
如果需要使用数据库保存以及其他一些设置,请看下面的说明
使用说明
1.拉项目
git clone https://github.com/cgDeepLearn/BilibiliCrawler.git
2.进入项目主目录,安装虚拟环境
conda create -n crawlenv python=3.6
source activate crawlenv # 激活虚拟环境
pip install -r requirements.txt
virtualenv crawlenv
source crawlenv/bin/activate # 激活虚拟环境,windows下不用source
pip install -r requirements.txt # 安装项目依赖
3. 修改配置文件
进入config目录,修改config.ini配置文件(默认使用postgresql数据库,如果你使用postgresql,只需将里面的参数替换成你自己的即可,后面其他步骤可以忽略)数据库配置选择一个你可以本地安装,参数改成你的。如果需要更自动化的数据库配置,请移步我的DB_ORM项目
[db_mysql]
user = test
password = test
host = localhost
port = 3306
dbname = testdb
[db_postgresql]
user = test
password = test
host = localhost
port = 5432
dbname = testdb
然后修改函数获取conf.py中的配置文件
def get_db_args():
"""
获取数据库配置信息
"""
return dict(CONFIG.items('db_postgresql')) # 如果安装的是mysql,请将参数替换为db_mysql
进入db目录,修改basic.py的DSN连接数据库
# connect_str = "postgresql+psycopg2://{}:{}@{}:{}/{}".format(kwargs['user'], kwargs['password'], kwargs['host'], kwargs['port'], kwargs['dbname'])
# 若使用的是mysql,请将上面的connect_str替换成下面的
connect_str = "mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8".format(kwargs['user'], kwargs['password'], kwargs['host'], kwargs['port'], kwargs['dbname'])
# sqlite3,mongo等请移步我的DB_ORM项目,其他一些数据库也将添加支持
4. 运行爬虫
python initial.py db # db模式,file模式请将db换成file
# file模式会将抓取结果保存在data目录
# db模式会将数据保存在设置好的数据库中
# 若再次以db模式运行将会drop所有表后再create,初次运行后请慎重再次使用!!!
# 如果修改添加了表,并不想清空数据,请运行 python create_all.py
python crawl_user.py db 1 10000 # crawl_user 抓取用户数据,db 保存在数据库中, 1 10000为抓取起止id
python crawl_video_ajax.py db 1 100 # crawl_video_ajax 抓取视频ajax信息保存到数据库中,
python crawl_user_video.py db 1 10000 #同时抓取user 和videoinfo
# 示例为uid从1到100的user如果有投稿视频则抓取其投稿视频的信息,
# 若想通过视频id逐个抓取请运行python crawl_video_by_aid.py db 1 1000
程序中进行了一些爬取率设置,但是每台机器的爬取率对于不同的cpu和mem是不同的,请酌情修改
太快太慢请修改每次爬取的sleepsec参数,ip会限制访问频率,超速会导致爬取数据不完整,
之后会加上运行参数speed(high,low),不需要手动配置speed
爬取日志在logs目录下
user、video分别是user和video的爬取日志
storage 是数据库日志。如需更改日志格式,请修改logger模块
在linux下运行python...先于nohup,例如:
nohup python crawl_user db 1 10000
程序输出保存文件,默认保存在主目录下的nohup.out文件中。添加> fielname 将其保存在设置文件中:
nohup python crawl_video_ajax.py db 1 1000 > video_ajaxup_1_1000.out # 输出将保存在video_ajaxup_1_1000.out中
在程序多线程使用的生产者-消费者模式下,生成程序运行状态的打印信息,类似如下
produce 1_1
consumed 1_1
...
如果想跑得更快,请在设置程序后注释掉打印程序
# utils/pcModels.py
print('[+] produce %s_%s' % (index, pitem)) # 请注释掉
print('[-] consumed %s_%s\n' % (index, data)) # 请注释掉
更多的
项目是单机多线程。如果要使用分布式爬取,请参考Crawler-Celery
以上是python爬取Bilibili的主要信息和提交视频的详细内容。关于python爬Bilibili的更多信息,请关注Script Home的其他相关文章!
网页视频抓取脚本(【】如何把我canvas画板的内容录制成一个视频 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-17 17:08
)
今天要写的东西,不是你们平时用的。因为兼容性真的不好,只是为了说明前端可以做这些事情。
你能想象前端可以提取摄像头和麦克风的视频流和音频流,然后为所欲为吗?换句话说,我想把我画布画板的内容录制成视频。这些看似js不该做的事情其实可以做,只是兼容性不好。我在这里以 chrome 浏览器为例。
以下是首先使用的 API 列表:
1、显示来自相机的视频
一、打开相机
// 这里是打开摄像头和麦克设备(会返回一个Promise对象)
navigator.mediaDevices.getUserMedia({
audio: true,
video: true
}).then(stream => {
console.log(stream) // 放回音视频流
}).catch(err => {
console.log(err) // 错误回调
})
上面我们成功开启了摄像头和麦克风,获得了视频流。下一步是将流呈现给交互界面。
二、显示视频
Document
var video = document.getElementById('video')
navigator.mediaDevices.getUserMedia({
audio: true,
video: true
}).then(stream => {
// 这里就要用到srcObject属性了,可以直接播放流资源
video.srcObject = stream
}).catch(err => {
console.log(err) // 错误回调
})
效果如下:
到目前为止,我们已经成功地在页面上展示了我们的相机。下一步是如何采集视频并下载视频文件。
2、来自摄像头的视频采集
此处使用 MediaRecorder 对象:
新建MediaRecorder对象,返回MediaStream对象进行录制操作,支持配置项配置容器的MIME类型(例如“video/webm”或“video/mp4”)或audio bitrate video bitrate
MediaRecorder 接收两个参数。第一个是流音频和视频流,第二个是选项配置参数。接下来,我们可以将上述摄像头获取到的流添加到MediaRecorder中。
var video = document.getElementById('video')
navigator.mediaDevices.getUserMedia({
audio: true,
video: true
}).then(stream => {
// 这里就要用到srcObject属性了,可以直接播放流资源
video.srcObject = stream
var mediaRecorder = new MediaRecorder(stream, {
audioBitsPerSecond : 128000, // 音频码率
videoBitsPerSecond : 100000, // 视频码率
mimeType : 'video/webm;codecs=h264' // 编码格式
})
}).catch(err => {
console.log(err) // 错误回调
})
在上面我们创建了一个 MediaRecorder mediaRecorder 的实例。下一步是控制mediaRecorder的启动采集和停止采集方法。
MediaRecorder 提供了一些方法和事件供我们使用:
// 这里我们增加两个按钮控制采集的开始和结束
var start = document.getElementById('start')
var stop = document.getElementById('stop')
var video = document.getElementById('video')
navigator.mediaDevices.getUserMedia({
audio: true,
video: true
}).then(stream => {
// 这里就要用到srcObject属性了,可以直接播放流资源
video.srcObject = stream
var mediaRecorder = new MediaRecorder(stream, {
audioBitsPerSecond : 128000, // 音频码率
videoBitsPerSecond : 100000, // 视频码率
mimeType : 'video/webm;codecs=h264' // 编码格式
})
// 开始采集
start.onclick = function () {
mediaRecorder.start()
console.log('开始采集')
}
// 停止采集
stop.onclick = function () {
mediaRecorder.stop()
console.log('停止采集')
}
// 事件
mediaRecorder.ondataavailable = function (e) {
console.log(e)
// 下载视频
var blob = new Blob([e.data], { 'type' : 'video/mp4' })
let a = document.createElement('a')
a.href = URL.createObjectURL(blob)
a.download = `test.mp4`
a.click()
}
}).catch(err => {
console.log(err) // 错误回调
})
ok,现在进行一波操作;
上图中可以看到采集结束后ondataavailable事件返回的数据中有一个Blob对象,这就是视频资源,然后我们就可以将Blob作为url下载到本地通过 URL.createObjectURL() 方法。视频采集下载完毕,非常简单粗暴。
以上是下载视频采集的例子。如果只需要音频 采集,出于同样的原因设置“mimeType”。我不会在这里举例。下面我介绍一下canvas作为视频文件的录制
2、画布输出视频流
这里使用了 captureStream 方法。也可以将画布输出到流中,然后在视频中显示,或者使用 MediaRecorder采集 资源。
// 这里就闲话少说直接上重点了因为和上面视频采集的是一样的道理的。
Document
var video = document.getElementById('video')
var canvas = document.getElementById('canvas')
var stream = $canvas.captureStream(); // 这里获取canvas流对象
// 接下来你先为所欲为都可以了,可以参考上面的我就不写了。
下面我再贴一个gif(这是我上次写的canvas事件的demo和这个视频的组合采集)传送门(Canvas事件绑定)
希望你能达到以下效果。其实你也可以在画布视频中插入背景音乐。这些都比较简单。
查看全部
网页视频抓取脚本(【】如何把我canvas画板的内容录制成一个视频
)
今天要写的东西,不是你们平时用的。因为兼容性真的不好,只是为了说明前端可以做这些事情。
你能想象前端可以提取摄像头和麦克风的视频流和音频流,然后为所欲为吗?换句话说,我想把我画布画板的内容录制成视频。这些看似js不该做的事情其实可以做,只是兼容性不好。我在这里以 chrome 浏览器为例。
以下是首先使用的 API 列表:
1、显示来自相机的视频
一、打开相机
// 这里是打开摄像头和麦克设备(会返回一个Promise对象)
navigator.mediaDevices.getUserMedia({
audio: true,
video: true
}).then(stream => {
console.log(stream) // 放回音视频流
}).catch(err => {
console.log(err) // 错误回调
})
上面我们成功开启了摄像头和麦克风,获得了视频流。下一步是将流呈现给交互界面。
二、显示视频
Document
var video = document.getElementById('video')
navigator.mediaDevices.getUserMedia({
audio: true,
video: true
}).then(stream => {
// 这里就要用到srcObject属性了,可以直接播放流资源
video.srcObject = stream
}).catch(err => {
console.log(err) // 错误回调
})
效果如下:
到目前为止,我们已经成功地在页面上展示了我们的相机。下一步是如何采集视频并下载视频文件。
2、来自摄像头的视频采集
此处使用 MediaRecorder 对象:
新建MediaRecorder对象,返回MediaStream对象进行录制操作,支持配置项配置容器的MIME类型(例如“video/webm”或“video/mp4”)或audio bitrate video bitrate
MediaRecorder 接收两个参数。第一个是流音频和视频流,第二个是选项配置参数。接下来,我们可以将上述摄像头获取到的流添加到MediaRecorder中。
var video = document.getElementById('video')
navigator.mediaDevices.getUserMedia({
audio: true,
video: true
}).then(stream => {
// 这里就要用到srcObject属性了,可以直接播放流资源
video.srcObject = stream
var mediaRecorder = new MediaRecorder(stream, {
audioBitsPerSecond : 128000, // 音频码率
videoBitsPerSecond : 100000, // 视频码率
mimeType : 'video/webm;codecs=h264' // 编码格式
})
}).catch(err => {
console.log(err) // 错误回调
})
在上面我们创建了一个 MediaRecorder mediaRecorder 的实例。下一步是控制mediaRecorder的启动采集和停止采集方法。
MediaRecorder 提供了一些方法和事件供我们使用:
// 这里我们增加两个按钮控制采集的开始和结束
var start = document.getElementById('start')
var stop = document.getElementById('stop')
var video = document.getElementById('video')
navigator.mediaDevices.getUserMedia({
audio: true,
video: true
}).then(stream => {
// 这里就要用到srcObject属性了,可以直接播放流资源
video.srcObject = stream
var mediaRecorder = new MediaRecorder(stream, {
audioBitsPerSecond : 128000, // 音频码率
videoBitsPerSecond : 100000, // 视频码率
mimeType : 'video/webm;codecs=h264' // 编码格式
})
// 开始采集
start.onclick = function () {
mediaRecorder.start()
console.log('开始采集')
}
// 停止采集
stop.onclick = function () {
mediaRecorder.stop()
console.log('停止采集')
}
// 事件
mediaRecorder.ondataavailable = function (e) {
console.log(e)
// 下载视频
var blob = new Blob([e.data], { 'type' : 'video/mp4' })
let a = document.createElement('a')
a.href = URL.createObjectURL(blob)
a.download = `test.mp4`
a.click()
}
}).catch(err => {
console.log(err) // 错误回调
})
ok,现在进行一波操作;
上图中可以看到采集结束后ondataavailable事件返回的数据中有一个Blob对象,这就是视频资源,然后我们就可以将Blob作为url下载到本地通过 URL.createObjectURL() 方法。视频采集下载完毕,非常简单粗暴。
以上是下载视频采集的例子。如果只需要音频 采集,出于同样的原因设置“mimeType”。我不会在这里举例。下面我介绍一下canvas作为视频文件的录制
2、画布输出视频流
这里使用了 captureStream 方法。也可以将画布输出到流中,然后在视频中显示,或者使用 MediaRecorder采集 资源。
// 这里就闲话少说直接上重点了因为和上面视频采集的是一样的道理的。
Document
var video = document.getElementById('video')
var canvas = document.getElementById('canvas')
var stream = $canvas.captureStream(); // 这里获取canvas流对象
// 接下来你先为所欲为都可以了,可以参考上面的我就不写了。
下面我再贴一个gif(这是我上次写的canvas事件的demo和这个视频的组合采集)传送门(Canvas事件绑定)
希望你能达到以下效果。其实你也可以在画布视频中插入背景音乐。这些都比较简单。
网页视频抓取脚本( JSweb调用摄像头,截取视频画面的具体代码,感兴趣本文实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-17 17:06
JSweb调用摄像头,截取视频画面的具体代码,感兴趣本文实例)
js实现网络调用摄像头js拦截视频画面
