
网站内容采集
网站内容采集(蝙蝠侠IT做一个同类型的网站:采集外链有排名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-08 10:18
在做SEO的时候,偶尔我们总会遇到各种各样的问题。最近有个SEO小伙伴咨询我这个问题:
同时制作一个相同类型的网站:
①采集+外链,有排名。
②每天坚持原创,而不是收录。
其实回答这个问题还是需要多方面思考的。
那么,采集外链有排名,原创没有收录,为什么呢?
蝙蝠侠IT将根据以往搜索引擎优化经验,详细阐述以下内容:
1、采集 加外链有排名
毫无疑问,我们通常会在搜索引擎上发布采集的内容,存在内容来源问题。如果你的采集内容在搜索引擎中缺失,比如:今日头条自媒体,常见的权重站策略。
这时候你的采集的内容都是搜索引擎的原创,自然会匹配给你排名。
但是如果你的内容采集来源于搜索引擎中的重复内容,这时候你的网站就有了一定的排名,影响这个问题的因素比较多,比如:
①目标页面的外链增幅非常高,都是来自垂直网站的优质外链。
②页面的段落和逻辑非常高,有利于页面的阅读体验。
③网站页面打开速度非常快,提高了页面加载速度。
④ 网站 结构提高相关性,使用页面结构排名。
⑤网站域名的历史使用情况等。
2、每天原创无收录
对于每天没有收录原创的情况,这可能是我们经常遇到的一个关联问题,通常我们认为主要的问题包括以下几点:
①新网站一般收录周期为15-30天。
②页面服务器不稳定,出现不间断卡顿等现象,影响抓取和页面体验。
③内容没有一定的搜索要求。
④是否提交到相关搜索引擎,是否有网站的抓取频率。
⑤是否遇到恶意的采集,网站的内容一直是采集。
⑥域名网站是否处于右下状态,是否在搜索引擎的黑名单中。
⑦网站是否被黑,是否存在恶意链接等。
总结:采集外链有排名,原创没有收录,还有很多细节可以讨论,以上内容仅供参考!
蝙蝠侠IT转载需要授权! 查看全部
网站内容采集(蝙蝠侠IT做一个同类型的网站:采集外链有排名)
在做SEO的时候,偶尔我们总会遇到各种各样的问题。最近有个SEO小伙伴咨询我这个问题:
同时制作一个相同类型的网站:
①采集+外链,有排名。
②每天坚持原创,而不是收录。
其实回答这个问题还是需要多方面思考的。

那么,采集外链有排名,原创没有收录,为什么呢?
蝙蝠侠IT将根据以往搜索引擎优化经验,详细阐述以下内容:
1、采集 加外链有排名
毫无疑问,我们通常会在搜索引擎上发布采集的内容,存在内容来源问题。如果你的采集内容在搜索引擎中缺失,比如:今日头条自媒体,常见的权重站策略。
这时候你的采集的内容都是搜索引擎的原创,自然会匹配给你排名。
但是如果你的内容采集来源于搜索引擎中的重复内容,这时候你的网站就有了一定的排名,影响这个问题的因素比较多,比如:
①目标页面的外链增幅非常高,都是来自垂直网站的优质外链。
②页面的段落和逻辑非常高,有利于页面的阅读体验。
③网站页面打开速度非常快,提高了页面加载速度。
④ 网站 结构提高相关性,使用页面结构排名。
⑤网站域名的历史使用情况等。
2、每天原创无收录
对于每天没有收录原创的情况,这可能是我们经常遇到的一个关联问题,通常我们认为主要的问题包括以下几点:
①新网站一般收录周期为15-30天。
②页面服务器不稳定,出现不间断卡顿等现象,影响抓取和页面体验。
③内容没有一定的搜索要求。
④是否提交到相关搜索引擎,是否有网站的抓取频率。
⑤是否遇到恶意的采集,网站的内容一直是采集。
⑥域名网站是否处于右下状态,是否在搜索引擎的黑名单中。
⑦网站是否被黑,是否存在恶意链接等。
总结:采集外链有排名,原创没有收录,还有很多细节可以讨论,以上内容仅供参考!
蝙蝠侠IT转载需要授权!
网站内容采集(中国论文网关键词:网站网页内容采集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-08 08:10
摘要:网页内容采集主要是指将某个网站的整个网站网页内容或部分网页内容抓取到自己的网站,非法网页内容采集,不仅无法有效保护版权信息,而且在批量处理采集时,尤其是收录多媒体元素和软件的页面为采集时,会造成网站的位置@> 服务器负载增加,普通用户浏览速度下降。中国论文网关键词:网站 网页内容采集 中文图书馆分类号: 文献识别码:A 文章 编号:1007-9416(2010)05- 0000-00 所谓网页采集无非是采集 对于我们浏览的网页内容,包括文字信息、图片信息和视频、声音、软件信息等,采集通过编写采集程序或通过许多cms函数系统本身,并编写采集规则来获取所需的内容。采集的方法一般都有拦截和过滤两种,即拦截指定区域的HTML代码,过滤掉这部分代码不需要的内容,比如广告信息、版权采集@采集的过程一般遵循以下步骤:先读取文章的列表,再读取内容文章 根据文章列表中的链接,一一过滤文章的内容,获取所有需要的信息。根据采集的方法和步骤,我们可以从两个方面进行防范:增加列表采集的难度,防止采集出现在内容页。可以使用技术手段来防止将采集人挡在外面,使他们无法访问和阅读采集页面。
或者,为了处理采集页面的内容,增加采集的难度,这样即使采集人采集数据,采集收到的信息不能使用或直接使用。确定来源,阻止访问。判断同一IP在一定时间内访问本站页面的次数。如果明显高于正常人的浏览速度,说明源IP有采集的可能性,则拒绝IP访问,否则释放。. 这种方法不难实现。在动态网站中,可以通过在页面头部添加部分程序代码来实现,静态页面可以通过javascript代码实现。这个策略对于防止采集非常有效,但会严重影响搜索引擎蜘蛛对本站内容的收录。对于不太依赖搜索引擎的网站,可以采用这种方法。在列表中增加批量难度信息采集采集,从获取信息列表开始,从信息列表中的超链接开始,然后是采集二级页面内容,所以列表页面被封采集,这也屏蔽了其他内容页面的采集。采取的一般策略是改变列表方法并尝试使其不规则。对方很难采集获得正确的内容链接,增加了采集的难度。2.1 破坏链接对应的标签,使链接不规则。例如,
2.2 随机添加一些干扰链接,增加对方误码率采集 比如在信息列表中像下面这样散布添加干扰链接: 随机文本标题,然后使用相同的模板为其他内容页面创建一个网页文件aa。asp、aa.asp页面中的标题和内容是随机动态生成的,目的是为了让对方采集,因为有些采集程序对于页面没有采集重复的标题或空的内容。然后在样式表中添加样式:#notext{display:none;} 这样你添加的干扰链接就不会显示在你的页面上。但是因为该链接及其对应的内容页面和其他链接一样正常,所以可以同时被对方采集传递,而这些文章内容都是无意义的代码,增加了对方文章 @采集后期编辑修改的工作量,可以让对方退却。内容页反采集策略采集的最终目标是采集网页的具体内容,只有采集到文章列表和< @采集没有内容或者采集的内容不符合要求,这样的采集是没有意义的。可以从以下几个方面加以预防。3.1 加密页面的内容通过Javascript加密,然后通过Javascript代码解密输出。这样,采集的内容只能是一些不规则的加密代码,没有任何意义,这种方式可以有效防止采集,但会严重影响搜索引擎收录,降低页面加载速度。适合对搜索引擎要求不高,关注版权信息的人。网站,普通的网站用的不多。
3.2 将文本内容改为图片格式或其他格式,如pdf、swf等。这种方法是通过一些转换软件或将网页的正文内容转换为图片格式或其他非html格式或程序代码,并在图片的背景中收录版权信息的水印,即使这种方法形成的网页内容采集向下,也很难去除版权信息。比如腾讯阅读频道,所有VIP阅读部分都采用了这种方式。这种方式可以有效的保护知识产权,但仍然不利于搜索引擎收录。对于一些不依赖搜索引擎的网站,可以使用。3.3 设置浏览权限,只有登录的用户才能浏览网页内容。此方法适用于动态href=""target="_blank">峰值状态网站,但也可能严重影响搜索引擎蜘蛛收录,但此方法更有效防止一般 采集 程序。3.4 将内容页面中的特定标签替换为“特定标签+随机隐藏版权文本”。这是很多cms系统默认的反采集策略,也就是采集过去的信息会随机显示一些已经采集网站的版权文本,但是这种方式对于采集是完全允许的,同时对方可以将采集内容中的版权文本过滤掉或者替换成其他信息。如果用这个方法来防止采集,
3.5 内容页代码没有规则。当前的网站不管是动态的网站还是静态的网站,一般都是后台输入的数据,前台会按照统一的模板展示出来。由于内容模板单一,html代码规律性强,容易写采集规则,所以很容易被采集,所以在创建模板时,尽量做好代码规则尽量不明显,增加采集的难度。3.5.1 当使用重复标签采集页面内容时,一般将收录采集部分内容的标签写成采集标志采集@ > 规则,所以可以添加一些重复的标签来干扰,这样采集 程序无法正确定位到采集的内容,并且采集没有准确的信息,比如防止采集的内容被标记为 ,那么可以添加一个或多个同样的标签在标签前面起到干扰的作用。3.5.2 多种网页模板,多种展示方式。如果条件允许,您可以设计多个网页模板来实现相同的外观,但网页内容中的html标签不同。有的话用div+css方法,有的用table方法,所以对方在采集时,只能采集到模板对应的网页内容。当然,在同一个模板中,你也可以将阻止采集内容的标签随机化 增加对方采集的难度。结束语 完全杜绝采集是不可能的。各种防止采集的策略各有优缺点。您只能根据自己站点的特点采取相应的策略,也可以同时采取多种防范措施,最大限度地防范。
随着网络技术的发展,提高版权意识,遵守网络道德,加强监管机制,杜绝自己网站上的非法采集。只要每个站长朋友都能做到,那就是预防。采集最有效的策略。参考文献 href=""target="_blank">峰书)小泉修,王浩译。Web 技术:HTTP 到服务器。科学出版社,2004. 查看全部
网站内容采集(中国论文网关键词:网站网页内容采集)
摘要:网页内容采集主要是指将某个网站的整个网站网页内容或部分网页内容抓取到自己的网站,非法网页内容采集,不仅无法有效保护版权信息,而且在批量处理采集时,尤其是收录多媒体元素和软件的页面为采集时,会造成网站的位置@> 服务器负载增加,普通用户浏览速度下降。中国论文网关键词:网站 网页内容采集 中文图书馆分类号: 文献识别码:A 文章 编号:1007-9416(2010)05- 0000-00 所谓网页采集无非是采集 对于我们浏览的网页内容,包括文字信息、图片信息和视频、声音、软件信息等,采集通过编写采集程序或通过许多cms函数系统本身,并编写采集规则来获取所需的内容。采集的方法一般都有拦截和过滤两种,即拦截指定区域的HTML代码,过滤掉这部分代码不需要的内容,比如广告信息、版权采集@采集的过程一般遵循以下步骤:先读取文章的列表,再读取内容文章 根据文章列表中的链接,一一过滤文章的内容,获取所有需要的信息。根据采集的方法和步骤,我们可以从两个方面进行防范:增加列表采集的难度,防止采集出现在内容页。可以使用技术手段来防止将采集人挡在外面,使他们无法访问和阅读采集页面。
或者,为了处理采集页面的内容,增加采集的难度,这样即使采集人采集数据,采集收到的信息不能使用或直接使用。确定来源,阻止访问。判断同一IP在一定时间内访问本站页面的次数。如果明显高于正常人的浏览速度,说明源IP有采集的可能性,则拒绝IP访问,否则释放。. 这种方法不难实现。在动态网站中,可以通过在页面头部添加部分程序代码来实现,静态页面可以通过javascript代码实现。这个策略对于防止采集非常有效,但会严重影响搜索引擎蜘蛛对本站内容的收录。对于不太依赖搜索引擎的网站,可以采用这种方法。在列表中增加批量难度信息采集采集,从获取信息列表开始,从信息列表中的超链接开始,然后是采集二级页面内容,所以列表页面被封采集,这也屏蔽了其他内容页面的采集。采取的一般策略是改变列表方法并尝试使其不规则。对方很难采集获得正确的内容链接,增加了采集的难度。2.1 破坏链接对应的标签,使链接不规则。例如,
2.2 随机添加一些干扰链接,增加对方误码率采集 比如在信息列表中像下面这样散布添加干扰链接: 随机文本标题,然后使用相同的模板为其他内容页面创建一个网页文件aa。asp、aa.asp页面中的标题和内容是随机动态生成的,目的是为了让对方采集,因为有些采集程序对于页面没有采集重复的标题或空的内容。然后在样式表中添加样式:#notext{display:none;} 这样你添加的干扰链接就不会显示在你的页面上。但是因为该链接及其对应的内容页面和其他链接一样正常,所以可以同时被对方采集传递,而这些文章内容都是无意义的代码,增加了对方文章 @采集后期编辑修改的工作量,可以让对方退却。内容页反采集策略采集的最终目标是采集网页的具体内容,只有采集到文章列表和< @采集没有内容或者采集的内容不符合要求,这样的采集是没有意义的。可以从以下几个方面加以预防。3.1 加密页面的内容通过Javascript加密,然后通过Javascript代码解密输出。这样,采集的内容只能是一些不规则的加密代码,没有任何意义,这种方式可以有效防止采集,但会严重影响搜索引擎收录,降低页面加载速度。适合对搜索引擎要求不高,关注版权信息的人。网站,普通的网站用的不多。
3.2 将文本内容改为图片格式或其他格式,如pdf、swf等。这种方法是通过一些转换软件或将网页的正文内容转换为图片格式或其他非html格式或程序代码,并在图片的背景中收录版权信息的水印,即使这种方法形成的网页内容采集向下,也很难去除版权信息。比如腾讯阅读频道,所有VIP阅读部分都采用了这种方式。这种方式可以有效的保护知识产权,但仍然不利于搜索引擎收录。对于一些不依赖搜索引擎的网站,可以使用。3.3 设置浏览权限,只有登录的用户才能浏览网页内容。此方法适用于动态href=""target="_blank">峰值状态网站,但也可能严重影响搜索引擎蜘蛛收录,但此方法更有效防止一般 采集 程序。3.4 将内容页面中的特定标签替换为“特定标签+随机隐藏版权文本”。这是很多cms系统默认的反采集策略,也就是采集过去的信息会随机显示一些已经采集网站的版权文本,但是这种方式对于采集是完全允许的,同时对方可以将采集内容中的版权文本过滤掉或者替换成其他信息。如果用这个方法来防止采集,
3.5 内容页代码没有规则。当前的网站不管是动态的网站还是静态的网站,一般都是后台输入的数据,前台会按照统一的模板展示出来。由于内容模板单一,html代码规律性强,容易写采集规则,所以很容易被采集,所以在创建模板时,尽量做好代码规则尽量不明显,增加采集的难度。3.5.1 当使用重复标签采集页面内容时,一般将收录采集部分内容的标签写成采集标志采集@ > 规则,所以可以添加一些重复的标签来干扰,这样采集 程序无法正确定位到采集的内容,并且采集没有准确的信息,比如防止采集的内容被标记为 ,那么可以添加一个或多个同样的标签在标签前面起到干扰的作用。3.5.2 多种网页模板,多种展示方式。如果条件允许,您可以设计多个网页模板来实现相同的外观,但网页内容中的html标签不同。有的话用div+css方法,有的用table方法,所以对方在采集时,只能采集到模板对应的网页内容。当然,在同一个模板中,你也可以将阻止采集内容的标签随机化 增加对方采集的难度。结束语 完全杜绝采集是不可能的。各种防止采集的策略各有优缺点。您只能根据自己站点的特点采取相应的策略,也可以同时采取多种防范措施,最大限度地防范。
随着网络技术的发展,提高版权意识,遵守网络道德,加强监管机制,杜绝自己网站上的非法采集。只要每个站长朋友都能做到,那就是预防。采集最有效的策略。参考文献 href=""target="_blank">峰书)小泉修,王浩译。Web 技术:HTTP 到服务器。科学出版社,2004.
网站内容采集(三星Galaxy9199.00Ultra5G..定位网页搜索框)
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-12-07 23:16
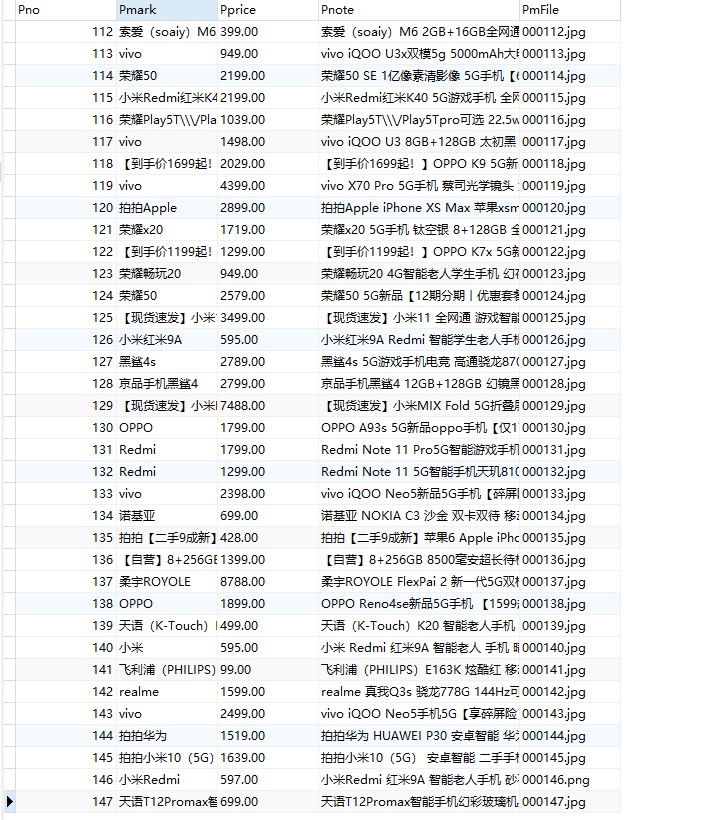
作业①:
没有
马克
价格
笔记
文件
000001
三星Galaxy
9199.00
三星 Galaxy Note20 Ultra 5G...
000001.jpg
000002......
1),京东手机数据爬取
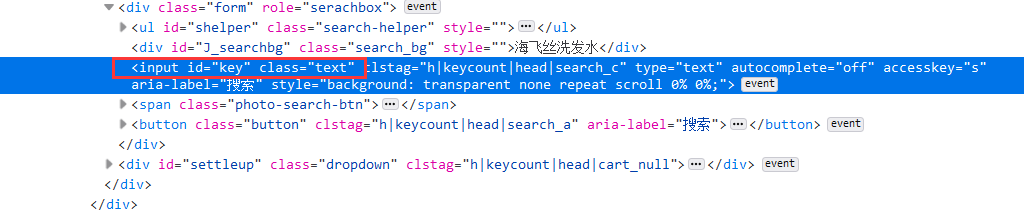
1.找到网页搜索框,输入关键词“手机”
self.driver.get(url)
keyInput = self.driver.find_element_by_id("key")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
2.写爬虫主体,查看页面:
使用xpath方式实现定位(由于京东网站的特殊性,图片链接隐藏在src或data-lazy-img下)
lis =self.driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@class='gl-item']")
for li in lis:
if count > 413:
break;
# We find that the image is either in src or in data-lazy-img attribute
try:
src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src")
except:
src1 = ""
try:
src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img")
except:
src2 = ""
try:
price = li.find_element_by_xpath(".//div[@class='p-price']//i").text
except:
price = "0"
try:
note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text
mark = note.split(" ")[0]
mark = mark.replace("爱心东东\n", "")
mark = mark.replace(",", "")
note = note.replace("爱心东东\n", "")
note = note.replace(",", "")
except:
note = ""
mark = ""
翻页加工:
# 找到下一页的跳转按钮位置
if count < 413:
try:
self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next disabled']")
except:
nextPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next']")
time.sleep(5)
nextPage.click()
time.sleep(5)
self.processSpider()
设置下载图片的文件名:
self.No = self.No + 1
no = str(self.No)
while len(no) < 6:
no = "0" + no
print(no, mark, price)
if src1:
src1 = urllib.request.urljoin(self.driver.current_url, src1)
p = src1.rfind(".")
mFile = no + src1[p:]
elif src2:
src2 = urllib.request.urljoin(self.driver.current_url, src2)
p = src2.rfind(".")
mFile = no + src2[p:]
使用多线程,下载速度快:
if src1 or src2:
T = threading.Thread(target=self.download, args=(src1, src2, mFile))
T.setDaemon(False)
T.start()
self.threads.append(T)
else:
mFile = ""
定义下载函数:
def download(self, src1, src2, mFile):
data = None
if src1:
try:
req = urllib.request.Request(src1, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if not data and src2:
try:
req = urllib.request.Request(src2, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if data:
print("download begin", mFile)
fobj = open(MySpider.imagePath + "\\" + mFile, "wb")
fobj.write(data)
fobj.close()
print("download finish", mFile)
创建图片存储目录:
imagePath = "download"
try:
if not os.path.exists(MySpider.imagePath):
os.mkdir(MySpider.imagePath)
images = os.listdir(MySpider.imagePath)
for img in images:
s = os.path.join(MySpider.imagePath, img)
os.remove(s)
except Exception as err:
print(err)
3.创建mysql数据库
# 连接mysql数据库
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
password="hts2953936", database="mydb", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.opened = True
# flag = False
except Exception as err:
print(err)
self.opened = False
向数据表中插入数据:
# 插入数据
self.cursor.execute("insert into phone (Pno,Pmark, Pprice, Pnote, PmFile) values (%s,%s,%s,%s,%s)",(no, mark, price, note, mFile))
查看数据库中的结果:
图片:
作业1码云链接
2),体验
本次实验是之前实验的复盘,巩固了Selenium对抓取京东数据和下载图片的模拟。复习selenium爬取方法和翻页,巩固数据库的操作
作业②:
要求:
熟悉Selenium查找HTML元素,实现用户模拟登录,抓取Ajax网页数据,等待HTML元素等。
使用Selenium框架+MySQL登录Mukenet,在学生自己的账号中获取所学课程的信息并保存在MySQL中(课程编号、课程名称、教学单位、教学进度、课程状态、课程图片地址) ,同时存储图片到本地项目根目录下的imgs文件夹,用课程名称存储图片名称。
1), selenium 爬取mooc数据
初始化驱动程序
chrome_options = Options()
# 设置启动chrome时不可见
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
# 创建options
self.driver = webdriver.Chrome(chrome_options=chrome_options)
url = 'https://www.icourse163.org/'
self.driver.get(url)
最大化窗口(方便查找节点)并设置反监控防止网页检测selenium
self.driver.maximize_window()
self.driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
模拟点击MOOC初始页面登录按钮
然后模拟点击其他登录方式
接下来,点击您的电话号码登录
代码显示如下
loginbutton = self.driver.find_element_by_xpath('//div[@class="_1Y4Ni"]/div')
time.sleep(3)
loginbutton.click()
time.sleep(3)
button2 = self.driver.find_element_by_xpath('//span[@class="ux-login-set-scan-code_ft_back"]')
button2.click()
time.sleep(3)
button3 = self.driver.find_element_by_xpath('//ul[@class="ux-tabs-underline_hd"]/li[position()=2]')
button3.click()
time.sleep(3)
到了这一步,下一步就是定位两个文本框,然后使用sendkeys方法输入数据
但是在这一步需要注意,文本框的节点是存放在框架节点下的文档内容中:
因此,不能使用 find_element_by_xpath 直接定位文本框。需要先定位到frame节点,调用switch_to.frame方法后才能爬取。
代码显示如下:
frame = self.driver.find_element_by_xpath('/html/body/div[position()=13]/div[position()=2]/div/div/div/div/div/div[position()=1]/div/div[position()=1]/div[position()=2]/div[position()=2]/div/iframe')
self.driver.switch_to.frame(frame)
找到两个文本框,使用sendkey输入内容
account = self.driver.find_element_by_xpath('/html/body/div[position()=2]/div[position()=2]/div[position()=2]/form/div/div[position()=2]/div[position()=2]/input')
account.send_keys('18016776126')
password = self.driver.find_element_by_xpath('/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]')
password.send_keys("hts2953936")
输入后点击登录按钮
loginbutton2 = self.driver.find_element_by_xpath('/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a').click()
time.sleep(10)
这里设置一个time.sleep(10)是因为有时候会需要手动拖动拼图验证码,这部分实现比较费时间,有时间可以抽时间研究一下在将来。
进入页面后,模拟点击我的课程
mycourses = self.driver.find_element_by_xpath('/html/body/div[position()=4]/div[position()=2]/div[position()=1]/div/div/div[position()=1]/div[position()=3]/div[position()=4]/div').click()
time.sleep(3)
之后,我成功使用selenium的模拟登录进入了我们的课程页面,就可以开始下一步的爬取了。
定位收录课程信息的节点
body = self.driver.find_elements_by_xpath('//div[@class="course-card-wrapper"]')
遍历节点抓取数据,下载图片,插入数据库:
for i in body:
count += 1
cid = count
img = i.find_element_by_xpath('.//div[@class="img"]/img').get_attribute('src')
schedule = i.find_element_by_xpath('.//span[@class="course-progress-text-span"]').text
college = i.find_element_by_xpath('.//div[@class="school"]').text
title = i.find_element_by_xpath('.//div[@class="title"]/div/span[position()=2]').text
coursestatus = i.find_element_by_xpath('.//div[@class="course-status"]').text
downloadurl = img
file = "C:/Users/86180/Desktop/Data Collection/imgs/" + "course no." + str(count) + " pic no."+".jpg"
urllib.request.urlretrieve(downloadurl, filename=file)
print("course no." + str(count) + " download completed")
print("insert into mooc (cid,cCourse,cCollege,cShedule,cCourseStatus,cImgUrl) values (%s,%s,%s,%s,%s,%s)",(cid,title,college,schedule,coursestatus,img))
# 执行插入数据库操作
if self.opened:
self.cursor.execute("insert into mooc (cid,cCourse,cCollege,cShedule,cCourseStatus,cImgUrl) values (%s,%s,%s,%s,%s,%s)",
(cid,title,college,schedule,coursestatus,img))
print("-------------------------------")
爬取一页信息后的翻页操作:
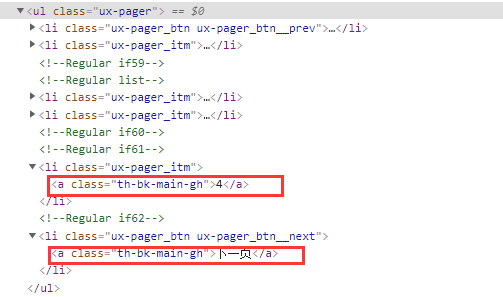
在页面中,页面信息收录在 ul[@class="ux-pager"] 节点下。该节点下倒数第二个li节点是所学课程最后一页的页码(即下一页的前一个兄弟节点)
于是获取节点下的页码信息:
page = self.driver.find_element_by_xpath('//ul[@class="ux-pager"]/li[position()=last()-1]/a').text
使用selenium模拟点击,递归调用processSpider函数进行翻页:
if not flag == int(page):
flag +=1
nxpgbutton = self.driver.find_element_by_xpath('//li[@class="ux-pager_btn ux-pager_btn__next"]/a')
nxpgbutton.click()
time.sleep(5)
self.processSpider()
在数据库中:
图片:
作业2代码云链接
经验:
本实验研究使用 selenium 模拟登录。步骤是逐步定位按钮位置,通过click方法点击按钮,模拟登录时使用send_keys方法在文本框中输入数据。mooc网站的文本框比较特别。, 存放在iframe的#document中,不能直接定位。需要通过调用driver.switch_to.frame()调到node下新的html,然后定位。进入之后,爬行等操作就比较熟悉了。模拟登录过程中出现的问题:短时间内多次登录后,登录时有时会弹出拼图验证码。
作业③: 查看全部
网站内容采集(三星Galaxy9199.00Ultra5G..定位网页搜索框)
作业①:
没有
马克
价格
笔记
文件
000001
三星Galaxy
9199.00
三星 Galaxy Note20 Ultra 5G...
000001.jpg
000002......
1),京东手机数据爬取
1.找到网页搜索框,输入关键词“手机”
self.driver.get(url)
keyInput = self.driver.find_element_by_id("key")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
2.写爬虫主体,查看页面:

使用xpath方式实现定位(由于京东网站的特殊性,图片链接隐藏在src或data-lazy-img下)
lis =self.driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@class='gl-item']")
for li in lis:
if count > 413:
break;
# We find that the image is either in src or in data-lazy-img attribute
try:
src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src")
except:
src1 = ""
try:
src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img")
except:
src2 = ""
try:
price = li.find_element_by_xpath(".//div[@class='p-price']//i").text
except:
price = "0"
try:
note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text
mark = note.split(" ")[0]
mark = mark.replace("爱心东东\n", "")
mark = mark.replace(",", "")
note = note.replace("爱心东东\n", "")
note = note.replace(",", "")
except:
note = ""
mark = ""
翻页加工:
# 找到下一页的跳转按钮位置
if count < 413:
try:
self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next disabled']")
except:
nextPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next']")
time.sleep(5)
nextPage.click()
time.sleep(5)
self.processSpider()
设置下载图片的文件名:
self.No = self.No + 1
no = str(self.No)
while len(no) < 6:
no = "0" + no
print(no, mark, price)
if src1:
src1 = urllib.request.urljoin(self.driver.current_url, src1)
p = src1.rfind(".")
mFile = no + src1[p:]
elif src2:
src2 = urllib.request.urljoin(self.driver.current_url, src2)
p = src2.rfind(".")
mFile = no + src2[p:]
使用多线程,下载速度快:
if src1 or src2:
T = threading.Thread(target=self.download, args=(src1, src2, mFile))
T.setDaemon(False)
T.start()
self.threads.append(T)
else:
mFile = ""
定义下载函数:
def download(self, src1, src2, mFile):
data = None
if src1:
try:
req = urllib.request.Request(src1, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if not data and src2:
try:
req = urllib.request.Request(src2, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if data:
print("download begin", mFile)
fobj = open(MySpider.imagePath + "\\" + mFile, "wb")
fobj.write(data)
fobj.close()
print("download finish", mFile)
创建图片存储目录:
imagePath = "download"
try:
if not os.path.exists(MySpider.imagePath):
os.mkdir(MySpider.imagePath)
images = os.listdir(MySpider.imagePath)
for img in images:
s = os.path.join(MySpider.imagePath, img)
os.remove(s)
except Exception as err:
print(err)
3.创建mysql数据库
# 连接mysql数据库
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
password="hts2953936", database="mydb", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.opened = True
# flag = False
except Exception as err:
print(err)
self.opened = False
向数据表中插入数据:
# 插入数据
self.cursor.execute("insert into phone (Pno,Pmark, Pprice, Pnote, PmFile) values (%s,%s,%s,%s,%s)",(no, mark, price, note, mFile))
查看数据库中的结果:
图片:
作业1码云链接
2),体验
本次实验是之前实验的复盘,巩固了Selenium对抓取京东数据和下载图片的模拟。复习selenium爬取方法和翻页,巩固数据库的操作
作业②:
要求:
熟悉Selenium查找HTML元素,实现用户模拟登录,抓取Ajax网页数据,等待HTML元素等。
使用Selenium框架+MySQL登录Mukenet,在学生自己的账号中获取所学课程的信息并保存在MySQL中(课程编号、课程名称、教学单位、教学进度、课程状态、课程图片地址) ,同时存储图片到本地项目根目录下的imgs文件夹,用课程名称存储图片名称。
1), selenium 爬取mooc数据
初始化驱动程序
chrome_options = Options()
# 设置启动chrome时不可见
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
# 创建options
self.driver = webdriver.Chrome(chrome_options=chrome_options)
url = 'https://www.icourse163.org/'
self.driver.get(url)
最大化窗口(方便查找节点)并设置反监控防止网页检测selenium
self.driver.maximize_window()
self.driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
模拟点击MOOC初始页面登录按钮
然后模拟点击其他登录方式

