
抓取网页音频
抓取网页音频(CME继续自己的创新性YourAudio在线免费服务可以处理音频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 359 次浏览 • 2021-10-26 12:05
芝商所继续自己的创新探索。这项名为“编辑您的音频”的免费在线服务可以帮助您在云端处理音频,它使用新算法来获得更好的结果。
首先,这是一项在线免费服务,只需访问即可使用(打开后可以在网页底部选择中文),上传音频文件进行在线云处理,所有处理都进行使用 CME 的在线服务器。不消耗本地电脑的资源,所以手机也可以上传。
此服务支持 30MB 以下多种格式的任何音频,包括:
目前共有三种服务(实际上都是基于相同的算法),包括:
这种基于云端的算法并没有使用传统的倒音方法,而是基于Deezer Institute的算法,分析人声的音频特征,并分离出具有该特征的音频。目前第一步只能对人声进行分析分离,下一步还可以对钢琴、鼓、贝司等乐器的声音进行分析分离,后续会持续更新。
由于原算法需要高速GPU处理,耗时长,计算量大,成本高,所以对个人电脑的要求较高。CME工程师对云计算进行了优化,可以利用云服务器的CPU进行快速处理,达到低成本大规模应用的水平。
大家不妨试一试,欢迎在留言中写下您的体验,帮助CME开发者不断完善服务: 查看全部
抓取网页音频(CME继续自己的创新性YourAudio在线免费服务可以处理音频)
芝商所继续自己的创新探索。这项名为“编辑您的音频”的免费在线服务可以帮助您在云端处理音频,它使用新算法来获得更好的结果。

首先,这是一项在线免费服务,只需访问即可使用(打开后可以在网页底部选择中文),上传音频文件进行在线云处理,所有处理都进行使用 CME 的在线服务器。不消耗本地电脑的资源,所以手机也可以上传。
此服务支持 30MB 以下多种格式的任何音频,包括:
目前共有三种服务(实际上都是基于相同的算法),包括:
这种基于云端的算法并没有使用传统的倒音方法,而是基于Deezer Institute的算法,分析人声的音频特征,并分离出具有该特征的音频。目前第一步只能对人声进行分析分离,下一步还可以对钢琴、鼓、贝司等乐器的声音进行分析分离,后续会持续更新。
由于原算法需要高速GPU处理,耗时长,计算量大,成本高,所以对个人电脑的要求较高。CME工程师对云计算进行了优化,可以利用云服务器的CPU进行快速处理,达到低成本大规模应用的水平。
大家不妨试一试,欢迎在留言中写下您的体验,帮助CME开发者不断完善服务:
抓取网页音频(android_read出现代码的逻辑很简单,主要是底层音频有问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-26 08:07
)
我们经常会遇到这样的问题。应用程序读取的音频有问题。您需要在tinyalsa中读取音频,以确认是底层音频问题还是应用程序处理后的问题。
于是,这个补丁出现了
代码逻辑很简单,主要是pcm_read的时候,数据同时写入文件,这个只能在调试的时候用,一直用的话,文件总是会变大,直到系统是不是存储到底有问题。
Android.mk 不再用于编写 android 代码。相反,使用 android.bp。如果需要收录头文件,这里需要修改。相关的文章是网上的一篮子,就不多说了。
有个指针处理,我觉得比较巧妙,喜欢研究代码的可以去github看源码。
如果你还是不明白代码,你可以去tinycap.c。解析和记录操作虽然简单,但对我们帮助很大。
代码修改的diff如下
diff --git a/external/tinyalsa/Android.bp b/external/tinyalsa/Android.bp
old mode 100644
new mode 100755
index 090d91c0f8..79a6ceaee2
--- a/external/tinyalsa/Android.bp
+++ b/external/tinyalsa/Android.bp
@@ -9,6 +9,7 @@ cc_library {
"mixer.c",
"pcm.c",
],
+ shared_libs: ["liblog"],
cflags: ["-Werror", "-Wno-macro-redefined"],
export_include_dirs: ["include"],
local_include_dirs: ["include"],
diff --git a/external/tinyalsa/pcm.c b/external/tinyalsa/pcm.c
old mode 100644
new mode 100755
index 4ae321bf93..de0deab9d0
--- a/external/tinyalsa/pcm.c
+++ b/external/tinyalsa/pcm.c
@@ -35,11 +35,17 @@
#include
#include
+#include
+#include
+#include
+
#include
#include
#include
#include
+#include
+
#include
#define __force
#define __bitwise
@@ -48,6 +54,10 @@
#include
+#define LOG_TAG "TINYALSA_QIFA"
+#define ALOGD(fmt, args...) __android_log_print(ANDROID_LOG_DEBUG, LOG_TAG, fmt, ##args)
+#define ALOGE(fmt, args...) __android_log_print(ANDROID_LOG_ERROR, LOG_TAG, fmt, ##args)
+
#define PARAM_MAX SNDRV_PCM_HW_PARAM_LAST_INTERVAL
/* Logs information into a string; follows snprintf() in that
@@ -242,6 +252,10 @@ static void param_init(struct snd_pcm_hw_params *p)
struct pcm {
int fd;
+ //int fd_test;
+ FILE *fd_test;
+ unsigned int size_test;
+ void *test_buffer;
unsigned int flags;
int running:1;
int prepared:1;
@@ -566,6 +580,7 @@ int pcm_read(struct pcm *pcm, void *data, unsigned int count)
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
}
}
@@ -864,6 +885,8 @@ int pcm_close(struct pcm *pcm)
if (pcm->fd >= 0)
close(pcm->fd);
+ if (pcm->fd_test >= 0)
+ fclose(pcm->fd_test);
pcm->prepared = 0;
pcm->running = 0;
pcm->buffer_size = 0;
@@ -872,6 +895,8 @@ int pcm_close(struct pcm *pcm)
return 0;
}
+
+
struct pcm *pcm_open(unsigned int card, unsigned int device,
unsigned int flags, struct pcm_config *config)
{
@@ -900,7 +925,12 @@ struct pcm *pcm_open(unsigned int card, unsigned int device,
oops(pcm, errno, "cannot open device '%s'", fn);
return pcm;
}
-
+ /*weiqifa*/
+ pcm->fd_test = fopen("/sdcard/ref_temp.pcm", "wb");
+ if (!pcm->fd_test) {
+ fprintf(stderr, "Unable to create file /sdcard/ref_temp.pcm\n");
+ } else ALOGD("creat /sdcard/ref_temp.pcm file success");
+
if (fcntl(pcm->fd, F_SETFL, fcntl(pcm->fd, F_GETFL) &
~O_NONBLOCK) config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
:
int running:1;
int prepared:1;
@@ -566,6 +580,7 @@ int pcm_read(struct pcm *pcm, void *data, unsigned int count)
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
}
}
@@ -864,6 +885,8 @@ int pcm_close(struct pcm *pcm)
if (pcm->fd >= 0)
close(pcm->fd);
+ if (pcm->fd_test >= 0)
+ fclose(pcm->fd_test);
pcm->prepared = 0;
pcm->running = 0;
pcm->buffer_size = 0;
@@ -872,6 +895,8 @@ int pcm_close(struct pcm *pcm)
return 0;
}
+
+
struct pcm *pcm_open(unsigned int card, unsigned int device,
unsigned int flags, struct pcm_config *config)
{
@@ -900,7 +925,12 @@ struct pcm *pcm_open(unsigned int card, unsigned int device,
oops(pcm, errno, "cannot open device '%s'", fn);
return pcm;
}
-
+ /*weiqifa*/
+ pcm->fd_test = fopen("/sdcard/ref_temp.pcm", "wb");
+ if (!pcm->fd_test) {
+ fprintf(stderr, "Unable to create file /sdcard/ref_temp.pcm\n");
+ } else ALOGD("creat /sdcard/ref_temp.pcm file success");
+
if (fcntl(pcm->fd, F_SETFL, fcntl(pcm->fd, F_GETFL) &
~O_NONBLOCK) flags & PCM_IN))
return -EINVAL;
x.buf = data;
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd, SNDRV_PCM_IOCTL_READI_FRAMES, &x)) {
pcm->prepared = 0;
pcm->running = 0;
if (errno == EPIPE) {
/* we failed to make our window -- try to restart */
pcm->underruns++;
continue;
}
return oops(pcm, errno, "cannot read stream data");
}
if (fwrite(x.buf, 1, count, pcm->fd_test) != count) {
fprintf(stderr,"Error capturing sample\n");
ALOGE("Error capturing sample");
}
return 0;
}
}
x.buf 是一个指针,但是这个指针使用的是应用传下来的地址,所以不需要为 x.buf 分配空间。详情请参考tinycap。
在 tinycap 中,还会将标题写入音频文件。我们没有在这里写。没关系。打开音频时,可以直接导入原创音频。
xxx:/ # ls -al /sdcard/ref_temp.pcm
-rw-rw---- 1 root sdcard_rw 79298560 2021-01-08 15:24 /sdcard/ref_temp.pcm
xxx:/ #
完整代码如下:
查看全部
抓取网页音频(android_read出现代码的逻辑很简单,主要是底层音频有问题
)
我们经常会遇到这样的问题。应用程序读取的音频有问题。您需要在tinyalsa中读取音频,以确认是底层音频问题还是应用程序处理后的问题。
于是,这个补丁出现了
代码逻辑很简单,主要是pcm_read的时候,数据同时写入文件,这个只能在调试的时候用,一直用的话,文件总是会变大,直到系统是不是存储到底有问题。
Android.mk 不再用于编写 android 代码。相反,使用 android.bp。如果需要收录头文件,这里需要修改。相关的文章是网上的一篮子,就不多说了。
有个指针处理,我觉得比较巧妙,喜欢研究代码的可以去github看源码。
如果你还是不明白代码,你可以去tinycap.c。解析和记录操作虽然简单,但对我们帮助很大。
代码修改的diff如下
diff --git a/external/tinyalsa/Android.bp b/external/tinyalsa/Android.bp
old mode 100644
new mode 100755
index 090d91c0f8..79a6ceaee2
--- a/external/tinyalsa/Android.bp
+++ b/external/tinyalsa/Android.bp
@@ -9,6 +9,7 @@ cc_library {
"mixer.c",
"pcm.c",
],
+ shared_libs: ["liblog"],
cflags: ["-Werror", "-Wno-macro-redefined"],
export_include_dirs: ["include"],
local_include_dirs: ["include"],
diff --git a/external/tinyalsa/pcm.c b/external/tinyalsa/pcm.c
old mode 100644
new mode 100755
index 4ae321bf93..de0deab9d0
--- a/external/tinyalsa/pcm.c
+++ b/external/tinyalsa/pcm.c
@@ -35,11 +35,17 @@
#include
#include
+#include
+#include
+#include
+
#include
#include
#include
#include
+#include
+
#include
#define __force
#define __bitwise
@@ -48,6 +54,10 @@
#include
+#define LOG_TAG "TINYALSA_QIFA"
+#define ALOGD(fmt, args...) __android_log_print(ANDROID_LOG_DEBUG, LOG_TAG, fmt, ##args)
+#define ALOGE(fmt, args...) __android_log_print(ANDROID_LOG_ERROR, LOG_TAG, fmt, ##args)
+
#define PARAM_MAX SNDRV_PCM_HW_PARAM_LAST_INTERVAL
/* Logs information into a string; follows snprintf() in that
@@ -242,6 +252,10 @@ static void param_init(struct snd_pcm_hw_params *p)
struct pcm {
int fd;
+ //int fd_test;
+ FILE *fd_test;
+ unsigned int size_test;
+ void *test_buffer;
unsigned int flags;
int running:1;
int prepared:1;
@@ -566,6 +580,7 @@ int pcm_read(struct pcm *pcm, void *data, unsigned int count)
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
}
}
@@ -864,6 +885,8 @@ int pcm_close(struct pcm *pcm)
if (pcm->fd >= 0)
close(pcm->fd);
+ if (pcm->fd_test >= 0)
+ fclose(pcm->fd_test);
pcm->prepared = 0;
pcm->running = 0;
pcm->buffer_size = 0;
@@ -872,6 +895,8 @@ int pcm_close(struct pcm *pcm)
return 0;
}
+
+
struct pcm *pcm_open(unsigned int card, unsigned int device,
unsigned int flags, struct pcm_config *config)
{
@@ -900,7 +925,12 @@ struct pcm *pcm_open(unsigned int card, unsigned int device,
oops(pcm, errno, "cannot open device '%s'", fn);
return pcm;
}
-
+ /*weiqifa*/
+ pcm->fd_test = fopen("/sdcard/ref_temp.pcm", "wb");
+ if (!pcm->fd_test) {
+ fprintf(stderr, "Unable to create file /sdcard/ref_temp.pcm\n");
+ } else ALOGD("creat /sdcard/ref_temp.pcm file success");
+
if (fcntl(pcm->fd, F_SETFL, fcntl(pcm->fd, F_GETFL) &
~O_NONBLOCK) config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
:
int running:1;
int prepared:1;
@@ -566,6 +580,7 @@ int pcm_read(struct pcm *pcm, void *data, unsigned int count)
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
}
}
@@ -864,6 +885,8 @@ int pcm_close(struct pcm *pcm)
if (pcm->fd >= 0)
close(pcm->fd);
+ if (pcm->fd_test >= 0)
+ fclose(pcm->fd_test);
pcm->prepared = 0;
pcm->running = 0;
pcm->buffer_size = 0;
@@ -872,6 +895,8 @@ int pcm_close(struct pcm *pcm)
return 0;
}
+
+
struct pcm *pcm_open(unsigned int card, unsigned int device,
unsigned int flags, struct pcm_config *config)
{
@@ -900,7 +925,12 @@ struct pcm *pcm_open(unsigned int card, unsigned int device,
oops(pcm, errno, "cannot open device '%s'", fn);
return pcm;
}
-
+ /*weiqifa*/
+ pcm->fd_test = fopen("/sdcard/ref_temp.pcm", "wb");
+ if (!pcm->fd_test) {
+ fprintf(stderr, "Unable to create file /sdcard/ref_temp.pcm\n");
+ } else ALOGD("creat /sdcard/ref_temp.pcm file success");
+
if (fcntl(pcm->fd, F_SETFL, fcntl(pcm->fd, F_GETFL) &
~O_NONBLOCK) flags & PCM_IN))
return -EINVAL;
x.buf = data;
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd, SNDRV_PCM_IOCTL_READI_FRAMES, &x)) {
pcm->prepared = 0;
pcm->running = 0;
if (errno == EPIPE) {
/* we failed to make our window -- try to restart */
pcm->underruns++;
continue;
}
return oops(pcm, errno, "cannot read stream data");
}
if (fwrite(x.buf, 1, count, pcm->fd_test) != count) {
fprintf(stderr,"Error capturing sample\n");
ALOGE("Error capturing sample");
}
return 0;
}
}
x.buf 是一个指针,但是这个指针使用的是应用传下来的地址,所以不需要为 x.buf 分配空间。详情请参考tinycap。
在 tinycap 中,还会将标题写入音频文件。我们没有在这里写。没关系。打开音频时,可以直接导入原创音频。
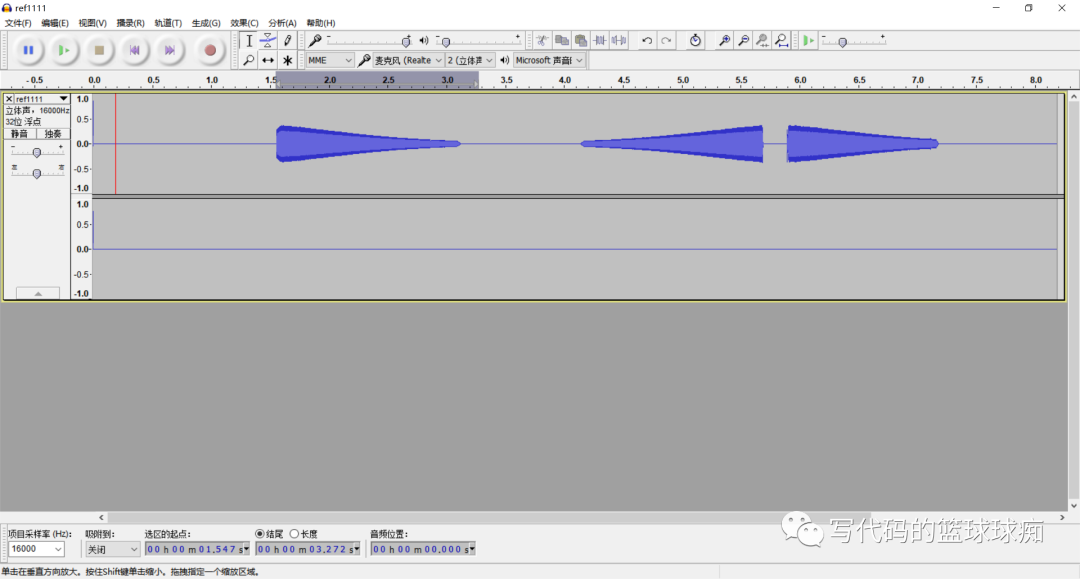
xxx:/ # ls -al /sdcard/ref_temp.pcm
-rw-rw---- 1 root sdcard_rw 79298560 2021-01-08 15:24 /sdcard/ref_temp.pcm
xxx:/ #
完整代码如下:

抓取网页音频(邮箱抓取器绿色版的小伙伴快来体验吧!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-23 06:12
绿色版邮箱抓取器是一款非常好用的邮箱工具,使用简单,解压即可。强大的区分功能助您完成工作任务,营销效果一流!有兴趣的朋友快来体验吧!
PC版邮箱抓取器介绍
邮箱抓取工具是一款邮箱抓取工具,可以提取网页显示的邮箱地址。用于采集各种电子邮件信息,然后您可以通过群发邮件软件将您的相关网络营销信息发送到获得的邮箱中。如果用户没有邮箱软件,获得的邮箱可以作为您在线销售的重要客户信息,达到在线营销的目的。
专刊
能够通过给定的网页 URL 捕获网页中的所有电子邮件地址信息
可以通过深度设置抓取网页中链接的网页,深度越深,抓取的网页越多
可以将抓到的邮箱信息实时保存到指定文件,使用更方便
采用多线程同时抓取,抓取速度更快,分分钟采集所有相关网页
不追求华丽的外表,只追求卓越的性能,让您的网络营销更强大
版本介绍
免费版:
可以抓取指定网页上的所有邮箱信息;
您可以通过升级将免费版升级为专业版。
专业版:
可以指定爬取深度,即指定的网页以及与该网页关联的链接网页上的邮箱都可以
带爬取,同时爬取多个任务,爬取速度极快;
可以将抓到的邮箱信息保存在本地文件中,方便营销。
指示
1. 双机“mymail.exe”打开软件,设置爬取的网址
2. 设置保存路径
3. 设置爬取深度
4. 点击“开始”按钮开始爬取
5. 点击“停止”按钮停止抓取操作
6. 打开保存目录查看爬取结果 查看全部
抓取网页音频(邮箱抓取器绿色版的小伙伴快来体验吧!(组图))
绿色版邮箱抓取器是一款非常好用的邮箱工具,使用简单,解压即可。强大的区分功能助您完成工作任务,营销效果一流!有兴趣的朋友快来体验吧!
PC版邮箱抓取器介绍
邮箱抓取工具是一款邮箱抓取工具,可以提取网页显示的邮箱地址。用于采集各种电子邮件信息,然后您可以通过群发邮件软件将您的相关网络营销信息发送到获得的邮箱中。如果用户没有邮箱软件,获得的邮箱可以作为您在线销售的重要客户信息,达到在线营销的目的。

专刊
能够通过给定的网页 URL 捕获网页中的所有电子邮件地址信息
可以通过深度设置抓取网页中链接的网页,深度越深,抓取的网页越多
可以将抓到的邮箱信息实时保存到指定文件,使用更方便
采用多线程同时抓取,抓取速度更快,分分钟采集所有相关网页
不追求华丽的外表,只追求卓越的性能,让您的网络营销更强大
版本介绍
免费版:
可以抓取指定网页上的所有邮箱信息;
您可以通过升级将免费版升级为专业版。
专业版:
可以指定爬取深度,即指定的网页以及与该网页关联的链接网页上的邮箱都可以
带爬取,同时爬取多个任务,爬取速度极快;
可以将抓到的邮箱信息保存在本地文件中,方便营销。
指示
1. 双机“mymail.exe”打开软件,设置爬取的网址
2. 设置保存路径
3. 设置爬取深度
4. 点击“开始”按钮开始爬取
5. 点击“停止”按钮停止抓取操作
6. 打开保存目录查看爬取结果
抓取网页音频(配套软件版本:V9及更低集搜客网络爬虫软件新版本对应教程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-18 19:01
)
配套软件版本:V9及以下 极助网络爬虫软件
新版对应教程:V10及更高版本数据管家-增强版网络爬虫对应教程为《使用网络爬虫软件自动下载网络文件》
请注意:从V9.0.0开始,文件下载功能有了很大的提升。虽然本教程中解释的方法仍然有效,但这种方法很难理解。你应该使用V9.0.0版本的新方法,下载文件不需要定义第二条规则,只需在第一条规则中勾选“下载内容”,选择下载文件类型即可。Firefox 的插件版本不再需要解决特定的场景问题。详情请参考教程《使用网络爬虫软件自动下载网页文件》 1、下载功能说明
1) 使用Gooseeker获取网页内容时,如果获取的内容是文件链接,通常的方式是获取链接地址。
2)Gooseeker 可以自动下载链接对应的文件吗?答案是肯定的。
2.配置文件的存放路径及处理方法
如果你不配置它,下载文件后,你总是会被问到要做什么。这种查询会阻止爬虫继续运行。为了关闭查询,需要做相应的配置。
2.1、纪助浏览器
极手客浏览器有自己的配置,如下图
点击图中所示的配置按钮,进入如下窗口
在 Mime 选项卡下,有多种文件类型的设置按钮。点击它们可以设置不提示文件处理方式。
2.2、火狐插件版爬虫
1)配置火狐的下载功能。火狐浏览器:工具菜单=>选项=>常规=>下载,选择“保存文件到指定文件夹”
2)配置 Firefox 浏览器处理特定文件类型的方式。Firefox:Option => Application,将要下载的文件类型的“Action”更改为“Save File”。比如要下载pdf文件,修改pdf文件类型的动作。
3.定义爬虫规则并运行
本案例假设需要两层规则(参考“采集URL to make levels采集”采集 层级):
第一层:采集文档列表和下载链接,假设主题名称为pdfpage999
级别2:使用下载链接下载pdf文件,假设主题名称为pdf_download999
下面对二级规则的定义方法进行说明。
3.1、采集文档列表和下载链接
在极手客浏览器加载文档列表页面,进入定义规则模式,定义捕获文件链接的规则。规则名称是“pdfpage999”。基本定义规则方法不再赘述,请参考“采集网页数据”,下面重点介绍下载文件相关的设置
1)勾选链接字段捕获文件到“下级线索”
2)在“爬虫路由”的目标主题中填写之前定义的自动下载规则名称“pdf_download999”
从上面的步骤可以看出,它和普通的分层爬取没有什么区别。不同之处在于二级规则的定义。
3.2、定义执行下载操作的规则
创建专门用于自动下载的新规则。规则的名称是“pdf_download999”。规则的内容可以是在任何简单的网页上抓取一个字段并保存规则。
这一步可能很难理解。这是规则的第二层。在这个级别,只下载一个 pdf 文件,没有特殊的网页内容。因此,我找不到合适的示例页面作为规则使用,因此您必须找到一个页面,但始终定义一个抓取内容。为了不影响规则的运行,使用一个每个页面都有的内容作为爬取的内容。这样,在运行规则时,就不会出现规则不适用的提示。
例如,您可以选择抓取 html 头节点甚至 html 节点。此类规则通用性极高,目的只是为了保证爬取成功,不会遇到规则不适用的问题。只要适应了规则,就会自动触发下载。
3.3、操作规则
就像普通级别采集
1.运行规则pdfpage999,生成pdf_download999的线索
2、运行规则pdf_download999,吉首客的网络爬虫会自动下载线程URL对应的文件,在设置的存储文件夹中可以看到下载的文件。
如有疑问,您可以或
查看全部
抓取网页音频(配套软件版本:V9及更低集搜客网络爬虫软件新版本对应教程
)
配套软件版本:V9及以下 极助网络爬虫软件
新版对应教程:V10及更高版本数据管家-增强版网络爬虫对应教程为《使用网络爬虫软件自动下载网络文件》
请注意:从V9.0.0开始,文件下载功能有了很大的提升。虽然本教程中解释的方法仍然有效,但这种方法很难理解。你应该使用V9.0.0版本的新方法,下载文件不需要定义第二条规则,只需在第一条规则中勾选“下载内容”,选择下载文件类型即可。Firefox 的插件版本不再需要解决特定的场景问题。详情请参考教程《使用网络爬虫软件自动下载网页文件》 1、下载功能说明
1) 使用Gooseeker获取网页内容时,如果获取的内容是文件链接,通常的方式是获取链接地址。
2)Gooseeker 可以自动下载链接对应的文件吗?答案是肯定的。
2.配置文件的存放路径及处理方法
如果你不配置它,下载文件后,你总是会被问到要做什么。这种查询会阻止爬虫继续运行。为了关闭查询,需要做相应的配置。
2.1、纪助浏览器
极手客浏览器有自己的配置,如下图

