
网站内容采集
网站内容采集(Facebook和谷歌:所谓的社交小工具被网站所搜集 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-03-04 17:05
)
网易科技讯5月19日消息,据华尔街日报报道,当网民点击Facebook的“Like”和Twitter的“Tweet”按钮分享内容时,这些小玩意让他们的互联网浏览行为被网站采集。
根据华尔街日报所做的研究,这些所谓的社交小工具让 Facebook 和 Twitter 可以了解用户的浏览行为,即使他们没有点击按钮。
这个小工具每年都会添加到数百万个网页中。根据这项研究,Facebook 按钮出现在全球浏览量最高的 1,000 个 网站 页面中的三分之一上,而 Twitter 和 Google 按钮出现在这些 网站 页面上的频率高达 20% 和 25% .
创建这些小工具最初是为了让用户更轻松地共享内容并帮助 网站 吸引用户,但现在它们已成为 网站 跟踪用户浏览行为的强大方式。他们可以将用户的浏览习惯发送到社交网站,而这些网站 上面有用户的名字。
研究表明,用户可以通过在过去一个月内仅登录一次 Facebook 或 Twitter 来跟踪他们的行为。即使在用户关闭浏览器或电脑后,这些网站仍可以继续采集用户的浏览信息,直到用户完全退出Facebook或Twitter账户。
Facebook 和谷歌表示他们将浏览数据“匿名化”,这样采集的信息就不会指向特定用户。Facebook 表示将在 90 天内删除这些数据,而谷歌则表示将在两周内删除这些数据。Facebook 和谷歌表示他们使用这些信息来评估小工具的有效性并帮助 网站 推动用户访问。
Twitter指出它没有使用浏览数据并“很快”将其删除。一位发言人表示,该公司理论上可以在未来使用这些数据向用户“提供更好的内容”。
前 Google 工程师 Brian Kennish 进行了一项调查,他检查了前 1,000 个 Google 广告网络中超过 200,000 个页面的 网站。Kenish 发现 Facebook 从 331 个站点获取浏览数据,谷歌从 250 个站点获取浏览数据,而 Twitter 从 200 个站点采集浏览信息。
直到最近,一些 Facebook 小工具还在采集从未登录过的用户的浏览数据。Facebook 今年早些时候表示,它已经停止了这种做法,并在荷兰研究人员曝光后称其为“错误”。(编译/徐建林)
查看全部
网站内容采集(Facebook和谷歌:所谓的社交小工具被网站所搜集
)
网易科技讯5月19日消息,据华尔街日报报道,当网民点击Facebook的“Like”和Twitter的“Tweet”按钮分享内容时,这些小玩意让他们的互联网浏览行为被网站采集。
根据华尔街日报所做的研究,这些所谓的社交小工具让 Facebook 和 Twitter 可以了解用户的浏览行为,即使他们没有点击按钮。
这个小工具每年都会添加到数百万个网页中。根据这项研究,Facebook 按钮出现在全球浏览量最高的 1,000 个 网站 页面中的三分之一上,而 Twitter 和 Google 按钮出现在这些 网站 页面上的频率高达 20% 和 25% .
创建这些小工具最初是为了让用户更轻松地共享内容并帮助 网站 吸引用户,但现在它们已成为 网站 跟踪用户浏览行为的强大方式。他们可以将用户的浏览习惯发送到社交网站,而这些网站 上面有用户的名字。
研究表明,用户可以通过在过去一个月内仅登录一次 Facebook 或 Twitter 来跟踪他们的行为。即使在用户关闭浏览器或电脑后,这些网站仍可以继续采集用户的浏览信息,直到用户完全退出Facebook或Twitter账户。
Facebook 和谷歌表示他们将浏览数据“匿名化”,这样采集的信息就不会指向特定用户。Facebook 表示将在 90 天内删除这些数据,而谷歌则表示将在两周内删除这些数据。Facebook 和谷歌表示他们使用这些信息来评估小工具的有效性并帮助 网站 推动用户访问。
Twitter指出它没有使用浏览数据并“很快”将其删除。一位发言人表示,该公司理论上可以在未来使用这些数据向用户“提供更好的内容”。
前 Google 工程师 Brian Kennish 进行了一项调查,他检查了前 1,000 个 Google 广告网络中超过 200,000 个页面的 网站。Kenish 发现 Facebook 从 331 个站点获取浏览数据,谷歌从 250 个站点获取浏览数据,而 Twitter 从 200 个站点采集浏览信息。
直到最近,一些 Facebook 小工具还在采集从未登录过的用户的浏览数据。Facebook 今年早些时候表示,它已经停止了这种做法,并在荷兰研究人员曝光后称其为“错误”。(编译/徐建林)
网站内容采集(具体分析一下企业网站建设中正确的采集方式是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-03-04 17:00
采集可以在短时间内大大提高一个网站的收录(前提是你的网站的权重足够高),网络可以大大提高。部分流量,并抢夺其他竞争对手的流量。但是大量的采集会让百度认为你的网站是个垃圾站。如果你今天采集100条,明天采集200条,后天没有采集@采集现在,这是一个不均匀的更新频率,百度会付出更多注意你。
采集内容的弊端还是很明显的,尤其是抄袭采集和大面积采集会对网站造成不良影响,所以一定要掌握正确采集方法,从而充分发挥内容采集的优势。下面我们来分析一下网站企业建设中正确的采集方法。
1、最好采集内容。 采集选择与网站相关的内容,尽量保持新鲜。如果太旧,尤其是新闻内容,不仅对搜索引擎不利,对用户也不利。好的。另外,关于技术帖,可以适量使用采集,因为大部分技术帖不会很快过时,能给用户带来一些实际的帮助。
2, 采集不要改变任何东西。完全抄袭采集绝对不可取。严重时网站会被K,甚至涉嫌侵权。 采集其他文章的时候,最好把它们混在一起几次文章,然后把它们拼接成一个拼接平滑的新文章,或者在最后一次 标题或第一段。这不仅更有利于搜索引擎的收录,也为企业降低了一些风险。
总之,采集不是目的,采集是手段。如果使用不好,你的网站也有被降级的风险。但如果合理采集和使用,对网站的发展会有很大的帮助。 查看全部
网站内容采集(具体分析一下企业网站建设中正确的采集方式是什么?)
采集可以在短时间内大大提高一个网站的收录(前提是你的网站的权重足够高),网络可以大大提高。部分流量,并抢夺其他竞争对手的流量。但是大量的采集会让百度认为你的网站是个垃圾站。如果你今天采集100条,明天采集200条,后天没有采集@采集现在,这是一个不均匀的更新频率,百度会付出更多注意你。
采集内容的弊端还是很明显的,尤其是抄袭采集和大面积采集会对网站造成不良影响,所以一定要掌握正确采集方法,从而充分发挥内容采集的优势。下面我们来分析一下网站企业建设中正确的采集方法。
1、最好采集内容。 采集选择与网站相关的内容,尽量保持新鲜。如果太旧,尤其是新闻内容,不仅对搜索引擎不利,对用户也不利。好的。另外,关于技术帖,可以适量使用采集,因为大部分技术帖不会很快过时,能给用户带来一些实际的帮助。
2, 采集不要改变任何东西。完全抄袭采集绝对不可取。严重时网站会被K,甚至涉嫌侵权。 采集其他文章的时候,最好把它们混在一起几次文章,然后把它们拼接成一个拼接平滑的新文章,或者在最后一次 标题或第一段。这不仅更有利于搜索引擎的收录,也为企业降低了一些风险。
总之,采集不是目的,采集是手段。如果使用不好,你的网站也有被降级的风险。但如果合理采集和使用,对网站的发展会有很大的帮助。
网站内容采集( 如何使用Scrapy结合PhantomJS采集天猫商品内容的小程序?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-04 03:13
如何使用Scrapy结合PhantomJS采集天猫商品内容的小程序?)
1、简介
最近一直在看Scrapy爬虫框架,尝试用Scrapy框架写一个可以实现网页信息的简单小程序采集。在尝试的过程中遇到了很多小问题,希望大家多多指教。
本文主要介绍如何结合PhantomJS使用Scrapy采集天猫产品内容。文章为需要加载js的采集动态网页内容定制了一个DOWNLOADER_MIDDLEWARES。看了很多DOWNLOADER_MIDDLEWARES的资料,总之,好用,但是会阻塞框架,所以性能不好。有资料提到自定义DOWNLOADER_HANDLER或者使用scrapyjs可以解决框架阻塞的问题。有兴趣的小伙伴可以研究一下,这里就不多说了。
2、具体实现2.1、环境要求
准备Python开发和运行环境需要以下步骤:
Python--官网下载安装部署环境变量(本文使用的Python版本为3.5.1)
lxml--从官网库下载对应版本的.whl文件,然后在命令行界面执行“pip install .whl文件路径”
Scrapy--在命令行界面执行“pip install Scrapy”,详见“Scrapy的首次运行测试”
selenium--命令行界面执行“pip install selenium”
PhantomJS——官网下载
以上步骤展示了两种安装方式: 1. 将下载好的wheel包安装到本地; 2. 使用 Python 安装管理器进行远程下载和安装。注意:包的版本需要与python版本相匹配
2.2、开发测试流程
首先找到需要采集的网页,这里是一个简单的天猫产品,网址,页面如下:
然后开始写代码,下面的代码默认在命令行界面执行
1),创建scrapy爬虫项目tmSpider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建middlewares文件夹,然后在文件夹中创建middleware.py文件,代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和PhantomJS编写一个网页内容下载器,同样在上一步创建的middlewares文件夹中创建一个downloader.py文件,代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5) 创建爬虫模块
在工程目录E:python-3.5.1tmSpider,执行如下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
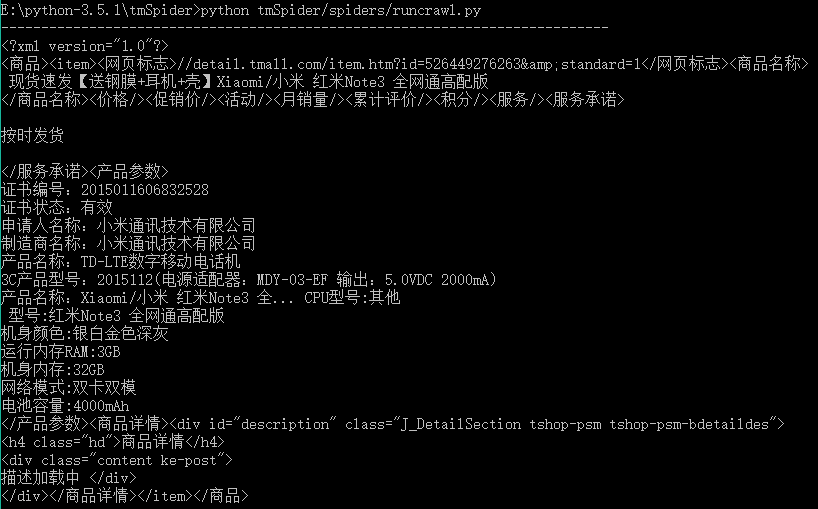
执行后会在工程目录E:python-3.5.1tmSpidertmSpiderspiders下自动生成tmall.py程序文件。该程序中的parse函数对scrapy下载器返回的网页内容进行处理。 采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/526449276263.htm',
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫
在E:python-3.5.1tmSpider工程目录下执行命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:
请记住,上述命令一次只能启动一个爬虫。如果你想同时启动多个呢?然后需要自定义一个爬虫启动模块,在spiders下创建模块文件runcrawl.py,代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件并输出结果:
3、展望
通过自定义DOWNLOADER_MIDDLEWARES调用PhantomJs的方式实现爬虫后,被框架阻塞的问题纠结了好久,一直在想解决办法。以后会研究scrapyjs、splash等方式调用浏览器,看看能不能有效解决这个问题。
4、相关文件
1、Python即时网络爬虫:API说明
5、Jisouke GooSeeker开源代码下载源码
1、GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
1, 2016-07-04: V1.0 查看全部
网站内容采集(
如何使用Scrapy结合PhantomJS采集天猫商品内容的小程序?)

1、简介
最近一直在看Scrapy爬虫框架,尝试用Scrapy框架写一个可以实现网页信息的简单小程序采集。在尝试的过程中遇到了很多小问题,希望大家多多指教。
本文主要介绍如何结合PhantomJS使用Scrapy采集天猫产品内容。文章为需要加载js的采集动态网页内容定制了一个DOWNLOADER_MIDDLEWARES。看了很多DOWNLOADER_MIDDLEWARES的资料,总之,好用,但是会阻塞框架,所以性能不好。有资料提到自定义DOWNLOADER_HANDLER或者使用scrapyjs可以解决框架阻塞的问题。有兴趣的小伙伴可以研究一下,这里就不多说了。
2、具体实现2.1、环境要求
准备Python开发和运行环境需要以下步骤:
Python--官网下载安装部署环境变量(本文使用的Python版本为3.5.1)
lxml--从官网库下载对应版本的.whl文件,然后在命令行界面执行“pip install .whl文件路径”
Scrapy--在命令行界面执行“pip install Scrapy”,详见“Scrapy的首次运行测试”
selenium--命令行界面执行“pip install selenium”
PhantomJS——官网下载
以上步骤展示了两种安装方式: 1. 将下载好的wheel包安装到本地; 2. 使用 Python 安装管理器进行远程下载和安装。注意:包的版本需要与python版本相匹配
2.2、开发测试流程
首先找到需要采集的网页,这里是一个简单的天猫产品,网址,页面如下:
然后开始写代码,下面的代码默认在命令行界面执行
1),创建scrapy爬虫项目tmSpider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建middlewares文件夹,然后在文件夹中创建middleware.py文件,代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和PhantomJS编写一个网页内容下载器,同样在上一步创建的middlewares文件夹中创建一个downloader.py文件,代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5) 创建爬虫模块
在工程目录E:python-3.5.1tmSpider,执行如下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后会在工程目录E:python-3.5.1tmSpidertmSpiderspiders下自动生成tmall.py程序文件。该程序中的parse函数对scrapy下载器返回的网页内容进行处理。 采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/526449276263.htm',
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫
在E:python-3.5.1tmSpider工程目录下执行命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:

请记住,上述命令一次只能启动一个爬虫。如果你想同时启动多个呢?然后需要自定义一个爬虫启动模块,在spiders下创建模块文件runcrawl.py,代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件并输出结果:
3、展望
通过自定义DOWNLOADER_MIDDLEWARES调用PhantomJs的方式实现爬虫后,被框架阻塞的问题纠结了好久,一直在想解决办法。以后会研究scrapyjs、splash等方式调用浏览器,看看能不能有效解决这个问题。
4、相关文件
1、Python即时网络爬虫:API说明
5、Jisouke GooSeeker开源代码下载源码
1、GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
1, 2016-07-04: V1.0
网站内容采集( 如何使用Scrapy结合PhantomJS采集天猫商品内容的小程序?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-03-04 03:09
如何使用Scrapy结合PhantomJS采集天猫商品内容的小程序?)
1、简介
最近一直在看Scrapy爬虫框架,尝试用Scrapy框架写一个可以实现网页信息的简单小程序采集。在尝试的过程中遇到了很多小问题,希望大家多多指教。
本文主要介绍如何结合PhantomJS使用Scrapy采集天猫产品内容。文章为需要加载js的采集动态网页内容定制了一个DOWNLOADER_MIDDLEWARES。看了很多DOWNLOADER_MIDDLEWARES的资料,总之,好用,但是会阻塞框架,所以性能不好。有资料提到自定义DOWNLOADER_HANDLER或者使用scrapyjs可以解决框架阻塞的问题。有兴趣的小伙伴可以研究一下,这里就不多说了。
2、具体实现2.1、环境要求
准备Python开发和运行环境需要以下步骤:
Python--官网下载安装部署环境变量(本文使用的Python版本为3.5.1)
lxml--从官网库下载对应版本的.whl文件,然后在命令行界面执行“pip install .whl文件路径”
Scrapy--在命令行界面执行“pip install Scrapy”,详见“Scrapy的首次运行测试”
selenium--命令行界面执行“pip install selenium”
PhantomJS——官网下载
以上步骤展示了两种安装方式: 1. 将下载好的wheel包安装到本地; 2. 使用 Python 安装管理器进行远程下载和安装。注意:包的版本需要与python版本相匹配
2.2、开发测试流程
首先找到需要采集的网页,这里是一个简单的天猫产品,网址,页面如下:
然后开始写代码,下面的代码默认在命令行界面执行
1),创建scrapy爬虫项目tmSpider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建middlewares文件夹,然后在文件夹中创建middleware.py文件,代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和PhantomJS编写一个网页内容下载器,同样在上一步创建的middlewares文件夹中创建一个downloader.py文件,代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5) 创建爬虫模块
在工程目录E:python-3.5.1tmSpider,执行如下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后会在工程目录E:python-3.5.1tmSpidertmSpiderspiders下自动生成tmall.py程序文件。该程序中的parse函数对scrapy下载器返回的网页内容进行处理。 采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/526449276263.htm',
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫
在E:python-3.5.1tmSpider工程目录下执行命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:
请记住,上述命令一次只能启动一个爬虫。如果你想同时启动多个呢?然后需要自定义一个爬虫启动模块,在spiders下创建模块文件runcrawl.py,代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件并输出结果:
3、展望
通过自定义DOWNLOADER_MIDDLEWARES调用PhantomJs的方式实现爬虫后,被框架阻塞的问题纠结了好久,一直在想解决办法。以后会研究scrapyjs、splash等方式调用浏览器,看看能不能有效解决这个问题。
4、相关文件
1、Python即时网络爬虫:API说明
5、Jisouke GooSeeker开源代码下载源码
1、GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
1, 2016-07-04: V1.0 查看全部
网站内容采集(
如何使用Scrapy结合PhantomJS采集天猫商品内容的小程序?)
1、简介
最近一直在看Scrapy爬虫框架,尝试用Scrapy框架写一个可以实现网页信息的简单小程序采集。在尝试的过程中遇到了很多小问题,希望大家多多指教。
本文主要介绍如何结合PhantomJS使用Scrapy采集天猫产品内容。文章为需要加载js的采集动态网页内容定制了一个DOWNLOADER_MIDDLEWARES。看了很多DOWNLOADER_MIDDLEWARES的资料,总之,好用,但是会阻塞框架,所以性能不好。有资料提到自定义DOWNLOADER_HANDLER或者使用scrapyjs可以解决框架阻塞的问题。有兴趣的小伙伴可以研究一下,这里就不多说了。
2、具体实现2.1、环境要求
准备Python开发和运行环境需要以下步骤:
Python--官网下载安装部署环境变量(本文使用的Python版本为3.5.1)
lxml--从官网库下载对应版本的.whl文件,然后在命令行界面执行“pip install .whl文件路径”
Scrapy--在命令行界面执行“pip install Scrapy”,详见“Scrapy的首次运行测试”
selenium--命令行界面执行“pip install selenium”
PhantomJS——官网下载
以上步骤展示了两种安装方式: 1. 将下载好的wheel包安装到本地; 2. 使用 Python 安装管理器进行远程下载和安装。注意:包的版本需要与python版本相匹配
2.2、开发测试流程
首先找到需要采集的网页,这里是一个简单的天猫产品,网址,页面如下:
然后开始写代码,下面的代码默认在命令行界面执行
1),创建scrapy爬虫项目tmSpider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建middlewares文件夹,然后在文件夹中创建middleware.py文件,代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和PhantomJS编写一个网页内容下载器,同样在上一步创建的middlewares文件夹中创建一个downloader.py文件,代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5) 创建爬虫模块
在工程目录E:python-3.5.1tmSpider,执行如下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后会在工程目录E:python-3.5.1tmSpidertmSpiderspiders下自动生成tmall.py程序文件。该程序中的parse函数对scrapy下载器返回的网页内容进行处理。 采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/526449276263.htm',
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫
在E:python-3.5.1tmSpider工程目录下执行命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:
请记住,上述命令一次只能启动一个爬虫。如果你想同时启动多个呢?然后需要自定义一个爬虫启动模块,在spiders下创建模块文件runcrawl.py,代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件并输出结果:
3、展望
通过自定义DOWNLOADER_MIDDLEWARES调用PhantomJs的方式实现爬虫后,被框架阻塞的问题纠结了好久,一直在想解决办法。以后会研究scrapyjs、splash等方式调用浏览器,看看能不能有效解决这个问题。
4、相关文件
1、Python即时网络爬虫:API说明
5、Jisouke GooSeeker开源代码下载源码
1、GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
1, 2016-07-04: V1.0
网站内容采集(盘点一下网站更新哪些内容会遭到惩罚呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-03-03 04:12
现在越来越多的用户使用网站,对网站的依赖也越来越强,这就促使站长们不断更新网站的内容来维护网站的操作,去抢用户和增加流量。但是,内容更新确实是有限的。有些内容很容易因为每天更新而受到惩罚。我们来看看网站更新会有哪些内容被惩罚?
1、采集内容
随着互联网的飞速发展,互联网上采集内容的现象非常泛滥。很多人采集内容不择手段,有些人采集甚至文章内容都没有。看,直接复制。文章内容中收录竞争对手公司名称或者内部链接等,不知道。很多时候采集还帮别人做婚纱。由于互联网上90%以上的内容是采集内容,很多内容重复性太强,对搜索引擎来说不新鲜;这样的采集内容更新太多网站,很容易被搜索引擎惩罚。
2、广告内容
是不是经常看到很多医疗网站的广告,内容太多,很多夸大医疗效果。治疗XX病的成功率是100%,很多文章本来是介绍给XX病的,但是内容都变成了广告宣传的内容,并没有解决用户的真正需求。针对这种类型的网站,搜索引擎已经开始进行打击。
3、低质量的内容
网站 内容的一部分是牛头和马嘴。明明是一篇文章文章前半部分是文章关于食物的介绍,后半部分是卖衣服的文章,内容完全是从别人那里复制粘贴过来的网站,填充字数;文章根本看不懂等等。这种低质量的内容根本看不懂,就算有排名也就是暂时的,一段时间后排名都会下降时间。
_创新互联,为您提供网站策划、做网站、网站建设公司、微信小程序、软件开发、营销型网站建设 查看全部
网站内容采集(盘点一下网站更新哪些内容会遭到惩罚呢?(图))
现在越来越多的用户使用网站,对网站的依赖也越来越强,这就促使站长们不断更新网站的内容来维护网站的操作,去抢用户和增加流量。但是,内容更新确实是有限的。有些内容很容易因为每天更新而受到惩罚。我们来看看网站更新会有哪些内容被惩罚?
