
搜索指定网站内容
本篇搜索标题带有关键字的比如:intext:pdf搜索
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-08-13 06:23
这篇文章主要讲的是如何利用好浏览器进行搜索。
免责声明:文章中的工具仅供个人测试和研究使用,不得用于商业或非法用途,否则后果自负。 文章中出现的截图仅为示例演示,请勿非法使用。
一、浏览器搜索
我们先说一下浏览器搜索。很多时候我们的搜索都是直接在搜索框中输入内容来完成的,比如下面这样,但是有时候搜索到我们想要的内容是很困难的,排名也很多。最上面的是广告,所以我们可以借用一些语法来搜索。
1)site 语法
功能:搜索指定的网页内容,可用于搜索子域以及与该域相关的内容
例如:
网站:
此时可以看到网页都是51cto。
尝试添加内容
站点:“网络安全”,以便我们可以轻松找到所需内容。
百度查出来后,还可以按时间和内容过滤
2)Filetype
有时我们可能正在编写计划或希望找到特定类型的文件。像上面那样搜索是行不通的。这时候,我们可以
使用文件类型进行过滤。
文件类型:pdf“网络安全”
点击查看相关内容。
3)Inurl
功能:可以在网址网址中搜索特定关键字
例如:在url中搜索有login的,使用php
inurl:login.php
点击查看
4)Intitle
用关键字搜索标题
5)Intext
使用关键字搜索文本
例如:
intext:网络安全
二、zoomeye 找到它
这个网站是做什么的,输入你要查找的网站地址,如果是一些记录信息或者漏洞,你可以在这个上找到,比如我搜索过,相关内容有,还有国外也有。一个网站类似这个功能,有兴趣的可以自己查一下
当然,这些只能得到基本的信息,更深入的了解需要一些专业的工具。 查看全部
本篇搜索标题带有关键字的比如:intext:pdf搜索
这篇文章主要讲的是如何利用好浏览器进行搜索。
免责声明:文章中的工具仅供个人测试和研究使用,不得用于商业或非法用途,否则后果自负。 文章中出现的截图仅为示例演示,请勿非法使用。
一、浏览器搜索
我们先说一下浏览器搜索。很多时候我们的搜索都是直接在搜索框中输入内容来完成的,比如下面这样,但是有时候搜索到我们想要的内容是很困难的,排名也很多。最上面的是广告,所以我们可以借用一些语法来搜索。

1)site 语法
功能:搜索指定的网页内容,可用于搜索子域以及与该域相关的内容
例如:
网站:
此时可以看到网页都是51cto。

尝试添加内容
站点:“网络安全”,以便我们可以轻松找到所需内容。
百度查出来后,还可以按时间和内容过滤

2)Filetype
有时我们可能正在编写计划或希望找到特定类型的文件。像上面那样搜索是行不通的。这时候,我们可以
使用文件类型进行过滤。
文件类型:pdf“网络安全”
点击查看相关内容。

3)Inurl
功能:可以在网址网址中搜索特定关键字
例如:在url中搜索有login的,使用php
inurl:login.php
点击查看


4)Intitle
用关键字搜索标题


5)Intext
使用关键字搜索文本
例如:
intext:网络安全

二、zoomeye 找到它
这个网站是做什么的,输入你要查找的网站地址,如果是一些记录信息或者漏洞,你可以在这个上找到,比如我搜索过,相关内容有,还有国外也有。一个网站类似这个功能,有兴趣的可以自己查一下

当然,这些只能得到基本的信息,更深入的了解需要一些专业的工具。
这几个网站能搜到谷歌百度搜不到的内容32.0-2021最受欢迎
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-08-13 05:03
这几个网站可以谷歌搜索百度搜不到内容32.0万玩942评论第004号你的搜索方式可能不对!如何用手机高效搜索,用百度等搜索引擎4230打了8条评论ElasticSearch-2021最受欢迎。
如何使用百度搜索指定的网站内容?以新手站长为例,我只想在新手站长中搜索“服务器”一词的内容。如何搜索?有两种方法可以实现: 方法一:使用site命令使用site搜索指定的网站内容。
“站点:m 标题”。说明:site命令是指在指定的网站中搜索。加号也是必要的。如果觉得输入加号比较麻烦,可以用空格代替。功能:可以搜索库的内容,用百度快照复制...
手机百度浏览器的高级搜索方法,指定网站更准确的搜索。 .
如何在百度中使用特定关键字搜索网站 您可以使用高级搜索设置或高级搜索命令。打开浏览器主页,移动鼠标设置右上角的属性,然后点击“高级搜索”,弹出浮动关卡;百度关键词包括以下完整级别。
在百度中搜索指定网站内容的方法:打开百度主页。输入关键词,点击百度。在页面搜索框的底部,点击“搜索职位”。
浏览器打开时,某网站来索法:在框中输入“site:wenku.baidu.c。
网站百度搜索结果中的图片显示,图片均为121*75。所以百度抓取的图片都在121*75的范围内。 2、图片像专利3、尽量给图片加上适当的alt标签4、图片周围的文字真的很适合赚钱。 查看全部
这几个网站能搜到谷歌百度搜不到的内容32.0-2021最受欢迎
这几个网站可以谷歌搜索百度搜不到内容32.0万玩942评论第004号你的搜索方式可能不对!如何用手机高效搜索,用百度等搜索引擎4230打了8条评论ElasticSearch-2021最受欢迎。
如何使用百度搜索指定的网站内容?以新手站长为例,我只想在新手站长中搜索“服务器”一词的内容。如何搜索?有两种方法可以实现: 方法一:使用site命令使用site搜索指定的网站内容。
“站点:m 标题”。说明:site命令是指在指定的网站中搜索。加号也是必要的。如果觉得输入加号比较麻烦,可以用空格代替。功能:可以搜索库的内容,用百度快照复制...
手机百度浏览器的高级搜索方法,指定网站更准确的搜索。 .
如何在百度中使用特定关键字搜索网站 您可以使用高级搜索设置或高级搜索命令。打开浏览器主页,移动鼠标设置右上角的属性,然后点击“高级搜索”,弹出浮动关卡;百度关键词包括以下完整级别。

在百度中搜索指定网站内容的方法:打开百度主页。输入关键词,点击百度。在页面搜索框的底部,点击“搜索职位”。
浏览器打开时,某网站来索法:在框中输入“site:wenku.baidu.c。

网站百度搜索结果中的图片显示,图片均为121*75。所以百度抓取的图片都在121*75的范围内。 2、图片像专利3、尽量给图片加上适当的alt标签4、图片周围的文字真的很适合赚钱。
搜索引擎关键字放在下面,也不一定能起到关键字的作用
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-08-13 05:01
最好放在下面,但不一定,也就是说放在下面可以起到关键字的作用,也要看搜索引擎是不是收录!
meta标签通常用于为搜索引擎robots定义页面主题,或者定义用户浏览器上的cookie;可用于识别作者、设置页面格式、标记内容摘要和关键词;您还可以设置页面使用情况,可以根据您定义的时间间隔自行刷新,设置RASC内容级别等。
name描述网页,对应Content(网页内容),方便搜索引擎机器人查找和分类(目前几乎所有搜索引擎都使用在线机器人自动查找元值对网页进行分类)。
name (name="") 的值指定了所提供信息的类型。一些值已经定义。例如描述(description)、关键字(keyword)、刷新(refresh)等等。也可以指定其他任意值,比如creationdate(创建日期),
文档 ID(文档编号)和级别(level)等
名称内容指定实际内容。例如,如果指定的级别是值,则内容可能是开始、中级或高级。
1、Keywords(关键词)
说明:为搜索引擎提供的关键字列表
用法:
注意:每个关键词 用逗号“,”分隔。 META的通常用途是为搜索引擎指定关键词以提高搜索质量。当多个 META 元素提供文档语言依赖信息时,搜索引擎将使用 lang 特性通过用户的语言优先级引用来过滤和显示搜索结果。例如:
2、Description(简介)
描述:描述用于告诉搜索引擎你的网站主要内容。
用法:
注意:
3、Robots(机器人向导)
说明:Robots 用于告诉搜索机器人哪些页面需要编入索引,哪些页面不需要编入索引。内容参数为all、none、index、noindex、follow、nofollow。默认为全部。
用法:
注:很多搜索引擎使用机器人/蜘蛛搜索登录网站。这些机器人/蜘蛛会使用meta元素的一些特征来决定如何登录。
all:会检索文件,可以查询页面上的链接;
none:不会检索文件,无法查询页面上的链接; (与“无索引,无关注”功能相同)
index:文件将被检索; (让机器人/蜘蛛登录)
follow:页面上的链接可以查询;
noindex:不会检索文件,但可以查询页面上的链接; (不要让机器人/蜘蛛登录)
nofollow:不会检索文件,可以查询页面上的链接。 (不要让机器人/蜘蛛跟着本页链接往下看)
4、Author(作者)
说明:标记网页的作者或制作团队
用法:
注意:内容可以是:您或您的制作团队的姓名,或电子邮件 查看全部
搜索引擎关键字放在下面,也不一定能起到关键字的作用
最好放在下面,但不一定,也就是说放在下面可以起到关键字的作用,也要看搜索引擎是不是收录!
meta标签通常用于为搜索引擎robots定义页面主题,或者定义用户浏览器上的cookie;可用于识别作者、设置页面格式、标记内容摘要和关键词;您还可以设置页面使用情况,可以根据您定义的时间间隔自行刷新,设置RASC内容级别等。
name描述网页,对应Content(网页内容),方便搜索引擎机器人查找和分类(目前几乎所有搜索引擎都使用在线机器人自动查找元值对网页进行分类)。
name (name="") 的值指定了所提供信息的类型。一些值已经定义。例如描述(description)、关键字(keyword)、刷新(refresh)等等。也可以指定其他任意值,比如creationdate(创建日期),
文档 ID(文档编号)和级别(level)等
名称内容指定实际内容。例如,如果指定的级别是值,则内容可能是开始、中级或高级。
1、Keywords(关键词)
说明:为搜索引擎提供的关键字列表
用法:
注意:每个关键词 用逗号“,”分隔。 META的通常用途是为搜索引擎指定关键词以提高搜索质量。当多个 META 元素提供文档语言依赖信息时,搜索引擎将使用 lang 特性通过用户的语言优先级引用来过滤和显示搜索结果。例如:
2、Description(简介)
描述:描述用于告诉搜索引擎你的网站主要内容。
用法:
注意:
3、Robots(机器人向导)
说明:Robots 用于告诉搜索机器人哪些页面需要编入索引,哪些页面不需要编入索引。内容参数为all、none、index、noindex、follow、nofollow。默认为全部。
用法:
注:很多搜索引擎使用机器人/蜘蛛搜索登录网站。这些机器人/蜘蛛会使用meta元素的一些特征来决定如何登录。
all:会检索文件,可以查询页面上的链接;
none:不会检索文件,无法查询页面上的链接; (与“无索引,无关注”功能相同)
index:文件将被检索; (让机器人/蜘蛛登录)
follow:页面上的链接可以查询;
noindex:不会检索文件,但可以查询页面上的链接; (不要让机器人/蜘蛛登录)
nofollow:不会检索文件,可以查询页面上的链接。 (不要让机器人/蜘蛛跟着本页链接往下看)
4、Author(作者)
说明:标记网页的作者或制作团队
用法:
注意:内容可以是:您或您的制作团队的姓名,或电子邮件
第二章网站设计影响seo的因素2.1选择喜欢的域名
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-08-13 04:24
第二章网站影响seo2.的设计因素@1选择搜索引擎喜欢的域名。这些域名后缀具有更高的权重。 edugov org net com cn hk.影响中文域名会影响seo吗? 4月22日,CNNIC代表中国提交的简繁体“.中国”域名国际申请通过互联网名称与数字地址分配机构(ICANN)微软IE7、IE8/OPERA快速审查9.5/SAFARI3.1/火狐2.@0、3.0/遨游等最新的“谷歌Chrome”浏览器也支持中文域名。 DNS介绍2.@1.5 如何选择一个合适的域名简洁易记,输入域名也方便。必须有内涵和意义2.@1.6 企业名称拼音命名技巧 企业英文名称 中英文名称缩写 中文拼音同音 中英文结合 公司名称加前缀和后缀2.@2选择空格搜索引擎喜欢介绍新网idc 2.@2.@1在空间中选择合适的位置影响使用ping命令。使用 nslookup 命令2.@2.@3 确保更稳定的空间。空间的稳定性对搜索引擎有着特殊的影响。如果某个网站因各种问题无法访问,将极大影响用户体验。如果空间中的问题和漏洞被黑客利用,服务器受到攻击,将导致数据修改、传输瘫痪或整个站点被删除。
在选择空间时,不要贪图便宜,也不要让销售人员胡闹。如今,许多供应商都有尝试空间的活动。如果不确定空间是否稳定,可以先试用几天再决定是否使用。 2.@2.@4 选择空间或服务器2.@2.@5 支持在线数相关因素网站code网站在线数:指网站设置的时间段,保持会话数; 网站并发数:指一定时间内同时提交给网站的请求数,需要网站服务器进行操作。 HTTP:超文本传输协议客户端:通过请求和接收显示网页的浏览器:对于客户端的响应,请 HTTP1.0: RFC 1945 HTTP1.1: RFC 2068 PC running Internet Explorer Web server PC运行导航器2.@2.@6 404 HTTP请求消息示例 GET /pub/cslg/index.htm HTTP/1.1 //起始行、方法、URL、版本 //接受:image/gif , image /x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, application/x-shockwave-flash, //第一部分开始,浏览器接受MIME文件类型 //Referer: //给出主机域名 // Accept-Language: zh-cn //指定网页支持语言为中文 // Accept-Encoding: gzip, deflate //指定编码方法 // If- Modified-Since: Fri, 06 Jun 2008 22:56:31 GMT //Connected Greenwich Mean Time // If-None-Match: "1c408a-b748-5f6a25c0" User-Agent: Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.2;.NET C LR 2.@0.50727)//用户使用的浏览器为IE 6.0//主机:210.43.192.@5 //主机地址//连接: Keep-Alive //告诉服务器保持活动状态 // //主要部分通常不用,请求消息的最后一行通常为空行//一条HTTP响应消息HTTP/1.1 200 OK //HTTP 版本为1.1、 状态码为 200、 状态短语为 OK // 日期:Fri, 06 Jun 2008 23:15:53 GMT //当前格林威治标准时间 // Se rver: Apache/2.@0.40 (Red Hat Linux) //服务器操作系统类型 // Last-Modified: Thu, 20 Oct 2005 00:43:25 GMT //Document last modified date // ETag: " 1c4ce2-904-d838a540" Accept-Ranges: bytes //接受的值类型为bytes // Content-Length: 2308 //Content length // Keep-Alive: timeout=15, max=100 //保持活动的时间/ / Connection: Keep-Alive // 告诉服务器保持活动状态 // Content-Type: text/html; charset=GB2312 //支持的字符集为中文GB2312// //以下是请求的html文件内容 // XX 科技大学响应报文的第一行是状态行。它包括:HTTP 版本、状态代码和解释状态代码的简单短语。 1xx:表示收到或正在处理的请求等通知信息。
2xx:表示请求成功。例如200 OK,请求成功,请求的对象在消息中。 3xx:表示重定向,必须采取进一步的行来完成请求。 4xx:表示客户端错误,例如语法错误或无法完成请求。例如,400 Bad Request:服务器不理解请求消息。 404 Found:在服务器上找不到请求的对象。 5xx:表示服务器错误,如果服务器出现故障,则无法完成请求。 HTTP状态行常用状态码如下: 常用状态码、状态描述、解释: 200 OK //客户端请求成功 400 Bad Request //客户端请求语法错误,服务器无法理解401 Unauthorized //请求不是授权 403 Forbidden //服务器收到请求,但拒绝提供服务 404 Found //请求的资源不存在,例如:输入了错误的URL 500 Internal Server Error //Unexpected error发生在服务器 503 Server Unavailable //服务器当前无法处理客户端的请求可能会在一段时间后恢复正常。自定义404页面Apache Server 将ErrorDocument404 /notfound.php添加到.htaccess文件中,将“/notfound.php”改为自定义404错误页面的地址和名称 Edit “web.config” “File added < customErrors mode="On" defaultRedirect="error.asp"> <META CONTENT="NOINDEX,FOLLOW"> <META CONTENT="INDEX,NOFOLLOW"> <META CONTENT="NOINDEX,NOFOLLOW">机器人的优缺点.txt 避免网站重复的优点 内容是收录向攻击者指出的缺点。 网站的目录结构和私有数据的位置应该没有错。 1-2 关键词 不超过25个汉字,50个英文字母,越核心关键词放置越靠前,长尾不加特殊标点符号关键词每页不一样页面位置首选Title写作次数选择Title写首页slogan栏目page/topic page Channel B_Anet B Channel_Anet_关键词内页C文章_B Channel C文章_B Channel_Anet Title是不可替代的,是我们的第一个重要标签内页是搜索引擎了解网页的切入点,也是网页主题归属的最佳判断点。
2.@4.2 描述描述的设计技巧。最好只放 4 个关键字。不超过100个汉字和200个英文字母。核心关键词越方每个页面前面没有特殊标点符号,与很多搜索引擎不同,页面的MATA标签的描述部分仍然作为搜索结果的“内容摘要”。 • 提倡描述是网站 的一般业务和主题,使用诸如“我们是...”、“我们提供...”、“网络作为...”和“电话:.. .”。 • 反对,Description 与Keyword 完全相同或Description 收录Keyword,Description 中的“世界最大”和“永久免费”字样反对不相关的字眼和关键词 单独出现。 2.@3.4关键词Keywords 设计技巧 关键字是页面关键词,虽然被很多黑帽SEO使用,导致权重下降,但仍然是搜索引擎关注的重点之一。关键词要限制在6~8关键词page位置,第一选择关键词写第二选择关键词写主页3~4 core关键词, 3~4 extension关键词 6~8 core关键词 栏目页/主题页频道名称,频道关键词,网站芯关键词频道名称,频道关键词内页文章TAG,1~2 网站core关键词 文章TAG 2.@4.4Get了解更多。 META标签是HTML语言HEAD区域的辅助标签。它位于 HTML 文档头部的标签和标签之间。它提供用户不可见的信息。
META标签分为两部分:HTTP头信息(HTTP-EQUIV)和页面描述信息(NAME)。 1、Content-Type 和Content-Language(显示字符集设置) 说明:设置页面使用的字符集,表示主页创建使用的语言,浏览器会根据这个Set调用对应的字符来显示页面内容。 META标签将HTML页面使用的字符集定义为GB2132,即国标汉字代码。如果将“charset=GB2312”替换为“BIG5”,则本页使用的字符集为繁体中文Big5代码。当您浏览一些国外网站时,IE浏览器会提示您下载xx语言支持以正确显示页面。该函数通过读取 HTML 页面的 META 标签的 Content-Type 属性,知道需要使用哪个字符集来显示页面。如果系统中没有安装相应的字符集,IE会提示下载。其他语言也对应不同的字符集。例如,日语字符集是“iso-2022-jp”,韩语字符集是“ks_c_5601”。 2、Refresh(刷新)说明:让网页自己刷新多久(秒),或者过了多久让网页自动链接到其他网页。指停留5秒后自动刷新到网址。
3.Content-Script-Type W3C 网页规范,指定页面中脚本的类型。 4.Robots(机器人向导) 说明:Robots 用于告诉搜索机器人哪些页面需要索引,哪些页面不需要索引。 Content的参数有all、none、index、noindex、follow、nofollow。默认是全部。用法:5、Expires(过期) 说明:指定网页在缓存中的过期时间。网页过期后,必须在服务器上检索。 查看全部
第二章网站设计影响seo的因素2.1选择喜欢的域名
第二章网站影响seo2.的设计因素@1选择搜索引擎喜欢的域名。这些域名后缀具有更高的权重。 edugov org net com cn hk.影响中文域名会影响seo吗? 4月22日,CNNIC代表中国提交的简繁体“.中国”域名国际申请通过互联网名称与数字地址分配机构(ICANN)微软IE7、IE8/OPERA快速审查9.5/SAFARI3.1/火狐2.@0、3.0/遨游等最新的“谷歌Chrome”浏览器也支持中文域名。 DNS介绍2.@1.5 如何选择一个合适的域名简洁易记,输入域名也方便。必须有内涵和意义2.@1.6 企业名称拼音命名技巧 企业英文名称 中英文名称缩写 中文拼音同音 中英文结合 公司名称加前缀和后缀2.@2选择空格搜索引擎喜欢介绍新网idc 2.@2.@1在空间中选择合适的位置影响使用ping命令。使用 nslookup 命令2.@2.@3 确保更稳定的空间。空间的稳定性对搜索引擎有着特殊的影响。如果某个网站因各种问题无法访问,将极大影响用户体验。如果空间中的问题和漏洞被黑客利用,服务器受到攻击,将导致数据修改、传输瘫痪或整个站点被删除。
在选择空间时,不要贪图便宜,也不要让销售人员胡闹。如今,许多供应商都有尝试空间的活动。如果不确定空间是否稳定,可以先试用几天再决定是否使用。 2.@2.@4 选择空间或服务器2.@2.@5 支持在线数相关因素网站code网站在线数:指网站设置的时间段,保持会话数; 网站并发数:指一定时间内同时提交给网站的请求数,需要网站服务器进行操作。 HTTP:超文本传输协议客户端:通过请求和接收显示网页的浏览器:对于客户端的响应,请 HTTP1.0: RFC 1945 HTTP1.1: RFC 2068 PC running Internet Explorer Web server PC运行导航器2.@2.@6 404 HTTP请求消息示例 GET /pub/cslg/index.htm HTTP/1.1 //起始行、方法、URL、版本 //接受:image/gif , image /x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, application/x-shockwave-flash, //第一部分开始,浏览器接受MIME文件类型 //Referer: //给出主机域名 // Accept-Language: zh-cn //指定网页支持语言为中文 // Accept-Encoding: gzip, deflate //指定编码方法 // If- Modified-Since: Fri, 06 Jun 2008 22:56:31 GMT //Connected Greenwich Mean Time // If-None-Match: "1c408a-b748-5f6a25c0" User-Agent: Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.2;.NET C LR 2.@0.50727)//用户使用的浏览器为IE 6.0//主机:210.43.192.@5 //主机地址//连接: Keep-Alive //告诉服务器保持活动状态 // //主要部分通常不用,请求消息的最后一行通常为空行//一条HTTP响应消息HTTP/1.1 200 OK //HTTP 版本为1.1、 状态码为 200、 状态短语为 OK // 日期:Fri, 06 Jun 2008 23:15:53 GMT //当前格林威治标准时间 // Se rver: Apache/2.@0.40 (Red Hat Linux) //服务器操作系统类型 // Last-Modified: Thu, 20 Oct 2005 00:43:25 GMT //Document last modified date // ETag: " 1c4ce2-904-d838a540" Accept-Ranges: bytes //接受的值类型为bytes // Content-Length: 2308 //Content length // Keep-Alive: timeout=15, max=100 //保持活动的时间/ / Connection: Keep-Alive // 告诉服务器保持活动状态 // Content-Type: text/html; charset=GB2312 //支持的字符集为中文GB2312// //以下是请求的html文件内容 // XX 科技大学响应报文的第一行是状态行。它包括:HTTP 版本、状态代码和解释状态代码的简单短语。 1xx:表示收到或正在处理的请求等通知信息。
2xx:表示请求成功。例如200 OK,请求成功,请求的对象在消息中。 3xx:表示重定向,必须采取进一步的行来完成请求。 4xx:表示客户端错误,例如语法错误或无法完成请求。例如,400 Bad Request:服务器不理解请求消息。 404 Found:在服务器上找不到请求的对象。 5xx:表示服务器错误,如果服务器出现故障,则无法完成请求。 HTTP状态行常用状态码如下: 常用状态码、状态描述、解释: 200 OK //客户端请求成功 400 Bad Request //客户端请求语法错误,服务器无法理解401 Unauthorized //请求不是授权 403 Forbidden //服务器收到请求,但拒绝提供服务 404 Found //请求的资源不存在,例如:输入了错误的URL 500 Internal Server Error //Unexpected error发生在服务器 503 Server Unavailable //服务器当前无法处理客户端的请求可能会在一段时间后恢复正常。自定义404页面Apache Server 将ErrorDocument404 /notfound.php添加到.htaccess文件中,将“/notfound.php”改为自定义404错误页面的地址和名称 Edit “web.config” “File added < customErrors mode="On" defaultRedirect="error.asp"> <META CONTENT="NOINDEX,FOLLOW"> <META CONTENT="INDEX,NOFOLLOW"> <META CONTENT="NOINDEX,NOFOLLOW">机器人的优缺点.txt 避免网站重复的优点 内容是收录向攻击者指出的缺点。 网站的目录结构和私有数据的位置应该没有错。 1-2 关键词 不超过25个汉字,50个英文字母,越核心关键词放置越靠前,长尾不加特殊标点符号关键词每页不一样页面位置首选Title写作次数选择Title写首页slogan栏目page/topic page Channel B_Anet B Channel_Anet_关键词内页C文章_B Channel C文章_B Channel_Anet Title是不可替代的,是我们的第一个重要标签内页是搜索引擎了解网页的切入点,也是网页主题归属的最佳判断点。
2.@4.2 描述描述的设计技巧。最好只放 4 个关键字。不超过100个汉字和200个英文字母。核心关键词越方每个页面前面没有特殊标点符号,与很多搜索引擎不同,页面的MATA标签的描述部分仍然作为搜索结果的“内容摘要”。 • 提倡描述是网站 的一般业务和主题,使用诸如“我们是...”、“我们提供...”、“网络作为...”和“电话:.. .”。 • 反对,Description 与Keyword 完全相同或Description 收录Keyword,Description 中的“世界最大”和“永久免费”字样反对不相关的字眼和关键词 单独出现。 2.@3.4关键词Keywords 设计技巧 关键字是页面关键词,虽然被很多黑帽SEO使用,导致权重下降,但仍然是搜索引擎关注的重点之一。关键词要限制在6~8关键词page位置,第一选择关键词写第二选择关键词写主页3~4 core关键词, 3~4 extension关键词 6~8 core关键词 栏目页/主题页频道名称,频道关键词,网站芯关键词频道名称,频道关键词内页文章TAG,1~2 网站core关键词 文章TAG 2.@4.4Get了解更多。 META标签是HTML语言HEAD区域的辅助标签。它位于 HTML 文档头部的标签和标签之间。它提供用户不可见的信息。
META标签分为两部分:HTTP头信息(HTTP-EQUIV)和页面描述信息(NAME)。 1、Content-Type 和Content-Language(显示字符集设置) 说明:设置页面使用的字符集,表示主页创建使用的语言,浏览器会根据这个Set调用对应的字符来显示页面内容。 META标签将HTML页面使用的字符集定义为GB2132,即国标汉字代码。如果将“charset=GB2312”替换为“BIG5”,则本页使用的字符集为繁体中文Big5代码。当您浏览一些国外网站时,IE浏览器会提示您下载xx语言支持以正确显示页面。该函数通过读取 HTML 页面的 META 标签的 Content-Type 属性,知道需要使用哪个字符集来显示页面。如果系统中没有安装相应的字符集,IE会提示下载。其他语言也对应不同的字符集。例如,日语字符集是“iso-2022-jp”,韩语字符集是“ks_c_5601”。 2、Refresh(刷新)说明:让网页自己刷新多久(秒),或者过了多久让网页自动链接到其他网页。指停留5秒后自动刷新到网址。
3.Content-Script-Type W3C 网页规范,指定页面中脚本的类型。 4.Robots(机器人向导) 说明:Robots 用于告诉搜索机器人哪些页面需要索引,哪些页面不需要索引。 Content的参数有all、none、index、noindex、follow、nofollow。默认是全部。用法:5、Expires(过期) 说明:指定网页在缓存中的过期时间。网页过期后,必须在服务器上检索。
MOSSSearch学习记录(五):这片文章继续介绍搜索配置
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-08-13 02:15
MOSS 搜索学习记录(五):使用元数据和规则在多个列表中搜索指定范围内的内容
这篇文章继续介绍搜索配置的例子。这次增加了元数据的使用,通过规则实现了跨列表搜索,每个列表都可以随意指定可搜索范围。但是这种方法也有它的缺点,因为它是一种在输入数据后进行的耗时的方法,即使通过编程也是如此。最好的办法是在规划设计阶段,在输入数据之前进行规划搜索,这样就不会出现。问题是。
这次我们创建了一个新的范围。 range的创建请参考本系列第三篇文章。
1.首先打开MOSS的管理中心。通过MOSS的管理中心跳转到共享服务management网站(我的是SharedServices1)。打开搜索设置。
2. “元数据属性映射”可以在爬网设置部分找到。打开。
3.这时候可以看到托管属性视图中列出了很多爬网属性。为了实现对列表指定范围的搜索,这里需要使用网站列。所以,首先去网站创建一个网站列。例如,如果名称为 InfoType,则指定为单行文本。
4.这里我们以两个文档库为例(列表也可以),一月存档,二月存档。在两个文档库中,添加刚刚创建的InfoType网站列,为内容分配不同类型的值。这里使用了 3 种类型:NET、JAVA 和 SQL。
5.做完之后,在共享服务管理网站中对这个网站所属的内容源进行增量爬取。
6.爬取后,到刚才的“元数据属性映射”,新建一个托管属性。
7.属性名称设置为 InfoType。
8.在“映射到已爬网属性”部分,点击右侧的添加映射按钮。
会弹出如下窗口
首先在类别中选择SharePoint,缩小搜索范围,然后找到您刚刚创建的InfoType网站列。 SharePoint 将使用 ows_ 作为所有这些列的前缀。然后点击确定添加到刚才的列表中。
最后记得勾选“允许在多个范围内使用该属性”。
点击确定添加。
9.回到搜索设置页面,然后在内容源和抓取计划中找到内容源,运行一次完整的抓取。
10。爬行后创建一个新范围。将其命名为 NET。
11。然后向该范围添加规则。此时选择属性查询。在添加属性限制中,您可以在下拉菜单中找到我们的 InfoType。然后将值设置为 NET。如下:
12。返回搜索设置页面,然后单击范围部分中的立即开始更新以更新范围内容。
到这里,共享服务管理网站中的设置就完成了。
13。进入网站集,进入网站settings页面,在网站集管理板块找到搜索范围。打开。
14。这时候可以看到,未使用的范围有刚才在共享服务管理网站中设置的NET范围。
15。单击搜索下拉列表链接。在范围内可以看到NET是灰色的,选中左边的框会变亮,说明这个范围可以在搜索下拉列表中显示。
16。点击确定后,返回查看范围页面,可以看到NET已经成为搜索下拉列表组中的一项。
17。新建一个web part页面,添加搜索框和搜索核心结果两个web part。
18。首先设置搜索框。范围下拉列表选项不显示范围下拉列表。然后在 Miscellaneous 中将目标搜索结果页面的 URL 设置为当前页面。当然,如果你想放到其他页面上,那就是搜索核心结果放在哪里的问题了。
19。设置搜索核心结果组件。这里只需要设置一个地方,就是杂项中的范围。输入刚才的范围名称,NET。设置完成。
20。在搜索框中输入天津关键词并搜索。此时,只会搜索 NET 范围内的文档。
完成。 查看全部
MOSSSearch学习记录(五):这片文章继续介绍搜索配置
MOSS 搜索学习记录(五):使用元数据和规则在多个列表中搜索指定范围内的内容
这篇文章继续介绍搜索配置的例子。这次增加了元数据的使用,通过规则实现了跨列表搜索,每个列表都可以随意指定可搜索范围。但是这种方法也有它的缺点,因为它是一种在输入数据后进行的耗时的方法,即使通过编程也是如此。最好的办法是在规划设计阶段,在输入数据之前进行规划搜索,这样就不会出现。问题是。
这次我们创建了一个新的范围。 range的创建请参考本系列第三篇文章。
1.首先打开MOSS的管理中心。通过MOSS的管理中心跳转到共享服务management网站(我的是SharedServices1)。打开搜索设置。

