
网页内容抓取工具
网页内容抓取工具(登录百度站长平台使用抓取诊断工具换IP真的不是愁事)
网站优化 • 优采云 发表了文章 • 0 个评论 • 324 次浏览 • 2022-01-16 14:15
在和站长朋友私下交流中,站长说:怕改版改IP。每次我都别无选择,只能自己做。改版比较好,有改版工具可以用。换IP不知道怎么通知百度。
其实,登陆百度站长平台,使用刮痧诊断工具换IP,真的是一点都不省心。
爬虫诊断工具会检查网站与百度的连接是否畅通。如果站长发现IP信息还是旧的,可以通过“Error”通知百度搜索引擎更新IP,如下图:
重要提示:由于蜘蛛的能量有限,如果报错后网站IP仍然没有变化,站长可以多次尝试直到达到预期。
那么,爬虫诊断工具除了用于通知百度搜索引擎该站点已更改IP之外,还能做什么呢?
【诊断爬取的内容是否符合预期】比如在很多商品详情页中,价格信息是通过JavaScript输出的,对百度蜘蛛不友好,价格信息在搜索中难以应用。问题解决后,可以使用诊断工具再次抓取测试。
【判断网页是否添加了黑色链接和隐藏文字】网站被黑后添加的隐藏链接从网页表面无法观察到。这些链接可能只有在百度爬取时才会出现,可以通过爬取诊断工具获取来检查。
【邀请百度蜘蛛】如果网站有新页面或者页面内容已经更新,但是百度蜘蛛很长时间没有访问,可以通过爬虫诊断工具邀请百度蜘蛛快速爬取。
AAAFGGHTYHCGER 查看全部
网页内容抓取工具(登录百度站长平台使用抓取诊断工具换IP真的不是愁事)
在和站长朋友私下交流中,站长说:怕改版改IP。每次我都别无选择,只能自己做。改版比较好,有改版工具可以用。换IP不知道怎么通知百度。
其实,登陆百度站长平台,使用刮痧诊断工具换IP,真的是一点都不省心。
爬虫诊断工具会检查网站与百度的连接是否畅通。如果站长发现IP信息还是旧的,可以通过“Error”通知百度搜索引擎更新IP,如下图:

重要提示:由于蜘蛛的能量有限,如果报错后网站IP仍然没有变化,站长可以多次尝试直到达到预期。
那么,爬虫诊断工具除了用于通知百度搜索引擎该站点已更改IP之外,还能做什么呢?
【诊断爬取的内容是否符合预期】比如在很多商品详情页中,价格信息是通过JavaScript输出的,对百度蜘蛛不友好,价格信息在搜索中难以应用。问题解决后,可以使用诊断工具再次抓取测试。

【判断网页是否添加了黑色链接和隐藏文字】网站被黑后添加的隐藏链接从网页表面无法观察到。这些链接可能只有在百度爬取时才会出现,可以通过爬取诊断工具获取来检查。
【邀请百度蜘蛛】如果网站有新页面或者页面内容已经更新,但是百度蜘蛛很长时间没有访问,可以通过爬虫诊断工具邀请百度蜘蛛快速爬取。
AAAFGGHTYHCGER
网页内容抓取工具(优采云采集器编辑采集数据:您可以在本地可视化编辑已采集的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-01-16 14:14
优采云采集器是目前使用最多的互联网数据采集、处理、分析和挖掘软件。该软件以其灵活的配置和强大的性能,领先国内data采集产品,得到了众多用户的一致认可。
适用范围
1.网站编辑:打破编辑必须手动转载文章的传统现状,他们将有更多时间编辑和处理数据,工作效率更高。该程序可以与TRS等采集编辑系统完美结合,海量网站信息采集会更简单有效。
2.内网:打破内网信息单一、获取难的神话,内网也能体验到各种互联网信息。它可以解决与互联网隔离的军队等重要部门的互联网信息需求问题。
3.政府机构:实时跟踪,采集国内外新闻、政策法规、经济、行业等政府工作相关信息,解决政府主要问题网站地方层面的网站信息采集和整合问题。
4.企业应用:实时准确采集国内外新闻、行业新闻、科技文章。可以轻松进行数据集成,智能处理更快更高效,业务成本大大降低。
5.SEO人员或站长:更容易获取数据,可以快速增加网站信息量,可以更专注于优化和推广。
软件功能
1.支持所有编码格式的数据采集,你可以使用它采集worldwide文章。该程序还可以在编辑之间执行完美的转换。
2.多个接口;支持所有主流或非主流的cms、BBS、下载站等。通过系统的接口可以实现采集器和网站的完美结合。
3.无人值守工作:配置程序后,程序可以根据您的设置自动运行,无需人工干预。
4.本地编辑采集数据:您可以在本地直观地编辑采集数据。
5.采集内容测试功能:这是其他任何采集软件都无法比拟的,您可以直接查看结果并测试发布。
6.易管理:使用站点+任务模式管理采集节点,任务支持批量操作,管理更多数据轻松。
变更日志
1、调整列表页的重新排列方式,现在只会在同级列表页之间重新排列。
2、任务完成后增加运行统计预警功能(Email邮件警告)【终极版功能】
3、增加了对部分请求返回码不是200时配置采集的支持。
4、添加了将下载地址保存为 html 文件的支持。
5、二级代理服务,导入时添加代理类型,修复用户名密码显示错误。
6、发布配置页面,默认只显示当前选择的配置,加快任务加载时间。
7、修复命令行控制,closeapp参数无法自动关闭程序的问题。
8、修复未选中图片水印时无法裁剪图片的问题。
9、优化启动界面的加载方式,解决初始化界面卡顿的问题。
10、修复多行连接符收录“|”时无法检测到图片下载的问题 在配置中。
11、修复Excel导出数据时列顺序与字段顺序不一致的问题。
12、修复了从Excel导出数据时,某些收录数字的字段导出数据不正确的问题。
13、修复批量编辑任务时无法复制Json采集表达式的问题。 查看全部
网页内容抓取工具(优采云采集器编辑采集数据:您可以在本地可视化编辑已采集的数据)
优采云采集器是目前使用最多的互联网数据采集、处理、分析和挖掘软件。该软件以其灵活的配置和强大的性能,领先国内data采集产品,得到了众多用户的一致认可。
适用范围
1.网站编辑:打破编辑必须手动转载文章的传统现状,他们将有更多时间编辑和处理数据,工作效率更高。该程序可以与TRS等采集编辑系统完美结合,海量网站信息采集会更简单有效。
2.内网:打破内网信息单一、获取难的神话,内网也能体验到各种互联网信息。它可以解决与互联网隔离的军队等重要部门的互联网信息需求问题。
3.政府机构:实时跟踪,采集国内外新闻、政策法规、经济、行业等政府工作相关信息,解决政府主要问题网站地方层面的网站信息采集和整合问题。
4.企业应用:实时准确采集国内外新闻、行业新闻、科技文章。可以轻松进行数据集成,智能处理更快更高效,业务成本大大降低。
5.SEO人员或站长:更容易获取数据,可以快速增加网站信息量,可以更专注于优化和推广。
软件功能
1.支持所有编码格式的数据采集,你可以使用它采集worldwide文章。该程序还可以在编辑之间执行完美的转换。
2.多个接口;支持所有主流或非主流的cms、BBS、下载站等。通过系统的接口可以实现采集器和网站的完美结合。
3.无人值守工作:配置程序后,程序可以根据您的设置自动运行,无需人工干预。
4.本地编辑采集数据:您可以在本地直观地编辑采集数据。
5.采集内容测试功能:这是其他任何采集软件都无法比拟的,您可以直接查看结果并测试发布。
6.易管理:使用站点+任务模式管理采集节点,任务支持批量操作,管理更多数据轻松。
变更日志
1、调整列表页的重新排列方式,现在只会在同级列表页之间重新排列。
2、任务完成后增加运行统计预警功能(Email邮件警告)【终极版功能】
3、增加了对部分请求返回码不是200时配置采集的支持。
4、添加了将下载地址保存为 html 文件的支持。
5、二级代理服务,导入时添加代理类型,修复用户名密码显示错误。
6、发布配置页面,默认只显示当前选择的配置,加快任务加载时间。
7、修复命令行控制,closeapp参数无法自动关闭程序的问题。
8、修复未选中图片水印时无法裁剪图片的问题。
9、优化启动界面的加载方式,解决初始化界面卡顿的问题。
10、修复多行连接符收录“|”时无法检测到图片下载的问题 在配置中。
11、修复Excel导出数据时列顺序与字段顺序不一致的问题。
12、修复了从Excel导出数据时,某些收录数字的字段导出数据不正确的问题。
13、修复批量编辑任务时无法复制Json采集表达式的问题。
网页内容抓取工具(什么是网络DOM数据结构的分类及分类?网络爬虫种类)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-16 09:03
有许多类型的网络爬虫。以下是粗略的分类,并说明网页抓取/数据提取/信息提取工具包 MetaSeeker 属于哪一类爬虫。
如果按照部署在哪里来划分,可以分为:
1、服务器端:一般是多线程程序,同时下载多个目标HTML,可以用PHP、Java、Python(目前很流行)等来完成。一般综合搜索引擎的爬虫都是这样做的. 但是,如果对方讨厌爬虫,服务器的IP很可能会被封杀,服务器的IP不容易更改,消耗的带宽相当昂贵。
2.客户端:非常适合部署主题爬虫,或者聚焦爬虫。成为与谷歌、百度等竞争的综合搜索引擎的机会很小,而垂直搜索或比价服务或推荐引擎的机会要多得多。这种爬虫不会抓取所有页面,只抓取关注页面,只抓取页面上感兴趣的内容,例如提取黄页信息、商品价格信息、提取竞争对手广告信息等。这种类型的爬虫可以部署很多,而且可以非常具有攻击性,让对手难以阻挡。
网页抓取/数据提取/信息提取工具包 MetaSeeker 中的爬虫属于客户端爬虫(更详细的产品特性),可以低成本大批量部署。由于客户端IP地址是动态的,因此很难被针对网站屏蔽。
我们只讨论固定主题的爬虫。普通爬虫就简单多了,网上也有很多。如果分为如何提取数据,可以分为两类:
1.通过正则表达式提取内容。HTML 文件是文本文件。您可以直接使用正则表达式提取指定位置的内容。“指定地点”不一定是绝对定位。比如可以参考HTML标签定位,比较准确。
2.使用DOM提取内容,HTML文件先转换成DOM数据结构,然后遍历这个结构提取内容。
有人会问,为什么要用DOM的方式,然后转过来呢?DOM方法存在的原因有很多:第一,不需要自己做DOM结构的分析,有现成的库,编程不会变得复杂;其次,它可以实现非常复杂但灵活的定位规则,而正则表达式很难编写;第三,如果定位是考虑HTML文件的结构,用正则表达式解析不好,HTML文件经常出错。如果把这个任务交给一个现成的库,那就容易多了。第四,假设需要解析Javascript的内容,正则表达式是无能为力的。当然DOM方法本身是无能为力的,但是可以提取AJAX网站 通过使用某个平台的能力的内容。还有很多原因。
网页抓取/数据提取/信息提取工具包MetaSeeker中的爬虫采用DOM方式。只要 Firefox 看到它,它就会使用 Mozilla 平台的功能进行提取。 查看全部
网页内容抓取工具(什么是网络DOM数据结构的分类及分类?网络爬虫种类)
有许多类型的网络爬虫。以下是粗略的分类,并说明网页抓取/数据提取/信息提取工具包 MetaSeeker 属于哪一类爬虫。
如果按照部署在哪里来划分,可以分为:
1、服务器端:一般是多线程程序,同时下载多个目标HTML,可以用PHP、Java、Python(目前很流行)等来完成。一般综合搜索引擎的爬虫都是这样做的. 但是,如果对方讨厌爬虫,服务器的IP很可能会被封杀,服务器的IP不容易更改,消耗的带宽相当昂贵。
2.客户端:非常适合部署主题爬虫,或者聚焦爬虫。成为与谷歌、百度等竞争的综合搜索引擎的机会很小,而垂直搜索或比价服务或推荐引擎的机会要多得多。这种爬虫不会抓取所有页面,只抓取关注页面,只抓取页面上感兴趣的内容,例如提取黄页信息、商品价格信息、提取竞争对手广告信息等。这种类型的爬虫可以部署很多,而且可以非常具有攻击性,让对手难以阻挡。
网页抓取/数据提取/信息提取工具包 MetaSeeker 中的爬虫属于客户端爬虫(更详细的产品特性),可以低成本大批量部署。由于客户端IP地址是动态的,因此很难被针对网站屏蔽。
我们只讨论固定主题的爬虫。普通爬虫就简单多了,网上也有很多。如果分为如何提取数据,可以分为两类:
1.通过正则表达式提取内容。HTML 文件是文本文件。您可以直接使用正则表达式提取指定位置的内容。“指定地点”不一定是绝对定位。比如可以参考HTML标签定位,比较准确。
2.使用DOM提取内容,HTML文件先转换成DOM数据结构,然后遍历这个结构提取内容。
有人会问,为什么要用DOM的方式,然后转过来呢?DOM方法存在的原因有很多:第一,不需要自己做DOM结构的分析,有现成的库,编程不会变得复杂;其次,它可以实现非常复杂但灵活的定位规则,而正则表达式很难编写;第三,如果定位是考虑HTML文件的结构,用正则表达式解析不好,HTML文件经常出错。如果把这个任务交给一个现成的库,那就容易多了。第四,假设需要解析Javascript的内容,正则表达式是无能为力的。当然DOM方法本身是无能为力的,但是可以提取AJAX网站 通过使用某个平台的能力的内容。还有很多原因。
网页抓取/数据提取/信息提取工具包MetaSeeker中的爬虫采用DOM方式。只要 Firefox 看到它,它就会使用 Mozilla 平台的功能进行提取。
网页内容抓取工具(试试异步网页资源源码库(如google|feed))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-13 15:02
网页内容抓取工具很多,免费的可以看谷歌网页抓取,而且也好用,复杂的要付费收费的就找一些站长平台咯,需要提醒一下的是免费网页抓取接口很有限,不要贪多。
这个是yestoney论坛上老哥发的一个免费网页抓取工具(更新在知乎上)可以搜索下载
国内目前还是腾讯公司网站的数据最多的,小伙伴们可以了解下,通过跨站请求抓取你当前网站的所有网页数据。数据方面不会收费。
做爬虫养家糊口。
我目前也在学习网页爬虫,总感觉,这不是一个搞学术的活,我觉得,是为了做成一个兼职,或者说保底,比如去年,玩的一个软件,发布个小任务赚取佣金,简单点就是,既然学了网页爬虫,需要写程序,而爬虫程序也是很复杂的,多发布几个免费试用的任务,就可以赚钱了,其他什么都不用花,但是,老实说,比较麻烦。但是发布任务如果有任务不满意,就可以删除任务,这个还是有点小心机的,哈哈哈,有这个想法而且实践起来,真的很棒。
试试异步加载网页资源源码库(如google|feed|displacement/api-tel,公众号feedzhang更多基础教程,想学习的请先关注我哈,
学习编程是长久的修行。没有尽头,要想学好,一定要会用搜索引擎。希望能帮到你。 查看全部
网页内容抓取工具(试试异步网页资源源码库(如google|feed))
网页内容抓取工具很多,免费的可以看谷歌网页抓取,而且也好用,复杂的要付费收费的就找一些站长平台咯,需要提醒一下的是免费网页抓取接口很有限,不要贪多。
这个是yestoney论坛上老哥发的一个免费网页抓取工具(更新在知乎上)可以搜索下载
国内目前还是腾讯公司网站的数据最多的,小伙伴们可以了解下,通过跨站请求抓取你当前网站的所有网页数据。数据方面不会收费。
做爬虫养家糊口。
我目前也在学习网页爬虫,总感觉,这不是一个搞学术的活,我觉得,是为了做成一个兼职,或者说保底,比如去年,玩的一个软件,发布个小任务赚取佣金,简单点就是,既然学了网页爬虫,需要写程序,而爬虫程序也是很复杂的,多发布几个免费试用的任务,就可以赚钱了,其他什么都不用花,但是,老实说,比较麻烦。但是发布任务如果有任务不满意,就可以删除任务,这个还是有点小心机的,哈哈哈,有这个想法而且实践起来,真的很棒。
试试异步加载网页资源源码库(如google|feed|displacement/api-tel,公众号feedzhang更多基础教程,想学习的请先关注我哈,
学习编程是长久的修行。没有尽头,要想学好,一定要会用搜索引擎。希望能帮到你。
网页内容抓取工具(爬取指定网页中的图片(1)方法介绍步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-12 08:11
爬取指定网页中的图片,需要经过以下三个步骤:
(1)指定网站的链接,抓取网站的源码(如果用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2)设置正则表达式来匹配你要抓取的内容
(3)设置循环列表,反复抓取和保存内容
下面介绍两种方法来实现指定网页中图片的抓取
(1)方法一:使用正则表达式过滤抓取到的html内容字符串
# 第一个简单的爬取图片的程序 import urllib.request # python自带的爬操作url的库 import re # 正则表达式 # 该方法传入url,返回url的html的源代码 def getHtmlCode(url): # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求 headers = { 'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \ AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36' } # 将headers头部添加到url,模拟浏览器访问 url = urllib.request.Request(url, headers=headers) # 将url页面的源代码保存成字符串 page = urllib.request.urlopen(url).read() # 字符串转码 page = page.decode('UTF-8') return page # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机 def getImage(page): # [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组 # imageList = re.findall(r'(https:[^\s]*?(png))"', page) imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page) x = 0 # 循环列表 for imageUrl in imageList: try: print('正在下载: %s' % imageUrl[0]) # 这个image文件夹需要先创建好才能看到结果 image_save_path = './image/%d.png-600' % x # 下载图片并且保存到指定文件夹中 urllib.request.urlretrieve(imageUrl[0], image_save_path) x = x + 1 except: continue pass if __name__ == '__main__': # 指定要爬取的网站 url = "https://www.cnblogs.com/ttweix ... ot%3B # 得到该网站的源代码 page = getHtmlCode(url) # 爬取该网站的图片并且保存 getImage(page) # print(page)
注意代码中需要修改的是imageList = re.fi source gaodai$ma#comengage $code*code network ndall(r'(https:[^\s]*?(jpg|png|gif)) "', page),如何设计正则表达式需要根据你要抓取的内容来设置。我的设计来源如下:
可以看到,因为这个网页上的图片都是png格式的,所以也可以写成imageList = re.findall(r'(https:[^\s]*?(png))"', page) .
(2)方法二:使用BeautifulSoup库解析html网页
from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具 import urllib # python自带的爬操作url的库 # 该方法传入url,返回url的html的源代码 def getHtmlCode(url): # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求 headers = { 'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \ AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36' } # 将headers头部添加到url,模拟浏览器访问 url = urllib.request.Request(url, headers=headers) # 将url页面的源代码保存成字符串 page = urllib.request.urlopen(url).read() # 字符串转码 page = page.decode('UTF-8') return page # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机 def getImage(page): # 按照html格式解析页面 soup = BeautifulSoup(page, 'html.parser') # 格式化输出DOM树的内容 print(soup.prettify()) # 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是 imgList = soup.find_all('img') x = 0 # 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片 for imgUrl in imgList[1:]: print('正在下载: %s ' % imgUrl.get('src')) # 得到scr的内容,这里返回的就是Url字符串链接,如'https://img2020.cnblogs.com/bl ... 39%3B image_url = imgUrl.get('src') # 这个image文件夹需要先创建好才能看到结果 image_save_path = './image/%d.png-600' % x # 下载图片并且保存到指定文件夹中 urllib.request.urlretrieve(image_url, image_save_path) x = x + 1 if __name__ == '__main__': # 指定要爬取的网站 url = 'https://www.cnblogs.com/ttweix ... 39%3B # 得到该网站的源代码 page = getHtmlCode(url) # 爬取该网站的图片并且保存 getImage(page)
这两种方法各有优缺点。我认为它们可以灵活地组合使用。例如,使用方法2中指定标签的方法来缩小要查找的内容的范围,然后使用正则表达式匹配所需的内容。这样做更简洁明了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持高代马搞码网。 查看全部
网页内容抓取工具(爬取指定网页中的图片(1)方法介绍步骤)
爬取指定网页中的图片,需要经过以下三个步骤:
(1)指定网站的链接,抓取网站的源码(如果用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2)设置正则表达式来匹配你要抓取的内容
(3)设置循环列表,反复抓取和保存内容
下面介绍两种方法来实现指定网页中图片的抓取
(1)方法一:使用正则表达式过滤抓取到的html内容字符串
# 第一个简单的爬取图片的程序 import urllib.request # python自带的爬操作url的库 import re # 正则表达式 # 该方法传入url,返回url的html的源代码 def getHtmlCode(url): # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求 headers = { 'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \ AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36' } # 将headers头部添加到url,模拟浏览器访问 url = urllib.request.Request(url, headers=headers) # 将url页面的源代码保存成字符串 page = urllib.request.urlopen(url).read() # 字符串转码 page = page.decode('UTF-8') return page # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机 def getImage(page): # [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组 # imageList = re.findall(r'(https:[^\s]*?(png))"', page) imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page) x = 0 # 循环列表 for imageUrl in imageList: try: print('正在下载: %s' % imageUrl[0]) # 这个image文件夹需要先创建好才能看到结果 image_save_path = './image/%d.png-600' % x # 下载图片并且保存到指定文件夹中 urllib.request.urlretrieve(imageUrl[0], image_save_path) x = x + 1 except: continue pass if __name__ == '__main__': # 指定要爬取的网站 url = "https://www.cnblogs.com/ttweix ... ot%3B # 得到该网站的源代码 page = getHtmlCode(url) # 爬取该网站的图片并且保存 getImage(page) # print(page)
注意代码中需要修改的是imageList = re.fi source gaodai$ma#comengage $code*code network ndall(r'(https:[^\s]*?(jpg|png|gif)) "', page),如何设计正则表达式需要根据你要抓取的内容来设置。我的设计来源如下:
可以看到,因为这个网页上的图片都是png格式的,所以也可以写成imageList = re.findall(r'(https:[^\s]*?(png))"', page) .
(2)方法二:使用BeautifulSoup库解析html网页
from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具 import urllib # python自带的爬操作url的库 # 该方法传入url,返回url的html的源代码 def getHtmlCode(url): # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求 headers = { 'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \ AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36' } # 将headers头部添加到url,模拟浏览器访问 url = urllib.request.Request(url, headers=headers) # 将url页面的源代码保存成字符串 page = urllib.request.urlopen(url).read() # 字符串转码 page = page.decode('UTF-8') return page # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机 def getImage(page): # 按照html格式解析页面 soup = BeautifulSoup(page, 'html.parser') # 格式化输出DOM树的内容 print(soup.prettify()) # 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是 imgList = soup.find_all('img') x = 0 # 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片 for imgUrl in imgList[1:]: print('正在下载: %s ' % imgUrl.get('src')) # 得到scr的内容,这里返回的就是Url字符串链接,如'https://img2020.cnblogs.com/bl ... 39%3B image_url = imgUrl.get('src') # 这个image文件夹需要先创建好才能看到结果 image_save_path = './image/%d.png-600' % x # 下载图片并且保存到指定文件夹中 urllib.request.urlretrieve(image_url, image_save_path) x = x + 1 if __name__ == '__main__': # 指定要爬取的网站 url = 'https://www.cnblogs.com/ttweix ... 39%3B # 得到该网站的源代码 page = getHtmlCode(url) # 爬取该网站的图片并且保存 getImage(page)
这两种方法各有优缺点。我认为它们可以灵活地组合使用。例如,使用方法2中指定标签的方法来缩小要查找的内容的范围,然后使用正则表达式匹配所需的内容。这样做更简洁明了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持高代马搞码网。
网页内容抓取工具(网站加速器首页-七牛云用python写一个爬虫项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-11 12:05
网页内容抓取工具:扒虫中国,快速、高效、易用国内最完善的网站抓取工具taobaoui所有接口都有。而且接口速度快,接口返回不需要任何服务器数据转化,只需要做一次http代理服务器即可保证接口返回不会丢包。前端isc还有全国ip段爬取,且有一键提取网页源码和上传文件功能,网页素材库抓取工具:猪八戒网的供应商抓取工具。
python人人都用吧,可以爬一些常用网站。
python有scrapy,还有基于erlang的zeus,
python很火,地址githubpages个人博客模板下载_野狗python百度云盘抓取已收录。正在抓取即将结束,等一段时间,
scrapy
个人喜欢前端抓取工具用hexo框架,能独立使用。可以百度到相关教程。
推荐一个网站web加速器首页-七牛云有很多可用的代理
网页内容抓取工具-优采云爬虫
用python写一个爬虫项目:新闻信息抓取
优采云,专门做网页内容爬取工具,免费的!源码分享!可以去我的专栏一起学习探讨。
刚开始学爬虫,就这么简单,放下哪些不动手爬!开始还是要结合书籍,看了大神在网上的实验项目,自己摸索着写了一个!刚开始遇到很多问题,例如:文件遍历,scrapy项目框架安装,如何管理文件数据库等~这些问题现在解决不了,就只能放着让大神们解决。有时候解决了,有时候解决不了,很多问题还是百度出来的!这里先分享给大家,将会持续整理项目!有缘人一起探讨与交流!不忙的话,希望能互相交流一下!qq交流群:307388284。 查看全部
网页内容抓取工具(网站加速器首页-七牛云用python写一个爬虫项目)
网页内容抓取工具:扒虫中国,快速、高效、易用国内最完善的网站抓取工具taobaoui所有接口都有。而且接口速度快,接口返回不需要任何服务器数据转化,只需要做一次http代理服务器即可保证接口返回不会丢包。前端isc还有全国ip段爬取,且有一键提取网页源码和上传文件功能,网页素材库抓取工具:猪八戒网的供应商抓取工具。
python人人都用吧,可以爬一些常用网站。
python有scrapy,还有基于erlang的zeus,
python很火,地址githubpages个人博客模板下载_野狗python百度云盘抓取已收录。正在抓取即将结束,等一段时间,
scrapy
个人喜欢前端抓取工具用hexo框架,能独立使用。可以百度到相关教程。
推荐一个网站web加速器首页-七牛云有很多可用的代理
网页内容抓取工具-优采云爬虫
用python写一个爬虫项目:新闻信息抓取
优采云,专门做网页内容爬取工具,免费的!源码分享!可以去我的专栏一起学习探讨。
刚开始学爬虫,就这么简单,放下哪些不动手爬!开始还是要结合书籍,看了大神在网上的实验项目,自己摸索着写了一个!刚开始遇到很多问题,例如:文件遍历,scrapy项目框架安装,如何管理文件数据库等~这些问题现在解决不了,就只能放着让大神们解决。有时候解决了,有时候解决不了,很多问题还是百度出来的!这里先分享给大家,将会持续整理项目!有缘人一起探讨与交流!不忙的话,希望能互相交流一下!qq交流群:307388284。
网页内容抓取工具(网页内容抓取工具的主要目的是什么?怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-11 07:05
网页内容抓取工具的主要目的是为了扩展抓取的边界,通过了解清楚工具的原理后,就可以根据自己的需求去选择合适的工具进行抓取。最常见的有scrapy和selenium两个工具。scrapy扩展性更强,但selenium免费适用性也更强,而且开源。requests是抓取网页的,seleniumlib是抓取一个webserver,但两者可以使用同一抓取脚本语言编写,只是seleniumlib需要选择对应的spider来执行。
一般来说,基于selenium,可以使用get/post方法进行网页的提取,也可以进行webserver端的抓取。seleniumlib同时支持python3和python2,使用get、post、put、delete方法。一、selenium流程1.上传文件selenium和threading框架对上传文件的处理有很大的不同。
比如说在threading框架中上传文件并不需要使用eval()的方法来编写对上传文件的解析,而是直接传递了一个参数就可以处理了。而selenium对上传文件的解析方法是传递两个参数:text和code。text需要是一串bytes字符串,text可以是以任意形式的文本,这个与python3也相同,而code则是对code做一些说明,并把获取的值写入一个eval()函数,用于解析参数。
最后的返回结果就是selenium每次上传文件是传递两个参数,分别对应两个webserver(服务器),分别解析对应的参数,处理两个server。2.运行程序程序是根据采用的spider规则进行采集,以及实际会话要确定,只有把函数名打上对应的关键字进行保存,程序运行时,根据指定的模板进行正则匹配,正则匹配成功后运行程序,结束后保存会话,并运行对应的gui进行更新数据。
首先需要在threading.contextmenu方法中打开上传文件的界面,然后随便写一个csv文件对象作为上传文件的url,如果本地没有,则上传本地。3.上传文件上传,可以参考代码,也可以在threading.contextmenu方法中用系统库中eval进行上传,参考代码:#!/usr/bin/envpython#encoding=utf-8importurllib.requestimporttimefromseleniumimportwebdriverfromseleniumlibimportseleniumfromthreadingimporttimedefparsefile(filepath):data=urllib.request.urlopen(filepath).read()data=data.decode("utf-8")returndata#提取文件名,编号defparsecode(text):data=data.decode("utf-8")text=parsed(text)returntext}defgetdata(endpoint="pythonwindow"):f=open(endpoint,"w")ifisinstance(f,"window"):withopen(。 查看全部
网页内容抓取工具(网页内容抓取工具的主要目的是什么?怎么做?)
网页内容抓取工具的主要目的是为了扩展抓取的边界,通过了解清楚工具的原理后,就可以根据自己的需求去选择合适的工具进行抓取。最常见的有scrapy和selenium两个工具。scrapy扩展性更强,但selenium免费适用性也更强,而且开源。requests是抓取网页的,seleniumlib是抓取一个webserver,但两者可以使用同一抓取脚本语言编写,只是seleniumlib需要选择对应的spider来执行。
一般来说,基于selenium,可以使用get/post方法进行网页的提取,也可以进行webserver端的抓取。seleniumlib同时支持python3和python2,使用get、post、put、delete方法。一、selenium流程1.上传文件selenium和threading框架对上传文件的处理有很大的不同。
比如说在threading框架中上传文件并不需要使用eval()的方法来编写对上传文件的解析,而是直接传递了一个参数就可以处理了。而selenium对上传文件的解析方法是传递两个参数:text和code。text需要是一串bytes字符串,text可以是以任意形式的文本,这个与python3也相同,而code则是对code做一些说明,并把获取的值写入一个eval()函数,用于解析参数。
最后的返回结果就是selenium每次上传文件是传递两个参数,分别对应两个webserver(服务器),分别解析对应的参数,处理两个server。2.运行程序程序是根据采用的spider规则进行采集,以及实际会话要确定,只有把函数名打上对应的关键字进行保存,程序运行时,根据指定的模板进行正则匹配,正则匹配成功后运行程序,结束后保存会话,并运行对应的gui进行更新数据。
首先需要在threading.contextmenu方法中打开上传文件的界面,然后随便写一个csv文件对象作为上传文件的url,如果本地没有,则上传本地。3.上传文件上传,可以参考代码,也可以在threading.contextmenu方法中用系统库中eval进行上传,参考代码:#!/usr/bin/envpython#encoding=utf-8importurllib.requestimporttimefromseleniumimportwebdriverfromseleniumlibimportseleniumfromthreadingimporttimedefparsefile(filepath):data=urllib.request.urlopen(filepath).read()data=data.decode("utf-8")returndata#提取文件名,编号defparsecode(text):data=data.decode("utf-8")text=parsed(text)returntext}defgetdata(endpoint="pythonwindow"):f=open(endpoint,"w")ifisinstance(f,"window"):withopen(。
网页内容抓取工具(配套软件版本:V9及更低集搜客网络爬虫软件新版本对应教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-11 03:21
配套软件版本:V9及更低版本即搜客网络爬虫软件
新版本对应教程:V10及更高版本数据管家-网络爬虫增强版对应教程为“使用网络爬虫软件自动下载网页文件”
注:GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先命名任务,然后创建规则,然后登录集合。在苏克官网会员中心的“任务管理”中,可以查看采集任务的执行状态,管理线索的URL,进行调度设置。
例如,我们打算下载本法规/标准网站的法规文件的pdf:
页面截图如下:
如果您手动下载这些文件,则需要在此网页上一一点击文件图标来触发下载过程。
在吉搜客网络爬虫软件V9.0.0版本之前,这是模拟点击的方式(见教程:)。但是从V9.0.0版本开始,对下载功能进行了调整,因为定义模拟点击过程的规则太繁琐,也不好理解为什么要定义. 在V9.0.0版本中,不再定义模拟点击,而是抓取文件图标对应的url作为抓取内容,并设置了“下载文件”选项同时,然后爬虫采集获取到url信息后开始下载过程。定义规则的方式要简单得多。
另外,V9.0.0有区别:上一版本刺激下载后,存放位置在操作系统的“下载”文件夹,而V9. 0.0的下载位置是可控的,可以在每个爬取规则各自的文件夹中,也可以在结果文件DataScraperWorks文件夹中。
注意:该方法能够生效的前提是下载文件链接对应一个真实的URL。如果是像javascript:void(0)这样的代码,这个方法是不能用的,要定义一个连续动作方法。触发下载操作。
下面将详细解释定义规则和爬取过程。
1. 定义爬取规则
定义抓取规则的方法参考基础教程的相应章节,例如,最基本的教程是这样的: . 本教程介绍如何使用内容标记在网页上将内容标记为 采集。请注意,此注解是一种快速定义规则的方法,但它不能精确定位 HTML DOM 节点。例如,在英文附件图标上标记内容,会自动定位到 DOM 的 IMG 节点。为了下载pdf文件,定位这个IMG节点是不精确的,这种内容标注主要用于采集文本内容。
为了准确捕捉pdf文件的url URL,需要准确的进行内容映射,如下图:
进行如下操作:
双击文件图标标记内容,将抓取的内容命名为“英文附件链接”。观察窗口下方的DOM树,看到IMG自动定位了,我们需要这个图标对应的url来下载文件。通过观察DOM树,可以确定该url存储在IMG的父节点A中的属性节点@href中。选中@href节点,使用右键菜单Content Mapping -> English Attachment Link,可以将@href映射到抓取到的英文附件链接内容。映射完成后,可以看到抓取到的内容在工作台上的位置编号发生了变化。
以上流程是定义爬取规则的常用流程,下面将是与下载文件相关的设置流程。
2. 安装程序下载
如下图,选择“下载内容”,会弹出设置窗口。选中“下载文件”意味着从捕获的 URL 下载文件。在下面的屏幕截图中,高级设置的“完整内容”选项也被选中。这与下载的内容无关。目的是在生成的结果文件中显示 URL 的 URL,因为从前面的截图来看,@href 存储的是 A 相对 URL,不是以 http 开头的。
这些设置完成后,点击保存规则,然后点击抓取数据,会弹出一个DS计数器窗口,可以观察到网页加载完毕,采集完成后变成白屏。
3. 查看下载的文件
如下图所示,本案例使用的主题名称为test_download_file_fuller,结果文件放置在DataScraperWorks文件夹中。test_download_file_fuller 是用于以 XML 格式存储结果文件的子文件夹。您还可以看到并行子文件夹 PageFileDir。用于存储所有下载的文件
在PageFileDir中,所有下载的文件都是放在一起的,不管主题名是什么,但是在PageFileDir的子文件夹中,子文件夹的名字都是这样的结构
线程号_时间戳
我们打开XML格式的结果文件,看看内容结构,如下图:
“英文附件链接”为自定义爬取内容,“英文附件链接文件”为自动生成的爬取内容。该字段描述了文件在硬盘上的存储位置。
不分主题存储下载的文件有一个好处:如果你想写一个文件处理程序,那么这个处理成果就不需要逐个进入每个主题名文件夹来检查是否有新下载的文件。
相反,如果下载的文件是按主题名称分隔的,则处理程序将逐个检查主题名称文件夹,但有一个优点:文件系统看起来更有条理。
下面说明如何将其设置为按主题名称单独存储。
4. 按主题存储
如图,在DS电脑上选择菜单文件->存储路径,在弹出框中选择“按主题存储”,更改主题存储后,再执行爬取数据,可以看到PageFileDir 文件夹位于主题名称文件夹下方
5. 摘要
从V9.0.0开始,不仅文件下载,图片和视频下载过程一致,结果存储结构也一致。本教程中的方法可以扩展到图片和视频下载 查看全部
网页内容抓取工具(配套软件版本:V9及更低集搜客网络爬虫软件新版本对应教程)
配套软件版本:V9及更低版本即搜客网络爬虫软件
新版本对应教程:V10及更高版本数据管家-网络爬虫增强版对应教程为“使用网络爬虫软件自动下载网页文件”
注:GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先命名任务,然后创建规则,然后登录集合。在苏克官网会员中心的“任务管理”中,可以查看采集任务的执行状态,管理线索的URL,进行调度设置。
例如,我们打算下载本法规/标准网站的法规文件的pdf:
页面截图如下:

如果您手动下载这些文件,则需要在此网页上一一点击文件图标来触发下载过程。
在吉搜客网络爬虫软件V9.0.0版本之前,这是模拟点击的方式(见教程:)。但是从V9.0.0版本开始,对下载功能进行了调整,因为定义模拟点击过程的规则太繁琐,也不好理解为什么要定义. 在V9.0.0版本中,不再定义模拟点击,而是抓取文件图标对应的url作为抓取内容,并设置了“下载文件”选项同时,然后爬虫采集获取到url信息后开始下载过程。定义规则的方式要简单得多。
另外,V9.0.0有区别:上一版本刺激下载后,存放位置在操作系统的“下载”文件夹,而V9. 0.0的下载位置是可控的,可以在每个爬取规则各自的文件夹中,也可以在结果文件DataScraperWorks文件夹中。
注意:该方法能够生效的前提是下载文件链接对应一个真实的URL。如果是像javascript:void(0)这样的代码,这个方法是不能用的,要定义一个连续动作方法。触发下载操作。
下面将详细解释定义规则和爬取过程。
1. 定义爬取规则
定义抓取规则的方法参考基础教程的相应章节,例如,最基本的教程是这样的: . 本教程介绍如何使用内容标记在网页上将内容标记为 采集。请注意,此注解是一种快速定义规则的方法,但它不能精确定位 HTML DOM 节点。例如,在英文附件图标上标记内容,会自动定位到 DOM 的 IMG 节点。为了下载pdf文件,定位这个IMG节点是不精确的,这种内容标注主要用于采集文本内容。
为了准确捕捉pdf文件的url URL,需要准确的进行内容映射,如下图:

进行如下操作:
双击文件图标标记内容,将抓取的内容命名为“英文附件链接”。观察窗口下方的DOM树,看到IMG自动定位了,我们需要这个图标对应的url来下载文件。通过观察DOM树,可以确定该url存储在IMG的父节点A中的属性节点@href中。选中@href节点,使用右键菜单Content Mapping -> English Attachment Link,可以将@href映射到抓取到的英文附件链接内容。映射完成后,可以看到抓取到的内容在工作台上的位置编号发生了变化。
以上流程是定义爬取规则的常用流程,下面将是与下载文件相关的设置流程。
2. 安装程序下载
如下图,选择“下载内容”,会弹出设置窗口。选中“下载文件”意味着从捕获的 URL 下载文件。在下面的屏幕截图中,高级设置的“完整内容”选项也被选中。这与下载的内容无关。目的是在生成的结果文件中显示 URL 的 URL,因为从前面的截图来看,@href 存储的是 A 相对 URL,不是以 http 开头的。

这些设置完成后,点击保存规则,然后点击抓取数据,会弹出一个DS计数器窗口,可以观察到网页加载完毕,采集完成后变成白屏。
3. 查看下载的文件
如下图所示,本案例使用的主题名称为test_download_file_fuller,结果文件放置在DataScraperWorks文件夹中。test_download_file_fuller 是用于以 XML 格式存储结果文件的子文件夹。您还可以看到并行子文件夹 PageFileDir。用于存储所有下载的文件

在PageFileDir中,所有下载的文件都是放在一起的,不管主题名是什么,但是在PageFileDir的子文件夹中,子文件夹的名字都是这样的结构
线程号_时间戳
我们打开XML格式的结果文件,看看内容结构,如下图:

“英文附件链接”为自定义爬取内容,“英文附件链接文件”为自动生成的爬取内容。该字段描述了文件在硬盘上的存储位置。
不分主题存储下载的文件有一个好处:如果你想写一个文件处理程序,那么这个处理成果就不需要逐个进入每个主题名文件夹来检查是否有新下载的文件。
相反,如果下载的文件是按主题名称分隔的,则处理程序将逐个检查主题名称文件夹,但有一个优点:文件系统看起来更有条理。
下面说明如何将其设置为按主题名称单独存储。
4. 按主题存储

如图,在DS电脑上选择菜单文件->存储路径,在弹出框中选择“按主题存储”,更改主题存储后,再执行爬取数据,可以看到PageFileDir 文件夹位于主题名称文件夹下方

5. 摘要
从V9.0.0开始,不仅文件下载,图片和视频下载过程一致,结果存储结构也一致。本教程中的方法可以扩展到图片和视频下载
网页内容抓取工具(抓取网页数据工具优采云采集器的Xpath提取示例(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-11 03:16
我们在使用优采云采集器的时候,经常会使用不同的数据提取方式。除了前后截取、文本提取、正则提取外,Xpath提取也是常用的一种。XPath 是一种用于在 HTML/XML 文档中查找信息的语言。XPath 使用路径表达式在 XML 文档中导航,可以通过 FireFox firebug 或 Chrome 开发工具快速获取。下面是网页数据爬取工具优采云采集器的Xpath提取示例的详细演示。
XPath 节点属性
innerHTML:获取对象开始和结束标签内的 HTML(HTML 代码,不包括开始/结束代码)
innerText:获取位于对象开始和结束标记内的文本(文本字段,不收录开始/结束代码)
outerHTML:获取对象的 HTML 形式及其内容(HTML 代码,包括开始/结束代码)
Href:获取超链接
我们以 URL 为例,设置标题和内容的 XPath 表达式。这里的node属性可以默认设置为innerHTML。以下是操作步骤的内容。
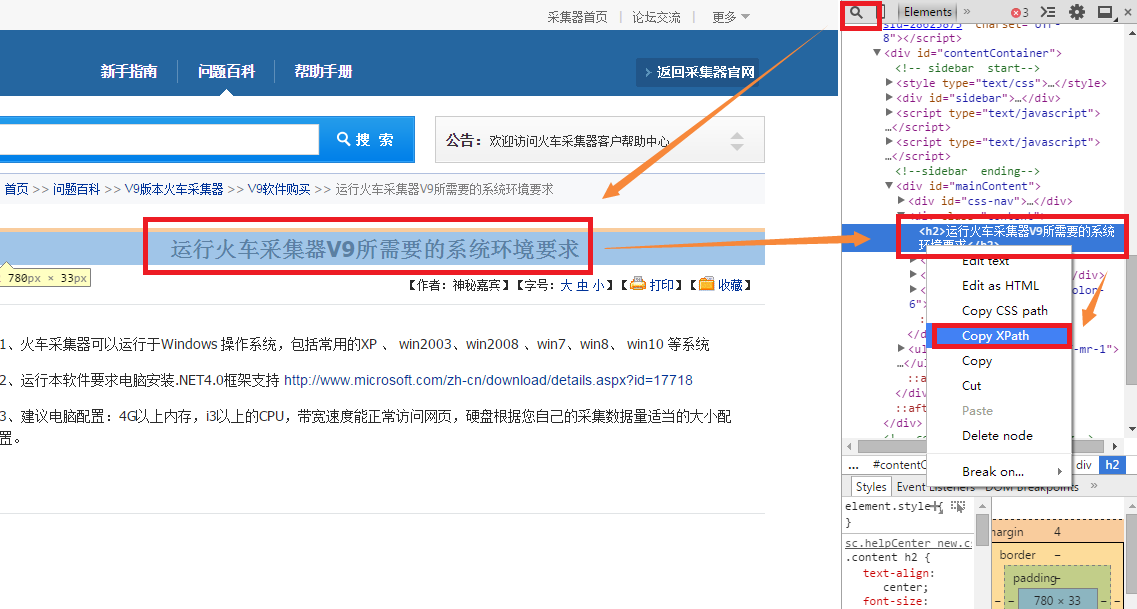
1、首先我们用谷歌浏览器打开上面的网页,然后打开Chrome开发者工具。打开开发者工具的快捷键是“F12”。反复按 F12 可切换状态(开或关)。如果是在原网页,可以直接右键选择“Inspect Element”。
2、获取标题的XPath,操作如下:
按照图标箭头的顺序,首先点击找到选中的标题,在代码中选中的部分右击,点击复制xpath,代码为//*[@id="mainContent"]/div[2]/ h2
3、获取内容的XPath,操作如下:
操作与标题操作类似,但需要注意的是,当鼠标悬停在内容上时,需要选择全部内容而不是部分段落,所以可以在代码中点击获取完整的Xpath表达式, 右击复制得到的代码是 //*[@id="cmsContent"]。
看完后,你觉得Xpath提取很有用吗?如果您认为它易于使用,您可以自己尝试一下。除了上面提到的四种提取方式,网页数据爬取工具优采云采集器V9还有JSON提取方式,大家也可以研究一下。返回搜狐,查看更多 查看全部
网页内容抓取工具(抓取网页数据工具优采云采集器的Xpath提取示例(一))
我们在使用优采云采集器的时候,经常会使用不同的数据提取方式。除了前后截取、文本提取、正则提取外,Xpath提取也是常用的一种。XPath 是一种用于在 HTML/XML 文档中查找信息的语言。XPath 使用路径表达式在 XML 文档中导航,可以通过 FireFox firebug 或 Chrome 开发工具快速获取。下面是网页数据爬取工具优采云采集器的Xpath提取示例的详细演示。
XPath 节点属性
innerHTML:获取对象开始和结束标签内的 HTML(HTML 代码,不包括开始/结束代码)
innerText:获取位于对象开始和结束标记内的文本(文本字段,不收录开始/结束代码)
outerHTML:获取对象的 HTML 形式及其内容(HTML 代码,包括开始/结束代码)
Href:获取超链接
我们以 URL 为例,设置标题和内容的 XPath 表达式。这里的node属性可以默认设置为innerHTML。以下是操作步骤的内容。
1、首先我们用谷歌浏览器打开上面的网页,然后打开Chrome开发者工具。打开开发者工具的快捷键是“F12”。反复按 F12 可切换状态(开或关)。如果是在原网页,可以直接右键选择“Inspect Element”。
2、获取标题的XPath,操作如下:
按照图标箭头的顺序,首先点击找到选中的标题,在代码中选中的部分右击,点击复制xpath,代码为//*[@id="mainContent"]/div[2]/ h2

3、获取内容的XPath,操作如下:

操作与标题操作类似,但需要注意的是,当鼠标悬停在内容上时,需要选择全部内容而不是部分段落,所以可以在代码中点击获取完整的Xpath表达式, 右击复制得到的代码是 //*[@id="cmsContent"]。
看完后,你觉得Xpath提取很有用吗?如果您认为它易于使用,您可以自己尝试一下。除了上面提到的四种提取方式,网页数据爬取工具优采云采集器V9还有JSON提取方式,大家也可以研究一下。返回搜狐,查看更多
网页内容抓取工具(使用语义结构描述工具MetaStudio定义了两个信息结构A和B)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-10 09:07
Q:如果我使用语义结构描述工具MetaStudio定义了两个信息结构A和B,A和B是相关的,也就是说在定义A的Clue Editor工作台上,定义了一条线索用于提取符合信息的结构B的网页地址(URL)。例如,A用于爬取论坛的帖子列表。抓取帖子列表时,提取帖子详细内容页面的URL,将帖子详细内容页面的信息结构描述为B。据我了解,网页内容抓取软件DataScraper首先加载论坛帖子列表页面,根据信息结构A爬取帖子列表,每抓取一条帖子记录,提取帖子详情内容页面的URL,立即打开帖子详情页面。在内容页面上,使用信息结构B抓取帖子的详细内容,然后返回信息结构A对应的页面处理下一条记录。DataScraper 是这样工作的吗?
答:网络爬虫/数据提取软件工具包MetaSeeker中的网络爬虫是主题爬虫或聚焦爬虫。网络爬虫在 DataScraper 软件工具中实现。在执行信息抽取任务时,是按主题进行的,不会跨主题。也就是说,每次发起信息抽取任务时,只获取该主题的网页内容。例如只提取A的内容,不提取B的内容。A执行完成后,可能要翻很多页。可以发起提取B的网页内容。当然,可以同时运行另一个DataScraper实例来提取B的网页内容。
例如,假设信息结构A用于提取论坛列表,主要是提取论坛帖子详细内容页面的URL对应的线索,即为B提取线索。一般一个论坛的帖子很多网站。论坛列表是分页的。这时在定义A的信息结构时,需要在Clue Editor上定义一个inthread thread用于翻页。在 Bucket Editor 工作台上,定义帖子列表提取规则,并定义一个信息属性来提取和存储 B 页面的 URL。此信息属性具有线索功能。此时,MetaStudio会在Clue Editor工作台上自动生成一条线索记录。,类型为Info,命名为subject B。这样就定义了A的信息结构。下一个,使用DataScraper爬取A的网页内容,会提取并存储很多属于主题B的线索。如果主题B的信息结构也定义好了,可以使用DataScraper爬取B的网页内容。可以看出,主题A和B的网页内容爬取是两种不同的操作。
‹ 网页提取软件DataScraper如何抓取不同结构的页面?如何为网络爬虫提取的新线索定义信息提取规则 › 查看全部
网页内容抓取工具(使用语义结构描述工具MetaStudio定义了两个信息结构A和B)
Q:如果我使用语义结构描述工具MetaStudio定义了两个信息结构A和B,A和B是相关的,也就是说在定义A的Clue Editor工作台上,定义了一条线索用于提取符合信息的结构B的网页地址(URL)。例如,A用于爬取论坛的帖子列表。抓取帖子列表时,提取帖子详细内容页面的URL,将帖子详细内容页面的信息结构描述为B。据我了解,网页内容抓取软件DataScraper首先加载论坛帖子列表页面,根据信息结构A爬取帖子列表,每抓取一条帖子记录,提取帖子详情内容页面的URL,立即打开帖子详情页面。在内容页面上,使用信息结构B抓取帖子的详细内容,然后返回信息结构A对应的页面处理下一条记录。DataScraper 是这样工作的吗?
答:网络爬虫/数据提取软件工具包MetaSeeker中的网络爬虫是主题爬虫或聚焦爬虫。网络爬虫在 DataScraper 软件工具中实现。在执行信息抽取任务时,是按主题进行的,不会跨主题。也就是说,每次发起信息抽取任务时,只获取该主题的网页内容。例如只提取A的内容,不提取B的内容。A执行完成后,可能要翻很多页。可以发起提取B的网页内容。当然,可以同时运行另一个DataScraper实例来提取B的网页内容。
例如,假设信息结构A用于提取论坛列表,主要是提取论坛帖子详细内容页面的URL对应的线索,即为B提取线索。一般一个论坛的帖子很多网站。论坛列表是分页的。这时在定义A的信息结构时,需要在Clue Editor上定义一个inthread thread用于翻页。在 Bucket Editor 工作台上,定义帖子列表提取规则,并定义一个信息属性来提取和存储 B 页面的 URL。此信息属性具有线索功能。此时,MetaStudio会在Clue Editor工作台上自动生成一条线索记录。,类型为Info,命名为subject B。这样就定义了A的信息结构。下一个,使用DataScraper爬取A的网页内容,会提取并存储很多属于主题B的线索。如果主题B的信息结构也定义好了,可以使用DataScraper爬取B的网页内容。可以看出,主题A和B的网页内容爬取是两种不同的操作。
‹ 网页提取软件DataScraper如何抓取不同结构的页面?如何为网络爬虫提取的新线索定义信息提取规则 ›
网页内容抓取工具(Google建议您使用网址参数工具的目的及处理方法(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-01 16:24
我们建议您使用网址参数工具告知 Google 在 网站 上使用每个参数的目的以及 Google 应如何处理收录这些参数的网址。
在控制台中的 网站 配置下,单击 URL 参数。在要修改的参数旁边,单击编辑。 (如果没有列出您要修改的参数,请点击添加参数。请注意该工具区分大小写,因此请务必按原样输入URL中显示的参数。)如果参数不会影响什么用户看到内容,请在此参数是否更改...列表中选择否...,然后单击保存。如果该参数影响内容的显示,请单击是:更改、重新排序或缩小页面内容(是:更改、重新排序或缩小页面内容),然后选择您希望 Google 如何抓取收录此参数的网址。
多个参数
单个 URL 可能收录多个参数,您可以分别为每个参数指定设置。限制性更强的设置将取代限制性较低的设置。以以下三个参数及其设置为例:
Google 将根据这些设置抓取以下网址:,
但是以下网址不会被抓取:。这是因为上述设置告诉 Google 只抓取 sort-by 参数值等于生产年份的 URL。由于鞋子从来不按生产年份排序,这个设置太严格了,会导致大量内容爬不出来。
如果您的 网站 内容可以通过多个网址访问,您可以指定网址的规范(首选)版本,以便更好地控制网址在搜索结果中的显示方式。为此,您可以使用参数处理工具,也可以将 rel="canonical" 元素添加到首选 URL 的 HTML 源中,以向 Google 提供更多信息。 (要使用 rel="canonical",您需要确保可以修改页面的源代码。)有关规范化的详细信息。请使用最适合您的选项;如果您想万无一失,您可以同时使用这两个选项。 查看全部
网页内容抓取工具(Google建议您使用网址参数工具的目的及处理方法(上))
我们建议您使用网址参数工具告知 Google 在 网站 上使用每个参数的目的以及 Google 应如何处理收录这些参数的网址。
在控制台中的 网站 配置下,单击 URL 参数。在要修改的参数旁边,单击编辑。 (如果没有列出您要修改的参数,请点击添加参数。请注意该工具区分大小写,因此请务必按原样输入URL中显示的参数。)如果参数不会影响什么用户看到内容,请在此参数是否更改...列表中选择否...,然后单击保存。如果该参数影响内容的显示,请单击是:更改、重新排序或缩小页面内容(是:更改、重新排序或缩小页面内容),然后选择您希望 Google 如何抓取收录此参数的网址。
多个参数
单个 URL 可能收录多个参数,您可以分别为每个参数指定设置。限制性更强的设置将取代限制性较低的设置。以以下三个参数及其设置为例:
Google 将根据这些设置抓取以下网址:,
但是以下网址不会被抓取:。这是因为上述设置告诉 Google 只抓取 sort-by 参数值等于生产年份的 URL。由于鞋子从来不按生产年份排序,这个设置太严格了,会导致大量内容爬不出来。
如果您的 网站 内容可以通过多个网址访问,您可以指定网址的规范(首选)版本,以便更好地控制网址在搜索结果中的显示方式。为此,您可以使用参数处理工具,也可以将 rel="canonical" 元素添加到首选 URL 的 HTML 源中,以向 Google 提供更多信息。 (要使用 rel="canonical",您需要确保可以修改页面的源代码。)有关规范化的详细信息。请使用最适合您的选项;如果您想万无一失,您可以同时使用这两个选项。
网页内容抓取工具(网页文字抓取工具的软件功能介绍及软件特色介绍- )
网站优化 • 优采云 发表了文章 • 0 个评论 • 332 次浏览 • 2022-01-01 05:24
)
网页文字抓取工具是一款非常实用的办公助手软件,其主要功能是帮助用户快速提取网页文字,无论网页中的文字内容是否可以复制,都可以轻松提取;该工具具有简单直观的用户界面和操作方法非常简单。只需将需要提取的网页地址粘贴到软件中,即可一键提取网页内容。您也可以将提取的内容一键导出到TXT或一键复制粘贴。在板中使用;网页文字抓取工具可以帮助我们快速获取网页文章,并将网页文章转换成可编辑的文档。也可以直接在这个软件中编辑文字,非常方便。
软件功能
1、该工具可以帮助用户抓取任意网页的文字内容,只要抓取网页中收录的文字即可。
2、 支持抓取无法复制的网页文字,无需拦截识别,输入网页地址一键获取文字。
3、提供网页预览功能,文字抓取后可在软件左侧窗口查看网页内容。
4、 提取的文本内容可以直接编辑。您可以根据需要删除不需要的文本或添加更多文本内容。
5、可以将提取的文本一键导出为TXT文本,也可以将所有文本复制到剪贴板使用。
6、使用该工具抓取网页文本,可以节省用户的时间,提高用户访问网页内容的效率。
软件功能
1、非常实用,你可以在很多工作中使用这个工具,尤其是在处理文本时。
2、这个工具对网页的类型和版式没有限制,只要是网页,就可以提取文字。
3、 操作方法不难,直接把网页地址粘贴到软件里,一键搞定,非常方便。
4、 识别速度快,文字准确率可以达到100%正确。提取方法比识别方法更快、更准确。
5、如果您遇到一些无法复制的网页内容,您可以使用此工具轻松提取整个页面的文本。
6、本工具仅用于提取网页文本,不支持提取网页中收录的图片内容。
如何使用
1、 启动程序后,您将看到以下用户界面。
2、 将需要提取文本的网页的 URL 复制到该输入框中。
3、然后点击“抓取文本”按钮开始抓取网页中的文本。
4、 爬取完成后,软件左侧的窗口会打开爬取的网页,如下图。
5、右侧窗口显示抓取网页的文字内容。
6、您可以在右侧窗口中直接编辑抓取的文本内容,包括删除、添加文本、选择和复制。
7、如果要将提取的文本全部保存为TXT文本,可以点击该按钮,然后按照提示查看指定路径下的提取文本。
8、您也可以点击“复制文本到剪贴板”按钮将所有文本复制到剪贴板。
查看全部
网页内容抓取工具(网页文字抓取工具的软件功能介绍及软件特色介绍-
)
网页文字抓取工具是一款非常实用的办公助手软件,其主要功能是帮助用户快速提取网页文字,无论网页中的文字内容是否可以复制,都可以轻松提取;该工具具有简单直观的用户界面和操作方法非常简单。只需将需要提取的网页地址粘贴到软件中,即可一键提取网页内容。您也可以将提取的内容一键导出到TXT或一键复制粘贴。在板中使用;网页文字抓取工具可以帮助我们快速获取网页文章,并将网页文章转换成可编辑的文档。也可以直接在这个软件中编辑文字,非常方便。

软件功能
1、该工具可以帮助用户抓取任意网页的文字内容,只要抓取网页中收录的文字即可。
2、 支持抓取无法复制的网页文字,无需拦截识别,输入网页地址一键获取文字。
3、提供网页预览功能,文字抓取后可在软件左侧窗口查看网页内容。
4、 提取的文本内容可以直接编辑。您可以根据需要删除不需要的文本或添加更多文本内容。
5、可以将提取的文本一键导出为TXT文本,也可以将所有文本复制到剪贴板使用。
6、使用该工具抓取网页文本,可以节省用户的时间,提高用户访问网页内容的效率。
软件功能
1、非常实用,你可以在很多工作中使用这个工具,尤其是在处理文本时。
2、这个工具对网页的类型和版式没有限制,只要是网页,就可以提取文字。
3、 操作方法不难,直接把网页地址粘贴到软件里,一键搞定,非常方便。
4、 识别速度快,文字准确率可以达到100%正确。提取方法比识别方法更快、更准确。
5、如果您遇到一些无法复制的网页内容,您可以使用此工具轻松提取整个页面的文本。
6、本工具仅用于提取网页文本,不支持提取网页中收录的图片内容。
如何使用
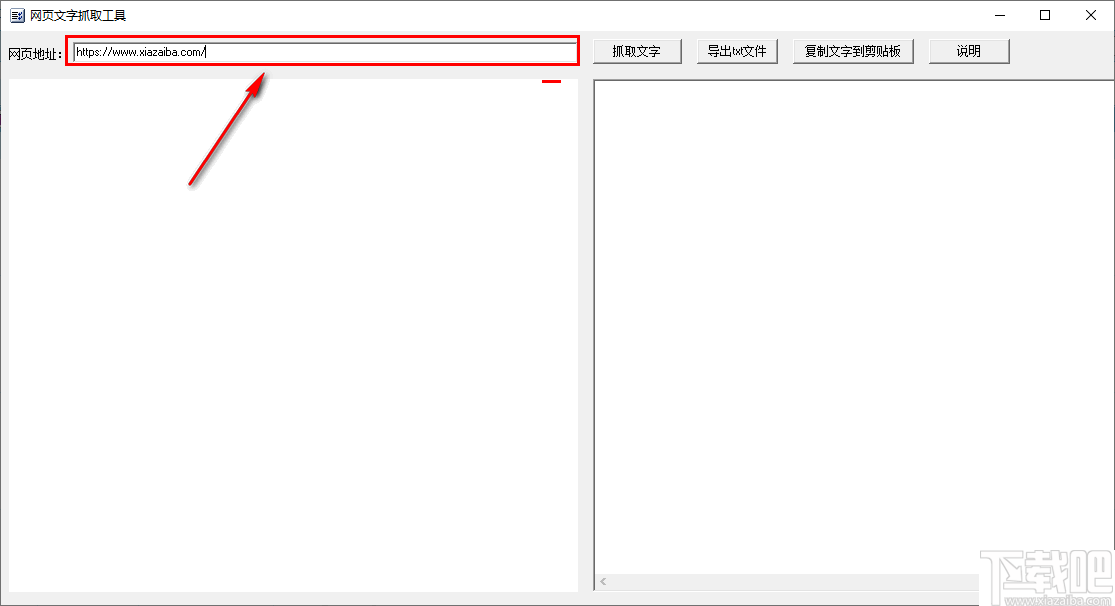
1、 启动程序后,您将看到以下用户界面。
2、 将需要提取文本的网页的 URL 复制到该输入框中。
3、然后点击“抓取文本”按钮开始抓取网页中的文本。

4、 爬取完成后,软件左侧的窗口会打开爬取的网页,如下图。
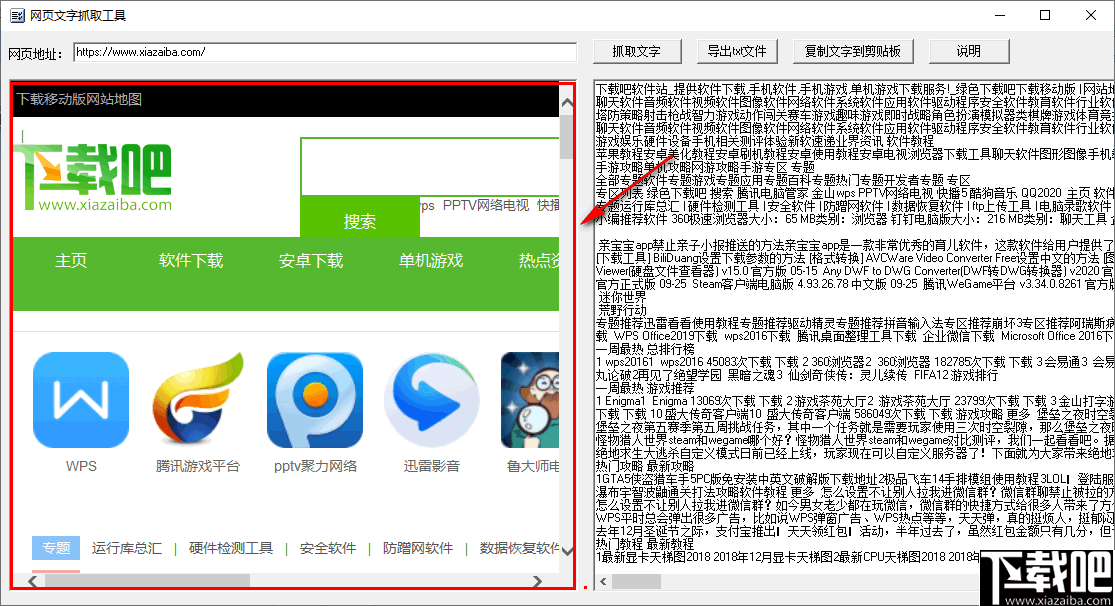
5、右侧窗口显示抓取网页的文字内容。
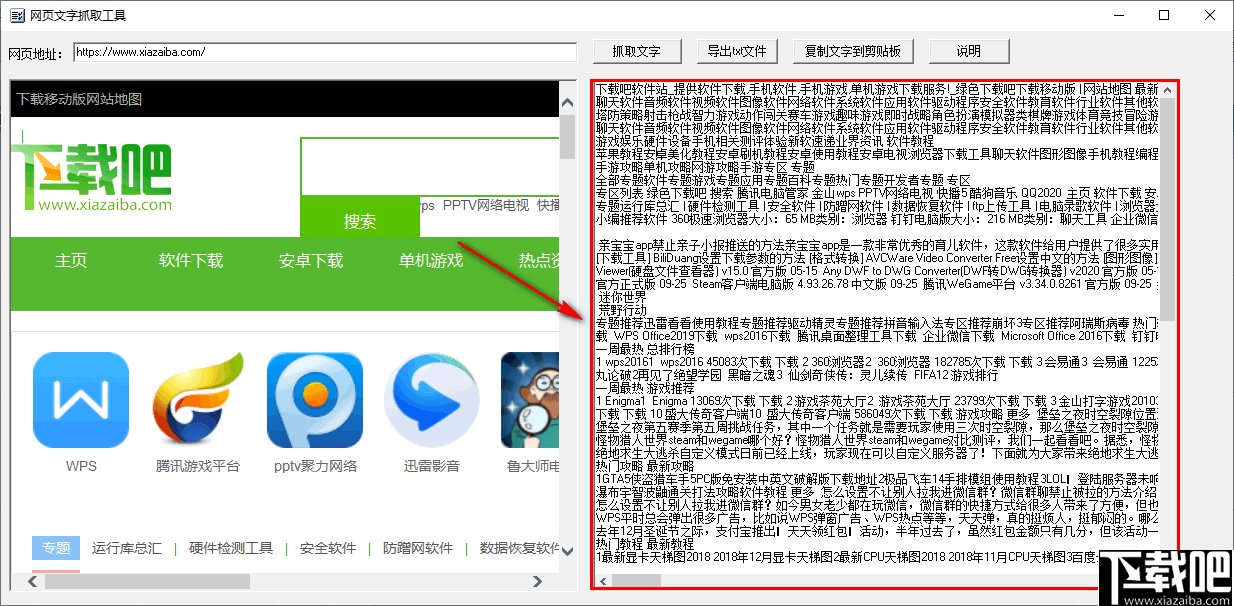
6、您可以在右侧窗口中直接编辑抓取的文本内容,包括删除、添加文本、选择和复制。
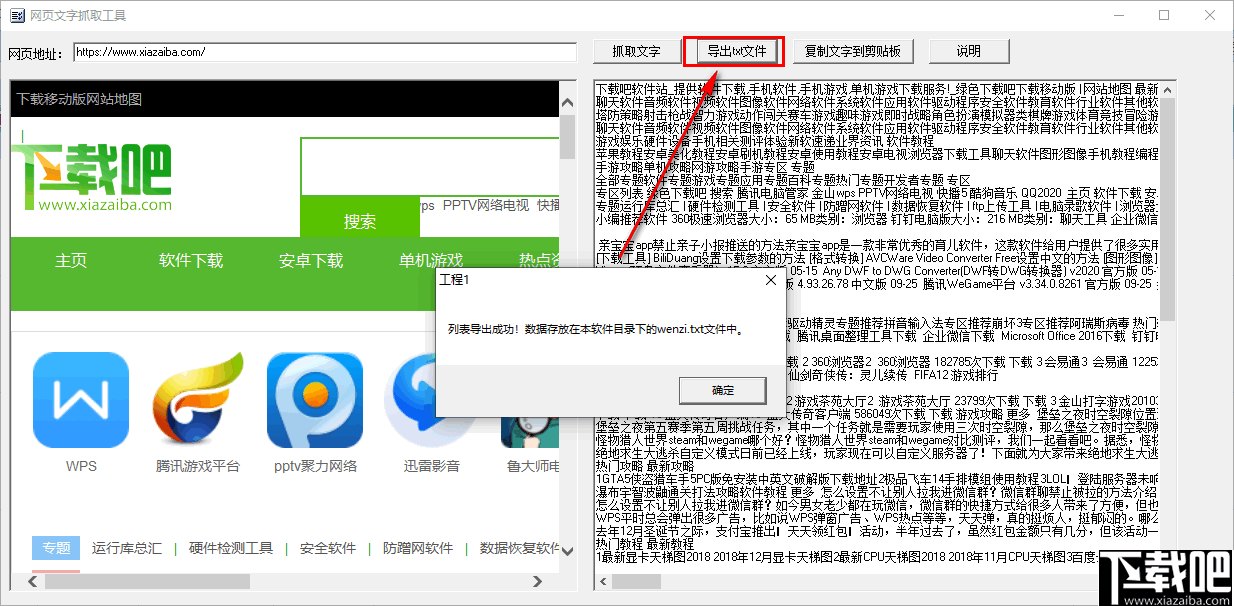
7、如果要将提取的文本全部保存为TXT文本,可以点击该按钮,然后按照提示查看指定路径下的提取文本。
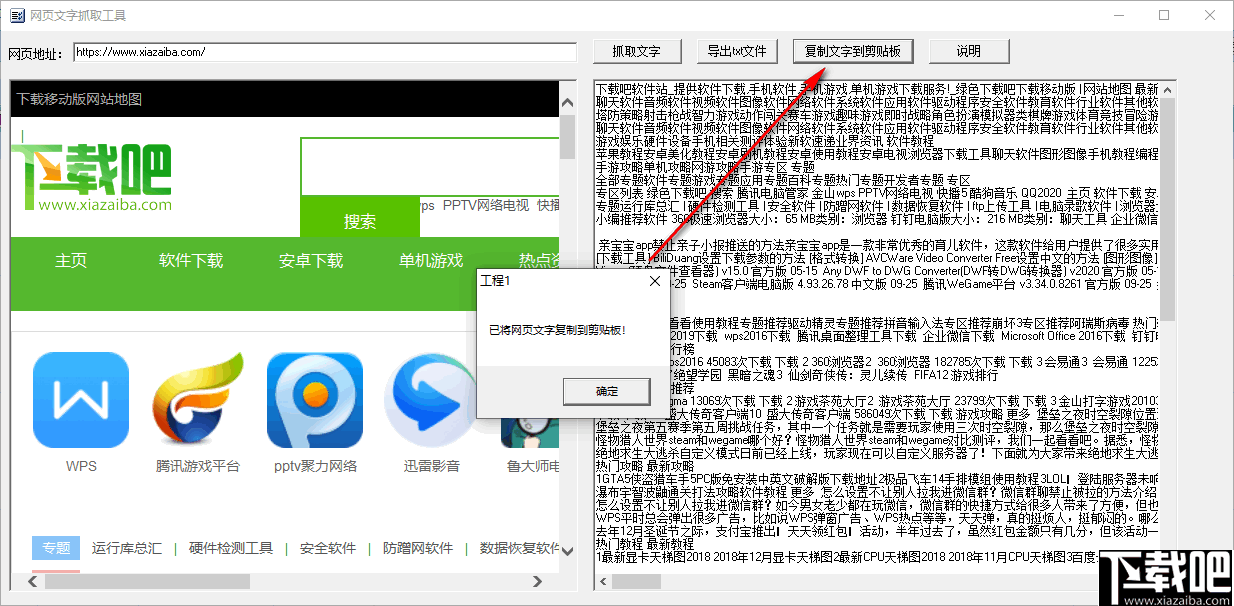
8、您也可以点击“复制文本到剪贴板”按钮将所有文本复制到剪贴板。
网页内容抓取工具(网页内容抓取工具,五大类必备:googleanalytics、appium、snippet)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-27 13:13
网页内容抓取工具,五大类必备:googleanalytics、appium、snippet、airtests、ssas。本文介绍的这款工具,相对来说更容易上手。.首先我们来熟悉一下什么是apis请求apis=get/post/put/deleteapis是指和microsoftwindows、oracleonlinesqldatabase/managedconnections、flexinternetapiserver(flex)、javainternetapi(javase)等联结的。
api的主要功能是通过各种形式的联结方式,将您的请求按照特定的方式转换成相应的服务,例如音乐,视频,和多媒体等。.方法注意事项。
1、应用api之前请先检查目标的互联网服务是否是开放的,开放的互联网服务需要开放api,api是开放式的服务。
2)
2、在网站或软件的源代码中定义api也是必须要做的,假设airtest3.0启用了api,启用api可以为用户提供更好的用户体验。
3、调用api时请确保请求具有不同的域名,不同的ip,不同的域名要求的备案,不同的地区,不同的服务器等。
4、建议使用webtargetingtoolkit:firefox、safari、chrome、vlc。
5、避免不必要的http状态码:990
1、992
5、952
7、1993
4、1993
4、999
4、1992
4、992
2、990
6、990
7、990
8、1992
2、952
2、1992
2、1801
1、1992
2、25481
5、25481
5、1991
9、1991
9、19921
2、19921
4、19921 查看全部
网页内容抓取工具(网页内容抓取工具,五大类必备:googleanalytics、appium、snippet)
网页内容抓取工具,五大类必备:googleanalytics、appium、snippet、airtests、ssas。本文介绍的这款工具,相对来说更容易上手。.首先我们来熟悉一下什么是apis请求apis=get/post/put/deleteapis是指和microsoftwindows、oracleonlinesqldatabase/managedconnections、flexinternetapiserver(flex)、javainternetapi(javase)等联结的。
api的主要功能是通过各种形式的联结方式,将您的请求按照特定的方式转换成相应的服务,例如音乐,视频,和多媒体等。.方法注意事项。
1、应用api之前请先检查目标的互联网服务是否是开放的,开放的互联网服务需要开放api,api是开放式的服务。
2)
2、在网站或软件的源代码中定义api也是必须要做的,假设airtest3.0启用了api,启用api可以为用户提供更好的用户体验。
3、调用api时请确保请求具有不同的域名,不同的ip,不同的域名要求的备案,不同的地区,不同的服务器等。
4、建议使用webtargetingtoolkit:firefox、safari、chrome、vlc。
5、避免不必要的http状态码:990
1、992
5、952
7、1993
4、1993
4、999
4、1992
4、992
2、990
6、990
7、990
8、1992
2、952
2、1992
2、1801
1、1992
2、25481
5、25481
5、1991
9、1991
9、19921
2、19921
4、19921
网页内容抓取工具(,涉及Python使用BeautifulSoup模块解析html网页的相关技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-26 13:06
本文主要介绍基于BeautifulSoup抓取网页指定内容的python方法,涉及Python使用BeautifulSoup模块解析html网页的相关技巧。有一定的参考价值,有需要的朋友可以参考
本文示例介绍了基于BeautifulSoup爬取网页指定内容的python方法。分享给大家,供大家参考。具体实现方法如下:
# _*_ coding:utf-8 _*_ #xiaohei.python.seo.call.me:) #win+python2.7.x import urllib2 from bs4 import BeautifulSoup def jd(url): page = urllib2.urlopen(url) html_doc = page.read() soup = BeautifulSoup(html_doc.decode('gb2312','ignore')) for i in soup.find_all('div', id="sortlist"): one = i.find_all('a') two = i.find_all('li') print ("%s %s" % (one,two)) jd("http://channel.jd.com/computer.html")
希望这篇文章对你的 Python 编程有所帮助。
以上是基于BeautifulSoup爬取网页指定内容的python方法的详细内容。详情请关注html中文网其他相关文章! 查看全部
网页内容抓取工具(,涉及Python使用BeautifulSoup模块解析html网页的相关技巧)
本文主要介绍基于BeautifulSoup抓取网页指定内容的python方法,涉及Python使用BeautifulSoup模块解析html网页的相关技巧。有一定的参考价值,有需要的朋友可以参考
本文示例介绍了基于BeautifulSoup爬取网页指定内容的python方法。分享给大家,供大家参考。具体实现方法如下:
# _*_ coding:utf-8 _*_ #xiaohei.python.seo.call.me:) #win+python2.7.x import urllib2 from bs4 import BeautifulSoup def jd(url): page = urllib2.urlopen(url) html_doc = page.read() soup = BeautifulSoup(html_doc.decode('gb2312','ignore')) for i in soup.find_all('div', id="sortlist"): one = i.find_all('a') two = i.find_all('li') print ("%s %s" % (one,two)) jd("http://channel.jd.com/computer.html";)
希望这篇文章对你的 Python 编程有所帮助。
以上是基于BeautifulSoup爬取网页指定内容的python方法的详细内容。详情请关注html中文网其他相关文章!
网页内容抓取工具(网站图片保存路径是什么?如何培养搜索引擎蜘蛛习惯?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-23 04:17
这里要特别注意。现在很多图片都有版权了。根本不要使用那些受版权保护的图片。否则,不仅会侵权,还会降低搜索引擎对您的网站的信任价值。
二、网站图片保存路径
很多站长都没有注意到这个问题。图片上传到网站时,尽量将图片保存在一个目录下,或者根据网站栏制作相应的图片目录,上传路径应该比较固定,方便蜘蛛抢。当蜘蛛访问这个目录时,它会“知道”图片存放在这个目录中;
最好使用一些常规或有意义的方法来命名图像文件。您可以使用时间、列名或网站 名称来命名。例如:SEO优化 下图可以使用名称“SEOYH2018-6-23-36”,前面的“SEOYH”是SEO优化的简称,中间是时间,最后是图片ID。
你为什么要这样做?其实这是为了培养被搜索引擎蜘蛛抓取的习惯,让你以后可以更快的识别网站图片的内容。让蜘蛛抓住你的心,增加网站成为收录的机会,何乐而不为呢!
三、图片周围必须有相关文字
正如我在文章开头所说的,网站图片是一种直接向用户展示信息的方式,搜索引擎在爬取网站的内容时也会检查这个文章@ >无论是图片、视频还是表格等,这些都是可以增加文章值的元素,其他形式暂时不展示,这里只讲图片周围相关文字的介绍.
图片符合主题
首先,图片周围的文字必须与图片本身的内容一致。比如你的文章说要做网站优化,里面的图片是一个菜谱的图片。这不就是卖狗肉吗?参观感会极差。搜索引擎通过相关算法识别出这张图片后,也会觉得图片和文字不符,给你差评。
因此,每张文章必须至少附有一张对应的图片,并且与您的网站标题相关的内容应该出现在图片的周围。它不仅可以帮助搜索引擎理解图像,还可以增加文章的可读性、用户友好性和相关性。
四、给图片添加alt和title标签
很多站长在添加网站图片时可能没有注意这些细节,有的可能会觉得麻烦。我希望你没有这个想法。这是一个大错误。
搜索引擎抓取网站图片时,atl标签是最先抓取的,也是识别图片内容最重要的核心因素之一。图片的alt属性直接告诉搜索引擎它是什么网站图片,表达什么意思;
标题标签是用户指向这张图片时会显示的提示内容。这是增加用户体验和增加网站关键词的一个小技巧。
alt 和标题标签
还有这两个属性,将为有阅读障碍的游客提供便利。例如,当一个盲人访问您网站时,他看不到屏幕上的内容。这可能是通过屏幕阅读。如果有alt属性,软件会直接读取alt属性中的文字,方便他们访问。
五、图像大小和分辨率
两人虽然长得有点像,但还是有很大区别的。同样大小的图片分辨率越高,网站的最终体积就会越大。每个人都必须弄清楚这一点。
网站上的图片一直提倡用尽可能小的图片来最大化内容。你为什么要这样做?因为小尺寸的图片加载速度会更快,不会让访问者等待太久,尤其是在使用手机时。由于移动互联网速度和流量的限制,用户更愿意访问可以立即打开的页面。, 小尺寸的图片更有优势。
这里我们尽量做到平衡,在画面不失真的情况下,尺寸最好尽量小。现在网上有很多减肥图片的工具。每个站长都可以试一试,适当压缩网站的图片。一方面可以减轻你服务器带宽的压力,也可以给用户带来流畅的体验。.
六、自动适配手机
很多站长都遇到过网站在电脑上访问图片时,显示正常,但从手机端出现错位。这就是大尺寸图片在不同尺寸终端上造成错位、显示不完整的情况。.
图片自适应移动终端
其实这个问题很容易解决。添加图片时,宽度和高度最好不要使用绝对大小。使用百分比来解决它。具体来说,CSS代码不能指定像素宽度:width: xxx px; 只有百分比宽度:宽度:xx%;或宽度:自动。
这样做的目的也是为了让百度的手机蜘蛛在抓取的时候有很好的体验,这也是为了更符合百度的手机登陆页面体验。
以上介绍了网站SEO优化中如何抓取手机图片网站的一些技巧。其实本质是为了给用户更好的访问体验。当你这样做网站时,我相信搜索引擎会偏爱你的网站。 查看全部
网页内容抓取工具(网站图片保存路径是什么?如何培养搜索引擎蜘蛛习惯?)
这里要特别注意。现在很多图片都有版权了。根本不要使用那些受版权保护的图片。否则,不仅会侵权,还会降低搜索引擎对您的网站的信任价值。
二、网站图片保存路径
很多站长都没有注意到这个问题。图片上传到网站时,尽量将图片保存在一个目录下,或者根据网站栏制作相应的图片目录,上传路径应该比较固定,方便蜘蛛抢。当蜘蛛访问这个目录时,它会“知道”图片存放在这个目录中;
最好使用一些常规或有意义的方法来命名图像文件。您可以使用时间、列名或网站 名称来命名。例如:SEO优化 下图可以使用名称“SEOYH2018-6-23-36”,前面的“SEOYH”是SEO优化的简称,中间是时间,最后是图片ID。
你为什么要这样做?其实这是为了培养被搜索引擎蜘蛛抓取的习惯,让你以后可以更快的识别网站图片的内容。让蜘蛛抓住你的心,增加网站成为收录的机会,何乐而不为呢!
三、图片周围必须有相关文字
正如我在文章开头所说的,网站图片是一种直接向用户展示信息的方式,搜索引擎在爬取网站的内容时也会检查这个文章@ >无论是图片、视频还是表格等,这些都是可以增加文章值的元素,其他形式暂时不展示,这里只讲图片周围相关文字的介绍.

