
网页视频抓取脚本
网页视频抓取脚本( 分析网页视频存储形式以及加密格式() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-17 14:15
分析网页视频存储形式以及加密格式()
)
高级爬虫-视频采集(视频加密分割案例) 中国职业培训在线网
.
1.分析网络视频存储和加密格式
一般我们在做视频采集的视频大多是:https:指向一个视频文件,但是在大多数网站中,目前主流的视频加密格式大都是分成上百个小片段。播放并不断加载新剪辑。中国职业培训在线视频网视频示例:
.
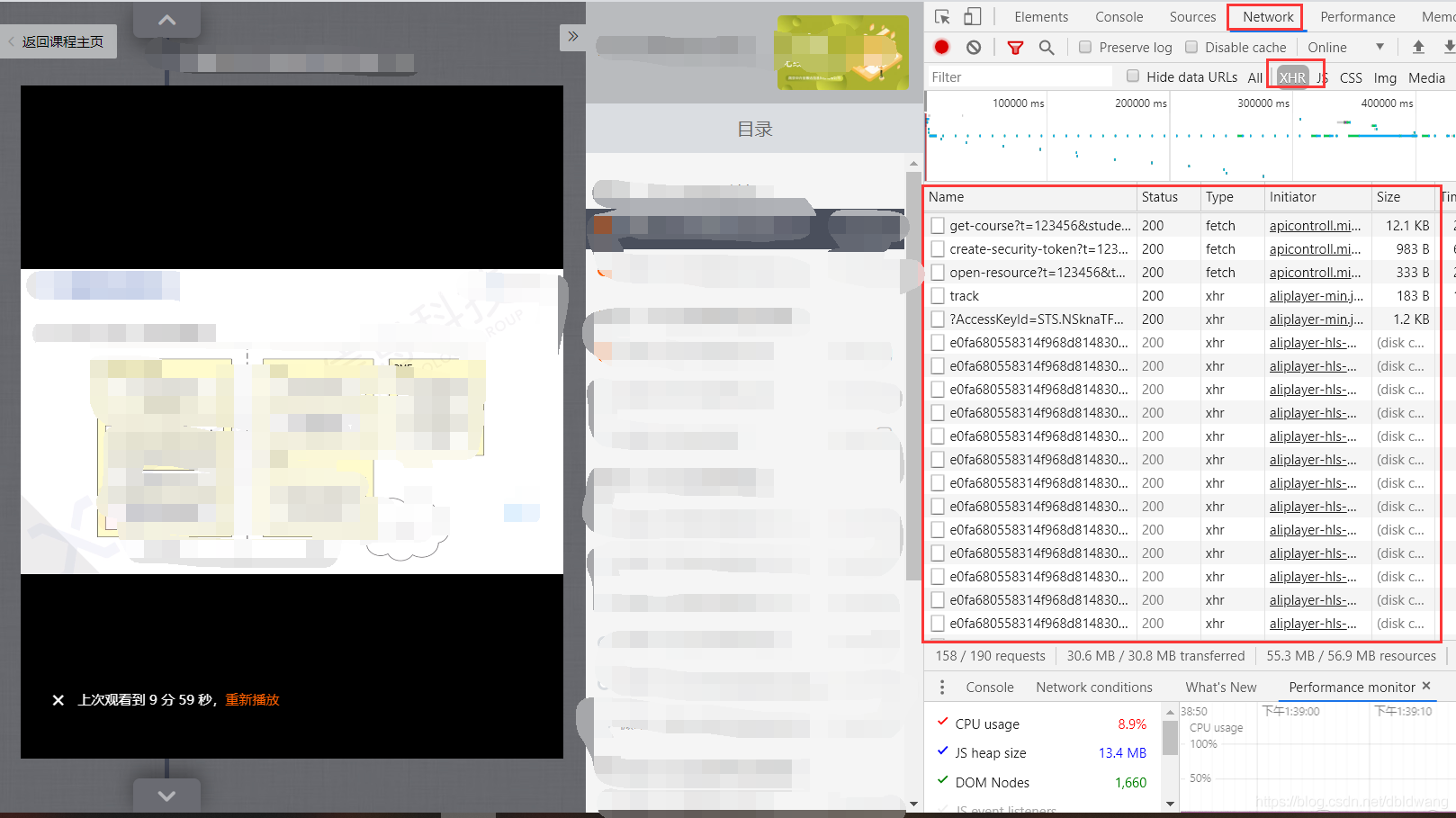
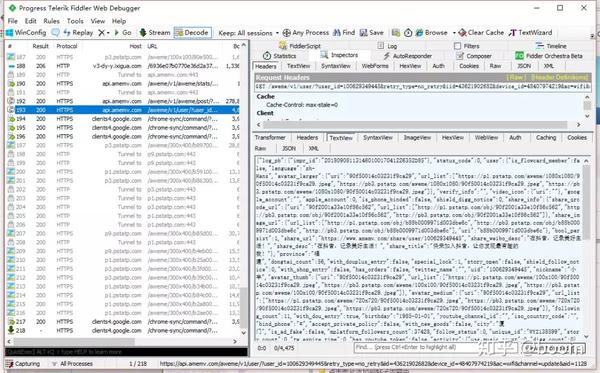
要通过 F12 按钮查看 Web 缓存,请选择顶部的网络和 xhr:
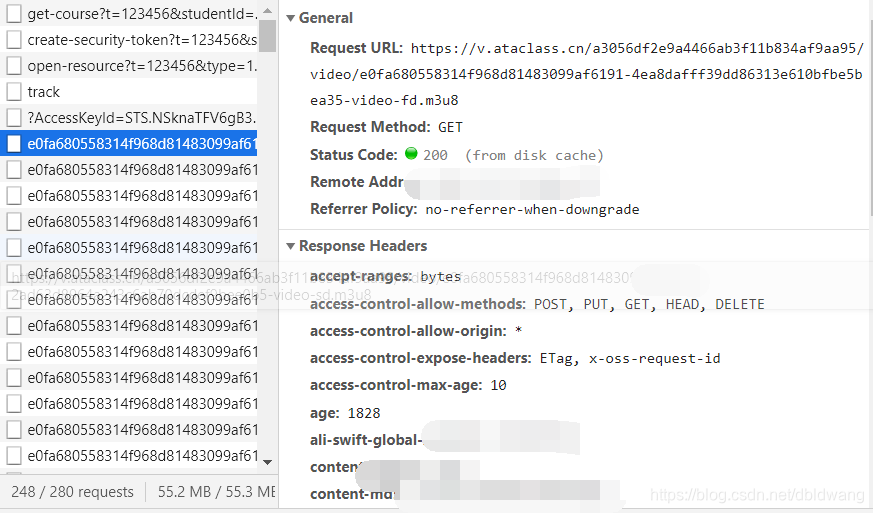
注:目前主要的视频分割技术使用.m3u8文件来记录视频片段总数。后缀为 .m3u8 的文件收录所有视频剪辑的文件名。大多数视频剪辑文件都是.ts文件,所以我们目前的开发者在工具中找到对应的.m3u8文件
如下:
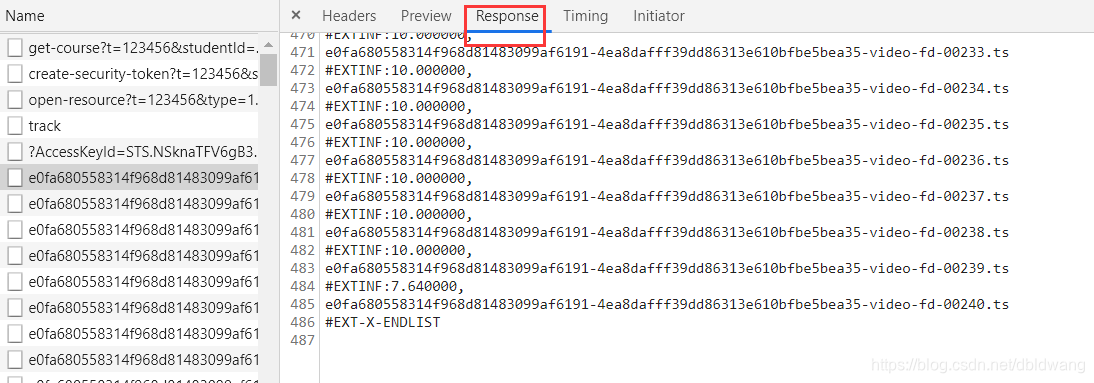
点击查看文件内容:
可以观察到所有的视频剪辑文件都在这里,从00001.ts-00240.ts
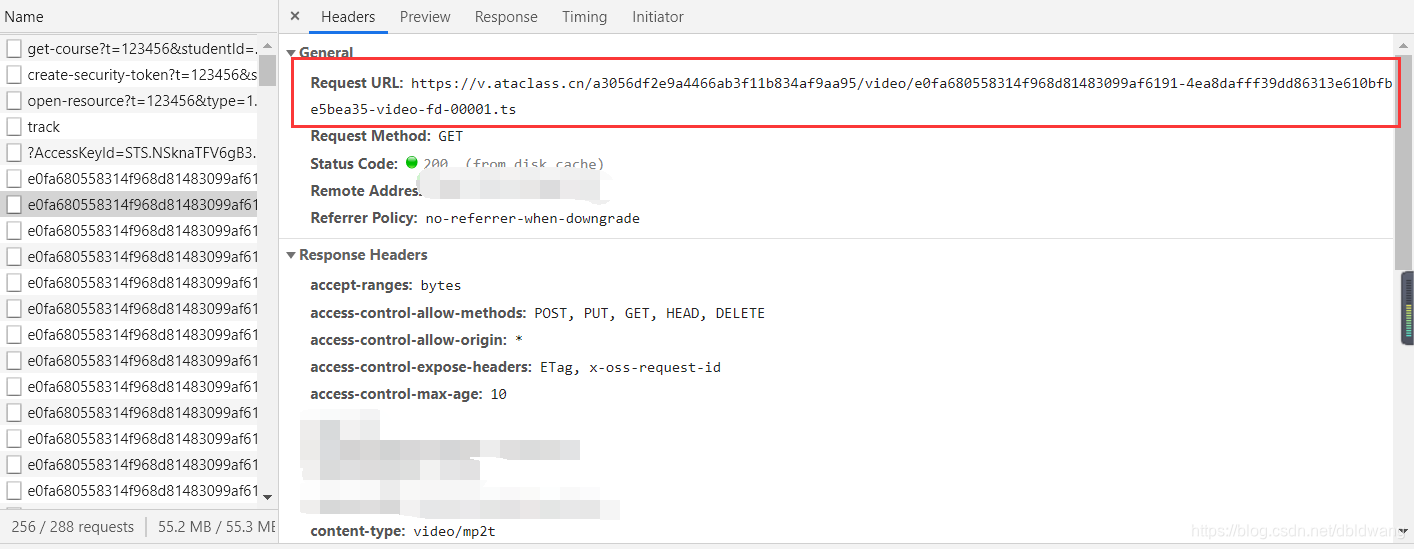
接下来我们需要重建这些视频剪辑的 url:
以此类推到 00240.ts
接下来,开始构建请求视频的所有片段并将它们合并成一个新的mp4文件的代码:
<p>import requests
import requests
import os
import time
def run(i,html,referer):
#做了一个字符串替换避免出现001或者0011等异常情况:正确——>00001.ts 00011.ts 00111.ts
if int(i)=10 and int(i) 查看全部
网页视频抓取脚本(
分析网页视频存储形式以及加密格式()
)
高级爬虫-视频采集(视频加密分割案例) 中国职业培训在线网
.
1.分析网络视频存储和加密格式
一般我们在做视频采集的视频大多是:https:指向一个视频文件,但是在大多数网站中,目前主流的视频加密格式大都是分成上百个小片段。播放并不断加载新剪辑。中国职业培训在线视频网视频示例:
.
要通过 F12 按钮查看 Web 缓存,请选择顶部的网络和 xhr:
注:目前主要的视频分割技术使用.m3u8文件来记录视频片段总数。后缀为 .m3u8 的文件收录所有视频剪辑的文件名。大多数视频剪辑文件都是.ts文件,所以我们目前的开发者在工具中找到对应的.m3u8文件
如下:
点击查看文件内容:
可以观察到所有的视频剪辑文件都在这里,从00001.ts-00240.ts
接下来我们需要重建这些视频剪辑的 url:
以此类推到 00240.ts
接下来,开始构建请求视频的所有片段并将它们合并成一个新的mp4文件的代码:
<p>import requests
import requests
import os
import time
def run(i,html,referer):
#做了一个字符串替换避免出现001或者0011等异常情况:正确——>00001.ts 00011.ts 00111.ts
if int(i)=10 and int(i)
网页视频抓取脚本( 其它命令参数用法,同url网址方式,和wget用法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-16 12:29
其它命令参数用法,同url网址方式,和wget用法)
其他命令参数的用法与URL方式相同,这里不再赘述。
更多curl和wget的用法如ftp协议、迭代子目录等,可以查看man中的帮助手册
知识拓展:
在国内,由于某些原因,一般很难直接访问一些敏感的海外网站,需要通过VPN或代理服务器访问。
如果校园网和教育网有IPv6,可以通过免费代理访问facebook、twitter、六维空间等网站
其实除了VPN和IPv6+代理,普通用户还有其他方式访问国外网站
这里有两个著名的自由球员网站:
(全球数十个国家的自由代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
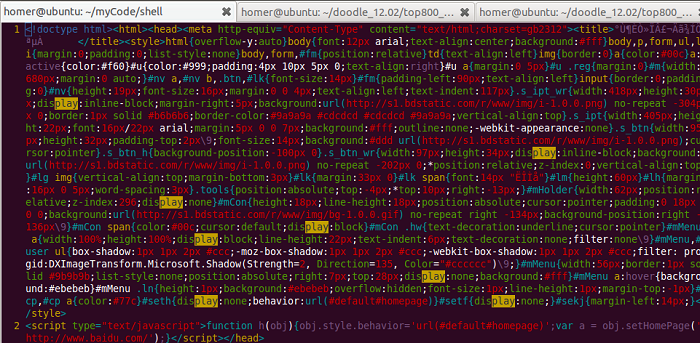
curl 项目示例
使用curl+free agent实现全球12个国家googleplay游戏排名的网页抓取和趋势图查询(抓取网页模块全部由Shell编写,核心代码1000行左右)
爬取google play游戏排名网页,首先需要分析网页的特点和规律:
1、Google play游戏排名页面是“总分”格式,即一个页面URL显示了几个排名(比如24),这样的页面有几个构成了所有游戏的总排名
2、 在每个页面的URL中,点击每个单独的游戏链接可以查看游戏的属性信息(如评分星级、发布日期、版本号、SDK版本号、游戏类别、下载量等)
需要解决的问题:
1、如何抓取所有游戏的总排名?
2、抓取整体排名后,如何拼接网址抓取各个游戏网页?
3、获取各个单独的游戏网页后,如何提取网页中游戏的属性信息(即评分星级、发布日期...)?
4、提取出各个游戏的属性信息后,如何保存(mysql)、生成日报(html)、发送日报(email)?
5、根据抓取到的游戏属性信息资源,如何查询贵公司的游戏排名(JSP)以及如何清晰的展示游戏排名(JFreeChart图表)?
6、 更难的是谷歌玩游戏排名没有统一的全球排名。Google 使用本地化策略。数十个国家/地区都有自己的一套排名算法和规则。如何在12个国家实现游戏排名?
设计方案与技术选择
分析完上述问题和需求,如何一一解决,分解,是不是我们需要思考、设计和解决的问题(模块流程和技术实现)?
基于以上分析提出的问题,将一一进行模块设计和技术方案选择如下:
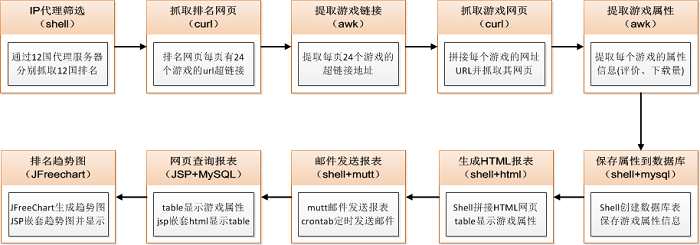
1、为了抓取12个国家的游戏排名,需要分别租用12个国家的代理服务器来抓取各个国家的游戏排名(12个国家的游戏排名算法和语言是不同,包括中文、英文、日文、俄文、西班牙文...)
2、 抓取网页,使用curl+proxy代理;提取下载的网页信息,使用awk文本分析工具(需要对html语法tag、id等元素有很好的理解才能准确的使用awk提取游戏属性信息)
3、由于IP代理筛选系统、网页爬取程序、游戏属性信息提取等模块都是由脚本完成的,为了保持编程语言的一致性,还实现了数据库的创建和记录插入通过 shell 脚本。
4、 捕捉到的每款游戏的属性信息,采用html+table的网页形式展示,清晰直观。一个shell脚本用来拼接html字符串(table+tr+td+info)
5、 生成的html网页会以每日邮件的形式定期发送给产品总监、PM、RD、QA,了解公司发布的游戏排名,以及上升最快、最流行的游戏趋势在世界上
6、开发JSP网页查询系统,根据输入的游戏名或游戏包名查询某款游戏的排名和趋势,并在趋势图下显示该游戏的所有详细属性信息
模块技术实现
1、IP代理过滤
成本考虑,每个国家租用代理服务器(VPN),以市场最低价1000元/月计算,12000元一年,12个国家总费用为12x12000=144000,也就是大约140000/年的VPN租用费
基于成本的考虑,我后来通过对代理服务器和免费ip的深入研究,提出设计开发一套免费ip代理服务器筛选系统来抓取12个国家的游戏排名。
免费代理IP主要来自上一篇博客介绍的两个网站:和
IP代理筛选系统,由于文本预处理和筛选逻辑实现的复杂性,将在下一篇博客中单独介绍
2、 抓取排名页面
仔细分析google play游戏排名页面,发现有一定的规律可循:
第一页的Top24 URL:
第二页的Top48 URL
第三页的Top72 URL
此时,观察每个页面URL的最后一串?start=24&num=24,你已经找到了模式^_^ 其实网页的第一页是从start=0开始的,也可以写成:
首页的Top24 URL
根据上面的规则,可以使用curl+proxy通过循环拼接字符串来爬取排名网页(start='expr $start + 24')
3、提取游戏链接
排名页面,每个页面收录24个游戏网址超链接,如何提取这24个游戏网址超链接?
当时就考虑使用xml解析,因为html是一种分层组织的类似xml的格式,但是有些网页并不是所有标准的html格式(比如左括号后没有右括号闭包),这会导致xml被错误解析
后来结合我学到的html和js知识,分析了爬行排名网页的内容结构,发现每个游戏链接前面都有一个独特的具体格式如下(以篮球投篮为例):
Basketball Shoot
这样就可以通过awk顺利提取附近的文本内容,具体实现如下:
# split url_24
page_key='class="title"'
page_output='output_page.log'
page_output_url_start='https://play.google.com/store/apps/'
page_output_url='output_top800_url.log'
function page_split(){
grep $page_key $(ls $url_output* | sort -t "_" -k6 -n) > tmp_page_grepURL.log # use $url_output
awk -F'[]' '{for(i=1;i> $log
echo "================= $date ================" >> $log
# mysql database and table to create
HOST='localhost'
PORT='3306'
USER='root'
PWD='xxxxxx'
DBNAME='top800'
TABLENAME='gametop800'
mysql_login=''
mysql_create_db=''
mysql_create_table=''
function mysql_create(){
echo "login mysql $HOST:$PORT ..." >> $log
mysql_login="mysql -h $HOST -P $PORT -u $USER -p$PWD" # mysql -h host -P port -u root -p pwd
echo | ${mysql_login}
if [ $? -ne 0 ]; then
echo "login mysql ${HOST}:${PORT} failed.." >> $log
exit 1
else
echo "login mysql ${HOST}:${PORT} success!" >> $log
fi
echo "create database $DBNAME ..." >> $log
mysql_create_db="create database if not exists $DBNAME"
echo ${mysql_create_db} | ${mysql_login}
if [ $? -ne 0 ]; then
echo "create db ${DBNAME} failed.." >> $log
else
echo "create db ${DBNAME} success!" >> $log
fi
echo "create table $TABLENAME ..." >> $log
mysql_create_table="create table $TABLENAME(
id char(50) not null,
url char(255),
top int,
name char(100),
category char(50),
rating char(10),
ratingcount char(20),
download char(30),
price char(20),
publishdate char(20),
version char(40),
filesize char(40),
requireandroid char(40),
contentrating char(40),
country char(10) not null,
dtime date not null default \"2011-01-01\",
primary key(id, country, dtime)
)"
echo ${mysql_create_table} | ${mysql_login} ${DBNAME}
if [ $? -ne 0 ]; then
echo "create table ${TABLENAME} fail..." >> $log
else
echo "create table ${TABLENAME} success!" >> $log
fi
}
脚本功能说明:
首先登录mysql数据库,判断mysql服务器、端口号、用户名和密码是否正确。如果不正确,则登录失败并退出(exit1);如果正确,则登录成功,继续下一步
然后,创建数据库名,判断数据库是否存在,如果不存在,则创建;如果存在,继续下一步(注意:创建数据库时,需要验证是否登录数据库成功,否则无法操作)
最后创建数据库表,首先设计数据库表的各个字段,然后创建数据库表,具体判断方法与创建数据库名称相同
遍历游戏属性信息的文本,全部插入到mysql数据库中统一存储和管理
# Author : yanggang
# Datetime : 2011.10.24 21:45:09
# ============================================================
#!/bin/sh
# insert mysql
file_input='output_top800_url_page'
file_output='sql_output'
HOST='localhost'
PORT='3306'
USER='root'
PWD='xxxxxx'
DBNAME='top800'
TABLENAME='gametop800'
col_id=''
col_url=''
col_top=1
col_name=''
col_category=''
col_rating=''
col_ratingcount=''
col_download=''
col_price=''
col_publishdate=''
col_version=''
col_filesize=''
col_requireandroid=''
col_contentrating=''
col_country=''
col_dtime=''
sql_insert='insert into gametop800 values("com.mobile.games", "url", 3, "minesweeping",
"games", "4.8", "89789", "1000000-5000000000", "free", "2011-2-30", "1.2.1", "1.5M", "1.5 up", "middle", "china", "2011-10-10")'
function mysql_insert(){
rm -rf $file_output
touch $file_output
DBNAME=$1
col_dtime=$2
col_country=$3
echo 'col_dtime========='$col_dtime
while read line
do
col_id=$(echo $line | cut -f 1 -d "%" | cut -f 1 -d "&" | cut -f 2 -d "=")
col_url=$(echo $line | cut -f 1 -d "%")
col_name=$(echo $line | cut -f 2 -d "%")
col_category=$(echo $line | cut -f 3 -d "%")
col_rating=$(echo $line | cut -f 4 -d "%")
col_ratingcount=$(echo $line | cut -f 5 -d "%")
col_download=$(echo $line | cut -f 6 -d "%")
col_price=$(echo $line | cut -f 7 -d "%")
col_publishdate=$(echo $line | cut -f 8 -d "%")
col_version=$(echo $line | cut -f 9 -d "%")
col_filesize=$(echo $line | cut -f 10 -d "%")
col_requireandroid=$(echo $line | cut -f 11 -d "%")
col_contentrating=$(echo $line | cut -f 12 -d "%")
sql_insert='insert into '$TABLENAME' values('"\"$col_id\", \"$col_url\", $col_top,
\"$col_name\", \"$col_category\", \"$col_rating\", \"$col_ratingcount\", \"$col_download\",
\"$col_price\", \"$col_publishdate\", \"$col_version\", \"$col_filesize\", \"$col_requireandroid\",
\"$col_contentrating\", \"$col_country\", \"$col_dtime\""');'
echo $sql_insert >> $file_output
mysql -h $HOST -P $PORT -u $USER -p$PWD -e "use $DBNAME; $sql_insert"
col_top=`expr $col_top + 1`
done < $file_input
}
脚本功能说明:
插入数据库脚本比较简单,主要实现两个功能:游戏排名号(col_top)和数据库语句插入($sql_insert)
通过while read line循环,读取模块5提取的游戏属性信息文本文件,分割每一行得到对应的字段(cut -f 2 -d "%"),赋值给insert语句(sql_insert)
最后通过mysql -h $HOST -P $PORT -u $USER-p$PWD -e "use $DBNAME; $sql_insert",登录mysql数据库,执行插入语句$sql_insert
7、生成HTML报告
shell 通过连接字符串 table + tr + td + info 来生成 html web 报告。详细请参考我之前的博客:shell将txt转换为html
8、通过电子邮件发送报告
邮件发送模块主要采用/usr/bin/mutt的方式。邮件正文显示html报告(默认为美国),其他国家以附件形式发送。详细请参考我之前的博客:linuxshell发送邮件附件
使用 crontab 命令定期发送电子邮件。具体配置和使用可以参考我之前写的博客:linux定时运行命令script-crontab
9、网页查询报告
使用JSP提取MySQL中存储的游戏属性信息,循环生成游戏排名的网页信息,请参考我之前写的博客:LinuxJSP连接MySQL数据库
10、 排名趋势图
趋势图,使用第三方JFreeChart图表生成工具,请参考我之前的博客:JFreeChart学习实例
游戏排名趋势图生成后,需要嵌套到JSP网页中进行展示。完整的排名趋势图可以参考我之前的博客:JFreeChart Project Example
自动化主控制脚本
12国游戏排名系统,过滤免费ip代理——“网络爬虫——”数据库保存——“生成排名报告——”定时邮件报告——“游戏排名查询——”趋势图生成
都实现了整个流程的自动化,以下是各个模块的脚本实现和功能说明:
通过配置服务器的crontab定时运行进程命令,每天早上00:01:00(早上零时1分零秒),主控脚本top10_all.sh会自动启动
每天生成的日报使用主控脚本自动生成当天的文件夹,保存当天的抓包数据、分析数据、结果数据,如下图:
注:以上文件夹数据为去年测试数据的副本,排名并非本人笔记本截图
因为通过远程代理爬取12个国家排名前800的TOP800需要消耗网络资源、内存资源和时间,严重影响我的上网体验~~~~(>_ 查看全部
网页视频抓取脚本(
其它命令参数用法,同url网址方式,和wget用法)
其他命令参数的用法与URL方式相同,这里不再赘述。
更多curl和wget的用法如ftp协议、迭代子目录等,可以查看man中的帮助手册
知识拓展:
在国内,由于某些原因,一般很难直接访问一些敏感的海外网站,需要通过VPN或代理服务器访问。
如果校园网和教育网有IPv6,可以通过免费代理访问facebook、twitter、六维空间等网站
其实除了VPN和IPv6+代理,普通用户还有其他方式访问国外网站
这里有两个著名的自由球员网站:
(全球数十个国家的自由代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
curl 项目示例
使用curl+free agent实现全球12个国家googleplay游戏排名的网页抓取和趋势图查询(抓取网页模块全部由Shell编写,核心代码1000行左右)
爬取google play游戏排名网页,首先需要分析网页的特点和规律:
1、Google play游戏排名页面是“总分”格式,即一个页面URL显示了几个排名(比如24),这样的页面有几个构成了所有游戏的总排名
2、 在每个页面的URL中,点击每个单独的游戏链接可以查看游戏的属性信息(如评分星级、发布日期、版本号、SDK版本号、游戏类别、下载量等)
需要解决的问题:
1、如何抓取所有游戏的总排名?
2、抓取整体排名后,如何拼接网址抓取各个游戏网页?
3、获取各个单独的游戏网页后,如何提取网页中游戏的属性信息(即评分星级、发布日期...)?
4、提取出各个游戏的属性信息后,如何保存(mysql)、生成日报(html)、发送日报(email)?
5、根据抓取到的游戏属性信息资源,如何查询贵公司的游戏排名(JSP)以及如何清晰的展示游戏排名(JFreeChart图表)?
6、 更难的是谷歌玩游戏排名没有统一的全球排名。Google 使用本地化策略。数十个国家/地区都有自己的一套排名算法和规则。如何在12个国家实现游戏排名?
设计方案与技术选择
分析完上述问题和需求,如何一一解决,分解,是不是我们需要思考、设计和解决的问题(模块流程和技术实现)?
基于以上分析提出的问题,将一一进行模块设计和技术方案选择如下:
1、为了抓取12个国家的游戏排名,需要分别租用12个国家的代理服务器来抓取各个国家的游戏排名(12个国家的游戏排名算法和语言是不同,包括中文、英文、日文、俄文、西班牙文...)
2、 抓取网页,使用curl+proxy代理;提取下载的网页信息,使用awk文本分析工具(需要对html语法tag、id等元素有很好的理解才能准确的使用awk提取游戏属性信息)
3、由于IP代理筛选系统、网页爬取程序、游戏属性信息提取等模块都是由脚本完成的,为了保持编程语言的一致性,还实现了数据库的创建和记录插入通过 shell 脚本。
4、 捕捉到的每款游戏的属性信息,采用html+table的网页形式展示,清晰直观。一个shell脚本用来拼接html字符串(table+tr+td+info)
5、 生成的html网页会以每日邮件的形式定期发送给产品总监、PM、RD、QA,了解公司发布的游戏排名,以及上升最快、最流行的游戏趋势在世界上
6、开发JSP网页查询系统,根据输入的游戏名或游戏包名查询某款游戏的排名和趋势,并在趋势图下显示该游戏的所有详细属性信息
模块技术实现
1、IP代理过滤
成本考虑,每个国家租用代理服务器(VPN),以市场最低价1000元/月计算,12000元一年,12个国家总费用为12x12000=144000,也就是大约140000/年的VPN租用费
基于成本的考虑,我后来通过对代理服务器和免费ip的深入研究,提出设计开发一套免费ip代理服务器筛选系统来抓取12个国家的游戏排名。
免费代理IP主要来自上一篇博客介绍的两个网站:和
IP代理筛选系统,由于文本预处理和筛选逻辑实现的复杂性,将在下一篇博客中单独介绍
2、 抓取排名页面
仔细分析google play游戏排名页面,发现有一定的规律可循:
第一页的Top24 URL:
第二页的Top48 URL
第三页的Top72 URL
此时,观察每个页面URL的最后一串?start=24&num=24,你已经找到了模式^_^ 其实网页的第一页是从start=0开始的,也可以写成:
首页的Top24 URL
根据上面的规则,可以使用curl+proxy通过循环拼接字符串来爬取排名网页(start='expr $start + 24')
3、提取游戏链接
排名页面,每个页面收录24个游戏网址超链接,如何提取这24个游戏网址超链接?
当时就考虑使用xml解析,因为html是一种分层组织的类似xml的格式,但是有些网页并不是所有标准的html格式(比如左括号后没有右括号闭包),这会导致xml被错误解析
后来结合我学到的html和js知识,分析了爬行排名网页的内容结构,发现每个游戏链接前面都有一个独特的具体格式如下(以篮球投篮为例):
Basketball Shoot
这样就可以通过awk顺利提取附近的文本内容,具体实现如下:
# split url_24
page_key='class="title"'
page_output='output_page.log'
page_output_url_start='https://play.google.com/store/apps/'
page_output_url='output_top800_url.log'
function page_split(){
grep $page_key $(ls $url_output* | sort -t "_" -k6 -n) > tmp_page_grepURL.log # use $url_output
awk -F'[]' '{for(i=1;i> $log
echo "================= $date ================" >> $log
# mysql database and table to create
HOST='localhost'
PORT='3306'
USER='root'
PWD='xxxxxx'
DBNAME='top800'
TABLENAME='gametop800'
mysql_login=''
mysql_create_db=''
mysql_create_table=''
function mysql_create(){
echo "login mysql $HOST:$PORT ..." >> $log
mysql_login="mysql -h $HOST -P $PORT -u $USER -p$PWD" # mysql -h host -P port -u root -p pwd
echo | ${mysql_login}
if [ $? -ne 0 ]; then
echo "login mysql ${HOST}:${PORT} failed.." >> $log
exit 1
else
echo "login mysql ${HOST}:${PORT} success!" >> $log
fi
echo "create database $DBNAME ..." >> $log
mysql_create_db="create database if not exists $DBNAME"
echo ${mysql_create_db} | ${mysql_login}
if [ $? -ne 0 ]; then
echo "create db ${DBNAME} failed.." >> $log
else
echo "create db ${DBNAME} success!" >> $log
fi
echo "create table $TABLENAME ..." >> $log
mysql_create_table="create table $TABLENAME(
id char(50) not null,
url char(255),
top int,
name char(100),
category char(50),
rating char(10),
ratingcount char(20),
download char(30),
price char(20),
publishdate char(20),
version char(40),
filesize char(40),
requireandroid char(40),
contentrating char(40),
country char(10) not null,
dtime date not null default \"2011-01-01\",
primary key(id, country, dtime)
)"
echo ${mysql_create_table} | ${mysql_login} ${DBNAME}
if [ $? -ne 0 ]; then
echo "create table ${TABLENAME} fail..." >> $log
else
echo "create table ${TABLENAME} success!" >> $log
fi
}
脚本功能说明:
首先登录mysql数据库,判断mysql服务器、端口号、用户名和密码是否正确。如果不正确,则登录失败并退出(exit1);如果正确,则登录成功,继续下一步
然后,创建数据库名,判断数据库是否存在,如果不存在,则创建;如果存在,继续下一步(注意:创建数据库时,需要验证是否登录数据库成功,否则无法操作)
最后创建数据库表,首先设计数据库表的各个字段,然后创建数据库表,具体判断方法与创建数据库名称相同
遍历游戏属性信息的文本,全部插入到mysql数据库中统一存储和管理
# Author : yanggang
# Datetime : 2011.10.24 21:45:09
# ============================================================
#!/bin/sh
# insert mysql
file_input='output_top800_url_page'
file_output='sql_output'
HOST='localhost'
PORT='3306'
USER='root'
PWD='xxxxxx'
DBNAME='top800'
TABLENAME='gametop800'
col_id=''
col_url=''
col_top=1
col_name=''
col_category=''
col_rating=''
col_ratingcount=''
col_download=''
col_price=''
col_publishdate=''
col_version=''
col_filesize=''
col_requireandroid=''
col_contentrating=''
col_country=''
col_dtime=''
sql_insert='insert into gametop800 values("com.mobile.games", "url", 3, "minesweeping",
"games", "4.8", "89789", "1000000-5000000000", "free", "2011-2-30", "1.2.1", "1.5M", "1.5 up", "middle", "china", "2011-10-10")'
function mysql_insert(){
rm -rf $file_output
touch $file_output
DBNAME=$1
col_dtime=$2
col_country=$3
echo 'col_dtime========='$col_dtime
while read line
do
col_id=$(echo $line | cut -f 1 -d "%" | cut -f 1 -d "&" | cut -f 2 -d "=")
col_url=$(echo $line | cut -f 1 -d "%")
col_name=$(echo $line | cut -f 2 -d "%")
col_category=$(echo $line | cut -f 3 -d "%")
col_rating=$(echo $line | cut -f 4 -d "%")
col_ratingcount=$(echo $line | cut -f 5 -d "%")
col_download=$(echo $line | cut -f 6 -d "%")
col_price=$(echo $line | cut -f 7 -d "%")
col_publishdate=$(echo $line | cut -f 8 -d "%")
col_version=$(echo $line | cut -f 9 -d "%")
col_filesize=$(echo $line | cut -f 10 -d "%")
col_requireandroid=$(echo $line | cut -f 11 -d "%")
col_contentrating=$(echo $line | cut -f 12 -d "%")
sql_insert='insert into '$TABLENAME' values('"\"$col_id\", \"$col_url\", $col_top,
\"$col_name\", \"$col_category\", \"$col_rating\", \"$col_ratingcount\", \"$col_download\",
\"$col_price\", \"$col_publishdate\", \"$col_version\", \"$col_filesize\", \"$col_requireandroid\",
\"$col_contentrating\", \"$col_country\", \"$col_dtime\""');'
echo $sql_insert >> $file_output
mysql -h $HOST -P $PORT -u $USER -p$PWD -e "use $DBNAME; $sql_insert"
col_top=`expr $col_top + 1`
done < $file_input
}
脚本功能说明:
插入数据库脚本比较简单,主要实现两个功能:游戏排名号(col_top)和数据库语句插入($sql_insert)
通过while read line循环,读取模块5提取的游戏属性信息文本文件,分割每一行得到对应的字段(cut -f 2 -d "%"),赋值给insert语句(sql_insert)
最后通过mysql -h $HOST -P $PORT -u $USER-p$PWD -e "use $DBNAME; $sql_insert",登录mysql数据库,执行插入语句$sql_insert
7、生成HTML报告
shell 通过连接字符串 table + tr + td + info 来生成 html web 报告。详细请参考我之前的博客:shell将txt转换为html
8、通过电子邮件发送报告
邮件发送模块主要采用/usr/bin/mutt的方式。邮件正文显示html报告(默认为美国),其他国家以附件形式发送。详细请参考我之前的博客:linuxshell发送邮件附件
使用 crontab 命令定期发送电子邮件。具体配置和使用可以参考我之前写的博客:linux定时运行命令script-crontab
9、网页查询报告
使用JSP提取MySQL中存储的游戏属性信息,循环生成游戏排名的网页信息,请参考我之前写的博客:LinuxJSP连接MySQL数据库
10、 排名趋势图
趋势图,使用第三方JFreeChart图表生成工具,请参考我之前的博客:JFreeChart学习实例
游戏排名趋势图生成后,需要嵌套到JSP网页中进行展示。完整的排名趋势图可以参考我之前的博客:JFreeChart Project Example
自动化主控制脚本
12国游戏排名系统,过滤免费ip代理——“网络爬虫——”数据库保存——“生成排名报告——”定时邮件报告——“游戏排名查询——”趋势图生成
都实现了整个流程的自动化,以下是各个模块的脚本实现和功能说明:
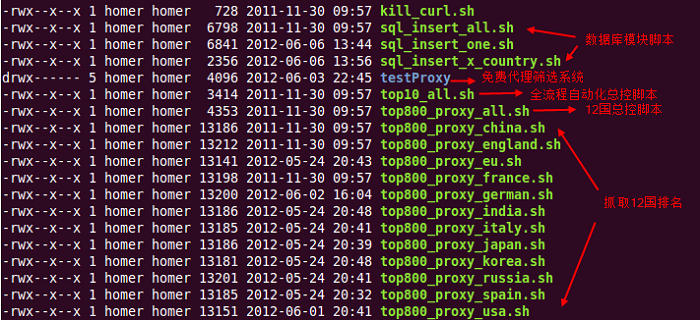
通过配置服务器的crontab定时运行进程命令,每天早上00:01:00(早上零时1分零秒),主控脚本top10_all.sh会自动启动
每天生成的日报使用主控脚本自动生成当天的文件夹,保存当天的抓包数据、分析数据、结果数据,如下图:

注:以上文件夹数据为去年测试数据的副本,排名并非本人笔记本截图
因为通过远程代理爬取12个国家排名前800的TOP800需要消耗网络资源、内存资源和时间,严重影响我的上网体验~~~~(>_
网页视频抓取脚本(FBIWARNING具体脚本可以参考前言(图)劫持的姿势 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-16 12:26
)
联邦调查局警告
具体脚本可以参考
前言
之前我们已经学会了xhr劫持的姿势
现在来实战,通过xhr劫持直接获取返回的内容
通常通过xhr劫持可以达到两种效果,一是在xhr发送数据前获取并篡改数据,二是在xhr返回后获取数据。
我们可以输入 %7B%22impr_id%22%3A%225634fdbddc0100fff0030a1217e00000001a54c1a3%22%7D&enter_from=undefined
通过 f12 抓包
粗略查了一下资料,发现+(Windows+NT+10.0%3B+Win64%3B+x64)+AppleWebKit%2F537.36+(KHTML,+like+ Gecko )+Chrome%2F92.0.4515.159+Safari%2F537.36&browser_online=true&_signature=_02B4Z6wo00d01gP1vzgAAIDCg.dFeeve9w7dme,我们怀疑是来自mashlist的一个链接想要解密是极其麻烦的,所以这里我们可以直接输入一个xhr劫持来获取返回的内容
在这个网页中,我们可以通过获取视频的视频链接来获取v26开头的前缀,于是我们找了一个json在线格式化工具,粘贴数据并解析,搜索v26
我发现很多地方都有v26的链接。我挑选了一些进行测试。终于发现video.play_addr.url_list是一个没有水印的链接。
所以这是一个xhr劫持
<p> function addXMLRequestCallback(callback){
var oldSend, i;
if( XMLHttpRequest.callbacks ) {
// we've already overridden send() so just add the callback
XMLHttpRequest.callbacks.push( callback );
} else {
// create a callback queue
XMLHttpRequest.callbacks = [callback];
// store the native send()
oldSend = XMLHttpRequest.prototype.send;
// override the native send()
XMLHttpRequest.prototype.send = function(){
// process the callback queue
// the xhr instance is passed into each callback but seems pretty useless
// you can't tell what its destination is or call abort() without an error
// so only really good for logging that a request has happened
// I could be wrong, I hope so...
// EDIT: I suppose you could override the onreadystatechange handler though
for( i = 0; i < XMLHttpRequest.callbacks.length; i++ ) {
XMLHttpRequest.callbacks[i]( this );
}
// call the native send()
oldSend.apply(this, arguments);
}
}
}
// e.g.
addXMLRequestCallback( function( xhr ) {
xhr.addEventListener("load", function(){
if ( xhr.readyState == 4 && xhr.status == 200 ) {
if(xhr.responseURL.indexOf('/web/aweme/post')!==-1){
console.log('触发了加载')
let list=JSON.parse(xhr.response)
if(list.aweme_list!==undefined){
for(let index=0;index 查看全部
网页视频抓取脚本(FBIWARNING具体脚本可以参考前言(图)劫持的姿势
)
联邦调查局警告
具体脚本可以参考
前言
之前我们已经学会了xhr劫持的姿势
现在来实战,通过xhr劫持直接获取返回的内容
通常通过xhr劫持可以达到两种效果,一是在xhr发送数据前获取并篡改数据,二是在xhr返回后获取数据。
我们可以输入 %7B%22impr_id%22%3A%225634fdbddc0100fff0030a1217e00000001a54c1a3%22%7D&enter_from=undefined
通过 f12 抓包
粗略查了一下资料,发现+(Windows+NT+10.0%3B+Win64%3B+x64)+AppleWebKit%2F537.36+(KHTML,+like+ Gecko )+Chrome%2F92.0.4515.159+Safari%2F537.36&browser_online=true&_signature=_02B4Z6wo00d01gP1vzgAAIDCg.dFeeve9w7dme,我们怀疑是来自mashlist的一个链接想要解密是极其麻烦的,所以这里我们可以直接输入一个xhr劫持来获取返回的内容

在这个网页中,我们可以通过获取视频的视频链接来获取v26开头的前缀,于是我们找了一个json在线格式化工具,粘贴数据并解析,搜索v26
我发现很多地方都有v26的链接。我挑选了一些进行测试。终于发现video.play_addr.url_list是一个没有水印的链接。

所以这是一个xhr劫持
<p> function addXMLRequestCallback(callback){
var oldSend, i;
if( XMLHttpRequest.callbacks ) {
// we've already overridden send() so just add the callback
XMLHttpRequest.callbacks.push( callback );
} else {
// create a callback queue
XMLHttpRequest.callbacks = [callback];
// store the native send()
oldSend = XMLHttpRequest.prototype.send;
// override the native send()
XMLHttpRequest.prototype.send = function(){
// process the callback queue
// the xhr instance is passed into each callback but seems pretty useless
// you can't tell what its destination is or call abort() without an error
// so only really good for logging that a request has happened
// I could be wrong, I hope so...
// EDIT: I suppose you could override the onreadystatechange handler though
for( i = 0; i < XMLHttpRequest.callbacks.length; i++ ) {
XMLHttpRequest.callbacks[i]( this );
}
// call the native send()
oldSend.apply(this, arguments);
}
}
}
// e.g.
addXMLRequestCallback( function( xhr ) {
xhr.addEventListener("load", function(){
if ( xhr.readyState == 4 && xhr.status == 200 ) {
if(xhr.responseURL.indexOf('/web/aweme/post')!==-1){
console.log('触发了加载')
let list=JSON.parse(xhr.response)
if(list.aweme_list!==undefined){
for(let index=0;index
网页视频抓取脚本( Python构建的尖端网页抓取技术,启动您的大数据项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-15 05:21
Python构建的尖端网页抓取技术,启动您的大数据项目)
使用Python内置的尖端网页捕获技术启动您的大数据项目
你会学到什么
如何理论化和开发用于数据分析和研究的网络爬虫和爬行器
什么是刮刀和蜘蛛
刮刀和蜘蛛有什么区别
刮刀和蜘蛛是如何用于研究的
如何使用请求和美化库构建scraper
如何构建一个多线程的复杂刮板
类型:电子学习| mp4 |视频:h2641280×720 |音频:AAC,48.0 kHz
语言:英文+中英文字幕(根据原英文字幕机器翻译更准确|解压后大小:9GB |持续时间:10h 26m
描述
该网络充满了难以置信的强大数据,存储在数十亿不同的网站、数据库和应用程序编程接口中。金融数据,如股票价格和加密货币趋势,来自几十个国家数千个不同城市的天气数据,以及关于你最喜欢的演员的有趣传记信息:所有这些信息都是现成的,但如果没有一点帮助和自动化,就不可能真正使用它
scraper和spider是非常强大的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据,并将其用于大量不同的应用程序,从创建数据源到采集数据以提供机器学习和人工智能算法。本课程为财务分析、链接图构建和社交媒体研究提供了一种实用的方法来构建一个真实且可用的蜘蛛。在本课程结束时,学生们将能够使用Python从头开始开发爬行器和刮板,并且只会受到他们想象力的限制。通过学习如何开发自动铲运机,我们可以掌握互联网的强大力量
这门课程是为初学者设计的。尽管之前的Python编程经验很有帮助,但您可以在不编写代码的情况下开始本课程
这门课程是为谁开设的:
来自各行各业的互联网研究人员都想学习如何利用网络上的信息为更大的兴趣服务
对数据科学和网络爬虫感兴趣的人
对数据采集和管理感兴趣的人
初级Python开发人员
类型:在线学习MP4视频:H2641280×720音频:AAC,48.0 KHz
语言:英语|尺寸:8.85 GB |持续时间:10小时26米
使用Python构建的尖端web抓取技术为您的大数据项目提供动力
你会学到什么
如何理论化和开发用于数据分析和研究的web scraper和spider
什么是刮刀和蜘蛛
刮刀和蜘蛛有什么区别
刮刀和蜘蛛是如何用于研究的
如何使用Requests和BeautifulSoup库来构建scraper
如何构建多线程、复杂的刮刀
描述
网络充满了难以置信的强大数据,存储在数十亿个不同的网站、数据库和API中。股票价格和加密货币趋势等金融数据,数十个国家数千个不同城市的天气数据,以及关于你最喜欢的演员的有趣传记信息:所有这些信息都在你的指尖上,但如果没有一点帮助和自动化,就不可能真正驾驭这一切
scraper和spider是功能强大得难以置信的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据,并将其用于各种不同的应用程序,从创建数据源到采集数据以提供机器学习和人工智能算法。本课程提供了一种在现实环境中构建真实、可用的蜘蛛的实践方法,如财务分析、链接图构建和社交媒体研究等。到本课程结束时,学生将能够使用Python从头开始开发spider和scraper,并且只受自己想象力的限制。今天,通过学习如何开发自动刮板,让您掌握互联网的巨大力量
本课程是为初学者而设计的,虽然之前的Python编程经验很有帮助,但您可以在不编写任何代码的情况下开始本课程
本课程面向谁:
来自各行各业的互联网研究人员希望学习如何利用网络上的信息实现更大的利益
对数据科学和网络抓取感兴趣的人
对数据采集和整理感兴趣的人
初级Python开发人员
隐藏内容:******,下载
下载说明:
1、电脑端:浏览器打开网页获取资料,奖励后自动显示百度在线盘链接。如果没有显示,请刷新网页
2、移动终端:您需要在微信中打开材料网页,奖励后返回原材料页面,在线磁盘链接即可自动显示
3、默认资源是百度在线磁盘链接。如果链接失败或无法获得,请联系客服微信云桥网解决
5、云桥网络继续更新国外CG软件教程材料和相关资源。感谢您的关注和支持
Python教程
肖云云
海报链接 查看全部
网页视频抓取脚本(
Python构建的尖端网页抓取技术,启动您的大数据项目)

使用Python内置的尖端网页捕获技术启动您的大数据项目
你会学到什么
如何理论化和开发用于数据分析和研究的网络爬虫和爬行器
什么是刮刀和蜘蛛
刮刀和蜘蛛有什么区别
刮刀和蜘蛛是如何用于研究的
如何使用请求和美化库构建scraper
如何构建一个多线程的复杂刮板
类型:电子学习| mp4 |视频:h2641280×720 |音频:AAC,48.0 kHz
语言:英文+中英文字幕(根据原英文字幕机器翻译更准确|解压后大小:9GB |持续时间:10h 26m
描述
该网络充满了难以置信的强大数据,存储在数十亿不同的网站、数据库和应用程序编程接口中。金融数据,如股票价格和加密货币趋势,来自几十个国家数千个不同城市的天气数据,以及关于你最喜欢的演员的有趣传记信息:所有这些信息都是现成的,但如果没有一点帮助和自动化,就不可能真正使用它
scraper和spider是非常强大的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据,并将其用于大量不同的应用程序,从创建数据源到采集数据以提供机器学习和人工智能算法。本课程为财务分析、链接图构建和社交媒体研究提供了一种实用的方法来构建一个真实且可用的蜘蛛。在本课程结束时,学生们将能够使用Python从头开始开发爬行器和刮板,并且只会受到他们想象力的限制。通过学习如何开发自动铲运机,我们可以掌握互联网的强大力量
这门课程是为初学者设计的。尽管之前的Python编程经验很有帮助,但您可以在不编写代码的情况下开始本课程
这门课程是为谁开设的:
来自各行各业的互联网研究人员都想学习如何利用网络上的信息为更大的兴趣服务
对数据科学和网络爬虫感兴趣的人
对数据采集和管理感兴趣的人
初级Python开发人员
类型:在线学习MP4视频:H2641280×720音频:AAC,48.0 KHz
语言:英语|尺寸:8.85 GB |持续时间:10小时26米
使用Python构建的尖端web抓取技术为您的大数据项目提供动力
你会学到什么
如何理论化和开发用于数据分析和研究的web scraper和spider
什么是刮刀和蜘蛛
刮刀和蜘蛛有什么区别
刮刀和蜘蛛是如何用于研究的
如何使用Requests和BeautifulSoup库来构建scraper
如何构建多线程、复杂的刮刀
描述
网络充满了难以置信的强大数据,存储在数十亿个不同的网站、数据库和API中。股票价格和加密货币趋势等金融数据,数十个国家数千个不同城市的天气数据,以及关于你最喜欢的演员的有趣传记信息:所有这些信息都在你的指尖上,但如果没有一点帮助和自动化,就不可能真正驾驭这一切
scraper和spider是功能强大得难以置信的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据,并将其用于各种不同的应用程序,从创建数据源到采集数据以提供机器学习和人工智能算法。本课程提供了一种在现实环境中构建真实、可用的蜘蛛的实践方法,如财务分析、链接图构建和社交媒体研究等。到本课程结束时,学生将能够使用Python从头开始开发spider和scraper,并且只受自己想象力的限制。今天,通过学习如何开发自动刮板,让您掌握互联网的巨大力量
本课程是为初学者而设计的,虽然之前的Python编程经验很有帮助,但您可以在不编写任何代码的情况下开始本课程
本课程面向谁:
来自各行各业的互联网研究人员希望学习如何利用网络上的信息实现更大的利益
对数据科学和网络抓取感兴趣的人
对数据采集和整理感兴趣的人
初级Python开发人员
隐藏内容:******,下载
下载说明:
1、电脑端:浏览器打开网页获取资料,奖励后自动显示百度在线盘链接。如果没有显示,请刷新网页
2、移动终端:您需要在微信中打开材料网页,奖励后返回原材料页面,在线磁盘链接即可自动显示
3、默认资源是百度在线磁盘链接。如果链接失败或无法获得,请联系客服微信云桥网解决
5、云桥网络继续更新国外CG软件教程材料和相关资源。感谢您的关注和支持
Python教程
肖云云
海报链接
网页视频抓取脚本(1.为什么需要JS前面3篇文章讲了一些基本操作的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 24 次浏览 • 2021-12-13 20:29
1. 为什么我们需要JS
前面3篇文章讲了Selenium的一些基本操作。使用这部分技巧,可以顺利完成网站的大部分自动化。
但是,有一些网站 web操作使用WebDriver API无法完成,有些功能即使使用WebDriver API实现也不兼容。经常需要维护这组脚本,比如浏览器的位置。滑动、元素点击失效、日期选择等。
这时候使用JavaScript直接操作网页内部元素,可以帮助我们完成Selenium自动化测试无法覆盖的功能。
2. 使用方法
Selenium 提供了以下方法:
driver.execute_script(js_code)
其中,js_code是一个JS脚本。常见的JS脚本包括:设置元素属性、移除属性、设置元素值、设置窗口位置等。
使用 Selenium CSS Selector 类型,使用 JS 查找元素的方式包括以下 6 种类型:
# 1、通过元素id属性,获取元素
document.getElementById('id');
# 2、通过元素name属性,获取元素
document.getElementsByName('name');
# 3、通过标签名,获取元素列表
# 获取的是一个列表
document.getElementsByTagName('tag_name');
# 4、通过类名,获取元素列表
document.getElementsByClassName("class_name");
# 5、通过选择器,获取一个元素
document.querySelector("css selector")
# 6、通过CSS选择器,获取元素列表
document.querySelectorAll("css selector")
获取元素后,可以操作元素属性,例如:
# 操作属性值
# 设置元素某一个元素值
element.setAttribute('属性名','属性值')
# 设置元素值
element.value="element_value";
# 删除属性
element.removeAttribute('属性名')
结合以上3个操作,就可以通过JS改变一个网页元素的值了。
# 待执行的js语句
exec_js = 'document.getElementById(element_id).value="element_value";'
# 执行js语句改变元素的值
driver.execute_script(exec_js)
3. 常用操作
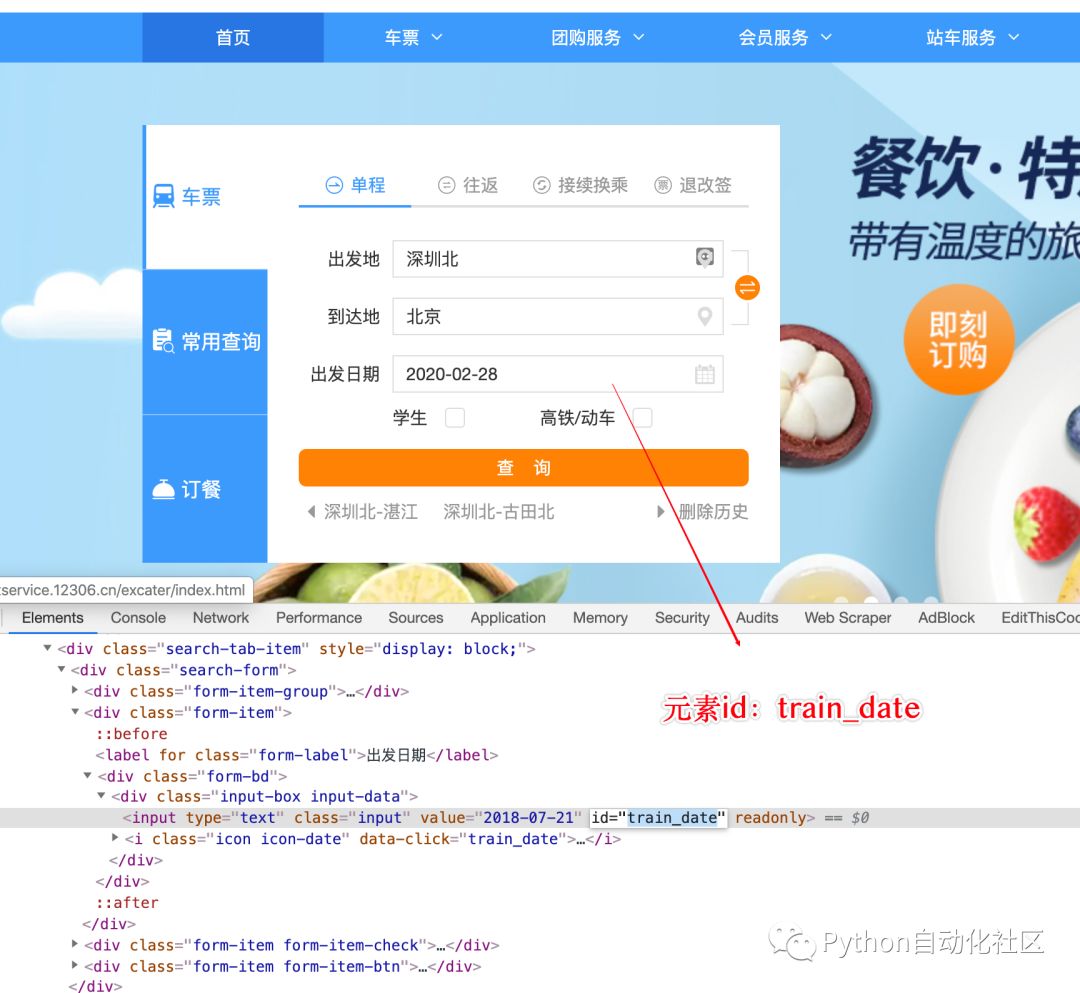
以12306网站为例,选择出发日期。
先用普通模式写一波自动化,用WebDriver查找元素,然后直接给元素设置一个日期值。
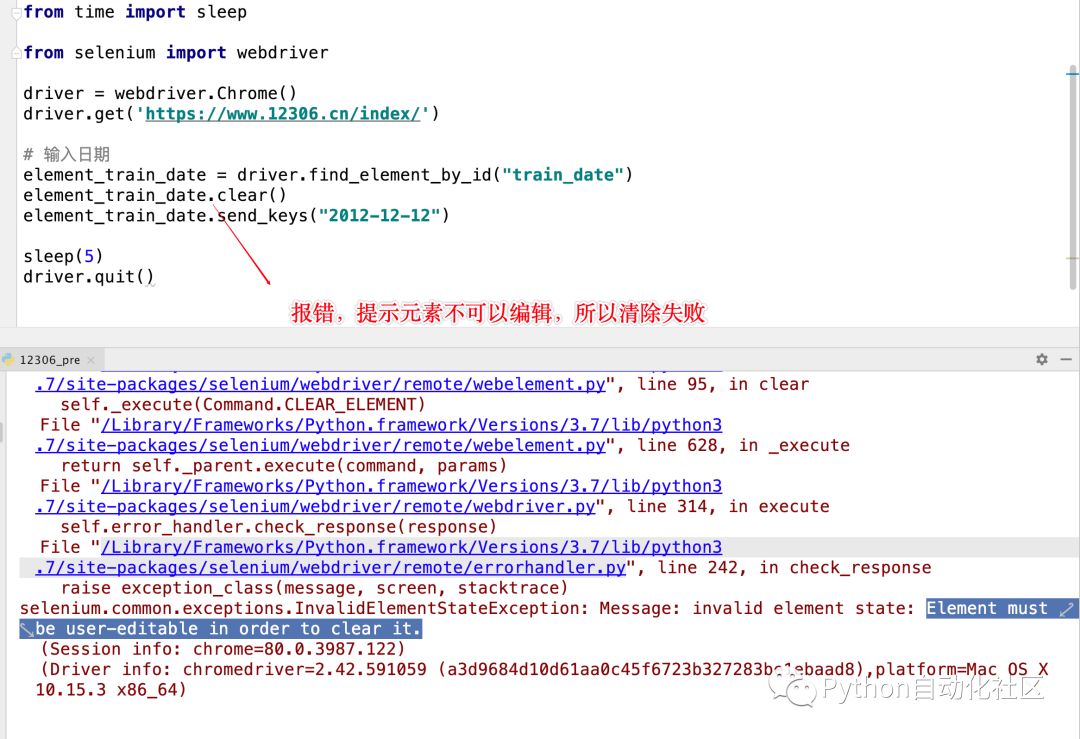
运行后直接报错,运行日志会提示目标元素有不可编辑的属性-只读
这时候就可以通过JS的方法方便的去掉这个属性,然后再添加元素的属性操作,就可以正常设置日期了。
改写后的代码如下:
from time import sleep
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.12306.cn/index/')
# 去除掉元素的属性
exec_js = 'document.getElementById("train_date").removeAttribute("readonly");'
driver.execute_script(exec_js)
# 输入日期
element_train_date = driver.find_element_by_id("train_date")
element_train_date.clear()
element_train_date.send_keys("2012-12-12")
sleep(5)
driver.quit()
当然,除了去除元素属性之外,还可以使用JS搜索元素语法来获取目标元素,然后直接在元素上设置一个日期,也可以满足我们的需求。
# 找到元素,直接设置一个容器
exec_js = 'document.getElementById("train_date").value="2012-12-12";'
# 执行js代码
driver.execute_script(exec_js)
4. 其他
Selenium 自动化的很多操作都可以转成JS 语句,然后使用execute_script() 来完成同样的功能。
但是在自动化的实际使用中,JS只是作为一个补充,帮助我们完成一些WebDriver无法实现的功能。 查看全部
网页视频抓取脚本(1.为什么需要JS前面3篇文章讲了一些基本操作的方法)
1. 为什么我们需要JS
前面3篇文章讲了Selenium的一些基本操作。使用这部分技巧,可以顺利完成网站的大部分自动化。
但是,有一些网站 web操作使用WebDriver API无法完成,有些功能即使使用WebDriver API实现也不兼容。经常需要维护这组脚本,比如浏览器的位置。滑动、元素点击失效、日期选择等。
这时候使用JavaScript直接操作网页内部元素,可以帮助我们完成Selenium自动化测试无法覆盖的功能。
2. 使用方法
Selenium 提供了以下方法:
driver.execute_script(js_code)
其中,js_code是一个JS脚本。常见的JS脚本包括:设置元素属性、移除属性、设置元素值、设置窗口位置等。
使用 Selenium CSS Selector 类型,使用 JS 查找元素的方式包括以下 6 种类型:
# 1、通过元素id属性,获取元素
document.getElementById('id');
# 2、通过元素name属性,获取元素
document.getElementsByName('name');
# 3、通过标签名,获取元素列表
# 获取的是一个列表
document.getElementsByTagName('tag_name');
# 4、通过类名,获取元素列表
document.getElementsByClassName("class_name");
# 5、通过选择器,获取一个元素
document.querySelector("css selector")
# 6、通过CSS选择器,获取元素列表
document.querySelectorAll("css selector")
获取元素后,可以操作元素属性,例如:
# 操作属性值
# 设置元素某一个元素值
element.setAttribute('属性名','属性值')
# 设置元素值
element.value="element_value";
# 删除属性
element.removeAttribute('属性名')
结合以上3个操作,就可以通过JS改变一个网页元素的值了。
# 待执行的js语句
exec_js = 'document.getElementById(element_id).value="element_value";'
# 执行js语句改变元素的值
driver.execute_script(exec_js)
3. 常用操作
以12306网站为例,选择出发日期。
先用普通模式写一波自动化,用WebDriver查找元素,然后直接给元素设置一个日期值。
运行后直接报错,运行日志会提示目标元素有不可编辑的属性-只读
这时候就可以通过JS的方法方便的去掉这个属性,然后再添加元素的属性操作,就可以正常设置日期了。
改写后的代码如下:
from time import sleep
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.12306.cn/index/')
# 去除掉元素的属性
exec_js = 'document.getElementById("train_date").removeAttribute("readonly");'
driver.execute_script(exec_js)
# 输入日期
element_train_date = driver.find_element_by_id("train_date")
element_train_date.clear()
element_train_date.send_keys("2012-12-12")
sleep(5)
driver.quit()
当然,除了去除元素属性之外,还可以使用JS搜索元素语法来获取目标元素,然后直接在元素上设置一个日期,也可以满足我们的需求。
# 找到元素,直接设置一个容器
exec_js = 'document.getElementById("train_date").value="2012-12-12";'
# 执行js代码
driver.execute_script(exec_js)
4. 其他
Selenium 自动化的很多操作都可以转成JS 语句,然后使用execute_script() 来完成同样的功能。
但是在自动化的实际使用中,JS只是作为一个补充,帮助我们完成一些WebDriver无法实现的功能。
网页视频抓取脚本(Python是什么呢?Python经验总结什么叫网络爬虫网络蜘蛛)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-13 20:25
什么是 Python?
Python 是一种全栈开发语言。如果你能学好Python,前端、后端、测试、大数据分析、爬虫等都可以胜任。
我不会详细介绍 Python 现在的流行程度。Python的功能是什么?
根据我多年的 Python 经验,Python 主要有以下四种应用:
接下来跟大家聊聊这几个方面:
网络爬虫
什么是网络爬虫?
网络爬虫,又称网络蜘蛛,是指按照一定的规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个网站进入其他网站,获取需要的内容。
爬虫有什么用?
做一个垂直搜索引擎(谷歌、百度等)。
科学研究:在线人类行为、在线社区进化、人类动力学研究、定量社会学、复杂网络、数据挖掘等领域的实证研究需要大量数据。网络爬虫是采集相关数据的强大工具。
偷窥、黑客、垃圾邮件……
爬行是搜索引擎的第一步,也是最简单的一步。
爬虫用什么语言写的?
C、C++。效率高,速度快,适合一般搜索引擎爬取全网。缺点,开发慢,又臭又长,例如:天网搜索源码。
脚本语言:Perl、Python、Java、Ruby。简单易学,好的文字处理可以方便对网页内容进行详细的提取,但效率往往不高,适合少量网站集中抓取
C#?
为什么 Python 是当下最热门的?
就个人而言,我已经用 c# 和 java 编写了爬虫。区别不大,原则是用好正则表达式。只是平台问题。后来才知道很多爬虫都是用python写的,所以一发不可收拾。
Python有很多优点。总结两个要点:
1) 抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。python中有优秀的第三方包帮你搞定,比如Requests,mechanize
2)网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
网站开发
开发网站需要什么知识?
1、Python基础,因为是用python开发的,python规定你需要知道,至少要知道条件、循环、函数、类;
2、html和css的基础知识,因为要开发网站,网页都是html和css写的,至少你得知道这方面的知识,即使你不知道怎么做写一个前端,你不能开发出特别漂亮的页面,网站,至少你要能看懂html标签;
3、数据库基础知识,因为如果你开发了一个网站,数据存在的地方,就在数据库中,那你至少要知道如何对数据库进行增删改查,否则如何保存数据和检索数据?
如果以上知识掌握好,开发一个简单的小网站就没有问题了。如果你想开发一个比较大的网站,业务逻辑比较复杂,那你就得借助其他的知识,比如redis,MQ等。
人工智能
人工智能(Artificial Intelligence),英文缩写是AI。它是研究和开发用于模拟、扩展和扩展人类智能的理论、方法、技术和应用系统的一门新的技术科学。
人工智能是计算机科学的一个分支。它试图理解智能的本质,并生产出一种能够以类似于人类智能的方式做出反应的新型智能机器。该领域的研究包括机器人技术、语言识别、图像识别、自然语言处理和专家系统等。
人工智能诞生以来,理论和技术日趋成熟,应用领域也不断扩大。可以想象,未来人工智能带来的科技产品将是人类智能的“容器”,并且可能会超越人类智能。
Python 正在成为机器学习的语言。大多数机器语言课程都是用 Python 编写的,大量的大公司也使用 Python,让很多人认为它是未来的主要编程语言。
有人认为PYTHON效率很高,说不能支持多线程。好吧,这有点正确,但我想问一下,有多少人看过这篇文章 做过搜索引擎开发?有多少个网站并发开发,亿级PV?有多少人看过LINUX内核源代码?如果没有,请先乖乖的学习入门语言~
自动化运维
Python可以满足大部分自动化运维的需求。它也可以用作后端 C/S 架构。还可以使用WEB框架快速开发高大的WEB界面。只有当你有能力做出运维自动化系统时,你的价值才会体现出来。
那么问题来了
Python国内工资高吗?
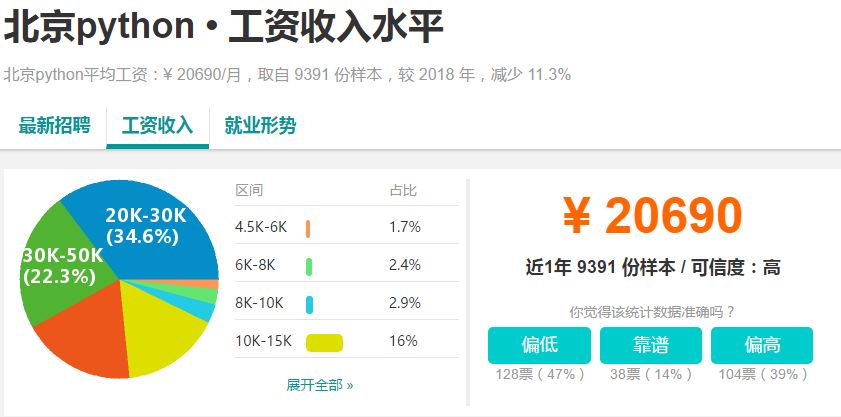
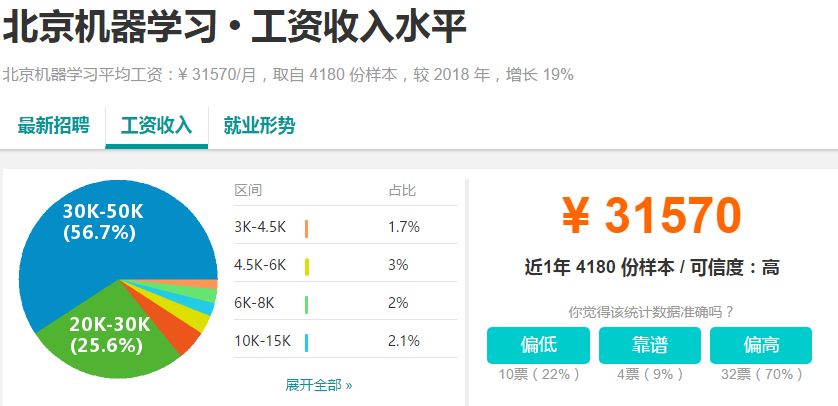
那么,既然Python这么好,那么Python目前国内就业工资高吗?
在工作人员集合上搜索Python相关职位,可以看到北京蟒蛇的平均工资:¥20690/月,取自9391个样本。
而相关的人工智能、机器学习等岗位,薪资更是高达3万多元。
随着国内各大互联网公司开始使用Python进行后端开发、大数据分析、运维测试、人工智能等,今年Python的地位会更高。
不仅是一线城市,在武汉、西安等二线城市,Python工程师的年薪都超过11000元。
那么,你准备好学习 Python 了吗? 查看全部
网页视频抓取脚本(Python是什么呢?Python经验总结什么叫网络爬虫网络蜘蛛)
什么是 Python?

Python 是一种全栈开发语言。如果你能学好Python,前端、后端、测试、大数据分析、爬虫等都可以胜任。
我不会详细介绍 Python 现在的流行程度。Python的功能是什么?
根据我多年的 Python 经验,Python 主要有以下四种应用:
接下来跟大家聊聊这几个方面:
网络爬虫
什么是网络爬虫?
网络爬虫,又称网络蜘蛛,是指按照一定的规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个网站进入其他网站,获取需要的内容。
爬虫有什么用?
做一个垂直搜索引擎(谷歌、百度等)。
科学研究:在线人类行为、在线社区进化、人类动力学研究、定量社会学、复杂网络、数据挖掘等领域的实证研究需要大量数据。网络爬虫是采集相关数据的强大工具。
偷窥、黑客、垃圾邮件……
爬行是搜索引擎的第一步,也是最简单的一步。
爬虫用什么语言写的?
C、C++。效率高,速度快,适合一般搜索引擎爬取全网。缺点,开发慢,又臭又长,例如:天网搜索源码。
脚本语言:Perl、Python、Java、Ruby。简单易学,好的文字处理可以方便对网页内容进行详细的提取,但效率往往不高,适合少量网站集中抓取
C#?
为什么 Python 是当下最热门的?
就个人而言,我已经用 c# 和 java 编写了爬虫。区别不大,原则是用好正则表达式。只是平台问题。后来才知道很多爬虫都是用python写的,所以一发不可收拾。
Python有很多优点。总结两个要点:
1) 抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。python中有优秀的第三方包帮你搞定,比如Requests,mechanize
2)网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
网站开发
开发网站需要什么知识?
1、Python基础,因为是用python开发的,python规定你需要知道,至少要知道条件、循环、函数、类;
2、html和css的基础知识,因为要开发网站,网页都是html和css写的,至少你得知道这方面的知识,即使你不知道怎么做写一个前端,你不能开发出特别漂亮的页面,网站,至少你要能看懂html标签;
3、数据库基础知识,因为如果你开发了一个网站,数据存在的地方,就在数据库中,那你至少要知道如何对数据库进行增删改查,否则如何保存数据和检索数据?
如果以上知识掌握好,开发一个简单的小网站就没有问题了。如果你想开发一个比较大的网站,业务逻辑比较复杂,那你就得借助其他的知识,比如redis,MQ等。
人工智能
人工智能(Artificial Intelligence),英文缩写是AI。它是研究和开发用于模拟、扩展和扩展人类智能的理论、方法、技术和应用系统的一门新的技术科学。
人工智能是计算机科学的一个分支。它试图理解智能的本质,并生产出一种能够以类似于人类智能的方式做出反应的新型智能机器。该领域的研究包括机器人技术、语言识别、图像识别、自然语言处理和专家系统等。
人工智能诞生以来,理论和技术日趋成熟,应用领域也不断扩大。可以想象,未来人工智能带来的科技产品将是人类智能的“容器”,并且可能会超越人类智能。
Python 正在成为机器学习的语言。大多数机器语言课程都是用 Python 编写的,大量的大公司也使用 Python,让很多人认为它是未来的主要编程语言。
有人认为PYTHON效率很高,说不能支持多线程。好吧,这有点正确,但我想问一下,有多少人看过这篇文章 做过搜索引擎开发?有多少个网站并发开发,亿级PV?有多少人看过LINUX内核源代码?如果没有,请先乖乖的学习入门语言~
自动化运维
Python可以满足大部分自动化运维的需求。它也可以用作后端 C/S 架构。还可以使用WEB框架快速开发高大的WEB界面。只有当你有能力做出运维自动化系统时,你的价值才会体现出来。
那么问题来了
Python国内工资高吗?
那么,既然Python这么好,那么Python目前国内就业工资高吗?
在工作人员集合上搜索Python相关职位,可以看到北京蟒蛇的平均工资:¥20690/月,取自9391个样本。
而相关的人工智能、机器学习等岗位,薪资更是高达3万多元。
随着国内各大互联网公司开始使用Python进行后端开发、大数据分析、运维测试、人工智能等,今年Python的地位会更高。
不仅是一线城市,在武汉、西安等二线城市,Python工程师的年薪都超过11000元。

那么,你准备好学习 Python 了吗?
网页视频抓取脚本(网页视频抓取脚本小程序数据、音频、声带、性格)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-08 18:04
网页视频抓取脚本小程序数据、音频、声带、性格、血型、星座、血压等多方位抓取,喜欢的可以关注我一下,及时发布抓取有精力的可以根据需要针对资源进行下载。1.通过https传输数据网址:,将原视频和音频都传输到后台,地址如下::针对不同页面传输不同的数据,如:1.1媒体文件/news文件,类型为jpg;1.2文字为\m\n,浏览器检测为”中文”jpg图片更改类型为bmp(需要修改host);1.3图片为\t\r\e,浏览器检测为”像素图”svg;1.4图片为\r\t,浏览器检测为”点阵图”zip解压解压后,查看中心页的地址::”update“选择传输的类型是”jpg“或”svg“,前者服务器无法传输,后者建议不要上传完成解压后看这个页面也是如下:/smqnzn/521111一大段,这个页面需要针对jpg和svg进行下载的;针对于这个页面,我们进行下载以后,再传输到这个网址:,在ie浏览器(或者其他各种浏览器)中,点击链接缩略图,再点击鼠标左键(鼠标右键)弹出来的下拉列表里点击下载选项即可:如果想更精准的传输ip,可以单独建立一个下载列表,如:网页内容中心为,可以对于这个页面的浏览器会员进行进行充值:我们分别用了一个url”””””“””为下载地址,输入不同的密码可以轻松下载全部页面,现在去下载咯~我们来看看下载成功的截图:这样就下载完成啦,不同页面下载成功的截图:2.遍历列表页面数据网址:,分别找出看到的不同内容,可以包括图片、文字、关注话题、统计信息等等:/360402cj一大堆,根据实际的需要做不同的下载,详细可以关注我,在我们这块有一些分享的文章希望对你有帮助。
抓取动画与视频类数据用到“查看“,”翻页”,”首页“命令“3.查看博客详情页4.知乎号添加话题列表!5.检测输入错误页面数据网址:,分别对页面中的字段进行检测,如::6.ajax缓存处理用到“查看”、“检查”等命令7.设置断点,在需要检测的位置检测,如:”#apikey””#apiv“”,使用方法同上1.使用python2.17更新抓取教程。 查看全部
网页视频抓取脚本(网页视频抓取脚本小程序数据、音频、声带、性格)
网页视频抓取脚本小程序数据、音频、声带、性格、血型、星座、血压等多方位抓取,喜欢的可以关注我一下,及时发布抓取有精力的可以根据需要针对资源进行下载。1.通过https传输数据网址:,将原视频和音频都传输到后台,地址如下::针对不同页面传输不同的数据,如:1.1媒体文件/news文件,类型为jpg;1.2文字为\m\n,浏览器检测为”中文”jpg图片更改类型为bmp(需要修改host);1.3图片为\t\r\e,浏览器检测为”像素图”svg;1.4图片为\r\t,浏览器检测为”点阵图”zip解压解压后,查看中心页的地址::”update“选择传输的类型是”jpg“或”svg“,前者服务器无法传输,后者建议不要上传完成解压后看这个页面也是如下:/smqnzn/521111一大段,这个页面需要针对jpg和svg进行下载的;针对于这个页面,我们进行下载以后,再传输到这个网址:,在ie浏览器(或者其他各种浏览器)中,点击链接缩略图,再点击鼠标左键(鼠标右键)弹出来的下拉列表里点击下载选项即可:如果想更精准的传输ip,可以单独建立一个下载列表,如:网页内容中心为,可以对于这个页面的浏览器会员进行进行充值:我们分别用了一个url”””””“””为下载地址,输入不同的密码可以轻松下载全部页面,现在去下载咯~我们来看看下载成功的截图:这样就下载完成啦,不同页面下载成功的截图:2.遍历列表页面数据网址:,分别找出看到的不同内容,可以包括图片、文字、关注话题、统计信息等等:/360402cj一大堆,根据实际的需要做不同的下载,详细可以关注我,在我们这块有一些分享的文章希望对你有帮助。
抓取动画与视频类数据用到“查看“,”翻页”,”首页“命令“3.查看博客详情页4.知乎号添加话题列表!5.检测输入错误页面数据网址:,分别对页面中的字段进行检测,如::6.ajax缓存处理用到“查看”、“检查”等命令7.设置断点,在需要检测的位置检测,如:”#apikey””#apiv“”,使用方法同上1.使用python2.17更新抓取教程。
网页视频抓取脚本(可以帮助用户抓取网页图片,使用爬虫技术帮助用户分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-07 04:49
)
北海小王子图片下载器可以帮助用户抓取网页图片,利用爬虫技术帮助用户分析网页上的图片,下载所有与链接相关的图片,用户可以在软件中设置爬虫深度,只抓取当前网页,可以继续抓取当前网页附带的URL地址的图片,实现多层搜索。进入网站首页从子网页抓取图片,满足不同用户搜索图片的需求。软件提供多种参数设置,可以限制图片大小,可以限制图片数量,软件界面显示抓取进度,抓取完成后自动下载图片。如果您需要此软件,请下载它!
软件功能
1、北海小王子图片下载器可以帮助用户快速下载图片
2、输入网址自动抓取图片
3、 可以自动抓取整个网页,自动识别图片文件
4、 可以自己设置爬虫深度,可以爬取更多的网页
5、可以设置图片大小,比如设置200KB,下面的图片不会被抓取
6、 支持图片张数设置,比如这次抓取100张图片,抓取数量达到100张会自动停止
7、 显示进程统计,第29页正在被爬取,56页爬取成功,1页爬取失败
软件特点
1、北海小王子图片下载器可以在网上免费下载图片
2、输入图片地址立即下载
3、可以输入一个网站首页地址进行爬取
4、可以输入HTML地址抓取图片
5、软件界面简单,左边可以显示抓包过程,右边可以显示设置参数
指示
1、打开Linging4Images-v1.0.exe软件,直接输入需要抓包的网站地址
2、选择爬取深度,深度1表示只爬取网站输入的内容1,2表示继续访问1中网站内容中出现的url,以及3 in 2 在基础上继续跳,以此类推,一般2层就够了
3、 设置图片大小,默认为500KB,可以适当缩小图片大小,比如抓取50KB以上的图片,小于设置的图片大小就不会抓取。
4、 设置图片数量,需要抓取多少张图片,自己输入即可,点击底部“去吧,皮卡丘”开始抓取
5、 可以在软件界面上显示抓拍的信息,可以点击停止按钮停止搜索图片
6、进入主程序所在文件夹,打开图片查看图片
7、编辑器抓到的图片是这样的,到此操作结束,如果需要从网络抓图,选择北海小王子图片下载器
查看全部
网页视频抓取脚本(可以帮助用户抓取网页图片,使用爬虫技术帮助用户分析
)
北海小王子图片下载器可以帮助用户抓取网页图片,利用爬虫技术帮助用户分析网页上的图片,下载所有与链接相关的图片,用户可以在软件中设置爬虫深度,只抓取当前网页,可以继续抓取当前网页附带的URL地址的图片,实现多层搜索。进入网站首页从子网页抓取图片,满足不同用户搜索图片的需求。软件提供多种参数设置,可以限制图片大小,可以限制图片数量,软件界面显示抓取进度,抓取完成后自动下载图片。如果您需要此软件,请下载它!

