
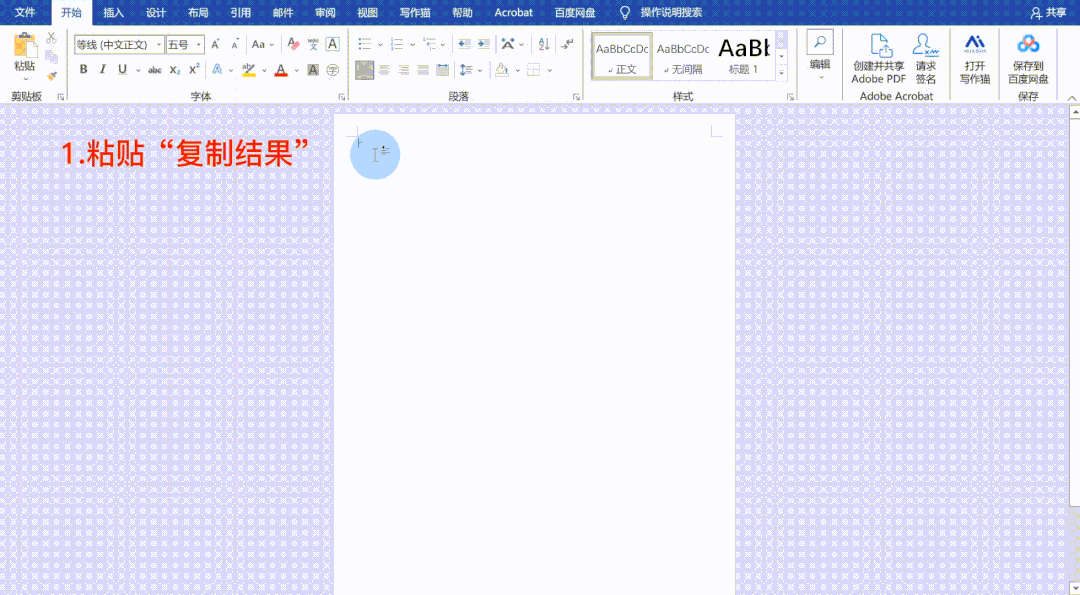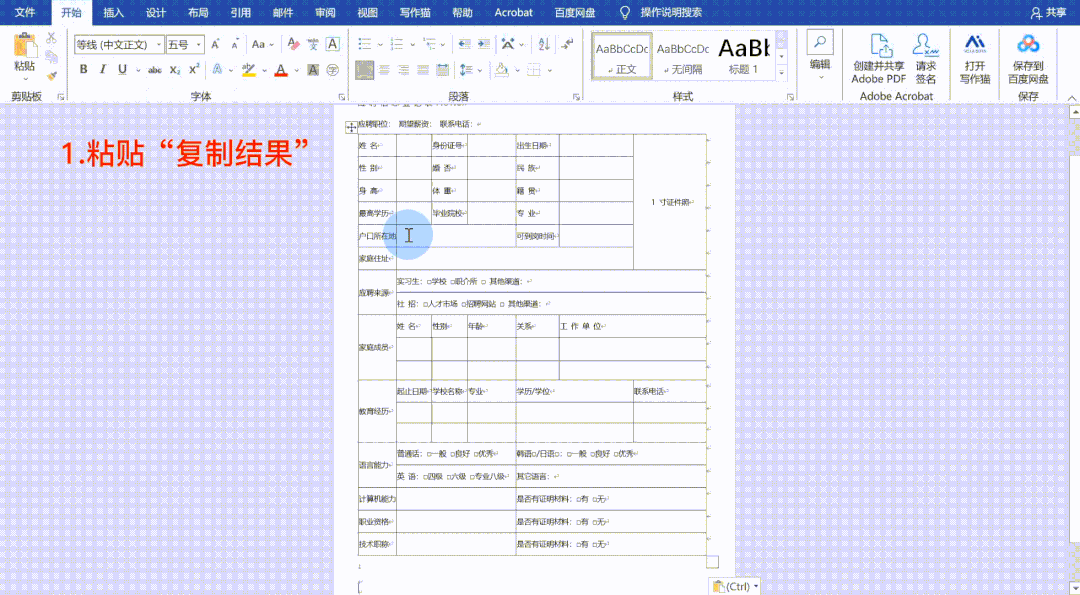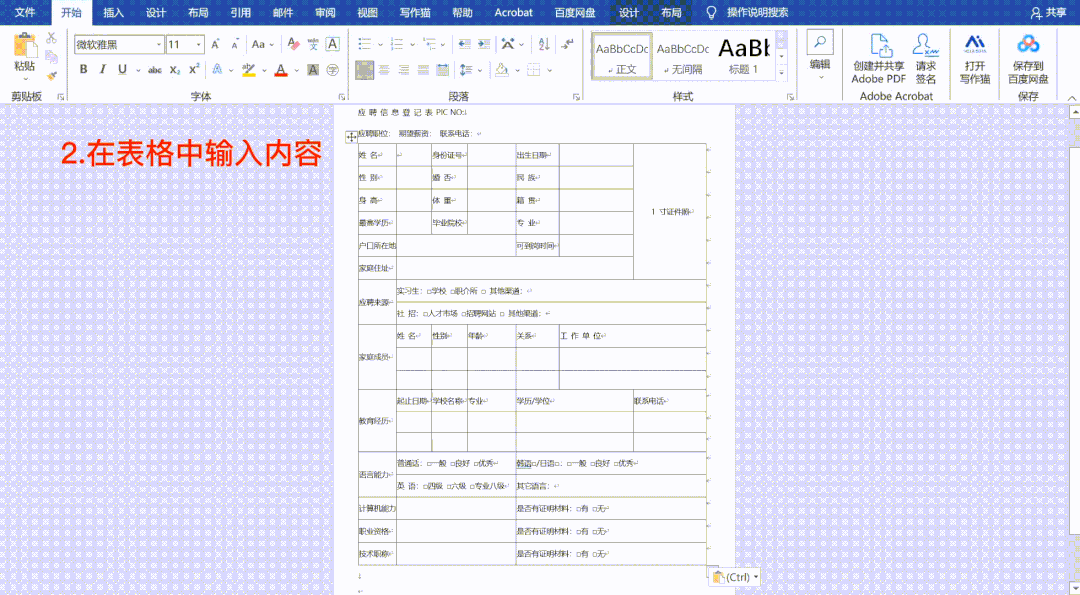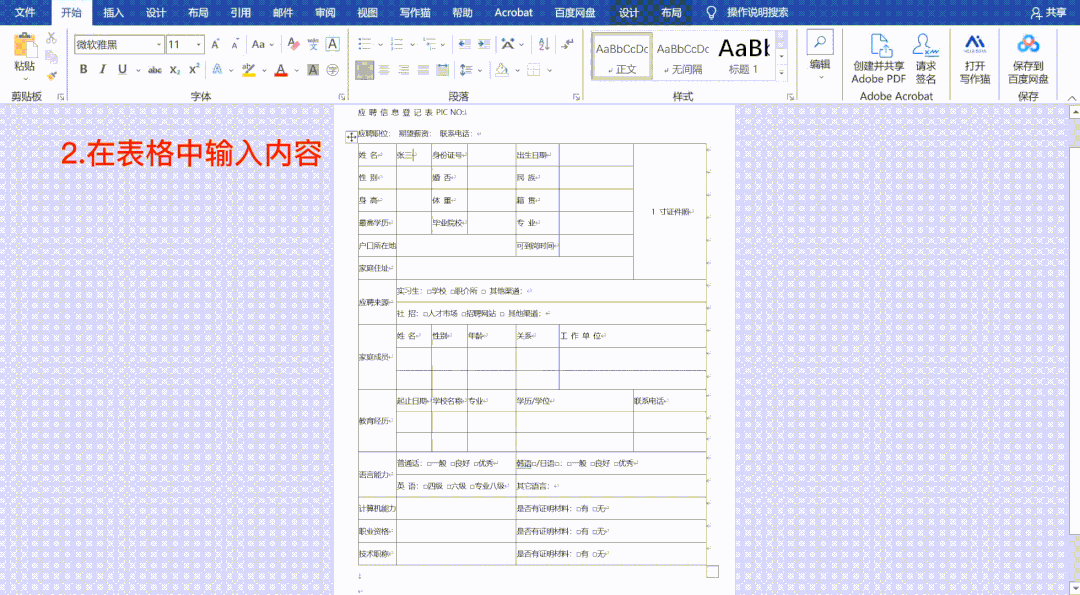
浏览器抓取网页
浏览器抓取网页(免费资源网,第11行c#获取浏览器页面内容的资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-14 11:15
免费资源网络,
private void timer1_Tick(object sender, EventArgs e)
{
lock (currentLock)
{
System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
if (_leftClick)
{
timer1.Stop();
_leftClick = false;
_lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
if (_lastDocument != null)
{
if (_getDocument)
{
_getDocument = true;
try
{
string url = _lastDocument.url;
string html = _lastDocument.documentElement.outerHTML;
string cookie = _lastDocument.cookie;
string domain = _lastDocument.domain;
var resolveParams = new ResolveParam
{
Url = new Uri(url),
Html = html,
PageCookie = cookie,
Domain = domain
};
RequetResove(resolveParams);
}
catch (Exception ex)
{
System.Windows.MessageBox.Show(ex.Message);
Console.WriteLine(ex.Message);
Console.WriteLine(ex.StackTrace);
}
}
}
else
{
new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
}
_getDocument = false;
}
else
{
_pointFrm.Left = MousePoint.X + 10;
_pointFrm.Top = MousePoint.Y + 10;
}
}
}
在第11行的GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))分解下,首先从鼠标坐标获取页面的句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
{
IntPtr handle = Win32APIsFull.WindowFromPoint(p);
if (handle != IntPtr.Zero)
{
System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
if (Win32APIsFull.GetWindowRect(handle, out rect))
{
return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
}
}
return IntPtr.Zero;
}
接下来根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
{
IntPtr result = Marshal.AllocHGlobal(4);
Object obj = null;
Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
if (Marshal.ReadInt32(result) != 0)
{
Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
}
Marshal.FreeHGlobal(result);
return obj as HTMLDocument;
}
一般原则:
向IE表单发送消息,获取一个指向IE浏览器内存块的指针(非托管),然后根据这个指针获取HTMLDocument对象。
这个方法涉及到win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
);
以上是c#从IE浏览器获取当前页面内容的详细内容。更多关于c#获取浏览器页面内容的信息,请关注其他相关文章!
免费资源网络, 查看全部
浏览器抓取网页(免费资源网,第11行c#获取浏览器页面内容的资料)
免费资源网络,
private void timer1_Tick(object sender, EventArgs e)
{
lock (currentLock)
{
System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
if (_leftClick)
{
timer1.Stop();
_leftClick = false;
_lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
if (_lastDocument != null)
{
if (_getDocument)
{
_getDocument = true;
try
{
string url = _lastDocument.url;
string html = _lastDocument.documentElement.outerHTML;
string cookie = _lastDocument.cookie;
string domain = _lastDocument.domain;
var resolveParams = new ResolveParam
{
Url = new Uri(url),
Html = html,
PageCookie = cookie,
Domain = domain
};
RequetResove(resolveParams);
}
catch (Exception ex)
{
System.Windows.MessageBox.Show(ex.Message);
Console.WriteLine(ex.Message);
Console.WriteLine(ex.StackTrace);
}
}
}
else
{
new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
}
_getDocument = false;
}
else
{
_pointFrm.Left = MousePoint.X + 10;
_pointFrm.Top = MousePoint.Y + 10;
}
}
}
在第11行的GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))分解下,首先从鼠标坐标获取页面的句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
{
IntPtr handle = Win32APIsFull.WindowFromPoint(p);
if (handle != IntPtr.Zero)
{
System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
if (Win32APIsFull.GetWindowRect(handle, out rect))
{
return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
}
}
return IntPtr.Zero;
}
接下来根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
{
IntPtr result = Marshal.AllocHGlobal(4);
Object obj = null;
Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
if (Marshal.ReadInt32(result) != 0)
{
Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
}
Marshal.FreeHGlobal(result);
return obj as HTMLDocument;
}
一般原则:

向IE表单发送消息,获取一个指向IE浏览器内存块的指针(非托管),然后根据这个指针获取HTMLDocument对象。
这个方法涉及到win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
);
以上是c#从IE浏览器获取当前页面内容的详细内容。更多关于c#获取浏览器页面内容的信息,请关注其他相关文章!
免费资源网络,
浏览器抓取网页(民间大神提取的小米浏览器很好用,你懂得吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 378 次浏览 • 2021-10-09 05:22
手机制造商的定制ROM中有一些非常有用的应用程序。还有民间大神提取的官方发布和独立安装版本。
其中,最著名的APP就是“锤子便签”,这款便签真的好用。本笔记属于官方单机版。还有一些提取的版本,比如百度云索尼定制版,不限速=_=
今天这就是民间大神提取出来的小米浏览器。不能说它很容易使用。毕竟和UC差别不大,功能也不如UC。
第一次安装会有一个“使用声明”对话框。
如果剪贴板的最后剪辑内容是“网络链接”,系统会询问您是否要打开它。
这种浏览器其实挺“UC”的,国内大部分浏览器都是设计这种UI交互的。而Chrome完全是两种风格。但单手操作更好。如果Chrome浏览器系统中没有“菜单按钮”,则必须使用Chrome自带的右上角菜单按钮。单手操作相当棘手。
这个浏览器的布局并不奇怪。
左侧屏幕上还有一个新闻聚合阅读页面。UC,QQ,都是这样。拥有一两个这样的浏览器并不奇怪。
(顶栏的文字好熟悉)
相似,不仅仅是相似。但是,在全屏阅读新闻时,搜索栏会保留。也可以看出它是一个浏览器。
软件设置不多。这只是一个很小的区别。
小米浏览器版本为8.1.6。
另外,H5网页上的视频不能离线。这与某些浏览器相差甚远。
不过保存网页的能力是值得称赞的,UC也需要一个插件。
几乎没有找到隐私浏览,只在多窗口页面的顶部找到它。字体不明显。你懂。
环顾四周,最大的优势就是RAM的占用没有UC那么大。但是差别不大。
另外,这个浏览器也没有发现任何广告,所以不排除被大神提取的时候,顺便把广告去掉了。
软件体积30M,操控还不错。Android MarshMallow 自带的浏览器安装包为37MB。
一些第三方浏览器可以使用自己的浏览器。所以可以很好的控制,甚至低于1MB。和Chrome一样独立,46MB也很正常。
这个浏览器在“捆绑浏览器”这个分类中还是比较OK的。纵观浏览器市场,似乎很不起眼。
不过,我也很高兴看到一些国际大厂的内置浏览器也“本地化”了。比如LG G5自带的浏览器。嗯,这很UC。底部导航栏什么的。
如果你想要一个主浏览器,不推荐。如果需要备胎,可以考虑。流畅度还是很OK的。 查看全部
浏览器抓取网页(民间大神提取的小米浏览器很好用,你懂得吗?)
手机制造商的定制ROM中有一些非常有用的应用程序。还有民间大神提取的官方发布和独立安装版本。
其中,最著名的APP就是“锤子便签”,这款便签真的好用。本笔记属于官方单机版。还有一些提取的版本,比如百度云索尼定制版,不限速=_=
今天这就是民间大神提取出来的小米浏览器。不能说它很容易使用。毕竟和UC差别不大,功能也不如UC。
第一次安装会有一个“使用声明”对话框。

如果剪贴板的最后剪辑内容是“网络链接”,系统会询问您是否要打开它。

这种浏览器其实挺“UC”的,国内大部分浏览器都是设计这种UI交互的。而Chrome完全是两种风格。但单手操作更好。如果Chrome浏览器系统中没有“菜单按钮”,则必须使用Chrome自带的右上角菜单按钮。单手操作相当棘手。

这个浏览器的布局并不奇怪。

左侧屏幕上还有一个新闻聚合阅读页面。UC,QQ,都是这样。拥有一两个这样的浏览器并不奇怪。
(顶栏的文字好熟悉)

相似,不仅仅是相似。但是,在全屏阅读新闻时,搜索栏会保留。也可以看出它是一个浏览器。

软件设置不多。这只是一个很小的区别。

小米浏览器版本为8.1.6。

另外,H5网页上的视频不能离线。这与某些浏览器相差甚远。


不过保存网页的能力是值得称赞的,UC也需要一个插件。

几乎没有找到隐私浏览,只在多窗口页面的顶部找到它。字体不明显。你懂。


环顾四周,最大的优势就是RAM的占用没有UC那么大。但是差别不大。
另外,这个浏览器也没有发现任何广告,所以不排除被大神提取的时候,顺便把广告去掉了。
软件体积30M,操控还不错。Android MarshMallow 自带的浏览器安装包为37MB。
一些第三方浏览器可以使用自己的浏览器。所以可以很好的控制,甚至低于1MB。和Chrome一样独立,46MB也很正常。
这个浏览器在“捆绑浏览器”这个分类中还是比较OK的。纵观浏览器市场,似乎很不起眼。
不过,我也很高兴看到一些国际大厂的内置浏览器也“本地化”了。比如LG G5自带的浏览器。嗯,这很UC。底部导航栏什么的。
如果你想要一个主浏览器,不推荐。如果需要备胎,可以考虑。流畅度还是很OK的。
浏览器抓取网页(小小课堂SEO学网带来的是《》《》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-09 03:05
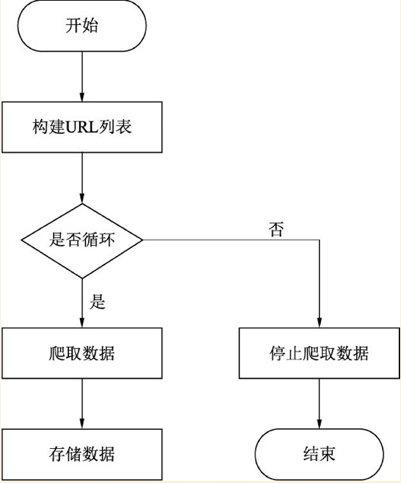
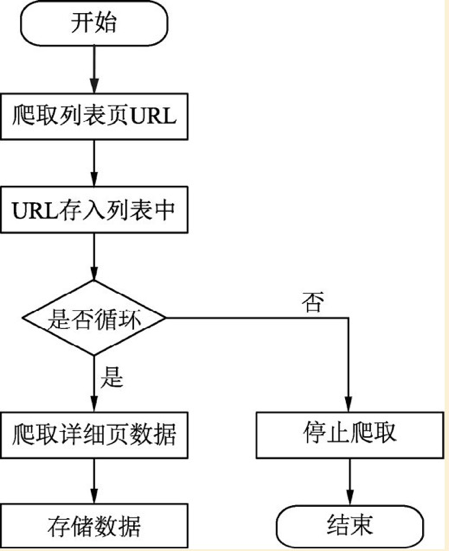
URL,统一资源定位器,通过对URL的分析,可以更好的了解页面的爬取过程。
今天,小小课堂SEO学习网就为大家简单介绍一下页面抓取的过程。希望本次SEO技术培训对大家有所帮助。
一、url是什么意思?
URL英文叫做“uniform resource locator”,中文翻译为“uniform resource locator”。
在网站优化中,要求每个页面有一个且只有一个唯一的统一资源定位符(URL),但往往很多网站同一个页面对应多个URL,如果都被搜索引擎搜索到的话收录且没有URL重定向,权重不集中,通常称为URL不规则。
二、url的组成
统一资源定位符(URL)由三部分组成:协议方案、主机名和资源名。
三、页面爬取过程简述
不管是我们平时使用的网络浏览器,还是网络爬虫,虽然有两个不同的客户端,但是获取页面的方式是一样的。页面抓取过程如下:
① 连接DNS服务器
客户端首先会连接到DNS域名服务器,DNS服务器将主机名转换成IP地址并发回给客户端。
PS:原来我们用的地址是111.152。151.45 访问某个网站。为了便于记忆和使用,我们使用了DNS域名系统对其进行了转换。这就是 DNS 域名系统的作用。
②连接IP地址服务器
这个IP服务器下可能有很多程序(网站),可以通过端口号来区分。同时每个程序(网站)都会监听端口上是否有新的连接请求,HTTP网站默认为80,HTTPS网站默认为443。
不过一般情况下,80和443端口号默认是不会出现的。
③ 建立连接并发送寻呼请求
客户端与服务器建立连接后,会发送一个页面请求,通常是get或者post。 查看全部
浏览器抓取网页(小小课堂SEO学网带来的是《》《》)
URL,统一资源定位器,通过对URL的分析,可以更好的了解页面的爬取过程。
今天,小小课堂SEO学习网就为大家简单介绍一下页面抓取的过程。希望本次SEO技术培训对大家有所帮助。