图片符合主题
首先,图片周围的文字必须与图片本身的内容一致。比如你的文章说要做网站优化,里面的图片是一个菜谱的图片。这不就是卖狗肉吗?参观感会极差。搜索引擎通过相关算法识别出这张图片后,也会觉得图片和文字不符,给你差评。
因此,每张文章必须至少附有一张对应的图片,并且与您的网站标题相关的内容应该出现在图片的周围。它不仅可以帮助搜索引擎理解图像,还可以增加文章的可读性、用户友好性和相关性。
四、给图片添加alt和title标签
很多站长在添加网站图片时可能没有注意这些细节,有的可能会觉得麻烦。我希望你没有这个想法。这是一个大错误。
搜索引擎抓取网站图片时,atl标签是最先抓取的,也是识别图片内容最重要的核心因素之一。图片的alt属性直接告诉搜索引擎它是什么网站图片,表达什么意思;
标题标签是用户指向这张图片时会显示的提示内容。这是增加用户体验和增加网站关键词的一个小技巧。

alt 和标题标签
还有这两个属性,将为有阅读障碍的游客提供便利。例如,当一个盲人访问您网站时,他看不到屏幕上的内容。这可能是通过屏幕阅读。如果有alt属性,软件会直接读取alt属性中的文字,方便他们访问。
五、图像大小和分辨率
两人虽然长得有点像,但还是有很大区别的。同样大小的图片分辨率越高,网站的最终体积就会越大。每个人都必须弄清楚这一点。
网站上的图片一直提倡用尽可能小的图片来最大化内容。你为什么要这样做?因为小尺寸的图片加载速度会更快,不会让访问者等待太久,尤其是在使用手机时。由于移动互联网速度和流量的限制,用户更愿意访问可以立即打开的页面。, 小尺寸的图片更有优势。
这里我们尽量做到平衡,在画面不失真的情况下,尺寸最好尽量小。现在网上有很多减肥图片的工具。每个站长都可以试一试,适当压缩网站的图片。一方面可以减轻你服务器带宽的压力,也可以给用户带来流畅的体验。.
六、自动适配手机
很多站长都遇到过网站在电脑上访问图片时,显示正常,但从手机端出现错位。这就是大尺寸图片在不同尺寸终端上造成错位、显示不完整的情况。.

