
搜索指定网站内容
搜索指定网站内容(提高搜索效率和质量的一些方法,包含搜索指令、以图搜图技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-22 18:12
文字/一周进展·安哥拉
在信息过载的时刻,即使我们不主动获取信息,各种应用程序推荐和用户制作的内容也会迫使我们,但真正有价值的内容可能很少
每个人都将面临“有限时间”的限制。如何从信息浪潮中快速找到所需的高质量内容,已成为几乎每个现代人都必须面对的问题
除了寻找高质量的信息源,更重要的是使用良好的搜索,因为你想知道的80%都可以在网上找到
因此,在今天的文章中,我整理了一些提高搜索效率和质量的方法,包括搜索说明、地图搜索技能、屏蔽网站和广告。我希望这些内容对你有帮助
01.搜索指令
① 过滤器关键词
在关键词后面使用减号,并添加要筛选的关键词以删除标题中已筛选的关键词搜索结果
例如,当百度使用关键词“学习应用程序”搜索时,知乎的内容默认位于搜索结果的顶部
为了比较前后的效果,请使用“learning app-知乎”再次搜索,返回的结果将过滤知乎中的内容@
② 在指定的网站中搜索@
在关键词之后添加site:URL,在指定的网站中搜索关键词,这更适合使用垂直且易于记忆的URL的网站。您可以直接使用关键词进行搜索,无需打开网站
以查找国防ppt模板为例,直接使用“国防ppt”进行搜索。返回的结果来自不同的网站,包括ppt教程的内容和ppt模板网站,这两个模板都很混乱
如果只想搜索从PPT模板返回的结果,请尝试将搜索范围限制为PPT模板网站,例如Microsoft Home模板网站,以便搜索结果更准确
值得一提的是,该站点:以后添加的URL不需要带或,否则返回的结果将显示找不到相关内容
③ 指定文件类型
在关键词之后添加filetype:file format以指定搜索结果返回的文件类型。此处的文件格式包括但不限于PPT、Doc、PDF、xls等
以国防ppt为例,在关键词之后添加“filetype:ppt”,这样返回的结果仅限于ppt格式的文档,不会使其他类型的文件杂乱无章
需要注意的是,自office2013以来,office增加了三种兼容格式pptx、docx和xlsx,但百度的文件类型指令不支持这三种新格式,这三种格式在谷歌中可以正常使用
④ 精确匹配
有时当我们使用关键词进行搜索时,搜索引擎会将我们的关键词分成两个小短语进行搜索,结果不令人满意
为了解决这个问题,我们可以将关键词放在引号中,这样搜索引擎将返回收录完整关键词的结果,而不会将关键词无序地分割成多个短语
这里的引号可以是中文也可以是英文。使用中文或英文引号不会影响搜索返回的结果
如下图所示,使用“城市地铁”搜索时,返回的结果完全匹配,与不加引号时相比,可以适当提高搜索效率
⑤ 通配符搜索
俗话说:“好记性胜过坏笔”。有时我们听到或想到的东西没有及时记录下来,很快我们的脑海中可能只剩下零碎的东西
就像你模模糊糊地记得一部叫做《四月XX号谎言》的动画,但你就是记不起中间的部分。此时,您可以使用星号*来通知搜索引擎仍有一些您不知道的内容
这里的星号*称为通配符,通常用于模糊搜索场景。当您不知道完整文本时,可以使用通配符而不是一个或多个字符,以便尽可能接近要搜索的内容
⑥ 合格职称关键词
在关键词A:关键词b之后添加intitle,这有点像数学中的交集,即返回的搜索结果的标题必须同时收录关键词A和关键词b
以下图为例,使用“learning网站intitle:clip”搜索,下面返回的搜索结果将同时收录关键词,使搜索结果更加集中
虽然每个搜索命令都是单独引入的,但在实际的搜索场景中,我们可以组合两个或多个搜索命令,并与不同的命令协作,以提高搜索的效率和质量
02.Baidu高级搜索
刚接触过这些搜索说明的朋友在早期可能仍然记得它们,但如果他们以后不自觉地使用它们,这些说明将随着时间的推移慢慢被遗忘
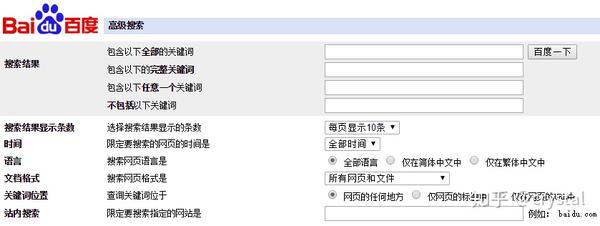
幸运的是,百度还提供了类似搜索说明的高级搜索。它以一种更容易理解的形式呈现在我们面前的搜索说明
点击百度搜索页面右上角的“设置”打开“高级搜索”
理解前面说明的含义后,请查看下图中的advanced search(高级搜索)面板,应该很好地理解该面板
以搜索关键词为例。完整的关键词对应于完全匹配的命令,不包括关键词对应的filter关键词命令
在完整的关键词输入框中输入关键词“城市地铁”,然后单击底部的高级搜索。在打开的搜索页面中,它将自动为关键词添加双引号,这与上述搜索命令一致
此外,高级搜索面板还可以限制搜索返回的文档格式。这里列出的文档格式更清晰,包括PDF、Doc、xls、PPT和RTF文件
03.搜索图片
很多朋友可能知道百度的“图片搜索”功能。通过将本地图片上传到百度,它将帮助我们找到与此图片相关的其他图片
但每次大多数人使用百度搜索图片时,他们可能会先在百度搜索图片,然后打开百度地图识别页面,最后上传图片。整个过程有点麻烦
为了帮助您更有效地使用“按地图搜索”,以下是按地图搜索的两个提示:
① 图形搜索
这是百度图片的功能。使用百度搜索特定图片时,将鼠标移动到返回图片的顶部。右下角将有两个按钮,一个是下载,另一个是按图片搜索
点击“按图像搜索”,将调用百度的图像搜索功能,查找与当前图像相关的所有内容
另外,当您点击图像的缩略图查看图像的详细信息时,点击图像下方的“按图像搜索”,也可以实现按图像搜索的操作
② 按图像搜索
上面提到的“图片搜索”的缺点是它只能在百度图片页面上工作。对于其他网页的图片,你不能直接调用百度的图片搜索功能
“按图像搜索”是一个功能强大的图像搜索插件。它集成了30多个搜索引擎,可以将任何网页的图像上传到不同的搜索引擎,以查找与当前图像相关的图像或内容
安装插件后,右击任意图片,选择“按图像搜索”,即可看到不同搜索引擎提供的地图搜索功能。选择百度将直接打开百度地图识别页面
打开插件的设置页面,查看插件集成的所有图像搜索引擎。选中发动机前面的复选框以启用它。长按并拖动可更改发动机的位置,这将影响右键单击菜单中发动机的上下顺序
04.Shield网站
搜索时,除了过滤不必要的关键词,我们可能还想屏蔽我们不喜欢的网站,比如各种软件下载站、2345网站等等
我对屏蔽网站的理想期望是它不会出现在搜索结果中,但百度搜索目前无法做到这一点。想要屏蔽的网站仍将出现在搜索结果中,并且只有在网站打开时才能屏蔽
为了间接屏蔽网站,我们需要为浏览器安装一个插件-简单拦截器。就像它的名字一样,屏蔽网站的操作非常简单
安装插件后,点击右上角的插件图标,打开插件配置页面,将要阻止的网站URL粘贴到网站屏蔽列表网站拦截器中,点击下方的“保存拦截器列表”按钮保存
之后,当您在屏蔽列表中打开网站时,网站会跳转到simple blocker的拦截页面,并提示当前页面已被拦截
也许这种屏蔽插件的正确用法不是这样的。正确的用法可能是屏蔽不适合儿童的东西,但我只能用它来屏蔽那些恶心的人的网站
简单拦截器插件的下载地址:
05.Block广告
斯帕 查看全部
搜索指定网站内容(提高搜索效率和质量的一些方法,包含搜索指令、以图搜图技巧)
文字/一周进展·安哥拉
在信息过载的时刻,即使我们不主动获取信息,各种应用程序推荐和用户制作的内容也会迫使我们,但真正有价值的内容可能很少
每个人都将面临“有限时间”的限制。如何从信息浪潮中快速找到所需的高质量内容,已成为几乎每个现代人都必须面对的问题
除了寻找高质量的信息源,更重要的是使用良好的搜索,因为你想知道的80%都可以在网上找到
因此,在今天的文章中,我整理了一些提高搜索效率和质量的方法,包括搜索说明、地图搜索技能、屏蔽网站和广告。我希望这些内容对你有帮助
01.搜索指令
① 过滤器关键词

在关键词后面使用减号,并添加要筛选的关键词以删除标题中已筛选的关键词搜索结果
例如,当百度使用关键词“学习应用程序”搜索时,知乎的内容默认位于搜索结果的顶部
为了比较前后的效果,请使用“learning app-知乎”再次搜索,返回的结果将过滤知乎中的内容@

② 在指定的网站中搜索@

在关键词之后添加site:URL,在指定的网站中搜索关键词,这更适合使用垂直且易于记忆的URL的网站。您可以直接使用关键词进行搜索,无需打开网站
以查找国防ppt模板为例,直接使用“国防ppt”进行搜索。返回的结果来自不同的网站,包括ppt教程的内容和ppt模板网站,这两个模板都很混乱
如果只想搜索从PPT模板返回的结果,请尝试将搜索范围限制为PPT模板网站,例如Microsoft Home模板网站,以便搜索结果更准确

值得一提的是,该站点:以后添加的URL不需要带或,否则返回的结果将显示找不到相关内容

③ 指定文件类型

在关键词之后添加filetype:file format以指定搜索结果返回的文件类型。此处的文件格式包括但不限于PPT、Doc、PDF、xls等
以国防ppt为例,在关键词之后添加“filetype:ppt”,这样返回的结果仅限于ppt格式的文档,不会使其他类型的文件杂乱无章

需要注意的是,自office2013以来,office增加了三种兼容格式pptx、docx和xlsx,但百度的文件类型指令不支持这三种新格式,这三种格式在谷歌中可以正常使用
④ 精确匹配

有时当我们使用关键词进行搜索时,搜索引擎会将我们的关键词分成两个小短语进行搜索,结果不令人满意
为了解决这个问题,我们可以将关键词放在引号中,这样搜索引擎将返回收录完整关键词的结果,而不会将关键词无序地分割成多个短语
这里的引号可以是中文也可以是英文。使用中文或英文引号不会影响搜索返回的结果
如下图所示,使用“城市地铁”搜索时,返回的结果完全匹配,与不加引号时相比,可以适当提高搜索效率

⑤ 通配符搜索

俗话说:“好记性胜过坏笔”。有时我们听到或想到的东西没有及时记录下来,很快我们的脑海中可能只剩下零碎的东西
就像你模模糊糊地记得一部叫做《四月XX号谎言》的动画,但你就是记不起中间的部分。此时,您可以使用星号*来通知搜索引擎仍有一些您不知道的内容
这里的星号*称为通配符,通常用于模糊搜索场景。当您不知道完整文本时,可以使用通配符而不是一个或多个字符,以便尽可能接近要搜索的内容

⑥ 合格职称关键词

在关键词A:关键词b之后添加intitle,这有点像数学中的交集,即返回的搜索结果的标题必须同时收录关键词A和关键词b
以下图为例,使用“learning网站intitle:clip”搜索,下面返回的搜索结果将同时收录关键词,使搜索结果更加集中

虽然每个搜索命令都是单独引入的,但在实际的搜索场景中,我们可以组合两个或多个搜索命令,并与不同的命令协作,以提高搜索的效率和质量
02.Baidu高级搜索
刚接触过这些搜索说明的朋友在早期可能仍然记得它们,但如果他们以后不自觉地使用它们,这些说明将随着时间的推移慢慢被遗忘
幸运的是,百度还提供了类似搜索说明的高级搜索。它以一种更容易理解的形式呈现在我们面前的搜索说明
点击百度搜索页面右上角的“设置”打开“高级搜索”

理解前面说明的含义后,请查看下图中的advanced search(高级搜索)面板,应该很好地理解该面板
以搜索关键词为例。完整的关键词对应于完全匹配的命令,不包括关键词对应的filter关键词命令

在完整的关键词输入框中输入关键词“城市地铁”,然后单击底部的高级搜索。在打开的搜索页面中,它将自动为关键词添加双引号,这与上述搜索命令一致

此外,高级搜索面板还可以限制搜索返回的文档格式。这里列出的文档格式更清晰,包括PDF、Doc、xls、PPT和RTF文件

03.搜索图片
很多朋友可能知道百度的“图片搜索”功能。通过将本地图片上传到百度,它将帮助我们找到与此图片相关的其他图片
但每次大多数人使用百度搜索图片时,他们可能会先在百度搜索图片,然后打开百度地图识别页面,最后上传图片。整个过程有点麻烦

为了帮助您更有效地使用“按地图搜索”,以下是按地图搜索的两个提示:
① 图形搜索
这是百度图片的功能。使用百度搜索特定图片时,将鼠标移动到返回图片的顶部。右下角将有两个按钮,一个是下载,另一个是按图片搜索
点击“按图像搜索”,将调用百度的图像搜索功能,查找与当前图像相关的所有内容

另外,当您点击图像的缩略图查看图像的详细信息时,点击图像下方的“按图像搜索”,也可以实现按图像搜索的操作

② 按图像搜索
上面提到的“图片搜索”的缺点是它只能在百度图片页面上工作。对于其他网页的图片,你不能直接调用百度的图片搜索功能
“按图像搜索”是一个功能强大的图像搜索插件。它集成了30多个搜索引擎,可以将任何网页的图像上传到不同的搜索引擎,以查找与当前图像相关的图像或内容

安装插件后,右击任意图片,选择“按图像搜索”,即可看到不同搜索引擎提供的地图搜索功能。选择百度将直接打开百度地图识别页面

打开插件的设置页面,查看插件集成的所有图像搜索引擎。选中发动机前面的复选框以启用它。长按并拖动可更改发动机的位置,这将影响右键单击菜单中发动机的上下顺序

04.Shield网站
搜索时,除了过滤不必要的关键词,我们可能还想屏蔽我们不喜欢的网站,比如各种软件下载站、2345网站等等
我对屏蔽网站的理想期望是它不会出现在搜索结果中,但百度搜索目前无法做到这一点。想要屏蔽的网站仍将出现在搜索结果中,并且只有在网站打开时才能屏蔽
为了间接屏蔽网站,我们需要为浏览器安装一个插件-简单拦截器。就像它的名字一样,屏蔽网站的操作非常简单

安装插件后,点击右上角的插件图标,打开插件配置页面,将要阻止的网站URL粘贴到网站屏蔽列表网站拦截器中,点击下方的“保存拦截器列表”按钮保存

之后,当您在屏蔽列表中打开网站时,网站会跳转到simple blocker的拦截页面,并提示当前页面已被拦截

也许这种屏蔽插件的正确用法不是这样的。正确的用法可能是屏蔽不适合儿童的东西,但我只能用它来屏蔽那些恶心的人的网站
简单拦截器插件的下载地址:
05.Block广告
斯帕
搜索指定网站内容(如何让浏览器种获取到精准的问题答案?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2021-09-19 11:14
当人们对某个问题有疑问时,他们会询问人们并翻阅书籍寻找证据。如今,人们获取信息非常简单。只需用手指键入几个单词,他们就可以在浏览器中搜索大量感兴趣的问题和答案
然而,随着时代的发展和广告的盛行,企业需要从广告中获得更高的利润
因此,我们很难从浏览器中获得准确的答案。您一定遇到了一个搜索问题,其中充满了广告图片:
那么我们如何才能得到准确的答案呢
搜索广告
如果你想避免令人讨厌的广告,首先要学会这个技巧
在关键词搜索后添加“-advision”(减号前需要空格)
使用这种方法,虽然广告不能完全删除,但页面会更干净整洁。我们真正想看的内容会更高。如果百度没有回应,我们可以刷新几次
精确搜索
你一定有过这种经历。我们搜索整个句子,但搜索结果将以红色标记为关键词。因此,我们可以利用此功能进行"k4"搜索,从而实现更快速,更准确的搜索
之前:
之后:
如图所示,带引号的搜索结果一目了然。有一种惊讶的感觉吗
受限文件类型搜索
你的办公室工作人员必须深刻理解寻找文件的痛苦
例如,如果你想找到一个单词分类账模板、一个PPT课件等,你必须从百度上翻阅条目才能找到你真正想要的,有时搜索是徒劳的
尝试以下方法:
“文件类型:文件类型+搜索词”。目前,文件类型支持“Doc、docx、xlsx、xls、PPT、pptx”等
之前:
之后:
以这种方式搜索的内容是准确的ppt
特定网站search
你必须有你最喜欢的网站,但有时网站有一个通用搜索功能。这时,我们可以用百度的“站点:域名+搜索词”来搜索
之前:
之后:
加性多关键词搜索
在我们的日常搜索中,如果有2~3个关键词,我们可以使用加法搜索
方法:关键词1+ 关键词2"
之前:
之后:
如何,你从未尝试过的每一种搜索方法?使用上述方法进行简单、高效和省时的搜索。快速点击采集 查看全部
搜索指定网站内容(如何让浏览器种获取到精准的问题答案?(一))
当人们对某个问题有疑问时,他们会询问人们并翻阅书籍寻找证据。如今,人们获取信息非常简单。只需用手指键入几个单词,他们就可以在浏览器中搜索大量感兴趣的问题和答案
然而,随着时代的发展和广告的盛行,企业需要从广告中获得更高的利润
因此,我们很难从浏览器中获得准确的答案。您一定遇到了一个搜索问题,其中充满了广告图片:

那么我们如何才能得到准确的答案呢
搜索广告
如果你想避免令人讨厌的广告,首先要学会这个技巧
在关键词搜索后添加“-advision”(减号前需要空格)

使用这种方法,虽然广告不能完全删除,但页面会更干净整洁。我们真正想看的内容会更高。如果百度没有回应,我们可以刷新几次
精确搜索
你一定有过这种经历。我们搜索整个句子,但搜索结果将以红色标记为关键词。因此,我们可以利用此功能进行"k4"搜索,从而实现更快速,更准确的搜索
之前:
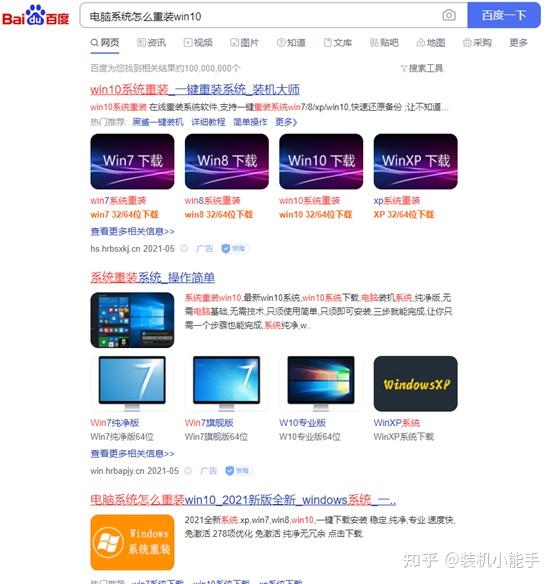
之后:

如图所示,带引号的搜索结果一目了然。有一种惊讶的感觉吗
受限文件类型搜索
你的办公室工作人员必须深刻理解寻找文件的痛苦
例如,如果你想找到一个单词分类账模板、一个PPT课件等,你必须从百度上翻阅条目才能找到你真正想要的,有时搜索是徒劳的
尝试以下方法:
“文件类型:文件类型+搜索词”。目前,文件类型支持“Doc、docx、xlsx、xls、PPT、pptx”等
之前:
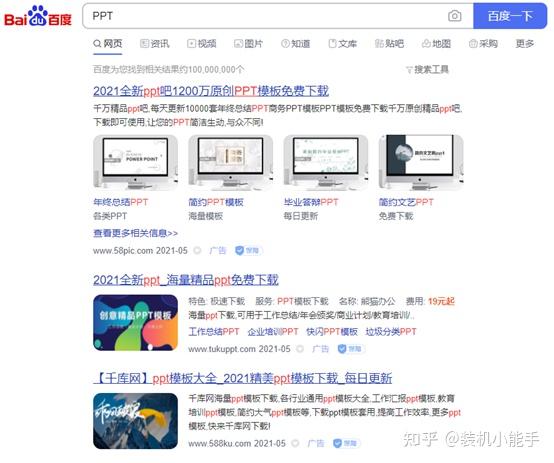
之后:
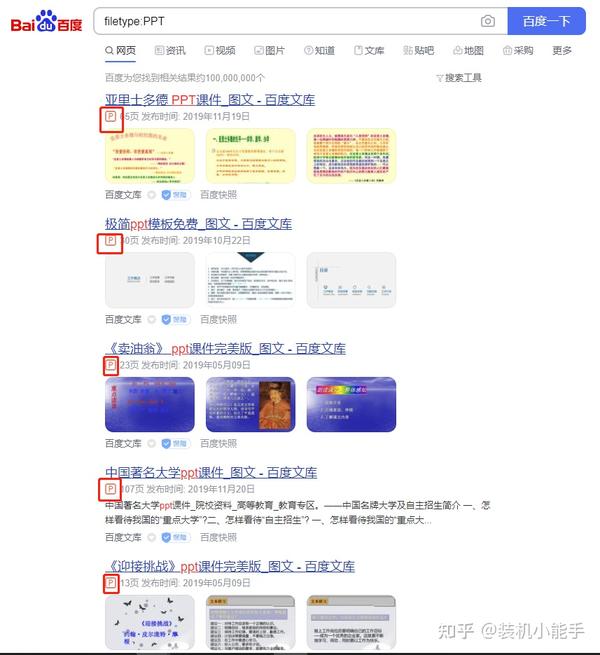
以这种方式搜索的内容是准确的ppt
特定网站search
你必须有你最喜欢的网站,但有时网站有一个通用搜索功能。这时,我们可以用百度的“站点:域名+搜索词”来搜索
之前:

之后:
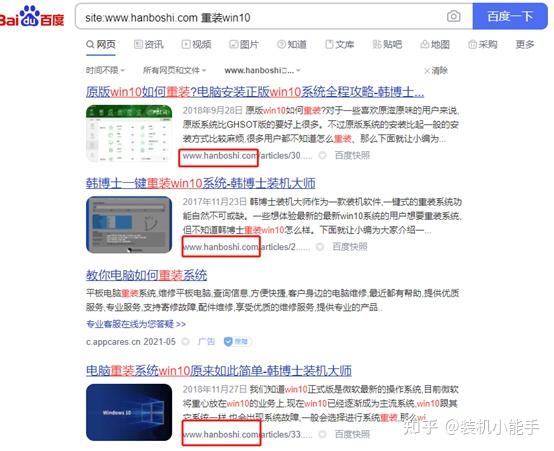
加性多关键词搜索
在我们的日常搜索中,如果有2~3个关键词,我们可以使用加法搜索
方法:关键词1+ 关键词2"
之前:
之后:
如何,你从未尝试过的每一种搜索方法?使用上述方法进行简单、高效和省时的搜索。快速点击采集
搜索指定网站内容(网站语法格式及其应用方法介绍-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-09-19 10:17
语法格式:
网址:website关键词
或关键词站点:
注意事项:
1、site:下面的冒号必须是英文“:”,而中文的全角冒号“:”是无用的
2、url正面不能接受
3、url不能使用反斜杠“/”。事实上,它不能在任何地方使用/
4、url除非有特殊目的,否则不要在中使用WWW
使用www会导致您错过网站中的内容,因为许多网站频道没有www
其他说明:
1、关键词搜索结果可以在“站点:”之前或之后相同
但是,无论谁在前面或后面,关键词和“site:”都必须在2、中留空,因为“site:”搜索,关键词可以是多个,多个关键词之间用空格分隔
3、支持与其他复杂的搜索语法混合,并且每个语法和关键词之间都有一个空格@
4、除了网站之外,您还可以搜索网站的频道,但只能搜索那些没有“/”的频道
5、a网站可能有多种语言
因此,“搜索所有网站”和“搜索中文(简体)网页”之间存在差异
当然,如果网站只指定了一种语言,那么选择是相同的
目的:
1、可用于限制网站类型。教育部和组织机构的学术材料将更加简洁,政府相关信息可能更容易在政府机构中找到
2、使用域名后缀,如edu、org、net和gov,不会使用此后缀搜索所有网站
只搜索以该后缀结尾的网站和后缀为CN、US、Si等国家和地区的edu.jp
Gov.us、org.it等不在搜索范围内,因此您需要单独搜索
3、搜索一种语言或网站在指定国家/地区@
4、有些网站不提供现场搜索,或者信息结构混乱,内容多,很难找到东西
然后你可以使用“site:”来检索这个网站
谷歌的“站点:”功能比大多数网站自己的站点搜索更容易使用,如果你不检查的话
动态数据库,时效性要求不高
5、search不欢迎您搜索和免费使用数据库的一部分网站
6、use“site:”在死链接网站和关闭的网站中搜索信息@
例如:
打开
输入:站点:百度知道
输入:百度知道
输入:百度知道
你知道这三者的区别吗 查看全部
搜索指定网站内容(网站语法格式及其应用方法介绍-上海怡健医学)
语法格式:
网址:website关键词
或关键词站点:
注意事项:
1、site:下面的冒号必须是英文“:”,而中文的全角冒号“:”是无用的
2、url正面不能接受
3、url不能使用反斜杠“/”。事实上,它不能在任何地方使用/
4、url除非有特殊目的,否则不要在中使用WWW
使用www会导致您错过网站中的内容,因为许多网站频道没有www
其他说明:
1、关键词搜索结果可以在“站点:”之前或之后相同
但是,无论谁在前面或后面,关键词和“site:”都必须在2、中留空,因为“site:”搜索,关键词可以是多个,多个关键词之间用空格分隔
3、支持与其他复杂的搜索语法混合,并且每个语法和关键词之间都有一个空格@
4、除了网站之外,您还可以搜索网站的频道,但只能搜索那些没有“/”的频道
5、a网站可能有多种语言
因此,“搜索所有网站”和“搜索中文(简体)网页”之间存在差异
当然,如果网站只指定了一种语言,那么选择是相同的
目的:
1、可用于限制网站类型。教育部和组织机构的学术材料将更加简洁,政府相关信息可能更容易在政府机构中找到
2、使用域名后缀,如edu、org、net和gov,不会使用此后缀搜索所有网站
只搜索以该后缀结尾的网站和后缀为CN、US、Si等国家和地区的edu.jp
Gov.us、org.it等不在搜索范围内,因此您需要单独搜索
3、搜索一种语言或网站在指定国家/地区@
4、有些网站不提供现场搜索,或者信息结构混乱,内容多,很难找到东西
然后你可以使用“site:”来检索这个网站
谷歌的“站点:”功能比大多数网站自己的站点搜索更容易使用,如果你不检查的话
动态数据库,时效性要求不高
5、search不欢迎您搜索和免费使用数据库的一部分网站
6、use“site:”在死链接网站和关闭的网站中搜索信息@
例如:
打开
输入:站点:百度知道
输入:百度知道
输入:百度知道
你知道这三者的区别吗
搜索指定网站内容( Www_com那怎样才算是较为成功的突破口呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-19 06:03
Www_com那怎样才算是较为成功的突破口呢?)
内容建设是第一个重要问题
如前所述,网站如果你想提供太多的内容,并且你想快速推广你的网站你需要找到一个突破,但我没有说清楚什么样的突破才是更成功的突破。同样,我忽略了内容建设是新发展中的第一个重要问题网站. 万维网
那么,什么是更成功的突破?笔者认为主要的寻找方向如下:中国站长站
首先是一些别人没有注意到的内容
例如,你可能想提供有关互联网的信息,但是如果这个行业的人一般都到基层网络,你认为不先上网吗?我认为是这样。Www~~com
例如,如果你想提供一些关于文学的东西,起点比你好得多。你怎么能让别人来找你?所以当你提供它时,你不能网站提供它,而你只是提供它。在你的网站成功背后,是别人没有注意到、也没有提供的东西,即避开边缘,避开新环境。站长。站
当二、选择突破时,考虑你的目标客户群
首先,你要想一想,你的目标客户群是谁?例如,如果你选择情绪化的文章作为你的网站突破点,这没有问题。也许你的网站流量在短时间内真的很大,而且有很多读者,但是如果你仔细看看,你的目标客户群是否与你最初的想法不同。因为内容很多,你的目标客户群必须分散,我们发现它不能形成一个清晰的整体。站长。站
对于一家新成立的网站公司来说,内容建设首当其冲。中国火车站。龙火车站
如何吸引别人看到你的网站,即使你吸引了很多人,网站也不能展示更多更好的内容,网站也会处于尴尬的境地。即使不是为了读者,也应该从搜索引擎的角度来考虑。只有当你的网站沉淀了大量有价值的内容时,你的网站才会被搜索引擎不断捕获和更新,只有大量的内容,读者才会通过搜索引擎到达你的网站网站,一些读者最终会成为你的网站忠实用户
那么如何构建网站content\uucom呢
这里有一个简单的提示:网站内容构建不是大量的复制和粘贴。首先,你需要选择一个主题。所谓选题就是在网站选择适合你的内容并进行编辑;其次,正确添加标签,便于搜索引擎捕获。当然,读者来到您的网站网站更方便,更有利于提高您的网站公关价值。Www~~com 查看全部
搜索指定网站内容(
Www_com那怎样才算是较为成功的突破口呢?)

