
网页数据抓取软件
网页数据抓取软件( 基于IE浏览器的实用型自行定义,实时高效接入数据自动化处理流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-12 01:16
基于IE浏览器的实用型自行定义,实时高效接入数据自动化处理流程)
Net Detector是一款基于IE浏览器的实用网页数据监控软件。它没有任何反爬虫技术手段的感觉。只要能在IE浏览器中正常浏览网页,就可以监控其中的所有数据。直观的查看数据趋势,浏览网页即可监控,支持自定义创建、修改、删除等。
特征
1:基于IE浏览器
没有任何反爬虫技术手段的感觉,只要能在IE浏览器中正常浏览网页,里面的所有数据都可以被监控
2:网页数据抓取
两种数据采集方式,文本匹配和文档结构分析,可单独使用或组合使用,使数据采集更简单、更准确
3:数据对比验证
自动判断最近更新的数据,支持自定义数据比对校验公式,筛选出用户最感兴趣的数据内容
4:及时通知用户
用户注册后,既可以将验证过的数据发送到你的微信,也可以推送到指定接口重新处理数据
5:同时处理多任务
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据
6:任务之间互相调用
监控任务A(必须是URL)得到的结果可以传递给监控任务B执行,从而获得更丰富的数据结果
7:打开通知界面
直接连接自己的程序,自己定义后续处理流程,实时高效接入数据自动处理流程
8:抓取公式在线分享
“大家为我,我为大家”分享任意网页的爬取公式,免去公式编辑的烦恼
9:无人值守长期运行
低资源消耗,内置内存管理模块,自动清除运行时产生的内存垃圾,守护进程长时间无人值守运行 查看全部
网页数据抓取软件(
基于IE浏览器的实用型自行定义,实时高效接入数据自动化处理流程)

Net Detector是一款基于IE浏览器的实用网页数据监控软件。它没有任何反爬虫技术手段的感觉。只要能在IE浏览器中正常浏览网页,就可以监控其中的所有数据。直观的查看数据趋势,浏览网页即可监控,支持自定义创建、修改、删除等。

特征
1:基于IE浏览器
没有任何反爬虫技术手段的感觉,只要能在IE浏览器中正常浏览网页,里面的所有数据都可以被监控
2:网页数据抓取
两种数据采集方式,文本匹配和文档结构分析,可单独使用或组合使用,使数据采集更简单、更准确
3:数据对比验证
自动判断最近更新的数据,支持自定义数据比对校验公式,筛选出用户最感兴趣的数据内容
4:及时通知用户
用户注册后,既可以将验证过的数据发送到你的微信,也可以推送到指定接口重新处理数据
5:同时处理多任务
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据
6:任务之间互相调用
监控任务A(必须是URL)得到的结果可以传递给监控任务B执行,从而获得更丰富的数据结果
7:打开通知界面
直接连接自己的程序,自己定义后续处理流程,实时高效接入数据自动处理流程
8:抓取公式在线分享
“大家为我,我为大家”分享任意网页的爬取公式,免去公式编辑的烦恼
9:无人值守长期运行
低资源消耗,内置内存管理模块,自动清除运行时产生的内存垃圾,守护进程长时间无人值守运行
网页数据抓取软件(一个自动重启Webserver的小程序总结崩溃了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-11 20:27
我每天维护学校的教务管理系统。流量少的时候还好。当流量很大时,服务器会时不时崩溃。. 有同学写了一个自动重启Web服务器的小程序,果断用它学了。
Web服务器部署在Linux操作系统上,IDE使用Weblogic Workshop。如果访问量超过 Weblogic 连接池的最大容量,服务器就会崩溃。. Weblogic 有一个带有自己网页的控制台,其中有一个监控页面 Monitor。显示当前连接数、最大连接数等值。所以你可以写一个程序来实时捕捉监控页面的数据来决定什么时候自动重启。
使用 wget 命令下载网页,使用 system 命令执行语句。
如 wget -O baidu_index.html
这样,在当前目录下,百度的主页就被抓取到baidu_index.html文件中。
写在程序中,使用system("wget -O baidu_index.html"); 运行后就相当于执行了上面的命令。同样,编写 system("startWeblogic.sh &"); 相当于重启Weblogic。
这很简单。使用wget下载到监控页面后,读取当前连接数。如果大于某个值,重启就大功告成了~(因为监控页面的边框是固定的,所以在固定的行数读取数字就好了。O(∩_∩)O~~) .
写完程序,我觉得我还差得很远,加油吧! 查看全部
网页数据抓取软件(一个自动重启Webserver的小程序总结崩溃了)
我每天维护学校的教务管理系统。流量少的时候还好。当流量很大时,服务器会时不时崩溃。. 有同学写了一个自动重启Web服务器的小程序,果断用它学了。
Web服务器部署在Linux操作系统上,IDE使用Weblogic Workshop。如果访问量超过 Weblogic 连接池的最大容量,服务器就会崩溃。. Weblogic 有一个带有自己网页的控制台,其中有一个监控页面 Monitor。显示当前连接数、最大连接数等值。所以你可以写一个程序来实时捕捉监控页面的数据来决定什么时候自动重启。
使用 wget 命令下载网页,使用 system 命令执行语句。
如 wget -O baidu_index.html
这样,在当前目录下,百度的主页就被抓取到baidu_index.html文件中。
写在程序中,使用system("wget -O baidu_index.html"); 运行后就相当于执行了上面的命令。同样,编写 system("startWeblogic.sh &"); 相当于重启Weblogic。
这很简单。使用wget下载到监控页面后,读取当前连接数。如果大于某个值,重启就大功告成了~(因为监控页面的边框是固定的,所以在固定的行数读取数字就好了。O(∩_∩)O~~) .
写完程序,我觉得我还差得很远,加油吧!
网页数据抓取软件(网页抓取工具优采云采集器自有应对方案——数据处理(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-02-05 01:13
网页抓取工具的数据预处理本文关键词:预处理、爬取、网页、工具、数据
网页抓取工具的数据预处理本文介绍:网页抓取工具的数据预处理提取的数据不能直接使用?文件还没下载?格式等不符合要求?别担心,网络抓取工具 优采云采集器 有自己的解决方案——数据处理。网络爬虫的数据处理功能包括三个部分,即内容处理、文件下载和内容过滤。下面依次为大家介绍:1、内容处理:替换从内容页面提取的数据,过滤标签,
网页抓取工具的数据预处理本文内容:
网络爬虫的数据预处理
提取出来的数据不能直接使用吗?文件还没下载?格式等不符合要求?别担心,网络抓取工具 优采云采集器 有自己的解决方案——数据处理。
网络爬虫的数据处理功能包括三个部分,即内容处理、文件下载和内容过滤。下面依次为大家介绍:
1、内容处理:为了进一步处理从内容页面提取的数据,比如替换、标签过滤、分词等,我们可以同时添加多个操作,但是这里需要注意的是,当有多个操作,按照上面的顺序依次执行,即上一步的结果会作为下一步的参数。
让我们一一介绍:
①提取的内容为空:如果内容不能准确提取或者通过之前的规则提取的内容为空,则选择此项,应用该项后,将通过正则匹配从原页面再次提取。
②内容替换/排除:将采集中的内容替换为字符串。如果需要排除,可以用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数等替换字符串(与工具栏中的同义词替换不同)。
③html标签过滤:过滤指定的html标签,比如标签的图片地址。
比如直接图片地址,或者不规则图片源代码,采集器会被视为文件下载。
①将相对地址补全为绝对地址:勾选后将标签采集的相对地址补全为绝对地址。
②下载图片:勾选后下载源代码中标准样式的代码图片。
③检测文件真实地址但不下载:有时采集到达附件的下载地址而不是真实的下载地址,点击后会有跳转。在这种情况下,勾选该选项会显示真实地址采集,但只获取下载地址,不下载。
④检测文件并下载:检查后可以从采集下载任意格式的文件附件。
3、内容过滤:通过设置内容过滤,可以删除部分不符合条件的记录或标记为不接受。内容过滤有以下几种处理方式:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件。
②采集结果不能为空:该功能可以防止某个字段出现空内容。
③采集结果不能重复:该功能可以防止字段内容重复。设置此项前,请确保没有采集数据,或者需要先清除采集数据。
④当内容长度小于(大于、等于、不等于)N时过滤:符号或字母或数字或汉字计为一个。
注意:如果满足以上四项中的一项或多项,可以在采集器的其他设置功能中直接删除这条记录,或者在采集下将该记录标记为不为采集 再次运行任务时。
在网页抓取工具优采云采集器中配备了一系列数据处理的好处是,当我们只需要一个小操作时,就不需要编写插件,生成和编译,并且可以通过一键将数据处理成我们需要的方式。 查看全部
网页数据抓取软件(网页抓取工具优采云采集器自有应对方案——数据处理(一))
网页抓取工具的数据预处理本文关键词:预处理、爬取、网页、工具、数据
网页抓取工具的数据预处理本文介绍:网页抓取工具的数据预处理提取的数据不能直接使用?文件还没下载?格式等不符合要求?别担心,网络抓取工具 优采云采集器 有自己的解决方案——数据处理。网络爬虫的数据处理功能包括三个部分,即内容处理、文件下载和内容过滤。下面依次为大家介绍:1、内容处理:替换从内容页面提取的数据,过滤标签,
网页抓取工具的数据预处理本文内容:
网络爬虫的数据预处理
提取出来的数据不能直接使用吗?文件还没下载?格式等不符合要求?别担心,网络抓取工具 优采云采集器 有自己的解决方案——数据处理。
网络爬虫的数据处理功能包括三个部分,即内容处理、文件下载和内容过滤。下面依次为大家介绍:
1、内容处理:为了进一步处理从内容页面提取的数据,比如替换、标签过滤、分词等,我们可以同时添加多个操作,但是这里需要注意的是,当有多个操作,按照上面的顺序依次执行,即上一步的结果会作为下一步的参数。
让我们一一介绍:
①提取的内容为空:如果内容不能准确提取或者通过之前的规则提取的内容为空,则选择此项,应用该项后,将通过正则匹配从原页面再次提取。
②内容替换/排除:将采集中的内容替换为字符串。如果需要排除,可以用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数等替换字符串(与工具栏中的同义词替换不同)。
③html标签过滤:过滤指定的html标签,比如标签的图片地址。
比如直接图片地址,或者不规则图片源代码,采集器会被视为文件下载。
①将相对地址补全为绝对地址:勾选后将标签采集的相对地址补全为绝对地址。
②下载图片:勾选后下载源代码中标准样式的代码图片。
③检测文件真实地址但不下载:有时采集到达附件的下载地址而不是真实的下载地址,点击后会有跳转。在这种情况下,勾选该选项会显示真实地址采集,但只获取下载地址,不下载。
④检测文件并下载:检查后可以从采集下载任意格式的文件附件。
3、内容过滤:通过设置内容过滤,可以删除部分不符合条件的记录或标记为不接受。内容过滤有以下几种处理方式:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件。
②采集结果不能为空:该功能可以防止某个字段出现空内容。
③采集结果不能重复:该功能可以防止字段内容重复。设置此项前,请确保没有采集数据,或者需要先清除采集数据。
④当内容长度小于(大于、等于、不等于)N时过滤:符号或字母或数字或汉字计为一个。
注意:如果满足以上四项中的一项或多项,可以在采集器的其他设置功能中直接删除这条记录,或者在采集下将该记录标记为不为采集 再次运行任务时。
在网页抓取工具优采云采集器中配备了一系列数据处理的好处是,当我们只需要一个小操作时,就不需要编写插件,生成和编译,并且可以通过一键将数据处理成我们需要的方式。
网页数据抓取软件(就是出如下弹窗的意思就是让我们去把手机wifi中代理改了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-02-04 07:10
)
其实简单理解就是一个抓包软件,可能大家比较少见,但是大家应该都听说过fiddler和wirehack。事实上,功能几乎相同。
你为什么推荐这个?
其实不管是app抓包还是PC抓包,还有其他的软件,但是Charles有win版、macos版和linux版。
因此它与许多平台兼容。
废话不多说,我们直接开始整件事情(这里使用macos系统进行演示,其他系统类似)。
准备工作:电脑、手机、wifi
第一步当然是下载软件。这里就不多说了,尽量搜索pj版,因为charles是需要付费的,不过也会有30天的试用期。
接下来我们打开软件charles,找到菜单栏Proxy->Proxy Settings
这里我们设置为8888端口,默认为8888,无需重新设置。
之后,我们进入 Proxy->SSL Proxying Settings
将地址添加为 * 并将端口添加为 443
安装证书
安装完成后,我们可以看到如下证书
这意味着我们的证书安装完成。
接下来,我们必须继续安装证书。
点击后会弹出如下弹窗
大意是让我们在手机的wifi中更改代理。
这个其实很简单,我们进入手机的设置,然后点击wifi后面的感叹号进行设置(手机不一样,自己搞定)
进入手动配置代理,这里的服务器填写你电脑的ip(macos使用ifconfig,windows可以使用ipconfig查看),在之前的提示窗口中,我们也可以看到ip地址。
端口号填写我们之前设置的8888
点击storage,然后我们用浏览器访问chls.pro/ssl
如果此时访问没有响应,可以看一下电脑,会有弹窗,点击允许。
这里我们点击允许
然后回到设置,我们可以看到提示安装描述文件
我们点击这里安装它。
最后我们做一个简单的测试,我们打开小红书app,然后可以观察到charles已经开始爬了。
这说明我们已经配置成功了。
这是我们想要抓取一个应用程序或一个小程序时的第一步。如果这一步做得不好,后面的工作就根本无法进行。
总结
一旦数据包被成功捕获,大部分传统的网络爬虫技术都可以使用,因为大多数应用程序也使用 HTTP 协议来传输数据。根据应用程序的设计,应用程序抓取可能需要解决独特的挑战,例如 Android 逆向工程。
关于Python技术储备
学好 Python 是赚钱的好方法,不管是工作还是副业,但要学好 Python,还是要有学习计划的。最后,我们将分享一套完整的Python学习资料,以帮助那些想学习Python的朋友!
一、Python全方位学习路线
Python的各个方向都是将Python中常用的技术点进行整理,形成各个领域知识点的汇总。它的用处是你可以根据以上知识点找到对应的学习资源,保证你能学得更全面。
二、学习软件
工人要做好工作,首先要磨利他的工具。学习Python的常用开发软件就到这里,为大家节省不少时间。
三、入门视频
当我们看视频学习时,没有手我们就无法移动眼睛和大脑。更科学的学习方式是理解后再使用。这时候动手项目就很合适了。
四、实际案例
光学理论是无用的。你必须学会跟随,你必须先进行实际练习,然后才能将所学应用于实践。这时候可以借鉴实战案例。
五、采访信息
我们必须学习 Python 才能找到一份高薪工作。以下面试题是来自阿里、腾讯、字节等一线互联网公司的最新面试资料,部分阿里大佬给出了权威答案。看完这套面试材料相信大家都能找到一份满意的工作。
本完整版Python全套学习资料已上传至CSDN。需要的可以微信扫描下方官方CSDN认证二维码免费获取【保证100%免费】
查看全部
网页数据抓取软件(就是出如下弹窗的意思就是让我们去把手机wifi中代理改了
)
其实简单理解就是一个抓包软件,可能大家比较少见,但是大家应该都听说过fiddler和wirehack。事实上,功能几乎相同。
你为什么推荐这个?
其实不管是app抓包还是PC抓包,还有其他的软件,但是Charles有win版、macos版和linux版。
因此它与许多平台兼容。
废话不多说,我们直接开始整件事情(这里使用macos系统进行演示,其他系统类似)。
准备工作:电脑、手机、wifi
第一步当然是下载软件。这里就不多说了,尽量搜索pj版,因为charles是需要付费的,不过也会有30天的试用期。
接下来我们打开软件charles,找到菜单栏Proxy->Proxy Settings

这里我们设置为8888端口,默认为8888,无需重新设置。

之后,我们进入 Proxy->SSL Proxying Settings

将地址添加为 * 并将端口添加为 443

安装证书

安装完成后,我们可以看到如下证书

这意味着我们的证书安装完成。
接下来,我们必须继续安装证书。

点击后会弹出如下弹窗

大意是让我们在手机的wifi中更改代理。
这个其实很简单,我们进入手机的设置,然后点击wifi后面的感叹号进行设置(手机不一样,自己搞定)

进入手动配置代理,这里的服务器填写你电脑的ip(macos使用ifconfig,windows可以使用ipconfig查看),在之前的提示窗口中,我们也可以看到ip地址。
端口号填写我们之前设置的8888

点击storage,然后我们用浏览器访问chls.pro/ssl
如果此时访问没有响应,可以看一下电脑,会有弹窗,点击允许。

这里我们点击允许
然后回到设置,我们可以看到提示安装描述文件

我们点击这里安装它。

最后我们做一个简单的测试,我们打开小红书app,然后可以观察到charles已经开始爬了。

这说明我们已经配置成功了。
这是我们想要抓取一个应用程序或一个小程序时的第一步。如果这一步做得不好,后面的工作就根本无法进行。
总结
一旦数据包被成功捕获,大部分传统的网络爬虫技术都可以使用,因为大多数应用程序也使用 HTTP 协议来传输数据。根据应用程序的设计,应用程序抓取可能需要解决独特的挑战,例如 Android 逆向工程。
关于Python技术储备
学好 Python 是赚钱的好方法,不管是工作还是副业,但要学好 Python,还是要有学习计划的。最后,我们将分享一套完整的Python学习资料,以帮助那些想学习Python的朋友!
一、Python全方位学习路线
Python的各个方向都是将Python中常用的技术点进行整理,形成各个领域知识点的汇总。它的用处是你可以根据以上知识点找到对应的学习资源,保证你能学得更全面。

二、学习软件
工人要做好工作,首先要磨利他的工具。学习Python的常用开发软件就到这里,为大家节省不少时间。

三、入门视频
当我们看视频学习时,没有手我们就无法移动眼睛和大脑。更科学的学习方式是理解后再使用。这时候动手项目就很合适了。
四、实际案例
光学理论是无用的。你必须学会跟随,你必须先进行实际练习,然后才能将所学应用于实践。这时候可以借鉴实战案例。

五、采访信息
我们必须学习 Python 才能找到一份高薪工作。以下面试题是来自阿里、腾讯、字节等一线互联网公司的最新面试资料,部分阿里大佬给出了权威答案。看完这套面试材料相信大家都能找到一份满意的工作。