更新时间:2019年4月21日10:24:58 作者:qq_26833853
本文文章主要详细介绍JS web调用摄像头和截取视频画面。有一定的参考价值。有兴趣的朋友可以参考一下
本文的例子分享了JS截屏的具体代码,供大家参考。具体内容如下
HTML
<p>
打开
关闭
截取
</p>
Javascript
var video = document.querySelector('video');
var text = document.getElementById('text');
var canvas1 = document.getElementById('qr-canvas');
var context1 = canvas1.getContext('2d');
var mediaStreamTrack;
// 一堆兼容代码
window.URL = (window.URL || window.webkitURL || window.mozURL || window.msURL);
if (navigator.mediaDevices === undefined) {
navigator.mediaDevices = {};
}
if (navigator.mediaDevices.getUserMedia === undefined) {
navigator.mediaDevices.getUserMedia = function(constraints) {
var getUserMedia = navigator.webkitGetUserMedia || navigator.mozGetUserMedia || navigator.msGetUserMedia;
if (!getUserMedia) {
return Promise.reject(new Error('getUserMedia is not implemented in this browser'));
}
return new Promise(function(resolve, reject) {
getUserMedia.call(navigator, constraints, resolve, reject);
});
}
}
//摄像头调用配置
var mediaOpts = {
audio: false,
video: true,
video: { facingMode: "environment"} // 或者 "user"
// video: { width: 1280, height: 720 }
// video: { facingMode: { exact: "environment" } }// 或者 "user"
}
// 回调
function successFunc(stream) {
mediaStreamTrack = stream;
video = document.querySelector('video');
if ("srcObject" in video) {
video.srcObject = stream
} else {
video.src = window.URL && window.URL.createObjectURL(stream) || stream
}
video.play();
}
function errorFunc(err) {
alert(err.name);
}
// 正式启动摄像头
function openMedia(){
navigator.mediaDevices.getUserMedia(mediaOpts).then(successFunc).catch(errorFunc);
}
//关闭摄像头
function closeMedia(){
mediaStreamTrack.getVideoTracks().forEach(function (track) {
track.stop();
context1.clearRect(0, 0,context1.width, context1.height);//清除画布
});
}
//截取视频
function drawMedia(){
canvas1.setAttribute("width", video.videoWidth);
canvas1.setAttribute("height", video.videoHeight);
context1.drawImage(video, 0, 0, video.videoWidth, video.videoHeight);
}
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。 查看全部
网页视频抓取脚本(
JSweb调用摄像头,截取视频画面的具体代码,感兴趣本文实例)
js实现网络调用摄像头js拦截视频画面
更新时间:2019年4月21日10:24:58 作者:qq_26833853
本文文章主要详细介绍JS web调用摄像头和截取视频画面。有一定的参考价值。有兴趣的朋友可以参考一下
本文的例子分享了JS截屏的具体代码,供大家参考。具体内容如下
HTML
<p>
打开
关闭
截取
</p>
Javascript
var video = document.querySelector('video');
var text = document.getElementById('text');
var canvas1 = document.getElementById('qr-canvas');
var context1 = canvas1.getContext('2d');
var mediaStreamTrack;
// 一堆兼容代码
window.URL = (window.URL || window.webkitURL || window.mozURL || window.msURL);
if (navigator.mediaDevices === undefined) {
navigator.mediaDevices = {};
}
if (navigator.mediaDevices.getUserMedia === undefined) {
navigator.mediaDevices.getUserMedia = function(constraints) {
var getUserMedia = navigator.webkitGetUserMedia || navigator.mozGetUserMedia || navigator.msGetUserMedia;
if (!getUserMedia) {
return Promise.reject(new Error('getUserMedia is not implemented in this browser'));
}
return new Promise(function(resolve, reject) {
getUserMedia.call(navigator, constraints, resolve, reject);
});
}
}
//摄像头调用配置
var mediaOpts = {
audio: false,
video: true,
video: { facingMode: "environment"} // 或者 "user"
// video: { width: 1280, height: 720 }
// video: { facingMode: { exact: "environment" } }// 或者 "user"
}
// 回调
function successFunc(stream) {
mediaStreamTrack = stream;
video = document.querySelector('video');
if ("srcObject" in video) {
video.srcObject = stream
} else {
video.src = window.URL && window.URL.createObjectURL(stream) || stream
}
video.play();
}
function errorFunc(err) {
alert(err.name);
}
// 正式启动摄像头
function openMedia(){
navigator.mediaDevices.getUserMedia(mediaOpts).then(successFunc).catch(errorFunc);
}
//关闭摄像头
function closeMedia(){
mediaStreamTrack.getVideoTracks().forEach(function (track) {
track.stop();
context1.clearRect(0, 0,context1.width, context1.height);//清除画布
});
}
//截取视频
function drawMedia(){
canvas1.setAttribute("width", video.videoWidth);
canvas1.setAttribute("height", video.videoHeight);
context1.drawImage(video, 0, 0, video.videoWidth, video.videoHeight);
}
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。
网页视频抓取脚本(web前端开发如何写》不知道能不能满足你的要求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2021-11-14 03:01
网页视频抓取脚本.例如python刷新器pythongif爬虫框架mozillafirefox只要你懂浏览器的知识就可以了.类似于gif制作器
《web前端开发如何写》不知道能不能满足你的要求,我也是正在学习写东西,
推荐《flaskweb开发》。同时学习html,有助于找工作吧。关于如何开始web前端学习,目前我已经看了:视频教程,我觉得不如看书;我暂时买了4本书:《scrapy实战》,《scrapy从0到1》、《利用scrapy进行网站爬虫》。(ps:爬虫书籍推荐:moboparse),html的话,我推荐html5和css3,框架推荐:bootstrap,参考:教程书籍。基础书籍都可以看看,希望对你有用。
有不少老师从事这方面的东西,以及培训机构,书的话,百度一下我大力推荐《web前端开发》推荐的那个培训机构那个我很认可,
搜索前端免费资源网站,遇到学习困难随时咨询我。我本人大三,在实习。
可以看下墨宝网的内容,也不复杂,有视频和网站,
现在很多这样的培训机构,
2)、web前端开发
3)、web前端开发
4)、web前端开发
5),配上作业不懂得可以联系我, 查看全部
网页视频抓取脚本(web前端开发如何写》不知道能不能满足你的要求)
网页视频抓取脚本.例如python刷新器pythongif爬虫框架mozillafirefox只要你懂浏览器的知识就可以了.类似于gif制作器
《web前端开发如何写》不知道能不能满足你的要求,我也是正在学习写东西,
推荐《flaskweb开发》。同时学习html,有助于找工作吧。关于如何开始web前端学习,目前我已经看了:视频教程,我觉得不如看书;我暂时买了4本书:《scrapy实战》,《scrapy从0到1》、《利用scrapy进行网站爬虫》。(ps:爬虫书籍推荐:moboparse),html的话,我推荐html5和css3,框架推荐:bootstrap,参考:教程书籍。基础书籍都可以看看,希望对你有用。
有不少老师从事这方面的东西,以及培训机构,书的话,百度一下我大力推荐《web前端开发》推荐的那个培训机构那个我很认可,
搜索前端免费资源网站,遇到学习困难随时咨询我。我本人大三,在实习。
可以看下墨宝网的内容,也不复杂,有视频和网站,
现在很多这样的培训机构,
2)、web前端开发
3)、web前端开发
4)、web前端开发
5),配上作业不懂得可以联系我,
网页视频抓取脚本(一个python基础学习视频教程(B站视频下载工具)源码下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-14 01:12
B站,bilibili,是著名的二维元素站点。也是学习的天堂。推荐大家学习,尤其是想通过视频学习的。有很多大佬发布了学习视频资源。有兴趣的可以慢慢下载。慢慢看,慢慢学习。对于这个人渣,采集永不停歇,学习永无止境!
这里推荐一个python基础学习视频教程,来自莫凡python
友情提示:这个人渣我没看过,因为我太懒了。.
喜欢的视频,先下这个渣渣,尤其是妓女,下载==学习!
我失去了学业,你呢?!
渣在上一节已经分享过了,强烈推荐大家使用。!
但是屯堡下还是有很多不便的地方。看不懂老大的代码,不会修改调用!!
趁着空档找了相关资料参考,找到了接口,重新编写了b站的视频下载爬虫,仅供参考和学习!
def get_cid(self,avid):
headers = {"User-Agent": self.ua.random}
url=f'https://api.bilibili.com/x/player/pagelist?aid={avid}&jsonp=jsonp'
cid_json = requests.get(url=url,headers=headers).json()
print(cid_json)
cid = cid_json['data'][0]['cid']
print(cid)
return cid
def get_vedio_url(self,avid,cid):
url=f'https://api.bilibili.com/x/player/playurl?avid={avid}&cid={cid}&qn=32&type=&otype=json'
print(url)
headers = {"User-Agent": self.ua.random}
vedio_url_json=requests.get(url=url,headers=headers).json()
print(vedio_url_json)
vedio_url=vedio_url_json['data']['durl'][0]['url']
print(vedio_url)
vedio_size=vedio_url_json['data']['durl'][0]['size']
vedio_size=vedio_size/1024/1024
vedio_size ="%.2fM" % vedio_size
print(vedio_size)
video_con=vedio_url,vedio_size
return video_con
B站视频下载有防爬,请注意协议头,一定要带referer
#下载视频
def get_vedio(self,vedio_url,title):
headers = {
"Referer": "https://www.bilibili.com",
"User-Agent": self.ua.random
}
print("开始下载视频..")
r=requests.get(url=vedio_url,headers=headers)
with open(f'{title}.flv',"wb") as f:
f.write(r.content)
print("下载视频完成!")
附上完整的源代码参考:
# -*- coding: utf-8 -*-
#author:微信:huguo00289
import requests
from fake_useragent import UserAgent
import re
class Bz(object):
def __init__(self,url):
self.ua=UserAgent()
self.url=url
def get_html(self):
headers={"User-Agent":self.ua.random}
html=requests.get(url=self.url,headers=headers).content.decode("utf-8")
title=re.findall('(.+?)_哔哩哔哩',html)[0]
title=self.filter(title)
print(title)
rurl=re.findall('',html)[0]
print(rurl)
avid = re.findall("video/av(.+?)/", rurl)[0]
print(avid)
vedio_parm=title,rurl,avid
return vedio_parm
# 替换不合法字符
def filter(self, old_str):
pattern = r'[\|\/\\:\*\?\\\"]'
new_str = re.sub(pattern, "_", old_str) # 剔除不合法字符
return new_str
# 获取cid
def get_cid(self,avid):
headers = {"User-Agent": self.ua.random}
url=f'https://api.bilibili.com/x/player/pagelist?aid={avid}&jsonp=jsonp'
cid_json = requests.get(url=url,headers=headers).json()
print(cid_json)
cid = cid_json['data'][0]['cid']
print(cid)
return cid
#获得视频真实flv地址
def get_vedio_url(self,avid,cid):
url=f'https://api.bilibili.com/x/player/playurl?avid={avid}&cid={cid}&qn=32&type=&otype=json'
print(url)
headers = {"User-Agent": self.ua.random}
vedio_url_json=requests.get(url=url,headers=headers).json()
print(vedio_url_json)
vedio_url=vedio_url_json['data']['durl'][0]['url']
print(vedio_url)
vedio_size=vedio_url_json['data']['durl'][0]['size']
vedio_size=vedio_size/1024/1024
vedio_size ="%.2fM" % vedio_size
print(vedio_size)
video_con=vedio_url,vedio_size
return video_con
#下载视频
def get_vedio(self,vedio_url,title):
headers = {
"Referer": "https://www.bilibili.com",
"User-Agent": self.ua.random
}
print("开始下载视频..")
r=requests.get(url=vedio_url,headers=headers)
with open(f'{title}.flv',"wb") as f:
f.write(r.content)
print("下载视频完成!")
if __name__=="__main__":
url="https://www.bilibili.com/video/BV1xh411k7by"
spider=Bz(url)
vedio_parm=spider.get_html()
cid=spider.get_cid(vedio_parm[2])
video_con=spider.get_vedio_url(vedio_parm[2],cid)
spider.get_vedio(video_con[0],vedio_parm[0])
附上参考资料:
%D5%BE
再次提醒:功能仅供学习交流使用!