点击图中所示的配置按钮,进入如下窗口

在 Mime 选项卡下,有多种文件类型的设置按钮。点击它们可以设置不提示文件处理方式。
2.2、火狐插件版爬虫
1)配置火狐的下载功能。火狐浏览器:工具菜单=>选项=>常规=>下载,选择“保存文件到指定文件夹”
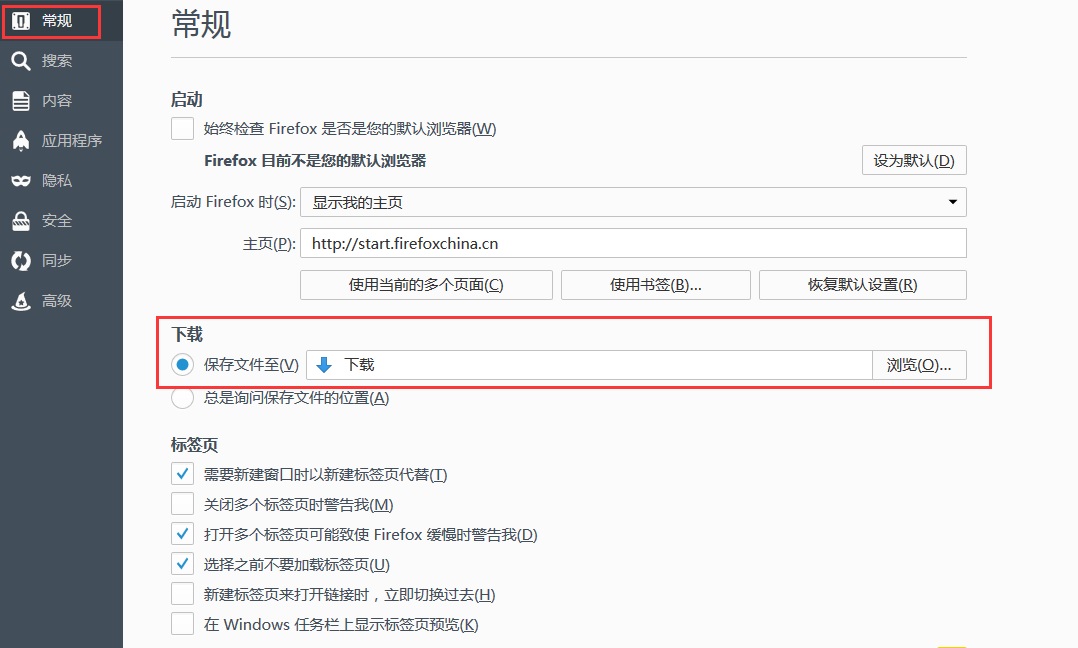
2)配置 Firefox 浏览器处理特定文件类型的方式。Firefox:Option => Application,将要下载的文件类型的“Action”更改为“Save File”。比如要下载pdf文件,修改pdf文件类型的动作。

3.定义爬虫规则并运行
本案例假设需要两层规则(参考“采集URL to make levels采集”采集 层级):
第一层:采集文档列表和下载链接,假设主题名称为pdfpage999
级别2:使用下载链接下载pdf文件,假设主题名称为pdf_download999
下面对二级规则的定义方法进行说明。
3.1、采集文档列表和下载链接
在极手客浏览器加载文档列表页面,进入定义规则模式,定义捕获文件链接的规则。规则名称是“pdfpage999”。基本定义规则方法不再赘述,请参考“采集网页数据”,下面重点介绍下载文件相关的设置
1)勾选链接字段捕获文件到“下级线索”

2)在“爬虫路由”的目标主题中填写之前定义的自动下载规则名称“pdf_download999”

从上面的步骤可以看出,它和普通的分层爬取没有什么区别。不同之处在于二级规则的定义。
3.2、定义执行下载操作的规则
创建专门用于自动下载的新规则。规则的名称是“pdf_download999”。规则的内容可以是在任何简单的网页上抓取一个字段并保存规则。
这一步可能很难理解。这是规则的第二层。在这个级别,只下载一个 pdf 文件,没有特殊的网页内容。因此,我找不到合适的示例页面作为规则使用,因此您必须找到一个页面,但始终定义一个抓取内容。为了不影响规则的运行,使用一个每个页面都有的内容作为爬取的内容。这样,在运行规则时,就不会出现规则不适用的提示。
例如,您可以选择抓取 html 头节点甚至 html 节点。此类规则通用性极高,目的只是为了保证爬取成功,不会遇到规则不适用的问题。只要适应了规则,就会自动触发下载。
3.3、操作规则
就像普通级别采集
1.运行规则pdfpage999,生成pdf_download999的线索
2、运行规则pdf_download999,吉首客的网络爬虫会自动下载线程URL对应的文件,在设置的存储文件夹中可以看到下载的文件。
如有疑问,您可以或

抓取网页音频(如何从一个网页中提取出文章的正文正文内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-07 21:35
通常打开一个网页,除了文章的正文内容,通常还会有很多导航、广告等信息。这个博客的目的是解释如何从网页中提取文章的正文内容,同时转出其他不相关的信息。
我们先来看看demo:
此方法基于文本密度。最初的想法来自哈尔滨工业大学的《基于行块分布函数的通用网页文本提取算法》。本文在此基础上做了一些小的修改。
习俗:
本文根据网页的不同行进行统计。因此,假设网页的内容没有被压缩,则说明网页有正常的换行符。
对于一些新闻页面,新闻的文字内容可能比较短,但是里面嵌入了一个视频文件。因此,我会给视频更高的权重;这也适用于图片。这里有一个缺点。它应该基于图片的大小。确定权重,但本文的方法未能做到这一点。
因为广告,这些非文字内容的导航通常以超链接的形式出现,所以文字会给超链接的文字权重为零。
假设正文的内容是连续的,不收录非文本内容。所以,其实提取正文就是找出正文的起止位置。
步:
首先清除网页中的CSS、Javascript、评论、Meta、Ins标签中的内容,清除空白行。
计算每一行的处理值(1)
计算上面得到的每行文本数的最大正子串的起止位置
第二步需要说明:
对于每一行,我们需要计算一个值,计算如下:
一个图片标签img,相当于一个长度为50个字符(给定权重)x1的文本,
嵌入的视频标签,相当于 1000 个字符的文本,x2
一行 x3 中所有链接的标签 a 的文本长度,
其他标签的文本长度 x4
每行的值 = 50 * x1 它的出现次数 + 1000 * x2 它的出现次数 + x4-8
//说明,-8 因为我们要计算一个最大的正子串,所以需要减去一个正数。至于这个数字应该有多大,我觉得还是用经验比较好。
完整代码
<p>#coding:utf-8
import re
def remove_js_css (content):
""" remove the the javascript and the stylesheet and the comment content (.... and .... ) """
r = re.compile(r\'\'\'\'\'\',\'\',s)
return s.strip()
def remove_any_tag_but_a (s):
text = re.findall (r\'\'\']*>(.*?)</a>\'\'\',s,re.I|re.S|re.S)
text_b = remove_any_tag (s)
return len(\'\'.join(text)),len(text_b)
def remove_image (s,n=50):
image = \'a\' * n
r = re.compile (r\'\'\'\'\'\',re.I|re.M|re.S)
s = r.sub(image,s)
return s
def remove_video (s,n=1000):
video = \'a\' * n
r = re.compile (r\'\'\'\'\'\',re.I|re.M|re.S)
s = r.sub(video,s)
return s
def sum_max (values):
cur_max = values[0]
glo_max = -999999
left,right = 0,0
for index,value in enumerate (values):
cur_max += value
if (cur_max > glo_max) :
glo_max = cur_max
right = index
elif (cur_max 查看全部
抓取网页音频(如何从一个网页中提取出文章的正文正文内容?)
通常打开一个网页,除了文章的正文内容,通常还会有很多导航、广告等信息。这个博客的目的是解释如何从网页中提取文章的正文内容,同时转出其他不相关的信息。
我们先来看看demo:
此方法基于文本密度。最初的想法来自哈尔滨工业大学的《基于行块分布函数的通用网页文本提取算法》。本文在此基础上做了一些小的修改。
习俗:
本文根据网页的不同行进行统计。因此,假设网页的内容没有被压缩,则说明网页有正常的换行符。
对于一些新闻页面,新闻的文字内容可能比较短,但是里面嵌入了一个视频文件。因此,我会给视频更高的权重;这也适用于图片。这里有一个缺点。它应该基于图片的大小。确定权重,但本文的方法未能做到这一点。
因为广告,这些非文字内容的导航通常以超链接的形式出现,所以文字会给超链接的文字权重为零。
假设正文的内容是连续的,不收录非文本内容。所以,其实提取正文就是找出正文的起止位置。
步:
首先清除网页中的CSS、Javascript、评论、Meta、Ins标签中的内容,清除空白行。
计算每一行的处理值(1)
计算上面得到的每行文本数的最大正子串的起止位置
第二步需要说明:
对于每一行,我们需要计算一个值,计算如下:
一个图片标签img,相当于一个长度为50个字符(给定权重)x1的文本,
嵌入的视频标签,相当于 1000 个字符的文本,x2
一行 x3 中所有链接的标签 a 的文本长度,
其他标签的文本长度 x4
每行的值 = 50 * x1 它的出现次数 + 1000 * x2 它的出现次数 + x4-8
//说明,-8 因为我们要计算一个最大的正子串,所以需要减去一个正数。至于这个数字应该有多大,我觉得还是用经验比较好。
完整代码
<p>#coding:utf-8
import re
def remove_js_css (content):
""" remove the the javascript and the stylesheet and the comment content (.... and .... ) """
r = re.compile(r\'\'\'\'\'\',\'\',s)
return s.strip()
def remove_any_tag_but_a (s):
text = re.findall (r\'\'\']*>(.*?)</a>\'\'\',s,re.I|re.S|re.S)
text_b = remove_any_tag (s)
return len(\'\'.join(text)),len(text_b)
def remove_image (s,n=50):
image = \'a\' * n
r = re.compile (r\'\'\'\'\'\',re.I|re.M|re.S)
s = r.sub(image,s)
return s
def remove_video (s,n=1000):
video = \'a\' * n
r = re.compile (r\'\'\'\'\'\',re.I|re.M|re.S)
s = r.sub(video,s)
return s
def sum_max (values):
cur_max = values[0]
glo_max = -999999
left,right = 0,0
for index,value in enumerate (values):
cur_max += value
if (cur_max > glo_max) :
glo_max = cur_max
right = index
elif (cur_max
抓取网页音频(新人都可以使用的音乐片段,就是简单的删除你不需要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-10-06 15:15
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。但是,你也会遇到这样的问题,就是无法下载。版权,所以这个时候只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获!
工具特点:
工具太多了,不妨试试。Fast Audio Converter 是一款多功能音频编辑处理软件。该软件具有四个功能:音频剪切、音频提取、音频合并和音频转换。支持单文件操作。还支持文件批量操作!确实是一个不错的选择。
音频转换器
第一步:打开工具
在网页上准备好音乐,然后打开工具到界面,可以尝试简单了解一下。
第 2 步:添加音频文件
今天是提取音乐,所以你找到音频提取按钮,点击它,就会出现它的界面。它的界面中有两个添加文件和添加文件夹。您可以根据自己的编号添加文件。
第 3 步:添加和删除片段指南
接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加的片段指南就是你提取的音乐片段,删除片段指南就是简单的删除你不需要的音乐片段,可以被忽悠了。提取进度条,最后点击确定。
第 4 步:设置保存提取音频的位置
不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。
第五步成功
点击后,提取需要时间,但是这个时间非常快,只要看到对勾就说明提取成功了,以后想查看的可以在你设置的文件中查看。
无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。 查看全部
抓取网页音频(新人都可以使用的音乐片段,就是简单的删除你不需要)
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。但是,你也会遇到这样的问题,就是无法下载。版权,所以这个时候只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获!

工具特点:
工具太多了,不妨试试。Fast Audio Converter 是一款多功能音频编辑处理软件。该软件具有四个功能:音频剪切、音频提取、音频合并和音频转换。支持单文件操作。还支持文件批量操作!确实是一个不错的选择。
音频转换器
第一步:打开工具
在网页上准备好音乐,然后打开工具到界面,可以尝试简单了解一下。
第 2 步:添加音频文件
今天是提取音乐,所以你找到音频提取按钮,点击它,就会出现它的界面。它的界面中有两个添加文件和添加文件夹。您可以根据自己的编号添加文件。
第 3 步:添加和删除片段指南
接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加的片段指南就是你提取的音乐片段,删除片段指南就是简单的删除你不需要的音乐片段,可以被忽悠了。提取进度条,最后点击确定。
第 4 步:设置保存提取音频的位置
不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。
第五步成功
点击后,提取需要时间,但是这个时间非常快,只要看到对勾就说明提取成功了,以后想查看的可以在你设置的文件中查看。
无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。
抓取网页音频(新人都可以使用的音乐片段,就是简单的删除你不需要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-06 15:14
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。但是,你也会遇到这样的问题,就是无法下载。版权,所以这个时候只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获!
工具特点:
工具太多了,不妨试试。Fast Audio Converter 是一款多功能音频编辑处理软件。该软件具有四个功能:音频剪切、音频提取、音频合并和音频转换。支持单文件操作。还支持文件批量操作!确实是一个不错的选择。
音频转换器
第一步:打开工具
在网页上准备好音乐,然后打开工具到界面,可以尝试简单了解一下。
第 2 步:添加音频文件
今天是提取音乐,所以你找到音频提取按钮,点击它,就会出现它的界面。它的界面中有两个添加文件和添加文件夹。您可以根据自己的编号添加文件。
第 3 步:添加和删除片段指南
接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加的片段指南就是你提取的音乐片段,删除片段指南就是简单的删除你不需要的音乐片段,可以被忽悠了。提取进度条,最后点击确定。
第 4 步:设置保存提取音频的位置
不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。
第五步成功
点击后,提取需要时间,但是这个时间非常快,只要看到对勾就说明提取成功了,以后想查看的可以在你设置的文件中查看。
无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。 查看全部
抓取网页音频(新人都可以使用的音乐片段,就是简单的删除你不需要)
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。但是,你也会遇到这样的问题,就是无法下载。版权,所以这个时候只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获!

工具特点:
工具太多了,不妨试试。Fast Audio Converter 是一款多功能音频编辑处理软件。该软件具有四个功能:音频剪切、音频提取、音频合并和音频转换。支持单文件操作。还支持文件批量操作!确实是一个不错的选择。
音频转换器
第一步:打开工具
在网页上准备好音乐,然后打开工具到界面,可以尝试简单了解一下。

第 2 步:添加音频文件
今天是提取音乐,所以你找到音频提取按钮,点击它,就会出现它的界面。它的界面中有两个添加文件和添加文件夹。您可以根据自己的编号添加文件。

第 3 步:添加和删除片段指南
接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加的片段指南就是你提取的音乐片段,删除片段指南就是简单的删除你不需要的音乐片段,可以被忽悠了。提取进度条,最后点击确定。

第 4 步:设置保存提取音频的位置
不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。

第五步成功
点击后,提取需要时间,但是这个时间非常快,只要看到对勾就说明提取成功了,以后想查看的可以在你设置的文件中查看。

无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。
抓取网页音频(如何用IDM巧妙的批量音效素材?下载器抓取功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-10-05 23:01
IDM下载器站点抓取功能,可以抓取网站上的图片、音频、视频、PDF、压缩包等文件。更重要的是,可以实现批量抓取操作,省时省力。今天我们就来看看如何使用IDM来巧妙的批量抓取音效素材。
1、进入音效编译界面,复制链接地址
打开搜狗浏览器,在百度上搜索“音效大全”,选择一个音效网站,进入网页后点击进入音效分类编译界面,即一个大的目录界面音效链接地址的数量。然后复制这个接口的链接地址。
图1:音效编译页面
2、 运行“网站抓取”功能抓取音效
现在返回IDM主界面,鼠标左键点击右上角的“Site Capture”按钮,将复制的链接地址粘贴到“Start Page/Address”栏,然后点击下方的“Forward”按钮.
图2:网站抓取-链接输入页面
3、 建议将“探索指定链接深度”修改为“3”
在步骤2中点击转发。在步骤3中,建议将“探索指定链接深度”中的根站点“2”的深度修改为根站点“3”的深度,然后选择“转发”按钮。
这一步是获取音效下载页面的链接。当探索链接深度为1时,IDM的探索对象为当前页面;当探索链接深度为2时,IDM的探索对象为点击链接后要跳转的当前页面。探索链接深度为3时,IDM的探索对象为当前页面链接进行二次跳转的页面。
图3:网站爬取界面
4、更改下载的文件类型
将文件类型“所有文件”更改为需要下载的文件类型,即“音频文件”,然后单击“转发”。
图 4:文件类型更改页面
5、等待网站爬取成功并保存文件
此页面显示捕获的图像,等待站点完成捕获,即可保存文件。
图5:文件捕获信息页面
经过上面的操作,已经下载了很多音效文件,并且可以使用站点抓取进行多窗口抓取,这样我们就可以同时抓取几个分类的音效文件,真的很方便!
但是大家一定要确保音效网站保存的音效文件格式是:mp3、wma或者waw。如果网站的文件保存格式不是这三种后缀格式,IDM可能无法识别! 查看全部
抓取网页音频(如何用IDM巧妙的批量音效素材?下载器抓取功能)
IDM下载器站点抓取功能,可以抓取网站上的图片、音频、视频、PDF、压缩包等文件。更重要的是,可以实现批量抓取操作,省时省力。今天我们就来看看如何使用IDM来巧妙的批量抓取音效素材。
1、进入音效编译界面,复制链接地址
打开搜狗浏览器,在百度上搜索“音效大全”,选择一个音效网站,进入网页后点击进入音效分类编译界面,即一个大的目录界面音效链接地址的数量。然后复制这个接口的链接地址。
图1:音效编译页面
2、 运行“网站抓取”功能抓取音效
现在返回IDM主界面,鼠标左键点击右上角的“Site Capture”按钮,将复制的链接地址粘贴到“Start Page/Address”栏,然后点击下方的“Forward”按钮.

图2:网站抓取-链接输入页面
3、 建议将“探索指定链接深度”修改为“3”
在步骤2中点击转发。在步骤3中,建议将“探索指定链接深度”中的根站点“2”的深度修改为根站点“3”的深度,然后选择“转发”按钮。
这一步是获取音效下载页面的链接。当探索链接深度为1时,IDM的探索对象为当前页面;当探索链接深度为2时,IDM的探索对象为点击链接后要跳转的当前页面。探索链接深度为3时,IDM的探索对象为当前页面链接进行二次跳转的页面。
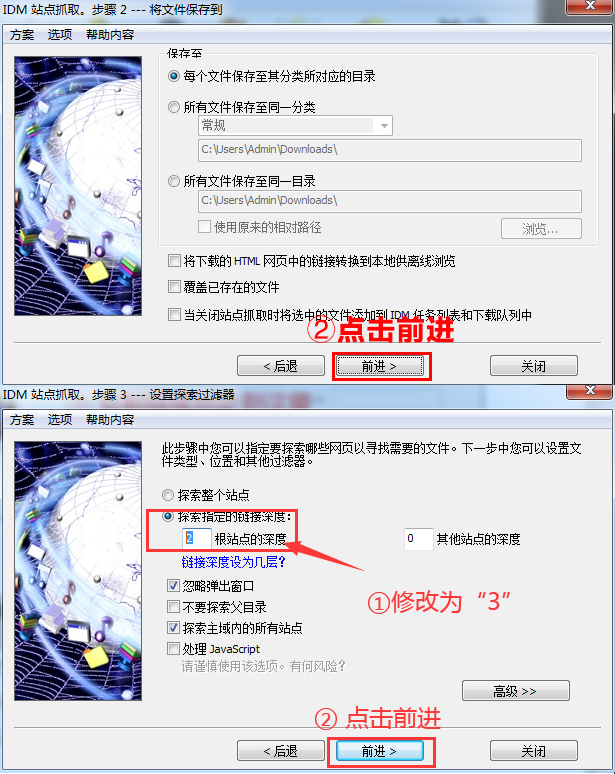
图3:网站爬取界面
4、更改下载的文件类型
将文件类型“所有文件”更改为需要下载的文件类型,即“音频文件”,然后单击“转发”。
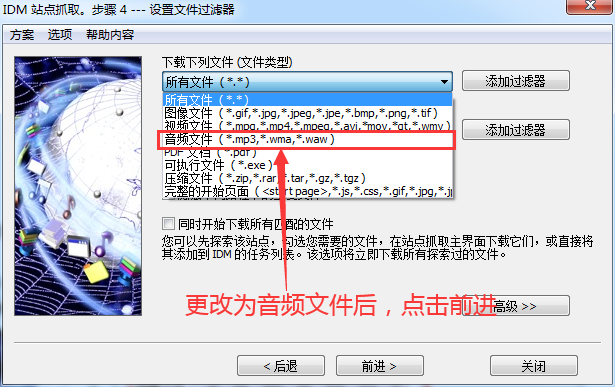
图 4:文件类型更改页面
5、等待网站爬取成功并保存文件
此页面显示捕获的图像,等待站点完成捕获,即可保存文件。