本完整版Python全套学习资料已上传至CSDN。需要的可以微信扫描下方官方CSDN认证二维码免费获取【保证100%免费】

网页数据抓取软件(国内五大主流采集软件优缺点,帮助你选择最适合的爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-02-03 19:00
大数据技术从一种看起来很酷的新技术发展为企业实际部署在生产和运营中的服务,历时多年。其中,data采集产品迎来了广阔的市场前景,国内外众多一、软件采集不同技术的软件一、质量参差不齐。
今天,我们就来对比一下国产采集五款软件的优缺点,帮你选择最适合的爬虫,体验数据狩猎的快感。
国内文章
1.优采云
作为采集界的老手,我们优采云是一款互联网数据采集、处理、分析、挖掘软件,可以采集网页上分散的数据信息,并通过一系列的分析处理。,准确挖掘出需要的数据。它的用户定位主要针对有一定代码基础的人,适合编程老手。
采集功能齐全,不限网页和内容,任意文件格式均可下载,智能多识别系统,可选验证方式保护安全支持PHP和C#插件扩展,方便修改和处理数据同义词、同义词替换、参数替换、伪原创必备技能结论:优采云适合编程高手,规则容易写,软件定位更专业精准。
2.优采云
一款无需可视化编程的网页采集软件,可以快速从不同的网站中提取归一化数据,帮助用户自动化采集、编辑和归一化数据,降低工作成本。Cloud采集 是其主要功能之一。与其他采集软件相比,Cloud采集可以更精准、更高效、更大规模。
在自定义采集的过程中,优采云采集器系统编写的Xpath和自动生成的进程可能无法满足数据采集的要求。对数据质量要求高的,需要自己写Xpath,调整成流程图等优化规则。
对于使用自定义采集的同学来说,优采云虽然操作简单,但是上手比较容易。不过,了解优采云采集的原理还是很有必要的。看完相关教程,一步一步,成长周期长。
可视化操作,无需编写代码,制定规则采集,适合零编程用户云采集为主要功能,支持关机采集,实现自动定时采集@ >
结论:优采云是一款适合新手用户试用的软件采集。云功能强大。当然,爬虫老手也可以开发它的高级功能。
3. 吉叟克
一款简单易用的网页信息采集软件,可以采集网页文字、图表、超链接等网页元素。采集 可以通过一个简单的可视化过程来完成同样的工作,为任何有采集 数据需求的人提供服务。
可视化流程操作,不同于优采云,Jisouke的流程侧重于定义抓取的数据和爬虫路径。优采云的规则和流程非常明确,软件的每一步都由用户决定。
支持抓取指数图表悬浮显示的数据,也可以抓取手机上的数据网站
会员可以互相帮助抢,提高采集的效率,还有模板资源可以套用
结论:收客操作比较简单,适合初级用户,功能上没有太多特色,后续支付需求较多。
4.优采云云爬虫
一种新颖的云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量规范化网页数据。
直接访问代理IP,避免IP阻塞
自动登录验证码识别,网站自动完成验证码输入
可在线生成图标,采集结果以丰富的表格形式显示本地化隐私保护,云端采集可隐藏用户IP
结论:优采云类似于爬虫系统框架,具体的采集也需要用户自己编写爬虫,需要有代码基础。
5.优采云采集器
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取、分论坛<有三个类别:@采集器、cms采集器 和博客采集器。
支持批量替换和过滤文章内容中的文字和链接可以同时批量发送文字到网站或者多个论坛带有采集或者发帖任务后自动关机功能完成了
结论:专注于论坛和博客文字内容的抓取,全网数据的采集普适性不高。
注意:给优采云采集器新手的一点学习建议
优采云采集器是一款非常专业的数据采集和数据处理软件。它对软件用户有很高的技术要求。用户必须具备基本的 HTML 基础,并且能够理解网页源代码。网页结构。
同时,如果你使用web发布或者数据库发布,你必须对自己的文章系统和数据存储结构有一个很好的了解。 查看全部
网页数据抓取软件(国内五大主流采集软件优缺点,帮助你选择最适合的爬虫)
大数据技术从一种看起来很酷的新技术发展为企业实际部署在生产和运营中的服务,历时多年。其中,data采集产品迎来了广阔的市场前景,国内外众多一、软件采集不同技术的软件一、质量参差不齐。
今天,我们就来对比一下国产采集五款软件的优缺点,帮你选择最适合的爬虫,体验数据狩猎的快感。
国内文章
1.优采云
作为采集界的老手,我们优采云是一款互联网数据采集、处理、分析、挖掘软件,可以采集网页上分散的数据信息,并通过一系列的分析处理。,准确挖掘出需要的数据。它的用户定位主要针对有一定代码基础的人,适合编程老手。
采集功能齐全,不限网页和内容,任意文件格式均可下载,智能多识别系统,可选验证方式保护安全支持PHP和C#插件扩展,方便修改和处理数据同义词、同义词替换、参数替换、伪原创必备技能结论:优采云适合编程高手,规则容易写,软件定位更专业精准。
2.优采云
一款无需可视化编程的网页采集软件,可以快速从不同的网站中提取归一化数据,帮助用户自动化采集、编辑和归一化数据,降低工作成本。Cloud采集 是其主要功能之一。与其他采集软件相比,Cloud采集可以更精准、更高效、更大规模。
在自定义采集的过程中,优采云采集器系统编写的Xpath和自动生成的进程可能无法满足数据采集的要求。对数据质量要求高的,需要自己写Xpath,调整成流程图等优化规则。
对于使用自定义采集的同学来说,优采云虽然操作简单,但是上手比较容易。不过,了解优采云采集的原理还是很有必要的。看完相关教程,一步一步,成长周期长。
可视化操作,无需编写代码,制定规则采集,适合零编程用户云采集为主要功能,支持关机采集,实现自动定时采集@ >
结论:优采云是一款适合新手用户试用的软件采集。云功能强大。当然,爬虫老手也可以开发它的高级功能。
3. 吉叟克
一款简单易用的网页信息采集软件,可以采集网页文字、图表、超链接等网页元素。采集 可以通过一个简单的可视化过程来完成同样的工作,为任何有采集 数据需求的人提供服务。
可视化流程操作,不同于优采云,Jisouke的流程侧重于定义抓取的数据和爬虫路径。优采云的规则和流程非常明确,软件的每一步都由用户决定。
支持抓取指数图表悬浮显示的数据,也可以抓取手机上的数据网站
会员可以互相帮助抢,提高采集的效率,还有模板资源可以套用
结论:收客操作比较简单,适合初级用户,功能上没有太多特色,后续支付需求较多。
4.优采云云爬虫
一种新颖的云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量规范化网页数据。
直接访问代理IP,避免IP阻塞
自动登录验证码识别,网站自动完成验证码输入
可在线生成图标,采集结果以丰富的表格形式显示本地化隐私保护,云端采集可隐藏用户IP
结论:优采云类似于爬虫系统框架,具体的采集也需要用户自己编写爬虫,需要有代码基础。
5.优采云采集器
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取、分论坛<有三个类别:@采集器、cms采集器 和博客采集器。
支持批量替换和过滤文章内容中的文字和链接可以同时批量发送文字到网站或者多个论坛带有采集或者发帖任务后自动关机功能完成了
结论:专注于论坛和博客文字内容的抓取,全网数据的采集普适性不高。
注意:给优采云采集器新手的一点学习建议
优采云采集器是一款非常专业的数据采集和数据处理软件。它对软件用户有很高的技术要求。用户必须具备基本的 HTML 基础,并且能够理解网页源代码。网页结构。
同时,如果你使用web发布或者数据库发布,你必须对自己的文章系统和数据存储结构有一个很好的了解。
网页数据抓取软件(美丽购的爬虫软件开发者作品提供多的功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-02-03 08:04
网页数据抓取软件在都可以使用,怎么样,是不是很好用啊,是不是想试试?但是如果开发者做得不好,不仅会连带着给卖家带来麻烦,而且网页数据抓取软件使用简单,但是对于新手来说,学会开发功能,才能让这款软件对你真正有用,才能有更好的用户体验。下面就给大家介绍一款美丽购的爬虫软件开发者作品,并且提供非常多的功能。
其实说实话,爬虫软件最容易理解的,这款软件都有,但是又能打通购物车,发送短信,这些对于新手来说,一时难以理解掌握,这款软件它如何打通各项功能,就是用到的第三方库,就是scrapy和nginx。nginx必须要懂一些linux系统的操作,而scrapy这款软件他本身提供了web的api接口,其实主要功能是接受非静态网页,然后提取网页的内容,然后对此进行解析生成数据并且把内容自动提交给后端的用户。
网页数据抓取软件主要就是这样做的,对于没有开发基础的人来说,这些功能要理解起来,需要你有很多的心血,比如linux系统,linux操作相对来说还是不错的,linux相对windows来说,命令要多一些,很多操作都要用到linux操作系统,自然要有更多的学习成本,要想更快的学会功能就要从基础入手,当你能很快的掌握各种开发者提供的功能,能很快搭建一个小的demo出来的时候,就说明你开发能力的上升了。
当我们知道开发它需要解决哪些方面的问题和我们能利用哪些第三方库实现我们的功能,我们就可以说自己具备了开发者的资格,当然也需要有很好的开发者背景来跟这个软件匹配,如果你什么开发背景都没有,也有一些开发者也是非常喜欢开发这个软件的,因为功能都集成起来省事,效率高,通常一个主题化的规划非常符合现在开发软件的趋势,比如:1.p_video6.ftp7.googleassistant,而这款软件大部分功能都是通过插件实现的,如果你想了解具体的用法和内容请访问。
大家如果有更好的开发者开发的此类的,这些插件,我们可以帮助他们改善在更好的用户体验的同时,提高功能扩展性,比如我们可以有文本爬虫软件,比如多加入的文本地图文字搜索,比如一些功能是提供给那些做网站的人使用的,如果做网站的人可以使用,那我们使用起来也会更容易。最后我们祝你学习进步,欢迎大家交流!。 查看全部
网页数据抓取软件(美丽购的爬虫软件开发者作品提供多的功能)
网页数据抓取软件在都可以使用,怎么样,是不是很好用啊,是不是想试试?但是如果开发者做得不好,不仅会连带着给卖家带来麻烦,而且网页数据抓取软件使用简单,但是对于新手来说,学会开发功能,才能让这款软件对你真正有用,才能有更好的用户体验。下面就给大家介绍一款美丽购的爬虫软件开发者作品,并且提供非常多的功能。
其实说实话,爬虫软件最容易理解的,这款软件都有,但是又能打通购物车,发送短信,这些对于新手来说,一时难以理解掌握,这款软件它如何打通各项功能,就是用到的第三方库,就是scrapy和nginx。nginx必须要懂一些linux系统的操作,而scrapy这款软件他本身提供了web的api接口,其实主要功能是接受非静态网页,然后提取网页的内容,然后对此进行解析生成数据并且把内容自动提交给后端的用户。
网页数据抓取软件主要就是这样做的,对于没有开发基础的人来说,这些功能要理解起来,需要你有很多的心血,比如linux系统,linux操作相对来说还是不错的,linux相对windows来说,命令要多一些,很多操作都要用到linux操作系统,自然要有更多的学习成本,要想更快的学会功能就要从基础入手,当你能很快的掌握各种开发者提供的功能,能很快搭建一个小的demo出来的时候,就说明你开发能力的上升了。
当我们知道开发它需要解决哪些方面的问题和我们能利用哪些第三方库实现我们的功能,我们就可以说自己具备了开发者的资格,当然也需要有很好的开发者背景来跟这个软件匹配,如果你什么开发背景都没有,也有一些开发者也是非常喜欢开发这个软件的,因为功能都集成起来省事,效率高,通常一个主题化的规划非常符合现在开发软件的趋势,比如:1.p_video6.ftp7.googleassistant,而这款软件大部分功能都是通过插件实现的,如果你想了解具体的用法和内容请访问。
大家如果有更好的开发者开发的此类的,这些插件,我们可以帮助他们改善在更好的用户体验的同时,提高功能扩展性,比如我们可以有文本爬虫软件,比如多加入的文本地图文字搜索,比如一些功能是提供给那些做网站的人使用的,如果做网站的人可以使用,那我们使用起来也会更容易。最后我们祝你学习进步,欢迎大家交流!。
网页数据抓取软件(我们为什么要选择笔记软件大部分笔记软件(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-01-31 19:10
)
为什么要选择笔记软件
市面上大部分的笔记软件,无非就是文件级别的这三种存储方式。因为笔记软件众多,新产品不断出现,我们不得不选择一些主流厂商出品的笔记软件来为我们的知识赋能。协助组织我们的工作和日常生活。我们如何选择存储我们的笔记决定了我们在多大程度上支配了我们的个人笔记。
数据安全
云型笔记数据存储在云端,后台管理员有权查看我们的笔记,威胁到我们的隐私。如果存储一些敏感内容,可能会被审查,类似于百度云盘审查机制。选择纯云笔记时,一定要仔细检查云存储是否支持加密上传。
鸡蛋需要放在两个篮子里,一个篮子坏了,剩下一个篮子。纯云笔记自动托管在服务提供商处。备份真的不容易。OneNote 也可以本地备份,直接使用桌面版。可以在不改变原创文件格式的情况下打开。像wolai这样的云笔记备份到本地只能一个一个导出。难免要用本地软件打开这些备份文件,然后再组织结构,增加了工作量,吃亏。
个人观点:非本地的笔记软件并不完全值得信赖。本地+云是最好的存储方式。用户可以选择将私人笔记保存在本地,非私人笔记可以公开放置在云端。如何保存文件由用户自由决定。
常用笔记软件对比1、OneNote:
OneNote分为桌面版(办公套件中常用的2016)和uwp版,这是我用的第一款笔记软件,生态不错,word和excel联动真的是强,很多笔记软件对表格的支持比较弱,但是OneNote可以自己创建表格或者插入excel表格,甚至可以嵌套表格。
OneNote还具备双链笔记的原型功能。通过将链接复制到段落中,可以实现注释之间的联动。用法与超链接一词相同。
也可以通过这种方式手动制作目录,可以使用宏插件自动生成目录,但是生成的目录不能做到这个段落级别。下面的每个例子都是单独的注释,目录链接是截取的段落链接,而不是自动生成的子页面级链接,粒度更细。
OneNote 没有大纲功能。如果页面内容太多,根据标题定位真的很不方便。您可以使用插件“当前页面目录”自动生成当前页面的目录链接,该链接会出现在文档顶部。每次使用时都需要滑动它。去笔记的开头找链接有点麻烦。
OneNote支持本地+云端,使用自己的onedrive也很方便,只是同步速度时快时慢。自由排版,可以在单机上任意位置输入内容,简单易用,控制台和word基本一致,支持手写,具备基本的笔记功能,完全具备普通人做笔记的能力。还是值得信赖的。
注意:OneNote UWP 版本完全基于云,可以从 Microsoft Store 下载。桌面版在办公套件中。
2、我会:
我来云笔记是纯云笔记,界面美观。它们是“块”类型的笔记。当时因为外观问题想放弃OneNote,但为了笔记文件的安全,我还是把它当成辅助软件。标题图像和图标的形式确实为外观加分。
做个人工作台,方便明了,还有点神奇的温暖。每个块可以转换成一个页面,页面可以嵌套在一个页面内,相当于一个文件夹的集合。
导入OneNote的笔记,每条笔记都会独立创建一个页面,返回上一级是不同形式的目录,方便快捷,无需制作目录链接。
我来毕竟是纯云注。断网时无法使用纯云笔记。wolai似乎已经退出了离线模式(类似于飞行模式),但还是过于依赖网络,页面太多图片的加载速度大大降低。页面对块数和字数也有一定的限制。如果超过20,000字,可能会变得异常卡顿。我曾尝试将一个1.12MB 500,000字的文件导入wolai,但它直接崩溃了,粘贴和导入两种方法都不能幸免。. 当我把反馈给客服人员的时候,我也让我分了。我只能用思源笔记。打开思源笔记毫无压力,速度也很快。毕竟是本地软件。
关系图:支持页面关系图,显示方式分为2D和3D。
分享:我来笔记支持分享,权限可以选择是否允许他人一键复制。不能复制,只能查看,一定程度上保证了笔记的安全。分享后,关闭分享按钮或删除笔记,对方无法查看。
3、思源笔记
目前主要个人软件支持本地+云端,云端可以加密上传。最近正在测试同步功能,云功能会越来越好用。软件理念基于本地优先,安全有保障,支持第三方同步磁盘备份。块编辑模式,所见即所得,块级支持嵌入和引用,每个文档也可以是块,块是源注释的最基本形式,块之间相互转换和拆分不会影响文档之间的连接关系。
界面美化:支持插入页眉图片,包括市面上海量的主题、模板和图标,持续更新。
格式支持:包罗万象,markdown支持,富文本编辑。支持代码、latex、IFrame、视频、音频、脑图、流程图、时序图、甘特图、图表、员工等。
分享:支持复制到公众号、知乎和鱼雀平台。
双向链接:反向链接和提及,使文档和文档具有连接关系,便于追溯。使知识可重用。
文件导出:支持导出为markdown、word、PDF、HTML文件格式。
关系图:关系图支持页面关系图和全局关系图,与wolai一致。关系图再现了我们大脑的结构并将知识可视化。随着音符的增加,像脑细胞一样的点也越来越多。在观看的同时,我们也获得了内心的丰富感。
虽然无法像 OneNote 那样自由输入,但借助超级块功能,依然可以重现 OneNote 的形式。
这是 OneNote
这是思源笔记
吊坠:群里有很多大佬都研发了自己的吊坠。后续版本会增加挂件市场,会有越来越多完整的挂件供用户食用。通过 IFrame 链接实现。
吊坠 - 卡片视图
吊坠 - 日历视图
4、思维导图软件
Curtain、Xmind 和 mindmaster 都是用于思维导图的优秀笔记软件。
屏幕是大纲笔记,可以一键生成思维导图,有笔记社区,可以分享或复制别人的笔记当成自己的,还有很多section分类,很多笔记没有——拿软件,分享自己的笔记。,分享知识,获得点击,算是对自己努力的认可。不知道能不能开启购买笔记功能,暂时还没有找到。
xmind 和 mindmaster 都是专业的思维导图工具。您可以简单地选择这两个进行思维导图。丰富的模板和布局选项,一键美化你的脑图。还支持大纲视图以方便文本输出。支持多平台使用,也可以在手机上编辑。
票据费
OneNote、wolai、思源笔记都可以免费使用。
如果 OneNote 不喜欢同步盘慢,可用空间小,就必须使用 21Vianet。价格约400元/年,实价为宝。购买office365家庭版一年40元左右。我从来没有买过这些。大概在这个范围内。如果深入使用,购买Gem插件的成本会高很多,但其实并不便宜。
我来目前限时优惠128/年。免费版对块数没有限制。如果需要插入文件,需要购买专业版。目前免费版和专业版的区别似乎不是很大。邀请其他用户注册并使用邀请码获得积分,可用于兑换专业版的使用时间。
思源笔记有教育邮箱64元/年,普通邮箱96元/年。目前,有早鸟优惠。现在首付可终身购买,教育邮箱过期不涨价。您可以更改邮箱绑定。通过邀请其他用户付费订阅,双方可以获得为期 7 天的会员资格和永久增加 500MB 的云空间。邀请 32 个付费订阅帐户升级为永久会员。
目前,思源笔记已将所有本地功能免费开放。以后只对与“云”相关的功能收费。无需为同步付费。伺服功能也是免费的。您可以将 Android 用作移动服务器。,电脑和手机在同一个局域网内,可以用电脑访问手机的思源笔记。
这一次,思源笔记的所有本地功能都是免费的。为了感谢用户的测试,他们免费赠送了180天的会员资格。真是良心软件。原生功能的付费订阅支持退款,付费订阅后 7 天内无理由退款。思源从不恶意搞噱头让用户付费,而是不断寻找志同道合的合作伙伴,以您的诚意换取您的有偿支持。
看到某个不付费就不能编辑的软件的操作,着实让我震惊,资本家的脸色一目了然。
总结
市面上纸币上千种,琳琅满目,各种概念,一体机,双链纸币……不胜枚举。软件毕竟是工具,要“为我所用”,毕竟一个笔记软件会陪伴你很久,你需要的时候是你的得力助手,是你最可靠的时候你寻求它。助手,是你独处时的沟通伙伴。笔记软件是一种生产力工具。它必须符合你的气质和使用习惯,你可以轻松使用它。在这个同质化的时代,想要找到一把适合自己手的武器,是需要付出很多努力的。建议上网。找攻略和视频,然后加入软件交流群,找到你真正的屠龙者。
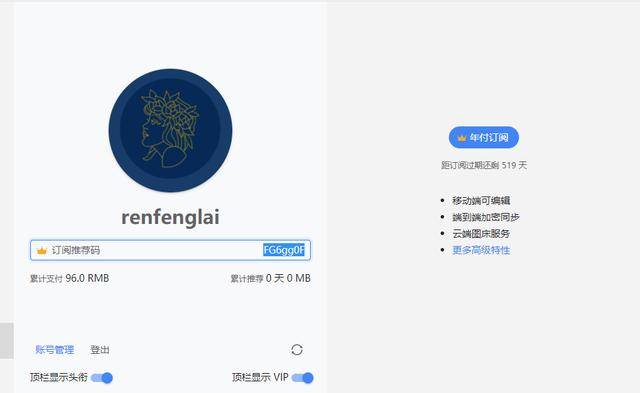
我的思源笔记邀请码FG6gg0F,如果您有付费订阅,请考虑使用思源笔记创建您的数字花园。
查看全部
网页数据抓取软件(我们为什么要选择笔记软件大部分笔记软件(组图)
)
为什么要选择笔记软件
市面上大部分的笔记软件,无非就是文件级别的这三种存储方式。因为笔记软件众多,新产品不断出现,我们不得不选择一些主流厂商出品的笔记软件来为我们的知识赋能。协助组织我们的工作和日常生活。我们如何选择存储我们的笔记决定了我们在多大程度上支配了我们的个人笔记。
数据安全
云型笔记数据存储在云端,后台管理员有权查看我们的笔记,威胁到我们的隐私。如果存储一些敏感内容,可能会被审查,类似于百度云盘审查机制。选择纯云笔记时,一定要仔细检查云存储是否支持加密上传。
鸡蛋需要放在两个篮子里,一个篮子坏了,剩下一个篮子。纯云笔记自动托管在服务提供商处。备份真的不容易。OneNote 也可以本地备份,直接使用桌面版。可以在不改变原创文件格式的情况下打开。像wolai这样的云笔记备份到本地只能一个一个导出。难免要用本地软件打开这些备份文件,然后再组织结构,增加了工作量,吃亏。
个人观点:非本地的笔记软件并不完全值得信赖。本地+云是最好的存储方式。用户可以选择将私人笔记保存在本地,非私人笔记可以公开放置在云端。如何保存文件由用户自由决定。
常用笔记软件对比1、OneNote:
OneNote分为桌面版(办公套件中常用的2016)和uwp版,这是我用的第一款笔记软件,生态不错,word和excel联动真的是强,很多笔记软件对表格的支持比较弱,但是OneNote可以自己创建表格或者插入excel表格,甚至可以嵌套表格。
OneNote还具备双链笔记的原型功能。通过将链接复制到段落中,可以实现注释之间的联动。用法与超链接一词相同。
也可以通过这种方式手动制作目录,可以使用宏插件自动生成目录,但是生成的目录不能做到这个段落级别。下面的每个例子都是单独的注释,目录链接是截取的段落链接,而不是自动生成的子页面级链接,粒度更细。
OneNote 没有大纲功能。如果页面内容太多,根据标题定位真的很不方便。您可以使用插件“当前页面目录”自动生成当前页面的目录链接,该链接会出现在文档顶部。每次使用时都需要滑动它。去笔记的开头找链接有点麻烦。
OneNote支持本地+云端,使用自己的onedrive也很方便,只是同步速度时快时慢。自由排版,可以在单机上任意位置输入内容,简单易用,控制台和word基本一致,支持手写,具备基本的笔记功能,完全具备普通人做笔记的能力。还是值得信赖的。
注意:OneNote UWP 版本完全基于云,可以从 Microsoft Store 下载。桌面版在办公套件中。
2、我会:
我来云笔记是纯云笔记,界面美观。它们是“块”类型的笔记。当时因为外观问题想放弃OneNote,但为了笔记文件的安全,我还是把它当成辅助软件。标题图像和图标的形式确实为外观加分。
做个人工作台,方便明了,还有点神奇的温暖。每个块可以转换成一个页面,页面可以嵌套在一个页面内,相当于一个文件夹的集合。
导入OneNote的笔记,每条笔记都会独立创建一个页面,返回上一级是不同形式的目录,方便快捷,无需制作目录链接。
我来毕竟是纯云注。断网时无法使用纯云笔记。wolai似乎已经退出了离线模式(类似于飞行模式),但还是过于依赖网络,页面太多图片的加载速度大大降低。页面对块数和字数也有一定的限制。如果超过20,000字,可能会变得异常卡顿。我曾尝试将一个1.12MB 500,000字的文件导入wolai,但它直接崩溃了,粘贴和导入两种方法都不能幸免。. 当我把反馈给客服人员的时候,我也让我分了。我只能用思源笔记。打开思源笔记毫无压力,速度也很快。毕竟是本地软件。
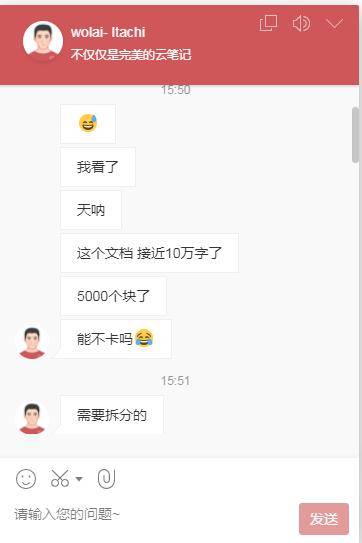
关系图:支持页面关系图,显示方式分为2D和3D。
分享:我来笔记支持分享,权限可以选择是否允许他人一键复制。不能复制,只能查看,一定程度上保证了笔记的安全。分享后,关闭分享按钮或删除笔记,对方无法查看。
3、思源笔记
目前主要个人软件支持本地+云端,云端可以加密上传。最近正在测试同步功能,云功能会越来越好用。软件理念基于本地优先,安全有保障,支持第三方同步磁盘备份。块编辑模式,所见即所得,块级支持嵌入和引用,每个文档也可以是块,块是源注释的最基本形式,块之间相互转换和拆分不会影响文档之间的连接关系。
界面美化:支持插入页眉图片,包括市面上海量的主题、模板和图标,持续更新。
格式支持:包罗万象,markdown支持,富文本编辑。支持代码、latex、IFrame、视频、音频、脑图、流程图、时序图、甘特图、图表、员工等。
分享:支持复制到公众号、知乎和鱼雀平台。

双向链接:反向链接和提及,使文档和文档具有连接关系,便于追溯。使知识可重用。
文件导出:支持导出为markdown、word、PDF、HTML文件格式。
关系图:关系图支持页面关系图和全局关系图,与wolai一致。关系图再现了我们大脑的结构并将知识可视化。随着音符的增加,像脑细胞一样的点也越来越多。在观看的同时,我们也获得了内心的丰富感。
虽然无法像 OneNote 那样自由输入,但借助超级块功能,依然可以重现 OneNote 的形式。
这是 OneNote
这是思源笔记
吊坠:群里有很多大佬都研发了自己的吊坠。后续版本会增加挂件市场,会有越来越多完整的挂件供用户食用。通过 IFrame 链接实现。
吊坠 - 卡片视图
吊坠 - 日历视图
4、思维导图软件
Curtain、Xmind 和 mindmaster 都是用于思维导图的优秀笔记软件。
屏幕是大纲笔记,可以一键生成思维导图,有笔记社区,可以分享或复制别人的笔记当成自己的,还有很多section分类,很多笔记没有——拿软件,分享自己的笔记。,分享知识,获得点击,算是对自己努力的认可。不知道能不能开启购买笔记功能,暂时还没有找到。
xmind 和 mindmaster 都是专业的思维导图工具。您可以简单地选择这两个进行思维导图。丰富的模板和布局选项,一键美化你的脑图。还支持大纲视图以方便文本输出。支持多平台使用,也可以在手机上编辑。
票据费
OneNote、wolai、思源笔记都可以免费使用。
如果 OneNote 不喜欢同步盘慢,可用空间小,就必须使用 21Vianet。价格约400元/年,实价为宝。购买office365家庭版一年40元左右。我从来没有买过这些。大概在这个范围内。如果深入使用,购买Gem插件的成本会高很多,但其实并不便宜。
我来目前限时优惠128/年。免费版对块数没有限制。如果需要插入文件,需要购买专业版。目前免费版和专业版的区别似乎不是很大。邀请其他用户注册并使用邀请码获得积分,可用于兑换专业版的使用时间。
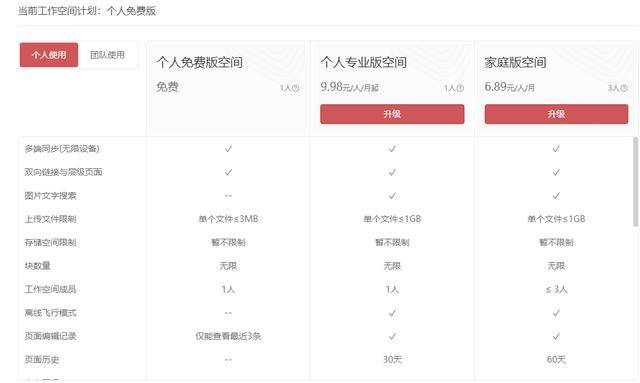
思源笔记有教育邮箱64元/年,普通邮箱96元/年。目前,有早鸟优惠。现在首付可终身购买,教育邮箱过期不涨价。您可以更改邮箱绑定。通过邀请其他用户付费订阅,双方可以获得为期 7 天的会员资格和永久增加 500MB 的云空间。邀请 32 个付费订阅帐户升级为永久会员。
目前,思源笔记已将所有本地功能免费开放。以后只对与“云”相关的功能收费。无需为同步付费。伺服功能也是免费的。您可以将 Android 用作移动服务器。,电脑和手机在同一个局域网内,可以用电脑访问手机的思源笔记。
这一次,思源笔记的所有本地功能都是免费的。为了感谢用户的测试,他们免费赠送了180天的会员资格。真是良心软件。原生功能的付费订阅支持退款,付费订阅后 7 天内无理由退款。思源从不恶意搞噱头让用户付费,而是不断寻找志同道合的合作伙伴,以您的诚意换取您的有偿支持。
看到某个不付费就不能编辑的软件的操作,着实让我震惊,资本家的脸色一目了然。
总结
市面上纸币上千种,琳琅满目,各种概念,一体机,双链纸币……不胜枚举。软件毕竟是工具,要“为我所用”,毕竟一个笔记软件会陪伴你很久,你需要的时候是你的得力助手,是你最可靠的时候你寻求它。助手,是你独处时的沟通伙伴。笔记软件是一种生产力工具。它必须符合你的气质和使用习惯,你可以轻松使用它。在这个同质化的时代,想要找到一把适合自己手的武器,是需要付出很多努力的。建议上网。找攻略和视频,然后加入软件交流群,找到你真正的屠龙者。
我的思源笔记邀请码FG6gg0F,如果您有付费订阅,请考虑使用思源笔记创建您的数字花园。
网页数据抓取软件(touchforms7mac破解教程下载好TouchFormsPro7forMac )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-31 19:09
)
Touch Forms Pro 7 for Mac 是一款实用的 Web 表单生成工具。touch forms 7 mac版支持拖拽添加,编辑表单更方便。新版 touch forms 7 mac 破解版带来了新的和改进的文件格式、新的格式检查器面板、新的拖放编辑器等,以获得更好的性能和稳定性。
touch forms 7 mac破解教程
下载Touch Forms Pro 7安装包后,双击安装包进行安装。安装程序弹出后,点击“继续”,如下图:
点击“安装”,如下图:
如果您的电脑设置了密码,请输入密码并点击“安装软件”,如下图:
提示安装成功后,点击“关闭”,如下图:
touch forms 7 for mac 官方介绍
Touch Forms Pro 7 是一个易于使用的拖放式 Web 表单创建器,用于构建您自己的 网站 联系表单、调查、反馈表单、数据采集表单等。
Touch Forms Pro 允许您使用直观的拖放设计器构建漂亮的 Web 表单,以通过 FTP 发布到您自己的 Web 主机。
Touch forms pro mac版软件功能
- 拖放设计器,需要零编码
- 支持无限数量的网络表单
- 通过 FTP 发布到您自己的 网站
- 与 Google reCAPTCHA 的内置集成,这是一个很棒的小部件,可以保护您的 网站 免受垃圾邮件的侵害。
- 支持将表单导出为静态 PDF 文档格式
- 文本字段和段落字段,可选择将单个字段指定为“强制完成”
- 带有内置电子邮件地址格式验证的电子邮件字段
- 表单提交被发送到指定为表单答案收件人的电子邮件地址。指定主要和次要电子邮件地址的选项。辅助地址是可选的,但建议备份。
- 输入带有圆角、可调整边框颜色、边框宽度和不同边框样式选项的字段样式格式
- 多选单选按钮和多选复选框
- 智能机器人检查器小部件旨在通过呈现简单的动态生成的数学问题来减少垃圾邮件。当添加到表单设计中时,在填写表单之前需要一个完整的小部件问题。- 表单源代码查看器。表单代码在 php 脚本中生成。
- 悬停颜色支持形状和文本
- 支持表格网格
- 表单通过电子邮件 SMTP 身份验证选项,让用户可以选择通过经过身份验证的 SMTP 服务器发送 Web 表单响应。
- 支持将表单提交者 IP 地址作为表单回复电子邮件的一部分的选项
查看全部
网页数据抓取软件(touchforms7mac破解教程下载好TouchFormsPro7forMac
)
Touch Forms Pro 7 for Mac 是一款实用的 Web 表单生成工具。touch forms 7 mac版支持拖拽添加,编辑表单更方便。新版 touch forms 7 mac 破解版带来了新的和改进的文件格式、新的格式检查器面板、新的拖放编辑器等,以获得更好的性能和稳定性。
touch forms 7 mac破解教程
下载Touch Forms Pro 7安装包后,双击安装包进行安装。安装程序弹出后,点击“继续”,如下图:
点击“安装”,如下图:
如果您的电脑设置了密码,请输入密码并点击“安装软件”,如下图:
提示安装成功后,点击“关闭”,如下图:
touch forms 7 for mac 官方介绍
Touch Forms Pro 7 是一个易于使用的拖放式 Web 表单创建器,用于构建您自己的 网站 联系表单、调查、反馈表单、数据采集表单等。
Touch Forms Pro 允许您使用直观的拖放设计器构建漂亮的 Web 表单,以通过 FTP 发布到您自己的 Web 主机。
Touch forms pro mac版软件功能
- 拖放设计器,需要零编码
- 支持无限数量的网络表单
- 通过 FTP 发布到您自己的 网站
- 与 Google reCAPTCHA 的内置集成,这是一个很棒的小部件,可以保护您的 网站 免受垃圾邮件的侵害。
- 支持将表单导出为静态 PDF 文档格式
- 文本字段和段落字段,可选择将单个字段指定为“强制完成”
- 带有内置电子邮件地址格式验证的电子邮件字段
- 表单提交被发送到指定为表单答案收件人的电子邮件地址。指定主要和次要电子邮件地址的选项。辅助地址是可选的,但建议备份。
- 输入带有圆角、可调整边框颜色、边框宽度和不同边框样式选项的字段样式格式
- 多选单选按钮和多选复选框
- 智能机器人检查器小部件旨在通过呈现简单的动态生成的数学问题来减少垃圾邮件。当添加到表单设计中时,在填写表单之前需要一个完整的小部件问题。- 表单源代码查看器。表单代码在 php 脚本中生成。
- 悬停颜色支持形状和文本
- 支持表格网格
- 表单通过电子邮件 SMTP 身份验证选项,让用户可以选择通过经过身份验证的 SMTP 服务器发送 Web 表单响应。
- 支持将表单提交者 IP 地址作为表单回复电子邮件的一部分的选项
网页数据抓取软件(套壳MikuTools是支持PWA技术的,谓之工具细节大家可以自行体验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-31 19:04
MikuTools 作为一个工具采集网站,属于实用型。
单媒体类中各大平台的视频、音乐、图片下载,可以直击用户的痛点。还有很多其他有趣的工具,比如生成带标语牌的凌河风格或者PronHub风格或者Youtube风格的图片等等,你甚至不需要安装软件,只要有一个浏览器就可以做这些事情。
由于工具太多,本期主要介绍 MikuTools 的网页功能。您可以自己体验每个工具的具体细节。
▎实用
MikuTools提供的工具更偏媒体化,基本覆盖国内外主流网站。
媒体类别下的使用方法完全相同。用户只需复制对应平台的链接,然后将链接粘贴到MikuTools对应的分类中即可。分析工作全部交给工具,用户只需要等待直链解析完成即可。但是,这个过程不会花很长时间。
▎袖子
MikuTools 支持 PWA 技术。简而言之,它是一种将网页离线运行到本地的技术,称为Web APP。实现 PWA 的标准有两个,一个是网页本身的支持,一个是浏览器的支持。MikuTools是国内支持这项技术的网站之一。浏览器方面,Chrome、Firefox、Safari等都支持。
▎账号
MikuTools 支持账号登录,但不同于常规的账号系统,不同步数据等。它更有趣。具体操作是输入一个固定的用户名“miku”,然后随便输入。输入密码,然后点击登录。
目前 MikuTools 中账号系统的功能是开启隐藏工具。与用户选择隐藏的工具不同,这是官方默认隐藏的。至于为什么要隐藏,肯定有值得隐藏的理由,这里不便多说。
▎最后
作为一个工具集,MikuTools 能做的事情在不断增加,每一次都是一个“热更新”的过程。新添加的工具将标有小蓝点。客户端和 PWA 版本的用户只要连接到 Internet 就可以访问该页面。获取更新,而不必每次都更新客户端。
MikuTools官网地址: 查看全部
网页数据抓取软件(套壳MikuTools是支持PWA技术的,谓之工具细节大家可以自行体验)
MikuTools 作为一个工具采集网站,属于实用型。
单媒体类中各大平台的视频、音乐、图片下载,可以直击用户的痛点。还有很多其他有趣的工具,比如生成带标语牌的凌河风格或者PronHub风格或者Youtube风格的图片等等,你甚至不需要安装软件,只要有一个浏览器就可以做这些事情。
由于工具太多,本期主要介绍 MikuTools 的网页功能。您可以自己体验每个工具的具体细节。
▎实用
MikuTools提供的工具更偏媒体化,基本覆盖国内外主流网站。