内容建设是第一个重要问题
如前所述,网站如果你想提供太多的内容,并且你想快速推广你的网站你需要找到一个突破,但我没有说清楚什么样的突破才是更成功的突破。同样,我忽略了内容建设是新发展中的第一个重要问题网站. 万维网
那么,什么是更成功的突破?笔者认为主要的寻找方向如下:中国站长站
首先是一些别人没有注意到的内容
例如,你可能想提供有关互联网的信息,但是如果这个行业的人一般都到基层网络,你认为不先上网吗?我认为是这样。Www~~com
例如,如果你想提供一些关于文学的东西,起点比你好得多。你怎么能让别人来找你?所以当你提供它时,你不能网站提供它,而你只是提供它。在你的网站成功背后,是别人没有注意到、也没有提供的东西,即避开边缘,避开新环境。站长。站
当二、选择突破时,考虑你的目标客户群
首先,你要想一想,你的目标客户群是谁?例如,如果你选择情绪化的文章作为你的网站突破点,这没有问题。也许你的网站流量在短时间内真的很大,而且有很多读者,但是如果你仔细看看,你的目标客户群是否与你最初的想法不同。因为内容很多,你的目标客户群必须分散,我们发现它不能形成一个清晰的整体。站长。站
对于一家新成立的网站公司来说,内容建设首当其冲。中国火车站。龙火车站
如何吸引别人看到你的网站,即使你吸引了很多人,网站也不能展示更多更好的内容,网站也会处于尴尬的境地。即使不是为了读者,也应该从搜索引擎的角度来考虑。只有当你的网站沉淀了大量有价值的内容时,你的网站才会被搜索引擎不断捕获和更新,只有大量的内容,读者才会通过搜索引擎到达你的网站网站,一些读者最终会成为你的网站忠实用户
那么如何构建网站content\uucom呢
这里有一个简单的提示:网站内容构建不是大量的复制和粘贴。首先,你需要选择一个主题。所谓选题就是在网站选择适合你的内容并进行编辑;其次,正确添加标签,便于搜索引擎捕获。当然,读者来到您的网站网站更方便,更有利于提高您的网站公关价值。Www~~com
搜索指定网站内容(微软AZURE全球版技术文档网站搜索API将从认知服务迁移到必应搜索)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-09-19 05:01
您正在访问Microsoft azure全局技术文档网站。如果您需要访问由21vianet运营的Microsoft azure中国技术文档网站,请访问
筛选搜索响应中收录的结果
警告
Bing搜索API将从认知服务迁移到Bing搜索服务。从2020年10月30日起,Bing搜索的任何新实例都需要根据此处描述的流程进行预配置。使用认知服务预配置的Bing搜索API将在未来三年内或企业协议结束前(以先到者为准)得到支持。有关迁移说明,请参阅Bing搜索服务
在查询web时,Bing会返回它为搜索找到的所有相关内容。例如,如果搜索查询为“帆船+小船”,则响应可能收录以下结果:
{
"_type" : "SearchResponse",
"webPages" : {
"webSearchUrl" : "https:\/\/www.bing.com\/cr?IG=3A43C...",
"totalEstimatedMatches" : 262000,
"value" : [...]
},
"images" : {
"id" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/#Images",
"readLink" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/images\/search?q=sail...",
"webSearchUrl" : "https:\/\/www.bing.com\/cr?IG=3A43CA5CA6464E5D...",
"isFamilyFriendly" : true,
"value" : [...]
},
"rankingResponse" : {
"mainline" : {
"items" : [...]
}
}
}
查询参数
要过滤Bing返回的结果,请在调用API时使用以下查询参数
响应滤波器
您可以使用查询参数(以逗号分隔的结果列表)过滤Bing在响应中提供的结果类型(例如,图像、视频和新闻)。如果Bing发现了什么,响应将收录结果
要从响应中排除特定结果(如图像),请在结果类型之前添加-字符。例如:
&responseFilter=-images,-videos
下面显示如何使用responsefilter请求“帆船”的图像、视频和新闻。对查询字符串进行编码时,逗号更改为%2C
GET https://api.cognitive.microsof ... en-us HTTP/1.1
Ocp-Apim-Subscription-Key: 123456789ABCDE
User-Agent: Mozilla/5.0 (compatible; MSIE 10.0; Windows Phone 8.0; Trident/6.0; IEMobile/10.0; ARM; Touch; NOKIA; Lumia 822)
X-Search-ClientIP: 999.999.999.999
X-Search-Location: 47.60357;long:-122.3295;re:100
X-MSEdge-ClientID:
Host: api.cognitive.microsoft.com
下面显示对上一个查询的响应。因为Bing没有找到相关的视频和新闻结果,所以他们没有被包括在回复中
{
"_type" : "SearchResponse",
"images" : {
"id" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/#Images",
"readLink" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/images\/search?q=sail...",
"webSearchUrl" : "https:\/\/www.bing.com\/cr?IG=3AD78B183C56456C...",
"isFamilyFriendly" : true,
"value" : [...]
},
"rankingResponse" : {
"mainline" : {
"items" : [{
"answerType" : "Images",
"value" : {
"id" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/#Images"
}
}]
}
}
}
虽然Bing在之前的回复中没有返回视频和新闻结果,但这并不意味着这些视频和新闻内容不存在。这仅表示页面不收录。但是,如果翻页浏览更多结果,这些内容可能会收录在后续页面中。此外,如果直接调用视频搜索API和新闻搜索API端点,则结果可能会收录在响应中
不建议使用responsefilter从单个API获取结果。如果您需要来自单个Bing API的内容,可以直接调用该API。例如,如果只希望接收图像,可以向图像搜索API端点或其他端点发送请求。调用单个API很重要,这不仅是出于性能原因,还因为特定于内容的API提供了更丰富的结果。例如,可以使用不适用于Web搜索API的筛选器筛选结果
场地
要从特定域获取搜索结果,请在查询字符串中收录site:query参数
https://api.cognitive.microsof ... en-us
评论
如果使用site:query操作符,则仍然可以在响应中收录成人内容,而不管设置如何,具体取决于查询。站点:仅当网站内容已知且方案允许使用成人内容时才应使用
新鲜度
要将Web响应结果限制为必须在特定时间段内发现的页面,请将查询参数设置为以下值之一(不区分大小写):
您还可以将此参数设置为yyyy-mm-dd格式的用户定义日期范围。。年月日
/必应/v7.0/search?q=ipad+更新和新鲜度=2019-02-01..2019-05-30
要将结果限制为单个日期,请将freshness参数设置为特定日期:
/必应/v7.0/search?q=ipad+更新和新鲜度=2019-02-04
如果Bing满足筛选条件的页面数小于您请求的页面数(或Bing返回的默认页面数),则结果可能包括指定时间段以外的页面
限制响应中检索结果的数量
Bing可以在JSON响应中返回多个结果类型。例如,如果您查询“销售+小艇”,必应可能会返回网页、图像、视频和相关搜索
{
"_type" : "SearchResponse",
"queryContext" : {
"originalQuery" : "sailing dinghies"
},
"webPages" : {...},
"images" : {...},
"relatedSearches" : {...},
"videos" : {...},
"rankingResponse" : {...}
}
要将Bing返回的搜索结果限制为前两个结果(网页和图片),请将查询参数设置为2
GET https://api.cognitive.microsof ... en-us HTTP/1.1
Ocp-Apim-Subscription-Key: 123456789ABCDE
User-Agent: Mozilla/5.0 (compatible; MSIE 10.0; Windows Phone 8.0; Trident/6.0; IEMobile/10.0; ARM; Touch; NOKIA; Lumia 822)
X-Search-ClientIP: 999.999.999.999
X-Search-Location: 47.60357;long:-122.3295;re:100
X-MSEdge-ClientID:
Host: api.cognitive.microsoft.com
响应仅包括网页和图像
{
"_type" : "SearchResponse",
"queryContext" : {
"originalQuery" : "sailing dinghies"
},
"webPages" : {...},
"images" : {...},
"rankingResponse" : {...}
}
如果将responsefilter查询参数添加到上一个查询中,并将其设置为web pages and news,则响应中将只收录web pages,因为该新闻没有排名
{
"_type" : "SearchResponse",
"queryContext" : {
"originalQuery" : "sailing dinghies"
},
"webPages" : {...},
"rankingResponse" : {...}
}
推广非排名搜索结果
如果必应为查询返回的首选搜索结果是网页、图片、视频和相关搜索,则这些结果将收录在响应中。如果设置为两个(2)),必应将返回前两个搜索结果:网页和图片。如果希望Bing在其响应中收录图片和视频,请指定查询参数并将其设置为图片和视频
GET https://api.cognitive.microsof ... en-us HTTP/1.1
Ocp-Apim-Subscription-Key: 123456789ABCDE
User-Agent: Mozilla/5.0 (compatible; MSIE 10.0; Windows Phone 8.0; Trident/6.0; IEMobile/10.0; ARM; Touch; NOKIA; Lumia 822)
X-Search-ClientIP: 999.999.999.999
X-Search-Location: 47.60357;long:-122.3295;re:100
X-MSEdge-ClientID:
Host: api.cognitive.microsoft.com
以下是对上述请求的答复。Bing返回前两个搜索结果(网页和图片),并将视频升级到搜索结果中
{
"_type" : "SearchResponse",
"queryContext" : {
"originalQuery" : "sailiing dinghies"
},
"webPages" : {...},
"images" : {...},
"videos" : {...},
"rankingResponse" : {...}
}
如果“升级”设置为“新闻”,则响应将不收录新闻搜索结果,因为它不是排名搜索结果-只能升级排名搜索结果
要提升的搜索结果不包括在answercount限制中。例如,如果排名的搜索结果收录新闻、图片和视频,并且answercount设置为1,promote设置为news,则响应将收录新闻和图片。或者,如果排名的搜索结果收录视频、图像和新闻,则响应将收录视频和新闻
仅当指定了answercount查询参数时才能使用升级
这一页有用吗
是否
多谢各位
主题 查看全部
搜索指定网站内容(微软AZURE全球版技术文档网站搜索API将从认知服务迁移到必应搜索)
您正在访问Microsoft azure全局技术文档网站。如果您需要访问由21vianet运营的Microsoft azure中国技术文档网站,请访问
筛选搜索响应中收录的结果
警告
Bing搜索API将从认知服务迁移到Bing搜索服务。从2020年10月30日起,Bing搜索的任何新实例都需要根据此处描述的流程进行预配置。使用认知服务预配置的Bing搜索API将在未来三年内或企业协议结束前(以先到者为准)得到支持。有关迁移说明,请参阅Bing搜索服务
在查询web时,Bing会返回它为搜索找到的所有相关内容。例如,如果搜索查询为“帆船+小船”,则响应可能收录以下结果:
{
"_type" : "SearchResponse",
"webPages" : {
"webSearchUrl" : "https:\/\/www.bing.com\/cr?IG=3A43C...",
"totalEstimatedMatches" : 262000,
"value" : [...]
},
"images" : {
"id" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/#Images",
"readLink" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/images\/search?q=sail...",
"webSearchUrl" : "https:\/\/www.bing.com\/cr?IG=3A43CA5CA6464E5D...",
"isFamilyFriendly" : true,
"value" : [...]
},
"rankingResponse" : {
"mainline" : {
"items" : [...]
}
}
}
查询参数
要过滤Bing返回的结果,请在调用API时使用以下查询参数
响应滤波器
您可以使用查询参数(以逗号分隔的结果列表)过滤Bing在响应中提供的结果类型(例如,图像、视频和新闻)。如果Bing发现了什么,响应将收录结果
要从响应中排除特定结果(如图像),请在结果类型之前添加-字符。例如:
&responseFilter=-images,-videos
下面显示如何使用responsefilter请求“帆船”的图像、视频和新闻。对查询字符串进行编码时,逗号更改为%2C
GET https://api.cognitive.microsof ... en-us HTTP/1.1
Ocp-Apim-Subscription-Key: 123456789ABCDE
User-Agent: Mozilla/5.0 (compatible; MSIE 10.0; Windows Phone 8.0; Trident/6.0; IEMobile/10.0; ARM; Touch; NOKIA; Lumia 822)
X-Search-ClientIP: 999.999.999.999
X-Search-Location: 47.60357;long:-122.3295;re:100
X-MSEdge-ClientID:
Host: api.cognitive.microsoft.com
下面显示对上一个查询的响应。因为Bing没有找到相关的视频和新闻结果,所以他们没有被包括在回复中
{
"_type" : "SearchResponse",
"images" : {
"id" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/#Images",
"readLink" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/images\/search?q=sail...",
"webSearchUrl" : "https:\/\/www.bing.com\/cr?IG=3AD78B183C56456C...",
"isFamilyFriendly" : true,
"value" : [...]
},
"rankingResponse" : {
"mainline" : {
"items" : [{
"answerType" : "Images",
"value" : {
"id" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/#Images"
}
}]
}
}
}
虽然Bing在之前的回复中没有返回视频和新闻结果,但这并不意味着这些视频和新闻内容不存在。这仅表示页面不收录。但是,如果翻页浏览更多结果,这些内容可能会收录在后续页面中。此外,如果直接调用视频搜索API和新闻搜索API端点,则结果可能会收录在响应中
不建议使用responsefilter从单个API获取结果。如果您需要来自单个Bing API的内容,可以直接调用该API。例如,如果只希望接收图像,可以向图像搜索API端点或其他端点发送请求。调用单个API很重要,这不仅是出于性能原因,还因为特定于内容的API提供了更丰富的结果。例如,可以使用不适用于Web搜索API的筛选器筛选结果
场地
要从特定域获取搜索结果,请在查询字符串中收录site:query参数
https://api.cognitive.microsof ... en-us
评论
如果使用site:query操作符,则仍然可以在响应中收录成人内容,而不管设置如何,具体取决于查询。站点:仅当网站内容已知且方案允许使用成人内容时才应使用
新鲜度
要将Web响应结果限制为必须在特定时间段内发现的页面,请将查询参数设置为以下值之一(不区分大小写):
您还可以将此参数设置为yyyy-mm-dd格式的用户定义日期范围。。年月日
/必应/v7.0/search?q=ipad+更新和新鲜度=2019-02-01..2019-05-30
要将结果限制为单个日期,请将freshness参数设置为特定日期:
/必应/v7.0/search?q=ipad+更新和新鲜度=2019-02-04
如果Bing满足筛选条件的页面数小于您请求的页面数(或Bing返回的默认页面数),则结果可能包括指定时间段以外的页面
限制响应中检索结果的数量
Bing可以在JSON响应中返回多个结果类型。例如,如果您查询“销售+小艇”,必应可能会返回网页、图像、视频和相关搜索
{
"_type" : "SearchResponse",
"queryContext" : {
"originalQuery" : "sailing dinghies"
},
"webPages" : {...},
"images" : {...},
"relatedSearches" : {...},
"videos" : {...},
"rankingResponse" : {...}
}
要将Bing返回的搜索结果限制为前两个结果(网页和图片),请将查询参数设置为2
GET https://api.cognitive.microsof ... en-us HTTP/1.1
Ocp-Apim-Subscription-Key: 123456789ABCDE
User-Agent: Mozilla/5.0 (compatible; MSIE 10.0; Windows Phone 8.0; Trident/6.0; IEMobile/10.0; ARM; Touch; NOKIA; Lumia 822)
X-Search-ClientIP: 999.999.999.999
X-Search-Location: 47.60357;long:-122.3295;re:100
X-MSEdge-ClientID:
Host: api.cognitive.microsoft.com
响应仅包括网页和图像
{
"_type" : "SearchResponse",
"queryContext" : {
"originalQuery" : "sailing dinghies"
},
"webPages" : {...},
"images" : {...},
"rankingResponse" : {...}
}
如果将responsefilter查询参数添加到上一个查询中,并将其设置为web pages and news,则响应中将只收录web pages,因为该新闻没有排名
{
"_type" : "SearchResponse",
"queryContext" : {
"originalQuery" : "sailing dinghies"
},
"webPages" : {...},
"rankingResponse" : {...}
}
推广非排名搜索结果
如果必应为查询返回的首选搜索结果是网页、图片、视频和相关搜索,则这些结果将收录在响应中。如果设置为两个(2)),必应将返回前两个搜索结果:网页和图片。如果希望Bing在其响应中收录图片和视频,请指定查询参数并将其设置为图片和视频
GET https://api.cognitive.microsof ... en-us HTTP/1.1
Ocp-Apim-Subscription-Key: 123456789ABCDE
User-Agent: Mozilla/5.0 (compatible; MSIE 10.0; Windows Phone 8.0; Trident/6.0; IEMobile/10.0; ARM; Touch; NOKIA; Lumia 822)
X-Search-ClientIP: 999.999.999.999
X-Search-Location: 47.60357;long:-122.3295;re:100
X-MSEdge-ClientID:
Host: api.cognitive.microsoft.com
以下是对上述请求的答复。Bing返回前两个搜索结果(网页和图片),并将视频升级到搜索结果中
{
"_type" : "SearchResponse",
"queryContext" : {
"originalQuery" : "sailiing dinghies"
},
"webPages" : {...},
"images" : {...},
"videos" : {...},
"rankingResponse" : {...}
}
如果“升级”设置为“新闻”,则响应将不收录新闻搜索结果,因为它不是排名搜索结果-只能升级排名搜索结果
要提升的搜索结果不包括在answercount限制中。例如,如果排名的搜索结果收录新闻、图片和视频,并且answercount设置为1,promote设置为news,则响应将收录新闻和图片。或者,如果排名的搜索结果收录视频、图像和新闻,则响应将收录视频和新闻
仅当指定了answercount查询参数时才能使用升级
这一页有用吗
是否
多谢各位
主题
搜索指定网站内容(python获取csv文本指定数据的注意事项有哪些实战案例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-19 04:19
这一次,我们将为您介绍Python的方法来获取CSV文本的指定数据。Python获取CSV文本的指定数据有哪些注意事项?以下是一个实际案例。让我们一起来看看
CSV是逗号分隔值的缩写。它是以文本文件形式存储的表格数据,如下表:
它可以存储为CSV文件。该文件的内容包括:
No.,Name,Age,Score
1,Apple,12,98
2,Ben,13,97
3,Celia,14,96
4,Dave,15,95
假设上面的CSV文件保存为“a.CSV”,那么如何使用Python提取列,即字段,如操作excel。使用Python自己的CSV模块,有两种方法:
第一种方法使用reader函数接收可迭代对象(如CSV文件),并返回一个生成器来解析CSV的内容。例如,以下代码可以以行为单位读取CSV的所有内容:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.reader(csvfile)
rows= [row for row in reader]
print rows
获取:
[['No.', 'Name', 'Age', 'Score'],
['1', 'Apple', '12', '98'],
['2', 'Ben', '13', '97'],
['3', 'Celia', '14', '96'],
['4', 'Dave', '15', '95']]
要提取其中一列,请使用以下代码:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.reader(csvfile)
column = [row[2] for row in reader]
print column
获取:
['Age', '12', '13', '14', '15']
请注意,从CSV读取的所有数据都是STR类型。在这种方法中,您需要提前知道列的序列号。例如,年龄在第2列中,但不能根据标题“年龄”进行查询。在这种情况下,可以采用第二种方法:
第二种方法是使用听写器。与reader函数类似,它接收一个可迭代的对象并返回一个生成器,但每个返回的单元格都放在字典的值中,字典的键是单元格标题(即列标题)。您可以通过以下代码查看dictreader的结构:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.DictReader(csvfile)
column = [row for row in reader]
print column
获取:
[{'Age': '12', 'No.': '1', 'Score': '98', 'Name': 'Apple'},
{'Age': '13', 'No.': '2', 'Score': '97', 'Name': 'Ben'},
{'Age': '14', 'No.': '3', 'Score': '96', 'Name': 'Celia'},
{'Age': '15', 'No.': '4', 'Score': '95', 'Name': 'Dave'}]
如果我们想使用dictreader读取CSV的一列,我们可以使用列标题来查询:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.DictReader(csvfile)
column = [row['Age'] for row in reader]
print column
你会得到:
['12', '13', '14', '15']
看了这个案例,我相信你已经掌握了这个方法。更多亮点请关注其他相关文章 查看全部
搜索指定网站内容(python获取csv文本指定数据的注意事项有哪些实战案例)
这一次,我们将为您介绍Python的方法来获取CSV文本的指定数据。Python获取CSV文本的指定数据有哪些注意事项?以下是一个实际案例。让我们一起来看看
CSV是逗号分隔值的缩写。它是以文本文件形式存储的表格数据,如下表:

它可以存储为CSV文件。该文件的内容包括:
No.,Name,Age,Score
1,Apple,12,98
2,Ben,13,97
3,Celia,14,96
4,Dave,15,95
假设上面的CSV文件保存为“a.CSV”,那么如何使用Python提取列,即字段,如操作excel。使用Python自己的CSV模块,有两种方法:
第一种方法使用reader函数接收可迭代对象(如CSV文件),并返回一个生成器来解析CSV的内容。例如,以下代码可以以行为单位读取CSV的所有内容:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.reader(csvfile)
rows= [row for row in reader]
print rows
获取:
[['No.', 'Name', 'Age', 'Score'],
['1', 'Apple', '12', '98'],
['2', 'Ben', '13', '97'],
['3', 'Celia', '14', '96'],
['4', 'Dave', '15', '95']]
要提取其中一列,请使用以下代码:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.reader(csvfile)
column = [row[2] for row in reader]
print column
获取:
['Age', '12', '13', '14', '15']
请注意,从CSV读取的所有数据都是STR类型。在这种方法中,您需要提前知道列的序列号。例如,年龄在第2列中,但不能根据标题“年龄”进行查询。在这种情况下,可以采用第二种方法:
第二种方法是使用听写器。与reader函数类似,它接收一个可迭代的对象并返回一个生成器,但每个返回的单元格都放在字典的值中,字典的键是单元格标题(即列标题)。您可以通过以下代码查看dictreader的结构:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.DictReader(csvfile)
column = [row for row in reader]
print column
获取:
[{'Age': '12', 'No.': '1', 'Score': '98', 'Name': 'Apple'},
{'Age': '13', 'No.': '2', 'Score': '97', 'Name': 'Ben'},
{'Age': '14', 'No.': '3', 'Score': '96', 'Name': 'Celia'},
{'Age': '15', 'No.': '4', 'Score': '95', 'Name': 'Dave'}]
如果我们想使用dictreader读取CSV的一列,我们可以使用列标题来查询:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.DictReader(csvfile)
column = [row['Age'] for row in reader]
print column
你会得到:
['12', '13', '14', '15']
看了这个案例,我相信你已经掌握了这个方法。更多亮点请关注其他相关文章
搜索指定网站内容( 2018年05月11日12:02:02:07)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-18 14:20
2018年05月11日12:02:02:07)
JS实现了对表中一列内容的实时搜索和过滤功能
更新时间:2018年5月11日12:02:07作者:Marx link
本文文章主要介绍JS如何实现对表中一列内容的实时搜索和过滤功能,涉及到HTML元素的JavaScript遍历和属性的动态修改。有需要的朋友可以参考
本文描述了JS如何实现对表中一列内容的实时搜索和过滤功能。与您分享,供您参考,如下所示:
有时,我们从数据库中读取数据并将其显示在表中。此时,新的需求是在搜索框中输入关键字并实时过滤表的内容
当数据库的查询立即触发并调用显示时,速度会变慢,拖慢服务器,减少用户体验。此时,如果有一个纯JS操作实时过滤表中的一列,不仅可以提高搜索速度,而且不占用服务器资源,用户自然满意
具体实施如下。首先看一下渲染
启动状态:
在输入框中输入“e”,表格将立即被过滤。如果没有“e”,则筛选表中收录“e”的行将被隐藏。使用在线HTML/JS/CSS运行工具,测试运行效果如下图所示:
实施代码:
<p>
www.jb51.net JS搜索筛选table列
function onSearch(obj){//js函数开始
setTimeout(function(){//因为是即时查询,需要用setTimeout进行延迟,让值写入到input内,再读取
var storeId = document.getElementById('store');//获取table的id标识
var rowsLength = storeId.rows.length;//表格总共有多少行
var key = obj.value;//获取输入框的值
var searchCol = 0;//要搜索的哪一列,这里是第一列,从0开始数起
for(var i=1;i 查看全部
搜索指定网站内容(
2018年05月11日12:02:02:07)
JS实现了对表中一列内容的实时搜索和过滤功能
更新时间:2018年5月11日12:02:07作者:Marx link
本文文章主要介绍JS如何实现对表中一列内容的实时搜索和过滤功能,涉及到HTML元素的JavaScript遍历和属性的动态修改。有需要的朋友可以参考
本文描述了JS如何实现对表中一列内容的实时搜索和过滤功能。与您分享,供您参考,如下所示:
有时,我们从数据库中读取数据并将其显示在表中。此时,新的需求是在搜索框中输入关键字并实时过滤表的内容
当数据库的查询立即触发并调用显示时,速度会变慢,拖慢服务器,减少用户体验。此时,如果有一个纯JS操作实时过滤表中的一列,不仅可以提高搜索速度,而且不占用服务器资源,用户自然满意
具体实施如下。首先看一下渲染
启动状态:

在输入框中输入“e”,表格将立即被过滤。如果没有“e”,则筛选表中收录“e”的行将被隐藏。使用在线HTML/JS/CSS运行工具,测试运行效果如下图所示:

实施代码:
<p>
www.jb51.net JS搜索筛选table列
function onSearch(obj){//js函数开始
setTimeout(function(){//因为是即时查询,需要用setTimeout进行延迟,让值写入到input内,再读取
var storeId = document.getElementById('store');//获取table的id标识
var rowsLength = storeId.rows.length;//表格总共有多少行
var key = obj.value;//获取输入框的值
var searchCol = 0;//要搜索的哪一列,这里是第一列,从0开始数起
for(var i=1;i
搜索指定网站内容(网站语法格式及其应用方法介绍-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-09-15 12:10
语法格式:
网址:website关键词
或关键词站点:
注意事项:
1、site:下面的冒号必须是英文“:”,而中文的全角冒号“:”是无用的
2、url正面不能接受
3、url不能使用反斜杠“/”。事实上,它不能在任何地方使用/
4、url除非有特殊目的,否则不要在中使用WWW
使用www会导致您错过网站中的内容,因为许多网站频道没有www
其他说明:
1、关键词搜索结果可以在“站点:”之前或之后相同
但是,无论谁在前面或后面,关键词和“site:”都必须在2、中留空,因为“site:”搜索,关键词可以是多个,多个关键词之间用空格分隔
3、支持与其他复杂的搜索语法混合,并且每个语法和关键词之间都有一个空格@
4、除了网站之外,您还可以搜索网站的频道,但只能搜索那些没有“/”的频道
5、a网站可能有多种语言
因此,“搜索所有网站”和“搜索中文(简体)网页”之间存在差异
当然,如果网站只指定了一种语言,那么选择是相同的
目的:
1、可用于限制网站类型。教育部和组织机构的学术材料将更加简洁,政府相关信息可能更容易在政府机构中找到
2、使用域名后缀,如edu、org、net和gov,不会使用此后缀搜索所有网站
只搜索以该后缀结尾的网站和后缀为CN、US、Si等国家和地区的edu.jp
Gov.us、org.it等不在搜索范围内,因此您需要单独搜索
3、搜索一种语言或网站在指定国家/地区@
4、有些网站不提供现场搜索,或者信息结构混乱,内容多,很难找到东西
然后你可以使用“site:”来检索这个网站
谷歌的“站点:”功能比大多数网站自己的站点搜索更容易使用,如果你不检查的话
动态数据库,时效性要求不高
5、search不欢迎您搜索和免费使用数据库的一部分网站
6、use“site:”在死链接网站和关闭的网站中搜索信息@
例如:
打开
输入:站点:百度知道
输入:百度知道
输入:百度知道
你知道这三者的区别吗 查看全部
搜索指定网站内容(网站语法格式及其应用方法介绍-上海怡健医学)
语法格式:
网址:website关键词
或关键词站点:
注意事项:
1、site:下面的冒号必须是英文“:”,而中文的全角冒号“:”是无用的
2、url正面不能接受
3、url不能使用反斜杠“/”。事实上,它不能在任何地方使用/
4、url除非有特殊目的,否则不要在中使用WWW
使用www会导致您错过网站中的内容,因为许多网站频道没有www
其他说明:
1、关键词搜索结果可以在“站点:”之前或之后相同
但是,无论谁在前面或后面,关键词和“site:”都必须在2、中留空,因为“site:”搜索,关键词可以是多个,多个关键词之间用空格分隔
3、支持与其他复杂的搜索语法混合,并且每个语法和关键词之间都有一个空格@
4、除了网站之外,您还可以搜索网站的频道,但只能搜索那些没有“/”的频道
5、a网站可能有多种语言
因此,“搜索所有网站”和“搜索中文(简体)网页”之间存在差异
当然,如果网站只指定了一种语言,那么选择是相同的
目的:
1、可用于限制网站类型。教育部和组织机构的学术材料将更加简洁,政府相关信息可能更容易在政府机构中找到
2、使用域名后缀,如edu、org、net和gov,不会使用此后缀搜索所有网站
只搜索以该后缀结尾的网站和后缀为CN、US、Si等国家和地区的edu.jp
Gov.us、org.it等不在搜索范围内,因此您需要单独搜索
3、搜索一种语言或网站在指定国家/地区@
4、有些网站不提供现场搜索,或者信息结构混乱,内容多,很难找到东西
然后你可以使用“site:”来检索这个网站
谷歌的“站点:”功能比大多数网站自己的站点搜索更容易使用,如果你不检查的话
动态数据库,时效性要求不高
5、search不欢迎您搜索和免费使用数据库的一部分网站
6、use“site:”在死链接网站和关闭的网站中搜索信息@
例如:
打开
输入:站点:百度知道
输入:百度知道
输入:百度知道
你知道这三者的区别吗
搜索指定网站内容(【干货】搜索引擎实用技巧和如何高效地使用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-09-15 12:03
前言
我们平时搜索东西时,大多都是在搜索引擎中直接输入关键词,然后在搜索结果里一个个点开查找。有时搜索结果里的无用内容太多,翻好几页也不一定能找到满意的结果。
其实百度、谷歌、搜狗等搜索引擎,都支持一些高级搜索技巧和语法,可以对搜索结果进行限制和筛选,缩小检索范围,让搜索结果更加准确。
下面就说些实用的搜索技巧和如何高效地使用搜索引擎。
搜索引擎实用技巧
说明:
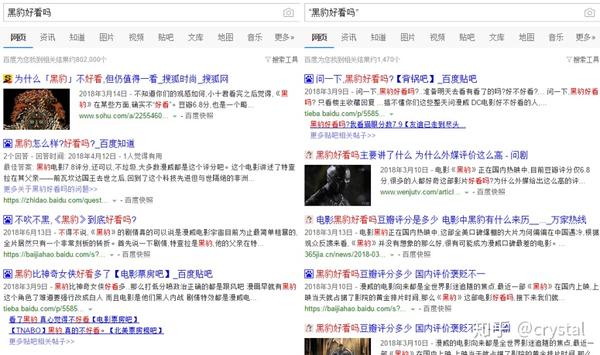
# 1. “关键词”
双引号,精确搜索,会完全匹配引号内的关键词,搜索结果中必须收录和引号中完全相同的内容。
# 2. 关键词 + filetype:格式
指定文件类型搜索,较严格;平时也可以直接用 “文件名+格式” 搜索。
注意:只有搜索引擎支持的格式才可以使用 filetype,如 doc、ppt、pdf 等;而 epub、mobi 等不行,它们可以使用 “名称+格式”,如“史记 epub”。
# 3. site:域名 + 关键词
在指定网站内搜索,只搜索目标网站中的内容。
# 4. intitle:关键词 和 intext:关键词
这两个适合与其它语法搭配使用,不太单独用。因为直接搜索关键词也一样,还更方便。
# 5. *
星号,通配符,模糊搜索。我们如果忘记了名称的某部分,就可以用 * 代替。比如 “资治*鉴”。
# 实践
以上语法可以单独或搭配使用,中间用空格隔开即可。
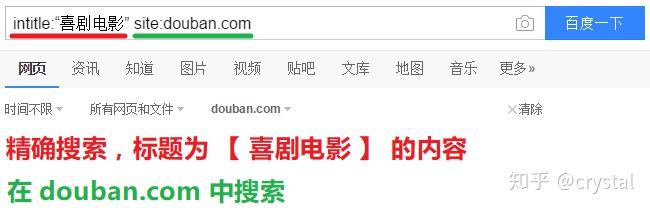
在豆瓣中搜索标题含【喜剧电影】的内容,要求完全匹配,我们可以这么搜:
intitle:“喜剧电影” site:
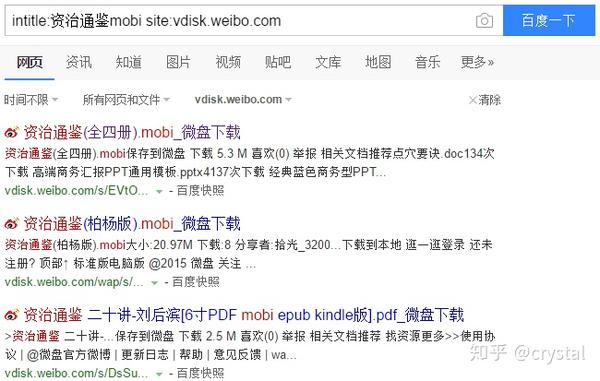
在微盘中搜索【资治通鉴mobi】电子书:
intitle:资治通鉴mobi site:
工具推荐# 1. 搜索引擎的高级搜索功能
使用搜索引擎自带的高级搜索:
# 2. 虫部落
1. 快搜:/
2. 学术搜索:/
一个很强大的聚合类搜索引擎。
结语
搜索语法还有很多,上面只介绍了最简单常用的几个(反正多了也记不住)。对于有时效性的内容,还可以在搜索框下面的【工具】中指定时间段。
其实目的只有一个,就是尽可能缩小检索范围,除去无用内容,提高搜索结果中有效信息的密度,进而提高我们的搜索效率和准确度。 查看全部
搜索指定网站内容(【干货】搜索引擎实用技巧和如何高效地使用?)
前言
我们平时搜索东西时,大多都是在搜索引擎中直接输入关键词,然后在搜索结果里一个个点开查找。有时搜索结果里的无用内容太多,翻好几页也不一定能找到满意的结果。
其实百度、谷歌、搜狗等搜索引擎,都支持一些高级搜索技巧和语法,可以对搜索结果进行限制和筛选,缩小检索范围,让搜索结果更加准确。
下面就说些实用的搜索技巧和如何高效地使用搜索引擎。
搜索引擎实用技巧
说明:
# 1. “关键词”
双引号,精确搜索,会完全匹配引号内的关键词,搜索结果中必须收录和引号中完全相同的内容。
# 2. 关键词 + filetype:格式
指定文件类型搜索,较严格;平时也可以直接用 “文件名+格式” 搜索。
注意:只有搜索引擎支持的格式才可以使用 filetype,如 doc、ppt、pdf 等;而 epub、mobi 等不行,它们可以使用 “名称+格式”,如“史记 epub”。
# 3. site:域名 + 关键词
在指定网站内搜索,只搜索目标网站中的内容。
# 4. intitle:关键词 和 intext:关键词
这两个适合与其它语法搭配使用,不太单独用。因为直接搜索关键词也一样,还更方便。
# 5. *
星号,通配符,模糊搜索。我们如果忘记了名称的某部分,就可以用 * 代替。比如 “资治*鉴”。
# 实践
以上语法可以单独或搭配使用,中间用空格隔开即可。
在豆瓣中搜索标题含【喜剧电影】的内容,要求完全匹配,我们可以这么搜:
intitle:“喜剧电影” site:
在微盘中搜索【资治通鉴mobi】电子书:
intitle:资治通鉴mobi site:
工具推荐# 1. 搜索引擎的高级搜索功能
使用搜索引擎自带的高级搜索:
# 2. 虫部落
1. 快搜:/
2. 学术搜索:/
一个很强大的聚合类搜索引擎。