图5:文件捕获信息页面
经过上面的操作,已经下载了很多音效文件,并且可以使用站点抓取进行多窗口抓取,这样我们就可以同时抓取几个分类的音效文件,真的很方便!
但是大家一定要确保音效网站保存的音效文件格式是:mp3、wma或者waw。如果网站的文件保存格式不是这三种后缀格式,IDM可能无法识别!
抓取网页音频(Python绿色通道铁粉集中营上有球友要求布置一个数据的作业)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-01 22:19
这两天,知识星球蟒蛇绿色通道铁扇集中营的一些高尔夫球手要求分配一个工作来抓取App数据,所以我二话不说就答应了。
效果图如下
我们过去常常在网络上抓取数据,我们很少在移动应用程序中抓取数据。那么我们如何抓取移动应用中的数据呢?一般我们使用抓包工具来抓数据。
常用的抓包工具有Fiddles和Charles,其他今天主要讲一下Charles的使用。与 Fiddles 相比,Charles 更强大,更易于使用。所以一般我建议使用 Charles 进行数据包捕获。
下载并安装查尔斯
下载安装Charles然后破解Charles,这里是文章教程,我就不多说了
预防措施:
如果获取的数据出现乱码,需要在Charles ==>proxy==>SSL Proxying Settings ==>Add 443的菜单栏中设置连接SSL证书,如上图所示。那么当你真正在抓数据的时候,记得把这个关掉,以免抓不到数据
使用查尔斯
这里我直接放两张图给大家使用看看就明白了
一起来分析一下这个项目。
# 这里有点递归的意味
max_id = datas[-1]['publish_time_stamp']
if self.max_id != max_id:
self.max_id = max_id
self.request_data()
else:
print('数据抓取完毕!')
完整代码:
import requests
import time
import json
from dedao.ExeclUtils import ExeclUtils
import os
class dedao(object):
def __init__(self):
# self.rows_title = [u'招聘标题', u'公司名称', u'公司地址', u'待遇', u'发布日期', u'招聘链接', u'招聘要求描述']
# sheet_name = u'51job_Python招聘'
self.rows_title = [u'来源目录', u'标题', u'图片', u'分享标题', u'mp3地址', u'音频时长', u'文件大小']
sheet_name = u'逻辑思维音频'
return_execl = ExeclUtils.create_execl(sheet_name, self.rows_title)
self.execl_f = return_execl[0]
self.sheet_table = return_execl[1]
self.audio_info = [] # 存放每一条数据中的各元素,
self.count = 0 # 数据插入从1开始的
self.base_url = 'https://entree.igetget.com/acr ... 27%3B
self.max_id = 0
self.headers = {
'Host': 'entree.igetget.com',
'X-OS': 'iOS',
'X-NET': 'wifi',
'Accept': '*/*',
'X-Nonce': '779b79d1d51d43fa',
'Accept-Encoding': 'br, gzip, deflate',
# 'Content-Length': ' 67',
'X-TARGET': 'main',
'User-Agent': '%E5%BE%97%E5%88%B0/4.0.13 CFNetwork/901.1 Darwin/17.6.0',
'X-CHIL': 'appstore',
'Cookie ': 'acw_tc=AQAAAC0YfiuHegUAxkvoZRLraUMQyRfH; aliyungf_tc=AQAAAKwCD1dINAUAxkvoZTppW+jezS/9',
'X-UID': '34556154',
'X-AV ': '4.0.0',
'X-SEID ': '',
'X-SCR ': '1242*2208',
'X-DT': 'phone',
'X-S': '91a46b7a31ffc7a2',
'X-Sign': 'ZTBiZjQyNTI1OTU2MTgwZjYwMWRhMjc5ZjhmMGRlNGI=',
'Accept-Language': 'zh-cn',
'X-D': 'ca3c83fca6e84a2d869f95829964ebb8',
'X-THUMB': 'l',
'X-T': 'json',
'X-Timestamp': '1528195376',
'X-TS': '1528195376',
'X-U': '34556154',
'X-App-Key': 'ios-4.0.0',
'X-OV': '11.4',
'Connection': 'keep-alive',
'X-ADV': '1',
'Content-Type': 'application/x-www-form-urlencoded',
'X-V': '2',
'X-IS_JAILBREAK ': 'NO',
'X-DV': 'iPhone10,2',
}
def request_data(self):
try:
data = {
'max_id': self.max_id,
'since_id': 0,
'column_id': 2,
'count': 20,
'order': 1,
'section': 0
}
response = requests.post(self.base_url, headers=self.headers, data=data)
if 200 == response.status_code:
self.parse_data(response)
except Exception as e:
print(e)
time.sleep(2)
pass
def parse_data(self, response):
dict_json = json.loads(response.text)
datas = dict_json['c']['list'] # 这里取得数据列表
# print(datas)
for data in datas:
source_name = data['audio_detail']['source_name']
title = data['audio_detail']['title']
icon = data['audio_detail']['icon']
share_title = data['audio_detail']['share_title']
mp3_url = data['audio_detail']['mp3_play_url']
duction = str(data['audio_detail']['duration']) + '秒'
size = data['audio_detail']['size'] / (1000 * 1000)
size = '%.2fM' % size
self.download_mp3(mp3_url)
self.audio_info.append(source_name)
self.audio_info.append(title)
self.audio_info.append(icon)
self.audio_info.append(share_title)
self.audio_info.append(mp3_url)
self.audio_info.append(duction)
self.audio_info.append(size)
self.count = self.count + 1
ExeclUtils.write_execl(self.execl_f, self.sheet_table, self.count, self.audio_info, u'逻辑思维音频.xlsx')
print('采集了{}条数据'.format(self.count))
# 清空集合,为再次存放数据做准备
self.audio_info = []
time.sleep(3) # 不要请求太快, 小心查水表
max_id = datas[-1]['publish_time_stamp']
if self.max_id != max_id:
self.max_id = max_id
self.request_data()
else:
print('数据抓取完毕!')
pass
def download_mp3(self, mp3_url):
try:
# 补全文件目录
mp3_path = u'D:/store/mp3/{}'.format(mp3_url.split('/')[-1])
print(mp3_path)
# 判断文件是否存在。
if not os.path.exists(mp3_path):
# 注意这里是写入文件,要用二进制格式写入。
with open(mp3_path, 'wb') as f:
f.write(requests.get(mp3_url).content)
except Exception as e:
print(e)
if __name__ == '__main__':
d = dedao()
d.request_data()
目前这只是一个比较简单的手机App数据抓取。如何操作更复杂的数据采集?如何抓取朋友圈的数据?如何抓取微信公众号数据?敬请关注! 查看全部
抓取网页音频(Python绿色通道铁粉集中营上有球友要求布置一个数据的作业)
这两天,知识星球蟒蛇绿色通道铁扇集中营的一些高尔夫球手要求分配一个工作来抓取App数据,所以我二话不说就答应了。
效果图如下
我们过去常常在网络上抓取数据,我们很少在移动应用程序中抓取数据。那么我们如何抓取移动应用中的数据呢?一般我们使用抓包工具来抓数据。
常用的抓包工具有Fiddles和Charles,其他今天主要讲一下Charles的使用。与 Fiddles 相比,Charles 更强大,更易于使用。所以一般我建议使用 Charles 进行数据包捕获。
下载并安装查尔斯
下载安装Charles然后破解Charles,这里是文章教程,我就不多说了
预防措施:
如果获取的数据出现乱码,需要在Charles ==>proxy==>SSL Proxying Settings ==>Add 443的菜单栏中设置连接SSL证书,如上图所示。那么当你真正在抓数据的时候,记得把这个关掉,以免抓不到数据
使用查尔斯
这里我直接放两张图给大家使用看看就明白了
一起来分析一下这个项目。
# 这里有点递归的意味
max_id = datas[-1]['publish_time_stamp']
if self.max_id != max_id:
self.max_id = max_id
self.request_data()
else:
print('数据抓取完毕!')
完整代码:
import requests
import time
import json
from dedao.ExeclUtils import ExeclUtils
import os
class dedao(object):
def __init__(self):
# self.rows_title = [u'招聘标题', u'公司名称', u'公司地址', u'待遇', u'发布日期', u'招聘链接', u'招聘要求描述']
# sheet_name = u'51job_Python招聘'
self.rows_title = [u'来源目录', u'标题', u'图片', u'分享标题', u'mp3地址', u'音频时长', u'文件大小']
sheet_name = u'逻辑思维音频'
return_execl = ExeclUtils.create_execl(sheet_name, self.rows_title)
self.execl_f = return_execl[0]
self.sheet_table = return_execl[1]
self.audio_info = [] # 存放每一条数据中的各元素,
self.count = 0 # 数据插入从1开始的
self.base_url = 'https://entree.igetget.com/acr ... 27%3B
self.max_id = 0
self.headers = {
'Host': 'entree.igetget.com',
'X-OS': 'iOS',
'X-NET': 'wifi',
'Accept': '*/*',
'X-Nonce': '779b79d1d51d43fa',
'Accept-Encoding': 'br, gzip, deflate',
# 'Content-Length': ' 67',
'X-TARGET': 'main',
'User-Agent': '%E5%BE%97%E5%88%B0/4.0.13 CFNetwork/901.1 Darwin/17.6.0',
'X-CHIL': 'appstore',
'Cookie ': 'acw_tc=AQAAAC0YfiuHegUAxkvoZRLraUMQyRfH; aliyungf_tc=AQAAAKwCD1dINAUAxkvoZTppW+jezS/9',
'X-UID': '34556154',
'X-AV ': '4.0.0',
'X-SEID ': '',
'X-SCR ': '1242*2208',
'X-DT': 'phone',
'X-S': '91a46b7a31ffc7a2',
'X-Sign': 'ZTBiZjQyNTI1OTU2MTgwZjYwMWRhMjc5ZjhmMGRlNGI=',
'Accept-Language': 'zh-cn',
'X-D': 'ca3c83fca6e84a2d869f95829964ebb8',
'X-THUMB': 'l',
'X-T': 'json',
'X-Timestamp': '1528195376',
'X-TS': '1528195376',
'X-U': '34556154',
'X-App-Key': 'ios-4.0.0',
'X-OV': '11.4',
'Connection': 'keep-alive',
'X-ADV': '1',
'Content-Type': 'application/x-www-form-urlencoded',
'X-V': '2',
'X-IS_JAILBREAK ': 'NO',
'X-DV': 'iPhone10,2',
}
def request_data(self):
try:
data = {
'max_id': self.max_id,
'since_id': 0,
'column_id': 2,
'count': 20,
'order': 1,
'section': 0
}
response = requests.post(self.base_url, headers=self.headers, data=data)
if 200 == response.status_code:
self.parse_data(response)
except Exception as e:
print(e)
time.sleep(2)
pass
def parse_data(self, response):
dict_json = json.loads(response.text)
datas = dict_json['c']['list'] # 这里取得数据列表
# print(datas)
for data in datas:
source_name = data['audio_detail']['source_name']
title = data['audio_detail']['title']
icon = data['audio_detail']['icon']
share_title = data['audio_detail']['share_title']
mp3_url = data['audio_detail']['mp3_play_url']
duction = str(data['audio_detail']['duration']) + '秒'
size = data['audio_detail']['size'] / (1000 * 1000)
size = '%.2fM' % size
self.download_mp3(mp3_url)
self.audio_info.append(source_name)
self.audio_info.append(title)
self.audio_info.append(icon)
self.audio_info.append(share_title)
self.audio_info.append(mp3_url)
self.audio_info.append(duction)
self.audio_info.append(size)
self.count = self.count + 1
ExeclUtils.write_execl(self.execl_f, self.sheet_table, self.count, self.audio_info, u'逻辑思维音频.xlsx')
print('采集了{}条数据'.format(self.count))
# 清空集合,为再次存放数据做准备
self.audio_info = []
time.sleep(3) # 不要请求太快, 小心查水表
max_id = datas[-1]['publish_time_stamp']
if self.max_id != max_id:
self.max_id = max_id
self.request_data()
else:
print('数据抓取完毕!')
pass
def download_mp3(self, mp3_url):
try:
# 补全文件目录
mp3_path = u'D:/store/mp3/{}'.format(mp3_url.split('/')[-1])
print(mp3_path)
# 判断文件是否存在。
if not os.path.exists(mp3_path):
# 注意这里是写入文件,要用二进制格式写入。
with open(mp3_path, 'wb') as f:
f.write(requests.get(mp3_url).content)
except Exception as e:
print(e)
if __name__ == '__main__':
d = dedao()
d.request_data()
目前这只是一个比较简单的手机App数据抓取。如何操作更复杂的数据采集?如何抓取朋友圈的数据?如何抓取微信公众号数据?敬请关注!
抓取网页音频(糖果负面搜索如何获取真正的下载地址,你可以随便看)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-30 19:05
这是技术人员的爱好。研究一下别人的网站是怎么做的,得到真正的下载地址,用candy访问网站就可以了,所有http数据包都没有泄露,你可以随便看看。
丰富的网络分析功能
糖果浏览器内置支持 Alexa、PageRank、GoogleTrends、百度指数、Google Insights 等功能。在糖果浏览器中,您可以随时了解某个网站的流量和某个关键词在百度和谷歌搜索引擎中的出现频率。.
多种糖果,支持换肤
糖果浏览器支持更换软件皮肤,可以改变糖果浏览器的外观;您可以修改糖果皮肤包中的图片文件来定制个性化的浏览器!如何更换皮肤:工具菜单 | 更改软件皮肤
网站排名实时显示
(Alexa/PageRank)
在IE中,需要安装alexa插件/谷歌工具栏才能看到alexa排名和PageRank。在糖果浏览器中显示网站alexa 排名,Google PageRank 是一个内置功能。
IE 临时文件提取器
IE 临时文件夹保存浏览过的网页中的所有内容(文字、图片、音乐、视频等)。Candy 的 IE 临时文件提取器可以轻松提取任何文件。您无需前往 IE 临时文件夹的浩瀚海洋。在里面找。
糖果否定搜索功能
Candy Negative Search 从整个互联网(尤其是各大论坛和各种博客)中搜索有关关键字的负面信息。这些信息是消费者最真实的反馈。建议您在花钱(购买产品或与他人合作)之前使用糖果的负面搜索来检查对方。
更人性化的 URL 输入框
可以在糖果浏览器的网址框中输入网址或搜索关键字,英文+Enter会自动添加,English+Ctrl+Enter会自动添加,English+Space+Enter开始搜索,中文+Return 汽车将开始搜索
视频提取和播放
想把土豆网、56、刘建芳等视频网站提取到本机?糖果浏览器可以做到。糖果浏览器可以检测大部分视频网站的flv视频文件的下载地址,可以播放本机的flv视频。
内置 MP3 音乐播放器
糖果浏览器的前身是糖果播放器。不难理解为什么candy的音乐功能如此强大:它可以自动匹配歌词、显示音乐频谱、给歌曲评分、设置智能播放列表,适合喜欢音乐的朋友在音乐冲浪中上网。
制作和播放音乐幻灯片
在candy中制作音乐幻灯片很简单:播放一首歌曲,然后添加你的照片,一个收录照片、歌词、音乐等的神奇电影就完成了,然后你就可以将这个幻灯片导出为exe自己播放文件了。
mp3音乐批量下载
糖果浏览器可以批量下载百度mp3排行榜,百度音乐大师批量下载,听音乐排行榜,搜索粤语新歌排行榜,新浪音乐港台排行榜,大陆排行榜,英国流行音乐排行榜,美国公告牌排行榜,LastFM Weekly单曲排行榜、日韩流行音乐排行榜等音乐排行榜,以及相声小品批量下载、古典音乐批量下载、奥斯卡金曲批量下载、格莱美金曲批量下载;
支持批量下载任意歌曲名称列表。批量下载时,您可以指定同时下载任务的数量、音乐类型(mp3 或 wma)和文件大小。
WMA 到 MP3 批量转换工具
Candy Browser可以批量转换wma文件为mp3文件,转换时可以指定mp3的压缩率(使用Lame压缩算法,可以指定是使用动态码率还是静态码率编码)。
定时关机功能
糖果浏览器支持定时关机(点击左下角循环播放按钮),睡前播放一首轻音乐,设置定时关机,就可以在音乐中入睡。
提供免费安装版,无需更改注册表
Windows 系统的性能会随着时间的推移而下降。原因是安装的各种软件在注册表中添加了各种内容。糖果浏览器很少更改系统注册表(设置默认浏览器时需要),不会导致系统出现各种莫名其妙的问题。
感染病毒后自我报警
糖果浏览器具有自扫描功能。一旦软件被病毒、木马或人为修改,就会向用户报告。
病毒感染程序需要修改程序的入口代码。糖果浏览器对入口代码进行自检,修改后会报警。
内存使用率低
糖果浏览器支持压缩内存模式,比IE、Firefox、傲游、Chrome等其他浏览器占用内存少很多,大家可以实际测试一下。
对流氓插件免疫
糖果浏览器不受 IE 各种流氓插件的影响。如果你的 IE 被各种插件折腾了,你仍然可以毫无问题地使用它。 查看全部
抓取网页音频(糖果负面搜索如何获取真正的下载地址,你可以随便看)
这是技术人员的爱好。研究一下别人的网站是怎么做的,得到真正的下载地址,用candy访问网站就可以了,所有http数据包都没有泄露,你可以随便看看。
丰富的网络分析功能
糖果浏览器内置支持 Alexa、PageRank、GoogleTrends、百度指数、Google Insights 等功能。在糖果浏览器中,您可以随时了解某个网站的流量和某个关键词在百度和谷歌搜索引擎中的出现频率。.
多种糖果,支持换肤
糖果浏览器支持更换软件皮肤,可以改变糖果浏览器的外观;您可以修改糖果皮肤包中的图片文件来定制个性化的浏览器!如何更换皮肤:工具菜单 | 更改软件皮肤
网站排名实时显示
(Alexa/PageRank)
在IE中,需要安装alexa插件/谷歌工具栏才能看到alexa排名和PageRank。在糖果浏览器中显示网站alexa 排名,Google PageRank 是一个内置功能。
IE 临时文件提取器
IE 临时文件夹保存浏览过的网页中的所有内容(文字、图片、音乐、视频等)。Candy 的 IE 临时文件提取器可以轻松提取任何文件。您无需前往 IE 临时文件夹的浩瀚海洋。在里面找。
糖果否定搜索功能
Candy Negative Search 从整个互联网(尤其是各大论坛和各种博客)中搜索有关关键字的负面信息。这些信息是消费者最真实的反馈。建议您在花钱(购买产品或与他人合作)之前使用糖果的负面搜索来检查对方。
更人性化的 URL 输入框
可以在糖果浏览器的网址框中输入网址或搜索关键字,英文+Enter会自动添加,English+Ctrl+Enter会自动添加,English+Space+Enter开始搜索,中文+Return 汽车将开始搜索
视频提取和播放
想把土豆网、56、刘建芳等视频网站提取到本机?糖果浏览器可以做到。糖果浏览器可以检测大部分视频网站的flv视频文件的下载地址,可以播放本机的flv视频。
内置 MP3 音乐播放器
糖果浏览器的前身是糖果播放器。不难理解为什么candy的音乐功能如此强大:它可以自动匹配歌词、显示音乐频谱、给歌曲评分、设置智能播放列表,适合喜欢音乐的朋友在音乐冲浪中上网。
制作和播放音乐幻灯片
在candy中制作音乐幻灯片很简单:播放一首歌曲,然后添加你的照片,一个收录照片、歌词、音乐等的神奇电影就完成了,然后你就可以将这个幻灯片导出为exe自己播放文件了。
mp3音乐批量下载
糖果浏览器可以批量下载百度mp3排行榜,百度音乐大师批量下载,听音乐排行榜,搜索粤语新歌排行榜,新浪音乐港台排行榜,大陆排行榜,英国流行音乐排行榜,美国公告牌排行榜,LastFM Weekly单曲排行榜、日韩流行音乐排行榜等音乐排行榜,以及相声小品批量下载、古典音乐批量下载、奥斯卡金曲批量下载、格莱美金曲批量下载;
支持批量下载任意歌曲名称列表。批量下载时,您可以指定同时下载任务的数量、音乐类型(mp3 或 wma)和文件大小。
WMA 到 MP3 批量转换工具
Candy Browser可以批量转换wma文件为mp3文件,转换时可以指定mp3的压缩率(使用Lame压缩算法,可以指定是使用动态码率还是静态码率编码)。
定时关机功能
糖果浏览器支持定时关机(点击左下角循环播放按钮),睡前播放一首轻音乐,设置定时关机,就可以在音乐中入睡。
提供免费安装版,无需更改注册表
Windows 系统的性能会随着时间的推移而下降。原因是安装的各种软件在注册表中添加了各种内容。糖果浏览器很少更改系统注册表(设置默认浏览器时需要),不会导致系统出现各种莫名其妙的问题。
感染病毒后自我报警
糖果浏览器具有自扫描功能。一旦软件被病毒、木马或人为修改,就会向用户报告。
病毒感染程序需要修改程序的入口代码。糖果浏览器对入口代码进行自检,修改后会报警。
内存使用率低
糖果浏览器支持压缩内存模式,比IE、Firefox、傲游、Chrome等其他浏览器占用内存少很多,大家可以实际测试一下。
对流氓插件免疫
糖果浏览器不受 IE 各种流氓插件的影响。如果你的 IE 被各种插件折腾了,你仍然可以毫无问题地使用它。
抓取网页音频(抓取网页音频不需要爬虫,爬虫()(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-09-30 11:02
抓取网页音频不需要爬虫,爬虫只是从服务器下载文件然后在浏览器播放而已,如果需要获取里面包含的音频文件,直接下载就可以。推荐用httpclient,也有人说是用httpclient爬虫,个人感觉是不错的爬虫,但有人说httpclient比较吃配置,不建议选择httpclient。1.首先你要有一个浏览器。
2.随便打开一个http页面,输入://-2017112617:42//?ws2allcheck=all&platform=windows&encoding=utf-83.验证输入是否正确。4.验证无误后,浏览器会自动打开404页面,并且所有需要下载的页面都存在,接下来就是分析请求请求的参数:'default':'-{if__name__=='__main__'}','host':'','http':'','request':'','user-agent':'','cookie':'','x-age':'','timestamp':'','content-type':'text/plain','user-agent':'','scheme':'','user-agent':'','referer':'','connection':'keep-alive','user-agent':'','cookie':'','port':'','pagenum':'','download':'','opener':'','documenturl':'','saveurl':'','savebox':'','x-age':'','userid':'','referer':'','name':'','name':'','complete':'','title':'','type':'','auth':'','maxurl':'','username':'','password':'','content':'','response':'','robots':'','rule':'','form':'','login':'','date':'','blogurl':'','path':'','type':'','version':'','proxy':'','lang':'','login':'','location':'','username':'','remember_track':'','logout':'','name':'','sign':'','mail':'','openid':'','signin':'','openurl':'','tab':'','author':'','s':'','p':'','password':'','b':'','p':'','s':'','a':'','t':'','t':'','t':'','t':'','c':'','h``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c`。 查看全部
抓取网页音频(抓取网页音频不需要爬虫,爬虫()(图))
抓取网页音频不需要爬虫,爬虫只是从服务器下载文件然后在浏览器播放而已,如果需要获取里面包含的音频文件,直接下载就可以。推荐用httpclient,也有人说是用httpclient爬虫,个人感觉是不错的爬虫,但有人说httpclient比较吃配置,不建议选择httpclient。1.首先你要有一个浏览器。
2.随便打开一个http页面,输入://-2017112617:42//?ws2allcheck=all&platform=windows&encoding=utf-83.验证输入是否正确。4.验证无误后,浏览器会自动打开404页面,并且所有需要下载的页面都存在,接下来就是分析请求请求的参数:'default':'-{if__name__=='__main__'}','host':'','http':'','request':'','user-agent':'','cookie':'','x-age':'','timestamp':'','content-type':'text/plain','user-agent':'','scheme':'','user-agent':'','referer':'','connection':'keep-alive','user-agent':'','cookie':'','port':'','pagenum':'','download':'','opener':'','documenturl':'','saveurl':'','savebox':'','x-age':'','userid':'','referer':'','name':'','name':'','complete':'','title':'','type':'','auth':'','maxurl':'','username':'','password':'','content':'','response':'','robots':'','rule':'','form':'','login':'','date':'','blogurl':'','path':'','type':'','version':'','proxy':'','lang':'','login':'','location':'','username':'','remember_track':'','logout':'','name':'','sign':'','mail':'','openid':'','signin':'','openurl':'','tab':'','author':'','s':'','p':'','password':'','b':'','p':'','s':'','a':'','t':'','t':'','t':'','t':'','c':'','h``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c`。
抓取网页音频(python爬虫简单的版本,那个时候还不懂原理,现在算是收尾吧 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-30 10:42
)
今天又浪费了一天。Python爬虫,之前写过一个简单的版本,当时没看懂原理。现在是结束了。
之前对网络爬虫一无所知,感觉很神奇,但是揭开这个面纱,似乎里面的原理不难掌握。首先了解一个概念,HTTP协议,为什么叫超文本协议。超文本的概念是几乎所有的数据都是以文本方式传输的,包括文本、图片等。那么,在一个网页中,需要做的就是解析这些字符数据,还原成原创文件。
爬虫的概念是以网页为起点,从中找到更多的链接和数据信息,然后展开成树状,可以想象成一棵树。对于每个网页,都需要根据需求对数据进行过滤(查找图片,或搜索关键字,或搜索音频等),最后根据过滤后的URL下载数据。一般步骤是:
网页==》网页树==》过滤信息==》下载
笔者这里以网页图片为例:
例如,一个网页中可能有很多图片。最基本的就是能够识别这个网页中的所有图片链接。这里的一般方法是根据正则表达式匹配网页的文本,从而采集内容。图片的链接。eg: reg = r"""src\s*="?(\S+)\.jpg"""。其次,把这些链接归档。看起来很抽象的东西可以通过这两步来实现。然后,网络树有点难,你需要从网上找到有用的网页链接,然后再过滤这些链接,有点像递归。这里有很多难点,比如当网页链接很多的时候,如何有效地过滤有效链接,如何控制搜索深度,如何分配进程等等。
另外,由于很多国外的网站无法上传,部分网页数据下载需要通过代理;另外,考虑到部分机器性能更好,也实现了多线程机制。笔者进行了一天的研究,终于通过了调试。这是代码:
<p>import re
import os
import sys
import time
import threading
import socket
import urllib
import urllib2
server = \'127.0.0.1\'
port = \'8087\'
timeout = 720
socket.setdefaulttimeout(timeout)
class timer(threading.Thread): #The timer class is derived from the class threading.Thread
def __init__(self, num, interval,dir,url):
threading.Thread.__init__(self)
self.thread_num = num
self.interval = interval
self.url = url
self.dir = dir
self.thread_stop = False
def run(self): #Overwrite run() method, put what you want the thread do here
#while not self.thread_stop:
DownloadImgs(self.interval,self.url,self.dir)
#print \'Thread Object(%d), Time:%s\' %(self.thread_num, time.ctime())
#time.sleep(self.interval)
def stop(self):
self.thread_stop = True
def getContent(url,type):
print(">>start connecting:%s" % url)
from urllib2 import Request, urlopen, URLError, HTTPError
proxy = urllib2.ProxyHandler({\'http\':\'http://127.0.0.1:8087\'})
opener = urllib2.build_opener(proxy,urllib2.HTTPHandler)
urllib2.install_opener(opener)
try:
urlHandler = urllib2.urlopen(url)
headers = urlHandler.info().headers
length = 0
for header in headers:
if header.find(\'Length\') != -1:
length = header.split(\':\')[-1].strip()
length = int(length)
if(type=="img" and length 查看全部
抓取网页音频(python爬虫简单的版本,那个时候还不懂原理,现在算是收尾吧
)
今天又浪费了一天。Python爬虫,之前写过一个简单的版本,当时没看懂原理。现在是结束了。
之前对网络爬虫一无所知,感觉很神奇,但是揭开这个面纱,似乎里面的原理不难掌握。首先了解一个概念,HTTP协议,为什么叫超文本协议。超文本的概念是几乎所有的数据都是以文本方式传输的,包括文本、图片等。那么,在一个网页中,需要做的就是解析这些字符数据,还原成原创文件。
爬虫的概念是以网页为起点,从中找到更多的链接和数据信息,然后展开成树状,可以想象成一棵树。对于每个网页,都需要根据需求对数据进行过滤(查找图片,或搜索关键字,或搜索音频等),最后根据过滤后的URL下载数据。一般步骤是:
网页==》网页树==》过滤信息==》下载
笔者这里以网页图片为例:
例如,一个网页中可能有很多图片。最基本的就是能够识别这个网页中的所有图片链接。这里的一般方法是根据正则表达式匹配网页的文本,从而采集内容。图片的链接。eg: reg = r"""src\s*="?(\S+)\.jpg"""。其次,把这些链接归档。看起来很抽象的东西可以通过这两步来实现。然后,网络树有点难,你需要从网上找到有用的网页链接,然后再过滤这些链接,有点像递归。这里有很多难点,比如当网页链接很多的时候,如何有效地过滤有效链接,如何控制搜索深度,如何分配进程等等。
另外,由于很多国外的网站无法上传,部分网页数据下载需要通过代理;另外,考虑到部分机器性能更好,也实现了多线程机制。笔者进行了一天的研究,终于通过了调试。这是代码:
<p>import re
import os
import sys
import time
import threading
import socket
import urllib
import urllib2
server = \'127.0.0.1\'
port = \'8087\'
timeout = 720
socket.setdefaulttimeout(timeout)
class timer(threading.Thread): #The timer class is derived from the class threading.Thread
def __init__(self, num, interval,dir,url):
threading.Thread.__init__(self)
self.thread_num = num
self.interval = interval
self.url = url
self.dir = dir
self.thread_stop = False
def run(self): #Overwrite run() method, put what you want the thread do here
#while not self.thread_stop:
DownloadImgs(self.interval,self.url,self.dir)
#print \'Thread Object(%d), Time:%s\' %(self.thread_num, time.ctime())
#time.sleep(self.interval)
def stop(self):
self.thread_stop = True
def getContent(url,type):
print(">>start connecting:%s" % url)
from urllib2 import Request, urlopen, URLError, HTTPError
proxy = urllib2.ProxyHandler({\'http\':\'http://127.0.0.1:8087\'})
opener = urllib2.build_opener(proxy,urllib2.HTTPHandler)
urllib2.install_opener(opener)
try:
urlHandler = urllib2.urlopen(url)
headers = urlHandler.info().headers
length = 0
for header in headers:
if header.find(\'Length\') != -1:
length = header.split(\':\')[-1].strip()
length = int(length)
if(type=="img" and length
抓取网页音频(requestslxml案例查找所有关于title标签其中的有个案例 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-09-30 10:38
)
2.1.2、目的2.1.3、目标类型三、启动爬虫本章是对爬虫程序的介绍,因此我们只需要安装几个Python库,如下所示:
requests | pip install requests
bs4 | pip install bs4
lxml | pip install lxml
发送请求
当我们每天访问百度时,它实际上是一个请求。此请求的功能是使用代码模拟我们人类向网站发送请求。首先,我们需要导入请求库,如下所示:
import requests # 导入requests库
导入后,我们可以使用请求库中的方法。例如,我们需要在我的CSDN中获得一个文章
r = requests.get('https://www.jianshu.com')
现在,我们有一个名为:R的响应对象,也就是说,当我们访问网站时,网站肯定会给我们提供数据。一些参数如下:
r.status_code # 查看访问状态码 200为ok 是成功的
200
# 然后获取网页源码
r.text # 就是整个网页的html代码
对于HTML源代码,通常使用常规匹配数据,但这太麻烦了。我们选择一个更简单的Python库来解析HTML
就这样
from bs4 import BeautifulSoup
拿一个案例来查找关于title标签的所有信息
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
html = '网页源码'
soup = BeautifulSoup(html, 'lxml')
title = soup.find_all('title')
print(title)
>>> [The Dormouse's story]
有一个lxml,它是一个lxml HTML解析器,安装在
说一些美的重要功能
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
html = '网页源码'
soup = BeautifulSoup(html, 'lxml')
soup.find_all('a') # 获取整个网页所有a标签
soup.find_all('p') # 获取整个网页所有p标签
soup.find('p') # 获取网页第一个p标签
soup.select('#stro p') # 这个是按照css选择器获取元素的 和css几乎相同 查看全部
抓取网页音频(requestslxml案例查找所有关于title标签其中的有个案例
)
2.1.2、目的2.1.3、目标类型三、启动爬虫本章是对爬虫程序的介绍,因此我们只需要安装几个Python库,如下所示:
requests | pip install requests
bs4 | pip install bs4
lxml | pip install lxml
发送请求
当我们每天访问百度时,它实际上是一个请求。此请求的功能是使用代码模拟我们人类向网站发送请求。首先,我们需要导入请求库,如下所示:
import requests # 导入requests库
导入后,我们可以使用请求库中的方法。例如,我们需要在我的CSDN中获得一个文章
r = requests.get('https://www.jianshu.com')
现在,我们有一个名为:R的响应对象,也就是说,当我们访问网站时,网站肯定会给我们提供数据。一些参数如下:
r.status_code # 查看访问状态码 200为ok 是成功的
200
# 然后获取网页源码
r.text # 就是整个网页的html代码
对于HTML源代码,通常使用常规匹配数据,但这太麻烦了。我们选择一个更简单的Python库来解析HTML
就这样
from bs4 import BeautifulSoup
拿一个案例来查找关于title标签的所有信息
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
html = '网页源码'
soup = BeautifulSoup(html, 'lxml')
title = soup.find_all('title')
print(title)
>>> [The Dormouse's story]
有一个lxml,它是一个lxml HTML解析器,安装在
说一些美的重要功能
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
html = '网页源码'
soup = BeautifulSoup(html, 'lxml')
soup.find_all('a') # 获取整个网页所有a标签
soup.find_all('p') # 获取整个网页所有p标签
soup.find('p') # 获取网页第一个p标签
soup.select('#stro p') # 这个是按照css选择器获取元素的 和css几乎相同
抓取网页音频(如何巧妙批量音效素材?下载器的站点抓取功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 749 次浏览 • 2021-09-29 11:55
今天,小编接到了一个任务:制作视频。但是小编突然发现电脑里的音效文件太少了,而音效网站几乎只提供单个文件下载,暂时下载太费时间了。于是想到了Internet Download Manager(简称IDM)的网站爬取功能。如果使用站点抓取功能,可以批量下载音效文件吗?
IDM下载器的站点抓取功能可以抓取网站上的图片、音频、视频、PDF、压缩包等文件。更重要的是,可以实现批量抓取操作,省时省力。今天小编就来给大家展示一下如何巧妙的批量捕捉音效素材。
第一步:下载并安装软件
输入IDM中文网站下载安装包。下载完成后,安装,然后打开软件,进入程序主界面。
图1:程序主界面
第二步:进入音效编译界面,复制链接地址
打开搜狗浏览器,在百度上搜索“音效大全”,选择一个音效网站(这里以站长素材网为例),进入后点击进入音效分类编译界面网页,即大量音效链接地址的目录界面。然后复制这个接口的链接地址。
图 2:音效采集页面
第三步:运行“Site Capture”功能捕捉声音效果
现在返回IDM主界面,鼠标左键点击右上角的“Site Capture”按钮,将复制的链接地址粘贴到“Start Page/Address”栏,然后点击下方的“Forward”按钮.
图3:网站爬取-链接输入页面
第四步:建议将“探索指定链接深度”修改为“3”
在步骤2中点击转发。在步骤3中,建议将“探索指定链接深度”中的根站点“2”的深度修改为根站点“3”的深度,然后选择“转发”按钮。
这一步是获取音效下载页面的链接。当探索链接深度为1时,IDM的探索对象为当前页面;当探索链接深度为2时,IDM的探索对象为点击链接后要跳转的当前页面。探索链接深度为3时,IDM的探索对象为当前页面链接进行二次跳转的页面。
图4:网站爬取界面
第 5 步:更改下载的文件类型
将文件类型“所有文件”更改为需要下载的文件类型,即“音频文件”,然后单击“转发”。
图 5:文件类型更改页面
第六步:等待站点获取成功,并保存文件
此页面显示捕获的图像,等待站点完成捕获,即可保存文件。
图6:文件抓取信息页面
经过以上操作,编辑器得到了大量的音效文件,而且可以通过站点抓取进行多窗口抓取,所以编辑器可以同时抓取多个分类的音效文件,真的很方便!
但是大家一定要确保音效网站保存的音效文件格式是:mp3、wma或者waw。如果网站的文件保存格式不是这三种后缀格式,IDM可能无法识别!
以上就是巧妙利用IDM批量抓取音效素材的所有内容。点击IDM教程,了解更多使用技巧,抓紧一起学习。 查看全部
抓取网页音频(如何巧妙批量音效素材?下载器的站点抓取功能)
今天,小编接到了一个任务:制作视频。但是小编突然发现电脑里的音效文件太少了,而音效网站几乎只提供单个文件下载,暂时下载太费时间了。于是想到了Internet Download Manager(简称IDM)的网站爬取功能。如果使用站点抓取功能,可以批量下载音效文件吗?
IDM下载器的站点抓取功能可以抓取网站上的图片、音频、视频、PDF、压缩包等文件。更重要的是,可以实现批量抓取操作,省时省力。今天小编就来给大家展示一下如何巧妙的批量捕捉音效素材。
第一步:下载并安装软件
输入IDM中文网站下载安装包。下载完成后,安装,然后打开软件,进入程序主界面。
.png)
图1:程序主界面
第二步:进入音效编译界面,复制链接地址
打开搜狗浏览器,在百度上搜索“音效大全”,选择一个音效网站(这里以站长素材网为例),进入后点击进入音效分类编译界面网页,即大量音效链接地址的目录界面。然后复制这个接口的链接地址。
.png)
图 2:音效采集页面
第三步:运行“Site Capture”功能捕捉声音效果
现在返回IDM主界面,鼠标左键点击右上角的“Site Capture”按钮,将复制的链接地址粘贴到“Start Page/Address”栏,然后点击下方的“Forward”按钮.
.png)
图3:网站爬取-链接输入页面
第四步:建议将“探索指定链接深度”修改为“3”
在步骤2中点击转发。在步骤3中,建议将“探索指定链接深度”中的根站点“2”的深度修改为根站点“3”的深度,然后选择“转发”按钮。
这一步是获取音效下载页面的链接。当探索链接深度为1时,IDM的探索对象为当前页面;当探索链接深度为2时,IDM的探索对象为点击链接后要跳转的当前页面。探索链接深度为3时,IDM的探索对象为当前页面链接进行二次跳转的页面。
.jpeg)
图4:网站爬取界面
第 5 步:更改下载的文件类型
将文件类型“所有文件”更改为需要下载的文件类型,即“音频文件”,然后单击“转发”。
.png)
图 5:文件类型更改页面
第六步:等待站点获取成功,并保存文件
此页面显示捕获的图像,等待站点完成捕获,即可保存文件。
.png)
图6:文件抓取信息页面
经过以上操作,编辑器得到了大量的音效文件,而且可以通过站点抓取进行多窗口抓取,所以编辑器可以同时抓取多个分类的音效文件,真的很方便!
但是大家一定要确保音效网站保存的音效文件格式是:mp3、wma或者waw。如果网站的文件保存格式不是这三种后缀格式,IDM可能无法识别!
以上就是巧妙利用IDM批量抓取音效素材的所有内容。点击IDM教程,了解更多使用技巧,抓紧一起学习。
抓取网页音频( 1.如何发送报告支持?发送应用程序报告发送报告)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-28 07:15
1.如何发送报告支持?发送应用程序报告发送报告)
特征
1.Trackhunter(音乐抓取工具)是一款易于使用的音乐下载工具,可让您跟踪来自您喜爱的在线数字商店的最新音乐,包括:Amazon Mp3、Beatport、DJ Tunes、iTunes、Juno下载等。
2. 寻找早期的电子舞曲变得非常快速和容易。它使您可以听到所有新音乐,无论流派如何,因此您无需跟随任何人就可以创建自己的风格。
3.Trackhunter(音乐抓取工具)可配置的快听自动跟踪跳过模式,可以让你在几分钟内快速听完几个小时的音轨,还可以进行其他操作。
精选亮点
1.Trackhunter(音乐抓取工具)可以记住您已经听过的内容并将其过滤掉,这样您就不会浪费时间听同一首歌两次。
2. 将 WAV 转换为 AIFF 并自动标记它们(包括封面)以节省购买无损 WAV 曲目的时间,无论它们来自何处。
3. 显示哪家商店以最便宜的价格出售它,这样您就可以使用集成购物车在您购买的每首曲目上省钱。
常见问题
1.如何发送报告支持?
要发送申请报告以获得支持,请执行以下程序:
启动跟踪程序
切换到“帮助”菜单,选择调试模式(调试时应该出现在调试模式旁边)
打开调试后,在 Trackhunter 中执行任何非工作工作以捕获相关信息。
然后,返回帮助菜单并选择发送应用程序报告以发送报告。
您应该在 24 小时内获得支持(周末或节假日可能更多)。
2.如何从我最喜欢的艺术家或唱片中获取音乐?
您可以关注特定的艺术家或标签。您可以通过右键单击曲目并选择关注来选择关注播放列表中的艺术家或标签。或者转到“设置”菜单并选择“过滤”选项。如果您想跟踪标签“MuZic 录音”,那么您将创建一个具有以下设置的过滤器:
操作:跟随,类型:包括,值:MuZIC 录音
然后,您应该使用 GET latest (followed by) 选项为您的后续艺术家和标签查找新音乐。
系统城温馨提示:
用户下载本网站中的软件,即视为已阅读并同意本声明的内容。系统城所有软件和资料均来自互联网,仅供个人学习和研究使用,不得用于任何商业用途。如果您侵犯了您的商标、版权或其他合法权利,请联系我们并按照网站公告中的投诉程序提供相关证明材料。本站将尽快核实处理。 查看全部
抓取网页音频(
1.如何发送报告支持?发送应用程序报告发送报告)

