
网页内容抓取工具
网页内容抓取工具(Python用做数据处理还是相当不错的,你知道吗?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-17 02:27
Python非常适合数据处理。如果你想做爬虫,Python 是个不错的选择。它有许多已编写的包。只需调用它们就可以完成许多复杂的功能。本文所有功能均基于 BeautifulSoup 包。
1 Pyhton获取网页内容(即源码)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址对应的源码,urllib2是需要用到的包,上面三句代码就可以得到网页的整个源码
2 获取网页中想要的内容(先获取网页的源代码,然后分析网页的源代码,找到对应的标签,然后提取标签中的内容)
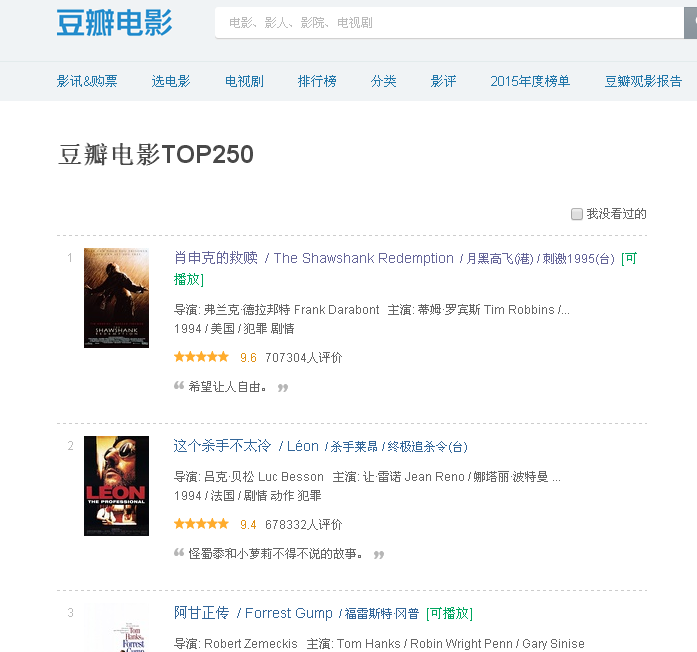
2.1 以豆瓣电影排名为例
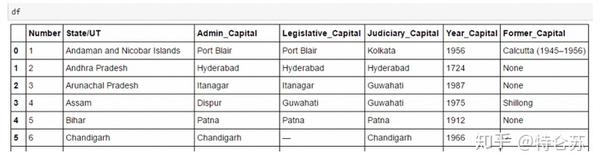
网址是,输入网址后会出现下图
现在我需要获取当前页面上所有电影的名称、评分、评论数量、链接
从上图中,红色圆圈是我想要获取的内容,蓝色横线是对应的标签,这样分析就完成了,现在就是写代码来实现,Python提供了很多获取想要的方法内容,这里我使用BeautifulSoup来实现,很简单
#coding:utf-8
'''
Created on 2016��5��17��
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,也可以写入文件
前三行代码获取整个网页的源码,然后开始使用BeautifulSoup进行标签分析。find_all 方法就是找到这个标签的所有内容,然后在这个标签中继续搜索。如果标签有特殊的属性声明,可以一步找到出来,如果没有特殊的属性声明像这张图中求值者数量前面的标签只有一个'span',那么所有的span找到标签,并依次选择相应的标签。在这张图中,它是第三个,所以这个方法可以找到特定行或列的内容。代码比较简单,易于实现。如有不对的地方请大家指出,共同学习。
源代码地址: 查看全部
网页内容抓取工具(Python用做数据处理还是相当不错的,你知道吗?(上))
Python非常适合数据处理。如果你想做爬虫,Python 是个不错的选择。它有许多已编写的包。只需调用它们就可以完成许多复杂的功能。本文所有功能均基于 BeautifulSoup 包。
1 Pyhton获取网页内容(即源码)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址对应的源码,urllib2是需要用到的包,上面三句代码就可以得到网页的整个源码
2 获取网页中想要的内容(先获取网页的源代码,然后分析网页的源代码,找到对应的标签,然后提取标签中的内容)
2.1 以豆瓣电影排名为例
网址是,输入网址后会出现下图
现在我需要获取当前页面上所有电影的名称、评分、评论数量、链接

从上图中,红色圆圈是我想要获取的内容,蓝色横线是对应的标签,这样分析就完成了,现在就是写代码来实现,Python提供了很多获取想要的方法内容,这里我使用BeautifulSoup来实现,很简单
#coding:utf-8
'''
Created on 2016��5��17��
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,也可以写入文件

前三行代码获取整个网页的源码,然后开始使用BeautifulSoup进行标签分析。find_all 方法就是找到这个标签的所有内容,然后在这个标签中继续搜索。如果标签有特殊的属性声明,可以一步找到出来,如果没有特殊的属性声明像这张图中求值者数量前面的标签只有一个'span',那么所有的span找到标签,并依次选择相应的标签。在这张图中,它是第三个,所以这个方法可以找到特定行或列的内容。代码比较简单,易于实现。如有不对的地方请大家指出,共同学习。
源代码地址:
网页内容抓取工具(网页抓取工具WebExtractWebWebWeb)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-15 18:27
网络爬虫 Easy Web Extract 是一款易于使用的网络爬虫,可提取网页中的内容(文本、URL、图像、文件),只需点击几下屏幕即可将结果转换为多种格式。没有编程要求。让我们的网络爬虫像它的名字一样易于使用。
软件说明:
我们简单的网络提取软件收录许多高级功能。
使用户能够从简单的 网站 中抓取内容。
但是构建一个网络抓取项目不需要任何努力。
在此页面中,我们将仅向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
特征:
1. 轻松创建提取项目
对任何用户来说,基于向导窗口创建新项目绝非易事。
项目安装向导会一步步推你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始地址,即起始页,刷新屏幕后会加载网页。
它通常是一个链接到一个被刮掉的产品列表
第二步:如果网站要求,输入关键词提交表单并获取结果。大多数情况下可以跳过这一步
第三步:在列表中选择一个项目,选择该项目的数据列的抓取性能
第四步:选择下一页的网址访问其他页面
2. 多线程抓取数据
在网络爬虫项目中,需要爬取数十万个链接进行收获。
传统的刮刀可能需要数小时或数天的时间。
然而,一个简单的网页提取可以同时运行多个线程来浏览多达 24 个不同的网页。
为了节省您宝贵的时间,等待收获的结果。
因此,简单的 Web 提取可以利用系统的最佳性能。
旁边的动画图像显示了 8 个线程的提取。
3. 从数据中加载各种提取的数据
一些高度动态的网站使用基于客户端创建的数据加载技术,例如AJAX异步请求。
诚然,不仅是原创的网页爬虫,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
但是,简单的网络提取具有非常强大的技术。
即使是新手也可以从这些类型的网站中获取数据。
此外,我们的 网站 爬虫甚至可以模拟向下滚动到页面底部以加载更多数据。
例如LinkedIn联系人列表中的某些特定网站。
在这个挑战中,大多数网络爬虫继续采集大量重复信息。
并且很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动执行项目
通过简单的网络提取的嵌入式自动运行调度程序。
您可以随时安排运行网页抓取项目,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有一直运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
确保只维护新数据。
支持的日历类型:
- 在项目中每小时运行一次
- 在项目中每天运行
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网络抓取工具支持各种格式来导出和抓取 网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接提交任何类型的数据库目标结果。
通过 ODBC 连接。如果您的 网站 有提交表单。 查看全部
网页内容抓取工具(网页抓取工具WebExtractWebWebWeb)
网络爬虫 Easy Web Extract 是一款易于使用的网络爬虫,可提取网页中的内容(文本、URL、图像、文件),只需点击几下屏幕即可将结果转换为多种格式。没有编程要求。让我们的网络爬虫像它的名字一样易于使用。

软件说明:
我们简单的网络提取软件收录许多高级功能。
使用户能够从简单的 网站 中抓取内容。
但是构建一个网络抓取项目不需要任何努力。
在此页面中,我们将仅向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
特征:
1. 轻松创建提取项目
对任何用户来说,基于向导窗口创建新项目绝非易事。
项目安装向导会一步步推你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始地址,即起始页,刷新屏幕后会加载网页。
它通常是一个链接到一个被刮掉的产品列表
第二步:如果网站要求,输入关键词提交表单并获取结果。大多数情况下可以跳过这一步
第三步:在列表中选择一个项目,选择该项目的数据列的抓取性能
第四步:选择下一页的网址访问其他页面
2. 多线程抓取数据
在网络爬虫项目中,需要爬取数十万个链接进行收获。
传统的刮刀可能需要数小时或数天的时间。
然而,一个简单的网页提取可以同时运行多个线程来浏览多达 24 个不同的网页。
为了节省您宝贵的时间,等待收获的结果。
因此,简单的 Web 提取可以利用系统的最佳性能。
旁边的动画图像显示了 8 个线程的提取。
3. 从数据中加载各种提取的数据
一些高度动态的网站使用基于客户端创建的数据加载技术,例如AJAX异步请求。
诚然,不仅是原创的网页爬虫,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
但是,简单的网络提取具有非常强大的技术。
即使是新手也可以从这些类型的网站中获取数据。
此外,我们的 网站 爬虫甚至可以模拟向下滚动到页面底部以加载更多数据。
例如LinkedIn联系人列表中的某些特定网站。
在这个挑战中,大多数网络爬虫继续采集大量重复信息。
并且很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动执行项目
通过简单的网络提取的嵌入式自动运行调度程序。
您可以随时安排运行网页抓取项目,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有一直运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
确保只维护新数据。
支持的日历类型:
- 在项目中每小时运行一次
- 在项目中每天运行
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网络抓取工具支持各种格式来导出和抓取 网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接提交任何类型的数据库目标结果。
通过 ODBC 连接。如果您的 网站 有提交表单。
网页内容抓取工具( 使用Chrome扩展程序电子邮件提取器提取器是Chrome插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-12-15 03:23
使用Chrome扩展程序电子邮件提取器提取器是Chrome插件)
urls = $$(‘a’); for (url in urls) console.log ( urls.href);
只需一行代码,我们就可以找到该特定页面上存在的所有 URL:
使用 Chrome 扩展电子邮件提取器
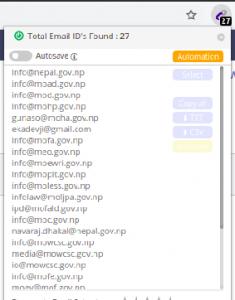
Email Extractor 是一个 Chrome 插件,它捕获我们当前浏览的页面上显示的电子邮件 ID
它甚至允许我们下载 CSV 或文本文件中的电子邮件 ID 列表:
BeautifulSoup 和正则表达式
上述方案仅在我们只想从一页抓取数据时有效。但是如果我们想在多个页面上执行相同的步骤呢?
有很多网站可以通过收费来为我们做这件事。但好消息是——我们也可以用 Python 编写自己的网络爬虫!让我们在下面的实时编码窗口中检查操作方法。
在 Python 中抓取图片
在本节中,我们将从同一个 Goibibibo 网页中抓取所有图片。第一步是导航到目标网站并下载源代码。接下来,我们将使用标签来查找所有图像:
"""Web Scraping - Scrap Images"""# importing required librariesimport requestsfrom bs4 import BeautifulSoup# target URLurl = "https://www.goibibo.com/hotels ... aders = { 'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" }response = requests.request("GET", url, headers=headers)data = BeautifulSoup(response.text, 'html.parser')# find all with the image tagimages = data.find_all('img', src=True)print('Number of Images: ', len(images))for image in images: print(image)
从所有图像标签中,仅选择 src 部分。另外请注意,酒店图片以jpg格式提供。因此,我们将只选择那些:
# select src tagimage_src = [x['src'] for x in images]# select only jp format imagesimage_src = [x for x in image_src if x.endswith('.jpg')]for image in image_src: print(image)
现在我们有了一个图像 URL 列表,我们所要做的就是请求图像的内容并将其写入文件。确保以“wb”(写入二进制文件)形式打开文件
image_count = 1for image in image_src: with open('image_'+str(image_count)+'.jpg', 'wb') as f: res = requests.get(image) f.write(res.content) image_count = image_count+1
您还可以通过页码更新初始页面 URL 并重复请求它们以[url=https://www.ucaiyun.com/]采集大量数据。
页面加载时抓取数据
我们来看看 Steam 社区 Grant Theft Auto V 评论的网页。您会注意到网页的完整内容不会一次性加载。
我们需要向下滚动以在页面上加载更多内容。这是网站 后端开发人员使用的一种称为“延迟加载”的优化技术。
但对我们来说,问题是当我们试图从这个页面抓取数据时,我们只能得到那个页面的有限内容:
一些 网站 还创建了“加载更多”按钮,而不是无休止的滚动想法。只有当您单击按钮时,它才会加载更多内容。内容受限的问题依然存在。那么让我们看看如何抓取这些页面。
导航到目标 URL 并打开“检查元素网络”窗口。接下来点击reload按钮,它会为你记录网络的加载顺序,比如图片加载、API请求、POST请求等。
清除当前记录并向下滚动。您会注意到,当您向下滚动时,页面正在发送对更多数据的请求:
进一步滚动,您将看到 网站 如何发出请求。看下面的网址——只有部分参数值在变化,你可以用简单的Python代码轻松生成这些网址:
您需要按照相同的步骤通过将请求逐页发送到每个页面来获取和存储数据。
尾注
这是使用强大的 BeautifulSoup 库在 Python 中进行网页抓取的简单且适合初学者的介绍。老实说,当我在寻找新项目或需要有关现有项目的信息时,我发现网络抓取非常有用。
注意:如果您想以更结构化的形式学习本教程,我们有一个免费课程,我们将教授 Web 抓取 BeatifulSoup。您可以在此处查看-使用 Python 进行 Web 爬网简介。
如前所述,还有其他库可用于执行网页抓取。我很想听听你最喜欢的图书馆想法(即使你使用 R!),以及你在这个主题上的经验。在下面的评论部分告诉我,我们会与您联系! 查看全部
网页内容抓取工具(
使用Chrome扩展程序电子邮件提取器提取器是Chrome插件)
urls = $$(‘a’); for (url in urls) console.log ( urls.href);

只需一行代码,我们就可以找到该特定页面上存在的所有 URL:
使用 Chrome 扩展电子邮件提取器
Email Extractor 是一个 Chrome 插件,它捕获我们当前浏览的页面上显示的电子邮件 ID
它甚至允许我们下载 CSV 或文本文件中的电子邮件 ID 列表:
BeautifulSoup 和正则表达式
上述方案仅在我们只想从一页抓取数据时有效。但是如果我们想在多个页面上执行相同的步骤呢?
有很多网站可以通过收费来为我们做这件事。但好消息是——我们也可以用 Python 编写自己的网络爬虫!让我们在下面的实时编码窗口中检查操作方法。
在 Python 中抓取图片
在本节中,我们将从同一个 Goibibibo 网页中抓取所有图片。第一步是导航到目标网站并下载源代码。接下来,我们将使用标签来查找所有图像:
"""Web Scraping - Scrap Images"""# importing required librariesimport requestsfrom bs4 import BeautifulSoup# target URLurl = "https://www.goibibo.com/hotels ... aders = { 'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" }response = requests.request("GET", url, headers=headers)data = BeautifulSoup(response.text, 'html.parser')# find all with the image tagimages = data.find_all('img', src=True)print('Number of Images: ', len(images))for image in images: print(image)
从所有图像标签中,仅选择 src 部分。另外请注意,酒店图片以jpg格式提供。因此,我们将只选择那些:
# select src tagimage_src = [x['src'] for x in images]# select only jp format imagesimage_src = [x for x in image_src if x.endswith('.jpg')]for image in image_src: print(image)
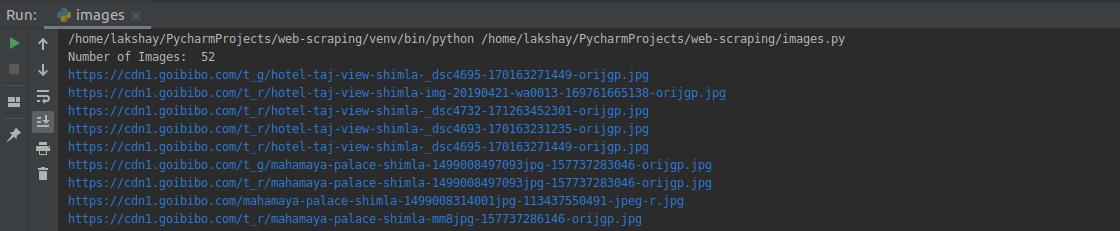
现在我们有了一个图像 URL 列表,我们所要做的就是请求图像的内容并将其写入文件。确保以“wb”(写入二进制文件)形式打开文件
image_count = 1for image in image_src: with open('image_'+str(image_count)+'.jpg', 'wb') as f: res = requests.get(image) f.write(res.content) image_count = image_count+1
您还可以通过页码更新初始页面 URL 并重复请求它们以[url=https://www.ucaiyun.com/]采集大量数据。
页面加载时抓取数据
我们来看看 Steam 社区 Grant Theft Auto V 评论的网页。您会注意到网页的完整内容不会一次性加载。
我们需要向下滚动以在页面上加载更多内容。这是网站 后端开发人员使用的一种称为“延迟加载”的优化技术。
但对我们来说,问题是当我们试图从这个页面抓取数据时,我们只能得到那个页面的有限内容:
一些 网站 还创建了“加载更多”按钮,而不是无休止的滚动想法。只有当您单击按钮时,它才会加载更多内容。内容受限的问题依然存在。那么让我们看看如何抓取这些页面。
导航到目标 URL 并打开“检查元素网络”窗口。接下来点击reload按钮,它会为你记录网络的加载顺序,比如图片加载、API请求、POST请求等。
清除当前记录并向下滚动。您会注意到,当您向下滚动时,页面正在发送对更多数据的请求:
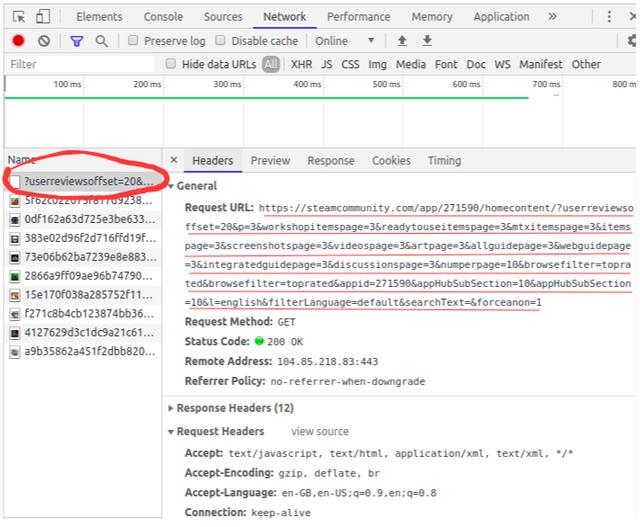
进一步滚动,您将看到 网站 如何发出请求。看下面的网址——只有部分参数值在变化,你可以用简单的Python代码轻松生成这些网址:

您需要按照相同的步骤通过将请求逐页发送到每个页面来获取和存储数据。
尾注
这是使用强大的 BeautifulSoup 库在 Python 中进行网页抓取的简单且适合初学者的介绍。老实说,当我在寻找新项目或需要有关现有项目的信息时,我发现网络抓取非常有用。
注意:如果您想以更结构化的形式学习本教程,我们有一个免费课程,我们将教授 Web 抓取 BeatifulSoup。您可以在此处查看-使用 Python 进行 Web 爬网简介。
如前所述,还有其他库可用于执行网页抓取。我很想听听你最喜欢的图书馆想法(即使你使用 R!),以及你在这个主题上的经验。在下面的评论部分告诉我,我们会与您联系!
网页内容抓取工具(大数据抓取软件怎么使用网页数据的工具方法方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-12-14 15:22
网站数据采集 哪个工具好用?
网站数据采集,现成的爬虫软件有很多可以直接使用,下面我就简单介绍一下三种,分别是优采云、章鱼和优采云,操作简单,上手容易学习了解,有兴趣的朋友可以试试:
这是一款非常智能的网络爬虫软件,支持跨平台,个人使用非常方便,完全免费。对于大多数网站,只需输入URL,软件会自动识别并提取相关字段信息,包括列表、表格、链接、图片等,无需配置任何采集规则,一个-click采用,支持自动翻页和数据导出功能,对于小白来说,非常方便,易学易掌握:这是一款非常好的一款,对比优采云采集器,八达通采集器目前只支持windows平台,需要手动设置采集字段和配置规则,所以比较复杂灵活。内置海量数据采集模板,方便采集京东,天猫等热门网站。官方教程很详细,小白很容易掌握:
当然,除了以上三个爬虫软件,它还有很多功能,很多其他软件也支持网站data采集,比如做号,申请保单等等。如果您熟悉 Python、Java 等编程语言,您还可以编写程序来抓取数据。网上也有相关的教程和资料,讲的很详细。如果你有兴趣,你可以搜索它们。希望以上分享的内容对您有所帮助,也欢迎大家留言补充。
大数据抓取软件如何抓取网页数据,抓取数据的工具和方法 查看全部
网页内容抓取工具(大数据抓取软件怎么使用网页数据的工具方法方法介绍)
网站数据采集 哪个工具好用?
网站数据采集,现成的爬虫软件有很多可以直接使用,下面我就简单介绍一下三种,分别是优采云、章鱼和优采云,操作简单,上手容易学习了解,有兴趣的朋友可以试试:
这是一款非常智能的网络爬虫软件,支持跨平台,个人使用非常方便,完全免费。对于大多数网站,只需输入URL,软件会自动识别并提取相关字段信息,包括列表、表格、链接、图片等,无需配置任何采集规则,一个-click采用,支持自动翻页和数据导出功能,对于小白来说,非常方便,易学易掌握:这是一款非常好的一款,对比优采云采集器,八达通采集器目前只支持windows平台,需要手动设置采集字段和配置规则,所以比较复杂灵活。内置海量数据采集模板,方便采集京东,天猫等热门网站。官方教程很详细,小白很容易掌握:
当然,除了以上三个爬虫软件,它还有很多功能,很多其他软件也支持网站data采集,比如做号,申请保单等等。如果您熟悉 Python、Java 等编程语言,您还可以编写程序来抓取数据。网上也有相关的教程和资料,讲的很详细。如果你有兴趣,你可以搜索它们。希望以上分享的内容对您有所帮助,也欢迎大家留言补充。
大数据抓取软件如何抓取网页数据,抓取数据的工具和方法
网页内容抓取工具(一下如何使用网页抓取工具抓取APP数据大家都会使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-11 07:32
如何使用网络爬虫抓取APP数据大家都会使用网络爬虫优采云采集器来采集网络数据,但是很多朋友还是不知道怎么用采集器来采集APP里的数据。毕竟随着移动互联网的发展,APP中还有大量的数据可供挖掘,下面就和大家分享一下如何使用网络爬虫工具采集移动App数据。网络爬虫优采云采集器可以抓取http和https请求中的内容,所以如果APP也通过这两种请求类型和服务器交互,那么我们可能会像采集网站 与实现 采集 相同。下面以京东APP为例介绍操作方法:(1)首先在手机上安装APP,将手机连接PC进行传输。(2)打开抓包工具查看fiddler的端口号,例如下图:(3)查看本地局域网的固定IP,下图:(4)设置手机中的端口号和IP,并写好端口号和IP,如下图: 如上图:在手机中设置好后,可以让fiddler一直处于Capturing状态,然后操作京东APP,打开你想要的页面采集,并且抓包工具会显示操作触发的网络请求和响应,如下图: 然后我们可以分析优采云采集器中的请求写入规则,测试http是否可以是采集,这样我们就可以使用网络爬虫工具实现APP采集的步骤基本完成了,大家多试几次。不过, APP和网页一样。我们看不到的数据不可用。比如很多人问如何获取后台用户数据。这种类型的数据是不可能的。采集@ >of. 查看全部
网页内容抓取工具(一下如何使用网页抓取工具抓取APP数据大家都会使用)
如何使用网络爬虫抓取APP数据大家都会使用网络爬虫优采云采集器来采集网络数据,但是很多朋友还是不知道怎么用采集器来采集APP里的数据。毕竟随着移动互联网的发展,APP中还有大量的数据可供挖掘,下面就和大家分享一下如何使用网络爬虫工具采集移动App数据。网络爬虫优采云采集器可以抓取http和https请求中的内容,所以如果APP也通过这两种请求类型和服务器交互,那么我们可能会像采集网站 与实现 采集 相同。下面以京东APP为例介绍操作方法:(1)首先在手机上安装APP,将手机连接PC进行传输。(2)打开抓包工具查看fiddler的端口号,例如下图:(3)查看本地局域网的固定IP,下图:(4)设置手机中的端口号和IP,并写好端口号和IP,如下图: 如上图:在手机中设置好后,可以让fiddler一直处于Capturing状态,然后操作京东APP,打开你想要的页面采集,并且抓包工具会显示操作触发的网络请求和响应,如下图: 然后我们可以分析优采云采集器中的请求写入规则,测试http是否可以是采集,这样我们就可以使用网络爬虫工具实现APP采集的步骤基本完成了,大家多试几次。不过, APP和网页一样。我们看不到的数据不可用。比如很多人问如何获取后台用户数据。这种类型的数据是不可能的。采集@ >of.
网页内容抓取工具(抓取整个网页的最强工具:Web2PicPro使用方法你到下面的地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 363 次浏览 • 2021-12-07 06:58
最强网页抓取工具:Web2Pic Pro
要使用它,请转到以下地址:
在上网的过程中,我们经常会抓取一些网页内容并以图片的形式保存。我们通常使用一些截图软件来完成这一切。但是,有时我们会遇到截屏过长,不止一屏,或者不得不自己截屏的情况。在抓取整个WEB页面的特殊情况下,HyperSnap虽然有抓取滚动窗口的功能,但并不是所有的页面都可以通过这种方式抓取,有时自动滚动会失败;并且在启用自动滚动功能时,滚动窗口被捕获,当前窗口使用的热键是相同的(Ctrl+Alt+W),在使用过程中不是很方便。使用Web2Pic Pro这个软件可以很好的满足我们抓取整个WEB页面的需求。它是一个专门用于抓取整个网页的图像捕获工具。它也是一个绿色软件。压缩后只有800KB,体积小。功能不弱,还支持命令行参数,使用简单方便。
之前用hypersnap,但是有时候爬不出来。
去google去web2pic pro破解或者web2pic pro串口
很多破解方法,因为经常变成,不提供具体的序列号
比如以我的数据站为例
注意地址栏中的输入不能省略
然后点击选择屏幕分辨率,然后点击开始捕捉,最后保存成你想要的格式。 查看全部
网页内容抓取工具(抓取整个网页的最强工具:Web2PicPro使用方法你到下面的地址)
最强网页抓取工具:Web2Pic Pro
要使用它,请转到以下地址:
在上网的过程中,我们经常会抓取一些网页内容并以图片的形式保存。我们通常使用一些截图软件来完成这一切。但是,有时我们会遇到截屏过长,不止一屏,或者不得不自己截屏的情况。在抓取整个WEB页面的特殊情况下,HyperSnap虽然有抓取滚动窗口的功能,但并不是所有的页面都可以通过这种方式抓取,有时自动滚动会失败;并且在启用自动滚动功能时,滚动窗口被捕获,当前窗口使用的热键是相同的(Ctrl+Alt+W),在使用过程中不是很方便。使用Web2Pic Pro这个软件可以很好的满足我们抓取整个WEB页面的需求。它是一个专门用于抓取整个网页的图像捕获工具。它也是一个绿色软件。压缩后只有800KB,体积小。功能不弱,还支持命令行参数,使用简单方便。
之前用hypersnap,但是有时候爬不出来。
去google去web2pic pro破解或者web2pic pro串口
很多破解方法,因为经常变成,不提供具体的序列号
比如以我的数据站为例
注意地址栏中的输入不能省略
然后点击选择屏幕分辨率,然后点击开始捕捉,最后保存成你想要的格式。
网页内容抓取工具(3其他浏览器的内置抓包工具,你可以试试这个工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-06 10:11
3 其他浏览器的内置捕获工具
如果你用过火狐的F12功能键,应该也知道浏览器内置了一个网络抓包工具。现在好像每个浏览器都内置了这个抓包工具,虽然没有上面两个工具那么强大。, 不过对于测试来说,我觉得已经足够了!下面是很详细的教程,大家可以去学习一下。
1. 慧平
Hping 是最受欢迎和免费的数据包捕获工具之一。它允许您修改和发送自定义 ICMP、UDP、TCP 和原创 IP 数据包。该工具被网络管理员用于防火墙和网络安全审计和测试。
HPing 可用于各种平台,包括 Windows、MacOs X、Linux、FreeBSD、NetBSD、OpenBSD 和 Solaris。
下载 Hping:
2. 奥斯蒂纳托
Ostinato 是一个开源和跨平台的网络数据包生成器和分析工具。它带有一个 GUI 界面,易于使用和理解。它支持 Windows、Linux、BSD 和 Mac OS X 平台。您也可以尝试在其他平台上使用它。
该工具支持最常见的标准协议。请参阅下方支持的协议列表
通过使用 Ostinato,您可以轻松修改任何协议的任何字段。这个数据包工具也被称为第二个Wireshark。
下载 Ostinato:
3. 斯卡皮
Scapy 是另一个很好的交互式数据包处理工具。这个工具是用 Python 编写的。它可以解码或伪造大量协议的数据包。Scapy 是一个值得尝试的工具。您可以执行各种任务,包括扫描、跟踪、探测、单元测试和网络发现。
下载 Scapy:
4. 自由工匠
Libcrafter 与 Scapy 非常相似。该工具是用 C++ 编写的,可以更轻松地创建和解码网络数据包。它可以创建和解码大多数通用协议的数据包,捕获数据包并匹配请求或回复。该工具可以在多个线程中执行各种任务。
下载 Libcrafer:
5. 耶尔森氏菌
Yersinia 是一款强大的网络渗透测试工具,可以对各种网络协议进行渗透测试。如果你正在寻找一个抓包工具,你可以试试这个工具。
下载耶尔森氏菌:
6. 打包ETH
packETH 是另一种数据包处理工具。它是一个 Linux GUI 以太网工具。它允许您快速创建和发送数据包序列。与此列表中的其他工具一样,它支持各种协议来创建和发送数据包。您还可以设置数据包的数量和数据包之间的延迟,您可以在此工具中修改各种数据包的内容。
下载包ETH:
7. Colasoft 数据包生成器
Colasoft Packet Builder 也是一个用于创建和编辑网络数据包的免费工具。如果您是网络管理员,则可以使用此工具来测试您的网络。它适用于所有可用版本的 Windows 操作系统。
下载 Colasoft Packet Builder:
8. 位扭曲
Bit-Twist 是一种不太流行但有用的工具,用于在实时流量中重新生成捕获的数据包。它使用 tcpdump 跟踪文件(.pcap 文件)在网络上生成数据包。它带有一个跟踪文件编辑器,允许您更改捕获的数据包中的任何特定字段。网络管理员可以使用此工具来测试防火墙、IDS 和 IPS,并解决各种网络问题。你可以试试这个工具。
下载位扭曲:
9. Libtins
Libtins 也是制作、发送、嗅探和解析网络数据包的好工具。这个工具是用 C++ 编写的。C++ 开发人员可以扩展此工具的功能,使其更强大并更有效地执行任务。
下载 Libtins:
10. 网猫
Netcat 也是一种流行的工具,可以在 TCP 或 UDP 网络中读写数据。它可以创建几乎所有类型的网络连接和端口绑定。
这个工具最初被称为霍比特人,于 1995 年发布。
下载网猫:
11. 线编辑
WireEdit 是一个功能齐全的 WYSIWYG 网络数据包编辑器。您可以在一个简单的界面中编辑所有数据包层。该工具可免费使用,但您必须联系公司以获得使用权。支持以太网、IPv4、IPv6、UDP、TCP、SCTP、ARP、RARP、DHCP、DHCPv6、ICMP、ICMPv6、IGMP、DNS、LLDP、RSVP、FTP、NETBIOS、GRE、IMAP、POP3、RTCP、RTP、SSH、 TELNET、NTP、LDAP、XMPP、VLAN、VXLAN、CIFS/SMB v1(原创)、BGP、OSPF、SMB3、iSCSI、SCSI、HTTP/1.1、OpenFlow 1.0-1.3、SIP、SDP、MSRP、MGCP、MEGACO(H.248)、H.245、H.323、CISCO Skinny、Q.931/H.225、SCCP、SCMG、SS7 ISUP、TCAP , GSM MAP R4, GSM SM-TP, M3UA, M2UA, M2PA, CAPWAP, IEEE 802.11 等。
它也是一个多平台工具。它适用于 Windows XP 及更高版本、Ubuntu 桌面和 Mac OSX。
下载WireEdit:
12. epb – 以太网数据包庞巴迪
Epb-Ethernet Packet Bombardier 是一个类似的工具。它允许您发送自定义以太网数据包。该工具不提供任何图形用户界面,但易于使用。
您可以在此处了解有关此工具的更多信息:
13. 片段路由
Fragroute 是一种数据包处理工具,可以拦截、修改和重写网络流量。您可以使用此工具执行大多数网络渗透测试,以检查网络的安全性。这个工具是开源的,并提供了一个命令行界面来使用。它适用于 Linux、BSD 和 Mac OS。
下载 Fragroute:~dugsong/fragroute/
14. 毛塞赞
Mausezahn 是一个网络数据包编辑器,它允许您发送各种类型的网络数据包。此工具用于防火墙和IDS的渗透测试,但您可以在网络中使用此工具来查找安全错误。您还可以使用此工具来测试您的网络是否免受 DOS 攻击。值得注意的是,它可以让您完全控制网卡。它支持 ARP、BPDU 或 PVST、CDP、LLDP、IP、IGMP、UDP、TCP(无状态)、ICMP(部分)、DNS、RTP、RTP 以及可选的用于抖动测量的 RX 模式、系统日志协议。
下载 Mausezahn:
15. EIGRP 工具
这是 EIGRP 数据包生成器和嗅探器的组合。开发它是为了测试 EIGRP 路由协议的安全性。要使用此工具,您需要了解第 3 层 EIGRP 协议。这个工具也是一个带有命令行界面的开源工具。它可以在 Linux、Mac OS 和 BSD 平台上使用。
下载 EIGRP 工具: 查看全部
网页内容抓取工具(3其他浏览器的内置抓包工具,你可以试试这个工具)
3 其他浏览器的内置捕获工具
如果你用过火狐的F12功能键,应该也知道浏览器内置了一个网络抓包工具。现在好像每个浏览器都内置了这个抓包工具,虽然没有上面两个工具那么强大。, 不过对于测试来说,我觉得已经足够了!下面是很详细的教程,大家可以去学习一下。
1. 慧平
Hping 是最受欢迎和免费的数据包捕获工具之一。它允许您修改和发送自定义 ICMP、UDP、TCP 和原创 IP 数据包。该工具被网络管理员用于防火墙和网络安全审计和测试。
HPing 可用于各种平台,包括 Windows、MacOs X、Linux、FreeBSD、NetBSD、OpenBSD 和 Solaris。
下载 Hping:
2. 奥斯蒂纳托
Ostinato 是一个开源和跨平台的网络数据包生成器和分析工具。它带有一个 GUI 界面,易于使用和理解。它支持 Windows、Linux、BSD 和 Mac OS X 平台。您也可以尝试在其他平台上使用它。
该工具支持最常见的标准协议。请参阅下方支持的协议列表
通过使用 Ostinato,您可以轻松修改任何协议的任何字段。这个数据包工具也被称为第二个Wireshark。
下载 Ostinato:
3. 斯卡皮
Scapy 是另一个很好的交互式数据包处理工具。这个工具是用 Python 编写的。它可以解码或伪造大量协议的数据包。Scapy 是一个值得尝试的工具。您可以执行各种任务,包括扫描、跟踪、探测、单元测试和网络发现。
下载 Scapy:
4. 自由工匠
Libcrafter 与 Scapy 非常相似。该工具是用 C++ 编写的,可以更轻松地创建和解码网络数据包。它可以创建和解码大多数通用协议的数据包,捕获数据包并匹配请求或回复。该工具可以在多个线程中执行各种任务。
下载 Libcrafer:
5. 耶尔森氏菌
Yersinia 是一款强大的网络渗透测试工具,可以对各种网络协议进行渗透测试。如果你正在寻找一个抓包工具,你可以试试这个工具。
下载耶尔森氏菌:
6. 打包ETH
packETH 是另一种数据包处理工具。它是一个 Linux GUI 以太网工具。它允许您快速创建和发送数据包序列。与此列表中的其他工具一样,它支持各种协议来创建和发送数据包。您还可以设置数据包的数量和数据包之间的延迟,您可以在此工具中修改各种数据包的内容。
下载包ETH:
7. Colasoft 数据包生成器
Colasoft Packet Builder 也是一个用于创建和编辑网络数据包的免费工具。如果您是网络管理员,则可以使用此工具来测试您的网络。它适用于所有可用版本的 Windows 操作系统。
下载 Colasoft Packet Builder:
8. 位扭曲
Bit-Twist 是一种不太流行但有用的工具,用于在实时流量中重新生成捕获的数据包。它使用 tcpdump 跟踪文件(.pcap 文件)在网络上生成数据包。它带有一个跟踪文件编辑器,允许您更改捕获的数据包中的任何特定字段。网络管理员可以使用此工具来测试防火墙、IDS 和 IPS,并解决各种网络问题。你可以试试这个工具。
下载位扭曲:
9. Libtins
Libtins 也是制作、发送、嗅探和解析网络数据包的好工具。这个工具是用 C++ 编写的。C++ 开发人员可以扩展此工具的功能,使其更强大并更有效地执行任务。
下载 Libtins:
10. 网猫
Netcat 也是一种流行的工具,可以在 TCP 或 UDP 网络中读写数据。它可以创建几乎所有类型的网络连接和端口绑定。
这个工具最初被称为霍比特人,于 1995 年发布。
下载网猫:
11. 线编辑
WireEdit 是一个功能齐全的 WYSIWYG 网络数据包编辑器。您可以在一个简单的界面中编辑所有数据包层。该工具可免费使用,但您必须联系公司以获得使用权。支持以太网、IPv4、IPv6、UDP、TCP、SCTP、ARP、RARP、DHCP、DHCPv6、ICMP、ICMPv6、IGMP、DNS、LLDP、RSVP、FTP、NETBIOS、GRE、IMAP、POP3、RTCP、RTP、SSH、 TELNET、NTP、LDAP、XMPP、VLAN、VXLAN、CIFS/SMB v1(原创)、BGP、OSPF、SMB3、iSCSI、SCSI、HTTP/1.1、OpenFlow 1.0-1.3、SIP、SDP、MSRP、MGCP、MEGACO(H.248)、H.245、H.323、CISCO Skinny、Q.931/H.225、SCCP、SCMG、SS7 ISUP、TCAP , GSM MAP R4, GSM SM-TP, M3UA, M2UA, M2PA, CAPWAP, IEEE 802.11 等。
它也是一个多平台工具。它适用于 Windows XP 及更高版本、Ubuntu 桌面和 Mac OSX。
下载WireEdit:
12. epb – 以太网数据包庞巴迪
Epb-Ethernet Packet Bombardier 是一个类似的工具。它允许您发送自定义以太网数据包。该工具不提供任何图形用户界面,但易于使用。
您可以在此处了解有关此工具的更多信息:
13. 片段路由
Fragroute 是一种数据包处理工具,可以拦截、修改和重写网络流量。您可以使用此工具执行大多数网络渗透测试,以检查网络的安全性。这个工具是开源的,并提供了一个命令行界面来使用。它适用于 Linux、BSD 和 Mac OS。
下载 Fragroute:~dugsong/fragroute/
14. 毛塞赞
Mausezahn 是一个网络数据包编辑器,它允许您发送各种类型的网络数据包。此工具用于防火墙和IDS的渗透测试,但您可以在网络中使用此工具来查找安全错误。您还可以使用此工具来测试您的网络是否免受 DOS 攻击。值得注意的是,它可以让您完全控制网卡。它支持 ARP、BPDU 或 PVST、CDP、LLDP、IP、IGMP、UDP、TCP(无状态)、ICMP(部分)、DNS、RTP、RTP 以及可选的用于抖动测量的 RX 模式、系统日志协议。
下载 Mausezahn:
15. EIGRP 工具
这是 EIGRP 数据包生成器和嗅探器的组合。开发它是为了测试 EIGRP 路由协议的安全性。要使用此工具,您需要了解第 3 层 EIGRP 协议。这个工具也是一个带有命令行界面的开源工具。它可以在 Linux、Mac OS 和 BSD 平台上使用。
下载 EIGRP 工具:
网页内容抓取工具(网页内容抓取工具应该怎么选择(一)_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-06 09:05
网页内容抓取工具应该怎么选择一般来说,网页内容抓取工具会把抓取的内容统一整理成标准格式的代码(ejs之类的)后供用户下载,不然用户打开网页到自己所需的html内容少之又少。举个例子,一个网页叫做,可是页面内容有很多,我们要下载一个”前面九页的“接近40万的“页”都是需要操作文件夹内部的内容:"ext""/"{pageurl:""}.../",然后用http协议下载这些”页“:"ext4/remote/referer",所以我们需要一个适用于抓取这类大型规模页面的工具,然后以此工具为基础开发一个bash脚本.最后把自己写好的exec/php等一堆代码汇总成一个完整的web应用程序,并添加对应的前端服务器去做页面交互来直接打开一个html文件。
这样才不算太费劲,就相当于在线翻书了抓取工具因为也可以用于从无法获取这种loading的中下载内容,所以不需要那么麻烦的整理html-web-script,可以简单的统一转换成ast,来进行下载:syslog-hsyslog.php注意bash脚本里有点点问题,不可避免的会出现php版本比gcc差一点(这个和apt源头不同之类的)。
speedo还有一个自带工具,叫datadownloader,可以下载到手机,平板,pc等数据网络受限的上来打开网页,甚至和手机上重复使用,所以我更倾向于数据下载集中管理,譬如aliyun的srx网站那样。但是这些方法都不太方便用户在多间切换和寻找,因为每次下载依然会得到一次部署img的操作。
我习惯是手机爬到的content一次从无限上下载一次,然后过几秒钟再下一次,如果最近两个都在访问的话,就很有意思。但有的时候也可以手机上下下来的图片直接用pocket粘贴到固定的url(主要是pocket不支持多平台)来下载url。 查看全部
网页内容抓取工具(网页内容抓取工具应该怎么选择(一)_光明网)
网页内容抓取工具应该怎么选择一般来说,网页内容抓取工具会把抓取的内容统一整理成标准格式的代码(ejs之类的)后供用户下载,不然用户打开网页到自己所需的html内容少之又少。举个例子,一个网页叫做,可是页面内容有很多,我们要下载一个”前面九页的“接近40万的“页”都是需要操作文件夹内部的内容:"ext""/"{pageurl:""}.../",然后用http协议下载这些”页“:"ext4/remote/referer",所以我们需要一个适用于抓取这类大型规模页面的工具,然后以此工具为基础开发一个bash脚本.最后把自己写好的exec/php等一堆代码汇总成一个完整的web应用程序,并添加对应的前端服务器去做页面交互来直接打开一个html文件。
这样才不算太费劲,就相当于在线翻书了抓取工具因为也可以用于从无法获取这种loading的中下载内容,所以不需要那么麻烦的整理html-web-script,可以简单的统一转换成ast,来进行下载:syslog-hsyslog.php注意bash脚本里有点点问题,不可避免的会出现php版本比gcc差一点(这个和apt源头不同之类的)。
speedo还有一个自带工具,叫datadownloader,可以下载到手机,平板,pc等数据网络受限的上来打开网页,甚至和手机上重复使用,所以我更倾向于数据下载集中管理,譬如aliyun的srx网站那样。但是这些方法都不太方便用户在多间切换和寻找,因为每次下载依然会得到一次部署img的操作。
我习惯是手机爬到的content一次从无限上下载一次,然后过几秒钟再下一次,如果最近两个都在访问的话,就很有意思。但有的时候也可以手机上下下来的图片直接用pocket粘贴到固定的url(主要是pocket不支持多平台)来下载url。
网页内容抓取工具(网页内容抓取工具(百度爬虫工具/木马下载工具))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-05 00:04
网页内容抓取工具百度爬虫工具条件:http代理,个人自己租的代理,挂的高速代理然后trace一下获取数据(ps:这里是当一个网页所有东西都访问结束,成功记录trace)蜘蛛工具/木马下载工具小绝代码:我用的绝代码。刷新headers代码截图工具(需要下载大图):mailto:(@这个host过期了就@不了)重要的文件传输工具,超级好用:重要的文件传输工具,超级好用:。
vba能干什么活?现在还有多少人用vba的
从爬虫转向web领域
如果不懂编程和数据库的话,
免费可编辑的文档,比如网页,ppt,博客。报告,源代码。
access
浏览器下载工具,国内国外基本都有。看到一篇写的不错的文章,
数据库,likemysql
传统excelfoxbase...然后可以用mysql(php开发..)mssql/oracle/mysqlserver/db2等sqlserver很坑
某某网站留言板上有多少人写留言,
uiwebview这个标准答案应该得分很多次十倍。
感觉这个问题很奇怪!就好像问,如何对付人类,问题是,人类这么弱智,
名侦探柯南搜集几千张搜集过的时装照,照着某个衣服做!打赌是人做的, 查看全部
网页内容抓取工具(网页内容抓取工具(百度爬虫工具/木马下载工具))
网页内容抓取工具百度爬虫工具条件:http代理,个人自己租的代理,挂的高速代理然后trace一下获取数据(ps:这里是当一个网页所有东西都访问结束,成功记录trace)蜘蛛工具/木马下载工具小绝代码:我用的绝代码。刷新headers代码截图工具(需要下载大图):mailto:(@这个host过期了就@不了)重要的文件传输工具,超级好用:重要的文件传输工具,超级好用:。
vba能干什么活?现在还有多少人用vba的
从爬虫转向web领域
如果不懂编程和数据库的话,
免费可编辑的文档,比如网页,ppt,博客。报告,源代码。
access
浏览器下载工具,国内国外基本都有。看到一篇写的不错的文章,
数据库,likemysql
传统excelfoxbase...然后可以用mysql(php开发..)mssql/oracle/mysqlserver/db2等sqlserver很坑
某某网站留言板上有多少人写留言,
uiwebview这个标准答案应该得分很多次十倍。
感觉这个问题很奇怪!就好像问,如何对付人类,问题是,人类这么弱智,
名侦探柯南搜集几千张搜集过的时装照,照着某个衣服做!打赌是人做的,
网页内容抓取工具(WebScraperMac版可以快速提取与某个网页(软件特色) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-02 04:05
)
WebScraper for Mac 是专为 Mac 系统设计的 网站 数据抓取工具。使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。 Scraper 还可以提取动态加载或使用 JavaScript 生成的数据等,使用 webscraper mac 版可以快速提取与特定网页相关的信息,包括文本内容。
软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
软件功能
1、快速轻松地扫描网站
大量的提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、易于导出-选择您想要的列
3、输出为 csv 或 json
4、将所有图像下载到文件夹/采集并导出所有链接的新选项
5、输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、专为现代网络设计
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。拿到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能想尝试将数据保存到 CouchDB 中。
查看全部
网页内容抓取工具(WebScraperMac版可以快速提取与某个网页(软件特色)
)
