
网站调用新浪微博内容
网站调用新浪微博内容(微博开放平台注册开发者并获取app和appsecret百度很容易)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-01 04:24
前言:微博开放平台提供了微博数据的api接口。不仅可以直接使用api调用微博服务发布微博查询微博,更重要的是可以通过自己的网站 API授权获取新浪微博,调用微博的一些内容,好像我们看到了在网站、文章想分享到微博或其他社交网站,非常方便。
下面就让我们来探究一下其中的奥秘。
1.注册开发者,获取app key和app secret
百度很容易找到微博开放平台的入口,登录微博账号,点击账号头像,会提示编辑开发者信息。
可以看到如下页面,按照提示填写即可,紧急联系人可以自己填写,网站无所谓,自己填写百度即可。
提交后,您需要在我的应用程序中验证您的真实姓名。上传图片时请耐心等待。有点慢,没有上传进度。上传后,点击返回跳转到新页面:
根据您的需要选择,然后创建您自己的应用程序。至于各个应用术语的含义,我不是很清楚。我选择了其他应用
创建后,您将收到一封收录应用密钥和应用机密的电子邮件。这是获得授权的关键。
2.获取令牌
在首页点击api接口,会跳转到api接口文档页面。你会发现这个api有很多功能,包括创建微博、删除微博、关注/取消关注等很多接口,但是每个接口都需要一个token才能访问。令牌从哪里来?
一是要拿到code,二是要有调用接口的网址(因为我申请的是web应用)。
设置关联的 URL:
单击您的应用程序名称,然后在左侧菜单中找到高级信息,然后您可以对其进行编辑。
在api界面下点击
, 进入授权界面查看使用情况
根据示例,您需要发送收录 client_id 和 redirect_uri 的 get 请求。可以直接拼接。
https://api.weibo.com/oauth2/a ... Dcode
其中client_id是你申请的app key,redirect_uri是你要回调的接口地址,api会原样返回。可以直接在浏览器中输入url,如下图:
这个页面是不是很熟悉?授权后网页会跳转回redirect_uri页面,url后面会写code。所以代码在那里
接下来获取授权token,第二个授权接口:
页面上有详细的用法,发送http post请求,我是用java http-client4.5来做的,其实其他方法也可以。
代码写得不好,但多少有用。5 个必需的参数值。我们已经拿到了最后两个,前两个在邮件里。代码将不会发布。打理好自己的打字,会帮助你熟悉用法,以后难免会提出各种要求。
至此,我们已经授权成功,返回值中就是需要的token值了。如果返回错误,请查看错误信息或百度错误信息。
之后,您只需要带上令牌来请求各种接口。虽然有次数限制,但正常使用应该足够了。
后记:
1. 本来想做一些爬虫类的功能。我想在微博开放界面获取一些数据。不过从API来看,大部分都是基于web应用的微博分享功能。
比如自己的微博、粉丝、发微博、关注等,都不是你需要的。
2. 前面说过,微博开放api主要是第三方网站或者app用来访问微博,用微博登录或者通过api分享微博,所以这方面是完全需要的您可以深入研究 api 接口。
在3.api接口中,所有的get请求都可以通过直接拼接字符串的方式获取,但是对于刚刚请求授权的get请求,需要用户的账号同意向应用授权,所以必须登录用户帐户。如果浏览器保留了微博登录的cookie,那么浏览器可以自动登录获取目标码,如果没有会提示登录
所以这个请求适合在浏览器上做,因为发送带有代码的请求模拟登录,或者登录后使用cookies都非常麻烦。但是api中的其他get请求不会有这个问题,直接带上token就可以了。模拟登录可以使用selenium的webdriver来获取cookies。其他模拟登录的方法一般都很麻烦。
当然,如果你把它嵌入到网站上,那么登录是用户的事。
4.以发送微博为例:
@Test
public void test2() throws IOException {
CloseableHttpClient client = HttpClients.createDefault();
CloseableHttpResponse response = null;
RequestConfig config =
RequestConfig.custom().setConnectTimeout(10000)
.setSocketTimeout(10000).build();
HttpPost post = new HttpPost("https://api.weibo.com/2/statuses/update.json");
post.setConfig(config);
List pairs = new ArrayList();
BasicNameValuePair p1 = new BasicNameValuePair("access_token","");
String content = "本条微博通过微博开放接口发送";
BasicNameValuePair p2 = new BasicNameValuePair("status",
content);
BasicNameValuePair p3 = new BasicNameValuePair("visible","0");
pairs.add(p1);
pairs.add(p2);
pairs.add(p3);
post.setEntity(new UrlEncodedFormEntity(pairs,"utf-8"));
response = client.execute(post);
HttpEntity entities = response.getEntity();
System.out.println(EntityUtils.toString(entities,"UTF-8"));
}
5.如果自己把开放的api嵌入到自己的网站中,一般的做法是:在分享微博按钮(第三方登录按钮)上,发送微博授权认证,用户点击授权后web页面,后台获取code,根据code获取token。之后,如果您需要提取微博的用户名,您可以直接在后台发送请求。如果分享到微博,也可以通过api来完成。
如果以后在实践中用到这些功能,请做好记录。本文到此结束。
来自维兹 查看全部
网站调用新浪微博内容(微博开放平台注册开发者并获取app和appsecret百度很容易)
前言:微博开放平台提供了微博数据的api接口。不仅可以直接使用api调用微博服务发布微博查询微博,更重要的是可以通过自己的网站 API授权获取新浪微博,调用微博的一些内容,好像我们看到了在网站、文章想分享到微博或其他社交网站,非常方便。
下面就让我们来探究一下其中的奥秘。
1.注册开发者,获取app key和app secret
百度很容易找到微博开放平台的入口,登录微博账号,点击账号头像,会提示编辑开发者信息。
可以看到如下页面,按照提示填写即可,紧急联系人可以自己填写,网站无所谓,自己填写百度即可。
提交后,您需要在我的应用程序中验证您的真实姓名。上传图片时请耐心等待。有点慢,没有上传进度。上传后,点击返回跳转到新页面:
根据您的需要选择,然后创建您自己的应用程序。至于各个应用术语的含义,我不是很清楚。我选择了其他应用
创建后,您将收到一封收录应用密钥和应用机密的电子邮件。这是获得授权的关键。
2.获取令牌
在首页点击api接口,会跳转到api接口文档页面。你会发现这个api有很多功能,包括创建微博、删除微博、关注/取消关注等很多接口,但是每个接口都需要一个token才能访问。令牌从哪里来?
一是要拿到code,二是要有调用接口的网址(因为我申请的是web应用)。
设置关联的 URL:
单击您的应用程序名称,然后在左侧菜单中找到高级信息,然后您可以对其进行编辑。
在api界面下点击
, 进入授权界面查看使用情况
根据示例,您需要发送收录 client_id 和 redirect_uri 的 get 请求。可以直接拼接。
https://api.weibo.com/oauth2/a ... Dcode
其中client_id是你申请的app key,redirect_uri是你要回调的接口地址,api会原样返回。可以直接在浏览器中输入url,如下图:
这个页面是不是很熟悉?授权后网页会跳转回redirect_uri页面,url后面会写code。所以代码在那里
接下来获取授权token,第二个授权接口:
页面上有详细的用法,发送http post请求,我是用java http-client4.5来做的,其实其他方法也可以。
代码写得不好,但多少有用。5 个必需的参数值。我们已经拿到了最后两个,前两个在邮件里。代码将不会发布。打理好自己的打字,会帮助你熟悉用法,以后难免会提出各种要求。
至此,我们已经授权成功,返回值中就是需要的token值了。如果返回错误,请查看错误信息或百度错误信息。
之后,您只需要带上令牌来请求各种接口。虽然有次数限制,但正常使用应该足够了。
后记:
1. 本来想做一些爬虫类的功能。我想在微博开放界面获取一些数据。不过从API来看,大部分都是基于web应用的微博分享功能。
比如自己的微博、粉丝、发微博、关注等,都不是你需要的。
2. 前面说过,微博开放api主要是第三方网站或者app用来访问微博,用微博登录或者通过api分享微博,所以这方面是完全需要的您可以深入研究 api 接口。
在3.api接口中,所有的get请求都可以通过直接拼接字符串的方式获取,但是对于刚刚请求授权的get请求,需要用户的账号同意向应用授权,所以必须登录用户帐户。如果浏览器保留了微博登录的cookie,那么浏览器可以自动登录获取目标码,如果没有会提示登录
所以这个请求适合在浏览器上做,因为发送带有代码的请求模拟登录,或者登录后使用cookies都非常麻烦。但是api中的其他get请求不会有这个问题,直接带上token就可以了。模拟登录可以使用selenium的webdriver来获取cookies。其他模拟登录的方法一般都很麻烦。
当然,如果你把它嵌入到网站上,那么登录是用户的事。
4.以发送微博为例:
@Test
public void test2() throws IOException {
CloseableHttpClient client = HttpClients.createDefault();
CloseableHttpResponse response = null;
RequestConfig config =
RequestConfig.custom().setConnectTimeout(10000)
.setSocketTimeout(10000).build();
HttpPost post = new HttpPost("https://api.weibo.com/2/statuses/update.json";);
post.setConfig(config);
List pairs = new ArrayList();
BasicNameValuePair p1 = new BasicNameValuePair("access_token","");
String content = "本条微博通过微博开放接口发送";
BasicNameValuePair p2 = new BasicNameValuePair("status",
content);
BasicNameValuePair p3 = new BasicNameValuePair("visible","0");
pairs.add(p1);
pairs.add(p2);
pairs.add(p3);
post.setEntity(new UrlEncodedFormEntity(pairs,"utf-8"));
response = client.execute(post);
HttpEntity entities = response.getEntity();
System.out.println(EntityUtils.toString(entities,"UTF-8"));
}
5.如果自己把开放的api嵌入到自己的网站中,一般的做法是:在分享微博按钮(第三方登录按钮)上,发送微博授权认证,用户点击授权后web页面,后台获取code,根据code获取token。之后,如果您需要提取微博的用户名,您可以直接在后台发送请求。如果分享到微博,也可以通过api来完成。
如果以后在实践中用到这些功能,请做好记录。本文到此结束。
来自维兹
网站调用新浪微博内容(项目招商找A5快速获取精准代理名单站长网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-30 20:14
项目招商找A5快速获取精准代理商名单
网管网6月12日报道,今天,在以构建中小企业微博产业链为主题的万网、新浪微博、CNNIC战略合作发布会上,万网宣布与新浪微博、CNNIC联合启动针对中小企业。“万网微站”产品。微博作为万网与新浪微博联合推出的一款特色应用,结合了微博与网站的交互,用户可以以网站的形式自动生成微博的图文内容。内容与微博保持同步,支持多终端移动访问。万网官网表示,中小企业用户可以在短短五秒内自动生成网站与官方微博互动。同时,开通微博一条龙服务,中小企业也可以自动将实名注册材料带入新浪企业。微博认证,更快开通新浪企业微博,更丰富的微博展示和营销互动服务。
麦友集团微站演示
七哥TOP潮品微现场演示
易果网微站演示
万网还针对微型站点应用推出了“微型站点域名”相关产品。收取使用费88元/年,采用“解析即绑定,实名即备案”的形式,允许用户将微站绑定到CN域名或“.中国”域名。通过微站应用,中小型企业和站长可以更方便地将微博内容自动转换为网站,布局简洁美观。在开展微博营销的同时,为中小企业和站长提供全新的营销推广渠道,更好地向用户展示公司的产品和服务。
据了解,用户在访问微博时,可以像微博一样转发评论,再将内容导入微博进行传播。提高互动性和信息传播范围。目前,中国微博用户已超过3亿,每天微博信息的产生和访问量和信息传播速度已经颠覆了传统的网站。微博品牌营销正在影响传统的中小企业和网站 站长。作为中国最大的域名注册和托管服务商,万网也拥有大量的企业和站长用户。微博的推出意味着传统的网站将进一步加强与微博的联系,为微博营销和企业网站建设提供新思路。(文/阳阳来源:
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇! 查看全部
网站调用新浪微博内容(项目招商找A5快速获取精准代理名单站长网(组图))
项目招商找A5快速获取精准代理商名单
网管网6月12日报道,今天,在以构建中小企业微博产业链为主题的万网、新浪微博、CNNIC战略合作发布会上,万网宣布与新浪微博、CNNIC联合启动针对中小企业。“万网微站”产品。微博作为万网与新浪微博联合推出的一款特色应用,结合了微博与网站的交互,用户可以以网站的形式自动生成微博的图文内容。内容与微博保持同步,支持多终端移动访问。万网官网表示,中小企业用户可以在短短五秒内自动生成网站与官方微博互动。同时,开通微博一条龙服务,中小企业也可以自动将实名注册材料带入新浪企业。微博认证,更快开通新浪企业微博,更丰富的微博展示和营销互动服务。
麦友集团微站演示
七哥TOP潮品微现场演示
易果网微站演示
万网还针对微型站点应用推出了“微型站点域名”相关产品。收取使用费88元/年,采用“解析即绑定,实名即备案”的形式,允许用户将微站绑定到CN域名或“.中国”域名。通过微站应用,中小型企业和站长可以更方便地将微博内容自动转换为网站,布局简洁美观。在开展微博营销的同时,为中小企业和站长提供全新的营销推广渠道,更好地向用户展示公司的产品和服务。
据了解,用户在访问微博时,可以像微博一样转发评论,再将内容导入微博进行传播。提高互动性和信息传播范围。目前,中国微博用户已超过3亿,每天微博信息的产生和访问量和信息传播速度已经颠覆了传统的网站。微博品牌营销正在影响传统的中小企业和网站 站长。作为中国最大的域名注册和托管服务商,万网也拥有大量的企业和站长用户。微博的推出意味着传统的网站将进一步加强与微博的联系,为微博营销和企业网站建设提供新思路。(文/阳阳来源:
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇!
网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-09-30 06:13
日志条目
新浪微博登录常用界面:
对应主界面:
不过我个人推荐使用手机微博入口:
对应主界面:
原因是手机数据比较轻,基础数据齐全。可能缺少一些基本的个人信息,比如“个人资料补全”、“个人等级”等,同时粉丝ID和关注者ID只能显示20页,但可以作为大部分的语料库验证。
通过对比下面两张图,在PC端和手机端,可以发现内容基本一致:
手机端如下图,图片相对较小,内容更加精简。
完整的源代码
下面的代码主要分为三部分:
1.登录微博(用户名,密码) 登录微博
2.VisitPersonPage(user_id) 访问人物网站获取个人信息
3.翻页获取微博内容
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471")会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/")
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num 查看全部
网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
日志条目
新浪微博登录常用界面:
对应主界面:
不过我个人推荐使用手机微博入口:
对应主界面:
原因是手机数据比较轻,基础数据齐全。可能缺少一些基本的个人信息,比如“个人资料补全”、“个人等级”等,同时粉丝ID和关注者ID只能显示20页,但可以作为大部分的语料库验证。
通过对比下面两张图,在PC端和手机端,可以发现内容基本一致:

手机端如下图,图片相对较小,内容更加精简。

完整的源代码
下面的代码主要分为三部分:
1.登录微博(用户名,密码) 登录微博
2.VisitPersonPage(user_id) 访问人物网站获取个人信息
3.翻页获取微博内容
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471";)会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/";)
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num
网站调用新浪微博内容(Scrapy爬取豆瓣网站信息怎么破?如何破解HTTP请求 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-09-26 00:05
)
一、回顾
当scrapy爬行豆瓣菜网站信息时,我们通过加载目标URL返回的响应直接获得所需的值。当我稍后爬网时知乎网站,我通过模拟登录输入目标URL,并通过返回的响应获得所需的值
这一次,我们将通过解析网站的HTTP请求来抓取所需的数据,以破解获取数据的API
二、找到微博用户的独特标识:oid
一般来说,当爬行网站时,首选m站,其次是WAP站,最后考虑PC站,因为PC站具有最多的验证。当然,这不是绝对的。有时,PC站拥有最完整的信息,而您只需要所有信息,因此PC站是您的首选。通常,m个站点以m开头,后跟域名。这一次,我们分析了微博的HTTP请求
注:
1)打开页面并单击“网络”选项卡时,将不会显示任何信息。当你打开页面时,我们需要刷新它
2)为了防止由于页面突然跳转而导致信息丢失,请务必勾选保留的无线电框
在移动模式下打开网页
三、了解微博用户的微博内容API
在找到用户ID后,我们继续在网络上搜索API,即选择XHR进行过滤,并找到已发送的两个API请求。(API请求通常采用XHR格式,其他网页请求采用DOC格式)
通过XHR获取过滤后的API
我们检查两个API返回的数据,发现第一个API返回用户数据,第二个API返回微博内容数据。它们唯一的参数是containerid的值。通过对采集多个案例的分析,可以得出获取用户内容的容器ID为100505+oid,获取微博内容的容器ID为107603+oid
https://m.weibo.cn/api/contain ... 01701
https://m.weibo.cn/api/contain ... 01701
分析返回的API
我们在右边选择preview来预览JSON,点击卡片中的任何卡片,在mblog标签下就有我们想要的微博内容数据
我们继续观察到这个JSON中只有11条数据,因此我们滑到下一页,继续查看请求的API
查看全部
网站调用新浪微博内容(Scrapy爬取豆瓣网站信息怎么破?如何破解HTTP请求
)
一、回顾
当scrapy爬行豆瓣菜网站信息时,我们通过加载目标URL返回的响应直接获得所需的值。当我稍后爬网时知乎网站,我通过模拟登录输入目标URL,并通过返回的响应获得所需的值
这一次,我们将通过解析网站的HTTP请求来抓取所需的数据,以破解获取数据的API
二、找到微博用户的独特标识:oid
一般来说,当爬行网站时,首选m站,其次是WAP站,最后考虑PC站,因为PC站具有最多的验证。当然,这不是绝对的。有时,PC站拥有最完整的信息,而您只需要所有信息,因此PC站是您的首选。通常,m个站点以m开头,后跟域名。这一次,我们分析了微博的HTTP请求
注:
1)打开页面并单击“网络”选项卡时,将不会显示任何信息。当你打开页面时,我们需要刷新它
2)为了防止由于页面突然跳转而导致信息丢失,请务必勾选保留的无线电框

在移动模式下打开网页
三、了解微博用户的微博内容API
在找到用户ID后,我们继续在网络上搜索API,即选择XHR进行过滤,并找到已发送的两个API请求。(API请求通常采用XHR格式,其他网页请求采用DOC格式)
通过XHR获取过滤后的API
我们检查两个API返回的数据,发现第一个API返回用户数据,第二个API返回微博内容数据。它们唯一的参数是containerid的值。通过对采集多个案例的分析,可以得出获取用户内容的容器ID为100505+oid,获取微博内容的容器ID为107603+oid
https://m.weibo.cn/api/contain ... 01701
https://m.weibo.cn/api/contain ... 01701
分析返回的API
我们在右边选择preview来预览JSON,点击卡片中的任何卡片,在mblog标签下就有我们想要的微博内容数据
我们继续观察到这个JSON中只有11条数据,因此我们滑到下一页,继续查看请求的API
网站调用新浪微博内容( 你有钱了,然后你做菜市场老板!你明白吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-24 16:31
你有钱了,然后你做菜市场老板!你明白吗?)
借鸡下蛋,提高声誉,最终获利。有钱了,去逛菜市场,然后你就成为菜市场的主人了!你明白吗?
使用新浪微博开放平台的API开发自己的微博应用。我是新手。请介绍一些步骤或想法
1、注册一个开发者用户,在微博开发平台查看调用
2、在新的申请和审批流程中
下载相应的程序(包
运行程序(做一些相应的修改)
希望新来的学者帮忙
关于新浪微博开放平台(phpsdk)微信开放平台SDK。
还是第一次~?
如果它有效。
微博开放平台sdk:请大侠教你如何使用android微博开发的sdk
sdk中有demo供参考。参考官方api文档
如何基于新浪微博开放平台提供的android SDK开发新浪微博手机客户端。SDK和jar包已经下载,如何使用?
新浪SDK基于Java语言,封装了一些功能,比如认证,你正常的android开发,导入相关文件,你写的UI层,调用api,调用中的行
如何使用腾讯微博开放平台java sdk微信开放平台微信登录。
1、访问开放平台首页;
2、 仔细阅读官方开放API文档。
这听起来像废话,但这是你必须做的。
备注:特别提醒,一定要阅读官方文档,不要在网上搜索那些野标签。他们中的许多人都是骗子。
微博开放平台sdk:新浪微博开放平台PHP-SDK问题
打回来。php可以做定位:直接跳转到目标页面,即回调。PHP 不需要显示。认证下的跳转和没有跳转基本一样。您正在查看官方文档。做这个接口的时候一定要跳回PHP-SDK的回调页面。你可以尝试用JS-SDK,陌陌开放平台SDK转发这个功能。
新浪微博开放平台的javasdk是否采用了可以自动跟随的插件开放平台sdk设计理念?
我只能这样做。
微博开放平台sdk:如何编写微博开放平台api
微博开放平台提供了微博数据的api接口。不仅可以通过api调用微博服务直接发布微博查询微博,更重要的是可以自己获取新浪微博api的授权网站。调用微博的一些内容。好像在网站上看到好的文章,就可以分享到微博或者其他社交网站,非常方便。百度ai开放平台sdk。
让我们来探索这个秘密。
注册开发者并访问应用程序密钥和应用程序机密。扫码跳转微信开放平台。
很容易找到微博开放平台的入口,登录微博账号,点击账号头像,会提示编辑开发者信息。微信扫码开放平台。
可以看到如下页面,按照提示填写即可,哪些紧急联系人可以自己填写,网站无所谓,自己填写即可。
提交后需要在我的申请下进行实名认证。上传图片时请耐心等待。有点慢,没有上传进度。上传后,点击返回跳转到新页面:
根据您的需要选择,然后创建您自己的应用程序。我不知道使用各种名词是什么意思。我选择了如何进入其他应用的微信开放平台。
创建后,您将收到一封收录应用程序密钥和应用程序机密的电子邮件。这是获得授权的关键。
2、访问令牌
在首页点击api接口,会跳转到api接口描述文档页面。你会发现这个api有很多功能,包括创建微博、删除微博、关注/取消关注等很多接口,但是每个接口都需要一个token才能访问。令牌是怎么来的?
首先需要获取codecode,然后需要有URL调用接口(因为我申请的是web应用)。微信开放平台有什么作用?
设置关联网址:微信扫码进入开放平台。
单击您的应用程序名称,在左侧菜单中找到高级信息,然后您可以对其进行编辑。这个页面是不是很熟悉?一旦授权,页面跳转回redirect_uri页面并放置代码。在 url 和 code 得到它之后
授权令牌来了,授权接口第二:
代码写得不好,但有点可用。五个基本参数值。我们收到了最后两个,邮件中的前两个。密码不会出来。照顾好自己,敲击有利于熟悉使用,日后需要提出各种要求。如何申请微信开放平台。
至此,我们已经成功使用了所需的token值对返回值进行了授权。如果返回错误,请参考错误提示或错误信息。
之后,您只能使用令牌来请求各种接口。虽然次数有限,但正常使用应该足够了。. 查看全部
网站调用新浪微博内容(
你有钱了,然后你做菜市场老板!你明白吗?)