特征
1.Trackhunter(音乐抓取工具)是一款易于使用的音乐下载工具,可让您跟踪来自您喜爱的在线数字商店的最新音乐,包括:Amazon Mp3、Beatport、DJ Tunes、iTunes、Juno下载等。
2. 寻找早期的电子舞曲变得非常快速和容易。它使您可以听到所有新音乐,无论流派如何,因此您无需跟随任何人就可以创建自己的风格。
3.Trackhunter(音乐抓取工具)可配置的快听自动跟踪跳过模式,可以让你在几分钟内快速听完几个小时的音轨,还可以进行其他操作。
精选亮点
1.Trackhunter(音乐抓取工具)可以记住您已经听过的内容并将其过滤掉,这样您就不会浪费时间听同一首歌两次。
2. 将 WAV 转换为 AIFF 并自动标记它们(包括封面)以节省购买无损 WAV 曲目的时间,无论它们来自何处。
3. 显示哪家商店以最便宜的价格出售它,这样您就可以使用集成购物车在您购买的每首曲目上省钱。
常见问题
1.如何发送报告支持?
要发送申请报告以获得支持,请执行以下程序:
启动跟踪程序
切换到“帮助”菜单,选择调试模式(调试时应该出现在调试模式旁边)
打开调试后,在 Trackhunter 中执行任何非工作工作以捕获相关信息。
然后,返回帮助菜单并选择发送应用程序报告以发送报告。
您应该在 24 小时内获得支持(周末或节假日可能更多)。
2.如何从我最喜欢的艺术家或唱片中获取音乐?
您可以关注特定的艺术家或标签。您可以通过右键单击曲目并选择关注来选择关注播放列表中的艺术家或标签。或者转到“设置”菜单并选择“过滤”选项。如果您想跟踪标签“MuZic 录音”,那么您将创建一个具有以下设置的过滤器:
操作:跟随,类型:包括,值:MuZIC 录音
然后,您应该使用 GET latest (followed by) 选项为您的后续艺术家和标签查找新音乐。
系统城温馨提示:
用户下载本网站中的软件,即视为已阅读并同意本声明的内容。系统城所有软件和资料均来自互联网,仅供个人学习和研究使用,不得用于任何商业用途。如果您侵犯了您的商标、版权或其他合法权利,请联系我们并按照网站公告中的投诉程序提供相关证明材料。本站将尽快核实处理。
抓取网页音频(视频音频提取电脑版介绍一个的视频提取音频信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 348 次浏览 • 2021-09-27 20:10
)
视音频提取软件是一种主要功能是提取音频信息的工具。功能非常全面。它可以从各种文件格式中提取音频。操作比较简单,使用方便。它还可以自定义输出文件夹。有兴趣的朋友快来体验吧!
音视频提取电脑版介绍
这是一款专业的视频提取工具,用于提取音频信息。软件功能比较齐全。软件可以提取mp4、avi、mtv、wmv、rm、rmvb等多种常见视频文件格式的音频,并允许输出为mp3、ogg、acc等音频格式.
音视频提取正式版功能
- 完全从视频中提取音频内容。
- 支持mp3、ogg、aac等多种常见音频输出格式。
- 支持自定义设置输出文件夹。
-Abelssoft MusicExtractor 可以帮助用户从视频中提取音频。
- 提取的音频可以最大程度保留原创音频效果。
- 一次只能从一个视频文件中提取音频,不支持批处理。
软件特点
- 直观可靠的软件解决方案,使用户能够轻松地从选定的视频中提取音轨并将其保存为 MP3。
- 一次加载和处理一个视频
- 自动提取视频的音轨
- 该实用程序的 GUI(图形用户界面)非常直观,因此即使是计算机知识很少的人也可以使用其功能。
- 您只需要浏览到计算机上的视频文件并将其加载到应用程序中即可。支持的源格式有很多,例如 WMV、AVI、FLV、SWF、MOV、MP4、RM、MKV、MPEG 或 MTS。
- 下一步也是最后一步,只需按下专用按钮并等待 Music Extractor 分析您加载的剪辑,而无需您的任何输入。
-该过程完成后,会自动生成一个MP3文件并保存到您指定的位置-您也可以通过单击鼠标打开收录的文件夹。
- 从视频中提取音轨的无忧应用程序
- 音乐提取器对于所有有兴趣只保留所选视频中的音轨的人都非常有用。
- 考虑到您不需要配置任何复杂的设置,如果您是新手,此实用程序尤其方便。另一方面,专业用户可能对Music Extractor 提供的有限功能设置不满意,因为它几乎无法控制输出MP3 文件(例如,无法定义起点和终点,也无法修改音量)。
查看全部
抓取网页音频(视频音频提取电脑版介绍一个的视频提取音频信息
)
视音频提取软件是一种主要功能是提取音频信息的工具。功能非常全面。它可以从各种文件格式中提取音频。操作比较简单,使用方便。它还可以自定义输出文件夹。有兴趣的朋友快来体验吧!
音视频提取电脑版介绍
这是一款专业的视频提取工具,用于提取音频信息。软件功能比较齐全。软件可以提取mp4、avi、mtv、wmv、rm、rmvb等多种常见视频文件格式的音频,并允许输出为mp3、ogg、acc等音频格式.

音视频提取正式版功能
- 完全从视频中提取音频内容。
- 支持mp3、ogg、aac等多种常见音频输出格式。
- 支持自定义设置输出文件夹。
-Abelssoft MusicExtractor 可以帮助用户从视频中提取音频。
- 提取的音频可以最大程度保留原创音频效果。
- 一次只能从一个视频文件中提取音频,不支持批处理。
软件特点
- 直观可靠的软件解决方案,使用户能够轻松地从选定的视频中提取音轨并将其保存为 MP3。
- 一次加载和处理一个视频
- 自动提取视频的音轨
- 该实用程序的 GUI(图形用户界面)非常直观,因此即使是计算机知识很少的人也可以使用其功能。
- 您只需要浏览到计算机上的视频文件并将其加载到应用程序中即可。支持的源格式有很多,例如 WMV、AVI、FLV、SWF、MOV、MP4、RM、MKV、MPEG 或 MTS。
- 下一步也是最后一步,只需按下专用按钮并等待 Music Extractor 分析您加载的剪辑,而无需您的任何输入。
-该过程完成后,会自动生成一个MP3文件并保存到您指定的位置-您也可以通过单击鼠标打开收录的文件夹。
- 从视频中提取音轨的无忧应用程序
- 音乐提取器对于所有有兴趣只保留所选视频中的音轨的人都非常有用。
- 考虑到您不需要配置任何复杂的设置,如果您是新手,此实用程序尤其方便。另一方面,专业用户可能对Music Extractor 提供的有限功能设置不满意,因为它几乎无法控制输出MP3 文件(例如,无法定义起点和终点,也无法修改音量)。