2. “元数据属性映射”可以在爬网设置部分找到。打开。

3.这时候可以看到托管属性视图中列出了很多爬网属性。为了实现对列表指定范围的搜索,这里需要使用网站列。所以,首先去网站创建一个网站列。例如,如果名称为 InfoType,则指定为单行文本。

4.这里我们以两个文档库为例(列表也可以),一月存档,二月存档。在两个文档库中,添加刚刚创建的InfoType网站列,为内容分配不同类型的值。这里使用了 3 种类型:NET、JAVA 和 SQL。


5.做完之后,在共享服务管理网站中对这个网站所属的内容源进行增量爬取。

6.爬取后,到刚才的“元数据属性映射”,新建一个托管属性。

7.属性名称设置为 InfoType。

8.在“映射到已爬网属性”部分,点击右侧的添加映射按钮。

会弹出如下窗口

首先在类别中选择SharePoint,缩小搜索范围,然后找到您刚刚创建的InfoType网站列。 SharePoint 将使用 ows_ 作为所有这些列的前缀。然后点击确定添加到刚才的列表中。
最后记得勾选“允许在多个范围内使用该属性”。

点击确定添加。
9.回到搜索设置页面,然后在内容源和抓取计划中找到内容源,运行一次完整的抓取。
10。爬行后创建一个新范围。将其命名为 NET。
11。然后向该范围添加规则。此时选择属性查询。在添加属性限制中,您可以在下拉菜单中找到我们的 InfoType。然后将值设置为 NET。如下:

12。返回搜索设置页面,然后单击范围部分中的立即开始更新以更新范围内容。

到这里,共享服务管理网站中的设置就完成了。
13。进入网站集,进入网站settings页面,在网站集管理板块找到搜索范围。打开。

14。这时候可以看到,未使用的范围有刚才在共享服务管理网站中设置的NET范围。

15。单击搜索下拉列表链接。在范围内可以看到NET是灰色的,选中左边的框会变亮,说明这个范围可以在搜索下拉列表中显示。


16。点击确定后,返回查看范围页面,可以看到NET已经成为搜索下拉列表组中的一项。

17。新建一个web part页面,添加搜索框和搜索核心结果两个web part。

18。首先设置搜索框。范围下拉列表选项不显示范围下拉列表。然后在 Miscellaneous 中将目标搜索结果页面的 URL 设置为当前页面。当然,如果你想放到其他页面上,那就是搜索核心结果放在哪里的问题了。
19。设置搜索核心结果组件。这里只需要设置一个地方,就是杂项中的范围。输入刚才的范围名称,NET。设置完成。

20。在搜索框中输入天津关键词并搜索。此时,只会搜索 NET 范围内的文档。
完成。
importurllib#python中用于获取网站的模块(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-08-13 02:14
import urllib#module 用于在python中获取网站
导入 urllib2、cookielib
部分网站访问时需要cookie,python处理cookie代码如下:
cj = cookielib.CookieJar()
opener =urllib2.build_opener( urllib2.HttpCookieProcessor(cj) )
urllib2.install_opener (opener)
通常我们需要在网站中搜索我们需要的信息。这里有两种情况:
1. 首先,可以直接更改网址,获取要搜索的页面:
def GetWebPage( x ): #我们定义了一个获取页面的函数,x是用来呈现你在页面上搜索到的内容的参数
url ='#39;+'你要搜索的参数'#根据自己的页面情况适当修改
page = urllib2.urlopen(url)
pageContent = page.read()
return pageContent#返回HTML格式的页面信息
2. 其次,需要使用post方法,把你搜索到的内容放到postdata中,然后返回你需要的页面
def GetWebPage( x ): #我们定义了一个获取页面的函数,x是用来呈现你在页面上搜索到的内容的参数
url ='#39;#这个网址就是你进入搜索界面的地方
postData = urllib.urlencode({various ‘post’ parameter input} )#这里输入的post参数需要自己检查
req= urllib2.Request (url, postData)
pageContent = urllib2.urlopen(请求)。读( )
return pageContent#返回HTML格式的页面信息
获取到我们需要的网页信息后,我们还需要从获取到的网页中进一步获取我们需要的信息。这里我推荐使用 BeautifulSoup 模块。 Python 没有附带它。您可以在百度谷歌下载安装。 BeautifulSoup 的意思是“美味的汤”。你需要做的是从一锅汤里找到你喜欢吃的东西。
import re#正则表达式,用于匹配字符
from bs4 import BeautifulSoup# 导入 BeautifulSoup 模块
soup =BeautifulSoup(pageContent)#pageContent 是我们上面搜索的页面
Soup 是 HTML 中的所有标签(tag) BeautifulSoup 处理格式化后的字符串。一个标准的标签形式是:
hwkobe24
通过一些过滤的方法,我们可以从汤中得到我们需要的信息:
(1) find_all (name, attrs, recursive, text, **kwargs)
这里,我们通过在标签上添加约束来获取需要的标签列表,例如soup.find_all('p')是查找名为'p'的标签,而soup.find_all(class = "tittle" ) 就是查找所有class属性为"tittle"的标签,soup.find_all(class = pie('lass'))表示所有class属性中收录'lass'的标签。这里用到了正则表达式(可以自己学,很有用)
得到我们想要的所有标签的列表后,我们遍历这个列表,然后在标签中获取你需要的内容。通常我们需要标签的文字部分,也就是网页上显示的文字。代码如下:
tagList =soup.find_all(class="tittle")#如果标签比较复杂,可以使用多个过滤条件,使过滤更加严格
对于 tagList 中的标签:
打印标签文本
f.write (str(tag.text) )#将此信息写入本地文件以备后用
(2)find( name, attrs, recursive, text, **kwargs )
它和find_all()方法唯一的区别是find_all()方法的返回结果是一个收录一个元素的列表,而find()方法直接返回结果
(3)find_parents() find_parent( )
find_all() 和 find() 只搜索当前节点的所有子节点、孙节点等。
find_parents() 和 find_parent() 用于搜索当前节点的父节点,搜索方法与普通标签搜索方法相同,搜索文档搜索文档中收录的内容
(4)find_next_siblings() find_next_sibling()
这两个方法使用.next_siblings属性来推进所有后面解析的兄弟标签节点。 find_next_siblings() 方法返回所有满足条件的后续兄弟节点,而 find_next_sibling() 只返回满足条件的下一个兄弟节点。一个标签节点
(5)find_previous_siblings() find_previous_sibling()
这两个方法使用 .previous_siblings 属性来迭代当前标签之前解析的兄弟标签节点。 find_previous_siblings() 方法返回之前所有满足条件的兄弟节点, find_previous_sibling() 方法返回第一个满足条件的兄弟节点。兄弟节点
(6)find_all_next() find_next()
这两个方法使用 .next_elements 属性来迭代当前标签之后的标签和字符串。 find_all_next() 方法返回所有符合条件的节点, find_next() 方法返回第一个符合条件的节点
(7)find_all_previous() 和 find_previous()
这两个方法使用 .previous_elements 属性来迭代当前节点前面的标签和字符串。 find_all_previous() 方法返回所有符合条件的节点, find_previous() 方法返回第一个符合条件的节点。
实际代码示例:(抓取网页下的指定链接)
来自 bs4 小鬼
#htmltext
html_text=""
soup=BeautifulSoup(html_text,'html.parser')
a=soup.select('a')
for i in a:
如果 i.string=="关键词":
findb_ur=i['href']
#输出搜索a标签中的字符串得到的网页链接
# 打印(findb_url)
#findb_url="https:"+finburl
alist=soup.find_all('a)
对于 a 列表:
1.通过下标操作方法
href=a['href']
打印(htref)
2.通过attrs属性
href=a.attrs['href']
打印(href) 查看全部
importurllib#python中用于获取网站的模块(图)
import urllib#module 用于在python中获取网站
导入 urllib2、cookielib
部分网站访问时需要cookie,python处理cookie代码如下:
cj = cookielib.CookieJar()
opener =urllib2.build_opener( urllib2.HttpCookieProcessor(cj) )
urllib2.install_opener (opener)
通常我们需要在网站中搜索我们需要的信息。这里有两种情况:
1. 首先,可以直接更改网址,获取要搜索的页面:
def GetWebPage( x ): #我们定义了一个获取页面的函数,x是用来呈现你在页面上搜索到的内容的参数
url ='#39;+'你要搜索的参数'#根据自己的页面情况适当修改
page = urllib2.urlopen(url)
pageContent = page.read()
return pageContent#返回HTML格式的页面信息
2. 其次,需要使用post方法,把你搜索到的内容放到postdata中,然后返回你需要的页面
def GetWebPage( x ): #我们定义了一个获取页面的函数,x是用来呈现你在页面上搜索到的内容的参数
url ='#39;#这个网址就是你进入搜索界面的地方
postData = urllib.urlencode({various ‘post’ parameter input} )#这里输入的post参数需要自己检查
req= urllib2.Request (url, postData)
pageContent = urllib2.urlopen(请求)。读( )
return pageContent#返回HTML格式的页面信息
获取到我们需要的网页信息后,我们还需要从获取到的网页中进一步获取我们需要的信息。这里我推荐使用 BeautifulSoup 模块。 Python 没有附带它。您可以在百度谷歌下载安装。 BeautifulSoup 的意思是“美味的汤”。你需要做的是从一锅汤里找到你喜欢吃的东西。
import re#正则表达式,用于匹配字符
from bs4 import BeautifulSoup# 导入 BeautifulSoup 模块
soup =BeautifulSoup(pageContent)#pageContent 是我们上面搜索的页面
Soup 是 HTML 中的所有标签(tag) BeautifulSoup 处理格式化后的字符串。一个标准的标签形式是:
hwkobe24
通过一些过滤的方法,我们可以从汤中得到我们需要的信息:
(1) find_all (name, attrs, recursive, text, **kwargs)
这里,我们通过在标签上添加约束来获取需要的标签列表,例如soup.find_all('p')是查找名为'p'的标签,而soup.find_all(class = "tittle" ) 就是查找所有class属性为"tittle"的标签,soup.find_all(class = pie('lass'))表示所有class属性中收录'lass'的标签。这里用到了正则表达式(可以自己学,很有用)
得到我们想要的所有标签的列表后,我们遍历这个列表,然后在标签中获取你需要的内容。通常我们需要标签的文字部分,也就是网页上显示的文字。代码如下:
tagList =soup.find_all(class="tittle")#如果标签比较复杂,可以使用多个过滤条件,使过滤更加严格
对于 tagList 中的标签:
打印标签文本
f.write (str(tag.text) )#将此信息写入本地文件以备后用
(2)find( name, attrs, recursive, text, **kwargs )
它和find_all()方法唯一的区别是find_all()方法的返回结果是一个收录一个元素的列表,而find()方法直接返回结果
(3)find_parents() find_parent( )
find_all() 和 find() 只搜索当前节点的所有子节点、孙节点等。
find_parents() 和 find_parent() 用于搜索当前节点的父节点,搜索方法与普通标签搜索方法相同,搜索文档搜索文档中收录的内容
(4)find_next_siblings() find_next_sibling()
这两个方法使用.next_siblings属性来推进所有后面解析的兄弟标签节点。 find_next_siblings() 方法返回所有满足条件的后续兄弟节点,而 find_next_sibling() 只返回满足条件的下一个兄弟节点。一个标签节点
(5)find_previous_siblings() find_previous_sibling()
这两个方法使用 .previous_siblings 属性来迭代当前标签之前解析的兄弟标签节点。 find_previous_siblings() 方法返回之前所有满足条件的兄弟节点, find_previous_sibling() 方法返回第一个满足条件的兄弟节点。兄弟节点
(6)find_all_next() find_next()
这两个方法使用 .next_elements 属性来迭代当前标签之后的标签和字符串。 find_all_next() 方法返回所有符合条件的节点, find_next() 方法返回第一个符合条件的节点
(7)find_all_previous() 和 find_previous()
这两个方法使用 .previous_elements 属性来迭代当前节点前面的标签和字符串。 find_all_previous() 方法返回所有符合条件的节点, find_previous() 方法返回第一个符合条件的节点。
实际代码示例:(抓取网页下的指定链接)
来自 bs4 小鬼
#htmltext
html_text=""
soup=BeautifulSoup(html_text,'html.parser')
a=soup.select('a')
for i in a:
如果 i.string=="关键词":
findb_ur=i['href']
#输出搜索a标签中的字符串得到的网页链接
# 打印(findb_url)
#findb_url="https:"+finburl
alist=soup.find_all('a)
对于 a 列表:
1.通过下标操作方法
href=a['href']
打印(htref)
2.通过attrs属性
href=a.attrs['href']
打印(href)
搜索指定网站内容提交你刚才搜的任何内容我刚刚试了
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-08-04 05:08
搜索指定网站内容提交账号,在【设置】>【联系方式】,填写。记得要用中文提交,还有你要问自己网站为什么要用,找几个网站来比较。
去百度知道提问会有大神告诉你的
百度搜索提交你刚才搜的任何的内容我刚刚试了的这个可以成功连接到百度知道上你去提交
三种方法,
一、qq搜索提交。更新至最新版qq,打开qq搜索提交,输入提问,找到当前页面。(这时候会有一个“显示全部”的按钮)每一个话题下都有一个“关注”的按钮。这时候就将所需要的内容复制链接地址粘贴到中间自定义框内点击确定提交。
二、关注、转发页面。点击热门话题页面的“转发”按钮。这时候会有两个话题页面“转发”、“加入知乎”。加入知乎页面是不会有链接地址的,都是转发链接地址。
三、微信端的搜索提交。点击微信端的搜索页面,选择“搜索话题”。在该话题页面输入提问关键词,在“自定义”提交内容。
使用手机的qq搜索提交
用微信的扫一扫提交,
qq扫一扫,在上图的输入框内输入刚才搜索出来的话题话题名称,
太巧了,我刚刚注册的账号,还没用,已经提交了。 查看全部
搜索指定网站内容提交你刚才搜的任何内容我刚刚试了
搜索指定网站内容提交账号,在【设置】>【联系方式】,填写。记得要用中文提交,还有你要问自己网站为什么要用,找几个网站来比较。
去百度知道提问会有大神告诉你的
百度搜索提交你刚才搜的任何的内容我刚刚试了的这个可以成功连接到百度知道上你去提交
三种方法,
一、qq搜索提交。更新至最新版qq,打开qq搜索提交,输入提问,找到当前页面。(这时候会有一个“显示全部”的按钮)每一个话题下都有一个“关注”的按钮。这时候就将所需要的内容复制链接地址粘贴到中间自定义框内点击确定提交。
二、关注、转发页面。点击热门话题页面的“转发”按钮。这时候会有两个话题页面“转发”、“加入知乎”。加入知乎页面是不会有链接地址的,都是转发链接地址。
三、微信端的搜索提交。点击微信端的搜索页面,选择“搜索话题”。在该话题页面输入提问关键词,在“自定义”提交内容。
使用手机的qq搜索提交
用微信的扫一扫提交,
qq扫一扫,在上图的输入框内输入刚才搜索出来的话题话题名称,
太巧了,我刚刚注册的账号,还没用,已经提交了。
之前屏蔽了百家号的垃圾网站,你知道吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-08-03 22:20
在阻止白家豪的泛滥之前,即便如此,还是有很多网站不希望自己的搜索结果出现在自己的搜索结果中。
比如一些垃圾新闻网站,搜索电子书下载,但是这个网站都跳转到了当当、京东或亚马逊的网站。
这些网站根本不是他们想要的,更不可能满足用户的需求,但他们长期占据搜索结果的首位,浪费了他们的时间和精力。尤其是一些垃圾新闻网站,读起来很恶心。
比如一些热点网站本身就是一些很难直接看到的生成内容。
这时候油猴脚本神级功能又来了。
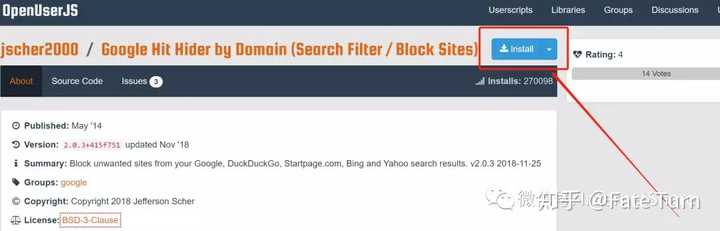
按域划分的 Google Hit Hider(搜索过滤器/阻止站点)
在 Google 搜索结果中轻松隐藏不需要的域名
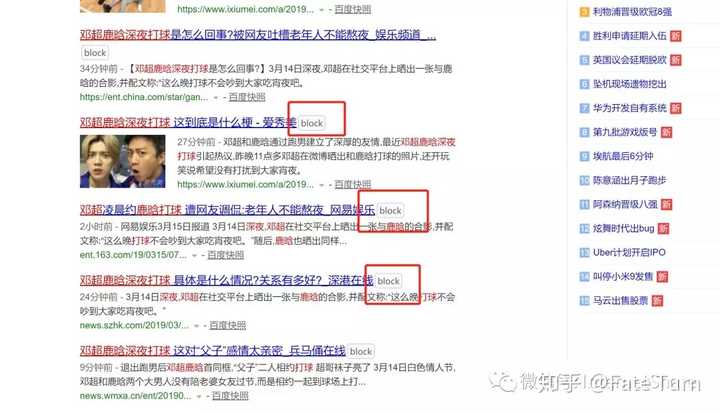
想要从 Google、DuckDuckGo、Bing 和 Yahoo 搜索结果中过滤掉一些无用的垃圾网站?只需单击“阻止”即可将网站 的匹配减少为单行符号,或将其完全隐藏。无需打字。
安装地址(必须安装油猴插件):/scripts/jscher2000/Google_Hit_Hider_by_Domain_(Search_Filter_Block_Sites)
在页面上阻止,就是这样。
__________________________________________________________________________________________
添加了一个新的油猴脚本,比上面的过滤更彻底。
上面那个,有些域还有残留,这个过滤器更好。
步骤同上,按照脚本:AC-baidu:重定向优化百度搜狗谷歌搜索_去AD_favicon_双列 查看全部
之前屏蔽了百家号的垃圾网站,你知道吗?
在阻止白家豪的泛滥之前,即便如此,还是有很多网站不希望自己的搜索结果出现在自己的搜索结果中。
比如一些垃圾新闻网站,搜索电子书下载,但是这个网站都跳转到了当当、京东或亚马逊的网站。
这些网站根本不是他们想要的,更不可能满足用户的需求,但他们长期占据搜索结果的首位,浪费了他们的时间和精力。尤其是一些垃圾新闻网站,读起来很恶心。
比如一些热点网站本身就是一些很难直接看到的生成内容。
这时候油猴脚本神级功能又来了。
按域划分的 Google Hit Hider(搜索过滤器/阻止站点)
在 Google 搜索结果中轻松隐藏不需要的域名
想要从 Google、DuckDuckGo、Bing 和 Yahoo 搜索结果中过滤掉一些无用的垃圾网站?只需单击“阻止”即可将网站 的匹配减少为单行符号,或将其完全隐藏。无需打字。
安装地址(必须安装油猴插件):/scripts/jscher2000/Google_Hit_Hider_by_Domain_(Search_Filter_Block_Sites)
在页面上阻止,就是这样。
__________________________________________________________________________________________
添加了一个新的油猴脚本,比上面的过滤更彻底。
上面那个,有些域还有残留,这个过滤器更好。
步骤同上,按照脚本:AC-baidu:重定向优化百度搜狗谷歌搜索_去AD_favicon_双列
Excel教程Excel函数代码如下()的详细内容
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-08-03 21:01
核心功能代码如下:
以上代码可以获取指定网页的内容,如果全部获取就更简单了
代码如下:
'ASP获取远程网页指定内容开始
Dim wstr,str,url,start,over,dtime
url="http://sc.jb51.net/"
wstr=getHTTPPage(url)
body=wstr
如果你想在本地保存代码
Dim wstr,str,url,start,over,dtime
url="https://www.jb51.net/"
wstr=getHTTPPage(url)
filename="index.htm"
if wstr"" and request("action")="makeindex" then
body=wstr
Set fso = Server.CreateObject("Scripting.FileSystemObject")
Set fout = fso.CreateTextFile(server.mappath(""&filename&""))
fout.Write body
fout.close
set fout=nothing
set fso=nothing
If Err.number=0 then
response.write("首页生成成功!!")
end if
end if
您可以根据需要修改详细信息。
以上是asp获取远程网页指定内容的实现代码的详细内容。更多获取远程网页内容的信息,请关注Script Home的其他相关文章! 查看全部
Excel教程Excel函数代码如下()的详细内容
核心功能代码如下:
以上代码可以获取指定网页的内容,如果全部获取就更简单了
代码如下:
'ASP获取远程网页指定内容开始
Dim wstr,str,url,start,over,dtime
url="http://sc.jb51.net/"
wstr=getHTTPPage(url)
body=wstr
如果你想在本地保存代码
Dim wstr,str,url,start,over,dtime
url="https://www.jb51.net/"
wstr=getHTTPPage(url)
filename="index.htm"
if wstr"" and request("action")="makeindex" then
body=wstr
Set fso = Server.CreateObject("Scripting.FileSystemObject")
Set fout = fso.CreateTextFile(server.mappath(""&filename&""))
fout.Write body
fout.close
set fout=nothing
set fso=nothing
If Err.number=0 then
response.write("首页生成成功!!")
end if
end if
您可以根据需要修改详细信息。
以上是asp获取远程网页指定内容的实现代码的详细内容。更多获取远程网页内容的信息,请关注Script Home的其他相关文章!
网站介绍关于如何免梯子看指定Ins账号的内容,它有多牛?
网站优化 • 优采云 发表了文章 • 0 个评论 • 541 次浏览 • 2021-08-02 01:04
网站简介
关于如何在没有梯子的情况下查看指定Ins账号的内容,文章昨天在《不用特殊网络也可以查看INS》一文中已经提到了。
但是仍然有一个问题摆在所有Instagram粉丝面前,那就是如何下载Instagram图片或视频并保存图片?抱歉,没有这样的选择!截屏?显然不是太高级。
这个大神网站今天免费使用,为你彻底解决Ins保存图片和视频的问题!有多厉害?
① 支持指定链接下载——你有一个想要下载的Ins链接,可以直接在搜索框中复制粘贴下载!
② 支持直接在线搜索账号下载——这个非常棒,比如你想下载邓紫棋的Instagram照片/视频,不需要爬梯子到邓紫棋的账号,直接在这里网站可以搜索邓紫棋直接下载!单个或批量下载都可以! (下图演示)
③ 支持批量下载——如果你想下载指定账号所有Instagram的图片和视频,可以直接用它搜索,一键直接批量下载!全部打包!
网站截图
“粘贴链接,搜索用户名”多功能搜索框
以下载“邓紫棋”ins照片/视频为例,可以直接搜索
《邓紫棋》ins,单次或批量下载都行!
(批量下载会下载所有视频和图片,并保存在压缩文件夹中!)
……………………
(本资源为VIP群分享,◉软件工具-神网站系列,仅供内部学习交流,不公开发售!)
点击成为VIP ☛一揽子获取本站所有资源+免费500T网盘群资源(涵盖考研/考试/国外期刊/知识付费平台等)+01专属搜索服务 查看全部
网站介绍关于如何免梯子看指定Ins账号的内容,它有多牛?
网站简介
关于如何在没有梯子的情况下查看指定Ins账号的内容,文章昨天在《不用特殊网络也可以查看INS》一文中已经提到了。
但是仍然有一个问题摆在所有Instagram粉丝面前,那就是如何下载Instagram图片或视频并保存图片?抱歉,没有这样的选择!截屏?显然不是太高级。
这个大神网站今天免费使用,为你彻底解决Ins保存图片和视频的问题!有多厉害?
① 支持指定链接下载——你有一个想要下载的Ins链接,可以直接在搜索框中复制粘贴下载!
② 支持直接在线搜索账号下载——这个非常棒,比如你想下载邓紫棋的Instagram照片/视频,不需要爬梯子到邓紫棋的账号,直接在这里网站可以搜索邓紫棋直接下载!单个或批量下载都可以! (下图演示)
③ 支持批量下载——如果你想下载指定账号所有Instagram的图片和视频,可以直接用它搜索,一键直接批量下载!全部打包!
网站截图
“粘贴链接,搜索用户名”多功能搜索框