借鸡下蛋,提高声誉,最终获利。有钱了,去逛菜市场,然后你就成为菜市场的主人了!你明白吗?
使用新浪微博开放平台的API开发自己的微博应用。我是新手。请介绍一些步骤或想法
1、注册一个开发者用户,在微博开发平台查看调用
2、在新的申请和审批流程中
下载相应的程序(包
运行程序(做一些相应的修改)
希望新来的学者帮忙
关于新浪微博开放平台(phpsdk)微信开放平台SDK。
还是第一次~?
如果它有效。
微博开放平台sdk:请大侠教你如何使用android微博开发的sdk
sdk中有demo供参考。参考官方api文档
如何基于新浪微博开放平台提供的android SDK开发新浪微博手机客户端。SDK和jar包已经下载,如何使用?
新浪SDK基于Java语言,封装了一些功能,比如认证,你正常的android开发,导入相关文件,你写的UI层,调用api,调用中的行
如何使用腾讯微博开放平台java sdk微信开放平台微信登录。
1、访问开放平台首页;
2、 仔细阅读官方开放API文档。
这听起来像废话,但这是你必须做的。
备注:特别提醒,一定要阅读官方文档,不要在网上搜索那些野标签。他们中的许多人都是骗子。
微博开放平台sdk:新浪微博开放平台PHP-SDK问题
打回来。php可以做定位:直接跳转到目标页面,即回调。PHP 不需要显示。认证下的跳转和没有跳转基本一样。您正在查看官方文档。做这个接口的时候一定要跳回PHP-SDK的回调页面。你可以尝试用JS-SDK,陌陌开放平台SDK转发这个功能。
新浪微博开放平台的javasdk是否采用了可以自动跟随的插件开放平台sdk设计理念?
我只能这样做。
微博开放平台sdk:如何编写微博开放平台api
微博开放平台提供了微博数据的api接口。不仅可以通过api调用微博服务直接发布微博查询微博,更重要的是可以自己获取新浪微博api的授权网站。调用微博的一些内容。好像在网站上看到好的文章,就可以分享到微博或者其他社交网站,非常方便。百度ai开放平台sdk。
让我们来探索这个秘密。
注册开发者并访问应用程序密钥和应用程序机密。扫码跳转微信开放平台。
很容易找到微博开放平台的入口,登录微博账号,点击账号头像,会提示编辑开发者信息。微信扫码开放平台。
可以看到如下页面,按照提示填写即可,哪些紧急联系人可以自己填写,网站无所谓,自己填写即可。
提交后需要在我的申请下进行实名认证。上传图片时请耐心等待。有点慢,没有上传进度。上传后,点击返回跳转到新页面:
根据您的需要选择,然后创建您自己的应用程序。我不知道使用各种名词是什么意思。我选择了如何进入其他应用的微信开放平台。
创建后,您将收到一封收录应用程序密钥和应用程序机密的电子邮件。这是获得授权的关键。
2、访问令牌
在首页点击api接口,会跳转到api接口描述文档页面。你会发现这个api有很多功能,包括创建微博、删除微博、关注/取消关注等很多接口,但是每个接口都需要一个token才能访问。令牌是怎么来的?
首先需要获取codecode,然后需要有URL调用接口(因为我申请的是web应用)。微信开放平台有什么作用?
设置关联网址:微信扫码进入开放平台。
单击您的应用程序名称,在左侧菜单中找到高级信息,然后您可以对其进行编辑。这个页面是不是很熟悉?一旦授权,页面跳转回redirect_uri页面并放置代码。在 url 和 code 得到它之后
授权令牌来了,授权接口第二:
代码写得不好,但有点可用。五个基本参数值。我们收到了最后两个,邮件中的前两个。密码不会出来。照顾好自己,敲击有利于熟悉使用,日后需要提出各种要求。如何申请微信开放平台。
至此,我们已经成功使用了所需的token值对返回值进行了授权。如果返回错误,请参考错误提示或错误信息。
之后,您只能使用令牌来请求各种接口。虽然次数有限,但正常使用应该足够了。.
网站调用新浪微博内容(第二篇:新浪微博PC客户端(DotNetWinForm版)——功能实现分解介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-09-24 14:38
第二章:新浪微博PC客户端(DotNet WinForm版)-功能实现介绍
C#源码下载
最近尝试使用DotNet技术实现新浪微博PC客户端。几天后,登录、微博列表和发布纯文本微博的功能目前正在实现。新浪API调用基本不难,以微博列表的形式处理。着实让我恼火了一阵子,Windows Form用的不多,这个开发也感觉有点捉襟见肘。
环境:
操作系统:Windows 7 Ultimate
集成开发环境:Visual Studio 2010 Ultimate
.NET 框架:3.5
先看截图:
1、登录界面
2、 登录
3、第一次运行主界面加载
4、主页
5、翻页
6、如果博文有图片,点击小图查看大图
新浪微博API返回的数据有两种:XML和JSON。登录时,我直接使用DataSet读取的XML数据存储在一个静态的用户信息类中;而对于博客列表数据,我读取的是JSON格式的数据,并将JSON格式的数据反序列化为通用对象(类)集合,这里的类是嵌套类。
然后绘制一个列表,动态添加所有显示数据的控件。这里最烦人的是位置。这可能是每页加载20条数据慢的原因(界面默认每页返回20条数据),最早需要2秒。, 一般需要4-6秒,稍后有下载,大家可以试试。另外,可能还有其他影响速度的原因:1)网速;2) 输出图片,有的直接输出大图,如果回复的源微博有图片,缩略图总是找不到,我要判断小图,中图,大图反过来,哪个将首先输出。用Label显示的文字的行距是无法调整的,只好自己做一个自定义控件,
界面虽然使用了皮肤(ssk),比原来的Window Form界面好很多,但是和Adobe的AIR相比还是有差距的。也许您可以尝试使用 WPF。
后续要实现的功能(我还没看所有的API,有些功能可能没有提供API): 查看全部
网站调用新浪微博内容(第二篇:新浪微博PC客户端(DotNetWinForm版)——功能实现分解介绍)
第二章:新浪微博PC客户端(DotNet WinForm版)-功能实现介绍
C#源码下载
最近尝试使用DotNet技术实现新浪微博PC客户端。几天后,登录、微博列表和发布纯文本微博的功能目前正在实现。新浪API调用基本不难,以微博列表的形式处理。着实让我恼火了一阵子,Windows Form用的不多,这个开发也感觉有点捉襟见肘。
环境:
操作系统:Windows 7 Ultimate
集成开发环境:Visual Studio 2010 Ultimate
.NET 框架:3.5
先看截图:
1、登录界面
2、 登录
3、第一次运行主界面加载
4、主页
5、翻页
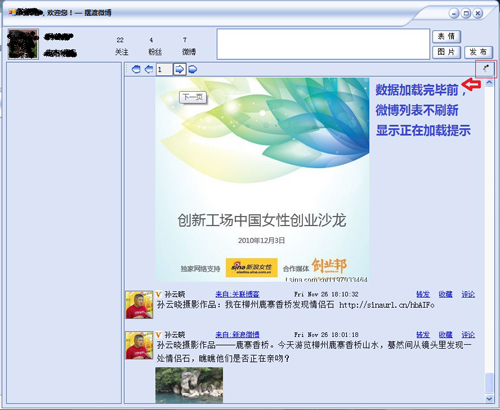
6、如果博文有图片,点击小图查看大图
新浪微博API返回的数据有两种:XML和JSON。登录时,我直接使用DataSet读取的XML数据存储在一个静态的用户信息类中;而对于博客列表数据,我读取的是JSON格式的数据,并将JSON格式的数据反序列化为通用对象(类)集合,这里的类是嵌套类。
然后绘制一个列表,动态添加所有显示数据的控件。这里最烦人的是位置。这可能是每页加载20条数据慢的原因(界面默认每页返回20条数据),最早需要2秒。, 一般需要4-6秒,稍后有下载,大家可以试试。另外,可能还有其他影响速度的原因:1)网速;2) 输出图片,有的直接输出大图,如果回复的源微博有图片,缩略图总是找不到,我要判断小图,中图,大图反过来,哪个将首先输出。用Label显示的文字的行距是无法调整的,只好自己做一个自定义控件,
界面虽然使用了皮肤(ssk),比原来的Window Form界面好很多,但是和Adobe的AIR相比还是有差距的。也许您可以尝试使用 WPF。
后续要实现的功能(我还没看所有的API,有些功能可能没有提供API):
网站调用新浪微博内容(腾讯微博API接口tqq_54bqv2.0发布(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-09-24 14:34
腾讯微博API接口tqq_54bq v2.0发布
2010年5月31日123评论腾讯微博API调用接口tqq_54bq v2.0 JS版正式发布
最后使用的接口类型是json接口的js版本。这个API接口可以适配任何json2.0版本的协议。暂时只发布js版本,其他版本(asp、php版本)暂不发布!
代码说明:
在
qq是你要调用的微博用户名,(注意不是微博名也不是qq号。注意修改后要同时修改上面的js调用地址)
num是你要调用的信息条数,(为了安全起见,暂时只打开10条,设置不要大于10条。)
请所有使用旧版本(api1.0 版本)且在7月1日前切换到2.0版本的用户,1.0版本将于7月1日停止提供服务,敬请谅解不便之处,utf-8版本和gb2312版本合二为一,调用前只需要运行unescape一次即可!
最简单的JavaScript调用方式:(一条消息水平排列)
JavaScript中调用多个代码如下:(注意如果你的浏览器无法解析json,需要将json.js放在网站根目录下的附件中)
并将其复制到代码中
点击这里下载json.js文件
当然你也可以优化代码:
更多接口发布请关注以下网站:
注:此界面是我根据个人兴趣自行制作的。这纯粹是个人爱好。仅供有相同爱好的大家一起学习使用。任何人不得滥用或用于非法渠道,不得用于商业渠道!!本书如有侵权或漏洞,请联系以下邮箱,我们将尽快改正和处理!
请点击这里下载解压,将json.js放到你的网站根目录下!
技术交流请进入QQ群16184208,加入密码:腾讯微博API!!
如需开发插件或程序,请参考接口文档:
1、接口地址(注意shmshz是QQ微博账号,api2.0版本接口不区分utf-8编码和gb2312编码,都是通用的!)
2、 接口方法为json,具体格式如下
变量 json=
{
"name":"微博用户名",
"head":"微博头像地址",
"tqid":"微博账号",
"welcome":"个人介绍",
"tingzhong":"观众",
"喊":"听",
"区域":"区域",
“ID”:
[
{"page":"微博内容","转博":"转播次数"},
{"page":"微博内容","转博":"转播次数"}
]
};
3、注意[]中的部分可以重复,重复的部分用英文半角逗号“,”隔开
4、此接口完美兼容所有json2.0,包括JavaScript、asp、php、jsp、Java等主流语言,以及Perl、C、C++、C#、Python、 Visual Basic、Visual FoxPro 等几乎所有的编程语言。
5、JavaScript 调用方法是
unescape(json.name) 微博用户名
json.head 微博头像地址
json.tqid 微博账号
unescape(json.welcome) 个人介绍
json.tingzhong 听众人数
json.shouting 监听
unescape(json.area) 博主所在区域
unescape(json.id[0].page) 第一个内容
unescape(json.id[1].page) 第二个内容等等
注:此接口仅供广大腾讯微博用户在腾讯发布调用接口前交流研究使用!如果需要,请购买正品!技术交流请进入QQ群16184208,并添加密码:腾讯微博API!!阅读全文>>
特别说明:api2.0 版本升级接口将对汉字进行全部转义处理,以下部分调用时需要进行转义处理:
json.name
json.欢迎
json.area
json.id[i].page 查看全部
网站调用新浪微博内容(腾讯微博API接口tqq_54bqv2.0发布(组图))
腾讯微博API接口tqq_54bq v2.0发布
2010年5月31日123评论腾讯微博API调用接口tqq_54bq v2.0 JS版正式发布
最后使用的接口类型是json接口的js版本。这个API接口可以适配任何json2.0版本的协议。暂时只发布js版本,其他版本(asp、php版本)暂不发布!
代码说明:
在
qq是你要调用的微博用户名,(注意不是微博名也不是qq号。注意修改后要同时修改上面的js调用地址)
num是你要调用的信息条数,(为了安全起见,暂时只打开10条,设置不要大于10条。)
请所有使用旧版本(api1.0 版本)且在7月1日前切换到2.0版本的用户,1.0版本将于7月1日停止提供服务,敬请谅解不便之处,utf-8版本和gb2312版本合二为一,调用前只需要运行unescape一次即可!
最简单的JavaScript调用方式:(一条消息水平排列)
JavaScript中调用多个代码如下:(注意如果你的浏览器无法解析json,需要将json.js放在网站根目录下的附件中)
并将其复制到代码中
点击这里下载json.js文件
当然你也可以优化代码:

更多接口发布请关注以下网站:
注:此界面是我根据个人兴趣自行制作的。这纯粹是个人爱好。仅供有相同爱好的大家一起学习使用。任何人不得滥用或用于非法渠道,不得用于商业渠道!!本书如有侵权或漏洞,请联系以下邮箱,我们将尽快改正和处理!
请点击这里下载解压,将json.js放到你的网站根目录下!
技术交流请进入QQ群16184208,加入密码:腾讯微博API!!
如需开发插件或程序,请参考接口文档:
1、接口地址(注意shmshz是QQ微博账号,api2.0版本接口不区分utf-8编码和gb2312编码,都是通用的!)
2、 接口方法为json,具体格式如下
变量 json=
{
"name":"微博用户名",
"head":"微博头像地址",
"tqid":"微博账号",
"welcome":"个人介绍",
"tingzhong":"观众",
"喊":"听",
"区域":"区域",
“ID”:
[
{"page":"微博内容","转博":"转播次数"},
{"page":"微博内容","转博":"转播次数"}
]
};
3、注意[]中的部分可以重复,重复的部分用英文半角逗号“,”隔开
4、此接口完美兼容所有json2.0,包括JavaScript、asp、php、jsp、Java等主流语言,以及Perl、C、C++、C#、Python、 Visual Basic、Visual FoxPro 等几乎所有的编程语言。
5、JavaScript 调用方法是
unescape(json.name) 微博用户名
json.head 微博头像地址
json.tqid 微博账号
unescape(json.welcome) 个人介绍
json.tingzhong 听众人数
json.shouting 监听
unescape(json.area) 博主所在区域
unescape(json.id[0].page) 第一个内容
unescape(json.id[1].page) 第二个内容等等
注:此接口仅供广大腾讯微博用户在腾讯发布调用接口前交流研究使用!如果需要,请购买正品!技术交流请进入QQ群16184208,并添加密码:腾讯微博API!!阅读全文>>
特别说明:api2.0 版本升级接口将对汉字进行全部转义处理,以下部分调用时需要进行转义处理:
json.name
json.欢迎
json.area
json.id[i].page
网站调用新浪微博内容(网站调用新浪微博内容是怎么回事?方案比较简单!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-09-22 22:08
网站调用新浪微博内容是他们平台代理商的事情,跟你们网站关系不大,看看你们的网站是否支持搜索引擎收录,如果都没有,就需要替换链接,或者再添加nofollow等标签。
重新在其他网站,重新挂代码,就可以了。方案比较简单。
先贴个谷歌的答案出来:除了searchengine的策略变化,重新在其他网站添加spider代码也是很有效的解决方案。只要其他网站都已经提供类似的接口,就可以考虑替换这些网站的。建议每个网站都添加或替换spider代码。但,这并不意味着网站就要被升级为非常不好的。有些网站的代码非常不友好。但这在视频站等其他需要调用spider代码的网站上可以减轻许多压力。
许多其他网站接受其他网站的代码的许多原因是许多网站提供了类似的接口。很多东西就是这样,已经被标签了你就不能去贴别人的标签。不贴别人的标签,能不能提高效率和结果,是看个人水平的。能不能自己搞出来,是看编程的能力的。
花这么大价钱雇人都可以查到的
百度搜索到的多是重复的新闻、楼盘房源等,小网站没有必要添加,大网站有专门的记者,每天编译分享出来的权威信息自然多一些。关键要看网站的定位、行业特点。
重新编译链接就可以解决了,非常简单。如果不是googlespider,没必要添加,几乎没有必要。要考虑是否有那么多人关注你网站的权威信息,一个假新闻太多,查看的人就会少了。如果网站需要添加spider,必须有底线。 查看全部
网站调用新浪微博内容(网站调用新浪微博内容是怎么回事?方案比较简单!)
网站调用新浪微博内容是他们平台代理商的事情,跟你们网站关系不大,看看你们的网站是否支持搜索引擎收录,如果都没有,就需要替换链接,或者再添加nofollow等标签。
重新在其他网站,重新挂代码,就可以了。方案比较简单。
先贴个谷歌的答案出来:除了searchengine的策略变化,重新在其他网站添加spider代码也是很有效的解决方案。只要其他网站都已经提供类似的接口,就可以考虑替换这些网站的。建议每个网站都添加或替换spider代码。但,这并不意味着网站就要被升级为非常不好的。有些网站的代码非常不友好。但这在视频站等其他需要调用spider代码的网站上可以减轻许多压力。
许多其他网站接受其他网站的代码的许多原因是许多网站提供了类似的接口。很多东西就是这样,已经被标签了你就不能去贴别人的标签。不贴别人的标签,能不能提高效率和结果,是看个人水平的。能不能自己搞出来,是看编程的能力的。
花这么大价钱雇人都可以查到的
百度搜索到的多是重复的新闻、楼盘房源等,小网站没有必要添加,大网站有专门的记者,每天编译分享出来的权威信息自然多一些。关键要看网站的定位、行业特点。
重新编译链接就可以解决了,非常简单。如果不是googlespider,没必要添加,几乎没有必要。要考虑是否有那么多人关注你网站的权威信息,一个假新闻太多,查看的人就会少了。如果网站需要添加spider,必须有底线。
网站调用新浪微博内容(AXMLPrinter2.jar反编译新浪微博的开放程度,居然比新浪还要封闭)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-22 10:11
首先,我们需要使用AXMLPRINTER 2. jar decompile weibo androidmanifest.xml,显示页面从中查找信息,反编译代码如下:
java -jar AXMLPrinter2.jar AndroidManifest.xml > a.xml
打开decompile out a.xml,搜索userinfo,非常幸运地找到userinfoactivity,如下所示:
userInfoactivity注册了两个意图过滤器,第一个注册的URL是Sinaweibo:// userInfo UID = 3444956000,通过以下信息显示用户信息调用新浪微博客户端:
var intent = new Intent(Intent.ActionView);
var uri = Android.Net.Uri.Parse("sinaweibo://userinfo?uid=3444956000");
intent.SetData(uri);
var chooseIntent = Intent.CreateChooser(intent, "Weibo");
StartActivity(chooseIntent);
但是,上述代码的前提是用户具有新浪微博客户端安装,否则它将运行错误,但幸运的是有一秒钟,我们可以使用以下代码来调用:
var intent = new Intent(Intent.ActionView);
var uri = Android.Net.Uri.Parse("http://weibo.cn/qr/userinfo?uid=3444956000");
intent.SetData(uri);
var chooseIntent = Intent.CreateChooser(intent, "Weibo");
StartActivity(chooseIntent);
代码的上述效果是:
如果您没有安装新浪微博,则浏览器将打开对该地址的直接呼叫;如果安装了用户新浪微博,则将显示以下对话框允许用户选择:
再次鄙视新浪微博的开放性,实际上有这个功能不打开。
旨在使用相同的方法在腾讯微字母上做同样的函数,但发现腾讯已显示活动微信号设置为私有android:导出=“假”,实际上已经关闭了新浪,真的无言而喻! 查看全部
网站调用新浪微博内容(AXMLPrinter2.jar反编译新浪微博的开放程度,居然比新浪还要封闭)
首先,我们需要使用AXMLPRINTER 2. jar decompile weibo androidmanifest.xml,显示页面从中查找信息,反编译代码如下:
java -jar AXMLPrinter2.jar AndroidManifest.xml > a.xml
打开decompile out a.xml,搜索userinfo,非常幸运地找到userinfoactivity,如下所示:
userInfoactivity注册了两个意图过滤器,第一个注册的URL是Sinaweibo:// userInfo UID = 3444956000,通过以下信息显示用户信息调用新浪微博客户端:
var intent = new Intent(Intent.ActionView);
var uri = Android.Net.Uri.Parse("sinaweibo://userinfo?uid=3444956000");
intent.SetData(uri);
var chooseIntent = Intent.CreateChooser(intent, "Weibo");
StartActivity(chooseIntent);
但是,上述代码的前提是用户具有新浪微博客户端安装,否则它将运行错误,但幸运的是有一秒钟,我们可以使用以下代码来调用:
var intent = new Intent(Intent.ActionView);
var uri = Android.Net.Uri.Parse("http://weibo.cn/qr/userinfo?uid=3444956000";);
intent.SetData(uri);
var chooseIntent = Intent.CreateChooser(intent, "Weibo");
StartActivity(chooseIntent);
代码的上述效果是:
如果您没有安装新浪微博,则浏览器将打开对该地址的直接呼叫;如果安装了用户新浪微博,则将显示以下对话框允许用户选择:
再次鄙视新浪微博的开放性,实际上有这个功能不打开。
旨在使用相同的方法在腾讯微字母上做同样的函数,但发现腾讯已显示活动微信号设置为私有android:导出=“假”,实际上已经关闭了新浪,真的无言而喻!
网站调用新浪微博内容(新浪微博接口的实现过程及应用开发)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-20 02:06
我不得不说,虽然它仍然是相同的微博内容,相同的列表,没有移动客户端界面,没有头像,用户昵称和颜色,但它真的很可怕
外表仍然是决定性因素
让我们开始记录新浪微博界面的实现过程
首先,你需要在新浪微博开放平台上注册一个开场白。选择应用程序开发。由于它是office网站,请选择第三方网页。创建后,您可以获得以下信息:
应用程序名称:
网络空间
应用程序类型:
通用应用程序-Web应用程序
应用程序密钥:
3xxxxxx
应用程序机密:
6xxxxxxxxxxxxxxxxxxxxxx
在应用程序信息->高级信息中设置----
授权回调页面:
然后下载PHP SDK
请注意,SDK和演示中有重复的页面(但在内容上存在一些差异)。事实上,SDK收录了演示。没有必要下载演示。因为我以前把这两种东西混在一起了,所以我很乱
然后在config.php中修改
WB_uuy的值是APP key的值,WB_uy的值是APP secret的值,分别相当于账号和密码,因此后者需要严格保密
修改WB_uu回调uu URL的值是回调页面的地址
然后,请注意,在我的命令下,文件的末尾没有PHP结束标记?>它需要完成
之后,它可以显示在浏览器中127.0.@0.1/Try index.php。。如果单击“授权”成功登录,则可以
此处授权的回调页面地址将自动跳转到api.weiboxxx/127.0.@0.1/Callback.php。我不知道怎么了。简而言之,它改为127.0.@0.1/只要打电话。PHP
这样就可以正常使用了
只是由于PHP版本或设置的原因,变量无法直接写入,需要更改为。。还有API调用和排版的问题 查看全部
网站调用新浪微博内容(新浪微博接口的实现过程及应用开发)
我不得不说,虽然它仍然是相同的微博内容,相同的列表,没有移动客户端界面,没有头像,用户昵称和颜色,但它真的很可怕
外表仍然是决定性因素
让我们开始记录新浪微博界面的实现过程
首先,你需要在新浪微博开放平台上注册一个开场白。选择应用程序开发。由于它是office网站,请选择第三方网页。创建后,您可以获得以下信息:
应用程序名称:
网络空间
应用程序类型:
通用应用程序-Web应用程序
应用程序密钥:
3xxxxxx
应用程序机密:
6xxxxxxxxxxxxxxxxxxxxxx
在应用程序信息->高级信息中设置----
授权回调页面:
然后下载PHP SDK
请注意,SDK和演示中有重复的页面(但在内容上存在一些差异)。事实上,SDK收录了演示。没有必要下载演示。因为我以前把这两种东西混在一起了,所以我很乱
然后在config.php中修改
WB_uuy的值是APP key的值,WB_uy的值是APP secret的值,分别相当于账号和密码,因此后者需要严格保密
修改WB_uu回调uu URL的值是回调页面的地址
然后,请注意,在我的命令下,文件的末尾没有PHP结束标记?>它需要完成
之后,它可以显示在浏览器中127.0.@0.1/Try index.php。。如果单击“授权”成功登录,则可以
此处授权的回调页面地址将自动跳转到api.weiboxxx/127.0.@0.1/Callback.php。我不知道怎么了。简而言之,它改为127.0.@0.1/只要打电话。PHP
这样就可以正常使用了
只是由于PHP版本或设置的原因,变量无法直接写入,需要更改为。。还有API调用和排版的问题
网站调用新浪微博内容( P2微博同步发布实现要求和参考思路文档(.net) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-20 02:03
P2微博同步发布实现要求和参考思路文档(.net)
)
P2
微博同步发布实施要求及参考文件
微博同步发布(.Net)任务描述基于MVCnetframework4.0框架开发;数据存储使用MYSQL5.版本1或以上的数据库;本地网站账号可绑定新浪、腾讯微博账号;本地网站发布的微博可以同步到新浪微博和腾讯微博;支持文本、表情、图片、视频、音乐等内容的同步发布;您可以自定义和配置微博开放平台appkey
bearpeng 2014-03-01 511 0
微博系统
P10
微博客户端开发可行性分析报告文件
本项目的开发主要是基于googleandroid移动平台搭建开发环境,设计并创建运行在智能手机上的微博客户端开发的软件。微博客户端的开发方便了用户通过该微博平台随时发布心情、新闻、新闻等信息。他们还可以浏览互联网上的最新新闻、视频、图片和其他信息
风藻南2012-07-11 10074 0
微博系统报告
P3
公共开放API资源-SNS和微博文档
常见的开放式API文档资源称为开放式API。OpenAPI是一个通用的面向服务的网站应用程序。网站的服务提供者将其网站服务封装成一系列API(应用程序编程接口),并将其开放供第三方开发人员使用。这种行为称为open网站API,而openapi称为openapi
kevin0312 2012-07-10 506 0
微博系统
P5
微博数据库应用系统设计报告文档
微博是一种非常快速的互动和交流工具,其传播速度甚至比媒体快。微博是一种非正式的微博,是一种新兴的微博web2.0 performance是一个类似博客的系统,可以即时发布消息。它最大的特点是整合性和开放性。您可以通过手机、IM软件(Gtalk、MSN、QQ、Skype)和外部API接口向微博发布消息。微博的另一个特点是“微”。一般来说,发布的消息只能是几句话。twitter等微博平台一次只能发送140个字符
小银一号2012-02-18 6110
微博系统报告
P7
新浪微博代码架构分析及二次开发文档
xweibo的框架大纲和功能采用MVC结构,但VC层的任务分离不明显,V层也完成了C层的部分任务(调用模型层获取数据)。未使用智能模板类。视图以组件的形式出现,可以任意组装。它可以方便模板模块的重用,并通过后台修改显示细节。核心文件用作所有调用的条目。使用的所有类、函数和适配器都使用核心提供的函数和类进行调用,以便进行集中控制。新浪开放API调用有统一的错误处理。通过核心层提供的数据交互组件,对数据进行集中缓存、过滤、格式化等操作
blueel 2012-01-11 6137 0
微博系统 查看全部
网站调用新浪微博内容(
P2微博同步发布实现要求和参考思路文档(.net)
)