抓取网页音频(BeautifulSoup一个灵活又方便的网页解析库,处理高效,支持多种解析器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-27 19:01
2、美汤
一个灵活方便的网页解析库,处理高效,支持多种解析器。
使用它无需编写正则表达式,轻松实现网页信息抓取。
3、安装及介绍:
pip install requests
pip install BeautifulSoup
import requests
from bs4 import BeautifulSoup as bf
二、目标网站
需要手动点击下载mp3文件网站,因为需要下载数百个文件,手动操作比较困难。
三:获取并解析网页源代码
1、使用requests获取目标的源码网站
r = requests.get('http://www.goodkejian.com/ertonggushi.htm')
所有下载链接都存储在标签中,并且具有固定长度。去掉amp后可以直接下载链接;
2、使用BeautifulSoup解析网页内容并从中提取标签
soup = bf(r.text, 'html.parser')
res = soup.find_all('a')
四:下载
经过上面的步骤, res 变成了一个收录所有目标标签的数组。如果要下载网页上的所有mp3文件,只需要循环将res中的元组转换成字符串,经过过滤、裁剪等操作,就变成了一个链接。可以使用request来访问,返回值是mp3文件的二进制表示,直接以二进制的形式写入文件即可。
整个代码如下:
import requests
from bs4 import BeautifulSoup as bf
r = requests.get('http://www.goodkejian.com/ertonggushi.htm')
soup = bf(r.text, 'html.parser')
res = soup.find_all('a')
recorder = 1
# 长度为126的是要找的图标
for i in res:
dst = str(i)
if dst.__len__() == 126:
url1 = dst[9:53]
url2 = dst[57:62]
url = url1 + url2
print(url)
xjh_request = requests.get(url)
with open("./res/" + str(recorder) + ".rar", 'wb') as file:
file.write(xjh_request.content)
file.close()
recorder += 1
print("ok")
以上就是文章《如何在python中抓取并自动下载网页音频文件》的全部内容,感谢阅读!相信大家都有一定的了解,希望分享的内容对大家有所帮助。如果您想了解更多,请关注一宿云行业资讯频道! 查看全部
抓取网页音频(BeautifulSoup一个灵活又方便的网页解析库,处理高效,支持多种解析器)
2、美汤
一个灵活方便的网页解析库,处理高效,支持多种解析器。
使用它无需编写正则表达式,轻松实现网页信息抓取。
3、安装及介绍:
pip install requests
pip install BeautifulSoup
import requests
from bs4 import BeautifulSoup as bf
二、目标网站
需要手动点击下载mp3文件网站,因为需要下载数百个文件,手动操作比较困难。
三:获取并解析网页源代码
1、使用requests获取目标的源码网站
r = requests.get('http://www.goodkejian.com/ertonggushi.htm')
所有下载链接都存储在标签中,并且具有固定长度。去掉amp后可以直接下载链接;
2、使用BeautifulSoup解析网页内容并从中提取标签
soup = bf(r.text, 'html.parser')
res = soup.find_all('a')
四:下载
经过上面的步骤, res 变成了一个收录所有目标标签的数组。如果要下载网页上的所有mp3文件,只需要循环将res中的元组转换成字符串,经过过滤、裁剪等操作,就变成了一个链接。可以使用request来访问,返回值是mp3文件的二进制表示,直接以二进制的形式写入文件即可。
整个代码如下:
import requests
from bs4 import BeautifulSoup as bf
r = requests.get('http://www.goodkejian.com/ertonggushi.htm')
soup = bf(r.text, 'html.parser')
res = soup.find_all('a')
recorder = 1
# 长度为126的是要找的图标
for i in res:
dst = str(i)
if dst.__len__() == 126:
url1 = dst[9:53]
url2 = dst[57:62]
url = url1 + url2
print(url)
xjh_request = requests.get(url)
with open("./res/" + str(recorder) + ".rar", 'wb') as file:
file.write(xjh_request.content)
file.close()
recorder += 1
print("ok")
以上就是文章《如何在python中抓取并自动下载网页音频文件》的全部内容,感谢阅读!相信大家都有一定的了解,希望分享的内容对大家有所帮助。如果您想了解更多,请关注一宿云行业资讯频道!
抓取网页音频(小象音频提取免费最新版软件更新(图)下载地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 288 次浏览 • 2021-09-27 18:19
Baby Elephant Audio Extraction Free 最新版本是一款非常好用的音频提取软件。威特软件园为您提供最新版小象音频提取免费下载、小象音频提取免费最新版软件介绍和小象音频提取免费最新版体验,该软件可以帮助用户非常方便地提取音频。
小象音频提取免费软件最新版介绍
一款简单易用的视频音频提取软件,旨在帮助您从mp4、mpeg、mkv、wmv、avi、m4v、rmvb等各种主流视频文件中提取音频,并输出音频作为 MP3 格式。
小象音频提取免费最新版软件使用说明
当您需要从 MV 中提取歌曲和从电影中提取原创声音时,该软件非常有用。它具有直观的界面设计,导入要转换的媒体文件,然后一键提取。提取完成后,可以在与源文件相同的目录中找到提取的音频。
最新版免费软件的特点
1、 另外,为了获得最佳的输出效果,提取的音频可以有效保持原创质量。
2、帮助从各种主视频中提取音频,将提取的音频文件保存为mp3格式,从电影中提取原创声音进行二次制作,从MV和视频歌曲中提取音轨。
小象音频提取免费软件最新版亮点
1、 为用户提供良好、优质的服务,让每一位用户在软件中获得最好、最舒适的体验。
2、通过简单直观的操作界面,提取只需简单两步。显示音频提取过程的内置日志功能。一次只能处理一个视频文件,提取的音频文件可以自动保存在与源文件相同的目录中。
Baby Elephant Audio Extraction 免费最新版软件更新
1、修复bug,优化部分交互体验
2、 优化程序稳定性,使其更流畅
3、 调整了部分页面布局,使界面更加整洁美观
4、新模块 查看全部
抓取网页音频(小象音频提取免费最新版软件更新(图)下载地址)
Baby Elephant Audio Extraction Free 最新版本是一款非常好用的音频提取软件。威特软件园为您提供最新版小象音频提取免费下载、小象音频提取免费最新版软件介绍和小象音频提取免费最新版体验,该软件可以帮助用户非常方便地提取音频。
小象音频提取免费软件最新版介绍
一款简单易用的视频音频提取软件,旨在帮助您从mp4、mpeg、mkv、wmv、avi、m4v、rmvb等各种主流视频文件中提取音频,并输出音频作为 MP3 格式。
小象音频提取免费最新版软件使用说明
当您需要从 MV 中提取歌曲和从电影中提取原创声音时,该软件非常有用。它具有直观的界面设计,导入要转换的媒体文件,然后一键提取。提取完成后,可以在与源文件相同的目录中找到提取的音频。
最新版免费软件的特点
1、 另外,为了获得最佳的输出效果,提取的音频可以有效保持原创质量。
2、帮助从各种主视频中提取音频,将提取的音频文件保存为mp3格式,从电影中提取原创声音进行二次制作,从MV和视频歌曲中提取音轨。
小象音频提取免费软件最新版亮点
1、 为用户提供良好、优质的服务,让每一位用户在软件中获得最好、最舒适的体验。
2、通过简单直观的操作界面,提取只需简单两步。显示音频提取过程的内置日志功能。一次只能处理一个视频文件,提取的音频文件可以自动保存在与源文件相同的目录中。
Baby Elephant Audio Extraction 免费最新版软件更新
1、修复bug,优化部分交互体验
2、 优化程序稳定性,使其更流畅
3、 调整了部分页面布局,使界面更加整洁美观
4、新模块
抓取网页音频(我来更新一下(前面两段话是知乎逼迫的,百度搜不到,想骂微信写原文就好了))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-09-23 10:04
抓取网页音频和视频常见的方法有两种,一种是利用收费app去帮助获取一些网页音频和视频的歌词,另一种是找正规渠道下载音频和视频,比如去qq音乐搜索音频,也可以下载音频,但是肯定不会有视频歌词帮助你查看。如果是要下载新闻搜索播放器里面收录的音频和视频,比如动车站视频和人民日报播放的文字,音乐都可以是可以去试试。更多网站的访问访问,可以找我。
百度没有在线试听
如果原网站已经下架可以去百度下载找到你想要的资源也是可以下的
这个真的就是音频格式了!不能通过收藏关键词找得到的!
谢邀,
这种就是歌词文件,下载下来就可以播放,百度搜歌词文件,
百度里,
中国大众音乐网有
qq音乐里下载
感谢你,让我找到这么一个良心音乐软件。
我来更新一下(前面两段话是知乎逼迫的,百度搜不到,知乎也搜不到,想骂微信写原文就好了)百度搜不到直接用手机搜一个网站,有歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词。 查看全部
抓取网页音频(我来更新一下(前面两段话是知乎逼迫的,百度搜不到,想骂微信写原文就好了))
抓取网页音频和视频常见的方法有两种,一种是利用收费app去帮助获取一些网页音频和视频的歌词,另一种是找正规渠道下载音频和视频,比如去qq音乐搜索音频,也可以下载音频,但是肯定不会有视频歌词帮助你查看。如果是要下载新闻搜索播放器里面收录的音频和视频,比如动车站视频和人民日报播放的文字,音乐都可以是可以去试试。更多网站的访问访问,可以找我。
百度没有在线试听
如果原网站已经下架可以去百度下载找到你想要的资源也是可以下的
这个真的就是音频格式了!不能通过收藏关键词找得到的!
谢邀,
这种就是歌词文件,下载下来就可以播放,百度搜歌词文件,
百度里,
中国大众音乐网有
qq音乐里下载
感谢你,让我找到这么一个良心音乐软件。
我来更新一下(前面两段话是知乎逼迫的,百度搜不到,知乎也搜不到,想骂微信写原文就好了)百度搜不到直接用手机搜一个网站,有歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词。
抓取网页音频(试试soundhound音乐宝?应该是什么样的app?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-09-22 21:01
抓取网页音频的app有两种,一种是soundhound,一种是网易云音乐的app版本,其他的都不是很推荐。(比如app里有集合全网音乐,可以听全网歌曲,没那么好用)soundhound是一款ios和android软件,是非常强大的音乐资源提供商。内置收费音乐18元一首,而免费歌曲可以无限听,我对他们家的平台感觉很好,一个账号在里面无限听别人的歌曲,不想听的还可以用不同app听。
网易云是一款android软件,专门听音乐的,质量不是很高,没有比较推荐,他家的有个电台“小白电台”,还有app里的上一首歌、下一首歌的回放,都不错。强烈推荐qq音乐,离线可听。因为音质原因可能比网易云差一点,但是全部是原创音乐,歌曲质量比较高。还可以根据你自己的喜好创建一个“歌单”,创建多音乐条目,让你的“歌单”更强大,除了qq音乐的内置歌单,你还可以添加其他的音乐。
所以不如找个安卓的啊,android就weico好用了。都有识别功能。只能回答的更详细一点。现在已经有相应的软件了。
请用国内的,比如网易云音乐。这个功能还是不错的,特别适合听音乐。而且我跟我女朋友最近一直在用。
手机上的话不知道lp好不好但我用qq音乐的版本比较容易和同步。网易云本身界面就是悲剧。
试试soundhound音乐宝?应该是这个 查看全部
抓取网页音频(试试soundhound音乐宝?应该是什么样的app?)
抓取网页音频的app有两种,一种是soundhound,一种是网易云音乐的app版本,其他的都不是很推荐。(比如app里有集合全网音乐,可以听全网歌曲,没那么好用)soundhound是一款ios和android软件,是非常强大的音乐资源提供商。内置收费音乐18元一首,而免费歌曲可以无限听,我对他们家的平台感觉很好,一个账号在里面无限听别人的歌曲,不想听的还可以用不同app听。
网易云是一款android软件,专门听音乐的,质量不是很高,没有比较推荐,他家的有个电台“小白电台”,还有app里的上一首歌、下一首歌的回放,都不错。强烈推荐qq音乐,离线可听。因为音质原因可能比网易云差一点,但是全部是原创音乐,歌曲质量比较高。还可以根据你自己的喜好创建一个“歌单”,创建多音乐条目,让你的“歌单”更强大,除了qq音乐的内置歌单,你还可以添加其他的音乐。
所以不如找个安卓的啊,android就weico好用了。都有识别功能。只能回答的更详细一点。现在已经有相应的软件了。
请用国内的,比如网易云音乐。这个功能还是不错的,特别适合听音乐。而且我跟我女朋友最近一直在用。
手机上的话不知道lp好不好但我用qq音乐的版本比较容易和同步。网易云本身界面就是悲剧。
试试soundhound音乐宝?应该是这个
抓取网页音频(CME继续自己的创新性YourAudio在线免费服务可以处理音频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 359 次浏览 • 2021-10-26 12:05
芝商所继续自己的创新探索。这项名为“编辑您的音频”的免费在线服务可以帮助您在云端处理音频,它使用新算法来获得更好的结果。
首先,这是一项在线免费服务,只需访问即可使用(打开后可以在网页底部选择中文),上传音频文件进行在线云处理,所有处理都进行使用 CME 的在线服务器。不消耗本地电脑的资源,所以手机也可以上传。
此服务支持 30MB 以下多种格式的任何音频,包括:
目前共有三种服务(实际上都是基于相同的算法),包括:
这种基于云端的算法并没有使用传统的倒音方法,而是基于Deezer Institute的算法,分析人声的音频特征,并分离出具有该特征的音频。目前第一步只能对人声进行分析分离,下一步还可以对钢琴、鼓、贝司等乐器的声音进行分析分离,后续会持续更新。
由于原算法需要高速GPU处理,耗时长,计算量大,成本高,所以对个人电脑的要求较高。CME工程师对云计算进行了优化,可以利用云服务器的CPU进行快速处理,达到低成本大规模应用的水平。
大家不妨试一试,欢迎在留言中写下您的体验,帮助CME开发者不断完善服务: 查看全部
抓取网页音频(CME继续自己的创新性YourAudio在线免费服务可以处理音频)
芝商所继续自己的创新探索。这项名为“编辑您的音频”的免费在线服务可以帮助您在云端处理音频,它使用新算法来获得更好的结果。
首先,这是一项在线免费服务,只需访问即可使用(打开后可以在网页底部选择中文),上传音频文件进行在线云处理,所有处理都进行使用 CME 的在线服务器。不消耗本地电脑的资源,所以手机也可以上传。
此服务支持 30MB 以下多种格式的任何音频,包括:
目前共有三种服务(实际上都是基于相同的算法),包括:
这种基于云端的算法并没有使用传统的倒音方法,而是基于Deezer Institute的算法,分析人声的音频特征,并分离出具有该特征的音频。目前第一步只能对人声进行分析分离,下一步还可以对钢琴、鼓、贝司等乐器的声音进行分析分离,后续会持续更新。
由于原算法需要高速GPU处理,耗时长,计算量大,成本高,所以对个人电脑的要求较高。CME工程师对云计算进行了优化,可以利用云服务器的CPU进行快速处理,达到低成本大规模应用的水平。
大家不妨试一试,欢迎在留言中写下您的体验,帮助CME开发者不断完善服务:
抓取网页音频(android_read出现代码的逻辑很简单,主要是底层音频有问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-26 08:07
)
我们经常会遇到这样的问题。应用程序读取的音频有问题。您需要在tinyalsa中读取音频,以确认是底层音频问题还是应用程序处理后的问题。
于是,这个补丁出现了
代码逻辑很简单,主要是pcm_read的时候,数据同时写入文件,这个只能在调试的时候用,一直用的话,文件总是会变大,直到系统是不是存储到底有问题。
Android.mk 不再用于编写 android 代码。相反,使用 android.bp。如果需要收录头文件,这里需要修改。相关的文章是网上的一篮子,就不多说了。
有个指针处理,我觉得比较巧妙,喜欢研究代码的可以去github看源码。
如果你还是不明白代码,你可以去tinycap.c。解析和记录操作虽然简单,但对我们帮助很大。
代码修改的diff如下
diff --git a/external/tinyalsa/Android.bp b/external/tinyalsa/Android.bp
old mode 100644
new mode 100755
index 090d91c0f8..79a6ceaee2
--- a/external/tinyalsa/Android.bp
+++ b/external/tinyalsa/Android.bp
@@ -9,6 +9,7 @@ cc_library {
"mixer.c",
"pcm.c",
],
+ shared_libs: ["liblog"],
cflags: ["-Werror", "-Wno-macro-redefined"],
export_include_dirs: ["include"],
local_include_dirs: ["include"],
diff --git a/external/tinyalsa/pcm.c b/external/tinyalsa/pcm.c
old mode 100644
new mode 100755
index 4ae321bf93..de0deab9d0
--- a/external/tinyalsa/pcm.c
+++ b/external/tinyalsa/pcm.c
@@ -35,11 +35,17 @@
#include
#include
+#include
+#include
+#include
+
#include
#include
#include
#include
+#include
+
#include
#define __force
#define __bitwise
@@ -48,6 +54,10 @@
#include
+#define LOG_TAG "TINYALSA_QIFA"
+#define ALOGD(fmt, args...) __android_log_print(ANDROID_LOG_DEBUG, LOG_TAG, fmt, ##args)
+#define ALOGE(fmt, args...) __android_log_print(ANDROID_LOG_ERROR, LOG_TAG, fmt, ##args)
+
#define PARAM_MAX SNDRV_PCM_HW_PARAM_LAST_INTERVAL
/* Logs information into a string; follows snprintf() in that
@@ -242,6 +252,10 @@ static void param_init(struct snd_pcm_hw_params *p)
struct pcm {
int fd;
+ //int fd_test;
+ FILE *fd_test;
+ unsigned int size_test;
+ void *test_buffer;
unsigned int flags;
int running:1;
int prepared:1;
@@ -566,6 +580,7 @@ int pcm_read(struct pcm *pcm, void *data, unsigned int count)
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
}
}
@@ -864,6 +885,8 @@ int pcm_close(struct pcm *pcm)
if (pcm->fd >= 0)
close(pcm->fd);
+ if (pcm->fd_test >= 0)
+ fclose(pcm->fd_test);
pcm->prepared = 0;
pcm->running = 0;
pcm->buffer_size = 0;
@@ -872,6 +895,8 @@ int pcm_close(struct pcm *pcm)
return 0;
}
+
+
struct pcm *pcm_open(unsigned int card, unsigned int device,
unsigned int flags, struct pcm_config *config)
{
@@ -900,7 +925,12 @@ struct pcm *pcm_open(unsigned int card, unsigned int device,
oops(pcm, errno, "cannot open device '%s'", fn);
return pcm;
}
-
+ /*weiqifa*/
+ pcm->fd_test = fopen("/sdcard/ref_temp.pcm", "wb");
+ if (!pcm->fd_test) {
+ fprintf(stderr, "Unable to create file /sdcard/ref_temp.pcm\n");
+ } else ALOGD("creat /sdcard/ref_temp.pcm file success");
+
if (fcntl(pcm->fd, F_SETFL, fcntl(pcm->fd, F_GETFL) &
~O_NONBLOCK) config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
:
int running:1;
int prepared:1;
@@ -566,6 +580,7 @@ int pcm_read(struct pcm *pcm, void *data, unsigned int count)
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
}
}
@@ -864,6 +885,8 @@ int pcm_close(struct pcm *pcm)
if (pcm->fd >= 0)
close(pcm->fd);
+ if (pcm->fd_test >= 0)
+ fclose(pcm->fd_test);
pcm->prepared = 0;
pcm->running = 0;
pcm->buffer_size = 0;
@@ -872,6 +895,8 @@ int pcm_close(struct pcm *pcm)
return 0;
}
+
+
struct pcm *pcm_open(unsigned int card, unsigned int device,
unsigned int flags, struct pcm_config *config)
{
@@ -900,7 +925,12 @@ struct pcm *pcm_open(unsigned int card, unsigned int device,
oops(pcm, errno, "cannot open device '%s'", fn);
return pcm;
}
-
+ /*weiqifa*/
+ pcm->fd_test = fopen("/sdcard/ref_temp.pcm", "wb");
+ if (!pcm->fd_test) {
+ fprintf(stderr, "Unable to create file /sdcard/ref_temp.pcm\n");
+ } else ALOGD("creat /sdcard/ref_temp.pcm file success");
+
if (fcntl(pcm->fd, F_SETFL, fcntl(pcm->fd, F_GETFL) &
~O_NONBLOCK) flags & PCM_IN))
return -EINVAL;
x.buf = data;
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd, SNDRV_PCM_IOCTL_READI_FRAMES, &x)) {
pcm->prepared = 0;
pcm->running = 0;
if (errno == EPIPE) {
/* we failed to make our window -- try to restart */
pcm->underruns++;
continue;
}
return oops(pcm, errno, "cannot read stream data");
}
if (fwrite(x.buf, 1, count, pcm->fd_test) != count) {
fprintf(stderr,"Error capturing sample\n");
ALOGE("Error capturing sample");
}
return 0;
}
}
x.buf 是一个指针,但是这个指针使用的是应用传下来的地址,所以不需要为 x.buf 分配空间。详情请参考tinycap。
在 tinycap 中,还会将标题写入音频文件。我们没有在这里写。没关系。打开音频时,可以直接导入原创音频。
xxx:/ # ls -al /sdcard/ref_temp.pcm
-rw-rw---- 1 root sdcard_rw 79298560 2021-01-08 15:24 /sdcard/ref_temp.pcm
xxx:/ #
完整代码如下:
查看全部
抓取网页音频(android_read出现代码的逻辑很简单,主要是底层音频有问题
)
我们经常会遇到这样的问题。应用程序读取的音频有问题。您需要在tinyalsa中读取音频,以确认是底层音频问题还是应用程序处理后的问题。
于是,这个补丁出现了
代码逻辑很简单,主要是pcm_read的时候,数据同时写入文件,这个只能在调试的时候用,一直用的话,文件总是会变大,直到系统是不是存储到底有问题。
Android.mk 不再用于编写 android 代码。相反,使用 android.bp。如果需要收录头文件,这里需要修改。相关的文章是网上的一篮子,就不多说了。
有个指针处理,我觉得比较巧妙,喜欢研究代码的可以去github看源码。
如果你还是不明白代码,你可以去tinycap.c。解析和记录操作虽然简单,但对我们帮助很大。
代码修改的diff如下
diff --git a/external/tinyalsa/Android.bp b/external/tinyalsa/Android.bp
old mode 100644
new mode 100755
index 090d91c0f8..79a6ceaee2
--- a/external/tinyalsa/Android.bp
+++ b/external/tinyalsa/Android.bp
@@ -9,6 +9,7 @@ cc_library {
"mixer.c",
"pcm.c",
],
+ shared_libs: ["liblog"],
cflags: ["-Werror", "-Wno-macro-redefined"],
export_include_dirs: ["include"],
local_include_dirs: ["include"],
diff --git a/external/tinyalsa/pcm.c b/external/tinyalsa/pcm.c
old mode 100644
new mode 100755
index 4ae321bf93..de0deab9d0
--- a/external/tinyalsa/pcm.c
+++ b/external/tinyalsa/pcm.c
@@ -35,11 +35,17 @@
#include
#include
+#include
+#include
+#include
+
#include
#include
#include
#include
+#include
+
#include
#define __force
#define __bitwise
@@ -48,6 +54,10 @@
#include
+#define LOG_TAG "TINYALSA_QIFA"
+#define ALOGD(fmt, args...) __android_log_print(ANDROID_LOG_DEBUG, LOG_TAG, fmt, ##args)
+#define ALOGE(fmt, args...) __android_log_print(ANDROID_LOG_ERROR, LOG_TAG, fmt, ##args)
+
#define PARAM_MAX SNDRV_PCM_HW_PARAM_LAST_INTERVAL
/* Logs information into a string; follows snprintf() in that
@@ -242,6 +252,10 @@ static void param_init(struct snd_pcm_hw_params *p)
struct pcm {
int fd;
+ //int fd_test;
+ FILE *fd_test;
+ unsigned int size_test;
+ void *test_buffer;
unsigned int flags;
int running:1;
int prepared:1;
@@ -566,6 +580,7 @@ int pcm_read(struct pcm *pcm, void *data, unsigned int count)
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
}
}
@@ -864,6 +885,8 @@ int pcm_close(struct pcm *pcm)
if (pcm->fd >= 0)
close(pcm->fd);
+ if (pcm->fd_test >= 0)
+ fclose(pcm->fd_test);
pcm->prepared = 0;
pcm->running = 0;
pcm->buffer_size = 0;
@@ -872,6 +895,8 @@ int pcm_close(struct pcm *pcm)
return 0;
}
+
+
struct pcm *pcm_open(unsigned int card, unsigned int device,
unsigned int flags, struct pcm_config *config)
{
@@ -900,7 +925,12 @@ struct pcm *pcm_open(unsigned int card, unsigned int device,
oops(pcm, errno, "cannot open device '%s'", fn);
return pcm;
}
-
+ /*weiqifa*/
+ pcm->fd_test = fopen("/sdcard/ref_temp.pcm", "wb");
+ if (!pcm->fd_test) {
+ fprintf(stderr, "Unable to create file /sdcard/ref_temp.pcm\n");
+ } else ALOGD("creat /sdcard/ref_temp.pcm file success");
+
if (fcntl(pcm->fd, F_SETFL, fcntl(pcm->fd, F_GETFL) &
~O_NONBLOCK) config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
:
int running:1;
int prepared:1;
@@ -566,6 +580,7 @@ int pcm_read(struct pcm *pcm, void *data, unsigned int count)
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
}
}
@@ -864,6 +885,8 @@ int pcm_close(struct pcm *pcm)
if (pcm->fd >= 0)
close(pcm->fd);
+ if (pcm->fd_test >= 0)
+ fclose(pcm->fd_test);
pcm->prepared = 0;
pcm->running = 0;
pcm->buffer_size = 0;
@@ -872,6 +895,8 @@ int pcm_close(struct pcm *pcm)
return 0;
}
+
+
struct pcm *pcm_open(unsigned int card, unsigned int device,
unsigned int flags, struct pcm_config *config)
{
@@ -900,7 +925,12 @@ struct pcm *pcm_open(unsigned int card, unsigned int device,
oops(pcm, errno, "cannot open device '%s'", fn);
return pcm;
}
-
+ /*weiqifa*/
+ pcm->fd_test = fopen("/sdcard/ref_temp.pcm", "wb");
+ if (!pcm->fd_test) {
+ fprintf(stderr, "Unable to create file /sdcard/ref_temp.pcm\n");
+ } else ALOGD("creat /sdcard/ref_temp.pcm file success");