图片自适应移动终端
其实这个问题很容易解决。添加图片时,宽度和高度最好不要使用绝对大小。使用百分比来解决它。具体来说,CSS代码不能指定像素宽度:width: xxx px; 只有百分比宽度:宽度:xx%;或宽度:自动。
这样做的目的也是为了让百度的手机蜘蛛在抓取的时候有很好的体验,这也是为了更符合百度的手机登陆页面体验。
以上介绍了网站SEO优化中如何抓取手机图片网站的一些技巧。其实本质是为了给用户更好的访问体验。当你这样做网站时,我相信搜索引擎会偏爱你的网站。
网页内容抓取工具( 如何随意提取单机游戏和网络游戏模型和贴图模型的软件?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-12-22 15:01
如何随意提取单机游戏和网络游戏模型和贴图模型的软件?)
如何获得游戏网站制作资料
可以随意为单机游戏和网络游戏提取模型和纹理的软件:一般来说,应用比较广泛的有3D RIPPER、GAMEASSASSIN、NINJA RIPPER。
1、3DRIPPER更适合初学者,操作简单。
不过模型有轻微变形,需要自行调整。
2、GAMEASSASSIN 支持很多游戏,是一款奇迹式的拦截器。
3、NINJA RIPPER在客户端注入HOOK,可以截取非常整齐的模型(人物双手平举,坐标重置为零)。
注:部分特定游戏有特殊的拦截工具,如Unreal的UMODEL、DOTA2的GCFScape等。
另外,有些游戏戒备得很严,提不出来也是很常见的。
1、软件(中国大陆和香港术语,台湾称为软件,英文:Software)是按特定顺序组织起来的计算机数据和指令的集合。
一般来说,软件分为系统软件、应用软件和中间件。
软件不仅包括可以在计算机上运行的计算机程序(这里的计算机是指广义的计算机),与这些计算机程序相关的文件一般都被认为是软件的一部分。
简单地说,软件是程序和文档的集合。
也指社会结构中的管理体制、意识形态、思想政治意识、法律法规等。
2、软件特性(1)是无形的,没有物理形式。你只能通过运行条件来了解功能、特性和质量。
(2)软件需要大量脑力劳动。人类的逻辑思维、智能活动和技术水平是软件产品的关键。
(3)软件不会像硬件一样磨损,但有缺陷维护和技术更新。
(4)软件的开发和运行必须依赖于特定的计算机系统环境,并且依赖于硬件。为了减少依赖,在开发中提出了软件的可移植性。
(5)软件是可复用的,软件开发时很容易被复制,从而形成多个副本。
...
如何从网络游戏中的文件中提取图片(游戏加载并读取一些图片)。
如何...
所需工具:VisualBoyAdvance(中文版) 其实VisualBoyAdvance模拟器就是一个解压器,不需要下载其他工具。用GBA打开游戏,当有你喜欢的行走画面时,点击模拟器菜单中的工具--对象属性查看器(有时因为版本不同或Sinicizer名称不同,反正一般是第6个工具的项目),然后会弹出一个盒子,里面有很多项目,但是你有看到左上角可以拉动的棍子吗?当你拉它时,左边的图像框会随着你拉它而改变图片,拉它,你会发现你想要的行走图片在图像框中。你在等什么!快速按下方的保存进行保存和下载!提取步行图像的步骤大概是这样的,但是这种方法有一些麻烦。当然,提取站立图像很容易,但提取步行图像有点困难。您必须打开对象属性查看器并放置它。模拟器旁边,不要让它挡住我们模拟器的视线,还要在打勾的左下角自动刷新对象属性查看器,然后在游戏角色行走时快速点击对象属性查看器(这是为了让模拟器停止,这样我们就可以提取游戏人物行走的图片),然后按照上面提到的方法提取素材。提取后,排列设置好透明色后,就是一张自动移动的图片了!(温馨提示:为了准确提取游戏人物行走的形象,我们可以从模拟器菜单的选项-跳过帧-速度调整来减慢游戏速度)注:有时由于限制,一张图片会被分成两块或几块。通常这些碎片靠得很近,所以只需轻轻拉动棍子或在棍子旁边的值上加 1 即可找到它。本教程到此结束,祝大家制作出更精彩的游戏。^-^ 补充:其实这个方法不仅仅是提取人物的行走图。一般来说,游戏中的移动物体会再次出现在这里。在GBA中,我们称之为精灵,对象属性查看器专用于图像区域的精灵。所以只需轻轻拉动棍子或在棍子旁边的值上加 1 即可找到它。本教程到此结束,祝大家制作出更精彩的游戏。^-^ 补充:其实这个方法不仅仅是提取人物的行走图。一般来说,游戏中的移动物体会再次出现在这里。在GBA中,我们称之为精灵,对象属性查看器专用于图像区域的精灵。所以只需轻轻拉动棍子或在棍子旁边的值上加 1 即可找到它。本教程到此结束,祝大家制作出更精彩的游戏。^-^ 补充:其实这个方法不仅仅是提取人物的行走图。一般来说,游戏中的移动物体会再次出现在这里。在GBA中,我们称之为精灵,对象属性查看器专用于图像区域的精灵。
转载请注明出处51数据库»网页游戏素材提取软件 查看全部
网页内容抓取工具(
如何随意提取单机游戏和网络游戏模型和贴图模型的软件?)
如何获得游戏网站制作资料
可以随意为单机游戏和网络游戏提取模型和纹理的软件:一般来说,应用比较广泛的有3D RIPPER、GAMEASSASSIN、NINJA RIPPER。
1、3DRIPPER更适合初学者,操作简单。
不过模型有轻微变形,需要自行调整。
2、GAMEASSASSIN 支持很多游戏,是一款奇迹式的拦截器。
3、NINJA RIPPER在客户端注入HOOK,可以截取非常整齐的模型(人物双手平举,坐标重置为零)。
注:部分特定游戏有特殊的拦截工具,如Unreal的UMODEL、DOTA2的GCFScape等。
另外,有些游戏戒备得很严,提不出来也是很常见的。
1、软件(中国大陆和香港术语,台湾称为软件,英文:Software)是按特定顺序组织起来的计算机数据和指令的集合。
一般来说,软件分为系统软件、应用软件和中间件。
软件不仅包括可以在计算机上运行的计算机程序(这里的计算机是指广义的计算机),与这些计算机程序相关的文件一般都被认为是软件的一部分。
简单地说,软件是程序和文档的集合。
也指社会结构中的管理体制、意识形态、思想政治意识、法律法规等。
2、软件特性(1)是无形的,没有物理形式。你只能通过运行条件来了解功能、特性和质量。
(2)软件需要大量脑力劳动。人类的逻辑思维、智能活动和技术水平是软件产品的关键。
(3)软件不会像硬件一样磨损,但有缺陷维护和技术更新。
(4)软件的开发和运行必须依赖于特定的计算机系统环境,并且依赖于硬件。为了减少依赖,在开发中提出了软件的可移植性。
(5)软件是可复用的,软件开发时很容易被复制,从而形成多个副本。
...
如何从网络游戏中的文件中提取图片(游戏加载并读取一些图片)。
如何...
所需工具:VisualBoyAdvance(中文版) 其实VisualBoyAdvance模拟器就是一个解压器,不需要下载其他工具。用GBA打开游戏,当有你喜欢的行走画面时,点击模拟器菜单中的工具--对象属性查看器(有时因为版本不同或Sinicizer名称不同,反正一般是第6个工具的项目),然后会弹出一个盒子,里面有很多项目,但是你有看到左上角可以拉动的棍子吗?当你拉它时,左边的图像框会随着你拉它而改变图片,拉它,你会发现你想要的行走图片在图像框中。你在等什么!快速按下方的保存进行保存和下载!提取步行图像的步骤大概是这样的,但是这种方法有一些麻烦。当然,提取站立图像很容易,但提取步行图像有点困难。您必须打开对象属性查看器并放置它。模拟器旁边,不要让它挡住我们模拟器的视线,还要在打勾的左下角自动刷新对象属性查看器,然后在游戏角色行走时快速点击对象属性查看器(这是为了让模拟器停止,这样我们就可以提取游戏人物行走的图片),然后按照上面提到的方法提取素材。提取后,排列设置好透明色后,就是一张自动移动的图片了!(温馨提示:为了准确提取游戏人物行走的形象,我们可以从模拟器菜单的选项-跳过帧-速度调整来减慢游戏速度)注:有时由于限制,一张图片会被分成两块或几块。通常这些碎片靠得很近,所以只需轻轻拉动棍子或在棍子旁边的值上加 1 即可找到它。本教程到此结束,祝大家制作出更精彩的游戏。^-^ 补充:其实这个方法不仅仅是提取人物的行走图。一般来说,游戏中的移动物体会再次出现在这里。在GBA中,我们称之为精灵,对象属性查看器专用于图像区域的精灵。所以只需轻轻拉动棍子或在棍子旁边的值上加 1 即可找到它。本教程到此结束,祝大家制作出更精彩的游戏。^-^ 补充:其实这个方法不仅仅是提取人物的行走图。一般来说,游戏中的移动物体会再次出现在这里。在GBA中,我们称之为精灵,对象属性查看器专用于图像区域的精灵。所以只需轻轻拉动棍子或在棍子旁边的值上加 1 即可找到它。本教程到此结束,祝大家制作出更精彩的游戏。^-^ 补充:其实这个方法不仅仅是提取人物的行走图。一般来说,游戏中的移动物体会再次出现在这里。在GBA中,我们称之为精灵,对象属性查看器专用于图像区域的精灵。
转载请注明出处51数据库»网页游戏素材提取软件
网页内容抓取工具(网页内容抓取工具,好用,不占硬盘存储和网速)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-22 14:05
网页内容抓取工具,好用,不占硬盘存储和网速,自带sql查询语言,适合一些初学者。支持安卓手机和苹果ios手机,已内置laravel语言,建议两端通吃。
我这里有一个网页抓取工具,
两个都用过,用pc推荐网页采集器,在网上广泛宣传,手机同样推荐网页采集器,它会提供相应的功能,不多说。爬虫是发现页面的规律,目前抓取不容易出现重复的页面。
初学,推荐beautifulsoup,如何得到页面信息,实现内容抓取。然后laya,正则表达式实现爬虫的到页面抓取。然后python自带,推荐python爬虫程序设计,http权威指南。当然,如果不喜欢看书,那可以使用爬虫工具。
pc上推荐scrapy()是一个高级的开源爬虫框架。目前大部分linux下应用基本都是基于scrapy开发的。scrapy已经包含了所有可爬取任务的爬虫功能。如果觉得scrapy还不够好,可以选择python的scrapy框架。
推荐用mysql
pc端的话推荐网页抓取器,手机端的推荐米筐,不太清楚你的专业,但数据可视化看你对哪方面用的多,linux下的shell编程的话直接lsb_release,python对win的虚拟机支持不错,虽然不如win系统做的好,但python是一个大数据容器。
hyperloglog手机端的话tornadolibtornado很简单,很容易学,感兴趣可以试试。 查看全部
网页内容抓取工具(网页内容抓取工具,好用,不占硬盘存储和网速)
网页内容抓取工具,好用,不占硬盘存储和网速,自带sql查询语言,适合一些初学者。支持安卓手机和苹果ios手机,已内置laravel语言,建议两端通吃。
我这里有一个网页抓取工具,
两个都用过,用pc推荐网页采集器,在网上广泛宣传,手机同样推荐网页采集器,它会提供相应的功能,不多说。爬虫是发现页面的规律,目前抓取不容易出现重复的页面。
初学,推荐beautifulsoup,如何得到页面信息,实现内容抓取。然后laya,正则表达式实现爬虫的到页面抓取。然后python自带,推荐python爬虫程序设计,http权威指南。当然,如果不喜欢看书,那可以使用爬虫工具。
pc上推荐scrapy()是一个高级的开源爬虫框架。目前大部分linux下应用基本都是基于scrapy开发的。scrapy已经包含了所有可爬取任务的爬虫功能。如果觉得scrapy还不够好,可以选择python的scrapy框架。
推荐用mysql
pc端的话推荐网页抓取器,手机端的推荐米筐,不太清楚你的专业,但数据可视化看你对哪方面用的多,linux下的shell编程的话直接lsb_release,python对win的虚拟机支持不错,虽然不如win系统做的好,但python是一个大数据容器。
hyperloglog手机端的话tornadolibtornado很简单,很容易学,感兴趣可以试试。
网页内容抓取工具(URLExtractor内容提取WK下载永久钻石支付宝下载(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-19 12:07
URL Extractor 是一个 Cocoa 应用程序,用于从文件中提取电子邮件地址和 URL,这些文件也可以通过搜索引擎找到。它可以从单个网页开始,浏览所有内部链接,找到要提取的电子邮件或URL,并将所有链接保存在用户HD上。它还可以从任何嵌套级别的单个文件或 HD 上文件夹的所有内容中提取。完成后,它可以将 URL Extractor 文档保存到磁盘,其中收录特定文件夹或文件或网页的所有设置,可以重复使用。或者,提取的数据可以作为文本文件保存在磁盘上以供用户使用。
它允许用户指定要用作导航起点的网页列表,并使用交叉导航转到其他网页。您还可以指定一系列关键字;然后通过搜索引擎搜索与关键字相关的网页,并开始页面的交叉导航,采集网址。在Web提取模式下无需用户交互即可导航数小时,提取在所有无人值守网页中找到的所有URL;或从使用关键字的单个搜索引擎开始,在无限制的导航和 URL 中查看提取过程中的所有结果和链接页面。
特征
本站统一解压密码:
免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。
URL Extractor 内容提取
WK网友下载永久钻石
支付宝扫一扫
微信扫一扫>打赏采集海报链接 查看全部
网页内容抓取工具(URLExtractor内容提取WK下载永久钻石支付宝下载(组图))
URL Extractor 是一个 Cocoa 应用程序,用于从文件中提取电子邮件地址和 URL,这些文件也可以通过搜索引擎找到。它可以从单个网页开始,浏览所有内部链接,找到要提取的电子邮件或URL,并将所有链接保存在用户HD上。它还可以从任何嵌套级别的单个文件或 HD 上文件夹的所有内容中提取。完成后,它可以将 URL Extractor 文档保存到磁盘,其中收录特定文件夹或文件或网页的所有设置,可以重复使用。或者,提取的数据可以作为文本文件保存在磁盘上以供用户使用。
它允许用户指定要用作导航起点的网页列表,并使用交叉导航转到其他网页。您还可以指定一系列关键字;然后通过搜索引擎搜索与关键字相关的网页,并开始页面的交叉导航,采集网址。在Web提取模式下无需用户交互即可导航数小时,提取在所有无人值守网页中找到的所有URL;或从使用关键字的单个搜索引擎开始,在无限制的导航和 URL 中查看提取过程中的所有结果和链接页面。
特征
 https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />
https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" /> https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />
https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" /> https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />
https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />本站统一解压密码:
免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。
URL Extractor 内容提取
WK网友下载永久钻石
 WX20211214-222443@2x.png" />
WX20211214-222443@2x.png" />支付宝扫一扫
WX20211214-222554@2x.png" />微信扫一扫>打赏采集海报链接
网页内容抓取工具(一个翻页循环网页数据能采集到哪些数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-12-19 12:05
采集可以从网页数据中得到什么数据
刚接触数据采集的同学可能会有这样的疑问:哪些网页数据可以是采集?
简单地说,互联网收录了丰富的开放数据资源。这些直接可见的互联网公开数据可以是采集,但是采集的难易程度存在差异。具体到数据类型,大数据的数据主要是网络日志、视频、图片、地理位置等网络信息,可以通过多种方式实现采集。
我们可以使用采集工具高效便捷的实现各种网页和各类网页数据采集。优采云是一个可视化的网页数据采集器,可以是采集99%的网页。以下是完整的使用优采云、采集的豆瓣电影短评示例。
第一步:创建采集任务
1)进入主界面,选择“自定义模式”
2)将采集的网址复制粘贴到网站的输入框中,点击“保存网址”
采集可以从网页数据中得到什么数据 图2
第 2 步:创建翻页循环
1)在页面右上角,打开“流程”,显示“流程设计器”和“自定义当前操作”两个部分。网页打开后,下拉页面,找到并点击“更多短评”按钮,选择“点击此链接”
采集可以从网页数据中得到什么数据 图3
2) 将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,
选择“更多操作”
采集可以从网页数据中得到什么数据 图4
选择“循环点击单个链接”创建翻页循环
采集可以从网页数据中得到什么数据 图5
第 3 步:创建列表循环并提取数据
1)移动鼠标选择页面上的第一个电影评论块。系统会识别该块中的子元素,在操作提示框中选择“选择子元素”
采集可以从网页数据中得到什么数据 图6
2) 系统会自动识别页面其他相似元素,在操作提示框中选择“全选”创建列表循环
采集可以从网页数据中得到什么数据 图7
3) 我们可以看到页面第一个电影评论块中的所有元素都被选中并变成了绿色。选择“采集以下数据”
采集可以从网页数据中得到什么数据 图8
4)选择一个字段并点击垃圾桶图标删除不需要的字段
采集可以从网页数据中得到什么数据 图9
5) 字段选择完成后,选择对应的字段,自定义字段的命名。完成后,点击左上角的“保存并启动”
采集可以从网页数据中得到什么数据 图10
6)选择“启动本地采集”
采集可以从网页数据中得到什么数据 图11
第四步:数据采集并导出
1)采集 完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
采集可以从网页数据中得到什么数据 图12
2)这里我们选择excel作为导出格式,导出数据如下图
采集可以从网页数据中得到什么数据 图13
注:未登录时,豆瓣电影短评页面只能翻8次,采集约160条短评数据。采集更多资料,请先登录。登录请参考以下两个教程:单文输入点击登录方式(/tutorialdetail-1/srdl_v70.html)和cookie登录方式(/tutorialdetail-1/cookie70.html)。
在示例中,采集的豆瓣电影的评论信息,以及视频、图片、地理位置等其他数据类型的采集的评论信息相对复杂一些。视频:可用 采集 其 URL。图片:可以批量处理采集图片网址,然后使用优采云批量导出工具将网址导出为图片。地理位置(经纬度),如地图网站(百度地图、高德地图
该信息在搜狗地图源码中可以找到,可以从源码采集获取。
相关 采集 教程: 查看全部
网页内容抓取工具(一个翻页循环网页数据能采集到哪些数据(组图))
采集可以从网页数据中得到什么数据
刚接触数据采集的同学可能会有这样的疑问:哪些网页数据可以是采集?
简单地说,互联网收录了丰富的开放数据资源。这些直接可见的互联网公开数据可以是采集,但是采集的难易程度存在差异。具体到数据类型,大数据的数据主要是网络日志、视频、图片、地理位置等网络信息,可以通过多种方式实现采集。
我们可以使用采集工具高效便捷的实现各种网页和各类网页数据采集。优采云是一个可视化的网页数据采集器,可以是采集99%的网页。以下是完整的使用优采云、采集的豆瓣电影短评示例。
第一步:创建采集任务
1)进入主界面,选择“自定义模式”
2)将采集的网址复制粘贴到网站的输入框中,点击“保存网址”
采集可以从网页数据中得到什么数据 图2
第 2 步:创建翻页循环
1)在页面右上角,打开“流程”,显示“流程设计器”和“自定义当前操作”两个部分。网页打开后,下拉页面,找到并点击“更多短评”按钮,选择“点击此链接”
采集可以从网页数据中得到什么数据 图3
2) 将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,
选择“更多操作”
采集可以从网页数据中得到什么数据 图4
选择“循环点击单个链接”创建翻页循环
采集可以从网页数据中得到什么数据 图5
第 3 步:创建列表循环并提取数据
1)移动鼠标选择页面上的第一个电影评论块。系统会识别该块中的子元素,在操作提示框中选择“选择子元素”
采集可以从网页数据中得到什么数据 图6
2) 系统会自动识别页面其他相似元素,在操作提示框中选择“全选”创建列表循环
采集可以从网页数据中得到什么数据 图7
3) 我们可以看到页面第一个电影评论块中的所有元素都被选中并变成了绿色。选择“采集以下数据”
采集可以从网页数据中得到什么数据 图8
4)选择一个字段并点击垃圾桶图标删除不需要的字段
采集可以从网页数据中得到什么数据 图9
5) 字段选择完成后,选择对应的字段,自定义字段的命名。完成后,点击左上角的“保存并启动”
采集可以从网页数据中得到什么数据 图10
6)选择“启动本地采集”
采集可以从网页数据中得到什么数据 图11
第四步:数据采集并导出
1)采集 完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
采集可以从网页数据中得到什么数据 图12
2)这里我们选择excel作为导出格式,导出数据如下图
采集可以从网页数据中得到什么数据 图13
注:未登录时,豆瓣电影短评页面只能翻8次,采集约160条短评数据。采集更多资料,请先登录。登录请参考以下两个教程:单文输入点击登录方式(/tutorialdetail-1/srdl_v70.html)和cookie登录方式(/tutorialdetail-1/cookie70.html)。
在示例中,采集的豆瓣电影的评论信息,以及视频、图片、地理位置等其他数据类型的采集的评论信息相对复杂一些。视频:可用 采集 其 URL。图片:可以批量处理采集图片网址,然后使用优采云批量导出工具将网址导出为图片。地理位置(经纬度),如地图网站(百度地图、高德地图
该信息在搜狗地图源码中可以找到,可以从源码采集获取。
相关 采集 教程:
网页内容抓取工具(WebScraperforMac永久激活版是您的不错选择!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-18 17:07
如果您正在寻找一款好用的网站数据抓取工具,那么WebScraper for Mac永久激活版是您不错的选择!有需要的朋友可以下载!
WebScraper Mac 软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper Mac 软件功能
1、快速轻松地扫描网站
大量的提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、易于导出-选择您想要的列
3、输出为 csv 或 json
4、将所有图像下载到文件夹/采集并导出所有链接的新选项
5、输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
WebScraper Mac 软件功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、专为现代网络设计
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。拿到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能想尝试将数据保存到 CouchDB 中。 查看全部
网页内容抓取工具(WebScraperforMac永久激活版是您的不错选择!!)
如果您正在寻找一款好用的网站数据抓取工具,那么WebScraper for Mac永久激活版是您不错的选择!有需要的朋友可以下载!
WebScraper Mac 软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper Mac 软件功能
1、快速轻松地扫描网站
大量的提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、易于导出-选择您想要的列
3、输出为 csv 或 json
4、将所有图像下载到文件夹/采集并导出所有链接的新选项
5、输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
WebScraper Mac 软件功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、专为现代网络设计
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。拿到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能想尝试将数据保存到 CouchDB 中。
网页内容抓取工具(登录百度站长平台使用抓取诊断工具换IP真的不是愁事)
网站优化 • 优采云 发表了文章 • 0 个评论 • 324 次浏览 • 2022-01-16 14:15
在和站长朋友私下交流中,站长说:怕改版改IP。每次我都别无选择,只能自己做。改版比较好,有改版工具可以用。换IP不知道怎么通知百度。
其实,登陆百度站长平台,使用刮痧诊断工具换IP,真的是一点都不省心。
爬虫诊断工具会检查网站与百度的连接是否畅通。如果站长发现IP信息还是旧的,可以通过“Error”通知百度搜索引擎更新IP,如下图:
重要提示:由于蜘蛛的能量有限,如果报错后网站IP仍然没有变化,站长可以多次尝试直到达到预期。
那么,爬虫诊断工具除了用于通知百度搜索引擎该站点已更改IP之外,还能做什么呢?
【诊断爬取的内容是否符合预期】比如在很多商品详情页中,价格信息是通过JavaScript输出的,对百度蜘蛛不友好,价格信息在搜索中难以应用。问题解决后,可以使用诊断工具再次抓取测试。
【判断网页是否添加了黑色链接和隐藏文字】网站被黑后添加的隐藏链接从网页表面无法观察到。这些链接可能只有在百度爬取时才会出现,可以通过爬取诊断工具获取来检查。
【邀请百度蜘蛛】如果网站有新页面或者页面内容已经更新,但是百度蜘蛛很长时间没有访问,可以通过爬虫诊断工具邀请百度蜘蛛快速爬取。
AAAFGGHTYHCGER 查看全部
网页内容抓取工具(登录百度站长平台使用抓取诊断工具换IP真的不是愁事)
在和站长朋友私下交流中,站长说:怕改版改IP。每次我都别无选择,只能自己做。改版比较好,有改版工具可以用。换IP不知道怎么通知百度。
其实,登陆百度站长平台,使用刮痧诊断工具换IP,真的是一点都不省心。
爬虫诊断工具会检查网站与百度的连接是否畅通。如果站长发现IP信息还是旧的,可以通过“Error”通知百度搜索引擎更新IP,如下图:
重要提示:由于蜘蛛的能量有限,如果报错后网站IP仍然没有变化,站长可以多次尝试直到达到预期。
那么,爬虫诊断工具除了用于通知百度搜索引擎该站点已更改IP之外,还能做什么呢?
【诊断爬取的内容是否符合预期】比如在很多商品详情页中,价格信息是通过JavaScript输出的,对百度蜘蛛不友好,价格信息在搜索中难以应用。问题解决后,可以使用诊断工具再次抓取测试。
【判断网页是否添加了黑色链接和隐藏文字】网站被黑后添加的隐藏链接从网页表面无法观察到。这些链接可能只有在百度爬取时才会出现,可以通过爬取诊断工具获取来检查。
【邀请百度蜘蛛】如果网站有新页面或者页面内容已经更新,但是百度蜘蛛很长时间没有访问,可以通过爬虫诊断工具邀请百度蜘蛛快速爬取。
AAAFGGHTYHCGER
网页内容抓取工具(优采云采集器编辑采集数据:您可以在本地可视化编辑已采集的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-01-16 14:14
优采云采集器是目前使用最多的互联网数据采集、处理、分析和挖掘软件。该软件以其灵活的配置和强大的性能,领先国内data采集产品,得到了众多用户的一致认可。
适用范围
1.网站编辑:打破编辑必须手动转载文章的传统现状,他们将有更多时间编辑和处理数据,工作效率更高。该程序可以与TRS等采集编辑系统完美结合,海量网站信息采集会更简单有效。
2.内网:打破内网信息单一、获取难的神话,内网也能体验到各种互联网信息。它可以解决与互联网隔离的军队等重要部门的互联网信息需求问题。
3.政府机构:实时跟踪,采集国内外新闻、政策法规、经济、行业等政府工作相关信息,解决政府主要问题网站地方层面的网站信息采集和整合问题。
4.企业应用:实时准确采集国内外新闻、行业新闻、科技文章。可以轻松进行数据集成,智能处理更快更高效,业务成本大大降低。
5.SEO人员或站长:更容易获取数据,可以快速增加网站信息量,可以更专注于优化和推广。
软件功能
1.支持所有编码格式的数据采集,你可以使用它采集worldwide文章。该程序还可以在编辑之间执行完美的转换。
2.多个接口;支持所有主流或非主流的cms、BBS、下载站等。通过系统的接口可以实现采集器和网站的完美结合。
3.无人值守工作:配置程序后,程序可以根据您的设置自动运行,无需人工干预。
4.本地编辑采集数据:您可以在本地直观地编辑采集数据。
5.采集内容测试功能:这是其他任何采集软件都无法比拟的,您可以直接查看结果并测试发布。
6.易管理:使用站点+任务模式管理采集节点,任务支持批量操作,管理更多数据轻松。
变更日志
1、调整列表页的重新排列方式,现在只会在同级列表页之间重新排列。
2、任务完成后增加运行统计预警功能(Email邮件警告)【终极版功能】
3、增加了对部分请求返回码不是200时配置采集的支持。
4、添加了将下载地址保存为 html 文件的支持。
5、二级代理服务,导入时添加代理类型,修复用户名密码显示错误。
6、发布配置页面,默认只显示当前选择的配置,加快任务加载时间。
7、修复命令行控制,closeapp参数无法自动关闭程序的问题。
8、修复未选中图片水印时无法裁剪图片的问题。
9、优化启动界面的加载方式,解决初始化界面卡顿的问题。
10、修复多行连接符收录“|”时无法检测到图片下载的问题 在配置中。
11、修复Excel导出数据时列顺序与字段顺序不一致的问题。
12、修复了从Excel导出数据时,某些收录数字的字段导出数据不正确的问题。
13、修复批量编辑任务时无法复制Json采集表达式的问题。 查看全部
网页内容抓取工具(优采云采集器编辑采集数据:您可以在本地可视化编辑已采集的数据)
优采云采集器是目前使用最多的互联网数据采集、处理、分析和挖掘软件。该软件以其灵活的配置和强大的性能,领先国内data采集产品,得到了众多用户的一致认可。
适用范围
1.网站编辑:打破编辑必须手动转载文章的传统现状,他们将有更多时间编辑和处理数据,工作效率更高。该程序可以与TRS等采集编辑系统完美结合,海量网站信息采集会更简单有效。
2.内网:打破内网信息单一、获取难的神话,内网也能体验到各种互联网信息。它可以解决与互联网隔离的军队等重要部门的互联网信息需求问题。
3.政府机构:实时跟踪,采集国内外新闻、政策法规、经济、行业等政府工作相关信息,解决政府主要问题网站地方层面的网站信息采集和整合问题。
4.企业应用:实时准确采集国内外新闻、行业新闻、科技文章。可以轻松进行数据集成,智能处理更快更高效,业务成本大大降低。
5.SEO人员或站长:更容易获取数据,可以快速增加网站信息量,可以更专注于优化和推广。
软件功能
1.支持所有编码格式的数据采集,你可以使用它采集worldwide文章。该程序还可以在编辑之间执行完美的转换。
2.多个接口;支持所有主流或非主流的cms、BBS、下载站等。通过系统的接口可以实现采集器和网站的完美结合。
3.无人值守工作:配置程序后,程序可以根据您的设置自动运行,无需人工干预。
4.本地编辑采集数据:您可以在本地直观地编辑采集数据。
5.采集内容测试功能:这是其他任何采集软件都无法比拟的,您可以直接查看结果并测试发布。
6.易管理:使用站点+任务模式管理采集节点,任务支持批量操作,管理更多数据轻松。
变更日志
1、调整列表页的重新排列方式,现在只会在同级列表页之间重新排列。
2、任务完成后增加运行统计预警功能(Email邮件警告)【终极版功能】
3、增加了对部分请求返回码不是200时配置采集的支持。
4、添加了将下载地址保存为 html 文件的支持。
5、二级代理服务,导入时添加代理类型,修复用户名密码显示错误。
6、发布配置页面,默认只显示当前选择的配置,加快任务加载时间。
7、修复命令行控制,closeapp参数无法自动关闭程序的问题。
8、修复未选中图片水印时无法裁剪图片的问题。