1、采集内容
随着互联网的飞速发展,互联网上采集内容的现象非常泛滥。很多人采集内容不择手段,有些人采集甚至文章内容都没有。看,直接复制。文章内容中收录竞争对手公司名称或者内部链接等,不知道。很多时候采集还帮别人做婚纱。由于互联网上90%以上的内容是采集内容,很多内容重复性太强,对搜索引擎来说不新鲜;这样的采集内容更新太多网站,很容易被搜索引擎惩罚。
2、广告内容
是不是经常看到很多医疗网站的广告,内容太多,很多夸大医疗效果。治疗XX病的成功率是100%,很多文章本来是介绍给XX病的,但是内容都变成了广告宣传的内容,并没有解决用户的真正需求。针对这种类型的网站,搜索引擎已经开始进行打击。
3、低质量的内容
网站 内容的一部分是牛头和马嘴。明明是一篇文章文章前半部分是文章关于食物的介绍,后半部分是卖衣服的文章,内容完全是从别人那里复制粘贴过来的网站,填充字数;文章根本看不懂等等。这种低质量的内容根本看不懂,就算有排名也就是暂时的,一段时间后排名都会下降时间。
_创新互联,为您提供网站策划、做网站、网站建设公司、微信小程序、软件开发、营销型网站建设
网站内容采集(就是为什么常说的就是内容增加过快,导致内容质量度降低)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-03-01 17:24
对于个人网站管理员来说,任何网站最重要的是内容填充。这就是为什么许多网站管理员拼命将 网站 内容添加到他们的 网站 中的原因。但是站长需要增加内容后,网站质量问题难免会被忽略,这也是为什么常说内容增加过快,导致内容质量下降的原因,这也是从另一个方面证实。事实是,你不能同时拥有鱼和熊掌。
一些新手站长总是问这样的问题,说为什么那些大网站和采集 网站都归采集 其他人所有,而且他们的排名仍然那么好。其实很多人都遇到过这样的问题。文章采集来了,内容的质量不是越来越差了吗?然而,他们并没有看到他们的体重和流量下降。. 其实很多因素会决定哪些大站和高权重网站,我们无法比较,还是要脚踏实地从每一步做起。只有这样,网站才能随着时间的推移越来越被认可。那么,如何保证来自采集的内容在质量上可以得到其他分数。
修改标题和描述以及 关键词 标签
之前,新闻网站上流传着这样一个词“标题党”。事实上,这些头条党每天都在做的就是寻找互联网热门内容,从而修改标题,从而赢得用户的关注,让用户输入网站,满足用户对热点内容的好奇。另外,搜索引擎会对热门内容偏爱某些节目,对人的内容进行搜索和聚合,迎合了标题党对热门内容的排序,搜索引擎也能快速呈现。可以说,这种方法非常合适。满足当前用户对热点内容的呈现。
对于 关键词 标签和描述,这些头条新闻还将更多地关注搜索引擎抓取和用户点击好奇心。所以,我们在采集内容的时候,应该尽量多借鉴一下标题党的一些方法,在标题和描述以及关键词标签上做一些改动,以便区分三者原创内容的主要页面。元素。
充分利用排版的差异
我们都知道有些网站喜欢分页来增加PV。但是,这样做的缺点是很明显,一个完整的内容被分割了,给用户阅读造成了一些障碍。用户必须点击下一页才能查看他们想要的内容。反过来,如果他们想要区分原创内容网站,他们必须做出不同的排版方法。比如上面提到的,如果对方进行分页,我们可以把内容组织在一起(在文章不太长的情况下),这样搜索引擎就很容易爬取整个内容。,用户无需翻页即可查看。可以说,这种方式在排版上有很大的不同,也提升了用户体验。
网站内容部分和副标题的使用
在查看一段内容时,如果标题准确,我们可以从标题中知道内容是关于什么的?但是如果作者写的太长,整个内容的中心点就会模糊,这样用户就很容易把握不住作者真正想要表达的概念。此时,对于内容采集,适当区分段落并添加相应的副标题。这样会减少用户观看内容的时间,很容易知道每个段落或者之前的作者想要表达什么?后一位作者建立了什么观点等等。
使用这两种方式,整个内容可以合理划分,表达作者的观点应该没有冲突,尽量设置字幕,保证作者的独到想法。
采集尽量不要超过一定的时间
当我们记住某件事时,我们可以在有限的时间内清楚地记住它。并确保你不会忘记它,它会在指定的时间后慢慢消失。事实上,搜索引擎也是如此。他们也更喜欢新的内容搜索引擎,他们会在最短的时间内抓取并呈现给用户。但是,时间久了,内容的新鲜度已经过去,搜索引擎很难抓取到相同的内容。我们可以利用这一点,搜索引擎更喜欢新的文章、采集 内容,一天之内尝试采集。永远不要采集 已经存在很长时间的内容。
添加高清图片
采集中的一些内容,原来的网站没有添加图片,所以我们可以添加高清图片。虽然添加图片对文章影响不大,因为我们是采集的内容,尽量在采集的内容调整上做一定的改变,不要采集 >不做任何修改就来这里。更重要的是,一个人的衣着决定了一个人的好感度。实际上,添加图片是为了增加搜索引擎的好感度。
我们的采集别人的内容,首先从搜索引擎的角度来看,属于重复抄袭。从搜索引擎的角度来看,我们的内容与原创内容相比,在质量得分方面已经下降了很多。但是,我们可以在某些方面弥补分数的下降,这需要个别站长在内容体验和网站经验上下功夫。 查看全部
网站内容采集(就是为什么常说的就是内容增加过快,导致内容质量度降低)
对于个人网站管理员来说,任何网站最重要的是内容填充。这就是为什么许多网站管理员拼命将 网站 内容添加到他们的 网站 中的原因。但是站长需要增加内容后,网站质量问题难免会被忽略,这也是为什么常说内容增加过快,导致内容质量下降的原因,这也是从另一个方面证实。事实是,你不能同时拥有鱼和熊掌。
一些新手站长总是问这样的问题,说为什么那些大网站和采集 网站都归采集 其他人所有,而且他们的排名仍然那么好。其实很多人都遇到过这样的问题。文章采集来了,内容的质量不是越来越差了吗?然而,他们并没有看到他们的体重和流量下降。. 其实很多因素会决定哪些大站和高权重网站,我们无法比较,还是要脚踏实地从每一步做起。只有这样,网站才能随着时间的推移越来越被认可。那么,如何保证来自采集的内容在质量上可以得到其他分数。
修改标题和描述以及 关键词 标签
之前,新闻网站上流传着这样一个词“标题党”。事实上,这些头条党每天都在做的就是寻找互联网热门内容,从而修改标题,从而赢得用户的关注,让用户输入网站,满足用户对热点内容的好奇。另外,搜索引擎会对热门内容偏爱某些节目,对人的内容进行搜索和聚合,迎合了标题党对热门内容的排序,搜索引擎也能快速呈现。可以说,这种方法非常合适。满足当前用户对热点内容的呈现。
对于 关键词 标签和描述,这些头条新闻还将更多地关注搜索引擎抓取和用户点击好奇心。所以,我们在采集内容的时候,应该尽量多借鉴一下标题党的一些方法,在标题和描述以及关键词标签上做一些改动,以便区分三者原创内容的主要页面。元素。
充分利用排版的差异
我们都知道有些网站喜欢分页来增加PV。但是,这样做的缺点是很明显,一个完整的内容被分割了,给用户阅读造成了一些障碍。用户必须点击下一页才能查看他们想要的内容。反过来,如果他们想要区分原创内容网站,他们必须做出不同的排版方法。比如上面提到的,如果对方进行分页,我们可以把内容组织在一起(在文章不太长的情况下),这样搜索引擎就很容易爬取整个内容。,用户无需翻页即可查看。可以说,这种方式在排版上有很大的不同,也提升了用户体验。
网站内容部分和副标题的使用
在查看一段内容时,如果标题准确,我们可以从标题中知道内容是关于什么的?但是如果作者写的太长,整个内容的中心点就会模糊,这样用户就很容易把握不住作者真正想要表达的概念。此时,对于内容采集,适当区分段落并添加相应的副标题。这样会减少用户观看内容的时间,很容易知道每个段落或者之前的作者想要表达什么?后一位作者建立了什么观点等等。
使用这两种方式,整个内容可以合理划分,表达作者的观点应该没有冲突,尽量设置字幕,保证作者的独到想法。
采集尽量不要超过一定的时间
当我们记住某件事时,我们可以在有限的时间内清楚地记住它。并确保你不会忘记它,它会在指定的时间后慢慢消失。事实上,搜索引擎也是如此。他们也更喜欢新的内容搜索引擎,他们会在最短的时间内抓取并呈现给用户。但是,时间久了,内容的新鲜度已经过去,搜索引擎很难抓取到相同的内容。我们可以利用这一点,搜索引擎更喜欢新的文章、采集 内容,一天之内尝试采集。永远不要采集 已经存在很长时间的内容。
添加高清图片
采集中的一些内容,原来的网站没有添加图片,所以我们可以添加高清图片。虽然添加图片对文章影响不大,因为我们是采集的内容,尽量在采集的内容调整上做一定的改变,不要采集 >不做任何修改就来这里。更重要的是,一个人的衣着决定了一个人的好感度。实际上,添加图片是为了增加搜索引擎的好感度。
我们的采集别人的内容,首先从搜索引擎的角度来看,属于重复抄袭。从搜索引擎的角度来看,我们的内容与原创内容相比,在质量得分方面已经下降了很多。但是,我们可以在某些方面弥补分数的下降,这需要个别站长在内容体验和网站经验上下功夫。
网站内容采集(互联网寻找电子合同的免费模板是比较安全有效率的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-28 13:01
网站内容采集,你可以根据网站有效信息生成标准体量的电子合同,再加公证、对等、三方公证认证等多方认证手段固化电子合同法律效力,也可通过互联网电子证据公证平台的发布系统、展示系统,或标准的合同电子数据接口,生成标准可靠的电子合同样本文件,直接做接口授权下发即可,如此即可保证电子合同的效力。可参考我们的“电子合同样本展示及接口授权授权”方案或邮件咨询:。
可以去到一些比较大的电子合同网站看看,一般都会有详细的合同模板和标准,
谢邀,但我不懂。能想到的办法有两个,一个是基于中国人民大学刘宪宁教授的“电子签名”,电子合同,建立电子文件。一个就是去威客网或者市场找一些提供电子合同模板的人,应该有希望。
合同模板,互联网平台都会有的,
以前有一个人在传输合同,
可以在比如wordpress站点可以找到,而且对于每年1万多块的域名费,还不如搞这个看起来不得一点事。至于在wordpress站点上找不到的,我们没试过。如果你需要合同标准化,大家可以互相给一个模板,这样可以确保合同履行的唯一性,而且还可以根据对方人员来确定合同受益人。
随着网络合同的兴起,整个法律及司法环境都正在迅速变化着。电子合同无论是对于我们的法律还是整个社会管理来说,我们都很期待它真正的大范围的应用。因此,每家律师事务所都在努力试验,但是电子合同尚未在中国推广应用。在这种情况下,互联网寻找电子合同的免费模板是一个比较安全有效率的方法。下面我简单为大家介绍一下。
一、在互联网上,电子合同正在通过两种方式寻找:第一种就是通过中国人民大学法学院主办的法律服务中心;另一种则是通过互联网找合同,主要通过互联网站点发布。如下面这些电子合同网站,虽然都没有司法实体资质,但是它们都可以提供法律服务,只要提供企业名称、邮箱、联系电话等相关基本信息,就能够为广大客户提供电子合同服务。
如通过互联网向新浪科技分享合同模板你可以在网络上获取模板、案例、样例等,用户通过联系在线服务人员获取有关电子合同方面的服务。新浪科技是中国最大的网上交易平台,同时也是全国最大的网络司法保障机构。自己找合同就在互联网上,但是想要把它发布到网上,首先是要准备好一个互联网专门提供电子合同模板、案例、样例等各种模板的平台;当你成功申请平台后,点击要发布的电子合同模板之后,需要这个电子合同样本(pdf格式);如果需要制作个人专门的电子合同,就需要一个个人专门发布合同的平台。 查看全部
网站内容采集(互联网寻找电子合同的免费模板是比较安全有效率的方法)
网站内容采集,你可以根据网站有效信息生成标准体量的电子合同,再加公证、对等、三方公证认证等多方认证手段固化电子合同法律效力,也可通过互联网电子证据公证平台的发布系统、展示系统,或标准的合同电子数据接口,生成标准可靠的电子合同样本文件,直接做接口授权下发即可,如此即可保证电子合同的效力。可参考我们的“电子合同样本展示及接口授权授权”方案或邮件咨询:。
可以去到一些比较大的电子合同网站看看,一般都会有详细的合同模板和标准,
谢邀,但我不懂。能想到的办法有两个,一个是基于中国人民大学刘宪宁教授的“电子签名”,电子合同,建立电子文件。一个就是去威客网或者市场找一些提供电子合同模板的人,应该有希望。
合同模板,互联网平台都会有的,
以前有一个人在传输合同,
可以在比如wordpress站点可以找到,而且对于每年1万多块的域名费,还不如搞这个看起来不得一点事。至于在wordpress站点上找不到的,我们没试过。如果你需要合同标准化,大家可以互相给一个模板,这样可以确保合同履行的唯一性,而且还可以根据对方人员来确定合同受益人。
随着网络合同的兴起,整个法律及司法环境都正在迅速变化着。电子合同无论是对于我们的法律还是整个社会管理来说,我们都很期待它真正的大范围的应用。因此,每家律师事务所都在努力试验,但是电子合同尚未在中国推广应用。在这种情况下,互联网寻找电子合同的免费模板是一个比较安全有效率的方法。下面我简单为大家介绍一下。
一、在互联网上,电子合同正在通过两种方式寻找:第一种就是通过中国人民大学法学院主办的法律服务中心;另一种则是通过互联网找合同,主要通过互联网站点发布。如下面这些电子合同网站,虽然都没有司法实体资质,但是它们都可以提供法律服务,只要提供企业名称、邮箱、联系电话等相关基本信息,就能够为广大客户提供电子合同服务。
如通过互联网向新浪科技分享合同模板你可以在网络上获取模板、案例、样例等,用户通过联系在线服务人员获取有关电子合同方面的服务。新浪科技是中国最大的网上交易平台,同时也是全国最大的网络司法保障机构。自己找合同就在互联网上,但是想要把它发布到网上,首先是要准备好一个互联网专门提供电子合同模板、案例、样例等各种模板的平台;当你成功申请平台后,点击要发布的电子合同模板之后,需要这个电子合同样本(pdf格式);如果需要制作个人专门的电子合同,就需要一个个人专门发布合同的平台。
网站内容采集(百度的飓风算法就是,如何采集内容最好呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-02-28 06:07
很多买seo插件的朋友发现,我们在做手动优化的时候,基本都有采集的情况,但是采集也有很多技巧。其实百度一直在攻击自己的采集,采集其实更影响百度搜索引擎的效率,百度的飓风算法就是打击这种网站,防止垃圾站霸占百度大量的资源,造成浪费。
飓风算法推出后,对很多客户产生了一定的影响。一些客户从 收录 数万增加到数百。
很多用户都有问题。网站如果不依赖采集手动填写大量信息,其实很多用户在建站之前就搞错了。首先,新网站不应该有太多的类别。、专栏等。以论坛门户为例。很多人一口气就有了20多个论坛版块和几十个专栏。这样的网站内容填充成了最大的问题,因为大部分站长都是个人。在维护不是公司,一个人就很填20多个论坛内容,只能采集。个人网站前期一定要重点关注一两点,不要一口气做太多栏目。网站排名的高低与列数无关。
采集内容如何才能最好?采集内容建议可以手动将多条内容组合成一条内容,而不是直接采集返回信息,通过关键字替换或伪原创如果以后直接发布,这样的内容基本不会通过百度的算法。
内容不仅适用于蜘蛛,还考虑了用户如何看待它。采集 内容必须可读,这是最重要的!怎么让它可读又快采集内容,这里面的技术很高,每个人的方法不一样,大家可以动动脑筋,
采集内容好吗?事实上,很多人都有这个疑问。采集 的内容取决于起点是什么。如果只是为了欺骗蜘蛛,最好不要直接采集。如果是为了方便用户,可以将采集返回大量信息进行整理分类,让用户在最短的时间内看到你网站上的所有信息,但是对于用户来说还是蜘蛛没问题的。
一个简单的个人 网站 根本不需要 采集。对于百度来说,内容也有高低之分。采集 的内容必须是低档的,原创 的内容必须优于 采集 的内容。也简单认为原创的内容可以给网站的内容加10分,采集的内容也会加1分。如果采集个别方法错了,也会给网站扣分。好不好由你自己判断。
很多人的采集内容创意都是为了欺骗蜘蛛。又不是他们参与进来写东西,然后采集自己填内容。事实上,如果这个采集使用不当,就会成为一个定时炸弹。前期网站用了很多采集,排名非常好。结果百度更新了算法,你的收录掉了,你的排名基本没了。这就像盖房子一样。如果你偷空间减少地基,如果你想盖一座高楼,它肯定会倒塌。 查看全部
网站内容采集(百度的飓风算法就是,如何采集内容最好呢?(图))
很多买seo插件的朋友发现,我们在做手动优化的时候,基本都有采集的情况,但是采集也有很多技巧。其实百度一直在攻击自己的采集,采集其实更影响百度搜索引擎的效率,百度的飓风算法就是打击这种网站,防止垃圾站霸占百度大量的资源,造成浪费。
飓风算法推出后,对很多客户产生了一定的影响。一些客户从 收录 数万增加到数百。
很多用户都有问题。网站如果不依赖采集手动填写大量信息,其实很多用户在建站之前就搞错了。首先,新网站不应该有太多的类别。、专栏等。以论坛门户为例。很多人一口气就有了20多个论坛版块和几十个专栏。这样的网站内容填充成了最大的问题,因为大部分站长都是个人。在维护不是公司,一个人就很填20多个论坛内容,只能采集。个人网站前期一定要重点关注一两点,不要一口气做太多栏目。网站排名的高低与列数无关。
采集内容如何才能最好?采集内容建议可以手动将多条内容组合成一条内容,而不是直接采集返回信息,通过关键字替换或伪原创如果以后直接发布,这样的内容基本不会通过百度的算法。
内容不仅适用于蜘蛛,还考虑了用户如何看待它。采集 内容必须可读,这是最重要的!怎么让它可读又快采集内容,这里面的技术很高,每个人的方法不一样,大家可以动动脑筋,
采集内容好吗?事实上,很多人都有这个疑问。采集 的内容取决于起点是什么。如果只是为了欺骗蜘蛛,最好不要直接采集。如果是为了方便用户,可以将采集返回大量信息进行整理分类,让用户在最短的时间内看到你网站上的所有信息,但是对于用户来说还是蜘蛛没问题的。
一个简单的个人 网站 根本不需要 采集。对于百度来说,内容也有高低之分。采集 的内容必须是低档的,原创 的内容必须优于 采集 的内容。也简单认为原创的内容可以给网站的内容加10分,采集的内容也会加1分。如果采集个别方法错了,也会给网站扣分。好不好由你自己判断。
很多人的采集内容创意都是为了欺骗蜘蛛。又不是他们参与进来写东西,然后采集自己填内容。事实上,如果这个采集使用不当,就会成为一个定时炸弹。前期网站用了很多采集,排名非常好。结果百度更新了算法,你的收录掉了,你的排名基本没了。这就像盖房子一样。如果你偷空间减少地基,如果你想盖一座高楼,它肯定会倒塌。
网站内容采集(Thinkphp内核小说自动采集程序网站源码后台更新5个采集规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-02-26 08:11
Thinkphp内核小说自动采集程序网站源码
后台更新了5条采集规则,允许采集30万本小说10G左右。
背景:URL+/admin
默认用户名和密码 admin/123456
抱歉,此资源仅供VIP下载,请先登录
☆下载协议☆下载前请阅读本协议。如已下载,本站将视为您已阅读并接受以下协议。
1.下载内容不包括其技术服务。小白不建议下载。如果您需要本站有偿技术服务,请联系我们。
2.本站所有资源均来源于网络,分享目的仅供参考和学习。用于商业用途,请选择正规渠道购买正版!
3.不保证本站所有资源都能正常演示。如果您有下载后可以正常使用的心态,请不要下载!一经下载,不支持任何争议,请自行选择。
下载
下载价格:VIP专属
本资源只开放VIP下载
☆下载协议☆下载前请阅读本协议。如已下载,本站将视为您已阅读并接受以下协议。
1.下载内容不包括其技术服务。小白不建议下载。如果您需要本站有偿技术服务,请联系我们。
2.本站所有资源均来源于网络,分享目的仅供参考和学习。用于商业用途,请选择正规渠道购买正版!
3.不保证本站所有资源都能正常演示。如果您有下载后可以正常使用的心态,请不要下载!一经下载,不支持任何争议,请自行选择。 查看全部
网站内容采集(Thinkphp内核小说自动采集程序网站源码后台更新5个采集规则)
Thinkphp内核小说自动采集程序网站源码
后台更新了5条采集规则,允许采集30万本小说10G左右。
背景:URL+/admin
默认用户名和密码 admin/123456
抱歉,此资源仅供VIP下载,请先登录
☆下载协议☆下载前请阅读本协议。如已下载,本站将视为您已阅读并接受以下协议。
1.下载内容不包括其技术服务。小白不建议下载。如果您需要本站有偿技术服务,请联系我们。
2.本站所有资源均来源于网络,分享目的仅供参考和学习。用于商业用途,请选择正规渠道购买正版!
3.不保证本站所有资源都能正常演示。如果您有下载后可以正常使用的心态,请不要下载!一经下载,不支持任何争议,请自行选择。
下载
下载价格:VIP专属
本资源只开放VIP下载
☆下载协议☆下载前请阅读本协议。如已下载,本站将视为您已阅读并接受以下协议。
1.下载内容不包括其技术服务。小白不建议下载。如果您需要本站有偿技术服务,请联系我们。
2.本站所有资源均来源于网络,分享目的仅供参考和学习。用于商业用途,请选择正规渠道购买正版!
3.不保证本站所有资源都能正常演示。如果您有下载后可以正常使用的心态,请不要下载!一经下载,不支持任何争议,请自行选择。
网站内容采集(网站内容不收录,受那些因素影响?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-25 07:18
近年来搜索引擎不断调整算法,导致很多网站的排名波动很大,所以网站的流量也不稳定,甚至有的网站在一开始是正常的收录,后来收录没有太多,所以网站的内容不是收录,是什么因素?
1、网站修订
原因:网站未修改,已提交百度,会有大改大更新。交换类别和标题。有时会有测试,或其他与 网站 无关的东西。这些是 seo 的一大禁忌。
解决方案:定位好并坚持你想做的任何站。可以添加新的类别和内容。最好不要乱删旧内容。如果您要更改空间,最好提前进行。保证之前的空间内容会继续存在一段时间,以防万一。
2、网站架构
原因:网站结构不清晰,死链接导致搜索引擎在网站上迷路。
解决方法:一一清除死链接,制作一张网站图。
3、网站域名
原因:曾被发动机K撞过或处罚过。我们可以看看这个域名之前有没有被使用过。
解决方法:在申请域名之前,直接在引擎中输入你要注册的域名。如:如果主要引擎不返回数据,则应该是未使用的。
4、网站主题
原因:网站题主是引擎屏蔽了关键词或者违法。应该有很多人做垃圾站。
解决方法:现在是和谐社会,最好不要多碰,也最好不要参与敏感话题的讨论。
5、网站内容采集
原因:内容几乎全部出自采集,是采集的一个非常热门的文章。百度一下会收录你上千页,但是百度收录之后一定时间会重新找回。如果您的内容没有价值,它将被丢弃。
解决方法:采集完成后,手动增加原创文章的个数,为什么要加引号。因为 原创 不容易写。教你一个简单的小方法来欺骗蜘蛛找到相关类型的文章。更改标题。打乱里面的段落格式。如果你有自己的看法,你可以自己在里面写一段。正是这样一个 原创文章 被创建了。然后,让你的 原创 的 文章 在主页上多出现几个。
6、网站过度优化
原因:优化过度,如堆砌关键词、隐藏文字等。如果出现这种情况,就算百度有收录你,也不要庆幸自己上当了,因为它会在过程中慢慢被淘汰更新。
解决方法:新版网站上线,先不要做太多SEO,标题关键词重复不要超过2次,描述中关键词重复不要超过3次,不要不要在主页上堆放关键词。故意把首页的关键词在那些重要的地方堆积起来,尽量控制在34个左右。标题里留三四个关键词就够了,太多的搜索引擎不喜欢。建议设置为页面主题+主题名称+网站名称。至于关键词,加不加也没关系,但至少页面上应该有一些相关的内容。描述的设置很简单,只要语言流利,对页面做一个大概的概括,出现两三个关键词就够了。
7、网站文章更新不稳定
原因:网站未能保持稳定的更新量文章,有时一天更新数百个文章,有时一个月不更新一个文章。
解决方法:定时定量连续添加文章,清除冗余码,添加最新信息原创文章。毕竟,只有网站有了新的页面,才能吸引蜘蛛爬行,让搜索引擎对你产生好感。
8、网站链接
原因:网站缺少外链,或者外链逐渐减少,百度当然会少关注你的网站,逐渐减少收录的内容。链接的质量很重要,最好不要有垃圾链接,还要去掉死链接。另外,检查你的页面,如果有被屏蔽网站的链接,你的网站也会受到牵连。
解决方法:查看网站外部连接,如果少了就去交流一下,或者去一些大论坛发些能引起别人兴趣的帖子,然后离开连接。回复的人越多越好。如果站内有指向被封锁站的链接,请尽快删除。避免与一些垃圾邮件网站的附属链接,因为它们会对您的 网站 产生负面影响。
网站内容不是收录,是不是受那些因素影响?现在做SEO优化,如果想让你的网站有更好的排名,那么优化网站的相关细节不可忽视,同时网站的质量和价值@>内容一定要改进,让网站的排名越来越好。 查看全部
网站内容采集(网站内容不收录,受那些因素影响?-八维教育)
近年来搜索引擎不断调整算法,导致很多网站的排名波动很大,所以网站的流量也不稳定,甚至有的网站在一开始是正常的收录,后来收录没有太多,所以网站的内容不是收录,是什么因素?