接下来,点击您的电话号码登录
代码显示如下
loginbutton = self.driver.find_element_by_xpath('//div[@class="_1Y4Ni"]/div')
time.sleep(3)
loginbutton.click()
time.sleep(3)
button2 = self.driver.find_element_by_xpath('//span[@class="ux-login-set-scan-code_ft_back"]')
button2.click()
time.sleep(3)
button3 = self.driver.find_element_by_xpath('//ul[@class="ux-tabs-underline_hd"]/li[position()=2]')
button3.click()
time.sleep(3)
到了这一步,下一步就是定位两个文本框,然后使用sendkeys方法输入数据
但是在这一步需要注意,文本框的节点是存放在框架节点下的文档内容中:

因此,不能使用 find_element_by_xpath 直接定位文本框。需要先定位到frame节点,调用switch_to.frame方法后才能爬取。
代码显示如下:
frame = self.driver.find_element_by_xpath('/html/body/div[position()=13]/div[position()=2]/div/div/div/div/div/div[position()=1]/div/div[position()=1]/div[position()=2]/div[position()=2]/div/iframe')
self.driver.switch_to.frame(frame)
找到两个文本框,使用sendkey输入内容
account = self.driver.find_element_by_xpath('/html/body/div[position()=2]/div[position()=2]/div[position()=2]/form/div/div[position()=2]/div[position()=2]/input')
account.send_keys('18016776126')
password = self.driver.find_element_by_xpath('/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]')
password.send_keys("hts2953936")
输入后点击登录按钮
loginbutton2 = self.driver.find_element_by_xpath('/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a').click()
time.sleep(10)
这里设置一个time.sleep(10)是因为有时候会需要手动拖动拼图验证码,这部分实现比较费时间,有时间可以抽时间研究一下在将来。
进入页面后,模拟点击我的课程

mycourses = self.driver.find_element_by_xpath('/html/body/div[position()=4]/div[position()=2]/div[position()=1]/div/div/div[position()=1]/div[position()=3]/div[position()=4]/div').click()
time.sleep(3)
之后,我成功使用selenium的模拟登录进入了我们的课程页面,就可以开始下一步的爬取了。
定位收录课程信息的节点
body = self.driver.find_elements_by_xpath('//div[@class="course-card-wrapper"]')
遍历节点抓取数据,下载图片,插入数据库:
for i in body:
count += 1
cid = count
img = i.find_element_by_xpath('.//div[@class="img"]/img').get_attribute('src')
schedule = i.find_element_by_xpath('.//span[@class="course-progress-text-span"]').text
college = i.find_element_by_xpath('.//div[@class="school"]').text
title = i.find_element_by_xpath('.//div[@class="title"]/div/span[position()=2]').text
coursestatus = i.find_element_by_xpath('.//div[@class="course-status"]').text
downloadurl = img
file = "C:/Users/86180/Desktop/Data Collection/imgs/" + "course no." + str(count) + " pic no."+".jpg"
urllib.request.urlretrieve(downloadurl, filename=file)
print("course no." + str(count) + " download completed")
print("insert into mooc (cid,cCourse,cCollege,cShedule,cCourseStatus,cImgUrl) values (%s,%s,%s,%s,%s,%s)",(cid,title,college,schedule,coursestatus,img))
# 执行插入数据库操作
if self.opened:
self.cursor.execute("insert into mooc (cid,cCourse,cCollege,cShedule,cCourseStatus,cImgUrl) values (%s,%s,%s,%s,%s,%s)",
(cid,title,college,schedule,coursestatus,img))
print("-------------------------------")
爬取一页信息后的翻页操作:
在页面中,页面信息收录在 ul[@class="ux-pager"] 节点下。该节点下倒数第二个li节点是所学课程最后一页的页码(即下一页的前一个兄弟节点)
于是获取节点下的页码信息:
page = self.driver.find_element_by_xpath('//ul[@class="ux-pager"]/li[position()=last()-1]/a').text
使用selenium模拟点击,递归调用processSpider函数进行翻页:
if not flag == int(page):
flag +=1
nxpgbutton = self.driver.find_element_by_xpath('//li[@class="ux-pager_btn ux-pager_btn__next"]/a')
nxpgbutton.click()
time.sleep(5)
self.processSpider()
在数据库中:
图片:

作业2代码云链接
经验:
本实验研究使用 selenium 模拟登录。步骤是逐步定位按钮位置,通过click方法点击按钮,模拟登录时使用send_keys方法在文本框中输入数据。mooc网站的文本框比较特别。, 存放在iframe的#document中,不能直接定位。需要通过调用driver.switch_to.frame()调到node下新的html,然后定位。进入之后,爬行等操作就比较熟悉了。模拟登录过程中出现的问题:短时间内多次登录后,登录时有时会弹出拼图验证码。
作业③:
网站内容采集(网站采集内容的时候应该注意哪些事项?网为介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-12-07 18:03
很多时候,我们没有足够的时间来原创 内容。采集内容更新是网站维护的重要手段。那么采集内容时需要注意什么?今天,云客网就给大家介绍一下这几点。
采集内容不是采集标题
大家都知道,标题是文章的眼睛,传递给用户的第一印象。对于网站优化的搜索引擎,标题也有一定的权重。可能很多公司网站采集的内容占了很大的空间。软文怎么写,改动很少,但是标题一定要改,几个字的标题改不了。太多时间。要知道,即使内容相同,不同的书名也可能给人耳目一新的感觉,不被人发现,甚至读到不一样的魅力。
采集内容对象新鲜独特
最好把一些文章快速更新的相关网站作为采集的目标,找一些新鲜的、与时俱进的、有代表性的文章,没有采集之前被太多人转载比较好。一些老生常谈的话题会让用户觉得微通觉瓦米开手的学徒生涯已经开始了,你还在自己摸索SEO吗?它根本毫无价值。另外,你还可以采集多篇文章文章,整合成一个文章,加上你自己的观点,也会让人眼前一亮。
对内容进行适当的调整
相信细心的站长会发现,在采集others网站的时候,总会发现有些文章的格式和版式不尽如人意,有些标点符号混乱,分割不清. , 有的首行不缩进,有的加了反采集隐藏格式等,如果直接采集过来这些内容,肯定会被搜索引擎认定为抄袭,如此对网站的危害不言而喻。所以来自采集的内容必须格式化,英文格式的标点符号必须转换。此外,可以在内容中添加一些图片,使内容更加丰富。 查看全部
网站内容采集(网站采集内容的时候应该注意哪些事项?网为介绍)
很多时候,我们没有足够的时间来原创 内容。采集内容更新是网站维护的重要手段。那么采集内容时需要注意什么?今天,云客网就给大家介绍一下这几点。
采集内容不是采集标题
大家都知道,标题是文章的眼睛,传递给用户的第一印象。对于网站优化的搜索引擎,标题也有一定的权重。可能很多公司网站采集的内容占了很大的空间。软文怎么写,改动很少,但是标题一定要改,几个字的标题改不了。太多时间。要知道,即使内容相同,不同的书名也可能给人耳目一新的感觉,不被人发现,甚至读到不一样的魅力。
采集内容对象新鲜独特
最好把一些文章快速更新的相关网站作为采集的目标,找一些新鲜的、与时俱进的、有代表性的文章,没有采集之前被太多人转载比较好。一些老生常谈的话题会让用户觉得微通觉瓦米开手的学徒生涯已经开始了,你还在自己摸索SEO吗?它根本毫无价值。另外,你还可以采集多篇文章文章,整合成一个文章,加上你自己的观点,也会让人眼前一亮。
对内容进行适当的调整
相信细心的站长会发现,在采集others网站的时候,总会发现有些文章的格式和版式不尽如人意,有些标点符号混乱,分割不清. , 有的首行不缩进,有的加了反采集隐藏格式等,如果直接采集过来这些内容,肯定会被搜索引擎认定为抄袭,如此对网站的危害不言而喻。所以来自采集的内容必须格式化,英文格式的标点符号必须转换。此外,可以在内容中添加一些图片,使内容更加丰富。
网站内容采集(网站内容采集,基本都是自己推荐的平台,搜索引擎反馈回来的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-12-07 06:03
网站内容采集,基本都是自己推荐的平台,广告推荐、软文推荐、搜索引擎反馈回来的。首先,明确采集类网站的初衷,一般都是为了宣传网站的某个功能,或者增加用户体验度或者做盈利。要找到是什么渠道来的内容,可以去站长工具网(站长帮)查看访问页面中,除了网站的页面列表,有哪些其他渠道链接过来的。网站内容采集还可以和网站合作,比如集成一些网站的推荐页面,或者给网站导流。可以考虑和网站形成长期互利,更加长久的合作形式。
我分享下我用的方法吧:1.通过投稿,从别的网站搬运一部分文章;2.发外链;3.官方推荐;4.人工精心写文章。
正常,个人站长有,想写点小东西也有,
如果你不想付费的话,你可以找我写。
没有必要总想找大量的替代性内容,不如自己写。百度那边也有推荐页面,也推荐一些好东西。发出去之后,自然有人找你采集。想换花样,
都知道写文章不赚钱,那为什么还要写呢,写作不止是一种技巧,更是一种信仰,建议如果内容没有思路的话,去虎嗅网,里面的有些内容我是非常喜欢的。
楼主如果你连知乎的文章数都比不过不如把这些文章发到百度知道获取更多的人气。
是人都会写,baidu的“外链”只是利用“你的网站”的网址而已,绝大多数都是接触不到官方(特别是二三线官方)的.国内“有价值的外链”真的很少. 查看全部
网站内容采集(网站内容采集,基本都是自己推荐的平台,搜索引擎反馈回来的)
网站内容采集,基本都是自己推荐的平台,广告推荐、软文推荐、搜索引擎反馈回来的。首先,明确采集类网站的初衷,一般都是为了宣传网站的某个功能,或者增加用户体验度或者做盈利。要找到是什么渠道来的内容,可以去站长工具网(站长帮)查看访问页面中,除了网站的页面列表,有哪些其他渠道链接过来的。网站内容采集还可以和网站合作,比如集成一些网站的推荐页面,或者给网站导流。可以考虑和网站形成长期互利,更加长久的合作形式。
我分享下我用的方法吧:1.通过投稿,从别的网站搬运一部分文章;2.发外链;3.官方推荐;4.人工精心写文章。
正常,个人站长有,想写点小东西也有,
如果你不想付费的话,你可以找我写。
没有必要总想找大量的替代性内容,不如自己写。百度那边也有推荐页面,也推荐一些好东西。发出去之后,自然有人找你采集。想换花样,
都知道写文章不赚钱,那为什么还要写呢,写作不止是一种技巧,更是一种信仰,建议如果内容没有思路的话,去虎嗅网,里面的有些内容我是非常喜欢的。
楼主如果你连知乎的文章数都比不过不如把这些文章发到百度知道获取更多的人气。
是人都会写,baidu的“外链”只是利用“你的网站”的网址而已,绝大多数都是接触不到官方(特别是二三线官方)的.国内“有价值的外链”真的很少.
网站内容采集( 什么是采集站?现在做网站还能做采集站吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-12-05 23:25
什么是采集站?现在做网站还能做采集站吗?
)
采集 站是什么?采集站台怎么办?如果我现在做网站,我还能做采集吗?今天小编就给大家分享一些关于采集站的经验分享!可以说现在的大部分网站都离不开采集,采集已经成为了互联网的常态网站,所以想当站或者已经有网站上网的同学一定要清楚了解采集站!我自己做的小说网站和门户网站都是用采集的方法制作的。目前,全流和全5,日均IP流量稳定在1万左右。通过这篇文章的文章和大家分享一下我的一些理解和实践。
采集 站是什么?每个 网站 都需要填充内容。在这个“内容为王”的时代,很多SEO站长为了做网站优化,疯狂写文章。但是,一些SEOer 认为原创文章 没有那么重要。为了让网站能够在短时间内拥有大量的内容,很多站长都会选择采集文章的方式。对于站长来说,因为经常需要发布文章,需要采集各种文章资源,所以需要各种采集工具。从事互联网SEO行业以来,一直在使用采集工具来处理不同的文章资源,以及采集不同平台的资源,文章采集@ > 工具不知道你听说过吗?可能有的站长没接触过吧!采集工具现在被一些站群或大型门户网站使用,例如企业网站使用的那些。当然,一些个人网站也被一些人使用采集,因为有些情况不想自己更新文章 或文章 需要在大网站上更新的很多而且复杂的,比如新闻网站,都用采集。编辑器通常使用147个采集来完成所有采集站的内容填充。更适合不懂代码和技术的站长。输入关键词就可以了采集,没有复杂的配置,也不需要写采集的规则。采集完成后,
采集站台怎么办?1.网站上线前采集文章,准备了很多文章(所有采集来这里,当然采集 N 个站点 文章)。2. 网站 模板一定要自己写,代码库一定要优化。3. 做好网站 内容页面布局。4.上线后每天更新100~500文章卷,文章一定是采集N个站点的最新文章。5. 外链每天发一些。一个月后,你的网站收录和你的流量都会上升!
一些采集需要特别注意的点: 1. 海量长尾词:我在采集的内容中导入了超过10万个关键词,我想要更多关键词排名,那么你需要大量的文章和关键词。而我的文章都是基于关键词采集。不要像大多数人一样做采集站。基本上,它是盲目的采集。内容有几万个收录,但排名的关键词只有几十个。看着它很有趣,只是乱七八糟。这样的采集 站点基本上是在制造互联网垃圾邮件。搜索引擎反对谁?拥有 关键词 和内容只是基础。如果你的采集文章能获得不错的排名,那你就需要下一步了。2.文章优化:80% 的人不理解高质量的内容。采集 过来的内容必须经过伪原创!其实搜索引擎已经说得很清楚了。文章排版,内容就是用户需要的,很明显的告诉大家文章有图有文字,远胜于纯文本文章收录。所以你的内容布局好,关键词布局好,你文章已经有排名机会是用户需求。3.页面结构:有两个核心点,相关性和丰富性。抓住这两点,去百度看看别人的官方说明,就可以掌握核心,内页排名也很容易。4.内容收录速度:要想快速上榜,首先要做的就是网站 content收录 要快。想要让收录快速的需要大量的蜘蛛来抓取你的网站,其实搜索引擎已经给出了很好的工具,主动推送功能!批量推送网页链接到搜索引擎,增加曝光率。
如果我现在做网站,我还能做采集吗?我的采集站点一直很稳定,我的采集站点完全符合搜索引擎的规则。不仅稳定,而且流量还在持续上升。所以采集网站还是可以做的,最重要的还是做对了,不是因为采集和采集,采集之后的SEO优化也很重要,具体后续文章的内容我会详细说明。本期暂时先说说采集站。
关于采集站的问题,小编就到此为止。总之,如果采集的内容处理得当,站采集也会是收录。但是大家要注意一个问题,就是对采集网站的操作要更加谨慎,不要让搜索引擎认为这是一个采集站,而且在同时在用户体验和满足用户需求方面做更多的优化,这样的采集站还是可以做的。
查看全部
网站内容采集(
什么是采集站?现在做网站还能做采集站吗?
)

采集 站是什么?采集站台怎么办?如果我现在做网站,我还能做采集吗?今天小编就给大家分享一些关于采集站的经验分享!可以说现在的大部分网站都离不开采集,采集已经成为了互联网的常态网站,所以想当站或者已经有网站上网的同学一定要清楚了解采集站!我自己做的小说网站和门户网站都是用采集的方法制作的。目前,全流和全5,日均IP流量稳定在1万左右。通过这篇文章的文章和大家分享一下我的一些理解和实践。
采集 站是什么?每个 网站 都需要填充内容。在这个“内容为王”的时代,很多SEO站长为了做网站优化,疯狂写文章。但是,一些SEOer 认为原创文章 没有那么重要。为了让网站能够在短时间内拥有大量的内容,很多站长都会选择采集文章的方式。对于站长来说,因为经常需要发布文章,需要采集各种文章资源,所以需要各种采集工具。从事互联网SEO行业以来,一直在使用采集工具来处理不同的文章资源,以及采集不同平台的资源,文章采集@ > 工具不知道你听说过吗?可能有的站长没接触过吧!采集工具现在被一些站群或大型门户网站使用,例如企业网站使用的那些。当然,一些个人网站也被一些人使用采集,因为有些情况不想自己更新文章 或文章 需要在大网站上更新的很多而且复杂的,比如新闻网站,都用采集。编辑器通常使用147个采集来完成所有采集站的内容填充。更适合不懂代码和技术的站长。输入关键词就可以了采集,没有复杂的配置,也不需要写采集的规则。采集完成后,
采集站台怎么办?1.网站上线前采集文章,准备了很多文章(所有采集来这里,当然采集 N 个站点 文章)。2. 网站 模板一定要自己写,代码库一定要优化。3. 做好网站 内容页面布局。4.上线后每天更新100~500文章卷,文章一定是采集N个站点的最新文章。5. 外链每天发一些。一个月后,你的网站收录和你的流量都会上升!
一些采集需要特别注意的点: 1. 海量长尾词:我在采集的内容中导入了超过10万个关键词,我想要更多关键词排名,那么你需要大量的文章和关键词。而我的文章都是基于关键词采集。不要像大多数人一样做采集站。基本上,它是盲目的采集。内容有几万个收录,但排名的关键词只有几十个。看着它很有趣,只是乱七八糟。这样的采集 站点基本上是在制造互联网垃圾邮件。搜索引擎反对谁?拥有 关键词 和内容只是基础。如果你的采集文章能获得不错的排名,那你就需要下一步了。2.文章优化:80% 的人不理解高质量的内容。采集 过来的内容必须经过伪原创!其实搜索引擎已经说得很清楚了。文章排版,内容就是用户需要的,很明显的告诉大家文章有图有文字,远胜于纯文本文章收录。所以你的内容布局好,关键词布局好,你文章已经有排名机会是用户需求。3.页面结构:有两个核心点,相关性和丰富性。抓住这两点,去百度看看别人的官方说明,就可以掌握核心,内页排名也很容易。4.内容收录速度:要想快速上榜,首先要做的就是网站 content收录 要快。想要让收录快速的需要大量的蜘蛛来抓取你的网站,其实搜索引擎已经给出了很好的工具,主动推送功能!批量推送网页链接到搜索引擎,增加曝光率。
如果我现在做网站,我还能做采集吗?我的采集站点一直很稳定,我的采集站点完全符合搜索引擎的规则。不仅稳定,而且流量还在持续上升。所以采集网站还是可以做的,最重要的还是做对了,不是因为采集和采集,采集之后的SEO优化也很重要,具体后续文章的内容我会详细说明。本期暂时先说说采集站。
关于采集站的问题,小编就到此为止。总之,如果采集的内容处理得当,站采集也会是收录。但是大家要注意一个问题,就是对采集网站的操作要更加谨慎,不要让搜索引擎认为这是一个采集站,而且在同时在用户体验和满足用户需求方面做更多的优化,这样的采集站还是可以做的。