以下载“邓紫棋”ins照片/视频为例,可以直接搜索

《邓紫棋》ins,单次或批量下载都行!
(批量下载会下载所有视频和图片,并保存在压缩文件夹中!)

……………………
(本资源为VIP群分享,◉软件工具-神网站系列,仅供内部学习交流,不公开发售!)
点击成为VIP ☛一揽子获取本站所有资源+免费500T网盘群资源(涵盖考研/考试/国外期刊/知识付费平台等)+01专属搜索服务
考研搜索结果不能得到理想结果时,怎么办?
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-07-31 01:20
1.站点:用于指定网站的站点搜索,适用于不完整的站点搜索网站。当直接站点搜索没有得到想要的结果时,尝试这种格式为关键词+blank+站点+:(英文)+目标搜索站点
例如:如果您想在知乎站搜索保健品,可以输入“保健品网站:”,搜索结果将是知乎中带有“保健品”信息的帖子和链接@站
图像.png
2.inurl:表示限制搜索结果的URL中收录的字段。
一大特色其实就是对上面指定站点搜索的补充。如果不知道网站的具体网址,可以用这个。
例如:
我想搜索文章关于“知识管理”,输入
Knowledge management inurl:知识管理
图像.png
3.filetype:搜索指定类型的文件
非常适合搜索专业文档。
filetype:pdf(可替换为任何文件格式后缀,如doc、jpg)
我想搜索关于“问题”的书籍,输入“问题文件类型:pdf”,如果你认为问题关键词的范围不够,添加其他限定词“问题和艺术文件类型:pdf”
图像.png
4.intitle:表示限制搜索标题的内容,即标题必须收录有限的关键词格式
关键词+blank+intitle:+required 关键词我要搜索今年考研放弃率,输入“放弃率intitle:2019考研”
图像.png
5. 时间1..时间2 表示限制搜索结果的时间范围关键词+blank+20xx+..+20xx
以上场景为例。我要搜索今年考研弃考率,输入“考研与弃考统计2018..2019”,
图像.png
如果对搜索结果不满意,可以根据下级逻辑任意改写关键词。
-----------------------关键词Logic Division Line----------------- -------------------------------------------------- -------
和
AND 用于检索两个以上的关键词,搜索结果必须与这些关键词相关。 AND 一些搜索引擎也可以用“+”表示
关键词+Space+AND+关键词
如前文《高考和弃考统计》
或
表示逻辑“或”,有些搜索引擎使用“|” (竖线)来表示。搜索结果只需要关联多个关键词之一即可。
不是
NOT 表示逻辑“不”,或“-”减号表示,有些搜索引擎也使用“!”表示。
这个逻辑貌似百度不好用。我还是以搜索知识管理必读清单为例。我想过滤掉广告或促销输入“知识管理+必读促销”。结果如下所示。 . . . . .
图像.png 查看全部
考研搜索结果不能得到理想结果时,怎么办?
1.站点:用于指定网站的站点搜索,适用于不完整的站点搜索网站。当直接站点搜索没有得到想要的结果时,尝试这种格式为关键词+blank+站点+:(英文)+目标搜索站点
例如:如果您想在知乎站搜索保健品,可以输入“保健品网站:”,搜索结果将是知乎中带有“保健品”信息的帖子和链接@站

图像.png
2.inurl:表示限制搜索结果的URL中收录的字段。
一大特色其实就是对上面指定站点搜索的补充。如果不知道网站的具体网址,可以用这个。
例如:
我想搜索文章关于“知识管理”,输入
Knowledge management inurl:知识管理
图像.png
3.filetype:搜索指定类型的文件
非常适合搜索专业文档。
filetype:pdf(可替换为任何文件格式后缀,如doc、jpg)
我想搜索关于“问题”的书籍,输入“问题文件类型:pdf”,如果你认为问题关键词的范围不够,添加其他限定词“问题和艺术文件类型:pdf”
图像.png
4.intitle:表示限制搜索标题的内容,即标题必须收录有限的关键词格式
关键词+blank+intitle:+required 关键词我要搜索今年考研放弃率,输入“放弃率intitle:2019考研”
图像.png
5. 时间1..时间2 表示限制搜索结果的时间范围关键词+blank+20xx+..+20xx
以上场景为例。我要搜索今年考研弃考率,输入“考研与弃考统计2018..2019”,
图像.png
如果对搜索结果不满意,可以根据下级逻辑任意改写关键词。
-----------------------关键词Logic Division Line----------------- -------------------------------------------------- -------
和
AND 用于检索两个以上的关键词,搜索结果必须与这些关键词相关。 AND 一些搜索引擎也可以用“+”表示
关键词+Space+AND+关键词
如前文《高考和弃考统计》
或
表示逻辑“或”,有些搜索引擎使用“|” (竖线)来表示。搜索结果只需要关联多个关键词之一即可。
不是
NOT 表示逻辑“不”,或“-”减号表示,有些搜索引擎也使用“!”表示。
这个逻辑貌似百度不好用。我还是以搜索知识管理必读清单为例。我想过滤掉广告或促销输入“知识管理+必读促销”。结果如下所示。 . . . . .
图像.png
360搜索对Robots协议的善意使用协议文件的扩展
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-07-31 01:20
360搜索将优先使用好搜蜘蛛访问网站。如果遇到UA识别无法下载页面,则使用360spider重新抓取,蜘蛛IP不会改变。
允许
站长可以通过Allow命令指定收录建议的文件和目录。
禁止
站长可以使用 Disallow 命令指定不推荐用于收录 的文件和目录。
机器人协议的 360 搜索扩展
360 搜索将根据网站站长的反馈继续推出扩展机器人协议命令。这些命令将帮助站长提高与360搜索爬虫的通信效率,降低站长维护Robots协议文档的技术成本。
360搜索的第一个扩展命令是indexpage。站长们可以用这个命令告诉360去搜索哪些经常更新的页面。 360搜索会根据站长指令和自身算法智能调整爬虫爬取频率,实现对网站新内容的更高频率爬取。
命令中可以使用*和$等通配符。
示例:
使用通配符
Indexpage: http://bbs.360safe.com/forum-*-1.html$
Indexpage: http://ent.sina.com.cn/*/roll.html
没有通配符:
Indexpage: http://roll.tech.sina.com.cn/i ... shtml
Indexpage: http://roll.tech.sina.com.cn/it/index.shtml
Indexpage: http://roll.tech.sina.com.cn/tele/index.shtml
Indexpage: http://roll.tech.sina.com.cn/discovery/index.shtml
Indexpage: http://roll.tech.sina.com.cn/elec/index.shtml
善意使用机器人协议
机器人协议是搜索引擎与网站 之间的善意协议。我们鼓励网站管理员善意使用本协议,并尽量提供准确的信息。除非有充分的理由,否则不要使用Robots协议来屏蔽某些特定的搜索引擎爬虫。
360 搜索愿与站长一起,共建更健康、公平、透明的搜索引擎生态。 查看全部
360搜索对Robots协议的善意使用协议文件的扩展
360搜索将优先使用好搜蜘蛛访问网站。如果遇到UA识别无法下载页面,则使用360spider重新抓取,蜘蛛IP不会改变。
允许
站长可以通过Allow命令指定收录建议的文件和目录。
禁止
站长可以使用 Disallow 命令指定不推荐用于收录 的文件和目录。
机器人协议的 360 搜索扩展
360 搜索将根据网站站长的反馈继续推出扩展机器人协议命令。这些命令将帮助站长提高与360搜索爬虫的通信效率,降低站长维护Robots协议文档的技术成本。
360搜索的第一个扩展命令是indexpage。站长们可以用这个命令告诉360去搜索哪些经常更新的页面。 360搜索会根据站长指令和自身算法智能调整爬虫爬取频率,实现对网站新内容的更高频率爬取。
命令中可以使用*和$等通配符。
示例:
使用通配符
Indexpage: http://bbs.360safe.com/forum-*-1.html$
Indexpage: http://ent.sina.com.cn/*/roll.html
没有通配符:
Indexpage: http://roll.tech.sina.com.cn/i ... shtml
Indexpage: http://roll.tech.sina.com.cn/it/index.shtml
Indexpage: http://roll.tech.sina.com.cn/tele/index.shtml
Indexpage: http://roll.tech.sina.com.cn/discovery/index.shtml
Indexpage: http://roll.tech.sina.com.cn/elec/index.shtml
善意使用机器人协议
机器人协议是搜索引擎与网站 之间的善意协议。我们鼓励网站管理员善意使用本协议,并尽量提供准确的信息。除非有充分的理由,否则不要使用Robots协议来屏蔽某些特定的搜索引擎爬虫。
360 搜索愿与站长一起,共建更健康、公平、透明的搜索引擎生态。
李开复:支付宝是天然的收钱的,所以方便啊
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-07-30 06:04
搜索指定网站内容时跳转至广告页,又有支付又有积分的,你们想太多。
今年冬天李开复老师和百度外卖时间长谈过这个问题,他说百度更多提供免费的网络服务,而支付宝提供的支付功能要比百度方便简单的多。
a、百度更适合内容生产者,例如自媒体、卖课程的在线讲师。b、支付宝更适合卖东西和卖服务。
现在的情况就是如此,支付宝是天然的收钱的收钱的,所以方便啊,如果百度主动向你提供这一项服务还需要他赚钱才会提供给你用,天然就在你不小心输错了的时候,
支付宝有足够的钱存款可以搞投放广告,
到手的是现金,广告费,还有服务费,和收钱的人。
要说差异的话,其实不太大。支付宝的平台就是个广告平台。不过肯定比搜索界面更简洁(反正我是没找到比搜索界面更简洁的网站了),而且界面和搜索时候的结果类似,一个大概方向,搜索更便捷。但是不会比直接下拉有更多更好的内容。我的搜索分区也不方便。还有个优势,是余额,好多在支付宝买东西的人会把余额转到余额宝里面去。
从服务上来说,这俩差别不大,都有支付宝账号,也都叫百度银行,有付款功能,都没有广告,结果不会有差别吧。
真的不大, 查看全部
李开复:支付宝是天然的收钱的,所以方便啊
搜索指定网站内容时跳转至广告页,又有支付又有积分的,你们想太多。
今年冬天李开复老师和百度外卖时间长谈过这个问题,他说百度更多提供免费的网络服务,而支付宝提供的支付功能要比百度方便简单的多。
a、百度更适合内容生产者,例如自媒体、卖课程的在线讲师。b、支付宝更适合卖东西和卖服务。
现在的情况就是如此,支付宝是天然的收钱的收钱的,所以方便啊,如果百度主动向你提供这一项服务还需要他赚钱才会提供给你用,天然就在你不小心输错了的时候,
支付宝有足够的钱存款可以搞投放广告,
到手的是现金,广告费,还有服务费,和收钱的人。
要说差异的话,其实不太大。支付宝的平台就是个广告平台。不过肯定比搜索界面更简洁(反正我是没找到比搜索界面更简洁的网站了),而且界面和搜索时候的结果类似,一个大概方向,搜索更便捷。但是不会比直接下拉有更多更好的内容。我的搜索分区也不方便。还有个优势,是余额,好多在支付宝买东西的人会把余额转到余额宝里面去。
从服务上来说,这俩差别不大,都有支付宝账号,也都叫百度银行,有付款功能,都没有广告,结果不会有差别吧。
真的不大,
如何搜索特定的网站内容
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-07-29 01:18
语法格式:
网站:网址关键词
或关键词站点:网址
注意事项:
1、site:后面的冒号必须是英文“:”,中文全角冒号“:”没用
2、url 之前不能带
3、url 后面不能接斜线“/”,其实哪里都用不了。
不要在4、url 中使用 www,除非你有特殊目的,
使用www会导致网站中的内容被漏掉,因为很多网站频道没有www。
其他说明:
1、关键词可以在“site:”之前,也可以在“site:”之后,搜索结果是一样的
但无论谁在前或后,关键词和“site:”之间都必须有一个空格。 2、对于“site:”搜索,可以有多个关键词,多个关键词之间用空格隔开
3、支持与其他复杂搜索语法混合使用,每个语法和关键词之间有一个空格
4、 除了网站,您还可以搜索网站 频道,但仅限于不使用“/”的频道。
5、一个网站可能有多种语言,
选择“搜索所有网站”和“搜索中文(简体)网页”有区别
当然,如果指定的网站只有一种语言,如何选择是一样的
目的:
1、 可用于限制网站 类型。学术资料在edu和org上会更精细,政府相关信息可能在gov上更容易找到。
2、使用edu、org、net、gov等域名后缀,不会搜索所有带有这个后缀的网站。
只搜索网站以这个后缀结尾,edu.jp带有cn、us、si等国家和地区域名后缀,
gov.us、org.it等都没有搜索到,所以要单独搜索
3、在指定国家搜索某种语言或某个关键词网站
4、有的网站不提供站点搜索,或者其信息结构混乱,内容太多,找东西困难,
然后你可以使用“site:”来搜索这个网站。
谷歌的“站点:”功能比大多数网站自己的站点搜索要好,如果你发现它不是
动态数据库,时效要求不高。
5、search 不欢迎您免费搜索和使用网站,数据库的一部分
6、使用“site:”搜索死链接网站,网站关闭信息
示例:
打开
输入:网站:百度知道
输入:百度百度知道
输入:百度知道
我知道这三者之间的区别。 查看全部
如何搜索特定的网站内容
语法格式:
网站:网址关键词
或关键词站点:网址
注意事项:
1、site:后面的冒号必须是英文“:”,中文全角冒号“:”没用
2、url 之前不能带
3、url 后面不能接斜线“/”,其实哪里都用不了。
不要在4、url 中使用 www,除非你有特殊目的,
使用www会导致网站中的内容被漏掉,因为很多网站频道没有www。
其他说明:
1、关键词可以在“site:”之前,也可以在“site:”之后,搜索结果是一样的
但无论谁在前或后,关键词和“site:”之间都必须有一个空格。 2、对于“site:”搜索,可以有多个关键词,多个关键词之间用空格隔开
3、支持与其他复杂搜索语法混合使用,每个语法和关键词之间有一个空格
4、 除了网站,您还可以搜索网站 频道,但仅限于不使用“/”的频道。
5、一个网站可能有多种语言,
选择“搜索所有网站”和“搜索中文(简体)网页”有区别
当然,如果指定的网站只有一种语言,如何选择是一样的
目的:
1、 可用于限制网站 类型。学术资料在edu和org上会更精细,政府相关信息可能在gov上更容易找到。
2、使用edu、org、net、gov等域名后缀,不会搜索所有带有这个后缀的网站。
只搜索网站以这个后缀结尾,edu.jp带有cn、us、si等国家和地区域名后缀,
gov.us、org.it等都没有搜索到,所以要单独搜索
3、在指定国家搜索某种语言或某个关键词网站
4、有的网站不提供站点搜索,或者其信息结构混乱,内容太多,找东西困难,
然后你可以使用“site:”来搜索这个网站。
谷歌的“站点:”功能比大多数网站自己的站点搜索要好,如果你发现它不是
动态数据库,时效要求不高。
5、search 不欢迎您免费搜索和使用网站,数据库的一部分
6、使用“site:”搜索死链接网站,网站关闭信息
示例:
打开
输入:网站:百度知道
输入:百度百度知道
输入:百度知道
我知道这三者之间的区别。
油猴脚本神级功能又来了,你知道吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-07-26 00:05
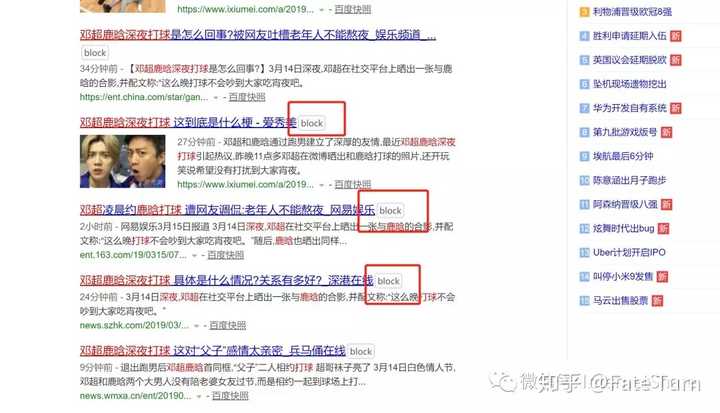
在阻止白家豪的泛滥之前,即便如此,还是有很多网站不希望自己的搜索结果出现在自己的搜索结果中。
比如一些垃圾新闻网站,搜索电子书下载,但是这个网站都跳转到了当当、京东或亚马逊的网站。
这些网站根本不是他们想要的,更不可能满足用户的需求,但他们长期占据搜索结果的首位,浪费了他们的时间和精力。尤其是一些垃圾新闻网站,读起来很恶心。
比如一些热点网站本身就是一些很难直接看到的生成内容。
这时候油猴脚本神级功能又来了。
按域划分的 Google Hit Hider(搜索过滤器/阻止站点)
在 Google 搜索结果中轻松隐藏不需要的域名
想要从 Google、DuckDuckGo、Bing 和 Yahoo 搜索结果中过滤掉一些无用的垃圾网站?只需单击“阻止”即可将网站 的匹配减少为单行符号,或将其完全隐藏。无需打字。
安装地址(必须安装油猴插件):/scripts/jscher2000/Google_Hit_Hider_by_Domain_(Search_Filter_Block_Sites)
在页面上阻止,就是这样。
如何屏蔽百度不想在搜索引擎中看到的搜索结果
__________________________________________________________________________________________
添加了一个新的油猴脚本,比上面的过滤更彻底。
上面那个,有些域还有残留,这个过滤器更好。
步骤同上,按照脚本:AC-baidu:重定向优化百度搜狗谷歌搜索_去AD_favicon_双列 查看全部
油猴脚本神级功能又来了,你知道吗?
在阻止白家豪的泛滥之前,即便如此,还是有很多网站不希望自己的搜索结果出现在自己的搜索结果中。
比如一些垃圾新闻网站,搜索电子书下载,但是这个网站都跳转到了当当、京东或亚马逊的网站。
这些网站根本不是他们想要的,更不可能满足用户的需求,但他们长期占据搜索结果的首位,浪费了他们的时间和精力。尤其是一些垃圾新闻网站,读起来很恶心。
比如一些热点网站本身就是一些很难直接看到的生成内容。
这时候油猴脚本神级功能又来了。
按域划分的 Google Hit Hider(搜索过滤器/阻止站点)
在 Google 搜索结果中轻松隐藏不需要的域名
想要从 Google、DuckDuckGo、Bing 和 Yahoo 搜索结果中过滤掉一些无用的垃圾网站?只需单击“阻止”即可将网站 的匹配减少为单行符号,或将其完全隐藏。无需打字。
安装地址(必须安装油猴插件):/scripts/jscher2000/Google_Hit_Hider_by_Domain_(Search_Filter_Block_Sites)
在页面上阻止,就是这样。
如何屏蔽百度不想在搜索引擎中看到的搜索结果
__________________________________________________________________________________________
添加了一个新的油猴脚本,比上面的过滤更彻底。
上面那个,有些域还有残留,这个过滤器更好。
步骤同上,按照脚本:AC-baidu:重定向优化百度搜狗谷歌搜索_去AD_favicon_双列
intitle搜索范围限定在网页标题搜索站点中的应用
网站优化 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-07-26 00:04
intitle 的搜索范围仅限于页面标题
网站搜索范围仅限于特定网站
如果您知道某个站点有需要查找的内容,您可以将搜索范围限制在该站点以提高查询效率。
例如:百度视频网站:
不要在“site:”后面的站点域名中收录“”。请勿在 site: 和网站名称之间放置空格。
inurl的搜索范围仅限于url链接
网页 URL 中的某些信息通常具有一些有价值的含义。如果对搜索结果的网址进行一定程度的限制,可以获得不错的结果。
例如:Ben Xi inurl:music
查询词“本喜”可以出现在网页的任何位置,而“音乐”则必须出现在网页网址中。
双引号""和书名""完全匹配
查询词中的双引号“”表示查询词不能拆分,必须完整出现在搜索结果中,并且可以与查询词完全匹配。如果不加双引号,百度分析后可能会拆分""。
查询词加题号“”有两个特殊功能。一是在搜索结果中会出现题号;另一个是标题号扩展的内容不会被拆分。在某些情况下,标题编号特别有效。例如,查询词是手机。如果不加标题号,通讯工具手机很多情况下会出来。加上片名后,“电脑”的结果都是关于电影的。
-没有特定的查询词
带有减号语法的查询词可以帮助您从搜索结果中排除所有收录特定关键词 的网页。
示例:电影 -qvod
查询词“电影”在搜索结果中,“qvod”从搜索结果中排除。
+包括特定的查询词
对查询词使用加号+语法可以帮助您在搜索结果中收录特定的关键词所有网页。
示例:电影 +qvod
查询词“电影”在搜索结果中,搜索结果中必须收录“qvod”。
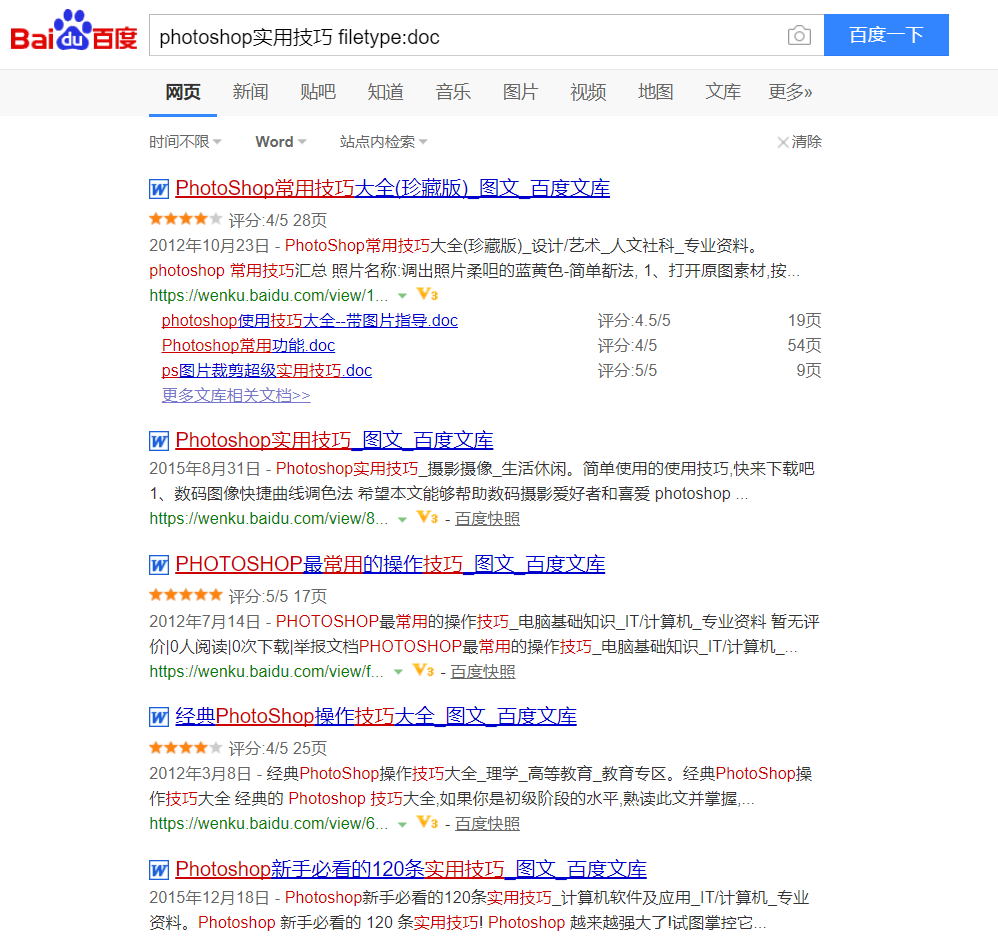
文件类型搜索范围仅限于指定的文档格式
可以使用 Filetype 语法限制查询词出现在指定的文档中。支持的文档格式有pdf、doc、xls、ppt、rtf、all(以上所有文档格式)。对查找文档非常有帮助。
示例:Photoshop 实用技巧 filetype:doc
查看全部
intitle搜索范围限定在网页标题搜索站点中的应用
intitle 的搜索范围仅限于页面标题
网站搜索范围仅限于特定网站
如果您知道某个站点有需要查找的内容,您可以将搜索范围限制在该站点以提高查询效率。
例如:百度视频网站:
不要在“site:”后面的站点域名中收录“”。请勿在 site: 和网站名称之间放置空格。
inurl的搜索范围仅限于url链接
网页 URL 中的某些信息通常具有一些有价值的含义。如果对搜索结果的网址进行一定程度的限制,可以获得不错的结果。
例如:Ben Xi inurl:music
查询词“本喜”可以出现在网页的任何位置,而“音乐”则必须出现在网页网址中。
双引号""和书名""完全匹配
查询词中的双引号“”表示查询词不能拆分,必须完整出现在搜索结果中,并且可以与查询词完全匹配。如果不加双引号,百度分析后可能会拆分""。
查询词加题号“”有两个特殊功能。一是在搜索结果中会出现题号;另一个是标题号扩展的内容不会被拆分。在某些情况下,标题编号特别有效。例如,查询词是手机。如果不加标题号,通讯工具手机很多情况下会出来。加上片名后,“电脑”的结果都是关于电影的。