+
if (fcntl(pcm->fd, F_SETFL, fcntl(pcm->fd, F_GETFL) &
~O_NONBLOCK) flags & PCM_IN))
return -EINVAL;
x.buf = data;
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd, SNDRV_PCM_IOCTL_READI_FRAMES, &x)) {
pcm->prepared = 0;
pcm->running = 0;
if (errno == EPIPE) {
/* we failed to make our window -- try to restart */
pcm->underruns++;
continue;
}
return oops(pcm, errno, "cannot read stream data");
}
if (fwrite(x.buf, 1, count, pcm->fd_test) != count) {
fprintf(stderr,"Error capturing sample\n");
ALOGE("Error capturing sample");
}
return 0;
}
}
x.buf 是一个指针,但是这个指针使用的是应用传下来的地址,所以不需要为 x.buf 分配空间。详情请参考tinycap。
在 tinycap 中,还会将标题写入音频文件。我们没有在这里写。没关系。打开音频时,可以直接导入原创音频。
xxx:/ # ls -al /sdcard/ref_temp.pcm
-rw-rw---- 1 root sdcard_rw 79298560 2021-01-08 15:24 /sdcard/ref_temp.pcm
xxx:/ #
完整代码如下:
抓取网页音频(邮箱抓取器绿色版的小伙伴快来体验吧!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-23 06:12
绿色版邮箱抓取器是一款非常好用的邮箱工具,使用简单,解压即可。强大的区分功能助您完成工作任务,营销效果一流!有兴趣的朋友快来体验吧!
PC版邮箱抓取器介绍
邮箱抓取工具是一款邮箱抓取工具,可以提取网页显示的邮箱地址。用于采集各种电子邮件信息,然后您可以通过群发邮件软件将您的相关网络营销信息发送到获得的邮箱中。如果用户没有邮箱软件,获得的邮箱可以作为您在线销售的重要客户信息,达到在线营销的目的。
专刊
能够通过给定的网页 URL 捕获网页中的所有电子邮件地址信息
可以通过深度设置抓取网页中链接的网页,深度越深,抓取的网页越多
可以将抓到的邮箱信息实时保存到指定文件,使用更方便
采用多线程同时抓取,抓取速度更快,分分钟采集所有相关网页
不追求华丽的外表,只追求卓越的性能,让您的网络营销更强大
版本介绍
免费版:
可以抓取指定网页上的所有邮箱信息;
您可以通过升级将免费版升级为专业版。
专业版:
可以指定爬取深度,即指定的网页以及与该网页关联的链接网页上的邮箱都可以
带爬取,同时爬取多个任务,爬取速度极快;
可以将抓到的邮箱信息保存在本地文件中,方便营销。
指示
1. 双机“mymail.exe”打开软件,设置爬取的网址
2. 设置保存路径
3. 设置爬取深度
4. 点击“开始”按钮开始爬取
5. 点击“停止”按钮停止抓取操作
6. 打开保存目录查看爬取结果 查看全部
抓取网页音频(邮箱抓取器绿色版的小伙伴快来体验吧!(组图))
绿色版邮箱抓取器是一款非常好用的邮箱工具,使用简单,解压即可。强大的区分功能助您完成工作任务,营销效果一流!有兴趣的朋友快来体验吧!
PC版邮箱抓取器介绍
邮箱抓取工具是一款邮箱抓取工具,可以提取网页显示的邮箱地址。用于采集各种电子邮件信息,然后您可以通过群发邮件软件将您的相关网络营销信息发送到获得的邮箱中。如果用户没有邮箱软件,获得的邮箱可以作为您在线销售的重要客户信息,达到在线营销的目的。
专刊
能够通过给定的网页 URL 捕获网页中的所有电子邮件地址信息
可以通过深度设置抓取网页中链接的网页,深度越深,抓取的网页越多
可以将抓到的邮箱信息实时保存到指定文件,使用更方便
采用多线程同时抓取,抓取速度更快,分分钟采集所有相关网页
不追求华丽的外表,只追求卓越的性能,让您的网络营销更强大
版本介绍
免费版:
可以抓取指定网页上的所有邮箱信息;
您可以通过升级将免费版升级为专业版。
专业版:
可以指定爬取深度,即指定的网页以及与该网页关联的链接网页上的邮箱都可以
带爬取,同时爬取多个任务,爬取速度极快;
可以将抓到的邮箱信息保存在本地文件中,方便营销。
指示
1. 双机“mymail.exe”打开软件,设置爬取的网址
2. 设置保存路径
3. 设置爬取深度
4. 点击“开始”按钮开始爬取
5. 点击“停止”按钮停止抓取操作
6. 打开保存目录查看爬取结果
抓取网页音频(配套软件版本:V9及更低集搜客网络爬虫软件新版本对应教程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-18 19:01
)
配套软件版本:V9及以下 极助网络爬虫软件
新版对应教程:V10及更高版本数据管家-增强版网络爬虫对应教程为《使用网络爬虫软件自动下载网络文件》
请注意:从V9.0.0开始,文件下载功能有了很大的提升。虽然本教程中解释的方法仍然有效,但这种方法很难理解。你应该使用V9.0.0版本的新方法,下载文件不需要定义第二条规则,只需在第一条规则中勾选“下载内容”,选择下载文件类型即可。Firefox 的插件版本不再需要解决特定的场景问题。详情请参考教程《使用网络爬虫软件自动下载网页文件》 1、下载功能说明
1) 使用Gooseeker获取网页内容时,如果获取的内容是文件链接,通常的方式是获取链接地址。
2)Gooseeker 可以自动下载链接对应的文件吗?答案是肯定的。
2.配置文件的存放路径及处理方法
如果你不配置它,下载文件后,你总是会被问到要做什么。这种查询会阻止爬虫继续运行。为了关闭查询,需要做相应的配置。
2.1、纪助浏览器
极手客浏览器有自己的配置,如下图
点击图中所示的配置按钮,进入如下窗口
在 Mime 选项卡下,有多种文件类型的设置按钮。点击它们可以设置不提示文件处理方式。
2.2、火狐插件版爬虫
1)配置火狐的下载功能。火狐浏览器:工具菜单=>选项=>常规=>下载,选择“保存文件到指定文件夹”
2)配置 Firefox 浏览器处理特定文件类型的方式。Firefox:Option => Application,将要下载的文件类型的“Action”更改为“Save File”。比如要下载pdf文件,修改pdf文件类型的动作。
3.定义爬虫规则并运行
本案例假设需要两层规则(参考“采集URL to make levels采集”采集 层级):
第一层:采集文档列表和下载链接,假设主题名称为pdfpage999
级别2:使用下载链接下载pdf文件,假设主题名称为pdf_download999
下面对二级规则的定义方法进行说明。
3.1、采集文档列表和下载链接
在极手客浏览器加载文档列表页面,进入定义规则模式,定义捕获文件链接的规则。规则名称是“pdfpage999”。基本定义规则方法不再赘述,请参考“采集网页数据”,下面重点介绍下载文件相关的设置
1)勾选链接字段捕获文件到“下级线索”
2)在“爬虫路由”的目标主题中填写之前定义的自动下载规则名称“pdf_download999”
从上面的步骤可以看出,它和普通的分层爬取没有什么区别。不同之处在于二级规则的定义。
3.2、定义执行下载操作的规则
创建专门用于自动下载的新规则。规则的名称是“pdf_download999”。规则的内容可以是在任何简单的网页上抓取一个字段并保存规则。
这一步可能很难理解。这是规则的第二层。在这个级别,只下载一个 pdf 文件,没有特殊的网页内容。因此,我找不到合适的示例页面作为规则使用,因此您必须找到一个页面,但始终定义一个抓取内容。为了不影响规则的运行,使用一个每个页面都有的内容作为爬取的内容。这样,在运行规则时,就不会出现规则不适用的提示。
例如,您可以选择抓取 html 头节点甚至 html 节点。此类规则通用性极高,目的只是为了保证爬取成功,不会遇到规则不适用的问题。只要适应了规则,就会自动触发下载。
3.3、操作规则
就像普通级别采集
1.运行规则pdfpage999,生成pdf_download999的线索
2、运行规则pdf_download999,吉首客的网络爬虫会自动下载线程URL对应的文件,在设置的存储文件夹中可以看到下载的文件。
如有疑问,您可以或
查看全部
抓取网页音频(配套软件版本:V9及更低集搜客网络爬虫软件新版本对应教程
)
配套软件版本:V9及以下 极助网络爬虫软件
新版对应教程:V10及更高版本数据管家-增强版网络爬虫对应教程为《使用网络爬虫软件自动下载网络文件》
请注意:从V9.0.0开始,文件下载功能有了很大的提升。虽然本教程中解释的方法仍然有效,但这种方法很难理解。你应该使用V9.0.0版本的新方法,下载文件不需要定义第二条规则,只需在第一条规则中勾选“下载内容”,选择下载文件类型即可。Firefox 的插件版本不再需要解决特定的场景问题。详情请参考教程《使用网络爬虫软件自动下载网页文件》 1、下载功能说明
1) 使用Gooseeker获取网页内容时,如果获取的内容是文件链接,通常的方式是获取链接地址。
2)Gooseeker 可以自动下载链接对应的文件吗?答案是肯定的。
2.配置文件的存放路径及处理方法
如果你不配置它,下载文件后,你总是会被问到要做什么。这种查询会阻止爬虫继续运行。为了关闭查询,需要做相应的配置。
2.1、纪助浏览器
极手客浏览器有自己的配置,如下图
点击图中所示的配置按钮,进入如下窗口
在 Mime 选项卡下,有多种文件类型的设置按钮。点击它们可以设置不提示文件处理方式。
2.2、火狐插件版爬虫
1)配置火狐的下载功能。火狐浏览器:工具菜单=>选项=>常规=>下载,选择“保存文件到指定文件夹”
2)配置 Firefox 浏览器处理特定文件类型的方式。Firefox:Option => Application,将要下载的文件类型的“Action”更改为“Save File”。比如要下载pdf文件,修改pdf文件类型的动作。
3.定义爬虫规则并运行
本案例假设需要两层规则(参考“采集URL to make levels采集”采集 层级):
第一层:采集文档列表和下载链接,假设主题名称为pdfpage999
级别2:使用下载链接下载pdf文件,假设主题名称为pdf_download999
下面对二级规则的定义方法进行说明。
3.1、采集文档列表和下载链接
在极手客浏览器加载文档列表页面,进入定义规则模式,定义捕获文件链接的规则。规则名称是“pdfpage999”。基本定义规则方法不再赘述,请参考“采集网页数据”,下面重点介绍下载文件相关的设置
1)勾选链接字段捕获文件到“下级线索”
2)在“爬虫路由”的目标主题中填写之前定义的自动下载规则名称“pdf_download999”
从上面的步骤可以看出,它和普通的分层爬取没有什么区别。不同之处在于二级规则的定义。
3.2、定义执行下载操作的规则
创建专门用于自动下载的新规则。规则的名称是“pdf_download999”。规则的内容可以是在任何简单的网页上抓取一个字段并保存规则。
这一步可能很难理解。这是规则的第二层。在这个级别,只下载一个 pdf 文件,没有特殊的网页内容。因此,我找不到合适的示例页面作为规则使用,因此您必须找到一个页面,但始终定义一个抓取内容。为了不影响规则的运行,使用一个每个页面都有的内容作为爬取的内容。这样,在运行规则时,就不会出现规则不适用的提示。
例如,您可以选择抓取 html 头节点甚至 html 节点。此类规则通用性极高,目的只是为了保证爬取成功,不会遇到规则不适用的问题。只要适应了规则,就会自动触发下载。
3.3、操作规则
就像普通级别采集
1.运行规则pdfpage999,生成pdf_download999的线索
2、运行规则pdf_download999,吉首客的网络爬虫会自动下载线程URL对应的文件,在设置的存储文件夹中可以看到下载的文件。
如有疑问,您可以或
抓取网页音频(如何从一个网页中提取出文章的正文正文内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-07 21:35
通常打开一个网页,除了文章的正文内容,通常还会有很多导航、广告等信息。这个博客的目的是解释如何从网页中提取文章的正文内容,同时转出其他不相关的信息。
我们先来看看demo:
此方法基于文本密度。最初的想法来自哈尔滨工业大学的《基于行块分布函数的通用网页文本提取算法》。本文在此基础上做了一些小的修改。
习俗:
本文根据网页的不同行进行统计。因此,假设网页的内容没有被压缩,则说明网页有正常的换行符。
对于一些新闻页面,新闻的文字内容可能比较短,但是里面嵌入了一个视频文件。因此,我会给视频更高的权重;这也适用于图片。这里有一个缺点。它应该基于图片的大小。确定权重,但本文的方法未能做到这一点。
因为广告,这些非文字内容的导航通常以超链接的形式出现,所以文字会给超链接的文字权重为零。
假设正文的内容是连续的,不收录非文本内容。所以,其实提取正文就是找出正文的起止位置。
步:
首先清除网页中的CSS、Javascript、评论、Meta、Ins标签中的内容,清除空白行。
计算每一行的处理值(1)
计算上面得到的每行文本数的最大正子串的起止位置
第二步需要说明:
对于每一行,我们需要计算一个值,计算如下:
一个图片标签img,相当于一个长度为50个字符(给定权重)x1的文本,
嵌入的视频标签,相当于 1000 个字符的文本,x2
一行 x3 中所有链接的标签 a 的文本长度,
其他标签的文本长度 x4
每行的值 = 50 * x1 它的出现次数 + 1000 * x2 它的出现次数 + x4-8
//说明,-8 因为我们要计算一个最大的正子串,所以需要减去一个正数。至于这个数字应该有多大,我觉得还是用经验比较好。
完整代码
<p>#coding:utf-8
import re
def remove_js_css (content):
""" remove the the javascript and the stylesheet and the comment content (.... and .... ) """
r = re.compile(r\'\'\'\'\'\',\'\',s)
return s.strip()
def remove_any_tag_but_a (s):
text = re.findall (r\'\'\']*>(.*?)</a>\'\'\',s,re.I|re.S|re.S)
text_b = remove_any_tag (s)
return len(\'\'.join(text)),len(text_b)
def remove_image (s,n=50):
image = \'a\' * n
r = re.compile (r\'\'\'\'\'\',re.I|re.M|re.S)
s = r.sub(image,s)
return s
def remove_video (s,n=1000):
video = \'a\' * n
r = re.compile (r\'\'\'\'\'\',re.I|re.M|re.S)
s = r.sub(video,s)
return s
def sum_max (values):
cur_max = values[0]
glo_max = -999999
left,right = 0,0
for index,value in enumerate (values):
cur_max += value
if (cur_max > glo_max) :
glo_max = cur_max
right = index
elif (cur_max 查看全部
抓取网页音频(如何从一个网页中提取出文章的正文正文内容?)
通常打开一个网页,除了文章的正文内容,通常还会有很多导航、广告等信息。这个博客的目的是解释如何从网页中提取文章的正文内容,同时转出其他不相关的信息。
我们先来看看demo:
此方法基于文本密度。最初的想法来自哈尔滨工业大学的《基于行块分布函数的通用网页文本提取算法》。本文在此基础上做了一些小的修改。
习俗:
本文根据网页的不同行进行统计。因此,假设网页的内容没有被压缩,则说明网页有正常的换行符。
对于一些新闻页面,新闻的文字内容可能比较短,但是里面嵌入了一个视频文件。因此,我会给视频更高的权重;这也适用于图片。这里有一个缺点。它应该基于图片的大小。确定权重,但本文的方法未能做到这一点。
因为广告,这些非文字内容的导航通常以超链接的形式出现,所以文字会给超链接的文字权重为零。
假设正文的内容是连续的,不收录非文本内容。所以,其实提取正文就是找出正文的起止位置。
步:
首先清除网页中的CSS、Javascript、评论、Meta、Ins标签中的内容,清除空白行。
计算每一行的处理值(1)
计算上面得到的每行文本数的最大正子串的起止位置
第二步需要说明:
对于每一行,我们需要计算一个值,计算如下:
一个图片标签img,相当于一个长度为50个字符(给定权重)x1的文本,
嵌入的视频标签,相当于 1000 个字符的文本,x2
一行 x3 中所有链接的标签 a 的文本长度,
其他标签的文本长度 x4
每行的值 = 50 * x1 它的出现次数 + 1000 * x2 它的出现次数 + x4-8
//说明,-8 因为我们要计算一个最大的正子串,所以需要减去一个正数。至于这个数字应该有多大,我觉得还是用经验比较好。
完整代码
<p>#coding:utf-8
import re
def remove_js_css (content):
""" remove the the javascript and the stylesheet and the comment content (.... and .... ) """
r = re.compile(r\'\'\'\'\'\',\'\',s)
return s.strip()
def remove_any_tag_but_a (s):
text = re.findall (r\'\'\']*>(.*?)</a>\'\'\',s,re.I|re.S|re.S)
text_b = remove_any_tag (s)
return len(\'\'.join(text)),len(text_b)
def remove_image (s,n=50):
image = \'a\' * n
r = re.compile (r\'\'\'\'\'\',re.I|re.M|re.S)
s = r.sub(image,s)
return s
def remove_video (s,n=1000):
video = \'a\' * n
r = re.compile (r\'\'\'\'\'\',re.I|re.M|re.S)
s = r.sub(video,s)
return s
def sum_max (values):
cur_max = values[0]
glo_max = -999999
left,right = 0,0
for index,value in enumerate (values):
cur_max += value
if (cur_max > glo_max) :
glo_max = cur_max
right = index
elif (cur_max
抓取网页音频(新人都可以使用的音乐片段,就是简单的删除你不需要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-10-06 15:15
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。但是,你也会遇到这样的问题,就是无法下载。版权,所以这个时候只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获!
工具特点:
工具太多了,不妨试试。Fast Audio Converter 是一款多功能音频编辑处理软件。该软件具有四个功能:音频剪切、音频提取、音频合并和音频转换。支持单文件操作。还支持文件批量操作!确实是一个不错的选择。
音频转换器
第一步:打开工具
在网页上准备好音乐,然后打开工具到界面,可以尝试简单了解一下。
第 2 步:添加音频文件
今天是提取音乐,所以你找到音频提取按钮,点击它,就会出现它的界面。它的界面中有两个添加文件和添加文件夹。您可以根据自己的编号添加文件。
第 3 步:添加和删除片段指南
接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加的片段指南就是你提取的音乐片段,删除片段指南就是简单的删除你不需要的音乐片段,可以被忽悠了。提取进度条,最后点击确定。
第 4 步:设置保存提取音频的位置
不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。
第五步成功
点击后,提取需要时间,但是这个时间非常快,只要看到对勾就说明提取成功了,以后想查看的可以在你设置的文件中查看。
无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。 查看全部
抓取网页音频(新人都可以使用的音乐片段,就是简单的删除你不需要)
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。但是,你也会遇到这样的问题,就是无法下载。版权,所以这个时候只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获!
工具特点:
工具太多了,不妨试试。Fast Audio Converter 是一款多功能音频编辑处理软件。该软件具有四个功能:音频剪切、音频提取、音频合并和音频转换。支持单文件操作。还支持文件批量操作!确实是一个不错的选择。
音频转换器
第一步:打开工具
在网页上准备好音乐,然后打开工具到界面,可以尝试简单了解一下。
第 2 步:添加音频文件
今天是提取音乐,所以你找到音频提取按钮,点击它,就会出现它的界面。它的界面中有两个添加文件和添加文件夹。您可以根据自己的编号添加文件。
第 3 步:添加和删除片段指南
接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加的片段指南就是你提取的音乐片段,删除片段指南就是简单的删除你不需要的音乐片段,可以被忽悠了。提取进度条,最后点击确定。
第 4 步:设置保存提取音频的位置
不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。
第五步成功
点击后,提取需要时间,但是这个时间非常快,只要看到对勾就说明提取成功了,以后想查看的可以在你设置的文件中查看。
无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。
抓取网页音频(新人都可以使用的音乐片段,就是简单的删除你不需要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-06 15:14
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。但是,你也会遇到这样的问题,就是无法下载。版权,所以这个时候只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获!
工具特点:
工具太多了,不妨试试。Fast Audio Converter 是一款多功能音频编辑处理软件。该软件具有四个功能:音频剪切、音频提取、音频合并和音频转换。支持单文件操作。还支持文件批量操作!确实是一个不错的选择。
音频转换器
第一步:打开工具
在网页上准备好音乐,然后打开工具到界面,可以尝试简单了解一下。
第 2 步:添加音频文件
今天是提取音乐,所以你找到音频提取按钮,点击它,就会出现它的界面。它的界面中有两个添加文件和添加文件夹。您可以根据自己的编号添加文件。
第 3 步:添加和删除片段指南
接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加的片段指南就是你提取的音乐片段,删除片段指南就是简单的删除你不需要的音乐片段,可以被忽悠了。提取进度条,最后点击确定。
第 4 步:设置保存提取音频的位置
不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。
第五步成功
点击后,提取需要时间,但是这个时间非常快,只要看到对勾就说明提取成功了,以后想查看的可以在你设置的文件中查看。
无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。 查看全部
抓取网页音频(新人都可以使用的音乐片段,就是简单的删除你不需要)
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。但是,你也会遇到这样的问题,就是无法下载。版权,所以这个时候只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获!
工具特点:
工具太多了,不妨试试。Fast Audio Converter 是一款多功能音频编辑处理软件。该软件具有四个功能:音频剪切、音频提取、音频合并和音频转换。支持单文件操作。还支持文件批量操作!确实是一个不错的选择。
音频转换器
第一步:打开工具
在网页上准备好音乐,然后打开工具到界面,可以尝试简单了解一下。
第 2 步:添加音频文件
今天是提取音乐,所以你找到音频提取按钮,点击它,就会出现它的界面。它的界面中有两个添加文件和添加文件夹。您可以根据自己的编号添加文件。
第 3 步:添加和删除片段指南
接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加的片段指南就是你提取的音乐片段,删除片段指南就是简单的删除你不需要的音乐片段,可以被忽悠了。提取进度条,最后点击确定。
第 4 步:设置保存提取音频的位置
不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。
第五步成功
点击后,提取需要时间,但是这个时间非常快,只要看到对勾就说明提取成功了,以后想查看的可以在你设置的文件中查看。
无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。
抓取网页音频(如何用IDM巧妙的批量音效素材?下载器抓取功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-10-05 23:01
IDM下载器站点抓取功能,可以抓取网站上的图片、音频、视频、PDF、压缩包等文件。更重要的是,可以实现批量抓取操作,省时省力。今天我们就来看看如何使用IDM来巧妙的批量抓取音效素材。
1、进入音效编译界面,复制链接地址
打开搜狗浏览器,在百度上搜索“音效大全”,选择一个音效网站,进入网页后点击进入音效分类编译界面,即一个大的目录界面音效链接地址的数量。然后复制这个接口的链接地址。
图1:音效编译页面
2、 运行“网站抓取”功能抓取音效
现在返回IDM主界面,鼠标左键点击右上角的“Site Capture”按钮,将复制的链接地址粘贴到“Start Page/Address”栏,然后点击下方的“Forward”按钮.
图2:网站抓取-链接输入页面
3、 建议将“探索指定链接深度”修改为“3”
在步骤2中点击转发。在步骤3中,建议将“探索指定链接深度”中的根站点“2”的深度修改为根站点“3”的深度,然后选择“转发”按钮。
这一步是获取音效下载页面的链接。当探索链接深度为1时,IDM的探索对象为当前页面;当探索链接深度为2时,IDM的探索对象为点击链接后要跳转的当前页面。探索链接深度为3时,IDM的探索对象为当前页面链接进行二次跳转的页面。
图3:网站爬取界面
4、更改下载的文件类型
将文件类型“所有文件”更改为需要下载的文件类型,即“音频文件”,然后单击“转发”。
图 4:文件类型更改页面
5、等待网站爬取成功并保存文件
此页面显示捕获的图像,等待站点完成捕获,即可保存文件。
图5:文件捕获信息页面
经过上面的操作,已经下载了很多音效文件,并且可以使用站点抓取进行多窗口抓取,这样我们就可以同时抓取几个分类的音效文件,真的很方便!
但是大家一定要确保音效网站保存的音效文件格式是:mp3、wma或者waw。如果网站的文件保存格式不是这三种后缀格式,IDM可能无法识别! 查看全部
抓取网页音频(如何用IDM巧妙的批量音效素材?下载器抓取功能)
IDM下载器站点抓取功能,可以抓取网站上的图片、音频、视频、PDF、压缩包等文件。更重要的是,可以实现批量抓取操作,省时省力。今天我们就来看看如何使用IDM来巧妙的批量抓取音效素材。
1、进入音效编译界面,复制链接地址
打开搜狗浏览器,在百度上搜索“音效大全”,选择一个音效网站,进入网页后点击进入音效分类编译界面,即一个大的目录界面音效链接地址的数量。然后复制这个接口的链接地址。
图1:音效编译页面
2、 运行“网站抓取”功能抓取音效
现在返回IDM主界面,鼠标左键点击右上角的“Site Capture”按钮,将复制的链接地址粘贴到“Start Page/Address”栏,然后点击下方的“Forward”按钮.
图2:网站抓取-链接输入页面
3、 建议将“探索指定链接深度”修改为“3”
在步骤2中点击转发。在步骤3中,建议将“探索指定链接深度”中的根站点“2”的深度修改为根站点“3”的深度,然后选择“转发”按钮。
这一步是获取音效下载页面的链接。当探索链接深度为1时,IDM的探索对象为当前页面;当探索链接深度为2时,IDM的探索对象为点击链接后要跳转的当前页面。探索链接深度为3时,IDM的探索对象为当前页面链接进行二次跳转的页面。
图3:网站爬取界面
4、更改下载的文件类型
将文件类型“所有文件”更改为需要下载的文件类型,即“音频文件”,然后单击“转发”。
图 4:文件类型更改页面
5、等待网站爬取成功并保存文件
此页面显示捕获的图像,等待站点完成捕获,即可保存文件。
图5:文件捕获信息页面
经过上面的操作,已经下载了很多音效文件,并且可以使用站点抓取进行多窗口抓取,这样我们就可以同时抓取几个分类的音效文件,真的很方便!
但是大家一定要确保音效网站保存的音效文件格式是:mp3、wma或者waw。如果网站的文件保存格式不是这三种后缀格式,IDM可能无法识别!
抓取网页音频(Python绿色通道铁粉集中营上有球友要求布置一个数据的作业)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-01 22:19
这两天,知识星球蟒蛇绿色通道铁扇集中营的一些高尔夫球手要求分配一个工作来抓取App数据,所以我二话不说就答应了。
效果图如下
我们过去常常在网络上抓取数据,我们很少在移动应用程序中抓取数据。那么我们如何抓取移动应用中的数据呢?一般我们使用抓包工具来抓数据。
常用的抓包工具有Fiddles和Charles,其他今天主要讲一下Charles的使用。与 Fiddles 相比,Charles 更强大,更易于使用。所以一般我建议使用 Charles 进行数据包捕获。
下载并安装查尔斯
下载安装Charles然后破解Charles,这里是文章教程,我就不多说了
预防措施:
如果获取的数据出现乱码,需要在Charles ==>proxy==>SSL Proxying Settings ==>Add 443的菜单栏中设置连接SSL证书,如上图所示。那么当你真正在抓数据的时候,记得把这个关掉,以免抓不到数据
使用查尔斯
这里我直接放两张图给大家使用看看就明白了
一起来分析一下这个项目。
# 这里有点递归的意味
max_id = datas[-1]['publish_time_stamp']
if self.max_id != max_id:
self.max_id = max_id
self.request_data()
else:
print('数据抓取完毕!')
完整代码:
import requests
import time
import json
from dedao.ExeclUtils import ExeclUtils
import os
class dedao(object):
def __init__(self):
# self.rows_title = [u'招聘标题', u'公司名称', u'公司地址', u'待遇', u'发布日期', u'招聘链接', u'招聘要求描述']
# sheet_name = u'51job_Python招聘'
self.rows_title = [u'来源目录', u'标题', u'图片', u'分享标题', u'mp3地址', u'音频时长', u'文件大小']
sheet_name = u'逻辑思维音频'
return_execl = ExeclUtils.create_execl(sheet_name, self.rows_title)
self.execl_f = return_execl[0]
self.sheet_table = return_execl[1]
self.audio_info = [] # 存放每一条数据中的各元素,
self.count = 0 # 数据插入从1开始的
self.base_url = 'https://entree.igetget.com/acr ... 27%3B
self.max_id = 0
self.headers = {
'Host': 'entree.igetget.com',
'X-OS': 'iOS',
'X-NET': 'wifi',
'Accept': '*/*',
'X-Nonce': '779b79d1d51d43fa',
'Accept-Encoding': 'br, gzip, deflate',
# 'Content-Length': ' 67',
'X-TARGET': 'main',
'User-Agent': '%E5%BE%97%E5%88%B0/4.0.13 CFNetwork/901.1 Darwin/17.6.0',
'X-CHIL': 'appstore',
'Cookie ': 'acw_tc=AQAAAC0YfiuHegUAxkvoZRLraUMQyRfH; aliyungf_tc=AQAAAKwCD1dINAUAxkvoZTppW+jezS/9',
'X-UID': '34556154',
'X-AV ': '4.0.0',
'X-SEID ': '',
'X-SCR ': '1242*2208',
'X-DT': 'phone',
'X-S': '91a46b7a31ffc7a2',
'X-Sign': 'ZTBiZjQyNTI1OTU2MTgwZjYwMWRhMjc5ZjhmMGRlNGI=',
'Accept-Language': 'zh-cn',
'X-D': 'ca3c83fca6e84a2d869f95829964ebb8',
'X-THUMB': 'l',
'X-T': 'json',
'X-Timestamp': '1528195376',
'X-TS': '1528195376',
'X-U': '34556154',
'X-App-Key': 'ios-4.0.0',
'X-OV': '11.4',
'Connection': 'keep-alive',
'X-ADV': '1',