1、网站修订
原因:网站未修改,已提交百度,会有大改大更新。交换类别和标题。有时会有测试,或其他与 网站 无关的东西。这些是 seo 的一大禁忌。
解决方案:定位好并坚持你想做的任何站。可以添加新的类别和内容。最好不要乱删旧内容。如果您要更改空间,最好提前进行。保证之前的空间内容会继续存在一段时间,以防万一。

2、网站架构
原因:网站结构不清晰,死链接导致搜索引擎在网站上迷路。
解决方法:一一清除死链接,制作一张网站图。
3、网站域名
原因:曾被发动机K撞过或处罚过。我们可以看看这个域名之前有没有被使用过。
解决方法:在申请域名之前,直接在引擎中输入你要注册的域名。如:如果主要引擎不返回数据,则应该是未使用的。
4、网站主题
原因:网站题主是引擎屏蔽了关键词或者违法。应该有很多人做垃圾站。
解决方法:现在是和谐社会,最好不要多碰,也最好不要参与敏感话题的讨论。
5、网站内容采集
原因:内容几乎全部出自采集,是采集的一个非常热门的文章。百度一下会收录你上千页,但是百度收录之后一定时间会重新找回。如果您的内容没有价值,它将被丢弃。
解决方法:采集完成后,手动增加原创文章的个数,为什么要加引号。因为 原创 不容易写。教你一个简单的小方法来欺骗蜘蛛找到相关类型的文章。更改标题。打乱里面的段落格式。如果你有自己的看法,你可以自己在里面写一段。正是这样一个 原创文章 被创建了。然后,让你的 原创 的 文章 在主页上多出现几个。
6、网站过度优化
原因:优化过度,如堆砌关键词、隐藏文字等。如果出现这种情况,就算百度有收录你,也不要庆幸自己上当了,因为它会在过程中慢慢被淘汰更新。
解决方法:新版网站上线,先不要做太多SEO,标题关键词重复不要超过2次,描述中关键词重复不要超过3次,不要不要在主页上堆放关键词。故意把首页的关键词在那些重要的地方堆积起来,尽量控制在34个左右。标题里留三四个关键词就够了,太多的搜索引擎不喜欢。建议设置为页面主题+主题名称+网站名称。至于关键词,加不加也没关系,但至少页面上应该有一些相关的内容。描述的设置很简单,只要语言流利,对页面做一个大概的概括,出现两三个关键词就够了。

7、网站文章更新不稳定
原因:网站未能保持稳定的更新量文章,有时一天更新数百个文章,有时一个月不更新一个文章。
解决方法:定时定量连续添加文章,清除冗余码,添加最新信息原创文章。毕竟,只有网站有了新的页面,才能吸引蜘蛛爬行,让搜索引擎对你产生好感。
8、网站链接
原因:网站缺少外链,或者外链逐渐减少,百度当然会少关注你的网站,逐渐减少收录的内容。链接的质量很重要,最好不要有垃圾链接,还要去掉死链接。另外,检查你的页面,如果有被屏蔽网站的链接,你的网站也会受到牵连。
解决方法:查看网站外部连接,如果少了就去交流一下,或者去一些大论坛发些能引起别人兴趣的帖子,然后离开连接。回复的人越多越好。如果站内有指向被封锁站的链接,请尽快删除。避免与一些垃圾邮件网站的附属链接,因为它们会对您的 网站 产生负面影响。
网站内容不是收录,是不是受那些因素影响?现在做SEO优化,如果想让你的网站有更好的排名,那么优化网站的相关细节不可忽视,同时网站的质量和价值@>内容一定要改进,让网站的排名越来越好。
网站内容采集(百度是如何在互联网上复制这么多重复的内容的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-02-22 21:18
重复内容一直是 SEO 行业关注的问题。重复内容是否会受到搜索引擎的惩罚是一个经常讨论的话题。百度最近大大降低了其内容合集网站的使用权,但仍有不少朋友发现自己的文章被转发,排名高于原版文章。那么百度是如何在互联网上复制这么多重复内容的呢?
1、百度最终会惩罚抄袭内容吗?
首先,我们需要对重复内容和采集网站有一个清晰的认识,否则会有一定的差异。目前,百度没有明显打击重复内容的迹象。百度不处罚重复内容也是可以理解的。
虽然许多 SEO 专家在进行站点诊断时会讨论外部站点上重复内容的数量,但他们通常使用网站管理员工具来计算是否附加了原创链接。
这里我们一直在努力解决这个问题:文章被转发后排名比自己高。百度一直在努力解决这个问题,但仍处于测试阶段。可以看到,希望最近上线的熊掌号,授权站长,可以在原创内容下提交原创保护。尤其是 文章 发布所需的时间。精确到秒:
这是一个很明确的信号,有原创这个受保护的网站,一旦提交的链接被批准,就会在手机搜索显示中标上原创标签,自然排名会高于转发文章。
2、为什么采集的内容排名这么高?
这个采集的内容应该分为两部分,主要有以下两种情况:
全站采集
权威网站转发,熊掌号上线后百度将显着提升。那么百度为什么给这些网站的转发内容排名更高,这与网站的权威性和原创的比例有一定的关系。同时,为了更好的在搜索结果页面展示高质量的文章,应该从信息传播和权限转换的角度来理解网站。发送时会附上版权链接,同时也会建立到新的网站的友好外部链接。
整个网站采集完全不一样,内容很多采集,虽然网站会保持不断更新的频率,我也觉得采集不错,但是采集 内容几乎没有排名,这也是外链新闻能存活下来的一个小原因!
百度推出飓风算法后,很明显会打击恶劣的采集网站,似乎连收录都会成为未来的泡沫。
3、内部抄袭有罚金吗?
对于这个问题,百度的表述比较模糊。在最近的清风算法中,百度强调不要过多的优化标题,以提升排名的形式积累关键词,避免过多的重复标题。
此前,一些SEO专家指出:
目前不建议使用同义词或伪装关键词作为标题创建多个页面覆盖关键词,尽量简化为一个文章,如:
植物的功效
植物的价值
这两个标题,你会在很多食物上看到不同的页面网站,但就内容而言,答案几乎是一样的,百度要你把这两个问题放在一起,比如:植物的营养价值,它们的功效和作用?SEO是一种策略,尤其是面对重复的内容和内容采集,有时很难判断,很多站长都处于临界点。 查看全部
网站内容采集(百度是如何在互联网上复制这么多重复的内容的呢?)
重复内容一直是 SEO 行业关注的问题。重复内容是否会受到搜索引擎的惩罚是一个经常讨论的话题。百度最近大大降低了其内容合集网站的使用权,但仍有不少朋友发现自己的文章被转发,排名高于原版文章。那么百度是如何在互联网上复制这么多重复内容的呢?
1、百度最终会惩罚抄袭内容吗?
首先,我们需要对重复内容和采集网站有一个清晰的认识,否则会有一定的差异。目前,百度没有明显打击重复内容的迹象。百度不处罚重复内容也是可以理解的。
虽然许多 SEO 专家在进行站点诊断时会讨论外部站点上重复内容的数量,但他们通常使用网站管理员工具来计算是否附加了原创链接。
这里我们一直在努力解决这个问题:文章被转发后排名比自己高。百度一直在努力解决这个问题,但仍处于测试阶段。可以看到,希望最近上线的熊掌号,授权站长,可以在原创内容下提交原创保护。尤其是 文章 发布所需的时间。精确到秒:
这是一个很明确的信号,有原创这个受保护的网站,一旦提交的链接被批准,就会在手机搜索显示中标上原创标签,自然排名会高于转发文章。
2、为什么采集的内容排名这么高?
这个采集的内容应该分为两部分,主要有以下两种情况:
全站采集
权威网站转发,熊掌号上线后百度将显着提升。那么百度为什么给这些网站的转发内容排名更高,这与网站的权威性和原创的比例有一定的关系。同时,为了更好的在搜索结果页面展示高质量的文章,应该从信息传播和权限转换的角度来理解网站。发送时会附上版权链接,同时也会建立到新的网站的友好外部链接。
整个网站采集完全不一样,内容很多采集,虽然网站会保持不断更新的频率,我也觉得采集不错,但是采集 内容几乎没有排名,这也是外链新闻能存活下来的一个小原因!
百度推出飓风算法后,很明显会打击恶劣的采集网站,似乎连收录都会成为未来的泡沫。
3、内部抄袭有罚金吗?
对于这个问题,百度的表述比较模糊。在最近的清风算法中,百度强调不要过多的优化标题,以提升排名的形式积累关键词,避免过多的重复标题。
此前,一些SEO专家指出:
目前不建议使用同义词或伪装关键词作为标题创建多个页面覆盖关键词,尽量简化为一个文章,如:
植物的功效
植物的价值
这两个标题,你会在很多食物上看到不同的页面网站,但就内容而言,答案几乎是一样的,百度要你把这两个问题放在一起,比如:植物的营养价值,它们的功效和作用?SEO是一种策略,尤其是面对重复的内容和内容采集,有时很难判断,很多站长都处于临界点。
网站内容采集(网站采集项目是不是很简单,如果真的这么简单!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-22 21:16
相信很多朋友都操作过采集网站项目,有的手动复制,有的使用采集软件和插件快速获取内容。即使搜索引擎推出各种算法来处理采集垃圾邮件网站,也有人做得更好,当然,这些肯定没有我们想象的那么简单。不只是我们需要构建网站,然后手动复制,软件采集,或者伪原创等等,包括我们看到群里很多网友都在做真的很好。网站 已经卖到几万了,很羡慕。
其实我们看到的网站采集项目是不是很简单呢?如果只是简单的模仿、复制,甚至是软件采集,你会不会发现效果不明显,甚至根本没有收录。这有什么问题?前段时间,老姜也找了几位献身采集网站的朋友,好好聊了聊。事实上,从表面上看,我们看到他们做得很好,而且他们通常没有太多事情要做。我吹牛聊天,其实人家也付出不少。
在本文章中,我将简要梳理和介绍正确的采集网站项目的流程。我可以告诉你的是,它实际上并没有那么简单,如果它真的那么简单的话。我们都会效仿吗?我们的效率和建站速度肯定会超过大部分用户,为什么不做呢?这意味着有一定的门槛。
文章目录隐藏
带权重的域名 一、
编号 二、 优质内容
编号 三、 推广权重
循环 四、 效果
带权重的域名 一、
做网站的朋友应该知道,如果我们新注册一个域名,至少要3到6个月才能有一定的权重。除非您的内容绝对有价值,否则您开始更新的任何内容都需要很长时间才能被搜索引擎识别。这称为累积权重,有些 网站 甚至需要数年才能获得一定的权重。
在这里我们可以看到有很多站长是采集网站,他们都购买了优质的权威域名。有的直接买别人的网站,有的买旧域名,抢一些过期域名。之前,老姜还专门针对这些朋友的需求,专门写了几篇关于老域名抢注方法的文章。其实他们是想买一些老域名来缩短域名评估期。
1、老域名在哪里买,买老域名要注意什么
2、Dynadot域名注册商抢购过期域名及提高成功率的方法
3、实用老域名挖掘与GoDaddy商户老域名购买图文教程方法
编号 二、 优质内容
看到标题,很多朋友肯定会想说,这不是废话吗,如果是优质内容,我绝对不会去采集内容。这里的优质内容不是让我们文章写我们的每一篇文章原创。取而代之的是,我们在选择内容的时候需要垂直,在选择内容的时候我们必须是流量词。比如之前有个采集老江部落网站技术内容的朋友。事实上,技术含量的用户群很小,词库中也无法生成任何单词,所以流量基本上很小。
如果我们选择像电影和游戏这样的内容,一旦被收录发布,很容易带来流量。因为以后我们做网站不管是自己卖还是做广告,都需要流量,有流量的话,销售的单价比较高。当然,买家也需要在站长工具中查看你的网站数据信息。如果选择没有词汇的内容,基本上很难卖。
而我们在制作内容的时候,无论是你原创、采集、复制还是其他,都必须进行二次加工。直接复制很难成功。毕竟,你的 网站 质量肯定不如来自原创来源的内容。
编号 三、 推广权重
我们做的任何网站自然肯定不会带来权重和流量,还是需要推广的。根据网友的反馈,即使是采集网站,也会像普通的网站一开始更新内容和推广,只会得到很多当它们达到一定的重量值和效果时。采集。如果你开始很多采集,你网站如果你没有开始可能会被直接惩罚。
同时,在我们后续的网站操作中,有网友告诉他们每个月要花几十万元购买人脉、软文等资源,增加软文的权重。 @网站。我们看到还是认为我们不这样做?不像那样。
循环 四、 效果
我们很多人都认为采集网站很容易做,是的,做起来很简单,但是还是需要一定的时间才能产生效果。比如我们前几天看了几个网站,效果不错,也是采集或者综合内容。但是,其他人需要半年到一年的时间才能见效。所以我们在做采集网站这个项目的时候,也需要考虑时间段,不可能几个月就见效。
就算几个月有效,当你卖网站时,买家会分析你的网站是否被骗,如果是,你的价格不会高或者对方是不要. 当然,我们通过以上一系列流程进行操作,几个月后不会见效,也不应该有任何投机行为。
最后但同样重要的是,我们在采集网站时也需要注意版权,有些网站声明内容版权,你不能去采集或复制,目前我们公司的版权意识也在加强,不少站长都收到了律师的来信。 查看全部
网站内容采集(网站采集项目是不是很简单,如果真的这么简单!)
相信很多朋友都操作过采集网站项目,有的手动复制,有的使用采集软件和插件快速获取内容。即使搜索引擎推出各种算法来处理采集垃圾邮件网站,也有人做得更好,当然,这些肯定没有我们想象的那么简单。不只是我们需要构建网站,然后手动复制,软件采集,或者伪原创等等,包括我们看到群里很多网友都在做真的很好。网站 已经卖到几万了,很羡慕。
其实我们看到的网站采集项目是不是很简单呢?如果只是简单的模仿、复制,甚至是软件采集,你会不会发现效果不明显,甚至根本没有收录。这有什么问题?前段时间,老姜也找了几位献身采集网站的朋友,好好聊了聊。事实上,从表面上看,我们看到他们做得很好,而且他们通常没有太多事情要做。我吹牛聊天,其实人家也付出不少。
在本文章中,我将简要梳理和介绍正确的采集网站项目的流程。我可以告诉你的是,它实际上并没有那么简单,如果它真的那么简单的话。我们都会效仿吗?我们的效率和建站速度肯定会超过大部分用户,为什么不做呢?这意味着有一定的门槛。
文章目录隐藏
带权重的域名 一、
编号 二、 优质内容
编号 三、 推广权重
循环 四、 效果
带权重的域名 一、
做网站的朋友应该知道,如果我们新注册一个域名,至少要3到6个月才能有一定的权重。除非您的内容绝对有价值,否则您开始更新的任何内容都需要很长时间才能被搜索引擎识别。这称为累积权重,有些 网站 甚至需要数年才能获得一定的权重。
在这里我们可以看到有很多站长是采集网站,他们都购买了优质的权威域名。有的直接买别人的网站,有的买旧域名,抢一些过期域名。之前,老姜还专门针对这些朋友的需求,专门写了几篇关于老域名抢注方法的文章。其实他们是想买一些老域名来缩短域名评估期。
1、老域名在哪里买,买老域名要注意什么
2、Dynadot域名注册商抢购过期域名及提高成功率的方法
3、实用老域名挖掘与GoDaddy商户老域名购买图文教程方法
编号 二、 优质内容
看到标题,很多朋友肯定会想说,这不是废话吗,如果是优质内容,我绝对不会去采集内容。这里的优质内容不是让我们文章写我们的每一篇文章原创。取而代之的是,我们在选择内容的时候需要垂直,在选择内容的时候我们必须是流量词。比如之前有个采集老江部落网站技术内容的朋友。事实上,技术含量的用户群很小,词库中也无法生成任何单词,所以流量基本上很小。
如果我们选择像电影和游戏这样的内容,一旦被收录发布,很容易带来流量。因为以后我们做网站不管是自己卖还是做广告,都需要流量,有流量的话,销售的单价比较高。当然,买家也需要在站长工具中查看你的网站数据信息。如果选择没有词汇的内容,基本上很难卖。
而我们在制作内容的时候,无论是你原创、采集、复制还是其他,都必须进行二次加工。直接复制很难成功。毕竟,你的 网站 质量肯定不如来自原创来源的内容。
编号 三、 推广权重
我们做的任何网站自然肯定不会带来权重和流量,还是需要推广的。根据网友的反馈,即使是采集网站,也会像普通的网站一开始更新内容和推广,只会得到很多当它们达到一定的重量值和效果时。采集。如果你开始很多采集,你网站如果你没有开始可能会被直接惩罚。
同时,在我们后续的网站操作中,有网友告诉他们每个月要花几十万元购买人脉、软文等资源,增加软文的权重。 @网站。我们看到还是认为我们不这样做?不像那样。
循环 四、 效果
我们很多人都认为采集网站很容易做,是的,做起来很简单,但是还是需要一定的时间才能产生效果。比如我们前几天看了几个网站,效果不错,也是采集或者综合内容。但是,其他人需要半年到一年的时间才能见效。所以我们在做采集网站这个项目的时候,也需要考虑时间段,不可能几个月就见效。
就算几个月有效,当你卖网站时,买家会分析你的网站是否被骗,如果是,你的价格不会高或者对方是不要. 当然,我们通过以上一系列流程进行操作,几个月后不会见效,也不应该有任何投机行为。
最后但同样重要的是,我们在采集网站时也需要注意版权,有些网站声明内容版权,你不能去采集或复制,目前我们公司的版权意识也在加强,不少站长都收到了律师的来信。
网站内容采集(当我们网站建设成功之后,第一个面临的重要问题(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-18 15:13
网站构建成功后,我们面临的第一个重要问题就是丰富网站的内容,因为只有一个网站的内容越丰富,才能让网站有吸引力权力更高,但对于草根站长来说,一个人创作原创内容显然是不现实的,会耗费站长巨大的精力,短时间内也难以完成。但是,我们的网站建设成功后,不可能再等几个月甚至几年的时间让我们挥霍。我们需要能够在相对较短的时间内为 网站 产生一定的流量。.
但遗憾的是,目前很多站长朋友都害怕内容采集,因为内容采集现在有害无益。采集 的内容将使 网站 面临降级和处罚的风险。所以,很多站长朋友都在硬着头皮建设原创的内容,但即便如此,网站的排名和流量也没有提升。那么网站在操作过程中还能做到采集吗?
笔者认为采集的内容还是可行的,因为采集的内容并不是百害而无一利。其实内容采集的好处还是很多的,至少有以下几个兴趣。
一是可以在短时间内丰富网站的内容,让百度蜘蛛正常遍历一个网站,还可以让用户登录到网站,可以看到一些内容,虽然这个内容比较老,但是总比没有内容给用户看要好很多。
二、内容采集可以快速获取本网站的最新相关内容。因为采集的内容可以基于网站的关键词的内容和相关栏目采集的内容,而这些内容可以是最新鲜的内容,所以用户浏览网站,也可以快速获取相关内容,无需通过搜索引擎再次搜索,一定程度上提升了网站的用户体验。
当然,采集内容的弊端还是很明显的,尤其是抄袭采集和大规模采集会对网站造成不良影响,所以作为站长,你必须掌握正确的采集方法,才能充分发挥内容采集的优势。下面我们来详细分析一下正确的采集方法。
首先,优先考虑 采集 内容。也就是说,选择与网站相关的内容,尽量新鲜。如果太陈旧了,尤其是新闻内容,陈旧的内容不需要采集,但是对于技术帖,那么就能够妥妥的采集了,因为这些技术帖对于很多新人都有很好的帮助作用。
那么 采集 的内容应该适当地改变标题。这里的标题更改不是要采集人做头条党,而是根据内容主题更改相应的标题。比如原标题是“减肥产品安全吗”,可以改成“减肥产品安全吗?对身体好吗?” 等,文字内容不同,但表达的内涵是一样的,让采集的内容标题和内容思想一一对应,杜绝了卖狗肉内容的发生.
最后就是适当调整内容。这里的内容调整不需要简单的段落替换,也不需要使用伪原创替换同义词或同义词。这样的替换只会使内容混乱,用户的阅读体验会大打折扣。而现在百度已经严厉打击了这样的伪原创内容,所以网站的优化效果会产生严重的负面影响。在调整内容的时候,可以适当的改写,尤其是首尾两段,需要改写,然后适当添加相应的图片,可以有效提高内容的质量,也可以为百度蜘蛛上诉产生更好的效果。
<p>总而言之,网站内容采集这个工作根本不需要打死。其实只需要对传统粗略的采集进行适当的优化,改成细化的采集即可,虽然采集的时间会比较长,但比 查看全部
网站内容采集(当我们网站建设成功之后,第一个面临的重要问题(图))
网站构建成功后,我们面临的第一个重要问题就是丰富网站的内容,因为只有一个网站的内容越丰富,才能让网站有吸引力权力更高,但对于草根站长来说,一个人创作原创内容显然是不现实的,会耗费站长巨大的精力,短时间内也难以完成。但是,我们的网站建设成功后,不可能再等几个月甚至几年的时间让我们挥霍。我们需要能够在相对较短的时间内为 网站 产生一定的流量。.
但遗憾的是,目前很多站长朋友都害怕内容采集,因为内容采集现在有害无益。采集 的内容将使 网站 面临降级和处罚的风险。所以,很多站长朋友都在硬着头皮建设原创的内容,但即便如此,网站的排名和流量也没有提升。那么网站在操作过程中还能做到采集吗?
笔者认为采集的内容还是可行的,因为采集的内容并不是百害而无一利。其实内容采集的好处还是很多的,至少有以下几个兴趣。
一是可以在短时间内丰富网站的内容,让百度蜘蛛正常遍历一个网站,还可以让用户登录到网站,可以看到一些内容,虽然这个内容比较老,但是总比没有内容给用户看要好很多。
二、内容采集可以快速获取本网站的最新相关内容。因为采集的内容可以基于网站的关键词的内容和相关栏目采集的内容,而这些内容可以是最新鲜的内容,所以用户浏览网站,也可以快速获取相关内容,无需通过搜索引擎再次搜索,一定程度上提升了网站的用户体验。
当然,采集内容的弊端还是很明显的,尤其是抄袭采集和大规模采集会对网站造成不良影响,所以作为站长,你必须掌握正确的采集方法,才能充分发挥内容采集的优势。下面我们来详细分析一下正确的采集方法。
首先,优先考虑 采集 内容。也就是说,选择与网站相关的内容,尽量新鲜。如果太陈旧了,尤其是新闻内容,陈旧的内容不需要采集,但是对于技术帖,那么就能够妥妥的采集了,因为这些技术帖对于很多新人都有很好的帮助作用。
那么 采集 的内容应该适当地改变标题。这里的标题更改不是要采集人做头条党,而是根据内容主题更改相应的标题。比如原标题是“减肥产品安全吗”,可以改成“减肥产品安全吗?对身体好吗?” 等,文字内容不同,但表达的内涵是一样的,让采集的内容标题和内容思想一一对应,杜绝了卖狗肉内容的发生.
最后就是适当调整内容。这里的内容调整不需要简单的段落替换,也不需要使用伪原创替换同义词或同义词。这样的替换只会使内容混乱,用户的阅读体验会大打折扣。而现在百度已经严厉打击了这样的伪原创内容,所以网站的优化效果会产生严重的负面影响。在调整内容的时候,可以适当的改写,尤其是首尾两段,需要改写,然后适当添加相应的图片,可以有效提高内容的质量,也可以为百度蜘蛛上诉产生更好的效果。
<p>总而言之,网站内容采集这个工作根本不需要打死。其实只需要对传统粗略的采集进行适当的优化,改成细化的采集即可,虽然采集的时间会比较长,但比
网站内容采集( WordpressWordpress采集插件解决网站收录问题的几种方法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-17 15:13
WordpressWordpress采集插件解决网站收录问题的几种方法!)
Wordpress采集插件是为了方便需要采集建站的wordpresscms站长。现在建网站越来越方便了。只需获得一个开源程序和一个虚拟主机,您就可以使用它。网站易于构建。有了网站,肯定有内容要填,那么问题来了,网站内容已经成为网站可持续发展的老大难问题,所以,很多站长都会使用Wordpress采集 采集文章 插件。既然提到了Wordpress采集插件这个词,显然不是复制粘贴一两篇文章那么简单。随着程序越来越多样化,采集插件的出现让采集内容的工作可以批量自动化,
Wordpress采集插件是一个好的采集网站的前提。前提是内容处理一定要做好。内容处理离不开搜索引擎已有的内容。搜索引擎上的内容处理是很多采集站长最头疼的事情之一;采集 一个网站离不开采集这个工具。Wordpress采集插件是网站内容采集处理工具,是采集站的重中之重!
wordpress 采集插件,网站完成内容构建后如何解决采集的收录问题。第一个一、修改模板,搜索引擎更喜欢唯一的网站,如果你的网站模板和很多网站一样,就会失去优势。所以你下载喜欢的模板后,一定要进行适当的修改,让你的网站模板在搜索引擎眼中是独一无二的。二、的内容修改,采集的内容必须修改。我通常的做法是修改 文章 标题。如果你有更多的时间,你还可以修改第一段和最后一段的内容,然后改变图片的大小和ALT属性。
第一个三、侧重于外部链接的构建,因为网站的大部分内容属于采集,失去了原创的优势,所以只能使用外部链接链接提升网站的整体权重,外链的建设可谓是采集站的重中之重。建议30%的外部链接导入首页(锚文本链接、超链接、纯文本链接),其余大部分导入已开发的栏目页和较热的长尾关键词页。通过这三种方法,基本可以解决采集站的收录问题。采集 不是目的,采集 只是一种手段,如果使用不当,就有可能失去你的力量给你的<
wordpress采集的插件数量级比较多,采集之后还有排名,更多的是采集不同的来源,比如:你从新媒体获取内容< @采集,而事实上,它可能是搜索引擎的全新内容。采集行业比较分散,不同行业的内容采集有一定的内容。此外,独特的页面结构、合理的聚合、清晰的结构可以快速解决用户的搜索需求。页面访问速度好,色彩丰富,元素组合有利于用户体验,如:短视频和音频解说等。页面上有些元素可以让用户受益。合理控制采集音量的比例,而整个网站的内容输出依然以符合搜索需求的优质内容为主。这也是使用Wordpress 采集 插件后网站 需要改进的地方。改进后,网站的收录的排名权重可以提高更多更快。 查看全部
网站内容采集(
WordpressWordpress采集插件解决网站收录问题的几种方法!)