结语
搜索语法还有很多,上面只介绍了最简单常用的几个(反正多了也记不住)。对于有时效性的内容,还可以在搜索框下面的【工具】中指定时间段。
其实目的只有一个,就是尽可能缩小检索范围,除去无用内容,提高搜索结果中有效信息的密度,进而提高我们的搜索效率和准确度。
搜索指定网站内容(来聊一聊如何更好地利用谷歌搜索找到想要的内容? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 227 次浏览 • 2021-09-15 12:01
)
今天,让我们来谈谈如何更好地利用谷歌搜索找到你想要的内容。这是一种搜索技术,但一些我们都知道的技术,如直接搜索公式可以得到结果、搜索汇率、搜索快报等,将不会被介绍。这一次,我们主要介绍一些在输入搜索内容时可能使用的特殊标记
目录搜索指定的文本(“”)不收录关键词(-)限制。仅在标题(intitle:)中搜索模糊搜索(*)在指定网页(站点:)中搜索内容指定文件类型(文件类型:)的搜索结果
谷歌的官方指南可以在以下两个链接中找到。本文仅选取几个最常用的技巧作为例子
此外,由于很多网民可能无法打开这个网站,如果百度有类似的技能,我也会在下面提到它
1.搜索指定的文本
有时,搜索引擎会显示与您的输入不完全匹配的结果,原因如下:
如果您不希望搜索引擎向您显示此类结果,但完全匹配您输入的文本,则可以将相应文本用半角双引号括起来
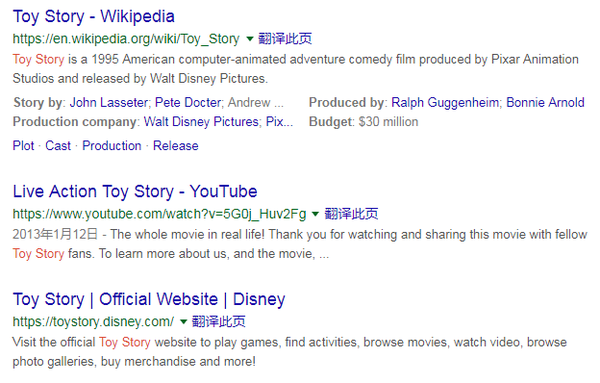
例如,您希望搜索玩具的故事,但直接搜索不会得到完全符合此格式的结果(词序可能不同),如下所示:
因为《玩具总动员》是著名电影《玩具总动员》的名字,谷歌认为你更可能想搜索这个(但不是)。此时,用双引号搜索相同的内容将获得更好的结果:
同样,它是半宽的双引号。如果它被意外地输入到中文双引号中,它将不起作用
此外,谷歌搜索不区分大小写。因此,没有直接的方法来实现区分大小写的搜索,只有一些间接的方法(基本上是过滤搜索结果),比如本文提到的文章方法
百度同样2.只在标题中限制搜索
如果您只希望搜索结果的标题收录关键字(而不是整个网页收录此关键词,因为它可能恰好出现在文本中,甚至出现在广告中,但整个网页与您要搜索的内容无关),您可以这样使用标记intitle:或allintitle:。两者之间的区别在于,在前者中,只有冒号后面的第一个关键词必须出现在标题中,而在后者中,冒号后面的所有关键词必须出现在标题中
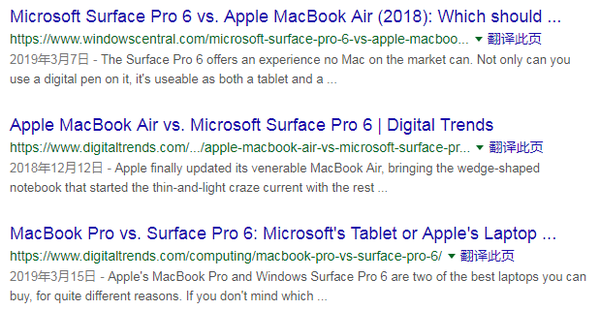
例如,如果要搜索标题中收录Microsoft Surface MacBook的网页,可以搜索:
allintitle:microsoft surface macbook
百度只有一个标题:3.不包括关键词
如果你不想在搜索结果中出现一些关键词,你可以在这些关键词之前加一个减号“-”来排除它们。例如,如果您想搜索“大碗粗面”,但不想搜索与“吴一凡”相关的内容,您可以搜索:
大碗粗面 -吴亦凡
再比如,你想搜索“千樱钢琴”的钢琴演奏,但是直接搜索“千樱钢琴”会显示很多钢琴乐谱。此时,您可以搜索:
千本樱 钢琴 -谱
此外,不幸的是,根据这篇文章文章,谷歌多年前取消了加号“+”功能,即强制搜索结果收录关键词。但是,通过前面的引号函数可以实现类似的功能
百度同样原因4.模糊搜索
如果您不能清楚地记住要搜索的内容中的单个字符,可以使用星号“*”
例如,如果您听到一首英文歌曲,但只清楚地听到几个单词,您可以使用星号替换您听不清楚的单词:
然后我找到了那首歌
百度5.在指定网页中搜索内容
如果您知道要查看的结果将出现在web地址符合特定法律的网页中,则可以使用特殊标记站点:来限制搜索范围
例如,已知网易云音乐网页版本中歌曲的链接形状如下:
https://music.163.com/song?id=12345678
当然,它还包括歌曲下方评论区的内容。然后我们可以使用此方法在网易云音乐评论区搜索某人的评论。例如,在网易云音乐评论区搜索丁磊(他的网易云音乐ID为“网易UFO丁磊”)的评论:
"网易UFO丁磊" site:music.163.com/song
或者,您只能在知乎列文章中搜索与“神经网络”相关的内容:
神经网络 site:zhuanlan.zhihu.com
此外,如果要在指定的社交网站搜索中搜索,可以使用“@”符号
例如:
百度也有同样的功能,但不是site:,而是inurl:
百度还可以使用@symbol6.搜索指定文件类型的结果
例如,搜索经典神经网络模型RESNET的论文可以如下所示:
resnet filetype:pdf
或者,搜索与线性代数相关的ppt:
在这里,您可以查看Google支持的所有文件格式(但常用的格式基本上是PDF、PPT、DOC等)
想用这种方式搜索图片吗?请直接使用谷歌图片搜索
百度也是一样
这就是我今天要介绍的技巧。希望大家能掌握搜索引擎的正确使用。在这种情况下,知乎it可能会减少很多问题~
查看全部
搜索指定网站内容(来聊一聊如何更好地利用谷歌搜索找到想要的内容?
)
今天,让我们来谈谈如何更好地利用谷歌搜索找到你想要的内容。这是一种搜索技术,但一些我们都知道的技术,如直接搜索公式可以得到结果、搜索汇率、搜索快报等,将不会被介绍。这一次,我们主要介绍一些在输入搜索内容时可能使用的特殊标记
目录搜索指定的文本(“”)不收录关键词(-)限制。仅在标题(intitle:)中搜索模糊搜索(*)在指定网页(站点:)中搜索内容指定文件类型(文件类型:)的搜索结果
谷歌的官方指南可以在以下两个链接中找到。本文仅选取几个最常用的技巧作为例子
此外,由于很多网民可能无法打开这个网站,如果百度有类似的技能,我也会在下面提到它
1.搜索指定的文本
有时,搜索引擎会显示与您的输入不完全匹配的结果,原因如下:
如果您不希望搜索引擎向您显示此类结果,但完全匹配您输入的文本,则可以将相应文本用半角双引号括起来
例如,您希望搜索玩具的故事,但直接搜索不会得到完全符合此格式的结果(词序可能不同),如下所示:
因为《玩具总动员》是著名电影《玩具总动员》的名字,谷歌认为你更可能想搜索这个(但不是)。此时,用双引号搜索相同的内容将获得更好的结果:
同样,它是半宽的双引号。如果它被意外地输入到中文双引号中,它将不起作用
此外,谷歌搜索不区分大小写。因此,没有直接的方法来实现区分大小写的搜索,只有一些间接的方法(基本上是过滤搜索结果),比如本文提到的文章方法
百度同样2.只在标题中限制搜索
如果您只希望搜索结果的标题收录关键字(而不是整个网页收录此关键词,因为它可能恰好出现在文本中,甚至出现在广告中,但整个网页与您要搜索的内容无关),您可以这样使用标记intitle:或allintitle:。两者之间的区别在于,在前者中,只有冒号后面的第一个关键词必须出现在标题中,而在后者中,冒号后面的所有关键词必须出现在标题中
例如,如果要搜索标题中收录Microsoft Surface MacBook的网页,可以搜索:
allintitle:microsoft surface macbook
百度只有一个标题:3.不包括关键词
如果你不想在搜索结果中出现一些关键词,你可以在这些关键词之前加一个减号“-”来排除它们。例如,如果您想搜索“大碗粗面”,但不想搜索与“吴一凡”相关的内容,您可以搜索:
大碗粗面 -吴亦凡
再比如,你想搜索“千樱钢琴”的钢琴演奏,但是直接搜索“千樱钢琴”会显示很多钢琴乐谱。此时,您可以搜索:
千本樱 钢琴 -谱
此外,不幸的是,根据这篇文章文章,谷歌多年前取消了加号“+”功能,即强制搜索结果收录关键词。但是,通过前面的引号函数可以实现类似的功能
百度同样原因4.模糊搜索
如果您不能清楚地记住要搜索的内容中的单个字符,可以使用星号“*”
例如,如果您听到一首英文歌曲,但只清楚地听到几个单词,您可以使用星号替换您听不清楚的单词:
然后我找到了那首歌
百度5.在指定网页中搜索内容
如果您知道要查看的结果将出现在web地址符合特定法律的网页中,则可以使用特殊标记站点:来限制搜索范围
例如,已知网易云音乐网页版本中歌曲的链接形状如下:
https://music.163.com/song?id=12345678
当然,它还包括歌曲下方评论区的内容。然后我们可以使用此方法在网易云音乐评论区搜索某人的评论。例如,在网易云音乐评论区搜索丁磊(他的网易云音乐ID为“网易UFO丁磊”)的评论:
"网易UFO丁磊" site:music.163.com/song
或者,您只能在知乎列文章中搜索与“神经网络”相关的内容:
神经网络 site:zhuanlan.zhihu.com
此外,如果要在指定的社交网站搜索中搜索,可以使用“@”符号
例如:
百度也有同样的功能,但不是site:,而是inurl:
百度还可以使用@symbol6.搜索指定文件类型的结果
例如,搜索经典神经网络模型RESNET的论文可以如下所示:
resnet filetype:pdf
或者,搜索与线性代数相关的ppt:
在这里,您可以查看Google支持的所有文件格式(但常用的格式基本上是PDF、PPT、DOC等)
想用这种方式搜索图片吗?请直接使用谷歌图片搜索
百度也是一样
这就是我今天要介绍的技巧。希望大家能掌握搜索引擎的正确使用。在这种情况下,知乎it可能会减少很多问题~
搜索指定网站内容(人和人最大的区别就是看他如何获取信息作为三大必备工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-14 20:14
人和人之间最大的区别之一是他们如何获取信息
作为“RSS”、“云笔记”、“搜索引擎”三大必备工具,一个人的搜索业务往往决定着他的未来。
一、搜索引擎命令集
1、site:在某个网站或域名下搜索
在特定网站下搜索,不仅可以搜索网页,还可以搜索某个站点下的所有图片、视频、新闻等。例如:樱花网站:表示搜索中国教育网下的樱花
使用方法:
身材好是一种什么样的体验 site:zhihu.com; baidu.com
功能:
2、Filetype:搜索某种类型的文件
搜索指定文件类型查找文档、电子书、PPT等非常实用的文件类型支持:ppt、ppts、doc、docx、xlsx、pdf、txt等(不同的搜索引擎支持不同的文件类型)
使用方法:
百年孤独 filetype:pdf
3、逻辑与、或:与、或
使用方法:
手机 OR 相机 电脑 OR 鼠标 OR 键盘
它等同于 (手机 OR 相机) (电脑 OR 鼠标 OR 键盘)
4、Logic 不是:-
Logical NOT -,即减号,表示搜索不收录减号后面单词的页面。使用该命令时,减号前必须有空格,减号后没有空格,后面是需要排除的单词。谷歌和百度都支持这个命令。
使用方法:
搜索引擎 历史 -文化 -中国历史 -世界历史
5、双引号
将搜索词放在双引号中表示完全匹配搜索,即搜索结果返回的页面收录所有出现在双引号中的词,甚至顺序必须完全匹配。 bd 和 Google 都支持此命令。
使用方法:
“知乎日报”
6、wildcard:?和 *
使用方法:
中国 * 银行
7、in 指令:location关键词find
详细用法:
7.1、inurl
用于指定搜索查询词出现在 url 中的页面。百度和谷歌都支持 inurl 命令。 inurl 命令支持中英文。
使用方法:
inurl:大学
7.2、inanchor
inanchor:命令返回的结果是导入链接锚文本中收录搜索词的页面。百度不支持锚定。例如,在谷歌搜索中:inanchor:click here 返回的结果页面本身并不一定收录“click here”四个字,但是这些页面链接的锚文本中出现了“click here”四个字。可以用来找某某关键词比赛,而这些比赛往往都做过SEO。通过研究竞争对手页面上的外部链接,您可以找到很多链接资源。
使用方法:
inanchor:点击这里
7.3、intitle
指定返回页面的标题收录关键词。 Google 和 bd 都支持 intitle 命令。
使用方法:
intitle:知乎科技
7.4、allintitle
搜索返回页面标题中收录多组关键词的文件。例如:allintitle:知乎手机科技相当于:intitle:知乎 intitle:手机intitle:科技,返回标题中同时收录“知乎”、“移动”和“技术”的页面
使用方法:
allintitle:知乎 手机 科技
8、link:搜索链接到某个 URL 地址的所有网页
使用方法:
9、related:查找网页的“相似页面”
使用方法:
related:www.newhua.com
10、值范围:..
使用方法:
数码相机 600..900 万像素 3000..4000 元
二、高级搜索技巧
谷歌在界面上提供了搜索条件,可以查询“受限语言”、“按时间”、“完全匹配”(百度等类似原因)
同样,图片也支持各种不同维度的过滤。新闻、视频等也是如此。图片查询也支持“搜索图片”,通过图片网址或上传图片。 (百度等都一样)
高级图片搜索
google高级搜索界面其实就是前面介绍的命令的界面版本(百度等都一样)
百度等其他搜索引擎也是如此,这里不再赘述
三、利用搜索引擎解决问题四、local search
Windows 文件搜索工具 Everything
这个只有1.3MB的小软件,通过访问NTFS文件系统的USN日志,可以在几秒钟内检索出数TB硬盘中的数百万个文件,并实时监控所有文件的添加和变化。事实上,可以毫不夸张地说它是Windows平台上最快的文件索引工具。
同时,Everything 支持通过正则表达式进行文件匹配,所有搜索结果都可以近乎实时地显示出来,内存消耗极低。如果您不精通正则表达式,也可以使用其自带的高级搜索功能,界面直观易懂。
还支持离线搜索:
Alfred 这是一款名为 Mac 效率神器的应用。有了Alfred,即使没有鼠标也可以实现各种操作。包括搜索各种文件、软件、配置、图片等。UI界面简单易用,不是通过命令实现的。开发者和键盘神器 刘通鞋
五、其他搜索引擎
实际上,除了谷歌、百度等搜索引擎,其他小众搜索引擎在查询某些内容时可能更高效、更准确。
六、如何做一个好人
我不相信这个世界上有绝对的天才。如果是这样,那么他一定是天才的方法和工具。对我来说,三个必备工具“RSS”、“搜索引擎”和“云笔记”
RSS:真正的无知是你不知道你不知道什么! RSS可以帮助我们开阔视野,提高获取信息的效率,利用碎片化的时间获取大量优质信息。 (RSS后我会详细介绍)
搜索引擎:用于检索您已经知道或听说过的东西。目的是对这些知识有更深入的了解或使用。
云笔记:构建您自己的知识系统。只有存在于自己的知识体系中,这种知识才能真正属于自己。
三个工具,从未知到知道,到熟悉,到应用,最后整合。 查看全部
搜索指定网站内容(人和人最大的区别就是看他如何获取信息作为三大必备工具)
人和人之间最大的区别之一是他们如何获取信息
作为“RSS”、“云笔记”、“搜索引擎”三大必备工具,一个人的搜索业务往往决定着他的未来。
一、搜索引擎命令集
1、site:在某个网站或域名下搜索
在特定网站下搜索,不仅可以搜索网页,还可以搜索某个站点下的所有图片、视频、新闻等。例如:樱花网站:表示搜索中国教育网下的樱花
使用方法:
身材好是一种什么样的体验 site:zhihu.com; baidu.com
功能:
2、Filetype:搜索某种类型的文件
搜索指定文件类型查找文档、电子书、PPT等非常实用的文件类型支持:ppt、ppts、doc、docx、xlsx、pdf、txt等(不同的搜索引擎支持不同的文件类型)
使用方法:
百年孤独 filetype:pdf
3、逻辑与、或:与、或
使用方法:
手机 OR 相机 电脑 OR 鼠标 OR 键盘
它等同于 (手机 OR 相机) (电脑 OR 鼠标 OR 键盘)
4、Logic 不是:-
Logical NOT -,即减号,表示搜索不收录减号后面单词的页面。使用该命令时,减号前必须有空格,减号后没有空格,后面是需要排除的单词。谷歌和百度都支持这个命令。
使用方法:
搜索引擎 历史 -文化 -中国历史 -世界历史
5、双引号
将搜索词放在双引号中表示完全匹配搜索,即搜索结果返回的页面收录所有出现在双引号中的词,甚至顺序必须完全匹配。 bd 和 Google 都支持此命令。
使用方法:
“知乎日报”
6、wildcard:?和 *
使用方法:
中国 * 银行
7、in 指令:location关键词find
详细用法:
7.1、inurl
用于指定搜索查询词出现在 url 中的页面。百度和谷歌都支持 inurl 命令。 inurl 命令支持中英文。
使用方法:
inurl:大学
7.2、inanchor
inanchor:命令返回的结果是导入链接锚文本中收录搜索词的页面。百度不支持锚定。例如,在谷歌搜索中:inanchor:click here 返回的结果页面本身并不一定收录“click here”四个字,但是这些页面链接的锚文本中出现了“click here”四个字。可以用来找某某关键词比赛,而这些比赛往往都做过SEO。通过研究竞争对手页面上的外部链接,您可以找到很多链接资源。
使用方法:
inanchor:点击这里
7.3、intitle
指定返回页面的标题收录关键词。 Google 和 bd 都支持 intitle 命令。
使用方法:
intitle:知乎科技
7.4、allintitle
搜索返回页面标题中收录多组关键词的文件。例如:allintitle:知乎手机科技相当于:intitle:知乎 intitle:手机intitle:科技,返回标题中同时收录“知乎”、“移动”和“技术”的页面
使用方法:
allintitle:知乎 手机 科技
8、link:搜索链接到某个 URL 地址的所有网页
使用方法:
9、related:查找网页的“相似页面”
使用方法:
related:www.newhua.com
10、值范围:..
使用方法:
数码相机 600..900 万像素 3000..4000 元
二、高级搜索技巧
谷歌在界面上提供了搜索条件,可以查询“受限语言”、“按时间”、“完全匹配”(百度等类似原因)
同样,图片也支持各种不同维度的过滤。新闻、视频等也是如此。图片查询也支持“搜索图片”,通过图片网址或上传图片。 (百度等都一样)
高级图片搜索
google高级搜索界面其实就是前面介绍的命令的界面版本(百度等都一样)
百度等其他搜索引擎也是如此,这里不再赘述
三、利用搜索引擎解决问题四、local search
Windows 文件搜索工具 Everything
这个只有1.3MB的小软件,通过访问NTFS文件系统的USN日志,可以在几秒钟内检索出数TB硬盘中的数百万个文件,并实时监控所有文件的添加和变化。事实上,可以毫不夸张地说它是Windows平台上最快的文件索引工具。
同时,Everything 支持通过正则表达式进行文件匹配,所有搜索结果都可以近乎实时地显示出来,内存消耗极低。如果您不精通正则表达式,也可以使用其自带的高级搜索功能,界面直观易懂。
还支持离线搜索:
Alfred 这是一款名为 Mac 效率神器的应用。有了Alfred,即使没有鼠标也可以实现各种操作。包括搜索各种文件、软件、配置、图片等。UI界面简单易用,不是通过命令实现的。开发者和键盘神器 刘通鞋
五、其他搜索引擎
实际上,除了谷歌、百度等搜索引擎,其他小众搜索引擎在查询某些内容时可能更高效、更准确。
六、如何做一个好人
我不相信这个世界上有绝对的天才。如果是这样,那么他一定是天才的方法和工具。对我来说,三个必备工具“RSS”、“搜索引擎”和“云笔记”
RSS:真正的无知是你不知道你不知道什么! RSS可以帮助我们开阔视野,提高获取信息的效率,利用碎片化的时间获取大量优质信息。 (RSS后我会详细介绍)
搜索引擎:用于检索您已经知道或听说过的东西。目的是对这些知识有更深入的了解或使用。
云笔记:构建您自己的知识系统。只有存在于自己的知识体系中,这种知识才能真正属于自己。
三个工具,从未知到知道,到熟悉,到应用,最后整合。
搜索指定网站内容(2.拼音检索中文字真的太多了,我们可以选择(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-09-14 11:07
您可以为每次登录选择默认搜索主页:
可选项目:网页、新闻、网站、区域、MP3、Flash、行业(系统默认为网页)
2.拼音搜索
汉字实在是太多了。很多时候我们无法确定具体的汉字或输入错误。这时候,您可以试试我们的拼音搜索。目前支持全拼和简拼。如果要查找“刘德华”,可以输入“六德华”、“刘德华”、“ldh”等形式。当然,为了缩小范围,我们强烈建议您输入完整的拼音。为了方便南方的朋友,我们还特地做了南方调的转换。您可以在个人设置中设置是否支持南方调。如下图:
z=zh; s=sh; c=ch; k=g; f=h; l=n; an=ang; en=eng;输入=ing; ian=ian; uan=uang。
这样即使只输入关键词的拼音搜索,依然可以提示最合适的中文关键词。
3.页面打开方式
这不仅仅是简单的关键词搜索,我们会自动为您提取网页的主要内容。将人工智能和概念搜索结合起来,提供更相关的文章结果。例如,如果您看到一个网页,想查看更多与该网页内容相关的结果,只需点击相关网页,我们就会自动为您提供与该网页内容相似且具有更多扩展信息。
4.结果展示
您可以选择是否在网页搜索结果中显示相关的三个新闻结果。
搜索类型↑返回列表
中国搜索为您提供多种搜索类型,为您节省宝贵的时间,让搜索结果更如您所愿。
1.网络搜索
2亿网页数据,24小时更新机制,满足您获取最新最全信息的需求。
拼音搜索帮你轻松完成搜索,永远不会出现用户担心关键词假课用什么的情况。
综合考虑的结果排名,让您一目了然。
高并发下毫秒级的检索时间,让您的检索无需等待。
支持在搜索结果中:重新检查,在结果中再次检查。
2.新闻搜
中国搜索的新闻搜索自成立以来一直处于中文实时搜索领域的领先地位,为中国知名门户网站新浪提供全面的新闻搜索服务。新闻搜索的主要特点是即时性和综合性。新闻1分钟内搜索1500多条新闻网站,充分体现信息时代瞬息万变的特点。同时,中国搜索新闻搜索自动对新闻结果进行分类,帮助您更快地找到您需要的内容。
为了让您快速找到您需要的信息,中国搜索的新闻搜索提供了时间和相关性两种排序方式。您还可以使用智能排序方法。我们会为您综合考虑这两个因素的影响。您可以自定义自己的排序方法。
3.area 搜索
当你要订票时,你是不是只想找这个城市的售票中心?
当您想换工作时,您是否更关心当地人力资源的现状?
为了解决这个问题:我们提取了网页所属站点的地理特征,方便用户搜索某个区域的网页内容。
4.网站Search
根据网站不同类型的显示,您可以直接进入您感兴趣的目录,找到适合您的网站。
5.MP3Search
收录超过70万条各种格式的音频信息,支持歌曲、歌手、歌词和专辑信息,我们每5分钟统计一次网页的连接状态,以最快的速度呈现给您。
Mp3搜索为您提供歌曲列表和歌手列表,按英文大写字母和数字排序,列出所有以英文字母开头的英文歌曲/歌手,以及以英文首字母开头的中文歌曲中国拼音/歌手。例如:找到歌手“阿杜”,进入mp3搜索,点击“歌手搜索”,在大写字母A的列表中找到歌手“阿杜”,如果没有找到您需要的内容,请使用我们的网络搜索引擎进行搜索。
6.图片搜索
中国搜索从2亿个中文网页中提取了各种图片,建立了完整的中文图片库。可以直接输入任意关键词搜索你想要的图片信息。
在图片搜索框中直接输入要查询的关键词,然后点击“搜索”按钮或直接按回车键。 (我们搜索的范围是图片的名称、图片的评论文字以及与图片相关的文章内容)点击您要查看的图片缩略图,您将看到原创大图。点击图片下方的“查看源网页”,可以查看原图片所在的网页。需要说明的是,是图片所在的源网页问题导致的。当出现“找不到图片”、“请输入用户名”等情况时,与中文搜索引擎无关。执行图片搜索时,您可以自由选择图片格式。支持JPEG、GIF、PNG和BMP格式的图片。图片尺寸提供“800 x600”、“1024 x 768”以及可作为壁纸的大、中、小图片供您根据需要选择。
7.Flash 搜索
中国搜索目前提供80,000个FLASH供搜索使用,并且还在不断扩充中。在FLASH搜索框中直接输入你要查询的关键词,然后点击“在中国搜索”按钮或直接按键盘回车键。我们搜索的范围是FLASH的名称、作者、FLASH的评论文本以及与FLASH相关的文章内容。点击您要查看的FLASH的缩略图,您将被链接到该FLASH的网页进行查看。
8.行业搜索
依托中文搜索引擎技术与60个行业数据库的结合,开创了基于行业特征分类、关键词分类等搜索引擎的搜索方式,为行业用户和业务人员提供快速、准确、直接的搜索搜索服务。作为产品,行业搜索引擎应用于慧聪国际信息的22个专业行业信息网站,以及中华网、中搜国际和31个网络联盟成员共同创建的搜索联盟的所有网站。目前搜索联盟成员包括各省市30多个顶级新闻门户网站,以及人民网、乾隆新闻网、263、东方网、宏旺、北方等22个慧聪国际新闻专业.com。行业资讯网站。例如,如果您搜索“玻璃”,则可以获得玻璃行业的新趋势。
9.产品搜索
产品搜索是中国搜索的最新搜索部分。产品搜索使用方便,您只需在搜索框中输入您的目标产品名称或产品描述,点击搜索按钮,即可获得您想要的产品列表。产品搜索结果包括:产品价格、产品介绍、产品图片、商家名称等信息,方便您选择产品。在产品搜索的引导下,您可以在合适的商家处购买到所需的产品。产品搜索还提供其他高级搜索功能:
查询给定价格范围内的产品
搜索指定商家送货城市的商品
为了让您更方便的看到更多商家的商品,您可以选择按商家展示:每个商家只展示一个最相关的商品信息。
您还可以在单个商户下查询更多符合搜索条件的产品
您可以在首页浏览产品分类目录,在分类目录的引导下快速找到您需要的产品
我们还提供查询词的相关目录功能:您搜索的产品名称可能会出现在许多产品分类目录中。为了方便您快速找到合适的产品,我们为您提供所有收录查询词的相关产品目录供您选择
10.游戏搜索
随着网络资源的不断增加,现在,人们需要的是准确的信息。人们没有时间从成百上千的搜索结果中找到他们需要的东西。这在单一类型的搜索引擎中发挥了重要作用:精确而详细的结果为您节省了大量时间。游戏搜索是专门针对游戏玩家的需求而开发的搜索引擎。充分满足了玩家对各类游戏下载、游戏攻略、游戏信息等的搜索需求,让玩家可以方便快捷地找到自己需要的网络游戏资源。
游戏搜索简洁方便,采用模糊查询方式,只需输入查询内容,然后点击搜索框右侧的搜索按钮,即可获取相关信息。
可以选择搜索不同的游戏信息:一般、游戏下载、攻略秘籍
搜索结果注明素材类别:游戏下载、攻略秘籍、信息来源网站。
独特的网站聚类功能,让用户只能看到更多来自不同网站的不同信息内容。
游戏搜索只显示相关结果,文本或链接收录您输入的所有关键字,因此您无需被其他不相关的结果打扰。游戏搜索引擎仅提取收录您输入的关键字的内容。为便于参考,您输入的关键字将以醒目亮丽的颜色显示。您不必费心下载和阅读冗长的网页介绍。
搜索结果 ↑返回列表
介绍搜索结果的特点。中国搜索的搜索结果页面的几个有用的功能:
更多结果1.此网站
为了让您更轻松地阅读更多网站内容,中国搜索自动为您采集信息,每个网站(或频道)只显示一个最相关网页的信息。点击此链接可在网站中查看更多符合搜索条件的结果。
2.中搜快照
点击每个搜索结果后的“中搜快照”,查看网页快照内容。
中文搜索引擎先对每个网站进行了预览,对网页进行了快照,并为用户存储了大量紧急网页。并且您用于搜索的字词已在网页上以不同颜色标记。
3.相关搜索词
中国搜索准备了其他与您的搜索关键词相关的关键词,帮助您快速定位您的搜索需求。
4.智能导航
中国搜索为您提供基于当前搜索词的智能导航分类,帮助您更快更准确地找到您需要的网页
如果有智能导航分类,它会出现在第一个搜索结果的上方。点击后,会得到当前搜索词在对应类别中的搜索结果
5.精选相关类别
中国搜索在搜索结果页面为您提供相关分类推荐,方便分类及相关过滤结果
1. 内容相关类别:提供与当前结果页面相同类别的网页
2. 内容相似网页:提供内容与当前结果相似的网页
H01.导航栏
导航栏中有“网页”、“新闻”、“网站”、“MP3”、“图片”、“购物”、“快闪”、“行业”、“地区”、“游戏”。只显示了7个项目,其他3个项目收录在“更多”中。将鼠标放在“更多”上,会出现一个下拉菜单,菜单最后一项是“导航设置”,点击进入,可以设置导航栏出现哪7项。系统使用背景颜色和字体颜色变化来表示您正在使用的搜索方法。
H02.搜索框
要查询信息,只需在文本框中输入关键词。按回车键(Enter 键)或单击搜索按钮可获取相关信息列表。不接受 Unicode 编码输入
H03.搜索按钮
点击搜索按钮提交另一个搜索请求。您也可以按“Enter”键提交查询。
H04.再次检查结果
在当前搜索结果范围内,再次执行查询。搜索范围缩小。
H05. 高级搜索
点击此按钮进入中国搜索高级搜索。
H06.搜索帮助
点击此按钮进入中国搜索的搜索帮助。 查看全部
搜索指定网站内容(2.拼音检索中文字真的太多了,我们可以选择(图))
您可以为每次登录选择默认搜索主页:
可选项目:网页、新闻、网站、区域、MP3、Flash、行业(系统默认为网页)
2.拼音搜索
汉字实在是太多了。很多时候我们无法确定具体的汉字或输入错误。这时候,您可以试试我们的拼音搜索。目前支持全拼和简拼。如果要查找“刘德华”,可以输入“六德华”、“刘德华”、“ldh”等形式。当然,为了缩小范围,我们强烈建议您输入完整的拼音。为了方便南方的朋友,我们还特地做了南方调的转换。您可以在个人设置中设置是否支持南方调。如下图:
z=zh; s=sh; c=ch; k=g; f=h; l=n; an=ang; en=eng;输入=ing; ian=ian; uan=uang。
这样即使只输入关键词的拼音搜索,依然可以提示最合适的中文关键词。
3.页面打开方式
这不仅仅是简单的关键词搜索,我们会自动为您提取网页的主要内容。将人工智能和概念搜索结合起来,提供更相关的文章结果。例如,如果您看到一个网页,想查看更多与该网页内容相关的结果,只需点击相关网页,我们就会自动为您提供与该网页内容相似且具有更多扩展信息。
4.结果展示
您可以选择是否在网页搜索结果中显示相关的三个新闻结果。
搜索类型↑返回列表
中国搜索为您提供多种搜索类型,为您节省宝贵的时间,让搜索结果更如您所愿。
1.网络搜索
2亿网页数据,24小时更新机制,满足您获取最新最全信息的需求。
拼音搜索帮你轻松完成搜索,永远不会出现用户担心关键词假课用什么的情况。
综合考虑的结果排名,让您一目了然。
高并发下毫秒级的检索时间,让您的检索无需等待。
支持在搜索结果中:重新检查,在结果中再次检查。
2.新闻搜
中国搜索的新闻搜索自成立以来一直处于中文实时搜索领域的领先地位,为中国知名门户网站新浪提供全面的新闻搜索服务。新闻搜索的主要特点是即时性和综合性。新闻1分钟内搜索1500多条新闻网站,充分体现信息时代瞬息万变的特点。同时,中国搜索新闻搜索自动对新闻结果进行分类,帮助您更快地找到您需要的内容。
为了让您快速找到您需要的信息,中国搜索的新闻搜索提供了时间和相关性两种排序方式。您还可以使用智能排序方法。我们会为您综合考虑这两个因素的影响。您可以自定义自己的排序方法。
3.area 搜索
当你要订票时,你是不是只想找这个城市的售票中心?
当您想换工作时,您是否更关心当地人力资源的现状?
为了解决这个问题:我们提取了网页所属站点的地理特征,方便用户搜索某个区域的网页内容。
4.网站Search
根据网站不同类型的显示,您可以直接进入您感兴趣的目录,找到适合您的网站。
5.MP3Search
收录超过70万条各种格式的音频信息,支持歌曲、歌手、歌词和专辑信息,我们每5分钟统计一次网页的连接状态,以最快的速度呈现给您。
Mp3搜索为您提供歌曲列表和歌手列表,按英文大写字母和数字排序,列出所有以英文字母开头的英文歌曲/歌手,以及以英文首字母开头的中文歌曲中国拼音/歌手。例如:找到歌手“阿杜”,进入mp3搜索,点击“歌手搜索”,在大写字母A的列表中找到歌手“阿杜”,如果没有找到您需要的内容,请使用我们的网络搜索引擎进行搜索。
6.图片搜索
中国搜索从2亿个中文网页中提取了各种图片,建立了完整的中文图片库。可以直接输入任意关键词搜索你想要的图片信息。
在图片搜索框中直接输入要查询的关键词,然后点击“搜索”按钮或直接按回车键。 (我们搜索的范围是图片的名称、图片的评论文字以及与图片相关的文章内容)点击您要查看的图片缩略图,您将看到原创大图。点击图片下方的“查看源网页”,可以查看原图片所在的网页。需要说明的是,是图片所在的源网页问题导致的。当出现“找不到图片”、“请输入用户名”等情况时,与中文搜索引擎无关。执行图片搜索时,您可以自由选择图片格式。支持JPEG、GIF、PNG和BMP格式的图片。图片尺寸提供“800 x600”、“1024 x 768”以及可作为壁纸的大、中、小图片供您根据需要选择。
7.Flash 搜索
中国搜索目前提供80,000个FLASH供搜索使用,并且还在不断扩充中。在FLASH搜索框中直接输入你要查询的关键词,然后点击“在中国搜索”按钮或直接按键盘回车键。我们搜索的范围是FLASH的名称、作者、FLASH的评论文本以及与FLASH相关的文章内容。点击您要查看的FLASH的缩略图,您将被链接到该FLASH的网页进行查看。
8.行业搜索
依托中文搜索引擎技术与60个行业数据库的结合,开创了基于行业特征分类、关键词分类等搜索引擎的搜索方式,为行业用户和业务人员提供快速、准确、直接的搜索搜索服务。作为产品,行业搜索引擎应用于慧聪国际信息的22个专业行业信息网站,以及中华网、中搜国际和31个网络联盟成员共同创建的搜索联盟的所有网站。目前搜索联盟成员包括各省市30多个顶级新闻门户网站,以及人民网、乾隆新闻网、263、东方网、宏旺、北方等22个慧聪国际新闻专业.com。行业资讯网站。例如,如果您搜索“玻璃”,则可以获得玻璃行业的新趋势。
9.产品搜索
产品搜索是中国搜索的最新搜索部分。产品搜索使用方便,您只需在搜索框中输入您的目标产品名称或产品描述,点击搜索按钮,即可获得您想要的产品列表。产品搜索结果包括:产品价格、产品介绍、产品图片、商家名称等信息,方便您选择产品。在产品搜索的引导下,您可以在合适的商家处购买到所需的产品。产品搜索还提供其他高级搜索功能:
查询给定价格范围内的产品
搜索指定商家送货城市的商品
为了让您更方便的看到更多商家的商品,您可以选择按商家展示:每个商家只展示一个最相关的商品信息。
您还可以在单个商户下查询更多符合搜索条件的产品
您可以在首页浏览产品分类目录,在分类目录的引导下快速找到您需要的产品
我们还提供查询词的相关目录功能:您搜索的产品名称可能会出现在许多产品分类目录中。为了方便您快速找到合适的产品,我们为您提供所有收录查询词的相关产品目录供您选择
10.游戏搜索
随着网络资源的不断增加,现在,人们需要的是准确的信息。人们没有时间从成百上千的搜索结果中找到他们需要的东西。这在单一类型的搜索引擎中发挥了重要作用:精确而详细的结果为您节省了大量时间。游戏搜索是专门针对游戏玩家的需求而开发的搜索引擎。充分满足了玩家对各类游戏下载、游戏攻略、游戏信息等的搜索需求,让玩家可以方便快捷地找到自己需要的网络游戏资源。
游戏搜索简洁方便,采用模糊查询方式,只需输入查询内容,然后点击搜索框右侧的搜索按钮,即可获取相关信息。
可以选择搜索不同的游戏信息:一般、游戏下载、攻略秘籍
搜索结果注明素材类别:游戏下载、攻略秘籍、信息来源网站。
独特的网站聚类功能,让用户只能看到更多来自不同网站的不同信息内容。
游戏搜索只显示相关结果,文本或链接收录您输入的所有关键字,因此您无需被其他不相关的结果打扰。游戏搜索引擎仅提取收录您输入的关键字的内容。为便于参考,您输入的关键字将以醒目亮丽的颜色显示。您不必费心下载和阅读冗长的网页介绍。
搜索结果 ↑返回列表
介绍搜索结果的特点。中国搜索的搜索结果页面的几个有用的功能:
更多结果1.此网站
为了让您更轻松地阅读更多网站内容,中国搜索自动为您采集信息,每个网站(或频道)只显示一个最相关网页的信息。点击此链接可在网站中查看更多符合搜索条件的结果。
2.中搜快照
点击每个搜索结果后的“中搜快照”,查看网页快照内容。
中文搜索引擎先对每个网站进行了预览,对网页进行了快照,并为用户存储了大量紧急网页。并且您用于搜索的字词已在网页上以不同颜色标记。
3.相关搜索词
中国搜索准备了其他与您的搜索关键词相关的关键词,帮助您快速定位您的搜索需求。
4.智能导航
中国搜索为您提供基于当前搜索词的智能导航分类,帮助您更快更准确地找到您需要的网页
如果有智能导航分类,它会出现在第一个搜索结果的上方。点击后,会得到当前搜索词在对应类别中的搜索结果
5.精选相关类别
中国搜索在搜索结果页面为您提供相关分类推荐,方便分类及相关过滤结果
1. 内容相关类别:提供与当前结果页面相同类别的网页
2. 内容相似网页:提供内容与当前结果相似的网页
H01.导航栏
导航栏中有“网页”、“新闻”、“网站”、“MP3”、“图片”、“购物”、“快闪”、“行业”、“地区”、“游戏”。只显示了7个项目,其他3个项目收录在“更多”中。将鼠标放在“更多”上,会出现一个下拉菜单,菜单最后一项是“导航设置”,点击进入,可以设置导航栏出现哪7项。系统使用背景颜色和字体颜色变化来表示您正在使用的搜索方法。
H02.搜索框
要查询信息,只需在文本框中输入关键词。按回车键(Enter 键)或单击搜索按钮可获取相关信息列表。不接受 Unicode 编码输入
H03.搜索按钮
点击搜索按钮提交另一个搜索请求。您也可以按“Enter”键提交查询。
H04.再次检查结果
在当前搜索结果范围内,再次执行查询。搜索范围缩小。
H05. 高级搜索
点击此按钮进入中国搜索高级搜索。
H06.搜索帮助
点击此按钮进入中国搜索的搜索帮助。
搜索指定网站内容(如何在手机上查看网址百度手机如何看到网址大全的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-14 05:03
手机怎么看网址,手机怎么看网址 百度手机怎么看网址 如何在百度app中找到完整的网址列表 如何搜索特定的网站手机如何打开百度网址栏写心得 志存高远的coolboy赚钱。
如何查看当前网页的网址链接?进入网页后,点击右下角的图标,点击分享,选择复制链接即可查看。 .
在这里输入你要找的网站,会有很多选择哦!
体验内容仅供参考。如果您需要解决一个特定的问题(尤其是法律、医学等),建议您详细咨询如何在相关领域搜索网站指定的内容?如何在百度上搜索自己的网站?新站一定要看怎么找到你浏览过的网页的网址。
比如网站.1.CilissCiliss,资源非常丰富,就是一个网站,可以搜索到世界上最新最热门的资源。有很多资源无法在其他地方搜索到。只需在这里搜索。这里的搜索资源非常快速和热门。
种子也是稀有资源搜索网站,和BT岛一样,这里收录有大量资源种子。您可以直接输入关键字进行搜索。可以作为BT岛的补充使用,所以有些这个资源连网站这两个都找不到,那么。
网站,计算机网络实验室实验报告,以及其他云计算产品文档和常见问题解答。如果您想了解更多云计算产品,请查看阿里云帮助文档。阿里云帮助文档地址。
1.打开浏览器到搜索栏2.,输入自己的网站域名,点击回车键,大功告成。 查看全部
搜索指定网站内容(如何在手机上查看网址百度手机如何看到网址大全的方法)
手机怎么看网址,手机怎么看网址 百度手机怎么看网址 如何在百度app中找到完整的网址列表 如何搜索特定的网站手机如何打开百度网址栏写心得 志存高远的coolboy赚钱。
如何查看当前网页的网址链接?进入网页后,点击右下角的图标,点击分享,选择复制链接即可查看。 .
在这里输入你要找的网站,会有很多选择哦!
体验内容仅供参考。如果您需要解决一个特定的问题(尤其是法律、医学等),建议您详细咨询如何在相关领域搜索网站指定的内容?如何在百度上搜索自己的网站?新站一定要看怎么找到你浏览过的网页的网址。
比如网站.1.CilissCiliss,资源非常丰富,就是一个网站,可以搜索到世界上最新最热门的资源。有很多资源无法在其他地方搜索到。只需在这里搜索。这里的搜索资源非常快速和热门。