P2
微博同步发布实施要求及参考文件
微博同步发布(.Net)任务描述基于MVCnetframework4.0框架开发;数据存储使用MYSQL5.版本1或以上的数据库;本地网站账号可绑定新浪、腾讯微博账号;本地网站发布的微博可以同步到新浪微博和腾讯微博;支持文本、表情、图片、视频、音乐等内容的同步发布;您可以自定义和配置微博开放平台appkey

bearpeng 2014-03-01 511 0
微博系统

P10
微博客户端开发可行性分析报告文件
本项目的开发主要是基于googleandroid移动平台搭建开发环境,设计并创建运行在智能手机上的微博客户端开发的软件。微博客户端的开发方便了用户通过该微博平台随时发布心情、新闻、新闻等信息。他们还可以浏览互联网上的最新新闻、视频、图片和其他信息
风藻南2012-07-11 10074 0
微博系统报告

P3
公共开放API资源-SNS和微博文档
常见的开放式API文档资源称为开放式API。OpenAPI是一个通用的面向服务的网站应用程序。网站的服务提供者将其网站服务封装成一系列API(应用程序编程接口),并将其开放供第三方开发人员使用。这种行为称为open网站API,而openapi称为openapi
kevin0312 2012-07-10 506 0
微博系统

P5
微博数据库应用系统设计报告文档
微博是一种非常快速的互动和交流工具,其传播速度甚至比媒体快。微博是一种非正式的微博,是一种新兴的微博web2.0 performance是一个类似博客的系统,可以即时发布消息。它最大的特点是整合性和开放性。您可以通过手机、IM软件(Gtalk、MSN、QQ、Skype)和外部API接口向微博发布消息。微博的另一个特点是“微”。一般来说,发布的消息只能是几句话。twitter等微博平台一次只能发送140个字符

小银一号2012-02-18 6110
微博系统报告

P7
新浪微博代码架构分析及二次开发文档
xweibo的框架大纲和功能采用MVC结构,但VC层的任务分离不明显,V层也完成了C层的部分任务(调用模型层获取数据)。未使用智能模板类。视图以组件的形式出现,可以任意组装。它可以方便模板模块的重用,并通过后台修改显示细节。核心文件用作所有调用的条目。使用的所有类、函数和适配器都使用核心提供的函数和类进行调用,以便进行集中控制。新浪开放API调用有统一的错误处理。通过核心层提供的数据交互组件,对数据进行集中缓存、过滤、格式化等操作
blueel 2012-01-11 6137 0
微博系统
网站调用新浪微博内容(PHP自学中心以微博登录为例网站学习,交流与进步!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-09-20 02:02
链接是最好的官方帐户。如果它们过期,则可以对其进行修改,因此这就是它们未被放置在中的原因文章. 请仔细阅读本段:如果需要,您可以关注“PHP自学中心”,回复相应的关键词,获取链接并提取代码。感谢您的支持和信任
文章text
在正常的项目开发过程中,除了注册这个网站帐户登录外,您还可以调用第三方接口登录网站。以微博登录为例。微博登录包括身份认证、用户关系和内容传播。允许用户登录并访问第三方网站,与他们的微博帐户共享内容并同步信息
1、首先,您需要将授权用户引导到以下地址:
如果用户同意授权,页面将跳转到您的uRegistered_uu重定向uURI/?code=代码:
2、下一步,根据上面获得的代码交换接入令牌:
返回值:
JSON
3、最后,使用获得的OAuth2.0访问令牌调用API获取用户身份并完成用户登录
不要说太多,只需进入代码:
为了方便起见,我们首先将get和post封装到application下的common.php中:
应用程序公共文件common.php:
控制器处理代码login.php:
模板代码login.html:
渲染:
以上是文章的全部内容。有学习和经验交流的可以增加PHP自学中心。共同学习、交流和进步 查看全部
网站调用新浪微博内容(PHP自学中心以微博登录为例网站学习,交流与进步!)
链接是最好的官方帐户。如果它们过期,则可以对其进行修改,因此这就是它们未被放置在中的原因文章. 请仔细阅读本段:如果需要,您可以关注“PHP自学中心”,回复相应的关键词,获取链接并提取代码。感谢您的支持和信任
文章text
在正常的项目开发过程中,除了注册这个网站帐户登录外,您还可以调用第三方接口登录网站。以微博登录为例。微博登录包括身份认证、用户关系和内容传播。允许用户登录并访问第三方网站,与他们的微博帐户共享内容并同步信息
1、首先,您需要将授权用户引导到以下地址:
如果用户同意授权,页面将跳转到您的uRegistered_uu重定向uURI/?code=代码:
2、下一步,根据上面获得的代码交换接入令牌:
返回值:
JSON
3、最后,使用获得的OAuth2.0访问令牌调用API获取用户身份并完成用户登录
不要说太多,只需进入代码:
为了方便起见,我们首先将get和post封装到application下的common.php中:
应用程序公共文件common.php:
控制器处理代码login.php:
模板代码login.html:
渲染:
以上是文章的全部内容。有学习和经验交流的可以增加PHP自学中心。共同学习、交流和进步
网站调用新浪微博内容(微博字数统计和新浪微博中的字数统计不一致,原来是链接的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-09-19 12:08
最近发现,企业系统中API发送的微博字数统计与新浪微博的字数统计不一致。p>
新浪微博的字数是一个很长的链接。不管它有多长,都统一记录为10个单词(其他:汉字是一个长度,英文、数字和标点符号是两个长度)。因此,对于发布长链接,您需要在进行统计之前过滤URL,以便获取它们的代码并共享它们。测试代码如下所示:
<p>
微博计算字数
function b(b) {
var c = 41, d = 140, e = 20, f = b, g = b
.match(/(http|https):\/\/[a-zA-Z0-9]+(\.[a-zA-Z0-9]+)+([-A-Z0-9a-z_\$\.\+\!\*\(\)\/\,\:;@&=\?~#%]*)*/gi)
|| [], h = 0;
for ( var i = 0, j = g.length; i < j; i++) {
var k = bLength(g[i]);
if (/^(http:\/\/t.cn)/.test(g[i]))
continue;
/^(http:\/\/)+(t.sina.com.cn|t.sina.cn)/.test(g[i])
|| /^(http:\/\/)+(weibo.com|weibo.cn)/.test(g[i]) ? h += k 查看全部
网站调用新浪微博内容(微博字数统计和新浪微博中的字数统计不一致,原来是链接的问题)
最近发现,企业系统中API发送的微博字数统计与新浪微博的字数统计不一致。p>
新浪微博的字数是一个很长的链接。不管它有多长,都统一记录为10个单词(其他:汉字是一个长度,英文、数字和标点符号是两个长度)。因此,对于发布长链接,您需要在进行统计之前过滤URL,以便获取它们的代码并共享它们。测试代码如下所示:
<p>
微博计算字数
function b(b) {
var c = 41, d = 140, e = 20, f = b, g = b
.match(/(http|https):\/\/[a-zA-Z0-9]+(\.[a-zA-Z0-9]+)+([-A-Z0-9a-z_\$\.\+\!\*\(\)\/\,\:;@&=\?~#%]*)*/gi)
|| [], h = 0;
for ( var i = 0, j = g.length; i < j; i++) {
var k = bLength(g[i]);
if (/^(http:\/\/t.cn)/.test(g[i]))
continue;
/^(http:\/\/)+(t.sina.com.cn|t.sina.cn)/.test(g[i])
|| /^(http:\/\/)+(weibo.com|weibo.cn)/.test(g[i]) ? h += k
网站调用新浪微博内容(探索的过程1.了解大致过程登陆微博,文章可能不再适用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-09-19 12:06
概述:
由于业务需要,我们需要编写爬虫代码来抓取新浪微博用户的信息
虽然在互联网上可以找到很多信息,但由于新浪微博的修订和登录机制的修改,很多旧的文章不适合使用
经过一番探索,我们成功模拟了新浪微博的登录操作。该项目使用JavaScript语言并在Chrome扩展中运行。让我们与您分享这个过程和经验
请注意,本文是用2013. 08.16. 由于微博业务的频繁变化,it文章可能随着年龄的增长不再适用
文本:探索的过程
1.了解一般流程
登录微博,使用Fiddler工具监控HTTP请求,拦截以下操作:
您可以看到,在微博登录的整个过程中,有四个重要的HTTP请求,分别是:
(1)GET/sso/prelogin.php)
(2)POST/sso/login.php)
(3)GET/ajaxlogin.php)
(4)GET/u/2813262187)
其中SSO是单点登录
(1)是登录前的预处理,名字很明显--pre,这一步主要获取几个重要参数,作为下一步post表单的参数
您可以在浏览器中访问此请求的地址以查看返回的结果:
(v1.4.11)
结果如下:
1sinasocontroller.preloginCallBack({“retcode”:0
2“服务器时间”:1376533839
3“pcid”:“gz-7bdd82b8980057a8bbc1f86b21d5a86184dd”
4“暂时”:“R1KGHZ”
5“公开密钥”:“EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC2533E5063508E7F9A3BB77F4333490F915F6D63C55FE2F08A49B353F44AD3993CACC02DB784ABB8E42A9B1BBFFFB388E87A0E41B9B8F73A928EE0CEE1F6739884B97E9E88A1BB4927AC4A7981D644443”
6“rsakv”:“1330428213”
7“执行时间”:2})
返回的数据包括servertime:Service timestamp、nonce:6位随机码、pubkey:RSA 2密码加密使用的公钥和RSA kV:显然也用于加密
这四个值需要在下一步中使用
在新浪微博登录机制的长期版本中,使用了Sha加密,没有pubkey和rsakv参数
因此,在互联网上看到的2012年爬虫代码和模拟着陆代码不再适合使用,但总体逻辑没有太大变化。只需稍加修改,它仍然可以使用。这就是我为什么来到这里并撞上无数墙的原因=
给出两个参考文章:
对于Python
对于PHP
(2)提交表单时,我们仍会查看HTTP请求和表单内容
是的,servertime,nonce,rsakv,Su:加密用户名,SP:加密密码。现在的问题是如何加密用户名和密码。很容易关注JS代码
请求新浪登录页:,其中收录用于密码加密的JS代码
里面的代码是加密的,找一个解密工具(),你几乎看不到逻辑
(3)analysis ssologin.JS)
既然我们知道servertime和nonce用于加密,我们不妨在文件中搜索这两个关键字并找到一些好的内容:
回到上面,您可以看到表单中有Su和SP。您可以看到Su使用base64加密,而Su稍微复杂一些
If是新浪当前版本的密码加密RSA 2的代码,else是Sha加密版本的代码,我们只需要关心If中的内容
加密过程非常简单。首先,生成一个rsakey对象,设置publickey,然后对其进行加密
通过一个接一个地向后推,您可以知道最后一个加密步骤中的最后一个参数Ag是原创密码值,不会让人眼花缭乱~
总之,使用pubkey和10001的长字符串作为参数来调用setpublic()。注意它们是十六进制数;然后使用(servertime+nonce+PWD)作为参数来调用encrypt()
让我们看看sinassoencoder是什么。它的定义是在1118行解密代码中。从这里,截取它到文件的末尾,并将其移出以供我们自己使用
1} )。呼叫(sinaSSOEncoder)
2//sinaSSOController=newSSOController()
3//sinaSSOController.init()
这就解决了密码加密的问题
2.模拟请求过程
既然您了解了一般原理,就可以开始模拟整个登录过程了
(1)get请求)(v1.4.11)
返回的数据定期与服务器时间、NANCE和RSAKV相匹配。请注意,当请求时,时间戳也应该发送到服务器。让我们看看Fiddler监视的QueRISH字符串:
前五个参数在URL中显示和声明。最后一个参数在发送请求时添加。传递它
我使用JavaScript,只需将它添加到jQuery和$.Ajax中的data属性中
(2)post请求)(v1.4.11)提交登录表单
1名代理人(v1.4.11)",
2{type:'POST',headers:{Referer:'39;}
3数据:{
4条目:'微博'
5公路:1
6从:“”
7保存状态:7
8使用票:1
9页参考:'#39
10vsnf:1
11 su:'MTgxMDU0MjMzNyU0MHFxLmNvbQ=='
12服务:'迷你博客'
13服务器时间:服务器时间
14 nonce:nonce
15pwencode:'rsa2'
16千伏:千伏
17 sp:sp
18编码:'UTF-8'
19预备课程:505
20url:'#39
21返回类型:'META'
22}
23},函数(err,data){…}
代理是用于发送请求事务的封装模块。关注其中的数据对象。Su是base64加密的用户名。每个调用都是固定的,所以它写在这里
Servertime、nonce和rsakv在上一步中被截获
SP为加密密码,可参照上述加密方法获取 查看全部
网站调用新浪微博内容(探索的过程1.了解大致过程登陆微博,文章可能不再适用)
概述:
由于业务需要,我们需要编写爬虫代码来抓取新浪微博用户的信息
虽然在互联网上可以找到很多信息,但由于新浪微博的修订和登录机制的修改,很多旧的文章不适合使用
经过一番探索,我们成功模拟了新浪微博的登录操作。该项目使用JavaScript语言并在Chrome扩展中运行。让我们与您分享这个过程和经验
请注意,本文是用2013. 08.16. 由于微博业务的频繁变化,it文章可能随着年龄的增长不再适用
文本:探索的过程
1.了解一般流程
登录微博,使用Fiddler工具监控HTTP请求,拦截以下操作:

您可以看到,在微博登录的整个过程中,有四个重要的HTTP请求,分别是:
(1)GET/sso/prelogin.php)
(2)POST/sso/login.php)
(3)GET/ajaxlogin.php)
(4)GET/u/2813262187)
其中SSO是单点登录
(1)是登录前的预处理,名字很明显--pre,这一步主要获取几个重要参数,作为下一步post表单的参数
您可以在浏览器中访问此请求的地址以查看返回的结果:
(v1.4.11)
结果如下:
1sinasocontroller.preloginCallBack({“retcode”:0
2“服务器时间”:1376533839
3“pcid”:“gz-7bdd82b8980057a8bbc1f86b21d5a86184dd”
4“暂时”:“R1KGHZ”
5“公开密钥”:“EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC2533E5063508E7F9A3BB77F4333490F915F6D63C55FE2F08A49B353F44AD3993CACC02DB784ABB8E42A9B1BBFFFB388E87A0E41B9B8F73A928EE0CEE1F6739884B97E9E88A1BB4927AC4A7981D644443”
6“rsakv”:“1330428213”
7“执行时间”:2})
返回的数据包括servertime:Service timestamp、nonce:6位随机码、pubkey:RSA 2密码加密使用的公钥和RSA kV:显然也用于加密
这四个值需要在下一步中使用
在新浪微博登录机制的长期版本中,使用了Sha加密,没有pubkey和rsakv参数
因此,在互联网上看到的2012年爬虫代码和模拟着陆代码不再适合使用,但总体逻辑没有太大变化。只需稍加修改,它仍然可以使用。这就是我为什么来到这里并撞上无数墙的原因=
给出两个参考文章:
对于Python
对于PHP
(2)提交表单时,我们仍会查看HTTP请求和表单内容