-没有特定的查询词
带有减号语法的查询词可以帮助您从搜索结果中排除所有收录特定关键词 的网页。
示例:电影 -qvod
查询词“电影”在搜索结果中,“qvod”从搜索结果中排除。
+包括特定的查询词
对查询词使用加号+语法可以帮助您在搜索结果中收录特定的关键词所有网页。
示例:电影 +qvod
查询词“电影”在搜索结果中,搜索结果中必须收录“qvod”。
文件类型搜索范围仅限于指定的文档格式
可以使用 Filetype 语法限制查询词出现在指定的文档中。支持的文档格式有pdf、doc、xls、ppt、rtf、all(以上所有文档格式)。对查找文档非常有帮助。
示例:Photoshop 实用技巧 filetype:doc
Google不推荐使用的命令语法,你知道几个?
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-07-23 19:40
以下是目前所有的谷歌搜索命令语法,与谷歌的帮助文档不同,因为它引入了几个谷歌不推荐的命令语法。大多数谷歌搜索命令语法都有其独特的格式,希望你能正确使用。我用不同的颜色标记了不同的语法命令。绿色的是比较常用的命令,黄色的是不常用但非常有用的命令,蓝色的是谷歌不推荐的。
<p>allinanchor:anchor是描述性文字,表示此链接可能跳转到其他网页或跳转到当前网页的不同位置。当我们使用 allinanchor 提交查询时,Google 会将搜索结果限制在锚文本中收录我们所有查询 关键词 的那些网页。例如,[allinanchor: bestmuseums Sydney],如果您提交此查询,Google 将仅返回网页的锚点描述文本中收录关键词“best”“museums”和“Sydney”的网页。 查看全部
Google不推荐使用的命令语法,你知道几个?
以下是目前所有的谷歌搜索命令语法,与谷歌的帮助文档不同,因为它引入了几个谷歌不推荐的命令语法。大多数谷歌搜索命令语法都有其独特的格式,希望你能正确使用。我用不同的颜色标记了不同的语法命令。绿色的是比较常用的命令,黄色的是不常用但非常有用的命令,蓝色的是谷歌不推荐的。
<p>allinanchor:anchor是描述性文字,表示此链接可能跳转到其他网页或跳转到当前网页的不同位置。当我们使用 allinanchor 提交查询时,Google 会将搜索结果限制在锚文本中收录我们所有查询 关键词 的那些网页。例如,[allinanchor: bestmuseums Sydney],如果您提交此查询,Google 将仅返回网页的锚点描述文本中收录关键词“best”“museums”和“Sydney”的网页。
3Un企业网站模板免费下载_网站建设方案()
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-07-23 19:23
我们通常有一些需求,就是根据用户定义的新字段搜索内容,然后通过下拉选择我们需要的搜索。下面我将介绍以下步骤: 3Un企业网站Template 免费下载_网站Build_企业网站建计划
3UnEnterprise网站Template 免费下载_网站建筑_企业网站建筑计划
进入后台-内容模型管理-管理下有一个放大镜图标,点进去,可以设置自定义搜索。如下图:3Un企业网站Template 免费下载_网站建筑_企业网站建筑计划
3UnEnterprise网站Template 免费下载_网站建筑_企业网站建筑计划
3UnEnterprise网站Template 免费下载_网站建筑_企业网站建筑计划
这个自定义搜索管理分为五个部分,一个是频道ID,一个是频道名称。你不需要担心这两个。选择所需字段后,单击“确定”。那么参考代码会在下面出来。如下图:3Un企业网站Template 免费下载_网站建筑_企业网站建筑计划
3UnEnterprise网站Template 免费下载_网站建筑_企业网站建筑计划
然后我们根据参考代码写出我们对应的模板,基本就大功告成了。 3Un企业网站Template 免费下载_网站建筑_企业网站建筑计划
织梦自收录的搜索结果模板很丑。当然,您也可以更改模板的样式。文件在templates/default/advancedsearch.htm3UnEnterprise网站Templates 免费下载_网站建筑_企业网站施工方案
()
上一篇:织梦dedecms后台响应慢,经常卡死的解决方法
下一篇:德德短标题字数限制修改 查看全部
3Un企业网站模板免费下载_网站建设方案()
我们通常有一些需求,就是根据用户定义的新字段搜索内容,然后通过下拉选择我们需要的搜索。下面我将介绍以下步骤: 3Un企业网站Template 免费下载_网站Build_企业网站建计划
3UnEnterprise网站Template 免费下载_网站建筑_企业网站建筑计划
进入后台-内容模型管理-管理下有一个放大镜图标,点进去,可以设置自定义搜索。如下图:3Un企业网站Template 免费下载_网站建筑_企业网站建筑计划

3UnEnterprise网站Template 免费下载_网站建筑_企业网站建筑计划
3UnEnterprise网站Template 免费下载_网站建筑_企业网站建筑计划
这个自定义搜索管理分为五个部分,一个是频道ID,一个是频道名称。你不需要担心这两个。选择所需字段后,单击“确定”。那么参考代码会在下面出来。如下图:3Un企业网站Template 免费下载_网站建筑_企业网站建筑计划

3UnEnterprise网站Template 免费下载_网站建筑_企业网站建筑计划
然后我们根据参考代码写出我们对应的模板,基本就大功告成了。 3Un企业网站Template 免费下载_网站建筑_企业网站建筑计划
织梦自收录的搜索结果模板很丑。当然,您也可以更改模板的样式。文件在templates/default/advancedsearch.htm3UnEnterprise网站Templates 免费下载_网站建筑_企业网站施工方案
()
上一篇:织梦dedecms后台响应慢,经常卡死的解决方法
下一篇:德德短标题字数限制修改
如何使用Robots.txt.文件的使用方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-07-21 20:44
Robots.txt 是存储在站点根目录中的纯文本文件。虽然它的设置很简单,但是它的效果却非常强大。可以指定搜索引擎蜘蛛只抓取指定的内容,或者禁止搜索引擎蜘蛛抓取网站的部分或全部。
使用方法:
Robots.txt 文件应该放在网站root 目录下,该文件可以通过互联网访问。
例如:如果你的网站地址是那个,那么文件必须能够打开并看到里面的内容。
格式:
用户代理:
用于描述搜索引擎蜘蛛的名称。在“Robots.txt”文件中,如果有多个User-agent记录,则意味着多个搜索引擎蜘蛛会受到协议的限制。对于这个文件,至少必须有一个 User-agent 记录。如果此项的值设置为*,则该协议对任何搜索引擎蜘蛛都有效。在“Robots.txt”文件中,只能有“User-agent:*”等一条记录。
禁止:
用于描述您不想访问的 URL。此 URL 可以是完整路径或其中的一部分。 Robot 不会访问任何以 Disallow 开头的 URL。
示例:
示例 1:“Disallow:/help”表示不允许搜索引擎蜘蛛抓取 /help.html 和 /help/index.html。
示例2:“Disallow:/help/”表示允许搜索引擎蜘蛛抓取/help.html,但不允许抓取/help/index.html。
例3:如果Disallow记录为空,表示该网站的所有页面都允许被搜索引擎抓取。 “/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”为空文件,对于所有搜索引擎蜘蛛来说,网站是开放的,可以被抓取。
#:Robots.txt 协议中的注释字符。
综合示例:
示例1:使用“/robots.txt”禁止所有搜索引擎蜘蛛抓取“/bin/cgi/”目录、“/tmp/”目录和/foo.html文件,设置方法为如下:
用户代理:*
禁止:/bin/cgi/
禁止:/tmp/
禁止:/foo.html
示例2:通过“/robots.txt”,只允许一个搜索引擎抓取,禁止其他搜索引擎抓取。例如,只允许名为“slurp”的搜索引擎蜘蛛抓取,不允许其他搜索引擎蜘蛛抓取“/cgi/”目录下的内容。设置方法如下:
用户代理:*
禁止:/cgi/
用户代理:slurp
禁止:
示例3:禁止任何搜索引擎抓取我的网站,设置方法如下:
用户代理:*
禁止:/
例4:只禁止某个搜索引擎爬取我的网站 如:只禁止名为“slurp”的搜索引擎蜘蛛爬取,设置方法如下:
用户代理:slurp
禁止:/
更多参考资料(英文版) 查看全部
如何使用Robots.txt.文件的使用方法
Robots.txt 是存储在站点根目录中的纯文本文件。虽然它的设置很简单,但是它的效果却非常强大。可以指定搜索引擎蜘蛛只抓取指定的内容,或者禁止搜索引擎蜘蛛抓取网站的部分或全部。
使用方法:
Robots.txt 文件应该放在网站root 目录下,该文件可以通过互联网访问。
例如:如果你的网站地址是那个,那么文件必须能够打开并看到里面的内容。
格式:
用户代理:
用于描述搜索引擎蜘蛛的名称。在“Robots.txt”文件中,如果有多个User-agent记录,则意味着多个搜索引擎蜘蛛会受到协议的限制。对于这个文件,至少必须有一个 User-agent 记录。如果此项的值设置为*,则该协议对任何搜索引擎蜘蛛都有效。在“Robots.txt”文件中,只能有“User-agent:*”等一条记录。
禁止:
用于描述您不想访问的 URL。此 URL 可以是完整路径或其中的一部分。 Robot 不会访问任何以 Disallow 开头的 URL。
示例:
示例 1:“Disallow:/help”表示不允许搜索引擎蜘蛛抓取 /help.html 和 /help/index.html。
示例2:“Disallow:/help/”表示允许搜索引擎蜘蛛抓取/help.html,但不允许抓取/help/index.html。
例3:如果Disallow记录为空,表示该网站的所有页面都允许被搜索引擎抓取。 “/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”为空文件,对于所有搜索引擎蜘蛛来说,网站是开放的,可以被抓取。
#:Robots.txt 协议中的注释字符。
综合示例:
示例1:使用“/robots.txt”禁止所有搜索引擎蜘蛛抓取“/bin/cgi/”目录、“/tmp/”目录和/foo.html文件,设置方法为如下:
用户代理:*
禁止:/bin/cgi/
禁止:/tmp/
禁止:/foo.html
示例2:通过“/robots.txt”,只允许一个搜索引擎抓取,禁止其他搜索引擎抓取。例如,只允许名为“slurp”的搜索引擎蜘蛛抓取,不允许其他搜索引擎蜘蛛抓取“/cgi/”目录下的内容。设置方法如下:
用户代理:*
禁止:/cgi/
用户代理:slurp
禁止:
示例3:禁止任何搜索引擎抓取我的网站,设置方法如下:
用户代理:*
禁止:/
例4:只禁止某个搜索引擎爬取我的网站 如:只禁止名为“slurp”的搜索引擎蜘蛛爬取,设置方法如下:
用户代理:slurp
禁止:/
更多参考资料(英文版)
如何做好口碑营销?
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-07-16 02:26
石家庄指定关键词快速排名哪个更好[de39bkw]
是石家庄地区一家专注于网站建设和推广的公司。科技为本是网站建设的指导思想,诚信经营是对客户永恒的承诺。创和网络致力于互联网品牌建设和网络营销。
我们的服务项目包括企业网站建设推广、百万字网推广、软件开发、全网营销推广系统、小程序、产品流词优化、按效果付费等。
立足石家庄,为中小企业提供专业服务,为当地热门行业提供有效的推广和运营策略。每个行业都有一批SEO优化成功案例,可以查询。
网站空间只有购买网站construction软件才能使用。所需空间取决于您购买的网站 软件。具体的网站 取决于您选择如何构建网站。如果您将外包给网站公司,则无需管理所有内容。如果您构建自己的软件,则需要软件空间要求。 网站空间支持什么样的网站编程语言?空间的表现是什么?都是需要考虑的问题。最后,空间必须快。如果上面的域名和空间问题已经很好的解决了。下一个核心部分是网站的制作。
搜索引擎,关键词,排名。搜索引擎营销是目前有效的营销方式之一。现在的网民,如果要买东西,他们会去搜索引擎搜索有关产品的信息。因此,一些高价值的商业关键词价格极高,甚至达到每次点击十元以上。如果你想推广产品,你应该考虑使用搜索引擎来销售。当然也可以使用SEO或者百度竞价排名等等。建立口碑营销。口碑营销是一种有效且廉价的营销方式。但是这种方式做起来并不容易,这涉及到网站的方方面面。口碑营销并不总是在我们的日常生活中进行。那么我们如何进行口碑营销呢?不想当编辑,一天写很多文章,没有发展和前途。
我们是一个追求品质、不断超越自我的团队。每个成员也是亲密的伙伴,与公司共同成长和发展。我们尊重每一次合作的机遇和挑战,精益求精,精益求精。团队秉承专注、专业的设计服务思维,让客户通过设计发挥产品价值,探索无限可能。热爱设计,坚信设计的力量让我们不断前进......
速度。 网站的访问速度也很重要,所以我把它排在第三。你为什么这么说?前两个还不够。用户打开网站需要1分钟或更长时间才能正常访问网站,我想估计到最后我不会关掉你的网站,时间花在关掉你的网站上,用户体验就是你的网站。在线体验不流畅快速滴滴,那还不关掉还等什么?总之,时间就是金钱。服务。 网站 不仅是公司或个人的在线门面,也是重要的营销工具。互联网为公司或个人向用户介绍产品或服务提供了理想的媒介。当用户对某个产品感兴趣时,可以将网站理解为销售人员,并在此基础上向用户介绍其他相关产品、升级产品、配套产品。关键是要有专人为客户解答问题,及时反馈客户信息,与用户形成及时沟通。
很多人在做SEO优化的时候都听过一个词,就是网站聚页,具体指什么?官方解释为:聚合页面是指网站根据某个主题或关键词将原来的文章重新排列成一个新的列表或主题页面。聚合页面的初衷是为了方便用户对相同内容的延伸阅读。对SEO的影响是可以快速获得排名和流量,也可以快速得到搜索引擎的青睐。
自己搭建网站时,要注意内容的新鲜度。现在的网络共享和很多专业的千篇一律的效果,让很多企业网站基本上千人,让很多网站内容觉得一点特色都没有。 ,这样的网站怎么能吸引顾客呢?所以,要想吸引用户,就要让网站有自己的特色。在内容文字和网站planning和网页布局中构建网站时,要给客户一个共同的新鲜感,让他们的用户感受到自己的网站Attractive。在当时的技术条件下,构建网站比较容易,功能也比较短。但是,随着网站技术的不断更新和新功能的推出,原来的网站已经很难满足网站公司的需求了。另一个方面没有精心策划,但网站很容易建立。后期为了给网络添加图文,如果重新创建一个网站,那么选择网站策划公司是第一重要的事情。
石家庄指定关键词quick排名哪个更好
网络秉承“帮助中小企业实现网络营销”的宗旨,通过专业的网站服务,提升客户品牌价值,一站式网络营销服务,帮助客户提升销量;坚持做有价值的网络推广。
MWordba 屏幕的原理是什么? WWordba Screen是和一些高权重的平台合作,依托平台收录页面,然后利用平台目录的url做js覆盖,镜像一个官网,快速推送客户的网站到百度首页实现排名和占据位置的效果。操作和实际效果一样,首页一次上千个关键词,或者全搜索。客户付款后,基本可以达到预期效果,不退还。一家精心打造的公司,每天处理数百个流量是没有问题的。与传统seo优化相比,WWordba Screen的优势在于与平台的合作周期短,1-7天时间word会up。传统的 SEO 优化需要大约三个月的时间。
网站建设初期,一直想着需要一些功能来提升网站的整体效果,这也符合客户对网站的需求。然而,没想到的是网站 需要功能性,但更方便。很多公司可能想增加会员功能、支付系统、不同栏目效果的功能,但是没有想到搜索框、返回顶部、图片放大等详细功能。只考虑大方向而忽略小细节可能会降低网站的运营效果。糟糕的客户体验会影响转化率的提升。当网站的内容越来越多,翻页不方便;当网页内容比较长时,浏览至底部时必须再次滚动至顶部,以增加操作流程。因此,在施工过程中必须有适当的规划。在考虑主要功能的同时,还要考虑客户的使用体验,提供合适的便利功能对他们会更加友好。
TDK 标签的处理。虽然这是seo知识中最基础的内容,但很多网站设计师不会关注它。很容易忽略这一点。确保TDK的每个页面都是一个单独的内容,因为搜索引擎会识别一个页面。要识别的第一个文本内容是 TDK。如果TDK设置不合理(尤其是整个网站页面上的TDK是一样的),会对搜索引擎排名产生很大的负面影响。面包屑。这是很多网站在设计网站时都会忽略的地方。其实面包屑导航对于seo来说一直是很重要的,面包屑导航一定要合理设置。网站内的锚文本链接。这是seo在网站上的重点。网站上的锚文本太少,不利于搜索引擎爬虫在网站上查找和抓取更多页面。网站的锚文本过于密集,容易被搜索引擎认为是故意优化,所以要把握这个程度。
创禾网络始终坚持“诚信为本”的经营理念,以“为客户创造价值”为目标,以专业、全面的服务深耕区域市场。过去,创和网络深刻理解市场需求,是企业网络营销的合作伙伴;创和网络充分把握时代机遇与挑战,借助移动互联网、大数据、人工智能等新兴技术,推动传统产业转型升级;未来,新科网络将继续努力。
目前随着互联网的发展,网站的数量可以说是上亿。互联网数据信息增长非常快。人们越来越多地通过搜索引擎搜索数据信息,但同时也让人们更难找到目标信息。因此,搜索引擎的出现充当了用户和数据之间的桥梁,给人们带来了极大的便利。根据人们的习惯和心理,一般网站在搜索引擎中的排名越高,被点击的机会就越大。反之,网站的排名越低,获得的搜索流量就越少。据统计,全球500强企业中有90%以上在网站企业中使用了SEO技术。
网站优化推广过程中,网站不知为何突然失去了关键词收录的排名,或者网站被搜索引擎降级。这时候,SEO人员无疑是感觉崩溃了,毕竟这么努力优化了很久的网站说降级就降级,心情好不了。然而,困难总会出现,而且总是需要解决。企业网站被搜索引擎降级如何解决?在处理企业网站降权的问题时,首先要了解哪些因素会导致网站的彻头彻尾。在有经验的 SEO 优化者看来,网站 被搜索引擎降级的原因如下:
石家庄指定关键词quick排名哪个更好 查看全部
如何做好口碑营销?
石家庄指定关键词快速排名哪个更好[de39bkw]
是石家庄地区一家专注于网站建设和推广的公司。科技为本是网站建设的指导思想,诚信经营是对客户永恒的承诺。创和网络致力于互联网品牌建设和网络营销。
我们的服务项目包括企业网站建设推广、百万字网推广、软件开发、全网营销推广系统、小程序、产品流词优化、按效果付费等。
立足石家庄,为中小企业提供专业服务,为当地热门行业提供有效的推广和运营策略。每个行业都有一批SEO优化成功案例,可以查询。

网站空间只有购买网站construction软件才能使用。所需空间取决于您购买的网站 软件。具体的网站 取决于您选择如何构建网站。如果您将外包给网站公司,则无需管理所有内容。如果您构建自己的软件,则需要软件空间要求。 网站空间支持什么样的网站编程语言?空间的表现是什么?都是需要考虑的问题。最后,空间必须快。如果上面的域名和空间问题已经很好的解决了。下一个核心部分是网站的制作。
搜索引擎,关键词,排名。搜索引擎营销是目前有效的营销方式之一。现在的网民,如果要买东西,他们会去搜索引擎搜索有关产品的信息。因此,一些高价值的商业关键词价格极高,甚至达到每次点击十元以上。如果你想推广产品,你应该考虑使用搜索引擎来销售。当然也可以使用SEO或者百度竞价排名等等。建立口碑营销。口碑营销是一种有效且廉价的营销方式。但是这种方式做起来并不容易,这涉及到网站的方方面面。口碑营销并不总是在我们的日常生活中进行。那么我们如何进行口碑营销呢?不想当编辑,一天写很多文章,没有发展和前途。
我们是一个追求品质、不断超越自我的团队。每个成员也是亲密的伙伴,与公司共同成长和发展。我们尊重每一次合作的机遇和挑战,精益求精,精益求精。团队秉承专注、专业的设计服务思维,让客户通过设计发挥产品价值,探索无限可能。热爱设计,坚信设计的力量让我们不断前进......