媒体类别下的使用方法完全相同。用户只需复制对应平台的链接,然后将链接粘贴到MikuTools对应的分类中即可。分析工作全部交给工具,用户只需要等待直链解析完成即可。但是,这个过程不会花很长时间。

▎袖子
MikuTools 支持 PWA 技术。简而言之,它是一种将网页离线运行到本地的技术,称为Web APP。实现 PWA 的标准有两个,一个是网页本身的支持,一个是浏览器的支持。MikuTools是国内支持这项技术的网站之一。浏览器方面,Chrome、Firefox、Safari等都支持。
▎账号
MikuTools 支持账号登录,但不同于常规的账号系统,不同步数据等。它更有趣。具体操作是输入一个固定的用户名“miku”,然后随便输入。输入密码,然后点击登录。

目前 MikuTools 中账号系统的功能是开启隐藏工具。与用户选择隐藏的工具不同,这是官方默认隐藏的。至于为什么要隐藏,肯定有值得隐藏的理由,这里不便多说。
▎最后
作为一个工具集,MikuTools 能做的事情在不断增加,每一次都是一个“热更新”的过程。新添加的工具将标有小蓝点。客户端和 PWA 版本的用户只要连接到 Internet 就可以访问该页面。获取更新,而不必每次都更新客户端。

MikuTools官网地址:
网页数据抓取软件(什么是HTML?框架是什么意思?HTML文档总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-31 03:05
总结:
1、通过指定的URL抓取网页数据,获取页面信息,然后对带有DOM的页面进行NODE分析,处理原创的HTML数据。这样做的好处是处理某条数据的灵活性很高。 , 难点在于节算法需要优化。当页面的HTML信息较大时,算法不好,会影响处理效率。
2、htmlparser框架,对于HTML页面处理的数据结构,HtmlParser采用经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode和Tag来描述HTML页面的各个元素。 htmlparser基本可以满足垂直搜索引擎页面处理分析的需求,映射HTML标签,轻松获取标签中的HTML CODE。
Htmlparser官方介绍:htmlparser是一个纯java编写的html解析库。不依赖其他java库文件,主要用于转换或提取html。它解析 html 的速度非常快而且没有错误。 htmlparser 的最新版本现在是 2.0。毫不夸张地说,htmlparser是目前最好的html解析分析工具。
3、nekohtml框架,nekohtml在容错性、性能等方面比htmlparser有更好的口碑(包括htmlunit也使用nekohtml),nokehtml类似于xml解析的原理,html标签是解析为dom,是的,对应DOM树中对应的元素进行处理。
NekoHTML 官方介绍:NekoHTML 是Java 语言的HTML 扫描器和标签平衡器,它使程序能够解析HTML 文档并使用标准的XML 接口来访问其中的信息。此解析器能够扫描 HTML 文档并“修复”作者(人或机器)在编写 HTML 文档时所犯的许多常见错误。
NekoHTML 可以补充缺失的父元素,自动用结束标签关闭对应的元素,以及不匹配的内联元素标签。 NekoHTML 是使用 Xerces 本地接口 (XNI) 开发的,它是 Xerces2 实现的基础。 查看全部
网页数据抓取软件(什么是HTML?框架是什么意思?HTML文档总结)
总结:
1、通过指定的URL抓取网页数据,获取页面信息,然后对带有DOM的页面进行NODE分析,处理原创的HTML数据。这样做的好处是处理某条数据的灵活性很高。 , 难点在于节算法需要优化。当页面的HTML信息较大时,算法不好,会影响处理效率。
2、htmlparser框架,对于HTML页面处理的数据结构,HtmlParser采用经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode和Tag来描述HTML页面的各个元素。 htmlparser基本可以满足垂直搜索引擎页面处理分析的需求,映射HTML标签,轻松获取标签中的HTML CODE。
Htmlparser官方介绍:htmlparser是一个纯java编写的html解析库。不依赖其他java库文件,主要用于转换或提取html。它解析 html 的速度非常快而且没有错误。 htmlparser 的最新版本现在是 2.0。毫不夸张地说,htmlparser是目前最好的html解析分析工具。
3、nekohtml框架,nekohtml在容错性、性能等方面比htmlparser有更好的口碑(包括htmlunit也使用nekohtml),nokehtml类似于xml解析的原理,html标签是解析为dom,是的,对应DOM树中对应的元素进行处理。
NekoHTML 官方介绍:NekoHTML 是Java 语言的HTML 扫描器和标签平衡器,它使程序能够解析HTML 文档并使用标准的XML 接口来访问其中的信息。此解析器能够扫描 HTML 文档并“修复”作者(人或机器)在编写 HTML 文档时所犯的许多常见错误。
NekoHTML 可以补充缺失的父元素,自动用结束标签关闭对应的元素,以及不匹配的内联元素标签。 NekoHTML 是使用 Xerces 本地接口 (XNI) 开发的,它是 Xerces2 实现的基础。
网页数据抓取软件(从技术来讲,利用googletoolbar能抓取页面完全是可行的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-27 02:06
从技术角度来看,使用google工具栏爬取页面是完全可行的。因为使用 IE 和谷歌工具栏访问网页会将浏览数据发送给谷歌。围棋编程客栈 google 可以根据这些数据立即发送爬虫爬取页面。但我们需要考虑以下问题:
1. 当今搜索引擎的核心使命不是收录更多页面。搜索引擎需要抓取更多有效信息。但现阶段,似乎不是收录的数量,而是收录的质量。即使有这么多网站每天都是由谷歌手动提交的,谷歌编程客栈也为时不晚。
2.现有的收录机制基本保证了真正优质的网站是收录。因为根据搜索引擎现有的收录机制,几乎90%或更多的真正优质网站将是收录。
3、谷歌更相信链接计算标准,这种方法更有利于价值信息的判断。依靠链接来发现网站比手动提交更有价值。因为它更难以轻松操作。现阶段搜索引擎的问题是缺少收录站点的信息,需要判断站点是否值得收录。要做出这样的判断,仍然需要依赖链接或人工决策等复杂算法。
4. 对不使用工具栏的用户极为不公平。同时,也增加了合拍的负担。每个站点打开时,工具栏需要检查自己数据库中是否是收录,然后根据自己的复杂系统判断是否应该是收录。
5.根本不需要让侧边栏临时做这些工作。相比编程客栈,工具栏比较复杂,最好用google搜索域名。如果没有收录,google 会去收录。您可以使用您网站的搜索框架来执行此操作。目前工具栏最大的作用就是方便大家更方便的使用google搜索。
当然,以上分析是基于目前的搜索情况。从谷歌的角度来看,使用yLZee工具栏可以采集大量的用户行为,这对于提高搜索质量和了解网民的习惯是非常有益的。不排除在未来的某一天,Google 会使用工具栏中的用户行为统计数据作为判断是否对收录 和关键词 进行排名的工具。
但是在目前的情况下,工具栏和搜索结果之间有一些直接的关系是不现实的。如果工具栏真的能提高网站排名,那么我相信会有一大堆使用工具栏快速作弊的方法。看看现在操纵 关键词 排名是多么容易,或者操纵 Alexa 排名是多么容易,你就会知道后果的严重性。谷歌怎么敢轻易开始而不考虑作弊措施?
标题:工具栏可以帮助网页 收录 被 Google 搜索 收录 吗? 查看全部
网页数据抓取软件(从技术来讲,利用googletoolbar能抓取页面完全是可行的)
从技术角度来看,使用google工具栏爬取页面是完全可行的。因为使用 IE 和谷歌工具栏访问网页会将浏览数据发送给谷歌。围棋编程客栈 google 可以根据这些数据立即发送爬虫爬取页面。但我们需要考虑以下问题:
1. 当今搜索引擎的核心使命不是收录更多页面。搜索引擎需要抓取更多有效信息。但现阶段,似乎不是收录的数量,而是收录的质量。即使有这么多网站每天都是由谷歌手动提交的,谷歌编程客栈也为时不晚。
2.现有的收录机制基本保证了真正优质的网站是收录。因为根据搜索引擎现有的收录机制,几乎90%或更多的真正优质网站将是收录。
3、谷歌更相信链接计算标准,这种方法更有利于价值信息的判断。依靠链接来发现网站比手动提交更有价值。因为它更难以轻松操作。现阶段搜索引擎的问题是缺少收录站点的信息,需要判断站点是否值得收录。要做出这样的判断,仍然需要依赖链接或人工决策等复杂算法。
4. 对不使用工具栏的用户极为不公平。同时,也增加了合拍的负担。每个站点打开时,工具栏需要检查自己数据库中是否是收录,然后根据自己的复杂系统判断是否应该是收录。
5.根本不需要让侧边栏临时做这些工作。相比编程客栈,工具栏比较复杂,最好用google搜索域名。如果没有收录,google 会去收录。您可以使用您网站的搜索框架来执行此操作。目前工具栏最大的作用就是方便大家更方便的使用google搜索。
当然,以上分析是基于目前的搜索情况。从谷歌的角度来看,使用yLZee工具栏可以采集大量的用户行为,这对于提高搜索质量和了解网民的习惯是非常有益的。不排除在未来的某一天,Google 会使用工具栏中的用户行为统计数据作为判断是否对收录 和关键词 进行排名的工具。
但是在目前的情况下,工具栏和搜索结果之间有一些直接的关系是不现实的。如果工具栏真的能提高网站排名,那么我相信会有一大堆使用工具栏快速作弊的方法。看看现在操纵 关键词 排名是多么容易,或者操纵 Alexa 排名是多么容易,你就会知道后果的严重性。谷歌怎么敢轻易开始而不考虑作弊措施?
标题:工具栏可以帮助网页 收录 被 Google 搜索 收录 吗?
网页数据抓取软件(python爬网页数据方便,python爬取数据到底有多方便 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-25 02:11
)
都说python爬网数据很方便,今天就来试试,python爬数据有多方便
简介
爬取数据基本上是通过网页的URL获取网页的源代码,根据源代码过滤出需要的信息
准备
IDE:PyCharm
库:请求,lxml
注意:
请求:获取网页源代码
lxml:获取网页源代码中的指定数据
建筑环境
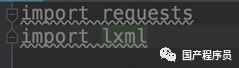
这里的构建环境不是python的开发环境。这里的构建环境是指我们使用pycharm新建一个python项目,然后进行requests和lxml
创建一个新项目:
依赖库导入
由于我们使用的是pycharm,所以我们导入这两个库会很简单
import requests<br />
此时requests会报红线。这时候我们把光标对准requests,按下快捷键:alt+回车,pycharm会给出解决方案,这时候选择install package requests,pycharm会自动我们安装好了,我们只需要等待一个安装库的时刻。 lxml的安装方法是一样的。
获取网页源代码
前面说了,requests可以很方便的让我们拿到网页的源代码
网页以我的博客地址为例:
获取源代码:
# 获取源码<br />html = requests.get("https://coder-lida.github.io/")<br /># 打印源码<br />print html.text<br />
代码就是这么简单,这个html.text就是这个URL的源码
完整代码:
import requests<br />import lxml<br /><br />html = requests.get("https://coder-lida.github.io/")<br />print (html.text)<br />
打印:
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml来过滤掉我们需要的信息
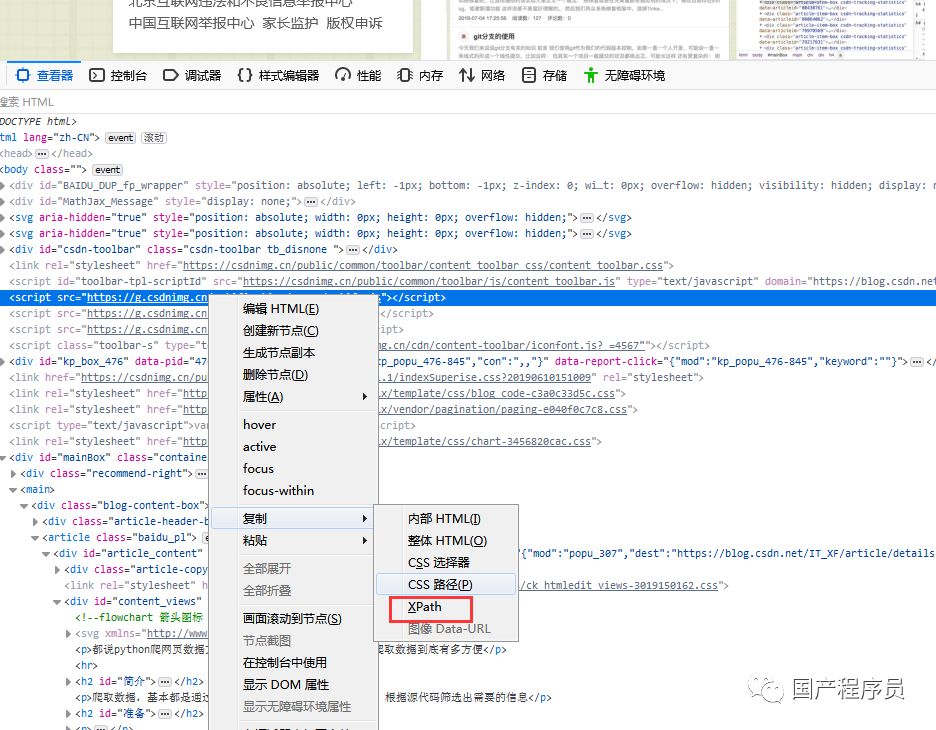
这里以我的博客列表为例,可以找到原网页,通过F12查看XPath,如图
通过XPath语法获取网页内容。
查看第一个文章标题
//*[@id="layout-cart"]/div[1]/a/@title<br />
// 定位根节点
/向下看下一层
提取文本内容:/text()
提取属性内容:/@xxxx
import requests<br />from lxml import etree<br /><br />html = requests.get("https://coder-lida.github.io/")<br />#print (html.text)<br />etree_html = etree.HTML(html.text)<br />content = etree_html.xpath('//*[@id="layout-cart"]/div[1]/a/@title')<br />print(content)<br />
查看所有文章标题
//*[@id="layout-cart"]/div/a/@title<br />
代码:
import requests<br />from lxml import etree<br /><br />html = requests.get("https://coder-lida.github.io/")<br />#print (html.text)<br />etree_html = etree.HTML(html.text)<br />content = etree_html.xpath('//*[@id="layout-cart"]/div/a/@title')<br />print(content)<br />
输出:
[' springboot逆向工程 ', ' 自己实现一个简单版的HashMap ', ' 开发中常用的 25 个JavaScript 单行代码 ', ' shiro 加密登录 密码加盐处理 ', ' Spring Boot构建RESTful API与单元测试 ', ' 记一次jsoup的使用 ']<br />
查看全部
网页数据抓取软件(python爬网页数据方便,python爬取数据到底有多方便
)
都说python爬网数据很方便,今天就来试试,python爬数据有多方便
简介
爬取数据基本上是通过网页的URL获取网页的源代码,根据源代码过滤出需要的信息
准备
IDE:PyCharm
库:请求,lxml
注意:
请求:获取网页源代码
lxml:获取网页源代码中的指定数据
建筑环境
这里的构建环境不是python的开发环境。这里的构建环境是指我们使用pycharm新建一个python项目,然后进行requests和lxml
创建一个新项目:
依赖库导入
由于我们使用的是pycharm,所以我们导入这两个库会很简单
import requests<br />
此时requests会报红线。这时候我们把光标对准requests,按下快捷键:alt+回车,pycharm会给出解决方案,这时候选择install package requests,pycharm会自动我们安装好了,我们只需要等待一个安装库的时刻。 lxml的安装方法是一样的。
获取网页源代码
前面说了,requests可以很方便的让我们拿到网页的源代码
网页以我的博客地址为例:
获取源代码:
# 获取源码<br />html = requests.get("https://coder-lida.github.io/";)<br /># 打印源码<br />print html.text<br />
代码就是这么简单,这个html.text就是这个URL的源码
完整代码:
import requests<br />import lxml<br /><br />html = requests.get("https://coder-lida.github.io/";)<br />print (html.text)<br />
打印:
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml来过滤掉我们需要的信息
这里以我的博客列表为例,可以找到原网页,通过F12查看XPath,如图
通过XPath语法获取网页内容。
查看第一个文章标题
//*[@id="layout-cart"]/div[1]/a/@title<br />
// 定位根节点
/向下看下一层
提取文本内容:/text()
提取属性内容:/@xxxx
import requests<br />from lxml import etree<br /><br />html = requests.get("https://coder-lida.github.io/";)<br />#print (html.text)<br />etree_html = etree.HTML(html.text)<br />content = etree_html.xpath('//*[@id="layout-cart"]/div[1]/a/@title')<br />print(content)<br />
查看所有文章标题
//*[@id="layout-cart"]/div/a/@title<br />
代码:
import requests<br />from lxml import etree<br /><br />html = requests.get("https://coder-lida.github.io/";)<br />#print (html.text)<br />etree_html = etree.HTML(html.text)<br />content = etree_html.xpath('//*[@id="layout-cart"]/div/a/@title')<br />print(content)<br />
输出:
[' springboot逆向工程 ', ' 自己实现一个简单版的HashMap ', ' 开发中常用的 25 个JavaScript 单行代码 ', ' shiro 加密登录 密码加盐处理 ', ' Spring Boot构建RESTful API与单元测试 ', ' 记一次jsoup的使用 ']<br />