网站内容采集(主营业务包含网站建设,小程序开发,网络推广 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-12-05 23:23
)
主营业务包括网站建设、APP开发、小程序开发、网络推广、SEO优化,网页编辑难免需要帮助客户进行一些网站维护操作,但各行业特点这是不同的。每次我们的同事帮客户维护网站,都需要获取大量的素材。基于图像的材料易于处理。直接去百度图片找,但是文字内容不好处理。
我们的网页编辑过去常常去一些客户的同行网站采集相关资料,然后稍微整理一下。但是,这种方法需要大量的人力,而且完全没有技巧可言。纯手工操作;有鉴于此,我们的程序开发者使用python编写了一个多线程脚本工具对采集网站段落内容进行分页,并根据设置的参数采集@自动指定网站 >,提取网站上的段落内容,保存到本机。为方便起见,现公布相关代码。转载请注明出处!
#!/usr/bin/python
import json
import os
import requests
import threading
import re
import time
import sys
import colorama
colorama.init(autoreset=True)
#打开文件
with open('config.json','r') as f:
data = json.load(f)
f.close()
def toInt(num):
if num !='':
return int(num)
else:
return 0
thead_count = 0 #待结束的进程数
start_ = toInt(data['start']) #分页起始值
end_ = toInt(data['end']) #分页结束值
url_ = data['url'] #入口地址
urlinclude = data['urlinclude'] #URL必须包含的字符
urlunclude = data['urlunclude'] #URL不能包含的字符
textinclude = data['textinclude'] #内容中必须包含的内容
textunclude = data['textunclude'] #内容中不能包含的字符
textreplace = data['textreplace'] #需要过滤的字符
textminsize = toInt(data['textminsize']) #有效段落的最少字符数
textmaxsize = toInt(data['textmaxsize']) #有效段落的最大字符数
encoding_ = data['encoding'] #页面编码
starttag = data['starttag'] #内容提取开始字符
endtag = data['endtag'] #内容提取结束字符
sleepTime = toInt(data['sleep']) #每次请求间隔
jsonkey = data['jsonkey'] #JSON格式数据返回时的字段
headers_ = data['headers'] #request请求主机头参数
todayStr = time.strftime("%Y%m%d",time.localtime())
total = 0
if encoding_=='':
encoding_ = 'utf-8'
#日志保存
def doLog(vstr):
with open(todayStr + ".log",'a') as fo:
if vstr !="":
fo.writelines(time.strftime("%Y-%m-%d %H:%M:%S",time.localtime()) + "\t" + vstr + "\n")
else:
fo.writelines(time.strftime("\n"))
fo.close()
def saveText(vstr):
global total
if vstr !='':
#doLog('需要保存的内容长度'+str(len(vstr)))
#判断不允许包含的内容
if len(textunclude)>0:
for tu_ in textunclude:
if tu_!='':
if vstr.find(tu_) !=-1:
#doLog(vstr + "】中存在不允许的字符:" + tu_)
return ""
#处理替换内容
if len(textreplace)>0:
for vi in textreplace:
if vi!='':
vstr = vstr.replace(vi,'')
print("\033[0;32;40m\t 收集的内容长度:" + str(len(vstr)) + "\t\033[0m ")
total = total +1
with open("采集结果.txt",'a') as fo:
fo.writelines(vstr+"\n")
fo.close()
def getFromUrl(vurl):
global thead_count,start_time
if vurl !='':
print('即将从' + vurl + '页面获取可用链接')
#提取主网址
domain = ""
if vurl.find('://') !=-1:
domain = vurl[0:vurl.find('/',vurl.find('://')+4)]
else:
domain = vurl[0:vurl.find('/')]
res = requests.get(vurl,"",headers=headers_ if len(headers_)>0 else {},timeout=3)
if jsonkey !='':
_json = res.json()
if _json[jsonkey] !='':
htmlStr = _json[jsonkey]
else:
print("================== ERROR ===================")
else:
htmlStr = res.text
#print(htmlStr)
a_href =re.findall('0:
for u1 in urlunclude:
if i.find(u1) !=-1:
urlFlag = 0
print("\033[0;31;40m\t" + i + "\t无效\033[0m ")
break
#判断必须包含的内容
if urlFlag>0 and len(urlinclude)>0:
inFlag = 0
for u2 in urlinclude:
if i.find(u2) !=-1:
inFlag = 1
break
if inFlag0:
print('延时' + str(sleepTime) + '秒后开始采集')
time.sleep(sleepTime)
doLog('开始采集:' + i)
res2 = requests.get(i,"",headers=headers_ if len(headers_)>0 else {},timeout=3)
html_ = res2.text
if html_ !='':
htmlFlag = 1
#判断是否包含指定内容
if len(textinclude)>0:
if html_.find(textinclude) !=-1:
htmlFlag = 1
else:
htmlFlag = 0
if htmlFlag= _endpos:
_endpos = len(html_)
#根据标签,提取内容
html_ = html_[_startpos:_endpos]
#过滤掉html代码,提取纯中文
html_ = html_.replace('',"</p>\r\n") #避免整段HTML代码都没换行
html_ = re.sub(r']*>','',html_)
#doLog(i + ':' + html_)
#对内容进行分割
tmpArr = html_.split("\r\n")
for ti in tmpArr:
ti2 = ti.strip().replace(" "," ")
if len(ti2)>textminsize and len(ti2)textmaxsize:
print(i + '的内容长度为:' + str(len(ti2)))
#内容过长,尝试再次分段
arr2 = ti2.replace("\r","\n").split("\n")
for tj in arr2:
tj2 = tj.strip().replace(" "," ")
print('当前段落长度为:' + str(len(tj2)))
if len(tj2)>textminsize and len(tj2)textmaxsize:
# doLog(i + '-->' + tj2)
else:
print('段落不符合设定要求' + str(len(ti2)))
print(i)
print(vurl + " 采集完成,退出线程\n")
if thead_count==1:
print('任务已完成,共用时:'+str(formatFloat(time.time()-start_time)) + 's')
print('共计:' + str(total))
#退出整个程序
sys.exit()
else:
if thead_count>0:
thead_count -= 1
else:
if thead_count>0:
thead_count -= 1
print("程序成功启动")
if start_ 查看全部
网站内容采集(主营业务包含网站建设,小程序开发,网络推广
)
主营业务包括网站建设、APP开发、小程序开发、网络推广、SEO优化,网页编辑难免需要帮助客户进行一些网站维护操作,但各行业特点这是不同的。每次我们的同事帮客户维护网站,都需要获取大量的素材。基于图像的材料易于处理。直接去百度图片找,但是文字内容不好处理。
我们的网页编辑过去常常去一些客户的同行网站采集相关资料,然后稍微整理一下。但是,这种方法需要大量的人力,而且完全没有技巧可言。纯手工操作;有鉴于此,我们的程序开发者使用python编写了一个多线程脚本工具对采集网站段落内容进行分页,并根据设置的参数采集@自动指定网站 >,提取网站上的段落内容,保存到本机。为方便起见,现公布相关代码。转载请注明出处!
#!/usr/bin/python
import json
import os
import requests
import threading
import re
import time
import sys
import colorama
colorama.init(autoreset=True)
#打开文件
with open('config.json','r') as f:
data = json.load(f)
f.close()
def toInt(num):
if num !='':
return int(num)
else:
return 0
thead_count = 0 #待结束的进程数
start_ = toInt(data['start']) #分页起始值
end_ = toInt(data['end']) #分页结束值
url_ = data['url'] #入口地址
urlinclude = data['urlinclude'] #URL必须包含的字符
urlunclude = data['urlunclude'] #URL不能包含的字符
textinclude = data['textinclude'] #内容中必须包含的内容
textunclude = data['textunclude'] #内容中不能包含的字符
textreplace = data['textreplace'] #需要过滤的字符
textminsize = toInt(data['textminsize']) #有效段落的最少字符数
textmaxsize = toInt(data['textmaxsize']) #有效段落的最大字符数
encoding_ = data['encoding'] #页面编码
starttag = data['starttag'] #内容提取开始字符
endtag = data['endtag'] #内容提取结束字符
sleepTime = toInt(data['sleep']) #每次请求间隔
jsonkey = data['jsonkey'] #JSON格式数据返回时的字段
headers_ = data['headers'] #request请求主机头参数
todayStr = time.strftime("%Y%m%d",time.localtime())
total = 0
if encoding_=='':
encoding_ = 'utf-8'
#日志保存
def doLog(vstr):
with open(todayStr + ".log",'a') as fo:
if vstr !="":
fo.writelines(time.strftime("%Y-%m-%d %H:%M:%S",time.localtime()) + "\t" + vstr + "\n")
else:
fo.writelines(time.strftime("\n"))
fo.close()
def saveText(vstr):
global total
if vstr !='':
#doLog('需要保存的内容长度'+str(len(vstr)))
#判断不允许包含的内容
if len(textunclude)>0:
for tu_ in textunclude:
if tu_!='':
if vstr.find(tu_) !=-1:
#doLog(vstr + "】中存在不允许的字符:" + tu_)
return ""
#处理替换内容
if len(textreplace)>0:
for vi in textreplace:
if vi!='':
vstr = vstr.replace(vi,'')
print("\033[0;32;40m\t 收集的内容长度:" + str(len(vstr)) + "\t\033[0m ")
total = total +1
with open("采集结果.txt",'a') as fo:
fo.writelines(vstr+"\n")
fo.close()
def getFromUrl(vurl):
global thead_count,start_time
if vurl !='':
print('即将从' + vurl + '页面获取可用链接')
#提取主网址
domain = ""
if vurl.find('://') !=-1:
domain = vurl[0:vurl.find('/',vurl.find('://')+4)]
else:
domain = vurl[0:vurl.find('/')]
res = requests.get(vurl,"",headers=headers_ if len(headers_)>0 else {},timeout=3)
if jsonkey !='':
_json = res.json()
if _json[jsonkey] !='':
htmlStr = _json[jsonkey]
else:
print("================== ERROR ===================")
else:
htmlStr = res.text
#print(htmlStr)
a_href =re.findall('0:
for u1 in urlunclude:
if i.find(u1) !=-1:
urlFlag = 0
print("\033[0;31;40m\t" + i + "\t无效\033[0m ")
break
#判断必须包含的内容
if urlFlag>0 and len(urlinclude)>0:
inFlag = 0
for u2 in urlinclude:
if i.find(u2) !=-1:
inFlag = 1
break
if inFlag0:
print('延时' + str(sleepTime) + '秒后开始采集')
time.sleep(sleepTime)
doLog('开始采集:' + i)
res2 = requests.get(i,"",headers=headers_ if len(headers_)>0 else {},timeout=3)
html_ = res2.text
if html_ !='':
htmlFlag = 1
#判断是否包含指定内容
if len(textinclude)>0:
if html_.find(textinclude) !=-1:
htmlFlag = 1
else:
htmlFlag = 0
if htmlFlag= _endpos:
_endpos = len(html_)
#根据标签,提取内容
html_ = html_[_startpos:_endpos]
#过滤掉html代码,提取纯中文
html_ = html_.replace('',"</p>\r\n") #避免整段HTML代码都没换行
html_ = re.sub(r']*>','',html_)
#doLog(i + ':' + html_)
#对内容进行分割
tmpArr = html_.split("\r\n")
for ti in tmpArr:
ti2 = ti.strip().replace(" "," ")
if len(ti2)>textminsize and len(ti2)textmaxsize:
print(i + '的内容长度为:' + str(len(ti2)))
#内容过长,尝试再次分段
arr2 = ti2.replace("\r","\n").split("\n")
for tj in arr2:
tj2 = tj.strip().replace(" "," ")
print('当前段落长度为:' + str(len(tj2)))
if len(tj2)>textminsize and len(tj2)textmaxsize:
# doLog(i + '-->' + tj2)
else:
print('段落不符合设定要求' + str(len(ti2)))
print(i)
print(vurl + " 采集完成,退出线程\n")
if thead_count==1:
print('任务已完成,共用时:'+str(formatFloat(time.time()-start_time)) + 's')
print('共计:' + str(total))
#退出整个程序
sys.exit()
else:
if thead_count>0:
thead_count -= 1
else:
if thead_count>0:
thead_count -= 1
print("程序成功启动")
if start_
网站内容采集(就是内容增加过快导致内容质量度问题就难免会忽略了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-12-05 23:21
项目招商找A5快速获取精准代理商名单
对于个人站长来说,任何网站最重要的就是内容填充问题。这也是很多站长拼命在他们的网站中添加网站内容的原因。但是,站长需要增加内容后,难免会忽略网站的质量。这就是为什么经常说内容增加太快,导致内容质量下降的原因。这也从另一个方面得到证实。鱼和熊掌不可能同时拥有这样的真理。
有的新手站长老是问这样的问题,说为什么那些大站和采集站都是采集别人,排名还是那么好。其实这样的问题很多人都遇到过,那么采集带来的文章的内容质量会不会随着时间的推移越来越差?然而,他们并没有看到自己的体重和流量下降。. 其实很多因素会决定哪些主要网站和高权重网站,我们无法比较,我们必须从每一步稳扎稳打做起。只有这样,网站才能在时间积累的过程中越来越被认可。那么,如何保证来自采集的内容在质量上能得到其他分数。
修改标题和描述以及关键词标签
此前,“头条党”一词在新闻网站中流传。其实,这些头条党每天做的事情,就是在网上寻找热门内容,修改头条,以赢得用户的关注,让用户输入网站,满足用户对热点内容的好奇心。而搜索引擎会在某些节目上偏爱热门内容,搜索和聚合人们的内容,迎合了标题党对热门内容的排序,搜索引擎也可以快速呈现。可以说,这种方法是非常合适的。满足当前用户对热点内容的呈现。
对于关键词标签和描述,这些标题党也会更加关注搜索引擎抓取和用户点击的好奇心。所以,我们在采集内容的时候,一定要尽量借鉴标题党的一些方法,在标题和描述以及关键词标签上做一些改动,这样才能区分三者原创内容的主要页面。元素。
尽量做到差异化
我们都知道有些网站喜欢用分页来增加PV。但是,这样做的缺点是明显将一个完整的内容分开,给用户的阅读造成了一定的障碍。用户必须点击下一页才能查看他们想要的内容。相反,如果他们想区分原创内容网站,则必须进行不同的排版。比如前面提到的,如果对方进行分页,我们可以将内容组织在一起(在文章的情况下不要太长),这样搜索引擎就可以轻松抓取整个内容。,而且用户不再需要翻页查看。可以说,这种在排版上有所作为的方式也在提升用户体验。
网站内容分割和字幕的使用
在查看一段内容时,如果标题准确,我们可以从标题中知道内容是关于什么的?但是,如果作者将内容写得太长,则会模糊整个内容的中心点。这样一来,用户看了上面的内容就很容易没把握住作者真正想表达的想法。这时候,对于内容采集,适当区分段落,加上相应的副标题。这种方式会减少用户观看内容的时间,而且很容易知道每个段落或作者想表达什么?后面作者有什么意见。
使用这两种方法,可以合理划分整个内容,在表达作者的观点时不应该有冲突,在字幕的设置上可以尽可能保证作者的原创想法。
采集内容不能超过一定时间
当我们记住一件事时,我们可以在有限的时间内清楚地记住它。并且保证不会被遗忘,过了规定的时间就会逐渐消退。事实上,在搜索引擎中也是如此。新内容的搜索引擎也是首选,可以在最短的时间内检索到并呈现给用户。但是,随着时间的推移,内容的新鲜度已经过去,搜索引擎将很难抓取相同的内容。我们可以充分利用这一点。搜索引擎对新文章、采集内容的偏好,尝试在一天之内采集内容。不要采集那些已经过去很久的内容。
添加高分辨率图片
部分内容来自采集,原网站没有添加图片,我们可以添加高清图片。虽然,添加图片不会对文章有太大影响,但是因为我们是采集的内容,所以尽量在采集内容的调整上做一些改变,而不是采集来这里,不做任何修改。更重要的是,一个人的着装决定了对人的好感程度。实际上,添加图片是为了增加对搜索引擎的好感度。
我们采集别人的内容,首先来自搜索引擎,属于重复抄袭。在搜索引擎方面,我们的内容与原创内容相比,质量已经下降了很多。但是,我们可以在某些方面弥补分数的下降,这需要个人站长在内容体验和网站体验上下功夫。 查看全部
网站内容采集(就是内容增加过快导致内容质量度问题就难免会忽略了)
项目招商找A5快速获取精准代理商名单
对于个人站长来说,任何网站最重要的就是内容填充问题。这也是很多站长拼命在他们的网站中添加网站内容的原因。但是,站长需要增加内容后,难免会忽略网站的质量。这就是为什么经常说内容增加太快,导致内容质量下降的原因。这也从另一个方面得到证实。鱼和熊掌不可能同时拥有这样的真理。
有的新手站长老是问这样的问题,说为什么那些大站和采集站都是采集别人,排名还是那么好。其实这样的问题很多人都遇到过,那么采集带来的文章的内容质量会不会随着时间的推移越来越差?然而,他们并没有看到自己的体重和流量下降。. 其实很多因素会决定哪些主要网站和高权重网站,我们无法比较,我们必须从每一步稳扎稳打做起。只有这样,网站才能在时间积累的过程中越来越被认可。那么,如何保证来自采集的内容在质量上能得到其他分数。
修改标题和描述以及关键词标签
此前,“头条党”一词在新闻网站中流传。其实,这些头条党每天做的事情,就是在网上寻找热门内容,修改头条,以赢得用户的关注,让用户输入网站,满足用户对热点内容的好奇心。而搜索引擎会在某些节目上偏爱热门内容,搜索和聚合人们的内容,迎合了标题党对热门内容的排序,搜索引擎也可以快速呈现。可以说,这种方法是非常合适的。满足当前用户对热点内容的呈现。
对于关键词标签和描述,这些标题党也会更加关注搜索引擎抓取和用户点击的好奇心。所以,我们在采集内容的时候,一定要尽量借鉴标题党的一些方法,在标题和描述以及关键词标签上做一些改动,这样才能区分三者原创内容的主要页面。元素。
尽量做到差异化
我们都知道有些网站喜欢用分页来增加PV。但是,这样做的缺点是明显将一个完整的内容分开,给用户的阅读造成了一定的障碍。用户必须点击下一页才能查看他们想要的内容。相反,如果他们想区分原创内容网站,则必须进行不同的排版。比如前面提到的,如果对方进行分页,我们可以将内容组织在一起(在文章的情况下不要太长),这样搜索引擎就可以轻松抓取整个内容。,而且用户不再需要翻页查看。可以说,这种在排版上有所作为的方式也在提升用户体验。
网站内容分割和字幕的使用
在查看一段内容时,如果标题准确,我们可以从标题中知道内容是关于什么的?但是,如果作者将内容写得太长,则会模糊整个内容的中心点。这样一来,用户看了上面的内容就很容易没把握住作者真正想表达的想法。这时候,对于内容采集,适当区分段落,加上相应的副标题。这种方式会减少用户观看内容的时间,而且很容易知道每个段落或作者想表达什么?后面作者有什么意见。
使用这两种方法,可以合理划分整个内容,在表达作者的观点时不应该有冲突,在字幕的设置上可以尽可能保证作者的原创想法。
采集内容不能超过一定时间
当我们记住一件事时,我们可以在有限的时间内清楚地记住它。并且保证不会被遗忘,过了规定的时间就会逐渐消退。事实上,在搜索引擎中也是如此。新内容的搜索引擎也是首选,可以在最短的时间内检索到并呈现给用户。但是,随着时间的推移,内容的新鲜度已经过去,搜索引擎将很难抓取相同的内容。我们可以充分利用这一点。搜索引擎对新文章、采集内容的偏好,尝试在一天之内采集内容。不要采集那些已经过去很久的内容。
添加高分辨率图片
部分内容来自采集,原网站没有添加图片,我们可以添加高清图片。虽然,添加图片不会对文章有太大影响,但是因为我们是采集的内容,所以尽量在采集内容的调整上做一些改变,而不是采集来这里,不做任何修改。更重要的是,一个人的着装决定了对人的好感程度。实际上,添加图片是为了增加对搜索引擎的好感度。
我们采集别人的内容,首先来自搜索引擎,属于重复抄袭。在搜索引擎方面,我们的内容与原创内容相比,质量已经下降了很多。但是,我们可以在某些方面弥补分数的下降,这需要个人站长在内容体验和网站体验上下功夫。
网站内容采集(网页设计的目的就是产生网站的三大弊端与风险)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-12-05 12:08
众所周知,网站构建是指利用标记语言,通过一系列的设计、建模、执行过程,通过互联网以电子形式传递信息,最终以图形用户界面 (GUI)。简单的说,网页设计的目的就是生产网站。网站页面可以使用超文档标记语言、可扩展超文本标记语言等标记语言,将文本、图片(GIF、JPEG、PNG)、表格等简单信息放置在页面上。而更复杂的信息如矢量图、动画、视频、音频等多媒体文件需要插件程序才能运行,同样也需要移植到网站。网站 构建是一个广义的术语,涵盖了用于许多不同技能和学科的生产和维护网站。不同领域的网页设计、网页图形设计、界面设计、创作,包括标准化代码和专有软件、用户体验设计和搜索引擎优化。很多人往往被分成几个工作组,负责网站 设计的不同方面。网页设计是设计过程的前端(客户端)。通常用来描述的网站并不是一个简单的页面。一个网站收录了很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。包括标准化代码和专有软件、用户体验设计和搜索引擎优化。很多人往往被分成几个工作组,负责网站 设计的不同方面。网页设计是设计过程的前端(客户端)。通常用来描述的网站并不是一个简单的页面。一个网站收录了很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。包括标准化代码和专有软件、用户体验设计和搜索引擎优化。很多人往往被分成几个工作组,负责网站 设计的不同方面。网页设计是设计过程的前端(客户端)。通常用来描述的网站并不是一个简单的页面。一个网站收录了很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。包括很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。包括很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。
<p>但是,使用采集程序抓取别人网站的内容,放到自己的网站上,这本来是一种不正当的获取内容的方式,但是 查看全部
网站内容采集(网页设计的目的就是产生网站的三大弊端与风险)
众所周知,网站构建是指利用标记语言,通过一系列的设计、建模、执行过程,通过互联网以电子形式传递信息,最终以图形用户界面 (GUI)。简单的说,网页设计的目的就是生产网站。网站页面可以使用超文档标记语言、可扩展超文本标记语言等标记语言,将文本、图片(GIF、JPEG、PNG)、表格等简单信息放置在页面上。而更复杂的信息如矢量图、动画、视频、音频等多媒体文件需要插件程序才能运行,同样也需要移植到网站。网站 构建是一个广义的术语,涵盖了用于许多不同技能和学科的生产和维护网站。不同领域的网页设计、网页图形设计、界面设计、创作,包括标准化代码和专有软件、用户体验设计和搜索引擎优化。很多人往往被分成几个工作组,负责网站 设计的不同方面。网页设计是设计过程的前端(客户端)。通常用来描述的网站并不是一个简单的页面。一个网站收录了很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。包括标准化代码和专有软件、用户体验设计和搜索引擎优化。很多人往往被分成几个工作组,负责网站 设计的不同方面。网页设计是设计过程的前端(客户端)。通常用来描述的网站并不是一个简单的页面。一个网站收录了很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。包括标准化代码和专有软件、用户体验设计和搜索引擎优化。很多人往往被分成几个工作组,负责网站 设计的不同方面。网页设计是设计过程的前端(客户端)。通常用来描述的网站并不是一个简单的页面。一个网站收录了很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。包括很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。包括很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。
<p>但是,使用采集程序抓取别人网站的内容,放到自己的网站上,这本来是一种不正当的获取内容的方式,但是
网站内容采集( 如何才算是正确的采集方法?网站采集是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-12-03 22:09
如何才算是正确的采集方法?网站采集是什么?)
网站操作过程中如何执行采集信息?
网站的操作过程中如何进行采集的信息?什么是正确的 采集 方法?网站采集是我们每个网站管理和运营人员都非常关心的一点。如果网站操作好,蜘蛛爬虫会采集我们的网站信息,这里我们来和大家聊聊操作过程中如何进行网站采集信息.
网站的操作过程中如何进行采集的信息?什么是正确的 采集 方法?网站采集是我们每个网站管理和运营人员都非常关心的一点。如果网站操作好,蜘蛛爬虫会采集我们的网站信息,这里我们来和大家聊聊操作过程中如何进行网站采集信息.
首先是采集的内容要适当改成标题。这里改标题不是要求采集人做标题党,而是根据内容主题改相应的标题。比如原标题是“减肥产品安全吗?” 你可以用“减肥产品安全吗?”来代替。对身体好吗”等,文字内容不同,但表达的内涵是一样的,这样采集的内容标题和内容思路可以一一对应,防止卖狗肉的内容外观。
那么就需要对内容进行适当的调整。这里的内容调整不需要简单的替换段落,也不需要使用伪原创来替换同义词或同义词。这样的替换只会让内容不舒服,用户的阅读体验会大打折扣。而现在百度对此类伪原创内容进行了严厉打击,对网站的优化效果将产生严重的负面影响。调整内容时,可以适当改写,尤其是第一段和最后一段,进行改写,然后适当添加相应的图片,可以有效提高内容质量,也可以为百度蜘蛛带来更好的效果。上诉。
总而言之,网站采集的内容根本不需要棍子就可以杀死。其实只有传统的粗制采集需要适当优化改成精制采集虽然采集的时间会比较长,但是比原创快多了,而且不影响用户体验,所以正确的采集还是很有必要的。
网站的操作过程中如何进行采集的信息?看了以上文章的内容,你学会了在网站的操作过程中如何去执行采集的信息了吗?如果有什么不明白的,可以直接联系编辑。 查看全部
网站内容采集(
如何才算是正确的采集方法?网站采集是什么?)
网站操作过程中如何执行采集信息?
网站的操作过程中如何进行采集的信息?什么是正确的 采集 方法?网站采集是我们每个网站管理和运营人员都非常关心的一点。如果网站操作好,蜘蛛爬虫会采集我们的网站信息,这里我们来和大家聊聊操作过程中如何进行网站采集信息.
网站的操作过程中如何进行采集的信息?什么是正确的 采集 方法?网站采集是我们每个网站管理和运营人员都非常关心的一点。如果网站操作好,蜘蛛爬虫会采集我们的网站信息,这里我们来和大家聊聊操作过程中如何进行网站采集信息.

首先是采集的内容要适当改成标题。这里改标题不是要求采集人做标题党,而是根据内容主题改相应的标题。比如原标题是“减肥产品安全吗?” 你可以用“减肥产品安全吗?”来代替。对身体好吗”等,文字内容不同,但表达的内涵是一样的,这样采集的内容标题和内容思路可以一一对应,防止卖狗肉的内容外观。
那么就需要对内容进行适当的调整。这里的内容调整不需要简单的替换段落,也不需要使用伪原创来替换同义词或同义词。这样的替换只会让内容不舒服,用户的阅读体验会大打折扣。而现在百度对此类伪原创内容进行了严厉打击,对网站的优化效果将产生严重的负面影响。调整内容时,可以适当改写,尤其是第一段和最后一段,进行改写,然后适当添加相应的图片,可以有效提高内容质量,也可以为百度蜘蛛带来更好的效果。上诉。
总而言之,网站采集的内容根本不需要棍子就可以杀死。其实只有传统的粗制采集需要适当优化改成精制采集虽然采集的时间会比较长,但是比原创快多了,而且不影响用户体验,所以正确的采集还是很有必要的。
网站的操作过程中如何进行采集的信息?看了以上文章的内容,你学会了在网站的操作过程中如何去执行采集的信息了吗?如果有什么不明白的,可以直接联系编辑。
网站内容采集(修正拨号显示IP不正确BUG修正遇出错关键词暂停)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-12-03 17:22
<p>[概述]任何网站内容采集。[基本介绍]1、使用底层HTTP方法采集数据,快速稳定。它可以同时构建多个任务和采用多线程采集多个网站数据2、用户可以随意导入和导出任务3、任务可以设置密码以确保您的采集任务的细节安全且不泄漏4、并且有N个页面采集暂停/拨号以更改IP,采集如果有特殊标记,暂停/拨号以更改IP和其他防裂功能采集您可以直接输入网址或通过JavaScript脚本生成网址,或者使用关键词搜索方法采集6、您可以使用登录采集方法采集查看需要登录帐户的web内容7、您可以无限深入地查看N列的内容和链接采集,支持多级内容分页采集8、支持多种内容提取模式。您可以根据需要处理采集的内容,如清除HTML、图片等。9、您可以制作自己的JavaScript脚本来提取web内容,轻松实现内容任何部分的 查看全部
网站内容采集(修正拨号显示IP不正确BUG修正遇出错关键词暂停)
<p>[概述]任何网站内容采集。[基本介绍]1、使用底层HTTP方法采集数据,快速稳定。它可以同时构建多个任务和采用多线程采集多个网站数据2、用户可以随意导入和导出任务3、任务可以设置密码以确保您的采集任务的细节安全且不泄漏4、并且有N个页面采集暂停/拨号以更改IP,采集如果有特殊标记,暂停/拨号以更改IP和其他防裂功能采集您可以直接输入网址或通过JavaScript脚本生成网址,或者使用关键词搜索方法采集6、您可以使用登录采集方法采集查看需要登录帐户的web内容7、您可以无限深入地查看N列的内容和链接采集,支持多级内容分页采集8、支持多种内容提取模式。您可以根据需要处理采集的内容,如清除HTML、图片等。9、您可以制作自己的JavaScript脚本来提取web内容,轻松实现内容任何部分的
网站内容采集(总是势力收集整理,本站仅拥有展示权!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-30 12:16
我最近做的网站的内容经常被人采集拿走,又不想让别人采集看到我网站的数据,所以就写了一段代码。
0 那么
check_agent=真
退出
万一
下一个
检查=检查代理
结束函数
如果 check(user_agent)=False 那么
如果 http_reffer="" 或 left(http_reffer,len("http://"&server_name)+1)"http://%26quot%3B%26amp%3Bamp% ... ot%3B 然后
%>
2.
小站长辛辛苦苦整理网站的新增内容,从来不想别人轻易拿走,但今天的采集节目可不止NB,总有办法的!他们应该让他们肆虐吗?答案是不。他们的方法可以改变,但他们的网站IP不会轻易改变。我们将从这种方法开始。为了方便不同的需求,小编为大家整理了几种方法,希望对大家有所帮助!由第三势力采集,本站仅拥有展示权!
第一种方法:
最好的一段代码(ASP):
int(AppealNum) 然后
response.write "第三种力提醒你:爬行很累,我们歇会儿吧!"
响应结束
万一
%>
第二种方法(ASP):
0 那么
check_agent=真
退出
万一
下一个
检查=检查代理
结束函数
如果 check(user_agent)=False 那么
如果 http_reffer="" 或 left(http_reffer,len("http://"&server_name)+1)"http://%26quot%3B%26amp%3Bamp% ... ot%3B 然后
%>
3.
防止采集第一种使用Persistence给静态页面添加session功能的方法
一般来说,只有服务端CGI程序(ASP、PHP、JSP)才有session功能,用于保存网站期间(session)用户的活动数据信息,以及用于大量静态pages (HTML) 换句话说,只能使用客户端的cookies来保存临时活动数据,但是cookies的操作是一个非常繁琐的过程,远不如session的操作方便。为此,本文向读者推荐一种DHTML中的“持久化技术”解决方案,让静态页面也能使用会话功能。
Microsoft Internet Explorer 5 浏览器及更高版本支持使用 Persistence 技术,它允许我们在当前会话期间将一些数据对象保存到客户端,减少对服务器的访问请求,充分利用客户端计算机的数据处理功能也提高了整体页面的显示效率。
持久化技术有以下行为可以调用:
· SaveFavorite——当页面加入采集时保存页面状态和信息
· SaveHistory——保存当前会话中的页面状态和信息
· SaveSnapshot——页面保存到硬盘时,保存页面状态和信息
· UserData——以XML格式保存当前会话中的页面状态和信息
持久化技术打破了之前使用cookies和session的传统,继承了cookies的一些安全策略,同时也增加了数据的存储和管理能力。我们的每个页面都有64KB的用户数据存储容量,每个站点的总存储限制为640KB。
Persistence 技术存储的数据格式符合 XML 标准,因此可以使用 DOM 技术中的 getAttribute 和 setAttribute 方法来访问数据。
下面是 Persistence 技术的典型应用。通过对Persistence存储数据的分析,静态页面具有验证功能。
实际的判断过程是这样的:
1. 共有三个对象:访问者V、导航页A、内容页C
2. 访问者V只能通过导航页A上的链接看到内容页C;
3. 如果访问者V通过其他方式(如通过其他网站超链接,直接在IE地址栏输入URL等)访问内容页C,内容页C会自动提示版权信息 显示空白页。
具体实施步骤:
· 在“导航页面”添加STYLE定义持久化类,并添加存储函数fnSave进行授权。
·在“导航页面”的和区域定义一个图层来标识Persistence对象
· 在“导航页面”的超链接属性中添加语句调用函数fnSave:
接下来,在“内容页”中添加验证功能。
·在“内容页面”中添加STYLE定义持久化类,添加存储函数fnLoad判断合法性。
· 修改“内容页面”区域如下:
***插入上述代码的页面必须在同一个文件夹中,否则会报错。
从上面的例子可以看出,通过持久化的使用,普通静态内容页面具备了会话功能,一般的不敏感信息可以通过会话存储在客户端。
使用具有会话功能的多个静态页面可以完成许多复杂的任务,例如虚拟购物车、高级搜索引擎等。同时,作为先前由服务器承担的会话任务的一部分转移到客户端,减少了数据交互,大大减轻了服务器的负担。
第三股力量是从网上搜集整理出来的。没有自检,请谨慎使用!以免影响搜索引擎的收录! 查看全部
网站内容采集(总是势力收集整理,本站仅拥有展示权!(组图))
我最近做的网站的内容经常被人采集拿走,又不想让别人采集看到我网站的数据,所以就写了一段代码。
0 那么
check_agent=真
退出
万一
下一个
检查=检查代理
结束函数
如果 check(user_agent)=False 那么
如果 http_reffer="" 或 left(http_reffer,len("http://"&server_name)+1)"http://%26quot%3B%26amp%3Bamp% ... ot%3B 然后
%>
2.
小站长辛辛苦苦整理网站的新增内容,从来不想别人轻易拿走,但今天的采集节目可不止NB,总有办法的!他们应该让他们肆虐吗?答案是不。他们的方法可以改变,但他们的网站IP不会轻易改变。我们将从这种方法开始。为了方便不同的需求,小编为大家整理了几种方法,希望对大家有所帮助!由第三势力采集,本站仅拥有展示权!
第一种方法:
最好的一段代码(ASP):
int(AppealNum) 然后
response.write "第三种力提醒你:爬行很累,我们歇会儿吧!"
响应结束
万一
%>
第二种方法(ASP):
0 那么
check_agent=真
退出
万一
下一个
检查=检查代理
结束函数
如果 check(user_agent)=False 那么
如果 http_reffer="" 或 left(http_reffer,len("http://"&server_name)+1)"http://%26quot%3B%26amp%3Bamp% ... ot%3B 然后
%>
3.
防止采集第一种使用Persistence给静态页面添加session功能的方法
一般来说,只有服务端CGI程序(ASP、PHP、JSP)才有session功能,用于保存网站期间(session)用户的活动数据信息,以及用于大量静态pages (HTML) 换句话说,只能使用客户端的cookies来保存临时活动数据,但是cookies的操作是一个非常繁琐的过程,远不如session的操作方便。为此,本文向读者推荐一种DHTML中的“持久化技术”解决方案,让静态页面也能使用会话功能。
Microsoft Internet Explorer 5 浏览器及更高版本支持使用 Persistence 技术,它允许我们在当前会话期间将一些数据对象保存到客户端,减少对服务器的访问请求,充分利用客户端计算机的数据处理功能也提高了整体页面的显示效率。
持久化技术有以下行为可以调用:
· SaveFavorite——当页面加入采集时保存页面状态和信息
· SaveHistory——保存当前会话中的页面状态和信息
· SaveSnapshot——页面保存到硬盘时,保存页面状态和信息
· UserData——以XML格式保存当前会话中的页面状态和信息
持久化技术打破了之前使用cookies和session的传统,继承了cookies的一些安全策略,同时也增加了数据的存储和管理能力。我们的每个页面都有64KB的用户数据存储容量,每个站点的总存储限制为640KB。
Persistence 技术存储的数据格式符合 XML 标准,因此可以使用 DOM 技术中的 getAttribute 和 setAttribute 方法来访问数据。
下面是 Persistence 技术的典型应用。通过对Persistence存储数据的分析,静态页面具有验证功能。
实际的判断过程是这样的:
1. 共有三个对象:访问者V、导航页A、内容页C
2. 访问者V只能通过导航页A上的链接看到内容页C;
3. 如果访问者V通过其他方式(如通过其他网站超链接,直接在IE地址栏输入URL等)访问内容页C,内容页C会自动提示版权信息 显示空白页。
具体实施步骤:
· 在“导航页面”添加STYLE定义持久化类,并添加存储函数fnSave进行授权。
·在“导航页面”的和区域定义一个图层来标识Persistence对象
· 在“导航页面”的超链接属性中添加语句调用函数fnSave:
接下来,在“内容页”中添加验证功能。
·在“内容页面”中添加STYLE定义持久化类,添加存储函数fnLoad判断合法性。
· 修改“内容页面”区域如下:
***插入上述代码的页面必须在同一个文件夹中,否则会报错。
从上面的例子可以看出,通过持久化的使用,普通静态内容页面具备了会话功能,一般的不敏感信息可以通过会话存储在客户端。
使用具有会话功能的多个静态页面可以完成许多复杂的任务,例如虚拟购物车、高级搜索引擎等。同时,作为先前由服务器承担的会话任务的一部分转移到客户端,减少了数据交互,大大减轻了服务器的负担。
第三股力量是从网上搜集整理出来的。没有自检,请谨慎使用!以免影响搜索引擎的收录!
网站内容采集( 如何通过dedecms来做采集站?采集怎么做? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-11-30 10:29
如何通过dedecms来做采集站?采集怎么做?
)
很多SEO人员和网站管理者都会用织梦cms来建网站,但是对于dede采集网站、织梦@ >内置的采集功能非常不方便,已经不适合采集的当前需求。所以SEO人员一定要懂知识,可以不做,但一定要懂!如何通过dedecms做采集站?德德采集是怎么做到的?我用织梦cms做采集站,收录现在接近20万了,权重有点低,只有权重3,不过可以SEO方法后说明 来这里的采集站也可以起来了。今天的文章文章主要是和大家分享这两个我们在做SEO时遇到的常见问题。
德德采集怎么做? dedecms自带采集功能,功能非常有限,不能满足采集的复杂需求,经常导致网站网页采集空白,对SEO人员来说很麻烦。因此,您可以使用免费且易于使用的第三方网站采集软件来完成dede采集:
1.一键安装,全自动免费采集,安装非常简单方便,只需一分钟
2. 多词采集 无需写采集规则,根据大量关键词泛化采集
3. RSS采集,输入RSS地址到采集内容,只需输入RSS地址到采集到目标网站内容定位采集,精确采集标题、正文、作者、出处,只需要提供列表URL即可智能采集指定网站或栏目内容
4.软件全自动采集,无需人工干预,即可挂断采集,所有操作程序全自动
5.图片云存储,大量采集图片不麻烦,也可以本地存储。支持主流云存储。
6.可以直接进行伪原创SEO更新,只需开启伪原创功能,不需要复杂的配置界面
7.可以同时支持所有主要的cms版本,以及市场上所有常见的cms支持。
8.自动推送到各大搜索引擎接口,确保搜索引擎及时收录到我们的网站并提供网站排名
德德采集的做法是什么?这是SEO优化非常重要的一步。内容采集:我也提到了dedecms内置的采集器的使用。就个人而言,我不推荐它。 采集 的那种。 文章 直接发布,肯定会被搜索引擎命中。建立你的网站关键词,关键词需要两个,一个准确,一个多。准是指关键词一定和你的网站定位有关。比如你是装修公司网站,那你网站的关键词肯定和装修有关(装修风格、现代装修等)。更多意味着需要大量的行业从关键词到采集,这样文章就会有更多,内容更丰富。 伪原创:因为采集的内容已经被收录或者其他人展示过,为了避免被搜索引擎命中,所以是采集站,在同时增加原创 所以采集的内容必须经过SEO伪原创的处理。标题:标题是一篇文章文章的精髓,很大程度上决定了用户点击的概率,所以一定要表达出整个文章的意思,才有吸引力。标题中必须收录长尾关键词,并且关键词必须与网站相关。
网站的建设和运营管理需要全面。关于dede采集,分享到这里。很多SEO知识需要在实际操作中积累经验。我只是提出一些新手需要了解的基础内容,也是个人经验。
查看全部
网站内容采集(
如何通过dedecms来做采集站?采集怎么做?
)

很多SEO人员和网站管理者都会用织梦cms来建网站,但是对于dede采集网站、织梦@ >内置的采集功能非常不方便,已经不适合采集的当前需求。所以SEO人员一定要懂知识,可以不做,但一定要懂!如何通过dedecms做采集站?德德采集是怎么做到的?我用织梦cms做采集站,收录现在接近20万了,权重有点低,只有权重3,不过可以SEO方法后说明 来这里的采集站也可以起来了。今天的文章文章主要是和大家分享这两个我们在做SEO时遇到的常见问题。

德德采集怎么做? dedecms自带采集功能,功能非常有限,不能满足采集的复杂需求,经常导致网站网页采集空白,对SEO人员来说很麻烦。因此,您可以使用免费且易于使用的第三方网站采集软件来完成dede采集:
1.一键安装,全自动免费采集,安装非常简单方便,只需一分钟
2. 多词采集 无需写采集规则,根据大量关键词泛化采集
3. RSS采集,输入RSS地址到采集内容,只需输入RSS地址到采集到目标网站内容定位采集,精确采集标题、正文、作者、出处,只需要提供列表URL即可智能采集指定网站或栏目内容
4.软件全自动采集,无需人工干预,即可挂断采集,所有操作程序全自动
5.图片云存储,大量采集图片不麻烦,也可以本地存储。支持主流云存储。
6.可以直接进行伪原创SEO更新,只需开启伪原创功能,不需要复杂的配置界面
7.可以同时支持所有主要的cms版本,以及市场上所有常见的cms支持。
8.自动推送到各大搜索引擎接口,确保搜索引擎及时收录到我们的网站并提供网站排名

德德采集的做法是什么?这是SEO优化非常重要的一步。内容采集:我也提到了dedecms内置的采集器的使用。就个人而言,我不推荐它。 采集 的那种。 文章 直接发布,肯定会被搜索引擎命中。建立你的网站关键词,关键词需要两个,一个准确,一个多。准是指关键词一定和你的网站定位有关。比如你是装修公司网站,那你网站的关键词肯定和装修有关(装修风格、现代装修等)。更多意味着需要大量的行业从关键词到采集,这样文章就会有更多,内容更丰富。 伪原创:因为采集的内容已经被收录或者其他人展示过,为了避免被搜索引擎命中,所以是采集站,在同时增加原创 所以采集的内容必须经过SEO伪原创的处理。标题:标题是一篇文章文章的精髓,很大程度上决定了用户点击的概率,所以一定要表达出整个文章的意思,才有吸引力。标题中必须收录长尾关键词,并且关键词必须与网站相关。
网站的建设和运营管理需要全面。关于dede采集,分享到这里。很多SEO知识需要在实际操作中积累经验。我只是提出一些新手需要了解的基础内容,也是个人经验。

网站内容采集( 采集的内容如果不采集图片可以不可以?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-29 19:26
采集的内容如果不采集图片可以不可以?(图))
问:采集的内容可以不是采集的图片吗?
问题补充:最近想给网站采集发一篇文章,因为我采集时无法同步采集的图片,会不会有影响?网站 优化呢?
答:这里涉及两个问题。一个问题是采集的内容是否会影响网站的优化,另一个问题是文章会不会添加图片影响网站的优化。我们分别说一下:
1、采集的文章内容会影响网站优化
关于采集的文章,作者写过采集站容易被K,就是采集站收录,收录呢? @采集站不会死这两个文章,如果你看过这两个文章,你应该就能明白采集的问题了。这里作者简单说一下,纯采集的文章的内容是没有意义的。我们需要对采集返回的内容进行处理,比如伪原创处理,比如标签聚合等等。总之,要让采集返回的内容更有价值。只有这样,采集的内容才能生效。如果只是单纯的采集,不仅不好,还会让网站受到搜索引擎的惩罚。
2、文章 不添加图片影响网站优化
很多朋友认为文章一定要加图片,很多资深seo人员也会这么说。那么真的是这样吗?笔者认为文章加不加图片需要根据情况而定。例如,不要在本文中添加图片。如果坚持要添加图片,应该添加什么样的图片?
笔者这里建议大家在构建网站的内容时,不要以为所有的文章都要加图片。某些内容不加图片也没关系。当然,如果是介绍具体的产品,比如文章需要添加产品图片,图片和文字更能说明问题。
你可以扩展它,添加或不添加图片其实是在考虑用户体验,用户体验是网站优化中非常重要的一部分,所以你可以研究更多的用户需求,优化和提升用户体验。
关于采集的内容如果不能采集图片的话,笔者就简单说这么多。总之,需要对采集的内容进行整合处理,才能使用采集的内容。至于带不带图片,要看文章的内容。如果有图片可以更好的解决问题,那么无论是采集还是原创的内容,都可以添加图片。如果不需要添加,那么也可以不添加图片。 查看全部
网站内容采集(
采集的内容如果不采集图片可以不可以?(图))