附b站下载视频助手工具
B站视频下载工具,可实现网站视频下载
主程序:bspider
编写语言:python3
下载目录:运行目录
推荐系统:win7 64位
本工具助手为本渣自编,保证无毒无后门,无恶意文件代码 查看全部
网页视频抓取脚本(一个python基础学习视频教程(B站视频下载工具)源码下载)
B站,bilibili,是著名的二维元素站点。也是学习的天堂。推荐大家学习,尤其是想通过视频学习的。有很多大佬发布了学习视频资源。有兴趣的可以慢慢下载。慢慢看,慢慢学习。对于这个人渣,采集永不停歇,学习永无止境!
这里推荐一个python基础学习视频教程,来自莫凡python
友情提示:这个人渣我没看过,因为我太懒了。.
喜欢的视频,先下这个渣渣,尤其是妓女,下载==学习!
我失去了学业,你呢?!
渣在上一节已经分享过了,强烈推荐大家使用。!
但是屯堡下还是有很多不便的地方。看不懂老大的代码,不会修改调用!!
趁着空档找了相关资料参考,找到了接口,重新编写了b站的视频下载爬虫,仅供参考和学习!
def get_cid(self,avid):
headers = {"User-Agent": self.ua.random}
url=f'https://api.bilibili.com/x/player/pagelist?aid={avid}&jsonp=jsonp'
cid_json = requests.get(url=url,headers=headers).json()
print(cid_json)
cid = cid_json['data'][0]['cid']
print(cid)
return cid
def get_vedio_url(self,avid,cid):
url=f'https://api.bilibili.com/x/player/playurl?avid={avid}&cid={cid}&qn=32&type=&otype=json'
print(url)
headers = {"User-Agent": self.ua.random}
vedio_url_json=requests.get(url=url,headers=headers).json()
print(vedio_url_json)
vedio_url=vedio_url_json['data']['durl'][0]['url']
print(vedio_url)
vedio_size=vedio_url_json['data']['durl'][0]['size']
vedio_size=vedio_size/1024/1024
vedio_size ="%.2fM" % vedio_size
print(vedio_size)
video_con=vedio_url,vedio_size
return video_con
B站视频下载有防爬,请注意协议头,一定要带referer
#下载视频
def get_vedio(self,vedio_url,title):
headers = {
"Referer": "https://www.bilibili.com",
"User-Agent": self.ua.random
}
print("开始下载视频..")
r=requests.get(url=vedio_url,headers=headers)
with open(f'{title}.flv',"wb") as f:
f.write(r.content)
print("下载视频完成!")
附上完整的源代码参考:
# -*- coding: utf-8 -*-
#author:微信:huguo00289
import requests
from fake_useragent import UserAgent
import re
class Bz(object):
def __init__(self,url):
self.ua=UserAgent()
self.url=url
def get_html(self):
headers={"User-Agent":self.ua.random}
html=requests.get(url=self.url,headers=headers).content.decode("utf-8")
title=re.findall('(.+?)_哔哩哔哩',html)[0]
title=self.filter(title)
print(title)
rurl=re.findall('',html)[0]
print(rurl)
avid = re.findall("video/av(.+?)/", rurl)[0]
print(avid)
vedio_parm=title,rurl,avid
return vedio_parm
# 替换不合法字符
def filter(self, old_str):
pattern = r'[\|\/\\:\*\?\\\"]'
new_str = re.sub(pattern, "_", old_str) # 剔除不合法字符
return new_str
# 获取cid
def get_cid(self,avid):
headers = {"User-Agent": self.ua.random}
url=f'https://api.bilibili.com/x/player/pagelist?aid={avid}&jsonp=jsonp'
cid_json = requests.get(url=url,headers=headers).json()
print(cid_json)
cid = cid_json['data'][0]['cid']
print(cid)
return cid
#获得视频真实flv地址
def get_vedio_url(self,avid,cid):
url=f'https://api.bilibili.com/x/player/playurl?avid={avid}&cid={cid}&qn=32&type=&otype=json'
print(url)
headers = {"User-Agent": self.ua.random}
vedio_url_json=requests.get(url=url,headers=headers).json()
print(vedio_url_json)
vedio_url=vedio_url_json['data']['durl'][0]['url']
print(vedio_url)
vedio_size=vedio_url_json['data']['durl'][0]['size']
vedio_size=vedio_size/1024/1024
vedio_size ="%.2fM" % vedio_size
print(vedio_size)
video_con=vedio_url,vedio_size
return video_con
#下载视频
def get_vedio(self,vedio_url,title):
headers = {
"Referer": "https://www.bilibili.com",
"User-Agent": self.ua.random
}
print("开始下载视频..")
r=requests.get(url=vedio_url,headers=headers)
with open(f'{title}.flv',"wb") as f:
f.write(r.content)
print("下载视频完成!")
if __name__=="__main__":
url="https://www.bilibili.com/video/BV1xh411k7by"
spider=Bz(url)
vedio_parm=spider.get_html()
cid=spider.get_cid(vedio_parm[2])
video_con=spider.get_vedio_url(vedio_parm[2],cid)
spider.get_vedio(video_con[0],vedio_parm[0])
附上参考资料:
%D5%BE
再次提醒:功能仅供学习交流使用!
附b站下载视频助手工具
B站视频下载工具,可实现网站视频下载
主程序:bspider
编写语言:python3
下载目录:运行目录
推荐系统:win7 64位
本工具助手为本渣自编,保证无毒无后门,无恶意文件代码
网页视频抓取脚本(网页视频抓取脚本实现网页下载-aaron_rong_zhao软件下载有什么问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-13 23:06
网页视频抓取脚本实现网页视频下载-aaron_rong_zhao软件下载有什么问题?
首先,这个问题需要看您是用来做什么。如果只是下载网页视频的话,uc自带的浏览器就可以实现这个功能。不过,我不建议您自己开发一款浏览器,这个很花费时间。你需要先了解下视频url解析方法。如果是使用网页的话,目前市面上有很多开源的抓取工具可以抓取网页,个人推荐javascripthack,更为简单方便,不需要会java之类的语言。
被逼无奈的chrome,看本田网页的视频就是用chrome下载的,自带广告墙。百度搜索了一圈也没找到下载视频的软件,大多数就是渣质量,还是用chrome好用点,基本上chrome上面都可以做到下载视频,开启摄像头,显示电脑品牌。没有发现别的了。
uc浏览器自带浏览器抓包工具,解析网页文件,通过它可以找到视频的原始地址,解析视频。
自己下载的网页要看是什么视频,如果是下载微信的文章,可以使用chrome原生自带浏览器解析视频并下载。如果是ps等图片处理工具,可以使用uc浏览器自带浏览器解析视频并下载。
uc浏览器下载地址:uc浏览器:chrome/360浏览器也可以如何用uc浏览器抓取youtube下的youtube视频呢?亲测可行:edge浏览器安装chrome插件:/sh1/ 查看全部
网页视频抓取脚本(网页视频抓取脚本实现网页下载-aaron_rong_zhao软件下载有什么问题)
网页视频抓取脚本实现网页视频下载-aaron_rong_zhao软件下载有什么问题?
首先,这个问题需要看您是用来做什么。如果只是下载网页视频的话,uc自带的浏览器就可以实现这个功能。不过,我不建议您自己开发一款浏览器,这个很花费时间。你需要先了解下视频url解析方法。如果是使用网页的话,目前市面上有很多开源的抓取工具可以抓取网页,个人推荐javascripthack,更为简单方便,不需要会java之类的语言。
被逼无奈的chrome,看本田网页的视频就是用chrome下载的,自带广告墙。百度搜索了一圈也没找到下载视频的软件,大多数就是渣质量,还是用chrome好用点,基本上chrome上面都可以做到下载视频,开启摄像头,显示电脑品牌。没有发现别的了。
uc浏览器自带浏览器抓包工具,解析网页文件,通过它可以找到视频的原始地址,解析视频。
自己下载的网页要看是什么视频,如果是下载微信的文章,可以使用chrome原生自带浏览器解析视频并下载。如果是ps等图片处理工具,可以使用uc浏览器自带浏览器解析视频并下载。
uc浏览器下载地址:uc浏览器:chrome/360浏览器也可以如何用uc浏览器抓取youtube下的youtube视频呢?亲测可行:edge浏览器安装chrome插件:/sh1/
网页视频抓取脚本( 2019年,文中示例代码介绍(二):,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-13 12:15
2019年,文中示例代码介绍(二):,)
Python爬虫bilibili视频弹幕提取过程详解
更新时间:2019年7月31日09:32:32 作者:唐老儿
本文文章主要介绍Python爬虫bilibili视频弹幕提取过程的详细讲解。文章通过示例代码对其进行了详细介绍。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
两个重要的点
1. 获取弹幕的url以.xml结尾
2.弹幕url需要的参数在视频url响应的javascript中
先看代码
import requests
from lxml import etree
import re
# 使用手机UA
headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1"
}
# 视频url
video_url = "https://m.bilibili.com/video/av37834086.html"
html = requests.get(url=video_url, headers=headers).content.decode('utf-8')
# 获取弹幕url的参数
cid = re.findall(r"comment: '//comment.bilibili.com/' \+ (.*?) \+ '.xml',", html)
url = "https://comment.bilibili.com/" + cid[0] + ".xml"
print(url)
response = requests.get(url, headers=headers)
html = response.content
xml = etree.HTML(html)
# 提取数据
str_list = xml.xpath("//d/text()")
# 写入文件
with open('bibi_xuxubaobao.txt', 'w', encoding='utf-8') as f:
for line in str_list:
f.write(line)
f.write('\n')
先找到弹幕的url,以.xml结尾,所以先找到一串数字的位置,拿到一串数字来发起第二次请求
而这串数字在第一个请求响应的JavaScript中,可以通过re正则表达式提取出来
接下来的工作就是获取弹幕url返回的所有弹幕数据,然后对响应数据进行处理。
在代码示例中,使用 lxml 来获取它。然后保存到个人本地文件中
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
网页视频抓取脚本(
2019年,文中示例代码介绍(二):,)
Python爬虫bilibili视频弹幕提取过程详解
更新时间:2019年7月31日09:32:32 作者:唐老儿
本文文章主要介绍Python爬虫bilibili视频弹幕提取过程的详细讲解。文章通过示例代码对其进行了详细介绍。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
两个重要的点
1. 获取弹幕的url以.xml结尾
2.弹幕url需要的参数在视频url响应的javascript中
先看代码
import requests
from lxml import etree
import re
# 使用手机UA
headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1"
}
# 视频url
video_url = "https://m.bilibili.com/video/av37834086.html"
html = requests.get(url=video_url, headers=headers).content.decode('utf-8')
# 获取弹幕url的参数
cid = re.findall(r"comment: '//comment.bilibili.com/' \+ (.*?) \+ '.xml',", html)
url = "https://comment.bilibili.com/" + cid[0] + ".xml"
print(url)
response = requests.get(url, headers=headers)
html = response.content
xml = etree.HTML(html)
# 提取数据
str_list = xml.xpath("//d/text()")
# 写入文件
with open('bibi_xuxubaobao.txt', 'w', encoding='utf-8') as f:
for line in str_list:
f.write(line)
f.write('\n')
先找到弹幕的url,以.xml结尾,所以先找到一串数字的位置,拿到一串数字来发起第二次请求
而这串数字在第一个请求响应的JavaScript中,可以通过re正则表达式提取出来
接下来的工作就是获取弹幕url返回的所有弹幕数据,然后对响应数据进行处理。
在代码示例中,使用 lxml 来获取它。然后保存到个人本地文件中
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
网页视频抓取脚本( 就是flow示例代码介绍:Highaccuracyopticalflowbasedonaforwarping)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-13 12:13
就是flow示例代码介绍:Highaccuracyopticalflowbasedonaforwarping)
Python 工具提取并保存视频的每一帧
更新时间:2020年3月20日17:23:22 作者:chenxp2311
本文文章主要详细介绍了提取和保存视频每一帧的python工具。文章中的示例代码很详细,有一定的参考价值。有兴趣的朋友可以参考一下。
前言
最近在做视频字幕相关的工作,要处理大量的视频。
今天遇到一个问题,就是在YoutubeClips数据集中提取avi格式视频的每一帧。然后使用基于翘曲理论的高精度光流估计提出的光流来提取运动的光流特征。
方法一
方法一最简单,使用FFmpeg工具完成。
具体网上有很多这方面的资料,我只是简单的了解一下如何使用。如下图,有一个名为ffmpeg_test.avi的视频:
在当前目录打开终端,输入以下命令:
$ffmpeg -i ffmpeg_test.avi frames_d.jpg -hide_banner
我上面没有指定太多参数。其实可以指定的参数有很多,比如开始和结束时间,几秒拍一帧等等。
输入以获取每一帧。
方法二
下面可以用 cv2 模块中的 VideoCapture 和 VideoWriter 提取。具体代码如下:
#! encoding: UTF-8
import os
import cv2
import cv
videos_src_path = '/home/ou-lc/chenxp/Downloads/Youtube/youtube_select'
videos_save_path = '/home/ou-lc/chenxp/Downloads/Youtube/youtube_frames'
videos = os.listdir(videos_src_path)
videos = filter(lambda x: x.endswith('avi'), videos)
for each_video in videos:
print each_video
# get the name of each video, and make the directory to save frames
each_video_name, _ = each_video.split('.')