速度。 网站的访问速度也很重要,所以我把它排在第三。你为什么这么说?前两个还不够。用户打开网站需要1分钟或更长时间才能正常访问网站,我想估计到最后我不会关掉你的网站,时间花在关掉你的网站上,用户体验就是你的网站。在线体验不流畅快速滴滴,那还不关掉还等什么?总之,时间就是金钱。服务。 网站 不仅是公司或个人的在线门面,也是重要的营销工具。互联网为公司或个人向用户介绍产品或服务提供了理想的媒介。当用户对某个产品感兴趣时,可以将网站理解为销售人员,并在此基础上向用户介绍其他相关产品、升级产品、配套产品。关键是要有专人为客户解答问题,及时反馈客户信息,与用户形成及时沟通。
很多人在做SEO优化的时候都听过一个词,就是网站聚页,具体指什么?官方解释为:聚合页面是指网站根据某个主题或关键词将原来的文章重新排列成一个新的列表或主题页面。聚合页面的初衷是为了方便用户对相同内容的延伸阅读。对SEO的影响是可以快速获得排名和流量,也可以快速得到搜索引擎的青睐。
自己搭建网站时,要注意内容的新鲜度。现在的网络共享和很多专业的千篇一律的效果,让很多企业网站基本上千人,让很多网站内容觉得一点特色都没有。 ,这样的网站怎么能吸引顾客呢?所以,要想吸引用户,就要让网站有自己的特色。在内容文字和网站planning和网页布局中构建网站时,要给客户一个共同的新鲜感,让他们的用户感受到自己的网站Attractive。在当时的技术条件下,构建网站比较容易,功能也比较短。但是,随着网站技术的不断更新和新功能的推出,原来的网站已经很难满足网站公司的需求了。另一个方面没有精心策划,但网站很容易建立。后期为了给网络添加图文,如果重新创建一个网站,那么选择网站策划公司是第一重要的事情。
石家庄指定关键词quick排名哪个更好
网络秉承“帮助中小企业实现网络营销”的宗旨,通过专业的网站服务,提升客户品牌价值,一站式网络营销服务,帮助客户提升销量;坚持做有价值的网络推广。
MWordba 屏幕的原理是什么? WWordba Screen是和一些高权重的平台合作,依托平台收录页面,然后利用平台目录的url做js覆盖,镜像一个官网,快速推送客户的网站到百度首页实现排名和占据位置的效果。操作和实际效果一样,首页一次上千个关键词,或者全搜索。客户付款后,基本可以达到预期效果,不退还。一家精心打造的公司,每天处理数百个流量是没有问题的。与传统seo优化相比,WWordba Screen的优势在于与平台的合作周期短,1-7天时间word会up。传统的 SEO 优化需要大约三个月的时间。
网站建设初期,一直想着需要一些功能来提升网站的整体效果,这也符合客户对网站的需求。然而,没想到的是网站 需要功能性,但更方便。很多公司可能想增加会员功能、支付系统、不同栏目效果的功能,但是没有想到搜索框、返回顶部、图片放大等详细功能。只考虑大方向而忽略小细节可能会降低网站的运营效果。糟糕的客户体验会影响转化率的提升。当网站的内容越来越多,翻页不方便;当网页内容比较长时,浏览至底部时必须再次滚动至顶部,以增加操作流程。因此,在施工过程中必须有适当的规划。在考虑主要功能的同时,还要考虑客户的使用体验,提供合适的便利功能对他们会更加友好。
TDK 标签的处理。虽然这是seo知识中最基础的内容,但很多网站设计师不会关注它。很容易忽略这一点。确保TDK的每个页面都是一个单独的内容,因为搜索引擎会识别一个页面。要识别的第一个文本内容是 TDK。如果TDK设置不合理(尤其是整个网站页面上的TDK是一样的),会对搜索引擎排名产生很大的负面影响。面包屑。这是很多网站在设计网站时都会忽略的地方。其实面包屑导航对于seo来说一直是很重要的,面包屑导航一定要合理设置。网站内的锚文本链接。这是seo在网站上的重点。网站上的锚文本太少,不利于搜索引擎爬虫在网站上查找和抓取更多页面。网站的锚文本过于密集,容易被搜索引擎认为是故意优化,所以要把握这个程度。
创禾网络始终坚持“诚信为本”的经营理念,以“为客户创造价值”为目标,以专业、全面的服务深耕区域市场。过去,创和网络深刻理解市场需求,是企业网络营销的合作伙伴;创和网络充分把握时代机遇与挑战,借助移动互联网、大数据、人工智能等新兴技术,推动传统产业转型升级;未来,新科网络将继续努力。