Wordpress采集插件是为了方便需要采集建站的wordpresscms站长。现在建网站越来越方便了。只需获得一个开源程序和一个虚拟主机,您就可以使用它。网站易于构建。有了网站,肯定有内容要填,那么问题来了,网站内容已经成为网站可持续发展的老大难问题,所以,很多站长都会使用Wordpress采集 采集文章 插件。既然提到了Wordpress采集插件这个词,显然不是复制粘贴一两篇文章那么简单。随着程序越来越多样化,采集插件的出现让采集内容的工作可以批量自动化,


Wordpress采集插件是一个好的采集网站的前提。前提是内容处理一定要做好。内容处理离不开搜索引擎已有的内容。搜索引擎上的内容处理是很多采集站长最头疼的事情之一;采集 一个网站离不开采集这个工具。Wordpress采集插件是网站内容采集处理工具,是采集站的重中之重!
wordpress 采集插件,网站完成内容构建后如何解决采集的收录问题。第一个一、修改模板,搜索引擎更喜欢唯一的网站,如果你的网站模板和很多网站一样,就会失去优势。所以你下载喜欢的模板后,一定要进行适当的修改,让你的网站模板在搜索引擎眼中是独一无二的。二、的内容修改,采集的内容必须修改。我通常的做法是修改 文章 标题。如果你有更多的时间,你还可以修改第一段和最后一段的内容,然后改变图片的大小和ALT属性。

第一个三、侧重于外部链接的构建,因为网站的大部分内容属于采集,失去了原创的优势,所以只能使用外部链接链接提升网站的整体权重,外链的建设可谓是采集站的重中之重。建议30%的外部链接导入首页(锚文本链接、超链接、纯文本链接),其余大部分导入已开发的栏目页和较热的长尾关键词页。通过这三种方法,基本可以解决采集站的收录问题。采集 不是目的,采集 只是一种手段,如果使用不当,就有可能失去你的力量给你的<
wordpress采集的插件数量级比较多,采集之后还有排名,更多的是采集不同的来源,比如:你从新媒体获取内容< @采集,而事实上,它可能是搜索引擎的全新内容。采集行业比较分散,不同行业的内容采集有一定的内容。此外,独特的页面结构、合理的聚合、清晰的结构可以快速解决用户的搜索需求。页面访问速度好,色彩丰富,元素组合有利于用户体验,如:短视频和音频解说等。页面上有些元素可以让用户受益。合理控制采集音量的比例,而整个网站的内容输出依然以符合搜索需求的优质内容为主。这也是使用Wordpress 采集 插件后网站 需要改进的地方。改进后,网站的收录的排名权重可以提高更多更快。
网站内容采集( 标题一样与原标题完全不相同,道理很简单!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-02-17 13:15
标题一样与原标题完全不相同,道理很简单!)
网站优化应该如何正确使用采集优化后的内容?
首先,采集content 对象是特殊的。找别人刚刚发布的内容作为采集的目标很好,在被太多人转载之前采集过来,但内容的前提是先进、新鲜并且具有代表性,而不是一些陈词滥调的话题,否则给用户的口味是一样的,根本就一文不值。既然是采集内容,自然比原创简单很多,也不需要花太多时间去编辑内容。毕竟采集的内容没有原创的直接作用,所以需要同时多找几个采集的内容来弥补蜘蛛。
其次,采集content 没有采集title。大家都知道,当你阅读一篇文章文章时,首先要看的是标题。对于网站优化的搜索引擎,标题也有一定的权重。采集的内容有一定的长度,不能改太多,但是标题只有几个字,修改起来比较容易,所以标题修改是必须的,而且比较好将标题更改为与原创标题完全不同。原因很简单。当你看到一个文章标题相同,实质内容完全不同的时候,会给读者一些误解,认为两者的内容是一样的。相反,即使内容相同,标题也完全不同。不同的,
然后,对内容进行适当的调整。我试过采集给我的网站的站长,细心的人难免会发现直接复制的内容还是有格式问题的,因为一些精明的原创用户正在努力防止如果内容为采集,通常会在内容中添加一些隐藏的格式,甚至在图片的ALT信息中都会标明版权。网站的危险不言而喻。因此,采集中的内容必须进行格式化,英文格式的标点符号必须进行转换。另外,可以在内容中加入一些图片,让内容更加丰富。如果内容本身有图片,不要直接复制,保存后重新上传到网站,添加自己的ALT信息制作采集的内容
总之,网站采集的内容也不是完全没用,关键看你怎么用采集,只要能灵活使用采集的内容,就可以带网站有一定的好处,但是站长需要注意一定要掌握一定的采集方法。 查看全部
网站内容采集(
标题一样与原标题完全不相同,道理很简单!)
网站优化应该如何正确使用采集优化后的内容?
首先,采集content 对象是特殊的。找别人刚刚发布的内容作为采集的目标很好,在被太多人转载之前采集过来,但内容的前提是先进、新鲜并且具有代表性,而不是一些陈词滥调的话题,否则给用户的口味是一样的,根本就一文不值。既然是采集内容,自然比原创简单很多,也不需要花太多时间去编辑内容。毕竟采集的内容没有原创的直接作用,所以需要同时多找几个采集的内容来弥补蜘蛛。
其次,采集content 没有采集title。大家都知道,当你阅读一篇文章文章时,首先要看的是标题。对于网站优化的搜索引擎,标题也有一定的权重。采集的内容有一定的长度,不能改太多,但是标题只有几个字,修改起来比较容易,所以标题修改是必须的,而且比较好将标题更改为与原创标题完全不同。原因很简单。当你看到一个文章标题相同,实质内容完全不同的时候,会给读者一些误解,认为两者的内容是一样的。相反,即使内容相同,标题也完全不同。不同的,
然后,对内容进行适当的调整。我试过采集给我的网站的站长,细心的人难免会发现直接复制的内容还是有格式问题的,因为一些精明的原创用户正在努力防止如果内容为采集,通常会在内容中添加一些隐藏的格式,甚至在图片的ALT信息中都会标明版权。网站的危险不言而喻。因此,采集中的内容必须进行格式化,英文格式的标点符号必须进行转换。另外,可以在内容中加入一些图片,让内容更加丰富。如果内容本身有图片,不要直接复制,保存后重新上传到网站,添加自己的ALT信息制作采集的内容
总之,网站采集的内容也不是完全没用,关键看你怎么用采集,只要能灵活使用采集的内容,就可以带网站有一定的好处,但是站长需要注意一定要掌握一定的采集方法。
网站内容采集(如何正确使用采集内容内容?重视原创内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-02-15 23:03
在网站的优化圈里,站长们都知道搜索引擎看重原创的内容,但即使是最优秀的SEOer在面对长期的内容原创时也会面临一定的困难,不仅限于资源和写作能力也有局限性,因此,整个网站,包括每个部分的内容,都离不开采集。
但是搜索引擎强调采集内容对网站意义不大,尤其是出于优化目的,甚至采集内容也会被当作垃圾邮件,导致网站' s 负担其实并非如此。即使采集的内容对网站有一定的风险,只要采集合理,还是有用的,同时可以减少原创@ >不用担心,得到同样的优化效果。那么,如何正确使用 采集 内容呢?
首先,采集content 对象是特殊的。最好找别人刚刚发布的内容作为采集目标,在被太多人转载之前采集过来,但内容的前提是要超前,新鲜而有代表性,不是一些老套的话题,否则对用户来说,就跟打蜡一样,一文不值。既然是采集内容,自然比原创简单很多,也不需要花太多时间去编辑内容。毕竟采集的内容没有原创的直接作用,所以需要同时多找几个采集的内容来弥补蜘蛛。
其次,采集content 没有采集title。大家都知道,阅读一篇文章文章首先要看的是标题。对于网站优化的搜索引擎,标题也有一定的权重。采集的内容是有一定长度的,不能改太多,但是标题只有几个字,而且修改起来比较容易,所以标题修改是必要的,最好是更改标题。它与原标题完全不同。原因很简单。当你看到一个文章标题相同,内容完全不同的时候,会给读者一些误解,认为两者的内容是一样的。相反,即使内容相同,标题也完全不同,
最后,对内容进行适当的调整。我试过采集给我的网站的站长,细心的人难免会发现直接复制的内容还是有格式问题的,因为一些精明的原创用户正在努力防止如果内容为采集,通常会在内容中添加一些隐藏格式,甚至在图片的ALT信息中都标明了版权。如果不注意,自然会被搜索引擎认定为抄袭。网站的危险不言而喻。因此,采集中的内容必须进行格式化,英文格式的标点符号必须进行转换。另外,可以在内容中加入一些图片,让内容更加丰富。如果内容本身有图片,请勿直接复制,
总之,网站采集的内容也不是完全没用,关键看你怎么用采集,只要能灵活使用采集的内容,就可以带网站有一定的好处,但是站长需要注意一定要掌握一定的采集方法。 查看全部
网站内容采集(如何正确使用采集内容内容?重视原创内容?)
在网站的优化圈里,站长们都知道搜索引擎看重原创的内容,但即使是最优秀的SEOer在面对长期的内容原创时也会面临一定的困难,不仅限于资源和写作能力也有局限性,因此,整个网站,包括每个部分的内容,都离不开采集。
但是搜索引擎强调采集内容对网站意义不大,尤其是出于优化目的,甚至采集内容也会被当作垃圾邮件,导致网站' s 负担其实并非如此。即使采集的内容对网站有一定的风险,只要采集合理,还是有用的,同时可以减少原创@ >不用担心,得到同样的优化效果。那么,如何正确使用 采集 内容呢?
首先,采集content 对象是特殊的。最好找别人刚刚发布的内容作为采集目标,在被太多人转载之前采集过来,但内容的前提是要超前,新鲜而有代表性,不是一些老套的话题,否则对用户来说,就跟打蜡一样,一文不值。既然是采集内容,自然比原创简单很多,也不需要花太多时间去编辑内容。毕竟采集的内容没有原创的直接作用,所以需要同时多找几个采集的内容来弥补蜘蛛。
其次,采集content 没有采集title。大家都知道,阅读一篇文章文章首先要看的是标题。对于网站优化的搜索引擎,标题也有一定的权重。采集的内容是有一定长度的,不能改太多,但是标题只有几个字,而且修改起来比较容易,所以标题修改是必要的,最好是更改标题。它与原标题完全不同。原因很简单。当你看到一个文章标题相同,内容完全不同的时候,会给读者一些误解,认为两者的内容是一样的。相反,即使内容相同,标题也完全不同,
最后,对内容进行适当的调整。我试过采集给我的网站的站长,细心的人难免会发现直接复制的内容还是有格式问题的,因为一些精明的原创用户正在努力防止如果内容为采集,通常会在内容中添加一些隐藏格式,甚至在图片的ALT信息中都标明了版权。如果不注意,自然会被搜索引擎认定为抄袭。网站的危险不言而喻。因此,采集中的内容必须进行格式化,英文格式的标点符号必须进行转换。另外,可以在内容中加入一些图片,让内容更加丰富。如果内容本身有图片,请勿直接复制,
总之,网站采集的内容也不是完全没用,关键看你怎么用采集,只要能灵活使用采集的内容,就可以带网站有一定的好处,但是站长需要注意一定要掌握一定的采集方法。
网站内容采集(引擎推出飓风算法全文如下百度预计流量权重百度(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-02-15 14:27
seo 采集 数据怎么结束,看流量如果流量很低,即使排名很高,权重也不会积累很多,但是可以加起来规则权重百度权重没有百度权重百度估计流量权重百度;预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 权重百度预估流量权重 百度估算流量权重 百度估算流量权重 百度估算流量高于百度权重是为优化网站排名而推出的站长工具!
seo采集数据怎么样,你的统计,你有没有很长时间不关心你的流量来自哪些搜索?这是站长们经常遇到也经常不赞成的事情,但在实践中我们是非常清晰和好的页面;停留时间有利于增加搜索引擎的信任度。如果我们不关心用户,高跳出率很容易影响下一次搜索引擎给出的排名估计。表面停留时间有利于增加搜索引擎的信任度。如果我们不关心用户,高跳出率很容易影响下次搜索引擎给出的排名估计。
seo 采集数据应该如何基于用户体验?用户体验应该以网站服务器的相应速度为准。在优化过程中,内容和外链是积累网站权重的重要工具!同时,段落也是造成降级的重要因素。网站优化心态很重要。必须从用户的角度考虑内容和外部链接。始终保持“从不缺乏”的原则,稳步提升,实现这些网站基本避免跌倒。重要的是,无论是内容还是外链,都必须站在用户的角度考虑,始终保持“宁可缺少,不宜过度”的原则。实现这些网站 基本上可以避免降权的问题。由于技术和思想等原因,人工智能理论出现得较早!
如何seo采集Data Theory 取消回复NamerequiredAdditional URLOptional◎欢迎参与讨论请在此发表您的意见交流您的意见请填写您的广告代码或删除此行文字日期百度搜索引擎;推出飓风算法 全文如下 百度推出飓风算法打击不良采集百度搜索近期推出飓风算法打击不良主要内容采集网站同时百度!引擎 飓风算法上线全文如下 百度上线飓风算法打击不良采集百度搜索近期上线飓风算法打击不良主要内容采集网站同时,百度搜索将从收录的不良采集链接库中彻底剔除,为优质的原创内容提供更多展示机会,推动搜索生态发展。飓风算法会例行产生惩罚数据,并根据情况随时调整迭代反映!
seo如何采集数据化后,可以大大增加向目标客户展示产品或服务的机会,从而增加影响力,提高产品的知名度。例如,如果用户正在搜索产品,则应该是 网站 才能出现;现在前几个可以获得更多的用户点击,这些用户可能是竞争对手、潜在客户或需要相关信息的人,沟通可以赚更多;当用户搜索时,网站可以出现在前几个地方,可以获得更多的用户点击,而这些用户可能是竞争对手、潜在客户或相关信息需求者。广泛传播可以让更多人关注您的信息或产品并与用户互动。 查看全部
网站内容采集(引擎推出飓风算法全文如下百度预计流量权重百度(组图))
seo 采集 数据怎么结束,看流量如果流量很低,即使排名很高,权重也不会积累很多,但是可以加起来规则权重百度权重没有百度权重百度估计流量权重百度;预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 权重百度预估流量权重 百度估算流量权重 百度估算流量权重 百度估算流量高于百度权重是为优化网站排名而推出的站长工具!

seo采集数据怎么样,你的统计,你有没有很长时间不关心你的流量来自哪些搜索?这是站长们经常遇到也经常不赞成的事情,但在实践中我们是非常清晰和好的页面;停留时间有利于增加搜索引擎的信任度。如果我们不关心用户,高跳出率很容易影响下一次搜索引擎给出的排名估计。表面停留时间有利于增加搜索引擎的信任度。如果我们不关心用户,高跳出率很容易影响下次搜索引擎给出的排名估计。

seo 采集数据应该如何基于用户体验?用户体验应该以网站服务器的相应速度为准。在优化过程中,内容和外链是积累网站权重的重要工具!同时,段落也是造成降级的重要因素。网站优化心态很重要。必须从用户的角度考虑内容和外部链接。始终保持“从不缺乏”的原则,稳步提升,实现这些网站基本避免跌倒。重要的是,无论是内容还是外链,都必须站在用户的角度考虑,始终保持“宁可缺少,不宜过度”的原则。实现这些网站 基本上可以避免降权的问题。由于技术和思想等原因,人工智能理论出现得较早!

如何seo采集Data Theory 取消回复NamerequiredAdditional URLOptional◎欢迎参与讨论请在此发表您的意见交流您的意见请填写您的广告代码或删除此行文字日期百度搜索引擎;推出飓风算法 全文如下 百度推出飓风算法打击不良采集百度搜索近期推出飓风算法打击不良主要内容采集网站同时百度!引擎 飓风算法上线全文如下 百度上线飓风算法打击不良采集百度搜索近期上线飓风算法打击不良主要内容采集网站同时,百度搜索将从收录的不良采集链接库中彻底剔除,为优质的原创内容提供更多展示机会,推动搜索生态发展。飓风算法会例行产生惩罚数据,并根据情况随时调整迭代反映!

seo如何采集数据化后,可以大大增加向目标客户展示产品或服务的机会,从而增加影响力,提高产品的知名度。例如,如果用户正在搜索产品,则应该是 网站 才能出现;现在前几个可以获得更多的用户点击,这些用户可能是竞争对手、潜在客户或需要相关信息的人,沟通可以赚更多;当用户搜索时,网站可以出现在前几个地方,可以获得更多的用户点击,而这些用户可能是竞争对手、潜在客户或相关信息需求者。广泛传播可以让更多人关注您的信息或产品并与用户互动。
网站内容采集(学习SEO技术不仅仅是要学会怎么去伪原创、去优化关键字)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-02-14 21:01
学习SEO技巧,不仅是学习伪原创,优化关键词排名,还要采集竞争对手数据。并学习使用这些信息作为参考来优化您的网站。
那么,新站长如何采集他们想要分析的数据呢?以下是我采集数据的一点经验:
问题一:如何采集符合要求的数据
在采集符合条件的网站时,我使用以下方法:
1、 蜘蛛搜索方法
1):首先进入导航网站查找相关站点,逐一查找符合要求的站点;
2):其次,找到符合要求的网站后,再从他们的友情链接中找到符合要求的网站;
3):最后,在第二个符合条件的站点继续上述方法。
注意:前提是浏览器中安装了ALEXA统计插件。(采集目标是多少ALEXA rank)
2、传送门子频道
为什么要去门户的子频道寻找目标?因为门户网站的子频道好友链质量非常高,符合要求的网站很多。这为下一次分析节省了大量时间。
3、网站联盟
每个行业站点都有自己的联盟站群。寻找与您的网站相关联的会员站群网站 来采集数据也是一个好主意。
总结:
1):这是我用来采集数据的三种方法,虽然很费力,减少了重复的发生。
2):数据采集的过程很枯燥,关键在于持久性和强执行力。
问题二、如何分析采集到的站点
所需数据已采集完毕,接下来的工作是分析采集到的站点。段璇会解释分析一个网站需要哪些数据作为参考:
首先,我换了个角度思考:如果我是站长寻找友情链接,需要哪些数据作为参考。
第二,如何提炼这些数据,让看数据的人一眼就能明白是怎么回事。
假设:如果我做一个友好的链接,我将需要以下数据作为参考:
ALEXA排名、谷歌PR值、百度权重、雅虎外链、百度快照、百度/谷歌收录量、PR产值、关键词密度、域名注册信息、日均流量。如图所示:
总结:只有确定你从哪个角度看待采集到的数据,以及你想从数据中得到哪些有用的数据,才能在分析数据时轻松提取有价值的信息。请记住:同理心是分析数据的第一要素。
问题三、如何提取有价值的数据?
初步采集资料后,我觉得排版还是不够让人一眼看出什么是有价值的,什么是不有价值的。因为我第一次采集数据的时候是按照网站名字的字数排序的,如图:
后来我按照网站ALEXA的排名排序。只有表格美观,人们才能理解表格中数据的价值。如图所示:
说明:与第一个报告相比,改进后的报告可以让人一眼看到网站的排名,其他分析项目自然一目了然。
总结:在数据采集和分析的过程中,需要有明确的采集目标和美观易懂的表格数据,才能更清晰的了解竞争对手的基本情况。
嗯,段璇希望这篇文章能给新站长一点参考和帮助,在数据的采集和分析上。同时也欢迎各位站长互相交流。 查看全部
网站内容采集(学习SEO技术不仅仅是要学会怎么去伪原创、去优化关键字)
学习SEO技巧,不仅是学习伪原创,优化关键词排名,还要采集竞争对手数据。并学习使用这些信息作为参考来优化您的网站。
那么,新站长如何采集他们想要分析的数据呢?以下是我采集数据的一点经验:
问题一:如何采集符合要求的数据
在采集符合条件的网站时,我使用以下方法:
1、 蜘蛛搜索方法
1):首先进入导航网站查找相关站点,逐一查找符合要求的站点;
2):其次,找到符合要求的网站后,再从他们的友情链接中找到符合要求的网站;
3):最后,在第二个符合条件的站点继续上述方法。
注意:前提是浏览器中安装了ALEXA统计插件。(采集目标是多少ALEXA rank)
2、传送门子频道
为什么要去门户的子频道寻找目标?因为门户网站的子频道好友链质量非常高,符合要求的网站很多。这为下一次分析节省了大量时间。
3、网站联盟
每个行业站点都有自己的联盟站群。寻找与您的网站相关联的会员站群网站 来采集数据也是一个好主意。
总结:
1):这是我用来采集数据的三种方法,虽然很费力,减少了重复的发生。
2):数据采集的过程很枯燥,关键在于持久性和强执行力。
问题二、如何分析采集到的站点
所需数据已采集完毕,接下来的工作是分析采集到的站点。段璇会解释分析一个网站需要哪些数据作为参考:
首先,我换了个角度思考:如果我是站长寻找友情链接,需要哪些数据作为参考。
第二,如何提炼这些数据,让看数据的人一眼就能明白是怎么回事。
假设:如果我做一个友好的链接,我将需要以下数据作为参考:
ALEXA排名、谷歌PR值、百度权重、雅虎外链、百度快照、百度/谷歌收录量、PR产值、关键词密度、域名注册信息、日均流量。如图所示:
总结:只有确定你从哪个角度看待采集到的数据,以及你想从数据中得到哪些有用的数据,才能在分析数据时轻松提取有价值的信息。请记住:同理心是分析数据的第一要素。
问题三、如何提取有价值的数据?
初步采集资料后,我觉得排版还是不够让人一眼看出什么是有价值的,什么是不有价值的。因为我第一次采集数据的时候是按照网站名字的字数排序的,如图:
后来我按照网站ALEXA的排名排序。只有表格美观,人们才能理解表格中数据的价值。如图所示:
说明:与第一个报告相比,改进后的报告可以让人一眼看到网站的排名,其他分析项目自然一目了然。
总结:在数据采集和分析的过程中,需要有明确的采集目标和美观易懂的表格数据,才能更清晰的了解竞争对手的基本情况。
嗯,段璇希望这篇文章能给新站长一点参考和帮助,在数据的采集和分析上。同时也欢迎各位站长互相交流。
网站内容采集(网站采集内容容易被K站内容为王,高质量的内容不可取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-02-14 14:25
第一:容易入驻K。内容为王,优质的内容可以提供网站权重。站长不得不承认这个观点,网站有了高质量的内容,权重的增加会更快。抛开采集网站的权重,对于普通的网站,蜘蛛经常爬采集其他人的内容的频率会降低。蜘蛛喜欢新鲜,它们会存储在数据库中。当相同内容过多时,会考虑屏蔽一些相同内容,同时网站采集内容过多,蜘蛛会认为这样的网站是作弊,尤其是新站点,不要为了快速增加网站的内容而去采集内容,这种方法是不可取的。
<p>第二:内容无法控制。为了节省时间,很多站长使用采集的工具。采集 的工具也很不完善。采集 的内容不智能。@文章内容不能去掉别人的信息,所以是无意间帮助别人宣传的,别人写的 查看全部
网站内容采集(网站采集内容容易被K站内容为王,高质量的内容不可取)
第一:容易入驻K。内容为王,优质的内容可以提供网站权重。站长不得不承认这个观点,网站有了高质量的内容,权重的增加会更快。抛开采集网站的权重,对于普通的网站,蜘蛛经常爬采集其他人的内容的频率会降低。蜘蛛喜欢新鲜,它们会存储在数据库中。当相同内容过多时,会考虑屏蔽一些相同内容,同时网站采集内容过多,蜘蛛会认为这样的网站是作弊,尤其是新站点,不要为了快速增加网站的内容而去采集内容,这种方法是不可取的。
<p>第二:内容无法控制。为了节省时间,很多站长使用采集的工具。采集 的工具也很不完善。采集 的内容不智能。@文章内容不能去掉别人的信息,所以是无意间帮助别人宣传的,别人写的
网站内容采集(百度算法对网站页面的质量要求很高,是否会给网站带来什么严重影响?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-11 18:15
<p>百度算法对网站页面的质量要求很高,百度官方也明确表示将惩处垃圾网站和低质量网站。为避免网站大量采集内容被处罚,站长选择删除网站采集的内容页面,以及已经被 查看全部
网站内容采集(百度算法对网站页面的质量要求很高,是否会给网站带来什么严重影响?)