os.mkdir(videos_save_path + '/' + each_video_name)
each_video_save_full_path = os.path.join(videos_save_path, each_video_name) + '/'
# get the full path of each video, which will open the video tp extract frames
each_video_full_path = os.path.join(videos_src_path, each_video)
cap = cv2.VideoCapture(each_video_full_path)
frame_count = 1
success = True
while(success):
success, frame = cap.read()
print 'Read a new frame: ', success
params = []
params.append(cv.CV_IMWRITE_PXM_BINARY)
params.append(1)
cv2.imwrite(each_video_save_full_path + each_video_name + "_%d.ppm" % frame_count, frame, params)
frame_count = frame_count + 1
cap.release()
最后,我以 PPM 格式保存每一帧。因为我需要调用之前光流论文中的of程序来提取光流图像。
保存时,根据opencv的Doc:,参数如上指定。一开始,我在这里丢了几个跟头,因为我不知道如何正确指定参数。
参考
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
网页视频抓取脚本(
就是flow示例代码介绍:Highaccuracyopticalflowbasedonaforwarping)
Python 工具提取并保存视频的每一帧
更新时间:2020年3月20日17:23:22 作者:chenxp2311
本文文章主要详细介绍了提取和保存视频每一帧的python工具。文章中的示例代码很详细,有一定的参考价值。有兴趣的朋友可以参考一下。
前言
最近在做视频字幕相关的工作,要处理大量的视频。
今天遇到一个问题,就是在YoutubeClips数据集中提取avi格式视频的每一帧。然后使用基于翘曲理论的高精度光流估计提出的光流来提取运动的光流特征。
方法一
方法一最简单,使用FFmpeg工具完成。
具体网上有很多这方面的资料,我只是简单的了解一下如何使用。如下图,有一个名为ffmpeg_test.avi的视频:
在当前目录打开终端,输入以下命令:
$ffmpeg -i ffmpeg_test.avi frames_d.jpg -hide_banner
我上面没有指定太多参数。其实可以指定的参数有很多,比如开始和结束时间,几秒拍一帧等等。
输入以获取每一帧。
方法二
下面可以用 cv2 模块中的 VideoCapture 和 VideoWriter 提取。具体代码如下:
#! encoding: UTF-8
import os
import cv2
import cv
videos_src_path = '/home/ou-lc/chenxp/Downloads/Youtube/youtube_select'
videos_save_path = '/home/ou-lc/chenxp/Downloads/Youtube/youtube_frames'
videos = os.listdir(videos_src_path)
videos = filter(lambda x: x.endswith('avi'), videos)
for each_video in videos:
print each_video
# get the name of each video, and make the directory to save frames
each_video_name, _ = each_video.split('.')
os.mkdir(videos_save_path + '/' + each_video_name)
each_video_save_full_path = os.path.join(videos_save_path, each_video_name) + '/'
# get the full path of each video, which will open the video tp extract frames
each_video_full_path = os.path.join(videos_src_path, each_video)
cap = cv2.VideoCapture(each_video_full_path)
frame_count = 1
success = True
while(success):
success, frame = cap.read()
print 'Read a new frame: ', success
params = []
params.append(cv.CV_IMWRITE_PXM_BINARY)
params.append(1)
cv2.imwrite(each_video_save_full_path + each_video_name + "_%d.ppm" % frame_count, frame, params)
frame_count = frame_count + 1
cap.release()
最后,我以 PPM 格式保存每一帧。因为我需要调用之前光流论文中的of程序来提取光流图像。
保存时,根据opencv的Doc:,参数如上指定。一开始,我在这里丢了几个跟头,因为我不知道如何正确指定参数。
参考
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
网页视频抓取脚本( 2020年02月21日15:50:04)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-13 12:11
2020年02月21日15:50:04)
Python ffmpeg任意提取视频帧的方法
更新时间:2020年2月21日15:50:04 作者:anoyi
本文文章主要介绍python ffmpeg任意提取视频帧的方法。文章通过示例代码进行了详细介绍,对大家的学习或工作具有一定的参考学习价值。有需要的朋友可以关注下方小编一起学习
环境准备
1、安装FFmpeg
音视频工具FFmpeg简易安装文档
2、安装ffmpeg-python
pip3 install ffmpeg-python
3、[可选] 安装 opencv-python
pip3 install opencv-python
4、[可选] 安装 numpy
pip3 install numpy
视频帧提取
准备视频素材
抖音视频素材下载:
根据视频帧数提取任意帧
import ffmpeg
import numpy
import cv2
import sys
import random
def read_frame_as_jpeg(in_file, frame_num):
"""
指定帧数读取任意帧
"""
out, err = (
ffmpeg.input(in_file)
.filter('select', 'gte(n,{})'.format(frame_num))
.output('pipe:', vframes=1, format='image2', vcodec='mjpeg')
.run(capture_stdout=True)
)
return out
def get_video_info(in_file):
"""
获取视频基本信息
"""
try:
probe = ffmpeg.probe(in_file)
video_stream = next((stream for stream in probe['streams'] if stream['codec_type'] == 'video'), None)
if video_stream is None:
print('No video stream found', file=sys.stderr)
sys.exit(1)
return video_stream
except ffmpeg.Error as err:
print(str(err.stderr, encoding='utf8'))
sys.exit(1)
if __name__ == '__main__':
file_path = '/Users/admin/Downloads/拜无忧.mp4'
video_info = get_video_info(file_path)
total_frames = int(video_info['nb_frames'])
print('总帧数:' + str(total_frames))
random_frame = random.randint(1, total_frames)
print('随机帧:' + str(random_frame))
out = read_frame_as_jpeg(file_path, random_frame)
image_array = numpy.asarray(bytearray(out), dtype="uint8")
image = cv2.imdecode(image_array, cv2.IMREAD_COLOR)
cv2.imshow('frame', image)
cv2.waitKey()
根据时间提取任何帧
import ffmpeg
import numpy
import cv2
import sys
import random
def read_frame_by_time(in_file, time):
"""
指定时间节点读取任意帧
"""
out, err = (
ffmpeg.input(in_file, ss=time)
.output('pipe:', vframes=1, format='image2', vcodec='mjpeg')
.run(capture_stdout=True)
)
return out
def get_video_info(in_file):
"""
获取视频基本信息
"""
try:
probe = ffmpeg.probe(in_file)
video_stream = next((stream for stream in probe['streams'] if stream['codec_type'] == 'video'), None)
if video_stream is None:
print('No video stream found', file=sys.stderr)
sys.exit(1)
return video_stream
except ffmpeg.Error as err:
print(str(err.stderr, encoding='utf8'))
sys.exit(1)
if __name__ == '__main__':
file_path = '/Users/admin/Downloads/拜无忧.mp4'
video_info = get_video_info(file_path)
total_duration = video_info['duration']
print('总时间:' + total_duration + 's')
random_time = random.randint(1, int(float(total_duration)) - 1) + random.random()
print('随机时间:' + str(random_time) + 's')
out = read_frame_by_time(file_path, random_time)
image_array = numpy.asarray(bytearray(out), dtype="uint8")
image = cv2.imdecode(image_array, cv2.IMREAD_COLOR)
cv2.imshow('frame', image)
cv2.waitKey()
相关信息
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
网页视频抓取脚本(
2020年02月21日15:50:04)
Python ffmpeg任意提取视频帧的方法
更新时间:2020年2月21日15:50:04 作者:anoyi
本文文章主要介绍python ffmpeg任意提取视频帧的方法。文章通过示例代码进行了详细介绍,对大家的学习或工作具有一定的参考学习价值。有需要的朋友可以关注下方小编一起学习
环境准备
1、安装FFmpeg
音视频工具FFmpeg简易安装文档
2、安装ffmpeg-python
pip3 install ffmpeg-python
3、[可选] 安装 opencv-python
pip3 install opencv-python
4、[可选] 安装 numpy
pip3 install numpy
视频帧提取
准备视频素材
抖音视频素材下载:
根据视频帧数提取任意帧
import ffmpeg
import numpy
import cv2
import sys
import random
def read_frame_as_jpeg(in_file, frame_num):
"""
指定帧数读取任意帧
"""
out, err = (
ffmpeg.input(in_file)
.filter('select', 'gte(n,{})'.format(frame_num))
.output('pipe:', vframes=1, format='image2', vcodec='mjpeg')
.run(capture_stdout=True)
)
return out
def get_video_info(in_file):
"""
获取视频基本信息
"""
try:
probe = ffmpeg.probe(in_file)
video_stream = next((stream for stream in probe['streams'] if stream['codec_type'] == 'video'), None)
if video_stream is None:
print('No video stream found', file=sys.stderr)
sys.exit(1)
return video_stream
except ffmpeg.Error as err:
print(str(err.stderr, encoding='utf8'))
sys.exit(1)
if __name__ == '__main__':
file_path = '/Users/admin/Downloads/拜无忧.mp4'
video_info = get_video_info(file_path)
total_frames = int(video_info['nb_frames'])
print('总帧数:' + str(total_frames))
random_frame = random.randint(1, total_frames)
print('随机帧:' + str(random_frame))
out = read_frame_as_jpeg(file_path, random_frame)
image_array = numpy.asarray(bytearray(out), dtype="uint8")
image = cv2.imdecode(image_array, cv2.IMREAD_COLOR)
cv2.imshow('frame', image)
cv2.waitKey()
根据时间提取任何帧
import ffmpeg
import numpy
import cv2
import sys
import random
def read_frame_by_time(in_file, time):
"""
指定时间节点读取任意帧
"""
out, err = (
ffmpeg.input(in_file, ss=time)
.output('pipe:', vframes=1, format='image2', vcodec='mjpeg')
.run(capture_stdout=True)
)
return out
def get_video_info(in_file):
"""
获取视频基本信息
"""
try:
probe = ffmpeg.probe(in_file)
video_stream = next((stream for stream in probe['streams'] if stream['codec_type'] == 'video'), None)
if video_stream is None:
print('No video stream found', file=sys.stderr)
sys.exit(1)
return video_stream
except ffmpeg.Error as err:
print(str(err.stderr, encoding='utf8'))
sys.exit(1)
if __name__ == '__main__':
file_path = '/Users/admin/Downloads/拜无忧.mp4'
video_info = get_video_info(file_path)
total_duration = video_info['duration']
print('总时间:' + total_duration + 's')
random_time = random.randint(1, int(float(total_duration)) - 1) + random.random()
print('随机时间:' + str(random_time) + 's')
out = read_frame_by_time(file_path, random_time)
image_array = numpy.asarray(bytearray(out), dtype="uint8")
image = cv2.imdecode(image_array, cv2.IMREAD_COLOR)
cv2.imshow('frame', image)
cv2.waitKey()
相关信息
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
网页视频抓取脚本( 2019年08月16日python文中批量爬取下载抖音视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-12 20:15
2019年08月16日python文中批量爬取下载抖音视频)
Python爬虫批量抓取下载抖音视频代码示例
更新时间:2019-08-16 16:45:00 作者:听雪楼肖一清
本文文章主要介绍Python爬虫批量抓取下载抖音视频代码示例。文章通过示例代码介绍了非常详细的例子。对大家的学习或工作,有需要的朋友有一定的参考学习价值。可以参考
本次文章主要为大家详细介绍python批量抓取下载抖音视频。有一定的参考价值,感兴趣的朋友可以参考。
项目源码展示:
'''
在学习过程中有什么不懂得可以加我的
python学习交流扣扣qun,934109170
群里有不错的学习教程、开发工具与电子书籍。
与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容。
'''
# -*- coding:utf-8 -*-
from contextlib import closing
import requests, json, re, os, sys, random
from ipaddress import ip_address
from subprocess import Popen, PIPE
import urllib
class DouYin(object):
def __init__(self, width = 500, height = 300):
"""
抖音App视频下载
"""
rip = ip_address('0.0.0.0')
while rip.is_private:
rip = ip_address('.'.join(map(str, (random.randint(0, 255) for _ in range(4)))))
self.headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Linux; U; Android 5.1.1; zh-cn; MI 4S Build/LMY47V) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/53.0.2785.146 Mobile Safari/537.36 XiaoMi/MiuiBrowser/9.1.3',
'X-Real-IP': str(rip),
'X-Forwarded-For': str(rip),
}
def get_video_urls(self, user_id, type_flag='f'):
"""
获得视频播放地址
Parameters:
user_id:查询的用户UID
Returns:
video_names: 视频名字列表
video_urls: 视频链接列表
nickname: 用户昵称
"""
video_names = []
video_urls = []
share_urls = []
max_cursor = 0
has_more = 1
i = 0
share_user_url = 'https://www.douyin.com/share/user/%s' % user_id
share_user = requests.get(share_user_url, headers=self.headers)
while share_user.status_code != 200:
share_user = requests.get(share_user_url, headers=self.headers)
_dytk_re = re.compile(r"dytk\s*:\s*'(.+)'")
dytk = _dytk_re.search(share_user.text).group(1)
_nickname_re = re.compile(r'<p class="nickname">(.+?)')