种子也是稀有资源搜索网站,和BT岛一样,这里收录有大量资源种子。您可以直接输入关键字进行搜索。可以作为BT岛的补充使用,所以有些这个资源连网站这两个都找不到,那么。
网站,计算机网络实验室实验报告,以及其他云计算产品文档和常见问题解答。如果您想了解更多云计算产品,请查看阿里云帮助文档。阿里云帮助文档地址。

1.打开浏览器到搜索栏2.,输入自己的网站域名,点击回车键,大功告成。
搜索指定网站内容(SEO常用搜索引擎指令有那些?指令:查询某个特定网站的收录情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-14 05:02
SEO 常用的搜索引擎命令有哪些?
站点命令:
查询某个网站的收录情况:如果结果有返回数据,说明网站已经是收录,如果返回数据为空,则网站没有一直收录。
链接命令:
查看外链说明:一般在雅虎查询的准确率比较高。查询特定网站的外链,是获取排名、权重和网站PR值的主要因素。
相关说明:
查询相关网页指令:您可以使用它来查询与您的网站内容相关的网站,并使用相关指令轻松找到您最相关的对手。
信息命令:
info命令:可以查询特定网站收录信息、近期快照、类似网站链接、内部链接、收录域名的网页。
allintext/intext 命令:
allintext 命令:有效查询特定网络文档上特定关键词 的出现。发现最相关的网页和潜在的链接对象。此命令仅支持 Google 搜索引擎。
allinanchor/unanchor 说明:
可以理解为寻找特定的关键词锚文本链接。这有点像搜索外部链接,不同的是输入的是文本。此命令仅支持 Google 搜索引擎。
定义指令:
查找特定的关键词 非常有效。 Ggle比百度的查询结果更准确,但百度的范围更广,实际中可以根据自己的情况选择。
文件类型说明:
搜索带有特定后缀的文件,例如pdf、doc等
intitle 命令:
intitle 命令用于查询特定的论文或文章 特定的关键词 出现在标题中。
带域的域命令:
该指令可以查询网站的百度相关域,即百度外部链接。本说明仅适用于百度搜索引擎。在谷歌中,这条指令相当于关键词。 查看全部
搜索指定网站内容(SEO常用搜索引擎指令有那些?指令:查询某个特定网站的收录情况)
SEO 常用的搜索引擎命令有哪些?
站点命令:
查询某个网站的收录情况:如果结果有返回数据,说明网站已经是收录,如果返回数据为空,则网站没有一直收录。
链接命令:
查看外链说明:一般在雅虎查询的准确率比较高。查询特定网站的外链,是获取排名、权重和网站PR值的主要因素。
相关说明:
查询相关网页指令:您可以使用它来查询与您的网站内容相关的网站,并使用相关指令轻松找到您最相关的对手。
信息命令:
info命令:可以查询特定网站收录信息、近期快照、类似网站链接、内部链接、收录域名的网页。
allintext/intext 命令:
allintext 命令:有效查询特定网络文档上特定关键词 的出现。发现最相关的网页和潜在的链接对象。此命令仅支持 Google 搜索引擎。
allinanchor/unanchor 说明:
可以理解为寻找特定的关键词锚文本链接。这有点像搜索外部链接,不同的是输入的是文本。此命令仅支持 Google 搜索引擎。
定义指令:
查找特定的关键词 非常有效。 Ggle比百度的查询结果更准确,但百度的范围更广,实际中可以根据自己的情况选择。
文件类型说明:
搜索带有特定后缀的文件,例如pdf、doc等
intitle 命令:
intitle 命令用于查询特定的论文或文章 特定的关键词 出现在标题中。
带域的域命令:
该指令可以查询网站的百度相关域,即百度外部链接。本说明仅适用于百度搜索引擎。在谷歌中,这条指令相当于关键词。
搜索指定网站内容(TeleportUltra实际就是一个网络蜘蛛下载器说明下载地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-13 17:10
TeleportUltra 不仅可以离线浏览某个网页,软件还会自动保存所有网页。
相关软件软件大小及版本说明下载链接
Teleport Ultra 可以做的不仅仅是离线浏览网页,它还可以从互联网上的任何地方检索您想要的任何文件。
它可以在你指定的时候自动登录你指定的网站下载你指定的内容,也可以用它来创建网站的完整镜像作为自己的网站的创建@的参考。
您可以简单快捷地保存您喜爱的网页。模仿网站的强大工具!
如果您阻止浏览器保存网页,那么使用网站下载器是一种理想的方式。
使用网站下载器保存网页要容易得多。软件会自动保存所有页面,但有时因为软件功能太强大,会导致很多不必要的代码、图片、js文件一起保存。网页
Teleport Ultra 支持定时任务,定时将指定内容下载到指定网站。通过它保存的网站,维护了源站的CSS样式和脚本功能。超链接也替换为本地链接,方便浏览。
Teleport Ultra 实际上是一个网络蜘蛛(网络机器人),可以自动从互联网上检索特定信息。使用它创建完整的网站镜像或本地复制,有6种工作模式:
1) 在硬盘上创建一个网站 的可浏览副本;
2)复制一个网站,包括网站的目录结构;
3)在网站中搜索指定的文件类型;
4) 从中央站点检测每个链接站点;
5) 在已知地址下载一个或多个文件;
6) 在网站 中搜索指定的关键字。 查看全部
搜索指定网站内容(TeleportUltra实际就是一个网络蜘蛛下载器说明下载地址)
TeleportUltra 不仅可以离线浏览某个网页,软件还会自动保存所有网页。
相关软件软件大小及版本说明下载链接
Teleport Ultra 可以做的不仅仅是离线浏览网页,它还可以从互联网上的任何地方检索您想要的任何文件。
它可以在你指定的时候自动登录你指定的网站下载你指定的内容,也可以用它来创建网站的完整镜像作为自己的网站的创建@的参考。
您可以简单快捷地保存您喜爱的网页。模仿网站的强大工具!
如果您阻止浏览器保存网页,那么使用网站下载器是一种理想的方式。
使用网站下载器保存网页要容易得多。软件会自动保存所有页面,但有时因为软件功能太强大,会导致很多不必要的代码、图片、js文件一起保存。网页

Teleport Ultra 支持定时任务,定时将指定内容下载到指定网站。通过它保存的网站,维护了源站的CSS样式和脚本功能。超链接也替换为本地链接,方便浏览。
Teleport Ultra 实际上是一个网络蜘蛛(网络机器人),可以自动从互联网上检索特定信息。使用它创建完整的网站镜像或本地复制,有6种工作模式:
1) 在硬盘上创建一个网站 的可浏览副本;
2)复制一个网站,包括网站的目录结构;
3)在网站中搜索指定的文件类型;
4) 从中央站点检测每个链接站点;
5) 在已知地址下载一个或多个文件;
6) 在网站 中搜索指定的关键字。
搜索指定网站内容(黑客们是如何使用搜索引擎,发动攻击的呢的? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-13 17:05
)
搜索引擎已经成为上网必不可少的工具之一。聪明的黑客发现搜索引擎也可以用来发动网络攻击。
Google Hacking 最初是指利用 Google 搜索引擎搜索信息进行入侵的技术和行为。现在它不再局限于谷歌。泛指利用各种搜索引擎进行黑客攻击的技术和行为。
黑客如何利用搜索引擎发起攻击?
在搜索引擎的搜索框中,用户输入关键词,回车后会显示想要的结果。事实上,这个看似简单的搜索框隐藏着神秘。
除了输入关键词,搜索引擎还提供了多种语法帮助用户提高搜索效率。
比如搜索某部网络小说时,使用文件类型语法搜索对应格式的文件。
这些可以方便用户提高搜索效率的语法已经成为黑客手中的入侵武器。他们可以利用这些语法发现目标网站的后台管理地址,进行端口扫描、SQL注入等。
那么,黑客是如何使用这些语法的?
站点:在特定 URL 中搜索
搜索关键词时,搜索引擎显示的结果全部收录网站,有时不方便。如果您只想在搜索结果中显示特定的网站 内容,您可以使用站点语法。比如要在微软官网上搜索漏洞编号,在搜索引擎中输入“漏洞编号站点:微软”即可。
inurl:在 URL 中搜索指定的内容链接
Inurl 语法可以搜索链接的内容。对于普通用户来说,比起链接的内容,他们更关心网页的内容。这种语法没有意义。但对于黑客来说,它是一种武器。例如在搜索引擎中输入inurl:.php?id=或inurl:.jsp?id=,搜索可能的SQL注入链接。
filetype:限制搜索的文件类型
Filetype 可以限制搜索的文件类型。普通用户可能会使用这个语法来搜索电子书、视频、图片等资源。在黑客眼中,filetype 可以用于SQL 数据库挖掘。例如:filetype:sql + "IDENTIFIED BY" -cvs
intitle:搜索网页标题中收录指定内容的网页
页面标题一般表示页面内容,比如搜索“网络安全”,显示的结果都是与网络安全相关的。黑客会使用 intitle 语法来搜索“背景”和“登录”。这时候会暴露一些网站后台登录页面。
以上只是基础语法,对于黑客来说只是小儿科。有经验的黑客经常使用多种语法,比如端口扫描结合 inurl: 和 intext。甚至还有一个网站,采集了很多搜索语句。登录此网站copy 搜索一些无法正常搜索的内容。
查看全部
搜索指定网站内容(黑客们是如何使用搜索引擎,发动攻击的呢的?
)
搜索引擎已经成为上网必不可少的工具之一。聪明的黑客发现搜索引擎也可以用来发动网络攻击。

Google Hacking 最初是指利用 Google 搜索引擎搜索信息进行入侵的技术和行为。现在它不再局限于谷歌。泛指利用各种搜索引擎进行黑客攻击的技术和行为。

黑客如何利用搜索引擎发起攻击?
在搜索引擎的搜索框中,用户输入关键词,回车后会显示想要的结果。事实上,这个看似简单的搜索框隐藏着神秘。
除了输入关键词,搜索引擎还提供了多种语法帮助用户提高搜索效率。
比如搜索某部网络小说时,使用文件类型语法搜索对应格式的文件。

这些可以方便用户提高搜索效率的语法已经成为黑客手中的入侵武器。他们可以利用这些语法发现目标网站的后台管理地址,进行端口扫描、SQL注入等。
那么,黑客是如何使用这些语法的?
站点:在特定 URL 中搜索
搜索关键词时,搜索引擎显示的结果全部收录网站,有时不方便。如果您只想在搜索结果中显示特定的网站 内容,您可以使用站点语法。比如要在微软官网上搜索漏洞编号,在搜索引擎中输入“漏洞编号站点:微软”即可。

inurl:在 URL 中搜索指定的内容链接
Inurl 语法可以搜索链接的内容。对于普通用户来说,比起链接的内容,他们更关心网页的内容。这种语法没有意义。但对于黑客来说,它是一种武器。例如在搜索引擎中输入inurl:.php?id=或inurl:.jsp?id=,搜索可能的SQL注入链接。

filetype:限制搜索的文件类型
Filetype 可以限制搜索的文件类型。普通用户可能会使用这个语法来搜索电子书、视频、图片等资源。在黑客眼中,filetype 可以用于SQL 数据库挖掘。例如:filetype:sql + "IDENTIFIED BY" -cvs

intitle:搜索网页标题中收录指定内容的网页
页面标题一般表示页面内容,比如搜索“网络安全”,显示的结果都是与网络安全相关的。黑客会使用 intitle 语法来搜索“背景”和“登录”。这时候会暴露一些网站后台登录页面。

以上只是基础语法,对于黑客来说只是小儿科。有经验的黑客经常使用多种语法,比如端口扫描结合 inurl: 和 intext。甚至还有一个网站,采集了很多搜索语句。登录此网站copy 搜索一些无法正常搜索的内容。

搜索指定网站内容(网站聚合了多种搜索引擎,,如何使用无解搜?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-13 17:03
)
网站可以对大量内容进行排序和搜索,电子书、音乐、电影、软件等
网站聚合多个搜索引擎,
如何使用不搜索?
无界搜是聚合搜索网站。简单来说就是方便搜索打开指定网站的搜索结果。例如,我们来演示一下电脑版和手机版的搜索过程。
计算机搜索过程
开始第一次搜索
在搜索框中输入您要查询的内容,然后按回车键(或点击搜索框右侧的搜索按钮)即可获取您想要的内容。例如:如果要查找某部电影,直接在搜索框中输入“电影名称,如(速度与激情)”,按回车键(或点击搜索按钮),即可得到相应的结果马上!
当然,这个搜索结果可能很多,但不一定是最准确的,所以我们可以进一步选择相关的分类,改变搜索源,得到更准确的结果。比如搜索关键词(速度和激情)是针对影视类,然后从左上角选择影视类,在搜索框下方的搜索源中替换网站,得到更准确的结果。
手机搜索过程
在搜索框中输入您要查询的内容,然后按回车键(或点击搜索框右侧的搜索按钮)即可获取您想要的内容。例如:如果要查找某部电影,直接在搜索框中输入“电影名称,如(速度与激情)”,按回车键(或点击搜索按钮),即可得到相应的结果马上!
当然,这个搜索结果可能很多,但不一定是最准确的,所以我们可以进一步选择相关的分类,改变搜索源,得到更准确的结果。比如搜索关键词(速度和激情)是影视类,然后从左上角选择影视类,在搜索框左侧的搜索源中替换网站即可得到更准确的结果。
网站地址:
标签:搜索
查看全部
搜索指定网站内容(网站聚合了多种搜索引擎,,如何使用无解搜?(图)
)
网站可以对大量内容进行排序和搜索,电子书、音乐、电影、软件等
网站聚合多个搜索引擎,
如何使用不搜索?
无界搜是聚合搜索网站。简单来说就是方便搜索打开指定网站的搜索结果。例如,我们来演示一下电脑版和手机版的搜索过程。
计算机搜索过程
开始第一次搜索
在搜索框中输入您要查询的内容,然后按回车键(或点击搜索框右侧的搜索按钮)即可获取您想要的内容。例如:如果要查找某部电影,直接在搜索框中输入“电影名称,如(速度与激情)”,按回车键(或点击搜索按钮),即可得到相应的结果马上!

当然,这个搜索结果可能很多,但不一定是最准确的,所以我们可以进一步选择相关的分类,改变搜索源,得到更准确的结果。比如搜索关键词(速度和激情)是针对影视类,然后从左上角选择影视类,在搜索框下方的搜索源中替换网站,得到更准确的结果。

手机搜索过程
在搜索框中输入您要查询的内容,然后按回车键(或点击搜索框右侧的搜索按钮)即可获取您想要的内容。例如:如果要查找某部电影,直接在搜索框中输入“电影名称,如(速度与激情)”,按回车键(或点击搜索按钮),即可得到相应的结果马上!

当然,这个搜索结果可能很多,但不一定是最准确的,所以我们可以进一步选择相关的分类,改变搜索源,得到更准确的结果。比如搜索关键词(速度和激情)是影视类,然后从左上角选择影视类,在搜索框左侧的搜索源中替换网站即可得到更准确的结果。


网站地址:
标签:搜索



搜索指定网站内容(怎样使页面不被收录是个值得思考的问题?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-09-09 22:16
如何防止页面被收录是一个值得思考的问题。没意识到严重性的童鞋们可以想想网站上有多少抄袭内容、低质量内容、各种非搜索价值,但用户却觉得内容方便
图 8173-1:
一般来说,试图让搜索引擎抓取和索引更多内容是SEO经常头疼的问题。没有收录和索引,就没有办法谈论排名。尤其对于已经达到一定规模的网站,做网站Full收录是一个比较麻烦的SEO技巧。当页面达到数十万时,例如,无论网站架构如何设计或优化,100%收录都是不可能的,只能尝试提高收录率。
但是有时候怎么屏蔽搜索引擎收录也会成为问题,而且最近越来越成为问题。需要防止收录的情况,如机密信息、复制内容、广告链接等。过去常用的拦截收录的方法有密码保护、把内容放在表单后面、使用JS/Ajax、使用Flash、等
使用闪光灯
谷歌几年前就开始尝试抓取 Flash 内容,简单的文本内容已经可以抓取了。也可以跟踪 Flash 中的链接。
表格
Google 蜘蛛还可以填写表单并抓取 POST 请求页面。这已经可以在日志中看到了。
JS/Ajax
使用JS链接一直被认为是一种非搜索引擎友好的方式,所以可以防止蜘蛛爬行,但是两三年前我看到JS链接不能阻止谷歌蜘蛛爬行,不仅仅是URL出现在JS中会Climbing,执行简单的JS就可以找到更多的网址。
前几天,有人发现网站使用的facebook评论插件中有很多评论被爬取,收录。插件本身是一个ajax。这是个好消息。我的一个实验性电商网站product评论功能就是因为这个。使用facebook评论插件的好处是很大的。具体的好处将在后面讨论。唯一的问题是注释是AJAX实现的,不能被捕获。拿,产品评论是收录的目的之一(生成原创内容)。想了半天也没有解决办法,于是傻傻的装上了Facebook评论插件,开启了购物车本身的评论功能。那么现在Facebook评论中的评论可以是收录,所以不需要两套评论功能。
机器人文件
目前,robots 文件禁止确保内容不是收录 的唯一方法。但也有一个缺点。它会减肥。虽然内容不能再收录,但是页面变成了只接受链接权重,不流出权重的无底洞。
不关注
Nofollow 不保证不会是收录。即使你网站给页面的所有链接添加NF,也不能保证其他人网站不会链接到这个页面,搜索引擎仍然可以找到这个页面。
meta Noindex + 关注
(11月3日新增)读者no1se提醒,为了防止收录传权重,页面上可以使用meta noindex和meta follow,这样页面就不是收录了,但重量可以流出。的确,这也是一种更好的方法。还有一个问题,还是会浪费蜘蛛爬行的时间。哪位读者有办法防止收录,既不减肥,又不浪费爬行时间,请留言,对SEO社区大有裨益。
如何防止页面被收录是一个值得思考的问题。没意识到严重性的童鞋们可以想想网站上有多少抄袭内容、低质量内容、各种非搜索价值(不过用户觉得方便有用,所以拿不走) 对 URL 进行排序和过滤。 查看全部
搜索指定网站内容(怎样使页面不被收录是个值得思考的问题?)
如何防止页面被收录是一个值得思考的问题。没意识到严重性的童鞋们可以想想网站上有多少抄袭内容、低质量内容、各种非搜索价值,但用户却觉得内容方便