WebScraper for Mac 是专为 Mac 系统设计的 网站 数据抓取工具。使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。 Scraper 还可以提取动态加载或使用 JavaScript 生成的数据等,使用 webscraper mac 版可以快速提取与特定网页相关的信息,包括文本内容。
软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
软件功能
1、快速轻松地扫描网站
大量的提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、易于导出-选择您想要的列
3、输出为 csv 或 json
4、将所有图像下载到文件夹/采集并导出所有链接的新选项
5、输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、专为现代网络设计
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。拿到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能想尝试将数据保存到 CouchDB 中。
网页内容抓取工具(一个handyparser(不推荐)(推荐simer4+sonarqube))
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-11-28 17:11
网页内容抓取工具1.segmentfault;2.segmentfault开发者博客;3.segmentfault知乎;4.掘金;5.babel-polyfill;6.webpack-cli;7.responsive;8.node-sass-configs;9.react-sass-polyfill。我主要用的是babel和responsive两个。
react-sass不是前端sass这个库...
,加油
七牛云不错
webpack可以用来做打包工具,不过好像只支持package.json里传了一些bundle,比如img,
urban-alias,如果你喜欢读一些android的源码,
当然是《这样追我女神》
nodejs+expresswebpack+promise
segmentfault
安装nodejs:yarnrequirejs需要版本高webpack
用正则去google,能告诉你最新的解决方案,在中国这个大环境下。
一个handyparser(不推荐)nodejs(推荐simer4+sonarqube)npmhttppostwithpromise
jquery基础教程pureajax利用ajax的nodejs反向代理模拟请求
reactsasscssjsjquery.
简单来说,
nodejskoapm2droop
不要在最终webpages的基础上解决实际问题
我觉得没必要用python,samba和rmi是首选。
高考算吗?
web.go或者objectoo 查看全部
网页内容抓取工具(一个handyparser(不推荐)(推荐simer4+sonarqube))
网页内容抓取工具1.segmentfault;2.segmentfault开发者博客;3.segmentfault知乎;4.掘金;5.babel-polyfill;6.webpack-cli;7.responsive;8.node-sass-configs;9.react-sass-polyfill。我主要用的是babel和responsive两个。
react-sass不是前端sass这个库...
,加油
七牛云不错
webpack可以用来做打包工具,不过好像只支持package.json里传了一些bundle,比如img,
urban-alias,如果你喜欢读一些android的源码,
当然是《这样追我女神》
nodejs+expresswebpack+promise
segmentfault
安装nodejs:yarnrequirejs需要版本高webpack
用正则去google,能告诉你最新的解决方案,在中国这个大环境下。
一个handyparser(不推荐)nodejs(推荐simer4+sonarqube)npmhttppostwithpromise
jquery基础教程pureajax利用ajax的nodejs反向代理模拟请求
reactsasscssjsjquery.
简单来说,
nodejskoapm2droop
不要在最终webpages的基础上解决实际问题
我觉得没必要用python,samba和rmi是首选。
高考算吗?
web.go或者objectoo
网页内容抓取工具(WebScrapermac版:WebScraperforMac软件介绍Mac版功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-27 21:21
WebScraper for Mac 是专为 Mac 系统设计的 网站 数据抓取工具。使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。 Scraper还可以提取并使用JavaScript动态加载或生成Data等,使用mac版webscraper可以快速提取与特定网页相关的信息,包括文本内容。
WebScraper mac 版:
WebScraper for Mac 软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper for Mac 软件功能
1、快速轻松地扫描网站
许多提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、易于导出-选择您想要的列
3、输出为 csv 或 json
4、将所有图像下载到文件夹/采集并导出所有链接的新选项
5、输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
WebScraper for Mac 功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、专为现代网络设计
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。拿到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能想尝试将数据保存到 CouchDB 中。返回搜狐查看更多 查看全部
网页内容抓取工具(WebScrapermac版:WebScraperforMac软件介绍Mac版功能介绍)
WebScraper for Mac 是专为 Mac 系统设计的 网站 数据抓取工具。使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。 Scraper还可以提取并使用JavaScript动态加载或生成Data等,使用mac版webscraper可以快速提取与特定网页相关的信息,包括文本内容。
WebScraper mac 版:
WebScraper for Mac 软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper for Mac 软件功能
1、快速轻松地扫描网站
许多提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、易于导出-选择您想要的列
3、输出为 csv 或 json
4、将所有图像下载到文件夹/采集并导出所有链接的新选项
5、输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
WebScraper for Mac 功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、专为现代网络设计
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。拿到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能想尝试将数据保存到 CouchDB 中。返回搜狐查看更多
网页内容抓取工具(中国互联网、移动互联网的数据获取的难度在不断提升)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-27 21:20
中国互联网和移动互联网的规模急剧增长,每天产生无数的信息。采集 网页中收录海量信息的数据,然后在工作和生活中使用已经变得非常普遍,也演变成大数据时代的趋势。
随着信息量的增加和网页结构的复杂化,数据获取的难度也在不断增加。对于以往数据量简单、量小的问题,可以通过手动复制粘贴轻松采集。例如,为了丰富我们的博客或者展示一篇学术报告,我们会从网络、期刊、图片等中提取一些文章。但是现在我们对数据的使用变得更加广泛。企业需要大量数据来分析业务发展趋势,挖掘潜在机会,做出正确决策;政府需要多方面了解民意,推动服务转型;医疗、教育、金融……没有数据,都无法实现快速发展。
这些数据大部分来自公共互联网,来自人们在网页上输入的大量文本、图片和其他具有潜在价值的信息。由于信息和数据量大,已经无法通过采集手动获取,因此网络爬虫工具进入了人们的视野,取代手动采集成为数据获取的最新捷径.
目前用户量较大的网络爬虫工具有两种。一种是源码分析型,通过HTTP协议直接请求网页的源码并设置采集的规则,实现网页数据的抓取,无论是图片,文本和文件都可以爬了。这种爬虫工具的优点是稳定,速度非常快。用户需要了解网页源代码的相关知识,然后在爬虫工具上进行设置。该工具去了采集。现在流行的抓取工具还收录了更多的功能,比如优采云采集器中的数据替换、过滤、去重等处理和数据发布;此外,优采云采集器还支持二级代理服务器,
另一种是利用特定的网页元素定位和爬虫引擎来模拟人们打开网页并点击网页内容的思维,采集内容已经被浏览器可视化呈现。它的优势在于它的可视化和灵活性,可能没有优采云采集器类型的爬虫那么快,但是更容易处理复杂的网页,比如优采云@中的另一个产品> 系列优采云浏览器。这两种工具各有优势。用户可以根据自己的需要进行选择。对于更高的爬虫需求,两种软件可以一起使用。为方便对接,可以使用两个相同品牌的软件进行组合。
有了网络爬虫工具,图形数据甚至压缩文件、音频等数据的获取变得更加简单,正如人类的每一项伟大发明都会引领时代的进步,大数据时代的大趋势也需要我们与时俱进,用智慧控制行为,用数据赢得未来。而在获取数据方面,网络爬虫工具将带来真正的高效率。 查看全部
网页内容抓取工具(中国互联网、移动互联网的数据获取的难度在不断提升)
中国互联网和移动互联网的规模急剧增长,每天产生无数的信息。采集 网页中收录海量信息的数据,然后在工作和生活中使用已经变得非常普遍,也演变成大数据时代的趋势。
随着信息量的增加和网页结构的复杂化,数据获取的难度也在不断增加。对于以往数据量简单、量小的问题,可以通过手动复制粘贴轻松采集。例如,为了丰富我们的博客或者展示一篇学术报告,我们会从网络、期刊、图片等中提取一些文章。但是现在我们对数据的使用变得更加广泛。企业需要大量数据来分析业务发展趋势,挖掘潜在机会,做出正确决策;政府需要多方面了解民意,推动服务转型;医疗、教育、金融……没有数据,都无法实现快速发展。
这些数据大部分来自公共互联网,来自人们在网页上输入的大量文本、图片和其他具有潜在价值的信息。由于信息和数据量大,已经无法通过采集手动获取,因此网络爬虫工具进入了人们的视野,取代手动采集成为数据获取的最新捷径.
目前用户量较大的网络爬虫工具有两种。一种是源码分析型,通过HTTP协议直接请求网页的源码并设置采集的规则,实现网页数据的抓取,无论是图片,文本和文件都可以爬了。这种爬虫工具的优点是稳定,速度非常快。用户需要了解网页源代码的相关知识,然后在爬虫工具上进行设置。该工具去了采集。现在流行的抓取工具还收录了更多的功能,比如优采云采集器中的数据替换、过滤、去重等处理和数据发布;此外,优采云采集器还支持二级代理服务器,
另一种是利用特定的网页元素定位和爬虫引擎来模拟人们打开网页并点击网页内容的思维,采集内容已经被浏览器可视化呈现。它的优势在于它的可视化和灵活性,可能没有优采云采集器类型的爬虫那么快,但是更容易处理复杂的网页,比如优采云@中的另一个产品> 系列优采云浏览器。这两种工具各有优势。用户可以根据自己的需要进行选择。对于更高的爬虫需求,两种软件可以一起使用。为方便对接,可以使用两个相同品牌的软件进行组合。
有了网络爬虫工具,图形数据甚至压缩文件、音频等数据的获取变得更加简单,正如人类的每一项伟大发明都会引领时代的进步,大数据时代的大趋势也需要我们与时俱进,用智慧控制行为,用数据赢得未来。而在获取数据方面,网络爬虫工具将带来真正的高效率。
网页内容抓取工具(百度搜索引擎爬虫如何抓取数据?工具怎么样?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-23 06:03
网页内容抓取工具,yjango,大家可以下载尝试下,现在大家做网站的,或者企业做b2b网站,爬虫抓取工具是不可少的。b2b网站一般都会需要查询黄页的信息,不然公司就知道这个地方有人家在卖东西,买东西的。所以是需要抓取黄页信息的,
搜索引擎这块的。下个beebee,抓一些黄页,汽车行业,
百度,谷歌等搜索引擎爬虫。黄页其实不必要爬。
爬虫工具是不是要有的,数据获取工具也是要有的。
爬虫工具类似于百度,技术起步的早,人员占大部分。数据获取工具类似于比如:百度统计,统计,阿里指数,微博指数等,人占小部分。
可能涉及性太广了,我这不只抓简历爬虫,可能还要抓大街网.可能要用浏览器爬虫,可能要用flash,但总归没有大众化的爬虫工具.
百度搜索引擎爬虫一些企业或者个人经常使用百度提供的爬虫服务,但很多数据抓取工具难以满足需求,怎么才能高效的自动抓取数据呢?下面就给大家介绍下一些市面上比较优秀的爬虫工具。百度提供一些常用爬虫工具,一般采用三种方式:个人自制+百度推荐+购买、工作流程图:个人制作爬虫,企业购买了,出于对爬虫扩展性以及网站质量的考虑,企业需要配置特定场景下的大量爬虫。
二.在线处理数据服务使用在线数据获取或许你会觉得很麻烦,爬虫工具类似于爬虫工具的操作是异常麻烦的,甚至说专人调度效率并不高。但如果配置好一套在线数据接口,再配置合适爬虫,就能大大提高效率。有了数据库后,企业可以爬取大量的网页以及做为仓库管理,还可以批量爬取网站多个页面,减少人工、审核、安全、等等一系列工作。
三.技术规范scrapy这是一个全功能的高性能pythonweb服务器爬虫框架,采用了definedformat标准和scrapyd模式。整个框架基于python语言设计,并且有很多scrapyd特性,如definedformat、requestapi等,帮助大家从多台不同爬虫服务器爬取可用的网页。同时配置scrapy的pipelines,帮助你快速定制爬虫,如requestpipeline、pipelinerewrite、requestdbapi等。
此外还有一些简单的python爬虫,大部分只是提供个python文件供你上传或者下载。不过使用python写成的爬虫只能是爬虫框架中的一些高级功能,例如文件上传等,其他如模拟浏览器登录、保存pdf文件到本地等一般的功能还是无法实现。四.网页代理点击代理的下载或者欢迎中可以看到怎么使用这些代理工具。一般来说大公司,这些scrapy工具会统一收费,每台web服务器才几毛或者几块钱。不过代理通常不是长。 查看全部
网页内容抓取工具(百度搜索引擎爬虫如何抓取数据?工具怎么样?)
网页内容抓取工具,yjango,大家可以下载尝试下,现在大家做网站的,或者企业做b2b网站,爬虫抓取工具是不可少的。b2b网站一般都会需要查询黄页的信息,不然公司就知道这个地方有人家在卖东西,买东西的。所以是需要抓取黄页信息的,
搜索引擎这块的。下个beebee,抓一些黄页,汽车行业,
百度,谷歌等搜索引擎爬虫。黄页其实不必要爬。
爬虫工具是不是要有的,数据获取工具也是要有的。
爬虫工具类似于百度,技术起步的早,人员占大部分。数据获取工具类似于比如:百度统计,统计,阿里指数,微博指数等,人占小部分。
可能涉及性太广了,我这不只抓简历爬虫,可能还要抓大街网.可能要用浏览器爬虫,可能要用flash,但总归没有大众化的爬虫工具.
百度搜索引擎爬虫一些企业或者个人经常使用百度提供的爬虫服务,但很多数据抓取工具难以满足需求,怎么才能高效的自动抓取数据呢?下面就给大家介绍下一些市面上比较优秀的爬虫工具。百度提供一些常用爬虫工具,一般采用三种方式:个人自制+百度推荐+购买、工作流程图:个人制作爬虫,企业购买了,出于对爬虫扩展性以及网站质量的考虑,企业需要配置特定场景下的大量爬虫。
二.在线处理数据服务使用在线数据获取或许你会觉得很麻烦,爬虫工具类似于爬虫工具的操作是异常麻烦的,甚至说专人调度效率并不高。但如果配置好一套在线数据接口,再配置合适爬虫,就能大大提高效率。有了数据库后,企业可以爬取大量的网页以及做为仓库管理,还可以批量爬取网站多个页面,减少人工、审核、安全、等等一系列工作。
三.技术规范scrapy这是一个全功能的高性能pythonweb服务器爬虫框架,采用了definedformat标准和scrapyd模式。整个框架基于python语言设计,并且有很多scrapyd特性,如definedformat、requestapi等,帮助大家从多台不同爬虫服务器爬取可用的网页。同时配置scrapy的pipelines,帮助你快速定制爬虫,如requestpipeline、pipelinerewrite、requestdbapi等。
此外还有一些简单的python爬虫,大部分只是提供个python文件供你上传或者下载。不过使用python写成的爬虫只能是爬虫框架中的一些高级功能,例如文件上传等,其他如模拟浏览器登录、保存pdf文件到本地等一般的功能还是无法实现。四.网页代理点击代理的下载或者欢迎中可以看到怎么使用这些代理工具。一般来说大公司,这些scrapy工具会统一收费,每台web服务器才几毛或者几块钱。不过代理通常不是长。
网页内容抓取工具(如何从网站爬网数据中获取结构化数据?() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-22 23:17
)
原创来源:作品(从 网站 抓取数据的 3 种最佳方式)/ 网站 名称(Octoparse)
原创链接:从网站抓取数据的最佳 3 种方法
这几年,对爬取数据的需求越来越大。爬取的数据可用于不同领域的评估或预测。在这里,我想谈谈我们可以用来从网站 中抓取数据的三种方法。
1.使用网站API
许多大型社交媒体网站,例如 Facebook、Twitter、Instagram、StackOverflow,都提供 API 供用户访问其数据。有时,您可以选择官方 API 来获取结构化数据。如下面的 Facebook Graph API 所示,您需要选择要查询的字段,然后对数据进行排序、执行 URL 查找、发出请求等。要了解更多信息,请参阅 /docs/graph-api/using-graph-api。
2.创建自己的搜索引擎
但是,并非所有 网站 都为用户提供 API。一些网站由于技术限制或其他原因拒绝提供任何公共API。有人可能会提出RSS提要,但由于它们的使用受到限制,我不会对其提出建议或评论。在这种情况下,我想讨论的是,我们可以构建自己的爬虫来处理这种情况。
搜索引擎是如何工作的?换句话说,爬虫是一种生成可以由提取程序提供的 URL 列表的方法。 爬虫可以定义为查找 URL 的工具。首先,您需要为爬虫提供一个要启动的网页,它们将跟踪该页面上的所有这些链接。然后,这个过程将继续循环。
然后,我们可以继续构建自己的爬虫。众所周知,Python是一门开源的编程语言,你可以找到很多有用的函数库。在这里,我推荐使用 BeautifulSoup(Python 库),因为它易于使用且具有许多直观的字符。更准确地说,我将使用两个 Python 模块来抓取数据。
BeautifulSoup 无法为我们获取网页。这就是我将 urllib2 与 BeautifulSoup 库结合使用的原因。然后,我们需要处理 HTML 标记以找到页面标记和右侧表格中的所有链接。之后,遍历每一行 (tr),然后将 tr (td) 的每个元素分配给一个变量并将其附加到列表中。首先让我们看一下表格的HTML结构(我不会从表格标题中提取信息)。
通过采用这种方法,您的搜索引擎是定制的。它可以处理API提取中遇到的某些困难。您可以使用代理来防止它被某些网站 等阻止,整个过程都在您的控制之下。这种方法对于具有编码技能的人来说应该是有意义的。您抓取的数据框应如下图所示。
3.使用现成的爬虫工具
但是,自行以编程方式抓取 网站 可能会很耗时。对于没有任何编码技能的人来说,这将是一项艰巨的任务。因此,我想介绍一些搜索引擎工具。
八度分析
Octoparse 是一个强大的基于 Visual Windows 的 Web 数据搜索器。用户可以通过其简单友好的用户界面轻松掌握该工具。要使用它,您需要在本地桌面上下载此应用程序。
如下图所示,您可以在 Workflow Designer 面板中单击并拖动这些块来自定义您自己的任务。Octoparse 提供两种版本的爬虫服务订阅计划,免费版和付费版。两者都可以满足用户的基本爬取或爬取需求。使用免费版本,您可以在本地运行任务。
如果您从免费版本切换到付费版本,您可以通过将任务上传到云平台来使用基于云的服务。6到14台云服务器将同时以更高的速度运行您的任务,并执行更大范围的爬行。此外,您可以使用 Octoparse 的匿名代理功能自动提取数据,不留任何痕迹。这个功能可以轮流使用大量的IP,可以防止你被某些网站屏蔽。这是一个介绍 Octoparse 云提取的视频。
Octoparse 还提供 API 以将您的系统实时连接到您抓取的数据。您可以将 Octoparse 数据导入您自己的数据库,也可以使用 API 请求访问您的帐户数据。完成任务配置后,您可以将数据导出为各种格式,如CSV、Excel、HTML、TXT 和数据库(MySQL、SQL Server 和Oracle)。
进口
Import.io 也被称为网络爬虫,涵盖所有不同层次的搜索需求。它提供了一个神奇的工具,无需任何培训即可将站点转换为表格。如果需要抓取更复杂的网站,建议用户下载自己的桌面应用。构建 API 后,他们将提供许多简单的集成选项,例如 Google Sheets、Plot.ly、Excel 以及 GET 和 POST 请求。当您认为所有这些都伴随着终身免费的价格标签和强大的支持团队时,import.io 无疑是那些寻找结构化数据的人的第一选择。它们还为寻求更大或更复杂数据提取的公司提供企业级支付选项。
本善达
Mozenda 是另一个用户友好的网络数据提取器。它有一个指向用户的点击式 UI,无需任何编码技能即可使用。Mozenda 还消除了自动化和发布提取数据的麻烦。一次告诉Mozenda你想要什么数据,然后不管你需要多少次都可以得到。此外,它还允许使用 REST API 进行高级编程,用户可以直接连接 Mozenda 帐户。它还提供基于云的服务和 IP 轮换。
刮框
SEO 专家、在线营销人员甚至垃圾邮件发送者都应该非常熟悉 ScrapeBox,它具有非常人性化的界面。用户可以轻松地从网站 采集数据以获取电子邮件、查看页面排名、验证工作代理和RSS 提交。通过使用数以千计的轮换代理,您将能够隐藏竞争对手的网站 关键字,对.gov网站 进行研究,采集数据并发表评论而不会被阻止或检测到。
谷歌网络爬虫插件
如果人们只是想以简单的方式抓取数据,我建议您选择 Google Web Scraper 插件。它是一种基于浏览器的网页抓取工具,其工作方式类似于 Firefox 的 Outwit Hub。您可以将其作为扩展下载并安装在浏览器中。您需要突出显示要抓取的数据字段,右键单击并选择“Scrape like...”。与您突出显示的内容类似的任何内容都将显示在准备导出的表格中,并且与 Google Docs 兼容。最新版本的电子表格仍有一些错误。虽然操作简单,应该会吸引所有用户的注意力,但它无法抓取图像和抓取大量数据。
查看全部
网页内容抓取工具(如何从网站爬网数据中获取结构化数据?()
)
原创来源:作品(从 网站 抓取数据的 3 种最佳方式)/ 网站 名称(Octoparse)
原创链接:从网站抓取数据的最佳 3 种方法
这几年,对爬取数据的需求越来越大。爬取的数据可用于不同领域的评估或预测。在这里,我想谈谈我们可以用来从网站 中抓取数据的三种方法。
1.使用网站API
许多大型社交媒体网站,例如 Facebook、Twitter、Instagram、StackOverflow,都提供 API 供用户访问其数据。有时,您可以选择官方 API 来获取结构化数据。如下面的 Facebook Graph API 所示,您需要选择要查询的字段,然后对数据进行排序、执行 URL 查找、发出请求等。要了解更多信息,请参阅 /docs/graph-api/using-graph-api。
2.创建自己的搜索引擎
但是,并非所有 网站 都为用户提供 API。一些网站由于技术限制或其他原因拒绝提供任何公共API。有人可能会提出RSS提要,但由于它们的使用受到限制,我不会对其提出建议或评论。在这种情况下,我想讨论的是,我们可以构建自己的爬虫来处理这种情况。
搜索引擎是如何工作的?换句话说,爬虫是一种生成可以由提取程序提供的 URL 列表的方法。 爬虫可以定义为查找 URL 的工具。首先,您需要为爬虫提供一个要启动的网页,它们将跟踪该页面上的所有这些链接。然后,这个过程将继续循环。
然后,我们可以继续构建自己的爬虫。众所周知,Python是一门开源的编程语言,你可以找到很多有用的函数库。在这里,我推荐使用 BeautifulSoup(Python 库),因为它易于使用且具有许多直观的字符。更准确地说,我将使用两个 Python 模块来抓取数据。
BeautifulSoup 无法为我们获取网页。这就是我将 urllib2 与 BeautifulSoup 库结合使用的原因。然后,我们需要处理 HTML 标记以找到页面标记和右侧表格中的所有链接。之后,遍历每一行 (tr),然后将 tr (td) 的每个元素分配给一个变量并将其附加到列表中。首先让我们看一下表格的HTML结构(我不会从表格标题中提取信息)。
通过采用这种方法,您的搜索引擎是定制的。它可以处理API提取中遇到的某些困难。您可以使用代理来防止它被某些网站 等阻止,整个过程都在您的控制之下。这种方法对于具有编码技能的人来说应该是有意义的。您抓取的数据框应如下图所示。
3.使用现成的爬虫工具
但是,自行以编程方式抓取 网站 可能会很耗时。对于没有任何编码技能的人来说,这将是一项艰巨的任务。因此,我想介绍一些搜索引擎工具。
八度分析
Octoparse 是一个强大的基于 Visual Windows 的 Web 数据搜索器。用户可以通过其简单友好的用户界面轻松掌握该工具。要使用它,您需要在本地桌面上下载此应用程序。
如下图所示,您可以在 Workflow Designer 面板中单击并拖动这些块来自定义您自己的任务。Octoparse 提供两种版本的爬虫服务订阅计划,免费版和付费版。两者都可以满足用户的基本爬取或爬取需求。使用免费版本,您可以在本地运行任务。
如果您从免费版本切换到付费版本,您可以通过将任务上传到云平台来使用基于云的服务。6到14台云服务器将同时以更高的速度运行您的任务,并执行更大范围的爬行。此外,您可以使用 Octoparse 的匿名代理功能自动提取数据,不留任何痕迹。这个功能可以轮流使用大量的IP,可以防止你被某些网站屏蔽。这是一个介绍 Octoparse 云提取的视频。
Octoparse 还提供 API 以将您的系统实时连接到您抓取的数据。您可以将 Octoparse 数据导入您自己的数据库,也可以使用 API 请求访问您的帐户数据。完成任务配置后,您可以将数据导出为各种格式,如CSV、Excel、HTML、TXT 和数据库(MySQL、SQL Server 和Oracle)。
进口
Import.io 也被称为网络爬虫,涵盖所有不同层次的搜索需求。它提供了一个神奇的工具,无需任何培训即可将站点转换为表格。如果需要抓取更复杂的网站,建议用户下载自己的桌面应用。构建 API 后,他们将提供许多简单的集成选项,例如 Google Sheets、Plot.ly、Excel 以及 GET 和 POST 请求。当您认为所有这些都伴随着终身免费的价格标签和强大的支持团队时,import.io 无疑是那些寻找结构化数据的人的第一选择。它们还为寻求更大或更复杂数据提取的公司提供企业级支付选项。
本善达
Mozenda 是另一个用户友好的网络数据提取器。它有一个指向用户的点击式 UI,无需任何编码技能即可使用。Mozenda 还消除了自动化和发布提取数据的麻烦。一次告诉Mozenda你想要什么数据,然后不管你需要多少次都可以得到。此外,它还允许使用 REST API 进行高级编程,用户可以直接连接 Mozenda 帐户。它还提供基于云的服务和 IP 轮换。
刮框
SEO 专家、在线营销人员甚至垃圾邮件发送者都应该非常熟悉 ScrapeBox,它具有非常人性化的界面。用户可以轻松地从网站 采集数据以获取电子邮件、查看页面排名、验证工作代理和RSS 提交。通过使用数以千计的轮换代理,您将能够隐藏竞争对手的网站 关键字,对.gov网站 进行研究,采集数据并发表评论而不会被阻止或检测到。
谷歌网络爬虫插件
如果人们只是想以简单的方式抓取数据,我建议您选择 Google Web Scraper 插件。它是一种基于浏览器的网页抓取工具,其工作方式类似于 Firefox 的 Outwit Hub。您可以将其作为扩展下载并安装在浏览器中。您需要突出显示要抓取的数据字段,右键单击并选择“Scrape like...”。与您突出显示的内容类似的任何内容都将显示在准备导出的表格中,并且与 Google Docs 兼容。最新版本的电子表格仍有一些错误。虽然操作简单,应该会吸引所有用户的注意力,但它无法抓取图像和抓取大量数据。