nickname = _nickname_re.search(share_user.text).group(1)
urllib.request.urlretrieve('https://raw.githubusercontent.com/Jack-Cherish/python-spider/master/douyin/fuck-byted-acrawler.js', 'fuck-byted-acrawler.js')
try:
Popen(['node', '-v'], stdout=PIPE, stderr=PIPE).communicate()
except (OSError, IOError) as err:
print('请先安装 node.js: https://nodejs.org/')
sys.exit()
user_url_prefix = 'https://www.douyin.com/aweme/v1/aweme/favorite' if type_flag == 'f' else 'https://www.douyin.com/aweme/v1/aweme/post'
print('解析视频链接中')
while has_more != 0:
process = Popen(['node', 'fuck-byted-acrawler.js', str(user_id)], stdout=PIPE, stderr=PIPE)
_sign = process.communicate()[0].decode().strip('\n').strip('\r')
user_url = user_url_prefix + '/?user_id=%s&max_cursor=%s&count=21&aid=1128&_signature=%s&dytk=%s' % (user_id, max_cursor, _sign, dytk)
req = requests.get(user_url, headers=self.headers)
while req.status_code != 200:
req = requests.get(user_url, headers=self.headers)
html = json.loads(req.text)
try:
while html['aweme_list'] == []:
i = i + 1
sys.stdout.write('已重新链接' + str(i) + '次 (若超过100次,请ctrl+c强制停止再重来)' + '\r')
sys.stdout.flush()
process = Popen(['node', 'fuck-byted-acrawler.js', str(user_id)], stdout=PIPE, stderr=PIPE)
_sign = process.communicate()[0].decode().strip('\n').strip('\r')
user_url = user_url_prefix + '/?user_id=%s&max_cursor=%s&count=21&aid=1128&_signature=%s&dytk=%s' % (user_id, max_cursor, _sign, dytk)
req = requests.get(user_url, headers=self.headers)
while req.status_code != 200:
req = requests.get(user_url, headers=self.headers)
html = json.loads(req.text)
except:
pass
i = 0
for each in html['aweme_list']:
try:
url = 'https://aweme.snssdk.com/aweme/v1/play/?video_id=%s&line=0&ratio=720p&media_type=4&vr_type=0&test_cdn=None&improve_bitrate=0'
uri = each['video']['play_addr']['uri']
video_url = url % uri
except:
continue
share_desc = each['share_info']['share_desc']
if os.name == 'nt':
for c in r'\/:*?"|':
nickname = nickname.replace(c, '').strip().strip('\.')
share_desc = share_desc.replace(c, '').strip()
share_id = each['aweme_id']
if share_desc in ['抖音-原创音乐短视频社区', 'TikTok', '']:
video_names.append(share_id + '.mp4')
else:
video_names.append(share_id + '-' + share_desc + '.mp4')
share_urls.append(each['share_info']['share_url'])
video_urls.append(video_url)
max_cursor = html['max_cursor']
has_more = html['has_more']
return video_names, video_urls, share_urls, nickname
def get_download_url(self, video_url, watermark_flag):
"""
获得带水印的视频播放地址
Parameters:
video_url:带水印的视频播放地址
Returns:
download_url: 带水印的视频下载地址
"""
# 带水印视频
if watermark_flag == True:
download_url = video_url.replace('/play/', '/playwm/')
# 无水印视频
else:
download_url = video_url.replace('/playwm/', '/play/')
return download_url
def video_downloader(self, video_url, video_name, watermark_flag=False):
"""
视频下载
Parameters:
video_url: 带水印的视频地址
video_name: 视频名
watermark_flag: 是否下载带水印的视频
Returns:
无
"""
size = 0
video_url = self.get_download_url(video_url, watermark_flag=watermark_flag)
with closing(requests.get(video_url, headers=self.headers, stream=True)) as response:
chunk_size = 1024
content_size = int(response.headers['content-length'])
if response.status_code == 200:
sys.stdout.write(' [文件大小]:%0.2f MB\n' % (content_size / chunk_size / 1024))
with open(video_name, 'wb') as file:
for data in response.iter_content(chunk_size = chunk_size):
file.write(data)
size += len(data)
file.flush()
sys.stdout.write(' [下载进度]:%.2f%%' % float(size / content_size * 100) + '\r')
sys.stdout.flush()
def run(self):
"""
运行函数
Parameters:
None
Returns:
None
"""
self.hello()
print('搜索api需要登录,暂时使用UID下载\n分享用户页面,用浏览器打开短链接,原始链接中/share/user/后的数字即是UID')
user_id = input('请输入ID (例如95006183):')
user_id = user_id if user_id else '95006183'
watermark_flag = input('是否下载带水印的视频 (0-否(默认), 1-是):')
watermark_flag = watermark_flag if watermark_flag!='' else '0'
watermark_flag = bool(int(watermark_flag))
type_flag = input('f-收藏的(默认), p-上传的:')
type_flag = type_flag if type_flag!='' else 'f'
save_dir = input('保存路径 (例如"E:/Download/", 默认"./Download/"):')
save_dir = save_dir if save_dir else "./Download/"
video_names, video_urls, share_urls, nickname = self.get_video_urls(user_id, type_flag)
nickname_dir = os.path.join(save_dir, nickname)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
if nickname not in os.listdir(save_dir):
os.mkdir(nickname_dir)
if type_flag == 'f':
if 'favorite' not in os.listdir(nickname_dir):
os.mkdir(os.path.join(nickname_dir, 'favorite'))
print('视频下载中:共有%d个作品!\n' % len(video_urls))
for num in range(len(video_urls)):
print(' 解析第%d个视频链接 [%s] 中,请稍后!\n' % (num + 1, share_urls[num]))
if '\\' in video_names[num]:
video_name = video_names[num].replace('\\', '')
elif '/' in video_names[num]:
video_name = video_names[num].replace('/', '')
else:
video_name = video_names[num]
video_path = os.path.join(nickname_dir, video_name) if type_flag!='f' else os.path.join(nickname_dir, 'favorite', video_name)
if os.path.isfile(video_path):
print('视频已存在')
else:
self.video_downloader(video_urls[num], video_path, watermark_flag)
print('\n')
print('下载完成!')
def hello(self):
"""
打印欢迎界面
Parameters:
None
Returns:
None
"""
print('*' * 100)
print('\t\t\t\t抖音App视频下载小助手')
print('\t\t作者:Jack Cui、steven7851')
print('*' * 100)
if __name__ == '__main__':
douyin = DouYin()
douyin.run()
操作结果:
抓取结果截图
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
网页视频抓取脚本(
2019年08月16日python文中批量爬取下载抖音视频)
Python爬虫批量抓取下载抖音视频代码示例
更新时间:2019-08-16 16:45:00 作者:听雪楼肖一清
本文文章主要介绍Python爬虫批量抓取下载抖音视频代码示例。文章通过示例代码介绍了非常详细的例子。对大家的学习或工作,有需要的朋友有一定的参考学习价值。可以参考
本次文章主要为大家详细介绍python批量抓取下载抖音视频。有一定的参考价值,感兴趣的朋友可以参考。
项目源码展示:
'''
在学习过程中有什么不懂得可以加我的
python学习交流扣扣qun,934109170
群里有不错的学习教程、开发工具与电子书籍。
与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容。
'''
# -*- coding:utf-8 -*-
from contextlib import closing
import requests, json, re, os, sys, random
from ipaddress import ip_address
from subprocess import Popen, PIPE
import urllib
class DouYin(object):
def __init__(self, width = 500, height = 300):
"""
抖音App视频下载
"""
rip = ip_address('0.0.0.0')
while rip.is_private:
rip = ip_address('.'.join(map(str, (random.randint(0, 255) for _ in range(4)))))
self.headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Linux; U; Android 5.1.1; zh-cn; MI 4S Build/LMY47V) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/53.0.2785.146 Mobile Safari/537.36 XiaoMi/MiuiBrowser/9.1.3',
'X-Real-IP': str(rip),
'X-Forwarded-For': str(rip),
}
def get_video_urls(self, user_id, type_flag='f'):
"""
获得视频播放地址
Parameters:
user_id:查询的用户UID
Returns:
video_names: 视频名字列表
video_urls: 视频链接列表
nickname: 用户昵称
"""
video_names = []
video_urls = []
share_urls = []
max_cursor = 0
has_more = 1
i = 0
share_user_url = 'https://www.douyin.com/share/user/%s' % user_id
share_user = requests.get(share_user_url, headers=self.headers)
while share_user.status_code != 200:
share_user = requests.get(share_user_url, headers=self.headers)
_dytk_re = re.compile(r"dytk\s*:\s*'(.+)'")
dytk = _dytk_re.search(share_user.text).group(1)
_nickname_re = re.compile(r'<p class="nickname">(.+?)')
nickname = _nickname_re.search(share_user.text).group(1)
urllib.request.urlretrieve('https://raw.githubusercontent.com/Jack-Cherish/python-spider/master/douyin/fuck-byted-acrawler.js', 'fuck-byted-acrawler.js')
try:
Popen(['node', '-v'], stdout=PIPE, stderr=PIPE).communicate()
except (OSError, IOError) as err:
print('请先安装 node.js: https://nodejs.org/')
sys.exit()
user_url_prefix = 'https://www.douyin.com/aweme/v1/aweme/favorite' if type_flag == 'f' else 'https://www.douyin.com/aweme/v1/aweme/post'
print('解析视频链接中')
while has_more != 0:
process = Popen(['node', 'fuck-byted-acrawler.js', str(user_id)], stdout=PIPE, stderr=PIPE)
_sign = process.communicate()[0].decode().strip('\n').strip('\r')
user_url = user_url_prefix + '/?user_id=%s&max_cursor=%s&count=21&aid=1128&_signature=%s&dytk=%s' % (user_id, max_cursor, _sign, dytk)
req = requests.get(user_url, headers=self.headers)
while req.status_code != 200:
req = requests.get(user_url, headers=self.headers)
html = json.loads(req.text)
try:
while html['aweme_list'] == []:
i = i + 1
sys.stdout.write('已重新链接' + str(i) + '次 (若超过100次,请ctrl+c强制停止再重来)' + '\r')
sys.stdout.flush()
process = Popen(['node', 'fuck-byted-acrawler.js', str(user_id)], stdout=PIPE, stderr=PIPE)
_sign = process.communicate()[0].decode().strip('\n').strip('\r')
user_url = user_url_prefix + '/?user_id=%s&max_cursor=%s&count=21&aid=1128&_signature=%s&dytk=%s' % (user_id, max_cursor, _sign, dytk)
req = requests.get(user_url, headers=self.headers)
while req.status_code != 200:
req = requests.get(user_url, headers=self.headers)
html = json.loads(req.text)
except:
pass
i = 0
for each in html['aweme_list']:
try:
url = 'https://aweme.snssdk.com/aweme/v1/play/?video_id=%s&line=0&ratio=720p&media_type=4&vr_type=0&test_cdn=None&improve_bitrate=0'
uri = each['video']['play_addr']['uri']
video_url = url % uri
except:
continue
share_desc = each['share_info']['share_desc']
if os.name == 'nt':
for c in r'\/:*?"|':
nickname = nickname.replace(c, '').strip().strip('\.')