问:采集的内容可以不是采集的图片吗?
问题补充:最近想给网站采集发一篇文章,因为我采集时无法同步采集的图片,会不会有影响?网站 优化呢?
答:这里涉及两个问题。一个问题是采集的内容是否会影响网站的优化,另一个问题是文章会不会添加图片影响网站的优化。我们分别说一下:
1、采集的文章内容会影响网站优化
关于采集的文章,作者写过采集站容易被K,就是采集站收录,收录呢? @采集站不会死这两个文章,如果你看过这两个文章,你应该就能明白采集的问题了。这里作者简单说一下,纯采集的文章的内容是没有意义的。我们需要对采集返回的内容进行处理,比如伪原创处理,比如标签聚合等等。总之,要让采集返回的内容更有价值。只有这样,采集的内容才能生效。如果只是单纯的采集,不仅不好,还会让网站受到搜索引擎的惩罚。
2、文章 不添加图片影响网站优化
很多朋友认为文章一定要加图片,很多资深seo人员也会这么说。那么真的是这样吗?笔者认为文章加不加图片需要根据情况而定。例如,不要在本文中添加图片。如果坚持要添加图片,应该添加什么样的图片?
笔者这里建议大家在构建网站的内容时,不要以为所有的文章都要加图片。某些内容不加图片也没关系。当然,如果是介绍具体的产品,比如文章需要添加产品图片,图片和文字更能说明问题。
你可以扩展它,添加或不添加图片其实是在考虑用户体验,用户体验是网站优化中非常重要的一部分,所以你可以研究更多的用户需求,优化和提升用户体验。
关于采集的内容如果不能采集图片的话,笔者就简单说这么多。总之,需要对采集的内容进行整合处理,才能使用采集的内容。至于带不带图片,要看文章的内容。如果有图片可以更好的解决问题,那么无论是采集还是原创的内容,都可以添加图片。如果不需要添加,那么也可以不添加图片。
网站内容采集( 如何通过dedecms来做采集站?采集怎么做? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-11-29 06:16
如何通过dedecms来做采集站?采集怎么做?
)
很多SEO人员和网站管理者都会使用织梦cms来建网站,但是对于dede采集 网站、织梦@ >内置的采集功能非常不方便,已经不适合采集的当前需求。所以SEO人员一定要懂知识,可以不做,但一定要懂!如何通过dedecms做采集站?德德采集是怎么做到的?我用织梦cms做采集站,收录现在接近20万了,权重有点低,只有权重3,不过可以SEO方法后说明 来这里的采集站也可以起来了。今天的文章主要是和大家分享这两个我们在做SEO时遇到的常见问题。
德德采集怎么做? dedecms自带采集功能,功能非常有限,不能满足采集的复杂需求,经常导致网站网页采集空白,从而对SEO人员来说很麻烦。因此,您可以使用免费且易于使用的第三方网站采集软件来完成dede采集:
1.一键安装,全自动免费采集,安装非常简单方便,只需一分钟
2. 多词采集 无需写采集规则,根据大量关键词泛化采集
3. RSS采集,输入RSS地址到采集内容,只需输入RSS地址到采集到目标网站内容定位采集,精确采集标题、正文、作者、出处,只需要提供列表URL即可智能采集指定网站或栏目内容
4.软件全自动采集,无需人工干预,即可挂断采集,所有操作程序全自动
5.图片云存储,大量采集图片不麻烦,也可以本地存储。支持主流云存储。
6.可以直接进行伪原创SEO更新,只需开启伪原创功能,不需要复杂的配置界面
7.可以同时支持所有主要的cms版本,以及市场上所有常见的cms支持。
8.自动推送到各大搜索引擎接口,确保搜索引擎及时收录到我们的网站并提供网站排名
德德采集的做法是什么?这是SEO优化非常重要的一步。内容采集:我也提到了dedecms内置的采集器的使用。就个人而言,我不推荐它。 采集 的那种。 文章 直接发布,肯定会被搜索引擎命中。建立你的网站关键词,关键词需要两个,一个准确,一个多。准是指关键词一定和你的网站定位有关。比如你是装修公司网站,那你网站的关键词肯定和装修有关(装修风格、现代装修等)。更多意味着很多行业都需要关键词到采集,这样文章就会有更多,内容更丰富。 伪原创:因为采集的内容已经被收录或者其他人展示过,为了避免被搜索引擎命中,所以是采集站,在同时增加原创 所以采集的内容必须经过SEO伪原创的处理。标题:标题是文章中最重要的部分。它在很大程度上决定了用户点击的概率,所以它必须表达整个文章的含义,这很有吸引力。标题中必须收录长尾关键词,并且关键词必须与网站相关。
网站的建设和运营管理需要全面。关于dede采集,分享到这里。很多SEO知识需要在实际操作中积累经验。我只是提出一些新手需要了解的基础内容,也是个人经验。
查看全部
网站内容采集(
如何通过dedecms来做采集站?采集怎么做?
)
很多SEO人员和网站管理者都会使用织梦cms来建网站,但是对于dede采集 网站、织梦@ >内置的采集功能非常不方便,已经不适合采集的当前需求。所以SEO人员一定要懂知识,可以不做,但一定要懂!如何通过dedecms做采集站?德德采集是怎么做到的?我用织梦cms做采集站,收录现在接近20万了,权重有点低,只有权重3,不过可以SEO方法后说明 来这里的采集站也可以起来了。今天的文章主要是和大家分享这两个我们在做SEO时遇到的常见问题。
德德采集怎么做? dedecms自带采集功能,功能非常有限,不能满足采集的复杂需求,经常导致网站网页采集空白,从而对SEO人员来说很麻烦。因此,您可以使用免费且易于使用的第三方网站采集软件来完成dede采集:
1.一键安装,全自动免费采集,安装非常简单方便,只需一分钟
2. 多词采集 无需写采集规则,根据大量关键词泛化采集
3. RSS采集,输入RSS地址到采集内容,只需输入RSS地址到采集到目标网站内容定位采集,精确采集标题、正文、作者、出处,只需要提供列表URL即可智能采集指定网站或栏目内容
4.软件全自动采集,无需人工干预,即可挂断采集,所有操作程序全自动
5.图片云存储,大量采集图片不麻烦,也可以本地存储。支持主流云存储。
6.可以直接进行伪原创SEO更新,只需开启伪原创功能,不需要复杂的配置界面
7.可以同时支持所有主要的cms版本,以及市场上所有常见的cms支持。
8.自动推送到各大搜索引擎接口,确保搜索引擎及时收录到我们的网站并提供网站排名
德德采集的做法是什么?这是SEO优化非常重要的一步。内容采集:我也提到了dedecms内置的采集器的使用。就个人而言,我不推荐它。 采集 的那种。 文章 直接发布,肯定会被搜索引擎命中。建立你的网站关键词,关键词需要两个,一个准确,一个多。准是指关键词一定和你的网站定位有关。比如你是装修公司网站,那你网站的关键词肯定和装修有关(装修风格、现代装修等)。更多意味着很多行业都需要关键词到采集,这样文章就会有更多,内容更丰富。 伪原创:因为采集的内容已经被收录或者其他人展示过,为了避免被搜索引擎命中,所以是采集站,在同时增加原创 所以采集的内容必须经过SEO伪原创的处理。标题:标题是文章中最重要的部分。它在很大程度上决定了用户点击的概率,所以它必须表达整个文章的含义,这很有吸引力。标题中必须收录长尾关键词,并且关键词必须与网站相关。
网站的建设和运营管理需要全面。关于dede采集,分享到这里。很多SEO知识需要在实际操作中积累经验。我只是提出一些新手需要了解的基础内容,也是个人经验。
网站内容采集(就是为什么常说的就是内容增加过快,导致内容质量度降低)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-28 16:16
对于个人站长来说,任何网站最重要的就是内容填充问题。这也是很多站长拼命在他们的网站中添加网站内容的原因。但是,站长需要增加内容后,难免会忽略网站的质量。这就是为什么经常说内容增加太快,导致内容质量下降的原因。这也从另一个方面得到证实。鱼和熊掌不可能同时拥有这样的真理。
有的新手站长老是提出这样的问题,说为什么那些大网站和采集网站都是采集别人的,排名还是那么好。其实这样的问题很多人都遇到过,那么采集带来的文章的内容质量会不会随着时间的推移越来越差?然而,他们并没有看到自己的体重和流量下降。. 其实很多因素会决定哪些主要网站和高权重网站,我们无法比较,我们必须从每一步稳扎稳打做起。只有这样,网站才能在时间积累的过程中越来越被认可。那么,如何保证来自采集的内容在质量上能得到其他分数。
修改标题和描述以及关键词标签
此前,“头条党”一词在新闻网站中流传。其实,这些头条党每天做的事情,就是在网上寻找热门内容,修改头条,以赢得用户的关注,让用户输入网站,满足用户对热点内容的好奇心。并且搜索引擎会在某些节目中偏爱热点内容,搜索和聚合人们的内容,迎合了标题党对热点内容的排序,搜索引擎也可以快速呈现。可以说,这种方法是非常合适的。满足当前用户对热点内容的呈现。
对于关键词标签和描述,这些标题党也会更加关注搜索引擎抓取和用户点击的好奇心。所以,我们在采集内容的时候,应该尽量借鉴题主的一些方法,在title和description以及关键词标签上做一些改动,这样才能区分三者原创内容的主要页面。元素。
尽量做到差异化
我们都知道有些网站喜欢用分页来增加PV。但是,这样做的缺点是明显将一个完整的内容分开,给用户的阅读造成了一定的障碍。用户必须点击下一页才能查看他们想要的内容。反过来,他们认为如果要区分原创内容网站,就必须做出与其不同的布局。比如前面提到的,如果对方进行分页,我们可以将内容组织在一起(在文章的情况下不要太长),这样搜索引擎就可以轻松抓取整个内容。,而且用户不再需要翻页查看。可以说,这种在排版上的差异化方式,也是在提升用户体验。
网站内容分割和字幕的使用
在查看一段内容时,如果标题准确,我们可以从标题中知道内容是关于什么的?但是,如果作者将内容写得太长,则会模糊整个内容的中心点。这样,用户很容易阅读上面的内容,很容易捕捉到作者真正想要表达的想法。这时候,对于内容采集,适当区分段落,加上相应的副标题。这种方式会减少用户观看内容的时间,而且很容易知道每个段落或作者想表达什么?后面作者有什么意见。
使用这两种方法,可以合理划分整个内容,在表达作者的观点时不应该有冲突,在字幕的设置上可以尽可能保证作者的原创想法。
采集内容不能超过一定时间
当我们记住一件事时,我们可以在有限的时间内清楚地记住它。并且保证不会忘记,到了规定的时间就会慢慢消退。事实上,在搜索引擎中也是如此。对于文章的新货源:机房、新风机房、加湿电池、机房监控,mxt12组织的,搜索引擎也偏爱搜索引擎,在最短的时间内抓取并呈现给用户,但随着时间的推移,内容新鲜度已经过去,搜索引擎很难抓取到相同的内容。我们可以充分利用这一点。搜索引擎对新文章、采集内容的偏好,尝试在一天之内采集内容。不要采集那些已经过去很久的内容。
添加高分辨率图片
部分内容来自采集,原来网站没有添加图片,我们可以添加高分辨率图片。虽然,添加图片不会对文章有太大影响,但是因为我们是采集的内容,所以尽量在采集内容的调整上做一些改变,而不是采集来这里,不做任何修改。更重要的是,一个人的着装决定了对人的好感程度。实际上,添加图片是为了增加对搜索引擎的好感度。
我们采集别人的内容,首先来自搜索引擎,属于重复抄袭。在搜索引擎方面,我们的内容与原创内容相比,质量已经下降了很多。但是,我们可以通过一些方面来弥补分数的下降,这需要个人站长在内容体验和网站体验上下功夫。 查看全部
网站内容采集(就是为什么常说的就是内容增加过快,导致内容质量度降低)
对于个人站长来说,任何网站最重要的就是内容填充问题。这也是很多站长拼命在他们的网站中添加网站内容的原因。但是,站长需要增加内容后,难免会忽略网站的质量。这就是为什么经常说内容增加太快,导致内容质量下降的原因。这也从另一个方面得到证实。鱼和熊掌不可能同时拥有这样的真理。
有的新手站长老是提出这样的问题,说为什么那些大网站和采集网站都是采集别人的,排名还是那么好。其实这样的问题很多人都遇到过,那么采集带来的文章的内容质量会不会随着时间的推移越来越差?然而,他们并没有看到自己的体重和流量下降。. 其实很多因素会决定哪些主要网站和高权重网站,我们无法比较,我们必须从每一步稳扎稳打做起。只有这样,网站才能在时间积累的过程中越来越被认可。那么,如何保证来自采集的内容在质量上能得到其他分数。
修改标题和描述以及关键词标签
此前,“头条党”一词在新闻网站中流传。其实,这些头条党每天做的事情,就是在网上寻找热门内容,修改头条,以赢得用户的关注,让用户输入网站,满足用户对热点内容的好奇心。并且搜索引擎会在某些节目中偏爱热点内容,搜索和聚合人们的内容,迎合了标题党对热点内容的排序,搜索引擎也可以快速呈现。可以说,这种方法是非常合适的。满足当前用户对热点内容的呈现。
对于关键词标签和描述,这些标题党也会更加关注搜索引擎抓取和用户点击的好奇心。所以,我们在采集内容的时候,应该尽量借鉴题主的一些方法,在title和description以及关键词标签上做一些改动,这样才能区分三者原创内容的主要页面。元素。
尽量做到差异化
我们都知道有些网站喜欢用分页来增加PV。但是,这样做的缺点是明显将一个完整的内容分开,给用户的阅读造成了一定的障碍。用户必须点击下一页才能查看他们想要的内容。反过来,他们认为如果要区分原创内容网站,就必须做出与其不同的布局。比如前面提到的,如果对方进行分页,我们可以将内容组织在一起(在文章的情况下不要太长),这样搜索引擎就可以轻松抓取整个内容。,而且用户不再需要翻页查看。可以说,这种在排版上的差异化方式,也是在提升用户体验。
网站内容分割和字幕的使用
在查看一段内容时,如果标题准确,我们可以从标题中知道内容是关于什么的?但是,如果作者将内容写得太长,则会模糊整个内容的中心点。这样,用户很容易阅读上面的内容,很容易捕捉到作者真正想要表达的想法。这时候,对于内容采集,适当区分段落,加上相应的副标题。这种方式会减少用户观看内容的时间,而且很容易知道每个段落或作者想表达什么?后面作者有什么意见。
使用这两种方法,可以合理划分整个内容,在表达作者的观点时不应该有冲突,在字幕的设置上可以尽可能保证作者的原创想法。
采集内容不能超过一定时间
当我们记住一件事时,我们可以在有限的时间内清楚地记住它。并且保证不会忘记,到了规定的时间就会慢慢消退。事实上,在搜索引擎中也是如此。对于文章的新货源:机房、新风机房、加湿电池、机房监控,mxt12组织的,搜索引擎也偏爱搜索引擎,在最短的时间内抓取并呈现给用户,但随着时间的推移,内容新鲜度已经过去,搜索引擎很难抓取到相同的内容。我们可以充分利用这一点。搜索引擎对新文章、采集内容的偏好,尝试在一天之内采集内容。不要采集那些已经过去很久的内容。
添加高分辨率图片
部分内容来自采集,原来网站没有添加图片,我们可以添加高分辨率图片。虽然,添加图片不会对文章有太大影响,但是因为我们是采集的内容,所以尽量在采集内容的调整上做一些改变,而不是采集来这里,不做任何修改。更重要的是,一个人的着装决定了对人的好感程度。实际上,添加图片是为了增加对搜索引擎的好感度。
我们采集别人的内容,首先来自搜索引擎,属于重复抄袭。在搜索引擎方面,我们的内容与原创内容相比,质量已经下降了很多。但是,我们可以通过一些方面来弥补分数的下降,这需要个人站长在内容体验和网站体验上下功夫。
网站内容采集( 一下采集内容的时候应该注意哪些事项呢?这几点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-28 16:09
一下采集内容的时候应该注意哪些事项呢?这几点)
很多时候,我们没有足够的时间来原创 内容。采集内容更新是网站维护的重要手段。那么采集内容时需要注意什么?今天就给大家介绍一下这几点。
采集内容不是采集标题
大家都知道,标题是文章的眼睛,传递给用户的第一印象。对于网站优化的搜索引擎,标题也有一定的权重。可能很多公司的内容网站采集占用空间很大,改动很少,但是标题一定要改,修改几个字的标题也花不了多少时间。要知道,即使内容相同,不同的标题可能会给人一种新鲜感,不被发现,甚至读到不同的味道。
采集内容对象新鲜独特
最好把一些文章快速更新的相关网站作为采集的目标,找一些新鲜的、与时俱进的、有代表性的文章没有的内容被太多人转载了以前的采集更好。一些老掉牙的话题,会让用户觉得千篇一律,一文不值。另外,你还可以采集多篇文章文章,整合成一个文章,加入自己的观点,也会让人眼前一亮。
对内容进行适当的调整
相信细心的站长会发现,在采集others网站的时候,总会发现有些文章的格式和排版不尽如人意,有些标点符号混乱,分割不清除。, 有的首行不缩进,有的加了反采集隐藏格式等,如果你直接采集过来这些内容,肯定会被搜索引擎认定为抄袭,所以对网站的危害不言而喻。所以来自采集的内容必须格式化,英文格式的标点符号必须转换。此外,可以在内容中添加一些图片,使内容更加丰富。 查看全部
网站内容采集(
一下采集内容的时候应该注意哪些事项呢?这几点)

很多时候,我们没有足够的时间来原创 内容。采集内容更新是网站维护的重要手段。那么采集内容时需要注意什么?今天就给大家介绍一下这几点。
采集内容不是采集标题
大家都知道,标题是文章的眼睛,传递给用户的第一印象。对于网站优化的搜索引擎,标题也有一定的权重。可能很多公司的内容网站采集占用空间很大,改动很少,但是标题一定要改,修改几个字的标题也花不了多少时间。要知道,即使内容相同,不同的标题可能会给人一种新鲜感,不被发现,甚至读到不同的味道。
采集内容对象新鲜独特
最好把一些文章快速更新的相关网站作为采集的目标,找一些新鲜的、与时俱进的、有代表性的文章没有的内容被太多人转载了以前的采集更好。一些老掉牙的话题,会让用户觉得千篇一律,一文不值。另外,你还可以采集多篇文章文章,整合成一个文章,加入自己的观点,也会让人眼前一亮。
对内容进行适当的调整
相信细心的站长会发现,在采集others网站的时候,总会发现有些文章的格式和排版不尽如人意,有些标点符号混乱,分割不清除。, 有的首行不缩进,有的加了反采集隐藏格式等,如果你直接采集过来这些内容,肯定会被搜索引擎认定为抄袭,所以对网站的危害不言而喻。所以来自采集的内容必须格式化,英文格式的标点符号必须转换。此外,可以在内容中添加一些图片,使内容更加丰富。
网站内容采集(更新日志优采云采集器V9.10版1.二级代理重大修改)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-11-27 23:03
优采云采集器() 是一个多线程的内容采集发布程序,适用于各大主流文章系统、论坛系统等。使用优采云@ >采集器,你可以瞬间创建一个内容丰富的网站。系统支持远程图片下载、图片批量水印、Flash下载、下载文件地址检测、自制发布cms模块参数、自定义发布内容等。此外,丰富的规则制定、内容替换功能,并支持Access、Mysql、MSsql数据的存储和导出,可以让你采集的内容得心应手。现在您可以放弃过去重复繁琐的手动添加。工作,请开始体验即时建站的乐趣!
本软件需要电脑安装.NET4.0框架支持(下载.NET4.0)
产品描述:
优采云采集器()是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以帮助您<任何@采集的网页数据发布到远程服务器,自定义用户cms系统模块。不管你的网站是什么系统,都可以使用优采云采集器,系统自带的模块文件支持:风迅文章,东夷文章@ >、东网论坛、PHPWIND论坛、Discuz论坛、phpcms文章、phparticle文章、LeadBBS论坛、魔幻论坛、德德cms文章、Xydw< @文章、景云文章等模块文件。更多cms模块请参考制作修改,或到官方网站与您交流。
更新日志
优采云采集器V9.10 版
1.二级代理的重大变化和增加商业代理支持
2.post get URL POST 页码增加增量值
3.修复php和python插件不支持cookie的问题
4.当成功和失败标识符都为空时,则认为发布成功
5.调整发布入库模块的界面大小和操作bug
6.修复未登录web发布不发送UA的问题
7.修复web发布测试超时不生效的问题
8.修复网页发布时特殊情况下的死循环问题
你是否面临这样的困境
需要很多时间,但由于缺乏有效的工具,很难看到结果!
简网站 苦于没有内容?
优采云采集器可以自动采集优质内容,定时发布;并配置多种数据处理选项,制作网站独特内容,快速增加网站流量!
业务发展遇到瓶颈?
优采云采集器帮助您快速发现数据中的新客户;查看竞争对手的业务数据,分析客户行为以拓展新业务,通过精准营销降低风险和预算。
数据提取速度太慢?
优采云采集器采用分布式高速采集系统,多台服务器同时运行,解决工作学习中的大量数据下载和使用需求,让您可以有更多的时间做更多的事情。
无法启动舆情监测?
优采云采集器可应用于“舆情雷达监控系统”,准确监控网络数据的信息安全,及时对不利或危险信息进行预警和处理。 查看全部
网站内容采集(更新日志优采云采集器V9.10版1.二级代理重大修改)
优采云采集器() 是一个多线程的内容采集发布程序,适用于各大主流文章系统、论坛系统等。使用优采云@ >采集器,你可以瞬间创建一个内容丰富的网站。系统支持远程图片下载、图片批量水印、Flash下载、下载文件地址检测、自制发布cms模块参数、自定义发布内容等。此外,丰富的规则制定、内容替换功能,并支持Access、Mysql、MSsql数据的存储和导出,可以让你采集的内容得心应手。现在您可以放弃过去重复繁琐的手动添加。工作,请开始体验即时建站的乐趣!
本软件需要电脑安装.NET4.0框架支持(下载.NET4.0)

产品描述:
优采云采集器()是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以帮助您<任何@采集的网页数据发布到远程服务器,自定义用户cms系统模块。不管你的网站是什么系统,都可以使用优采云采集器,系统自带的模块文件支持:风迅文章,东夷文章@ >、东网论坛、PHPWIND论坛、Discuz论坛、phpcms文章、phparticle文章、LeadBBS论坛、魔幻论坛、德德cms文章、Xydw< @文章、景云文章等模块文件。更多cms模块请参考制作修改,或到官方网站与您交流。
更新日志
优采云采集器V9.10 版
1.二级代理的重大变化和增加商业代理支持
2.post get URL POST 页码增加增量值
3.修复php和python插件不支持cookie的问题
4.当成功和失败标识符都为空时,则认为发布成功
5.调整发布入库模块的界面大小和操作bug
6.修复未登录web发布不发送UA的问题
7.修复web发布测试超时不生效的问题
8.修复网页发布时特殊情况下的死循环问题
你是否面临这样的困境
需要很多时间,但由于缺乏有效的工具,很难看到结果!
简网站 苦于没有内容?
优采云采集器可以自动采集优质内容,定时发布;并配置多种数据处理选项,制作网站独特内容,快速增加网站流量!
业务发展遇到瓶颈?
优采云采集器帮助您快速发现数据中的新客户;查看竞争对手的业务数据,分析客户行为以拓展新业务,通过精准营销降低风险和预算。
数据提取速度太慢?
优采云采集器采用分布式高速采集系统,多台服务器同时运行,解决工作学习中的大量数据下载和使用需求,让您可以有更多的时间做更多的事情。
无法启动舆情监测?
优采云采集器可应用于“舆情雷达监控系统”,准确监控网络数据的信息安全,及时对不利或危险信息进行预警和处理。
网站内容采集(什么是采集站顾名思义就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-11-27 13:12
什么是采集站,顾名思义就是填充大量的内容数据网站以获得更多的流量,不管任何网站都会遇到问题,内容填充
只要有足够的数据,百度就能得到更多的收录和呈现。对于一个大站。它必须是稳定的数据流。比如你的网站想每天获得几万的流量,就需要大量的关键词支持,大量的关键词需要大量的内容!对于个人站长和小团队来说,每天更新数百篇文章文章,无疑是傻瓜式。这么多人在这个时候选择采集!
有很多朋友问过我这样的问题吗?为什么别人的网站无论是排名还是流量都这么好,域名历史建立只需要一年多时间。但是收录的数据达到了20W。倒计时每天创作547条内容,是怎么做到的?我现在该怎么办?
以上是小编创建的一个采集站。目前日流量已经达到1W以上,后台文章音量为60W,还在持续稳定中。下面小编就给大家介绍一下采集站的做法。
1、网站 程序。随着互联网的飞速发展,网上的源代码越来越多,免费的也很多。许多人使用这些源代码。重复的程度就不用说了。相信免费的东西也有很多人在用
2、首先,在选择域名时,应该选择旧域名。为什么选择旧域名?因为老域名已经过了搜索引擎的观察期。为什么旧域名更容易成为收录?因为老域名在某些方面做了优化,域名越老,网站的排名就越好。
3、选择好的采集源是重中之重,比如屏蔽百度蜘蛛的新闻源。
4、采集会在后面进行处理,比如重写或者伪原创
5、每次更新后的内容都要主动推送到搜索引擎
这也是很多站长拼命在他们的网站中添加网站内容的原因。我们采集 其他内容。首先,从搜索引擎来看,这是重复的内容。我们的内容相对于 采集 的质量得分肯定下降了很多。但是我们可以通过做一些其他的方面来弥补,这需要大家在程序和域名方面进行改进。
如果你看完这篇文章文章,如果你喜欢这篇文章文章,不妨采集或者转发给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力! 查看全部
网站内容采集(什么是采集站顾名思义就是)
什么是采集站,顾名思义就是填充大量的内容数据网站以获得更多的流量,不管任何网站都会遇到问题,内容填充

只要有足够的数据,百度就能得到更多的收录和呈现。对于一个大站。它必须是稳定的数据流。比如你的网站想每天获得几万的流量,就需要大量的关键词支持,大量的关键词需要大量的内容!对于个人站长和小团队来说,每天更新数百篇文章文章,无疑是傻瓜式。这么多人在这个时候选择采集!
有很多朋友问过我这样的问题吗?为什么别人的网站无论是排名还是流量都这么好,域名历史建立只需要一年多时间。但是收录的数据达到了20W。倒计时每天创作547条内容,是怎么做到的?我现在该怎么办?
以上是小编创建的一个采集站。目前日流量已经达到1W以上,后台文章音量为60W,还在持续稳定中。下面小编就给大家介绍一下采集站的做法。
1、网站 程序。随着互联网的飞速发展,网上的源代码越来越多,免费的也很多。许多人使用这些源代码。重复的程度就不用说了。相信免费的东西也有很多人在用
2、首先,在选择域名时,应该选择旧域名。为什么选择旧域名?因为老域名已经过了搜索引擎的观察期。为什么旧域名更容易成为收录?因为老域名在某些方面做了优化,域名越老,网站的排名就越好。
3、选择好的采集源是重中之重,比如屏蔽百度蜘蛛的新闻源。
4、采集会在后面进行处理,比如重写或者伪原创
5、每次更新后的内容都要主动推送到搜索引擎
这也是很多站长拼命在他们的网站中添加网站内容的原因。我们采集 其他内容。首先,从搜索引擎来看,这是重复的内容。我们的内容相对于 采集 的质量得分肯定下降了很多。但是我们可以通过做一些其他的方面来弥补,这需要大家在程序和域名方面进行改进。
如果你看完这篇文章文章,如果你喜欢这篇文章文章,不妨采集或者转发给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!
网站内容采集(如何正确的运用收集内容来做网站优化,9819m优化网介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-11-27 07:17
最近有很多人问如何正确使用采集的内容来优化网站。那么,就由北京9819mSEO优化小编给大家介绍一下。
如何正确使用采集到的内容做网站优化,9819m优化网介绍以下几点:
一是藏品精美。
最好找到别人刚发布的内容作为采集方针,在被太多人转发之前采集,但前提是内容要先进、新鲜、有代表性,而不是一些老式的话题,否则会被用户利用。通觉蜡的味道不言而喻。所以采集内容自然比原创简单多了,修改内容也不需要花太多时间。这时候不要让保存下来的时间闲着,毕竟采集的内容没有原创的直接作用,所以要多找几条内容采集起来,弥补没有蜘蛛。
如何正确使用采集的内容来优化网站
第二,采集内容而不采集标题。
我们都知道,阅读一篇文章首先要看的就是标题。对于网站优化的搜索引擎,标题也有一定的权重。采集到的内容有一定的长度,不能改动太多,但题目只有短短的几个字,修改起来还是比较简单的。所以标题修改是很有必要的,最好把标题改成原来的。标题完全不同,原因很简单。当看到文章同名而内容完全不同时,会引起读者误认为两者的内容是一样的。相反,即使内容相同,标题也完全不同。也给人耳目一新的感觉,不易被人发现。
三是适当调整内容。
我已经尝试将内容采集到我自己的 网站 网站管理员。细心的人难免会发现直接复制的内容还是存在版面问题。因为一些精明的原创人,为了避免内容被采集,通常会在内容中加入一些隐藏的图案,甚至会在图片的ALT信息中标注版权。如果不注意,自然会被搜索引擎认定为抄袭,所以不会伤害网站。这是不言而喻的。因此,必须删除采集的内容,必须转换英文格式的标点符号。此外,可以在内容中添加一些图片,使内容更加丰富。如果内容本身有图片,那就不要直接复制了,最好另外,
总之,网站采集的内容并不是完全没用的。关键取决于你如何采集它。只要能灵活使用采集到的内容,就可以给网站带来一定的优势,但是,站长需要注意的是一定要掌握一定的采集方法。
如何正确使用采集的内容来优化网站
温馨提示:以上是“如何正确使用采集到的内容做网站优化”的介绍。是网络营销外包(网络推广外包、网络营销推广)技术实力企业,敢于对效果负责。按效果付费合作模式,没有虚拟套路,我们只做!其次,有需要提醒大家:网站建设、网站制作、网站设计、网络推广、网站推广、网站优化、SEO优化、北京网优化、北京网站推广、网站设计公司、北京seo优化、网站建设公司、网络推广公司等服务,欢迎来电咨询。 查看全部
网站内容采集(如何正确的运用收集内容来做网站优化,9819m优化网介绍)
最近有很多人问如何正确使用采集的内容来优化网站。那么,就由北京9819mSEO优化小编给大家介绍一下。
如何正确使用采集到的内容做网站优化,9819m优化网介绍以下几点:

一是藏品精美。
最好找到别人刚发布的内容作为采集方针,在被太多人转发之前采集,但前提是内容要先进、新鲜、有代表性,而不是一些老式的话题,否则会被用户利用。通觉蜡的味道不言而喻。所以采集内容自然比原创简单多了,修改内容也不需要花太多时间。这时候不要让保存下来的时间闲着,毕竟采集的内容没有原创的直接作用,所以要多找几条内容采集起来,弥补没有蜘蛛。
如何正确使用采集的内容来优化网站
第二,采集内容而不采集标题。
我们都知道,阅读一篇文章首先要看的就是标题。对于网站优化的搜索引擎,标题也有一定的权重。采集到的内容有一定的长度,不能改动太多,但题目只有短短的几个字,修改起来还是比较简单的。所以标题修改是很有必要的,最好把标题改成原来的。标题完全不同,原因很简单。当看到文章同名而内容完全不同时,会引起读者误认为两者的内容是一样的。相反,即使内容相同,标题也完全不同。也给人耳目一新的感觉,不易被人发现。
三是适当调整内容。
我已经尝试将内容采集到我自己的 网站 网站管理员。细心的人难免会发现直接复制的内容还是存在版面问题。因为一些精明的原创人,为了避免内容被采集,通常会在内容中加入一些隐藏的图案,甚至会在图片的ALT信息中标注版权。如果不注意,自然会被搜索引擎认定为抄袭,所以不会伤害网站。这是不言而喻的。因此,必须删除采集的内容,必须转换英文格式的标点符号。此外,可以在内容中添加一些图片,使内容更加丰富。如果内容本身有图片,那就不要直接复制了,最好另外,
总之,网站采集的内容并不是完全没用的。关键取决于你如何采集它。只要能灵活使用采集到的内容,就可以给网站带来一定的优势,但是,站长需要注意的是一定要掌握一定的采集方法。
如何正确使用采集的内容来优化网站
温馨提示:以上是“如何正确使用采集到的内容做网站优化”的介绍。是网络营销外包(网络推广外包、网络营销推广)技术实力企业,敢于对效果负责。按效果付费合作模式,没有虚拟套路,我们只做!其次,有需要提醒大家:网站建设、网站制作、网站设计、网络推广、网站推广、网站优化、SEO优化、北京网优化、北京网站推广、网站设计公司、北京seo优化、网站建设公司、网络推广公司等服务,欢迎来电咨询。
网站内容采集(蝙蝠侠IT做一个同类型的网站:采集外链有排名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-08 10:18
在做SEO的时候,偶尔我们总会遇到各种各样的问题。最近有个SEO小伙伴咨询我这个问题:
同时制作一个相同类型的网站:
①采集+外链,有排名。
②每天坚持原创,而不是收录。
其实回答这个问题还是需要多方面思考的。
那么,采集外链有排名,原创没有收录,为什么呢?
蝙蝠侠IT将根据以往搜索引擎优化经验,详细阐述以下内容:
1、采集 加外链有排名
毫无疑问,我们通常会在搜索引擎上发布采集的内容,存在内容来源问题。如果你的采集内容在搜索引擎中缺失,比如:今日头条自媒体,常见的权重站策略。
这时候你的采集的内容都是搜索引擎的原创,自然会匹配给你排名。
但是如果你的内容采集来源于搜索引擎中的重复内容,这时候你的网站就有了一定的排名,影响这个问题的因素比较多,比如:
①目标页面的外链增幅非常高,都是来自垂直网站的优质外链。
②页面的段落和逻辑非常高,有利于页面的阅读体验。
③网站页面打开速度非常快,提高了页面加载速度。
④ 网站 结构提高相关性,使用页面结构排名。
⑤网站域名的历史使用情况等。
2、每天原创无收录
对于每天没有收录原创的情况,这可能是我们经常遇到的一个关联问题,通常我们认为主要的问题包括以下几点:
①新网站一般收录周期为15-30天。
②页面服务器不稳定,出现不间断卡顿等现象,影响抓取和页面体验。
③内容没有一定的搜索要求。
④是否提交到相关搜索引擎,是否有网站的抓取频率。
⑤是否遇到恶意的采集,网站的内容一直是采集。
⑥域名网站是否处于右下状态,是否在搜索引擎的黑名单中。
⑦网站是否被黑,是否存在恶意链接等。
总结:采集外链有排名,原创没有收录,还有很多细节可以讨论,以上内容仅供参考!
蝙蝠侠IT转载需要授权! 查看全部
网站内容采集(蝙蝠侠IT做一个同类型的网站:采集外链有排名)
在做SEO的时候,偶尔我们总会遇到各种各样的问题。最近有个SEO小伙伴咨询我这个问题:
同时制作一个相同类型的网站:
①采集+外链,有排名。
②每天坚持原创,而不是收录。
其实回答这个问题还是需要多方面思考的。
那么,采集外链有排名,原创没有收录,为什么呢?
蝙蝠侠IT将根据以往搜索引擎优化经验,详细阐述以下内容:
1、采集 加外链有排名
毫无疑问,我们通常会在搜索引擎上发布采集的内容,存在内容来源问题。如果你的采集内容在搜索引擎中缺失,比如:今日头条自媒体,常见的权重站策略。
这时候你的采集的内容都是搜索引擎的原创,自然会匹配给你排名。
但是如果你的内容采集来源于搜索引擎中的重复内容,这时候你的网站就有了一定的排名,影响这个问题的因素比较多,比如:
①目标页面的外链增幅非常高,都是来自垂直网站的优质外链。
②页面的段落和逻辑非常高,有利于页面的阅读体验。
③网站页面打开速度非常快,提高了页面加载速度。
④ 网站 结构提高相关性,使用页面结构排名。
⑤网站域名的历史使用情况等。
2、每天原创无收录
对于每天没有收录原创的情况,这可能是我们经常遇到的一个关联问题,通常我们认为主要的问题包括以下几点:
①新网站一般收录周期为15-30天。
②页面服务器不稳定,出现不间断卡顿等现象,影响抓取和页面体验。
③内容没有一定的搜索要求。
④是否提交到相关搜索引擎,是否有网站的抓取频率。
⑤是否遇到恶意的采集,网站的内容一直是采集。
⑥域名网站是否处于右下状态,是否在搜索引擎的黑名单中。
⑦网站是否被黑,是否存在恶意链接等。
总结:采集外链有排名,原创没有收录,还有很多细节可以讨论,以上内容仅供参考!
蝙蝠侠IT转载需要授权!
网站内容采集(中国论文网关键词:网站网页内容采集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-08 08:10
摘要:网页内容采集主要是指将某个网站的整个网站网页内容或部分网页内容抓取到自己的网站,非法网页内容采集,不仅无法有效保护版权信息,而且在批量处理采集时,尤其是收录多媒体元素和软件的页面为采集时,会造成网站的位置@> 服务器负载增加,普通用户浏览速度下降。中国论文网关键词:网站 网页内容采集 中文图书馆分类号: 文献识别码:A 文章 编号:1007-9416(2010)05- 0000-00 所谓网页采集无非是采集 对于我们浏览的网页内容,包括文字信息、图片信息和视频、声音、软件信息等,采集通过编写采集程序或通过许多cms函数系统本身,并编写采集规则来获取所需的内容。采集的方法一般都有拦截和过滤两种,即拦截指定区域的HTML代码,过滤掉这部分代码不需要的内容,比如广告信息、版权采集@采集的过程一般遵循以下步骤:先读取文章的列表,再读取内容文章 根据文章列表中的链接,一一过滤文章的内容,获取所有需要的信息。根据采集的方法和步骤,我们可以从两个方面进行防范:增加列表采集的难度,防止采集出现在内容页。可以使用技术手段来防止将采集人挡在外面,使他们无法访问和阅读采集页面。
或者,为了处理采集页面的内容,增加采集的难度,这样即使采集人采集数据,采集收到的信息不能使用或直接使用。确定来源,阻止访问。判断同一IP在一定时间内访问本站页面的次数。如果明显高于正常人的浏览速度,说明源IP有采集的可能性,则拒绝IP访问,否则释放。. 这种方法不难实现。在动态网站中,可以通过在页面头部添加部分程序代码来实现,静态页面可以通过javascript代码实现。这个策略对于防止采集非常有效,但会严重影响搜索引擎蜘蛛对本站内容的收录。对于不太依赖搜索引擎的网站,可以采用这种方法。在列表中增加批量难度信息采集采集,从获取信息列表开始,从信息列表中的超链接开始,然后是采集二级页面内容,所以列表页面被封采集,这也屏蔽了其他内容页面的采集。采取的一般策略是改变列表方法并尝试使其不规则。对方很难采集获得正确的内容链接,增加了采集的难度。2.1 破坏链接对应的标签,使链接不规则。例如,
2.2 随机添加一些干扰链接,增加对方误码率采集 比如在信息列表中像下面这样散布添加干扰链接: 随机文本标题,然后使用相同的模板为其他内容页面创建一个网页文件aa。asp、aa.asp页面中的标题和内容是随机动态生成的,目的是为了让对方采集,因为有些采集程序对于页面没有采集重复的标题或空的内容。然后在样式表中添加样式:#notext{display:none;} 这样你添加的干扰链接就不会显示在你的页面上。但是因为该链接及其对应的内容页面和其他链接一样正常,所以可以同时被对方采集传递,而这些文章内容都是无意义的代码,增加了对方文章 @采集后期编辑修改的工作量,可以让对方退却。内容页反采集策略采集的最终目标是采集网页的具体内容,只有采集到文章列表和< @采集没有内容或者采集的内容不符合要求,这样的采集是没有意义的。可以从以下几个方面加以预防。3.1 加密页面的内容通过Javascript加密,然后通过Javascript代码解密输出。这样,采集的内容只能是一些不规则的加密代码,没有任何意义,这种方式可以有效防止采集,但会严重影响搜索引擎收录,降低页面加载速度。适合对搜索引擎要求不高,关注版权信息的人。网站,普通的网站用的不多。
3.2 将文本内容改为图片格式或其他格式,如pdf、swf等。这种方法是通过一些转换软件或将网页的正文内容转换为图片格式或其他非html格式或程序代码,并在图片的背景中收录版权信息的水印,即使这种方法形成的网页内容采集向下,也很难去除版权信息。比如腾讯阅读频道,所有VIP阅读部分都采用了这种方式。这种方式可以有效的保护知识产权,但仍然不利于搜索引擎收录。对于一些不依赖搜索引擎的网站,可以使用。3.3 设置浏览权限,只有登录的用户才能浏览网页内容。此方法适用于动态href=""target="_blank">峰值状态网站,但也可能严重影响搜索引擎蜘蛛收录,但此方法更有效防止一般 采集 程序。3.4 将内容页面中的特定标签替换为“特定标签+随机隐藏版权文本”。这是很多cms系统默认的反采集策略,也就是采集过去的信息会随机显示一些已经采集网站的版权文本,但是这种方式对于采集是完全允许的,同时对方可以将采集内容中的版权文本过滤掉或者替换成其他信息。如果用这个方法来防止采集,
3.5 内容页代码没有规则。当前的网站不管是动态的网站还是静态的网站,一般都是后台输入的数据,前台会按照统一的模板展示出来。由于内容模板单一,html代码规律性强,容易写采集规则,所以很容易被采集,所以在创建模板时,尽量做好代码规则尽量不明显,增加采集的难度。3.5.1 当使用重复标签采集页面内容时,一般将收录采集部分内容的标签写成采集标志采集@ > 规则,所以可以添加一些重复的标签来干扰,这样采集 程序无法正确定位到采集的内容,并且采集没有准确的信息,比如防止采集的内容被标记为 ,那么可以添加一个或多个同样的标签在标签前面起到干扰的作用。3.5.2 多种网页模板,多种展示方式。如果条件允许,您可以设计多个网页模板来实现相同的外观,但网页内容中的html标签不同。有的话用div+css方法,有的用table方法,所以对方在采集时,只能采集到模板对应的网页内容。当然,在同一个模板中,你也可以将阻止采集内容的标签随机化 增加对方采集的难度。结束语 完全杜绝采集是不可能的。各种防止采集的策略各有优缺点。您只能根据自己站点的特点采取相应的策略,也可以同时采取多种防范措施,最大限度地防范。
随着网络技术的发展,提高版权意识,遵守网络道德,加强监管机制,杜绝自己网站上的非法采集。只要每个站长朋友都能做到,那就是预防。采集最有效的策略。参考文献 href=""target="_blank">峰书)小泉修,王浩译。Web 技术:HTTP 到服务器。科学出版社,2004. 查看全部
网站内容采集(中国论文网关键词:网站网页内容采集)
摘要:网页内容采集主要是指将某个网站的整个网站网页内容或部分网页内容抓取到自己的网站,非法网页内容采集,不仅无法有效保护版权信息,而且在批量处理采集时,尤其是收录多媒体元素和软件的页面为采集时,会造成网站的位置@> 服务器负载增加,普通用户浏览速度下降。中国论文网关键词:网站 网页内容采集 中文图书馆分类号: 文献识别码:A 文章 编号:1007-9416(2010)05- 0000-00 所谓网页采集无非是采集 对于我们浏览的网页内容,包括文字信息、图片信息和视频、声音、软件信息等,采集通过编写采集程序或通过许多cms函数系统本身,并编写采集规则来获取所需的内容。采集的方法一般都有拦截和过滤两种,即拦截指定区域的HTML代码,过滤掉这部分代码不需要的内容,比如广告信息、版权采集@采集的过程一般遵循以下步骤:先读取文章的列表,再读取内容文章 根据文章列表中的链接,一一过滤文章的内容,获取所有需要的信息。根据采集的方法和步骤,我们可以从两个方面进行防范:增加列表采集的难度,防止采集出现在内容页。可以使用技术手段来防止将采集人挡在外面,使他们无法访问和阅读采集页面。
或者,为了处理采集页面的内容,增加采集的难度,这样即使采集人采集数据,采集收到的信息不能使用或直接使用。确定来源,阻止访问。判断同一IP在一定时间内访问本站页面的次数。如果明显高于正常人的浏览速度,说明源IP有采集的可能性,则拒绝IP访问,否则释放。. 这种方法不难实现。在动态网站中,可以通过在页面头部添加部分程序代码来实现,静态页面可以通过javascript代码实现。这个策略对于防止采集非常有效,但会严重影响搜索引擎蜘蛛对本站内容的收录。对于不太依赖搜索引擎的网站,可以采用这种方法。在列表中增加批量难度信息采集采集,从获取信息列表开始,从信息列表中的超链接开始,然后是采集二级页面内容,所以列表页面被封采集,这也屏蔽了其他内容页面的采集。采取的一般策略是改变列表方法并尝试使其不规则。对方很难采集获得正确的内容链接,增加了采集的难度。2.1 破坏链接对应的标签,使链接不规则。例如,
2.2 随机添加一些干扰链接,增加对方误码率采集 比如在信息列表中像下面这样散布添加干扰链接: 随机文本标题,然后使用相同的模板为其他内容页面创建一个网页文件aa。asp、aa.asp页面中的标题和内容是随机动态生成的,目的是为了让对方采集,因为有些采集程序对于页面没有采集重复的标题或空的内容。然后在样式表中添加样式:#notext{display:none;} 这样你添加的干扰链接就不会显示在你的页面上。但是因为该链接及其对应的内容页面和其他链接一样正常,所以可以同时被对方采集传递,而这些文章内容都是无意义的代码,增加了对方文章 @采集后期编辑修改的工作量,可以让对方退却。内容页反采集策略采集的最终目标是采集网页的具体内容,只有采集到文章列表和< @采集没有内容或者采集的内容不符合要求,这样的采集是没有意义的。可以从以下几个方面加以预防。3.1 加密页面的内容通过Javascript加密,然后通过Javascript代码解密输出。这样,采集的内容只能是一些不规则的加密代码,没有任何意义,这种方式可以有效防止采集,但会严重影响搜索引擎收录,降低页面加载速度。适合对搜索引擎要求不高,关注版权信息的人。网站,普通的网站用的不多。
3.2 将文本内容改为图片格式或其他格式,如pdf、swf等。这种方法是通过一些转换软件或将网页的正文内容转换为图片格式或其他非html格式或程序代码,并在图片的背景中收录版权信息的水印,即使这种方法形成的网页内容采集向下,也很难去除版权信息。比如腾讯阅读频道,所有VIP阅读部分都采用了这种方式。这种方式可以有效的保护知识产权,但仍然不利于搜索引擎收录。对于一些不依赖搜索引擎的网站,可以使用。3.3 设置浏览权限,只有登录的用户才能浏览网页内容。此方法适用于动态href=""target="_blank">峰值状态网站,但也可能严重影响搜索引擎蜘蛛收录,但此方法更有效防止一般 采集 程序。3.4 将内容页面中的特定标签替换为“特定标签+随机隐藏版权文本”。这是很多cms系统默认的反采集策略,也就是采集过去的信息会随机显示一些已经采集网站的版权文本,但是这种方式对于采集是完全允许的,同时对方可以将采集内容中的版权文本过滤掉或者替换成其他信息。如果用这个方法来防止采集,
3.5 内容页代码没有规则。当前的网站不管是动态的网站还是静态的网站,一般都是后台输入的数据,前台会按照统一的模板展示出来。由于内容模板单一,html代码规律性强,容易写采集规则,所以很容易被采集,所以在创建模板时,尽量做好代码规则尽量不明显,增加采集的难度。3.5.1 当使用重复标签采集页面内容时,一般将收录采集部分内容的标签写成采集标志采集@ > 规则,所以可以添加一些重复的标签来干扰,这样采集 程序无法正确定位到采集的内容,并且采集没有准确的信息,比如防止采集的内容被标记为 ,那么可以添加一个或多个同样的标签在标签前面起到干扰的作用。3.5.2 多种网页模板,多种展示方式。如果条件允许,您可以设计多个网页模板来实现相同的外观,但网页内容中的html标签不同。有的话用div+css方法,有的用table方法,所以对方在采集时,只能采集到模板对应的网页内容。当然,在同一个模板中,你也可以将阻止采集内容的标签随机化 增加对方采集的难度。结束语 完全杜绝采集是不可能的。各种防止采集的策略各有优缺点。您只能根据自己站点的特点采取相应的策略,也可以同时采取多种防范措施,最大限度地防范。
随着网络技术的发展,提高版权意识,遵守网络道德,加强监管机制,杜绝自己网站上的非法采集。只要每个站长朋友都能做到,那就是预防。采集最有效的策略。参考文献 href=""target="_blank">峰书)小泉修,王浩译。Web 技术:HTTP 到服务器。科学出版社,2004.
网站内容采集(三星Galaxy9199.00Ultra5G..定位网页搜索框)
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-12-07 23:16
作业①:
没有
马克
价格
笔记
文件
000001
三星Galaxy
9199.00
三星 Galaxy Note20 Ultra 5G...
000001.jpg
000002......
1),京东手机数据爬取
1.找到网页搜索框,输入关键词“手机”
self.driver.get(url)
keyInput = self.driver.find_element_by_id("key")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
2.写爬虫主体,查看页面:
使用xpath方式实现定位(由于京东网站的特殊性,图片链接隐藏在src或data-lazy-img下)
lis =self.driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@class='gl-item']")
for li in lis:
if count > 413:
break;
# We find that the image is either in src or in data-lazy-img attribute
try:
src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src")
except:
src1 = ""
try:
src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img")
except:
src2 = ""
try:
price = li.find_element_by_xpath(".//div[@class='p-price']//i").text
except:
price = "0"
try:
note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text
mark = note.split(" ")[0]
mark = mark.replace("爱心东东\n", "")
mark = mark.replace(",", "")
note = note.replace("爱心东东\n", "")
note = note.replace(",", "")
except:
note = ""
mark = ""
翻页加工:
# 找到下一页的跳转按钮位置
if count < 413:
try:
self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next disabled']")
except:
nextPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next']")
time.sleep(5)
nextPage.click()
time.sleep(5)
self.processSpider()
设置下载图片的文件名:
self.No = self.No + 1
no = str(self.No)
while len(no) < 6:
no = "0" + no
print(no, mark, price)
if src1:
src1 = urllib.request.urljoin(self.driver.current_url, src1)
p = src1.rfind(".")
mFile = no + src1[p:]
elif src2:
src2 = urllib.request.urljoin(self.driver.current_url, src2)
p = src2.rfind(".")
mFile = no + src2[p:]
使用多线程,下载速度快:
if src1 or src2:
T = threading.Thread(target=self.download, args=(src1, src2, mFile))
T.setDaemon(False)
T.start()
self.threads.append(T)
else:
mFile = ""
定义下载函数:
def download(self, src1, src2, mFile):
data = None
if src1:
try:
req = urllib.request.Request(src1, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if not data and src2:
try:
req = urllib.request.Request(src2, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if data:
print("download begin", mFile)
fobj = open(MySpider.imagePath + "\\" + mFile, "wb")
fobj.write(data)
fobj.close()
print("download finish", mFile)
创建图片存储目录:
imagePath = "download"
try:
if not os.path.exists(MySpider.imagePath):
os.mkdir(MySpider.imagePath)
images = os.listdir(MySpider.imagePath)
for img in images:
s = os.path.join(MySpider.imagePath, img)
os.remove(s)
except Exception as err:
print(err)
3.创建mysql数据库
# 连接mysql数据库
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
password="hts2953936", database="mydb", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.opened = True
# flag = False
except Exception as err:
print(err)
self.opened = False
向数据表中插入数据:
# 插入数据
self.cursor.execute("insert into phone (Pno,Pmark, Pprice, Pnote, PmFile) values (%s,%s,%s,%s,%s)",(no, mark, price, note, mFile))
查看数据库中的结果:
图片:
作业1码云链接
2),体验
本次实验是之前实验的复盘,巩固了Selenium对抓取京东数据和下载图片的模拟。复习selenium爬取方法和翻页,巩固数据库的操作
作业②:
要求:
熟悉Selenium查找HTML元素,实现用户模拟登录,抓取Ajax网页数据,等待HTML元素等。
使用Selenium框架+MySQL登录Mukenet,在学生自己的账号中获取所学课程的信息并保存在MySQL中(课程编号、课程名称、教学单位、教学进度、课程状态、课程图片地址) ,同时存储图片到本地项目根目录下的imgs文件夹,用课程名称存储图片名称。
1), selenium 爬取mooc数据
初始化驱动程序
chrome_options = Options()
# 设置启动chrome时不可见
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
# 创建options
self.driver = webdriver.Chrome(chrome_options=chrome_options)
url = 'https://www.icourse163.org/'
self.driver.get(url)
最大化窗口(方便查找节点)并设置反监控防止网页检测selenium
self.driver.maximize_window()
self.driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
模拟点击MOOC初始页面登录按钮
然后模拟点击其他登录方式
接下来,点击您的电话号码登录
代码显示如下
loginbutton = self.driver.find_element_by_xpath('//div[@class="_1Y4Ni"]/div')
time.sleep(3)
loginbutton.click()
time.sleep(3)
button2 = self.driver.find_element_by_xpath('//span[@class="ux-login-set-scan-code_ft_back"]')
button2.click()
time.sleep(3)
button3 = self.driver.find_element_by_xpath('//ul[@class="ux-tabs-underline_hd"]/li[position()=2]')
button3.click()
time.sleep(3)
到了这一步,下一步就是定位两个文本框,然后使用sendkeys方法输入数据
但是在这一步需要注意,文本框的节点是存放在框架节点下的文档内容中:
因此,不能使用 find_element_by_xpath 直接定位文本框。需要先定位到frame节点,调用switch_to.frame方法后才能爬取。
代码显示如下:
frame = self.driver.find_element_by_xpath('/html/body/div[position()=13]/div[position()=2]/div/div/div/div/div/div[position()=1]/div/div[position()=1]/div[position()=2]/div[position()=2]/div/iframe')
self.driver.switch_to.frame(frame)
找到两个文本框,使用sendkey输入内容
account = self.driver.find_element_by_xpath('/html/body/div[position()=2]/div[position()=2]/div[position()=2]/form/div/div[position()=2]/div[position()=2]/input')
account.send_keys('18016776126')
password = self.driver.find_element_by_xpath('/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]')
password.send_keys("hts2953936")
输入后点击登录按钮
loginbutton2 = self.driver.find_element_by_xpath('/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a').click()
time.sleep(10)
这里设置一个time.sleep(10)是因为有时候会需要手动拖动拼图验证码,这部分实现比较费时间,有时间可以抽时间研究一下在将来。
进入页面后,模拟点击我的课程
mycourses = self.driver.find_element_by_xpath('/html/body/div[position()=4]/div[position()=2]/div[position()=1]/div/div/div[position()=1]/div[position()=3]/div[position()=4]/div').click()
time.sleep(3)
之后,我成功使用selenium的模拟登录进入了我们的课程页面,就可以开始下一步的爬取了。
定位收录课程信息的节点
body = self.driver.find_elements_by_xpath('//div[@class="course-card-wrapper"]')
遍历节点抓取数据,下载图片,插入数据库:
for i in body:
count += 1
cid = count
img = i.find_element_by_xpath('.//div[@class="img"]/img').get_attribute('src')
schedule = i.find_element_by_xpath('.//span[@class="course-progress-text-span"]').text
college = i.find_element_by_xpath('.//div[@class="school"]').text
title = i.find_element_by_xpath('.//div[@class="title"]/div/span[position()=2]').text
coursestatus = i.find_element_by_xpath('.//div[@class="course-status"]').text
downloadurl = img
file = "C:/Users/86180/Desktop/Data Collection/imgs/" + "course no." + str(count) + " pic no."+".jpg"
urllib.request.urlretrieve(downloadurl, filename=file)
print("course no." + str(count) + " download completed")
print("insert into mooc (cid,cCourse,cCollege,cShedule,cCourseStatus,cImgUrl) values (%s,%s,%s,%s,%s,%s)",(cid,title,college,schedule,coursestatus,img))
# 执行插入数据库操作
if self.opened:
self.cursor.execute("insert into mooc (cid,cCourse,cCollege,cShedule,cCourseStatus,cImgUrl) values (%s,%s,%s,%s,%s,%s)",
(cid,title,college,schedule,coursestatus,img))
print("-------------------------------")
爬取一页信息后的翻页操作:
在页面中,页面信息收录在 ul[@class="ux-pager"] 节点下。该节点下倒数第二个li节点是所学课程最后一页的页码(即下一页的前一个兄弟节点)
于是获取节点下的页码信息:
page = self.driver.find_element_by_xpath('//ul[@class="ux-pager"]/li[position()=last()-1]/a').text
使用selenium模拟点击,递归调用processSpider函数进行翻页:
if not flag == int(page):
flag +=1
nxpgbutton = self.driver.find_element_by_xpath('//li[@class="ux-pager_btn ux-pager_btn__next"]/a')
nxpgbutton.click()
time.sleep(5)
self.processSpider()
在数据库中:
图片:
作业2代码云链接
经验:
本实验研究使用 selenium 模拟登录。步骤是逐步定位按钮位置,通过click方法点击按钮,模拟登录时使用send_keys方法在文本框中输入数据。mooc网站的文本框比较特别。, 存放在iframe的#document中,不能直接定位。需要通过调用driver.switch_to.frame()调到node下新的html,然后定位。进入之后,爬行等操作就比较熟悉了。模拟登录过程中出现的问题:短时间内多次登录后,登录时有时会弹出拼图验证码。
作业③: 查看全部
网站内容采集(三星Galaxy9199.00Ultra5G..定位网页搜索框)
作业①:
没有
马克
价格
笔记
文件
000001
三星Galaxy
9199.00
三星 Galaxy Note20 Ultra 5G...
000001.jpg
000002......
1),京东手机数据爬取
1.找到网页搜索框,输入关键词“手机”
self.driver.get(url)
keyInput = self.driver.find_element_by_id("key")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
2.写爬虫主体,查看页面:
使用xpath方式实现定位(由于京东网站的特殊性,图片链接隐藏在src或data-lazy-img下)
lis =self.driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@class='gl-item']")
for li in lis:
if count > 413:
break;
# We find that the image is either in src or in data-lazy-img attribute
try:
src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src")
except:
src1 = ""
try:
src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img")
except:
src2 = ""
try:
price = li.find_element_by_xpath(".//div[@class='p-price']//i").text
except:
price = "0"
try:
note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text
mark = note.split(" ")[0]
mark = mark.replace("爱心东东\n", "")
mark = mark.replace(",", "")
note = note.replace("爱心东东\n", "")
note = note.replace(",", "")
except:
note = ""
mark = ""
翻页加工:
# 找到下一页的跳转按钮位置
if count < 413:
try:
self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next disabled']")
except:
nextPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next']")
time.sleep(5)
nextPage.click()
time.sleep(5)
self.processSpider()
设置下载图片的文件名:
self.No = self.No + 1
no = str(self.No)
while len(no) < 6:
no = "0" + no