9、优化启动界面的加载方式,解决初始化界面卡顿的问题。
10、修复多行连接符收录“|”时无法检测到图片下载的问题 在配置中。
11、修复Excel导出数据时列顺序与字段顺序不一致的问题。
12、修复了从Excel导出数据时,某些收录数字的字段导出数据不正确的问题。
13、修复批量编辑任务时无法复制Json采集表达式的问题。
网页内容抓取工具(什么是网络DOM数据结构的分类及分类?网络爬虫种类)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-16 09:03
有许多类型的网络爬虫。以下是粗略的分类,并说明网页抓取/数据提取/信息提取工具包 MetaSeeker 属于哪一类爬虫。
如果按照部署在哪里来划分,可以分为:
1、服务器端:一般是多线程程序,同时下载多个目标HTML,可以用PHP、Java、Python(目前很流行)等来完成。一般综合搜索引擎的爬虫都是这样做的. 但是,如果对方讨厌爬虫,服务器的IP很可能会被封杀,服务器的IP不容易更改,消耗的带宽相当昂贵。
2.客户端:非常适合部署主题爬虫,或者聚焦爬虫。成为与谷歌、百度等竞争的综合搜索引擎的机会很小,而垂直搜索或比价服务或推荐引擎的机会要多得多。这种爬虫不会抓取所有页面,只抓取关注页面,只抓取页面上感兴趣的内容,例如提取黄页信息、商品价格信息、提取竞争对手广告信息等。这种类型的爬虫可以部署很多,而且可以非常具有攻击性,让对手难以阻挡。
网页抓取/数据提取/信息提取工具包 MetaSeeker 中的爬虫属于客户端爬虫(更详细的产品特性),可以低成本大批量部署。由于客户端IP地址是动态的,因此很难被针对网站屏蔽。
我们只讨论固定主题的爬虫。普通爬虫就简单多了,网上也有很多。如果分为如何提取数据,可以分为两类:
1.通过正则表达式提取内容。HTML 文件是文本文件。您可以直接使用正则表达式提取指定位置的内容。“指定地点”不一定是绝对定位。比如可以参考HTML标签定位,比较准确。
2.使用DOM提取内容,HTML文件先转换成DOM数据结构,然后遍历这个结构提取内容。
有人会问,为什么要用DOM的方式,然后转过来呢?DOM方法存在的原因有很多:第一,不需要自己做DOM结构的分析,有现成的库,编程不会变得复杂;其次,它可以实现非常复杂但灵活的定位规则,而正则表达式很难编写;第三,如果定位是考虑HTML文件的结构,用正则表达式解析不好,HTML文件经常出错。如果把这个任务交给一个现成的库,那就容易多了。第四,假设需要解析Javascript的内容,正则表达式是无能为力的。当然DOM方法本身是无能为力的,但是可以提取AJAX网站 通过使用某个平台的能力的内容。还有很多原因。
网页抓取/数据提取/信息提取工具包MetaSeeker中的爬虫采用DOM方式。只要 Firefox 看到它,它就会使用 Mozilla 平台的功能进行提取。 查看全部
网页内容抓取工具(什么是网络DOM数据结构的分类及分类?网络爬虫种类)
有许多类型的网络爬虫。以下是粗略的分类,并说明网页抓取/数据提取/信息提取工具包 MetaSeeker 属于哪一类爬虫。
如果按照部署在哪里来划分,可以分为:
1、服务器端:一般是多线程程序,同时下载多个目标HTML,可以用PHP、Java、Python(目前很流行)等来完成。一般综合搜索引擎的爬虫都是这样做的. 但是,如果对方讨厌爬虫,服务器的IP很可能会被封杀,服务器的IP不容易更改,消耗的带宽相当昂贵。
2.客户端:非常适合部署主题爬虫,或者聚焦爬虫。成为与谷歌、百度等竞争的综合搜索引擎的机会很小,而垂直搜索或比价服务或推荐引擎的机会要多得多。这种爬虫不会抓取所有页面,只抓取关注页面,只抓取页面上感兴趣的内容,例如提取黄页信息、商品价格信息、提取竞争对手广告信息等。这种类型的爬虫可以部署很多,而且可以非常具有攻击性,让对手难以阻挡。
网页抓取/数据提取/信息提取工具包 MetaSeeker 中的爬虫属于客户端爬虫(更详细的产品特性),可以低成本大批量部署。由于客户端IP地址是动态的,因此很难被针对网站屏蔽。
我们只讨论固定主题的爬虫。普通爬虫就简单多了,网上也有很多。如果分为如何提取数据,可以分为两类:
1.通过正则表达式提取内容。HTML 文件是文本文件。您可以直接使用正则表达式提取指定位置的内容。“指定地点”不一定是绝对定位。比如可以参考HTML标签定位,比较准确。
2.使用DOM提取内容,HTML文件先转换成DOM数据结构,然后遍历这个结构提取内容。
有人会问,为什么要用DOM的方式,然后转过来呢?DOM方法存在的原因有很多:第一,不需要自己做DOM结构的分析,有现成的库,编程不会变得复杂;其次,它可以实现非常复杂但灵活的定位规则,而正则表达式很难编写;第三,如果定位是考虑HTML文件的结构,用正则表达式解析不好,HTML文件经常出错。如果把这个任务交给一个现成的库,那就容易多了。第四,假设需要解析Javascript的内容,正则表达式是无能为力的。当然DOM方法本身是无能为力的,但是可以提取AJAX网站 通过使用某个平台的能力的内容。还有很多原因。
网页抓取/数据提取/信息提取工具包MetaSeeker中的爬虫采用DOM方式。只要 Firefox 看到它,它就会使用 Mozilla 平台的功能进行提取。
网页内容抓取工具(试试异步网页资源源码库(如google|feed))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-13 15:02
网页内容抓取工具很多,免费的可以看谷歌网页抓取,而且也好用,复杂的要付费收费的就找一些站长平台咯,需要提醒一下的是免费网页抓取接口很有限,不要贪多。
这个是yestoney论坛上老哥发的一个免费网页抓取工具(更新在知乎上)可以搜索下载
国内目前还是腾讯公司网站的数据最多的,小伙伴们可以了解下,通过跨站请求抓取你当前网站的所有网页数据。数据方面不会收费。
做爬虫养家糊口。
我目前也在学习网页爬虫,总感觉,这不是一个搞学术的活,我觉得,是为了做成一个兼职,或者说保底,比如去年,玩的一个软件,发布个小任务赚取佣金,简单点就是,既然学了网页爬虫,需要写程序,而爬虫程序也是很复杂的,多发布几个免费试用的任务,就可以赚钱了,其他什么都不用花,但是,老实说,比较麻烦。但是发布任务如果有任务不满意,就可以删除任务,这个还是有点小心机的,哈哈哈,有这个想法而且实践起来,真的很棒。
试试异步加载网页资源源码库(如google|feed|displacement/api-tel,公众号feedzhang更多基础教程,想学习的请先关注我哈,
学习编程是长久的修行。没有尽头,要想学好,一定要会用搜索引擎。希望能帮到你。 查看全部
网页内容抓取工具(试试异步网页资源源码库(如google|feed))
网页内容抓取工具很多,免费的可以看谷歌网页抓取,而且也好用,复杂的要付费收费的就找一些站长平台咯,需要提醒一下的是免费网页抓取接口很有限,不要贪多。
这个是yestoney论坛上老哥发的一个免费网页抓取工具(更新在知乎上)可以搜索下载
国内目前还是腾讯公司网站的数据最多的,小伙伴们可以了解下,通过跨站请求抓取你当前网站的所有网页数据。数据方面不会收费。
做爬虫养家糊口。
我目前也在学习网页爬虫,总感觉,这不是一个搞学术的活,我觉得,是为了做成一个兼职,或者说保底,比如去年,玩的一个软件,发布个小任务赚取佣金,简单点就是,既然学了网页爬虫,需要写程序,而爬虫程序也是很复杂的,多发布几个免费试用的任务,就可以赚钱了,其他什么都不用花,但是,老实说,比较麻烦。但是发布任务如果有任务不满意,就可以删除任务,这个还是有点小心机的,哈哈哈,有这个想法而且实践起来,真的很棒。
试试异步加载网页资源源码库(如google|feed|displacement/api-tel,公众号feedzhang更多基础教程,想学习的请先关注我哈,
学习编程是长久的修行。没有尽头,要想学好,一定要会用搜索引擎。希望能帮到你。
网页内容抓取工具(爬取指定网页中的图片(1)方法介绍步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-12 08:11
爬取指定网页中的图片,需要经过以下三个步骤:
(1)指定网站的链接,抓取网站的源码(如果用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2)设置正则表达式来匹配你要抓取的内容
(3)设置循环列表,反复抓取和保存内容
下面介绍两种方法来实现指定网页中图片的抓取
(1)方法一:使用正则表达式过滤抓取到的html内容字符串
# 第一个简单的爬取图片的程序 import urllib.request # python自带的爬操作url的库 import re # 正则表达式 # 该方法传入url,返回url的html的源代码 def getHtmlCode(url): # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求 headers = { 'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \ AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36' } # 将headers头部添加到url,模拟浏览器访问 url = urllib.request.Request(url, headers=headers) # 将url页面的源代码保存成字符串 page = urllib.request.urlopen(url).read() # 字符串转码 page = page.decode('UTF-8') return page # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机 def getImage(page): # [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组 # imageList = re.findall(r'(https:[^\s]*?(png))"', page) imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page) x = 0 # 循环列表 for imageUrl in imageList: try: print('正在下载: %s' % imageUrl[0]) # 这个image文件夹需要先创建好才能看到结果 image_save_path = './image/%d.png-600' % x # 下载图片并且保存到指定文件夹中 urllib.request.urlretrieve(imageUrl[0], image_save_path) x = x + 1 except: continue pass if __name__ == '__main__': # 指定要爬取的网站 url = "https://www.cnblogs.com/ttweix ... ot%3B # 得到该网站的源代码 page = getHtmlCode(url) # 爬取该网站的图片并且保存 getImage(page) # print(page)
注意代码中需要修改的是imageList = re.fi source gaodai$ma#comengage $code*code network ndall(r'(https:[^\s]*?(jpg|png|gif)) "', page),如何设计正则表达式需要根据你要抓取的内容来设置。我的设计来源如下:
可以看到,因为这个网页上的图片都是png格式的,所以也可以写成imageList = re.findall(r'(https:[^\s]*?(png))"', page) .
(2)方法二:使用BeautifulSoup库解析html网页
from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具 import urllib # python自带的爬操作url的库 # 该方法传入url,返回url的html的源代码 def getHtmlCode(url): # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求 headers = { 'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \ AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36' } # 将headers头部添加到url,模拟浏览器访问 url = urllib.request.Request(url, headers=headers) # 将url页面的源代码保存成字符串 page = urllib.request.urlopen(url).read() # 字符串转码 page = page.decode('UTF-8') return page # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机 def getImage(page): # 按照html格式解析页面 soup = BeautifulSoup(page, 'html.parser') # 格式化输出DOM树的内容 print(soup.prettify()) # 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是 imgList = soup.find_all('img') x = 0 # 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片 for imgUrl in imgList[1:]: print('正在下载: %s ' % imgUrl.get('src')) # 得到scr的内容,这里返回的就是Url字符串链接,如'https://img2020.cnblogs.com/bl ... 39%3B image_url = imgUrl.get('src') # 这个image文件夹需要先创建好才能看到结果 image_save_path = './image/%d.png-600' % x # 下载图片并且保存到指定文件夹中 urllib.request.urlretrieve(image_url, image_save_path) x = x + 1 if __name__ == '__main__': # 指定要爬取的网站 url = 'https://www.cnblogs.com/ttweix ... 39%3B # 得到该网站的源代码 page = getHtmlCode(url) # 爬取该网站的图片并且保存 getImage(page)
这两种方法各有优缺点。我认为它们可以灵活地组合使用。例如,使用方法2中指定标签的方法来缩小要查找的内容的范围,然后使用正则表达式匹配所需的内容。这样做更简洁明了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持高代马搞码网。 查看全部
网页内容抓取工具(爬取指定网页中的图片(1)方法介绍步骤)
爬取指定网页中的图片,需要经过以下三个步骤:
(1)指定网站的链接,抓取网站的源码(如果用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2)设置正则表达式来匹配你要抓取的内容
(3)设置循环列表,反复抓取和保存内容
下面介绍两种方法来实现指定网页中图片的抓取
(1)方法一:使用正则表达式过滤抓取到的html内容字符串
# 第一个简单的爬取图片的程序 import urllib.request # python自带的爬操作url的库 import re # 正则表达式 # 该方法传入url,返回url的html的源代码 def getHtmlCode(url): # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求 headers = { 'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \ AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36' } # 将headers头部添加到url,模拟浏览器访问 url = urllib.request.Request(url, headers=headers) # 将url页面的源代码保存成字符串 page = urllib.request.urlopen(url).read() # 字符串转码 page = page.decode('UTF-8') return page # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机 def getImage(page): # [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组 # imageList = re.findall(r'(https:[^\s]*?(png))"', page) imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page) x = 0 # 循环列表 for imageUrl in imageList: try: print('正在下载: %s' % imageUrl[0]) # 这个image文件夹需要先创建好才能看到结果 image_save_path = './image/%d.png-600' % x # 下载图片并且保存到指定文件夹中 urllib.request.urlretrieve(imageUrl[0], image_save_path) x = x + 1 except: continue pass if __name__ == '__main__': # 指定要爬取的网站 url = "https://www.cnblogs.com/ttweix ... ot%3B # 得到该网站的源代码 page = getHtmlCode(url) # 爬取该网站的图片并且保存 getImage(page) # print(page)
注意代码中需要修改的是imageList = re.fi source gaodai$ma#comengage $code*code network ndall(r'(https:[^\s]*?(jpg|png|gif)) "', page),如何设计正则表达式需要根据你要抓取的内容来设置。我的设计来源如下:
可以看到,因为这个网页上的图片都是png格式的,所以也可以写成imageList = re.findall(r'(https:[^\s]*?(png))"', page) .
(2)方法二:使用BeautifulSoup库解析html网页
from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具 import urllib # python自带的爬操作url的库 # 该方法传入url,返回url的html的源代码 def getHtmlCode(url): # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求 headers = { 'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \ AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36' } # 将headers头部添加到url,模拟浏览器访问 url = urllib.request.Request(url, headers=headers) # 将url页面的源代码保存成字符串 page = urllib.request.urlopen(url).read() # 字符串转码 page = page.decode('UTF-8') return page # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机 def getImage(page): # 按照html格式解析页面 soup = BeautifulSoup(page, 'html.parser') # 格式化输出DOM树的内容 print(soup.prettify()) # 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是 imgList = soup.find_all('img') x = 0 # 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片 for imgUrl in imgList[1:]: print('正在下载: %s ' % imgUrl.get('src')) # 得到scr的内容,这里返回的就是Url字符串链接,如'https://img2020.cnblogs.com/bl ... 39%3B image_url = imgUrl.get('src') # 这个image文件夹需要先创建好才能看到结果 image_save_path = './image/%d.png-600' % x # 下载图片并且保存到指定文件夹中 urllib.request.urlretrieve(image_url, image_save_path) x = x + 1 if __name__ == '__main__': # 指定要爬取的网站 url = 'https://www.cnblogs.com/ttweix ... 39%3B # 得到该网站的源代码 page = getHtmlCode(url) # 爬取该网站的图片并且保存 getImage(page)
这两种方法各有优缺点。我认为它们可以灵活地组合使用。例如,使用方法2中指定标签的方法来缩小要查找的内容的范围,然后使用正则表达式匹配所需的内容。这样做更简洁明了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持高代马搞码网。
网页内容抓取工具(网站加速器首页-七牛云用python写一个爬虫项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-11 12:05
网页内容抓取工具:扒虫中国,快速、高效、易用国内最完善的网站抓取工具taobaoui所有接口都有。而且接口速度快,接口返回不需要任何服务器数据转化,只需要做一次http代理服务器即可保证接口返回不会丢包。前端isc还有全国ip段爬取,且有一键提取网页源码和上传文件功能,网页素材库抓取工具:猪八戒网的供应商抓取工具。
python人人都用吧,可以爬一些常用网站。
python有scrapy,还有基于erlang的zeus,
python很火,地址githubpages个人博客模板下载_野狗python百度云盘抓取已收录。正在抓取即将结束,等一段时间,
scrapy
个人喜欢前端抓取工具用hexo框架,能独立使用。可以百度到相关教程。
推荐一个网站web加速器首页-七牛云有很多可用的代理
网页内容抓取工具-优采云爬虫
用python写一个爬虫项目:新闻信息抓取
优采云,专门做网页内容爬取工具,免费的!源码分享!可以去我的专栏一起学习探讨。
刚开始学爬虫,就这么简单,放下哪些不动手爬!开始还是要结合书籍,看了大神在网上的实验项目,自己摸索着写了一个!刚开始遇到很多问题,例如:文件遍历,scrapy项目框架安装,如何管理文件数据库等~这些问题现在解决不了,就只能放着让大神们解决。有时候解决了,有时候解决不了,很多问题还是百度出来的!这里先分享给大家,将会持续整理项目!有缘人一起探讨与交流!不忙的话,希望能互相交流一下!qq交流群:307388284。 查看全部
网页内容抓取工具(网站加速器首页-七牛云用python写一个爬虫项目)
网页内容抓取工具:扒虫中国,快速、高效、易用国内最完善的网站抓取工具taobaoui所有接口都有。而且接口速度快,接口返回不需要任何服务器数据转化,只需要做一次http代理服务器即可保证接口返回不会丢包。前端isc还有全国ip段爬取,且有一键提取网页源码和上传文件功能,网页素材库抓取工具:猪八戒网的供应商抓取工具。
python人人都用吧,可以爬一些常用网站。
python有scrapy,还有基于erlang的zeus,
python很火,地址githubpages个人博客模板下载_野狗python百度云盘抓取已收录。正在抓取即将结束,等一段时间,
scrapy
个人喜欢前端抓取工具用hexo框架,能独立使用。可以百度到相关教程。
推荐一个网站web加速器首页-七牛云有很多可用的代理
网页内容抓取工具-优采云爬虫
用python写一个爬虫项目:新闻信息抓取
优采云,专门做网页内容爬取工具,免费的!源码分享!可以去我的专栏一起学习探讨。
刚开始学爬虫,就这么简单,放下哪些不动手爬!开始还是要结合书籍,看了大神在网上的实验项目,自己摸索着写了一个!刚开始遇到很多问题,例如:文件遍历,scrapy项目框架安装,如何管理文件数据库等~这些问题现在解决不了,就只能放着让大神们解决。有时候解决了,有时候解决不了,很多问题还是百度出来的!这里先分享给大家,将会持续整理项目!有缘人一起探讨与交流!不忙的话,希望能互相交流一下!qq交流群:307388284。
网页内容抓取工具(网页内容抓取工具的主要目的是什么?怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-11 07:05
网页内容抓取工具的主要目的是为了扩展抓取的边界,通过了解清楚工具的原理后,就可以根据自己的需求去选择合适的工具进行抓取。最常见的有scrapy和selenium两个工具。scrapy扩展性更强,但selenium免费适用性也更强,而且开源。requests是抓取网页的,seleniumlib是抓取一个webserver,但两者可以使用同一抓取脚本语言编写,只是seleniumlib需要选择对应的spider来执行。
一般来说,基于selenium,可以使用get/post方法进行网页的提取,也可以进行webserver端的抓取。seleniumlib同时支持python3和python2,使用get、post、put、delete方法。一、selenium流程1.上传文件selenium和threading框架对上传文件的处理有很大的不同。
比如说在threading框架中上传文件并不需要使用eval()的方法来编写对上传文件的解析,而是直接传递了一个参数就可以处理了。而selenium对上传文件的解析方法是传递两个参数:text和code。text需要是一串bytes字符串,text可以是以任意形式的文本,这个与python3也相同,而code则是对code做一些说明,并把获取的值写入一个eval()函数,用于解析参数。
最后的返回结果就是selenium每次上传文件是传递两个参数,分别对应两个webserver(服务器),分别解析对应的参数,处理两个server。2.运行程序程序是根据采用的spider规则进行采集,以及实际会话要确定,只有把函数名打上对应的关键字进行保存,程序运行时,根据指定的模板进行正则匹配,正则匹配成功后运行程序,结束后保存会话,并运行对应的gui进行更新数据。
首先需要在threading.contextmenu方法中打开上传文件的界面,然后随便写一个csv文件对象作为上传文件的url,如果本地没有,则上传本地。3.上传文件上传,可以参考代码,也可以在threading.contextmenu方法中用系统库中eval进行上传,参考代码:#!/usr/bin/envpython#encoding=utf-8importurllib.requestimporttimefromseleniumimportwebdriverfromseleniumlibimportseleniumfromthreadingimporttimedefparsefile(filepath):data=urllib.request.urlopen(filepath).read()data=data.decode("utf-8")returndata#提取文件名,编号defparsecode(text):data=data.decode("utf-8")text=parsed(text)returntext}defgetdata(endpoint="pythonwindow"):f=open(endpoint,"w")ifisinstance(f,"window"):withopen(。 查看全部
网页内容抓取工具(网页内容抓取工具的主要目的是什么?怎么做?)
网页内容抓取工具的主要目的是为了扩展抓取的边界,通过了解清楚工具的原理后,就可以根据自己的需求去选择合适的工具进行抓取。最常见的有scrapy和selenium两个工具。scrapy扩展性更强,但selenium免费适用性也更强,而且开源。requests是抓取网页的,seleniumlib是抓取一个webserver,但两者可以使用同一抓取脚本语言编写,只是seleniumlib需要选择对应的spider来执行。
一般来说,基于selenium,可以使用get/post方法进行网页的提取,也可以进行webserver端的抓取。seleniumlib同时支持python3和python2,使用get、post、put、delete方法。一、selenium流程1.上传文件selenium和threading框架对上传文件的处理有很大的不同。
比如说在threading框架中上传文件并不需要使用eval()的方法来编写对上传文件的解析,而是直接传递了一个参数就可以处理了。而selenium对上传文件的解析方法是传递两个参数:text和code。text需要是一串bytes字符串,text可以是以任意形式的文本,这个与python3也相同,而code则是对code做一些说明,并把获取的值写入一个eval()函数,用于解析参数。
最后的返回结果就是selenium每次上传文件是传递两个参数,分别对应两个webserver(服务器),分别解析对应的参数,处理两个server。2.运行程序程序是根据采用的spider规则进行采集,以及实际会话要确定,只有把函数名打上对应的关键字进行保存,程序运行时,根据指定的模板进行正则匹配,正则匹配成功后运行程序,结束后保存会话,并运行对应的gui进行更新数据。
首先需要在threading.contextmenu方法中打开上传文件的界面,然后随便写一个csv文件对象作为上传文件的url,如果本地没有,则上传本地。3.上传文件上传,可以参考代码,也可以在threading.contextmenu方法中用系统库中eval进行上传,参考代码:#!/usr/bin/envpython#encoding=utf-8importurllib.requestimporttimefromseleniumimportwebdriverfromseleniumlibimportseleniumfromthreadingimporttimedefparsefile(filepath):data=urllib.request.urlopen(filepath).read()data=data.decode("utf-8")returndata#提取文件名,编号defparsecode(text):data=data.decode("utf-8")text=parsed(text)returntext}defgetdata(endpoint="pythonwindow"):f=open(endpoint,"w")ifisinstance(f,"window"):withopen(。
网页内容抓取工具(配套软件版本:V9及更低集搜客网络爬虫软件新版本对应教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-11 03:21
配套软件版本:V9及更低版本即搜客网络爬虫软件
新版本对应教程:V10及更高版本数据管家-网络爬虫增强版对应教程为“使用网络爬虫软件自动下载网页文件”
注:GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先命名任务,然后创建规则,然后登录集合。在苏克官网会员中心的“任务管理”中,可以查看采集任务的执行状态,管理线索的URL,进行调度设置。
例如,我们打算下载本法规/标准网站的法规文件的pdf:
页面截图如下:
如果您手动下载这些文件,则需要在此网页上一一点击文件图标来触发下载过程。
在吉搜客网络爬虫软件V9.0.0版本之前,这是模拟点击的方式(见教程:)。但是从V9.0.0版本开始,对下载功能进行了调整,因为定义模拟点击过程的规则太繁琐,也不好理解为什么要定义. 在V9.0.0版本中,不再定义模拟点击,而是抓取文件图标对应的url作为抓取内容,并设置了“下载文件”选项同时,然后爬虫采集获取到url信息后开始下载过程。定义规则的方式要简单得多。
另外,V9.0.0有区别:上一版本刺激下载后,存放位置在操作系统的“下载”文件夹,而V9. 0.0的下载位置是可控的,可以在每个爬取规则各自的文件夹中,也可以在结果文件DataScraperWorks文件夹中。
注意:该方法能够生效的前提是下载文件链接对应一个真实的URL。如果是像javascript:void(0)这样的代码,这个方法是不能用的,要定义一个连续动作方法。触发下载操作。
下面将详细解释定义规则和爬取过程。
1. 定义爬取规则
定义抓取规则的方法参考基础教程的相应章节,例如,最基本的教程是这样的: . 本教程介绍如何使用内容标记在网页上将内容标记为 采集。请注意,此注解是一种快速定义规则的方法,但它不能精确定位 HTML DOM 节点。例如,在英文附件图标上标记内容,会自动定位到 DOM 的 IMG 节点。为了下载pdf文件,定位这个IMG节点是不精确的,这种内容标注主要用于采集文本内容。
为了准确捕捉pdf文件的url URL,需要准确的进行内容映射,如下图:
进行如下操作:
双击文件图标标记内容,将抓取的内容命名为“英文附件链接”。观察窗口下方的DOM树,看到IMG自动定位了,我们需要这个图标对应的url来下载文件。通过观察DOM树,可以确定该url存储在IMG的父节点A中的属性节点@href中。选中@href节点,使用右键菜单Content Mapping -> English Attachment Link,可以将@href映射到抓取到的英文附件链接内容。映射完成后,可以看到抓取到的内容在工作台上的位置编号发生了变化。
以上流程是定义爬取规则的常用流程,下面将是与下载文件相关的设置流程。
2. 安装程序下载
如下图,选择“下载内容”,会弹出设置窗口。选中“下载文件”意味着从捕获的 URL 下载文件。在下面的屏幕截图中,高级设置的“完整内容”选项也被选中。这与下载的内容无关。目的是在生成的结果文件中显示 URL 的 URL,因为从前面的截图来看,@href 存储的是 A 相对 URL,不是以 http 开头的。
这些设置完成后,点击保存规则,然后点击抓取数据,会弹出一个DS计数器窗口,可以观察到网页加载完毕,采集完成后变成白屏。
3. 查看下载的文件
如下图所示,本案例使用的主题名称为test_download_file_fuller,结果文件放置在DataScraperWorks文件夹中。test_download_file_fuller 是用于以 XML 格式存储结果文件的子文件夹。您还可以看到并行子文件夹 PageFileDir。用于存储所有下载的文件
在PageFileDir中,所有下载的文件都是放在一起的,不管主题名是什么,但是在PageFileDir的子文件夹中,子文件夹的名字都是这样的结构
线程号_时间戳
我们打开XML格式的结果文件,看看内容结构,如下图:
“英文附件链接”为自定义爬取内容,“英文附件链接文件”为自动生成的爬取内容。该字段描述了文件在硬盘上的存储位置。
不分主题存储下载的文件有一个好处:如果你想写一个文件处理程序,那么这个处理成果就不需要逐个进入每个主题名文件夹来检查是否有新下载的文件。
相反,如果下载的文件是按主题名称分隔的,则处理程序将逐个检查主题名称文件夹,但有一个优点:文件系统看起来更有条理。
下面说明如何将其设置为按主题名称单独存储。
4. 按主题存储
如图,在DS电脑上选择菜单文件->存储路径,在弹出框中选择“按主题存储”,更改主题存储后,再执行爬取数据,可以看到PageFileDir 文件夹位于主题名称文件夹下方
5. 摘要
从V9.0.0开始,不仅文件下载,图片和视频下载过程一致,结果存储结构也一致。本教程中的方法可以扩展到图片和视频下载 查看全部
网页内容抓取工具(配套软件版本:V9及更低集搜客网络爬虫软件新版本对应教程)
配套软件版本:V9及更低版本即搜客网络爬虫软件
新版本对应教程:V10及更高版本数据管家-网络爬虫增强版对应教程为“使用网络爬虫软件自动下载网页文件”
注:GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先命名任务,然后创建规则,然后登录集合。在苏克官网会员中心的“任务管理”中,可以查看采集任务的执行状态,管理线索的URL,进行调度设置。
例如,我们打算下载本法规/标准网站的法规文件的pdf:
页面截图如下:
如果您手动下载这些文件,则需要在此网页上一一点击文件图标来触发下载过程。
在吉搜客网络爬虫软件V9.0.0版本之前,这是模拟点击的方式(见教程:)。但是从V9.0.0版本开始,对下载功能进行了调整,因为定义模拟点击过程的规则太繁琐,也不好理解为什么要定义. 在V9.0.0版本中,不再定义模拟点击,而是抓取文件图标对应的url作为抓取内容,并设置了“下载文件”选项同时,然后爬虫采集获取到url信息后开始下载过程。定义规则的方式要简单得多。
另外,V9.0.0有区别:上一版本刺激下载后,存放位置在操作系统的“下载”文件夹,而V9. 0.0的下载位置是可控的,可以在每个爬取规则各自的文件夹中,也可以在结果文件DataScraperWorks文件夹中。
注意:该方法能够生效的前提是下载文件链接对应一个真实的URL。如果是像javascript:void(0)这样的代码,这个方法是不能用的,要定义一个连续动作方法。触发下载操作。
下面将详细解释定义规则和爬取过程。
1. 定义爬取规则
定义抓取规则的方法参考基础教程的相应章节,例如,最基本的教程是这样的: . 本教程介绍如何使用内容标记在网页上将内容标记为 采集。请注意,此注解是一种快速定义规则的方法,但它不能精确定位 HTML DOM 节点。例如,在英文附件图标上标记内容,会自动定位到 DOM 的 IMG 节点。为了下载pdf文件,定位这个IMG节点是不精确的,这种内容标注主要用于采集文本内容。
为了准确捕捉pdf文件的url URL,需要准确的进行内容映射,如下图:
进行如下操作:
双击文件图标标记内容,将抓取的内容命名为“英文附件链接”。观察窗口下方的DOM树,看到IMG自动定位了,我们需要这个图标对应的url来下载文件。通过观察DOM树,可以确定该url存储在IMG的父节点A中的属性节点@href中。选中@href节点,使用右键菜单Content Mapping -> English Attachment Link,可以将@href映射到抓取到的英文附件链接内容。映射完成后,可以看到抓取到的内容在工作台上的位置编号发生了变化。
以上流程是定义爬取规则的常用流程,下面将是与下载文件相关的设置流程。
2. 安装程序下载
如下图,选择“下载内容”,会弹出设置窗口。选中“下载文件”意味着从捕获的 URL 下载文件。在下面的屏幕截图中,高级设置的“完整内容”选项也被选中。这与下载的内容无关。目的是在生成的结果文件中显示 URL 的 URL,因为从前面的截图来看,@href 存储的是 A 相对 URL,不是以 http 开头的。
这些设置完成后,点击保存规则,然后点击抓取数据,会弹出一个DS计数器窗口,可以观察到网页加载完毕,采集完成后变成白屏。
3. 查看下载的文件
如下图所示,本案例使用的主题名称为test_download_file_fuller,结果文件放置在DataScraperWorks文件夹中。test_download_file_fuller 是用于以 XML 格式存储结果文件的子文件夹。您还可以看到并行子文件夹 PageFileDir。用于存储所有下载的文件
在PageFileDir中,所有下载的文件都是放在一起的,不管主题名是什么,但是在PageFileDir的子文件夹中,子文件夹的名字都是这样的结构
线程号_时间戳
我们打开XML格式的结果文件,看看内容结构,如下图:
“英文附件链接”为自定义爬取内容,“英文附件链接文件”为自动生成的爬取内容。该字段描述了文件在硬盘上的存储位置。
不分主题存储下载的文件有一个好处:如果你想写一个文件处理程序,那么这个处理成果就不需要逐个进入每个主题名文件夹来检查是否有新下载的文件。
相反,如果下载的文件是按主题名称分隔的,则处理程序将逐个检查主题名称文件夹,但有一个优点:文件系统看起来更有条理。
下面说明如何将其设置为按主题名称单独存储。
4. 按主题存储
如图,在DS电脑上选择菜单文件->存储路径,在弹出框中选择“按主题存储”,更改主题存储后,再执行爬取数据,可以看到PageFileDir 文件夹位于主题名称文件夹下方
5. 摘要
从V9.0.0开始,不仅文件下载,图片和视频下载过程一致,结果存储结构也一致。本教程中的方法可以扩展到图片和视频下载
网页内容抓取工具(抓取网页数据工具优采云采集器的Xpath提取示例(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-11 03:16
我们在使用优采云采集器的时候,经常会使用不同的数据提取方式。除了前后截取、文本提取、正则提取外,Xpath提取也是常用的一种。XPath 是一种用于在 HTML/XML 文档中查找信息的语言。XPath 使用路径表达式在 XML 文档中导航,可以通过 FireFox firebug 或 Chrome 开发工具快速获取。下面是网页数据爬取工具优采云采集器的Xpath提取示例的详细演示。
XPath 节点属性
innerHTML:获取对象开始和结束标签内的 HTML(HTML 代码,不包括开始/结束代码)
innerText:获取位于对象开始和结束标记内的文本(文本字段,不收录开始/结束代码)
outerHTML:获取对象的 HTML 形式及其内容(HTML 代码,包括开始/结束代码)
Href:获取超链接
我们以 URL 为例,设置标题和内容的 XPath 表达式。这里的node属性可以默认设置为innerHTML。以下是操作步骤的内容。
1、首先我们用谷歌浏览器打开上面的网页,然后打开Chrome开发者工具。打开开发者工具的快捷键是“F12”。反复按 F12 可切换状态(开或关)。如果是在原网页,可以直接右键选择“Inspect Element”。
2、获取标题的XPath,操作如下:
按照图标箭头的顺序,首先点击找到选中的标题,在代码中选中的部分右击,点击复制xpath,代码为//*[@id="mainContent"]/div[2]/ h2
3、获取内容的XPath,操作如下:
操作与标题操作类似,但需要注意的是,当鼠标悬停在内容上时,需要选择全部内容而不是部分段落,所以可以在代码中点击获取完整的Xpath表达式, 右击复制得到的代码是 //*[@id="cmsContent"]。
看完后,你觉得Xpath提取很有用吗?如果您认为它易于使用,您可以自己尝试一下。除了上面提到的四种提取方式,网页数据爬取工具优采云采集器V9还有JSON提取方式,大家也可以研究一下。返回搜狐,查看更多 查看全部
网页内容抓取工具(抓取网页数据工具优采云采集器的Xpath提取示例(一))
我们在使用优采云采集器的时候,经常会使用不同的数据提取方式。除了前后截取、文本提取、正则提取外,Xpath提取也是常用的一种。XPath 是一种用于在 HTML/XML 文档中查找信息的语言。XPath 使用路径表达式在 XML 文档中导航,可以通过 FireFox firebug 或 Chrome 开发工具快速获取。下面是网页数据爬取工具优采云采集器的Xpath提取示例的详细演示。
XPath 节点属性
innerHTML:获取对象开始和结束标签内的 HTML(HTML 代码,不包括开始/结束代码)
innerText:获取位于对象开始和结束标记内的文本(文本字段,不收录开始/结束代码)
outerHTML:获取对象的 HTML 形式及其内容(HTML 代码,包括开始/结束代码)
Href:获取超链接
我们以 URL 为例,设置标题和内容的 XPath 表达式。这里的node属性可以默认设置为innerHTML。以下是操作步骤的内容。
1、首先我们用谷歌浏览器打开上面的网页,然后打开Chrome开发者工具。打开开发者工具的快捷键是“F12”。反复按 F12 可切换状态(开或关)。如果是在原网页,可以直接右键选择“Inspect Element”。
2、获取标题的XPath,操作如下:
按照图标箭头的顺序,首先点击找到选中的标题,在代码中选中的部分右击,点击复制xpath,代码为//*[@id="mainContent"]/div[2]/ h2
3、获取内容的XPath,操作如下:
操作与标题操作类似,但需要注意的是,当鼠标悬停在内容上时,需要选择全部内容而不是部分段落,所以可以在代码中点击获取完整的Xpath表达式, 右击复制得到的代码是 //*[@id="cmsContent"]。
看完后,你觉得Xpath提取很有用吗?如果您认为它易于使用,您可以自己尝试一下。除了上面提到的四种提取方式,网页数据爬取工具优采云采集器V9还有JSON提取方式,大家也可以研究一下。返回搜狐,查看更多
网页内容抓取工具(使用语义结构描述工具MetaStudio定义了两个信息结构A和B)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-10 09:07
Q:如果我使用语义结构描述工具MetaStudio定义了两个信息结构A和B,A和B是相关的,也就是说在定义A的Clue Editor工作台上,定义了一条线索用于提取符合信息的结构B的网页地址(URL)。例如,A用于爬取论坛的帖子列表。抓取帖子列表时,提取帖子详细内容页面的URL,将帖子详细内容页面的信息结构描述为B。据我了解,网页内容抓取软件DataScraper首先加载论坛帖子列表页面,根据信息结构A爬取帖子列表,每抓取一条帖子记录,提取帖子详情内容页面的URL,立即打开帖子详情页面。在内容页面上,使用信息结构B抓取帖子的详细内容,然后返回信息结构A对应的页面处理下一条记录。DataScraper 是这样工作的吗?
答:网络爬虫/数据提取软件工具包MetaSeeker中的网络爬虫是主题爬虫或聚焦爬虫。网络爬虫在 DataScraper 软件工具中实现。在执行信息抽取任务时,是按主题进行的,不会跨主题。也就是说,每次发起信息抽取任务时,只获取该主题的网页内容。例如只提取A的内容,不提取B的内容。A执行完成后,可能要翻很多页。可以发起提取B的网页内容。当然,可以同时运行另一个DataScraper实例来提取B的网页内容。
例如,假设信息结构A用于提取论坛列表,主要是提取论坛帖子详细内容页面的URL对应的线索,即为B提取线索。一般一个论坛的帖子很多网站。论坛列表是分页的。这时在定义A的信息结构时,需要在Clue Editor上定义一个inthread thread用于翻页。在 Bucket Editor 工作台上,定义帖子列表提取规则,并定义一个信息属性来提取和存储 B 页面的 URL。此信息属性具有线索功能。此时,MetaStudio会在Clue Editor工作台上自动生成一条线索记录。,类型为Info,命名为subject B。这样就定义了A的信息结构。下一个,使用DataScraper爬取A的网页内容,会提取并存储很多属于主题B的线索。如果主题B的信息结构也定义好了,可以使用DataScraper爬取B的网页内容。可以看出,主题A和B的网页内容爬取是两种不同的操作。
‹ 网页提取软件DataScraper如何抓取不同结构的页面?如何为网络爬虫提取的新线索定义信息提取规则 › 查看全部
网页内容抓取工具(使用语义结构描述工具MetaStudio定义了两个信息结构A和B)
Q:如果我使用语义结构描述工具MetaStudio定义了两个信息结构A和B,A和B是相关的,也就是说在定义A的Clue Editor工作台上,定义了一条线索用于提取符合信息的结构B的网页地址(URL)。例如,A用于爬取论坛的帖子列表。抓取帖子列表时,提取帖子详细内容页面的URL,将帖子详细内容页面的信息结构描述为B。据我了解,网页内容抓取软件DataScraper首先加载论坛帖子列表页面,根据信息结构A爬取帖子列表,每抓取一条帖子记录,提取帖子详情内容页面的URL,立即打开帖子详情页面。在内容页面上,使用信息结构B抓取帖子的详细内容,然后返回信息结构A对应的页面处理下一条记录。DataScraper 是这样工作的吗?
答:网络爬虫/数据提取软件工具包MetaSeeker中的网络爬虫是主题爬虫或聚焦爬虫。网络爬虫在 DataScraper 软件工具中实现。在执行信息抽取任务时,是按主题进行的,不会跨主题。也就是说,每次发起信息抽取任务时,只获取该主题的网页内容。例如只提取A的内容,不提取B的内容。A执行完成后,可能要翻很多页。可以发起提取B的网页内容。当然,可以同时运行另一个DataScraper实例来提取B的网页内容。
例如,假设信息结构A用于提取论坛列表,主要是提取论坛帖子详细内容页面的URL对应的线索,即为B提取线索。一般一个论坛的帖子很多网站。论坛列表是分页的。这时在定义A的信息结构时,需要在Clue Editor上定义一个inthread thread用于翻页。在 Bucket Editor 工作台上,定义帖子列表提取规则,并定义一个信息属性来提取和存储 B 页面的 URL。此信息属性具有线索功能。此时,MetaStudio会在Clue Editor工作台上自动生成一条线索记录。,类型为Info,命名为subject B。这样就定义了A的信息结构。下一个,使用DataScraper爬取A的网页内容,会提取并存储很多属于主题B的线索。如果主题B的信息结构也定义好了,可以使用DataScraper爬取B的网页内容。可以看出,主题A和B的网页内容爬取是两种不同的操作。
‹ 网页提取软件DataScraper如何抓取不同结构的页面?如何为网络爬虫提取的新线索定义信息提取规则 ›
网页内容抓取工具(Google建议您使用网址参数工具的目的及处理方法(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-01 16:24
我们建议您使用网址参数工具告知 Google 在 网站 上使用每个参数的目的以及 Google 应如何处理收录这些参数的网址。
在控制台中的 网站 配置下,单击 URL 参数。在要修改的参数旁边,单击编辑。 (如果没有列出您要修改的参数,请点击添加参数。请注意该工具区分大小写,因此请务必按原样输入URL中显示的参数。)如果参数不会影响什么用户看到内容,请在此参数是否更改...列表中选择否...,然后单击保存。如果该参数影响内容的显示,请单击是:更改、重新排序或缩小页面内容(是:更改、重新排序或缩小页面内容),然后选择您希望 Google 如何抓取收录此参数的网址。
多个参数
单个 URL 可能收录多个参数,您可以分别为每个参数指定设置。限制性更强的设置将取代限制性较低的设置。以以下三个参数及其设置为例:
Google 将根据这些设置抓取以下网址:,
但是以下网址不会被抓取:。这是因为上述设置告诉 Google 只抓取 sort-by 参数值等于生产年份的 URL。由于鞋子从来不按生产年份排序,这个设置太严格了,会导致大量内容爬不出来。
如果您的 网站 内容可以通过多个网址访问,您可以指定网址的规范(首选)版本,以便更好地控制网址在搜索结果中的显示方式。为此,您可以使用参数处理工具,也可以将 rel="canonical" 元素添加到首选 URL 的 HTML 源中,以向 Google 提供更多信息。 (要使用 rel="canonical",您需要确保可以修改页面的源代码。)有关规范化的详细信息。请使用最适合您的选项;如果您想万无一失,您可以同时使用这两个选项。 查看全部
网页内容抓取工具(Google建议您使用网址参数工具的目的及处理方法(上))
我们建议您使用网址参数工具告知 Google 在 网站 上使用每个参数的目的以及 Google 应如何处理收录这些参数的网址。
在控制台中的 网站 配置下,单击 URL 参数。在要修改的参数旁边,单击编辑。 (如果没有列出您要修改的参数,请点击添加参数。请注意该工具区分大小写,因此请务必按原样输入URL中显示的参数。)如果参数不会影响什么用户看到内容,请在此参数是否更改...列表中选择否...,然后单击保存。如果该参数影响内容的显示,请单击是:更改、重新排序或缩小页面内容(是:更改、重新排序或缩小页面内容),然后选择您希望 Google 如何抓取收录此参数的网址。
多个参数
单个 URL 可能收录多个参数,您可以分别为每个参数指定设置。限制性更强的设置将取代限制性较低的设置。以以下三个参数及其设置为例:
Google 将根据这些设置抓取以下网址:,
但是以下网址不会被抓取:。这是因为上述设置告诉 Google 只抓取 sort-by 参数值等于生产年份的 URL。由于鞋子从来不按生产年份排序,这个设置太严格了,会导致大量内容爬不出来。
如果您的 网站 内容可以通过多个网址访问,您可以指定网址的规范(首选)版本,以便更好地控制网址在搜索结果中的显示方式。为此,您可以使用参数处理工具,也可以将 rel="canonical" 元素添加到首选 URL 的 HTML 源中,以向 Google 提供更多信息。 (要使用 rel="canonical",您需要确保可以修改页面的源代码。)有关规范化的详细信息。请使用最适合您的选项;如果您想万无一失,您可以同时使用这两个选项。
网页内容抓取工具(网页文字抓取工具的软件功能介绍及软件特色介绍- )
网站优化 • 优采云 发表了文章 • 0 个评论 • 332 次浏览 • 2022-01-01 05:24
)
网页文字抓取工具是一款非常实用的办公助手软件,其主要功能是帮助用户快速提取网页文字,无论网页中的文字内容是否可以复制,都可以轻松提取;该工具具有简单直观的用户界面和操作方法非常简单。只需将需要提取的网页地址粘贴到软件中,即可一键提取网页内容。您也可以将提取的内容一键导出到TXT或一键复制粘贴。在板中使用;网页文字抓取工具可以帮助我们快速获取网页文章,并将网页文章转换成可编辑的文档。也可以直接在这个软件中编辑文字,非常方便。
软件功能
1、该工具可以帮助用户抓取任意网页的文字内容,只要抓取网页中收录的文字即可。
2、 支持抓取无法复制的网页文字,无需拦截识别,输入网页地址一键获取文字。
3、提供网页预览功能,文字抓取后可在软件左侧窗口查看网页内容。
4、 提取的文本内容可以直接编辑。您可以根据需要删除不需要的文本或添加更多文本内容。
5、可以将提取的文本一键导出为TXT文本,也可以将所有文本复制到剪贴板使用。
6、使用该工具抓取网页文本,可以节省用户的时间,提高用户访问网页内容的效率。
软件功能
1、非常实用,你可以在很多工作中使用这个工具,尤其是在处理文本时。
2、这个工具对网页的类型和版式没有限制,只要是网页,就可以提取文字。
3、 操作方法不难,直接把网页地址粘贴到软件里,一键搞定,非常方便。
4、 识别速度快,文字准确率可以达到100%正确。提取方法比识别方法更快、更准确。
5、如果您遇到一些无法复制的网页内容,您可以使用此工具轻松提取整个页面的文本。
6、本工具仅用于提取网页文本,不支持提取网页中收录的图片内容。
如何使用
1、 启动程序后,您将看到以下用户界面。
2、 将需要提取文本的网页的 URL 复制到该输入框中。
3、然后点击“抓取文本”按钮开始抓取网页中的文本。
4、 爬取完成后,软件左侧的窗口会打开爬取的网页,如下图。
5、右侧窗口显示抓取网页的文字内容。
6、您可以在右侧窗口中直接编辑抓取的文本内容,包括删除、添加文本、选择和复制。
7、如果要将提取的文本全部保存为TXT文本,可以点击该按钮,然后按照提示查看指定路径下的提取文本。
8、您也可以点击“复制文本到剪贴板”按钮将所有文本复制到剪贴板。
查看全部
网页内容抓取工具(网页文字抓取工具的软件功能介绍及软件特色介绍-
)
网页文字抓取工具是一款非常实用的办公助手软件,其主要功能是帮助用户快速提取网页文字,无论网页中的文字内容是否可以复制,都可以轻松提取;该工具具有简单直观的用户界面和操作方法非常简单。只需将需要提取的网页地址粘贴到软件中,即可一键提取网页内容。您也可以将提取的内容一键导出到TXT或一键复制粘贴。在板中使用;网页文字抓取工具可以帮助我们快速获取网页文章,并将网页文章转换成可编辑的文档。也可以直接在这个软件中编辑文字,非常方便。
软件功能
1、该工具可以帮助用户抓取任意网页的文字内容,只要抓取网页中收录的文字即可。
2、 支持抓取无法复制的网页文字,无需拦截识别,输入网页地址一键获取文字。
3、提供网页预览功能,文字抓取后可在软件左侧窗口查看网页内容。
4、 提取的文本内容可以直接编辑。您可以根据需要删除不需要的文本或添加更多文本内容。
5、可以将提取的文本一键导出为TXT文本,也可以将所有文本复制到剪贴板使用。
6、使用该工具抓取网页文本,可以节省用户的时间,提高用户访问网页内容的效率。
软件功能
1、非常实用,你可以在很多工作中使用这个工具,尤其是在处理文本时。
2、这个工具对网页的类型和版式没有限制,只要是网页,就可以提取文字。
3、 操作方法不难,直接把网页地址粘贴到软件里,一键搞定,非常方便。
4、 识别速度快,文字准确率可以达到100%正确。提取方法比识别方法更快、更准确。
5、如果您遇到一些无法复制的网页内容,您可以使用此工具轻松提取整个页面的文本。
6、本工具仅用于提取网页文本,不支持提取网页中收录的图片内容。
如何使用
1、 启动程序后,您将看到以下用户界面。
2、 将需要提取文本的网页的 URL 复制到该输入框中。
3、然后点击“抓取文本”按钮开始抓取网页中的文本。
4、 爬取完成后,软件左侧的窗口会打开爬取的网页,如下图。
5、右侧窗口显示抓取网页的文字内容。
6、您可以在右侧窗口中直接编辑抓取的文本内容,包括删除、添加文本、选择和复制。
7、如果要将提取的文本全部保存为TXT文本,可以点击该按钮,然后按照提示查看指定路径下的提取文本。
8、您也可以点击“复制文本到剪贴板”按钮将所有文本复制到剪贴板。
网页内容抓取工具(网页内容抓取工具,五大类必备:googleanalytics、appium、snippet)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-27 13:13
网页内容抓取工具,五大类必备:googleanalytics、appium、snippet、airtests、ssas。本文介绍的这款工具,相对来说更容易上手。.首先我们来熟悉一下什么是apis请求apis=get/post/put/deleteapis是指和microsoftwindows、oracleonlinesqldatabase/managedconnections、flexinternetapiserver(flex)、javainternetapi(javase)等联结的。
api的主要功能是通过各种形式的联结方式,将您的请求按照特定的方式转换成相应的服务,例如音乐,视频,和多媒体等。.方法注意事项。
1、应用api之前请先检查目标的互联网服务是否是开放的,开放的互联网服务需要开放api,api是开放式的服务。
2)
2、在网站或软件的源代码中定义api也是必须要做的,假设airtest3.0启用了api,启用api可以为用户提供更好的用户体验。
3、调用api时请确保请求具有不同的域名,不同的ip,不同的域名要求的备案,不同的地区,不同的服务器等。
4、建议使用webtargetingtoolkit:firefox、safari、chrome、vlc。
5、避免不必要的http状态码:990
1、992
5、952
7、1993
4、1993
4、999
4、1992
4、992
2、990
6、990
7、990
8、1992
2、952
2、1992
2、1801
1、1992
2、25481
5、25481
5、1991
9、1991
9、19921
2、19921
4、19921 查看全部
网页内容抓取工具(网页内容抓取工具,五大类必备:googleanalytics、appium、snippet)
网页内容抓取工具,五大类必备:googleanalytics、appium、snippet、airtests、ssas。本文介绍的这款工具,相对来说更容易上手。.首先我们来熟悉一下什么是apis请求apis=get/post/put/deleteapis是指和microsoftwindows、oracleonlinesqldatabase/managedconnections、flexinternetapiserver(flex)、javainternetapi(javase)等联结的。
api的主要功能是通过各种形式的联结方式,将您的请求按照特定的方式转换成相应的服务,例如音乐,视频,和多媒体等。.方法注意事项。
1、应用api之前请先检查目标的互联网服务是否是开放的,开放的互联网服务需要开放api,api是开放式的服务。
2)
2、在网站或软件的源代码中定义api也是必须要做的,假设airtest3.0启用了api,启用api可以为用户提供更好的用户体验。
3、调用api时请确保请求具有不同的域名,不同的ip,不同的域名要求的备案,不同的地区,不同的服务器等。
4、建议使用webtargetingtoolkit:firefox、safari、chrome、vlc。
5、避免不必要的http状态码:990
1、992
5、952
7、1993
4、1993
4、999
4、1992
4、992
2、990
6、990
7、990
8、1992
2、952
2、1992
2、1801
1、1992
2、25481
5、25481
5、1991
9、1991
9、19921
2、19921
4、19921
网页内容抓取工具(,涉及Python使用BeautifulSoup模块解析html网页的相关技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-26 13:06
本文主要介绍基于BeautifulSoup抓取网页指定内容的python方法,涉及Python使用BeautifulSoup模块解析html网页的相关技巧。有一定的参考价值,有需要的朋友可以参考
本文示例介绍了基于BeautifulSoup爬取网页指定内容的python方法。分享给大家,供大家参考。具体实现方法如下:
# _*_ coding:utf-8 _*_ #xiaohei.python.seo.call.me:) #win+python2.7.x import urllib2 from bs4 import BeautifulSoup def jd(url): page = urllib2.urlopen(url) html_doc = page.read() soup = BeautifulSoup(html_doc.decode('gb2312','ignore')) for i in soup.find_all('div', id="sortlist"): one = i.find_all('a') two = i.find_all('li') print ("%s %s" % (one,two)) jd("http://channel.jd.com/computer.html")
希望这篇文章对你的 Python 编程有所帮助。
以上是基于BeautifulSoup爬取网页指定内容的python方法的详细内容。详情请关注html中文网其他相关文章! 查看全部
网页内容抓取工具(,涉及Python使用BeautifulSoup模块解析html网页的相关技巧)
本文主要介绍基于BeautifulSoup抓取网页指定内容的python方法,涉及Python使用BeautifulSoup模块解析html网页的相关技巧。有一定的参考价值,有需要的朋友可以参考
本文示例介绍了基于BeautifulSoup爬取网页指定内容的python方法。分享给大家,供大家参考。具体实现方法如下:
# _*_ coding:utf-8 _*_ #xiaohei.python.seo.call.me:) #win+python2.7.x import urllib2 from bs4 import BeautifulSoup def jd(url): page = urllib2.urlopen(url) html_doc = page.read() soup = BeautifulSoup(html_doc.decode('gb2312','ignore')) for i in soup.find_all('div', id="sortlist"): one = i.find_all('a') two = i.find_all('li') print ("%s %s" % (one,two)) jd("http://channel.jd.com/computer.html";)
希望这篇文章对你的 Python 编程有所帮助。