share_desc = share_desc.replace(c, '').strip()
share_id = each['aweme_id']
if share_desc in ['抖音-原创音乐短视频社区', 'TikTok', '']:
video_names.append(share_id + '.mp4')
else:
video_names.append(share_id + '-' + share_desc + '.mp4')
share_urls.append(each['share_info']['share_url'])
video_urls.append(video_url)
max_cursor = html['max_cursor']
has_more = html['has_more']
return video_names, video_urls, share_urls, nickname
def get_download_url(self, video_url, watermark_flag):
"""
获得带水印的视频播放地址
Parameters:
video_url:带水印的视频播放地址
Returns:
download_url: 带水印的视频下载地址
"""
# 带水印视频
if watermark_flag == True:
download_url = video_url.replace('/play/', '/playwm/')
# 无水印视频
else:
download_url = video_url.replace('/playwm/', '/play/')
return download_url
def video_downloader(self, video_url, video_name, watermark_flag=False):
"""
视频下载
Parameters:
video_url: 带水印的视频地址
video_name: 视频名
watermark_flag: 是否下载带水印的视频
Returns:
无
"""
size = 0
video_url = self.get_download_url(video_url, watermark_flag=watermark_flag)
with closing(requests.get(video_url, headers=self.headers, stream=True)) as response:
chunk_size = 1024
content_size = int(response.headers['content-length'])
if response.status_code == 200:
sys.stdout.write(' [文件大小]:%0.2f MB\n' % (content_size / chunk_size / 1024))
with open(video_name, 'wb') as file:
for data in response.iter_content(chunk_size = chunk_size):
file.write(data)
size += len(data)
file.flush()
sys.stdout.write(' [下载进度]:%.2f%%' % float(size / content_size * 100) + '\r')
sys.stdout.flush()
def run(self):
"""
运行函数
Parameters:
None
Returns:
None
"""
self.hello()
print('搜索api需要登录,暂时使用UID下载\n分享用户页面,用浏览器打开短链接,原始链接中/share/user/后的数字即是UID')
user_id = input('请输入ID (例如95006183):')
user_id = user_id if user_id else '95006183'
watermark_flag = input('是否下载带水印的视频 (0-否(默认), 1-是):')
watermark_flag = watermark_flag if watermark_flag!='' else '0'
watermark_flag = bool(int(watermark_flag))
type_flag = input('f-收藏的(默认), p-上传的:')
type_flag = type_flag if type_flag!='' else 'f'
save_dir = input('保存路径 (例如"E:/Download/", 默认"./Download/"):')
save_dir = save_dir if save_dir else "./Download/"
video_names, video_urls, share_urls, nickname = self.get_video_urls(user_id, type_flag)
nickname_dir = os.path.join(save_dir, nickname)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
if nickname not in os.listdir(save_dir):
os.mkdir(nickname_dir)
if type_flag == 'f':
if 'favorite' not in os.listdir(nickname_dir):
os.mkdir(os.path.join(nickname_dir, 'favorite'))
print('视频下载中:共有%d个作品!\n' % len(video_urls))
for num in range(len(video_urls)):
print(' 解析第%d个视频链接 [%s] 中,请稍后!\n' % (num + 1, share_urls[num]))
if '\\' in video_names[num]:
video_name = video_names[num].replace('\\', '')
elif '/' in video_names[num]:
video_name = video_names[num].replace('/', '')
else:
video_name = video_names[num]
video_path = os.path.join(nickname_dir, video_name) if type_flag!='f' else os.path.join(nickname_dir, 'favorite', video_name)
if os.path.isfile(video_path):
print('视频已存在')
else:
self.video_downloader(video_urls[num], video_path, watermark_flag)
print('\n')
print('下载完成!')
def hello(self):
"""
打印欢迎界面
Parameters:
None
Returns:
None
"""
print('*' * 100)
print('\t\t\t\t抖音App视频下载小助手')
print('\t\t作者:Jack Cui、steven7851')
print('*' * 100)
if __name__ == '__main__':
douyin = DouYin()
douyin.run()
操作结果:
抓取结果截图
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
网页视频抓取脚本(手机模拟器抓取抖音用户信息的研究方法和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-12 20:13
之前的 文章 研究是关于 fdder 抓取 抖音 用户信息。有兴趣的可以点击我的头像看最后一个帖子。帖子回复不多,大部分人都表示看不懂。这次我们再说一遍。
尽量使用通俗易懂的语言。也许我说错了什么。首先,我将谈谈 fidder。Fidder 非常强大。可以在手机模拟器中拦截抖音与服务器之间的网络请求数据。我们想抓住它。它是一个 https 协议请求。你现在浏览的大部分 网站 都是 http 和 https 请求。https 比 http 请求安全得多。拦截https需要安装证书。Fiider有自己的证书。您可以下载并安装在安卓模拟器上。具体详情百度。安装后,你会在 fdder 上看到来自 抖音 的各种网络请求。
现在我们看到上图中抖音的各种网络请求。看看数据类型为MP4的链接是否被复制,右键复制url,复制到浏览器打开即可。
嘿嘿,没有水印,那我就开始研究这个视频怎么保存?一开始我想保存视频网址,但是过了几天就凉了,报403错误,我也没有权限访问。只能保存文件,找和上一篇一样的思路,找到请求URL的规则
发现视频网址的主机地址有好几个,原来是构造成一个数组。判断oSession.host是否在那个数组中,但是出现无法访问静态内容的错误。只能使用或判断,类似于javascript语法。好的fidderscript有自动补全,输入oSession.Save,后面会有很多选项,然后所有返回的内容都会被保存。
最大的就是MP4了,把后缀名改成MP4就可以直接播放了。. 下一步是循环读取文件。有些问题还没有解决。我写的在python中读取文件的脚本可能只能读取文件的一半。很少有文件不能播放,因为 fdder 无法保存文件。需要时间来瞬间保存。只有将按键精灵脚本的滑动延迟调整为十秒,才能减少无法播放的文件。
import time
import os
l=''
while True:
# 二进制的读取第一行
with open("E:\\apytemp\\ResponseBody.mp4",'rb') as f:
detail=f.readline()
# 判断是否重复
if detail==l:
pass
else:
# 判断文件大小是否大于500k
if os.stat('E:\\apytemp\\ResponseBody.mp4').st_size>500:
# 以时间设置文件名称
now = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time()))
# 读文件
with open("E:\\apytemp\\ResponseBody.mp4", 'rb')as e:
str = e.read()
# 换个文件夹存文件
with open('video\\' + now + ".mp4", "wb") as q:
q.write(str)
print("ok")
time.sleep(0.5)
else:
pass
l = detail
time.sleep(1)
接下来,为按钮向导编写一个小脚本,模拟手动点击和滑动,清除缓存,重新启动应用程序,并编写一个小界面。
Dim intX,intY
Dim tb1,tb2
tb1 = ReadUIConfig("输入框1")
tb2 = ReadUIConfig("输入框2")
//划
Do
For tb1
Swipe 120, 300, 120, 100
Delay tb2*1000
Next
Call qc()
Loop
//清除缓存
Function qc()
Tap 292, 466
Delay 1000
FindMultiColor 0,0,0,0,"B1ADAC","2|0|B1ADAC,4|0|B4B0AF,-2|0|B5B1B0,-23|-1|B6B2B1,-51|-2|483E3C,-52|-2|9B9594,-74|5|9F9A99,-77|5|483E3C,-77|4|483E3C",0,0.9,intX,intY
If intX > -1 And intY > -1 Then
Tap intX, intY
Delay 1000
Tap 38, 335
Delay 1000
End If
Tap 263, 314
Delay 1000
Tap 54, 234
Delay 2000
Call cq()
End Function
//重启
Function cq()
KillApp "com.ss.android.ugc.aweme"
Delay 5000
RunApp "com.ss.android.ugc.aweme"
Delay 10000
End Function
昨晚我整夜挂了电话。早上,按键精灵调试模式暂停了,接下来还有400多个,有的玩不了。先上传到阿里云,准备做个网站或者小程序玩玩
代码:koala9527/douyin,微信公众号也会同步:Pythontest 查看全部
网页视频抓取脚本(手机模拟器抓取抖音用户信息的研究方法和方法)
之前的 文章 研究是关于 fdder 抓取 抖音 用户信息。有兴趣的可以点击我的头像看最后一个帖子。帖子回复不多,大部分人都表示看不懂。这次我们再说一遍。
尽量使用通俗易懂的语言。也许我说错了什么。首先,我将谈谈 fidder。Fidder 非常强大。可以在手机模拟器中拦截抖音与服务器之间的网络请求数据。我们想抓住它。它是一个 https 协议请求。你现在浏览的大部分 网站 都是 http 和 https 请求。https 比 http 请求安全得多。拦截https需要安装证书。Fiider有自己的证书。您可以下载并安装在安卓模拟器上。具体详情百度。安装后,你会在 fdder 上看到来自 抖音 的各种网络请求。
现在我们看到上图中抖音的各种网络请求。看看数据类型为MP4的链接是否被复制,右键复制url,复制到浏览器打开即可。
嘿嘿,没有水印,那我就开始研究这个视频怎么保存?一开始我想保存视频网址,但是过了几天就凉了,报403错误,我也没有权限访问。只能保存文件,找和上一篇一样的思路,找到请求URL的规则
发现视频网址的主机地址有好几个,原来是构造成一个数组。判断oSession.host是否在那个数组中,但是出现无法访问静态内容的错误。只能使用或判断,类似于javascript语法。好的fidderscript有自动补全,输入oSession.Save,后面会有很多选项,然后所有返回的内容都会被保存。
最大的就是MP4了,把后缀名改成MP4就可以直接播放了。. 下一步是循环读取文件。有些问题还没有解决。我写的在python中读取文件的脚本可能只能读取文件的一半。很少有文件不能播放,因为 fdder 无法保存文件。需要时间来瞬间保存。只有将按键精灵脚本的滑动延迟调整为十秒,才能减少无法播放的文件。
import time
import os
l=''
while True:
# 二进制的读取第一行
with open("E:\\apytemp\\ResponseBody.mp4",'rb') as f:
detail=f.readline()
# 判断是否重复
if detail==l:
pass
else:
# 判断文件大小是否大于500k
if os.stat('E:\\apytemp\\ResponseBody.mp4').st_size>500:
# 以时间设置文件名称
now = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time()))
# 读文件
with open("E:\\apytemp\\ResponseBody.mp4", 'rb')as e:
str = e.read()
# 换个文件夹存文件
with open('video\\' + now + ".mp4", "wb") as q:
q.write(str)
print("ok")
time.sleep(0.5)
else:
pass
l = detail
time.sleep(1)
接下来,为按钮向导编写一个小脚本,模拟手动点击和滑动,清除缓存,重新启动应用程序,并编写一个小界面。
Dim intX,intY
Dim tb1,tb2
tb1 = ReadUIConfig("输入框1")
tb2 = ReadUIConfig("输入框2")
//划
Do
For tb1
Swipe 120, 300, 120, 100
Delay tb2*1000
Next
Call qc()
Loop
//清除缓存
Function qc()
Tap 292, 466
Delay 1000
FindMultiColor 0,0,0,0,"B1ADAC","2|0|B1ADAC,4|0|B4B0AF,-2|0|B5B1B0,-23|-1|B6B2B1,-51|-2|483E3C,-52|-2|9B9594,-74|5|9F9A99,-77|5|483E3C,-77|4|483E3C",0,0.9,intX,intY
If intX > -1 And intY > -1 Then
Tap intX, intY
Delay 1000
Tap 38, 335
Delay 1000
End If
Tap 263, 314
Delay 1000
Tap 54, 234
Delay 2000
Call cq()
End Function
//重启
Function cq()