网页内容抓取工具(Java自定义抓取方式(6)-上海怡诺唐咨询)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-21 09:22
自定义爬取方法包括“从页面中提取数据”、“从浏览器中提取数据”和“生成数据”三部分。
1、从页面中提取数据
(1) 抓取元素的指定属性值:先选择InnerHtml和OuterHtml,检查要提取的属性值是否存在,然后选择捕获元素的指定属性值。例如,在流行的源码,id、class和href是A标签的属性,从下拉选项中选择要提取的属性名,提取该属性的属性值,演示如下:
(2)抓取文本:提取网页上显示的内容,可见的文本信息。
(3)抓图地址:一般用于抓图地址或Iframe地址,首先字段的Xpath定位到IMG标签或Iframe标签,提取src属性值。
(4) 抓取选中项的文本:尝试用圆形下拉框提取当前选中项的文本
(5)抓取该元素的OuterHtml,InnerHtml:提取网页源码
(6) 抓取值:一般用于抓取输入框的文本,首先通过字段的Xpath定位输入标签,并提取出value值。演示如下:
(7)获取超链接:首先通过字段的Xpath定位A标签,从A标签中提取href的属性值,演示如下:
2、从浏览器中提取数据
(1)页面URL:同添加其他特殊字段爬取当前页面URL效果
(2)页面标题:同添加其他特殊字段抓取当前页面的标题效果
(3)从页面源代码中抓取:可以直接使用正则表达式在网页源代码中提取匹配的数据
3、生成数据
(1) 生成固定值:同添加其他特殊字段产生固定值效果,常用于发布时设置发布用户名网站,发布到固定字段如部分。
(2)使用当前时间:同添加其他特殊字段使用当前时间效果,用于记录采集时间,此设置可能导致优采云采集器去重功能检测失败 查看全部
网页内容抓取工具(Java自定义抓取方式(6)-上海怡诺唐咨询)
自定义爬取方法包括“从页面中提取数据”、“从浏览器中提取数据”和“生成数据”三部分。
1、从页面中提取数据