print(no, mark, price)
if src1:
src1 = urllib.request.urljoin(self.driver.current_url, src1)
p = src1.rfind(".")
mFile = no + src1[p:]
elif src2:
src2 = urllib.request.urljoin(self.driver.current_url, src2)
p = src2.rfind(".")
mFile = no + src2[p:]
使用多线程,下载速度快:
if src1 or src2:
T = threading.Thread(target=self.download, args=(src1, src2, mFile))
T.setDaemon(False)
T.start()
self.threads.append(T)
else:
mFile = ""
定义下载函数:
def download(self, src1, src2, mFile):
data = None
if src1:
try:
req = urllib.request.Request(src1, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if not data and src2:
try:
req = urllib.request.Request(src2, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if data:
print("download begin", mFile)
fobj = open(MySpider.imagePath + "\\" + mFile, "wb")
fobj.write(data)
fobj.close()
print("download finish", mFile)
创建图片存储目录:
imagePath = "download"
try:
if not os.path.exists(MySpider.imagePath):
os.mkdir(MySpider.imagePath)
images = os.listdir(MySpider.imagePath)
for img in images:
s = os.path.join(MySpider.imagePath, img)
os.remove(s)
except Exception as err:
print(err)
3.创建mysql数据库
# 连接mysql数据库
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
password="hts2953936", database="mydb", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.opened = True
# flag = False
except Exception as err:
print(err)
self.opened = False
向数据表中插入数据:
# 插入数据
self.cursor.execute("insert into phone (Pno,Pmark, Pprice, Pnote, PmFile) values (%s,%s,%s,%s,%s)",(no, mark, price, note, mFile))
查看数据库中的结果:
图片:
作业1码云链接
2),体验
本次实验是之前实验的复盘,巩固了Selenium对抓取京东数据和下载图片的模拟。复习selenium爬取方法和翻页,巩固数据库的操作
作业②:
要求:
熟悉Selenium查找HTML元素,实现用户模拟登录,抓取Ajax网页数据,等待HTML元素等。
使用Selenium框架+MySQL登录Mukenet,在学生自己的账号中获取所学课程的信息并保存在MySQL中(课程编号、课程名称、教学单位、教学进度、课程状态、课程图片地址) ,同时存储图片到本地项目根目录下的imgs文件夹,用课程名称存储图片名称。
1), selenium 爬取mooc数据
初始化驱动程序
chrome_options = Options()
# 设置启动chrome时不可见
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
# 创建options
self.driver = webdriver.Chrome(chrome_options=chrome_options)
url = 'https://www.icourse163.org/'
self.driver.get(url)
最大化窗口(方便查找节点)并设置反监控防止网页检测selenium
self.driver.maximize_window()
self.driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
模拟点击MOOC初始页面登录按钮
然后模拟点击其他登录方式
接下来,点击您的电话号码登录
代码显示如下
loginbutton = self.driver.find_element_by_xpath('//div[@class="_1Y4Ni"]/div')
time.sleep(3)
loginbutton.click()
time.sleep(3)
button2 = self.driver.find_element_by_xpath('//span[@class="ux-login-set-scan-code_ft_back"]')
button2.click()
time.sleep(3)
button3 = self.driver.find_element_by_xpath('//ul[@class="ux-tabs-underline_hd"]/li[position()=2]')
button3.click()
time.sleep(3)
到了这一步,下一步就是定位两个文本框,然后使用sendkeys方法输入数据
但是在这一步需要注意,文本框的节点是存放在框架节点下的文档内容中:
因此,不能使用 find_element_by_xpath 直接定位文本框。需要先定位到frame节点,调用switch_to.frame方法后才能爬取。
代码显示如下:
frame = self.driver.find_element_by_xpath('/html/body/div[position()=13]/div[position()=2]/div/div/div/div/div/div[position()=1]/div/div[position()=1]/div[position()=2]/div[position()=2]/div/iframe')
self.driver.switch_to.frame(frame)
找到两个文本框,使用sendkey输入内容
account = self.driver.find_element_by_xpath('/html/body/div[position()=2]/div[position()=2]/div[position()=2]/form/div/div[position()=2]/div[position()=2]/input')
account.send_keys('18016776126')
password = self.driver.find_element_by_xpath('/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]')
password.send_keys("hts2953936")
输入后点击登录按钮
loginbutton2 = self.driver.find_element_by_xpath('/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a').click()
time.sleep(10)
这里设置一个time.sleep(10)是因为有时候会需要手动拖动拼图验证码,这部分实现比较费时间,有时间可以抽时间研究一下在将来。
进入页面后,模拟点击我的课程
mycourses = self.driver.find_element_by_xpath('/html/body/div[position()=4]/div[position()=2]/div[position()=1]/div/div/div[position()=1]/div[position()=3]/div[position()=4]/div').click()
time.sleep(3)
之后,我成功使用selenium的模拟登录进入了我们的课程页面,就可以开始下一步的爬取了。
定位收录课程信息的节点
body = self.driver.find_elements_by_xpath('//div[@class="course-card-wrapper"]')
遍历节点抓取数据,下载图片,插入数据库:
for i in body:
count += 1
cid = count
img = i.find_element_by_xpath('.//div[@class="img"]/img').get_attribute('src')
schedule = i.find_element_by_xpath('.//span[@class="course-progress-text-span"]').text
college = i.find_element_by_xpath('.//div[@class="school"]').text
title = i.find_element_by_xpath('.//div[@class="title"]/div/span[position()=2]').text
coursestatus = i.find_element_by_xpath('.//div[@class="course-status"]').text
downloadurl = img
file = "C:/Users/86180/Desktop/Data Collection/imgs/" + "course no." + str(count) + " pic no."+".jpg"
urllib.request.urlretrieve(downloadurl, filename=file)
print("course no." + str(count) + " download completed")
print("insert into mooc (cid,cCourse,cCollege,cShedule,cCourseStatus,cImgUrl) values (%s,%s,%s,%s,%s,%s)",(cid,title,college,schedule,coursestatus,img))
# 执行插入数据库操作
if self.opened:
self.cursor.execute("insert into mooc (cid,cCourse,cCollege,cShedule,cCourseStatus,cImgUrl) values (%s,%s,%s,%s,%s,%s)",
(cid,title,college,schedule,coursestatus,img))
print("-------------------------------")
爬取一页信息后的翻页操作:
在页面中,页面信息收录在 ul[@class="ux-pager"] 节点下。该节点下倒数第二个li节点是所学课程最后一页的页码(即下一页的前一个兄弟节点)
于是获取节点下的页码信息:
page = self.driver.find_element_by_xpath('//ul[@class="ux-pager"]/li[position()=last()-1]/a').text
使用selenium模拟点击,递归调用processSpider函数进行翻页:
if not flag == int(page):
flag +=1
nxpgbutton = self.driver.find_element_by_xpath('//li[@class="ux-pager_btn ux-pager_btn__next"]/a')
nxpgbutton.click()
time.sleep(5)
self.processSpider()
在数据库中:
图片:
作业2代码云链接
经验:
本实验研究使用 selenium 模拟登录。步骤是逐步定位按钮位置,通过click方法点击按钮,模拟登录时使用send_keys方法在文本框中输入数据。mooc网站的文本框比较特别。, 存放在iframe的#document中,不能直接定位。需要通过调用driver.switch_to.frame()调到node下新的html,然后定位。进入之后,爬行等操作就比较熟悉了。模拟登录过程中出现的问题:短时间内多次登录后,登录时有时会弹出拼图验证码。
作业③:
网站内容采集(网站采集内容的时候应该注意哪些事项?网为介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-12-07 18:03
很多时候,我们没有足够的时间来原创 内容。采集内容更新是网站维护的重要手段。那么采集内容时需要注意什么?今天,云客网就给大家介绍一下这几点。
采集内容不是采集标题
大家都知道,标题是文章的眼睛,传递给用户的第一印象。对于网站优化的搜索引擎,标题也有一定的权重。可能很多公司网站采集的内容占了很大的空间。软文怎么写,改动很少,但是标题一定要改,几个字的标题改不了。太多时间。要知道,即使内容相同,不同的书名也可能给人耳目一新的感觉,不被人发现,甚至读到不一样的魅力。
采集内容对象新鲜独特
最好把一些文章快速更新的相关网站作为采集的目标,找一些新鲜的、与时俱进的、有代表性的文章,没有采集之前被太多人转载比较好。一些老生常谈的话题会让用户觉得微通觉瓦米开手的学徒生涯已经开始了,你还在自己摸索SEO吗?它根本毫无价值。另外,你还可以采集多篇文章文章,整合成一个文章,加上你自己的观点,也会让人眼前一亮。
对内容进行适当的调整
相信细心的站长会发现,在采集others网站的时候,总会发现有些文章的格式和版式不尽如人意,有些标点符号混乱,分割不清. , 有的首行不缩进,有的加了反采集隐藏格式等,如果直接采集过来这些内容,肯定会被搜索引擎认定为抄袭,如此对网站的危害不言而喻。所以来自采集的内容必须格式化,英文格式的标点符号必须转换。此外,可以在内容中添加一些图片,使内容更加丰富。 查看全部
网站内容采集(网站采集内容的时候应该注意哪些事项?网为介绍)
很多时候,我们没有足够的时间来原创 内容。采集内容更新是网站维护的重要手段。那么采集内容时需要注意什么?今天,云客网就给大家介绍一下这几点。
采集内容不是采集标题
大家都知道,标题是文章的眼睛,传递给用户的第一印象。对于网站优化的搜索引擎,标题也有一定的权重。可能很多公司网站采集的内容占了很大的空间。软文怎么写,改动很少,但是标题一定要改,几个字的标题改不了。太多时间。要知道,即使内容相同,不同的书名也可能给人耳目一新的感觉,不被人发现,甚至读到不一样的魅力。
采集内容对象新鲜独特
最好把一些文章快速更新的相关网站作为采集的目标,找一些新鲜的、与时俱进的、有代表性的文章,没有采集之前被太多人转载比较好。一些老生常谈的话题会让用户觉得微通觉瓦米开手的学徒生涯已经开始了,你还在自己摸索SEO吗?它根本毫无价值。另外,你还可以采集多篇文章文章,整合成一个文章,加上你自己的观点,也会让人眼前一亮。
对内容进行适当的调整
相信细心的站长会发现,在采集others网站的时候,总会发现有些文章的格式和版式不尽如人意,有些标点符号混乱,分割不清. , 有的首行不缩进,有的加了反采集隐藏格式等,如果直接采集过来这些内容,肯定会被搜索引擎认定为抄袭,如此对网站的危害不言而喻。所以来自采集的内容必须格式化,英文格式的标点符号必须转换。此外,可以在内容中添加一些图片,使内容更加丰富。
网站内容采集(网站内容采集,基本都是自己推荐的平台,搜索引擎反馈回来的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-12-07 06:03
网站内容采集,基本都是自己推荐的平台,广告推荐、软文推荐、搜索引擎反馈回来的。首先,明确采集类网站的初衷,一般都是为了宣传网站的某个功能,或者增加用户体验度或者做盈利。要找到是什么渠道来的内容,可以去站长工具网(站长帮)查看访问页面中,除了网站的页面列表,有哪些其他渠道链接过来的。网站内容采集还可以和网站合作,比如集成一些网站的推荐页面,或者给网站导流。可以考虑和网站形成长期互利,更加长久的合作形式。
我分享下我用的方法吧:1.通过投稿,从别的网站搬运一部分文章;2.发外链;3.官方推荐;4.人工精心写文章。
正常,个人站长有,想写点小东西也有,
如果你不想付费的话,你可以找我写。
没有必要总想找大量的替代性内容,不如自己写。百度那边也有推荐页面,也推荐一些好东西。发出去之后,自然有人找你采集。想换花样,
都知道写文章不赚钱,那为什么还要写呢,写作不止是一种技巧,更是一种信仰,建议如果内容没有思路的话,去虎嗅网,里面的有些内容我是非常喜欢的。
楼主如果你连知乎的文章数都比不过不如把这些文章发到百度知道获取更多的人气。
是人都会写,baidu的“外链”只是利用“你的网站”的网址而已,绝大多数都是接触不到官方(特别是二三线官方)的.国内“有价值的外链”真的很少. 查看全部
网站内容采集(网站内容采集,基本都是自己推荐的平台,搜索引擎反馈回来的)
网站内容采集,基本都是自己推荐的平台,广告推荐、软文推荐、搜索引擎反馈回来的。首先,明确采集类网站的初衷,一般都是为了宣传网站的某个功能,或者增加用户体验度或者做盈利。要找到是什么渠道来的内容,可以去站长工具网(站长帮)查看访问页面中,除了网站的页面列表,有哪些其他渠道链接过来的。网站内容采集还可以和网站合作,比如集成一些网站的推荐页面,或者给网站导流。可以考虑和网站形成长期互利,更加长久的合作形式。
我分享下我用的方法吧:1.通过投稿,从别的网站搬运一部分文章;2.发外链;3.官方推荐;4.人工精心写文章。
正常,个人站长有,想写点小东西也有,
如果你不想付费的话,你可以找我写。
没有必要总想找大量的替代性内容,不如自己写。百度那边也有推荐页面,也推荐一些好东西。发出去之后,自然有人找你采集。想换花样,
都知道写文章不赚钱,那为什么还要写呢,写作不止是一种技巧,更是一种信仰,建议如果内容没有思路的话,去虎嗅网,里面的有些内容我是非常喜欢的。
楼主如果你连知乎的文章数都比不过不如把这些文章发到百度知道获取更多的人气。
是人都会写,baidu的“外链”只是利用“你的网站”的网址而已,绝大多数都是接触不到官方(特别是二三线官方)的.国内“有价值的外链”真的很少.
网站内容采集( 什么是采集站?现在做网站还能做采集站吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-12-05 23:25
什么是采集站?现在做网站还能做采集站吗?
)
采集 站是什么?采集站台怎么办?如果我现在做网站,我还能做采集吗?今天小编就给大家分享一些关于采集站的经验分享!可以说现在的大部分网站都离不开采集,采集已经成为了互联网的常态网站,所以想当站或者已经有网站上网的同学一定要清楚了解采集站!我自己做的小说网站和门户网站都是用采集的方法制作的。目前,全流和全5,日均IP流量稳定在1万左右。通过这篇文章的文章和大家分享一下我的一些理解和实践。
采集 站是什么?每个 网站 都需要填充内容。在这个“内容为王”的时代,很多SEO站长为了做网站优化,疯狂写文章。但是,一些SEOer 认为原创文章 没有那么重要。为了让网站能够在短时间内拥有大量的内容,很多站长都会选择采集文章的方式。对于站长来说,因为经常需要发布文章,需要采集各种文章资源,所以需要各种采集工具。从事互联网SEO行业以来,一直在使用采集工具来处理不同的文章资源,以及采集不同平台的资源,文章采集@ > 工具不知道你听说过吗?可能有的站长没接触过吧!采集工具现在被一些站群或大型门户网站使用,例如企业网站使用的那些。当然,一些个人网站也被一些人使用采集,因为有些情况不想自己更新文章 或文章 需要在大网站上更新的很多而且复杂的,比如新闻网站,都用采集。编辑器通常使用147个采集来完成所有采集站的内容填充。更适合不懂代码和技术的站长。输入关键词就可以了采集,没有复杂的配置,也不需要写采集的规则。采集完成后,
采集站台怎么办?1.网站上线前采集文章,准备了很多文章(所有采集来这里,当然采集 N 个站点 文章)。2. 网站 模板一定要自己写,代码库一定要优化。3. 做好网站 内容页面布局。4.上线后每天更新100~500文章卷,文章一定是采集N个站点的最新文章。5. 外链每天发一些。一个月后,你的网站收录和你的流量都会上升!
一些采集需要特别注意的点: 1. 海量长尾词:我在采集的内容中导入了超过10万个关键词,我想要更多关键词排名,那么你需要大量的文章和关键词。而我的文章都是基于关键词采集。不要像大多数人一样做采集站。基本上,它是盲目的采集。内容有几万个收录,但排名的关键词只有几十个。看着它很有趣,只是乱七八糟。这样的采集 站点基本上是在制造互联网垃圾邮件。搜索引擎反对谁?拥有 关键词 和内容只是基础。如果你的采集文章能获得不错的排名,那你就需要下一步了。2.文章优化:80% 的人不理解高质量的内容。采集 过来的内容必须经过伪原创!其实搜索引擎已经说得很清楚了。文章排版,内容就是用户需要的,很明显的告诉大家文章有图有文字,远胜于纯文本文章收录。所以你的内容布局好,关键词布局好,你文章已经有排名机会是用户需求。3.页面结构:有两个核心点,相关性和丰富性。抓住这两点,去百度看看别人的官方说明,就可以掌握核心,内页排名也很容易。4.内容收录速度:要想快速上榜,首先要做的就是网站 content收录 要快。想要让收录快速的需要大量的蜘蛛来抓取你的网站,其实搜索引擎已经给出了很好的工具,主动推送功能!批量推送网页链接到搜索引擎,增加曝光率。
如果我现在做网站,我还能做采集吗?我的采集站点一直很稳定,我的采集站点完全符合搜索引擎的规则。不仅稳定,而且流量还在持续上升。所以采集网站还是可以做的,最重要的还是做对了,不是因为采集和采集,采集之后的SEO优化也很重要,具体后续文章的内容我会详细说明。本期暂时先说说采集站。
关于采集站的问题,小编就到此为止。总之,如果采集的内容处理得当,站采集也会是收录。但是大家要注意一个问题,就是对采集网站的操作要更加谨慎,不要让搜索引擎认为这是一个采集站,而且在同时在用户体验和满足用户需求方面做更多的优化,这样的采集站还是可以做的。
查看全部
网站内容采集(
什么是采集站?现在做网站还能做采集站吗?
)
采集 站是什么?采集站台怎么办?如果我现在做网站,我还能做采集吗?今天小编就给大家分享一些关于采集站的经验分享!可以说现在的大部分网站都离不开采集,采集已经成为了互联网的常态网站,所以想当站或者已经有网站上网的同学一定要清楚了解采集站!我自己做的小说网站和门户网站都是用采集的方法制作的。目前,全流和全5,日均IP流量稳定在1万左右。通过这篇文章的文章和大家分享一下我的一些理解和实践。
采集 站是什么?每个 网站 都需要填充内容。在这个“内容为王”的时代,很多SEO站长为了做网站优化,疯狂写文章。但是,一些SEOer 认为原创文章 没有那么重要。为了让网站能够在短时间内拥有大量的内容,很多站长都会选择采集文章的方式。对于站长来说,因为经常需要发布文章,需要采集各种文章资源,所以需要各种采集工具。从事互联网SEO行业以来,一直在使用采集工具来处理不同的文章资源,以及采集不同平台的资源,文章采集@ > 工具不知道你听说过吗?可能有的站长没接触过吧!采集工具现在被一些站群或大型门户网站使用,例如企业网站使用的那些。当然,一些个人网站也被一些人使用采集,因为有些情况不想自己更新文章 或文章 需要在大网站上更新的很多而且复杂的,比如新闻网站,都用采集。编辑器通常使用147个采集来完成所有采集站的内容填充。更适合不懂代码和技术的站长。输入关键词就可以了采集,没有复杂的配置,也不需要写采集的规则。采集完成后,
采集站台怎么办?1.网站上线前采集文章,准备了很多文章(所有采集来这里,当然采集 N 个站点 文章)。2. 网站 模板一定要自己写,代码库一定要优化。3. 做好网站 内容页面布局。4.上线后每天更新100~500文章卷,文章一定是采集N个站点的最新文章。5. 外链每天发一些。一个月后,你的网站收录和你的流量都会上升!
一些采集需要特别注意的点: 1. 海量长尾词:我在采集的内容中导入了超过10万个关键词,我想要更多关键词排名,那么你需要大量的文章和关键词。而我的文章都是基于关键词采集。不要像大多数人一样做采集站。基本上,它是盲目的采集。内容有几万个收录,但排名的关键词只有几十个。看着它很有趣,只是乱七八糟。这样的采集 站点基本上是在制造互联网垃圾邮件。搜索引擎反对谁?拥有 关键词 和内容只是基础。如果你的采集文章能获得不错的排名,那你就需要下一步了。2.文章优化:80% 的人不理解高质量的内容。采集 过来的内容必须经过伪原创!其实搜索引擎已经说得很清楚了。文章排版,内容就是用户需要的,很明显的告诉大家文章有图有文字,远胜于纯文本文章收录。所以你的内容布局好,关键词布局好,你文章已经有排名机会是用户需求。3.页面结构:有两个核心点,相关性和丰富性。抓住这两点,去百度看看别人的官方说明,就可以掌握核心,内页排名也很容易。4.内容收录速度:要想快速上榜,首先要做的就是网站 content收录 要快。想要让收录快速的需要大量的蜘蛛来抓取你的网站,其实搜索引擎已经给出了很好的工具,主动推送功能!批量推送网页链接到搜索引擎,增加曝光率。
如果我现在做网站,我还能做采集吗?我的采集站点一直很稳定,我的采集站点完全符合搜索引擎的规则。不仅稳定,而且流量还在持续上升。所以采集网站还是可以做的,最重要的还是做对了,不是因为采集和采集,采集之后的SEO优化也很重要,具体后续文章的内容我会详细说明。本期暂时先说说采集站。
关于采集站的问题,小编就到此为止。总之,如果采集的内容处理得当,站采集也会是收录。但是大家要注意一个问题,就是对采集网站的操作要更加谨慎,不要让搜索引擎认为这是一个采集站,而且在同时在用户体验和满足用户需求方面做更多的优化,这样的采集站还是可以做的。
网站内容采集(主营业务包含网站建设,小程序开发,网络推广 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-12-05 23:23
)
主营业务包括网站建设、APP开发、小程序开发、网络推广、SEO优化,网页编辑难免需要帮助客户进行一些网站维护操作,但各行业特点这是不同的。每次我们的同事帮客户维护网站,都需要获取大量的素材。基于图像的材料易于处理。直接去百度图片找,但是文字内容不好处理。
我们的网页编辑过去常常去一些客户的同行网站采集相关资料,然后稍微整理一下。但是,这种方法需要大量的人力,而且完全没有技巧可言。纯手工操作;有鉴于此,我们的程序开发者使用python编写了一个多线程脚本工具对采集网站段落内容进行分页,并根据设置的参数采集@自动指定网站 >,提取网站上的段落内容,保存到本机。为方便起见,现公布相关代码。转载请注明出处!
#!/usr/bin/python
import json
import os
import requests
import threading
import re
import time
import sys
import colorama
colorama.init(autoreset=True)
#打开文件
with open('config.json','r') as f:
data = json.load(f)
f.close()
def toInt(num):
if num !='':
return int(num)
else:
return 0
thead_count = 0 #待结束的进程数
start_ = toInt(data['start']) #分页起始值
end_ = toInt(data['end']) #分页结束值
url_ = data['url'] #入口地址
urlinclude = data['urlinclude'] #URL必须包含的字符
urlunclude = data['urlunclude'] #URL不能包含的字符
textinclude = data['textinclude'] #内容中必须包含的内容
textunclude = data['textunclude'] #内容中不能包含的字符
textreplace = data['textreplace'] #需要过滤的字符
textminsize = toInt(data['textminsize']) #有效段落的最少字符数
textmaxsize = toInt(data['textmaxsize']) #有效段落的最大字符数
encoding_ = data['encoding'] #页面编码
starttag = data['starttag'] #内容提取开始字符
endtag = data['endtag'] #内容提取结束字符
sleepTime = toInt(data['sleep']) #每次请求间隔
jsonkey = data['jsonkey'] #JSON格式数据返回时的字段
headers_ = data['headers'] #request请求主机头参数
todayStr = time.strftime("%Y%m%d",time.localtime())
total = 0
if encoding_=='':
encoding_ = 'utf-8'
#日志保存
def doLog(vstr):
with open(todayStr + ".log",'a') as fo:
if vstr !="":
fo.writelines(time.strftime("%Y-%m-%d %H:%M:%S",time.localtime()) + "\t" + vstr + "\n")
else:
fo.writelines(time.strftime("\n"))
fo.close()
def saveText(vstr):
global total
if vstr !='':
#doLog('需要保存的内容长度'+str(len(vstr)))
#判断不允许包含的内容
if len(textunclude)>0:
for tu_ in textunclude:
if tu_!='':
if vstr.find(tu_) !=-1:
#doLog(vstr + "】中存在不允许的字符:" + tu_)
return ""
#处理替换内容
if len(textreplace)>0:
for vi in textreplace:
if vi!='':
vstr = vstr.replace(vi,'')
print("\033[0;32;40m\t 收集的内容长度:" + str(len(vstr)) + "\t\033[0m ")
total = total +1
with open("采集结果.txt",'a') as fo:
fo.writelines(vstr+"\n")
fo.close()
def getFromUrl(vurl):
global thead_count,start_time
if vurl !='':
print('即将从' + vurl + '页面获取可用链接')
#提取主网址
domain = ""
if vurl.find('://') !=-1:
domain = vurl[0:vurl.find('/',vurl.find('://')+4)]
else:
domain = vurl[0:vurl.find('/')]
res = requests.get(vurl,"",headers=headers_ if len(headers_)>0 else {},timeout=3)
if jsonkey !='':
_json = res.json()
if _json[jsonkey] !='':
htmlStr = _json[jsonkey]
else:
print("================== ERROR ===================")
else:
htmlStr = res.text
#print(htmlStr)
a_href =re.findall('0:
for u1 in urlunclude:
if i.find(u1) !=-1:
urlFlag = 0
print("\033[0;31;40m\t" + i + "\t无效\033[0m ")
break
#判断必须包含的内容
if urlFlag>0 and len(urlinclude)>0:
inFlag = 0
for u2 in urlinclude:
if i.find(u2) !=-1:
inFlag = 1
break
if inFlag0:
print('延时' + str(sleepTime) + '秒后开始采集')
time.sleep(sleepTime)
doLog('开始采集:' + i)
res2 = requests.get(i,"",headers=headers_ if len(headers_)>0 else {},timeout=3)
html_ = res2.text
if html_ !='':
htmlFlag = 1
#判断是否包含指定内容
if len(textinclude)>0:
if html_.find(textinclude) !=-1:
htmlFlag = 1
else:
htmlFlag = 0
if htmlFlag= _endpos:
_endpos = len(html_)
#根据标签,提取内容
html_ = html_[_startpos:_endpos]
#过滤掉html代码,提取纯中文
html_ = html_.replace('',"</p>\r\n") #避免整段HTML代码都没换行
html_ = re.sub(r']*>','',html_)
#doLog(i + ':' + html_)
#对内容进行分割
tmpArr = html_.split("\r\n")
for ti in tmpArr:
ti2 = ti.strip().replace(" "," ")
if len(ti2)>textminsize and len(ti2)textmaxsize:
print(i + '的内容长度为:' + str(len(ti2)))
#内容过长,尝试再次分段
arr2 = ti2.replace("\r","\n").split("\n")
for tj in arr2:
tj2 = tj.strip().replace(" "," ")
print('当前段落长度为:' + str(len(tj2)))
if len(tj2)>textminsize and len(tj2)textmaxsize:
# doLog(i + '-->' + tj2)
else:
print('段落不符合设定要求' + str(len(ti2)))
print(i)
print(vurl + " 采集完成,退出线程\n")
if thead_count==1:
print('任务已完成,共用时:'+str(formatFloat(time.time()-start_time)) + 's')
print('共计:' + str(total))
#退出整个程序
sys.exit()
else:
if thead_count>0:
thead_count -= 1
else:
if thead_count>0:
thead_count -= 1
print("程序成功启动")
if start_ 查看全部
网站内容采集(主营业务包含网站建设,小程序开发,网络推广
)
主营业务包括网站建设、APP开发、小程序开发、网络推广、SEO优化,网页编辑难免需要帮助客户进行一些网站维护操作,但各行业特点这是不同的。每次我们的同事帮客户维护网站,都需要获取大量的素材。基于图像的材料易于处理。直接去百度图片找,但是文字内容不好处理。
我们的网页编辑过去常常去一些客户的同行网站采集相关资料,然后稍微整理一下。但是,这种方法需要大量的人力,而且完全没有技巧可言。纯手工操作;有鉴于此,我们的程序开发者使用python编写了一个多线程脚本工具对采集网站段落内容进行分页,并根据设置的参数采集@自动指定网站 >,提取网站上的段落内容,保存到本机。为方便起见,现公布相关代码。转载请注明出处!
#!/usr/bin/python
import json
import os
import requests
import threading
import re
import time
import sys
import colorama
colorama.init(autoreset=True)
#打开文件
with open('config.json','r') as f:
data = json.load(f)