软件功能
1、北海小王子图片下载器可以帮助用户快速下载图片
2、输入网址自动抓取图片
3、 可以自动抓取整个网页,自动识别图片文件
4、 可以自己设置爬虫深度,可以爬取更多的网页
5、可以设置图片大小,比如设置200KB,下面的图片不会被抓取
6、 支持图片张数设置,比如这次抓取100张图片,抓取数量达到100张会自动停止
7、 显示进程统计,第29页正在被爬取,56页爬取成功,1页爬取失败
软件特点
1、北海小王子图片下载器可以在网上免费下载图片
2、输入图片地址立即下载
3、可以输入一个网站首页地址进行爬取
4、可以输入HTML地址抓取图片
5、软件界面简单,左边可以显示抓包过程,右边可以显示设置参数
指示
1、打开Linging4Images-v1.0.exe软件,直接输入需要抓包的网站地址

2、选择爬取深度,深度1表示只爬取网站输入的内容1,2表示继续访问1中网站内容中出现的url,以及3 in 2 在基础上继续跳,以此类推,一般2层就够了

3、 设置图片大小,默认为500KB,可以适当缩小图片大小,比如抓取50KB以上的图片,小于设置的图片大小就不会抓取。

4、 设置图片数量,需要抓取多少张图片,自己输入即可,点击底部“去吧,皮卡丘”开始抓取

5、 可以在软件界面上显示抓拍的信息,可以点击停止按钮停止搜索图片

6、进入主程序所在文件夹,打开图片查看图片

7、编辑器抓到的图片是这样的,到此操作结束,如果需要从网络抓图,选择北海小王子图片下载器

网页视频抓取脚本(一点js脚本的保存方法还有很多,你很想试一试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-06 20:05
这两天有点闲,想了一个小js脚本,作用是把当前网页的所有图片一次性保存到本地,以免图片被右键每次。
测试环境:Chrome开发者模式(启动Chrome,按F12)
测试页面:知乎一个问题
原理很简单,就是利用a标签的href和download属性和点击事件。
直接贴代码:
<p> 1 //一个对象,存储页面图片数量和下载的数量
2 var monitorObj = {
3 imgTotal: 0,
4 imgLoaded: 0
5 }
6 //创建a标签,赋予图片对象相关属性,并插入body
7 var createA = function (obj) {
8 var a = document.createElement("a");
9 a.id = obj.id;
10 a.target = "_blank";//注意:要在新页面打开
11 a.href = obj.url;
12 a.download = obj.url;
13
14 document.body.appendChild(a);
15 }
16
17 //获取页面的图片
18 var imgs = document.images;
19 //创建每个图片对象的对应a标签
20 for (var i = 0; i < imgs.length;i++){
21 var obj = {
22 id: "img_" + i,
23 url: imgs[i].src
24 }
25 //过滤掉不属于这几种类型的图片
26 if (["JPG", "JPEG", "PNG","GIF"].indexOf(obj.url.substr(obj.url.lastIndexOf(".")+1).toUpperCase()) < 0) {
27 continue;
28 }
29 //这里是为了去掉知乎用户头像的图片,头像大小是50*50
30 if (imgs[i].width 查看全部
网页视频抓取脚本(一点js脚本的保存方法还有很多,你很想试一试)
这两天有点闲,想了一个小js脚本,作用是把当前网页的所有图片一次性保存到本地,以免图片被右键每次。
测试环境:Chrome开发者模式(启动Chrome,按F12)
测试页面:知乎一个问题
原理很简单,就是利用a标签的href和download属性和点击事件。
直接贴代码:
<p> 1 //一个对象,存储页面图片数量和下载的数量
2 var monitorObj = {
3 imgTotal: 0,
4 imgLoaded: 0
5 }
6 //创建a标签,赋予图片对象相关属性,并插入body
7 var createA = function (obj) {
8 var a = document.createElement("a");
9 a.id = obj.id;
10 a.target = "_blank";//注意:要在新页面打开
11 a.href = obj.url;
12 a.download = obj.url;
13
14 document.body.appendChild(a);
15 }
16
17 //获取页面的图片
18 var imgs = document.images;
19 //创建每个图片对象的对应a标签
20 for (var i = 0; i < imgs.length;i++){
21 var obj = {
22 id: "img_" + i,
23 url: imgs[i].src
24 }
25 //过滤掉不属于这几种类型的图片
26 if (["JPG", "JPEG", "PNG","GIF"].indexOf(obj.url.substr(obj.url.lastIndexOf(".")+1).toUpperCase()) < 0) {
27 continue;
28 }
29 //这里是为了去掉知乎用户头像的图片,头像大小是50*50
30 if (imgs[i].width
网页视频抓取脚本(excel做数据驱动(二)--如何面对博文被)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-06 08:28
>>>
================ 重新启动:C:\Users\mx11\Desktop\webcatch.py ============== == =
Java接口测试,用excel做数据驱动(二)
----------------------------------------------- ---------------
如何面对被抓取的博文
----------------------------------------------- ---------------
javascript 设计模式-发布订阅模式
----------------------------------------------- ---------------
网络虚拟化
----------------------------------------------- ---------------
【学习的艺术】钱会来吗?
----------------------------------------------- ---------------
docker、oci、runc 和 kubernetes 组合
----------------------------------------------- ---------------
从Android开发的角度来说说Airbnb的Lottie! ! !
----------------------------------------------- ---------------
深入学习-webkit-overflow-scrolling:touch和ios滚动
----------------------------------------------- ---------------
为什么列存储可以大大提高数据查询性能?
----------------------------------------------- ---------------
MySQL slave_exec_mode 参数说明
----------------------------------------------- ---------------
阿里安全 Pandora Labs 首次完美越狱 Apple iOS 11.2
----------------------------------------------- ---------------
《RabbitMQ教程》翻译第3章发布与订阅
----------------------------------------------- ---------------
Android HandlerThread的使用介绍及源码分析
----------------------------------------------- ---------------
(四):C++分布式实时应用框架-状态中心模块
----------------------------------------------- ---------------
感知器学习与实践
----------------------------------------------- ---------------
SQLServer 审查文档 1(使用 C#)
----------------------------------------------- ---------------
分布式监控系统Zabbix3.2 数据库连接数警告
----------------------------------------------- ---------------
ABP模块-零+AdminLTE+Bootstrap Table+jQuery权限管理系统第16节-SignalR和ABP框架Abp.Web.SignalR和扩展
----------------------------------------------- ---------------
Docker:限制容器可用的内存
----------------------------------------------- ---------------
javascript 设计模式-迭代器模式
----------------------------------------------- ---------------
>>> 查看全部
网页视频抓取脚本(excel做数据驱动(二)--如何面对博文被)
>>>
================ 重新启动:C:\Users\mx11\Desktop\webcatch.py ============== == =
Java接口测试,用excel做数据驱动(二)
----------------------------------------------- ---------------
如何面对被抓取的博文
----------------------------------------------- ---------------
javascript 设计模式-发布订阅模式
----------------------------------------------- ---------------
网络虚拟化
----------------------------------------------- ---------------
【学习的艺术】钱会来吗?
----------------------------------------------- ---------------
docker、oci、runc 和 kubernetes 组合
----------------------------------------------- ---------------
从Android开发的角度来说说Airbnb的Lottie! ! !
----------------------------------------------- ---------------
深入学习-webkit-overflow-scrolling:touch和ios滚动
----------------------------------------------- ---------------
为什么列存储可以大大提高数据查询性能?
----------------------------------------------- ---------------
MySQL slave_exec_mode 参数说明
----------------------------------------------- ---------------
阿里安全 Pandora Labs 首次完美越狱 Apple iOS 11.2
----------------------------------------------- ---------------
《RabbitMQ教程》翻译第3章发布与订阅
----------------------------------------------- ---------------
Android HandlerThread的使用介绍及源码分析
----------------------------------------------- ---------------
(四):C++分布式实时应用框架-状态中心模块
----------------------------------------------- ---------------
感知器学习与实践
----------------------------------------------- ---------------
SQLServer 审查文档 1(使用 C#)
----------------------------------------------- ---------------
分布式监控系统Zabbix3.2 数据库连接数警告
----------------------------------------------- ---------------
ABP模块-零+AdminLTE+Bootstrap Table+jQuery权限管理系统第16节-SignalR和ABP框架Abp.Web.SignalR和扩展
----------------------------------------------- ---------------
Docker:限制容器可用的内存
----------------------------------------------- ---------------
javascript 设计模式-迭代器模式
----------------------------------------------- ---------------
>>>
网页视频抓取脚本(会把v2版本打成exe运行先看v1版本import,,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-12-06 04:07
编写了两个脚本,分别是 v1 和 v2。
所有python调用mediainfo工具提取视频元数据信息
v1版本在pycharm中使用测试运行,指定视频路径
v2版本终于交付运行运行了,v2版本会以exe的形式运行
先看v1版本
导入 os,subprocess,json,re,locale,sys
导入 xlwt、时间、关闭
#获取当前文件所在的绝对目录路径
# this_path=os.path.abspath('.')
# print('当前路径为----',this_path)
# dir_path=this_path
#视频文件所在目录
dir_path='I:\\3 分钟午餐'
# print(os.listdir(this_path))
打印('---------------------------------')
print('--------------程序即将启动----------------')
# dir_path=this_path
#定义一个列表来存放每个文件的绝对路径,方便后面的操作
init_list=[]
# dir_path='F:\\Dollhouse 总视频'
#创建一个方法,统计每个文件路径,并附加到列表中。这里注释掉递归,不获取子目录,只获取dir_path下的视频
def get_all_file(dir_path,init_list):
对于 os.listdir(dir_path) 中的文件:
# 打印(文件)
filepath=os.path.join(dir_path,file)
# 打印(文件路径)
如果 os.path.isdir(filepath):
print('遇到子目录---%s---此版本暂时不提取子目录视频信息--'%(filepath))
time.sleep(2)
# get_all_file(文件路径)
其他:
如果不是 file.endswith('exe'):
init_list.append(文件路径)
返回init_list
#执行上述方法,将每个文件的绝对路径追加到列表中
file_list=get_all_file(dir_path,init_list)
print("读完文件-----3秒后,开始获取详细视频信息-----")
time.sleep(3)
#定义一个方法来获取单个媒体文件的元数据并作为字典数据返回
#这个程序的核心是调用mediainfo工具提取视频信息
def get_media_info(file):
pname='D:\mediainfo_i386\MediaInfo.exe "%s" --Output=JSON'%(file)
result=subprocess.Popen(pname,shell=False,stdout=subprocess.PIPE).stdout
list_std=result.readlines()
str_tmp=''
对于 list_std 中的项目:
str_tmp+=bytes.decode(item.strip())
json_data=json.loads(str_tmp)
返回json_data
#定义一个传递字典数据的方法,返回你想要的字段数据,返回一个值列表
def get_dict_data(json_data):
#获取文件大小
filesize=json_data['media']['track'][0]['FileSize']
#获取比特率
malv=json_data['media']['track'][0]['OverallBitRate'][0:4]
#获取播放时长
duration=json_data['media']['track'][0]['Duration'].split('.')[0]
#获取文件类型
file_format=json_data['media']['track'][0]['Format']
#获取边框宽度
samp_width=json_data['media']['track'][1]['Sampled_Width']
#获取框架高度
samp_height=json_data['media']['track'][1]['Sampled_Height']
返回 [filesize,malv,duration,file_format,samp_width,samp_height]
#定义一个获取文件名的方法,它是key,它的值是目标列表,返回值是一个字典,参数是文件列表
dict_all={}
#定义保存和提取日志失败的视频文件名
f_fail=open('提取失败 log.log','a',encoding='utf-8') # 追加模式
def get_all_dict(file_list,f_fail):
对于 file_list 中的文件:
filename=os.path.split(file)[1]
打印(文件名)
time.sleep(0.1)
试试:
info_list=get_dict_data(get_media_info(file))
dict_all[文件名]=info_list
例外为 e:
print(filename,'------提取此文件信息失败---------')
f_fail.write(文件名+'\r\n')
f_fail.close()
get_all_dict(file_list,f_fail)
# 用于 dict_all 中的项目:
# print(item,dict_all[item])
#创建一个excel表格存放文件路径信息,第一列是目录,第二列是文件名
wb = xlwt.Workbook()
sh = wb.add_sheet('元数据')
#写第一行
row_count=0
sh.write(row_count,0,"文件名")
sh.write(row_count,1,"文件大小")
sh.write(row_count,2,"比特率")
sh.write(row_count,3,"总持续时间")
sh.write(row_count,4,"视频格式")
sh.write(row_count,5,"帧宽度")
sh.write(row_count,6,"frame height")
#批量写入视频信息
row_count=1
对于 dict_all 中的项目:
sh.write(row_count,0,item)
sh.write(row_count,1,dict_all[item][0])
sh.write(row_count,2,dict_all[item][1])
sh.write(row_count,3,dict_all[item][2])
sh.write(row_count,4,dict_all[item][3])
sh.write(row_count,5,dict_all[item][4])
sh.write(row_count,6,dict_all[item][5])
row_count+=1
#
wb.save("元数据统计.xls")
#
看v2版本
v2版本是提取当前目录下的视频
导入 os,subprocess,json,re,locale,sys
导入 xlwt、时间、关闭
#获取当前文件所在的绝对目录路径
this_path=os.path.abspath('.')
print('当前路径为----', this_path)
dir_path=this_path
# print(os.listdir(this_path))
打印('---------------------------------')
print('--------------程序即将启动----------------')
# dir_path=this_path
#定义一个列表来存放每个文件路径,方便后面的操作
init_list=[]
# dir_path='I:\\3 分钟午餐'
# dir_path='F:\\Dollhouse 总视频'
#创建一个方法,统计每个文件路径,并附加到列表中。使用递归,这里没有获取子目录
def get_all_file(dir_path,init_list):
对于 os.listdir(dir_path) 中的文件:
# 打印(文件)
filepath=os.path.join(dir_path,file)
# 打印(文件路径)
如果 os.path.isdir(filepath):
print('遇到子目录---%s---此版本暂时不提取子目录视频信息--'%(filepath))
time.sleep(2)
# get_all_file(文件路径)
其他:
如果不是 file.endswith('exe'):
init_list.append(文件路径)
返回init_list
#执行上述方法,将每个文件的绝对路径追加到列表中
file_list=get_all_file(dir_path,init_list)
print("读完文件-----3秒后,开始获取详细视频信息-----")
time.sleep(3)
#定义一个方法来获取单个媒体文件的元数据并作为字典数据返回
def get_media_info(file):
pname='D:\mediainfo_i386\MediaInfo.exe "%s" --Output=JSON'%(file)
result=subprocess.Popen(pname,shell=False,stdout=subprocess.PIPE).stdout
list_std=result.readlines()
str_tmp=''
对于 list_std 中的项目:
str_tmp+=bytes.decode(item.strip())
json_data=json.loads(str_tmp)
返回json_data
#定义一个传递字典数据的方法,返回你想要的字段数据,返回一个值列表
def get_dict_data(json_data):
#获取文件大小
filesize=json_data['media']['track'][0]['FileSize']
#获取比特率
malv=json_data['media']['track'][0]['OverallBitRate'][0:4]
#获取播放时长
duration=json_data['media']['track'][0]['Duration'].split('.')[0]
#获取文件类型
file_format=json_data['media']['track'][0]['Format']
#获取边框宽度
samp_width=json_data['media']['track'][1]['Sampled_Width']
#获取框架高度
samp_height=json_data['media']['track'][1]['Sampled_Height']
返回 [filesize,malv,duration,file_format,samp_width,samp_height]
#定义一个获取文件名的方法,它是key,它的值是目标列表,返回值是一个字典,参数是文件列表
dict_all={}
f_fail=open('提取失败 log.log','a',encoding='utf-8') # 追加模式
def get_all_dict(file_list,f_fail):
对于 file_list 中的文件:
filename=os.path.split(file)[1]
打印(文件名)
time.sleep(0.1)
试试:
info_list=get_dict_data(get_media_info(file))
dict_all[文件名]=info_list
例外为 e:
print(filename,'------提取此文件信息失败---------')
f_fail.write(文件名+'\r\n')
f_fail.close()
get_all_dict(file_list,f_fail)
# 用于 dict_all 中的项目:
# print(item,dict_all[item])
#创建一个excel表格存放文件路径信息,第一列是目录,第二列是文件名
wb = xlwt.Workbook()
sh = wb.add_sheet('元数据')
#写第一行
row_count=0
sh.write(row_count,0,"文件名")
sh.write(row_count,1,"文件大小")
sh.write(row_count,2,"比特率")
sh.write(row_count,3,"总持续时间")
sh.write(row_count,4,"视频格式")
sh.write(row_count,5,"帧宽度")
sh.write(row_count,6,"frame height")
row_count=1
对于 dict_all 中的项目:
sh.write(row_count,0,item)
sh.write(row_count,1,dict_all[item][0])
sh.write(row_count,2,dict_all[item][1])
sh.write(row_count,3,dict_all[item][2])
sh.write(row_count,4,dict_all[item][3])
sh.write(row_count,5,dict_all[item][4])
sh.write(row_count,6,dict_all[item][5])
row_count+=1
#
wb.save("元数据统计.xls")
将 v2 版本输入到 exe 文件中
将这个exe文件复制到以下路径
这个程序可以交付给运维同事
测试和验证部分
如何使用,把程序放在视频的同级目录
根据代码缩写,如果视频运行成功:
1、本程序不会处理哈哈目录
2、对于abc.123等无法识别的文件(可能不是视频文件,或损坏的视频文件),本程序会记录日志,不会中断程序的正常运行。
3、程序运行后会有一个失败log.log文件,里面记录了提取信息失败的视频名称,把提取成功的视频文件放在“Metadata Statistics.xls”中
正在测试验证
双击运行
操作结束
Excel 信息
文件大小以字节为单位。如果要以MB或GB显示,可以使用excel表格中的内置公式进行处理。
字段很多,比特率,时长等,这里因为操作只需要下面几个字段,把这些提取出来
如果你把这个exe程序发给你的操作同事,你需要把D盘的mediainfo_i386文件夹一起给他们,这个文件必须放在D盘 查看全部
网页视频抓取脚本(会把v2版本打成exe运行先看v1版本import,,)
编写了两个脚本,分别是 v1 和 v2。
所有python调用mediainfo工具提取视频元数据信息
v1版本在pycharm中使用测试运行,指定视频路径
v2版本终于交付运行运行了,v2版本会以exe的形式运行
先看v1版本
导入 os,subprocess,json,re,locale,sys
导入 xlwt、时间、关闭
#获取当前文件所在的绝对目录路径
# this_path=os.path.abspath('.')
# print('当前路径为----',this_path)
# dir_path=this_path
#视频文件所在目录
dir_path='I:\\3 分钟午餐'
# print(os.listdir(this_path))
打印('---------------------------------')
print('--------------程序即将启动----------------')
# dir_path=this_path
#定义一个列表来存放每个文件的绝对路径,方便后面的操作
init_list=[]
# dir_path='F:\\Dollhouse 总视频'
#创建一个方法,统计每个文件路径,并附加到列表中。这里注释掉递归,不获取子目录,只获取dir_path下的视频
def get_all_file(dir_path,init_list):
对于 os.listdir(dir_path) 中的文件:
# 打印(文件)
filepath=os.path.join(dir_path,file)
# 打印(文件路径)
如果 os.path.isdir(filepath):
print('遇到子目录---%s---此版本暂时不提取子目录视频信息--'%(filepath))
time.sleep(2)
# get_all_file(文件路径)
其他:
如果不是 file.endswith('exe'):
init_list.append(文件路径)
返回init_list
#执行上述方法,将每个文件的绝对路径追加到列表中
file_list=get_all_file(dir_path,init_list)
print("读完文件-----3秒后,开始获取详细视频信息-----")
time.sleep(3)
#定义一个方法来获取单个媒体文件的元数据并作为字典数据返回
#这个程序的核心是调用mediainfo工具提取视频信息
def get_media_info(file):
pname='D:\mediainfo_i386\MediaInfo.exe "%s" --Output=JSON'%(file)
result=subprocess.Popen(pname,shell=False,stdout=subprocess.PIPE).stdout
list_std=result.readlines()
str_tmp=''
对于 list_std 中的项目:
str_tmp+=bytes.decode(item.strip())
json_data=json.loads(str_tmp)
返回json_data
#定义一个传递字典数据的方法,返回你想要的字段数据,返回一个值列表
def get_dict_data(json_data):
#获取文件大小
filesize=json_data['media']['track'][0]['FileSize']
#获取比特率
malv=json_data['media']['track'][0]['OverallBitRate'][0:4]
#获取播放时长
duration=json_data['media']['track'][0]['Duration'].split('.')[0]
#获取文件类型
file_format=json_data['media']['track'][0]['Format']
#获取边框宽度
samp_width=json_data['media']['track'][1]['Sampled_Width']
#获取框架高度
samp_height=json_data['media']['track'][1]['Sampled_Height']
返回 [filesize,malv,duration,file_format,samp_width,samp_height]
#定义一个获取文件名的方法,它是key,它的值是目标列表,返回值是一个字典,参数是文件列表
dict_all={}
#定义保存和提取日志失败的视频文件名
f_fail=open('提取失败 log.log','a',encoding='utf-8') # 追加模式
def get_all_dict(file_list,f_fail):
对于 file_list 中的文件:
filename=os.path.split(file)[1]
打印(文件名)
time.sleep(0.1)
试试:
info_list=get_dict_data(get_media_info(file))
dict_all[文件名]=info_list
例外为 e:
print(filename,'------提取此文件信息失败---------')
f_fail.write(文件名+'\r\n')
f_fail.close()
get_all_dict(file_list,f_fail)
# 用于 dict_all 中的项目:
# print(item,dict_all[item])
#创建一个excel表格存放文件路径信息,第一列是目录,第二列是文件名
wb = xlwt.Workbook()
sh = wb.add_sheet('元数据')
#写第一行
row_count=0
sh.write(row_count,0,"文件名")
sh.write(row_count,1,"文件大小")
sh.write(row_count,2,"比特率")
sh.write(row_count,3,"总持续时间")
sh.write(row_count,4,"视频格式")
sh.write(row_count,5,"帧宽度")
sh.write(row_count,6,"frame height")
#批量写入视频信息
row_count=1
对于 dict_all 中的项目:
sh.write(row_count,0,item)
sh.write(row_count,1,dict_all[item][0])
sh.write(row_count,2,dict_all[item][1])
sh.write(row_count,3,dict_all[item][2])
sh.write(row_count,4,dict_all[item][3])
sh.write(row_count,5,dict_all[item][4])
sh.write(row_count,6,dict_all[item][5])
row_count+=1
#
wb.save("元数据统计.xls")
#
看v2版本
v2版本是提取当前目录下的视频
导入 os,subprocess,json,re,locale,sys
导入 xlwt、时间、关闭
#获取当前文件所在的绝对目录路径
this_path=os.path.abspath('.')
print('当前路径为----', this_path)
dir_path=this_path
# print(os.listdir(this_path))
打印('---------------------------------')
print('--------------程序即将启动----------------')
# dir_path=this_path
#定义一个列表来存放每个文件路径,方便后面的操作
init_list=[]
# dir_path='I:\\3 分钟午餐'
# dir_path='F:\\Dollhouse 总视频'
#创建一个方法,统计每个文件路径,并附加到列表中。使用递归,这里没有获取子目录
def get_all_file(dir_path,init_list):
对于 os.listdir(dir_path) 中的文件:
# 打印(文件)
filepath=os.path.join(dir_path,file)
# 打印(文件路径)
如果 os.path.isdir(filepath):
print('遇到子目录---%s---此版本暂时不提取子目录视频信息--'%(filepath))
time.sleep(2)
# get_all_file(文件路径)
其他:
如果不是 file.endswith('exe'):
init_list.append(文件路径)
返回init_list
#执行上述方法,将每个文件的绝对路径追加到列表中
file_list=get_all_file(dir_path,init_list)
print("读完文件-----3秒后,开始获取详细视频信息-----")
time.sleep(3)
#定义一个方法来获取单个媒体文件的元数据并作为字典数据返回
def get_media_info(file):
pname='D:\mediainfo_i386\MediaInfo.exe "%s" --Output=JSON'%(file)
result=subprocess.Popen(pname,shell=False,stdout=subprocess.PIPE).stdout
list_std=result.readlines()
str_tmp=''
对于 list_std 中的项目:
str_tmp+=bytes.decode(item.strip())
json_data=json.loads(str_tmp)
返回json_data
#定义一个传递字典数据的方法,返回你想要的字段数据,返回一个值列表
def get_dict_data(json_data):
#获取文件大小
filesize=json_data['media']['track'][0]['FileSize']
#获取比特率
malv=json_data['media']['track'][0]['OverallBitRate'][0:4]
#获取播放时长
duration=json_data['media']['track'][0]['Duration'].split('.')[0]
#获取文件类型
file_format=json_data['media']['track'][0]['Format']
#获取边框宽度
samp_width=json_data['media']['track'][1]['Sampled_Width']
#获取框架高度
samp_height=json_data['media']['track'][1]['Sampled_Height']
返回 [filesize,malv,duration,file_format,samp_width,samp_height]
#定义一个获取文件名的方法,它是key,它的值是目标列表,返回值是一个字典,参数是文件列表
dict_all={}
f_fail=open('提取失败 log.log','a',encoding='utf-8') # 追加模式
def get_all_dict(file_list,f_fail):
对于 file_list 中的文件:
filename=os.path.split(file)[1]
打印(文件名)
time.sleep(0.1)
试试:
info_list=get_dict_data(get_media_info(file))
dict_all[文件名]=info_list
例外为 e:
print(filename,'------提取此文件信息失败---------')
f_fail.write(文件名+'\r\n')
f_fail.close()
get_all_dict(file_list,f_fail)
# 用于 dict_all 中的项目:
# print(item,dict_all[item])
#创建一个excel表格存放文件路径信息,第一列是目录,第二列是文件名
wb = xlwt.Workbook()
sh = wb.add_sheet('元数据')
#写第一行
row_count=0
sh.write(row_count,0,"文件名")
sh.write(row_count,1,"文件大小")
sh.write(row_count,2,"比特率")
sh.write(row_count,3,"总持续时间")
sh.write(row_count,4,"视频格式")
sh.write(row_count,5,"帧宽度")
sh.write(row_count,6,"frame height")
row_count=1
对于 dict_all 中的项目:
sh.write(row_count,0,item)
sh.write(row_count,1,dict_all[item][0])
sh.write(row_count,2,dict_all[item][1])
sh.write(row_count,3,dict_all[item][2])
sh.write(row_count,4,dict_all[item][3])
sh.write(row_count,5,dict_all[item][4])
sh.write(row_count,6,dict_all[item][5])
row_count+=1
#
wb.save("元数据统计.xls")
将 v2 版本输入到 exe 文件中
将这个exe文件复制到以下路径

这个程序可以交付给运维同事
测试和验证部分
如何使用,把程序放在视频的同级目录
根据代码缩写,如果视频运行成功:
1、本程序不会处理哈哈目录
2、对于abc.123等无法识别的文件(可能不是视频文件,或损坏的视频文件),本程序会记录日志,不会中断程序的正常运行。
3、程序运行后会有一个失败log.log文件,里面记录了提取信息失败的视频名称,把提取成功的视频文件放在“Metadata Statistics.xls”中
正在测试验证
双击运行
操作结束

Excel 信息
文件大小以字节为单位。如果要以MB或GB显示,可以使用excel表格中的内置公式进行处理。
字段很多,比特率,时长等,这里因为操作只需要下面几个字段,把这些提取出来

如果你把这个exe程序发给你的操作同事,你需要把D盘的mediainfo_i386文件夹一起给他们,这个文件必须放在D盘
网页视频抓取脚本(Android手机上的抖音详细操作内容介绍-脚本之家)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-05 23:12
既然抖音的火爆大家有目共睹,小编在网上发现了一些好玩的东西,就是爬取一些网站,所以我也考虑是否可以进行。 抖音@抖音上解决的案例,经过实际操作,真正实现了。使用自动化工具,它可以很容易地实现。后来有小伙伴建议,去除了苹果,减肥后就可以实现了。然后看详细操作。内容。
1、mitmproxy/mitmdump 抓包
import requests
path = 'D:/video/'
num = 1788
def response(flow):
global num
target_urls = ['url']
for url in target_urls:
if flow.request.url.startswith(url):
filename = path + str(num) + '.mp4
res = requests.get(flow.request.url, stream=True)
with open(filename, 'ab') as f:
f.write(res.content)
f.flush()
print(filename + '下载完成')
num += 1
2、Appium 模拟手机操作
使用启动服务器按钮启动appium服务
再次点击Start Session,在Android手机上启动抖音app,进入启动页面
3、python脚本驱动app,直接在pycharm中运行即可
示例扩展:
import requests
import json
import re
import os
from pprint import pprint as pp
import queue
class DouYin:
header = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1',
}
def __init__(self, url=None):
self.url = self.get_RealAddress(url)
# 获取用户视频的url
self.user_video_url = 'https://www.douyin.com/aweme/v1/aweme/post/?{0}'
self.user_id = re.search(r'user/(.*)\?', self.url).group(1) # 用户id
requests.packages.urllib3.disable_warnings()
self.session = requests.Session()
self.target_folder = '' # 创建文件的路径
self.queue = queue.Queue() # 生成一个队列对象
def user_info(self):
self.mkdir_dir()
p = os.popen('node fuck.js %s' % self.user_id) # 获取加密的signature
signature = p.readlines()[0]
user_video_params = {
'user_id': str(self.user_id),
'count': '21',
'max_cursor': '0',
'aid': '1128',
'_signature': signature
}
# 获取下载视频的列表
def get_aweme_list(max_cursor=None):
if max_cursor:
user_video_params['max_cursor'] = str(max_cursor)
user_video_url = self.user_video_url.format(
'&'.join([key + '=' + user_video_params[key] for key in user_video_params])) # 拼接参数
response = requests.get(
url=user_video_url, headers=self.header, verify=False)
contentJson = json.loads(response.content.decode('utf-8')) # 将返回的进行utf8编码
aweme_list = contentJson.get('aweme_list', [])
for aweme in aweme_list:
video_name = aweme.get(
'share_info', None).get('share_desc', None) # 视频的名字
video_url = aweme.get('video', None).get('play_addr', None).get(
'url_list', None)[0].replace('playwm', 'play') # 视频链接
self.queue.put((video_name, video_url)) # 将数据进队列
if contentJson.get('has_more') == 1: # 判断后面是不是还有是1就是还有
return get_aweme_list(contentJson.get('max_cursor')) # 有的话获取参数max_cursor
get_aweme_list()
# 下载视频
def get_download(self):
while True:
video_name, video_url = self.queue.get()
file_name = video_name + '.mp4'
file_path = os.path.join(self.target_folder, file_name)
if not os.path.isfile(file_path):
print('download %s form %s.\n' % (file_name, video_url))
times = 0
while times < 10:
try:
response = requests.get(
url=video_url, stream=True, timeout=10, verify=False) # 开启流下载
with open(file_path, 'wb') as f:
for chunk in response.iter_content(1024): # 返回迭代对象
f.write(chunk)
print('下载成功')
break
except:
print('下载失败')
times += 1
# 创建对应的文件夹
def mkdir_dir(self):
current_folder = os.getcwd()
self.target_folder = os.path.join(
current_folder, 'download/%s' % self.user_id)
if not os.path.isdir(self.target_folder):
os.mkdir(self.target_folder)
# 短链接转长地址
def get_RealAddress(self, url):
if url.find('v.douyin.com') < 0:
return url
response = requests.get(
url=url, headers=self.header, allow_redirects=False) # allow_redirects 允许跳转
return response.headers['Location']
if __name__ == '__main__':
douyin = DouYin(url='http://v.douyin.com/J2B9Sk/')
douyin.user_info()
douyin.get_download()
这篇关于文章关于python爬取抖音视频实例分析的文章介绍到这里,更多关于如何使用python爬取抖音视频内容,请搜索脚本首页之前的文章或者继续浏览以下相关的文章希望大家以后多多支持Script Home! 查看全部
网页视频抓取脚本(Android手机上的抖音详细操作内容介绍-脚本之家)
既然抖音的火爆大家有目共睹,小编在网上发现了一些好玩的东西,就是爬取一些网站,所以我也考虑是否可以进行。 抖音@抖音上解决的案例,经过实际操作,真正实现了。使用自动化工具,它可以很容易地实现。后来有小伙伴建议,去除了苹果,减肥后就可以实现了。然后看详细操作。内容。
1、mitmproxy/mitmdump 抓包
import requests
path = 'D:/video/'
num = 1788
def response(flow):
global num
target_urls = ['url']
for url in target_urls:
if flow.request.url.startswith(url):
filename = path + str(num) + '.mp4
res = requests.get(flow.request.url, stream=True)
with open(filename, 'ab') as f:
f.write(res.content)
f.flush()
print(filename + '下载完成')
num += 1
2、Appium 模拟手机操作
使用启动服务器按钮启动appium服务