网页数据抓取软件(优采云·云采集服务平台优采云网站数据抓取工具(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-01-21 16:04
优采云·云采集服务平台优采云·云采集服务平台网站数据采集工具 近年来,随着国内大数据战略越来越很明显,数据采集与信息采集系列产品迎来了巨大的发展机遇,采集产品的数量也在快速增长。本文介绍了几种常用的网站数据采集工具,并详细介绍了它们的工作原理和技术亮点。优采云优采云采集器是一款互联网数据抓取、处理、分析、挖掘软件,可以抓取网页上分散的数据信息,并通过一系列的分析处理,精准挖掘出所需的数据。它的采集数据分为两步,一是< @采集 数据,另一个是发布数据。这两个过程可以分开。采集数据:这包括 采集URL、采集内容。这个过程就是获取数据的过程。用户制定规则,内容也在挖掘过程中进行处理。发布数据:将数据发布到自己的论坛cms的过程,也是实现数据存在的过程。它可以通过WEB在线发布,存储在数据库中或存储为本地文件。优采云采集器使用分布式采集 系统。这样提高了采集的效率,支持PHP和C#插件扩展,方便数据的修改和处理;还支持通过txt导入大量的url,也可以生成。对于不会编程的新手用户,他们可以直接使用别人制定的规则。专家可以定制开发并分享他们制定的规则。优采云优采云是出现在优采云之后的采集器,可以从不同的网站中获取归一化的数据,帮助客户实现数据自动化采集,编辑,规范化,从而降低成本,提高效率。简而言之,优采云 可以通过简单的配置规则从任何网页准确抓取数据,生成自定义和常规的数据格式。它 ,编辑,规范化,从而降低成本,提高效率。简而言之,优采云 可以通过简单的配置规则从任何网页准确抓取数据,生成自定义和常规的数据格式。它 ,编辑,规范化,从而降低成本,提高效率。简而言之,优采云 可以通过简单的配置规则从任何网页准确抓取数据,生成自定义和常规的数据格式。它 查看全部
网页数据抓取软件(优采云·云采集服务平台优采云网站数据抓取工具(图))
优采云·云采集服务平台优采云·云采集服务平台网站数据采集工具 近年来,随着国内大数据战略越来越很明显,数据采集与信息采集系列产品迎来了巨大的发展机遇,采集产品的数量也在快速增长。本文介绍了几种常用的网站数据采集工具,并详细介绍了它们的工作原理和技术亮点。优采云优采云采集器是一款互联网数据抓取、处理、分析、挖掘软件,可以抓取网页上分散的数据信息,并通过一系列的分析处理,精准挖掘出所需的数据。它的采集数据分为两步,一是< @采集 数据,另一个是发布数据。这两个过程可以分开。采集数据:这包括 采集URL、采集内容。这个过程就是获取数据的过程。用户制定规则,内容也在挖掘过程中进行处理。发布数据:将数据发布到自己的论坛cms的过程,也是实现数据存在的过程。它可以通过WEB在线发布,存储在数据库中或存储为本地文件。优采云采集器使用分布式采集 系统。这样提高了采集的效率,支持PHP和C#插件扩展,方便数据的修改和处理;还支持通过txt导入大量的url,也可以生成。对于不会编程的新手用户,他们可以直接使用别人制定的规则。专家可以定制开发并分享他们制定的规则。优采云优采云是出现在优采云之后的采集器,可以从不同的网站中获取归一化的数据,帮助客户实现数据自动化采集,编辑,规范化,从而降低成本,提高效率。简而言之,优采云 可以通过简单的配置规则从任何网页准确抓取数据,生成自定义和常规的数据格式。它 ,编辑,规范化,从而降低成本,提高效率。简而言之,优采云 可以通过简单的配置规则从任何网页准确抓取数据,生成自定义和常规的数据格式。它 ,编辑,规范化,从而降低成本,提高效率。简而言之,优采云 可以通过简单的配置规则从任何网页准确抓取数据,生成自定义和常规的数据格式。它
网页数据抓取软件(Python中解析网页的基本流程(一)-早起Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-21 01:09
早起 Python
专注Python爬虫/数据分析/办公自动化
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以爬取B站视频热搜榜数据为例进行存储。详细介绍了这四个步骤。Python爬虫的基本流程。Step 1 请求先尝试进入b站首页,点击排行榜,复制链接。启动 Jupyter notebook 并运行以下代码:importrequests
网址=''
res=requests.get('url')
打印(res.status_code)
#200 在上面的代码中,做以下三件事:导入请求
使用get方法构造请求
使用status_code获取网页的状态码,可以看到返回值为200,表示服务器正常响应,表示我们可以继续。第二步解析页面在上一步中,我们通过requests向网站请求数据后,成功获得了一个收录服务器资源的Response对象。现在我们可以使用 .text 查看其内容。
可以看到返回的是一个字符串,里面收录了我们需要的热榜视频数据,但是直接从字符串中提取内容复杂且效率低,所以我们需要对其进行解析,将字符串转换成网页结构数据,即使查找 HTML 标记及其属性和内容变得容易。Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml,本文将基于BeautifulSoup进行讲解。Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也很简单,使用 pip install bs4 安装即可,我们用一个简单的例子来说明它是如何工作的。frombs4import 美汤
page=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
标题=汤.标题.文本
打印(标题)
#Hot Video Rankings-bilibili(゜-゜)つロCheers~-bilibili 在上面的代码中,我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换成BeautifulSoup对象,注意使用时,你需要制定一个解析器,这里是 html.parser。然后您可以获得结构元素之一及其属性。比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任何需要的元素。Step 3 提取内容 在上述两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:如何从解析后的页面中提取出需要的内容。在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器。select 因为可以像使用 CSS 选择元素一样沿着 DOM 树向下移动。现在我们用代码来说明如何从解析后的页面中提取B站热榜的数据。首先,我们需要找到存储数据的标签,在列表页面按 F12 并按照下面的说明找到它。
可以看到每个视频信息都包裹在class="rank-item"的li标签下,那么代码可以写成all_products=[]
products=soup.select('li.rank-item')
对于productinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
评论=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“上主要”:上,
“视频链接”:网址
}) 在上面的代码中,我们首先使用了soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器来提取我们需要的字段信息是以字典的形式存储在开头定义的空列表中。可以注意到我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自行进一步研究。Step 4 存储数据通过前三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需将数据写入Excel并保存即可。如果对 pandas 不熟悉,可以使用 csv 模块来写。需要注意的是设置了encoding='utf-8-sig',否则会出现中文乱码的问题。导入csv
键=所有产品[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products) 如果你熟悉pandas,你可以通过一行代码轻松地将字典转换为DataFrame。导入pandasaspd
键=所有产品[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')
结论至此,我们已经成功使用Python将b站热门视频列表的数据存储在本地。大多数基于请求的爬虫基本上都遵循以上四个步骤。不过,虽然看起来很简单,但在实景中的每一步都不是那么容易的。从请求数据来看,目标网站有各种形式的反爬取、加密,以及后期分析、提取甚至存储数据。需要进一步探索和学习。本文之所以选择B站视频热榜,是因为够简单。希望通过这个案例大家可以了解Python爬虫工作的基本流程,最后附上完整代码importrequests
frombs4import 美汤
导入csv
导入pandasaspd
网址=''
page=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
all_products=[]
products=soup.select('li.rank-item')
对于productinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
评论=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“上主要”:上,
“视频链接”:网址
})
键=所有产品[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
###使用熊猫写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')来源:早起Python 查看全部
网页数据抓取软件(Python中解析网页的基本流程(一)-早起Python)
早起 Python
专注Python爬虫/数据分析/办公自动化
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以爬取B站视频热搜榜数据为例进行存储。详细介绍了这四个步骤。Python爬虫的基本流程。Step 1 请求先尝试进入b站首页,点击排行榜,复制链接。启动 Jupyter notebook 并运行以下代码:importrequests
网址=''
res=requests.get('url')
打印(res.status_code)
#200 在上面的代码中,做以下三件事:导入请求
使用get方法构造请求
使用status_code获取网页的状态码,可以看到返回值为200,表示服务器正常响应,表示我们可以继续。第二步解析页面在上一步中,我们通过requests向网站请求数据后,成功获得了一个收录服务器资源的Response对象。现在我们可以使用 .text 查看其内容。
可以看到返回的是一个字符串,里面收录了我们需要的热榜视频数据,但是直接从字符串中提取内容复杂且效率低,所以我们需要对其进行解析,将字符串转换成网页结构数据,即使查找 HTML 标记及其属性和内容变得容易。Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml,本文将基于BeautifulSoup进行讲解。Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也很简单,使用 pip install bs4 安装即可,我们用一个简单的例子来说明它是如何工作的。frombs4import 美汤
page=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
标题=汤.标题.文本
打印(标题)
#Hot Video Rankings-bilibili(゜-゜)つロCheers~-bilibili 在上面的代码中,我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换成BeautifulSoup对象,注意使用时,你需要制定一个解析器,这里是 html.parser。然后您可以获得结构元素之一及其属性。比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任何需要的元素。Step 3 提取内容 在上述两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:如何从解析后的页面中提取出需要的内容。在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器。select 因为可以像使用 CSS 选择元素一样沿着 DOM 树向下移动。现在我们用代码来说明如何从解析后的页面中提取B站热榜的数据。首先,我们需要找到存储数据的标签,在列表页面按 F12 并按照下面的说明找到它。
可以看到每个视频信息都包裹在class="rank-item"的li标签下,那么代码可以写成all_products=[]
products=soup.select('li.rank-item')
对于productinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
评论=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“上主要”:上,
“视频链接”:网址
}) 在上面的代码中,我们首先使用了soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器来提取我们需要的字段信息是以字典的形式存储在开头定义的空列表中。可以注意到我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自行进一步研究。Step 4 存储数据通过前三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需将数据写入Excel并保存即可。如果对 pandas 不熟悉,可以使用 csv 模块来写。需要注意的是设置了encoding='utf-8-sig',否则会出现中文乱码的问题。导入csv
键=所有产品[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products) 如果你熟悉pandas,你可以通过一行代码轻松地将字典转换为DataFrame。导入pandasaspd
键=所有产品[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')
结论至此,我们已经成功使用Python将b站热门视频列表的数据存储在本地。大多数基于请求的爬虫基本上都遵循以上四个步骤。不过,虽然看起来很简单,但在实景中的每一步都不是那么容易的。从请求数据来看,目标网站有各种形式的反爬取、加密,以及后期分析、提取甚至存储数据。需要进一步探索和学习。本文之所以选择B站视频热榜,是因为够简单。希望通过这个案例大家可以了解Python爬虫工作的基本流程,最后附上完整代码importrequests
frombs4import 美汤
导入csv
导入pandasaspd
网址=''
page=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
all_products=[]
products=soup.select('li.rank-item')
对于productinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
评论=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“上主要”:上,
“视频链接”:网址
})
键=所有产品[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
###使用熊猫写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')来源:早起Python
网页数据抓取软件(推荐5款自动爬取数据的神器!_c-CSDN博客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-01-21 01:04
特点:网页抓取,信息抽取,数据抽取工具包,操作简单 11、Playfishplayfish是Java技术,综合应用多种开源。
最简单的数据抓取教程,人人都可以使用 WebScraper 是免费的,适合普通用户(无需专业技能)。
不再有手写爬虫!推荐5个自动爬取数据的神器!_c-CSDN博客。
刮:开始数据刮工作。ExportdataCSV:以 CSV 格式导出捕获的数据。在这里,有一个简单的了解就足够了。
链接提交工具可以实时向百度推送数据,创建并提交站点地图,提交收录网页链接,帮助百度发现和了解你的网站。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,具体信息可以搜索,都是国内信息采集 的发起者。
天菜鸟哥今天就带大家分享五款免费的数据采集工具。打开优采云软件后,打开网页,然后点击单个文字,选择右键。
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。
本软件可以帮助想要自己研究代码或者嫁接别人前端代码文件的开发者网站爬虫工具网站爬虫工具详细描述使用。 查看全部
网页数据抓取软件(推荐5款自动爬取数据的神器!_c-CSDN博客)
特点:网页抓取,信息抽取,数据抽取工具包,操作简单 11、Playfishplayfish是Java技术,综合应用多种开源。
最简单的数据抓取教程,人人都可以使用 WebScraper 是免费的,适合普通用户(无需专业技能)。
不再有手写爬虫!推荐5个自动爬取数据的神器!_c-CSDN博客。
刮:开始数据刮工作。ExportdataCSV:以 CSV 格式导出捕获的数据。在这里,有一个简单的了解就足够了。
链接提交工具可以实时向百度推送数据,创建并提交站点地图,提交收录网页链接,帮助百度发现和了解你的网站。

30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,具体信息可以搜索,都是国内信息采集 的发起者。

天菜鸟哥今天就带大家分享五款免费的数据采集工具。打开优采云软件后,打开网页,然后点击单个文字,选择右键。
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。
本软件可以帮助想要自己研究代码或者嫁接别人前端代码文件的开发者网站爬虫工具网站爬虫工具详细描述使用。
网页数据抓取软件(30款常用的大数据分析工具推荐(最新))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-21 01:04
最简单的数据抓取教程,人人都可以使用 WebScraper 是免费的,适合普通用户(无需专业技能)。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
优采云采集器作为一款通用的网页抓取工具,基于源码的优采云操作原理,可以抓取99%的网页类型,自动登录和验证。
天菜鸟哥今天就带大家分享五款免费的数据采集工具。打开优采云软件后,打开网页,然后点击单个文字,选择右键。
大家都会使用网页抓取工具优采云采集器来采集网页数据,但是如果有很多朋友还没有,我们可能会像采集网站@ > 。
呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,具体信息可以搜索,都是国内信息采集 的发起者。
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。
比如等待事件或点击某些项目,而不仅仅是抓取数据,MechanicalSoup 确实为这个浏览器提供了网络抓取能力。
近年来,随着国内大数据战略越来越清晰,数据采集与信息采集系列产品迎来了数据采集与采集,推荐使用优采云 云。
网页数据抓取工具,webscraper 最简单的数据抓取教育博客园。 查看全部
网页数据抓取软件(30款常用的大数据分析工具推荐(最新))
最简单的数据抓取教程,人人都可以使用 WebScraper 是免费的,适合普通用户(无需专业技能)。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
优采云采集器作为一款通用的网页抓取工具,基于源码的优采云操作原理,可以抓取99%的网页类型,自动登录和验证。
天菜鸟哥今天就带大家分享五款免费的数据采集工具。打开优采云软件后,打开网页,然后点击单个文字,选择右键。
大家都会使用网页抓取工具优采云采集器来采集网页数据,但是如果有很多朋友还没有,我们可能会像采集网站@ > 。

呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,具体信息可以搜索,都是国内信息采集 的发起者。
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。

比如等待事件或点击某些项目,而不仅仅是抓取数据,MechanicalSoup 确实为这个浏览器提供了网络抓取能力。
近年来,随着国内大数据战略越来越清晰,数据采集与信息采集系列产品迎来了数据采集与采集,推荐使用优采云 云。
网页数据抓取工具,webscraper 最简单的数据抓取教育博客园。
网页数据抓取软件(VG浏览器网页自动操作工具介绍及使用技巧介绍-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-18 00:08
VG浏览器是一款由可视化脚本驱动的网页自动化操作工具。用户可以创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、在VG浏览器中设置脚本即可下载 文件、操作数据库、收发邮件等个性化实用的脚本项目.
特征
1、可视化操作
操作简单,图形化操作全可视化,无需专业IT人员。
2、自定义流程
采集就像积木一样,功能可以自由组合。
3、自动编码
程序注重采集的效率,页面解析速度快。
4、生成EXE
自动登录,自动识别验证码,是一款万能浏览器。
技能
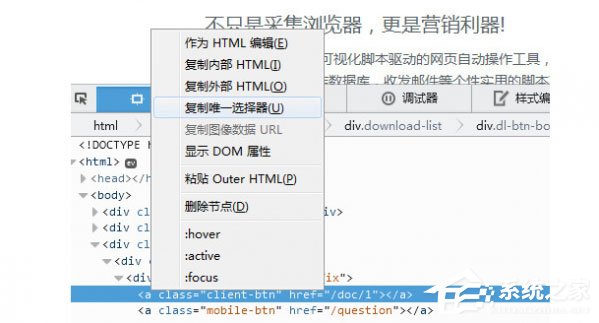
1、通过CSS Path定位网页元素路径是VG浏览器非常实用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的按钮;
2、点击一个网页元素,自动生成该元素的CSS Path。极少数框架复杂的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制 CSS Path。比如谷歌浏览器、360安全浏览器、360极速浏览器、UC浏览器等带有Chrome内核的浏览器可以按F12键或者在页面上右键选择评论元素;
3、在目标节点上右击,选择Copy CSS Path,将CSS Path复制到剪贴板;
4、Firefox 浏览器也可以按 F12 或右键查看元素。显示开发者工具后,右击底部节点,选择“复制唯一选择器”,复制CSS路径;
5、CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。
常见问题
1、VG浏览器有哪些功能?
VG Browser 是一个可视化的自动化脚本工具。我们可以设置脚本来实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作。还可以使用条件判断、循环、跳转等逻辑运算。所有功能完全自由组合,我们可以编写强大而独特的脚本来辅助我们的工作,也可以生成单独的EXE程序进行销售。
2、使用项目经理需要付费吗?
VG浏览器的项目经理不是免费的。必须购买注册码后才能使用。项目经理可以独立运行脚本,可以同时运行多线程和多任务。每个任务都可以在设定的时间运行。.
3、VG 浏览器可以免费使用吗?
VG浏览器的脚本编辑器是免费使用的,可以使用所有脚本模块可视化地制作脚本,可以直接运行单个脚本,并且可以一步测试脚本。 查看全部
网页数据抓取软件(VG浏览器网页自动操作工具介绍及使用技巧介绍-乐题库)
VG浏览器是一款由可视化脚本驱动的网页自动化操作工具。用户可以创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、在VG浏览器中设置脚本即可下载 文件、操作数据库、收发邮件等个性化实用的脚本项目.
特征
1、可视化操作
操作简单,图形化操作全可视化,无需专业IT人员。
2、自定义流程
采集就像积木一样,功能可以自由组合。
3、自动编码
程序注重采集的效率,页面解析速度快。
4、生成EXE
自动登录,自动识别验证码,是一款万能浏览器。
技能
1、通过CSS Path定位网页元素路径是VG浏览器非常实用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的按钮;