f.close()
def toInt(num):
if num !='':
return int(num)
else:
return 0
thead_count = 0 #待结束的进程数
start_ = toInt(data['start']) #分页起始值
end_ = toInt(data['end']) #分页结束值
url_ = data['url'] #入口地址
urlinclude = data['urlinclude'] #URL必须包含的字符
urlunclude = data['urlunclude'] #URL不能包含的字符
textinclude = data['textinclude'] #内容中必须包含的内容
textunclude = data['textunclude'] #内容中不能包含的字符
textreplace = data['textreplace'] #需要过滤的字符
textminsize = toInt(data['textminsize']) #有效段落的最少字符数
textmaxsize = toInt(data['textmaxsize']) #有效段落的最大字符数
encoding_ = data['encoding'] #页面编码
starttag = data['starttag'] #内容提取开始字符
endtag = data['endtag'] #内容提取结束字符
sleepTime = toInt(data['sleep']) #每次请求间隔
jsonkey = data['jsonkey'] #JSON格式数据返回时的字段
headers_ = data['headers'] #request请求主机头参数
todayStr = time.strftime("%Y%m%d",time.localtime())
total = 0
if encoding_=='':
encoding_ = 'utf-8'
#日志保存
def doLog(vstr):
with open(todayStr + ".log",'a') as fo:
if vstr !="":
fo.writelines(time.strftime("%Y-%m-%d %H:%M:%S",time.localtime()) + "\t" + vstr + "\n")
else:
fo.writelines(time.strftime("\n"))
fo.close()
def saveText(vstr):
global total
if vstr !='':
#doLog('需要保存的内容长度'+str(len(vstr)))
#判断不允许包含的内容
if len(textunclude)>0:
for tu_ in textunclude:
if tu_!='':
if vstr.find(tu_) !=-1:
#doLog(vstr + "】中存在不允许的字符:" + tu_)
return ""
#处理替换内容
if len(textreplace)>0:
for vi in textreplace:
if vi!='':
vstr = vstr.replace(vi,'')
print("\033[0;32;40m\t 收集的内容长度:" + str(len(vstr)) + "\t\033[0m ")
total = total +1
with open("采集结果.txt",'a') as fo:
fo.writelines(vstr+"\n")
fo.close()
def getFromUrl(vurl):
global thead_count,start_time
if vurl !='':
print('即将从' + vurl + '页面获取可用链接')
#提取主网址
domain = ""
if vurl.find('://') !=-1:
domain = vurl[0:vurl.find('/',vurl.find('://')+4)]
else:
domain = vurl[0:vurl.find('/')]
res = requests.get(vurl,"",headers=headers_ if len(headers_)>0 else {},timeout=3)
if jsonkey !='':
_json = res.json()
if _json[jsonkey] !='':
htmlStr = _json[jsonkey]
else:
print("================== ERROR ===================")
else:
htmlStr = res.text
#print(htmlStr)
a_href =re.findall('0:
for u1 in urlunclude:
if i.find(u1) !=-1:
urlFlag = 0
print("\033[0;31;40m\t" + i + "\t无效\033[0m ")
break
#判断必须包含的内容
if urlFlag>0 and len(urlinclude)>0:
inFlag = 0
for u2 in urlinclude:
if i.find(u2) !=-1:
inFlag = 1
break
if inFlag0:
print('延时' + str(sleepTime) + '秒后开始采集')
time.sleep(sleepTime)
doLog('开始采集:' + i)
res2 = requests.get(i,"",headers=headers_ if len(headers_)>0 else {},timeout=3)
html_ = res2.text
if html_ !='':
htmlFlag = 1
#判断是否包含指定内容
if len(textinclude)>0:
if html_.find(textinclude) !=-1:
htmlFlag = 1
else:
htmlFlag = 0
if htmlFlag= _endpos:
_endpos = len(html_)
#根据标签,提取内容
html_ = html_[_startpos:_endpos]
#过滤掉html代码,提取纯中文
html_ = html_.replace('',"</p>\r\n") #避免整段HTML代码都没换行
html_ = re.sub(r']*>','',html_)
#doLog(i + ':' + html_)
#对内容进行分割
tmpArr = html_.split("\r\n")
for ti in tmpArr:
ti2 = ti.strip().replace(" "," ")
if len(ti2)>textminsize and len(ti2)textmaxsize:
print(i + '的内容长度为:' + str(len(ti2)))
#内容过长,尝试再次分段
arr2 = ti2.replace("\r","\n").split("\n")
for tj in arr2:
tj2 = tj.strip().replace(" "," ")
print('当前段落长度为:' + str(len(tj2)))
if len(tj2)>textminsize and len(tj2)textmaxsize:
# doLog(i + '-->' + tj2)
else:
print('段落不符合设定要求' + str(len(ti2)))
print(i)
print(vurl + " 采集完成,退出线程\n")
if thead_count==1:
print('任务已完成,共用时:'+str(formatFloat(time.time()-start_time)) + 's')
print('共计:' + str(total))
#退出整个程序
sys.exit()
else:
if thead_count>0:
thead_count -= 1
else:
if thead_count>0:
thead_count -= 1
print("程序成功启动")
if start_
网站内容采集(就是内容增加过快导致内容质量度问题就难免会忽略了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-12-05 23:21
项目招商找A5快速获取精准代理商名单
对于个人站长来说,任何网站最重要的就是内容填充问题。这也是很多站长拼命在他们的网站中添加网站内容的原因。但是,站长需要增加内容后,难免会忽略网站的质量。这就是为什么经常说内容增加太快,导致内容质量下降的原因。这也从另一个方面得到证实。鱼和熊掌不可能同时拥有这样的真理。
有的新手站长老是问这样的问题,说为什么那些大站和采集站都是采集别人,排名还是那么好。其实这样的问题很多人都遇到过,那么采集带来的文章的内容质量会不会随着时间的推移越来越差?然而,他们并没有看到自己的体重和流量下降。. 其实很多因素会决定哪些主要网站和高权重网站,我们无法比较,我们必须从每一步稳扎稳打做起。只有这样,网站才能在时间积累的过程中越来越被认可。那么,如何保证来自采集的内容在质量上能得到其他分数。
修改标题和描述以及关键词标签
此前,“头条党”一词在新闻网站中流传。其实,这些头条党每天做的事情,就是在网上寻找热门内容,修改头条,以赢得用户的关注,让用户输入网站,满足用户对热点内容的好奇心。而搜索引擎会在某些节目上偏爱热门内容,搜索和聚合人们的内容,迎合了标题党对热门内容的排序,搜索引擎也可以快速呈现。可以说,这种方法是非常合适的。满足当前用户对热点内容的呈现。
对于关键词标签和描述,这些标题党也会更加关注搜索引擎抓取和用户点击的好奇心。所以,我们在采集内容的时候,一定要尽量借鉴标题党的一些方法,在标题和描述以及关键词标签上做一些改动,这样才能区分三者原创内容的主要页面。元素。
尽量做到差异化
我们都知道有些网站喜欢用分页来增加PV。但是,这样做的缺点是明显将一个完整的内容分开,给用户的阅读造成了一定的障碍。用户必须点击下一页才能查看他们想要的内容。相反,如果他们想区分原创内容网站,则必须进行不同的排版。比如前面提到的,如果对方进行分页,我们可以将内容组织在一起(在文章的情况下不要太长),这样搜索引擎就可以轻松抓取整个内容。,而且用户不再需要翻页查看。可以说,这种在排版上有所作为的方式也在提升用户体验。
网站内容分割和字幕的使用
在查看一段内容时,如果标题准确,我们可以从标题中知道内容是关于什么的?但是,如果作者将内容写得太长,则会模糊整个内容的中心点。这样一来,用户看了上面的内容就很容易没把握住作者真正想表达的想法。这时候,对于内容采集,适当区分段落,加上相应的副标题。这种方式会减少用户观看内容的时间,而且很容易知道每个段落或作者想表达什么?后面作者有什么意见。
使用这两种方法,可以合理划分整个内容,在表达作者的观点时不应该有冲突,在字幕的设置上可以尽可能保证作者的原创想法。
采集内容不能超过一定时间
当我们记住一件事时,我们可以在有限的时间内清楚地记住它。并且保证不会被遗忘,过了规定的时间就会逐渐消退。事实上,在搜索引擎中也是如此。新内容的搜索引擎也是首选,可以在最短的时间内检索到并呈现给用户。但是,随着时间的推移,内容的新鲜度已经过去,搜索引擎将很难抓取相同的内容。我们可以充分利用这一点。搜索引擎对新文章、采集内容的偏好,尝试在一天之内采集内容。不要采集那些已经过去很久的内容。
添加高分辨率图片
部分内容来自采集,原网站没有添加图片,我们可以添加高清图片。虽然,添加图片不会对文章有太大影响,但是因为我们是采集的内容,所以尽量在采集内容的调整上做一些改变,而不是采集来这里,不做任何修改。更重要的是,一个人的着装决定了对人的好感程度。实际上,添加图片是为了增加对搜索引擎的好感度。
我们采集别人的内容,首先来自搜索引擎,属于重复抄袭。在搜索引擎方面,我们的内容与原创内容相比,质量已经下降了很多。但是,我们可以在某些方面弥补分数的下降,这需要个人站长在内容体验和网站体验上下功夫。 查看全部
网站内容采集(就是内容增加过快导致内容质量度问题就难免会忽略了)
项目招商找A5快速获取精准代理商名单
对于个人站长来说,任何网站最重要的就是内容填充问题。这也是很多站长拼命在他们的网站中添加网站内容的原因。但是,站长需要增加内容后,难免会忽略网站的质量。这就是为什么经常说内容增加太快,导致内容质量下降的原因。这也从另一个方面得到证实。鱼和熊掌不可能同时拥有这样的真理。
有的新手站长老是问这样的问题,说为什么那些大站和采集站都是采集别人,排名还是那么好。其实这样的问题很多人都遇到过,那么采集带来的文章的内容质量会不会随着时间的推移越来越差?然而,他们并没有看到自己的体重和流量下降。. 其实很多因素会决定哪些主要网站和高权重网站,我们无法比较,我们必须从每一步稳扎稳打做起。只有这样,网站才能在时间积累的过程中越来越被认可。那么,如何保证来自采集的内容在质量上能得到其他分数。
修改标题和描述以及关键词标签
此前,“头条党”一词在新闻网站中流传。其实,这些头条党每天做的事情,就是在网上寻找热门内容,修改头条,以赢得用户的关注,让用户输入网站,满足用户对热点内容的好奇心。而搜索引擎会在某些节目上偏爱热门内容,搜索和聚合人们的内容,迎合了标题党对热门内容的排序,搜索引擎也可以快速呈现。可以说,这种方法是非常合适的。满足当前用户对热点内容的呈现。
对于关键词标签和描述,这些标题党也会更加关注搜索引擎抓取和用户点击的好奇心。所以,我们在采集内容的时候,一定要尽量借鉴标题党的一些方法,在标题和描述以及关键词标签上做一些改动,这样才能区分三者原创内容的主要页面。元素。
尽量做到差异化
我们都知道有些网站喜欢用分页来增加PV。但是,这样做的缺点是明显将一个完整的内容分开,给用户的阅读造成了一定的障碍。用户必须点击下一页才能查看他们想要的内容。相反,如果他们想区分原创内容网站,则必须进行不同的排版。比如前面提到的,如果对方进行分页,我们可以将内容组织在一起(在文章的情况下不要太长),这样搜索引擎就可以轻松抓取整个内容。,而且用户不再需要翻页查看。可以说,这种在排版上有所作为的方式也在提升用户体验。
网站内容分割和字幕的使用
在查看一段内容时,如果标题准确,我们可以从标题中知道内容是关于什么的?但是,如果作者将内容写得太长,则会模糊整个内容的中心点。这样一来,用户看了上面的内容就很容易没把握住作者真正想表达的想法。这时候,对于内容采集,适当区分段落,加上相应的副标题。这种方式会减少用户观看内容的时间,而且很容易知道每个段落或作者想表达什么?后面作者有什么意见。
使用这两种方法,可以合理划分整个内容,在表达作者的观点时不应该有冲突,在字幕的设置上可以尽可能保证作者的原创想法。
采集内容不能超过一定时间
当我们记住一件事时,我们可以在有限的时间内清楚地记住它。并且保证不会被遗忘,过了规定的时间就会逐渐消退。事实上,在搜索引擎中也是如此。新内容的搜索引擎也是首选,可以在最短的时间内检索到并呈现给用户。但是,随着时间的推移,内容的新鲜度已经过去,搜索引擎将很难抓取相同的内容。我们可以充分利用这一点。搜索引擎对新文章、采集内容的偏好,尝试在一天之内采集内容。不要采集那些已经过去很久的内容。
添加高分辨率图片
部分内容来自采集,原网站没有添加图片,我们可以添加高清图片。虽然,添加图片不会对文章有太大影响,但是因为我们是采集的内容,所以尽量在采集内容的调整上做一些改变,而不是采集来这里,不做任何修改。更重要的是,一个人的着装决定了对人的好感程度。实际上,添加图片是为了增加对搜索引擎的好感度。
我们采集别人的内容,首先来自搜索引擎,属于重复抄袭。在搜索引擎方面,我们的内容与原创内容相比,质量已经下降了很多。但是,我们可以在某些方面弥补分数的下降,这需要个人站长在内容体验和网站体验上下功夫。
网站内容采集(网页设计的目的就是产生网站的三大弊端与风险)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-12-05 12:08
众所周知,网站构建是指利用标记语言,通过一系列的设计、建模、执行过程,通过互联网以电子形式传递信息,最终以图形用户界面 (GUI)。简单的说,网页设计的目的就是生产网站。网站页面可以使用超文档标记语言、可扩展超文本标记语言等标记语言,将文本、图片(GIF、JPEG、PNG)、表格等简单信息放置在页面上。而更复杂的信息如矢量图、动画、视频、音频等多媒体文件需要插件程序才能运行,同样也需要移植到网站。网站 构建是一个广义的术语,涵盖了用于许多不同技能和学科的生产和维护网站。不同领域的网页设计、网页图形设计、界面设计、创作,包括标准化代码和专有软件、用户体验设计和搜索引擎优化。很多人往往被分成几个工作组,负责网站 设计的不同方面。网页设计是设计过程的前端(客户端)。通常用来描述的网站并不是一个简单的页面。一个网站收录了很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。包括标准化代码和专有软件、用户体验设计和搜索引擎优化。很多人往往被分成几个工作组,负责网站 设计的不同方面。网页设计是设计过程的前端(客户端)。通常用来描述的网站并不是一个简单的页面。一个网站收录了很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。包括标准化代码和专有软件、用户体验设计和搜索引擎优化。很多人往往被分成几个工作组,负责网站 设计的不同方面。网页设计是设计过程的前端(客户端)。通常用来描述的网站并不是一个简单的页面。一个网站收录了很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。包括很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。包括很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。
<p>但是,使用采集程序抓取别人网站的内容,放到自己的网站上,这本来是一种不正当的获取内容的方式,但是 查看全部
网站内容采集(网页设计的目的就是产生网站的三大弊端与风险)
众所周知,网站构建是指利用标记语言,通过一系列的设计、建模、执行过程,通过互联网以电子形式传递信息,最终以图形用户界面 (GUI)。简单的说,网页设计的目的就是生产网站。网站页面可以使用超文档标记语言、可扩展超文本标记语言等标记语言,将文本、图片(GIF、JPEG、PNG)、表格等简单信息放置在页面上。而更复杂的信息如矢量图、动画、视频、音频等多媒体文件需要插件程序才能运行,同样也需要移植到网站。网站 构建是一个广义的术语,涵盖了用于许多不同技能和学科的生产和维护网站。不同领域的网页设计、网页图形设计、界面设计、创作,包括标准化代码和专有软件、用户体验设计和搜索引擎优化。很多人往往被分成几个工作组,负责网站 设计的不同方面。网页设计是设计过程的前端(客户端)。通常用来描述的网站并不是一个简单的页面。一个网站收录了很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。包括标准化代码和专有软件、用户体验设计和搜索引擎优化。很多人往往被分成几个工作组,负责网站 设计的不同方面。网页设计是设计过程的前端(客户端)。通常用来描述的网站并不是一个简单的页面。一个网站收录了很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。包括标准化代码和专有软件、用户体验设计和搜索引擎优化。很多人往往被分成几个工作组,负责网站 设计的不同方面。网页设计是设计过程的前端(客户端)。通常用来描述的网站并不是一个简单的页面。一个网站收录了很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。包括很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。包括很多工作,包括域名注册设计的渲染。布局页面、编写代码等任务。
<p>但是,使用采集程序抓取别人网站的内容,放到自己的网站上,这本来是一种不正当的获取内容的方式,但是
网站内容采集( 如何才算是正确的采集方法?网站采集是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-12-03 22:09
如何才算是正确的采集方法?网站采集是什么?)
网站操作过程中如何执行采集信息?
网站的操作过程中如何进行采集的信息?什么是正确的 采集 方法?网站采集是我们每个网站管理和运营人员都非常关心的一点。如果网站操作好,蜘蛛爬虫会采集我们的网站信息,这里我们来和大家聊聊操作过程中如何进行网站采集信息.
网站的操作过程中如何进行采集的信息?什么是正确的 采集 方法?网站采集是我们每个网站管理和运营人员都非常关心的一点。如果网站操作好,蜘蛛爬虫会采集我们的网站信息,这里我们来和大家聊聊操作过程中如何进行网站采集信息.
首先是采集的内容要适当改成标题。这里改标题不是要求采集人做标题党,而是根据内容主题改相应的标题。比如原标题是“减肥产品安全吗?” 你可以用“减肥产品安全吗?”来代替。对身体好吗”等,文字内容不同,但表达的内涵是一样的,这样采集的内容标题和内容思路可以一一对应,防止卖狗肉的内容外观。
那么就需要对内容进行适当的调整。这里的内容调整不需要简单的替换段落,也不需要使用伪原创来替换同义词或同义词。这样的替换只会让内容不舒服,用户的阅读体验会大打折扣。而现在百度对此类伪原创内容进行了严厉打击,对网站的优化效果将产生严重的负面影响。调整内容时,可以适当改写,尤其是第一段和最后一段,进行改写,然后适当添加相应的图片,可以有效提高内容质量,也可以为百度蜘蛛带来更好的效果。上诉。
总而言之,网站采集的内容根本不需要棍子就可以杀死。其实只有传统的粗制采集需要适当优化改成精制采集虽然采集的时间会比较长,但是比原创快多了,而且不影响用户体验,所以正确的采集还是很有必要的。
网站的操作过程中如何进行采集的信息?看了以上文章的内容,你学会了在网站的操作过程中如何去执行采集的信息了吗?如果有什么不明白的,可以直接联系编辑。 查看全部
网站内容采集(
如何才算是正确的采集方法?网站采集是什么?)
网站操作过程中如何执行采集信息?
网站的操作过程中如何进行采集的信息?什么是正确的 采集 方法?网站采集是我们每个网站管理和运营人员都非常关心的一点。如果网站操作好,蜘蛛爬虫会采集我们的网站信息,这里我们来和大家聊聊操作过程中如何进行网站采集信息.
网站的操作过程中如何进行采集的信息?什么是正确的 采集 方法?网站采集是我们每个网站管理和运营人员都非常关心的一点。如果网站操作好,蜘蛛爬虫会采集我们的网站信息,这里我们来和大家聊聊操作过程中如何进行网站采集信息.
首先是采集的内容要适当改成标题。这里改标题不是要求采集人做标题党,而是根据内容主题改相应的标题。比如原标题是“减肥产品安全吗?” 你可以用“减肥产品安全吗?”来代替。对身体好吗”等,文字内容不同,但表达的内涵是一样的,这样采集的内容标题和内容思路可以一一对应,防止卖狗肉的内容外观。
那么就需要对内容进行适当的调整。这里的内容调整不需要简单的替换段落,也不需要使用伪原创来替换同义词或同义词。这样的替换只会让内容不舒服,用户的阅读体验会大打折扣。而现在百度对此类伪原创内容进行了严厉打击,对网站的优化效果将产生严重的负面影响。调整内容时,可以适当改写,尤其是第一段和最后一段,进行改写,然后适当添加相应的图片,可以有效提高内容质量,也可以为百度蜘蛛带来更好的效果。上诉。
总而言之,网站采集的内容根本不需要棍子就可以杀死。其实只有传统的粗制采集需要适当优化改成精制采集虽然采集的时间会比较长,但是比原创快多了,而且不影响用户体验,所以正确的采集还是很有必要的。
网站的操作过程中如何进行采集的信息?看了以上文章的内容,你学会了在网站的操作过程中如何去执行采集的信息了吗?如果有什么不明白的,可以直接联系编辑。
网站内容采集(修正拨号显示IP不正确BUG修正遇出错关键词暂停)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-12-03 17:22
<p>[概述]任何网站内容采集。[基本介绍]1、使用底层HTTP方法采集数据,快速稳定。它可以同时构建多个任务和采用多线程采集多个网站数据2、用户可以随意导入和导出任务3、任务可以设置密码以确保您的采集任务的细节安全且不泄漏4、并且有N个页面采集暂停/拨号以更改IP,采集如果有特殊标记,暂停/拨号以更改IP和其他防裂功能采集您可以直接输入网址或通过JavaScript脚本生成网址,或者使用关键词搜索方法采集6、您可以使用登录采集方法采集查看需要登录帐户的web内容7、您可以无限深入地查看N列的内容和链接采集,支持多级内容分页采集8、支持多种内容提取模式。您可以根据需要处理采集的内容,如清除HTML、图片等。9、您可以制作自己的JavaScript脚本来提取web内容,轻松实现内容任何部分的 查看全部
网站内容采集(修正拨号显示IP不正确BUG修正遇出错关键词暂停)
<p>[概述]任何网站内容采集。[基本介绍]1、使用底层HTTP方法采集数据,快速稳定。它可以同时构建多个任务和采用多线程采集多个网站数据2、用户可以随意导入和导出任务3、任务可以设置密码以确保您的采集任务的细节安全且不泄漏4、并且有N个页面采集暂停/拨号以更改IP,采集如果有特殊标记,暂停/拨号以更改IP和其他防裂功能采集您可以直接输入网址或通过JavaScript脚本生成网址,或者使用关键词搜索方法采集6、您可以使用登录采集方法采集查看需要登录帐户的web内容7、您可以无限深入地查看N列的内容和链接采集,支持多级内容分页采集8、支持多种内容提取模式。您可以根据需要处理采集的内容,如清除HTML、图片等。9、您可以制作自己的JavaScript脚本来提取web内容,轻松实现内容任何部分的
网站内容采集(总是势力收集整理,本站仅拥有展示权!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-30 12:16
我最近做的网站的内容经常被人采集拿走,又不想让别人采集看到我网站的数据,所以就写了一段代码。
0 那么
check_agent=真
退出
万一
下一个
检查=检查代理
结束函数
如果 check(user_agent)=False 那么
如果 http_reffer="" 或 left(http_reffer,len("http://"&server_name)+1)"http://%26quot%3B%26amp%3Bamp% ... ot%3B 然后
%>
2.
小站长辛辛苦苦整理网站的新增内容,从来不想别人轻易拿走,但今天的采集节目可不止NB,总有办法的!他们应该让他们肆虐吗?答案是不。他们的方法可以改变,但他们的网站IP不会轻易改变。我们将从这种方法开始。为了方便不同的需求,小编为大家整理了几种方法,希望对大家有所帮助!由第三势力采集,本站仅拥有展示权!
第一种方法:
最好的一段代码(ASP):
int(AppealNum) 然后
response.write "第三种力提醒你:爬行很累,我们歇会儿吧!"
响应结束
万一
%>
第二种方法(ASP):
0 那么
check_agent=真
退出
万一
下一个
检查=检查代理
结束函数
如果 check(user_agent)=False 那么
如果 http_reffer="" 或 left(http_reffer,len("http://"&server_name)+1)"http://%26quot%3B%26amp%3Bamp% ... ot%3B 然后
%>
3.
防止采集第一种使用Persistence给静态页面添加session功能的方法
一般来说,只有服务端CGI程序(ASP、PHP、JSP)才有session功能,用于保存网站期间(session)用户的活动数据信息,以及用于大量静态pages (HTML) 换句话说,只能使用客户端的cookies来保存临时活动数据,但是cookies的操作是一个非常繁琐的过程,远不如session的操作方便。为此,本文向读者推荐一种DHTML中的“持久化技术”解决方案,让静态页面也能使用会话功能。
Microsoft Internet Explorer 5 浏览器及更高版本支持使用 Persistence 技术,它允许我们在当前会话期间将一些数据对象保存到客户端,减少对服务器的访问请求,充分利用客户端计算机的数据处理功能也提高了整体页面的显示效率。
持久化技术有以下行为可以调用:
· SaveFavorite——当页面加入采集时保存页面状态和信息
· SaveHistory——保存当前会话中的页面状态和信息
· SaveSnapshot——页面保存到硬盘时,保存页面状态和信息
· UserData——以XML格式保存当前会话中的页面状态和信息
持久化技术打破了之前使用cookies和session的传统,继承了cookies的一些安全策略,同时也增加了数据的存储和管理能力。我们的每个页面都有64KB的用户数据存储容量,每个站点的总存储限制为640KB。
Persistence 技术存储的数据格式符合 XML 标准,因此可以使用 DOM 技术中的 getAttribute 和 setAttribute 方法来访问数据。
下面是 Persistence 技术的典型应用。通过对Persistence存储数据的分析,静态页面具有验证功能。
实际的判断过程是这样的:
1. 共有三个对象:访问者V、导航页A、内容页C
2. 访问者V只能通过导航页A上的链接看到内容页C;
3. 如果访问者V通过其他方式(如通过其他网站超链接,直接在IE地址栏输入URL等)访问内容页C,内容页C会自动提示版权信息 显示空白页。
具体实施步骤:
· 在“导航页面”添加STYLE定义持久化类,并添加存储函数fnSave进行授权。
·在“导航页面”的和区域定义一个图层来标识Persistence对象
· 在“导航页面”的超链接属性中添加语句调用函数fnSave:
接下来,在“内容页”中添加验证功能。
·在“内容页面”中添加STYLE定义持久化类,添加存储函数fnLoad判断合法性。
· 修改“内容页面”区域如下:
***插入上述代码的页面必须在同一个文件夹中,否则会报错。
从上面的例子可以看出,通过持久化的使用,普通静态内容页面具备了会话功能,一般的不敏感信息可以通过会话存储在客户端。
使用具有会话功能的多个静态页面可以完成许多复杂的任务,例如虚拟购物车、高级搜索引擎等。同时,作为先前由服务器承担的会话任务的一部分转移到客户端,减少了数据交互,大大减轻了服务器的负担。
第三股力量是从网上搜集整理出来的。没有自检,请谨慎使用!以免影响搜索引擎的收录! 查看全部
网站内容采集(总是势力收集整理,本站仅拥有展示权!(组图))
我最近做的网站的内容经常被人采集拿走,又不想让别人采集看到我网站的数据,所以就写了一段代码。
0 那么
check_agent=真
退出
万一
下一个
检查=检查代理
结束函数
如果 check(user_agent)=False 那么
如果 http_reffer="" 或 left(http_reffer,len("http://"&server_name)+1)"http://%26quot%3B%26amp%3Bamp% ... ot%3B 然后
%>
2.
小站长辛辛苦苦整理网站的新增内容,从来不想别人轻易拿走,但今天的采集节目可不止NB,总有办法的!他们应该让他们肆虐吗?答案是不。他们的方法可以改变,但他们的网站IP不会轻易改变。我们将从这种方法开始。为了方便不同的需求,小编为大家整理了几种方法,希望对大家有所帮助!由第三势力采集,本站仅拥有展示权!
第一种方法:
最好的一段代码(ASP):
int(AppealNum) 然后
response.write "第三种力提醒你:爬行很累,我们歇会儿吧!"
响应结束
万一
%>
第二种方法(ASP):
0 那么
check_agent=真
退出
万一
下一个
检查=检查代理
结束函数
如果 check(user_agent)=False 那么
如果 http_reffer="" 或 left(http_reffer,len("http://"&server_name)+1)"http://%26quot%3B%26amp%3Bamp% ... ot%3B 然后
%>
3.
防止采集第一种使用Persistence给静态页面添加session功能的方法
一般来说,只有服务端CGI程序(ASP、PHP、JSP)才有session功能,用于保存网站期间(session)用户的活动数据信息,以及用于大量静态pages (HTML) 换句话说,只能使用客户端的cookies来保存临时活动数据,但是cookies的操作是一个非常繁琐的过程,远不如session的操作方便。为此,本文向读者推荐一种DHTML中的“持久化技术”解决方案,让静态页面也能使用会话功能。
Microsoft Internet Explorer 5 浏览器及更高版本支持使用 Persistence 技术,它允许我们在当前会话期间将一些数据对象保存到客户端,减少对服务器的访问请求,充分利用客户端计算机的数据处理功能也提高了整体页面的显示效率。
持久化技术有以下行为可以调用:
· SaveFavorite——当页面加入采集时保存页面状态和信息
· SaveHistory——保存当前会话中的页面状态和信息
· SaveSnapshot——页面保存到硬盘时,保存页面状态和信息
· UserData——以XML格式保存当前会话中的页面状态和信息
持久化技术打破了之前使用cookies和session的传统,继承了cookies的一些安全策略,同时也增加了数据的存储和管理能力。我们的每个页面都有64KB的用户数据存储容量,每个站点的总存储限制为640KB。
Persistence 技术存储的数据格式符合 XML 标准,因此可以使用 DOM 技术中的 getAttribute 和 setAttribute 方法来访问数据。
下面是 Persistence 技术的典型应用。通过对Persistence存储数据的分析,静态页面具有验证功能。
实际的判断过程是这样的:
1. 共有三个对象:访问者V、导航页A、内容页C
2. 访问者V只能通过导航页A上的链接看到内容页C;
3. 如果访问者V通过其他方式(如通过其他网站超链接,直接在IE地址栏输入URL等)访问内容页C,内容页C会自动提示版权信息 显示空白页。
具体实施步骤:
· 在“导航页面”添加STYLE定义持久化类,并添加存储函数fnSave进行授权。
·在“导航页面”的和区域定义一个图层来标识Persistence对象
· 在“导航页面”的超链接属性中添加语句调用函数fnSave:
接下来,在“内容页”中添加验证功能。
·在“内容页面”中添加STYLE定义持久化类,添加存储函数fnLoad判断合法性。
· 修改“内容页面”区域如下:
***插入上述代码的页面必须在同一个文件夹中,否则会报错。
从上面的例子可以看出,通过持久化的使用,普通静态内容页面具备了会话功能,一般的不敏感信息可以通过会话存储在客户端。
使用具有会话功能的多个静态页面可以完成许多复杂的任务,例如虚拟购物车、高级搜索引擎等。同时,作为先前由服务器承担的会话任务的一部分转移到客户端,减少了数据交互,大大减轻了服务器的负担。
第三股力量是从网上搜集整理出来的。没有自检,请谨慎使用!以免影响搜索引擎的收录!
网站内容采集( 如何通过dedecms来做采集站?采集怎么做? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-11-30 10:29
如何通过dedecms来做采集站?采集怎么做?
)
很多SEO人员和网站管理者都会用织梦cms来建网站,但是对于dede采集网站、织梦@ >内置的采集功能非常不方便,已经不适合采集的当前需求。所以SEO人员一定要懂知识,可以不做,但一定要懂!如何通过dedecms做采集站?德德采集是怎么做到的?我用织梦cms做采集站,收录现在接近20万了,权重有点低,只有权重3,不过可以SEO方法后说明 来这里的采集站也可以起来了。今天的文章文章主要是和大家分享这两个我们在做SEO时遇到的常见问题。
德德采集怎么做? dedecms自带采集功能,功能非常有限,不能满足采集的复杂需求,经常导致网站网页采集空白,对SEO人员来说很麻烦。因此,您可以使用免费且易于使用的第三方网站采集软件来完成dede采集:
1.一键安装,全自动免费采集,安装非常简单方便,只需一分钟
2. 多词采集 无需写采集规则,根据大量关键词泛化采集
3. RSS采集,输入RSS地址到采集内容,只需输入RSS地址到采集到目标网站内容定位采集,精确采集标题、正文、作者、出处,只需要提供列表URL即可智能采集指定网站或栏目内容
4.软件全自动采集,无需人工干预,即可挂断采集,所有操作程序全自动
5.图片云存储,大量采集图片不麻烦,也可以本地存储。支持主流云存储。
6.可以直接进行伪原创SEO更新,只需开启伪原创功能,不需要复杂的配置界面
7.可以同时支持所有主要的cms版本,以及市场上所有常见的cms支持。
8.自动推送到各大搜索引擎接口,确保搜索引擎及时收录到我们的网站并提供网站排名