图 8173-1:
一般来说,试图让搜索引擎抓取和索引更多内容是SEO经常头疼的问题。没有收录和索引,就没有办法谈论排名。尤其对于已经达到一定规模的网站,做网站Full收录是一个比较麻烦的SEO技巧。当页面达到数十万时,例如,无论网站架构如何设计或优化,100%收录都是不可能的,只能尝试提高收录率。
但是有时候怎么屏蔽搜索引擎收录也会成为问题,而且最近越来越成为问题。需要防止收录的情况,如机密信息、复制内容、广告链接等。过去常用的拦截收录的方法有密码保护、把内容放在表单后面、使用JS/Ajax、使用Flash、等
使用闪光灯
谷歌几年前就开始尝试抓取 Flash 内容,简单的文本内容已经可以抓取了。也可以跟踪 Flash 中的链接。
表格
Google 蜘蛛还可以填写表单并抓取 POST 请求页面。这已经可以在日志中看到了。
JS/Ajax
使用JS链接一直被认为是一种非搜索引擎友好的方式,所以可以防止蜘蛛爬行,但是两三年前我看到JS链接不能阻止谷歌蜘蛛爬行,不仅仅是URL出现在JS中会Climbing,执行简单的JS就可以找到更多的网址。
前几天,有人发现网站使用的facebook评论插件中有很多评论被爬取,收录。插件本身是一个ajax。这是个好消息。我的一个实验性电商网站product评论功能就是因为这个。使用facebook评论插件的好处是很大的。具体的好处将在后面讨论。唯一的问题是注释是AJAX实现的,不能被捕获。拿,产品评论是收录的目的之一(生成原创内容)。想了半天也没有解决办法,于是傻傻的装上了Facebook评论插件,开启了购物车本身的评论功能。那么现在Facebook评论中的评论可以是收录,所以不需要两套评论功能。
机器人文件
目前,robots 文件禁止确保内容不是收录 的唯一方法。但也有一个缺点。它会减肥。虽然内容不能再收录,但是页面变成了只接受链接权重,不流出权重的无底洞。
不关注
Nofollow 不保证不会是收录。即使你网站给页面的所有链接添加NF,也不能保证其他人网站不会链接到这个页面,搜索引擎仍然可以找到这个页面。
meta Noindex + 关注
(11月3日新增)读者no1se提醒,为了防止收录传权重,页面上可以使用meta noindex和meta follow,这样页面就不是收录了,但重量可以流出。的确,这也是一种更好的方法。还有一个问题,还是会浪费蜘蛛爬行的时间。哪位读者有办法防止收录,既不减肥,又不浪费爬行时间,请留言,对SEO社区大有裨益。
如何防止页面被收录是一个值得思考的问题。没意识到严重性的童鞋们可以想想网站上有多少抄袭内容、低质量内容、各种非搜索价值(不过用户觉得方便有用,所以拿不走) 对 URL 进行排序和过滤。
搜索指定网站内容(importurllib#python中用于获取网站的模块(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-09-08 17:19
import urllib #module 用于在python中获取网站
导入 urllib2、cookielib
部分网站访问时需要cookie,python处理cookie代码如下:
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HttpCookieProcessor(cj))
urllib2.install_opener (opener)
通常我们需要在网站中搜索我们需要的信息。这里有两种情况:
1. 首先,可以直接更改网址,获取要搜索的页面:
def GetWebPage( x ): #我们定义了一个获取页面的函数,x是用来呈现你在页面上搜索到的内容的参数
url ='#39; + ‘要搜索的参数’#根据自己的页面情况适当修改
page = urllib2.urlopen(url)
pageContent = page.read()
return pageContent #返回HTML格式的页面信息
2. 其次,需要使用post方法,把你搜索到的内容放到postdata中,然后返回你需要的页面
def GetWebPage( x ): #我们定义了一个获取页面的函数,x是用来呈现你在页面上搜索到的内容的参数
url ='#39; #这个网址就是你进入搜索界面的地方
postData = urllib.urlencode( {various ‘post’ parameter input}) #这里输入的post参数需要自己检查
req= urllib2.Request (url, postData)
pageContent = urllib2.urlopen(请求)。读( )
return pageContent #返回HTML格式的页面信息
获取到我们需要的网页信息后,我们还需要从获取到的网页中进一步获取我们需要的信息。这里我推荐使用 BeautifulSoup 模块。 Python 没有附带它。您可以在百度谷歌下载安装。 BeautifulSoup 的意思是“美味的汤”。你需要做的是从一锅汤里找到你喜欢吃的东西。
import re #正则表达式,用于匹配字符
from bs4 import BeautifulSoup # 导入 BeautifulSoup 模块
soup = BeautifulSoup(pageContent) #pageContent 是我们上面搜索的页面
Soup 是 HTML 中的所有标签(tag) BeautifulSoup 处理格式化的字符串,一个标准的标签形式是:
hwkobe24
通过一些过滤的方法,我们可以从汤中得到我们需要的信息:
(1) find_all (name, attrs, recursive, text, **kwargs)
这里,我们通过在标签上添加约束来得到我们需要的标签列表,例如soup.find_all('p')是查找名为'p'的标签,而soup.find_all(class = "tittle" ) 就是查找所有class属性为"tittle"的标签,soup.find_all(class = pie('lass'))表示所有class属性中收录'lass'的标签。这里用到了正则表达式(可以自己学,很有用)
得到我们想要的所有标签的列表后,我们遍历这个列表,然后在标签中获取你需要的内容。通常我们需要标签的文字部分,也就是网页上显示的文字。代码如下:
tagList =soup.find_all(class="tittle") #如果标签比较复杂,可以使用多个过滤条件,使过滤更加严格
对于 tagList 中的标签:
打印标签文本
f.write(str(tag.text)) #将此信息写入本地文件,以备后用
(2)find( name, attrs, recursive, text, **kwargs )
它和find_all()方法唯一的区别是find_all()方法返回的结果是一个收录一个元素的值列表,而find()方法直接返回结果
(3)find_parents() find_parent( )
find_all() 和 find() 只搜索当前节点的所有子节点、孙节点等。
find_parents() 和 find_parent() 用于搜索当前节点的父节点,搜索方法与普通标签的搜索方法相同,搜索文档搜索文档中收录的内容
(4)find_next_siblings() find_next_sibling()
这两个方法使用.next_siblings属性来更新所有后面解析的兄弟标签节点。 find_next_siblings() 方法返回所有满足条件的后续兄弟,而 find_next_sibling() 只返回下一个满足条件的兄弟。一个标签节点
(5)find_previous_siblings() find_previous_sibling()
这两个方法使用 .previous_siblings 属性来迭代当前标签之前解析的兄弟标签节点。 find_previous_siblings() 方法返回之前所有满足条件的兄弟节点, find_previous_sibling() 方法返回第一个满足条件的兄弟节点。兄弟节点
(6)find_all_next() find_next()
这两个方法使用 .next_elements 属性来迭代当前标签之后的标签和字符串。 find_all_next() 方法返回所有符合条件的节点, find_next() 方法返回第一个符合条件的节点
(7)find_all_previous() 和 find_previous()
这两个方法使用 .previous_elements 属性来迭代当前节点前面的标签和字符串。 find_all_previous() 方法返回所有符合条件的节点, find_previous() 方法返回第一个符合条件的节点。
实际代码示例:(抓取网页下的指定链接)
来自 bs4 小鬼
#htmltext
html_text=""
soup=BeautifulSoup(html_text,'html.parser')
a=soup.select('a')
for i in a:
如果 i.string=="关键词":
findb_ur=i['href']
#输出搜索a标签中的字符串得到的网页链接
# 打印(findb_url)
#findb_url="https:"+finburl
alist=soup.find_all('a)
对于 a 列表:
1.通过下标操作方法
href=a['href']
打印(htref)
2.通过attrs属性
href=a.attrs['href']
打印(href) 查看全部
搜索指定网站内容(importurllib#python中用于获取网站的模块(图))
import urllib #module 用于在python中获取网站
导入 urllib2、cookielib
部分网站访问时需要cookie,python处理cookie代码如下:
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HttpCookieProcessor(cj))
urllib2.install_opener (opener)
通常我们需要在网站中搜索我们需要的信息。这里有两种情况:
1. 首先,可以直接更改网址,获取要搜索的页面:
def GetWebPage( x ): #我们定义了一个获取页面的函数,x是用来呈现你在页面上搜索到的内容的参数
url ='#39; + ‘要搜索的参数’#根据自己的页面情况适当修改
page = urllib2.urlopen(url)
pageContent = page.read()
return pageContent #返回HTML格式的页面信息
2. 其次,需要使用post方法,把你搜索到的内容放到postdata中,然后返回你需要的页面
def GetWebPage( x ): #我们定义了一个获取页面的函数,x是用来呈现你在页面上搜索到的内容的参数
url ='#39; #这个网址就是你进入搜索界面的地方
postData = urllib.urlencode( {various ‘post’ parameter input}) #这里输入的post参数需要自己检查
req= urllib2.Request (url, postData)
pageContent = urllib2.urlopen(请求)。读( )
return pageContent #返回HTML格式的页面信息
获取到我们需要的网页信息后,我们还需要从获取到的网页中进一步获取我们需要的信息。这里我推荐使用 BeautifulSoup 模块。 Python 没有附带它。您可以在百度谷歌下载安装。 BeautifulSoup 的意思是“美味的汤”。你需要做的是从一锅汤里找到你喜欢吃的东西。
import re #正则表达式,用于匹配字符
from bs4 import BeautifulSoup # 导入 BeautifulSoup 模块
soup = BeautifulSoup(pageContent) #pageContent 是我们上面搜索的页面
Soup 是 HTML 中的所有标签(tag) BeautifulSoup 处理格式化的字符串,一个标准的标签形式是:
hwkobe24
通过一些过滤的方法,我们可以从汤中得到我们需要的信息:
(1) find_all (name, attrs, recursive, text, **kwargs)
这里,我们通过在标签上添加约束来得到我们需要的标签列表,例如soup.find_all('p')是查找名为'p'的标签,而soup.find_all(class = "tittle" ) 就是查找所有class属性为"tittle"的标签,soup.find_all(class = pie('lass'))表示所有class属性中收录'lass'的标签。这里用到了正则表达式(可以自己学,很有用)
得到我们想要的所有标签的列表后,我们遍历这个列表,然后在标签中获取你需要的内容。通常我们需要标签的文字部分,也就是网页上显示的文字。代码如下:
tagList =soup.find_all(class="tittle") #如果标签比较复杂,可以使用多个过滤条件,使过滤更加严格
对于 tagList 中的标签:
打印标签文本
f.write(str(tag.text)) #将此信息写入本地文件,以备后用
(2)find( name, attrs, recursive, text, **kwargs )
它和find_all()方法唯一的区别是find_all()方法返回的结果是一个收录一个元素的值列表,而find()方法直接返回结果
(3)find_parents() find_parent( )
find_all() 和 find() 只搜索当前节点的所有子节点、孙节点等。
find_parents() 和 find_parent() 用于搜索当前节点的父节点,搜索方法与普通标签的搜索方法相同,搜索文档搜索文档中收录的内容
(4)find_next_siblings() find_next_sibling()
这两个方法使用.next_siblings属性来更新所有后面解析的兄弟标签节点。 find_next_siblings() 方法返回所有满足条件的后续兄弟,而 find_next_sibling() 只返回下一个满足条件的兄弟。一个标签节点
(5)find_previous_siblings() find_previous_sibling()
这两个方法使用 .previous_siblings 属性来迭代当前标签之前解析的兄弟标签节点。 find_previous_siblings() 方法返回之前所有满足条件的兄弟节点, find_previous_sibling() 方法返回第一个满足条件的兄弟节点。兄弟节点
(6)find_all_next() find_next()
这两个方法使用 .next_elements 属性来迭代当前标签之后的标签和字符串。 find_all_next() 方法返回所有符合条件的节点, find_next() 方法返回第一个符合条件的节点
(7)find_all_previous() 和 find_previous()
这两个方法使用 .previous_elements 属性来迭代当前节点前面的标签和字符串。 find_all_previous() 方法返回所有符合条件的节点, find_previous() 方法返回第一个符合条件的节点。
实际代码示例:(抓取网页下的指定链接)
来自 bs4 小鬼
#htmltext
html_text=""
soup=BeautifulSoup(html_text,'html.parser')
a=soup.select('a')
for i in a:
如果 i.string=="关键词":
findb_ur=i['href']
#输出搜索a标签中的字符串得到的网页链接
# 打印(findb_url)
#findb_url="https:"+finburl
alist=soup.find_all('a)
对于 a 列表:
1.通过下标操作方法
href=a['href']
打印(htref)
2.通过attrs属性
href=a.attrs['href']
打印(href)
搜索指定网站内容(以有针对性的方式可以使用不同的策略来隔离内容推送)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-09-08 05:14
与访问者相比,有针对性地在搜索引擎中展示特定内容
可以使用不同的策略来隔离内容推送。最基本的方法是使用不可抓取的格式提供搜索引擎看不到的内容(如在图片、flash 文件和插件等中放置文本)。例如,它只能用于提供改进的用户体验)。在这种情况下,您可以以可抓取的格式在搜索引擎中显示相同的内容。如果您想向搜索引擎提供您不希望访问者看到的内容,您可以使用 CSS 样式表。不要使用 display: none 或基于 JavaScript、用户代理、cookie 或会话的推送,或 IP 推送(根据用户的 IP 地址显示内容),因为搜索引擎使用过滤器来专门监控这一点。未使用。
使用这些技术时应特别小心。如前所述,搜索引擎在其指南中明确禁止使用欺骗行为,而不是欺骗搜索引擎,例如使用隐藏技术来提高意图和用户体验(例如,使用隐藏技术来提高质量网站的用户经验))但是,搜索引擎仍然非常重视这些技术,这可能会惩罚或禁止某些串通或恶意操纵搜索引擎的网站。另外,如果你有一个好的起点,搜索引擎可能会认为它是恶意的并惩罚你。使用 robots.txt 文件
该文件位于您域名的根目录中。它是一个多功能工具,允许搜索爬虫确定哪些网站 内容已被访问。您可以使用 robots.txt。
防止爬虫访问您的网站 隐私部分。
防止搜索引擎访问索引脚本、实用程序或其他类型的代码。
避免为 网站 上的重复内容编制索引,例如 HTML 页面的打印版本或产品目录中的多个排序顺序。
自动发现:当您告诉搜索引擎漫游器不要访问特定页面时,此文件将阻止爬虫抓取该页面。图6-35直观地展示了搜索引擎何时看到机器人不抓取特定页面的命令。 txt 然后会发生什么。 查看全部
搜索指定网站内容(以有针对性的方式可以使用不同的策略来隔离内容推送)
与访问者相比,有针对性地在搜索引擎中展示特定内容
可以使用不同的策略来隔离内容推送。最基本的方法是使用不可抓取的格式提供搜索引擎看不到的内容(如在图片、flash 文件和插件等中放置文本)。例如,它只能用于提供改进的用户体验)。在这种情况下,您可以以可抓取的格式在搜索引擎中显示相同的内容。如果您想向搜索引擎提供您不希望访问者看到的内容,您可以使用 CSS 样式表。不要使用 display: none 或基于 JavaScript、用户代理、cookie 或会话的推送,或 IP 推送(根据用户的 IP 地址显示内容),因为搜索引擎使用过滤器来专门监控这一点。未使用。
使用这些技术时应特别小心。如前所述,搜索引擎在其指南中明确禁止使用欺骗行为,而不是欺骗搜索引擎,例如使用隐藏技术来提高意图和用户体验(例如,使用隐藏技术来提高质量网站的用户经验))但是,搜索引擎仍然非常重视这些技术,这可能会惩罚或禁止某些串通或恶意操纵搜索引擎的网站。另外,如果你有一个好的起点,搜索引擎可能会认为它是恶意的并惩罚你。使用 robots.txt 文件
该文件位于您域名的根目录中。它是一个多功能工具,允许搜索爬虫确定哪些网站 内容已被访问。您可以使用 robots.txt。
防止爬虫访问您的网站 隐私部分。
防止搜索引擎访问索引脚本、实用程序或其他类型的代码。
避免为 网站 上的重复内容编制索引,例如 HTML 页面的打印版本或产品目录中的多个排序顺序。
自动发现:当您告诉搜索引擎漫游器不要访问特定页面时,此文件将阻止爬虫抓取该页面。图6-35直观地展示了搜索引擎何时看到机器人不抓取特定页面的命令。 txt 然后会发生什么。
搜索指定网站内容(提高搜索效率和质量的一些方法,包含搜索指令、以图搜图技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-22 18:12
文字/一周进展·安哥拉
在信息过载的时刻,即使我们不主动获取信息,各种应用程序推荐和用户制作的内容也会迫使我们,但真正有价值的内容可能很少
每个人都将面临“有限时间”的限制。如何从信息浪潮中快速找到所需的高质量内容,已成为几乎每个现代人都必须面对的问题
除了寻找高质量的信息源,更重要的是使用良好的搜索,因为你想知道的80%都可以在网上找到
因此,在今天的文章中,我整理了一些提高搜索效率和质量的方法,包括搜索说明、地图搜索技能、屏蔽网站和广告。我希望这些内容对你有帮助
01.搜索指令
① 过滤器关键词
在关键词后面使用减号,并添加要筛选的关键词以删除标题中已筛选的关键词搜索结果
例如,当百度使用关键词“学习应用程序”搜索时,知乎的内容默认位于搜索结果的顶部
为了比较前后的效果,请使用“learning app-知乎”再次搜索,返回的结果将过滤知乎中的内容@
② 在指定的网站中搜索@
在关键词之后添加site:URL,在指定的网站中搜索关键词,这更适合使用垂直且易于记忆的URL的网站。您可以直接使用关键词进行搜索,无需打开网站
以查找国防ppt模板为例,直接使用“国防ppt”进行搜索。返回的结果来自不同的网站,包括ppt教程的内容和ppt模板网站,这两个模板都很混乱
如果只想搜索从PPT模板返回的结果,请尝试将搜索范围限制为PPT模板网站,例如Microsoft Home模板网站,以便搜索结果更准确
值得一提的是,该站点:以后添加的URL不需要带或,否则返回的结果将显示找不到相关内容
③ 指定文件类型
在关键词之后添加filetype:file format以指定搜索结果返回的文件类型。此处的文件格式包括但不限于PPT、Doc、PDF、xls等
以国防ppt为例,在关键词之后添加“filetype:ppt”,这样返回的结果仅限于ppt格式的文档,不会使其他类型的文件杂乱无章
需要注意的是,自office2013以来,office增加了三种兼容格式pptx、docx和xlsx,但百度的文件类型指令不支持这三种新格式,这三种格式在谷歌中可以正常使用
④ 精确匹配
有时当我们使用关键词进行搜索时,搜索引擎会将我们的关键词分成两个小短语进行搜索,结果不令人满意
为了解决这个问题,我们可以将关键词放在引号中,这样搜索引擎将返回收录完整关键词的结果,而不会将关键词无序地分割成多个短语
这里的引号可以是中文也可以是英文。使用中文或英文引号不会影响搜索返回的结果
如下图所示,使用“城市地铁”搜索时,返回的结果完全匹配,与不加引号时相比,可以适当提高搜索效率
⑤ 通配符搜索
俗话说:“好记性胜过坏笔”。有时我们听到或想到的东西没有及时记录下来,很快我们的脑海中可能只剩下零碎的东西
就像你模模糊糊地记得一部叫做《四月XX号谎言》的动画,但你就是记不起中间的部分。此时,您可以使用星号*来通知搜索引擎仍有一些您不知道的内容
这里的星号*称为通配符,通常用于模糊搜索场景。当您不知道完整文本时,可以使用通配符而不是一个或多个字符,以便尽可能接近要搜索的内容
⑥ 合格职称关键词
在关键词A:关键词b之后添加intitle,这有点像数学中的交集,即返回的搜索结果的标题必须同时收录关键词A和关键词b
以下图为例,使用“learning网站intitle:clip”搜索,下面返回的搜索结果将同时收录关键词,使搜索结果更加集中
虽然每个搜索命令都是单独引入的,但在实际的搜索场景中,我们可以组合两个或多个搜索命令,并与不同的命令协作,以提高搜索的效率和质量
02.Baidu高级搜索
刚接触过这些搜索说明的朋友在早期可能仍然记得它们,但如果他们以后不自觉地使用它们,这些说明将随着时间的推移慢慢被遗忘
幸运的是,百度还提供了类似搜索说明的高级搜索。它以一种更容易理解的形式呈现在我们面前的搜索说明
点击百度搜索页面右上角的“设置”打开“高级搜索”
理解前面说明的含义后,请查看下图中的advanced search(高级搜索)面板,应该很好地理解该面板
以搜索关键词为例。完整的关键词对应于完全匹配的命令,不包括关键词对应的filter关键词命令
在完整的关键词输入框中输入关键词“城市地铁”,然后单击底部的高级搜索。在打开的搜索页面中,它将自动为关键词添加双引号,这与上述搜索命令一致
此外,高级搜索面板还可以限制搜索返回的文档格式。这里列出的文档格式更清晰,包括PDF、Doc、xls、PPT和RTF文件
03.搜索图片
很多朋友可能知道百度的“图片搜索”功能。通过将本地图片上传到百度,它将帮助我们找到与此图片相关的其他图片
但每次大多数人使用百度搜索图片时,他们可能会先在百度搜索图片,然后打开百度地图识别页面,最后上传图片。整个过程有点麻烦
为了帮助您更有效地使用“按地图搜索”,以下是按地图搜索的两个提示:
① 图形搜索
这是百度图片的功能。使用百度搜索特定图片时,将鼠标移动到返回图片的顶部。右下角将有两个按钮,一个是下载,另一个是按图片搜索
点击“按图像搜索”,将调用百度的图像搜索功能,查找与当前图像相关的所有内容
另外,当您点击图像的缩略图查看图像的详细信息时,点击图像下方的“按图像搜索”,也可以实现按图像搜索的操作
② 按图像搜索
上面提到的“图片搜索”的缺点是它只能在百度图片页面上工作。对于其他网页的图片,你不能直接调用百度的图片搜索功能
“按图像搜索”是一个功能强大的图像搜索插件。它集成了30多个搜索引擎,可以将任何网页的图像上传到不同的搜索引擎,以查找与当前图像相关的图像或内容
安装插件后,右击任意图片,选择“按图像搜索”,即可看到不同搜索引擎提供的地图搜索功能。选择百度将直接打开百度地图识别页面
打开插件的设置页面,查看插件集成的所有图像搜索引擎。选中发动机前面的复选框以启用它。长按并拖动可更改发动机的位置,这将影响右键单击菜单中发动机的上下顺序
04.Shield网站
搜索时,除了过滤不必要的关键词,我们可能还想屏蔽我们不喜欢的网站,比如各种软件下载站、2345网站等等
我对屏蔽网站的理想期望是它不会出现在搜索结果中,但百度搜索目前无法做到这一点。想要屏蔽的网站仍将出现在搜索结果中,并且只有在网站打开时才能屏蔽
为了间接屏蔽网站,我们需要为浏览器安装一个插件-简单拦截器。就像它的名字一样,屏蔽网站的操作非常简单
安装插件后,点击右上角的插件图标,打开插件配置页面,将要阻止的网站URL粘贴到网站屏蔽列表网站拦截器中,点击下方的“保存拦截器列表”按钮保存
之后,当您在屏蔽列表中打开网站时,网站会跳转到simple blocker的拦截页面,并提示当前页面已被拦截
也许这种屏蔽插件的正确用法不是这样的。正确的用法可能是屏蔽不适合儿童的东西,但我只能用它来屏蔽那些恶心的人的网站
简单拦截器插件的下载地址:
05.Block广告
斯帕 查看全部
搜索指定网站内容(提高搜索效率和质量的一些方法,包含搜索指令、以图搜图技巧)
文字/一周进展·安哥拉
在信息过载的时刻,即使我们不主动获取信息,各种应用程序推荐和用户制作的内容也会迫使我们,但真正有价值的内容可能很少
每个人都将面临“有限时间”的限制。如何从信息浪潮中快速找到所需的高质量内容,已成为几乎每个现代人都必须面对的问题
除了寻找高质量的信息源,更重要的是使用良好的搜索,因为你想知道的80%都可以在网上找到
因此,在今天的文章中,我整理了一些提高搜索效率和质量的方法,包括搜索说明、地图搜索技能、屏蔽网站和广告。我希望这些内容对你有帮助
01.搜索指令
① 过滤器关键词
在关键词后面使用减号,并添加要筛选的关键词以删除标题中已筛选的关键词搜索结果
例如,当百度使用关键词“学习应用程序”搜索时,知乎的内容默认位于搜索结果的顶部
为了比较前后的效果,请使用“learning app-知乎”再次搜索,返回的结果将过滤知乎中的内容@
② 在指定的网站中搜索@
在关键词之后添加site:URL,在指定的网站中搜索关键词,这更适合使用垂直且易于记忆的URL的网站。您可以直接使用关键词进行搜索,无需打开网站
以查找国防ppt模板为例,直接使用“国防ppt”进行搜索。返回的结果来自不同的网站,包括ppt教程的内容和ppt模板网站,这两个模板都很混乱
如果只想搜索从PPT模板返回的结果,请尝试将搜索范围限制为PPT模板网站,例如Microsoft Home模板网站,以便搜索结果更准确
值得一提的是,该站点:以后添加的URL不需要带或,否则返回的结果将显示找不到相关内容
③ 指定文件类型
在关键词之后添加filetype:file format以指定搜索结果返回的文件类型。此处的文件格式包括但不限于PPT、Doc、PDF、xls等
以国防ppt为例,在关键词之后添加“filetype:ppt”,这样返回的结果仅限于ppt格式的文档,不会使其他类型的文件杂乱无章
需要注意的是,自office2013以来,office增加了三种兼容格式pptx、docx和xlsx,但百度的文件类型指令不支持这三种新格式,这三种格式在谷歌中可以正常使用
④ 精确匹配
有时当我们使用关键词进行搜索时,搜索引擎会将我们的关键词分成两个小短语进行搜索,结果不令人满意
为了解决这个问题,我们可以将关键词放在引号中,这样搜索引擎将返回收录完整关键词的结果,而不会将关键词无序地分割成多个短语
这里的引号可以是中文也可以是英文。使用中文或英文引号不会影响搜索返回的结果
如下图所示,使用“城市地铁”搜索时,返回的结果完全匹配,与不加引号时相比,可以适当提高搜索效率
⑤ 通配符搜索
俗话说:“好记性胜过坏笔”。有时我们听到或想到的东西没有及时记录下来,很快我们的脑海中可能只剩下零碎的东西
就像你模模糊糊地记得一部叫做《四月XX号谎言》的动画,但你就是记不起中间的部分。此时,您可以使用星号*来通知搜索引擎仍有一些您不知道的内容
这里的星号*称为通配符,通常用于模糊搜索场景。当您不知道完整文本时,可以使用通配符而不是一个或多个字符,以便尽可能接近要搜索的内容
⑥ 合格职称关键词
在关键词A:关键词b之后添加intitle,这有点像数学中的交集,即返回的搜索结果的标题必须同时收录关键词A和关键词b
以下图为例,使用“learning网站intitle:clip”搜索,下面返回的搜索结果将同时收录关键词,使搜索结果更加集中
虽然每个搜索命令都是单独引入的,但在实际的搜索场景中,我们可以组合两个或多个搜索命令,并与不同的命令协作,以提高搜索的效率和质量
02.Baidu高级搜索
刚接触过这些搜索说明的朋友在早期可能仍然记得它们,但如果他们以后不自觉地使用它们,这些说明将随着时间的推移慢慢被遗忘
幸运的是,百度还提供了类似搜索说明的高级搜索。它以一种更容易理解的形式呈现在我们面前的搜索说明
点击百度搜索页面右上角的“设置”打开“高级搜索”
理解前面说明的含义后,请查看下图中的advanced search(高级搜索)面板,应该很好地理解该面板
以搜索关键词为例。完整的关键词对应于完全匹配的命令,不包括关键词对应的filter关键词命令
在完整的关键词输入框中输入关键词“城市地铁”,然后单击底部的高级搜索。在打开的搜索页面中,它将自动为关键词添加双引号,这与上述搜索命令一致
此外,高级搜索面板还可以限制搜索返回的文档格式。这里列出的文档格式更清晰,包括PDF、Doc、xls、PPT和RTF文件
03.搜索图片
很多朋友可能知道百度的“图片搜索”功能。通过将本地图片上传到百度,它将帮助我们找到与此图片相关的其他图片
但每次大多数人使用百度搜索图片时,他们可能会先在百度搜索图片,然后打开百度地图识别页面,最后上传图片。整个过程有点麻烦
为了帮助您更有效地使用“按地图搜索”,以下是按地图搜索的两个提示:
① 图形搜索
这是百度图片的功能。使用百度搜索特定图片时,将鼠标移动到返回图片的顶部。右下角将有两个按钮,一个是下载,另一个是按图片搜索
点击“按图像搜索”,将调用百度的图像搜索功能,查找与当前图像相关的所有内容
另外,当您点击图像的缩略图查看图像的详细信息时,点击图像下方的“按图像搜索”,也可以实现按图像搜索的操作
② 按图像搜索
上面提到的“图片搜索”的缺点是它只能在百度图片页面上工作。对于其他网页的图片,你不能直接调用百度的图片搜索功能
“按图像搜索”是一个功能强大的图像搜索插件。它集成了30多个搜索引擎,可以将任何网页的图像上传到不同的搜索引擎,以查找与当前图像相关的图像或内容
安装插件后,右击任意图片,选择“按图像搜索”,即可看到不同搜索引擎提供的地图搜索功能。选择百度将直接打开百度地图识别页面
打开插件的设置页面,查看插件集成的所有图像搜索引擎。选中发动机前面的复选框以启用它。长按并拖动可更改发动机的位置,这将影响右键单击菜单中发动机的上下顺序
04.Shield网站
搜索时,除了过滤不必要的关键词,我们可能还想屏蔽我们不喜欢的网站,比如各种软件下载站、2345网站等等
我对屏蔽网站的理想期望是它不会出现在搜索结果中,但百度搜索目前无法做到这一点。想要屏蔽的网站仍将出现在搜索结果中,并且只有在网站打开时才能屏蔽
为了间接屏蔽网站,我们需要为浏览器安装一个插件-简单拦截器。就像它的名字一样,屏蔽网站的操作非常简单
安装插件后,点击右上角的插件图标,打开插件配置页面,将要阻止的网站URL粘贴到网站屏蔽列表网站拦截器中,点击下方的“保存拦截器列表”按钮保存
之后,当您在屏蔽列表中打开网站时,网站会跳转到simple blocker的拦截页面,并提示当前页面已被拦截
也许这种屏蔽插件的正确用法不是这样的。正确的用法可能是屏蔽不适合儿童的东西,但我只能用它来屏蔽那些恶心的人的网站
简单拦截器插件的下载地址:
05.Block广告
斯帕
搜索指定网站内容(如何让浏览器种获取到精准的问题答案?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2021-09-19 11:14
当人们对某个问题有疑问时,他们会询问人们并翻阅书籍寻找证据。如今,人们获取信息非常简单。只需用手指键入几个单词,他们就可以在浏览器中搜索大量感兴趣的问题和答案
然而,随着时代的发展和广告的盛行,企业需要从广告中获得更高的利润
因此,我们很难从浏览器中获得准确的答案。您一定遇到了一个搜索问题,其中充满了广告图片:
那么我们如何才能得到准确的答案呢
搜索广告
如果你想避免令人讨厌的广告,首先要学会这个技巧
在关键词搜索后添加“-advision”(减号前需要空格)
使用这种方法,虽然广告不能完全删除,但页面会更干净整洁。我们真正想看的内容会更高。如果百度没有回应,我们可以刷新几次
精确搜索
你一定有过这种经历。我们搜索整个句子,但搜索结果将以红色标记为关键词。因此,我们可以利用此功能进行"k4"搜索,从而实现更快速,更准确的搜索
之前:
之后:
如图所示,带引号的搜索结果一目了然。有一种惊讶的感觉吗
受限文件类型搜索
你的办公室工作人员必须深刻理解寻找文件的痛苦
例如,如果你想找到一个单词分类账模板、一个PPT课件等,你必须从百度上翻阅条目才能找到你真正想要的,有时搜索是徒劳的
尝试以下方法:
“文件类型:文件类型+搜索词”。目前,文件类型支持“Doc、docx、xlsx、xls、PPT、pptx”等
之前:
之后:
以这种方式搜索的内容是准确的ppt
特定网站search
你必须有你最喜欢的网站,但有时网站有一个通用搜索功能。这时,我们可以用百度的“站点:域名+搜索词”来搜索
之前:
之后:
加性多关键词搜索
在我们的日常搜索中,如果有2~3个关键词,我们可以使用加法搜索
方法:关键词1+ 关键词2"
之前:
之后:
如何,你从未尝试过的每一种搜索方法?使用上述方法进行简单、高效和省时的搜索。快速点击采集 查看全部
搜索指定网站内容(如何让浏览器种获取到精准的问题答案?(一))
当人们对某个问题有疑问时,他们会询问人们并翻阅书籍寻找证据。如今,人们获取信息非常简单。只需用手指键入几个单词,他们就可以在浏览器中搜索大量感兴趣的问题和答案
然而,随着时代的发展和广告的盛行,企业需要从广告中获得更高的利润
因此,我们很难从浏览器中获得准确的答案。您一定遇到了一个搜索问题,其中充满了广告图片:
那么我们如何才能得到准确的答案呢
搜索广告
如果你想避免令人讨厌的广告,首先要学会这个技巧
在关键词搜索后添加“-advision”(减号前需要空格)
使用这种方法,虽然广告不能完全删除,但页面会更干净整洁。我们真正想看的内容会更高。如果百度没有回应,我们可以刷新几次
精确搜索
你一定有过这种经历。我们搜索整个句子,但搜索结果将以红色标记为关键词。因此,我们可以利用此功能进行"k4"搜索,从而实现更快速,更准确的搜索
之前:
之后:
如图所示,带引号的搜索结果一目了然。有一种惊讶的感觉吗
受限文件类型搜索
你的办公室工作人员必须深刻理解寻找文件的痛苦
例如,如果你想找到一个单词分类账模板、一个PPT课件等,你必须从百度上翻阅条目才能找到你真正想要的,有时搜索是徒劳的
尝试以下方法:
“文件类型:文件类型+搜索词”。目前,文件类型支持“Doc、docx、xlsx、xls、PPT、pptx”等
之前:
之后:
以这种方式搜索的内容是准确的ppt
特定网站search
你必须有你最喜欢的网站,但有时网站有一个通用搜索功能。这时,我们可以用百度的“站点:域名+搜索词”来搜索
之前:
之后:
加性多关键词搜索
在我们的日常搜索中,如果有2~3个关键词,我们可以使用加法搜索
方法:关键词1+ 关键词2"
之前:
之后:
如何,你从未尝试过的每一种搜索方法?使用上述方法进行简单、高效和省时的搜索。快速点击采集
搜索指定网站内容(网站语法格式及其应用方法介绍-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-09-19 10:17
语法格式:
网址:website关键词
或关键词站点:
注意事项:
1、site:下面的冒号必须是英文“:”,而中文的全角冒号“:”是无用的
2、url正面不能接受
3、url不能使用反斜杠“/”。事实上,它不能在任何地方使用/
4、url除非有特殊目的,否则不要在中使用WWW
使用www会导致您错过网站中的内容,因为许多网站频道没有www
其他说明:
1、关键词搜索结果可以在“站点:”之前或之后相同
但是,无论谁在前面或后面,关键词和“site:”都必须在2、中留空,因为“site:”搜索,关键词可以是多个,多个关键词之间用空格分隔
3、支持与其他复杂的搜索语法混合,并且每个语法和关键词之间都有一个空格@
4、除了网站之外,您还可以搜索网站的频道,但只能搜索那些没有“/”的频道
5、a网站可能有多种语言
因此,“搜索所有网站”和“搜索中文(简体)网页”之间存在差异
当然,如果网站只指定了一种语言,那么选择是相同的
目的:
1、可用于限制网站类型。教育部和组织机构的学术材料将更加简洁,政府相关信息可能更容易在政府机构中找到
2、使用域名后缀,如edu、org、net和gov,不会使用此后缀搜索所有网站
只搜索以该后缀结尾的网站和后缀为CN、US、Si等国家和地区的edu.jp
Gov.us、org.it等不在搜索范围内,因此您需要单独搜索
3、搜索一种语言或网站在指定国家/地区@
4、有些网站不提供现场搜索,或者信息结构混乱,内容多,很难找到东西
然后你可以使用“site:”来检索这个网站
谷歌的“站点:”功能比大多数网站自己的站点搜索更容易使用,如果你不检查的话
动态数据库,时效性要求不高
5、search不欢迎您搜索和免费使用数据库的一部分网站
6、use“site:”在死链接网站和关闭的网站中搜索信息@
例如:
打开
输入:站点:百度知道
输入:百度知道
输入:百度知道
你知道这三者的区别吗 查看全部
搜索指定网站内容(网站语法格式及其应用方法介绍-上海怡健医学)
语法格式:
网址:website关键词
或关键词站点:
注意事项:
1、site:下面的冒号必须是英文“:”,而中文的全角冒号“:”是无用的
2、url正面不能接受
3、url不能使用反斜杠“/”。事实上,它不能在任何地方使用/
4、url除非有特殊目的,否则不要在中使用WWW
使用www会导致您错过网站中的内容,因为许多网站频道没有www
其他说明:
1、关键词搜索结果可以在“站点:”之前或之后相同
但是,无论谁在前面或后面,关键词和“site:”都必须在2、中留空,因为“site:”搜索,关键词可以是多个,多个关键词之间用空格分隔
3、支持与其他复杂的搜索语法混合,并且每个语法和关键词之间都有一个空格@
4、除了网站之外,您还可以搜索网站的频道,但只能搜索那些没有“/”的频道
5、a网站可能有多种语言
因此,“搜索所有网站”和“搜索中文(简体)网页”之间存在差异
当然,如果网站只指定了一种语言,那么选择是相同的
目的:
1、可用于限制网站类型。教育部和组织机构的学术材料将更加简洁,政府相关信息可能更容易在政府机构中找到
2、使用域名后缀,如edu、org、net和gov,不会使用此后缀搜索所有网站
只搜索以该后缀结尾的网站和后缀为CN、US、Si等国家和地区的edu.jp
Gov.us、org.it等不在搜索范围内,因此您需要单独搜索
3、搜索一种语言或网站在指定国家/地区@
4、有些网站不提供现场搜索,或者信息结构混乱,内容多,很难找到东西
然后你可以使用“site:”来检索这个网站
谷歌的“站点:”功能比大多数网站自己的站点搜索更容易使用,如果你不检查的话
动态数据库,时效性要求不高
5、search不欢迎您搜索和免费使用数据库的一部分网站