再次点击Start Session,在Android手机上启动抖音app,进入启动页面
3、python脚本驱动app,直接在pycharm中运行即可
示例扩展:
import requests
import json
import re
import os
from pprint import pprint as pp
import queue
class DouYin:
header = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1',
}
def __init__(self, url=None):
self.url = self.get_RealAddress(url)
# 获取用户视频的url
self.user_video_url = 'https://www.douyin.com/aweme/v1/aweme/post/?{0}'
self.user_id = re.search(r'user/(.*)\?', self.url).group(1) # 用户id
requests.packages.urllib3.disable_warnings()
self.session = requests.Session()
self.target_folder = '' # 创建文件的路径
self.queue = queue.Queue() # 生成一个队列对象
def user_info(self):
self.mkdir_dir()
p = os.popen('node fuck.js %s' % self.user_id) # 获取加密的signature
signature = p.readlines()[0]
user_video_params = {
'user_id': str(self.user_id),
'count': '21',
'max_cursor': '0',
'aid': '1128',
'_signature': signature
}
# 获取下载视频的列表
def get_aweme_list(max_cursor=None):
if max_cursor:
user_video_params['max_cursor'] = str(max_cursor)
user_video_url = self.user_video_url.format(
'&'.join([key + '=' + user_video_params[key] for key in user_video_params])) # 拼接参数
response = requests.get(
url=user_video_url, headers=self.header, verify=False)
contentJson = json.loads(response.content.decode('utf-8')) # 将返回的进行utf8编码
aweme_list = contentJson.get('aweme_list', [])
for aweme in aweme_list:
video_name = aweme.get(
'share_info', None).get('share_desc', None) # 视频的名字
video_url = aweme.get('video', None).get('play_addr', None).get(
'url_list', None)[0].replace('playwm', 'play') # 视频链接
self.queue.put((video_name, video_url)) # 将数据进队列
if contentJson.get('has_more') == 1: # 判断后面是不是还有是1就是还有
return get_aweme_list(contentJson.get('max_cursor')) # 有的话获取参数max_cursor
get_aweme_list()
# 下载视频
def get_download(self):
while True:
video_name, video_url = self.queue.get()
file_name = video_name + '.mp4'
file_path = os.path.join(self.target_folder, file_name)
if not os.path.isfile(file_path):
print('download %s form %s.\n' % (file_name, video_url))
times = 0
while times < 10:
try:
response = requests.get(
url=video_url, stream=True, timeout=10, verify=False) # 开启流下载
with open(file_path, 'wb') as f:
for chunk in response.iter_content(1024): # 返回迭代对象
f.write(chunk)
print('下载成功')
break
except:
print('下载失败')
times += 1
# 创建对应的文件夹
def mkdir_dir(self):
current_folder = os.getcwd()
self.target_folder = os.path.join(
current_folder, 'download/%s' % self.user_id)
if not os.path.isdir(self.target_folder):
os.mkdir(self.target_folder)
# 短链接转长地址
def get_RealAddress(self, url):
if url.find('v.douyin.com') < 0:
return url
response = requests.get(
url=url, headers=self.header, allow_redirects=False) # allow_redirects 允许跳转
return response.headers['Location']
if __name__ == '__main__':
douyin = DouYin(url='http://v.douyin.com/J2B9Sk/')
douyin.user_info()
douyin.get_download()
这篇关于文章关于python爬取抖音视频实例分析的文章介绍到这里,更多关于如何使用python爬取抖音视频内容,请搜索脚本首页之前的文章或者继续浏览以下相关的文章希望大家以后多多支持Script Home!
网页视频抓取脚本(Java网页视频抓取脚本的使用步骤及使用方法【图文】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-05 16:15
网页视频抓取脚本是想自己录制视频点击观看呢,还是想用脚本实现一些小功能呢。之前我用的不太好的视频抓取脚本bt天下就大功告成,但是该轮到暴风影音投屏到你电脑了吧!它发现你在播放电脑里的视频,就会自动投屏到电脑屏幕上。但是今天要推荐的一个脚本,它可以跟你要的这个投屏功能一毛钱关系都没有哦!仅仅有一个路由器,就可以让你视频投屏到电脑上观看。
这个脚本名叫:web网页视频抓取脚本,作者:airzipx。从名字就能知道,这个脚本主要是讲解网页上的视频提取的。这个脚本主要的功能非常简单,能把百度云的视频转成文本,然后你就可以把它转换成文件了。来给大家演示一下具体的使用步骤:1.我们可以把它的脚本直接分享给你要用到的队友。2.把你要分享的网址发给队友,队友就可以将你发的网址复制粘贴在浏览器输入3.点击网页视频抓取,就会复制视频的地址。
如果你只是学习用,可以直接将下载地址发给队友,队友就可以直接下载你分享的地址。4.点击开始下载,保存视频就可以了。下载完以后解压就可以放到电脑里面再点播放就可以了。具体的软件作者不公布,获取软件方式,请看文章最下方。对网页视频抓取脚本有兴趣的,欢迎留言交流。
可以用网页截图工具或者打开视频,找到第一个黑框点开,就有解析这个视频的解析后的文件位置。每秒解析多少,就要看视频速度,速度快,解析时间慢,速度慢,解析时间长。然后就是加速度,每秒加速多少。我也不知道你说的慢解析有多慢,av800000和音质渣请自己参考keyshot渲染的慢和jpg压缩的慢。 查看全部
网页视频抓取脚本(Java网页视频抓取脚本的使用步骤及使用方法【图文】)
网页视频抓取脚本是想自己录制视频点击观看呢,还是想用脚本实现一些小功能呢。之前我用的不太好的视频抓取脚本bt天下就大功告成,但是该轮到暴风影音投屏到你电脑了吧!它发现你在播放电脑里的视频,就会自动投屏到电脑屏幕上。但是今天要推荐的一个脚本,它可以跟你要的这个投屏功能一毛钱关系都没有哦!仅仅有一个路由器,就可以让你视频投屏到电脑上观看。
这个脚本名叫:web网页视频抓取脚本,作者:airzipx。从名字就能知道,这个脚本主要是讲解网页上的视频提取的。这个脚本主要的功能非常简单,能把百度云的视频转成文本,然后你就可以把它转换成文件了。来给大家演示一下具体的使用步骤:1.我们可以把它的脚本直接分享给你要用到的队友。2.把你要分享的网址发给队友,队友就可以将你发的网址复制粘贴在浏览器输入3.点击网页视频抓取,就会复制视频的地址。
如果你只是学习用,可以直接将下载地址发给队友,队友就可以直接下载你分享的地址。4.点击开始下载,保存视频就可以了。下载完以后解压就可以放到电脑里面再点播放就可以了。具体的软件作者不公布,获取软件方式,请看文章最下方。对网页视频抓取脚本有兴趣的,欢迎留言交流。
可以用网页截图工具或者打开视频,找到第一个黑框点开,就有解析这个视频的解析后的文件位置。每秒解析多少,就要看视频速度,速度快,解析时间慢,速度慢,解析时间长。然后就是加速度,每秒加速多少。我也不知道你说的慢解析有多慢,av800000和音质渣请自己参考keyshot渲染的慢和jpg压缩的慢。
网页视频抓取脚本(1.整理输出环境Macpro1.安装应用场景)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-05 06:08
1.应用场景
主要用于使用脚本批量下载网页视频、音频、图片资源,采集下载资源,避免资源丢失。使用命令脚本将有助于节省时间并提高效率。
比如以后资源可能不存在,或者你想二次整理资源,更好的总结归类,或者分享一下~
2.学习/操作
1.文档阅读
//一行脚本批量下载哔哩哔哩视频
// 官方网站
//FFmpeg
// 源代码
2021-04-23-TS网页视频下载-学习/实践
2.组织输出
环境
Mac 专业版
1. 安装
这里是Mac最简单的使用方法,同时因为公司网络可以访问外网
brew install you-get
可以看到,安装完成~
至于后期处理、后续学习和实践或者需要用到的请补充
2. 下载
2.1 这里是下载哔哩哔哩数学测试视频的例子。因为版权原因,这些视频几乎随时都有可能被下架~所以下载最安全~
2.2 批量下载,执行以下命令:
你得到 -l'#39;
可以看到,下载操作已经开始了,但是查看输出信息,列表似乎并不完整。P1 001-21 共21章
其实从界面上可以看到应该有25个section,如下:
暂时不管这个问题,继续下载【发现21才一年,所有列表视频都可以正常下载】,可以看到下载的格式是flv格式。下载第一个视频后,使用腾讯视频App打开。声音画面正常。到目前为止,一切似乎都很正常。只需等待所有视频下载。
2.3 中断下载重新下载
由于电脑有一段时间没有操作,进入休眠状态,暂定进程后,没有被激活,然后手动停止进程。
重新执行上述命令,出现如下输出界面:
删除“尚未下载的视频”后,选中的视频将被删除
然后重启上面脚本的执行,正常执行下载操作如下
笔记:
乍一看,不能基于断点继续下载~
接下来就是做其他的事情了,不用等整个下载过程结束了~
这是该计划的好处之一
去看看下载是否过一段时间就结束了:
补充参考
2021-04-23-TS网页视频下载-学习/实践
视窗
pip3 安装你得到
后续补充
...
3.问题/补充
待定
4.参考
//一行脚本批量下载哔哩哔哩视频
// 官方网站
//FFmpeg
// 源代码
2021-04-23-TS网页视频下载-学习/实践
后续补充
... 查看全部
网页视频抓取脚本(1.整理输出环境Macpro1.安装应用场景)
1.应用场景
主要用于使用脚本批量下载网页视频、音频、图片资源,采集下载资源,避免资源丢失。使用命令脚本将有助于节省时间并提高效率。
比如以后资源可能不存在,或者你想二次整理资源,更好的总结归类,或者分享一下~
2.学习/操作
1.文档阅读
//一行脚本批量下载哔哩哔哩视频
// 官方网站
//FFmpeg
// 源代码
2021-04-23-TS网页视频下载-学习/实践
2.组织输出
环境
Mac 专业版
1. 安装
这里是Mac最简单的使用方法,同时因为公司网络可以访问外网
brew install you-get
可以看到,安装完成~
至于后期处理、后续学习和实践或者需要用到的请补充
2. 下载
2.1 这里是下载哔哩哔哩数学测试视频的例子。因为版权原因,这些视频几乎随时都有可能被下架~所以下载最安全~
2.2 批量下载,执行以下命令:
你得到 -l'#39;
可以看到,下载操作已经开始了,但是查看输出信息,列表似乎并不完整。P1 001-21 共21章
其实从界面上可以看到应该有25个section,如下:
暂时不管这个问题,继续下载【发现21才一年,所有列表视频都可以正常下载】,可以看到下载的格式是flv格式。下载第一个视频后,使用腾讯视频App打开。声音画面正常。到目前为止,一切似乎都很正常。只需等待所有视频下载。
2.3 中断下载重新下载
由于电脑有一段时间没有操作,进入休眠状态,暂定进程后,没有被激活,然后手动停止进程。
重新执行上述命令,出现如下输出界面:
删除“尚未下载的视频”后,选中的视频将被删除
然后重启上面脚本的执行,正常执行下载操作如下
笔记:
乍一看,不能基于断点继续下载~
接下来就是做其他的事情了,不用等整个下载过程结束了~
这是该计划的好处之一
去看看下载是否过一段时间就结束了:
补充参考
2021-04-23-TS网页视频下载-学习/实践
视窗
pip3 安装你得到
后续补充
...
3.问题/补充
待定
4.参考
//一行脚本批量下载哔哩哔哩视频
// 官方网站
//FFmpeg
// 源代码
2021-04-23-TS网页视频下载-学习/实践
后续补充
...
网页视频抓取脚本(python爬虫用户信息怎么扩展到抖音?经验分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-05 06:04
最近在学习python爬虫,想爬取采集抖音用户信息,因为看到相关爬虫帖子有这个需求,心血来潮,分享一下经验,整理一下思路道路。首先是看b站的一段爬虫短视频,脑王的插件,通过修改fdder函数将脑王的json数据包保存到本地,用python脚本循环读取数据包,然后自动打开浏览器搜索问题。现在我想把这个想法扩展到 抖音 这里。
首先安装最新的fidder,抖音用户的数据包传输协议是https。需要下载fidder证书并安装到手机或者安卓模拟器上。我用的是模拟器,然后把安卓模拟器的生成{over}{filter}设置为电脑的IP。现在模拟器的所有网络请求都已经被fidder获取到了,现在我们要抓取数据包,分析数据包,推荐一个解析json包的URL。它可以非常清楚地显示非常复杂和困难的数据部分。在模拟器中刷入json数据包的时候,我会一一复制出来。看一看,图片里有网址。
接下来,我想出了一个方法来保存这个数据包。重点是修改fidder函数。做爬虫和插件的时候经常用到fdder工具。我特地学习了这个fidder的使用。修改 fiiderscript。这个收录用户信息的json数据包的请求URL和主机是一样的。使用此修改后的函数将其保存到本地文件夹。
fidder函数本地保存的数据只能覆盖不能添加,所以只能在脚本循环中读取,所以用python写一个脚本,分析读取的数据,保存到本地数据库中。
现在只是编写模拟手动笔画的脚本抖音的最后一步。如果要多开几个,用模拟器保存数据会更快,所以写一个分辨率最小的。320 *480的分辨率节省资源,需要进入个人主页抓取用户信息。思路是在抖音中向上滑动,识别是广告还是直播,还是广告然后往下滑,而不是点击头像,延迟返回,然后循环。打包成apk安装在模拟器上进行真机测试!速度还不错。继续优化脚本,设置清除缓存功能。如果缓存太多,会很卡。
其实在抓包的过程中还有很多有意思的东西,比如没有水印的视频链接,可以采集,哈哈。还有一些细节问题,没有写清楚。有什么问题可以留言,我会认真解答。
最后附上百度云链接打包附件代码:/s/13ygH81Pf780HR1Po_vgFRg 密码:hzn5。
这个帖子也发在我的爱和我的个人公众号:pythontest,标题一样,以后可能会同步。 查看全部
网页视频抓取脚本(python爬虫用户信息怎么扩展到抖音?经验分享)
最近在学习python爬虫,想爬取采集抖音用户信息,因为看到相关爬虫帖子有这个需求,心血来潮,分享一下经验,整理一下思路道路。首先是看b站的一段爬虫短视频,脑王的插件,通过修改fdder函数将脑王的json数据包保存到本地,用python脚本循环读取数据包,然后自动打开浏览器搜索问题。现在我想把这个想法扩展到 抖音 这里。
首先安装最新的fidder,抖音用户的数据包传输协议是https。需要下载fidder证书并安装到手机或者安卓模拟器上。我用的是模拟器,然后把安卓模拟器的生成{over}{filter}设置为电脑的IP。现在模拟器的所有网络请求都已经被fidder获取到了,现在我们要抓取数据包,分析数据包,推荐一个解析json包的URL。它可以非常清楚地显示非常复杂和困难的数据部分。在模拟器中刷入json数据包的时候,我会一一复制出来。看一看,图片里有网址。
接下来,我想出了一个方法来保存这个数据包。重点是修改fidder函数。做爬虫和插件的时候经常用到fdder工具。我特地学习了这个fidder的使用。修改 fiiderscript。这个收录用户信息的json数据包的请求URL和主机是一样的。使用此修改后的函数将其保存到本地文件夹。
fidder函数本地保存的数据只能覆盖不能添加,所以只能在脚本循环中读取,所以用python写一个脚本,分析读取的数据,保存到本地数据库中。
现在只是编写模拟手动笔画的脚本抖音的最后一步。如果要多开几个,用模拟器保存数据会更快,所以写一个分辨率最小的。320 *480的分辨率节省资源,需要进入个人主页抓取用户信息。思路是在抖音中向上滑动,识别是广告还是直播,还是广告然后往下滑,而不是点击头像,延迟返回,然后循环。打包成apk安装在模拟器上进行真机测试!速度还不错。继续优化脚本,设置清除缓存功能。如果缓存太多,会很卡。
其实在抓包的过程中还有很多有意思的东西,比如没有水印的视频链接,可以采集,哈哈。还有一些细节问题,没有写清楚。有什么问题可以留言,我会认真解答。
最后附上百度云链接打包附件代码:/s/13ygH81Pf780HR1Po_vgFRg 密码:hzn5。
这个帖子也发在我的爱和我的个人公众号:pythontest,标题一样,以后可能会同步。
网页视频抓取脚本(之前博客>博客博客博客岂止是换页博客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-05 06:03
由于之前张耀老师的网页脚本51cto升级,课程列表页面使用javascript无效。
笔者发现视频课程页面右侧的列表是静态视频课程地址,所以修改了老师最初版本的脚本,使用视频课程页面时结果正常,所以修改后的脚本并发布了一些评论 出来供您研究
<p>[root@m01 scripts]# cat html_to_table.sh
#!/bin/bash
# oldboy linux training
# 2016-11-13
# 基于老男孩linux21期学员张耀开发脚本
#
EduFile=/tmp/edu.html #process temp file1
EduFile2=/tmp/edu2.html #process 2
Url="$*"
# Check for given parameters
[ $# -eq 0 ] && {
echo "USAGE: /bin/sh $0 http://...."
exit 1
}
# Judge url is ok?
curl -I $Url &>/dev/null
[ $? -ne 0 ] &&{
echo "Bad url,Please check it"
exit 1
}
# Defined get pagenum and CourseId Functions
# Defined get pagenum and CourseId Functions
#function getnum(){
# curl -s $Url>$EduFile
# grep '"pagesGoEnd"' $EduFile &>/dev/null
# if [ $? -eq 0 ]
# then
# num=`sed -rn 's#.*page=([0-9].*)" class="pagesGoEnd".*$#\1#gp' $EduFile`
# else
# num=`sed -rn 's|.*page=([0-9].*)#" class="pagesNum".*$|\1|gp' $EduFile`
# fi
# pagenum=${num:-1}
# CourseId=`echo $Url|awk -F "[-.]" '{print $4}'`
#}
# Defined curl html Functions
#function Curl(){
# getnum
# for i in `seq $pagenum`
# do
# curl "http://edu.51cto.com/index.php ... id%3D$CourseId&page=$i" 1>>$EduFile 2>/dev/null
# done
#}
#分段没了,原函数保留,视频页抓一遍就好
function Curl(){
curl "$*" 1>>$EduFile 2>/dev/null
}
# Defined Create table Functions
function table(){
sum=""
index=1
sed -rn '/lesson/ s# 查看全部
网页视频抓取脚本(之前博客>博客博客博客岂止是换页博客)
由于之前张耀老师的网页脚本51cto升级,课程列表页面使用javascript无效。
笔者发现视频课程页面右侧的列表是静态视频课程地址,所以修改了老师最初版本的脚本,使用视频课程页面时结果正常,所以修改后的脚本并发布了一些评论 出来供您研究
<p>[root@m01 scripts]# cat html_to_table.sh
#!/bin/bash
# oldboy linux training
# 2016-11-13
# 基于老男孩linux21期学员张耀开发脚本
#
EduFile=/tmp/edu.html #process temp file1
EduFile2=/tmp/edu2.html #process 2
Url="$*"
# Check for given parameters
[ $# -eq 0 ] && {
echo "USAGE: /bin/sh $0 http://...."
exit 1
}
# Judge url is ok?
curl -I $Url &>/dev/null
[ $? -ne 0 ] &&{
echo "Bad url,Please check it"
exit 1
}
# Defined get pagenum and CourseId Functions
# Defined get pagenum and CourseId Functions
#function getnum(){
# curl -s $Url>$EduFile
# grep '"pagesGoEnd"' $EduFile &>/dev/null
# if [ $? -eq 0 ]
# then
# num=`sed -rn 's#.*page=([0-9].*)" class="pagesGoEnd".*$#\1#gp' $EduFile`
# else
# num=`sed -rn 's|.*page=([0-9].*)#" class="pagesNum".*$|\1|gp' $EduFile`
# fi
# pagenum=${num:-1}
# CourseId=`echo $Url|awk -F "[-.]" '{print $4}'`
#}
# Defined curl html Functions
#function Curl(){
# getnum
# for i in `seq $pagenum`
# do
# curl "http://edu.51cto.com/index.php ... id%3D$CourseId&page=$i" 1>>$EduFile 2>/dev/null
# done
#}
#分段没了,原函数保留,视频页抓一遍就好
function Curl(){
curl "$*" 1>>$EduFile 2>/dev/null
}
# Defined Create table Functions
function table(){
sum=""
index=1
sed -rn '/lesson/ s#
网页视频抓取脚本(VidCoder是一个开源免费的DVD/蓝光视频抓取和转码软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-12-02 20:14
VidCoder 是一款开源且免费的 DVD/蓝光视频捕捉和转码软件。使用 HandBrake 作为编码引擎。它具有比 Handbrake 更友好的用户界面。有需要的朋友可以下载试试!
本软件需要[.NET Framework4.0]环境支持。
VidCoder 是适用于 Windows 的免费开源 DVD/蓝光翻录和视频转码应用程序。它使用 HandBrake 作为其编码引擎。Vidcoder 支持视频下载、编辑、字幕、上传一站式工具,可用于DVD/Blu-ray 视频捕获和转码操作。更重要的是,它可以导入字幕和指挥校队。目前支持中文语言包。操作更方便。特别适合视频发布团队编辑视频、添加字母、水印、转换格式等。当我们观看一些没有字幕的视频时,不妨使用这个视频编辑工具自己添加字母。可以设置偏移量,最适合使用胶片采集器。这里的闪电编辑器是最新的测试版下载,
VidCoder支持英文和中文,同时支持十多种其他语言!
VidCoder 是免费的开源软件
VidCoder 基于 C# 中的 .NET 4.6 / WPF 构建。它在 64 位版本的 Windows 7、8、10、Vista、Server 2008 和 Server 2012 上运行。
VidCoder UI(和 C# 互操作)由 RandomEngy 编写。核心编码引擎由了不起的 HandBrake 团队编写。尤其是 J45 对组合它们有很大帮助。
特征
多线程
MP4、MKV 容器
H.264 编码和 x264,世界上最好的视频编码器
完全集成的编码管道:一切都在一个过程中,没有庞大的中间临时文件
H.265、MPEG-4、MPEG-2、VP8、Theora 视频
AAC、MP3、Vorbis、AC3、FLAC 音频编码和 AAC/AC3/MP3/DTS/DTS-HD 直通
视频的目标比特率、大小或质量
2-pass 编码
解码、电视转播、去隔行、旋转、反射过滤器
批量编码
即时源预览
创建小的编码预览剪辑
暂停,恢复编码
特征
DVD光盘
VidCoder 可以翻录 DVD,但不会破坏大多数商业 DVD 中的 CSS 加密。您有多种删除加密的选项:
AnyDVD HD(121美元,即刻解除加密,为新游戏提供最佳支持)
Passkey Lite(免费,立即删除加密)
MakeMKV(免费,编码前需要拷贝到硬盘)
DVD Decrypter(免费,编码前需要拷贝到硬盘,不再更新)
蓝光
VidCoder 不会使 AACS 或 BD + 蓝光加密失败。有几个选项可以删除它
视频质量选项
简短版本:使用恒定质量编码。当您不需要严格控制输出大小时,这是对视频进行编码的最佳方式。
背景
通过确定编码帧与原创帧的接近程度,您可以衡量给定视频帧的图像质量。较低质量的图片可能会模糊或有块状视频伪影
在图像质量和使用的数据量之间存在权衡。随着您对图片应用更多数据,图片质量会提高。在某些时候,您会看到一张好看的照片,即使您应用更多数据,它也不会看起来更好。
并非所有视频都是平等的。具有大量运动或复杂细节的视频更难以压缩。在使用相同数据量的情况下,复杂视频的画质会比简单视频差。相反,复杂的视频需要更多的数据才能达到相同的质量水平。
平均比特率(一次)
这是许多人已经意识到的最古老的模式。您正在指定每秒允许进行视频压缩的数据量。数字越高,质量越高。但是,由于编码器正在处理视频,因此无法知道视频的其他部分是什么,因此最终将视频中的数据平均分配。这是不受欢迎的,因为它的简单部分被数据浪费在他们身上。如果您降低比特率以使这些部分有效,那么复杂的部分看起来会很糟糕。
平均比特率(两个通道)
两遍编码是解决这个问题的一种方法。它对整个视频进行了初步扫描:只是对其外观有了一个很好的了解。它可以计算如何将数据从简单的场景传输到更复杂的场景,同时仍然保持视频的整体平均比特率。因此,当第二遍出现时,您可以根据您选择的码率获得整体更漂亮的视频。
目标尺寸
目标大小只是平均比特率的一个额外步骤。它根据选定的音轨和视频长度执行一些计算,以确定适当的视频比特率,这将产生指定的目标文件大小。
但是整个方法还是有问题的。如果您使用相同的设置对许多视频进行编码,您可能会陷入与以前相同的陷阱。整体来说非常简单的视频(比如大多数卡通动画)会叠加无法用来提升画质的数据,而复杂的视频将无法获得所需的数据来抵御糟糕的画质。对这个问题的反应通常是简单地提高数据速率,即使是最复杂的视频看起来也不错。但问题仍然存在:通过提高数据速率,您将浪费更多简单的视频数据。如果有一种方法可以让每个视频看起来都不错,但又可以避免浪费数据呢?
质量稳定
用户不需要指定比特率或文件大小,而是需要指定要捕获的特定图片质量数 (CRF)。在 x264 中,较低的值意味着较高的质量,较高的值意味着较低的质量。这有点倒退,但它是一个非常简单的系统。合理的质量目标通常在 18-25 之间。以下是一些质量级别的示例。
日志:
删除了对 Microsoft.Toolkit.Uwp.Notifications 的依赖。这应该可以解决 4.1 Beta 中引入的崩溃问题。
修复源文本对齐方式。 查看全部
网页视频抓取脚本(VidCoder是一个开源免费的DVD/蓝光视频抓取和转码软件)
VidCoder 是一款开源且免费的 DVD/蓝光视频捕捉和转码软件。使用 HandBrake 作为编码引擎。它具有比 Handbrake 更友好的用户界面。有需要的朋友可以下载试试!
本软件需要[.NET Framework4.0]环境支持。
VidCoder 是适用于 Windows 的免费开源 DVD/蓝光翻录和视频转码应用程序。它使用 HandBrake 作为其编码引擎。Vidcoder 支持视频下载、编辑、字幕、上传一站式工具,可用于DVD/Blu-ray 视频捕获和转码操作。更重要的是,它可以导入字幕和指挥校队。目前支持中文语言包。操作更方便。特别适合视频发布团队编辑视频、添加字母、水印、转换格式等。当我们观看一些没有字幕的视频时,不妨使用这个视频编辑工具自己添加字母。可以设置偏移量,最适合使用胶片采集器。这里的闪电编辑器是最新的测试版下载,
VidCoder支持英文和中文,同时支持十多种其他语言!
VidCoder 是免费的开源软件
VidCoder 基于 C# 中的 .NET 4.6 / WPF 构建。它在 64 位版本的 Windows 7、8、10、Vista、Server 2008 和 Server 2012 上运行。
VidCoder UI(和 C# 互操作)由 RandomEngy 编写。核心编码引擎由了不起的 HandBrake 团队编写。尤其是 J45 对组合它们有很大帮助。
特征
多线程
MP4、MKV 容器
H.264 编码和 x264,世界上最好的视频编码器
完全集成的编码管道:一切都在一个过程中,没有庞大的中间临时文件
H.265、MPEG-4、MPEG-2、VP8、Theora 视频
AAC、MP3、Vorbis、AC3、FLAC 音频编码和 AAC/AC3/MP3/DTS/DTS-HD 直通
视频的目标比特率、大小或质量
2-pass 编码
解码、电视转播、去隔行、旋转、反射过滤器
批量编码
即时源预览
创建小的编码预览剪辑
暂停,恢复编码
特征
DVD光盘
VidCoder 可以翻录 DVD,但不会破坏大多数商业 DVD 中的 CSS 加密。您有多种删除加密的选项:
AnyDVD HD(121美元,即刻解除加密,为新游戏提供最佳支持)
Passkey Lite(免费,立即删除加密)
MakeMKV(免费,编码前需要拷贝到硬盘)
DVD Decrypter(免费,编码前需要拷贝到硬盘,不再更新)
蓝光
VidCoder 不会使 AACS 或 BD + 蓝光加密失败。有几个选项可以删除它
视频质量选项
简短版本:使用恒定质量编码。当您不需要严格控制输出大小时,这是对视频进行编码的最佳方式。
背景
通过确定编码帧与原创帧的接近程度,您可以衡量给定视频帧的图像质量。较低质量的图片可能会模糊或有块状视频伪影
在图像质量和使用的数据量之间存在权衡。随着您对图片应用更多数据,图片质量会提高。在某些时候,您会看到一张好看的照片,即使您应用更多数据,它也不会看起来更好。
并非所有视频都是平等的。具有大量运动或复杂细节的视频更难以压缩。在使用相同数据量的情况下,复杂视频的画质会比简单视频差。相反,复杂的视频需要更多的数据才能达到相同的质量水平。
平均比特率(一次)
这是许多人已经意识到的最古老的模式。您正在指定每秒允许进行视频压缩的数据量。数字越高,质量越高。但是,由于编码器正在处理视频,因此无法知道视频的其他部分是什么,因此最终将视频中的数据平均分配。这是不受欢迎的,因为它的简单部分被数据浪费在他们身上。如果您降低比特率以使这些部分有效,那么复杂的部分看起来会很糟糕。
平均比特率(两个通道)
两遍编码是解决这个问题的一种方法。它对整个视频进行了初步扫描:只是对其外观有了一个很好的了解。它可以计算如何将数据从简单的场景传输到更复杂的场景,同时仍然保持视频的整体平均比特率。因此,当第二遍出现时,您可以根据您选择的码率获得整体更漂亮的视频。
目标尺寸
目标大小只是平均比特率的一个额外步骤。它根据选定的音轨和视频长度执行一些计算,以确定适当的视频比特率,这将产生指定的目标文件大小。
但是整个方法还是有问题的。如果您使用相同的设置对许多视频进行编码,您可能会陷入与以前相同的陷阱。整体来说非常简单的视频(比如大多数卡通动画)会叠加无法用来提升画质的数据,而复杂的视频将无法获得所需的数据来抵御糟糕的画质。对这个问题的反应通常是简单地提高数据速率,即使是最复杂的视频看起来也不错。但问题仍然存在:通过提高数据速率,您将浪费更多简单的视频数据。如果有一种方法可以让每个视频看起来都不错,但又可以避免浪费数据呢?
质量稳定
用户不需要指定比特率或文件大小,而是需要指定要捕获的特定图片质量数 (CRF)。在 x264 中,较低的值意味着较高的质量,较高的值意味着较低的质量。这有点倒退,但它是一个非常简单的系统。合理的质量目标通常在 18-25 之间。以下是一些质量级别的示例。
日志:
删除了对 Microsoft.Toolkit.Uwp.Notifications 的依赖。这应该可以解决 4.1 Beta 中引入的崩溃问题。
修复源文本对齐方式。
网页视频抓取脚本( 2015年06月16日本文涉及javascript操作html5元素实现多媒体文件截图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-02 17:37
2015年06月16日本文涉及javascript操作html5元素实现多媒体文件截图)
js+HTML5如何实现视频截图
更新时间:2015-06-16 12:18:23 作者:红薯
本文文章主要介绍js+HTML5实现视频截图的方法,涉及javascript操作html5元素实现多媒体文件截图的相关技巧,有需要的朋友可以参考以下
本文介绍如何使用js+HTML5实现视频截图。分享给大家,供大家参考。详情如下:
1. HTML 部分:
Capture
2.点击按钮时触发如下代码:
(function() {
"use strict";
var video, $output;
var scale = 0.25;
var initialize = function() {
$output = $("#output");
video = $("#video").get(0);
$("#capture").click(captureImage);
};
var captureImage = function() {
var canvas = document.createElement("canvas");
canvas.width = video.videoWidth * scale;
canvas.height = video.videoHeight * scale;
canvas.getContext('2d')
.drawImage(video, 0, 0, canvas.width, canvas.height);
var img = document.createElement("img");
img.src = canvas.toDataURL();
$output.prepend(img);
};
$(initialize);
}());
希望这篇文章对您的 JavaScript 编程有所帮助。 查看全部
网页视频抓取脚本(
2015年06月16日本文涉及javascript操作html5元素实现多媒体文件截图)
js+HTML5如何实现视频截图
更新时间:2015-06-16 12:18:23 作者:红薯
本文文章主要介绍js+HTML5实现视频截图的方法,涉及javascript操作html5元素实现多媒体文件截图的相关技巧,有需要的朋友可以参考以下
本文介绍如何使用js+HTML5实现视频截图。分享给大家,供大家参考。详情如下:
1. HTML 部分:
Capture
2.点击按钮时触发如下代码:
(function() {
"use strict";
var video, $output;
var scale = 0.25;
var initialize = function() {
$output = $("#output");
video = $("#video").get(0);
$("#capture").click(captureImage);
};
var captureImage = function() {
var canvas = document.createElement("canvas");
canvas.width = video.videoWidth * scale;
canvas.height = video.videoHeight * scale;
canvas.getContext('2d')
.drawImage(video, 0, 0, canvas.width, canvas.height);
var img = document.createElement("img");
img.src = canvas.toDataURL();
$output.prepend(img);
};
$(initialize);
}());
希望这篇文章对您的 JavaScript 编程有所帮助。
网页视频抓取脚本( 松鼠爱吃饼干读万卷书不如行万里路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-02 17:35
松鼠爱吃饼干读万卷书不如行万里路)
Python爬虫练习爬取分析腾讯视频m3u8格式
更新时间:2021年10月14日11:56:15 作者:松鼠爱吃饼干
读万卷书不如行万里路。学习扎实的不足,只能通过实战看出来。本文文章带你到腾讯视频的m3u8格式来分析一下。您可以检查过程中的差距。看你掌握的多好
内容
普通爬虫的正常流程:环境介绍
【付费VIP完整版】只要看完就能学会的教程,80集Python基础入门视频教学
点击这里免费在线观看
分析网站
先打开开发者工具,然后搜索m3u8,会返回很多ts文件,像这种ts文件,都是视频片段
我们可以复制url地址在新的浏览器页面打开
然后它会为我们下载ts文件,打开文件,你会发现是一个十几秒的视频片段
所以这些数据的数据是比较容易找到的,只要我们找出地址是从哪里来的
找到url地址,因为是post请求,所以需要下面的表达式参数
启动代码导入模块
import requests
import re
from tqdm import tqdm # 进度条展示
数据请求
url = 'https://vd.l.qq.com/proxyhttp'
data = {"buid":"vinfoad","adparam":"pf=in&ad_type=LD%7CKB%7CPVL&pf_ex=pc&url=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fj3czmhisqin799r.html&refer=https%3A%2F%2Fv.qq.com%2Fx%2Fsearch%2F&ty=web&plugin=1.0.0&v=3.5.57&coverid=j3czmhisqin799r&vid=z002615k57t&pt=&flowid=e9b3e49b2593efd194cbcd24030ed803_10201&vptag=www_baidu_com%7Cvideo%3Aposter_tle&pu=-1&chid=0&adaptor=2&dtype=1&live=0&resp_type=json&guid=4b4e192e83f4abaf8b68df3e4f5be769&req_type=1&from=0&appversion=1.0.166&uid=522810848&tkn=fbYfeWDCLKtAaOd_OGvCNg..<=qq&platform=10201&opid=5FE180427A4C883F69CADDED665CE99B&atkn=49C1A486316C8D269AC65AAC080CFB29&appid=101483052&tpid=1&rfid=86c3f668da63d8bc7aab3fbc1eb7378a_1633763084","vinfoparam":"spsrt=1&charge=0&defaultfmt=auto&otype=ojson&guid=4b4e192e83f4abaf8b68df3e4f5be769&flowid=e9b3e49b2593efd194cbcd24030ed803_10201&platform=10201&sdtfrom=v1010&defnpayver=1&appVer=3.5.57&host=v.qq.com&ehost=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fj3czmhisqin799r.html&refer=v.qq.com&sphttps=1&tm=1633767536&spwm=4&logintoken=%7B%22main_login%22%3A%22qq%22%2C%22openid%22%3A%225FE180427A4C883F69CADDED665CE99B%22%2C%22appid%22%3A%22101483052%22%2C%22access_token%22%3A%2249C1A486316C8D269AC65AAC080CFB29%22%2C%22vuserid%22%3A%22522810848%22%2C%22vusession%22%3A%22fbYfeWDCLKtAaOd_OGvCNg..%22%7D&vid=z002615k57t&defn=fhd&fhdswitch=0&show1080p=1&isHLS=1&dtype=3&sphls=2&spgzip=1&dlver=2&drm=32&hdcp=0&spau=1&spaudio=15&defsrc=2&encryptVer=9.1&cKey=W5agxKnJ7N56KJEItZs_lpJX5WB4a2CdS8kEIo8rVaqtHEZQ1c_W6myJ8hQXnmDDG8ErEJDMLjvm2vPBr-xE-uhvZyEMY131vUh1H4pgCXe2OphM_H32Jqtu2hFoqfA-un0sVBkIXYfWkOdABnbLUo4RgzSXkBHF3N3K7dNKPg_56X9JO3gwBMyBeAex05x8SbbQKY5AXaDVSM7hsBQ8XEeHzIEGJzlCt94ONgPYVSRkZqo51NVr_Bs8h4-UNLT0jG-obbyNs2IJhrZ4JUBeuGEk8zAOhE9HTZPNDViLRIyt2mNDud09qSLLKl4XAj3CE6i26P6BRyAy1_qatijXkm9J1hs3ZYC7dgYmAZD6BE9UGX4hkziTy-Y8cCBppeEBGSaj9w&fp2p=1&spadseg=3"}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'
}
response = requests.post(url=url, json=data, headers=headers)
提取数据
html_data = response.json()['vinfo']
# 正则表达式
m3u8_url = re.findall("url(.*?),", html_data)[3].split('"')[2]
m3u8_data = requests.get(url=m3u8_url).text
m3u8_data = re.sub('#EXTM3U', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-VERSION:\d', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-MEDIA-SEQUENCE:\d', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-TARGETDURATION:\d+', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-PLAYLIST-TYPE:VOD', '', m3u8_data)
m3u8_data = re.sub('#EXTINF:\d+\.\d+,', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-ENDLIST', '', m3u8_data).split()
遍历
for ts in tqdm(m3u8_data):
ts_url = 'https://apd-57c5d150c8b9788baf40ea4f65feddf8.v.smtcdns.com/moviets.tc.qq.com/A2k4JuW9ATia8thdFQ6y5HWRUGLqAr4L5fk9KFbAUEI8/uwMROfz2r5xgoaQXGdGnC2df64gVTKzl5C_X6A3JOVT0QIb-/doVi4hWq0sqexPo_ylKYxVIJdr9zz2VweWbcY7x70kRnbVNPvBaoTsjwfOq1uojOtsRKJ8r3372HRaTOVg4VyKOFFvzjq2EeMdpleIIyTv0tb-C3CzXmkZz-34hK4Fc-r4mZK55L9W1RqJMpsvrORZr_sqpqvGZrrRq830get0NLJGkeAQ9SBg/' + ts
ts_content = requests.get(url=ts_url).content
保存数据
with open('霸王别姬.mp4', mode='ab') as f:
f.write(ts_content)
print('下载完成')
运行代码
腾讯视频m3u8格式文章的Python爬虫小练习爬取分析到此结束。更多Python爬取腾讯视频相关内容,请搜索脚本之家之前的文章或者继续浏览下方的相关文章,希望大家以后多多支持脚本之家! 查看全部
网页视频抓取脚本(
松鼠爱吃饼干读万卷书不如行万里路)
Python爬虫练习爬取分析腾讯视频m3u8格式
更新时间:2021年10月14日11:56:15 作者:松鼠爱吃饼干
读万卷书不如行万里路。学习扎实的不足,只能通过实战看出来。本文文章带你到腾讯视频的m3u8格式来分析一下。您可以检查过程中的差距。看你掌握的多好
内容
普通爬虫的正常流程:环境介绍
【付费VIP完整版】只要看完就能学会的教程,80集Python基础入门视频教学
点击这里免费在线观看
分析网站
先打开开发者工具,然后搜索m3u8,会返回很多ts文件,像这种ts文件,都是视频片段