以上是基于BeautifulSoup爬取网页指定内容的python方法的详细内容。详情请关注html中文网其他相关文章!
网页内容抓取工具(网站图片保存路径是什么?如何培养搜索引擎蜘蛛习惯?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-23 04:17
这里要特别注意。现在很多图片都有版权了。根本不要使用那些受版权保护的图片。否则,不仅会侵权,还会降低搜索引擎对您的网站的信任价值。
二、网站图片保存路径
很多站长都没有注意到这个问题。图片上传到网站时,尽量将图片保存在一个目录下,或者根据网站栏制作相应的图片目录,上传路径应该比较固定,方便蜘蛛抢。当蜘蛛访问这个目录时,它会“知道”图片存放在这个目录中;
最好使用一些常规或有意义的方法来命名图像文件。您可以使用时间、列名或网站 名称来命名。例如:SEO优化 下图可以使用名称“SEOYH2018-6-23-36”,前面的“SEOYH”是SEO优化的简称,中间是时间,最后是图片ID。
你为什么要这样做?其实这是为了培养被搜索引擎蜘蛛抓取的习惯,让你以后可以更快的识别网站图片的内容。让蜘蛛抓住你的心,增加网站成为收录的机会,何乐而不为呢!
三、图片周围必须有相关文字
正如我在文章开头所说的,网站图片是一种直接向用户展示信息的方式,搜索引擎在爬取网站的内容时也会检查这个文章@ >无论是图片、视频还是表格等,这些都是可以增加文章值的元素,其他形式暂时不展示,这里只讲图片周围相关文字的介绍.
图片符合主题
首先,图片周围的文字必须与图片本身的内容一致。比如你的文章说要做网站优化,里面的图片是一个菜谱的图片。这不就是卖狗肉吗?参观感会极差。搜索引擎通过相关算法识别出这张图片后,也会觉得图片和文字不符,给你差评。
因此,每张文章必须至少附有一张对应的图片,并且与您的网站标题相关的内容应该出现在图片的周围。它不仅可以帮助搜索引擎理解图像,还可以增加文章的可读性、用户友好性和相关性。
四、给图片添加alt和title标签
很多站长在添加网站图片时可能没有注意这些细节,有的可能会觉得麻烦。我希望你没有这个想法。这是一个大错误。
搜索引擎抓取网站图片时,atl标签是最先抓取的,也是识别图片内容最重要的核心因素之一。图片的alt属性直接告诉搜索引擎它是什么网站图片,表达什么意思;
标题标签是用户指向这张图片时会显示的提示内容。这是增加用户体验和增加网站关键词的一个小技巧。
alt 和标题标签
还有这两个属性,将为有阅读障碍的游客提供便利。例如,当一个盲人访问您网站时,他看不到屏幕上的内容。这可能是通过屏幕阅读。如果有alt属性,软件会直接读取alt属性中的文字,方便他们访问。
五、图像大小和分辨率
两人虽然长得有点像,但还是有很大区别的。同样大小的图片分辨率越高,网站的最终体积就会越大。每个人都必须弄清楚这一点。
网站上的图片一直提倡用尽可能小的图片来最大化内容。你为什么要这样做?因为小尺寸的图片加载速度会更快,不会让访问者等待太久,尤其是在使用手机时。由于移动互联网速度和流量的限制,用户更愿意访问可以立即打开的页面。, 小尺寸的图片更有优势。
这里我们尽量做到平衡,在画面不失真的情况下,尺寸最好尽量小。现在网上有很多减肥图片的工具。每个站长都可以试一试,适当压缩网站的图片。一方面可以减轻你服务器带宽的压力,也可以给用户带来流畅的体验。.
六、自动适配手机
很多站长都遇到过网站在电脑上访问图片时,显示正常,但从手机端出现错位。这就是大尺寸图片在不同尺寸终端上造成错位、显示不完整的情况。.
图片自适应移动终端
其实这个问题很容易解决。添加图片时,宽度和高度最好不要使用绝对大小。使用百分比来解决它。具体来说,CSS代码不能指定像素宽度:width: xxx px; 只有百分比宽度:宽度:xx%;或宽度:自动。
这样做的目的也是为了让百度的手机蜘蛛在抓取的时候有很好的体验,这也是为了更符合百度的手机登陆页面体验。
以上介绍了网站SEO优化中如何抓取手机图片网站的一些技巧。其实本质是为了给用户更好的访问体验。当你这样做网站时,我相信搜索引擎会偏爱你的网站。 查看全部
网页内容抓取工具(网站图片保存路径是什么?如何培养搜索引擎蜘蛛习惯?)
这里要特别注意。现在很多图片都有版权了。根本不要使用那些受版权保护的图片。否则,不仅会侵权,还会降低搜索引擎对您的网站的信任价值。
二、网站图片保存路径
很多站长都没有注意到这个问题。图片上传到网站时,尽量将图片保存在一个目录下,或者根据网站栏制作相应的图片目录,上传路径应该比较固定,方便蜘蛛抢。当蜘蛛访问这个目录时,它会“知道”图片存放在这个目录中;
最好使用一些常规或有意义的方法来命名图像文件。您可以使用时间、列名或网站 名称来命名。例如:SEO优化 下图可以使用名称“SEOYH2018-6-23-36”,前面的“SEOYH”是SEO优化的简称,中间是时间,最后是图片ID。
你为什么要这样做?其实这是为了培养被搜索引擎蜘蛛抓取的习惯,让你以后可以更快的识别网站图片的内容。让蜘蛛抓住你的心,增加网站成为收录的机会,何乐而不为呢!
三、图片周围必须有相关文字
正如我在文章开头所说的,网站图片是一种直接向用户展示信息的方式,搜索引擎在爬取网站的内容时也会检查这个文章@ >无论是图片、视频还是表格等,这些都是可以增加文章值的元素,其他形式暂时不展示,这里只讲图片周围相关文字的介绍.
图片符合主题
首先,图片周围的文字必须与图片本身的内容一致。比如你的文章说要做网站优化,里面的图片是一个菜谱的图片。这不就是卖狗肉吗?参观感会极差。搜索引擎通过相关算法识别出这张图片后,也会觉得图片和文字不符,给你差评。
因此,每张文章必须至少附有一张对应的图片,并且与您的网站标题相关的内容应该出现在图片的周围。它不仅可以帮助搜索引擎理解图像,还可以增加文章的可读性、用户友好性和相关性。
四、给图片添加alt和title标签
很多站长在添加网站图片时可能没有注意这些细节,有的可能会觉得麻烦。我希望你没有这个想法。这是一个大错误。
搜索引擎抓取网站图片时,atl标签是最先抓取的,也是识别图片内容最重要的核心因素之一。图片的alt属性直接告诉搜索引擎它是什么网站图片,表达什么意思;
标题标签是用户指向这张图片时会显示的提示内容。这是增加用户体验和增加网站关键词的一个小技巧。
alt 和标题标签
还有这两个属性,将为有阅读障碍的游客提供便利。例如,当一个盲人访问您网站时,他看不到屏幕上的内容。这可能是通过屏幕阅读。如果有alt属性,软件会直接读取alt属性中的文字,方便他们访问。
五、图像大小和分辨率
两人虽然长得有点像,但还是有很大区别的。同样大小的图片分辨率越高,网站的最终体积就会越大。每个人都必须弄清楚这一点。
网站上的图片一直提倡用尽可能小的图片来最大化内容。你为什么要这样做?因为小尺寸的图片加载速度会更快,不会让访问者等待太久,尤其是在使用手机时。由于移动互联网速度和流量的限制,用户更愿意访问可以立即打开的页面。, 小尺寸的图片更有优势。
这里我们尽量做到平衡,在画面不失真的情况下,尺寸最好尽量小。现在网上有很多减肥图片的工具。每个站长都可以试一试,适当压缩网站的图片。一方面可以减轻你服务器带宽的压力,也可以给用户带来流畅的体验。.
六、自动适配手机
很多站长都遇到过网站在电脑上访问图片时,显示正常,但从手机端出现错位。这就是大尺寸图片在不同尺寸终端上造成错位、显示不完整的情况。.
图片自适应移动终端
其实这个问题很容易解决。添加图片时,宽度和高度最好不要使用绝对大小。使用百分比来解决它。具体来说,CSS代码不能指定像素宽度:width: xxx px; 只有百分比宽度:宽度:xx%;或宽度:自动。
这样做的目的也是为了让百度的手机蜘蛛在抓取的时候有很好的体验,这也是为了更符合百度的手机登陆页面体验。
以上介绍了网站SEO优化中如何抓取手机图片网站的一些技巧。其实本质是为了给用户更好的访问体验。当你这样做网站时,我相信搜索引擎会偏爱你的网站。
网页内容抓取工具( 如何随意提取单机游戏和网络游戏模型和贴图模型的软件?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-12-22 15:01
如何随意提取单机游戏和网络游戏模型和贴图模型的软件?)
如何获得游戏网站制作资料
可以随意为单机游戏和网络游戏提取模型和纹理的软件:一般来说,应用比较广泛的有3D RIPPER、GAMEASSASSIN、NINJA RIPPER。
1、3DRIPPER更适合初学者,操作简单。
不过模型有轻微变形,需要自行调整。
2、GAMEASSASSIN 支持很多游戏,是一款奇迹式的拦截器。
3、NINJA RIPPER在客户端注入HOOK,可以截取非常整齐的模型(人物双手平举,坐标重置为零)。
注:部分特定游戏有特殊的拦截工具,如Unreal的UMODEL、DOTA2的GCFScape等。
另外,有些游戏戒备得很严,提不出来也是很常见的。
1、软件(中国大陆和香港术语,台湾称为软件,英文:Software)是按特定顺序组织起来的计算机数据和指令的集合。
一般来说,软件分为系统软件、应用软件和中间件。
软件不仅包括可以在计算机上运行的计算机程序(这里的计算机是指广义的计算机),与这些计算机程序相关的文件一般都被认为是软件的一部分。
简单地说,软件是程序和文档的集合。
也指社会结构中的管理体制、意识形态、思想政治意识、法律法规等。
2、软件特性(1)是无形的,没有物理形式。你只能通过运行条件来了解功能、特性和质量。
(2)软件需要大量脑力劳动。人类的逻辑思维、智能活动和技术水平是软件产品的关键。
(3)软件不会像硬件一样磨损,但有缺陷维护和技术更新。
(4)软件的开发和运行必须依赖于特定的计算机系统环境,并且依赖于硬件。为了减少依赖,在开发中提出了软件的可移植性。
(5)软件是可复用的,软件开发时很容易被复制,从而形成多个副本。
...
如何从网络游戏中的文件中提取图片(游戏加载并读取一些图片)。
如何...
所需工具:VisualBoyAdvance(中文版) 其实VisualBoyAdvance模拟器就是一个解压器,不需要下载其他工具。用GBA打开游戏,当有你喜欢的行走画面时,点击模拟器菜单中的工具--对象属性查看器(有时因为版本不同或Sinicizer名称不同,反正一般是第6个工具的项目),然后会弹出一个盒子,里面有很多项目,但是你有看到左上角可以拉动的棍子吗?当你拉它时,左边的图像框会随着你拉它而改变图片,拉它,你会发现你想要的行走图片在图像框中。你在等什么!快速按下方的保存进行保存和下载!提取步行图像的步骤大概是这样的,但是这种方法有一些麻烦。当然,提取站立图像很容易,但提取步行图像有点困难。您必须打开对象属性查看器并放置它。模拟器旁边,不要让它挡住我们模拟器的视线,还要在打勾的左下角自动刷新对象属性查看器,然后在游戏角色行走时快速点击对象属性查看器(这是为了让模拟器停止,这样我们就可以提取游戏人物行走的图片),然后按照上面提到的方法提取素材。提取后,排列设置好透明色后,就是一张自动移动的图片了!(温馨提示:为了准确提取游戏人物行走的形象,我们可以从模拟器菜单的选项-跳过帧-速度调整来减慢游戏速度)注:有时由于限制,一张图片会被分成两块或几块。通常这些碎片靠得很近,所以只需轻轻拉动棍子或在棍子旁边的值上加 1 即可找到它。本教程到此结束,祝大家制作出更精彩的游戏。^-^ 补充:其实这个方法不仅仅是提取人物的行走图。一般来说,游戏中的移动物体会再次出现在这里。在GBA中,我们称之为精灵,对象属性查看器专用于图像区域的精灵。所以只需轻轻拉动棍子或在棍子旁边的值上加 1 即可找到它。本教程到此结束,祝大家制作出更精彩的游戏。^-^ 补充:其实这个方法不仅仅是提取人物的行走图。一般来说,游戏中的移动物体会再次出现在这里。在GBA中,我们称之为精灵,对象属性查看器专用于图像区域的精灵。所以只需轻轻拉动棍子或在棍子旁边的值上加 1 即可找到它。本教程到此结束,祝大家制作出更精彩的游戏。^-^ 补充:其实这个方法不仅仅是提取人物的行走图。一般来说,游戏中的移动物体会再次出现在这里。在GBA中,我们称之为精灵,对象属性查看器专用于图像区域的精灵。
转载请注明出处51数据库»网页游戏素材提取软件 查看全部
网页内容抓取工具(
如何随意提取单机游戏和网络游戏模型和贴图模型的软件?)
如何获得游戏网站制作资料
可以随意为单机游戏和网络游戏提取模型和纹理的软件:一般来说,应用比较广泛的有3D RIPPER、GAMEASSASSIN、NINJA RIPPER。
1、3DRIPPER更适合初学者,操作简单。
不过模型有轻微变形,需要自行调整。
2、GAMEASSASSIN 支持很多游戏,是一款奇迹式的拦截器。
3、NINJA RIPPER在客户端注入HOOK,可以截取非常整齐的模型(人物双手平举,坐标重置为零)。
注:部分特定游戏有特殊的拦截工具,如Unreal的UMODEL、DOTA2的GCFScape等。
另外,有些游戏戒备得很严,提不出来也是很常见的。
1、软件(中国大陆和香港术语,台湾称为软件,英文:Software)是按特定顺序组织起来的计算机数据和指令的集合。
一般来说,软件分为系统软件、应用软件和中间件。
软件不仅包括可以在计算机上运行的计算机程序(这里的计算机是指广义的计算机),与这些计算机程序相关的文件一般都被认为是软件的一部分。
简单地说,软件是程序和文档的集合。
也指社会结构中的管理体制、意识形态、思想政治意识、法律法规等。
2、软件特性(1)是无形的,没有物理形式。你只能通过运行条件来了解功能、特性和质量。
(2)软件需要大量脑力劳动。人类的逻辑思维、智能活动和技术水平是软件产品的关键。
(3)软件不会像硬件一样磨损,但有缺陷维护和技术更新。
(4)软件的开发和运行必须依赖于特定的计算机系统环境,并且依赖于硬件。为了减少依赖,在开发中提出了软件的可移植性。
(5)软件是可复用的,软件开发时很容易被复制,从而形成多个副本。
...
如何从网络游戏中的文件中提取图片(游戏加载并读取一些图片)。
如何...
所需工具:VisualBoyAdvance(中文版) 其实VisualBoyAdvance模拟器就是一个解压器,不需要下载其他工具。用GBA打开游戏,当有你喜欢的行走画面时,点击模拟器菜单中的工具--对象属性查看器(有时因为版本不同或Sinicizer名称不同,反正一般是第6个工具的项目),然后会弹出一个盒子,里面有很多项目,但是你有看到左上角可以拉动的棍子吗?当你拉它时,左边的图像框会随着你拉它而改变图片,拉它,你会发现你想要的行走图片在图像框中。你在等什么!快速按下方的保存进行保存和下载!提取步行图像的步骤大概是这样的,但是这种方法有一些麻烦。当然,提取站立图像很容易,但提取步行图像有点困难。您必须打开对象属性查看器并放置它。模拟器旁边,不要让它挡住我们模拟器的视线,还要在打勾的左下角自动刷新对象属性查看器,然后在游戏角色行走时快速点击对象属性查看器(这是为了让模拟器停止,这样我们就可以提取游戏人物行走的图片),然后按照上面提到的方法提取素材。提取后,排列设置好透明色后,就是一张自动移动的图片了!(温馨提示:为了准确提取游戏人物行走的形象,我们可以从模拟器菜单的选项-跳过帧-速度调整来减慢游戏速度)注:有时由于限制,一张图片会被分成两块或几块。通常这些碎片靠得很近,所以只需轻轻拉动棍子或在棍子旁边的值上加 1 即可找到它。本教程到此结束,祝大家制作出更精彩的游戏。^-^ 补充:其实这个方法不仅仅是提取人物的行走图。一般来说,游戏中的移动物体会再次出现在这里。在GBA中,我们称之为精灵,对象属性查看器专用于图像区域的精灵。所以只需轻轻拉动棍子或在棍子旁边的值上加 1 即可找到它。本教程到此结束,祝大家制作出更精彩的游戏。^-^ 补充:其实这个方法不仅仅是提取人物的行走图。一般来说,游戏中的移动物体会再次出现在这里。在GBA中,我们称之为精灵,对象属性查看器专用于图像区域的精灵。所以只需轻轻拉动棍子或在棍子旁边的值上加 1 即可找到它。本教程到此结束,祝大家制作出更精彩的游戏。^-^ 补充:其实这个方法不仅仅是提取人物的行走图。一般来说,游戏中的移动物体会再次出现在这里。在GBA中,我们称之为精灵,对象属性查看器专用于图像区域的精灵。
转载请注明出处51数据库»网页游戏素材提取软件
网页内容抓取工具(网页内容抓取工具,好用,不占硬盘存储和网速)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-22 14:05
网页内容抓取工具,好用,不占硬盘存储和网速,自带sql查询语言,适合一些初学者。支持安卓手机和苹果ios手机,已内置laravel语言,建议两端通吃。
我这里有一个网页抓取工具,
两个都用过,用pc推荐网页采集器,在网上广泛宣传,手机同样推荐网页采集器,它会提供相应的功能,不多说。爬虫是发现页面的规律,目前抓取不容易出现重复的页面。
初学,推荐beautifulsoup,如何得到页面信息,实现内容抓取。然后laya,正则表达式实现爬虫的到页面抓取。然后python自带,推荐python爬虫程序设计,http权威指南。当然,如果不喜欢看书,那可以使用爬虫工具。
pc上推荐scrapy()是一个高级的开源爬虫框架。目前大部分linux下应用基本都是基于scrapy开发的。scrapy已经包含了所有可爬取任务的爬虫功能。如果觉得scrapy还不够好,可以选择python的scrapy框架。
推荐用mysql
pc端的话推荐网页抓取器,手机端的推荐米筐,不太清楚你的专业,但数据可视化看你对哪方面用的多,linux下的shell编程的话直接lsb_release,python对win的虚拟机支持不错,虽然不如win系统做的好,但python是一个大数据容器。
hyperloglog手机端的话tornadolibtornado很简单,很容易学,感兴趣可以试试。 查看全部
网页内容抓取工具(网页内容抓取工具,好用,不占硬盘存储和网速)
网页内容抓取工具,好用,不占硬盘存储和网速,自带sql查询语言,适合一些初学者。支持安卓手机和苹果ios手机,已内置laravel语言,建议两端通吃。
我这里有一个网页抓取工具,
两个都用过,用pc推荐网页采集器,在网上广泛宣传,手机同样推荐网页采集器,它会提供相应的功能,不多说。爬虫是发现页面的规律,目前抓取不容易出现重复的页面。
初学,推荐beautifulsoup,如何得到页面信息,实现内容抓取。然后laya,正则表达式实现爬虫的到页面抓取。然后python自带,推荐python爬虫程序设计,http权威指南。当然,如果不喜欢看书,那可以使用爬虫工具。
pc上推荐scrapy()是一个高级的开源爬虫框架。目前大部分linux下应用基本都是基于scrapy开发的。scrapy已经包含了所有可爬取任务的爬虫功能。如果觉得scrapy还不够好,可以选择python的scrapy框架。
推荐用mysql
pc端的话推荐网页抓取器,手机端的推荐米筐,不太清楚你的专业,但数据可视化看你对哪方面用的多,linux下的shell编程的话直接lsb_release,python对win的虚拟机支持不错,虽然不如win系统做的好,但python是一个大数据容器。
hyperloglog手机端的话tornadolibtornado很简单,很容易学,感兴趣可以试试。
网页内容抓取工具(URLExtractor内容提取WK下载永久钻石支付宝下载(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-19 12:07
URL Extractor 是一个 Cocoa 应用程序,用于从文件中提取电子邮件地址和 URL,这些文件也可以通过搜索引擎找到。它可以从单个网页开始,浏览所有内部链接,找到要提取的电子邮件或URL,并将所有链接保存在用户HD上。它还可以从任何嵌套级别的单个文件或 HD 上文件夹的所有内容中提取。完成后,它可以将 URL Extractor 文档保存到磁盘,其中收录特定文件夹或文件或网页的所有设置,可以重复使用。或者,提取的数据可以作为文本文件保存在磁盘上以供用户使用。
它允许用户指定要用作导航起点的网页列表,并使用交叉导航转到其他网页。您还可以指定一系列关键字;然后通过搜索引擎搜索与关键字相关的网页,并开始页面的交叉导航,采集网址。在Web提取模式下无需用户交互即可导航数小时,提取在所有无人值守网页中找到的所有URL;或从使用关键字的单个搜索引擎开始,在无限制的导航和 URL 中查看提取过程中的所有结果和链接页面。
特征
本站统一解压密码:
免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。
URL Extractor 内容提取
WK网友下载永久钻石
支付宝扫一扫
微信扫一扫>打赏采集海报链接 查看全部
网页内容抓取工具(URLExtractor内容提取WK下载永久钻石支付宝下载(组图))
URL Extractor 是一个 Cocoa 应用程序,用于从文件中提取电子邮件地址和 URL,这些文件也可以通过搜索引擎找到。它可以从单个网页开始,浏览所有内部链接,找到要提取的电子邮件或URL,并将所有链接保存在用户HD上。它还可以从任何嵌套级别的单个文件或 HD 上文件夹的所有内容中提取。完成后,它可以将 URL Extractor 文档保存到磁盘,其中收录特定文件夹或文件或网页的所有设置,可以重复使用。或者,提取的数据可以作为文本文件保存在磁盘上以供用户使用。
它允许用户指定要用作导航起点的网页列表,并使用交叉导航转到其他网页。您还可以指定一系列关键字;然后通过搜索引擎搜索与关键字相关的网页,并开始页面的交叉导航,采集网址。在Web提取模式下无需用户交互即可导航数小时,提取在所有无人值守网页中找到的所有URL;或从使用关键字的单个搜索引擎开始,在无限制的导航和 URL 中查看提取过程中的所有结果和链接页面。
特征
https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />本站统一解压密码:
免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。
URL Extractor 内容提取
WK网友下载永久钻石
WX20211214-222443@2x.png" />支付宝扫一扫
WX20211214-222554@2x.png" />微信扫一扫>打赏采集海报链接
网页内容抓取工具(一个翻页循环网页数据能采集到哪些数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-12-19 12:05
采集可以从网页数据中得到什么数据
刚接触数据采集的同学可能会有这样的疑问:哪些网页数据可以是采集?
简单地说,互联网收录了丰富的开放数据资源。这些直接可见的互联网公开数据可以是采集,但是采集的难易程度存在差异。具体到数据类型,大数据的数据主要是网络日志、视频、图片、地理位置等网络信息,可以通过多种方式实现采集。
我们可以使用采集工具高效便捷的实现各种网页和各类网页数据采集。优采云是一个可视化的网页数据采集器,可以是采集99%的网页。以下是完整的使用优采云、采集的豆瓣电影短评示例。
第一步:创建采集任务
1)进入主界面,选择“自定义模式”
2)将采集的网址复制粘贴到网站的输入框中,点击“保存网址”
采集可以从网页数据中得到什么数据 图2
第 2 步:创建翻页循环
1)在页面右上角,打开“流程”,显示“流程设计器”和“自定义当前操作”两个部分。网页打开后,下拉页面,找到并点击“更多短评”按钮,选择“点击此链接”
采集可以从网页数据中得到什么数据 图3
2) 将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,
选择“更多操作”
采集可以从网页数据中得到什么数据 图4
选择“循环点击单个链接”创建翻页循环
采集可以从网页数据中得到什么数据 图5
第 3 步:创建列表循环并提取数据
1)移动鼠标选择页面上的第一个电影评论块。系统会识别该块中的子元素,在操作提示框中选择“选择子元素”
采集可以从网页数据中得到什么数据 图6
2) 系统会自动识别页面其他相似元素,在操作提示框中选择“全选”创建列表循环
采集可以从网页数据中得到什么数据 图7
3) 我们可以看到页面第一个电影评论块中的所有元素都被选中并变成了绿色。选择“采集以下数据”
采集可以从网页数据中得到什么数据 图8
4)选择一个字段并点击垃圾桶图标删除不需要的字段
采集可以从网页数据中得到什么数据 图9
5) 字段选择完成后,选择对应的字段,自定义字段的命名。完成后,点击左上角的“保存并启动”
采集可以从网页数据中得到什么数据 图10
6)选择“启动本地采集”
采集可以从网页数据中得到什么数据 图11
第四步:数据采集并导出
1)采集 完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
采集可以从网页数据中得到什么数据 图12
2)这里我们选择excel作为导出格式,导出数据如下图
采集可以从网页数据中得到什么数据 图13
注:未登录时,豆瓣电影短评页面只能翻8次,采集约160条短评数据。采集更多资料,请先登录。登录请参考以下两个教程:单文输入点击登录方式(/tutorialdetail-1/srdl_v70.html)和cookie登录方式(/tutorialdetail-1/cookie70.html)。
在示例中,采集的豆瓣电影的评论信息,以及视频、图片、地理位置等其他数据类型的采集的评论信息相对复杂一些。视频:可用 采集 其 URL。图片:可以批量处理采集图片网址,然后使用优采云批量导出工具将网址导出为图片。地理位置(经纬度),如地图网站(百度地图、高德地图
该信息在搜狗地图源码中可以找到,可以从源码采集获取。
相关 采集 教程: 查看全部
网页内容抓取工具(一个翻页循环网页数据能采集到哪些数据(组图))
采集可以从网页数据中得到什么数据
刚接触数据采集的同学可能会有这样的疑问:哪些网页数据可以是采集?
简单地说,互联网收录了丰富的开放数据资源。这些直接可见的互联网公开数据可以是采集,但是采集的难易程度存在差异。具体到数据类型,大数据的数据主要是网络日志、视频、图片、地理位置等网络信息,可以通过多种方式实现采集。
我们可以使用采集工具高效便捷的实现各种网页和各类网页数据采集。优采云是一个可视化的网页数据采集器,可以是采集99%的网页。以下是完整的使用优采云、采集的豆瓣电影短评示例。
第一步:创建采集任务
1)进入主界面,选择“自定义模式”
2)将采集的网址复制粘贴到网站的输入框中,点击“保存网址”
采集可以从网页数据中得到什么数据 图2
第 2 步:创建翻页循环
1)在页面右上角,打开“流程”,显示“流程设计器”和“自定义当前操作”两个部分。网页打开后,下拉页面,找到并点击“更多短评”按钮,选择“点击此链接”
采集可以从网页数据中得到什么数据 图3
2) 将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,
选择“更多操作”
采集可以从网页数据中得到什么数据 图4
选择“循环点击单个链接”创建翻页循环
采集可以从网页数据中得到什么数据 图5
第 3 步:创建列表循环并提取数据
1)移动鼠标选择页面上的第一个电影评论块。系统会识别该块中的子元素,在操作提示框中选择“选择子元素”
采集可以从网页数据中得到什么数据 图6
2) 系统会自动识别页面其他相似元素,在操作提示框中选择“全选”创建列表循环
采集可以从网页数据中得到什么数据 图7
3) 我们可以看到页面第一个电影评论块中的所有元素都被选中并变成了绿色。选择“采集以下数据”
采集可以从网页数据中得到什么数据 图8
4)选择一个字段并点击垃圾桶图标删除不需要的字段
采集可以从网页数据中得到什么数据 图9
5) 字段选择完成后,选择对应的字段,自定义字段的命名。完成后,点击左上角的“保存并启动”
采集可以从网页数据中得到什么数据 图10
6)选择“启动本地采集”
采集可以从网页数据中得到什么数据 图11
第四步:数据采集并导出
1)采集 完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
采集可以从网页数据中得到什么数据 图12
2)这里我们选择excel作为导出格式,导出数据如下图
采集可以从网页数据中得到什么数据 图13
注:未登录时,豆瓣电影短评页面只能翻8次,采集约160条短评数据。采集更多资料,请先登录。登录请参考以下两个教程:单文输入点击登录方式(/tutorialdetail-1/srdl_v70.html)和cookie登录方式(/tutorialdetail-1/cookie70.html)。
在示例中,采集的豆瓣电影的评论信息,以及视频、图片、地理位置等其他数据类型的采集的评论信息相对复杂一些。视频:可用 采集 其 URL。图片:可以批量处理采集图片网址,然后使用优采云批量导出工具将网址导出为图片。地理位置(经纬度),如地图网站(百度地图、高德地图
该信息在搜狗地图源码中可以找到,可以从源码采集获取。
相关 采集 教程:
网页内容抓取工具(WebScraperforMac永久激活版是您的不错选择!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-18 17:07
如果您正在寻找一款好用的网站数据抓取工具,那么WebScraper for Mac永久激活版是您不错的选择!有需要的朋友可以下载!
WebScraper Mac 软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper Mac 软件功能
1、快速轻松地扫描网站
大量的提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、易于导出-选择您想要的列
3、输出为 csv 或 json
4、将所有图像下载到文件夹/采集并导出所有链接的新选项
5、输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
WebScraper Mac 软件功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、专为现代网络设计
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。拿到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能想尝试将数据保存到 CouchDB 中。 查看全部
网页内容抓取工具(WebScraperforMac永久激活版是您的不错选择!!)
如果您正在寻找一款好用的网站数据抓取工具,那么WebScraper for Mac永久激活版是您不错的选择!有需要的朋友可以下载!
WebScraper Mac 软件介绍
WebScraper Mac 版是 Mac 平台上的一个简单的应用程序,可以将数据导出为 JSON 或 CSV。 WebScraper Mac 版可以快速提取与网页相关的信息(包括文本内容)。 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper Mac 软件功能
1、快速轻松地扫描网站
大量的提取选项;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
2、易于导出-选择您想要的列
3、输出为 csv 或 json
4、将所有图像下载到文件夹/采集并导出所有链接的新选项
5、输出单个文本文件的新选项(用于存档文本内容、markdown 或纯文本)
6、丰富的选项/配置
WebScraper Mac 软件功能介绍
1、从动态网页中提取数据
使用 Web Scraper,您可以构建一个站点地图来导航站点并提取数据。使用不同的类型选择器,Web Scraper 将导航站点并提取多种类型的数据——文本、表格、图像、链接等。
2、专为现代网络设计
与仅从 HTML Web 中提取数据的其他抓取工具不同,Scraper 还可以提取使用 JavaScript 动态加载或生成的数据。 Web Scraper可以:-等待页面加载动态数据-点击分页按钮通过AJAX加载数据-点击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或存储在CouchDB中
Web Scrapper 是一个独立的 chrome 扩展。站点地图构建、数据提取和导出都在浏览器中完成。拿到你的网站后,就可以下载CSV格式的数据了。对于高级用例,您可能想尝试将数据保存到 CouchDB 中。

