
抓取网页音频
抓取网页音频(使用Python爬取任意网页的资源文件,一键爬取资源媒体文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-12-30 07:07
前言
使用Python抓取任意网页的资源文件,如图片、音频、视频等;一种常见的方法是通过XPath或者正则请求网页的HTML来获取你想要的资源。这里我做了一个爬虫工具软件,可以一键爬取资源媒体文件;但需要注意的是,这里对资源文件的爬取只针对现有的HTML文件。如果需要第二次请求,就爬不出来了,比如酷狗音乐播放器界面,因为需要做。匹配不同网站的通用工具!!!
这里是图片抓取的主推,有需要图片素材的可以输入网址一键抓取!
还有就是在抓取视频的时候磁力链接会被抓取下来!可以使用第三方下载工具下载!
代码爬取资源文件
这里唯一需要说明的是,有些图片资源不是url链接,而是data:image格式。这里需要转换存储!
def getResourceUrlList(url ,isImage, isAudio, isVideo):
global imgType_list, audioType_list, videoType_list
imageUrlList = []
audioUrlList = []
videoUrlList = []
url = url.rstrip().rstrip('/')
htmlStr = str(requestsDataBase(url))
# print(htmlStr)
Wopen = open('reptileHtml.txt','w')
Wopen.write(htmlStr)
Wopen.close()
Ropen = open('reptileHtml.txt','r')
imageUrlList = []
for line in Ropen:
line = line.replace("'", '"')
segmenterStr = '"'
if "'" in line:
segmenterStr = "'"
lineList = line.split(segmenterStr)
for partLine in lineList:
if isImage == True:
# 查找图片
if 'data:image' in partLine:
base64List = partLine.split('base64,')
imgData = base64.urlsafe_b64decode(base64List[-1] + '=' * (4 - len(base64List[-1]) % 4))
base64ImgType = base64List[0].split('/')[-1].rstrip(';')
imageName = zfjTools.getTimestamp() + '.' + base64ImgType
imageUrlList.append(imageName + '$==$' + base64ImgType)
# 查找图片
for imageType in imgType_list:
if imageType in partLine:
imgUrl = partLine[:partLine.find(imageType) + len(imageType)].split(segmenterStr)[-1]
# 修复URL
imgUrl = repairUrl(imgUrl, url)
sizeType = '_{' + 'size' + '}'
if sizeType in imgUrl:
imgUrl = imgUrl.replace(sizeType, '')
imgUrl = imgUrl.strip()
if imgUrl.startswith('http://') or imgUrl.startswith('https://') and imgUrl not in imageUrlList:
imageUrlList.append(imgUrl)
else:
imgUrl = ''
if isAudio == True:
# 查找音频
for audioType in audioType_list:
if audioType in partLine or audioType.lower() in partLine:
audioType = audioType.lower() if audioType.lower() in partLine else audioType
audioUrl = partLine[:partLine.find(audioType) + len(audioType)].split(segmenterStr)[-1]
# 修复URL
audioUrl = repairUrl(audioUrl, url)
if audioUrl.startswith('http://') or audioUrl.startswith('https://') and audioUrl not in audioUrlList:
audioUrlList.append(audioUrl)
else:
audioUrl = ''
if isVideo == True:
# 查找视频
for videoType in videoType_list:
if videoType in partLine or videoType.lower() in partLine:
videoType = videoType.lower() if videoType.lower() in partLine else videoType
videoUrl = partLine[:partLine.find(videoType) + len(videoType)].split(segmenterStr)[-1]
# 修复URL
videoUrl = repairUrl(videoUrl, url)
if videoUrl.startswith('http://') or videoUrl.startswith('https://') or videoUrl.startswith('ed2k://') or videoUrl.startswith('magnet:?') or videoUrl.startswith('ftp://') and videoUrl not in videoUrlList:
videoUrlList.append(videoUrl)
else:
videoUrl = ''
return (imageUrlList, audioUrlList, videoUrlList)
复制代码
爬取自定义节点
# 统配节点爬取
def getNoteInfors(url, fatherNode, childNode):
url = url.rstrip().rstrip('/')
htmlStr = requestsDataBase(url)
Wopen = open('reptileHtml.txt','w')
Wopen.write(htmlStr)
Wopen.close()
html_etree = etree.HTML(htmlStr)
dataArray = []
if html_etree != None:
nodes_list = html_etree.xpath(fatherNode)
for k_value in nodes_list:
partValue = k_value.xpath(childNode)
if len(partValue) > 0:
dataArray.append(partValue[0])
return dataArray
复制代码
软件
软件下载地址/zfj1128/ZFJ...
使用教学视频
资源爬取:链接:/s/1xa9ruF_h...密码:1zpg
节点爬取:链接:/s/1ebWWYtjo...密码:cosa
使用截图如下:
结束语
欢迎大家提出宝贵意见和建议!!!! 查看全部
抓取网页音频(使用Python爬取任意网页的资源文件,一键爬取资源媒体文件)
前言
使用Python抓取任意网页的资源文件,如图片、音频、视频等;一种常见的方法是通过XPath或者正则请求网页的HTML来获取你想要的资源。这里我做了一个爬虫工具软件,可以一键爬取资源媒体文件;但需要注意的是,这里对资源文件的爬取只针对现有的HTML文件。如果需要第二次请求,就爬不出来了,比如酷狗音乐播放器界面,因为需要做。匹配不同网站的通用工具!!!
这里是图片抓取的主推,有需要图片素材的可以输入网址一键抓取!
还有就是在抓取视频的时候磁力链接会被抓取下来!可以使用第三方下载工具下载!
代码爬取资源文件
这里唯一需要说明的是,有些图片资源不是url链接,而是data:image格式。这里需要转换存储!
def getResourceUrlList(url ,isImage, isAudio, isVideo):
global imgType_list, audioType_list, videoType_list
imageUrlList = []
audioUrlList = []
videoUrlList = []
url = url.rstrip().rstrip('/')
htmlStr = str(requestsDataBase(url))
# print(htmlStr)
Wopen = open('reptileHtml.txt','w')
Wopen.write(htmlStr)
Wopen.close()
Ropen = open('reptileHtml.txt','r')
imageUrlList = []
for line in Ropen:
line = line.replace("'", '"')
segmenterStr = '"'
if "'" in line:
segmenterStr = "'"
lineList = line.split(segmenterStr)
for partLine in lineList:
if isImage == True:
# 查找图片
if 'data:image' in partLine:
base64List = partLine.split('base64,')
imgData = base64.urlsafe_b64decode(base64List[-1] + '=' * (4 - len(base64List[-1]) % 4))
base64ImgType = base64List[0].split('/')[-1].rstrip(';')
imageName = zfjTools.getTimestamp() + '.' + base64ImgType
imageUrlList.append(imageName + '$==$' + base64ImgType)
# 查找图片
for imageType in imgType_list:
if imageType in partLine:
imgUrl = partLine[:partLine.find(imageType) + len(imageType)].split(segmenterStr)[-1]
# 修复URL
imgUrl = repairUrl(imgUrl, url)
sizeType = '_{' + 'size' + '}'
if sizeType in imgUrl:
imgUrl = imgUrl.replace(sizeType, '')
imgUrl = imgUrl.strip()
if imgUrl.startswith('http://') or imgUrl.startswith('https://') and imgUrl not in imageUrlList:
imageUrlList.append(imgUrl)
else:
imgUrl = ''
if isAudio == True:
# 查找音频
for audioType in audioType_list:
if audioType in partLine or audioType.lower() in partLine:
audioType = audioType.lower() if audioType.lower() in partLine else audioType
audioUrl = partLine[:partLine.find(audioType) + len(audioType)].split(segmenterStr)[-1]
# 修复URL
audioUrl = repairUrl(audioUrl, url)
if audioUrl.startswith('http://') or audioUrl.startswith('https://') and audioUrl not in audioUrlList:
audioUrlList.append(audioUrl)
else:
audioUrl = ''
if isVideo == True:
# 查找视频
for videoType in videoType_list:
if videoType in partLine or videoType.lower() in partLine:
videoType = videoType.lower() if videoType.lower() in partLine else videoType
videoUrl = partLine[:partLine.find(videoType) + len(videoType)].split(segmenterStr)[-1]
# 修复URL
videoUrl = repairUrl(videoUrl, url)
if videoUrl.startswith('http://') or videoUrl.startswith('https://') or videoUrl.startswith('ed2k://') or videoUrl.startswith('magnet:?') or videoUrl.startswith('ftp://') and videoUrl not in videoUrlList:
videoUrlList.append(videoUrl)
else:
videoUrl = ''
return (imageUrlList, audioUrlList, videoUrlList)
复制代码
爬取自定义节点
# 统配节点爬取
def getNoteInfors(url, fatherNode, childNode):
url = url.rstrip().rstrip('/')
htmlStr = requestsDataBase(url)
Wopen = open('reptileHtml.txt','w')
Wopen.write(htmlStr)
Wopen.close()
html_etree = etree.HTML(htmlStr)
dataArray = []
if html_etree != None:
nodes_list = html_etree.xpath(fatherNode)
for k_value in nodes_list:
partValue = k_value.xpath(childNode)
if len(partValue) > 0:
dataArray.append(partValue[0])
return dataArray
复制代码
软件
软件下载地址/zfj1128/ZFJ...
使用教学视频
资源爬取:链接:/s/1xa9ruF_h...密码:1zpg
节点爬取:链接:/s/1ebWWYtjo...密码:cosa
使用截图如下:
结束语
欢迎大家提出宝贵意见和建议!!!!
抓取网页音频( 视音频视音频数据的获取方法及实现要素数据获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-30 04:06
视音频视音频数据的获取方法及实现要素数据获取)
本发明涉及数据处理领域,尤其涉及一种视听数据的获取方法。
背景技术
随着互联网的逐渐普及,越来越多的人接触到互联网。视频和音频作为互联网应用的重要成员,凭借其娱乐和学习的特性,已经成为用户接收网络数据不可或缺的一部分。作为网络音视频应用的主要载体,用户基本上是用它来在线观看各种网络音视频。
互联网上现有的视听数据资源包括授权的视听数据资源和未授权的视听数据资源。未经授权的资源可能携带恶意软件或病毒,造成终端损坏。因此,大多数用户在授权资源中下载视频和音频数据。从现有授权资源中下载视音频数据的方法繁琐、操作复杂,给用户带来了极大的不便。
技术实现要素:
本发明的目的在于提供一种基于类型码和附加码的获取视音频数据的方法,一次获取预览片段数据和原创
节目数据,通过授权码。权限、流程简单、操作方便,给用户带来了极大的方便,从而提高了用户体验。
有鉴于此,本发明实施例提供了一种视音频数据的获取方法,包括:
用户终端接收用户输入的视音频码并发送给服务器;其中,视音频码包括类型码和附加码。
服务器解析视音频码,得到类型码和附加码;
服务器在视频和音频数据库中搜索类型代码;
当找到类型码时,根据类型码在视音频数据库中获取对应的类型数据列表;
根据附加码查询类型数据列表中是否有附加码;
当找到附加码时,根据附加码获取类型数据列表中对应的链接地址;
根据链接地址获取视音频数据包;
解析视音频数据包,获取预览片段数据和原创
节目数据;
向用户终端发送预览片段数据;
用户终端分析并播放预览片段数据;
服务器接收用户终端发送的确认指令;其中,确认指令包括终端id和视音频码;
解析确认指令,获取终端id和视音频码;
服务器根据视音频编码获取授权码数据库中对应的授权码;
根据视音频编码和授权码生成授权码提示信息,发送给用户终端;
建立授权码和终端id的关联关系,存储在授权码数据库中;
用户终端接收用户输入的授权码,生成视音频数据播放请求并发送给服务器;其中,视音频数据播放请求携带终端id;
服务器在授权码数据库中查询解析的授权码和解析的终端id是否有关联关系;
当查询到授权码与终端id的关联关系时,将原创
节目数据发送给用户终端。
优选地,授权码具有属性信息;属性信息包括第一属性和第二属性。
进一步优选地,根据视音频编码获取授权码数据库中对应的授权码的服务器具体为:
根据视音频编码获取授权码库中第一个属性的授权码。
进一步优选地,服务器根据视音频编码在授权码数据库中获取对应的授权码后,该方法还包括:
修改授权码的属性信息为第二个属性。
优选地,该方法还包括:
记录每个视音频码被查询的次数,并根据被查询的次数生成第一推送值数据;
记录每个视音频码对应的授权码被获取的次数,并根据获取次数生成第二推送值数据;
分别获取第一推送值数据和第二推送值数据的权重值数据;
根据第一推送值数据、第二推送值数据以及对应的权重值数据进行加权处理,根据加权处理结果确定各个视音频码的推送索引。
进一步优选地,服务器在视音频数据库中搜索类型码后,该方法还包括:
当没有找到类型码时,获取推送索引最高的视音频码;
根据视频和音频编码,得到相应的预览片段数据并发送给用户终端。
优选地,在根据附加码查询类型数据列表中是否有附加码后,该方法还包括:
当没有找到附加码时,服务器将附加码与类型数据库中的附加码进行匹配,得到匹配度最高的附加码;
根据类型码和匹配度最高的附加码生成推送信息,并发送给用户终端。
进一步优选地,根据类型码和匹配度最高的附加码生成推送信息发送给用户终端之后,该方法还包括:
服务器接收用户终端发送的推送指令;
根据匹配度最高的附加码获取类型数据列表中对应的链接地址。
优选地,服务器接收到用户终端发送的确认指令后,该方法还包括:
服务器根据视音频码获取价格信息,根据视音频码和价格信息生成订单信息,发送给用户终端;
用户终端接收用户输入的支付指令并发送给服务器。
优选地,在查询授权码数据库中的授权码和终端id是否有关联关系之后,该方法还包括:
当未找到授权码与终端id的关联关系时,生成获取失败提示消息并发送给用户终端。
本发明实施例提供的视音频数据获取方法根据类型码和附加码一次性获取预览片段数据和原创
节目数据,并可以通过授权码获取视音频数据的播放权限,流程简单,操作方便,给用户带来了极大的方便,从而提高了用户体验。
图纸说明
如图。图1为本发明实施例提供的获取视音频数据的方法的流程图。
详细说明
下面通过附图和实施例对本发明的技术方案作进一步详细说明。
本实施例提供的视音频数据获取方法在用户终端的应用中实现,基于视音频编码和授权码实现视音频数据获取过程。
图1为本发明实施例提供的一种视音频数据的获取方法的流程图。如图1所示,该方法包括:
步骤101:用户终端接收用户输入的视音频码并发送给服务器。
其中,用户终端可以是智能手机或智能电视。
视频和音频编码用于表示视频和音频数据,最好是数字组合;视音频编码包括类型编码和附加码两部分;类型编码用于表示视音频数据的类型信息,类型信息可以包括电影、电视剧、综艺、纪录片、歌曲等,每个流派信息对应不同的流派代码,每个流派代码对应一个流派数据列表,方便搜索视听数据。
一个类型数据列表中可以有一个或多个附加代码,每个附加代码对应一个视音频数据的链接地址。因此,在类型数据列表中,附加码是对视音频数据的唯一标识。
具体的,用户终端通过登录网页向服务器发送获取请求;服务器根据获取请求向用户终端发送用户界面;用户终端显示用户界面,接收用户想观看的视频和音频在用户界面上输入Encoding;用户终端将视音频编码发送给服务器。
需要说明的是,在步骤101之前,服务器将视音频数据库中的视音频数据的名称信息和对应的视音频代码以文本、视频或音频的形式发送给用户终端,并且用户终端将响应视频和音频数据。可以显示或播放用户的姓名信息和视音频码,以便用户记录感兴趣的视音频码。
步骤102:服务器解析视音频码,得到类型码和附加码。
在一个具体示例中,服务器根据预设规则解析视音频编码,预设规则为视音频编码的前3位代表类型码,后4位代表附加码。服务器获取视音频码的前3位获取用户选择的类型码,然后获取视音频码的后4位获取附加码。
步骤103:服务器在视音频数据库中查找类型码。
当找到类型代码时,执行步骤104,根据类型代码在视音频数据库中获取对应的类型数据列表。
在类型数据列表中,存储了同一类别的视频和音频数据的附加代码和对应的链接地址。
步骤105:根据附加码查询类型数据列表中是否有附加码。
当找到附加代码时,执行步骤106,根据附加代码获取类型数据列表中对应的链接地址。
当未找到附加代码时,执行步骤118至步骤121。
步骤118:服务器将附加码与类型数据库中的附加码进行匹配,得到匹配度最高的附加码。
具体地,将同类型数据库中的其他附加码与用户输入的附加码进行区分,差异最小的就是匹配度最高的附加码。
步骤119,根据类型码和匹配度最高的附加码生成推送信息,发送给用户终端。
其中,推送信息包括推送确认码。
在一个具体的例子中,用户终端显示推送信息,推送信息为“您输入的视音频码1249699不存在,如果选择1249698,请按1键确认”。
步骤120:服务器接收用户终端发送的推送指令。
在步骤119所述的例子中,用户终端接收用户输入的1号按键,生成推送指令,发送给服务器。
步骤121:服务器根据匹配度最高的附加码获取类型数据列表中对应的链接地址。
在步骤121之后执行步骤107。
步骤107:根据链接地址获取视音频数据包;解析视音频数据包,得到预览片段数据和原创
节目数据。
其中,视音频数据包包括预览片段数据和原创
节目数据。
预览片段数据是指原创
节目数据的一部分,例如视频或音频宣传片断。
根据链接地址可以一次性获取预览段数据和原节目数据,避免两者分开获取,节省时间和流程。
在步骤108中,将预览片段数据发送给用户终端。
具体地,将预览片段数据发送到用户终端,缓存原节目数据,使得用户在获取原节目时,可以快速播放原节目,避免二次获取,节省时间和流程。
步骤109:用户终端解析并播放预览片段数据。
具体地,用户终端解析预览片段数据,将预览片段数据的格式转换为与用户终端匹配的格式,然后播放,部分显示原节目的内容,以便用户进行初步的欣赏原节目并理解。
步骤110:服务器接收用户终端发送的确认指令。
其中,确认指令包括终端id和视音频编码。
具体的,服务器向用户终端发送确认获取信息,用户终端显示确认获取信息,接收用户根据确认获取信息输入的确认指令,发送给服务器。在一个具体的例子中,确认获取信息为“要确认获取原节目,请按1号键”。
在一个优选实施例中,部分原创节目需要付费,因此在步骤111之后,该方法还包括:服务器根据视音频编码获取价格信息,根据视音频编码和价格信息生成订单信息,发送给用户终端:用户终端接收用户输入的支付指令,发送给服务器。
步骤111:解析确认指令,获取终端id和视音频码。
步骤112:服务器根据视音频编码在授权码数据库中获取对应的授权码。
其中,授权码数据库中存储有影音码和授权码,一个影音码对应多个授权码,供不同用户获取播放权限。
授权码有属性信息;属性信息包括第一属性和第二属性。第一个属性没有使用,用于表示授权码还没有发送给用户;使用第二个属性,用于表示授权码已经发送给用户,不能再发送给其他用户。
具体地,根据视音频编码,从授权码数据库中随机获取属性信息为第一属性的授权码。
获取后,将授权码的属性信息改为第二属性并存储。
步骤113:根据视音频编码和授权码生成授权码提示信息,发送给用户终端。
其中,授权码提示信息可以通过文字或音频的方式发送给用户终端,用户终端显示授权码提示信息。在一个具体的例子中,授权码提示信息为:您要观看的电影的代码为1249698,授权码为8574。
步骤114:建立授权码与终端id的关联关系,保存在授权码数据库中。
步骤113和步骤114同时执行。
步骤115:用户终端接收用户输入的授权码,生成视音频数据播放请求,发送给服务器。
其中,视音频数据播放请求中携带终端id。
具体的,用户终端可以访问播放验证界面,接收用户在播放验证界面输入的授权码,生成视音频数据播放请求并发送给服务器。
步骤116:服务器在授权码数据库中查询解析的授权码与解析的终端id是否有关联关系。
在步骤116之前,该方法还包括:服务器解析用户终端发送的视音频数据播放请求,获取当前用户终端的终端id和视音频数据播放请求中的授权码。
在实际应用中,用户获取授权码后,与其他用户共享授权码,其他用户通过授权码再次获取视音频数据,造成商户损失;
因此,在本发明中,用户用于观看的用户终端必须是与授权码关联的用户终端,以防止多个用户使用同一个授权码观看视频和音频数据,从而保证用户的利益。的商人。
当查询到授权码与终端id的关联关系时,执行步骤117,将原创
节目数据发送给用户终端。
用户终端对原创
节目数据进行分析和播放。
当未查询到授权码与终端id的关联关系时,执行步骤122,生成获取失败提示消息并发送给用户终端。
其中,用户终端显示获取失败的提示信息,提示用户终端id与授权码不匹配,无法获取原节目。
在一个优选的实施例中,为了能够向用户推荐最流行的视音频数据,该方法还包括: 在步骤106之后,记录每个视音频码被查询的次数,并生成第一个number 根据查询的数量。推送价值数据;并且,在步骤112之后,记录每个视音频码对应的授权码的获取次数,并根据获取次数生成第二推送值数据。分别获取第一推送值数据和第二推送值数据的权值数据,其中权值数据是预设的,本领域技术人员可以根据需要设置权值数据;根据第一推值数据,
在一个具体的例子中,查询某个视频码的次数为80次,即第一推值数据为80次,获取该视音频码对应的授权码的次数为50次次,即第二次推送值数据。为50,第一推值数据的预设权重值为0.3,第二推值数据的预设权重值为0.7,视音频号的推送索引为80 ×0.3+50×0.7=59。
推送指数越高,视频和音频数据越受用户欢迎,因此可以通过上述推送指数推送视频和音频数据。
因此,在步骤103之后,该方法还包括:当未找到类型码时,执行步骤123,获取推送索引最高的视音频码。
步骤124:根据视音频编码获取对应的预览片段数据,发送给用户终端。
在步骤124之后执行步骤109。
需要说明的是,在执行上述步骤101至124的过程中,用户可以通过返回码放弃当前的操作。返回码可以是*键;具体的,用户终端接收用户输入的返回码,生成返回指令发送给服务器,然后执行步骤101。
本发明实施例提供的获取视音频数据的方法根据类型码和附加码一次性获取预览片段数据和原创
节目数据,通过授权码。工艺简单,操作方便。给用户的使用带来了极大的便利,从而提升了用户体验。
专业人士还应进一步意识到,本文所公开的实施例中所描述的实施例的单元和算法步骤可以通过电子硬件、计算机软件或两者的结合来实现,为清楚地说明硬件和软件的可互换性,在上面的描述,每个例子的组成和步骤已经按照功能进行了大体描述。这些功能究竟是由硬件还是软件来执行,取决于技术方案的具体应用和设计约束条件。专业人员和技术人员可以针对每个具体的应用使用不同的方法来实现所描述的功能,但不应认为这种实现超出了本发明的范围。
结合本文所公开的实施例描述的方法或算法的步骤可以通过硬件、处理器执行的软件模块,或者两者的结合来实现。软件模块可以放置在随机存取存储器(ram)、内部存储器、只读存储器(rom)、电可编程rom、电可擦可编程rom、寄存器、硬盘、可移动磁盘、cd-rom或任何地方技术领域。任何其他已知的存储介质。
通过上述具体实施例,对本发明的目的、技术方案和有益效果作了进一步详细的说明。应当理解,以上描述仅为本发明的具体实施例而已,并不用于限制本发明的范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应收录
在本发明的保护范围之内。
当前页 1 12 查看全部
抓取网页音频(
视音频视音频数据的获取方法及实现要素数据获取)