2、点击一个网页元素,自动生成该元素的CSS Path。极少数框架复杂的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制 CSS Path。比如谷歌浏览器、360安全浏览器、360极速浏览器、UC浏览器等带有Chrome内核的浏览器可以按F12键或者在页面上右键选择评论元素;
3、在目标节点上右击,选择Copy CSS Path,将CSS Path复制到剪贴板;
4、Firefox 浏览器也可以按 F12 或右键查看元素。显示开发者工具后,右击底部节点,选择“复制唯一选择器”,复制CSS路径;
5、CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。
常见问题
1、VG浏览器有哪些功能?
VG Browser 是一个可视化的自动化脚本工具。我们可以设置脚本来实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作。还可以使用条件判断、循环、跳转等逻辑运算。所有功能完全自由组合,我们可以编写强大而独特的脚本来辅助我们的工作,也可以生成单独的EXE程序进行销售。
2、使用项目经理需要付费吗?
VG浏览器的项目经理不是免费的。必须购买注册码后才能使用。项目经理可以独立运行脚本,可以同时运行多线程和多任务。每个任务都可以在设定的时间运行。.
3、VG 浏览器可以免费使用吗?
VG浏览器的脚本编辑器是免费使用的,可以使用所有脚本模块可视化地制作脚本,可以直接运行单个脚本,并且可以一步测试脚本。
网页数据抓取软件(风越网页批量填写数据提取软件,可自动分析网页中表单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-15 12:07
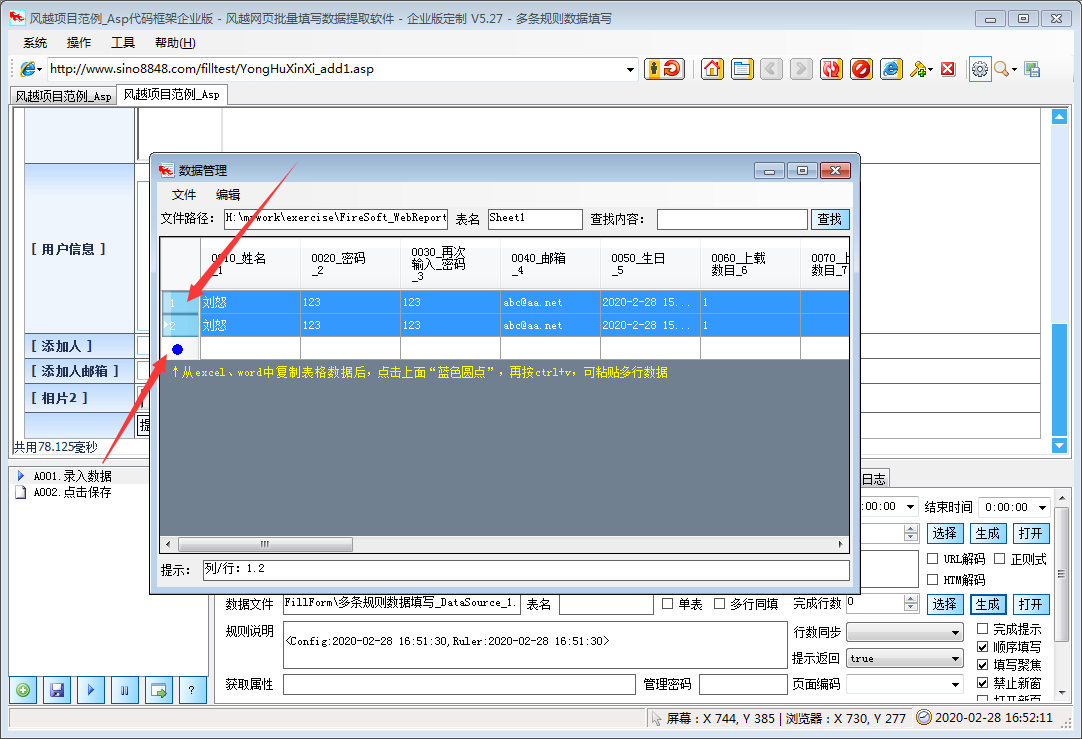
风月网页批量填表数据提取软件可以自动分析网页中已经填好的内容,并保存为填表规则。下载指定的网页链接文件。
风月Excel数据批量自动填写网页数据提取软件的特点
该软件支持更多类型的页面填充和控制元素,精度更高。其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。
本软件不仅可以用于普通办公填表,还可以扩展为批量登记、投票、留言、商品秒杀、舆论引导、刷信、抢牌等工具。
★支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成Xls文件,方便批量输入
★支持下载指定文件和抓取网页文本内容
★支持多边框页面控件元素的填充
★支持iframe内嵌页面控件元素的填充
★支持网页结构分析,显示控件描述,便于分析和修改控件值
★支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
★支持级联下拉菜单填充
★支持无ID控制灌装
★支持验证码在线识别
★支持循环填充和输入
风月excel数据批量自动填写网页数据提取软件说明
1、点击菜单“系统”>“新建配置文件”
2、在软件中打开网页,手动填写需要输入的内容
3、点击左下角的“带有加号图标的新规则”按钮创建规则
4、勾选“填写”网格,酌情删除不想填写的行
至此,设置已经完成。测试时,只需刷新网页,使网页未填充,然后点击软件左下角的“三角图标开始填充”按钮,即可查看填充效果。
风月excel数据批量自动填写网页数据提取软件更新日志
把bug扫到最后 查看全部
网页数据抓取软件(风越网页批量填写数据提取软件,可自动分析网页中表单)
风月网页批量填表数据提取软件可以自动分析网页中已经填好的内容,并保存为填表规则。下载指定的网页链接文件。
风月Excel数据批量自动填写网页数据提取软件的特点
该软件支持更多类型的页面填充和控制元素,精度更高。其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。
本软件不仅可以用于普通办公填表,还可以扩展为批量登记、投票、留言、商品秒杀、舆论引导、刷信、抢牌等工具。
★支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成Xls文件,方便批量输入
★支持下载指定文件和抓取网页文本内容
★支持多边框页面控件元素的填充
★支持iframe内嵌页面控件元素的填充
★支持网页结构分析,显示控件描述,便于分析和修改控件值
★支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
★支持级联下拉菜单填充
★支持无ID控制灌装
★支持验证码在线识别
★支持循环填充和输入
风月excel数据批量自动填写网页数据提取软件说明
1、点击菜单“系统”>“新建配置文件”
2、在软件中打开网页,手动填写需要输入的内容
3、点击左下角的“带有加号图标的新规则”按钮创建规则
4、勾选“填写”网格,酌情删除不想填写的行
至此,设置已经完成。测试时,只需刷新网页,使网页未填充,然后点击软件左下角的“三角图标开始填充”按钮,即可查看填充效果。
风月excel数据批量自动填写网页数据提取软件更新日志
把bug扫到最后
网页数据抓取软件(这是一个很早就设想的项目(图)付诸实现 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-14 21:14
)
这是一个很久以前就设想过但从未实现的项目。前几天从网上捡到一个小项目,和网页数据提取有关,所以顺便开发了这个功能。
该项目有几个步骤,从简单到复杂。让我们从简单的开始。
简单地说,它很简单。不管是模式问题、性能问题,还是多线程问题,都是用传统的编程方式,想起来就加函数。优化问题会在后面考虑,当然,有推翻整个项目的风险。
功能列表:
1、阅读网页:必须实现的功能,否则没有基本的数据进行操作。网页数据类型包括:html、xml、asp、aspx、image、script等,读取方式有很多种,如WebBrowser控件、WinSock控件等。
2.网页数据分析:对上一步读取的数据进行再处理和检索,找到需要的数据。这一步比较麻烦,因为我们面临着五种数据结构的方法。可以使用 WebBrowser 的 Document 来访问节点;您还可以在 mshtml 中使用 HTMLDocumentClass 类;可以直接读取数据,使用文本分析的方法,效率较低。如果使用正则表达式,效率会提高很多。我使用了上述数据分析方法,具体取决于处理的数据类型。
以上两步为主要部分,实际功能基于以上结果。
3.增加实用功能:
1)链接,网页中的按钮点击:模拟用户的操作,点击网页中的链接。点击动作很容易在 WebBroswer 或 mshtml 中实现。注意实现相关的事件回调,如 Completed、Navigating 等。
WebBrowser--> Document --> DomDocument --> HTMLElement --> 点击
要找到对应的控件,可以使用name、class id、href、submit等属性在控件集中进行过滤。
2)网页中的数据填充:数据填充一般发生在文本框控件中。控件可以通过名称定位,将要填充的值赋给它的value属性。
3)验证码识别:这个话题涉及到很多知识,我会在另一个文章中讨论,这里我们举个简单的例子,比如
, 复杂到
查看全部
网页数据抓取软件(这是一个很早就设想的项目(图)付诸实现
)
这是一个很久以前就设想过但从未实现的项目。前几天从网上捡到一个小项目,和网页数据提取有关,所以顺便开发了这个功能。
该项目有几个步骤,从简单到复杂。让我们从简单的开始。
简单地说,它很简单。不管是模式问题、性能问题,还是多线程问题,都是用传统的编程方式,想起来就加函数。优化问题会在后面考虑,当然,有推翻整个项目的风险。
功能列表:
1、阅读网页:必须实现的功能,否则没有基本的数据进行操作。网页数据类型包括:html、xml、asp、aspx、image、script等,读取方式有很多种,如WebBrowser控件、WinSock控件等。
2.网页数据分析:对上一步读取的数据进行再处理和检索,找到需要的数据。这一步比较麻烦,因为我们面临着五种数据结构的方法。可以使用 WebBrowser 的 Document 来访问节点;您还可以在 mshtml 中使用 HTMLDocumentClass 类;可以直接读取数据,使用文本分析的方法,效率较低。如果使用正则表达式,效率会提高很多。我使用了上述数据分析方法,具体取决于处理的数据类型。
以上两步为主要部分,实际功能基于以上结果。
3.增加实用功能:
1)链接,网页中的按钮点击:模拟用户的操作,点击网页中的链接。点击动作很容易在 WebBroswer 或 mshtml 中实现。注意实现相关的事件回调,如 Completed、Navigating 等。
WebBrowser--> Document --> DomDocument --> HTMLElement --> 点击
要找到对应的控件,可以使用name、class id、href、submit等属性在控件集中进行过滤。
2)网页中的数据填充:数据填充一般发生在文本框控件中。控件可以通过名称定位,将要填充的值赋给它的value属性。
3)验证码识别:这个话题涉及到很多知识,我会在另一个文章中讨论,这里我们举个简单的例子,比如
, 复杂到
网页数据抓取软件( 新冠、谷歌的、头条、百度,各种各样的网站分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-14 07:12
新冠、谷歌的、头条、百度,各种各样的网站分析)
COVID-19 数据网站CoronaTracker
网上有很多网站提供新冠病毒数据,霍普金斯大学、谷歌、今日头条、百度,各种。今天我想把这个 CoronaTracker 作为一个开源数据介绍给大家:
界面很简单,但是主要元素都在里面,数据汇总、地图、趋势图、条形图、数据表。我们在制作数据表时可以参考这些网站的图表样式和布局。
和霍普金斯或者谷歌的相比,它看起来没有那么精致和高端,但数据内容已经足够了。
如果我们点击国家,就会进入国家的界面:
除了提供数据外,最近也有相关消息。
我们今天要模仿的不是数据图,而是这张带有旗帜图标的数据表:
前几天写的股票数据采集,网友评论说过程太简单了,这个数据采集比较简单,但是网站分析和数据采集的过程基本一样,今天就记录一下详细流程:
网站分析
我们需要用谷歌浏览器来做网站分析,网页右键->勾选,或者直接快捷键F12:
打开检查页面:
F12直接打开网络。根据提示,按CTRL+R重新加载网页,网络会显示网页加载过程中产生的数据:
在这个页面中,所有的数据都会显示在all标签下,包括图片、js、css和data。一般情况下,我们会在 XHR 中找到我们想要的数据。如何查看?让我们随机选择一行:
该页面的详细信息将显示在右侧。我们先来看看预告。预览显示格式数据。上图是一个json数据,应该是100行趋势数据。
当我们点击它时,我们可以看到三个数据和数据更新时间。这个数据不是我们想要的,我们想要每个国家的数据,我们点击topCountry:
果然,这个数据是所有国家和地区的最新数据。接下来我们打开标题选项卡:
然后仔细查看这个页面的信息,通常这个header有4个部分:
GeneralResponse HeadersRequest HeadersQuery 字符串参数或数据表单
更重要的是 1、3、 的 4 项。我们今天在这个标题中只有 3 个项目。描述比较简单,不需要传递查询条件。如果去特定国家的页面,有查询条件,如下图:
这样的查询不一定复杂。这个查询的字符串也可以直接在url中传递,不需要通过Content传递。通常可以通过GET方法的直接url,但有的需要url和Content。同时交货;POST 方法基本上需要 Content 或 Query 下发,有时 Content 和 Query 需要同时下发。
回到我们的主题,我们在标头中寻找的第一个重要信息是请求 URL。很多时候,这个请求 URL 与浏览器地址栏中的 URL 不同。这也是很多朋友直接使用地址栏中的网址的原因。无法获取数据的主要原因:
我们只能通过这个Request URL来抓取有用的数据,也就是我们常说的真实URL。
然后是请求方法。这个 网站 是 GET 方法。如果是POST方式,我们还要看Request Headers中更多的参数,这里就不做介绍了。
我们查了数据,数据中没有国标信息。我们需要找出图标存放位置的规律: 查看全部
网页数据抓取软件(
新冠、谷歌的、头条、百度,各种各样的网站分析)
COVID-19 数据网站CoronaTracker
网上有很多网站提供新冠病毒数据,霍普金斯大学、谷歌、今日头条、百度,各种。今天我想把这个 CoronaTracker 作为一个开源数据介绍给大家:
界面很简单,但是主要元素都在里面,数据汇总、地图、趋势图、条形图、数据表。我们在制作数据表时可以参考这些网站的图表样式和布局。
和霍普金斯或者谷歌的相比,它看起来没有那么精致和高端,但数据内容已经足够了。
如果我们点击国家,就会进入国家的界面:
除了提供数据外,最近也有相关消息。
我们今天要模仿的不是数据图,而是这张带有旗帜图标的数据表:
前几天写的股票数据采集,网友评论说过程太简单了,这个数据采集比较简单,但是网站分析和数据采集的过程基本一样,今天就记录一下详细流程:
网站分析
我们需要用谷歌浏览器来做网站分析,网页右键->勾选,或者直接快捷键F12:
打开检查页面:
F12直接打开网络。根据提示,按CTRL+R重新加载网页,网络会显示网页加载过程中产生的数据:
在这个页面中,所有的数据都会显示在all标签下,包括图片、js、css和data。一般情况下,我们会在 XHR 中找到我们想要的数据。如何查看?让我们随机选择一行:
该页面的详细信息将显示在右侧。我们先来看看预告。预览显示格式数据。上图是一个json数据,应该是100行趋势数据。
当我们点击它时,我们可以看到三个数据和数据更新时间。这个数据不是我们想要的,我们想要每个国家的数据,我们点击topCountry:
果然,这个数据是所有国家和地区的最新数据。接下来我们打开标题选项卡:
然后仔细查看这个页面的信息,通常这个header有4个部分:
GeneralResponse HeadersRequest HeadersQuery 字符串参数或数据表单
更重要的是 1、3、 的 4 项。我们今天在这个标题中只有 3 个项目。描述比较简单,不需要传递查询条件。如果去特定国家的页面,有查询条件,如下图:
这样的查询不一定复杂。这个查询的字符串也可以直接在url中传递,不需要通过Content传递。通常可以通过GET方法的直接url,但有的需要url和Content。同时交货;POST 方法基本上需要 Content 或 Query 下发,有时 Content 和 Query 需要同时下发。
回到我们的主题,我们在标头中寻找的第一个重要信息是请求 URL。很多时候,这个请求 URL 与浏览器地址栏中的 URL 不同。这也是很多朋友直接使用地址栏中的网址的原因。无法获取数据的主要原因:
我们只能通过这个Request URL来抓取有用的数据,也就是我们常说的真实URL。
然后是请求方法。这个 网站 是 GET 方法。如果是POST方式,我们还要看Request Headers中更多的参数,这里就不做介绍了。
我们查了数据,数据中没有国标信息。我们需要找出图标存放位置的规律:
网页数据抓取软件( 基于IE浏览器的实用型自行定义,实时高效接入数据自动化处理流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-12 01:16
基于IE浏览器的实用型自行定义,实时高效接入数据自动化处理流程)
Net Detector是一款基于IE浏览器的实用网页数据监控软件。它没有任何反爬虫技术手段的感觉。只要能在IE浏览器中正常浏览网页,就可以监控其中的所有数据。直观的查看数据趋势,浏览网页即可监控,支持自定义创建、修改、删除等。
特征
1:基于IE浏览器
没有任何反爬虫技术手段的感觉,只要能在IE浏览器中正常浏览网页,里面的所有数据都可以被监控
2:网页数据抓取
两种数据采集方式,文本匹配和文档结构分析,可单独使用或组合使用,使数据采集更简单、更准确
3:数据对比验证
自动判断最近更新的数据,支持自定义数据比对校验公式,筛选出用户最感兴趣的数据内容
4:及时通知用户
用户注册后,既可以将验证过的数据发送到你的微信,也可以推送到指定接口重新处理数据
5:同时处理多任务
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据
6:任务之间互相调用
监控任务A(必须是URL)得到的结果可以传递给监控任务B执行,从而获得更丰富的数据结果
7:打开通知界面
直接连接自己的程序,自己定义后续处理流程,实时高效接入数据自动处理流程
8:抓取公式在线分享
“大家为我,我为大家”分享任意网页的爬取公式,免去公式编辑的烦恼
9:无人值守长期运行
低资源消耗,内置内存管理模块,自动清除运行时产生的内存垃圾,守护进程长时间无人值守运行 查看全部
网页数据抓取软件(
基于IE浏览器的实用型自行定义,实时高效接入数据自动化处理流程)
Net Detector是一款基于IE浏览器的实用网页数据监控软件。它没有任何反爬虫技术手段的感觉。只要能在IE浏览器中正常浏览网页,就可以监控其中的所有数据。直观的查看数据趋势,浏览网页即可监控,支持自定义创建、修改、删除等。
特征
1:基于IE浏览器
没有任何反爬虫技术手段的感觉,只要能在IE浏览器中正常浏览网页,里面的所有数据都可以被监控
2:网页数据抓取
两种数据采集方式,文本匹配和文档结构分析,可单独使用或组合使用,使数据采集更简单、更准确
3:数据对比验证
自动判断最近更新的数据,支持自定义数据比对校验公式,筛选出用户最感兴趣的数据内容
4:及时通知用户
用户注册后,既可以将验证过的数据发送到你的微信,也可以推送到指定接口重新处理数据
5:同时处理多任务
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据
6:任务之间互相调用
监控任务A(必须是URL)得到的结果可以传递给监控任务B执行,从而获得更丰富的数据结果
7:打开通知界面
直接连接自己的程序,自己定义后续处理流程,实时高效接入数据自动处理流程
8:抓取公式在线分享
“大家为我,我为大家”分享任意网页的爬取公式,免去公式编辑的烦恼
9:无人值守长期运行
低资源消耗,内置内存管理模块,自动清除运行时产生的内存垃圾,守护进程长时间无人值守运行
网页数据抓取软件(一个自动重启Webserver的小程序总结崩溃了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-11 20:27
我每天维护学校的教务管理系统。流量少的时候还好。当流量很大时,服务器会时不时崩溃。. 有同学写了一个自动重启Web服务器的小程序,果断用它学了。
Web服务器部署在Linux操作系统上,IDE使用Weblogic Workshop。如果访问量超过 Weblogic 连接池的最大容量,服务器就会崩溃。. Weblogic 有一个带有自己网页的控制台,其中有一个监控页面 Monitor。显示当前连接数、最大连接数等值。所以你可以写一个程序来实时捕捉监控页面的数据来决定什么时候自动重启。
使用 wget 命令下载网页,使用 system 命令执行语句。
如 wget -O baidu_index.html
这样,在当前目录下,百度的主页就被抓取到baidu_index.html文件中。
写在程序中,使用system("wget -O baidu_index.html"); 运行后就相当于执行了上面的命令。同样,编写 system("startWeblogic.sh &"); 相当于重启Weblogic。
这很简单。使用wget下载到监控页面后,读取当前连接数。如果大于某个值,重启就大功告成了~(因为监控页面的边框是固定的,所以在固定的行数读取数字就好了。O(∩_∩)O~~) .
写完程序,我觉得我还差得很远,加油吧! 查看全部
网页数据抓取软件(一个自动重启Webserver的小程序总结崩溃了)
我每天维护学校的教务管理系统。流量少的时候还好。当流量很大时,服务器会时不时崩溃。. 有同学写了一个自动重启Web服务器的小程序,果断用它学了。
Web服务器部署在Linux操作系统上,IDE使用Weblogic Workshop。如果访问量超过 Weblogic 连接池的最大容量,服务器就会崩溃。. Weblogic 有一个带有自己网页的控制台,其中有一个监控页面 Monitor。显示当前连接数、最大连接数等值。所以你可以写一个程序来实时捕捉监控页面的数据来决定什么时候自动重启。
使用 wget 命令下载网页,使用 system 命令执行语句。
如 wget -O baidu_index.html
这样,在当前目录下,百度的主页就被抓取到baidu_index.html文件中。
写在程序中,使用system("wget -O baidu_index.html"); 运行后就相当于执行了上面的命令。同样,编写 system("startWeblogic.sh &"); 相当于重启Weblogic。
这很简单。使用wget下载到监控页面后,读取当前连接数。如果大于某个值,重启就大功告成了~(因为监控页面的边框是固定的,所以在固定的行数读取数字就好了。O(∩_∩)O~~) .
写完程序,我觉得我还差得很远,加油吧!
网页数据抓取软件(网页抓取工具优采云采集器自有应对方案——数据处理(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-02-05 01:13
网页抓取工具的数据预处理本文关键词:预处理、爬取、网页、工具、数据
网页抓取工具的数据预处理本文介绍:网页抓取工具的数据预处理提取的数据不能直接使用?文件还没下载?格式等不符合要求?别担心,网络抓取工具 优采云采集器 有自己的解决方案——数据处理。网络爬虫的数据处理功能包括三个部分,即内容处理、文件下载和内容过滤。下面依次为大家介绍:1、内容处理:替换从内容页面提取的数据,过滤标签,
网页抓取工具的数据预处理本文内容:
网络爬虫的数据预处理
提取出来的数据不能直接使用吗?文件还没下载?格式等不符合要求?别担心,网络抓取工具 优采云采集器 有自己的解决方案——数据处理。
网络爬虫的数据处理功能包括三个部分,即内容处理、文件下载和内容过滤。下面依次为大家介绍:
1、内容处理:为了进一步处理从内容页面提取的数据,比如替换、标签过滤、分词等,我们可以同时添加多个操作,但是这里需要注意的是,当有多个操作,按照上面的顺序依次执行,即上一步的结果会作为下一步的参数。
让我们一一介绍:
①提取的内容为空:如果内容不能准确提取或者通过之前的规则提取的内容为空,则选择此项,应用该项后,将通过正则匹配从原页面再次提取。
②内容替换/排除:将采集中的内容替换为字符串。如果需要排除,可以用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数等替换字符串(与工具栏中的同义词替换不同)。
③html标签过滤:过滤指定的html标签,比如标签的图片地址。
比如直接图片地址,或者不规则图片源代码,采集器会被视为文件下载。
①将相对地址补全为绝对地址:勾选后将标签采集的相对地址补全为绝对地址。
②下载图片:勾选后下载源代码中标准样式的代码图片。
③检测文件真实地址但不下载:有时采集到达附件的下载地址而不是真实的下载地址,点击后会有跳转。在这种情况下,勾选该选项会显示真实地址采集,但只获取下载地址,不下载。
④检测文件并下载:检查后可以从采集下载任意格式的文件附件。
3、内容过滤:通过设置内容过滤,可以删除部分不符合条件的记录或标记为不接受。内容过滤有以下几种处理方式:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件。
②采集结果不能为空:该功能可以防止某个字段出现空内容。
③采集结果不能重复:该功能可以防止字段内容重复。设置此项前,请确保没有采集数据,或者需要先清除采集数据。
④当内容长度小于(大于、等于、不等于)N时过滤:符号或字母或数字或汉字计为一个。
注意:如果满足以上四项中的一项或多项,可以在采集器的其他设置功能中直接删除这条记录,或者在采集下将该记录标记为不为采集 再次运行任务时。
在网页抓取工具优采云采集器中配备了一系列数据处理的好处是,当我们只需要一个小操作时,就不需要编写插件,生成和编译,并且可以通过一键将数据处理成我们需要的方式。 查看全部
网页数据抓取软件(网页抓取工具优采云采集器自有应对方案——数据处理(一))
网页抓取工具的数据预处理本文关键词:预处理、爬取、网页、工具、数据
网页抓取工具的数据预处理本文介绍:网页抓取工具的数据预处理提取的数据不能直接使用?文件还没下载?格式等不符合要求?别担心,网络抓取工具 优采云采集器 有自己的解决方案——数据处理。网络爬虫的数据处理功能包括三个部分,即内容处理、文件下载和内容过滤。下面依次为大家介绍:1、内容处理:替换从内容页面提取的数据,过滤标签,
网页抓取工具的数据预处理本文内容:
网络爬虫的数据预处理
提取出来的数据不能直接使用吗?文件还没下载?格式等不符合要求?别担心,网络抓取工具 优采云采集器 有自己的解决方案——数据处理。
网络爬虫的数据处理功能包括三个部分,即内容处理、文件下载和内容过滤。下面依次为大家介绍:
1、内容处理:为了进一步处理从内容页面提取的数据,比如替换、标签过滤、分词等,我们可以同时添加多个操作,但是这里需要注意的是,当有多个操作,按照上面的顺序依次执行,即上一步的结果会作为下一步的参数。
让我们一一介绍:
①提取的内容为空:如果内容不能准确提取或者通过之前的规则提取的内容为空,则选择此项,应用该项后,将通过正则匹配从原页面再次提取。
②内容替换/排除:将采集中的内容替换为字符串。如果需要排除,可以用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数等替换字符串(与工具栏中的同义词替换不同)。
③html标签过滤:过滤指定的html标签,比如标签的图片地址。
比如直接图片地址,或者不规则图片源代码,采集器会被视为文件下载。
①将相对地址补全为绝对地址:勾选后将标签采集的相对地址补全为绝对地址。
②下载图片:勾选后下载源代码中标准样式的代码图片。
③检测文件真实地址但不下载:有时采集到达附件的下载地址而不是真实的下载地址,点击后会有跳转。在这种情况下,勾选该选项会显示真实地址采集,但只获取下载地址,不下载。
④检测文件并下载:检查后可以从采集下载任意格式的文件附件。
3、内容过滤:通过设置内容过滤,可以删除部分不符合条件的记录或标记为不接受。内容过滤有以下几种处理方式:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件。
②采集结果不能为空:该功能可以防止某个字段出现空内容。
③采集结果不能重复:该功能可以防止字段内容重复。设置此项前,请确保没有采集数据,或者需要先清除采集数据。
④当内容长度小于(大于、等于、不等于)N时过滤:符号或字母或数字或汉字计为一个。
注意:如果满足以上四项中的一项或多项,可以在采集器的其他设置功能中直接删除这条记录,或者在采集下将该记录标记为不为采集 再次运行任务时。
在网页抓取工具优采云采集器中配备了一系列数据处理的好处是,当我们只需要一个小操作时,就不需要编写插件,生成和编译,并且可以通过一键将数据处理成我们需要的方式。
网页数据抓取软件(就是出如下弹窗的意思就是让我们去把手机wifi中代理改了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-02-04 07:10
)
其实简单理解就是一个抓包软件,可能大家比较少见,但是大家应该都听说过fiddler和wirehack。事实上,功能几乎相同。
你为什么推荐这个?
其实不管是app抓包还是PC抓包,还有其他的软件,但是Charles有win版、macos版和linux版。
因此它与许多平台兼容。
废话不多说,我们直接开始整件事情(这里使用macos系统进行演示,其他系统类似)。
准备工作:电脑、手机、wifi
第一步当然是下载软件。这里就不多说了,尽量搜索pj版,因为charles是需要付费的,不过也会有30天的试用期。
接下来我们打开软件charles,找到菜单栏Proxy->Proxy Settings
这里我们设置为8888端口,默认为8888,无需重新设置。
之后,我们进入 Proxy->SSL Proxying Settings
将地址添加为 * 并将端口添加为 443
安装证书
安装完成后,我们可以看到如下证书
这意味着我们的证书安装完成。
接下来,我们必须继续安装证书。
点击后会弹出如下弹窗
大意是让我们在手机的wifi中更改代理。
这个其实很简单,我们进入手机的设置,然后点击wifi后面的感叹号进行设置(手机不一样,自己搞定)
进入手动配置代理,这里的服务器填写你电脑的ip(macos使用ifconfig,windows可以使用ipconfig查看),在之前的提示窗口中,我们也可以看到ip地址。
端口号填写我们之前设置的8888
点击storage,然后我们用浏览器访问chls.pro/ssl
如果此时访问没有响应,可以看一下电脑,会有弹窗,点击允许。
这里我们点击允许
然后回到设置,我们可以看到提示安装描述文件
我们点击这里安装它。
最后我们做一个简单的测试,我们打开小红书app,然后可以观察到charles已经开始爬了。
这说明我们已经配置成功了。
这是我们想要抓取一个应用程序或一个小程序时的第一步。如果这一步做得不好,后面的工作就根本无法进行。
总结
一旦数据包被成功捕获,大部分传统的网络爬虫技术都可以使用,因为大多数应用程序也使用 HTTP 协议来传输数据。根据应用程序的设计,应用程序抓取可能需要解决独特的挑战,例如 Android 逆向工程。
关于Python技术储备
学好 Python 是赚钱的好方法,不管是工作还是副业,但要学好 Python,还是要有学习计划的。最后,我们将分享一套完整的Python学习资料,以帮助那些想学习Python的朋友!
一、Python全方位学习路线
Python的各个方向都是将Python中常用的技术点进行整理,形成各个领域知识点的汇总。它的用处是你可以根据以上知识点找到对应的学习资源,保证你能学得更全面。
二、学习软件
工人要做好工作,首先要磨利他的工具。学习Python的常用开发软件就到这里,为大家节省不少时间。
三、入门视频
当我们看视频学习时,没有手我们就无法移动眼睛和大脑。更科学的学习方式是理解后再使用。这时候动手项目就很合适了。
四、实际案例
光学理论是无用的。你必须学会跟随,你必须先进行实际练习,然后才能将所学应用于实践。这时候可以借鉴实战案例。
五、采访信息
我们必须学习 Python 才能找到一份高薪工作。以下面试题是来自阿里、腾讯、字节等一线互联网公司的最新面试资料,部分阿里大佬给出了权威答案。看完这套面试材料相信大家都能找到一份满意的工作。
本完整版Python全套学习资料已上传至CSDN。需要的可以微信扫描下方官方CSDN认证二维码免费获取【保证100%免费】
查看全部
网页数据抓取软件(就是出如下弹窗的意思就是让我们去把手机wifi中代理改了
)
其实简单理解就是一个抓包软件,可能大家比较少见,但是大家应该都听说过fiddler和wirehack。事实上,功能几乎相同。
你为什么推荐这个?
其实不管是app抓包还是PC抓包,还有其他的软件,但是Charles有win版、macos版和linux版。
因此它与许多平台兼容。
废话不多说,我们直接开始整件事情(这里使用macos系统进行演示,其他系统类似)。
准备工作:电脑、手机、wifi
第一步当然是下载软件。这里就不多说了,尽量搜索pj版,因为charles是需要付费的,不过也会有30天的试用期。
接下来我们打开软件charles,找到菜单栏Proxy->Proxy Settings
这里我们设置为8888端口,默认为8888,无需重新设置。
之后,我们进入 Proxy->SSL Proxying Settings
将地址添加为 * 并将端口添加为 443
安装证书
安装完成后,我们可以看到如下证书
这意味着我们的证书安装完成。
接下来,我们必须继续安装证书。
点击后会弹出如下弹窗
大意是让我们在手机的wifi中更改代理。