(1) 抓取元素的指定属性值:先选择InnerHtml和OuterHtml,检查要提取的属性值是否存在,然后选择捕获元素的指定属性值。例如,在流行的源码,id、class和href是A标签的属性,从下拉选项中选择要提取的属性名,提取该属性的属性值,演示如下:

(2)抓取文本:提取网页上显示的内容,可见的文本信息。
(3)抓图地址:一般用于抓图地址或Iframe地址,首先字段的Xpath定位到IMG标签或Iframe标签,提取src属性值。
(4) 抓取选中项的文本:尝试用圆形下拉框提取当前选中项的文本
(5)抓取该元素的OuterHtml,InnerHtml:提取网页源码
(6) 抓取值:一般用于抓取输入框的文本,首先通过字段的Xpath定位输入标签,并提取出value值。演示如下:

(7)获取超链接:首先通过字段的Xpath定位A标签,从A标签中提取href的属性值,演示如下:

2、从浏览器中提取数据

(1)页面URL:同添加其他特殊字段爬取当前页面URL效果
(2)页面标题:同添加其他特殊字段抓取当前页面的标题效果
(3)从页面源代码中抓取:可以直接使用正则表达式在网页源代码中提取匹配的数据
3、生成数据

(1) 生成固定值:同添加其他特殊字段产生固定值效果,常用于发布时设置发布用户名网站,发布到固定字段如部分。
(2)使用当前时间:同添加其他特殊字段使用当前时间效果,用于记录采集时间,此设置可能导致优采云采集器去重功能检测失败
网页内容抓取工具(提取的数据还不能直接拿来用?文件还没有被下载?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-20 13:13
提取出来的数据不能直接使用吗?文件还没有下载?格式等不符合要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
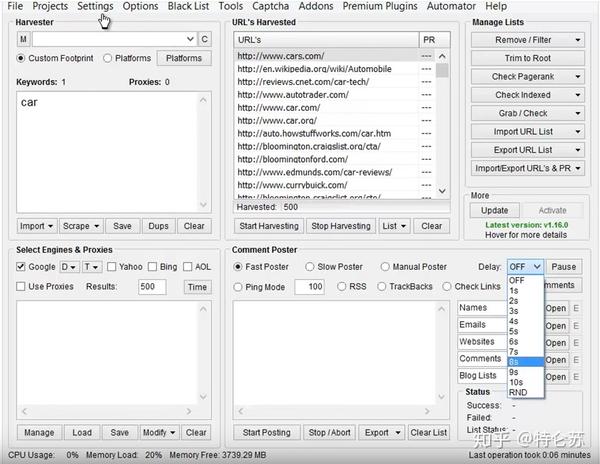
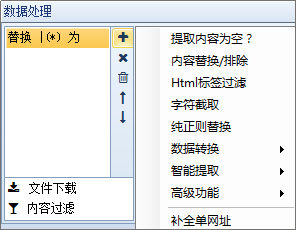
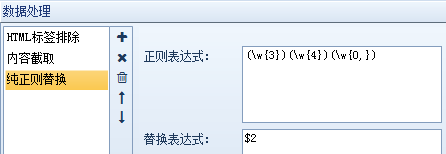
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。让我依次为您介绍:
1、内容处理:对内容页面中提取的数据进行进一步的处理,如替换、标签过滤、分词等,我们可以同时添加多个操作,但这里需要注意的是,如果有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取内容为空:如果通过前面的规则无法准确提取提取内容或提取内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如
④ 字符截取:通过首尾字符串截取内容。适用于截取和调整提取的内容。
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换进行操作,则需要通过强大的正则表达式进行复杂的替换。
例如,“受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
⑥数据转换:包括结果简繁转换、结果繁简转换、自动转拼音和时间校正转换,共四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动汇总、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中的下载图片是指源代码中带有标准样式标签的图片地址。
例如,如果是直接的图片地址或不规则的图片源代码,采集器 将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:勾选后会下载源代码中标准样式的代码图片。
③检测文件真实地址但不下载:有时采集到达附件下载地址而不是真实下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或者将该记录标记为不在采集采集将在下次运行任务时重复。
网页抓取工具优采云采集器配备了一系列数据处理的优势在于,当我们只需要做一个小操作时,无需编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。返回搜狐查看更多 查看全部
网页内容抓取工具(提取的数据还不能直接拿来用?文件还没有被下载?)
提取出来的数据不能直接使用吗?文件还没有下载?格式等不符合要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。让我依次为您介绍:
1、内容处理:对内容页面中提取的数据进行进一步的处理,如替换、标签过滤、分词等,我们可以同时添加多个操作,但这里需要注意的是,如果有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取内容为空:如果通过前面的规则无法准确提取提取内容或提取内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如
④ 字符截取:通过首尾字符串截取内容。适用于截取和调整提取的内容。
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换进行操作,则需要通过强大的正则表达式进行复杂的替换。
例如,“受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
⑥数据转换:包括结果简繁转换、结果繁简转换、自动转拼音和时间校正转换,共四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动汇总、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中的下载图片是指源代码中带有标准样式标签的图片地址。
例如,如果是直接的图片地址或不规则的图片源代码,采集器 将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:勾选后会下载源代码中标准样式的代码图片。
③检测文件真实地址但不下载:有时采集到达附件下载地址而不是真实下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或者将该记录标记为不在采集采集将在下次运行任务时重复。
网页抓取工具优采云采集器配备了一系列数据处理的优势在于,当我们只需要做一个小操作时,无需编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。返回搜狐查看更多
网页内容抓取工具(URLExtractor内容提取wkhub永久钻石支付宝微信扫一扫(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-18 22:16
URL Extractor 是一个 Cocoa 应用程序,用于从文件中提取电子邮件地址和 URL,这些文件也可以通过搜索引擎找到。它可以从单个网页开始,浏览里面的所有链接,找到要提取的email或URL,并将所有链接保存在用户HD上。它还可以从任何嵌套级别的单个文件或 HD 上文件夹的所有内容中提取。完成后,它可以将 URL Extractor 文档保存到磁盘,其中收录特定文件夹或文件或网页的所有设置,可以重复使用。或者,提取的数据可以作为文本文件保存在磁盘上以供用户使用。
它允许用户指定要用作导航起点的网页列表,并使用交叉导航转到其他网页。您还可以指定一系列关键字;然后通过搜索引擎搜索与关键字相关的网页,并开始页面的交叉导航,采集网址。它可以在网页提取模式下无需用户交互的情况下导航数小时,提取在所有无人值守网页中找到的所有 URL;或从使用关键字的单个搜索引擎开始,在无限制的导航和 URL 中查看提取过程中的所有结果和链接页面。
特征
本站统一解压密码:
免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。
URL Extractor 内容提取
wkhub 永久钻石
支付宝扫一扫
微信扫一扫>打赏采集海报链接 查看全部
网页内容抓取工具(URLExtractor内容提取wkhub永久钻石支付宝微信扫一扫(组图))
URL Extractor 是一个 Cocoa 应用程序,用于从文件中提取电子邮件地址和 URL,这些文件也可以通过搜索引擎找到。它可以从单个网页开始,浏览里面的所有链接,找到要提取的email或URL,并将所有链接保存在用户HD上。它还可以从任何嵌套级别的单个文件或 HD 上文件夹的所有内容中提取。完成后,它可以将 URL Extractor 文档保存到磁盘,其中收录特定文件夹或文件或网页的所有设置,可以重复使用。或者,提取的数据可以作为文本文件保存在磁盘上以供用户使用。
它允许用户指定要用作导航起点的网页列表,并使用交叉导航转到其他网页。您还可以指定一系列关键字;然后通过搜索引擎搜索与关键字相关的网页,并开始页面的交叉导航,采集网址。它可以在网页提取模式下无需用户交互的情况下导航数小时,提取在所有无人值守网页中找到的所有 URL;或从使用关键字的单个搜索引擎开始,在无限制的导航和 URL 中查看提取过程中的所有结果和链接页面。
特征
 https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />
https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" /> https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />
https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" /> https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />
https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />本站统一解压密码:
免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。
URL Extractor 内容提取
wkhub 永久钻石

支付宝扫一扫
微信扫一扫>打赏采集海报链接
网页内容抓取工具(网页表格数据采集器软件可立刻解决你的问题呢? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-11-18 22:15
)
亲,你有很多网页表单数据要复制吗,采集,抓紧吗?您是否正在为如何复制这些数百、数千甚至数万页的表格数据而烦恼?是不是觉得键盘打字、鼠标点击、效率低下太累太难了?重复枯燥的工作太让人抓狂了
, 有没有可以立即解决您的问题的软件?当你读到这些话的时候,我想告诉你,你已经看到了曙光,没错,就是这个页面给你介绍的软件——网页表单数据采集器。
web表单数据采集器软件支持在一个网站上连续无限页面批量采集相同表单数据,支持采集@指定表单数据在一个采集 page>,也支持采集一个页面中具有通用数据的多个表数据,采集可以根据网页上的“下一页”等链接的后续页面进行无限采集@ >,也可以根据网址采集中的页数来指定连续页中的表格数据,或者根据您自己指定的网址列表。可以采集,并且可以自动过滤隐藏的干扰码,采集的结果可以显示为文本表格,另存为文本,
下面是我们的软件界面截图,软件下载地址如下
采集 支持单格数据链接
仅支持采集指定的字段
该软件可以连续或定时采集指定与网站上来回关联的标准二维表,操作非常简单方便,用于网页的连续批量<需要的@文章采集,请在本店另选一款软件-网文采集大师。
网页表单数据采集器软件现已更新至V2.38版。最新版本的下载地址如下。请复制地址,用浏览器或其他下载工具下载。
关于本软件的更多信息,请查看软件官网论坛
web表单数据采集软件的使用也很简单。熟悉的话,表单采集 一键搞定。以下是使用该软件的简单步骤:
1、首先在地址栏中输入采集的网页地址。如果采集的网页已经在IE浏览器中打开过,这个地址会自动添加到软件的网址列表中。
2、 然后点击爬取测试按钮,网页中收录的表数和页眉信息会自动显示在软件左上角的列表框中,同时自动识别您可能想要抓取并选择此表。如果网页表单中有多个页面,并且网页中有“下一页”的链接,程序会自动在“根据链接或按钮关键字打开下一页”输入框中输入“下一页”。
3、从表数列表中选择要抓取的表。此时,“表格首行第一行”输入框的输入框中会显示表格左上角的文字或前三个文字。收录的字段(列)会显示在软件左侧的中间列表中(注意,您也可以点击“表格第一行第一部分”的标签,输入会变成“表格每一行的公共部分”判断表格是否收录某个字符串,用于识别网页中的表格,也可以输入为“所有表格中的序号”,输入表格序号表单列表框中显示的编号,并确定用于识别网页中表单的标记)。
4、 然后选择你要采集的表数据的字段(列)。如果不选中,则设置表采集的所有列。
5、选择是否要抓取表格的标题行,保存时是否显示表格行。如果web表单的字段中有链接,可以选择是否收录链接地址,如果是并且需要采集其链接地址,则不能同时选择收录标题行时间。
6、 如果你想让采集的表单数据只有一个网页,那么现在可以直接点击抓取表格。如果您不选择收录表格行,表格数据将以 CVS 格式保存。这种格式可以直接用微软EXCEL软件打开,转换成EXCEL格式。如果选择在前面收录表格行,表格数据会以TXT格式保存,可以用记事本软件打开查看。表行直接可用,也很清楚。
7、如果想让采集的表单数据有多个连续的页面,并且想要采集向下,那么请重新设置程序采集下一页并后续页面的方式可以是根据链接名称打开下一个页面。几乎大多数页面的链接名称都是“下一页”。您可以查看页面,找到后输入。如果页面没有下一页的链接,但是URL收录页数,那么你也可以根据URL中的页数选择打开。可以从前到后选择,比如从第1页到第10页。也可以从后到前选择,比如从第10页到第1页,在页码里输入就行了,
8、 然后选择定时采集或者等待网页打开加载采集后立即加载,定时采集是程序根据设定的小时间间隔判断打开如果页面中有你想要的表单,可以采集,页面加载后,采集只要采集的页面已经打开,程序就会马上着手采集,两者各有特点,看需要选择。
9、最后,只需点击抢表按钮,就可以泡杯咖啡出发啦!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入需要的信息不经过爬取测试等操作,直接点击爬取表格。
时间,一寸光阴,一寸金。寸金难买寸光阴。我们不能把有限的钱浪费在一些重复和无聊的工作上。有现成的软件。为什么不使用软件?再说了,现在的30元,你在菜市场什么都买不到。这么便宜的价格,你不能再犹豫了。如果您需要,请尽快开始。
下单时请在备注栏中填写邮箱地址和软件打开后显示的机器码。购买后,我们将向您发送正式版。如果需要,我们还可以为您进行远程演示操作。
如果现有方案不能满足您的需求,我们也可以支持方案定制。如果需要,请先增加费用。
406
客户的评论和不断的好评。尤其是这款软件还可以持续捕捉店铺评论和评论,以及宝贝销售记录。如果您需要采集已售出的婴儿数据,它带有一个已售出的婴儿数据管理器:
感谢您的好评,您的好评是对我不断升级完善本软件的最大支持
另外,购买本软件后,如果想要treeView和ListView数据采集器,也可以向楼主索取
查看全部
网页内容抓取工具(网页表格数据采集器软件可立刻解决你的问题呢?
)
亲,你有很多网页表单数据要复制吗,采集,抓紧吗?您是否正在为如何复制这些数百、数千甚至数万页的表格数据而烦恼?是不是觉得键盘打字、鼠标点击、效率低下太累太难了?重复枯燥的工作太让人抓狂了

, 有没有可以立即解决您的问题的软件?当你读到这些话的时候,我想告诉你,你已经看到了曙光,没错,就是这个页面给你介绍的软件——网页表单数据采集器。
web表单数据采集器软件支持在一个网站上连续无限页面批量采集相同表单数据,支持采集@指定表单数据在一个采集 page>,也支持采集一个页面中具有通用数据的多个表数据,采集可以根据网页上的“下一页”等链接的后续页面进行无限采集@ >,也可以根据网址采集中的页数来指定连续页中的表格数据,或者根据您自己指定的网址列表。可以采集,并且可以自动过滤隐藏的干扰码,采集的结果可以显示为文本表格,另存为文本,
下面是我们的软件界面截图,软件下载地址如下

采集 支持单格数据链接

仅支持采集指定的字段
该软件可以连续或定时采集指定与网站上来回关联的标准二维表,操作非常简单方便,用于网页的连续批量<需要的@文章采集,请在本店另选一款软件-网文采集大师。
网页表单数据采集器软件现已更新至V2.38版。最新版本的下载地址如下。请复制地址,用浏览器或其他下载工具下载。
关于本软件的更多信息,请查看软件官网论坛
web表单数据采集软件的使用也很简单。熟悉的话,表单采集 一键搞定。以下是使用该软件的简单步骤:
1、首先在地址栏中输入采集的网页地址。如果采集的网页已经在IE浏览器中打开过,这个地址会自动添加到软件的网址列表中。
2、 然后点击爬取测试按钮,网页中收录的表数和页眉信息会自动显示在软件左上角的列表框中,同时自动识别您可能想要抓取并选择此表。如果网页表单中有多个页面,并且网页中有“下一页”的链接,程序会自动在“根据链接或按钮关键字打开下一页”输入框中输入“下一页”。
3、从表数列表中选择要抓取的表。此时,“表格首行第一行”输入框的输入框中会显示表格左上角的文字或前三个文字。收录的字段(列)会显示在软件左侧的中间列表中(注意,您也可以点击“表格第一行第一部分”的标签,输入会变成“表格每一行的公共部分”判断表格是否收录某个字符串,用于识别网页中的表格,也可以输入为“所有表格中的序号”,输入表格序号表单列表框中显示的编号,并确定用于识别网页中表单的标记)。
4、 然后选择你要采集的表数据的字段(列)。如果不选中,则设置表采集的所有列。
5、选择是否要抓取表格的标题行,保存时是否显示表格行。如果web表单的字段中有链接,可以选择是否收录链接地址,如果是并且需要采集其链接地址,则不能同时选择收录标题行时间。
6、 如果你想让采集的表单数据只有一个网页,那么现在可以直接点击抓取表格。如果您不选择收录表格行,表格数据将以 CVS 格式保存。这种格式可以直接用微软EXCEL软件打开,转换成EXCEL格式。如果选择在前面收录表格行,表格数据会以TXT格式保存,可以用记事本软件打开查看。表行直接可用,也很清楚。
7、如果想让采集的表单数据有多个连续的页面,并且想要采集向下,那么请重新设置程序采集下一页并后续页面的方式可以是根据链接名称打开下一个页面。几乎大多数页面的链接名称都是“下一页”。您可以查看页面,找到后输入。如果页面没有下一页的链接,但是URL收录页数,那么你也可以根据URL中的页数选择打开。可以从前到后选择,比如从第1页到第10页。也可以从后到前选择,比如从第10页到第1页,在页码里输入就行了,
8、 然后选择定时采集或者等待网页打开加载采集后立即加载,定时采集是程序根据设定的小时间间隔判断打开如果页面中有你想要的表单,可以采集,页面加载后,采集只要采集的页面已经打开,程序就会马上着手采集,两者各有特点,看需要选择。
9、最后,只需点击抢表按钮,就可以泡杯咖啡出发啦!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入需要的信息不经过爬取测试等操作,直接点击爬取表格。
时间,一寸光阴,一寸金。寸金难买寸光阴。我们不能把有限的钱浪费在一些重复和无聊的工作上。有现成的软件。为什么不使用软件?再说了,现在的30元,你在菜市场什么都买不到。这么便宜的价格,你不能再犹豫了。如果您需要,请尽快开始。
下单时请在备注栏中填写邮箱地址和软件打开后显示的机器码。购买后,我们将向您发送正式版。如果需要,我们还可以为您进行远程演示操作。
如果现有方案不能满足您的需求,我们也可以支持方案定制。如果需要,请先增加费用。
406