本发明涉及数据处理领域,尤其涉及一种视听数据的获取方法。
背景技术
随着互联网的逐渐普及,越来越多的人接触到互联网。视频和音频作为互联网应用的重要成员,凭借其娱乐和学习的特性,已经成为用户接收网络数据不可或缺的一部分。作为网络音视频应用的主要载体,用户基本上是用它来在线观看各种网络音视频。
互联网上现有的视听数据资源包括授权的视听数据资源和未授权的视听数据资源。未经授权的资源可能携带恶意软件或病毒,造成终端损坏。因此,大多数用户在授权资源中下载视频和音频数据。从现有授权资源中下载视音频数据的方法繁琐、操作复杂,给用户带来了极大的不便。
技术实现要素:
本发明的目的在于提供一种基于类型码和附加码的获取视音频数据的方法,一次获取预览片段数据和原创
节目数据,通过授权码。权限、流程简单、操作方便,给用户带来了极大的方便,从而提高了用户体验。
有鉴于此,本发明实施例提供了一种视音频数据的获取方法,包括:
用户终端接收用户输入的视音频码并发送给服务器;其中,视音频码包括类型码和附加码。
服务器解析视音频码,得到类型码和附加码;
服务器在视频和音频数据库中搜索类型代码;
当找到类型码时,根据类型码在视音频数据库中获取对应的类型数据列表;
根据附加码查询类型数据列表中是否有附加码;
当找到附加码时,根据附加码获取类型数据列表中对应的链接地址;
根据链接地址获取视音频数据包;
解析视音频数据包,获取预览片段数据和原创
节目数据;
向用户终端发送预览片段数据;
用户终端分析并播放预览片段数据;
服务器接收用户终端发送的确认指令;其中,确认指令包括终端id和视音频码;
解析确认指令,获取终端id和视音频码;
服务器根据视音频编码获取授权码数据库中对应的授权码;
根据视音频编码和授权码生成授权码提示信息,发送给用户终端;
建立授权码和终端id的关联关系,存储在授权码数据库中;
用户终端接收用户输入的授权码,生成视音频数据播放请求并发送给服务器;其中,视音频数据播放请求携带终端id;
服务器在授权码数据库中查询解析的授权码和解析的终端id是否有关联关系;
当查询到授权码与终端id的关联关系时,将原创
节目数据发送给用户终端。
优选地,授权码具有属性信息;属性信息包括第一属性和第二属性。
进一步优选地,根据视音频编码获取授权码数据库中对应的授权码的服务器具体为:
根据视音频编码获取授权码库中第一个属性的授权码。
进一步优选地,服务器根据视音频编码在授权码数据库中获取对应的授权码后,该方法还包括:
修改授权码的属性信息为第二个属性。
优选地,该方法还包括:
记录每个视音频码被查询的次数,并根据被查询的次数生成第一推送值数据;
记录每个视音频码对应的授权码被获取的次数,并根据获取次数生成第二推送值数据;
分别获取第一推送值数据和第二推送值数据的权重值数据;
根据第一推送值数据、第二推送值数据以及对应的权重值数据进行加权处理,根据加权处理结果确定各个视音频码的推送索引。
进一步优选地,服务器在视音频数据库中搜索类型码后,该方法还包括:
当没有找到类型码时,获取推送索引最高的视音频码;
根据视频和音频编码,得到相应的预览片段数据并发送给用户终端。
优选地,在根据附加码查询类型数据列表中是否有附加码后,该方法还包括:
当没有找到附加码时,服务器将附加码与类型数据库中的附加码进行匹配,得到匹配度最高的附加码;
根据类型码和匹配度最高的附加码生成推送信息,并发送给用户终端。
进一步优选地,根据类型码和匹配度最高的附加码生成推送信息发送给用户终端之后,该方法还包括:
服务器接收用户终端发送的推送指令;
根据匹配度最高的附加码获取类型数据列表中对应的链接地址。
优选地,服务器接收到用户终端发送的确认指令后,该方法还包括:
服务器根据视音频码获取价格信息,根据视音频码和价格信息生成订单信息,发送给用户终端;
用户终端接收用户输入的支付指令并发送给服务器。
优选地,在查询授权码数据库中的授权码和终端id是否有关联关系之后,该方法还包括:
当未找到授权码与终端id的关联关系时,生成获取失败提示消息并发送给用户终端。
本发明实施例提供的视音频数据获取方法根据类型码和附加码一次性获取预览片段数据和原创
节目数据,并可以通过授权码获取视音频数据的播放权限,流程简单,操作方便,给用户带来了极大的方便,从而提高了用户体验。
图纸说明
如图。图1为本发明实施例提供的获取视音频数据的方法的流程图。
详细说明
下面通过附图和实施例对本发明的技术方案作进一步详细说明。
本实施例提供的视音频数据获取方法在用户终端的应用中实现,基于视音频编码和授权码实现视音频数据获取过程。
图1为本发明实施例提供的一种视音频数据的获取方法的流程图。如图1所示,该方法包括:
步骤101:用户终端接收用户输入的视音频码并发送给服务器。
其中,用户终端可以是智能手机或智能电视。
视频和音频编码用于表示视频和音频数据,最好是数字组合;视音频编码包括类型编码和附加码两部分;类型编码用于表示视音频数据的类型信息,类型信息可以包括电影、电视剧、综艺、纪录片、歌曲等,每个流派信息对应不同的流派代码,每个流派代码对应一个流派数据列表,方便搜索视听数据。
一个类型数据列表中可以有一个或多个附加代码,每个附加代码对应一个视音频数据的链接地址。因此,在类型数据列表中,附加码是对视音频数据的唯一标识。
具体的,用户终端通过登录网页向服务器发送获取请求;服务器根据获取请求向用户终端发送用户界面;用户终端显示用户界面,接收用户想观看的视频和音频在用户界面上输入Encoding;用户终端将视音频编码发送给服务器。
需要说明的是,在步骤101之前,服务器将视音频数据库中的视音频数据的名称信息和对应的视音频代码以文本、视频或音频的形式发送给用户终端,并且用户终端将响应视频和音频数据。可以显示或播放用户的姓名信息和视音频码,以便用户记录感兴趣的视音频码。
步骤102:服务器解析视音频码,得到类型码和附加码。
在一个具体示例中,服务器根据预设规则解析视音频编码,预设规则为视音频编码的前3位代表类型码,后4位代表附加码。服务器获取视音频码的前3位获取用户选择的类型码,然后获取视音频码的后4位获取附加码。
步骤103:服务器在视音频数据库中查找类型码。
当找到类型代码时,执行步骤104,根据类型代码在视音频数据库中获取对应的类型数据列表。
在类型数据列表中,存储了同一类别的视频和音频数据的附加代码和对应的链接地址。
步骤105:根据附加码查询类型数据列表中是否有附加码。
当找到附加代码时,执行步骤106,根据附加代码获取类型数据列表中对应的链接地址。
当未找到附加代码时,执行步骤118至步骤121。
步骤118:服务器将附加码与类型数据库中的附加码进行匹配,得到匹配度最高的附加码。
具体地,将同类型数据库中的其他附加码与用户输入的附加码进行区分,差异最小的就是匹配度最高的附加码。
步骤119,根据类型码和匹配度最高的附加码生成推送信息,发送给用户终端。
其中,推送信息包括推送确认码。
在一个具体的例子中,用户终端显示推送信息,推送信息为“您输入的视音频码1249699不存在,如果选择1249698,请按1键确认”。
步骤120:服务器接收用户终端发送的推送指令。
在步骤119所述的例子中,用户终端接收用户输入的1号按键,生成推送指令,发送给服务器。
步骤121:服务器根据匹配度最高的附加码获取类型数据列表中对应的链接地址。
在步骤121之后执行步骤107。
步骤107:根据链接地址获取视音频数据包;解析视音频数据包,得到预览片段数据和原创
节目数据。
其中,视音频数据包包括预览片段数据和原创
节目数据。
预览片段数据是指原创
节目数据的一部分,例如视频或音频宣传片断。
根据链接地址可以一次性获取预览段数据和原节目数据,避免两者分开获取,节省时间和流程。
在步骤108中,将预览片段数据发送给用户终端。
具体地,将预览片段数据发送到用户终端,缓存原节目数据,使得用户在获取原节目时,可以快速播放原节目,避免二次获取,节省时间和流程。
步骤109:用户终端解析并播放预览片段数据。
具体地,用户终端解析预览片段数据,将预览片段数据的格式转换为与用户终端匹配的格式,然后播放,部分显示原节目的内容,以便用户进行初步的欣赏原节目并理解。
步骤110:服务器接收用户终端发送的确认指令。
其中,确认指令包括终端id和视音频编码。
具体的,服务器向用户终端发送确认获取信息,用户终端显示确认获取信息,接收用户根据确认获取信息输入的确认指令,发送给服务器。在一个具体的例子中,确认获取信息为“要确认获取原节目,请按1号键”。
在一个优选实施例中,部分原创节目需要付费,因此在步骤111之后,该方法还包括:服务器根据视音频编码获取价格信息,根据视音频编码和价格信息生成订单信息,发送给用户终端:用户终端接收用户输入的支付指令,发送给服务器。
步骤111:解析确认指令,获取终端id和视音频码。
步骤112:服务器根据视音频编码在授权码数据库中获取对应的授权码。
其中,授权码数据库中存储有影音码和授权码,一个影音码对应多个授权码,供不同用户获取播放权限。
授权码有属性信息;属性信息包括第一属性和第二属性。第一个属性没有使用,用于表示授权码还没有发送给用户;使用第二个属性,用于表示授权码已经发送给用户,不能再发送给其他用户。
具体地,根据视音频编码,从授权码数据库中随机获取属性信息为第一属性的授权码。
获取后,将授权码的属性信息改为第二属性并存储。
步骤113:根据视音频编码和授权码生成授权码提示信息,发送给用户终端。
其中,授权码提示信息可以通过文字或音频的方式发送给用户终端,用户终端显示授权码提示信息。在一个具体的例子中,授权码提示信息为:您要观看的电影的代码为1249698,授权码为8574。
步骤114:建立授权码与终端id的关联关系,保存在授权码数据库中。
步骤113和步骤114同时执行。
步骤115:用户终端接收用户输入的授权码,生成视音频数据播放请求,发送给服务器。
其中,视音频数据播放请求中携带终端id。
具体的,用户终端可以访问播放验证界面,接收用户在播放验证界面输入的授权码,生成视音频数据播放请求并发送给服务器。
步骤116:服务器在授权码数据库中查询解析的授权码与解析的终端id是否有关联关系。
在步骤116之前,该方法还包括:服务器解析用户终端发送的视音频数据播放请求,获取当前用户终端的终端id和视音频数据播放请求中的授权码。
在实际应用中,用户获取授权码后,与其他用户共享授权码,其他用户通过授权码再次获取视音频数据,造成商户损失;
因此,在本发明中,用户用于观看的用户终端必须是与授权码关联的用户终端,以防止多个用户使用同一个授权码观看视频和音频数据,从而保证用户的利益。的商人。
当查询到授权码与终端id的关联关系时,执行步骤117,将原创
节目数据发送给用户终端。
用户终端对原创
节目数据进行分析和播放。
当未查询到授权码与终端id的关联关系时,执行步骤122,生成获取失败提示消息并发送给用户终端。
其中,用户终端显示获取失败的提示信息,提示用户终端id与授权码不匹配,无法获取原节目。
在一个优选的实施例中,为了能够向用户推荐最流行的视音频数据,该方法还包括: 在步骤106之后,记录每个视音频码被查询的次数,并生成第一个number 根据查询的数量。推送价值数据;并且,在步骤112之后,记录每个视音频码对应的授权码的获取次数,并根据获取次数生成第二推送值数据。分别获取第一推送值数据和第二推送值数据的权值数据,其中权值数据是预设的,本领域技术人员可以根据需要设置权值数据;根据第一推值数据,
在一个具体的例子中,查询某个视频码的次数为80次,即第一推值数据为80次,获取该视音频码对应的授权码的次数为50次次,即第二次推送值数据。为50,第一推值数据的预设权重值为0.3,第二推值数据的预设权重值为0.7,视音频号的推送索引为80 ×0.3+50×0.7=59。
推送指数越高,视频和音频数据越受用户欢迎,因此可以通过上述推送指数推送视频和音频数据。
因此,在步骤103之后,该方法还包括:当未找到类型码时,执行步骤123,获取推送索引最高的视音频码。
步骤124:根据视音频编码获取对应的预览片段数据,发送给用户终端。
在步骤124之后执行步骤109。
需要说明的是,在执行上述步骤101至124的过程中,用户可以通过返回码放弃当前的操作。返回码可以是*键;具体的,用户终端接收用户输入的返回码,生成返回指令发送给服务器,然后执行步骤101。
本发明实施例提供的获取视音频数据的方法根据类型码和附加码一次性获取预览片段数据和原创
节目数据,通过授权码。工艺简单,操作方便。给用户的使用带来了极大的便利,从而提升了用户体验。
专业人士还应进一步意识到,本文所公开的实施例中所描述的实施例的单元和算法步骤可以通过电子硬件、计算机软件或两者的结合来实现,为清楚地说明硬件和软件的可互换性,在上面的描述,每个例子的组成和步骤已经按照功能进行了大体描述。这些功能究竟是由硬件还是软件来执行,取决于技术方案的具体应用和设计约束条件。专业人员和技术人员可以针对每个具体的应用使用不同的方法来实现所描述的功能,但不应认为这种实现超出了本发明的范围。
结合本文所公开的实施例描述的方法或算法的步骤可以通过硬件、处理器执行的软件模块,或者两者的结合来实现。软件模块可以放置在随机存取存储器(ram)、内部存储器、只读存储器(rom)、电可编程rom、电可擦可编程rom、寄存器、硬盘、可移动磁盘、cd-rom或任何地方技术领域。任何其他已知的存储介质。
通过上述具体实施例,对本发明的目的、技术方案和有益效果作了进一步详细的说明。应当理解,以上描述仅为本发明的具体实施例而已,并不用于限制本发明的范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应收录
在本发明的保护范围之内。
当前页 1 12
抓取网页音频( 一下进度条添加事件监听的功能介绍及项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-30 04:05
一下进度条添加事件监听的功能介绍及项目)
Beyond-光辉岁月
Daniel Powter-Free Loop
周杰伦、费玉清-千里之外
接下来我们就开始逐步实现上面提到的功能吧,先来完成播放和暂停功能,在按下播放按钮时我们要做到进度条随歌曲进度前进,播放时间也逐渐增加,同时播放按钮变成暂停按钮,播放列表的样式也对应改变。
在做这个功能之前,我们首先要获取三个audio标签的id,并存入一个数组中,以备后续使用。
var music1= document.getElementById("music1");
var music2= document.getElementById("music2");
var music3= document.getElementById("music3");
var mList = [music1,music2,music3];
播放和暂停:
现在我们就可以完成播放按钮的功能了。首先设置一个标志来标记音乐的播放状态,然后为数组的索引设置一个默认值:
然后判断播放状态,调用对应的函数,修改list的flag值和对应的item样式:
var flag = true;
var index = 0;
function playMusic(){
if(flag&&mList[index].paused){
mList[index].play();
document.getElementById("m"+index).style.backgroundColor = "#A71307";
document.getElementById("m"+index).style.color = "white";
progressBar();
playTimes();
play.style.backgroundImage = "url(media/pause.png)";
flag = false;
}else{
mList[index].pause();
flag = true;
play.style.backgroundImage = "url(media/play.png)";
}
}
上面HTML页面的代码中调用了多个函数,其中play和pause是audio标签自带的方法,其他函数由我们自己定义。下面我们来看看这些功能是如何实现的,分别对应哪些功能。
进度条和播放时间:
首先是进度条功能,获取歌曲的完整时长,然后根据当前播放进度乘以进度条总长度计算出进度条的位置。
function progressBar(){
var lenth=mList[index].duration;
timer1=setInterval(function(){
cur=mList[index].currentTime;//获取当前的播放时间
progress.style.width=""+parseFloat(cur/lenth)*300+"px";
progressBtn.style.left= 60+parseFloat(cur/lenth)*300+"px";
},10)
}
下面是改变播放时间的功能。这里我们设置了一个定时函数,每隔一段时间执行一次来改变播放时间。因为我们得到的歌曲的时长是以秒计算的,所以我们需要使用if语句来判断转换的时长,并将播放时间改为分秒的形式显示。
<p>function playTimes(){
timer2=setInterval(function(){
cur=parseInt(mList[index].currentTime);//秒数
var minute=parseInt(cur/60);
if (minute 查看全部
抓取网页音频(
一下进度条添加事件监听的功能介绍及项目)
Beyond-光辉岁月
Daniel Powter-Free Loop
周杰伦、费玉清-千里之外
接下来我们就开始逐步实现上面提到的功能吧,先来完成播放和暂停功能,在按下播放按钮时我们要做到进度条随歌曲进度前进,播放时间也逐渐增加,同时播放按钮变成暂停按钮,播放列表的样式也对应改变。
在做这个功能之前,我们首先要获取三个audio标签的id,并存入一个数组中,以备后续使用。
var music1= document.getElementById("music1");
var music2= document.getElementById("music2");
var music3= document.getElementById("music3");
var mList = [music1,music2,music3];
播放和暂停:
现在我们就可以完成播放按钮的功能了。首先设置一个标志来标记音乐的播放状态,然后为数组的索引设置一个默认值:
然后判断播放状态,调用对应的函数,修改list的flag值和对应的item样式:
var flag = true;
var index = 0;
function playMusic(){
if(flag&&mList[index].paused){
mList[index].play();
document.getElementById("m"+index).style.backgroundColor = "#A71307";
document.getElementById("m"+index).style.color = "white";
progressBar();
playTimes();
play.style.backgroundImage = "url(media/pause.png)";
flag = false;
}else{
mList[index].pause();
flag = true;
play.style.backgroundImage = "url(media/play.png)";
}
}
上面HTML页面的代码中调用了多个函数,其中play和pause是audio标签自带的方法,其他函数由我们自己定义。下面我们来看看这些功能是如何实现的,分别对应哪些功能。
进度条和播放时间:
首先是进度条功能,获取歌曲的完整时长,然后根据当前播放进度乘以进度条总长度计算出进度条的位置。
function progressBar(){
var lenth=mList[index].duration;
timer1=setInterval(function(){
cur=mList[index].currentTime;//获取当前的播放时间
progress.style.width=""+parseFloat(cur/lenth)*300+"px";
progressBtn.style.left= 60+parseFloat(cur/lenth)*300+"px";
},10)
}
下面是改变播放时间的功能。这里我们设置了一个定时函数,每隔一段时间执行一次来改变播放时间。因为我们得到的歌曲的时长是以秒计算的,所以我们需要使用if语句来判断转换的时长,并将播放时间改为分秒的形式显示。
<p>function playTimes(){
timer2=setInterval(function(){
cur=parseInt(mList[index].currentTime);//秒数
var minute=parseInt(cur/60);
if (minute
抓取网页音频(怎么下载别人小程序里的图标呀?如何操作?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-12-28 02:14
01
故事的开始
“怎么下载别人小程序里的图标?”
“如何抓取小程序的图片、图标等?”
“如果有批量下载的工具就好了”
其实这个问题一直困扰我到现在。闲暇之余,我会思考如何制作一个可以实现这些功能的小工具。
为了提高有效抓取的质量,做了过滤请求功能,只要你过滤范围内的文件都可以正常下载
02
痛点解决
很多开发者或外包公司或小型创业团队在开发小程序、公众号、app等应用时,由于不擅长美术,只能在网上搜索资料,但免费资料并不多,别说是满足你需求的素材了,所以根本满足不了开发者的需求。
另一种方法是以目标小程序为参考,从这些目标小程序中提取基本满足你需求的类似素材。这些素材的UI效果都是一流的,毕竟是专业的设计师。工作。
(图片来自网络)
邀请一位月薪少则三五千,多则几万元的艺术家或设计师。如果按照稿子付费,一个海报设计起码要100左右。三十到五十不是个小数目。向上。
经过上面的过程,我终于决定自己写一个小工具,可以抓取小程序、公众号、APP等素材。
03
简单但不简单
界面小巧实用
拥有这个小工具后,我的工作效率提高了很多。
霸气成名:Master Grab-小程序素材抓取软件
直接抓取素材,方便快捷,一键获取,批量下载。
下面我简单介绍一下它的操作方法。
第一步:打开软件后,点击开始爬行按钮
第二步:打开微信小程序(PC端打开)
第三步:一键下载(方便),在软件同级目录下的【downloadFile】文件夹中
软件操作非常简单,主要是帮助开发者节省找资料和设计图片的时间,提高开发者构建小程序的效率。
04
写在最后
时间宝贵,怎能浪费?
所以我在业余时间研究了一个小程序素材抓取软件,希望对大家有帮助。
注:本软件仅供学习交流使用,不得用于商业或非法用途。
如何区分小程序逆向脚本是否有效
如何深入分析小程序的运行原理?
谈谈保护小程序代码的方法
浅谈防阻:如何保证微信小程序代码的安全
介绍一个跨平台的微信小程序反编译客户端
小技巧分享:通过sourcemap恢复vue项目代码 查看全部
抓取网页音频(怎么下载别人小程序里的图标呀?如何操作?)
01
故事的开始
“怎么下载别人小程序里的图标?”
“如何抓取小程序的图片、图标等?”
“如果有批量下载的工具就好了”
其实这个问题一直困扰我到现在。闲暇之余,我会思考如何制作一个可以实现这些功能的小工具。
为了提高有效抓取的质量,做了过滤请求功能,只要你过滤范围内的文件都可以正常下载
02
痛点解决
很多开发者或外包公司或小型创业团队在开发小程序、公众号、app等应用时,由于不擅长美术,只能在网上搜索资料,但免费资料并不多,别说是满足你需求的素材了,所以根本满足不了开发者的需求。
另一种方法是以目标小程序为参考,从这些目标小程序中提取基本满足你需求的类似素材。这些素材的UI效果都是一流的,毕竟是专业的设计师。工作。

(图片来自网络)
邀请一位月薪少则三五千,多则几万元的艺术家或设计师。如果按照稿子付费,一个海报设计起码要100左右。三十到五十不是个小数目。向上。
经过上面的过程,我终于决定自己写一个小工具,可以抓取小程序、公众号、APP等素材。
03
简单但不简单
界面小巧实用

拥有这个小工具后,我的工作效率提高了很多。
霸气成名:Master Grab-小程序素材抓取软件
直接抓取素材,方便快捷,一键获取,批量下载。
下面我简单介绍一下它的操作方法。
第一步:打开软件后,点击开始爬行按钮

第二步:打开微信小程序(PC端打开)

第三步:一键下载(方便),在软件同级目录下的【downloadFile】文件夹中

软件操作非常简单,主要是帮助开发者节省找资料和设计图片的时间,提高开发者构建小程序的效率。
04
写在最后
时间宝贵,怎能浪费?
所以我在业余时间研究了一个小程序素材抓取软件,希望对大家有帮助。
注:本软件仅供学习交流使用,不得用于商业或非法用途。

如何区分小程序逆向脚本是否有效

如何深入分析小程序的运行原理?