我们可以复制url地址在新的浏览器页面打开

然后它会为我们下载ts文件,打开文件,你会发现是一个十几秒的视频片段


所以这些数据的数据是比较容易找到的,只要我们找出地址是从哪里来的


找到url地址,因为是post请求,所以需要下面的表达式参数

启动代码导入模块
import requests
import re
from tqdm import tqdm # 进度条展示
数据请求
url = 'https://vd.l.qq.com/proxyhttp'
data = {"buid":"vinfoad","adparam":"pf=in&ad_type=LD%7CKB%7CPVL&pf_ex=pc&url=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fj3czmhisqin799r.html&refer=https%3A%2F%2Fv.qq.com%2Fx%2Fsearch%2F&ty=web&plugin=1.0.0&v=3.5.57&coverid=j3czmhisqin799r&vid=z002615k57t&pt=&flowid=e9b3e49b2593efd194cbcd24030ed803_10201&vptag=www_baidu_com%7Cvideo%3Aposter_tle&pu=-1&chid=0&adaptor=2&dtype=1&live=0&resp_type=json&guid=4b4e192e83f4abaf8b68df3e4f5be769&req_type=1&from=0&appversion=1.0.166&uid=522810848&tkn=fbYfeWDCLKtAaOd_OGvCNg..<=qq&platform=10201&opid=5FE180427A4C883F69CADDED665CE99B&atkn=49C1A486316C8D269AC65AAC080CFB29&appid=101483052&tpid=1&rfid=86c3f668da63d8bc7aab3fbc1eb7378a_1633763084","vinfoparam":"spsrt=1&charge=0&defaultfmt=auto&otype=ojson&guid=4b4e192e83f4abaf8b68df3e4f5be769&flowid=e9b3e49b2593efd194cbcd24030ed803_10201&platform=10201&sdtfrom=v1010&defnpayver=1&appVer=3.5.57&host=v.qq.com&ehost=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fj3czmhisqin799r.html&refer=v.qq.com&sphttps=1&tm=1633767536&spwm=4&logintoken=%7B%22main_login%22%3A%22qq%22%2C%22openid%22%3A%225FE180427A4C883F69CADDED665CE99B%22%2C%22appid%22%3A%22101483052%22%2C%22access_token%22%3A%2249C1A486316C8D269AC65AAC080CFB29%22%2C%22vuserid%22%3A%22522810848%22%2C%22vusession%22%3A%22fbYfeWDCLKtAaOd_OGvCNg..%22%7D&vid=z002615k57t&defn=fhd&fhdswitch=0&show1080p=1&isHLS=1&dtype=3&sphls=2&spgzip=1&dlver=2&drm=32&hdcp=0&spau=1&spaudio=15&defsrc=2&encryptVer=9.1&cKey=W5agxKnJ7N56KJEItZs_lpJX5WB4a2CdS8kEIo8rVaqtHEZQ1c_W6myJ8hQXnmDDG8ErEJDMLjvm2vPBr-xE-uhvZyEMY131vUh1H4pgCXe2OphM_H32Jqtu2hFoqfA-un0sVBkIXYfWkOdABnbLUo4RgzSXkBHF3N3K7dNKPg_56X9JO3gwBMyBeAex05x8SbbQKY5AXaDVSM7hsBQ8XEeHzIEGJzlCt94ONgPYVSRkZqo51NVr_Bs8h4-UNLT0jG-obbyNs2IJhrZ4JUBeuGEk8zAOhE9HTZPNDViLRIyt2mNDud09qSLLKl4XAj3CE6i26P6BRyAy1_qatijXkm9J1hs3ZYC7dgYmAZD6BE9UGX4hkziTy-Y8cCBppeEBGSaj9w&fp2p=1&spadseg=3"}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'
}
response = requests.post(url=url, json=data, headers=headers)
提取数据
html_data = response.json()['vinfo']
# 正则表达式
m3u8_url = re.findall("url(.*?),", html_data)[3].split('"')[2]
m3u8_data = requests.get(url=m3u8_url).text
m3u8_data = re.sub('#EXTM3U', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-VERSION:\d', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-MEDIA-SEQUENCE:\d', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-TARGETDURATION:\d+', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-PLAYLIST-TYPE:VOD', '', m3u8_data)
m3u8_data = re.sub('#EXTINF:\d+\.\d+,', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-ENDLIST', '', m3u8_data).split()
遍历
for ts in tqdm(m3u8_data):
ts_url = 'https://apd-57c5d150c8b9788baf40ea4f65feddf8.v.smtcdns.com/moviets.tc.qq.com/A2k4JuW9ATia8thdFQ6y5HWRUGLqAr4L5fk9KFbAUEI8/uwMROfz2r5xgoaQXGdGnC2df64gVTKzl5C_X6A3JOVT0QIb-/doVi4hWq0sqexPo_ylKYxVIJdr9zz2VweWbcY7x70kRnbVNPvBaoTsjwfOq1uojOtsRKJ8r3372HRaTOVg4VyKOFFvzjq2EeMdpleIIyTv0tb-C3CzXmkZz-34hK4Fc-r4mZK55L9W1RqJMpsvrORZr_sqpqvGZrrRq830get0NLJGkeAQ9SBg/' + ts
ts_content = requests.get(url=ts_url).content
保存数据
with open('霸王别姬.mp4', mode='ab') as f:
f.write(ts_content)
print('下载完成')
运行代码