目前随着互联网的发展,网站的数量可以说是上亿。互联网数据信息增长非常快。人们越来越多地通过搜索引擎搜索数据信息,但同时也让人们更难找到目标信息。因此,搜索引擎的出现充当了用户和数据之间的桥梁,给人们带来了极大的便利。根据人们的习惯和心理,一般网站在搜索引擎中的排名越高,被点击的机会就越大。反之,网站的排名越低,获得的搜索流量就越少。据统计,全球500强企业中有90%以上在网站企业中使用了SEO技术。
网站优化推广过程中,网站不知为何突然失去了关键词收录的排名,或者网站被搜索引擎降级。这时候,SEO人员无疑是感觉崩溃了,毕竟这么努力优化了很久的网站说降级就降级,心情好不了。然而,困难总会出现,而且总是需要解决。企业网站被搜索引擎降级如何解决?在处理企业网站降权的问题时,首先要了解哪些因素会导致网站的彻头彻尾。在有经验的 SEO 优化者看来,网站 被搜索引擎降级的原因如下:
石家庄指定关键词quick排名哪个更好
本篇搜索标题带有关键字的比如:intext:pdf搜索
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-08-13 06:23
这篇文章主要讲的是如何利用好浏览器进行搜索。
免责声明:文章中的工具仅供个人测试和研究使用,不得用于商业或非法用途,否则后果自负。 文章中出现的截图仅为示例演示,请勿非法使用。
一、浏览器搜索
我们先说一下浏览器搜索。很多时候我们的搜索都是直接在搜索框中输入内容来完成的,比如下面这样,但是有时候搜索到我们想要的内容是很困难的,排名也很多。最上面的是广告,所以我们可以借用一些语法来搜索。
1)site 语法
功能:搜索指定的网页内容,可用于搜索子域以及与该域相关的内容
例如:
网站:
此时可以看到网页都是51cto。
尝试添加内容
站点:“网络安全”,以便我们可以轻松找到所需内容。
百度查出来后,还可以按时间和内容过滤
2)Filetype
有时我们可能正在编写计划或希望找到特定类型的文件。像上面那样搜索是行不通的。这时候,我们可以
使用文件类型进行过滤。
文件类型:pdf“网络安全”
点击查看相关内容。
3)Inurl
功能:可以在网址网址中搜索特定关键字
例如:在url中搜索有login的,使用php
inurl:login.php
点击查看
4)Intitle
用关键字搜索标题
5)Intext
使用关键字搜索文本
例如:
intext:网络安全
二、zoomeye 找到它
这个网站是做什么的,输入你要查找的网站地址,如果是一些记录信息或者漏洞,你可以在这个上找到,比如我搜索过,相关内容有,还有国外也有。一个网站类似这个功能,有兴趣的可以自己查一下
当然,这些只能得到基本的信息,更深入的了解需要一些专业的工具。 查看全部
本篇搜索标题带有关键字的比如:intext:pdf搜索
这篇文章主要讲的是如何利用好浏览器进行搜索。
免责声明:文章中的工具仅供个人测试和研究使用,不得用于商业或非法用途,否则后果自负。 文章中出现的截图仅为示例演示,请勿非法使用。
一、浏览器搜索
我们先说一下浏览器搜索。很多时候我们的搜索都是直接在搜索框中输入内容来完成的,比如下面这样,但是有时候搜索到我们想要的内容是很困难的,排名也很多。最上面的是广告,所以我们可以借用一些语法来搜索。
1)site 语法
功能:搜索指定的网页内容,可用于搜索子域以及与该域相关的内容
例如:
网站:
此时可以看到网页都是51cto。
尝试添加内容
站点:“网络安全”,以便我们可以轻松找到所需内容。
百度查出来后,还可以按时间和内容过滤
2)Filetype
有时我们可能正在编写计划或希望找到特定类型的文件。像上面那样搜索是行不通的。这时候,我们可以
使用文件类型进行过滤。
文件类型:pdf“网络安全”
点击查看相关内容。
3)Inurl
功能:可以在网址网址中搜索特定关键字
例如:在url中搜索有login的,使用php
inurl:login.php
点击查看
4)Intitle
用关键字搜索标题
5)Intext
使用关键字搜索文本
例如:
intext:网络安全
二、zoomeye 找到它
这个网站是做什么的,输入你要查找的网站地址,如果是一些记录信息或者漏洞,你可以在这个上找到,比如我搜索过,相关内容有,还有国外也有。一个网站类似这个功能,有兴趣的可以自己查一下
当然,这些只能得到基本的信息,更深入的了解需要一些专业的工具。
这几个网站能搜到谷歌百度搜不到的内容32.0-2021最受欢迎
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-08-13 05:03
这几个网站可以谷歌搜索百度搜不到内容32.0万玩942评论第004号你的搜索方式可能不对!如何用手机高效搜索,用百度等搜索引擎4230打了8条评论ElasticSearch-2021最受欢迎。
如何使用百度搜索指定的网站内容?以新手站长为例,我只想在新手站长中搜索“服务器”一词的内容。如何搜索?有两种方法可以实现: 方法一:使用site命令使用site搜索指定的网站内容。
“站点:m 标题”。说明:site命令是指在指定的网站中搜索。加号也是必要的。如果觉得输入加号比较麻烦,可以用空格代替。功能:可以搜索库的内容,用百度快照复制...
手机百度浏览器的高级搜索方法,指定网站更准确的搜索。 .
如何在百度中使用特定关键字搜索网站 您可以使用高级搜索设置或高级搜索命令。打开浏览器主页,移动鼠标设置右上角的属性,然后点击“高级搜索”,弹出浮动关卡;百度关键词包括以下完整级别。
在百度中搜索指定网站内容的方法:打开百度主页。输入关键词,点击百度。在页面搜索框的底部,点击“搜索职位”。
浏览器打开时,某网站来索法:在框中输入“site:wenku.baidu.c。
网站百度搜索结果中的图片显示,图片均为121*75。所以百度抓取的图片都在121*75的范围内。 2、图片像专利3、尽量给图片加上适当的alt标签4、图片周围的文字真的很适合赚钱。 查看全部
这几个网站能搜到谷歌百度搜不到的内容32.0-2021最受欢迎
这几个网站可以谷歌搜索百度搜不到内容32.0万玩942评论第004号你的搜索方式可能不对!如何用手机高效搜索,用百度等搜索引擎4230打了8条评论ElasticSearch-2021最受欢迎。
如何使用百度搜索指定的网站内容?以新手站长为例,我只想在新手站长中搜索“服务器”一词的内容。如何搜索?有两种方法可以实现: 方法一:使用site命令使用site搜索指定的网站内容。
“站点:m 标题”。说明:site命令是指在指定的网站中搜索。加号也是必要的。如果觉得输入加号比较麻烦,可以用空格代替。功能:可以搜索库的内容,用百度快照复制...
手机百度浏览器的高级搜索方法,指定网站更准确的搜索。 .
如何在百度中使用特定关键字搜索网站 您可以使用高级搜索设置或高级搜索命令。打开浏览器主页,移动鼠标设置右上角的属性,然后点击“高级搜索”,弹出浮动关卡;百度关键词包括以下完整级别。
在百度中搜索指定网站内容的方法:打开百度主页。输入关键词,点击百度。在页面搜索框的底部,点击“搜索职位”。
浏览器打开时,某网站来索法:在框中输入“site:wenku.baidu.c。
网站百度搜索结果中的图片显示,图片均为121*75。所以百度抓取的图片都在121*75的范围内。 2、图片像专利3、尽量给图片加上适当的alt标签4、图片周围的文字真的很适合赚钱。
搜索引擎关键字放在下面,也不一定能起到关键字的作用
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-08-13 05:01
最好放在下面,但不一定,也就是说放在下面可以起到关键字的作用,也要看搜索引擎是不是收录!
meta标签通常用于为搜索引擎robots定义页面主题,或者定义用户浏览器上的cookie;可用于识别作者、设置页面格式、标记内容摘要和关键词;您还可以设置页面使用情况,可以根据您定义的时间间隔自行刷新,设置RASC内容级别等。
name描述网页,对应Content(网页内容),方便搜索引擎机器人查找和分类(目前几乎所有搜索引擎都使用在线机器人自动查找元值对网页进行分类)。
name (name="") 的值指定了所提供信息的类型。一些值已经定义。例如描述(description)、关键字(keyword)、刷新(refresh)等等。也可以指定其他任意值,比如creationdate(创建日期),
文档 ID(文档编号)和级别(level)等
名称内容指定实际内容。例如,如果指定的级别是值,则内容可能是开始、中级或高级。
1、Keywords(关键词)
说明:为搜索引擎提供的关键字列表
用法:
注意:每个关键词 用逗号“,”分隔。 META的通常用途是为搜索引擎指定关键词以提高搜索质量。当多个 META 元素提供文档语言依赖信息时,搜索引擎将使用 lang 特性通过用户的语言优先级引用来过滤和显示搜索结果。例如:
2、Description(简介)
描述:描述用于告诉搜索引擎你的网站主要内容。
用法:
注意:
3、Robots(机器人向导)
说明:Robots 用于告诉搜索机器人哪些页面需要编入索引,哪些页面不需要编入索引。内容参数为all、none、index、noindex、follow、nofollow。默认为全部。
用法:
注:很多搜索引擎使用机器人/蜘蛛搜索登录网站。这些机器人/蜘蛛会使用meta元素的一些特征来决定如何登录。
all:会检索文件,可以查询页面上的链接;
none:不会检索文件,无法查询页面上的链接; (与“无索引,无关注”功能相同)
index:文件将被检索; (让机器人/蜘蛛登录)
follow:页面上的链接可以查询;
noindex:不会检索文件,但可以查询页面上的链接; (不要让机器人/蜘蛛登录)
nofollow:不会检索文件,可以查询页面上的链接。 (不要让机器人/蜘蛛跟着本页链接往下看)
4、Author(作者)
说明:标记网页的作者或制作团队
用法:
注意:内容可以是:您或您的制作团队的姓名,或电子邮件 查看全部
搜索引擎关键字放在下面,也不一定能起到关键字的作用
最好放在下面,但不一定,也就是说放在下面可以起到关键字的作用,也要看搜索引擎是不是收录!
meta标签通常用于为搜索引擎robots定义页面主题,或者定义用户浏览器上的cookie;可用于识别作者、设置页面格式、标记内容摘要和关键词;您还可以设置页面使用情况,可以根据您定义的时间间隔自行刷新,设置RASC内容级别等。
name描述网页,对应Content(网页内容),方便搜索引擎机器人查找和分类(目前几乎所有搜索引擎都使用在线机器人自动查找元值对网页进行分类)。
name (name="") 的值指定了所提供信息的类型。一些值已经定义。例如描述(description)、关键字(keyword)、刷新(refresh)等等。也可以指定其他任意值,比如creationdate(创建日期),
文档 ID(文档编号)和级别(level)等
名称内容指定实际内容。例如,如果指定的级别是值,则内容可能是开始、中级或高级。
1、Keywords(关键词)
说明:为搜索引擎提供的关键字列表
用法:
注意:每个关键词 用逗号“,”分隔。 META的通常用途是为搜索引擎指定关键词以提高搜索质量。当多个 META 元素提供文档语言依赖信息时,搜索引擎将使用 lang 特性通过用户的语言优先级引用来过滤和显示搜索结果。例如:
2、Description(简介)
描述:描述用于告诉搜索引擎你的网站主要内容。
用法:
注意:
3、Robots(机器人向导)
说明:Robots 用于告诉搜索机器人哪些页面需要编入索引,哪些页面不需要编入索引。内容参数为all、none、index、noindex、follow、nofollow。默认为全部。
用法:
注:很多搜索引擎使用机器人/蜘蛛搜索登录网站。这些机器人/蜘蛛会使用meta元素的一些特征来决定如何登录。
all:会检索文件,可以查询页面上的链接;
none:不会检索文件,无法查询页面上的链接; (与“无索引,无关注”功能相同)
index:文件将被检索; (让机器人/蜘蛛登录)
follow:页面上的链接可以查询;
noindex:不会检索文件,但可以查询页面上的链接; (不要让机器人/蜘蛛登录)
nofollow:不会检索文件,可以查询页面上的链接。 (不要让机器人/蜘蛛跟着本页链接往下看)
4、Author(作者)
说明:标记网页的作者或制作团队
用法:
注意:内容可以是:您或您的制作团队的姓名,或电子邮件
第二章网站设计影响seo的因素2.1选择喜欢的域名
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-08-13 04:24
第二章网站影响seo2.的设计因素@1选择搜索引擎喜欢的域名。这些域名后缀具有更高的权重。 edugov org net com cn hk.影响中文域名会影响seo吗? 4月22日,CNNIC代表中国提交的简繁体“.中国”域名国际申请通过互联网名称与数字地址分配机构(ICANN)微软IE7、IE8/OPERA快速审查9.5/SAFARI3.1/火狐2.@0、3.0/遨游等最新的“谷歌Chrome”浏览器也支持中文域名。 DNS介绍2.@1.5 如何选择一个合适的域名简洁易记,输入域名也方便。必须有内涵和意义2.@1.6 企业名称拼音命名技巧 企业英文名称 中英文名称缩写 中文拼音同音 中英文结合 公司名称加前缀和后缀2.@2选择空格搜索引擎喜欢介绍新网idc 2.@2.@1在空间中选择合适的位置影响使用ping命令。使用 nslookup 命令2.@2.@3 确保更稳定的空间。空间的稳定性对搜索引擎有着特殊的影响。如果某个网站因各种问题无法访问,将极大影响用户体验。如果空间中的问题和漏洞被黑客利用,服务器受到攻击,将导致数据修改、传输瘫痪或整个站点被删除。
在选择空间时,不要贪图便宜,也不要让销售人员胡闹。如今,许多供应商都有尝试空间的活动。如果不确定空间是否稳定,可以先试用几天再决定是否使用。 2.@2.@4 选择空间或服务器2.@2.@5 支持在线数相关因素网站code网站在线数:指网站设置的时间段,保持会话数; 网站并发数:指一定时间内同时提交给网站的请求数,需要网站服务器进行操作。 HTTP:超文本传输协议客户端:通过请求和接收显示网页的浏览器:对于客户端的响应,请 HTTP1.0: RFC 1945 HTTP1.1: RFC 2068 PC running Internet Explorer Web server PC运行导航器2.@2.@6 404 HTTP请求消息示例 GET /pub/cslg/index.htm HTTP/1.1 //起始行、方法、URL、版本 //接受:image/gif , image /x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, application/x-shockwave-flash, //第一部分开始,浏览器接受MIME文件类型 //Referer: //给出主机域名 // Accept-Language: zh-cn //指定网页支持语言为中文 // Accept-Encoding: gzip, deflate //指定编码方法 // If- Modified-Since: Fri, 06 Jun 2008 22:56:31 GMT //Connected Greenwich Mean Time // If-None-Match: "1c408a-b748-5f6a25c0" User-Agent: Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.2;.NET C LR 2.@0.50727)//用户使用的浏览器为IE 6.0//主机:210.43.192.@5 //主机地址//连接: Keep-Alive //告诉服务器保持活动状态 // //主要部分通常不用,请求消息的最后一行通常为空行//一条HTTP响应消息HTTP/1.1 200 OK //HTTP 版本为1.1、 状态码为 200、 状态短语为 OK // 日期:Fri, 06 Jun 2008 23:15:53 GMT //当前格林威治标准时间 // Se rver: Apache/2.@0.40 (Red Hat Linux) //服务器操作系统类型 // Last-Modified: Thu, 20 Oct 2005 00:43:25 GMT //Document last modified date // ETag: " 1c4ce2-904-d838a540" Accept-Ranges: bytes //接受的值类型为bytes // Content-Length: 2308 //Content length // Keep-Alive: timeout=15, max=100 //保持活动的时间/ / Connection: Keep-Alive // 告诉服务器保持活动状态 // Content-Type: text/html; charset=GB2312 //支持的字符集为中文GB2312// //以下是请求的html文件内容 // XX 科技大学响应报文的第一行是状态行。它包括:HTTP 版本、状态代码和解释状态代码的简单短语。 1xx:表示收到或正在处理的请求等通知信息。
2xx:表示请求成功。例如200 OK,请求成功,请求的对象在消息中。 3xx:表示重定向,必须采取进一步的行来完成请求。 4xx:表示客户端错误,例如语法错误或无法完成请求。例如,400 Bad Request:服务器不理解请求消息。 404 Found:在服务器上找不到请求的对象。 5xx:表示服务器错误,如果服务器出现故障,则无法完成请求。 HTTP状态行常用状态码如下: 常用状态码、状态描述、解释: 200 OK //客户端请求成功 400 Bad Request //客户端请求语法错误,服务器无法理解401 Unauthorized //请求不是授权 403 Forbidden //服务器收到请求,但拒绝提供服务 404 Found //请求的资源不存在,例如:输入了错误的URL 500 Internal Server Error //Unexpected error发生在服务器 503 Server Unavailable //服务器当前无法处理客户端的请求可能会在一段时间后恢复正常。自定义404页面Apache Server 将ErrorDocument404 /notfound.php添加到.htaccess文件中,将“/notfound.php”改为自定义404错误页面的地址和名称 Edit “web.config” “File added < customErrors mode="On" defaultRedirect="error.asp"> <META CONTENT="NOINDEX,FOLLOW"> <META CONTENT="INDEX,NOFOLLOW"> <META CONTENT="NOINDEX,NOFOLLOW">机器人的优缺点.txt 避免网站重复的优点 内容是收录向攻击者指出的缺点。 网站的目录结构和私有数据的位置应该没有错。 1-2 关键词 不超过25个汉字,50个英文字母,越核心关键词放置越靠前,长尾不加特殊标点符号关键词每页不一样页面位置首选Title写作次数选择Title写首页slogan栏目page/topic page Channel B_Anet B Channel_Anet_关键词内页C文章_B Channel C文章_B Channel_Anet Title是不可替代的,是我们的第一个重要标签内页是搜索引擎了解网页的切入点,也是网页主题归属的最佳判断点。
2.@4.2 描述描述的设计技巧。最好只放 4 个关键字。不超过100个汉字和200个英文字母。核心关键词越方每个页面前面没有特殊标点符号,与很多搜索引擎不同,页面的MATA标签的描述部分仍然作为搜索结果的“内容摘要”。 • 提倡描述是网站 的一般业务和主题,使用诸如“我们是...”、“我们提供...”、“网络作为...”和“电话:.. .”。 • 反对,Description 与Keyword 完全相同或Description 收录Keyword,Description 中的“世界最大”和“永久免费”字样反对不相关的字眼和关键词 单独出现。 2.@3.4关键词Keywords 设计技巧 关键字是页面关键词,虽然被很多黑帽SEO使用,导致权重下降,但仍然是搜索引擎关注的重点之一。关键词要限制在6~8关键词page位置,第一选择关键词写第二选择关键词写主页3~4 core关键词, 3~4 extension关键词 6~8 core关键词 栏目页/主题页频道名称,频道关键词,网站芯关键词频道名称,频道关键词内页文章TAG,1~2 网站core关键词 文章TAG 2.@4.4Get了解更多。 META标签是HTML语言HEAD区域的辅助标签。它位于 HTML 文档头部的标签和标签之间。它提供用户不可见的信息。
META标签分为两部分:HTTP头信息(HTTP-EQUIV)和页面描述信息(NAME)。 1、Content-Type 和Content-Language(显示字符集设置) 说明:设置页面使用的字符集,表示主页创建使用的语言,浏览器会根据这个Set调用对应的字符来显示页面内容。 META标签将HTML页面使用的字符集定义为GB2132,即国标汉字代码。如果将“charset=GB2312”替换为“BIG5”,则本页使用的字符集为繁体中文Big5代码。当您浏览一些国外网站时,IE浏览器会提示您下载xx语言支持以正确显示页面。该函数通过读取 HTML 页面的 META 标签的 Content-Type 属性,知道需要使用哪个字符集来显示页面。如果系统中没有安装相应的字符集,IE会提示下载。其他语言也对应不同的字符集。例如,日语字符集是“iso-2022-jp”,韩语字符集是“ks_c_5601”。 2、Refresh(刷新)说明:让网页自己刷新多久(秒),或者过了多久让网页自动链接到其他网页。指停留5秒后自动刷新到网址。
3.Content-Script-Type W3C 网页规范,指定页面中脚本的类型。 4.Robots(机器人向导) 说明:Robots 用于告诉搜索机器人哪些页面需要索引,哪些页面不需要索引。 Content的参数有all、none、index、noindex、follow、nofollow。默认是全部。用法:5、Expires(过期) 说明:指定网页在缓存中的过期时间。网页过期后,必须在服务器上检索。 查看全部
第二章网站设计影响seo的因素2.1选择喜欢的域名
第二章网站影响seo2.的设计因素@1选择搜索引擎喜欢的域名。这些域名后缀具有更高的权重。 edugov org net com cn hk.影响中文域名会影响seo吗? 4月22日,CNNIC代表中国提交的简繁体“.中国”域名国际申请通过互联网名称与数字地址分配机构(ICANN)微软IE7、IE8/OPERA快速审查9.5/SAFARI3.1/火狐2.@0、3.0/遨游等最新的“谷歌Chrome”浏览器也支持中文域名。 DNS介绍2.@1.5 如何选择一个合适的域名简洁易记,输入域名也方便。必须有内涵和意义2.@1.6 企业名称拼音命名技巧 企业英文名称 中英文名称缩写 中文拼音同音 中英文结合 公司名称加前缀和后缀2.@2选择空格搜索引擎喜欢介绍新网idc 2.@2.@1在空间中选择合适的位置影响使用ping命令。使用 nslookup 命令2.@2.@3 确保更稳定的空间。空间的稳定性对搜索引擎有着特殊的影响。如果某个网站因各种问题无法访问,将极大影响用户体验。如果空间中的问题和漏洞被黑客利用,服务器受到攻击,将导致数据修改、传输瘫痪或整个站点被删除。
在选择空间时,不要贪图便宜,也不要让销售人员胡闹。如今,许多供应商都有尝试空间的活动。如果不确定空间是否稳定,可以先试用几天再决定是否使用。 2.@2.@4 选择空间或服务器2.@2.@5 支持在线数相关因素网站code网站在线数:指网站设置的时间段,保持会话数; 网站并发数:指一定时间内同时提交给网站的请求数,需要网站服务器进行操作。 HTTP:超文本传输协议客户端:通过请求和接收显示网页的浏览器:对于客户端的响应,请 HTTP1.0: RFC 1945 HTTP1.1: RFC 2068 PC running Internet Explorer Web server PC运行导航器2.@2.@6 404 HTTP请求消息示例 GET /pub/cslg/index.htm HTTP/1.1 //起始行、方法、URL、版本 //接受:image/gif , image /x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, application/x-shockwave-flash, //第一部分开始,浏览器接受MIME文件类型 //Referer: //给出主机域名 // Accept-Language: zh-cn //指定网页支持语言为中文 // Accept-Encoding: gzip, deflate //指定编码方法 // If- Modified-Since: Fri, 06 Jun 2008 22:56:31 GMT //Connected Greenwich Mean Time // If-None-Match: "1c408a-b748-5f6a25c0" User-Agent: Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.2;.NET C LR 2.@0.50727)//用户使用的浏览器为IE 6.0//主机:210.43.192.@5 //主机地址//连接: Keep-Alive //告诉服务器保持活动状态 // //主要部分通常不用,请求消息的最后一行通常为空行//一条HTTP响应消息HTTP/1.1 200 OK //HTTP 版本为1.1、 状态码为 200、 状态短语为 OK // 日期:Fri, 06 Jun 2008 23:15:53 GMT //当前格林威治标准时间 // Se rver: Apache/2.@0.40 (Red Hat Linux) //服务器操作系统类型 // Last-Modified: Thu, 20 Oct 2005 00:43:25 GMT //Document last modified date // ETag: " 1c4ce2-904-d838a540" Accept-Ranges: bytes //接受的值类型为bytes // Content-Length: 2308 //Content length // Keep-Alive: timeout=15, max=100 //保持活动的时间/ / Connection: Keep-Alive // 告诉服务器保持活动状态 // Content-Type: text/html; charset=GB2312 //支持的字符集为中文GB2312// //以下是请求的html文件内容 // XX 科技大学响应报文的第一行是状态行。它包括:HTTP 版本、状态代码和解释状态代码的简单短语。 1xx:表示收到或正在处理的请求等通知信息。
2xx:表示请求成功。例如200 OK,请求成功,请求的对象在消息中。 3xx:表示重定向,必须采取进一步的行来完成请求。 4xx:表示客户端错误,例如语法错误或无法完成请求。例如,400 Bad Request:服务器不理解请求消息。 404 Found:在服务器上找不到请求的对象。 5xx:表示服务器错误,如果服务器出现故障,则无法完成请求。 HTTP状态行常用状态码如下: 常用状态码、状态描述、解释: 200 OK //客户端请求成功 400 Bad Request //客户端请求语法错误,服务器无法理解401 Unauthorized //请求不是授权 403 Forbidden //服务器收到请求,但拒绝提供服务 404 Found //请求的资源不存在,例如:输入了错误的URL 500 Internal Server Error //Unexpected error发生在服务器 503 Server Unavailable //服务器当前无法处理客户端的请求可能会在一段时间后恢复正常。自定义404页面Apache Server 将ErrorDocument404 /notfound.php添加到.htaccess文件中,将“/notfound.php”改为自定义404错误页面的地址和名称 Edit “web.config” “File added < customErrors mode="On" defaultRedirect="error.asp"> <META CONTENT="NOINDEX,FOLLOW"> <META CONTENT="INDEX,NOFOLLOW"> <META CONTENT="NOINDEX,NOFOLLOW">机器人的优缺点.txt 避免网站重复的优点 内容是收录向攻击者指出的缺点。 网站的目录结构和私有数据的位置应该没有错。 1-2 关键词 不超过25个汉字,50个英文字母,越核心关键词放置越靠前,长尾不加特殊标点符号关键词每页不一样页面位置首选Title写作次数选择Title写首页slogan栏目page/topic page Channel B_Anet B Channel_Anet_关键词内页C文章_B Channel C文章_B Channel_Anet Title是不可替代的,是我们的第一个重要标签内页是搜索引擎了解网页的切入点,也是网页主题归属的最佳判断点。
2.@4.2 描述描述的设计技巧。最好只放 4 个关键字。不超过100个汉字和200个英文字母。核心关键词越方每个页面前面没有特殊标点符号,与很多搜索引擎不同,页面的MATA标签的描述部分仍然作为搜索结果的“内容摘要”。 • 提倡描述是网站 的一般业务和主题,使用诸如“我们是...”、“我们提供...”、“网络作为...”和“电话:.. .”。 • 反对,Description 与Keyword 完全相同或Description 收录Keyword,Description 中的“世界最大”和“永久免费”字样反对不相关的字眼和关键词 单独出现。 2.@3.4关键词Keywords 设计技巧 关键字是页面关键词,虽然被很多黑帽SEO使用,导致权重下降,但仍然是搜索引擎关注的重点之一。关键词要限制在6~8关键词page位置,第一选择关键词写第二选择关键词写主页3~4 core关键词, 3~4 extension关键词 6~8 core关键词 栏目页/主题页频道名称,频道关键词,网站芯关键词频道名称,频道关键词内页文章TAG,1~2 网站core关键词 文章TAG 2.@4.4Get了解更多。 META标签是HTML语言HEAD区域的辅助标签。它位于 HTML 文档头部的标签和标签之间。它提供用户不可见的信息。
META标签分为两部分:HTTP头信息(HTTP-EQUIV)和页面描述信息(NAME)。 1、Content-Type 和Content-Language(显示字符集设置) 说明:设置页面使用的字符集,表示主页创建使用的语言,浏览器会根据这个Set调用对应的字符来显示页面内容。 META标签将HTML页面使用的字符集定义为GB2132,即国标汉字代码。如果将“charset=GB2312”替换为“BIG5”,则本页使用的字符集为繁体中文Big5代码。当您浏览一些国外网站时,IE浏览器会提示您下载xx语言支持以正确显示页面。该函数通过读取 HTML 页面的 META 标签的 Content-Type 属性,知道需要使用哪个字符集来显示页面。如果系统中没有安装相应的字符集,IE会提示下载。其他语言也对应不同的字符集。例如,日语字符集是“iso-2022-jp”,韩语字符集是“ks_c_5601”。 2、Refresh(刷新)说明:让网页自己刷新多久(秒),或者过了多久让网页自动链接到其他网页。指停留5秒后自动刷新到网址。
3.Content-Script-Type W3C 网页规范,指定页面中脚本的类型。 4.Robots(机器人向导) 说明:Robots 用于告诉搜索机器人哪些页面需要索引,哪些页面不需要索引。 Content的参数有all、none、index、noindex、follow、nofollow。默认是全部。用法:5、Expires(过期) 说明:指定网页在缓存中的过期时间。网页过期后,必须在服务器上检索。
MOSSSearch学习记录(五):这片文章继续介绍搜索配置
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-08-13 02:15
MOSS 搜索学习记录(五):使用元数据和规则在多个列表中搜索指定范围内的内容
这篇文章继续介绍搜索配置的例子。这次增加了元数据的使用,通过规则实现了跨列表搜索,每个列表都可以随意指定可搜索范围。但是这种方法也有它的缺点,因为它是一种在输入数据后进行的耗时的方法,即使通过编程也是如此。最好的办法是在规划设计阶段,在输入数据之前进行规划搜索,这样就不会出现。问题是。
这次我们创建了一个新的范围。 range的创建请参考本系列第三篇文章。
1.首先打开MOSS的管理中心。通过MOSS的管理中心跳转到共享服务management网站(我的是SharedServices1)。打开搜索设置。
2. “元数据属性映射”可以在爬网设置部分找到。打开。
3.这时候可以看到托管属性视图中列出了很多爬网属性。为了实现对列表指定范围的搜索,这里需要使用网站列。所以,首先去网站创建一个网站列。例如,如果名称为 InfoType,则指定为单行文本。
4.这里我们以两个文档库为例(列表也可以),一月存档,二月存档。在两个文档库中,添加刚刚创建的InfoType网站列,为内容分配不同类型的值。这里使用了 3 种类型:NET、JAVA 和 SQL。
5.做完之后,在共享服务管理网站中对这个网站所属的内容源进行增量爬取。
6.爬取后,到刚才的“元数据属性映射”,新建一个托管属性。
7.属性名称设置为 InfoType。
8.在“映射到已爬网属性”部分,点击右侧的添加映射按钮。
会弹出如下窗口
首先在类别中选择SharePoint,缩小搜索范围,然后找到您刚刚创建的InfoType网站列。 SharePoint 将使用 ows_ 作为所有这些列的前缀。然后点击确定添加到刚才的列表中。
最后记得勾选“允许在多个范围内使用该属性”。
点击确定添加。
9.回到搜索设置页面,然后在内容源和抓取计划中找到内容源,运行一次完整的抓取。
10。爬行后创建一个新范围。将其命名为 NET。
11。然后向该范围添加规则。此时选择属性查询。在添加属性限制中,您可以在下拉菜单中找到我们的 InfoType。然后将值设置为 NET。如下:
12。返回搜索设置页面,然后单击范围部分中的立即开始更新以更新范围内容。
到这里,共享服务管理网站中的设置就完成了。
13。进入网站集,进入网站settings页面,在网站集管理板块找到搜索范围。打开。
14。这时候可以看到,未使用的范围有刚才在共享服务管理网站中设置的NET范围。
15。单击搜索下拉列表链接。在范围内可以看到NET是灰色的,选中左边的框会变亮,说明这个范围可以在搜索下拉列表中显示。
16。点击确定后,返回查看范围页面,可以看到NET已经成为搜索下拉列表组中的一项。
17。新建一个web part页面,添加搜索框和搜索核心结果两个web part。
18。首先设置搜索框。范围下拉列表选项不显示范围下拉列表。然后在 Miscellaneous 中将目标搜索结果页面的 URL 设置为当前页面。当然,如果你想放到其他页面上,那就是搜索核心结果放在哪里的问题了。
19。设置搜索核心结果组件。这里只需要设置一个地方,就是杂项中的范围。输入刚才的范围名称,NET。设置完成。
20。在搜索框中输入天津关键词并搜索。此时,只会搜索 NET 范围内的文档。
完成。 查看全部
MOSSSearch学习记录(五):这片文章继续介绍搜索配置
MOSS 搜索学习记录(五):使用元数据和规则在多个列表中搜索指定范围内的内容
这篇文章继续介绍搜索配置的例子。这次增加了元数据的使用,通过规则实现了跨列表搜索,每个列表都可以随意指定可搜索范围。但是这种方法也有它的缺点,因为它是一种在输入数据后进行的耗时的方法,即使通过编程也是如此。最好的办法是在规划设计阶段,在输入数据之前进行规划搜索,这样就不会出现。问题是。
这次我们创建了一个新的范围。 range的创建请参考本系列第三篇文章。
1.首先打开MOSS的管理中心。通过MOSS的管理中心跳转到共享服务management网站(我的是SharedServices1)。打开搜索设置。
2. “元数据属性映射”可以在爬网设置部分找到。打开。
3.这时候可以看到托管属性视图中列出了很多爬网属性。为了实现对列表指定范围的搜索,这里需要使用网站列。所以,首先去网站创建一个网站列。例如,如果名称为 InfoType,则指定为单行文本。
4.这里我们以两个文档库为例(列表也可以),一月存档,二月存档。在两个文档库中,添加刚刚创建的InfoType网站列,为内容分配不同类型的值。这里使用了 3 种类型:NET、JAVA 和 SQL。
5.做完之后,在共享服务管理网站中对这个网站所属的内容源进行增量爬取。
6.爬取后,到刚才的“元数据属性映射”,新建一个托管属性。
7.属性名称设置为 InfoType。
8.在“映射到已爬网属性”部分,点击右侧的添加映射按钮。
会弹出如下窗口