谈谈保护小程序代码的方法

浅谈防阻:如何保证微信小程序代码的安全

介绍一个跨平台的微信小程序反编译客户端

小技巧分享:通过sourcemap恢复vue项目代码
抓取网页音频(基于所述音频片段服务器的生成方法和部署步骤(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-27 11:11
1、 一种生成音频片段服务器的方法,其特征在于包括:获取音频数据;截取音频数据的片段数据;根据预设规则将音频片段数据部署到相应的服务器,生成音频片段服务器。
2、如权利要求1所述的方法,其特征在于,所述截取音频段数据的步骤包括: 对音频数据进行解码,得到音频数据的原创
波形数据;从数据文件头中获取原创
波形数据的采样频率、通道数、量化位数;根据采样频率、通道数和量化位数计算预设时间阈值的原创
波形数据;计算预设时间阈值的原创
波形数据,生成音频片段数据。
3、如权利要求2所述的方法,其特征在于,所述截取音频片段数据的步骤还包括: 对预设时间阈值的原创
波形数据中某段时间的尾部数据进行音量控制。淡出处理。
4、如权利要求1、2或3所述的方法,其特征在于,所述获取音频数据的步骤包括:获取所述音频数据的种子站点URL,所述种子站点URL包括种子站点URL,以及Torrent 站点所代表的页面中所有超链接的 URL;如果种子站点URL合法,则会有针对性地捕获相应的音频数据。
5、如权利要求4所述的方法,还包括: 保存捕获的音频数据以形成音频数据库。
6、如权利要求5所述的方法,还包括: 解析所述音频数据的文件头格式以确定其是否为音频数据;如果没有,从音频数据库中删除数据。
7、根据权利要求1、2或3所述的方法,其特征在于,有多个服务器,音频片段数据部署步骤包括: 为每个服务器分配标识信息;采用hash算法计算音频片段数据对应的URL的hash值;根据哈希值和服务器数量计算目标服务器的标识信息;将音频段数据部署到目标服务器。
8、一种音频搜索方法,其特征在于包括:接收用户提交的音频搜索请求;根据音频搜索请求匹配获取对应的音频数据,根据音频数据的URL从音频片段服务器获取对应的音频数据,从数据中提取对应的音频片段数据;将音频搜索结果返回给用户,音频搜索结果包括音频片段数据的信息。
9、如权利要求8所述的方法,其特征在于,音频片段服务器有多个,每个服务器带有标识信息,提取音频片段数据的步骤包括: 使用哈希算法计算音频片段数据的哈希值音频数据 URL;根据哈希值和服务器数量计算目标服务器的标识信息;从目标服务器中提取相应的音频片段数据。
10、如权利要求9所述的方法,其特征在于,所述音频数据是在音频数据库中匹配得到的,所述音频数据库是通过获取音频数据的种子站点的URL得到的,在种子站点在合法的情况下,有针对性地抓取并生成相应的音频数据;种子站点URL包括种子站点的URL和种子站点所代表的页面中所有超链接的URL。
11、如权利要求10所述的方法,其特征在于,所述音频片段数据是音频数据在一定时间段内的片段数据,其产生步骤为:对捕获的音频数据进行解码,获取原创
波形数据音频数据;从音频数据的文件头中获取原创
波形数据的采样频率、声道数、量化位数;根据采样频率、通道数和量化位数计算预设。设置时间阈值的原创
波形数据;对预设时间阈值的原创
波形数据进行编码,生成音频片段数据。
12、如权利要求8所述的方法,其中以嵌入在Flash程序中的网页的形式显示所述音频搜索结果。
13、一种音频搜索中预听片段的方法,其特征在于,包括:接收用户对某个音频搜索结果的获取请求,所述搜索结果中包括音频片段数据的信息,所述音频片段根据音频搜索请求匹配相应音频数据的URL得到数据,从音频片段服务器中提取;根据获取请求提取相应的音频片段数据返回给用户。
14、 一种音频片段服务器生成装置,其特征在于包括: 音频数据获取单元,用于获取音频数据;音频片段截取单元,用于截取音频数据的片段数据;音频片段部署单元,用于根据预设规则将音频片段数据部署到对应的服务器,生成音频片段服务器。
15、如权利要求14所述的装置,其特征在于,所述服务器为多个,所述音频片段部署单元还包括: 标识分配子单元,用于为每个服务器分配标识信息;哈希计算子单元用于通过哈希算法计算音频剪辑数据对应的URL的哈希值;目标服务器确定子单元,用于根据哈希值和服务器数量信息计算目标服务器的身份;音频段定位子单元,用于将音频段数据部署到目标服务器。
16、 一种音频搜索装置,其特征在于包括: 音频片段服务器,用于存储音频片段数据;搜索请求接收单元,用于接收用户提交的音频搜索请求;匹配单元,用于根据音频搜索请求进行匹配,得到相应的音频数据,并根据音频数据的URL从音频片段服务器中提取相应的音频片段数据;搜索结果返回单元,用于将音频搜索结果返回给用户,音频搜索结果包括音频片段数据的信息。
17、一种音频搜索中预听片段的装置,其特征在于包括:音频片段服务器,用于存储音频片段数据;预收听请求接收单元,用于接收用户对某个音频的搜索结果发起的获取请求,搜索结果包括音频片段数据的信息,音频片段数据是根据获取相应音频数据的URL对音频搜索请求匹配,从音频片段服务器中提取;预听段返回单元用于根据获取请求提取相应的音频段数据返回给用户。
18、一种音频搜索服务器,其特征在于包括:音频片段服务器,用于存储音频片段数据;搜索请求接收模块,用于接收用户提交的音频搜索请求;匹配模块依赖于匹配音频搜索请求,获取对应的音频数据,根据音频数据的URL从音频片段服务器中提取对应的音频片段数据;搜索结果返回模块用于将音频搜索结果返回给用户。音频搜索结果包括音频片段数据的信息;预听请求接收模块,用于接收用户对某个音频搜索结果的获取请求; 查看全部
抓取网页音频(基于所述音频片段服务器的生成方法和部署步骤(一))
1、 一种生成音频片段服务器的方法,其特征在于包括:获取音频数据;截取音频数据的片段数据;根据预设规则将音频片段数据部署到相应的服务器,生成音频片段服务器。
2、如权利要求1所述的方法,其特征在于,所述截取音频段数据的步骤包括: 对音频数据进行解码,得到音频数据的原创
波形数据;从数据文件头中获取原创
波形数据的采样频率、通道数、量化位数;根据采样频率、通道数和量化位数计算预设时间阈值的原创
波形数据;计算预设时间阈值的原创
波形数据,生成音频片段数据。
3、如权利要求2所述的方法,其特征在于,所述截取音频片段数据的步骤还包括: 对预设时间阈值的原创
波形数据中某段时间的尾部数据进行音量控制。淡出处理。
4、如权利要求1、2或3所述的方法,其特征在于,所述获取音频数据的步骤包括:获取所述音频数据的种子站点URL,所述种子站点URL包括种子站点URL,以及Torrent 站点所代表的页面中所有超链接的 URL;如果种子站点URL合法,则会有针对性地捕获相应的音频数据。
5、如权利要求4所述的方法,还包括: 保存捕获的音频数据以形成音频数据库。
6、如权利要求5所述的方法,还包括: 解析所述音频数据的文件头格式以确定其是否为音频数据;如果没有,从音频数据库中删除数据。
7、根据权利要求1、2或3所述的方法,其特征在于,有多个服务器,音频片段数据部署步骤包括: 为每个服务器分配标识信息;采用hash算法计算音频片段数据对应的URL的hash值;根据哈希值和服务器数量计算目标服务器的标识信息;将音频段数据部署到目标服务器。
8、一种音频搜索方法,其特征在于包括:接收用户提交的音频搜索请求;根据音频搜索请求匹配获取对应的音频数据,根据音频数据的URL从音频片段服务器获取对应的音频数据,从数据中提取对应的音频片段数据;将音频搜索结果返回给用户,音频搜索结果包括音频片段数据的信息。
9、如权利要求8所述的方法,其特征在于,音频片段服务器有多个,每个服务器带有标识信息,提取音频片段数据的步骤包括: 使用哈希算法计算音频片段数据的哈希值音频数据 URL;根据哈希值和服务器数量计算目标服务器的标识信息;从目标服务器中提取相应的音频片段数据。
10、如权利要求9所述的方法,其特征在于,所述音频数据是在音频数据库中匹配得到的,所述音频数据库是通过获取音频数据的种子站点的URL得到的,在种子站点在合法的情况下,有针对性地抓取并生成相应的音频数据;种子站点URL包括种子站点的URL和种子站点所代表的页面中所有超链接的URL。
11、如权利要求10所述的方法,其特征在于,所述音频片段数据是音频数据在一定时间段内的片段数据,其产生步骤为:对捕获的音频数据进行解码,获取原创
波形数据音频数据;从音频数据的文件头中获取原创
波形数据的采样频率、声道数、量化位数;根据采样频率、通道数和量化位数计算预设。设置时间阈值的原创
波形数据;对预设时间阈值的原创
波形数据进行编码,生成音频片段数据。
12、如权利要求8所述的方法,其中以嵌入在Flash程序中的网页的形式显示所述音频搜索结果。
13、一种音频搜索中预听片段的方法,其特征在于,包括:接收用户对某个音频搜索结果的获取请求,所述搜索结果中包括音频片段数据的信息,所述音频片段根据音频搜索请求匹配相应音频数据的URL得到数据,从音频片段服务器中提取;根据获取请求提取相应的音频片段数据返回给用户。
14、 一种音频片段服务器生成装置,其特征在于包括: 音频数据获取单元,用于获取音频数据;音频片段截取单元,用于截取音频数据的片段数据;音频片段部署单元,用于根据预设规则将音频片段数据部署到对应的服务器,生成音频片段服务器。
15、如权利要求14所述的装置,其特征在于,所述服务器为多个,所述音频片段部署单元还包括: 标识分配子单元,用于为每个服务器分配标识信息;哈希计算子单元用于通过哈希算法计算音频剪辑数据对应的URL的哈希值;目标服务器确定子单元,用于根据哈希值和服务器数量信息计算目标服务器的身份;音频段定位子单元,用于将音频段数据部署到目标服务器。
16、 一种音频搜索装置,其特征在于包括: 音频片段服务器,用于存储音频片段数据;搜索请求接收单元,用于接收用户提交的音频搜索请求;匹配单元,用于根据音频搜索请求进行匹配,得到相应的音频数据,并根据音频数据的URL从音频片段服务器中提取相应的音频片段数据;搜索结果返回单元,用于将音频搜索结果返回给用户,音频搜索结果包括音频片段数据的信息。
17、一种音频搜索中预听片段的装置,其特征在于包括:音频片段服务器,用于存储音频片段数据;预收听请求接收单元,用于接收用户对某个音频的搜索结果发起的获取请求,搜索结果包括音频片段数据的信息,音频片段数据是根据获取相应音频数据的URL对音频搜索请求匹配,从音频片段服务器中提取;预听段返回单元用于根据获取请求提取相应的音频段数据返回给用户。
18、一种音频搜索服务器,其特征在于包括:音频片段服务器,用于存储音频片段数据;搜索请求接收模块,用于接收用户提交的音频搜索请求;匹配模块依赖于匹配音频搜索请求,获取对应的音频数据,根据音频数据的URL从音频片段服务器中提取对应的音频片段数据;搜索结果返回模块用于将音频搜索结果返回给用户。音频搜索结果包括音频片段数据的信息;预听请求接收模块,用于接收用户对某个音频搜索结果的获取请求;
抓取网页音频(在Win11时代,有哪些软件已经迎来没落的命运、再难有用武之地?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-26 08:16
微软发布了最新一代的Windows 11,在惊叹系统界面的巨大变化的同时,也不得不感受到时代浪潮的冲击。Windows也顺应潮流,推出了更先进的WinUI,并努力完善系统功能,尝试改变应用生态。新的互联网时代,即使是像Windows这样的大船也得掉头,更别提搭载的各种软件了。
Win11时代,软件也大不相同
回首过去,许多曾经繁荣的软件随着前一波的浪潮,慢慢地淡出了历史舞台。这些经典产品越来越少被提及。Win11时代,有什么软件,再难用,又迎来了没落的命运?今天就来聊聊这个话题。
防毒软件
只要你用了几年电脑,你就会一直听到那些曾经雷鸣般的名字,比如“瑞星”、“金山”、“江民”等等……但在21世纪初,自由软杀的趋势盛行。吸引了无数互联网公司的纷至沓来。除了领跑风头的“360”,“可牛”、“百度”、“优采云
”等英雄们纷纷出招,令人目不暇接。比较“有见识”的人,折腾了很多国外比较“专业”的产品,比如“小红伞”、“AVG”、“avast”、“Bitdefender”、“卡巴斯基”......安全论坛上的访客。
被玩家津津乐道的杀手
然而,近年来,反软件的热潮似乎已经消退。反软件市场不仅没有掀起新的浪潮,而且似乎也在走下坡路。无论国内百度指数,还是国外谷歌走势,2012年以来,反软件热度都未能止住下滑趋势。
国内百度指数,杀毒软件热度一路下滑
在全球范围内,杀毒软件的流行程度也与谷歌趋势中显示的数据相同
如今,几乎没有人宣布要在杀毒市场上闹,甚至一大批用户不再需要自己安装任何杀毒软件。为什么杀毒软件变的这么火?或许不是杀毒本身的原因,而是个人系统安全环境这些年的剧变。
首先,Antisoft迎来了最强的竞争对手——微软。以360为首的免费杀毒软件已经够吸引人了吧?但系统中预装的MSE/Defender只是一种犯规级别的拉客行为。同时,微软MSE/Defender的业务能力也很不错。在AVTEST等专业的反软件评测中,其性能多年位居前列。比起国内一些连测试都不敢参加的产品,我不知道它在哪里。向上。
微软自带 Security Center Defender
在最新的AV-TEST测试中,微软取得了满分
在Win11时代,Defender已经成为系统预装。而微软正计划将 Defender 打造成跨平台产品,以进一步增强实力。杀毒软件是一种高科技产品。谁比微软更懂Windows系统的代码?其他反软件想要与微软抗衡,难度不小。
其次,操作系统本身的安全性有了很大的提高。在Windows 9X甚至XP时代,代码可以轻松修改操作系统内核。Vista之后,由于用户层的架构和内核的隔离,恶意代码更难操纵。Win11默认开启虚拟化隔离内核,使用TPM芯片进行硬件级加密。反软件的作用不再像以前那么重要了。
再者,移动互联网并没有为反软件带来新的市场。iOS和Android都有严格的安装包管理机制。原则上,他们不需要使用任何反软件。Apple 甚至禁止将声称是反软件的产品放在 App Store 上。iOS 机制消除了大多数未知代码。跑的机会,借助漏洞(比如越狱)可以跑起来的代码,绝不会被杀毒挡住。反软件可以在移动平台上发挥作用,无非就是识别某个App是否是假钓鱼之类的,很多Android系统都自带这个功能。在新兴市场是无利可图的,难怪杀软的生意越来越难做。
iOS 中的应用程序无法实现病毒扫描功能。Apple 已禁止 App Store 中声称具有防病毒功能的应用程序。
毫无疑问,反软件已经沦陷了。或许在某些使用环境下还是有用的,比如识别钓鱼网站、使用旧系统,但是在以Win11为代表的新使用环境下,它的用处就没有以前那么好了。杀毒软件的衰落对安全厂商来说可能是件坏事,但客观上也说明了这些年来用户环境越来越安全,我们应该为此感到高兴。
P2P下载工具
如果您是老司机,应该非常怀念使用P2P下载工具在网上驰骋的日子。在那个BT软件为王,电骡软件为王的时代,各种资源仿佛触手可及。随便开个论坛,或者直接输入关键词搜索,种子就一路来,叫上朋友朋友来种草,下个片子时间不长。
很多朋友都用过以BitComet为代表的P2P下载器,但是现在用户群已经明显减少了
然而,如今专用的P2P下载工具早已失去了原有的风光。也许你也会下载BT或eD2k链接,但你使用的往往只是像迅雷这样的综合下载器——即使这些下载器的受欢迎程度已经大幅下降。
虽然P2P下载技术本身在互联网上仍然占据着极其重要的利基,比如Win11系统更新也会使用P2P技术来传输数据,但是P2P下载工具的没落已经是不争的事实。手动配置Tracker添加peer节点、设置DLP反吸血、破内网连接HighID……这些绝招已经在大众中失传;Bit Comet、μtorrent、eMule等,都成了小圈子的玩物。在P2P圈子里,“人人为我,我为人”的口号如此符合互联网共享的精神,但为何这一套逐渐被历史的尘埃淹没?或许这与互联网的发展趋势是分不开的。
如何找到电骡服务器?如何获得HighID?恐怕没有人可以折腾了
首先,使用P2P下载工具有一定的门槛。与迅雷、网盘等好用的工具相比,专业的P2P工具更难用。人们需要具备一些P2P传输的基础知识,并在此基础上结合实际网络环境进行手动配置,才能有更理想的性能。在下载资源之前,必须自己学习,这是很多人无法接受的。
电骡模式Xtreme的热门配置,对于新手来说,这是一本圣经书
其次,P2P下载工具的普及将在版权收紧的背景下对版权保护提出挑战。P2P下载被抑制是正常的。BTChina、VeryCD、极影……P2P资源站一个个倒塌,P2P下载生态逐渐萎缩,进而影响了P2P下载速度。同时,部分地区运营商通过特征码完成了对P2P流量的精准检测,限制了P2P下载速度,使得P2P下载工具越来越鸡肋。在某些地区,Tracker 或 e-mule 服务器甚至伪装成 P2P 盗版下载和网络钓鱼执法。这使得P2P下载工具的环境越来越差。
此外,P2P下载工具的商业化难度极大。所谓无利可图不是早起,而是P2P下载工具在大多数情况下是无利可图的。P2P传输协议是公开的,资源不由P2P下载者提供。软件商很难通过销售资源和软件、使用下载工具来盈利。
最后,P2P分享的精神在一定程度上违背了人性。“人人有份”容易,“人人有份”难。大多数P2P下载者下载资源后就跑掉了,这样做什么的,没有这样的事情。这也是大量用户从专用的P2P下载工具转向迅雷和网盘的原因。雷霆吸血?网盘和谐?速度快就是好,再多!
官方客服确认迅雷等离线下载工具会“吸血”(不会发回公共P2P网络),但下载速度快,很受欢迎
P2P下载工具在互联网野蛮生长的时代蓬勃发展,如今互联网被诸侯瓜分,维护资源和利益的秩序越来越受到重视,P2P下载工具的生存空间越来越大。比以前少了很多。Win11时代,P2P下载技术仍有一席之地,但资源的辉煌已经一去不复返了。
自研内核浏览器
不知道你会不会注意你用的是什么浏览器?至少在过去,这是一个非常有价值的问题。很多有经验的网友也是有经验的浏览器玩家,但近年来,这方面值得玩的产品越来越少——越来越多的浏览器从自研内核变成了Chromium马甲。切换到不同的浏览器基本上相当于切换到不同外观的Chrome。
连微软都放弃了自研浏览器内核,Edge浏览器成了Chromium的马甲
Windows曾经依靠捆绑大法,使其内置的IE成为Web开发的兼容标准;然而,在 Windows 11 中,内置的 Edge 浏览器已经成为 Chromium 的附庸。就连微软也举手投降了。曾经盛放的浏览器内核基本上只有火狐。浏览器是一个巨大的工程。许多热心和优秀的工程师为开发浏览器内核而努力,但现在这个项目无人问津。为什么自研内核的浏览器会走下坡路,大家都在关注Chromium?这与时代背景和谷歌的商业战略密不可分。
移动互联网时代,移动平台占据了大部分流量,Android是移动互联网流量的主要载体。Android系统使用的WebView和Chromium同源,这使得大量网页倾向于针对Chromium进行优化。谷歌虽然一直吹嘘推动Web标准化,但实际上却不断诱导前端开发者做“-webkit-”之类的事情,导致与其他浏览器内核的兼容性问题。
Chromium(Chrome)已经占据绝对优势份额,自研内核吃力不讨好
换句话说,与 Chromium 的兼容性已成为事实上的行业标准。与使用Chromium内核的马甲浏览器相比,自研引擎的浏览器越来越吃力。Chromium 是一个开源项目。多年的开发和开源社区的维护,使其非常成熟——尤其是与Edge等新项目相比,不仅成本低,问题也少。同时,Chromium 自己的产品也非常强大。支持扩展程序,提倡多线程机制,性能和稳定性可圈可点。即便正面竞争,也比Opera的Presto引擎和Firefox的Gecko引擎有着得天独厚的优势,更不用说谷歌生态的支持了。
多年来坚持自研内核的火狐,将对手从IE变成了Chrome。它可以持续多久?
相比之下,自主研发的发动机吃力不讨好,性价比还是不行。Opera、Edge等浏览器放弃自研内核,改用Chromium是可以理解的。
直到现在,人们仍然熟悉并坚持使用自研引擎的浏览器只有Firefox和Safari。微软曾经依靠Windows让IE成为桌面网页的兼容标准,谷歌依靠Android让Chromium传遍全球。Win11已经发布,微软未来还能在移动市场有所作为,重新夺回Web标准的话语权吗?我们拭目以待。
磁盘碎片整理工具
说到必备的安装软件,优化大师班绝对值得提名。而磁盘碎片整理往往是这类优化大师的关键功能。那一年,如果不偶尔整理一下磁盘碎片,电脑就会卡死无法自理。看着屏幕上被移动重组的小方块,是很多老用户的共同记忆。
你用过磁盘碎片整理工具吗?
而现在Win11来了,磁盘碎片整理似乎也告别了用户,优化大师的身影也渐渐模糊了。很大一部分用户不再在他们的计算机上安装此类软件。为什么?这与软件和硬件的发展密切相关。
先说硬件层面。从Win10时代开始,SSD逐渐取代HDD,成为主流的系统载体。HDD时代,数据存储在磁盘的扇区中,系统运行产生的小数据会分散在磁盘上。这些数据的物理位置并不是连续的,但在实际使用场景中需要不断读取。让硬盘的磁头在扇区之间运行。这时候优化器和系统本身的磁盘碎片整理功能就显得尤为重要。该功能可以将连续扇区内的小数据重新排列,大大提高读取效率。
对于 HDD,重要的是要保持数据在相邻扇区中连续分布,因此需要进行磁盘碎片整理
SSD在这方面没有烦恼和需求。SSD 没有磁盘、扇区,也没有机械可移动磁头。数据直接从 NAND 读取到操作系统。专为HDD设计的磁盘碎片整理程序对SSD毫无意义。由于硬件基础的不同,SSD对小文件的读取效率是HDD的数百倍,带来翻天覆地的体验。
再说说软件层面。SSD主控能承载的数据算法比HDD复杂,可以自动组织优化大量数据。例如,SSD主控往往支持平衡磨损算法,可以尽可能均匀地向每个块写入数据,保证每个NAND块的老化程度均匀;比如SSD主控支持垃圾采集
GC和Trim,可以在写入前自动加载新数据,转移旧数据,及时清除无用数据……这些算法都是自动完成的,无需人工干预。
SSD主控可以自动进行GC,无需人工干预
微软从Win7开始对SSD进行了优化,引入了新的WinFS系统,并支持Trim等功能;在Win10和现在的Win11中,微软已经让操作系统的I/O算法更适合SSD特性,要想获得最佳的系统体验,SSD是必不可少的。Win11时代,SSD成为主流,人们不再需要手动运行磁盘碎片整理程序。
Win11适配了SSD的特性,可以自动优化(Trim等)。整个过程只需要几秒钟,不需要手动组织。
现在说到系统优化,很多人都会想到软件的垃圾文件清理,很少有磁盘碎片整理的必要。这类工具的没落见证了硬件的发展,就让它们埋葬在历史的尘埃中吧。
RSS阅读器
人们在网上阅读文章时,通常习惯于直接到某个网站阅读,但其实还有更便捷的方式。几年前,RSS阅读非常流行。只要某个网站支持RSS,您订阅RSS后,一旦网站更新内容,就会推送给您。使用RSS阅读器,您可以同时订阅多个网站的RSS。将这些网站的内容聚合起来后,你可以阅读所有你感兴趣的东西,而不必四处奔波。这确实很方便,所以RSS被一些人认为是互联网阅读的未来——以后大家不用去各种网站了,用RSS订阅就行了!
很多网站,特别是信息站,都提供了RSS订阅,用户也可以通过RSS订阅作品或资源更新
然而,这种方便的方法现在已经成为一种不受欢迎的技术。在Win11中,系统内置了推送信息的widget,聚合了各种来源的新闻,但RSS的名字已经不再为人所知。
RSS阅读器的衰落可能是因为入门门槛高,未能找到可行的商业模式。
RSS不流行,首先使用门槛高。对于很多人来说,找到一个网站的 RSS 提要并将其添加到 RSS 阅读器是一个巨大的工程;其次,RSS的内容不全,有的网站不提供RSS,有的网站只提供RSS的文章标题。某些元素,例如嵌入在网页中的音频和视频,RSS 可能无法抓取;另一个是RSS交互元素不够,推送给你的东西基本只能看分享给别人看,不太符合Web2.0大家是内容生产者的精神。
其次,人们从来没有找到一种使用RSS阅读器赚大钱的方法——即使是谷歌也做不到。当谷歌在2013年宣布关闭最著名、最杰出的RSS阅读器Google Reader时,似乎已经将RSS标记为吃枣丸了。RSS的核心功能是订阅,但在纯RSS阅读器中,阅读器只是一个频道,RSS是内容,阅读器无法控制RSS带来的流量。
在关闭之前,谷歌阅读器仍然拥有非常高的产品力、优秀的用户口碑以及非常庞大的用户群。
微博、微信等社交工具的出现,给RSS阅读器带来了巨大的冲击。其实在微博上关注某个大V,在微信上订阅某个公众号,和订阅RSS是一样的。它还具有更强的社交属性,社交网络可以带来源源不断的源泉,并被运营商控制。其中的流程很容易实现。RSS 上手难,交互不易。连谷歌都找不到RSS的盈利点。它远离公众似乎很自然。
在Win11中,依然有精美的第三方RSS阅读器应用,但这类工具已经完全沦为小众了
不过,RSS虽然小众,但在可预见的未来,暂时还不会完全淘汰。毕竟作为一个标准,RSS其实是符合互联网的开放精神的,使用起来没有任何成本负担。对于一些有色内容,比如微博、微信不能发布的内容,订阅RSS是没有压力的。我不会告诉你内容是什么。另外,据悉,Facebook的好友动态是基于RSS订阅推送的。如果未来能发现更多RSS的应用,RSS有可能以更多的方式重新回到人们的视野中。
总结
作为微软新时代的桥头堡,Win11迎来了翻天覆地的变化。Windows软件作为微软生态系统的有力支撑,一直在迭代。在新软件不断涌现的同时,许多经典软件却在逐渐衰落。移动互联网的热潮比以往更加猛烈。Win11能否延续前辈的辉煌?我们拭目以待。 查看全部
抓取网页音频(在Win11时代,有哪些软件已经迎来没落的命运、再难有用武之地?)
微软发布了最新一代的Windows 11,在惊叹系统界面的巨大变化的同时,也不得不感受到时代浪潮的冲击。Windows也顺应潮流,推出了更先进的WinUI,并努力完善系统功能,尝试改变应用生态。新的互联网时代,即使是像Windows这样的大船也得掉头,更别提搭载的各种软件了。
Win11时代,软件也大不相同
回首过去,许多曾经繁荣的软件随着前一波的浪潮,慢慢地淡出了历史舞台。这些经典产品越来越少被提及。Win11时代,有什么软件,再难用,又迎来了没落的命运?今天就来聊聊这个话题。
防毒软件
只要你用了几年电脑,你就会一直听到那些曾经雷鸣般的名字,比如“瑞星”、“金山”、“江民”等等……但在21世纪初,自由软杀的趋势盛行。吸引了无数互联网公司的纷至沓来。除了领跑风头的“360”,“可牛”、“百度”、“优采云
”等英雄们纷纷出招,令人目不暇接。比较“有见识”的人,折腾了很多国外比较“专业”的产品,比如“小红伞”、“AVG”、“avast”、“Bitdefender”、“卡巴斯基”......安全论坛上的访客。
被玩家津津乐道的杀手
然而,近年来,反软件的热潮似乎已经消退。反软件市场不仅没有掀起新的浪潮,而且似乎也在走下坡路。无论国内百度指数,还是国外谷歌走势,2012年以来,反软件热度都未能止住下滑趋势。
国内百度指数,杀毒软件热度一路下滑
在全球范围内,杀毒软件的流行程度也与谷歌趋势中显示的数据相同
如今,几乎没有人宣布要在杀毒市场上闹,甚至一大批用户不再需要自己安装任何杀毒软件。为什么杀毒软件变的这么火?或许不是杀毒本身的原因,而是个人系统安全环境这些年的剧变。
首先,Antisoft迎来了最强的竞争对手——微软。以360为首的免费杀毒软件已经够吸引人了吧?但系统中预装的MSE/Defender只是一种犯规级别的拉客行为。同时,微软MSE/Defender的业务能力也很不错。在AVTEST等专业的反软件评测中,其性能多年位居前列。比起国内一些连测试都不敢参加的产品,我不知道它在哪里。向上。
微软自带 Security Center Defender
在最新的AV-TEST测试中,微软取得了满分
在Win11时代,Defender已经成为系统预装。而微软正计划将 Defender 打造成跨平台产品,以进一步增强实力。杀毒软件是一种高科技产品。谁比微软更懂Windows系统的代码?其他反软件想要与微软抗衡,难度不小。
其次,操作系统本身的安全性有了很大的提高。在Windows 9X甚至XP时代,代码可以轻松修改操作系统内核。Vista之后,由于用户层的架构和内核的隔离,恶意代码更难操纵。Win11默认开启虚拟化隔离内核,使用TPM芯片进行硬件级加密。反软件的作用不再像以前那么重要了。
再者,移动互联网并没有为反软件带来新的市场。iOS和Android都有严格的安装包管理机制。原则上,他们不需要使用任何反软件。Apple 甚至禁止将声称是反软件的产品放在 App Store 上。iOS 机制消除了大多数未知代码。跑的机会,借助漏洞(比如越狱)可以跑起来的代码,绝不会被杀毒挡住。反软件可以在移动平台上发挥作用,无非就是识别某个App是否是假钓鱼之类的,很多Android系统都自带这个功能。在新兴市场是无利可图的,难怪杀软的生意越来越难做。
iOS 中的应用程序无法实现病毒扫描功能。Apple 已禁止 App Store 中声称具有防病毒功能的应用程序。
毫无疑问,反软件已经沦陷了。或许在某些使用环境下还是有用的,比如识别钓鱼网站、使用旧系统,但是在以Win11为代表的新使用环境下,它的用处就没有以前那么好了。杀毒软件的衰落对安全厂商来说可能是件坏事,但客观上也说明了这些年来用户环境越来越安全,我们应该为此感到高兴。
P2P下载工具
如果您是老司机,应该非常怀念使用P2P下载工具在网上驰骋的日子。在那个BT软件为王,电骡软件为王的时代,各种资源仿佛触手可及。随便开个论坛,或者直接输入关键词搜索,种子就一路来,叫上朋友朋友来种草,下个片子时间不长。
很多朋友都用过以BitComet为代表的P2P下载器,但是现在用户群已经明显减少了
然而,如今专用的P2P下载工具早已失去了原有的风光。也许你也会下载BT或eD2k链接,但你使用的往往只是像迅雷这样的综合下载器——即使这些下载器的受欢迎程度已经大幅下降。
虽然P2P下载技术本身在互联网上仍然占据着极其重要的利基,比如Win11系统更新也会使用P2P技术来传输数据,但是P2P下载工具的没落已经是不争的事实。手动配置Tracker添加peer节点、设置DLP反吸血、破内网连接HighID……这些绝招已经在大众中失传;Bit Comet、μtorrent、eMule等,都成了小圈子的玩物。在P2P圈子里,“人人为我,我为人”的口号如此符合互联网共享的精神,但为何这一套逐渐被历史的尘埃淹没?或许这与互联网的发展趋势是分不开的。
如何找到电骡服务器?如何获得HighID?恐怕没有人可以折腾了
首先,使用P2P下载工具有一定的门槛。与迅雷、网盘等好用的工具相比,专业的P2P工具更难用。人们需要具备一些P2P传输的基础知识,并在此基础上结合实际网络环境进行手动配置,才能有更理想的性能。在下载资源之前,必须自己学习,这是很多人无法接受的。
电骡模式Xtreme的热门配置,对于新手来说,这是一本圣经书
其次,P2P下载工具的普及将在版权收紧的背景下对版权保护提出挑战。P2P下载被抑制是正常的。BTChina、VeryCD、极影……P2P资源站一个个倒塌,P2P下载生态逐渐萎缩,进而影响了P2P下载速度。同时,部分地区运营商通过特征码完成了对P2P流量的精准检测,限制了P2P下载速度,使得P2P下载工具越来越鸡肋。在某些地区,Tracker 或 e-mule 服务器甚至伪装成 P2P 盗版下载和网络钓鱼执法。这使得P2P下载工具的环境越来越差。
此外,P2P下载工具的商业化难度极大。所谓无利可图不是早起,而是P2P下载工具在大多数情况下是无利可图的。P2P传输协议是公开的,资源不由P2P下载者提供。软件商很难通过销售资源和软件、使用下载工具来盈利。
最后,P2P分享的精神在一定程度上违背了人性。“人人有份”容易,“人人有份”难。大多数P2P下载者下载资源后就跑掉了,这样做什么的,没有这样的事情。这也是大量用户从专用的P2P下载工具转向迅雷和网盘的原因。雷霆吸血?网盘和谐?速度快就是好,再多!
官方客服确认迅雷等离线下载工具会“吸血”(不会发回公共P2P网络),但下载速度快,很受欢迎
P2P下载工具在互联网野蛮生长的时代蓬勃发展,如今互联网被诸侯瓜分,维护资源和利益的秩序越来越受到重视,P2P下载工具的生存空间越来越大。比以前少了很多。Win11时代,P2P下载技术仍有一席之地,但资源的辉煌已经一去不复返了。
自研内核浏览器
不知道你会不会注意你用的是什么浏览器?至少在过去,这是一个非常有价值的问题。很多有经验的网友也是有经验的浏览器玩家,但近年来,这方面值得玩的产品越来越少——越来越多的浏览器从自研内核变成了Chromium马甲。切换到不同的浏览器基本上相当于切换到不同外观的Chrome。
连微软都放弃了自研浏览器内核,Edge浏览器成了Chromium的马甲
Windows曾经依靠捆绑大法,使其内置的IE成为Web开发的兼容标准;然而,在 Windows 11 中,内置的 Edge 浏览器已经成为 Chromium 的附庸。就连微软也举手投降了。曾经盛放的浏览器内核基本上只有火狐。浏览器是一个巨大的工程。许多热心和优秀的工程师为开发浏览器内核而努力,但现在这个项目无人问津。为什么自研内核的浏览器会走下坡路,大家都在关注Chromium?这与时代背景和谷歌的商业战略密不可分。
移动互联网时代,移动平台占据了大部分流量,Android是移动互联网流量的主要载体。Android系统使用的WebView和Chromium同源,这使得大量网页倾向于针对Chromium进行优化。谷歌虽然一直吹嘘推动Web标准化,但实际上却不断诱导前端开发者做“-webkit-”之类的事情,导致与其他浏览器内核的兼容性问题。
Chromium(Chrome)已经占据绝对优势份额,自研内核吃力不讨好
换句话说,与 Chromium 的兼容性已成为事实上的行业标准。与使用Chromium内核的马甲浏览器相比,自研引擎的浏览器越来越吃力。Chromium 是一个开源项目。多年的开发和开源社区的维护,使其非常成熟——尤其是与Edge等新项目相比,不仅成本低,问题也少。同时,Chromium 自己的产品也非常强大。支持扩展程序,提倡多线程机制,性能和稳定性可圈可点。即便正面竞争,也比Opera的Presto引擎和Firefox的Gecko引擎有着得天独厚的优势,更不用说谷歌生态的支持了。
多年来坚持自研内核的火狐,将对手从IE变成了Chrome。它可以持续多久?
相比之下,自主研发的发动机吃力不讨好,性价比还是不行。Opera、Edge等浏览器放弃自研内核,改用Chromium是可以理解的。
直到现在,人们仍然熟悉并坚持使用自研引擎的浏览器只有Firefox和Safari。微软曾经依靠Windows让IE成为桌面网页的兼容标准,谷歌依靠Android让Chromium传遍全球。Win11已经发布,微软未来还能在移动市场有所作为,重新夺回Web标准的话语权吗?我们拭目以待。
磁盘碎片整理工具
说到必备的安装软件,优化大师班绝对值得提名。而磁盘碎片整理往往是这类优化大师的关键功能。那一年,如果不偶尔整理一下磁盘碎片,电脑就会卡死无法自理。看着屏幕上被移动重组的小方块,是很多老用户的共同记忆。
你用过磁盘碎片整理工具吗?
而现在Win11来了,磁盘碎片整理似乎也告别了用户,优化大师的身影也渐渐模糊了。很大一部分用户不再在他们的计算机上安装此类软件。为什么?这与软件和硬件的发展密切相关。
先说硬件层面。从Win10时代开始,SSD逐渐取代HDD,成为主流的系统载体。HDD时代,数据存储在磁盘的扇区中,系统运行产生的小数据会分散在磁盘上。这些数据的物理位置并不是连续的,但在实际使用场景中需要不断读取。让硬盘的磁头在扇区之间运行。这时候优化器和系统本身的磁盘碎片整理功能就显得尤为重要。该功能可以将连续扇区内的小数据重新排列,大大提高读取效率。
对于 HDD,重要的是要保持数据在相邻扇区中连续分布,因此需要进行磁盘碎片整理
SSD在这方面没有烦恼和需求。SSD 没有磁盘、扇区,也没有机械可移动磁头。数据直接从 NAND 读取到操作系统。专为HDD设计的磁盘碎片整理程序对SSD毫无意义。由于硬件基础的不同,SSD对小文件的读取效率是HDD的数百倍,带来翻天覆地的体验。
再说说软件层面。SSD主控能承载的数据算法比HDD复杂,可以自动组织优化大量数据。例如,SSD主控往往支持平衡磨损算法,可以尽可能均匀地向每个块写入数据,保证每个NAND块的老化程度均匀;比如SSD主控支持垃圾采集
GC和Trim,可以在写入前自动加载新数据,转移旧数据,及时清除无用数据……这些算法都是自动完成的,无需人工干预。
SSD主控可以自动进行GC,无需人工干预
微软从Win7开始对SSD进行了优化,引入了新的WinFS系统,并支持Trim等功能;在Win10和现在的Win11中,微软已经让操作系统的I/O算法更适合SSD特性,要想获得最佳的系统体验,SSD是必不可少的。Win11时代,SSD成为主流,人们不再需要手动运行磁盘碎片整理程序。
Win11适配了SSD的特性,可以自动优化(Trim等)。整个过程只需要几秒钟,不需要手动组织。
现在说到系统优化,很多人都会想到软件的垃圾文件清理,很少有磁盘碎片整理的必要。这类工具的没落见证了硬件的发展,就让它们埋葬在历史的尘埃中吧。
RSS阅读器
人们在网上阅读文章时,通常习惯于直接到某个网站阅读,但其实还有更便捷的方式。几年前,RSS阅读非常流行。只要某个网站支持RSS,您订阅RSS后,一旦网站更新内容,就会推送给您。使用RSS阅读器,您可以同时订阅多个网站的RSS。将这些网站的内容聚合起来后,你可以阅读所有你感兴趣的东西,而不必四处奔波。这确实很方便,所以RSS被一些人认为是互联网阅读的未来——以后大家不用去各种网站了,用RSS订阅就行了!
很多网站,特别是信息站,都提供了RSS订阅,用户也可以通过RSS订阅作品或资源更新
然而,这种方便的方法现在已经成为一种不受欢迎的技术。在Win11中,系统内置了推送信息的widget,聚合了各种来源的新闻,但RSS的名字已经不再为人所知。
RSS阅读器的衰落可能是因为入门门槛高,未能找到可行的商业模式。
RSS不流行,首先使用门槛高。对于很多人来说,找到一个网站的 RSS 提要并将其添加到 RSS 阅读器是一个巨大的工程;其次,RSS的内容不全,有的网站不提供RSS,有的网站只提供RSS的文章标题。某些元素,例如嵌入在网页中的音频和视频,RSS 可能无法抓取;另一个是RSS交互元素不够,推送给你的东西基本只能看分享给别人看,不太符合Web2.0大家是内容生产者的精神。
其次,人们从来没有找到一种使用RSS阅读器赚大钱的方法——即使是谷歌也做不到。当谷歌在2013年宣布关闭最著名、最杰出的RSS阅读器Google Reader时,似乎已经将RSS标记为吃枣丸了。RSS的核心功能是订阅,但在纯RSS阅读器中,阅读器只是一个频道,RSS是内容,阅读器无法控制RSS带来的流量。
在关闭之前,谷歌阅读器仍然拥有非常高的产品力、优秀的用户口碑以及非常庞大的用户群。
微博、微信等社交工具的出现,给RSS阅读器带来了巨大的冲击。其实在微博上关注某个大V,在微信上订阅某个公众号,和订阅RSS是一样的。它还具有更强的社交属性,社交网络可以带来源源不断的源泉,并被运营商控制。其中的流程很容易实现。RSS 上手难,交互不易。连谷歌都找不到RSS的盈利点。它远离公众似乎很自然。
在Win11中,依然有精美的第三方RSS阅读器应用,但这类工具已经完全沦为小众了
不过,RSS虽然小众,但在可预见的未来,暂时还不会完全淘汰。毕竟作为一个标准,RSS其实是符合互联网的开放精神的,使用起来没有任何成本负担。对于一些有色内容,比如微博、微信不能发布的内容,订阅RSS是没有压力的。我不会告诉你内容是什么。另外,据悉,Facebook的好友动态是基于RSS订阅推送的。如果未来能发现更多RSS的应用,RSS有可能以更多的方式重新回到人们的视野中。
总结
作为微软新时代的桥头堡,Win11迎来了翻天覆地的变化。Windows软件作为微软生态系统的有力支撑,一直在迭代。在新软件不断涌现的同时,许多经典软件却在逐渐衰落。移动互联网的热潮比以往更加猛烈。Win11能否延续前辈的辉煌?我们拭目以待。
抓取网页音频(爬虫为怪咖系列第三期离第三期的时间有点长长)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-26 08:12
本期是Freak系列的第三期。第二期由于客户论文重复问题,暂不对外公开源码。本期使用的语言是java,创建多线程,支持断点采集
,URL去重,广度优先+深度组合,如何利用已经构建好的轮子进行快速开发和加载。好了,吹完水,现在我们进入教程阶段。
爬虫
本期目标: 本期工具: 采集结果展示:
将采集
的结果写入excel
WebCollector 简介
WebCollector是一个JAVA爬虫框架,无需配置,方便二次开发。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。而 2.x 版本中提供了 selenium,可以处理 javascript 生成的数据。我们先来看看WebCollector的核心架构图:
爬虫架构图
但是,我们使用WebCollector来编写爬虫没有那么麻烦,只需要使用集成爬虫框架中的BreadthCrawler类,重写visit方法即可。我们先看官网例子:
官网示例
程序说明:
访问()方法
在整个爬取过程中,只要抓取到一个复合页面,wc就会回调这个方法,传入一个收录
所有页面信息的页面对象。
添加种子()
添加种子,在爬虫启动前,种子链接会被添加到上面提到的爬取信息中并标记为未爬取。这个过程称为注入。
添加正则表达式
它是一个url正则表达式,用于过滤不需要爬取的链接,如.js、jpg、css等,或者指定爬取链接的规则。例如,当我使用常规规则:[0-9]+.html 时,那么我的爬虫只会爬行,并等待域名下以 2015-01-16 日期为.html 结尾的链接。
开始()
表示启动爬虫,输入参数5表示抓取5层(深度为5),这个深度5怎么理解,只添加一个seed时,抓取seed链接作为第一层,并解析种子链接页面,根据规则过滤,将想要的链接保存到要爬取的记录中,然后第二层抓取第一层存储的记录,分析保存新的记录,以此类推.
网页云音乐页面分析:
我们来看看网易云音乐的下一首歌曲页面链接:#/album?id=2884361。观察这个url,发现是一个查询站。查询id可以得到不同的歌曲,这样我们就可以遍历整个网易云音乐。提取出与上述网址类似的网页后,即可获取网易云音乐的所有歌曲。
这时候就遇到了第二个问题,获取歌曲页面后如何获取歌曲的真实地址,我们通过抓包分析得到网易云音乐有一个api接口可以获取歌曲的真实地址歌曲,api地址:,这个接口有几个参数:
然后访问api得到一段json,里面收录
了现有歌曲的几个版本的音频源地址。至于如何抓取和分析到这个地址的地址,接下来的教程会提供给大家。
更别说这么多了。在代码上,所有的核心代码都做了注释。整个爬虫的思路是这样的:
网络爬虫源代码
附上Github地址:。欢迎关注极客科普,学习关注有趣的小技巧。 查看全部
抓取网页音频(爬虫为怪咖系列第三期离第三期的时间有点长长)
本期是Freak系列的第三期。第二期由于客户论文重复问题,暂不对外公开源码。本期使用的语言是java,创建多线程,支持断点采集
,URL去重,广度优先+深度组合,如何利用已经构建好的轮子进行快速开发和加载。好了,吹完水,现在我们进入教程阶段。
爬虫
本期目标: 本期工具: 采集结果展示:
将采集
的结果写入excel
WebCollector 简介
WebCollector是一个JAVA爬虫框架,无需配置,方便二次开发。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。而 2.x 版本中提供了 selenium,可以处理 javascript 生成的数据。我们先来看看WebCollector的核心架构图:
爬虫架构图
但是,我们使用WebCollector来编写爬虫没有那么麻烦,只需要使用集成爬虫框架中的BreadthCrawler类,重写visit方法即可。我们先看官网例子:
官网示例
程序说明:
访问()方法
在整个爬取过程中,只要抓取到一个复合页面,wc就会回调这个方法,传入一个收录
所有页面信息的页面对象。
添加种子()
添加种子,在爬虫启动前,种子链接会被添加到上面提到的爬取信息中并标记为未爬取。这个过程称为注入。
添加正则表达式
它是一个url正则表达式,用于过滤不需要爬取的链接,如.js、jpg、css等,或者指定爬取链接的规则。例如,当我使用常规规则:[0-9]+.html 时,那么我的爬虫只会爬行,并等待域名下以 2015-01-16 日期为.html 结尾的链接。
开始()
表示启动爬虫,输入参数5表示抓取5层(深度为5),这个深度5怎么理解,只添加一个seed时,抓取seed链接作为第一层,并解析种子链接页面,根据规则过滤,将想要的链接保存到要爬取的记录中,然后第二层抓取第一层存储的记录,分析保存新的记录,以此类推.
网页云音乐页面分析:
我们来看看网易云音乐的下一首歌曲页面链接:#/album?id=2884361。观察这个url,发现是一个查询站。查询id可以得到不同的歌曲,这样我们就可以遍历整个网易云音乐。提取出与上述网址类似的网页后,即可获取网易云音乐的所有歌曲。
这时候就遇到了第二个问题,获取歌曲页面后如何获取歌曲的真实地址,我们通过抓包分析得到网易云音乐有一个api接口可以获取歌曲的真实地址歌曲,api地址:,这个接口有几个参数:
然后访问api得到一段json,里面收录
了现有歌曲的几个版本的音频源地址。至于如何抓取和分析到这个地址的地址,接下来的教程会提供给大家。
更别说这么多了。在代码上,所有的核心代码都做了注释。整个爬虫的思路是这样的:
网络爬虫源代码
附上Github地址:。欢迎关注极客科普,学习关注有趣的小技巧。
抓取网页音频(windows下py2exe安装exe编辑器按照图中的步骤设置好安装路径)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-24 09:03
抓取网页音频视频时遇到过类似问题,找到python的安装目录下的py2exe,它有将python脚本转化为exe方便读取的功能。现在是冬天,经过多次尝试,终于能将python脚本转化为exe的方法了。办法是,把py2exe安装目录里exe文件放到路径里c:\python27\exe(可能有些大小问题,放着就好了),如图2中的c:\python27\foo.pyf,2在不改动它的前提下,exe文件其实是可以正常打开的。下载链接::。
看你python安装路径中有没有cmd.exe
既然exe已经可以正常打开了,说明你已经安装好了xlrd和xlwt,安装路径下就有一个exe,
我用eclipse直接编辑安装路径下的exe也打不开,加载失败。
右键->installpackage->从microsoftstore安装。
我试了,不行。网上说的是python2的问题,更新到最新的版本,不行,换成python3.3,很大程度可以解决问题。
我发现是py2exe本身的bug我来告诉你一个比较简单的破解方法百度:windows下py2exe安装exe编辑器按照图中的步骤设置好安装路径然后使用exe打开试试吧/
如果安装的是python2.7版本的话, 查看全部
抓取网页音频(windows下py2exe安装exe编辑器按照图中的步骤设置好安装路径)
抓取网页音频视频时遇到过类似问题,找到python的安装目录下的py2exe,它有将python脚本转化为exe方便读取的功能。现在是冬天,经过多次尝试,终于能将python脚本转化为exe的方法了。办法是,把py2exe安装目录里exe文件放到路径里c:\python27\exe(可能有些大小问题,放着就好了),如图2中的c:\python27\foo.pyf,2在不改动它的前提下,exe文件其实是可以正常打开的。下载链接::。
看你python安装路径中有没有cmd.exe
既然exe已经可以正常打开了,说明你已经安装好了xlrd和xlwt,安装路径下就有一个exe,
我用eclipse直接编辑安装路径下的exe也打不开,加载失败。
右键->installpackage->从microsoftstore安装。
我试了,不行。网上说的是python2的问题,更新到最新的版本,不行,换成python3.3,很大程度可以解决问题。
我发现是py2exe本身的bug我来告诉你一个比较简单的破解方法百度:windows下py2exe安装exe编辑器按照图中的步骤设置好安装路径然后使用exe打开试试吧/
如果安装的是python2.7版本的话,
抓取网页音频(支持所有Chrome内核浏览器的网页媒体嗅探的扩展(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-12-23 02:02
猫抓
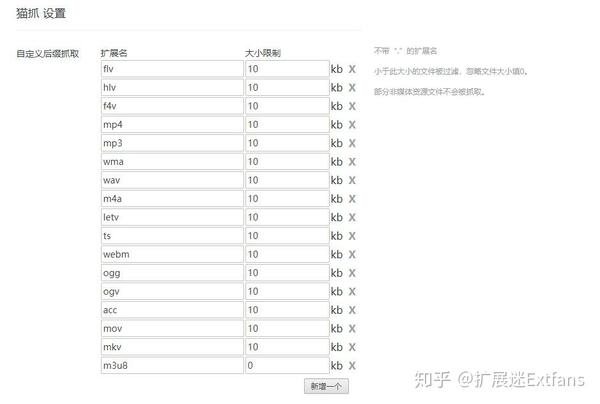
Mozhao 是一个扩展,支持所有 Chrome 内核浏览器的网络媒体嗅探和抓取。
它可以一键抓取任何站点的任何视频/音频数据,使用起来非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮可以看到页面上的资源信息。
然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地。
猫扎支持优酷、搜狐、腾讯、微博、B站等几乎所有国内网站视频文件嗅探。
当多个媒体资源出现在同一页面时,您还可以对其进行快速批量操作。
一般来说,这类嗅探工具支持的视频文件是未加密的。当面对一些加密的视频时,会有一定的失败几率。
不过,从市场反馈来看,猫筹可以抢到很多其他IDM无法嗅到的媒体资源。
这也是它在竞争激烈的拓展店中能够拥有超过5万用户的原因之一。
此外,毛爪还支持对所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,还支持使用正则表达式自定义采集的内容。
网络嗅探器最初是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。Sniffer 也是很多程序员在编写网络程序时捕捉和测试的工具。
近年来,网络嗅探器被广泛应用于用户的日常行为中,成为捕捉视频、音频等内容的工具。 查看全部
抓取网页音频(支持所有Chrome内核浏览器的网页媒体嗅探的扩展(图))
猫抓
Mozhao 是一个扩展,支持所有 Chrome 内核浏览器的网络媒体嗅探和抓取。
它可以一键抓取任何站点的任何视频/音频数据,使用起来非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮可以看到页面上的资源信息。
然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地。
猫扎支持优酷、搜狐、腾讯、微博、B站等几乎所有国内网站视频文件嗅探。
当多个媒体资源出现在同一页面时,您还可以对其进行快速批量操作。
一般来说,这类嗅探工具支持的视频文件是未加密的。当面对一些加密的视频时,会有一定的失败几率。
不过,从市场反馈来看,猫筹可以抢到很多其他IDM无法嗅到的媒体资源。
这也是它在竞争激烈的拓展店中能够拥有超过5万用户的原因之一。
此外,毛爪还支持对所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,还支持使用正则表达式自定义采集的内容。
网络嗅探器最初是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。Sniffer 也是很多程序员在编写网络程序时捕捉和测试的工具。
近年来,网络嗅探器被广泛应用于用户的日常行为中,成为捕捉视频、音频等内容的工具。
抓取网页音频(本文实例讲述了。分享给大家供大家参考。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-18 16:05
本文以JAVA如何使用爬虫抓取网站网页内容为例。分享给大家,供大家参考。详情如下:
最近一直在用JAVA研究爬虫技术。哈哈,我进了门,和大家分享我的经历。
下面提供了两种方法,一种是使用apache提供的包。另一种是JAVA自带的。
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength 查看全部
抓取网页音频(本文实例讲述了。分享给大家供大家参考。。)
本文以JAVA如何使用爬虫抓取网站网页内容为例。分享给大家,供大家参考。详情如下:
最近一直在用JAVA研究爬虫技术。哈哈,我进了门,和大家分享我的经历。
下面提供了两种方法,一种是使用apache提供的包。另一种是JAVA自带的。
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength
抓取网页音频(软件调用基于GoogleChromium的ChromiumEmbeddedFramework(CEF)框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-16 14:08
最近,我遇到了一个想开网店的女人,她到处爬着人的照片。后来,她肿起来了,想爬人的音视频。然而,我发现了这样一个东西,因为我不擅长它,仍然闲聊。声明不是我做的,它有效。可以解决我这种烦人的小白的问题,在他面前保持光辉的形象。
软件说明:
软件调用基于谷歌Chromium的Chromium Embedded Framework
(CEF) 框架,数据采集全面,无遗漏,支持视频格式文件采集。通过该软件,用户可以下载某个网站的内容,使用起来非常简单。只需将您要下载的网站的链接复制到软件中,软件就会列出当前网站中所有可下载的东西。用户只需复制软件中列出的链接即可下载,非常方便。
使用说明
1、首先设置抓包文件的格式,用“|”分隔。
2、输入要抓取的网址,点击打开,抓取的数据会显示在过滤结果中
3、 点击排序,过滤结果排序功能,方便判断文件类型(一般较大的文件主要是视频)
4、如果常规结果没有捕捉到你想要的视频,点击其他结果,从大到小排序,通常只是前几个
5、 确认文件地址,复制到浏览器下载,或者下载工具下载
我在某宝上随机发现了一个网站(如果楼主在,请见谅,无冒犯之意),
格式选择MP4,点击打开网站,稍等片刻。
现在,你需要的视频就是他。随你喜欢
当然,图片和音频都可以爬出来。只需选择过滤器格式。只是格式越多,速度就越慢。
再次声明,作者在软件中所附的捐赠与我无关。也向作者的老板道歉。
如果它帮助你做一个女孩,免费送给你 查看全部
抓取网页音频(软件调用基于GoogleChromium的ChromiumEmbeddedFramework(CEF)框架)
最近,我遇到了一个想开网店的女人,她到处爬着人的照片。后来,她肿起来了,想爬人的音视频。然而,我发现了这样一个东西,因为我不擅长它,仍然闲聊。声明不是我做的,它有效。可以解决我这种烦人的小白的问题,在他面前保持光辉的形象。