6、use“site:”在死链接网站和关闭的网站中搜索信息@
例如:
打开
输入:站点:百度知道
输入:百度知道
输入:百度知道
你知道这三者的区别吗
搜索指定网站内容( Www_com那怎样才算是较为成功的突破口呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-19 06:03
Www_com那怎样才算是较为成功的突破口呢?)
内容建设是第一个重要问题
如前所述,网站如果你想提供太多的内容,并且你想快速推广你的网站你需要找到一个突破,但我没有说清楚什么样的突破才是更成功的突破。同样,我忽略了内容建设是新发展中的第一个重要问题网站. 万维网
那么,什么是更成功的突破?笔者认为主要的寻找方向如下:中国站长站
首先是一些别人没有注意到的内容
例如,你可能想提供有关互联网的信息,但是如果这个行业的人一般都到基层网络,你认为不先上网吗?我认为是这样。Www~~com
例如,如果你想提供一些关于文学的东西,起点比你好得多。你怎么能让别人来找你?所以当你提供它时,你不能网站提供它,而你只是提供它。在你的网站成功背后,是别人没有注意到、也没有提供的东西,即避开边缘,避开新环境。站长。站
当二、选择突破时,考虑你的目标客户群
首先,你要想一想,你的目标客户群是谁?例如,如果你选择情绪化的文章作为你的网站突破点,这没有问题。也许你的网站流量在短时间内真的很大,而且有很多读者,但是如果你仔细看看,你的目标客户群是否与你最初的想法不同。因为内容很多,你的目标客户群必须分散,我们发现它不能形成一个清晰的整体。站长。站
对于一家新成立的网站公司来说,内容建设首当其冲。中国火车站。龙火车站
如何吸引别人看到你的网站,即使你吸引了很多人,网站也不能展示更多更好的内容,网站也会处于尴尬的境地。即使不是为了读者,也应该从搜索引擎的角度来考虑。只有当你的网站沉淀了大量有价值的内容时,你的网站才会被搜索引擎不断捕获和更新,只有大量的内容,读者才会通过搜索引擎到达你的网站网站,一些读者最终会成为你的网站忠实用户
那么如何构建网站content\uucom呢
这里有一个简单的提示:网站内容构建不是大量的复制和粘贴。首先,你需要选择一个主题。所谓选题就是在网站选择适合你的内容并进行编辑;其次,正确添加标签,便于搜索引擎捕获。当然,读者来到您的网站网站更方便,更有利于提高您的网站公关价值。Www~~com 查看全部
搜索指定网站内容(
Www_com那怎样才算是较为成功的突破口呢?)
内容建设是第一个重要问题
如前所述,网站如果你想提供太多的内容,并且你想快速推广你的网站你需要找到一个突破,但我没有说清楚什么样的突破才是更成功的突破。同样,我忽略了内容建设是新发展中的第一个重要问题网站. 万维网
那么,什么是更成功的突破?笔者认为主要的寻找方向如下:中国站长站
首先是一些别人没有注意到的内容
例如,你可能想提供有关互联网的信息,但是如果这个行业的人一般都到基层网络,你认为不先上网吗?我认为是这样。Www~~com
例如,如果你想提供一些关于文学的东西,起点比你好得多。你怎么能让别人来找你?所以当你提供它时,你不能网站提供它,而你只是提供它。在你的网站成功背后,是别人没有注意到、也没有提供的东西,即避开边缘,避开新环境。站长。站
当二、选择突破时,考虑你的目标客户群
首先,你要想一想,你的目标客户群是谁?例如,如果你选择情绪化的文章作为你的网站突破点,这没有问题。也许你的网站流量在短时间内真的很大,而且有很多读者,但是如果你仔细看看,你的目标客户群是否与你最初的想法不同。因为内容很多,你的目标客户群必须分散,我们发现它不能形成一个清晰的整体。站长。站
对于一家新成立的网站公司来说,内容建设首当其冲。中国火车站。龙火车站
如何吸引别人看到你的网站,即使你吸引了很多人,网站也不能展示更多更好的内容,网站也会处于尴尬的境地。即使不是为了读者,也应该从搜索引擎的角度来考虑。只有当你的网站沉淀了大量有价值的内容时,你的网站才会被搜索引擎不断捕获和更新,只有大量的内容,读者才会通过搜索引擎到达你的网站网站,一些读者最终会成为你的网站忠实用户
那么如何构建网站content\uucom呢
这里有一个简单的提示:网站内容构建不是大量的复制和粘贴。首先,你需要选择一个主题。所谓选题就是在网站选择适合你的内容并进行编辑;其次,正确添加标签,便于搜索引擎捕获。当然,读者来到您的网站网站更方便,更有利于提高您的网站公关价值。Www~~com
搜索指定网站内容(微软AZURE全球版技术文档网站搜索API将从认知服务迁移到必应搜索)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-09-19 05:01
您正在访问Microsoft azure全局技术文档网站。如果您需要访问由21vianet运营的Microsoft azure中国技术文档网站,请访问
筛选搜索响应中收录的结果
警告
Bing搜索API将从认知服务迁移到Bing搜索服务。从2020年10月30日起,Bing搜索的任何新实例都需要根据此处描述的流程进行预配置。使用认知服务预配置的Bing搜索API将在未来三年内或企业协议结束前(以先到者为准)得到支持。有关迁移说明,请参阅Bing搜索服务
在查询web时,Bing会返回它为搜索找到的所有相关内容。例如,如果搜索查询为“帆船+小船”,则响应可能收录以下结果:
{
"_type" : "SearchResponse",
"webPages" : {
"webSearchUrl" : "https:\/\/www.bing.com\/cr?IG=3A43C...",
"totalEstimatedMatches" : 262000,
"value" : [...]
},
"images" : {
"id" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/#Images",
"readLink" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/images\/search?q=sail...",
"webSearchUrl" : "https:\/\/www.bing.com\/cr?IG=3A43CA5CA6464E5D...",
"isFamilyFriendly" : true,
"value" : [...]
},
"rankingResponse" : {
"mainline" : {
"items" : [...]
}
}
}
查询参数
要过滤Bing返回的结果,请在调用API时使用以下查询参数
响应滤波器
您可以使用查询参数(以逗号分隔的结果列表)过滤Bing在响应中提供的结果类型(例如,图像、视频和新闻)。如果Bing发现了什么,响应将收录结果
要从响应中排除特定结果(如图像),请在结果类型之前添加-字符。例如:
&responseFilter=-images,-videos
下面显示如何使用responsefilter请求“帆船”的图像、视频和新闻。对查询字符串进行编码时,逗号更改为%2C
GET https://api.cognitive.microsof ... en-us HTTP/1.1
Ocp-Apim-Subscription-Key: 123456789ABCDE
User-Agent: Mozilla/5.0 (compatible; MSIE 10.0; Windows Phone 8.0; Trident/6.0; IEMobile/10.0; ARM; Touch; NOKIA; Lumia 822)
X-Search-ClientIP: 999.999.999.999
X-Search-Location: 47.60357;long:-122.3295;re:100
X-MSEdge-ClientID:
Host: api.cognitive.microsoft.com
下面显示对上一个查询的响应。因为Bing没有找到相关的视频和新闻结果,所以他们没有被包括在回复中
{
"_type" : "SearchResponse",
"images" : {
"id" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/#Images",
"readLink" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/images\/search?q=sail...",
"webSearchUrl" : "https:\/\/www.bing.com\/cr?IG=3AD78B183C56456C...",
"isFamilyFriendly" : true,
"value" : [...]
},
"rankingResponse" : {
"mainline" : {
"items" : [{
"answerType" : "Images",
"value" : {
"id" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/#Images"
}
}]
}
}
}
虽然Bing在之前的回复中没有返回视频和新闻结果,但这并不意味着这些视频和新闻内容不存在。这仅表示页面不收录。但是,如果翻页浏览更多结果,这些内容可能会收录在后续页面中。此外,如果直接调用视频搜索API和新闻搜索API端点,则结果可能会收录在响应中
不建议使用responsefilter从单个API获取结果。如果您需要来自单个Bing API的内容,可以直接调用该API。例如,如果只希望接收图像,可以向图像搜索API端点或其他端点发送请求。调用单个API很重要,这不仅是出于性能原因,还因为特定于内容的API提供了更丰富的结果。例如,可以使用不适用于Web搜索API的筛选器筛选结果
场地
要从特定域获取搜索结果,请在查询字符串中收录site:query参数
https://api.cognitive.microsof ... en-us
评论
如果使用site:query操作符,则仍然可以在响应中收录成人内容,而不管设置如何,具体取决于查询。站点:仅当网站内容已知且方案允许使用成人内容时才应使用
新鲜度
要将Web响应结果限制为必须在特定时间段内发现的页面,请将查询参数设置为以下值之一(不区分大小写):
您还可以将此参数设置为yyyy-mm-dd格式的用户定义日期范围。。年月日
/必应/v7.0/search?q=ipad+更新和新鲜度=2019-02-01..2019-05-30
要将结果限制为单个日期,请将freshness参数设置为特定日期:
/必应/v7.0/search?q=ipad+更新和新鲜度=2019-02-04
如果Bing满足筛选条件的页面数小于您请求的页面数(或Bing返回的默认页面数),则结果可能包括指定时间段以外的页面
限制响应中检索结果的数量
Bing可以在JSON响应中返回多个结果类型。例如,如果您查询“销售+小艇”,必应可能会返回网页、图像、视频和相关搜索
{
"_type" : "SearchResponse",
"queryContext" : {
"originalQuery" : "sailing dinghies"
},
"webPages" : {...},
"images" : {...},
"relatedSearches" : {...},
"videos" : {...},
"rankingResponse" : {...}
}
要将Bing返回的搜索结果限制为前两个结果(网页和图片),请将查询参数设置为2
GET https://api.cognitive.microsof ... en-us HTTP/1.1
Ocp-Apim-Subscription-Key: 123456789ABCDE
User-Agent: Mozilla/5.0 (compatible; MSIE 10.0; Windows Phone 8.0; Trident/6.0; IEMobile/10.0; ARM; Touch; NOKIA; Lumia 822)
X-Search-ClientIP: 999.999.999.999
X-Search-Location: 47.60357;long:-122.3295;re:100
X-MSEdge-ClientID:
Host: api.cognitive.microsoft.com
响应仅包括网页和图像
{
"_type" : "SearchResponse",
"queryContext" : {
"originalQuery" : "sailing dinghies"
},
"webPages" : {...},
"images" : {...},
"rankingResponse" : {...}
}
如果将responsefilter查询参数添加到上一个查询中,并将其设置为web pages and news,则响应中将只收录web pages,因为该新闻没有排名
{
"_type" : "SearchResponse",
"queryContext" : {
"originalQuery" : "sailing dinghies"
},
"webPages" : {...},
"rankingResponse" : {...}
}
推广非排名搜索结果
如果必应为查询返回的首选搜索结果是网页、图片、视频和相关搜索,则这些结果将收录在响应中。如果设置为两个(2)),必应将返回前两个搜索结果:网页和图片。如果希望Bing在其响应中收录图片和视频,请指定查询参数并将其设置为图片和视频
GET https://api.cognitive.microsof ... en-us HTTP/1.1
Ocp-Apim-Subscription-Key: 123456789ABCDE
User-Agent: Mozilla/5.0 (compatible; MSIE 10.0; Windows Phone 8.0; Trident/6.0; IEMobile/10.0; ARM; Touch; NOKIA; Lumia 822)
X-Search-ClientIP: 999.999.999.999
X-Search-Location: 47.60357;long:-122.3295;re:100
X-MSEdge-ClientID:
Host: api.cognitive.microsoft.com
以下是对上述请求的答复。Bing返回前两个搜索结果(网页和图片),并将视频升级到搜索结果中
{
"_type" : "SearchResponse",
"queryContext" : {
"originalQuery" : "sailiing dinghies"
},
"webPages" : {...},
"images" : {...},
"videos" : {...},
"rankingResponse" : {...}
}
如果“升级”设置为“新闻”,则响应将不收录新闻搜索结果,因为它不是排名搜索结果-只能升级排名搜索结果
要提升的搜索结果不包括在answercount限制中。例如,如果排名的搜索结果收录新闻、图片和视频,并且answercount设置为1,promote设置为news,则响应将收录新闻和图片。或者,如果排名的搜索结果收录视频、图像和新闻,则响应将收录视频和新闻
仅当指定了answercount查询参数时才能使用升级
这一页有用吗
是否
多谢各位
主题 查看全部
搜索指定网站内容(微软AZURE全球版技术文档网站搜索API将从认知服务迁移到必应搜索)
您正在访问Microsoft azure全局技术文档网站。如果您需要访问由21vianet运营的Microsoft azure中国技术文档网站,请访问
筛选搜索响应中收录的结果
警告
Bing搜索API将从认知服务迁移到Bing搜索服务。从2020年10月30日起,Bing搜索的任何新实例都需要根据此处描述的流程进行预配置。使用认知服务预配置的Bing搜索API将在未来三年内或企业协议结束前(以先到者为准)得到支持。有关迁移说明,请参阅Bing搜索服务
在查询web时,Bing会返回它为搜索找到的所有相关内容。例如,如果搜索查询为“帆船+小船”,则响应可能收录以下结果:
{
"_type" : "SearchResponse",
"webPages" : {
"webSearchUrl" : "https:\/\/www.bing.com\/cr?IG=3A43C...",
"totalEstimatedMatches" : 262000,
"value" : [...]
},
"images" : {
"id" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/#Images",
"readLink" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/images\/search?q=sail...",
"webSearchUrl" : "https:\/\/www.bing.com\/cr?IG=3A43CA5CA6464E5D...",
"isFamilyFriendly" : true,
"value" : [...]
},
"rankingResponse" : {
"mainline" : {
"items" : [...]
}
}
}
查询参数
要过滤Bing返回的结果,请在调用API时使用以下查询参数
响应滤波器
您可以使用查询参数(以逗号分隔的结果列表)过滤Bing在响应中提供的结果类型(例如,图像、视频和新闻)。如果Bing发现了什么,响应将收录结果
要从响应中排除特定结果(如图像),请在结果类型之前添加-字符。例如:
&responseFilter=-images,-videos
下面显示如何使用responsefilter请求“帆船”的图像、视频和新闻。对查询字符串进行编码时,逗号更改为%2C
GET https://api.cognitive.microsof ... en-us HTTP/1.1
Ocp-Apim-Subscription-Key: 123456789ABCDE
User-Agent: Mozilla/5.0 (compatible; MSIE 10.0; Windows Phone 8.0; Trident/6.0; IEMobile/10.0; ARM; Touch; NOKIA; Lumia 822)
X-Search-ClientIP: 999.999.999.999
X-Search-Location: 47.60357;long:-122.3295;re:100
X-MSEdge-ClientID:
Host: api.cognitive.microsoft.com
下面显示对上一个查询的响应。因为Bing没有找到相关的视频和新闻结果,所以他们没有被包括在回复中
{
"_type" : "SearchResponse",
"images" : {
"id" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/#Images",
"readLink" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/images\/search?q=sail...",
"webSearchUrl" : "https:\/\/www.bing.com\/cr?IG=3AD78B183C56456C...",
"isFamilyFriendly" : true,
"value" : [...]
},
"rankingResponse" : {
"mainline" : {
"items" : [{
"answerType" : "Images",
"value" : {
"id" : "https:\/\/api.cognitive.microsoft.com\/api\/v7\/#Images"
}
}]
}
}
}
虽然Bing在之前的回复中没有返回视频和新闻结果,但这并不意味着这些视频和新闻内容不存在。这仅表示页面不收录。但是,如果翻页浏览更多结果,这些内容可能会收录在后续页面中。此外,如果直接调用视频搜索API和新闻搜索API端点,则结果可能会收录在响应中
不建议使用responsefilter从单个API获取结果。如果您需要来自单个Bing API的内容,可以直接调用该API。例如,如果只希望接收图像,可以向图像搜索API端点或其他端点发送请求。调用单个API很重要,这不仅是出于性能原因,还因为特定于内容的API提供了更丰富的结果。例如,可以使用不适用于Web搜索API的筛选器筛选结果
场地
要从特定域获取搜索结果,请在查询字符串中收录site:query参数
https://api.cognitive.microsof ... en-us
评论
如果使用site:query操作符,则仍然可以在响应中收录成人内容,而不管设置如何,具体取决于查询。站点:仅当网站内容已知且方案允许使用成人内容时才应使用
新鲜度
要将Web响应结果限制为必须在特定时间段内发现的页面,请将查询参数设置为以下值之一(不区分大小写):
您还可以将此参数设置为yyyy-mm-dd格式的用户定义日期范围。。年月日
/必应/v7.0/search?q=ipad+更新和新鲜度=2019-02-01..2019-05-30
要将结果限制为单个日期,请将freshness参数设置为特定日期:
/必应/v7.0/search?q=ipad+更新和新鲜度=2019-02-04
如果Bing满足筛选条件的页面数小于您请求的页面数(或Bing返回的默认页面数),则结果可能包括指定时间段以外的页面
限制响应中检索结果的数量
Bing可以在JSON响应中返回多个结果类型。例如,如果您查询“销售+小艇”,必应可能会返回网页、图像、视频和相关搜索
{
"_type" : "SearchResponse",
"queryContext" : {
"originalQuery" : "sailing dinghies"
},
"webPages" : {...},
"images" : {...},
"relatedSearches" : {...},
"videos" : {...},
"rankingResponse" : {...}
}
要将Bing返回的搜索结果限制为前两个结果(网页和图片),请将查询参数设置为2
GET https://api.cognitive.microsof ... en-us HTTP/1.1
Ocp-Apim-Subscription-Key: 123456789ABCDE
User-Agent: Mozilla/5.0 (compatible; MSIE 10.0; Windows Phone 8.0; Trident/6.0; IEMobile/10.0; ARM; Touch; NOKIA; Lumia 822)
X-Search-ClientIP: 999.999.999.999
X-Search-Location: 47.60357;long:-122.3295;re:100
X-MSEdge-ClientID:
Host: api.cognitive.microsoft.com
响应仅包括网页和图像
{
"_type" : "SearchResponse",
"queryContext" : {
"originalQuery" : "sailing dinghies"
},
"webPages" : {...},
"images" : {...},
"rankingResponse" : {...}
}
如果将responsefilter查询参数添加到上一个查询中,并将其设置为web pages and news,则响应中将只收录web pages,因为该新闻没有排名
{
"_type" : "SearchResponse",
"queryContext" : {
"originalQuery" : "sailing dinghies"
},
"webPages" : {...},
"rankingResponse" : {...}
}
推广非排名搜索结果
如果必应为查询返回的首选搜索结果是网页、图片、视频和相关搜索,则这些结果将收录在响应中。如果设置为两个(2)),必应将返回前两个搜索结果:网页和图片。如果希望Bing在其响应中收录图片和视频,请指定查询参数并将其设置为图片和视频
GET https://api.cognitive.microsof ... en-us HTTP/1.1
Ocp-Apim-Subscription-Key: 123456789ABCDE
User-Agent: Mozilla/5.0 (compatible; MSIE 10.0; Windows Phone 8.0; Trident/6.0; IEMobile/10.0; ARM; Touch; NOKIA; Lumia 822)
X-Search-ClientIP: 999.999.999.999
X-Search-Location: 47.60357;long:-122.3295;re:100
X-MSEdge-ClientID:
Host: api.cognitive.microsoft.com
以下是对上述请求的答复。Bing返回前两个搜索结果(网页和图片),并将视频升级到搜索结果中
{
"_type" : "SearchResponse",
"queryContext" : {
"originalQuery" : "sailiing dinghies"
},
"webPages" : {...},
"images" : {...},
"videos" : {...},
"rankingResponse" : {...}
}
如果“升级”设置为“新闻”,则响应将不收录新闻搜索结果,因为它不是排名搜索结果-只能升级排名搜索结果
要提升的搜索结果不包括在answercount限制中。例如,如果排名的搜索结果收录新闻、图片和视频,并且answercount设置为1,promote设置为news,则响应将收录新闻和图片。或者,如果排名的搜索结果收录视频、图像和新闻,则响应将收录视频和新闻
仅当指定了answercount查询参数时才能使用升级
这一页有用吗
是否
多谢各位
主题
搜索指定网站内容(python获取csv文本指定数据的注意事项有哪些实战案例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-19 04:19
这一次,我们将为您介绍Python的方法来获取CSV文本的指定数据。Python获取CSV文本的指定数据有哪些注意事项?以下是一个实际案例。让我们一起来看看
CSV是逗号分隔值的缩写。它是以文本文件形式存储的表格数据,如下表:
它可以存储为CSV文件。该文件的内容包括:
No.,Name,Age,Score
1,Apple,12,98
2,Ben,13,97
3,Celia,14,96
4,Dave,15,95
假设上面的CSV文件保存为“a.CSV”,那么如何使用Python提取列,即字段,如操作excel。使用Python自己的CSV模块,有两种方法:
第一种方法使用reader函数接收可迭代对象(如CSV文件),并返回一个生成器来解析CSV的内容。例如,以下代码可以以行为单位读取CSV的所有内容:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.reader(csvfile)
rows= [row for row in reader]
print rows
获取:
[['No.', 'Name', 'Age', 'Score'],
['1', 'Apple', '12', '98'],
['2', 'Ben', '13', '97'],
['3', 'Celia', '14', '96'],
['4', 'Dave', '15', '95']]
要提取其中一列,请使用以下代码:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.reader(csvfile)
column = [row[2] for row in reader]
print column
获取:
['Age', '12', '13', '14', '15']
请注意,从CSV读取的所有数据都是STR类型。在这种方法中,您需要提前知道列的序列号。例如,年龄在第2列中,但不能根据标题“年龄”进行查询。在这种情况下,可以采用第二种方法:
第二种方法是使用听写器。与reader函数类似,它接收一个可迭代的对象并返回一个生成器,但每个返回的单元格都放在字典的值中,字典的键是单元格标题(即列标题)。您可以通过以下代码查看dictreader的结构:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.DictReader(csvfile)
column = [row for row in reader]
print column
获取:
[{'Age': '12', 'No.': '1', 'Score': '98', 'Name': 'Apple'},
{'Age': '13', 'No.': '2', 'Score': '97', 'Name': 'Ben'},
{'Age': '14', 'No.': '3', 'Score': '96', 'Name': 'Celia'},
{'Age': '15', 'No.': '4', 'Score': '95', 'Name': 'Dave'}]
如果我们想使用dictreader读取CSV的一列,我们可以使用列标题来查询:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.DictReader(csvfile)
column = [row['Age'] for row in reader]
print column
你会得到:
['12', '13', '14', '15']
看了这个案例,我相信你已经掌握了这个方法。更多亮点请关注其他相关文章 查看全部
搜索指定网站内容(python获取csv文本指定数据的注意事项有哪些实战案例)
这一次,我们将为您介绍Python的方法来获取CSV文本的指定数据。Python获取CSV文本的指定数据有哪些注意事项?以下是一个实际案例。让我们一起来看看
CSV是逗号分隔值的缩写。它是以文本文件形式存储的表格数据,如下表:
它可以存储为CSV文件。该文件的内容包括:
No.,Name,Age,Score
1,Apple,12,98
2,Ben,13,97
3,Celia,14,96
4,Dave,15,95
假设上面的CSV文件保存为“a.CSV”,那么如何使用Python提取列,即字段,如操作excel。使用Python自己的CSV模块,有两种方法:
第一种方法使用reader函数接收可迭代对象(如CSV文件),并返回一个生成器来解析CSV的内容。例如,以下代码可以以行为单位读取CSV的所有内容:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.reader(csvfile)
rows= [row for row in reader]
print rows
获取:
[['No.', 'Name', 'Age', 'Score'],
['1', 'Apple', '12', '98'],
['2', 'Ben', '13', '97'],
['3', 'Celia', '14', '96'],
['4', 'Dave', '15', '95']]
要提取其中一列,请使用以下代码:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.reader(csvfile)
column = [row[2] for row in reader]
print column
获取:
['Age', '12', '13', '14', '15']
请注意,从CSV读取的所有数据都是STR类型。在这种方法中,您需要提前知道列的序列号。例如,年龄在第2列中,但不能根据标题“年龄”进行查询。在这种情况下,可以采用第二种方法:
第二种方法是使用听写器。与reader函数类似,它接收一个可迭代的对象并返回一个生成器,但每个返回的单元格都放在字典的值中,字典的键是单元格标题(即列标题)。您可以通过以下代码查看dictreader的结构:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.DictReader(csvfile)
column = [row for row in reader]
print column
获取:
[{'Age': '12', 'No.': '1', 'Score': '98', 'Name': 'Apple'},
{'Age': '13', 'No.': '2', 'Score': '97', 'Name': 'Ben'},
{'Age': '14', 'No.': '3', 'Score': '96', 'Name': 'Celia'},
{'Age': '15', 'No.': '4', 'Score': '95', 'Name': 'Dave'}]
如果我们想使用dictreader读取CSV的一列,我们可以使用列标题来查询:
import csv
with open('A.csv','rb') as csvfile:
reader = csv.DictReader(csvfile)
column = [row['Age'] for row in reader]
print column
你会得到:
['12', '13', '14', '15']
看了这个案例,我相信你已经掌握了这个方法。更多亮点请关注其他相关文章
搜索指定网站内容( 2018年05月11日12:02:02:07)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-18 14:20
2018年05月11日12:02:02:07)
JS实现了对表中一列内容的实时搜索和过滤功能
更新时间:2018年5月11日12:02:07作者:Marx link
本文文章主要介绍JS如何实现对表中一列内容的实时搜索和过滤功能,涉及到HTML元素的JavaScript遍历和属性的动态修改。有需要的朋友可以参考
本文描述了JS如何实现对表中一列内容的实时搜索和过滤功能。与您分享,供您参考,如下所示:
有时,我们从数据库中读取数据并将其显示在表中。此时,新的需求是在搜索框中输入关键字并实时过滤表的内容
当数据库的查询立即触发并调用显示时,速度会变慢,拖慢服务器,减少用户体验。此时,如果有一个纯JS操作实时过滤表中的一列,不仅可以提高搜索速度,而且不占用服务器资源,用户自然满意
具体实施如下。首先看一下渲染
启动状态:
在输入框中输入“e”,表格将立即被过滤。如果没有“e”,则筛选表中收录“e”的行将被隐藏。使用在线HTML/JS/CSS运行工具,测试运行效果如下图所示:
实施代码:
<p>
www.jb51.net JS搜索筛选table列
function onSearch(obj){//js函数开始
setTimeout(function(){//因为是即时查询,需要用setTimeout进行延迟,让值写入到input内,再读取
var storeId = document.getElementById('store');//获取table的id标识
var rowsLength = storeId.rows.length;//表格总共有多少行
var key = obj.value;//获取输入框的值
var searchCol = 0;//要搜索的哪一列,这里是第一列,从0开始数起
for(var i=1;i 查看全部
搜索指定网站内容(
2018年05月11日12:02:02:07)
JS实现了对表中一列内容的实时搜索和过滤功能
更新时间:2018年5月11日12:02:07作者:Marx link
本文文章主要介绍JS如何实现对表中一列内容的实时搜索和过滤功能,涉及到HTML元素的JavaScript遍历和属性的动态修改。有需要的朋友可以参考
本文描述了JS如何实现对表中一列内容的实时搜索和过滤功能。与您分享,供您参考,如下所示:
有时,我们从数据库中读取数据并将其显示在表中。此时,新的需求是在搜索框中输入关键字并实时过滤表的内容
当数据库的查询立即触发并调用显示时,速度会变慢,拖慢服务器,减少用户体验。此时,如果有一个纯JS操作实时过滤表中的一列,不仅可以提高搜索速度,而且不占用服务器资源,用户自然满意
具体实施如下。首先看一下渲染
启动状态:
在输入框中输入“e”,表格将立即被过滤。如果没有“e”,则筛选表中收录“e”的行将被隐藏。使用在线HTML/JS/CSS运行工具,测试运行效果如下图所示:
实施代码:
<p>
www.jb51.net JS搜索筛选table列
function onSearch(obj){//js函数开始
setTimeout(function(){//因为是即时查询,需要用setTimeout进行延迟,让值写入到input内,再读取
var storeId = document.getElementById('store');//获取table的id标识
var rowsLength = storeId.rows.length;//表格总共有多少行
var key = obj.value;//获取输入框的值
var searchCol = 0;//要搜索的哪一列,这里是第一列,从0开始数起
for(var i=1;i
搜索指定网站内容(网站语法格式及其应用方法介绍-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-09-15 12:10
语法格式:
网址:website关键词
或关键词站点:
注意事项:
1、site:下面的冒号必须是英文“:”,而中文的全角冒号“:”是无用的
2、url正面不能接受
3、url不能使用反斜杠“/”。事实上,它不能在任何地方使用/
4、url除非有特殊目的,否则不要在中使用WWW
使用www会导致您错过网站中的内容,因为许多网站频道没有www
其他说明:
1、关键词搜索结果可以在“站点:”之前或之后相同
但是,无论谁在前面或后面,关键词和“site:”都必须在2、中留空,因为“site:”搜索,关键词可以是多个,多个关键词之间用空格分隔
3、支持与其他复杂的搜索语法混合,并且每个语法和关键词之间都有一个空格@
4、除了网站之外,您还可以搜索网站的频道,但只能搜索那些没有“/”的频道
5、a网站可能有多种语言
因此,“搜索所有网站”和“搜索中文(简体)网页”之间存在差异
当然,如果网站只指定了一种语言,那么选择是相同的
目的:
1、可用于限制网站类型。教育部和组织机构的学术材料将更加简洁,政府相关信息可能更容易在政府机构中找到
2、使用域名后缀,如edu、org、net和gov,不会使用此后缀搜索所有网站
只搜索以该后缀结尾的网站和后缀为CN、US、Si等国家和地区的edu.jp
Gov.us、org.it等不在搜索范围内,因此您需要单独搜索
3、搜索一种语言或网站在指定国家/地区@
4、有些网站不提供现场搜索,或者信息结构混乱,内容多,很难找到东西
然后你可以使用“site:”来检索这个网站
谷歌的“站点:”功能比大多数网站自己的站点搜索更容易使用,如果你不检查的话
动态数据库,时效性要求不高
5、search不欢迎您搜索和免费使用数据库的一部分网站
6、use“site:”在死链接网站和关闭的网站中搜索信息@
例如:
打开
输入:站点:百度知道
输入:百度知道
输入:百度知道
你知道这三者的区别吗 查看全部
搜索指定网站内容(网站语法格式及其应用方法介绍-上海怡健医学)
语法格式:
网址:website关键词
或关键词站点:
注意事项:
1、site:下面的冒号必须是英文“:”,而中文的全角冒号“:”是无用的
2、url正面不能接受
3、url不能使用反斜杠“/”。事实上,它不能在任何地方使用/
4、url除非有特殊目的,否则不要在中使用WWW
使用www会导致您错过网站中的内容,因为许多网站频道没有www
其他说明:
1、关键词搜索结果可以在“站点:”之前或之后相同
但是,无论谁在前面或后面,关键词和“site:”都必须在2、中留空,因为“site:”搜索,关键词可以是多个,多个关键词之间用空格分隔
3、支持与其他复杂的搜索语法混合,并且每个语法和关键词之间都有一个空格@
4、除了网站之外,您还可以搜索网站的频道,但只能搜索那些没有“/”的频道
5、a网站可能有多种语言
因此,“搜索所有网站”和“搜索中文(简体)网页”之间存在差异
当然,如果网站只指定了一种语言,那么选择是相同的
目的:
1、可用于限制网站类型。教育部和组织机构的学术材料将更加简洁,政府相关信息可能更容易在政府机构中找到