'Content-Type': 'application/x-www-form-urlencoded',
'X-V': '2',
'X-IS_JAILBREAK ': 'NO',
'X-DV': 'iPhone10,2',
}
def request_data(self):
try:
data = {
'max_id': self.max_id,
'since_id': 0,
'column_id': 2,
'count': 20,
'order': 1,
'section': 0
}
response = requests.post(self.base_url, headers=self.headers, data=data)
if 200 == response.status_code:
self.parse_data(response)
except Exception as e:
print(e)
time.sleep(2)
pass
def parse_data(self, response):
dict_json = json.loads(response.text)
datas = dict_json['c']['list'] # 这里取得数据列表
# print(datas)
for data in datas:
source_name = data['audio_detail']['source_name']
title = data['audio_detail']['title']
icon = data['audio_detail']['icon']
share_title = data['audio_detail']['share_title']
mp3_url = data['audio_detail']['mp3_play_url']
duction = str(data['audio_detail']['duration']) + '秒'
size = data['audio_detail']['size'] / (1000 * 1000)
size = '%.2fM' % size
self.download_mp3(mp3_url)
self.audio_info.append(source_name)
self.audio_info.append(title)
self.audio_info.append(icon)
self.audio_info.append(share_title)
self.audio_info.append(mp3_url)
self.audio_info.append(duction)
self.audio_info.append(size)
self.count = self.count + 1
ExeclUtils.write_execl(self.execl_f, self.sheet_table, self.count, self.audio_info, u'逻辑思维音频.xlsx')
print('采集了{}条数据'.format(self.count))
# 清空集合,为再次存放数据做准备
self.audio_info = []
time.sleep(3) # 不要请求太快, 小心查水表
max_id = datas[-1]['publish_time_stamp']
if self.max_id != max_id:
self.max_id = max_id
self.request_data()
else:
print('数据抓取完毕!')
pass
def download_mp3(self, mp3_url):
try:
# 补全文件目录
mp3_path = u'D:/store/mp3/{}'.format(mp3_url.split('/')[-1])
print(mp3_path)
# 判断文件是否存在。
if not os.path.exists(mp3_path):
# 注意这里是写入文件,要用二进制格式写入。
with open(mp3_path, 'wb') as f:
f.write(requests.get(mp3_url).content)
except Exception as e:
print(e)
if __name__ == '__main__':
d = dedao()
d.request_data()
目前这只是一个比较简单的手机App数据抓取。如何操作更复杂的数据采集?如何抓取朋友圈的数据?如何抓取微信公众号数据?敬请关注! 查看全部
抓取网页音频(Python绿色通道铁粉集中营上有球友要求布置一个数据的作业)
这两天,知识星球蟒蛇绿色通道铁扇集中营的一些高尔夫球手要求分配一个工作来抓取App数据,所以我二话不说就答应了。
效果图如下
我们过去常常在网络上抓取数据,我们很少在移动应用程序中抓取数据。那么我们如何抓取移动应用中的数据呢?一般我们使用抓包工具来抓数据。
常用的抓包工具有Fiddles和Charles,其他今天主要讲一下Charles的使用。与 Fiddles 相比,Charles 更强大,更易于使用。所以一般我建议使用 Charles 进行数据包捕获。
下载并安装查尔斯
下载安装Charles然后破解Charles,这里是文章教程,我就不多说了
预防措施:
如果获取的数据出现乱码,需要在Charles ==>proxy==>SSL Proxying Settings ==>Add 443的菜单栏中设置连接SSL证书,如上图所示。那么当你真正在抓数据的时候,记得把这个关掉,以免抓不到数据
使用查尔斯
这里我直接放两张图给大家使用看看就明白了
一起来分析一下这个项目。
# 这里有点递归的意味
max_id = datas[-1]['publish_time_stamp']
if self.max_id != max_id:
self.max_id = max_id
self.request_data()
else:
print('数据抓取完毕!')
完整代码:
import requests
import time
import json
from dedao.ExeclUtils import ExeclUtils
import os
class dedao(object):
def __init__(self):
# self.rows_title = [u'招聘标题', u'公司名称', u'公司地址', u'待遇', u'发布日期', u'招聘链接', u'招聘要求描述']
# sheet_name = u'51job_Python招聘'
self.rows_title = [u'来源目录', u'标题', u'图片', u'分享标题', u'mp3地址', u'音频时长', u'文件大小']
sheet_name = u'逻辑思维音频'
return_execl = ExeclUtils.create_execl(sheet_name, self.rows_title)
self.execl_f = return_execl[0]
self.sheet_table = return_execl[1]
self.audio_info = [] # 存放每一条数据中的各元素,
self.count = 0 # 数据插入从1开始的
self.base_url = 'https://entree.igetget.com/acr ... 27%3B
self.max_id = 0
self.headers = {
'Host': 'entree.igetget.com',
'X-OS': 'iOS',
'X-NET': 'wifi',
'Accept': '*/*',
'X-Nonce': '779b79d1d51d43fa',
'Accept-Encoding': 'br, gzip, deflate',
# 'Content-Length': ' 67',
'X-TARGET': 'main',
'User-Agent': '%E5%BE%97%E5%88%B0/4.0.13 CFNetwork/901.1 Darwin/17.6.0',
'X-CHIL': 'appstore',
'Cookie ': 'acw_tc=AQAAAC0YfiuHegUAxkvoZRLraUMQyRfH; aliyungf_tc=AQAAAKwCD1dINAUAxkvoZTppW+jezS/9',
'X-UID': '34556154',
'X-AV ': '4.0.0',
'X-SEID ': '',
'X-SCR ': '1242*2208',
'X-DT': 'phone',
'X-S': '91a46b7a31ffc7a2',
'X-Sign': 'ZTBiZjQyNTI1OTU2MTgwZjYwMWRhMjc5ZjhmMGRlNGI=',
'Accept-Language': 'zh-cn',
'X-D': 'ca3c83fca6e84a2d869f95829964ebb8',
'X-THUMB': 'l',
'X-T': 'json',
'X-Timestamp': '1528195376',
'X-TS': '1528195376',
'X-U': '34556154',
'X-App-Key': 'ios-4.0.0',
'X-OV': '11.4',
'Connection': 'keep-alive',
'X-ADV': '1',
'Content-Type': 'application/x-www-form-urlencoded',
'X-V': '2',
'X-IS_JAILBREAK ': 'NO',
'X-DV': 'iPhone10,2',
}
def request_data(self):
try:
data = {
'max_id': self.max_id,
'since_id': 0,
'column_id': 2,
'count': 20,
'order': 1,
'section': 0
}
response = requests.post(self.base_url, headers=self.headers, data=data)
if 200 == response.status_code:
self.parse_data(response)
except Exception as e:
print(e)
time.sleep(2)
pass
def parse_data(self, response):
dict_json = json.loads(response.text)
datas = dict_json['c']['list'] # 这里取得数据列表
# print(datas)
for data in datas:
source_name = data['audio_detail']['source_name']
title = data['audio_detail']['title']
icon = data['audio_detail']['icon']
share_title = data['audio_detail']['share_title']
mp3_url = data['audio_detail']['mp3_play_url']
duction = str(data['audio_detail']['duration']) + '秒'
size = data['audio_detail']['size'] / (1000 * 1000)
size = '%.2fM' % size
self.download_mp3(mp3_url)
self.audio_info.append(source_name)
self.audio_info.append(title)
self.audio_info.append(icon)
self.audio_info.append(share_title)
self.audio_info.append(mp3_url)
self.audio_info.append(duction)
self.audio_info.append(size)
self.count = self.count + 1
ExeclUtils.write_execl(self.execl_f, self.sheet_table, self.count, self.audio_info, u'逻辑思维音频.xlsx')
print('采集了{}条数据'.format(self.count))
# 清空集合,为再次存放数据做准备
self.audio_info = []
time.sleep(3) # 不要请求太快, 小心查水表
max_id = datas[-1]['publish_time_stamp']
if self.max_id != max_id:
self.max_id = max_id
self.request_data()
else:
print('数据抓取完毕!')
pass
def download_mp3(self, mp3_url):
try:
# 补全文件目录
mp3_path = u'D:/store/mp3/{}'.format(mp3_url.split('/')[-1])
print(mp3_path)
# 判断文件是否存在。
if not os.path.exists(mp3_path):
# 注意这里是写入文件,要用二进制格式写入。
with open(mp3_path, 'wb') as f:
f.write(requests.get(mp3_url).content)
except Exception as e:
print(e)
if __name__ == '__main__':
d = dedao()
d.request_data()
目前这只是一个比较简单的手机App数据抓取。如何操作更复杂的数据采集?如何抓取朋友圈的数据?如何抓取微信公众号数据?敬请关注!
抓取网页音频(糖果负面搜索如何获取真正的下载地址,你可以随便看)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-30 19:05
这是技术人员的爱好。研究一下别人的网站是怎么做的,得到真正的下载地址,用candy访问网站就可以了,所有http数据包都没有泄露,你可以随便看看。
丰富的网络分析功能
糖果浏览器内置支持 Alexa、PageRank、GoogleTrends、百度指数、Google Insights 等功能。在糖果浏览器中,您可以随时了解某个网站的流量和某个关键词在百度和谷歌搜索引擎中的出现频率。.
多种糖果,支持换肤
糖果浏览器支持更换软件皮肤,可以改变糖果浏览器的外观;您可以修改糖果皮肤包中的图片文件来定制个性化的浏览器!如何更换皮肤:工具菜单 | 更改软件皮肤
网站排名实时显示
(Alexa/PageRank)
在IE中,需要安装alexa插件/谷歌工具栏才能看到alexa排名和PageRank。在糖果浏览器中显示网站alexa 排名,Google PageRank 是一个内置功能。
IE 临时文件提取器
IE 临时文件夹保存浏览过的网页中的所有内容(文字、图片、音乐、视频等)。Candy 的 IE 临时文件提取器可以轻松提取任何文件。您无需前往 IE 临时文件夹的浩瀚海洋。在里面找。
糖果否定搜索功能
Candy Negative Search 从整个互联网(尤其是各大论坛和各种博客)中搜索有关关键字的负面信息。这些信息是消费者最真实的反馈。建议您在花钱(购买产品或与他人合作)之前使用糖果的负面搜索来检查对方。
更人性化的 URL 输入框
可以在糖果浏览器的网址框中输入网址或搜索关键字,英文+Enter会自动添加,English+Ctrl+Enter会自动添加,English+Space+Enter开始搜索,中文+Return 汽车将开始搜索
视频提取和播放
想把土豆网、56、刘建芳等视频网站提取到本机?糖果浏览器可以做到。糖果浏览器可以检测大部分视频网站的flv视频文件的下载地址,可以播放本机的flv视频。
内置 MP3 音乐播放器
糖果浏览器的前身是糖果播放器。不难理解为什么candy的音乐功能如此强大:它可以自动匹配歌词、显示音乐频谱、给歌曲评分、设置智能播放列表,适合喜欢音乐的朋友在音乐冲浪中上网。
制作和播放音乐幻灯片
在candy中制作音乐幻灯片很简单:播放一首歌曲,然后添加你的照片,一个收录照片、歌词、音乐等的神奇电影就完成了,然后你就可以将这个幻灯片导出为exe自己播放文件了。
mp3音乐批量下载
糖果浏览器可以批量下载百度mp3排行榜,百度音乐大师批量下载,听音乐排行榜,搜索粤语新歌排行榜,新浪音乐港台排行榜,大陆排行榜,英国流行音乐排行榜,美国公告牌排行榜,LastFM Weekly单曲排行榜、日韩流行音乐排行榜等音乐排行榜,以及相声小品批量下载、古典音乐批量下载、奥斯卡金曲批量下载、格莱美金曲批量下载;
支持批量下载任意歌曲名称列表。批量下载时,您可以指定同时下载任务的数量、音乐类型(mp3 或 wma)和文件大小。
WMA 到 MP3 批量转换工具
Candy Browser可以批量转换wma文件为mp3文件,转换时可以指定mp3的压缩率(使用Lame压缩算法,可以指定是使用动态码率还是静态码率编码)。
定时关机功能
糖果浏览器支持定时关机(点击左下角循环播放按钮),睡前播放一首轻音乐,设置定时关机,就可以在音乐中入睡。
提供免费安装版,无需更改注册表
Windows 系统的性能会随着时间的推移而下降。原因是安装的各种软件在注册表中添加了各种内容。糖果浏览器很少更改系统注册表(设置默认浏览器时需要),不会导致系统出现各种莫名其妙的问题。
感染病毒后自我报警
糖果浏览器具有自扫描功能。一旦软件被病毒、木马或人为修改,就会向用户报告。
病毒感染程序需要修改程序的入口代码。糖果浏览器对入口代码进行自检,修改后会报警。
内存使用率低
糖果浏览器支持压缩内存模式,比IE、Firefox、傲游、Chrome等其他浏览器占用内存少很多,大家可以实际测试一下。
对流氓插件免疫
糖果浏览器不受 IE 各种流氓插件的影响。如果你的 IE 被各种插件折腾了,你仍然可以毫无问题地使用它。 查看全部
抓取网页音频(糖果负面搜索如何获取真正的下载地址,你可以随便看)
这是技术人员的爱好。研究一下别人的网站是怎么做的,得到真正的下载地址,用candy访问网站就可以了,所有http数据包都没有泄露,你可以随便看看。
丰富的网络分析功能
糖果浏览器内置支持 Alexa、PageRank、GoogleTrends、百度指数、Google Insights 等功能。在糖果浏览器中,您可以随时了解某个网站的流量和某个关键词在百度和谷歌搜索引擎中的出现频率。.
多种糖果,支持换肤
糖果浏览器支持更换软件皮肤,可以改变糖果浏览器的外观;您可以修改糖果皮肤包中的图片文件来定制个性化的浏览器!如何更换皮肤:工具菜单 | 更改软件皮肤
网站排名实时显示
(Alexa/PageRank)
在IE中,需要安装alexa插件/谷歌工具栏才能看到alexa排名和PageRank。在糖果浏览器中显示网站alexa 排名,Google PageRank 是一个内置功能。
IE 临时文件提取器
IE 临时文件夹保存浏览过的网页中的所有内容(文字、图片、音乐、视频等)。Candy 的 IE 临时文件提取器可以轻松提取任何文件。您无需前往 IE 临时文件夹的浩瀚海洋。在里面找。
糖果否定搜索功能
Candy Negative Search 从整个互联网(尤其是各大论坛和各种博客)中搜索有关关键字的负面信息。这些信息是消费者最真实的反馈。建议您在花钱(购买产品或与他人合作)之前使用糖果的负面搜索来检查对方。
更人性化的 URL 输入框
可以在糖果浏览器的网址框中输入网址或搜索关键字,英文+Enter会自动添加,English+Ctrl+Enter会自动添加,English+Space+Enter开始搜索,中文+Return 汽车将开始搜索
视频提取和播放
想把土豆网、56、刘建芳等视频网站提取到本机?糖果浏览器可以做到。糖果浏览器可以检测大部分视频网站的flv视频文件的下载地址,可以播放本机的flv视频。
内置 MP3 音乐播放器
糖果浏览器的前身是糖果播放器。不难理解为什么candy的音乐功能如此强大:它可以自动匹配歌词、显示音乐频谱、给歌曲评分、设置智能播放列表,适合喜欢音乐的朋友在音乐冲浪中上网。
制作和播放音乐幻灯片
在candy中制作音乐幻灯片很简单:播放一首歌曲,然后添加你的照片,一个收录照片、歌词、音乐等的神奇电影就完成了,然后你就可以将这个幻灯片导出为exe自己播放文件了。
mp3音乐批量下载
糖果浏览器可以批量下载百度mp3排行榜,百度音乐大师批量下载,听音乐排行榜,搜索粤语新歌排行榜,新浪音乐港台排行榜,大陆排行榜,英国流行音乐排行榜,美国公告牌排行榜,LastFM Weekly单曲排行榜、日韩流行音乐排行榜等音乐排行榜,以及相声小品批量下载、古典音乐批量下载、奥斯卡金曲批量下载、格莱美金曲批量下载;
支持批量下载任意歌曲名称列表。批量下载时,您可以指定同时下载任务的数量、音乐类型(mp3 或 wma)和文件大小。
WMA 到 MP3 批量转换工具
Candy Browser可以批量转换wma文件为mp3文件,转换时可以指定mp3的压缩率(使用Lame压缩算法,可以指定是使用动态码率还是静态码率编码)。
定时关机功能
糖果浏览器支持定时关机(点击左下角循环播放按钮),睡前播放一首轻音乐,设置定时关机,就可以在音乐中入睡。
提供免费安装版,无需更改注册表
Windows 系统的性能会随着时间的推移而下降。原因是安装的各种软件在注册表中添加了各种内容。糖果浏览器很少更改系统注册表(设置默认浏览器时需要),不会导致系统出现各种莫名其妙的问题。
感染病毒后自我报警
糖果浏览器具有自扫描功能。一旦软件被病毒、木马或人为修改,就会向用户报告。
病毒感染程序需要修改程序的入口代码。糖果浏览器对入口代码进行自检,修改后会报警。
内存使用率低
糖果浏览器支持压缩内存模式,比IE、Firefox、傲游、Chrome等其他浏览器占用内存少很多,大家可以实际测试一下。
对流氓插件免疫
糖果浏览器不受 IE 各种流氓插件的影响。如果你的 IE 被各种插件折腾了,你仍然可以毫无问题地使用它。
抓取网页音频(抓取网页音频不需要爬虫,爬虫()(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-09-30 11:02
抓取网页音频不需要爬虫,爬虫只是从服务器下载文件然后在浏览器播放而已,如果需要获取里面包含的音频文件,直接下载就可以。推荐用httpclient,也有人说是用httpclient爬虫,个人感觉是不错的爬虫,但有人说httpclient比较吃配置,不建议选择httpclient。1.首先你要有一个浏览器。
2.随便打开一个http页面,输入://-2017112617:42//?ws2allcheck=all&platform=windows&encoding=utf-83.验证输入是否正确。4.验证无误后,浏览器会自动打开404页面,并且所有需要下载的页面都存在,接下来就是分析请求请求的参数:'default':'-{if__name__=='__main__'}','host':'','http':'','request':'','user-agent':'','cookie':'','x-age':'','timestamp':'','content-type':'text/plain','user-agent':'','scheme':'','user-agent':'','referer':'','connection':'keep-alive','user-agent':'','cookie':'','port':'','pagenum':'','download':'','opener':'','documenturl':'','saveurl':'','savebox':'','x-age':'','userid':'','referer':'','name':'','name':'','complete':'','title':'','type':'','auth':'','maxurl':'','username':'','password':'','content':'','response':'','robots':'','rule':'','form':'','login':'','date':'','blogurl':'','path':'','type':'','version':'','proxy':'','lang':'','login':'','location':'','username':'','remember_track':'','logout':'','name':'','sign':'','mail':'','openid':'','signin':'','openurl':'','tab':'','author':'','s':'','p':'','password':'','b':'','p':'','s':'','a':'','t':'','t':'','t':'','t':'','c':'','h``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c`。 查看全部
抓取网页音频(抓取网页音频不需要爬虫,爬虫()(图))
抓取网页音频不需要爬虫,爬虫只是从服务器下载文件然后在浏览器播放而已,如果需要获取里面包含的音频文件,直接下载就可以。推荐用httpclient,也有人说是用httpclient爬虫,个人感觉是不错的爬虫,但有人说httpclient比较吃配置,不建议选择httpclient。1.首先你要有一个浏览器。
2.随便打开一个http页面,输入://-2017112617:42//?ws2allcheck=all&platform=windows&encoding=utf-83.验证输入是否正确。4.验证无误后,浏览器会自动打开404页面,并且所有需要下载的页面都存在,接下来就是分析请求请求的参数:'default':'-{if__name__=='__main__'}','host':'','http':'','request':'','user-agent':'','cookie':'','x-age':'','timestamp':'','content-type':'text/plain','user-agent':'','scheme':'','user-agent':'','referer':'','connection':'keep-alive','user-agent':'','cookie':'','port':'','pagenum':'','download':'','opener':'','documenturl':'','saveurl':'','savebox':'','x-age':'','userid':'','referer':'','name':'','name':'','complete':'','title':'','type':'','auth':'','maxurl':'','username':'','password':'','content':'','response':'','robots':'','rule':'','form':'','login':'','date':'','blogurl':'','path':'','type':'','version':'','proxy':'','lang':'','login':'','location':'','username':'','remember_track':'','logout':'','name':'','sign':'','mail':'','openid':'','signin':'','openurl':'','tab':'','author':'','s':'','p':'','password':'','b':'','p':'','s':'','a':'','t':'','t':'','t':'','t':'','c':'','h``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c``c`。
抓取网页音频(python爬虫简单的版本,那个时候还不懂原理,现在算是收尾吧 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-30 10:42
)
今天又浪费了一天。Python爬虫,之前写过一个简单的版本,当时没看懂原理。现在是结束了。
之前对网络爬虫一无所知,感觉很神奇,但是揭开这个面纱,似乎里面的原理不难掌握。首先了解一个概念,HTTP协议,为什么叫超文本协议。超文本的概念是几乎所有的数据都是以文本方式传输的,包括文本、图片等。那么,在一个网页中,需要做的就是解析这些字符数据,还原成原创文件。
爬虫的概念是以网页为起点,从中找到更多的链接和数据信息,然后展开成树状,可以想象成一棵树。对于每个网页,都需要根据需求对数据进行过滤(查找图片,或搜索关键字,或搜索音频等),最后根据过滤后的URL下载数据。一般步骤是:
网页==》网页树==》过滤信息==》下载
笔者这里以网页图片为例:
例如,一个网页中可能有很多图片。最基本的就是能够识别这个网页中的所有图片链接。这里的一般方法是根据正则表达式匹配网页的文本,从而采集内容。图片的链接。eg: reg = r"""src\s*="?(\S+)\.jpg"""。其次,把这些链接归档。看起来很抽象的东西可以通过这两步来实现。然后,网络树有点难,你需要从网上找到有用的网页链接,然后再过滤这些链接,有点像递归。这里有很多难点,比如当网页链接很多的时候,如何有效地过滤有效链接,如何控制搜索深度,如何分配进程等等。
另外,由于很多国外的网站无法上传,部分网页数据下载需要通过代理;另外,考虑到部分机器性能更好,也实现了多线程机制。笔者进行了一天的研究,终于通过了调试。这是代码:
<p>import re
import os
import sys
import time
import threading
import socket
import urllib
import urllib2
server = \'127.0.0.1\'
port = \'8087\'
timeout = 720
socket.setdefaulttimeout(timeout)
class timer(threading.Thread): #The timer class is derived from the class threading.Thread
def __init__(self, num, interval,dir,url):
threading.Thread.__init__(self)
self.thread_num = num
self.interval = interval
self.url = url
self.dir = dir
self.thread_stop = False
def run(self): #Overwrite run() method, put what you want the thread do here
#while not self.thread_stop:
DownloadImgs(self.interval,self.url,self.dir)
#print \'Thread Object(%d), Time:%s\' %(self.thread_num, time.ctime())
#time.sleep(self.interval)
def stop(self):
self.thread_stop = True
def getContent(url,type):
print(">>start connecting:%s" % url)
from urllib2 import Request, urlopen, URLError, HTTPError
proxy = urllib2.ProxyHandler({\'http\':\'http://127.0.0.1:8087\'})
opener = urllib2.build_opener(proxy,urllib2.HTTPHandler)
urllib2.install_opener(opener)
try:
urlHandler = urllib2.urlopen(url)
headers = urlHandler.info().headers
length = 0
for header in headers:
if header.find(\'Length\') != -1:
length = header.split(\':\')[-1].strip()
length = int(length)
if(type=="img" and length 查看全部
抓取网页音频(python爬虫简单的版本,那个时候还不懂原理,现在算是收尾吧
)
今天又浪费了一天。Python爬虫,之前写过一个简单的版本,当时没看懂原理。现在是结束了。
之前对网络爬虫一无所知,感觉很神奇,但是揭开这个面纱,似乎里面的原理不难掌握。首先了解一个概念,HTTP协议,为什么叫超文本协议。超文本的概念是几乎所有的数据都是以文本方式传输的,包括文本、图片等。那么,在一个网页中,需要做的就是解析这些字符数据,还原成原创文件。
爬虫的概念是以网页为起点,从中找到更多的链接和数据信息,然后展开成树状,可以想象成一棵树。对于每个网页,都需要根据需求对数据进行过滤(查找图片,或搜索关键字,或搜索音频等),最后根据过滤后的URL下载数据。一般步骤是:
网页==》网页树==》过滤信息==》下载
笔者这里以网页图片为例:
例如,一个网页中可能有很多图片。最基本的就是能够识别这个网页中的所有图片链接。这里的一般方法是根据正则表达式匹配网页的文本,从而采集内容。图片的链接。eg: reg = r"""src\s*="?(\S+)\.jpg"""。其次,把这些链接归档。看起来很抽象的东西可以通过这两步来实现。然后,网络树有点难,你需要从网上找到有用的网页链接,然后再过滤这些链接,有点像递归。这里有很多难点,比如当网页链接很多的时候,如何有效地过滤有效链接,如何控制搜索深度,如何分配进程等等。
另外,由于很多国外的网站无法上传,部分网页数据下载需要通过代理;另外,考虑到部分机器性能更好,也实现了多线程机制。笔者进行了一天的研究,终于通过了调试。这是代码:
<p>import re
import os
import sys
import time
import threading
import socket
import urllib
import urllib2
server = \'127.0.0.1\'
port = \'8087\'
timeout = 720
socket.setdefaulttimeout(timeout)
class timer(threading.Thread): #The timer class is derived from the class threading.Thread
def __init__(self, num, interval,dir,url):
threading.Thread.__init__(self)
self.thread_num = num
self.interval = interval
self.url = url
self.dir = dir
self.thread_stop = False