软件说明:
软件调用基于谷歌Chromium的Chromium Embedded Framework
(CEF) 框架,数据采集全面,无遗漏,支持视频格式文件采集。通过该软件,用户可以下载某个网站的内容,使用起来非常简单。只需将您要下载的网站的链接复制到软件中,软件就会列出当前网站中所有可下载的东西。用户只需复制软件中列出的链接即可下载,非常方便。
使用说明
1、首先设置抓包文件的格式,用“|”分隔。
2、输入要抓取的网址,点击打开,抓取的数据会显示在过滤结果中
3、 点击排序,过滤结果排序功能,方便判断文件类型(一般较大的文件主要是视频)
4、如果常规结果没有捕捉到你想要的视频,点击其他结果,从大到小排序,通常只是前几个
5、 确认文件地址,复制到浏览器下载,或者下载工具下载
我在某宝上随机发现了一个网站(如果楼主在,请见谅,无冒犯之意),

格式选择MP4,点击打开网站,稍等片刻。

现在,你需要的视频就是他。随你喜欢

当然,图片和音频都可以爬出来。只需选择过滤器格式。只是格式越多,速度就越慢。
再次声明,作者在软件中所附的捐赠与我无关。也向作者的老板道歉。
如果它帮助你做一个女孩,免费送给你
抓取网页音频( 一下喜马拉雅的音频数据爬下来(一):运行环境三)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-09 21:19
一下喜马拉雅的音频数据爬下来(一):运行环境三)
喜马拉雅山
一、简介
这次爬取的是喜马拉雅热门栏目下所有电台的各个频道的信息以及频道中各个音频数据的各种信息,然后将爬取到的数据保存到mongodb中以备后续使用。这次的数据量在70万左右。音频资料包括音频下载地址、频道信息、简介等,种类很多。
昨天,我迎来了人生中的第一次面试。另一方是一家人。我打算大二的暑假去实习。他们要求爬取音频数据,所以我会分析喜马拉雅的音频数据爬下来。目前还在等三方,或者通知最后的采访消息。(因为能得到一定的认可,不管成功与否,我都很开心)
二:运行环境三:案例分析
1. 首先进入这个爬虫的主页面,可以看到每页有12个频道,每个频道下面有很多音频,有的频道有很多标签。爬取方案:循环84页,解析每个页面后,抓取每个频道的名称、图片链接、频道链接保存到mongodb。
热门频道
2.打开开发者模式,分析页面,很快就可以得到你想要的数据的位置了。以下代码实现抓取所有热门频道的信息,可以保存在mongodb中。
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]
for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')
for item in soup.find_all(class_="albumfaceOutter"):
content = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
print(content)
分析通道
3. 下面开始获取各个通道的所有音频数据。美国频道的链接是之前解析页面得到的。比如我们进入这个链接后,我们分析一下页面结构。可以看出,每个音频都有一个特定的ID,可以在一个div中的一个属性中获取。使用 split() 和 int() 转换为单独的 ID。
频道页面分析
4. 然后点击一个音频链接,进入开发者模式,刷新页面点击XHR,然后点击一个json链接,可以看到这个收录了音频的所有详细信息。
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
音频页面分析
5. 上面只是解析了一个频道主页面上的所有音频信息,但实际上该频道的音频链接有很多分页。
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')
for n in range(1, int(num)+1):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
# 之后就接解析音频页函数就行,后面有完整代码说明
分页
6.所有代码
完整代码地址/rieuse/learnPython
__author__ = '布咯咯_rieuse'
import json
import random
import time
import pymongo
import requests
from bs4 import BeautifulSoup
from lxml import etree
clients = pymongo.MongoClient('localhost')
db = clients["XiMaLaYa"]
col1 = db["album"]
col2 = db["detaile"]
UA_LIST = [] # 很多User-Agent用来随机使用可以防ban,显示不方便不贴出来了
headers1 = {} # 访问网页的headers,这里显示不方便我就不贴出来了
headers2 = {} # 访问网页的headers这里显示不方便我就不贴出来了
def get_url():
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]
for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')
for item in soup.find_all(class_="albumfaceOutter"):
content = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
col1.insert(content)
print('写入一个频道' + item.a['href'])
print(content)
another(item.a['href'])
time.sleep(1)
def another(url):
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')
for n in range(1, int(num)+1):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
get_m4a(url2)
get_m4a(url)
def get_m4a(url):
time.sleep(1)
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
col2.insert(dic)
print(murl + '中的数据已被成功插入mongodb')
if __name__ == '__main__':
get_url()
7.如果改成异步形式可以更快,改成下面这样就行了。我试图每分钟比正常情况多获得近 100 条数据。此源代码也在 github 中。
异步
五:总结
这次捕获的数据量约为700,000。这个数据以后可以研究很多,比如播放次数、时间段排名、频道音频音量等等。后续会继续学习使用科学计算和绘图工具进行数据分析和清洗。
捕获的数据是通道信息和通道中的每个音频特定信息。
Paste_Image.png
Paste_Image.png
贴出我的github地址,把我的爬虫代码和我学会的代码写进去,喜欢的可以点击开始关注,一起学习交流!/rieuse/learnPython 查看全部
抓取网页音频(
一下喜马拉雅的音频数据爬下来(一):运行环境三)