2、使用域名后缀,如edu、org、net和gov,不会使用此后缀搜索所有网站
只搜索以该后缀结尾的网站和后缀为CN、US、Si等国家和地区的edu.jp
Gov.us、org.it等不在搜索范围内,因此您需要单独搜索
3、搜索一种语言或网站在指定国家/地区@
4、有些网站不提供现场搜索,或者信息结构混乱,内容多,很难找到东西
然后你可以使用“site:”来检索这个网站
谷歌的“站点:”功能比大多数网站自己的站点搜索更容易使用,如果你不检查的话
动态数据库,时效性要求不高
5、search不欢迎您搜索和免费使用数据库的一部分网站
6、use“site:”在死链接网站和关闭的网站中搜索信息@
例如:
打开
输入:站点:百度知道
输入:百度知道
输入:百度知道
你知道这三者的区别吗
搜索指定网站内容(【干货】搜索引擎实用技巧和如何高效地使用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-09-15 12:03
前言
我们平时搜索东西时,大多都是在搜索引擎中直接输入关键词,然后在搜索结果里一个个点开查找。有时搜索结果里的无用内容太多,翻好几页也不一定能找到满意的结果。
其实百度、谷歌、搜狗等搜索引擎,都支持一些高级搜索技巧和语法,可以对搜索结果进行限制和筛选,缩小检索范围,让搜索结果更加准确。
下面就说些实用的搜索技巧和如何高效地使用搜索引擎。
搜索引擎实用技巧
说明:
# 1. “关键词”
双引号,精确搜索,会完全匹配引号内的关键词,搜索结果中必须收录和引号中完全相同的内容。
# 2. 关键词 + filetype:格式
指定文件类型搜索,较严格;平时也可以直接用 “文件名+格式” 搜索。
注意:只有搜索引擎支持的格式才可以使用 filetype,如 doc、ppt、pdf 等;而 epub、mobi 等不行,它们可以使用 “名称+格式”,如“史记 epub”。
# 3. site:域名 + 关键词
在指定网站内搜索,只搜索目标网站中的内容。
# 4. intitle:关键词 和 intext:关键词
这两个适合与其它语法搭配使用,不太单独用。因为直接搜索关键词也一样,还更方便。
# 5. *
星号,通配符,模糊搜索。我们如果忘记了名称的某部分,就可以用 * 代替。比如 “资治*鉴”。
# 实践
以上语法可以单独或搭配使用,中间用空格隔开即可。
在豆瓣中搜索标题含【喜剧电影】的内容,要求完全匹配,我们可以这么搜:
intitle:“喜剧电影” site:
在微盘中搜索【资治通鉴mobi】电子书:
intitle:资治通鉴mobi site:
工具推荐# 1. 搜索引擎的高级搜索功能
使用搜索引擎自带的高级搜索:
# 2. 虫部落
1. 快搜:/
2. 学术搜索:/
一个很强大的聚合类搜索引擎。
结语
搜索语法还有很多,上面只介绍了最简单常用的几个(反正多了也记不住)。对于有时效性的内容,还可以在搜索框下面的【工具】中指定时间段。
其实目的只有一个,就是尽可能缩小检索范围,除去无用内容,提高搜索结果中有效信息的密度,进而提高我们的搜索效率和准确度。 查看全部
搜索指定网站内容(【干货】搜索引擎实用技巧和如何高效地使用?)
前言
我们平时搜索东西时,大多都是在搜索引擎中直接输入关键词,然后在搜索结果里一个个点开查找。有时搜索结果里的无用内容太多,翻好几页也不一定能找到满意的结果。
其实百度、谷歌、搜狗等搜索引擎,都支持一些高级搜索技巧和语法,可以对搜索结果进行限制和筛选,缩小检索范围,让搜索结果更加准确。
下面就说些实用的搜索技巧和如何高效地使用搜索引擎。
搜索引擎实用技巧
说明:
# 1. “关键词”
双引号,精确搜索,会完全匹配引号内的关键词,搜索结果中必须收录和引号中完全相同的内容。
# 2. 关键词 + filetype:格式
指定文件类型搜索,较严格;平时也可以直接用 “文件名+格式” 搜索。
注意:只有搜索引擎支持的格式才可以使用 filetype,如 doc、ppt、pdf 等;而 epub、mobi 等不行,它们可以使用 “名称+格式”,如“史记 epub”。
# 3. site:域名 + 关键词
在指定网站内搜索,只搜索目标网站中的内容。
# 4. intitle:关键词 和 intext:关键词
这两个适合与其它语法搭配使用,不太单独用。因为直接搜索关键词也一样,还更方便。
# 5. *
星号,通配符,模糊搜索。我们如果忘记了名称的某部分,就可以用 * 代替。比如 “资治*鉴”。
# 实践
以上语法可以单独或搭配使用,中间用空格隔开即可。
在豆瓣中搜索标题含【喜剧电影】的内容,要求完全匹配,我们可以这么搜:
intitle:“喜剧电影” site:
在微盘中搜索【资治通鉴mobi】电子书:
intitle:资治通鉴mobi site:
工具推荐# 1. 搜索引擎的高级搜索功能
使用搜索引擎自带的高级搜索:
# 2. 虫部落
1. 快搜:/
2. 学术搜索:/
一个很强大的聚合类搜索引擎。
结语
搜索语法还有很多,上面只介绍了最简单常用的几个(反正多了也记不住)。对于有时效性的内容,还可以在搜索框下面的【工具】中指定时间段。
其实目的只有一个,就是尽可能缩小检索范围,除去无用内容,提高搜索结果中有效信息的密度,进而提高我们的搜索效率和准确度。
搜索指定网站内容(来聊一聊如何更好地利用谷歌搜索找到想要的内容? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 227 次浏览 • 2021-09-15 12:01
)
今天,让我们来谈谈如何更好地利用谷歌搜索找到你想要的内容。这是一种搜索技术,但一些我们都知道的技术,如直接搜索公式可以得到结果、搜索汇率、搜索快报等,将不会被介绍。这一次,我们主要介绍一些在输入搜索内容时可能使用的特殊标记
目录搜索指定的文本(“”)不收录关键词(-)限制。仅在标题(intitle:)中搜索模糊搜索(*)在指定网页(站点:)中搜索内容指定文件类型(文件类型:)的搜索结果
谷歌的官方指南可以在以下两个链接中找到。本文仅选取几个最常用的技巧作为例子
此外,由于很多网民可能无法打开这个网站,如果百度有类似的技能,我也会在下面提到它
1.搜索指定的文本
有时,搜索引擎会显示与您的输入不完全匹配的结果,原因如下:
如果您不希望搜索引擎向您显示此类结果,但完全匹配您输入的文本,则可以将相应文本用半角双引号括起来
例如,您希望搜索玩具的故事,但直接搜索不会得到完全符合此格式的结果(词序可能不同),如下所示:
因为《玩具总动员》是著名电影《玩具总动员》的名字,谷歌认为你更可能想搜索这个(但不是)。此时,用双引号搜索相同的内容将获得更好的结果:
同样,它是半宽的双引号。如果它被意外地输入到中文双引号中,它将不起作用
此外,谷歌搜索不区分大小写。因此,没有直接的方法来实现区分大小写的搜索,只有一些间接的方法(基本上是过滤搜索结果),比如本文提到的文章方法
百度同样2.只在标题中限制搜索
如果您只希望搜索结果的标题收录关键字(而不是整个网页收录此关键词,因为它可能恰好出现在文本中,甚至出现在广告中,但整个网页与您要搜索的内容无关),您可以这样使用标记intitle:或allintitle:。两者之间的区别在于,在前者中,只有冒号后面的第一个关键词必须出现在标题中,而在后者中,冒号后面的所有关键词必须出现在标题中
例如,如果要搜索标题中收录Microsoft Surface MacBook的网页,可以搜索:
allintitle:microsoft surface macbook
百度只有一个标题:3.不包括关键词
如果你不想在搜索结果中出现一些关键词,你可以在这些关键词之前加一个减号“-”来排除它们。例如,如果您想搜索“大碗粗面”,但不想搜索与“吴一凡”相关的内容,您可以搜索:
大碗粗面 -吴亦凡
再比如,你想搜索“千樱钢琴”的钢琴演奏,但是直接搜索“千樱钢琴”会显示很多钢琴乐谱。此时,您可以搜索:
千本樱 钢琴 -谱
此外,不幸的是,根据这篇文章文章,谷歌多年前取消了加号“+”功能,即强制搜索结果收录关键词。但是,通过前面的引号函数可以实现类似的功能
百度同样原因4.模糊搜索
如果您不能清楚地记住要搜索的内容中的单个字符,可以使用星号“*”
例如,如果您听到一首英文歌曲,但只清楚地听到几个单词,您可以使用星号替换您听不清楚的单词:
然后我找到了那首歌
百度5.在指定网页中搜索内容
如果您知道要查看的结果将出现在web地址符合特定法律的网页中,则可以使用特殊标记站点:来限制搜索范围
例如,已知网易云音乐网页版本中歌曲的链接形状如下:
https://music.163.com/song?id=12345678
当然,它还包括歌曲下方评论区的内容。然后我们可以使用此方法在网易云音乐评论区搜索某人的评论。例如,在网易云音乐评论区搜索丁磊(他的网易云音乐ID为“网易UFO丁磊”)的评论:
"网易UFO丁磊" site:music.163.com/song
或者,您只能在知乎列文章中搜索与“神经网络”相关的内容:
神经网络 site:zhuanlan.zhihu.com
此外,如果要在指定的社交网站搜索中搜索,可以使用“@”符号
例如:
百度也有同样的功能,但不是site:,而是inurl:
百度还可以使用@symbol6.搜索指定文件类型的结果
例如,搜索经典神经网络模型RESNET的论文可以如下所示:
resnet filetype:pdf
或者,搜索与线性代数相关的ppt:
在这里,您可以查看Google支持的所有文件格式(但常用的格式基本上是PDF、PPT、DOC等)
想用这种方式搜索图片吗?请直接使用谷歌图片搜索
百度也是一样
这就是我今天要介绍的技巧。希望大家能掌握搜索引擎的正确使用。在这种情况下,知乎it可能会减少很多问题~
查看全部
搜索指定网站内容(来聊一聊如何更好地利用谷歌搜索找到想要的内容?
)
今天,让我们来谈谈如何更好地利用谷歌搜索找到你想要的内容。这是一种搜索技术,但一些我们都知道的技术,如直接搜索公式可以得到结果、搜索汇率、搜索快报等,将不会被介绍。这一次,我们主要介绍一些在输入搜索内容时可能使用的特殊标记
目录搜索指定的文本(“”)不收录关键词(-)限制。仅在标题(intitle:)中搜索模糊搜索(*)在指定网页(站点:)中搜索内容指定文件类型(文件类型:)的搜索结果
谷歌的官方指南可以在以下两个链接中找到。本文仅选取几个最常用的技巧作为例子
此外,由于很多网民可能无法打开这个网站,如果百度有类似的技能,我也会在下面提到它
1.搜索指定的文本
有时,搜索引擎会显示与您的输入不完全匹配的结果,原因如下:
如果您不希望搜索引擎向您显示此类结果,但完全匹配您输入的文本,则可以将相应文本用半角双引号括起来
例如,您希望搜索玩具的故事,但直接搜索不会得到完全符合此格式的结果(词序可能不同),如下所示:
因为《玩具总动员》是著名电影《玩具总动员》的名字,谷歌认为你更可能想搜索这个(但不是)。此时,用双引号搜索相同的内容将获得更好的结果:
同样,它是半宽的双引号。如果它被意外地输入到中文双引号中,它将不起作用
此外,谷歌搜索不区分大小写。因此,没有直接的方法来实现区分大小写的搜索,只有一些间接的方法(基本上是过滤搜索结果),比如本文提到的文章方法
百度同样2.只在标题中限制搜索
如果您只希望搜索结果的标题收录关键字(而不是整个网页收录此关键词,因为它可能恰好出现在文本中,甚至出现在广告中,但整个网页与您要搜索的内容无关),您可以这样使用标记intitle:或allintitle:。两者之间的区别在于,在前者中,只有冒号后面的第一个关键词必须出现在标题中,而在后者中,冒号后面的所有关键词必须出现在标题中
例如,如果要搜索标题中收录Microsoft Surface MacBook的网页,可以搜索:
allintitle:microsoft surface macbook
百度只有一个标题:3.不包括关键词
如果你不想在搜索结果中出现一些关键词,你可以在这些关键词之前加一个减号“-”来排除它们。例如,如果您想搜索“大碗粗面”,但不想搜索与“吴一凡”相关的内容,您可以搜索:
大碗粗面 -吴亦凡
再比如,你想搜索“千樱钢琴”的钢琴演奏,但是直接搜索“千樱钢琴”会显示很多钢琴乐谱。此时,您可以搜索:
千本樱 钢琴 -谱
此外,不幸的是,根据这篇文章文章,谷歌多年前取消了加号“+”功能,即强制搜索结果收录关键词。但是,通过前面的引号函数可以实现类似的功能
百度同样原因4.模糊搜索
如果您不能清楚地记住要搜索的内容中的单个字符,可以使用星号“*”
例如,如果您听到一首英文歌曲,但只清楚地听到几个单词,您可以使用星号替换您听不清楚的单词:
然后我找到了那首歌
百度5.在指定网页中搜索内容
如果您知道要查看的结果将出现在web地址符合特定法律的网页中,则可以使用特殊标记站点:来限制搜索范围
例如,已知网易云音乐网页版本中歌曲的链接形状如下:
https://music.163.com/song?id=12345678
当然,它还包括歌曲下方评论区的内容。然后我们可以使用此方法在网易云音乐评论区搜索某人的评论。例如,在网易云音乐评论区搜索丁磊(他的网易云音乐ID为“网易UFO丁磊”)的评论:
"网易UFO丁磊" site:music.163.com/song
或者,您只能在知乎列文章中搜索与“神经网络”相关的内容:
神经网络 site:zhuanlan.zhihu.com
此外,如果要在指定的社交网站搜索中搜索,可以使用“@”符号
例如:
百度也有同样的功能,但不是site:,而是inurl:
百度还可以使用@symbol6.搜索指定文件类型的结果
例如,搜索经典神经网络模型RESNET的论文可以如下所示:
resnet filetype:pdf
或者,搜索与线性代数相关的ppt:
在这里,您可以查看Google支持的所有文件格式(但常用的格式基本上是PDF、PPT、DOC等)
想用这种方式搜索图片吗?请直接使用谷歌图片搜索
百度也是一样
这就是我今天要介绍的技巧。希望大家能掌握搜索引擎的正确使用。在这种情况下,知乎it可能会减少很多问题~
搜索指定网站内容(人和人最大的区别就是看他如何获取信息作为三大必备工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-14 20:14
人和人之间最大的区别之一是他们如何获取信息
作为“RSS”、“云笔记”、“搜索引擎”三大必备工具,一个人的搜索业务往往决定着他的未来。
一、搜索引擎命令集
1、site:在某个网站或域名下搜索
在特定网站下搜索,不仅可以搜索网页,还可以搜索某个站点下的所有图片、视频、新闻等。例如:樱花网站:表示搜索中国教育网下的樱花
使用方法:
身材好是一种什么样的体验 site:zhihu.com; baidu.com
功能:
2、Filetype:搜索某种类型的文件
搜索指定文件类型查找文档、电子书、PPT等非常实用的文件类型支持:ppt、ppts、doc、docx、xlsx、pdf、txt等(不同的搜索引擎支持不同的文件类型)
使用方法:
百年孤独 filetype:pdf
3、逻辑与、或:与、或
使用方法:
手机 OR 相机 电脑 OR 鼠标 OR 键盘
它等同于 (手机 OR 相机) (电脑 OR 鼠标 OR 键盘)
4、Logic 不是:-
Logical NOT -,即减号,表示搜索不收录减号后面单词的页面。使用该命令时,减号前必须有空格,减号后没有空格,后面是需要排除的单词。谷歌和百度都支持这个命令。
使用方法:
搜索引擎 历史 -文化 -中国历史 -世界历史
5、双引号
将搜索词放在双引号中表示完全匹配搜索,即搜索结果返回的页面收录所有出现在双引号中的词,甚至顺序必须完全匹配。 bd 和 Google 都支持此命令。
使用方法:
“知乎日报”
6、wildcard:?和 *
使用方法:
中国 * 银行
7、in 指令:location关键词find
详细用法:
7.1、inurl
用于指定搜索查询词出现在 url 中的页面。百度和谷歌都支持 inurl 命令。 inurl 命令支持中英文。
使用方法:
inurl:大学
7.2、inanchor
inanchor:命令返回的结果是导入链接锚文本中收录搜索词的页面。百度不支持锚定。例如,在谷歌搜索中:inanchor:click here 返回的结果页面本身并不一定收录“click here”四个字,但是这些页面链接的锚文本中出现了“click here”四个字。可以用来找某某关键词比赛,而这些比赛往往都做过SEO。通过研究竞争对手页面上的外部链接,您可以找到很多链接资源。
使用方法:
inanchor:点击这里
7.3、intitle
指定返回页面的标题收录关键词。 Google 和 bd 都支持 intitle 命令。
使用方法:
intitle:知乎科技
7.4、allintitle
搜索返回页面标题中收录多组关键词的文件。例如:allintitle:知乎手机科技相当于:intitle:知乎 intitle:手机intitle:科技,返回标题中同时收录“知乎”、“移动”和“技术”的页面
使用方法:
allintitle:知乎 手机 科技
8、link:搜索链接到某个 URL 地址的所有网页
使用方法:
9、related:查找网页的“相似页面”
使用方法:
related:www.newhua.com
10、值范围:..
使用方法:
数码相机 600..900 万像素 3000..4000 元
二、高级搜索技巧
谷歌在界面上提供了搜索条件,可以查询“受限语言”、“按时间”、“完全匹配”(百度等类似原因)
同样,图片也支持各种不同维度的过滤。新闻、视频等也是如此。图片查询也支持“搜索图片”,通过图片网址或上传图片。 (百度等都一样)
高级图片搜索
google高级搜索界面其实就是前面介绍的命令的界面版本(百度等都一样)
百度等其他搜索引擎也是如此,这里不再赘述
三、利用搜索引擎解决问题四、local search
Windows 文件搜索工具 Everything
这个只有1.3MB的小软件,通过访问NTFS文件系统的USN日志,可以在几秒钟内检索出数TB硬盘中的数百万个文件,并实时监控所有文件的添加和变化。事实上,可以毫不夸张地说它是Windows平台上最快的文件索引工具。
同时,Everything 支持通过正则表达式进行文件匹配,所有搜索结果都可以近乎实时地显示出来,内存消耗极低。如果您不精通正则表达式,也可以使用其自带的高级搜索功能,界面直观易懂。
还支持离线搜索:
Alfred 这是一款名为 Mac 效率神器的应用。有了Alfred,即使没有鼠标也可以实现各种操作。包括搜索各种文件、软件、配置、图片等。UI界面简单易用,不是通过命令实现的。开发者和键盘神器 刘通鞋
五、其他搜索引擎
实际上,除了谷歌、百度等搜索引擎,其他小众搜索引擎在查询某些内容时可能更高效、更准确。
六、如何做一个好人
我不相信这个世界上有绝对的天才。如果是这样,那么他一定是天才的方法和工具。对我来说,三个必备工具“RSS”、“搜索引擎”和“云笔记”
RSS:真正的无知是你不知道你不知道什么! RSS可以帮助我们开阔视野,提高获取信息的效率,利用碎片化的时间获取大量优质信息。 (RSS后我会详细介绍)
搜索引擎:用于检索您已经知道或听说过的东西。目的是对这些知识有更深入的了解或使用。
云笔记:构建您自己的知识系统。只有存在于自己的知识体系中,这种知识才能真正属于自己。
三个工具,从未知到知道,到熟悉,到应用,最后整合。 查看全部
搜索指定网站内容(人和人最大的区别就是看他如何获取信息作为三大必备工具)
人和人之间最大的区别之一是他们如何获取信息
作为“RSS”、“云笔记”、“搜索引擎”三大必备工具,一个人的搜索业务往往决定着他的未来。
一、搜索引擎命令集
1、site:在某个网站或域名下搜索
在特定网站下搜索,不仅可以搜索网页,还可以搜索某个站点下的所有图片、视频、新闻等。例如:樱花网站:表示搜索中国教育网下的樱花
使用方法:
身材好是一种什么样的体验 site:zhihu.com; baidu.com
功能:
2、Filetype:搜索某种类型的文件
搜索指定文件类型查找文档、电子书、PPT等非常实用的文件类型支持:ppt、ppts、doc、docx、xlsx、pdf、txt等(不同的搜索引擎支持不同的文件类型)
使用方法:
百年孤独 filetype:pdf
3、逻辑与、或:与、或
使用方法:
手机 OR 相机 电脑 OR 鼠标 OR 键盘
它等同于 (手机 OR 相机) (电脑 OR 鼠标 OR 键盘)
4、Logic 不是:-
Logical NOT -,即减号,表示搜索不收录减号后面单词的页面。使用该命令时,减号前必须有空格,减号后没有空格,后面是需要排除的单词。谷歌和百度都支持这个命令。
使用方法:
搜索引擎 历史 -文化 -中国历史 -世界历史
5、双引号
将搜索词放在双引号中表示完全匹配搜索,即搜索结果返回的页面收录所有出现在双引号中的词,甚至顺序必须完全匹配。 bd 和 Google 都支持此命令。
使用方法:
“知乎日报”
6、wildcard:?和 *
使用方法:
中国 * 银行
7、in 指令:location关键词find
详细用法:
7.1、inurl
用于指定搜索查询词出现在 url 中的页面。百度和谷歌都支持 inurl 命令。 inurl 命令支持中英文。
使用方法:
inurl:大学
7.2、inanchor
inanchor:命令返回的结果是导入链接锚文本中收录搜索词的页面。百度不支持锚定。例如,在谷歌搜索中:inanchor:click here 返回的结果页面本身并不一定收录“click here”四个字,但是这些页面链接的锚文本中出现了“click here”四个字。可以用来找某某关键词比赛,而这些比赛往往都做过SEO。通过研究竞争对手页面上的外部链接,您可以找到很多链接资源。
使用方法:
inanchor:点击这里
7.3、intitle
指定返回页面的标题收录关键词。 Google 和 bd 都支持 intitle 命令。
使用方法:
intitle:知乎科技
7.4、allintitle
搜索返回页面标题中收录多组关键词的文件。例如:allintitle:知乎手机科技相当于:intitle:知乎 intitle:手机intitle:科技,返回标题中同时收录“知乎”、“移动”和“技术”的页面
使用方法:
allintitle:知乎 手机 科技
8、link:搜索链接到某个 URL 地址的所有网页
使用方法:
9、related:查找网页的“相似页面”
使用方法:
related:www.newhua.com
10、值范围:..
使用方法:
数码相机 600..900 万像素 3000..4000 元
二、高级搜索技巧
谷歌在界面上提供了搜索条件,可以查询“受限语言”、“按时间”、“完全匹配”(百度等类似原因)
同样,图片也支持各种不同维度的过滤。新闻、视频等也是如此。图片查询也支持“搜索图片”,通过图片网址或上传图片。 (百度等都一样)
高级图片搜索
google高级搜索界面其实就是前面介绍的命令的界面版本(百度等都一样)
百度等其他搜索引擎也是如此,这里不再赘述
三、利用搜索引擎解决问题四、local search
Windows 文件搜索工具 Everything
这个只有1.3MB的小软件,通过访问NTFS文件系统的USN日志,可以在几秒钟内检索出数TB硬盘中的数百万个文件,并实时监控所有文件的添加和变化。事实上,可以毫不夸张地说它是Windows平台上最快的文件索引工具。
同时,Everything 支持通过正则表达式进行文件匹配,所有搜索结果都可以近乎实时地显示出来,内存消耗极低。如果您不精通正则表达式,也可以使用其自带的高级搜索功能,界面直观易懂。
还支持离线搜索:
Alfred 这是一款名为 Mac 效率神器的应用。有了Alfred,即使没有鼠标也可以实现各种操作。包括搜索各种文件、软件、配置、图片等。UI界面简单易用,不是通过命令实现的。开发者和键盘神器 刘通鞋
五、其他搜索引擎
实际上,除了谷歌、百度等搜索引擎,其他小众搜索引擎在查询某些内容时可能更高效、更准确。
六、如何做一个好人
我不相信这个世界上有绝对的天才。如果是这样,那么他一定是天才的方法和工具。对我来说,三个必备工具“RSS”、“搜索引擎”和“云笔记”
RSS:真正的无知是你不知道你不知道什么! RSS可以帮助我们开阔视野,提高获取信息的效率,利用碎片化的时间获取大量优质信息。 (RSS后我会详细介绍)
搜索引擎:用于检索您已经知道或听说过的东西。目的是对这些知识有更深入的了解或使用。
云笔记:构建您自己的知识系统。只有存在于自己的知识体系中,这种知识才能真正属于自己。
三个工具,从未知到知道,到熟悉,到应用,最后整合。
搜索指定网站内容(2.拼音检索中文字真的太多了,我们可以选择(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-09-14 11:07
您可以为每次登录选择默认搜索主页:
可选项目:网页、新闻、网站、区域、MP3、Flash、行业(系统默认为网页)
2.拼音搜索
汉字实在是太多了。很多时候我们无法确定具体的汉字或输入错误。这时候,您可以试试我们的拼音搜索。目前支持全拼和简拼。如果要查找“刘德华”,可以输入“六德华”、“刘德华”、“ldh”等形式。当然,为了缩小范围,我们强烈建议您输入完整的拼音。为了方便南方的朋友,我们还特地做了南方调的转换。您可以在个人设置中设置是否支持南方调。如下图:
z=zh; s=sh; c=ch; k=g; f=h; l=n; an=ang; en=eng;输入=ing; ian=ian; uan=uang。
这样即使只输入关键词的拼音搜索,依然可以提示最合适的中文关键词。
3.页面打开方式
这不仅仅是简单的关键词搜索,我们会自动为您提取网页的主要内容。将人工智能和概念搜索结合起来,提供更相关的文章结果。例如,如果您看到一个网页,想查看更多与该网页内容相关的结果,只需点击相关网页,我们就会自动为您提供与该网页内容相似且具有更多扩展信息。
4.结果展示
您可以选择是否在网页搜索结果中显示相关的三个新闻结果。
搜索类型↑返回列表
中国搜索为您提供多种搜索类型,为您节省宝贵的时间,让搜索结果更如您所愿。
1.网络搜索
2亿网页数据,24小时更新机制,满足您获取最新最全信息的需求。
拼音搜索帮你轻松完成搜索,永远不会出现用户担心关键词假课用什么的情况。
综合考虑的结果排名,让您一目了然。
高并发下毫秒级的检索时间,让您的检索无需等待。
支持在搜索结果中:重新检查,在结果中再次检查。
2.新闻搜
中国搜索的新闻搜索自成立以来一直处于中文实时搜索领域的领先地位,为中国知名门户网站新浪提供全面的新闻搜索服务。新闻搜索的主要特点是即时性和综合性。新闻1分钟内搜索1500多条新闻网站,充分体现信息时代瞬息万变的特点。同时,中国搜索新闻搜索自动对新闻结果进行分类,帮助您更快地找到您需要的内容。
为了让您快速找到您需要的信息,中国搜索的新闻搜索提供了时间和相关性两种排序方式。您还可以使用智能排序方法。我们会为您综合考虑这两个因素的影响。您可以自定义自己的排序方法。
3.area 搜索
当你要订票时,你是不是只想找这个城市的售票中心?
当您想换工作时,您是否更关心当地人力资源的现状?
为了解决这个问题:我们提取了网页所属站点的地理特征,方便用户搜索某个区域的网页内容。
4.网站Search
根据网站不同类型的显示,您可以直接进入您感兴趣的目录,找到适合您的网站。
5.MP3Search
收录超过70万条各种格式的音频信息,支持歌曲、歌手、歌词和专辑信息,我们每5分钟统计一次网页的连接状态,以最快的速度呈现给您。
Mp3搜索为您提供歌曲列表和歌手列表,按英文大写字母和数字排序,列出所有以英文字母开头的英文歌曲/歌手,以及以英文首字母开头的中文歌曲中国拼音/歌手。例如:找到歌手“阿杜”,进入mp3搜索,点击“歌手搜索”,在大写字母A的列表中找到歌手“阿杜”,如果没有找到您需要的内容,请使用我们的网络搜索引擎进行搜索。
6.图片搜索
中国搜索从2亿个中文网页中提取了各种图片,建立了完整的中文图片库。可以直接输入任意关键词搜索你想要的图片信息。
在图片搜索框中直接输入要查询的关键词,然后点击“搜索”按钮或直接按回车键。 (我们搜索的范围是图片的名称、图片的评论文字以及与图片相关的文章内容)点击您要查看的图片缩略图,您将看到原创大图。点击图片下方的“查看源网页”,可以查看原图片所在的网页。需要说明的是,是图片所在的源网页问题导致的。当出现“找不到图片”、“请输入用户名”等情况时,与中文搜索引擎无关。执行图片搜索时,您可以自由选择图片格式。支持JPEG、GIF、PNG和BMP格式的图片。图片尺寸提供“800 x600”、“1024 x 768”以及可作为壁纸的大、中、小图片供您根据需要选择。
7.Flash 搜索
中国搜索目前提供80,000个FLASH供搜索使用,并且还在不断扩充中。在FLASH搜索框中直接输入你要查询的关键词,然后点击“在中国搜索”按钮或直接按键盘回车键。我们搜索的范围是FLASH的名称、作者、FLASH的评论文本以及与FLASH相关的文章内容。点击您要查看的FLASH的缩略图,您将被链接到该FLASH的网页进行查看。
8.行业搜索
依托中文搜索引擎技术与60个行业数据库的结合,开创了基于行业特征分类、关键词分类等搜索引擎的搜索方式,为行业用户和业务人员提供快速、准确、直接的搜索搜索服务。作为产品,行业搜索引擎应用于慧聪国际信息的22个专业行业信息网站,以及中华网、中搜国际和31个网络联盟成员共同创建的搜索联盟的所有网站。目前搜索联盟成员包括各省市30多个顶级新闻门户网站,以及人民网、乾隆新闻网、263、东方网、宏旺、北方等22个慧聪国际新闻专业.com。行业资讯网站。例如,如果您搜索“玻璃”,则可以获得玻璃行业的新趋势。
9.产品搜索
产品搜索是中国搜索的最新搜索部分。产品搜索使用方便,您只需在搜索框中输入您的目标产品名称或产品描述,点击搜索按钮,即可获得您想要的产品列表。产品搜索结果包括:产品价格、产品介绍、产品图片、商家名称等信息,方便您选择产品。在产品搜索的引导下,您可以在合适的商家处购买到所需的产品。产品搜索还提供其他高级搜索功能:
查询给定价格范围内的产品
搜索指定商家送货城市的商品
为了让您更方便的看到更多商家的商品,您可以选择按商家展示:每个商家只展示一个最相关的商品信息。
您还可以在单个商户下查询更多符合搜索条件的产品
您可以在首页浏览产品分类目录,在分类目录的引导下快速找到您需要的产品
我们还提供查询词的相关目录功能:您搜索的产品名称可能会出现在许多产品分类目录中。为了方便您快速找到合适的产品,我们为您提供所有收录查询词的相关产品目录供您选择
10.游戏搜索
随着网络资源的不断增加,现在,人们需要的是准确的信息。人们没有时间从成百上千的搜索结果中找到他们需要的东西。这在单一类型的搜索引擎中发挥了重要作用:精确而详细的结果为您节省了大量时间。游戏搜索是专门针对游戏玩家的需求而开发的搜索引擎。充分满足了玩家对各类游戏下载、游戏攻略、游戏信息等的搜索需求,让玩家可以方便快捷地找到自己需要的网络游戏资源。
游戏搜索简洁方便,采用模糊查询方式,只需输入查询内容,然后点击搜索框右侧的搜索按钮,即可获取相关信息。
可以选择搜索不同的游戏信息:一般、游戏下载、攻略秘籍
搜索结果注明素材类别:游戏下载、攻略秘籍、信息来源网站。
独特的网站聚类功能,让用户只能看到更多来自不同网站的不同信息内容。
游戏搜索只显示相关结果,文本或链接收录您输入的所有关键字,因此您无需被其他不相关的结果打扰。游戏搜索引擎仅提取收录您输入的关键字的内容。为便于参考,您输入的关键字将以醒目亮丽的颜色显示。您不必费心下载和阅读冗长的网页介绍。
搜索结果 ↑返回列表
介绍搜索结果的特点。中国搜索的搜索结果页面的几个有用的功能:
更多结果1.此网站
为了让您更轻松地阅读更多网站内容,中国搜索自动为您采集信息,每个网站(或频道)只显示一个最相关网页的信息。点击此链接可在网站中查看更多符合搜索条件的结果。
2.中搜快照
点击每个搜索结果后的“中搜快照”,查看网页快照内容。
中文搜索引擎先对每个网站进行了预览,对网页进行了快照,并为用户存储了大量紧急网页。并且您用于搜索的字词已在网页上以不同颜色标记。
3.相关搜索词
中国搜索准备了其他与您的搜索关键词相关的关键词,帮助您快速定位您的搜索需求。
4.智能导航
中国搜索为您提供基于当前搜索词的智能导航分类,帮助您更快更准确地找到您需要的网页
如果有智能导航分类,它会出现在第一个搜索结果的上方。点击后,会得到当前搜索词在对应类别中的搜索结果
5.精选相关类别
中国搜索在搜索结果页面为您提供相关分类推荐,方便分类及相关过滤结果
1. 内容相关类别:提供与当前结果页面相同类别的网页
2. 内容相似网页:提供内容与当前结果相似的网页
H01.导航栏
导航栏中有“网页”、“新闻”、“网站”、“MP3”、“图片”、“购物”、“快闪”、“行业”、“地区”、“游戏”。只显示了7个项目,其他3个项目收录在“更多”中。将鼠标放在“更多”上,会出现一个下拉菜单,菜单最后一项是“导航设置”,点击进入,可以设置导航栏出现哪7项。系统使用背景颜色和字体颜色变化来表示您正在使用的搜索方法。
H02.搜索框
要查询信息,只需在文本框中输入关键词。按回车键(Enter 键)或单击搜索按钮可获取相关信息列表。不接受 Unicode 编码输入
H03.搜索按钮
点击搜索按钮提交另一个搜索请求。您也可以按“Enter”键提交查询。
H04.再次检查结果
在当前搜索结果范围内,再次执行查询。搜索范围缩小。
H05. 高级搜索
点击此按钮进入中国搜索高级搜索。
H06.搜索帮助
点击此按钮进入中国搜索的搜索帮助。 查看全部
搜索指定网站内容(2.拼音检索中文字真的太多了,我们可以选择(图))
您可以为每次登录选择默认搜索主页:
可选项目:网页、新闻、网站、区域、MP3、Flash、行业(系统默认为网页)
2.拼音搜索
汉字实在是太多了。很多时候我们无法确定具体的汉字或输入错误。这时候,您可以试试我们的拼音搜索。目前支持全拼和简拼。如果要查找“刘德华”,可以输入“六德华”、“刘德华”、“ldh”等形式。当然,为了缩小范围,我们强烈建议您输入完整的拼音。为了方便南方的朋友,我们还特地做了南方调的转换。您可以在个人设置中设置是否支持南方调。如下图:
z=zh; s=sh; c=ch; k=g; f=h; l=n; an=ang; en=eng;输入=ing; ian=ian; uan=uang。
这样即使只输入关键词的拼音搜索,依然可以提示最合适的中文关键词。
3.页面打开方式
这不仅仅是简单的关键词搜索,我们会自动为您提取网页的主要内容。将人工智能和概念搜索结合起来,提供更相关的文章结果。例如,如果您看到一个网页,想查看更多与该网页内容相关的结果,只需点击相关网页,我们就会自动为您提供与该网页内容相似且具有更多扩展信息。
4.结果展示
您可以选择是否在网页搜索结果中显示相关的三个新闻结果。
搜索类型↑返回列表
中国搜索为您提供多种搜索类型,为您节省宝贵的时间,让搜索结果更如您所愿。
1.网络搜索
2亿网页数据,24小时更新机制,满足您获取最新最全信息的需求。
拼音搜索帮你轻松完成搜索,永远不会出现用户担心关键词假课用什么的情况。
综合考虑的结果排名,让您一目了然。
高并发下毫秒级的检索时间,让您的检索无需等待。
支持在搜索结果中:重新检查,在结果中再次检查。
2.新闻搜
中国搜索的新闻搜索自成立以来一直处于中文实时搜索领域的领先地位,为中国知名门户网站新浪提供全面的新闻搜索服务。新闻搜索的主要特点是即时性和综合性。新闻1分钟内搜索1500多条新闻网站,充分体现信息时代瞬息万变的特点。同时,中国搜索新闻搜索自动对新闻结果进行分类,帮助您更快地找到您需要的内容。
为了让您快速找到您需要的信息,中国搜索的新闻搜索提供了时间和相关性两种排序方式。您还可以使用智能排序方法。我们会为您综合考虑这两个因素的影响。您可以自定义自己的排序方法。
3.area 搜索
当你要订票时,你是不是只想找这个城市的售票中心?
当您想换工作时,您是否更关心当地人力资源的现状?
为了解决这个问题:我们提取了网页所属站点的地理特征,方便用户搜索某个区域的网页内容。
4.网站Search
根据网站不同类型的显示,您可以直接进入您感兴趣的目录,找到适合您的网站。
5.MP3Search
收录超过70万条各种格式的音频信息,支持歌曲、歌手、歌词和专辑信息,我们每5分钟统计一次网页的连接状态,以最快的速度呈现给您。
Mp3搜索为您提供歌曲列表和歌手列表,按英文大写字母和数字排序,列出所有以英文字母开头的英文歌曲/歌手,以及以英文首字母开头的中文歌曲中国拼音/歌手。例如:找到歌手“阿杜”,进入mp3搜索,点击“歌手搜索”,在大写字母A的列表中找到歌手“阿杜”,如果没有找到您需要的内容,请使用我们的网络搜索引擎进行搜索。
6.图片搜索
中国搜索从2亿个中文网页中提取了各种图片,建立了完整的中文图片库。可以直接输入任意关键词搜索你想要的图片信息。
在图片搜索框中直接输入要查询的关键词,然后点击“搜索”按钮或直接按回车键。 (我们搜索的范围是图片的名称、图片的评论文字以及与图片相关的文章内容)点击您要查看的图片缩略图,您将看到原创大图。点击图片下方的“查看源网页”,可以查看原图片所在的网页。需要说明的是,是图片所在的源网页问题导致的。当出现“找不到图片”、“请输入用户名”等情况时,与中文搜索引擎无关。执行图片搜索时,您可以自由选择图片格式。支持JPEG、GIF、PNG和BMP格式的图片。图片尺寸提供“800 x600”、“1024 x 768”以及可作为壁纸的大、中、小图片供您根据需要选择。
7.Flash 搜索
中国搜索目前提供80,000个FLASH供搜索使用,并且还在不断扩充中。在FLASH搜索框中直接输入你要查询的关键词,然后点击“在中国搜索”按钮或直接按键盘回车键。我们搜索的范围是FLASH的名称、作者、FLASH的评论文本以及与FLASH相关的文章内容。点击您要查看的FLASH的缩略图,您将被链接到该FLASH的网页进行查看。
8.行业搜索
依托中文搜索引擎技术与60个行业数据库的结合,开创了基于行业特征分类、关键词分类等搜索引擎的搜索方式,为行业用户和业务人员提供快速、准确、直接的搜索搜索服务。作为产品,行业搜索引擎应用于慧聪国际信息的22个专业行业信息网站,以及中华网、中搜国际和31个网络联盟成员共同创建的搜索联盟的所有网站。目前搜索联盟成员包括各省市30多个顶级新闻门户网站,以及人民网、乾隆新闻网、263、东方网、宏旺、北方等22个慧聪国际新闻专业.com。行业资讯网站。例如,如果您搜索“玻璃”,则可以获得玻璃行业的新趋势。
9.产品搜索
产品搜索是中国搜索的最新搜索部分。产品搜索使用方便,您只需在搜索框中输入您的目标产品名称或产品描述,点击搜索按钮,即可获得您想要的产品列表。产品搜索结果包括:产品价格、产品介绍、产品图片、商家名称等信息,方便您选择产品。在产品搜索的引导下,您可以在合适的商家处购买到所需的产品。产品搜索还提供其他高级搜索功能:
查询给定价格范围内的产品
搜索指定商家送货城市的商品
为了让您更方便的看到更多商家的商品,您可以选择按商家展示:每个商家只展示一个最相关的商品信息。
您还可以在单个商户下查询更多符合搜索条件的产品
您可以在首页浏览产品分类目录,在分类目录的引导下快速找到您需要的产品
我们还提供查询词的相关目录功能:您搜索的产品名称可能会出现在许多产品分类目录中。为了方便您快速找到合适的产品,我们为您提供所有收录查询词的相关产品目录供您选择
10.游戏搜索
随着网络资源的不断增加,现在,人们需要的是准确的信息。人们没有时间从成百上千的搜索结果中找到他们需要的东西。这在单一类型的搜索引擎中发挥了重要作用:精确而详细的结果为您节省了大量时间。游戏搜索是专门针对游戏玩家的需求而开发的搜索引擎。充分满足了玩家对各类游戏下载、游戏攻略、游戏信息等的搜索需求,让玩家可以方便快捷地找到自己需要的网络游戏资源。
游戏搜索简洁方便,采用模糊查询方式,只需输入查询内容,然后点击搜索框右侧的搜索按钮,即可获取相关信息。
可以选择搜索不同的游戏信息:一般、游戏下载、攻略秘籍
搜索结果注明素材类别:游戏下载、攻略秘籍、信息来源网站。
独特的网站聚类功能,让用户只能看到更多来自不同网站的不同信息内容。
游戏搜索只显示相关结果,文本或链接收录您输入的所有关键字,因此您无需被其他不相关的结果打扰。游戏搜索引擎仅提取收录您输入的关键字的内容。为便于参考,您输入的关键字将以醒目亮丽的颜色显示。您不必费心下载和阅读冗长的网页介绍。
搜索结果 ↑返回列表
介绍搜索结果的特点。中国搜索的搜索结果页面的几个有用的功能:
更多结果1.此网站
为了让您更轻松地阅读更多网站内容,中国搜索自动为您采集信息,每个网站(或频道)只显示一个最相关网页的信息。点击此链接可在网站中查看更多符合搜索条件的结果。
2.中搜快照
点击每个搜索结果后的“中搜快照”,查看网页快照内容。
中文搜索引擎先对每个网站进行了预览,对网页进行了快照,并为用户存储了大量紧急网页。并且您用于搜索的字词已在网页上以不同颜色标记。
3.相关搜索词
中国搜索准备了其他与您的搜索关键词相关的关键词,帮助您快速定位您的搜索需求。
4.智能导航
中国搜索为您提供基于当前搜索词的智能导航分类,帮助您更快更准确地找到您需要的网页
如果有智能导航分类,它会出现在第一个搜索结果的上方。点击后,会得到当前搜索词在对应类别中的搜索结果
5.精选相关类别