客户的评论和不断的好评。尤其是这款软件还可以持续捕捉店铺评论和评论,以及宝贝销售记录。如果您需要采集已售出的婴儿数据,它带有一个已售出的婴儿数据管理器:

感谢您的好评,您的好评是对我不断升级完善本软件的最大支持

另外,购买本软件后,如果想要treeView和ListView数据采集器,也可以向楼主索取

网页内容抓取工具(JSP众筹管理系统.5开发java语言设计系统源码特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-15 20:22
一、 源码特点 JSP众筹管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统具有完整的源代码和数据库,系统主要采用B/S模式。发展。 二、功能介绍 前台主要功能:显示项目信息及项目周边相关信息 后台主要功能:(1)权限管理:添加、删除、修改、查看权限信息(2)用户管理:添加、删除、修改、查看用户信息(3)项目分类管理:添加、删除、修改、查看项目分类信息(4)项目管理:添加项目信息),删除、修改和查看(5)日志管理:添加、删除、修改和查看日志信息(6)项目支持管理:添加、删除、修改和查看项目支持信息(7)Project审核管理:添加、删除、修改和查看项目审核信息(8)报告管理:添加、删除、修改和查看报告信息(9)消息管理:对消息信息的添加、删除、修改和查看(8) 招生管理:添加、删除、修改和查看招生信息编队三、注意事项1、管理员账号:admin 密码:admin 数据库配置文件DBO.java2、开发环境为TOMCAT7.0,Myeclipse8.5,数据库为mysql,使用java语言开发。3、数据库文件名为jspfgongchou .mysql,系统名gongchou4、地址:xiangmu.jsp 查看全部
网页内容抓取工具(JSP众筹管理系统.5开发java语言设计系统源码特点)
一、 源码特点 JSP众筹管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统具有完整的源代码和数据库,系统主要采用B/S模式。发展。 二、功能介绍 前台主要功能:显示项目信息及项目周边相关信息 后台主要功能:(1)权限管理:添加、删除、修改、查看权限信息(2)用户管理:添加、删除、修改、查看用户信息(3)项目分类管理:添加、删除、修改、查看项目分类信息(4)项目管理:添加项目信息),删除、修改和查看(5)日志管理:添加、删除、修改和查看日志信息(6)项目支持管理:添加、删除、修改和查看项目支持信息(7)Project审核管理:添加、删除、修改和查看项目审核信息(8)报告管理:添加、删除、修改和查看报告信息(9)消息管理:对消息信息的添加、删除、修改和查看(8) 招生管理:添加、删除、修改和查看招生信息编队三、注意事项1、管理员账号:admin 密码:admin 数据库配置文件DBO.java2、开发环境为TOMCAT7.0,Myeclipse8.5,数据库为mysql,使用java语言开发。3、数据库文件名为jspfgongchou .mysql,系统名gongchou4、地址:xiangmu.jsp
网页内容抓取工具(Python用做数据处理还是相当不错的,你知道吗?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-17 02:27
Python非常适合数据处理。如果你想做爬虫,Python 是个不错的选择。它有许多已编写的包。只需调用它们就可以完成许多复杂的功能。本文所有功能均基于 BeautifulSoup 包。
1 Pyhton获取网页内容(即源码)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址对应的源码,urllib2是需要用到的包,上面三句代码就可以得到网页的整个源码
2 获取网页中想要的内容(先获取网页的源代码,然后分析网页的源代码,找到对应的标签,然后提取标签中的内容)
2.1 以豆瓣电影排名为例
网址是,输入网址后会出现下图
现在我需要获取当前页面上所有电影的名称、评分、评论数量、链接
从上图中,红色圆圈是我想要获取的内容,蓝色横线是对应的标签,这样分析就完成了,现在就是写代码来实现,Python提供了很多获取想要的方法内容,这里我使用BeautifulSoup来实现,很简单
#coding:utf-8
'''
Created on 2016��5��17��
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,也可以写入文件
前三行代码获取整个网页的源码,然后开始使用BeautifulSoup进行标签分析。find_all 方法就是找到这个标签的所有内容,然后在这个标签中继续搜索。如果标签有特殊的属性声明,可以一步找到出来,如果没有特殊的属性声明像这张图中求值者数量前面的标签只有一个'span',那么所有的span找到标签,并依次选择相应的标签。在这张图中,它是第三个,所以这个方法可以找到特定行或列的内容。代码比较简单,易于实现。如有不对的地方请大家指出,共同学习。
源代码地址: 查看全部
网页内容抓取工具(Python用做数据处理还是相当不错的,你知道吗?(上))
Python非常适合数据处理。如果你想做爬虫,Python 是个不错的选择。它有许多已编写的包。只需调用它们就可以完成许多复杂的功能。本文所有功能均基于 BeautifulSoup 包。
1 Pyhton获取网页内容(即源码)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址对应的源码,urllib2是需要用到的包,上面三句代码就可以得到网页的整个源码
2 获取网页中想要的内容(先获取网页的源代码,然后分析网页的源代码,找到对应的标签,然后提取标签中的内容)
2.1 以豆瓣电影排名为例
网址是,输入网址后会出现下图
现在我需要获取当前页面上所有电影的名称、评分、评论数量、链接
从上图中,红色圆圈是我想要获取的内容,蓝色横线是对应的标签,这样分析就完成了,现在就是写代码来实现,Python提供了很多获取想要的方法内容,这里我使用BeautifulSoup来实现,很简单
#coding:utf-8
'''
Created on 2016��5��17��
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,也可以写入文件
前三行代码获取整个网页的源码,然后开始使用BeautifulSoup进行标签分析。find_all 方法就是找到这个标签的所有内容,然后在这个标签中继续搜索。如果标签有特殊的属性声明,可以一步找到出来,如果没有特殊的属性声明像这张图中求值者数量前面的标签只有一个'span',那么所有的span找到标签,并依次选择相应的标签。在这张图中,它是第三个,所以这个方法可以找到特定行或列的内容。代码比较简单,易于实现。如有不对的地方请大家指出,共同学习。
源代码地址:
网页内容抓取工具(网页抓取工具WebExtractWebWebWeb)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-15 18:27
网络爬虫 Easy Web Extract 是一款易于使用的网络爬虫,可提取网页中的内容(文本、URL、图像、文件),只需点击几下屏幕即可将结果转换为多种格式。没有编程要求。让我们的网络爬虫像它的名字一样易于使用。
软件说明:
我们简单的网络提取软件收录许多高级功能。
使用户能够从简单的 网站 中抓取内容。
但是构建一个网络抓取项目不需要任何努力。
在此页面中,我们将仅向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
特征:
1. 轻松创建提取项目
对任何用户来说,基于向导窗口创建新项目绝非易事。
项目安装向导会一步步推你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始地址,即起始页,刷新屏幕后会加载网页。
它通常是一个链接到一个被刮掉的产品列表
第二步:如果网站要求,输入关键词提交表单并获取结果。大多数情况下可以跳过这一步
第三步:在列表中选择一个项目,选择该项目的数据列的抓取性能
第四步:选择下一页的网址访问其他页面
2. 多线程抓取数据
在网络爬虫项目中,需要爬取数十万个链接进行收获。
传统的刮刀可能需要数小时或数天的时间。
然而,一个简单的网页提取可以同时运行多个线程来浏览多达 24 个不同的网页。
为了节省您宝贵的时间,等待收获的结果。
因此,简单的 Web 提取可以利用系统的最佳性能。
旁边的动画图像显示了 8 个线程的提取。
3. 从数据中加载各种提取的数据
一些高度动态的网站使用基于客户端创建的数据加载技术,例如AJAX异步请求。
诚然,不仅是原创的网页爬虫,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
但是,简单的网络提取具有非常强大的技术。
即使是新手也可以从这些类型的网站中获取数据。
此外,我们的 网站 爬虫甚至可以模拟向下滚动到页面底部以加载更多数据。
例如LinkedIn联系人列表中的某些特定网站。
在这个挑战中,大多数网络爬虫继续采集大量重复信息。
并且很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动执行项目
通过简单的网络提取的嵌入式自动运行调度程序。
您可以随时安排运行网页抓取项目,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有一直运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
确保只维护新数据。
支持的日历类型:
- 在项目中每小时运行一次
- 在项目中每天运行
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网络抓取工具支持各种格式来导出和抓取 网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接提交任何类型的数据库目标结果。
通过 ODBC 连接。如果您的 网站 有提交表单。 查看全部
网页内容抓取工具(网页抓取工具WebExtractWebWebWeb)
网络爬虫 Easy Web Extract 是一款易于使用的网络爬虫,可提取网页中的内容(文本、URL、图像、文件),只需点击几下屏幕即可将结果转换为多种格式。没有编程要求。让我们的网络爬虫像它的名字一样易于使用。
软件说明:
我们简单的网络提取软件收录许多高级功能。
使用户能够从简单的 网站 中抓取内容。
但是构建一个网络抓取项目不需要任何努力。
在此页面中,我们将仅向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
特征:
1. 轻松创建提取项目
对任何用户来说,基于向导窗口创建新项目绝非易事。
项目安装向导会一步步推你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始地址,即起始页,刷新屏幕后会加载网页。
它通常是一个链接到一个被刮掉的产品列表
第二步:如果网站要求,输入关键词提交表单并获取结果。大多数情况下可以跳过这一步
第三步:在列表中选择一个项目,选择该项目的数据列的抓取性能
第四步:选择下一页的网址访问其他页面
2. 多线程抓取数据
在网络爬虫项目中,需要爬取数十万个链接进行收获。
传统的刮刀可能需要数小时或数天的时间。
然而,一个简单的网页提取可以同时运行多个线程来浏览多达 24 个不同的网页。
为了节省您宝贵的时间,等待收获的结果。
因此,简单的 Web 提取可以利用系统的最佳性能。
旁边的动画图像显示了 8 个线程的提取。
3. 从数据中加载各种提取的数据
一些高度动态的网站使用基于客户端创建的数据加载技术,例如AJAX异步请求。
诚然,不仅是原创的网页爬虫,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
但是,简单的网络提取具有非常强大的技术。
即使是新手也可以从这些类型的网站中获取数据。
此外,我们的 网站 爬虫甚至可以模拟向下滚动到页面底部以加载更多数据。
例如LinkedIn联系人列表中的某些特定网站。
在这个挑战中,大多数网络爬虫继续采集大量重复信息。
并且很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动执行项目
通过简单的网络提取的嵌入式自动运行调度程序。
您可以随时安排运行网页抓取项目,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有一直运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
确保只维护新数据。
支持的日历类型:
- 在项目中每小时运行一次
- 在项目中每天运行
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网络抓取工具支持各种格式来导出和抓取 网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接提交任何类型的数据库目标结果。
通过 ODBC 连接。如果您的 网站 有提交表单。
网页内容抓取工具( 使用Chrome扩展程序电子邮件提取器提取器是Chrome插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-12-15 03:23
使用Chrome扩展程序电子邮件提取器提取器是Chrome插件)
urls = $$(‘a’); for (url in urls) console.log ( urls.href);
只需一行代码,我们就可以找到该特定页面上存在的所有 URL:
使用 Chrome 扩展电子邮件提取器
Email Extractor 是一个 Chrome 插件,它捕获我们当前浏览的页面上显示的电子邮件 ID
它甚至允许我们下载 CSV 或文本文件中的电子邮件 ID 列表:
BeautifulSoup 和正则表达式
上述方案仅在我们只想从一页抓取数据时有效。但是如果我们想在多个页面上执行相同的步骤呢?
有很多网站可以通过收费来为我们做这件事。但好消息是——我们也可以用 Python 编写自己的网络爬虫!让我们在下面的实时编码窗口中检查操作方法。
在 Python 中抓取图片
在本节中,我们将从同一个 Goibibibo 网页中抓取所有图片。第一步是导航到目标网站并下载源代码。接下来,我们将使用标签来查找所有图像:
"""Web Scraping - Scrap Images"""# importing required librariesimport requestsfrom bs4 import BeautifulSoup# target URLurl = "https://www.goibibo.com/hotels ... aders = { 'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" }response = requests.request("GET", url, headers=headers)data = BeautifulSoup(response.text, 'html.parser')# find all with the image tagimages = data.find_all('img', src=True)print('Number of Images: ', len(images))for image in images: print(image)
从所有图像标签中,仅选择 src 部分。另外请注意,酒店图片以jpg格式提供。因此,我们将只选择那些:
# select src tagimage_src = [x['src'] for x in images]# select only jp format imagesimage_src = [x for x in image_src if x.endswith('.jpg')]for image in image_src: print(image)
现在我们有了一个图像 URL 列表,我们所要做的就是请求图像的内容并将其写入文件。确保以“wb”(写入二进制文件)形式打开文件
image_count = 1for image in image_src: with open('image_'+str(image_count)+'.jpg', 'wb') as f: res = requests.get(image) f.write(res.content) image_count = image_count+1
您还可以通过页码更新初始页面 URL 并重复请求它们以[url=https://www.ucaiyun.com/]采集大量数据。
页面加载时抓取数据
我们来看看 Steam 社区 Grant Theft Auto V 评论的网页。您会注意到网页的完整内容不会一次性加载。
我们需要向下滚动以在页面上加载更多内容。这是网站 后端开发人员使用的一种称为“延迟加载”的优化技术。
但对我们来说,问题是当我们试图从这个页面抓取数据时,我们只能得到那个页面的有限内容:
一些 网站 还创建了“加载更多”按钮,而不是无休止的滚动想法。只有当您单击按钮时,它才会加载更多内容。内容受限的问题依然存在。那么让我们看看如何抓取这些页面。
导航到目标 URL 并打开“检查元素网络”窗口。接下来点击reload按钮,它会为你记录网络的加载顺序,比如图片加载、API请求、POST请求等。
清除当前记录并向下滚动。您会注意到,当您向下滚动时,页面正在发送对更多数据的请求:
进一步滚动,您将看到 网站 如何发出请求。看下面的网址——只有部分参数值在变化,你可以用简单的Python代码轻松生成这些网址:
您需要按照相同的步骤通过将请求逐页发送到每个页面来获取和存储数据。
尾注
这是使用强大的 BeautifulSoup 库在 Python 中进行网页抓取的简单且适合初学者的介绍。老实说,当我在寻找新项目或需要有关现有项目的信息时,我发现网络抓取非常有用。
注意:如果您想以更结构化的形式学习本教程,我们有一个免费课程,我们将教授 Web 抓取 BeatifulSoup。您可以在此处查看-使用 Python 进行 Web 爬网简介。
如前所述,还有其他库可用于执行网页抓取。我很想听听你最喜欢的图书馆想法(即使你使用 R!),以及你在这个主题上的经验。在下面的评论部分告诉我,我们会与您联系! 查看全部
网页内容抓取工具(
使用Chrome扩展程序电子邮件提取器提取器是Chrome插件)
urls = $$(‘a’); for (url in urls) console.log ( urls.href);
只需一行代码,我们就可以找到该特定页面上存在的所有 URL:
使用 Chrome 扩展电子邮件提取器
Email Extractor 是一个 Chrome 插件,它捕获我们当前浏览的页面上显示的电子邮件 ID
它甚至允许我们下载 CSV 或文本文件中的电子邮件 ID 列表:
BeautifulSoup 和正则表达式
上述方案仅在我们只想从一页抓取数据时有效。但是如果我们想在多个页面上执行相同的步骤呢?
有很多网站可以通过收费来为我们做这件事。但好消息是——我们也可以用 Python 编写自己的网络爬虫!让我们在下面的实时编码窗口中检查操作方法。
在 Python 中抓取图片
在本节中,我们将从同一个 Goibibibo 网页中抓取所有图片。第一步是导航到目标网站并下载源代码。接下来,我们将使用标签来查找所有图像:
"""Web Scraping - Scrap Images"""# importing required librariesimport requestsfrom bs4 import BeautifulSoup# target URLurl = "https://www.goibibo.com/hotels ... aders = { 'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" }response = requests.request("GET", url, headers=headers)data = BeautifulSoup(response.text, 'html.parser')# find all with the image tagimages = data.find_all('img', src=True)print('Number of Images: ', len(images))for image in images: print(image)
从所有图像标签中,仅选择 src 部分。另外请注意,酒店图片以jpg格式提供。因此,我们将只选择那些:
# select src tagimage_src = [x['src'] for x in images]# select only jp format imagesimage_src = [x for x in image_src if x.endswith('.jpg')]for image in image_src: print(image)
现在我们有了一个图像 URL 列表,我们所要做的就是请求图像的内容并将其写入文件。确保以“wb”(写入二进制文件)形式打开文件
image_count = 1for image in image_src: with open('image_'+str(image_count)+'.jpg', 'wb') as f: res = requests.get(image) f.write(res.content) image_count = image_count+1
您还可以通过页码更新初始页面 URL 并重复请求它们以[url=https://www.ucaiyun.com/]采集大量数据。
页面加载时抓取数据
我们来看看 Steam 社区 Grant Theft Auto V 评论的网页。您会注意到网页的完整内容不会一次性加载。
我们需要向下滚动以在页面上加载更多内容。这是网站 后端开发人员使用的一种称为“延迟加载”的优化技术。
但对我们来说,问题是当我们试图从这个页面抓取数据时,我们只能得到那个页面的有限内容:
一些 网站 还创建了“加载更多”按钮,而不是无休止的滚动想法。只有当您单击按钮时,它才会加载更多内容。内容受限的问题依然存在。那么让我们看看如何抓取这些页面。
导航到目标 URL 并打开“检查元素网络”窗口。接下来点击reload按钮,它会为你记录网络的加载顺序,比如图片加载、API请求、POST请求等。
清除当前记录并向下滚动。您会注意到,当您向下滚动时,页面正在发送对更多数据的请求:
进一步滚动,您将看到 网站 如何发出请求。看下面的网址——只有部分参数值在变化,你可以用简单的Python代码轻松生成这些网址:
您需要按照相同的步骤通过将请求逐页发送到每个页面来获取和存储数据。
尾注
这是使用强大的 BeautifulSoup 库在 Python 中进行网页抓取的简单且适合初学者的介绍。老实说,当我在寻找新项目或需要有关现有项目的信息时,我发现网络抓取非常有用。
注意:如果您想以更结构化的形式学习本教程,我们有一个免费课程,我们将教授 Web 抓取 BeatifulSoup。您可以在此处查看-使用 Python 进行 Web 爬网简介。
如前所述,还有其他库可用于执行网页抓取。我很想听听你最喜欢的图书馆想法(即使你使用 R!),以及你在这个主题上的经验。在下面的评论部分告诉我,我们会与您联系!
网页内容抓取工具(大数据抓取软件怎么使用网页数据的工具方法方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-12-14 15:22
网站数据采集 哪个工具好用?
网站数据采集,现成的爬虫软件有很多可以直接使用,下面我就简单介绍一下三种,分别是优采云、章鱼和优采云,操作简单,上手容易学习了解,有兴趣的朋友可以试试:
这是一款非常智能的网络爬虫软件,支持跨平台,个人使用非常方便,完全免费。对于大多数网站,只需输入URL,软件会自动识别并提取相关字段信息,包括列表、表格、链接、图片等,无需配置任何采集规则,一个-click采用,支持自动翻页和数据导出功能,对于小白来说,非常方便,易学易掌握:这是一款非常好的一款,对比优采云采集器,八达通采集器目前只支持windows平台,需要手动设置采集字段和配置规则,所以比较复杂灵活。内置海量数据采集模板,方便采集京东,天猫等热门网站。官方教程很详细,小白很容易掌握:
当然,除了以上三个爬虫软件,它还有很多功能,很多其他软件也支持网站data采集,比如做号,申请保单等等。如果您熟悉 Python、Java 等编程语言,您还可以编写程序来抓取数据。网上也有相关的教程和资料,讲的很详细。如果你有兴趣,你可以搜索它们。希望以上分享的内容对您有所帮助,也欢迎大家留言补充。
大数据抓取软件如何抓取网页数据,抓取数据的工具和方法 查看全部
网页内容抓取工具(大数据抓取软件怎么使用网页数据的工具方法方法介绍)
网站数据采集 哪个工具好用?
网站数据采集,现成的爬虫软件有很多可以直接使用,下面我就简单介绍一下三种,分别是优采云、章鱼和优采云,操作简单,上手容易学习了解,有兴趣的朋友可以试试:
这是一款非常智能的网络爬虫软件,支持跨平台,个人使用非常方便,完全免费。对于大多数网站,只需输入URL,软件会自动识别并提取相关字段信息,包括列表、表格、链接、图片等,无需配置任何采集规则,一个-click采用,支持自动翻页和数据导出功能,对于小白来说,非常方便,易学易掌握:这是一款非常好的一款,对比优采云采集器,八达通采集器目前只支持windows平台,需要手动设置采集字段和配置规则,所以比较复杂灵活。内置海量数据采集模板,方便采集京东,天猫等热门网站。官方教程很详细,小白很容易掌握:
当然,除了以上三个爬虫软件,它还有很多功能,很多其他软件也支持网站data采集,比如做号,申请保单等等。如果您熟悉 Python、Java 等编程语言,您还可以编写程序来抓取数据。网上也有相关的教程和资料,讲的很详细。如果你有兴趣,你可以搜索它们。希望以上分享的内容对您有所帮助,也欢迎大家留言补充。
大数据抓取软件如何抓取网页数据,抓取数据的工具和方法
网页内容抓取工具(一下如何使用网页抓取工具抓取APP数据大家都会使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-11 07:32
如何使用网络爬虫抓取APP数据大家都会使用网络爬虫优采云采集器来采集网络数据,但是很多朋友还是不知道怎么用采集器来采集APP里的数据。毕竟随着移动互联网的发展,APP中还有大量的数据可供挖掘,下面就和大家分享一下如何使用网络爬虫工具采集移动App数据。网络爬虫优采云采集器可以抓取http和https请求中的内容,所以如果APP也通过这两种请求类型和服务器交互,那么我们可能会像采集网站 与实现 采集 相同。下面以京东APP为例介绍操作方法:(1)首先在手机上安装APP,将手机连接PC进行传输。(2)打开抓包工具查看fiddler的端口号,例如下图:(3)查看本地局域网的固定IP,下图:(4)设置手机中的端口号和IP,并写好端口号和IP,如下图: 如上图:在手机中设置好后,可以让fiddler一直处于Capturing状态,然后操作京东APP,打开你想要的页面采集,并且抓包工具会显示操作触发的网络请求和响应,如下图: 然后我们可以分析优采云采集器中的请求写入规则,测试http是否可以是采集,这样我们就可以使用网络爬虫工具实现APP采集的步骤基本完成了,大家多试几次。不过, APP和网页一样。我们看不到的数据不可用。比如很多人问如何获取后台用户数据。这种类型的数据是不可能的。采集@ >of. 查看全部
网页内容抓取工具(一下如何使用网页抓取工具抓取APP数据大家都会使用)
如何使用网络爬虫抓取APP数据大家都会使用网络爬虫优采云采集器来采集网络数据,但是很多朋友还是不知道怎么用采集器来采集APP里的数据。毕竟随着移动互联网的发展,APP中还有大量的数据可供挖掘,下面就和大家分享一下如何使用网络爬虫工具采集移动App数据。网络爬虫优采云采集器可以抓取http和https请求中的内容,所以如果APP也通过这两种请求类型和服务器交互,那么我们可能会像采集网站 与实现 采集 相同。下面以京东APP为例介绍操作方法:(1)首先在手机上安装APP,将手机连接PC进行传输。(2)打开抓包工具查看fiddler的端口号,例如下图:(3)查看本地局域网的固定IP,下图:(4)设置手机中的端口号和IP,并写好端口号和IP,如下图: 如上图:在手机中设置好后,可以让fiddler一直处于Capturing状态,然后操作京东APP,打开你想要的页面采集,并且抓包工具会显示操作触发的网络请求和响应,如下图: 然后我们可以分析优采云采集器中的请求写入规则,测试http是否可以是采集,这样我们就可以使用网络爬虫工具实现APP采集的步骤基本完成了,大家多试几次。不过, APP和网页一样。我们看不到的数据不可用。比如很多人问如何获取后台用户数据。这种类型的数据是不可能的。采集@ >of.
网页内容抓取工具(抓取整个网页的最强工具:Web2PicPro使用方法你到下面的地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 363 次浏览 • 2021-12-07 06:58
最强网页抓取工具:Web2Pic Pro
要使用它,请转到以下地址:
在上网的过程中,我们经常会抓取一些网页内容并以图片的形式保存。我们通常使用一些截图软件来完成这一切。但是,有时我们会遇到截屏过长,不止一屏,或者不得不自己截屏的情况。在抓取整个WEB页面的特殊情况下,HyperSnap虽然有抓取滚动窗口的功能,但并不是所有的页面都可以通过这种方式抓取,有时自动滚动会失败;并且在启用自动滚动功能时,滚动窗口被捕获,当前窗口使用的热键是相同的(Ctrl+Alt+W),在使用过程中不是很方便。使用Web2Pic Pro这个软件可以很好的满足我们抓取整个WEB页面的需求。它是一个专门用于抓取整个网页的图像捕获工具。它也是一个绿色软件。压缩后只有800KB,体积小。功能不弱,还支持命令行参数,使用简单方便。
之前用hypersnap,但是有时候爬不出来。
去google去web2pic pro破解或者web2pic pro串口
很多破解方法,因为经常变成,不提供具体的序列号
比如以我的数据站为例
注意地址栏中的输入不能省略
然后点击选择屏幕分辨率,然后点击开始捕捉,最后保存成你想要的格式。 查看全部
网页内容抓取工具(抓取整个网页的最强工具:Web2PicPro使用方法你到下面的地址)
最强网页抓取工具:Web2Pic Pro
要使用它,请转到以下地址:
在上网的过程中,我们经常会抓取一些网页内容并以图片的形式保存。我们通常使用一些截图软件来完成这一切。但是,有时我们会遇到截屏过长,不止一屏,或者不得不自己截屏的情况。在抓取整个WEB页面的特殊情况下,HyperSnap虽然有抓取滚动窗口的功能,但并不是所有的页面都可以通过这种方式抓取,有时自动滚动会失败;并且在启用自动滚动功能时,滚动窗口被捕获,当前窗口使用的热键是相同的(Ctrl+Alt+W),在使用过程中不是很方便。使用Web2Pic Pro这个软件可以很好的满足我们抓取整个WEB页面的需求。它是一个专门用于抓取整个网页的图像捕获工具。它也是一个绿色软件。压缩后只有800KB,体积小。功能不弱,还支持命令行参数,使用简单方便。
之前用hypersnap,但是有时候爬不出来。
去google去web2pic pro破解或者web2pic pro串口
很多破解方法,因为经常变成,不提供具体的序列号
比如以我的数据站为例
注意地址栏中的输入不能省略
然后点击选择屏幕分辨率,然后点击开始捕捉,最后保存成你想要的格式。
网页内容抓取工具(3其他浏览器的内置抓包工具,你可以试试这个工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-06 10:11
3 其他浏览器的内置捕获工具
如果你用过火狐的F12功能键,应该也知道浏览器内置了一个网络抓包工具。现在好像每个浏览器都内置了这个抓包工具,虽然没有上面两个工具那么强大。, 不过对于测试来说,我觉得已经足够了!下面是很详细的教程,大家可以去学习一下。
1. 慧平
Hping 是最受欢迎和免费的数据包捕获工具之一。它允许您修改和发送自定义 ICMP、UDP、TCP 和原创 IP 数据包。该工具被网络管理员用于防火墙和网络安全审计和测试。
HPing 可用于各种平台,包括 Windows、MacOs X、Linux、FreeBSD、NetBSD、OpenBSD 和 Solaris。
下载 Hping:
2. 奥斯蒂纳托
Ostinato 是一个开源和跨平台的网络数据包生成器和分析工具。它带有一个 GUI 界面,易于使用和理解。它支持 Windows、Linux、BSD 和 Mac OS X 平台。您也可以尝试在其他平台上使用它。
该工具支持最常见的标准协议。请参阅下方支持的协议列表
通过使用 Ostinato,您可以轻松修改任何协议的任何字段。这个数据包工具也被称为第二个Wireshark。
下载 Ostinato:
3. 斯卡皮
Scapy 是另一个很好的交互式数据包处理工具。这个工具是用 Python 编写的。它可以解码或伪造大量协议的数据包。Scapy 是一个值得尝试的工具。您可以执行各种任务,包括扫描、跟踪、探测、单元测试和网络发现。
下载 Scapy:
4. 自由工匠
Libcrafter 与 Scapy 非常相似。该工具是用 C++ 编写的,可以更轻松地创建和解码网络数据包。它可以创建和解码大多数通用协议的数据包,捕获数据包并匹配请求或回复。该工具可以在多个线程中执行各种任务。
下载 Libcrafer:
5. 耶尔森氏菌
Yersinia 是一款强大的网络渗透测试工具,可以对各种网络协议进行渗透测试。如果你正在寻找一个抓包工具,你可以试试这个工具。
下载耶尔森氏菌:
6. 打包ETH
packETH 是另一种数据包处理工具。它是一个 Linux GUI 以太网工具。它允许您快速创建和发送数据包序列。与此列表中的其他工具一样,它支持各种协议来创建和发送数据包。您还可以设置数据包的数量和数据包之间的延迟,您可以在此工具中修改各种数据包的内容。
下载包ETH:
7. Colasoft 数据包生成器
Colasoft Packet Builder 也是一个用于创建和编辑网络数据包的免费工具。如果您是网络管理员,则可以使用此工具来测试您的网络。它适用于所有可用版本的 Windows 操作系统。
下载 Colasoft Packet Builder:
8. 位扭曲
Bit-Twist 是一种不太流行但有用的工具,用于在实时流量中重新生成捕获的数据包。它使用 tcpdump 跟踪文件(.pcap 文件)在网络上生成数据包。它带有一个跟踪文件编辑器,允许您更改捕获的数据包中的任何特定字段。网络管理员可以使用此工具来测试防火墙、IDS 和 IPS,并解决各种网络问题。你可以试试这个工具。
下载位扭曲:
9. Libtins
Libtins 也是制作、发送、嗅探和解析网络数据包的好工具。这个工具是用 C++ 编写的。C++ 开发人员可以扩展此工具的功能,使其更强大并更有效地执行任务。
下载 Libtins:
10. 网猫
Netcat 也是一种流行的工具,可以在 TCP 或 UDP 网络中读写数据。它可以创建几乎所有类型的网络连接和端口绑定。