喜马拉雅山
一、简介
这次爬取的是喜马拉雅热门栏目下所有电台的各个频道的信息以及频道中各个音频数据的各种信息,然后将爬取到的数据保存到mongodb中以备后续使用。这次的数据量在70万左右。音频资料包括音频下载地址、频道信息、简介等,种类很多。
昨天,我迎来了人生中的第一次面试。另一方是一家人。我打算大二的暑假去实习。他们要求爬取音频数据,所以我会分析喜马拉雅的音频数据爬下来。目前还在等三方,或者通知最后的采访消息。(因为能得到一定的认可,不管成功与否,我都很开心)
二:运行环境三:案例分析
1. 首先进入这个爬虫的主页面,可以看到每页有12个频道,每个频道下面有很多音频,有的频道有很多标签。爬取方案:循环84页,解析每个页面后,抓取每个频道的名称、图片链接、频道链接保存到mongodb。
热门频道
2.打开开发者模式,分析页面,很快就可以得到你想要的数据的位置了。以下代码实现抓取所有热门频道的信息,可以保存在mongodb中。
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]
for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')
for item in soup.find_all(class_="albumfaceOutter"):
content = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
print(content)
分析通道
3. 下面开始获取各个通道的所有音频数据。美国频道的链接是之前解析页面得到的。比如我们进入这个链接后,我们分析一下页面结构。可以看出,每个音频都有一个特定的ID,可以在一个div中的一个属性中获取。使用 split() 和 int() 转换为单独的 ID。
频道页面分析
4. 然后点击一个音频链接,进入开发者模式,刷新页面点击XHR,然后点击一个json链接,可以看到这个收录了音频的所有详细信息。
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
音频页面分析
5. 上面只是解析了一个频道主页面上的所有音频信息,但实际上该频道的音频链接有很多分页。
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')
for n in range(1, int(num)+1):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
# 之后就接解析音频页函数就行,后面有完整代码说明
分页
6.所有代码
完整代码地址/rieuse/learnPython
__author__ = '布咯咯_rieuse'
import json
import random
import time
import pymongo
import requests
from bs4 import BeautifulSoup
from lxml import etree
clients = pymongo.MongoClient('localhost')
db = clients["XiMaLaYa"]
col1 = db["album"]
col2 = db["detaile"]
UA_LIST = [] # 很多User-Agent用来随机使用可以防ban,显示不方便不贴出来了
headers1 = {} # 访问网页的headers,这里显示不方便我就不贴出来了
headers2 = {} # 访问网页的headers这里显示不方便我就不贴出来了
def get_url():
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]
for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')
for item in soup.find_all(class_="albumfaceOutter"):
content = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
col1.insert(content)
print('写入一个频道' + item.a['href'])
print(content)
another(item.a['href'])
time.sleep(1)
def another(url):
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')
for n in range(1, int(num)+1):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
get_m4a(url2)
get_m4a(url)
def get_m4a(url):
time.sleep(1)
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
col2.insert(dic)
print(murl + '中的数据已被成功插入mongodb')
if __name__ == '__main__':
get_url()
7.如果改成异步形式可以更快,改成下面这样就行了。我试图每分钟比正常情况多获得近 100 条数据。此源代码也在 github 中。
异步
五:总结
这次捕获的数据量约为700,000。这个数据以后可以研究很多,比如播放次数、时间段排名、频道音频音量等等。后续会继续学习使用科学计算和绘图工具进行数据分析和清洗。
捕获的数据是通道信息和通道中的每个音频特定信息。
Paste_Image.png
Paste_Image.png
贴出我的github地址,把我的爬虫代码和我学会的代码写进去,喜欢的可以点击开始关注,一起学习交流!/rieuse/learnPython
抓取网页音频(一下一个爬虫爬虫框架的常见网页更新策略框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-09 16:24
文章内容
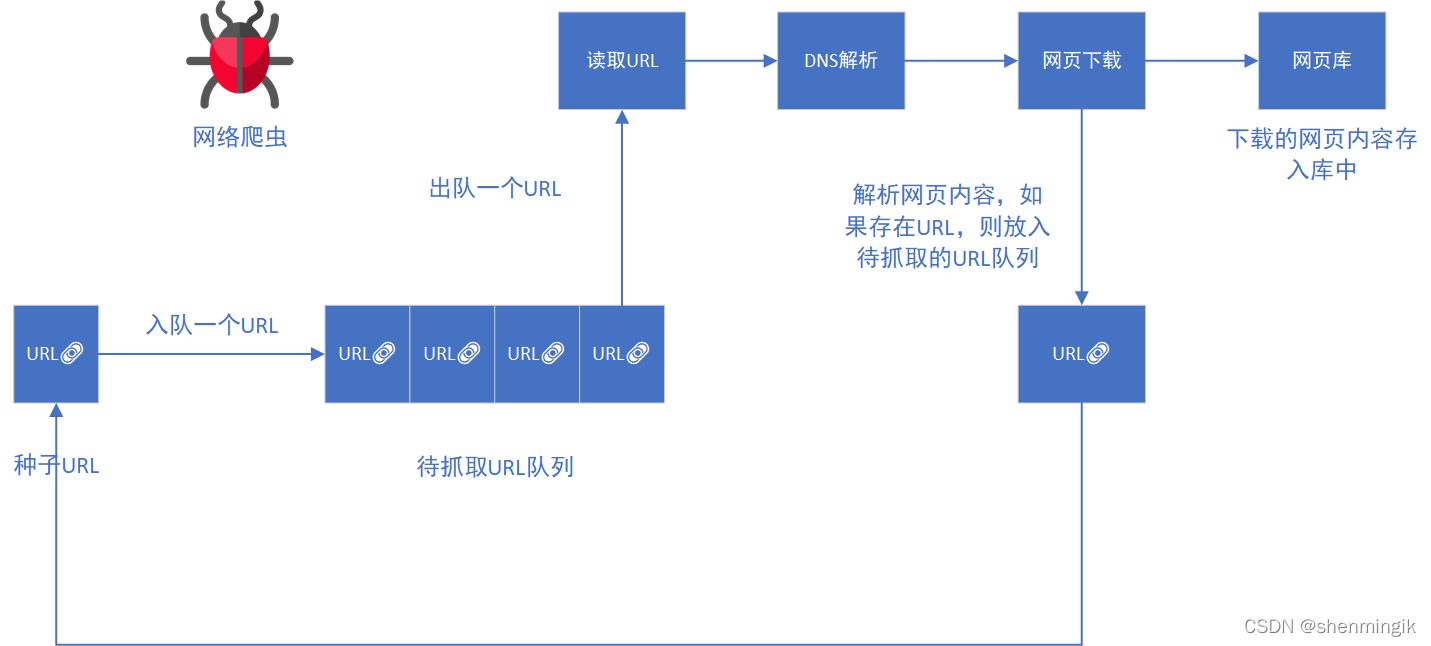
网络爬虫的原理
首先,让我们谈谈什么是爬虫。目前,搜索引擎对象往往是数百个网页,因此搜索引擎面临的主要问题是如何将这些网页存储在本地。用于获取这些网页的工具称为爬虫。
我们来看一个爬虫框架。首先手动选择网页的一部分作为初始网页放入待抓取的URL队列中,然后爬虫框架开始从待抓取的URL队列中取出URL,并下载该网页的内容根据这个网址。这项工作通常由网页下载模块负责。下载网页后,会做两步:
分析网页的内容。如果网页中存在网址,则此时将其放入网址队列中进行抓取。这里需要注意的是对这个操作进行去重。网页存储在网页库中
履带式
爬虫主要分为以下几类:
但是我们要注意的是,无论是哪种爬虫,如果遇到爬虫禁止协议,都不会继续爬取。
爬虫禁止协议一般分为两种情况:
首先是告诉爬虫不要索引网页的内容,标记为noindex:
另一种是告诉爬虫不要抓取网页中收录的链接,使用nofollow作为标记:
爬虫爬取策略
在爬虫框架中,要爬取的URL队列是一个非常关键的部分。需要爬虫爬取的网页的网址排列,形成队列结构。每个爬虫都会从中获取 URL 并爬取内容。爬虫的不同爬取策略是根据不同的方法来确定要爬取的URL队列中URL的优先级。
网页更新策略
网页经常动态变化。因此,对于已经爬取过的网页,爬虫还要负责保持其内容与网页内容同步,这取决于爬虫所采用的网页更新策略。
常见的网页更新策略如下:
参考
[1] 这是搜索引擎 查看全部
抓取网页音频(一下一个爬虫爬虫框架的常见网页更新策略框架)
文章内容
网络爬虫的原理
首先,让我们谈谈什么是爬虫。目前,搜索引擎对象往往是数百个网页,因此搜索引擎面临的主要问题是如何将这些网页存储在本地。用于获取这些网页的工具称为爬虫。
我们来看一个爬虫框架。首先手动选择网页的一部分作为初始网页放入待抓取的URL队列中,然后爬虫框架开始从待抓取的URL队列中取出URL,并下载该网页的内容根据这个网址。这项工作通常由网页下载模块负责。下载网页后,会做两步:
分析网页的内容。如果网页中存在网址,则此时将其放入网址队列中进行抓取。这里需要注意的是对这个操作进行去重。网页存储在网页库中
履带式
爬虫主要分为以下几类:
但是我们要注意的是,无论是哪种爬虫,如果遇到爬虫禁止协议,都不会继续爬取。
爬虫禁止协议一般分为两种情况:
首先是告诉爬虫不要索引网页的内容,标记为noindex:
另一种是告诉爬虫不要抓取网页中收录的链接,使用nofollow作为标记:
爬虫爬取策略
在爬虫框架中,要爬取的URL队列是一个非常关键的部分。需要爬虫爬取的网页的网址排列,形成队列结构。每个爬虫都会从中获取 URL 并爬取内容。爬虫的不同爬取策略是根据不同的方法来确定要爬取的URL队列中URL的优先级。
网页更新策略
网页经常动态变化。因此,对于已经爬取过的网页,爬虫还要负责保持其内容与网页内容同步,这取决于爬虫所采用的网页更新策略。
常见的网页更新策略如下:
参考
[1] 这是搜索引擎
抓取网页音频( 风中蹦迪12-0911:18阅读3关注搜索引擎面对的是互联网万亿网页,如何高效抓取这么多网页到本地镜像?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-09 16:23
风中蹦迪12-0911:18阅读3关注搜索引擎面对的是互联网万亿网页,如何高效抓取这么多网页到本地镜像?)
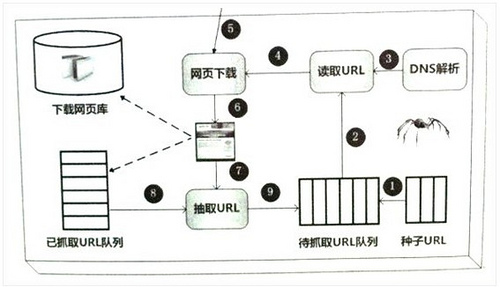
在风中弹跳
12-09 11:18 阅读3
专注于
如何吸引搜索引擎蜘蛛?(蜘蛛抓取网页的规则)
搜索引擎面对互联网上数以万亿计的网页。如何高效抓取这么多网页到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都在与它密切接触
一、爬虫框架
上图是一个简单的网络爬虫框架图。从seed URL开始,如图,一步一步的工作,最后将网页保存到数据库中。当然,勤奋的蜘蛛可能需要做更多的工作,例如:网页去重和反作弊网页。
或许,我们可以把网络当成蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容放在胃里。
过期页面。蜘蛛每次都爬很多网页,有的在肚子里坏了。
要下载的网页。蜘蛛看到食物,就会抓住它。
知乎网页。它还没有被下载和发现,但蜘蛛可以感觉到它们并且迟早会抓住它。
不可知的页面。互联网如此之大,以至于很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及他们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切都很特别。根据功能不同,蜘蛛系统也存在一些差异。
二、爬虫的类型
1. 大量蜘蛛。
这种蜘蛛有明确的爬行范围和目标,当蜘蛛完成目标和任务时停止爬行。具体目标是什么?可能是抓取的页面数量、页面大小、抓取时间等。
2.增量蜘蛛
这种蜘蛛与批量蜘蛛的不同之处在于它们会不断地爬取,并且会周期性地爬取和更新被爬取的网页。由于互联网上的网页在不断更新,增量蜘蛛需要能够反映这种更新。
3.垂直蜘蛛
该蜘蛛只关注特定主题或特定行业网页。以健康网站为例,这种专门的蜘蛛只会抓取健康相关的主题,其他主题内容的网页不会被抓取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛爬行。
三、爬取策略
蜘蛛通过种子网址进行爬取和扩展,列出了大量需要爬取的网址。但是要爬取的网址数量庞大,蜘蛛是如何确定爬取顺序的呢?蜘蛛爬取的策略有很多,但最终的目标是一个:先爬取重要的网页。为了评估页面是否重要,蜘蛛会根据页面内容的原创度、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略
宽度优先是指蜘蛛爬完一个网页后,它会继续按顺序爬取该网页中收录的其他页面。这种想法看似简单,但实际上非常实用。因为大多数网页都是按优先级排序的,重要的页面会优先推荐在页面上。
2. PageRank 策略
PageRank是一种非常著名的链接分析方法,主要用于衡量网页的权重。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法,我们可以找出哪些页面更重要,然后蜘蛛先抓取这些重要的页面。
3.大站点优先策略
这很容易理解。大网站通常内容页比较多,质量会高一些。蜘蛛会先分析网站的分类和属性。如果这个网站已经收录很多,或者在搜索引擎系统中的权重很高,那么优先收录。
四、网页更新
互联网上的大部分页面都是保持更新的,因此也要求蜘蛛存储的页面及时更新以保持一致性。打个比方:一个网页之前排名很好,如果页面被删除了,还排名,那体验就很糟糕了。因此,搜索引擎需要知道这些并随时更新页面,并将最新的页面提供给用户。常用的网页更新策略有三种:历史参考策略和用户体验策略。集群抽样策略。
1.历史参考策略
这是基于假设的更新策略。例如,如果你的网页之前定期更新过,那么搜索引擎也会认为你的网页以后会经常更新,蜘蛛就会定期来网站按照这个规则抓取网页。这也是为什么电水一直强调网站的内容需要定期更新。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人看后面的页面。用户体验策略就是根据用户的这个特点更新搜索引擎。例如,一个网页可能发布较早,有一段时间没有更新,但用户仍然觉得有用,点击浏览,那么搜索引擎可能不会更新这些过时的网页。这就是为什么在搜索结果中,最新的页面不一定排名靠前。排名更依赖于该页面的质量,而不是更新的时间。
3. 聚类抽样策略
以上两种更新策略主要参考网页的历史信息。然而,存储大量的历史信息对搜索引擎来说是一种负担。另外,如果收录是一个新的网页,没有历史资料可以参考,我该怎么办?聚类抽样策略是指根据网页上显示的一些属性对许多相似的网页进行分类,分类后的网页按照相同的规则进行更新。
通过了解搜索引擎蜘蛛工作原理的过程,我们会知道:网站内容的相关性,网站与网页内容的更新规律,网页上的链接分布,而网站的权重等因素会影响蜘蛛的爬行效率。识敌,让蜘蛛来的更猛烈! 查看全部
抓取网页音频(
风中蹦迪12-0911:18阅读3关注搜索引擎面对的是互联网万亿网页,如何高效抓取这么多网页到本地镜像?)