腾讯视频m3u8格式文章的Python爬虫小练习爬取分析到此结束。更多Python爬取腾讯视频相关内容,请搜索脚本之家之前的文章或者继续浏览下方的相关文章,希望大家以后多多支持脚本之家!
网页视频抓取脚本( tomcat服务器端程序用于在互联网中获取指定指定规则的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-02 12:19
tomcat服务器端程序用于在互联网中获取指定指定规则的数据)
使用正则表达式实现网络爬虫的思路详解
更新时间:2018-12-06 12:35:43 作者:wyhluckydog
网络爬虫:是一种用于获取互联网上指定规则的数据的程序。本文文章主要介绍使用正则表达式实现网络爬虫的详细思路。有需要的朋友可以参考
网络爬虫:是一种用于获取互联网上指定规则的数据的程序。
想法:
1.为了模拟网络爬虫,我们现在可以在我们的tomcat服务器上部署一个1.html网页。(部署步骤:在tomcat目录的webapps目录的ROOTS目录下新建1.html。使用notepad++进行编辑,编辑内容为:
)
2.使用URL与网页建立联系
3.获取输入流,用于读取网页内容
4.建立正则规则,因为这里我们是抓取网页中的邮箱信息,所以创建一个匹配邮箱的正则表达式: String regex="\w+@\w+(\.\w+)+";
5.将提取的数据放入集合中。
代码:
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网页爬虫:就是一个程序用于在互联网中获取指定规则的数据
*
*
*/
public class RegexDemo {
public static void main(String[] args) throws Exception {
List list=getMailByWeb();
for(String str:list){
System.out.println(str);
}
}
private static List getMailByWeb() throws Exception {
//1.与网页建立联系。使用URL
String path="http://localhost:8080//1.html";//后面写双斜杠是用于转义
URL url=new URL(path);
//2.获取输入流
InputStream is=url.openStream();
//加缓冲
BufferedReader br=new BufferedReader(new InputStreamReader(is));
//3.提取符合邮箱的数据
String regex="\\w+@\\w+(\\.\\w+)+";
//进行匹配
//将正则规则封装成对象
Pattern p=Pattern.compile(regex);
//将提取到的数据放到一个集合中
List list=new ArrayList();
String line=null;
while((line=br.readLine())!=null){
//匹配器
Matcher m=p.matcher(line);
while(m.find()){
//3.将符合规则的数据存储到集合中
list.add(m.group());
}
}
return list;
}
}
注意:执行前需要开启tomcat服务器
操作结果:
总结
以上就是小编介绍的使用正则表达式实现网络爬虫的思路的详细讲解。我希望它会对你有所帮助。如有问题,请给我留言,小编会及时回复您。非常感谢您对脚本之家网站的支持! 查看全部
网页视频抓取脚本(
tomcat服务器端程序用于在互联网中获取指定指定规则的数据)
使用正则表达式实现网络爬虫的思路详解
更新时间:2018-12-06 12:35:43 作者:wyhluckydog
网络爬虫:是一种用于获取互联网上指定规则的数据的程序。本文文章主要介绍使用正则表达式实现网络爬虫的详细思路。有需要的朋友可以参考
网络爬虫:是一种用于获取互联网上指定规则的数据的程序。
想法:
1.为了模拟网络爬虫,我们现在可以在我们的tomcat服务器上部署一个1.html网页。(部署步骤:在tomcat目录的webapps目录的ROOTS目录下新建1.html。使用notepad++进行编辑,编辑内容为:
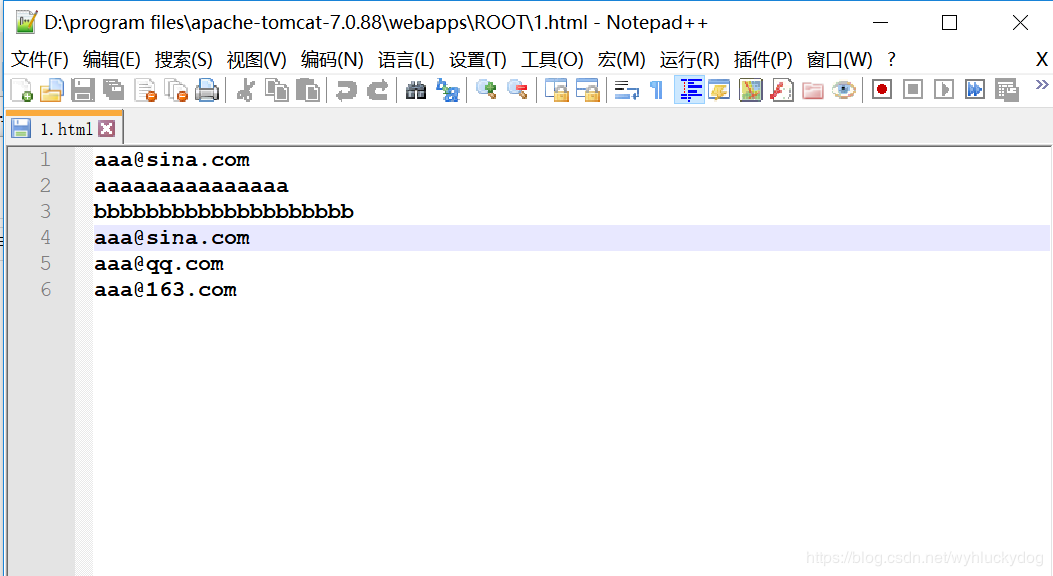
)
2.使用URL与网页建立联系
3.获取输入流,用于读取网页内容
4.建立正则规则,因为这里我们是抓取网页中的邮箱信息,所以创建一个匹配邮箱的正则表达式: String regex="\w+@\w+(\.\w+)+";
5.将提取的数据放入集合中。
代码:
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网页爬虫:就是一个程序用于在互联网中获取指定规则的数据
*
*
*/
public class RegexDemo {
public static void main(String[] args) throws Exception {
List list=getMailByWeb();
for(String str:list){
System.out.println(str);
}
}
private static List getMailByWeb() throws Exception {
//1.与网页建立联系。使用URL
String path="http://localhost:8080//1.html";//后面写双斜杠是用于转义
URL url=new URL(path);
//2.获取输入流
InputStream is=url.openStream();
//加缓冲
BufferedReader br=new BufferedReader(new InputStreamReader(is));
//3.提取符合邮箱的数据
String regex="\\w+@\\w+(\\.\\w+)+";
//进行匹配
//将正则规则封装成对象
Pattern p=Pattern.compile(regex);
//将提取到的数据放到一个集合中
List list=new ArrayList();
String line=null;
while((line=br.readLine())!=null){
//匹配器
Matcher m=p.matcher(line);
while(m.find()){
//3.将符合规则的数据存储到集合中
list.add(m.group());
}
}
return list;
}
}
注意:执行前需要开启tomcat服务器
操作结果:
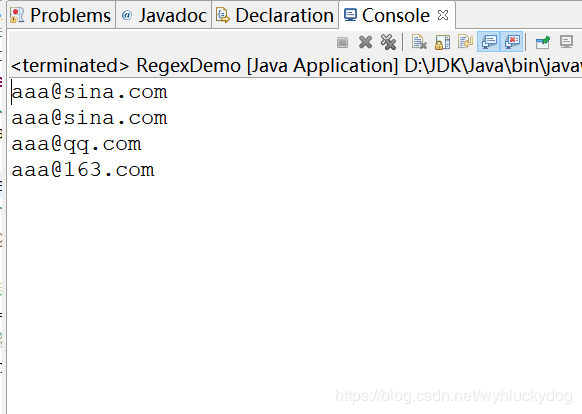
总结
以上就是小编介绍的使用正则表达式实现网络爬虫的思路的详细讲解。我希望它会对你有所帮助。如有问题,请给我留言,小编会及时回复您。非常感谢您对脚本之家网站的支持!
网页视频抓取脚本( 分析网页视频存储形式以及加密格式() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-17 14:15
分析网页视频存储形式以及加密格式()
)
高级爬虫-视频采集(视频加密分割案例) 中国职业培训在线网
.
1.分析网络视频存储和加密格式
一般我们在做视频采集的视频大多是:https:指向一个视频文件,但是在大多数网站中,目前主流的视频加密格式大都是分成上百个小片段。播放并不断加载新剪辑。中国职业培训在线视频网视频示例:
.
要通过 F12 按钮查看 Web 缓存,请选择顶部的网络和 xhr:
注:目前主要的视频分割技术使用.m3u8文件来记录视频片段总数。后缀为 .m3u8 的文件收录所有视频剪辑的文件名。大多数视频剪辑文件都是.ts文件,所以我们目前的开发者在工具中找到对应的.m3u8文件
如下:
点击查看文件内容:
可以观察到所有的视频剪辑文件都在这里,从00001.ts-00240.ts
接下来我们需要重建这些视频剪辑的 url:
以此类推到 00240.ts
接下来,开始构建请求视频的所有片段并将它们合并成一个新的mp4文件的代码:
<p>import requests
import requests
import os
import time
def run(i,html,referer):
#做了一个字符串替换避免出现001或者0011等异常情况:正确——>00001.ts 00011.ts 00111.ts
if int(i)=10 and int(i) 查看全部
网页视频抓取脚本(
分析网页视频存储形式以及加密格式()
)
高级爬虫-视频采集(视频加密分割案例) 中国职业培训在线网
.
1.分析网络视频存储和加密格式
一般我们在做视频采集的视频大多是:https:指向一个视频文件,但是在大多数网站中,目前主流的视频加密格式大都是分成上百个小片段。播放并不断加载新剪辑。中国职业培训在线视频网视频示例:
.
要通过 F12 按钮查看 Web 缓存,请选择顶部的网络和 xhr:
注:目前主要的视频分割技术使用.m3u8文件来记录视频片段总数。后缀为 .m3u8 的文件收录所有视频剪辑的文件名。大多数视频剪辑文件都是.ts文件,所以我们目前的开发者在工具中找到对应的.m3u8文件
如下:
点击查看文件内容:
可以观察到所有的视频剪辑文件都在这里,从00001.ts-00240.ts
接下来我们需要重建这些视频剪辑的 url:
以此类推到 00240.ts
接下来,开始构建请求视频的所有片段并将它们合并成一个新的mp4文件的代码:
<p>import requests
import requests
import os
import time
def run(i,html,referer):
#做了一个字符串替换避免出现001或者0011等异常情况:正确——>00001.ts 00011.ts 00111.ts
if int(i)=10 and int(i)
网页视频抓取脚本( 其它命令参数用法,同url网址方式,和wget用法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-16 12:29
其它命令参数用法,同url网址方式,和wget用法)
其他命令参数的用法与URL方式相同,这里不再赘述。
更多curl和wget的用法如ftp协议、迭代子目录等,可以查看man中的帮助手册
知识拓展:
在国内,由于某些原因,一般很难直接访问一些敏感的海外网站,需要通过VPN或代理服务器访问。
如果校园网和教育网有IPv6,可以通过免费代理访问facebook、twitter、六维空间等网站
其实除了VPN和IPv6+代理,普通用户还有其他方式访问国外网站
这里有两个著名的自由球员网站:
(全球数十个国家的自由代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
curl 项目示例
使用curl+free agent实现全球12个国家googleplay游戏排名的网页抓取和趋势图查询(抓取网页模块全部由Shell编写,核心代码1000行左右)
爬取google play游戏排名网页,首先需要分析网页的特点和规律:
1、Google play游戏排名页面是“总分”格式,即一个页面URL显示了几个排名(比如24),这样的页面有几个构成了所有游戏的总排名
2、 在每个页面的URL中,点击每个单独的游戏链接可以查看游戏的属性信息(如评分星级、发布日期、版本号、SDK版本号、游戏类别、下载量等)
需要解决的问题:
1、如何抓取所有游戏的总排名?
2、抓取整体排名后,如何拼接网址抓取各个游戏网页?
3、获取各个单独的游戏网页后,如何提取网页中游戏的属性信息(即评分星级、发布日期...)?
4、提取出各个游戏的属性信息后,如何保存(mysql)、生成日报(html)、发送日报(email)?
5、根据抓取到的游戏属性信息资源,如何查询贵公司的游戏排名(JSP)以及如何清晰的展示游戏排名(JFreeChart图表)?
6、 更难的是谷歌玩游戏排名没有统一的全球排名。Google 使用本地化策略。数十个国家/地区都有自己的一套排名算法和规则。如何在12个国家实现游戏排名?
设计方案与技术选择
分析完上述问题和需求,如何一一解决,分解,是不是我们需要思考、设计和解决的问题(模块流程和技术实现)?
基于以上分析提出的问题,将一一进行模块设计和技术方案选择如下:
1、为了抓取12个国家的游戏排名,需要分别租用12个国家的代理服务器来抓取各个国家的游戏排名(12个国家的游戏排名算法和语言是不同,包括中文、英文、日文、俄文、西班牙文...)
2、 抓取网页,使用curl+proxy代理;提取下载的网页信息,使用awk文本分析工具(需要对html语法tag、id等元素有很好的理解才能准确的使用awk提取游戏属性信息)
3、由于IP代理筛选系统、网页爬取程序、游戏属性信息提取等模块都是由脚本完成的,为了保持编程语言的一致性,还实现了数据库的创建和记录插入通过 shell 脚本。
4、 捕捉到的每款游戏的属性信息,采用html+table的网页形式展示,清晰直观。一个shell脚本用来拼接html字符串(table+tr+td+info)
5、 生成的html网页会以每日邮件的形式定期发送给产品总监、PM、RD、QA,了解公司发布的游戏排名,以及上升最快、最流行的游戏趋势在世界上
6、开发JSP网页查询系统,根据输入的游戏名或游戏包名查询某款游戏的排名和趋势,并在趋势图下显示该游戏的所有详细属性信息
模块技术实现
1、IP代理过滤
成本考虑,每个国家租用代理服务器(VPN),以市场最低价1000元/月计算,12000元一年,12个国家总费用为12x12000=144000,也就是大约140000/年的VPN租用费
基于成本的考虑,我后来通过对代理服务器和免费ip的深入研究,提出设计开发一套免费ip代理服务器筛选系统来抓取12个国家的游戏排名。
免费代理IP主要来自上一篇博客介绍的两个网站:和
IP代理筛选系统,由于文本预处理和筛选逻辑实现的复杂性,将在下一篇博客中单独介绍
2、 抓取排名页面
仔细分析google play游戏排名页面,发现有一定的规律可循:
第一页的Top24 URL:
第二页的Top48 URL
第三页的Top72 URL
此时,观察每个页面URL的最后一串?start=24&num=24,你已经找到了模式^_^ 其实网页的第一页是从start=0开始的,也可以写成:
首页的Top24 URL
根据上面的规则,可以使用curl+proxy通过循环拼接字符串来爬取排名网页(start='expr $start + 24')
3、提取游戏链接
排名页面,每个页面收录24个游戏网址超链接,如何提取这24个游戏网址超链接?
当时就考虑使用xml解析,因为html是一种分层组织的类似xml的格式,但是有些网页并不是所有标准的html格式(比如左括号后没有右括号闭包),这会导致xml被错误解析
后来结合我学到的html和js知识,分析了爬行排名网页的内容结构,发现每个游戏链接前面都有一个独特的具体格式如下(以篮球投篮为例):
Basketball Shoot
这样就可以通过awk顺利提取附近的文本内容,具体实现如下:
# split url_24
page_key='class="title"'
page_output='output_page.log'
page_output_url_start='https://play.google.com/store/apps/'
page_output_url='output_top800_url.log'
function page_split(){
grep $page_key $(ls $url_output* | sort -t "_" -k6 -n) > tmp_page_grepURL.log # use $url_output
awk -F'[]' '{for(i=1;i> $log
echo "================= $date ================" >> $log
# mysql database and table to create
HOST='localhost'
PORT='3306'
USER='root'
PWD='xxxxxx'
DBNAME='top800'
TABLENAME='gametop800'
mysql_login=''
mysql_create_db=''
mysql_create_table=''
function mysql_create(){
echo "login mysql $HOST:$PORT ..." >> $log
mysql_login="mysql -h $HOST -P $PORT -u $USER -p$PWD" # mysql -h host -P port -u root -p pwd
echo | ${mysql_login}
if [ $? -ne 0 ]; then
echo "login mysql ${HOST}:${PORT} failed.." >> $log
exit 1
else
echo "login mysql ${HOST}:${PORT} success!" >> $log
fi
echo "create database $DBNAME ..." >> $log
mysql_create_db="create database if not exists $DBNAME"
echo ${mysql_create_db} | ${mysql_login}
if [ $? -ne 0 ]; then
echo "create db ${DBNAME} failed.." >> $log
else
echo "create db ${DBNAME} success!" >> $log
fi
echo "create table $TABLENAME ..." >> $log
mysql_create_table="create table $TABLENAME(
id char(50) not null,
url char(255),
top int,
name char(100),
category char(50),
rating char(10),
ratingcount char(20),
download char(30),
price char(20),
publishdate char(20),
version char(40),
filesize char(40),
requireandroid char(40),
contentrating char(40),
country char(10) not null,
dtime date not null default \"2011-01-01\",
primary key(id, country, dtime)
)"
echo ${mysql_create_table} | ${mysql_login} ${DBNAME}
if [ $? -ne 0 ]; then
echo "create table ${TABLENAME} fail..." >> $log
else
echo "create table ${TABLENAME} success!" >> $log
fi
}
脚本功能说明:
首先登录mysql数据库,判断mysql服务器、端口号、用户名和密码是否正确。如果不正确,则登录失败并退出(exit1);如果正确,则登录成功,继续下一步
然后,创建数据库名,判断数据库是否存在,如果不存在,则创建;如果存在,继续下一步(注意:创建数据库时,需要验证是否登录数据库成功,否则无法操作)
最后创建数据库表,首先设计数据库表的各个字段,然后创建数据库表,具体判断方法与创建数据库名称相同
遍历游戏属性信息的文本,全部插入到mysql数据库中统一存储和管理
# Author : yanggang
# Datetime : 2011.10.24 21:45:09
# ============================================================
#!/bin/sh
# insert mysql
file_input='output_top800_url_page'
file_output='sql_output'
HOST='localhost'
PORT='3306'
USER='root'
PWD='xxxxxx'
DBNAME='top800'
TABLENAME='gametop800'
col_id=''
col_url=''
col_top=1
col_name=''
col_category=''
col_rating=''
col_ratingcount=''
col_download=''
col_price=''
col_publishdate=''
col_version=''
col_filesize=''
col_requireandroid=''
col_contentrating=''
col_country=''
col_dtime=''
sql_insert='insert into gametop800 values("com.mobile.games", "url", 3, "minesweeping",
"games", "4.8", "89789", "1000000-5000000000", "free", "2011-2-30", "1.2.1", "1.5M", "1.5 up", "middle", "china", "2011-10-10")'
function mysql_insert(){
rm -rf $file_output
touch $file_output
DBNAME=$1
col_dtime=$2
col_country=$3
echo 'col_dtime========='$col_dtime
while read line
do
col_id=$(echo $line | cut -f 1 -d "%" | cut -f 1 -d "&" | cut -f 2 -d "=")
col_url=$(echo $line | cut -f 1 -d "%")
col_name=$(echo $line | cut -f 2 -d "%")
col_category=$(echo $line | cut -f 3 -d "%")
col_rating=$(echo $line | cut -f 4 -d "%")
col_ratingcount=$(echo $line | cut -f 5 -d "%")
col_download=$(echo $line | cut -f 6 -d "%")
col_price=$(echo $line | cut -f 7 -d "%")
col_publishdate=$(echo $line | cut -f 8 -d "%")
col_version=$(echo $line | cut -f 9 -d "%")
col_filesize=$(echo $line | cut -f 10 -d "%")
col_requireandroid=$(echo $line | cut -f 11 -d "%")
col_contentrating=$(echo $line | cut -f 12 -d "%")
sql_insert='insert into '$TABLENAME' values('"\"$col_id\", \"$col_url\", $col_top,
\"$col_name\", \"$col_category\", \"$col_rating\", \"$col_ratingcount\", \"$col_download\",
\"$col_price\", \"$col_publishdate\", \"$col_version\", \"$col_filesize\", \"$col_requireandroid\",
\"$col_contentrating\", \"$col_country\", \"$col_dtime\""');'
echo $sql_insert >> $file_output
mysql -h $HOST -P $PORT -u $USER -p$PWD -e "use $DBNAME; $sql_insert"
col_top=`expr $col_top + 1`
done < $file_input
}
脚本功能说明:
插入数据库脚本比较简单,主要实现两个功能:游戏排名号(col_top)和数据库语句插入($sql_insert)
通过while read line循环,读取模块5提取的游戏属性信息文本文件,分割每一行得到对应的字段(cut -f 2 -d "%"),赋值给insert语句(sql_insert)
最后通过mysql -h $HOST -P $PORT -u $USER-p$PWD -e "use $DBNAME; $sql_insert",登录mysql数据库,执行插入语句$sql_insert
7、生成HTML报告
shell 通过连接字符串 table + tr + td + info 来生成 html web 报告。详细请参考我之前的博客:shell将txt转换为html
8、通过电子邮件发送报告
邮件发送模块主要采用/usr/bin/mutt的方式。邮件正文显示html报告(默认为美国),其他国家以附件形式发送。详细请参考我之前的博客:linuxshell发送邮件附件
使用 crontab 命令定期发送电子邮件。具体配置和使用可以参考我之前写的博客:linux定时运行命令script-crontab
9、网页查询报告
使用JSP提取MySQL中存储的游戏属性信息,循环生成游戏排名的网页信息,请参考我之前写的博客:LinuxJSP连接MySQL数据库
10、 排名趋势图
趋势图,使用第三方JFreeChart图表生成工具,请参考我之前的博客:JFreeChart学习实例
游戏排名趋势图生成后,需要嵌套到JSP网页中进行展示。完整的排名趋势图可以参考我之前的博客:JFreeChart Project Example
自动化主控制脚本
12国游戏排名系统,过滤免费ip代理——“网络爬虫——”数据库保存——“生成排名报告——”定时邮件报告——“游戏排名查询——”趋势图生成
都实现了整个流程的自动化,以下是各个模块的脚本实现和功能说明:
通过配置服务器的crontab定时运行进程命令,每天早上00:01:00(早上零时1分零秒),主控脚本top10_all.sh会自动启动
每天生成的日报使用主控脚本自动生成当天的文件夹,保存当天的抓包数据、分析数据、结果数据,如下图:
注:以上文件夹数据为去年测试数据的副本,排名并非本人笔记本截图
因为通过远程代理爬取12个国家排名前800的TOP800需要消耗网络资源、内存资源和时间,严重影响我的上网体验~~~~(>_ 查看全部
网页视频抓取脚本(
其它命令参数用法,同url网址方式,和wget用法)
其他命令参数的用法与URL方式相同,这里不再赘述。
更多curl和wget的用法如ftp协议、迭代子目录等,可以查看man中的帮助手册
知识拓展:
在国内,由于某些原因,一般很难直接访问一些敏感的海外网站,需要通过VPN或代理服务器访问。
如果校园网和教育网有IPv6,可以通过免费代理访问facebook、twitter、六维空间等网站
其实除了VPN和IPv6+代理,普通用户还有其他方式访问国外网站
这里有两个著名的自由球员网站:
(全球数十个国家的自由代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
curl 项目示例
使用curl+free agent实现全球12个国家googleplay游戏排名的网页抓取和趋势图查询(抓取网页模块全部由Shell编写,核心代码1000行左右)
爬取google play游戏排名网页,首先需要分析网页的特点和规律:
1、Google play游戏排名页面是“总分”格式,即一个页面URL显示了几个排名(比如24),这样的页面有几个构成了所有游戏的总排名
2、 在每个页面的URL中,点击每个单独的游戏链接可以查看游戏的属性信息(如评分星级、发布日期、版本号、SDK版本号、游戏类别、下载量等)
需要解决的问题:
1、如何抓取所有游戏的总排名?
2、抓取整体排名后,如何拼接网址抓取各个游戏网页?
3、获取各个单独的游戏网页后,如何提取网页中游戏的属性信息(即评分星级、发布日期...)?
4、提取出各个游戏的属性信息后,如何保存(mysql)、生成日报(html)、发送日报(email)?
5、根据抓取到的游戏属性信息资源,如何查询贵公司的游戏排名(JSP)以及如何清晰的展示游戏排名(JFreeChart图表)?
6、 更难的是谷歌玩游戏排名没有统一的全球排名。Google 使用本地化策略。数十个国家/地区都有自己的一套排名算法和规则。如何在12个国家实现游戏排名?
设计方案与技术选择
分析完上述问题和需求,如何一一解决,分解,是不是我们需要思考、设计和解决的问题(模块流程和技术实现)?
基于以上分析提出的问题,将一一进行模块设计和技术方案选择如下:
1、为了抓取12个国家的游戏排名,需要分别租用12个国家的代理服务器来抓取各个国家的游戏排名(12个国家的游戏排名算法和语言是不同,包括中文、英文、日文、俄文、西班牙文...)
2、 抓取网页,使用curl+proxy代理;提取下载的网页信息,使用awk文本分析工具(需要对html语法tag、id等元素有很好的理解才能准确的使用awk提取游戏属性信息)
3、由于IP代理筛选系统、网页爬取程序、游戏属性信息提取等模块都是由脚本完成的,为了保持编程语言的一致性,还实现了数据库的创建和记录插入通过 shell 脚本。
4、 捕捉到的每款游戏的属性信息,采用html+table的网页形式展示,清晰直观。一个shell脚本用来拼接html字符串(table+tr+td+info)
5、 生成的html网页会以每日邮件的形式定期发送给产品总监、PM、RD、QA,了解公司发布的游戏排名,以及上升最快、最流行的游戏趋势在世界上
6、开发JSP网页查询系统,根据输入的游戏名或游戏包名查询某款游戏的排名和趋势,并在趋势图下显示该游戏的所有详细属性信息
模块技术实现
1、IP代理过滤
成本考虑,每个国家租用代理服务器(VPN),以市场最低价1000元/月计算,12000元一年,12个国家总费用为12x12000=144000,也就是大约140000/年的VPN租用费
基于成本的考虑,我后来通过对代理服务器和免费ip的深入研究,提出设计开发一套免费ip代理服务器筛选系统来抓取12个国家的游戏排名。
免费代理IP主要来自上一篇博客介绍的两个网站:和
IP代理筛选系统,由于文本预处理和筛选逻辑实现的复杂性,将在下一篇博客中单独介绍
2、 抓取排名页面
仔细分析google play游戏排名页面,发现有一定的规律可循:
第一页的Top24 URL:
第二页的Top48 URL
第三页的Top72 URL
此时,观察每个页面URL的最后一串?start=24&num=24,你已经找到了模式^_^ 其实网页的第一页是从start=0开始的,也可以写成:
首页的Top24 URL
根据上面的规则,可以使用curl+proxy通过循环拼接字符串来爬取排名网页(start='expr $start + 24')
3、提取游戏链接
排名页面,每个页面收录24个游戏网址超链接,如何提取这24个游戏网址超链接?
当时就考虑使用xml解析,因为html是一种分层组织的类似xml的格式,但是有些网页并不是所有标准的html格式(比如左括号后没有右括号闭包),这会导致xml被错误解析
后来结合我学到的html和js知识,分析了爬行排名网页的内容结构,发现每个游戏链接前面都有一个独特的具体格式如下(以篮球投篮为例):
Basketball Shoot
这样就可以通过awk顺利提取附近的文本内容,具体实现如下:
# split url_24
page_key='class="title"'
page_output='output_page.log'
page_output_url_start='https://play.google.com/store/apps/'
page_output_url='output_top800_url.log'
function page_split(){
grep $page_key $(ls $url_output* | sort -t "_" -k6 -n) > tmp_page_grepURL.log # use $url_output
awk -F'[]' '{for(i=1;i> $log
echo "================= $date ================" >> $log
# mysql database and table to create
HOST='localhost'
PORT='3306'
USER='root'
PWD='xxxxxx'
DBNAME='top800'
TABLENAME='gametop800'
mysql_login=''
mysql_create_db=''
mysql_create_table=''
function mysql_create(){
echo "login mysql $HOST:$PORT ..." >> $log
mysql_login="mysql -h $HOST -P $PORT -u $USER -p$PWD" # mysql -h host -P port -u root -p pwd
echo | ${mysql_login}
if [ $? -ne 0 ]; then
echo "login mysql ${HOST}:${PORT} failed.." >> $log
exit 1
else
echo "login mysql ${HOST}:${PORT} success!" >> $log
fi
echo "create database $DBNAME ..." >> $log
mysql_create_db="create database if not exists $DBNAME"
echo ${mysql_create_db} | ${mysql_login}
if [ $? -ne 0 ]; then
echo "create db ${DBNAME} failed.." >> $log
else
echo "create db ${DBNAME} success!" >> $log
fi
echo "create table $TABLENAME ..." >> $log
mysql_create_table="create table $TABLENAME(
id char(50) not null,
url char(255),
top int,
name char(100),
category char(50),
rating char(10),
ratingcount char(20),
download char(30),
price char(20),
publishdate char(20),
version char(40),
filesize char(40),
requireandroid char(40),
contentrating char(40),
country char(10) not null,
dtime date not null default \"2011-01-01\",
primary key(id, country, dtime)
)"
echo ${mysql_create_table} | ${mysql_login} ${DBNAME}
if [ $? -ne 0 ]; then
echo "create table ${TABLENAME} fail..." >> $log
else
echo "create table ${TABLENAME} success!" >> $log
fi
}
脚本功能说明:
首先登录mysql数据库,判断mysql服务器、端口号、用户名和密码是否正确。如果不正确,则登录失败并退出(exit1);如果正确,则登录成功,继续下一步
然后,创建数据库名,判断数据库是否存在,如果不存在,则创建;如果存在,继续下一步(注意:创建数据库时,需要验证是否登录数据库成功,否则无法操作)
最后创建数据库表,首先设计数据库表的各个字段,然后创建数据库表,具体判断方法与创建数据库名称相同
遍历游戏属性信息的文本,全部插入到mysql数据库中统一存储和管理
# Author : yanggang
# Datetime : 2011.10.24 21:45:09
# ============================================================
#!/bin/sh
# insert mysql
file_input='output_top800_url_page'
file_output='sql_output'
HOST='localhost'
PORT='3306'
USER='root'
PWD='xxxxxx'
DBNAME='top800'
TABLENAME='gametop800'
col_id=''
col_url=''
col_top=1
col_name=''
col_category=''
col_rating=''
col_ratingcount=''
col_download=''
col_price=''
col_publishdate=''
col_version=''
col_filesize=''
col_requireandroid=''
col_contentrating=''
col_country=''
col_dtime=''
sql_insert='insert into gametop800 values("com.mobile.games", "url", 3, "minesweeping",
"games", "4.8", "89789", "1000000-5000000000", "free", "2011-2-30", "1.2.1", "1.5M", "1.5 up", "middle", "china", "2011-10-10")'
function mysql_insert(){
rm -rf $file_output
touch $file_output
DBNAME=$1
col_dtime=$2
col_country=$3
echo 'col_dtime========='$col_dtime
while read line
do
col_id=$(echo $line | cut -f 1 -d "%" | cut -f 1 -d "&" | cut -f 2 -d "=")
col_url=$(echo $line | cut -f 1 -d "%")
col_name=$(echo $line | cut -f 2 -d "%")
col_category=$(echo $line | cut -f 3 -d "%")
col_rating=$(echo $line | cut -f 4 -d "%")
col_ratingcount=$(echo $line | cut -f 5 -d "%")
col_download=$(echo $line | cut -f 6 -d "%")
col_price=$(echo $line | cut -f 7 -d "%")
col_publishdate=$(echo $line | cut -f 8 -d "%")
col_version=$(echo $line | cut -f 9 -d "%")
col_filesize=$(echo $line | cut -f 10 -d "%")
col_requireandroid=$(echo $line | cut -f 11 -d "%")
col_contentrating=$(echo $line | cut -f 12 -d "%")
sql_insert='insert into '$TABLENAME' values('"\"$col_id\", \"$col_url\", $col_top,
\"$col_name\", \"$col_category\", \"$col_rating\", \"$col_ratingcount\", \"$col_download\",
\"$col_price\", \"$col_publishdate\", \"$col_version\", \"$col_filesize\", \"$col_requireandroid\",
\"$col_contentrating\", \"$col_country\", \"$col_dtime\""');'
echo $sql_insert >> $file_output
mysql -h $HOST -P $PORT -u $USER -p$PWD -e "use $DBNAME; $sql_insert"
col_top=`expr $col_top + 1`
done < $file_input
}
脚本功能说明:
插入数据库脚本比较简单,主要实现两个功能:游戏排名号(col_top)和数据库语句插入($sql_insert)
通过while read line循环,读取模块5提取的游戏属性信息文本文件,分割每一行得到对应的字段(cut -f 2 -d "%"),赋值给insert语句(sql_insert)
最后通过mysql -h $HOST -P $PORT -u $USER-p$PWD -e "use $DBNAME; $sql_insert",登录mysql数据库,执行插入语句$sql_insert
7、生成HTML报告
shell 通过连接字符串 table + tr + td + info 来生成 html web 报告。详细请参考我之前的博客:shell将txt转换为html
8、通过电子邮件发送报告
邮件发送模块主要采用/usr/bin/mutt的方式。邮件正文显示html报告(默认为美国),其他国家以附件形式发送。详细请参考我之前的博客:linuxshell发送邮件附件
使用 crontab 命令定期发送电子邮件。具体配置和使用可以参考我之前写的博客:linux定时运行命令script-crontab
9、网页查询报告
使用JSP提取MySQL中存储的游戏属性信息,循环生成游戏排名的网页信息,请参考我之前写的博客:LinuxJSP连接MySQL数据库
10、 排名趋势图
趋势图,使用第三方JFreeChart图表生成工具,请参考我之前的博客:JFreeChart学习实例
游戏排名趋势图生成后,需要嵌套到JSP网页中进行展示。完整的排名趋势图可以参考我之前的博客:JFreeChart Project Example
自动化主控制脚本
12国游戏排名系统,过滤免费ip代理——“网络爬虫——”数据库保存——“生成排名报告——”定时邮件报告——“游戏排名查询——”趋势图生成
都实现了整个流程的自动化,以下是各个模块的脚本实现和功能说明:
通过配置服务器的crontab定时运行进程命令,每天早上00:01:00(早上零时1分零秒),主控脚本top10_all.sh会自动启动
每天生成的日报使用主控脚本自动生成当天的文件夹,保存当天的抓包数据、分析数据、结果数据,如下图:
注:以上文件夹数据为去年测试数据的副本,排名并非本人笔记本截图
因为通过远程代理爬取12个国家排名前800的TOP800需要消耗网络资源、内存资源和时间,严重影响我的上网体验~~~~(>_
网页视频抓取脚本(FBIWARNING具体脚本可以参考前言(图)劫持的姿势 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-16 12:26
)
联邦调查局警告
具体脚本可以参考
前言
之前我们已经学会了xhr劫持的姿势
现在来实战,通过xhr劫持直接获取返回的内容
通常通过xhr劫持可以达到两种效果,一是在xhr发送数据前获取并篡改数据,二是在xhr返回后获取数据。
我们可以输入 %7B%22impr_id%22%3A%225634fdbddc0100fff0030a1217e00000001a54c1a3%22%7D&enter_from=undefined
通过 f12 抓包
粗略查了一下资料,发现+(Windows+NT+10.0%3B+Win64%3B+x64)+AppleWebKit%2F537.36+(KHTML,+like+ Gecko )+Chrome%2F92.0.4515.159+Safari%2F537.36&browser_online=true&_signature=_02B4Z6wo00d01gP1vzgAAIDCg.dFeeve9w7dme,我们怀疑是来自mashlist的一个链接想要解密是极其麻烦的,所以这里我们可以直接输入一个xhr劫持来获取返回的内容
在这个网页中,我们可以通过获取视频的视频链接来获取v26开头的前缀,于是我们找了一个json在线格式化工具,粘贴数据并解析,搜索v26
我发现很多地方都有v26的链接。我挑选了一些进行测试。终于发现video.play_addr.url_list是一个没有水印的链接。
所以这是一个xhr劫持
<p> function addXMLRequestCallback(callback){
var oldSend, i;
if( XMLHttpRequest.callbacks ) {
// we've already overridden send() so just add the callback
XMLHttpRequest.callbacks.push( callback );
} else {
// create a callback queue
XMLHttpRequest.callbacks = [callback];
// store the native send()
oldSend = XMLHttpRequest.prototype.send;
// override the native send()
XMLHttpRequest.prototype.send = function(){
// process the callback queue
// the xhr instance is passed into each callback but seems pretty useless
// you can't tell what its destination is or call abort() without an error
// so only really good for logging that a request has happened
// I could be wrong, I hope so...
// EDIT: I suppose you could override the onreadystatechange handler though
for( i = 0; i < XMLHttpRequest.callbacks.length; i++ ) {
XMLHttpRequest.callbacks[i]( this );
}
// call the native send()
oldSend.apply(this, arguments);
}
}
}
// e.g.
addXMLRequestCallback( function( xhr ) {
xhr.addEventListener("load", function(){
if ( xhr.readyState == 4 && xhr.status == 200 ) {
if(xhr.responseURL.indexOf('/web/aweme/post')!==-1){
console.log('触发了加载')
let list=JSON.parse(xhr.response)
if(list.aweme_list!==undefined){
for(let index=0;index 查看全部
网页视频抓取脚本(FBIWARNING具体脚本可以参考前言(图)劫持的姿势
)
联邦调查局警告
具体脚本可以参考
前言
之前我们已经学会了xhr劫持的姿势
现在来实战,通过xhr劫持直接获取返回的内容
通常通过xhr劫持可以达到两种效果,一是在xhr发送数据前获取并篡改数据,二是在xhr返回后获取数据。
我们可以输入 %7B%22impr_id%22%3A%225634fdbddc0100fff0030a1217e00000001a54c1a3%22%7D&enter_from=undefined
通过 f12 抓包
粗略查了一下资料,发现+(Windows+NT+10.0%3B+Win64%3B+x64)+AppleWebKit%2F537.36+(KHTML,+like+ Gecko )+Chrome%2F92.0.4515.159+Safari%2F537.36&browser_online=true&_signature=_02B4Z6wo00d01gP1vzgAAIDCg.dFeeve9w7dme,我们怀疑是来自mashlist的一个链接想要解密是极其麻烦的,所以这里我们可以直接输入一个xhr劫持来获取返回的内容
在这个网页中,我们可以通过获取视频的视频链接来获取v26开头的前缀,于是我们找了一个json在线格式化工具,粘贴数据并解析,搜索v26
我发现很多地方都有v26的链接。我挑选了一些进行测试。终于发现video.play_addr.url_list是一个没有水印的链接。
所以这是一个xhr劫持
<p> function addXMLRequestCallback(callback){
var oldSend, i;
if( XMLHttpRequest.callbacks ) {
// we've already overridden send() so just add the callback
XMLHttpRequest.callbacks.push( callback );
} else {
// create a callback queue
XMLHttpRequest.callbacks = [callback];
// store the native send()
oldSend = XMLHttpRequest.prototype.send;
// override the native send()
XMLHttpRequest.prototype.send = function(){
// process the callback queue
// the xhr instance is passed into each callback but seems pretty useless
// you can't tell what its destination is or call abort() without an error
// so only really good for logging that a request has happened
// I could be wrong, I hope so...
// EDIT: I suppose you could override the onreadystatechange handler though
for( i = 0; i < XMLHttpRequest.callbacks.length; i++ ) {
XMLHttpRequest.callbacks[i]( this );
}
// call the native send()
oldSend.apply(this, arguments);
}
}
}
// e.g.
addXMLRequestCallback( function( xhr ) {
xhr.addEventListener("load", function(){
if ( xhr.readyState == 4 && xhr.status == 200 ) {
if(xhr.responseURL.indexOf('/web/aweme/post')!==-1){
console.log('触发了加载')
let list=JSON.parse(xhr.response)
if(list.aweme_list!==undefined){
for(let index=0;index
网页视频抓取脚本( Python构建的尖端网页抓取技术,启动您的大数据项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-15 05:21
Python构建的尖端网页抓取技术,启动您的大数据项目)
使用Python内置的尖端网页捕获技术启动您的大数据项目
你会学到什么
如何理论化和开发用于数据分析和研究的网络爬虫和爬行器
什么是刮刀和蜘蛛
刮刀和蜘蛛有什么区别
刮刀和蜘蛛是如何用于研究的
如何使用请求和美化库构建scraper
如何构建一个多线程的复杂刮板
类型:电子学习| mp4 |视频:h2641280×720 |音频:AAC,48.0 kHz
语言:英文+中英文字幕(根据原英文字幕机器翻译更准确|解压后大小:9GB |持续时间:10h 26m
描述
该网络充满了难以置信的强大数据,存储在数十亿不同的网站、数据库和应用程序编程接口中。金融数据,如股票价格和加密货币趋势,来自几十个国家数千个不同城市的天气数据,以及关于你最喜欢的演员的有趣传记信息:所有这些信息都是现成的,但如果没有一点帮助和自动化,就不可能真正使用它
scraper和spider是非常强大的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据,并将其用于大量不同的应用程序,从创建数据源到采集数据以提供机器学习和人工智能算法。本课程为财务分析、链接图构建和社交媒体研究提供了一种实用的方法来构建一个真实且可用的蜘蛛。在本课程结束时,学生们将能够使用Python从头开始开发爬行器和刮板,并且只会受到他们想象力的限制。通过学习如何开发自动铲运机,我们可以掌握互联网的强大力量
这门课程是为初学者设计的。尽管之前的Python编程经验很有帮助,但您可以在不编写代码的情况下开始本课程
这门课程是为谁开设的:
来自各行各业的互联网研究人员都想学习如何利用网络上的信息为更大的兴趣服务
对数据科学和网络爬虫感兴趣的人
对数据采集和管理感兴趣的人
初级Python开发人员
类型:在线学习MP4视频:H2641280×720音频:AAC,48.0 KHz
语言:英语|尺寸:8.85 GB |持续时间:10小时26米
使用Python构建的尖端web抓取技术为您的大数据项目提供动力
你会学到什么
如何理论化和开发用于数据分析和研究的web scraper和spider
什么是刮刀和蜘蛛
刮刀和蜘蛛有什么区别
刮刀和蜘蛛是如何用于研究的
如何使用Requests和BeautifulSoup库来构建scraper
如何构建多线程、复杂的刮刀
描述
网络充满了难以置信的强大数据,存储在数十亿个不同的网站、数据库和API中。股票价格和加密货币趋势等金融数据,数十个国家数千个不同城市的天气数据,以及关于你最喜欢的演员的有趣传记信息:所有这些信息都在你的指尖上,但如果没有一点帮助和自动化,就不可能真正驾驭这一切
scraper和spider是功能强大得难以置信的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据,并将其用于各种不同的应用程序,从创建数据源到采集数据以提供机器学习和人工智能算法。本课程提供了一种在现实环境中构建真实、可用的蜘蛛的实践方法,如财务分析、链接图构建和社交媒体研究等。到本课程结束时,学生将能够使用Python从头开始开发spider和scraper,并且只受自己想象力的限制。今天,通过学习如何开发自动刮板,让您掌握互联网的巨大力量
本课程是为初学者而设计的,虽然之前的Python编程经验很有帮助,但您可以在不编写任何代码的情况下开始本课程
本课程面向谁:
来自各行各业的互联网研究人员希望学习如何利用网络上的信息实现更大的利益
对数据科学和网络抓取感兴趣的人
对数据采集和整理感兴趣的人
初级Python开发人员
隐藏内容:******,下载
下载说明:
1、电脑端:浏览器打开网页获取资料,奖励后自动显示百度在线盘链接。如果没有显示,请刷新网页
2、移动终端:您需要在微信中打开材料网页,奖励后返回原材料页面,在线磁盘链接即可自动显示
3、默认资源是百度在线磁盘链接。如果链接失败或无法获得,请联系客服微信云桥网解决
5、云桥网络继续更新国外CG软件教程材料和相关资源。感谢您的关注和支持
Python教程
肖云云
海报链接 查看全部
网页视频抓取脚本(
Python构建的尖端网页抓取技术,启动您的大数据项目)
使用Python内置的尖端网页捕获技术启动您的大数据项目
你会学到什么
如何理论化和开发用于数据分析和研究的网络爬虫和爬行器
什么是刮刀和蜘蛛
刮刀和蜘蛛有什么区别
刮刀和蜘蛛是如何用于研究的
如何使用请求和美化库构建scraper
如何构建一个多线程的复杂刮板
类型:电子学习| mp4 |视频:h2641280×720 |音频:AAC,48.0 kHz
语言:英文+中英文字幕(根据原英文字幕机器翻译更准确|解压后大小:9GB |持续时间:10h 26m
描述
该网络充满了难以置信的强大数据,存储在数十亿不同的网站、数据库和应用程序编程接口中。金融数据,如股票价格和加密货币趋势,来自几十个国家数千个不同城市的天气数据,以及关于你最喜欢的演员的有趣传记信息:所有这些信息都是现成的,但如果没有一点帮助和自动化,就不可能真正使用它
scraper和spider是非常强大的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据,并将其用于大量不同的应用程序,从创建数据源到采集数据以提供机器学习和人工智能算法。本课程为财务分析、链接图构建和社交媒体研究提供了一种实用的方法来构建一个真实且可用的蜘蛛。在本课程结束时,学生们将能够使用Python从头开始开发爬行器和刮板,并且只会受到他们想象力的限制。通过学习如何开发自动铲运机,我们可以掌握互联网的强大力量
这门课程是为初学者设计的。尽管之前的Python编程经验很有帮助,但您可以在不编写代码的情况下开始本课程
这门课程是为谁开设的:
来自各行各业的互联网研究人员都想学习如何利用网络上的信息为更大的兴趣服务
对数据科学和网络爬虫感兴趣的人
对数据采集和管理感兴趣的人
初级Python开发人员
类型:在线学习MP4视频:H2641280×720音频:AAC,48.0 KHz
语言:英语|尺寸:8.85 GB |持续时间:10小时26米
使用Python构建的尖端web抓取技术为您的大数据项目提供动力
你会学到什么
如何理论化和开发用于数据分析和研究的web scraper和spider
什么是刮刀和蜘蛛
刮刀和蜘蛛有什么区别
刮刀和蜘蛛是如何用于研究的
如何使用Requests和BeautifulSoup库来构建scraper
如何构建多线程、复杂的刮刀
描述
网络充满了难以置信的强大数据,存储在数十亿个不同的网站、数据库和API中。股票价格和加密货币趋势等金融数据,数十个国家数千个不同城市的天气数据,以及关于你最喜欢的演员的有趣传记信息:所有这些信息都在你的指尖上,但如果没有一点帮助和自动化,就不可能真正驾驭这一切
scraper和spider是功能强大得难以置信的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据,并将其用于各种不同的应用程序,从创建数据源到采集数据以提供机器学习和人工智能算法。本课程提供了一种在现实环境中构建真实、可用的蜘蛛的实践方法,如财务分析、链接图构建和社交媒体研究等。到本课程结束时,学生将能够使用Python从头开始开发spider和scraper,并且只受自己想象力的限制。今天,通过学习如何开发自动刮板,让您掌握互联网的巨大力量
本课程是为初学者而设计的,虽然之前的Python编程经验很有帮助,但您可以在不编写任何代码的情况下开始本课程
本课程面向谁:
来自各行各业的互联网研究人员希望学习如何利用网络上的信息实现更大的利益
对数据科学和网络抓取感兴趣的人
对数据采集和整理感兴趣的人
初级Python开发人员
隐藏内容:******,下载
下载说明:
1、电脑端:浏览器打开网页获取资料,奖励后自动显示百度在线盘链接。如果没有显示,请刷新网页
2、移动终端:您需要在微信中打开材料网页,奖励后返回原材料页面,在线磁盘链接即可自动显示
3、默认资源是百度在线磁盘链接。如果链接失败或无法获得,请联系客服微信云桥网解决
5、云桥网络继续更新国外CG软件教程材料和相关资源。感谢您的关注和支持
Python教程
肖云云
海报链接
网页视频抓取脚本(1.为什么需要JS前面3篇文章讲了一些基本操作的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 24 次浏览 • 2021-12-13 20:29
1. 为什么我们需要JS
前面3篇文章讲了Selenium的一些基本操作。使用这部分技巧,可以顺利完成网站的大部分自动化。
但是,有一些网站 web操作使用WebDriver API无法完成,有些功能即使使用WebDriver API实现也不兼容。经常需要维护这组脚本,比如浏览器的位置。滑动、元素点击失效、日期选择等。
这时候使用JavaScript直接操作网页内部元素,可以帮助我们完成Selenium自动化测试无法覆盖的功能。
2. 使用方法
Selenium 提供了以下方法:
driver.execute_script(js_code)
其中,js_code是一个JS脚本。常见的JS脚本包括:设置元素属性、移除属性、设置元素值、设置窗口位置等。
使用 Selenium CSS Selector 类型,使用 JS 查找元素的方式包括以下 6 种类型:
# 1、通过元素id属性,获取元素
document.getElementById('id');
# 2、通过元素name属性,获取元素
document.getElementsByName('name');
# 3、通过标签名,获取元素列表
# 获取的是一个列表
document.getElementsByTagName('tag_name');
# 4、通过类名,获取元素列表
document.getElementsByClassName("class_name");
# 5、通过选择器,获取一个元素
document.querySelector("css selector")
# 6、通过CSS选择器,获取元素列表
document.querySelectorAll("css selector")
获取元素后,可以操作元素属性,例如:
# 操作属性值
# 设置元素某一个元素值
element.setAttribute('属性名','属性值')
# 设置元素值
element.value="element_value";
# 删除属性
element.removeAttribute('属性名')
结合以上3个操作,就可以通过JS改变一个网页元素的值了。
# 待执行的js语句
exec_js = 'document.getElementById(element_id).value="element_value";'
# 执行js语句改变元素的值
driver.execute_script(exec_js)
3. 常用操作
以12306网站为例,选择出发日期。
先用普通模式写一波自动化,用WebDriver查找元素,然后直接给元素设置一个日期值。
运行后直接报错,运行日志会提示目标元素有不可编辑的属性-只读
这时候就可以通过JS的方法方便的去掉这个属性,然后再添加元素的属性操作,就可以正常设置日期了。
改写后的代码如下:
from time import sleep
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.12306.cn/index/')
# 去除掉元素的属性
exec_js = 'document.getElementById("train_date").removeAttribute("readonly");'
driver.execute_script(exec_js)
# 输入日期
element_train_date = driver.find_element_by_id("train_date")
element_train_date.clear()
element_train_date.send_keys("2012-12-12")
sleep(5)
driver.quit()
当然,除了去除元素属性之外,还可以使用JS搜索元素语法来获取目标元素,然后直接在元素上设置一个日期,也可以满足我们的需求。
# 找到元素,直接设置一个容器
exec_js = 'document.getElementById("train_date").value="2012-12-12";'
# 执行js代码
driver.execute_script(exec_js)
4. 其他
Selenium 自动化的很多操作都可以转成JS 语句,然后使用execute_script() 来完成同样的功能。
但是在自动化的实际使用中,JS只是作为一个补充,帮助我们完成一些WebDriver无法实现的功能。 查看全部
网页视频抓取脚本(1.为什么需要JS前面3篇文章讲了一些基本操作的方法)
1. 为什么我们需要JS
前面3篇文章讲了Selenium的一些基本操作。使用这部分技巧,可以顺利完成网站的大部分自动化。
但是,有一些网站 web操作使用WebDriver API无法完成,有些功能即使使用WebDriver API实现也不兼容。经常需要维护这组脚本,比如浏览器的位置。滑动、元素点击失效、日期选择等。
这时候使用JavaScript直接操作网页内部元素,可以帮助我们完成Selenium自动化测试无法覆盖的功能。
2. 使用方法
Selenium 提供了以下方法:
driver.execute_script(js_code)
其中,js_code是一个JS脚本。常见的JS脚本包括:设置元素属性、移除属性、设置元素值、设置窗口位置等。
使用 Selenium CSS Selector 类型,使用 JS 查找元素的方式包括以下 6 种类型:
# 1、通过元素id属性,获取元素
document.getElementById('id');
# 2、通过元素name属性,获取元素
document.getElementsByName('name');
# 3、通过标签名,获取元素列表
# 获取的是一个列表
document.getElementsByTagName('tag_name');
# 4、通过类名,获取元素列表
document.getElementsByClassName("class_name");
# 5、通过选择器,获取一个元素
document.querySelector("css selector")
# 6、通过CSS选择器,获取元素列表
document.querySelectorAll("css selector")
获取元素后,可以操作元素属性,例如:
# 操作属性值
# 设置元素某一个元素值
element.setAttribute('属性名','属性值')
# 设置元素值
element.value="element_value";
# 删除属性
element.removeAttribute('属性名')
结合以上3个操作,就可以通过JS改变一个网页元素的值了。
# 待执行的js语句
exec_js = 'document.getElementById(element_id).value="element_value";'