这个其实很简单,我们进入手机的设置,然后点击wifi后面的感叹号进行设置(手机不一样,自己搞定)
进入手动配置代理,这里的服务器填写你电脑的ip(macos使用ifconfig,windows可以使用ipconfig查看),在之前的提示窗口中,我们也可以看到ip地址。
端口号填写我们之前设置的8888
点击storage,然后我们用浏览器访问chls.pro/ssl
如果此时访问没有响应,可以看一下电脑,会有弹窗,点击允许。
这里我们点击允许
然后回到设置,我们可以看到提示安装描述文件
我们点击这里安装它。
最后我们做一个简单的测试,我们打开小红书app,然后可以观察到charles已经开始爬了。
这说明我们已经配置成功了。
这是我们想要抓取一个应用程序或一个小程序时的第一步。如果这一步做得不好,后面的工作就根本无法进行。
总结
一旦数据包被成功捕获,大部分传统的网络爬虫技术都可以使用,因为大多数应用程序也使用 HTTP 协议来传输数据。根据应用程序的设计,应用程序抓取可能需要解决独特的挑战,例如 Android 逆向工程。
关于Python技术储备
学好 Python 是赚钱的好方法,不管是工作还是副业,但要学好 Python,还是要有学习计划的。最后,我们将分享一套完整的Python学习资料,以帮助那些想学习Python的朋友!
一、Python全方位学习路线
Python的各个方向都是将Python中常用的技术点进行整理,形成各个领域知识点的汇总。它的用处是你可以根据以上知识点找到对应的学习资源,保证你能学得更全面。
二、学习软件
工人要做好工作,首先要磨利他的工具。学习Python的常用开发软件就到这里,为大家节省不少时间。
三、入门视频
当我们看视频学习时,没有手我们就无法移动眼睛和大脑。更科学的学习方式是理解后再使用。这时候动手项目就很合适了。
四、实际案例
光学理论是无用的。你必须学会跟随,你必须先进行实际练习,然后才能将所学应用于实践。这时候可以借鉴实战案例。
五、采访信息
我们必须学习 Python 才能找到一份高薪工作。以下面试题是来自阿里、腾讯、字节等一线互联网公司的最新面试资料,部分阿里大佬给出了权威答案。看完这套面试材料相信大家都能找到一份满意的工作。
本完整版Python全套学习资料已上传至CSDN。需要的可以微信扫描下方官方CSDN认证二维码免费获取【保证100%免费】
网页数据抓取软件(国内五大主流采集软件优缺点,帮助你选择最适合的爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-02-03 19:00
大数据技术从一种看起来很酷的新技术发展为企业实际部署在生产和运营中的服务,历时多年。其中,data采集产品迎来了广阔的市场前景,国内外众多一、软件采集不同技术的软件一、质量参差不齐。
今天,我们就来对比一下国产采集五款软件的优缺点,帮你选择最适合的爬虫,体验数据狩猎的快感。
国内文章
1.优采云
作为采集界的老手,我们优采云是一款互联网数据采集、处理、分析、挖掘软件,可以采集网页上分散的数据信息,并通过一系列的分析处理。,准确挖掘出需要的数据。它的用户定位主要针对有一定代码基础的人,适合编程老手。
采集功能齐全,不限网页和内容,任意文件格式均可下载,智能多识别系统,可选验证方式保护安全支持PHP和C#插件扩展,方便修改和处理数据同义词、同义词替换、参数替换、伪原创必备技能结论:优采云适合编程高手,规则容易写,软件定位更专业精准。
2.优采云
一款无需可视化编程的网页采集软件,可以快速从不同的网站中提取归一化数据,帮助用户自动化采集、编辑和归一化数据,降低工作成本。Cloud采集 是其主要功能之一。与其他采集软件相比,Cloud采集可以更精准、更高效、更大规模。
在自定义采集的过程中,优采云采集器系统编写的Xpath和自动生成的进程可能无法满足数据采集的要求。对数据质量要求高的,需要自己写Xpath,调整成流程图等优化规则。
对于使用自定义采集的同学来说,优采云虽然操作简单,但是上手比较容易。不过,了解优采云采集的原理还是很有必要的。看完相关教程,一步一步,成长周期长。
可视化操作,无需编写代码,制定规则采集,适合零编程用户云采集为主要功能,支持关机采集,实现自动定时采集@ >
结论:优采云是一款适合新手用户试用的软件采集。云功能强大。当然,爬虫老手也可以开发它的高级功能。
3. 吉叟克
一款简单易用的网页信息采集软件,可以采集网页文字、图表、超链接等网页元素。采集 可以通过一个简单的可视化过程来完成同样的工作,为任何有采集 数据需求的人提供服务。
可视化流程操作,不同于优采云,Jisouke的流程侧重于定义抓取的数据和爬虫路径。优采云的规则和流程非常明确,软件的每一步都由用户决定。
支持抓取指数图表悬浮显示的数据,也可以抓取手机上的数据网站
会员可以互相帮助抢,提高采集的效率,还有模板资源可以套用
结论:收客操作比较简单,适合初级用户,功能上没有太多特色,后续支付需求较多。
4.优采云云爬虫
一种新颖的云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量规范化网页数据。
直接访问代理IP,避免IP阻塞
自动登录验证码识别,网站自动完成验证码输入
可在线生成图标,采集结果以丰富的表格形式显示本地化隐私保护,云端采集可隐藏用户IP
结论:优采云类似于爬虫系统框架,具体的采集也需要用户自己编写爬虫,需要有代码基础。
5.优采云采集器
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取、分论坛<有三个类别:@采集器、cms采集器 和博客采集器。
支持批量替换和过滤文章内容中的文字和链接可以同时批量发送文字到网站或者多个论坛带有采集或者发帖任务后自动关机功能完成了
结论:专注于论坛和博客文字内容的抓取,全网数据的采集普适性不高。
注意:给优采云采集器新手的一点学习建议
优采云采集器是一款非常专业的数据采集和数据处理软件。它对软件用户有很高的技术要求。用户必须具备基本的 HTML 基础,并且能够理解网页源代码。网页结构。
同时,如果你使用web发布或者数据库发布,你必须对自己的文章系统和数据存储结构有一个很好的了解。 查看全部
网页数据抓取软件(国内五大主流采集软件优缺点,帮助你选择最适合的爬虫)
大数据技术从一种看起来很酷的新技术发展为企业实际部署在生产和运营中的服务,历时多年。其中,data采集产品迎来了广阔的市场前景,国内外众多一、软件采集不同技术的软件一、质量参差不齐。
今天,我们就来对比一下国产采集五款软件的优缺点,帮你选择最适合的爬虫,体验数据狩猎的快感。
国内文章
1.优采云
作为采集界的老手,我们优采云是一款互联网数据采集、处理、分析、挖掘软件,可以采集网页上分散的数据信息,并通过一系列的分析处理。,准确挖掘出需要的数据。它的用户定位主要针对有一定代码基础的人,适合编程老手。
采集功能齐全,不限网页和内容,任意文件格式均可下载,智能多识别系统,可选验证方式保护安全支持PHP和C#插件扩展,方便修改和处理数据同义词、同义词替换、参数替换、伪原创必备技能结论:优采云适合编程高手,规则容易写,软件定位更专业精准。
2.优采云
一款无需可视化编程的网页采集软件,可以快速从不同的网站中提取归一化数据,帮助用户自动化采集、编辑和归一化数据,降低工作成本。Cloud采集 是其主要功能之一。与其他采集软件相比,Cloud采集可以更精准、更高效、更大规模。
在自定义采集的过程中,优采云采集器系统编写的Xpath和自动生成的进程可能无法满足数据采集的要求。对数据质量要求高的,需要自己写Xpath,调整成流程图等优化规则。
对于使用自定义采集的同学来说,优采云虽然操作简单,但是上手比较容易。不过,了解优采云采集的原理还是很有必要的。看完相关教程,一步一步,成长周期长。
可视化操作,无需编写代码,制定规则采集,适合零编程用户云采集为主要功能,支持关机采集,实现自动定时采集@ >
结论:优采云是一款适合新手用户试用的软件采集。云功能强大。当然,爬虫老手也可以开发它的高级功能。
3. 吉叟克
一款简单易用的网页信息采集软件,可以采集网页文字、图表、超链接等网页元素。采集 可以通过一个简单的可视化过程来完成同样的工作,为任何有采集 数据需求的人提供服务。
可视化流程操作,不同于优采云,Jisouke的流程侧重于定义抓取的数据和爬虫路径。优采云的规则和流程非常明确,软件的每一步都由用户决定。
支持抓取指数图表悬浮显示的数据,也可以抓取手机上的数据网站
会员可以互相帮助抢,提高采集的效率,还有模板资源可以套用
结论:收客操作比较简单,适合初级用户,功能上没有太多特色,后续支付需求较多。
4.优采云云爬虫
一种新颖的云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量规范化网页数据。
直接访问代理IP,避免IP阻塞
自动登录验证码识别,网站自动完成验证码输入
可在线生成图标,采集结果以丰富的表格形式显示本地化隐私保护,云端采集可隐藏用户IP
结论:优采云类似于爬虫系统框架,具体的采集也需要用户自己编写爬虫,需要有代码基础。
5.优采云采集器
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取、分论坛<有三个类别:@采集器、cms采集器 和博客采集器。
支持批量替换和过滤文章内容中的文字和链接可以同时批量发送文字到网站或者多个论坛带有采集或者发帖任务后自动关机功能完成了
结论:专注于论坛和博客文字内容的抓取,全网数据的采集普适性不高。
注意:给优采云采集器新手的一点学习建议
优采云采集器是一款非常专业的数据采集和数据处理软件。它对软件用户有很高的技术要求。用户必须具备基本的 HTML 基础,并且能够理解网页源代码。网页结构。
同时,如果你使用web发布或者数据库发布,你必须对自己的文章系统和数据存储结构有一个很好的了解。
网页数据抓取软件(美丽购的爬虫软件开发者作品提供多的功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-02-03 08:04
网页数据抓取软件在都可以使用,怎么样,是不是很好用啊,是不是想试试?但是如果开发者做得不好,不仅会连带着给卖家带来麻烦,而且网页数据抓取软件使用简单,但是对于新手来说,学会开发功能,才能让这款软件对你真正有用,才能有更好的用户体验。下面就给大家介绍一款美丽购的爬虫软件开发者作品,并且提供非常多的功能。
其实说实话,爬虫软件最容易理解的,这款软件都有,但是又能打通购物车,发送短信,这些对于新手来说,一时难以理解掌握,这款软件它如何打通各项功能,就是用到的第三方库,就是scrapy和nginx。nginx必须要懂一些linux系统的操作,而scrapy这款软件他本身提供了web的api接口,其实主要功能是接受非静态网页,然后提取网页的内容,然后对此进行解析生成数据并且把内容自动提交给后端的用户。
网页数据抓取软件主要就是这样做的,对于没有开发基础的人来说,这些功能要理解起来,需要你有很多的心血,比如linux系统,linux操作相对来说还是不错的,linux相对windows来说,命令要多一些,很多操作都要用到linux操作系统,自然要有更多的学习成本,要想更快的学会功能就要从基础入手,当你能很快的掌握各种开发者提供的功能,能很快搭建一个小的demo出来的时候,就说明你开发能力的上升了。
当我们知道开发它需要解决哪些方面的问题和我们能利用哪些第三方库实现我们的功能,我们就可以说自己具备了开发者的资格,当然也需要有很好的开发者背景来跟这个软件匹配,如果你什么开发背景都没有,也有一些开发者也是非常喜欢开发这个软件的,因为功能都集成起来省事,效率高,通常一个主题化的规划非常符合现在开发软件的趋势,比如:1.p_video6.ftp7.googleassistant,而这款软件大部分功能都是通过插件实现的,如果你想了解具体的用法和内容请访问。
大家如果有更好的开发者开发的此类的,这些插件,我们可以帮助他们改善在更好的用户体验的同时,提高功能扩展性,比如我们可以有文本爬虫软件,比如多加入的文本地图文字搜索,比如一些功能是提供给那些做网站的人使用的,如果做网站的人可以使用,那我们使用起来也会更容易。最后我们祝你学习进步,欢迎大家交流!。 查看全部
网页数据抓取软件(美丽购的爬虫软件开发者作品提供多的功能)
网页数据抓取软件在都可以使用,怎么样,是不是很好用啊,是不是想试试?但是如果开发者做得不好,不仅会连带着给卖家带来麻烦,而且网页数据抓取软件使用简单,但是对于新手来说,学会开发功能,才能让这款软件对你真正有用,才能有更好的用户体验。下面就给大家介绍一款美丽购的爬虫软件开发者作品,并且提供非常多的功能。
其实说实话,爬虫软件最容易理解的,这款软件都有,但是又能打通购物车,发送短信,这些对于新手来说,一时难以理解掌握,这款软件它如何打通各项功能,就是用到的第三方库,就是scrapy和nginx。nginx必须要懂一些linux系统的操作,而scrapy这款软件他本身提供了web的api接口,其实主要功能是接受非静态网页,然后提取网页的内容,然后对此进行解析生成数据并且把内容自动提交给后端的用户。
网页数据抓取软件主要就是这样做的,对于没有开发基础的人来说,这些功能要理解起来,需要你有很多的心血,比如linux系统,linux操作相对来说还是不错的,linux相对windows来说,命令要多一些,很多操作都要用到linux操作系统,自然要有更多的学习成本,要想更快的学会功能就要从基础入手,当你能很快的掌握各种开发者提供的功能,能很快搭建一个小的demo出来的时候,就说明你开发能力的上升了。
当我们知道开发它需要解决哪些方面的问题和我们能利用哪些第三方库实现我们的功能,我们就可以说自己具备了开发者的资格,当然也需要有很好的开发者背景来跟这个软件匹配,如果你什么开发背景都没有,也有一些开发者也是非常喜欢开发这个软件的,因为功能都集成起来省事,效率高,通常一个主题化的规划非常符合现在开发软件的趋势,比如:1.p_video6.ftp7.googleassistant,而这款软件大部分功能都是通过插件实现的,如果你想了解具体的用法和内容请访问。
大家如果有更好的开发者开发的此类的,这些插件,我们可以帮助他们改善在更好的用户体验的同时,提高功能扩展性,比如我们可以有文本爬虫软件,比如多加入的文本地图文字搜索,比如一些功能是提供给那些做网站的人使用的,如果做网站的人可以使用,那我们使用起来也会更容易。最后我们祝你学习进步,欢迎大家交流!。
网页数据抓取软件(我们为什么要选择笔记软件大部分笔记软件(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-01-31 19:10
)
为什么要选择笔记软件
市面上大部分的笔记软件,无非就是文件级别的这三种存储方式。因为笔记软件众多,新产品不断出现,我们不得不选择一些主流厂商出品的笔记软件来为我们的知识赋能。协助组织我们的工作和日常生活。我们如何选择存储我们的笔记决定了我们在多大程度上支配了我们的个人笔记。
数据安全
云型笔记数据存储在云端,后台管理员有权查看我们的笔记,威胁到我们的隐私。如果存储一些敏感内容,可能会被审查,类似于百度云盘审查机制。选择纯云笔记时,一定要仔细检查云存储是否支持加密上传。
鸡蛋需要放在两个篮子里,一个篮子坏了,剩下一个篮子。纯云笔记自动托管在服务提供商处。备份真的不容易。OneNote 也可以本地备份,直接使用桌面版。可以在不改变原创文件格式的情况下打开。像wolai这样的云笔记备份到本地只能一个一个导出。难免要用本地软件打开这些备份文件,然后再组织结构,增加了工作量,吃亏。
个人观点:非本地的笔记软件并不完全值得信赖。本地+云是最好的存储方式。用户可以选择将私人笔记保存在本地,非私人笔记可以公开放置在云端。如何保存文件由用户自由决定。
常用笔记软件对比1、OneNote:
OneNote分为桌面版(办公套件中常用的2016)和uwp版,这是我用的第一款笔记软件,生态不错,word和excel联动真的是强,很多笔记软件对表格的支持比较弱,但是OneNote可以自己创建表格或者插入excel表格,甚至可以嵌套表格。
OneNote还具备双链笔记的原型功能。通过将链接复制到段落中,可以实现注释之间的联动。用法与超链接一词相同。
也可以通过这种方式手动制作目录,可以使用宏插件自动生成目录,但是生成的目录不能做到这个段落级别。下面的每个例子都是单独的注释,目录链接是截取的段落链接,而不是自动生成的子页面级链接,粒度更细。
OneNote 没有大纲功能。如果页面内容太多,根据标题定位真的很不方便。您可以使用插件“当前页面目录”自动生成当前页面的目录链接,该链接会出现在文档顶部。每次使用时都需要滑动它。去笔记的开头找链接有点麻烦。
OneNote支持本地+云端,使用自己的onedrive也很方便,只是同步速度时快时慢。自由排版,可以在单机上任意位置输入内容,简单易用,控制台和word基本一致,支持手写,具备基本的笔记功能,完全具备普通人做笔记的能力。还是值得信赖的。
注意:OneNote UWP 版本完全基于云,可以从 Microsoft Store 下载。桌面版在办公套件中。
2、我会:
我来云笔记是纯云笔记,界面美观。它们是“块”类型的笔记。当时因为外观问题想放弃OneNote,但为了笔记文件的安全,我还是把它当成辅助软件。标题图像和图标的形式确实为外观加分。
做个人工作台,方便明了,还有点神奇的温暖。每个块可以转换成一个页面,页面可以嵌套在一个页面内,相当于一个文件夹的集合。
导入OneNote的笔记,每条笔记都会独立创建一个页面,返回上一级是不同形式的目录,方便快捷,无需制作目录链接。
我来毕竟是纯云注。断网时无法使用纯云笔记。wolai似乎已经退出了离线模式(类似于飞行模式),但还是过于依赖网络,页面太多图片的加载速度大大降低。页面对块数和字数也有一定的限制。如果超过20,000字,可能会变得异常卡顿。我曾尝试将一个1.12MB 500,000字的文件导入wolai,但它直接崩溃了,粘贴和导入两种方法都不能幸免。. 当我把反馈给客服人员的时候,我也让我分了。我只能用思源笔记。打开思源笔记毫无压力,速度也很快。毕竟是本地软件。
关系图:支持页面关系图,显示方式分为2D和3D。
分享:我来笔记支持分享,权限可以选择是否允许他人一键复制。不能复制,只能查看,一定程度上保证了笔记的安全。分享后,关闭分享按钮或删除笔记,对方无法查看。
3、思源笔记
目前主要个人软件支持本地+云端,云端可以加密上传。最近正在测试同步功能,云功能会越来越好用。软件理念基于本地优先,安全有保障,支持第三方同步磁盘备份。块编辑模式,所见即所得,块级支持嵌入和引用,每个文档也可以是块,块是源注释的最基本形式,块之间相互转换和拆分不会影响文档之间的连接关系。
界面美化:支持插入页眉图片,包括市面上海量的主题、模板和图标,持续更新。
格式支持:包罗万象,markdown支持,富文本编辑。支持代码、latex、IFrame、视频、音频、脑图、流程图、时序图、甘特图、图表、员工等。
分享:支持复制到公众号、知乎和鱼雀平台。
双向链接:反向链接和提及,使文档和文档具有连接关系,便于追溯。使知识可重用。
文件导出:支持导出为markdown、word、PDF、HTML文件格式。
关系图:关系图支持页面关系图和全局关系图,与wolai一致。关系图再现了我们大脑的结构并将知识可视化。随着音符的增加,像脑细胞一样的点也越来越多。在观看的同时,我们也获得了内心的丰富感。
虽然无法像 OneNote 那样自由输入,但借助超级块功能,依然可以重现 OneNote 的形式。
这是 OneNote
这是思源笔记
吊坠:群里有很多大佬都研发了自己的吊坠。后续版本会增加挂件市场,会有越来越多完整的挂件供用户食用。通过 IFrame 链接实现。
吊坠 - 卡片视图
吊坠 - 日历视图
4、思维导图软件
Curtain、Xmind 和 mindmaster 都是用于思维导图的优秀笔记软件。
屏幕是大纲笔记,可以一键生成思维导图,有笔记社区,可以分享或复制别人的笔记当成自己的,还有很多section分类,很多笔记没有——拿软件,分享自己的笔记。,分享知识,获得点击,算是对自己努力的认可。不知道能不能开启购买笔记功能,暂时还没有找到。
xmind 和 mindmaster 都是专业的思维导图工具。您可以简单地选择这两个进行思维导图。丰富的模板和布局选项,一键美化你的脑图。还支持大纲视图以方便文本输出。支持多平台使用,也可以在手机上编辑。
票据费
OneNote、wolai、思源笔记都可以免费使用。
如果 OneNote 不喜欢同步盘慢,可用空间小,就必须使用 21Vianet。价格约400元/年,实价为宝。购买office365家庭版一年40元左右。我从来没有买过这些。大概在这个范围内。如果深入使用,购买Gem插件的成本会高很多,但其实并不便宜。
我来目前限时优惠128/年。免费版对块数没有限制。如果需要插入文件,需要购买专业版。目前免费版和专业版的区别似乎不是很大。邀请其他用户注册并使用邀请码获得积分,可用于兑换专业版的使用时间。
思源笔记有教育邮箱64元/年,普通邮箱96元/年。目前,有早鸟优惠。现在首付可终身购买,教育邮箱过期不涨价。您可以更改邮箱绑定。通过邀请其他用户付费订阅,双方可以获得为期 7 天的会员资格和永久增加 500MB 的云空间。邀请 32 个付费订阅帐户升级为永久会员。
目前,思源笔记已将所有本地功能免费开放。以后只对与“云”相关的功能收费。无需为同步付费。伺服功能也是免费的。您可以将 Android 用作移动服务器。,电脑和手机在同一个局域网内,可以用电脑访问手机的思源笔记。
这一次,思源笔记的所有本地功能都是免费的。为了感谢用户的测试,他们免费赠送了180天的会员资格。真是良心软件。原生功能的付费订阅支持退款,付费订阅后 7 天内无理由退款。思源从不恶意搞噱头让用户付费,而是不断寻找志同道合的合作伙伴,以您的诚意换取您的有偿支持。
看到某个不付费就不能编辑的软件的操作,着实让我震惊,资本家的脸色一目了然。
总结
市面上纸币上千种,琳琅满目,各种概念,一体机,双链纸币……不胜枚举。软件毕竟是工具,要“为我所用”,毕竟一个笔记软件会陪伴你很久,你需要的时候是你的得力助手,是你最可靠的时候你寻求它。助手,是你独处时的沟通伙伴。笔记软件是一种生产力工具。它必须符合你的气质和使用习惯,你可以轻松使用它。在这个同质化的时代,想要找到一把适合自己手的武器,是需要付出很多努力的。建议上网。找攻略和视频,然后加入软件交流群,找到你真正的屠龙者。
我的思源笔记邀请码FG6gg0F,如果您有付费订阅,请考虑使用思源笔记创建您的数字花园。
查看全部
网页数据抓取软件(我们为什么要选择笔记软件大部分笔记软件(组图)
)
为什么要选择笔记软件
市面上大部分的笔记软件,无非就是文件级别的这三种存储方式。因为笔记软件众多,新产品不断出现,我们不得不选择一些主流厂商出品的笔记软件来为我们的知识赋能。协助组织我们的工作和日常生活。我们如何选择存储我们的笔记决定了我们在多大程度上支配了我们的个人笔记。
数据安全
云型笔记数据存储在云端,后台管理员有权查看我们的笔记,威胁到我们的隐私。如果存储一些敏感内容,可能会被审查,类似于百度云盘审查机制。选择纯云笔记时,一定要仔细检查云存储是否支持加密上传。
鸡蛋需要放在两个篮子里,一个篮子坏了,剩下一个篮子。纯云笔记自动托管在服务提供商处。备份真的不容易。OneNote 也可以本地备份,直接使用桌面版。可以在不改变原创文件格式的情况下打开。像wolai这样的云笔记备份到本地只能一个一个导出。难免要用本地软件打开这些备份文件,然后再组织结构,增加了工作量,吃亏。
个人观点:非本地的笔记软件并不完全值得信赖。本地+云是最好的存储方式。用户可以选择将私人笔记保存在本地,非私人笔记可以公开放置在云端。如何保存文件由用户自由决定。
常用笔记软件对比1、OneNote:
OneNote分为桌面版(办公套件中常用的2016)和uwp版,这是我用的第一款笔记软件,生态不错,word和excel联动真的是强,很多笔记软件对表格的支持比较弱,但是OneNote可以自己创建表格或者插入excel表格,甚至可以嵌套表格。
OneNote还具备双链笔记的原型功能。通过将链接复制到段落中,可以实现注释之间的联动。用法与超链接一词相同。
也可以通过这种方式手动制作目录,可以使用宏插件自动生成目录,但是生成的目录不能做到这个段落级别。下面的每个例子都是单独的注释,目录链接是截取的段落链接,而不是自动生成的子页面级链接,粒度更细。
OneNote 没有大纲功能。如果页面内容太多,根据标题定位真的很不方便。您可以使用插件“当前页面目录”自动生成当前页面的目录链接,该链接会出现在文档顶部。每次使用时都需要滑动它。去笔记的开头找链接有点麻烦。
OneNote支持本地+云端,使用自己的onedrive也很方便,只是同步速度时快时慢。自由排版,可以在单机上任意位置输入内容,简单易用,控制台和word基本一致,支持手写,具备基本的笔记功能,完全具备普通人做笔记的能力。还是值得信赖的。
注意:OneNote UWP 版本完全基于云,可以从 Microsoft Store 下载。桌面版在办公套件中。
2、我会:
我来云笔记是纯云笔记,界面美观。它们是“块”类型的笔记。当时因为外观问题想放弃OneNote,但为了笔记文件的安全,我还是把它当成辅助软件。标题图像和图标的形式确实为外观加分。
做个人工作台,方便明了,还有点神奇的温暖。每个块可以转换成一个页面,页面可以嵌套在一个页面内,相当于一个文件夹的集合。
导入OneNote的笔记,每条笔记都会独立创建一个页面,返回上一级是不同形式的目录,方便快捷,无需制作目录链接。
我来毕竟是纯云注。断网时无法使用纯云笔记。wolai似乎已经退出了离线模式(类似于飞行模式),但还是过于依赖网络,页面太多图片的加载速度大大降低。页面对块数和字数也有一定的限制。如果超过20,000字,可能会变得异常卡顿。我曾尝试将一个1.12MB 500,000字的文件导入wolai,但它直接崩溃了,粘贴和导入两种方法都不能幸免。. 当我把反馈给客服人员的时候,我也让我分了。我只能用思源笔记。打开思源笔记毫无压力,速度也很快。毕竟是本地软件。
关系图:支持页面关系图,显示方式分为2D和3D。
分享:我来笔记支持分享,权限可以选择是否允许他人一键复制。不能复制,只能查看,一定程度上保证了笔记的安全。分享后,关闭分享按钮或删除笔记,对方无法查看。
3、思源笔记
目前主要个人软件支持本地+云端,云端可以加密上传。最近正在测试同步功能,云功能会越来越好用。软件理念基于本地优先,安全有保障,支持第三方同步磁盘备份。块编辑模式,所见即所得,块级支持嵌入和引用,每个文档也可以是块,块是源注释的最基本形式,块之间相互转换和拆分不会影响文档之间的连接关系。
界面美化:支持插入页眉图片,包括市面上海量的主题、模板和图标,持续更新。
格式支持:包罗万象,markdown支持,富文本编辑。支持代码、latex、IFrame、视频、音频、脑图、流程图、时序图、甘特图、图表、员工等。
分享:支持复制到公众号、知乎和鱼雀平台。
双向链接:反向链接和提及,使文档和文档具有连接关系,便于追溯。使知识可重用。
文件导出:支持导出为markdown、word、PDF、HTML文件格式。
关系图:关系图支持页面关系图和全局关系图,与wolai一致。关系图再现了我们大脑的结构并将知识可视化。随着音符的增加,像脑细胞一样的点也越来越多。在观看的同时,我们也获得了内心的丰富感。
虽然无法像 OneNote 那样自由输入,但借助超级块功能,依然可以重现 OneNote 的形式。
这是 OneNote
这是思源笔记
吊坠:群里有很多大佬都研发了自己的吊坠。后续版本会增加挂件市场,会有越来越多完整的挂件供用户食用。通过 IFrame 链接实现。
吊坠 - 卡片视图
吊坠 - 日历视图
4、思维导图软件
Curtain、Xmind 和 mindmaster 都是用于思维导图的优秀笔记软件。
屏幕是大纲笔记,可以一键生成思维导图,有笔记社区,可以分享或复制别人的笔记当成自己的,还有很多section分类,很多笔记没有——拿软件,分享自己的笔记。,分享知识,获得点击,算是对自己努力的认可。不知道能不能开启购买笔记功能,暂时还没有找到。
xmind 和 mindmaster 都是专业的思维导图工具。您可以简单地选择这两个进行思维导图。丰富的模板和布局选项,一键美化你的脑图。还支持大纲视图以方便文本输出。支持多平台使用,也可以在手机上编辑。
票据费
OneNote、wolai、思源笔记都可以免费使用。
如果 OneNote 不喜欢同步盘慢,可用空间小,就必须使用 21Vianet。价格约400元/年,实价为宝。购买office365家庭版一年40元左右。我从来没有买过这些。大概在这个范围内。如果深入使用,购买Gem插件的成本会高很多,但其实并不便宜。
我来目前限时优惠128/年。免费版对块数没有限制。如果需要插入文件,需要购买专业版。目前免费版和专业版的区别似乎不是很大。邀请其他用户注册并使用邀请码获得积分,可用于兑换专业版的使用时间。
思源笔记有教育邮箱64元/年,普通邮箱96元/年。目前,有早鸟优惠。现在首付可终身购买,教育邮箱过期不涨价。您可以更改邮箱绑定。通过邀请其他用户付费订阅,双方可以获得为期 7 天的会员资格和永久增加 500MB 的云空间。邀请 32 个付费订阅帐户升级为永久会员。
目前,思源笔记已将所有本地功能免费开放。以后只对与“云”相关的功能收费。无需为同步付费。伺服功能也是免费的。您可以将 Android 用作移动服务器。,电脑和手机在同一个局域网内,可以用电脑访问手机的思源笔记。
这一次,思源笔记的所有本地功能都是免费的。为了感谢用户的测试,他们免费赠送了180天的会员资格。真是良心软件。原生功能的付费订阅支持退款,付费订阅后 7 天内无理由退款。思源从不恶意搞噱头让用户付费,而是不断寻找志同道合的合作伙伴,以您的诚意换取您的有偿支持。
看到某个不付费就不能编辑的软件的操作,着实让我震惊,资本家的脸色一目了然。
总结
市面上纸币上千种,琳琅满目,各种概念,一体机,双链纸币……不胜枚举。软件毕竟是工具,要“为我所用”,毕竟一个笔记软件会陪伴你很久,你需要的时候是你的得力助手,是你最可靠的时候你寻求它。助手,是你独处时的沟通伙伴。笔记软件是一种生产力工具。它必须符合你的气质和使用习惯,你可以轻松使用它。在这个同质化的时代,想要找到一把适合自己手的武器,是需要付出很多努力的。建议上网。找攻略和视频,然后加入软件交流群,找到你真正的屠龙者。
我的思源笔记邀请码FG6gg0F,如果您有付费订阅,请考虑使用思源笔记创建您的数字花园。
网页数据抓取软件(touchforms7mac破解教程下载好TouchFormsPro7forMac )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-31 19:09
)
Touch Forms Pro 7 for Mac 是一款实用的 Web 表单生成工具。touch forms 7 mac版支持拖拽添加,编辑表单更方便。新版 touch forms 7 mac 破解版带来了新的和改进的文件格式、新的格式检查器面板、新的拖放编辑器等,以获得更好的性能和稳定性。
touch forms 7 mac破解教程
下载Touch Forms Pro 7安装包后,双击安装包进行安装。安装程序弹出后,点击“继续”,如下图:
点击“安装”,如下图:
如果您的电脑设置了密码,请输入密码并点击“安装软件”,如下图:
提示安装成功后,点击“关闭”,如下图:
touch forms 7 for mac 官方介绍
Touch Forms Pro 7 是一个易于使用的拖放式 Web 表单创建器,用于构建您自己的 网站 联系表单、调查、反馈表单、数据采集表单等。
Touch Forms Pro 允许您使用直观的拖放设计器构建漂亮的 Web 表单,以通过 FTP 发布到您自己的 Web 主机。
Touch forms pro mac版软件功能
- 拖放设计器,需要零编码
- 支持无限数量的网络表单
- 通过 FTP 发布到您自己的 网站
- 与 Google reCAPTCHA 的内置集成,这是一个很棒的小部件,可以保护您的 网站 免受垃圾邮件的侵害。
- 支持将表单导出为静态 PDF 文档格式
- 文本字段和段落字段,可选择将单个字段指定为“强制完成”
- 带有内置电子邮件地址格式验证的电子邮件字段
- 表单提交被发送到指定为表单答案收件人的电子邮件地址。指定主要和次要电子邮件地址的选项。辅助地址是可选的,但建议备份。