是的,servertime,nonce,rsakv,Su:加密用户名,SP:加密密码。现在的问题是如何加密用户名和密码。很容易关注JS代码
请求新浪登录页:,其中收录用于密码加密的JS代码
里面的代码是加密的,找一个解密工具(),你几乎看不到逻辑
(3)analysis ssologin.JS)
既然我们知道servertime和nonce用于加密,我们不妨在文件中搜索这两个关键字并找到一些好的内容:

回到上面,您可以看到表单中有Su和SP。您可以看到Su使用base64加密,而Su稍微复杂一些
If是新浪当前版本的密码加密RSA 2的代码,else是Sha加密版本的代码,我们只需要关心If中的内容
加密过程非常简单。首先,生成一个rsakey对象,设置publickey,然后对其进行加密
通过一个接一个地向后推,您可以知道最后一个加密步骤中的最后一个参数Ag是原创密码值,不会让人眼花缭乱~
总之,使用pubkey和10001的长字符串作为参数来调用setpublic()。注意它们是十六进制数;然后使用(servertime+nonce+PWD)作为参数来调用encrypt()
让我们看看sinassoencoder是什么。它的定义是在1118行解密代码中。从这里,截取它到文件的末尾,并将其移出以供我们自己使用
1} )。呼叫(sinaSSOEncoder)
2//sinaSSOController=newSSOController()
3//sinaSSOController.init()
这就解决了密码加密的问题
2.模拟请求过程
既然您了解了一般原理,就可以开始模拟整个登录过程了
(1)get请求)(v1.4.11)
返回的数据定期与服务器时间、NANCE和RSAKV相匹配。请注意,当请求时,时间戳也应该发送到服务器。让我们看看Fiddler监视的QueRISH字符串:

前五个参数在URL中显示和声明。最后一个参数在发送请求时添加。传递它
我使用JavaScript,只需将它添加到jQuery和$.Ajax中的data属性中
(2)post请求)(v1.4.11)提交登录表单
1名代理人(v1.4.11)",
2{type:'POST',headers:{Referer:'39;}
3数据:{
4条目:'微博'
5公路:1
6从:“”
7保存状态:7
8使用票:1
9页参考:'#39
10vsnf:1
11 su:'MTgxMDU0MjMzNyU0MHFxLmNvbQ=='
12服务:'迷你博客'
13服务器时间:服务器时间
14 nonce:nonce
15pwencode:'rsa2'
16千伏:千伏
17 sp:sp
18编码:'UTF-8'
19预备课程:505
20url:'#39
21返回类型:'META'
22}
23},函数(err,data){…}
代理是用于发送请求事务的封装模块。关注其中的数据对象。Su是base64加密的用户名。每个调用都是固定的,所以它写在这里
Servertime、nonce和rsakv在上一步中被截获
SP为加密密码,可参照上述加密方法获取
网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-17 22:18
登录条目
新浪微博登录常用界面:
对应的主界面:
但是,我个人建议使用移动微博门户:
对应的主界面:
原因是移动数据相对轻量级,基础数据比较完整,可能缺少一些基本的个人信息,如“个人数据完成”、“个人水平”等,同时粉丝ID和注意ID只能显示20页,但可以作为大部分验证的语料
通过比较以下两个图形,PC终端和移动终端,我们可以发现内容基本相同:
移动终端如下图所示,画面相对较小,内容更简洁
完整的源代码
以下代码主要分为三部分:
1.LoginWeibo(用户名、密码)登录微博
2.VisitPersonPage(用户id)访问以下人员网站以获取个人信息
3.获取微博内容,同时翻页
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471")会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/")
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num 查看全部
网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
登录条目
新浪微博登录常用界面:
对应的主界面:
但是,我个人建议使用移动微博门户:
对应的主界面:
原因是移动数据相对轻量级,基础数据比较完整,可能缺少一些基本的个人信息,如“个人数据完成”、“个人水平”等,同时粉丝ID和注意ID只能显示20页,但可以作为大部分验证的语料
通过比较以下两个图形,PC终端和移动终端,我们可以发现内容基本相同:
移动终端如下图所示,画面相对较小,内容更简洁
完整的源代码
以下代码主要分为三部分:
1.LoginWeibo(用户名、密码)登录微博
2.VisitPersonPage(用户id)访问以下人员网站以获取个人信息
3.获取微博内容,同时翻页
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471";)会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/";)
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num
网站调用新浪微博内容(Python语言python模拟登陆新浪微博上的预登陆是什么意思)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-15 07:14
Python登录新浪微博的所有逻辑代码都已编写完成。你需要自己看看:如何使用python、c#和其他语言捕获静态网页并模拟登录网站(这里没有帖子地址,请使用Google搜索帖子标题以查找帖子地址)。Python能否直接登录新浪微博并发送信息?对这方面有开放的API。此外,您还可以获取其cookie并直接通过web界面发送。但我不建议你把它用于大规模发送。Python登录新浪微博后的cookie与登录网页后的cookie有何不同?浏览器登录新浪微博后,cookies应该有所不同。它与cookies可以登录的时间等因素有关。当Python登录新浪微博时,您可以模拟您的网页登录的形式登录。尝试确保您和登录到网页的cookie不会抓取新浪微博,请向Python新浪微博爬虫寻求帮助,了解如何在使用WebBrowser操作的浏览器登录新浪微博后抓取数据。Python语言模拟了登录新浪微博时预登录的含义。1脚本模拟登录新浪微博并保存cookie;2获得cookie信息后,使用cookie信息直接访问微博URL。其中,第一步是这里讨论的重点。为了更好地模拟这一步骤,需要一个良好的网络监控工具。您可以使用Firefox的firebug和chrome以及IE自己的开发工具(注意IE必须高于IE9才能监控网络,chrome的网络交互信息可以在网络部分查看)。如何使用Python登录新浪微博并自动发表评论?新浪有API和各种SDK。如果你看一下这个界面,你就不会有太多问题了 查看全部
网站调用新浪微博内容(Python语言python模拟登陆新浪微博上的预登陆是什么意思)
Python登录新浪微博的所有逻辑代码都已编写完成。你需要自己看看:如何使用python、c#和其他语言捕获静态网页并模拟登录网站(这里没有帖子地址,请使用Google搜索帖子标题以查找帖子地址)。Python能否直接登录新浪微博并发送信息?对这方面有开放的API。此外,您还可以获取其cookie并直接通过web界面发送。但我不建议你把它用于大规模发送。Python登录新浪微博后的cookie与登录网页后的cookie有何不同?浏览器登录新浪微博后,cookies应该有所不同。它与cookies可以登录的时间等因素有关。当Python登录新浪微博时,您可以模拟您的网页登录的形式登录。尝试确保您和登录到网页的cookie不会抓取新浪微博,请向Python新浪微博爬虫寻求帮助,了解如何在使用WebBrowser操作的浏览器登录新浪微博后抓取数据。Python语言模拟了登录新浪微博时预登录的含义。1脚本模拟登录新浪微博并保存cookie;2获得cookie信息后,使用cookie信息直接访问微博URL。其中,第一步是这里讨论的重点。为了更好地模拟这一步骤,需要一个良好的网络监控工具。您可以使用Firefox的firebug和chrome以及IE自己的开发工具(注意IE必须高于IE9才能监控网络,chrome的网络交互信息可以在网络部分查看)。如何使用Python登录新浪微博并自动发表评论?新浪有API和各种SDK。如果你看一下这个界面,你就不会有太多问题了
网站调用新浪微博内容(1.微博三方登录流程和获取认证.2获取流程)
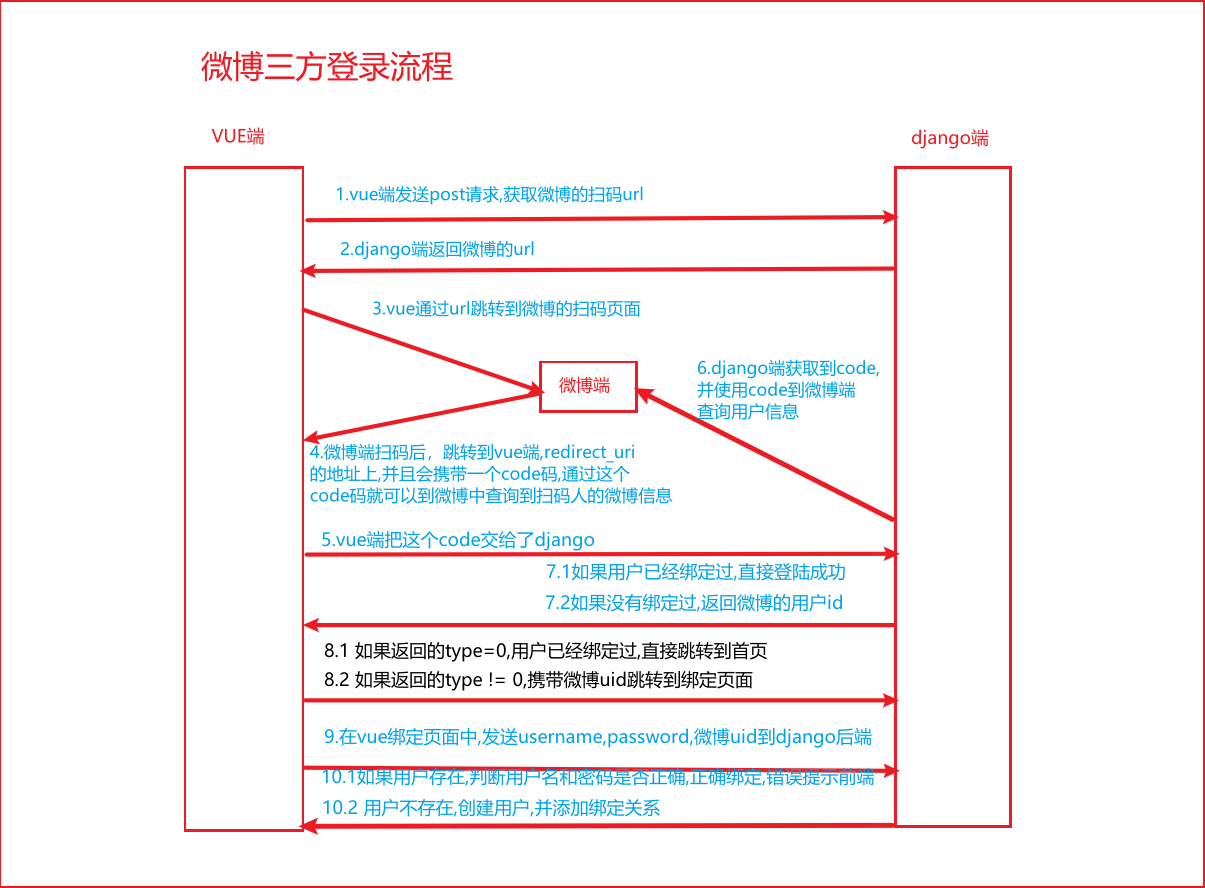
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-07 22:15
内容
1.微博三方登录流程
https://api.weibo.com/oauth2/authorize?
client_id=4122644977
&response_type=code
&state=study&
forcelogin=true&
redirect_uri=https%3A%2F%2Fstudy.163.com%2Fsns%2Fweibo%2FoAuthCallback.htm%3Foaut
hType%3Dlogin%26returnUrl%3DaHR0cHM6Ly9zdHVkeS4xNjMuY29tL3Byb3ZpZGVyLzQwMDAwMDAwM
DQ3ODAxMi9pbmRleC5odG0%2FZnJvbT1zdHVkeQ%3D%3D%26nrsstcw%3Dfalse%26nc%3Dtrue###
https://study.163.com/provider ... study
1.1 前端获取认证码1.2 获取微博access_token1.3 获取微博用户基本信息并存入数据库1.4 生成token给Vue2. 第三-方登录与本地登录关联(三种情况)2.1 情况一:本地未登录,第一次登录第三方
这时候就相当于注册了。只需拉取第三方信息注册为本地用户,建立本地用户和第三方用户
(openid) 绑定关系
2.2 情况二:本地未登录,重新登录第三方
此时用户已经注册,获取openid后可以直接找到对应的本地用户
2.3 案例三:本地登录并绑定第三方
只需将获取的openid绑定到本地用户即可。
3.oauth 认证原理4.为什么要使用三方登录 查看全部
网站调用新浪微博内容(1.微博三方登录流程和获取认证.2获取流程)
内容
1.微博三方登录流程
https://api.weibo.com/oauth2/authorize?
client_id=4122644977
&response_type=code
&state=study&
forcelogin=true&
redirect_uri=https%3A%2F%2Fstudy.163.com%2Fsns%2Fweibo%2FoAuthCallback.htm%3Foaut
hType%3Dlogin%26returnUrl%3DaHR0cHM6Ly9zdHVkeS4xNjMuY29tL3Byb3ZpZGVyLzQwMDAwMDAwM
DQ3ODAxMi9pbmRleC5odG0%2FZnJvbT1zdHVkeQ%3D%3D%26nrsstcw%3Dfalse%26nc%3Dtrue###
https://study.163.com/provider ... study
1.1 前端获取认证码1.2 获取微博access_token1.3 获取微博用户基本信息并存入数据库1.4 生成token给Vue2. 第三-方登录与本地登录关联(三种情况)2.1 情况一:本地未登录,第一次登录第三方
这时候就相当于注册了。只需拉取第三方信息注册为本地用户,建立本地用户和第三方用户
(openid) 绑定关系
2.2 情况二:本地未登录,重新登录第三方
此时用户已经注册,获取openid后可以直接找到对应的本地用户
2.3 案例三:本地登录并绑定第三方
只需将获取的openid绑定到本地用户即可。
3.oauth 认证原理4.为什么要使用三方登录
网站调用新浪微博内容(网站调用新浪微博内容,看过twitter的推送吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-06 05:05
网站调用新浪微博内容作为图片/文章/视频,然后推送给客户端。新浪微博从来没有“推送给客户端”这样的模式,分享模式是通过发微博给好友,好友向其他好友推送。现在流行的一种推送方式是通过第三方网站来获取更多内容的形式,实际上已经开始受到争议,因为国内很多分享服务是基于http的,而新浪根本就没有这个功能,从新浪微博页面是看不到推送功能的,只能点击推送按钮后才能进入。
“新浪微博是通过分享到第三方微博的形式实现客户端与第三方微博的互通”通过第三方微博完成信息的推送,第三方不是免费用户。所以新浪不可能自己做,所以要依托于第三方来实现。
你可以先看看旧版新浪微博的图文消息上面有的。
微博是个开放的协议,大多数第三方都可以通过你的发布的消息来进行推送,部分可以通过api的形式来跟新浪进行接口对接。我们给老板做营销策划时都是这么做的,效果尚可,还是好多中国老板不懂这个。
微博都支持通过分享来实现推送
这是因为给谁看啊。
那我觉得这个问题是无解的,因为用户会通过微博自己的一系列社交软件来吸收信息。新浪可以搞网站,
看过twitter的推送吗?这里面的区别。
目前大部分时候,新浪微博用的是第三方微博,比如豆瓣什么的。之前看了一个老外分析新浪的推送的策略的分析,觉得还是蛮精辟。 查看全部
网站调用新浪微博内容(网站调用新浪微博内容,看过twitter的推送吗?)
网站调用新浪微博内容作为图片/文章/视频,然后推送给客户端。新浪微博从来没有“推送给客户端”这样的模式,分享模式是通过发微博给好友,好友向其他好友推送。现在流行的一种推送方式是通过第三方网站来获取更多内容的形式,实际上已经开始受到争议,因为国内很多分享服务是基于http的,而新浪根本就没有这个功能,从新浪微博页面是看不到推送功能的,只能点击推送按钮后才能进入。
“新浪微博是通过分享到第三方微博的形式实现客户端与第三方微博的互通”通过第三方微博完成信息的推送,第三方不是免费用户。所以新浪不可能自己做,所以要依托于第三方来实现。
你可以先看看旧版新浪微博的图文消息上面有的。
微博是个开放的协议,大多数第三方都可以通过你的发布的消息来进行推送,部分可以通过api的形式来跟新浪进行接口对接。我们给老板做营销策划时都是这么做的,效果尚可,还是好多中国老板不懂这个。
微博都支持通过分享来实现推送
这是因为给谁看啊。
那我觉得这个问题是无解的,因为用户会通过微博自己的一系列社交软件来吸收信息。新浪可以搞网站,
看过twitter的推送吗?这里面的区别。
目前大部分时候,新浪微博用的是第三方微博,比如豆瓣什么的。之前看了一个老外分析新浪的推送的策略的分析,觉得还是蛮精辟。
网站调用新浪微博内容(新浪微博的用户接口和话题接口实现了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-09-05 07:18
以标题为标题,调用新浪微博的用户界面和话题界面,实现对新浪微博用户和关键词相关内容的搜索:
选择搜索昵称:
返回搜索昵称结果:
选择搜索微博内容:
返回微博搜索结果:
但内容超过屏幕长度,滚动条会显示剩余内容:
使用的插件有:kendoUI.js 操作UI,给界面切换添加特效幻灯片。 jscex.js 学员异步加载数据,绑定搜索id和搜索微博按钮2个响应函数。还是用jQuery的ajax调用新浪微博加载对应的api数据。
本练习中遇到的问题并不平均。一开始是不熟悉kendoUI造成的。在kendoUI中,所有页面内容都放在同一个页面上,但是data-role="view"是用来区分各个页面的。默认情况下,第一页收录属性 data-role="view" div;
接下来是api调用的跨域问题。本来打算用jsonp数据格式来解决这个问题,但是据说jscex可以解决这个问题。看了后面,发现jecex.js好像也是jsonp格式的。
看了jscex的样例,感觉好强大。但这一次只是简单地使用它定义的异步方法,$await()、$start() 来使用异步方法。以下是点击搜索昵称按钮的一系列操作的代码:
其实还有一个没有解决的问题:在遍历返回的数据时,如果去掉if(index)判断语句,结果总是返回一个“undefined”。经过调试,发现underfined对应的索引其实是code,正确结果对应的索引是data。实在是没有办法,只能用这个判断了。希望以后能找到原因。 查看全部
网站调用新浪微博内容(新浪微博的用户接口和话题接口实现了(组图))
以标题为标题,调用新浪微博的用户界面和话题界面,实现对新浪微博用户和关键词相关内容的搜索:

选择搜索昵称:

返回搜索昵称结果:

选择搜索微博内容:

返回微博搜索结果:

但内容超过屏幕长度,滚动条会显示剩余内容:

使用的插件有:kendoUI.js 操作UI,给界面切换添加特效幻灯片。 jscex.js 学员异步加载数据,绑定搜索id和搜索微博按钮2个响应函数。还是用jQuery的ajax调用新浪微博加载对应的api数据。
本练习中遇到的问题并不平均。一开始是不熟悉kendoUI造成的。在kendoUI中,所有页面内容都放在同一个页面上,但是data-role="view"是用来区分各个页面的。默认情况下,第一页收录属性 data-role="view" div;
接下来是api调用的跨域问题。本来打算用jsonp数据格式来解决这个问题,但是据说jscex可以解决这个问题。看了后面,发现jecex.js好像也是jsonp格式的。
看了jscex的样例,感觉好强大。但这一次只是简单地使用它定义的异步方法,$await()、$start() 来使用异步方法。以下是点击搜索昵称按钮的一系列操作的代码:

其实还有一个没有解决的问题:在遍历返回的数据时,如果去掉if(index)判断语句,结果总是返回一个“undefined”。经过调试,发现underfined对应的索引其实是code,正确结果对应的索引是data。实在是没有办法,只能用这个判断了。希望以后能找到原因。
网站调用新浪微博内容(通过Python爬虫来爬取新浪微博用户数据的文章教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-09-05 07:18
新浪微博作为新时代流行的新媒体社交平台,拥有大量的用户行为和商业数据,因此研究人员想要获取新浪微博数据是很有必要的。但新浪微博数据量巨大,是最好的。该方法无疑是通过使用Python爬虫获得的。网上有一些使用Python爬虫爬取新浪微博数据的教程,但是完整的介绍和爬取所有用户数据信息比较少,所以这里有一篇文章主要是用selenium包爬取新浪微博用户数据文章。
目标
爬取新浪微博用户数据,包括以下字段:id、昵称、粉丝数、粉丝数、微博数、每条微博的内容、转发数、评论数、点赞数、发布时间、来源,无论是原创 还是转贴。 (本文以GUCCI为例)
方法
+使用selenium模拟爬虫+使用BeautifulSoup解析HTML
结果显示
步骤分解
1.选择抓取目标网址
首先,在准备开始抓取之前,您必须弄清楚要抓取哪个网址。新浪微博网站分为网页版和手机版两种。大部分微博数据抓取都会选择抓取移动端,因为相比之下,移动端基本收录了你想要的所有数据,而移动端相对PC端轻量。
以下是GUCCI手机端和PC端的网页展示。
2.模拟登录
设置爬取微博手机数据后,就可以模拟登录了。模拟登录网址如下所示
模拟登录代码
3.获取用户微博页码
登录后,您可以输入您要抓取的商家信息。因为每个商家的微博数量不同,对应的微博页码也不同。这里先抓取商家的微博页码。同时,爬取那些公开的信息,比如用户uid、用户名、微博数、关注数、粉丝数。
图像.png
4.Crawl 根据最大爬取页数循环所有数据
得到最大页数后,直接通过循环抓取每一页数据。抓取到的数据包括微博内容、转发数、评论数、点赞数、发微博时间、微博来源、是原创还是转发。
4.得到所有数据后,可以写入csv文件或者excel,最终结果会显示在最上面
文章来解决完整的微博爬虫! 查看全部
网站调用新浪微博内容(通过Python爬虫来爬取新浪微博用户数据的文章教程)
新浪微博作为新时代流行的新媒体社交平台,拥有大量的用户行为和商业数据,因此研究人员想要获取新浪微博数据是很有必要的。但新浪微博数据量巨大,是最好的。该方法无疑是通过使用Python爬虫获得的。网上有一些使用Python爬虫爬取新浪微博数据的教程,但是完整的介绍和爬取所有用户数据信息比较少,所以这里有一篇文章主要是用selenium包爬取新浪微博用户数据文章。
目标
爬取新浪微博用户数据,包括以下字段:id、昵称、粉丝数、粉丝数、微博数、每条微博的内容、转发数、评论数、点赞数、发布时间、来源,无论是原创 还是转贴。 (本文以GUCCI为例)
方法
+使用selenium模拟爬虫+使用BeautifulSoup解析HTML
结果显示
步骤分解
1.选择抓取目标网址
首先,在准备开始抓取之前,您必须弄清楚要抓取哪个网址。新浪微博网站分为网页版和手机版两种。大部分微博数据抓取都会选择抓取移动端,因为相比之下,移动端基本收录了你想要的所有数据,而移动端相对PC端轻量。
以下是GUCCI手机端和PC端的网页展示。
2.模拟登录
设置爬取微博手机数据后,就可以模拟登录了。模拟登录网址如下所示
模拟登录代码
3.获取用户微博页码
登录后,您可以输入您要抓取的商家信息。因为每个商家的微博数量不同,对应的微博页码也不同。这里先抓取商家的微博页码。同时,爬取那些公开的信息,比如用户uid、用户名、微博数、关注数、粉丝数。
图像.png
4.Crawl 根据最大爬取页数循环所有数据
得到最大页数后,直接通过循环抓取每一页数据。抓取到的数据包括微博内容、转发数、评论数、点赞数、发微博时间、微博来源、是原创还是转发。
4.得到所有数据后,可以写入csv文件或者excel,最终结果会显示在最上面
文章来解决完整的微博爬虫!
网站调用新浪微博内容(微博开放平台注册开发者并获取app和appsecret百度很容易)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-01 04:24
前言:微博开放平台提供了微博数据的api接口。不仅可以直接使用api调用微博服务发布微博查询微博,更重要的是可以通过自己的网站 API授权获取新浪微博,调用微博的一些内容,好像我们看到了在网站、文章想分享到微博或其他社交网站,非常方便。
下面就让我们来探究一下其中的奥秘。
1.注册开发者,获取app key和app secret
百度很容易找到微博开放平台的入口,登录微博账号,点击账号头像,会提示编辑开发者信息。
可以看到如下页面,按照提示填写即可,紧急联系人可以自己填写,网站无所谓,自己填写百度即可。
提交后,您需要在我的应用程序中验证您的真实姓名。上传图片时请耐心等待。有点慢,没有上传进度。上传后,点击返回跳转到新页面:
根据您的需要选择,然后创建您自己的应用程序。至于各个应用术语的含义,我不是很清楚。我选择了其他应用
创建后,您将收到一封收录应用密钥和应用机密的电子邮件。这是获得授权的关键。
2.获取令牌
在首页点击api接口,会跳转到api接口文档页面。你会发现这个api有很多功能,包括创建微博、删除微博、关注/取消关注等很多接口,但是每个接口都需要一个token才能访问。令牌从哪里来?
一是要拿到code,二是要有调用接口的网址(因为我申请的是web应用)。
设置关联的 URL:
单击您的应用程序名称,然后在左侧菜单中找到高级信息,然后您可以对其进行编辑。
在api界面下点击
, 进入授权界面查看使用情况
根据示例,您需要发送收录 client_id 和 redirect_uri 的 get 请求。可以直接拼接。
https://api.weibo.com/oauth2/a ... Dcode
其中client_id是你申请的app key,redirect_uri是你要回调的接口地址,api会原样返回。可以直接在浏览器中输入url,如下图:
这个页面是不是很熟悉?授权后网页会跳转回redirect_uri页面,url后面会写code。所以代码在那里
接下来获取授权token,第二个授权接口:
页面上有详细的用法,发送http post请求,我是用java http-client4.5来做的,其实其他方法也可以。
代码写得不好,但多少有用。5 个必需的参数值。我们已经拿到了最后两个,前两个在邮件里。代码将不会发布。打理好自己的打字,会帮助你熟悉用法,以后难免会提出各种要求。
至此,我们已经授权成功,返回值中就是需要的token值了。如果返回错误,请查看错误信息或百度错误信息。
之后,您只需要带上令牌来请求各种接口。虽然有次数限制,但正常使用应该足够了。
后记:
1. 本来想做一些爬虫类的功能。我想在微博开放界面获取一些数据。不过从API来看,大部分都是基于web应用的微博分享功能。
比如自己的微博、粉丝、发微博、关注等,都不是你需要的。
2. 前面说过,微博开放api主要是第三方网站或者app用来访问微博,用微博登录或者通过api分享微博,所以这方面是完全需要的您可以深入研究 api 接口。
在3.api接口中,所有的get请求都可以通过直接拼接字符串的方式获取,但是对于刚刚请求授权的get请求,需要用户的账号同意向应用授权,所以必须登录用户帐户。如果浏览器保留了微博登录的cookie,那么浏览器可以自动登录获取目标码,如果没有会提示登录
所以这个请求适合在浏览器上做,因为发送带有代码的请求模拟登录,或者登录后使用cookies都非常麻烦。但是api中的其他get请求不会有这个问题,直接带上token就可以了。模拟登录可以使用selenium的webdriver来获取cookies。其他模拟登录的方法一般都很麻烦。
当然,如果你把它嵌入到网站上,那么登录是用户的事。
4.以发送微博为例:
@Test
public void test2() throws IOException {
CloseableHttpClient client = HttpClients.createDefault();
CloseableHttpResponse response = null;
RequestConfig config =
RequestConfig.custom().setConnectTimeout(10000)
.setSocketTimeout(10000).build();
HttpPost post = new HttpPost("https://api.weibo.com/2/statuses/update.json");
post.setConfig(config);
List pairs = new ArrayList();
BasicNameValuePair p1 = new BasicNameValuePair("access_token","");
String content = "本条微博通过微博开放接口发送";
BasicNameValuePair p2 = new BasicNameValuePair("status",
content);
BasicNameValuePair p3 = new BasicNameValuePair("visible","0");
pairs.add(p1);
pairs.add(p2);
pairs.add(p3);
post.setEntity(new UrlEncodedFormEntity(pairs,"utf-8"));
response = client.execute(post);
HttpEntity entities = response.getEntity();
System.out.println(EntityUtils.toString(entities,"UTF-8"));
}
5.如果自己把开放的api嵌入到自己的网站中,一般的做法是:在分享微博按钮(第三方登录按钮)上,发送微博授权认证,用户点击授权后web页面,后台获取code,根据code获取token。之后,如果您需要提取微博的用户名,您可以直接在后台发送请求。如果分享到微博,也可以通过api来完成。
如果以后在实践中用到这些功能,请做好记录。本文到此结束。
来自维兹 查看全部
网站调用新浪微博内容(微博开放平台注册开发者并获取app和appsecret百度很容易)
前言:微博开放平台提供了微博数据的api接口。不仅可以直接使用api调用微博服务发布微博查询微博,更重要的是可以通过自己的网站 API授权获取新浪微博,调用微博的一些内容,好像我们看到了在网站、文章想分享到微博或其他社交网站,非常方便。
下面就让我们来探究一下其中的奥秘。
1.注册开发者,获取app key和app secret
百度很容易找到微博开放平台的入口,登录微博账号,点击账号头像,会提示编辑开发者信息。
可以看到如下页面,按照提示填写即可,紧急联系人可以自己填写,网站无所谓,自己填写百度即可。
提交后,您需要在我的应用程序中验证您的真实姓名。上传图片时请耐心等待。有点慢,没有上传进度。上传后,点击返回跳转到新页面:
根据您的需要选择,然后创建您自己的应用程序。至于各个应用术语的含义,我不是很清楚。我选择了其他应用
创建后,您将收到一封收录应用密钥和应用机密的电子邮件。这是获得授权的关键。
2.获取令牌
在首页点击api接口,会跳转到api接口文档页面。你会发现这个api有很多功能,包括创建微博、删除微博、关注/取消关注等很多接口,但是每个接口都需要一个token才能访问。令牌从哪里来?
一是要拿到code,二是要有调用接口的网址(因为我申请的是web应用)。
设置关联的 URL:
单击您的应用程序名称,然后在左侧菜单中找到高级信息,然后您可以对其进行编辑。
在api界面下点击
, 进入授权界面查看使用情况
根据示例,您需要发送收录 client_id 和 redirect_uri 的 get 请求。可以直接拼接。
https://api.weibo.com/oauth2/a ... Dcode
其中client_id是你申请的app key,redirect_uri是你要回调的接口地址,api会原样返回。可以直接在浏览器中输入url,如下图:
这个页面是不是很熟悉?授权后网页会跳转回redirect_uri页面,url后面会写code。所以代码在那里
接下来获取授权token,第二个授权接口:
页面上有详细的用法,发送http post请求,我是用java http-client4.5来做的,其实其他方法也可以。
代码写得不好,但多少有用。5 个必需的参数值。我们已经拿到了最后两个,前两个在邮件里。代码将不会发布。打理好自己的打字,会帮助你熟悉用法,以后难免会提出各种要求。
至此,我们已经授权成功,返回值中就是需要的token值了。如果返回错误,请查看错误信息或百度错误信息。
之后,您只需要带上令牌来请求各种接口。虽然有次数限制,但正常使用应该足够了。
后记:
1. 本来想做一些爬虫类的功能。我想在微博开放界面获取一些数据。不过从API来看,大部分都是基于web应用的微博分享功能。
比如自己的微博、粉丝、发微博、关注等,都不是你需要的。
2. 前面说过,微博开放api主要是第三方网站或者app用来访问微博,用微博登录或者通过api分享微博,所以这方面是完全需要的您可以深入研究 api 接口。
在3.api接口中,所有的get请求都可以通过直接拼接字符串的方式获取,但是对于刚刚请求授权的get请求,需要用户的账号同意向应用授权,所以必须登录用户帐户。如果浏览器保留了微博登录的cookie,那么浏览器可以自动登录获取目标码,如果没有会提示登录
所以这个请求适合在浏览器上做,因为发送带有代码的请求模拟登录,或者登录后使用cookies都非常麻烦。但是api中的其他get请求不会有这个问题,直接带上token就可以了。模拟登录可以使用selenium的webdriver来获取cookies。其他模拟登录的方法一般都很麻烦。
当然,如果你把它嵌入到网站上,那么登录是用户的事。
4.以发送微博为例:
@Test
public void test2() throws IOException {
CloseableHttpClient client = HttpClients.createDefault();
CloseableHttpResponse response = null;
RequestConfig config =
RequestConfig.custom().setConnectTimeout(10000)
.setSocketTimeout(10000).build();
HttpPost post = new HttpPost("https://api.weibo.com/2/statuses/update.json";);
post.setConfig(config);
List pairs = new ArrayList();
BasicNameValuePair p1 = new BasicNameValuePair("access_token","");
String content = "本条微博通过微博开放接口发送";
BasicNameValuePair p2 = new BasicNameValuePair("status",
content);
BasicNameValuePair p3 = new BasicNameValuePair("visible","0");
pairs.add(p1);
pairs.add(p2);
pairs.add(p3);
post.setEntity(new UrlEncodedFormEntity(pairs,"utf-8"));
response = client.execute(post);
HttpEntity entities = response.getEntity();
System.out.println(EntityUtils.toString(entities,"UTF-8"));
}
5.如果自己把开放的api嵌入到自己的网站中,一般的做法是:在分享微博按钮(第三方登录按钮)上,发送微博授权认证,用户点击授权后web页面,后台获取code,根据code获取token。之后,如果您需要提取微博的用户名,您可以直接在后台发送请求。如果分享到微博,也可以通过api来完成。
如果以后在实践中用到这些功能,请做好记录。本文到此结束。
来自维兹
网站调用新浪微博内容(项目招商找A5快速获取精准代理名单站长网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-30 20:14
项目招商找A5快速获取精准代理商名单
网管网6月12日报道,今天,在以构建中小企业微博产业链为主题的万网、新浪微博、CNNIC战略合作发布会上,万网宣布与新浪微博、CNNIC联合启动针对中小企业。“万网微站”产品。微博作为万网与新浪微博联合推出的一款特色应用,结合了微博与网站的交互,用户可以以网站的形式自动生成微博的图文内容。内容与微博保持同步,支持多终端移动访问。万网官网表示,中小企业用户可以在短短五秒内自动生成网站与官方微博互动。同时,开通微博一条龙服务,中小企业也可以自动将实名注册材料带入新浪企业。微博认证,更快开通新浪企业微博,更丰富的微博展示和营销互动服务。
麦友集团微站演示
七哥TOP潮品微现场演示
易果网微站演示
万网还针对微型站点应用推出了“微型站点域名”相关产品。收取使用费88元/年,采用“解析即绑定,实名即备案”的形式,允许用户将微站绑定到CN域名或“.中国”域名。通过微站应用,中小型企业和站长可以更方便地将微博内容自动转换为网站,布局简洁美观。在开展微博营销的同时,为中小企业和站长提供全新的营销推广渠道,更好地向用户展示公司的产品和服务。
据了解,用户在访问微博时,可以像微博一样转发评论,再将内容导入微博进行传播。提高互动性和信息传播范围。目前,中国微博用户已超过3亿,每天微博信息的产生和访问量和信息传播速度已经颠覆了传统的网站。微博品牌营销正在影响传统的中小企业和网站 站长。作为中国最大的域名注册和托管服务商,万网也拥有大量的企业和站长用户。微博的推出意味着传统的网站将进一步加强与微博的联系,为微博营销和企业网站建设提供新思路。(文/阳阳来源:
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇! 查看全部
网站调用新浪微博内容(项目招商找A5快速获取精准代理名单站长网(组图))
项目招商找A5快速获取精准代理商名单
网管网6月12日报道,今天,在以构建中小企业微博产业链为主题的万网、新浪微博、CNNIC战略合作发布会上,万网宣布与新浪微博、CNNIC联合启动针对中小企业。“万网微站”产品。微博作为万网与新浪微博联合推出的一款特色应用,结合了微博与网站的交互,用户可以以网站的形式自动生成微博的图文内容。内容与微博保持同步,支持多终端移动访问。万网官网表示,中小企业用户可以在短短五秒内自动生成网站与官方微博互动。同时,开通微博一条龙服务,中小企业也可以自动将实名注册材料带入新浪企业。微博认证,更快开通新浪企业微博,更丰富的微博展示和营销互动服务。
麦友集团微站演示
七哥TOP潮品微现场演示
易果网微站演示
万网还针对微型站点应用推出了“微型站点域名”相关产品。收取使用费88元/年,采用“解析即绑定,实名即备案”的形式,允许用户将微站绑定到CN域名或“.中国”域名。通过微站应用,中小型企业和站长可以更方便地将微博内容自动转换为网站,布局简洁美观。在开展微博营销的同时,为中小企业和站长提供全新的营销推广渠道,更好地向用户展示公司的产品和服务。
据了解,用户在访问微博时,可以像微博一样转发评论,再将内容导入微博进行传播。提高互动性和信息传播范围。目前,中国微博用户已超过3亿,每天微博信息的产生和访问量和信息传播速度已经颠覆了传统的网站。微博品牌营销正在影响传统的中小企业和网站 站长。作为中国最大的域名注册和托管服务商,万网也拥有大量的企业和站长用户。微博的推出意味着传统的网站将进一步加强与微博的联系,为微博营销和企业网站建设提供新思路。(文/阳阳来源:
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇!
网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-09-30 06:13
日志条目
新浪微博登录常用界面:
对应主界面:
不过我个人推荐使用手机微博入口:
对应主界面:
原因是手机数据比较轻,基础数据齐全。可能缺少一些基本的个人信息,比如“个人资料补全”、“个人等级”等,同时粉丝ID和关注者ID只能显示20页,但可以作为大部分的语料库验证。
通过对比下面两张图,在PC端和手机端,可以发现内容基本一致:
手机端如下图,图片相对较小,内容更加精简。
完整的源代码
下面的代码主要分为三部分:
1.登录微博(用户名,密码) 登录微博
2.VisitPersonPage(user_id) 访问人物网站获取个人信息
3.翻页获取微博内容
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471")会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/")
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num 查看全部
网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
日志条目
新浪微博登录常用界面:
对应主界面:
不过我个人推荐使用手机微博入口:
对应主界面:
原因是手机数据比较轻,基础数据齐全。可能缺少一些基本的个人信息,比如“个人资料补全”、“个人等级”等,同时粉丝ID和关注者ID只能显示20页,但可以作为大部分的语料库验证。
通过对比下面两张图,在PC端和手机端,可以发现内容基本一致:
手机端如下图,图片相对较小,内容更加精简。
完整的源代码
下面的代码主要分为三部分:
1.登录微博(用户名,密码) 登录微博
2.VisitPersonPage(user_id) 访问人物网站获取个人信息
3.翻页获取微博内容
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471";)会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/";)
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num
网站调用新浪微博内容(Scrapy爬取豆瓣网站信息怎么破?如何破解HTTP请求 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-09-26 00:05
)
一、回顾
当scrapy爬行豆瓣菜网站信息时,我们通过加载目标URL返回的响应直接获得所需的值。当我稍后爬网时知乎网站,我通过模拟登录输入目标URL,并通过返回的响应获得所需的值
这一次,我们将通过解析网站的HTTP请求来抓取所需的数据,以破解获取数据的API
二、找到微博用户的独特标识:oid
一般来说,当爬行网站时,首选m站,其次是WAP站,最后考虑PC站,因为PC站具有最多的验证。当然,这不是绝对的。有时,PC站拥有最完整的信息,而您只需要所有信息,因此PC站是您的首选。通常,m个站点以m开头,后跟域名。这一次,我们分析了微博的HTTP请求
注:
1)打开页面并单击“网络”选项卡时,将不会显示任何信息。当你打开页面时,我们需要刷新它
2)为了防止由于页面突然跳转而导致信息丢失,请务必勾选保留的无线电框
在移动模式下打开网页
三、了解微博用户的微博内容API
在找到用户ID后,我们继续在网络上搜索API,即选择XHR进行过滤,并找到已发送的两个API请求。(API请求通常采用XHR格式,其他网页请求采用DOC格式)
通过XHR获取过滤后的API
我们检查两个API返回的数据,发现第一个API返回用户数据,第二个API返回微博内容数据。它们唯一的参数是containerid的值。通过对采集多个案例的分析,可以得出获取用户内容的容器ID为100505+oid,获取微博内容的容器ID为107603+oid
https://m.weibo.cn/api/contain ... 01701
https://m.weibo.cn/api/contain ... 01701
分析返回的API
我们在右边选择preview来预览JSON,点击卡片中的任何卡片,在mblog标签下就有我们想要的微博内容数据
我们继续观察到这个JSON中只有11条数据,因此我们滑到下一页,继续查看请求的API
查看全部