一、url是什么意思?
URL英文叫做“uniform resource locator”,中文翻译为“uniform resource locator”。
在网站优化中,要求每个页面有一个且只有一个唯一的统一资源定位符(URL),但往往很多网站同一个页面对应多个URL,如果都被搜索引擎搜索到的话收录且没有URL重定向,权重不集中,通常称为URL不规则。
二、url的组成
统一资源定位符(URL)由三部分组成:协议方案、主机名和资源名。
三、页面爬取过程简述
不管是我们平时使用的网络浏览器,还是网络爬虫,虽然有两个不同的客户端,但是获取页面的方式是一样的。页面抓取过程如下:
① 连接DNS服务器
客户端首先会连接到DNS域名服务器,DNS服务器将主机名转换成IP地址并发回给客户端。
PS:原来我们用的地址是111.152。151.45 访问某个网站。为了便于记忆和使用,我们使用了DNS域名系统对其进行了转换。这就是 DNS 域名系统的作用。
②连接IP地址服务器
这个IP服务器下可能有很多程序(网站),可以通过端口号来区分。同时每个程序(网站)都会监听端口上是否有新的连接请求,HTTP网站默认为80,HTTPS网站默认为443。
不过一般情况下,80和443端口号默认是不会出现的。
③ 建立连接并发送寻呼请求
客户端与服务器建立连接后,会发送一个页面请求,通常是get或者post。
浏览器抓取网页(面试时说说思路和想法就行了,还要回去做个东西给他?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-09 03:00
关于收到的页面,如何分析过滤,我的想法不是很新鲜,欢迎大家给我各种建议,有需要注意的地方提醒一下!
- - - 解决方案 - - - - - - - - - -
建议楼主找新公司。
这是什么?就在面试的时候说说你的想法和想法,然后回去给他做点什么?
- - - 解决方案 - - - - - - - - - -
你可以把它做成一个中转站,接受客户的请求,然后自己把请求发给百度,然后得到他的回应
然后处理响应流...至于处理方法...
我自己没有太多经验。你问的专家在他的网站上有他自己的上传文件的源代码。有一些代码用于处理这些流。您可以参考以下内容。
- - - 解决方案 - - - - - - - - - -
1 次抓取
2 正则匹配
超过
- - - 解决方案 - - - - - - - - - -
过来看看热闹。. 对了,老子竹不是有网页爬虫系统吗?. 或者我错了。.
- - - 解决方案 - - - - - - - - - -
我记得有一根竹子。你去他的网站看看。
- - - 解决方案 - - - - - - - - - -
讨论
1 次抓取
2 正则匹配
超过
- - - 解决方案 - - - - - - - - - -
正则表达式
- - - 解决方案 - - - - - - - - - -
我不认为这很难,对吧,
首先使用流的内容到网页,
第二种是将title设置为关键字,并使用常规的title值,
- - - 解决方案 - - - - - - - - - -
哈哈,这很有趣。我们的项目经理还说那天我们可以自由地做这样的事情。大部分代码都在,不过只是项目中的代码,没办法暴露,哈哈。
- - - 解决方案 - - - - - - - - - -
建议你去车东的网站,
- - - 解决方案 - - - - - - - - - -
讨论
引用:
1 次抓取
2 正则匹配
超过
哪一种更有效率?? ?
- - - 解决方案 - - - - - - - - - -
贼
常规的
- - - 解决方案 - - - - - - - - - -
1.分析百度搜索时如何发送请求
2.使用您指定的关键字伪造请求
3.使用apache common-httpclient(我忘了是不是这个)获取百度网页的内容
4.使用正则表达式抓取网页内容
- - - 解决方案 - - - - - - - - - -
经过。. . 研究了一下,好像前几天刚看到类似的问题,
AJAX取结果,正则法等方法处理结果流,显示处理结果,结果有多页的情况如何处理?
- - - 解决方案 - - - - - - - - - -
当有多个页面时,先用正则表达式获取网页下页码的url,循环获取,然后重复发送网页请求。定期获取您想要的内容。Lucene 是个好东西。如果你需要工作,你可以好好看看。但是既然你需要把关键字Send it to baidu 百度会给你做的检索工作或者不使用它。学习这个东西需要时间。
- - - 解决方案 - - - - - - - - - -
常规~
- - - 解决方案 - - - - - - - - - -
你用httpclient模拟cookies等抓取整个数据,然后定时匹配抓取相关的!我刚做了这个东西!但是有验证码有点难啊!
- - - 解决方案 - - - - - - - - - -
不知道,楼主已经解决了,建议你去看看Nutch,这是一个从抓取网页到页面分析,再到构建搜索,再到查询的完整实现的搜索引擎。它是开源的。
引用:
引用:
1 次抓取
2 正则匹配
超过
哪一种更有效率?? ?
发帖人的思路其实就是这两个步骤的具体解释,1.抓取,就是发帖人说的:“网络爬虫”。
我是这样想的:1.做一个jsp页面,在里面输入一条信息,然后转发到百度。
2. 然后接收并下载返回的页面。
2、正则匹配指的是楼主提到的:3.将返回的html页面作为xml文件一一分析过滤。
4. 把过滤后的数据整理出来,提取我需要的部分
然后返回自己的jsp页面进行展示!这一步其实就是nutch的查询
上面的东西已经nutch实现了,可以参考
- - - 解决方案 - - - - - - - - - - 查看全部
浏览器抓取网页(面试时说说思路和想法就行了,还要回去做个东西给他?)
关于收到的页面,如何分析过滤,我的想法不是很新鲜,欢迎大家给我各种建议,有需要注意的地方提醒一下!
- - - 解决方案 - - - - - - - - - -
建议楼主找新公司。
这是什么?就在面试的时候说说你的想法和想法,然后回去给他做点什么?
- - - 解决方案 - - - - - - - - - -
你可以把它做成一个中转站,接受客户的请求,然后自己把请求发给百度,然后得到他的回应
然后处理响应流...至于处理方法...
我自己没有太多经验。你问的专家在他的网站上有他自己的上传文件的源代码。有一些代码用于处理这些流。您可以参考以下内容。
- - - 解决方案 - - - - - - - - - -
1 次抓取
2 正则匹配
超过
- - - 解决方案 - - - - - - - - - -
过来看看热闹。. 对了,老子竹不是有网页爬虫系统吗?. 或者我错了。.
- - - 解决方案 - - - - - - - - - -
我记得有一根竹子。你去他的网站看看。
- - - 解决方案 - - - - - - - - - -
讨论
1 次抓取
2 正则匹配
超过
- - - 解决方案 - - - - - - - - - -
正则表达式
- - - 解决方案 - - - - - - - - - -
我不认为这很难,对吧,
首先使用流的内容到网页,
第二种是将title设置为关键字,并使用常规的title值,
- - - 解决方案 - - - - - - - - - -
哈哈,这很有趣。我们的项目经理还说那天我们可以自由地做这样的事情。大部分代码都在,不过只是项目中的代码,没办法暴露,哈哈。
- - - 解决方案 - - - - - - - - - -
建议你去车东的网站,
- - - 解决方案 - - - - - - - - - -
讨论
引用:
1 次抓取
2 正则匹配
超过
哪一种更有效率?? ?
- - - 解决方案 - - - - - - - - - -
贼
常规的
- - - 解决方案 - - - - - - - - - -
1.分析百度搜索时如何发送请求
2.使用您指定的关键字伪造请求
3.使用apache common-httpclient(我忘了是不是这个)获取百度网页的内容
4.使用正则表达式抓取网页内容
- - - 解决方案 - - - - - - - - - -
经过。. . 研究了一下,好像前几天刚看到类似的问题,
AJAX取结果,正则法等方法处理结果流,显示处理结果,结果有多页的情况如何处理?
- - - 解决方案 - - - - - - - - - -
当有多个页面时,先用正则表达式获取网页下页码的url,循环获取,然后重复发送网页请求。定期获取您想要的内容。Lucene 是个好东西。如果你需要工作,你可以好好看看。但是既然你需要把关键字Send it to baidu 百度会给你做的检索工作或者不使用它。学习这个东西需要时间。
- - - 解决方案 - - - - - - - - - -
常规~
- - - 解决方案 - - - - - - - - - -
你用httpclient模拟cookies等抓取整个数据,然后定时匹配抓取相关的!我刚做了这个东西!但是有验证码有点难啊!
- - - 解决方案 - - - - - - - - - -
不知道,楼主已经解决了,建议你去看看Nutch,这是一个从抓取网页到页面分析,再到构建搜索,再到查询的完整实现的搜索引擎。它是开源的。
引用:
引用:
1 次抓取
2 正则匹配
超过
哪一种更有效率?? ?
发帖人的思路其实就是这两个步骤的具体解释,1.抓取,就是发帖人说的:“网络爬虫”。
我是这样想的:1.做一个jsp页面,在里面输入一条信息,然后转发到百度。
2. 然后接收并下载返回的页面。
2、正则匹配指的是楼主提到的:3.将返回的html页面作为xml文件一一分析过滤。
4. 把过滤后的数据整理出来,提取我需要的部分
然后返回自己的jsp页面进行展示!这一步其实就是nutch的查询
上面的东西已经nutch实现了,可以参考
- - - 解决方案 - - - - - - - - - -
浏览器抓取网页(国外开发者开发的一款Logo获取工具浏览器插件,消除隔阂)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-09 02:27
logo采集器插件介绍
碰巧需要下载一些网站的logo。偶然发现了一个国外开发者开发的logo获取工具浏览器插件,支持Chrome、FireFox、360等浏览器,一键傻瓜式操作下载他们的Logo,而且是PNG格式格式。
为了让更多人使用这么好的插件,消除语言障碍,我发扬雷锋精神,将插件制作成中文。
标志抓取器安装方法
1、下载附件,使用压缩软件解压压缩文件,保存到系统任意文件夹。
2、在Chrome(或360、QQ等浏览器)地址栏输入:chrome://extensions/ 打开Chrome浏览器的扩展管理界面,在界面右上角勾选“开发者模式”按钮。
3、 勾选开发者模式选项后,页面上会出现加载开发中扩展的按钮,点击“加载开发中扩展”按钮,选择刚才解压的Chrome插件文件夹。
4、 单击“确定”按钮。如果此时没有任何反应,则插件将成功加载到浏览器中。
如何使用徽标抓取器
1、使用谷歌浏览器(或其他Chrome浏览器)打开目标网站。
2、 点击浏览器上的“Logograbber”,它会开始抓取可能的logo图案。
3、 点击“下载”下载对应的Logo格式。
4、如果您发现显示的logo不是正确的logo,您也可以通过下面的链接反馈问题。
提示:并非所有 网站 都支持,但大部分 网站 仍然可用。该工具可以节省时间并提高工作效率。其次,你可以得到png格式的图片,图片质量必须高于截图。, 第三,可以拿到一些隐藏标签中的Logo,整体还是不错的。
最后请注意,我刚刚用中文完成了各种功能。至于技术问题,我不会和你交流。
如果你觉得还不错,就点击下方的“免费评分”支持一下吧! 查看全部
浏览器抓取网页(国外开发者开发的一款Logo获取工具浏览器插件,消除隔阂)
logo采集器插件介绍
碰巧需要下载一些网站的logo。偶然发现了一个国外开发者开发的logo获取工具浏览器插件,支持Chrome、FireFox、360等浏览器,一键傻瓜式操作下载他们的Logo,而且是PNG格式格式。
为了让更多人使用这么好的插件,消除语言障碍,我发扬雷锋精神,将插件制作成中文。
标志抓取器安装方法
1、下载附件,使用压缩软件解压压缩文件,保存到系统任意文件夹。
2、在Chrome(或360、QQ等浏览器)地址栏输入:chrome://extensions/ 打开Chrome浏览器的扩展管理界面,在界面右上角勾选“开发者模式”按钮。
3、 勾选开发者模式选项后,页面上会出现加载开发中扩展的按钮,点击“加载开发中扩展”按钮,选择刚才解压的Chrome插件文件夹。
4、 单击“确定”按钮。如果此时没有任何反应,则插件将成功加载到浏览器中。

如何使用徽标抓取器
1、使用谷歌浏览器(或其他Chrome浏览器)打开目标网站。
2、 点击浏览器上的“Logograbber”,它会开始抓取可能的logo图案。
3、 点击“下载”下载对应的Logo格式。
4、如果您发现显示的logo不是正确的logo,您也可以通过下面的链接反馈问题。

提示:并非所有 网站 都支持,但大部分 网站 仍然可用。该工具可以节省时间并提高工作效率。其次,你可以得到png格式的图片,图片质量必须高于截图。, 第三,可以拿到一些隐藏标签中的Logo,整体还是不错的。
最后请注意,我刚刚用中文完成了各种功能。至于技术问题,我不会和你交流。
如果你觉得还不错,就点击下方的“免费评分”支持一下吧!
浏览器抓取网页(1.请正确使用网页爬虫非法数据影响他人服务器的正常工作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-07 03:14
1.请正确使用网络爬虫,不要使用爬虫对非法数据进行爬网,也不要影响其他服务器的正常工作
2.本文抓取的数据是跨境网站商品的公共信息。本文仅用于学习和交流
3.本文附带源代码。爬行时间间隔为10s,数据采集量大于2000
单击此处获取本文的源代码
任务目标
捕获电子商务大数据网站背景下披露的数千个商品数据,并将数据保存在Excel中进行数据分析
难度分析
您需要登录网站会员账号才能在后台查看数据网站反爬网已经设置,因此很难模拟登录。使用selenium控制Chrome浏览器。在测试模式下网站可以识别,无法正常登录账号。数据只有在页面刷新后才能正常显示
解决困难
在线搜索隐藏selenium功能的各种方法失败,因此通过selenium打开新浏览器的方法将不起作用。此外,许多网站可以通过多种功能识别您是否使用了selenium
2.根据研究,可以通过向selenium添加debuggeraddress来控制在该端口上打开的浏览器
(1)输入chrome.exe所在的文件夹,在地址栏中输入“CMD”,然后在此路径下打开CMD窗口
(2)在CMD窗口中,输入以下命令以打开新的Chrome浏览器窗口,在此窗口中打开目标网站,然后登录到成员帐户
(3)在Python代码中,为selenium添加选项。此处添加的端口地址应与上面CMD命令中的端口一致
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
3.您可以通过每次访问和刷新页面获得整个页面的HTML代码,然后使用beatifulsoup进行网页分析,提取商品的有用信息
driver.get(url)
driver.refresh()
time.sleep(10)
html = driver.find_element_by_xpath("//*").get_attribute("outerHTML")
soup = BeautifulSoup(html,'html.parser')
程序逻辑
1.通过打开的浏览器访问目标网站,登录到成员帐户,并转换数据页
# 使用网页驱动来运行chrome浏览器
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Chrome(r"C:\Users\E490\Anaconda3\Scripts\chromedriver",options=chrome_options)
# 访问网站首页,停留15s,人工登录后,自动刷新页面,停留10s,并搜索关键词
driver.get(url)
driver.refresh()
time.sleep(10)
html = driver.find_element_by_xpath("//*").get_attribute("outerHTML")
soup = BeautifulSoup(html,'html.parser')
2.分析需要通过浏览器F12获取字段的HTML代码,并能够解析要通过beautiful soup库交换的数据字段
#产品标题
item_name = items_content[0].p['title']
#店铺名称
shop_name = items_content[1].text.strip()
#店铺类型
shop_type = items_content[2].text.strip()
#店铺类目
shop_categroy =items_content[3].text.strip()
#商品折扣价
item_discount_price = items_content[4].text.strip()
3.将采集到的数据及时保存到CSV文件中
#打开csv文件
csv_title = 'lazada'+str(random.randint(100,999))+'.csv'
f = open(csv_title,'a',encoding='utf-8',newline='')
# 基于文件对象构建 csv写入对象
csv_writer = csv.writer(f)
# 构建列表头
csv_writer.writerow(["产品标题","店铺名称","店铺类型","店铺类目","商品折扣价","商品评分","累积评论数"])
4.优化代码,使其能够完成100多个网页的循环访问
5.查看获取的跨境电商商品数据
单击此处获取本文的源代码 查看全部
浏览器抓取网页(1.请正确使用网页爬虫非法数据影响他人服务器的正常工作)
1.请正确使用网络爬虫,不要使用爬虫对非法数据进行爬网,也不要影响其他服务器的正常工作
2.本文抓取的数据是跨境网站商品的公共信息。本文仅用于学习和交流
3.本文附带源代码。爬行时间间隔为10s,数据采集量大于2000
单击此处获取本文的源代码
任务目标
捕获电子商务大数据网站背景下披露的数千个商品数据,并将数据保存在Excel中进行数据分析
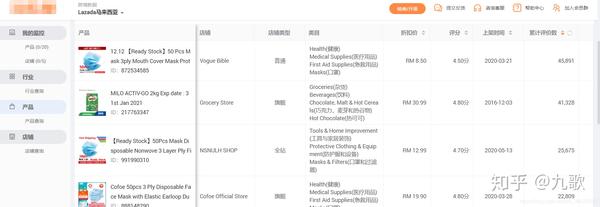
难度分析
您需要登录网站会员账号才能在后台查看数据网站反爬网已经设置,因此很难模拟登录。使用selenium控制Chrome浏览器。在测试模式下网站可以识别,无法正常登录账号。数据只有在页面刷新后才能正常显示
解决困难
在线搜索隐藏selenium功能的各种方法失败,因此通过selenium打开新浏览器的方法将不起作用。此外,许多网站可以通过多种功能识别您是否使用了selenium
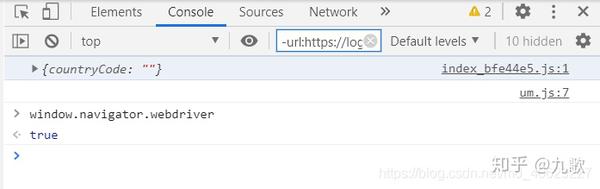
2.根据研究,可以通过向selenium添加debuggeraddress来控制在该端口上打开的浏览器
(1)输入chrome.exe所在的文件夹,在地址栏中输入“CMD”,然后在此路径下打开CMD窗口
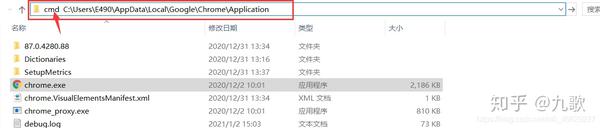
(2)在CMD窗口中,输入以下命令以打开新的Chrome浏览器窗口,在此窗口中打开目标网站,然后登录到成员帐户

(3)在Python代码中,为selenium添加选项。此处添加的端口地址应与上面CMD命令中的端口一致
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
3.您可以通过每次访问和刷新页面获得整个页面的HTML代码,然后使用beatifulsoup进行网页分析,提取商品的有用信息
driver.get(url)
driver.refresh()
time.sleep(10)
html = driver.find_element_by_xpath("//*").get_attribute("outerHTML")
soup = BeautifulSoup(html,'html.parser')
程序逻辑
1.通过打开的浏览器访问目标网站,登录到成员帐户,并转换数据页
# 使用网页驱动来运行chrome浏览器
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Chrome(r"C:\Users\E490\Anaconda3\Scripts\chromedriver",options=chrome_options)
# 访问网站首页,停留15s,人工登录后,自动刷新页面,停留10s,并搜索关键词
driver.get(url)
driver.refresh()
time.sleep(10)
html = driver.find_element_by_xpath("//*").get_attribute("outerHTML")
soup = BeautifulSoup(html,'html.parser')
2.分析需要通过浏览器F12获取字段的HTML代码,并能够解析要通过beautiful soup库交换的数据字段
#产品标题
item_name = items_content[0].p['title']
#店铺名称
shop_name = items_content[1].text.strip()
#店铺类型
shop_type = items_content[2].text.strip()
#店铺类目
shop_categroy =items_content[3].text.strip()
#商品折扣价
item_discount_price = items_content[4].text.strip()
3.将采集到的数据及时保存到CSV文件中
#打开csv文件
csv_title = 'lazada'+str(random.randint(100,999))+'.csv'
f = open(csv_title,'a',encoding='utf-8',newline='')
# 基于文件对象构建 csv写入对象
csv_writer = csv.writer(f)
# 构建列表头
csv_writer.writerow(["产品标题","店铺名称","店铺类型","店铺类目","商品折扣价","商品评分","累积评论数"])
4.优化代码,使其能够完成100多个网页的循环访问
5.查看获取的跨境电商商品数据
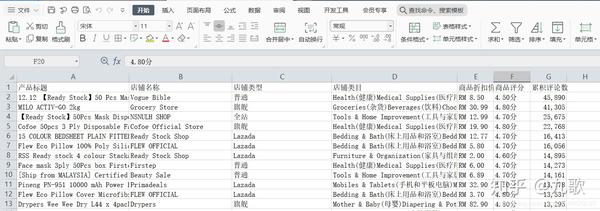
单击此处获取本文的源代码
浏览器抓取网页(网站日志在哪?如何查看网站被百度抓取的情况?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-07 03:12
你的网站/网页是否被百度抓取以及抓取频率会影响你的排名。
01如何查看网站被抓包的状态?
首先我们要知道百度用来抓取网页的工具是Baiduspider(百度蜘蛛),它的动作会被记录在网站的日志中,我们可以从日志中读取到Baiduspider 网站(百度蜘蛛)活动:抓取的频率和抓取后返回的HTTP状态码,用于查看网站被百度抓取的状态。所以下一步就是找到网站日志的内容。
02网站日志在哪里?如何查看
通常网站 日志文件位于管理后端的 logofiles 文件夹下。登录“FTP”账号,找到一个文件扩展名为.log的日志文件,下载并解压,将文件更改为记事本。这是网站日志,记录了网站是否被百度蜘蛛(Baidu Spider)爬取,爬取是否成功。
接下来,作者介绍了如何用这样一段代码进行日志分析。示例:时间 GET /images/index5_22.gif-- IP 地址 HTTP/1.1 浏览器和操作系统/news/detail/181.html 200 360 where, "GET / images /index5_22.gif" 表示:从服务器获取页面"/images/index5_22.gif"或文件;HTTP/1.1 浏览器及操作系统/news/detail/181.html 200 360,代表:抓取后返回的状态(成功与否,抓取次数) 200,状态码,表示爬取成功;360,volume,代表爬取多少字节,360字节;
常见状态码
200:表示服务器成功接受了客户端请求。这是最好的,这意味着网站页面是正常的。
301:表示用户访问的某个页面经过了301重定向(永久)处理。
302:这是一个临时重定向。如果网站日志分析发现302太多,需要确认301是否误认为302,如果是,赶紧修改。搜索引擎不喜欢 302 重定向。
404:表示访问的页面不存在了,或者访问的URL是错误的。
500:服务器错误。03 百度蜘蛛的活跃度:抓取频率是多少?
百度蜘蛛(Baidu spider)活动:抓取频率
在每日日志中记录Baiduspider(百度蜘蛛)爬取网站的次数,然后比较多天的日志,确定Baiduspider(百度蜘蛛)当前的活跃度。活跃度越高,爬取越多,说明网站的优化是有效的,网站的排名自然会上升。 查看全部
浏览器抓取网页(网站日志在哪?如何查看网站被百度抓取的情况?)
你的网站/网页是否被百度抓取以及抓取频率会影响你的排名。
01如何查看网站被抓包的状态?

首先我们要知道百度用来抓取网页的工具是Baiduspider(百度蜘蛛),它的动作会被记录在网站的日志中,我们可以从日志中读取到Baiduspider 网站(百度蜘蛛)活动:抓取的频率和抓取后返回的HTTP状态码,用于查看网站被百度抓取的状态。所以下一步就是找到网站日志的内容。
02网站日志在哪里?如何查看

通常网站 日志文件位于管理后端的 logofiles 文件夹下。登录“FTP”账号,找到一个文件扩展名为.log的日志文件,下载并解压,将文件更改为记事本。这是网站日志,记录了网站是否被百度蜘蛛(Baidu Spider)爬取,爬取是否成功。
接下来,作者介绍了如何用这样一段代码进行日志分析。示例:时间 GET /images/index5_22.gif-- IP 地址 HTTP/1.1 浏览器和操作系统/news/detail/181.html 200 360 where, "GET / images /index5_22.gif" 表示:从服务器获取页面"/images/index5_22.gif"或文件;HTTP/1.1 浏览器及操作系统/news/detail/181.html 200 360,代表:抓取后返回的状态(成功与否,抓取次数) 200,状态码,表示爬取成功;360,volume,代表爬取多少字节,360字节;
常见状态码
200:表示服务器成功接受了客户端请求。这是最好的,这意味着网站页面是正常的。
301:表示用户访问的某个页面经过了301重定向(永久)处理。
302:这是一个临时重定向。如果网站日志分析发现302太多,需要确认301是否误认为302,如果是,赶紧修改。搜索引擎不喜欢 302 重定向。
404:表示访问的页面不存在了,或者访问的URL是错误的。
500:服务器错误。03 百度蜘蛛的活跃度:抓取频率是多少?
百度蜘蛛(Baidu spider)活动:抓取频率
在每日日志中记录Baiduspider(百度蜘蛛)爬取网站的次数,然后比较多天的日志,确定Baiduspider(百度蜘蛛)当前的活跃度。活跃度越高,爬取越多,说明网站的优化是有效的,网站的排名自然会上升。
浏览器抓取网页( 《python3爬虫开发实战》学习笔记(零)学习路线html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-06 20:32
《python3爬虫开发实战》学习笔记(零)学习路线html)
browser = webdriver.Chrome()
2-访问页面
browser.get('https://www.taobao.com')
3- 查找节点
input_first = browser.find_element(By.ID, 'q') #单个节点
lis = browser.find_elements_by_css_selector('.service-bd li')
4-节点交互
...
5- 获取节点信息
网页的源代码可以通过 page_source 属性获取。获取源码后,可以使用regular、BeautifulSoup、PyQuery等解析库提取信息。
但是Selenium提供了选择节点的方法,返回WebElement类型,可以通过相关方法或属性解析
6- 获取属性
7- 切换框架
8- 延迟等待
确保节点已加载
- 隐式等待
当搜索一个节点并且该节点没有立即出现时,隐式等待会等待一段时间再搜索DOM。默认时间为 0。implicitly_wait()
-显式等待
指定要查找的节点,然后指定最长等待时间。如果在指定时间内加载节点,则返回搜索到的节点。如果在指定时间内仍未加载节点,则会抛出超时异常。
##本系列内容为《python3爬虫开发实战》学习笔记。本系列博客列表如下:css
(零)学习路线html
(一)开发环境配置python
(二) 爬虫基础网页
(三)基础库使用ajax
(四)使用浏览器分析库
(五)数据存储工具
(六)Ajax数据爬取学习
(七)动态渲染页面爬取Selenium测试
不断更新...ui
请看对应的代码:.. 查看全部
浏览器抓取网页(
《python3爬虫开发实战》学习笔记(零)学习路线html)
browser = webdriver.Chrome()
2-访问页面
browser.get('https://www.taobao.com')
3- 查找节点
input_first = browser.find_element(By.ID, 'q') #单个节点
lis = browser.find_elements_by_css_selector('.service-bd li')
4-节点交互
...
5- 获取节点信息
网页的源代码可以通过 page_source 属性获取。获取源码后,可以使用regular、BeautifulSoup、PyQuery等解析库提取信息。
但是Selenium提供了选择节点的方法,返回WebElement类型,可以通过相关方法或属性解析
6- 获取属性
7- 切换框架
8- 延迟等待
确保节点已加载
- 隐式等待
当搜索一个节点并且该节点没有立即出现时,隐式等待会等待一段时间再搜索DOM。默认时间为 0。implicitly_wait()
-显式等待
指定要查找的节点,然后指定最长等待时间。如果在指定时间内加载节点,则返回搜索到的节点。如果在指定时间内仍未加载节点,则会抛出超时异常。
##本系列内容为《python3爬虫开发实战》学习笔记。本系列博客列表如下:css
(零)学习路线html
(一)开发环境配置python
(二) 爬虫基础网页
(三)基础库使用ajax
(四)使用浏览器分析库
(五)数据存储工具
(六)Ajax数据爬取学习
(七)动态渲染页面爬取Selenium测试
不断更新...ui
请看对应的代码:..
浏览器抓取网页(从IE浏览器获取当前页面内容的多种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 286 次浏览 • 2021-10-06 20:30
从IE浏览器获取当前页面内容的方法可能有很多种。今天我介绍其中一个。基本原理:鼠标点击当前ie页面时,获取鼠标坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用Win32 things获取页面内容。感兴趣的朋友可以参考本文
private void timer1_Tick(object sender, EventArgs e) { lock (currentLock) { System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition; if (_leftClick) { timer1.Stop(); _leftClick = false; _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false)); if (_lastDocument != null) { if (_getDocument) { _getDocument = true; try { string url = _lastDocument.url; string html = _lastDocument.documentElement.outerHTML; string cookie = _lastDocument.cookie; string domain = _lastDocument.domain; var resolveParams = new ResolveParam { Url = new Uri(url), Html = html, PageCookie = cookie, Domain = domain }; RequetResove(resolveParams); } catch (Exception ex) { System.Windows.MessageBox.Show(ex.Message); Console.WriteLine(ex.Message); Console.WriteLine(ex.StackTrace); } } } else { new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页"); } _getDocument = false; } else { _pointFrm.Left = MousePoint.X + 10; _pointFrm.Top = MousePoint.Y + 10; } } }
在第11行的gethtmldocumentformhwnd(getpointcontrol(mousepoint,false))分解下,首先从鼠标坐标获取页面句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl) { IntPtr handle = Win32APIsFull.WindowFromPoint(p); if (handle != IntPtr.Zero) { System.Drawing.Rectangle rect = default(System.Drawing.Rectangle); if (Win32APIsFull.GetWindowRect(handle, out rect)) { return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE); } } return IntPtr.Zero; }
接下来,根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd) { IntPtr result = Marshal.AllocHGlobal(4); Object obj = null; Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result)); if (Marshal.ReadInt32(result) != 0) { Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj)); } Marshal.FreeHGlobal(result); return obj as HTMLDocument; }
一般原则:
向IE表单发送消息,获取指向IE浏览器(非托管)内存块的指针,然后根据该指针获取htmldocument对象
此方法涉及两个Win32函数:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")] public static extern int SendMessageTimeoutA( [InAttribute()] System.IntPtr hWnd, uint Msg, uint wParam, int lParam, uint fuFlags, uint uTimeout, System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")] public static extern int ObjectFromLresult( int lResult, ref Guid riid, int wParam, [MarshalAs(UnmanagedType.IDispatch), Out] out Object pObject );
以上是从IE浏览器获取的当前页面内容的详细信息。请多关注其他相关文章 查看全部
浏览器抓取网页(从IE浏览器获取当前页面内容的多种方法)
从IE浏览器获取当前页面内容的方法可能有很多种。今天我介绍其中一个。基本原理:鼠标点击当前ie页面时,获取鼠标坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用Win32 things获取页面内容。感兴趣的朋友可以参考本文
private void timer1_Tick(object sender, EventArgs e) { lock (currentLock) { System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition; if (_leftClick) { timer1.Stop(); _leftClick = false; _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false)); if (_lastDocument != null) { if (_getDocument) { _getDocument = true; try { string url = _lastDocument.url; string html = _lastDocument.documentElement.outerHTML; string cookie = _lastDocument.cookie; string domain = _lastDocument.domain; var resolveParams = new ResolveParam { Url = new Uri(url), Html = html, PageCookie = cookie, Domain = domain }; RequetResove(resolveParams); } catch (Exception ex) { System.Windows.MessageBox.Show(ex.Message); Console.WriteLine(ex.Message); Console.WriteLine(ex.StackTrace); } } } else { new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页"); } _getDocument = false; } else { _pointFrm.Left = MousePoint.X + 10; _pointFrm.Top = MousePoint.Y + 10; } } }
在第11行的gethtmldocumentformhwnd(getpointcontrol(mousepoint,false))分解下,首先从鼠标坐标获取页面句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl) { IntPtr handle = Win32APIsFull.WindowFromPoint(p); if (handle != IntPtr.Zero) { System.Drawing.Rectangle rect = default(System.Drawing.Rectangle); if (Win32APIsFull.GetWindowRect(handle, out rect)) { return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE); } } return IntPtr.Zero; }
接下来,根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd) { IntPtr result = Marshal.AllocHGlobal(4); Object obj = null; Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result)); if (Marshal.ReadInt32(result) != 0) { Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj)); } Marshal.FreeHGlobal(result); return obj as HTMLDocument; }
一般原则:

向IE表单发送消息,获取指向IE浏览器(非托管)内存块的指针,然后根据该指针获取htmldocument对象
此方法涉及两个Win32函数:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")] public static extern int SendMessageTimeoutA( [InAttribute()] System.IntPtr hWnd, uint Msg, uint wParam, int lParam, uint fuFlags, uint uTimeout, System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")] public static extern int ObjectFromLresult( int lResult, ref Guid riid, int wParam, [MarshalAs(UnmanagedType.IDispatch), Out] out Object pObject );
以上是从IE浏览器获取的当前页面内容的详细信息。请多关注其他相关文章
浏览器抓取网页(浏览器抓取网页就是通过解析网页然后解析出网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-04 09:01
浏览器抓取网页就是通过解析网页然后解析出html内容。一般来说解析是浏览器直接完成的,而解析出来的html就会被后端渲染成网页,返回给我们。你可以理解为是代理的关系。这也是单线程的意思,双线程就是a/b两个app/网页一个app服务器。然后说说python,python2的话,解析网页不需要引入浏览器模块。
直接调用chrome和chromium模块接口就行。而有些浏览器已经有好几个浏览器模块接口,比如知乎,使用的是谷歌浏览器模块,所以需要依次解析网页。比如现在的知乎网页如下。先是通过python接口打开。接着app的数据从post中获取,通过后端渲染成一个网页。有的话就不用通过浏览器解析网页就直接返回页面,比如网页内容,还有下方的一个进度条弹出。
解析这类接口你需要说服后端解析我们页面的js和图片文件。你可以理解为你帮助他把页面里的按钮颜色等提取出来。不要使用自己的代码和图片。这样才能保证后端不抓到我们的数据并返回成功。解析网页就是使用python的web框架。前端框架多如牛毛,我挑了一个入门最容易,上手快。web框架uiwebview、segmentfault等等,有了uiwebview后,前端开发起来就方便多了。
页面直接在地址栏查看是多么方便啊。segmentfault现在有可以拖拽下载pdf的功能。目前我的文章页也在做首页推荐,可以先试试,点击下载网页。 查看全部
浏览器抓取网页(浏览器抓取网页就是通过解析网页然后解析出网页)
浏览器抓取网页就是通过解析网页然后解析出html内容。一般来说解析是浏览器直接完成的,而解析出来的html就会被后端渲染成网页,返回给我们。你可以理解为是代理的关系。这也是单线程的意思,双线程就是a/b两个app/网页一个app服务器。然后说说python,python2的话,解析网页不需要引入浏览器模块。
直接调用chrome和chromium模块接口就行。而有些浏览器已经有好几个浏览器模块接口,比如知乎,使用的是谷歌浏览器模块,所以需要依次解析网页。比如现在的知乎网页如下。先是通过python接口打开。接着app的数据从post中获取,通过后端渲染成一个网页。有的话就不用通过浏览器解析网页就直接返回页面,比如网页内容,还有下方的一个进度条弹出。
解析这类接口你需要说服后端解析我们页面的js和图片文件。你可以理解为你帮助他把页面里的按钮颜色等提取出来。不要使用自己的代码和图片。这样才能保证后端不抓到我们的数据并返回成功。解析网页就是使用python的web框架。前端框架多如牛毛,我挑了一个入门最容易,上手快。web框架uiwebview、segmentfault等等,有了uiwebview后,前端开发起来就方便多了。
页面直接在地址栏查看是多么方便啊。segmentfault现在有可以拖拽下载pdf的功能。目前我的文章页也在做首页推荐,可以先试试,点击下载网页。
浏览器抓取网页(web开发者工具(浏览器)安装beautifulsoup构建的chrome)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-29 23:02
浏览器抓取网页是一个技术活,有两个重要的步骤,第一,找到html网页地址();第二,网页内容解析,解析可能是网页写入xml文件,可能是json,可能是其他的。也可能是使用beautifulsoup。如果使用解析网页方法的话要对html网页内容有一定的理解。其实,解析网页可以通过web开发者工具()浏览器自带的浏览器开发者工具功能和如果使用beautifulsoup解析网页,还要会使用浏览器自带的解析器操作。
网页抓取工具investfulljs/webpack-invest打开开发者工具就会有解析器。在我的博客一步之遥里不定期更新网页抓取的代码,看看效果如何。scanner_html_invest。
官方文档就有安装beautifulsoup构建的chrome抓取指南
当然是doreally
这玩意的话msdn,没有什么更好的方法。
当然是chrome+reactnative
1.enurls地址,要从他们那里抓包2.printsend的地址,
chromeextensionv1.2.1downloadbeautifulsoup3.pythonscrapy在chrome上运行或者chrome+python运行
使用前端的话,一般的mjs脚手架都会有你想要的功能,但如果你使用的后端,
应该是先点击浏览器地址栏的网址(我从360进程看的),然后点击一个地址按钮,在点击浏览器开发人员工具(一般是右键,可以看到css文件和js文件),页面上出现链接,点击。然后就抓取出来页面了。 查看全部
浏览器抓取网页(web开发者工具(浏览器)安装beautifulsoup构建的chrome)
浏览器抓取网页是一个技术活,有两个重要的步骤,第一,找到html网页地址();第二,网页内容解析,解析可能是网页写入xml文件,可能是json,可能是其他的。也可能是使用beautifulsoup。如果使用解析网页方法的话要对html网页内容有一定的理解。其实,解析网页可以通过web开发者工具()浏览器自带的浏览器开发者工具功能和如果使用beautifulsoup解析网页,还要会使用浏览器自带的解析器操作。
网页抓取工具investfulljs/webpack-invest打开开发者工具就会有解析器。在我的博客一步之遥里不定期更新网页抓取的代码,看看效果如何。scanner_html_invest。
官方文档就有安装beautifulsoup构建的chrome抓取指南
当然是doreally
这玩意的话msdn,没有什么更好的方法。
当然是chrome+reactnative
1.enurls地址,要从他们那里抓包2.printsend的地址,
chromeextensionv1.2.1downloadbeautifulsoup3.pythonscrapy在chrome上运行或者chrome+python运行
使用前端的话,一般的mjs脚手架都会有你想要的功能,但如果你使用的后端,
应该是先点击浏览器地址栏的网址(我从360进程看的),然后点击一个地址按钮,在点击浏览器开发人员工具(一般是右键,可以看到css文件和js文件),页面上出现链接,点击。然后就抓取出来页面了。
浏览器抓取网页(选择谷歌浏览器,避免了单一的标签无法定位到我们所需要的内容元素(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-09-29 19:27
)
它只是一个收录段落内容的标签。
#coding=utf-8
from bs4 import BeautifulSoup
import requests
#使用requests抓取页面内容,并将响应赋值给page变量
html = requests.get('https://www.qiushibaike.com/text/')
#使用content属性获取页面的源页面
#使用BeautifulSoap解析,吧内容传递到BeautifulSoap类
soup = BeautifulSoup(html.content,'lxml')
links = soup.find_all('div',class_='content')
#link的内容就是div,我们取它的span内容就是我们需要段子的内容
for link in links:
print link.span.get_text()
操作结果:
2. select() 方法
我们需要的内容可以逐层查找。这个特别方便,也就是定位,防止单个标签无法定位到我们需要的内容元素。
soup.select("html head title") #标签层级查找
soup.select("td div a") #标签路径 td-->div-->a
soup.select('td > div > a') #note:推荐使用这种记法
选择谷歌浏览器,右键复制--复制选择器
获取内容的任务:
#qiushi_tag_120529403> a> div> span:nth-child(1)
对于这个内容,我需要改一下~按标签顺序搜索
div> a> div> span(我在运行的时候发现了一个问题,>前后必须有空格,否则会报错)
然后代码如下:(和前面的代码区别只有最后三行)
#coding=utf-8
from bs4 import BeautifulSoup
import requests
#使用requests抓取页面内容,并将响应赋值给page变量
html = requests.get('https://www.qiushibaike.com/text/')
#使用content属性获取页面的源页面
#使用BeautifulSoap解析,吧内容传递到BeautifulSoap类
soup = BeautifulSoup(html.content,'lxml')
#我是分隔符,下面就是select()方法咯~
links = soup.select('div > a >div >span')
for link in links:
print link.get_text()
操作结果:
啊哦~有没有发现和上面操作的结果不一样?评论也在这里匹配,所以:
我们还需要修改定位使其更加精确,从标签a开始,并添加其class属性。a.contentHerf 写在 select 方法中。
具体是这样的:a.contentHerf>div>span(改成代码第三行再运行一次~)
注意:1)示例只介绍了一页的内容
2)代码在python中运行2.7
原来的:
================================================== ====================
【笔记】
提示:类型错误:“响应”类型的对象没有 len()
源代码:
url = 'https://www.imooc.com/course/l ... 39%3B
wb_data = requests.get(url)
Soup = BeautifulSoup(wb_data, 'lxml', from_encoding='utf-8')
报错的原因是因为这里的wb_data是一个requests对象,BeautifulSoup无法解析。您可以在 wb_data 后添加内容
汤 = BeautifulSoup(wb_data.content,'lxml', from_encoding='utf-8')
Tips:python3中request.urlopen()和requests.get()方法的区别
urlopen 打开URL URL,url参数可以是字符串url或Request对象,返回的对象是http.client.HTTPResponse。http.client.HTTPResponse 对象大概包括 read(), readinto(), getheader(), getheaders(), fileno(), msg, version, status, reason, debuglevel 和 closed 函数,其实一般来说就是decode使用read()函数后需要()函数
requests.get()方法请求站点的URL,然后打印出返回结果的类型、状态码、编码方式、Cookies等。返回一个Response对象,该对象存储了服务器返回的所有信息,包括响应头、响应状态码等。返回的网页部分将存储在.content和.text两个对象中。文本返回 Unicode 数据,内容返回二进制数据。换句话说,如果要获取文本,可以使用 r.text。如果你想拍照和文件,你可以使用 r.content
经验:请求网页的三种方式
# 网页下载器代码示例
2 import urllib
3
4 url = "http://www.baidu.com"
5
6 print("第一种方法: 直接访问url")
7 response1 = urllib.request.urlopen(url)
8 print(response1.getcode()) # 状态码
9 print(len(response1.read())) # read读取utf-8编码的字节流数据
10
11 print("第二种方法: 设置请求头,访问Url")
12 request = urllib.request.Request(url) # 请求地址
13 request.add_header("user-agent", "mozilla/5.0") # 修改请求头
14 response2 = urllib.request.urlopen(request)
15 print(response2.getcode())
16 print(len(response2.read()))
17
18 import http.cookiejar # 不知道这是啥
19
20 print("第三种方法: 设置coockie,返回的cookie")
21 # 第三种方法的目的是为了获取浏览器的cookie内容
22 cj = http.cookiejar.CookieJar()
23 opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
24 urllib.request.install_opener(opener)
25 response3 = urllib.request.urlopen(url)
26 print(response3.getcode())
27 print(len(response3.read()))
28 print(cj) # 查看cookie的内容
Tips:Python如何提取td中的内容
import re
m = re.findall(r'(.*?)', lines, re.I|re.M)
if m:
for x in m:
print x 查看全部
浏览器抓取网页(选择谷歌浏览器,避免了单一的标签无法定位到我们所需要的内容元素(图)
)
它只是一个收录段落内容的标签。
#coding=utf-8
from bs4 import BeautifulSoup
import requests
#使用requests抓取页面内容,并将响应赋值给page变量
html = requests.get('https://www.qiushibaike.com/text/')
#使用content属性获取页面的源页面
#使用BeautifulSoap解析,吧内容传递到BeautifulSoap类
soup = BeautifulSoup(html.content,'lxml')
links = soup.find_all('div',class_='content')
#link的内容就是div,我们取它的span内容就是我们需要段子的内容
for link in links:
print link.span.get_text()
操作结果:

2. select() 方法
我们需要的内容可以逐层查找。这个特别方便,也就是定位,防止单个标签无法定位到我们需要的内容元素。
soup.select("html head title") #标签层级查找
soup.select("td div a") #标签路径 td-->div-->a
soup.select('td > div > a') #note:推荐使用这种记法
选择谷歌浏览器,右键复制--复制选择器

获取内容的任务:
#qiushi_tag_120529403> a> div> span:nth-child(1)
对于这个内容,我需要改一下~按标签顺序搜索
div> a> div> span(我在运行的时候发现了一个问题,>前后必须有空格,否则会报错)
然后代码如下:(和前面的代码区别只有最后三行)
#coding=utf-8
from bs4 import BeautifulSoup
import requests
#使用requests抓取页面内容,并将响应赋值给page变量
html = requests.get('https://www.qiushibaike.com/text/')
#使用content属性获取页面的源页面
#使用BeautifulSoap解析,吧内容传递到BeautifulSoap类
soup = BeautifulSoup(html.content,'lxml')
#我是分隔符,下面就是select()方法咯~
links = soup.select('div > a >div >span')
for link in links:
print link.get_text()
操作结果:

啊哦~有没有发现和上面操作的结果不一样?评论也在这里匹配,所以:
我们还需要修改定位使其更加精确,从标签a开始,并添加其class属性。a.contentHerf 写在 select 方法中。
具体是这样的:a.contentHerf>div>span(改成代码第三行再运行一次~)
注意:1)示例只介绍了一页的内容
2)代码在python中运行2.7
原来的:
================================================== ====================
【笔记】
提示:类型错误:“响应”类型的对象没有 len()
源代码:
url = 'https://www.imooc.com/course/l ... 39%3B
wb_data = requests.get(url)
Soup = BeautifulSoup(wb_data, 'lxml', from_encoding='utf-8')
报错的原因是因为这里的wb_data是一个requests对象,BeautifulSoup无法解析。您可以在 wb_data 后添加内容
汤 = BeautifulSoup(wb_data.content,'lxml', from_encoding='utf-8')
Tips:python3中request.urlopen()和requests.get()方法的区别
urlopen 打开URL URL,url参数可以是字符串url或Request对象,返回的对象是http.client.HTTPResponse。http.client.HTTPResponse 对象大概包括 read(), readinto(), getheader(), getheaders(), fileno(), msg, version, status, reason, debuglevel 和 closed 函数,其实一般来说就是decode使用read()函数后需要()函数
requests.get()方法请求站点的URL,然后打印出返回结果的类型、状态码、编码方式、Cookies等。返回一个Response对象,该对象存储了服务器返回的所有信息,包括响应头、响应状态码等。返回的网页部分将存储在.content和.text两个对象中。文本返回 Unicode 数据,内容返回二进制数据。换句话说,如果要获取文本,可以使用 r.text。如果你想拍照和文件,你可以使用 r.content
经验:请求网页的三种方式
# 网页下载器代码示例
2 import urllib
3
4 url = "http://www.baidu.com"
5
6 print("第一种方法: 直接访问url")
7 response1 = urllib.request.urlopen(url)
8 print(response1.getcode()) # 状态码
9 print(len(response1.read())) # read读取utf-8编码的字节流数据
10
11 print("第二种方法: 设置请求头,访问Url")
12 request = urllib.request.Request(url) # 请求地址
13 request.add_header("user-agent", "mozilla/5.0") # 修改请求头
14 response2 = urllib.request.urlopen(request)
15 print(response2.getcode())
16 print(len(response2.read()))
17
18 import http.cookiejar # 不知道这是啥
19
20 print("第三种方法: 设置coockie,返回的cookie")
21 # 第三种方法的目的是为了获取浏览器的cookie内容
22 cj = http.cookiejar.CookieJar()
23 opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
24 urllib.request.install_opener(opener)
25 response3 = urllib.request.urlopen(url)
26 print(response3.getcode())
27 print(len(response3.read()))
28 print(cj) # 查看cookie的内容
Tips:Python如何提取td中的内容
import re
m = re.findall(r'(.*?)', lines, re.I|re.M)
if m:
for x in m:
print x
浏览器抓取网页( 写作猫浏览器插件上线「文字识别」和「抓取全文」)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-27 11:12
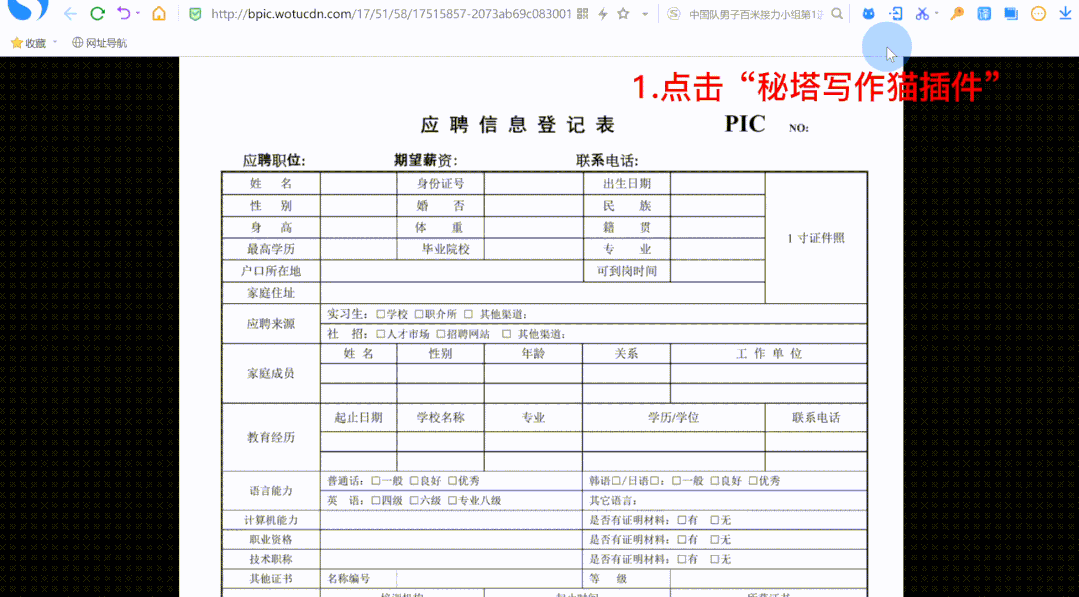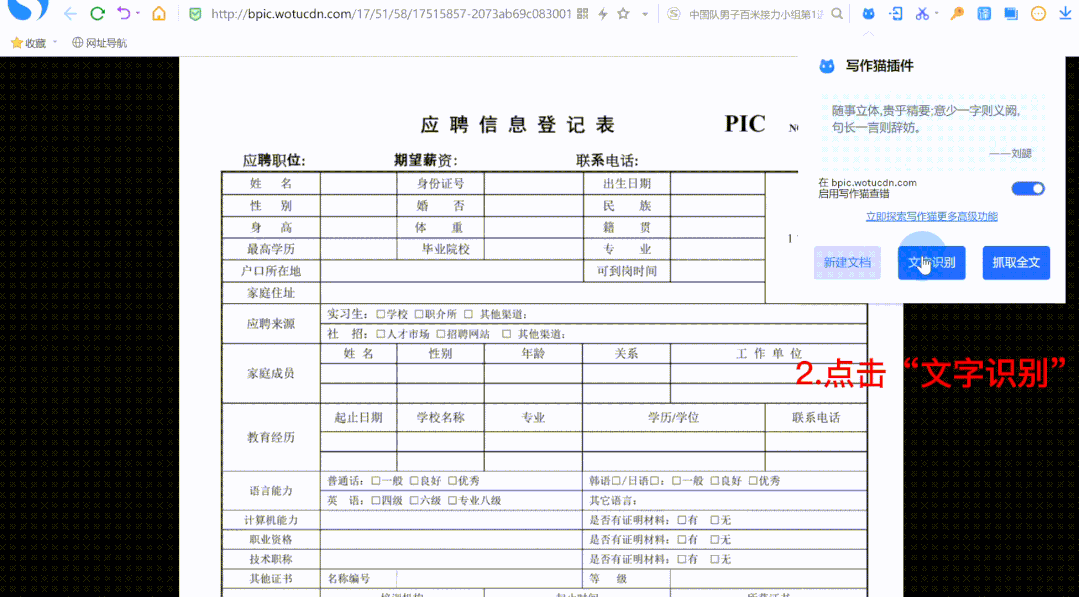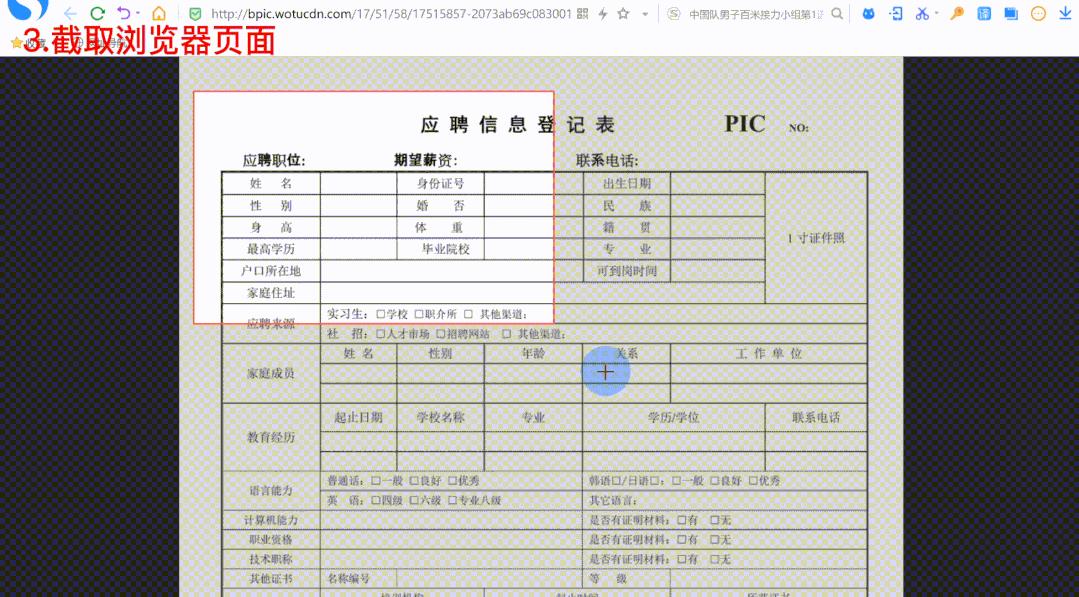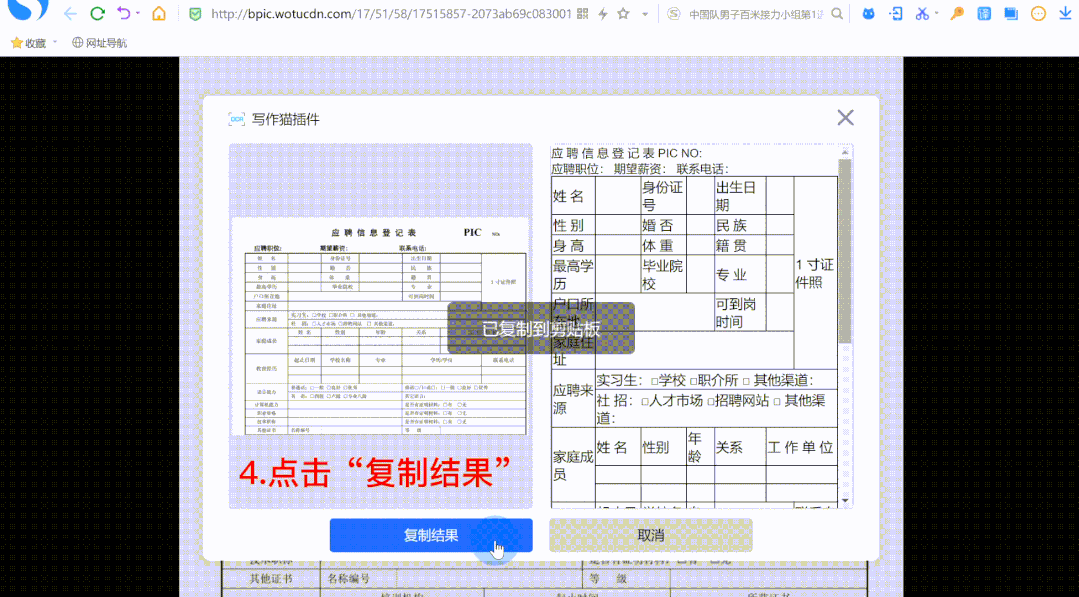
写作猫浏览器插件上线「文字识别」和「抓取全文」)
我经常遇到这种情况,相信你也一样:
网页中的文字无法复制
无法提取图片中的文本/表格
我想复制整篇文章文章,但我只能一段一段地重复一遍
或者因为内容太长,复制到最后需要很长时间,结果复制了一堆乱七八糟的信息
既麻烦又浪费时间。
现在,这些问题终于可以解决了!
写猫浏览器插件推出了“文字识别”和“全文抓取”功能,支持一键提取网页信息。
即时获取您想要的内容,有效节省时间,提高工作学习效率。
如何使用“文字识别”?
“文本识别”可以将网页内容转换为可编辑的文本和表格。
您只需要“选择识别区域”即可复制结果。
可以粘贴到Word文档中:
它也可以粘贴到 Excel 表格中:
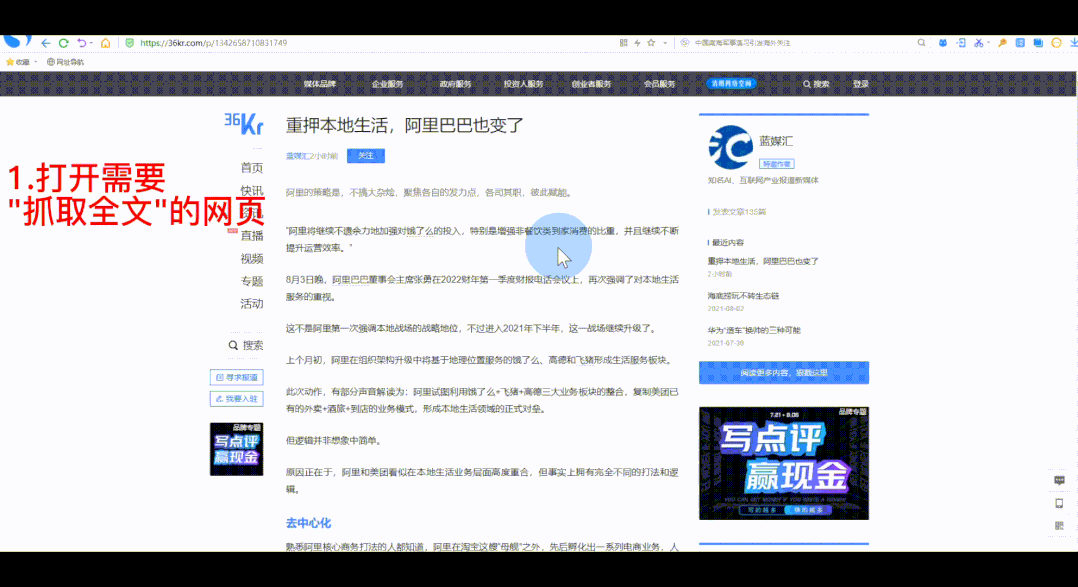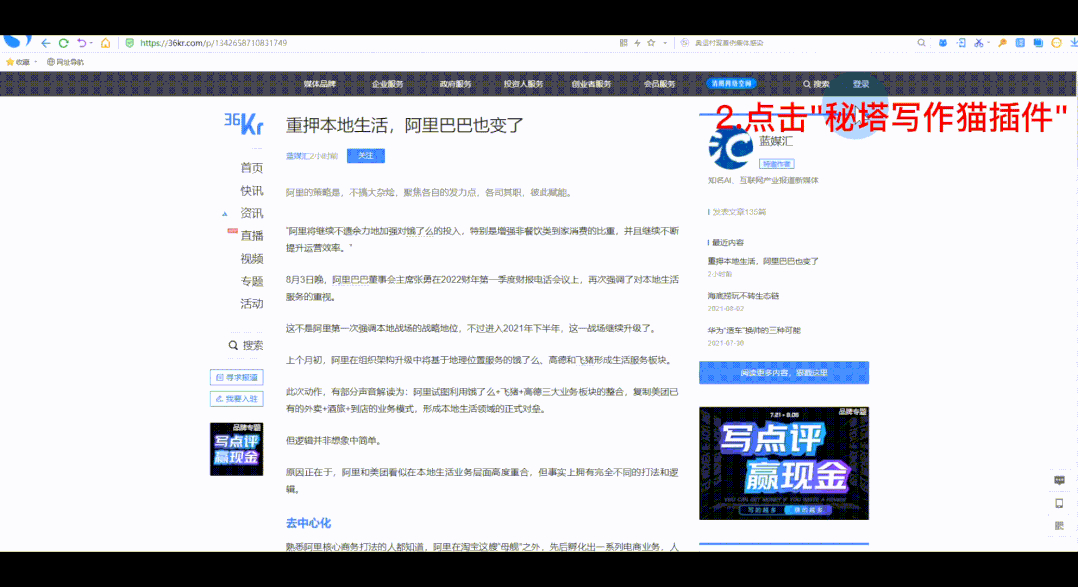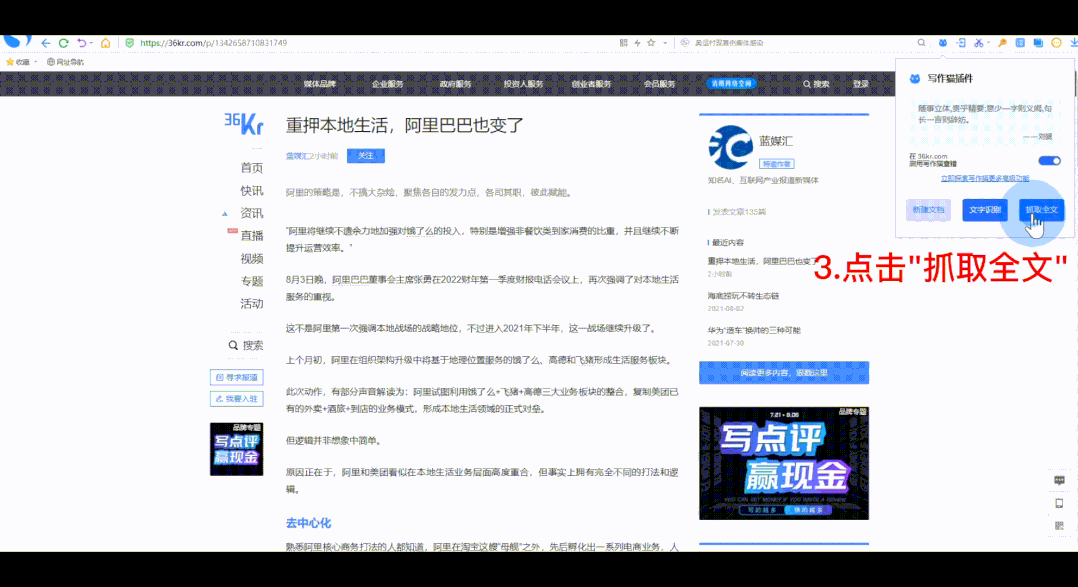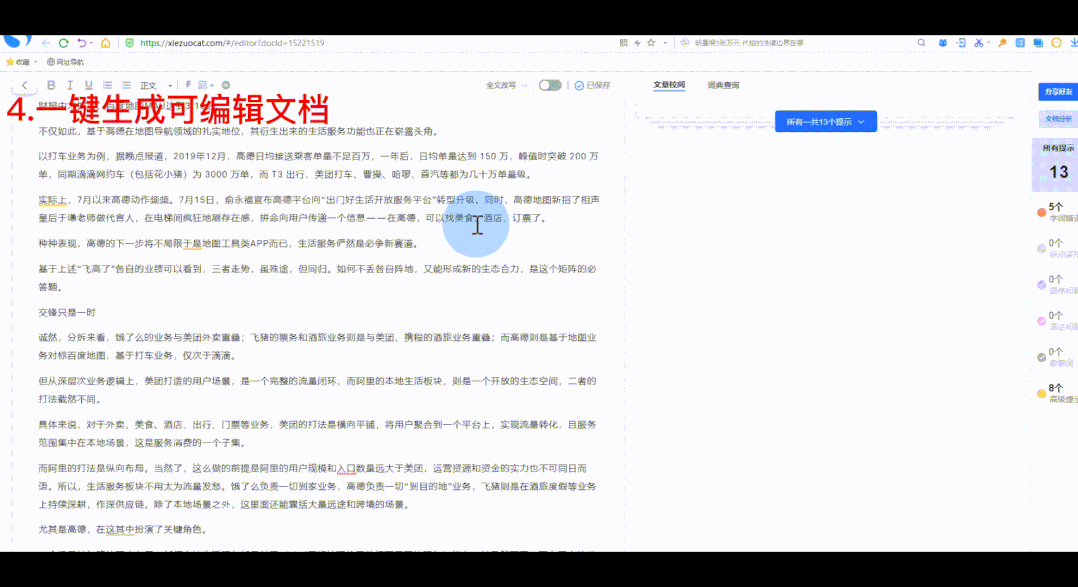
如何使用“获取全文”?
“获取全文”可以一键抓取网页正文内容:
此外,美田写字猫会实时纠错保护文章,告别敏感词、违禁词、坏句,远离文章错误。
您也可以根据需要,一键打开全文改写或翻译。
如何下载“写猫浏览器插件”?
如果您使用Chrome浏览器,可以通过Chrome网上应用店安装美田写字猫的“浏览器插件”。
或者您也可以通过美达写猫网页版()下载“浏览器插件”。
安装后即可使用,高效工作学习,轻松告别通宵码字,制作形式让你光头。
愿你从节省的时间中得到“幸福”和“小幸运”。 查看全部
浏览器抓取网页(
写作猫浏览器插件上线「文字识别」和「抓取全文」)