<p>百度算法对网站页面的质量要求很高,百度官方也明确表示将惩处垃圾网站和低质量网站。为避免网站大量采集内容被处罚,站长选择删除网站采集的内容页面,以及已经被
网站内容采集(Facebook和谷歌:所谓的社交小工具被网站所搜集 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-03-04 17:05
)
网易科技讯5月19日消息,据华尔街日报报道,当网民点击Facebook的“Like”和Twitter的“Tweet”按钮分享内容时,这些小玩意让他们的互联网浏览行为被网站采集。
根据华尔街日报所做的研究,这些所谓的社交小工具让 Facebook 和 Twitter 可以了解用户的浏览行为,即使他们没有点击按钮。
这个小工具每年都会添加到数百万个网页中。根据这项研究,Facebook 按钮出现在全球浏览量最高的 1,000 个 网站 页面中的三分之一上,而 Twitter 和 Google 按钮出现在这些 网站 页面上的频率高达 20% 和 25% .
创建这些小工具最初是为了让用户更轻松地共享内容并帮助 网站 吸引用户,但现在它们已成为 网站 跟踪用户浏览行为的强大方式。他们可以将用户的浏览习惯发送到社交网站,而这些网站 上面有用户的名字。
研究表明,用户可以通过在过去一个月内仅登录一次 Facebook 或 Twitter 来跟踪他们的行为。即使在用户关闭浏览器或电脑后,这些网站仍可以继续采集用户的浏览信息,直到用户完全退出Facebook或Twitter账户。
Facebook 和谷歌表示他们将浏览数据“匿名化”,这样采集的信息就不会指向特定用户。Facebook 表示将在 90 天内删除这些数据,而谷歌则表示将在两周内删除这些数据。Facebook 和谷歌表示他们使用这些信息来评估小工具的有效性并帮助 网站 推动用户访问。
Twitter指出它没有使用浏览数据并“很快”将其删除。一位发言人表示,该公司理论上可以在未来使用这些数据向用户“提供更好的内容”。
前 Google 工程师 Brian Kennish 进行了一项调查,他检查了前 1,000 个 Google 广告网络中超过 200,000 个页面的 网站。Kenish 发现 Facebook 从 331 个站点获取浏览数据,谷歌从 250 个站点获取浏览数据,而 Twitter 从 200 个站点采集浏览信息。
直到最近,一些 Facebook 小工具还在采集从未登录过的用户的浏览数据。Facebook 今年早些时候表示,它已经停止了这种做法,并在荷兰研究人员曝光后称其为“错误”。(编译/徐建林)
查看全部
网站内容采集(Facebook和谷歌:所谓的社交小工具被网站所搜集
)
网易科技讯5月19日消息,据华尔街日报报道,当网民点击Facebook的“Like”和Twitter的“Tweet”按钮分享内容时,这些小玩意让他们的互联网浏览行为被网站采集。
根据华尔街日报所做的研究,这些所谓的社交小工具让 Facebook 和 Twitter 可以了解用户的浏览行为,即使他们没有点击按钮。
这个小工具每年都会添加到数百万个网页中。根据这项研究,Facebook 按钮出现在全球浏览量最高的 1,000 个 网站 页面中的三分之一上,而 Twitter 和 Google 按钮出现在这些 网站 页面上的频率高达 20% 和 25% .
创建这些小工具最初是为了让用户更轻松地共享内容并帮助 网站 吸引用户,但现在它们已成为 网站 跟踪用户浏览行为的强大方式。他们可以将用户的浏览习惯发送到社交网站,而这些网站 上面有用户的名字。
研究表明,用户可以通过在过去一个月内仅登录一次 Facebook 或 Twitter 来跟踪他们的行为。即使在用户关闭浏览器或电脑后,这些网站仍可以继续采集用户的浏览信息,直到用户完全退出Facebook或Twitter账户。
Facebook 和谷歌表示他们将浏览数据“匿名化”,这样采集的信息就不会指向特定用户。Facebook 表示将在 90 天内删除这些数据,而谷歌则表示将在两周内删除这些数据。Facebook 和谷歌表示他们使用这些信息来评估小工具的有效性并帮助 网站 推动用户访问。
Twitter指出它没有使用浏览数据并“很快”将其删除。一位发言人表示,该公司理论上可以在未来使用这些数据向用户“提供更好的内容”。
前 Google 工程师 Brian Kennish 进行了一项调查,他检查了前 1,000 个 Google 广告网络中超过 200,000 个页面的 网站。Kenish 发现 Facebook 从 331 个站点获取浏览数据,谷歌从 250 个站点获取浏览数据,而 Twitter 从 200 个站点采集浏览信息。
直到最近,一些 Facebook 小工具还在采集从未登录过的用户的浏览数据。Facebook 今年早些时候表示,它已经停止了这种做法,并在荷兰研究人员曝光后称其为“错误”。(编译/徐建林)
网站内容采集(具体分析一下企业网站建设中正确的采集方式是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-03-04 17:00
采集可以在短时间内大大提高一个网站的收录(前提是你的网站的权重足够高),网络可以大大提高。部分流量,并抢夺其他竞争对手的流量。但是大量的采集会让百度认为你的网站是个垃圾站。如果你今天采集100条,明天采集200条,后天没有采集@采集现在,这是一个不均匀的更新频率,百度会付出更多注意你。
采集内容的弊端还是很明显的,尤其是抄袭采集和大面积采集会对网站造成不良影响,所以一定要掌握正确采集方法,从而充分发挥内容采集的优势。下面我们来分析一下网站企业建设中正确的采集方法。
1、最好采集内容。 采集选择与网站相关的内容,尽量保持新鲜。如果太旧,尤其是新闻内容,不仅对搜索引擎不利,对用户也不利。好的。另外,关于技术帖,可以适量使用采集,因为大部分技术帖不会很快过时,能给用户带来一些实际的帮助。
2, 采集不要改变任何东西。完全抄袭采集绝对不可取。严重时网站会被K,甚至涉嫌侵权。 采集其他文章的时候,最好把它们混在一起几次文章,然后把它们拼接成一个拼接平滑的新文章,或者在最后一次 标题或第一段。这不仅更有利于搜索引擎的收录,也为企业降低了一些风险。
总之,采集不是目的,采集是手段。如果使用不好,你的网站也有被降级的风险。但如果合理采集和使用,对网站的发展会有很大的帮助。 查看全部
网站内容采集(具体分析一下企业网站建设中正确的采集方式是什么?)
采集可以在短时间内大大提高一个网站的收录(前提是你的网站的权重足够高),网络可以大大提高。部分流量,并抢夺其他竞争对手的流量。但是大量的采集会让百度认为你的网站是个垃圾站。如果你今天采集100条,明天采集200条,后天没有采集@采集现在,这是一个不均匀的更新频率,百度会付出更多注意你。
采集内容的弊端还是很明显的,尤其是抄袭采集和大面积采集会对网站造成不良影响,所以一定要掌握正确采集方法,从而充分发挥内容采集的优势。下面我们来分析一下网站企业建设中正确的采集方法。
1、最好采集内容。 采集选择与网站相关的内容,尽量保持新鲜。如果太旧,尤其是新闻内容,不仅对搜索引擎不利,对用户也不利。好的。另外,关于技术帖,可以适量使用采集,因为大部分技术帖不会很快过时,能给用户带来一些实际的帮助。
2, 采集不要改变任何东西。完全抄袭采集绝对不可取。严重时网站会被K,甚至涉嫌侵权。 采集其他文章的时候,最好把它们混在一起几次文章,然后把它们拼接成一个拼接平滑的新文章,或者在最后一次 标题或第一段。这不仅更有利于搜索引擎的收录,也为企业降低了一些风险。
总之,采集不是目的,采集是手段。如果使用不好,你的网站也有被降级的风险。但如果合理采集和使用,对网站的发展会有很大的帮助。
网站内容采集( 如何使用Scrapy结合PhantomJS采集天猫商品内容的小程序?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-04 03:13
如何使用Scrapy结合PhantomJS采集天猫商品内容的小程序?)
1、简介
最近一直在看Scrapy爬虫框架,尝试用Scrapy框架写一个可以实现网页信息的简单小程序采集。在尝试的过程中遇到了很多小问题,希望大家多多指教。
本文主要介绍如何结合PhantomJS使用Scrapy采集天猫产品内容。文章为需要加载js的采集动态网页内容定制了一个DOWNLOADER_MIDDLEWARES。看了很多DOWNLOADER_MIDDLEWARES的资料,总之,好用,但是会阻塞框架,所以性能不好。有资料提到自定义DOWNLOADER_HANDLER或者使用scrapyjs可以解决框架阻塞的问题。有兴趣的小伙伴可以研究一下,这里就不多说了。
2、具体实现2.1、环境要求
准备Python开发和运行环境需要以下步骤:
Python--官网下载安装部署环境变量(本文使用的Python版本为3.5.1)
lxml--从官网库下载对应版本的.whl文件,然后在命令行界面执行“pip install .whl文件路径”
Scrapy--在命令行界面执行“pip install Scrapy”,详见“Scrapy的首次运行测试”
selenium--命令行界面执行“pip install selenium”
PhantomJS——官网下载
以上步骤展示了两种安装方式: 1. 将下载好的wheel包安装到本地; 2. 使用 Python 安装管理器进行远程下载和安装。注意:包的版本需要与python版本相匹配
2.2、开发测试流程
首先找到需要采集的网页,这里是一个简单的天猫产品,网址,页面如下:
然后开始写代码,下面的代码默认在命令行界面执行
1),创建scrapy爬虫项目tmSpider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建middlewares文件夹,然后在文件夹中创建middleware.py文件,代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和PhantomJS编写一个网页内容下载器,同样在上一步创建的middlewares文件夹中创建一个downloader.py文件,代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5) 创建爬虫模块
在工程目录E:python-3.5.1tmSpider,执行如下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后会在工程目录E:python-3.5.1tmSpidertmSpiderspiders下自动生成tmall.py程序文件。该程序中的parse函数对scrapy下载器返回的网页内容进行处理。 采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/526449276263.htm',
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫
在E:python-3.5.1tmSpider工程目录下执行命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:
请记住,上述命令一次只能启动一个爬虫。如果你想同时启动多个呢?然后需要自定义一个爬虫启动模块,在spiders下创建模块文件runcrawl.py,代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件并输出结果:
3、展望
通过自定义DOWNLOADER_MIDDLEWARES调用PhantomJs的方式实现爬虫后,被框架阻塞的问题纠结了好久,一直在想解决办法。以后会研究scrapyjs、splash等方式调用浏览器,看看能不能有效解决这个问题。
4、相关文件
1、Python即时网络爬虫:API说明
5、Jisouke GooSeeker开源代码下载源码
1、GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
1, 2016-07-04: V1.0 查看全部
网站内容采集(
如何使用Scrapy结合PhantomJS采集天猫商品内容的小程序?)
1、简介
最近一直在看Scrapy爬虫框架,尝试用Scrapy框架写一个可以实现网页信息的简单小程序采集。在尝试的过程中遇到了很多小问题,希望大家多多指教。
本文主要介绍如何结合PhantomJS使用Scrapy采集天猫产品内容。文章为需要加载js的采集动态网页内容定制了一个DOWNLOADER_MIDDLEWARES。看了很多DOWNLOADER_MIDDLEWARES的资料,总之,好用,但是会阻塞框架,所以性能不好。有资料提到自定义DOWNLOADER_HANDLER或者使用scrapyjs可以解决框架阻塞的问题。有兴趣的小伙伴可以研究一下,这里就不多说了。
2、具体实现2.1、环境要求
准备Python开发和运行环境需要以下步骤:
Python--官网下载安装部署环境变量(本文使用的Python版本为3.5.1)
lxml--从官网库下载对应版本的.whl文件,然后在命令行界面执行“pip install .whl文件路径”
Scrapy--在命令行界面执行“pip install Scrapy”,详见“Scrapy的首次运行测试”
selenium--命令行界面执行“pip install selenium”
PhantomJS——官网下载
以上步骤展示了两种安装方式: 1. 将下载好的wheel包安装到本地; 2. 使用 Python 安装管理器进行远程下载和安装。注意:包的版本需要与python版本相匹配
2.2、开发测试流程
首先找到需要采集的网页,这里是一个简单的天猫产品,网址,页面如下:
然后开始写代码,下面的代码默认在命令行界面执行
1),创建scrapy爬虫项目tmSpider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建middlewares文件夹,然后在文件夹中创建middleware.py文件,代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和PhantomJS编写一个网页内容下载器,同样在上一步创建的middlewares文件夹中创建一个downloader.py文件,代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5) 创建爬虫模块
在工程目录E:python-3.5.1tmSpider,执行如下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后会在工程目录E:python-3.5.1tmSpidertmSpiderspiders下自动生成tmall.py程序文件。该程序中的parse函数对scrapy下载器返回的网页内容进行处理。 采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/526449276263.htm',
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫
在E:python-3.5.1tmSpider工程目录下执行命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:
请记住,上述命令一次只能启动一个爬虫。如果你想同时启动多个呢?然后需要自定义一个爬虫启动模块,在spiders下创建模块文件runcrawl.py,代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件并输出结果:
3、展望
通过自定义DOWNLOADER_MIDDLEWARES调用PhantomJs的方式实现爬虫后,被框架阻塞的问题纠结了好久,一直在想解决办法。以后会研究scrapyjs、splash等方式调用浏览器,看看能不能有效解决这个问题。
4、相关文件
1、Python即时网络爬虫:API说明
5、Jisouke GooSeeker开源代码下载源码
1、GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
1, 2016-07-04: V1.0
网站内容采集( 如何使用Scrapy结合PhantomJS采集天猫商品内容的小程序?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-03-04 03:09
如何使用Scrapy结合PhantomJS采集天猫商品内容的小程序?)
1、简介
最近一直在看Scrapy爬虫框架,尝试用Scrapy框架写一个可以实现网页信息的简单小程序采集。在尝试的过程中遇到了很多小问题,希望大家多多指教。
本文主要介绍如何结合PhantomJS使用Scrapy采集天猫产品内容。文章为需要加载js的采集动态网页内容定制了一个DOWNLOADER_MIDDLEWARES。看了很多DOWNLOADER_MIDDLEWARES的资料,总之,好用,但是会阻塞框架,所以性能不好。有资料提到自定义DOWNLOADER_HANDLER或者使用scrapyjs可以解决框架阻塞的问题。有兴趣的小伙伴可以研究一下,这里就不多说了。
2、具体实现2.1、环境要求
准备Python开发和运行环境需要以下步骤:
Python--官网下载安装部署环境变量(本文使用的Python版本为3.5.1)
lxml--从官网库下载对应版本的.whl文件,然后在命令行界面执行“pip install .whl文件路径”
Scrapy--在命令行界面执行“pip install Scrapy”,详见“Scrapy的首次运行测试”
selenium--命令行界面执行“pip install selenium”
PhantomJS——官网下载
以上步骤展示了两种安装方式: 1. 将下载好的wheel包安装到本地; 2. 使用 Python 安装管理器进行远程下载和安装。注意:包的版本需要与python版本相匹配
2.2、开发测试流程
首先找到需要采集的网页,这里是一个简单的天猫产品,网址,页面如下:
然后开始写代码,下面的代码默认在命令行界面执行
1),创建scrapy爬虫项目tmSpider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建middlewares文件夹,然后在文件夹中创建middleware.py文件,代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和PhantomJS编写一个网页内容下载器,同样在上一步创建的middlewares文件夹中创建一个downloader.py文件,代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5) 创建爬虫模块
在工程目录E:python-3.5.1tmSpider,执行如下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后会在工程目录E:python-3.5.1tmSpidertmSpiderspiders下自动生成tmall.py程序文件。该程序中的parse函数对scrapy下载器返回的网页内容进行处理。 采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/526449276263.htm',
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫
在E:python-3.5.1tmSpider工程目录下执行命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:
请记住,上述命令一次只能启动一个爬虫。如果你想同时启动多个呢?然后需要自定义一个爬虫启动模块,在spiders下创建模块文件runcrawl.py,代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件并输出结果:
3、展望
通过自定义DOWNLOADER_MIDDLEWARES调用PhantomJs的方式实现爬虫后,被框架阻塞的问题纠结了好久,一直在想解决办法。以后会研究scrapyjs、splash等方式调用浏览器,看看能不能有效解决这个问题。
4、相关文件
1、Python即时网络爬虫:API说明
5、Jisouke GooSeeker开源代码下载源码
1、GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
1, 2016-07-04: V1.0 查看全部
网站内容采集(
如何使用Scrapy结合PhantomJS采集天猫商品内容的小程序?)
1、简介
最近一直在看Scrapy爬虫框架,尝试用Scrapy框架写一个可以实现网页信息的简单小程序采集。在尝试的过程中遇到了很多小问题,希望大家多多指教。
本文主要介绍如何结合PhantomJS使用Scrapy采集天猫产品内容。文章为需要加载js的采集动态网页内容定制了一个DOWNLOADER_MIDDLEWARES。看了很多DOWNLOADER_MIDDLEWARES的资料,总之,好用,但是会阻塞框架,所以性能不好。有资料提到自定义DOWNLOADER_HANDLER或者使用scrapyjs可以解决框架阻塞的问题。有兴趣的小伙伴可以研究一下,这里就不多说了。
2、具体实现2.1、环境要求
准备Python开发和运行环境需要以下步骤:
Python--官网下载安装部署环境变量(本文使用的Python版本为3.5.1)
lxml--从官网库下载对应版本的.whl文件,然后在命令行界面执行“pip install .whl文件路径”
Scrapy--在命令行界面执行“pip install Scrapy”,详见“Scrapy的首次运行测试”
selenium--命令行界面执行“pip install selenium”
PhantomJS——官网下载
以上步骤展示了两种安装方式: 1. 将下载好的wheel包安装到本地; 2. 使用 Python 安装管理器进行远程下载和安装。注意:包的版本需要与python版本相匹配
2.2、开发测试流程
首先找到需要采集的网页,这里是一个简单的天猫产品,网址,页面如下:
然后开始写代码,下面的代码默认在命令行界面执行
1),创建scrapy爬虫项目tmSpider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建middlewares文件夹,然后在文件夹中创建middleware.py文件,代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和PhantomJS编写一个网页内容下载器,同样在上一步创建的middlewares文件夹中创建一个downloader.py文件,代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5) 创建爬虫模块
在工程目录E:python-3.5.1tmSpider,执行如下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后会在工程目录E:python-3.5.1tmSpidertmSpiderspiders下自动生成tmall.py程序文件。该程序中的parse函数对scrapy下载器返回的网页内容进行处理。 采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/526449276263.htm',
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫
在E:python-3.5.1tmSpider工程目录下执行命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:
请记住,上述命令一次只能启动一个爬虫。如果你想同时启动多个呢?然后需要自定义一个爬虫启动模块,在spiders下创建模块文件runcrawl.py,代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件并输出结果:
3、展望
通过自定义DOWNLOADER_MIDDLEWARES调用PhantomJs的方式实现爬虫后,被框架阻塞的问题纠结了好久,一直在想解决办法。以后会研究scrapyjs、splash等方式调用浏览器,看看能不能有效解决这个问题。
4、相关文件
1、Python即时网络爬虫:API说明
5、Jisouke GooSeeker开源代码下载源码
1、GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
1, 2016-07-04: V1.0
网站内容采集(盘点一下网站更新哪些内容会遭到惩罚呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-03-03 04:12
现在越来越多的用户使用网站,对网站的依赖也越来越强,这就促使站长们不断更新网站的内容来维护网站的操作,去抢用户和增加流量。但是,内容更新确实是有限的。有些内容很容易因为每天更新而受到惩罚。我们来看看网站更新会有哪些内容被惩罚?
1、采集内容
随着互联网的飞速发展,互联网上采集内容的现象非常泛滥。很多人采集内容不择手段,有些人采集甚至文章内容都没有。看,直接复制。文章内容中收录竞争对手公司名称或者内部链接等,不知道。很多时候采集还帮别人做婚纱。由于互联网上90%以上的内容是采集内容,很多内容重复性太强,对搜索引擎来说不新鲜;这样的采集内容更新太多网站,很容易被搜索引擎惩罚。
2、广告内容
是不是经常看到很多医疗网站的广告,内容太多,很多夸大医疗效果。治疗XX病的成功率是100%,很多文章本来是介绍给XX病的,但是内容都变成了广告宣传的内容,并没有解决用户的真正需求。针对这种类型的网站,搜索引擎已经开始进行打击。
3、低质量的内容
网站 内容的一部分是牛头和马嘴。明明是一篇文章文章前半部分是文章关于食物的介绍,后半部分是卖衣服的文章,内容完全是从别人那里复制粘贴过来的网站,填充字数;文章根本看不懂等等。这种低质量的内容根本看不懂,就算有排名也就是暂时的,一段时间后排名都会下降时间。
_创新互联,为您提供网站策划、做网站、网站建设公司、微信小程序、软件开发、营销型网站建设 查看全部
网站内容采集(盘点一下网站更新哪些内容会遭到惩罚呢?(图))
现在越来越多的用户使用网站,对网站的依赖也越来越强,这就促使站长们不断更新网站的内容来维护网站的操作,去抢用户和增加流量。但是,内容更新确实是有限的。有些内容很容易因为每天更新而受到惩罚。我们来看看网站更新会有哪些内容被惩罚?