# 执行js语句改变元素的值
driver.execute_script(exec_js)
3. 常用操作
以12306网站为例,选择出发日期。
先用普通模式写一波自动化,用WebDriver查找元素,然后直接给元素设置一个日期值。
运行后直接报错,运行日志会提示目标元素有不可编辑的属性-只读
这时候就可以通过JS的方法方便的去掉这个属性,然后再添加元素的属性操作,就可以正常设置日期了。
改写后的代码如下:
from time import sleep
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.12306.cn/index/')
# 去除掉元素的属性
exec_js = 'document.getElementById("train_date").removeAttribute("readonly");'
driver.execute_script(exec_js)
# 输入日期
element_train_date = driver.find_element_by_id("train_date")
element_train_date.clear()
element_train_date.send_keys("2012-12-12")
sleep(5)
driver.quit()
当然,除了去除元素属性之外,还可以使用JS搜索元素语法来获取目标元素,然后直接在元素上设置一个日期,也可以满足我们的需求。
# 找到元素,直接设置一个容器
exec_js = 'document.getElementById("train_date").value="2012-12-12";'
# 执行js代码
driver.execute_script(exec_js)
4. 其他
Selenium 自动化的很多操作都可以转成JS 语句,然后使用execute_script() 来完成同样的功能。
但是在自动化的实际使用中,JS只是作为一个补充,帮助我们完成一些WebDriver无法实现的功能。
网页视频抓取脚本(Python是什么呢?Python经验总结什么叫网络爬虫网络蜘蛛)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-13 20:25
什么是 Python?
Python 是一种全栈开发语言。如果你能学好Python,前端、后端、测试、大数据分析、爬虫等都可以胜任。
我不会详细介绍 Python 现在的流行程度。Python的功能是什么?
根据我多年的 Python 经验,Python 主要有以下四种应用:
接下来跟大家聊聊这几个方面:
网络爬虫
什么是网络爬虫?
网络爬虫,又称网络蜘蛛,是指按照一定的规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个网站进入其他网站,获取需要的内容。
爬虫有什么用?
做一个垂直搜索引擎(谷歌、百度等)。
科学研究:在线人类行为、在线社区进化、人类动力学研究、定量社会学、复杂网络、数据挖掘等领域的实证研究需要大量数据。网络爬虫是采集相关数据的强大工具。
偷窥、黑客、垃圾邮件……
爬行是搜索引擎的第一步,也是最简单的一步。
爬虫用什么语言写的?
C、C++。效率高,速度快,适合一般搜索引擎爬取全网。缺点,开发慢,又臭又长,例如:天网搜索源码。
脚本语言:Perl、Python、Java、Ruby。简单易学,好的文字处理可以方便对网页内容进行详细的提取,但效率往往不高,适合少量网站集中抓取
C#?
为什么 Python 是当下最热门的?
就个人而言,我已经用 c# 和 java 编写了爬虫。区别不大,原则是用好正则表达式。只是平台问题。后来才知道很多爬虫都是用python写的,所以一发不可收拾。
Python有很多优点。总结两个要点:
1) 抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。python中有优秀的第三方包帮你搞定,比如Requests,mechanize
2)网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
网站开发
开发网站需要什么知识?
1、Python基础,因为是用python开发的,python规定你需要知道,至少要知道条件、循环、函数、类;
2、html和css的基础知识,因为要开发网站,网页都是html和css写的,至少你得知道这方面的知识,即使你不知道怎么做写一个前端,你不能开发出特别漂亮的页面,网站,至少你要能看懂html标签;
3、数据库基础知识,因为如果你开发了一个网站,数据存在的地方,就在数据库中,那你至少要知道如何对数据库进行增删改查,否则如何保存数据和检索数据?
如果以上知识掌握好,开发一个简单的小网站就没有问题了。如果你想开发一个比较大的网站,业务逻辑比较复杂,那你就得借助其他的知识,比如redis,MQ等。
人工智能
人工智能(Artificial Intelligence),英文缩写是AI。它是研究和开发用于模拟、扩展和扩展人类智能的理论、方法、技术和应用系统的一门新的技术科学。
人工智能是计算机科学的一个分支。它试图理解智能的本质,并生产出一种能够以类似于人类智能的方式做出反应的新型智能机器。该领域的研究包括机器人技术、语言识别、图像识别、自然语言处理和专家系统等。
人工智能诞生以来,理论和技术日趋成熟,应用领域也不断扩大。可以想象,未来人工智能带来的科技产品将是人类智能的“容器”,并且可能会超越人类智能。
Python 正在成为机器学习的语言。大多数机器语言课程都是用 Python 编写的,大量的大公司也使用 Python,让很多人认为它是未来的主要编程语言。
有人认为PYTHON效率很高,说不能支持多线程。好吧,这有点正确,但我想问一下,有多少人看过这篇文章 做过搜索引擎开发?有多少个网站并发开发,亿级PV?有多少人看过LINUX内核源代码?如果没有,请先乖乖的学习入门语言~
自动化运维
Python可以满足大部分自动化运维的需求。它也可以用作后端 C/S 架构。还可以使用WEB框架快速开发高大的WEB界面。只有当你有能力做出运维自动化系统时,你的价值才会体现出来。
那么问题来了
Python国内工资高吗?
那么,既然Python这么好,那么Python目前国内就业工资高吗?
在工作人员集合上搜索Python相关职位,可以看到北京蟒蛇的平均工资:¥20690/月,取自9391个样本。
而相关的人工智能、机器学习等岗位,薪资更是高达3万多元。
随着国内各大互联网公司开始使用Python进行后端开发、大数据分析、运维测试、人工智能等,今年Python的地位会更高。
不仅是一线城市,在武汉、西安等二线城市,Python工程师的年薪都超过11000元。
那么,你准备好学习 Python 了吗? 查看全部
网页视频抓取脚本(Python是什么呢?Python经验总结什么叫网络爬虫网络蜘蛛)
什么是 Python?
Python 是一种全栈开发语言。如果你能学好Python,前端、后端、测试、大数据分析、爬虫等都可以胜任。
我不会详细介绍 Python 现在的流行程度。Python的功能是什么?
根据我多年的 Python 经验,Python 主要有以下四种应用:
接下来跟大家聊聊这几个方面:
网络爬虫
什么是网络爬虫?
网络爬虫,又称网络蜘蛛,是指按照一定的规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个网站进入其他网站,获取需要的内容。
爬虫有什么用?
做一个垂直搜索引擎(谷歌、百度等)。
科学研究:在线人类行为、在线社区进化、人类动力学研究、定量社会学、复杂网络、数据挖掘等领域的实证研究需要大量数据。网络爬虫是采集相关数据的强大工具。
偷窥、黑客、垃圾邮件……
爬行是搜索引擎的第一步,也是最简单的一步。
爬虫用什么语言写的?
C、C++。效率高,速度快,适合一般搜索引擎爬取全网。缺点,开发慢,又臭又长,例如:天网搜索源码。
脚本语言:Perl、Python、Java、Ruby。简单易学,好的文字处理可以方便对网页内容进行详细的提取,但效率往往不高,适合少量网站集中抓取
C#?
为什么 Python 是当下最热门的?
就个人而言,我已经用 c# 和 java 编写了爬虫。区别不大,原则是用好正则表达式。只是平台问题。后来才知道很多爬虫都是用python写的,所以一发不可收拾。
Python有很多优点。总结两个要点:
1) 抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。python中有优秀的第三方包帮你搞定,比如Requests,mechanize
2)网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
网站开发
开发网站需要什么知识?
1、Python基础,因为是用python开发的,python规定你需要知道,至少要知道条件、循环、函数、类;
2、html和css的基础知识,因为要开发网站,网页都是html和css写的,至少你得知道这方面的知识,即使你不知道怎么做写一个前端,你不能开发出特别漂亮的页面,网站,至少你要能看懂html标签;
3、数据库基础知识,因为如果你开发了一个网站,数据存在的地方,就在数据库中,那你至少要知道如何对数据库进行增删改查,否则如何保存数据和检索数据?
如果以上知识掌握好,开发一个简单的小网站就没有问题了。如果你想开发一个比较大的网站,业务逻辑比较复杂,那你就得借助其他的知识,比如redis,MQ等。
人工智能
人工智能(Artificial Intelligence),英文缩写是AI。它是研究和开发用于模拟、扩展和扩展人类智能的理论、方法、技术和应用系统的一门新的技术科学。
人工智能是计算机科学的一个分支。它试图理解智能的本质,并生产出一种能够以类似于人类智能的方式做出反应的新型智能机器。该领域的研究包括机器人技术、语言识别、图像识别、自然语言处理和专家系统等。
人工智能诞生以来,理论和技术日趋成熟,应用领域也不断扩大。可以想象,未来人工智能带来的科技产品将是人类智能的“容器”,并且可能会超越人类智能。
Python 正在成为机器学习的语言。大多数机器语言课程都是用 Python 编写的,大量的大公司也使用 Python,让很多人认为它是未来的主要编程语言。
有人认为PYTHON效率很高,说不能支持多线程。好吧,这有点正确,但我想问一下,有多少人看过这篇文章 做过搜索引擎开发?有多少个网站并发开发,亿级PV?有多少人看过LINUX内核源代码?如果没有,请先乖乖的学习入门语言~
自动化运维
Python可以满足大部分自动化运维的需求。它也可以用作后端 C/S 架构。还可以使用WEB框架快速开发高大的WEB界面。只有当你有能力做出运维自动化系统时,你的价值才会体现出来。
那么问题来了
Python国内工资高吗?
那么,既然Python这么好,那么Python目前国内就业工资高吗?
在工作人员集合上搜索Python相关职位,可以看到北京蟒蛇的平均工资:¥20690/月,取自9391个样本。
而相关的人工智能、机器学习等岗位,薪资更是高达3万多元。
随着国内各大互联网公司开始使用Python进行后端开发、大数据分析、运维测试、人工智能等,今年Python的地位会更高。
不仅是一线城市,在武汉、西安等二线城市,Python工程师的年薪都超过11000元。
那么,你准备好学习 Python 了吗?
网页视频抓取脚本(网页视频抓取脚本小程序数据、音频、声带、性格)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-08 18:04
网页视频抓取脚本小程序数据、音频、声带、性格、血型、星座、血压等多方位抓取,喜欢的可以关注我一下,及时发布抓取有精力的可以根据需要针对资源进行下载。1.通过https传输数据网址:,将原视频和音频都传输到后台,地址如下::针对不同页面传输不同的数据,如:1.1媒体文件/news文件,类型为jpg;1.2文字为\m\n,浏览器检测为”中文”jpg图片更改类型为bmp(需要修改host);1.3图片为\t\r\e,浏览器检测为”像素图”svg;1.4图片为\r\t,浏览器检测为”点阵图”zip解压解压后,查看中心页的地址::”update“选择传输的类型是”jpg“或”svg“,前者服务器无法传输,后者建议不要上传完成解压后看这个页面也是如下:/smqnzn/521111一大段,这个页面需要针对jpg和svg进行下载的;针对于这个页面,我们进行下载以后,再传输到这个网址:,在ie浏览器(或者其他各种浏览器)中,点击链接缩略图,再点击鼠标左键(鼠标右键)弹出来的下拉列表里点击下载选项即可:如果想更精准的传输ip,可以单独建立一个下载列表,如:网页内容中心为,可以对于这个页面的浏览器会员进行进行充值:我们分别用了一个url”””””“””为下载地址,输入不同的密码可以轻松下载全部页面,现在去下载咯~我们来看看下载成功的截图:这样就下载完成啦,不同页面下载成功的截图:2.遍历列表页面数据网址:,分别找出看到的不同内容,可以包括图片、文字、关注话题、统计信息等等:/360402cj一大堆,根据实际的需要做不同的下载,详细可以关注我,在我们这块有一些分享的文章希望对你有帮助。
抓取动画与视频类数据用到“查看“,”翻页”,”首页“命令“3.查看博客详情页4.知乎号添加话题列表!5.检测输入错误页面数据网址:,分别对页面中的字段进行检测,如::6.ajax缓存处理用到“查看”、“检查”等命令7.设置断点,在需要检测的位置检测,如:”#apikey””#apiv“”,使用方法同上1.使用python2.17更新抓取教程。 查看全部
网页视频抓取脚本(网页视频抓取脚本小程序数据、音频、声带、性格)
网页视频抓取脚本小程序数据、音频、声带、性格、血型、星座、血压等多方位抓取,喜欢的可以关注我一下,及时发布抓取有精力的可以根据需要针对资源进行下载。1.通过https传输数据网址:,将原视频和音频都传输到后台,地址如下::针对不同页面传输不同的数据,如:1.1媒体文件/news文件,类型为jpg;1.2文字为\m\n,浏览器检测为”中文”jpg图片更改类型为bmp(需要修改host);1.3图片为\t\r\e,浏览器检测为”像素图”svg;1.4图片为\r\t,浏览器检测为”点阵图”zip解压解压后,查看中心页的地址::”update“选择传输的类型是”jpg“或”svg“,前者服务器无法传输,后者建议不要上传完成解压后看这个页面也是如下:/smqnzn/521111一大段,这个页面需要针对jpg和svg进行下载的;针对于这个页面,我们进行下载以后,再传输到这个网址:,在ie浏览器(或者其他各种浏览器)中,点击链接缩略图,再点击鼠标左键(鼠标右键)弹出来的下拉列表里点击下载选项即可:如果想更精准的传输ip,可以单独建立一个下载列表,如:网页内容中心为,可以对于这个页面的浏览器会员进行进行充值:我们分别用了一个url”””””“””为下载地址,输入不同的密码可以轻松下载全部页面,现在去下载咯~我们来看看下载成功的截图:这样就下载完成啦,不同页面下载成功的截图:2.遍历列表页面数据网址:,分别找出看到的不同内容,可以包括图片、文字、关注话题、统计信息等等:/360402cj一大堆,根据实际的需要做不同的下载,详细可以关注我,在我们这块有一些分享的文章希望对你有帮助。
抓取动画与视频类数据用到“查看“,”翻页”,”首页“命令“3.查看博客详情页4.知乎号添加话题列表!5.检测输入错误页面数据网址:,分别对页面中的字段进行检测,如::6.ajax缓存处理用到“查看”、“检查”等命令7.设置断点,在需要检测的位置检测,如:”#apikey””#apiv“”,使用方法同上1.使用python2.17更新抓取教程。
网页视频抓取脚本(可以帮助用户抓取网页图片,使用爬虫技术帮助用户分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-07 04:49
)
北海小王子图片下载器可以帮助用户抓取网页图片,利用爬虫技术帮助用户分析网页上的图片,下载所有与链接相关的图片,用户可以在软件中设置爬虫深度,只抓取当前网页,可以继续抓取当前网页附带的URL地址的图片,实现多层搜索。进入网站首页从子网页抓取图片,满足不同用户搜索图片的需求。软件提供多种参数设置,可以限制图片大小,可以限制图片数量,软件界面显示抓取进度,抓取完成后自动下载图片。如果您需要此软件,请下载它!
软件功能
1、北海小王子图片下载器可以帮助用户快速下载图片
2、输入网址自动抓取图片
3、 可以自动抓取整个网页,自动识别图片文件
4、 可以自己设置爬虫深度,可以爬取更多的网页
5、可以设置图片大小,比如设置200KB,下面的图片不会被抓取
6、 支持图片张数设置,比如这次抓取100张图片,抓取数量达到100张会自动停止
7、 显示进程统计,第29页正在被爬取,56页爬取成功,1页爬取失败
软件特点
1、北海小王子图片下载器可以在网上免费下载图片
2、输入图片地址立即下载
3、可以输入一个网站首页地址进行爬取
4、可以输入HTML地址抓取图片
5、软件界面简单,左边可以显示抓包过程,右边可以显示设置参数
指示
1、打开Linging4Images-v1.0.exe软件,直接输入需要抓包的网站地址
2、选择爬取深度,深度1表示只爬取网站输入的内容1,2表示继续访问1中网站内容中出现的url,以及3 in 2 在基础上继续跳,以此类推,一般2层就够了
3、 设置图片大小,默认为500KB,可以适当缩小图片大小,比如抓取50KB以上的图片,小于设置的图片大小就不会抓取。
4、 设置图片数量,需要抓取多少张图片,自己输入即可,点击底部“去吧,皮卡丘”开始抓取
5、 可以在软件界面上显示抓拍的信息,可以点击停止按钮停止搜索图片
6、进入主程序所在文件夹,打开图片查看图片
7、编辑器抓到的图片是这样的,到此操作结束,如果需要从网络抓图,选择北海小王子图片下载器
查看全部
网页视频抓取脚本(可以帮助用户抓取网页图片,使用爬虫技术帮助用户分析
)
北海小王子图片下载器可以帮助用户抓取网页图片,利用爬虫技术帮助用户分析网页上的图片,下载所有与链接相关的图片,用户可以在软件中设置爬虫深度,只抓取当前网页,可以继续抓取当前网页附带的URL地址的图片,实现多层搜索。进入网站首页从子网页抓取图片,满足不同用户搜索图片的需求。软件提供多种参数设置,可以限制图片大小,可以限制图片数量,软件界面显示抓取进度,抓取完成后自动下载图片。如果您需要此软件,请下载它!
软件功能
1、北海小王子图片下载器可以帮助用户快速下载图片
2、输入网址自动抓取图片
3、 可以自动抓取整个网页,自动识别图片文件
4、 可以自己设置爬虫深度,可以爬取更多的网页
5、可以设置图片大小,比如设置200KB,下面的图片不会被抓取
6、 支持图片张数设置,比如这次抓取100张图片,抓取数量达到100张会自动停止
7、 显示进程统计,第29页正在被爬取,56页爬取成功,1页爬取失败
软件特点
1、北海小王子图片下载器可以在网上免费下载图片
2、输入图片地址立即下载
3、可以输入一个网站首页地址进行爬取
4、可以输入HTML地址抓取图片
5、软件界面简单,左边可以显示抓包过程,右边可以显示设置参数
指示
1、打开Linging4Images-v1.0.exe软件,直接输入需要抓包的网站地址
2、选择爬取深度,深度1表示只爬取网站输入的内容1,2表示继续访问1中网站内容中出现的url,以及3 in 2 在基础上继续跳,以此类推,一般2层就够了
3、 设置图片大小,默认为500KB,可以适当缩小图片大小,比如抓取50KB以上的图片,小于设置的图片大小就不会抓取。
4、 设置图片数量,需要抓取多少张图片,自己输入即可,点击底部“去吧,皮卡丘”开始抓取
5、 可以在软件界面上显示抓拍的信息,可以点击停止按钮停止搜索图片
6、进入主程序所在文件夹,打开图片查看图片
7、编辑器抓到的图片是这样的,到此操作结束,如果需要从网络抓图,选择北海小王子图片下载器
网页视频抓取脚本(一点js脚本的保存方法还有很多,你很想试一试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-06 20:05
这两天有点闲,想了一个小js脚本,作用是把当前网页的所有图片一次性保存到本地,以免图片被右键每次。
测试环境:Chrome开发者模式(启动Chrome,按F12)
测试页面:知乎一个问题
原理很简单,就是利用a标签的href和download属性和点击事件。
直接贴代码:
<p> 1 //一个对象,存储页面图片数量和下载的数量
2 var monitorObj = {
3 imgTotal: 0,
4 imgLoaded: 0
5 }
6 //创建a标签,赋予图片对象相关属性,并插入body
7 var createA = function (obj) {
8 var a = document.createElement("a");
9 a.id = obj.id;
10 a.target = "_blank";//注意:要在新页面打开
11 a.href = obj.url;
12 a.download = obj.url;
13
14 document.body.appendChild(a);
15 }
16
17 //获取页面的图片
18 var imgs = document.images;
19 //创建每个图片对象的对应a标签
20 for (var i = 0; i < imgs.length;i++){
21 var obj = {
22 id: "img_" + i,
23 url: imgs[i].src
24 }
25 //过滤掉不属于这几种类型的图片
26 if (["JPG", "JPEG", "PNG","GIF"].indexOf(obj.url.substr(obj.url.lastIndexOf(".")+1).toUpperCase()) < 0) {
27 continue;
28 }
29 //这里是为了去掉知乎用户头像的图片,头像大小是50*50
30 if (imgs[i].width 查看全部
网页视频抓取脚本(一点js脚本的保存方法还有很多,你很想试一试)
这两天有点闲,想了一个小js脚本,作用是把当前网页的所有图片一次性保存到本地,以免图片被右键每次。
测试环境:Chrome开发者模式(启动Chrome,按F12)
测试页面:知乎一个问题
原理很简单,就是利用a标签的href和download属性和点击事件。
直接贴代码:
<p> 1 //一个对象,存储页面图片数量和下载的数量
2 var monitorObj = {
3 imgTotal: 0,
4 imgLoaded: 0
5 }
6 //创建a标签,赋予图片对象相关属性,并插入body
7 var createA = function (obj) {
8 var a = document.createElement("a");
9 a.id = obj.id;
10 a.target = "_blank";//注意:要在新页面打开
11 a.href = obj.url;
12 a.download = obj.url;
13
14 document.body.appendChild(a);
15 }
16
17 //获取页面的图片
18 var imgs = document.images;
19 //创建每个图片对象的对应a标签
20 for (var i = 0; i < imgs.length;i++){
21 var obj = {
22 id: "img_" + i,
23 url: imgs[i].src
24 }
25 //过滤掉不属于这几种类型的图片
26 if (["JPG", "JPEG", "PNG","GIF"].indexOf(obj.url.substr(obj.url.lastIndexOf(".")+1).toUpperCase()) < 0) {
27 continue;
28 }
29 //这里是为了去掉知乎用户头像的图片,头像大小是50*50
30 if (imgs[i].width
网页视频抓取脚本(excel做数据驱动(二)--如何面对博文被)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-06 08:28
>>>
================ 重新启动:C:\Users\mx11\Desktop\webcatch.py ============== == =
Java接口测试,用excel做数据驱动(二)
----------------------------------------------- ---------------
如何面对被抓取的博文
----------------------------------------------- ---------------
javascript 设计模式-发布订阅模式
----------------------------------------------- ---------------
网络虚拟化
----------------------------------------------- ---------------
【学习的艺术】钱会来吗?
----------------------------------------------- ---------------
docker、oci、runc 和 kubernetes 组合
----------------------------------------------- ---------------
从Android开发的角度来说说Airbnb的Lottie! ! !
----------------------------------------------- ---------------
深入学习-webkit-overflow-scrolling:touch和ios滚动
----------------------------------------------- ---------------
为什么列存储可以大大提高数据查询性能?
----------------------------------------------- ---------------
MySQL slave_exec_mode 参数说明
----------------------------------------------- ---------------
阿里安全 Pandora Labs 首次完美越狱 Apple iOS 11.2
----------------------------------------------- ---------------
《RabbitMQ教程》翻译第3章发布与订阅
----------------------------------------------- ---------------
Android HandlerThread的使用介绍及源码分析
----------------------------------------------- ---------------
(四):C++分布式实时应用框架-状态中心模块
----------------------------------------------- ---------------
感知器学习与实践
----------------------------------------------- ---------------
SQLServer 审查文档 1(使用 C#)
----------------------------------------------- ---------------
分布式监控系统Zabbix3.2 数据库连接数警告
----------------------------------------------- ---------------
ABP模块-零+AdminLTE+Bootstrap Table+jQuery权限管理系统第16节-SignalR和ABP框架Abp.Web.SignalR和扩展
----------------------------------------------- ---------------
Docker:限制容器可用的内存
----------------------------------------------- ---------------
javascript 设计模式-迭代器模式
----------------------------------------------- ---------------
>>> 查看全部
网页视频抓取脚本(excel做数据驱动(二)--如何面对博文被)
>>>
================ 重新启动:C:\Users\mx11\Desktop\webcatch.py ============== == =
Java接口测试,用excel做数据驱动(二)
----------------------------------------------- ---------------
如何面对被抓取的博文
----------------------------------------------- ---------------
javascript 设计模式-发布订阅模式
----------------------------------------------- ---------------
网络虚拟化
----------------------------------------------- ---------------
【学习的艺术】钱会来吗?
----------------------------------------------- ---------------
docker、oci、runc 和 kubernetes 组合
----------------------------------------------- ---------------
从Android开发的角度来说说Airbnb的Lottie! ! !
----------------------------------------------- ---------------
深入学习-webkit-overflow-scrolling:touch和ios滚动
----------------------------------------------- ---------------
为什么列存储可以大大提高数据查询性能?
----------------------------------------------- ---------------
MySQL slave_exec_mode 参数说明
----------------------------------------------- ---------------
阿里安全 Pandora Labs 首次完美越狱 Apple iOS 11.2
----------------------------------------------- ---------------
《RabbitMQ教程》翻译第3章发布与订阅
----------------------------------------------- ---------------
Android HandlerThread的使用介绍及源码分析
----------------------------------------------- ---------------
(四):C++分布式实时应用框架-状态中心模块
----------------------------------------------- ---------------
感知器学习与实践
----------------------------------------------- ---------------
SQLServer 审查文档 1(使用 C#)
----------------------------------------------- ---------------
分布式监控系统Zabbix3.2 数据库连接数警告
----------------------------------------------- ---------------
ABP模块-零+AdminLTE+Bootstrap Table+jQuery权限管理系统第16节-SignalR和ABP框架Abp.Web.SignalR和扩展
----------------------------------------------- ---------------
Docker:限制容器可用的内存
----------------------------------------------- ---------------
javascript 设计模式-迭代器模式
----------------------------------------------- ---------------
>>>
网页视频抓取脚本(会把v2版本打成exe运行先看v1版本import,,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-12-06 04:07
编写了两个脚本,分别是 v1 和 v2。
所有python调用mediainfo工具提取视频元数据信息
v1版本在pycharm中使用测试运行,指定视频路径
v2版本终于交付运行运行了,v2版本会以exe的形式运行
先看v1版本
导入 os,subprocess,json,re,locale,sys
导入 xlwt、时间、关闭
#获取当前文件所在的绝对目录路径
# this_path=os.path.abspath('.')
# print('当前路径为----',this_path)
# dir_path=this_path
#视频文件所在目录
dir_path='I:\\3 分钟午餐'
# print(os.listdir(this_path))
打印('---------------------------------')
print('--------------程序即将启动----------------')
# dir_path=this_path
#定义一个列表来存放每个文件的绝对路径,方便后面的操作
init_list=[]
# dir_path='F:\\Dollhouse 总视频'
#创建一个方法,统计每个文件路径,并附加到列表中。这里注释掉递归,不获取子目录,只获取dir_path下的视频
def get_all_file(dir_path,init_list):
对于 os.listdir(dir_path) 中的文件:
# 打印(文件)
filepath=os.path.join(dir_path,file)
# 打印(文件路径)
如果 os.path.isdir(filepath):
print('遇到子目录---%s---此版本暂时不提取子目录视频信息--'%(filepath))
time.sleep(2)
# get_all_file(文件路径)
其他:
如果不是 file.endswith('exe'):
init_list.append(文件路径)
返回init_list
#执行上述方法,将每个文件的绝对路径追加到列表中
file_list=get_all_file(dir_path,init_list)
print("读完文件-----3秒后,开始获取详细视频信息-----")
time.sleep(3)
#定义一个方法来获取单个媒体文件的元数据并作为字典数据返回
#这个程序的核心是调用mediainfo工具提取视频信息
def get_media_info(file):
pname='D:\mediainfo_i386\MediaInfo.exe "%s" --Output=JSON'%(file)
result=subprocess.Popen(pname,shell=False,stdout=subprocess.PIPE).stdout
list_std=result.readlines()
str_tmp=''
对于 list_std 中的项目:
str_tmp+=bytes.decode(item.strip())
json_data=json.loads(str_tmp)
返回json_data
#定义一个传递字典数据的方法,返回你想要的字段数据,返回一个值列表
def get_dict_data(json_data):
#获取文件大小
filesize=json_data['media']['track'][0]['FileSize']
#获取比特率
malv=json_data['media']['track'][0]['OverallBitRate'][0:4]
#获取播放时长
duration=json_data['media']['track'][0]['Duration'].split('.')[0]
#获取文件类型
file_format=json_data['media']['track'][0]['Format']
#获取边框宽度
samp_width=json_data['media']['track'][1]['Sampled_Width']
#获取框架高度
samp_height=json_data['media']['track'][1]['Sampled_Height']
返回 [filesize,malv,duration,file_format,samp_width,samp_height]
#定义一个获取文件名的方法,它是key,它的值是目标列表,返回值是一个字典,参数是文件列表
dict_all={}
#定义保存和提取日志失败的视频文件名
f_fail=open('提取失败 log.log','a',encoding='utf-8') # 追加模式
def get_all_dict(file_list,f_fail):
对于 file_list 中的文件:
filename=os.path.split(file)[1]
打印(文件名)
time.sleep(0.1)
试试:
info_list=get_dict_data(get_media_info(file))
dict_all[文件名]=info_list
例外为 e:
print(filename,'------提取此文件信息失败---------')
f_fail.write(文件名+'\r\n')
f_fail.close()
get_all_dict(file_list,f_fail)
# 用于 dict_all 中的项目:
# print(item,dict_all[item])
#创建一个excel表格存放文件路径信息,第一列是目录,第二列是文件名
wb = xlwt.Workbook()
sh = wb.add_sheet('元数据')
#写第一行
row_count=0
sh.write(row_count,0,"文件名")
sh.write(row_count,1,"文件大小")
sh.write(row_count,2,"比特率")
sh.write(row_count,3,"总持续时间")
sh.write(row_count,4,"视频格式")
sh.write(row_count,5,"帧宽度")
sh.write(row_count,6,"frame height")
#批量写入视频信息
row_count=1
对于 dict_all 中的项目:
sh.write(row_count,0,item)
sh.write(row_count,1,dict_all[item][0])
sh.write(row_count,2,dict_all[item][1])
sh.write(row_count,3,dict_all[item][2])
sh.write(row_count,4,dict_all[item][3])
sh.write(row_count,5,dict_all[item][4])
sh.write(row_count,6,dict_all[item][5])
row_count+=1
#
wb.save("元数据统计.xls")
#
看v2版本
v2版本是提取当前目录下的视频
导入 os,subprocess,json,re,locale,sys
导入 xlwt、时间、关闭
#获取当前文件所在的绝对目录路径
this_path=os.path.abspath('.')
print('当前路径为----', this_path)
dir_path=this_path
# print(os.listdir(this_path))
打印('---------------------------------')
print('--------------程序即将启动----------------')
# dir_path=this_path
#定义一个列表来存放每个文件路径,方便后面的操作
init_list=[]
# dir_path='I:\\3 分钟午餐'
# dir_path='F:\\Dollhouse 总视频'
#创建一个方法,统计每个文件路径,并附加到列表中。使用递归,这里没有获取子目录
def get_all_file(dir_path,init_list):
对于 os.listdir(dir_path) 中的文件:
# 打印(文件)
filepath=os.path.join(dir_path,file)
# 打印(文件路径)
如果 os.path.isdir(filepath):
print('遇到子目录---%s---此版本暂时不提取子目录视频信息--'%(filepath))
time.sleep(2)
# get_all_file(文件路径)
其他:
如果不是 file.endswith('exe'):
init_list.append(文件路径)
返回init_list
#执行上述方法,将每个文件的绝对路径追加到列表中
file_list=get_all_file(dir_path,init_list)
print("读完文件-----3秒后,开始获取详细视频信息-----")
time.sleep(3)
#定义一个方法来获取单个媒体文件的元数据并作为字典数据返回
def get_media_info(file):
pname='D:\mediainfo_i386\MediaInfo.exe "%s" --Output=JSON'%(file)
result=subprocess.Popen(pname,shell=False,stdout=subprocess.PIPE).stdout
list_std=result.readlines()
str_tmp=''
对于 list_std 中的项目:
str_tmp+=bytes.decode(item.strip())
json_data=json.loads(str_tmp)
返回json_data
#定义一个传递字典数据的方法,返回你想要的字段数据,返回一个值列表
def get_dict_data(json_data):
#获取文件大小
filesize=json_data['media']['track'][0]['FileSize']
#获取比特率
malv=json_data['media']['track'][0]['OverallBitRate'][0:4]
#获取播放时长
duration=json_data['media']['track'][0]['Duration'].split('.')[0]
#获取文件类型
file_format=json_data['media']['track'][0]['Format']
#获取边框宽度
samp_width=json_data['media']['track'][1]['Sampled_Width']
#获取框架高度
samp_height=json_data['media']['track'][1]['Sampled_Height']
返回 [filesize,malv,duration,file_format,samp_width,samp_height]
#定义一个获取文件名的方法,它是key,它的值是目标列表,返回值是一个字典,参数是文件列表
dict_all={}
f_fail=open('提取失败 log.log','a',encoding='utf-8') # 追加模式
def get_all_dict(file_list,f_fail):
对于 file_list 中的文件:
filename=os.path.split(file)[1]
打印(文件名)
time.sleep(0.1)
试试:
info_list=get_dict_data(get_media_info(file))
dict_all[文件名]=info_list
例外为 e:
print(filename,'------提取此文件信息失败---------')
f_fail.write(文件名+'\r\n')
f_fail.close()
get_all_dict(file_list,f_fail)
# 用于 dict_all 中的项目:
# print(item,dict_all[item])
#创建一个excel表格存放文件路径信息,第一列是目录,第二列是文件名
wb = xlwt.Workbook()
sh = wb.add_sheet('元数据')
#写第一行
row_count=0
sh.write(row_count,0,"文件名")
sh.write(row_count,1,"文件大小")
sh.write(row_count,2,"比特率")
sh.write(row_count,3,"总持续时间")
sh.write(row_count,4,"视频格式")
sh.write(row_count,5,"帧宽度")
sh.write(row_count,6,"frame height")
row_count=1
对于 dict_all 中的项目:
sh.write(row_count,0,item)
sh.write(row_count,1,dict_all[item][0])
sh.write(row_count,2,dict_all[item][1])
sh.write(row_count,3,dict_all[item][2])
sh.write(row_count,4,dict_all[item][3])
sh.write(row_count,5,dict_all[item][4])
sh.write(row_count,6,dict_all[item][5])
row_count+=1
#
wb.save("元数据统计.xls")
将 v2 版本输入到 exe 文件中
将这个exe文件复制到以下路径
这个程序可以交付给运维同事
测试和验证部分
如何使用,把程序放在视频的同级目录
根据代码缩写,如果视频运行成功:
1、本程序不会处理哈哈目录
2、对于abc.123等无法识别的文件(可能不是视频文件,或损坏的视频文件),本程序会记录日志,不会中断程序的正常运行。
3、程序运行后会有一个失败log.log文件,里面记录了提取信息失败的视频名称,把提取成功的视频文件放在“Metadata Statistics.xls”中
正在测试验证
双击运行
操作结束
Excel 信息
文件大小以字节为单位。如果要以MB或GB显示,可以使用excel表格中的内置公式进行处理。
字段很多,比特率,时长等,这里因为操作只需要下面几个字段,把这些提取出来
如果你把这个exe程序发给你的操作同事,你需要把D盘的mediainfo_i386文件夹一起给他们,这个文件必须放在D盘 查看全部
网页视频抓取脚本(会把v2版本打成exe运行先看v1版本import,,)
编写了两个脚本,分别是 v1 和 v2。
所有python调用mediainfo工具提取视频元数据信息
v1版本在pycharm中使用测试运行,指定视频路径
v2版本终于交付运行运行了,v2版本会以exe的形式运行
先看v1版本
导入 os,subprocess,json,re,locale,sys
导入 xlwt、时间、关闭
#获取当前文件所在的绝对目录路径
# this_path=os.path.abspath('.')
# print('当前路径为----',this_path)
# dir_path=this_path
#视频文件所在目录
dir_path='I:\\3 分钟午餐'
# print(os.listdir(this_path))
打印('---------------------------------')
print('--------------程序即将启动----------------')
# dir_path=this_path
#定义一个列表来存放每个文件的绝对路径,方便后面的操作
init_list=[]
# dir_path='F:\\Dollhouse 总视频'
#创建一个方法,统计每个文件路径,并附加到列表中。这里注释掉递归,不获取子目录,只获取dir_path下的视频
def get_all_file(dir_path,init_list):
对于 os.listdir(dir_path) 中的文件:
# 打印(文件)
filepath=os.path.join(dir_path,file)
# 打印(文件路径)
如果 os.path.isdir(filepath):
print('遇到子目录---%s---此版本暂时不提取子目录视频信息--'%(filepath))
time.sleep(2)
# get_all_file(文件路径)
其他:
如果不是 file.endswith('exe'):
init_list.append(文件路径)
返回init_list
#执行上述方法,将每个文件的绝对路径追加到列表中
file_list=get_all_file(dir_path,init_list)
print("读完文件-----3秒后,开始获取详细视频信息-----")
time.sleep(3)
#定义一个方法来获取单个媒体文件的元数据并作为字典数据返回
#这个程序的核心是调用mediainfo工具提取视频信息
def get_media_info(file):
pname='D:\mediainfo_i386\MediaInfo.exe "%s" --Output=JSON'%(file)
result=subprocess.Popen(pname,shell=False,stdout=subprocess.PIPE).stdout
list_std=result.readlines()
str_tmp=''
对于 list_std 中的项目:
str_tmp+=bytes.decode(item.strip())
json_data=json.loads(str_tmp)
返回json_data
#定义一个传递字典数据的方法,返回你想要的字段数据,返回一个值列表
def get_dict_data(json_data):
#获取文件大小
filesize=json_data['media']['track'][0]['FileSize']
#获取比特率
malv=json_data['media']['track'][0]['OverallBitRate'][0:4]
#获取播放时长
duration=json_data['media']['track'][0]['Duration'].split('.')[0]
#获取文件类型
file_format=json_data['media']['track'][0]['Format']
#获取边框宽度
samp_width=json_data['media']['track'][1]['Sampled_Width']
#获取框架高度
samp_height=json_data['media']['track'][1]['Sampled_Height']
返回 [filesize,malv,duration,file_format,samp_width,samp_height]
#定义一个获取文件名的方法,它是key,它的值是目标列表,返回值是一个字典,参数是文件列表
dict_all={}
#定义保存和提取日志失败的视频文件名
f_fail=open('提取失败 log.log','a',encoding='utf-8') # 追加模式
def get_all_dict(file_list,f_fail):
对于 file_list 中的文件:
filename=os.path.split(file)[1]
打印(文件名)
time.sleep(0.1)
试试:
info_list=get_dict_data(get_media_info(file))
dict_all[文件名]=info_list
例外为 e:
print(filename,'------提取此文件信息失败---------')
f_fail.write(文件名+'\r\n')
f_fail.close()
get_all_dict(file_list,f_fail)
# 用于 dict_all 中的项目:
# print(item,dict_all[item])
#创建一个excel表格存放文件路径信息,第一列是目录,第二列是文件名
wb = xlwt.Workbook()
sh = wb.add_sheet('元数据')
#写第一行
row_count=0
sh.write(row_count,0,"文件名")
sh.write(row_count,1,"文件大小")
sh.write(row_count,2,"比特率")
sh.write(row_count,3,"总持续时间")
sh.write(row_count,4,"视频格式")
sh.write(row_count,5,"帧宽度")
sh.write(row_count,6,"frame height")
#批量写入视频信息
row_count=1
对于 dict_all 中的项目:
sh.write(row_count,0,item)
sh.write(row_count,1,dict_all[item][0])
sh.write(row_count,2,dict_all[item][1])
sh.write(row_count,3,dict_all[item][2])
sh.write(row_count,4,dict_all[item][3])
sh.write(row_count,5,dict_all[item][4])
sh.write(row_count,6,dict_all[item][5])
row_count+=1
#
wb.save("元数据统计.xls")
#
看v2版本
v2版本是提取当前目录下的视频
导入 os,subprocess,json,re,locale,sys
导入 xlwt、时间、关闭
#获取当前文件所在的绝对目录路径
this_path=os.path.abspath('.')
print('当前路径为----', this_path)
dir_path=this_path
# print(os.listdir(this_path))
打印('---------------------------------')
print('--------------程序即将启动----------------')
# dir_path=this_path
#定义一个列表来存放每个文件路径,方便后面的操作
init_list=[]
# dir_path='I:\\3 分钟午餐'
# dir_path='F:\\Dollhouse 总视频'
#创建一个方法,统计每个文件路径,并附加到列表中。使用递归,这里没有获取子目录
def get_all_file(dir_path,init_list):
对于 os.listdir(dir_path) 中的文件:
# 打印(文件)
filepath=os.path.join(dir_path,file)
# 打印(文件路径)
如果 os.path.isdir(filepath):
print('遇到子目录---%s---此版本暂时不提取子目录视频信息--'%(filepath))
time.sleep(2)
# get_all_file(文件路径)
其他:
如果不是 file.endswith('exe'):
init_list.append(文件路径)
返回init_list
#执行上述方法,将每个文件的绝对路径追加到列表中
file_list=get_all_file(dir_path,init_list)
print("读完文件-----3秒后,开始获取详细视频信息-----")
time.sleep(3)
#定义一个方法来获取单个媒体文件的元数据并作为字典数据返回
def get_media_info(file):
pname='D:\mediainfo_i386\MediaInfo.exe "%s" --Output=JSON'%(file)
result=subprocess.Popen(pname,shell=False,stdout=subprocess.PIPE).stdout
list_std=result.readlines()
str_tmp=''
对于 list_std 中的项目:
str_tmp+=bytes.decode(item.strip())
json_data=json.loads(str_tmp)
返回json_data
#定义一个传递字典数据的方法,返回你想要的字段数据,返回一个值列表
def get_dict_data(json_data):
#获取文件大小
filesize=json_data['media']['track'][0]['FileSize']
#获取比特率
malv=json_data['media']['track'][0]['OverallBitRate'][0:4]
#获取播放时长
duration=json_data['media']['track'][0]['Duration'].split('.')[0]
#获取文件类型
file_format=json_data['media']['track'][0]['Format']
#获取边框宽度
samp_width=json_data['media']['track'][1]['Sampled_Width']
#获取框架高度
samp_height=json_data['media']['track'][1]['Sampled_Height']
返回 [filesize,malv,duration,file_format,samp_width,samp_height]
#定义一个获取文件名的方法,它是key,它的值是目标列表,返回值是一个字典,参数是文件列表
dict_all={}
f_fail=open('提取失败 log.log','a',encoding='utf-8') # 追加模式
def get_all_dict(file_list,f_fail):
对于 file_list 中的文件:
filename=os.path.split(file)[1]
打印(文件名)
time.sleep(0.1)
试试:
info_list=get_dict_data(get_media_info(file))
dict_all[文件名]=info_list
例外为 e:
print(filename,'------提取此文件信息失败---------')
f_fail.write(文件名+'\r\n')
f_fail.close()
get_all_dict(file_list,f_fail)
# 用于 dict_all 中的项目:
# print(item,dict_all[item])
#创建一个excel表格存放文件路径信息,第一列是目录,第二列是文件名
wb = xlwt.Workbook()
sh = wb.add_sheet('元数据')
#写第一行
row_count=0
sh.write(row_count,0,"文件名")
sh.write(row_count,1,"文件大小")
sh.write(row_count,2,"比特率")
sh.write(row_count,3,"总持续时间")
sh.write(row_count,4,"视频格式")
sh.write(row_count,5,"帧宽度")
sh.write(row_count,6,"frame height")
row_count=1
对于 dict_all 中的项目:
sh.write(row_count,0,item)
sh.write(row_count,1,dict_all[item][0])
sh.write(row_count,2,dict_all[item][1])
sh.write(row_count,3,dict_all[item][2])
sh.write(row_count,4,dict_all[item][3])
sh.write(row_count,5,dict_all[item][4])
sh.write(row_count,6,dict_all[item][5])
row_count+=1
#
wb.save("元数据统计.xls")
将 v2 版本输入到 exe 文件中
将这个exe文件复制到以下路径
这个程序可以交付给运维同事
测试和验证部分
如何使用,把程序放在视频的同级目录
根据代码缩写,如果视频运行成功:
1、本程序不会处理哈哈目录
2、对于abc.123等无法识别的文件(可能不是视频文件,或损坏的视频文件),本程序会记录日志,不会中断程序的正常运行。
3、程序运行后会有一个失败log.log文件,里面记录了提取信息失败的视频名称,把提取成功的视频文件放在“Metadata Statistics.xls”中
正在测试验证
双击运行
操作结束
Excel 信息
文件大小以字节为单位。如果要以MB或GB显示,可以使用excel表格中的内置公式进行处理。
字段很多,比特率,时长等,这里因为操作只需要下面几个字段,把这些提取出来
如果你把这个exe程序发给你的操作同事,你需要把D盘的mediainfo_i386文件夹一起给他们,这个文件必须放在D盘
网页视频抓取脚本(Android手机上的抖音详细操作内容介绍-脚本之家)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-05 23:12
既然抖音的火爆大家有目共睹,小编在网上发现了一些好玩的东西,就是爬取一些网站,所以我也考虑是否可以进行。 抖音@抖音上解决的案例,经过实际操作,真正实现了。使用自动化工具,它可以很容易地实现。后来有小伙伴建议,去除了苹果,减肥后就可以实现了。然后看详细操作。内容。
1、mitmproxy/mitmdump 抓包
import requests
path = 'D:/video/'
num = 1788
def response(flow):
global num
target_urls = ['url']
for url in target_urls:
if flow.request.url.startswith(url):
filename = path + str(num) + '.mp4
res = requests.get(flow.request.url, stream=True)
with open(filename, 'ab') as f:
f.write(res.content)
f.flush()
print(filename + '下载完成')
num += 1
2、Appium 模拟手机操作
使用启动服务器按钮启动appium服务
再次点击Start Session,在Android手机上启动抖音app,进入启动页面
3、python脚本驱动app,直接在pycharm中运行即可
示例扩展:
import requests
import json
import re
import os
from pprint import pprint as pp
import queue
class DouYin:
header = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1',
}
def __init__(self, url=None):
self.url = self.get_RealAddress(url)
# 获取用户视频的url
self.user_video_url = 'https://www.douyin.com/aweme/v1/aweme/post/?{0}'
self.user_id = re.search(r'user/(.*)\?', self.url).group(1) # 用户id
requests.packages.urllib3.disable_warnings()
self.session = requests.Session()
self.target_folder = '' # 创建文件的路径
self.queue = queue.Queue() # 生成一个队列对象
def user_info(self):
self.mkdir_dir()
p = os.popen('node fuck.js %s' % self.user_id) # 获取加密的signature
signature = p.readlines()[0]
user_video_params = {
'user_id': str(self.user_id),
'count': '21',
'max_cursor': '0',
'aid': '1128',
'_signature': signature
}
# 获取下载视频的列表
def get_aweme_list(max_cursor=None):
if max_cursor:
user_video_params['max_cursor'] = str(max_cursor)
user_video_url = self.user_video_url.format(
'&'.join([key + '=' + user_video_params[key] for key in user_video_params])) # 拼接参数
response = requests.get(
url=user_video_url, headers=self.header, verify=False)
contentJson = json.loads(response.content.decode('utf-8')) # 将返回的进行utf8编码
aweme_list = contentJson.get('aweme_list', [])
for aweme in aweme_list:
video_name = aweme.get(
'share_info', None).get('share_desc', None) # 视频的名字
video_url = aweme.get('video', None).get('play_addr', None).get(
'url_list', None)[0].replace('playwm', 'play') # 视频链接
self.queue.put((video_name, video_url)) # 将数据进队列
if contentJson.get('has_more') == 1: # 判断后面是不是还有是1就是还有
return get_aweme_list(contentJson.get('max_cursor')) # 有的话获取参数max_cursor
get_aweme_list()
# 下载视频
def get_download(self):
while True:
video_name, video_url = self.queue.get()