我经常遇到这种情况,相信你也一样:
网页中的文字无法复制
无法提取图片中的文本/表格
我想复制整篇文章文章,但我只能一段一段地重复一遍
或者因为内容太长,复制到最后需要很长时间,结果复制了一堆乱七八糟的信息
既麻烦又浪费时间。
现在,这些问题终于可以解决了!
写猫浏览器插件推出了“文字识别”和“全文抓取”功能,支持一键提取网页信息。
即时获取您想要的内容,有效节省时间,提高工作学习效率。

如何使用“文字识别”?
“文本识别”可以将网页内容转换为可编辑的文本和表格。
您只需要“选择识别区域”即可复制结果。
可以粘贴到Word文档中:
它也可以粘贴到 Excel 表格中:
如何使用“获取全文”?
“获取全文”可以一键抓取网页正文内容:
此外,美田写字猫会实时纠错保护文章,告别敏感词、违禁词、坏句,远离文章错误。
您也可以根据需要,一键打开全文改写或翻译。

如何下载“写猫浏览器插件”?
如果您使用Chrome浏览器,可以通过Chrome网上应用店安装美田写字猫的“浏览器插件”。
或者您也可以通过美达写猫网页版()下载“浏览器插件”。
安装后即可使用,高效工作学习,轻松告别通宵码字,制作形式让你光头。
愿你从节省的时间中得到“幸福”和“小幸运”。
浏览器抓取网页(代码访问当前域名的session添加一个数据条目会自动保存一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-09-27 07:08
以下代码访问当前域名的会话Storage对象,并使用Storage.setItem()访问向其添加数据项。
sessionStorage.setItem('myCat', 'Tom');
以下示例将自动保存文本输入框的内容。如果浏览器不小心刷新,文本输入框中的内容会恢复,所以写入的内容不会丢失。
// 获取文本输入框
let field = document.getElementById("field");
// 检测是否存在 autosave 键值
// (这个会在页面偶然被刷新的情况下存在)
if (sessionStorage.getItem("autosave")) {
// 恢复文本输入框的内容
field.value = sessionStorage.getItem("autosave");
}
// 监听文本输入框的 change 事件
field.addEventListener("change", function() {
// 保存结果到 sessionStorage 对象中
sessionStorage.setItem("autosave", field.value);
});
备注:完整的使用示例请参考Using Web Storage API一文。 查看全部
浏览器抓取网页(代码访问当前域名的session添加一个数据条目会自动保存一个)
以下代码访问当前域名的会话Storage对象,并使用Storage.setItem()访问向其添加数据项。
sessionStorage.setItem('myCat', 'Tom');
以下示例将自动保存文本输入框的内容。如果浏览器不小心刷新,文本输入框中的内容会恢复,所以写入的内容不会丢失。
// 获取文本输入框
let field = document.getElementById("field");
// 检测是否存在 autosave 键值
// (这个会在页面偶然被刷新的情况下存在)
if (sessionStorage.getItem("autosave")) {
// 恢复文本输入框的内容
field.value = sessionStorage.getItem("autosave");
}
// 监听文本输入框的 change 事件
field.addEventListener("change", function() {
// 保存结果到 sessionStorage 对象中
sessionStorage.setItem("autosave", field.value);
});
备注:完整的使用示例请参考Using Web Storage API一文。
浏览器抓取网页(,如何实时抓取动态网页数据?(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-25 12:04
网页数据实时抓取,实时网页数据,如何抓取实时动态网页数据?
我们生活的数字世界不断产生大量数据。动态大数据的使用已经成为企业数据分析的关键。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?
1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据可以帮助:
(1) 让数据驱动的决策更快
采集动态数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。有了所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出数据驱动的决策。
正如亚马逊首席执行官杰夫贝索斯在给股东的一封信中所说:“业务的速度至关重要。” “高速决策”对业务发展具有重要意义。
(2)建立更强大的数据库
随着数据量的不断增长,每条数据的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要通过持续不断的采集动态数据,构建一个全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度每年翻一番,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期的数据采集可以帮助解决近期的问题并做出较小的决策,而长期的数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2. 动态数据如何有效促进业务增长?
我们可以通过多种方式应用动态数据分析来促进业务发展,例如:
(1)产品监控
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从易趣上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的一种可靠且有效的方法。
(2)客户体验管理
公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超出客户期望的做法,从而提高客户满意度、忠诚度和拥护度”。
例如,提取亚马逊上某个产品的所有评论,并分析评论的正面和负面情绪,可以帮助企业了解客户对产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)营销策略
动态数据分析使公司能够了解过去哪些策略最有效,他们当前的营销策略有多有效,以及可以改进的地方。动态数据采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3. 如何轻松获取动态数据?
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网络爬虫工具,操作者无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是强大的网络爬虫工具可以让您轻松快速地抓取来自不同网站的信息,从而为您研究不同的网站结构节省大量时间。
(3)定时抓拍
这需要网络爬虫工具来支持云中的数据,而不仅仅是在本地计算机上运行。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云Cloud采集的功能远不止这些。
(4) 灵活的时间安排
优采云云采集支持随时随地抓取网页数据,时间和频率可根据需要调整。
(5)采集 更快
同时通过8-12台云服务器采集,对同一组数据的爬取速度可以比在本地计算机上运行快8-12倍。
(6) 降低数据获取成本
优采云Cloud采集支持在云端采集数据,并将采集接收到的数据存入云端的数据库中。企业无需担心高昂的硬件维护成本或采集 中断。
此外,优采云采集器的成本较市场同类竞争者降低50%。优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。
(7)API,自定义数据对接
虽然云端采集数据可以自动导出到用户数据库,但是通过API可以大大提高数据导出到自己系统的灵活性,轻松实现自己的系统和优采云采集器@ > 无缝对接。
你需要知道的是,优采云采集器的API有两种:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。
-------------------------------------------------- -------- 查看全部
浏览器抓取网页(,如何实时抓取动态网页数据?(一)(图))
网页数据实时抓取,实时网页数据,如何抓取实时动态网页数据?
我们生活的数字世界不断产生大量数据。动态大数据的使用已经成为企业数据分析的关键。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?

1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据可以帮助:
(1) 让数据驱动的决策更快
采集动态数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。有了所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出数据驱动的决策。
正如亚马逊首席执行官杰夫贝索斯在给股东的一封信中所说:“业务的速度至关重要。” “高速决策”对业务发展具有重要意义。
(2)建立更强大的数据库
随着数据量的不断增长,每条数据的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要通过持续不断的采集动态数据,构建一个全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度每年翻一番,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期的数据采集可以帮助解决近期的问题并做出较小的决策,而长期的数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2. 动态数据如何有效促进业务增长?
我们可以通过多种方式应用动态数据分析来促进业务发展,例如:
(1)产品监控
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从易趣上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的一种可靠且有效的方法。
(2)客户体验管理
公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超出客户期望的做法,从而提高客户满意度、忠诚度和拥护度”。
例如,提取亚马逊上某个产品的所有评论,并分析评论的正面和负面情绪,可以帮助企业了解客户对产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)营销策略
动态数据分析使公司能够了解过去哪些策略最有效,他们当前的营销策略有多有效,以及可以改进的地方。动态数据采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3. 如何轻松获取动态数据?
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网络爬虫工具,操作者无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是强大的网络爬虫工具可以让您轻松快速地抓取来自不同网站的信息,从而为您研究不同的网站结构节省大量时间。
(3)定时抓拍
这需要网络爬虫工具来支持云中的数据,而不仅仅是在本地计算机上运行。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云Cloud采集的功能远不止这些。
(4) 灵活的时间安排
优采云云采集支持随时随地抓取网页数据,时间和频率可根据需要调整。

(5)采集 更快
同时通过8-12台云服务器采集,对同一组数据的爬取速度可以比在本地计算机上运行快8-12倍。
(6) 降低数据获取成本
优采云Cloud采集支持在云端采集数据,并将采集接收到的数据存入云端的数据库中。企业无需担心高昂的硬件维护成本或采集 中断。
此外,优采云采集器的成本较市场同类竞争者降低50%。优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。

(7)API,自定义数据对接
虽然云端采集数据可以自动导出到用户数据库,但是通过API可以大大提高数据导出到自己系统的灵活性,轻松实现自己的系统和优采云采集器@ > 无缝对接。
你需要知道的是,优采云采集器的API有两种:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。
-------------------------------------------------- --------
浏览器抓取网页(你的低价机票被“虫子”吃了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-25 12:03
你的低价票被“虫子”吃掉了
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者。由于老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,就在小王正准备以“早熟”抢便宜机票时,他在网上看到一则新闻,航空公司发行的低价机票中,80%以上都是票务公司“爬虫”。 . 抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像网络上漫游的爬虫或蜘蛛,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上百亿个网页,需要依靠在庞大的“爬虫”集群上实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等多个领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现低价机票或热机票后,可以利用虚假客源的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据不同的爬虫任务和目标,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是怎么抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,甚至超过90%在高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取航空公司售票官网的信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,机票代理机构会在订单到期前添加虚假身份订单,继续“占用”低价机票,重复此过程,直到真正的找到并出售来源。
“上述操作流程构成了一个完整的机票销售链条。在这个过程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为售票机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段进行预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
第一,威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设置的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”剥头皮行为尚无明确规定,这使得恶意爬取信息成为法律法规“灰色地带”中的不当获利行为。
闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议称为“网络爬虫排除标准”。网站 可以通过这个协议告诉“爬虫”哪些页面和信息可以爬取,哪些页面和信息不能爬取。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还应通过完善管理和法律法规来限制此类行为。尤其是,法律方法可以证明其惩罚和威慑。. 航空公司也应加强对账期的管理,不提供给“爬虫”抢票的机会。
本报记者傅丽丽 查看全部
浏览器抓取网页(你的低价机票被“虫子”吃了(组图))
你的低价票被“虫子”吃掉了
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者。由于老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,就在小王正准备以“早熟”抢便宜机票时,他在网上看到一则新闻,航空公司发行的低价机票中,80%以上都是票务公司“爬虫”。 . 抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像网络上漫游的爬虫或蜘蛛,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上百亿个网页,需要依靠在庞大的“爬虫”集群上实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等多个领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现低价机票或热机票后,可以利用虚假客源的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据不同的爬虫任务和目标,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是怎么抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,甚至超过90%在高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取航空公司售票官网的信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,机票代理机构会在订单到期前添加虚假身份订单,继续“占用”低价机票,重复此过程,直到真正的找到并出售来源。
“上述操作流程构成了一个完整的机票销售链条。在这个过程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为售票机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段进行预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
第一,威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设置的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”剥头皮行为尚无明确规定,这使得恶意爬取信息成为法律法规“灰色地带”中的不当获利行为。
闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议称为“网络爬虫排除标准”。网站 可以通过这个协议告诉“爬虫”哪些页面和信息可以爬取,哪些页面和信息不能爬取。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还应通过完善管理和法律法规来限制此类行为。尤其是,法律方法可以证明其惩罚和威慑。. 航空公司也应加强对账期的管理,不提供给“爬虫”抢票的机会。
本报记者傅丽丽
浏览器抓取网页( 入门网络数据爬取,也就是Python爬虫现实中(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-09-25 03:28
入门网络数据爬取,也就是Python爬虫现实中(组图)
)
网络数据爬虫入门,即Python爬虫
在现实中,当我们使用浏览器访问网页时,网络是如何工作的,是做什么的?
首先要了解网络连接的基本流程原理,然后,就比较容易理解爬取的原理了。
1、网络连接原理
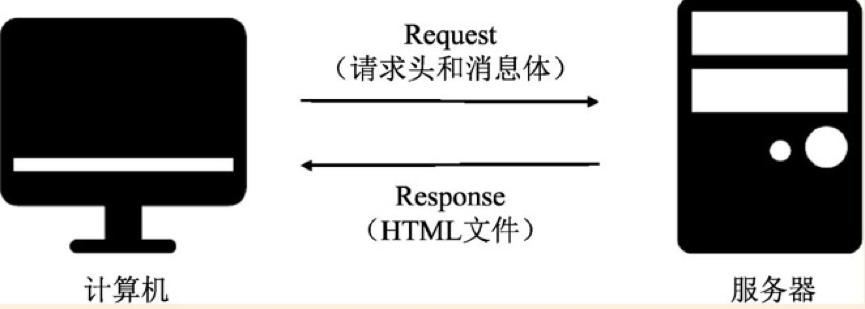
如上图,简单来说,网络连接就是计算机发起请求,服务器返回相应的HTML文件。至于请求头和消息体,详细说明了要爬取的链接。
2、爬取的原理
爬虫的原理是模拟计算机向服务器发起Request请求,接收并解析来自服务器的响应内容,提取需要的信息。
往往一次请求无法完全获取所有网页的信息和数据,则需要合理设计爬取流程,实现多页面跨页面爬取。
多页爬取的过程是怎样的?
基本思路:
1、由于多个页面的结构可能相似,可以手动翻页先观察网址
2、获取所有网址
3、根据每个页面URL的函数定义抓取数据
4、循环网址抓取存储
跨页爬取流程是什么?
基本思路:
1、查找所有网址
2、定义爬取详细页面的函数代码
3、进入详细页面查看详细数据
4、存储,循环完成,结束
3、网页是什么样子的?
右键单击并选择“检查”以打开网页的源代码。可以看到上面是HTML文件,下面是CSS样式。
我们浏览的网页是浏览器渲染的结果,是翻译HTML、CSS、JavaScript代码得到的页面界面。一个流行的比喻是:添加一个网页就是一个房子,HTML是房子的框架和布局,CSS是房子的软装饰风格,比如地板和油漆,而javaScript是电器。
比如打开百度搜索,将鼠标移动到“百度点击”按钮上,右击选择“检查”,就可以看到网页源代码的位置了。
或者直接打开右键源代码,点击网页源页面左上角的类似鼠标的图标,然后移动到网页的具体位置,就可以看到了。
总结一下:爬取数据就是发起一个请求,获取网页信息,然后找到自己想要的信息,但是在请求的过程中,很容易被逆转,禁止爬取。因此,绕过反拼字机制需要很多技巧。后续我们会一一解答。
——每天一小步,未来一大步!
查看全部
浏览器抓取网页(
入门网络数据爬取,也就是Python爬虫现实中(组图)
)

网络数据爬虫入门,即Python爬虫
在现实中,当我们使用浏览器访问网页时,网络是如何工作的,是做什么的?
首先要了解网络连接的基本流程原理,然后,就比较容易理解爬取的原理了。
1、网络连接原理
如上图,简单来说,网络连接就是计算机发起请求,服务器返回相应的HTML文件。至于请求头和消息体,详细说明了要爬取的链接。
2、爬取的原理
爬虫的原理是模拟计算机向服务器发起Request请求,接收并解析来自服务器的响应内容,提取需要的信息。
往往一次请求无法完全获取所有网页的信息和数据,则需要合理设计爬取流程,实现多页面跨页面爬取。
多页爬取的过程是怎样的?
基本思路:
1、由于多个页面的结构可能相似,可以手动翻页先观察网址
2、获取所有网址
3、根据每个页面URL的函数定义抓取数据
4、循环网址抓取存储
跨页爬取流程是什么?
基本思路:
1、查找所有网址
2、定义爬取详细页面的函数代码
3、进入详细页面查看详细数据
4、存储,循环完成,结束
3、网页是什么样子的?
右键单击并选择“检查”以打开网页的源代码。可以看到上面是HTML文件,下面是CSS样式。
我们浏览的网页是浏览器渲染的结果,是翻译HTML、CSS、JavaScript代码得到的页面界面。一个流行的比喻是:添加一个网页就是一个房子,HTML是房子的框架和布局,CSS是房子的软装饰风格,比如地板和油漆,而javaScript是电器。
比如打开百度搜索,将鼠标移动到“百度点击”按钮上,右击选择“检查”,就可以看到网页源代码的位置了。
或者直接打开右键源代码,点击网页源页面左上角的类似鼠标的图标,然后移动到网页的具体位置,就可以看到了。
总结一下:爬取数据就是发起一个请求,获取网页信息,然后找到自己想要的信息,但是在请求的过程中,很容易被逆转,禁止爬取。因此,绕过反拼字机制需要很多技巧。后续我们会一一解答。
——每天一小步,未来一大步!