在风中弹跳
12-09 11:18 阅读3
专注于
如何吸引搜索引擎蜘蛛?(蜘蛛抓取网页的规则)
搜索引擎面对互联网上数以万亿计的网页。如何高效抓取这么多网页到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都在与它密切接触
一、爬虫框架
上图是一个简单的网络爬虫框架图。从seed URL开始,如图,一步一步的工作,最后将网页保存到数据库中。当然,勤奋的蜘蛛可能需要做更多的工作,例如:网页去重和反作弊网页。
或许,我们可以把网络当成蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容放在胃里。
过期页面。蜘蛛每次都爬很多网页,有的在肚子里坏了。
要下载的网页。蜘蛛看到食物,就会抓住它。
知乎网页。它还没有被下载和发现,但蜘蛛可以感觉到它们并且迟早会抓住它。
不可知的页面。互联网如此之大,以至于很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及他们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切都很特别。根据功能不同,蜘蛛系统也存在一些差异。
二、爬虫的类型
1. 大量蜘蛛。
这种蜘蛛有明确的爬行范围和目标,当蜘蛛完成目标和任务时停止爬行。具体目标是什么?可能是抓取的页面数量、页面大小、抓取时间等。
2.增量蜘蛛
这种蜘蛛与批量蜘蛛的不同之处在于它们会不断地爬取,并且会周期性地爬取和更新被爬取的网页。由于互联网上的网页在不断更新,增量蜘蛛需要能够反映这种更新。
3.垂直蜘蛛
该蜘蛛只关注特定主题或特定行业网页。以健康网站为例,这种专门的蜘蛛只会抓取健康相关的主题,其他主题内容的网页不会被抓取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛爬行。
三、爬取策略
蜘蛛通过种子网址进行爬取和扩展,列出了大量需要爬取的网址。但是要爬取的网址数量庞大,蜘蛛是如何确定爬取顺序的呢?蜘蛛爬取的策略有很多,但最终的目标是一个:先爬取重要的网页。为了评估页面是否重要,蜘蛛会根据页面内容的原创度、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略
宽度优先是指蜘蛛爬完一个网页后,它会继续按顺序爬取该网页中收录的其他页面。这种想法看似简单,但实际上非常实用。因为大多数网页都是按优先级排序的,重要的页面会优先推荐在页面上。
2. PageRank 策略
PageRank是一种非常著名的链接分析方法,主要用于衡量网页的权重。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法,我们可以找出哪些页面更重要,然后蜘蛛先抓取这些重要的页面。
3.大站点优先策略
这很容易理解。大网站通常内容页比较多,质量会高一些。蜘蛛会先分析网站的分类和属性。如果这个网站已经收录很多,或者在搜索引擎系统中的权重很高,那么优先收录。
四、网页更新
互联网上的大部分页面都是保持更新的,因此也要求蜘蛛存储的页面及时更新以保持一致性。打个比方:一个网页之前排名很好,如果页面被删除了,还排名,那体验就很糟糕了。因此,搜索引擎需要知道这些并随时更新页面,并将最新的页面提供给用户。常用的网页更新策略有三种:历史参考策略和用户体验策略。集群抽样策略。
1.历史参考策略
这是基于假设的更新策略。例如,如果你的网页之前定期更新过,那么搜索引擎也会认为你的网页以后会经常更新,蜘蛛就会定期来网站按照这个规则抓取网页。这也是为什么电水一直强调网站的内容需要定期更新。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人看后面的页面。用户体验策略就是根据用户的这个特点更新搜索引擎。例如,一个网页可能发布较早,有一段时间没有更新,但用户仍然觉得有用,点击浏览,那么搜索引擎可能不会更新这些过时的网页。这就是为什么在搜索结果中,最新的页面不一定排名靠前。排名更依赖于该页面的质量,而不是更新的时间。
3. 聚类抽样策略
以上两种更新策略主要参考网页的历史信息。然而,存储大量的历史信息对搜索引擎来说是一种负担。另外,如果收录是一个新的网页,没有历史资料可以参考,我该怎么办?聚类抽样策略是指根据网页上显示的一些属性对许多相似的网页进行分类,分类后的网页按照相同的规则进行更新。
通过了解搜索引擎蜘蛛工作原理的过程,我们会知道:网站内容的相关性,网站与网页内容的更新规律,网页上的链接分布,而网站的权重等因素会影响蜘蛛的爬行效率。识敌,让蜘蛛来的更猛烈!
抓取网页音频( 本发明网页中音频与视频共存时的音频视频交互方法及系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-07 17:02
本发明网页中音频与视频共存时的音频视频交互方法及系统)
网页音视频共存时的音视频交互方法及系统制作方法
[专利摘要] 本发明公开了一种网页中音视频共存时的音视频交互方法,包括以下步骤: S1:接收视频打开指令,判断网页中是否有音频播放,如果因此,关闭音频并执行步骤S2,否则直接进行步骤S2;S2:根据视频打开指令在网页中插入视频对应的视频对象,在网页中播放视频对象;S3:判断是否接收到视频关闭指令,如果是,则停止播放视频对象;如果没有,视频对象将一直播放到结束。
[专利描述] 网页中音视频共存时的音视频交互方法及系统
【技术领域】
[0001] 本发明涉及计算机[技术领域],尤其涉及一种网页中音视频共存时的音视频交互方法及系统。
【背景技术】
[0002] 现有技术中,在浏览网页时,由于页面中往往嵌入了视频,部分视频是自动播放的,因此往往无法捕捉视频的播放、暂停等交互操作。当页面上同时存在音频和视频时,如果直接在页面上显示视频,则无法确定何时停止音频以及何时开始音频。音视频的播放容易产生干扰,导致两者播放效果不佳。
[发明概要]
[0003] 本发明要解决的技术问题是提供一种网页中音视频共存时的音视频交互方法及系统。
[0004] 本发明解决其技术问题所采用的技术方案是提供一种网页中音视频共存时的音视频交互方法,包括以下步骤:
[0005] S1:接收视频打开指令,判断网页中是否有音频播放,如果有,则关闭音频,执行步骤S2,如果没有,则直接执行步骤S2;
[0006] S2、根据视频打开指令在网页中插入视频对应的视频对象,并在网页中播放视频对象;
[0007] S3:判断是否接收到视频关闭指令,如果是,停止播放视频对象;如果没有,则播放视频对象直到结束。
[0008] 优选地,在步骤S1中,在网页中设置视频封面,当用户点击视频封面时,生成视频打开指令,网页接收视频打开指令并隐藏视频封面; 在步骤S2中,在视频封面的位置插入该视频对应的视频对象。
[0009] 优选地,在步骤S3中,在视频播放过程中,如果用户点击视频对象外的页面区域,则生成视频关闭指令打开音频;和/或在视频对象外设置关闭按钮,如果用户点击关闭按钮,视频关闭时,第一频率开启。
[0010] 优选地,在步骤S3中,当打开音频时,删除视频对象,或者删除视频对象并显示视频封面。
[0011] 优选地,所述网页为智能手机的网页;视频对象是 Iframe、Flash 或帧对象。
[0012] 还提供了一种网页中音视频共存时的音视频交互系统,包括:
[0013] 接收模块用于接收视频打开指令和视频关闭指令;
[0014] 第一判断模块用于根据视频打开指令判断网页中是否有音频播放,并输出第一判断结果。
[0015] 第二判断模块,用于判断是否接收到视频关闭指令,并输出第二判断结果;
[0016] 交互模块用于根据第一判断结果关闭音频,在网页中插入与视频对应的视频对象,并在网页中播放视频对象。并根据第二判断结果停止播放视频对象或播放视频对象直到结束。
[0017] 优选地,该系统还包括封面处理模块,封面处理模块用于在网页中设置视频封面,当用户点击视频封面时,生成视频打开指令输出给接收端模块; 交互模块还用于根据视频打开指令隐藏视频封面,在视频封面位置插入视频对应的视频对象。
[0018] 优选地,封面处理模块还用于当用户在视频播放过程中点击视频对象外的页面区域时,生成视频关闭指令并输出到接收模块,交互模块控制音频为打开; 和/或者,封面处理模块还用于在视频对象外设置关闭按钮,当用户点击关闭按钮时生成视频关闭指令,并将视频关闭指令输出到接收模块,交互模块控制要打开的音频。
[0019] 优选地,交互模块还用于在打开音频时删除视频对象,或者删除视频对象并显示视频封面。
[0020] 优选地,所述网页为智能手机的网页;视频对象是 Iframe、Flash 或帧对象。
[0021]实施本发明的有益效果是:本发明的网页中音视频共存时的音视频交互方法及系统,通过在接收到视频打开指令时切换音视频或视频关闭指令,避免视频和音频播放的干扰。
【专利图】
【图纸说明】
[0022] 下面结合附图和实施例对本发明作进一步说明。在附图中:
[0023] 图 附图说明图1为本发明实施例提供的网页中音视频共存时的音视频交互方法的流程图。
[0024] 图 图2为本发明实施例提供的网页中音视频共存时的音视频交互系统的模块示意图。
【详细方式】
[0025] 为了更清楚地理解本发明的技术特征、目的和效果,现结合附图对本发明进行详细说明。
[0026] 图 图1示出了本发明一些实施例中的一种音视频交互方法。该方法用于当网页中存在音视频共存时,根据相应的视频打开指令关闭音频并打开视频。对应的视频关闭指令关闭视频,使得音频的播放和视频的播放互不干扰。可以理解,网页可以是智能手机通过浏览器打开的网页,智能手机通过App应用打开的网页,电脑通过浏览器打开的网页,电脑通过应用打开的网页,以及很快。优选地,所述音视频交互方式为应用于Light APP网页的音视频交互方式。
[0027] 在一些实施例中,音视频交互方法包括以下步骤:
[0028] S1:接收视频打开指令,判断网页中是否有音频播放,如果有,则关闭音频,执行步骤S2,如果没有,则直接执行步骤S2。
[0029] 本步骤中需要说明的是,在接收到视频打开指令后,需要关闭播放音频,以免干扰要打开的视频。在这里,如果网页中没有音频或者没有正在播放的音频,则无需关闭音频,只需执行下一步打开视频即可。
[0030] 或者,接收视频打开指令可以有多种形式,例如:1)在网页中插入视频播放按钮,当用户点击该按钮时,网页接收视频打开操作说明; 2)在网页中插入链接,当用户点击链接时,网页收到视频打开指令;3)在网页中插入一个音频停止按钮,当用户点击该按钮时,网页接收到视频打开指令。接收视频打开指令的形式不限于上述几种,只要网页通过用户交互接收视频打开指令即可。
[0031] 在一些优选实施例中,接收视频打开指令的形式如下:在网页中设置视频封面,当用户点击视频封面时生成视频打开指令,网页接收视频打开指令,隐藏视频封面。或者,网页在接收到视频打开指令后也可以不隐藏视频封面。优选地,视频封面可以是视频对象的缩略图,或者视频封面也可以设置为带有视频打开按钮的缩略图。
[0032] S2、根据视频打开指令在网页中插入视频对应的视频对象,并在网页中播放视频对象。
[0033] 在本步骤中,需要说明的是,在设置视频封面的优选实施例中,在视频封面的位置插入视频对应的视频对象。或者,您可以直接在整个页面上插入视频对象,而不是在视频封面位置插入视频对象,以进行全屏播放。或者,当网页收到视频打开指令且不隐藏视频封面时,也可以直接在整个页面上插入视频对象进行全屏播放。
[0034] 或者,视频对象可以是Iframe、Flash或帧对象。优选地,视频对象是Iframe。
[0035] S3:判断是否接收到视频关闭指令,如果是,则停止播放视频对象;如果没有,则播放视频对象直到结束。
[0036] 本步骤中需要说明的是,在视频播放时,接收视频关闭指令的方式有多种:1)在视频对象外设置关闭按钮,当用户点击关闭按钮视频关闭指令;2) 设置在视频对象外的页面区域接收视频关闭指令的功能。如果用户点击视频对象外的页面区域,会产生视频关闭指令并打开音频。接收视频关闭指令的形式不限于上述几种,只要网页通过用户交互接收视频关闭指令即可。
[0037] 视频对象停止/播放后,还可以在打开音频时删除视频对象;或者,在设置视频封面的优选实施例中,也可以删除视频对象,删除之前隐藏的视频封面。
[0038] 图 图2示出了根据本发明一些实施例的网页中音频和视频共存时的音频和视频交互系统。该系统包括接收模块100、第一判断模块300、第二判断模块500、、交互模块700和封面处理模块900。可以理解,网页可以是一个智能手机通过浏览器打开的网页,智能手机通过App应用打开的网页,电脑通过浏览器打开的网页,电脑通过应用打开的网页等等。
[0039] 其中,封面处理模块900用于在网页中设置视频封面,当用户点击视频封面时,生成视频打开指令并输出至接收模块100。或者,封面可以设置或不设置处理模块900。
[0040] 接收模块100用于接收视频打开指令和视频关闭指令。接收模块100以如下形式接收视频打开指令:封面处理模块900设置视频封面,当用户点击视频封面时,生成视频打开指令,交互模块700根据以下方式隐藏视频封面视频打开指令,并在视频封面位置插入对应的视频封面 视频的视频对象。或者,交互模块700可以不隐藏视频封面。优选地,视频封面可以是视频对象的缩略图,或者视频封面也可以设置为带有视频打开按钮的缩略图。
[0041] 或者,当不设置封面处理模块900时,接收模块100可以接收多种形式的视频打开指令,例如:1)插入视频播放按钮,当用户点击该按钮时,接收模块100接收视频开启指令;2)插入链接,当用户点击链接时,接收模块100接收视频打开指令;3)插入音频停止按钮,当用户点击该按钮时,接收模块100接收视频打开指令。接收模块100接收视频开启指令的形式不限于以上所列,只要接收模块100可以通过用户交互接收视频开启指令即可。
[0042] 在视频播放过程中,接收模块100可以通过多种方式接收视频关闭指令:1)封面处理模块900在视频对象外设置关闭按钮,并在用户点击时生成视频关闭指令关闭按钮,并向接收模块100输出视频关闭指令;2)封面处理模块900在用户点击视频对象外的页面区域时,生成视频关闭指令并输出到接收模块100。
[0043] 或者,当不设置封面处理模块900时,在视频播放过程中,接收模块100可以通过多种方式接收视频关闭指令:1)用户点击设置在视频对象A外的关闭按钮此时生成视频关闭指令;2)用户点击视频对象外的页面区域产生视频关闭指令,接收模块100接收视频关闭指令。接收模块100接收视频关闭指令的方式不限于上述方式,只要接收模块100可以通过用户交互接收视频关闭指令即可。
[0044] 第一判断模块300,用于根据视频打开指令判断网页中是否有音频播放,并输出第一判断结果。可以理解的是,接收模块100接收到视频打开指令后,需要关闭播放音频,以避免干扰要打开的视频。在这里,如果网页中没有音频或者没有正在播放的音频,则无需关闭音频,只需执行下一步打开视频即可。
[0045] 第二判断模块500,用于判断是否接收到视频关闭指令,并输出第二判断结果。第二判断结果包括接收视频关闭指令和未接收视频关闭指令。
[0046] 交互模块700,用于根据第一判断结果关闭音频,在网页中插入与视频对应的视频对象,并在网页中播放视频对象。或者,视频对象可以是 Iframe、Flash 或帧对象。优选地,视频对象是Iframe。
[0047] 交互模块700还用于根据第二判断结果停止播放视频对象或播放视频对象直到结束。当第二判断结果为接收到视频关闭指令时,交互模块700停止播放视频对象;当第二判断结果为视频对象未停止时,交互模块700播放视频对象直至结束。
[0048] 在视频对象停止/播放后,交互模块700还用于同时打开音频和删除视频对象,或者,在一个优选实施例中,封面处理模块900设置视频封面,交互模块700还可以删除视频对象并显示视频封面。
[0049] 以上仅为本发明的优选实施例而已,本发明的保护范围不限于上述实施例。凡属于本发明构思之内的技术方案,均属于本发明的保护范围。需要指出的是,对于【技术领域】的普通技术人员来说,在不脱离本发明的原则的情况下,还有多种改进和修改,这些改进和修改也应视为本发明的保护范围。发明。
【权利要求】
1. 一种网页中音视频共存时的音视频交互方法,其特征在于包括以下步骤: S1:接收视频打开指令,判断网页中是否有音频播放;如果是,则关闭音频并执行步骤S2,如果不是,则直接进行步骤S2;S2、根据视频打开指令在网页中插入视频对应的视频对象,在网页上播放该视频对象;S3:判断是否收到视频关闭指令,如果是,停止播放视频对象;如果没有,则播放视频对象直到结束。
2.根据权利要求1所述的音视频交互方法,其特征在于,在步骤SI中,在网页中设置视频封面,当用户点击视频封面时生成视频打开指令,网页接收视频打开指令,隐藏视频封面;在步骤S2中,在视频封面的位置插入视频对应的视频对象。
3.根据权利要求2所述的音视频交互方法,其特征在于,在步骤S3中,在播放视频时,如果用户点击视频对象以外的页面区域,则视频关闭指令打开音频;和/或,在视频对象外设置关闭按钮,如果用户点击关闭按钮时产生视频关闭指令,则开启音频。
4.如权利要求3所述的音视频交互方法,其特征在于,在步骤S3中,当打开音频时,删除视频对象,或者删除视频对象并删除视频封面。
5.如权利要求1至4任一项所述的音视频交互方法,其特征在于,所述网页为智能手机网页;并且视频对象是 Iframe、Flash 或 frame 对象。
6.——网页中一频和视频共存时的一频视频交互系统,其特征在于包括:接收模块(100),用于接收视频打开指令和视频关闭指令; 判断模块(300),用于根据视频打开指令判断网页是否有音频播放,并输出第一判断结果;第二判断模块(500) ,用于判断是否接收到视频关闭指令并输出第二判断结果; 交互模块(700),用于根据第一判断结果关闭音频,并在其中插入视频对应的视频对象网页,播放网页中的视频对象;根据第二判断结果停止播放视频对象或播放视频对象直至结束。
7.根据权利要求6所述的音视频交互系统,其特征在于,该系统还包括封面处理模块(900),封面处理模块(900)用于A网页中设置视频封面,当用户点击视频封面时,生成视频打开指令并输出到接收模块(100);交互模块(700)为也用于根据视频打开指令隐藏视频封面,在视频封面位置插入视频对应的视频对象。
8.如权利要求6所述的音视频交互系统,其特征在于,所述封面处理模块(900)还用于当用户在播放视频时点击视频对象时。页面区域,生成视频关闭指令并输出到接收模块(100),交互模块(700)控制音频开启;和/或,封面处理)模块(900)还用于在视频对象外设置一个关闭按钮,在用户点击关闭按钮时生成视频关闭指令,并将视频关闭指令输出到接收模块(10< @0),交互模块(700))控制开启音频。
9.如权利要求7所述的音视频交互系统,其特征在于,所述交互模块(700)还用于在开启音频时删除视频对象,或者,删除视频对象并显示视频封面。
10.如权利要求6至9任一项所述的音视频交互系统,其特征在于,所述网页为智能手机网页;并且视频对象是 Iframe、Flash 或 frame 对象。
【文件编号】H04N21/472GK104202674SQ2
【出版日期】2014年12月10日申请日期:2014年8月29日优先权日期:2014年8月29日
【发明人】张晓刚、姜天雄申请人: 查看全部
抓取网页音频(
本发明网页中音频与视频共存时的音频视频交互方法及系统)
网页音视频共存时的音视频交互方法及系统制作方法
[专利摘要] 本发明公开了一种网页中音视频共存时的音视频交互方法,包括以下步骤: S1:接收视频打开指令,判断网页中是否有音频播放,如果因此,关闭音频并执行步骤S2,否则直接进行步骤S2;S2:根据视频打开指令在网页中插入视频对应的视频对象,在网页中播放视频对象;S3:判断是否接收到视频关闭指令,如果是,则停止播放视频对象;如果没有,视频对象将一直播放到结束。
[专利描述] 网页中音视频共存时的音视频交互方法及系统
【技术领域】
[0001] 本发明涉及计算机[技术领域],尤其涉及一种网页中音视频共存时的音视频交互方法及系统。
【背景技术】
[0002] 现有技术中,在浏览网页时,由于页面中往往嵌入了视频,部分视频是自动播放的,因此往往无法捕捉视频的播放、暂停等交互操作。当页面上同时存在音频和视频时,如果直接在页面上显示视频,则无法确定何时停止音频以及何时开始音频。音视频的播放容易产生干扰,导致两者播放效果不佳。
[发明概要]
[0003] 本发明要解决的技术问题是提供一种网页中音视频共存时的音视频交互方法及系统。
[0004] 本发明解决其技术问题所采用的技术方案是提供一种网页中音视频共存时的音视频交互方法,包括以下步骤:
[0005] S1:接收视频打开指令,判断网页中是否有音频播放,如果有,则关闭音频,执行步骤S2,如果没有,则直接执行步骤S2;
[0006] S2、根据视频打开指令在网页中插入视频对应的视频对象,并在网页中播放视频对象;
[0007] S3:判断是否接收到视频关闭指令,如果是,停止播放视频对象;如果没有,则播放视频对象直到结束。
[0008] 优选地,在步骤S1中,在网页中设置视频封面,当用户点击视频封面时,生成视频打开指令,网页接收视频打开指令并隐藏视频封面; 在步骤S2中,在视频封面的位置插入该视频对应的视频对象。
[0009] 优选地,在步骤S3中,在视频播放过程中,如果用户点击视频对象外的页面区域,则生成视频关闭指令打开音频;和/或在视频对象外设置关闭按钮,如果用户点击关闭按钮,视频关闭时,第一频率开启。
[0010] 优选地,在步骤S3中,当打开音频时,删除视频对象,或者删除视频对象并显示视频封面。
[0011] 优选地,所述网页为智能手机的网页;视频对象是 Iframe、Flash 或帧对象。
[0012] 还提供了一种网页中音视频共存时的音视频交互系统,包括:
[0013] 接收模块用于接收视频打开指令和视频关闭指令;
[0014] 第一判断模块用于根据视频打开指令判断网页中是否有音频播放,并输出第一判断结果。
[0015] 第二判断模块,用于判断是否接收到视频关闭指令,并输出第二判断结果;
[0016] 交互模块用于根据第一判断结果关闭音频,在网页中插入与视频对应的视频对象,并在网页中播放视频对象。并根据第二判断结果停止播放视频对象或播放视频对象直到结束。
[0017] 优选地,该系统还包括封面处理模块,封面处理模块用于在网页中设置视频封面,当用户点击视频封面时,生成视频打开指令输出给接收端模块; 交互模块还用于根据视频打开指令隐藏视频封面,在视频封面位置插入视频对应的视频对象。
[0018] 优选地,封面处理模块还用于当用户在视频播放过程中点击视频对象外的页面区域时,生成视频关闭指令并输出到接收模块,交互模块控制音频为打开; 和/或者,封面处理模块还用于在视频对象外设置关闭按钮,当用户点击关闭按钮时生成视频关闭指令,并将视频关闭指令输出到接收模块,交互模块控制要打开的音频。
[0019] 优选地,交互模块还用于在打开音频时删除视频对象,或者删除视频对象并显示视频封面。
[0020] 优选地,所述网页为智能手机的网页;视频对象是 Iframe、Flash 或帧对象。
[0021]实施本发明的有益效果是:本发明的网页中音视频共存时的音视频交互方法及系统,通过在接收到视频打开指令时切换音视频或视频关闭指令,避免视频和音频播放的干扰。
【专利图】
【图纸说明】
[0022] 下面结合附图和实施例对本发明作进一步说明。在附图中:
[0023] 图 附图说明图1为本发明实施例提供的网页中音视频共存时的音视频交互方法的流程图。
[0024] 图 图2为本发明实施例提供的网页中音视频共存时的音视频交互系统的模块示意图。
【详细方式】
[0025] 为了更清楚地理解本发明的技术特征、目的和效果,现结合附图对本发明进行详细说明。
[0026] 图 图1示出了本发明一些实施例中的一种音视频交互方法。该方法用于当网页中存在音视频共存时,根据相应的视频打开指令关闭音频并打开视频。对应的视频关闭指令关闭视频,使得音频的播放和视频的播放互不干扰。可以理解,网页可以是智能手机通过浏览器打开的网页,智能手机通过App应用打开的网页,电脑通过浏览器打开的网页,电脑通过应用打开的网页,以及很快。优选地,所述音视频交互方式为应用于Light APP网页的音视频交互方式。
[0027] 在一些实施例中,音视频交互方法包括以下步骤:
[0028] S1:接收视频打开指令,判断网页中是否有音频播放,如果有,则关闭音频,执行步骤S2,如果没有,则直接执行步骤S2。
[0029] 本步骤中需要说明的是,在接收到视频打开指令后,需要关闭播放音频,以免干扰要打开的视频。在这里,如果网页中没有音频或者没有正在播放的音频,则无需关闭音频,只需执行下一步打开视频即可。
[0030] 或者,接收视频打开指令可以有多种形式,例如:1)在网页中插入视频播放按钮,当用户点击该按钮时,网页接收视频打开操作说明; 2)在网页中插入链接,当用户点击链接时,网页收到视频打开指令;3)在网页中插入一个音频停止按钮,当用户点击该按钮时,网页接收到视频打开指令。接收视频打开指令的形式不限于上述几种,只要网页通过用户交互接收视频打开指令即可。
[0031] 在一些优选实施例中,接收视频打开指令的形式如下:在网页中设置视频封面,当用户点击视频封面时生成视频打开指令,网页接收视频打开指令,隐藏视频封面。或者,网页在接收到视频打开指令后也可以不隐藏视频封面。优选地,视频封面可以是视频对象的缩略图,或者视频封面也可以设置为带有视频打开按钮的缩略图。
[0032] S2、根据视频打开指令在网页中插入视频对应的视频对象,并在网页中播放视频对象。
[0033] 在本步骤中,需要说明的是,在设置视频封面的优选实施例中,在视频封面的位置插入视频对应的视频对象。或者,您可以直接在整个页面上插入视频对象,而不是在视频封面位置插入视频对象,以进行全屏播放。或者,当网页收到视频打开指令且不隐藏视频封面时,也可以直接在整个页面上插入视频对象进行全屏播放。
[0034] 或者,视频对象可以是Iframe、Flash或帧对象。优选地,视频对象是Iframe。
[0035] S3:判断是否接收到视频关闭指令,如果是,则停止播放视频对象;如果没有,则播放视频对象直到结束。
[0036] 本步骤中需要说明的是,在视频播放时,接收视频关闭指令的方式有多种:1)在视频对象外设置关闭按钮,当用户点击关闭按钮视频关闭指令;2) 设置在视频对象外的页面区域接收视频关闭指令的功能。如果用户点击视频对象外的页面区域,会产生视频关闭指令并打开音频。接收视频关闭指令的形式不限于上述几种,只要网页通过用户交互接收视频关闭指令即可。
[0037] 视频对象停止/播放后,还可以在打开音频时删除视频对象;或者,在设置视频封面的优选实施例中,也可以删除视频对象,删除之前隐藏的视频封面。
[0038] 图 图2示出了根据本发明一些实施例的网页中音频和视频共存时的音频和视频交互系统。该系统包括接收模块100、第一判断模块300、第二判断模块500、、交互模块700和封面处理模块900。可以理解,网页可以是一个智能手机通过浏览器打开的网页,智能手机通过App应用打开的网页,电脑通过浏览器打开的网页,电脑通过应用打开的网页等等。
[0039] 其中,封面处理模块900用于在网页中设置视频封面,当用户点击视频封面时,生成视频打开指令并输出至接收模块100。或者,封面可以设置或不设置处理模块900。
[0040] 接收模块100用于接收视频打开指令和视频关闭指令。接收模块100以如下形式接收视频打开指令:封面处理模块900设置视频封面,当用户点击视频封面时,生成视频打开指令,交互模块700根据以下方式隐藏视频封面视频打开指令,并在视频封面位置插入对应的视频封面 视频的视频对象。或者,交互模块700可以不隐藏视频封面。优选地,视频封面可以是视频对象的缩略图,或者视频封面也可以设置为带有视频打开按钮的缩略图。
[0041] 或者,当不设置封面处理模块900时,接收模块100可以接收多种形式的视频打开指令,例如:1)插入视频播放按钮,当用户点击该按钮时,接收模块100接收视频开启指令;2)插入链接,当用户点击链接时,接收模块100接收视频打开指令;3)插入音频停止按钮,当用户点击该按钮时,接收模块100接收视频打开指令。接收模块100接收视频开启指令的形式不限于以上所列,只要接收模块100可以通过用户交互接收视频开启指令即可。
[0042] 在视频播放过程中,接收模块100可以通过多种方式接收视频关闭指令:1)封面处理模块900在视频对象外设置关闭按钮,并在用户点击时生成视频关闭指令关闭按钮,并向接收模块100输出视频关闭指令;2)封面处理模块900在用户点击视频对象外的页面区域时,生成视频关闭指令并输出到接收模块100。
[0043] 或者,当不设置封面处理模块900时,在视频播放过程中,接收模块100可以通过多种方式接收视频关闭指令:1)用户点击设置在视频对象A外的关闭按钮此时生成视频关闭指令;2)用户点击视频对象外的页面区域产生视频关闭指令,接收模块100接收视频关闭指令。接收模块100接收视频关闭指令的方式不限于上述方式,只要接收模块100可以通过用户交互接收视频关闭指令即可。
[0044] 第一判断模块300,用于根据视频打开指令判断网页中是否有音频播放,并输出第一判断结果。可以理解的是,接收模块100接收到视频打开指令后,需要关闭播放音频,以避免干扰要打开的视频。在这里,如果网页中没有音频或者没有正在播放的音频,则无需关闭音频,只需执行下一步打开视频即可。
[0045] 第二判断模块500,用于判断是否接收到视频关闭指令,并输出第二判断结果。第二判断结果包括接收视频关闭指令和未接收视频关闭指令。
[0046] 交互模块700,用于根据第一判断结果关闭音频,在网页中插入与视频对应的视频对象,并在网页中播放视频对象。或者,视频对象可以是 Iframe、Flash 或帧对象。优选地,视频对象是Iframe。
[0047] 交互模块700还用于根据第二判断结果停止播放视频对象或播放视频对象直到结束。当第二判断结果为接收到视频关闭指令时,交互模块700停止播放视频对象;当第二判断结果为视频对象未停止时,交互模块700播放视频对象直至结束。
[0048] 在视频对象停止/播放后,交互模块700还用于同时打开音频和删除视频对象,或者,在一个优选实施例中,封面处理模块900设置视频封面,交互模块700还可以删除视频对象并显示视频封面。
[0049] 以上仅为本发明的优选实施例而已,本发明的保护范围不限于上述实施例。凡属于本发明构思之内的技术方案,均属于本发明的保护范围。需要指出的是,对于【技术领域】的普通技术人员来说,在不脱离本发明的原则的情况下,还有多种改进和修改,这些改进和修改也应视为本发明的保护范围。发明。
【权利要求】
1. 一种网页中音视频共存时的音视频交互方法,其特征在于包括以下步骤: S1:接收视频打开指令,判断网页中是否有音频播放;如果是,则关闭音频并执行步骤S2,如果不是,则直接进行步骤S2;S2、根据视频打开指令在网页中插入视频对应的视频对象,在网页上播放该视频对象;S3:判断是否收到视频关闭指令,如果是,停止播放视频对象;如果没有,则播放视频对象直到结束。
2.根据权利要求1所述的音视频交互方法,其特征在于,在步骤SI中,在网页中设置视频封面,当用户点击视频封面时生成视频打开指令,网页接收视频打开指令,隐藏视频封面;在步骤S2中,在视频封面的位置插入视频对应的视频对象。
3.根据权利要求2所述的音视频交互方法,其特征在于,在步骤S3中,在播放视频时,如果用户点击视频对象以外的页面区域,则视频关闭指令打开音频;和/或,在视频对象外设置关闭按钮,如果用户点击关闭按钮时产生视频关闭指令,则开启音频。
4.如权利要求3所述的音视频交互方法,其特征在于,在步骤S3中,当打开音频时,删除视频对象,或者删除视频对象并删除视频封面。
5.如权利要求1至4任一项所述的音视频交互方法,其特征在于,所述网页为智能手机网页;并且视频对象是 Iframe、Flash 或 frame 对象。
6.——网页中一频和视频共存时的一频视频交互系统,其特征在于包括:接收模块(100),用于接收视频打开指令和视频关闭指令; 判断模块(300),用于根据视频打开指令判断网页是否有音频播放,并输出第一判断结果;第二判断模块(500) ,用于判断是否接收到视频关闭指令并输出第二判断结果; 交互模块(700),用于根据第一判断结果关闭音频,并在其中插入视频对应的视频对象网页,播放网页中的视频对象;根据第二判断结果停止播放视频对象或播放视频对象直至结束。
7.根据权利要求6所述的音视频交互系统,其特征在于,该系统还包括封面处理模块(900),封面处理模块(900)用于A网页中设置视频封面,当用户点击视频封面时,生成视频打开指令并输出到接收模块(100);交互模块(700)为也用于根据视频打开指令隐藏视频封面,在视频封面位置插入视频对应的视频对象。
8.如权利要求6所述的音视频交互系统,其特征在于,所述封面处理模块(900)还用于当用户在播放视频时点击视频对象时。页面区域,生成视频关闭指令并输出到接收模块(100),交互模块(700)控制音频开启;和/或,封面处理)模块(900)还用于在视频对象外设置一个关闭按钮,在用户点击关闭按钮时生成视频关闭指令,并将视频关闭指令输出到接收模块(10< @0),交互模块(700))控制开启音频。
9.如权利要求7所述的音视频交互系统,其特征在于,所述交互模块(700)还用于在开启音频时删除视频对象,或者,删除视频对象并显示视频封面。
10.如权利要求6至9任一项所述的音视频交互系统,其特征在于,所述网页为智能手机网页;并且视频对象是 Iframe、Flash 或 frame 对象。
【文件编号】H04N21/472GK104202674SQ2
【出版日期】2014年12月10日申请日期:2014年8月29日优先权日期:2014年8月29日
【发明人】张晓刚、姜天雄申请人:
抓取网页音频(猫抓插件免费版下载体积小巧,占用内存空间非常少,运行速度快)
网站优化 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-12-06 03:10
Mozhao插件是一款专业可靠的网络媒体嗅探工具,可以读取和更改您正在访问的网站上的所有数据,并可以管理您的下载内容。使用它可以获取各大网站视频和音乐的地址,如优酷、搜狐、腾讯、微博、B站、网易云、QQ音乐、酷狗等平台资源地址,帮助用户快速获取视频链接数据和音乐网站 音频文件。该软件允许用户自定义要采集的视频和音频格式,还支持使用正则表达式自定义要采集的内容,然后可以对需要的地址资源进行批量快速的操作,高效又快捷。方便的。该软件的优点是可以嗅探检测IDM下载器无法检测到的资源 t嗅探,然后下载资源,可以很好的满足用户的需求。这里有免费下载的猫抓插件,体积小,占用内存空间小,运行速度快。不会造成系统其他程序的滞后,也不会减慢其他程序的运行速度。它不会影响系统。时刻保持稳定安全的运行状态,有需要的快来下载体验吧。
安装教程1、先在浏览器中输入chrome://extensions,然后就可以进入浏览器的扩展界面
2、将毛扎1.0.15文件夹直接移到扩展界面
3、 然后浏览器会显示猫爪图标,安装成功。
使用教程 1、 安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮,在页面可以看到资源信息
2、 然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地
3、猫扎插件支持几乎所有国内的网站视频文件嗅探,如优酷、搜狐、腾讯、微博、B站等,也可以在多个媒体资源出现在同一个页。对它们执行快速批处理操作
4、 此外,毛爪还支持所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间的音乐。在【选项】中,用户还可以自定义采集的视频和音频格式,也支持使用正则表达式自定义采集的内容
功能介绍1、 支持抓取任意站点任意数据;
2、多个站点可以同时更新;
3、 支持使用正则表达式自定义要抓取的内容。
精选亮点1、 是一款Chrome嗅探音乐视频插件,大小只有几十k。
2、 无论是看视频还是听音乐,都可以通过猫爪插件进行捕捉。您只需要点击即可下载。
3、也可以在设置中自定义配置,可以抓取图片、文档等各种资源文件。
4、当然还有更多,可以和IDM一起使用。拥有如此多的素材来源,您可以通过慢慢练习成为出色的剪辑大师。
软件特点1、可以抓取任意站点的视频和音频,可以下载;
2、 并支持批量下载;
3、已知插件支持网站优酷、爱奇艺、搜狐、微博、B站、乐视等知名视频门户。
哪里可以查看FAQ抓取的资源?
1、 点击插件图标查看爬取的资源;
2、 视频格式文件有播放按钮和下载按钮;
3、您可以根据需要下载文件。. 查看全部
抓取网页音频(猫抓插件免费版下载体积小巧,占用内存空间非常少,运行速度快)
Mozhao插件是一款专业可靠的网络媒体嗅探工具,可以读取和更改您正在访问的网站上的所有数据,并可以管理您的下载内容。使用它可以获取各大网站视频和音乐的地址,如优酷、搜狐、腾讯、微博、B站、网易云、QQ音乐、酷狗等平台资源地址,帮助用户快速获取视频链接数据和音乐网站 音频文件。该软件允许用户自定义要采集的视频和音频格式,还支持使用正则表达式自定义要采集的内容,然后可以对需要的地址资源进行批量快速的操作,高效又快捷。方便的。该软件的优点是可以嗅探检测IDM下载器无法检测到的资源 t嗅探,然后下载资源,可以很好的满足用户的需求。这里有免费下载的猫抓插件,体积小,占用内存空间小,运行速度快。不会造成系统其他程序的滞后,也不会减慢其他程序的运行速度。它不会影响系统。时刻保持稳定安全的运行状态,有需要的快来下载体验吧。
安装教程1、先在浏览器中输入chrome://extensions,然后就可以进入浏览器的扩展界面
2、将毛扎1.0.15文件夹直接移到扩展界面
3、 然后浏览器会显示猫爪图标,安装成功。