KillApp "com.ss.android.ugc.aweme"
Delay 5000
RunApp "com.ss.android.ugc.aweme"
Delay 10000
End Function
昨晚我整夜挂了电话。早上,按键精灵调试模式暂停了,接下来还有400多个,有的玩不了。先上传到阿里云,准备做个网站或者小程序玩玩
代码:koala9527/douyin,微信公众号也会同步:Pythontest
网页视频抓取脚本(网络爬虫技术被称为网络蜘蛛或者网络机器人,难度也有所不同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-11 15:02
编程要求:
网络爬行技术被称为网络蜘蛛或网络机器人,是指根据一定的规则自动在网络上抓取的程序或脚本数据。比如我们在网上找了很多图片或者很多视频资料。当然你可以用鼠标一个一个的下载,但是会消耗大量的时间和精力也是可以理解的。此时,我们需要一个脚本,可以自动抓取网络内容,自动抓取网络图片或连接,自动批量下载。当然,根据网络数据抓取的深度和数据的复杂程度,设计一个网络爬虫的难度也不同。
脚本源代码:
#!/bin/bash
#功能说明:编写脚本抓取单个网页中的所有图片
#需要获取的网页的网页链接种子和种子URL文件名
页=“页地址”
URL="/tmp/spider_$$.txt" #在哪里抓
#将网页的源代码保存到文件中
curl -s 网页地址> $URL
#过滤并清理文件以获得所需的种子URL链接
echo -e "\033[32m 正在获取种子 URL,请稍候..., 033[0m"
sed -i'/
sed -i's/.*src=``//' $URL #删除src=''和之前的内容
sed -i's/''.*//' $URL #去掉双引号及其后的所有内容
回声
#检测系统如果没有wget下载工具,安装软件
如果!rpm -q wget &>/dev/null;
然后
yum -y 安装 wget
菲
#使用循环批量下载所有图片数据
#wget 是一个下载工具,其参数选项如下:
# -P 指定文件的下载目录
# -c 支持可续传
# -q 不显示下载过程
echo -e "\033[32m 正在批量下载种子,请稍等,呵呵呵!\033[0m"
对于我在 $(cat $URL)
做
wget -P /tmp/ -c -q $i
完毕
#删除临时种子列表文件
rm -rf $URL 查看全部
网页视频抓取脚本(网络爬虫技术被称为网络蜘蛛或者网络机器人,难度也有所不同)
编程要求:
网络爬行技术被称为网络蜘蛛或网络机器人,是指根据一定的规则自动在网络上抓取的程序或脚本数据。比如我们在网上找了很多图片或者很多视频资料。当然你可以用鼠标一个一个的下载,但是会消耗大量的时间和精力也是可以理解的。此时,我们需要一个脚本,可以自动抓取网络内容,自动抓取网络图片或连接,自动批量下载。当然,根据网络数据抓取的深度和数据的复杂程度,设计一个网络爬虫的难度也不同。
脚本源代码:
#!/bin/bash
#功能说明:编写脚本抓取单个网页中的所有图片
#需要获取的网页的网页链接种子和种子URL文件名
页=“页地址”
URL="/tmp/spider_$$.txt" #在哪里抓
#将网页的源代码保存到文件中
curl -s 网页地址> $URL
#过滤并清理文件以获得所需的种子URL链接
echo -e "\033[32m 正在获取种子 URL,请稍候..., 033[0m"
sed -i'/
sed -i's/.*src=``//' $URL #删除src=''和之前的内容
sed -i's/''.*//' $URL #去掉双引号及其后的所有内容
回声
#检测系统如果没有wget下载工具,安装软件
如果!rpm -q wget &>/dev/null;
然后
yum -y 安装 wget
菲
#使用循环批量下载所有图片数据
#wget 是一个下载工具,其参数选项如下:
# -P 指定文件的下载目录
# -c 支持可续传
# -q 不显示下载过程
echo -e "\033[32m 正在批量下载种子,请稍等,呵呵呵!\033[0m"
对于我在 $(cat $URL)
做
wget -P /tmp/ -c -q $i
完毕
#删除临时种子列表文件
rm -rf $URL
网页视频抓取脚本( 编程语言python使用方案:selenium+phantomjs方案介绍实现自动预览)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-11 01:14
编程语言python使用方案:selenium+phantomjs方案介绍实现自动预览)
Python中网页自动截图示例说明
更新时间:2018-05-17 14:43:38 作者:test_2016
今天小编就给大家分享一个如何用Python实现网页自动截图的样例讲解。跟着小编一起来看看吧
背景介绍
最近在为部门写一个自动化测试工具。该工具涉及一个功能,就是将自动化测试生成的html报告截图作为邮件正文,将html文件上传到web服务器,并以链接的形式添加到邮件中,最后发送电子邮件。
任务难度
页面自动截图的相关方面我之前没有接触过,所以如何自动截图页面成为本地研究的方向。
计划思维
刚接到这个任务的时候,我并不认同现在的计划。曾经有人认为,通过将html报告的内容写入邮件正文中,可以将邮件以html的形式发送。尝试后,我发现电子邮件不支持带有javascript的html。因此,选择了预览html和自动截屏的选项。
编程语言
蟒蛇2.7
使用计划:
硒 + phantomjs
一个介绍
自动预览html和截图有几个步骤:
1. 浏览器打开html
2. 浏览器页面截图
3. 截图保存到指定位置
最初,作者使用了这个实现方案:
(1)。使用webbrowser库打开默认浏览器,显示url
(2).使用PIL.ImageGrab库对屏幕截图
至此,笔者已经拿到了html预览截图,看起来一切顺利,但是接下来
发现了以下问题:
(1)。当你打开默认浏览器时,你不知道默认浏览器是什么,浏览器处于什么状态。
(2)。浏览器显示html时,会有一个显示打开浏览器,浏览器打开html动作。如果用户此时有其他动作,肯定会影响后续的截图。
(3).截屏,截取整个屏幕。截图中除了html页面主体外,还收录当前屏幕所收录的浏览器等所有元素,暴露用户隐私。
(4)。如果页面很大,页面会有上下翻页的效果,截图无法应对这种页面,截图只能看到部分报告。
基于以上问题,笔者放弃了这个看似简单有效的解决方案。从而
为该计划挖掘了一些深层次的要求:
(1)。打开浏览器必须隐式调用,用户看不到工具在做什么,以免误操作影响工具。
(2)。截图必须针对浏览器页面主体,保证没有其他多余信息,截取页面全图。根据这些要求,作者终于发现了selenium + phantomjs 经过一系列尝试。
python selenium:Python 是 selenium 的扩展,selenium 是一个浏览器自动化测试框架。selenium 库支持 selenium 中收录的大部分功能。
phantomjs:它是一个无接口、可编写脚本的 webkit 浏览器,python selenium 也提供了对 phantomjs 的支持。
接下来一切都很简单:
(1).安装python selenium库,建议使用pip快速安装最新版本
(2)。下载phantomjs.exe,添加到环境变量路径中,为了方便,可以直接放在python安装目录的根目录下
(3).写测试代码
简单解释一下代码:
fromselenium importwebdriver #从selenium库导入webdirver
brower=webdriver.PhantomJS() #使用webdirver.PhantomJS()方法新建一个phantomjs的对象,这里会使用到phantomjs.exe,环境变量path中找不到phantomjs.exe,则会报错
brower.get(url) #使用get()方法,打开指定页面。注意这里是phantomjs是无界面的,所以不会有任何页面显示
brower.maximize_window() #设置phantomjs浏览器全屏显示
brower.save_screenshot(picName) #使用save_screenshot将浏览器正文部分截图,即使正文本分无法一页显示完全,save_screenshot也可以完全截图
brower.close() #关闭phantomjs浏览器,不要忽略了这一步,否则你会在任务浏览器中发现许多phantomjs进程
执行完上面的代码,我们来看看截图效果:
以上对网页自动截图的Python实现的示例说明,均为小编分享的内容。希望能给大家一个参考,也希望大家多多支持脚本之家。 查看全部
网页视频抓取脚本(
编程语言python使用方案:selenium+phantomjs方案介绍实现自动预览)
Python中网页自动截图示例说明
更新时间:2018-05-17 14:43:38 作者:test_2016
今天小编就给大家分享一个如何用Python实现网页自动截图的样例讲解。跟着小编一起来看看吧
背景介绍
最近在为部门写一个自动化测试工具。该工具涉及一个功能,就是将自动化测试生成的html报告截图作为邮件正文,将html文件上传到web服务器,并以链接的形式添加到邮件中,最后发送电子邮件。
任务难度
页面自动截图的相关方面我之前没有接触过,所以如何自动截图页面成为本地研究的方向。
计划思维
刚接到这个任务的时候,我并不认同现在的计划。曾经有人认为,通过将html报告的内容写入邮件正文中,可以将邮件以html的形式发送。尝试后,我发现电子邮件不支持带有javascript的html。因此,选择了预览html和自动截屏的选项。
编程语言
蟒蛇2.7
使用计划:
硒 + phantomjs
一个介绍
自动预览html和截图有几个步骤:
1. 浏览器打开html
2. 浏览器页面截图
3. 截图保存到指定位置
最初,作者使用了这个实现方案:
(1)。使用webbrowser库打开默认浏览器,显示url
(2).使用PIL.ImageGrab库对屏幕截图
至此,笔者已经拿到了html预览截图,看起来一切顺利,但是接下来
发现了以下问题:
(1)。当你打开默认浏览器时,你不知道默认浏览器是什么,浏览器处于什么状态。
(2)。浏览器显示html时,会有一个显示打开浏览器,浏览器打开html动作。如果用户此时有其他动作,肯定会影响后续的截图。
(3).截屏,截取整个屏幕。截图中除了html页面主体外,还收录当前屏幕所收录的浏览器等所有元素,暴露用户隐私。
(4)。如果页面很大,页面会有上下翻页的效果,截图无法应对这种页面,截图只能看到部分报告。
基于以上问题,笔者放弃了这个看似简单有效的解决方案。从而
为该计划挖掘了一些深层次的要求:
(1)。打开浏览器必须隐式调用,用户看不到工具在做什么,以免误操作影响工具。
(2)。截图必须针对浏览器页面主体,保证没有其他多余信息,截取页面全图。根据这些要求,作者终于发现了selenium + phantomjs 经过一系列尝试。
python selenium:Python 是 selenium 的扩展,selenium 是一个浏览器自动化测试框架。selenium 库支持 selenium 中收录的大部分功能。
phantomjs:它是一个无接口、可编写脚本的 webkit 浏览器,python selenium 也提供了对 phantomjs 的支持。
接下来一切都很简单:
(1).安装python selenium库,建议使用pip快速安装最新版本
(2)。下载phantomjs.exe,添加到环境变量路径中,为了方便,可以直接放在python安装目录的根目录下
(3).写测试代码
简单解释一下代码:
fromselenium importwebdriver #从selenium库导入webdirver
brower=webdriver.PhantomJS() #使用webdirver.PhantomJS()方法新建一个phantomjs的对象,这里会使用到phantomjs.exe,环境变量path中找不到phantomjs.exe,则会报错
brower.get(url) #使用get()方法,打开指定页面。注意这里是phantomjs是无界面的,所以不会有任何页面显示
brower.maximize_window() #设置phantomjs浏览器全屏显示
brower.save_screenshot(picName) #使用save_screenshot将浏览器正文部分截图,即使正文本分无法一页显示完全,save_screenshot也可以完全截图
brower.close() #关闭phantomjs浏览器,不要忽略了这一步,否则你会在任务浏览器中发现许多phantomjs进程
执行完上面的代码,我们来看看截图效果:
以上对网页自动截图的Python实现的示例说明,均为小编分享的内容。希望能给大家一个参考,也希望大家多多支持脚本之家。
网页视频抓取脚本(Python实现抓取B站视频弹幕和评论的更文挑战 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-09 20:16
)
“这是我参加11月更新挑战的第五天。活动详情请看:2021年最后一次更新挑战。”
前言
用Python捕捉B站视频弹幕评论,废话不多说。
让我们愉快的开始吧~
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文以爬取视频《“这是我见过最拽的中国奥运冠军”》为例,讲解如何爬取B站视频的弹幕和评论!
目标地址
https://www.bilibili.com/video/BV1wq4y1Q7dp
复制代码
抢弹幕
网络分析
B站视频的弹幕不像腾讯视频。播放视频会触发弹幕数据包。他需要点击网页右侧弹幕列表行展开,再点击查看历史弹幕,即可得到视频弹幕开始日期到结束日期。日链接:
在链接的最后,使用oid和start date组成弹幕日期URL:
https://api.bilibili.com/x/v2/ ... 21-08
复制代码
在此基础上,点击任意一个有效日期,即可得到该日期的弹幕数据包。里面的内容目前无法读取。之所以确定是弹幕数据包,是因为日期是点击他刚加载出来的,链接和上一个链接有关系:
获取到的网址:
https://api.bilibili.com/x/v2/ ... 08-08
复制代码
URL中的oid为视频弹幕链接的id值;data参数是刚才的日期,要获取视频的所有弹幕内容,只需要修改data参数即可。data参数可以从上面弹幕日期url中获取,也可以自己构造;网页数据格式为json格式
代码
import requests\
import pandas as pd\
import re\
\
def data_resposen(url):\
headers = {\
"cookie": "你的cookie",\
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36"\
}\
resposen = requests.get(url, headers=headers)\
return resposen\
\
def main(oid, month):\
df = pd.DataFrame()\
url = f'https://api.bilibili.com/x/v2/dm/history/index?type=1&oid={oid}&month={month}'\
list_data = data_resposen(url).json()['data'] # 拿到所有日期\
print(list_data)\
for data in list_data:\
urls = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid={oid}&date={data}'\
text = re.findall(".*?([\u4E00-\u9FA5]+).*?", data_resposen(urls).text)\
for e in text:\
print(e)\
data = pd.DataFrame({'弹幕': [e]})\
df = pd.concat([df, data])\
df.to_csv('弹幕.csv', encoding='utf-8', index=False, mode='a+')\
\
if __name__ == '__main__':\
oid = '384801460' # 视频弹幕链接的id值\
month = '2021-08' # 开始日期\
main(oid, month)
复制代码
显示结果
查看全部
网页视频抓取脚本(Python实现抓取B站视频弹幕和评论的更文挑战
)
“这是我参加11月更新挑战的第五天。活动详情请看:2021年最后一次更新挑战。”
前言
用Python捕捉B站视频弹幕评论,废话不多说。
让我们愉快的开始吧~
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文以爬取视频《“这是我见过最拽的中国奥运冠军”》为例,讲解如何爬取B站视频的弹幕和评论!