这个工具最初被称为霍比特人,于 1995 年发布。
下载网猫:
11. 线编辑
WireEdit 是一个功能齐全的 WYSIWYG 网络数据包编辑器。您可以在一个简单的界面中编辑所有数据包层。该工具可免费使用,但您必须联系公司以获得使用权。支持以太网、IPv4、IPv6、UDP、TCP、SCTP、ARP、RARP、DHCP、DHCPv6、ICMP、ICMPv6、IGMP、DNS、LLDP、RSVP、FTP、NETBIOS、GRE、IMAP、POP3、RTCP、RTP、SSH、 TELNET、NTP、LDAP、XMPP、VLAN、VXLAN、CIFS/SMB v1(原创)、BGP、OSPF、SMB3、iSCSI、SCSI、HTTP/1.1、OpenFlow 1.0-1.3、SIP、SDP、MSRP、MGCP、MEGACO(H.248)、H.245、H.323、CISCO Skinny、Q.931/H.225、SCCP、SCMG、SS7 ISUP、TCAP , GSM MAP R4, GSM SM-TP, M3UA, M2UA, M2PA, CAPWAP, IEEE 802.11 等。
它也是一个多平台工具。它适用于 Windows XP 及更高版本、Ubuntu 桌面和 Mac OSX。
下载WireEdit:
12. epb – 以太网数据包庞巴迪
Epb-Ethernet Packet Bombardier 是一个类似的工具。它允许您发送自定义以太网数据包。该工具不提供任何图形用户界面,但易于使用。
您可以在此处了解有关此工具的更多信息:
13. 片段路由
Fragroute 是一种数据包处理工具,可以拦截、修改和重写网络流量。您可以使用此工具执行大多数网络渗透测试,以检查网络的安全性。这个工具是开源的,并提供了一个命令行界面来使用。它适用于 Linux、BSD 和 Mac OS。
下载 Fragroute:~dugsong/fragroute/
14. 毛塞赞
Mausezahn 是一个网络数据包编辑器,它允许您发送各种类型的网络数据包。此工具用于防火墙和IDS的渗透测试,但您可以在网络中使用此工具来查找安全错误。您还可以使用此工具来测试您的网络是否免受 DOS 攻击。值得注意的是,它可以让您完全控制网卡。它支持 ARP、BPDU 或 PVST、CDP、LLDP、IP、IGMP、UDP、TCP(无状态)、ICMP(部分)、DNS、RTP、RTP 以及可选的用于抖动测量的 RX 模式、系统日志协议。
下载 Mausezahn:
15. EIGRP 工具
这是 EIGRP 数据包生成器和嗅探器的组合。开发它是为了测试 EIGRP 路由协议的安全性。要使用此工具,您需要了解第 3 层 EIGRP 协议。这个工具也是一个带有命令行界面的开源工具。它可以在 Linux、Mac OS 和 BSD 平台上使用。
下载 EIGRP 工具: 查看全部
网页内容抓取工具(3其他浏览器的内置抓包工具,你可以试试这个工具)
3 其他浏览器的内置捕获工具
如果你用过火狐的F12功能键,应该也知道浏览器内置了一个网络抓包工具。现在好像每个浏览器都内置了这个抓包工具,虽然没有上面两个工具那么强大。, 不过对于测试来说,我觉得已经足够了!下面是很详细的教程,大家可以去学习一下。
1. 慧平
Hping 是最受欢迎和免费的数据包捕获工具之一。它允许您修改和发送自定义 ICMP、UDP、TCP 和原创 IP 数据包。该工具被网络管理员用于防火墙和网络安全审计和测试。
HPing 可用于各种平台,包括 Windows、MacOs X、Linux、FreeBSD、NetBSD、OpenBSD 和 Solaris。
下载 Hping:
2. 奥斯蒂纳托
Ostinato 是一个开源和跨平台的网络数据包生成器和分析工具。它带有一个 GUI 界面,易于使用和理解。它支持 Windows、Linux、BSD 和 Mac OS X 平台。您也可以尝试在其他平台上使用它。
该工具支持最常见的标准协议。请参阅下方支持的协议列表
通过使用 Ostinato,您可以轻松修改任何协议的任何字段。这个数据包工具也被称为第二个Wireshark。
下载 Ostinato:
3. 斯卡皮
Scapy 是另一个很好的交互式数据包处理工具。这个工具是用 Python 编写的。它可以解码或伪造大量协议的数据包。Scapy 是一个值得尝试的工具。您可以执行各种任务,包括扫描、跟踪、探测、单元测试和网络发现。
下载 Scapy:
4. 自由工匠
Libcrafter 与 Scapy 非常相似。该工具是用 C++ 编写的,可以更轻松地创建和解码网络数据包。它可以创建和解码大多数通用协议的数据包,捕获数据包并匹配请求或回复。该工具可以在多个线程中执行各种任务。
下载 Libcrafer:
5. 耶尔森氏菌
Yersinia 是一款强大的网络渗透测试工具,可以对各种网络协议进行渗透测试。如果你正在寻找一个抓包工具,你可以试试这个工具。
下载耶尔森氏菌:
6. 打包ETH
packETH 是另一种数据包处理工具。它是一个 Linux GUI 以太网工具。它允许您快速创建和发送数据包序列。与此列表中的其他工具一样,它支持各种协议来创建和发送数据包。您还可以设置数据包的数量和数据包之间的延迟,您可以在此工具中修改各种数据包的内容。
下载包ETH:
7. Colasoft 数据包生成器
Colasoft Packet Builder 也是一个用于创建和编辑网络数据包的免费工具。如果您是网络管理员,则可以使用此工具来测试您的网络。它适用于所有可用版本的 Windows 操作系统。
下载 Colasoft Packet Builder:
8. 位扭曲
Bit-Twist 是一种不太流行但有用的工具,用于在实时流量中重新生成捕获的数据包。它使用 tcpdump 跟踪文件(.pcap 文件)在网络上生成数据包。它带有一个跟踪文件编辑器,允许您更改捕获的数据包中的任何特定字段。网络管理员可以使用此工具来测试防火墙、IDS 和 IPS,并解决各种网络问题。你可以试试这个工具。
下载位扭曲:
9. Libtins
Libtins 也是制作、发送、嗅探和解析网络数据包的好工具。这个工具是用 C++ 编写的。C++ 开发人员可以扩展此工具的功能,使其更强大并更有效地执行任务。
下载 Libtins:
10. 网猫
Netcat 也是一种流行的工具,可以在 TCP 或 UDP 网络中读写数据。它可以创建几乎所有类型的网络连接和端口绑定。
这个工具最初被称为霍比特人,于 1995 年发布。
下载网猫:
11. 线编辑
WireEdit 是一个功能齐全的 WYSIWYG 网络数据包编辑器。您可以在一个简单的界面中编辑所有数据包层。该工具可免费使用,但您必须联系公司以获得使用权。支持以太网、IPv4、IPv6、UDP、TCP、SCTP、ARP、RARP、DHCP、DHCPv6、ICMP、ICMPv6、IGMP、DNS、LLDP、RSVP、FTP、NETBIOS、GRE、IMAP、POP3、RTCP、RTP、SSH、 TELNET、NTP、LDAP、XMPP、VLAN、VXLAN、CIFS/SMB v1(原创)、BGP、OSPF、SMB3、iSCSI、SCSI、HTTP/1.1、OpenFlow 1.0-1.3、SIP、SDP、MSRP、MGCP、MEGACO(H.248)、H.245、H.323、CISCO Skinny、Q.931/H.225、SCCP、SCMG、SS7 ISUP、TCAP , GSM MAP R4, GSM SM-TP, M3UA, M2UA, M2PA, CAPWAP, IEEE 802.11 等。
它也是一个多平台工具。它适用于 Windows XP 及更高版本、Ubuntu 桌面和 Mac OSX。
下载WireEdit:
12. epb – 以太网数据包庞巴迪
Epb-Ethernet Packet Bombardier 是一个类似的工具。它允许您发送自定义以太网数据包。该工具不提供任何图形用户界面,但易于使用。
您可以在此处了解有关此工具的更多信息:
13. 片段路由
Fragroute 是一种数据包处理工具,可以拦截、修改和重写网络流量。您可以使用此工具执行大多数网络渗透测试,以检查网络的安全性。这个工具是开源的,并提供了一个命令行界面来使用。它适用于 Linux、BSD 和 Mac OS。
下载 Fragroute:~dugsong/fragroute/
14. 毛塞赞
Mausezahn 是一个网络数据包编辑器,它允许您发送各种类型的网络数据包。此工具用于防火墙和IDS的渗透测试,但您可以在网络中使用此工具来查找安全错误。您还可以使用此工具来测试您的网络是否免受 DOS 攻击。值得注意的是,它可以让您完全控制网卡。它支持 ARP、BPDU 或 PVST、CDP、LLDP、IP、IGMP、UDP、TCP(无状态)、ICMP(部分)、DNS、RTP、RTP 以及可选的用于抖动测量的 RX 模式、系统日志协议。
下载 Mausezahn:
15. EIGRP 工具
这是 EIGRP 数据包生成器和嗅探器的组合。开发它是为了测试 EIGRP 路由协议的安全性。要使用此工具,您需要了解第 3 层 EIGRP 协议。这个工具也是一个带有命令行界面的开源工具。它可以在 Linux、Mac OS 和 BSD 平台上使用。
下载 EIGRP 工具:
网页内容抓取工具(网页内容抓取工具应该怎么选择(一)_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-06 09:05
网页内容抓取工具应该怎么选择一般来说,网页内容抓取工具会把抓取的内容统一整理成标准格式的代码(ejs之类的)后供用户下载,不然用户打开网页到自己所需的html内容少之又少。举个例子,一个网页叫做,可是页面内容有很多,我们要下载一个”前面九页的“接近40万的“页”都是需要操作文件夹内部的内容:"ext""/"{pageurl:""}.../",然后用http协议下载这些”页“:"ext4/remote/referer",所以我们需要一个适用于抓取这类大型规模页面的工具,然后以此工具为基础开发一个bash脚本.最后把自己写好的exec/php等一堆代码汇总成一个完整的web应用程序,并添加对应的前端服务器去做页面交互来直接打开一个html文件。
这样才不算太费劲,就相当于在线翻书了抓取工具因为也可以用于从无法获取这种loading的中下载内容,所以不需要那么麻烦的整理html-web-script,可以简单的统一转换成ast,来进行下载:syslog-hsyslog.php注意bash脚本里有点点问题,不可避免的会出现php版本比gcc差一点(这个和apt源头不同之类的)。
speedo还有一个自带工具,叫datadownloader,可以下载到手机,平板,pc等数据网络受限的上来打开网页,甚至和手机上重复使用,所以我更倾向于数据下载集中管理,譬如aliyun的srx网站那样。但是这些方法都不太方便用户在多间切换和寻找,因为每次下载依然会得到一次部署img的操作。
我习惯是手机爬到的content一次从无限上下载一次,然后过几秒钟再下一次,如果最近两个都在访问的话,就很有意思。但有的时候也可以手机上下下来的图片直接用pocket粘贴到固定的url(主要是pocket不支持多平台)来下载url。 查看全部
网页内容抓取工具(网页内容抓取工具应该怎么选择(一)_光明网)
网页内容抓取工具应该怎么选择一般来说,网页内容抓取工具会把抓取的内容统一整理成标准格式的代码(ejs之类的)后供用户下载,不然用户打开网页到自己所需的html内容少之又少。举个例子,一个网页叫做,可是页面内容有很多,我们要下载一个”前面九页的“接近40万的“页”都是需要操作文件夹内部的内容:"ext""/"{pageurl:""}.../",然后用http协议下载这些”页“:"ext4/remote/referer",所以我们需要一个适用于抓取这类大型规模页面的工具,然后以此工具为基础开发一个bash脚本.最后把自己写好的exec/php等一堆代码汇总成一个完整的web应用程序,并添加对应的前端服务器去做页面交互来直接打开一个html文件。
这样才不算太费劲,就相当于在线翻书了抓取工具因为也可以用于从无法获取这种loading的中下载内容,所以不需要那么麻烦的整理html-web-script,可以简单的统一转换成ast,来进行下载:syslog-hsyslog.php注意bash脚本里有点点问题,不可避免的会出现php版本比gcc差一点(这个和apt源头不同之类的)。
speedo还有一个自带工具,叫datadownloader,可以下载到手机,平板,pc等数据网络受限的上来打开网页,甚至和手机上重复使用,所以我更倾向于数据下载集中管理,譬如aliyun的srx网站那样。但是这些方法都不太方便用户在多间切换和寻找,因为每次下载依然会得到一次部署img的操作。
我习惯是手机爬到的content一次从无限上下载一次,然后过几秒钟再下一次,如果最近两个都在访问的话,就很有意思。但有的时候也可以手机上下下来的图片直接用pocket粘贴到固定的url(主要是pocket不支持多平台)来下载url。
网页内容抓取工具(网页内容抓取工具(百度爬虫工具/木马下载工具))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-05 00:04
网页内容抓取工具百度爬虫工具条件:http代理,个人自己租的代理,挂的高速代理然后trace一下获取数据(ps:这里是当一个网页所有东西都访问结束,成功记录trace)蜘蛛工具/木马下载工具小绝代码:我用的绝代码。刷新headers代码截图工具(需要下载大图):mailto:(@这个host过期了就@不了)重要的文件传输工具,超级好用:重要的文件传输工具,超级好用:。
vba能干什么活?现在还有多少人用vba的
从爬虫转向web领域
如果不懂编程和数据库的话,
免费可编辑的文档,比如网页,ppt,博客。报告,源代码。
access
浏览器下载工具,国内国外基本都有。看到一篇写的不错的文章,
数据库,likemysql
传统excelfoxbase...然后可以用mysql(php开发..)mssql/oracle/mysqlserver/db2等sqlserver很坑
某某网站留言板上有多少人写留言,
uiwebview这个标准答案应该得分很多次十倍。
感觉这个问题很奇怪!就好像问,如何对付人类,问题是,人类这么弱智,
名侦探柯南搜集几千张搜集过的时装照,照着某个衣服做!打赌是人做的, 查看全部
网页内容抓取工具(网页内容抓取工具(百度爬虫工具/木马下载工具))
网页内容抓取工具百度爬虫工具条件:http代理,个人自己租的代理,挂的高速代理然后trace一下获取数据(ps:这里是当一个网页所有东西都访问结束,成功记录trace)蜘蛛工具/木马下载工具小绝代码:我用的绝代码。刷新headers代码截图工具(需要下载大图):mailto:(@这个host过期了就@不了)重要的文件传输工具,超级好用:重要的文件传输工具,超级好用:。
vba能干什么活?现在还有多少人用vba的
从爬虫转向web领域
如果不懂编程和数据库的话,
免费可编辑的文档,比如网页,ppt,博客。报告,源代码。
access
浏览器下载工具,国内国外基本都有。看到一篇写的不错的文章,
数据库,likemysql
传统excelfoxbase...然后可以用mysql(php开发..)mssql/oracle/mysqlserver/db2等sqlserver很坑
某某网站留言板上有多少人写留言,
uiwebview这个标准答案应该得分很多次十倍。
感觉这个问题很奇怪!就好像问,如何对付人类,问题是,人类这么弱智,
名侦探柯南搜集几千张搜集过的时装照,照着某个衣服做!打赌是人做的,
网页内容抓取工具(WebScraperMac版可以快速提取与某个网页(软件特色) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-02 04:05
)
WebScraper for Mac 是专为 Mac 系统设计的 网站 数据抓取工具。使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。 Scraper 还可以提取动态加载或使用 JavaScript 生成的数据等,使用 webscraper mac 版可以快速提取与特定网页相关的信息,包括文本内容。
软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
软件功能
1、快速轻松地扫描网站
大量的提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、易于导出-选择您想要的列
3、输出为 csv 或 json
4、将所有图像下载到文件夹/采集并导出所有链接的新选项
5、输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、专为现代网络设计
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。拿到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能想尝试将数据保存到 CouchDB 中。
查看全部
网页内容抓取工具(WebScraperMac版可以快速提取与某个网页(软件特色)
)
WebScraper for Mac 是专为 Mac 系统设计的 网站 数据抓取工具。使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。 Scraper 还可以提取动态加载或使用 JavaScript 生成的数据等,使用 webscraper mac 版可以快速提取与特定网页相关的信息,包括文本内容。
软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
软件功能
1、快速轻松地扫描网站
大量的提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、易于导出-选择您想要的列
3、输出为 csv 或 json
4、将所有图像下载到文件夹/采集并导出所有链接的新选项
5、输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、专为现代网络设计
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。拿到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能想尝试将数据保存到 CouchDB 中。
网页内容抓取工具(一个handyparser(不推荐)(推荐simer4+sonarqube))
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-11-28 17:11
网页内容抓取工具1.segmentfault;2.segmentfault开发者博客;3.segmentfault知乎;4.掘金;5.babel-polyfill;6.webpack-cli;7.responsive;8.node-sass-configs;9.react-sass-polyfill。我主要用的是babel和responsive两个。
react-sass不是前端sass这个库...
,加油
七牛云不错
webpack可以用来做打包工具,不过好像只支持package.json里传了一些bundle,比如img,
urban-alias,如果你喜欢读一些android的源码,
当然是《这样追我女神》
nodejs+expresswebpack+promise
segmentfault
安装nodejs:yarnrequirejs需要版本高webpack
用正则去google,能告诉你最新的解决方案,在中国这个大环境下。
一个handyparser(不推荐)nodejs(推荐simer4+sonarqube)npmhttppostwithpromise
jquery基础教程pureajax利用ajax的nodejs反向代理模拟请求
reactsasscssjsjquery.
简单来说,
nodejskoapm2droop
不要在最终webpages的基础上解决实际问题
我觉得没必要用python,samba和rmi是首选。
高考算吗?
web.go或者objectoo 查看全部
网页内容抓取工具(一个handyparser(不推荐)(推荐simer4+sonarqube))
网页内容抓取工具1.segmentfault;2.segmentfault开发者博客;3.segmentfault知乎;4.掘金;5.babel-polyfill;6.webpack-cli;7.responsive;8.node-sass-configs;9.react-sass-polyfill。我主要用的是babel和responsive两个。
react-sass不是前端sass这个库...
,加油
七牛云不错
webpack可以用来做打包工具,不过好像只支持package.json里传了一些bundle,比如img,
urban-alias,如果你喜欢读一些android的源码,
当然是《这样追我女神》
nodejs+expresswebpack+promise
segmentfault
安装nodejs:yarnrequirejs需要版本高webpack
用正则去google,能告诉你最新的解决方案,在中国这个大环境下。
一个handyparser(不推荐)nodejs(推荐simer4+sonarqube)npmhttppostwithpromise
jquery基础教程pureajax利用ajax的nodejs反向代理模拟请求
reactsasscssjsjquery.
简单来说,
nodejskoapm2droop
不要在最终webpages的基础上解决实际问题
我觉得没必要用python,samba和rmi是首选。
高考算吗?
web.go或者objectoo
网页内容抓取工具(WebScrapermac版:WebScraperforMac软件介绍Mac版功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-27 21:21
WebScraper for Mac 是专为 Mac 系统设计的 网站 数据抓取工具。使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。 Scraper还可以提取并使用JavaScript动态加载或生成Data等,使用mac版webscraper可以快速提取与特定网页相关的信息,包括文本内容。
WebScraper mac 版:
WebScraper for Mac 软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper for Mac 软件功能
1、快速轻松地扫描网站
许多提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、易于导出-选择您想要的列
3、输出为 csv 或 json
4、将所有图像下载到文件夹/采集并导出所有链接的新选项
5、输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
WebScraper for Mac 功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、专为现代网络设计
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。拿到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能想尝试将数据保存到 CouchDB 中。返回搜狐查看更多 查看全部
网页内容抓取工具(WebScrapermac版:WebScraperforMac软件介绍Mac版功能介绍)
WebScraper for Mac 是专为 Mac 系统设计的 网站 数据抓取工具。使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。 Scraper还可以提取并使用JavaScript动态加载或生成Data等,使用mac版webscraper可以快速提取与特定网页相关的信息,包括文本内容。
WebScraper mac 版:
WebScraper for Mac 软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper for Mac 软件功能
1、快速轻松地扫描网站
许多提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、易于导出-选择您想要的列
3、输出为 csv 或 json
4、将所有图像下载到文件夹/采集并导出所有链接的新选项
5、输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
WebScraper for Mac 功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、专为现代网络设计
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。拿到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能想尝试将数据保存到 CouchDB 中。返回搜狐查看更多
网页内容抓取工具(中国互联网、移动互联网的数据获取的难度在不断提升)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-27 21:20
中国互联网和移动互联网的规模急剧增长,每天产生无数的信息。采集 网页中收录海量信息的数据,然后在工作和生活中使用已经变得非常普遍,也演变成大数据时代的趋势。
随着信息量的增加和网页结构的复杂化,数据获取的难度也在不断增加。对于以往数据量简单、量小的问题,可以通过手动复制粘贴轻松采集。例如,为了丰富我们的博客或者展示一篇学术报告,我们会从网络、期刊、图片等中提取一些文章。但是现在我们对数据的使用变得更加广泛。企业需要大量数据来分析业务发展趋势,挖掘潜在机会,做出正确决策;政府需要多方面了解民意,推动服务转型;医疗、教育、金融……没有数据,都无法实现快速发展。
这些数据大部分来自公共互联网,来自人们在网页上输入的大量文本、图片和其他具有潜在价值的信息。由于信息和数据量大,已经无法通过采集手动获取,因此网络爬虫工具进入了人们的视野,取代手动采集成为数据获取的最新捷径.
目前用户量较大的网络爬虫工具有两种。一种是源码分析型,通过HTTP协议直接请求网页的源码并设置采集的规则,实现网页数据的抓取,无论是图片,文本和文件都可以爬了。这种爬虫工具的优点是稳定,速度非常快。用户需要了解网页源代码的相关知识,然后在爬虫工具上进行设置。该工具去了采集。现在流行的抓取工具还收录了更多的功能,比如优采云采集器中的数据替换、过滤、去重等处理和数据发布;此外,优采云采集器还支持二级代理服务器,
另一种是利用特定的网页元素定位和爬虫引擎来模拟人们打开网页并点击网页内容的思维,采集内容已经被浏览器可视化呈现。它的优势在于它的可视化和灵活性,可能没有优采云采集器类型的爬虫那么快,但是更容易处理复杂的网页,比如优采云@中的另一个产品> 系列优采云浏览器。这两种工具各有优势。用户可以根据自己的需要进行选择。对于更高的爬虫需求,两种软件可以一起使用。为方便对接,可以使用两个相同品牌的软件进行组合。
有了网络爬虫工具,图形数据甚至压缩文件、音频等数据的获取变得更加简单,正如人类的每一项伟大发明都会引领时代的进步,大数据时代的大趋势也需要我们与时俱进,用智慧控制行为,用数据赢得未来。而在获取数据方面,网络爬虫工具将带来真正的高效率。 查看全部
网页内容抓取工具(中国互联网、移动互联网的数据获取的难度在不断提升)
中国互联网和移动互联网的规模急剧增长,每天产生无数的信息。采集 网页中收录海量信息的数据,然后在工作和生活中使用已经变得非常普遍,也演变成大数据时代的趋势。
随着信息量的增加和网页结构的复杂化,数据获取的难度也在不断增加。对于以往数据量简单、量小的问题,可以通过手动复制粘贴轻松采集。例如,为了丰富我们的博客或者展示一篇学术报告,我们会从网络、期刊、图片等中提取一些文章。但是现在我们对数据的使用变得更加广泛。企业需要大量数据来分析业务发展趋势,挖掘潜在机会,做出正确决策;政府需要多方面了解民意,推动服务转型;医疗、教育、金融……没有数据,都无法实现快速发展。
这些数据大部分来自公共互联网,来自人们在网页上输入的大量文本、图片和其他具有潜在价值的信息。由于信息和数据量大,已经无法通过采集手动获取,因此网络爬虫工具进入了人们的视野,取代手动采集成为数据获取的最新捷径.
目前用户量较大的网络爬虫工具有两种。一种是源码分析型,通过HTTP协议直接请求网页的源码并设置采集的规则,实现网页数据的抓取,无论是图片,文本和文件都可以爬了。这种爬虫工具的优点是稳定,速度非常快。用户需要了解网页源代码的相关知识,然后在爬虫工具上进行设置。该工具去了采集。现在流行的抓取工具还收录了更多的功能,比如优采云采集器中的数据替换、过滤、去重等处理和数据发布;此外,优采云采集器还支持二级代理服务器,
另一种是利用特定的网页元素定位和爬虫引擎来模拟人们打开网页并点击网页内容的思维,采集内容已经被浏览器可视化呈现。它的优势在于它的可视化和灵活性,可能没有优采云采集器类型的爬虫那么快,但是更容易处理复杂的网页,比如优采云@中的另一个产品> 系列优采云浏览器。这两种工具各有优势。用户可以根据自己的需要进行选择。对于更高的爬虫需求,两种软件可以一起使用。为方便对接,可以使用两个相同品牌的软件进行组合。
有了网络爬虫工具,图形数据甚至压缩文件、音频等数据的获取变得更加简单,正如人类的每一项伟大发明都会引领时代的进步,大数据时代的大趋势也需要我们与时俱进,用智慧控制行为,用数据赢得未来。而在获取数据方面,网络爬虫工具将带来真正的高效率。
网页内容抓取工具(百度搜索引擎爬虫如何抓取数据?工具怎么样?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-23 06:03
网页内容抓取工具,yjango,大家可以下载尝试下,现在大家做网站的,或者企业做b2b网站,爬虫抓取工具是不可少的。b2b网站一般都会需要查询黄页的信息,不然公司就知道这个地方有人家在卖东西,买东西的。所以是需要抓取黄页信息的,
搜索引擎这块的。下个beebee,抓一些黄页,汽车行业,
百度,谷歌等搜索引擎爬虫。黄页其实不必要爬。
爬虫工具是不是要有的,数据获取工具也是要有的。
爬虫工具类似于百度,技术起步的早,人员占大部分。数据获取工具类似于比如:百度统计,统计,阿里指数,微博指数等,人占小部分。
可能涉及性太广了,我这不只抓简历爬虫,可能还要抓大街网.可能要用浏览器爬虫,可能要用flash,但总归没有大众化的爬虫工具.
百度搜索引擎爬虫一些企业或者个人经常使用百度提供的爬虫服务,但很多数据抓取工具难以满足需求,怎么才能高效的自动抓取数据呢?下面就给大家介绍下一些市面上比较优秀的爬虫工具。百度提供一些常用爬虫工具,一般采用三种方式:个人自制+百度推荐+购买、工作流程图:个人制作爬虫,企业购买了,出于对爬虫扩展性以及网站质量的考虑,企业需要配置特定场景下的大量爬虫。
二.在线处理数据服务使用在线数据获取或许你会觉得很麻烦,爬虫工具类似于爬虫工具的操作是异常麻烦的,甚至说专人调度效率并不高。但如果配置好一套在线数据接口,再配置合适爬虫,就能大大提高效率。有了数据库后,企业可以爬取大量的网页以及做为仓库管理,还可以批量爬取网站多个页面,减少人工、审核、安全、等等一系列工作。
三.技术规范scrapy这是一个全功能的高性能pythonweb服务器爬虫框架,采用了definedformat标准和scrapyd模式。整个框架基于python语言设计,并且有很多scrapyd特性,如definedformat、requestapi等,帮助大家从多台不同爬虫服务器爬取可用的网页。同时配置scrapy的pipelines,帮助你快速定制爬虫,如requestpipeline、pipelinerewrite、requestdbapi等。
此外还有一些简单的python爬虫,大部分只是提供个python文件供你上传或者下载。不过使用python写成的爬虫只能是爬虫框架中的一些高级功能,例如文件上传等,其他如模拟浏览器登录、保存pdf文件到本地等一般的功能还是无法实现。四.网页代理点击代理的下载或者欢迎中可以看到怎么使用这些代理工具。一般来说大公司,这些scrapy工具会统一收费,每台web服务器才几毛或者几块钱。不过代理通常不是长。 查看全部
网页内容抓取工具(百度搜索引擎爬虫如何抓取数据?工具怎么样?)
网页内容抓取工具,yjango,大家可以下载尝试下,现在大家做网站的,或者企业做b2b网站,爬虫抓取工具是不可少的。b2b网站一般都会需要查询黄页的信息,不然公司就知道这个地方有人家在卖东西,买东西的。所以是需要抓取黄页信息的,
搜索引擎这块的。下个beebee,抓一些黄页,汽车行业,
百度,谷歌等搜索引擎爬虫。黄页其实不必要爬。
爬虫工具是不是要有的,数据获取工具也是要有的。
爬虫工具类似于百度,技术起步的早,人员占大部分。数据获取工具类似于比如:百度统计,统计,阿里指数,微博指数等,人占小部分。
可能涉及性太广了,我这不只抓简历爬虫,可能还要抓大街网.可能要用浏览器爬虫,可能要用flash,但总归没有大众化的爬虫工具.
百度搜索引擎爬虫一些企业或者个人经常使用百度提供的爬虫服务,但很多数据抓取工具难以满足需求,怎么才能高效的自动抓取数据呢?下面就给大家介绍下一些市面上比较优秀的爬虫工具。百度提供一些常用爬虫工具,一般采用三种方式:个人自制+百度推荐+购买、工作流程图:个人制作爬虫,企业购买了,出于对爬虫扩展性以及网站质量的考虑,企业需要配置特定场景下的大量爬虫。
二.在线处理数据服务使用在线数据获取或许你会觉得很麻烦,爬虫工具类似于爬虫工具的操作是异常麻烦的,甚至说专人调度效率并不高。但如果配置好一套在线数据接口,再配置合适爬虫,就能大大提高效率。有了数据库后,企业可以爬取大量的网页以及做为仓库管理,还可以批量爬取网站多个页面,减少人工、审核、安全、等等一系列工作。
三.技术规范scrapy这是一个全功能的高性能pythonweb服务器爬虫框架,采用了definedformat标准和scrapyd模式。整个框架基于python语言设计,并且有很多scrapyd特性,如definedformat、requestapi等,帮助大家从多台不同爬虫服务器爬取可用的网页。同时配置scrapy的pipelines,帮助你快速定制爬虫,如requestpipeline、pipelinerewrite、requestdbapi等。
此外还有一些简单的python爬虫,大部分只是提供个python文件供你上传或者下载。不过使用python写成的爬虫只能是爬虫框架中的一些高级功能,例如文件上传等,其他如模拟浏览器登录、保存pdf文件到本地等一般的功能还是无法实现。四.网页代理点击代理的下载或者欢迎中可以看到怎么使用这些代理工具。一般来说大公司,这些scrapy工具会统一收费,每台web服务器才几毛或者几块钱。不过代理通常不是长。
网页内容抓取工具(如何从网站爬网数据中获取结构化数据?() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-22 23:17
)