使用教程 1、 安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮,在页面可以看到资源信息
2、 然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地

3、猫扎插件支持几乎所有国内的网站视频文件嗅探,如优酷、搜狐、腾讯、微博、B站等,也可以在多个媒体资源出现在同一个页。对它们执行快速批处理操作

4、 此外,毛爪还支持所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间的音乐。在【选项】中,用户还可以自定义采集的视频和音频格式,也支持使用正则表达式自定义采集的内容

功能介绍1、 支持抓取任意站点任意数据;
2、多个站点可以同时更新;
3、 支持使用正则表达式自定义要抓取的内容。
精选亮点1、 是一款Chrome嗅探音乐视频插件,大小只有几十k。
2、 无论是看视频还是听音乐,都可以通过猫爪插件进行捕捉。您只需要点击即可下载。
3、也可以在设置中自定义配置,可以抓取图片、文档等各种资源文件。
4、当然还有更多,可以和IDM一起使用。拥有如此多的素材来源,您可以通过慢慢练习成为出色的剪辑大师。

软件特点1、可以抓取任意站点的视频和音频,可以下载;
2、 并支持批量下载;
3、已知插件支持网站优酷、爱奇艺、搜狐、微博、B站、乐视等知名视频门户。
哪里可以查看FAQ抓取的资源?
1、 点击插件图标查看爬取的资源;
2、 视频格式文件有播放按钮和下载按钮;
3、您可以根据需要下载文件。.
抓取网页音频(InternetDownloadIDM功能——“站点抓取”的含义!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-06 03:08
Internet Download Manager(简称IDM)是一款功能强大的下载器。它采用多线程技术,大大提高文件下载速度。即使是非常大的文件也可以轻松快速地集成。它声称可以将您的下载速度提高多达 5 倍。
不过今天要给大家推荐的是我最近发现的一个IDM功能——“站点爬取”。我以前从不关心它。我最近才发现这个功能非常有用。下面就给大家介绍一下它的神奇之处。
“网站爬行”的含义
如图1所示,该功能允许您输入网页链接,选择您要下载的网页的指定内容,包括图片、音频、视频、文件,甚至收录网站@完整样式的离线文件>,并允许用户根据自己的需要自定义内容。定义站点抓取的内容和规则,并保存以方便下次调用。
图1:网站爬取界面
“网站爬取”功能的神奇使用
如果您在工作中遇到断开连接或网络不好的情况,请使用 Internet 下载管理器站点抓取并保存一些需要浏览的网页,以确保您的工作顺利进行。
如图2所示,根据要保存的内容进行选择。有“所有图片”、“所有视频”、“完整起始页”等,您可以根据需要选择。它收录在通用计划模板中,如果您没有,您可以自定义它。
图 2:IDM 程序模板
单击“前进”以选择文件保存位置。一般默认勾选“保存到同一目录”,点击“浏览”选择保存位置。
图3:选择文件保存位置
接下来,指定链接深度,可以根据需要设置。这也是这个强大的地方,不用网络也能深度浏览网页。
图4:站点爬取选择深度
在下一步中,您可以添加一些下载或非下载过滤器来过滤不需要的文件类型,以避免下载不需要的文件。
图 5:过滤文件
最后,下载开始。如果之前设置下载的内容不多,应该会快一些。
图6:下载情况
下载完成后,在指定文件夹中打开,就可以看到图8了。这样就可以在没有互联网的情况下点击浏览网页,非常方便。
图 7:打开的文件夹
以上就是IDM强大的网站爬取功能。有需要的可以访问IDM中文网站@>免费试用。但是在使用这个强大的功能时要注意不要侵犯或窃取他人的视频或音频。 查看全部
抓取网页音频(InternetDownloadIDM功能——“站点抓取”的含义!)
Internet Download Manager(简称IDM)是一款功能强大的下载器。它采用多线程技术,大大提高文件下载速度。即使是非常大的文件也可以轻松快速地集成。它声称可以将您的下载速度提高多达 5 倍。
不过今天要给大家推荐的是我最近发现的一个IDM功能——“站点爬取”。我以前从不关心它。我最近才发现这个功能非常有用。下面就给大家介绍一下它的神奇之处。
“网站爬行”的含义
如图1所示,该功能允许您输入网页链接,选择您要下载的网页的指定内容,包括图片、音频、视频、文件,甚至收录网站@完整样式的离线文件>,并允许用户根据自己的需要自定义内容。定义站点抓取的内容和规则,并保存以方便下次调用。
图1:网站爬取界面
“网站爬取”功能的神奇使用
如果您在工作中遇到断开连接或网络不好的情况,请使用 Internet 下载管理器站点抓取并保存一些需要浏览的网页,以确保您的工作顺利进行。
如图2所示,根据要保存的内容进行选择。有“所有图片”、“所有视频”、“完整起始页”等,您可以根据需要选择。它收录在通用计划模板中,如果您没有,您可以自定义它。
图 2:IDM 程序模板
单击“前进”以选择文件保存位置。一般默认勾选“保存到同一目录”,点击“浏览”选择保存位置。
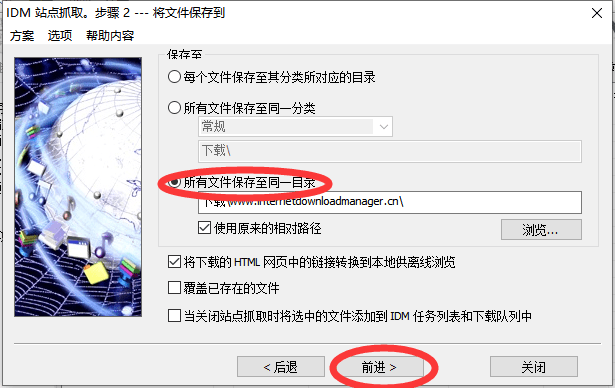
图3:选择文件保存位置
接下来,指定链接深度,可以根据需要设置。这也是这个强大的地方,不用网络也能深度浏览网页。
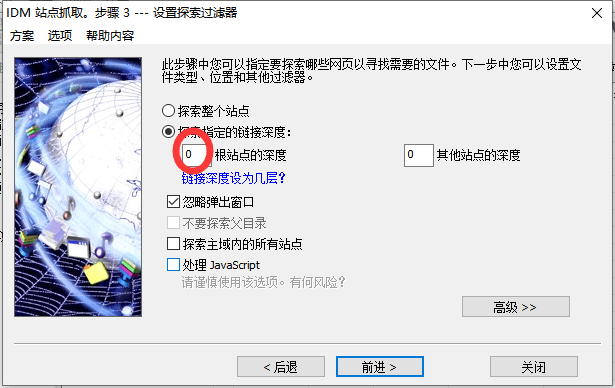
图4:站点爬取选择深度
在下一步中,您可以添加一些下载或非下载过滤器来过滤不需要的文件类型,以避免下载不需要的文件。
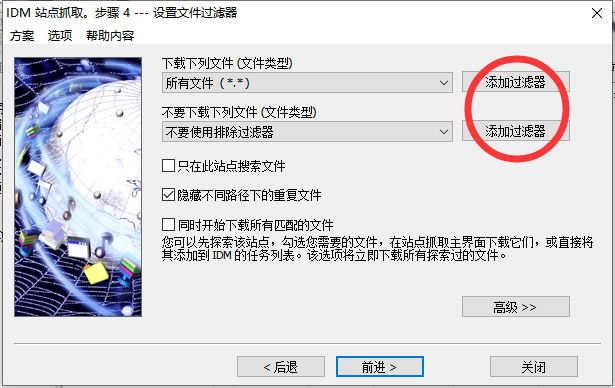
图 5:过滤文件
最后,下载开始。如果之前设置下载的内容不多,应该会快一些。
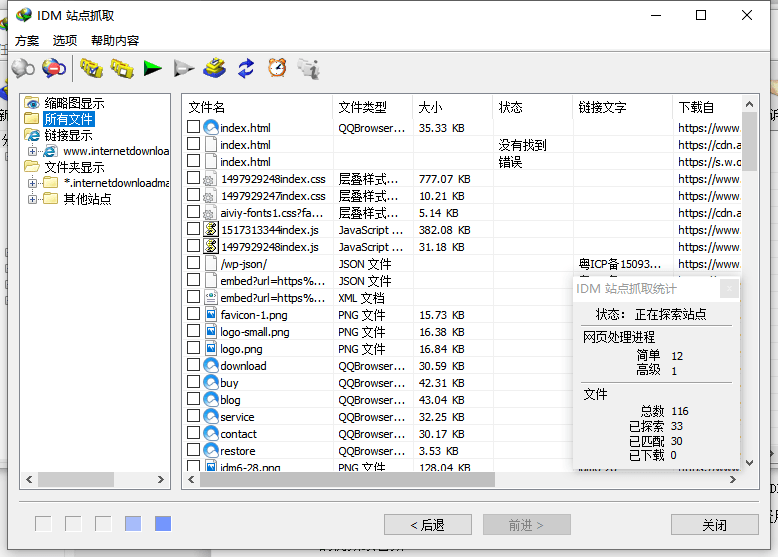
图6:下载情况
下载完成后,在指定文件夹中打开,就可以看到图8了。这样就可以在没有互联网的情况下点击浏览网页,非常方便。