- 输入带有圆角、可调整边框颜色、边框宽度和不同边框样式选项的字段样式格式
- 多选单选按钮和多选复选框
- 智能机器人检查器小部件旨在通过呈现简单的动态生成的数学问题来减少垃圾邮件。当添加到表单设计中时,在填写表单之前需要一个完整的小部件问题。- 表单源代码查看器。表单代码在 php 脚本中生成。
- 悬停颜色支持形状和文本
- 支持表格网格
- 表单通过电子邮件 SMTP 身份验证选项,让用户可以选择通过经过身份验证的 SMTP 服务器发送 Web 表单响应。
- 支持将表单提交者 IP 地址作为表单回复电子邮件的一部分的选项
查看全部
网页数据抓取软件(touchforms7mac破解教程下载好TouchFormsPro7forMac
)
Touch Forms Pro 7 for Mac 是一款实用的 Web 表单生成工具。touch forms 7 mac版支持拖拽添加,编辑表单更方便。新版 touch forms 7 mac 破解版带来了新的和改进的文件格式、新的格式检查器面板、新的拖放编辑器等,以获得更好的性能和稳定性。
touch forms 7 mac破解教程
下载Touch Forms Pro 7安装包后,双击安装包进行安装。安装程序弹出后,点击“继续”,如下图:
点击“安装”,如下图:
如果您的电脑设置了密码,请输入密码并点击“安装软件”,如下图:
提示安装成功后,点击“关闭”,如下图:
touch forms 7 for mac 官方介绍
Touch Forms Pro 7 是一个易于使用的拖放式 Web 表单创建器,用于构建您自己的 网站 联系表单、调查、反馈表单、数据采集表单等。
Touch Forms Pro 允许您使用直观的拖放设计器构建漂亮的 Web 表单,以通过 FTP 发布到您自己的 Web 主机。
Touch forms pro mac版软件功能
- 拖放设计器,需要零编码
- 支持无限数量的网络表单
- 通过 FTP 发布到您自己的 网站
- 与 Google reCAPTCHA 的内置集成,这是一个很棒的小部件,可以保护您的 网站 免受垃圾邮件的侵害。
- 支持将表单导出为静态 PDF 文档格式
- 文本字段和段落字段,可选择将单个字段指定为“强制完成”
- 带有内置电子邮件地址格式验证的电子邮件字段
- 表单提交被发送到指定为表单答案收件人的电子邮件地址。指定主要和次要电子邮件地址的选项。辅助地址是可选的,但建议备份。
- 输入带有圆角、可调整边框颜色、边框宽度和不同边框样式选项的字段样式格式
- 多选单选按钮和多选复选框
- 智能机器人检查器小部件旨在通过呈现简单的动态生成的数学问题来减少垃圾邮件。当添加到表单设计中时,在填写表单之前需要一个完整的小部件问题。- 表单源代码查看器。表单代码在 php 脚本中生成。
- 悬停颜色支持形状和文本
- 支持表格网格
- 表单通过电子邮件 SMTP 身份验证选项,让用户可以选择通过经过身份验证的 SMTP 服务器发送 Web 表单响应。
- 支持将表单提交者 IP 地址作为表单回复电子邮件的一部分的选项
网页数据抓取软件(套壳MikuTools是支持PWA技术的,谓之工具细节大家可以自行体验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-31 19:04
MikuTools 作为一个工具采集网站,属于实用型。
单媒体类中各大平台的视频、音乐、图片下载,可以直击用户的痛点。还有很多其他有趣的工具,比如生成带标语牌的凌河风格或者PronHub风格或者Youtube风格的图片等等,你甚至不需要安装软件,只要有一个浏览器就可以做这些事情。
由于工具太多,本期主要介绍 MikuTools 的网页功能。您可以自己体验每个工具的具体细节。
▎实用
MikuTools提供的工具更偏媒体化,基本覆盖国内外主流网站。
媒体类别下的使用方法完全相同。用户只需复制对应平台的链接,然后将链接粘贴到MikuTools对应的分类中即可。分析工作全部交给工具,用户只需要等待直链解析完成即可。但是,这个过程不会花很长时间。
▎袖子
MikuTools 支持 PWA 技术。简而言之,它是一种将网页离线运行到本地的技术,称为Web APP。实现 PWA 的标准有两个,一个是网页本身的支持,一个是浏览器的支持。MikuTools是国内支持这项技术的网站之一。浏览器方面,Chrome、Firefox、Safari等都支持。
▎账号
MikuTools 支持账号登录,但不同于常规的账号系统,不同步数据等。它更有趣。具体操作是输入一个固定的用户名“miku”,然后随便输入。输入密码,然后点击登录。
目前 MikuTools 中账号系统的功能是开启隐藏工具。与用户选择隐藏的工具不同,这是官方默认隐藏的。至于为什么要隐藏,肯定有值得隐藏的理由,这里不便多说。
▎最后
作为一个工具集,MikuTools 能做的事情在不断增加,每一次都是一个“热更新”的过程。新添加的工具将标有小蓝点。客户端和 PWA 版本的用户只要连接到 Internet 就可以访问该页面。获取更新,而不必每次都更新客户端。
MikuTools官网地址: 查看全部
网页数据抓取软件(套壳MikuTools是支持PWA技术的,谓之工具细节大家可以自行体验)
MikuTools 作为一个工具采集网站,属于实用型。
单媒体类中各大平台的视频、音乐、图片下载,可以直击用户的痛点。还有很多其他有趣的工具,比如生成带标语牌的凌河风格或者PronHub风格或者Youtube风格的图片等等,你甚至不需要安装软件,只要有一个浏览器就可以做这些事情。
由于工具太多,本期主要介绍 MikuTools 的网页功能。您可以自己体验每个工具的具体细节。
▎实用
MikuTools提供的工具更偏媒体化,基本覆盖国内外主流网站。
媒体类别下的使用方法完全相同。用户只需复制对应平台的链接,然后将链接粘贴到MikuTools对应的分类中即可。分析工作全部交给工具,用户只需要等待直链解析完成即可。但是,这个过程不会花很长时间。
▎袖子
MikuTools 支持 PWA 技术。简而言之,它是一种将网页离线运行到本地的技术,称为Web APP。实现 PWA 的标准有两个,一个是网页本身的支持,一个是浏览器的支持。MikuTools是国内支持这项技术的网站之一。浏览器方面,Chrome、Firefox、Safari等都支持。
▎账号
MikuTools 支持账号登录,但不同于常规的账号系统,不同步数据等。它更有趣。具体操作是输入一个固定的用户名“miku”,然后随便输入。输入密码,然后点击登录。
目前 MikuTools 中账号系统的功能是开启隐藏工具。与用户选择隐藏的工具不同,这是官方默认隐藏的。至于为什么要隐藏,肯定有值得隐藏的理由,这里不便多说。
▎最后
作为一个工具集,MikuTools 能做的事情在不断增加,每一次都是一个“热更新”的过程。新添加的工具将标有小蓝点。客户端和 PWA 版本的用户只要连接到 Internet 就可以访问该页面。获取更新,而不必每次都更新客户端。
MikuTools官网地址:
网页数据抓取软件(什么是HTML?框架是什么意思?HTML文档总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-31 03:05
总结:
1、通过指定的URL抓取网页数据,获取页面信息,然后对带有DOM的页面进行NODE分析,处理原创的HTML数据。这样做的好处是处理某条数据的灵活性很高。 , 难点在于节算法需要优化。当页面的HTML信息较大时,算法不好,会影响处理效率。
2、htmlparser框架,对于HTML页面处理的数据结构,HtmlParser采用经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode和Tag来描述HTML页面的各个元素。 htmlparser基本可以满足垂直搜索引擎页面处理分析的需求,映射HTML标签,轻松获取标签中的HTML CODE。
Htmlparser官方介绍:htmlparser是一个纯java编写的html解析库。不依赖其他java库文件,主要用于转换或提取html。它解析 html 的速度非常快而且没有错误。 htmlparser 的最新版本现在是 2.0。毫不夸张地说,htmlparser是目前最好的html解析分析工具。
3、nekohtml框架,nekohtml在容错性、性能等方面比htmlparser有更好的口碑(包括htmlunit也使用nekohtml),nokehtml类似于xml解析的原理,html标签是解析为dom,是的,对应DOM树中对应的元素进行处理。
NekoHTML 官方介绍:NekoHTML 是Java 语言的HTML 扫描器和标签平衡器,它使程序能够解析HTML 文档并使用标准的XML 接口来访问其中的信息。此解析器能够扫描 HTML 文档并“修复”作者(人或机器)在编写 HTML 文档时所犯的许多常见错误。
NekoHTML 可以补充缺失的父元素,自动用结束标签关闭对应的元素,以及不匹配的内联元素标签。 NekoHTML 是使用 Xerces 本地接口 (XNI) 开发的,它是 Xerces2 实现的基础。 查看全部
网页数据抓取软件(什么是HTML?框架是什么意思?HTML文档总结)
总结:
1、通过指定的URL抓取网页数据,获取页面信息,然后对带有DOM的页面进行NODE分析,处理原创的HTML数据。这样做的好处是处理某条数据的灵活性很高。 , 难点在于节算法需要优化。当页面的HTML信息较大时,算法不好,会影响处理效率。
2、htmlparser框架,对于HTML页面处理的数据结构,HtmlParser采用经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode和Tag来描述HTML页面的各个元素。 htmlparser基本可以满足垂直搜索引擎页面处理分析的需求,映射HTML标签,轻松获取标签中的HTML CODE。
Htmlparser官方介绍:htmlparser是一个纯java编写的html解析库。不依赖其他java库文件,主要用于转换或提取html。它解析 html 的速度非常快而且没有错误。 htmlparser 的最新版本现在是 2.0。毫不夸张地说,htmlparser是目前最好的html解析分析工具。
3、nekohtml框架,nekohtml在容错性、性能等方面比htmlparser有更好的口碑(包括htmlunit也使用nekohtml),nokehtml类似于xml解析的原理,html标签是解析为dom,是的,对应DOM树中对应的元素进行处理。
NekoHTML 官方介绍:NekoHTML 是Java 语言的HTML 扫描器和标签平衡器,它使程序能够解析HTML 文档并使用标准的XML 接口来访问其中的信息。此解析器能够扫描 HTML 文档并“修复”作者(人或机器)在编写 HTML 文档时所犯的许多常见错误。
NekoHTML 可以补充缺失的父元素,自动用结束标签关闭对应的元素,以及不匹配的内联元素标签。 NekoHTML 是使用 Xerces 本地接口 (XNI) 开发的,它是 Xerces2 实现的基础。
网页数据抓取软件(从技术来讲,利用googletoolbar能抓取页面完全是可行的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-27 02:06
从技术角度来看,使用google工具栏爬取页面是完全可行的。因为使用 IE 和谷歌工具栏访问网页会将浏览数据发送给谷歌。围棋编程客栈 google 可以根据这些数据立即发送爬虫爬取页面。但我们需要考虑以下问题:
1. 当今搜索引擎的核心使命不是收录更多页面。搜索引擎需要抓取更多有效信息。但现阶段,似乎不是收录的数量,而是收录的质量。即使有这么多网站每天都是由谷歌手动提交的,谷歌编程客栈也为时不晚。
2.现有的收录机制基本保证了真正优质的网站是收录。因为根据搜索引擎现有的收录机制,几乎90%或更多的真正优质网站将是收录。
3、谷歌更相信链接计算标准,这种方法更有利于价值信息的判断。依靠链接来发现网站比手动提交更有价值。因为它更难以轻松操作。现阶段搜索引擎的问题是缺少收录站点的信息,需要判断站点是否值得收录。要做出这样的判断,仍然需要依赖链接或人工决策等复杂算法。
4. 对不使用工具栏的用户极为不公平。同时,也增加了合拍的负担。每个站点打开时,工具栏需要检查自己数据库中是否是收录,然后根据自己的复杂系统判断是否应该是收录。
5.根本不需要让侧边栏临时做这些工作。相比编程客栈,工具栏比较复杂,最好用google搜索域名。如果没有收录,google 会去收录。您可以使用您网站的搜索框架来执行此操作。目前工具栏最大的作用就是方便大家更方便的使用google搜索。
当然,以上分析是基于目前的搜索情况。从谷歌的角度来看,使用yLZee工具栏可以采集大量的用户行为,这对于提高搜索质量和了解网民的习惯是非常有益的。不排除在未来的某一天,Google 会使用工具栏中的用户行为统计数据作为判断是否对收录 和关键词 进行排名的工具。
但是在目前的情况下,工具栏和搜索结果之间有一些直接的关系是不现实的。如果工具栏真的能提高网站排名,那么我相信会有一大堆使用工具栏快速作弊的方法。看看现在操纵 关键词 排名是多么容易,或者操纵 Alexa 排名是多么容易,你就会知道后果的严重性。谷歌怎么敢轻易开始而不考虑作弊措施?
标题:工具栏可以帮助网页 收录 被 Google 搜索 收录 吗? 查看全部
网页数据抓取软件(从技术来讲,利用googletoolbar能抓取页面完全是可行的)
从技术角度来看,使用google工具栏爬取页面是完全可行的。因为使用 IE 和谷歌工具栏访问网页会将浏览数据发送给谷歌。围棋编程客栈 google 可以根据这些数据立即发送爬虫爬取页面。但我们需要考虑以下问题:
1. 当今搜索引擎的核心使命不是收录更多页面。搜索引擎需要抓取更多有效信息。但现阶段,似乎不是收录的数量,而是收录的质量。即使有这么多网站每天都是由谷歌手动提交的,谷歌编程客栈也为时不晚。
2.现有的收录机制基本保证了真正优质的网站是收录。因为根据搜索引擎现有的收录机制,几乎90%或更多的真正优质网站将是收录。
3、谷歌更相信链接计算标准,这种方法更有利于价值信息的判断。依靠链接来发现网站比手动提交更有价值。因为它更难以轻松操作。现阶段搜索引擎的问题是缺少收录站点的信息,需要判断站点是否值得收录。要做出这样的判断,仍然需要依赖链接或人工决策等复杂算法。
4. 对不使用工具栏的用户极为不公平。同时,也增加了合拍的负担。每个站点打开时,工具栏需要检查自己数据库中是否是收录,然后根据自己的复杂系统判断是否应该是收录。
5.根本不需要让侧边栏临时做这些工作。相比编程客栈,工具栏比较复杂,最好用google搜索域名。如果没有收录,google 会去收录。您可以使用您网站的搜索框架来执行此操作。目前工具栏最大的作用就是方便大家更方便的使用google搜索。
当然,以上分析是基于目前的搜索情况。从谷歌的角度来看,使用yLZee工具栏可以采集大量的用户行为,这对于提高搜索质量和了解网民的习惯是非常有益的。不排除在未来的某一天,Google 会使用工具栏中的用户行为统计数据作为判断是否对收录 和关键词 进行排名的工具。
但是在目前的情况下,工具栏和搜索结果之间有一些直接的关系是不现实的。如果工具栏真的能提高网站排名,那么我相信会有一大堆使用工具栏快速作弊的方法。看看现在操纵 关键词 排名是多么容易,或者操纵 Alexa 排名是多么容易,你就会知道后果的严重性。谷歌怎么敢轻易开始而不考虑作弊措施?
标题:工具栏可以帮助网页 收录 被 Google 搜索 收录 吗?
网页数据抓取软件(python爬网页数据方便,python爬取数据到底有多方便 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-25 02:11
)
都说python爬网数据很方便,今天就来试试,python爬数据有多方便
简介
爬取数据基本上是通过网页的URL获取网页的源代码,根据源代码过滤出需要的信息
准备
IDE:PyCharm
库:请求,lxml
注意:
请求:获取网页源代码
lxml:获取网页源代码中的指定数据
建筑环境
这里的构建环境不是python的开发环境。这里的构建环境是指我们使用pycharm新建一个python项目,然后进行requests和lxml
创建一个新项目:
依赖库导入
由于我们使用的是pycharm,所以我们导入这两个库会很简单
import requests<br />
此时requests会报红线。这时候我们把光标对准requests,按下快捷键:alt+回车,pycharm会给出解决方案,这时候选择install package requests,pycharm会自动我们安装好了,我们只需要等待一个安装库的时刻。 lxml的安装方法是一样的。
获取网页源代码
前面说了,requests可以很方便的让我们拿到网页的源代码
网页以我的博客地址为例:
获取源代码:
# 获取源码<br />html = requests.get("https://coder-lida.github.io/")<br /># 打印源码<br />print html.text<br />
代码就是这么简单,这个html.text就是这个URL的源码
完整代码:
import requests<br />import lxml<br /><br />html = requests.get("https://coder-lida.github.io/")<br />print (html.text)<br />
打印:
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml来过滤掉我们需要的信息
这里以我的博客列表为例,可以找到原网页,通过F12查看XPath,如图
通过XPath语法获取网页内容。
查看第一个文章标题
//*[@id="layout-cart"]/div[1]/a/@title<br />
// 定位根节点
/向下看下一层
提取文本内容:/text()
提取属性内容:/@xxxx
import requests<br />from lxml import etree<br /><br />html = requests.get("https://coder-lida.github.io/")<br />#print (html.text)<br />etree_html = etree.HTML(html.text)<br />content = etree_html.xpath('//*[@id="layout-cart"]/div[1]/a/@title')<br />print(content)<br />
查看所有文章标题
//*[@id="layout-cart"]/div/a/@title<br />
代码:
import requests<br />from lxml import etree<br /><br />html = requests.get("https://coder-lida.github.io/")<br />#print (html.text)<br />etree_html = etree.HTML(html.text)<br />content = etree_html.xpath('//*[@id="layout-cart"]/div/a/@title')<br />print(content)<br />
输出:
[' springboot逆向工程 ', ' 自己实现一个简单版的HashMap ', ' 开发中常用的 25 个JavaScript 单行代码 ', ' shiro 加密登录 密码加盐处理 ', ' Spring Boot构建RESTful API与单元测试 ', ' 记一次jsoup的使用 ']<br />
查看全部
网页数据抓取软件(python爬网页数据方便,python爬取数据到底有多方便
)
都说python爬网数据很方便,今天就来试试,python爬数据有多方便
简介
爬取数据基本上是通过网页的URL获取网页的源代码,根据源代码过滤出需要的信息
准备
IDE:PyCharm
库:请求,lxml
注意:
请求:获取网页源代码
lxml:获取网页源代码中的指定数据
建筑环境
这里的构建环境不是python的开发环境。这里的构建环境是指我们使用pycharm新建一个python项目,然后进行requests和lxml
创建一个新项目:
依赖库导入
由于我们使用的是pycharm,所以我们导入这两个库会很简单
import requests<br />
此时requests会报红线。这时候我们把光标对准requests,按下快捷键:alt+回车,pycharm会给出解决方案,这时候选择install package requests,pycharm会自动我们安装好了,我们只需要等待一个安装库的时刻。 lxml的安装方法是一样的。
获取网页源代码
前面说了,requests可以很方便的让我们拿到网页的源代码
网页以我的博客地址为例:
获取源代码:
# 获取源码<br />html = requests.get("https://coder-lida.github.io/";)<br /># 打印源码<br />print html.text<br />
代码就是这么简单,这个html.text就是这个URL的源码
完整代码:
import requests<br />import lxml<br /><br />html = requests.get("https://coder-lida.github.io/";)<br />print (html.text)<br />
打印:
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml来过滤掉我们需要的信息
这里以我的博客列表为例,可以找到原网页,通过F12查看XPath,如图
通过XPath语法获取网页内容。
查看第一个文章标题
//*[@id="layout-cart"]/div[1]/a/@title<br />
// 定位根节点
/向下看下一层
提取文本内容:/text()
提取属性内容:/@xxxx
import requests<br />from lxml import etree<br /><br />html = requests.get("https://coder-lida.github.io/";)<br />#print (html.text)<br />etree_html = etree.HTML(html.text)<br />content = etree_html.xpath('//*[@id="layout-cart"]/div[1]/a/@title')<br />print(content)<br />
查看所有文章标题
//*[@id="layout-cart"]/div/a/@title<br />
代码:
import requests<br />from lxml import etree<br /><br />html = requests.get("https://coder-lida.github.io/";)<br />#print (html.text)<br />etree_html = etree.HTML(html.text)<br />content = etree_html.xpath('//*[@id="layout-cart"]/div/a/@title')<br />print(content)<br />
输出:
[' springboot逆向工程 ', ' 自己实现一个简单版的HashMap ', ' 开发中常用的 25 个JavaScript 单行代码 ', ' shiro 加密登录 密码加盐处理 ', ' Spring Boot构建RESTful API与单元测试 ', ' 记一次jsoup的使用 ']<br />
网页数据抓取软件(优采云·云采集服务平台优采云网站数据抓取工具(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-01-21 16:04
优采云·云采集服务平台优采云·云采集服务平台网站数据采集工具 近年来,随着国内大数据战略越来越很明显,数据采集与信息采集系列产品迎来了巨大的发展机遇,采集产品的数量也在快速增长。本文介绍了几种常用的网站数据采集工具,并详细介绍了它们的工作原理和技术亮点。优采云优采云采集器是一款互联网数据抓取、处理、分析、挖掘软件,可以抓取网页上分散的数据信息,并通过一系列的分析处理,精准挖掘出所需的数据。它的采集数据分为两步,一是< @采集 数据,另一个是发布数据。这两个过程可以分开。采集数据:这包括 采集URL、采集内容。这个过程就是获取数据的过程。用户制定规则,内容也在挖掘过程中进行处理。发布数据:将数据发布到自己的论坛cms的过程,也是实现数据存在的过程。它可以通过WEB在线发布,存储在数据库中或存储为本地文件。优采云采集器使用分布式采集 系统。这样提高了采集的效率,支持PHP和C#插件扩展,方便数据的修改和处理;还支持通过txt导入大量的url,也可以生成。对于不会编程的新手用户,他们可以直接使用别人制定的规则。专家可以定制开发并分享他们制定的规则。优采云优采云是出现在优采云之后的采集器,可以从不同的网站中获取归一化的数据,帮助客户实现数据自动化采集,编辑,规范化,从而降低成本,提高效率。简而言之,优采云 可以通过简单的配置规则从任何网页准确抓取数据,生成自定义和常规的数据格式。它 ,编辑,规范化,从而降低成本,提高效率。简而言之,优采云 可以通过简单的配置规则从任何网页准确抓取数据,生成自定义和常规的数据格式。它 ,编辑,规范化,从而降低成本,提高效率。简而言之,优采云 可以通过简单的配置规则从任何网页准确抓取数据,生成自定义和常规的数据格式。它 查看全部
网页数据抓取软件(优采云·云采集服务平台优采云网站数据抓取工具(图))
优采云·云采集服务平台优采云·云采集服务平台网站数据采集工具 近年来,随着国内大数据战略越来越很明显,数据采集与信息采集系列产品迎来了巨大的发展机遇,采集产品的数量也在快速增长。本文介绍了几种常用的网站数据采集工具,并详细介绍了它们的工作原理和技术亮点。优采云优采云采集器是一款互联网数据抓取、处理、分析、挖掘软件,可以抓取网页上分散的数据信息,并通过一系列的分析处理,精准挖掘出所需的数据。它的采集数据分为两步,一是< @采集 数据,另一个是发布数据。这两个过程可以分开。采集数据:这包括 采集URL、采集内容。这个过程就是获取数据的过程。用户制定规则,内容也在挖掘过程中进行处理。发布数据:将数据发布到自己的论坛cms的过程,也是实现数据存在的过程。它可以通过WEB在线发布,存储在数据库中或存储为本地文件。优采云采集器使用分布式采集 系统。这样提高了采集的效率,支持PHP和C#插件扩展,方便数据的修改和处理;还支持通过txt导入大量的url,也可以生成。对于不会编程的新手用户,他们可以直接使用别人制定的规则。专家可以定制开发并分享他们制定的规则。优采云优采云是出现在优采云之后的采集器,可以从不同的网站中获取归一化的数据,帮助客户实现数据自动化采集,编辑,规范化,从而降低成本,提高效率。简而言之,优采云 可以通过简单的配置规则从任何网页准确抓取数据,生成自定义和常规的数据格式。它 ,编辑,规范化,从而降低成本,提高效率。简而言之,优采云 可以通过简单的配置规则从任何网页准确抓取数据,生成自定义和常规的数据格式。它 ,编辑,规范化,从而降低成本,提高效率。简而言之,优采云 可以通过简单的配置规则从任何网页准确抓取数据,生成自定义和常规的数据格式。它
网页数据抓取软件(Python中解析网页的基本流程(一)-早起Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-21 01:09
早起 Python
专注Python爬虫/数据分析/办公自动化
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以爬取B站视频热搜榜数据为例进行存储。详细介绍了这四个步骤。Python爬虫的基本流程。Step 1 请求先尝试进入b站首页,点击排行榜,复制链接。启动 Jupyter notebook 并运行以下代码:importrequests
网址=''
res=requests.get('url')
打印(res.status_code)
#200 在上面的代码中,做以下三件事:导入请求
使用get方法构造请求
使用status_code获取网页的状态码,可以看到返回值为200,表示服务器正常响应,表示我们可以继续。第二步解析页面在上一步中,我们通过requests向网站请求数据后,成功获得了一个收录服务器资源的Response对象。现在我们可以使用 .text 查看其内容。
可以看到返回的是一个字符串,里面收录了我们需要的热榜视频数据,但是直接从字符串中提取内容复杂且效率低,所以我们需要对其进行解析,将字符串转换成网页结构数据,即使查找 HTML 标记及其属性和内容变得容易。Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml,本文将基于BeautifulSoup进行讲解。Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也很简单,使用 pip install bs4 安装即可,我们用一个简单的例子来说明它是如何工作的。frombs4import 美汤
page=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
标题=汤.标题.文本
打印(标题)
#Hot Video Rankings-bilibili(゜-゜)つロCheers~-bilibili 在上面的代码中,我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换成BeautifulSoup对象,注意使用时,你需要制定一个解析器,这里是 html.parser。然后您可以获得结构元素之一及其属性。比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任何需要的元素。Step 3 提取内容 在上述两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:如何从解析后的页面中提取出需要的内容。在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器。select 因为可以像使用 CSS 选择元素一样沿着 DOM 树向下移动。现在我们用代码来说明如何从解析后的页面中提取B站热榜的数据。首先,我们需要找到存储数据的标签,在列表页面按 F12 并按照下面的说明找到它。
可以看到每个视频信息都包裹在class="rank-item"的li标签下,那么代码可以写成all_products=[]
products=soup.select('li.rank-item')
对于productinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
评论=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“上主要”:上,
“视频链接”:网址
}) 在上面的代码中,我们首先使用了soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器来提取我们需要的字段信息是以字典的形式存储在开头定义的空列表中。可以注意到我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自行进一步研究。Step 4 存储数据通过前三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需将数据写入Excel并保存即可。如果对 pandas 不熟悉,可以使用 csv 模块来写。需要注意的是设置了encoding='utf-8-sig',否则会出现中文乱码的问题。导入csv
键=所有产品[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products) 如果你熟悉pandas,你可以通过一行代码轻松地将字典转换为DataFrame。导入pandasaspd