德德采集的做法是什么?这是SEO优化非常重要的一步。内容采集:我也提到了dedecms内置的采集器的使用。就个人而言,我不推荐它。 采集 的那种。 文章 直接发布,肯定会被搜索引擎命中。建立你的网站关键词,关键词需要两个,一个准确,一个多。准是指关键词一定和你的网站定位有关。比如你是装修公司网站,那你网站的关键词肯定和装修有关(装修风格、现代装修等)。更多意味着需要大量的行业从关键词到采集,这样文章就会有更多,内容更丰富。 伪原创:因为采集的内容已经被收录或者其他人展示过,为了避免被搜索引擎命中,所以是采集站,在同时增加原创 所以采集的内容必须经过SEO伪原创的处理。标题:标题是一篇文章文章的精髓,很大程度上决定了用户点击的概率,所以一定要表达出整个文章的意思,才有吸引力。标题中必须收录长尾关键词,并且关键词必须与网站相关。
网站的建设和运营管理需要全面。关于dede采集,分享到这里。很多SEO知识需要在实际操作中积累经验。我只是提出一些新手需要了解的基础内容,也是个人经验。
查看全部
网站内容采集(
如何通过dedecms来做采集站?采集怎么做?
)
很多SEO人员和网站管理者都会用织梦cms来建网站,但是对于dede采集网站、织梦@ >内置的采集功能非常不方便,已经不适合采集的当前需求。所以SEO人员一定要懂知识,可以不做,但一定要懂!如何通过dedecms做采集站?德德采集是怎么做到的?我用织梦cms做采集站,收录现在接近20万了,权重有点低,只有权重3,不过可以SEO方法后说明 来这里的采集站也可以起来了。今天的文章文章主要是和大家分享这两个我们在做SEO时遇到的常见问题。
德德采集怎么做? dedecms自带采集功能,功能非常有限,不能满足采集的复杂需求,经常导致网站网页采集空白,对SEO人员来说很麻烦。因此,您可以使用免费且易于使用的第三方网站采集软件来完成dede采集:
1.一键安装,全自动免费采集,安装非常简单方便,只需一分钟
2. 多词采集 无需写采集规则,根据大量关键词泛化采集
3. RSS采集,输入RSS地址到采集内容,只需输入RSS地址到采集到目标网站内容定位采集,精确采集标题、正文、作者、出处,只需要提供列表URL即可智能采集指定网站或栏目内容
4.软件全自动采集,无需人工干预,即可挂断采集,所有操作程序全自动
5.图片云存储,大量采集图片不麻烦,也可以本地存储。支持主流云存储。
6.可以直接进行伪原创SEO更新,只需开启伪原创功能,不需要复杂的配置界面
7.可以同时支持所有主要的cms版本,以及市场上所有常见的cms支持。
8.自动推送到各大搜索引擎接口,确保搜索引擎及时收录到我们的网站并提供网站排名
德德采集的做法是什么?这是SEO优化非常重要的一步。内容采集:我也提到了dedecms内置的采集器的使用。就个人而言,我不推荐它。 采集 的那种。 文章 直接发布,肯定会被搜索引擎命中。建立你的网站关键词,关键词需要两个,一个准确,一个多。准是指关键词一定和你的网站定位有关。比如你是装修公司网站,那你网站的关键词肯定和装修有关(装修风格、现代装修等)。更多意味着需要大量的行业从关键词到采集,这样文章就会有更多,内容更丰富。 伪原创:因为采集的内容已经被收录或者其他人展示过,为了避免被搜索引擎命中,所以是采集站,在同时增加原创 所以采集的内容必须经过SEO伪原创的处理。标题:标题是一篇文章文章的精髓,很大程度上决定了用户点击的概率,所以一定要表达出整个文章的意思,才有吸引力。标题中必须收录长尾关键词,并且关键词必须与网站相关。
网站的建设和运营管理需要全面。关于dede采集,分享到这里。很多SEO知识需要在实际操作中积累经验。我只是提出一些新手需要了解的基础内容,也是个人经验。
网站内容采集( 采集的内容如果不采集图片可以不可以?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-29 19:26
采集的内容如果不采集图片可以不可以?(图))
问:采集的内容可以不是采集的图片吗?
问题补充:最近想给网站采集发一篇文章,因为我采集时无法同步采集的图片,会不会有影响?网站 优化呢?
答:这里涉及两个问题。一个问题是采集的内容是否会影响网站的优化,另一个问题是文章会不会添加图片影响网站的优化。我们分别说一下:
1、采集的文章内容会影响网站优化
关于采集的文章,作者写过采集站容易被K,就是采集站收录,收录呢? @采集站不会死这两个文章,如果你看过这两个文章,你应该就能明白采集的问题了。这里作者简单说一下,纯采集的文章的内容是没有意义的。我们需要对采集返回的内容进行处理,比如伪原创处理,比如标签聚合等等。总之,要让采集返回的内容更有价值。只有这样,采集的内容才能生效。如果只是单纯的采集,不仅不好,还会让网站受到搜索引擎的惩罚。
2、文章 不添加图片影响网站优化
很多朋友认为文章一定要加图片,很多资深seo人员也会这么说。那么真的是这样吗?笔者认为文章加不加图片需要根据情况而定。例如,不要在本文中添加图片。如果坚持要添加图片,应该添加什么样的图片?
笔者这里建议大家在构建网站的内容时,不要以为所有的文章都要加图片。某些内容不加图片也没关系。当然,如果是介绍具体的产品,比如文章需要添加产品图片,图片和文字更能说明问题。
你可以扩展它,添加或不添加图片其实是在考虑用户体验,用户体验是网站优化中非常重要的一部分,所以你可以研究更多的用户需求,优化和提升用户体验。
关于采集的内容如果不能采集图片的话,笔者就简单说这么多。总之,需要对采集的内容进行整合处理,才能使用采集的内容。至于带不带图片,要看文章的内容。如果有图片可以更好的解决问题,那么无论是采集还是原创的内容,都可以添加图片。如果不需要添加,那么也可以不添加图片。 查看全部
网站内容采集(
采集的内容如果不采集图片可以不可以?(图))
问:采集的内容可以不是采集的图片吗?
问题补充:最近想给网站采集发一篇文章,因为我采集时无法同步采集的图片,会不会有影响?网站 优化呢?
答:这里涉及两个问题。一个问题是采集的内容是否会影响网站的优化,另一个问题是文章会不会添加图片影响网站的优化。我们分别说一下:
1、采集的文章内容会影响网站优化
关于采集的文章,作者写过采集站容易被K,就是采集站收录,收录呢? @采集站不会死这两个文章,如果你看过这两个文章,你应该就能明白采集的问题了。这里作者简单说一下,纯采集的文章的内容是没有意义的。我们需要对采集返回的内容进行处理,比如伪原创处理,比如标签聚合等等。总之,要让采集返回的内容更有价值。只有这样,采集的内容才能生效。如果只是单纯的采集,不仅不好,还会让网站受到搜索引擎的惩罚。
2、文章 不添加图片影响网站优化
很多朋友认为文章一定要加图片,很多资深seo人员也会这么说。那么真的是这样吗?笔者认为文章加不加图片需要根据情况而定。例如,不要在本文中添加图片。如果坚持要添加图片,应该添加什么样的图片?
笔者这里建议大家在构建网站的内容时,不要以为所有的文章都要加图片。某些内容不加图片也没关系。当然,如果是介绍具体的产品,比如文章需要添加产品图片,图片和文字更能说明问题。
你可以扩展它,添加或不添加图片其实是在考虑用户体验,用户体验是网站优化中非常重要的一部分,所以你可以研究更多的用户需求,优化和提升用户体验。
关于采集的内容如果不能采集图片的话,笔者就简单说这么多。总之,需要对采集的内容进行整合处理,才能使用采集的内容。至于带不带图片,要看文章的内容。如果有图片可以更好的解决问题,那么无论是采集还是原创的内容,都可以添加图片。如果不需要添加,那么也可以不添加图片。
网站内容采集( 如何通过dedecms来做采集站?采集怎么做? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-11-29 06:16
如何通过dedecms来做采集站?采集怎么做?
)
很多SEO人员和网站管理者都会使用织梦cms来建网站,但是对于dede采集 网站、织梦@ >内置的采集功能非常不方便,已经不适合采集的当前需求。所以SEO人员一定要懂知识,可以不做,但一定要懂!如何通过dedecms做采集站?德德采集是怎么做到的?我用织梦cms做采集站,收录现在接近20万了,权重有点低,只有权重3,不过可以SEO方法后说明 来这里的采集站也可以起来了。今天的文章主要是和大家分享这两个我们在做SEO时遇到的常见问题。
德德采集怎么做? dedecms自带采集功能,功能非常有限,不能满足采集的复杂需求,经常导致网站网页采集空白,从而对SEO人员来说很麻烦。因此,您可以使用免费且易于使用的第三方网站采集软件来完成dede采集:
1.一键安装,全自动免费采集,安装非常简单方便,只需一分钟
2. 多词采集 无需写采集规则,根据大量关键词泛化采集
3. RSS采集,输入RSS地址到采集内容,只需输入RSS地址到采集到目标网站内容定位采集,精确采集标题、正文、作者、出处,只需要提供列表URL即可智能采集指定网站或栏目内容
4.软件全自动采集,无需人工干预,即可挂断采集,所有操作程序全自动
5.图片云存储,大量采集图片不麻烦,也可以本地存储。支持主流云存储。
6.可以直接进行伪原创SEO更新,只需开启伪原创功能,不需要复杂的配置界面
7.可以同时支持所有主要的cms版本,以及市场上所有常见的cms支持。
8.自动推送到各大搜索引擎接口,确保搜索引擎及时收录到我们的网站并提供网站排名
德德采集的做法是什么?这是SEO优化非常重要的一步。内容采集:我也提到了dedecms内置的采集器的使用。就个人而言,我不推荐它。 采集 的那种。 文章 直接发布,肯定会被搜索引擎命中。建立你的网站关键词,关键词需要两个,一个准确,一个多。准是指关键词一定和你的网站定位有关。比如你是装修公司网站,那你网站的关键词肯定和装修有关(装修风格、现代装修等)。更多意味着很多行业都需要关键词到采集,这样文章就会有更多,内容更丰富。 伪原创:因为采集的内容已经被收录或者其他人展示过,为了避免被搜索引擎命中,所以是采集站,在同时增加原创 所以采集的内容必须经过SEO伪原创的处理。标题:标题是文章中最重要的部分。它在很大程度上决定了用户点击的概率,所以它必须表达整个文章的含义,这很有吸引力。标题中必须收录长尾关键词,并且关键词必须与网站相关。
网站的建设和运营管理需要全面。关于dede采集,分享到这里。很多SEO知识需要在实际操作中积累经验。我只是提出一些新手需要了解的基础内容,也是个人经验。
查看全部
网站内容采集(
如何通过dedecms来做采集站?采集怎么做?
)
很多SEO人员和网站管理者都会使用织梦cms来建网站,但是对于dede采集 网站、织梦@ >内置的采集功能非常不方便,已经不适合采集的当前需求。所以SEO人员一定要懂知识,可以不做,但一定要懂!如何通过dedecms做采集站?德德采集是怎么做到的?我用织梦cms做采集站,收录现在接近20万了,权重有点低,只有权重3,不过可以SEO方法后说明 来这里的采集站也可以起来了。今天的文章主要是和大家分享这两个我们在做SEO时遇到的常见问题。
德德采集怎么做? dedecms自带采集功能,功能非常有限,不能满足采集的复杂需求,经常导致网站网页采集空白,从而对SEO人员来说很麻烦。因此,您可以使用免费且易于使用的第三方网站采集软件来完成dede采集:
1.一键安装,全自动免费采集,安装非常简单方便,只需一分钟
2. 多词采集 无需写采集规则,根据大量关键词泛化采集
3. RSS采集,输入RSS地址到采集内容,只需输入RSS地址到采集到目标网站内容定位采集,精确采集标题、正文、作者、出处,只需要提供列表URL即可智能采集指定网站或栏目内容
4.软件全自动采集,无需人工干预,即可挂断采集,所有操作程序全自动
5.图片云存储,大量采集图片不麻烦,也可以本地存储。支持主流云存储。
6.可以直接进行伪原创SEO更新,只需开启伪原创功能,不需要复杂的配置界面
7.可以同时支持所有主要的cms版本,以及市场上所有常见的cms支持。
8.自动推送到各大搜索引擎接口,确保搜索引擎及时收录到我们的网站并提供网站排名
德德采集的做法是什么?这是SEO优化非常重要的一步。内容采集:我也提到了dedecms内置的采集器的使用。就个人而言,我不推荐它。 采集 的那种。 文章 直接发布,肯定会被搜索引擎命中。建立你的网站关键词,关键词需要两个,一个准确,一个多。准是指关键词一定和你的网站定位有关。比如你是装修公司网站,那你网站的关键词肯定和装修有关(装修风格、现代装修等)。更多意味着很多行业都需要关键词到采集,这样文章就会有更多,内容更丰富。 伪原创:因为采集的内容已经被收录或者其他人展示过,为了避免被搜索引擎命中,所以是采集站,在同时增加原创 所以采集的内容必须经过SEO伪原创的处理。标题:标题是文章中最重要的部分。它在很大程度上决定了用户点击的概率,所以它必须表达整个文章的含义,这很有吸引力。标题中必须收录长尾关键词,并且关键词必须与网站相关。
网站的建设和运营管理需要全面。关于dede采集,分享到这里。很多SEO知识需要在实际操作中积累经验。我只是提出一些新手需要了解的基础内容,也是个人经验。
网站内容采集(就是为什么常说的就是内容增加过快,导致内容质量度降低)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-28 16:16
对于个人站长来说,任何网站最重要的就是内容填充问题。这也是很多站长拼命在他们的网站中添加网站内容的原因。但是,站长需要增加内容后,难免会忽略网站的质量。这就是为什么经常说内容增加太快,导致内容质量下降的原因。这也从另一个方面得到证实。鱼和熊掌不可能同时拥有这样的真理。
有的新手站长老是提出这样的问题,说为什么那些大网站和采集网站都是采集别人的,排名还是那么好。其实这样的问题很多人都遇到过,那么采集带来的文章的内容质量会不会随着时间的推移越来越差?然而,他们并没有看到自己的体重和流量下降。. 其实很多因素会决定哪些主要网站和高权重网站,我们无法比较,我们必须从每一步稳扎稳打做起。只有这样,网站才能在时间积累的过程中越来越被认可。那么,如何保证来自采集的内容在质量上能得到其他分数。
修改标题和描述以及关键词标签
此前,“头条党”一词在新闻网站中流传。其实,这些头条党每天做的事情,就是在网上寻找热门内容,修改头条,以赢得用户的关注,让用户输入网站,满足用户对热点内容的好奇心。并且搜索引擎会在某些节目中偏爱热点内容,搜索和聚合人们的内容,迎合了标题党对热点内容的排序,搜索引擎也可以快速呈现。可以说,这种方法是非常合适的。满足当前用户对热点内容的呈现。
对于关键词标签和描述,这些标题党也会更加关注搜索引擎抓取和用户点击的好奇心。所以,我们在采集内容的时候,应该尽量借鉴题主的一些方法,在title和description以及关键词标签上做一些改动,这样才能区分三者原创内容的主要页面。元素。
尽量做到差异化
我们都知道有些网站喜欢用分页来增加PV。但是,这样做的缺点是明显将一个完整的内容分开,给用户的阅读造成了一定的障碍。用户必须点击下一页才能查看他们想要的内容。反过来,他们认为如果要区分原创内容网站,就必须做出与其不同的布局。比如前面提到的,如果对方进行分页,我们可以将内容组织在一起(在文章的情况下不要太长),这样搜索引擎就可以轻松抓取整个内容。,而且用户不再需要翻页查看。可以说,这种在排版上的差异化方式,也是在提升用户体验。
网站内容分割和字幕的使用
在查看一段内容时,如果标题准确,我们可以从标题中知道内容是关于什么的?但是,如果作者将内容写得太长,则会模糊整个内容的中心点。这样,用户很容易阅读上面的内容,很容易捕捉到作者真正想要表达的想法。这时候,对于内容采集,适当区分段落,加上相应的副标题。这种方式会减少用户观看内容的时间,而且很容易知道每个段落或作者想表达什么?后面作者有什么意见。
使用这两种方法,可以合理划分整个内容,在表达作者的观点时不应该有冲突,在字幕的设置上可以尽可能保证作者的原创想法。
采集内容不能超过一定时间
当我们记住一件事时,我们可以在有限的时间内清楚地记住它。并且保证不会忘记,到了规定的时间就会慢慢消退。事实上,在搜索引擎中也是如此。对于文章的新货源:机房、新风机房、加湿电池、机房监控,mxt12组织的,搜索引擎也偏爱搜索引擎,在最短的时间内抓取并呈现给用户,但随着时间的推移,内容新鲜度已经过去,搜索引擎很难抓取到相同的内容。我们可以充分利用这一点。搜索引擎对新文章、采集内容的偏好,尝试在一天之内采集内容。不要采集那些已经过去很久的内容。
添加高分辨率图片
部分内容来自采集,原来网站没有添加图片,我们可以添加高分辨率图片。虽然,添加图片不会对文章有太大影响,但是因为我们是采集的内容,所以尽量在采集内容的调整上做一些改变,而不是采集来这里,不做任何修改。更重要的是,一个人的着装决定了对人的好感程度。实际上,添加图片是为了增加对搜索引擎的好感度。
我们采集别人的内容,首先来自搜索引擎,属于重复抄袭。在搜索引擎方面,我们的内容与原创内容相比,质量已经下降了很多。但是,我们可以通过一些方面来弥补分数的下降,这需要个人站长在内容体验和网站体验上下功夫。 查看全部
网站内容采集(就是为什么常说的就是内容增加过快,导致内容质量度降低)
对于个人站长来说,任何网站最重要的就是内容填充问题。这也是很多站长拼命在他们的网站中添加网站内容的原因。但是,站长需要增加内容后,难免会忽略网站的质量。这就是为什么经常说内容增加太快,导致内容质量下降的原因。这也从另一个方面得到证实。鱼和熊掌不可能同时拥有这样的真理。
有的新手站长老是提出这样的问题,说为什么那些大网站和采集网站都是采集别人的,排名还是那么好。其实这样的问题很多人都遇到过,那么采集带来的文章的内容质量会不会随着时间的推移越来越差?然而,他们并没有看到自己的体重和流量下降。. 其实很多因素会决定哪些主要网站和高权重网站,我们无法比较,我们必须从每一步稳扎稳打做起。只有这样,网站才能在时间积累的过程中越来越被认可。那么,如何保证来自采集的内容在质量上能得到其他分数。
修改标题和描述以及关键词标签
此前,“头条党”一词在新闻网站中流传。其实,这些头条党每天做的事情,就是在网上寻找热门内容,修改头条,以赢得用户的关注,让用户输入网站,满足用户对热点内容的好奇心。并且搜索引擎会在某些节目中偏爱热点内容,搜索和聚合人们的内容,迎合了标题党对热点内容的排序,搜索引擎也可以快速呈现。可以说,这种方法是非常合适的。满足当前用户对热点内容的呈现。
对于关键词标签和描述,这些标题党也会更加关注搜索引擎抓取和用户点击的好奇心。所以,我们在采集内容的时候,应该尽量借鉴题主的一些方法,在title和description以及关键词标签上做一些改动,这样才能区分三者原创内容的主要页面。元素。
尽量做到差异化
我们都知道有些网站喜欢用分页来增加PV。但是,这样做的缺点是明显将一个完整的内容分开,给用户的阅读造成了一定的障碍。用户必须点击下一页才能查看他们想要的内容。反过来,他们认为如果要区分原创内容网站,就必须做出与其不同的布局。比如前面提到的,如果对方进行分页,我们可以将内容组织在一起(在文章的情况下不要太长),这样搜索引擎就可以轻松抓取整个内容。,而且用户不再需要翻页查看。可以说,这种在排版上的差异化方式,也是在提升用户体验。
网站内容分割和字幕的使用
在查看一段内容时,如果标题准确,我们可以从标题中知道内容是关于什么的?但是,如果作者将内容写得太长,则会模糊整个内容的中心点。这样,用户很容易阅读上面的内容,很容易捕捉到作者真正想要表达的想法。这时候,对于内容采集,适当区分段落,加上相应的副标题。这种方式会减少用户观看内容的时间,而且很容易知道每个段落或作者想表达什么?后面作者有什么意见。
使用这两种方法,可以合理划分整个内容,在表达作者的观点时不应该有冲突,在字幕的设置上可以尽可能保证作者的原创想法。
采集内容不能超过一定时间
当我们记住一件事时,我们可以在有限的时间内清楚地记住它。并且保证不会忘记,到了规定的时间就会慢慢消退。事实上,在搜索引擎中也是如此。对于文章的新货源:机房、新风机房、加湿电池、机房监控,mxt12组织的,搜索引擎也偏爱搜索引擎,在最短的时间内抓取并呈现给用户,但随着时间的推移,内容新鲜度已经过去,搜索引擎很难抓取到相同的内容。我们可以充分利用这一点。搜索引擎对新文章、采集内容的偏好,尝试在一天之内采集内容。不要采集那些已经过去很久的内容。
添加高分辨率图片
部分内容来自采集,原来网站没有添加图片,我们可以添加高分辨率图片。虽然,添加图片不会对文章有太大影响,但是因为我们是采集的内容,所以尽量在采集内容的调整上做一些改变,而不是采集来这里,不做任何修改。更重要的是,一个人的着装决定了对人的好感程度。实际上,添加图片是为了增加对搜索引擎的好感度。
我们采集别人的内容,首先来自搜索引擎,属于重复抄袭。在搜索引擎方面,我们的内容与原创内容相比,质量已经下降了很多。但是,我们可以通过一些方面来弥补分数的下降,这需要个人站长在内容体验和网站体验上下功夫。
网站内容采集( 一下采集内容的时候应该注意哪些事项呢?这几点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-28 16:09
一下采集内容的时候应该注意哪些事项呢?这几点)
很多时候,我们没有足够的时间来原创 内容。采集内容更新是网站维护的重要手段。那么采集内容时需要注意什么?今天就给大家介绍一下这几点。
采集内容不是采集标题
大家都知道,标题是文章的眼睛,传递给用户的第一印象。对于网站优化的搜索引擎,标题也有一定的权重。可能很多公司的内容网站采集占用空间很大,改动很少,但是标题一定要改,修改几个字的标题也花不了多少时间。要知道,即使内容相同,不同的标题可能会给人一种新鲜感,不被发现,甚至读到不同的味道。
采集内容对象新鲜独特
最好把一些文章快速更新的相关网站作为采集的目标,找一些新鲜的、与时俱进的、有代表性的文章没有的内容被太多人转载了以前的采集更好。一些老掉牙的话题,会让用户觉得千篇一律,一文不值。另外,你还可以采集多篇文章文章,整合成一个文章,加入自己的观点,也会让人眼前一亮。
对内容进行适当的调整
相信细心的站长会发现,在采集others网站的时候,总会发现有些文章的格式和排版不尽如人意,有些标点符号混乱,分割不清除。, 有的首行不缩进,有的加了反采集隐藏格式等,如果你直接采集过来这些内容,肯定会被搜索引擎认定为抄袭,所以对网站的危害不言而喻。所以来自采集的内容必须格式化,英文格式的标点符号必须转换。此外,可以在内容中添加一些图片,使内容更加丰富。 查看全部
网站内容采集(
一下采集内容的时候应该注意哪些事项呢?这几点)
很多时候,我们没有足够的时间来原创 内容。采集内容更新是网站维护的重要手段。那么采集内容时需要注意什么?今天就给大家介绍一下这几点。
采集内容不是采集标题
大家都知道,标题是文章的眼睛,传递给用户的第一印象。对于网站优化的搜索引擎,标题也有一定的权重。可能很多公司的内容网站采集占用空间很大,改动很少,但是标题一定要改,修改几个字的标题也花不了多少时间。要知道,即使内容相同,不同的标题可能会给人一种新鲜感,不被发现,甚至读到不同的味道。
采集内容对象新鲜独特
最好把一些文章快速更新的相关网站作为采集的目标,找一些新鲜的、与时俱进的、有代表性的文章没有的内容被太多人转载了以前的采集更好。一些老掉牙的话题,会让用户觉得千篇一律,一文不值。另外,你还可以采集多篇文章文章,整合成一个文章,加入自己的观点,也会让人眼前一亮。
对内容进行适当的调整
相信细心的站长会发现,在采集others网站的时候,总会发现有些文章的格式和排版不尽如人意,有些标点符号混乱,分割不清除。, 有的首行不缩进,有的加了反采集隐藏格式等,如果你直接采集过来这些内容,肯定会被搜索引擎认定为抄袭,所以对网站的危害不言而喻。所以来自采集的内容必须格式化,英文格式的标点符号必须转换。此外,可以在内容中添加一些图片,使内容更加丰富。
网站内容采集(更新日志优采云采集器V9.10版1.二级代理重大修改)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-11-27 23:03
优采云采集器() 是一个多线程的内容采集发布程序,适用于各大主流文章系统、论坛系统等。使用优采云@ >采集器,你可以瞬间创建一个内容丰富的网站。系统支持远程图片下载、图片批量水印、Flash下载、下载文件地址检测、自制发布cms模块参数、自定义发布内容等。此外,丰富的规则制定、内容替换功能,并支持Access、Mysql、MSsql数据的存储和导出,可以让你采集的内容得心应手。现在您可以放弃过去重复繁琐的手动添加。工作,请开始体验即时建站的乐趣!
本软件需要电脑安装.NET4.0框架支持(下载.NET4.0)
产品描述:
优采云采集器()是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以帮助您<任何@采集的网页数据发布到远程服务器,自定义用户cms系统模块。不管你的网站是什么系统,都可以使用优采云采集器,系统自带的模块文件支持:风迅文章,东夷文章@ >、东网论坛、PHPWIND论坛、Discuz论坛、phpcms文章、phparticle文章、LeadBBS论坛、魔幻论坛、德德cms文章、Xydw< @文章、景云文章等模块文件。更多cms模块请参考制作修改,或到官方网站与您交流。
更新日志
优采云采集器V9.10 版
1.二级代理的重大变化和增加商业代理支持
2.post get URL POST 页码增加增量值
3.修复php和python插件不支持cookie的问题
4.当成功和失败标识符都为空时,则认为发布成功
5.调整发布入库模块的界面大小和操作bug
6.修复未登录web发布不发送UA的问题
7.修复web发布测试超时不生效的问题
8.修复网页发布时特殊情况下的死循环问题
你是否面临这样的困境
需要很多时间,但由于缺乏有效的工具,很难看到结果!
简网站 苦于没有内容?
优采云采集器可以自动采集优质内容,定时发布;并配置多种数据处理选项,制作网站独特内容,快速增加网站流量!
业务发展遇到瓶颈?
优采云采集器帮助您快速发现数据中的新客户;查看竞争对手的业务数据,分析客户行为以拓展新业务,通过精准营销降低风险和预算。
数据提取速度太慢?
优采云采集器采用分布式高速采集系统,多台服务器同时运行,解决工作学习中的大量数据下载和使用需求,让您可以有更多的时间做更多的事情。
无法启动舆情监测?
优采云采集器可应用于“舆情雷达监控系统”,准确监控网络数据的信息安全,及时对不利或危险信息进行预警和处理。 查看全部
网站内容采集(更新日志优采云采集器V9.10版1.二级代理重大修改)
优采云采集器() 是一个多线程的内容采集发布程序,适用于各大主流文章系统、论坛系统等。使用优采云@ >采集器,你可以瞬间创建一个内容丰富的网站。系统支持远程图片下载、图片批量水印、Flash下载、下载文件地址检测、自制发布cms模块参数、自定义发布内容等。此外,丰富的规则制定、内容替换功能,并支持Access、Mysql、MSsql数据的存储和导出,可以让你采集的内容得心应手。现在您可以放弃过去重复繁琐的手动添加。工作,请开始体验即时建站的乐趣!
本软件需要电脑安装.NET4.0框架支持(下载.NET4.0)
产品描述:
优采云采集器()是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以帮助您<任何@采集的网页数据发布到远程服务器,自定义用户cms系统模块。不管你的网站是什么系统,都可以使用优采云采集器,系统自带的模块文件支持:风迅文章,东夷文章@ >、东网论坛、PHPWIND论坛、Discuz论坛、phpcms文章、phparticle文章、LeadBBS论坛、魔幻论坛、德德cms文章、Xydw< @文章、景云文章等模块文件。更多cms模块请参考制作修改,或到官方网站与您交流。
更新日志
优采云采集器V9.10 版
1.二级代理的重大变化和增加商业代理支持
2.post get URL POST 页码增加增量值
3.修复php和python插件不支持cookie的问题
4.当成功和失败标识符都为空时,则认为发布成功
5.调整发布入库模块的界面大小和操作bug
6.修复未登录web发布不发送UA的问题
7.修复web发布测试超时不生效的问题
8.修复网页发布时特殊情况下的死循环问题
你是否面临这样的困境
需要很多时间,但由于缺乏有效的工具,很难看到结果!
简网站 苦于没有内容?
优采云采集器可以自动采集优质内容,定时发布;并配置多种数据处理选项,制作网站独特内容,快速增加网站流量!
业务发展遇到瓶颈?
优采云采集器帮助您快速发现数据中的新客户;查看竞争对手的业务数据,分析客户行为以拓展新业务,通过精准营销降低风险和预算。
数据提取速度太慢?
优采云采集器采用分布式高速采集系统,多台服务器同时运行,解决工作学习中的大量数据下载和使用需求,让您可以有更多的时间做更多的事情。
无法启动舆情监测?
优采云采集器可应用于“舆情雷达监控系统”,准确监控网络数据的信息安全,及时对不利或危险信息进行预警和处理。
网站内容采集(什么是采集站顾名思义就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-11-27 13:12
什么是采集站,顾名思义就是填充大量的内容数据网站以获得更多的流量,不管任何网站都会遇到问题,内容填充
只要有足够的数据,百度就能得到更多的收录和呈现。对于一个大站。它必须是稳定的数据流。比如你的网站想每天获得几万的流量,就需要大量的关键词支持,大量的关键词需要大量的内容!对于个人站长和小团队来说,每天更新数百篇文章文章,无疑是傻瓜式。这么多人在这个时候选择采集!
有很多朋友问过我这样的问题吗?为什么别人的网站无论是排名还是流量都这么好,域名历史建立只需要一年多时间。但是收录的数据达到了20W。倒计时每天创作547条内容,是怎么做到的?我现在该怎么办?
以上是小编创建的一个采集站。目前日流量已经达到1W以上,后台文章音量为60W,还在持续稳定中。下面小编就给大家介绍一下采集站的做法。
1、网站 程序。随着互联网的飞速发展,网上的源代码越来越多,免费的也很多。许多人使用这些源代码。重复的程度就不用说了。相信免费的东西也有很多人在用
2、首先,在选择域名时,应该选择旧域名。为什么选择旧域名?因为老域名已经过了搜索引擎的观察期。为什么旧域名更容易成为收录?因为老域名在某些方面做了优化,域名越老,网站的排名就越好。
3、选择好的采集源是重中之重,比如屏蔽百度蜘蛛的新闻源。
4、采集会在后面进行处理,比如重写或者伪原创
5、每次更新后的内容都要主动推送到搜索引擎
这也是很多站长拼命在他们的网站中添加网站内容的原因。我们采集 其他内容。首先,从搜索引擎来看,这是重复的内容。我们的内容相对于 采集 的质量得分肯定下降了很多。但是我们可以通过做一些其他的方面来弥补,这需要大家在程序和域名方面进行改进。
如果你看完这篇文章文章,如果你喜欢这篇文章文章,不妨采集或者转发给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力! 查看全部
网站内容采集(什么是采集站顾名思义就是)
什么是采集站,顾名思义就是填充大量的内容数据网站以获得更多的流量,不管任何网站都会遇到问题,内容填充
只要有足够的数据,百度就能得到更多的收录和呈现。对于一个大站。它必须是稳定的数据流。比如你的网站想每天获得几万的流量,就需要大量的关键词支持,大量的关键词需要大量的内容!对于个人站长和小团队来说,每天更新数百篇文章文章,无疑是傻瓜式。这么多人在这个时候选择采集!
有很多朋友问过我这样的问题吗?为什么别人的网站无论是排名还是流量都这么好,域名历史建立只需要一年多时间。但是收录的数据达到了20W。倒计时每天创作547条内容,是怎么做到的?我现在该怎么办?
以上是小编创建的一个采集站。目前日流量已经达到1W以上,后台文章音量为60W,还在持续稳定中。下面小编就给大家介绍一下采集站的做法。
1、网站 程序。随着互联网的飞速发展,网上的源代码越来越多,免费的也很多。许多人使用这些源代码。重复的程度就不用说了。相信免费的东西也有很多人在用
2、首先,在选择域名时,应该选择旧域名。为什么选择旧域名?因为老域名已经过了搜索引擎的观察期。为什么旧域名更容易成为收录?因为老域名在某些方面做了优化,域名越老,网站的排名就越好。
3、选择好的采集源是重中之重,比如屏蔽百度蜘蛛的新闻源。
4、采集会在后面进行处理,比如重写或者伪原创
5、每次更新后的内容都要主动推送到搜索引擎
这也是很多站长拼命在他们的网站中添加网站内容的原因。我们采集 其他内容。首先,从搜索引擎来看,这是重复的内容。我们的内容相对于 采集 的质量得分肯定下降了很多。但是我们可以通过做一些其他的方面来弥补,这需要大家在程序和域名方面进行改进。
如果你看完这篇文章文章,如果你喜欢这篇文章文章,不妨采集或者转发给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!
网站内容采集(如何正确的运用收集内容来做网站优化,9819m优化网介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-11-27 07:17
最近有很多人问如何正确使用采集的内容来优化网站。那么,就由北京9819mSEO优化小编给大家介绍一下。
如何正确使用采集到的内容做网站优化,9819m优化网介绍以下几点:
一是藏品精美。
最好找到别人刚发布的内容作为采集方针,在被太多人转发之前采集,但前提是内容要先进、新鲜、有代表性,而不是一些老式的话题,否则会被用户利用。通觉蜡的味道不言而喻。所以采集内容自然比原创简单多了,修改内容也不需要花太多时间。这时候不要让保存下来的时间闲着,毕竟采集的内容没有原创的直接作用,所以要多找几条内容采集起来,弥补没有蜘蛛。
如何正确使用采集的内容来优化网站
第二,采集内容而不采集标题。
我们都知道,阅读一篇文章首先要看的就是标题。对于网站优化的搜索引擎,标题也有一定的权重。采集到的内容有一定的长度,不能改动太多,但题目只有短短的几个字,修改起来还是比较简单的。所以标题修改是很有必要的,最好把标题改成原来的。标题完全不同,原因很简单。当看到文章同名而内容完全不同时,会引起读者误认为两者的内容是一样的。相反,即使内容相同,标题也完全不同。也给人耳目一新的感觉,不易被人发现。
三是适当调整内容。
我已经尝试将内容采集到我自己的 网站 网站管理员。细心的人难免会发现直接复制的内容还是存在版面问题。因为一些精明的原创人,为了避免内容被采集,通常会在内容中加入一些隐藏的图案,甚至会在图片的ALT信息中标注版权。如果不注意,自然会被搜索引擎认定为抄袭,所以不会伤害网站。这是不言而喻的。因此,必须删除采集的内容,必须转换英文格式的标点符号。此外,可以在内容中添加一些图片,使内容更加丰富。如果内容本身有图片,那就不要直接复制了,最好另外,
总之,网站采集的内容并不是完全没用的。关键取决于你如何采集它。只要能灵活使用采集到的内容,就可以给网站带来一定的优势,但是,站长需要注意的是一定要掌握一定的采集方法。
如何正确使用采集的内容来优化网站
温馨提示:以上是“如何正确使用采集到的内容做网站优化”的介绍。是网络营销外包(网络推广外包、网络营销推广)技术实力企业,敢于对效果负责。按效果付费合作模式,没有虚拟套路,我们只做!其次,有需要提醒大家:网站建设、网站制作、网站设计、网络推广、网站推广、网站优化、SEO优化、北京网优化、北京网站推广、网站设计公司、北京seo优化、网站建设公司、网络推广公司等服务,欢迎来电咨询。 查看全部
网站内容采集(如何正确的运用收集内容来做网站优化,9819m优化网介绍)
最近有很多人问如何正确使用采集的内容来优化网站。那么,就由北京9819mSEO优化小编给大家介绍一下。
如何正确使用采集到的内容做网站优化,9819m优化网介绍以下几点:
一是藏品精美。
最好找到别人刚发布的内容作为采集方针,在被太多人转发之前采集,但前提是内容要先进、新鲜、有代表性,而不是一些老式的话题,否则会被用户利用。通觉蜡的味道不言而喻。所以采集内容自然比原创简单多了,修改内容也不需要花太多时间。这时候不要让保存下来的时间闲着,毕竟采集的内容没有原创的直接作用,所以要多找几条内容采集起来,弥补没有蜘蛛。
如何正确使用采集的内容来优化网站
第二,采集内容而不采集标题。
我们都知道,阅读一篇文章首先要看的就是标题。对于网站优化的搜索引擎,标题也有一定的权重。采集到的内容有一定的长度,不能改动太多,但题目只有短短的几个字,修改起来还是比较简单的。所以标题修改是很有必要的,最好把标题改成原来的。标题完全不同,原因很简单。当看到文章同名而内容完全不同时,会引起读者误认为两者的内容是一样的。相反,即使内容相同,标题也完全不同。也给人耳目一新的感觉,不易被人发现。
三是适当调整内容。
我已经尝试将内容采集到我自己的 网站 网站管理员。细心的人难免会发现直接复制的内容还是存在版面问题。因为一些精明的原创人,为了避免内容被采集,通常会在内容中加入一些隐藏的图案,甚至会在图片的ALT信息中标注版权。如果不注意,自然会被搜索引擎认定为抄袭,所以不会伤害网站。这是不言而喻的。因此,必须删除采集的内容,必须转换英文格式的标点符号。此外,可以在内容中添加一些图片,使内容更加丰富。如果内容本身有图片,那就不要直接复制了,最好另外,
总之,网站采集的内容并不是完全没用的。关键取决于你如何采集它。只要能灵活使用采集到的内容,就可以给网站带来一定的优势,但是,站长需要注意的是一定要掌握一定的采集方法。
如何正确使用采集的内容来优化网站
温馨提示:以上是“如何正确使用采集到的内容做网站优化”的介绍。是网络营销外包(网络推广外包、网络营销推广)技术实力企业,敢于对效果负责。按效果付费合作模式,没有虚拟套路,我们只做!其次,有需要提醒大家:网站建设、网站制作、网站设计、网络推广、网站推广、网站优化、SEO优化、北京网优化、北京网站推广、网站设计公司、北京seo优化、网站建设公司、网络推广公司等服务,欢迎来电咨询。