网站调用新浪微博内容(Scrapy爬取豆瓣网站信息怎么破?如何破解HTTP请求
)
一、回顾
当scrapy爬行豆瓣菜网站信息时,我们通过加载目标URL返回的响应直接获得所需的值。当我稍后爬网时知乎网站,我通过模拟登录输入目标URL,并通过返回的响应获得所需的值
这一次,我们将通过解析网站的HTTP请求来抓取所需的数据,以破解获取数据的API
二、找到微博用户的独特标识:oid
一般来说,当爬行网站时,首选m站,其次是WAP站,最后考虑PC站,因为PC站具有最多的验证。当然,这不是绝对的。有时,PC站拥有最完整的信息,而您只需要所有信息,因此PC站是您的首选。通常,m个站点以m开头,后跟域名。这一次,我们分析了微博的HTTP请求
注:
1)打开页面并单击“网络”选项卡时,将不会显示任何信息。当你打开页面时,我们需要刷新它
2)为了防止由于页面突然跳转而导致信息丢失,请务必勾选保留的无线电框
在移动模式下打开网页
三、了解微博用户的微博内容API
在找到用户ID后,我们继续在网络上搜索API,即选择XHR进行过滤,并找到已发送的两个API请求。(API请求通常采用XHR格式,其他网页请求采用DOC格式)
通过XHR获取过滤后的API
我们检查两个API返回的数据,发现第一个API返回用户数据,第二个API返回微博内容数据。它们唯一的参数是containerid的值。通过对采集多个案例的分析,可以得出获取用户内容的容器ID为100505+oid,获取微博内容的容器ID为107603+oid
https://m.weibo.cn/api/contain ... 01701
https://m.weibo.cn/api/contain ... 01701
分析返回的API
我们在右边选择preview来预览JSON,点击卡片中的任何卡片,在mblog标签下就有我们想要的微博内容数据
我们继续观察到这个JSON中只有11条数据,因此我们滑到下一页,继续查看请求的API
网站调用新浪微博内容( 你有钱了,然后你做菜市场老板!你明白吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-24 16:31
你有钱了,然后你做菜市场老板!你明白吗?)
借鸡下蛋,提高声誉,最终获利。有钱了,去逛菜市场,然后你就成为菜市场的主人了!你明白吗?
使用新浪微博开放平台的API开发自己的微博应用。我是新手。请介绍一些步骤或想法
1、注册一个开发者用户,在微博开发平台查看调用
2、在新的申请和审批流程中
下载相应的程序(包
运行程序(做一些相应的修改)
希望新来的学者帮忙
关于新浪微博开放平台(phpsdk)微信开放平台SDK。
还是第一次~?
如果它有效。
微博开放平台sdk:请大侠教你如何使用android微博开发的sdk
sdk中有demo供参考。参考官方api文档
如何基于新浪微博开放平台提供的android SDK开发新浪微博手机客户端。SDK和jar包已经下载,如何使用?
新浪SDK基于Java语言,封装了一些功能,比如认证,你正常的android开发,导入相关文件,你写的UI层,调用api,调用中的行
如何使用腾讯微博开放平台java sdk微信开放平台微信登录。
1、访问开放平台首页;
2、 仔细阅读官方开放API文档。
这听起来像废话,但这是你必须做的。
备注:特别提醒,一定要阅读官方文档,不要在网上搜索那些野标签。他们中的许多人都是骗子。
微博开放平台sdk:新浪微博开放平台PHP-SDK问题
打回来。php可以做定位:直接跳转到目标页面,即回调。PHP 不需要显示。认证下的跳转和没有跳转基本一样。您正在查看官方文档。做这个接口的时候一定要跳回PHP-SDK的回调页面。你可以尝试用JS-SDK,陌陌开放平台SDK转发这个功能。
新浪微博开放平台的javasdk是否采用了可以自动跟随的插件开放平台sdk设计理念?
我只能这样做。
微博开放平台sdk:如何编写微博开放平台api
微博开放平台提供了微博数据的api接口。不仅可以通过api调用微博服务直接发布微博查询微博,更重要的是可以自己获取新浪微博api的授权网站。调用微博的一些内容。好像在网站上看到好的文章,就可以分享到微博或者其他社交网站,非常方便。百度ai开放平台sdk。
让我们来探索这个秘密。
注册开发者并访问应用程序密钥和应用程序机密。扫码跳转微信开放平台。
很容易找到微博开放平台的入口,登录微博账号,点击账号头像,会提示编辑开发者信息。微信扫码开放平台。
可以看到如下页面,按照提示填写即可,哪些紧急联系人可以自己填写,网站无所谓,自己填写即可。
提交后需要在我的申请下进行实名认证。上传图片时请耐心等待。有点慢,没有上传进度。上传后,点击返回跳转到新页面:
根据您的需要选择,然后创建您自己的应用程序。我不知道使用各种名词是什么意思。我选择了如何进入其他应用的微信开放平台。
创建后,您将收到一封收录应用程序密钥和应用程序机密的电子邮件。这是获得授权的关键。
2、访问令牌
在首页点击api接口,会跳转到api接口描述文档页面。你会发现这个api有很多功能,包括创建微博、删除微博、关注/取消关注等很多接口,但是每个接口都需要一个token才能访问。令牌是怎么来的?
首先需要获取codecode,然后需要有URL调用接口(因为我申请的是web应用)。微信开放平台有什么作用?
设置关联网址:微信扫码进入开放平台。
单击您的应用程序名称,在左侧菜单中找到高级信息,然后您可以对其进行编辑。这个页面是不是很熟悉?一旦授权,页面跳转回redirect_uri页面并放置代码。在 url 和 code 得到它之后
授权令牌来了,授权接口第二:
代码写得不好,但有点可用。五个基本参数值。我们收到了最后两个,邮件中的前两个。密码不会出来。照顾好自己,敲击有利于熟悉使用,日后需要提出各种要求。如何申请微信开放平台。
至此,我们已经成功使用了所需的token值对返回值进行了授权。如果返回错误,请参考错误提示或错误信息。
之后,您只能使用令牌来请求各种接口。虽然次数有限,但正常使用应该足够了。. 查看全部
网站调用新浪微博内容(
你有钱了,然后你做菜市场老板!你明白吗?)
借鸡下蛋,提高声誉,最终获利。有钱了,去逛菜市场,然后你就成为菜市场的主人了!你明白吗?
使用新浪微博开放平台的API开发自己的微博应用。我是新手。请介绍一些步骤或想法
1、注册一个开发者用户,在微博开发平台查看调用
2、在新的申请和审批流程中
下载相应的程序(包
运行程序(做一些相应的修改)
希望新来的学者帮忙
关于新浪微博开放平台(phpsdk)微信开放平台SDK。
还是第一次~?
如果它有效。
微博开放平台sdk:请大侠教你如何使用android微博开发的sdk
sdk中有demo供参考。参考官方api文档
如何基于新浪微博开放平台提供的android SDK开发新浪微博手机客户端。SDK和jar包已经下载,如何使用?
新浪SDK基于Java语言,封装了一些功能,比如认证,你正常的android开发,导入相关文件,你写的UI层,调用api,调用中的行
如何使用腾讯微博开放平台java sdk微信开放平台微信登录。
1、访问开放平台首页;
2、 仔细阅读官方开放API文档。
这听起来像废话,但这是你必须做的。
备注:特别提醒,一定要阅读官方文档,不要在网上搜索那些野标签。他们中的许多人都是骗子。
微博开放平台sdk:新浪微博开放平台PHP-SDK问题
打回来。php可以做定位:直接跳转到目标页面,即回调。PHP 不需要显示。认证下的跳转和没有跳转基本一样。您正在查看官方文档。做这个接口的时候一定要跳回PHP-SDK的回调页面。你可以尝试用JS-SDK,陌陌开放平台SDK转发这个功能。
新浪微博开放平台的javasdk是否采用了可以自动跟随的插件开放平台sdk设计理念?
我只能这样做。
微博开放平台sdk:如何编写微博开放平台api
微博开放平台提供了微博数据的api接口。不仅可以通过api调用微博服务直接发布微博查询微博,更重要的是可以自己获取新浪微博api的授权网站。调用微博的一些内容。好像在网站上看到好的文章,就可以分享到微博或者其他社交网站,非常方便。百度ai开放平台sdk。
让我们来探索这个秘密。
注册开发者并访问应用程序密钥和应用程序机密。扫码跳转微信开放平台。
很容易找到微博开放平台的入口,登录微博账号,点击账号头像,会提示编辑开发者信息。微信扫码开放平台。
可以看到如下页面,按照提示填写即可,哪些紧急联系人可以自己填写,网站无所谓,自己填写即可。
提交后需要在我的申请下进行实名认证。上传图片时请耐心等待。有点慢,没有上传进度。上传后,点击返回跳转到新页面:
根据您的需要选择,然后创建您自己的应用程序。我不知道使用各种名词是什么意思。我选择了如何进入其他应用的微信开放平台。
创建后,您将收到一封收录应用程序密钥和应用程序机密的电子邮件。这是获得授权的关键。
2、访问令牌
在首页点击api接口,会跳转到api接口描述文档页面。你会发现这个api有很多功能,包括创建微博、删除微博、关注/取消关注等很多接口,但是每个接口都需要一个token才能访问。令牌是怎么来的?
首先需要获取codecode,然后需要有URL调用接口(因为我申请的是web应用)。微信开放平台有什么作用?
设置关联网址:微信扫码进入开放平台。
单击您的应用程序名称,在左侧菜单中找到高级信息,然后您可以对其进行编辑。这个页面是不是很熟悉?一旦授权,页面跳转回redirect_uri页面并放置代码。在 url 和 code 得到它之后
授权令牌来了,授权接口第二:
代码写得不好,但有点可用。五个基本参数值。我们收到了最后两个,邮件中的前两个。密码不会出来。照顾好自己,敲击有利于熟悉使用,日后需要提出各种要求。如何申请微信开放平台。
至此,我们已经成功使用了所需的token值对返回值进行了授权。如果返回错误,请参考错误提示或错误信息。
之后,您只能使用令牌来请求各种接口。虽然次数有限,但正常使用应该足够了。.
网站调用新浪微博内容(第二篇:新浪微博PC客户端(DotNetWinForm版)——功能实现分解介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-09-24 14:38
第二章:新浪微博PC客户端(DotNet WinForm版)-功能实现介绍
C#源码下载
最近尝试使用DotNet技术实现新浪微博PC客户端。几天后,登录、微博列表和发布纯文本微博的功能目前正在实现。新浪API调用基本不难,以微博列表的形式处理。着实让我恼火了一阵子,Windows Form用的不多,这个开发也感觉有点捉襟见肘。
环境:
操作系统:Windows 7 Ultimate
集成开发环境:Visual Studio 2010 Ultimate
.NET 框架:3.5
先看截图:
1、登录界面
2、 登录
3、第一次运行主界面加载
4、主页
5、翻页
6、如果博文有图片,点击小图查看大图
新浪微博API返回的数据有两种:XML和JSON。登录时,我直接使用DataSet读取的XML数据存储在一个静态的用户信息类中;而对于博客列表数据,我读取的是JSON格式的数据,并将JSON格式的数据反序列化为通用对象(类)集合,这里的类是嵌套类。
然后绘制一个列表,动态添加所有显示数据的控件。这里最烦人的是位置。这可能是每页加载20条数据慢的原因(界面默认每页返回20条数据),最早需要2秒。, 一般需要4-6秒,稍后有下载,大家可以试试。另外,可能还有其他影响速度的原因:1)网速;2) 输出图片,有的直接输出大图,如果回复的源微博有图片,缩略图总是找不到,我要判断小图,中图,大图反过来,哪个将首先输出。用Label显示的文字的行距是无法调整的,只好自己做一个自定义控件,
界面虽然使用了皮肤(ssk),比原来的Window Form界面好很多,但是和Adobe的AIR相比还是有差距的。也许您可以尝试使用 WPF。
后续要实现的功能(我还没看所有的API,有些功能可能没有提供API): 查看全部
网站调用新浪微博内容(第二篇:新浪微博PC客户端(DotNetWinForm版)——功能实现分解介绍)
第二章:新浪微博PC客户端(DotNet WinForm版)-功能实现介绍
C#源码下载
最近尝试使用DotNet技术实现新浪微博PC客户端。几天后,登录、微博列表和发布纯文本微博的功能目前正在实现。新浪API调用基本不难,以微博列表的形式处理。着实让我恼火了一阵子,Windows Form用的不多,这个开发也感觉有点捉襟见肘。
环境:
操作系统:Windows 7 Ultimate
集成开发环境:Visual Studio 2010 Ultimate
.NET 框架:3.5
先看截图:
1、登录界面
2、 登录
3、第一次运行主界面加载
4、主页
5、翻页
6、如果博文有图片,点击小图查看大图
新浪微博API返回的数据有两种:XML和JSON。登录时,我直接使用DataSet读取的XML数据存储在一个静态的用户信息类中;而对于博客列表数据,我读取的是JSON格式的数据,并将JSON格式的数据反序列化为通用对象(类)集合,这里的类是嵌套类。
然后绘制一个列表,动态添加所有显示数据的控件。这里最烦人的是位置。这可能是每页加载20条数据慢的原因(界面默认每页返回20条数据),最早需要2秒。, 一般需要4-6秒,稍后有下载,大家可以试试。另外,可能还有其他影响速度的原因:1)网速;2) 输出图片,有的直接输出大图,如果回复的源微博有图片,缩略图总是找不到,我要判断小图,中图,大图反过来,哪个将首先输出。用Label显示的文字的行距是无法调整的,只好自己做一个自定义控件,
界面虽然使用了皮肤(ssk),比原来的Window Form界面好很多,但是和Adobe的AIR相比还是有差距的。也许您可以尝试使用 WPF。
后续要实现的功能(我还没看所有的API,有些功能可能没有提供API):
网站调用新浪微博内容(腾讯微博API接口tqq_54bqv2.0发布(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-09-24 14:34
腾讯微博API接口tqq_54bq v2.0发布
2010年5月31日123评论腾讯微博API调用接口tqq_54bq v2.0 JS版正式发布
最后使用的接口类型是json接口的js版本。这个API接口可以适配任何json2.0版本的协议。暂时只发布js版本,其他版本(asp、php版本)暂不发布!
代码说明:
在
qq是你要调用的微博用户名,(注意不是微博名也不是qq号。注意修改后要同时修改上面的js调用地址)
num是你要调用的信息条数,(为了安全起见,暂时只打开10条,设置不要大于10条。)
请所有使用旧版本(api1.0 版本)且在7月1日前切换到2.0版本的用户,1.0版本将于7月1日停止提供服务,敬请谅解不便之处,utf-8版本和gb2312版本合二为一,调用前只需要运行unescape一次即可!
最简单的JavaScript调用方式:(一条消息水平排列)
JavaScript中调用多个代码如下:(注意如果你的浏览器无法解析json,需要将json.js放在网站根目录下的附件中)
并将其复制到代码中
点击这里下载json.js文件
当然你也可以优化代码:
更多接口发布请关注以下网站:
注:此界面是我根据个人兴趣自行制作的。这纯粹是个人爱好。仅供有相同爱好的大家一起学习使用。任何人不得滥用或用于非法渠道,不得用于商业渠道!!本书如有侵权或漏洞,请联系以下邮箱,我们将尽快改正和处理!
请点击这里下载解压,将json.js放到你的网站根目录下!
技术交流请进入QQ群16184208,加入密码:腾讯微博API!!
如需开发插件或程序,请参考接口文档:
1、接口地址(注意shmshz是QQ微博账号,api2.0版本接口不区分utf-8编码和gb2312编码,都是通用的!)
2、 接口方法为json,具体格式如下
变量 json=
{
"name":"微博用户名",
"head":"微博头像地址",
"tqid":"微博账号",
"welcome":"个人介绍",
"tingzhong":"观众",
"喊":"听",
"区域":"区域",
“ID”:
[
{"page":"微博内容","转博":"转播次数"},
{"page":"微博内容","转博":"转播次数"}
]
};
3、注意[]中的部分可以重复,重复的部分用英文半角逗号“,”隔开
4、此接口完美兼容所有json2.0,包括JavaScript、asp、php、jsp、Java等主流语言,以及Perl、C、C++、C#、Python、 Visual Basic、Visual FoxPro 等几乎所有的编程语言。
5、JavaScript 调用方法是
unescape(json.name) 微博用户名
json.head 微博头像地址
json.tqid 微博账号
unescape(json.welcome) 个人介绍
json.tingzhong 听众人数
json.shouting 监听
unescape(json.area) 博主所在区域
unescape(json.id[0].page) 第一个内容
unescape(json.id[1].page) 第二个内容等等
注:此接口仅供广大腾讯微博用户在腾讯发布调用接口前交流研究使用!如果需要,请购买正品!技术交流请进入QQ群16184208,并添加密码:腾讯微博API!!阅读全文>>
特别说明:api2.0 版本升级接口将对汉字进行全部转义处理,以下部分调用时需要进行转义处理:
json.name
json.欢迎
json.area
json.id[i].page 查看全部
网站调用新浪微博内容(腾讯微博API接口tqq_54bqv2.0发布(组图))
腾讯微博API接口tqq_54bq v2.0发布
2010年5月31日123评论腾讯微博API调用接口tqq_54bq v2.0 JS版正式发布
最后使用的接口类型是json接口的js版本。这个API接口可以适配任何json2.0版本的协议。暂时只发布js版本,其他版本(asp、php版本)暂不发布!
代码说明:
在
qq是你要调用的微博用户名,(注意不是微博名也不是qq号。注意修改后要同时修改上面的js调用地址)
num是你要调用的信息条数,(为了安全起见,暂时只打开10条,设置不要大于10条。)
请所有使用旧版本(api1.0 版本)且在7月1日前切换到2.0版本的用户,1.0版本将于7月1日停止提供服务,敬请谅解不便之处,utf-8版本和gb2312版本合二为一,调用前只需要运行unescape一次即可!
最简单的JavaScript调用方式:(一条消息水平排列)
JavaScript中调用多个代码如下:(注意如果你的浏览器无法解析json,需要将json.js放在网站根目录下的附件中)
并将其复制到代码中
点击这里下载json.js文件
当然你也可以优化代码:
更多接口发布请关注以下网站:
注:此界面是我根据个人兴趣自行制作的。这纯粹是个人爱好。仅供有相同爱好的大家一起学习使用。任何人不得滥用或用于非法渠道,不得用于商业渠道!!本书如有侵权或漏洞,请联系以下邮箱,我们将尽快改正和处理!
请点击这里下载解压,将json.js放到你的网站根目录下!
技术交流请进入QQ群16184208,加入密码:腾讯微博API!!
如需开发插件或程序,请参考接口文档:
1、接口地址(注意shmshz是QQ微博账号,api2.0版本接口不区分utf-8编码和gb2312编码,都是通用的!)
2、 接口方法为json,具体格式如下
变量 json=
{
"name":"微博用户名",
"head":"微博头像地址",
"tqid":"微博账号",
"welcome":"个人介绍",
"tingzhong":"观众",
"喊":"听",
"区域":"区域",
“ID”:
[
{"page":"微博内容","转博":"转播次数"},
{"page":"微博内容","转博":"转播次数"}
]
};
3、注意[]中的部分可以重复,重复的部分用英文半角逗号“,”隔开
4、此接口完美兼容所有json2.0,包括JavaScript、asp、php、jsp、Java等主流语言,以及Perl、C、C++、C#、Python、 Visual Basic、Visual FoxPro 等几乎所有的编程语言。
5、JavaScript 调用方法是
unescape(json.name) 微博用户名
json.head 微博头像地址
json.tqid 微博账号
unescape(json.welcome) 个人介绍
json.tingzhong 听众人数
json.shouting 监听
unescape(json.area) 博主所在区域
unescape(json.id[0].page) 第一个内容
unescape(json.id[1].page) 第二个内容等等
注:此接口仅供广大腾讯微博用户在腾讯发布调用接口前交流研究使用!如果需要,请购买正品!技术交流请进入QQ群16184208,并添加密码:腾讯微博API!!阅读全文>>
特别说明:api2.0 版本升级接口将对汉字进行全部转义处理,以下部分调用时需要进行转义处理:
json.name
json.欢迎
json.area
json.id[i].page
网站调用新浪微博内容(网站调用新浪微博内容是怎么回事?方案比较简单!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-09-22 22:08
网站调用新浪微博内容是他们平台代理商的事情,跟你们网站关系不大,看看你们的网站是否支持搜索引擎收录,如果都没有,就需要替换链接,或者再添加nofollow等标签。
重新在其他网站,重新挂代码,就可以了。方案比较简单。
先贴个谷歌的答案出来:除了searchengine的策略变化,重新在其他网站添加spider代码也是很有效的解决方案。只要其他网站都已经提供类似的接口,就可以考虑替换这些网站的。建议每个网站都添加或替换spider代码。但,这并不意味着网站就要被升级为非常不好的。有些网站的代码非常不友好。但这在视频站等其他需要调用spider代码的网站上可以减轻许多压力。
许多其他网站接受其他网站的代码的许多原因是许多网站提供了类似的接口。很多东西就是这样,已经被标签了你就不能去贴别人的标签。不贴别人的标签,能不能提高效率和结果,是看个人水平的。能不能自己搞出来,是看编程的能力的。
花这么大价钱雇人都可以查到的
百度搜索到的多是重复的新闻、楼盘房源等,小网站没有必要添加,大网站有专门的记者,每天编译分享出来的权威信息自然多一些。关键要看网站的定位、行业特点。
重新编译链接就可以解决了,非常简单。如果不是googlespider,没必要添加,几乎没有必要。要考虑是否有那么多人关注你网站的权威信息,一个假新闻太多,查看的人就会少了。如果网站需要添加spider,必须有底线。 查看全部
网站调用新浪微博内容(网站调用新浪微博内容是怎么回事?方案比较简单!)
网站调用新浪微博内容是他们平台代理商的事情,跟你们网站关系不大,看看你们的网站是否支持搜索引擎收录,如果都没有,就需要替换链接,或者再添加nofollow等标签。
重新在其他网站,重新挂代码,就可以了。方案比较简单。
先贴个谷歌的答案出来:除了searchengine的策略变化,重新在其他网站添加spider代码也是很有效的解决方案。只要其他网站都已经提供类似的接口,就可以考虑替换这些网站的。建议每个网站都添加或替换spider代码。但,这并不意味着网站就要被升级为非常不好的。有些网站的代码非常不友好。但这在视频站等其他需要调用spider代码的网站上可以减轻许多压力。
许多其他网站接受其他网站的代码的许多原因是许多网站提供了类似的接口。很多东西就是这样,已经被标签了你就不能去贴别人的标签。不贴别人的标签,能不能提高效率和结果,是看个人水平的。能不能自己搞出来,是看编程的能力的。
花这么大价钱雇人都可以查到的
百度搜索到的多是重复的新闻、楼盘房源等,小网站没有必要添加,大网站有专门的记者,每天编译分享出来的权威信息自然多一些。关键要看网站的定位、行业特点。
重新编译链接就可以解决了,非常简单。如果不是googlespider,没必要添加,几乎没有必要。要考虑是否有那么多人关注你网站的权威信息,一个假新闻太多,查看的人就会少了。如果网站需要添加spider,必须有底线。
网站调用新浪微博内容(AXMLPrinter2.jar反编译新浪微博的开放程度,居然比新浪还要封闭)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-22 10:11
首先,我们需要使用AXMLPRINTER 2. jar decompile weibo androidmanifest.xml,显示页面从中查找信息,反编译代码如下:
java -jar AXMLPrinter2.jar AndroidManifest.xml > a.xml
打开decompile out a.xml,搜索userinfo,非常幸运地找到userinfoactivity,如下所示:
userInfoactivity注册了两个意图过滤器,第一个注册的URL是Sinaweibo:// userInfo UID = 3444956000,通过以下信息显示用户信息调用新浪微博客户端:
var intent = new Intent(Intent.ActionView);
var uri = Android.Net.Uri.Parse("sinaweibo://userinfo?uid=3444956000");
intent.SetData(uri);
var chooseIntent = Intent.CreateChooser(intent, "Weibo");
StartActivity(chooseIntent);
但是,上述代码的前提是用户具有新浪微博客户端安装,否则它将运行错误,但幸运的是有一秒钟,我们可以使用以下代码来调用:
var intent = new Intent(Intent.ActionView);
var uri = Android.Net.Uri.Parse("http://weibo.cn/qr/userinfo?uid=3444956000");
intent.SetData(uri);
var chooseIntent = Intent.CreateChooser(intent, "Weibo");
StartActivity(chooseIntent);
代码的上述效果是:
如果您没有安装新浪微博,则浏览器将打开对该地址的直接呼叫;如果安装了用户新浪微博,则将显示以下对话框允许用户选择:
再次鄙视新浪微博的开放性,实际上有这个功能不打开。
旨在使用相同的方法在腾讯微字母上做同样的函数,但发现腾讯已显示活动微信号设置为私有android:导出=“假”,实际上已经关闭了新浪,真的无言而喻! 查看全部
网站调用新浪微博内容(AXMLPrinter2.jar反编译新浪微博的开放程度,居然比新浪还要封闭)
首先,我们需要使用AXMLPRINTER 2. jar decompile weibo androidmanifest.xml,显示页面从中查找信息,反编译代码如下:
java -jar AXMLPrinter2.jar AndroidManifest.xml > a.xml
打开decompile out a.xml,搜索userinfo,非常幸运地找到userinfoactivity,如下所示:
userInfoactivity注册了两个意图过滤器,第一个注册的URL是Sinaweibo:// userInfo UID = 3444956000,通过以下信息显示用户信息调用新浪微博客户端:
var intent = new Intent(Intent.ActionView);
var uri = Android.Net.Uri.Parse("sinaweibo://userinfo?uid=3444956000");
intent.SetData(uri);
var chooseIntent = Intent.CreateChooser(intent, "Weibo");
StartActivity(chooseIntent);
但是,上述代码的前提是用户具有新浪微博客户端安装,否则它将运行错误,但幸运的是有一秒钟,我们可以使用以下代码来调用:
var intent = new Intent(Intent.ActionView);
var uri = Android.Net.Uri.Parse("http://weibo.cn/qr/userinfo?uid=3444956000";);
intent.SetData(uri);
var chooseIntent = Intent.CreateChooser(intent, "Weibo");
StartActivity(chooseIntent);
代码的上述效果是:
如果您没有安装新浪微博,则浏览器将打开对该地址的直接呼叫;如果安装了用户新浪微博,则将显示以下对话框允许用户选择:
再次鄙视新浪微博的开放性,实际上有这个功能不打开。
旨在使用相同的方法在腾讯微字母上做同样的函数,但发现腾讯已显示活动微信号设置为私有android:导出=“假”,实际上已经关闭了新浪,真的无言而喻!
网站调用新浪微博内容(新浪微博接口的实现过程及应用开发)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-20 02:06
我不得不说,虽然它仍然是相同的微博内容,相同的列表,没有移动客户端界面,没有头像,用户昵称和颜色,但它真的很可怕
外表仍然是决定性因素
让我们开始记录新浪微博界面的实现过程
首先,你需要在新浪微博开放平台上注册一个开场白。选择应用程序开发。由于它是office网站,请选择第三方网页。创建后,您可以获得以下信息:
应用程序名称:
网络空间
应用程序类型:
通用应用程序-Web应用程序
应用程序密钥:
3xxxxxx
应用程序机密:
6xxxxxxxxxxxxxxxxxxxxxx
在应用程序信息->高级信息中设置----
授权回调页面:
然后下载PHP SDK
请注意,SDK和演示中有重复的页面(但在内容上存在一些差异)。事实上,SDK收录了演示。没有必要下载演示。因为我以前把这两种东西混在一起了,所以我很乱
然后在config.php中修改
WB_uuy的值是APP key的值,WB_uy的值是APP secret的值,分别相当于账号和密码,因此后者需要严格保密
修改WB_uu回调uu URL的值是回调页面的地址
然后,请注意,在我的命令下,文件的末尾没有PHP结束标记?>它需要完成
之后,它可以显示在浏览器中127.0.@0.1/Try index.php。。如果单击“授权”成功登录,则可以
此处授权的回调页面地址将自动跳转到api.weiboxxx/127.0.@0.1/Callback.php。我不知道怎么了。简而言之,它改为127.0.@0.1/只要打电话。PHP
这样就可以正常使用了
只是由于PHP版本或设置的原因,变量无法直接写入,需要更改为。。还有API调用和排版的问题 查看全部
网站调用新浪微博内容(新浪微博接口的实现过程及应用开发)
我不得不说,虽然它仍然是相同的微博内容,相同的列表,没有移动客户端界面,没有头像,用户昵称和颜色,但它真的很可怕
外表仍然是决定性因素
让我们开始记录新浪微博界面的实现过程
首先,你需要在新浪微博开放平台上注册一个开场白。选择应用程序开发。由于它是office网站,请选择第三方网页。创建后,您可以获得以下信息:
应用程序名称:
网络空间
应用程序类型:
通用应用程序-Web应用程序
应用程序密钥:
3xxxxxx
应用程序机密:
6xxxxxxxxxxxxxxxxxxxxxx
在应用程序信息->高级信息中设置----
授权回调页面:
然后下载PHP SDK
请注意,SDK和演示中有重复的页面(但在内容上存在一些差异)。事实上,SDK收录了演示。没有必要下载演示。因为我以前把这两种东西混在一起了,所以我很乱
然后在config.php中修改
WB_uuy的值是APP key的值,WB_uy的值是APP secret的值,分别相当于账号和密码,因此后者需要严格保密
修改WB_uu回调uu URL的值是回调页面的地址
然后,请注意,在我的命令下,文件的末尾没有PHP结束标记?>它需要完成
之后,它可以显示在浏览器中127.0.@0.1/Try index.php。。如果单击“授权”成功登录,则可以
此处授权的回调页面地址将自动跳转到api.weiboxxx/127.0.@0.1/Callback.php。我不知道怎么了。简而言之,它改为127.0.@0.1/只要打电话。PHP
这样就可以正常使用了
只是由于PHP版本或设置的原因,变量无法直接写入,需要更改为。。还有API调用和排版的问题
网站调用新浪微博内容( P2微博同步发布实现要求和参考思路文档(.net) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-20 02:03
P2微博同步发布实现要求和参考思路文档(.net)
)
P2
微博同步发布实施要求及参考文件
微博同步发布(.Net)任务描述基于MVCnetframework4.0框架开发;数据存储使用MYSQL5.版本1或以上的数据库;本地网站账号可绑定新浪、腾讯微博账号;本地网站发布的微博可以同步到新浪微博和腾讯微博;支持文本、表情、图片、视频、音乐等内容的同步发布;您可以自定义和配置微博开放平台appkey
bearpeng 2014-03-01 511 0
微博系统
P10
微博客户端开发可行性分析报告文件
本项目的开发主要是基于googleandroid移动平台搭建开发环境,设计并创建运行在智能手机上的微博客户端开发的软件。微博客户端的开发方便了用户通过该微博平台随时发布心情、新闻、新闻等信息。他们还可以浏览互联网上的最新新闻、视频、图片和其他信息
风藻南2012-07-11 10074 0
微博系统报告
P3
公共开放API资源-SNS和微博文档
常见的开放式API文档资源称为开放式API。OpenAPI是一个通用的面向服务的网站应用程序。网站的服务提供者将其网站服务封装成一系列API(应用程序编程接口),并将其开放供第三方开发人员使用。这种行为称为open网站API,而openapi称为openapi
kevin0312 2012-07-10 506 0
微博系统
P5
微博数据库应用系统设计报告文档
微博是一种非常快速的互动和交流工具,其传播速度甚至比媒体快。微博是一种非正式的微博,是一种新兴的微博web2.0 performance是一个类似博客的系统,可以即时发布消息。它最大的特点是整合性和开放性。您可以通过手机、IM软件(Gtalk、MSN、QQ、Skype)和外部API接口向微博发布消息。微博的另一个特点是“微”。一般来说,发布的消息只能是几句话。twitter等微博平台一次只能发送140个字符
小银一号2012-02-18 6110
微博系统报告
P7
新浪微博代码架构分析及二次开发文档
xweibo的框架大纲和功能采用MVC结构,但VC层的任务分离不明显,V层也完成了C层的部分任务(调用模型层获取数据)。未使用智能模板类。视图以组件的形式出现,可以任意组装。它可以方便模板模块的重用,并通过后台修改显示细节。核心文件用作所有调用的条目。使用的所有类、函数和适配器都使用核心提供的函数和类进行调用,以便进行集中控制。新浪开放API调用有统一的错误处理。通过核心层提供的数据交互组件,对数据进行集中缓存、过滤、格式化等操作
blueel 2012-01-11 6137 0
微博系统 查看全部
网站调用新浪微博内容(
P2微博同步发布实现要求和参考思路文档(.net)
)
P2
微博同步发布实施要求及参考文件
微博同步发布(.Net)任务描述基于MVCnetframework4.0框架开发;数据存储使用MYSQL5.版本1或以上的数据库;本地网站账号可绑定新浪、腾讯微博账号;本地网站发布的微博可以同步到新浪微博和腾讯微博;支持文本、表情、图片、视频、音乐等内容的同步发布;您可以自定义和配置微博开放平台appkey
bearpeng 2014-03-01 511 0
微博系统
P10
微博客户端开发可行性分析报告文件
本项目的开发主要是基于googleandroid移动平台搭建开发环境,设计并创建运行在智能手机上的微博客户端开发的软件。微博客户端的开发方便了用户通过该微博平台随时发布心情、新闻、新闻等信息。他们还可以浏览互联网上的最新新闻、视频、图片和其他信息
风藻南2012-07-11 10074 0
微博系统报告
P3
公共开放API资源-SNS和微博文档
常见的开放式API文档资源称为开放式API。OpenAPI是一个通用的面向服务的网站应用程序。网站的服务提供者将其网站服务封装成一系列API(应用程序编程接口),并将其开放供第三方开发人员使用。这种行为称为open网站API,而openapi称为openapi
kevin0312 2012-07-10 506 0
微博系统
P5
微博数据库应用系统设计报告文档
微博是一种非常快速的互动和交流工具,其传播速度甚至比媒体快。微博是一种非正式的微博,是一种新兴的微博web2.0 performance是一个类似博客的系统,可以即时发布消息。它最大的特点是整合性和开放性。您可以通过手机、IM软件(Gtalk、MSN、QQ、Skype)和外部API接口向微博发布消息。微博的另一个特点是“微”。一般来说,发布的消息只能是几句话。twitter等微博平台一次只能发送140个字符
小银一号2012-02-18 6110
微博系统报告
P7
新浪微博代码架构分析及二次开发文档
xweibo的框架大纲和功能采用MVC结构,但VC层的任务分离不明显,V层也完成了C层的部分任务(调用模型层获取数据)。未使用智能模板类。视图以组件的形式出现,可以任意组装。它可以方便模板模块的重用,并通过后台修改显示细节。核心文件用作所有调用的条目。使用的所有类、函数和适配器都使用核心提供的函数和类进行调用,以便进行集中控制。新浪开放API调用有统一的错误处理。通过核心层提供的数据交互组件,对数据进行集中缓存、过滤、格式化等操作
blueel 2012-01-11 6137 0
微博系统
网站调用新浪微博内容(PHP自学中心以微博登录为例网站学习,交流与进步!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-09-20 02:02
链接是最好的官方帐户。如果它们过期,则可以对其进行修改,因此这就是它们未被放置在中的原因文章. 请仔细阅读本段:如果需要,您可以关注“PHP自学中心”,回复相应的关键词,获取链接并提取代码。感谢您的支持和信任
文章text
在正常的项目开发过程中,除了注册这个网站帐户登录外,您还可以调用第三方接口登录网站。以微博登录为例。微博登录包括身份认证、用户关系和内容传播。允许用户登录并访问第三方网站,与他们的微博帐户共享内容并同步信息
1、首先,您需要将授权用户引导到以下地址:
如果用户同意授权,页面将跳转到您的uRegistered_uu重定向uURI/?code=代码:
2、下一步,根据上面获得的代码交换接入令牌:
返回值:
JSON
3、最后,使用获得的OAuth2.0访问令牌调用API获取用户身份并完成用户登录
不要说太多,只需进入代码:
为了方便起见,我们首先将get和post封装到application下的common.php中:
应用程序公共文件common.php:
控制器处理代码login.php:
模板代码login.html:
渲染:
以上是文章的全部内容。有学习和经验交流的可以增加PHP自学中心。共同学习、交流和进步 查看全部
网站调用新浪微博内容(PHP自学中心以微博登录为例网站学习,交流与进步!)
链接是最好的官方帐户。如果它们过期,则可以对其进行修改,因此这就是它们未被放置在中的原因文章. 请仔细阅读本段:如果需要,您可以关注“PHP自学中心”,回复相应的关键词,获取链接并提取代码。感谢您的支持和信任
文章text
在正常的项目开发过程中,除了注册这个网站帐户登录外,您还可以调用第三方接口登录网站。以微博登录为例。微博登录包括身份认证、用户关系和内容传播。允许用户登录并访问第三方网站,与他们的微博帐户共享内容并同步信息
1、首先,您需要将授权用户引导到以下地址:
如果用户同意授权,页面将跳转到您的uRegistered_uu重定向uURI/?code=代码:
2、下一步,根据上面获得的代码交换接入令牌:
返回值:
JSON
3、最后,使用获得的OAuth2.0访问令牌调用API获取用户身份并完成用户登录
不要说太多,只需进入代码:
为了方便起见,我们首先将get和post封装到application下的common.php中:
应用程序公共文件common.php:
控制器处理代码login.php:
模板代码login.html:
渲染:
以上是文章的全部内容。有学习和经验交流的可以增加PHP自学中心。共同学习、交流和进步
网站调用新浪微博内容(微博字数统计和新浪微博中的字数统计不一致,原来是链接的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-09-19 12:08
最近发现,企业系统中API发送的微博字数统计与新浪微博的字数统计不一致。p>
新浪微博的字数是一个很长的链接。不管它有多长,都统一记录为10个单词(其他:汉字是一个长度,英文、数字和标点符号是两个长度)。因此,对于发布长链接,您需要在进行统计之前过滤URL,以便获取它们的代码并共享它们。测试代码如下所示:
<p>
微博计算字数
function b(b) {
var c = 41, d = 140, e = 20, f = b, g = b
.match(/(http|https):\/\/[a-zA-Z0-9]+(\.[a-zA-Z0-9]+)+([-A-Z0-9a-z_\$\.\+\!\*\(\)\/\,\:;@&=\?~#%]*)*/gi)
|| [], h = 0;
for ( var i = 0, j = g.length; i < j; i++) {
var k = bLength(g[i]);
if (/^(http:\/\/t.cn)/.test(g[i]))
continue;
/^(http:\/\/)+(t.sina.com.cn|t.sina.cn)/.test(g[i])
|| /^(http:\/\/)+(weibo.com|weibo.cn)/.test(g[i]) ? h += k 查看全部
网站调用新浪微博内容(微博字数统计和新浪微博中的字数统计不一致,原来是链接的问题)
最近发现,企业系统中API发送的微博字数统计与新浪微博的字数统计不一致。p>
新浪微博的字数是一个很长的链接。不管它有多长,都统一记录为10个单词(其他:汉字是一个长度,英文、数字和标点符号是两个长度)。因此,对于发布长链接,您需要在进行统计之前过滤URL,以便获取它们的代码并共享它们。测试代码如下所示:
<p>
微博计算字数
function b(b) {
var c = 41, d = 140, e = 20, f = b, g = b
.match(/(http|https):\/\/[a-zA-Z0-9]+(\.[a-zA-Z0-9]+)+([-A-Z0-9a-z_\$\.\+\!\*\(\)\/\,\:;@&=\?~#%]*)*/gi)
|| [], h = 0;
for ( var i = 0, j = g.length; i < j; i++) {
var k = bLength(g[i]);
if (/^(http:\/\/t.cn)/.test(g[i]))
continue;
/^(http:\/\/)+(t.sina.com.cn|t.sina.cn)/.test(g[i])
|| /^(http:\/\/)+(weibo.com|weibo.cn)/.test(g[i]) ? h += k
网站调用新浪微博内容(探索的过程1.了解大致过程登陆微博,文章可能不再适用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-09-19 12:06
概述:
由于业务需要,我们需要编写爬虫代码来抓取新浪微博用户的信息
虽然在互联网上可以找到很多信息,但由于新浪微博的修订和登录机制的修改,很多旧的文章不适合使用
经过一番探索,我们成功模拟了新浪微博的登录操作。该项目使用JavaScript语言并在Chrome扩展中运行。让我们与您分享这个过程和经验
请注意,本文是用2013. 08.16. 由于微博业务的频繁变化,it文章可能随着年龄的增长不再适用
文本:探索的过程
1.了解一般流程
登录微博,使用Fiddler工具监控HTTP请求,拦截以下操作:
您可以看到,在微博登录的整个过程中,有四个重要的HTTP请求,分别是:
(1)GET/sso/prelogin.php)
(2)POST/sso/login.php)
(3)GET/ajaxlogin.php)
(4)GET/u/2813262187)
其中SSO是单点登录
(1)是登录前的预处理,名字很明显--pre,这一步主要获取几个重要参数,作为下一步post表单的参数
您可以在浏览器中访问此请求的地址以查看返回的结果:
(v1.4.11)
结果如下:
1sinasocontroller.preloginCallBack({“retcode”:0
2“服务器时间”:1376533839
3“pcid”:“gz-7bdd82b8980057a8bbc1f86b21d5a86184dd”
4“暂时”:“R1KGHZ”
5“公开密钥”:“EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC2533E5063508E7F9A3BB77F4333490F915F6D63C55FE2F08A49B353F44AD3993CACC02DB784ABB8E42A9B1BBFFFB388E87A0E41B9B8F73A928EE0CEE1F6739884B97E9E88A1BB4927AC4A7981D644443”
6“rsakv”:“1330428213”
7“执行时间”:2})
返回的数据包括servertime:Service timestamp、nonce:6位随机码、pubkey:RSA 2密码加密使用的公钥和RSA kV:显然也用于加密
这四个值需要在下一步中使用
在新浪微博登录机制的长期版本中,使用了Sha加密,没有pubkey和rsakv参数
因此,在互联网上看到的2012年爬虫代码和模拟着陆代码不再适合使用,但总体逻辑没有太大变化。只需稍加修改,它仍然可以使用。这就是我为什么来到这里并撞上无数墙的原因=
给出两个参考文章:
对于Python
对于PHP
(2)提交表单时,我们仍会查看HTTP请求和表单内容
是的,servertime,nonce,rsakv,Su:加密用户名,SP:加密密码。现在的问题是如何加密用户名和密码。很容易关注JS代码
请求新浪登录页:,其中收录用于密码加密的JS代码
里面的代码是加密的,找一个解密工具(),你几乎看不到逻辑
(3)analysis ssologin.JS)
既然我们知道servertime和nonce用于加密,我们不妨在文件中搜索这两个关键字并找到一些好的内容:
回到上面,您可以看到表单中有Su和SP。您可以看到Su使用base64加密,而Su稍微复杂一些
If是新浪当前版本的密码加密RSA 2的代码,else是Sha加密版本的代码,我们只需要关心If中的内容
加密过程非常简单。首先,生成一个rsakey对象,设置publickey,然后对其进行加密
通过一个接一个地向后推,您可以知道最后一个加密步骤中的最后一个参数Ag是原创密码值,不会让人眼花缭乱~
总之,使用pubkey和10001的长字符串作为参数来调用setpublic()。注意它们是十六进制数;然后使用(servertime+nonce+PWD)作为参数来调用encrypt()
让我们看看sinassoencoder是什么。它的定义是在1118行解密代码中。从这里,截取它到文件的末尾,并将其移出以供我们自己使用
1} )。呼叫(sinaSSOEncoder)
2//sinaSSOController=newSSOController()
3//sinaSSOController.init()
这就解决了密码加密的问题
2.模拟请求过程
既然您了解了一般原理,就可以开始模拟整个登录过程了
(1)get请求)(v1.4.11)
返回的数据定期与服务器时间、NANCE和RSAKV相匹配。请注意,当请求时,时间戳也应该发送到服务器。让我们看看Fiddler监视的QueRISH字符串:
前五个参数在URL中显示和声明。最后一个参数在发送请求时添加。传递它
我使用JavaScript,只需将它添加到jQuery和$.Ajax中的data属性中
(2)post请求)(v1.4.11)提交登录表单
1名代理人(v1.4.11)",
2{type:'POST',headers:{Referer:'39;}
3数据:{
4条目:'微博'
5公路:1
6从:“”
7保存状态:7
8使用票:1
9页参考:'#39
10vsnf:1
11 su:'MTgxMDU0MjMzNyU0MHFxLmNvbQ=='
12服务:'迷你博客'
13服务器时间:服务器时间
14 nonce:nonce
15pwencode:'rsa2'
16千伏:千伏
17 sp:sp
18编码:'UTF-8'
19预备课程:505
20url:'#39
21返回类型:'META'
22}
23},函数(err,data){…}
代理是用于发送请求事务的封装模块。关注其中的数据对象。Su是base64加密的用户名。每个调用都是固定的,所以它写在这里
Servertime、nonce和rsakv在上一步中被截获
SP为加密密码,可参照上述加密方法获取 查看全部
网站调用新浪微博内容(探索的过程1.了解大致过程登陆微博,文章可能不再适用)
概述:
由于业务需要,我们需要编写爬虫代码来抓取新浪微博用户的信息
虽然在互联网上可以找到很多信息,但由于新浪微博的修订和登录机制的修改,很多旧的文章不适合使用
经过一番探索,我们成功模拟了新浪微博的登录操作。该项目使用JavaScript语言并在Chrome扩展中运行。让我们与您分享这个过程和经验
请注意,本文是用2013. 08.16. 由于微博业务的频繁变化,it文章可能随着年龄的增长不再适用
文本:探索的过程
1.了解一般流程
登录微博,使用Fiddler工具监控HTTP请求,拦截以下操作:
您可以看到,在微博登录的整个过程中,有四个重要的HTTP请求,分别是:
(1)GET/sso/prelogin.php)
(2)POST/sso/login.php)
(3)GET/ajaxlogin.php)
(4)GET/u/2813262187)
其中SSO是单点登录
(1)是登录前的预处理,名字很明显--pre,这一步主要获取几个重要参数,作为下一步post表单的参数
您可以在浏览器中访问此请求的地址以查看返回的结果:
(v1.4.11)
结果如下:
1sinasocontroller.preloginCallBack({“retcode”:0
2“服务器时间”:1376533839
3“pcid”:“gz-7bdd82b8980057a8bbc1f86b21d5a86184dd”
4“暂时”:“R1KGHZ”
5“公开密钥”:“EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC2533E5063508E7F9A3BB77F4333490F915F6D63C55FE2F08A49B353F44AD3993CACC02DB784ABB8E42A9B1BBFFFB388E87A0E41B9B8F73A928EE0CEE1F6739884B97E9E88A1BB4927AC4A7981D644443”
6“rsakv”:“1330428213”
7“执行时间”:2})
返回的数据包括servertime:Service timestamp、nonce:6位随机码、pubkey:RSA 2密码加密使用的公钥和RSA kV:显然也用于加密
这四个值需要在下一步中使用
在新浪微博登录机制的长期版本中,使用了Sha加密,没有pubkey和rsakv参数
因此,在互联网上看到的2012年爬虫代码和模拟着陆代码不再适合使用,但总体逻辑没有太大变化。只需稍加修改,它仍然可以使用。这就是我为什么来到这里并撞上无数墙的原因=
给出两个参考文章:
对于Python
对于PHP
(2)提交表单时,我们仍会查看HTTP请求和表单内容
是的,servertime,nonce,rsakv,Su:加密用户名,SP:加密密码。现在的问题是如何加密用户名和密码。很容易关注JS代码
请求新浪登录页:,其中收录用于密码加密的JS代码
里面的代码是加密的,找一个解密工具(),你几乎看不到逻辑
(3)analysis ssologin.JS)
既然我们知道servertime和nonce用于加密,我们不妨在文件中搜索这两个关键字并找到一些好的内容:
回到上面,您可以看到表单中有Su和SP。您可以看到Su使用base64加密,而Su稍微复杂一些
If是新浪当前版本的密码加密RSA 2的代码,else是Sha加密版本的代码,我们只需要关心If中的内容
加密过程非常简单。首先,生成一个rsakey对象,设置publickey,然后对其进行加密
通过一个接一个地向后推,您可以知道最后一个加密步骤中的最后一个参数Ag是原创密码值,不会让人眼花缭乱~
总之,使用pubkey和10001的长字符串作为参数来调用setpublic()。注意它们是十六进制数;然后使用(servertime+nonce+PWD)作为参数来调用encrypt()
让我们看看sinassoencoder是什么。它的定义是在1118行解密代码中。从这里,截取它到文件的末尾,并将其移出以供我们自己使用
1} )。呼叫(sinaSSOEncoder)
2//sinaSSOController=newSSOController()
3//sinaSSOController.init()
这就解决了密码加密的问题
2.模拟请求过程
既然您了解了一般原理,就可以开始模拟整个登录过程了
(1)get请求)(v1.4.11)
返回的数据定期与服务器时间、NANCE和RSAKV相匹配。请注意,当请求时,时间戳也应该发送到服务器。让我们看看Fiddler监视的QueRISH字符串:
前五个参数在URL中显示和声明。最后一个参数在发送请求时添加。传递它
我使用JavaScript,只需将它添加到jQuery和$.Ajax中的data属性中
(2)post请求)(v1.4.11)提交登录表单
1名代理人(v1.4.11)",
2{type:'POST',headers:{Referer:'39;}
3数据:{
4条目:'微博'
5公路:1
6从:“”
7保存状态:7
8使用票:1
9页参考:'#39
10vsnf:1
11 su:'MTgxMDU0MjMzNyU0MHFxLmNvbQ=='
12服务:'迷你博客'
13服务器时间:服务器时间
14 nonce:nonce
15pwencode:'rsa2'
16千伏:千伏
17 sp:sp
18编码:'UTF-8'
19预备课程:505
20url:'#39
21返回类型:'META'
22}
23},函数(err,data){…}
代理是用于发送请求事务的封装模块。关注其中的数据对象。Su是base64加密的用户名。每个调用都是固定的,所以它写在这里
Servertime、nonce和rsakv在上一步中被截获
SP为加密密码,可参照上述加密方法获取
网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-17 22:18
登录条目
新浪微博登录常用界面:
对应的主界面:
但是,我个人建议使用移动微博门户:
对应的主界面:
原因是移动数据相对轻量级,基础数据比较完整,可能缺少一些基本的个人信息,如“个人数据完成”、“个人水平”等,同时粉丝ID和注意ID只能显示20页,但可以作为大部分验证的语料
通过比较以下两个图形,PC终端和移动终端,我们可以发现内容基本相同:
移动终端如下图所示,画面相对较小,内容更简洁
完整的源代码
以下代码主要分为三部分:
1.LoginWeibo(用户名、密码)登录微博
2.VisitPersonPage(用户id)访问以下人员网站以获取个人信息
3.获取微博内容,同时翻页
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471")会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/")
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num 查看全部
网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
登录条目
新浪微博登录常用界面:
对应的主界面:
但是,我个人建议使用移动微博门户:
对应的主界面:
原因是移动数据相对轻量级,基础数据比较完整,可能缺少一些基本的个人信息,如“个人数据完成”、“个人水平”等,同时粉丝ID和注意ID只能显示20页,但可以作为大部分验证的语料
通过比较以下两个图形,PC终端和移动终端,我们可以发现内容基本相同:
移动终端如下图所示,画面相对较小,内容更简洁
完整的源代码
以下代码主要分为三部分:
1.LoginWeibo(用户名、密码)登录微博
2.VisitPersonPage(用户id)访问以下人员网站以获取个人信息
3.获取微博内容,同时翻页
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471";)会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/";)
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num
网站调用新浪微博内容(Python语言python模拟登陆新浪微博上的预登陆是什么意思)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-15 07:14
Python登录新浪微博的所有逻辑代码都已编写完成。你需要自己看看:如何使用python、c#和其他语言捕获静态网页并模拟登录网站(这里没有帖子地址,请使用Google搜索帖子标题以查找帖子地址)。Python能否直接登录新浪微博并发送信息?对这方面有开放的API。此外,您还可以获取其cookie并直接通过web界面发送。但我不建议你把它用于大规模发送。Python登录新浪微博后的cookie与登录网页后的cookie有何不同?浏览器登录新浪微博后,cookies应该有所不同。它与cookies可以登录的时间等因素有关。当Python登录新浪微博时,您可以模拟您的网页登录的形式登录。尝试确保您和登录到网页的cookie不会抓取新浪微博,请向Python新浪微博爬虫寻求帮助,了解如何在使用WebBrowser操作的浏览器登录新浪微博后抓取数据。Python语言模拟了登录新浪微博时预登录的含义。1脚本模拟登录新浪微博并保存cookie;2获得cookie信息后,使用cookie信息直接访问微博URL。其中,第一步是这里讨论的重点。为了更好地模拟这一步骤,需要一个良好的网络监控工具。您可以使用Firefox的firebug和chrome以及IE自己的开发工具(注意IE必须高于IE9才能监控网络,chrome的网络交互信息可以在网络部分查看)。如何使用Python登录新浪微博并自动发表评论?新浪有API和各种SDK。如果你看一下这个界面,你就不会有太多问题了 查看全部
网站调用新浪微博内容(Python语言python模拟登陆新浪微博上的预登陆是什么意思)
Python登录新浪微博的所有逻辑代码都已编写完成。你需要自己看看:如何使用python、c#和其他语言捕获静态网页并模拟登录网站(这里没有帖子地址,请使用Google搜索帖子标题以查找帖子地址)。Python能否直接登录新浪微博并发送信息?对这方面有开放的API。此外,您还可以获取其cookie并直接通过web界面发送。但我不建议你把它用于大规模发送。Python登录新浪微博后的cookie与登录网页后的cookie有何不同?浏览器登录新浪微博后,cookies应该有所不同。它与cookies可以登录的时间等因素有关。当Python登录新浪微博时,您可以模拟您的网页登录的形式登录。尝试确保您和登录到网页的cookie不会抓取新浪微博,请向Python新浪微博爬虫寻求帮助,了解如何在使用WebBrowser操作的浏览器登录新浪微博后抓取数据。Python语言模拟了登录新浪微博时预登录的含义。1脚本模拟登录新浪微博并保存cookie;2获得cookie信息后,使用cookie信息直接访问微博URL。其中,第一步是这里讨论的重点。为了更好地模拟这一步骤,需要一个良好的网络监控工具。您可以使用Firefox的firebug和chrome以及IE自己的开发工具(注意IE必须高于IE9才能监控网络,chrome的网络交互信息可以在网络部分查看)。如何使用Python登录新浪微博并自动发表评论?新浪有API和各种SDK。如果你看一下这个界面,你就不会有太多问题了
网站调用新浪微博内容(1.微博三方登录流程和获取认证.2获取流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-07 22:15
内容
1.微博三方登录流程
https://api.weibo.com/oauth2/authorize?
client_id=4122644977
&response_type=code
&state=study&
forcelogin=true&
redirect_uri=https%3A%2F%2Fstudy.163.com%2Fsns%2Fweibo%2FoAuthCallback.htm%3Foaut
hType%3Dlogin%26returnUrl%3DaHR0cHM6Ly9zdHVkeS4xNjMuY29tL3Byb3ZpZGVyLzQwMDAwMDAwM
DQ3ODAxMi9pbmRleC5odG0%2FZnJvbT1zdHVkeQ%3D%3D%26nrsstcw%3Dfalse%26nc%3Dtrue###
https://study.163.com/provider ... study
1.1 前端获取认证码1.2 获取微博access_token1.3 获取微博用户基本信息并存入数据库1.4 生成token给Vue2. 第三-方登录与本地登录关联(三种情况)2.1 情况一:本地未登录,第一次登录第三方
这时候就相当于注册了。只需拉取第三方信息注册为本地用户,建立本地用户和第三方用户
(openid) 绑定关系
2.2 情况二:本地未登录,重新登录第三方
此时用户已经注册,获取openid后可以直接找到对应的本地用户
2.3 案例三:本地登录并绑定第三方
只需将获取的openid绑定到本地用户即可。
3.oauth 认证原理4.为什么要使用三方登录 查看全部
网站调用新浪微博内容(1.微博三方登录流程和获取认证.2获取流程)
内容
1.微博三方登录流程
https://api.weibo.com/oauth2/authorize?
client_id=4122644977
&response_type=code
&state=study&
forcelogin=true&
redirect_uri=https%3A%2F%2Fstudy.163.com%2Fsns%2Fweibo%2FoAuthCallback.htm%3Foaut
hType%3Dlogin%26returnUrl%3DaHR0cHM6Ly9zdHVkeS4xNjMuY29tL3Byb3ZpZGVyLzQwMDAwMDAwM
DQ3ODAxMi9pbmRleC5odG0%2FZnJvbT1zdHVkeQ%3D%3D%26nrsstcw%3Dfalse%26nc%3Dtrue###
https://study.163.com/provider ... study
1.1 前端获取认证码1.2 获取微博access_token1.3 获取微博用户基本信息并存入数据库1.4 生成token给Vue2. 第三-方登录与本地登录关联(三种情况)2.1 情况一:本地未登录,第一次登录第三方
这时候就相当于注册了。只需拉取第三方信息注册为本地用户,建立本地用户和第三方用户
(openid) 绑定关系
2.2 情况二:本地未登录,重新登录第三方
此时用户已经注册,获取openid后可以直接找到对应的本地用户
2.3 案例三:本地登录并绑定第三方
只需将获取的openid绑定到本地用户即可。
3.oauth 认证原理4.为什么要使用三方登录
网站调用新浪微博内容(网站调用新浪微博内容,看过twitter的推送吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-06 05:05
网站调用新浪微博内容作为图片/文章/视频,然后推送给客户端。新浪微博从来没有“推送给客户端”这样的模式,分享模式是通过发微博给好友,好友向其他好友推送。现在流行的一种推送方式是通过第三方网站来获取更多内容的形式,实际上已经开始受到争议,因为国内很多分享服务是基于http的,而新浪根本就没有这个功能,从新浪微博页面是看不到推送功能的,只能点击推送按钮后才能进入。
“新浪微博是通过分享到第三方微博的形式实现客户端与第三方微博的互通”通过第三方微博完成信息的推送,第三方不是免费用户。所以新浪不可能自己做,所以要依托于第三方来实现。
你可以先看看旧版新浪微博的图文消息上面有的。
微博是个开放的协议,大多数第三方都可以通过你的发布的消息来进行推送,部分可以通过api的形式来跟新浪进行接口对接。我们给老板做营销策划时都是这么做的,效果尚可,还是好多中国老板不懂这个。
微博都支持通过分享来实现推送
这是因为给谁看啊。
那我觉得这个问题是无解的,因为用户会通过微博自己的一系列社交软件来吸收信息。新浪可以搞网站,
看过twitter的推送吗?这里面的区别。
目前大部分时候,新浪微博用的是第三方微博,比如豆瓣什么的。之前看了一个老外分析新浪的推送的策略的分析,觉得还是蛮精辟。 查看全部
网站调用新浪微博内容(网站调用新浪微博内容,看过twitter的推送吗?)
网站调用新浪微博内容作为图片/文章/视频,然后推送给客户端。新浪微博从来没有“推送给客户端”这样的模式,分享模式是通过发微博给好友,好友向其他好友推送。现在流行的一种推送方式是通过第三方网站来获取更多内容的形式,实际上已经开始受到争议,因为国内很多分享服务是基于http的,而新浪根本就没有这个功能,从新浪微博页面是看不到推送功能的,只能点击推送按钮后才能进入。
“新浪微博是通过分享到第三方微博的形式实现客户端与第三方微博的互通”通过第三方微博完成信息的推送,第三方不是免费用户。所以新浪不可能自己做,所以要依托于第三方来实现。
你可以先看看旧版新浪微博的图文消息上面有的。
微博是个开放的协议,大多数第三方都可以通过你的发布的消息来进行推送,部分可以通过api的形式来跟新浪进行接口对接。我们给老板做营销策划时都是这么做的,效果尚可,还是好多中国老板不懂这个。
微博都支持通过分享来实现推送
这是因为给谁看啊。
那我觉得这个问题是无解的,因为用户会通过微博自己的一系列社交软件来吸收信息。新浪可以搞网站,
看过twitter的推送吗?这里面的区别。
目前大部分时候,新浪微博用的是第三方微博,比如豆瓣什么的。之前看了一个老外分析新浪的推送的策略的分析,觉得还是蛮精辟。
网站调用新浪微博内容(新浪微博的用户接口和话题接口实现了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-09-05 07:18
以标题为标题,调用新浪微博的用户界面和话题界面,实现对新浪微博用户和关键词相关内容的搜索:
选择搜索昵称:
返回搜索昵称结果:
选择搜索微博内容:
返回微博搜索结果:
但内容超过屏幕长度,滚动条会显示剩余内容:
使用的插件有:kendoUI.js 操作UI,给界面切换添加特效幻灯片。 jscex.js 学员异步加载数据,绑定搜索id和搜索微博按钮2个响应函数。还是用jQuery的ajax调用新浪微博加载对应的api数据。
本练习中遇到的问题并不平均。一开始是不熟悉kendoUI造成的。在kendoUI中,所有页面内容都放在同一个页面上,但是data-role="view"是用来区分各个页面的。默认情况下,第一页收录属性 data-role="view" div;
接下来是api调用的跨域问题。本来打算用jsonp数据格式来解决这个问题,但是据说jscex可以解决这个问题。看了后面,发现jecex.js好像也是jsonp格式的。
看了jscex的样例,感觉好强大。但这一次只是简单地使用它定义的异步方法,$await()、$start() 来使用异步方法。以下是点击搜索昵称按钮的一系列操作的代码:
其实还有一个没有解决的问题:在遍历返回的数据时,如果去掉if(index)判断语句,结果总是返回一个“undefined”。经过调试,发现underfined对应的索引其实是code,正确结果对应的索引是data。实在是没有办法,只能用这个判断了。希望以后能找到原因。 查看全部
网站调用新浪微博内容(新浪微博的用户接口和话题接口实现了(组图))
以标题为标题,调用新浪微博的用户界面和话题界面,实现对新浪微博用户和关键词相关内容的搜索:
选择搜索昵称:
返回搜索昵称结果:
选择搜索微博内容:
返回微博搜索结果:
但内容超过屏幕长度,滚动条会显示剩余内容:
使用的插件有:kendoUI.js 操作UI,给界面切换添加特效幻灯片。 jscex.js 学员异步加载数据,绑定搜索id和搜索微博按钮2个响应函数。还是用jQuery的ajax调用新浪微博加载对应的api数据。
本练习中遇到的问题并不平均。一开始是不熟悉kendoUI造成的。在kendoUI中,所有页面内容都放在同一个页面上,但是data-role="view"是用来区分各个页面的。默认情况下,第一页收录属性 data-role="view" div;
接下来是api调用的跨域问题。本来打算用jsonp数据格式来解决这个问题,但是据说jscex可以解决这个问题。看了后面,发现jecex.js好像也是jsonp格式的。
看了jscex的样例,感觉好强大。但这一次只是简单地使用它定义的异步方法,$await()、$start() 来使用异步方法。以下是点击搜索昵称按钮的一系列操作的代码:
其实还有一个没有解决的问题:在遍历返回的数据时,如果去掉if(index)判断语句,结果总是返回一个“undefined”。经过调试,发现underfined对应的索引其实是code,正确结果对应的索引是data。实在是没有办法,只能用这个判断了。希望以后能找到原因。
网站调用新浪微博内容(通过Python爬虫来爬取新浪微博用户数据的文章教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-09-05 07:18
新浪微博作为新时代流行的新媒体社交平台,拥有大量的用户行为和商业数据,因此研究人员想要获取新浪微博数据是很有必要的。但新浪微博数据量巨大,是最好的。该方法无疑是通过使用Python爬虫获得的。网上有一些使用Python爬虫爬取新浪微博数据的教程,但是完整的介绍和爬取所有用户数据信息比较少,所以这里有一篇文章主要是用selenium包爬取新浪微博用户数据文章。
目标
爬取新浪微博用户数据,包括以下字段:id、昵称、粉丝数、粉丝数、微博数、每条微博的内容、转发数、评论数、点赞数、发布时间、来源,无论是原创 还是转贴。 (本文以GUCCI为例)
方法
+使用selenium模拟爬虫+使用BeautifulSoup解析HTML
结果显示
步骤分解
1.选择抓取目标网址
首先,在准备开始抓取之前,您必须弄清楚要抓取哪个网址。新浪微博网站分为网页版和手机版两种。大部分微博数据抓取都会选择抓取移动端,因为相比之下,移动端基本收录了你想要的所有数据,而移动端相对PC端轻量。
以下是GUCCI手机端和PC端的网页展示。
2.模拟登录
设置爬取微博手机数据后,就可以模拟登录了。模拟登录网址如下所示
模拟登录代码
3.获取用户微博页码
登录后,您可以输入您要抓取的商家信息。因为每个商家的微博数量不同,对应的微博页码也不同。这里先抓取商家的微博页码。同时,爬取那些公开的信息,比如用户uid、用户名、微博数、关注数、粉丝数。
图像.png
4.Crawl 根据最大爬取页数循环所有数据
得到最大页数后,直接通过循环抓取每一页数据。抓取到的数据包括微博内容、转发数、评论数、点赞数、发微博时间、微博来源、是原创还是转发。
4.得到所有数据后,可以写入csv文件或者excel,最终结果会显示在最上面
文章来解决完整的微博爬虫! 查看全部
网站调用新浪微博内容(通过Python爬虫来爬取新浪微博用户数据的文章教程)
新浪微博作为新时代流行的新媒体社交平台,拥有大量的用户行为和商业数据,因此研究人员想要获取新浪微博数据是很有必要的。但新浪微博数据量巨大,是最好的。该方法无疑是通过使用Python爬虫获得的。网上有一些使用Python爬虫爬取新浪微博数据的教程,但是完整的介绍和爬取所有用户数据信息比较少,所以这里有一篇文章主要是用selenium包爬取新浪微博用户数据文章。
目标
爬取新浪微博用户数据,包括以下字段:id、昵称、粉丝数、粉丝数、微博数、每条微博的内容、转发数、评论数、点赞数、发布时间、来源,无论是原创 还是转贴。 (本文以GUCCI为例)
方法
+使用selenium模拟爬虫+使用BeautifulSoup解析HTML
结果显示
步骤分解
1.选择抓取目标网址
首先,在准备开始抓取之前,您必须弄清楚要抓取哪个网址。新浪微博网站分为网页版和手机版两种。大部分微博数据抓取都会选择抓取移动端,因为相比之下,移动端基本收录了你想要的所有数据,而移动端相对PC端轻量。
以下是GUCCI手机端和PC端的网页展示。
2.模拟登录
设置爬取微博手机数据后,就可以模拟登录了。模拟登录网址如下所示
模拟登录代码
3.获取用户微博页码
登录后,您可以输入您要抓取的商家信息。因为每个商家的微博数量不同,对应的微博页码也不同。这里先抓取商家的微博页码。同时,爬取那些公开的信息,比如用户uid、用户名、微博数、关注数、粉丝数。
图像.png
4.Crawl 根据最大爬取页数循环所有数据
得到最大页数后,直接通过循环抓取每一页数据。抓取到的数据包括微博内容、转发数、评论数、点赞数、发微博时间、微博来源、是原创还是转发。
4.得到所有数据后,可以写入csv文件或者excel,最终结果会显示在最上面
文章来解决完整的微博爬虫!