def run(self): #Overwrite run() method, put what you want the thread do here
#while not self.thread_stop:
DownloadImgs(self.interval,self.url,self.dir)
#print \'Thread Object(%d), Time:%s\' %(self.thread_num, time.ctime())
#time.sleep(self.interval)
def stop(self):
self.thread_stop = True
def getContent(url,type):
print(">>start connecting:%s" % url)
from urllib2 import Request, urlopen, URLError, HTTPError
proxy = urllib2.ProxyHandler({\'http\':\'http://127.0.0.1:8087\'})
opener = urllib2.build_opener(proxy,urllib2.HTTPHandler)
urllib2.install_opener(opener)
try:
urlHandler = urllib2.urlopen(url)
headers = urlHandler.info().headers
length = 0
for header in headers:
if header.find(\'Length\') != -1:
length = header.split(\':\')[-1].strip()
length = int(length)
if(type=="img" and length
抓取网页音频(requestslxml案例查找所有关于title标签其中的有个案例 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-09-30 10:38
)
2.1.2、目的2.1.3、目标类型三、启动爬虫本章是对爬虫程序的介绍,因此我们只需要安装几个Python库,如下所示:
requests | pip install requests
bs4 | pip install bs4
lxml | pip install lxml
发送请求
当我们每天访问百度时,它实际上是一个请求。此请求的功能是使用代码模拟我们人类向网站发送请求。首先,我们需要导入请求库,如下所示:
import requests # 导入requests库
导入后,我们可以使用请求库中的方法。例如,我们需要在我的CSDN中获得一个文章
r = requests.get('https://www.jianshu.com')
现在,我们有一个名为:R的响应对象,也就是说,当我们访问网站时,网站肯定会给我们提供数据。一些参数如下:
r.status_code # 查看访问状态码 200为ok 是成功的
200
# 然后获取网页源码
r.text # 就是整个网页的html代码
对于HTML源代码,通常使用常规匹配数据,但这太麻烦了。我们选择一个更简单的Python库来解析HTML
就这样
from bs4 import BeautifulSoup
拿一个案例来查找关于title标签的所有信息
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
html = '网页源码'
soup = BeautifulSoup(html, 'lxml')
title = soup.find_all('title')
print(title)
>>> [The Dormouse's story]
有一个lxml,它是一个lxml HTML解析器,安装在
说一些美的重要功能
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
html = '网页源码'
soup = BeautifulSoup(html, 'lxml')
soup.find_all('a') # 获取整个网页所有a标签
soup.find_all('p') # 获取整个网页所有p标签
soup.find('p') # 获取网页第一个p标签
soup.select('#stro p') # 这个是按照css选择器获取元素的 和css几乎相同 查看全部
抓取网页音频(requestslxml案例查找所有关于title标签其中的有个案例
)
2.1.2、目的2.1.3、目标类型三、启动爬虫本章是对爬虫程序的介绍,因此我们只需要安装几个Python库,如下所示:
requests | pip install requests
bs4 | pip install bs4
lxml | pip install lxml
发送请求
当我们每天访问百度时,它实际上是一个请求。此请求的功能是使用代码模拟我们人类向网站发送请求。首先,我们需要导入请求库,如下所示:
import requests # 导入requests库
导入后,我们可以使用请求库中的方法。例如,我们需要在我的CSDN中获得一个文章
r = requests.get('https://www.jianshu.com')
现在,我们有一个名为:R的响应对象,也就是说,当我们访问网站时,网站肯定会给我们提供数据。一些参数如下:
r.status_code # 查看访问状态码 200为ok 是成功的
200
# 然后获取网页源码
r.text # 就是整个网页的html代码
对于HTML源代码,通常使用常规匹配数据,但这太麻烦了。我们选择一个更简单的Python库来解析HTML
就这样
from bs4 import BeautifulSoup
拿一个案例来查找关于title标签的所有信息
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
html = '网页源码'
soup = BeautifulSoup(html, 'lxml')
title = soup.find_all('title')
print(title)
>>> [The Dormouse's story]
有一个lxml,它是一个lxml HTML解析器,安装在
说一些美的重要功能
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
html = '网页源码'
soup = BeautifulSoup(html, 'lxml')
soup.find_all('a') # 获取整个网页所有a标签
soup.find_all('p') # 获取整个网页所有p标签
soup.find('p') # 获取网页第一个p标签
soup.select('#stro p') # 这个是按照css选择器获取元素的 和css几乎相同
抓取网页音频(如何巧妙批量音效素材?下载器的站点抓取功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 749 次浏览 • 2021-09-29 11:55
今天,小编接到了一个任务:制作视频。但是小编突然发现电脑里的音效文件太少了,而音效网站几乎只提供单个文件下载,暂时下载太费时间了。于是想到了Internet Download Manager(简称IDM)的网站爬取功能。如果使用站点抓取功能,可以批量下载音效文件吗?
IDM下载器的站点抓取功能可以抓取网站上的图片、音频、视频、PDF、压缩包等文件。更重要的是,可以实现批量抓取操作,省时省力。今天小编就来给大家展示一下如何巧妙的批量捕捉音效素材。
第一步:下载并安装软件
输入IDM中文网站下载安装包。下载完成后,安装,然后打开软件,进入程序主界面。
图1:程序主界面
第二步:进入音效编译界面,复制链接地址
打开搜狗浏览器,在百度上搜索“音效大全”,选择一个音效网站(这里以站长素材网为例),进入后点击进入音效分类编译界面网页,即大量音效链接地址的目录界面。然后复制这个接口的链接地址。
图 2:音效采集页面
第三步:运行“Site Capture”功能捕捉声音效果
现在返回IDM主界面,鼠标左键点击右上角的“Site Capture”按钮,将复制的链接地址粘贴到“Start Page/Address”栏,然后点击下方的“Forward”按钮.
图3:网站爬取-链接输入页面
第四步:建议将“探索指定链接深度”修改为“3”
在步骤2中点击转发。在步骤3中,建议将“探索指定链接深度”中的根站点“2”的深度修改为根站点“3”的深度,然后选择“转发”按钮。
这一步是获取音效下载页面的链接。当探索链接深度为1时,IDM的探索对象为当前页面;当探索链接深度为2时,IDM的探索对象为点击链接后要跳转的当前页面。探索链接深度为3时,IDM的探索对象为当前页面链接进行二次跳转的页面。
图4:网站爬取界面
第 5 步:更改下载的文件类型
将文件类型“所有文件”更改为需要下载的文件类型,即“音频文件”,然后单击“转发”。
图 5:文件类型更改页面
第六步:等待站点获取成功,并保存文件
此页面显示捕获的图像,等待站点完成捕获,即可保存文件。
图6:文件抓取信息页面
经过以上操作,编辑器得到了大量的音效文件,而且可以通过站点抓取进行多窗口抓取,所以编辑器可以同时抓取多个分类的音效文件,真的很方便!
但是大家一定要确保音效网站保存的音效文件格式是:mp3、wma或者waw。如果网站的文件保存格式不是这三种后缀格式,IDM可能无法识别!
以上就是巧妙利用IDM批量抓取音效素材的所有内容。点击IDM教程,了解更多使用技巧,抓紧一起学习。 查看全部
抓取网页音频(如何巧妙批量音效素材?下载器的站点抓取功能)
今天,小编接到了一个任务:制作视频。但是小编突然发现电脑里的音效文件太少了,而音效网站几乎只提供单个文件下载,暂时下载太费时间了。于是想到了Internet Download Manager(简称IDM)的网站爬取功能。如果使用站点抓取功能,可以批量下载音效文件吗?
IDM下载器的站点抓取功能可以抓取网站上的图片、音频、视频、PDF、压缩包等文件。更重要的是,可以实现批量抓取操作,省时省力。今天小编就来给大家展示一下如何巧妙的批量捕捉音效素材。
第一步:下载并安装软件
输入IDM中文网站下载安装包。下载完成后,安装,然后打开软件,进入程序主界面。
图1:程序主界面
第二步:进入音效编译界面,复制链接地址
打开搜狗浏览器,在百度上搜索“音效大全”,选择一个音效网站(这里以站长素材网为例),进入后点击进入音效分类编译界面网页,即大量音效链接地址的目录界面。然后复制这个接口的链接地址。
图 2:音效采集页面
第三步:运行“Site Capture”功能捕捉声音效果
现在返回IDM主界面,鼠标左键点击右上角的“Site Capture”按钮,将复制的链接地址粘贴到“Start Page/Address”栏,然后点击下方的“Forward”按钮.
图3:网站爬取-链接输入页面
第四步:建议将“探索指定链接深度”修改为“3”
在步骤2中点击转发。在步骤3中,建议将“探索指定链接深度”中的根站点“2”的深度修改为根站点“3”的深度,然后选择“转发”按钮。
这一步是获取音效下载页面的链接。当探索链接深度为1时,IDM的探索对象为当前页面;当探索链接深度为2时,IDM的探索对象为点击链接后要跳转的当前页面。探索链接深度为3时,IDM的探索对象为当前页面链接进行二次跳转的页面。
图4:网站爬取界面
第 5 步:更改下载的文件类型
将文件类型“所有文件”更改为需要下载的文件类型,即“音频文件”,然后单击“转发”。
图 5:文件类型更改页面
第六步:等待站点获取成功,并保存文件
此页面显示捕获的图像,等待站点完成捕获,即可保存文件。
图6:文件抓取信息页面
经过以上操作,编辑器得到了大量的音效文件,而且可以通过站点抓取进行多窗口抓取,所以编辑器可以同时抓取多个分类的音效文件,真的很方便!
但是大家一定要确保音效网站保存的音效文件格式是:mp3、wma或者waw。如果网站的文件保存格式不是这三种后缀格式,IDM可能无法识别!
以上就是巧妙利用IDM批量抓取音效素材的所有内容。点击IDM教程,了解更多使用技巧,抓紧一起学习。
抓取网页音频( 1.如何发送报告支持?发送应用程序报告发送报告)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-28 07:15
1.如何发送报告支持?发送应用程序报告发送报告)
特征
1.Trackhunter(音乐抓取工具)是一款易于使用的音乐下载工具,可让您跟踪来自您喜爱的在线数字商店的最新音乐,包括:Amazon Mp3、Beatport、DJ Tunes、iTunes、Juno下载等。
2. 寻找早期的电子舞曲变得非常快速和容易。它使您可以听到所有新音乐,无论流派如何,因此您无需跟随任何人就可以创建自己的风格。
3.Trackhunter(音乐抓取工具)可配置的快听自动跟踪跳过模式,可以让你在几分钟内快速听完几个小时的音轨,还可以进行其他操作。
精选亮点
1.Trackhunter(音乐抓取工具)可以记住您已经听过的内容并将其过滤掉,这样您就不会浪费时间听同一首歌两次。
2. 将 WAV 转换为 AIFF 并自动标记它们(包括封面)以节省购买无损 WAV 曲目的时间,无论它们来自何处。
3. 显示哪家商店以最便宜的价格出售它,这样您就可以使用集成购物车在您购买的每首曲目上省钱。
常见问题
1.如何发送报告支持?
要发送申请报告以获得支持,请执行以下程序:
启动跟踪程序
切换到“帮助”菜单,选择调试模式(调试时应该出现在调试模式旁边)
打开调试后,在 Trackhunter 中执行任何非工作工作以捕获相关信息。
然后,返回帮助菜单并选择发送应用程序报告以发送报告。
您应该在 24 小时内获得支持(周末或节假日可能更多)。
2.如何从我最喜欢的艺术家或唱片中获取音乐?
您可以关注特定的艺术家或标签。您可以通过右键单击曲目并选择关注来选择关注播放列表中的艺术家或标签。或者转到“设置”菜单并选择“过滤”选项。如果您想跟踪标签“MuZic 录音”,那么您将创建一个具有以下设置的过滤器:
操作:跟随,类型:包括,值:MuZIC 录音
然后,您应该使用 GET latest (followed by) 选项为您的后续艺术家和标签查找新音乐。
系统城温馨提示:
用户下载本网站中的软件,即视为已阅读并同意本声明的内容。系统城所有软件和资料均来自互联网,仅供个人学习和研究使用,不得用于任何商业用途。如果您侵犯了您的商标、版权或其他合法权利,请联系我们并按照网站公告中的投诉程序提供相关证明材料。本站将尽快核实处理。 查看全部
抓取网页音频(
1.如何发送报告支持?发送应用程序报告发送报告)
特征
1.Trackhunter(音乐抓取工具)是一款易于使用的音乐下载工具,可让您跟踪来自您喜爱的在线数字商店的最新音乐,包括:Amazon Mp3、Beatport、DJ Tunes、iTunes、Juno下载等。
2. 寻找早期的电子舞曲变得非常快速和容易。它使您可以听到所有新音乐,无论流派如何,因此您无需跟随任何人就可以创建自己的风格。
3.Trackhunter(音乐抓取工具)可配置的快听自动跟踪跳过模式,可以让你在几分钟内快速听完几个小时的音轨,还可以进行其他操作。
精选亮点
1.Trackhunter(音乐抓取工具)可以记住您已经听过的内容并将其过滤掉,这样您就不会浪费时间听同一首歌两次。
2. 将 WAV 转换为 AIFF 并自动标记它们(包括封面)以节省购买无损 WAV 曲目的时间,无论它们来自何处。
3. 显示哪家商店以最便宜的价格出售它,这样您就可以使用集成购物车在您购买的每首曲目上省钱。
常见问题
1.如何发送报告支持?
要发送申请报告以获得支持,请执行以下程序:
启动跟踪程序
切换到“帮助”菜单,选择调试模式(调试时应该出现在调试模式旁边)
打开调试后,在 Trackhunter 中执行任何非工作工作以捕获相关信息。
然后,返回帮助菜单并选择发送应用程序报告以发送报告。
您应该在 24 小时内获得支持(周末或节假日可能更多)。
2.如何从我最喜欢的艺术家或唱片中获取音乐?
您可以关注特定的艺术家或标签。您可以通过右键单击曲目并选择关注来选择关注播放列表中的艺术家或标签。或者转到“设置”菜单并选择“过滤”选项。如果您想跟踪标签“MuZic 录音”,那么您将创建一个具有以下设置的过滤器:
操作:跟随,类型:包括,值:MuZIC 录音
然后,您应该使用 GET latest (followed by) 选项为您的后续艺术家和标签查找新音乐。
系统城温馨提示:
用户下载本网站中的软件,即视为已阅读并同意本声明的内容。系统城所有软件和资料均来自互联网,仅供个人学习和研究使用,不得用于任何商业用途。如果您侵犯了您的商标、版权或其他合法权利,请联系我们并按照网站公告中的投诉程序提供相关证明材料。本站将尽快核实处理。
抓取网页音频(视频音频提取电脑版介绍一个的视频提取音频信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 348 次浏览 • 2021-09-27 20:10
)
视音频提取软件是一种主要功能是提取音频信息的工具。功能非常全面。它可以从各种文件格式中提取音频。操作比较简单,使用方便。它还可以自定义输出文件夹。有兴趣的朋友快来体验吧!
音视频提取电脑版介绍
这是一款专业的视频提取工具,用于提取音频信息。软件功能比较齐全。软件可以提取mp4、avi、mtv、wmv、rm、rmvb等多种常见视频文件格式的音频,并允许输出为mp3、ogg、acc等音频格式.
音视频提取正式版功能
- 完全从视频中提取音频内容。
- 支持mp3、ogg、aac等多种常见音频输出格式。
- 支持自定义设置输出文件夹。
-Abelssoft MusicExtractor 可以帮助用户从视频中提取音频。
- 提取的音频可以最大程度保留原创音频效果。
- 一次只能从一个视频文件中提取音频,不支持批处理。
软件特点
- 直观可靠的软件解决方案,使用户能够轻松地从选定的视频中提取音轨并将其保存为 MP3。
- 一次加载和处理一个视频
- 自动提取视频的音轨
- 该实用程序的 GUI(图形用户界面)非常直观,因此即使是计算机知识很少的人也可以使用其功能。
- 您只需要浏览到计算机上的视频文件并将其加载到应用程序中即可。支持的源格式有很多,例如 WMV、AVI、FLV、SWF、MOV、MP4、RM、MKV、MPEG 或 MTS。
- 下一步也是最后一步,只需按下专用按钮并等待 Music Extractor 分析您加载的剪辑,而无需您的任何输入。
-该过程完成后,会自动生成一个MP3文件并保存到您指定的位置-您也可以通过单击鼠标打开收录的文件夹。
- 从视频中提取音轨的无忧应用程序
- 音乐提取器对于所有有兴趣只保留所选视频中的音轨的人都非常有用。
- 考虑到您不需要配置任何复杂的设置,如果您是新手,此实用程序尤其方便。另一方面,专业用户可能对Music Extractor 提供的有限功能设置不满意,因为它几乎无法控制输出MP3 文件(例如,无法定义起点和终点,也无法修改音量)。
查看全部
抓取网页音频(视频音频提取电脑版介绍一个的视频提取音频信息
)
视音频提取软件是一种主要功能是提取音频信息的工具。功能非常全面。它可以从各种文件格式中提取音频。操作比较简单,使用方便。它还可以自定义输出文件夹。有兴趣的朋友快来体验吧!
音视频提取电脑版介绍
这是一款专业的视频提取工具,用于提取音频信息。软件功能比较齐全。软件可以提取mp4、avi、mtv、wmv、rm、rmvb等多种常见视频文件格式的音频,并允许输出为mp3、ogg、acc等音频格式.
音视频提取正式版功能
- 完全从视频中提取音频内容。
- 支持mp3、ogg、aac等多种常见音频输出格式。
- 支持自定义设置输出文件夹。
-Abelssoft MusicExtractor 可以帮助用户从视频中提取音频。
- 提取的音频可以最大程度保留原创音频效果。
- 一次只能从一个视频文件中提取音频,不支持批处理。
软件特点
- 直观可靠的软件解决方案,使用户能够轻松地从选定的视频中提取音轨并将其保存为 MP3。
- 一次加载和处理一个视频
- 自动提取视频的音轨
- 该实用程序的 GUI(图形用户界面)非常直观,因此即使是计算机知识很少的人也可以使用其功能。
- 您只需要浏览到计算机上的视频文件并将其加载到应用程序中即可。支持的源格式有很多,例如 WMV、AVI、FLV、SWF、MOV、MP4、RM、MKV、MPEG 或 MTS。
- 下一步也是最后一步,只需按下专用按钮并等待 Music Extractor 分析您加载的剪辑,而无需您的任何输入。
-该过程完成后,会自动生成一个MP3文件并保存到您指定的位置-您也可以通过单击鼠标打开收录的文件夹。
- 从视频中提取音轨的无忧应用程序
- 音乐提取器对于所有有兴趣只保留所选视频中的音轨的人都非常有用。
- 考虑到您不需要配置任何复杂的设置,如果您是新手,此实用程序尤其方便。另一方面,专业用户可能对Music Extractor 提供的有限功能设置不满意,因为它几乎无法控制输出MP3 文件(例如,无法定义起点和终点,也无法修改音量)。
抓取网页音频(BeautifulSoup一个灵活又方便的网页解析库,处理高效,支持多种解析器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-27 19:01
2、美汤
一个灵活方便的网页解析库,处理高效,支持多种解析器。
使用它无需编写正则表达式,轻松实现网页信息抓取。
3、安装及介绍:
pip install requests
pip install BeautifulSoup
import requests
from bs4 import BeautifulSoup as bf
二、目标网站
需要手动点击下载mp3文件网站,因为需要下载数百个文件,手动操作比较困难。
三:获取并解析网页源代码
1、使用requests获取目标的源码网站
r = requests.get('http://www.goodkejian.com/ertonggushi.htm')
所有下载链接都存储在标签中,并且具有固定长度。去掉amp后可以直接下载链接;
2、使用BeautifulSoup解析网页内容并从中提取标签
soup = bf(r.text, 'html.parser')
res = soup.find_all('a')
四:下载
经过上面的步骤, res 变成了一个收录所有目标标签的数组。如果要下载网页上的所有mp3文件,只需要循环将res中的元组转换成字符串,经过过滤、裁剪等操作,就变成了一个链接。可以使用request来访问,返回值是mp3文件的二进制表示,直接以二进制的形式写入文件即可。
整个代码如下:
import requests
from bs4 import BeautifulSoup as bf
r = requests.get('http://www.goodkejian.com/ertonggushi.htm')
soup = bf(r.text, 'html.parser')
res = soup.find_all('a')
recorder = 1
# 长度为126的是要找的图标
for i in res:
dst = str(i)
if dst.__len__() == 126:
url1 = dst[9:53]
url2 = dst[57:62]
url = url1 + url2
print(url)
xjh_request = requests.get(url)
with open("./res/" + str(recorder) + ".rar", 'wb') as file:
file.write(xjh_request.content)
file.close()
recorder += 1
print("ok")
以上就是文章《如何在python中抓取并自动下载网页音频文件》的全部内容,感谢阅读!相信大家都有一定的了解,希望分享的内容对大家有所帮助。如果您想了解更多,请关注一宿云行业资讯频道! 查看全部
抓取网页音频(BeautifulSoup一个灵活又方便的网页解析库,处理高效,支持多种解析器)
2、美汤
一个灵活方便的网页解析库,处理高效,支持多种解析器。
使用它无需编写正则表达式,轻松实现网页信息抓取。
3、安装及介绍:
pip install requests
pip install BeautifulSoup
import requests
from bs4 import BeautifulSoup as bf
二、目标网站
需要手动点击下载mp3文件网站,因为需要下载数百个文件,手动操作比较困难。
三:获取并解析网页源代码
1、使用requests获取目标的源码网站
r = requests.get('http://www.goodkejian.com/ertonggushi.htm')
所有下载链接都存储在标签中,并且具有固定长度。去掉amp后可以直接下载链接;
2、使用BeautifulSoup解析网页内容并从中提取标签
soup = bf(r.text, 'html.parser')
res = soup.find_all('a')
四:下载
经过上面的步骤, res 变成了一个收录所有目标标签的数组。如果要下载网页上的所有mp3文件,只需要循环将res中的元组转换成字符串,经过过滤、裁剪等操作,就变成了一个链接。可以使用request来访问,返回值是mp3文件的二进制表示,直接以二进制的形式写入文件即可。
整个代码如下:
import requests
from bs4 import BeautifulSoup as bf
r = requests.get('http://www.goodkejian.com/ertonggushi.htm')
soup = bf(r.text, 'html.parser')
res = soup.find_all('a')
recorder = 1
# 长度为126的是要找的图标
for i in res:
dst = str(i)
if dst.__len__() == 126:
url1 = dst[9:53]
url2 = dst[57:62]
url = url1 + url2
print(url)
xjh_request = requests.get(url)
with open("./res/" + str(recorder) + ".rar", 'wb') as file:
file.write(xjh_request.content)
file.close()
recorder += 1
print("ok")
以上就是文章《如何在python中抓取并自动下载网页音频文件》的全部内容,感谢阅读!相信大家都有一定的了解,希望分享的内容对大家有所帮助。如果您想了解更多,请关注一宿云行业资讯频道!
抓取网页音频(小象音频提取免费最新版软件更新(图)下载地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 288 次浏览 • 2021-09-27 18:19
Baby Elephant Audio Extraction Free 最新版本是一款非常好用的音频提取软件。威特软件园为您提供最新版小象音频提取免费下载、小象音频提取免费最新版软件介绍和小象音频提取免费最新版体验,该软件可以帮助用户非常方便地提取音频。
小象音频提取免费软件最新版介绍
一款简单易用的视频音频提取软件,旨在帮助您从mp4、mpeg、mkv、wmv、avi、m4v、rmvb等各种主流视频文件中提取音频,并输出音频作为 MP3 格式。
小象音频提取免费最新版软件使用说明
当您需要从 MV 中提取歌曲和从电影中提取原创声音时,该软件非常有用。它具有直观的界面设计,导入要转换的媒体文件,然后一键提取。提取完成后,可以在与源文件相同的目录中找到提取的音频。
最新版免费软件的特点
1、 另外,为了获得最佳的输出效果,提取的音频可以有效保持原创质量。
2、帮助从各种主视频中提取音频,将提取的音频文件保存为mp3格式,从电影中提取原创声音进行二次制作,从MV和视频歌曲中提取音轨。
小象音频提取免费软件最新版亮点
1、 为用户提供良好、优质的服务,让每一位用户在软件中获得最好、最舒适的体验。
2、通过简单直观的操作界面,提取只需简单两步。显示音频提取过程的内置日志功能。一次只能处理一个视频文件,提取的音频文件可以自动保存在与源文件相同的目录中。
Baby Elephant Audio Extraction 免费最新版软件更新
1、修复bug,优化部分交互体验
2、 优化程序稳定性,使其更流畅
3、 调整了部分页面布局,使界面更加整洁美观
4、新模块 查看全部
抓取网页音频(小象音频提取免费最新版软件更新(图)下载地址)
Baby Elephant Audio Extraction Free 最新版本是一款非常好用的音频提取软件。威特软件园为您提供最新版小象音频提取免费下载、小象音频提取免费最新版软件介绍和小象音频提取免费最新版体验,该软件可以帮助用户非常方便地提取音频。
小象音频提取免费软件最新版介绍
一款简单易用的视频音频提取软件,旨在帮助您从mp4、mpeg、mkv、wmv、avi、m4v、rmvb等各种主流视频文件中提取音频,并输出音频作为 MP3 格式。
小象音频提取免费最新版软件使用说明
当您需要从 MV 中提取歌曲和从电影中提取原创声音时,该软件非常有用。它具有直观的界面设计,导入要转换的媒体文件,然后一键提取。提取完成后,可以在与源文件相同的目录中找到提取的音频。
最新版免费软件的特点
1、 另外,为了获得最佳的输出效果,提取的音频可以有效保持原创质量。
2、帮助从各种主视频中提取音频,将提取的音频文件保存为mp3格式,从电影中提取原创声音进行二次制作,从MV和视频歌曲中提取音轨。
小象音频提取免费软件最新版亮点
1、 为用户提供良好、优质的服务,让每一位用户在软件中获得最好、最舒适的体验。
2、通过简单直观的操作界面,提取只需简单两步。显示音频提取过程的内置日志功能。一次只能处理一个视频文件,提取的音频文件可以自动保存在与源文件相同的目录中。
Baby Elephant Audio Extraction 免费最新版软件更新
1、修复bug,优化部分交互体验
2、 优化程序稳定性,使其更流畅
3、 调整了部分页面布局,使界面更加整洁美观
4、新模块
抓取网页音频(我来更新一下(前面两段话是知乎逼迫的,百度搜不到,想骂微信写原文就好了))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-09-23 10:04
抓取网页音频和视频常见的方法有两种,一种是利用收费app去帮助获取一些网页音频和视频的歌词,另一种是找正规渠道下载音频和视频,比如去qq音乐搜索音频,也可以下载音频,但是肯定不会有视频歌词帮助你查看。如果是要下载新闻搜索播放器里面收录的音频和视频,比如动车站视频和人民日报播放的文字,音乐都可以是可以去试试。更多网站的访问访问,可以找我。
百度没有在线试听
如果原网站已经下架可以去百度下载找到你想要的资源也是可以下的
这个真的就是音频格式了!不能通过收藏关键词找得到的!
谢邀,
这种就是歌词文件,下载下来就可以播放,百度搜歌词文件,
百度里,
中国大众音乐网有
qq音乐里下载
感谢你,让我找到这么一个良心音乐软件。
我来更新一下(前面两段话是知乎逼迫的,百度搜不到,知乎也搜不到,想骂微信写原文就好了)百度搜不到直接用手机搜一个网站,有歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词。 查看全部
抓取网页音频(我来更新一下(前面两段话是知乎逼迫的,百度搜不到,想骂微信写原文就好了))
抓取网页音频和视频常见的方法有两种,一种是利用收费app去帮助获取一些网页音频和视频的歌词,另一种是找正规渠道下载音频和视频,比如去qq音乐搜索音频,也可以下载音频,但是肯定不会有视频歌词帮助你查看。如果是要下载新闻搜索播放器里面收录的音频和视频,比如动车站视频和人民日报播放的文字,音乐都可以是可以去试试。更多网站的访问访问,可以找我。
百度没有在线试听
如果原网站已经下架可以去百度下载找到你想要的资源也是可以下的
这个真的就是音频格式了!不能通过收藏关键词找得到的!
谢邀,
这种就是歌词文件,下载下来就可以播放,百度搜歌词文件,
百度里,
中国大众音乐网有
qq音乐里下载
感谢你,让我找到这么一个良心音乐软件。
我来更新一下(前面两段话是知乎逼迫的,百度搜不到,知乎也搜不到,想骂微信写原文就好了)百度搜不到直接用手机搜一个网站,有歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词歌词。
抓取网页音频(试试soundhound音乐宝?应该是什么样的app?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-09-22 21:01
抓取网页音频的app有两种,一种是soundhound,一种是网易云音乐的app版本,其他的都不是很推荐。(比如app里有集合全网音乐,可以听全网歌曲,没那么好用)soundhound是一款ios和android软件,是非常强大的音乐资源提供商。内置收费音乐18元一首,而免费歌曲可以无限听,我对他们家的平台感觉很好,一个账号在里面无限听别人的歌曲,不想听的还可以用不同app听。
网易云是一款android软件,专门听音乐的,质量不是很高,没有比较推荐,他家的有个电台“小白电台”,还有app里的上一首歌、下一首歌的回放,都不错。强烈推荐qq音乐,离线可听。因为音质原因可能比网易云差一点,但是全部是原创音乐,歌曲质量比较高。还可以根据你自己的喜好创建一个“歌单”,创建多音乐条目,让你的“歌单”更强大,除了qq音乐的内置歌单,你还可以添加其他的音乐。
所以不如找个安卓的啊,android就weico好用了。都有识别功能。只能回答的更详细一点。现在已经有相应的软件了。
请用国内的,比如网易云音乐。这个功能还是不错的,特别适合听音乐。而且我跟我女朋友最近一直在用。
手机上的话不知道lp好不好但我用qq音乐的版本比较容易和同步。网易云本身界面就是悲剧。
试试soundhound音乐宝?应该是这个 查看全部
抓取网页音频(试试soundhound音乐宝?应该是什么样的app?)
抓取网页音频的app有两种,一种是soundhound,一种是网易云音乐的app版本,其他的都不是很推荐。(比如app里有集合全网音乐,可以听全网歌曲,没那么好用)soundhound是一款ios和android软件,是非常强大的音乐资源提供商。内置收费音乐18元一首,而免费歌曲可以无限听,我对他们家的平台感觉很好,一个账号在里面无限听别人的歌曲,不想听的还可以用不同app听。
网易云是一款android软件,专门听音乐的,质量不是很高,没有比较推荐,他家的有个电台“小白电台”,还有app里的上一首歌、下一首歌的回放,都不错。强烈推荐qq音乐,离线可听。因为音质原因可能比网易云差一点,但是全部是原创音乐,歌曲质量比较高。还可以根据你自己的喜好创建一个“歌单”,创建多音乐条目,让你的“歌单”更强大,除了qq音乐的内置歌单,你还可以添加其他的音乐。
所以不如找个安卓的啊,android就weico好用了。都有识别功能。只能回答的更详细一点。现在已经有相应的软件了。
请用国内的,比如网易云音乐。这个功能还是不错的,特别适合听音乐。而且我跟我女朋友最近一直在用。
手机上的话不知道lp好不好但我用qq音乐的版本比较容易和同步。网易云本身界面就是悲剧。
试试soundhound音乐宝?应该是这个