file_name = video_name + '.mp4'
file_path = os.path.join(self.target_folder, file_name)
if not os.path.isfile(file_path):
print('download %s form %s.\n' % (file_name, video_url))
times = 0
while times < 10:
try:
response = requests.get(
url=video_url, stream=True, timeout=10, verify=False) # 开启流下载
with open(file_path, 'wb') as f:
for chunk in response.iter_content(1024): # 返回迭代对象
f.write(chunk)
print('下载成功')
break
except:
print('下载失败')
times += 1
# 创建对应的文件夹
def mkdir_dir(self):
current_folder = os.getcwd()
self.target_folder = os.path.join(
current_folder, 'download/%s' % self.user_id)
if not os.path.isdir(self.target_folder):
os.mkdir(self.target_folder)
# 短链接转长地址
def get_RealAddress(self, url):
if url.find('v.douyin.com') < 0:
return url
response = requests.get(
url=url, headers=self.header, allow_redirects=False) # allow_redirects 允许跳转
return response.headers['Location']
if __name__ == '__main__':
douyin = DouYin(url='http://v.douyin.com/J2B9Sk/')
douyin.user_info()
douyin.get_download()
这篇关于文章关于python爬取抖音视频实例分析的文章介绍到这里,更多关于如何使用python爬取抖音视频内容,请搜索脚本首页之前的文章或者继续浏览以下相关的文章希望大家以后多多支持Script Home! 查看全部
网页视频抓取脚本(Android手机上的抖音详细操作内容介绍-脚本之家)
既然抖音的火爆大家有目共睹,小编在网上发现了一些好玩的东西,就是爬取一些网站,所以我也考虑是否可以进行。 抖音@抖音上解决的案例,经过实际操作,真正实现了。使用自动化工具,它可以很容易地实现。后来有小伙伴建议,去除了苹果,减肥后就可以实现了。然后看详细操作。内容。
1、mitmproxy/mitmdump 抓包
import requests
path = 'D:/video/'
num = 1788
def response(flow):
global num
target_urls = ['url']
for url in target_urls:
if flow.request.url.startswith(url):
filename = path + str(num) + '.mp4
res = requests.get(flow.request.url, stream=True)
with open(filename, 'ab') as f:
f.write(res.content)
f.flush()
print(filename + '下载完成')
num += 1
2、Appium 模拟手机操作
使用启动服务器按钮启动appium服务
再次点击Start Session,在Android手机上启动抖音app,进入启动页面
3、python脚本驱动app,直接在pycharm中运行即可
示例扩展:
import requests
import json
import re
import os
from pprint import pprint as pp
import queue
class DouYin:
header = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1',
}
def __init__(self, url=None):
self.url = self.get_RealAddress(url)
# 获取用户视频的url
self.user_video_url = 'https://www.douyin.com/aweme/v1/aweme/post/?{0}'
self.user_id = re.search(r'user/(.*)\?', self.url).group(1) # 用户id
requests.packages.urllib3.disable_warnings()
self.session = requests.Session()
self.target_folder = '' # 创建文件的路径
self.queue = queue.Queue() # 生成一个队列对象
def user_info(self):
self.mkdir_dir()
p = os.popen('node fuck.js %s' % self.user_id) # 获取加密的signature
signature = p.readlines()[0]
user_video_params = {
'user_id': str(self.user_id),
'count': '21',
'max_cursor': '0',
'aid': '1128',
'_signature': signature
}
# 获取下载视频的列表
def get_aweme_list(max_cursor=None):
if max_cursor:
user_video_params['max_cursor'] = str(max_cursor)
user_video_url = self.user_video_url.format(
'&'.join([key + '=' + user_video_params[key] for key in user_video_params])) # 拼接参数
response = requests.get(
url=user_video_url, headers=self.header, verify=False)
contentJson = json.loads(response.content.decode('utf-8')) # 将返回的进行utf8编码
aweme_list = contentJson.get('aweme_list', [])
for aweme in aweme_list:
video_name = aweme.get(
'share_info', None).get('share_desc', None) # 视频的名字
video_url = aweme.get('video', None).get('play_addr', None).get(
'url_list', None)[0].replace('playwm', 'play') # 视频链接
self.queue.put((video_name, video_url)) # 将数据进队列
if contentJson.get('has_more') == 1: # 判断后面是不是还有是1就是还有
return get_aweme_list(contentJson.get('max_cursor')) # 有的话获取参数max_cursor
get_aweme_list()
# 下载视频
def get_download(self):
while True:
video_name, video_url = self.queue.get()
file_name = video_name + '.mp4'
file_path = os.path.join(self.target_folder, file_name)
if not os.path.isfile(file_path):
print('download %s form %s.\n' % (file_name, video_url))
times = 0
while times < 10:
try:
response = requests.get(
url=video_url, stream=True, timeout=10, verify=False) # 开启流下载
with open(file_path, 'wb') as f:
for chunk in response.iter_content(1024): # 返回迭代对象
f.write(chunk)
print('下载成功')
break
except:
print('下载失败')
times += 1
# 创建对应的文件夹
def mkdir_dir(self):
current_folder = os.getcwd()
self.target_folder = os.path.join(
current_folder, 'download/%s' % self.user_id)
if not os.path.isdir(self.target_folder):
os.mkdir(self.target_folder)
# 短链接转长地址
def get_RealAddress(self, url):
if url.find('v.douyin.com') < 0:
return url
response = requests.get(
url=url, headers=self.header, allow_redirects=False) # allow_redirects 允许跳转
return response.headers['Location']
if __name__ == '__main__':
douyin = DouYin(url='http://v.douyin.com/J2B9Sk/')
douyin.user_info()
douyin.get_download()
这篇关于文章关于python爬取抖音视频实例分析的文章介绍到这里,更多关于如何使用python爬取抖音视频内容,请搜索脚本首页之前的文章或者继续浏览以下相关的文章希望大家以后多多支持Script Home!
网页视频抓取脚本(Java网页视频抓取脚本的使用步骤及使用方法【图文】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-05 16:15
网页视频抓取脚本是想自己录制视频点击观看呢,还是想用脚本实现一些小功能呢。之前我用的不太好的视频抓取脚本bt天下就大功告成,但是该轮到暴风影音投屏到你电脑了吧!它发现你在播放电脑里的视频,就会自动投屏到电脑屏幕上。但是今天要推荐的一个脚本,它可以跟你要的这个投屏功能一毛钱关系都没有哦!仅仅有一个路由器,就可以让你视频投屏到电脑上观看。
这个脚本名叫:web网页视频抓取脚本,作者:airzipx。从名字就能知道,这个脚本主要是讲解网页上的视频提取的。这个脚本主要的功能非常简单,能把百度云的视频转成文本,然后你就可以把它转换成文件了。来给大家演示一下具体的使用步骤:1.我们可以把它的脚本直接分享给你要用到的队友。2.把你要分享的网址发给队友,队友就可以将你发的网址复制粘贴在浏览器输入3.点击网页视频抓取,就会复制视频的地址。
如果你只是学习用,可以直接将下载地址发给队友,队友就可以直接下载你分享的地址。4.点击开始下载,保存视频就可以了。下载完以后解压就可以放到电脑里面再点播放就可以了。具体的软件作者不公布,获取软件方式,请看文章最下方。对网页视频抓取脚本有兴趣的,欢迎留言交流。
可以用网页截图工具或者打开视频,找到第一个黑框点开,就有解析这个视频的解析后的文件位置。每秒解析多少,就要看视频速度,速度快,解析时间慢,速度慢,解析时间长。然后就是加速度,每秒加速多少。我也不知道你说的慢解析有多慢,av800000和音质渣请自己参考keyshot渲染的慢和jpg压缩的慢。 查看全部
网页视频抓取脚本(Java网页视频抓取脚本的使用步骤及使用方法【图文】)
网页视频抓取脚本是想自己录制视频点击观看呢,还是想用脚本实现一些小功能呢。之前我用的不太好的视频抓取脚本bt天下就大功告成,但是该轮到暴风影音投屏到你电脑了吧!它发现你在播放电脑里的视频,就会自动投屏到电脑屏幕上。但是今天要推荐的一个脚本,它可以跟你要的这个投屏功能一毛钱关系都没有哦!仅仅有一个路由器,就可以让你视频投屏到电脑上观看。
这个脚本名叫:web网页视频抓取脚本,作者:airzipx。从名字就能知道,这个脚本主要是讲解网页上的视频提取的。这个脚本主要的功能非常简单,能把百度云的视频转成文本,然后你就可以把它转换成文件了。来给大家演示一下具体的使用步骤:1.我们可以把它的脚本直接分享给你要用到的队友。2.把你要分享的网址发给队友,队友就可以将你发的网址复制粘贴在浏览器输入3.点击网页视频抓取,就会复制视频的地址。
如果你只是学习用,可以直接将下载地址发给队友,队友就可以直接下载你分享的地址。4.点击开始下载,保存视频就可以了。下载完以后解压就可以放到电脑里面再点播放就可以了。具体的软件作者不公布,获取软件方式,请看文章最下方。对网页视频抓取脚本有兴趣的,欢迎留言交流。
可以用网页截图工具或者打开视频,找到第一个黑框点开,就有解析这个视频的解析后的文件位置。每秒解析多少,就要看视频速度,速度快,解析时间慢,速度慢,解析时间长。然后就是加速度,每秒加速多少。我也不知道你说的慢解析有多慢,av800000和音质渣请自己参考keyshot渲染的慢和jpg压缩的慢。
网页视频抓取脚本(1.整理输出环境Macpro1.安装应用场景)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-05 06:08
1.应用场景
主要用于使用脚本批量下载网页视频、音频、图片资源,采集下载资源,避免资源丢失。使用命令脚本将有助于节省时间并提高效率。
比如以后资源可能不存在,或者你想二次整理资源,更好的总结归类,或者分享一下~
2.学习/操作
1.文档阅读
//一行脚本批量下载哔哩哔哩视频
// 官方网站
//FFmpeg
// 源代码
2021-04-23-TS网页视频下载-学习/实践
2.组织输出
环境
Mac 专业版
1. 安装
这里是Mac最简单的使用方法,同时因为公司网络可以访问外网
brew install you-get
可以看到,安装完成~
至于后期处理、后续学习和实践或者需要用到的请补充
2. 下载
2.1 这里是下载哔哩哔哩数学测试视频的例子。因为版权原因,这些视频几乎随时都有可能被下架~所以下载最安全~
2.2 批量下载,执行以下命令:
你得到 -l'#39;
可以看到,下载操作已经开始了,但是查看输出信息,列表似乎并不完整。P1 001-21 共21章
其实从界面上可以看到应该有25个section,如下:
暂时不管这个问题,继续下载【发现21才一年,所有列表视频都可以正常下载】,可以看到下载的格式是flv格式。下载第一个视频后,使用腾讯视频App打开。声音画面正常。到目前为止,一切似乎都很正常。只需等待所有视频下载。
2.3 中断下载重新下载
由于电脑有一段时间没有操作,进入休眠状态,暂定进程后,没有被激活,然后手动停止进程。
重新执行上述命令,出现如下输出界面:
删除“尚未下载的视频”后,选中的视频将被删除
然后重启上面脚本的执行,正常执行下载操作如下
笔记:
乍一看,不能基于断点继续下载~
接下来就是做其他的事情了,不用等整个下载过程结束了~
这是该计划的好处之一
去看看下载是否过一段时间就结束了:
补充参考
2021-04-23-TS网页视频下载-学习/实践
视窗
pip3 安装你得到
后续补充
...
3.问题/补充
待定
4.参考
//一行脚本批量下载哔哩哔哩视频
// 官方网站
//FFmpeg
// 源代码
2021-04-23-TS网页视频下载-学习/实践
后续补充
... 查看全部
网页视频抓取脚本(1.整理输出环境Macpro1.安装应用场景)
1.应用场景
主要用于使用脚本批量下载网页视频、音频、图片资源,采集下载资源,避免资源丢失。使用命令脚本将有助于节省时间并提高效率。
比如以后资源可能不存在,或者你想二次整理资源,更好的总结归类,或者分享一下~
2.学习/操作
1.文档阅读
//一行脚本批量下载哔哩哔哩视频
// 官方网站
//FFmpeg
// 源代码
2021-04-23-TS网页视频下载-学习/实践
2.组织输出
环境
Mac 专业版
1. 安装
这里是Mac最简单的使用方法,同时因为公司网络可以访问外网
brew install you-get
可以看到,安装完成~
至于后期处理、后续学习和实践或者需要用到的请补充
2. 下载
2.1 这里是下载哔哩哔哩数学测试视频的例子。因为版权原因,这些视频几乎随时都有可能被下架~所以下载最安全~
2.2 批量下载,执行以下命令:
你得到 -l'#39;
可以看到,下载操作已经开始了,但是查看输出信息,列表似乎并不完整。P1 001-21 共21章
其实从界面上可以看到应该有25个section,如下:
暂时不管这个问题,继续下载【发现21才一年,所有列表视频都可以正常下载】,可以看到下载的格式是flv格式。下载第一个视频后,使用腾讯视频App打开。声音画面正常。到目前为止,一切似乎都很正常。只需等待所有视频下载。
2.3 中断下载重新下载
由于电脑有一段时间没有操作,进入休眠状态,暂定进程后,没有被激活,然后手动停止进程。
重新执行上述命令,出现如下输出界面:
删除“尚未下载的视频”后,选中的视频将被删除
然后重启上面脚本的执行,正常执行下载操作如下
笔记:
乍一看,不能基于断点继续下载~
接下来就是做其他的事情了,不用等整个下载过程结束了~
这是该计划的好处之一
去看看下载是否过一段时间就结束了:
补充参考
2021-04-23-TS网页视频下载-学习/实践
视窗
pip3 安装你得到
后续补充
...
3.问题/补充
待定
4.参考
//一行脚本批量下载哔哩哔哩视频
// 官方网站
//FFmpeg
// 源代码
2021-04-23-TS网页视频下载-学习/实践
后续补充
...
网页视频抓取脚本(python爬虫用户信息怎么扩展到抖音?经验分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-05 06:04
最近在学习python爬虫,想爬取采集抖音用户信息,因为看到相关爬虫帖子有这个需求,心血来潮,分享一下经验,整理一下思路道路。首先是看b站的一段爬虫短视频,脑王的插件,通过修改fdder函数将脑王的json数据包保存到本地,用python脚本循环读取数据包,然后自动打开浏览器搜索问题。现在我想把这个想法扩展到 抖音 这里。
首先安装最新的fidder,抖音用户的数据包传输协议是https。需要下载fidder证书并安装到手机或者安卓模拟器上。我用的是模拟器,然后把安卓模拟器的生成{over}{filter}设置为电脑的IP。现在模拟器的所有网络请求都已经被fidder获取到了,现在我们要抓取数据包,分析数据包,推荐一个解析json包的URL。它可以非常清楚地显示非常复杂和困难的数据部分。在模拟器中刷入json数据包的时候,我会一一复制出来。看一看,图片里有网址。
接下来,我想出了一个方法来保存这个数据包。重点是修改fidder函数。做爬虫和插件的时候经常用到fdder工具。我特地学习了这个fidder的使用。修改 fiiderscript。这个收录用户信息的json数据包的请求URL和主机是一样的。使用此修改后的函数将其保存到本地文件夹。
fidder函数本地保存的数据只能覆盖不能添加,所以只能在脚本循环中读取,所以用python写一个脚本,分析读取的数据,保存到本地数据库中。
现在只是编写模拟手动笔画的脚本抖音的最后一步。如果要多开几个,用模拟器保存数据会更快,所以写一个分辨率最小的。320 *480的分辨率节省资源,需要进入个人主页抓取用户信息。思路是在抖音中向上滑动,识别是广告还是直播,还是广告然后往下滑,而不是点击头像,延迟返回,然后循环。打包成apk安装在模拟器上进行真机测试!速度还不错。继续优化脚本,设置清除缓存功能。如果缓存太多,会很卡。
其实在抓包的过程中还有很多有意思的东西,比如没有水印的视频链接,可以采集,哈哈。还有一些细节问题,没有写清楚。有什么问题可以留言,我会认真解答。
最后附上百度云链接打包附件代码:/s/13ygH81Pf780HR1Po_vgFRg 密码:hzn5。
这个帖子也发在我的爱和我的个人公众号:pythontest,标题一样,以后可能会同步。 查看全部
网页视频抓取脚本(python爬虫用户信息怎么扩展到抖音?经验分享)
最近在学习python爬虫,想爬取采集抖音用户信息,因为看到相关爬虫帖子有这个需求,心血来潮,分享一下经验,整理一下思路道路。首先是看b站的一段爬虫短视频,脑王的插件,通过修改fdder函数将脑王的json数据包保存到本地,用python脚本循环读取数据包,然后自动打开浏览器搜索问题。现在我想把这个想法扩展到 抖音 这里。
首先安装最新的fidder,抖音用户的数据包传输协议是https。需要下载fidder证书并安装到手机或者安卓模拟器上。我用的是模拟器,然后把安卓模拟器的生成{over}{filter}设置为电脑的IP。现在模拟器的所有网络请求都已经被fidder获取到了,现在我们要抓取数据包,分析数据包,推荐一个解析json包的URL。它可以非常清楚地显示非常复杂和困难的数据部分。在模拟器中刷入json数据包的时候,我会一一复制出来。看一看,图片里有网址。
接下来,我想出了一个方法来保存这个数据包。重点是修改fidder函数。做爬虫和插件的时候经常用到fdder工具。我特地学习了这个fidder的使用。修改 fiiderscript。这个收录用户信息的json数据包的请求URL和主机是一样的。使用此修改后的函数将其保存到本地文件夹。
fidder函数本地保存的数据只能覆盖不能添加,所以只能在脚本循环中读取,所以用python写一个脚本,分析读取的数据,保存到本地数据库中。
现在只是编写模拟手动笔画的脚本抖音的最后一步。如果要多开几个,用模拟器保存数据会更快,所以写一个分辨率最小的。320 *480的分辨率节省资源,需要进入个人主页抓取用户信息。思路是在抖音中向上滑动,识别是广告还是直播,还是广告然后往下滑,而不是点击头像,延迟返回,然后循环。打包成apk安装在模拟器上进行真机测试!速度还不错。继续优化脚本,设置清除缓存功能。如果缓存太多,会很卡。
其实在抓包的过程中还有很多有意思的东西,比如没有水印的视频链接,可以采集,哈哈。还有一些细节问题,没有写清楚。有什么问题可以留言,我会认真解答。
最后附上百度云链接打包附件代码:/s/13ygH81Pf780HR1Po_vgFRg 密码:hzn5。
这个帖子也发在我的爱和我的个人公众号:pythontest,标题一样,以后可能会同步。
网页视频抓取脚本(之前博客>博客博客博客岂止是换页博客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-05 06:03
由于之前张耀老师的网页脚本51cto升级,课程列表页面使用javascript无效。
笔者发现视频课程页面右侧的列表是静态视频课程地址,所以修改了老师最初版本的脚本,使用视频课程页面时结果正常,所以修改后的脚本并发布了一些评论 出来供您研究
<p>[root@m01 scripts]# cat html_to_table.sh
#!/bin/bash
# oldboy linux training
# 2016-11-13
# 基于老男孩linux21期学员张耀开发脚本
#
EduFile=/tmp/edu.html #process temp file1
EduFile2=/tmp/edu2.html #process 2
Url="$*"
# Check for given parameters
[ $# -eq 0 ] && {
echo "USAGE: /bin/sh $0 http://...."
exit 1
}
# Judge url is ok?
curl -I $Url &>/dev/null
[ $? -ne 0 ] &&{
echo "Bad url,Please check it"
exit 1
}
# Defined get pagenum and CourseId Functions
# Defined get pagenum and CourseId Functions
#function getnum(){
# curl -s $Url>$EduFile
# grep '"pagesGoEnd"' $EduFile &>/dev/null
# if [ $? -eq 0 ]
# then
# num=`sed -rn 's#.*page=([0-9].*)" class="pagesGoEnd".*$#\1#gp' $EduFile`
# else
# num=`sed -rn 's|.*page=([0-9].*)#" class="pagesNum".*$|\1|gp' $EduFile`
# fi
# pagenum=${num:-1}
# CourseId=`echo $Url|awk -F "[-.]" '{print $4}'`
#}
# Defined curl html Functions
#function Curl(){
# getnum
# for i in `seq $pagenum`
# do
# curl "http://edu.51cto.com/index.php ... id%3D$CourseId&page=$i" 1>>$EduFile 2>/dev/null
# done
#}
#分段没了,原函数保留,视频页抓一遍就好
function Curl(){
curl "$*" 1>>$EduFile 2>/dev/null
}
# Defined Create table Functions
function table(){
sum=""
index=1
sed -rn '/lesson/ s# 查看全部
网页视频抓取脚本(之前博客>博客博客博客岂止是换页博客)
由于之前张耀老师的网页脚本51cto升级,课程列表页面使用javascript无效。
笔者发现视频课程页面右侧的列表是静态视频课程地址,所以修改了老师最初版本的脚本,使用视频课程页面时结果正常,所以修改后的脚本并发布了一些评论 出来供您研究
<p>[root@m01 scripts]# cat html_to_table.sh
#!/bin/bash
# oldboy linux training
# 2016-11-13
# 基于老男孩linux21期学员张耀开发脚本
#
EduFile=/tmp/edu.html #process temp file1
EduFile2=/tmp/edu2.html #process 2
Url="$*"
# Check for given parameters
[ $# -eq 0 ] && {
echo "USAGE: /bin/sh $0 http://...."
exit 1
}
# Judge url is ok?
curl -I $Url &>/dev/null
[ $? -ne 0 ] &&{
echo "Bad url,Please check it"
exit 1
}
# Defined get pagenum and CourseId Functions
# Defined get pagenum and CourseId Functions
#function getnum(){
# curl -s $Url>$EduFile
# grep '"pagesGoEnd"' $EduFile &>/dev/null
# if [ $? -eq 0 ]
# then
# num=`sed -rn 's#.*page=([0-9].*)" class="pagesGoEnd".*$#\1#gp' $EduFile`
# else
# num=`sed -rn 's|.*page=([0-9].*)#" class="pagesNum".*$|\1|gp' $EduFile`
# fi
# pagenum=${num:-1}
# CourseId=`echo $Url|awk -F "[-.]" '{print $4}'`
#}
# Defined curl html Functions
#function Curl(){
# getnum
# for i in `seq $pagenum`
# do
# curl "http://edu.51cto.com/index.php ... id%3D$CourseId&page=$i" 1>>$EduFile 2>/dev/null
# done
#}
#分段没了,原函数保留,视频页抓一遍就好
function Curl(){
curl "$*" 1>>$EduFile 2>/dev/null
}
# Defined Create table Functions
function table(){
sum=""
index=1
sed -rn '/lesson/ s#
网页视频抓取脚本(VidCoder是一个开源免费的DVD/蓝光视频抓取和转码软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-12-02 20:14
VidCoder 是一款开源且免费的 DVD/蓝光视频捕捉和转码软件。使用 HandBrake 作为编码引擎。它具有比 Handbrake 更友好的用户界面。有需要的朋友可以下载试试!
本软件需要[.NET Framework4.0]环境支持。
VidCoder 是适用于 Windows 的免费开源 DVD/蓝光翻录和视频转码应用程序。它使用 HandBrake 作为其编码引擎。Vidcoder 支持视频下载、编辑、字幕、上传一站式工具,可用于DVD/Blu-ray 视频捕获和转码操作。更重要的是,它可以导入字幕和指挥校队。目前支持中文语言包。操作更方便。特别适合视频发布团队编辑视频、添加字母、水印、转换格式等。当我们观看一些没有字幕的视频时,不妨使用这个视频编辑工具自己添加字母。可以设置偏移量,最适合使用胶片采集器。这里的闪电编辑器是最新的测试版下载,
VidCoder支持英文和中文,同时支持十多种其他语言!
VidCoder 是免费的开源软件
VidCoder 基于 C# 中的 .NET 4.6 / WPF 构建。它在 64 位版本的 Windows 7、8、10、Vista、Server 2008 和 Server 2012 上运行。
VidCoder UI(和 C# 互操作)由 RandomEngy 编写。核心编码引擎由了不起的 HandBrake 团队编写。尤其是 J45 对组合它们有很大帮助。
特征
多线程
MP4、MKV 容器
H.264 编码和 x264,世界上最好的视频编码器
完全集成的编码管道:一切都在一个过程中,没有庞大的中间临时文件
H.265、MPEG-4、MPEG-2、VP8、Theora 视频
AAC、MP3、Vorbis、AC3、FLAC 音频编码和 AAC/AC3/MP3/DTS/DTS-HD 直通
视频的目标比特率、大小或质量
2-pass 编码
解码、电视转播、去隔行、旋转、反射过滤器
批量编码
即时源预览
创建小的编码预览剪辑
暂停,恢复编码
特征
DVD光盘
VidCoder 可以翻录 DVD,但不会破坏大多数商业 DVD 中的 CSS 加密。您有多种删除加密的选项:
AnyDVD HD(121美元,即刻解除加密,为新游戏提供最佳支持)
Passkey Lite(免费,立即删除加密)
MakeMKV(免费,编码前需要拷贝到硬盘)
DVD Decrypter(免费,编码前需要拷贝到硬盘,不再更新)
蓝光
VidCoder 不会使 AACS 或 BD + 蓝光加密失败。有几个选项可以删除它
视频质量选项
简短版本:使用恒定质量编码。当您不需要严格控制输出大小时,这是对视频进行编码的最佳方式。
背景
通过确定编码帧与原创帧的接近程度,您可以衡量给定视频帧的图像质量。较低质量的图片可能会模糊或有块状视频伪影
在图像质量和使用的数据量之间存在权衡。随着您对图片应用更多数据,图片质量会提高。在某些时候,您会看到一张好看的照片,即使您应用更多数据,它也不会看起来更好。
并非所有视频都是平等的。具有大量运动或复杂细节的视频更难以压缩。在使用相同数据量的情况下,复杂视频的画质会比简单视频差。相反,复杂的视频需要更多的数据才能达到相同的质量水平。
平均比特率(一次)
这是许多人已经意识到的最古老的模式。您正在指定每秒允许进行视频压缩的数据量。数字越高,质量越高。但是,由于编码器正在处理视频,因此无法知道视频的其他部分是什么,因此最终将视频中的数据平均分配。这是不受欢迎的,因为它的简单部分被数据浪费在他们身上。如果您降低比特率以使这些部分有效,那么复杂的部分看起来会很糟糕。
平均比特率(两个通道)
两遍编码是解决这个问题的一种方法。它对整个视频进行了初步扫描:只是对其外观有了一个很好的了解。它可以计算如何将数据从简单的场景传输到更复杂的场景,同时仍然保持视频的整体平均比特率。因此,当第二遍出现时,您可以根据您选择的码率获得整体更漂亮的视频。
目标尺寸
目标大小只是平均比特率的一个额外步骤。它根据选定的音轨和视频长度执行一些计算,以确定适当的视频比特率,这将产生指定的目标文件大小。
但是整个方法还是有问题的。如果您使用相同的设置对许多视频进行编码,您可能会陷入与以前相同的陷阱。整体来说非常简单的视频(比如大多数卡通动画)会叠加无法用来提升画质的数据,而复杂的视频将无法获得所需的数据来抵御糟糕的画质。对这个问题的反应通常是简单地提高数据速率,即使是最复杂的视频看起来也不错。但问题仍然存在:通过提高数据速率,您将浪费更多简单的视频数据。如果有一种方法可以让每个视频看起来都不错,但又可以避免浪费数据呢?
质量稳定
用户不需要指定比特率或文件大小,而是需要指定要捕获的特定图片质量数 (CRF)。在 x264 中,较低的值意味着较高的质量,较高的值意味着较低的质量。这有点倒退,但它是一个非常简单的系统。合理的质量目标通常在 18-25 之间。以下是一些质量级别的示例。
日志:
删除了对 Microsoft.Toolkit.Uwp.Notifications 的依赖。这应该可以解决 4.1 Beta 中引入的崩溃问题。
修复源文本对齐方式。 查看全部
网页视频抓取脚本(VidCoder是一个开源免费的DVD/蓝光视频抓取和转码软件)
VidCoder 是一款开源且免费的 DVD/蓝光视频捕捉和转码软件。使用 HandBrake 作为编码引擎。它具有比 Handbrake 更友好的用户界面。有需要的朋友可以下载试试!
本软件需要[.NET Framework4.0]环境支持。
VidCoder 是适用于 Windows 的免费开源 DVD/蓝光翻录和视频转码应用程序。它使用 HandBrake 作为其编码引擎。Vidcoder 支持视频下载、编辑、字幕、上传一站式工具,可用于DVD/Blu-ray 视频捕获和转码操作。更重要的是,它可以导入字幕和指挥校队。目前支持中文语言包。操作更方便。特别适合视频发布团队编辑视频、添加字母、水印、转换格式等。当我们观看一些没有字幕的视频时,不妨使用这个视频编辑工具自己添加字母。可以设置偏移量,最适合使用胶片采集器。这里的闪电编辑器是最新的测试版下载,
VidCoder支持英文和中文,同时支持十多种其他语言!
VidCoder 是免费的开源软件
VidCoder 基于 C# 中的 .NET 4.6 / WPF 构建。它在 64 位版本的 Windows 7、8、10、Vista、Server 2008 和 Server 2012 上运行。
VidCoder UI(和 C# 互操作)由 RandomEngy 编写。核心编码引擎由了不起的 HandBrake 团队编写。尤其是 J45 对组合它们有很大帮助。
特征
多线程
MP4、MKV 容器
H.264 编码和 x264,世界上最好的视频编码器
完全集成的编码管道:一切都在一个过程中,没有庞大的中间临时文件
H.265、MPEG-4、MPEG-2、VP8、Theora 视频
AAC、MP3、Vorbis、AC3、FLAC 音频编码和 AAC/AC3/MP3/DTS/DTS-HD 直通
视频的目标比特率、大小或质量
2-pass 编码
解码、电视转播、去隔行、旋转、反射过滤器
批量编码
即时源预览
创建小的编码预览剪辑
暂停,恢复编码
特征
DVD光盘
VidCoder 可以翻录 DVD,但不会破坏大多数商业 DVD 中的 CSS 加密。您有多种删除加密的选项:
AnyDVD HD(121美元,即刻解除加密,为新游戏提供最佳支持)
Passkey Lite(免费,立即删除加密)
MakeMKV(免费,编码前需要拷贝到硬盘)
DVD Decrypter(免费,编码前需要拷贝到硬盘,不再更新)
蓝光
VidCoder 不会使 AACS 或 BD + 蓝光加密失败。有几个选项可以删除它
视频质量选项
简短版本:使用恒定质量编码。当您不需要严格控制输出大小时,这是对视频进行编码的最佳方式。
背景
通过确定编码帧与原创帧的接近程度,您可以衡量给定视频帧的图像质量。较低质量的图片可能会模糊或有块状视频伪影
在图像质量和使用的数据量之间存在权衡。随着您对图片应用更多数据,图片质量会提高。在某些时候,您会看到一张好看的照片,即使您应用更多数据,它也不会看起来更好。
并非所有视频都是平等的。具有大量运动或复杂细节的视频更难以压缩。在使用相同数据量的情况下,复杂视频的画质会比简单视频差。相反,复杂的视频需要更多的数据才能达到相同的质量水平。
平均比特率(一次)
这是许多人已经意识到的最古老的模式。您正在指定每秒允许进行视频压缩的数据量。数字越高,质量越高。但是,由于编码器正在处理视频,因此无法知道视频的其他部分是什么,因此最终将视频中的数据平均分配。这是不受欢迎的,因为它的简单部分被数据浪费在他们身上。如果您降低比特率以使这些部分有效,那么复杂的部分看起来会很糟糕。
平均比特率(两个通道)
两遍编码是解决这个问题的一种方法。它对整个视频进行了初步扫描:只是对其外观有了一个很好的了解。它可以计算如何将数据从简单的场景传输到更复杂的场景,同时仍然保持视频的整体平均比特率。因此,当第二遍出现时,您可以根据您选择的码率获得整体更漂亮的视频。
目标尺寸
目标大小只是平均比特率的一个额外步骤。它根据选定的音轨和视频长度执行一些计算,以确定适当的视频比特率,这将产生指定的目标文件大小。
但是整个方法还是有问题的。如果您使用相同的设置对许多视频进行编码,您可能会陷入与以前相同的陷阱。整体来说非常简单的视频(比如大多数卡通动画)会叠加无法用来提升画质的数据,而复杂的视频将无法获得所需的数据来抵御糟糕的画质。对这个问题的反应通常是简单地提高数据速率,即使是最复杂的视频看起来也不错。但问题仍然存在:通过提高数据速率,您将浪费更多简单的视频数据。如果有一种方法可以让每个视频看起来都不错,但又可以避免浪费数据呢?
质量稳定
用户不需要指定比特率或文件大小,而是需要指定要捕获的特定图片质量数 (CRF)。在 x264 中,较低的值意味着较高的质量,较高的值意味着较低的质量。这有点倒退,但它是一个非常简单的系统。合理的质量目标通常在 18-25 之间。以下是一些质量级别的示例。
日志:
删除了对 Microsoft.Toolkit.Uwp.Notifications 的依赖。这应该可以解决 4.1 Beta 中引入的崩溃问题。
修复源文本对齐方式。
网页视频抓取脚本( 2015年06月16日本文涉及javascript操作html5元素实现多媒体文件截图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-02 17:37
2015年06月16日本文涉及javascript操作html5元素实现多媒体文件截图)
js+HTML5如何实现视频截图
更新时间:2015-06-16 12:18:23 作者:红薯
本文文章主要介绍js+HTML5实现视频截图的方法,涉及javascript操作html5元素实现多媒体文件截图的相关技巧,有需要的朋友可以参考以下
本文介绍如何使用js+HTML5实现视频截图。分享给大家,供大家参考。详情如下:
1. HTML 部分:
Capture
2.点击按钮时触发如下代码:
(function() {
"use strict";
var video, $output;
var scale = 0.25;
var initialize = function() {
$output = $("#output");
video = $("#video").get(0);
$("#capture").click(captureImage);
};
var captureImage = function() {
var canvas = document.createElement("canvas");
canvas.width = video.videoWidth * scale;
canvas.height = video.videoHeight * scale;
canvas.getContext('2d')
.drawImage(video, 0, 0, canvas.width, canvas.height);
var img = document.createElement("img");
img.src = canvas.toDataURL();
$output.prepend(img);
};
$(initialize);
}());
希望这篇文章对您的 JavaScript 编程有所帮助。 查看全部
网页视频抓取脚本(
2015年06月16日本文涉及javascript操作html5元素实现多媒体文件截图)
js+HTML5如何实现视频截图
更新时间:2015-06-16 12:18:23 作者:红薯
本文文章主要介绍js+HTML5实现视频截图的方法,涉及javascript操作html5元素实现多媒体文件截图的相关技巧,有需要的朋友可以参考以下
本文介绍如何使用js+HTML5实现视频截图。分享给大家,供大家参考。详情如下:
1. HTML 部分:
Capture
2.点击按钮时触发如下代码:
(function() {
"use strict";
var video, $output;
var scale = 0.25;
var initialize = function() {
$output = $("#output");
video = $("#video").get(0);
$("#capture").click(captureImage);
};
var captureImage = function() {
var canvas = document.createElement("canvas");
canvas.width = video.videoWidth * scale;
canvas.height = video.videoHeight * scale;
canvas.getContext('2d')
.drawImage(video, 0, 0, canvas.width, canvas.height);
var img = document.createElement("img");
img.src = canvas.toDataURL();
$output.prepend(img);
};
$(initialize);
}());
希望这篇文章对您的 JavaScript 编程有所帮助。
网页视频抓取脚本( 松鼠爱吃饼干读万卷书不如行万里路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-02 17:35
松鼠爱吃饼干读万卷书不如行万里路)
Python爬虫练习爬取分析腾讯视频m3u8格式
更新时间:2021年10月14日11:56:15 作者:松鼠爱吃饼干
读万卷书不如行万里路。学习扎实的不足,只能通过实战看出来。本文文章带你到腾讯视频的m3u8格式来分析一下。您可以检查过程中的差距。看你掌握的多好
内容
普通爬虫的正常流程:环境介绍
【付费VIP完整版】只要看完就能学会的教程,80集Python基础入门视频教学
点击这里免费在线观看
分析网站
先打开开发者工具,然后搜索m3u8,会返回很多ts文件,像这种ts文件,都是视频片段
我们可以复制url地址在新的浏览器页面打开
然后它会为我们下载ts文件,打开文件,你会发现是一个十几秒的视频片段
所以这些数据的数据是比较容易找到的,只要我们找出地址是从哪里来的
找到url地址,因为是post请求,所以需要下面的表达式参数
启动代码导入模块
import requests
import re
from tqdm import tqdm # 进度条展示
数据请求
url = 'https://vd.l.qq.com/proxyhttp'
data = {"buid":"vinfoad","adparam":"pf=in&ad_type=LD%7CKB%7CPVL&pf_ex=pc&url=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fj3czmhisqin799r.html&refer=https%3A%2F%2Fv.qq.com%2Fx%2Fsearch%2F&ty=web&plugin=1.0.0&v=3.5.57&coverid=j3czmhisqin799r&vid=z002615k57t&pt=&flowid=e9b3e49b2593efd194cbcd24030ed803_10201&vptag=www_baidu_com%7Cvideo%3Aposter_tle&pu=-1&chid=0&adaptor=2&dtype=1&live=0&resp_type=json&guid=4b4e192e83f4abaf8b68df3e4f5be769&req_type=1&from=0&appversion=1.0.166&uid=522810848&tkn=fbYfeWDCLKtAaOd_OGvCNg..<=qq&platform=10201&opid=5FE180427A4C883F69CADDED665CE99B&atkn=49C1A486316C8D269AC65AAC080CFB29&appid=101483052&tpid=1&rfid=86c3f668da63d8bc7aab3fbc1eb7378a_1633763084","vinfoparam":"spsrt=1&charge=0&defaultfmt=auto&otype=ojson&guid=4b4e192e83f4abaf8b68df3e4f5be769&flowid=e9b3e49b2593efd194cbcd24030ed803_10201&platform=10201&sdtfrom=v1010&defnpayver=1&appVer=3.5.57&host=v.qq.com&ehost=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fj3czmhisqin799r.html&refer=v.qq.com&sphttps=1&tm=1633767536&spwm=4&logintoken=%7B%22main_login%22%3A%22qq%22%2C%22openid%22%3A%225FE180427A4C883F69CADDED665CE99B%22%2C%22appid%22%3A%22101483052%22%2C%22access_token%22%3A%2249C1A486316C8D269AC65AAC080CFB29%22%2C%22vuserid%22%3A%22522810848%22%2C%22vusession%22%3A%22fbYfeWDCLKtAaOd_OGvCNg..%22%7D&vid=z002615k57t&defn=fhd&fhdswitch=0&show1080p=1&isHLS=1&dtype=3&sphls=2&spgzip=1&dlver=2&drm=32&hdcp=0&spau=1&spaudio=15&defsrc=2&encryptVer=9.1&cKey=W5agxKnJ7N56KJEItZs_lpJX5WB4a2CdS8kEIo8rVaqtHEZQ1c_W6myJ8hQXnmDDG8ErEJDMLjvm2vPBr-xE-uhvZyEMY131vUh1H4pgCXe2OphM_H32Jqtu2hFoqfA-un0sVBkIXYfWkOdABnbLUo4RgzSXkBHF3N3K7dNKPg_56X9JO3gwBMyBeAex05x8SbbQKY5AXaDVSM7hsBQ8XEeHzIEGJzlCt94ONgPYVSRkZqo51NVr_Bs8h4-UNLT0jG-obbyNs2IJhrZ4JUBeuGEk8zAOhE9HTZPNDViLRIyt2mNDud09qSLLKl4XAj3CE6i26P6BRyAy1_qatijXkm9J1hs3ZYC7dgYmAZD6BE9UGX4hkziTy-Y8cCBppeEBGSaj9w&fp2p=1&spadseg=3"}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'
}
response = requests.post(url=url, json=data, headers=headers)
提取数据
html_data = response.json()['vinfo']
# 正则表达式
m3u8_url = re.findall("url(.*?),", html_data)[3].split('"')[2]
m3u8_data = requests.get(url=m3u8_url).text
m3u8_data = re.sub('#EXTM3U', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-VERSION:\d', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-MEDIA-SEQUENCE:\d', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-TARGETDURATION:\d+', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-PLAYLIST-TYPE:VOD', '', m3u8_data)
m3u8_data = re.sub('#EXTINF:\d+\.\d+,', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-ENDLIST', '', m3u8_data).split()
遍历
for ts in tqdm(m3u8_data):
ts_url = 'https://apd-57c5d150c8b9788baf40ea4f65feddf8.v.smtcdns.com/moviets.tc.qq.com/A2k4JuW9ATia8thdFQ6y5HWRUGLqAr4L5fk9KFbAUEI8/uwMROfz2r5xgoaQXGdGnC2df64gVTKzl5C_X6A3JOVT0QIb-/doVi4hWq0sqexPo_ylKYxVIJdr9zz2VweWbcY7x70kRnbVNPvBaoTsjwfOq1uojOtsRKJ8r3372HRaTOVg4VyKOFFvzjq2EeMdpleIIyTv0tb-C3CzXmkZz-34hK4Fc-r4mZK55L9W1RqJMpsvrORZr_sqpqvGZrrRq830get0NLJGkeAQ9SBg/' + ts
ts_content = requests.get(url=ts_url).content
保存数据
with open('霸王别姬.mp4', mode='ab') as f:
f.write(ts_content)
print('下载完成')
运行代码
腾讯视频m3u8格式文章的Python爬虫小练习爬取分析到此结束。更多Python爬取腾讯视频相关内容,请搜索脚本之家之前的文章或者继续浏览下方的相关文章,希望大家以后多多支持脚本之家! 查看全部
网页视频抓取脚本(
松鼠爱吃饼干读万卷书不如行万里路)
Python爬虫练习爬取分析腾讯视频m3u8格式
更新时间:2021年10月14日11:56:15 作者:松鼠爱吃饼干
读万卷书不如行万里路。学习扎实的不足,只能通过实战看出来。本文文章带你到腾讯视频的m3u8格式来分析一下。您可以检查过程中的差距。看你掌握的多好
内容
普通爬虫的正常流程:环境介绍
【付费VIP完整版】只要看完就能学会的教程,80集Python基础入门视频教学
点击这里免费在线观看
分析网站
先打开开发者工具,然后搜索m3u8,会返回很多ts文件,像这种ts文件,都是视频片段
我们可以复制url地址在新的浏览器页面打开
然后它会为我们下载ts文件,打开文件,你会发现是一个十几秒的视频片段
所以这些数据的数据是比较容易找到的,只要我们找出地址是从哪里来的
找到url地址,因为是post请求,所以需要下面的表达式参数
启动代码导入模块
import requests
import re
from tqdm import tqdm # 进度条展示
数据请求
url = 'https://vd.l.qq.com/proxyhttp'
data = {"buid":"vinfoad","adparam":"pf=in&ad_type=LD%7CKB%7CPVL&pf_ex=pc&url=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fj3czmhisqin799r.html&refer=https%3A%2F%2Fv.qq.com%2Fx%2Fsearch%2F&ty=web&plugin=1.0.0&v=3.5.57&coverid=j3czmhisqin799r&vid=z002615k57t&pt=&flowid=e9b3e49b2593efd194cbcd24030ed803_10201&vptag=www_baidu_com%7Cvideo%3Aposter_tle&pu=-1&chid=0&adaptor=2&dtype=1&live=0&resp_type=json&guid=4b4e192e83f4abaf8b68df3e4f5be769&req_type=1&from=0&appversion=1.0.166&uid=522810848&tkn=fbYfeWDCLKtAaOd_OGvCNg..<=qq&platform=10201&opid=5FE180427A4C883F69CADDED665CE99B&atkn=49C1A486316C8D269AC65AAC080CFB29&appid=101483052&tpid=1&rfid=86c3f668da63d8bc7aab3fbc1eb7378a_1633763084","vinfoparam":"spsrt=1&charge=0&defaultfmt=auto&otype=ojson&guid=4b4e192e83f4abaf8b68df3e4f5be769&flowid=e9b3e49b2593efd194cbcd24030ed803_10201&platform=10201&sdtfrom=v1010&defnpayver=1&appVer=3.5.57&host=v.qq.com&ehost=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fj3czmhisqin799r.html&refer=v.qq.com&sphttps=1&tm=1633767536&spwm=4&logintoken=%7B%22main_login%22%3A%22qq%22%2C%22openid%22%3A%225FE180427A4C883F69CADDED665CE99B%22%2C%22appid%22%3A%22101483052%22%2C%22access_token%22%3A%2249C1A486316C8D269AC65AAC080CFB29%22%2C%22vuserid%22%3A%22522810848%22%2C%22vusession%22%3A%22fbYfeWDCLKtAaOd_OGvCNg..%22%7D&vid=z002615k57t&defn=fhd&fhdswitch=0&show1080p=1&isHLS=1&dtype=3&sphls=2&spgzip=1&dlver=2&drm=32&hdcp=0&spau=1&spaudio=15&defsrc=2&encryptVer=9.1&cKey=W5agxKnJ7N56KJEItZs_lpJX5WB4a2CdS8kEIo8rVaqtHEZQ1c_W6myJ8hQXnmDDG8ErEJDMLjvm2vPBr-xE-uhvZyEMY131vUh1H4pgCXe2OphM_H32Jqtu2hFoqfA-un0sVBkIXYfWkOdABnbLUo4RgzSXkBHF3N3K7dNKPg_56X9JO3gwBMyBeAex05x8SbbQKY5AXaDVSM7hsBQ8XEeHzIEGJzlCt94ONgPYVSRkZqo51NVr_Bs8h4-UNLT0jG-obbyNs2IJhrZ4JUBeuGEk8zAOhE9HTZPNDViLRIyt2mNDud09qSLLKl4XAj3CE6i26P6BRyAy1_qatijXkm9J1hs3ZYC7dgYmAZD6BE9UGX4hkziTy-Y8cCBppeEBGSaj9w&fp2p=1&spadseg=3"}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'
}
response = requests.post(url=url, json=data, headers=headers)
提取数据
html_data = response.json()['vinfo']
# 正则表达式
m3u8_url = re.findall("url(.*?),", html_data)[3].split('"')[2]
m3u8_data = requests.get(url=m3u8_url).text
m3u8_data = re.sub('#EXTM3U', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-VERSION:\d', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-MEDIA-SEQUENCE:\d', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-TARGETDURATION:\d+', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-PLAYLIST-TYPE:VOD', '', m3u8_data)
m3u8_data = re.sub('#EXTINF:\d+\.\d+,', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-ENDLIST', '', m3u8_data).split()
遍历
for ts in tqdm(m3u8_data):
ts_url = 'https://apd-57c5d150c8b9788baf40ea4f65feddf8.v.smtcdns.com/moviets.tc.qq.com/A2k4JuW9ATia8thdFQ6y5HWRUGLqAr4L5fk9KFbAUEI8/uwMROfz2r5xgoaQXGdGnC2df64gVTKzl5C_X6A3JOVT0QIb-/doVi4hWq0sqexPo_ylKYxVIJdr9zz2VweWbcY7x70kRnbVNPvBaoTsjwfOq1uojOtsRKJ8r3372HRaTOVg4VyKOFFvzjq2EeMdpleIIyTv0tb-C3CzXmkZz-34hK4Fc-r4mZK55L9W1RqJMpsvrORZr_sqpqvGZrrRq830get0NLJGkeAQ9SBg/' + ts
ts_content = requests.get(url=ts_url).content
保存数据
with open('霸王别姬.mp4', mode='ab') as f:
f.write(ts_content)
print('下载完成')
运行代码
腾讯视频m3u8格式文章的Python爬虫小练习爬取分析到此结束。更多Python爬取腾讯视频相关内容,请搜索脚本之家之前的文章或者继续浏览下方的相关文章,希望大家以后多多支持脚本之家!
网页视频抓取脚本( tomcat服务器端程序用于在互联网中获取指定指定规则的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-02 12:19
tomcat服务器端程序用于在互联网中获取指定指定规则的数据)
使用正则表达式实现网络爬虫的思路详解
更新时间:2018-12-06 12:35:43 作者:wyhluckydog
网络爬虫:是一种用于获取互联网上指定规则的数据的程序。本文文章主要介绍使用正则表达式实现网络爬虫的详细思路。有需要的朋友可以参考
网络爬虫:是一种用于获取互联网上指定规则的数据的程序。
想法:
1.为了模拟网络爬虫,我们现在可以在我们的tomcat服务器上部署一个1.html网页。(部署步骤:在tomcat目录的webapps目录的ROOTS目录下新建1.html。使用notepad++进行编辑,编辑内容为:
)
2.使用URL与网页建立联系
3.获取输入流,用于读取网页内容
4.建立正则规则,因为这里我们是抓取网页中的邮箱信息,所以创建一个匹配邮箱的正则表达式: String regex="\w+@\w+(\.\w+)+";
5.将提取的数据放入集合中。
代码:
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网页爬虫:就是一个程序用于在互联网中获取指定规则的数据
*
*
*/
public class RegexDemo {
public static void main(String[] args) throws Exception {
List list=getMailByWeb();
for(String str:list){
System.out.println(str);
}
}
private static List getMailByWeb() throws Exception {
//1.与网页建立联系。使用URL
String path="http://localhost:8080//1.html";//后面写双斜杠是用于转义
URL url=new URL(path);
//2.获取输入流
InputStream is=url.openStream();
//加缓冲
BufferedReader br=new BufferedReader(new InputStreamReader(is));
//3.提取符合邮箱的数据
String regex="\\w+@\\w+(\\.\\w+)+";
//进行匹配
//将正则规则封装成对象
Pattern p=Pattern.compile(regex);
//将提取到的数据放到一个集合中
List list=new ArrayList();
String line=null;
while((line=br.readLine())!=null){
//匹配器
Matcher m=p.matcher(line);
while(m.find()){
//3.将符合规则的数据存储到集合中
list.add(m.group());
}
}
return list;
}
}
注意:执行前需要开启tomcat服务器
操作结果:
总结
以上就是小编介绍的使用正则表达式实现网络爬虫的思路的详细讲解。我希望它会对你有所帮助。如有问题,请给我留言,小编会及时回复您。非常感谢您对脚本之家网站的支持! 查看全部
网页视频抓取脚本(
tomcat服务器端程序用于在互联网中获取指定指定规则的数据)
使用正则表达式实现网络爬虫的思路详解
更新时间:2018-12-06 12:35:43 作者:wyhluckydog
网络爬虫:是一种用于获取互联网上指定规则的数据的程序。本文文章主要介绍使用正则表达式实现网络爬虫的详细思路。有需要的朋友可以参考
网络爬虫:是一种用于获取互联网上指定规则的数据的程序。
想法:
1.为了模拟网络爬虫,我们现在可以在我们的tomcat服务器上部署一个1.html网页。(部署步骤:在tomcat目录的webapps目录的ROOTS目录下新建1.html。使用notepad++进行编辑,编辑内容为:
)
2.使用URL与网页建立联系
3.获取输入流,用于读取网页内容
4.建立正则规则,因为这里我们是抓取网页中的邮箱信息,所以创建一个匹配邮箱的正则表达式: String regex="\w+@\w+(\.\w+)+";
5.将提取的数据放入集合中。
代码:
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网页爬虫:就是一个程序用于在互联网中获取指定规则的数据
*
*
*/
public class RegexDemo {
public static void main(String[] args) throws Exception {
List list=getMailByWeb();
for(String str:list){
System.out.println(str);
}
}
private static List getMailByWeb() throws Exception {
//1.与网页建立联系。使用URL
String path="http://localhost:8080//1.html";//后面写双斜杠是用于转义
URL url=new URL(path);
//2.获取输入流
InputStream is=url.openStream();
//加缓冲
BufferedReader br=new BufferedReader(new InputStreamReader(is));
//3.提取符合邮箱的数据
String regex="\\w+@\\w+(\\.\\w+)+";
//进行匹配
//将正则规则封装成对象
Pattern p=Pattern.compile(regex);
//将提取到的数据放到一个集合中
List list=new ArrayList();
String line=null;
while((line=br.readLine())!=null){
//匹配器
Matcher m=p.matcher(line);
while(m.find()){
//3.将符合规则的数据存储到集合中
list.add(m.group());
}
}
return list;
}
}
注意:执行前需要开启tomcat服务器
操作结果:
总结
以上就是小编介绍的使用正则表达式实现网络爬虫的思路的详细讲解。我希望它会对你有所帮助。如有问题,请给我留言,小编会及时回复您。非常感谢您对脚本之家网站的支持!