1、采集内容
随着互联网的飞速发展,互联网上采集内容的现象非常泛滥。很多人采集内容不择手段,有些人采集甚至文章内容都没有。看,直接复制。文章内容中收录竞争对手公司名称或者内部链接等,不知道。很多时候采集还帮别人做婚纱。由于互联网上90%以上的内容是采集内容,很多内容重复性太强,对搜索引擎来说不新鲜;这样的采集内容更新太多网站,很容易被搜索引擎惩罚。
2、广告内容
是不是经常看到很多医疗网站的广告,内容太多,很多夸大医疗效果。治疗XX病的成功率是100%,很多文章本来是介绍给XX病的,但是内容都变成了广告宣传的内容,并没有解决用户的真正需求。针对这种类型的网站,搜索引擎已经开始进行打击。
3、低质量的内容
网站 内容的一部分是牛头和马嘴。明明是一篇文章文章前半部分是文章关于食物的介绍,后半部分是卖衣服的文章,内容完全是从别人那里复制粘贴过来的网站,填充字数;文章根本看不懂等等。这种低质量的内容根本看不懂,就算有排名也就是暂时的,一段时间后排名都会下降时间。
_创新互联,为您提供网站策划、做网站、网站建设公司、微信小程序、软件开发、营销型网站建设
网站内容采集(就是为什么常说的就是内容增加过快,导致内容质量度降低)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-03-01 17:24
对于个人网站管理员来说,任何网站最重要的是内容填充。这就是为什么许多网站管理员拼命将 网站 内容添加到他们的 网站 中的原因。但是站长需要增加内容后,网站质量问题难免会被忽略,这也是为什么常说内容增加过快,导致内容质量下降的原因,这也是从另一个方面证实。事实是,你不能同时拥有鱼和熊掌。
一些新手站长总是问这样的问题,说为什么那些大网站和采集 网站都归采集 其他人所有,而且他们的排名仍然那么好。其实很多人都遇到过这样的问题。文章采集来了,内容的质量不是越来越差了吗?然而,他们并没有看到他们的体重和流量下降。. 其实很多因素会决定哪些大站和高权重网站,我们无法比较,还是要脚踏实地从每一步做起。只有这样,网站才能随着时间的推移越来越被认可。那么,如何保证来自采集的内容在质量上可以得到其他分数。
修改标题和描述以及 关键词 标签
之前,新闻网站上流传着这样一个词“标题党”。事实上,这些头条党每天都在做的就是寻找互联网热门内容,从而修改标题,从而赢得用户的关注,让用户输入网站,满足用户对热点内容的好奇。另外,搜索引擎会对热门内容偏爱某些节目,对人的内容进行搜索和聚合,迎合了标题党对热门内容的排序,搜索引擎也能快速呈现。可以说,这种方法非常合适。满足当前用户对热点内容的呈现。
对于 关键词 标签和描述,这些头条新闻还将更多地关注搜索引擎抓取和用户点击好奇心。所以,我们在采集内容的时候,应该尽量多借鉴一下标题党的一些方法,在标题和描述以及关键词标签上做一些改动,以便区分三者原创内容的主要页面。元素。
充分利用排版的差异
我们都知道有些网站喜欢分页来增加PV。但是,这样做的缺点是很明显,一个完整的内容被分割了,给用户阅读造成了一些障碍。用户必须点击下一页才能查看他们想要的内容。反过来,如果他们想要区分原创内容网站,他们必须做出不同的排版方法。比如上面提到的,如果对方进行分页,我们可以把内容组织在一起(在文章不太长的情况下),这样搜索引擎就很容易爬取整个内容。,用户无需翻页即可查看。可以说,这种方式在排版上有很大的不同,也提升了用户体验。
网站内容部分和副标题的使用
在查看一段内容时,如果标题准确,我们可以从标题中知道内容是关于什么的?但是如果作者写的太长,整个内容的中心点就会模糊,这样用户就很容易把握不住作者真正想要表达的概念。此时,对于内容采集,适当区分段落并添加相应的副标题。这样会减少用户观看内容的时间,很容易知道每个段落或者之前的作者想要表达什么?后一位作者建立了什么观点等等。
使用这两种方式,整个内容可以合理划分,表达作者的观点应该没有冲突,尽量设置字幕,保证作者的独到想法。
采集尽量不要超过一定的时间
当我们记住某件事时,我们可以在有限的时间内清楚地记住它。并确保你不会忘记它,它会在指定的时间后慢慢消失。事实上,搜索引擎也是如此。他们也更喜欢新的内容搜索引擎,他们会在最短的时间内抓取并呈现给用户。但是,时间久了,内容的新鲜度已经过去,搜索引擎很难抓取到相同的内容。我们可以利用这一点,搜索引擎更喜欢新的文章、采集 内容,一天之内尝试采集。永远不要采集 已经存在很长时间的内容。
添加高清图片
采集中的一些内容,原来的网站没有添加图片,所以我们可以添加高清图片。虽然添加图片对文章影响不大,因为我们是采集的内容,尽量在采集的内容调整上做一定的改变,不要采集 >不做任何修改就来这里。更重要的是,一个人的衣着决定了一个人的好感度。实际上,添加图片是为了增加搜索引擎的好感度。
我们的采集别人的内容,首先从搜索引擎的角度来看,属于重复抄袭。从搜索引擎的角度来看,我们的内容与原创内容相比,在质量得分方面已经下降了很多。但是,我们可以在某些方面弥补分数的下降,这需要个别站长在内容体验和网站经验上下功夫。 查看全部
网站内容采集(就是为什么常说的就是内容增加过快,导致内容质量度降低)
对于个人网站管理员来说,任何网站最重要的是内容填充。这就是为什么许多网站管理员拼命将 网站 内容添加到他们的 网站 中的原因。但是站长需要增加内容后,网站质量问题难免会被忽略,这也是为什么常说内容增加过快,导致内容质量下降的原因,这也是从另一个方面证实。事实是,你不能同时拥有鱼和熊掌。
一些新手站长总是问这样的问题,说为什么那些大网站和采集 网站都归采集 其他人所有,而且他们的排名仍然那么好。其实很多人都遇到过这样的问题。文章采集来了,内容的质量不是越来越差了吗?然而,他们并没有看到他们的体重和流量下降。. 其实很多因素会决定哪些大站和高权重网站,我们无法比较,还是要脚踏实地从每一步做起。只有这样,网站才能随着时间的推移越来越被认可。那么,如何保证来自采集的内容在质量上可以得到其他分数。
修改标题和描述以及 关键词 标签
之前,新闻网站上流传着这样一个词“标题党”。事实上,这些头条党每天都在做的就是寻找互联网热门内容,从而修改标题,从而赢得用户的关注,让用户输入网站,满足用户对热点内容的好奇。另外,搜索引擎会对热门内容偏爱某些节目,对人的内容进行搜索和聚合,迎合了标题党对热门内容的排序,搜索引擎也能快速呈现。可以说,这种方法非常合适。满足当前用户对热点内容的呈现。
对于 关键词 标签和描述,这些头条新闻还将更多地关注搜索引擎抓取和用户点击好奇心。所以,我们在采集内容的时候,应该尽量多借鉴一下标题党的一些方法,在标题和描述以及关键词标签上做一些改动,以便区分三者原创内容的主要页面。元素。
充分利用排版的差异
我们都知道有些网站喜欢分页来增加PV。但是,这样做的缺点是很明显,一个完整的内容被分割了,给用户阅读造成了一些障碍。用户必须点击下一页才能查看他们想要的内容。反过来,如果他们想要区分原创内容网站,他们必须做出不同的排版方法。比如上面提到的,如果对方进行分页,我们可以把内容组织在一起(在文章不太长的情况下),这样搜索引擎就很容易爬取整个内容。,用户无需翻页即可查看。可以说,这种方式在排版上有很大的不同,也提升了用户体验。
网站内容部分和副标题的使用
在查看一段内容时,如果标题准确,我们可以从标题中知道内容是关于什么的?但是如果作者写的太长,整个内容的中心点就会模糊,这样用户就很容易把握不住作者真正想要表达的概念。此时,对于内容采集,适当区分段落并添加相应的副标题。这样会减少用户观看内容的时间,很容易知道每个段落或者之前的作者想要表达什么?后一位作者建立了什么观点等等。
使用这两种方式,整个内容可以合理划分,表达作者的观点应该没有冲突,尽量设置字幕,保证作者的独到想法。
采集尽量不要超过一定的时间
当我们记住某件事时,我们可以在有限的时间内清楚地记住它。并确保你不会忘记它,它会在指定的时间后慢慢消失。事实上,搜索引擎也是如此。他们也更喜欢新的内容搜索引擎,他们会在最短的时间内抓取并呈现给用户。但是,时间久了,内容的新鲜度已经过去,搜索引擎很难抓取到相同的内容。我们可以利用这一点,搜索引擎更喜欢新的文章、采集 内容,一天之内尝试采集。永远不要采集 已经存在很长时间的内容。
添加高清图片
采集中的一些内容,原来的网站没有添加图片,所以我们可以添加高清图片。虽然添加图片对文章影响不大,因为我们是采集的内容,尽量在采集的内容调整上做一定的改变,不要采集 >不做任何修改就来这里。更重要的是,一个人的衣着决定了一个人的好感度。实际上,添加图片是为了增加搜索引擎的好感度。
我们的采集别人的内容,首先从搜索引擎的角度来看,属于重复抄袭。从搜索引擎的角度来看,我们的内容与原创内容相比,在质量得分方面已经下降了很多。但是,我们可以在某些方面弥补分数的下降,这需要个别站长在内容体验和网站经验上下功夫。
网站内容采集(互联网寻找电子合同的免费模板是比较安全有效率的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-28 13:01
网站内容采集,你可以根据网站有效信息生成标准体量的电子合同,再加公证、对等、三方公证认证等多方认证手段固化电子合同法律效力,也可通过互联网电子证据公证平台的发布系统、展示系统,或标准的合同电子数据接口,生成标准可靠的电子合同样本文件,直接做接口授权下发即可,如此即可保证电子合同的效力。可参考我们的“电子合同样本展示及接口授权授权”方案或邮件咨询:。
可以去到一些比较大的电子合同网站看看,一般都会有详细的合同模板和标准,
谢邀,但我不懂。能想到的办法有两个,一个是基于中国人民大学刘宪宁教授的“电子签名”,电子合同,建立电子文件。一个就是去威客网或者市场找一些提供电子合同模板的人,应该有希望。
合同模板,互联网平台都会有的,
以前有一个人在传输合同,
可以在比如wordpress站点可以找到,而且对于每年1万多块的域名费,还不如搞这个看起来不得一点事。至于在wordpress站点上找不到的,我们没试过。如果你需要合同标准化,大家可以互相给一个模板,这样可以确保合同履行的唯一性,而且还可以根据对方人员来确定合同受益人。
随着网络合同的兴起,整个法律及司法环境都正在迅速变化着。电子合同无论是对于我们的法律还是整个社会管理来说,我们都很期待它真正的大范围的应用。因此,每家律师事务所都在努力试验,但是电子合同尚未在中国推广应用。在这种情况下,互联网寻找电子合同的免费模板是一个比较安全有效率的方法。下面我简单为大家介绍一下。
一、在互联网上,电子合同正在通过两种方式寻找:第一种就是通过中国人民大学法学院主办的法律服务中心;另一种则是通过互联网找合同,主要通过互联网站点发布。如下面这些电子合同网站,虽然都没有司法实体资质,但是它们都可以提供法律服务,只要提供企业名称、邮箱、联系电话等相关基本信息,就能够为广大客户提供电子合同服务。
如通过互联网向新浪科技分享合同模板你可以在网络上获取模板、案例、样例等,用户通过联系在线服务人员获取有关电子合同方面的服务。新浪科技是中国最大的网上交易平台,同时也是全国最大的网络司法保障机构。自己找合同就在互联网上,但是想要把它发布到网上,首先是要准备好一个互联网专门提供电子合同模板、案例、样例等各种模板的平台;当你成功申请平台后,点击要发布的电子合同模板之后,需要这个电子合同样本(pdf格式);如果需要制作个人专门的电子合同,就需要一个个人专门发布合同的平台。 查看全部
网站内容采集(互联网寻找电子合同的免费模板是比较安全有效率的方法)
网站内容采集,你可以根据网站有效信息生成标准体量的电子合同,再加公证、对等、三方公证认证等多方认证手段固化电子合同法律效力,也可通过互联网电子证据公证平台的发布系统、展示系统,或标准的合同电子数据接口,生成标准可靠的电子合同样本文件,直接做接口授权下发即可,如此即可保证电子合同的效力。可参考我们的“电子合同样本展示及接口授权授权”方案或邮件咨询:。
可以去到一些比较大的电子合同网站看看,一般都会有详细的合同模板和标准,
谢邀,但我不懂。能想到的办法有两个,一个是基于中国人民大学刘宪宁教授的“电子签名”,电子合同,建立电子文件。一个就是去威客网或者市场找一些提供电子合同模板的人,应该有希望。
合同模板,互联网平台都会有的,
以前有一个人在传输合同,
可以在比如wordpress站点可以找到,而且对于每年1万多块的域名费,还不如搞这个看起来不得一点事。至于在wordpress站点上找不到的,我们没试过。如果你需要合同标准化,大家可以互相给一个模板,这样可以确保合同履行的唯一性,而且还可以根据对方人员来确定合同受益人。
随着网络合同的兴起,整个法律及司法环境都正在迅速变化着。电子合同无论是对于我们的法律还是整个社会管理来说,我们都很期待它真正的大范围的应用。因此,每家律师事务所都在努力试验,但是电子合同尚未在中国推广应用。在这种情况下,互联网寻找电子合同的免费模板是一个比较安全有效率的方法。下面我简单为大家介绍一下。
一、在互联网上,电子合同正在通过两种方式寻找:第一种就是通过中国人民大学法学院主办的法律服务中心;另一种则是通过互联网找合同,主要通过互联网站点发布。如下面这些电子合同网站,虽然都没有司法实体资质,但是它们都可以提供法律服务,只要提供企业名称、邮箱、联系电话等相关基本信息,就能够为广大客户提供电子合同服务。
如通过互联网向新浪科技分享合同模板你可以在网络上获取模板、案例、样例等,用户通过联系在线服务人员获取有关电子合同方面的服务。新浪科技是中国最大的网上交易平台,同时也是全国最大的网络司法保障机构。自己找合同就在互联网上,但是想要把它发布到网上,首先是要准备好一个互联网专门提供电子合同模板、案例、样例等各种模板的平台;当你成功申请平台后,点击要发布的电子合同模板之后,需要这个电子合同样本(pdf格式);如果需要制作个人专门的电子合同,就需要一个个人专门发布合同的平台。
网站内容采集(百度的飓风算法就是,如何采集内容最好呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-02-28 06:07
很多买seo插件的朋友发现,我们在做手动优化的时候,基本都有采集的情况,但是采集也有很多技巧。其实百度一直在攻击自己的采集,采集其实更影响百度搜索引擎的效率,百度的飓风算法就是打击这种网站,防止垃圾站霸占百度大量的资源,造成浪费。
飓风算法推出后,对很多客户产生了一定的影响。一些客户从 收录 数万增加到数百。
很多用户都有问题。网站如果不依赖采集手动填写大量信息,其实很多用户在建站之前就搞错了。首先,新网站不应该有太多的类别。、专栏等。以论坛门户为例。很多人一口气就有了20多个论坛版块和几十个专栏。这样的网站内容填充成了最大的问题,因为大部分站长都是个人。在维护不是公司,一个人就很填20多个论坛内容,只能采集。个人网站前期一定要重点关注一两点,不要一口气做太多栏目。网站排名的高低与列数无关。
采集内容如何才能最好?采集内容建议可以手动将多条内容组合成一条内容,而不是直接采集返回信息,通过关键字替换或伪原创如果以后直接发布,这样的内容基本不会通过百度的算法。
内容不仅适用于蜘蛛,还考虑了用户如何看待它。采集 内容必须可读,这是最重要的!怎么让它可读又快采集内容,这里面的技术很高,每个人的方法不一样,大家可以动动脑筋,
采集内容好吗?事实上,很多人都有这个疑问。采集 的内容取决于起点是什么。如果只是为了欺骗蜘蛛,最好不要直接采集。如果是为了方便用户,可以将采集返回大量信息进行整理分类,让用户在最短的时间内看到你网站上的所有信息,但是对于用户来说还是蜘蛛没问题的。
一个简单的个人 网站 根本不需要 采集。对于百度来说,内容也有高低之分。采集 的内容必须是低档的,原创 的内容必须优于 采集 的内容。也简单认为原创的内容可以给网站的内容加10分,采集的内容也会加1分。如果采集个别方法错了,也会给网站扣分。好不好由你自己判断。
很多人的采集内容创意都是为了欺骗蜘蛛。又不是他们参与进来写东西,然后采集自己填内容。事实上,如果这个采集使用不当,就会成为一个定时炸弹。前期网站用了很多采集,排名非常好。结果百度更新了算法,你的收录掉了,你的排名基本没了。这就像盖房子一样。如果你偷空间减少地基,如果你想盖一座高楼,它肯定会倒塌。 查看全部
网站内容采集(百度的飓风算法就是,如何采集内容最好呢?(图))
很多买seo插件的朋友发现,我们在做手动优化的时候,基本都有采集的情况,但是采集也有很多技巧。其实百度一直在攻击自己的采集,采集其实更影响百度搜索引擎的效率,百度的飓风算法就是打击这种网站,防止垃圾站霸占百度大量的资源,造成浪费。
飓风算法推出后,对很多客户产生了一定的影响。一些客户从 收录 数万增加到数百。
很多用户都有问题。网站如果不依赖采集手动填写大量信息,其实很多用户在建站之前就搞错了。首先,新网站不应该有太多的类别。、专栏等。以论坛门户为例。很多人一口气就有了20多个论坛版块和几十个专栏。这样的网站内容填充成了最大的问题,因为大部分站长都是个人。在维护不是公司,一个人就很填20多个论坛内容,只能采集。个人网站前期一定要重点关注一两点,不要一口气做太多栏目。网站排名的高低与列数无关。
采集内容如何才能最好?采集内容建议可以手动将多条内容组合成一条内容,而不是直接采集返回信息,通过关键字替换或伪原创如果以后直接发布,这样的内容基本不会通过百度的算法。
内容不仅适用于蜘蛛,还考虑了用户如何看待它。采集 内容必须可读,这是最重要的!怎么让它可读又快采集内容,这里面的技术很高,每个人的方法不一样,大家可以动动脑筋,
采集内容好吗?事实上,很多人都有这个疑问。采集 的内容取决于起点是什么。如果只是为了欺骗蜘蛛,最好不要直接采集。如果是为了方便用户,可以将采集返回大量信息进行整理分类,让用户在最短的时间内看到你网站上的所有信息,但是对于用户来说还是蜘蛛没问题的。
一个简单的个人 网站 根本不需要 采集。对于百度来说,内容也有高低之分。采集 的内容必须是低档的,原创 的内容必须优于 采集 的内容。也简单认为原创的内容可以给网站的内容加10分,采集的内容也会加1分。如果采集个别方法错了,也会给网站扣分。好不好由你自己判断。
很多人的采集内容创意都是为了欺骗蜘蛛。又不是他们参与进来写东西,然后采集自己填内容。事实上,如果这个采集使用不当,就会成为一个定时炸弹。前期网站用了很多采集,排名非常好。结果百度更新了算法,你的收录掉了,你的排名基本没了。这就像盖房子一样。如果你偷空间减少地基,如果你想盖一座高楼,它肯定会倒塌。
网站内容采集(Thinkphp内核小说自动采集程序网站源码后台更新5个采集规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-02-26 08:11
Thinkphp内核小说自动采集程序网站源码
后台更新了5条采集规则,允许采集30万本小说10G左右。
背景:URL+/admin
默认用户名和密码 admin/123456
抱歉,此资源仅供VIP下载,请先登录
☆下载协议☆下载前请阅读本协议。如已下载,本站将视为您已阅读并接受以下协议。
1.下载内容不包括其技术服务。小白不建议下载。如果您需要本站有偿技术服务,请联系我们。
2.本站所有资源均来源于网络,分享目的仅供参考和学习。用于商业用途,请选择正规渠道购买正版!
3.不保证本站所有资源都能正常演示。如果您有下载后可以正常使用的心态,请不要下载!一经下载,不支持任何争议,请自行选择。
下载
下载价格:VIP专属
本资源只开放VIP下载
☆下载协议☆下载前请阅读本协议。如已下载,本站将视为您已阅读并接受以下协议。
1.下载内容不包括其技术服务。小白不建议下载。如果您需要本站有偿技术服务,请联系我们。
2.本站所有资源均来源于网络,分享目的仅供参考和学习。用于商业用途,请选择正规渠道购买正版!
3.不保证本站所有资源都能正常演示。如果您有下载后可以正常使用的心态,请不要下载!一经下载,不支持任何争议,请自行选择。 查看全部
网站内容采集(Thinkphp内核小说自动采集程序网站源码后台更新5个采集规则)
Thinkphp内核小说自动采集程序网站源码
后台更新了5条采集规则,允许采集30万本小说10G左右。
背景:URL+/admin
默认用户名和密码 admin/123456
抱歉,此资源仅供VIP下载,请先登录
☆下载协议☆下载前请阅读本协议。如已下载,本站将视为您已阅读并接受以下协议。
1.下载内容不包括其技术服务。小白不建议下载。如果您需要本站有偿技术服务,请联系我们。
2.本站所有资源均来源于网络,分享目的仅供参考和学习。用于商业用途,请选择正规渠道购买正版!
3.不保证本站所有资源都能正常演示。如果您有下载后可以正常使用的心态,请不要下载!一经下载,不支持任何争议,请自行选择。
下载
下载价格:VIP专属
本资源只开放VIP下载
☆下载协议☆下载前请阅读本协议。如已下载,本站将视为您已阅读并接受以下协议。
1.下载内容不包括其技术服务。小白不建议下载。如果您需要本站有偿技术服务,请联系我们。
2.本站所有资源均来源于网络,分享目的仅供参考和学习。用于商业用途,请选择正规渠道购买正版!
3.不保证本站所有资源都能正常演示。如果您有下载后可以正常使用的心态,请不要下载!一经下载,不支持任何争议,请自行选择。
网站内容采集(网站内容不收录,受那些因素影响?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-25 07:18
近年来搜索引擎不断调整算法,导致很多网站的排名波动很大,所以网站的流量也不稳定,甚至有的网站在一开始是正常的收录,后来收录没有太多,所以网站的内容不是收录,是什么因素?
1、网站修订
原因:网站未修改,已提交百度,会有大改大更新。交换类别和标题。有时会有测试,或其他与 网站 无关的东西。这些是 seo 的一大禁忌。
解决方案:定位好并坚持你想做的任何站。可以添加新的类别和内容。最好不要乱删旧内容。如果您要更改空间,最好提前进行。保证之前的空间内容会继续存在一段时间,以防万一。
2、网站架构
原因:网站结构不清晰,死链接导致搜索引擎在网站上迷路。
解决方法:一一清除死链接,制作一张网站图。
3、网站域名
原因:曾被发动机K撞过或处罚过。我们可以看看这个域名之前有没有被使用过。
解决方法:在申请域名之前,直接在引擎中输入你要注册的域名。如:如果主要引擎不返回数据,则应该是未使用的。
4、网站主题
原因:网站题主是引擎屏蔽了关键词或者违法。应该有很多人做垃圾站。
解决方法:现在是和谐社会,最好不要多碰,也最好不要参与敏感话题的讨论。
5、网站内容采集
原因:内容几乎全部出自采集,是采集的一个非常热门的文章。百度一下会收录你上千页,但是百度收录之后一定时间会重新找回。如果您的内容没有价值,它将被丢弃。
解决方法:采集完成后,手动增加原创文章的个数,为什么要加引号。因为 原创 不容易写。教你一个简单的小方法来欺骗蜘蛛找到相关类型的文章。更改标题。打乱里面的段落格式。如果你有自己的看法,你可以自己在里面写一段。正是这样一个 原创文章 被创建了。然后,让你的 原创 的 文章 在主页上多出现几个。
6、网站过度优化
原因:优化过度,如堆砌关键词、隐藏文字等。如果出现这种情况,就算百度有收录你,也不要庆幸自己上当了,因为它会在过程中慢慢被淘汰更新。
解决方法:新版网站上线,先不要做太多SEO,标题关键词重复不要超过2次,描述中关键词重复不要超过3次,不要不要在主页上堆放关键词。故意把首页的关键词在那些重要的地方堆积起来,尽量控制在34个左右。标题里留三四个关键词就够了,太多的搜索引擎不喜欢。建议设置为页面主题+主题名称+网站名称。至于关键词,加不加也没关系,但至少页面上应该有一些相关的内容。描述的设置很简单,只要语言流利,对页面做一个大概的概括,出现两三个关键词就够了。
7、网站文章更新不稳定
原因:网站未能保持稳定的更新量文章,有时一天更新数百个文章,有时一个月不更新一个文章。
解决方法:定时定量连续添加文章,清除冗余码,添加最新信息原创文章。毕竟,只有网站有了新的页面,才能吸引蜘蛛爬行,让搜索引擎对你产生好感。
8、网站链接
原因:网站缺少外链,或者外链逐渐减少,百度当然会少关注你的网站,逐渐减少收录的内容。链接的质量很重要,最好不要有垃圾链接,还要去掉死链接。另外,检查你的页面,如果有被屏蔽网站的链接,你的网站也会受到牵连。
解决方法:查看网站外部连接,如果少了就去交流一下,或者去一些大论坛发些能引起别人兴趣的帖子,然后离开连接。回复的人越多越好。如果站内有指向被封锁站的链接,请尽快删除。避免与一些垃圾邮件网站的附属链接,因为它们会对您的 网站 产生负面影响。
网站内容不是收录,是不是受那些因素影响?现在做SEO优化,如果想让你的网站有更好的排名,那么优化网站的相关细节不可忽视,同时网站的质量和价值@>内容一定要改进,让网站的排名越来越好。 查看全部
网站内容采集(网站内容不收录,受那些因素影响?-八维教育)
近年来搜索引擎不断调整算法,导致很多网站的排名波动很大,所以网站的流量也不稳定,甚至有的网站在一开始是正常的收录,后来收录没有太多,所以网站的内容不是收录,是什么因素?
1、网站修订
原因:网站未修改,已提交百度,会有大改大更新。交换类别和标题。有时会有测试,或其他与 网站 无关的东西。这些是 seo 的一大禁忌。
解决方案:定位好并坚持你想做的任何站。可以添加新的类别和内容。最好不要乱删旧内容。如果您要更改空间,最好提前进行。保证之前的空间内容会继续存在一段时间,以防万一。
2、网站架构
原因:网站结构不清晰,死链接导致搜索引擎在网站上迷路。
解决方法:一一清除死链接,制作一张网站图。
3、网站域名
原因:曾被发动机K撞过或处罚过。我们可以看看这个域名之前有没有被使用过。
解决方法:在申请域名之前,直接在引擎中输入你要注册的域名。如:如果主要引擎不返回数据,则应该是未使用的。
4、网站主题
原因:网站题主是引擎屏蔽了关键词或者违法。应该有很多人做垃圾站。
解决方法:现在是和谐社会,最好不要多碰,也最好不要参与敏感话题的讨论。
5、网站内容采集
原因:内容几乎全部出自采集,是采集的一个非常热门的文章。百度一下会收录你上千页,但是百度收录之后一定时间会重新找回。如果您的内容没有价值,它将被丢弃。
解决方法:采集完成后,手动增加原创文章的个数,为什么要加引号。因为 原创 不容易写。教你一个简单的小方法来欺骗蜘蛛找到相关类型的文章。更改标题。打乱里面的段落格式。如果你有自己的看法,你可以自己在里面写一段。正是这样一个 原创文章 被创建了。然后,让你的 原创 的 文章 在主页上多出现几个。
6、网站过度优化
原因:优化过度,如堆砌关键词、隐藏文字等。如果出现这种情况,就算百度有收录你,也不要庆幸自己上当了,因为它会在过程中慢慢被淘汰更新。
解决方法:新版网站上线,先不要做太多SEO,标题关键词重复不要超过2次,描述中关键词重复不要超过3次,不要不要在主页上堆放关键词。故意把首页的关键词在那些重要的地方堆积起来,尽量控制在34个左右。标题里留三四个关键词就够了,太多的搜索引擎不喜欢。建议设置为页面主题+主题名称+网站名称。至于关键词,加不加也没关系,但至少页面上应该有一些相关的内容。描述的设置很简单,只要语言流利,对页面做一个大概的概括,出现两三个关键词就够了。
7、网站文章更新不稳定
原因:网站未能保持稳定的更新量文章,有时一天更新数百个文章,有时一个月不更新一个文章。
解决方法:定时定量连续添加文章,清除冗余码,添加最新信息原创文章。毕竟,只有网站有了新的页面,才能吸引蜘蛛爬行,让搜索引擎对你产生好感。
8、网站链接
原因:网站缺少外链,或者外链逐渐减少,百度当然会少关注你的网站,逐渐减少收录的内容。链接的质量很重要,最好不要有垃圾链接,还要去掉死链接。另外,检查你的页面,如果有被屏蔽网站的链接,你的网站也会受到牵连。
解决方法:查看网站外部连接,如果少了就去交流一下,或者去一些大论坛发些能引起别人兴趣的帖子,然后离开连接。回复的人越多越好。如果站内有指向被封锁站的链接,请尽快删除。避免与一些垃圾邮件网站的附属链接,因为它们会对您的 网站 产生负面影响。
网站内容不是收录,是不是受那些因素影响?现在做SEO优化,如果想让你的网站有更好的排名,那么优化网站的相关细节不可忽视,同时网站的质量和价值@>内容一定要改进,让网站的排名越来越好。
网站内容采集(百度是如何在互联网上复制这么多重复的内容的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-02-22 21:18
重复内容一直是 SEO 行业关注的问题。重复内容是否会受到搜索引擎的惩罚是一个经常讨论的话题。百度最近大大降低了其内容合集网站的使用权,但仍有不少朋友发现自己的文章被转发,排名高于原版文章。那么百度是如何在互联网上复制这么多重复内容的呢?
1、百度最终会惩罚抄袭内容吗?
首先,我们需要对重复内容和采集网站有一个清晰的认识,否则会有一定的差异。目前,百度没有明显打击重复内容的迹象。百度不处罚重复内容也是可以理解的。
虽然许多 SEO 专家在进行站点诊断时会讨论外部站点上重复内容的数量,但他们通常使用网站管理员工具来计算是否附加了原创链接。
这里我们一直在努力解决这个问题:文章被转发后排名比自己高。百度一直在努力解决这个问题,但仍处于测试阶段。可以看到,希望最近上线的熊掌号,授权站长,可以在原创内容下提交原创保护。尤其是 文章 发布所需的时间。精确到秒:
这是一个很明确的信号,有原创这个受保护的网站,一旦提交的链接被批准,就会在手机搜索显示中标上原创标签,自然排名会高于转发文章。
2、为什么采集的内容排名这么高?
这个采集的内容应该分为两部分,主要有以下两种情况:
全站采集
权威网站转发,熊掌号上线后百度将显着提升。那么百度为什么给这些网站的转发内容排名更高,这与网站的权威性和原创的比例有一定的关系。同时,为了更好的在搜索结果页面展示高质量的文章,应该从信息传播和权限转换的角度来理解网站。发送时会附上版权链接,同时也会建立到新的网站的友好外部链接。
整个网站采集完全不一样,内容很多采集,虽然网站会保持不断更新的频率,我也觉得采集不错,但是采集 内容几乎没有排名,这也是外链新闻能存活下来的一个小原因!
百度推出飓风算法后,很明显会打击恶劣的采集网站,似乎连收录都会成为未来的泡沫。
3、内部抄袭有罚金吗?
对于这个问题,百度的表述比较模糊。在最近的清风算法中,百度强调不要过多的优化标题,以提升排名的形式积累关键词,避免过多的重复标题。
此前,一些SEO专家指出:
目前不建议使用同义词或伪装关键词作为标题创建多个页面覆盖关键词,尽量简化为一个文章,如:
植物的功效
植物的价值
这两个标题,你会在很多食物上看到不同的页面网站,但就内容而言,答案几乎是一样的,百度要你把这两个问题放在一起,比如:植物的营养价值,它们的功效和作用?SEO是一种策略,尤其是面对重复的内容和内容采集,有时很难判断,很多站长都处于临界点。 查看全部
网站内容采集(百度是如何在互联网上复制这么多重复的内容的呢?)
重复内容一直是 SEO 行业关注的问题。重复内容是否会受到搜索引擎的惩罚是一个经常讨论的话题。百度最近大大降低了其内容合集网站的使用权,但仍有不少朋友发现自己的文章被转发,排名高于原版文章。那么百度是如何在互联网上复制这么多重复内容的呢?
1、百度最终会惩罚抄袭内容吗?
首先,我们需要对重复内容和采集网站有一个清晰的认识,否则会有一定的差异。目前,百度没有明显打击重复内容的迹象。百度不处罚重复内容也是可以理解的。
虽然许多 SEO 专家在进行站点诊断时会讨论外部站点上重复内容的数量,但他们通常使用网站管理员工具来计算是否附加了原创链接。
这里我们一直在努力解决这个问题:文章被转发后排名比自己高。百度一直在努力解决这个问题,但仍处于测试阶段。可以看到,希望最近上线的熊掌号,授权站长,可以在原创内容下提交原创保护。尤其是 文章 发布所需的时间。精确到秒:
这是一个很明确的信号,有原创这个受保护的网站,一旦提交的链接被批准,就会在手机搜索显示中标上原创标签,自然排名会高于转发文章。
2、为什么采集的内容排名这么高?
这个采集的内容应该分为两部分,主要有以下两种情况:
全站采集
权威网站转发,熊掌号上线后百度将显着提升。那么百度为什么给这些网站的转发内容排名更高,这与网站的权威性和原创的比例有一定的关系。同时,为了更好的在搜索结果页面展示高质量的文章,应该从信息传播和权限转换的角度来理解网站。发送时会附上版权链接,同时也会建立到新的网站的友好外部链接。
整个网站采集完全不一样,内容很多采集,虽然网站会保持不断更新的频率,我也觉得采集不错,但是采集 内容几乎没有排名,这也是外链新闻能存活下来的一个小原因!
百度推出飓风算法后,很明显会打击恶劣的采集网站,似乎连收录都会成为未来的泡沫。
3、内部抄袭有罚金吗?
对于这个问题,百度的表述比较模糊。在最近的清风算法中,百度强调不要过多的优化标题,以提升排名的形式积累关键词,避免过多的重复标题。
此前,一些SEO专家指出:
目前不建议使用同义词或伪装关键词作为标题创建多个页面覆盖关键词,尽量简化为一个文章,如:
植物的功效
植物的价值
这两个标题,你会在很多食物上看到不同的页面网站,但就内容而言,答案几乎是一样的,百度要你把这两个问题放在一起,比如:植物的营养价值,它们的功效和作用?SEO是一种策略,尤其是面对重复的内容和内容采集,有时很难判断,很多站长都处于临界点。
网站内容采集(网站采集项目是不是很简单,如果真的这么简单!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-22 21:16
相信很多朋友都操作过采集网站项目,有的手动复制,有的使用采集软件和插件快速获取内容。即使搜索引擎推出各种算法来处理采集垃圾邮件网站,也有人做得更好,当然,这些肯定没有我们想象的那么简单。不只是我们需要构建网站,然后手动复制,软件采集,或者伪原创等等,包括我们看到群里很多网友都在做真的很好。网站 已经卖到几万了,很羡慕。
其实我们看到的网站采集项目是不是很简单呢?如果只是简单的模仿、复制,甚至是软件采集,你会不会发现效果不明显,甚至根本没有收录。这有什么问题?前段时间,老姜也找了几位献身采集网站的朋友,好好聊了聊。事实上,从表面上看,我们看到他们做得很好,而且他们通常没有太多事情要做。我吹牛聊天,其实人家也付出不少。
在本文章中,我将简要梳理和介绍正确的采集网站项目的流程。我可以告诉你的是,它实际上并没有那么简单,如果它真的那么简单的话。我们都会效仿吗?我们的效率和建站速度肯定会超过大部分用户,为什么不做呢?这意味着有一定的门槛。
文章目录隐藏
带权重的域名 一、
编号 二、 优质内容
编号 三、 推广权重
循环 四、 效果
带权重的域名 一、
做网站的朋友应该知道,如果我们新注册一个域名,至少要3到6个月才能有一定的权重。除非您的内容绝对有价值,否则您开始更新的任何内容都需要很长时间才能被搜索引擎识别。这称为累积权重,有些 网站 甚至需要数年才能获得一定的权重。
在这里我们可以看到有很多站长是采集网站,他们都购买了优质的权威域名。有的直接买别人的网站,有的买旧域名,抢一些过期域名。之前,老姜还专门针对这些朋友的需求,专门写了几篇关于老域名抢注方法的文章。其实他们是想买一些老域名来缩短域名评估期。
1、老域名在哪里买,买老域名要注意什么
2、Dynadot域名注册商抢购过期域名及提高成功率的方法
3、实用老域名挖掘与GoDaddy商户老域名购买图文教程方法
编号 二、 优质内容
看到标题,很多朋友肯定会想说,这不是废话吗,如果是优质内容,我绝对不会去采集内容。这里的优质内容不是让我们文章写我们的每一篇文章原创。取而代之的是,我们在选择内容的时候需要垂直,在选择内容的时候我们必须是流量词。比如之前有个采集老江部落网站技术内容的朋友。事实上,技术含量的用户群很小,词库中也无法生成任何单词,所以流量基本上很小。
如果我们选择像电影和游戏这样的内容,一旦被收录发布,很容易带来流量。因为以后我们做网站不管是自己卖还是做广告,都需要流量,有流量的话,销售的单价比较高。当然,买家也需要在站长工具中查看你的网站数据信息。如果选择没有词汇的内容,基本上很难卖。
而我们在制作内容的时候,无论是你原创、采集、复制还是其他,都必须进行二次加工。直接复制很难成功。毕竟,你的 网站 质量肯定不如来自原创来源的内容。
编号 三、 推广权重
我们做的任何网站自然肯定不会带来权重和流量,还是需要推广的。根据网友的反馈,即使是采集网站,也会像普通的网站一开始更新内容和推广,只会得到很多当它们达到一定的重量值和效果时。采集。如果你开始很多采集,你网站如果你没有开始可能会被直接惩罚。
同时,在我们后续的网站操作中,有网友告诉他们每个月要花几十万元购买人脉、软文等资源,增加软文的权重。 @网站。我们看到还是认为我们不这样做?不像那样。
循环 四、 效果
我们很多人都认为采集网站很容易做,是的,做起来很简单,但是还是需要一定的时间才能产生效果。比如我们前几天看了几个网站,效果不错,也是采集或者综合内容。但是,其他人需要半年到一年的时间才能见效。所以我们在做采集网站这个项目的时候,也需要考虑时间段,不可能几个月就见效。
就算几个月有效,当你卖网站时,买家会分析你的网站是否被骗,如果是,你的价格不会高或者对方是不要. 当然,我们通过以上一系列流程进行操作,几个月后不会见效,也不应该有任何投机行为。
最后但同样重要的是,我们在采集网站时也需要注意版权,有些网站声明内容版权,你不能去采集或复制,目前我们公司的版权意识也在加强,不少站长都收到了律师的来信。 查看全部
网站内容采集(网站采集项目是不是很简单,如果真的这么简单!)
相信很多朋友都操作过采集网站项目,有的手动复制,有的使用采集软件和插件快速获取内容。即使搜索引擎推出各种算法来处理采集垃圾邮件网站,也有人做得更好,当然,这些肯定没有我们想象的那么简单。不只是我们需要构建网站,然后手动复制,软件采集,或者伪原创等等,包括我们看到群里很多网友都在做真的很好。网站 已经卖到几万了,很羡慕。
其实我们看到的网站采集项目是不是很简单呢?如果只是简单的模仿、复制,甚至是软件采集,你会不会发现效果不明显,甚至根本没有收录。这有什么问题?前段时间,老姜也找了几位献身采集网站的朋友,好好聊了聊。事实上,从表面上看,我们看到他们做得很好,而且他们通常没有太多事情要做。我吹牛聊天,其实人家也付出不少。
在本文章中,我将简要梳理和介绍正确的采集网站项目的流程。我可以告诉你的是,它实际上并没有那么简单,如果它真的那么简单的话。我们都会效仿吗?我们的效率和建站速度肯定会超过大部分用户,为什么不做呢?这意味着有一定的门槛。
文章目录隐藏
带权重的域名 一、
编号 二、 优质内容
编号 三、 推广权重
循环 四、 效果
带权重的域名 一、
做网站的朋友应该知道,如果我们新注册一个域名,至少要3到6个月才能有一定的权重。除非您的内容绝对有价值,否则您开始更新的任何内容都需要很长时间才能被搜索引擎识别。这称为累积权重,有些 网站 甚至需要数年才能获得一定的权重。
在这里我们可以看到有很多站长是采集网站,他们都购买了优质的权威域名。有的直接买别人的网站,有的买旧域名,抢一些过期域名。之前,老姜还专门针对这些朋友的需求,专门写了几篇关于老域名抢注方法的文章。其实他们是想买一些老域名来缩短域名评估期。
1、老域名在哪里买,买老域名要注意什么
2、Dynadot域名注册商抢购过期域名及提高成功率的方法
3、实用老域名挖掘与GoDaddy商户老域名购买图文教程方法
编号 二、 优质内容
看到标题,很多朋友肯定会想说,这不是废话吗,如果是优质内容,我绝对不会去采集内容。这里的优质内容不是让我们文章写我们的每一篇文章原创。取而代之的是,我们在选择内容的时候需要垂直,在选择内容的时候我们必须是流量词。比如之前有个采集老江部落网站技术内容的朋友。事实上,技术含量的用户群很小,词库中也无法生成任何单词,所以流量基本上很小。
如果我们选择像电影和游戏这样的内容,一旦被收录发布,很容易带来流量。因为以后我们做网站不管是自己卖还是做广告,都需要流量,有流量的话,销售的单价比较高。当然,买家也需要在站长工具中查看你的网站数据信息。如果选择没有词汇的内容,基本上很难卖。
而我们在制作内容的时候,无论是你原创、采集、复制还是其他,都必须进行二次加工。直接复制很难成功。毕竟,你的 网站 质量肯定不如来自原创来源的内容。
编号 三、 推广权重
我们做的任何网站自然肯定不会带来权重和流量,还是需要推广的。根据网友的反馈,即使是采集网站,也会像普通的网站一开始更新内容和推广,只会得到很多当它们达到一定的重量值和效果时。采集。如果你开始很多采集,你网站如果你没有开始可能会被直接惩罚。
同时,在我们后续的网站操作中,有网友告诉他们每个月要花几十万元购买人脉、软文等资源,增加软文的权重。 @网站。我们看到还是认为我们不这样做?不像那样。
循环 四、 效果
我们很多人都认为采集网站很容易做,是的,做起来很简单,但是还是需要一定的时间才能产生效果。比如我们前几天看了几个网站,效果不错,也是采集或者综合内容。但是,其他人需要半年到一年的时间才能见效。所以我们在做采集网站这个项目的时候,也需要考虑时间段,不可能几个月就见效。
就算几个月有效,当你卖网站时,买家会分析你的网站是否被骗,如果是,你的价格不会高或者对方是不要. 当然,我们通过以上一系列流程进行操作,几个月后不会见效,也不应该有任何投机行为。
最后但同样重要的是,我们在采集网站时也需要注意版权,有些网站声明内容版权,你不能去采集或复制,目前我们公司的版权意识也在加强,不少站长都收到了律师的来信。
网站内容采集(当我们网站建设成功之后,第一个面临的重要问题(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-18 15:13
网站构建成功后,我们面临的第一个重要问题就是丰富网站的内容,因为只有一个网站的内容越丰富,才能让网站有吸引力权力更高,但对于草根站长来说,一个人创作原创内容显然是不现实的,会耗费站长巨大的精力,短时间内也难以完成。但是,我们的网站建设成功后,不可能再等几个月甚至几年的时间让我们挥霍。我们需要能够在相对较短的时间内为 网站 产生一定的流量。.
但遗憾的是,目前很多站长朋友都害怕内容采集,因为内容采集现在有害无益。采集 的内容将使 网站 面临降级和处罚的风险。所以,很多站长朋友都在硬着头皮建设原创的内容,但即便如此,网站的排名和流量也没有提升。那么网站在操作过程中还能做到采集吗?
笔者认为采集的内容还是可行的,因为采集的内容并不是百害而无一利。其实内容采集的好处还是很多的,至少有以下几个兴趣。
一是可以在短时间内丰富网站的内容,让百度蜘蛛正常遍历一个网站,还可以让用户登录到网站,可以看到一些内容,虽然这个内容比较老,但是总比没有内容给用户看要好很多。
二、内容采集可以快速获取本网站的最新相关内容。因为采集的内容可以基于网站的关键词的内容和相关栏目采集的内容,而这些内容可以是最新鲜的内容,所以用户浏览网站,也可以快速获取相关内容,无需通过搜索引擎再次搜索,一定程度上提升了网站的用户体验。
当然,采集内容的弊端还是很明显的,尤其是抄袭采集和大规模采集会对网站造成不良影响,所以作为站长,你必须掌握正确的采集方法,才能充分发挥内容采集的优势。下面我们来详细分析一下正确的采集方法。
首先,优先考虑 采集 内容。也就是说,选择与网站相关的内容,尽量新鲜。如果太陈旧了,尤其是新闻内容,陈旧的内容不需要采集,但是对于技术帖,那么就能够妥妥的采集了,因为这些技术帖对于很多新人都有很好的帮助作用。
那么 采集 的内容应该适当地改变标题。这里的标题更改不是要采集人做头条党,而是根据内容主题更改相应的标题。比如原标题是“减肥产品安全吗”,可以改成“减肥产品安全吗?对身体好吗?” 等,文字内容不同,但表达的内涵是一样的,让采集的内容标题和内容思想一一对应,杜绝了卖狗肉内容的发生.
最后就是适当调整内容。这里的内容调整不需要简单的段落替换,也不需要使用伪原创替换同义词或同义词。这样的替换只会使内容混乱,用户的阅读体验会大打折扣。而现在百度已经严厉打击了这样的伪原创内容,所以网站的优化效果会产生严重的负面影响。在调整内容的时候,可以适当的改写,尤其是首尾两段,需要改写,然后适当添加相应的图片,可以有效提高内容的质量,也可以为百度蜘蛛上诉产生更好的效果。
<p>总而言之,网站内容采集这个工作根本不需要打死。其实只需要对传统粗略的采集进行适当的优化,改成细化的采集即可,虽然采集的时间会比较长,但比 查看全部
网站内容采集(当我们网站建设成功之后,第一个面临的重要问题(图))
网站构建成功后,我们面临的第一个重要问题就是丰富网站的内容,因为只有一个网站的内容越丰富,才能让网站有吸引力权力更高,但对于草根站长来说,一个人创作原创内容显然是不现实的,会耗费站长巨大的精力,短时间内也难以完成。但是,我们的网站建设成功后,不可能再等几个月甚至几年的时间让我们挥霍。我们需要能够在相对较短的时间内为 网站 产生一定的流量。.
但遗憾的是,目前很多站长朋友都害怕内容采集,因为内容采集现在有害无益。采集 的内容将使 网站 面临降级和处罚的风险。所以,很多站长朋友都在硬着头皮建设原创的内容,但即便如此,网站的排名和流量也没有提升。那么网站在操作过程中还能做到采集吗?
笔者认为采集的内容还是可行的,因为采集的内容并不是百害而无一利。其实内容采集的好处还是很多的,至少有以下几个兴趣。
一是可以在短时间内丰富网站的内容,让百度蜘蛛正常遍历一个网站,还可以让用户登录到网站,可以看到一些内容,虽然这个内容比较老,但是总比没有内容给用户看要好很多。
二、内容采集可以快速获取本网站的最新相关内容。因为采集的内容可以基于网站的关键词的内容和相关栏目采集的内容,而这些内容可以是最新鲜的内容,所以用户浏览网站,也可以快速获取相关内容,无需通过搜索引擎再次搜索,一定程度上提升了网站的用户体验。
当然,采集内容的弊端还是很明显的,尤其是抄袭采集和大规模采集会对网站造成不良影响,所以作为站长,你必须掌握正确的采集方法,才能充分发挥内容采集的优势。下面我们来详细分析一下正确的采集方法。
首先,优先考虑 采集 内容。也就是说,选择与网站相关的内容,尽量新鲜。如果太陈旧了,尤其是新闻内容,陈旧的内容不需要采集,但是对于技术帖,那么就能够妥妥的采集了,因为这些技术帖对于很多新人都有很好的帮助作用。
那么 采集 的内容应该适当地改变标题。这里的标题更改不是要采集人做头条党,而是根据内容主题更改相应的标题。比如原标题是“减肥产品安全吗”,可以改成“减肥产品安全吗?对身体好吗?” 等,文字内容不同,但表达的内涵是一样的,让采集的内容标题和内容思想一一对应,杜绝了卖狗肉内容的发生.
最后就是适当调整内容。这里的内容调整不需要简单的段落替换,也不需要使用伪原创替换同义词或同义词。这样的替换只会使内容混乱,用户的阅读体验会大打折扣。而现在百度已经严厉打击了这样的伪原创内容,所以网站的优化效果会产生严重的负面影响。在调整内容的时候,可以适当的改写,尤其是首尾两段,需要改写,然后适当添加相应的图片,可以有效提高内容的质量,也可以为百度蜘蛛上诉产生更好的效果。
<p>总而言之,网站内容采集这个工作根本不需要打死。其实只需要对传统粗略的采集进行适当的优化,改成细化的采集即可,虽然采集的时间会比较长,但比
网站内容采集( WordpressWordpress采集插件解决网站收录问题的几种方法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-17 15:13
WordpressWordpress采集插件解决网站收录问题的几种方法!)
Wordpress采集插件是为了方便需要采集建站的wordpresscms站长。现在建网站越来越方便了。只需获得一个开源程序和一个虚拟主机,您就可以使用它。网站易于构建。有了网站,肯定有内容要填,那么问题来了,网站内容已经成为网站可持续发展的老大难问题,所以,很多站长都会使用Wordpress采集 采集文章 插件。既然提到了Wordpress采集插件这个词,显然不是复制粘贴一两篇文章那么简单。随着程序越来越多样化,采集插件的出现让采集内容的工作可以批量自动化,
Wordpress采集插件是一个好的采集网站的前提。前提是内容处理一定要做好。内容处理离不开搜索引擎已有的内容。搜索引擎上的内容处理是很多采集站长最头疼的事情之一;采集 一个网站离不开采集这个工具。Wordpress采集插件是网站内容采集处理工具,是采集站的重中之重!
wordpress 采集插件,网站完成内容构建后如何解决采集的收录问题。第一个一、修改模板,搜索引擎更喜欢唯一的网站,如果你的网站模板和很多网站一样,就会失去优势。所以你下载喜欢的模板后,一定要进行适当的修改,让你的网站模板在搜索引擎眼中是独一无二的。二、的内容修改,采集的内容必须修改。我通常的做法是修改 文章 标题。如果你有更多的时间,你还可以修改第一段和最后一段的内容,然后改变图片的大小和ALT属性。
第一个三、侧重于外部链接的构建,因为网站的大部分内容属于采集,失去了原创的优势,所以只能使用外部链接链接提升网站的整体权重,外链的建设可谓是采集站的重中之重。建议30%的外部链接导入首页(锚文本链接、超链接、纯文本链接),其余大部分导入已开发的栏目页和较热的长尾关键词页。通过这三种方法,基本可以解决采集站的收录问题。采集 不是目的,采集 只是一种手段,如果使用不当,就有可能失去你的力量给你的<
wordpress采集的插件数量级比较多,采集之后还有排名,更多的是采集不同的来源,比如:你从新媒体获取内容< @采集,而事实上,它可能是搜索引擎的全新内容。采集行业比较分散,不同行业的内容采集有一定的内容。此外,独特的页面结构、合理的聚合、清晰的结构可以快速解决用户的搜索需求。页面访问速度好,色彩丰富,元素组合有利于用户体验,如:短视频和音频解说等。页面上有些元素可以让用户受益。合理控制采集音量的比例,而整个网站的内容输出依然以符合搜索需求的优质内容为主。这也是使用Wordpress 采集 插件后网站 需要改进的地方。改进后,网站的收录的排名权重可以提高更多更快。 查看全部
网站内容采集(
WordpressWordpress采集插件解决网站收录问题的几种方法!)