原创来源:作品(从 网站 抓取数据的 3 种最佳方式)/ 网站 名称(Octoparse)
原创链接:从网站抓取数据的最佳 3 种方法
这几年,对爬取数据的需求越来越大。爬取的数据可用于不同领域的评估或预测。在这里,我想谈谈我们可以用来从网站 中抓取数据的三种方法。
1.使用网站API
许多大型社交媒体网站,例如 Facebook、Twitter、Instagram、StackOverflow,都提供 API 供用户访问其数据。有时,您可以选择官方 API 来获取结构化数据。如下面的 Facebook Graph API 所示,您需要选择要查询的字段,然后对数据进行排序、执行 URL 查找、发出请求等。要了解更多信息,请参阅 /docs/graph-api/using-graph-api。
2.创建自己的搜索引擎
但是,并非所有 网站 都为用户提供 API。一些网站由于技术限制或其他原因拒绝提供任何公共API。有人可能会提出RSS提要,但由于它们的使用受到限制,我不会对其提出建议或评论。在这种情况下,我想讨论的是,我们可以构建自己的爬虫来处理这种情况。
搜索引擎是如何工作的?换句话说,爬虫是一种生成可以由提取程序提供的 URL 列表的方法。 爬虫可以定义为查找 URL 的工具。首先,您需要为爬虫提供一个要启动的网页,它们将跟踪该页面上的所有这些链接。然后,这个过程将继续循环。
然后,我们可以继续构建自己的爬虫。众所周知,Python是一门开源的编程语言,你可以找到很多有用的函数库。在这里,我推荐使用 BeautifulSoup(Python 库),因为它易于使用且具有许多直观的字符。更准确地说,我将使用两个 Python 模块来抓取数据。
BeautifulSoup 无法为我们获取网页。这就是我将 urllib2 与 BeautifulSoup 库结合使用的原因。然后,我们需要处理 HTML 标记以找到页面标记和右侧表格中的所有链接。之后,遍历每一行 (tr),然后将 tr (td) 的每个元素分配给一个变量并将其附加到列表中。首先让我们看一下表格的HTML结构(我不会从表格标题中提取信息)。
通过采用这种方法,您的搜索引擎是定制的。它可以处理API提取中遇到的某些困难。您可以使用代理来防止它被某些网站 等阻止,整个过程都在您的控制之下。这种方法对于具有编码技能的人来说应该是有意义的。您抓取的数据框应如下图所示。
3.使用现成的爬虫工具
但是,自行以编程方式抓取 网站 可能会很耗时。对于没有任何编码技能的人来说,这将是一项艰巨的任务。因此,我想介绍一些搜索引擎工具。
八度分析
Octoparse 是一个强大的基于 Visual Windows 的 Web 数据搜索器。用户可以通过其简单友好的用户界面轻松掌握该工具。要使用它,您需要在本地桌面上下载此应用程序。
如下图所示,您可以在 Workflow Designer 面板中单击并拖动这些块来自定义您自己的任务。Octoparse 提供两种版本的爬虫服务订阅计划,免费版和付费版。两者都可以满足用户的基本爬取或爬取需求。使用免费版本,您可以在本地运行任务。
如果您从免费版本切换到付费版本,您可以通过将任务上传到云平台来使用基于云的服务。6到14台云服务器将同时以更高的速度运行您的任务,并执行更大范围的爬行。此外,您可以使用 Octoparse 的匿名代理功能自动提取数据,不留任何痕迹。这个功能可以轮流使用大量的IP,可以防止你被某些网站屏蔽。这是一个介绍 Octoparse 云提取的视频。
Octoparse 还提供 API 以将您的系统实时连接到您抓取的数据。您可以将 Octoparse 数据导入您自己的数据库,也可以使用 API 请求访问您的帐户数据。完成任务配置后,您可以将数据导出为各种格式,如CSV、Excel、HTML、TXT 和数据库(MySQL、SQL Server 和Oracle)。
进口
Import.io 也被称为网络爬虫,涵盖所有不同层次的搜索需求。它提供了一个神奇的工具,无需任何培训即可将站点转换为表格。如果需要抓取更复杂的网站,建议用户下载自己的桌面应用。构建 API 后,他们将提供许多简单的集成选项,例如 Google Sheets、Plot.ly、Excel 以及 GET 和 POST 请求。当您认为所有这些都伴随着终身免费的价格标签和强大的支持团队时,import.io 无疑是那些寻找结构化数据的人的第一选择。它们还为寻求更大或更复杂数据提取的公司提供企业级支付选项。
本善达
Mozenda 是另一个用户友好的网络数据提取器。它有一个指向用户的点击式 UI,无需任何编码技能即可使用。Mozenda 还消除了自动化和发布提取数据的麻烦。一次告诉Mozenda你想要什么数据,然后不管你需要多少次都可以得到。此外,它还允许使用 REST API 进行高级编程,用户可以直接连接 Mozenda 帐户。它还提供基于云的服务和 IP 轮换。
刮框
SEO 专家、在线营销人员甚至垃圾邮件发送者都应该非常熟悉 ScrapeBox,它具有非常人性化的界面。用户可以轻松地从网站 采集数据以获取电子邮件、查看页面排名、验证工作代理和RSS 提交。通过使用数以千计的轮换代理,您将能够隐藏竞争对手的网站 关键字,对.gov网站 进行研究,采集数据并发表评论而不会被阻止或检测到。
谷歌网络爬虫插件
如果人们只是想以简单的方式抓取数据,我建议您选择 Google Web Scraper 插件。它是一种基于浏览器的网页抓取工具,其工作方式类似于 Firefox 的 Outwit Hub。您可以将其作为扩展下载并安装在浏览器中。您需要突出显示要抓取的数据字段,右键单击并选择“Scrape like...”。与您突出显示的内容类似的任何内容都将显示在准备导出的表格中,并且与 Google Docs 兼容。最新版本的电子表格仍有一些错误。虽然操作简单,应该会吸引所有用户的注意力,但它无法抓取图像和抓取大量数据。
查看全部
网页内容抓取工具(如何从网站爬网数据中获取结构化数据?()
)
原创来源:作品(从 网站 抓取数据的 3 种最佳方式)/ 网站 名称(Octoparse)
原创链接:从网站抓取数据的最佳 3 种方法
这几年,对爬取数据的需求越来越大。爬取的数据可用于不同领域的评估或预测。在这里,我想谈谈我们可以用来从网站 中抓取数据的三种方法。
1.使用网站API
许多大型社交媒体网站,例如 Facebook、Twitter、Instagram、StackOverflow,都提供 API 供用户访问其数据。有时,您可以选择官方 API 来获取结构化数据。如下面的 Facebook Graph API 所示,您需要选择要查询的字段,然后对数据进行排序、执行 URL 查找、发出请求等。要了解更多信息,请参阅 /docs/graph-api/using-graph-api。
2.创建自己的搜索引擎
但是,并非所有 网站 都为用户提供 API。一些网站由于技术限制或其他原因拒绝提供任何公共API。有人可能会提出RSS提要,但由于它们的使用受到限制,我不会对其提出建议或评论。在这种情况下,我想讨论的是,我们可以构建自己的爬虫来处理这种情况。
搜索引擎是如何工作的?换句话说,爬虫是一种生成可以由提取程序提供的 URL 列表的方法。 爬虫可以定义为查找 URL 的工具。首先,您需要为爬虫提供一个要启动的网页,它们将跟踪该页面上的所有这些链接。然后,这个过程将继续循环。
然后,我们可以继续构建自己的爬虫。众所周知,Python是一门开源的编程语言,你可以找到很多有用的函数库。在这里,我推荐使用 BeautifulSoup(Python 库),因为它易于使用且具有许多直观的字符。更准确地说,我将使用两个 Python 模块来抓取数据。
BeautifulSoup 无法为我们获取网页。这就是我将 urllib2 与 BeautifulSoup 库结合使用的原因。然后,我们需要处理 HTML 标记以找到页面标记和右侧表格中的所有链接。之后,遍历每一行 (tr),然后将 tr (td) 的每个元素分配给一个变量并将其附加到列表中。首先让我们看一下表格的HTML结构(我不会从表格标题中提取信息)。
通过采用这种方法,您的搜索引擎是定制的。它可以处理API提取中遇到的某些困难。您可以使用代理来防止它被某些网站 等阻止,整个过程都在您的控制之下。这种方法对于具有编码技能的人来说应该是有意义的。您抓取的数据框应如下图所示。
3.使用现成的爬虫工具
但是,自行以编程方式抓取 网站 可能会很耗时。对于没有任何编码技能的人来说,这将是一项艰巨的任务。因此,我想介绍一些搜索引擎工具。
八度分析
Octoparse 是一个强大的基于 Visual Windows 的 Web 数据搜索器。用户可以通过其简单友好的用户界面轻松掌握该工具。要使用它,您需要在本地桌面上下载此应用程序。
如下图所示,您可以在 Workflow Designer 面板中单击并拖动这些块来自定义您自己的任务。Octoparse 提供两种版本的爬虫服务订阅计划,免费版和付费版。两者都可以满足用户的基本爬取或爬取需求。使用免费版本,您可以在本地运行任务。
如果您从免费版本切换到付费版本,您可以通过将任务上传到云平台来使用基于云的服务。6到14台云服务器将同时以更高的速度运行您的任务,并执行更大范围的爬行。此外,您可以使用 Octoparse 的匿名代理功能自动提取数据,不留任何痕迹。这个功能可以轮流使用大量的IP,可以防止你被某些网站屏蔽。这是一个介绍 Octoparse 云提取的视频。
Octoparse 还提供 API 以将您的系统实时连接到您抓取的数据。您可以将 Octoparse 数据导入您自己的数据库,也可以使用 API 请求访问您的帐户数据。完成任务配置后,您可以将数据导出为各种格式,如CSV、Excel、HTML、TXT 和数据库(MySQL、SQL Server 和Oracle)。
进口
Import.io 也被称为网络爬虫,涵盖所有不同层次的搜索需求。它提供了一个神奇的工具,无需任何培训即可将站点转换为表格。如果需要抓取更复杂的网站,建议用户下载自己的桌面应用。构建 API 后,他们将提供许多简单的集成选项,例如 Google Sheets、Plot.ly、Excel 以及 GET 和 POST 请求。当您认为所有这些都伴随着终身免费的价格标签和强大的支持团队时,import.io 无疑是那些寻找结构化数据的人的第一选择。它们还为寻求更大或更复杂数据提取的公司提供企业级支付选项。
本善达
Mozenda 是另一个用户友好的网络数据提取器。它有一个指向用户的点击式 UI,无需任何编码技能即可使用。Mozenda 还消除了自动化和发布提取数据的麻烦。一次告诉Mozenda你想要什么数据,然后不管你需要多少次都可以得到。此外,它还允许使用 REST API 进行高级编程,用户可以直接连接 Mozenda 帐户。它还提供基于云的服务和 IP 轮换。
刮框
SEO 专家、在线营销人员甚至垃圾邮件发送者都应该非常熟悉 ScrapeBox,它具有非常人性化的界面。用户可以轻松地从网站 采集数据以获取电子邮件、查看页面排名、验证工作代理和RSS 提交。通过使用数以千计的轮换代理,您将能够隐藏竞争对手的网站 关键字,对.gov网站 进行研究,采集数据并发表评论而不会被阻止或检测到。
谷歌网络爬虫插件
如果人们只是想以简单的方式抓取数据,我建议您选择 Google Web Scraper 插件。它是一种基于浏览器的网页抓取工具,其工作方式类似于 Firefox 的 Outwit Hub。您可以将其作为扩展下载并安装在浏览器中。您需要突出显示要抓取的数据字段,右键单击并选择“Scrape like...”。与您突出显示的内容类似的任何内容都将显示在准备导出的表格中,并且与 Google Docs 兼容。最新版本的电子表格仍有一些错误。虽然操作简单,应该会吸引所有用户的注意力,但它无法抓取图像和抓取大量数据。
网页内容抓取工具(Java自定义抓取方式(6)-上海怡诺唐咨询)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-21 09:22
自定义爬取方法包括“从页面中提取数据”、“从浏览器中提取数据”和“生成数据”三部分。
1、从页面中提取数据
(1) 抓取元素的指定属性值:先选择InnerHtml和OuterHtml,检查要提取的属性值是否存在,然后选择捕获元素的指定属性值。例如,在流行的源码,id、class和href是A标签的属性,从下拉选项中选择要提取的属性名,提取该属性的属性值,演示如下:
(2)抓取文本:提取网页上显示的内容,可见的文本信息。
(3)抓图地址:一般用于抓图地址或Iframe地址,首先字段的Xpath定位到IMG标签或Iframe标签,提取src属性值。
(4) 抓取选中项的文本:尝试用圆形下拉框提取当前选中项的文本
(5)抓取该元素的OuterHtml,InnerHtml:提取网页源码
(6) 抓取值:一般用于抓取输入框的文本,首先通过字段的Xpath定位输入标签,并提取出value值。演示如下:
(7)获取超链接:首先通过字段的Xpath定位A标签,从A标签中提取href的属性值,演示如下:
2、从浏览器中提取数据
(1)页面URL:同添加其他特殊字段爬取当前页面URL效果
(2)页面标题:同添加其他特殊字段抓取当前页面的标题效果
(3)从页面源代码中抓取:可以直接使用正则表达式在网页源代码中提取匹配的数据
3、生成数据
(1) 生成固定值:同添加其他特殊字段产生固定值效果,常用于发布时设置发布用户名网站,发布到固定字段如部分。
(2)使用当前时间:同添加其他特殊字段使用当前时间效果,用于记录采集时间,此设置可能导致优采云采集器去重功能检测失败 查看全部
网页内容抓取工具(Java自定义抓取方式(6)-上海怡诺唐咨询)
自定义爬取方法包括“从页面中提取数据”、“从浏览器中提取数据”和“生成数据”三部分。
1、从页面中提取数据
(1) 抓取元素的指定属性值:先选择InnerHtml和OuterHtml,检查要提取的属性值是否存在,然后选择捕获元素的指定属性值。例如,在流行的源码,id、class和href是A标签的属性,从下拉选项中选择要提取的属性名,提取该属性的属性值,演示如下:
(2)抓取文本:提取网页上显示的内容,可见的文本信息。
(3)抓图地址:一般用于抓图地址或Iframe地址,首先字段的Xpath定位到IMG标签或Iframe标签,提取src属性值。
(4) 抓取选中项的文本:尝试用圆形下拉框提取当前选中项的文本
(5)抓取该元素的OuterHtml,InnerHtml:提取网页源码
(6) 抓取值:一般用于抓取输入框的文本,首先通过字段的Xpath定位输入标签,并提取出value值。演示如下:
(7)获取超链接:首先通过字段的Xpath定位A标签,从A标签中提取href的属性值,演示如下:
2、从浏览器中提取数据
(1)页面URL:同添加其他特殊字段爬取当前页面URL效果
(2)页面标题:同添加其他特殊字段抓取当前页面的标题效果
(3)从页面源代码中抓取:可以直接使用正则表达式在网页源代码中提取匹配的数据
3、生成数据
(1) 生成固定值:同添加其他特殊字段产生固定值效果,常用于发布时设置发布用户名网站,发布到固定字段如部分。
(2)使用当前时间:同添加其他特殊字段使用当前时间效果,用于记录采集时间,此设置可能导致优采云采集器去重功能检测失败
网页内容抓取工具(提取的数据还不能直接拿来用?文件还没有被下载?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-20 13:13
提取出来的数据不能直接使用吗?文件还没有下载?格式等不符合要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。让我依次为您介绍:
1、内容处理:对内容页面中提取的数据进行进一步的处理,如替换、标签过滤、分词等,我们可以同时添加多个操作,但这里需要注意的是,如果有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取内容为空:如果通过前面的规则无法准确提取提取内容或提取内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如
④ 字符截取:通过首尾字符串截取内容。适用于截取和调整提取的内容。
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换进行操作,则需要通过强大的正则表达式进行复杂的替换。
例如,“受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
⑥数据转换:包括结果简繁转换、结果繁简转换、自动转拼音和时间校正转换,共四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动汇总、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中的下载图片是指源代码中带有标准样式标签的图片地址。
例如,如果是直接的图片地址或不规则的图片源代码,采集器 将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:勾选后会下载源代码中标准样式的代码图片。
③检测文件真实地址但不下载:有时采集到达附件下载地址而不是真实下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或者将该记录标记为不在采集采集将在下次运行任务时重复。
网页抓取工具优采云采集器配备了一系列数据处理的优势在于,当我们只需要做一个小操作时,无需编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。返回搜狐查看更多 查看全部
网页内容抓取工具(提取的数据还不能直接拿来用?文件还没有被下载?)
提取出来的数据不能直接使用吗?文件还没有下载?格式等不符合要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。让我依次为您介绍:
1、内容处理:对内容页面中提取的数据进行进一步的处理,如替换、标签过滤、分词等,我们可以同时添加多个操作,但这里需要注意的是,如果有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取内容为空:如果通过前面的规则无法准确提取提取内容或提取内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如
④ 字符截取:通过首尾字符串截取内容。适用于截取和调整提取的内容。
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换进行操作,则需要通过强大的正则表达式进行复杂的替换。
例如,“受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
⑥数据转换:包括结果简繁转换、结果繁简转换、自动转拼音和时间校正转换,共四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动汇总、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中的下载图片是指源代码中带有标准样式标签的图片地址。
例如,如果是直接的图片地址或不规则的图片源代码,采集器 将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:勾选后会下载源代码中标准样式的代码图片。
③检测文件真实地址但不下载:有时采集到达附件下载地址而不是真实下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或者将该记录标记为不在采集采集将在下次运行任务时重复。
网页抓取工具优采云采集器配备了一系列数据处理的优势在于,当我们只需要做一个小操作时,无需编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。返回搜狐查看更多
网页内容抓取工具(URLExtractor内容提取wkhub永久钻石支付宝微信扫一扫(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-18 22:16
URL Extractor 是一个 Cocoa 应用程序,用于从文件中提取电子邮件地址和 URL,这些文件也可以通过搜索引擎找到。它可以从单个网页开始,浏览里面的所有链接,找到要提取的email或URL,并将所有链接保存在用户HD上。它还可以从任何嵌套级别的单个文件或 HD 上文件夹的所有内容中提取。完成后,它可以将 URL Extractor 文档保存到磁盘,其中收录特定文件夹或文件或网页的所有设置,可以重复使用。或者,提取的数据可以作为文本文件保存在磁盘上以供用户使用。
它允许用户指定要用作导航起点的网页列表,并使用交叉导航转到其他网页。您还可以指定一系列关键字;然后通过搜索引擎搜索与关键字相关的网页,并开始页面的交叉导航,采集网址。它可以在网页提取模式下无需用户交互的情况下导航数小时,提取在所有无人值守网页中找到的所有 URL;或从使用关键字的单个搜索引擎开始,在无限制的导航和 URL 中查看提取过程中的所有结果和链接页面。
特征
本站统一解压密码:
免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。
URL Extractor 内容提取
wkhub 永久钻石
支付宝扫一扫
微信扫一扫>打赏采集海报链接 查看全部
网页内容抓取工具(URLExtractor内容提取wkhub永久钻石支付宝微信扫一扫(组图))
URL Extractor 是一个 Cocoa 应用程序,用于从文件中提取电子邮件地址和 URL,这些文件也可以通过搜索引擎找到。它可以从单个网页开始,浏览里面的所有链接,找到要提取的email或URL,并将所有链接保存在用户HD上。它还可以从任何嵌套级别的单个文件或 HD 上文件夹的所有内容中提取。完成后,它可以将 URL Extractor 文档保存到磁盘,其中收录特定文件夹或文件或网页的所有设置,可以重复使用。或者,提取的数据可以作为文本文件保存在磁盘上以供用户使用。
它允许用户指定要用作导航起点的网页列表,并使用交叉导航转到其他网页。您还可以指定一系列关键字;然后通过搜索引擎搜索与关键字相关的网页,并开始页面的交叉导航,采集网址。它可以在网页提取模式下无需用户交互的情况下导航数小时,提取在所有无人值守网页中找到的所有 URL;或从使用关键字的单个搜索引擎开始,在无限制的导航和 URL 中查看提取过程中的所有结果和链接页面。
特征
https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />本站统一解压密码:
免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。
URL Extractor 内容提取
wkhub 永久钻石
支付宝扫一扫
微信扫一扫>打赏采集海报链接
网页内容抓取工具(网页表格数据采集器软件可立刻解决你的问题呢? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-11-18 22:15
)
亲,你有很多网页表单数据要复制吗,采集,抓紧吗?您是否正在为如何复制这些数百、数千甚至数万页的表格数据而烦恼?是不是觉得键盘打字、鼠标点击、效率低下太累太难了?重复枯燥的工作太让人抓狂了
, 有没有可以立即解决您的问题的软件?当你读到这些话的时候,我想告诉你,你已经看到了曙光,没错,就是这个页面给你介绍的软件——网页表单数据采集器。
web表单数据采集器软件支持在一个网站上连续无限页面批量采集相同表单数据,支持采集@指定表单数据在一个采集 page>,也支持采集一个页面中具有通用数据的多个表数据,采集可以根据网页上的“下一页”等链接的后续页面进行无限采集@ >,也可以根据网址采集中的页数来指定连续页中的表格数据,或者根据您自己指定的网址列表。可以采集,并且可以自动过滤隐藏的干扰码,采集的结果可以显示为文本表格,另存为文本,
下面是我们的软件界面截图,软件下载地址如下
采集 支持单格数据链接
仅支持采集指定的字段
该软件可以连续或定时采集指定与网站上来回关联的标准二维表,操作非常简单方便,用于网页的连续批量<需要的@文章采集,请在本店另选一款软件-网文采集大师。
网页表单数据采集器软件现已更新至V2.38版。最新版本的下载地址如下。请复制地址,用浏览器或其他下载工具下载。
关于本软件的更多信息,请查看软件官网论坛
web表单数据采集软件的使用也很简单。熟悉的话,表单采集 一键搞定。以下是使用该软件的简单步骤:
1、首先在地址栏中输入采集的网页地址。如果采集的网页已经在IE浏览器中打开过,这个地址会自动添加到软件的网址列表中。
2、 然后点击爬取测试按钮,网页中收录的表数和页眉信息会自动显示在软件左上角的列表框中,同时自动识别您可能想要抓取并选择此表。如果网页表单中有多个页面,并且网页中有“下一页”的链接,程序会自动在“根据链接或按钮关键字打开下一页”输入框中输入“下一页”。
3、从表数列表中选择要抓取的表。此时,“表格首行第一行”输入框的输入框中会显示表格左上角的文字或前三个文字。收录的字段(列)会显示在软件左侧的中间列表中(注意,您也可以点击“表格第一行第一部分”的标签,输入会变成“表格每一行的公共部分”判断表格是否收录某个字符串,用于识别网页中的表格,也可以输入为“所有表格中的序号”,输入表格序号表单列表框中显示的编号,并确定用于识别网页中表单的标记)。
4、 然后选择你要采集的表数据的字段(列)。如果不选中,则设置表采集的所有列。
5、选择是否要抓取表格的标题行,保存时是否显示表格行。如果web表单的字段中有链接,可以选择是否收录链接地址,如果是并且需要采集其链接地址,则不能同时选择收录标题行时间。
6、 如果你想让采集的表单数据只有一个网页,那么现在可以直接点击抓取表格。如果您不选择收录表格行,表格数据将以 CVS 格式保存。这种格式可以直接用微软EXCEL软件打开,转换成EXCEL格式。如果选择在前面收录表格行,表格数据会以TXT格式保存,可以用记事本软件打开查看。表行直接可用,也很清楚。
7、如果想让采集的表单数据有多个连续的页面,并且想要采集向下,那么请重新设置程序采集下一页并后续页面的方式可以是根据链接名称打开下一个页面。几乎大多数页面的链接名称都是“下一页”。您可以查看页面,找到后输入。如果页面没有下一页的链接,但是URL收录页数,那么你也可以根据URL中的页数选择打开。可以从前到后选择,比如从第1页到第10页。也可以从后到前选择,比如从第10页到第1页,在页码里输入就行了,
8、 然后选择定时采集或者等待网页打开加载采集后立即加载,定时采集是程序根据设定的小时间间隔判断打开如果页面中有你想要的表单,可以采集,页面加载后,采集只要采集的页面已经打开,程序就会马上着手采集,两者各有特点,看需要选择。
9、最后,只需点击抢表按钮,就可以泡杯咖啡出发啦!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入需要的信息不经过爬取测试等操作,直接点击爬取表格。
时间,一寸光阴,一寸金。寸金难买寸光阴。我们不能把有限的钱浪费在一些重复和无聊的工作上。有现成的软件。为什么不使用软件?再说了,现在的30元,你在菜市场什么都买不到。这么便宜的价格,你不能再犹豫了。如果您需要,请尽快开始。
下单时请在备注栏中填写邮箱地址和软件打开后显示的机器码。购买后,我们将向您发送正式版。如果需要,我们还可以为您进行远程演示操作。
如果现有方案不能满足您的需求,我们也可以支持方案定制。如果需要,请先增加费用。
406
客户的评论和不断的好评。尤其是这款软件还可以持续捕捉店铺评论和评论,以及宝贝销售记录。如果您需要采集已售出的婴儿数据,它带有一个已售出的婴儿数据管理器:
感谢您的好评,您的好评是对我不断升级完善本软件的最大支持
另外,购买本软件后,如果想要treeView和ListView数据采集器,也可以向楼主索取
查看全部
网页内容抓取工具(网页表格数据采集器软件可立刻解决你的问题呢?
)
亲,你有很多网页表单数据要复制吗,采集,抓紧吗?您是否正在为如何复制这些数百、数千甚至数万页的表格数据而烦恼?是不是觉得键盘打字、鼠标点击、效率低下太累太难了?重复枯燥的工作太让人抓狂了
, 有没有可以立即解决您的问题的软件?当你读到这些话的时候,我想告诉你,你已经看到了曙光,没错,就是这个页面给你介绍的软件——网页表单数据采集器。
web表单数据采集器软件支持在一个网站上连续无限页面批量采集相同表单数据,支持采集@指定表单数据在一个采集 page>,也支持采集一个页面中具有通用数据的多个表数据,采集可以根据网页上的“下一页”等链接的后续页面进行无限采集@ >,也可以根据网址采集中的页数来指定连续页中的表格数据,或者根据您自己指定的网址列表。可以采集,并且可以自动过滤隐藏的干扰码,采集的结果可以显示为文本表格,另存为文本,
下面是我们的软件界面截图,软件下载地址如下
采集 支持单格数据链接
仅支持采集指定的字段
该软件可以连续或定时采集指定与网站上来回关联的标准二维表,操作非常简单方便,用于网页的连续批量<需要的@文章采集,请在本店另选一款软件-网文采集大师。
网页表单数据采集器软件现已更新至V2.38版。最新版本的下载地址如下。请复制地址,用浏览器或其他下载工具下载。
关于本软件的更多信息,请查看软件官网论坛
web表单数据采集软件的使用也很简单。熟悉的话,表单采集 一键搞定。以下是使用该软件的简单步骤:
1、首先在地址栏中输入采集的网页地址。如果采集的网页已经在IE浏览器中打开过,这个地址会自动添加到软件的网址列表中。
2、 然后点击爬取测试按钮,网页中收录的表数和页眉信息会自动显示在软件左上角的列表框中,同时自动识别您可能想要抓取并选择此表。如果网页表单中有多个页面,并且网页中有“下一页”的链接,程序会自动在“根据链接或按钮关键字打开下一页”输入框中输入“下一页”。
3、从表数列表中选择要抓取的表。此时,“表格首行第一行”输入框的输入框中会显示表格左上角的文字或前三个文字。收录的字段(列)会显示在软件左侧的中间列表中(注意,您也可以点击“表格第一行第一部分”的标签,输入会变成“表格每一行的公共部分”判断表格是否收录某个字符串,用于识别网页中的表格,也可以输入为“所有表格中的序号”,输入表格序号表单列表框中显示的编号,并确定用于识别网页中表单的标记)。
4、 然后选择你要采集的表数据的字段(列)。如果不选中,则设置表采集的所有列。
5、选择是否要抓取表格的标题行,保存时是否显示表格行。如果web表单的字段中有链接,可以选择是否收录链接地址,如果是并且需要采集其链接地址,则不能同时选择收录标题行时间。
6、 如果你想让采集的表单数据只有一个网页,那么现在可以直接点击抓取表格。如果您不选择收录表格行,表格数据将以 CVS 格式保存。这种格式可以直接用微软EXCEL软件打开,转换成EXCEL格式。如果选择在前面收录表格行,表格数据会以TXT格式保存,可以用记事本软件打开查看。表行直接可用,也很清楚。
7、如果想让采集的表单数据有多个连续的页面,并且想要采集向下,那么请重新设置程序采集下一页并后续页面的方式可以是根据链接名称打开下一个页面。几乎大多数页面的链接名称都是“下一页”。您可以查看页面,找到后输入。如果页面没有下一页的链接,但是URL收录页数,那么你也可以根据URL中的页数选择打开。可以从前到后选择,比如从第1页到第10页。也可以从后到前选择,比如从第10页到第1页,在页码里输入就行了,
8、 然后选择定时采集或者等待网页打开加载采集后立即加载,定时采集是程序根据设定的小时间间隔判断打开如果页面中有你想要的表单,可以采集,页面加载后,采集只要采集的页面已经打开,程序就会马上着手采集,两者各有特点,看需要选择。
9、最后,只需点击抢表按钮,就可以泡杯咖啡出发啦!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入需要的信息不经过爬取测试等操作,直接点击爬取表格。
时间,一寸光阴,一寸金。寸金难买寸光阴。我们不能把有限的钱浪费在一些重复和无聊的工作上。有现成的软件。为什么不使用软件?再说了,现在的30元,你在菜市场什么都买不到。这么便宜的价格,你不能再犹豫了。如果您需要,请尽快开始。
下单时请在备注栏中填写邮箱地址和软件打开后显示的机器码。购买后,我们将向您发送正式版。如果需要,我们还可以为您进行远程演示操作。
如果现有方案不能满足您的需求,我们也可以支持方案定制。如果需要,请先增加费用。
406
客户的评论和不断的好评。尤其是这款软件还可以持续捕捉店铺评论和评论,以及宝贝销售记录。如果您需要采集已售出的婴儿数据,它带有一个已售出的婴儿数据管理器:
感谢您的好评,您的好评是对我不断升级完善本软件的最大支持
另外,购买本软件后,如果想要treeView和ListView数据采集器,也可以向楼主索取
网页内容抓取工具(JSP众筹管理系统.5开发java语言设计系统源码特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-15 20:22
一、 源码特点 JSP众筹管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统具有完整的源代码和数据库,系统主要采用B/S模式。发展。 二、功能介绍 前台主要功能:显示项目信息及项目周边相关信息 后台主要功能:(1)权限管理:添加、删除、修改、查看权限信息(2)用户管理:添加、删除、修改、查看用户信息(3)项目分类管理:添加、删除、修改、查看项目分类信息(4)项目管理:添加项目信息),删除、修改和查看(5)日志管理:添加、删除、修改和查看日志信息(6)项目支持管理:添加、删除、修改和查看项目支持信息(7)Project审核管理:添加、删除、修改和查看项目审核信息(8)报告管理:添加、删除、修改和查看报告信息(9)消息管理:对消息信息的添加、删除、修改和查看(8) 招生管理:添加、删除、修改和查看招生信息编队三、注意事项1、管理员账号:admin 密码:admin 数据库配置文件DBO.java2、开发环境为TOMCAT7.0,Myeclipse8.5,数据库为mysql,使用java语言开发。3、数据库文件名为jspfgongchou .mysql,系统名gongchou4、地址:xiangmu.jsp 查看全部
网页内容抓取工具(JSP众筹管理系统.5开发java语言设计系统源码特点)
一、 源码特点 JSP众筹管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统具有完整的源代码和数据库,系统主要采用B/S模式。发展。 二、功能介绍 前台主要功能:显示项目信息及项目周边相关信息 后台主要功能:(1)权限管理:添加、删除、修改、查看权限信息(2)用户管理:添加、删除、修改、查看用户信息(3)项目分类管理:添加、删除、修改、查看项目分类信息(4)项目管理:添加项目信息),删除、修改和查看(5)日志管理:添加、删除、修改和查看日志信息(6)项目支持管理:添加、删除、修改和查看项目支持信息(7)Project审核管理:添加、删除、修改和查看项目审核信息(8)报告管理:添加、删除、修改和查看报告信息(9)消息管理:对消息信息的添加、删除、修改和查看(8) 招生管理:添加、删除、修改和查看招生信息编队三、注意事项1、管理员账号:admin 密码:admin 数据库配置文件DBO.java2、开发环境为TOMCAT7.0,Myeclipse8.5,数据库为mysql,使用java语言开发。3、数据库文件名为jspfgongchou .mysql,系统名gongchou4、地址:xiangmu.jsp