中国搜索在搜索结果页面为您提供相关分类推荐,方便分类及相关过滤结果
1. 内容相关类别:提供与当前结果页面相同类别的网页
2. 内容相似网页:提供内容与当前结果相似的网页
H01.导航栏
导航栏中有“网页”、“新闻”、“网站”、“MP3”、“图片”、“购物”、“快闪”、“行业”、“地区”、“游戏”。只显示了7个项目,其他3个项目收录在“更多”中。将鼠标放在“更多”上,会出现一个下拉菜单,菜单最后一项是“导航设置”,点击进入,可以设置导航栏出现哪7项。系统使用背景颜色和字体颜色变化来表示您正在使用的搜索方法。
H02.搜索框
要查询信息,只需在文本框中输入关键词。按回车键(Enter 键)或单击搜索按钮可获取相关信息列表。不接受 Unicode 编码输入
H03.搜索按钮
点击搜索按钮提交另一个搜索请求。您也可以按“Enter”键提交查询。
H04.再次检查结果
在当前搜索结果范围内,再次执行查询。搜索范围缩小。
H05. 高级搜索
点击此按钮进入中国搜索高级搜索。
H06.搜索帮助
点击此按钮进入中国搜索的搜索帮助。
搜索指定网站内容(如何在手机上查看网址百度手机如何看到网址大全的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-14 05:03
手机怎么看网址,手机怎么看网址 百度手机怎么看网址 如何在百度app中找到完整的网址列表 如何搜索特定的网站手机如何打开百度网址栏写心得 志存高远的coolboy赚钱。
如何查看当前网页的网址链接?进入网页后,点击右下角的图标,点击分享,选择复制链接即可查看。 .
在这里输入你要找的网站,会有很多选择哦!
体验内容仅供参考。如果您需要解决一个特定的问题(尤其是法律、医学等),建议您详细咨询如何在相关领域搜索网站指定的内容?如何在百度上搜索自己的网站?新站一定要看怎么找到你浏览过的网页的网址。
比如网站.1.CilissCiliss,资源非常丰富,就是一个网站,可以搜索到世界上最新最热门的资源。有很多资源无法在其他地方搜索到。只需在这里搜索。这里的搜索资源非常快速和热门。
种子也是稀有资源搜索网站,和BT岛一样,这里收录有大量资源种子。您可以直接输入关键字进行搜索。可以作为BT岛的补充使用,所以有些这个资源连网站这两个都找不到,那么。
网站,计算机网络实验室实验报告,以及其他云计算产品文档和常见问题解答。如果您想了解更多云计算产品,请查看阿里云帮助文档。阿里云帮助文档地址。
1.打开浏览器到搜索栏2.,输入自己的网站域名,点击回车键,大功告成。 查看全部
搜索指定网站内容(如何在手机上查看网址百度手机如何看到网址大全的方法)
手机怎么看网址,手机怎么看网址 百度手机怎么看网址 如何在百度app中找到完整的网址列表 如何搜索特定的网站手机如何打开百度网址栏写心得 志存高远的coolboy赚钱。
如何查看当前网页的网址链接?进入网页后,点击右下角的图标,点击分享,选择复制链接即可查看。 .
在这里输入你要找的网站,会有很多选择哦!
体验内容仅供参考。如果您需要解决一个特定的问题(尤其是法律、医学等),建议您详细咨询如何在相关领域搜索网站指定的内容?如何在百度上搜索自己的网站?新站一定要看怎么找到你浏览过的网页的网址。
比如网站.1.CilissCiliss,资源非常丰富,就是一个网站,可以搜索到世界上最新最热门的资源。有很多资源无法在其他地方搜索到。只需在这里搜索。这里的搜索资源非常快速和热门。
种子也是稀有资源搜索网站,和BT岛一样,这里收录有大量资源种子。您可以直接输入关键字进行搜索。可以作为BT岛的补充使用,所以有些这个资源连网站这两个都找不到,那么。
网站,计算机网络实验室实验报告,以及其他云计算产品文档和常见问题解答。如果您想了解更多云计算产品,请查看阿里云帮助文档。阿里云帮助文档地址。
1.打开浏览器到搜索栏2.,输入自己的网站域名,点击回车键,大功告成。
搜索指定网站内容(SEO常用搜索引擎指令有那些?指令:查询某个特定网站的收录情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-14 05:02
SEO 常用的搜索引擎命令有哪些?
站点命令:
查询某个网站的收录情况:如果结果有返回数据,说明网站已经是收录,如果返回数据为空,则网站没有一直收录。
链接命令:
查看外链说明:一般在雅虎查询的准确率比较高。查询特定网站的外链,是获取排名、权重和网站PR值的主要因素。
相关说明:
查询相关网页指令:您可以使用它来查询与您的网站内容相关的网站,并使用相关指令轻松找到您最相关的对手。
信息命令:
info命令:可以查询特定网站收录信息、近期快照、类似网站链接、内部链接、收录域名的网页。
allintext/intext 命令:
allintext 命令:有效查询特定网络文档上特定关键词 的出现。发现最相关的网页和潜在的链接对象。此命令仅支持 Google 搜索引擎。
allinanchor/unanchor 说明:
可以理解为寻找特定的关键词锚文本链接。这有点像搜索外部链接,不同的是输入的是文本。此命令仅支持 Google 搜索引擎。
定义指令:
查找特定的关键词 非常有效。 Ggle比百度的查询结果更准确,但百度的范围更广,实际中可以根据自己的情况选择。
文件类型说明:
搜索带有特定后缀的文件,例如pdf、doc等
intitle 命令:
intitle 命令用于查询特定的论文或文章 特定的关键词 出现在标题中。
带域的域命令:
该指令可以查询网站的百度相关域,即百度外部链接。本说明仅适用于百度搜索引擎。在谷歌中,这条指令相当于关键词。 查看全部
搜索指定网站内容(SEO常用搜索引擎指令有那些?指令:查询某个特定网站的收录情况)
SEO 常用的搜索引擎命令有哪些?
站点命令:
查询某个网站的收录情况:如果结果有返回数据,说明网站已经是收录,如果返回数据为空,则网站没有一直收录。
链接命令:
查看外链说明:一般在雅虎查询的准确率比较高。查询特定网站的外链,是获取排名、权重和网站PR值的主要因素。
相关说明:
查询相关网页指令:您可以使用它来查询与您的网站内容相关的网站,并使用相关指令轻松找到您最相关的对手。
信息命令:
info命令:可以查询特定网站收录信息、近期快照、类似网站链接、内部链接、收录域名的网页。
allintext/intext 命令:
allintext 命令:有效查询特定网络文档上特定关键词 的出现。发现最相关的网页和潜在的链接对象。此命令仅支持 Google 搜索引擎。
allinanchor/unanchor 说明:
可以理解为寻找特定的关键词锚文本链接。这有点像搜索外部链接,不同的是输入的是文本。此命令仅支持 Google 搜索引擎。
定义指令:
查找特定的关键词 非常有效。 Ggle比百度的查询结果更准确,但百度的范围更广,实际中可以根据自己的情况选择。
文件类型说明:
搜索带有特定后缀的文件,例如pdf、doc等
intitle 命令:
intitle 命令用于查询特定的论文或文章 特定的关键词 出现在标题中。
带域的域命令:
该指令可以查询网站的百度相关域,即百度外部链接。本说明仅适用于百度搜索引擎。在谷歌中,这条指令相当于关键词。
搜索指定网站内容(TeleportUltra实际就是一个网络蜘蛛下载器说明下载地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-13 17:10
TeleportUltra 不仅可以离线浏览某个网页,软件还会自动保存所有网页。
相关软件软件大小及版本说明下载链接
Teleport Ultra 可以做的不仅仅是离线浏览网页,它还可以从互联网上的任何地方检索您想要的任何文件。
它可以在你指定的时候自动登录你指定的网站下载你指定的内容,也可以用它来创建网站的完整镜像作为自己的网站的创建@的参考。
您可以简单快捷地保存您喜爱的网页。模仿网站的强大工具!
如果您阻止浏览器保存网页,那么使用网站下载器是一种理想的方式。
使用网站下载器保存网页要容易得多。软件会自动保存所有页面,但有时因为软件功能太强大,会导致很多不必要的代码、图片、js文件一起保存。网页
Teleport Ultra 支持定时任务,定时将指定内容下载到指定网站。通过它保存的网站,维护了源站的CSS样式和脚本功能。超链接也替换为本地链接,方便浏览。
Teleport Ultra 实际上是一个网络蜘蛛(网络机器人),可以自动从互联网上检索特定信息。使用它创建完整的网站镜像或本地复制,有6种工作模式:
1) 在硬盘上创建一个网站 的可浏览副本;
2)复制一个网站,包括网站的目录结构;
3)在网站中搜索指定的文件类型;
4) 从中央站点检测每个链接站点;
5) 在已知地址下载一个或多个文件;
6) 在网站 中搜索指定的关键字。 查看全部
搜索指定网站内容(TeleportUltra实际就是一个网络蜘蛛下载器说明下载地址)
TeleportUltra 不仅可以离线浏览某个网页,软件还会自动保存所有网页。
相关软件软件大小及版本说明下载链接
Teleport Ultra 可以做的不仅仅是离线浏览网页,它还可以从互联网上的任何地方检索您想要的任何文件。
它可以在你指定的时候自动登录你指定的网站下载你指定的内容,也可以用它来创建网站的完整镜像作为自己的网站的创建@的参考。
您可以简单快捷地保存您喜爱的网页。模仿网站的强大工具!
如果您阻止浏览器保存网页,那么使用网站下载器是一种理想的方式。
使用网站下载器保存网页要容易得多。软件会自动保存所有页面,但有时因为软件功能太强大,会导致很多不必要的代码、图片、js文件一起保存。网页
Teleport Ultra 支持定时任务,定时将指定内容下载到指定网站。通过它保存的网站,维护了源站的CSS样式和脚本功能。超链接也替换为本地链接,方便浏览。
Teleport Ultra 实际上是一个网络蜘蛛(网络机器人),可以自动从互联网上检索特定信息。使用它创建完整的网站镜像或本地复制,有6种工作模式:
1) 在硬盘上创建一个网站 的可浏览副本;
2)复制一个网站,包括网站的目录结构;
3)在网站中搜索指定的文件类型;
4) 从中央站点检测每个链接站点;
5) 在已知地址下载一个或多个文件;
6) 在网站 中搜索指定的关键字。
搜索指定网站内容(黑客们是如何使用搜索引擎,发动攻击的呢的? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-13 17:05
)
搜索引擎已经成为上网必不可少的工具之一。聪明的黑客发现搜索引擎也可以用来发动网络攻击。
Google Hacking 最初是指利用 Google 搜索引擎搜索信息进行入侵的技术和行为。现在它不再局限于谷歌。泛指利用各种搜索引擎进行黑客攻击的技术和行为。
黑客如何利用搜索引擎发起攻击?
在搜索引擎的搜索框中,用户输入关键词,回车后会显示想要的结果。事实上,这个看似简单的搜索框隐藏着神秘。
除了输入关键词,搜索引擎还提供了多种语法帮助用户提高搜索效率。
比如搜索某部网络小说时,使用文件类型语法搜索对应格式的文件。
这些可以方便用户提高搜索效率的语法已经成为黑客手中的入侵武器。他们可以利用这些语法发现目标网站的后台管理地址,进行端口扫描、SQL注入等。
那么,黑客是如何使用这些语法的?
站点:在特定 URL 中搜索
搜索关键词时,搜索引擎显示的结果全部收录网站,有时不方便。如果您只想在搜索结果中显示特定的网站 内容,您可以使用站点语法。比如要在微软官网上搜索漏洞编号,在搜索引擎中输入“漏洞编号站点:微软”即可。
inurl:在 URL 中搜索指定的内容链接
Inurl 语法可以搜索链接的内容。对于普通用户来说,比起链接的内容,他们更关心网页的内容。这种语法没有意义。但对于黑客来说,它是一种武器。例如在搜索引擎中输入inurl:.php?id=或inurl:.jsp?id=,搜索可能的SQL注入链接。
filetype:限制搜索的文件类型
Filetype 可以限制搜索的文件类型。普通用户可能会使用这个语法来搜索电子书、视频、图片等资源。在黑客眼中,filetype 可以用于SQL 数据库挖掘。例如:filetype:sql + "IDENTIFIED BY" -cvs
intitle:搜索网页标题中收录指定内容的网页
页面标题一般表示页面内容,比如搜索“网络安全”,显示的结果都是与网络安全相关的。黑客会使用 intitle 语法来搜索“背景”和“登录”。这时候会暴露一些网站后台登录页面。
以上只是基础语法,对于黑客来说只是小儿科。有经验的黑客经常使用多种语法,比如端口扫描结合 inurl: 和 intext。甚至还有一个网站,采集了很多搜索语句。登录此网站copy 搜索一些无法正常搜索的内容。
查看全部
搜索指定网站内容(黑客们是如何使用搜索引擎,发动攻击的呢的?
)
搜索引擎已经成为上网必不可少的工具之一。聪明的黑客发现搜索引擎也可以用来发动网络攻击。
Google Hacking 最初是指利用 Google 搜索引擎搜索信息进行入侵的技术和行为。现在它不再局限于谷歌。泛指利用各种搜索引擎进行黑客攻击的技术和行为。
黑客如何利用搜索引擎发起攻击?
在搜索引擎的搜索框中,用户输入关键词,回车后会显示想要的结果。事实上,这个看似简单的搜索框隐藏着神秘。
除了输入关键词,搜索引擎还提供了多种语法帮助用户提高搜索效率。
比如搜索某部网络小说时,使用文件类型语法搜索对应格式的文件。
这些可以方便用户提高搜索效率的语法已经成为黑客手中的入侵武器。他们可以利用这些语法发现目标网站的后台管理地址,进行端口扫描、SQL注入等。
那么,黑客是如何使用这些语法的?
站点:在特定 URL 中搜索
搜索关键词时,搜索引擎显示的结果全部收录网站,有时不方便。如果您只想在搜索结果中显示特定的网站 内容,您可以使用站点语法。比如要在微软官网上搜索漏洞编号,在搜索引擎中输入“漏洞编号站点:微软”即可。
inurl:在 URL 中搜索指定的内容链接
Inurl 语法可以搜索链接的内容。对于普通用户来说,比起链接的内容,他们更关心网页的内容。这种语法没有意义。但对于黑客来说,它是一种武器。例如在搜索引擎中输入inurl:.php?id=或inurl:.jsp?id=,搜索可能的SQL注入链接。
filetype:限制搜索的文件类型
Filetype 可以限制搜索的文件类型。普通用户可能会使用这个语法来搜索电子书、视频、图片等资源。在黑客眼中,filetype 可以用于SQL 数据库挖掘。例如:filetype:sql + "IDENTIFIED BY" -cvs
intitle:搜索网页标题中收录指定内容的网页
页面标题一般表示页面内容,比如搜索“网络安全”,显示的结果都是与网络安全相关的。黑客会使用 intitle 语法来搜索“背景”和“登录”。这时候会暴露一些网站后台登录页面。
以上只是基础语法,对于黑客来说只是小儿科。有经验的黑客经常使用多种语法,比如端口扫描结合 inurl: 和 intext。甚至还有一个网站,采集了很多搜索语句。登录此网站copy 搜索一些无法正常搜索的内容。
搜索指定网站内容(网站聚合了多种搜索引擎,,如何使用无解搜?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-13 17:03
)
网站可以对大量内容进行排序和搜索,电子书、音乐、电影、软件等
网站聚合多个搜索引擎,
如何使用不搜索?
无界搜是聚合搜索网站。简单来说就是方便搜索打开指定网站的搜索结果。例如,我们来演示一下电脑版和手机版的搜索过程。
计算机搜索过程
开始第一次搜索
在搜索框中输入您要查询的内容,然后按回车键(或点击搜索框右侧的搜索按钮)即可获取您想要的内容。例如:如果要查找某部电影,直接在搜索框中输入“电影名称,如(速度与激情)”,按回车键(或点击搜索按钮),即可得到相应的结果马上!
当然,这个搜索结果可能很多,但不一定是最准确的,所以我们可以进一步选择相关的分类,改变搜索源,得到更准确的结果。比如搜索关键词(速度和激情)是针对影视类,然后从左上角选择影视类,在搜索框下方的搜索源中替换网站,得到更准确的结果。
手机搜索过程
在搜索框中输入您要查询的内容,然后按回车键(或点击搜索框右侧的搜索按钮)即可获取您想要的内容。例如:如果要查找某部电影,直接在搜索框中输入“电影名称,如(速度与激情)”,按回车键(或点击搜索按钮),即可得到相应的结果马上!
当然,这个搜索结果可能很多,但不一定是最准确的,所以我们可以进一步选择相关的分类,改变搜索源,得到更准确的结果。比如搜索关键词(速度和激情)是影视类,然后从左上角选择影视类,在搜索框左侧的搜索源中替换网站即可得到更准确的结果。
网站地址:
标签:搜索
查看全部
搜索指定网站内容(网站聚合了多种搜索引擎,,如何使用无解搜?(图)
)
网站可以对大量内容进行排序和搜索,电子书、音乐、电影、软件等
网站聚合多个搜索引擎,
如何使用不搜索?
无界搜是聚合搜索网站。简单来说就是方便搜索打开指定网站的搜索结果。例如,我们来演示一下电脑版和手机版的搜索过程。
计算机搜索过程
开始第一次搜索
在搜索框中输入您要查询的内容,然后按回车键(或点击搜索框右侧的搜索按钮)即可获取您想要的内容。例如:如果要查找某部电影,直接在搜索框中输入“电影名称,如(速度与激情)”,按回车键(或点击搜索按钮),即可得到相应的结果马上!
当然,这个搜索结果可能很多,但不一定是最准确的,所以我们可以进一步选择相关的分类,改变搜索源,得到更准确的结果。比如搜索关键词(速度和激情)是针对影视类,然后从左上角选择影视类,在搜索框下方的搜索源中替换网站,得到更准确的结果。
手机搜索过程
在搜索框中输入您要查询的内容,然后按回车键(或点击搜索框右侧的搜索按钮)即可获取您想要的内容。例如:如果要查找某部电影,直接在搜索框中输入“电影名称,如(速度与激情)”,按回车键(或点击搜索按钮),即可得到相应的结果马上!
当然,这个搜索结果可能很多,但不一定是最准确的,所以我们可以进一步选择相关的分类,改变搜索源,得到更准确的结果。比如搜索关键词(速度和激情)是影视类,然后从左上角选择影视类,在搜索框左侧的搜索源中替换网站即可得到更准确的结果。
网站地址:
标签:搜索
搜索指定网站内容(怎样使页面不被收录是个值得思考的问题?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-09-09 22:16
如何防止页面被收录是一个值得思考的问题。没意识到严重性的童鞋们可以想想网站上有多少抄袭内容、低质量内容、各种非搜索价值,但用户却觉得内容方便
图 8173-1:
一般来说,试图让搜索引擎抓取和索引更多内容是SEO经常头疼的问题。没有收录和索引,就没有办法谈论排名。尤其对于已经达到一定规模的网站,做网站Full收录是一个比较麻烦的SEO技巧。当页面达到数十万时,例如,无论网站架构如何设计或优化,100%收录都是不可能的,只能尝试提高收录率。
但是有时候怎么屏蔽搜索引擎收录也会成为问题,而且最近越来越成为问题。需要防止收录的情况,如机密信息、复制内容、广告链接等。过去常用的拦截收录的方法有密码保护、把内容放在表单后面、使用JS/Ajax、使用Flash、等
使用闪光灯
谷歌几年前就开始尝试抓取 Flash 内容,简单的文本内容已经可以抓取了。也可以跟踪 Flash 中的链接。
表格
Google 蜘蛛还可以填写表单并抓取 POST 请求页面。这已经可以在日志中看到了。
JS/Ajax
使用JS链接一直被认为是一种非搜索引擎友好的方式,所以可以防止蜘蛛爬行,但是两三年前我看到JS链接不能阻止谷歌蜘蛛爬行,不仅仅是URL出现在JS中会Climbing,执行简单的JS就可以找到更多的网址。
前几天,有人发现网站使用的facebook评论插件中有很多评论被爬取,收录。插件本身是一个ajax。这是个好消息。我的一个实验性电商网站product评论功能就是因为这个。使用facebook评论插件的好处是很大的。具体的好处将在后面讨论。唯一的问题是注释是AJAX实现的,不能被捕获。拿,产品评论是收录的目的之一(生成原创内容)。想了半天也没有解决办法,于是傻傻的装上了Facebook评论插件,开启了购物车本身的评论功能。那么现在Facebook评论中的评论可以是收录,所以不需要两套评论功能。
机器人文件
目前,robots 文件禁止确保内容不是收录 的唯一方法。但也有一个缺点。它会减肥。虽然内容不能再收录,但是页面变成了只接受链接权重,不流出权重的无底洞。
不关注
Nofollow 不保证不会是收录。即使你网站给页面的所有链接添加NF,也不能保证其他人网站不会链接到这个页面,搜索引擎仍然可以找到这个页面。
meta Noindex + 关注
(11月3日新增)读者no1se提醒,为了防止收录传权重,页面上可以使用meta noindex和meta follow,这样页面就不是收录了,但重量可以流出。的确,这也是一种更好的方法。还有一个问题,还是会浪费蜘蛛爬行的时间。哪位读者有办法防止收录,既不减肥,又不浪费爬行时间,请留言,对SEO社区大有裨益。
如何防止页面被收录是一个值得思考的问题。没意识到严重性的童鞋们可以想想网站上有多少抄袭内容、低质量内容、各种非搜索价值(不过用户觉得方便有用,所以拿不走) 对 URL 进行排序和过滤。 查看全部
搜索指定网站内容(怎样使页面不被收录是个值得思考的问题?)
如何防止页面被收录是一个值得思考的问题。没意识到严重性的童鞋们可以想想网站上有多少抄袭内容、低质量内容、各种非搜索价值,但用户却觉得内容方便
图 8173-1:
一般来说,试图让搜索引擎抓取和索引更多内容是SEO经常头疼的问题。没有收录和索引,就没有办法谈论排名。尤其对于已经达到一定规模的网站,做网站Full收录是一个比较麻烦的SEO技巧。当页面达到数十万时,例如,无论网站架构如何设计或优化,100%收录都是不可能的,只能尝试提高收录率。
但是有时候怎么屏蔽搜索引擎收录也会成为问题,而且最近越来越成为问题。需要防止收录的情况,如机密信息、复制内容、广告链接等。过去常用的拦截收录的方法有密码保护、把内容放在表单后面、使用JS/Ajax、使用Flash、等
使用闪光灯
谷歌几年前就开始尝试抓取 Flash 内容,简单的文本内容已经可以抓取了。也可以跟踪 Flash 中的链接。
表格
Google 蜘蛛还可以填写表单并抓取 POST 请求页面。这已经可以在日志中看到了。
JS/Ajax
使用JS链接一直被认为是一种非搜索引擎友好的方式,所以可以防止蜘蛛爬行,但是两三年前我看到JS链接不能阻止谷歌蜘蛛爬行,不仅仅是URL出现在JS中会Climbing,执行简单的JS就可以找到更多的网址。
前几天,有人发现网站使用的facebook评论插件中有很多评论被爬取,收录。插件本身是一个ajax。这是个好消息。我的一个实验性电商网站product评论功能就是因为这个。使用facebook评论插件的好处是很大的。具体的好处将在后面讨论。唯一的问题是注释是AJAX实现的,不能被捕获。拿,产品评论是收录的目的之一(生成原创内容)。想了半天也没有解决办法,于是傻傻的装上了Facebook评论插件,开启了购物车本身的评论功能。那么现在Facebook评论中的评论可以是收录,所以不需要两套评论功能。
机器人文件
目前,robots 文件禁止确保内容不是收录 的唯一方法。但也有一个缺点。它会减肥。虽然内容不能再收录,但是页面变成了只接受链接权重,不流出权重的无底洞。
不关注
Nofollow 不保证不会是收录。即使你网站给页面的所有链接添加NF,也不能保证其他人网站不会链接到这个页面,搜索引擎仍然可以找到这个页面。
meta Noindex + 关注
(11月3日新增)读者no1se提醒,为了防止收录传权重,页面上可以使用meta noindex和meta follow,这样页面就不是收录了,但重量可以流出。的确,这也是一种更好的方法。还有一个问题,还是会浪费蜘蛛爬行的时间。哪位读者有办法防止收录,既不减肥,又不浪费爬行时间,请留言,对SEO社区大有裨益。
如何防止页面被收录是一个值得思考的问题。没意识到严重性的童鞋们可以想想网站上有多少抄袭内容、低质量内容、各种非搜索价值(不过用户觉得方便有用,所以拿不走) 对 URL 进行排序和过滤。
搜索指定网站内容(importurllib#python中用于获取网站的模块(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-09-08 17:19
import urllib #module 用于在python中获取网站
导入 urllib2、cookielib
部分网站访问时需要cookie,python处理cookie代码如下:
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HttpCookieProcessor(cj))
urllib2.install_opener (opener)
通常我们需要在网站中搜索我们需要的信息。这里有两种情况:
1. 首先,可以直接更改网址,获取要搜索的页面:
def GetWebPage( x ): #我们定义了一个获取页面的函数,x是用来呈现你在页面上搜索到的内容的参数
url ='#39; + ‘要搜索的参数’#根据自己的页面情况适当修改
page = urllib2.urlopen(url)
pageContent = page.read()
return pageContent #返回HTML格式的页面信息
2. 其次,需要使用post方法,把你搜索到的内容放到postdata中,然后返回你需要的页面
def GetWebPage( x ): #我们定义了一个获取页面的函数,x是用来呈现你在页面上搜索到的内容的参数
url ='#39; #这个网址就是你进入搜索界面的地方
postData = urllib.urlencode( {various ‘post’ parameter input}) #这里输入的post参数需要自己检查
req= urllib2.Request (url, postData)
pageContent = urllib2.urlopen(请求)。读( )
return pageContent #返回HTML格式的页面信息
获取到我们需要的网页信息后,我们还需要从获取到的网页中进一步获取我们需要的信息。这里我推荐使用 BeautifulSoup 模块。 Python 没有附带它。您可以在百度谷歌下载安装。 BeautifulSoup 的意思是“美味的汤”。你需要做的是从一锅汤里找到你喜欢吃的东西。
import re #正则表达式,用于匹配字符
from bs4 import BeautifulSoup # 导入 BeautifulSoup 模块
soup = BeautifulSoup(pageContent) #pageContent 是我们上面搜索的页面
Soup 是 HTML 中的所有标签(tag) BeautifulSoup 处理格式化的字符串,一个标准的标签形式是:
hwkobe24
通过一些过滤的方法,我们可以从汤中得到我们需要的信息:
(1) find_all (name, attrs, recursive, text, **kwargs)
这里,我们通过在标签上添加约束来得到我们需要的标签列表,例如soup.find_all('p')是查找名为'p'的标签,而soup.find_all(class = "tittle" ) 就是查找所有class属性为"tittle"的标签,soup.find_all(class = pie('lass'))表示所有class属性中收录'lass'的标签。这里用到了正则表达式(可以自己学,很有用)
得到我们想要的所有标签的列表后,我们遍历这个列表,然后在标签中获取你需要的内容。通常我们需要标签的文字部分,也就是网页上显示的文字。代码如下:
tagList =soup.find_all(class="tittle") #如果标签比较复杂,可以使用多个过滤条件,使过滤更加严格
对于 tagList 中的标签:
打印标签文本
f.write(str(tag.text)) #将此信息写入本地文件,以备后用
(2)find( name, attrs, recursive, text, **kwargs )
它和find_all()方法唯一的区别是find_all()方法返回的结果是一个收录一个元素的值列表,而find()方法直接返回结果
(3)find_parents() find_parent( )
find_all() 和 find() 只搜索当前节点的所有子节点、孙节点等。
find_parents() 和 find_parent() 用于搜索当前节点的父节点,搜索方法与普通标签的搜索方法相同,搜索文档搜索文档中收录的内容
(4)find_next_siblings() find_next_sibling()
这两个方法使用.next_siblings属性来更新所有后面解析的兄弟标签节点。 find_next_siblings() 方法返回所有满足条件的后续兄弟,而 find_next_sibling() 只返回下一个满足条件的兄弟。一个标签节点
(5)find_previous_siblings() find_previous_sibling()
这两个方法使用 .previous_siblings 属性来迭代当前标签之前解析的兄弟标签节点。 find_previous_siblings() 方法返回之前所有满足条件的兄弟节点, find_previous_sibling() 方法返回第一个满足条件的兄弟节点。兄弟节点
(6)find_all_next() find_next()
这两个方法使用 .next_elements 属性来迭代当前标签之后的标签和字符串。 find_all_next() 方法返回所有符合条件的节点, find_next() 方法返回第一个符合条件的节点
(7)find_all_previous() 和 find_previous()
这两个方法使用 .previous_elements 属性来迭代当前节点前面的标签和字符串。 find_all_previous() 方法返回所有符合条件的节点, find_previous() 方法返回第一个符合条件的节点。
实际代码示例:(抓取网页下的指定链接)
来自 bs4 小鬼
#htmltext
html_text=""
soup=BeautifulSoup(html_text,'html.parser')
a=soup.select('a')
for i in a:
如果 i.string=="关键词":
findb_ur=i['href']
#输出搜索a标签中的字符串得到的网页链接
# 打印(findb_url)
#findb_url="https:"+finburl
alist=soup.find_all('a)
对于 a 列表:
1.通过下标操作方法
href=a['href']
打印(htref)
2.通过attrs属性
href=a.attrs['href']
打印(href) 查看全部
搜索指定网站内容(importurllib#python中用于获取网站的模块(图))
import urllib #module 用于在python中获取网站
导入 urllib2、cookielib
部分网站访问时需要cookie,python处理cookie代码如下:
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HttpCookieProcessor(cj))
urllib2.install_opener (opener)
通常我们需要在网站中搜索我们需要的信息。这里有两种情况:
1. 首先,可以直接更改网址,获取要搜索的页面:
def GetWebPage( x ): #我们定义了一个获取页面的函数,x是用来呈现你在页面上搜索到的内容的参数
url ='#39; + ‘要搜索的参数’#根据自己的页面情况适当修改
page = urllib2.urlopen(url)
pageContent = page.read()
return pageContent #返回HTML格式的页面信息
2. 其次,需要使用post方法,把你搜索到的内容放到postdata中,然后返回你需要的页面
def GetWebPage( x ): #我们定义了一个获取页面的函数,x是用来呈现你在页面上搜索到的内容的参数
url ='#39; #这个网址就是你进入搜索界面的地方
postData = urllib.urlencode( {various ‘post’ parameter input}) #这里输入的post参数需要自己检查
req= urllib2.Request (url, postData)
pageContent = urllib2.urlopen(请求)。读( )
return pageContent #返回HTML格式的页面信息
获取到我们需要的网页信息后,我们还需要从获取到的网页中进一步获取我们需要的信息。这里我推荐使用 BeautifulSoup 模块。 Python 没有附带它。您可以在百度谷歌下载安装。 BeautifulSoup 的意思是“美味的汤”。你需要做的是从一锅汤里找到你喜欢吃的东西。
import re #正则表达式,用于匹配字符
from bs4 import BeautifulSoup # 导入 BeautifulSoup 模块
soup = BeautifulSoup(pageContent) #pageContent 是我们上面搜索的页面
Soup 是 HTML 中的所有标签(tag) BeautifulSoup 处理格式化的字符串,一个标准的标签形式是:
hwkobe24
通过一些过滤的方法,我们可以从汤中得到我们需要的信息:
(1) find_all (name, attrs, recursive, text, **kwargs)
这里,我们通过在标签上添加约束来得到我们需要的标签列表,例如soup.find_all('p')是查找名为'p'的标签,而soup.find_all(class = "tittle" ) 就是查找所有class属性为"tittle"的标签,soup.find_all(class = pie('lass'))表示所有class属性中收录'lass'的标签。这里用到了正则表达式(可以自己学,很有用)
得到我们想要的所有标签的列表后,我们遍历这个列表,然后在标签中获取你需要的内容。通常我们需要标签的文字部分,也就是网页上显示的文字。代码如下:
tagList =soup.find_all(class="tittle") #如果标签比较复杂,可以使用多个过滤条件,使过滤更加严格
对于 tagList 中的标签:
打印标签文本
f.write(str(tag.text)) #将此信息写入本地文件,以备后用
(2)find( name, attrs, recursive, text, **kwargs )
它和find_all()方法唯一的区别是find_all()方法返回的结果是一个收录一个元素的值列表,而find()方法直接返回结果
(3)find_parents() find_parent( )
find_all() 和 find() 只搜索当前节点的所有子节点、孙节点等。
find_parents() 和 find_parent() 用于搜索当前节点的父节点,搜索方法与普通标签的搜索方法相同,搜索文档搜索文档中收录的内容
(4)find_next_siblings() find_next_sibling()
这两个方法使用.next_siblings属性来更新所有后面解析的兄弟标签节点。 find_next_siblings() 方法返回所有满足条件的后续兄弟,而 find_next_sibling() 只返回下一个满足条件的兄弟。一个标签节点
(5)find_previous_siblings() find_previous_sibling()
这两个方法使用 .previous_siblings 属性来迭代当前标签之前解析的兄弟标签节点。 find_previous_siblings() 方法返回之前所有满足条件的兄弟节点, find_previous_sibling() 方法返回第一个满足条件的兄弟节点。兄弟节点
(6)find_all_next() find_next()
这两个方法使用 .next_elements 属性来迭代当前标签之后的标签和字符串。 find_all_next() 方法返回所有符合条件的节点, find_next() 方法返回第一个符合条件的节点
(7)find_all_previous() 和 find_previous()
这两个方法使用 .previous_elements 属性来迭代当前节点前面的标签和字符串。 find_all_previous() 方法返回所有符合条件的节点, find_previous() 方法返回第一个符合条件的节点。
实际代码示例:(抓取网页下的指定链接)
来自 bs4 小鬼
#htmltext
html_text=""
soup=BeautifulSoup(html_text,'html.parser')
a=soup.select('a')
for i in a:
如果 i.string=="关键词":
findb_ur=i['href']
#输出搜索a标签中的字符串得到的网页链接
# 打印(findb_url)
#findb_url="https:"+finburl
alist=soup.find_all('a)
对于 a 列表:
1.通过下标操作方法
href=a['href']
打印(htref)
2.通过attrs属性
href=a.attrs['href']
打印(href)
搜索指定网站内容(以有针对性的方式可以使用不同的策略来隔离内容推送)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-09-08 05:14
与访问者相比,有针对性地在搜索引擎中展示特定内容
可以使用不同的策略来隔离内容推送。最基本的方法是使用不可抓取的格式提供搜索引擎看不到的内容(如在图片、flash 文件和插件等中放置文本)。例如,它只能用于提供改进的用户体验)。在这种情况下,您可以以可抓取的格式在搜索引擎中显示相同的内容。如果您想向搜索引擎提供您不希望访问者看到的内容,您可以使用 CSS 样式表。不要使用 display: none 或基于 JavaScript、用户代理、cookie 或会话的推送,或 IP 推送(根据用户的 IP 地址显示内容),因为搜索引擎使用过滤器来专门监控这一点。未使用。
使用这些技术时应特别小心。如前所述,搜索引擎在其指南中明确禁止使用欺骗行为,而不是欺骗搜索引擎,例如使用隐藏技术来提高意图和用户体验(例如,使用隐藏技术来提高质量网站的用户经验))但是,搜索引擎仍然非常重视这些技术,这可能会惩罚或禁止某些串通或恶意操纵搜索引擎的网站。另外,如果你有一个好的起点,搜索引擎可能会认为它是恶意的并惩罚你。使用 robots.txt 文件
该文件位于您域名的根目录中。它是一个多功能工具,允许搜索爬虫确定哪些网站 内容已被访问。您可以使用 robots.txt。
防止爬虫访问您的网站 隐私部分。
防止搜索引擎访问索引脚本、实用程序或其他类型的代码。
避免为 网站 上的重复内容编制索引,例如 HTML 页面的打印版本或产品目录中的多个排序顺序。
自动发现:当您告诉搜索引擎漫游器不要访问特定页面时,此文件将阻止爬虫抓取该页面。图6-35直观地展示了搜索引擎何时看到机器人不抓取特定页面的命令。 txt 然后会发生什么。 查看全部
搜索指定网站内容(以有针对性的方式可以使用不同的策略来隔离内容推送)
与访问者相比,有针对性地在搜索引擎中展示特定内容
可以使用不同的策略来隔离内容推送。最基本的方法是使用不可抓取的格式提供搜索引擎看不到的内容(如在图片、flash 文件和插件等中放置文本)。例如,它只能用于提供改进的用户体验)。在这种情况下,您可以以可抓取的格式在搜索引擎中显示相同的内容。如果您想向搜索引擎提供您不希望访问者看到的内容,您可以使用 CSS 样式表。不要使用 display: none 或基于 JavaScript、用户代理、cookie 或会话的推送,或 IP 推送(根据用户的 IP 地址显示内容),因为搜索引擎使用过滤器来专门监控这一点。未使用。
使用这些技术时应特别小心。如前所述,搜索引擎在其指南中明确禁止使用欺骗行为,而不是欺骗搜索引擎,例如使用隐藏技术来提高意图和用户体验(例如,使用隐藏技术来提高质量网站的用户经验))但是,搜索引擎仍然非常重视这些技术,这可能会惩罚或禁止某些串通或恶意操纵搜索引擎的网站。另外,如果你有一个好的起点,搜索引擎可能会认为它是恶意的并惩罚你。使用 robots.txt 文件
该文件位于您域名的根目录中。它是一个多功能工具,允许搜索爬虫确定哪些网站 内容已被访问。您可以使用 robots.txt。
防止爬虫访问您的网站 隐私部分。
防止搜索引擎访问索引脚本、实用程序或其他类型的代码。
避免为 网站 上的重复内容编制索引,例如 HTML 页面的打印版本或产品目录中的多个排序顺序。
自动发现:当您告诉搜索引擎漫游器不要访问特定页面时,此文件将阻止爬虫抓取该页面。图6-35直观地展示了搜索引擎何时看到机器人不抓取特定页面的命令。 txt 然后会发生什么。