首先在类别中选择SharePoint,缩小搜索范围,然后找到您刚刚创建的InfoType网站列。 SharePoint 将使用 ows_ 作为所有这些列的前缀。然后点击确定添加到刚才的列表中。
最后记得勾选“允许在多个范围内使用该属性”。
点击确定添加。
9.回到搜索设置页面,然后在内容源和抓取计划中找到内容源,运行一次完整的抓取。
10。爬行后创建一个新范围。将其命名为 NET。
11。然后向该范围添加规则。此时选择属性查询。在添加属性限制中,您可以在下拉菜单中找到我们的 InfoType。然后将值设置为 NET。如下:
12。返回搜索设置页面,然后单击范围部分中的立即开始更新以更新范围内容。
到这里,共享服务管理网站中的设置就完成了。
13。进入网站集,进入网站settings页面,在网站集管理板块找到搜索范围。打开。
14。这时候可以看到,未使用的范围有刚才在共享服务管理网站中设置的NET范围。
15。单击搜索下拉列表链接。在范围内可以看到NET是灰色的,选中左边的框会变亮,说明这个范围可以在搜索下拉列表中显示。
16。点击确定后,返回查看范围页面,可以看到NET已经成为搜索下拉列表组中的一项。
17。新建一个web part页面,添加搜索框和搜索核心结果两个web part。
18。首先设置搜索框。范围下拉列表选项不显示范围下拉列表。然后在 Miscellaneous 中将目标搜索结果页面的 URL 设置为当前页面。当然,如果你想放到其他页面上,那就是搜索核心结果放在哪里的问题了。
19。设置搜索核心结果组件。这里只需要设置一个地方,就是杂项中的范围。输入刚才的范围名称,NET。设置完成。
20。在搜索框中输入天津关键词并搜索。此时,只会搜索 NET 范围内的文档。
完成。
importurllib#python中用于获取网站的模块(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-08-13 02:14
import urllib#module 用于在python中获取网站
导入 urllib2、cookielib
部分网站访问时需要cookie,python处理cookie代码如下:
cj = cookielib.CookieJar()
opener =urllib2.build_opener( urllib2.HttpCookieProcessor(cj) )
urllib2.install_opener (opener)
通常我们需要在网站中搜索我们需要的信息。这里有两种情况:
1. 首先,可以直接更改网址,获取要搜索的页面:
def GetWebPage( x ): #我们定义了一个获取页面的函数,x是用来呈现你在页面上搜索到的内容的参数
url ='#39;+'你要搜索的参数'#根据自己的页面情况适当修改
page = urllib2.urlopen(url)
pageContent = page.read()
return pageContent#返回HTML格式的页面信息
2. 其次,需要使用post方法,把你搜索到的内容放到postdata中,然后返回你需要的页面
def GetWebPage( x ): #我们定义了一个获取页面的函数,x是用来呈现你在页面上搜索到的内容的参数
url ='#39;#这个网址就是你进入搜索界面的地方
postData = urllib.urlencode({various ‘post’ parameter input} )#这里输入的post参数需要自己检查
req= urllib2.Request (url, postData)
pageContent = urllib2.urlopen(请求)。读( )
return pageContent#返回HTML格式的页面信息
获取到我们需要的网页信息后,我们还需要从获取到的网页中进一步获取我们需要的信息。这里我推荐使用 BeautifulSoup 模块。 Python 没有附带它。您可以在百度谷歌下载安装。 BeautifulSoup 的意思是“美味的汤”。你需要做的是从一锅汤里找到你喜欢吃的东西。
import re#正则表达式,用于匹配字符
from bs4 import BeautifulSoup# 导入 BeautifulSoup 模块
soup =BeautifulSoup(pageContent)#pageContent 是我们上面搜索的页面
Soup 是 HTML 中的所有标签(tag) BeautifulSoup 处理格式化后的字符串。一个标准的标签形式是:
hwkobe24
通过一些过滤的方法,我们可以从汤中得到我们需要的信息:
(1) find_all (name, attrs, recursive, text, **kwargs)
这里,我们通过在标签上添加约束来获取需要的标签列表,例如soup.find_all('p')是查找名为'p'的标签,而soup.find_all(class = "tittle" ) 就是查找所有class属性为"tittle"的标签,soup.find_all(class = pie('lass'))表示所有class属性中收录'lass'的标签。这里用到了正则表达式(可以自己学,很有用)
得到我们想要的所有标签的列表后,我们遍历这个列表,然后在标签中获取你需要的内容。通常我们需要标签的文字部分,也就是网页上显示的文字。代码如下:
tagList =soup.find_all(class="tittle")#如果标签比较复杂,可以使用多个过滤条件,使过滤更加严格
对于 tagList 中的标签:
打印标签文本
f.write (str(tag.text) )#将此信息写入本地文件以备后用
(2)find( name, attrs, recursive, text, **kwargs )
它和find_all()方法唯一的区别是find_all()方法的返回结果是一个收录一个元素的列表,而find()方法直接返回结果
(3)find_parents() find_parent( )
find_all() 和 find() 只搜索当前节点的所有子节点、孙节点等。
find_parents() 和 find_parent() 用于搜索当前节点的父节点,搜索方法与普通标签搜索方法相同,搜索文档搜索文档中收录的内容
(4)find_next_siblings() find_next_sibling()
这两个方法使用.next_siblings属性来推进所有后面解析的兄弟标签节点。 find_next_siblings() 方法返回所有满足条件的后续兄弟节点,而 find_next_sibling() 只返回满足条件的下一个兄弟节点。一个标签节点
(5)find_previous_siblings() find_previous_sibling()
这两个方法使用 .previous_siblings 属性来迭代当前标签之前解析的兄弟标签节点。 find_previous_siblings() 方法返回之前所有满足条件的兄弟节点, find_previous_sibling() 方法返回第一个满足条件的兄弟节点。兄弟节点
(6)find_all_next() find_next()
这两个方法使用 .next_elements 属性来迭代当前标签之后的标签和字符串。 find_all_next() 方法返回所有符合条件的节点, find_next() 方法返回第一个符合条件的节点
(7)find_all_previous() 和 find_previous()
这两个方法使用 .previous_elements 属性来迭代当前节点前面的标签和字符串。 find_all_previous() 方法返回所有符合条件的节点, find_previous() 方法返回第一个符合条件的节点。
实际代码示例:(抓取网页下的指定链接)
来自 bs4 小鬼
#htmltext
html_text=""
soup=BeautifulSoup(html_text,'html.parser')
a=soup.select('a')
for i in a:
如果 i.string=="关键词":
findb_ur=i['href']
#输出搜索a标签中的字符串得到的网页链接
# 打印(findb_url)
#findb_url="https:"+finburl
alist=soup.find_all('a)
对于 a 列表:
1.通过下标操作方法
href=a['href']
打印(htref)
2.通过attrs属性
href=a.attrs['href']
打印(href) 查看全部
importurllib#python中用于获取网站的模块(图)
import urllib#module 用于在python中获取网站
导入 urllib2、cookielib
部分网站访问时需要cookie,python处理cookie代码如下:
cj = cookielib.CookieJar()
opener =urllib2.build_opener( urllib2.HttpCookieProcessor(cj) )
urllib2.install_opener (opener)
通常我们需要在网站中搜索我们需要的信息。这里有两种情况:
1. 首先,可以直接更改网址,获取要搜索的页面:
def GetWebPage( x ): #我们定义了一个获取页面的函数,x是用来呈现你在页面上搜索到的内容的参数
url ='#39;+'你要搜索的参数'#根据自己的页面情况适当修改
page = urllib2.urlopen(url)
pageContent = page.read()
return pageContent#返回HTML格式的页面信息
2. 其次,需要使用post方法,把你搜索到的内容放到postdata中,然后返回你需要的页面
def GetWebPage( x ): #我们定义了一个获取页面的函数,x是用来呈现你在页面上搜索到的内容的参数
url ='#39;#这个网址就是你进入搜索界面的地方
postData = urllib.urlencode({various ‘post’ parameter input} )#这里输入的post参数需要自己检查
req= urllib2.Request (url, postData)
pageContent = urllib2.urlopen(请求)。读( )
return pageContent#返回HTML格式的页面信息
获取到我们需要的网页信息后,我们还需要从获取到的网页中进一步获取我们需要的信息。这里我推荐使用 BeautifulSoup 模块。 Python 没有附带它。您可以在百度谷歌下载安装。 BeautifulSoup 的意思是“美味的汤”。你需要做的是从一锅汤里找到你喜欢吃的东西。
import re#正则表达式,用于匹配字符
from bs4 import BeautifulSoup# 导入 BeautifulSoup 模块
soup =BeautifulSoup(pageContent)#pageContent 是我们上面搜索的页面
Soup 是 HTML 中的所有标签(tag) BeautifulSoup 处理格式化后的字符串。一个标准的标签形式是:
hwkobe24
通过一些过滤的方法,我们可以从汤中得到我们需要的信息:
(1) find_all (name, attrs, recursive, text, **kwargs)
这里,我们通过在标签上添加约束来获取需要的标签列表,例如soup.find_all('p')是查找名为'p'的标签,而soup.find_all(class = "tittle" ) 就是查找所有class属性为"tittle"的标签,soup.find_all(class = pie('lass'))表示所有class属性中收录'lass'的标签。这里用到了正则表达式(可以自己学,很有用)
得到我们想要的所有标签的列表后,我们遍历这个列表,然后在标签中获取你需要的内容。通常我们需要标签的文字部分,也就是网页上显示的文字。代码如下:
tagList =soup.find_all(class="tittle")#如果标签比较复杂,可以使用多个过滤条件,使过滤更加严格
对于 tagList 中的标签:
打印标签文本
f.write (str(tag.text) )#将此信息写入本地文件以备后用
(2)find( name, attrs, recursive, text, **kwargs )
它和find_all()方法唯一的区别是find_all()方法的返回结果是一个收录一个元素的列表,而find()方法直接返回结果
(3)find_parents() find_parent( )
find_all() 和 find() 只搜索当前节点的所有子节点、孙节点等。
find_parents() 和 find_parent() 用于搜索当前节点的父节点,搜索方法与普通标签搜索方法相同,搜索文档搜索文档中收录的内容
(4)find_next_siblings() find_next_sibling()
这两个方法使用.next_siblings属性来推进所有后面解析的兄弟标签节点。 find_next_siblings() 方法返回所有满足条件的后续兄弟节点,而 find_next_sibling() 只返回满足条件的下一个兄弟节点。一个标签节点
(5)find_previous_siblings() find_previous_sibling()
这两个方法使用 .previous_siblings 属性来迭代当前标签之前解析的兄弟标签节点。 find_previous_siblings() 方法返回之前所有满足条件的兄弟节点, find_previous_sibling() 方法返回第一个满足条件的兄弟节点。兄弟节点
(6)find_all_next() find_next()
这两个方法使用 .next_elements 属性来迭代当前标签之后的标签和字符串。 find_all_next() 方法返回所有符合条件的节点, find_next() 方法返回第一个符合条件的节点
(7)find_all_previous() 和 find_previous()
这两个方法使用 .previous_elements 属性来迭代当前节点前面的标签和字符串。 find_all_previous() 方法返回所有符合条件的节点, find_previous() 方法返回第一个符合条件的节点。
实际代码示例:(抓取网页下的指定链接)
来自 bs4 小鬼
#htmltext
html_text=""
soup=BeautifulSoup(html_text,'html.parser')
a=soup.select('a')
for i in a:
如果 i.string=="关键词":
findb_ur=i['href']
#输出搜索a标签中的字符串得到的网页链接
# 打印(findb_url)
#findb_url="https:"+finburl
alist=soup.find_all('a)
对于 a 列表:
1.通过下标操作方法
href=a['href']
打印(htref)
2.通过attrs属性
href=a.attrs['href']
打印(href)
搜索指定网站内容提交你刚才搜的任何内容我刚刚试了
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-08-04 05:08
搜索指定网站内容提交账号,在【设置】>【联系方式】,填写。记得要用中文提交,还有你要问自己网站为什么要用,找几个网站来比较。
去百度知道提问会有大神告诉你的
百度搜索提交你刚才搜的任何的内容我刚刚试了的这个可以成功连接到百度知道上你去提交
三种方法,
一、qq搜索提交。更新至最新版qq,打开qq搜索提交,输入提问,找到当前页面。(这时候会有一个“显示全部”的按钮)每一个话题下都有一个“关注”的按钮。这时候就将所需要的内容复制链接地址粘贴到中间自定义框内点击确定提交。
二、关注、转发页面。点击热门话题页面的“转发”按钮。这时候会有两个话题页面“转发”、“加入知乎”。加入知乎页面是不会有链接地址的,都是转发链接地址。
三、微信端的搜索提交。点击微信端的搜索页面,选择“搜索话题”。在该话题页面输入提问关键词,在“自定义”提交内容。
使用手机的qq搜索提交
用微信的扫一扫提交,
qq扫一扫,在上图的输入框内输入刚才搜索出来的话题话题名称,
太巧了,我刚刚注册的账号,还没用,已经提交了。 查看全部
搜索指定网站内容提交你刚才搜的任何内容我刚刚试了
搜索指定网站内容提交账号,在【设置】>【联系方式】,填写。记得要用中文提交,还有你要问自己网站为什么要用,找几个网站来比较。
去百度知道提问会有大神告诉你的
百度搜索提交你刚才搜的任何的内容我刚刚试了的这个可以成功连接到百度知道上你去提交
三种方法,
一、qq搜索提交。更新至最新版qq,打开qq搜索提交,输入提问,找到当前页面。(这时候会有一个“显示全部”的按钮)每一个话题下都有一个“关注”的按钮。这时候就将所需要的内容复制链接地址粘贴到中间自定义框内点击确定提交。
二、关注、转发页面。点击热门话题页面的“转发”按钮。这时候会有两个话题页面“转发”、“加入知乎”。加入知乎页面是不会有链接地址的,都是转发链接地址。
三、微信端的搜索提交。点击微信端的搜索页面,选择“搜索话题”。在该话题页面输入提问关键词,在“自定义”提交内容。
使用手机的qq搜索提交
用微信的扫一扫提交,
qq扫一扫,在上图的输入框内输入刚才搜索出来的话题话题名称,
太巧了,我刚刚注册的账号,还没用,已经提交了。
之前屏蔽了百家号的垃圾网站,你知道吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-08-03 22:20
在阻止白家豪的泛滥之前,即便如此,还是有很多网站不希望自己的搜索结果出现在自己的搜索结果中。
比如一些垃圾新闻网站,搜索电子书下载,但是这个网站都跳转到了当当、京东或亚马逊的网站。
这些网站根本不是他们想要的,更不可能满足用户的需求,但他们长期占据搜索结果的首位,浪费了他们的时间和精力。尤其是一些垃圾新闻网站,读起来很恶心。
比如一些热点网站本身就是一些很难直接看到的生成内容。
这时候油猴脚本神级功能又来了。
按域划分的 Google Hit Hider(搜索过滤器/阻止站点)
在 Google 搜索结果中轻松隐藏不需要的域名
想要从 Google、DuckDuckGo、Bing 和 Yahoo 搜索结果中过滤掉一些无用的垃圾网站?只需单击“阻止”即可将网站 的匹配减少为单行符号,或将其完全隐藏。无需打字。
安装地址(必须安装油猴插件):/scripts/jscher2000/Google_Hit_Hider_by_Domain_(Search_Filter_Block_Sites)
在页面上阻止,就是这样。
__________________________________________________________________________________________
添加了一个新的油猴脚本,比上面的过滤更彻底。
上面那个,有些域还有残留,这个过滤器更好。
步骤同上,按照脚本:AC-baidu:重定向优化百度搜狗谷歌搜索_去AD_favicon_双列 查看全部
之前屏蔽了百家号的垃圾网站,你知道吗?
在阻止白家豪的泛滥之前,即便如此,还是有很多网站不希望自己的搜索结果出现在自己的搜索结果中。
比如一些垃圾新闻网站,搜索电子书下载,但是这个网站都跳转到了当当、京东或亚马逊的网站。
这些网站根本不是他们想要的,更不可能满足用户的需求,但他们长期占据搜索结果的首位,浪费了他们的时间和精力。尤其是一些垃圾新闻网站,读起来很恶心。
比如一些热点网站本身就是一些很难直接看到的生成内容。
这时候油猴脚本神级功能又来了。
按域划分的 Google Hit Hider(搜索过滤器/阻止站点)
在 Google 搜索结果中轻松隐藏不需要的域名
想要从 Google、DuckDuckGo、Bing 和 Yahoo 搜索结果中过滤掉一些无用的垃圾网站?只需单击“阻止”即可将网站 的匹配减少为单行符号,或将其完全隐藏。无需打字。
安装地址(必须安装油猴插件):/scripts/jscher2000/Google_Hit_Hider_by_Domain_(Search_Filter_Block_Sites)
在页面上阻止,就是这样。
__________________________________________________________________________________________
添加了一个新的油猴脚本,比上面的过滤更彻底。
上面那个,有些域还有残留,这个过滤器更好。
步骤同上,按照脚本:AC-baidu:重定向优化百度搜狗谷歌搜索_去AD_favicon_双列
Excel教程Excel函数代码如下()的详细内容
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-08-03 21:01
核心功能代码如下:
以上代码可以获取指定网页的内容,如果全部获取就更简单了
代码如下:
'ASP获取远程网页指定内容开始
Dim wstr,str,url,start,over,dtime
url="http://sc.jb51.net/"
wstr=getHTTPPage(url)
body=wstr
如果你想在本地保存代码
Dim wstr,str,url,start,over,dtime
url="https://www.jb51.net/"
wstr=getHTTPPage(url)
filename="index.htm"
if wstr"" and request("action")="makeindex" then
body=wstr
Set fso = Server.CreateObject("Scripting.FileSystemObject")
Set fout = fso.CreateTextFile(server.mappath(""&filename&""))
fout.Write body
fout.close
set fout=nothing
set fso=nothing
If Err.number=0 then
response.write("首页生成成功!!")
end if
end if
您可以根据需要修改详细信息。
以上是asp获取远程网页指定内容的实现代码的详细内容。更多获取远程网页内容的信息,请关注Script Home的其他相关文章! 查看全部
Excel教程Excel函数代码如下()的详细内容
核心功能代码如下:
以上代码可以获取指定网页的内容,如果全部获取就更简单了
代码如下:
'ASP获取远程网页指定内容开始
Dim wstr,str,url,start,over,dtime
url="http://sc.jb51.net/"
wstr=getHTTPPage(url)
body=wstr
如果你想在本地保存代码
Dim wstr,str,url,start,over,dtime
url="https://www.jb51.net/"
wstr=getHTTPPage(url)
filename="index.htm"
if wstr"" and request("action")="makeindex" then
body=wstr
Set fso = Server.CreateObject("Scripting.FileSystemObject")
Set fout = fso.CreateTextFile(server.mappath(""&filename&""))
fout.Write body
fout.close
set fout=nothing
set fso=nothing
If Err.number=0 then
response.write("首页生成成功!!")
end if
end if
您可以根据需要修改详细信息。
以上是asp获取远程网页指定内容的实现代码的详细内容。更多获取远程网页内容的信息,请关注Script Home的其他相关文章!
网站介绍关于如何免梯子看指定Ins账号的内容,它有多牛?
网站优化 • 优采云 发表了文章 • 0 个评论 • 541 次浏览 • 2021-08-02 01:04
网站简介
关于如何在没有梯子的情况下查看指定Ins账号的内容,文章昨天在《不用特殊网络也可以查看INS》一文中已经提到了。
但是仍然有一个问题摆在所有Instagram粉丝面前,那就是如何下载Instagram图片或视频并保存图片?抱歉,没有这样的选择!截屏?显然不是太高级。
这个大神网站今天免费使用,为你彻底解决Ins保存图片和视频的问题!有多厉害?
① 支持指定链接下载——你有一个想要下载的Ins链接,可以直接在搜索框中复制粘贴下载!
② 支持直接在线搜索账号下载——这个非常棒,比如你想下载邓紫棋的Instagram照片/视频,不需要爬梯子到邓紫棋的账号,直接在这里网站可以搜索邓紫棋直接下载!单个或批量下载都可以! (下图演示)
③ 支持批量下载——如果你想下载指定账号所有Instagram的图片和视频,可以直接用它搜索,一键直接批量下载!全部打包!
网站截图
“粘贴链接,搜索用户名”多功能搜索框
以下载“邓紫棋”ins照片/视频为例,可以直接搜索
《邓紫棋》ins,单次或批量下载都行!
(批量下载会下载所有视频和图片,并保存在压缩文件夹中!)
……………………
(本资源为VIP群分享,◉软件工具-神网站系列,仅供内部学习交流,不公开发售!)
点击成为VIP ☛一揽子获取本站所有资源+免费500T网盘群资源(涵盖考研/考试/国外期刊/知识付费平台等)+01专属搜索服务 查看全部
网站介绍关于如何免梯子看指定Ins账号的内容,它有多牛?
网站简介
关于如何在没有梯子的情况下查看指定Ins账号的内容,文章昨天在《不用特殊网络也可以查看INS》一文中已经提到了。
但是仍然有一个问题摆在所有Instagram粉丝面前,那就是如何下载Instagram图片或视频并保存图片?抱歉,没有这样的选择!截屏?显然不是太高级。
这个大神网站今天免费使用,为你彻底解决Ins保存图片和视频的问题!有多厉害?
① 支持指定链接下载——你有一个想要下载的Ins链接,可以直接在搜索框中复制粘贴下载!
② 支持直接在线搜索账号下载——这个非常棒,比如你想下载邓紫棋的Instagram照片/视频,不需要爬梯子到邓紫棋的账号,直接在这里网站可以搜索邓紫棋直接下载!单个或批量下载都可以! (下图演示)
③ 支持批量下载——如果你想下载指定账号所有Instagram的图片和视频,可以直接用它搜索,一键直接批量下载!全部打包!
网站截图
“粘贴链接,搜索用户名”多功能搜索框
以下载“邓紫棋”ins照片/视频为例,可以直接搜索
《邓紫棋》ins,单次或批量下载都行!
(批量下载会下载所有视频和图片,并保存在压缩文件夹中!)
……………………
(本资源为VIP群分享,◉软件工具-神网站系列,仅供内部学习交流,不公开发售!)
点击成为VIP ☛一揽子获取本站所有资源+免费500T网盘群资源(涵盖考研/考试/国外期刊/知识付费平台等)+01专属搜索服务
考研搜索结果不能得到理想结果时,怎么办?
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-07-31 01:20
1.站点:用于指定网站的站点搜索,适用于不完整的站点搜索网站。当直接站点搜索没有得到想要的结果时,尝试这种格式为关键词+blank+站点+:(英文)+目标搜索站点
例如:如果您想在知乎站搜索保健品,可以输入“保健品网站:”,搜索结果将是知乎中带有“保健品”信息的帖子和链接@站
图像.png
2.inurl:表示限制搜索结果的URL中收录的字段。
一大特色其实就是对上面指定站点搜索的补充。如果不知道网站的具体网址,可以用这个。
例如:
我想搜索文章关于“知识管理”,输入
Knowledge management inurl:知识管理
图像.png
3.filetype:搜索指定类型的文件
非常适合搜索专业文档。
filetype:pdf(可替换为任何文件格式后缀,如doc、jpg)
我想搜索关于“问题”的书籍,输入“问题文件类型:pdf”,如果你认为问题关键词的范围不够,添加其他限定词“问题和艺术文件类型:pdf”
图像.png
4.intitle:表示限制搜索标题的内容,即标题必须收录有限的关键词格式
关键词+blank+intitle:+required 关键词我要搜索今年考研放弃率,输入“放弃率intitle:2019考研”
图像.png
5. 时间1..时间2 表示限制搜索结果的时间范围关键词+blank+20xx+..+20xx
以上场景为例。我要搜索今年考研弃考率,输入“考研与弃考统计2018..2019”,
图像.png
如果对搜索结果不满意,可以根据下级逻辑任意改写关键词。
-----------------------关键词Logic Division Line----------------- -------------------------------------------------- -------
和
AND 用于检索两个以上的关键词,搜索结果必须与这些关键词相关。 AND 一些搜索引擎也可以用“+”表示
关键词+Space+AND+关键词
如前文《高考和弃考统计》
或
表示逻辑“或”,有些搜索引擎使用“|” (竖线)来表示。搜索结果只需要关联多个关键词之一即可。
不是
NOT 表示逻辑“不”,或“-”减号表示,有些搜索引擎也使用“!”表示。
这个逻辑貌似百度不好用。我还是以搜索知识管理必读清单为例。我想过滤掉广告或促销输入“知识管理+必读促销”。结果如下所示。 . . . . .
图像.png 查看全部
考研搜索结果不能得到理想结果时,怎么办?
1.站点:用于指定网站的站点搜索,适用于不完整的站点搜索网站。当直接站点搜索没有得到想要的结果时,尝试这种格式为关键词+blank+站点+:(英文)+目标搜索站点
例如:如果您想在知乎站搜索保健品,可以输入“保健品网站:”,搜索结果将是知乎中带有“保健品”信息的帖子和链接@站
图像.png
2.inurl:表示限制搜索结果的URL中收录的字段。
一大特色其实就是对上面指定站点搜索的补充。如果不知道网站的具体网址,可以用这个。
例如:
我想搜索文章关于“知识管理”,输入
Knowledge management inurl:知识管理
图像.png
3.filetype:搜索指定类型的文件
非常适合搜索专业文档。
filetype:pdf(可替换为任何文件格式后缀,如doc、jpg)
我想搜索关于“问题”的书籍,输入“问题文件类型:pdf”,如果你认为问题关键词的范围不够,添加其他限定词“问题和艺术文件类型:pdf”
图像.png
4.intitle:表示限制搜索标题的内容,即标题必须收录有限的关键词格式
关键词+blank+intitle:+required 关键词我要搜索今年考研放弃率,输入“放弃率intitle:2019考研”
图像.png
5. 时间1..时间2 表示限制搜索结果的时间范围关键词+blank+20xx+..+20xx
以上场景为例。我要搜索今年考研弃考率,输入“考研与弃考统计2018..2019”,
图像.png
如果对搜索结果不满意,可以根据下级逻辑任意改写关键词。
-----------------------关键词Logic Division Line----------------- -------------------------------------------------- -------
和
AND 用于检索两个以上的关键词,搜索结果必须与这些关键词相关。 AND 一些搜索引擎也可以用“+”表示
关键词+Space+AND+关键词
如前文《高考和弃考统计》
或
表示逻辑“或”,有些搜索引擎使用“|” (竖线)来表示。搜索结果只需要关联多个关键词之一即可。
不是
NOT 表示逻辑“不”,或“-”减号表示,有些搜索引擎也使用“!”表示。
这个逻辑貌似百度不好用。我还是以搜索知识管理必读清单为例。我想过滤掉广告或促销输入“知识管理+必读促销”。结果如下所示。 . . . . .
图像.png
360搜索对Robots协议的善意使用协议文件的扩展
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-07-31 01:20
360搜索将优先使用好搜蜘蛛访问网站。如果遇到UA识别无法下载页面,则使用360spider重新抓取,蜘蛛IP不会改变。
允许
站长可以通过Allow命令指定收录建议的文件和目录。
禁止
站长可以使用 Disallow 命令指定不推荐用于收录 的文件和目录。
机器人协议的 360 搜索扩展
360 搜索将根据网站站长的反馈继续推出扩展机器人协议命令。这些命令将帮助站长提高与360搜索爬虫的通信效率,降低站长维护Robots协议文档的技术成本。
360搜索的第一个扩展命令是indexpage。站长们可以用这个命令告诉360去搜索哪些经常更新的页面。 360搜索会根据站长指令和自身算法智能调整爬虫爬取频率,实现对网站新内容的更高频率爬取。
命令中可以使用*和$等通配符。
示例:
使用通配符
Indexpage: http://bbs.360safe.com/forum-*-1.html$
Indexpage: http://ent.sina.com.cn/*/roll.html
没有通配符:
Indexpage: http://roll.tech.sina.com.cn/i ... shtml
Indexpage: http://roll.tech.sina.com.cn/it/index.shtml
Indexpage: http://roll.tech.sina.com.cn/tele/index.shtml
Indexpage: http://roll.tech.sina.com.cn/discovery/index.shtml
Indexpage: http://roll.tech.sina.com.cn/elec/index.shtml
善意使用机器人协议
机器人协议是搜索引擎与网站 之间的善意协议。我们鼓励网站管理员善意使用本协议,并尽量提供准确的信息。除非有充分的理由,否则不要使用Robots协议来屏蔽某些特定的搜索引擎爬虫。
360 搜索愿与站长一起,共建更健康、公平、透明的搜索引擎生态。 查看全部
360搜索对Robots协议的善意使用协议文件的扩展
360搜索将优先使用好搜蜘蛛访问网站。如果遇到UA识别无法下载页面,则使用360spider重新抓取,蜘蛛IP不会改变。
允许
站长可以通过Allow命令指定收录建议的文件和目录。
禁止
站长可以使用 Disallow 命令指定不推荐用于收录 的文件和目录。
机器人协议的 360 搜索扩展
360 搜索将根据网站站长的反馈继续推出扩展机器人协议命令。这些命令将帮助站长提高与360搜索爬虫的通信效率,降低站长维护Robots协议文档的技术成本。
360搜索的第一个扩展命令是indexpage。站长们可以用这个命令告诉360去搜索哪些经常更新的页面。 360搜索会根据站长指令和自身算法智能调整爬虫爬取频率,实现对网站新内容的更高频率爬取。
命令中可以使用*和$等通配符。
示例:
使用通配符
Indexpage: http://bbs.360safe.com/forum-*-1.html$
Indexpage: http://ent.sina.com.cn/*/roll.html
没有通配符:
Indexpage: http://roll.tech.sina.com.cn/i ... shtml
Indexpage: http://roll.tech.sina.com.cn/it/index.shtml
Indexpage: http://roll.tech.sina.com.cn/tele/index.shtml
Indexpage: http://roll.tech.sina.com.cn/discovery/index.shtml
Indexpage: http://roll.tech.sina.com.cn/elec/index.shtml
善意使用机器人协议
机器人协议是搜索引擎与网站 之间的善意协议。我们鼓励网站管理员善意使用本协议,并尽量提供准确的信息。除非有充分的理由,否则不要使用Robots协议来屏蔽某些特定的搜索引擎爬虫。
360 搜索愿与站长一起,共建更健康、公平、透明的搜索引擎生态。
李开复:支付宝是天然的收钱的,所以方便啊
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-07-30 06:04
搜索指定网站内容时跳转至广告页,又有支付又有积分的,你们想太多。
今年冬天李开复老师和百度外卖时间长谈过这个问题,他说百度更多提供免费的网络服务,而支付宝提供的支付功能要比百度方便简单的多。
a、百度更适合内容生产者,例如自媒体、卖课程的在线讲师。b、支付宝更适合卖东西和卖服务。
现在的情况就是如此,支付宝是天然的收钱的收钱的,所以方便啊,如果百度主动向你提供这一项服务还需要他赚钱才会提供给你用,天然就在你不小心输错了的时候,
支付宝有足够的钱存款可以搞投放广告,
到手的是现金,广告费,还有服务费,和收钱的人。