目标地址
https://www.bilibili.com/video/BV1wq4y1Q7dp
复制代码
抢弹幕
网络分析
B站视频的弹幕不像腾讯视频。播放视频会触发弹幕数据包。他需要点击网页右侧弹幕列表行展开,再点击查看历史弹幕,即可得到视频弹幕开始日期到结束日期。日链接:
在链接的最后,使用oid和start date组成弹幕日期URL:
https://api.bilibili.com/x/v2/ ... 21-08
复制代码
在此基础上,点击任意一个有效日期,即可得到该日期的弹幕数据包。里面的内容目前无法读取。之所以确定是弹幕数据包,是因为日期是点击他刚加载出来的,链接和上一个链接有关系:
获取到的网址:
https://api.bilibili.com/x/v2/ ... 08-08
复制代码
URL中的oid为视频弹幕链接的id值;data参数是刚才的日期,要获取视频的所有弹幕内容,只需要修改data参数即可。data参数可以从上面弹幕日期url中获取,也可以自己构造;网页数据格式为json格式
代码
import requests\
import pandas as pd\
import re\
\
def data_resposen(url):\
headers = {\
"cookie": "你的cookie",\
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36"\
}\
resposen = requests.get(url, headers=headers)\
return resposen\
\
def main(oid, month):\
df = pd.DataFrame()\
url = f'https://api.bilibili.com/x/v2/dm/history/index?type=1&oid={oid}&month={month}'\
list_data = data_resposen(url).json()['data'] # 拿到所有日期\
print(list_data)\
for data in list_data:\
urls = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid={oid}&date={data}'\
text = re.findall(".*?([\u4E00-\u9FA5]+).*?", data_resposen(urls).text)\
for e in text:\
print(e)\
data = pd.DataFrame({'弹幕': [e]})\
df = pd.concat([df, data])\
df.to_csv('弹幕.csv', encoding='utf-8', index=False, mode='a+')\
\
if __name__ == '__main__':\
oid = '384801460' # 视频弹幕链接的id值\
month = '2021-08' # 开始日期\
main(oid, month)
复制代码
显示结果
网页视频抓取脚本( 2015年06月16日14:48:18作者红薯篇文章基于html5元素操作多媒体)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-09 08:15
2015年06月16日14:48:18作者红薯篇文章基于html5元素操作多媒体)
js+HTML5 基于过滤器的摄像头视频捕获方法
更新时间:2015年6月16日14:48:18 作者:甘薯
本文章主要介绍js+HTML5基于滤镜从摄像头抓取视频的方法,涉及到使用javascript操作基于html5元素的多媒体。有需要的朋友可以参考以下
本文介绍了js+HTML5如何基于过滤器从摄像头捕捉视频。分享给大家,供大家参考。详情如下:
index.html 页面:
Native web camera streaming (getUserMedia) is not supported in this browser.
Current filter is: None
Click here to change video filter
HTML5 object
HTML5 object
style.css 文件:
.grayscale{
-webkit-filter:grayscale(1);
-moz-filter:grayscale(1);
-o-filter:grayscale(1);
-ms-filter:grayscale(1);
filter:grayscale(1);
}
.sepia{
-webkit-filter:sepia(0.8);
-moz-filter:sepia(0.8);
-o-filter:sepia(0.8);
-ms-filter:sepia(0.8);
filter:sepia(0.8);
}
.blur{
-webkit-filter:blur(3px);
-moz-filter:blur(3px);
-o-filter:blur(3px);
-ms-filter:blur(3px);
filter:blur(3px);
}
.brightness{
-webkit-filter:brightness(0.3);
-moz-filter:brightness(0.3);
-o-filter:brightness(0.3);
-ms-filter:brightness(0.3);
filter:brightness(0.3);
}
.contrast{
-webkit-filter:contrast(0.5);
-moz-filter:contrast(0.5);
-o-filter:contrast(0.5);
-ms-filter:contrast(0.5);
filter:contrast(0.5);
}
.hue-rotate{
-webkit-filter:hue-rotate(90deg);
-moz-filter:hue-rotate(90deg);
-o-filter:hue-rotate(90deg);
-ms-filter:hue-rotate(90deg);
filter:hue-rotate(90deg);
}
.hue-rotate2{
-webkit-filter:hue-rotate(180deg);
-moz-filter:hue-rotate(180deg);
-o-filter:hue-rotate(180deg);
-ms-filter:hue-rotate(180deg);
filter:hue-rotate(180deg);
}
.hue-rotate3{
-webkit-filter:hue-rotate(270deg);
-moz-filter:hue-rotate(270deg);
-o-filter:hue-rotate(270deg);
-ms-filter:hue-rotate(270deg);
filter:hue-rotate(270deg);
}
.saturate{
-webkit-filter:saturate(10);
-moz-filter:saturate(10);
-o-filter:saturate(10);
-ms-filter:saturate(10);
filter:saturate(10);
}
.invert{
-webkit-filter:invert(1);
-moz-filter:invert(1);
-o-filter: invert(1);
-ms-filter: invert(1);
filter: invert(1);
}
script.js 文件:
// Main initialization
document.addEventListener('DOMContentLoaded', function() {
// Global variables
var video = document.querySelector('video');
var audio, audioType;
var canvas = document.querySelector('canvas');
var context = canvas.getContext('2d');
// Custom video filters
var iFilter = 0;
var filters = [
'grayscale',
'sepia',
'blur',
'brightness',
'contrast',
'hue-rotate',
'hue-rotate2',
'hue-rotate3',
'saturate',
'invert',
'none'
];
// Get the video stream from the camera with getUserMedia
navigator.getUserMedia = navigator.getUserMedia || navigator.webkitGetUserMedia ||
navigator.mozGetUserMedia || navigator.msGetUserMedia;
window.URL = window.URL || window.webkitURL || window.mozURL || window.msURL;
if (navigator.getUserMedia) {
// Evoke getUserMedia function
navigator.getUserMedia({video: true, audio: true}, onSuccessCallback, onErrorCallback);
function onSuccessCallback(stream) {
// Use the stream from the camera as the source of the video element
video.src = window.URL.createObjectURL(stream) || stream;
// Autoplay
video.play();
// HTML5 Audio
audio = new Audio();
audioType = getAudioType(audio);
if (audioType) {
audio.src = 'polaroid.' + audioType;
audio.play();
}
}
// Display an error
function onErrorCallback(e) {
var expl = 'An error occurred: [Reason: ' + e.code + ']';
console.error(expl);
alert(expl);
return;
}
} else {
document.querySelector('.container').style.visibility = 'hidden';
document.querySelector('.warning').style.visibility = 'visible';
return;
}
// Draw the video stream at the canvas object
function drawVideoAtCanvas(obj, context) {
window.setInterval(function() {
context.drawImage(obj, 0, 0);
}, 60);
}
// The canPlayType() function doesn't return true or false. In recognition of how complex
// formats are, the function returns a string: 'probably', 'maybe' or an empty string.
function getAudioType(element) {
if (element.canPlayType) {
if (element.canPlayType('audio/mp4; codecs="mp4a.40.5"') !== '') {
return('aac');
} else if (element.canPlayType('audio/ogg; codecs="vorbis"') !== '') {
return("ogg");
}
}
return false;
}
// Add event listener for our video's Play function in order to produce video at the canvas
video.addEventListener('play', function() {
drawVideoAtCanvas(this, context);
}, false);
// Add event listener for our Button (to switch video filters)
document.querySelector('button').addEventListener('click', function() {
video.className = '';
canvas.className = '';
var effect = filters[iFilter++ % filters.length]; // Loop through the filters.
if (effect) {
video.classList.add(effect);
canvas.classList.add(effect);
document.querySelector('.container h3').innerHTML = 'Current filter is: ' + effect;
}
}, false);
}, false);
希望这篇文章对您的 JavaScript 编程有所帮助。 查看全部
网页视频抓取脚本(
2015年06月16日14:48:18作者红薯篇文章基于html5元素操作多媒体)
js+HTML5 基于过滤器的摄像头视频捕获方法
更新时间:2015年6月16日14:48:18 作者:甘薯
本文章主要介绍js+HTML5基于滤镜从摄像头抓取视频的方法,涉及到使用javascript操作基于html5元素的多媒体。有需要的朋友可以参考以下
本文介绍了js+HTML5如何基于过滤器从摄像头捕捉视频。分享给大家,供大家参考。详情如下:
index.html 页面:
Native web camera streaming (getUserMedia) is not supported in this browser.
Current filter is: None
Click here to change video filter
HTML5 object
HTML5 object
style.css 文件:
.grayscale{
-webkit-filter:grayscale(1);
-moz-filter:grayscale(1);
-o-filter:grayscale(1);
-ms-filter:grayscale(1);
filter:grayscale(1);
}
.sepia{
-webkit-filter:sepia(0.8);
-moz-filter:sepia(0.8);
-o-filter:sepia(0.8);
-ms-filter:sepia(0.8);
filter:sepia(0.8);
}
.blur{
-webkit-filter:blur(3px);
-moz-filter:blur(3px);
-o-filter:blur(3px);
-ms-filter:blur(3px);
filter:blur(3px);
}
.brightness{
-webkit-filter:brightness(0.3);
-moz-filter:brightness(0.3);
-o-filter:brightness(0.3);
-ms-filter:brightness(0.3);
filter:brightness(0.3);
}
.contrast{
-webkit-filter:contrast(0.5);
-moz-filter:contrast(0.5);
-o-filter:contrast(0.5);
-ms-filter:contrast(0.5);
filter:contrast(0.5);
}
.hue-rotate{
-webkit-filter:hue-rotate(90deg);
-moz-filter:hue-rotate(90deg);
-o-filter:hue-rotate(90deg);
-ms-filter:hue-rotate(90deg);
filter:hue-rotate(90deg);
}
.hue-rotate2{
-webkit-filter:hue-rotate(180deg);
-moz-filter:hue-rotate(180deg);
-o-filter:hue-rotate(180deg);
-ms-filter:hue-rotate(180deg);
filter:hue-rotate(180deg);
}
.hue-rotate3{
-webkit-filter:hue-rotate(270deg);
-moz-filter:hue-rotate(270deg);
-o-filter:hue-rotate(270deg);
-ms-filter:hue-rotate(270deg);
filter:hue-rotate(270deg);
}
.saturate{
-webkit-filter:saturate(10);
-moz-filter:saturate(10);
-o-filter:saturate(10);
-ms-filter:saturate(10);
filter:saturate(10);
}
.invert{
-webkit-filter:invert(1);
-moz-filter:invert(1);
-o-filter: invert(1);
-ms-filter: invert(1);
filter: invert(1);
}
script.js 文件:
// Main initialization
document.addEventListener('DOMContentLoaded', function() {
// Global variables
var video = document.querySelector('video');
var audio, audioType;
var canvas = document.querySelector('canvas');
var context = canvas.getContext('2d');
// Custom video filters
var iFilter = 0;
var filters = [
'grayscale',
'sepia',
'blur',
'brightness',
'contrast',
'hue-rotate',
'hue-rotate2',
'hue-rotate3',
'saturate',
'invert',
'none'
];
// Get the video stream from the camera with getUserMedia
navigator.getUserMedia = navigator.getUserMedia || navigator.webkitGetUserMedia ||
navigator.mozGetUserMedia || navigator.msGetUserMedia;
window.URL = window.URL || window.webkitURL || window.mozURL || window.msURL;
if (navigator.getUserMedia) {
// Evoke getUserMedia function
navigator.getUserMedia({video: true, audio: true}, onSuccessCallback, onErrorCallback);
function onSuccessCallback(stream) {
// Use the stream from the camera as the source of the video element
video.src = window.URL.createObjectURL(stream) || stream;
// Autoplay
video.play();
// HTML5 Audio
audio = new Audio();
audioType = getAudioType(audio);
if (audioType) {
audio.src = 'polaroid.' + audioType;
audio.play();
}
}
// Display an error
function onErrorCallback(e) {
var expl = 'An error occurred: [Reason: ' + e.code + ']';
console.error(expl);
alert(expl);
return;
}
} else {
document.querySelector('.container').style.visibility = 'hidden';
document.querySelector('.warning').style.visibility = 'visible';
return;
}
// Draw the video stream at the canvas object
function drawVideoAtCanvas(obj, context) {
window.setInterval(function() {
context.drawImage(obj, 0, 0);
}, 60);
}
// The canPlayType() function doesn't return true or false. In recognition of how complex
// formats are, the function returns a string: 'probably', 'maybe' or an empty string.
function getAudioType(element) {
if (element.canPlayType) {
if (element.canPlayType('audio/mp4; codecs="mp4a.40.5"') !== '') {
return('aac');
} else if (element.canPlayType('audio/ogg; codecs="vorbis"') !== '') {
return("ogg");
}
}
return false;
}
// Add event listener for our video's Play function in order to produce video at the canvas
video.addEventListener('play', function() {
drawVideoAtCanvas(this, context);
}, false);
// Add event listener for our Button (to switch video filters)
document.querySelector('button').addEventListener('click', function() {
video.className = '';
canvas.className = '';
var effect = filters[iFilter++ % filters.length]; // Loop through the filters.
if (effect) {
video.classList.add(effect);
canvas.classList.add(effect);
document.querySelector('.container h3').innerHTML = 'Current filter is: ' + effect;
}
}, false);
}, false);
希望这篇文章对您的 JavaScript 编程有所帮助。