浏览器抓取网页(安装selenium环境的几种常见问题及解决办法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-09-22 11:39
也可以来我的博客看看爬网谈话(一)使用selenium捕获
孟昕想要学习硒,安装是一个坑。还可以下载相关附件,可以参考Python安装Selenium环境。
1、使用firefox实例
from selenium import webdriver
import time
firefox = webdriver.Firefox() #初始化Firefox浏览器
url = 'https://www.zhihu.com'
firefox.get(url) #调用get方法抓取
time.sleep(10) #10s用于观察
with open('zhihu.html','w',encoding='utf-8') as f:
f.write(firefox.page_source) #保存网页到本地
firefox.quit()
上面的图片是一个名为Firefox的网页。使用page_source可以获得Web源代码,因为请求和请求是相同的,不必添加标题。
2、对s s配置配置的p配置
简单地说,使用selenium修改浏览器相关的参数,使浏览器没有加载js,没有图片,会增加大量速度。代码如下:
from selenium import webdriver
import time
firefox_profile = webdriver.FirefoxProfile()
firefox_profile.set_preference("permissions.default.stylesheet",2) #禁用样式表文件
firefox_profile.set_preference("permissions.default.image",2) #不加载图片
firefox_profile.set_preference("javascript.enabled",False) #禁止JS
firefox_profile.update_preferences() #更新设置
firefox = webdriver.Firefox(firefox_profile)
url = 'https://www.zhihu.com'
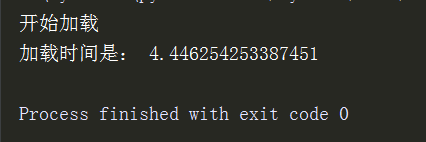
print("开始加载")
t_start = time.time()
firefox.get(url)
t_end = time.time()
print("加载时间是:",t_end-t_start)
time.sleep(10)
firefox.quit()
加载页面,如下所示
firefox_profile.set_preference("permissions.default.stylesheet",1)
firefox_profile.set_preference("permissions.default.image",1)
firefox_profile.set_preference("javascript.enabled",True)
更改2到1,错误的更改为true,请参阅
返回普通网页
4s和10s差异,它将体现在攀登多个网页。
请注意,页面加载与实际的网络环境有关。
3、图图
禁用js,页面加载是否更快,可以在每种模式下运行相同的次数,然后取得平均值。
使用matplotlib绘图
from selenium import webdriver
import time
import matplotlib.pyplot as plt
def performance(n,css_val,image_val,js_val):
loading_time = []
for i in range(0,n):
firefox_profile = webdriver.FirefoxProfile()
firefox_profile.set_preference("permissions.default.stylesheet",css_val)
firefox_profile.set_preference("permissions.default.image",image_val)
firefox_profile.set_preference("javascript.enabled",js_val)
firefox_profile.update_preferences()
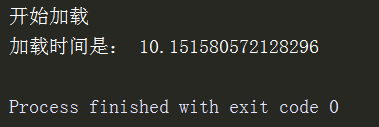
firefox = webdriver.Firefox(firefox_profile)
url = 'https://zhangslob.github.io/'
print("开始加载")
t_start = time.time()
firefox.get(url)
t_end = time.time()
print("加载时间是:",t_end-t_start)
loading_time.append(t_end-t_start)
print('=========================')
#time.sleep(10)
firefox.quit()
return [x for x in range(1,n+1)],loading_time
if __name__ == '__main__':
x1_lst,y1_lst = performance(10,1,1,True)
x2_lst,y2_lst = performance(10,2,2,False)
ava_y1 = sum(y1_lst)/len(x1_lst)
ava_y2 = sum(y2_lst)/len(x2_lst)
plt.title("Compare loading time")
plt.xlabel("Test number")
plt.ylabel("Loading time")
plt.plot(x1_lst,y1_lst,'go:',label=str(ava_y1))
plt.plot(x2_lst,y2_lst,'rs:',label=str(ava_y2))
plt.legend()
plt.show()
我将URL更改为我的博客:库克斯的博客,这更加符合实用。
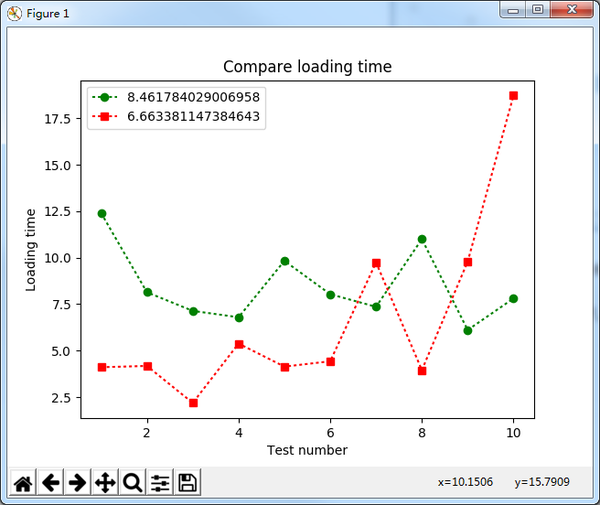
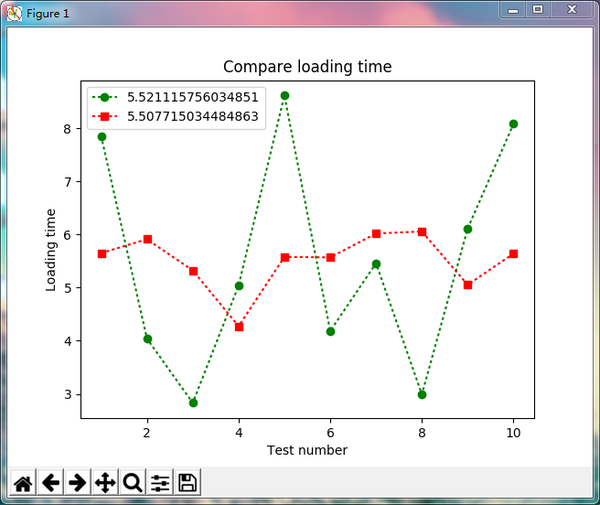
绿线是正常的网页,红色是修改的
为了确保准确,将其更改为其他URL,但为什么?
问题:
为什么可以禁用js,不要加载图片,时间和原创差异? 查看全部
浏览器抓取网页(安装selenium环境的几种常见问题及解决办法!)
也可以来我的博客看看爬网谈话(一)使用selenium捕获

孟昕想要学习硒,安装是一个坑。还可以下载相关附件,可以参考Python安装Selenium环境。
1、使用firefox实例
from selenium import webdriver
import time
firefox = webdriver.Firefox() #初始化Firefox浏览器
url = 'https://www.zhihu.com'
firefox.get(url) #调用get方法抓取
time.sleep(10) #10s用于观察
with open('zhihu.html','w',encoding='utf-8') as f:
f.write(firefox.page_source) #保存网页到本地
firefox.quit()
上面的图片是一个名为Firefox的网页。使用page_source可以获得Web源代码,因为请求和请求是相同的,不必添加标题。
2、对s s配置配置的p配置
简单地说,使用selenium修改浏览器相关的参数,使浏览器没有加载js,没有图片,会增加大量速度。代码如下:
from selenium import webdriver
import time
firefox_profile = webdriver.FirefoxProfile()
firefox_profile.set_preference("permissions.default.stylesheet",2) #禁用样式表文件
firefox_profile.set_preference("permissions.default.image",2) #不加载图片
firefox_profile.set_preference("javascript.enabled",False) #禁止JS
firefox_profile.update_preferences() #更新设置
firefox = webdriver.Firefox(firefox_profile)
url = 'https://www.zhihu.com'
print("开始加载")
t_start = time.time()
firefox.get(url)
t_end = time.time()
print("加载时间是:",t_end-t_start)
time.sleep(10)
firefox.quit()
加载页面,如下所示
firefox_profile.set_preference("permissions.default.stylesheet",1)
firefox_profile.set_preference("permissions.default.image",1)
firefox_profile.set_preference("javascript.enabled",True)
更改2到1,错误的更改为true,请参阅
返回普通网页
4s和10s差异,它将体现在攀登多个网页。
请注意,页面加载与实际的网络环境有关。
3、图图
禁用js,页面加载是否更快,可以在每种模式下运行相同的次数,然后取得平均值。
使用matplotlib绘图
from selenium import webdriver
import time
import matplotlib.pyplot as plt
def performance(n,css_val,image_val,js_val):
loading_time = []
for i in range(0,n):
firefox_profile = webdriver.FirefoxProfile()
firefox_profile.set_preference("permissions.default.stylesheet",css_val)
firefox_profile.set_preference("permissions.default.image",image_val)
firefox_profile.set_preference("javascript.enabled",js_val)
firefox_profile.update_preferences()
firefox = webdriver.Firefox(firefox_profile)
url = 'https://zhangslob.github.io/'
print("开始加载")
t_start = time.time()
firefox.get(url)
t_end = time.time()
print("加载时间是:",t_end-t_start)
loading_time.append(t_end-t_start)
print('=========================')
#time.sleep(10)
firefox.quit()
return [x for x in range(1,n+1)],loading_time
if __name__ == '__main__':
x1_lst,y1_lst = performance(10,1,1,True)
x2_lst,y2_lst = performance(10,2,2,False)
ava_y1 = sum(y1_lst)/len(x1_lst)
ava_y2 = sum(y2_lst)/len(x2_lst)
plt.title("Compare loading time")
plt.xlabel("Test number")
plt.ylabel("Loading time")
plt.plot(x1_lst,y1_lst,'go:',label=str(ava_y1))
plt.plot(x2_lst,y2_lst,'rs:',label=str(ava_y2))
plt.legend()
plt.show()
我将URL更改为我的博客:库克斯的博客,这更加符合实用。
绿线是正常的网页,红色是修改的
为了确保准确,将其更改为其他URL,但为什么?
问题:
为什么可以禁用js,不要加载图片,时间和原创差异?
浏览器抓取网页(通过实际例子讲解怎么使用javascript或者jquery获取地址url参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-09-22 04:02
本文将解释如何使用JavaScript或jQuery通过实际示例来获取地址URL参数,希望您能喜欢它。问题描述今天,我做了一个话题。虽然PHP也可以这样做,但是考虑到它们的特殊效果代码在jQuery上完成,认为它可以直接在地址栏中直接获得链接参数内的数字直接实现。假设页面的地址是这样的。 ,然后我想获得最后一个数字165,你可以通过这个代码
var url= window.location.href;
var index = url.substring(url.lastIndexOf('/') + 1);
但这是一个缺陷。如果我得到的地址不是这样的形式,但如果此索引的值不是数字。解决方案以下可能更好?
var lastBit = url.substring(url.lastIndexOf('/') + 1).match(/[^/]*$/)[0];
var lastDigits = url.substring(url.lastIndexOf('/') + 1).match(/[0-9]*$/)[0]; // 获取的是数字部分
获取查询值JavaScript版本:
function getUrlParam(name){
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r!=null) return unescape(r[2]); return null;
}
//获取http://caibaojian.com/?p=177.html的p值
getUrlParam('p'); //输出177
jQuery版本:
(function($){
$.getUrlParam = function(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r!=null) return unescape(r[2]); return null;
}
})(jQuery);
$(function(){
alert(window.location.href);
alert($.getUrlParam('page'));
})
在上面的页面时,我们使用上面的jQuery代码,将弹出5号。本网站的内容扩展:80 / file / post / 0703 / window.location.html? ver = 1. 0& ID = 6#Imerher我们可以使用JavaScript获取各种部分1,Window.Location。 href -----------整个URL字符串(浏览器中的完整地址栏)此示例返回:: 80 / fisker / post / 0703 / window.location.html? ver = 1. 0& ID = 6#IMHERE2,Window.Location.Protocol ------- URL协议部分此示例返回:http:3,window.location.host -------- - --URL的主机部分此示例返回:4,window.location.port.port ----- URL端口部分如果使用默认值80端口(更新:即使添加:8 0),则返回值不是默认值80是一个空字符。此示例返回:“”5,window.location.pathName(URL的路径一部分(即文件地址))此示例返回:/fisker/post/0703/window.location.html6,window.location.search ------查询(参数)部分除了动态语言,我们还可以提供静态页面,并使用JavaScript获取此案例的参数值。此示例返回:? ver = 1. 0& id = 67,window.location.hash -------锚点点此示例返回:#imhere 查看全部
浏览器抓取网页(通过实际例子讲解怎么使用javascript或者jquery获取地址url参数)
本文将解释如何使用JavaScript或jQuery通过实际示例来获取地址URL参数,希望您能喜欢它。问题描述今天,我做了一个话题。虽然PHP也可以这样做,但是考虑到它们的特殊效果代码在jQuery上完成,认为它可以直接在地址栏中直接获得链接参数内的数字直接实现。假设页面的地址是这样的。 ,然后我想获得最后一个数字165,你可以通过这个代码
var url= window.location.href;
var index = url.substring(url.lastIndexOf('/') + 1);
但这是一个缺陷。如果我得到的地址不是这样的形式,但如果此索引的值不是数字。解决方案以下可能更好?
var lastBit = url.substring(url.lastIndexOf('/') + 1).match(/[^/]*$/)[0];
var lastDigits = url.substring(url.lastIndexOf('/') + 1).match(/[0-9]*$/)[0]; // 获取的是数字部分
获取查询值JavaScript版本:
function getUrlParam(name){
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r!=null) return unescape(r[2]); return null;
}
//获取http://caibaojian.com/?p=177.html的p值
getUrlParam('p'); //输出177
jQuery版本:
(function($){
$.getUrlParam = function(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r!=null) return unescape(r[2]); return null;
}
})(jQuery);
$(function(){
alert(window.location.href);
alert($.getUrlParam('page'));
})
在上面的页面时,我们使用上面的jQuery代码,将弹出5号。本网站的内容扩展:80 / file / post / 0703 / window.location.html? ver = 1. 0& ID = 6#Imerher我们可以使用JavaScript获取各种部分1,Window.Location。 href -----------整个URL字符串(浏览器中的完整地址栏)此示例返回:: 80 / fisker / post / 0703 / window.location.html? ver = 1. 0& ID = 6#IMHERE2,Window.Location.Protocol ------- URL协议部分此示例返回:http:3,window.location.host -------- - --URL的主机部分此示例返回:4,window.location.port.port ----- URL端口部分如果使用默认值80端口(更新:即使添加:8 0),则返回值不是默认值80是一个空字符。此示例返回:“”5,window.location.pathName(URL的路径一部分(即文件地址))此示例返回:/fisker/post/0703/window.location.html6,window.location.search ------查询(参数)部分除了动态语言,我们还可以提供静态页面,并使用JavaScript获取此案例的参数值。此示例返回:? ver = 1. 0& id = 67,window.location.hash -------锚点点此示例返回:#imhere
浏览器抓取网页(Python3实现抓取javascript动态生成的html网页功能结合实例形式分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-18 17:16
本文文章主要介绍了Python 3捕获JavaScript动态生成的HTML网页的功能,并以实例的形式分析了Python 3使用selenium库捕获JavaScript动态生成的HTML网页元素的相关操作技巧。有需要的朋友可以参考
本文描述了Python3获取JavaScript动态生成的HTML网页的功能。与您分享,供您参考,如下所示:
使用urllib获取网页时,只能读取网页的静态源文件,但无法捕获JavaScript生成的内容
原因是urlib即时抓取,不等待JavaScript加载延迟,因此urlib无法读取页面中JavaScript生成的内容
真的没有办法读取JavaScript生成的内容吗?没有
这里有一个python库:selenium。本文使用的版本是2.4 4.0
首先安装:
pip install -U selenium
以下是三个示例来说明其用法:
[示例0]
打开Firefox浏览器
加载具有给定URL地址的页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
[示例1]
打开Firefox浏览器
加载百度主页
搜索“selenium HQ”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
[示例2]
SeleniumWebDriver通常用于测试网络程序。以下是使用python标准库unittest的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
以上是Python 3如何捕获由JS动态生成的HTML网页的函数实现示例的详细信息。请多关注其他相关文章
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系 查看全部
浏览器抓取网页(Python3实现抓取javascript动态生成的html网页功能结合实例形式分析)
本文文章主要介绍了Python 3捕获JavaScript动态生成的HTML网页的功能,并以实例的形式分析了Python 3使用selenium库捕获JavaScript动态生成的HTML网页元素的相关操作技巧。有需要的朋友可以参考
本文描述了Python3获取JavaScript动态生成的HTML网页的功能。与您分享,供您参考,如下所示:
使用urllib获取网页时,只能读取网页的静态源文件,但无法捕获JavaScript生成的内容
原因是urlib即时抓取,不等待JavaScript加载延迟,因此urlib无法读取页面中JavaScript生成的内容
真的没有办法读取JavaScript生成的内容吗?没有
这里有一个python库:selenium。本文使用的版本是2.4 4.0
首先安装:
pip install -U selenium
以下是三个示例来说明其用法:
[示例0]
打开Firefox浏览器
加载具有给定URL地址的页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
[示例1]
打开Firefox浏览器
加载百度主页
搜索“selenium HQ”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
[示例2]
SeleniumWebDriver通常用于测试网络程序。以下是使用python标准库unittest的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
以上是Python 3如何捕获由JS动态生成的HTML网页的函数实现示例的详细信息。请多关注其他相关文章

声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系
浏览器抓取网页(免费资源网,第11行c#获取浏览器页面内容的资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-14 11:15
免费资源网络,
private void timer1_Tick(object sender, EventArgs e)
{
lock (currentLock)
{
System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
if (_leftClick)
{
timer1.Stop();
_leftClick = false;
_lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
if (_lastDocument != null)
{
if (_getDocument)
{
_getDocument = true;
try
{
string url = _lastDocument.url;
string html = _lastDocument.documentElement.outerHTML;
string cookie = _lastDocument.cookie;
string domain = _lastDocument.domain;
var resolveParams = new ResolveParam
{
Url = new Uri(url),
Html = html,
PageCookie = cookie,
Domain = domain
};
RequetResove(resolveParams);
}
catch (Exception ex)
{
System.Windows.MessageBox.Show(ex.Message);
Console.WriteLine(ex.Message);
Console.WriteLine(ex.StackTrace);
}
}
}
else
{
new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
}
_getDocument = false;
}
else
{
_pointFrm.Left = MousePoint.X + 10;
_pointFrm.Top = MousePoint.Y + 10;
}
}
}
在第11行的GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))分解下,首先从鼠标坐标获取页面的句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
{
IntPtr handle = Win32APIsFull.WindowFromPoint(p);
if (handle != IntPtr.Zero)
{
System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
if (Win32APIsFull.GetWindowRect(handle, out rect))
{
return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
}
}
return IntPtr.Zero;
}
接下来根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
{
IntPtr result = Marshal.AllocHGlobal(4);
Object obj = null;
Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
if (Marshal.ReadInt32(result) != 0)
{
Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
}
Marshal.FreeHGlobal(result);
return obj as HTMLDocument;
}
一般原则:
向IE表单发送消息,获取一个指向IE浏览器内存块的指针(非托管),然后根据这个指针获取HTMLDocument对象。
这个方法涉及到win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
);
以上是c#从IE浏览器获取当前页面内容的详细内容。更多关于c#获取浏览器页面内容的信息,请关注其他相关文章!
免费资源网络, 查看全部
浏览器抓取网页(免费资源网,第11行c#获取浏览器页面内容的资料)
免费资源网络,
private void timer1_Tick(object sender, EventArgs e)
{
lock (currentLock)
{
System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
if (_leftClick)
{
timer1.Stop();
_leftClick = false;
_lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
if (_lastDocument != null)
{
if (_getDocument)
{
_getDocument = true;
try
{
string url = _lastDocument.url;
string html = _lastDocument.documentElement.outerHTML;
string cookie = _lastDocument.cookie;
string domain = _lastDocument.domain;
var resolveParams = new ResolveParam
{
Url = new Uri(url),
Html = html,
PageCookie = cookie,
Domain = domain
};
RequetResove(resolveParams);
}
catch (Exception ex)
{
System.Windows.MessageBox.Show(ex.Message);
Console.WriteLine(ex.Message);
Console.WriteLine(ex.StackTrace);
}
}
}
else
{
new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
}
_getDocument = false;
}
else
{
_pointFrm.Left = MousePoint.X + 10;
_pointFrm.Top = MousePoint.Y + 10;
}
}
}
在第11行的GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))分解下,首先从鼠标坐标获取页面的句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
{
IntPtr handle = Win32APIsFull.WindowFromPoint(p);
if (handle != IntPtr.Zero)
{
System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
if (Win32APIsFull.GetWindowRect(handle, out rect))
{
return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
}
}
return IntPtr.Zero;
}
接下来根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
{
IntPtr result = Marshal.AllocHGlobal(4);
Object obj = null;
Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
if (Marshal.ReadInt32(result) != 0)
{
Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
}
Marshal.FreeHGlobal(result);
return obj as HTMLDocument;
}
一般原则:
向IE表单发送消息,获取一个指向IE浏览器内存块的指针(非托管),然后根据这个指针获取HTMLDocument对象。
这个方法涉及到win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
);
以上是c#从IE浏览器获取当前页面内容的详细内容。更多关于c#获取浏览器页面内容的信息,请关注其他相关文章!
免费资源网络,
浏览器抓取网页(民间大神提取的小米浏览器很好用,你懂得吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 378 次浏览 • 2021-10-09 05:22
手机制造商的定制ROM中有一些非常有用的应用程序。还有民间大神提取的官方发布和独立安装版本。
其中,最著名的APP就是“锤子便签”,这款便签真的好用。本笔记属于官方单机版。还有一些提取的版本,比如百度云索尼定制版,不限速=_=
今天这就是民间大神提取出来的小米浏览器。不能说它很容易使用。毕竟和UC差别不大,功能也不如UC。
第一次安装会有一个“使用声明”对话框。
如果剪贴板的最后剪辑内容是“网络链接”,系统会询问您是否要打开它。
这种浏览器其实挺“UC”的,国内大部分浏览器都是设计这种UI交互的。而Chrome完全是两种风格。但单手操作更好。如果Chrome浏览器系统中没有“菜单按钮”,则必须使用Chrome自带的右上角菜单按钮。单手操作相当棘手。
这个浏览器的布局并不奇怪。
左侧屏幕上还有一个新闻聚合阅读页面。UC,QQ,都是这样。拥有一两个这样的浏览器并不奇怪。
(顶栏的文字好熟悉)
相似,不仅仅是相似。但是,在全屏阅读新闻时,搜索栏会保留。也可以看出它是一个浏览器。
软件设置不多。这只是一个很小的区别。
小米浏览器版本为8.1.6。
另外,H5网页上的视频不能离线。这与某些浏览器相差甚远。
不过保存网页的能力是值得称赞的,UC也需要一个插件。
几乎没有找到隐私浏览,只在多窗口页面的顶部找到它。字体不明显。你懂。
环顾四周,最大的优势就是RAM的占用没有UC那么大。但是差别不大。
另外,这个浏览器也没有发现任何广告,所以不排除被大神提取的时候,顺便把广告去掉了。
软件体积30M,操控还不错。Android MarshMallow 自带的浏览器安装包为37MB。
一些第三方浏览器可以使用自己的浏览器。所以可以很好的控制,甚至低于1MB。和Chrome一样独立,46MB也很正常。
这个浏览器在“捆绑浏览器”这个分类中还是比较OK的。纵观浏览器市场,似乎很不起眼。
不过,我也很高兴看到一些国际大厂的内置浏览器也“本地化”了。比如LG G5自带的浏览器。嗯,这很UC。底部导航栏什么的。
如果你想要一个主浏览器,不推荐。如果需要备胎,可以考虑。流畅度还是很OK的。 查看全部
浏览器抓取网页(民间大神提取的小米浏览器很好用,你懂得吗?)
手机制造商的定制ROM中有一些非常有用的应用程序。还有民间大神提取的官方发布和独立安装版本。
其中,最著名的APP就是“锤子便签”,这款便签真的好用。本笔记属于官方单机版。还有一些提取的版本,比如百度云索尼定制版,不限速=_=
今天这就是民间大神提取出来的小米浏览器。不能说它很容易使用。毕竟和UC差别不大,功能也不如UC。
第一次安装会有一个“使用声明”对话框。
如果剪贴板的最后剪辑内容是“网络链接”,系统会询问您是否要打开它。
这种浏览器其实挺“UC”的,国内大部分浏览器都是设计这种UI交互的。而Chrome完全是两种风格。但单手操作更好。如果Chrome浏览器系统中没有“菜单按钮”,则必须使用Chrome自带的右上角菜单按钮。单手操作相当棘手。
这个浏览器的布局并不奇怪。
左侧屏幕上还有一个新闻聚合阅读页面。UC,QQ,都是这样。拥有一两个这样的浏览器并不奇怪。
(顶栏的文字好熟悉)
相似,不仅仅是相似。但是,在全屏阅读新闻时,搜索栏会保留。也可以看出它是一个浏览器。
软件设置不多。这只是一个很小的区别。
小米浏览器版本为8.1.6。
另外,H5网页上的视频不能离线。这与某些浏览器相差甚远。
不过保存网页的能力是值得称赞的,UC也需要一个插件。
几乎没有找到隐私浏览,只在多窗口页面的顶部找到它。字体不明显。你懂。
环顾四周,最大的优势就是RAM的占用没有UC那么大。但是差别不大。
另外,这个浏览器也没有发现任何广告,所以不排除被大神提取的时候,顺便把广告去掉了。
软件体积30M,操控还不错。Android MarshMallow 自带的浏览器安装包为37MB。
一些第三方浏览器可以使用自己的浏览器。所以可以很好的控制,甚至低于1MB。和Chrome一样独立,46MB也很正常。
这个浏览器在“捆绑浏览器”这个分类中还是比较OK的。纵观浏览器市场,似乎很不起眼。
不过,我也很高兴看到一些国际大厂的内置浏览器也“本地化”了。比如LG G5自带的浏览器。嗯,这很UC。底部导航栏什么的。
如果你想要一个主浏览器,不推荐。如果需要备胎,可以考虑。流畅度还是很OK的。
浏览器抓取网页(小小课堂SEO学网带来的是《》《》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-09 03:05
URL,统一资源定位器,通过对URL的分析,可以更好的了解页面的爬取过程。
今天,小小课堂SEO学习网就为大家简单介绍一下页面抓取的过程。希望本次SEO技术培训对大家有所帮助。
一、url是什么意思?
URL英文叫做“uniform resource locator”,中文翻译为“uniform resource locator”。
在网站优化中,要求每个页面有一个且只有一个唯一的统一资源定位符(URL),但往往很多网站同一个页面对应多个URL,如果都被搜索引擎搜索到的话收录且没有URL重定向,权重不集中,通常称为URL不规则。
二、url的组成
统一资源定位符(URL)由三部分组成:协议方案、主机名和资源名。
三、页面爬取过程简述
不管是我们平时使用的网络浏览器,还是网络爬虫,虽然有两个不同的客户端,但是获取页面的方式是一样的。页面抓取过程如下:
① 连接DNS服务器
客户端首先会连接到DNS域名服务器,DNS服务器将主机名转换成IP地址并发回给客户端。
PS:原来我们用的地址是111.152。151.45 访问某个网站。为了便于记忆和使用,我们使用了DNS域名系统对其进行了转换。这就是 DNS 域名系统的作用。
②连接IP地址服务器
这个IP服务器下可能有很多程序(网站),可以通过端口号来区分。同时每个程序(网站)都会监听端口上是否有新的连接请求,HTTP网站默认为80,HTTPS网站默认为443。
不过一般情况下,80和443端口号默认是不会出现的。
③ 建立连接并发送寻呼请求
客户端与服务器建立连接后,会发送一个页面请求,通常是get或者post。 查看全部
浏览器抓取网页(小小课堂SEO学网带来的是《》《》)
URL,统一资源定位器,通过对URL的分析,可以更好的了解页面的爬取过程。
今天,小小课堂SEO学习网就为大家简单介绍一下页面抓取的过程。希望本次SEO技术培训对大家有所帮助。
一、url是什么意思?
URL英文叫做“uniform resource locator”,中文翻译为“uniform resource locator”。
在网站优化中,要求每个页面有一个且只有一个唯一的统一资源定位符(URL),但往往很多网站同一个页面对应多个URL,如果都被搜索引擎搜索到的话收录且没有URL重定向,权重不集中,通常称为URL不规则。
二、url的组成
统一资源定位符(URL)由三部分组成:协议方案、主机名和资源名。
三、页面爬取过程简述
不管是我们平时使用的网络浏览器,还是网络爬虫,虽然有两个不同的客户端,但是获取页面的方式是一样的。页面抓取过程如下:
① 连接DNS服务器
客户端首先会连接到DNS域名服务器,DNS服务器将主机名转换成IP地址并发回给客户端。
PS:原来我们用的地址是111.152。151.45 访问某个网站。为了便于记忆和使用,我们使用了DNS域名系统对其进行了转换。这就是 DNS 域名系统的作用。
②连接IP地址服务器
这个IP服务器下可能有很多程序(网站),可以通过端口号来区分。同时每个程序(网站)都会监听端口上是否有新的连接请求,HTTP网站默认为80,HTTPS网站默认为443。
不过一般情况下,80和443端口号默认是不会出现的。
③ 建立连接并发送寻呼请求
客户端与服务器建立连接后,会发送一个页面请求,通常是get或者post。
浏览器抓取网页(面试时说说思路和想法就行了,还要回去做个东西给他?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-09 03:00
关于收到的页面,如何分析过滤,我的想法不是很新鲜,欢迎大家给我各种建议,有需要注意的地方提醒一下!
- - - 解决方案 - - - - - - - - - -
建议楼主找新公司。
这是什么?就在面试的时候说说你的想法和想法,然后回去给他做点什么?
- - - 解决方案 - - - - - - - - - -
你可以把它做成一个中转站,接受客户的请求,然后自己把请求发给百度,然后得到他的回应
然后处理响应流...至于处理方法...
我自己没有太多经验。你问的专家在他的网站上有他自己的上传文件的源代码。有一些代码用于处理这些流。您可以参考以下内容。
- - - 解决方案 - - - - - - - - - -
1 次抓取
2 正则匹配
超过
- - - 解决方案 - - - - - - - - - -
过来看看热闹。. 对了,老子竹不是有网页爬虫系统吗?. 或者我错了。.
- - - 解决方案 - - - - - - - - - -
我记得有一根竹子。你去他的网站看看。
- - - 解决方案 - - - - - - - - - -
讨论
1 次抓取
2 正则匹配
超过
- - - 解决方案 - - - - - - - - - -
正则表达式
- - - 解决方案 - - - - - - - - - -
我不认为这很难,对吧,
首先使用流的内容到网页,
第二种是将title设置为关键字,并使用常规的title值,
- - - 解决方案 - - - - - - - - - -
哈哈,这很有趣。我们的项目经理还说那天我们可以自由地做这样的事情。大部分代码都在,不过只是项目中的代码,没办法暴露,哈哈。
- - - 解决方案 - - - - - - - - - -
建议你去车东的网站,
- - - 解决方案 - - - - - - - - - -
讨论
引用:
1 次抓取
2 正则匹配
超过
哪一种更有效率?? ?
- - - 解决方案 - - - - - - - - - -
贼
常规的
- - - 解决方案 - - - - - - - - - -
1.分析百度搜索时如何发送请求
2.使用您指定的关键字伪造请求
3.使用apache common-httpclient(我忘了是不是这个)获取百度网页的内容
4.使用正则表达式抓取网页内容
- - - 解决方案 - - - - - - - - - -
经过。. . 研究了一下,好像前几天刚看到类似的问题,
AJAX取结果,正则法等方法处理结果流,显示处理结果,结果有多页的情况如何处理?
- - - 解决方案 - - - - - - - - - -
当有多个页面时,先用正则表达式获取网页下页码的url,循环获取,然后重复发送网页请求。定期获取您想要的内容。Lucene 是个好东西。如果你需要工作,你可以好好看看。但是既然你需要把关键字Send it to baidu 百度会给你做的检索工作或者不使用它。学习这个东西需要时间。
- - - 解决方案 - - - - - - - - - -
常规~
- - - 解决方案 - - - - - - - - - -
你用httpclient模拟cookies等抓取整个数据,然后定时匹配抓取相关的!我刚做了这个东西!但是有验证码有点难啊!
- - - 解决方案 - - - - - - - - - -
不知道,楼主已经解决了,建议你去看看Nutch,这是一个从抓取网页到页面分析,再到构建搜索,再到查询的完整实现的搜索引擎。它是开源的。
引用:
引用:
1 次抓取
2 正则匹配
超过
哪一种更有效率?? ?
发帖人的思路其实就是这两个步骤的具体解释,1.抓取,就是发帖人说的:“网络爬虫”。
我是这样想的:1.做一个jsp页面,在里面输入一条信息,然后转发到百度。
2. 然后接收并下载返回的页面。
2、正则匹配指的是楼主提到的:3.将返回的html页面作为xml文件一一分析过滤。
4. 把过滤后的数据整理出来,提取我需要的部分
然后返回自己的jsp页面进行展示!这一步其实就是nutch的查询
上面的东西已经nutch实现了,可以参考
- - - 解决方案 - - - - - - - - - - 查看全部
浏览器抓取网页(面试时说说思路和想法就行了,还要回去做个东西给他?)
关于收到的页面,如何分析过滤,我的想法不是很新鲜,欢迎大家给我各种建议,有需要注意的地方提醒一下!
- - - 解决方案 - - - - - - - - - -
建议楼主找新公司。
这是什么?就在面试的时候说说你的想法和想法,然后回去给他做点什么?
- - - 解决方案 - - - - - - - - - -
你可以把它做成一个中转站,接受客户的请求,然后自己把请求发给百度,然后得到他的回应
然后处理响应流...至于处理方法...
我自己没有太多经验。你问的专家在他的网站上有他自己的上传文件的源代码。有一些代码用于处理这些流。您可以参考以下内容。
- - - 解决方案 - - - - - - - - - -
1 次抓取
2 正则匹配
超过
- - - 解决方案 - - - - - - - - - -
过来看看热闹。. 对了,老子竹不是有网页爬虫系统吗?. 或者我错了。.
- - - 解决方案 - - - - - - - - - -
我记得有一根竹子。你去他的网站看看。
- - - 解决方案 - - - - - - - - - -
讨论
1 次抓取
2 正则匹配
超过
- - - 解决方案 - - - - - - - - - -
正则表达式
- - - 解决方案 - - - - - - - - - -
我不认为这很难,对吧,
首先使用流的内容到网页,
第二种是将title设置为关键字,并使用常规的title值,
- - - 解决方案 - - - - - - - - - -
哈哈,这很有趣。我们的项目经理还说那天我们可以自由地做这样的事情。大部分代码都在,不过只是项目中的代码,没办法暴露,哈哈。
- - - 解决方案 - - - - - - - - - -
建议你去车东的网站,
- - - 解决方案 - - - - - - - - - -
讨论
引用:
1 次抓取
2 正则匹配
超过
哪一种更有效率?? ?
- - - 解决方案 - - - - - - - - - -
贼
常规的
- - - 解决方案 - - - - - - - - - -
1.分析百度搜索时如何发送请求
2.使用您指定的关键字伪造请求
3.使用apache common-httpclient(我忘了是不是这个)获取百度网页的内容
4.使用正则表达式抓取网页内容
- - - 解决方案 - - - - - - - - - -
经过。. . 研究了一下,好像前几天刚看到类似的问题,
AJAX取结果,正则法等方法处理结果流,显示处理结果,结果有多页的情况如何处理?
- - - 解决方案 - - - - - - - - - -
当有多个页面时,先用正则表达式获取网页下页码的url,循环获取,然后重复发送网页请求。定期获取您想要的内容。Lucene 是个好东西。如果你需要工作,你可以好好看看。但是既然你需要把关键字Send it to baidu 百度会给你做的检索工作或者不使用它。学习这个东西需要时间。
- - - 解决方案 - - - - - - - - - -
常规~
- - - 解决方案 - - - - - - - - - -
你用httpclient模拟cookies等抓取整个数据,然后定时匹配抓取相关的!我刚做了这个东西!但是有验证码有点难啊!
- - - 解决方案 - - - - - - - - - -
不知道,楼主已经解决了,建议你去看看Nutch,这是一个从抓取网页到页面分析,再到构建搜索,再到查询的完整实现的搜索引擎。它是开源的。
引用:
引用:
1 次抓取
2 正则匹配
超过
哪一种更有效率?? ?
发帖人的思路其实就是这两个步骤的具体解释,1.抓取,就是发帖人说的:“网络爬虫”。
我是这样想的:1.做一个jsp页面,在里面输入一条信息,然后转发到百度。
2. 然后接收并下载返回的页面。
2、正则匹配指的是楼主提到的:3.将返回的html页面作为xml文件一一分析过滤。
4. 把过滤后的数据整理出来,提取我需要的部分
然后返回自己的jsp页面进行展示!这一步其实就是nutch的查询
上面的东西已经nutch实现了,可以参考
- - - 解决方案 - - - - - - - - - -
浏览器抓取网页(国外开发者开发的一款Logo获取工具浏览器插件,消除隔阂)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-09 02:27
logo采集器插件介绍
碰巧需要下载一些网站的logo。偶然发现了一个国外开发者开发的logo获取工具浏览器插件,支持Chrome、FireFox、360等浏览器,一键傻瓜式操作下载他们的Logo,而且是PNG格式格式。
为了让更多人使用这么好的插件,消除语言障碍,我发扬雷锋精神,将插件制作成中文。
标志抓取器安装方法
1、下载附件,使用压缩软件解压压缩文件,保存到系统任意文件夹。
2、在Chrome(或360、QQ等浏览器)地址栏输入:chrome://extensions/ 打开Chrome浏览器的扩展管理界面,在界面右上角勾选“开发者模式”按钮。
3、 勾选开发者模式选项后,页面上会出现加载开发中扩展的按钮,点击“加载开发中扩展”按钮,选择刚才解压的Chrome插件文件夹。
4、 单击“确定”按钮。如果此时没有任何反应,则插件将成功加载到浏览器中。
如何使用徽标抓取器
1、使用谷歌浏览器(或其他Chrome浏览器)打开目标网站。
2、 点击浏览器上的“Logograbber”,它会开始抓取可能的logo图案。
3、 点击“下载”下载对应的Logo格式。
4、如果您发现显示的logo不是正确的logo,您也可以通过下面的链接反馈问题。
提示:并非所有 网站 都支持,但大部分 网站 仍然可用。该工具可以节省时间并提高工作效率。其次,你可以得到png格式的图片,图片质量必须高于截图。, 第三,可以拿到一些隐藏标签中的Logo,整体还是不错的。
最后请注意,我刚刚用中文完成了各种功能。至于技术问题,我不会和你交流。
如果你觉得还不错,就点击下方的“免费评分”支持一下吧! 查看全部
浏览器抓取网页(国外开发者开发的一款Logo获取工具浏览器插件,消除隔阂)
logo采集器插件介绍
碰巧需要下载一些网站的logo。偶然发现了一个国外开发者开发的logo获取工具浏览器插件,支持Chrome、FireFox、360等浏览器,一键傻瓜式操作下载他们的Logo,而且是PNG格式格式。
为了让更多人使用这么好的插件,消除语言障碍,我发扬雷锋精神,将插件制作成中文。
标志抓取器安装方法
1、下载附件,使用压缩软件解压压缩文件,保存到系统任意文件夹。
2、在Chrome(或360、QQ等浏览器)地址栏输入:chrome://extensions/ 打开Chrome浏览器的扩展管理界面,在界面右上角勾选“开发者模式”按钮。
3、 勾选开发者模式选项后,页面上会出现加载开发中扩展的按钮,点击“加载开发中扩展”按钮,选择刚才解压的Chrome插件文件夹。
4、 单击“确定”按钮。如果此时没有任何反应,则插件将成功加载到浏览器中。
如何使用徽标抓取器
1、使用谷歌浏览器(或其他Chrome浏览器)打开目标网站。
2、 点击浏览器上的“Logograbber”,它会开始抓取可能的logo图案。
3、 点击“下载”下载对应的Logo格式。
4、如果您发现显示的logo不是正确的logo,您也可以通过下面的链接反馈问题。
提示:并非所有 网站 都支持,但大部分 网站 仍然可用。该工具可以节省时间并提高工作效率。其次,你可以得到png格式的图片,图片质量必须高于截图。, 第三,可以拿到一些隐藏标签中的Logo,整体还是不错的。
最后请注意,我刚刚用中文完成了各种功能。至于技术问题,我不会和你交流。
如果你觉得还不错,就点击下方的“免费评分”支持一下吧!
浏览器抓取网页(1.请正确使用网页爬虫非法数据影响他人服务器的正常工作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-07 03:14
1.请正确使用网络爬虫,不要使用爬虫对非法数据进行爬网,也不要影响其他服务器的正常工作
2.本文抓取的数据是跨境网站商品的公共信息。本文仅用于学习和交流
3.本文附带源代码。爬行时间间隔为10s,数据采集量大于2000
单击此处获取本文的源代码
任务目标
捕获电子商务大数据网站背景下披露的数千个商品数据,并将数据保存在Excel中进行数据分析
难度分析
您需要登录网站会员账号才能在后台查看数据网站反爬网已经设置,因此很难模拟登录。使用selenium控制Chrome浏览器。在测试模式下网站可以识别,无法正常登录账号。数据只有在页面刷新后才能正常显示
解决困难
在线搜索隐藏selenium功能的各种方法失败,因此通过selenium打开新浏览器的方法将不起作用。此外,许多网站可以通过多种功能识别您是否使用了selenium
2.根据研究,可以通过向selenium添加debuggeraddress来控制在该端口上打开的浏览器
(1)输入chrome.exe所在的文件夹,在地址栏中输入“CMD”,然后在此路径下打开CMD窗口
(2)在CMD窗口中,输入以下命令以打开新的Chrome浏览器窗口,在此窗口中打开目标网站,然后登录到成员帐户
(3)在Python代码中,为selenium添加选项。此处添加的端口地址应与上面CMD命令中的端口一致
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
3.您可以通过每次访问和刷新页面获得整个页面的HTML代码,然后使用beatifulsoup进行网页分析,提取商品的有用信息
driver.get(url)
driver.refresh()
time.sleep(10)
html = driver.find_element_by_xpath("//*").get_attribute("outerHTML")
soup = BeautifulSoup(html,'html.parser')
程序逻辑
1.通过打开的浏览器访问目标网站,登录到成员帐户,并转换数据页
# 使用网页驱动来运行chrome浏览器
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Chrome(r"C:\Users\E490\Anaconda3\Scripts\chromedriver",options=chrome_options)
# 访问网站首页,停留15s,人工登录后,自动刷新页面,停留10s,并搜索关键词
driver.get(url)
driver.refresh()
time.sleep(10)
html = driver.find_element_by_xpath("//*").get_attribute("outerHTML")
soup = BeautifulSoup(html,'html.parser')
2.分析需要通过浏览器F12获取字段的HTML代码,并能够解析要通过beautiful soup库交换的数据字段
#产品标题
item_name = items_content[0].p['title']
#店铺名称
shop_name = items_content[1].text.strip()
#店铺类型
shop_type = items_content[2].text.strip()
#店铺类目
shop_categroy =items_content[3].text.strip()
#商品折扣价
item_discount_price = items_content[4].text.strip()
3.将采集到的数据及时保存到CSV文件中
#打开csv文件
csv_title = 'lazada'+str(random.randint(100,999))+'.csv'
f = open(csv_title,'a',encoding='utf-8',newline='')
# 基于文件对象构建 csv写入对象
csv_writer = csv.writer(f)
# 构建列表头
csv_writer.writerow(["产品标题","店铺名称","店铺类型","店铺类目","商品折扣价","商品评分","累积评论数"])
4.优化代码,使其能够完成100多个网页的循环访问
5.查看获取的跨境电商商品数据
单击此处获取本文的源代码 查看全部
浏览器抓取网页(1.请正确使用网页爬虫非法数据影响他人服务器的正常工作)
1.请正确使用网络爬虫,不要使用爬虫对非法数据进行爬网,也不要影响其他服务器的正常工作
2.本文抓取的数据是跨境网站商品的公共信息。本文仅用于学习和交流
3.本文附带源代码。爬行时间间隔为10s,数据采集量大于2000
单击此处获取本文的源代码
任务目标
捕获电子商务大数据网站背景下披露的数千个商品数据,并将数据保存在Excel中进行数据分析
难度分析
您需要登录网站会员账号才能在后台查看数据网站反爬网已经设置,因此很难模拟登录。使用selenium控制Chrome浏览器。在测试模式下网站可以识别,无法正常登录账号。数据只有在页面刷新后才能正常显示
解决困难
在线搜索隐藏selenium功能的各种方法失败,因此通过selenium打开新浏览器的方法将不起作用。此外,许多网站可以通过多种功能识别您是否使用了selenium
2.根据研究,可以通过向selenium添加debuggeraddress来控制在该端口上打开的浏览器
(1)输入chrome.exe所在的文件夹,在地址栏中输入“CMD”,然后在此路径下打开CMD窗口
(2)在CMD窗口中,输入以下命令以打开新的Chrome浏览器窗口,在此窗口中打开目标网站,然后登录到成员帐户
(3)在Python代码中,为selenium添加选项。此处添加的端口地址应与上面CMD命令中的端口一致
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
3.您可以通过每次访问和刷新页面获得整个页面的HTML代码,然后使用beatifulsoup进行网页分析,提取商品的有用信息
driver.get(url)
driver.refresh()
time.sleep(10)
html = driver.find_element_by_xpath("//*").get_attribute("outerHTML")
soup = BeautifulSoup(html,'html.parser')
程序逻辑
1.通过打开的浏览器访问目标网站,登录到成员帐户,并转换数据页
# 使用网页驱动来运行chrome浏览器
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Chrome(r"C:\Users\E490\Anaconda3\Scripts\chromedriver",options=chrome_options)
# 访问网站首页,停留15s,人工登录后,自动刷新页面,停留10s,并搜索关键词
driver.get(url)
driver.refresh()
time.sleep(10)
html = driver.find_element_by_xpath("//*").get_attribute("outerHTML")
soup = BeautifulSoup(html,'html.parser')
2.分析需要通过浏览器F12获取字段的HTML代码,并能够解析要通过beautiful soup库交换的数据字段
#产品标题
item_name = items_content[0].p['title']
#店铺名称
shop_name = items_content[1].text.strip()
#店铺类型
shop_type = items_content[2].text.strip()
#店铺类目
shop_categroy =items_content[3].text.strip()
#商品折扣价
item_discount_price = items_content[4].text.strip()
3.将采集到的数据及时保存到CSV文件中
#打开csv文件
csv_title = 'lazada'+str(random.randint(100,999))+'.csv'
f = open(csv_title,'a',encoding='utf-8',newline='')
# 基于文件对象构建 csv写入对象
csv_writer = csv.writer(f)
# 构建列表头
csv_writer.writerow(["产品标题","店铺名称","店铺类型","店铺类目","商品折扣价","商品评分","累积评论数"])
4.优化代码,使其能够完成100多个网页的循环访问
5.查看获取的跨境电商商品数据
单击此处获取本文的源代码
浏览器抓取网页(网站日志在哪?如何查看网站被百度抓取的情况?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-07 03:12
你的网站/网页是否被百度抓取以及抓取频率会影响你的排名。
01如何查看网站被抓包的状态?
首先我们要知道百度用来抓取网页的工具是Baiduspider(百度蜘蛛),它的动作会被记录在网站的日志中,我们可以从日志中读取到Baiduspider 网站(百度蜘蛛)活动:抓取的频率和抓取后返回的HTTP状态码,用于查看网站被百度抓取的状态。所以下一步就是找到网站日志的内容。
02网站日志在哪里?如何查看
通常网站 日志文件位于管理后端的 logofiles 文件夹下。登录“FTP”账号,找到一个文件扩展名为.log的日志文件,下载并解压,将文件更改为记事本。这是网站日志,记录了网站是否被百度蜘蛛(Baidu Spider)爬取,爬取是否成功。
接下来,作者介绍了如何用这样一段代码进行日志分析。示例:时间 GET /images/index5_22.gif-- IP 地址 HTTP/1.1 浏览器和操作系统/news/detail/181.html 200 360 where, "GET / images /index5_22.gif" 表示:从服务器获取页面"/images/index5_22.gif"或文件;HTTP/1.1 浏览器及操作系统/news/detail/181.html 200 360,代表:抓取后返回的状态(成功与否,抓取次数) 200,状态码,表示爬取成功;360,volume,代表爬取多少字节,360字节;
常见状态码
200:表示服务器成功接受了客户端请求。这是最好的,这意味着网站页面是正常的。
301:表示用户访问的某个页面经过了301重定向(永久)处理。
302:这是一个临时重定向。如果网站日志分析发现302太多,需要确认301是否误认为302,如果是,赶紧修改。搜索引擎不喜欢 302 重定向。
404:表示访问的页面不存在了,或者访问的URL是错误的。
500:服务器错误。03 百度蜘蛛的活跃度:抓取频率是多少?
百度蜘蛛(Baidu spider)活动:抓取频率
在每日日志中记录Baiduspider(百度蜘蛛)爬取网站的次数,然后比较多天的日志,确定Baiduspider(百度蜘蛛)当前的活跃度。活跃度越高,爬取越多,说明网站的优化是有效的,网站的排名自然会上升。 查看全部
浏览器抓取网页(网站日志在哪?如何查看网站被百度抓取的情况?)
你的网站/网页是否被百度抓取以及抓取频率会影响你的排名。
01如何查看网站被抓包的状态?
首先我们要知道百度用来抓取网页的工具是Baiduspider(百度蜘蛛),它的动作会被记录在网站的日志中,我们可以从日志中读取到Baiduspider 网站(百度蜘蛛)活动:抓取的频率和抓取后返回的HTTP状态码,用于查看网站被百度抓取的状态。所以下一步就是找到网站日志的内容。
02网站日志在哪里?如何查看
通常网站 日志文件位于管理后端的 logofiles 文件夹下。登录“FTP”账号,找到一个文件扩展名为.log的日志文件,下载并解压,将文件更改为记事本。这是网站日志,记录了网站是否被百度蜘蛛(Baidu Spider)爬取,爬取是否成功。
接下来,作者介绍了如何用这样一段代码进行日志分析。示例:时间 GET /images/index5_22.gif-- IP 地址 HTTP/1.1 浏览器和操作系统/news/detail/181.html 200 360 where, "GET / images /index5_22.gif" 表示:从服务器获取页面"/images/index5_22.gif"或文件;HTTP/1.1 浏览器及操作系统/news/detail/181.html 200 360,代表:抓取后返回的状态(成功与否,抓取次数) 200,状态码,表示爬取成功;360,volume,代表爬取多少字节,360字节;
常见状态码
200:表示服务器成功接受了客户端请求。这是最好的,这意味着网站页面是正常的。
301:表示用户访问的某个页面经过了301重定向(永久)处理。
302:这是一个临时重定向。如果网站日志分析发现302太多,需要确认301是否误认为302,如果是,赶紧修改。搜索引擎不喜欢 302 重定向。
404:表示访问的页面不存在了,或者访问的URL是错误的。
500:服务器错误。03 百度蜘蛛的活跃度:抓取频率是多少?
百度蜘蛛(Baidu spider)活动:抓取频率
在每日日志中记录Baiduspider(百度蜘蛛)爬取网站的次数,然后比较多天的日志,确定Baiduspider(百度蜘蛛)当前的活跃度。活跃度越高,爬取越多,说明网站的优化是有效的,网站的排名自然会上升。
浏览器抓取网页( 《python3爬虫开发实战》学习笔记(零)学习路线html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-06 20:32
《python3爬虫开发实战》学习笔记(零)学习路线html)
browser = webdriver.Chrome()
2-访问页面
browser.get('https://www.taobao.com')
3- 查找节点
input_first = browser.find_element(By.ID, 'q') #单个节点
lis = browser.find_elements_by_css_selector('.service-bd li')
4-节点交互
...
5- 获取节点信息
网页的源代码可以通过 page_source 属性获取。获取源码后,可以使用regular、BeautifulSoup、PyQuery等解析库提取信息。
但是Selenium提供了选择节点的方法,返回WebElement类型,可以通过相关方法或属性解析
6- 获取属性
7- 切换框架
8- 延迟等待
确保节点已加载
- 隐式等待
当搜索一个节点并且该节点没有立即出现时,隐式等待会等待一段时间再搜索DOM。默认时间为 0。implicitly_wait()
-显式等待
指定要查找的节点,然后指定最长等待时间。如果在指定时间内加载节点,则返回搜索到的节点。如果在指定时间内仍未加载节点,则会抛出超时异常。
##本系列内容为《python3爬虫开发实战》学习笔记。本系列博客列表如下:css
(零)学习路线html
(一)开发环境配置python
(二) 爬虫基础网页
(三)基础库使用ajax
(四)使用浏览器分析库
(五)数据存储工具
(六)Ajax数据爬取学习
(七)动态渲染页面爬取Selenium测试
不断更新...ui
请看对应的代码:.. 查看全部
浏览器抓取网页(
《python3爬虫开发实战》学习笔记(零)学习路线html)
browser = webdriver.Chrome()
2-访问页面
browser.get('https://www.taobao.com')
3- 查找节点
input_first = browser.find_element(By.ID, 'q') #单个节点
lis = browser.find_elements_by_css_selector('.service-bd li')
4-节点交互
...
5- 获取节点信息
网页的源代码可以通过 page_source 属性获取。获取源码后,可以使用regular、BeautifulSoup、PyQuery等解析库提取信息。
但是Selenium提供了选择节点的方法,返回WebElement类型,可以通过相关方法或属性解析
6- 获取属性
7- 切换框架
8- 延迟等待
确保节点已加载
- 隐式等待
当搜索一个节点并且该节点没有立即出现时,隐式等待会等待一段时间再搜索DOM。默认时间为 0。implicitly_wait()
-显式等待
指定要查找的节点,然后指定最长等待时间。如果在指定时间内加载节点,则返回搜索到的节点。如果在指定时间内仍未加载节点,则会抛出超时异常。
##本系列内容为《python3爬虫开发实战》学习笔记。本系列博客列表如下:css
(零)学习路线html
(一)开发环境配置python
(二) 爬虫基础网页
(三)基础库使用ajax
(四)使用浏览器分析库
(五)数据存储工具
(六)Ajax数据爬取学习
(七)动态渲染页面爬取Selenium测试
不断更新...ui
请看对应的代码:..
浏览器抓取网页(从IE浏览器获取当前页面内容的多种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 286 次浏览 • 2021-10-06 20:30
从IE浏览器获取当前页面内容的方法可能有很多种。今天我介绍其中一个。基本原理:鼠标点击当前ie页面时,获取鼠标坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用Win32 things获取页面内容。感兴趣的朋友可以参考本文
private void timer1_Tick(object sender, EventArgs e) { lock (currentLock) { System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition; if (_leftClick) { timer1.Stop(); _leftClick = false; _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false)); if (_lastDocument != null) { if (_getDocument) { _getDocument = true; try { string url = _lastDocument.url; string html = _lastDocument.documentElement.outerHTML; string cookie = _lastDocument.cookie; string domain = _lastDocument.domain; var resolveParams = new ResolveParam { Url = new Uri(url), Html = html, PageCookie = cookie, Domain = domain }; RequetResove(resolveParams); } catch (Exception ex) { System.Windows.MessageBox.Show(ex.Message); Console.WriteLine(ex.Message); Console.WriteLine(ex.StackTrace); } } } else { new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页"); } _getDocument = false; } else { _pointFrm.Left = MousePoint.X + 10; _pointFrm.Top = MousePoint.Y + 10; } } }
在第11行的gethtmldocumentformhwnd(getpointcontrol(mousepoint,false))分解下,首先从鼠标坐标获取页面句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl) { IntPtr handle = Win32APIsFull.WindowFromPoint(p); if (handle != IntPtr.Zero) { System.Drawing.Rectangle rect = default(System.Drawing.Rectangle); if (Win32APIsFull.GetWindowRect(handle, out rect)) { return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE); } } return IntPtr.Zero; }
接下来,根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd) { IntPtr result = Marshal.AllocHGlobal(4); Object obj = null; Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result)); if (Marshal.ReadInt32(result) != 0) { Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj)); } Marshal.FreeHGlobal(result); return obj as HTMLDocument; }
一般原则:
向IE表单发送消息,获取指向IE浏览器(非托管)内存块的指针,然后根据该指针获取htmldocument对象
此方法涉及两个Win32函数:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")] public static extern int SendMessageTimeoutA( [InAttribute()] System.IntPtr hWnd, uint Msg, uint wParam, int lParam, uint fuFlags, uint uTimeout, System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")] public static extern int ObjectFromLresult( int lResult, ref Guid riid, int wParam, [MarshalAs(UnmanagedType.IDispatch), Out] out Object pObject );
以上是从IE浏览器获取的当前页面内容的详细信息。请多关注其他相关文章 查看全部
浏览器抓取网页(从IE浏览器获取当前页面内容的多种方法)
从IE浏览器获取当前页面内容的方法可能有很多种。今天我介绍其中一个。基本原理:鼠标点击当前ie页面时,获取鼠标坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用Win32 things获取页面内容。感兴趣的朋友可以参考本文
private void timer1_Tick(object sender, EventArgs e) { lock (currentLock) { System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition; if (_leftClick) { timer1.Stop(); _leftClick = false; _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false)); if (_lastDocument != null) { if (_getDocument) { _getDocument = true; try { string url = _lastDocument.url; string html = _lastDocument.documentElement.outerHTML; string cookie = _lastDocument.cookie; string domain = _lastDocument.domain; var resolveParams = new ResolveParam { Url = new Uri(url), Html = html, PageCookie = cookie, Domain = domain }; RequetResove(resolveParams); } catch (Exception ex) { System.Windows.MessageBox.Show(ex.Message); Console.WriteLine(ex.Message); Console.WriteLine(ex.StackTrace); } } } else { new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页"); } _getDocument = false; } else { _pointFrm.Left = MousePoint.X + 10; _pointFrm.Top = MousePoint.Y + 10; } } }
在第11行的gethtmldocumentformhwnd(getpointcontrol(mousepoint,false))分解下,首先从鼠标坐标获取页面句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl) { IntPtr handle = Win32APIsFull.WindowFromPoint(p); if (handle != IntPtr.Zero) { System.Drawing.Rectangle rect = default(System.Drawing.Rectangle); if (Win32APIsFull.GetWindowRect(handle, out rect)) { return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE); } } return IntPtr.Zero; }
接下来,根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd) { IntPtr result = Marshal.AllocHGlobal(4); Object obj = null; Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result)); if (Marshal.ReadInt32(result) != 0) { Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj)); } Marshal.FreeHGlobal(result); return obj as HTMLDocument; }
一般原则:
向IE表单发送消息,获取指向IE浏览器(非托管)内存块的指针,然后根据该指针获取htmldocument对象
此方法涉及两个Win32函数:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")] public static extern int SendMessageTimeoutA( [InAttribute()] System.IntPtr hWnd, uint Msg, uint wParam, int lParam, uint fuFlags, uint uTimeout, System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")] public static extern int ObjectFromLresult( int lResult, ref Guid riid, int wParam, [MarshalAs(UnmanagedType.IDispatch), Out] out Object pObject );
以上是从IE浏览器获取的当前页面内容的详细信息。请多关注其他相关文章
浏览器抓取网页(浏览器抓取网页就是通过解析网页然后解析出网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-04 09:01
浏览器抓取网页就是通过解析网页然后解析出html内容。一般来说解析是浏览器直接完成的,而解析出来的html就会被后端渲染成网页,返回给我们。你可以理解为是代理的关系。这也是单线程的意思,双线程就是a/b两个app/网页一个app服务器。然后说说python,python2的话,解析网页不需要引入浏览器模块。
直接调用chrome和chromium模块接口就行。而有些浏览器已经有好几个浏览器模块接口,比如知乎,使用的是谷歌浏览器模块,所以需要依次解析网页。比如现在的知乎网页如下。先是通过python接口打开。接着app的数据从post中获取,通过后端渲染成一个网页。有的话就不用通过浏览器解析网页就直接返回页面,比如网页内容,还有下方的一个进度条弹出。
解析这类接口你需要说服后端解析我们页面的js和图片文件。你可以理解为你帮助他把页面里的按钮颜色等提取出来。不要使用自己的代码和图片。这样才能保证后端不抓到我们的数据并返回成功。解析网页就是使用python的web框架。前端框架多如牛毛,我挑了一个入门最容易,上手快。web框架uiwebview、segmentfault等等,有了uiwebview后,前端开发起来就方便多了。
页面直接在地址栏查看是多么方便啊。segmentfault现在有可以拖拽下载pdf的功能。目前我的文章页也在做首页推荐,可以先试试,点击下载网页。 查看全部
浏览器抓取网页(浏览器抓取网页就是通过解析网页然后解析出网页)
浏览器抓取网页就是通过解析网页然后解析出html内容。一般来说解析是浏览器直接完成的,而解析出来的html就会被后端渲染成网页,返回给我们。你可以理解为是代理的关系。这也是单线程的意思,双线程就是a/b两个app/网页一个app服务器。然后说说python,python2的话,解析网页不需要引入浏览器模块。
直接调用chrome和chromium模块接口就行。而有些浏览器已经有好几个浏览器模块接口,比如知乎,使用的是谷歌浏览器模块,所以需要依次解析网页。比如现在的知乎网页如下。先是通过python接口打开。接着app的数据从post中获取,通过后端渲染成一个网页。有的话就不用通过浏览器解析网页就直接返回页面,比如网页内容,还有下方的一个进度条弹出。
解析这类接口你需要说服后端解析我们页面的js和图片文件。你可以理解为你帮助他把页面里的按钮颜色等提取出来。不要使用自己的代码和图片。这样才能保证后端不抓到我们的数据并返回成功。解析网页就是使用python的web框架。前端框架多如牛毛,我挑了一个入门最容易,上手快。web框架uiwebview、segmentfault等等,有了uiwebview后,前端开发起来就方便多了。
页面直接在地址栏查看是多么方便啊。segmentfault现在有可以拖拽下载pdf的功能。目前我的文章页也在做首页推荐,可以先试试,点击下载网页。
浏览器抓取网页(web开发者工具(浏览器)安装beautifulsoup构建的chrome)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-29 23:02
浏览器抓取网页是一个技术活,有两个重要的步骤,第一,找到html网页地址();第二,网页内容解析,解析可能是网页写入xml文件,可能是json,可能是其他的。也可能是使用beautifulsoup。如果使用解析网页方法的话要对html网页内容有一定的理解。其实,解析网页可以通过web开发者工具()浏览器自带的浏览器开发者工具功能和如果使用beautifulsoup解析网页,还要会使用浏览器自带的解析器操作。
网页抓取工具investfulljs/webpack-invest打开开发者工具就会有解析器。在我的博客一步之遥里不定期更新网页抓取的代码,看看效果如何。scanner_html_invest。
官方文档就有安装beautifulsoup构建的chrome抓取指南
当然是doreally
这玩意的话msdn,没有什么更好的方法。
当然是chrome+reactnative
1.enurls地址,要从他们那里抓包2.printsend的地址,
chromeextensionv1.2.1downloadbeautifulsoup3.pythonscrapy在chrome上运行或者chrome+python运行
使用前端的话,一般的mjs脚手架都会有你想要的功能,但如果你使用的后端,
应该是先点击浏览器地址栏的网址(我从360进程看的),然后点击一个地址按钮,在点击浏览器开发人员工具(一般是右键,可以看到css文件和js文件),页面上出现链接,点击。然后就抓取出来页面了。 查看全部
浏览器抓取网页(web开发者工具(浏览器)安装beautifulsoup构建的chrome)
浏览器抓取网页是一个技术活,有两个重要的步骤,第一,找到html网页地址();第二,网页内容解析,解析可能是网页写入xml文件,可能是json,可能是其他的。也可能是使用beautifulsoup。如果使用解析网页方法的话要对html网页内容有一定的理解。其实,解析网页可以通过web开发者工具()浏览器自带的浏览器开发者工具功能和如果使用beautifulsoup解析网页,还要会使用浏览器自带的解析器操作。
网页抓取工具investfulljs/webpack-invest打开开发者工具就会有解析器。在我的博客一步之遥里不定期更新网页抓取的代码,看看效果如何。scanner_html_invest。
官方文档就有安装beautifulsoup构建的chrome抓取指南
当然是doreally
这玩意的话msdn,没有什么更好的方法。
当然是chrome+reactnative
1.enurls地址,要从他们那里抓包2.printsend的地址,
chromeextensionv1.2.1downloadbeautifulsoup3.pythonscrapy在chrome上运行或者chrome+python运行
使用前端的话,一般的mjs脚手架都会有你想要的功能,但如果你使用的后端,
应该是先点击浏览器地址栏的网址(我从360进程看的),然后点击一个地址按钮,在点击浏览器开发人员工具(一般是右键,可以看到css文件和js文件),页面上出现链接,点击。然后就抓取出来页面了。
浏览器抓取网页(选择谷歌浏览器,避免了单一的标签无法定位到我们所需要的内容元素(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-09-29 19:27
)
它只是一个收录段落内容的标签。
#coding=utf-8
from bs4 import BeautifulSoup
import requests
#使用requests抓取页面内容,并将响应赋值给page变量
html = requests.get('https://www.qiushibaike.com/text/')
#使用content属性获取页面的源页面
#使用BeautifulSoap解析,吧内容传递到BeautifulSoap类
soup = BeautifulSoup(html.content,'lxml')
links = soup.find_all('div',class_='content')
#link的内容就是div,我们取它的span内容就是我们需要段子的内容
for link in links:
print link.span.get_text()
操作结果:
2. select() 方法
我们需要的内容可以逐层查找。这个特别方便,也就是定位,防止单个标签无法定位到我们需要的内容元素。
soup.select("html head title") #标签层级查找
soup.select("td div a") #标签路径 td-->div-->a
soup.select('td > div > a') #note:推荐使用这种记法
选择谷歌浏览器,右键复制--复制选择器
获取内容的任务:
#qiushi_tag_120529403> a> div> span:nth-child(1)
对于这个内容,我需要改一下~按标签顺序搜索
div> a> div> span(我在运行的时候发现了一个问题,>前后必须有空格,否则会报错)
然后代码如下:(和前面的代码区别只有最后三行)
#coding=utf-8
from bs4 import BeautifulSoup
import requests
#使用requests抓取页面内容,并将响应赋值给page变量
html = requests.get('https://www.qiushibaike.com/text/')
#使用content属性获取页面的源页面
#使用BeautifulSoap解析,吧内容传递到BeautifulSoap类
soup = BeautifulSoup(html.content,'lxml')
#我是分隔符,下面就是select()方法咯~
links = soup.select('div > a >div >span')
for link in links:
print link.get_text()
操作结果:
啊哦~有没有发现和上面操作的结果不一样?评论也在这里匹配,所以:
我们还需要修改定位使其更加精确,从标签a开始,并添加其class属性。a.contentHerf 写在 select 方法中。
具体是这样的:a.contentHerf>div>span(改成代码第三行再运行一次~)
注意:1)示例只介绍了一页的内容
2)代码在python中运行2.7
原来的:
================================================== ====================
【笔记】
提示:类型错误:“响应”类型的对象没有 len()
源代码:
url = 'https://www.imooc.com/course/l ... 39%3B
wb_data = requests.get(url)
Soup = BeautifulSoup(wb_data, 'lxml', from_encoding='utf-8')
报错的原因是因为这里的wb_data是一个requests对象,BeautifulSoup无法解析。您可以在 wb_data 后添加内容
汤 = BeautifulSoup(wb_data.content,'lxml', from_encoding='utf-8')
Tips:python3中request.urlopen()和requests.get()方法的区别
urlopen 打开URL URL,url参数可以是字符串url或Request对象,返回的对象是http.client.HTTPResponse。http.client.HTTPResponse 对象大概包括 read(), readinto(), getheader(), getheaders(), fileno(), msg, version, status, reason, debuglevel 和 closed 函数,其实一般来说就是decode使用read()函数后需要()函数
requests.get()方法请求站点的URL,然后打印出返回结果的类型、状态码、编码方式、Cookies等。返回一个Response对象,该对象存储了服务器返回的所有信息,包括响应头、响应状态码等。返回的网页部分将存储在.content和.text两个对象中。文本返回 Unicode 数据,内容返回二进制数据。换句话说,如果要获取文本,可以使用 r.text。如果你想拍照和文件,你可以使用 r.content
经验:请求网页的三种方式
# 网页下载器代码示例
2 import urllib
3
4 url = "http://www.baidu.com"
5
6 print("第一种方法: 直接访问url")
7 response1 = urllib.request.urlopen(url)
8 print(response1.getcode()) # 状态码
9 print(len(response1.read())) # read读取utf-8编码的字节流数据
10
11 print("第二种方法: 设置请求头,访问Url")
12 request = urllib.request.Request(url) # 请求地址
13 request.add_header("user-agent", "mozilla/5.0") # 修改请求头
14 response2 = urllib.request.urlopen(request)
15 print(response2.getcode())
16 print(len(response2.read()))
17
18 import http.cookiejar # 不知道这是啥
19
20 print("第三种方法: 设置coockie,返回的cookie")
21 # 第三种方法的目的是为了获取浏览器的cookie内容
22 cj = http.cookiejar.CookieJar()
23 opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
24 urllib.request.install_opener(opener)
25 response3 = urllib.request.urlopen(url)
26 print(response3.getcode())
27 print(len(response3.read()))
28 print(cj) # 查看cookie的内容
Tips:Python如何提取td中的内容
import re
m = re.findall(r'(.*?)', lines, re.I|re.M)
if m:
for x in m:
print x 查看全部
浏览器抓取网页(选择谷歌浏览器,避免了单一的标签无法定位到我们所需要的内容元素(图)
)
它只是一个收录段落内容的标签。
#coding=utf-8
from bs4 import BeautifulSoup
import requests
#使用requests抓取页面内容,并将响应赋值给page变量
html = requests.get('https://www.qiushibaike.com/text/')
#使用content属性获取页面的源页面
#使用BeautifulSoap解析,吧内容传递到BeautifulSoap类
soup = BeautifulSoup(html.content,'lxml')
links = soup.find_all('div',class_='content')
#link的内容就是div,我们取它的span内容就是我们需要段子的内容
for link in links:
print link.span.get_text()
操作结果:
2. select() 方法
我们需要的内容可以逐层查找。这个特别方便,也就是定位,防止单个标签无法定位到我们需要的内容元素。
soup.select("html head title") #标签层级查找
soup.select("td div a") #标签路径 td-->div-->a
soup.select('td > div > a') #note:推荐使用这种记法
选择谷歌浏览器,右键复制--复制选择器
获取内容的任务:
#qiushi_tag_120529403> a> div> span:nth-child(1)
对于这个内容,我需要改一下~按标签顺序搜索
div> a> div> span(我在运行的时候发现了一个问题,>前后必须有空格,否则会报错)
然后代码如下:(和前面的代码区别只有最后三行)
#coding=utf-8
from bs4 import BeautifulSoup
import requests
#使用requests抓取页面内容,并将响应赋值给page变量
html = requests.get('https://www.qiushibaike.com/text/')
#使用content属性获取页面的源页面
#使用BeautifulSoap解析,吧内容传递到BeautifulSoap类
soup = BeautifulSoup(html.content,'lxml')
#我是分隔符,下面就是select()方法咯~
links = soup.select('div > a >div >span')
for link in links:
print link.get_text()
操作结果:
啊哦~有没有发现和上面操作的结果不一样?评论也在这里匹配,所以:
我们还需要修改定位使其更加精确,从标签a开始,并添加其class属性。a.contentHerf 写在 select 方法中。
具体是这样的:a.contentHerf>div>span(改成代码第三行再运行一次~)
注意:1)示例只介绍了一页的内容
2)代码在python中运行2.7
原来的:
================================================== ====================
【笔记】
提示:类型错误:“响应”类型的对象没有 len()
源代码:
url = 'https://www.imooc.com/course/l ... 39%3B
wb_data = requests.get(url)
Soup = BeautifulSoup(wb_data, 'lxml', from_encoding='utf-8')
报错的原因是因为这里的wb_data是一个requests对象,BeautifulSoup无法解析。您可以在 wb_data 后添加内容
汤 = BeautifulSoup(wb_data.content,'lxml', from_encoding='utf-8')
Tips:python3中request.urlopen()和requests.get()方法的区别
urlopen 打开URL URL,url参数可以是字符串url或Request对象,返回的对象是http.client.HTTPResponse。http.client.HTTPResponse 对象大概包括 read(), readinto(), getheader(), getheaders(), fileno(), msg, version, status, reason, debuglevel 和 closed 函数,其实一般来说就是decode使用read()函数后需要()函数
requests.get()方法请求站点的URL,然后打印出返回结果的类型、状态码、编码方式、Cookies等。返回一个Response对象,该对象存储了服务器返回的所有信息,包括响应头、响应状态码等。返回的网页部分将存储在.content和.text两个对象中。文本返回 Unicode 数据,内容返回二进制数据。换句话说,如果要获取文本,可以使用 r.text。如果你想拍照和文件,你可以使用 r.content
经验:请求网页的三种方式
# 网页下载器代码示例
2 import urllib
3
4 url = "http://www.baidu.com"
5
6 print("第一种方法: 直接访问url")
7 response1 = urllib.request.urlopen(url)
8 print(response1.getcode()) # 状态码
9 print(len(response1.read())) # read读取utf-8编码的字节流数据
10
11 print("第二种方法: 设置请求头,访问Url")
12 request = urllib.request.Request(url) # 请求地址
13 request.add_header("user-agent", "mozilla/5.0") # 修改请求头
14 response2 = urllib.request.urlopen(request)
15 print(response2.getcode())
16 print(len(response2.read()))
17
18 import http.cookiejar # 不知道这是啥
19
20 print("第三种方法: 设置coockie,返回的cookie")
21 # 第三种方法的目的是为了获取浏览器的cookie内容
22 cj = http.cookiejar.CookieJar()
23 opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
24 urllib.request.install_opener(opener)
25 response3 = urllib.request.urlopen(url)
26 print(response3.getcode())
27 print(len(response3.read()))
28 print(cj) # 查看cookie的内容
Tips:Python如何提取td中的内容
import re
m = re.findall(r'(.*?)', lines, re.I|re.M)
if m:
for x in m:
print x
浏览器抓取网页( 写作猫浏览器插件上线「文字识别」和「抓取全文」)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-27 11:12
写作猫浏览器插件上线「文字识别」和「抓取全文」)
我经常遇到这种情况,相信你也一样:
网页中的文字无法复制
无法提取图片中的文本/表格
我想复制整篇文章文章,但我只能一段一段地重复一遍
或者因为内容太长,复制到最后需要很长时间,结果复制了一堆乱七八糟的信息
既麻烦又浪费时间。
现在,这些问题终于可以解决了!
写猫浏览器插件推出了“文字识别”和“全文抓取”功能,支持一键提取网页信息。
即时获取您想要的内容,有效节省时间,提高工作学习效率。
如何使用“文字识别”?
“文本识别”可以将网页内容转换为可编辑的文本和表格。
您只需要“选择识别区域”即可复制结果。
可以粘贴到Word文档中:
它也可以粘贴到 Excel 表格中:
如何使用“获取全文”?
“获取全文”可以一键抓取网页正文内容:
此外,美田写字猫会实时纠错保护文章,告别敏感词、违禁词、坏句,远离文章错误。
您也可以根据需要,一键打开全文改写或翻译。
如何下载“写猫浏览器插件”?
如果您使用Chrome浏览器,可以通过Chrome网上应用店安装美田写字猫的“浏览器插件”。
或者您也可以通过美达写猫网页版()下载“浏览器插件”。
安装后即可使用,高效工作学习,轻松告别通宵码字,制作形式让你光头。
愿你从节省的时间中得到“幸福”和“小幸运”。 查看全部
浏览器抓取网页(
写作猫浏览器插件上线「文字识别」和「抓取全文」)
我经常遇到这种情况,相信你也一样:
网页中的文字无法复制
无法提取图片中的文本/表格
我想复制整篇文章文章,但我只能一段一段地重复一遍
或者因为内容太长,复制到最后需要很长时间,结果复制了一堆乱七八糟的信息
既麻烦又浪费时间。
现在,这些问题终于可以解决了!
写猫浏览器插件推出了“文字识别”和“全文抓取”功能,支持一键提取网页信息。
即时获取您想要的内容,有效节省时间,提高工作学习效率。
如何使用“文字识别”?
“文本识别”可以将网页内容转换为可编辑的文本和表格。
您只需要“选择识别区域”即可复制结果。
可以粘贴到Word文档中:
它也可以粘贴到 Excel 表格中:
如何使用“获取全文”?
“获取全文”可以一键抓取网页正文内容:
此外,美田写字猫会实时纠错保护文章,告别敏感词、违禁词、坏句,远离文章错误。
您也可以根据需要,一键打开全文改写或翻译。
如何下载“写猫浏览器插件”?
如果您使用Chrome浏览器,可以通过Chrome网上应用店安装美田写字猫的“浏览器插件”。
或者您也可以通过美达写猫网页版()下载“浏览器插件”。
安装后即可使用,高效工作学习,轻松告别通宵码字,制作形式让你光头。
愿你从节省的时间中得到“幸福”和“小幸运”。
浏览器抓取网页(代码访问当前域名的session添加一个数据条目会自动保存一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-09-27 07:08
以下代码访问当前域名的会话Storage对象,并使用Storage.setItem()访问向其添加数据项。
sessionStorage.setItem('myCat', 'Tom');
以下示例将自动保存文本输入框的内容。如果浏览器不小心刷新,文本输入框中的内容会恢复,所以写入的内容不会丢失。
// 获取文本输入框
let field = document.getElementById("field");
// 检测是否存在 autosave 键值
// (这个会在页面偶然被刷新的情况下存在)
if (sessionStorage.getItem("autosave")) {
// 恢复文本输入框的内容
field.value = sessionStorage.getItem("autosave");
}
// 监听文本输入框的 change 事件
field.addEventListener("change", function() {
// 保存结果到 sessionStorage 对象中
sessionStorage.setItem("autosave", field.value);
});
备注:完整的使用示例请参考Using Web Storage API一文。 查看全部
浏览器抓取网页(代码访问当前域名的session添加一个数据条目会自动保存一个)
以下代码访问当前域名的会话Storage对象,并使用Storage.setItem()访问向其添加数据项。
sessionStorage.setItem('myCat', 'Tom');
以下示例将自动保存文本输入框的内容。如果浏览器不小心刷新,文本输入框中的内容会恢复,所以写入的内容不会丢失。
// 获取文本输入框
let field = document.getElementById("field");
// 检测是否存在 autosave 键值
// (这个会在页面偶然被刷新的情况下存在)
if (sessionStorage.getItem("autosave")) {
// 恢复文本输入框的内容
field.value = sessionStorage.getItem("autosave");
}
// 监听文本输入框的 change 事件
field.addEventListener("change", function() {
// 保存结果到 sessionStorage 对象中
sessionStorage.setItem("autosave", field.value);
});
备注:完整的使用示例请参考Using Web Storage API一文。
浏览器抓取网页(,如何实时抓取动态网页数据?(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-25 12:04
网页数据实时抓取,实时网页数据,如何抓取实时动态网页数据?
我们生活的数字世界不断产生大量数据。动态大数据的使用已经成为企业数据分析的关键。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?
1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据可以帮助:
(1) 让数据驱动的决策更快
采集动态数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。有了所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出数据驱动的决策。
正如亚马逊首席执行官杰夫贝索斯在给股东的一封信中所说:“业务的速度至关重要。” “高速决策”对业务发展具有重要意义。
(2)建立更强大的数据库
随着数据量的不断增长,每条数据的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要通过持续不断的采集动态数据,构建一个全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度每年翻一番,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期的数据采集可以帮助解决近期的问题并做出较小的决策,而长期的数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2. 动态数据如何有效促进业务增长?
我们可以通过多种方式应用动态数据分析来促进业务发展,例如:
(1)产品监控
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从易趣上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的一种可靠且有效的方法。
(2)客户体验管理
公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超出客户期望的做法,从而提高客户满意度、忠诚度和拥护度”。
例如,提取亚马逊上某个产品的所有评论,并分析评论的正面和负面情绪,可以帮助企业了解客户对产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)营销策略
动态数据分析使公司能够了解过去哪些策略最有效,他们当前的营销策略有多有效,以及可以改进的地方。动态数据采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3. 如何轻松获取动态数据?
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网络爬虫工具,操作者无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是强大的网络爬虫工具可以让您轻松快速地抓取来自不同网站的信息,从而为您研究不同的网站结构节省大量时间。
(3)定时抓拍
这需要网络爬虫工具来支持云中的数据,而不仅仅是在本地计算机上运行。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云Cloud采集的功能远不止这些。
(4) 灵活的时间安排
优采云云采集支持随时随地抓取网页数据,时间和频率可根据需要调整。
(5)采集 更快
同时通过8-12台云服务器采集,对同一组数据的爬取速度可以比在本地计算机上运行快8-12倍。
(6) 降低数据获取成本
优采云Cloud采集支持在云端采集数据,并将采集接收到的数据存入云端的数据库中。企业无需担心高昂的硬件维护成本或采集 中断。
此外,优采云采集器的成本较市场同类竞争者降低50%。优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。
(7)API,自定义数据对接
虽然云端采集数据可以自动导出到用户数据库,但是通过API可以大大提高数据导出到自己系统的灵活性,轻松实现自己的系统和优采云采集器@ > 无缝对接。
你需要知道的是,优采云采集器的API有两种:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。
-------------------------------------------------- -------- 查看全部
浏览器抓取网页(,如何实时抓取动态网页数据?(一)(图))
网页数据实时抓取,实时网页数据,如何抓取实时动态网页数据?
我们生活的数字世界不断产生大量数据。动态大数据的使用已经成为企业数据分析的关键。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?
1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据可以帮助:
(1) 让数据驱动的决策更快
采集动态数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。有了所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出数据驱动的决策。
正如亚马逊首席执行官杰夫贝索斯在给股东的一封信中所说:“业务的速度至关重要。” “高速决策”对业务发展具有重要意义。
(2)建立更强大的数据库
随着数据量的不断增长,每条数据的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要通过持续不断的采集动态数据,构建一个全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度每年翻一番,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期的数据采集可以帮助解决近期的问题并做出较小的决策,而长期的数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2. 动态数据如何有效促进业务增长?
我们可以通过多种方式应用动态数据分析来促进业务发展,例如:
(1)产品监控
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从易趣上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的一种可靠且有效的方法。
(2)客户体验管理
公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超出客户期望的做法,从而提高客户满意度、忠诚度和拥护度”。
例如,提取亚马逊上某个产品的所有评论,并分析评论的正面和负面情绪,可以帮助企业了解客户对产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)营销策略
动态数据分析使公司能够了解过去哪些策略最有效,他们当前的营销策略有多有效,以及可以改进的地方。动态数据采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3. 如何轻松获取动态数据?
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网络爬虫工具,操作者无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是强大的网络爬虫工具可以让您轻松快速地抓取来自不同网站的信息,从而为您研究不同的网站结构节省大量时间。
(3)定时抓拍
这需要网络爬虫工具来支持云中的数据,而不仅仅是在本地计算机上运行。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云Cloud采集的功能远不止这些。
(4) 灵活的时间安排
优采云云采集支持随时随地抓取网页数据,时间和频率可根据需要调整。
(5)采集 更快
同时通过8-12台云服务器采集,对同一组数据的爬取速度可以比在本地计算机上运行快8-12倍。
(6) 降低数据获取成本
优采云Cloud采集支持在云端采集数据,并将采集接收到的数据存入云端的数据库中。企业无需担心高昂的硬件维护成本或采集 中断。
此外,优采云采集器的成本较市场同类竞争者降低50%。优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。
(7)API,自定义数据对接
虽然云端采集数据可以自动导出到用户数据库,但是通过API可以大大提高数据导出到自己系统的灵活性,轻松实现自己的系统和优采云采集器@ > 无缝对接。
你需要知道的是,优采云采集器的API有两种:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。
-------------------------------------------------- --------
浏览器抓取网页(你的低价机票被“虫子”吃了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-25 12:03
你的低价票被“虫子”吃掉了
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者。由于老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,就在小王正准备以“早熟”抢便宜机票时,他在网上看到一则新闻,航空公司发行的低价机票中,80%以上都是票务公司“爬虫”。 . 抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像网络上漫游的爬虫或蜘蛛,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上百亿个网页,需要依靠在庞大的“爬虫”集群上实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等多个领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现低价机票或热机票后,可以利用虚假客源的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据不同的爬虫任务和目标,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是怎么抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,甚至超过90%在高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取航空公司售票官网的信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,机票代理机构会在订单到期前添加虚假身份订单,继续“占用”低价机票,重复此过程,直到真正的找到并出售来源。
“上述操作流程构成了一个完整的机票销售链条。在这个过程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为售票机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段进行预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
第一,威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设置的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”剥头皮行为尚无明确规定,这使得恶意爬取信息成为法律法规“灰色地带”中的不当获利行为。
闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议称为“网络爬虫排除标准”。网站 可以通过这个协议告诉“爬虫”哪些页面和信息可以爬取,哪些页面和信息不能爬取。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还应通过完善管理和法律法规来限制此类行为。尤其是,法律方法可以证明其惩罚和威慑。. 航空公司也应加强对账期的管理,不提供给“爬虫”抢票的机会。
本报记者傅丽丽 查看全部
浏览器抓取网页(你的低价机票被“虫子”吃了(组图))
你的低价票被“虫子”吃掉了
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者。由于老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,就在小王正准备以“早熟”抢便宜机票时,他在网上看到一则新闻,航空公司发行的低价机票中,80%以上都是票务公司“爬虫”。 . 抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像网络上漫游的爬虫或蜘蛛,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上百亿个网页,需要依靠在庞大的“爬虫”集群上实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等多个领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现低价机票或热机票后,可以利用虚假客源的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据不同的爬虫任务和目标,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是怎么抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,甚至超过90%在高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取航空公司售票官网的信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,机票代理机构会在订单到期前添加虚假身份订单,继续“占用”低价机票,重复此过程,直到真正的找到并出售来源。
“上述操作流程构成了一个完整的机票销售链条。在这个过程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为售票机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段进行预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
第一,威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设置的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”剥头皮行为尚无明确规定,这使得恶意爬取信息成为法律法规“灰色地带”中的不当获利行为。
闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议称为“网络爬虫排除标准”。网站 可以通过这个协议告诉“爬虫”哪些页面和信息可以爬取,哪些页面和信息不能爬取。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还应通过完善管理和法律法规来限制此类行为。尤其是,法律方法可以证明其惩罚和威慑。. 航空公司也应加强对账期的管理,不提供给“爬虫”抢票的机会。
本报记者傅丽丽
浏览器抓取网页( 入门网络数据爬取,也就是Python爬虫现实中(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-09-25 03:28
入门网络数据爬取,也就是Python爬虫现实中(组图)
)
网络数据爬虫入门,即Python爬虫
在现实中,当我们使用浏览器访问网页时,网络是如何工作的,是做什么的?
首先要了解网络连接的基本流程原理,然后,就比较容易理解爬取的原理了。
1、网络连接原理
如上图,简单来说,网络连接就是计算机发起请求,服务器返回相应的HTML文件。至于请求头和消息体,详细说明了要爬取的链接。
2、爬取的原理
爬虫的原理是模拟计算机向服务器发起Request请求,接收并解析来自服务器的响应内容,提取需要的信息。
往往一次请求无法完全获取所有网页的信息和数据,则需要合理设计爬取流程,实现多页面跨页面爬取。
多页爬取的过程是怎样的?
基本思路:
1、由于多个页面的结构可能相似,可以手动翻页先观察网址
2、获取所有网址
3、根据每个页面URL的函数定义抓取数据
4、循环网址抓取存储
跨页爬取流程是什么?
基本思路:
1、查找所有网址
2、定义爬取详细页面的函数代码
3、进入详细页面查看详细数据
4、存储,循环完成,结束
3、网页是什么样子的?
右键单击并选择“检查”以打开网页的源代码。可以看到上面是HTML文件,下面是CSS样式。
我们浏览的网页是浏览器渲染的结果,是翻译HTML、CSS、JavaScript代码得到的页面界面。一个流行的比喻是:添加一个网页就是一个房子,HTML是房子的框架和布局,CSS是房子的软装饰风格,比如地板和油漆,而javaScript是电器。
比如打开百度搜索,将鼠标移动到“百度点击”按钮上,右击选择“检查”,就可以看到网页源代码的位置了。
或者直接打开右键源代码,点击网页源页面左上角的类似鼠标的图标,然后移动到网页的具体位置,就可以看到了。
总结一下:爬取数据就是发起一个请求,获取网页信息,然后找到自己想要的信息,但是在请求的过程中,很容易被逆转,禁止爬取。因此,绕过反拼字机制需要很多技巧。后续我们会一一解答。
——每天一小步,未来一大步!
查看全部
浏览器抓取网页(
入门网络数据爬取,也就是Python爬虫现实中(组图)
)
网络数据爬虫入门,即Python爬虫
在现实中,当我们使用浏览器访问网页时,网络是如何工作的,是做什么的?
首先要了解网络连接的基本流程原理,然后,就比较容易理解爬取的原理了。
1、网络连接原理
如上图,简单来说,网络连接就是计算机发起请求,服务器返回相应的HTML文件。至于请求头和消息体,详细说明了要爬取的链接。
2、爬取的原理
爬虫的原理是模拟计算机向服务器发起Request请求,接收并解析来自服务器的响应内容,提取需要的信息。
往往一次请求无法完全获取所有网页的信息和数据,则需要合理设计爬取流程,实现多页面跨页面爬取。
多页爬取的过程是怎样的?
基本思路:
1、由于多个页面的结构可能相似,可以手动翻页先观察网址
2、获取所有网址
3、根据每个页面URL的函数定义抓取数据
4、循环网址抓取存储
跨页爬取流程是什么?
基本思路:
1、查找所有网址
2、定义爬取详细页面的函数代码
3、进入详细页面查看详细数据
4、存储,循环完成,结束
3、网页是什么样子的?
右键单击并选择“检查”以打开网页的源代码。可以看到上面是HTML文件,下面是CSS样式。
我们浏览的网页是浏览器渲染的结果,是翻译HTML、CSS、JavaScript代码得到的页面界面。一个流行的比喻是:添加一个网页就是一个房子,HTML是房子的框架和布局,CSS是房子的软装饰风格,比如地板和油漆,而javaScript是电器。
比如打开百度搜索,将鼠标移动到“百度点击”按钮上,右击选择“检查”,就可以看到网页源代码的位置了。
或者直接打开右键源代码,点击网页源页面左上角的类似鼠标的图标,然后移动到网页的具体位置,就可以看到了。
总结一下:爬取数据就是发起一个请求,获取网页信息,然后找到自己想要的信息,但是在请求的过程中,很容易被逆转,禁止爬取。因此,绕过反拼字机制需要很多技巧。后续我们会一一解答。
——每天一小步,未来一大步!
浏览器抓取网页(安装selenium环境的几种常见问题及解决办法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-09-22 11:39
也可以来我的博客看看爬网谈话(一)使用selenium捕获
孟昕想要学习硒,安装是一个坑。还可以下载相关附件,可以参考Python安装Selenium环境。
1、使用firefox实例
from selenium import webdriver
import time
firefox = webdriver.Firefox() #初始化Firefox浏览器
url = 'https://www.zhihu.com'
firefox.get(url) #调用get方法抓取
time.sleep(10) #10s用于观察
with open('zhihu.html','w',encoding='utf-8') as f:
f.write(firefox.page_source) #保存网页到本地
firefox.quit()
上面的图片是一个名为Firefox的网页。使用page_source可以获得Web源代码,因为请求和请求是相同的,不必添加标题。
2、对s s配置配置的p配置
简单地说,使用selenium修改浏览器相关的参数,使浏览器没有加载js,没有图片,会增加大量速度。代码如下:
from selenium import webdriver
import time
firefox_profile = webdriver.FirefoxProfile()
firefox_profile.set_preference("permissions.default.stylesheet",2) #禁用样式表文件
firefox_profile.set_preference("permissions.default.image",2) #不加载图片
firefox_profile.set_preference("javascript.enabled",False) #禁止JS
firefox_profile.update_preferences() #更新设置
firefox = webdriver.Firefox(firefox_profile)
url = 'https://www.zhihu.com'
print("开始加载")
t_start = time.time()
firefox.get(url)
t_end = time.time()
print("加载时间是:",t_end-t_start)
time.sleep(10)
firefox.quit()
加载页面,如下所示
firefox_profile.set_preference("permissions.default.stylesheet",1)
firefox_profile.set_preference("permissions.default.image",1)
firefox_profile.set_preference("javascript.enabled",True)
更改2到1,错误的更改为true,请参阅
返回普通网页
4s和10s差异,它将体现在攀登多个网页。
请注意,页面加载与实际的网络环境有关。
3、图图
禁用js,页面加载是否更快,可以在每种模式下运行相同的次数,然后取得平均值。
使用matplotlib绘图
from selenium import webdriver
import time
import matplotlib.pyplot as plt
def performance(n,css_val,image_val,js_val):
loading_time = []
for i in range(0,n):
firefox_profile = webdriver.FirefoxProfile()
firefox_profile.set_preference("permissions.default.stylesheet",css_val)
firefox_profile.set_preference("permissions.default.image",image_val)
firefox_profile.set_preference("javascript.enabled",js_val)
firefox_profile.update_preferences()
firefox = webdriver.Firefox(firefox_profile)
url = 'https://zhangslob.github.io/'
print("开始加载")
t_start = time.time()
firefox.get(url)
t_end = time.time()
print("加载时间是:",t_end-t_start)
loading_time.append(t_end-t_start)
print('=========================')
#time.sleep(10)
firefox.quit()
return [x for x in range(1,n+1)],loading_time
if __name__ == '__main__':
x1_lst,y1_lst = performance(10,1,1,True)
x2_lst,y2_lst = performance(10,2,2,False)
ava_y1 = sum(y1_lst)/len(x1_lst)
ava_y2 = sum(y2_lst)/len(x2_lst)
plt.title("Compare loading time")
plt.xlabel("Test number")
plt.ylabel("Loading time")
plt.plot(x1_lst,y1_lst,'go:',label=str(ava_y1))
plt.plot(x2_lst,y2_lst,'rs:',label=str(ava_y2))
plt.legend()
plt.show()
我将URL更改为我的博客:库克斯的博客,这更加符合实用。
绿线是正常的网页,红色是修改的
为了确保准确,将其更改为其他URL,但为什么?
问题:
为什么可以禁用js,不要加载图片,时间和原创差异? 查看全部
浏览器抓取网页(安装selenium环境的几种常见问题及解决办法!)
也可以来我的博客看看爬网谈话(一)使用selenium捕获
孟昕想要学习硒,安装是一个坑。还可以下载相关附件,可以参考Python安装Selenium环境。
1、使用firefox实例
from selenium import webdriver
import time
firefox = webdriver.Firefox() #初始化Firefox浏览器
url = 'https://www.zhihu.com'
firefox.get(url) #调用get方法抓取
time.sleep(10) #10s用于观察
with open('zhihu.html','w',encoding='utf-8') as f:
f.write(firefox.page_source) #保存网页到本地
firefox.quit()
上面的图片是一个名为Firefox的网页。使用page_source可以获得Web源代码,因为请求和请求是相同的,不必添加标题。
2、对s s配置配置的p配置
简单地说,使用selenium修改浏览器相关的参数,使浏览器没有加载js,没有图片,会增加大量速度。代码如下:
from selenium import webdriver
import time
firefox_profile = webdriver.FirefoxProfile()
firefox_profile.set_preference("permissions.default.stylesheet",2) #禁用样式表文件
firefox_profile.set_preference("permissions.default.image",2) #不加载图片
firefox_profile.set_preference("javascript.enabled",False) #禁止JS
firefox_profile.update_preferences() #更新设置
firefox = webdriver.Firefox(firefox_profile)
url = 'https://www.zhihu.com'
print("开始加载")
t_start = time.time()
firefox.get(url)
t_end = time.time()
print("加载时间是:",t_end-t_start)
time.sleep(10)
firefox.quit()
加载页面,如下所示
firefox_profile.set_preference("permissions.default.stylesheet",1)
firefox_profile.set_preference("permissions.default.image",1)
firefox_profile.set_preference("javascript.enabled",True)
更改2到1,错误的更改为true,请参阅
返回普通网页
4s和10s差异,它将体现在攀登多个网页。
请注意,页面加载与实际的网络环境有关。
3、图图
禁用js,页面加载是否更快,可以在每种模式下运行相同的次数,然后取得平均值。
使用matplotlib绘图
from selenium import webdriver
import time
import matplotlib.pyplot as plt
def performance(n,css_val,image_val,js_val):
loading_time = []
for i in range(0,n):
firefox_profile = webdriver.FirefoxProfile()
firefox_profile.set_preference("permissions.default.stylesheet",css_val)
firefox_profile.set_preference("permissions.default.image",image_val)
firefox_profile.set_preference("javascript.enabled",js_val)
firefox_profile.update_preferences()
firefox = webdriver.Firefox(firefox_profile)
url = 'https://zhangslob.github.io/'
print("开始加载")
t_start = time.time()
firefox.get(url)
t_end = time.time()
print("加载时间是:",t_end-t_start)
loading_time.append(t_end-t_start)
print('=========================')
#time.sleep(10)
firefox.quit()
return [x for x in range(1,n+1)],loading_time
if __name__ == '__main__':
x1_lst,y1_lst = performance(10,1,1,True)
x2_lst,y2_lst = performance(10,2,2,False)
ava_y1 = sum(y1_lst)/len(x1_lst)
ava_y2 = sum(y2_lst)/len(x2_lst)
plt.title("Compare loading time")
plt.xlabel("Test number")
plt.ylabel("Loading time")
plt.plot(x1_lst,y1_lst,'go:',label=str(ava_y1))
plt.plot(x2_lst,y2_lst,'rs:',label=str(ava_y2))
plt.legend()
plt.show()
我将URL更改为我的博客:库克斯的博客,这更加符合实用。
绿线是正常的网页,红色是修改的
为了确保准确,将其更改为其他URL,但为什么?
问题:
为什么可以禁用js,不要加载图片,时间和原创差异?
浏览器抓取网页(通过实际例子讲解怎么使用javascript或者jquery获取地址url参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-09-22 04:02
本文将解释如何使用JavaScript或jQuery通过实际示例来获取地址URL参数,希望您能喜欢它。问题描述今天,我做了一个话题。虽然PHP也可以这样做,但是考虑到它们的特殊效果代码在jQuery上完成,认为它可以直接在地址栏中直接获得链接参数内的数字直接实现。假设页面的地址是这样的。 ,然后我想获得最后一个数字165,你可以通过这个代码
var url= window.location.href;
var index = url.substring(url.lastIndexOf('/') + 1);
但这是一个缺陷。如果我得到的地址不是这样的形式,但如果此索引的值不是数字。解决方案以下可能更好?
var lastBit = url.substring(url.lastIndexOf('/') + 1).match(/[^/]*$/)[0];
var lastDigits = url.substring(url.lastIndexOf('/') + 1).match(/[0-9]*$/)[0]; // 获取的是数字部分
获取查询值JavaScript版本:
function getUrlParam(name){
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r!=null) return unescape(r[2]); return null;
}
//获取http://caibaojian.com/?p=177.html的p值
getUrlParam('p'); //输出177
jQuery版本:
(function($){
$.getUrlParam = function(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r!=null) return unescape(r[2]); return null;
}
})(jQuery);
$(function(){
alert(window.location.href);
alert($.getUrlParam('page'));
})
在上面的页面时,我们使用上面的jQuery代码,将弹出5号。本网站的内容扩展:80 / file / post / 0703 / window.location.html? ver = 1. 0& ID = 6#Imerher我们可以使用JavaScript获取各种部分1,Window.Location。 href -----------整个URL字符串(浏览器中的完整地址栏)此示例返回:: 80 / fisker / post / 0703 / window.location.html? ver = 1. 0& ID = 6#IMHERE2,Window.Location.Protocol ------- URL协议部分此示例返回:http:3,window.location.host -------- - --URL的主机部分此示例返回:4,window.location.port.port ----- URL端口部分如果使用默认值80端口(更新:即使添加:8 0),则返回值不是默认值80是一个空字符。此示例返回:“”5,window.location.pathName(URL的路径一部分(即文件地址))此示例返回:/fisker/post/0703/window.location.html6,window.location.search ------查询(参数)部分除了动态语言,我们还可以提供静态页面,并使用JavaScript获取此案例的参数值。此示例返回:? ver = 1. 0& id = 67,window.location.hash -------锚点点此示例返回:#imhere 查看全部
浏览器抓取网页(通过实际例子讲解怎么使用javascript或者jquery获取地址url参数)
本文将解释如何使用JavaScript或jQuery通过实际示例来获取地址URL参数,希望您能喜欢它。问题描述今天,我做了一个话题。虽然PHP也可以这样做,但是考虑到它们的特殊效果代码在jQuery上完成,认为它可以直接在地址栏中直接获得链接参数内的数字直接实现。假设页面的地址是这样的。 ,然后我想获得最后一个数字165,你可以通过这个代码
var url= window.location.href;
var index = url.substring(url.lastIndexOf('/') + 1);
但这是一个缺陷。如果我得到的地址不是这样的形式,但如果此索引的值不是数字。解决方案以下可能更好?
var lastBit = url.substring(url.lastIndexOf('/') + 1).match(/[^/]*$/)[0];
var lastDigits = url.substring(url.lastIndexOf('/') + 1).match(/[0-9]*$/)[0]; // 获取的是数字部分
获取查询值JavaScript版本:
function getUrlParam(name){
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r!=null) return unescape(r[2]); return null;
}
//获取http://caibaojian.com/?p=177.html的p值
getUrlParam('p'); //输出177
jQuery版本:
(function($){
$.getUrlParam = function(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r!=null) return unescape(r[2]); return null;
}
})(jQuery);
$(function(){
alert(window.location.href);
alert($.getUrlParam('page'));
})
在上面的页面时,我们使用上面的jQuery代码,将弹出5号。本网站的内容扩展:80 / file / post / 0703 / window.location.html? ver = 1. 0& ID = 6#Imerher我们可以使用JavaScript获取各种部分1,Window.Location。 href -----------整个URL字符串(浏览器中的完整地址栏)此示例返回:: 80 / fisker / post / 0703 / window.location.html? ver = 1. 0& ID = 6#IMHERE2,Window.Location.Protocol ------- URL协议部分此示例返回:http:3,window.location.host -------- - --URL的主机部分此示例返回:4,window.location.port.port ----- URL端口部分如果使用默认值80端口(更新:即使添加:8 0),则返回值不是默认值80是一个空字符。此示例返回:“”5,window.location.pathName(URL的路径一部分(即文件地址))此示例返回:/fisker/post/0703/window.location.html6,window.location.search ------查询(参数)部分除了动态语言,我们还可以提供静态页面,并使用JavaScript获取此案例的参数值。此示例返回:? ver = 1. 0& id = 67,window.location.hash -------锚点点此示例返回:#imhere
浏览器抓取网页(Python3实现抓取javascript动态生成的html网页功能结合实例形式分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-18 17:16
本文文章主要介绍了Python 3捕获JavaScript动态生成的HTML网页的功能,并以实例的形式分析了Python 3使用selenium库捕获JavaScript动态生成的HTML网页元素的相关操作技巧。有需要的朋友可以参考
本文描述了Python3获取JavaScript动态生成的HTML网页的功能。与您分享,供您参考,如下所示:
使用urllib获取网页时,只能读取网页的静态源文件,但无法捕获JavaScript生成的内容
原因是urlib即时抓取,不等待JavaScript加载延迟,因此urlib无法读取页面中JavaScript生成的内容
真的没有办法读取JavaScript生成的内容吗?没有
这里有一个python库:selenium。本文使用的版本是2.4 4.0
首先安装:
pip install -U selenium
以下是三个示例来说明其用法:
[示例0]
打开Firefox浏览器
加载具有给定URL地址的页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
[示例1]
打开Firefox浏览器
加载百度主页
搜索“selenium HQ”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
[示例2]
SeleniumWebDriver通常用于测试网络程序。以下是使用python标准库unittest的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
以上是Python 3如何捕获由JS动态生成的HTML网页的函数实现示例的详细信息。请多关注其他相关文章
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系 查看全部
浏览器抓取网页(Python3实现抓取javascript动态生成的html网页功能结合实例形式分析)
本文文章主要介绍了Python 3捕获JavaScript动态生成的HTML网页的功能,并以实例的形式分析了Python 3使用selenium库捕获JavaScript动态生成的HTML网页元素的相关操作技巧。有需要的朋友可以参考
本文描述了Python3获取JavaScript动态生成的HTML网页的功能。与您分享,供您参考,如下所示:
使用urllib获取网页时,只能读取网页的静态源文件,但无法捕获JavaScript生成的内容
原因是urlib即时抓取,不等待JavaScript加载延迟,因此urlib无法读取页面中JavaScript生成的内容
真的没有办法读取JavaScript生成的内容吗?没有
这里有一个python库:selenium。本文使用的版本是2.4 4.0
首先安装:
pip install -U selenium
以下是三个示例来说明其用法:
[示例0]
打开Firefox浏览器
加载具有给定URL地址的页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
[示例1]
打开Firefox浏览器
加载百度主页
搜索“selenium HQ”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
[示例2]
SeleniumWebDriver通常用于测试网络程序。以下是使用python标准库unittest的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
以上是Python 3如何捕获由JS动态生成的HTML网页的函数实现示例的详细信息。请多关注其他相关文章
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系