键=所有产品[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')
结论至此,我们已经成功使用Python将b站热门视频列表的数据存储在本地。大多数基于请求的爬虫基本上都遵循以上四个步骤。不过,虽然看起来很简单,但在实景中的每一步都不是那么容易的。从请求数据来看,目标网站有各种形式的反爬取、加密,以及后期分析、提取甚至存储数据。需要进一步探索和学习。本文之所以选择B站视频热榜,是因为够简单。希望通过这个案例大家可以了解Python爬虫工作的基本流程,最后附上完整代码importrequests
frombs4import 美汤
导入csv
导入pandasaspd
网址=''
page=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
all_products=[]
products=soup.select('li.rank-item')
对于productinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
评论=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“上主要”:上,
“视频链接”:网址
})
键=所有产品[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
###使用熊猫写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')来源:早起Python 查看全部
网页数据抓取软件(Python中解析网页的基本流程(一)-早起Python)
早起 Python
专注Python爬虫/数据分析/办公自动化
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以爬取B站视频热搜榜数据为例进行存储。详细介绍了这四个步骤。Python爬虫的基本流程。Step 1 请求先尝试进入b站首页,点击排行榜,复制链接。启动 Jupyter notebook 并运行以下代码:importrequests
网址=''
res=requests.get('url')
打印(res.status_code)
#200 在上面的代码中,做以下三件事:导入请求
使用get方法构造请求
使用status_code获取网页的状态码,可以看到返回值为200,表示服务器正常响应,表示我们可以继续。第二步解析页面在上一步中,我们通过requests向网站请求数据后,成功获得了一个收录服务器资源的Response对象。现在我们可以使用 .text 查看其内容。
可以看到返回的是一个字符串,里面收录了我们需要的热榜视频数据,但是直接从字符串中提取内容复杂且效率低,所以我们需要对其进行解析,将字符串转换成网页结构数据,即使查找 HTML 标记及其属性和内容变得容易。Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml,本文将基于BeautifulSoup进行讲解。Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也很简单,使用 pip install bs4 安装即可,我们用一个简单的例子来说明它是如何工作的。frombs4import 美汤
page=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
标题=汤.标题.文本
打印(标题)
#Hot Video Rankings-bilibili(゜-゜)つロCheers~-bilibili 在上面的代码中,我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换成BeautifulSoup对象,注意使用时,你需要制定一个解析器,这里是 html.parser。然后您可以获得结构元素之一及其属性。比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任何需要的元素。Step 3 提取内容 在上述两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:如何从解析后的页面中提取出需要的内容。在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器。select 因为可以像使用 CSS 选择元素一样沿着 DOM 树向下移动。现在我们用代码来说明如何从解析后的页面中提取B站热榜的数据。首先,我们需要找到存储数据的标签,在列表页面按 F12 并按照下面的说明找到它。
可以看到每个视频信息都包裹在class="rank-item"的li标签下,那么代码可以写成all_products=[]
products=soup.select('li.rank-item')
对于productinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
评论=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“上主要”:上,
“视频链接”:网址
}) 在上面的代码中,我们首先使用了soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器来提取我们需要的字段信息是以字典的形式存储在开头定义的空列表中。可以注意到我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自行进一步研究。Step 4 存储数据通过前三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需将数据写入Excel并保存即可。如果对 pandas 不熟悉,可以使用 csv 模块来写。需要注意的是设置了encoding='utf-8-sig',否则会出现中文乱码的问题。导入csv
键=所有产品[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products) 如果你熟悉pandas,你可以通过一行代码轻松地将字典转换为DataFrame。导入pandasaspd
键=所有产品[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')
结论至此,我们已经成功使用Python将b站热门视频列表的数据存储在本地。大多数基于请求的爬虫基本上都遵循以上四个步骤。不过,虽然看起来很简单,但在实景中的每一步都不是那么容易的。从请求数据来看,目标网站有各种形式的反爬取、加密,以及后期分析、提取甚至存储数据。需要进一步探索和学习。本文之所以选择B站视频热榜,是因为够简单。希望通过这个案例大家可以了解Python爬虫工作的基本流程,最后附上完整代码importrequests
frombs4import 美汤
导入csv
导入pandasaspd
网址=''
page=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
all_products=[]
products=soup.select('li.rank-item')
对于productinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
评论=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“上主要”:上,
“视频链接”:网址
})
键=所有产品[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
###使用熊猫写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')来源:早起Python
网页数据抓取软件(推荐5款自动爬取数据的神器!_c-CSDN博客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-01-21 01:04
特点:网页抓取,信息抽取,数据抽取工具包,操作简单 11、Playfishplayfish是Java技术,综合应用多种开源。
最简单的数据抓取教程,人人都可以使用 WebScraper 是免费的,适合普通用户(无需专业技能)。
不再有手写爬虫!推荐5个自动爬取数据的神器!_c-CSDN博客。
刮:开始数据刮工作。ExportdataCSV:以 CSV 格式导出捕获的数据。在这里,有一个简单的了解就足够了。
链接提交工具可以实时向百度推送数据,创建并提交站点地图,提交收录网页链接,帮助百度发现和了解你的网站。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,具体信息可以搜索,都是国内信息采集 的发起者。
天菜鸟哥今天就带大家分享五款免费的数据采集工具。打开优采云软件后,打开网页,然后点击单个文字,选择右键。
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。
本软件可以帮助想要自己研究代码或者嫁接别人前端代码文件的开发者网站爬虫工具网站爬虫工具详细描述使用。 查看全部
网页数据抓取软件(推荐5款自动爬取数据的神器!_c-CSDN博客)
特点:网页抓取,信息抽取,数据抽取工具包,操作简单 11、Playfishplayfish是Java技术,综合应用多种开源。
最简单的数据抓取教程,人人都可以使用 WebScraper 是免费的,适合普通用户(无需专业技能)。
不再有手写爬虫!推荐5个自动爬取数据的神器!_c-CSDN博客。
刮:开始数据刮工作。ExportdataCSV:以 CSV 格式导出捕获的数据。在这里,有一个简单的了解就足够了。
链接提交工具可以实时向百度推送数据,创建并提交站点地图,提交收录网页链接,帮助百度发现和了解你的网站。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,具体信息可以搜索,都是国内信息采集 的发起者。
天菜鸟哥今天就带大家分享五款免费的数据采集工具。打开优采云软件后,打开网页,然后点击单个文字,选择右键。
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。
本软件可以帮助想要自己研究代码或者嫁接别人前端代码文件的开发者网站爬虫工具网站爬虫工具详细描述使用。
网页数据抓取软件(30款常用的大数据分析工具推荐(最新))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-21 01:04
最简单的数据抓取教程,人人都可以使用 WebScraper 是免费的,适合普通用户(无需专业技能)。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
优采云采集器作为一款通用的网页抓取工具,基于源码的优采云操作原理,可以抓取99%的网页类型,自动登录和验证。
天菜鸟哥今天就带大家分享五款免费的数据采集工具。打开优采云软件后,打开网页,然后点击单个文字,选择右键。
大家都会使用网页抓取工具优采云采集器来采集网页数据,但是如果有很多朋友还没有,我们可能会像采集网站@ > 。
呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,具体信息可以搜索,都是国内信息采集 的发起者。
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。
比如等待事件或点击某些项目,而不仅仅是抓取数据,MechanicalSoup 确实为这个浏览器提供了网络抓取能力。
近年来,随着国内大数据战略越来越清晰,数据采集与信息采集系列产品迎来了数据采集与采集,推荐使用优采云 云。
网页数据抓取工具,webscraper 最简单的数据抓取教育博客园。 查看全部
网页数据抓取软件(30款常用的大数据分析工具推荐(最新))
最简单的数据抓取教程,人人都可以使用 WebScraper 是免费的,适合普通用户(无需专业技能)。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
优采云采集器作为一款通用的网页抓取工具,基于源码的优采云操作原理,可以抓取99%的网页类型,自动登录和验证。
天菜鸟哥今天就带大家分享五款免费的数据采集工具。打开优采云软件后,打开网页,然后点击单个文字,选择右键。
大家都会使用网页抓取工具优采云采集器来采集网页数据,但是如果有很多朋友还没有,我们可能会像采集网站@ > 。
呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,具体信息可以搜索,都是国内信息采集 的发起者。
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。
比如等待事件或点击某些项目,而不仅仅是抓取数据,MechanicalSoup 确实为这个浏览器提供了网络抓取能力。
近年来,随着国内大数据战略越来越清晰,数据采集与信息采集系列产品迎来了数据采集与采集,推荐使用优采云 云。
网页数据抓取工具,webscraper 最简单的数据抓取教育博客园。
网页数据抓取软件(VG浏览器网页自动操作工具介绍及使用技巧介绍-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-18 00:08
VG浏览器是一款由可视化脚本驱动的网页自动化操作工具。用户可以创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、在VG浏览器中设置脚本即可下载 文件、操作数据库、收发邮件等个性化实用的脚本项目.
特征
1、可视化操作
操作简单,图形化操作全可视化,无需专业IT人员。
2、自定义流程
采集就像积木一样,功能可以自由组合。
3、自动编码
程序注重采集的效率,页面解析速度快。
4、生成EXE
自动登录,自动识别验证码,是一款万能浏览器。
技能
1、通过CSS Path定位网页元素路径是VG浏览器非常实用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的按钮;
2、点击一个网页元素,自动生成该元素的CSS Path。极少数框架复杂的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制 CSS Path。比如谷歌浏览器、360安全浏览器、360极速浏览器、UC浏览器等带有Chrome内核的浏览器可以按F12键或者在页面上右键选择评论元素;
3、在目标节点上右击,选择Copy CSS Path,将CSS Path复制到剪贴板;
4、Firefox 浏览器也可以按 F12 或右键查看元素。显示开发者工具后,右击底部节点,选择“复制唯一选择器”,复制CSS路径;
5、CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。
常见问题
1、VG浏览器有哪些功能?
VG Browser 是一个可视化的自动化脚本工具。我们可以设置脚本来实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作。还可以使用条件判断、循环、跳转等逻辑运算。所有功能完全自由组合,我们可以编写强大而独特的脚本来辅助我们的工作,也可以生成单独的EXE程序进行销售。
2、使用项目经理需要付费吗?
VG浏览器的项目经理不是免费的。必须购买注册码后才能使用。项目经理可以独立运行脚本,可以同时运行多线程和多任务。每个任务都可以在设定的时间运行。.
3、VG 浏览器可以免费使用吗?
VG浏览器的脚本编辑器是免费使用的,可以使用所有脚本模块可视化地制作脚本,可以直接运行单个脚本,并且可以一步测试脚本。 查看全部
网页数据抓取软件(VG浏览器网页自动操作工具介绍及使用技巧介绍-乐题库)
VG浏览器是一款由可视化脚本驱动的网页自动化操作工具。用户可以创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、在VG浏览器中设置脚本即可下载 文件、操作数据库、收发邮件等个性化实用的脚本项目.
特征
1、可视化操作
操作简单,图形化操作全可视化,无需专业IT人员。
2、自定义流程
采集就像积木一样,功能可以自由组合。
3、自动编码
程序注重采集的效率,页面解析速度快。
4、生成EXE
自动登录,自动识别验证码,是一款万能浏览器。
技能
1、通过CSS Path定位网页元素路径是VG浏览器非常实用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的按钮;
2、点击一个网页元素,自动生成该元素的CSS Path。极少数框架复杂的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制 CSS Path。比如谷歌浏览器、360安全浏览器、360极速浏览器、UC浏览器等带有Chrome内核的浏览器可以按F12键或者在页面上右键选择评论元素;
3、在目标节点上右击,选择Copy CSS Path,将CSS Path复制到剪贴板;
4、Firefox 浏览器也可以按 F12 或右键查看元素。显示开发者工具后,右击底部节点,选择“复制唯一选择器”,复制CSS路径;
5、CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你也可以自己编写 CSS Path。
常见问题
1、VG浏览器有哪些功能?
VG Browser 是一个可视化的自动化脚本工具。我们可以设置脚本来实现自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等操作。还可以使用条件判断、循环、跳转等逻辑运算。所有功能完全自由组合,我们可以编写强大而独特的脚本来辅助我们的工作,也可以生成单独的EXE程序进行销售。
2、使用项目经理需要付费吗?
VG浏览器的项目经理不是免费的。必须购买注册码后才能使用。项目经理可以独立运行脚本,可以同时运行多线程和多任务。每个任务都可以在设定的时间运行。.
3、VG 浏览器可以免费使用吗?
VG浏览器的脚本编辑器是免费使用的,可以使用所有脚本模块可视化地制作脚本,可以直接运行单个脚本,并且可以一步测试脚本。
网页数据抓取软件(风越网页批量填写数据提取软件,可自动分析网页中表单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-15 12:07
风月网页批量填表数据提取软件可以自动分析网页中已经填好的内容,并保存为填表规则。下载指定的网页链接文件。
风月Excel数据批量自动填写网页数据提取软件的特点
该软件支持更多类型的页面填充和控制元素,精度更高。其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。
本软件不仅可以用于普通办公填表,还可以扩展为批量登记、投票、留言、商品秒杀、舆论引导、刷信、抢牌等工具。
★支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成Xls文件,方便批量输入
★支持下载指定文件和抓取网页文本内容
★支持多边框页面控件元素的填充
★支持iframe内嵌页面控件元素的填充
★支持网页结构分析,显示控件描述,便于分析和修改控件值
★支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
★支持级联下拉菜单填充
★支持无ID控制灌装
★支持验证码在线识别
★支持循环填充和输入
风月excel数据批量自动填写网页数据提取软件说明
1、点击菜单“系统”>“新建配置文件”
2、在软件中打开网页,手动填写需要输入的内容
3、点击左下角的“带有加号图标的新规则”按钮创建规则
4、勾选“填写”网格,酌情删除不想填写的行
至此,设置已经完成。测试时,只需刷新网页,使网页未填充,然后点击软件左下角的“三角图标开始填充”按钮,即可查看填充效果。
风月excel数据批量自动填写网页数据提取软件更新日志
把bug扫到最后 查看全部
网页数据抓取软件(风越网页批量填写数据提取软件,可自动分析网页中表单)
风月网页批量填表数据提取软件可以自动分析网页中已经填好的内容,并保存为填表规则。下载指定的网页链接文件。
风月Excel数据批量自动填写网页数据提取软件的特点
该软件支持更多类型的页面填充和控制元素,精度更高。其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。
本软件不仅可以用于普通办公填表,还可以扩展为批量登记、投票、留言、商品秒杀、舆论引导、刷信、抢牌等工具。
★支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成Xls文件,方便批量输入
★支持下载指定文件和抓取网页文本内容
★支持多边框页面控件元素的填充
★支持iframe内嵌页面控件元素的填充
★支持网页结构分析,显示控件描述,便于分析和修改控件值
★支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
★支持级联下拉菜单填充
★支持无ID控制灌装
★支持验证码在线识别
★支持循环填充和输入
风月excel数据批量自动填写网页数据提取软件说明
1、点击菜单“系统”>“新建配置文件”
2、在软件中打开网页,手动填写需要输入的内容
3、点击左下角的“带有加号图标的新规则”按钮创建规则
4、勾选“填写”网格,酌情删除不想填写的行
至此,设置已经完成。测试时,只需刷新网页,使网页未填充,然后点击软件左下角的“三角图标开始填充”按钮,即可查看填充效果。
风月excel数据批量自动填写网页数据提取软件更新日志
把bug扫到最后
网页数据抓取软件(这是一个很早就设想的项目(图)付诸实现 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-14 21:14
)
这是一个很久以前就设想过但从未实现的项目。前几天从网上捡到一个小项目,和网页数据提取有关,所以顺便开发了这个功能。
该项目有几个步骤,从简单到复杂。让我们从简单的开始。
简单地说,它很简单。不管是模式问题、性能问题,还是多线程问题,都是用传统的编程方式,想起来就加函数。优化问题会在后面考虑,当然,有推翻整个项目的风险。
功能列表:
1、阅读网页:必须实现的功能,否则没有基本的数据进行操作。网页数据类型包括:html、xml、asp、aspx、image、script等,读取方式有很多种,如WebBrowser控件、WinSock控件等。
2.网页数据分析:对上一步读取的数据进行再处理和检索,找到需要的数据。这一步比较麻烦,因为我们面临着五种数据结构的方法。可以使用 WebBrowser 的 Document 来访问节点;您还可以在 mshtml 中使用 HTMLDocumentClass 类;可以直接读取数据,使用文本分析的方法,效率较低。如果使用正则表达式,效率会提高很多。我使用了上述数据分析方法,具体取决于处理的数据类型。
以上两步为主要部分,实际功能基于以上结果。
3.增加实用功能:
1)链接,网页中的按钮点击:模拟用户的操作,点击网页中的链接。点击动作很容易在 WebBroswer 或 mshtml 中实现。注意实现相关的事件回调,如 Completed、Navigating 等。
WebBrowser--> Document --> DomDocument --> HTMLElement --> 点击
要找到对应的控件,可以使用name、class id、href、submit等属性在控件集中进行过滤。
2)网页中的数据填充:数据填充一般发生在文本框控件中。控件可以通过名称定位,将要填充的值赋给它的value属性。
3)验证码识别:这个话题涉及到很多知识,我会在另一个文章中讨论,这里我们举个简单的例子,比如
, 复杂到
查看全部
网页数据抓取软件(这是一个很早就设想的项目(图)付诸实现
)
这是一个很久以前就设想过但从未实现的项目。前几天从网上捡到一个小项目,和网页数据提取有关,所以顺便开发了这个功能。
该项目有几个步骤,从简单到复杂。让我们从简单的开始。
简单地说,它很简单。不管是模式问题、性能问题,还是多线程问题,都是用传统的编程方式,想起来就加函数。优化问题会在后面考虑,当然,有推翻整个项目的风险。
功能列表:
1、阅读网页:必须实现的功能,否则没有基本的数据进行操作。网页数据类型包括:html、xml、asp、aspx、image、script等,读取方式有很多种,如WebBrowser控件、WinSock控件等。
2.网页数据分析:对上一步读取的数据进行再处理和检索,找到需要的数据。这一步比较麻烦,因为我们面临着五种数据结构的方法。可以使用 WebBrowser 的 Document 来访问节点;您还可以在 mshtml 中使用 HTMLDocumentClass 类;可以直接读取数据,使用文本分析的方法,效率较低。如果使用正则表达式,效率会提高很多。我使用了上述数据分析方法,具体取决于处理的数据类型。
以上两步为主要部分,实际功能基于以上结果。
3.增加实用功能:
1)链接,网页中的按钮点击:模拟用户的操作,点击网页中的链接。点击动作很容易在 WebBroswer 或 mshtml 中实现。注意实现相关的事件回调,如 Completed、Navigating 等。
WebBrowser--> Document --> DomDocument --> HTMLElement --> 点击
要找到对应的控件,可以使用name、class id、href、submit等属性在控件集中进行过滤。
2)网页中的数据填充:数据填充一般发生在文本框控件中。控件可以通过名称定位,将要填充的值赋给它的value属性。
3)验证码识别:这个话题涉及到很多知识,我会在另一个文章中讨论,这里我们举个简单的例子,比如
, 复杂到
网页数据抓取软件( 新冠、谷歌的、头条、百度,各种各样的网站分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-14 07:12
新冠、谷歌的、头条、百度,各种各样的网站分析)
COVID-19 数据网站CoronaTracker
网上有很多网站提供新冠病毒数据,霍普金斯大学、谷歌、今日头条、百度,各种。今天我想把这个 CoronaTracker 作为一个开源数据介绍给大家:
界面很简单,但是主要元素都在里面,数据汇总、地图、趋势图、条形图、数据表。我们在制作数据表时可以参考这些网站的图表样式和布局。
和霍普金斯或者谷歌的相比,它看起来没有那么精致和高端,但数据内容已经足够了。
如果我们点击国家,就会进入国家的界面:
除了提供数据外,最近也有相关消息。
我们今天要模仿的不是数据图,而是这张带有旗帜图标的数据表:
前几天写的股票数据采集,网友评论说过程太简单了,这个数据采集比较简单,但是网站分析和数据采集的过程基本一样,今天就记录一下详细流程:
网站分析
我们需要用谷歌浏览器来做网站分析,网页右键->勾选,或者直接快捷键F12:
打开检查页面:
F12直接打开网络。根据提示,按CTRL+R重新加载网页,网络会显示网页加载过程中产生的数据:
在这个页面中,所有的数据都会显示在all标签下,包括图片、js、css和data。一般情况下,我们会在 XHR 中找到我们想要的数据。如何查看?让我们随机选择一行:
该页面的详细信息将显示在右侧。我们先来看看预告。预览显示格式数据。上图是一个json数据,应该是100行趋势数据。
当我们点击它时,我们可以看到三个数据和数据更新时间。这个数据不是我们想要的,我们想要每个国家的数据,我们点击topCountry:
果然,这个数据是所有国家和地区的最新数据。接下来我们打开标题选项卡:
然后仔细查看这个页面的信息,通常这个header有4个部分:
GeneralResponse HeadersRequest HeadersQuery 字符串参数或数据表单
更重要的是 1、3、 的 4 项。我们今天在这个标题中只有 3 个项目。描述比较简单,不需要传递查询条件。如果去特定国家的页面,有查询条件,如下图:
这样的查询不一定复杂。这个查询的字符串也可以直接在url中传递,不需要通过Content传递。通常可以通过GET方法的直接url,但有的需要url和Content。同时交货;POST 方法基本上需要 Content 或 Query 下发,有时 Content 和 Query 需要同时下发。
回到我们的主题,我们在标头中寻找的第一个重要信息是请求 URL。很多时候,这个请求 URL 与浏览器地址栏中的 URL 不同。这也是很多朋友直接使用地址栏中的网址的原因。无法获取数据的主要原因:
我们只能通过这个Request URL来抓取有用的数据,也就是我们常说的真实URL。
然后是请求方法。这个 网站 是 GET 方法。如果是POST方式,我们还要看Request Headers中更多的参数,这里就不做介绍了。
我们查了数据,数据中没有国标信息。我们需要找出图标存放位置的规律: 查看全部
网页数据抓取软件(
新冠、谷歌的、头条、百度,各种各样的网站分析)
COVID-19 数据网站CoronaTracker
网上有很多网站提供新冠病毒数据,霍普金斯大学、谷歌、今日头条、百度,各种。今天我想把这个 CoronaTracker 作为一个开源数据介绍给大家:
界面很简单,但是主要元素都在里面,数据汇总、地图、趋势图、条形图、数据表。我们在制作数据表时可以参考这些网站的图表样式和布局。
和霍普金斯或者谷歌的相比,它看起来没有那么精致和高端,但数据内容已经足够了。
如果我们点击国家,就会进入国家的界面:
除了提供数据外,最近也有相关消息。
我们今天要模仿的不是数据图,而是这张带有旗帜图标的数据表:
前几天写的股票数据采集,网友评论说过程太简单了,这个数据采集比较简单,但是网站分析和数据采集的过程基本一样,今天就记录一下详细流程:
网站分析
我们需要用谷歌浏览器来做网站分析,网页右键->勾选,或者直接快捷键F12:
打开检查页面:
F12直接打开网络。根据提示,按CTRL+R重新加载网页,网络会显示网页加载过程中产生的数据:
在这个页面中,所有的数据都会显示在all标签下,包括图片、js、css和data。一般情况下,我们会在 XHR 中找到我们想要的数据。如何查看?让我们随机选择一行:
该页面的详细信息将显示在右侧。我们先来看看预告。预览显示格式数据。上图是一个json数据,应该是100行趋势数据。
当我们点击它时,我们可以看到三个数据和数据更新时间。这个数据不是我们想要的,我们想要每个国家的数据,我们点击topCountry:
果然,这个数据是所有国家和地区的最新数据。接下来我们打开标题选项卡:
然后仔细查看这个页面的信息,通常这个header有4个部分:
GeneralResponse HeadersRequest HeadersQuery 字符串参数或数据表单
更重要的是 1、3、 的 4 项。我们今天在这个标题中只有 3 个项目。描述比较简单,不需要传递查询条件。如果去特定国家的页面,有查询条件,如下图:
这样的查询不一定复杂。这个查询的字符串也可以直接在url中传递,不需要通过Content传递。通常可以通过GET方法的直接url,但有的需要url和Content。同时交货;POST 方法基本上需要 Content 或 Query 下发,有时 Content 和 Query 需要同时下发。
回到我们的主题,我们在标头中寻找的第一个重要信息是请求 URL。很多时候,这个请求 URL 与浏览器地址栏中的 URL 不同。这也是很多朋友直接使用地址栏中的网址的原因。无法获取数据的主要原因:
我们只能通过这个Request URL来抓取有用的数据,也就是我们常说的真实URL。
然后是请求方法。这个 网站 是 GET 方法。如果是POST方式,我们还要看Request Headers中更多的参数,这里就不做介绍了。
我们查了数据,数据中没有国标信息。我们需要找出图标存放位置的规律:

