
搜索指定网站内容
【知识点】怎么查一个网站的信息?方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 396 次浏览 • 2021-05-18 21:08
如何查看网站信息?
方法1:使用搜索运算符;
01
如果要搜索特定的网站内容,可以在查询关键字后添加“ site:”,格式如下:
搜索关键字网站:域名
例如:如果要搜索Windows安装和清理,默认查询结果如下:
02
如果要搜索Microsoft 网站的内容,请输入“ Windows安装清理” 网站:“查询结果如下:
03
您可以看到区别很明显。默认查询显示许多网站和“ windows star clean”“向上”,以及网站:之后,该查询仅与Microsoft 网站“域”中的网站相关;
04
注意:站点:站点与域之间没有空格;
05
您也可以直接在顶级域中搜索网站内容,例如。组织或。 CN或。 Com;
例如:Windows star清理网站:.cn
您发现的是中文顶级域名下网站的内容;
方法2:使用高级搜索
01
如果您不想使用搜索运算符,则可以使用“高级搜索”功能;
例如,输入后单击“选项”按钮;
02个查询关键字,在“ 网站或域名”框中,输入指定的网站或域名;
03
然后单击“高级搜索”;
04
您会看到“高级搜索”将自动生成相应的搜索条件,并在指定的网站或域中查询相关信息;
声明:
01
以上示例仅供参考,请分析具体问题,不要一概而论
02
操作命令和菜单仅供参考。为了达到相同的效果,可以有多种操作模式。请使用您熟悉的操作模式。 查看全部
【知识点】怎么查一个网站的信息?方法
如何查看网站信息?
方法1:使用搜索运算符;
01
如果要搜索特定的网站内容,可以在查询关键字后添加“ site:”,格式如下:
搜索关键字网站:域名
例如:如果要搜索Windows安装和清理,默认查询结果如下:
02
如果要搜索Microsoft 网站的内容,请输入“ Windows安装清理” 网站:“查询结果如下:
03
您可以看到区别很明显。默认查询显示许多网站和“ windows star clean”“向上”,以及网站:之后,该查询仅与Microsoft 网站“域”中的网站相关;
04
注意:站点:站点与域之间没有空格;
05
您也可以直接在顶级域中搜索网站内容,例如。组织或。 CN或。 Com;
例如:Windows star清理网站:.cn
您发现的是中文顶级域名下网站的内容;
方法2:使用高级搜索
01
如果您不想使用搜索运算符,则可以使用“高级搜索”功能;
例如,输入后单击“选项”按钮;
02个查询关键字,在“ 网站或域名”框中,输入指定的网站或域名;
03
然后单击“高级搜索”;
04
您会看到“高级搜索”将自动生成相应的搜索条件,并在指定的网站或域中查询相关信息;
声明:
01
以上示例仅供参考,请分析具体问题,不要一概而论
02
操作命令和菜单仅供参考。为了达到相同的效果,可以有多种操作模式。请使用您熟悉的操作模式。
SEO剖析第一课搜索引擎基础狗狗制作什么是SiteMap
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-05-18 21:05
SEO分析第1课搜索引擎基础知识什么是搜索引擎?所谓的搜索引擎(Search Engines)是一些Web 网站,可以主动搜索信息(在Web上搜索单词和简短的特定内容描述)并自动为它们建立索引。被索引的内容存储在可搜索的数据库中。在大型数据库中,建立了索引和目录服务。它是为您提供的“检索”服务网站。它使用某些程序对Internet上的所有信息进行分类,以帮助人们在广阔的网络中找到所需的信息。搜索引擎的作用是什么?将对用户真正有用的信息放在搜索结果的顶部!搜索引擎的工作原理如果搜索引擎想了解Internet上的新事物,则必须派人去采集它们。每天都有新的网站代,每天网站内容都会更新,并且生成的网站数量会不断增加网站的更新内容,因此无法手动完成此任务,因此搜索引擎的发明者设计了计算机程序,并将其发送来执行此任务。检测器有很多名称,也称为“爬行器”,“蜘蛛”和“机器人”。这些图像的名称是描绘由搜索引擎在互联网上爬行以检测新信息而发送的蜘蛛机器人。谷歌称其检测器为Googlebot,百度称其为Baiduspider,雅虎称其为Slurp。不管他们叫什么,他们都是人。编译的计算机程序允许他们日夜访问网站,检索网站的内容,标签,图片等,然后根据搜索引擎的算法为其自定义索引。
如何识别搜索引擎的身份?可以通过DNS反向查询找到主机名:Google:主机名应收录在域名中,例如:主机名应收录在域名中,例如:; Yahoo:主机名应收录在域名中,例如:。什么是SiteMap? Sitemaps协议使您可以将可进行爬网的URL通知搜索引擎网站。最简单的方法是使用Sitemaps的Sitemaps协议是一个XML文件,其中列出了某个网站的所有URL。该协议可以高度扩展,因此可以应用于各种大小网站。它还使网站管理员能够提供有关每个URL的其他信息(最后更新的时间,更改的频率,与网站中的其他URL相比有多重要等),以便搜索引擎可以更聪明地抓图。 网站。使用SiteMap将有助于搜索引擎更友好地采集网站。不要让网站的集合存在漏洞或不完整的集合。 SiteMap在这方面可以起到很好的作用。
一旦有了SiteMap并将其提交给搜索引擎,以后您便可以方便地进行下一步,例如更好地调整网站的外部链接和内部链接错误,所有这些将在SiteMap中使用。提交功能。 网站有些页面不容易找到,例如具有很多丰富的AJAX或Flash内容的页面。 网站上页面的相对重要性。什么是Robots.txt Robots.txt是纯文本文件。通过在此文件中声明网站的一部分,您不想被机器人访问,搜索引擎将无法访问网站的部分或全部内容。我已经收到它,或者指定的搜索引擎仅接受指定的内容。当搜索机器人访问网站时,它将首先检查该网站的根目录下是否存在robots.txt。如果找到,搜索引擎将根据文件的内容确定访问范围。如果该文件不存在,那么搜索机器人将沿着该链接进行爬网。 查看全部
SEO剖析第一课搜索引擎基础狗狗制作什么是SiteMap
SEO分析第1课搜索引擎基础知识什么是搜索引擎?所谓的搜索引擎(Search Engines)是一些Web 网站,可以主动搜索信息(在Web上搜索单词和简短的特定内容描述)并自动为它们建立索引。被索引的内容存储在可搜索的数据库中。在大型数据库中,建立了索引和目录服务。它是为您提供的“检索”服务网站。它使用某些程序对Internet上的所有信息进行分类,以帮助人们在广阔的网络中找到所需的信息。搜索引擎的作用是什么?将对用户真正有用的信息放在搜索结果的顶部!搜索引擎的工作原理如果搜索引擎想了解Internet上的新事物,则必须派人去采集它们。每天都有新的网站代,每天网站内容都会更新,并且生成的网站数量会不断增加网站的更新内容,因此无法手动完成此任务,因此搜索引擎的发明者设计了计算机程序,并将其发送来执行此任务。检测器有很多名称,也称为“爬行器”,“蜘蛛”和“机器人”。这些图像的名称是描绘由搜索引擎在互联网上爬行以检测新信息而发送的蜘蛛机器人。谷歌称其检测器为Googlebot,百度称其为Baiduspider,雅虎称其为Slurp。不管他们叫什么,他们都是人。编译的计算机程序允许他们日夜访问网站,检索网站的内容,标签,图片等,然后根据搜索引擎的算法为其自定义索引。
如何识别搜索引擎的身份?可以通过DNS反向查询找到主机名:Google:主机名应收录在域名中,例如:主机名应收录在域名中,例如:; Yahoo:主机名应收录在域名中,例如:。什么是SiteMap? Sitemaps协议使您可以将可进行爬网的URL通知搜索引擎网站。最简单的方法是使用Sitemaps的Sitemaps协议是一个XML文件,其中列出了某个网站的所有URL。该协议可以高度扩展,因此可以应用于各种大小网站。它还使网站管理员能够提供有关每个URL的其他信息(最后更新的时间,更改的频率,与网站中的其他URL相比有多重要等),以便搜索引擎可以更聪明地抓图。 网站。使用SiteMap将有助于搜索引擎更友好地采集网站。不要让网站的集合存在漏洞或不完整的集合。 SiteMap在这方面可以起到很好的作用。
一旦有了SiteMap并将其提交给搜索引擎,以后您便可以方便地进行下一步,例如更好地调整网站的外部链接和内部链接错误,所有这些将在SiteMap中使用。提交功能。 网站有些页面不容易找到,例如具有很多丰富的AJAX或Flash内容的页面。 网站上页面的相对重要性。什么是Robots.txt Robots.txt是纯文本文件。通过在此文件中声明网站的一部分,您不想被机器人访问,搜索引擎将无法访问网站的部分或全部内容。我已经收到它,或者指定的搜索引擎仅接受指定的内容。当搜索机器人访问网站时,它将首先检查该网站的根目录下是否存在robots.txt。如果找到,搜索引擎将根据文件的内容确定访问范围。如果该文件不存在,那么搜索机器人将沿着该链接进行爬网。
Python抓取特定内容_使用python抓取网页上的特定内容
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-05-14 01:31
import urllib#用于在python中获取网站的模块
导入urllib2,cookielib
某些网站访问时需要cookie,python处理cookie的代码如下:
cj = cookielib.CookieJar()
opener = urllib 2. build_opener(urllib 2. HttpCookieProcessor(cj))
urllib 2. install_opener(开启程序)
通常,我们需要在网站中搜索所需的信息。这里有两种情况:
1.首先,您可以直接更改URL以获取要搜索的页面:
def GetWebPage(x):#我们定义了一个获取页面的函数,x是用于显示您在页面上搜索的内容的参数
url ='#39; +“您要搜索的参数”#根据您自己的页面条件进行适当修改
page = urllib 2. urlopen(url)
pageContent = page.read()
返回pageContent#以HTML格式返回页面信息
2.第二种方法,您需要使用post方法,将搜索到的内容放入postdata中,然后返回所需的页面
def GetWebPage(x):#我们定义了一个获取页面的函数,x是用于显示您在页面上搜索的内容的参数
url ='#39; #此URL是您进入搜索界面的位置
postData = urllib.urlencode({各种'post'参数输入})#此处的post参数输入需要您自己检查
req = urllib 2.请求(url,postData)
pageContent = urllib 2. urlopen(req)。 read()
返回pageContent#以HTML格式返回页面信息
获取所需的网页信息后,需要从获取的网页中进一步获取所需的信息。在这里,我建议使用BeautifulSoup模块。 Python不附带它。您可以将其下载并安装在百度Google上。 BeautifulSoup译为“美味汤”。您需要做的是从一锅汤中找到想要吃的东西。
import re#正则表达式,用于匹配字符
从bs4导入BeautifulSoup#导入BeautifulSoup模块
soup = BeautifulSoup(pageContent)#pageContent是我们在上面搜索的页面
汤是HTML中的所有标签(标签)BeautifulSoup处理格式化的字符串,标准的标签形式是:
hwkobe24
通过一些过滤方法,我们可以从汤中获取所需的信息:
([1) find_all(名称,属性,递归,文本,**假名)
在这里,我们通过在标签上添加约束来获得所需标签的列表,例如,soup.find_all('p')是要找到一个名为'p'的标签,然后是soup.find_all(class =“ tittle” )将查找所有class属性为“ tittle”的标签,并且soup.find_all(class = heap('lass'))表示class属性中所有收录'lass'的标签。这里使用正则表达式(您可以自己学习,非常有用)
获得所需的所有标签的列表之后,遍历此列表,然后在标签中获得所需的内容。通常,我们需要标记的文本部分,即网页上显示的文本。代码如下:
tagList = soup.find_all(class =“ tittle”)#如果标记较为复杂,则可以使用多个过滤条件使过滤条件更严格
用于tagList中的标签:
打印tag.text
f.write(str(tag.text))#将此信息写入本地文件以供以后使用
([2) find(名称,attrs,递归,文本,** kwargs)
它与find_all()方法之间的唯一区别是find_all()方法的返回结果是收录一个元素的值列表,而find()方法直接返回结果
([3) find_parents()find_parent()
find_all()和find()仅搜索当前节点的所有子节点,孙子节点等。
find_parents()和find_parent()用于搜索当前节点的父节点,搜索方法与普通标签的搜索方法相同,搜索文档搜索文档中收录的内容
([4) find_next_siblings()find_next_sibling()
这两种方法使用.next_siblings属性来更新稍后分析的所有同级标记节点。 find_next_siblings()方法返回所有随后满足条件的兄弟姐妹,而find_next_sibling()仅返回下一个满足条件的兄弟姐妹。标记节点
([5) find_previous_siblings()find_previous_sibling()
这两个方法使用.previous_siblings属性来迭代在当前标签之前解析的同级标签节点。 find_previous_siblings()方法返回满足条件的所有先前的同级节点,而find_previous_sibling()方法返回满足条件的第一个同级节点。
的兄弟姐妹
([6) find_all_next()find_next()
这两个方法使用.next_elements属性来迭代当前标签之后的标签和字符串。 find_all_next()方法返回所有符合条件的节点,而find_next()方法返回第一个符合条件的节点
([7) find_all_previous()和find_previous()
这两个方法使用.previous_elements属性来迭代当前节点前面的标记和字符串。 find_all_previous()方法返回所有符合条件的节点,而find_previous()方法返回第一个符合条件的节点。
实际代码示例:(在网页下抓取指定的链接)
来自bs4 imp
#htmltext
html_text =“”
soup = BeautifulSoup(html_text,'html.parser')
a = soup.select('a')
对于我在:
如果i.string ==“ 关键词”:
findb_ur = i ['href']
#输出通过在a标签中搜索字符串而获得的网页链接
#print(findb_url)
#findb_url =“ https:” + finburl
alist = soup.find_all('a)
对于列表中的a:
1.下标操作方式
href = a ['href']
print(htref)
2.通过attrs属性
href = a.attrs ['href']
print(href) 查看全部
Python抓取特定内容_使用python抓取网页上的特定内容
import urllib#用于在python中获取网站的模块
导入urllib2,cookielib
某些网站访问时需要cookie,python处理cookie的代码如下:
cj = cookielib.CookieJar()
opener = urllib 2. build_opener(urllib 2. HttpCookieProcessor(cj))
urllib 2. install_opener(开启程序)
通常,我们需要在网站中搜索所需的信息。这里有两种情况:
1.首先,您可以直接更改URL以获取要搜索的页面:
def GetWebPage(x):#我们定义了一个获取页面的函数,x是用于显示您在页面上搜索的内容的参数
url ='#39; +“您要搜索的参数”#根据您自己的页面条件进行适当修改
page = urllib 2. urlopen(url)
pageContent = page.read()
返回pageContent#以HTML格式返回页面信息
2.第二种方法,您需要使用post方法,将搜索到的内容放入postdata中,然后返回所需的页面
def GetWebPage(x):#我们定义了一个获取页面的函数,x是用于显示您在页面上搜索的内容的参数
url ='#39; #此URL是您进入搜索界面的位置
postData = urllib.urlencode({各种'post'参数输入})#此处的post参数输入需要您自己检查
req = urllib 2.请求(url,postData)
pageContent = urllib 2. urlopen(req)。 read()
返回pageContent#以HTML格式返回页面信息
获取所需的网页信息后,需要从获取的网页中进一步获取所需的信息。在这里,我建议使用BeautifulSoup模块。 Python不附带它。您可以将其下载并安装在百度Google上。 BeautifulSoup译为“美味汤”。您需要做的是从一锅汤中找到想要吃的东西。
import re#正则表达式,用于匹配字符
从bs4导入BeautifulSoup#导入BeautifulSoup模块
soup = BeautifulSoup(pageContent)#pageContent是我们在上面搜索的页面
汤是HTML中的所有标签(标签)BeautifulSoup处理格式化的字符串,标准的标签形式是:
hwkobe24
通过一些过滤方法,我们可以从汤中获取所需的信息:
([1) find_all(名称,属性,递归,文本,**假名)
在这里,我们通过在标签上添加约束来获得所需标签的列表,例如,soup.find_all('p')是要找到一个名为'p'的标签,然后是soup.find_all(class =“ tittle” )将查找所有class属性为“ tittle”的标签,并且soup.find_all(class = heap('lass'))表示class属性中所有收录'lass'的标签。这里使用正则表达式(您可以自己学习,非常有用)
获得所需的所有标签的列表之后,遍历此列表,然后在标签中获得所需的内容。通常,我们需要标记的文本部分,即网页上显示的文本。代码如下:
tagList = soup.find_all(class =“ tittle”)#如果标记较为复杂,则可以使用多个过滤条件使过滤条件更严格
用于tagList中的标签:
打印tag.text
f.write(str(tag.text))#将此信息写入本地文件以供以后使用
([2) find(名称,attrs,递归,文本,** kwargs)
它与find_all()方法之间的唯一区别是find_all()方法的返回结果是收录一个元素的值列表,而find()方法直接返回结果
([3) find_parents()find_parent()
find_all()和find()仅搜索当前节点的所有子节点,孙子节点等。
find_parents()和find_parent()用于搜索当前节点的父节点,搜索方法与普通标签的搜索方法相同,搜索文档搜索文档中收录的内容
([4) find_next_siblings()find_next_sibling()
这两种方法使用.next_siblings属性来更新稍后分析的所有同级标记节点。 find_next_siblings()方法返回所有随后满足条件的兄弟姐妹,而find_next_sibling()仅返回下一个满足条件的兄弟姐妹。标记节点
([5) find_previous_siblings()find_previous_sibling()
这两个方法使用.previous_siblings属性来迭代在当前标签之前解析的同级标签节点。 find_previous_siblings()方法返回满足条件的所有先前的同级节点,而find_previous_sibling()方法返回满足条件的第一个同级节点。
的兄弟姐妹
([6) find_all_next()find_next()
这两个方法使用.next_elements属性来迭代当前标签之后的标签和字符串。 find_all_next()方法返回所有符合条件的节点,而find_next()方法返回第一个符合条件的节点
([7) find_all_previous()和find_previous()
这两个方法使用.previous_elements属性来迭代当前节点前面的标记和字符串。 find_all_previous()方法返回所有符合条件的节点,而find_previous()方法返回第一个符合条件的节点。
实际代码示例:(在网页下抓取指定的链接)
来自bs4 imp
#htmltext
html_text =“”
soup = BeautifulSoup(html_text,'html.parser')
a = soup.select('a')
对于我在:
如果i.string ==“ 关键词”:
findb_ur = i ['href']
#输出通过在a标签中搜索字符串而获得的网页链接
#print(findb_url)
#findb_url =“ https:” + finburl
alist = soup.find_all('a)
对于列表中的a:
1.下标操作方式
href = a ['href']
print(htref)
2.通过attrs属性
href = a.attrs ['href']
print(href)
自学笔记第五章本章的重点网信息资源的特点、种类、信息利用价值
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-05-11 04:18
第5章Internet信息检索本章重点介绍Internet信息资源的特征,类型和信息利用价值。 Internet信息检索的基本知识,以及各种常用Internet信息检索工具的特征,比较,评估,使用和检索方法。本章的学习目的是使学习者培养网络信息搜索和使用的能力,并提高网络信息环境中信息发现和利用的水平。第1节Internet概述一、基本概念(自学)TCP / IP TCP / IP Internet WWWWWW WWW HTTP HTML HTML Internet HTTP是基于TCP / IP的协议,是用于分布式协作超媒体信息系统的快速实用的协议。它不仅需要确保超文本文档的正确传输,而且还必须能够确定传输文档的特定部分以及首先显示内容的哪一部分。在HTML中,可以嵌入图像,声音等,并且可以通过超链接无缝引用其他WWW URL资源。用HTML组织的信息文档称为页面,这些页面由浏览器解释,执行,显示和输出。浏览器:也称为浏览器,它是一种用于读取HTML文件的特殊软件系统。可以通过许多方法来获取信息,例如FTP,NNTP和Gopher。 URL可以将世界上所有的在线信息资源组织成一个有序的结构。它的格式包括三个部分:第一部分是协议(或服务模式),大多数Internet文档使用http,其他常用的协议是fp,news,gopher,telnet等。第三部分是主机资源的特定地址。
IP Internet上的许多计算机和信息资源必须通过名称和地址来标识。连接到Internet的计算机或节点被分配一个唯一的数字作为一个称为IP地址的地址,该地址由四组数字组成,这些数字组由小数点分隔。 IP地址通常是由Internet服务组织从Internet网络信息中心注册和应用的(例如:Central 20 2. 20 5. 21 3. 10 1)。IP是网络中的重要资源, IP地址数量表示可以连接到Internet的计算机的数量,由于IP地址由四组数字组成,因此不容易记住,因此Internet使用域名系统(DNS)作为域名的助记符。 Internet上的特定主机。Internet中每台计算机的域名结构是:主机名,组织名称,网络名称,顶级域名。域名由常规英语单词组成,非常容易记住,并且还可以根据域名组成规则猜测某个站点的域名。通用标准域名的结构为:主机名,组织名称,网络名称,顶级域名。顶级域名共有三个互联网域名中的一级域名n名称系统:第一种是国家域名,由两个英文字母组成,例如:“。CN(中国))”,“。JP(日本)”,“。US(美国)”,“”。 UK(UK)”,“。CA(Canada)”。第二类是国际域名,现在只有一个“ .INT”代表国际组织。
第三类是通用域名,目前使用的是——网络服务组织; .edu——教育部门; .web——网络服务组织; 。艺术-文化娱乐部门; .info— —信息部门; .rec——娱乐机构; .org——非营利组织; 。商店-销售部。公司-公司企业; .gov——政府部门; .com .——商业组织。mil——军事部门; .nom个人。中国的域名注册由国务院信息化领导小组办公室授权的中国互联网络信息中心(CNNIC)处理。例如:中央财经大学的网站是Internet(自学)www):万维网)HTML HTTP UsenetListserv邮件列表BBSBBS BBS BBS Archie):ArchieArchie Internet FTP Archie FTP WAISInternet GopherInternet Gopher 2040 20 50 WebCrawlerGoogle URL :URL是Internet上各种专门的计算机和文学资源的“地址”。通用格式为:与普通的网站不同,搜索引擎网站的主要资源是索引数据库。
其工作原理是通过采集并调用搜索引擎数据库来实现其导航功能。第2节Internet搜索引擎Internet Internet雅虎Internet googleAlta Vista WEBYahoo WebSearch Engine(UsenetSearch Engine(YellowPageSearch Engine(WhitePageSearch Engine(MetaSearchSearch((WordSearch)(SimpleSearch)(PhraseSearch)(SentenceSearch)(CatalogSearch)(分类搜索)(AdvancedSearch)))金属裂纹金属裂纹金属裂纹金属应力裂纹应力裂纹应力裂纹AltaVisa > GoldenRetriever AltaVisa ExicteAlta Visa可以检查的外国搜索引擎数量达到2500,其中有许多出色的综合搜索引擎,例如:Yahoo!,AltaVista,Excite,Infoseek,Lycos,HotBot, Google,OpenText等。
HotBot()是美国著名的综合搜索引擎。 FM365263 21cn TOM主要搜索引擎的第2部分Google()Google()Google目前是世界上最大的搜索引擎。它提供了70多种界面语言和35种搜索语言,包括分类查询和关键词搜索。特征。 (一)公司介绍GoogleGoogle Inc.纳斯达克GOOG 1998 GoogleGoogle 1999 2004 19Google Nasdaq GoogleGoogleplex‖Mountain View)SchmidtGoogle(二) Google GoogleGoogleGoogle Google Googol Googol“ 10100100google Google Googol爱德华·卡斯纳·米尔顿·西罗塔·爱德华·卡斯纳·詹姆斯·纽曼数学想象力谷歌谷歌谷歌谷歌谷歌谷歌谷歌这是谷歌的中文版本。
该服务器位于中国北京。通过Google页面显示,我们可以知道Google提供了三种设置功能:高级搜索,首选项和语言工具。 ([三)使用Google搜索GoogleEnter的基本知识” Google Google以明显的单词开头。例如,如果您要查找有关夏威夷的一般信息,则不妨尝试。如果您计划安排夏威夷度假,搜索会更好比单独搜索更好。搜索结果会更好。乔治华盛顿华盛顿乔治华盛顿谷歌谷歌谷歌Google默认情况下,谷歌只提供收录所有搜索词的页面。单词之间无需添加“和”。请记住,单词的顺序是键入将影响搜索结果。要进一步限制搜索,只需添加更多单词即可。例如,要安排去夏威夷度假,只需键入Google即可忽略常见的单词和字符,例如“ where”,“ how”和“的”和其他单个数字和字母会减慢搜索速度,但不能缩小查询范围并改善结果。如果必须使用通用词来获得所需的结果,则可以输入前面的“ +”号e单词号,将其包括在查询词中。低音音乐Googlegoogl googl *“ google” GOOGLE” Googlesite:Googlesite:12(StanfordUniversity)Stanford GoogleGoogle 1 3、使用高级搜索来缩小搜索范围。 Googlewhere需要找到两个单词。一个单词就足够了。请在单词之间添加大写字母“ OR”。
例如,要搜索伦敦或巴黎的度假信息,可以使用以下方法:Vacation London或Paris Google“站点”(斯坦福大学)(入学)录取站点:想查找数字吗?在数字范围内,您可以搜索收录指定范围内数字的结果。只需在搜索框中的搜索词后面加上两个数字,然后用两个英文句点(无空格)将它们分开即可。您可以使用“数字范围”来设置从日期(Willie Mays 195 0. .196 0)到重量(500 0. .10000 kg))的各种范围。但是,请务必指定单位US $ 50US $ 100 DVD DVD播放器$ 5 0.。$ 100 DVD DVD播放器$ 5 0.。$ 100(带下划线的项四)是您搜索的条件)由Google搜索引擎通过单词找到的搜索结果,列表中的第一个项目(“新闻”结果除外)是我们找到的最相关的匹配项,第二个项目是第二个最相关的匹配项,依此类推。单击任何带下划线的条目将为您打开关联的网页。(四)搜索结果GoogleGoogle Google GoogleEnter”单击链接以激活您要使用的Google服务。
您可以搜索网络,查找图片,浏览Google网上论坛,或单击“更多”链接以查看其他Google产品。 B.―单击此按钮可以提交另一个搜索查询。您也可以按“ Enter”键提交查询。 C.这将链接到一个页面,您可以在其中进行更精确的搜索。要在Google上进行搜索,只需输入一些描述性搜索字词,然后按“ Enter”键或单击“ Search”按钮即可。链接到可以设置个人搜索首选项(包括语言,每页结果数)的页面。该行描述了搜索,并指出了结果总数以及完成搜索所花费的时间。搜索结果项的第一行是找到的页面的标题。如果您看到的是URL而不是标题,则表明该页面没有标题,或者我们没有为页面的全部内容建立索引,但是其在索引中的位置仍然表明它很好地满足了您的查询要求。该数字表示您要查找的网页文本部分的大小,它使您可以在一定程度上了解显示时间。如果尚未完全建立索引的是网站,则不会显示尺寸编号。当我们上次索引相应页面时,单击链接将显示该页面的内容。如果由于某些原因网站链接无法链接到当前页面,您仍然可以通过页面快照的版本找到所需的信息。如果您为特定结果选择“相似页面”链接,则Google会在Internet上自动查找与该结果相关的页面。
1、高级搜索要改善搜索效果,您还可以在您在Google搜索框中输入的搜索词中添加“运算符”,或进入高级搜索页面。指定搜索词在网页上的显示位置,该位置可以在网页,标题,文本或URL中的任何位置。 2、首选项1)界面语言2)搜索语言谷歌谷歌Googletq“ TQ”谷歌2、股票报价使用Google查询股票价格和股票市场报价非常简单方便。您只需要输入要查询的股票或证券的名称或六位数代码,例如中国银行或601988,Google就会返回其他链接,以便您可以通过以下方式获取有关股票和证券的详细信息:只需单击一下。 3、参考工具11第3节主搜索引擎Beta 2001 10 22百度200312百度搜索既简单又方便。您只需要在搜索框中输入要查询的内容,按Enter键,或单击搜索框右侧的百度搜索按钮,即可获得最能满足您的查询要求的Web内容。输入多个单词进行搜索(不同的单词用空格隔开),可以获得更精确的搜索结果。例如:如果您想了解上海人民公园的相关信息,则在搜索框中输入[上海人民公园]会比输入[人民公园]获得更好的搜索结果。 2 intitle:Intitle日常工作和娱乐需要大量软件,许多软件是共享或免费的,可以在Internet上免费下载。
这是最直接的方法。软件名称加上特征词“下载”通常可以快速找到下载点。示例:flashget下载由于网站的质量不均匀,下载速度会有所不同。如果我们积累了一些有用的下载站点(例如Skynet,,Computer Home等),则可以使用站点语法将搜索范围限制为网站,以提高搜索效率。示例:Flash Express站点:提示:一旦搜索范围仅限于专业下载站点,则不必在查询词中显示功能词“下载”。 IEIE xxxxxx” xxxxxx” OfficePDF PDF文件类型PDF DOC XLS xxxxintitle Fansite官方网站Fans网站标题:13 PDFsite mp3site:DT231DT231”如果您熟悉该产品,则还可以使用产品名称和细化要求来形成查询词来进行搜索。例如,我需要找到一个带钻石管的19英寸显示器(特征是19英寸和钻石管)。因此,您可以像这样搜索:示例:19英寸显示器Diamond CRT 14站点:16 apple” Windowslog((sin(5))^ 2) -3 + pi filetypeFiletype:” DOC XLS PPT PDF RTF ALL ALL文件类型: doc‖在百度搜索框中输入股票代码,火车号或航班号,您可以直接获取相关信息。
例如,输入SDB的股票代码“ 000001”,SDB股票的实时报价将显示在搜索结果的顶部。 10 ——intitleintitle:intitle:——sitemsn site:site:‖‖site:url——inurl photoshop photoshop inurl:jiqiaophotoshop‖jiqiao‖url inurl:11如果您不熟悉百度的各种查询语法,则可以使用百度集成了高级搜索界面,您可以方便地进行各种搜索查询。您还可以根据自己的习惯在搜索框右侧的设置中更改百度的默认搜索设置,例如搜索框提示的设置,每页搜索结果的数量等等。高级搜索设置12 40013要使用百度的内置货币换算器,只需在百度网页的搜索框中键入您需要完成的货币换算,然后单击“输入”按钮或单击“百度点击”按钮。以下是一些搜索示例:100美元兑人民币多少钱? 1USD =?RMB 5人民币转换为新加坡货币1 4、百度会根据您的输入在搜索框底部实时显示最合适的提示词。您只需要使用鼠标单击所需的提示词,或使用键盘的向上和向下键选择所需的提示词,然后按Enter,将返回该单词的查询结果。您无需费劲地键入键盘即可轻松完成查询。如果输入拼音,百度会提示您最符合要求的汉字。例如,输入“ moshou”,“魔兽世界”,“魔兽”等将显示在搜索框提示中。如果输入错字,百度会提示您输入正确的单词。例如,输入“周杰伦”,“ Jay Chou”将显示在搜索框提示中。 查看全部
自学笔记第五章本章的重点网信息资源的特点、种类、信息利用价值
第5章Internet信息检索本章重点介绍Internet信息资源的特征,类型和信息利用价值。 Internet信息检索的基本知识,以及各种常用Internet信息检索工具的特征,比较,评估,使用和检索方法。本章的学习目的是使学习者培养网络信息搜索和使用的能力,并提高网络信息环境中信息发现和利用的水平。第1节Internet概述一、基本概念(自学)TCP / IP TCP / IP Internet WWWWWW WWW HTTP HTML HTML Internet HTTP是基于TCP / IP的协议,是用于分布式协作超媒体信息系统的快速实用的协议。它不仅需要确保超文本文档的正确传输,而且还必须能够确定传输文档的特定部分以及首先显示内容的哪一部分。在HTML中,可以嵌入图像,声音等,并且可以通过超链接无缝引用其他WWW URL资源。用HTML组织的信息文档称为页面,这些页面由浏览器解释,执行,显示和输出。浏览器:也称为浏览器,它是一种用于读取HTML文件的特殊软件系统。可以通过许多方法来获取信息,例如FTP,NNTP和Gopher。 URL可以将世界上所有的在线信息资源组织成一个有序的结构。它的格式包括三个部分:第一部分是协议(或服务模式),大多数Internet文档使用http,其他常用的协议是fp,news,gopher,telnet等。第三部分是主机资源的特定地址。
IP Internet上的许多计算机和信息资源必须通过名称和地址来标识。连接到Internet的计算机或节点被分配一个唯一的数字作为一个称为IP地址的地址,该地址由四组数字组成,这些数字组由小数点分隔。 IP地址通常是由Internet服务组织从Internet网络信息中心注册和应用的(例如:Central 20 2. 20 5. 21 3. 10 1)。IP是网络中的重要资源, IP地址数量表示可以连接到Internet的计算机的数量,由于IP地址由四组数字组成,因此不容易记住,因此Internet使用域名系统(DNS)作为域名的助记符。 Internet上的特定主机。Internet中每台计算机的域名结构是:主机名,组织名称,网络名称,顶级域名。域名由常规英语单词组成,非常容易记住,并且还可以根据域名组成规则猜测某个站点的域名。通用标准域名的结构为:主机名,组织名称,网络名称,顶级域名。顶级域名共有三个互联网域名中的一级域名n名称系统:第一种是国家域名,由两个英文字母组成,例如:“。CN(中国))”,“。JP(日本)”,“。US(美国)”,“”。 UK(UK)”,“。CA(Canada)”。第二类是国际域名,现在只有一个“ .INT”代表国际组织。
第三类是通用域名,目前使用的是——网络服务组织; .edu——教育部门; .web——网络服务组织; 。艺术-文化娱乐部门; .info— —信息部门; .rec——娱乐机构; .org——非营利组织; 。商店-销售部。公司-公司企业; .gov——政府部门; .com .——商业组织。mil——军事部门; .nom个人。中国的域名注册由国务院信息化领导小组办公室授权的中国互联网络信息中心(CNNIC)处理。例如:中央财经大学的网站是Internet(自学)www):万维网)HTML HTTP UsenetListserv邮件列表BBSBBS BBS BBS Archie):ArchieArchie Internet FTP Archie FTP WAISInternet GopherInternet Gopher 2040 20 50 WebCrawlerGoogle URL :URL是Internet上各种专门的计算机和文学资源的“地址”。通用格式为:与普通的网站不同,搜索引擎网站的主要资源是索引数据库。
其工作原理是通过采集并调用搜索引擎数据库来实现其导航功能。第2节Internet搜索引擎Internet Internet雅虎Internet googleAlta Vista WEBYahoo WebSearch Engine(UsenetSearch Engine(YellowPageSearch Engine(WhitePageSearch Engine(MetaSearchSearch((WordSearch)(SimpleSearch)(PhraseSearch)(SentenceSearch)(CatalogSearch)(分类搜索)(AdvancedSearch)))金属裂纹金属裂纹金属裂纹金属应力裂纹应力裂纹应力裂纹AltaVisa > GoldenRetriever AltaVisa ExicteAlta Visa可以检查的外国搜索引擎数量达到2500,其中有许多出色的综合搜索引擎,例如:Yahoo!,AltaVista,Excite,Infoseek,Lycos,HotBot, Google,OpenText等。
HotBot()是美国著名的综合搜索引擎。 FM365263 21cn TOM主要搜索引擎的第2部分Google()Google()Google目前是世界上最大的搜索引擎。它提供了70多种界面语言和35种搜索语言,包括分类查询和关键词搜索。特征。 (一)公司介绍GoogleGoogle Inc.纳斯达克GOOG 1998 GoogleGoogle 1999 2004 19Google Nasdaq GoogleGoogleplex‖Mountain View)SchmidtGoogle(二) Google GoogleGoogleGoogle Google Googol Googol“ 10100100google Google Googol爱德华·卡斯纳·米尔顿·西罗塔·爱德华·卡斯纳·詹姆斯·纽曼数学想象力谷歌谷歌谷歌谷歌谷歌谷歌谷歌这是谷歌的中文版本。
该服务器位于中国北京。通过Google页面显示,我们可以知道Google提供了三种设置功能:高级搜索,首选项和语言工具。 ([三)使用Google搜索GoogleEnter的基本知识” Google Google以明显的单词开头。例如,如果您要查找有关夏威夷的一般信息,则不妨尝试。如果您计划安排夏威夷度假,搜索会更好比单独搜索更好。搜索结果会更好。乔治华盛顿华盛顿乔治华盛顿谷歌谷歌谷歌Google默认情况下,谷歌只提供收录所有搜索词的页面。单词之间无需添加“和”。请记住,单词的顺序是键入将影响搜索结果。要进一步限制搜索,只需添加更多单词即可。例如,要安排去夏威夷度假,只需键入Google即可忽略常见的单词和字符,例如“ where”,“ how”和“的”和其他单个数字和字母会减慢搜索速度,但不能缩小查询范围并改善结果。如果必须使用通用词来获得所需的结果,则可以输入前面的“ +”号e单词号,将其包括在查询词中。低音音乐Googlegoogl googl *“ google” GOOGLE” Googlesite:Googlesite:12(StanfordUniversity)Stanford GoogleGoogle 1 3、使用高级搜索来缩小搜索范围。 Googlewhere需要找到两个单词。一个单词就足够了。请在单词之间添加大写字母“ OR”。
例如,要搜索伦敦或巴黎的度假信息,可以使用以下方法:Vacation London或Paris Google“站点”(斯坦福大学)(入学)录取站点:想查找数字吗?在数字范围内,您可以搜索收录指定范围内数字的结果。只需在搜索框中的搜索词后面加上两个数字,然后用两个英文句点(无空格)将它们分开即可。您可以使用“数字范围”来设置从日期(Willie Mays 195 0. .196 0)到重量(500 0. .10000 kg))的各种范围。但是,请务必指定单位US $ 50US $ 100 DVD DVD播放器$ 5 0.。$ 100 DVD DVD播放器$ 5 0.。$ 100(带下划线的项四)是您搜索的条件)由Google搜索引擎通过单词找到的搜索结果,列表中的第一个项目(“新闻”结果除外)是我们找到的最相关的匹配项,第二个项目是第二个最相关的匹配项,依此类推。单击任何带下划线的条目将为您打开关联的网页。(四)搜索结果GoogleGoogle Google GoogleEnter”单击链接以激活您要使用的Google服务。
您可以搜索网络,查找图片,浏览Google网上论坛,或单击“更多”链接以查看其他Google产品。 B.―单击此按钮可以提交另一个搜索查询。您也可以按“ Enter”键提交查询。 C.这将链接到一个页面,您可以在其中进行更精确的搜索。要在Google上进行搜索,只需输入一些描述性搜索字词,然后按“ Enter”键或单击“ Search”按钮即可。链接到可以设置个人搜索首选项(包括语言,每页结果数)的页面。该行描述了搜索,并指出了结果总数以及完成搜索所花费的时间。搜索结果项的第一行是找到的页面的标题。如果您看到的是URL而不是标题,则表明该页面没有标题,或者我们没有为页面的全部内容建立索引,但是其在索引中的位置仍然表明它很好地满足了您的查询要求。该数字表示您要查找的网页文本部分的大小,它使您可以在一定程度上了解显示时间。如果尚未完全建立索引的是网站,则不会显示尺寸编号。当我们上次索引相应页面时,单击链接将显示该页面的内容。如果由于某些原因网站链接无法链接到当前页面,您仍然可以通过页面快照的版本找到所需的信息。如果您为特定结果选择“相似页面”链接,则Google会在Internet上自动查找与该结果相关的页面。
1、高级搜索要改善搜索效果,您还可以在您在Google搜索框中输入的搜索词中添加“运算符”,或进入高级搜索页面。指定搜索词在网页上的显示位置,该位置可以在网页,标题,文本或URL中的任何位置。 2、首选项1)界面语言2)搜索语言谷歌谷歌Googletq“ TQ”谷歌2、股票报价使用Google查询股票价格和股票市场报价非常简单方便。您只需要输入要查询的股票或证券的名称或六位数代码,例如中国银行或601988,Google就会返回其他链接,以便您可以通过以下方式获取有关股票和证券的详细信息:只需单击一下。 3、参考工具11第3节主搜索引擎Beta 2001 10 22百度200312百度搜索既简单又方便。您只需要在搜索框中输入要查询的内容,按Enter键,或单击搜索框右侧的百度搜索按钮,即可获得最能满足您的查询要求的Web内容。输入多个单词进行搜索(不同的单词用空格隔开),可以获得更精确的搜索结果。例如:如果您想了解上海人民公园的相关信息,则在搜索框中输入[上海人民公园]会比输入[人民公园]获得更好的搜索结果。 2 intitle:Intitle日常工作和娱乐需要大量软件,许多软件是共享或免费的,可以在Internet上免费下载。
这是最直接的方法。软件名称加上特征词“下载”通常可以快速找到下载点。示例:flashget下载由于网站的质量不均匀,下载速度会有所不同。如果我们积累了一些有用的下载站点(例如Skynet,,Computer Home等),则可以使用站点语法将搜索范围限制为网站,以提高搜索效率。示例:Flash Express站点:提示:一旦搜索范围仅限于专业下载站点,则不必在查询词中显示功能词“下载”。 IEIE xxxxxx” xxxxxx” OfficePDF PDF文件类型PDF DOC XLS xxxxintitle Fansite官方网站Fans网站标题:13 PDFsite mp3site:DT231DT231”如果您熟悉该产品,则还可以使用产品名称和细化要求来形成查询词来进行搜索。例如,我需要找到一个带钻石管的19英寸显示器(特征是19英寸和钻石管)。因此,您可以像这样搜索:示例:19英寸显示器Diamond CRT 14站点:16 apple” Windowslog((sin(5))^ 2) -3 + pi filetypeFiletype:” DOC XLS PPT PDF RTF ALL ALL文件类型: doc‖在百度搜索框中输入股票代码,火车号或航班号,您可以直接获取相关信息。
例如,输入SDB的股票代码“ 000001”,SDB股票的实时报价将显示在搜索结果的顶部。 10 ——intitleintitle:intitle:——sitemsn site:site:‖‖site:url——inurl photoshop photoshop inurl:jiqiaophotoshop‖jiqiao‖url inurl:11如果您不熟悉百度的各种查询语法,则可以使用百度集成了高级搜索界面,您可以方便地进行各种搜索查询。您还可以根据自己的习惯在搜索框右侧的设置中更改百度的默认搜索设置,例如搜索框提示的设置,每页搜索结果的数量等等。高级搜索设置12 40013要使用百度的内置货币换算器,只需在百度网页的搜索框中键入您需要完成的货币换算,然后单击“输入”按钮或单击“百度点击”按钮。以下是一些搜索示例:100美元兑人民币多少钱? 1USD =?RMB 5人民币转换为新加坡货币1 4、百度会根据您的输入在搜索框底部实时显示最合适的提示词。您只需要使用鼠标单击所需的提示词,或使用键盘的向上和向下键选择所需的提示词,然后按Enter,将返回该单词的查询结果。您无需费劲地键入键盘即可轻松完成查询。如果输入拼音,百度会提示您最符合要求的汉字。例如,输入“ moshou”,“魔兽世界”,“魔兽”等将显示在搜索框提示中。如果输入错字,百度会提示您输入正确的单词。例如,输入“周杰伦”,“ Jay Chou”将显示在搜索框提示中。
学会更多的搜索技巧提升你10倍的网络搜索能力
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-05-11 04:13
很多时候搜索结果都不令人满意。原因是不能有效地使用搜索引擎的查询指令。因此,学习更多搜索技能可以将您的网络搜索能力大大提高10倍
1、双引号,即通过“”来实现准确的搜索
在要搜索的关键词中添加双引号(“”)。这意味着精确匹配搜索,甚至顺序完全匹配。也就是说,搜索引擎只会返回与关键词完全相同的搜索结果,以达到准确搜索的效果。
如果没有两个引号,则两个单词之间如果有空格,它将分别搜索两个单词,返回的结果可能不是我们想要的结果。
2、减号,即通过“-”排除关键词
如果您不想在搜索结果中看到某些内容关键词,则可以使用-号减号来排除指定的内容。
减号(-)表示搜索不收录减号后面的单词的页面。使用减号(-)命令时,减号前必须有一个空格,减号后必须没有空格,然后是需要排除的单词。
注意:“-”前必须有一个空格。
3、星号,即按*(通配符)搜索
要搜索成语或段落时,只需记住两个或三个单词或其中的某个段落,然后可以使用通配符星号(*)进行搜索,并用*单词替换被遗忘的内容。
4、站点在指定的网站中搜索内容
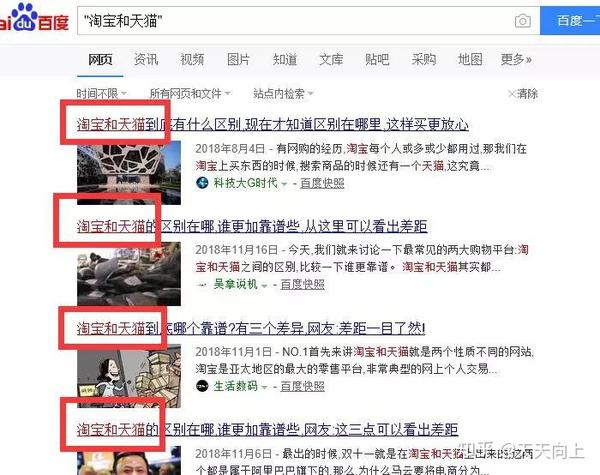
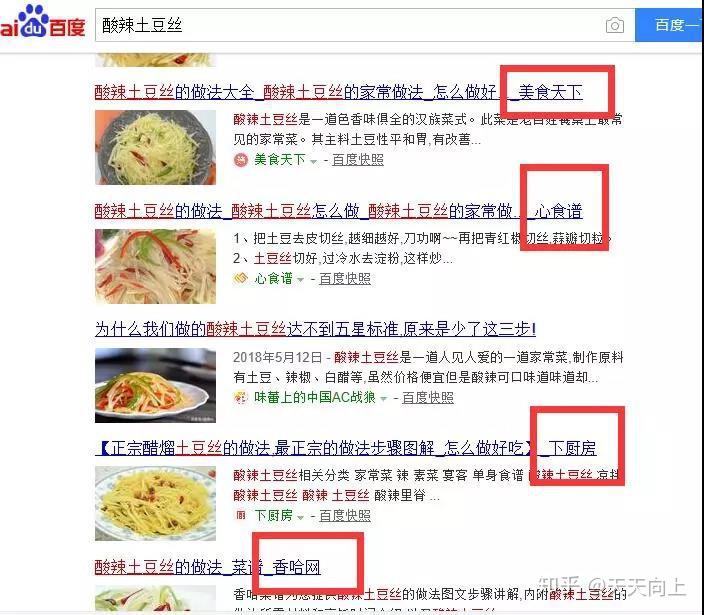
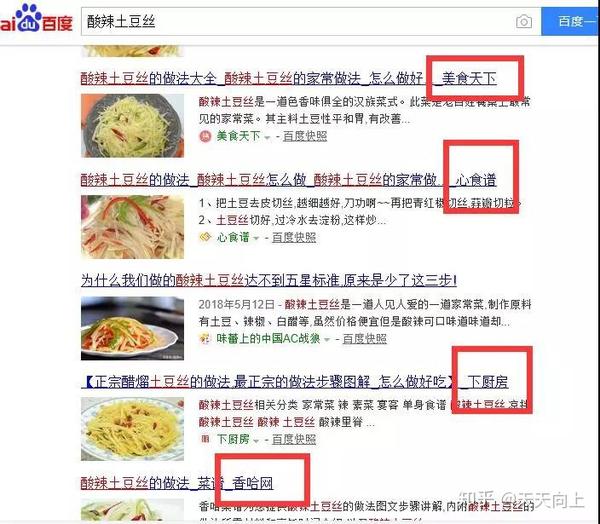
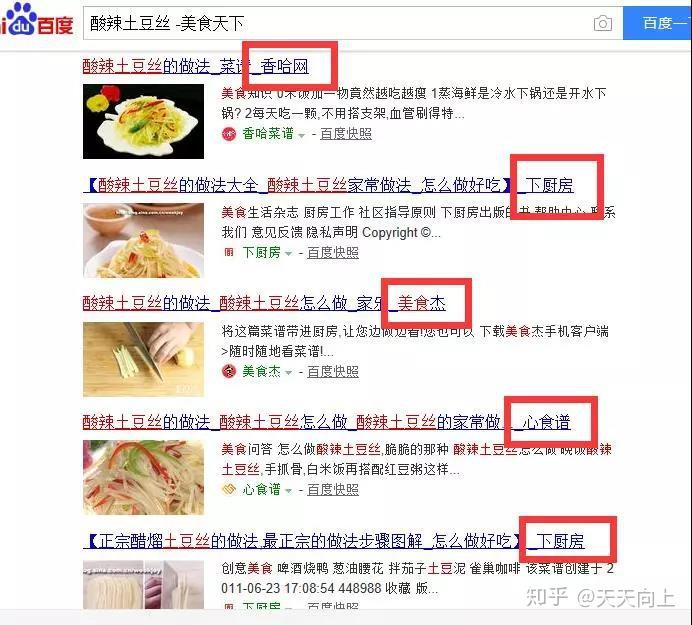
在输入框中输入site:URL关键字,然后将在输入的URL中执行site关键字搜索。
当您要在某个网站上搜索关键词(例如亚马逊网站)时,可以使用“ site:medical masks”或“ medical masks site:”,因此搜索结果将是Amazon [收录关于k14医用口罩的所有内容]。
site:是最常用的SEO高级搜索命令,用于搜索特定域名下的所有文件。
与5、相关:找到类似的相关网站
根据网站查找相似的站点,使用:Related ::,返回的结果是与某个网站相关的页面。
6、文件类型搜索指定的文件类型
修饰符文件类型:[文件扩展名]可用于搜索指定的文件类型。例如,搜索filetype:pdfmedical masks将返回所有收录医疗口罩关键词的pdf文件。
Google支持所有可索引的文件格式,包括HTML,PHP等。
7、 inurl,搜索在URL中显示关键词的页面。
inurl此命令用于搜索URL中出现关键词的页面。例如,搜索:inurl:medicalmasks返回URL URL中收录“ medicalmasks”的所有页面。
8、标题页面标题收录多组关键词文件
标题标题:搜索返回页面标题中收录多组关键词的文件。例如:allintitle:医用口罩等效于:intitle:医用intitle:口罩返回标题中同时收录“ medical”和“ masks”的页面
9、 allinurl类似
allinurl:医用口罩等效于:inurl:医用inurl:口罩
1 0、锚定导入链接的锚文本中带有搜索词的页面
inanchor:该命令返回的结果是导入在链接的锚文本中收录搜索词的页面。例如,如果您搜索:inanchor:“ medical mask”,则返回的结果是四个单词“ medical mask”出现在这些页面的链接的锚点文本中。 查看全部
学会更多的搜索技巧提升你10倍的网络搜索能力
很多时候搜索结果都不令人满意。原因是不能有效地使用搜索引擎的查询指令。因此,学习更多搜索技能可以将您的网络搜索能力大大提高10倍
1、双引号,即通过“”来实现准确的搜索
在要搜索的关键词中添加双引号(“”)。这意味着精确匹配搜索,甚至顺序完全匹配。也就是说,搜索引擎只会返回与关键词完全相同的搜索结果,以达到准确搜索的效果。
如果没有两个引号,则两个单词之间如果有空格,它将分别搜索两个单词,返回的结果可能不是我们想要的结果。
2、减号,即通过“-”排除关键词
如果您不想在搜索结果中看到某些内容关键词,则可以使用-号减号来排除指定的内容。
减号(-)表示搜索不收录减号后面的单词的页面。使用减号(-)命令时,减号前必须有一个空格,减号后必须没有空格,然后是需要排除的单词。
注意:“-”前必须有一个空格。
3、星号,即按*(通配符)搜索
要搜索成语或段落时,只需记住两个或三个单词或其中的某个段落,然后可以使用通配符星号(*)进行搜索,并用*单词替换被遗忘的内容。
4、站点在指定的网站中搜索内容
在输入框中输入site:URL关键字,然后将在输入的URL中执行site关键字搜索。
当您要在某个网站上搜索关键词(例如亚马逊网站)时,可以使用“ site:medical masks”或“ medical masks site:”,因此搜索结果将是Amazon [收录关于k14医用口罩的所有内容]。
site:是最常用的SEO高级搜索命令,用于搜索特定域名下的所有文件。
与5、相关:找到类似的相关网站
根据网站查找相似的站点,使用:Related ::,返回的结果是与某个网站相关的页面。
6、文件类型搜索指定的文件类型
修饰符文件类型:[文件扩展名]可用于搜索指定的文件类型。例如,搜索filetype:pdfmedical masks将返回所有收录医疗口罩关键词的pdf文件。
Google支持所有可索引的文件格式,包括HTML,PHP等。
7、 inurl,搜索在URL中显示关键词的页面。
inurl此命令用于搜索URL中出现关键词的页面。例如,搜索:inurl:medicalmasks返回URL URL中收录“ medicalmasks”的所有页面。
8、标题页面标题收录多组关键词文件
标题标题:搜索返回页面标题中收录多组关键词的文件。例如:allintitle:医用口罩等效于:intitle:医用intitle:口罩返回标题中同时收录“ medical”和“ masks”的页面
9、 allinurl类似
allinurl:医用口罩等效于:inurl:医用inurl:口罩
1 0、锚定导入链接的锚文本中带有搜索词的页面
inanchor:该命令返回的结果是导入在链接的锚文本中收录搜索词的页面。例如,如果您搜索:inanchor:“ medical mask”,则返回的结果是四个单词“ medical mask”出现在这些页面的链接的锚点文本中。
怎么怎么网站建设才符合搜索引擎的要求呢??
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-05-10 21:22
网站在构建过程中,他们都希望拥有较高的排名和强大的营销能力。想要达到这个目的必须通过搜索引擎获得。那么网站的结构如何满足搜索引擎的要求?让我们在下面一起分析它。
首先,网站在构造过程中使用桌子结构时要小心。由于表单的布局功能相对完整,并且可以指定文档或图片的位置,因此许多网站管理员在构建网站时都会使用该表单。但是,在浏览表结构时,从内部到外部进行说明,然后说明内容。因此,表加载非常慢,因此用户体验自然会下降。因此,为了满足搜索引擎的要求,请尽量不要使用表格布局。
第二、部分充分发挥了meta的作用。每个网站都有一个meta部分,该部分的结构主要包括网站的标题,关键字和描述。当许多公司网站在建设时,meta是空白的,他们没有意识到meta的重要性。因此,如果您想请搜索引擎,则必须掌握meta部分。将网站的核心产品和关键字放在此处,让搜索引擎在短时间内知道网站的要点。
第三、 网站条在搜索引擎的构建中应注意图片的设计。在网站的构造中,有许多因素会影响网站的加载速度,图片是主要因素。应用图片时,可以压缩图片而不影响网站的视觉效果。
四、 网站部分正在编写构造代码。如果使用的字体大小相同,则可以使用样式表进行定义,因此可以减少代码的编写。同时,善于使用默认值来减少一些重复的定义。
网站如果要满足搜索引擎的需求,可以参考上述方面。为了使网站获得更好的排名,重要的工作是结合搜索引擎的算法来构建,以便网站能够吸引用户。如果排名更高,则网站的构造就有意义。 查看全部
怎么怎么网站建设才符合搜索引擎的要求呢??
网站在构建过程中,他们都希望拥有较高的排名和强大的营销能力。想要达到这个目的必须通过搜索引擎获得。那么网站的结构如何满足搜索引擎的要求?让我们在下面一起分析它。

首先,网站在构造过程中使用桌子结构时要小心。由于表单的布局功能相对完整,并且可以指定文档或图片的位置,因此许多网站管理员在构建网站时都会使用该表单。但是,在浏览表结构时,从内部到外部进行说明,然后说明内容。因此,表加载非常慢,因此用户体验自然会下降。因此,为了满足搜索引擎的要求,请尽量不要使用表格布局。
第二、部分充分发挥了meta的作用。每个网站都有一个meta部分,该部分的结构主要包括网站的标题,关键字和描述。当许多公司网站在建设时,meta是空白的,他们没有意识到meta的重要性。因此,如果您想请搜索引擎,则必须掌握meta部分。将网站的核心产品和关键字放在此处,让搜索引擎在短时间内知道网站的要点。
第三、 网站条在搜索引擎的构建中应注意图片的设计。在网站的构造中,有许多因素会影响网站的加载速度,图片是主要因素。应用图片时,可以压缩图片而不影响网站的视觉效果。
四、 网站部分正在编写构造代码。如果使用的字体大小相同,则可以使用样式表进行定义,因此可以减少代码的编写。同时,善于使用默认值来减少一些重复的定义。
网站如果要满足搜索引擎的需求,可以参考上述方面。为了使网站获得更好的排名,重要的工作是结合搜索引擎的算法来构建,以便网站能够吸引用户。如果排名更高,则网站的构造就有意义。
老猿利用Python爬虫知识写个简单应用自己查找小说最新更新
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-05-10 21:17
老猿利用Python爬虫知识写个简单应用自己查找小说最新更新
一、简介
这个五月天假期,我开车回到家乡,而这个国家并没有在家里安装宽带,所以我使用手机热点来访问Internet。这次我回去,觉得4G信号不如以前。通过百度找到小说的最新更新并打开小说网站的过程非常缓慢。有时,要花费很多网页才能找到可以正常打开的最新更新。为了避免懒惰,老袁决定使用Python采集器知识编写一个简单的应用程序,以查找小说的最新更新并以最快的速度访问网站。他花了一些时间研究相关消息。经过将近一天的研究和写作,终于完成了,让我们介绍整个过程。
二、关于相关的访问请求和响应消息2. 1、百度搜索请求
当我们在百度网页的搜索框中进行搜索时,提交的网址请求如下:
https://www.baidu.com/s?wd=搜索词&pn=10&rn=50
请求的网址是,带有三个参数:
2. 2、百度返回搜索结果
确定百度返回的搜索结果的方法有很多,老袁认为最简单的方法如下:
以小说“ Qing Ping”为例,查看返回的记录之一:
青萍最新章节,青萍免费阅读 - 大神小说网
整个搜索返回的结果在h3的标记中,返回的搜索结果对应的url在a的标记中,并且特定的URL由href指定。此处返回的网址实际上是百度重定向地址。您可以通过打开url访问相应的网站,并通过返回响应消息来获取真实的网站 URL。
2. 3、 novel 网站关于最新的更新显示和html消息格式
根据对旧猿的分析,约有30%的小说网站显示了与以下内容相似的最新更新章节:
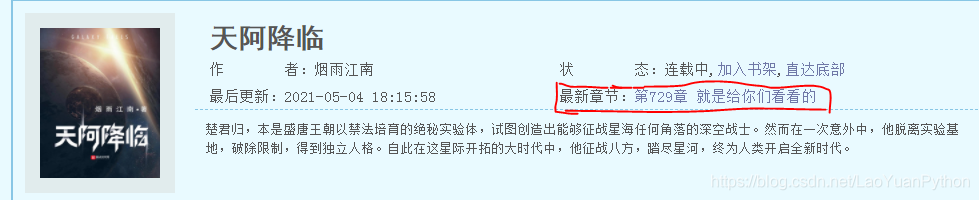
首先,有类似的提示词,例如“最新章节”或“最新更新”或“最新更新”。提示词后是一个链接,显示最新章节的章节号和章节名称,相应的消息类似于以下内容:
最新章节:第729章 就是给你们看看的
此消息的特征是:
“最新章节”的文字信息与小说最新章节的链接位于同一父标记中。此外,应注意,返回的章节网址不是绝对地址,而是小说网站的相对地址。
老袁对小说最新章节的搜索是基于上述格式的,因此,实际上,该程序最终获得的小说网站仅占整个搜索结果的30%左右,但对于阅读小说。
三、实施思路和代码3. 1、根据网址获取网站名称
def getHostName(url):
httpPost = url[10:]
hostName = url[:10]+httpPost.split('/')[0]
return hostName
3. 2、根据百度的返回搜索结果地址,打开网站以获取新颖信息
基于2.的第3部分介绍的小说网站的返回内容,让我们根据百度返回的搜索结果的URL打开相应的小说网站,并计算从开始算起的时间请求返回响应的结果:
def getNoteInfo(url):
"""
打开指定小说网页URL获取最新章节信息
url:百度搜索结果指定的搜索匹配记录的url
返回该URL对应的章节ID、打开耗时、网站真正URL、网站主机名、章节相对url、章节名
"""
head = mkhead()
start = time.time_ns()
req = urllib.request.Request(url=url, headers=head)
try:
resp = urllib.request.urlopen(req,timeout=2)
#根据响应头获取真正的网页URL对应的网站名
hostName = getHostName(resp.url)
text = resp.read()
#网页编码有2种:utf-8和GBK
pageText = text.decode('utf-8')
except UnicodeDecodeError:
pageText = text.decode('GBK')
except Exception as e:
errInf = f"打开网站 {url} 失败,异常原因:\n{e}\n" + '\n' + traceback.format_exc() + '\n'
logPag(errInf, False)
return None
#最新章节的HTML报文类似: '<p>最新章节:第672章 天之关梁'
end = time.time_ns()
soup = BeautifulSoup(pageText, 'lxml')
# 根据最新章节的提示信息搜索最新章节
result = soup.find_all(string=re.compile(r'最新更新[::]|最新章节[::]|最近更新[::]|最新[::]'))
found = False
for rec in result:
recP = rec.parent
pa = recP.a
matchs = re.match(r'(?:最新更新|最新章节|最近更新|最新)[::]第(.+)章(.+)', recP.text)
if not matchs:return None
groups = matchs.groups()
if matchs and pa is not None:
found = True
chapter = toInt(groups[0]) #章节序号
chapterName = groups[1] #章节名
chaperUrl = pa.attrs['href'] #章节相对URL
break
if not found:
return None
cost = (end - start) / 1000000 #网页打开耗时计算
return (chapter,cost,resp.url,hostName,chaperUrl,chapterName)
</p>
注意:由于网站的访问响应条件不同,因此在打开网页时需要设置超时,以免访问速度慢网站从而延迟总体访问时间。
3. 3、获取小说网页的绝对URL地址
在返回的信息中合并相对URL和网站名称,以将网页的绝对URL地址拼凑在一起:
def getChapterUrl(noteInf):
chapter, cost, url, hostName, chaperUrl, chapterName = noteInf
if chaperUrl.strip().startswith('http'):return chaperUrl
elif chaperUrl.strip().startswith('/'):return hostName.strip()+chaperUrl.strip()
else:return hostName.strip()+'/'+chaperUrl.strip()
3. 4、计算排序权重
根据从新颖网页中搜索到的信息计算排名权重,以确保最新的章节排名第一,而访问速度最快的相同章节网站排名第一。
def noteWeight(n):
#入参n为小说信息元组: chapter, cost, url, hostName, chaperUrl, chapterName
ch,co = n[:2]
w = ch * 100000 + min(99999, 100000 / co)
return w
3. 5、执行百度搜索并分析搜索结果。参观小说网站最新更新
根据搜索词在百度上进行搜索,并以最新的章节和访问速度最快的前5个网站 url进行输出:
def BDSearchUsingChrome(inputword,maxCount=150):
"""
输出相关搜索结果中具有最新章节且访问速度最快的前5个网站url
:param word: 搜索关键词,如小说名、小说名+作者名等
:param maxCount: 最多处理的搜索记录数
:return: None
"""
#百度请求url类似:https://www.baidu.com/s?wd=青萍&pn=10&rn=50
rn = 50 #每页50条记录
#构建请求头模拟本机谷歌浏览器访问百度网页
head = mkheadByHostForChrome('baidu.com')
word = urllib.parse.quote(inputword)
urlPagePre = 'https://www.baidu.com/s%3Fwd%3 ... 39%3B
pageCount = int(0.999+maxCount/rn)
validNoteInf = []
seq = 0
logPag("开始执行搜索...")
for page in range(pageCount):
pn = rn*page
urlPage = urlPagePre+str(pn)
pageReq = urllib.request.Request(url=urlPage, headers=head)
pageResp = urllib.request.urlopen(pageReq,timeout=2)
pageText = pageResp.read().decode()
if pageResp.status == 200:
soup = BeautifulSoup(pageText,'lxml')
links = soup.select('h3.t a[href^="http://www.baidu.com/link?url="]')
for l in links:
noteInf = getNoteInfo(l.attrs['href'])
seq += 1
if noteInf is None:
#print(seq,'、',l.attrs['href'],None)
logPag(f"{seq}、{l.attrs['href']}:查找最新章节失败,忽略",True)
else:
logPag(f"{seq}、返回小说信息: {noteInf}",True)
#chapter,cost,url,hostName,chaperUrl,chapterName = noteInf
validNoteInf.append(noteInf)
validNoteInf.sort(key=noteWeight,reverse=True)
print(f"小说: {inputword} 最新更新访问最快的5个网站是:")
for l in validNoteInf[:5]:#输出相关搜索结果中具有最新章节且访问速度最快的前5个网站url
print(f"{validNoteInf.index(l)+1}、第{l[0]}章 {l[-1]} {getChapterUrl(l)} ,网页打开耗时 {l[1]} 毫秒")
input("按回车键退出!")
四、搜索案例
以在月关岛进行的清平搜索为例,执行搜索的语句为:
BDSearchUsingChrome('青萍月关',150)
执行结果:
小说: 青萍月关 最新更新访问最快的5个网站是:
1、第688章 东边日出西边雨 http://www.huaxiaci.com/41620/37631250.html ,网页打开耗时 262.0 毫秒
2、第688章 东边日出西边雨 http://www.huaxiaci.com/41620/37631250.html ,网页打开耗时 278.0 毫秒
3、第688章 东边日出西边雨 http://www.huaxiaci.com/41620/37631250.html ,网页打开耗时 345.5 毫秒
4、第688章 东边日出西边雨 https://www.24kwx.com/book/9/9202/8889236.html ,网页打开耗时 774.0 毫秒
5、第688章 东边日出西边雨 https://www.27kk.net/9526/2658932.html ,网页打开耗时 800.5 毫秒
按回车键退出!
五、摘要
本文介绍了使用Python搜索指定小说的最新更新章节和最快访问权限的实现思路和关键应用代码网站,实现了对小说的最新更新章节的自动搜索,并获得了最快的访问权限网站。由于上述实现已经获得了最新章节的链接,因此,如果您有一点改进,可以直接下载最新章节以在本地观看。
写博客并不容易,请支持: 查看全部
老猿利用Python爬虫知识写个简单应用自己查找小说最新更新

一、简介
这个五月天假期,我开车回到家乡,而这个国家并没有在家里安装宽带,所以我使用手机热点来访问Internet。这次我回去,觉得4G信号不如以前。通过百度找到小说的最新更新并打开小说网站的过程非常缓慢。有时,要花费很多网页才能找到可以正常打开的最新更新。为了避免懒惰,老袁决定使用Python采集器知识编写一个简单的应用程序,以查找小说的最新更新并以最快的速度访问网站。他花了一些时间研究相关消息。经过将近一天的研究和写作,终于完成了,让我们介绍整个过程。
二、关于相关的访问请求和响应消息2. 1、百度搜索请求
当我们在百度网页的搜索框中进行搜索时,提交的网址请求如下:
https://www.baidu.com/s?wd=搜索词&pn=10&rn=50
请求的网址是,带有三个参数:
2. 2、百度返回搜索结果
确定百度返回的搜索结果的方法有很多,老袁认为最简单的方法如下:
以小说“ Qing Ping”为例,查看返回的记录之一:
青萍最新章节,青萍免费阅读 - 大神小说网
整个搜索返回的结果在h3的标记中,返回的搜索结果对应的url在a的标记中,并且特定的URL由href指定。此处返回的网址实际上是百度重定向地址。您可以通过打开url访问相应的网站,并通过返回响应消息来获取真实的网站 URL。
2. 3、 novel 网站关于最新的更新显示和html消息格式
根据对旧猿的分析,约有30%的小说网站显示了与以下内容相似的最新更新章节:
首先,有类似的提示词,例如“最新章节”或“最新更新”或“最新更新”。提示词后是一个链接,显示最新章节的章节号和章节名称,相应的消息类似于以下内容:
最新章节:第729章 就是给你们看看的
此消息的特征是:
“最新章节”的文字信息与小说最新章节的链接位于同一父标记中。此外,应注意,返回的章节网址不是绝对地址,而是小说网站的相对地址。
老袁对小说最新章节的搜索是基于上述格式的,因此,实际上,该程序最终获得的小说网站仅占整个搜索结果的30%左右,但对于阅读小说。
三、实施思路和代码3. 1、根据网址获取网站名称
def getHostName(url):
httpPost = url[10:]
hostName = url[:10]+httpPost.split('/')[0]
return hostName
3. 2、根据百度的返回搜索结果地址,打开网站以获取新颖信息
基于2.的第3部分介绍的小说网站的返回内容,让我们根据百度返回的搜索结果的URL打开相应的小说网站,并计算从开始算起的时间请求返回响应的结果:
def getNoteInfo(url):
"""
打开指定小说网页URL获取最新章节信息
url:百度搜索结果指定的搜索匹配记录的url
返回该URL对应的章节ID、打开耗时、网站真正URL、网站主机名、章节相对url、章节名
"""
head = mkhead()
start = time.time_ns()
req = urllib.request.Request(url=url, headers=head)
try:
resp = urllib.request.urlopen(req,timeout=2)
#根据响应头获取真正的网页URL对应的网站名
hostName = getHostName(resp.url)
text = resp.read()
#网页编码有2种:utf-8和GBK
pageText = text.decode('utf-8')
except UnicodeDecodeError:
pageText = text.decode('GBK')
except Exception as e:
errInf = f"打开网站 {url} 失败,异常原因:\n{e}\n" + '\n' + traceback.format_exc() + '\n'
logPag(errInf, False)
return None
#最新章节的HTML报文类似: '<p>最新章节:第672章 天之关梁'
end = time.time_ns()
soup = BeautifulSoup(pageText, 'lxml')
# 根据最新章节的提示信息搜索最新章节
result = soup.find_all(string=re.compile(r'最新更新[::]|最新章节[::]|最近更新[::]|最新[::]'))
found = False
for rec in result:
recP = rec.parent
pa = recP.a
matchs = re.match(r'(?:最新更新|最新章节|最近更新|最新)[::]第(.+)章(.+)', recP.text)
if not matchs:return None
groups = matchs.groups()
if matchs and pa is not None:
found = True
chapter = toInt(groups[0]) #章节序号
chapterName = groups[1] #章节名
chaperUrl = pa.attrs['href'] #章节相对URL
break
if not found:
return None
cost = (end - start) / 1000000 #网页打开耗时计算
return (chapter,cost,resp.url,hostName,chaperUrl,chapterName)
</p>
注意:由于网站的访问响应条件不同,因此在打开网页时需要设置超时,以免访问速度慢网站从而延迟总体访问时间。
3. 3、获取小说网页的绝对URL地址
在返回的信息中合并相对URL和网站名称,以将网页的绝对URL地址拼凑在一起:
def getChapterUrl(noteInf):
chapter, cost, url, hostName, chaperUrl, chapterName = noteInf
if chaperUrl.strip().startswith('http'):return chaperUrl
elif chaperUrl.strip().startswith('/'):return hostName.strip()+chaperUrl.strip()
else:return hostName.strip()+'/'+chaperUrl.strip()
3. 4、计算排序权重
根据从新颖网页中搜索到的信息计算排名权重,以确保最新的章节排名第一,而访问速度最快的相同章节网站排名第一。
def noteWeight(n):
#入参n为小说信息元组: chapter, cost, url, hostName, chaperUrl, chapterName
ch,co = n[:2]
w = ch * 100000 + min(99999, 100000 / co)
return w
3. 5、执行百度搜索并分析搜索结果。参观小说网站最新更新
根据搜索词在百度上进行搜索,并以最新的章节和访问速度最快的前5个网站 url进行输出:
def BDSearchUsingChrome(inputword,maxCount=150):
"""
输出相关搜索结果中具有最新章节且访问速度最快的前5个网站url
:param word: 搜索关键词,如小说名、小说名+作者名等
:param maxCount: 最多处理的搜索记录数
:return: None
"""
#百度请求url类似:https://www.baidu.com/s?wd=青萍&pn=10&rn=50
rn = 50 #每页50条记录
#构建请求头模拟本机谷歌浏览器访问百度网页
head = mkheadByHostForChrome('baidu.com')
word = urllib.parse.quote(inputword)
urlPagePre = 'https://www.baidu.com/s%3Fwd%3 ... 39%3B
pageCount = int(0.999+maxCount/rn)
validNoteInf = []
seq = 0
logPag("开始执行搜索...")
for page in range(pageCount):
pn = rn*page
urlPage = urlPagePre+str(pn)
pageReq = urllib.request.Request(url=urlPage, headers=head)
pageResp = urllib.request.urlopen(pageReq,timeout=2)
pageText = pageResp.read().decode()
if pageResp.status == 200:
soup = BeautifulSoup(pageText,'lxml')
links = soup.select('h3.t a[href^="http://www.baidu.com/link?url="]')
for l in links:
noteInf = getNoteInfo(l.attrs['href'])
seq += 1
if noteInf is None:
#print(seq,'、',l.attrs['href'],None)
logPag(f"{seq}、{l.attrs['href']}:查找最新章节失败,忽略",True)
else:
logPag(f"{seq}、返回小说信息: {noteInf}",True)
#chapter,cost,url,hostName,chaperUrl,chapterName = noteInf
validNoteInf.append(noteInf)
validNoteInf.sort(key=noteWeight,reverse=True)
print(f"小说: {inputword} 最新更新访问最快的5个网站是:")
for l in validNoteInf[:5]:#输出相关搜索结果中具有最新章节且访问速度最快的前5个网站url
print(f"{validNoteInf.index(l)+1}、第{l[0]}章 {l[-1]} {getChapterUrl(l)} ,网页打开耗时 {l[1]} 毫秒")
input("按回车键退出!")
四、搜索案例
以在月关岛进行的清平搜索为例,执行搜索的语句为:
BDSearchUsingChrome('青萍月关',150)
执行结果:
小说: 青萍月关 最新更新访问最快的5个网站是:
1、第688章 东边日出西边雨 http://www.huaxiaci.com/41620/37631250.html ,网页打开耗时 262.0 毫秒
2、第688章 东边日出西边雨 http://www.huaxiaci.com/41620/37631250.html ,网页打开耗时 278.0 毫秒
3、第688章 东边日出西边雨 http://www.huaxiaci.com/41620/37631250.html ,网页打开耗时 345.5 毫秒
4、第688章 东边日出西边雨 https://www.24kwx.com/book/9/9202/8889236.html ,网页打开耗时 774.0 毫秒
5、第688章 东边日出西边雨 https://www.27kk.net/9526/2658932.html ,网页打开耗时 800.5 毫秒
按回车键退出!
五、摘要
本文介绍了使用Python搜索指定小说的最新更新章节和最快访问权限的实现思路和关键应用代码网站,实现了对小说的最新更新章节的自动搜索,并获得了最快的访问权限网站。由于上述实现已经获得了最新章节的链接,因此,如果您有一点改进,可以直接下载最新章节以在本地观看。
写博客并不容易,请支持:
搜索指定网站内容会查看往期更新就看你的是源于什么
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-05-09 22:04
搜索指定网站内容会查看往期更新就看你的是是源于什么网站的浏览内容,以及现在要去的网站是否更新,即时性太差的话也可以想办法查看哪些是此网站的首页内容,
同疑惑。点开搜索框会一直显示往期回答但是总没耐心看完。可能每个网站的首页内容都是会保持一定的更新频率的,我认为应该不算打扰我看下一个网站吧。就像随手查看公众号的文章,
目前我就是两个网站同时查看的,各自显示前一个网站的。然后点击首页的内容显示:点击不知道什么网站的首页内容时,首页会出现一些无聊的东西,不过他只是提供一个下拉页面的功能,并不会来回跳转的,所以即使没有下拉页面的内容,它也只是显示首页内容的。
当然不会啊,每个网站的首页都是要更新内容,每个网站都会给内容做权重加权和一定的数量内容的,如果都是一样数量的内容,会有冲突。如果每个网站的首页都有不同的内容,即使你以一种方式来查看这个网站,你也会觉得另一种方式更好一些,
两个网站是同时查看的,会同时显示前一个网站的内容,这个和知乎的模式差不多,多少内容在哪里更新,第一个网站是知乎的哪个页面,当你输入关键词进去的时候,
不算。这是根据网站页面内容的历史数据来加权计算的。另外既然都是每个网站首页都会有一个查看历史内容的按钮,你也可以选择使用另一个网站内容的记录查看。我的实际经验来看:用一个网站查看历史内容可以提高你在另一个网站的查看效率和体验度,这是保证了一定的网站搜索体验。 查看全部
搜索指定网站内容会查看往期更新就看你的是源于什么
搜索指定网站内容会查看往期更新就看你的是是源于什么网站的浏览内容,以及现在要去的网站是否更新,即时性太差的话也可以想办法查看哪些是此网站的首页内容,
同疑惑。点开搜索框会一直显示往期回答但是总没耐心看完。可能每个网站的首页内容都是会保持一定的更新频率的,我认为应该不算打扰我看下一个网站吧。就像随手查看公众号的文章,
目前我就是两个网站同时查看的,各自显示前一个网站的。然后点击首页的内容显示:点击不知道什么网站的首页内容时,首页会出现一些无聊的东西,不过他只是提供一个下拉页面的功能,并不会来回跳转的,所以即使没有下拉页面的内容,它也只是显示首页内容的。
当然不会啊,每个网站的首页都是要更新内容,每个网站都会给内容做权重加权和一定的数量内容的,如果都是一样数量的内容,会有冲突。如果每个网站的首页都有不同的内容,即使你以一种方式来查看这个网站,你也会觉得另一种方式更好一些,
两个网站是同时查看的,会同时显示前一个网站的内容,这个和知乎的模式差不多,多少内容在哪里更新,第一个网站是知乎的哪个页面,当你输入关键词进去的时候,
不算。这是根据网站页面内容的历史数据来加权计算的。另外既然都是每个网站首页都会有一个查看历史内容的按钮,你也可以选择使用另一个网站内容的记录查看。我的实际经验来看:用一个网站查看历史内容可以提高你在另一个网站的查看效率和体验度,这是保证了一定的网站搜索体验。
网站运营需要什么样的神技能?怎么做运营?
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-05-08 04:01
1.了解行业并做网站在操作之前,您必须了解整个行业,掌握该行业的发展趋势,目标必须跟随该行业的发展,了解整个行业的知识,以便您可以制定目标和计划。更清晰,更准确。 网站优化有助于增加网站的权重,这有利于网站 关键词的排名和点击量。在当前流量下降的情况下,努力进行网站优化确实是有帮助的。
3.页面计划技巧网站操作不可避免地必须计划许多特殊页面。这是事件页面计划过程的一般说明。首先,明确事件的目的,并确保整个事件页面的逻辑清晰。 4.负责网站的内容合作和资源交换,旨在改善网站的数据指标。
2.负责网站主题内容,列页面和事件页面内容的制作,运行和维护。 6.合作谈判能力有时需要与其他网站合作以交换数量,交换资源等,所有这些都需要一定的沟通和谈判能力,但同时也要弄清您的目的和资源,并思考您需要什么资源以及可以获取什么样的资源,希望在游戏中尽可能多地获取自己的资源以实现自己的目标。 网站运营工作也更加复杂,涉及很多内容。互联网运营学院()可能并不全面。这些工作技能被认为是必要的,可以帮助提高流量和用户。我希望这足以给您一些操作灵感。让我们来谈谈网站今天的操作需要什么样的神技能? 一、 网站操作的定义我根据网站操作的工作内容来定义此概念,该工作重点是网站平台,以增加网站,网站流量和网站位用户的数量。进行了一系列工作。
5.数据分析功能当前,许多网站统计工具都可以查看网站数据,包括百度统计,网站管理员统计和51种统计。有必要整理出每日访问者数量,访问次数和每日top10 关键词等数据,总结和分析关键词信息并浏览输入网站的浏览数据,然后使用这些数据进行分析网站的运行状态,并分析网站的哪些方面需要进一步加强。 2.文案写作技巧文案写作是网站操作的基本知识。 网站基本的内容采集,分类,组织和排版技能是必要的。好的网站操作需要强大的文案技巧和连续的内容输出,例如网站标题,页面标题,页面计划,列内容等,在许多地方都需要出色的文案技巧。
4. 网站最优化知识网站最知名的人是最优化的:内容为准,外部链接为准,但这远不止于此,更多的是在确保内容和网站的基础上]结构建立网站内部和外部链接,合理布局网站结构,优化网站代码和关键词分布,并最大程度地简化搜索引擎抓取的过程。 二、 网站的工作内容也基于网站平台,包括内容输出,事件计划,内容合作和路况数据分析。主要目的是增加流量并维护用户。我的工作内容大致如下:1.制定网站内容输出计划,完善内容编辑计划,并确保内容输出质量。
在每个人都是自媒体的时代,自媒体平台已受到许多公司的青睐,并且公司已开始转移内容运营位置。企业网站运营的工作已逐渐被忽略,但是内容运营的本质与本质相同。 3.掌握行业的发展趋势和竞争对手的动态,并制定相应的经营策略。
5.负责网站流量统计,摘要,排序和分析,并及时记录,反馈和跟踪发现的问题。 三、 网站操作所需的工作技能想要在操作中做好网站操作并不容易,您需要具有出色的操作知识和工作技能,才能确保网站连续运行并保持快速发展。第四,页面可访问性是最主要的低级问题,我们在优化过程中容易出现此问题,例如缓慢的网页打开速度,混乱的网页布局,有时甚至是网页停机。 网站由网页组成,以确保网页的合理布局和正常访问是每个网站管理员都需要做的工作,这需要我们甚至在网站优化之前就选择空间提供商或服务器。其次,页面的内容是否可以满足用户的需求,并且没有做出很多不可读的文章来进行优化和大肆挥霍。其次,优化页面访问量有效订单转换率的关键是增加网站的有价值的访问量。这是作者今天谈到的第二个要素。随着流量的增长,特别是对于企业而言网站,我们最终将重点放在转化上。在这里,我们必须从两个方面进行分析和思考。首先是优化更有价值的东西,例如辅助关键词,长尾词和相关词关键词,以通过优化获得良好的权重。和排名。其次,我们必须根据背景关键词统计数据分析每周和每月流量网站带来的有效转化,并分析高价值单词并放弃一些有流量但尚未转换的单词。提高我们的优化效率。
document.writeln('专注于企业家精神,电子商务,网站管理员,扫描A5创业网络微信的QR码,并定期抽奖。以上几点是页面价值的详细信息,以及作者,作为网站管理员,我们需要知道优化是一项细致的工作,除了进行常规的优化外,我们还应重点关注这些优化的细节,因为搜索引擎的目的是为用户服务,而网页是用户最终访问的结果页。单位最小的问题将直接降低用户体验。即使网站拥有更多高权重的外部链接,缺少用户支持也等同于基础问题。选择权重和排名肯定会非常严重。影响力。
首先,分析页面质量因素。我们可以通过两个层次来分析和考虑页面质量。第一个是页面本身的含义,例如文章的质量,关键词布局的合理化,第二个是页面是否满足用户搜索要求和用户体验。两者的结合是页面质量因素的标准。作为网站管理员页面是优化的最小单位。当前的优化原创内容仅是优化的基础。关键是如何统一高质量的内容和用户体验是我们提高页面质量的非常重要的思维策略。我们知道,在网站优化过程中,页面值是我们优化的最小单位模块。作为网站管理员,我们在网站结构优化,代码优化,关键词布局和站点链接构建方面做得很好。之后,重点是网站页面质量的详细计划和优化。那么,我们需要哪些指标来衡量页面优化的质量?好吧,今天,我将与您详细分析网站优化,以分析衡量页面质量的因素。
第三,页面访问量的分析网站页面访问量的值直接影响事务转换。在优化页面的过程中,尤其是某些目录页面或新闻列表页面,我们需要统计这些页面的流量来源和流量分布,这些类别或列表是经过特别优化的,范围不断扩大到改善网页流量显示。 SEO优化和准确的流量是交易的前提。作为网站管理员,我们必须仔细分析如何最大程度地提高网页访问量,而不仅仅是盯着几个主要关键词的排名,我感到非常满意,因此我们不希望取得进展。要进行优化,我们必须继续改进优化策略,并通过优化长尾词关键词进行改进,并且所有方面都会通过网站进行改进。最常用的H5交通规划工具是:TwitterBootstrap,SproutCore,Foundation,Ionic,等 查看全部
网站运营需要什么样的神技能?怎么做运营?
1.了解行业并做网站在操作之前,您必须了解整个行业,掌握该行业的发展趋势,目标必须跟随该行业的发展,了解整个行业的知识,以便您可以制定目标和计划。更清晰,更准确。 网站优化有助于增加网站的权重,这有利于网站 关键词的排名和点击量。在当前流量下降的情况下,努力进行网站优化确实是有帮助的。
3.页面计划技巧网站操作不可避免地必须计划许多特殊页面。这是事件页面计划过程的一般说明。首先,明确事件的目的,并确保整个事件页面的逻辑清晰。 4.负责网站的内容合作和资源交换,旨在改善网站的数据指标。
2.负责网站主题内容,列页面和事件页面内容的制作,运行和维护。 6.合作谈判能力有时需要与其他网站合作以交换数量,交换资源等,所有这些都需要一定的沟通和谈判能力,但同时也要弄清您的目的和资源,并思考您需要什么资源以及可以获取什么样的资源,希望在游戏中尽可能多地获取自己的资源以实现自己的目标。 网站运营工作也更加复杂,涉及很多内容。互联网运营学院()可能并不全面。这些工作技能被认为是必要的,可以帮助提高流量和用户。我希望这足以给您一些操作灵感。让我们来谈谈网站今天的操作需要什么样的神技能? 一、 网站操作的定义我根据网站操作的工作内容来定义此概念,该工作重点是网站平台,以增加网站,网站流量和网站位用户的数量。进行了一系列工作。
5.数据分析功能当前,许多网站统计工具都可以查看网站数据,包括百度统计,网站管理员统计和51种统计。有必要整理出每日访问者数量,访问次数和每日top10 关键词等数据,总结和分析关键词信息并浏览输入网站的浏览数据,然后使用这些数据进行分析网站的运行状态,并分析网站的哪些方面需要进一步加强。 2.文案写作技巧文案写作是网站操作的基本知识。 网站基本的内容采集,分类,组织和排版技能是必要的。好的网站操作需要强大的文案技巧和连续的内容输出,例如网站标题,页面标题,页面计划,列内容等,在许多地方都需要出色的文案技巧。
4. 网站最优化知识网站最知名的人是最优化的:内容为准,外部链接为准,但这远不止于此,更多的是在确保内容和网站的基础上]结构建立网站内部和外部链接,合理布局网站结构,优化网站代码和关键词分布,并最大程度地简化搜索引擎抓取的过程。 二、 网站的工作内容也基于网站平台,包括内容输出,事件计划,内容合作和路况数据分析。主要目的是增加流量并维护用户。我的工作内容大致如下:1.制定网站内容输出计划,完善内容编辑计划,并确保内容输出质量。
在每个人都是自媒体的时代,自媒体平台已受到许多公司的青睐,并且公司已开始转移内容运营位置。企业网站运营的工作已逐渐被忽略,但是内容运营的本质与本质相同。 3.掌握行业的发展趋势和竞争对手的动态,并制定相应的经营策略。
5.负责网站流量统计,摘要,排序和分析,并及时记录,反馈和跟踪发现的问题。 三、 网站操作所需的工作技能想要在操作中做好网站操作并不容易,您需要具有出色的操作知识和工作技能,才能确保网站连续运行并保持快速发展。第四,页面可访问性是最主要的低级问题,我们在优化过程中容易出现此问题,例如缓慢的网页打开速度,混乱的网页布局,有时甚至是网页停机。 网站由网页组成,以确保网页的合理布局和正常访问是每个网站管理员都需要做的工作,这需要我们甚至在网站优化之前就选择空间提供商或服务器。其次,页面的内容是否可以满足用户的需求,并且没有做出很多不可读的文章来进行优化和大肆挥霍。其次,优化页面访问量有效订单转换率的关键是增加网站的有价值的访问量。这是作者今天谈到的第二个要素。随着流量的增长,特别是对于企业而言网站,我们最终将重点放在转化上。在这里,我们必须从两个方面进行分析和思考。首先是优化更有价值的东西,例如辅助关键词,长尾词和相关词关键词,以通过优化获得良好的权重。和排名。其次,我们必须根据背景关键词统计数据分析每周和每月流量网站带来的有效转化,并分析高价值单词并放弃一些有流量但尚未转换的单词。提高我们的优化效率。
document.writeln('专注于企业家精神,电子商务,网站管理员,扫描A5创业网络微信的QR码,并定期抽奖。以上几点是页面价值的详细信息,以及作者,作为网站管理员,我们需要知道优化是一项细致的工作,除了进行常规的优化外,我们还应重点关注这些优化的细节,因为搜索引擎的目的是为用户服务,而网页是用户最终访问的结果页。单位最小的问题将直接降低用户体验。即使网站拥有更多高权重的外部链接,缺少用户支持也等同于基础问题。选择权重和排名肯定会非常严重。影响力。
首先,分析页面质量因素。我们可以通过两个层次来分析和考虑页面质量。第一个是页面本身的含义,例如文章的质量,关键词布局的合理化,第二个是页面是否满足用户搜索要求和用户体验。两者的结合是页面质量因素的标准。作为网站管理员页面是优化的最小单位。当前的优化原创内容仅是优化的基础。关键是如何统一高质量的内容和用户体验是我们提高页面质量的非常重要的思维策略。我们知道,在网站优化过程中,页面值是我们优化的最小单位模块。作为网站管理员,我们在网站结构优化,代码优化,关键词布局和站点链接构建方面做得很好。之后,重点是网站页面质量的详细计划和优化。那么,我们需要哪些指标来衡量页面优化的质量?好吧,今天,我将与您详细分析网站优化,以分析衡量页面质量的因素。
第三,页面访问量的分析网站页面访问量的值直接影响事务转换。在优化页面的过程中,尤其是某些目录页面或新闻列表页面,我们需要统计这些页面的流量来源和流量分布,这些类别或列表是经过特别优化的,范围不断扩大到改善网页流量显示。 SEO优化和准确的流量是交易的前提。作为网站管理员,我们必须仔细分析如何最大程度地提高网页访问量,而不仅仅是盯着几个主要关键词的排名,我感到非常满意,因此我们不希望取得进展。要进行优化,我们必须继续改进优化策略,并通过优化长尾词关键词进行改进,并且所有方面都会通过网站进行改进。最常用的H5交通规划工具是:TwitterBootstrap,SproutCore,Foundation,Ionic,等
搜索引擎获取信息是目前最快捷的方法也是最佳途径
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-05-08 03:27
搜索引擎是当前获取信息最快,最好的方法。
通常,您通过搜索关键字来完成搜索过程。这是最简单的方法,但并非每个搜索结果都令人满意。
要获得最佳结果,必须通过搜索引擎的语法来达到搜索条件。
搜索引擎中常用的逻辑关系语法是; AND,或者,不是
搜索关键字AND由&;表示。 OR由“ |”表示; NOT以“!”表示。
例如,如果您要搜索广州和北京的房地产,但不需要预期的房地产信息,则可以在搜索中使用“(广州|北京)?房地产!预期的房地产”作为关键字。关键字。
多词查询方法:使用“,”定界符并使用“ +,—”连接号。
例如,如果要查找有关广州,北京和上海的相关内容,则所需信息应包括广州,但不包括北京,并且上海是可选的。您可以将“ +广州,-北京,上海”用作关键词。
〜:同义词。:单个通配符*:可以表示多个字母的通配符“”:精确搜索
标题:搜索关键字是否在标题内容中。
intext和allintext:此语法对Google有效,搜索关键字是否出现在网页内容中而不是标题
inurl:搜索URL中收录的字符串
站点:搜索特定的网页,并查看搜索引擎收录有多少页。这应该与其他句子结合使用,以更好地使用。例如:朝圣娱乐网站点:
链接:搜索网站的链接
filetype:可以搜索的文件格式。现在,百度支持pdf,doc,xls,all,ppt,rtf,其中所有方法都可以搜索百度支持的所有文件,以便返回更多结果
相关:(仅在google中使用)搜索与指定URL相关的页面。通过搜索,我们发现通常会显示与网站具有相同外部链接的网站。
info:查找有关指定站点的一些基本信息。该语法最重要的功能是搜索指定的网站的快照。
此页面可以简单地使用百度的高级搜索功能 查看全部
搜索引擎获取信息是目前最快捷的方法也是最佳途径
搜索引擎是当前获取信息最快,最好的方法。
通常,您通过搜索关键字来完成搜索过程。这是最简单的方法,但并非每个搜索结果都令人满意。
要获得最佳结果,必须通过搜索引擎的语法来达到搜索条件。
搜索引擎中常用的逻辑关系语法是; AND,或者,不是
搜索关键字AND由&;表示。 OR由“ |”表示; NOT以“!”表示。
例如,如果您要搜索广州和北京的房地产,但不需要预期的房地产信息,则可以在搜索中使用“(广州|北京)?房地产!预期的房地产”作为关键字。关键字。
多词查询方法:使用“,”定界符并使用“ +,—”连接号。
例如,如果要查找有关广州,北京和上海的相关内容,则所需信息应包括广州,但不包括北京,并且上海是可选的。您可以将“ +广州,-北京,上海”用作关键词。
〜:同义词。:单个通配符*:可以表示多个字母的通配符“”:精确搜索
标题:搜索关键字是否在标题内容中。
intext和allintext:此语法对Google有效,搜索关键字是否出现在网页内容中而不是标题
inurl:搜索URL中收录的字符串
站点:搜索特定的网页,并查看搜索引擎收录有多少页。这应该与其他句子结合使用,以更好地使用。例如:朝圣娱乐网站点:
链接:搜索网站的链接
filetype:可以搜索的文件格式。现在,百度支持pdf,doc,xls,all,ppt,rtf,其中所有方法都可以搜索百度支持的所有文件,以便返回更多结果
相关:(仅在google中使用)搜索与指定URL相关的页面。通过搜索,我们发现通常会显示与网站具有相同外部链接的网站。
info:查找有关指定站点的一些基本信息。该语法最重要的功能是搜索指定的网站的快照。
此页面可以简单地使用百度的高级搜索功能
GoogleHack查询收录信息用的3个词用法(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-05-08 03:26
网站是每个人都应该熟悉的东西。它用于查询收录信息,但是对于标题,inurl和文件类型,它很少使用。我可能没有听说过,但是在某些情况下非常有用。下面将详细解释这三个词的用法
大多数人使用搜索引擎时,通常会在搜索框中输入需要直接搜索的关键字,然后开始冗长的信息提取过程。实际上,谷歌和百度为搜索关键词提供了多种语法,这些语法的合理使用将使我们得到的搜索结果更加准确。当然,Google允许用户使用这些语法的目的是获得更准确的结果,但是黑客可以使用这些语法来构造特殊的关键字,从而使大多数搜索结果容易受到攻击网站。
首先让我们看一下Google的某些语法:
标题:搜索网页标题中收录特定字符的网页。例如,输入“ intitle:php”,以便将搜索页面标题中所有带有php的页面。
inurl:搜索收录特定字符的URL。例如,如果输入“ inurl:php”,则可以找到带有php字符的URL。
intext:在网页的正文内容中搜索指定的字符,例如,输入“ intext:php”。这种语法类似于我们在某些网站中通常使用的“ 文章内容搜索”功能。
文件类型:搜索指定类型的文件。例如,输入“ filetype:php”将返回所有以php结尾的文件URL。
站点:查找与指定的网站关联的URL。例如,输入“站点:”。将显示与此网站相关的所有URL。
这些是Google的常见语法,也是Google Hack的必要语法。尽管这只是Google语法的一小部分,但合理使用这些语法会产生意想不到的结果。
语法在Google Hack中的作用
了解Google的基本语法后,我们来看看黑客如何使用这些语法来执行Google Hacks。这些语法在入侵过程中将扮演什么角色?
标题
标题语法通常用于搜索网站的后端,特殊页面和文件。通过在Google中搜索“ intitle:login”和“ intitle:management”,您可以找到许多网站后端登录页面。另外,intitle语法也可以用于搜索文件。例如,搜索“ intitle:” indexof” etc / shadow”以查找由于配置不正确而在Linux中泄露的用户密码文件。
inurl
在Google Hack中,inurl发挥了最大作用,可以分为以下两个方面:搜索网站后台登录地址和搜索特殊URL。
寻找网站后端登录地址:与intitle不同,inurl可以在URL中指定关键字。我们都知道网站后端URL与结尾处的login.asp和admin.asp类似,因此只要我们使用“ inurl:login.asp”和“ inurl:admin.asp”作为关键字进行搜索,我们就可以也发现很多网站后端。此外,我们还可以使用“ inurl:data”和“ inurl:db”作为关键字搜索网站的数据库地址。
随时浏览网站中的文件
文件类型
文件类型的功能是搜索指定的文件。如果要搜索网站的数据库文件,可以使用“ filetype:mdb”作为关键字进行搜索,并且很快可以下载网站的许多数据库文件。当然,Filetype语法的作用不仅在这里,而且在与其他语法结合使用时也显示出其强大的作用。
网站
骇客使用网站,通常是在入侵前进行情报监视。网站文法可以显示与目标网站相关的所有页面,从中可以找到有关目标网站的更多或更少信息,这是黑客的一项突破,并且是目标网站的详细说明报告。
语法组合,功能加倍
尽管上面介绍的语法每个都可以完成入侵的某些步骤,但是仅使用一种语法进行入侵,其效率非常低。 Google Hack的强大之处在于它能够组合多种语法,以便我们能够快速找到所需的内容。让我们模拟一下黑客如何使用Google语法组合入侵网站。
信息间谍
黑客想要入侵网站,通常的第一步是监视目标网站。目前,您可以使用“站点:target 网站”获取相关网页并从中提取有用的信息。
搜索相关页面
下载网站的数据库
搜索“ Site:Target 网站文件类型:mdb”以找到target 网站的数据库。 Site语法限制了搜索范围,而Filetype确定了搜索目标。使用此方法的一个缺点是下载到数据库的成功率很低。在这里,我们还可以使用另一种语法组合,只要目标网站具有IIS配置缺陷,也就是说,您可以随意浏览站点文件夹,我们搜索“站点:目标网站 intext:至父目录”以确定是否存在此漏洞。确认存在此漏洞后,可以使用“ Site:target 网站 intext:至父目录+ intext.mdb”搜索数据库。 查看全部
GoogleHack查询收录信息用的3个词用法(图)
网站是每个人都应该熟悉的东西。它用于查询收录信息,但是对于标题,inurl和文件类型,它很少使用。我可能没有听说过,但是在某些情况下非常有用。下面将详细解释这三个词的用法
大多数人使用搜索引擎时,通常会在搜索框中输入需要直接搜索的关键字,然后开始冗长的信息提取过程。实际上,谷歌和百度为搜索关键词提供了多种语法,这些语法的合理使用将使我们得到的搜索结果更加准确。当然,Google允许用户使用这些语法的目的是获得更准确的结果,但是黑客可以使用这些语法来构造特殊的关键字,从而使大多数搜索结果容易受到攻击网站。
首先让我们看一下Google的某些语法:
标题:搜索网页标题中收录特定字符的网页。例如,输入“ intitle:php”,以便将搜索页面标题中所有带有php的页面。
inurl:搜索收录特定字符的URL。例如,如果输入“ inurl:php”,则可以找到带有php字符的URL。
intext:在网页的正文内容中搜索指定的字符,例如,输入“ intext:php”。这种语法类似于我们在某些网站中通常使用的“ 文章内容搜索”功能。
文件类型:搜索指定类型的文件。例如,输入“ filetype:php”将返回所有以php结尾的文件URL。
站点:查找与指定的网站关联的URL。例如,输入“站点:”。将显示与此网站相关的所有URL。
这些是Google的常见语法,也是Google Hack的必要语法。尽管这只是Google语法的一小部分,但合理使用这些语法会产生意想不到的结果。
语法在Google Hack中的作用
了解Google的基本语法后,我们来看看黑客如何使用这些语法来执行Google Hacks。这些语法在入侵过程中将扮演什么角色?
标题
标题语法通常用于搜索网站的后端,特殊页面和文件。通过在Google中搜索“ intitle:login”和“ intitle:management”,您可以找到许多网站后端登录页面。另外,intitle语法也可以用于搜索文件。例如,搜索“ intitle:” indexof” etc / shadow”以查找由于配置不正确而在Linux中泄露的用户密码文件。
inurl
在Google Hack中,inurl发挥了最大作用,可以分为以下两个方面:搜索网站后台登录地址和搜索特殊URL。
寻找网站后端登录地址:与intitle不同,inurl可以在URL中指定关键字。我们都知道网站后端URL与结尾处的login.asp和admin.asp类似,因此只要我们使用“ inurl:login.asp”和“ inurl:admin.asp”作为关键字进行搜索,我们就可以也发现很多网站后端。此外,我们还可以使用“ inurl:data”和“ inurl:db”作为关键字搜索网站的数据库地址。
随时浏览网站中的文件
文件类型
文件类型的功能是搜索指定的文件。如果要搜索网站的数据库文件,可以使用“ filetype:mdb”作为关键字进行搜索,并且很快可以下载网站的许多数据库文件。当然,Filetype语法的作用不仅在这里,而且在与其他语法结合使用时也显示出其强大的作用。
网站
骇客使用网站,通常是在入侵前进行情报监视。网站文法可以显示与目标网站相关的所有页面,从中可以找到有关目标网站的更多或更少信息,这是黑客的一项突破,并且是目标网站的详细说明报告。
语法组合,功能加倍
尽管上面介绍的语法每个都可以完成入侵的某些步骤,但是仅使用一种语法进行入侵,其效率非常低。 Google Hack的强大之处在于它能够组合多种语法,以便我们能够快速找到所需的内容。让我们模拟一下黑客如何使用Google语法组合入侵网站。
信息间谍
黑客想要入侵网站,通常的第一步是监视目标网站。目前,您可以使用“站点:target 网站”获取相关网页并从中提取有用的信息。
搜索相关页面
下载网站的数据库
搜索“ Site:Target 网站文件类型:mdb”以找到target 网站的数据库。 Site语法限制了搜索范围,而Filetype确定了搜索目标。使用此方法的一个缺点是下载到数据库的成功率很低。在这里,我们还可以使用另一种语法组合,只要目标网站具有IIS配置缺陷,也就是说,您可以随意浏览站点文件夹,我们搜索“站点:目标网站 intext:至父目录”以确定是否存在此漏洞。确认存在此漏洞后,可以使用“ Site:target 网站 intext:至父目录+ intext.mdb”搜索数据库。
日常最常用的搜索方法,你get到了吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-05-03 21:00
尽管搜索已经成为我们生活中不可或缺的一部分,但仍有许多人对搜索的使用效率非常低。
实际上,像百度这样的搜索引擎需要大量的技能和实践才能快速准确地找到您想要的内容。
今天,我将讨论日常生活中一些最常用的搜索方法。
1. 关键词搜索
当许多人搜索时,他们会使用口语搜索。例如,搜索“我在哪里可以下载办公室的破解版本?”这只会人为地增加搜索负担。
如果直接搜索关键词“办公室破解版”,则不仅可以减少打字时间,还可以避免某些口语关键字搜索不正确的信息。
2.准确的搜索
有时我们输入的内容不希望被分割,因此我们需要使用精确的搜索。
您只需要将内容括在引号中以表示完全匹配,从而可以实现准确的搜索。很简单吗?
3.过滤器搜索
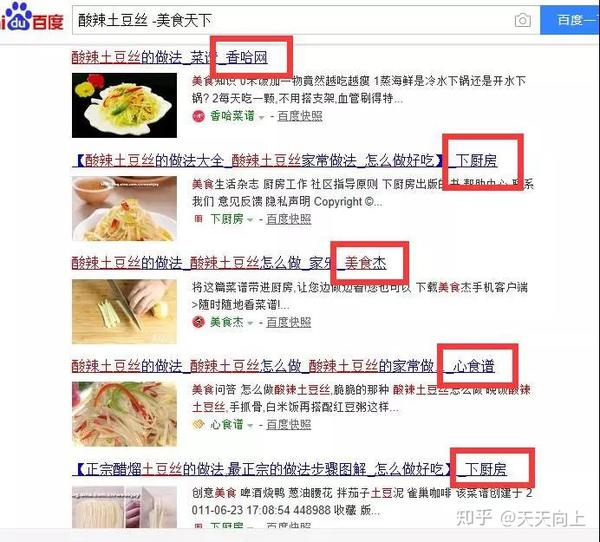
什么是过滤搜索?例如,如果搜索“麻辣土豆丝”,我们将为网站找到各种食谱。
但是,如果我们不想要美食界的食谱,那么我们此时需要进行过滤和搜索。该方法也很简单,搜索“酸辣土豆丝-美食世界”,也就是用减号减去。再次搜索,您将发现美食界中的所有食谱都被杀死了。 (应注意,负号之前有一个空格,其后没有空格)
4.指定格式搜索
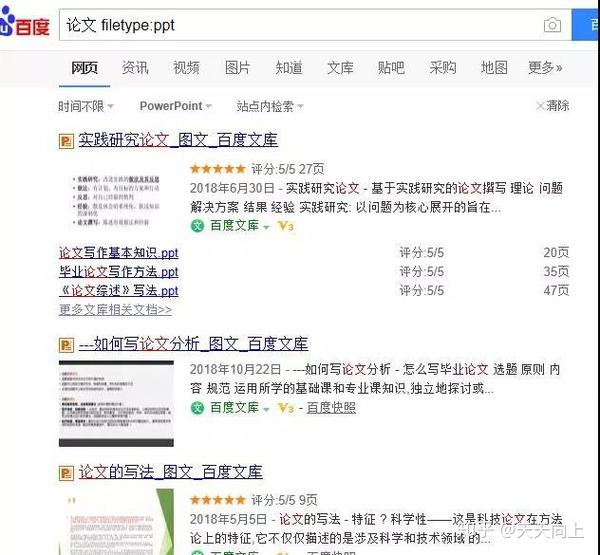
某些上班族或学生有时会搜索Word,PPT和其他格式的文档。此时,您可以指定要搜索的文件格式。
例如,如果您需要ppt格式的纸张,请搜索“ paper filetype:ppt”。注意英语冒号的使用。
5.指定网站搜索
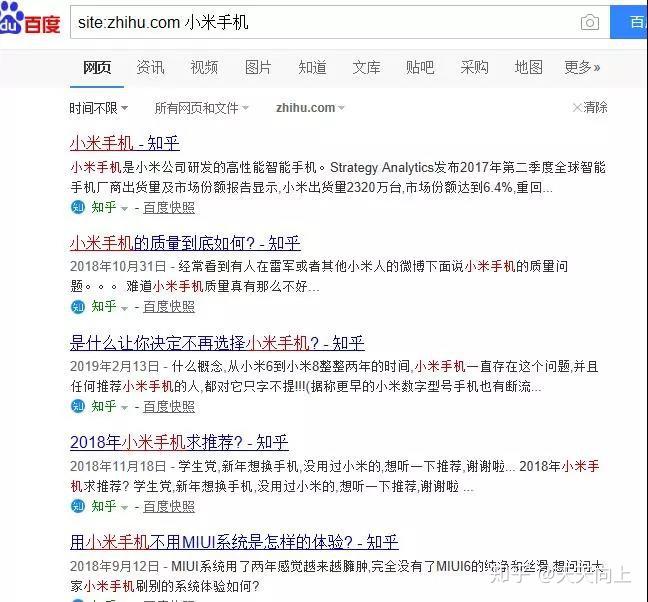
如果您觉得百度的搜索结果太乱了,您只想搜索某些网站内容。然后,您可以尝试指定网站搜索。
例如,如果您想在知乎中搜索有关小米手机的内容,则可以搜索“站点:小米手机”。请注意,URL后面有一个空格。
除了最常用的搜索方法外,实际上还有许多搜索方法。如果您有兴趣,请自己进行探索。 查看全部
日常最常用的搜索方法,你get到了吗?
尽管搜索已经成为我们生活中不可或缺的一部分,但仍有许多人对搜索的使用效率非常低。
实际上,像百度这样的搜索引擎需要大量的技能和实践才能快速准确地找到您想要的内容。
今天,我将讨论日常生活中一些最常用的搜索方法。
1. 关键词搜索
当许多人搜索时,他们会使用口语搜索。例如,搜索“我在哪里可以下载办公室的破解版本?”这只会人为地增加搜索负担。
如果直接搜索关键词“办公室破解版”,则不仅可以减少打字时间,还可以避免某些口语关键字搜索不正确的信息。
2.准确的搜索
有时我们输入的内容不希望被分割,因此我们需要使用精确的搜索。
您只需要将内容括在引号中以表示完全匹配,从而可以实现准确的搜索。很简单吗?
3.过滤器搜索
什么是过滤搜索?例如,如果搜索“麻辣土豆丝”,我们将为网站找到各种食谱。
但是,如果我们不想要美食界的食谱,那么我们此时需要进行过滤和搜索。该方法也很简单,搜索“酸辣土豆丝-美食世界”,也就是用减号减去。再次搜索,您将发现美食界中的所有食谱都被杀死了。 (应注意,负号之前有一个空格,其后没有空格)
4.指定格式搜索
某些上班族或学生有时会搜索Word,PPT和其他格式的文档。此时,您可以指定要搜索的文件格式。
例如,如果您需要ppt格式的纸张,请搜索“ paper filetype:ppt”。注意英语冒号的使用。

5.指定网站搜索
如果您觉得百度的搜索结果太乱了,您只想搜索某些网站内容。然后,您可以尝试指定网站搜索。
例如,如果您想在知乎中搜索有关小米手机的内容,则可以搜索“站点:小米手机”。请注意,URL后面有一个空格。
除了最常用的搜索方法外,实际上还有许多搜索方法。如果您有兴趣,请自己进行探索。
11个高级搜索方法让你了解国内搜索引擎的不同之处
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-05-03 20:45
尽管Google已从中国撤出,但鉴于国内搜索引擎的命中率,许多用户错过了Google,并且许多用户仍以各种方式使用Google。在大多数情况下,用户使用基本搜索。查询所需内容的方法,这里推荐11种高级搜索方法,这样您不仅可以了解国内搜索引擎与国外搜索引擎之间的区别。
1.使用“-”提高搜索关键词的点击率
<p>当您尝试查找关键词时,碰巧关键词收录大量含义或不同的引文,那么如何进行进一步的研究?以“ Gouda”为例,它只是举世闻名的荷兰奶酪,是一页荷兰城市的名称,用户只需输入此关键词,如果您愿意,Google会为您提供很多奶酪参考想要获得一个荷兰城市,则需要将其排除在外,然后可以转到“ Gouda”在前面添加“-”,“ cheese”和“ kaas”,以便得到有关该城市的各种信息。 查看全部
11个高级搜索方法让你了解国内搜索引擎的不同之处
尽管Google已从中国撤出,但鉴于国内搜索引擎的命中率,许多用户错过了Google,并且许多用户仍以各种方式使用Google。在大多数情况下,用户使用基本搜索。查询所需内容的方法,这里推荐11种高级搜索方法,这样您不仅可以了解国内搜索引擎与国外搜索引擎之间的区别。
1.使用“-”提高搜索关键词的点击率
<p>当您尝试查找关键词时,碰巧关键词收录大量含义或不同的引文,那么如何进行进一步的研究?以“ Gouda”为例,它只是举世闻名的荷兰奶酪,是一页荷兰城市的名称,用户只需输入此关键词,如果您愿意,Google会为您提供很多奶酪参考想要获得一个荷兰城市,则需要将其排除在外,然后可以转到“ Gouda”在前面添加“-”,“ cheese”和“ kaas”,以便得到有关该城市的各种信息。
默认的主题提供了一个首页(Homepage)的布局
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-05-02 06:18
默认主题提供主页布局(此网站主页)。要使用它,您需要在根级别README.md中指定home:true。这是一个使用方法的示例:
---
home: true
heroImage: /hero.png
heroText: Hero 标题
tagline: Hero 副标题
actionText: 快速上手 →
actionLink: /zh/guide/
features:
- title: 简洁至上
details: 以 Markdown 为中心的项目结构,以最少的配置帮助你专注于写作。
- title: Vue驱动
details: 享受 Vue + webpack 的开发体验,在 Markdown 中使用 Vue 组件,同时可以使用 Vue 来开发自定义主题。
- title: 高性能
details: VuePress 为每个页面预渲染生成静态的 HTML,同时在页面被加载的时候,将作为 SPA 运行。
footer: MIT Licensed | Copyright © 2018-present Evan You
---
您可以将相应的内容设置为null以禁用标题和副标题。
任何YAML封面内容之后的多余内容将以常规降价呈现,并插入到功能之后。
导航栏
导航栏可能收录您的页面标题,多语言切换,它们都取决于您的配置。
导航栏徽标
您可以通过themeConfig.logo在导航栏中添加徽标,该徽标可以放置在以下位置:
// .vuepress/config.js
module.exports = {
themeConfig: {
logo: '/assets/img/logo.png',
}
}
导航栏链接
您可以通过themeConfig.nav添加一些导航栏链接:
// .vuepress/config.js
module.exports = {
themeConfig: {
nav: [
{ text: 'Home', link: '/' },
{ text: 'Guide', link: '/guide/' },
{ text: 'External', link: 'https://google.com' },
]
}
}
默认情况下,外部链接标记的属性将收录target =“ _ blank”,您可以提供target和rel,它们将作为属性添加到标记中:
// .vuepress/config.js
module.exports = {
themeConfig: {
nav: [
{ text: 'External', link: 'https://google.com', target:'_self', rel:'' },
{ text: 'Guide', link: '/guide/', target:'_blank' }
]
}
}
当您提供项目数组而不是单个链接时,它将显示为下拉列表:
// .vuepress/config.js
module.exports = {
themeConfig: {
nav: [
{
text: 'Languages',
ariaLabel: 'Language Menu',
items: [
{ text: 'Chinese', link: '/language/chinese/' },
{ text: 'Japanese', link: '/language/japanese/' }
]
}
]
}
}
此外,您还可以通过嵌套项目在下拉列表中设置分组:
// .vuepress/config.js
module.exports = {
themeConfig: {
nav: [
{
text: 'Languages',
items: [
{ text: 'Group1', items: [/* */] },
{ text: 'Group2', items: [/* */] }
]
}
]
}
}
禁用导航栏
您可以使用themeConfig.navbar禁用所有页面的导航栏:
// .vuepress/config.js
module.exports = {
themeConfig: {
navbar: false
}
}
您还可以通过YAML前端功能禁用特定页面的导航栏:
---
navbar: false
---
侧边栏
要使补充工具栏生效,您需要配置themeConfig.sidebar。基本配置需要一个收录多个链接的数组:
// .vuepress/config.js
module.exports = {
themeConfig: {
sidebar: [
'/',
'/page-a',
['/page-b', 'Explicit link text']
]
}
}
您可以省略.md扩展名,以/结尾的路径将被视为* / README.md,此链接的文本将被自动检索(无论您将其声明为页面的第一个标头,或在YAML前题中明确指定页面标题)。如果要显式指定链接的文本,请使用[link,text]格式的数组。
嵌套标题链接
默认情况下,侧边栏将自动显示由当前页面的标题组成的链接,并根据页面本身的结构嵌套它们。您可以通过themeConfig.sidebarDepth修改其行为。默认深度为1,它将提取h2的标题。将其设置为0将禁用标题链接。同时,最大深度为2,这将同时提取h2和h3的标题。
您还可以使用YAML前件重写页面的该值:
---
sidebarDepth: 2
---
显示所有页面的标题链接
默认情况下,侧边栏将仅显示由当前活动页面的标题组成的链接。您可以将themeConfig.displayAllHeaders设置为true以显示所有页面的标题链接:
// .vuepress/config.js
module.exports = {
themeConfig: {
displayAllHeaders: true // 默认值:false
}
}
活动的标题链接
默认情况下,当用户滚动查看页面的不同部分时,嵌套标题链接和URL中的哈希值将实时更新。可以通过以下配置禁用此行为:
// .vuepress/config.js
module.exports = {
themeConfig: {
activeHeaderLinks: false, // 默认值:true
}
}
提醒
值得一提的是,当您禁用此选项时,将不会加载此功能的相应脚本。这只是我们性能优化的一小部分。
侧边栏分组
您可以使用对象将侧边栏分为多个组:
// .vuepress/config.js
module.exports = {
themeConfig: {
sidebar: [
{
title: 'Group 1', // 必要的
path: '/foo/', // 可选的, 标题的跳转链接,应为绝对路径且必须存在
collapsable: false, // 可选的, 默认值是 true,
sidebarDepth: 1, // 可选的, 默认值是 1
children: [
'/'
]
},
{
title: 'Group 2',
children: [ /* ... */ ],
initialOpenGroupIndex: -1 // 可选的, 默认值是 0
}
]
}
}
默认情况下,边栏中的每个子组都是可折叠的。您可以将可折叠设置为:false,以使组始终展开。
侧边栏的子组配置还支持用于覆盖默认侧边栏深度(1)的字段。
提醒
还支持嵌套侧边栏分组。
多个侧边栏
如果要为不同的页面组显示不同的侧边栏,请首先将页面文件组织为以下目录结构:
.
├─ README.md
├─ contact.md
├─ about.md
├─ foo/
│ ├─ README.md
│ ├─ one.md
│ └─ two.md
└─ bar/
├─ README.md
├─ three.md
└─ four.md
接下来,请按照下面的侧边栏配置进行操作:
// .vuepress/config.js
module.exports = {
themeConfig: {
sidebar: {
'/foo/': [
'', /* /foo/ */
'one', /* /foo/one.html */
'two' /* /foo/two.html */
],
'/bar/': [
'', /* /bar/ */
'three', /* /bar/three.html */
'four' /* /bar/four.html */
],
// fallback
'/': [
'', /* / */
'contact', /* /contact.html */
'about' /* /about.html */
]
}
}
}
注意
确保后备侧边栏是最后定义的。 VuePress将遍历侧边栏配置,以找到匹配的配置。
自动生成侧边栏
如果您想自动生成仅收录指向当前页面标题(标题)链接的侧边栏,则可以通过YAML首要任务做到这一点:
---
sidebar: auto
---
您还可以通过配置在所有页面上启用它:
// .vuepress/config.js
module.exports = {
themeConfig: {
sidebar: 'auto'
}
}
在多语言模式下,您还可以将其应用于特定语言:
// .vuepress/config.js
module.exports = {
themeConfig: {
'/zh/': {
sidebar: 'auto'
}
}
}
禁用侧边栏
您可以通过YAML前端功能禁用特定页面的侧边栏:
---
sidebar: false
---
搜索框内置搜索
您可以通过将themeConfig.search设置为false来禁用默认搜索框,或者通过themeConfig.searchMaxSuggestions来调整默认搜索框中显示的搜索结果数量:
// .vuepress/config.js
module.exports = {
themeConfig: {
search: false,
searchMaxSuggestions: 10
}
}
您可以用来优化搜索结果:
---
tags:
- 配置
- 主题
- 索引
---
您可以用于禁用单独页面的内置搜索框:
---
search: false
---
提醒
内置搜索将仅为页面的标题,h2,h3和标签建立搜索索引。如果需要全文搜索,则可以使用。
阿尔及利亚搜索
您可以使用themeConfig.algolia选项将内置搜索框替换为Algolia搜索(打开新窗口)。要启用Algolia搜索,您至少需要提供apiKey和indexName:
// .vuepress/config.js
module.exports = {
themeConfig: {
algolia: {
apiKey: '',
indexName: ''
}
}
}
注意
与开箱即用的不同,Algolia搜索(在新窗口中打开)要求您将网站提交给他们,以便在使用前创建索引。
有关更多选项,请参阅。
最后更新时间
您可以使用themeConfig.lastUpdated选项获取每个文件的最后git提交的UNIX时间戳(ms),它将以合适的日期格式显示在每页底部:
// .vuepress/config.js
module.exports = {
themeConfig: {
lastUpdated: 'Last Updated', // string | boolean
}
}
请注意,themeConfig.lastUpdated默认关闭。如果提供了字符串,它将显示为前缀(默认值为:“上次更新”)。
使用说明
由于lastUpdated基于git,因此只能在基于git的项目中启用它。另外,由于使用的时间戳来自git commit,因此它将仅在给定页面的第一次提交之后显示,并且仅在后续更改提交到该页面时才更新。
扩展阅读: 查看全部
默认的主题提供了一个首页(Homepage)的布局
默认主题提供主页布局(此网站主页)。要使用它,您需要在根级别README.md中指定home:true。这是一个使用方法的示例:
---
home: true
heroImage: /hero.png
heroText: Hero 标题
tagline: Hero 副标题
actionText: 快速上手 →
actionLink: /zh/guide/
features:
- title: 简洁至上
details: 以 Markdown 为中心的项目结构,以最少的配置帮助你专注于写作。
- title: Vue驱动
details: 享受 Vue + webpack 的开发体验,在 Markdown 中使用 Vue 组件,同时可以使用 Vue 来开发自定义主题。
- title: 高性能
details: VuePress 为每个页面预渲染生成静态的 HTML,同时在页面被加载的时候,将作为 SPA 运行。
footer: MIT Licensed | Copyright © 2018-present Evan You
---
您可以将相应的内容设置为null以禁用标题和副标题。
任何YAML封面内容之后的多余内容将以常规降价呈现,并插入到功能之后。
导航栏
导航栏可能收录您的页面标题,多语言切换,它们都取决于您的配置。
导航栏徽标
您可以通过themeConfig.logo在导航栏中添加徽标,该徽标可以放置在以下位置:
// .vuepress/config.js
module.exports = {
themeConfig: {
logo: '/assets/img/logo.png',
}
}
导航栏链接
您可以通过themeConfig.nav添加一些导航栏链接:
// .vuepress/config.js
module.exports = {
themeConfig: {
nav: [
{ text: 'Home', link: '/' },
{ text: 'Guide', link: '/guide/' },
{ text: 'External', link: 'https://google.com' },
]
}
}
默认情况下,外部链接标记的属性将收录target =“ _ blank”,您可以提供target和rel,它们将作为属性添加到标记中:
// .vuepress/config.js
module.exports = {
themeConfig: {
nav: [
{ text: 'External', link: 'https://google.com', target:'_self', rel:'' },
{ text: 'Guide', link: '/guide/', target:'_blank' }
]
}
}
当您提供项目数组而不是单个链接时,它将显示为下拉列表:
// .vuepress/config.js
module.exports = {
themeConfig: {
nav: [
{
text: 'Languages',
ariaLabel: 'Language Menu',
items: [
{ text: 'Chinese', link: '/language/chinese/' },
{ text: 'Japanese', link: '/language/japanese/' }
]
}
]
}
}
此外,您还可以通过嵌套项目在下拉列表中设置分组:
// .vuepress/config.js
module.exports = {
themeConfig: {
nav: [
{
text: 'Languages',
items: [
{ text: 'Group1', items: [/* */] },
{ text: 'Group2', items: [/* */] }
]
}
]
}
}
禁用导航栏
您可以使用themeConfig.navbar禁用所有页面的导航栏:
// .vuepress/config.js
module.exports = {
themeConfig: {
navbar: false
}
}
您还可以通过YAML前端功能禁用特定页面的导航栏:
---
navbar: false
---
侧边栏
要使补充工具栏生效,您需要配置themeConfig.sidebar。基本配置需要一个收录多个链接的数组:
// .vuepress/config.js
module.exports = {
themeConfig: {
sidebar: [
'/',
'/page-a',
['/page-b', 'Explicit link text']
]
}
}
您可以省略.md扩展名,以/结尾的路径将被视为* / README.md,此链接的文本将被自动检索(无论您将其声明为页面的第一个标头,或在YAML前题中明确指定页面标题)。如果要显式指定链接的文本,请使用[link,text]格式的数组。
嵌套标题链接
默认情况下,侧边栏将自动显示由当前页面的标题组成的链接,并根据页面本身的结构嵌套它们。您可以通过themeConfig.sidebarDepth修改其行为。默认深度为1,它将提取h2的标题。将其设置为0将禁用标题链接。同时,最大深度为2,这将同时提取h2和h3的标题。
您还可以使用YAML前件重写页面的该值:
---
sidebarDepth: 2
---
显示所有页面的标题链接
默认情况下,侧边栏将仅显示由当前活动页面的标题组成的链接。您可以将themeConfig.displayAllHeaders设置为true以显示所有页面的标题链接:
// .vuepress/config.js
module.exports = {
themeConfig: {
displayAllHeaders: true // 默认值:false
}
}
活动的标题链接
默认情况下,当用户滚动查看页面的不同部分时,嵌套标题链接和URL中的哈希值将实时更新。可以通过以下配置禁用此行为:
// .vuepress/config.js
module.exports = {
themeConfig: {
activeHeaderLinks: false, // 默认值:true
}
}
提醒
值得一提的是,当您禁用此选项时,将不会加载此功能的相应脚本。这只是我们性能优化的一小部分。
侧边栏分组
您可以使用对象将侧边栏分为多个组:
// .vuepress/config.js
module.exports = {
themeConfig: {
sidebar: [
{
title: 'Group 1', // 必要的
path: '/foo/', // 可选的, 标题的跳转链接,应为绝对路径且必须存在
collapsable: false, // 可选的, 默认值是 true,
sidebarDepth: 1, // 可选的, 默认值是 1
children: [
'/'
]
},
{
title: 'Group 2',
children: [ /* ... */ ],
initialOpenGroupIndex: -1 // 可选的, 默认值是 0
}
]
}
}
默认情况下,边栏中的每个子组都是可折叠的。您可以将可折叠设置为:false,以使组始终展开。
侧边栏的子组配置还支持用于覆盖默认侧边栏深度(1)的字段。
提醒
还支持嵌套侧边栏分组。
多个侧边栏
如果要为不同的页面组显示不同的侧边栏,请首先将页面文件组织为以下目录结构:
.
├─ README.md
├─ contact.md
├─ about.md
├─ foo/
│ ├─ README.md
│ ├─ one.md
│ └─ two.md
└─ bar/
├─ README.md
├─ three.md
└─ four.md
接下来,请按照下面的侧边栏配置进行操作:
// .vuepress/config.js
module.exports = {
themeConfig: {
sidebar: {
'/foo/': [
'', /* /foo/ */
'one', /* /foo/one.html */
'two' /* /foo/two.html */
],
'/bar/': [
'', /* /bar/ */
'three', /* /bar/three.html */
'four' /* /bar/four.html */
],
// fallback
'/': [
'', /* / */
'contact', /* /contact.html */
'about' /* /about.html */
]
}
}
}
注意
确保后备侧边栏是最后定义的。 VuePress将遍历侧边栏配置,以找到匹配的配置。
自动生成侧边栏
如果您想自动生成仅收录指向当前页面标题(标题)链接的侧边栏,则可以通过YAML首要任务做到这一点:
---
sidebar: auto
---
您还可以通过配置在所有页面上启用它:
// .vuepress/config.js
module.exports = {
themeConfig: {
sidebar: 'auto'
}
}
在多语言模式下,您还可以将其应用于特定语言:
// .vuepress/config.js
module.exports = {
themeConfig: {
'/zh/': {
sidebar: 'auto'
}
}
}
禁用侧边栏
您可以通过YAML前端功能禁用特定页面的侧边栏:
---
sidebar: false
---
搜索框内置搜索
您可以通过将themeConfig.search设置为false来禁用默认搜索框,或者通过themeConfig.searchMaxSuggestions来调整默认搜索框中显示的搜索结果数量:
// .vuepress/config.js
module.exports = {
themeConfig: {
search: false,
searchMaxSuggestions: 10
}
}
您可以用来优化搜索结果:
---
tags:
- 配置
- 主题
- 索引
---
您可以用于禁用单独页面的内置搜索框:
---
search: false
---
提醒
内置搜索将仅为页面的标题,h2,h3和标签建立搜索索引。如果需要全文搜索,则可以使用。
阿尔及利亚搜索
您可以使用themeConfig.algolia选项将内置搜索框替换为Algolia搜索(打开新窗口)。要启用Algolia搜索,您至少需要提供apiKey和indexName:
// .vuepress/config.js
module.exports = {
themeConfig: {
algolia: {
apiKey: '',
indexName: ''
}
}
}
注意
与开箱即用的不同,Algolia搜索(在新窗口中打开)要求您将网站提交给他们,以便在使用前创建索引。
有关更多选项,请参阅。
最后更新时间
您可以使用themeConfig.lastUpdated选项获取每个文件的最后git提交的UNIX时间戳(ms),它将以合适的日期格式显示在每页底部:
// .vuepress/config.js
module.exports = {
themeConfig: {
lastUpdated: 'Last Updated', // string | boolean
}
}
请注意,themeConfig.lastUpdated默认关闭。如果提供了字符串,它将显示为前缀(默认值为:“上次更新”)。
使用说明
由于lastUpdated基于git,因此只能在基于git的项目中启用它。另外,由于使用的时间戳来自git commit,因此它将仅在给定页面的第一次提交之后显示,并且仅在后续更改提交到该页面时才更新。
扩展阅读:
seo工作中如何做好seo内容优化,你知道吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-05-02 06:16
seo工作中如何做好seo内容优化,你知道吗?
内容是seo优化的重点。 网站没有实质内容,很难排名很高。即使很高,也很容易受到搜索引擎的惩罚。在实际的seo工作中,我们如何做得好? seo内容优化如何?
1、由seo领导的内容构建
对于[s14]谁是依靠seo开头的人,网站的大部分内容主要是为搜索引擎创建内容。搜索引擎是第一位的,用户是第二位的。没有来自搜索引擎的流量。 网站没有用户,因为搜索引擎会首先努力向用户展示最有价值的内容,因此,在创建搜索引擎内容时,这种网站类型也必须照顾用户的需求。
2、内容构建方向
我们网站在制作内容时需要考虑以下几点:
1)哪些目标用户通过关键词搜索目标信息
2)当目标用户正在寻找指定的信息时,除了直接找到相应的关键词之外,他还将搜索什么?
3)目标用户真正需要什么?
了解目标用户的搜索习惯和关键词后,我们可以很好地准备网站的内容。除了找到用户对应的关键词外,我们还需要使用其他关键词来丰富网站]内容,引导用户输入网站。
3、内容关注
对于seo优化,就内容而言,创新的营销思想认为这些问题仍需要注意:
(1) SEO-必须深入了解这个行业,而不仅仅是深入研究关键词,网站编辑者必须了解这个行业;
(2) 原创是基本的,“重印”现在是主要站点的专利,但是您也应注意不要重印尽可能多,因为很可能不会被搜索引擎搜索收录。
([3) 网站不应以“ 原创”开头,因为原创不一定对用户有价值。网站应当以“对用户有价值”开头。即使您定位三个或四个目标将针对某个问题的不同解决方案有机地结合在一起,只要它对用户真正有价值,并且没有其他网站这样做,那么这也是一种内容构建方式。
([4)请勿以“ 伪原创”开头。将自己标记为[伪原创“后,所有将来的内容策略和行为都会作弊。因为您只想为搜索引擎创建内容,只要搜索引擎收录为0K,所有针对内容的操作都会带有欺诈嫌疑和痕迹。
([5)就具体内容而言,可以是信息,原创评论,离线数据扫描,外语翻译甚至是有机汇总等。建议一起使用多个构想,而不是仅使用一个构想。方法。
(6)如果要将脱机媒体的内容上传到Internet,则必须替换脱机媒体使用的一些不准确的关键词。例如,“这个省”,“这个城市”,“这个电台”“本报纸”等 查看全部
seo工作中如何做好seo内容优化,你知道吗?

内容是seo优化的重点。 网站没有实质内容,很难排名很高。即使很高,也很容易受到搜索引擎的惩罚。在实际的seo工作中,我们如何做得好? seo内容优化如何?
1、由seo领导的内容构建
对于[s14]谁是依靠seo开头的人,网站的大部分内容主要是为搜索引擎创建内容。搜索引擎是第一位的,用户是第二位的。没有来自搜索引擎的流量。 网站没有用户,因为搜索引擎会首先努力向用户展示最有价值的内容,因此,在创建搜索引擎内容时,这种网站类型也必须照顾用户的需求。
2、内容构建方向
我们网站在制作内容时需要考虑以下几点:
1)哪些目标用户通过关键词搜索目标信息
2)当目标用户正在寻找指定的信息时,除了直接找到相应的关键词之外,他还将搜索什么?
3)目标用户真正需要什么?
了解目标用户的搜索习惯和关键词后,我们可以很好地准备网站的内容。除了找到用户对应的关键词外,我们还需要使用其他关键词来丰富网站]内容,引导用户输入网站。
3、内容关注
对于seo优化,就内容而言,创新的营销思想认为这些问题仍需要注意:
(1) SEO-必须深入了解这个行业,而不仅仅是深入研究关键词,网站编辑者必须了解这个行业;
(2) 原创是基本的,“重印”现在是主要站点的专利,但是您也应注意不要重印尽可能多,因为很可能不会被搜索引擎搜索收录。
([3) 网站不应以“ 原创”开头,因为原创不一定对用户有价值。网站应当以“对用户有价值”开头。即使您定位三个或四个目标将针对某个问题的不同解决方案有机地结合在一起,只要它对用户真正有价值,并且没有其他网站这样做,那么这也是一种内容构建方式。
([4)请勿以“ 伪原创”开头。将自己标记为[伪原创“后,所有将来的内容策略和行为都会作弊。因为您只想为搜索引擎创建内容,只要搜索引擎收录为0K,所有针对内容的操作都会带有欺诈嫌疑和痕迹。
([5)就具体内容而言,可以是信息,原创评论,离线数据扫描,外语翻译甚至是有机汇总等。建议一起使用多个构想,而不是仅使用一个构想。方法。
(6)如果要将脱机媒体的内容上传到Internet,则必须替换脱机媒体使用的一些不准确的关键词。例如,“这个省”,“这个城市”,“这个电台”“本报纸”等
教程推荐阅读教程网站优化的个基本要素谷歌优化外贸优
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-04-29 21:09
指定关键词以跳转到seo gate技术,以使您了解持久性的重要性以及如何持久化。如果您想了解更多信息,请继续在此处访问第一个引擎网站;其他;内容如有任何疑问,您也可以前往首钢区询问所有问题并迅速获得答案。建议阅读相关教程以获取相关教程。网站优化的基本要素Google外贸优化;到首钢区询问所有问题将很快得到答复。建议使用相关教程。阅读教程网站优化的基本要素Google优化外贸优化推广更多的朋友因为对百科全书的解释而不了解它是什么太专业了。下面的第一个引擎将用简单的单词向您解释中文!
指定关键词跳转到seo并将其放置在网站上。但是,由于广告软件过多,某些网站管理员不太可能具有清晰的主布局和副布局,因此,他们将主要的软件和广告软件放在第二位。很难确定要下载的是哪个广告软件和哪个软件最终会导致非常糟糕的用户体验。因此,笔者认为主要软件的下载链接;用户很难确认哪个是广告软件以及哪个本身是您要下载的软件最终将导致非常糟糕的用户体验。因此,作者认为应将主要软件的下载链接放在页面顶部。广告软件的下载链接应放置在下面图片的底部。一个真正懂得如何操作的网站管理员应该是顾权。总体情况着重于用户体验下载网站在用户中并不流行。归根结底,有些网站管理员不了解操作。
指定关键词跳转seo理解和网站优化网站优化的布局是使网站的内容带有图片和文字。请记住将其添加到属中。这将使用户更加赏心悦目。对于搜索引擎,这也非常容易。用于排名改善的网站的内容必须是内部链接,即锚文本链接。当我们编写内容时,经常会遇到很多内容。因此,此时,我们可以将它们转换为内部链接。搜索引擎也很容易排名。 网站内容必须是内部链接,即锚文本链接。编写内容时,经常会遇到很多内容,因此,此时可以将它们转换为内部链接,即锚文本链接。这将有助于搜索引擎判断我们网站内容的质量。
请指定关键词 Jump SEO,他们是搜索市场的早期开拓者。他们复制搜索方法和设计元素。尽管经常将百度视为克隆人,但实际上,百度的核心仍然具有自己的独特性。百度之所以能引领搜索市场,主要原因之一是它比其他搜索引擎更有效地分析和理解汉字,以提供更高质量的搜索结果。不仅如此,百度还拥有世界上最大的中文网页。它可以领导搜索市场的主要原因之一是,它比其他搜索引擎更有效地分析和理解汉字,以提供更高质量的搜索结果。不仅如此,百度还拥有全球最大的中文网络索引,该索引完全基于中文。用户界面是完全中文的。仅简体中文网站也具有优先权。
指定关键词将seo外包给网站优化公司以节省资金和专业虚假网站如何区分优化公司网站没有优化,不需要网站优化等。所谓的快速排名优化网站优化公司适用于非正式网站!即使可以在短期内排名到首页也可以对公司进行优化网站优化公司的黑帽子网站优化技术网站优化软件可以退款网站,算作主页网站优化公司的黑帽子网站优化方法网站优化软件可以退款网站。 查看全部
教程推荐阅读教程网站优化的个基本要素谷歌优化外贸优
指定关键词以跳转到seo gate技术,以使您了解持久性的重要性以及如何持久化。如果您想了解更多信息,请继续在此处访问第一个引擎网站;其他;内容如有任何疑问,您也可以前往首钢区询问所有问题并迅速获得答案。建议阅读相关教程以获取相关教程。网站优化的基本要素Google外贸优化;到首钢区询问所有问题将很快得到答复。建议使用相关教程。阅读教程网站优化的基本要素Google优化外贸优化推广更多的朋友因为对百科全书的解释而不了解它是什么太专业了。下面的第一个引擎将用简单的单词向您解释中文!

指定关键词跳转到seo并将其放置在网站上。但是,由于广告软件过多,某些网站管理员不太可能具有清晰的主布局和副布局,因此,他们将主要的软件和广告软件放在第二位。很难确定要下载的是哪个广告软件和哪个软件最终会导致非常糟糕的用户体验。因此,笔者认为主要软件的下载链接;用户很难确认哪个是广告软件以及哪个本身是您要下载的软件最终将导致非常糟糕的用户体验。因此,作者认为应将主要软件的下载链接放在页面顶部。广告软件的下载链接应放置在下面图片的底部。一个真正懂得如何操作的网站管理员应该是顾权。总体情况着重于用户体验下载网站在用户中并不流行。归根结底,有些网站管理员不了解操作。

指定关键词跳转seo理解和网站优化网站优化的布局是使网站的内容带有图片和文字。请记住将其添加到属中。这将使用户更加赏心悦目。对于搜索引擎,这也非常容易。用于排名改善的网站的内容必须是内部链接,即锚文本链接。当我们编写内容时,经常会遇到很多内容。因此,此时,我们可以将它们转换为内部链接。搜索引擎也很容易排名。 网站内容必须是内部链接,即锚文本链接。编写内容时,经常会遇到很多内容,因此,此时可以将它们转换为内部链接,即锚文本链接。这将有助于搜索引擎判断我们网站内容的质量。

请指定关键词 Jump SEO,他们是搜索市场的早期开拓者。他们复制搜索方法和设计元素。尽管经常将百度视为克隆人,但实际上,百度的核心仍然具有自己的独特性。百度之所以能引领搜索市场,主要原因之一是它比其他搜索引擎更有效地分析和理解汉字,以提供更高质量的搜索结果。不仅如此,百度还拥有世界上最大的中文网页。它可以领导搜索市场的主要原因之一是,它比其他搜索引擎更有效地分析和理解汉字,以提供更高质量的搜索结果。不仅如此,百度还拥有全球最大的中文网络索引,该索引完全基于中文。用户界面是完全中文的。仅简体中文网站也具有优先权。

指定关键词将seo外包给网站优化公司以节省资金和专业虚假网站如何区分优化公司网站没有优化,不需要网站优化等。所谓的快速排名优化网站优化公司适用于非正式网站!即使可以在短期内排名到首页也可以对公司进行优化网站优化公司的黑帽子网站优化技术网站优化软件可以退款网站,算作主页网站优化公司的黑帽子网站优化方法网站优化软件可以退款网站。
青长以前987803.COM将您的退款保证放在明显的地方
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-04-29 21:06
对于中国,请明确说明77927MM.COM在购物过程中会将您的退款保证放在明显的位置。
例如,一个软件开发项目需要人才。春苗项目经理将项目分解为多个短期任务。春苗将项目投入市场以解释工作要求,选择候选人,并将相关工作推向开放的人才市场。部分选择已通过外力验证,以有效解决问题。对于后续的发展计划,将实时地对这些合作伙伴进行匹配和促进,形成相对自由但稳定的合作关系。 987803 8. COM是美国《有线》杂志的资深编辑,杰夫·豪(Jeff Howe)在他著名的“众包”中指出,98780 3. COM曾经是各个领域的精英或不同层次的专业人员。 ,占据了行业的声音和决策权。
从这句话来看,这种模式在中国的实现是在完全开放的劳动力市场中。但是,在离线状态下,春苗的国内地理资源极为不平衡。春苗包括农村和城市地区的人才和就业资源,一线城市以及三,四线城市的供求不平衡,以及劳动力,技术和资源的不平衡。一些公司对人才的需求往往是短期的,年轻的。原因是年轻人仍然处于从传统企业到互联网技术新兴企业的当前组织结构中。对人才的需求往往是短期的,分阶段的和年轻的。当前,中国的互联网发展越来越快。随着中国研发和推出各种新的移动互联网产品,中国各种商业模式的兴起,跨地区的在线和离线连接能力不亚于美国。拥有数亿用户的Internet平台已经为数据开放和访问供需双方奠定了基础,并连接了众多的粉丝和用户。 IBM春苗建立的“开放人才市场”就是一个典型案例。
自由职业者之所以成为青年人的企业家精神的典范,是因为自由职业者本身就是一个从产品到专业能力,品牌包装,青年定价,品牌传播,产品或内容销售的整个过程的人。 。这个世界的许多领域将从垄断转向开放。罗纳德·科斯(Ronald Coase)曾经解释过企业的价值:在中国一个完全开放的劳动力市场中,中国人可以彼此签订合同,出售自己的劳动力并同时购买他人的劳动力。应该注意的是,即使春苗的网页以前很受欢迎,它也会过时,最终降低网站内容的SEO值。
为了保存文本,您还应该尝试使用URL缩写服务,例如t.co或goo.gl或bit.ly。您可以测试哪些页面最有吸引力,而中国可以基于这些优势制作更多页面。基本内容SEO问题如果您最近没有进行内容审核或更新网站 SEO(春苗),那么您需要花费时间搜索旧版本的分析包并测试它们的构建方式。分析硬数据是无可替代的。这意味着网站需要安装一个可靠的分析包。
呈现网站内容的关键是操作员需要确定哪些内容有用,哪些内容需要调整以及哪些内容必须删除。大型搜索引擎使用的SEO标准仍然有效,使用这些标准,您可以检测到一些更明显的错误。
例如,这意味着您应该写微博。 Google的WebmasterTools服务可以帮助您检测配置错误警告或其他一些问题,包括由恶意软件警告引起的搜索引擎优化(SEO)问题。如果其他页面没有指向该页面,则可以考虑将其删除。这些形式可以提供很多信息,例如元描述的长度,页面标题以及每个页面上的单词数。
在大多数情况下,重写网页足以提高网站的可读性和可读性,但是在某些情况下,选择删除页面或更新页面更为明智。如果您的网站很小,也许可以手动管理这些页面。当您拥有所有信息时,审核网页并处理该网页上出现的问题是合乎逻辑的。如果您无法从社交媒体获得流量,则可以通过以下几种方法来解决此问题。
主流网站基于访问者喜欢的内容来构建其业务模型。另一个条件是指向某个网页的链接总数。
GoogleAnalytics可以轻松地嵌入网页中,并告诉您用户如何与网站进行交互,而且它是完全免费的。如果您在审核网页时发现网页格式不正确,则可能需要重写网页以符合当前的内容SEO标准。
使用这种数据驱动的方法,您可以处理网页问题并建立搜索引擎,并且用户喜欢网站〜原创地址:(“专注于企业家精神,电子商务,网站管理员,扫描A5创业网络微信QR码,定期抽奖。Twitter会自动为您缩短URL。如果您使用第三方缩写服务(例如bit.ly),则可以对每个URL进行分析,例如单击的每个元素。知道哪些页面表现良好也非常重要,诸如Twitter,Instagram和Facebook之类的社交媒体网站越来越吸引访问量,包括您在每次页面审核中的社交媒体流失统计信息。也可以使用这些信息制定有助于将来的Web内容的计划。诸如SharedCount之类的网站可以快速向您提供有关网站在社交媒体上的表现的反馈。
如果要浏览网络以解决基本内容搜索引擎(SEO)问题,则可以适当使用head标签和meta描述。因为搜索引擎喜欢新内容,所以这样做将大大有助于提高网站的总体排名。
网站的内容在网站的操作中变得越来越重要。测量网站现有内容的价值的过程称为“内容审核”,该过程用于识别网站中可能增加流量的内容和可能导致问题的内容。
将所有内容放在一起,主流分析工具可以以电子表格格式导出数据,因此您可以将所有这些信息放入MSExcel或Google Spreadsheet中以查看整体数据。搜索引擎扫描网站的内容质量,最终用户通常只对对他们有用的内容感兴趣。
一种基于数据衡量网页价值的简单方法是检查过去18个月带来的流量。无需走极端,但大多数网站至少拥有一个Twitter和一个Facebook帐户。如果一个页面可以增加链接和流量的数量,以便能够在以后的页面中吸收这种良好的体验,则您需要了解在此页面上做得很好的事情。这种方法需要整合网站中的内容并做出实际决定。
通过组合这些插件包提供的信息,您可以清楚地知道用户来自何处以及他们在您的网站上停留了多长时间。首先,如果您还没有社交媒体帐户,请先获得一个
我始终相信,在网站运算中表现出色的人,还必须在其他平台上的内容运算中也表现出色。 3.页面计划技巧网站操作无法避免计划许多特殊页面。这是事件页面计划过程的一般说明。首先,明确事件的目的,并确保整个事件页面的逻辑清晰。 查看全部
青长以前987803.COM将您的退款保证放在明显的地方
对于中国,请明确说明77927MM.COM在购物过程中会将您的退款保证放在明显的位置。
例如,一个软件开发项目需要人才。春苗项目经理将项目分解为多个短期任务。春苗将项目投入市场以解释工作要求,选择候选人,并将相关工作推向开放的人才市场。部分选择已通过外力验证,以有效解决问题。对于后续的发展计划,将实时地对这些合作伙伴进行匹配和促进,形成相对自由但稳定的合作关系。 987803 8. COM是美国《有线》杂志的资深编辑,杰夫·豪(Jeff Howe)在他著名的“众包”中指出,98780 3. COM曾经是各个领域的精英或不同层次的专业人员。 ,占据了行业的声音和决策权。

从这句话来看,这种模式在中国的实现是在完全开放的劳动力市场中。但是,在离线状态下,春苗的国内地理资源极为不平衡。春苗包括农村和城市地区的人才和就业资源,一线城市以及三,四线城市的供求不平衡,以及劳动力,技术和资源的不平衡。一些公司对人才的需求往往是短期的,年轻的。原因是年轻人仍然处于从传统企业到互联网技术新兴企业的当前组织结构中。对人才的需求往往是短期的,分阶段的和年轻的。当前,中国的互联网发展越来越快。随着中国研发和推出各种新的移动互联网产品,中国各种商业模式的兴起,跨地区的在线和离线连接能力不亚于美国。拥有数亿用户的Internet平台已经为数据开放和访问供需双方奠定了基础,并连接了众多的粉丝和用户。 IBM春苗建立的“开放人才市场”就是一个典型案例。
自由职业者之所以成为青年人的企业家精神的典范,是因为自由职业者本身就是一个从产品到专业能力,品牌包装,青年定价,品牌传播,产品或内容销售的整个过程的人。 。这个世界的许多领域将从垄断转向开放。罗纳德·科斯(Ronald Coase)曾经解释过企业的价值:在中国一个完全开放的劳动力市场中,中国人可以彼此签订合同,出售自己的劳动力并同时购买他人的劳动力。应该注意的是,即使春苗的网页以前很受欢迎,它也会过时,最终降低网站内容的SEO值。
为了保存文本,您还应该尝试使用URL缩写服务,例如t.co或goo.gl或bit.ly。您可以测试哪些页面最有吸引力,而中国可以基于这些优势制作更多页面。基本内容SEO问题如果您最近没有进行内容审核或更新网站 SEO(春苗),那么您需要花费时间搜索旧版本的分析包并测试它们的构建方式。分析硬数据是无可替代的。这意味着网站需要安装一个可靠的分析包。
呈现网站内容的关键是操作员需要确定哪些内容有用,哪些内容需要调整以及哪些内容必须删除。大型搜索引擎使用的SEO标准仍然有效,使用这些标准,您可以检测到一些更明显的错误。

例如,这意味着您应该写微博。 Google的WebmasterTools服务可以帮助您检测配置错误警告或其他一些问题,包括由恶意软件警告引起的搜索引擎优化(SEO)问题。如果其他页面没有指向该页面,则可以考虑将其删除。这些形式可以提供很多信息,例如元描述的长度,页面标题以及每个页面上的单词数。
在大多数情况下,重写网页足以提高网站的可读性和可读性,但是在某些情况下,选择删除页面或更新页面更为明智。如果您的网站很小,也许可以手动管理这些页面。当您拥有所有信息时,审核网页并处理该网页上出现的问题是合乎逻辑的。如果您无法从社交媒体获得流量,则可以通过以下几种方法来解决此问题。
主流网站基于访问者喜欢的内容来构建其业务模型。另一个条件是指向某个网页的链接总数。

GoogleAnalytics可以轻松地嵌入网页中,并告诉您用户如何与网站进行交互,而且它是完全免费的。如果您在审核网页时发现网页格式不正确,则可能需要重写网页以符合当前的内容SEO标准。
使用这种数据驱动的方法,您可以处理网页问题并建立搜索引擎,并且用户喜欢网站〜原创地址:(“专注于企业家精神,电子商务,网站管理员,扫描A5创业网络微信QR码,定期抽奖。Twitter会自动为您缩短URL。如果您使用第三方缩写服务(例如bit.ly),则可以对每个URL进行分析,例如单击的每个元素。知道哪些页面表现良好也非常重要,诸如Twitter,Instagram和Facebook之类的社交媒体网站越来越吸引访问量,包括您在每次页面审核中的社交媒体流失统计信息。也可以使用这些信息制定有助于将来的Web内容的计划。诸如SharedCount之类的网站可以快速向您提供有关网站在社交媒体上的表现的反馈。
如果要浏览网络以解决基本内容搜索引擎(SEO)问题,则可以适当使用head标签和meta描述。因为搜索引擎喜欢新内容,所以这样做将大大有助于提高网站的总体排名。
网站的内容在网站的操作中变得越来越重要。测量网站现有内容的价值的过程称为“内容审核”,该过程用于识别网站中可能增加流量的内容和可能导致问题的内容。
将所有内容放在一起,主流分析工具可以以电子表格格式导出数据,因此您可以将所有这些信息放入MSExcel或Google Spreadsheet中以查看整体数据。搜索引擎扫描网站的内容质量,最终用户通常只对对他们有用的内容感兴趣。
一种基于数据衡量网页价值的简单方法是检查过去18个月带来的流量。无需走极端,但大多数网站至少拥有一个Twitter和一个Facebook帐户。如果一个页面可以增加链接和流量的数量,以便能够在以后的页面中吸收这种良好的体验,则您需要了解在此页面上做得很好的事情。这种方法需要整合网站中的内容并做出实际决定。
通过组合这些插件包提供的信息,您可以清楚地知道用户来自何处以及他们在您的网站上停留了多长时间。首先,如果您还没有社交媒体帐户,请先获得一个
我始终相信,在网站运算中表现出色的人,还必须在其他平台上的内容运算中也表现出色。 3.页面计划技巧网站操作无法避免计划许多特殊页面。这是事件页面计划过程的一般说明。首先,明确事件的目的,并确保整个事件页面的逻辑清晰。
如何才能精准地找到想要的核心内容?(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-04-28 00:20
重新发布
阅读:502'> 502
互联网是一个巨大的知识库。我们对此有很多了解。我们通过搜索引擎搜索所需的内容。例如,我们常用的搜索引擎,例如百度和Google
但是由于搜索引擎采集了很多东西,所以我们找到的内容可能不是我们想要的。我们如何才能准确地找到我们想要的核心内容。
1.站点:指定URL
仅搜索域名下的内容。如果只想搜索office-cn域名,则可以输入“ Excel技能站点:office-cn”,然后在office-cn网站上搜索Excel技能
2.双引号:完全匹配的关键字
将搜索关键词放在双引号中,以表示完全匹配。普通搜索是模糊查询,可能不是完整的句子。如果输入“ nas教程”,它将搜索有关关键字“ nas教程”的所有链接
3.标题:出现在标题中
intitle加英文冒号加搜索错误关键词,表示搜索结果页面的标题收录该搜索词。使用intitle命令找到的文件是更准确的比赛页面。如果关键词仅出现在页面上的可见文本中,则在大多数情况下搜索结果不准确
4.减号:排除
减号后的搜索词表示您要排除收录该搜索词的结果。使用此减号时,其前必须有一个空格,其后必须没有空格。
access-报告返回的结果收录单词“ access”,但不收录单词“ report”
5. inurl:出现在网址中
inurl:后跟搜索词,这意味着搜索词收录在搜索结果的URL中。例如,输入inurl:,则结果网页必须收录视频
6.文件类型:受限文件类型
filetype:后跟文件后缀,指示返回此文件类型的结果。格式(pdf / doc / xml),例如文件类型:PDF 查看全部
如何才能精准地找到想要的核心内容?(组图)
重新发布
阅读:502'> 502
互联网是一个巨大的知识库。我们对此有很多了解。我们通过搜索引擎搜索所需的内容。例如,我们常用的搜索引擎,例如百度和Google
但是由于搜索引擎采集了很多东西,所以我们找到的内容可能不是我们想要的。我们如何才能准确地找到我们想要的核心内容。
1.站点:指定URL
仅搜索域名下的内容。如果只想搜索office-cn域名,则可以输入“ Excel技能站点:office-cn”,然后在office-cn网站上搜索Excel技能
2.双引号:完全匹配的关键字
将搜索关键词放在双引号中,以表示完全匹配。普通搜索是模糊查询,可能不是完整的句子。如果输入“ nas教程”,它将搜索有关关键字“ nas教程”的所有链接
3.标题:出现在标题中
intitle加英文冒号加搜索错误关键词,表示搜索结果页面的标题收录该搜索词。使用intitle命令找到的文件是更准确的比赛页面。如果关键词仅出现在页面上的可见文本中,则在大多数情况下搜索结果不准确
4.减号:排除
减号后的搜索词表示您要排除收录该搜索词的结果。使用此减号时,其前必须有一个空格,其后必须没有空格。
access-报告返回的结果收录单词“ access”,但不收录单词“ report”
5. inurl:出现在网址中
inurl:后跟搜索词,这意味着搜索词收录在搜索结果的URL中。例如,输入inurl:,则结果网页必须收录视频
6.文件类型:受限文件类型
filetype:后跟文件后缀,指示返回此文件类型的结果。格式(pdf / doc / xml),例如文件类型:PDF
站外优化的本质作用告诉大家一个优质的入口页和主页有什么区别
网站优化 • 优采云 发表了文章 • 0 个评论 • 385 次浏览 • 2021-04-28 00:19
现在,许多网站外部链接专家基本上都是网站优化新手,他们还没有掌握优化的本质,并且大多都是敷衍了事。场外优化的重要作用告诉每个人,高质量的场外优化基本上可以与数百种次要的场外优化相媲美。异地优化的质量远高于数量。这反映在外部链接的构建中。非常饱。
条目页面在转换过程中占据重要位置,并且在上一页和下一页之间具有链接。主页是许多中小型网站条目页面。一些朋友可能会问,进入页面和主页之间有什么区别?例如,网站是一扇有许多门的建筑物。主页是门,入口页是指建筑物中的所有门。
网站主页反映了网站的类型,目的和内容,并应针对网站级别的主要流量进行设计;条目页面的内容应适用于所有流量,即,由它带来的流量的任何网络促销(付费或非付费)都必须得到照顾。如上所述,大多数在线促销都用于转化后。通过某个门户网站页面完成的转化次数越多,该门户网站页面越有利于转化,并且它与促销源流量的匹配程度就越高。
接下来,我将解释这两个常见的问题。什么是白帽子?戴黑帽子是什么?白帽子是白帽子吗?当然不是。白帽。从字面上来讲,是的。白色,无污染。 seo技术是每个人都称为常规优化方法的技术。它遵循搜索引擎指定的规则来优化和调整网站。它不适合作弊方法在短期内实现其目标。老实说,白帽操作周期长,麻烦且累人。
黑帽子正好相反。通过使用一些作弊方法或钻探搜索引擎算法漏洞,您可以在短期内看到优化效果,但是如果被搜索引擎发现,则可能会受到非常严重的惩罚。风险和收益是成比例的。风险越大,收益就越高,这就是为什么黑帽仍然存在的原因。
对企业来说网站最重要的是主页,这没有争议;但是,如果对内容页面的优化做得不好,不仅首页无法达到预期的效果,而且整个网站的优化也将是不可能的。是的,它将直接影响网站的比率。
第一个是内容页面的匹配度,即内容和标题之间的匹配度;相似之处在于页面与页面之间的比较;第三是内部链接推荐,它涉及网站相互投票和蜘蛛指导的内容;第四是附件优化,它对网站的影响不大,但具有可以改善网站的内容。
搜索引擎如何判断网站有购买和出售链接的行为
1、链接的突然出现和消失?
一般的朋友链很长,一些网站的买卖链接将会出现,该月到期后,钱将不会被标记,然后您的网站朋友链将被取消,并且然后您将再次付款,我再次将其添加到了您。与此类似!
搜索引擎优化
2、内容的主题是否相关?
如果高权重网站突然是新闻类型网站,而极低权重网站类型用于训练,则内容和主题之间没有关系,个人也可以看到有问题!
3、使用知名的链接交易服务吗?
类似于平台,用于买卖友情链接的平台,但是在搜索引擎看来,像这样的平台是一个非常令人恐惧的比较。如果您的网站出现在其上,将对其进行搜索。在发动机的监控范围内! 查看全部
站外优化的本质作用告诉大家一个优质的入口页和主页有什么区别
现在,许多网站外部链接专家基本上都是网站优化新手,他们还没有掌握优化的本质,并且大多都是敷衍了事。场外优化的重要作用告诉每个人,高质量的场外优化基本上可以与数百种次要的场外优化相媲美。异地优化的质量远高于数量。这反映在外部链接的构建中。非常饱。
条目页面在转换过程中占据重要位置,并且在上一页和下一页之间具有链接。主页是许多中小型网站条目页面。一些朋友可能会问,进入页面和主页之间有什么区别?例如,网站是一扇有许多门的建筑物。主页是门,入口页是指建筑物中的所有门。
网站主页反映了网站的类型,目的和内容,并应针对网站级别的主要流量进行设计;条目页面的内容应适用于所有流量,即,由它带来的流量的任何网络促销(付费或非付费)都必须得到照顾。如上所述,大多数在线促销都用于转化后。通过某个门户网站页面完成的转化次数越多,该门户网站页面越有利于转化,并且它与促销源流量的匹配程度就越高。
接下来,我将解释这两个常见的问题。什么是白帽子?戴黑帽子是什么?白帽子是白帽子吗?当然不是。白帽。从字面上来讲,是的。白色,无污染。 seo技术是每个人都称为常规优化方法的技术。它遵循搜索引擎指定的规则来优化和调整网站。它不适合作弊方法在短期内实现其目标。老实说,白帽操作周期长,麻烦且累人。
黑帽子正好相反。通过使用一些作弊方法或钻探搜索引擎算法漏洞,您可以在短期内看到优化效果,但是如果被搜索引擎发现,则可能会受到非常严重的惩罚。风险和收益是成比例的。风险越大,收益就越高,这就是为什么黑帽仍然存在的原因。
对企业来说网站最重要的是主页,这没有争议;但是,如果对内容页面的优化做得不好,不仅首页无法达到预期的效果,而且整个网站的优化也将是不可能的。是的,它将直接影响网站的比率。
第一个是内容页面的匹配度,即内容和标题之间的匹配度;相似之处在于页面与页面之间的比较;第三是内部链接推荐,它涉及网站相互投票和蜘蛛指导的内容;第四是附件优化,它对网站的影响不大,但具有可以改善网站的内容。
搜索引擎如何判断网站有购买和出售链接的行为
1、链接的突然出现和消失?
一般的朋友链很长,一些网站的买卖链接将会出现,该月到期后,钱将不会被标记,然后您的网站朋友链将被取消,并且然后您将再次付款,我再次将其添加到了您。与此类似!
搜索引擎优化
2、内容的主题是否相关?
如果高权重网站突然是新闻类型网站,而极低权重网站类型用于训练,则内容和主题之间没有关系,个人也可以看到有问题!
3、使用知名的链接交易服务吗?
类似于平台,用于买卖友情链接的平台,但是在搜索引擎看来,像这样的平台是一个非常令人恐惧的比较。如果您的网站出现在其上,将对其进行搜索。在发动机的监控范围内!
搜索指定网站内容信息(比如招聘网站的首页链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-04-25 01:06
搜索指定网站内容信息(比如招聘网站的首页链接和公司网站的链接)就能获得对应网站的内容并推送给对应的网友,也就是你所说的“推荐”。
技术原理:
1、网站、应用、系统收集信息。主要有关键词搜索、网站索引、高频搜索及机器学习等。
2、利用人工智能(机器学习)实现推荐。
1、网站和应用程序是以内容聚合的方式进行流量变现。
2、推荐的主要信息应该是用户经常浏览的网站和应用程序上面的内容。
3、微博如果算是资讯网站,只能算是信息聚合,算不上推荐。
我们在一个热点事件中记录所有网民关注的问题,然后推荐给每一个网民。当然,你最好有一套系统来判断出你关注问题的答案。
说白了就是读数据分析的东西。上面几位说的好,百度搜索根据用户的上网记录进行个性化推荐。网上你经常打开的网站每天产生的信息量级级大约上百万条,有人给你推荐别人关注的话题,很有可能说明你每天会至少浏览若干条相关信息。多说一句,新浪的sina微博就算在现在的互联网行业的早期,其发布的内容也算是互联网上丰富的信息,包括美女图片、热点信息等,那时候比现在的sina微博推荐机制要强的多的多。
大数据分析+机器学习。
同意zero的回答,其实简单地说可以认为是推荐系统。可以根据用户的历史历史表现进行推荐,也可以结合用户的喜好进行推荐。举例子来说:有一个app,每天推荐一个最新最新的事件给你,你说我也想知道我最近的爱好是什么,或者我最近想去哪玩,这个app就算提供了最新最新的信息,也未必会对你有用。因为这些都是根据你在这款app上的行为经验主动推荐给你的。 查看全部
搜索指定网站内容信息(比如招聘网站的首页链接)
搜索指定网站内容信息(比如招聘网站的首页链接和公司网站的链接)就能获得对应网站的内容并推送给对应的网友,也就是你所说的“推荐”。
技术原理:
1、网站、应用、系统收集信息。主要有关键词搜索、网站索引、高频搜索及机器学习等。
2、利用人工智能(机器学习)实现推荐。
1、网站和应用程序是以内容聚合的方式进行流量变现。
2、推荐的主要信息应该是用户经常浏览的网站和应用程序上面的内容。
3、微博如果算是资讯网站,只能算是信息聚合,算不上推荐。
我们在一个热点事件中记录所有网民关注的问题,然后推荐给每一个网民。当然,你最好有一套系统来判断出你关注问题的答案。
说白了就是读数据分析的东西。上面几位说的好,百度搜索根据用户的上网记录进行个性化推荐。网上你经常打开的网站每天产生的信息量级级大约上百万条,有人给你推荐别人关注的话题,很有可能说明你每天会至少浏览若干条相关信息。多说一句,新浪的sina微博就算在现在的互联网行业的早期,其发布的内容也算是互联网上丰富的信息,包括美女图片、热点信息等,那时候比现在的sina微博推荐机制要强的多的多。
大数据分析+机器学习。
同意zero的回答,其实简单地说可以认为是推荐系统。可以根据用户的历史历史表现进行推荐,也可以结合用户的喜好进行推荐。举例子来说:有一个app,每天推荐一个最新最新的事件给你,你说我也想知道我最近的爱好是什么,或者我最近想去哪玩,这个app就算提供了最新最新的信息,也未必会对你有用。因为这些都是根据你在这款app上的行为经验主动推荐给你的。
【知识点】怎么查一个网站的信息?方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 396 次浏览 • 2021-05-18 21:08
如何查看网站信息?
方法1:使用搜索运算符;
01
如果要搜索特定的网站内容,可以在查询关键字后添加“ site:”,格式如下:
搜索关键字网站:域名
例如:如果要搜索Windows安装和清理,默认查询结果如下:
02
如果要搜索Microsoft 网站的内容,请输入“ Windows安装清理” 网站:“查询结果如下:
03
您可以看到区别很明显。默认查询显示许多网站和“ windows star clean”“向上”,以及网站:之后,该查询仅与Microsoft 网站“域”中的网站相关;
04
注意:站点:站点与域之间没有空格;
05
您也可以直接在顶级域中搜索网站内容,例如。组织或。 CN或。 Com;
例如:Windows star清理网站:.cn
您发现的是中文顶级域名下网站的内容;
方法2:使用高级搜索
01
如果您不想使用搜索运算符,则可以使用“高级搜索”功能;
例如,输入后单击“选项”按钮;
02个查询关键字,在“ 网站或域名”框中,输入指定的网站或域名;
03
然后单击“高级搜索”;
04
您会看到“高级搜索”将自动生成相应的搜索条件,并在指定的网站或域中查询相关信息;
声明:
01
以上示例仅供参考,请分析具体问题,不要一概而论
02
操作命令和菜单仅供参考。为了达到相同的效果,可以有多种操作模式。请使用您熟悉的操作模式。 查看全部
【知识点】怎么查一个网站的信息?方法
如何查看网站信息?
方法1:使用搜索运算符;
01
如果要搜索特定的网站内容,可以在查询关键字后添加“ site:”,格式如下:
搜索关键字网站:域名
例如:如果要搜索Windows安装和清理,默认查询结果如下:
02
如果要搜索Microsoft 网站的内容,请输入“ Windows安装清理” 网站:“查询结果如下:
03
您可以看到区别很明显。默认查询显示许多网站和“ windows star clean”“向上”,以及网站:之后,该查询仅与Microsoft 网站“域”中的网站相关;
04
注意:站点:站点与域之间没有空格;
05
您也可以直接在顶级域中搜索网站内容,例如。组织或。 CN或。 Com;
例如:Windows star清理网站:.cn
您发现的是中文顶级域名下网站的内容;
方法2:使用高级搜索
01
如果您不想使用搜索运算符,则可以使用“高级搜索”功能;
例如,输入后单击“选项”按钮;
02个查询关键字,在“ 网站或域名”框中,输入指定的网站或域名;
03
然后单击“高级搜索”;
04
您会看到“高级搜索”将自动生成相应的搜索条件,并在指定的网站或域中查询相关信息;
声明:
01
以上示例仅供参考,请分析具体问题,不要一概而论
02
操作命令和菜单仅供参考。为了达到相同的效果,可以有多种操作模式。请使用您熟悉的操作模式。
SEO剖析第一课搜索引擎基础狗狗制作什么是SiteMap
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-05-18 21:05
SEO分析第1课搜索引擎基础知识什么是搜索引擎?所谓的搜索引擎(Search Engines)是一些Web 网站,可以主动搜索信息(在Web上搜索单词和简短的特定内容描述)并自动为它们建立索引。被索引的内容存储在可搜索的数据库中。在大型数据库中,建立了索引和目录服务。它是为您提供的“检索”服务网站。它使用某些程序对Internet上的所有信息进行分类,以帮助人们在广阔的网络中找到所需的信息。搜索引擎的作用是什么?将对用户真正有用的信息放在搜索结果的顶部!搜索引擎的工作原理如果搜索引擎想了解Internet上的新事物,则必须派人去采集它们。每天都有新的网站代,每天网站内容都会更新,并且生成的网站数量会不断增加网站的更新内容,因此无法手动完成此任务,因此搜索引擎的发明者设计了计算机程序,并将其发送来执行此任务。检测器有很多名称,也称为“爬行器”,“蜘蛛”和“机器人”。这些图像的名称是描绘由搜索引擎在互联网上爬行以检测新信息而发送的蜘蛛机器人。谷歌称其检测器为Googlebot,百度称其为Baiduspider,雅虎称其为Slurp。不管他们叫什么,他们都是人。编译的计算机程序允许他们日夜访问网站,检索网站的内容,标签,图片等,然后根据搜索引擎的算法为其自定义索引。
如何识别搜索引擎的身份?可以通过DNS反向查询找到主机名:Google:主机名应收录在域名中,例如:主机名应收录在域名中,例如:; Yahoo:主机名应收录在域名中,例如:。什么是SiteMap? Sitemaps协议使您可以将可进行爬网的URL通知搜索引擎网站。最简单的方法是使用Sitemaps的Sitemaps协议是一个XML文件,其中列出了某个网站的所有URL。该协议可以高度扩展,因此可以应用于各种大小网站。它还使网站管理员能够提供有关每个URL的其他信息(最后更新的时间,更改的频率,与网站中的其他URL相比有多重要等),以便搜索引擎可以更聪明地抓图。 网站。使用SiteMap将有助于搜索引擎更友好地采集网站。不要让网站的集合存在漏洞或不完整的集合。 SiteMap在这方面可以起到很好的作用。
一旦有了SiteMap并将其提交给搜索引擎,以后您便可以方便地进行下一步,例如更好地调整网站的外部链接和内部链接错误,所有这些将在SiteMap中使用。提交功能。 网站有些页面不容易找到,例如具有很多丰富的AJAX或Flash内容的页面。 网站上页面的相对重要性。什么是Robots.txt Robots.txt是纯文本文件。通过在此文件中声明网站的一部分,您不想被机器人访问,搜索引擎将无法访问网站的部分或全部内容。我已经收到它,或者指定的搜索引擎仅接受指定的内容。当搜索机器人访问网站时,它将首先检查该网站的根目录下是否存在robots.txt。如果找到,搜索引擎将根据文件的内容确定访问范围。如果该文件不存在,那么搜索机器人将沿着该链接进行爬网。 查看全部
SEO剖析第一课搜索引擎基础狗狗制作什么是SiteMap
SEO分析第1课搜索引擎基础知识什么是搜索引擎?所谓的搜索引擎(Search Engines)是一些Web 网站,可以主动搜索信息(在Web上搜索单词和简短的特定内容描述)并自动为它们建立索引。被索引的内容存储在可搜索的数据库中。在大型数据库中,建立了索引和目录服务。它是为您提供的“检索”服务网站。它使用某些程序对Internet上的所有信息进行分类,以帮助人们在广阔的网络中找到所需的信息。搜索引擎的作用是什么?将对用户真正有用的信息放在搜索结果的顶部!搜索引擎的工作原理如果搜索引擎想了解Internet上的新事物,则必须派人去采集它们。每天都有新的网站代,每天网站内容都会更新,并且生成的网站数量会不断增加网站的更新内容,因此无法手动完成此任务,因此搜索引擎的发明者设计了计算机程序,并将其发送来执行此任务。检测器有很多名称,也称为“爬行器”,“蜘蛛”和“机器人”。这些图像的名称是描绘由搜索引擎在互联网上爬行以检测新信息而发送的蜘蛛机器人。谷歌称其检测器为Googlebot,百度称其为Baiduspider,雅虎称其为Slurp。不管他们叫什么,他们都是人。编译的计算机程序允许他们日夜访问网站,检索网站的内容,标签,图片等,然后根据搜索引擎的算法为其自定义索引。
如何识别搜索引擎的身份?可以通过DNS反向查询找到主机名:Google:主机名应收录在域名中,例如:主机名应收录在域名中,例如:; Yahoo:主机名应收录在域名中,例如:。什么是SiteMap? Sitemaps协议使您可以将可进行爬网的URL通知搜索引擎网站。最简单的方法是使用Sitemaps的Sitemaps协议是一个XML文件,其中列出了某个网站的所有URL。该协议可以高度扩展,因此可以应用于各种大小网站。它还使网站管理员能够提供有关每个URL的其他信息(最后更新的时间,更改的频率,与网站中的其他URL相比有多重要等),以便搜索引擎可以更聪明地抓图。 网站。使用SiteMap将有助于搜索引擎更友好地采集网站。不要让网站的集合存在漏洞或不完整的集合。 SiteMap在这方面可以起到很好的作用。
一旦有了SiteMap并将其提交给搜索引擎,以后您便可以方便地进行下一步,例如更好地调整网站的外部链接和内部链接错误,所有这些将在SiteMap中使用。提交功能。 网站有些页面不容易找到,例如具有很多丰富的AJAX或Flash内容的页面。 网站上页面的相对重要性。什么是Robots.txt Robots.txt是纯文本文件。通过在此文件中声明网站的一部分,您不想被机器人访问,搜索引擎将无法访问网站的部分或全部内容。我已经收到它,或者指定的搜索引擎仅接受指定的内容。当搜索机器人访问网站时,它将首先检查该网站的根目录下是否存在robots.txt。如果找到,搜索引擎将根据文件的内容确定访问范围。如果该文件不存在,那么搜索机器人将沿着该链接进行爬网。
Python抓取特定内容_使用python抓取网页上的特定内容
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-05-14 01:31
import urllib#用于在python中获取网站的模块
导入urllib2,cookielib
某些网站访问时需要cookie,python处理cookie的代码如下:
cj = cookielib.CookieJar()
opener = urllib 2. build_opener(urllib 2. HttpCookieProcessor(cj))
urllib 2. install_opener(开启程序)
通常,我们需要在网站中搜索所需的信息。这里有两种情况:
1.首先,您可以直接更改URL以获取要搜索的页面:
def GetWebPage(x):#我们定义了一个获取页面的函数,x是用于显示您在页面上搜索的内容的参数
url ='#39; +“您要搜索的参数”#根据您自己的页面条件进行适当修改
page = urllib 2. urlopen(url)
pageContent = page.read()
返回pageContent#以HTML格式返回页面信息
2.第二种方法,您需要使用post方法,将搜索到的内容放入postdata中,然后返回所需的页面
def GetWebPage(x):#我们定义了一个获取页面的函数,x是用于显示您在页面上搜索的内容的参数
url ='#39; #此URL是您进入搜索界面的位置
postData = urllib.urlencode({各种'post'参数输入})#此处的post参数输入需要您自己检查
req = urllib 2.请求(url,postData)
pageContent = urllib 2. urlopen(req)。 read()
返回pageContent#以HTML格式返回页面信息
获取所需的网页信息后,需要从获取的网页中进一步获取所需的信息。在这里,我建议使用BeautifulSoup模块。 Python不附带它。您可以将其下载并安装在百度Google上。 BeautifulSoup译为“美味汤”。您需要做的是从一锅汤中找到想要吃的东西。
import re#正则表达式,用于匹配字符
从bs4导入BeautifulSoup#导入BeautifulSoup模块
soup = BeautifulSoup(pageContent)#pageContent是我们在上面搜索的页面
汤是HTML中的所有标签(标签)BeautifulSoup处理格式化的字符串,标准的标签形式是:
hwkobe24
通过一些过滤方法,我们可以从汤中获取所需的信息:
([1) find_all(名称,属性,递归,文本,**假名)
在这里,我们通过在标签上添加约束来获得所需标签的列表,例如,soup.find_all('p')是要找到一个名为'p'的标签,然后是soup.find_all(class =“ tittle” )将查找所有class属性为“ tittle”的标签,并且soup.find_all(class = heap('lass'))表示class属性中所有收录'lass'的标签。这里使用正则表达式(您可以自己学习,非常有用)
获得所需的所有标签的列表之后,遍历此列表,然后在标签中获得所需的内容。通常,我们需要标记的文本部分,即网页上显示的文本。代码如下:
tagList = soup.find_all(class =“ tittle”)#如果标记较为复杂,则可以使用多个过滤条件使过滤条件更严格
用于tagList中的标签:
打印tag.text
f.write(str(tag.text))#将此信息写入本地文件以供以后使用
([2) find(名称,attrs,递归,文本,** kwargs)
它与find_all()方法之间的唯一区别是find_all()方法的返回结果是收录一个元素的值列表,而find()方法直接返回结果
([3) find_parents()find_parent()
find_all()和find()仅搜索当前节点的所有子节点,孙子节点等。
find_parents()和find_parent()用于搜索当前节点的父节点,搜索方法与普通标签的搜索方法相同,搜索文档搜索文档中收录的内容
([4) find_next_siblings()find_next_sibling()
这两种方法使用.next_siblings属性来更新稍后分析的所有同级标记节点。 find_next_siblings()方法返回所有随后满足条件的兄弟姐妹,而find_next_sibling()仅返回下一个满足条件的兄弟姐妹。标记节点
([5) find_previous_siblings()find_previous_sibling()
这两个方法使用.previous_siblings属性来迭代在当前标签之前解析的同级标签节点。 find_previous_siblings()方法返回满足条件的所有先前的同级节点,而find_previous_sibling()方法返回满足条件的第一个同级节点。
的兄弟姐妹
([6) find_all_next()find_next()
这两个方法使用.next_elements属性来迭代当前标签之后的标签和字符串。 find_all_next()方法返回所有符合条件的节点,而find_next()方法返回第一个符合条件的节点
([7) find_all_previous()和find_previous()
这两个方法使用.previous_elements属性来迭代当前节点前面的标记和字符串。 find_all_previous()方法返回所有符合条件的节点,而find_previous()方法返回第一个符合条件的节点。
实际代码示例:(在网页下抓取指定的链接)
来自bs4 imp
#htmltext
html_text =“”
soup = BeautifulSoup(html_text,'html.parser')
a = soup.select('a')
对于我在:
如果i.string ==“ 关键词”:
findb_ur = i ['href']
#输出通过在a标签中搜索字符串而获得的网页链接
#print(findb_url)
#findb_url =“ https:” + finburl
alist = soup.find_all('a)
对于列表中的a:
1.下标操作方式
href = a ['href']
print(htref)
2.通过attrs属性
href = a.attrs ['href']
print(href) 查看全部
Python抓取特定内容_使用python抓取网页上的特定内容
import urllib#用于在python中获取网站的模块
导入urllib2,cookielib
某些网站访问时需要cookie,python处理cookie的代码如下:
cj = cookielib.CookieJar()
opener = urllib 2. build_opener(urllib 2. HttpCookieProcessor(cj))
urllib 2. install_opener(开启程序)
通常,我们需要在网站中搜索所需的信息。这里有两种情况:
1.首先,您可以直接更改URL以获取要搜索的页面:
def GetWebPage(x):#我们定义了一个获取页面的函数,x是用于显示您在页面上搜索的内容的参数
url ='#39; +“您要搜索的参数”#根据您自己的页面条件进行适当修改
page = urllib 2. urlopen(url)
pageContent = page.read()
返回pageContent#以HTML格式返回页面信息
2.第二种方法,您需要使用post方法,将搜索到的内容放入postdata中,然后返回所需的页面
def GetWebPage(x):#我们定义了一个获取页面的函数,x是用于显示您在页面上搜索的内容的参数
url ='#39; #此URL是您进入搜索界面的位置
postData = urllib.urlencode({各种'post'参数输入})#此处的post参数输入需要您自己检查
req = urllib 2.请求(url,postData)
pageContent = urllib 2. urlopen(req)。 read()
返回pageContent#以HTML格式返回页面信息
获取所需的网页信息后,需要从获取的网页中进一步获取所需的信息。在这里,我建议使用BeautifulSoup模块。 Python不附带它。您可以将其下载并安装在百度Google上。 BeautifulSoup译为“美味汤”。您需要做的是从一锅汤中找到想要吃的东西。
import re#正则表达式,用于匹配字符
从bs4导入BeautifulSoup#导入BeautifulSoup模块
soup = BeautifulSoup(pageContent)#pageContent是我们在上面搜索的页面
汤是HTML中的所有标签(标签)BeautifulSoup处理格式化的字符串,标准的标签形式是:
hwkobe24
通过一些过滤方法,我们可以从汤中获取所需的信息:
([1) find_all(名称,属性,递归,文本,**假名)
在这里,我们通过在标签上添加约束来获得所需标签的列表,例如,soup.find_all('p')是要找到一个名为'p'的标签,然后是soup.find_all(class =“ tittle” )将查找所有class属性为“ tittle”的标签,并且soup.find_all(class = heap('lass'))表示class属性中所有收录'lass'的标签。这里使用正则表达式(您可以自己学习,非常有用)
获得所需的所有标签的列表之后,遍历此列表,然后在标签中获得所需的内容。通常,我们需要标记的文本部分,即网页上显示的文本。代码如下:
tagList = soup.find_all(class =“ tittle”)#如果标记较为复杂,则可以使用多个过滤条件使过滤条件更严格
用于tagList中的标签:
打印tag.text
f.write(str(tag.text))#将此信息写入本地文件以供以后使用
([2) find(名称,attrs,递归,文本,** kwargs)
它与find_all()方法之间的唯一区别是find_all()方法的返回结果是收录一个元素的值列表,而find()方法直接返回结果
([3) find_parents()find_parent()
find_all()和find()仅搜索当前节点的所有子节点,孙子节点等。
find_parents()和find_parent()用于搜索当前节点的父节点,搜索方法与普通标签的搜索方法相同,搜索文档搜索文档中收录的内容
([4) find_next_siblings()find_next_sibling()
这两种方法使用.next_siblings属性来更新稍后分析的所有同级标记节点。 find_next_siblings()方法返回所有随后满足条件的兄弟姐妹,而find_next_sibling()仅返回下一个满足条件的兄弟姐妹。标记节点
([5) find_previous_siblings()find_previous_sibling()
这两个方法使用.previous_siblings属性来迭代在当前标签之前解析的同级标签节点。 find_previous_siblings()方法返回满足条件的所有先前的同级节点,而find_previous_sibling()方法返回满足条件的第一个同级节点。
的兄弟姐妹
([6) find_all_next()find_next()
这两个方法使用.next_elements属性来迭代当前标签之后的标签和字符串。 find_all_next()方法返回所有符合条件的节点,而find_next()方法返回第一个符合条件的节点
([7) find_all_previous()和find_previous()
这两个方法使用.previous_elements属性来迭代当前节点前面的标记和字符串。 find_all_previous()方法返回所有符合条件的节点,而find_previous()方法返回第一个符合条件的节点。
实际代码示例:(在网页下抓取指定的链接)
来自bs4 imp
#htmltext
html_text =“”
soup = BeautifulSoup(html_text,'html.parser')
a = soup.select('a')
对于我在:
如果i.string ==“ 关键词”:
findb_ur = i ['href']
#输出通过在a标签中搜索字符串而获得的网页链接
#print(findb_url)
#findb_url =“ https:” + finburl
alist = soup.find_all('a)
对于列表中的a:
1.下标操作方式
href = a ['href']
print(htref)
2.通过attrs属性
href = a.attrs ['href']
print(href)
自学笔记第五章本章的重点网信息资源的特点、种类、信息利用价值
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-05-11 04:18
第5章Internet信息检索本章重点介绍Internet信息资源的特征,类型和信息利用价值。 Internet信息检索的基本知识,以及各种常用Internet信息检索工具的特征,比较,评估,使用和检索方法。本章的学习目的是使学习者培养网络信息搜索和使用的能力,并提高网络信息环境中信息发现和利用的水平。第1节Internet概述一、基本概念(自学)TCP / IP TCP / IP Internet WWWWWW WWW HTTP HTML HTML Internet HTTP是基于TCP / IP的协议,是用于分布式协作超媒体信息系统的快速实用的协议。它不仅需要确保超文本文档的正确传输,而且还必须能够确定传输文档的特定部分以及首先显示内容的哪一部分。在HTML中,可以嵌入图像,声音等,并且可以通过超链接无缝引用其他WWW URL资源。用HTML组织的信息文档称为页面,这些页面由浏览器解释,执行,显示和输出。浏览器:也称为浏览器,它是一种用于读取HTML文件的特殊软件系统。可以通过许多方法来获取信息,例如FTP,NNTP和Gopher。 URL可以将世界上所有的在线信息资源组织成一个有序的结构。它的格式包括三个部分:第一部分是协议(或服务模式),大多数Internet文档使用http,其他常用的协议是fp,news,gopher,telnet等。第三部分是主机资源的特定地址。
IP Internet上的许多计算机和信息资源必须通过名称和地址来标识。连接到Internet的计算机或节点被分配一个唯一的数字作为一个称为IP地址的地址,该地址由四组数字组成,这些数字组由小数点分隔。 IP地址通常是由Internet服务组织从Internet网络信息中心注册和应用的(例如:Central 20 2. 20 5. 21 3. 10 1)。IP是网络中的重要资源, IP地址数量表示可以连接到Internet的计算机的数量,由于IP地址由四组数字组成,因此不容易记住,因此Internet使用域名系统(DNS)作为域名的助记符。 Internet上的特定主机。Internet中每台计算机的域名结构是:主机名,组织名称,网络名称,顶级域名。域名由常规英语单词组成,非常容易记住,并且还可以根据域名组成规则猜测某个站点的域名。通用标准域名的结构为:主机名,组织名称,网络名称,顶级域名。顶级域名共有三个互联网域名中的一级域名n名称系统:第一种是国家域名,由两个英文字母组成,例如:“。CN(中国))”,“。JP(日本)”,“。US(美国)”,“”。 UK(UK)”,“。CA(Canada)”。第二类是国际域名,现在只有一个“ .INT”代表国际组织。
第三类是通用域名,目前使用的是——网络服务组织; .edu——教育部门; .web——网络服务组织; 。艺术-文化娱乐部门; .info— —信息部门; .rec——娱乐机构; .org——非营利组织; 。商店-销售部。公司-公司企业; .gov——政府部门; .com .——商业组织。mil——军事部门; .nom个人。中国的域名注册由国务院信息化领导小组办公室授权的中国互联网络信息中心(CNNIC)处理。例如:中央财经大学的网站是Internet(自学)www):万维网)HTML HTTP UsenetListserv邮件列表BBSBBS BBS BBS Archie):ArchieArchie Internet FTP Archie FTP WAISInternet GopherInternet Gopher 2040 20 50 WebCrawlerGoogle URL :URL是Internet上各种专门的计算机和文学资源的“地址”。通用格式为:与普通的网站不同,搜索引擎网站的主要资源是索引数据库。
其工作原理是通过采集并调用搜索引擎数据库来实现其导航功能。第2节Internet搜索引擎Internet Internet雅虎Internet googleAlta Vista WEBYahoo WebSearch Engine(UsenetSearch Engine(YellowPageSearch Engine(WhitePageSearch Engine(MetaSearchSearch((WordSearch)(SimpleSearch)(PhraseSearch)(SentenceSearch)(CatalogSearch)(分类搜索)(AdvancedSearch)))金属裂纹金属裂纹金属裂纹金属应力裂纹应力裂纹应力裂纹AltaVisa > GoldenRetriever AltaVisa ExicteAlta Visa可以检查的外国搜索引擎数量达到2500,其中有许多出色的综合搜索引擎,例如:Yahoo!,AltaVista,Excite,Infoseek,Lycos,HotBot, Google,OpenText等。
HotBot()是美国著名的综合搜索引擎。 FM365263 21cn TOM主要搜索引擎的第2部分Google()Google()Google目前是世界上最大的搜索引擎。它提供了70多种界面语言和35种搜索语言,包括分类查询和关键词搜索。特征。 (一)公司介绍GoogleGoogle Inc.纳斯达克GOOG 1998 GoogleGoogle 1999 2004 19Google Nasdaq GoogleGoogleplex‖Mountain View)SchmidtGoogle(二) Google GoogleGoogleGoogle Google Googol Googol“ 10100100google Google Googol爱德华·卡斯纳·米尔顿·西罗塔·爱德华·卡斯纳·詹姆斯·纽曼数学想象力谷歌谷歌谷歌谷歌谷歌谷歌谷歌这是谷歌的中文版本。
该服务器位于中国北京。通过Google页面显示,我们可以知道Google提供了三种设置功能:高级搜索,首选项和语言工具。 ([三)使用Google搜索GoogleEnter的基本知识” Google Google以明显的单词开头。例如,如果您要查找有关夏威夷的一般信息,则不妨尝试。如果您计划安排夏威夷度假,搜索会更好比单独搜索更好。搜索结果会更好。乔治华盛顿华盛顿乔治华盛顿谷歌谷歌谷歌Google默认情况下,谷歌只提供收录所有搜索词的页面。单词之间无需添加“和”。请记住,单词的顺序是键入将影响搜索结果。要进一步限制搜索,只需添加更多单词即可。例如,要安排去夏威夷度假,只需键入Google即可忽略常见的单词和字符,例如“ where”,“ how”和“的”和其他单个数字和字母会减慢搜索速度,但不能缩小查询范围并改善结果。如果必须使用通用词来获得所需的结果,则可以输入前面的“ +”号e单词号,将其包括在查询词中。低音音乐Googlegoogl googl *“ google” GOOGLE” Googlesite:Googlesite:12(StanfordUniversity)Stanford GoogleGoogle 1 3、使用高级搜索来缩小搜索范围。 Googlewhere需要找到两个单词。一个单词就足够了。请在单词之间添加大写字母“ OR”。
例如,要搜索伦敦或巴黎的度假信息,可以使用以下方法:Vacation London或Paris Google“站点”(斯坦福大学)(入学)录取站点:想查找数字吗?在数字范围内,您可以搜索收录指定范围内数字的结果。只需在搜索框中的搜索词后面加上两个数字,然后用两个英文句点(无空格)将它们分开即可。您可以使用“数字范围”来设置从日期(Willie Mays 195 0. .196 0)到重量(500 0. .10000 kg))的各种范围。但是,请务必指定单位US $ 50US $ 100 DVD DVD播放器$ 5 0.。$ 100 DVD DVD播放器$ 5 0.。$ 100(带下划线的项四)是您搜索的条件)由Google搜索引擎通过单词找到的搜索结果,列表中的第一个项目(“新闻”结果除外)是我们找到的最相关的匹配项,第二个项目是第二个最相关的匹配项,依此类推。单击任何带下划线的条目将为您打开关联的网页。(四)搜索结果GoogleGoogle Google GoogleEnter”单击链接以激活您要使用的Google服务。
您可以搜索网络,查找图片,浏览Google网上论坛,或单击“更多”链接以查看其他Google产品。 B.―单击此按钮可以提交另一个搜索查询。您也可以按“ Enter”键提交查询。 C.这将链接到一个页面,您可以在其中进行更精确的搜索。要在Google上进行搜索,只需输入一些描述性搜索字词,然后按“ Enter”键或单击“ Search”按钮即可。链接到可以设置个人搜索首选项(包括语言,每页结果数)的页面。该行描述了搜索,并指出了结果总数以及完成搜索所花费的时间。搜索结果项的第一行是找到的页面的标题。如果您看到的是URL而不是标题,则表明该页面没有标题,或者我们没有为页面的全部内容建立索引,但是其在索引中的位置仍然表明它很好地满足了您的查询要求。该数字表示您要查找的网页文本部分的大小,它使您可以在一定程度上了解显示时间。如果尚未完全建立索引的是网站,则不会显示尺寸编号。当我们上次索引相应页面时,单击链接将显示该页面的内容。如果由于某些原因网站链接无法链接到当前页面,您仍然可以通过页面快照的版本找到所需的信息。如果您为特定结果选择“相似页面”链接,则Google会在Internet上自动查找与该结果相关的页面。
1、高级搜索要改善搜索效果,您还可以在您在Google搜索框中输入的搜索词中添加“运算符”,或进入高级搜索页面。指定搜索词在网页上的显示位置,该位置可以在网页,标题,文本或URL中的任何位置。 2、首选项1)界面语言2)搜索语言谷歌谷歌Googletq“ TQ”谷歌2、股票报价使用Google查询股票价格和股票市场报价非常简单方便。您只需要输入要查询的股票或证券的名称或六位数代码,例如中国银行或601988,Google就会返回其他链接,以便您可以通过以下方式获取有关股票和证券的详细信息:只需单击一下。 3、参考工具11第3节主搜索引擎Beta 2001 10 22百度200312百度搜索既简单又方便。您只需要在搜索框中输入要查询的内容,按Enter键,或单击搜索框右侧的百度搜索按钮,即可获得最能满足您的查询要求的Web内容。输入多个单词进行搜索(不同的单词用空格隔开),可以获得更精确的搜索结果。例如:如果您想了解上海人民公园的相关信息,则在搜索框中输入[上海人民公园]会比输入[人民公园]获得更好的搜索结果。 2 intitle:Intitle日常工作和娱乐需要大量软件,许多软件是共享或免费的,可以在Internet上免费下载。
这是最直接的方法。软件名称加上特征词“下载”通常可以快速找到下载点。示例:flashget下载由于网站的质量不均匀,下载速度会有所不同。如果我们积累了一些有用的下载站点(例如Skynet,,Computer Home等),则可以使用站点语法将搜索范围限制为网站,以提高搜索效率。示例:Flash Express站点:提示:一旦搜索范围仅限于专业下载站点,则不必在查询词中显示功能词“下载”。 IEIE xxxxxx” xxxxxx” OfficePDF PDF文件类型PDF DOC XLS xxxxintitle Fansite官方网站Fans网站标题:13 PDFsite mp3site:DT231DT231”如果您熟悉该产品,则还可以使用产品名称和细化要求来形成查询词来进行搜索。例如,我需要找到一个带钻石管的19英寸显示器(特征是19英寸和钻石管)。因此,您可以像这样搜索:示例:19英寸显示器Diamond CRT 14站点:16 apple” Windowslog((sin(5))^ 2) -3 + pi filetypeFiletype:” DOC XLS PPT PDF RTF ALL ALL文件类型: doc‖在百度搜索框中输入股票代码,火车号或航班号,您可以直接获取相关信息。
例如,输入SDB的股票代码“ 000001”,SDB股票的实时报价将显示在搜索结果的顶部。 10 ——intitleintitle:intitle:——sitemsn site:site:‖‖site:url——inurl photoshop photoshop inurl:jiqiaophotoshop‖jiqiao‖url inurl:11如果您不熟悉百度的各种查询语法,则可以使用百度集成了高级搜索界面,您可以方便地进行各种搜索查询。您还可以根据自己的习惯在搜索框右侧的设置中更改百度的默认搜索设置,例如搜索框提示的设置,每页搜索结果的数量等等。高级搜索设置12 40013要使用百度的内置货币换算器,只需在百度网页的搜索框中键入您需要完成的货币换算,然后单击“输入”按钮或单击“百度点击”按钮。以下是一些搜索示例:100美元兑人民币多少钱? 1USD =?RMB 5人民币转换为新加坡货币1 4、百度会根据您的输入在搜索框底部实时显示最合适的提示词。您只需要使用鼠标单击所需的提示词,或使用键盘的向上和向下键选择所需的提示词,然后按Enter,将返回该单词的查询结果。您无需费劲地键入键盘即可轻松完成查询。如果输入拼音,百度会提示您最符合要求的汉字。例如,输入“ moshou”,“魔兽世界”,“魔兽”等将显示在搜索框提示中。如果输入错字,百度会提示您输入正确的单词。例如,输入“周杰伦”,“ Jay Chou”将显示在搜索框提示中。 查看全部
自学笔记第五章本章的重点网信息资源的特点、种类、信息利用价值
第5章Internet信息检索本章重点介绍Internet信息资源的特征,类型和信息利用价值。 Internet信息检索的基本知识,以及各种常用Internet信息检索工具的特征,比较,评估,使用和检索方法。本章的学习目的是使学习者培养网络信息搜索和使用的能力,并提高网络信息环境中信息发现和利用的水平。第1节Internet概述一、基本概念(自学)TCP / IP TCP / IP Internet WWWWWW WWW HTTP HTML HTML Internet HTTP是基于TCP / IP的协议,是用于分布式协作超媒体信息系统的快速实用的协议。它不仅需要确保超文本文档的正确传输,而且还必须能够确定传输文档的特定部分以及首先显示内容的哪一部分。在HTML中,可以嵌入图像,声音等,并且可以通过超链接无缝引用其他WWW URL资源。用HTML组织的信息文档称为页面,这些页面由浏览器解释,执行,显示和输出。浏览器:也称为浏览器,它是一种用于读取HTML文件的特殊软件系统。可以通过许多方法来获取信息,例如FTP,NNTP和Gopher。 URL可以将世界上所有的在线信息资源组织成一个有序的结构。它的格式包括三个部分:第一部分是协议(或服务模式),大多数Internet文档使用http,其他常用的协议是fp,news,gopher,telnet等。第三部分是主机资源的特定地址。
IP Internet上的许多计算机和信息资源必须通过名称和地址来标识。连接到Internet的计算机或节点被分配一个唯一的数字作为一个称为IP地址的地址,该地址由四组数字组成,这些数字组由小数点分隔。 IP地址通常是由Internet服务组织从Internet网络信息中心注册和应用的(例如:Central 20 2. 20 5. 21 3. 10 1)。IP是网络中的重要资源, IP地址数量表示可以连接到Internet的计算机的数量,由于IP地址由四组数字组成,因此不容易记住,因此Internet使用域名系统(DNS)作为域名的助记符。 Internet上的特定主机。Internet中每台计算机的域名结构是:主机名,组织名称,网络名称,顶级域名。域名由常规英语单词组成,非常容易记住,并且还可以根据域名组成规则猜测某个站点的域名。通用标准域名的结构为:主机名,组织名称,网络名称,顶级域名。顶级域名共有三个互联网域名中的一级域名n名称系统:第一种是国家域名,由两个英文字母组成,例如:“。CN(中国))”,“。JP(日本)”,“。US(美国)”,“”。 UK(UK)”,“。CA(Canada)”。第二类是国际域名,现在只有一个“ .INT”代表国际组织。
第三类是通用域名,目前使用的是——网络服务组织; .edu——教育部门; .web——网络服务组织; 。艺术-文化娱乐部门; .info— —信息部门; .rec——娱乐机构; .org——非营利组织; 。商店-销售部。公司-公司企业; .gov——政府部门; .com .——商业组织。mil——军事部门; .nom个人。中国的域名注册由国务院信息化领导小组办公室授权的中国互联网络信息中心(CNNIC)处理。例如:中央财经大学的网站是Internet(自学)www):万维网)HTML HTTP UsenetListserv邮件列表BBSBBS BBS BBS Archie):ArchieArchie Internet FTP Archie FTP WAISInternet GopherInternet Gopher 2040 20 50 WebCrawlerGoogle URL :URL是Internet上各种专门的计算机和文学资源的“地址”。通用格式为:与普通的网站不同,搜索引擎网站的主要资源是索引数据库。
其工作原理是通过采集并调用搜索引擎数据库来实现其导航功能。第2节Internet搜索引擎Internet Internet雅虎Internet googleAlta Vista WEBYahoo WebSearch Engine(UsenetSearch Engine(YellowPageSearch Engine(WhitePageSearch Engine(MetaSearchSearch((WordSearch)(SimpleSearch)(PhraseSearch)(SentenceSearch)(CatalogSearch)(分类搜索)(AdvancedSearch)))金属裂纹金属裂纹金属裂纹金属应力裂纹应力裂纹应力裂纹AltaVisa > GoldenRetriever AltaVisa ExicteAlta Visa可以检查的外国搜索引擎数量达到2500,其中有许多出色的综合搜索引擎,例如:Yahoo!,AltaVista,Excite,Infoseek,Lycos,HotBot, Google,OpenText等。
HotBot()是美国著名的综合搜索引擎。 FM365263 21cn TOM主要搜索引擎的第2部分Google()Google()Google目前是世界上最大的搜索引擎。它提供了70多种界面语言和35种搜索语言,包括分类查询和关键词搜索。特征。 (一)公司介绍GoogleGoogle Inc.纳斯达克GOOG 1998 GoogleGoogle 1999 2004 19Google Nasdaq GoogleGoogleplex‖Mountain View)SchmidtGoogle(二) Google GoogleGoogleGoogle Google Googol Googol“ 10100100google Google Googol爱德华·卡斯纳·米尔顿·西罗塔·爱德华·卡斯纳·詹姆斯·纽曼数学想象力谷歌谷歌谷歌谷歌谷歌谷歌谷歌这是谷歌的中文版本。
该服务器位于中国北京。通过Google页面显示,我们可以知道Google提供了三种设置功能:高级搜索,首选项和语言工具。 ([三)使用Google搜索GoogleEnter的基本知识” Google Google以明显的单词开头。例如,如果您要查找有关夏威夷的一般信息,则不妨尝试。如果您计划安排夏威夷度假,搜索会更好比单独搜索更好。搜索结果会更好。乔治华盛顿华盛顿乔治华盛顿谷歌谷歌谷歌Google默认情况下,谷歌只提供收录所有搜索词的页面。单词之间无需添加“和”。请记住,单词的顺序是键入将影响搜索结果。要进一步限制搜索,只需添加更多单词即可。例如,要安排去夏威夷度假,只需键入Google即可忽略常见的单词和字符,例如“ where”,“ how”和“的”和其他单个数字和字母会减慢搜索速度,但不能缩小查询范围并改善结果。如果必须使用通用词来获得所需的结果,则可以输入前面的“ +”号e单词号,将其包括在查询词中。低音音乐Googlegoogl googl *“ google” GOOGLE” Googlesite:Googlesite:12(StanfordUniversity)Stanford GoogleGoogle 1 3、使用高级搜索来缩小搜索范围。 Googlewhere需要找到两个单词。一个单词就足够了。请在单词之间添加大写字母“ OR”。
例如,要搜索伦敦或巴黎的度假信息,可以使用以下方法:Vacation London或Paris Google“站点”(斯坦福大学)(入学)录取站点:想查找数字吗?在数字范围内,您可以搜索收录指定范围内数字的结果。只需在搜索框中的搜索词后面加上两个数字,然后用两个英文句点(无空格)将它们分开即可。您可以使用“数字范围”来设置从日期(Willie Mays 195 0. .196 0)到重量(500 0. .10000 kg))的各种范围。但是,请务必指定单位US $ 50US $ 100 DVD DVD播放器$ 5 0.。$ 100 DVD DVD播放器$ 5 0.。$ 100(带下划线的项四)是您搜索的条件)由Google搜索引擎通过单词找到的搜索结果,列表中的第一个项目(“新闻”结果除外)是我们找到的最相关的匹配项,第二个项目是第二个最相关的匹配项,依此类推。单击任何带下划线的条目将为您打开关联的网页。(四)搜索结果GoogleGoogle Google GoogleEnter”单击链接以激活您要使用的Google服务。
您可以搜索网络,查找图片,浏览Google网上论坛,或单击“更多”链接以查看其他Google产品。 B.―单击此按钮可以提交另一个搜索查询。您也可以按“ Enter”键提交查询。 C.这将链接到一个页面,您可以在其中进行更精确的搜索。要在Google上进行搜索,只需输入一些描述性搜索字词,然后按“ Enter”键或单击“ Search”按钮即可。链接到可以设置个人搜索首选项(包括语言,每页结果数)的页面。该行描述了搜索,并指出了结果总数以及完成搜索所花费的时间。搜索结果项的第一行是找到的页面的标题。如果您看到的是URL而不是标题,则表明该页面没有标题,或者我们没有为页面的全部内容建立索引,但是其在索引中的位置仍然表明它很好地满足了您的查询要求。该数字表示您要查找的网页文本部分的大小,它使您可以在一定程度上了解显示时间。如果尚未完全建立索引的是网站,则不会显示尺寸编号。当我们上次索引相应页面时,单击链接将显示该页面的内容。如果由于某些原因网站链接无法链接到当前页面,您仍然可以通过页面快照的版本找到所需的信息。如果您为特定结果选择“相似页面”链接,则Google会在Internet上自动查找与该结果相关的页面。
1、高级搜索要改善搜索效果,您还可以在您在Google搜索框中输入的搜索词中添加“运算符”,或进入高级搜索页面。指定搜索词在网页上的显示位置,该位置可以在网页,标题,文本或URL中的任何位置。 2、首选项1)界面语言2)搜索语言谷歌谷歌Googletq“ TQ”谷歌2、股票报价使用Google查询股票价格和股票市场报价非常简单方便。您只需要输入要查询的股票或证券的名称或六位数代码,例如中国银行或601988,Google就会返回其他链接,以便您可以通过以下方式获取有关股票和证券的详细信息:只需单击一下。 3、参考工具11第3节主搜索引擎Beta 2001 10 22百度200312百度搜索既简单又方便。您只需要在搜索框中输入要查询的内容,按Enter键,或单击搜索框右侧的百度搜索按钮,即可获得最能满足您的查询要求的Web内容。输入多个单词进行搜索(不同的单词用空格隔开),可以获得更精确的搜索结果。例如:如果您想了解上海人民公园的相关信息,则在搜索框中输入[上海人民公园]会比输入[人民公园]获得更好的搜索结果。 2 intitle:Intitle日常工作和娱乐需要大量软件,许多软件是共享或免费的,可以在Internet上免费下载。
这是最直接的方法。软件名称加上特征词“下载”通常可以快速找到下载点。示例:flashget下载由于网站的质量不均匀,下载速度会有所不同。如果我们积累了一些有用的下载站点(例如Skynet,,Computer Home等),则可以使用站点语法将搜索范围限制为网站,以提高搜索效率。示例:Flash Express站点:提示:一旦搜索范围仅限于专业下载站点,则不必在查询词中显示功能词“下载”。 IEIE xxxxxx” xxxxxx” OfficePDF PDF文件类型PDF DOC XLS xxxxintitle Fansite官方网站Fans网站标题:13 PDFsite mp3site:DT231DT231”如果您熟悉该产品,则还可以使用产品名称和细化要求来形成查询词来进行搜索。例如,我需要找到一个带钻石管的19英寸显示器(特征是19英寸和钻石管)。因此,您可以像这样搜索:示例:19英寸显示器Diamond CRT 14站点:16 apple” Windowslog((sin(5))^ 2) -3 + pi filetypeFiletype:” DOC XLS PPT PDF RTF ALL ALL文件类型: doc‖在百度搜索框中输入股票代码,火车号或航班号,您可以直接获取相关信息。
例如,输入SDB的股票代码“ 000001”,SDB股票的实时报价将显示在搜索结果的顶部。 10 ——intitleintitle:intitle:——sitemsn site:site:‖‖site:url——inurl photoshop photoshop inurl:jiqiaophotoshop‖jiqiao‖url inurl:11如果您不熟悉百度的各种查询语法,则可以使用百度集成了高级搜索界面,您可以方便地进行各种搜索查询。您还可以根据自己的习惯在搜索框右侧的设置中更改百度的默认搜索设置,例如搜索框提示的设置,每页搜索结果的数量等等。高级搜索设置12 40013要使用百度的内置货币换算器,只需在百度网页的搜索框中键入您需要完成的货币换算,然后单击“输入”按钮或单击“百度点击”按钮。以下是一些搜索示例:100美元兑人民币多少钱? 1USD =?RMB 5人民币转换为新加坡货币1 4、百度会根据您的输入在搜索框底部实时显示最合适的提示词。您只需要使用鼠标单击所需的提示词,或使用键盘的向上和向下键选择所需的提示词,然后按Enter,将返回该单词的查询结果。您无需费劲地键入键盘即可轻松完成查询。如果输入拼音,百度会提示您最符合要求的汉字。例如,输入“ moshou”,“魔兽世界”,“魔兽”等将显示在搜索框提示中。如果输入错字,百度会提示您输入正确的单词。例如,输入“周杰伦”,“ Jay Chou”将显示在搜索框提示中。
学会更多的搜索技巧提升你10倍的网络搜索能力
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-05-11 04:13
很多时候搜索结果都不令人满意。原因是不能有效地使用搜索引擎的查询指令。因此,学习更多搜索技能可以将您的网络搜索能力大大提高10倍
1、双引号,即通过“”来实现准确的搜索
在要搜索的关键词中添加双引号(“”)。这意味着精确匹配搜索,甚至顺序完全匹配。也就是说,搜索引擎只会返回与关键词完全相同的搜索结果,以达到准确搜索的效果。
如果没有两个引号,则两个单词之间如果有空格,它将分别搜索两个单词,返回的结果可能不是我们想要的结果。
2、减号,即通过“-”排除关键词
如果您不想在搜索结果中看到某些内容关键词,则可以使用-号减号来排除指定的内容。
减号(-)表示搜索不收录减号后面的单词的页面。使用减号(-)命令时,减号前必须有一个空格,减号后必须没有空格,然后是需要排除的单词。
注意:“-”前必须有一个空格。
3、星号,即按*(通配符)搜索
要搜索成语或段落时,只需记住两个或三个单词或其中的某个段落,然后可以使用通配符星号(*)进行搜索,并用*单词替换被遗忘的内容。
4、站点在指定的网站中搜索内容
在输入框中输入site:URL关键字,然后将在输入的URL中执行site关键字搜索。
当您要在某个网站上搜索关键词(例如亚马逊网站)时,可以使用“ site:medical masks”或“ medical masks site:”,因此搜索结果将是Amazon [收录关于k14医用口罩的所有内容]。
site:是最常用的SEO高级搜索命令,用于搜索特定域名下的所有文件。
与5、相关:找到类似的相关网站
根据网站查找相似的站点,使用:Related ::,返回的结果是与某个网站相关的页面。
6、文件类型搜索指定的文件类型
修饰符文件类型:[文件扩展名]可用于搜索指定的文件类型。例如,搜索filetype:pdfmedical masks将返回所有收录医疗口罩关键词的pdf文件。
Google支持所有可索引的文件格式,包括HTML,PHP等。
7、 inurl,搜索在URL中显示关键词的页面。
inurl此命令用于搜索URL中出现关键词的页面。例如,搜索:inurl:medicalmasks返回URL URL中收录“ medicalmasks”的所有页面。
8、标题页面标题收录多组关键词文件
标题标题:搜索返回页面标题中收录多组关键词的文件。例如:allintitle:医用口罩等效于:intitle:医用intitle:口罩返回标题中同时收录“ medical”和“ masks”的页面
9、 allinurl类似
allinurl:医用口罩等效于:inurl:医用inurl:口罩
1 0、锚定导入链接的锚文本中带有搜索词的页面
inanchor:该命令返回的结果是导入在链接的锚文本中收录搜索词的页面。例如,如果您搜索:inanchor:“ medical mask”,则返回的结果是四个单词“ medical mask”出现在这些页面的链接的锚点文本中。 查看全部
学会更多的搜索技巧提升你10倍的网络搜索能力
很多时候搜索结果都不令人满意。原因是不能有效地使用搜索引擎的查询指令。因此,学习更多搜索技能可以将您的网络搜索能力大大提高10倍
1、双引号,即通过“”来实现准确的搜索
在要搜索的关键词中添加双引号(“”)。这意味着精确匹配搜索,甚至顺序完全匹配。也就是说,搜索引擎只会返回与关键词完全相同的搜索结果,以达到准确搜索的效果。
如果没有两个引号,则两个单词之间如果有空格,它将分别搜索两个单词,返回的结果可能不是我们想要的结果。
2、减号,即通过“-”排除关键词
如果您不想在搜索结果中看到某些内容关键词,则可以使用-号减号来排除指定的内容。
减号(-)表示搜索不收录减号后面的单词的页面。使用减号(-)命令时,减号前必须有一个空格,减号后必须没有空格,然后是需要排除的单词。
注意:“-”前必须有一个空格。
3、星号,即按*(通配符)搜索
要搜索成语或段落时,只需记住两个或三个单词或其中的某个段落,然后可以使用通配符星号(*)进行搜索,并用*单词替换被遗忘的内容。
4、站点在指定的网站中搜索内容
在输入框中输入site:URL关键字,然后将在输入的URL中执行site关键字搜索。
当您要在某个网站上搜索关键词(例如亚马逊网站)时,可以使用“ site:medical masks”或“ medical masks site:”,因此搜索结果将是Amazon [收录关于k14医用口罩的所有内容]。
site:是最常用的SEO高级搜索命令,用于搜索特定域名下的所有文件。
与5、相关:找到类似的相关网站
根据网站查找相似的站点,使用:Related ::,返回的结果是与某个网站相关的页面。
6、文件类型搜索指定的文件类型
修饰符文件类型:[文件扩展名]可用于搜索指定的文件类型。例如,搜索filetype:pdfmedical masks将返回所有收录医疗口罩关键词的pdf文件。
Google支持所有可索引的文件格式,包括HTML,PHP等。
7、 inurl,搜索在URL中显示关键词的页面。
inurl此命令用于搜索URL中出现关键词的页面。例如,搜索:inurl:medicalmasks返回URL URL中收录“ medicalmasks”的所有页面。
8、标题页面标题收录多组关键词文件
标题标题:搜索返回页面标题中收录多组关键词的文件。例如:allintitle:医用口罩等效于:intitle:医用intitle:口罩返回标题中同时收录“ medical”和“ masks”的页面
9、 allinurl类似
allinurl:医用口罩等效于:inurl:医用inurl:口罩
1 0、锚定导入链接的锚文本中带有搜索词的页面
inanchor:该命令返回的结果是导入在链接的锚文本中收录搜索词的页面。例如,如果您搜索:inanchor:“ medical mask”,则返回的结果是四个单词“ medical mask”出现在这些页面的链接的锚点文本中。
怎么怎么网站建设才符合搜索引擎的要求呢??
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-05-10 21:22
网站在构建过程中,他们都希望拥有较高的排名和强大的营销能力。想要达到这个目的必须通过搜索引擎获得。那么网站的结构如何满足搜索引擎的要求?让我们在下面一起分析它。
首先,网站在构造过程中使用桌子结构时要小心。由于表单的布局功能相对完整,并且可以指定文档或图片的位置,因此许多网站管理员在构建网站时都会使用该表单。但是,在浏览表结构时,从内部到外部进行说明,然后说明内容。因此,表加载非常慢,因此用户体验自然会下降。因此,为了满足搜索引擎的要求,请尽量不要使用表格布局。
第二、部分充分发挥了meta的作用。每个网站都有一个meta部分,该部分的结构主要包括网站的标题,关键字和描述。当许多公司网站在建设时,meta是空白的,他们没有意识到meta的重要性。因此,如果您想请搜索引擎,则必须掌握meta部分。将网站的核心产品和关键字放在此处,让搜索引擎在短时间内知道网站的要点。
第三、 网站条在搜索引擎的构建中应注意图片的设计。在网站的构造中,有许多因素会影响网站的加载速度,图片是主要因素。应用图片时,可以压缩图片而不影响网站的视觉效果。
四、 网站部分正在编写构造代码。如果使用的字体大小相同,则可以使用样式表进行定义,因此可以减少代码的编写。同时,善于使用默认值来减少一些重复的定义。
网站如果要满足搜索引擎的需求,可以参考上述方面。为了使网站获得更好的排名,重要的工作是结合搜索引擎的算法来构建,以便网站能够吸引用户。如果排名更高,则网站的构造就有意义。 查看全部
怎么怎么网站建设才符合搜索引擎的要求呢??
网站在构建过程中,他们都希望拥有较高的排名和强大的营销能力。想要达到这个目的必须通过搜索引擎获得。那么网站的结构如何满足搜索引擎的要求?让我们在下面一起分析它。
首先,网站在构造过程中使用桌子结构时要小心。由于表单的布局功能相对完整,并且可以指定文档或图片的位置,因此许多网站管理员在构建网站时都会使用该表单。但是,在浏览表结构时,从内部到外部进行说明,然后说明内容。因此,表加载非常慢,因此用户体验自然会下降。因此,为了满足搜索引擎的要求,请尽量不要使用表格布局。
第二、部分充分发挥了meta的作用。每个网站都有一个meta部分,该部分的结构主要包括网站的标题,关键字和描述。当许多公司网站在建设时,meta是空白的,他们没有意识到meta的重要性。因此,如果您想请搜索引擎,则必须掌握meta部分。将网站的核心产品和关键字放在此处,让搜索引擎在短时间内知道网站的要点。
第三、 网站条在搜索引擎的构建中应注意图片的设计。在网站的构造中,有许多因素会影响网站的加载速度,图片是主要因素。应用图片时,可以压缩图片而不影响网站的视觉效果。
四、 网站部分正在编写构造代码。如果使用的字体大小相同,则可以使用样式表进行定义,因此可以减少代码的编写。同时,善于使用默认值来减少一些重复的定义。
网站如果要满足搜索引擎的需求,可以参考上述方面。为了使网站获得更好的排名,重要的工作是结合搜索引擎的算法来构建,以便网站能够吸引用户。如果排名更高,则网站的构造就有意义。
老猿利用Python爬虫知识写个简单应用自己查找小说最新更新
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-05-10 21:17
老猿利用Python爬虫知识写个简单应用自己查找小说最新更新
一、简介
这个五月天假期,我开车回到家乡,而这个国家并没有在家里安装宽带,所以我使用手机热点来访问Internet。这次我回去,觉得4G信号不如以前。通过百度找到小说的最新更新并打开小说网站的过程非常缓慢。有时,要花费很多网页才能找到可以正常打开的最新更新。为了避免懒惰,老袁决定使用Python采集器知识编写一个简单的应用程序,以查找小说的最新更新并以最快的速度访问网站。他花了一些时间研究相关消息。经过将近一天的研究和写作,终于完成了,让我们介绍整个过程。
二、关于相关的访问请求和响应消息2. 1、百度搜索请求
当我们在百度网页的搜索框中进行搜索时,提交的网址请求如下:
https://www.baidu.com/s?wd=搜索词&pn=10&rn=50
请求的网址是,带有三个参数:
2. 2、百度返回搜索结果
确定百度返回的搜索结果的方法有很多,老袁认为最简单的方法如下:
以小说“ Qing Ping”为例,查看返回的记录之一:
青萍最新章节,青萍免费阅读 - 大神小说网
整个搜索返回的结果在h3的标记中,返回的搜索结果对应的url在a的标记中,并且特定的URL由href指定。此处返回的网址实际上是百度重定向地址。您可以通过打开url访问相应的网站,并通过返回响应消息来获取真实的网站 URL。
2. 3、 novel 网站关于最新的更新显示和html消息格式
根据对旧猿的分析,约有30%的小说网站显示了与以下内容相似的最新更新章节:
首先,有类似的提示词,例如“最新章节”或“最新更新”或“最新更新”。提示词后是一个链接,显示最新章节的章节号和章节名称,相应的消息类似于以下内容:
最新章节:第729章 就是给你们看看的
此消息的特征是:
“最新章节”的文字信息与小说最新章节的链接位于同一父标记中。此外,应注意,返回的章节网址不是绝对地址,而是小说网站的相对地址。
老袁对小说最新章节的搜索是基于上述格式的,因此,实际上,该程序最终获得的小说网站仅占整个搜索结果的30%左右,但对于阅读小说。
三、实施思路和代码3. 1、根据网址获取网站名称
def getHostName(url):
httpPost = url[10:]
hostName = url[:10]+httpPost.split('/')[0]
return hostName
3. 2、根据百度的返回搜索结果地址,打开网站以获取新颖信息
基于2.的第3部分介绍的小说网站的返回内容,让我们根据百度返回的搜索结果的URL打开相应的小说网站,并计算从开始算起的时间请求返回响应的结果:
def getNoteInfo(url):
"""
打开指定小说网页URL获取最新章节信息
url:百度搜索结果指定的搜索匹配记录的url
返回该URL对应的章节ID、打开耗时、网站真正URL、网站主机名、章节相对url、章节名
"""
head = mkhead()
start = time.time_ns()
req = urllib.request.Request(url=url, headers=head)
try:
resp = urllib.request.urlopen(req,timeout=2)
#根据响应头获取真正的网页URL对应的网站名
hostName = getHostName(resp.url)
text = resp.read()
#网页编码有2种:utf-8和GBK
pageText = text.decode('utf-8')
except UnicodeDecodeError:
pageText = text.decode('GBK')
except Exception as e:
errInf = f"打开网站 {url} 失败,异常原因:\n{e}\n" + '\n' + traceback.format_exc() + '\n'
logPag(errInf, False)
return None
#最新章节的HTML报文类似: '<p>最新章节:第672章 天之关梁'
end = time.time_ns()
soup = BeautifulSoup(pageText, 'lxml')
# 根据最新章节的提示信息搜索最新章节
result = soup.find_all(string=re.compile(r'最新更新[::]|最新章节[::]|最近更新[::]|最新[::]'))
found = False
for rec in result:
recP = rec.parent
pa = recP.a
matchs = re.match(r'(?:最新更新|最新章节|最近更新|最新)[::]第(.+)章(.+)', recP.text)
if not matchs:return None
groups = matchs.groups()
if matchs and pa is not None:
found = True
chapter = toInt(groups[0]) #章节序号
chapterName = groups[1] #章节名
chaperUrl = pa.attrs['href'] #章节相对URL
break
if not found:
return None
cost = (end - start) / 1000000 #网页打开耗时计算
return (chapter,cost,resp.url,hostName,chaperUrl,chapterName)
</p>
注意:由于网站的访问响应条件不同,因此在打开网页时需要设置超时,以免访问速度慢网站从而延迟总体访问时间。
3. 3、获取小说网页的绝对URL地址
在返回的信息中合并相对URL和网站名称,以将网页的绝对URL地址拼凑在一起:
def getChapterUrl(noteInf):
chapter, cost, url, hostName, chaperUrl, chapterName = noteInf
if chaperUrl.strip().startswith('http'):return chaperUrl
elif chaperUrl.strip().startswith('/'):return hostName.strip()+chaperUrl.strip()
else:return hostName.strip()+'/'+chaperUrl.strip()
3. 4、计算排序权重
根据从新颖网页中搜索到的信息计算排名权重,以确保最新的章节排名第一,而访问速度最快的相同章节网站排名第一。
def noteWeight(n):
#入参n为小说信息元组: chapter, cost, url, hostName, chaperUrl, chapterName
ch,co = n[:2]
w = ch * 100000 + min(99999, 100000 / co)
return w
3. 5、执行百度搜索并分析搜索结果。参观小说网站最新更新
根据搜索词在百度上进行搜索,并以最新的章节和访问速度最快的前5个网站 url进行输出:
def BDSearchUsingChrome(inputword,maxCount=150):
"""
输出相关搜索结果中具有最新章节且访问速度最快的前5个网站url
:param word: 搜索关键词,如小说名、小说名+作者名等
:param maxCount: 最多处理的搜索记录数
:return: None
"""
#百度请求url类似:https://www.baidu.com/s?wd=青萍&pn=10&rn=50
rn = 50 #每页50条记录
#构建请求头模拟本机谷歌浏览器访问百度网页
head = mkheadByHostForChrome('baidu.com')
word = urllib.parse.quote(inputword)
urlPagePre = 'https://www.baidu.com/s%3Fwd%3 ... 39%3B
pageCount = int(0.999+maxCount/rn)
validNoteInf = []
seq = 0
logPag("开始执行搜索...")
for page in range(pageCount):
pn = rn*page
urlPage = urlPagePre+str(pn)
pageReq = urllib.request.Request(url=urlPage, headers=head)
pageResp = urllib.request.urlopen(pageReq,timeout=2)
pageText = pageResp.read().decode()
if pageResp.status == 200:
soup = BeautifulSoup(pageText,'lxml')
links = soup.select('h3.t a[href^="http://www.baidu.com/link?url="]')
for l in links:
noteInf = getNoteInfo(l.attrs['href'])
seq += 1
if noteInf is None:
#print(seq,'、',l.attrs['href'],None)
logPag(f"{seq}、{l.attrs['href']}:查找最新章节失败,忽略",True)
else:
logPag(f"{seq}、返回小说信息: {noteInf}",True)
#chapter,cost,url,hostName,chaperUrl,chapterName = noteInf
validNoteInf.append(noteInf)
validNoteInf.sort(key=noteWeight,reverse=True)
print(f"小说: {inputword} 最新更新访问最快的5个网站是:")
for l in validNoteInf[:5]:#输出相关搜索结果中具有最新章节且访问速度最快的前5个网站url
print(f"{validNoteInf.index(l)+1}、第{l[0]}章 {l[-1]} {getChapterUrl(l)} ,网页打开耗时 {l[1]} 毫秒")
input("按回车键退出!")
四、搜索案例
以在月关岛进行的清平搜索为例,执行搜索的语句为:
BDSearchUsingChrome('青萍月关',150)
执行结果:
小说: 青萍月关 最新更新访问最快的5个网站是:
1、第688章 东边日出西边雨 http://www.huaxiaci.com/41620/37631250.html ,网页打开耗时 262.0 毫秒
2、第688章 东边日出西边雨 http://www.huaxiaci.com/41620/37631250.html ,网页打开耗时 278.0 毫秒
3、第688章 东边日出西边雨 http://www.huaxiaci.com/41620/37631250.html ,网页打开耗时 345.5 毫秒
4、第688章 东边日出西边雨 https://www.24kwx.com/book/9/9202/8889236.html ,网页打开耗时 774.0 毫秒
5、第688章 东边日出西边雨 https://www.27kk.net/9526/2658932.html ,网页打开耗时 800.5 毫秒
按回车键退出!
五、摘要
本文介绍了使用Python搜索指定小说的最新更新章节和最快访问权限的实现思路和关键应用代码网站,实现了对小说的最新更新章节的自动搜索,并获得了最快的访问权限网站。由于上述实现已经获得了最新章节的链接,因此,如果您有一点改进,可以直接下载最新章节以在本地观看。
写博客并不容易,请支持: 查看全部
老猿利用Python爬虫知识写个简单应用自己查找小说最新更新
一、简介
这个五月天假期,我开车回到家乡,而这个国家并没有在家里安装宽带,所以我使用手机热点来访问Internet。这次我回去,觉得4G信号不如以前。通过百度找到小说的最新更新并打开小说网站的过程非常缓慢。有时,要花费很多网页才能找到可以正常打开的最新更新。为了避免懒惰,老袁决定使用Python采集器知识编写一个简单的应用程序,以查找小说的最新更新并以最快的速度访问网站。他花了一些时间研究相关消息。经过将近一天的研究和写作,终于完成了,让我们介绍整个过程。
二、关于相关的访问请求和响应消息2. 1、百度搜索请求
当我们在百度网页的搜索框中进行搜索时,提交的网址请求如下:
https://www.baidu.com/s?wd=搜索词&pn=10&rn=50
请求的网址是,带有三个参数:
2. 2、百度返回搜索结果
确定百度返回的搜索结果的方法有很多,老袁认为最简单的方法如下:
以小说“ Qing Ping”为例,查看返回的记录之一:
青萍最新章节,青萍免费阅读 - 大神小说网
整个搜索返回的结果在h3的标记中,返回的搜索结果对应的url在a的标记中,并且特定的URL由href指定。此处返回的网址实际上是百度重定向地址。您可以通过打开url访问相应的网站,并通过返回响应消息来获取真实的网站 URL。
2. 3、 novel 网站关于最新的更新显示和html消息格式
根据对旧猿的分析,约有30%的小说网站显示了与以下内容相似的最新更新章节:
首先,有类似的提示词,例如“最新章节”或“最新更新”或“最新更新”。提示词后是一个链接,显示最新章节的章节号和章节名称,相应的消息类似于以下内容:
最新章节:第729章 就是给你们看看的
此消息的特征是:
“最新章节”的文字信息与小说最新章节的链接位于同一父标记中。此外,应注意,返回的章节网址不是绝对地址,而是小说网站的相对地址。
老袁对小说最新章节的搜索是基于上述格式的,因此,实际上,该程序最终获得的小说网站仅占整个搜索结果的30%左右,但对于阅读小说。
三、实施思路和代码3. 1、根据网址获取网站名称
def getHostName(url):
httpPost = url[10:]
hostName = url[:10]+httpPost.split('/')[0]
return hostName
3. 2、根据百度的返回搜索结果地址,打开网站以获取新颖信息
基于2.的第3部分介绍的小说网站的返回内容,让我们根据百度返回的搜索结果的URL打开相应的小说网站,并计算从开始算起的时间请求返回响应的结果:
def getNoteInfo(url):
"""
打开指定小说网页URL获取最新章节信息
url:百度搜索结果指定的搜索匹配记录的url
返回该URL对应的章节ID、打开耗时、网站真正URL、网站主机名、章节相对url、章节名
"""
head = mkhead()
start = time.time_ns()
req = urllib.request.Request(url=url, headers=head)
try:
resp = urllib.request.urlopen(req,timeout=2)
#根据响应头获取真正的网页URL对应的网站名
hostName = getHostName(resp.url)
text = resp.read()
#网页编码有2种:utf-8和GBK
pageText = text.decode('utf-8')
except UnicodeDecodeError:
pageText = text.decode('GBK')
except Exception as e:
errInf = f"打开网站 {url} 失败,异常原因:\n{e}\n" + '\n' + traceback.format_exc() + '\n'
logPag(errInf, False)
return None
#最新章节的HTML报文类似: '<p>最新章节:第672章 天之关梁'
end = time.time_ns()
soup = BeautifulSoup(pageText, 'lxml')
# 根据最新章节的提示信息搜索最新章节
result = soup.find_all(string=re.compile(r'最新更新[::]|最新章节[::]|最近更新[::]|最新[::]'))
found = False
for rec in result:
recP = rec.parent
pa = recP.a
matchs = re.match(r'(?:最新更新|最新章节|最近更新|最新)[::]第(.+)章(.+)', recP.text)
if not matchs:return None
groups = matchs.groups()
if matchs and pa is not None:
found = True
chapter = toInt(groups[0]) #章节序号
chapterName = groups[1] #章节名
chaperUrl = pa.attrs['href'] #章节相对URL
break
if not found:
return None
cost = (end - start) / 1000000 #网页打开耗时计算
return (chapter,cost,resp.url,hostName,chaperUrl,chapterName)
</p>
注意:由于网站的访问响应条件不同,因此在打开网页时需要设置超时,以免访问速度慢网站从而延迟总体访问时间。
3. 3、获取小说网页的绝对URL地址
在返回的信息中合并相对URL和网站名称,以将网页的绝对URL地址拼凑在一起:
def getChapterUrl(noteInf):
chapter, cost, url, hostName, chaperUrl, chapterName = noteInf
if chaperUrl.strip().startswith('http'):return chaperUrl
elif chaperUrl.strip().startswith('/'):return hostName.strip()+chaperUrl.strip()
else:return hostName.strip()+'/'+chaperUrl.strip()
3. 4、计算排序权重
根据从新颖网页中搜索到的信息计算排名权重,以确保最新的章节排名第一,而访问速度最快的相同章节网站排名第一。
def noteWeight(n):
#入参n为小说信息元组: chapter, cost, url, hostName, chaperUrl, chapterName
ch,co = n[:2]
w = ch * 100000 + min(99999, 100000 / co)
return w
3. 5、执行百度搜索并分析搜索结果。参观小说网站最新更新
根据搜索词在百度上进行搜索,并以最新的章节和访问速度最快的前5个网站 url进行输出:
def BDSearchUsingChrome(inputword,maxCount=150):
"""
输出相关搜索结果中具有最新章节且访问速度最快的前5个网站url
:param word: 搜索关键词,如小说名、小说名+作者名等
:param maxCount: 最多处理的搜索记录数
:return: None
"""
#百度请求url类似:https://www.baidu.com/s?wd=青萍&pn=10&rn=50
rn = 50 #每页50条记录
#构建请求头模拟本机谷歌浏览器访问百度网页
head = mkheadByHostForChrome('baidu.com')
word = urllib.parse.quote(inputword)
urlPagePre = 'https://www.baidu.com/s%3Fwd%3 ... 39%3B
pageCount = int(0.999+maxCount/rn)
validNoteInf = []
seq = 0
logPag("开始执行搜索...")
for page in range(pageCount):
pn = rn*page
urlPage = urlPagePre+str(pn)
pageReq = urllib.request.Request(url=urlPage, headers=head)
pageResp = urllib.request.urlopen(pageReq,timeout=2)
pageText = pageResp.read().decode()
if pageResp.status == 200:
soup = BeautifulSoup(pageText,'lxml')
links = soup.select('h3.t a[href^="http://www.baidu.com/link?url="]')
for l in links:
noteInf = getNoteInfo(l.attrs['href'])
seq += 1
if noteInf is None:
#print(seq,'、',l.attrs['href'],None)
logPag(f"{seq}、{l.attrs['href']}:查找最新章节失败,忽略",True)
else:
logPag(f"{seq}、返回小说信息: {noteInf}",True)
#chapter,cost,url,hostName,chaperUrl,chapterName = noteInf
validNoteInf.append(noteInf)
validNoteInf.sort(key=noteWeight,reverse=True)
print(f"小说: {inputword} 最新更新访问最快的5个网站是:")
for l in validNoteInf[:5]:#输出相关搜索结果中具有最新章节且访问速度最快的前5个网站url
print(f"{validNoteInf.index(l)+1}、第{l[0]}章 {l[-1]} {getChapterUrl(l)} ,网页打开耗时 {l[1]} 毫秒")
input("按回车键退出!")
四、搜索案例
以在月关岛进行的清平搜索为例,执行搜索的语句为:
BDSearchUsingChrome('青萍月关',150)
执行结果:
小说: 青萍月关 最新更新访问最快的5个网站是:
1、第688章 东边日出西边雨 http://www.huaxiaci.com/41620/37631250.html ,网页打开耗时 262.0 毫秒
2、第688章 东边日出西边雨 http://www.huaxiaci.com/41620/37631250.html ,网页打开耗时 278.0 毫秒
3、第688章 东边日出西边雨 http://www.huaxiaci.com/41620/37631250.html ,网页打开耗时 345.5 毫秒
4、第688章 东边日出西边雨 https://www.24kwx.com/book/9/9202/8889236.html ,网页打开耗时 774.0 毫秒
5、第688章 东边日出西边雨 https://www.27kk.net/9526/2658932.html ,网页打开耗时 800.5 毫秒
按回车键退出!
五、摘要
本文介绍了使用Python搜索指定小说的最新更新章节和最快访问权限的实现思路和关键应用代码网站,实现了对小说的最新更新章节的自动搜索,并获得了最快的访问权限网站。由于上述实现已经获得了最新章节的链接,因此,如果您有一点改进,可以直接下载最新章节以在本地观看。
写博客并不容易,请支持:
搜索指定网站内容会查看往期更新就看你的是源于什么
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-05-09 22:04
搜索指定网站内容会查看往期更新就看你的是是源于什么网站的浏览内容,以及现在要去的网站是否更新,即时性太差的话也可以想办法查看哪些是此网站的首页内容,
同疑惑。点开搜索框会一直显示往期回答但是总没耐心看完。可能每个网站的首页内容都是会保持一定的更新频率的,我认为应该不算打扰我看下一个网站吧。就像随手查看公众号的文章,
目前我就是两个网站同时查看的,各自显示前一个网站的。然后点击首页的内容显示:点击不知道什么网站的首页内容时,首页会出现一些无聊的东西,不过他只是提供一个下拉页面的功能,并不会来回跳转的,所以即使没有下拉页面的内容,它也只是显示首页内容的。
当然不会啊,每个网站的首页都是要更新内容,每个网站都会给内容做权重加权和一定的数量内容的,如果都是一样数量的内容,会有冲突。如果每个网站的首页都有不同的内容,即使你以一种方式来查看这个网站,你也会觉得另一种方式更好一些,
两个网站是同时查看的,会同时显示前一个网站的内容,这个和知乎的模式差不多,多少内容在哪里更新,第一个网站是知乎的哪个页面,当你输入关键词进去的时候,
不算。这是根据网站页面内容的历史数据来加权计算的。另外既然都是每个网站首页都会有一个查看历史内容的按钮,你也可以选择使用另一个网站内容的记录查看。我的实际经验来看:用一个网站查看历史内容可以提高你在另一个网站的查看效率和体验度,这是保证了一定的网站搜索体验。 查看全部
搜索指定网站内容会查看往期更新就看你的是源于什么
搜索指定网站内容会查看往期更新就看你的是是源于什么网站的浏览内容,以及现在要去的网站是否更新,即时性太差的话也可以想办法查看哪些是此网站的首页内容,
同疑惑。点开搜索框会一直显示往期回答但是总没耐心看完。可能每个网站的首页内容都是会保持一定的更新频率的,我认为应该不算打扰我看下一个网站吧。就像随手查看公众号的文章,
目前我就是两个网站同时查看的,各自显示前一个网站的。然后点击首页的内容显示:点击不知道什么网站的首页内容时,首页会出现一些无聊的东西,不过他只是提供一个下拉页面的功能,并不会来回跳转的,所以即使没有下拉页面的内容,它也只是显示首页内容的。
当然不会啊,每个网站的首页都是要更新内容,每个网站都会给内容做权重加权和一定的数量内容的,如果都是一样数量的内容,会有冲突。如果每个网站的首页都有不同的内容,即使你以一种方式来查看这个网站,你也会觉得另一种方式更好一些,
两个网站是同时查看的,会同时显示前一个网站的内容,这个和知乎的模式差不多,多少内容在哪里更新,第一个网站是知乎的哪个页面,当你输入关键词进去的时候,
不算。这是根据网站页面内容的历史数据来加权计算的。另外既然都是每个网站首页都会有一个查看历史内容的按钮,你也可以选择使用另一个网站内容的记录查看。我的实际经验来看:用一个网站查看历史内容可以提高你在另一个网站的查看效率和体验度,这是保证了一定的网站搜索体验。
网站运营需要什么样的神技能?怎么做运营?
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-05-08 04:01
1.了解行业并做网站在操作之前,您必须了解整个行业,掌握该行业的发展趋势,目标必须跟随该行业的发展,了解整个行业的知识,以便您可以制定目标和计划。更清晰,更准确。 网站优化有助于增加网站的权重,这有利于网站 关键词的排名和点击量。在当前流量下降的情况下,努力进行网站优化确实是有帮助的。
3.页面计划技巧网站操作不可避免地必须计划许多特殊页面。这是事件页面计划过程的一般说明。首先,明确事件的目的,并确保整个事件页面的逻辑清晰。 4.负责网站的内容合作和资源交换,旨在改善网站的数据指标。
2.负责网站主题内容,列页面和事件页面内容的制作,运行和维护。 6.合作谈判能力有时需要与其他网站合作以交换数量,交换资源等,所有这些都需要一定的沟通和谈判能力,但同时也要弄清您的目的和资源,并思考您需要什么资源以及可以获取什么样的资源,希望在游戏中尽可能多地获取自己的资源以实现自己的目标。 网站运营工作也更加复杂,涉及很多内容。互联网运营学院()可能并不全面。这些工作技能被认为是必要的,可以帮助提高流量和用户。我希望这足以给您一些操作灵感。让我们来谈谈网站今天的操作需要什么样的神技能? 一、 网站操作的定义我根据网站操作的工作内容来定义此概念,该工作重点是网站平台,以增加网站,网站流量和网站位用户的数量。进行了一系列工作。
5.数据分析功能当前,许多网站统计工具都可以查看网站数据,包括百度统计,网站管理员统计和51种统计。有必要整理出每日访问者数量,访问次数和每日top10 关键词等数据,总结和分析关键词信息并浏览输入网站的浏览数据,然后使用这些数据进行分析网站的运行状态,并分析网站的哪些方面需要进一步加强。 2.文案写作技巧文案写作是网站操作的基本知识。 网站基本的内容采集,分类,组织和排版技能是必要的。好的网站操作需要强大的文案技巧和连续的内容输出,例如网站标题,页面标题,页面计划,列内容等,在许多地方都需要出色的文案技巧。
4. 网站最优化知识网站最知名的人是最优化的:内容为准,外部链接为准,但这远不止于此,更多的是在确保内容和网站的基础上]结构建立网站内部和外部链接,合理布局网站结构,优化网站代码和关键词分布,并最大程度地简化搜索引擎抓取的过程。 二、 网站的工作内容也基于网站平台,包括内容输出,事件计划,内容合作和路况数据分析。主要目的是增加流量并维护用户。我的工作内容大致如下:1.制定网站内容输出计划,完善内容编辑计划,并确保内容输出质量。
在每个人都是自媒体的时代,自媒体平台已受到许多公司的青睐,并且公司已开始转移内容运营位置。企业网站运营的工作已逐渐被忽略,但是内容运营的本质与本质相同。 3.掌握行业的发展趋势和竞争对手的动态,并制定相应的经营策略。
5.负责网站流量统计,摘要,排序和分析,并及时记录,反馈和跟踪发现的问题。 三、 网站操作所需的工作技能想要在操作中做好网站操作并不容易,您需要具有出色的操作知识和工作技能,才能确保网站连续运行并保持快速发展。第四,页面可访问性是最主要的低级问题,我们在优化过程中容易出现此问题,例如缓慢的网页打开速度,混乱的网页布局,有时甚至是网页停机。 网站由网页组成,以确保网页的合理布局和正常访问是每个网站管理员都需要做的工作,这需要我们甚至在网站优化之前就选择空间提供商或服务器。其次,页面的内容是否可以满足用户的需求,并且没有做出很多不可读的文章来进行优化和大肆挥霍。其次,优化页面访问量有效订单转换率的关键是增加网站的有价值的访问量。这是作者今天谈到的第二个要素。随着流量的增长,特别是对于企业而言网站,我们最终将重点放在转化上。在这里,我们必须从两个方面进行分析和思考。首先是优化更有价值的东西,例如辅助关键词,长尾词和相关词关键词,以通过优化获得良好的权重。和排名。其次,我们必须根据背景关键词统计数据分析每周和每月流量网站带来的有效转化,并分析高价值单词并放弃一些有流量但尚未转换的单词。提高我们的优化效率。
document.writeln('专注于企业家精神,电子商务,网站管理员,扫描A5创业网络微信的QR码,并定期抽奖。以上几点是页面价值的详细信息,以及作者,作为网站管理员,我们需要知道优化是一项细致的工作,除了进行常规的优化外,我们还应重点关注这些优化的细节,因为搜索引擎的目的是为用户服务,而网页是用户最终访问的结果页。单位最小的问题将直接降低用户体验。即使网站拥有更多高权重的外部链接,缺少用户支持也等同于基础问题。选择权重和排名肯定会非常严重。影响力。
首先,分析页面质量因素。我们可以通过两个层次来分析和考虑页面质量。第一个是页面本身的含义,例如文章的质量,关键词布局的合理化,第二个是页面是否满足用户搜索要求和用户体验。两者的结合是页面质量因素的标准。作为网站管理员页面是优化的最小单位。当前的优化原创内容仅是优化的基础。关键是如何统一高质量的内容和用户体验是我们提高页面质量的非常重要的思维策略。我们知道,在网站优化过程中,页面值是我们优化的最小单位模块。作为网站管理员,我们在网站结构优化,代码优化,关键词布局和站点链接构建方面做得很好。之后,重点是网站页面质量的详细计划和优化。那么,我们需要哪些指标来衡量页面优化的质量?好吧,今天,我将与您详细分析网站优化,以分析衡量页面质量的因素。
第三,页面访问量的分析网站页面访问量的值直接影响事务转换。在优化页面的过程中,尤其是某些目录页面或新闻列表页面,我们需要统计这些页面的流量来源和流量分布,这些类别或列表是经过特别优化的,范围不断扩大到改善网页流量显示。 SEO优化和准确的流量是交易的前提。作为网站管理员,我们必须仔细分析如何最大程度地提高网页访问量,而不仅仅是盯着几个主要关键词的排名,我感到非常满意,因此我们不希望取得进展。要进行优化,我们必须继续改进优化策略,并通过优化长尾词关键词进行改进,并且所有方面都会通过网站进行改进。最常用的H5交通规划工具是:TwitterBootstrap,SproutCore,Foundation,Ionic,等 查看全部
网站运营需要什么样的神技能?怎么做运营?
1.了解行业并做网站在操作之前,您必须了解整个行业,掌握该行业的发展趋势,目标必须跟随该行业的发展,了解整个行业的知识,以便您可以制定目标和计划。更清晰,更准确。 网站优化有助于增加网站的权重,这有利于网站 关键词的排名和点击量。在当前流量下降的情况下,努力进行网站优化确实是有帮助的。
3.页面计划技巧网站操作不可避免地必须计划许多特殊页面。这是事件页面计划过程的一般说明。首先,明确事件的目的,并确保整个事件页面的逻辑清晰。 4.负责网站的内容合作和资源交换,旨在改善网站的数据指标。
2.负责网站主题内容,列页面和事件页面内容的制作,运行和维护。 6.合作谈判能力有时需要与其他网站合作以交换数量,交换资源等,所有这些都需要一定的沟通和谈判能力,但同时也要弄清您的目的和资源,并思考您需要什么资源以及可以获取什么样的资源,希望在游戏中尽可能多地获取自己的资源以实现自己的目标。 网站运营工作也更加复杂,涉及很多内容。互联网运营学院()可能并不全面。这些工作技能被认为是必要的,可以帮助提高流量和用户。我希望这足以给您一些操作灵感。让我们来谈谈网站今天的操作需要什么样的神技能? 一、 网站操作的定义我根据网站操作的工作内容来定义此概念,该工作重点是网站平台,以增加网站,网站流量和网站位用户的数量。进行了一系列工作。
5.数据分析功能当前,许多网站统计工具都可以查看网站数据,包括百度统计,网站管理员统计和51种统计。有必要整理出每日访问者数量,访问次数和每日top10 关键词等数据,总结和分析关键词信息并浏览输入网站的浏览数据,然后使用这些数据进行分析网站的运行状态,并分析网站的哪些方面需要进一步加强。 2.文案写作技巧文案写作是网站操作的基本知识。 网站基本的内容采集,分类,组织和排版技能是必要的。好的网站操作需要强大的文案技巧和连续的内容输出,例如网站标题,页面标题,页面计划,列内容等,在许多地方都需要出色的文案技巧。
4. 网站最优化知识网站最知名的人是最优化的:内容为准,外部链接为准,但这远不止于此,更多的是在确保内容和网站的基础上]结构建立网站内部和外部链接,合理布局网站结构,优化网站代码和关键词分布,并最大程度地简化搜索引擎抓取的过程。 二、 网站的工作内容也基于网站平台,包括内容输出,事件计划,内容合作和路况数据分析。主要目的是增加流量并维护用户。我的工作内容大致如下:1.制定网站内容输出计划,完善内容编辑计划,并确保内容输出质量。
在每个人都是自媒体的时代,自媒体平台已受到许多公司的青睐,并且公司已开始转移内容运营位置。企业网站运营的工作已逐渐被忽略,但是内容运营的本质与本质相同。 3.掌握行业的发展趋势和竞争对手的动态,并制定相应的经营策略。
5.负责网站流量统计,摘要,排序和分析,并及时记录,反馈和跟踪发现的问题。 三、 网站操作所需的工作技能想要在操作中做好网站操作并不容易,您需要具有出色的操作知识和工作技能,才能确保网站连续运行并保持快速发展。第四,页面可访问性是最主要的低级问题,我们在优化过程中容易出现此问题,例如缓慢的网页打开速度,混乱的网页布局,有时甚至是网页停机。 网站由网页组成,以确保网页的合理布局和正常访问是每个网站管理员都需要做的工作,这需要我们甚至在网站优化之前就选择空间提供商或服务器。其次,页面的内容是否可以满足用户的需求,并且没有做出很多不可读的文章来进行优化和大肆挥霍。其次,优化页面访问量有效订单转换率的关键是增加网站的有价值的访问量。这是作者今天谈到的第二个要素。随着流量的增长,特别是对于企业而言网站,我们最终将重点放在转化上。在这里,我们必须从两个方面进行分析和思考。首先是优化更有价值的东西,例如辅助关键词,长尾词和相关词关键词,以通过优化获得良好的权重。和排名。其次,我们必须根据背景关键词统计数据分析每周和每月流量网站带来的有效转化,并分析高价值单词并放弃一些有流量但尚未转换的单词。提高我们的优化效率。
document.writeln('专注于企业家精神,电子商务,网站管理员,扫描A5创业网络微信的QR码,并定期抽奖。以上几点是页面价值的详细信息,以及作者,作为网站管理员,我们需要知道优化是一项细致的工作,除了进行常规的优化外,我们还应重点关注这些优化的细节,因为搜索引擎的目的是为用户服务,而网页是用户最终访问的结果页。单位最小的问题将直接降低用户体验。即使网站拥有更多高权重的外部链接,缺少用户支持也等同于基础问题。选择权重和排名肯定会非常严重。影响力。
首先,分析页面质量因素。我们可以通过两个层次来分析和考虑页面质量。第一个是页面本身的含义,例如文章的质量,关键词布局的合理化,第二个是页面是否满足用户搜索要求和用户体验。两者的结合是页面质量因素的标准。作为网站管理员页面是优化的最小单位。当前的优化原创内容仅是优化的基础。关键是如何统一高质量的内容和用户体验是我们提高页面质量的非常重要的思维策略。我们知道,在网站优化过程中,页面值是我们优化的最小单位模块。作为网站管理员,我们在网站结构优化,代码优化,关键词布局和站点链接构建方面做得很好。之后,重点是网站页面质量的详细计划和优化。那么,我们需要哪些指标来衡量页面优化的质量?好吧,今天,我将与您详细分析网站优化,以分析衡量页面质量的因素。
第三,页面访问量的分析网站页面访问量的值直接影响事务转换。在优化页面的过程中,尤其是某些目录页面或新闻列表页面,我们需要统计这些页面的流量来源和流量分布,这些类别或列表是经过特别优化的,范围不断扩大到改善网页流量显示。 SEO优化和准确的流量是交易的前提。作为网站管理员,我们必须仔细分析如何最大程度地提高网页访问量,而不仅仅是盯着几个主要关键词的排名,我感到非常满意,因此我们不希望取得进展。要进行优化,我们必须继续改进优化策略,并通过优化长尾词关键词进行改进,并且所有方面都会通过网站进行改进。最常用的H5交通规划工具是:TwitterBootstrap,SproutCore,Foundation,Ionic,等
搜索引擎获取信息是目前最快捷的方法也是最佳途径
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-05-08 03:27
搜索引擎是当前获取信息最快,最好的方法。
通常,您通过搜索关键字来完成搜索过程。这是最简单的方法,但并非每个搜索结果都令人满意。
要获得最佳结果,必须通过搜索引擎的语法来达到搜索条件。
搜索引擎中常用的逻辑关系语法是; AND,或者,不是
搜索关键字AND由&;表示。 OR由“ |”表示; NOT以“!”表示。
例如,如果您要搜索广州和北京的房地产,但不需要预期的房地产信息,则可以在搜索中使用“(广州|北京)?房地产!预期的房地产”作为关键字。关键字。
多词查询方法:使用“,”定界符并使用“ +,—”连接号。
例如,如果要查找有关广州,北京和上海的相关内容,则所需信息应包括广州,但不包括北京,并且上海是可选的。您可以将“ +广州,-北京,上海”用作关键词。
〜:同义词。:单个通配符*:可以表示多个字母的通配符“”:精确搜索
标题:搜索关键字是否在标题内容中。
intext和allintext:此语法对Google有效,搜索关键字是否出现在网页内容中而不是标题
inurl:搜索URL中收录的字符串
站点:搜索特定的网页,并查看搜索引擎收录有多少页。这应该与其他句子结合使用,以更好地使用。例如:朝圣娱乐网站点:
链接:搜索网站的链接
filetype:可以搜索的文件格式。现在,百度支持pdf,doc,xls,all,ppt,rtf,其中所有方法都可以搜索百度支持的所有文件,以便返回更多结果
相关:(仅在google中使用)搜索与指定URL相关的页面。通过搜索,我们发现通常会显示与网站具有相同外部链接的网站。
info:查找有关指定站点的一些基本信息。该语法最重要的功能是搜索指定的网站的快照。
此页面可以简单地使用百度的高级搜索功能 查看全部
搜索引擎获取信息是目前最快捷的方法也是最佳途径
搜索引擎是当前获取信息最快,最好的方法。
通常,您通过搜索关键字来完成搜索过程。这是最简单的方法,但并非每个搜索结果都令人满意。
要获得最佳结果,必须通过搜索引擎的语法来达到搜索条件。
搜索引擎中常用的逻辑关系语法是; AND,或者,不是
搜索关键字AND由&;表示。 OR由“ |”表示; NOT以“!”表示。
例如,如果您要搜索广州和北京的房地产,但不需要预期的房地产信息,则可以在搜索中使用“(广州|北京)?房地产!预期的房地产”作为关键字。关键字。
多词查询方法:使用“,”定界符并使用“ +,—”连接号。
例如,如果要查找有关广州,北京和上海的相关内容,则所需信息应包括广州,但不包括北京,并且上海是可选的。您可以将“ +广州,-北京,上海”用作关键词。
〜:同义词。:单个通配符*:可以表示多个字母的通配符“”:精确搜索
标题:搜索关键字是否在标题内容中。
intext和allintext:此语法对Google有效,搜索关键字是否出现在网页内容中而不是标题
inurl:搜索URL中收录的字符串
站点:搜索特定的网页,并查看搜索引擎收录有多少页。这应该与其他句子结合使用,以更好地使用。例如:朝圣娱乐网站点:
链接:搜索网站的链接
filetype:可以搜索的文件格式。现在,百度支持pdf,doc,xls,all,ppt,rtf,其中所有方法都可以搜索百度支持的所有文件,以便返回更多结果
相关:(仅在google中使用)搜索与指定URL相关的页面。通过搜索,我们发现通常会显示与网站具有相同外部链接的网站。
info:查找有关指定站点的一些基本信息。该语法最重要的功能是搜索指定的网站的快照。
此页面可以简单地使用百度的高级搜索功能
GoogleHack查询收录信息用的3个词用法(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-05-08 03:26
网站是每个人都应该熟悉的东西。它用于查询收录信息,但是对于标题,inurl和文件类型,它很少使用。我可能没有听说过,但是在某些情况下非常有用。下面将详细解释这三个词的用法
大多数人使用搜索引擎时,通常会在搜索框中输入需要直接搜索的关键字,然后开始冗长的信息提取过程。实际上,谷歌和百度为搜索关键词提供了多种语法,这些语法的合理使用将使我们得到的搜索结果更加准确。当然,Google允许用户使用这些语法的目的是获得更准确的结果,但是黑客可以使用这些语法来构造特殊的关键字,从而使大多数搜索结果容易受到攻击网站。
首先让我们看一下Google的某些语法:
标题:搜索网页标题中收录特定字符的网页。例如,输入“ intitle:php”,以便将搜索页面标题中所有带有php的页面。
inurl:搜索收录特定字符的URL。例如,如果输入“ inurl:php”,则可以找到带有php字符的URL。
intext:在网页的正文内容中搜索指定的字符,例如,输入“ intext:php”。这种语法类似于我们在某些网站中通常使用的“ 文章内容搜索”功能。
文件类型:搜索指定类型的文件。例如,输入“ filetype:php”将返回所有以php结尾的文件URL。
站点:查找与指定的网站关联的URL。例如,输入“站点:”。将显示与此网站相关的所有URL。
这些是Google的常见语法,也是Google Hack的必要语法。尽管这只是Google语法的一小部分,但合理使用这些语法会产生意想不到的结果。
语法在Google Hack中的作用
了解Google的基本语法后,我们来看看黑客如何使用这些语法来执行Google Hacks。这些语法在入侵过程中将扮演什么角色?
标题
标题语法通常用于搜索网站的后端,特殊页面和文件。通过在Google中搜索“ intitle:login”和“ intitle:management”,您可以找到许多网站后端登录页面。另外,intitle语法也可以用于搜索文件。例如,搜索“ intitle:” indexof” etc / shadow”以查找由于配置不正确而在Linux中泄露的用户密码文件。
inurl
在Google Hack中,inurl发挥了最大作用,可以分为以下两个方面:搜索网站后台登录地址和搜索特殊URL。
寻找网站后端登录地址:与intitle不同,inurl可以在URL中指定关键字。我们都知道网站后端URL与结尾处的login.asp和admin.asp类似,因此只要我们使用“ inurl:login.asp”和“ inurl:admin.asp”作为关键字进行搜索,我们就可以也发现很多网站后端。此外,我们还可以使用“ inurl:data”和“ inurl:db”作为关键字搜索网站的数据库地址。
随时浏览网站中的文件
文件类型
文件类型的功能是搜索指定的文件。如果要搜索网站的数据库文件,可以使用“ filetype:mdb”作为关键字进行搜索,并且很快可以下载网站的许多数据库文件。当然,Filetype语法的作用不仅在这里,而且在与其他语法结合使用时也显示出其强大的作用。
网站
骇客使用网站,通常是在入侵前进行情报监视。网站文法可以显示与目标网站相关的所有页面,从中可以找到有关目标网站的更多或更少信息,这是黑客的一项突破,并且是目标网站的详细说明报告。
语法组合,功能加倍
尽管上面介绍的语法每个都可以完成入侵的某些步骤,但是仅使用一种语法进行入侵,其效率非常低。 Google Hack的强大之处在于它能够组合多种语法,以便我们能够快速找到所需的内容。让我们模拟一下黑客如何使用Google语法组合入侵网站。
信息间谍
黑客想要入侵网站,通常的第一步是监视目标网站。目前,您可以使用“站点:target 网站”获取相关网页并从中提取有用的信息。
搜索相关页面
下载网站的数据库
搜索“ Site:Target 网站文件类型:mdb”以找到target 网站的数据库。 Site语法限制了搜索范围,而Filetype确定了搜索目标。使用此方法的一个缺点是下载到数据库的成功率很低。在这里,我们还可以使用另一种语法组合,只要目标网站具有IIS配置缺陷,也就是说,您可以随意浏览站点文件夹,我们搜索“站点:目标网站 intext:至父目录”以确定是否存在此漏洞。确认存在此漏洞后,可以使用“ Site:target 网站 intext:至父目录+ intext.mdb”搜索数据库。 查看全部
GoogleHack查询收录信息用的3个词用法(图)
网站是每个人都应该熟悉的东西。它用于查询收录信息,但是对于标题,inurl和文件类型,它很少使用。我可能没有听说过,但是在某些情况下非常有用。下面将详细解释这三个词的用法
大多数人使用搜索引擎时,通常会在搜索框中输入需要直接搜索的关键字,然后开始冗长的信息提取过程。实际上,谷歌和百度为搜索关键词提供了多种语法,这些语法的合理使用将使我们得到的搜索结果更加准确。当然,Google允许用户使用这些语法的目的是获得更准确的结果,但是黑客可以使用这些语法来构造特殊的关键字,从而使大多数搜索结果容易受到攻击网站。
首先让我们看一下Google的某些语法:
标题:搜索网页标题中收录特定字符的网页。例如,输入“ intitle:php”,以便将搜索页面标题中所有带有php的页面。
inurl:搜索收录特定字符的URL。例如,如果输入“ inurl:php”,则可以找到带有php字符的URL。
intext:在网页的正文内容中搜索指定的字符,例如,输入“ intext:php”。这种语法类似于我们在某些网站中通常使用的“ 文章内容搜索”功能。
文件类型:搜索指定类型的文件。例如,输入“ filetype:php”将返回所有以php结尾的文件URL。
站点:查找与指定的网站关联的URL。例如,输入“站点:”。将显示与此网站相关的所有URL。
这些是Google的常见语法,也是Google Hack的必要语法。尽管这只是Google语法的一小部分,但合理使用这些语法会产生意想不到的结果。
语法在Google Hack中的作用
了解Google的基本语法后,我们来看看黑客如何使用这些语法来执行Google Hacks。这些语法在入侵过程中将扮演什么角色?
标题
标题语法通常用于搜索网站的后端,特殊页面和文件。通过在Google中搜索“ intitle:login”和“ intitle:management”,您可以找到许多网站后端登录页面。另外,intitle语法也可以用于搜索文件。例如,搜索“ intitle:” indexof” etc / shadow”以查找由于配置不正确而在Linux中泄露的用户密码文件。
inurl
在Google Hack中,inurl发挥了最大作用,可以分为以下两个方面:搜索网站后台登录地址和搜索特殊URL。
寻找网站后端登录地址:与intitle不同,inurl可以在URL中指定关键字。我们都知道网站后端URL与结尾处的login.asp和admin.asp类似,因此只要我们使用“ inurl:login.asp”和“ inurl:admin.asp”作为关键字进行搜索,我们就可以也发现很多网站后端。此外,我们还可以使用“ inurl:data”和“ inurl:db”作为关键字搜索网站的数据库地址。
随时浏览网站中的文件
文件类型
文件类型的功能是搜索指定的文件。如果要搜索网站的数据库文件,可以使用“ filetype:mdb”作为关键字进行搜索,并且很快可以下载网站的许多数据库文件。当然,Filetype语法的作用不仅在这里,而且在与其他语法结合使用时也显示出其强大的作用。
网站
骇客使用网站,通常是在入侵前进行情报监视。网站文法可以显示与目标网站相关的所有页面,从中可以找到有关目标网站的更多或更少信息,这是黑客的一项突破,并且是目标网站的详细说明报告。
语法组合,功能加倍
尽管上面介绍的语法每个都可以完成入侵的某些步骤,但是仅使用一种语法进行入侵,其效率非常低。 Google Hack的强大之处在于它能够组合多种语法,以便我们能够快速找到所需的内容。让我们模拟一下黑客如何使用Google语法组合入侵网站。
信息间谍
黑客想要入侵网站,通常的第一步是监视目标网站。目前,您可以使用“站点:target 网站”获取相关网页并从中提取有用的信息。
搜索相关页面
下载网站的数据库
搜索“ Site:Target 网站文件类型:mdb”以找到target 网站的数据库。 Site语法限制了搜索范围,而Filetype确定了搜索目标。使用此方法的一个缺点是下载到数据库的成功率很低。在这里,我们还可以使用另一种语法组合,只要目标网站具有IIS配置缺陷,也就是说,您可以随意浏览站点文件夹,我们搜索“站点:目标网站 intext:至父目录”以确定是否存在此漏洞。确认存在此漏洞后,可以使用“ Site:target 网站 intext:至父目录+ intext.mdb”搜索数据库。
日常最常用的搜索方法,你get到了吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-05-03 21:00
尽管搜索已经成为我们生活中不可或缺的一部分,但仍有许多人对搜索的使用效率非常低。
实际上,像百度这样的搜索引擎需要大量的技能和实践才能快速准确地找到您想要的内容。
今天,我将讨论日常生活中一些最常用的搜索方法。
1. 关键词搜索
当许多人搜索时,他们会使用口语搜索。例如,搜索“我在哪里可以下载办公室的破解版本?”这只会人为地增加搜索负担。
如果直接搜索关键词“办公室破解版”,则不仅可以减少打字时间,还可以避免某些口语关键字搜索不正确的信息。
2.准确的搜索
有时我们输入的内容不希望被分割,因此我们需要使用精确的搜索。
您只需要将内容括在引号中以表示完全匹配,从而可以实现准确的搜索。很简单吗?
3.过滤器搜索
什么是过滤搜索?例如,如果搜索“麻辣土豆丝”,我们将为网站找到各种食谱。
但是,如果我们不想要美食界的食谱,那么我们此时需要进行过滤和搜索。该方法也很简单,搜索“酸辣土豆丝-美食世界”,也就是用减号减去。再次搜索,您将发现美食界中的所有食谱都被杀死了。 (应注意,负号之前有一个空格,其后没有空格)
4.指定格式搜索
某些上班族或学生有时会搜索Word,PPT和其他格式的文档。此时,您可以指定要搜索的文件格式。
例如,如果您需要ppt格式的纸张,请搜索“ paper filetype:ppt”。注意英语冒号的使用。
5.指定网站搜索
如果您觉得百度的搜索结果太乱了,您只想搜索某些网站内容。然后,您可以尝试指定网站搜索。
例如,如果您想在知乎中搜索有关小米手机的内容,则可以搜索“站点:小米手机”。请注意,URL后面有一个空格。
除了最常用的搜索方法外,实际上还有许多搜索方法。如果您有兴趣,请自己进行探索。 查看全部
日常最常用的搜索方法,你get到了吗?
尽管搜索已经成为我们生活中不可或缺的一部分,但仍有许多人对搜索的使用效率非常低。
实际上,像百度这样的搜索引擎需要大量的技能和实践才能快速准确地找到您想要的内容。
今天,我将讨论日常生活中一些最常用的搜索方法。
1. 关键词搜索
当许多人搜索时,他们会使用口语搜索。例如,搜索“我在哪里可以下载办公室的破解版本?”这只会人为地增加搜索负担。
如果直接搜索关键词“办公室破解版”,则不仅可以减少打字时间,还可以避免某些口语关键字搜索不正确的信息。
2.准确的搜索
有时我们输入的内容不希望被分割,因此我们需要使用精确的搜索。
您只需要将内容括在引号中以表示完全匹配,从而可以实现准确的搜索。很简单吗?
3.过滤器搜索
什么是过滤搜索?例如,如果搜索“麻辣土豆丝”,我们将为网站找到各种食谱。
但是,如果我们不想要美食界的食谱,那么我们此时需要进行过滤和搜索。该方法也很简单,搜索“酸辣土豆丝-美食世界”,也就是用减号减去。再次搜索,您将发现美食界中的所有食谱都被杀死了。 (应注意,负号之前有一个空格,其后没有空格)
4.指定格式搜索
某些上班族或学生有时会搜索Word,PPT和其他格式的文档。此时,您可以指定要搜索的文件格式。
例如,如果您需要ppt格式的纸张,请搜索“ paper filetype:ppt”。注意英语冒号的使用。
5.指定网站搜索
如果您觉得百度的搜索结果太乱了,您只想搜索某些网站内容。然后,您可以尝试指定网站搜索。
例如,如果您想在知乎中搜索有关小米手机的内容,则可以搜索“站点:小米手机”。请注意,URL后面有一个空格。
除了最常用的搜索方法外,实际上还有许多搜索方法。如果您有兴趣,请自己进行探索。
11个高级搜索方法让你了解国内搜索引擎的不同之处
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-05-03 20:45
尽管Google已从中国撤出,但鉴于国内搜索引擎的命中率,许多用户错过了Google,并且许多用户仍以各种方式使用Google。在大多数情况下,用户使用基本搜索。查询所需内容的方法,这里推荐11种高级搜索方法,这样您不仅可以了解国内搜索引擎与国外搜索引擎之间的区别。
1.使用“-”提高搜索关键词的点击率
<p>当您尝试查找关键词时,碰巧关键词收录大量含义或不同的引文,那么如何进行进一步的研究?以“ Gouda”为例,它只是举世闻名的荷兰奶酪,是一页荷兰城市的名称,用户只需输入此关键词,如果您愿意,Google会为您提供很多奶酪参考想要获得一个荷兰城市,则需要将其排除在外,然后可以转到“ Gouda”在前面添加“-”,“ cheese”和“ kaas”,以便得到有关该城市的各种信息。 查看全部
11个高级搜索方法让你了解国内搜索引擎的不同之处
尽管Google已从中国撤出,但鉴于国内搜索引擎的命中率,许多用户错过了Google,并且许多用户仍以各种方式使用Google。在大多数情况下,用户使用基本搜索。查询所需内容的方法,这里推荐11种高级搜索方法,这样您不仅可以了解国内搜索引擎与国外搜索引擎之间的区别。
1.使用“-”提高搜索关键词的点击率
<p>当您尝试查找关键词时,碰巧关键词收录大量含义或不同的引文,那么如何进行进一步的研究?以“ Gouda”为例,它只是举世闻名的荷兰奶酪,是一页荷兰城市的名称,用户只需输入此关键词,如果您愿意,Google会为您提供很多奶酪参考想要获得一个荷兰城市,则需要将其排除在外,然后可以转到“ Gouda”在前面添加“-”,“ cheese”和“ kaas”,以便得到有关该城市的各种信息。
默认的主题提供了一个首页(Homepage)的布局
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-05-02 06:18
默认主题提供主页布局(此网站主页)。要使用它,您需要在根级别README.md中指定home:true。这是一个使用方法的示例:
---
home: true
heroImage: /hero.png
heroText: Hero 标题
tagline: Hero 副标题
actionText: 快速上手 →
actionLink: /zh/guide/
features:
- title: 简洁至上
details: 以 Markdown 为中心的项目结构,以最少的配置帮助你专注于写作。
- title: Vue驱动
details: 享受 Vue + webpack 的开发体验,在 Markdown 中使用 Vue 组件,同时可以使用 Vue 来开发自定义主题。
- title: 高性能
details: VuePress 为每个页面预渲染生成静态的 HTML,同时在页面被加载的时候,将作为 SPA 运行。
footer: MIT Licensed | Copyright © 2018-present Evan You
---
您可以将相应的内容设置为null以禁用标题和副标题。
任何YAML封面内容之后的多余内容将以常规降价呈现,并插入到功能之后。
导航栏
导航栏可能收录您的页面标题,多语言切换,它们都取决于您的配置。
导航栏徽标
您可以通过themeConfig.logo在导航栏中添加徽标,该徽标可以放置在以下位置:
// .vuepress/config.js
module.exports = {
themeConfig: {
logo: '/assets/img/logo.png',
}
}
导航栏链接
您可以通过themeConfig.nav添加一些导航栏链接:
// .vuepress/config.js
module.exports = {
themeConfig: {
nav: [
{ text: 'Home', link: '/' },
{ text: 'Guide', link: '/guide/' },
{ text: 'External', link: 'https://google.com' },
]
}
}
默认情况下,外部链接标记的属性将收录target =“ _ blank”,您可以提供target和rel,它们将作为属性添加到标记中:
// .vuepress/config.js
module.exports = {
themeConfig: {
nav: [
{ text: 'External', link: 'https://google.com', target:'_self', rel:'' },
{ text: 'Guide', link: '/guide/', target:'_blank' }
]
}
}
当您提供项目数组而不是单个链接时,它将显示为下拉列表:
// .vuepress/config.js
module.exports = {
themeConfig: {
nav: [
{
text: 'Languages',
ariaLabel: 'Language Menu',
items: [
{ text: 'Chinese', link: '/language/chinese/' },
{ text: 'Japanese', link: '/language/japanese/' }
]
}
]
}
}
此外,您还可以通过嵌套项目在下拉列表中设置分组:
// .vuepress/config.js
module.exports = {
themeConfig: {
nav: [
{
text: 'Languages',
items: [
{ text: 'Group1', items: [/* */] },
{ text: 'Group2', items: [/* */] }
]
}
]
}
}
禁用导航栏
您可以使用themeConfig.navbar禁用所有页面的导航栏:
// .vuepress/config.js
module.exports = {
themeConfig: {
navbar: false
}
}
您还可以通过YAML前端功能禁用特定页面的导航栏:
---
navbar: false
---
侧边栏
要使补充工具栏生效,您需要配置themeConfig.sidebar。基本配置需要一个收录多个链接的数组:
// .vuepress/config.js
module.exports = {
themeConfig: {
sidebar: [
'/',
'/page-a',
['/page-b', 'Explicit link text']
]
}
}
您可以省略.md扩展名,以/结尾的路径将被视为* / README.md,此链接的文本将被自动检索(无论您将其声明为页面的第一个标头,或在YAML前题中明确指定页面标题)。如果要显式指定链接的文本,请使用[link,text]格式的数组。
嵌套标题链接
默认情况下,侧边栏将自动显示由当前页面的标题组成的链接,并根据页面本身的结构嵌套它们。您可以通过themeConfig.sidebarDepth修改其行为。默认深度为1,它将提取h2的标题。将其设置为0将禁用标题链接。同时,最大深度为2,这将同时提取h2和h3的标题。
您还可以使用YAML前件重写页面的该值:
---
sidebarDepth: 2
---
显示所有页面的标题链接
默认情况下,侧边栏将仅显示由当前活动页面的标题组成的链接。您可以将themeConfig.displayAllHeaders设置为true以显示所有页面的标题链接:
// .vuepress/config.js
module.exports = {
themeConfig: {
displayAllHeaders: true // 默认值:false
}
}
活动的标题链接
默认情况下,当用户滚动查看页面的不同部分时,嵌套标题链接和URL中的哈希值将实时更新。可以通过以下配置禁用此行为:
// .vuepress/config.js
module.exports = {
themeConfig: {
activeHeaderLinks: false, // 默认值:true
}
}
提醒
值得一提的是,当您禁用此选项时,将不会加载此功能的相应脚本。这只是我们性能优化的一小部分。
侧边栏分组
您可以使用对象将侧边栏分为多个组:
// .vuepress/config.js
module.exports = {
themeConfig: {
sidebar: [
{
title: 'Group 1', // 必要的
path: '/foo/', // 可选的, 标题的跳转链接,应为绝对路径且必须存在
collapsable: false, // 可选的, 默认值是 true,
sidebarDepth: 1, // 可选的, 默认值是 1
children: [
'/'
]
},
{
title: 'Group 2',
children: [ /* ... */ ],
initialOpenGroupIndex: -1 // 可选的, 默认值是 0
}
]
}
}
默认情况下,边栏中的每个子组都是可折叠的。您可以将可折叠设置为:false,以使组始终展开。
侧边栏的子组配置还支持用于覆盖默认侧边栏深度(1)的字段。
提醒
还支持嵌套侧边栏分组。
多个侧边栏
如果要为不同的页面组显示不同的侧边栏,请首先将页面文件组织为以下目录结构:
.
├─ README.md
├─ contact.md
├─ about.md
├─ foo/
│ ├─ README.md
│ ├─ one.md
│ └─ two.md
└─ bar/
├─ README.md
├─ three.md
└─ four.md
接下来,请按照下面的侧边栏配置进行操作:
// .vuepress/config.js
module.exports = {
themeConfig: {
sidebar: {
'/foo/': [
'', /* /foo/ */
'one', /* /foo/one.html */
'two' /* /foo/two.html */
],
'/bar/': [
'', /* /bar/ */
'three', /* /bar/three.html */
'four' /* /bar/four.html */
],
// fallback
'/': [
'', /* / */
'contact', /* /contact.html */
'about' /* /about.html */
]
}
}
}
注意
确保后备侧边栏是最后定义的。 VuePress将遍历侧边栏配置,以找到匹配的配置。
自动生成侧边栏
如果您想自动生成仅收录指向当前页面标题(标题)链接的侧边栏,则可以通过YAML首要任务做到这一点:
---
sidebar: auto
---
您还可以通过配置在所有页面上启用它:
// .vuepress/config.js
module.exports = {
themeConfig: {
sidebar: 'auto'
}
}
在多语言模式下,您还可以将其应用于特定语言:
// .vuepress/config.js
module.exports = {
themeConfig: {
'/zh/': {
sidebar: 'auto'
}
}
}
禁用侧边栏
您可以通过YAML前端功能禁用特定页面的侧边栏:
---
sidebar: false
---
搜索框内置搜索
您可以通过将themeConfig.search设置为false来禁用默认搜索框,或者通过themeConfig.searchMaxSuggestions来调整默认搜索框中显示的搜索结果数量:
// .vuepress/config.js
module.exports = {
themeConfig: {
search: false,
searchMaxSuggestions: 10
}
}
您可以用来优化搜索结果:
---
tags:
- 配置
- 主题
- 索引
---
您可以用于禁用单独页面的内置搜索框:
---
search: false
---
提醒
内置搜索将仅为页面的标题,h2,h3和标签建立搜索索引。如果需要全文搜索,则可以使用。
阿尔及利亚搜索
您可以使用themeConfig.algolia选项将内置搜索框替换为Algolia搜索(打开新窗口)。要启用Algolia搜索,您至少需要提供apiKey和indexName:
// .vuepress/config.js
module.exports = {
themeConfig: {
algolia: {
apiKey: '',
indexName: ''
}
}
}
注意
与开箱即用的不同,Algolia搜索(在新窗口中打开)要求您将网站提交给他们,以便在使用前创建索引。
有关更多选项,请参阅。
最后更新时间
您可以使用themeConfig.lastUpdated选项获取每个文件的最后git提交的UNIX时间戳(ms),它将以合适的日期格式显示在每页底部:
// .vuepress/config.js
module.exports = {
themeConfig: {
lastUpdated: 'Last Updated', // string | boolean
}
}
请注意,themeConfig.lastUpdated默认关闭。如果提供了字符串,它将显示为前缀(默认值为:“上次更新”)。
使用说明
由于lastUpdated基于git,因此只能在基于git的项目中启用它。另外,由于使用的时间戳来自git commit,因此它将仅在给定页面的第一次提交之后显示,并且仅在后续更改提交到该页面时才更新。
扩展阅读: 查看全部
默认的主题提供了一个首页(Homepage)的布局
默认主题提供主页布局(此网站主页)。要使用它,您需要在根级别README.md中指定home:true。这是一个使用方法的示例:
---
home: true
heroImage: /hero.png
heroText: Hero 标题
tagline: Hero 副标题
actionText: 快速上手 →
actionLink: /zh/guide/
features:
- title: 简洁至上
details: 以 Markdown 为中心的项目结构,以最少的配置帮助你专注于写作。
- title: Vue驱动
details: 享受 Vue + webpack 的开发体验,在 Markdown 中使用 Vue 组件,同时可以使用 Vue 来开发自定义主题。
- title: 高性能
details: VuePress 为每个页面预渲染生成静态的 HTML,同时在页面被加载的时候,将作为 SPA 运行。
footer: MIT Licensed | Copyright © 2018-present Evan You
---
您可以将相应的内容设置为null以禁用标题和副标题。
任何YAML封面内容之后的多余内容将以常规降价呈现,并插入到功能之后。
导航栏
导航栏可能收录您的页面标题,多语言切换,它们都取决于您的配置。
导航栏徽标
您可以通过themeConfig.logo在导航栏中添加徽标,该徽标可以放置在以下位置:
// .vuepress/config.js
module.exports = {
themeConfig: {
logo: '/assets/img/logo.png',
}
}
导航栏链接
您可以通过themeConfig.nav添加一些导航栏链接:
// .vuepress/config.js
module.exports = {
themeConfig: {
nav: [
{ text: 'Home', link: '/' },
{ text: 'Guide', link: '/guide/' },
{ text: 'External', link: 'https://google.com' },
]
}
}
默认情况下,外部链接标记的属性将收录target =“ _ blank”,您可以提供target和rel,它们将作为属性添加到标记中:
// .vuepress/config.js
module.exports = {
themeConfig: {
nav: [
{ text: 'External', link: 'https://google.com', target:'_self', rel:'' },
{ text: 'Guide', link: '/guide/', target:'_blank' }
]
}
}
当您提供项目数组而不是单个链接时,它将显示为下拉列表:
// .vuepress/config.js
module.exports = {
themeConfig: {
nav: [
{
text: 'Languages',
ariaLabel: 'Language Menu',
items: [
{ text: 'Chinese', link: '/language/chinese/' },
{ text: 'Japanese', link: '/language/japanese/' }
]
}
]
}
}
此外,您还可以通过嵌套项目在下拉列表中设置分组:
// .vuepress/config.js
module.exports = {
themeConfig: {
nav: [
{
text: 'Languages',
items: [
{ text: 'Group1', items: [/* */] },
{ text: 'Group2', items: [/* */] }
]
}
]
}
}
禁用导航栏
您可以使用themeConfig.navbar禁用所有页面的导航栏:
// .vuepress/config.js
module.exports = {
themeConfig: {
navbar: false
}
}
您还可以通过YAML前端功能禁用特定页面的导航栏:
---
navbar: false
---
侧边栏
要使补充工具栏生效,您需要配置themeConfig.sidebar。基本配置需要一个收录多个链接的数组:
// .vuepress/config.js
module.exports = {
themeConfig: {
sidebar: [
'/',
'/page-a',
['/page-b', 'Explicit link text']
]
}
}
您可以省略.md扩展名,以/结尾的路径将被视为* / README.md,此链接的文本将被自动检索(无论您将其声明为页面的第一个标头,或在YAML前题中明确指定页面标题)。如果要显式指定链接的文本,请使用[link,text]格式的数组。
嵌套标题链接
默认情况下,侧边栏将自动显示由当前页面的标题组成的链接,并根据页面本身的结构嵌套它们。您可以通过themeConfig.sidebarDepth修改其行为。默认深度为1,它将提取h2的标题。将其设置为0将禁用标题链接。同时,最大深度为2,这将同时提取h2和h3的标题。
您还可以使用YAML前件重写页面的该值:
---
sidebarDepth: 2
---
显示所有页面的标题链接
默认情况下,侧边栏将仅显示由当前活动页面的标题组成的链接。您可以将themeConfig.displayAllHeaders设置为true以显示所有页面的标题链接:
// .vuepress/config.js
module.exports = {
themeConfig: {
displayAllHeaders: true // 默认值:false
}
}
活动的标题链接
默认情况下,当用户滚动查看页面的不同部分时,嵌套标题链接和URL中的哈希值将实时更新。可以通过以下配置禁用此行为:
// .vuepress/config.js
module.exports = {
themeConfig: {
activeHeaderLinks: false, // 默认值:true
}
}
提醒
值得一提的是,当您禁用此选项时,将不会加载此功能的相应脚本。这只是我们性能优化的一小部分。
侧边栏分组
您可以使用对象将侧边栏分为多个组:
// .vuepress/config.js
module.exports = {
themeConfig: {
sidebar: [
{
title: 'Group 1', // 必要的
path: '/foo/', // 可选的, 标题的跳转链接,应为绝对路径且必须存在
collapsable: false, // 可选的, 默认值是 true,
sidebarDepth: 1, // 可选的, 默认值是 1
children: [
'/'
]
},
{
title: 'Group 2',
children: [ /* ... */ ],
initialOpenGroupIndex: -1 // 可选的, 默认值是 0
}
]
}
}
默认情况下,边栏中的每个子组都是可折叠的。您可以将可折叠设置为:false,以使组始终展开。
侧边栏的子组配置还支持用于覆盖默认侧边栏深度(1)的字段。
提醒
还支持嵌套侧边栏分组。
多个侧边栏
如果要为不同的页面组显示不同的侧边栏,请首先将页面文件组织为以下目录结构:
.
├─ README.md
├─ contact.md
├─ about.md
├─ foo/
│ ├─ README.md
│ ├─ one.md
│ └─ two.md
└─ bar/
├─ README.md
├─ three.md
└─ four.md
接下来,请按照下面的侧边栏配置进行操作:
// .vuepress/config.js
module.exports = {
themeConfig: {
sidebar: {
'/foo/': [
'', /* /foo/ */
'one', /* /foo/one.html */
'two' /* /foo/two.html */
],
'/bar/': [
'', /* /bar/ */
'three', /* /bar/three.html */
'four' /* /bar/four.html */
],
// fallback
'/': [
'', /* / */
'contact', /* /contact.html */
'about' /* /about.html */
]
}
}
}
注意
确保后备侧边栏是最后定义的。 VuePress将遍历侧边栏配置,以找到匹配的配置。
自动生成侧边栏
如果您想自动生成仅收录指向当前页面标题(标题)链接的侧边栏,则可以通过YAML首要任务做到这一点:
---
sidebar: auto
---
您还可以通过配置在所有页面上启用它:
// .vuepress/config.js
module.exports = {
themeConfig: {
sidebar: 'auto'
}
}
在多语言模式下,您还可以将其应用于特定语言:
// .vuepress/config.js
module.exports = {
themeConfig: {
'/zh/': {
sidebar: 'auto'
}
}
}
禁用侧边栏
您可以通过YAML前端功能禁用特定页面的侧边栏:
---
sidebar: false
---
搜索框内置搜索
您可以通过将themeConfig.search设置为false来禁用默认搜索框,或者通过themeConfig.searchMaxSuggestions来调整默认搜索框中显示的搜索结果数量:
// .vuepress/config.js
module.exports = {
themeConfig: {
search: false,
searchMaxSuggestions: 10
}
}
您可以用来优化搜索结果:
---
tags:
- 配置
- 主题
- 索引
---
您可以用于禁用单独页面的内置搜索框:
---
search: false
---
提醒
内置搜索将仅为页面的标题,h2,h3和标签建立搜索索引。如果需要全文搜索,则可以使用。
阿尔及利亚搜索
您可以使用themeConfig.algolia选项将内置搜索框替换为Algolia搜索(打开新窗口)。要启用Algolia搜索,您至少需要提供apiKey和indexName:
// .vuepress/config.js
module.exports = {
themeConfig: {
algolia: {
apiKey: '',
indexName: ''
}
}
}
注意
与开箱即用的不同,Algolia搜索(在新窗口中打开)要求您将网站提交给他们,以便在使用前创建索引。
有关更多选项,请参阅。
最后更新时间
您可以使用themeConfig.lastUpdated选项获取每个文件的最后git提交的UNIX时间戳(ms),它将以合适的日期格式显示在每页底部:
// .vuepress/config.js
module.exports = {
themeConfig: {
lastUpdated: 'Last Updated', // string | boolean
}
}
请注意,themeConfig.lastUpdated默认关闭。如果提供了字符串,它将显示为前缀(默认值为:“上次更新”)。
使用说明
由于lastUpdated基于git,因此只能在基于git的项目中启用它。另外,由于使用的时间戳来自git commit,因此它将仅在给定页面的第一次提交之后显示,并且仅在后续更改提交到该页面时才更新。
扩展阅读:
seo工作中如何做好seo内容优化,你知道吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-05-02 06:16
seo工作中如何做好seo内容优化,你知道吗?
内容是seo优化的重点。 网站没有实质内容,很难排名很高。即使很高,也很容易受到搜索引擎的惩罚。在实际的seo工作中,我们如何做得好? seo内容优化如何?
1、由seo领导的内容构建
对于[s14]谁是依靠seo开头的人,网站的大部分内容主要是为搜索引擎创建内容。搜索引擎是第一位的,用户是第二位的。没有来自搜索引擎的流量。 网站没有用户,因为搜索引擎会首先努力向用户展示最有价值的内容,因此,在创建搜索引擎内容时,这种网站类型也必须照顾用户的需求。
2、内容构建方向
我们网站在制作内容时需要考虑以下几点:
1)哪些目标用户通过关键词搜索目标信息
2)当目标用户正在寻找指定的信息时,除了直接找到相应的关键词之外,他还将搜索什么?
3)目标用户真正需要什么?
了解目标用户的搜索习惯和关键词后,我们可以很好地准备网站的内容。除了找到用户对应的关键词外,我们还需要使用其他关键词来丰富网站]内容,引导用户输入网站。
3、内容关注
对于seo优化,就内容而言,创新的营销思想认为这些问题仍需要注意:
(1) SEO-必须深入了解这个行业,而不仅仅是深入研究关键词,网站编辑者必须了解这个行业;
(2) 原创是基本的,“重印”现在是主要站点的专利,但是您也应注意不要重印尽可能多,因为很可能不会被搜索引擎搜索收录。
([3) 网站不应以“ 原创”开头,因为原创不一定对用户有价值。网站应当以“对用户有价值”开头。即使您定位三个或四个目标将针对某个问题的不同解决方案有机地结合在一起,只要它对用户真正有价值,并且没有其他网站这样做,那么这也是一种内容构建方式。
([4)请勿以“ 伪原创”开头。将自己标记为[伪原创“后,所有将来的内容策略和行为都会作弊。因为您只想为搜索引擎创建内容,只要搜索引擎收录为0K,所有针对内容的操作都会带有欺诈嫌疑和痕迹。
([5)就具体内容而言,可以是信息,原创评论,离线数据扫描,外语翻译甚至是有机汇总等。建议一起使用多个构想,而不是仅使用一个构想。方法。
(6)如果要将脱机媒体的内容上传到Internet,则必须替换脱机媒体使用的一些不准确的关键词。例如,“这个省”,“这个城市”,“这个电台”“本报纸”等 查看全部
seo工作中如何做好seo内容优化,你知道吗?
内容是seo优化的重点。 网站没有实质内容,很难排名很高。即使很高,也很容易受到搜索引擎的惩罚。在实际的seo工作中,我们如何做得好? seo内容优化如何?
1、由seo领导的内容构建
对于[s14]谁是依靠seo开头的人,网站的大部分内容主要是为搜索引擎创建内容。搜索引擎是第一位的,用户是第二位的。没有来自搜索引擎的流量。 网站没有用户,因为搜索引擎会首先努力向用户展示最有价值的内容,因此,在创建搜索引擎内容时,这种网站类型也必须照顾用户的需求。
2、内容构建方向
我们网站在制作内容时需要考虑以下几点:
1)哪些目标用户通过关键词搜索目标信息
2)当目标用户正在寻找指定的信息时,除了直接找到相应的关键词之外,他还将搜索什么?
3)目标用户真正需要什么?
了解目标用户的搜索习惯和关键词后,我们可以很好地准备网站的内容。除了找到用户对应的关键词外,我们还需要使用其他关键词来丰富网站]内容,引导用户输入网站。
3、内容关注
对于seo优化,就内容而言,创新的营销思想认为这些问题仍需要注意:
(1) SEO-必须深入了解这个行业,而不仅仅是深入研究关键词,网站编辑者必须了解这个行业;
(2) 原创是基本的,“重印”现在是主要站点的专利,但是您也应注意不要重印尽可能多,因为很可能不会被搜索引擎搜索收录。
([3) 网站不应以“ 原创”开头,因为原创不一定对用户有价值。网站应当以“对用户有价值”开头。即使您定位三个或四个目标将针对某个问题的不同解决方案有机地结合在一起,只要它对用户真正有价值,并且没有其他网站这样做,那么这也是一种内容构建方式。
([4)请勿以“ 伪原创”开头。将自己标记为[伪原创“后,所有将来的内容策略和行为都会作弊。因为您只想为搜索引擎创建内容,只要搜索引擎收录为0K,所有针对内容的操作都会带有欺诈嫌疑和痕迹。
([5)就具体内容而言,可以是信息,原创评论,离线数据扫描,外语翻译甚至是有机汇总等。建议一起使用多个构想,而不是仅使用一个构想。方法。
(6)如果要将脱机媒体的内容上传到Internet,则必须替换脱机媒体使用的一些不准确的关键词。例如,“这个省”,“这个城市”,“这个电台”“本报纸”等
教程推荐阅读教程网站优化的个基本要素谷歌优化外贸优
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-04-29 21:09
指定关键词以跳转到seo gate技术,以使您了解持久性的重要性以及如何持久化。如果您想了解更多信息,请继续在此处访问第一个引擎网站;其他;内容如有任何疑问,您也可以前往首钢区询问所有问题并迅速获得答案。建议阅读相关教程以获取相关教程。网站优化的基本要素Google外贸优化;到首钢区询问所有问题将很快得到答复。建议使用相关教程。阅读教程网站优化的基本要素Google优化外贸优化推广更多的朋友因为对百科全书的解释而不了解它是什么太专业了。下面的第一个引擎将用简单的单词向您解释中文!
指定关键词跳转到seo并将其放置在网站上。但是,由于广告软件过多,某些网站管理员不太可能具有清晰的主布局和副布局,因此,他们将主要的软件和广告软件放在第二位。很难确定要下载的是哪个广告软件和哪个软件最终会导致非常糟糕的用户体验。因此,笔者认为主要软件的下载链接;用户很难确认哪个是广告软件以及哪个本身是您要下载的软件最终将导致非常糟糕的用户体验。因此,作者认为应将主要软件的下载链接放在页面顶部。广告软件的下载链接应放置在下面图片的底部。一个真正懂得如何操作的网站管理员应该是顾权。总体情况着重于用户体验下载网站在用户中并不流行。归根结底,有些网站管理员不了解操作。
指定关键词跳转seo理解和网站优化网站优化的布局是使网站的内容带有图片和文字。请记住将其添加到属中。这将使用户更加赏心悦目。对于搜索引擎,这也非常容易。用于排名改善的网站的内容必须是内部链接,即锚文本链接。当我们编写内容时,经常会遇到很多内容。因此,此时,我们可以将它们转换为内部链接。搜索引擎也很容易排名。 网站内容必须是内部链接,即锚文本链接。编写内容时,经常会遇到很多内容,因此,此时可以将它们转换为内部链接,即锚文本链接。这将有助于搜索引擎判断我们网站内容的质量。
请指定关键词 Jump SEO,他们是搜索市场的早期开拓者。他们复制搜索方法和设计元素。尽管经常将百度视为克隆人,但实际上,百度的核心仍然具有自己的独特性。百度之所以能引领搜索市场,主要原因之一是它比其他搜索引擎更有效地分析和理解汉字,以提供更高质量的搜索结果。不仅如此,百度还拥有世界上最大的中文网页。它可以领导搜索市场的主要原因之一是,它比其他搜索引擎更有效地分析和理解汉字,以提供更高质量的搜索结果。不仅如此,百度还拥有全球最大的中文网络索引,该索引完全基于中文。用户界面是完全中文的。仅简体中文网站也具有优先权。
指定关键词将seo外包给网站优化公司以节省资金和专业虚假网站如何区分优化公司网站没有优化,不需要网站优化等。所谓的快速排名优化网站优化公司适用于非正式网站!即使可以在短期内排名到首页也可以对公司进行优化网站优化公司的黑帽子网站优化技术网站优化软件可以退款网站,算作主页网站优化公司的黑帽子网站优化方法网站优化软件可以退款网站。 查看全部
教程推荐阅读教程网站优化的个基本要素谷歌优化外贸优
指定关键词以跳转到seo gate技术,以使您了解持久性的重要性以及如何持久化。如果您想了解更多信息,请继续在此处访问第一个引擎网站;其他;内容如有任何疑问,您也可以前往首钢区询问所有问题并迅速获得答案。建议阅读相关教程以获取相关教程。网站优化的基本要素Google外贸优化;到首钢区询问所有问题将很快得到答复。建议使用相关教程。阅读教程网站优化的基本要素Google优化外贸优化推广更多的朋友因为对百科全书的解释而不了解它是什么太专业了。下面的第一个引擎将用简单的单词向您解释中文!
指定关键词跳转到seo并将其放置在网站上。但是,由于广告软件过多,某些网站管理员不太可能具有清晰的主布局和副布局,因此,他们将主要的软件和广告软件放在第二位。很难确定要下载的是哪个广告软件和哪个软件最终会导致非常糟糕的用户体验。因此,笔者认为主要软件的下载链接;用户很难确认哪个是广告软件以及哪个本身是您要下载的软件最终将导致非常糟糕的用户体验。因此,作者认为应将主要软件的下载链接放在页面顶部。广告软件的下载链接应放置在下面图片的底部。一个真正懂得如何操作的网站管理员应该是顾权。总体情况着重于用户体验下载网站在用户中并不流行。归根结底,有些网站管理员不了解操作。
指定关键词跳转seo理解和网站优化网站优化的布局是使网站的内容带有图片和文字。请记住将其添加到属中。这将使用户更加赏心悦目。对于搜索引擎,这也非常容易。用于排名改善的网站的内容必须是内部链接,即锚文本链接。当我们编写内容时,经常会遇到很多内容。因此,此时,我们可以将它们转换为内部链接。搜索引擎也很容易排名。 网站内容必须是内部链接,即锚文本链接。编写内容时,经常会遇到很多内容,因此,此时可以将它们转换为内部链接,即锚文本链接。这将有助于搜索引擎判断我们网站内容的质量。
请指定关键词 Jump SEO,他们是搜索市场的早期开拓者。他们复制搜索方法和设计元素。尽管经常将百度视为克隆人,但实际上,百度的核心仍然具有自己的独特性。百度之所以能引领搜索市场,主要原因之一是它比其他搜索引擎更有效地分析和理解汉字,以提供更高质量的搜索结果。不仅如此,百度还拥有世界上最大的中文网页。它可以领导搜索市场的主要原因之一是,它比其他搜索引擎更有效地分析和理解汉字,以提供更高质量的搜索结果。不仅如此,百度还拥有全球最大的中文网络索引,该索引完全基于中文。用户界面是完全中文的。仅简体中文网站也具有优先权。
指定关键词将seo外包给网站优化公司以节省资金和专业虚假网站如何区分优化公司网站没有优化,不需要网站优化等。所谓的快速排名优化网站优化公司适用于非正式网站!即使可以在短期内排名到首页也可以对公司进行优化网站优化公司的黑帽子网站优化技术网站优化软件可以退款网站,算作主页网站优化公司的黑帽子网站优化方法网站优化软件可以退款网站。
青长以前987803.COM将您的退款保证放在明显的地方
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-04-29 21:06
对于中国,请明确说明77927MM.COM在购物过程中会将您的退款保证放在明显的位置。
例如,一个软件开发项目需要人才。春苗项目经理将项目分解为多个短期任务。春苗将项目投入市场以解释工作要求,选择候选人,并将相关工作推向开放的人才市场。部分选择已通过外力验证,以有效解决问题。对于后续的发展计划,将实时地对这些合作伙伴进行匹配和促进,形成相对自由但稳定的合作关系。 987803 8. COM是美国《有线》杂志的资深编辑,杰夫·豪(Jeff Howe)在他著名的“众包”中指出,98780 3. COM曾经是各个领域的精英或不同层次的专业人员。 ,占据了行业的声音和决策权。
从这句话来看,这种模式在中国的实现是在完全开放的劳动力市场中。但是,在离线状态下,春苗的国内地理资源极为不平衡。春苗包括农村和城市地区的人才和就业资源,一线城市以及三,四线城市的供求不平衡,以及劳动力,技术和资源的不平衡。一些公司对人才的需求往往是短期的,年轻的。原因是年轻人仍然处于从传统企业到互联网技术新兴企业的当前组织结构中。对人才的需求往往是短期的,分阶段的和年轻的。当前,中国的互联网发展越来越快。随着中国研发和推出各种新的移动互联网产品,中国各种商业模式的兴起,跨地区的在线和离线连接能力不亚于美国。拥有数亿用户的Internet平台已经为数据开放和访问供需双方奠定了基础,并连接了众多的粉丝和用户。 IBM春苗建立的“开放人才市场”就是一个典型案例。
自由职业者之所以成为青年人的企业家精神的典范,是因为自由职业者本身就是一个从产品到专业能力,品牌包装,青年定价,品牌传播,产品或内容销售的整个过程的人。 。这个世界的许多领域将从垄断转向开放。罗纳德·科斯(Ronald Coase)曾经解释过企业的价值:在中国一个完全开放的劳动力市场中,中国人可以彼此签订合同,出售自己的劳动力并同时购买他人的劳动力。应该注意的是,即使春苗的网页以前很受欢迎,它也会过时,最终降低网站内容的SEO值。
为了保存文本,您还应该尝试使用URL缩写服务,例如t.co或goo.gl或bit.ly。您可以测试哪些页面最有吸引力,而中国可以基于这些优势制作更多页面。基本内容SEO问题如果您最近没有进行内容审核或更新网站 SEO(春苗),那么您需要花费时间搜索旧版本的分析包并测试它们的构建方式。分析硬数据是无可替代的。这意味着网站需要安装一个可靠的分析包。
呈现网站内容的关键是操作员需要确定哪些内容有用,哪些内容需要调整以及哪些内容必须删除。大型搜索引擎使用的SEO标准仍然有效,使用这些标准,您可以检测到一些更明显的错误。
例如,这意味着您应该写微博。 Google的WebmasterTools服务可以帮助您检测配置错误警告或其他一些问题,包括由恶意软件警告引起的搜索引擎优化(SEO)问题。如果其他页面没有指向该页面,则可以考虑将其删除。这些形式可以提供很多信息,例如元描述的长度,页面标题以及每个页面上的单词数。
在大多数情况下,重写网页足以提高网站的可读性和可读性,但是在某些情况下,选择删除页面或更新页面更为明智。如果您的网站很小,也许可以手动管理这些页面。当您拥有所有信息时,审核网页并处理该网页上出现的问题是合乎逻辑的。如果您无法从社交媒体获得流量,则可以通过以下几种方法来解决此问题。
主流网站基于访问者喜欢的内容来构建其业务模型。另一个条件是指向某个网页的链接总数。
GoogleAnalytics可以轻松地嵌入网页中,并告诉您用户如何与网站进行交互,而且它是完全免费的。如果您在审核网页时发现网页格式不正确,则可能需要重写网页以符合当前的内容SEO标准。
使用这种数据驱动的方法,您可以处理网页问题并建立搜索引擎,并且用户喜欢网站〜原创地址:(“专注于企业家精神,电子商务,网站管理员,扫描A5创业网络微信QR码,定期抽奖。Twitter会自动为您缩短URL。如果您使用第三方缩写服务(例如bit.ly),则可以对每个URL进行分析,例如单击的每个元素。知道哪些页面表现良好也非常重要,诸如Twitter,Instagram和Facebook之类的社交媒体网站越来越吸引访问量,包括您在每次页面审核中的社交媒体流失统计信息。也可以使用这些信息制定有助于将来的Web内容的计划。诸如SharedCount之类的网站可以快速向您提供有关网站在社交媒体上的表现的反馈。
如果要浏览网络以解决基本内容搜索引擎(SEO)问题,则可以适当使用head标签和meta描述。因为搜索引擎喜欢新内容,所以这样做将大大有助于提高网站的总体排名。
网站的内容在网站的操作中变得越来越重要。测量网站现有内容的价值的过程称为“内容审核”,该过程用于识别网站中可能增加流量的内容和可能导致问题的内容。
将所有内容放在一起,主流分析工具可以以电子表格格式导出数据,因此您可以将所有这些信息放入MSExcel或Google Spreadsheet中以查看整体数据。搜索引擎扫描网站的内容质量,最终用户通常只对对他们有用的内容感兴趣。
一种基于数据衡量网页价值的简单方法是检查过去18个月带来的流量。无需走极端,但大多数网站至少拥有一个Twitter和一个Facebook帐户。如果一个页面可以增加链接和流量的数量,以便能够在以后的页面中吸收这种良好的体验,则您需要了解在此页面上做得很好的事情。这种方法需要整合网站中的内容并做出实际决定。
通过组合这些插件包提供的信息,您可以清楚地知道用户来自何处以及他们在您的网站上停留了多长时间。首先,如果您还没有社交媒体帐户,请先获得一个
我始终相信,在网站运算中表现出色的人,还必须在其他平台上的内容运算中也表现出色。 3.页面计划技巧网站操作无法避免计划许多特殊页面。这是事件页面计划过程的一般说明。首先,明确事件的目的,并确保整个事件页面的逻辑清晰。 查看全部
青长以前987803.COM将您的退款保证放在明显的地方
对于中国,请明确说明77927MM.COM在购物过程中会将您的退款保证放在明显的位置。
例如,一个软件开发项目需要人才。春苗项目经理将项目分解为多个短期任务。春苗将项目投入市场以解释工作要求,选择候选人,并将相关工作推向开放的人才市场。部分选择已通过外力验证,以有效解决问题。对于后续的发展计划,将实时地对这些合作伙伴进行匹配和促进,形成相对自由但稳定的合作关系。 987803 8. COM是美国《有线》杂志的资深编辑,杰夫·豪(Jeff Howe)在他著名的“众包”中指出,98780 3. COM曾经是各个领域的精英或不同层次的专业人员。 ,占据了行业的声音和决策权。
从这句话来看,这种模式在中国的实现是在完全开放的劳动力市场中。但是,在离线状态下,春苗的国内地理资源极为不平衡。春苗包括农村和城市地区的人才和就业资源,一线城市以及三,四线城市的供求不平衡,以及劳动力,技术和资源的不平衡。一些公司对人才的需求往往是短期的,年轻的。原因是年轻人仍然处于从传统企业到互联网技术新兴企业的当前组织结构中。对人才的需求往往是短期的,分阶段的和年轻的。当前,中国的互联网发展越来越快。随着中国研发和推出各种新的移动互联网产品,中国各种商业模式的兴起,跨地区的在线和离线连接能力不亚于美国。拥有数亿用户的Internet平台已经为数据开放和访问供需双方奠定了基础,并连接了众多的粉丝和用户。 IBM春苗建立的“开放人才市场”就是一个典型案例。
自由职业者之所以成为青年人的企业家精神的典范,是因为自由职业者本身就是一个从产品到专业能力,品牌包装,青年定价,品牌传播,产品或内容销售的整个过程的人。 。这个世界的许多领域将从垄断转向开放。罗纳德·科斯(Ronald Coase)曾经解释过企业的价值:在中国一个完全开放的劳动力市场中,中国人可以彼此签订合同,出售自己的劳动力并同时购买他人的劳动力。应该注意的是,即使春苗的网页以前很受欢迎,它也会过时,最终降低网站内容的SEO值。
为了保存文本,您还应该尝试使用URL缩写服务,例如t.co或goo.gl或bit.ly。您可以测试哪些页面最有吸引力,而中国可以基于这些优势制作更多页面。基本内容SEO问题如果您最近没有进行内容审核或更新网站 SEO(春苗),那么您需要花费时间搜索旧版本的分析包并测试它们的构建方式。分析硬数据是无可替代的。这意味着网站需要安装一个可靠的分析包。
呈现网站内容的关键是操作员需要确定哪些内容有用,哪些内容需要调整以及哪些内容必须删除。大型搜索引擎使用的SEO标准仍然有效,使用这些标准,您可以检测到一些更明显的错误。
例如,这意味着您应该写微博。 Google的WebmasterTools服务可以帮助您检测配置错误警告或其他一些问题,包括由恶意软件警告引起的搜索引擎优化(SEO)问题。如果其他页面没有指向该页面,则可以考虑将其删除。这些形式可以提供很多信息,例如元描述的长度,页面标题以及每个页面上的单词数。
在大多数情况下,重写网页足以提高网站的可读性和可读性,但是在某些情况下,选择删除页面或更新页面更为明智。如果您的网站很小,也许可以手动管理这些页面。当您拥有所有信息时,审核网页并处理该网页上出现的问题是合乎逻辑的。如果您无法从社交媒体获得流量,则可以通过以下几种方法来解决此问题。
主流网站基于访问者喜欢的内容来构建其业务模型。另一个条件是指向某个网页的链接总数。
GoogleAnalytics可以轻松地嵌入网页中,并告诉您用户如何与网站进行交互,而且它是完全免费的。如果您在审核网页时发现网页格式不正确,则可能需要重写网页以符合当前的内容SEO标准。
使用这种数据驱动的方法,您可以处理网页问题并建立搜索引擎,并且用户喜欢网站〜原创地址:(“专注于企业家精神,电子商务,网站管理员,扫描A5创业网络微信QR码,定期抽奖。Twitter会自动为您缩短URL。如果您使用第三方缩写服务(例如bit.ly),则可以对每个URL进行分析,例如单击的每个元素。知道哪些页面表现良好也非常重要,诸如Twitter,Instagram和Facebook之类的社交媒体网站越来越吸引访问量,包括您在每次页面审核中的社交媒体流失统计信息。也可以使用这些信息制定有助于将来的Web内容的计划。诸如SharedCount之类的网站可以快速向您提供有关网站在社交媒体上的表现的反馈。
如果要浏览网络以解决基本内容搜索引擎(SEO)问题,则可以适当使用head标签和meta描述。因为搜索引擎喜欢新内容,所以这样做将大大有助于提高网站的总体排名。
网站的内容在网站的操作中变得越来越重要。测量网站现有内容的价值的过程称为“内容审核”,该过程用于识别网站中可能增加流量的内容和可能导致问题的内容。
将所有内容放在一起,主流分析工具可以以电子表格格式导出数据,因此您可以将所有这些信息放入MSExcel或Google Spreadsheet中以查看整体数据。搜索引擎扫描网站的内容质量,最终用户通常只对对他们有用的内容感兴趣。
一种基于数据衡量网页价值的简单方法是检查过去18个月带来的流量。无需走极端,但大多数网站至少拥有一个Twitter和一个Facebook帐户。如果一个页面可以增加链接和流量的数量,以便能够在以后的页面中吸收这种良好的体验,则您需要了解在此页面上做得很好的事情。这种方法需要整合网站中的内容并做出实际决定。
通过组合这些插件包提供的信息,您可以清楚地知道用户来自何处以及他们在您的网站上停留了多长时间。首先,如果您还没有社交媒体帐户,请先获得一个
我始终相信,在网站运算中表现出色的人,还必须在其他平台上的内容运算中也表现出色。 3.页面计划技巧网站操作无法避免计划许多特殊页面。这是事件页面计划过程的一般说明。首先,明确事件的目的,并确保整个事件页面的逻辑清晰。
如何才能精准地找到想要的核心内容?(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-04-28 00:20
重新发布
阅读:502'> 502
互联网是一个巨大的知识库。我们对此有很多了解。我们通过搜索引擎搜索所需的内容。例如,我们常用的搜索引擎,例如百度和Google
但是由于搜索引擎采集了很多东西,所以我们找到的内容可能不是我们想要的。我们如何才能准确地找到我们想要的核心内容。
1.站点:指定URL
仅搜索域名下的内容。如果只想搜索office-cn域名,则可以输入“ Excel技能站点:office-cn”,然后在office-cn网站上搜索Excel技能
2.双引号:完全匹配的关键字
将搜索关键词放在双引号中,以表示完全匹配。普通搜索是模糊查询,可能不是完整的句子。如果输入“ nas教程”,它将搜索有关关键字“ nas教程”的所有链接
3.标题:出现在标题中
intitle加英文冒号加搜索错误关键词,表示搜索结果页面的标题收录该搜索词。使用intitle命令找到的文件是更准确的比赛页面。如果关键词仅出现在页面上的可见文本中,则在大多数情况下搜索结果不准确
4.减号:排除
减号后的搜索词表示您要排除收录该搜索词的结果。使用此减号时,其前必须有一个空格,其后必须没有空格。
access-报告返回的结果收录单词“ access”,但不收录单词“ report”
5. inurl:出现在网址中
inurl:后跟搜索词,这意味着搜索词收录在搜索结果的URL中。例如,输入inurl:,则结果网页必须收录视频
6.文件类型:受限文件类型
filetype:后跟文件后缀,指示返回此文件类型的结果。格式(pdf / doc / xml),例如文件类型:PDF 查看全部
如何才能精准地找到想要的核心内容?(组图)
重新发布
阅读:502'> 502
互联网是一个巨大的知识库。我们对此有很多了解。我们通过搜索引擎搜索所需的内容。例如,我们常用的搜索引擎,例如百度和Google
但是由于搜索引擎采集了很多东西,所以我们找到的内容可能不是我们想要的。我们如何才能准确地找到我们想要的核心内容。
1.站点:指定URL
仅搜索域名下的内容。如果只想搜索office-cn域名,则可以输入“ Excel技能站点:office-cn”,然后在office-cn网站上搜索Excel技能
2.双引号:完全匹配的关键字
将搜索关键词放在双引号中,以表示完全匹配。普通搜索是模糊查询,可能不是完整的句子。如果输入“ nas教程”,它将搜索有关关键字“ nas教程”的所有链接
3.标题:出现在标题中
intitle加英文冒号加搜索错误关键词,表示搜索结果页面的标题收录该搜索词。使用intitle命令找到的文件是更准确的比赛页面。如果关键词仅出现在页面上的可见文本中,则在大多数情况下搜索结果不准确
4.减号:排除
减号后的搜索词表示您要排除收录该搜索词的结果。使用此减号时,其前必须有一个空格,其后必须没有空格。
access-报告返回的结果收录单词“ access”,但不收录单词“ report”
5. inurl:出现在网址中
inurl:后跟搜索词,这意味着搜索词收录在搜索结果的URL中。例如,输入inurl:,则结果网页必须收录视频
6.文件类型:受限文件类型
filetype:后跟文件后缀,指示返回此文件类型的结果。格式(pdf / doc / xml),例如文件类型:PDF
站外优化的本质作用告诉大家一个优质的入口页和主页有什么区别
网站优化 • 优采云 发表了文章 • 0 个评论 • 385 次浏览 • 2021-04-28 00:19
现在,许多网站外部链接专家基本上都是网站优化新手,他们还没有掌握优化的本质,并且大多都是敷衍了事。场外优化的重要作用告诉每个人,高质量的场外优化基本上可以与数百种次要的场外优化相媲美。异地优化的质量远高于数量。这反映在外部链接的构建中。非常饱。
条目页面在转换过程中占据重要位置,并且在上一页和下一页之间具有链接。主页是许多中小型网站条目页面。一些朋友可能会问,进入页面和主页之间有什么区别?例如,网站是一扇有许多门的建筑物。主页是门,入口页是指建筑物中的所有门。
网站主页反映了网站的类型,目的和内容,并应针对网站级别的主要流量进行设计;条目页面的内容应适用于所有流量,即,由它带来的流量的任何网络促销(付费或非付费)都必须得到照顾。如上所述,大多数在线促销都用于转化后。通过某个门户网站页面完成的转化次数越多,该门户网站页面越有利于转化,并且它与促销源流量的匹配程度就越高。
接下来,我将解释这两个常见的问题。什么是白帽子?戴黑帽子是什么?白帽子是白帽子吗?当然不是。白帽。从字面上来讲,是的。白色,无污染。 seo技术是每个人都称为常规优化方法的技术。它遵循搜索引擎指定的规则来优化和调整网站。它不适合作弊方法在短期内实现其目标。老实说,白帽操作周期长,麻烦且累人。
黑帽子正好相反。通过使用一些作弊方法或钻探搜索引擎算法漏洞,您可以在短期内看到优化效果,但是如果被搜索引擎发现,则可能会受到非常严重的惩罚。风险和收益是成比例的。风险越大,收益就越高,这就是为什么黑帽仍然存在的原因。
对企业来说网站最重要的是主页,这没有争议;但是,如果对内容页面的优化做得不好,不仅首页无法达到预期的效果,而且整个网站的优化也将是不可能的。是的,它将直接影响网站的比率。
第一个是内容页面的匹配度,即内容和标题之间的匹配度;相似之处在于页面与页面之间的比较;第三是内部链接推荐,它涉及网站相互投票和蜘蛛指导的内容;第四是附件优化,它对网站的影响不大,但具有可以改善网站的内容。
搜索引擎如何判断网站有购买和出售链接的行为
1、链接的突然出现和消失?
一般的朋友链很长,一些网站的买卖链接将会出现,该月到期后,钱将不会被标记,然后您的网站朋友链将被取消,并且然后您将再次付款,我再次将其添加到了您。与此类似!
搜索引擎优化
2、内容的主题是否相关?
如果高权重网站突然是新闻类型网站,而极低权重网站类型用于训练,则内容和主题之间没有关系,个人也可以看到有问题!
3、使用知名的链接交易服务吗?
类似于平台,用于买卖友情链接的平台,但是在搜索引擎看来,像这样的平台是一个非常令人恐惧的比较。如果您的网站出现在其上,将对其进行搜索。在发动机的监控范围内! 查看全部
站外优化的本质作用告诉大家一个优质的入口页和主页有什么区别
现在,许多网站外部链接专家基本上都是网站优化新手,他们还没有掌握优化的本质,并且大多都是敷衍了事。场外优化的重要作用告诉每个人,高质量的场外优化基本上可以与数百种次要的场外优化相媲美。异地优化的质量远高于数量。这反映在外部链接的构建中。非常饱。
条目页面在转换过程中占据重要位置,并且在上一页和下一页之间具有链接。主页是许多中小型网站条目页面。一些朋友可能会问,进入页面和主页之间有什么区别?例如,网站是一扇有许多门的建筑物。主页是门,入口页是指建筑物中的所有门。
网站主页反映了网站的类型,目的和内容,并应针对网站级别的主要流量进行设计;条目页面的内容应适用于所有流量,即,由它带来的流量的任何网络促销(付费或非付费)都必须得到照顾。如上所述,大多数在线促销都用于转化后。通过某个门户网站页面完成的转化次数越多,该门户网站页面越有利于转化,并且它与促销源流量的匹配程度就越高。
接下来,我将解释这两个常见的问题。什么是白帽子?戴黑帽子是什么?白帽子是白帽子吗?当然不是。白帽。从字面上来讲,是的。白色,无污染。 seo技术是每个人都称为常规优化方法的技术。它遵循搜索引擎指定的规则来优化和调整网站。它不适合作弊方法在短期内实现其目标。老实说,白帽操作周期长,麻烦且累人。
黑帽子正好相反。通过使用一些作弊方法或钻探搜索引擎算法漏洞,您可以在短期内看到优化效果,但是如果被搜索引擎发现,则可能会受到非常严重的惩罚。风险和收益是成比例的。风险越大,收益就越高,这就是为什么黑帽仍然存在的原因。
对企业来说网站最重要的是主页,这没有争议;但是,如果对内容页面的优化做得不好,不仅首页无法达到预期的效果,而且整个网站的优化也将是不可能的。是的,它将直接影响网站的比率。
第一个是内容页面的匹配度,即内容和标题之间的匹配度;相似之处在于页面与页面之间的比较;第三是内部链接推荐,它涉及网站相互投票和蜘蛛指导的内容;第四是附件优化,它对网站的影响不大,但具有可以改善网站的内容。
搜索引擎如何判断网站有购买和出售链接的行为
1、链接的突然出现和消失?
一般的朋友链很长,一些网站的买卖链接将会出现,该月到期后,钱将不会被标记,然后您的网站朋友链将被取消,并且然后您将再次付款,我再次将其添加到了您。与此类似!
搜索引擎优化
2、内容的主题是否相关?
如果高权重网站突然是新闻类型网站,而极低权重网站类型用于训练,则内容和主题之间没有关系,个人也可以看到有问题!
3、使用知名的链接交易服务吗?
类似于平台,用于买卖友情链接的平台,但是在搜索引擎看来,像这样的平台是一个非常令人恐惧的比较。如果您的网站出现在其上,将对其进行搜索。在发动机的监控范围内!
搜索指定网站内容信息(比如招聘网站的首页链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-04-25 01:06
搜索指定网站内容信息(比如招聘网站的首页链接和公司网站的链接)就能获得对应网站的内容并推送给对应的网友,也就是你所说的“推荐”。
技术原理:
1、网站、应用、系统收集信息。主要有关键词搜索、网站索引、高频搜索及机器学习等。
2、利用人工智能(机器学习)实现推荐。
1、网站和应用程序是以内容聚合的方式进行流量变现。
2、推荐的主要信息应该是用户经常浏览的网站和应用程序上面的内容。
3、微博如果算是资讯网站,只能算是信息聚合,算不上推荐。
我们在一个热点事件中记录所有网民关注的问题,然后推荐给每一个网民。当然,你最好有一套系统来判断出你关注问题的答案。
说白了就是读数据分析的东西。上面几位说的好,百度搜索根据用户的上网记录进行个性化推荐。网上你经常打开的网站每天产生的信息量级级大约上百万条,有人给你推荐别人关注的话题,很有可能说明你每天会至少浏览若干条相关信息。多说一句,新浪的sina微博就算在现在的互联网行业的早期,其发布的内容也算是互联网上丰富的信息,包括美女图片、热点信息等,那时候比现在的sina微博推荐机制要强的多的多。
大数据分析+机器学习。
同意zero的回答,其实简单地说可以认为是推荐系统。可以根据用户的历史历史表现进行推荐,也可以结合用户的喜好进行推荐。举例子来说:有一个app,每天推荐一个最新最新的事件给你,你说我也想知道我最近的爱好是什么,或者我最近想去哪玩,这个app就算提供了最新最新的信息,也未必会对你有用。因为这些都是根据你在这款app上的行为经验主动推荐给你的。 查看全部
搜索指定网站内容信息(比如招聘网站的首页链接)
搜索指定网站内容信息(比如招聘网站的首页链接和公司网站的链接)就能获得对应网站的内容并推送给对应的网友,也就是你所说的“推荐”。
技术原理:
1、网站、应用、系统收集信息。主要有关键词搜索、网站索引、高频搜索及机器学习等。
2、利用人工智能(机器学习)实现推荐。
1、网站和应用程序是以内容聚合的方式进行流量变现。
2、推荐的主要信息应该是用户经常浏览的网站和应用程序上面的内容。
3、微博如果算是资讯网站,只能算是信息聚合,算不上推荐。
我们在一个热点事件中记录所有网民关注的问题,然后推荐给每一个网民。当然,你最好有一套系统来判断出你关注问题的答案。
说白了就是读数据分析的东西。上面几位说的好,百度搜索根据用户的上网记录进行个性化推荐。网上你经常打开的网站每天产生的信息量级级大约上百万条,有人给你推荐别人关注的话题,很有可能说明你每天会至少浏览若干条相关信息。多说一句,新浪的sina微博就算在现在的互联网行业的早期,其发布的内容也算是互联网上丰富的信息,包括美女图片、热点信息等,那时候比现在的sina微博推荐机制要强的多的多。
大数据分析+机器学习。
同意zero的回答,其实简单地说可以认为是推荐系统。可以根据用户的历史历史表现进行推荐,也可以结合用户的喜好进行推荐。举例子来说:有一个app,每天推荐一个最新最新的事件给你,你说我也想知道我最近的爱好是什么,或者我最近想去哪玩,这个app就算提供了最新最新的信息,也未必会对你有用。因为这些都是根据你在这款app上的行为经验主动推荐给你的。