要说差异的话,其实不太大。支付宝的平台就是个广告平台。不过肯定比搜索界面更简洁(反正我是没找到比搜索界面更简洁的网站了),而且界面和搜索时候的结果类似,一个大概方向,搜索更便捷。但是不会比直接下拉有更多更好的内容。我的搜索分区也不方便。还有个优势,是余额,好多在支付宝买东西的人会把余额转到余额宝里面去。
从服务上来说,这俩差别不大,都有支付宝账号,也都叫百度银行,有付款功能,都没有广告,结果不会有差别吧。
真的不大, 查看全部
李开复:支付宝是天然的收钱的,所以方便啊
搜索指定网站内容时跳转至广告页,又有支付又有积分的,你们想太多。
今年冬天李开复老师和百度外卖时间长谈过这个问题,他说百度更多提供免费的网络服务,而支付宝提供的支付功能要比百度方便简单的多。
a、百度更适合内容生产者,例如自媒体、卖课程的在线讲师。b、支付宝更适合卖东西和卖服务。
现在的情况就是如此,支付宝是天然的收钱的收钱的,所以方便啊,如果百度主动向你提供这一项服务还需要他赚钱才会提供给你用,天然就在你不小心输错了的时候,
支付宝有足够的钱存款可以搞投放广告,
到手的是现金,广告费,还有服务费,和收钱的人。
要说差异的话,其实不太大。支付宝的平台就是个广告平台。不过肯定比搜索界面更简洁(反正我是没找到比搜索界面更简洁的网站了),而且界面和搜索时候的结果类似,一个大概方向,搜索更便捷。但是不会比直接下拉有更多更好的内容。我的搜索分区也不方便。还有个优势,是余额,好多在支付宝买东西的人会把余额转到余额宝里面去。
从服务上来说,这俩差别不大,都有支付宝账号,也都叫百度银行,有付款功能,都没有广告,结果不会有差别吧。
真的不大,
如何搜索特定的网站内容
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-07-29 01:18
语法格式:
网站:网址关键词
或关键词站点:网址
注意事项:
1、site:后面的冒号必须是英文“:”,中文全角冒号“:”没用
2、url 之前不能带
3、url 后面不能接斜线“/”,其实哪里都用不了。
不要在4、url 中使用 www,除非你有特殊目的,
使用www会导致网站中的内容被漏掉,因为很多网站频道没有www。
其他说明:
1、关键词可以在“site:”之前,也可以在“site:”之后,搜索结果是一样的
但无论谁在前或后,关键词和“site:”之间都必须有一个空格。 2、对于“site:”搜索,可以有多个关键词,多个关键词之间用空格隔开
3、支持与其他复杂搜索语法混合使用,每个语法和关键词之间有一个空格
4、 除了网站,您还可以搜索网站 频道,但仅限于不使用“/”的频道。
5、一个网站可能有多种语言,
选择“搜索所有网站”和“搜索中文(简体)网页”有区别
当然,如果指定的网站只有一种语言,如何选择是一样的
目的:
1、 可用于限制网站 类型。学术资料在edu和org上会更精细,政府相关信息可能在gov上更容易找到。
2、使用edu、org、net、gov等域名后缀,不会搜索所有带有这个后缀的网站。
只搜索网站以这个后缀结尾,edu.jp带有cn、us、si等国家和地区域名后缀,
gov.us、org.it等都没有搜索到,所以要单独搜索
3、在指定国家搜索某种语言或某个关键词网站
4、有的网站不提供站点搜索,或者其信息结构混乱,内容太多,找东西困难,
然后你可以使用“site:”来搜索这个网站。
谷歌的“站点:”功能比大多数网站自己的站点搜索要好,如果你发现它不是
动态数据库,时效要求不高。
5、search 不欢迎您免费搜索和使用网站,数据库的一部分
6、使用“site:”搜索死链接网站,网站关闭信息
示例:
打开
输入:网站:百度知道
输入:百度百度知道
输入:百度知道
我知道这三者之间的区别。 查看全部
如何搜索特定的网站内容
语法格式:
网站:网址关键词
或关键词站点:网址
注意事项:
1、site:后面的冒号必须是英文“:”,中文全角冒号“:”没用
2、url 之前不能带
3、url 后面不能接斜线“/”,其实哪里都用不了。
不要在4、url 中使用 www,除非你有特殊目的,
使用www会导致网站中的内容被漏掉,因为很多网站频道没有www。
其他说明:
1、关键词可以在“site:”之前,也可以在“site:”之后,搜索结果是一样的
但无论谁在前或后,关键词和“site:”之间都必须有一个空格。 2、对于“site:”搜索,可以有多个关键词,多个关键词之间用空格隔开
3、支持与其他复杂搜索语法混合使用,每个语法和关键词之间有一个空格
4、 除了网站,您还可以搜索网站 频道,但仅限于不使用“/”的频道。
5、一个网站可能有多种语言,
选择“搜索所有网站”和“搜索中文(简体)网页”有区别
当然,如果指定的网站只有一种语言,如何选择是一样的
目的:
1、 可用于限制网站 类型。学术资料在edu和org上会更精细,政府相关信息可能在gov上更容易找到。
2、使用edu、org、net、gov等域名后缀,不会搜索所有带有这个后缀的网站。
只搜索网站以这个后缀结尾,edu.jp带有cn、us、si等国家和地区域名后缀,
gov.us、org.it等都没有搜索到,所以要单独搜索
3、在指定国家搜索某种语言或某个关键词网站
4、有的网站不提供站点搜索,或者其信息结构混乱,内容太多,找东西困难,
然后你可以使用“site:”来搜索这个网站。
谷歌的“站点:”功能比大多数网站自己的站点搜索要好,如果你发现它不是
动态数据库,时效要求不高。
5、search 不欢迎您免费搜索和使用网站,数据库的一部分
6、使用“site:”搜索死链接网站,网站关闭信息
示例:
打开
输入:网站:百度知道
输入:百度百度知道
输入:百度知道
我知道这三者之间的区别。
油猴脚本神级功能又来了,你知道吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-07-26 00:05
在阻止白家豪的泛滥之前,即便如此,还是有很多网站不希望自己的搜索结果出现在自己的搜索结果中。
比如一些垃圾新闻网站,搜索电子书下载,但是这个网站都跳转到了当当、京东或亚马逊的网站。
这些网站根本不是他们想要的,更不可能满足用户的需求,但他们长期占据搜索结果的首位,浪费了他们的时间和精力。尤其是一些垃圾新闻网站,读起来很恶心。
比如一些热点网站本身就是一些很难直接看到的生成内容。
这时候油猴脚本神级功能又来了。
按域划分的 Google Hit Hider(搜索过滤器/阻止站点)
在 Google 搜索结果中轻松隐藏不需要的域名
想要从 Google、DuckDuckGo、Bing 和 Yahoo 搜索结果中过滤掉一些无用的垃圾网站?只需单击“阻止”即可将网站 的匹配减少为单行符号,或将其完全隐藏。无需打字。
安装地址(必须安装油猴插件):/scripts/jscher2000/Google_Hit_Hider_by_Domain_(Search_Filter_Block_Sites)
在页面上阻止,就是这样。
如何屏蔽百度不想在搜索引擎中看到的搜索结果
__________________________________________________________________________________________
添加了一个新的油猴脚本,比上面的过滤更彻底。
上面那个,有些域还有残留,这个过滤器更好。
步骤同上,按照脚本:AC-baidu:重定向优化百度搜狗谷歌搜索_去AD_favicon_双列 查看全部
油猴脚本神级功能又来了,你知道吗?
在阻止白家豪的泛滥之前,即便如此,还是有很多网站不希望自己的搜索结果出现在自己的搜索结果中。
比如一些垃圾新闻网站,搜索电子书下载,但是这个网站都跳转到了当当、京东或亚马逊的网站。
这些网站根本不是他们想要的,更不可能满足用户的需求,但他们长期占据搜索结果的首位,浪费了他们的时间和精力。尤其是一些垃圾新闻网站,读起来很恶心。
比如一些热点网站本身就是一些很难直接看到的生成内容。
这时候油猴脚本神级功能又来了。
按域划分的 Google Hit Hider(搜索过滤器/阻止站点)
在 Google 搜索结果中轻松隐藏不需要的域名
想要从 Google、DuckDuckGo、Bing 和 Yahoo 搜索结果中过滤掉一些无用的垃圾网站?只需单击“阻止”即可将网站 的匹配减少为单行符号,或将其完全隐藏。无需打字。
安装地址(必须安装油猴插件):/scripts/jscher2000/Google_Hit_Hider_by_Domain_(Search_Filter_Block_Sites)
在页面上阻止,就是这样。
如何屏蔽百度不想在搜索引擎中看到的搜索结果
__________________________________________________________________________________________
添加了一个新的油猴脚本,比上面的过滤更彻底。
上面那个,有些域还有残留,这个过滤器更好。
步骤同上,按照脚本:AC-baidu:重定向优化百度搜狗谷歌搜索_去AD_favicon_双列
intitle搜索范围限定在网页标题搜索站点中的应用
网站优化 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-07-26 00:04
intitle 的搜索范围仅限于页面标题
网站搜索范围仅限于特定网站
如果您知道某个站点有需要查找的内容,您可以将搜索范围限制在该站点以提高查询效率。
例如:百度视频网站:
不要在“site:”后面的站点域名中收录“”。请勿在 site: 和网站名称之间放置空格。
inurl的搜索范围仅限于url链接
网页 URL 中的某些信息通常具有一些有价值的含义。如果对搜索结果的网址进行一定程度的限制,可以获得不错的结果。
例如:Ben Xi inurl:music
查询词“本喜”可以出现在网页的任何位置,而“音乐”则必须出现在网页网址中。
双引号""和书名""完全匹配
查询词中的双引号“”表示查询词不能拆分,必须完整出现在搜索结果中,并且可以与查询词完全匹配。如果不加双引号,百度分析后可能会拆分""。
查询词加题号“”有两个特殊功能。一是在搜索结果中会出现题号;另一个是标题号扩展的内容不会被拆分。在某些情况下,标题编号特别有效。例如,查询词是手机。如果不加标题号,通讯工具手机很多情况下会出来。加上片名后,“电脑”的结果都是关于电影的。
-没有特定的查询词
带有减号语法的查询词可以帮助您从搜索结果中排除所有收录特定关键词 的网页。
示例:电影 -qvod
查询词“电影”在搜索结果中,“qvod”从搜索结果中排除。
+包括特定的查询词
对查询词使用加号+语法可以帮助您在搜索结果中收录特定的关键词所有网页。
示例:电影 +qvod
查询词“电影”在搜索结果中,搜索结果中必须收录“qvod”。
文件类型搜索范围仅限于指定的文档格式
可以使用 Filetype 语法限制查询词出现在指定的文档中。支持的文档格式有pdf、doc、xls、ppt、rtf、all(以上所有文档格式)。对查找文档非常有帮助。
示例:Photoshop 实用技巧 filetype:doc
查看全部
intitle搜索范围限定在网页标题搜索站点中的应用
intitle 的搜索范围仅限于页面标题
网站搜索范围仅限于特定网站
如果您知道某个站点有需要查找的内容,您可以将搜索范围限制在该站点以提高查询效率。
例如:百度视频网站:
不要在“site:”后面的站点域名中收录“”。请勿在 site: 和网站名称之间放置空格。
inurl的搜索范围仅限于url链接
网页 URL 中的某些信息通常具有一些有价值的含义。如果对搜索结果的网址进行一定程度的限制,可以获得不错的结果。
例如:Ben Xi inurl:music
查询词“本喜”可以出现在网页的任何位置,而“音乐”则必须出现在网页网址中。
双引号""和书名""完全匹配
查询词中的双引号“”表示查询词不能拆分,必须完整出现在搜索结果中,并且可以与查询词完全匹配。如果不加双引号,百度分析后可能会拆分""。
查询词加题号“”有两个特殊功能。一是在搜索结果中会出现题号;另一个是标题号扩展的内容不会被拆分。在某些情况下,标题编号特别有效。例如,查询词是手机。如果不加标题号,通讯工具手机很多情况下会出来。加上片名后,“电脑”的结果都是关于电影的。
-没有特定的查询词
带有减号语法的查询词可以帮助您从搜索结果中排除所有收录特定关键词 的网页。
示例:电影 -qvod
查询词“电影”在搜索结果中,“qvod”从搜索结果中排除。
+包括特定的查询词
对查询词使用加号+语法可以帮助您在搜索结果中收录特定的关键词所有网页。
示例:电影 +qvod
查询词“电影”在搜索结果中,搜索结果中必须收录“qvod”。
文件类型搜索范围仅限于指定的文档格式
可以使用 Filetype 语法限制查询词出现在指定的文档中。支持的文档格式有pdf、doc、xls、ppt、rtf、all(以上所有文档格式)。对查找文档非常有帮助。
示例:Photoshop 实用技巧 filetype:doc
Google不推荐使用的命令语法,你知道几个?
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-07-23 19:40
以下是目前所有的谷歌搜索命令语法,与谷歌的帮助文档不同,因为它引入了几个谷歌不推荐的命令语法。大多数谷歌搜索命令语法都有其独特的格式,希望你能正确使用。我用不同的颜色标记了不同的语法命令。绿色的是比较常用的命令,黄色的是不常用但非常有用的命令,蓝色的是谷歌不推荐的。
<p>allinanchor:anchor是描述性文字,表示此链接可能跳转到其他网页或跳转到当前网页的不同位置。当我们使用 allinanchor 提交查询时,Google 会将搜索结果限制在锚文本中收录我们所有查询 关键词 的那些网页。例如,[allinanchor: bestmuseums Sydney],如果您提交此查询,Google 将仅返回网页的锚点描述文本中收录关键词“best”“museums”和“Sydney”的网页。 查看全部
Google不推荐使用的命令语法,你知道几个?
以下是目前所有的谷歌搜索命令语法,与谷歌的帮助文档不同,因为它引入了几个谷歌不推荐的命令语法。大多数谷歌搜索命令语法都有其独特的格式,希望你能正确使用。我用不同的颜色标记了不同的语法命令。绿色的是比较常用的命令,黄色的是不常用但非常有用的命令,蓝色的是谷歌不推荐的。
<p>allinanchor:anchor是描述性文字,表示此链接可能跳转到其他网页或跳转到当前网页的不同位置。当我们使用 allinanchor 提交查询时,Google 会将搜索结果限制在锚文本中收录我们所有查询 关键词 的那些网页。例如,[allinanchor: bestmuseums Sydney],如果您提交此查询,Google 将仅返回网页的锚点描述文本中收录关键词“best”“museums”和“Sydney”的网页。
3Un企业网站模板免费下载_网站建设方案()
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-07-23 19:23
我们通常有一些需求,就是根据用户定义的新字段搜索内容,然后通过下拉选择我们需要的搜索。下面我将介绍以下步骤: 3Un企业网站Template 免费下载_网站Build_企业网站建计划
3UnEnterprise网站Template 免费下载_网站建筑_企业网站建筑计划
进入后台-内容模型管理-管理下有一个放大镜图标,点进去,可以设置自定义搜索。如下图:3Un企业网站Template 免费下载_网站建筑_企业网站建筑计划
3UnEnterprise网站Template 免费下载_网站建筑_企业网站建筑计划
3UnEnterprise网站Template 免费下载_网站建筑_企业网站建筑计划
这个自定义搜索管理分为五个部分,一个是频道ID,一个是频道名称。你不需要担心这两个。选择所需字段后,单击“确定”。那么参考代码会在下面出来。如下图:3Un企业网站Template 免费下载_网站建筑_企业网站建筑计划
3UnEnterprise网站Template 免费下载_网站建筑_企业网站建筑计划
然后我们根据参考代码写出我们对应的模板,基本就大功告成了。 3Un企业网站Template 免费下载_网站建筑_企业网站建筑计划
织梦自收录的搜索结果模板很丑。当然,您也可以更改模板的样式。文件在templates/default/advancedsearch.htm3UnEnterprise网站Templates 免费下载_网站建筑_企业网站施工方案
()
上一篇:织梦dedecms后台响应慢,经常卡死的解决方法
下一篇:德德短标题字数限制修改 查看全部
3Un企业网站模板免费下载_网站建设方案()
我们通常有一些需求,就是根据用户定义的新字段搜索内容,然后通过下拉选择我们需要的搜索。下面我将介绍以下步骤: 3Un企业网站Template 免费下载_网站Build_企业网站建计划
3UnEnterprise网站Template 免费下载_网站建筑_企业网站建筑计划
进入后台-内容模型管理-管理下有一个放大镜图标,点进去,可以设置自定义搜索。如下图:3Un企业网站Template 免费下载_网站建筑_企业网站建筑计划
3UnEnterprise网站Template 免费下载_网站建筑_企业网站建筑计划
3UnEnterprise网站Template 免费下载_网站建筑_企业网站建筑计划
这个自定义搜索管理分为五个部分,一个是频道ID,一个是频道名称。你不需要担心这两个。选择所需字段后,单击“确定”。那么参考代码会在下面出来。如下图:3Un企业网站Template 免费下载_网站建筑_企业网站建筑计划
3UnEnterprise网站Template 免费下载_网站建筑_企业网站建筑计划
然后我们根据参考代码写出我们对应的模板,基本就大功告成了。 3Un企业网站Template 免费下载_网站建筑_企业网站建筑计划
织梦自收录的搜索结果模板很丑。当然,您也可以更改模板的样式。文件在templates/default/advancedsearch.htm3UnEnterprise网站Templates 免费下载_网站建筑_企业网站施工方案
()
上一篇:织梦dedecms后台响应慢,经常卡死的解决方法
下一篇:德德短标题字数限制修改
如何使用Robots.txt.文件的使用方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-07-21 20:44
Robots.txt 是存储在站点根目录中的纯文本文件。虽然它的设置很简单,但是它的效果却非常强大。可以指定搜索引擎蜘蛛只抓取指定的内容,或者禁止搜索引擎蜘蛛抓取网站的部分或全部。
使用方法:
Robots.txt 文件应该放在网站root 目录下,该文件可以通过互联网访问。
例如:如果你的网站地址是那个,那么文件必须能够打开并看到里面的内容。
格式:
用户代理:
用于描述搜索引擎蜘蛛的名称。在“Robots.txt”文件中,如果有多个User-agent记录,则意味着多个搜索引擎蜘蛛会受到协议的限制。对于这个文件,至少必须有一个 User-agent 记录。如果此项的值设置为*,则该协议对任何搜索引擎蜘蛛都有效。在“Robots.txt”文件中,只能有“User-agent:*”等一条记录。
禁止:
用于描述您不想访问的 URL。此 URL 可以是完整路径或其中的一部分。 Robot 不会访问任何以 Disallow 开头的 URL。
示例:
示例 1:“Disallow:/help”表示不允许搜索引擎蜘蛛抓取 /help.html 和 /help/index.html。
示例2:“Disallow:/help/”表示允许搜索引擎蜘蛛抓取/help.html,但不允许抓取/help/index.html。
例3:如果Disallow记录为空,表示该网站的所有页面都允许被搜索引擎抓取。 “/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”为空文件,对于所有搜索引擎蜘蛛来说,网站是开放的,可以被抓取。
#:Robots.txt 协议中的注释字符。
综合示例:
示例1:使用“/robots.txt”禁止所有搜索引擎蜘蛛抓取“/bin/cgi/”目录、“/tmp/”目录和/foo.html文件,设置方法为如下:
用户代理:*
禁止:/bin/cgi/
禁止:/tmp/
禁止:/foo.html
示例2:通过“/robots.txt”,只允许一个搜索引擎抓取,禁止其他搜索引擎抓取。例如,只允许名为“slurp”的搜索引擎蜘蛛抓取,不允许其他搜索引擎蜘蛛抓取“/cgi/”目录下的内容。设置方法如下:
用户代理:*
禁止:/cgi/
用户代理:slurp
禁止:
示例3:禁止任何搜索引擎抓取我的网站,设置方法如下:
用户代理:*
禁止:/
例4:只禁止某个搜索引擎爬取我的网站 如:只禁止名为“slurp”的搜索引擎蜘蛛爬取,设置方法如下:
用户代理:slurp
禁止:/
更多参考资料(英文版) 查看全部
如何使用Robots.txt.文件的使用方法
Robots.txt 是存储在站点根目录中的纯文本文件。虽然它的设置很简单,但是它的效果却非常强大。可以指定搜索引擎蜘蛛只抓取指定的内容,或者禁止搜索引擎蜘蛛抓取网站的部分或全部。
使用方法:
Robots.txt 文件应该放在网站root 目录下,该文件可以通过互联网访问。
例如:如果你的网站地址是那个,那么文件必须能够打开并看到里面的内容。
格式:
用户代理:
用于描述搜索引擎蜘蛛的名称。在“Robots.txt”文件中,如果有多个User-agent记录,则意味着多个搜索引擎蜘蛛会受到协议的限制。对于这个文件,至少必须有一个 User-agent 记录。如果此项的值设置为*,则该协议对任何搜索引擎蜘蛛都有效。在“Robots.txt”文件中,只能有“User-agent:*”等一条记录。
禁止:
用于描述您不想访问的 URL。此 URL 可以是完整路径或其中的一部分。 Robot 不会访问任何以 Disallow 开头的 URL。
示例:
示例 1:“Disallow:/help”表示不允许搜索引擎蜘蛛抓取 /help.html 和 /help/index.html。
示例2:“Disallow:/help/”表示允许搜索引擎蜘蛛抓取/help.html,但不允许抓取/help/index.html。
例3:如果Disallow记录为空,表示该网站的所有页面都允许被搜索引擎抓取。 “/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”为空文件,对于所有搜索引擎蜘蛛来说,网站是开放的,可以被抓取。
#:Robots.txt 协议中的注释字符。
综合示例:
示例1:使用“/robots.txt”禁止所有搜索引擎蜘蛛抓取“/bin/cgi/”目录、“/tmp/”目录和/foo.html文件,设置方法为如下:
用户代理:*
禁止:/bin/cgi/
禁止:/tmp/
禁止:/foo.html
示例2:通过“/robots.txt”,只允许一个搜索引擎抓取,禁止其他搜索引擎抓取。例如,只允许名为“slurp”的搜索引擎蜘蛛抓取,不允许其他搜索引擎蜘蛛抓取“/cgi/”目录下的内容。设置方法如下:
用户代理:*
禁止:/cgi/
用户代理:slurp
禁止:
示例3:禁止任何搜索引擎抓取我的网站,设置方法如下:
用户代理:*
禁止:/
例4:只禁止某个搜索引擎爬取我的网站 如:只禁止名为“slurp”的搜索引擎蜘蛛爬取,设置方法如下:
用户代理:slurp
禁止:/
更多参考资料(英文版)
如何做好口碑营销?
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-07-16 02:26
石家庄指定关键词快速排名哪个更好[de39bkw]
是石家庄地区一家专注于网站建设和推广的公司。科技为本是网站建设的指导思想,诚信经营是对客户永恒的承诺。创和网络致力于互联网品牌建设和网络营销。
我们的服务项目包括企业网站建设推广、百万字网推广、软件开发、全网营销推广系统、小程序、产品流词优化、按效果付费等。
立足石家庄,为中小企业提供专业服务,为当地热门行业提供有效的推广和运营策略。每个行业都有一批SEO优化成功案例,可以查询。
网站空间只有购买网站construction软件才能使用。所需空间取决于您购买的网站 软件。具体的网站 取决于您选择如何构建网站。如果您将外包给网站公司,则无需管理所有内容。如果您构建自己的软件,则需要软件空间要求。 网站空间支持什么样的网站编程语言?空间的表现是什么?都是需要考虑的问题。最后,空间必须快。如果上面的域名和空间问题已经很好的解决了。下一个核心部分是网站的制作。
搜索引擎,关键词,排名。搜索引擎营销是目前有效的营销方式之一。现在的网民,如果要买东西,他们会去搜索引擎搜索有关产品的信息。因此,一些高价值的商业关键词价格极高,甚至达到每次点击十元以上。如果你想推广产品,你应该考虑使用搜索引擎来销售。当然也可以使用SEO或者百度竞价排名等等。建立口碑营销。口碑营销是一种有效且廉价的营销方式。但是这种方式做起来并不容易,这涉及到网站的方方面面。口碑营销并不总是在我们的日常生活中进行。那么我们如何进行口碑营销呢?不想当编辑,一天写很多文章,没有发展和前途。
我们是一个追求品质、不断超越自我的团队。每个成员也是亲密的伙伴,与公司共同成长和发展。我们尊重每一次合作的机遇和挑战,精益求精,精益求精。团队秉承专注、专业的设计服务思维,让客户通过设计发挥产品价值,探索无限可能。热爱设计,坚信设计的力量让我们不断前进......
速度。 网站的访问速度也很重要,所以我把它排在第三。你为什么这么说?前两个还不够。用户打开网站需要1分钟或更长时间才能正常访问网站,我想估计到最后我不会关掉你的网站,时间花在关掉你的网站上,用户体验就是你的网站。在线体验不流畅快速滴滴,那还不关掉还等什么?总之,时间就是金钱。服务。 网站 不仅是公司或个人的在线门面,也是重要的营销工具。互联网为公司或个人向用户介绍产品或服务提供了理想的媒介。当用户对某个产品感兴趣时,可以将网站理解为销售人员,并在此基础上向用户介绍其他相关产品、升级产品、配套产品。关键是要有专人为客户解答问题,及时反馈客户信息,与用户形成及时沟通。
很多人在做SEO优化的时候都听过一个词,就是网站聚页,具体指什么?官方解释为:聚合页面是指网站根据某个主题或关键词将原来的文章重新排列成一个新的列表或主题页面。聚合页面的初衷是为了方便用户对相同内容的延伸阅读。对SEO的影响是可以快速获得排名和流量,也可以快速得到搜索引擎的青睐。
自己搭建网站时,要注意内容的新鲜度。现在的网络共享和很多专业的千篇一律的效果,让很多企业网站基本上千人,让很多网站内容觉得一点特色都没有。 ,这样的网站怎么能吸引顾客呢?所以,要想吸引用户,就要让网站有自己的特色。在内容文字和网站planning和网页布局中构建网站时,要给客户一个共同的新鲜感,让他们的用户感受到自己的网站Attractive。在当时的技术条件下,构建网站比较容易,功能也比较短。但是,随着网站技术的不断更新和新功能的推出,原来的网站已经很难满足网站公司的需求了。另一个方面没有精心策划,但网站很容易建立。后期为了给网络添加图文,如果重新创建一个网站,那么选择网站策划公司是第一重要的事情。
石家庄指定关键词quick排名哪个更好
网络秉承“帮助中小企业实现网络营销”的宗旨,通过专业的网站服务,提升客户品牌价值,一站式网络营销服务,帮助客户提升销量;坚持做有价值的网络推广。
MWordba 屏幕的原理是什么? WWordba Screen是和一些高权重的平台合作,依托平台收录页面,然后利用平台目录的url做js覆盖,镜像一个官网,快速推送客户的网站到百度首页实现排名和占据位置的效果。操作和实际效果一样,首页一次上千个关键词,或者全搜索。客户付款后,基本可以达到预期效果,不退还。一家精心打造的公司,每天处理数百个流量是没有问题的。与传统seo优化相比,WWordba Screen的优势在于与平台的合作周期短,1-7天时间word会up。传统的 SEO 优化需要大约三个月的时间。
网站建设初期,一直想着需要一些功能来提升网站的整体效果,这也符合客户对网站的需求。然而,没想到的是网站 需要功能性,但更方便。很多公司可能想增加会员功能、支付系统、不同栏目效果的功能,但是没有想到搜索框、返回顶部、图片放大等详细功能。只考虑大方向而忽略小细节可能会降低网站的运营效果。糟糕的客户体验会影响转化率的提升。当网站的内容越来越多,翻页不方便;当网页内容比较长时,浏览至底部时必须再次滚动至顶部,以增加操作流程。因此,在施工过程中必须有适当的规划。在考虑主要功能的同时,还要考虑客户的使用体验,提供合适的便利功能对他们会更加友好。
TDK 标签的处理。虽然这是seo知识中最基础的内容,但很多网站设计师不会关注它。很容易忽略这一点。确保TDK的每个页面都是一个单独的内容,因为搜索引擎会识别一个页面。要识别的第一个文本内容是 TDK。如果TDK设置不合理(尤其是整个网站页面上的TDK是一样的),会对搜索引擎排名产生很大的负面影响。面包屑。这是很多网站在设计网站时都会忽略的地方。其实面包屑导航对于seo来说一直是很重要的,面包屑导航一定要合理设置。网站内的锚文本链接。这是seo在网站上的重点。网站上的锚文本太少,不利于搜索引擎爬虫在网站上查找和抓取更多页面。网站的锚文本过于密集,容易被搜索引擎认为是故意优化,所以要把握这个程度。
创禾网络始终坚持“诚信为本”的经营理念,以“为客户创造价值”为目标,以专业、全面的服务深耕区域市场。过去,创和网络深刻理解市场需求,是企业网络营销的合作伙伴;创和网络充分把握时代机遇与挑战,借助移动互联网、大数据、人工智能等新兴技术,推动传统产业转型升级;未来,新科网络将继续努力。
目前随着互联网的发展,网站的数量可以说是上亿。互联网数据信息增长非常快。人们越来越多地通过搜索引擎搜索数据信息,但同时也让人们更难找到目标信息。因此,搜索引擎的出现充当了用户和数据之间的桥梁,给人们带来了极大的便利。根据人们的习惯和心理,一般网站在搜索引擎中的排名越高,被点击的机会就越大。反之,网站的排名越低,获得的搜索流量就越少。据统计,全球500强企业中有90%以上在网站企业中使用了SEO技术。
网站优化推广过程中,网站不知为何突然失去了关键词收录的排名,或者网站被搜索引擎降级。这时候,SEO人员无疑是感觉崩溃了,毕竟这么努力优化了很久的网站说降级就降级,心情好不了。然而,困难总会出现,而且总是需要解决。企业网站被搜索引擎降级如何解决?在处理企业网站降权的问题时,首先要了解哪些因素会导致网站的彻头彻尾。在有经验的 SEO 优化者看来,网站 被搜索引擎降级的原因如下:
石家庄指定关键词quick排名哪个更好 查看全部
如何做好口碑营销?
石家庄指定关键词快速排名哪个更好[de39bkw]
是石家庄地区一家专注于网站建设和推广的公司。科技为本是网站建设的指导思想,诚信经营是对客户永恒的承诺。创和网络致力于互联网品牌建设和网络营销。
我们的服务项目包括企业网站建设推广、百万字网推广、软件开发、全网营销推广系统、小程序、产品流词优化、按效果付费等。
立足石家庄,为中小企业提供专业服务,为当地热门行业提供有效的推广和运营策略。每个行业都有一批SEO优化成功案例,可以查询。
网站空间只有购买网站construction软件才能使用。所需空间取决于您购买的网站 软件。具体的网站 取决于您选择如何构建网站。如果您将外包给网站公司,则无需管理所有内容。如果您构建自己的软件,则需要软件空间要求。 网站空间支持什么样的网站编程语言?空间的表现是什么?都是需要考虑的问题。最后,空间必须快。如果上面的域名和空间问题已经很好的解决了。下一个核心部分是网站的制作。
搜索引擎,关键词,排名。搜索引擎营销是目前有效的营销方式之一。现在的网民,如果要买东西,他们会去搜索引擎搜索有关产品的信息。因此,一些高价值的商业关键词价格极高,甚至达到每次点击十元以上。如果你想推广产品,你应该考虑使用搜索引擎来销售。当然也可以使用SEO或者百度竞价排名等等。建立口碑营销。口碑营销是一种有效且廉价的营销方式。但是这种方式做起来并不容易,这涉及到网站的方方面面。口碑营销并不总是在我们的日常生活中进行。那么我们如何进行口碑营销呢?不想当编辑,一天写很多文章,没有发展和前途。
我们是一个追求品质、不断超越自我的团队。每个成员也是亲密的伙伴,与公司共同成长和发展。我们尊重每一次合作的机遇和挑战,精益求精,精益求精。团队秉承专注、专业的设计服务思维,让客户通过设计发挥产品价值,探索无限可能。热爱设计,坚信设计的力量让我们不断前进......
速度。 网站的访问速度也很重要,所以我把它排在第三。你为什么这么说?前两个还不够。用户打开网站需要1分钟或更长时间才能正常访问网站,我想估计到最后我不会关掉你的网站,时间花在关掉你的网站上,用户体验就是你的网站。在线体验不流畅快速滴滴,那还不关掉还等什么?总之,时间就是金钱。服务。 网站 不仅是公司或个人的在线门面,也是重要的营销工具。互联网为公司或个人向用户介绍产品或服务提供了理想的媒介。当用户对某个产品感兴趣时,可以将网站理解为销售人员,并在此基础上向用户介绍其他相关产品、升级产品、配套产品。关键是要有专人为客户解答问题,及时反馈客户信息,与用户形成及时沟通。
很多人在做SEO优化的时候都听过一个词,就是网站聚页,具体指什么?官方解释为:聚合页面是指网站根据某个主题或关键词将原来的文章重新排列成一个新的列表或主题页面。聚合页面的初衷是为了方便用户对相同内容的延伸阅读。对SEO的影响是可以快速获得排名和流量,也可以快速得到搜索引擎的青睐。
自己搭建网站时,要注意内容的新鲜度。现在的网络共享和很多专业的千篇一律的效果,让很多企业网站基本上千人,让很多网站内容觉得一点特色都没有。 ,这样的网站怎么能吸引顾客呢?所以,要想吸引用户,就要让网站有自己的特色。在内容文字和网站planning和网页布局中构建网站时,要给客户一个共同的新鲜感,让他们的用户感受到自己的网站Attractive。在当时的技术条件下,构建网站比较容易,功能也比较短。但是,随着网站技术的不断更新和新功能的推出,原来的网站已经很难满足网站公司的需求了。另一个方面没有精心策划,但网站很容易建立。后期为了给网络添加图文,如果重新创建一个网站,那么选择网站策划公司是第一重要的事情。
石家庄指定关键词quick排名哪个更好
网络秉承“帮助中小企业实现网络营销”的宗旨,通过专业的网站服务,提升客户品牌价值,一站式网络营销服务,帮助客户提升销量;坚持做有价值的网络推广。
MWordba 屏幕的原理是什么? WWordba Screen是和一些高权重的平台合作,依托平台收录页面,然后利用平台目录的url做js覆盖,镜像一个官网,快速推送客户的网站到百度首页实现排名和占据位置的效果。操作和实际效果一样,首页一次上千个关键词,或者全搜索。客户付款后,基本可以达到预期效果,不退还。一家精心打造的公司,每天处理数百个流量是没有问题的。与传统seo优化相比,WWordba Screen的优势在于与平台的合作周期短,1-7天时间word会up。传统的 SEO 优化需要大约三个月的时间。
网站建设初期,一直想着需要一些功能来提升网站的整体效果,这也符合客户对网站的需求。然而,没想到的是网站 需要功能性,但更方便。很多公司可能想增加会员功能、支付系统、不同栏目效果的功能,但是没有想到搜索框、返回顶部、图片放大等详细功能。只考虑大方向而忽略小细节可能会降低网站的运营效果。糟糕的客户体验会影响转化率的提升。当网站的内容越来越多,翻页不方便;当网页内容比较长时,浏览至底部时必须再次滚动至顶部,以增加操作流程。因此,在施工过程中必须有适当的规划。在考虑主要功能的同时,还要考虑客户的使用体验,提供合适的便利功能对他们会更加友好。
TDK 标签的处理。虽然这是seo知识中最基础的内容,但很多网站设计师不会关注它。很容易忽略这一点。确保TDK的每个页面都是一个单独的内容,因为搜索引擎会识别一个页面。要识别的第一个文本内容是 TDK。如果TDK设置不合理(尤其是整个网站页面上的TDK是一样的),会对搜索引擎排名产生很大的负面影响。面包屑。这是很多网站在设计网站时都会忽略的地方。其实面包屑导航对于seo来说一直是很重要的,面包屑导航一定要合理设置。网站内的锚文本链接。这是seo在网站上的重点。网站上的锚文本太少,不利于搜索引擎爬虫在网站上查找和抓取更多页面。网站的锚文本过于密集,容易被搜索引擎认为是故意优化,所以要把握这个程度。
创禾网络始终坚持“诚信为本”的经营理念,以“为客户创造价值”为目标,以专业、全面的服务深耕区域市场。过去,创和网络深刻理解市场需求,是企业网络营销的合作伙伴;创和网络充分把握时代机遇与挑战,借助移动互联网、大数据、人工智能等新兴技术,推动传统产业转型升级;未来,新科网络将继续努力。
目前随着互联网的发展,网站的数量可以说是上亿。互联网数据信息增长非常快。人们越来越多地通过搜索引擎搜索数据信息,但同时也让人们更难找到目标信息。因此,搜索引擎的出现充当了用户和数据之间的桥梁,给人们带来了极大的便利。根据人们的习惯和心理,一般网站在搜索引擎中的排名越高,被点击的机会就越大。反之,网站的排名越低,获得的搜索流量就越少。据统计,全球500强企业中有90%以上在网站企业中使用了SEO技术。
网站优化推广过程中,网站不知为何突然失去了关键词收录的排名,或者网站被搜索引擎降级。这时候,SEO人员无疑是感觉崩溃了,毕竟这么努力优化了很久的网站说降级就降级,心情好不了。然而,困难总会出现,而且总是需要解决。企业网站被搜索引擎降级如何解决?在处理企业网站降权的问题时,首先要了解哪些因素会导致网站的彻头彻尾。在有经验的 SEO 优化者看来,网站 被搜索引擎降级的原因如下:
石家庄指定关键词quick排名哪个更好