Wordpress采集插件是为了方便需要采集建站的wordpresscms站长。现在建网站越来越方便了。只需获得一个开源程序和一个虚拟主机,您就可以使用它。网站易于构建。有了网站,肯定有内容要填,那么问题来了,网站内容已经成为网站可持续发展的老大难问题,所以,很多站长都会使用Wordpress采集 采集文章 插件。既然提到了Wordpress采集插件这个词,显然不是复制粘贴一两篇文章那么简单。随着程序越来越多样化,采集插件的出现让采集内容的工作可以批量自动化,
Wordpress采集插件是一个好的采集网站的前提。前提是内容处理一定要做好。内容处理离不开搜索引擎已有的内容。搜索引擎上的内容处理是很多采集站长最头疼的事情之一;采集 一个网站离不开采集这个工具。Wordpress采集插件是网站内容采集处理工具,是采集站的重中之重!
wordpress 采集插件,网站完成内容构建后如何解决采集的收录问题。第一个一、修改模板,搜索引擎更喜欢唯一的网站,如果你的网站模板和很多网站一样,就会失去优势。所以你下载喜欢的模板后,一定要进行适当的修改,让你的网站模板在搜索引擎眼中是独一无二的。二、的内容修改,采集的内容必须修改。我通常的做法是修改 文章 标题。如果你有更多的时间,你还可以修改第一段和最后一段的内容,然后改变图片的大小和ALT属性。
第一个三、侧重于外部链接的构建,因为网站的大部分内容属于采集,失去了原创的优势,所以只能使用外部链接链接提升网站的整体权重,外链的建设可谓是采集站的重中之重。建议30%的外部链接导入首页(锚文本链接、超链接、纯文本链接),其余大部分导入已开发的栏目页和较热的长尾关键词页。通过这三种方法,基本可以解决采集站的收录问题。采集 不是目的,采集 只是一种手段,如果使用不当,就有可能失去你的力量给你的<
wordpress采集的插件数量级比较多,采集之后还有排名,更多的是采集不同的来源,比如:你从新媒体获取内容< @采集,而事实上,它可能是搜索引擎的全新内容。采集行业比较分散,不同行业的内容采集有一定的内容。此外,独特的页面结构、合理的聚合、清晰的结构可以快速解决用户的搜索需求。页面访问速度好,色彩丰富,元素组合有利于用户体验,如:短视频和音频解说等。页面上有些元素可以让用户受益。合理控制采集音量的比例,而整个网站的内容输出依然以符合搜索需求的优质内容为主。这也是使用Wordpress 采集 插件后网站 需要改进的地方。改进后,网站的收录的排名权重可以提高更多更快。
网站内容采集( 标题一样与原标题完全不相同,道理很简单!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-02-17 13:15
标题一样与原标题完全不相同,道理很简单!)
网站优化应该如何正确使用采集优化后的内容?
首先,采集content 对象是特殊的。找别人刚刚发布的内容作为采集的目标很好,在被太多人转载之前采集过来,但内容的前提是先进、新鲜并且具有代表性,而不是一些陈词滥调的话题,否则给用户的口味是一样的,根本就一文不值。既然是采集内容,自然比原创简单很多,也不需要花太多时间去编辑内容。毕竟采集的内容没有原创的直接作用,所以需要同时多找几个采集的内容来弥补蜘蛛。
其次,采集content 没有采集title。大家都知道,当你阅读一篇文章文章时,首先要看的是标题。对于网站优化的搜索引擎,标题也有一定的权重。采集的内容有一定的长度,不能改太多,但是标题只有几个字,修改起来比较容易,所以标题修改是必须的,而且比较好将标题更改为与原创标题完全不同。原因很简单。当你看到一个文章标题相同,实质内容完全不同的时候,会给读者一些误解,认为两者的内容是一样的。相反,即使内容相同,标题也完全不同。不同的,
然后,对内容进行适当的调整。我试过采集给我的网站的站长,细心的人难免会发现直接复制的内容还是有格式问题的,因为一些精明的原创用户正在努力防止如果内容为采集,通常会在内容中添加一些隐藏的格式,甚至在图片的ALT信息中都会标明版权。网站的危险不言而喻。因此,采集中的内容必须进行格式化,英文格式的标点符号必须进行转换。另外,可以在内容中加入一些图片,让内容更加丰富。如果内容本身有图片,不要直接复制,保存后重新上传到网站,添加自己的ALT信息制作采集的内容
总之,网站采集的内容也不是完全没用,关键看你怎么用采集,只要能灵活使用采集的内容,就可以带网站有一定的好处,但是站长需要注意一定要掌握一定的采集方法。 查看全部
网站内容采集(
标题一样与原标题完全不相同,道理很简单!)
网站优化应该如何正确使用采集优化后的内容?
首先,采集content 对象是特殊的。找别人刚刚发布的内容作为采集的目标很好,在被太多人转载之前采集过来,但内容的前提是先进、新鲜并且具有代表性,而不是一些陈词滥调的话题,否则给用户的口味是一样的,根本就一文不值。既然是采集内容,自然比原创简单很多,也不需要花太多时间去编辑内容。毕竟采集的内容没有原创的直接作用,所以需要同时多找几个采集的内容来弥补蜘蛛。
其次,采集content 没有采集title。大家都知道,当你阅读一篇文章文章时,首先要看的是标题。对于网站优化的搜索引擎,标题也有一定的权重。采集的内容有一定的长度,不能改太多,但是标题只有几个字,修改起来比较容易,所以标题修改是必须的,而且比较好将标题更改为与原创标题完全不同。原因很简单。当你看到一个文章标题相同,实质内容完全不同的时候,会给读者一些误解,认为两者的内容是一样的。相反,即使内容相同,标题也完全不同。不同的,
然后,对内容进行适当的调整。我试过采集给我的网站的站长,细心的人难免会发现直接复制的内容还是有格式问题的,因为一些精明的原创用户正在努力防止如果内容为采集,通常会在内容中添加一些隐藏的格式,甚至在图片的ALT信息中都会标明版权。网站的危险不言而喻。因此,采集中的内容必须进行格式化,英文格式的标点符号必须进行转换。另外,可以在内容中加入一些图片,让内容更加丰富。如果内容本身有图片,不要直接复制,保存后重新上传到网站,添加自己的ALT信息制作采集的内容
总之,网站采集的内容也不是完全没用,关键看你怎么用采集,只要能灵活使用采集的内容,就可以带网站有一定的好处,但是站长需要注意一定要掌握一定的采集方法。
网站内容采集(如何正确使用采集内容内容?重视原创内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-02-15 23:03
在网站的优化圈里,站长们都知道搜索引擎看重原创的内容,但即使是最优秀的SEOer在面对长期的内容原创时也会面临一定的困难,不仅限于资源和写作能力也有局限性,因此,整个网站,包括每个部分的内容,都离不开采集。
但是搜索引擎强调采集内容对网站意义不大,尤其是出于优化目的,甚至采集内容也会被当作垃圾邮件,导致网站' s 负担其实并非如此。即使采集的内容对网站有一定的风险,只要采集合理,还是有用的,同时可以减少原创@ >不用担心,得到同样的优化效果。那么,如何正确使用 采集 内容呢?
首先,采集content 对象是特殊的。最好找别人刚刚发布的内容作为采集目标,在被太多人转载之前采集过来,但内容的前提是要超前,新鲜而有代表性,不是一些老套的话题,否则对用户来说,就跟打蜡一样,一文不值。既然是采集内容,自然比原创简单很多,也不需要花太多时间去编辑内容。毕竟采集的内容没有原创的直接作用,所以需要同时多找几个采集的内容来弥补蜘蛛。
其次,采集content 没有采集title。大家都知道,阅读一篇文章文章首先要看的是标题。对于网站优化的搜索引擎,标题也有一定的权重。采集的内容是有一定长度的,不能改太多,但是标题只有几个字,而且修改起来比较容易,所以标题修改是必要的,最好是更改标题。它与原标题完全不同。原因很简单。当你看到一个文章标题相同,内容完全不同的时候,会给读者一些误解,认为两者的内容是一样的。相反,即使内容相同,标题也完全不同,
最后,对内容进行适当的调整。我试过采集给我的网站的站长,细心的人难免会发现直接复制的内容还是有格式问题的,因为一些精明的原创用户正在努力防止如果内容为采集,通常会在内容中添加一些隐藏格式,甚至在图片的ALT信息中都标明了版权。如果不注意,自然会被搜索引擎认定为抄袭。网站的危险不言而喻。因此,采集中的内容必须进行格式化,英文格式的标点符号必须进行转换。另外,可以在内容中加入一些图片,让内容更加丰富。如果内容本身有图片,请勿直接复制,
总之,网站采集的内容也不是完全没用,关键看你怎么用采集,只要能灵活使用采集的内容,就可以带网站有一定的好处,但是站长需要注意一定要掌握一定的采集方法。 查看全部
网站内容采集(如何正确使用采集内容内容?重视原创内容?)
在网站的优化圈里,站长们都知道搜索引擎看重原创的内容,但即使是最优秀的SEOer在面对长期的内容原创时也会面临一定的困难,不仅限于资源和写作能力也有局限性,因此,整个网站,包括每个部分的内容,都离不开采集。
但是搜索引擎强调采集内容对网站意义不大,尤其是出于优化目的,甚至采集内容也会被当作垃圾邮件,导致网站' s 负担其实并非如此。即使采集的内容对网站有一定的风险,只要采集合理,还是有用的,同时可以减少原创@ >不用担心,得到同样的优化效果。那么,如何正确使用 采集 内容呢?
首先,采集content 对象是特殊的。最好找别人刚刚发布的内容作为采集目标,在被太多人转载之前采集过来,但内容的前提是要超前,新鲜而有代表性,不是一些老套的话题,否则对用户来说,就跟打蜡一样,一文不值。既然是采集内容,自然比原创简单很多,也不需要花太多时间去编辑内容。毕竟采集的内容没有原创的直接作用,所以需要同时多找几个采集的内容来弥补蜘蛛。
其次,采集content 没有采集title。大家都知道,阅读一篇文章文章首先要看的是标题。对于网站优化的搜索引擎,标题也有一定的权重。采集的内容是有一定长度的,不能改太多,但是标题只有几个字,而且修改起来比较容易,所以标题修改是必要的,最好是更改标题。它与原标题完全不同。原因很简单。当你看到一个文章标题相同,内容完全不同的时候,会给读者一些误解,认为两者的内容是一样的。相反,即使内容相同,标题也完全不同,
最后,对内容进行适当的调整。我试过采集给我的网站的站长,细心的人难免会发现直接复制的内容还是有格式问题的,因为一些精明的原创用户正在努力防止如果内容为采集,通常会在内容中添加一些隐藏格式,甚至在图片的ALT信息中都标明了版权。如果不注意,自然会被搜索引擎认定为抄袭。网站的危险不言而喻。因此,采集中的内容必须进行格式化,英文格式的标点符号必须进行转换。另外,可以在内容中加入一些图片,让内容更加丰富。如果内容本身有图片,请勿直接复制,
总之,网站采集的内容也不是完全没用,关键看你怎么用采集,只要能灵活使用采集的内容,就可以带网站有一定的好处,但是站长需要注意一定要掌握一定的采集方法。
网站内容采集(引擎推出飓风算法全文如下百度预计流量权重百度(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-02-15 14:27
seo 采集 数据怎么结束,看流量如果流量很低,即使排名很高,权重也不会积累很多,但是可以加起来规则权重百度权重没有百度权重百度估计流量权重百度;预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 权重百度预估流量权重 百度估算流量权重 百度估算流量权重 百度估算流量高于百度权重是为优化网站排名而推出的站长工具!
seo采集数据怎么样,你的统计,你有没有很长时间不关心你的流量来自哪些搜索?这是站长们经常遇到也经常不赞成的事情,但在实践中我们是非常清晰和好的页面;停留时间有利于增加搜索引擎的信任度。如果我们不关心用户,高跳出率很容易影响下一次搜索引擎给出的排名估计。表面停留时间有利于增加搜索引擎的信任度。如果我们不关心用户,高跳出率很容易影响下次搜索引擎给出的排名估计。
seo 采集数据应该如何基于用户体验?用户体验应该以网站服务器的相应速度为准。在优化过程中,内容和外链是积累网站权重的重要工具!同时,段落也是造成降级的重要因素。网站优化心态很重要。必须从用户的角度考虑内容和外部链接。始终保持“从不缺乏”的原则,稳步提升,实现这些网站基本避免跌倒。重要的是,无论是内容还是外链,都必须站在用户的角度考虑,始终保持“宁可缺少,不宜过度”的原则。实现这些网站 基本上可以避免降权的问题。由于技术和思想等原因,人工智能理论出现得较早!
如何seo采集Data Theory 取消回复NamerequiredAdditional URLOptional◎欢迎参与讨论请在此发表您的意见交流您的意见请填写您的广告代码或删除此行文字日期百度搜索引擎;推出飓风算法 全文如下 百度推出飓风算法打击不良采集百度搜索近期推出飓风算法打击不良主要内容采集网站同时百度!引擎 飓风算法上线全文如下 百度上线飓风算法打击不良采集百度搜索近期上线飓风算法打击不良主要内容采集网站同时,百度搜索将从收录的不良采集链接库中彻底剔除,为优质的原创内容提供更多展示机会,推动搜索生态发展。飓风算法会例行产生惩罚数据,并根据情况随时调整迭代反映!
seo如何采集数据化后,可以大大增加向目标客户展示产品或服务的机会,从而增加影响力,提高产品的知名度。例如,如果用户正在搜索产品,则应该是 网站 才能出现;现在前几个可以获得更多的用户点击,这些用户可能是竞争对手、潜在客户或需要相关信息的人,沟通可以赚更多;当用户搜索时,网站可以出现在前几个地方,可以获得更多的用户点击,而这些用户可能是竞争对手、潜在客户或相关信息需求者。广泛传播可以让更多人关注您的信息或产品并与用户互动。 查看全部
网站内容采集(引擎推出飓风算法全文如下百度预计流量权重百度(组图))
seo 采集 数据怎么结束,看流量如果流量很低,即使排名很高,权重也不会积累很多,但是可以加起来规则权重百度权重没有百度权重百度估计流量权重百度;预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 百度预估流量权重 权重百度预估流量权重 百度估算流量权重 百度估算流量权重 百度估算流量高于百度权重是为优化网站排名而推出的站长工具!
seo采集数据怎么样,你的统计,你有没有很长时间不关心你的流量来自哪些搜索?这是站长们经常遇到也经常不赞成的事情,但在实践中我们是非常清晰和好的页面;停留时间有利于增加搜索引擎的信任度。如果我们不关心用户,高跳出率很容易影响下一次搜索引擎给出的排名估计。表面停留时间有利于增加搜索引擎的信任度。如果我们不关心用户,高跳出率很容易影响下次搜索引擎给出的排名估计。
seo 采集数据应该如何基于用户体验?用户体验应该以网站服务器的相应速度为准。在优化过程中,内容和外链是积累网站权重的重要工具!同时,段落也是造成降级的重要因素。网站优化心态很重要。必须从用户的角度考虑内容和外部链接。始终保持“从不缺乏”的原则,稳步提升,实现这些网站基本避免跌倒。重要的是,无论是内容还是外链,都必须站在用户的角度考虑,始终保持“宁可缺少,不宜过度”的原则。实现这些网站 基本上可以避免降权的问题。由于技术和思想等原因,人工智能理论出现得较早!
如何seo采集Data Theory 取消回复NamerequiredAdditional URLOptional◎欢迎参与讨论请在此发表您的意见交流您的意见请填写您的广告代码或删除此行文字日期百度搜索引擎;推出飓风算法 全文如下 百度推出飓风算法打击不良采集百度搜索近期推出飓风算法打击不良主要内容采集网站同时百度!引擎 飓风算法上线全文如下 百度上线飓风算法打击不良采集百度搜索近期上线飓风算法打击不良主要内容采集网站同时,百度搜索将从收录的不良采集链接库中彻底剔除,为优质的原创内容提供更多展示机会,推动搜索生态发展。飓风算法会例行产生惩罚数据,并根据情况随时调整迭代反映!
seo如何采集数据化后,可以大大增加向目标客户展示产品或服务的机会,从而增加影响力,提高产品的知名度。例如,如果用户正在搜索产品,则应该是 网站 才能出现;现在前几个可以获得更多的用户点击,这些用户可能是竞争对手、潜在客户或需要相关信息的人,沟通可以赚更多;当用户搜索时,网站可以出现在前几个地方,可以获得更多的用户点击,而这些用户可能是竞争对手、潜在客户或相关信息需求者。广泛传播可以让更多人关注您的信息或产品并与用户互动。
网站内容采集(学习SEO技术不仅仅是要学会怎么去伪原创、去优化关键字)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-02-14 21:01
学习SEO技巧,不仅是学习伪原创,优化关键词排名,还要采集竞争对手数据。并学习使用这些信息作为参考来优化您的网站。
那么,新站长如何采集他们想要分析的数据呢?以下是我采集数据的一点经验:
问题一:如何采集符合要求的数据
在采集符合条件的网站时,我使用以下方法:
1、 蜘蛛搜索方法
1):首先进入导航网站查找相关站点,逐一查找符合要求的站点;
2):其次,找到符合要求的网站后,再从他们的友情链接中找到符合要求的网站;
3):最后,在第二个符合条件的站点继续上述方法。
注意:前提是浏览器中安装了ALEXA统计插件。(采集目标是多少ALEXA rank)
2、传送门子频道
为什么要去门户的子频道寻找目标?因为门户网站的子频道好友链质量非常高,符合要求的网站很多。这为下一次分析节省了大量时间。
3、网站联盟
每个行业站点都有自己的联盟站群。寻找与您的网站相关联的会员站群网站 来采集数据也是一个好主意。
总结:
1):这是我用来采集数据的三种方法,虽然很费力,减少了重复的发生。
2):数据采集的过程很枯燥,关键在于持久性和强执行力。
问题二、如何分析采集到的站点
所需数据已采集完毕,接下来的工作是分析采集到的站点。段璇会解释分析一个网站需要哪些数据作为参考:
首先,我换了个角度思考:如果我是站长寻找友情链接,需要哪些数据作为参考。
第二,如何提炼这些数据,让看数据的人一眼就能明白是怎么回事。
假设:如果我做一个友好的链接,我将需要以下数据作为参考:
ALEXA排名、谷歌PR值、百度权重、雅虎外链、百度快照、百度/谷歌收录量、PR产值、关键词密度、域名注册信息、日均流量。如图所示:
总结:只有确定你从哪个角度看待采集到的数据,以及你想从数据中得到哪些有用的数据,才能在分析数据时轻松提取有价值的信息。请记住:同理心是分析数据的第一要素。
问题三、如何提取有价值的数据?
初步采集资料后,我觉得排版还是不够让人一眼看出什么是有价值的,什么是不有价值的。因为我第一次采集数据的时候是按照网站名字的字数排序的,如图:
后来我按照网站ALEXA的排名排序。只有表格美观,人们才能理解表格中数据的价值。如图所示:
说明:与第一个报告相比,改进后的报告可以让人一眼看到网站的排名,其他分析项目自然一目了然。
总结:在数据采集和分析的过程中,需要有明确的采集目标和美观易懂的表格数据,才能更清晰的了解竞争对手的基本情况。
嗯,段璇希望这篇文章能给新站长一点参考和帮助,在数据的采集和分析上。同时也欢迎各位站长互相交流。 查看全部
网站内容采集(学习SEO技术不仅仅是要学会怎么去伪原创、去优化关键字)
学习SEO技巧,不仅是学习伪原创,优化关键词排名,还要采集竞争对手数据。并学习使用这些信息作为参考来优化您的网站。
那么,新站长如何采集他们想要分析的数据呢?以下是我采集数据的一点经验:
问题一:如何采集符合要求的数据
在采集符合条件的网站时,我使用以下方法:
1、 蜘蛛搜索方法
1):首先进入导航网站查找相关站点,逐一查找符合要求的站点;
2):其次,找到符合要求的网站后,再从他们的友情链接中找到符合要求的网站;
3):最后,在第二个符合条件的站点继续上述方法。
注意:前提是浏览器中安装了ALEXA统计插件。(采集目标是多少ALEXA rank)
2、传送门子频道
为什么要去门户的子频道寻找目标?因为门户网站的子频道好友链质量非常高,符合要求的网站很多。这为下一次分析节省了大量时间。
3、网站联盟
每个行业站点都有自己的联盟站群。寻找与您的网站相关联的会员站群网站 来采集数据也是一个好主意。
总结:
1):这是我用来采集数据的三种方法,虽然很费力,减少了重复的发生。
2):数据采集的过程很枯燥,关键在于持久性和强执行力。
问题二、如何分析采集到的站点
所需数据已采集完毕,接下来的工作是分析采集到的站点。段璇会解释分析一个网站需要哪些数据作为参考:
首先,我换了个角度思考:如果我是站长寻找友情链接,需要哪些数据作为参考。
第二,如何提炼这些数据,让看数据的人一眼就能明白是怎么回事。
假设:如果我做一个友好的链接,我将需要以下数据作为参考:
ALEXA排名、谷歌PR值、百度权重、雅虎外链、百度快照、百度/谷歌收录量、PR产值、关键词密度、域名注册信息、日均流量。如图所示:
总结:只有确定你从哪个角度看待采集到的数据,以及你想从数据中得到哪些有用的数据,才能在分析数据时轻松提取有价值的信息。请记住:同理心是分析数据的第一要素。
问题三、如何提取有价值的数据?
初步采集资料后,我觉得排版还是不够让人一眼看出什么是有价值的,什么是不有价值的。因为我第一次采集数据的时候是按照网站名字的字数排序的,如图:
后来我按照网站ALEXA的排名排序。只有表格美观,人们才能理解表格中数据的价值。如图所示:
说明:与第一个报告相比,改进后的报告可以让人一眼看到网站的排名,其他分析项目自然一目了然。
总结:在数据采集和分析的过程中,需要有明确的采集目标和美观易懂的表格数据,才能更清晰的了解竞争对手的基本情况。
嗯,段璇希望这篇文章能给新站长一点参考和帮助,在数据的采集和分析上。同时也欢迎各位站长互相交流。
网站内容采集(网站采集内容容易被K站内容为王,高质量的内容不可取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-02-14 14:25
第一:容易入驻K。内容为王,优质的内容可以提供网站权重。站长不得不承认这个观点,网站有了高质量的内容,权重的增加会更快。抛开采集网站的权重,对于普通的网站,蜘蛛经常爬采集其他人的内容的频率会降低。蜘蛛喜欢新鲜,它们会存储在数据库中。当相同内容过多时,会考虑屏蔽一些相同内容,同时网站采集内容过多,蜘蛛会认为这样的网站是作弊,尤其是新站点,不要为了快速增加网站的内容而去采集内容,这种方法是不可取的。
<p>第二:内容无法控制。为了节省时间,很多站长使用采集的工具。采集 的工具也很不完善。采集 的内容不智能。@文章内容不能去掉别人的信息,所以是无意间帮助别人宣传的,别人写的 查看全部
网站内容采集(网站采集内容容易被K站内容为王,高质量的内容不可取)
第一:容易入驻K。内容为王,优质的内容可以提供网站权重。站长不得不承认这个观点,网站有了高质量的内容,权重的增加会更快。抛开采集网站的权重,对于普通的网站,蜘蛛经常爬采集其他人的内容的频率会降低。蜘蛛喜欢新鲜,它们会存储在数据库中。当相同内容过多时,会考虑屏蔽一些相同内容,同时网站采集内容过多,蜘蛛会认为这样的网站是作弊,尤其是新站点,不要为了快速增加网站的内容而去采集内容,这种方法是不可取的。
<p>第二:内容无法控制。为了节省时间,很多站长使用采集的工具。采集 的工具也很不完善。采集 的内容不智能。@文章内容不能去掉别人的信息,所以是无意间帮助别人宣传的,别人写的
网站内容采集(百度算法对网站页面的质量要求很高,是否会给网站带来什么严重影响?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-11 18:15
<p>百度算法对网站页面的质量要求很高,百度官方也明确表示将惩处垃圾网站和低质量网站。为避免网站大量采集内容被处罚,站长选择删除网站采集的内容页面,以及已经被 查看全部
网站内容采集(百度算法对网站页面的质量要求很高,是否会给网站带来什么严重影响?)
<p>百度算法对网站页面的质量要求很高,百度官方也明确表示将惩处垃圾网站和低质量网站。为避免网站大量采集内容被处罚,站长选择删除网站采集的内容页面,以及已经被