图 7:打开的文件夹
以上就是IDM强大的网站爬取功能。有需要的可以访问IDM中文网站@>免费试用。但是在使用这个强大的功能时要注意不要侵犯或窃取他人的视频或音频。
抓取网页音频(通用搜索引擎如何有效地提取并利用这些信息成为一个巨大的挑战)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-05 07:11
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的入口和向导。但是,这些通用的搜索引擎也有一定的局限性。例如:(1)不同领域、不同背景的用户往往有不同的搜索目的和需求。搜索引擎返回的结果中收录了大量不关注网页的用户。(2)目标一般搜索引擎的目的是最大化网络覆盖。有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。(3) 随着万维网上数据形式的丰富和网络技术的不断发展,大量的图片、数据库、音频、视频、多媒体等不同的数据大量出现。一般搜索引擎往往对这些信息内容密集、有一定结构的数据无能为力,不能很好地发现和获取。(4)一般搜索引擎大多提供基于关键字的检索,难以支持基于语义的查询为了解决上述问题,出现了针对相关网络资源的聚焦爬虫,聚焦爬虫是一个自动下载网页的程序,根据既定的爬取目标,有选择地访问万维网上的网页和相关链接,获取所需信息。与通用网络爬虫不同,聚焦爬虫不追求大Cover,目标是抓取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
1 重点介绍爬虫的工作原理和关键技术概述。网络爬虫是一种自动提取网页的程序。它从万维网上下载网页供搜索引擎使用,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一步要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并为以后的查询和检索建立索引;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并为以后的查询和检索建立索引;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。 查看全部
抓取网页音频(通用搜索引擎如何有效地提取并利用这些信息成为一个巨大的挑战)
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的入口和向导。但是,这些通用的搜索引擎也有一定的局限性。例如:(1)不同领域、不同背景的用户往往有不同的搜索目的和需求。搜索引擎返回的结果中收录了大量不关注网页的用户。(2)目标一般搜索引擎的目的是最大化网络覆盖。有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。(3) 随着万维网上数据形式的丰富和网络技术的不断发展,大量的图片、数据库、音频、视频、多媒体等不同的数据大量出现。一般搜索引擎往往对这些信息内容密集、有一定结构的数据无能为力,不能很好地发现和获取。(4)一般搜索引擎大多提供基于关键字的检索,难以支持基于语义的查询为了解决上述问题,出现了针对相关网络资源的聚焦爬虫,聚焦爬虫是一个自动下载网页的程序,根据既定的爬取目标,有选择地访问万维网上的网页和相关链接,获取所需信息。与通用网络爬虫不同,聚焦爬虫不追求大Cover,目标是抓取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
1 重点介绍爬虫的工作原理和关键技术概述。网络爬虫是一种自动提取网页的程序。它从万维网上下载网页供搜索引擎使用,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一步要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并为以后的查询和检索建立索引;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并为以后的查询和检索建立索引;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。
抓取网页音频(1.的基于Ajax的新闻网页动态数据的抓取方法-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-01 17:23
技术特点:
1.基于Ajax的新闻网页动态数据捕获方法的特点是如下步骤:
步骤(101):建立新闻网页抓取内容库,设置新闻网页抓取内容库的编码方式;获取待抓取新闻网页的新闻列表页面的URL地址;
步骤(102):访问要获取的新闻页面的新闻列表页面的URL地址,使用浏览器开发工具判断新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具找到Ajax请求的数据源;如果没有,则结束;
步骤(103):判断Ajax请求的数据源是否与步骤(101))的编码方式一致,如果不一致,则对数据源进行编码转换,然后进行步骤(104); 如果一致,则直接进行步骤(104);
步骤(104):解析数据格式:将数据源的格式解析为新闻列表页面后台语言处理的对象格式或数组格式;
步骤(105):将步骤(104)中解析的数据封装成对象或数组类型;判断是否封装成功,如果成功则直接进行步骤(106) ;否则,将数据作为字符串处理;完成后,转步骤(106);
步骤(106):遍历数据对象或数组类型并输出列表;
Step (107): 使用网络爬虫采集 step (106)获取输出列表;
步骤(108):将来自采集的数据存入数据库。
2.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于:
步骤(101) URL地址包括临时URL地址、重定向地址和添加时间戳参数或签名参数后访问的URL地址;
步骤(101),新闻网页抓取内容库的字段包括:新闻标题、新闻发布时间、新闻抓取时间、新闻来源、新闻内容;
步骤(101)中,新闻网页抓取的内容库的编码方式包括:UTF-8编码或GBK编码。
3.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于,步骤(102))的浏览器开发工具包括:谷歌浏览器开发者工具。
4.根据权利要求1所述的基于Ajax的新闻网页动态数据捕获方法,其特征在于,步骤(103)如果Ajax请求的数据源中存在特殊字符或乱码,特殊字符或乱码批量替换,转换为可处理的字符。
5.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于,步骤(103):如果编码方式不同,则统一统一采用编码方式UTF-8 编码方式。
6.根据权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于,步骤(102)和步骤(103))之间设置为如下:
步骤(1020):如果Ajax请求是跨域请求,通过PHP的CURL方法模拟传入页面,通过主机获取请求数据地址;
步骤(1021):如果Ajax请求是POST请求,使用PHP语言http_build_query函数模拟HTTP POST请求,获取POST请求返回的数据;
步骤(1022):如果获取不到数据内容,则利用PHP的CURL伪造传入页面访问Ajax请求的数据源;
步骤(1020))通过PHP函数修改Referer模拟域名下的请求,可以得到请求数据地址返回的结果,从而解决了无权限获取的问题跨域请求中的数据。
7.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于:
描述的步骤(104)如下:
步骤(1041):如果数据是JSON格式,直接进入步骤(105);
步骤(1042):如果数据是JSONP格式,则进行过滤处理;过滤处理是去除JSONP格式数据的请求头和括号,然后进行步骤(105)@ >;
步骤(1043):如果返回的内容中存在中英文单双引号使用不规范的问题,通过PHP语言的字符替换功能过滤,将特殊字符替换为空字符。
8.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于:
步骤 (105):
如果步骤(104))解析的数据不是键值对类型,则将步骤(104))解析的数据封装为数据对象,
如果步骤(104))解析的数据为键值对类型,则将步骤(104))解析的数据转换为数组类型。
9.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于:
步骤(106))的输出列表包括:新闻标题、新闻发布时间、新闻爬取时间、新闻来源、新闻内容、新闻链接。
10. 一个基于Ajax的新闻网页动态数据抓取系统,其特点是:
建库模块:建立新闻网络爬取内容库,设置新闻网络爬取内容库的编码方式;获取要爬取的新闻网页的新闻列表页的URL地址;
访问模块:访问要获取的新闻页面的新闻列表页面的URL地址,使用浏览器开发工具判断新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具Source找到Ajax请求的数据;如果没有,结束;
判断模块:判断Ajax请求的数据源是否与步骤(101) @4); 如果一致,直接进入步骤(104);
解析数据格式模块:将数据源的格式解析为新闻列表页面后台语言处理的对象格式或数组格式;
封装模块:将解析后的数据封装成对象或数组类型;判断是否封装成功,如果成功,直接进入输出模块;否则,将数据作为字符串处理;完成后进入输出模块;
输出模块:遍历数据对象或数组类型的输出列表;使用网络爬虫获取的输出列表采集;将采集收到的数据存入数据库。 查看全部
抓取网页音频(1.的基于Ajax的新闻网页动态数据的抓取方法-苏州安嘉)
技术特点:
1.基于Ajax的新闻网页动态数据捕获方法的特点是如下步骤:
步骤(101):建立新闻网页抓取内容库,设置新闻网页抓取内容库的编码方式;获取待抓取新闻网页的新闻列表页面的URL地址;
步骤(102):访问要获取的新闻页面的新闻列表页面的URL地址,使用浏览器开发工具判断新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具找到Ajax请求的数据源;如果没有,则结束;
步骤(103):判断Ajax请求的数据源是否与步骤(101))的编码方式一致,如果不一致,则对数据源进行编码转换,然后进行步骤(104); 如果一致,则直接进行步骤(104);
步骤(104):解析数据格式:将数据源的格式解析为新闻列表页面后台语言处理的对象格式或数组格式;
步骤(105):将步骤(104)中解析的数据封装成对象或数组类型;判断是否封装成功,如果成功则直接进行步骤(106) ;否则,将数据作为字符串处理;完成后,转步骤(106);
步骤(106):遍历数据对象或数组类型并输出列表;
Step (107): 使用网络爬虫采集 step (106)获取输出列表;
步骤(108):将来自采集的数据存入数据库。
2.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于:
步骤(101) URL地址包括临时URL地址、重定向地址和添加时间戳参数或签名参数后访问的URL地址;
步骤(101),新闻网页抓取内容库的字段包括:新闻标题、新闻发布时间、新闻抓取时间、新闻来源、新闻内容;
步骤(101)中,新闻网页抓取的内容库的编码方式包括:UTF-8编码或GBK编码。
3.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于,步骤(102))的浏览器开发工具包括:谷歌浏览器开发者工具。
4.根据权利要求1所述的基于Ajax的新闻网页动态数据捕获方法,其特征在于,步骤(103)如果Ajax请求的数据源中存在特殊字符或乱码,特殊字符或乱码批量替换,转换为可处理的字符。
5.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于,步骤(103):如果编码方式不同,则统一统一采用编码方式UTF-8 编码方式。
6.根据权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于,步骤(102)和步骤(103))之间设置为如下:
步骤(1020):如果Ajax请求是跨域请求,通过PHP的CURL方法模拟传入页面,通过主机获取请求数据地址;
步骤(1021):如果Ajax请求是POST请求,使用PHP语言http_build_query函数模拟HTTP POST请求,获取POST请求返回的数据;
步骤(1022):如果获取不到数据内容,则利用PHP的CURL伪造传入页面访问Ajax请求的数据源;
步骤(1020))通过PHP函数修改Referer模拟域名下的请求,可以得到请求数据地址返回的结果,从而解决了无权限获取的问题跨域请求中的数据。
7.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于:
描述的步骤(104)如下:
步骤(1041):如果数据是JSON格式,直接进入步骤(105);
步骤(1042):如果数据是JSONP格式,则进行过滤处理;过滤处理是去除JSONP格式数据的请求头和括号,然后进行步骤(105)@ >;
步骤(1043):如果返回的内容中存在中英文单双引号使用不规范的问题,通过PHP语言的字符替换功能过滤,将特殊字符替换为空字符。
8.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于:
步骤 (105):
如果步骤(104))解析的数据不是键值对类型,则将步骤(104))解析的数据封装为数据对象,
如果步骤(104))解析的数据为键值对类型,则将步骤(104))解析的数据转换为数组类型。
9.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于:
步骤(106))的输出列表包括:新闻标题、新闻发布时间、新闻爬取时间、新闻来源、新闻内容、新闻链接。
10. 一个基于Ajax的新闻网页动态数据抓取系统,其特点是:
建库模块:建立新闻网络爬取内容库,设置新闻网络爬取内容库的编码方式;获取要爬取的新闻网页的新闻列表页的URL地址;
访问模块:访问要获取的新闻页面的新闻列表页面的URL地址,使用浏览器开发工具判断新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具Source找到Ajax请求的数据;如果没有,结束;
判断模块:判断Ajax请求的数据源是否与步骤(101) @4); 如果一致,直接进入步骤(104);
解析数据格式模块:将数据源的格式解析为新闻列表页面后台语言处理的对象格式或数组格式;
封装模块:将解析后的数据封装成对象或数组类型;判断是否封装成功,如果成功,直接进入输出模块;否则,将数据作为字符串处理;完成后进入输出模块;
输出模块:遍历数据对象或数组类型的输出列表;使用网络爬虫获取的输出列表采集;将采集收到的数据存入数据库。
抓取网页音频(这款视频转换器不但可以对常见视频格式文件转换的格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-01 10:05
随着互联网的发展,短视频逐渐流行起来。我们经常被短视频神奇的背景音乐所影响。
洗脑,但这些背景音乐通常是没有出处的mp4格式,所以如果你想简单地把mp4
如果视频中的音频被提取了怎么办?此时,我们可以使用 Swift Video Converter 中的视频
频率转换从视频文件中提取音频。我们来看看这个带有编辑器的视频转换器。
提取音频!
1、 运行 Swift Video Converter 后,您可以看到该软件的主界面,带有分割视频,
合并视频,制作GIF等功能,这个工具不仅是视频转换器,还是一个
用于转换音频格式的音频转换器。
2、点击功能中的视频转换功能,然后可以看到上面的“添加文件”按钮
将下载的 mp4 视频文件添加到此视频格式转换器。添加时可以添加一个
也可以将多个文件添加到一个文件中。
3、 然后可以看到软件底部有一个输出格式按钮,点击这个Annie,在下拉框中
选择要转换的格式,您可以在“音频”栏中轻松找到 MP3 格式。
4、 然后在下面的设置参数中,可以将mp3格式的音频文件设置为“高品质”,
当然,您也可以点击“自定义”按钮,自行设置音频编码、码率、采样频率等参数。
然后单击输出路径中的更改路径并将文件保存在桌面上。
5、最后点击右下角的“转换”按钮。转换完成后就可以看到转换了
更改完成后提示。您可以单击后面的“打开”按钮快速打开转换后的文件。
这是一个关于将 mp4 视频格式文件转换为 MP3 音频格式文件的教程。这个视频转
转换器不仅可以转换常见的视频格式文件,还可以转换常见的音频格式文件。
它还支持音频和视频文件的编辑!
视频转换器 查看全部
抓取网页音频(这款视频转换器不但可以对常见视频格式文件转换的格式)
随着互联网的发展,短视频逐渐流行起来。我们经常被短视频神奇的背景音乐所影响。
洗脑,但这些背景音乐通常是没有出处的mp4格式,所以如果你想简单地把mp4
如果视频中的音频被提取了怎么办?此时,我们可以使用 Swift Video Converter 中的视频
频率转换从视频文件中提取音频。我们来看看这个带有编辑器的视频转换器。
提取音频!
1、 运行 Swift Video Converter 后,您可以看到该软件的主界面,带有分割视频,
合并视频,制作GIF等功能,这个工具不仅是视频转换器,还是一个
用于转换音频格式的音频转换器。
2、点击功能中的视频转换功能,然后可以看到上面的“添加文件”按钮
将下载的 mp4 视频文件添加到此视频格式转换器。添加时可以添加一个
也可以将多个文件添加到一个文件中。
3、 然后可以看到软件底部有一个输出格式按钮,点击这个Annie,在下拉框中
选择要转换的格式,您可以在“音频”栏中轻松找到 MP3 格式。
4、 然后在下面的设置参数中,可以将mp3格式的音频文件设置为“高品质”,
当然,您也可以点击“自定义”按钮,自行设置音频编码、码率、采样频率等参数。
然后单击输出路径中的更改路径并将文件保存在桌面上。
5、最后点击右下角的“转换”按钮。转换完成后就可以看到转换了
更改完成后提示。您可以单击后面的“打开”按钮快速打开转换后的文件。
这是一个关于将 mp4 视频格式文件转换为 MP3 音频格式文件的教程。这个视频转
转换器不仅可以转换常见的视频格式文件,还可以转换常见的音频格式文件。
它还支持音频和视频文件的编辑!
视频转换器
抓取网页音频(使用Python爬取任意网页的资源文件,一键爬取资源媒体文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-12-30 07:07
前言
使用Python抓取任意网页的资源文件,如图片、音频、视频等;一种常见的方法是通过XPath或者正则请求网页的HTML来获取你想要的资源。这里我做了一个爬虫工具软件,可以一键爬取资源媒体文件;但需要注意的是,这里对资源文件的爬取只针对现有的HTML文件。如果需要第二次请求,就爬不出来了,比如酷狗音乐播放器界面,因为需要做。匹配不同网站的通用工具!!!
这里是图片抓取的主推,有需要图片素材的可以输入网址一键抓取!
还有就是在抓取视频的时候磁力链接会被抓取下来!可以使用第三方下载工具下载!
代码爬取资源文件
这里唯一需要说明的是,有些图片资源不是url链接,而是data:image格式。这里需要转换存储!
def getResourceUrlList(url ,isImage, isAudio, isVideo):
global imgType_list, audioType_list, videoType_list
imageUrlList = []
audioUrlList = []
videoUrlList = []
url = url.rstrip().rstrip('/')
htmlStr = str(requestsDataBase(url))
# print(htmlStr)
Wopen = open('reptileHtml.txt','w')
Wopen.write(htmlStr)
Wopen.close()
Ropen = open('reptileHtml.txt','r')
imageUrlList = []
for line in Ropen:
line = line.replace("'", '"')
segmenterStr = '"'
if "'" in line:
segmenterStr = "'"
lineList = line.split(segmenterStr)
for partLine in lineList:
if isImage == True:
# 查找图片
if 'data:image' in partLine:
base64List = partLine.split('base64,')
imgData = base64.urlsafe_b64decode(base64List[-1] + '=' * (4 - len(base64List[-1]) % 4))
base64ImgType = base64List[0].split('/')[-1].rstrip(';')
imageName = zfjTools.getTimestamp() + '.' + base64ImgType
imageUrlList.append(imageName + '$==$' + base64ImgType)
# 查找图片
for imageType in imgType_list:
if imageType in partLine:
imgUrl = partLine[:partLine.find(imageType) + len(imageType)].split(segmenterStr)[-1]
# 修复URL
imgUrl = repairUrl(imgUrl, url)
sizeType = '_{' + 'size' + '}'
if sizeType in imgUrl:
imgUrl = imgUrl.replace(sizeType, '')
imgUrl = imgUrl.strip()
if imgUrl.startswith('http://') or imgUrl.startswith('https://') and imgUrl not in imageUrlList:
imageUrlList.append(imgUrl)
else:
imgUrl = ''
if isAudio == True:
# 查找音频
for audioType in audioType_list:
if audioType in partLine or audioType.lower() in partLine:
audioType = audioType.lower() if audioType.lower() in partLine else audioType
audioUrl = partLine[:partLine.find(audioType) + len(audioType)].split(segmenterStr)[-1]
# 修复URL
audioUrl = repairUrl(audioUrl, url)
if audioUrl.startswith('http://') or audioUrl.startswith('https://') and audioUrl not in audioUrlList:
audioUrlList.append(audioUrl)
else:
audioUrl = ''
if isVideo == True:
# 查找视频
for videoType in videoType_list:
if videoType in partLine or videoType.lower() in partLine:
videoType = videoType.lower() if videoType.lower() in partLine else videoType
videoUrl = partLine[:partLine.find(videoType) + len(videoType)].split(segmenterStr)[-1]
# 修复URL
videoUrl = repairUrl(videoUrl, url)
if videoUrl.startswith('http://') or videoUrl.startswith('https://') or videoUrl.startswith('ed2k://') or videoUrl.startswith('magnet:?') or videoUrl.startswith('ftp://') and videoUrl not in videoUrlList:
videoUrlList.append(videoUrl)
else:
videoUrl = ''
return (imageUrlList, audioUrlList, videoUrlList)
复制代码
爬取自定义节点
# 统配节点爬取
def getNoteInfors(url, fatherNode, childNode):
url = url.rstrip().rstrip('/')
htmlStr = requestsDataBase(url)
Wopen = open('reptileHtml.txt','w')
Wopen.write(htmlStr)
Wopen.close()
html_etree = etree.HTML(htmlStr)
dataArray = []
if html_etree != None:
nodes_list = html_etree.xpath(fatherNode)
for k_value in nodes_list:
partValue = k_value.xpath(childNode)
if len(partValue) > 0:
dataArray.append(partValue[0])
return dataArray
复制代码
软件
软件下载地址/zfj1128/ZFJ...
使用教学视频
资源爬取:链接:/s/1xa9ruF_h...密码:1zpg
节点爬取:链接:/s/1ebWWYtjo...密码:cosa
使用截图如下:
结束语
欢迎大家提出宝贵意见和建议!!!! 查看全部
抓取网页音频(使用Python爬取任意网页的资源文件,一键爬取资源媒体文件)
前言
使用Python抓取任意网页的资源文件,如图片、音频、视频等;一种常见的方法是通过XPath或者正则请求网页的HTML来获取你想要的资源。这里我做了一个爬虫工具软件,可以一键爬取资源媒体文件;但需要注意的是,这里对资源文件的爬取只针对现有的HTML文件。如果需要第二次请求,就爬不出来了,比如酷狗音乐播放器界面,因为需要做。匹配不同网站的通用工具!!!
这里是图片抓取的主推,有需要图片素材的可以输入网址一键抓取!
还有就是在抓取视频的时候磁力链接会被抓取下来!可以使用第三方下载工具下载!
代码爬取资源文件
这里唯一需要说明的是,有些图片资源不是url链接,而是data:image格式。这里需要转换存储!
def getResourceUrlList(url ,isImage, isAudio, isVideo):
global imgType_list, audioType_list, videoType_list
imageUrlList = []
audioUrlList = []
videoUrlList = []
url = url.rstrip().rstrip('/')
htmlStr = str(requestsDataBase(url))
# print(htmlStr)
Wopen = open('reptileHtml.txt','w')
Wopen.write(htmlStr)
Wopen.close()
Ropen = open('reptileHtml.txt','r')
imageUrlList = []
for line in Ropen:
line = line.replace("'", '"')
segmenterStr = '"'
if "'" in line:
segmenterStr = "'"
lineList = line.split(segmenterStr)
for partLine in lineList:
if isImage == True:
# 查找图片
if 'data:image' in partLine:
base64List = partLine.split('base64,')
imgData = base64.urlsafe_b64decode(base64List[-1] + '=' * (4 - len(base64List[-1]) % 4))
base64ImgType = base64List[0].split('/')[-1].rstrip(';')
imageName = zfjTools.getTimestamp() + '.' + base64ImgType
imageUrlList.append(imageName + '$==$' + base64ImgType)
# 查找图片
for imageType in imgType_list:
if imageType in partLine:
imgUrl = partLine[:partLine.find(imageType) + len(imageType)].split(segmenterStr)[-1]
# 修复URL
imgUrl = repairUrl(imgUrl, url)
sizeType = '_{' + 'size' + '}'
if sizeType in imgUrl:
imgUrl = imgUrl.replace(sizeType, '')
imgUrl = imgUrl.strip()
if imgUrl.startswith('http://') or imgUrl.startswith('https://') and imgUrl not in imageUrlList:
imageUrlList.append(imgUrl)
else:
imgUrl = ''
if isAudio == True:
# 查找音频
for audioType in audioType_list:
if audioType in partLine or audioType.lower() in partLine:
audioType = audioType.lower() if audioType.lower() in partLine else audioType
audioUrl = partLine[:partLine.find(audioType) + len(audioType)].split(segmenterStr)[-1]
# 修复URL
audioUrl = repairUrl(audioUrl, url)
if audioUrl.startswith('http://') or audioUrl.startswith('https://') and audioUrl not in audioUrlList:
audioUrlList.append(audioUrl)
else:
audioUrl = ''
if isVideo == True:
# 查找视频
for videoType in videoType_list:
if videoType in partLine or videoType.lower() in partLine:
videoType = videoType.lower() if videoType.lower() in partLine else videoType
videoUrl = partLine[:partLine.find(videoType) + len(videoType)].split(segmenterStr)[-1]
# 修复URL
videoUrl = repairUrl(videoUrl, url)
if videoUrl.startswith('http://') or videoUrl.startswith('https://') or videoUrl.startswith('ed2k://') or videoUrl.startswith('magnet:?') or videoUrl.startswith('ftp://') and videoUrl not in videoUrlList:
videoUrlList.append(videoUrl)
else:
videoUrl = ''
return (imageUrlList, audioUrlList, videoUrlList)
复制代码
爬取自定义节点
# 统配节点爬取
def getNoteInfors(url, fatherNode, childNode):
url = url.rstrip().rstrip('/')
htmlStr = requestsDataBase(url)
Wopen = open('reptileHtml.txt','w')
Wopen.write(htmlStr)
Wopen.close()
html_etree = etree.HTML(htmlStr)
dataArray = []
if html_etree != None:
nodes_list = html_etree.xpath(fatherNode)
for k_value in nodes_list:
partValue = k_value.xpath(childNode)
if len(partValue) > 0:
dataArray.append(partValue[0])
return dataArray
复制代码
软件
软件下载地址/zfj1128/ZFJ...
使用教学视频
资源爬取:链接:/s/1xa9ruF_h...密码:1zpg
节点爬取:链接:/s/1ebWWYtjo...密码:cosa
使用截图如下:
结束语
欢迎大家提出宝贵意见和建议!!!!
抓取网页音频( 视音频视音频数据的获取方法及实现要素数据获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-30 04:06
视音频视音频数据的获取方法及实现要素数据获取)
本发明涉及数据处理领域,尤其涉及一种视听数据的获取方法。
背景技术
随着互联网的逐渐普及,越来越多的人接触到互联网。视频和音频作为互联网应用的重要成员,凭借其娱乐和学习的特性,已经成为用户接收网络数据不可或缺的一部分。作为网络音视频应用的主要载体,用户基本上是用它来在线观看各种网络音视频。
互联网上现有的视听数据资源包括授权的视听数据资源和未授权的视听数据资源。未经授权的资源可能携带恶意软件或病毒,造成终端损坏。因此,大多数用户在授权资源中下载视频和音频数据。从现有授权资源中下载视音频数据的方法繁琐、操作复杂,给用户带来了极大的不便。
技术实现要素:
本发明的目的在于提供一种基于类型码和附加码的获取视音频数据的方法,一次获取预览片段数据和原创
节目数据,通过授权码。权限、流程简单、操作方便,给用户带来了极大的方便,从而提高了用户体验。
有鉴于此,本发明实施例提供了一种视音频数据的获取方法,包括:
用户终端接收用户输入的视音频码并发送给服务器;其中,视音频码包括类型码和附加码。
服务器解析视音频码,得到类型码和附加码;
服务器在视频和音频数据库中搜索类型代码;
当找到类型码时,根据类型码在视音频数据库中获取对应的类型数据列表;
根据附加码查询类型数据列表中是否有附加码;
当找到附加码时,根据附加码获取类型数据列表中对应的链接地址;
根据链接地址获取视音频数据包;
解析视音频数据包,获取预览片段数据和原创
节目数据;
向用户终端发送预览片段数据;
用户终端分析并播放预览片段数据;
服务器接收用户终端发送的确认指令;其中,确认指令包括终端id和视音频码;
解析确认指令,获取终端id和视音频码;
服务器根据视音频编码获取授权码数据库中对应的授权码;
根据视音频编码和授权码生成授权码提示信息,发送给用户终端;
建立授权码和终端id的关联关系,存储在授权码数据库中;
用户终端接收用户输入的授权码,生成视音频数据播放请求并发送给服务器;其中,视音频数据播放请求携带终端id;
服务器在授权码数据库中查询解析的授权码和解析的终端id是否有关联关系;
当查询到授权码与终端id的关联关系时,将原创
节目数据发送给用户终端。
优选地,授权码具有属性信息;属性信息包括第一属性和第二属性。
进一步优选地,根据视音频编码获取授权码数据库中对应的授权码的服务器具体为:
根据视音频编码获取授权码库中第一个属性的授权码。
进一步优选地,服务器根据视音频编码在授权码数据库中获取对应的授权码后,该方法还包括:
修改授权码的属性信息为第二个属性。
优选地,该方法还包括:
记录每个视音频码被查询的次数,并根据被查询的次数生成第一推送值数据;
记录每个视音频码对应的授权码被获取的次数,并根据获取次数生成第二推送值数据;
分别获取第一推送值数据和第二推送值数据的权重值数据;
根据第一推送值数据、第二推送值数据以及对应的权重值数据进行加权处理,根据加权处理结果确定各个视音频码的推送索引。
进一步优选地,服务器在视音频数据库中搜索类型码后,该方法还包括:
当没有找到类型码时,获取推送索引最高的视音频码;
根据视频和音频编码,得到相应的预览片段数据并发送给用户终端。
优选地,在根据附加码查询类型数据列表中是否有附加码后,该方法还包括:
当没有找到附加码时,服务器将附加码与类型数据库中的附加码进行匹配,得到匹配度最高的附加码;
根据类型码和匹配度最高的附加码生成推送信息,并发送给用户终端。
进一步优选地,根据类型码和匹配度最高的附加码生成推送信息发送给用户终端之后,该方法还包括:
服务器接收用户终端发送的推送指令;
根据匹配度最高的附加码获取类型数据列表中对应的链接地址。
优选地,服务器接收到用户终端发送的确认指令后,该方法还包括:
服务器根据视音频码获取价格信息,根据视音频码和价格信息生成订单信息,发送给用户终端;
用户终端接收用户输入的支付指令并发送给服务器。
优选地,在查询授权码数据库中的授权码和终端id是否有关联关系之后,该方法还包括:
当未找到授权码与终端id的关联关系时,生成获取失败提示消息并发送给用户终端。
本发明实施例提供的视音频数据获取方法根据类型码和附加码一次性获取预览片段数据和原创
节目数据,并可以通过授权码获取视音频数据的播放权限,流程简单,操作方便,给用户带来了极大的方便,从而提高了用户体验。
图纸说明
如图。图1为本发明实施例提供的获取视音频数据的方法的流程图。
详细说明
下面通过附图和实施例对本发明的技术方案作进一步详细说明。
本实施例提供的视音频数据获取方法在用户终端的应用中实现,基于视音频编码和授权码实现视音频数据获取过程。
图1为本发明实施例提供的一种视音频数据的获取方法的流程图。如图1所示,该方法包括:
步骤101:用户终端接收用户输入的视音频码并发送给服务器。
其中,用户终端可以是智能手机或智能电视。
视频和音频编码用于表示视频和音频数据,最好是数字组合;视音频编码包括类型编码和附加码两部分;类型编码用于表示视音频数据的类型信息,类型信息可以包括电影、电视剧、综艺、纪录片、歌曲等,每个流派信息对应不同的流派代码,每个流派代码对应一个流派数据列表,方便搜索视听数据。
一个类型数据列表中可以有一个或多个附加代码,每个附加代码对应一个视音频数据的链接地址。因此,在类型数据列表中,附加码是对视音频数据的唯一标识。
具体的,用户终端通过登录网页向服务器发送获取请求;服务器根据获取请求向用户终端发送用户界面;用户终端显示用户界面,接收用户想观看的视频和音频在用户界面上输入Encoding;用户终端将视音频编码发送给服务器。
需要说明的是,在步骤101之前,服务器将视音频数据库中的视音频数据的名称信息和对应的视音频代码以文本、视频或音频的形式发送给用户终端,并且用户终端将响应视频和音频数据。可以显示或播放用户的姓名信息和视音频码,以便用户记录感兴趣的视音频码。
步骤102:服务器解析视音频码,得到类型码和附加码。
在一个具体示例中,服务器根据预设规则解析视音频编码,预设规则为视音频编码的前3位代表类型码,后4位代表附加码。服务器获取视音频码的前3位获取用户选择的类型码,然后获取视音频码的后4位获取附加码。
步骤103:服务器在视音频数据库中查找类型码。
当找到类型代码时,执行步骤104,根据类型代码在视音频数据库中获取对应的类型数据列表。
在类型数据列表中,存储了同一类别的视频和音频数据的附加代码和对应的链接地址。
步骤105:根据附加码查询类型数据列表中是否有附加码。
当找到附加代码时,执行步骤106,根据附加代码获取类型数据列表中对应的链接地址。
当未找到附加代码时,执行步骤118至步骤121。
步骤118:服务器将附加码与类型数据库中的附加码进行匹配,得到匹配度最高的附加码。
具体地,将同类型数据库中的其他附加码与用户输入的附加码进行区分,差异最小的就是匹配度最高的附加码。
步骤119,根据类型码和匹配度最高的附加码生成推送信息,发送给用户终端。
其中,推送信息包括推送确认码。
在一个具体的例子中,用户终端显示推送信息,推送信息为“您输入的视音频码1249699不存在,如果选择1249698,请按1键确认”。
步骤120:服务器接收用户终端发送的推送指令。
在步骤119所述的例子中,用户终端接收用户输入的1号按键,生成推送指令,发送给服务器。
步骤121:服务器根据匹配度最高的附加码获取类型数据列表中对应的链接地址。
在步骤121之后执行步骤107。
步骤107:根据链接地址获取视音频数据包;解析视音频数据包,得到预览片段数据和原创
节目数据。
其中,视音频数据包包括预览片段数据和原创
节目数据。
预览片段数据是指原创
节目数据的一部分,例如视频或音频宣传片断。
根据链接地址可以一次性获取预览段数据和原节目数据,避免两者分开获取,节省时间和流程。
在步骤108中,将预览片段数据发送给用户终端。
具体地,将预览片段数据发送到用户终端,缓存原节目数据,使得用户在获取原节目时,可以快速播放原节目,避免二次获取,节省时间和流程。
步骤109:用户终端解析并播放预览片段数据。
具体地,用户终端解析预览片段数据,将预览片段数据的格式转换为与用户终端匹配的格式,然后播放,部分显示原节目的内容,以便用户进行初步的欣赏原节目并理解。
步骤110:服务器接收用户终端发送的确认指令。
其中,确认指令包括终端id和视音频编码。
具体的,服务器向用户终端发送确认获取信息,用户终端显示确认获取信息,接收用户根据确认获取信息输入的确认指令,发送给服务器。在一个具体的例子中,确认获取信息为“要确认获取原节目,请按1号键”。
在一个优选实施例中,部分原创节目需要付费,因此在步骤111之后,该方法还包括:服务器根据视音频编码获取价格信息,根据视音频编码和价格信息生成订单信息,发送给用户终端:用户终端接收用户输入的支付指令,发送给服务器。
步骤111:解析确认指令,获取终端id和视音频码。
步骤112:服务器根据视音频编码在授权码数据库中获取对应的授权码。
其中,授权码数据库中存储有影音码和授权码,一个影音码对应多个授权码,供不同用户获取播放权限。
授权码有属性信息;属性信息包括第一属性和第二属性。第一个属性没有使用,用于表示授权码还没有发送给用户;使用第二个属性,用于表示授权码已经发送给用户,不能再发送给其他用户。
具体地,根据视音频编码,从授权码数据库中随机获取属性信息为第一属性的授权码。
获取后,将授权码的属性信息改为第二属性并存储。
步骤113:根据视音频编码和授权码生成授权码提示信息,发送给用户终端。
其中,授权码提示信息可以通过文字或音频的方式发送给用户终端,用户终端显示授权码提示信息。在一个具体的例子中,授权码提示信息为:您要观看的电影的代码为1249698,授权码为8574。
步骤114:建立授权码与终端id的关联关系,保存在授权码数据库中。
步骤113和步骤114同时执行。
步骤115:用户终端接收用户输入的授权码,生成视音频数据播放请求,发送给服务器。
其中,视音频数据播放请求中携带终端id。
具体的,用户终端可以访问播放验证界面,接收用户在播放验证界面输入的授权码,生成视音频数据播放请求并发送给服务器。
步骤116:服务器在授权码数据库中查询解析的授权码与解析的终端id是否有关联关系。
在步骤116之前,该方法还包括:服务器解析用户终端发送的视音频数据播放请求,获取当前用户终端的终端id和视音频数据播放请求中的授权码。
在实际应用中,用户获取授权码后,与其他用户共享授权码,其他用户通过授权码再次获取视音频数据,造成商户损失;
因此,在本发明中,用户用于观看的用户终端必须是与授权码关联的用户终端,以防止多个用户使用同一个授权码观看视频和音频数据,从而保证用户的利益。的商人。
当查询到授权码与终端id的关联关系时,执行步骤117,将原创
节目数据发送给用户终端。
用户终端对原创
节目数据进行分析和播放。
当未查询到授权码与终端id的关联关系时,执行步骤122,生成获取失败提示消息并发送给用户终端。
其中,用户终端显示获取失败的提示信息,提示用户终端id与授权码不匹配,无法获取原节目。
在一个优选的实施例中,为了能够向用户推荐最流行的视音频数据,该方法还包括: 在步骤106之后,记录每个视音频码被查询的次数,并生成第一个number 根据查询的数量。推送价值数据;并且,在步骤112之后,记录每个视音频码对应的授权码的获取次数,并根据获取次数生成第二推送值数据。分别获取第一推送值数据和第二推送值数据的权值数据,其中权值数据是预设的,本领域技术人员可以根据需要设置权值数据;根据第一推值数据,
在一个具体的例子中,查询某个视频码的次数为80次,即第一推值数据为80次,获取该视音频码对应的授权码的次数为50次次,即第二次推送值数据。为50,第一推值数据的预设权重值为0.3,第二推值数据的预设权重值为0.7,视音频号的推送索引为80 ×0.3+50×0.7=59。
推送指数越高,视频和音频数据越受用户欢迎,因此可以通过上述推送指数推送视频和音频数据。
因此,在步骤103之后,该方法还包括:当未找到类型码时,执行步骤123,获取推送索引最高的视音频码。
步骤124:根据视音频编码获取对应的预览片段数据,发送给用户终端。
在步骤124之后执行步骤109。
需要说明的是,在执行上述步骤101至124的过程中,用户可以通过返回码放弃当前的操作。返回码可以是*键;具体的,用户终端接收用户输入的返回码,生成返回指令发送给服务器,然后执行步骤101。
本发明实施例提供的获取视音频数据的方法根据类型码和附加码一次性获取预览片段数据和原创
节目数据,通过授权码。工艺简单,操作方便。给用户的使用带来了极大的便利,从而提升了用户体验。
专业人士还应进一步意识到,本文所公开的实施例中所描述的实施例的单元和算法步骤可以通过电子硬件、计算机软件或两者的结合来实现,为清楚地说明硬件和软件的可互换性,在上面的描述,每个例子的组成和步骤已经按照功能进行了大体描述。这些功能究竟是由硬件还是软件来执行,取决于技术方案的具体应用和设计约束条件。专业人员和技术人员可以针对每个具体的应用使用不同的方法来实现所描述的功能,但不应认为这种实现超出了本发明的范围。
结合本文所公开的实施例描述的方法或算法的步骤可以通过硬件、处理器执行的软件模块,或者两者的结合来实现。软件模块可以放置在随机存取存储器(ram)、内部存储器、只读存储器(rom)、电可编程rom、电可擦可编程rom、寄存器、硬盘、可移动磁盘、cd-rom或任何地方技术领域。任何其他已知的存储介质。
通过上述具体实施例,对本发明的目的、技术方案和有益效果作了进一步详细的说明。应当理解,以上描述仅为本发明的具体实施例而已,并不用于限制本发明的范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应收录
在本发明的保护范围之内。
当前页 1 12 查看全部
抓取网页音频(
视音频视音频数据的获取方法及实现要素数据获取)
本发明涉及数据处理领域,尤其涉及一种视听数据的获取方法。
背景技术
随着互联网的逐渐普及,越来越多的人接触到互联网。视频和音频作为互联网应用的重要成员,凭借其娱乐和学习的特性,已经成为用户接收网络数据不可或缺的一部分。作为网络音视频应用的主要载体,用户基本上是用它来在线观看各种网络音视频。
互联网上现有的视听数据资源包括授权的视听数据资源和未授权的视听数据资源。未经授权的资源可能携带恶意软件或病毒,造成终端损坏。因此,大多数用户在授权资源中下载视频和音频数据。从现有授权资源中下载视音频数据的方法繁琐、操作复杂,给用户带来了极大的不便。
技术实现要素:
本发明的目的在于提供一种基于类型码和附加码的获取视音频数据的方法,一次获取预览片段数据和原创
节目数据,通过授权码。权限、流程简单、操作方便,给用户带来了极大的方便,从而提高了用户体验。
有鉴于此,本发明实施例提供了一种视音频数据的获取方法,包括:
用户终端接收用户输入的视音频码并发送给服务器;其中,视音频码包括类型码和附加码。
服务器解析视音频码,得到类型码和附加码;
服务器在视频和音频数据库中搜索类型代码;
当找到类型码时,根据类型码在视音频数据库中获取对应的类型数据列表;
根据附加码查询类型数据列表中是否有附加码;
当找到附加码时,根据附加码获取类型数据列表中对应的链接地址;
根据链接地址获取视音频数据包;
解析视音频数据包,获取预览片段数据和原创
节目数据;
向用户终端发送预览片段数据;
用户终端分析并播放预览片段数据;
服务器接收用户终端发送的确认指令;其中,确认指令包括终端id和视音频码;
解析确认指令,获取终端id和视音频码;
服务器根据视音频编码获取授权码数据库中对应的授权码;
根据视音频编码和授权码生成授权码提示信息,发送给用户终端;
建立授权码和终端id的关联关系,存储在授权码数据库中;
用户终端接收用户输入的授权码,生成视音频数据播放请求并发送给服务器;其中,视音频数据播放请求携带终端id;
服务器在授权码数据库中查询解析的授权码和解析的终端id是否有关联关系;
当查询到授权码与终端id的关联关系时,将原创
节目数据发送给用户终端。
优选地,授权码具有属性信息;属性信息包括第一属性和第二属性。
进一步优选地,根据视音频编码获取授权码数据库中对应的授权码的服务器具体为:
根据视音频编码获取授权码库中第一个属性的授权码。
进一步优选地,服务器根据视音频编码在授权码数据库中获取对应的授权码后,该方法还包括:
修改授权码的属性信息为第二个属性。
优选地,该方法还包括:
记录每个视音频码被查询的次数,并根据被查询的次数生成第一推送值数据;
记录每个视音频码对应的授权码被获取的次数,并根据获取次数生成第二推送值数据;
分别获取第一推送值数据和第二推送值数据的权重值数据;
根据第一推送值数据、第二推送值数据以及对应的权重值数据进行加权处理,根据加权处理结果确定各个视音频码的推送索引。
进一步优选地,服务器在视音频数据库中搜索类型码后,该方法还包括:
当没有找到类型码时,获取推送索引最高的视音频码;
根据视频和音频编码,得到相应的预览片段数据并发送给用户终端。
优选地,在根据附加码查询类型数据列表中是否有附加码后,该方法还包括:
当没有找到附加码时,服务器将附加码与类型数据库中的附加码进行匹配,得到匹配度最高的附加码;
根据类型码和匹配度最高的附加码生成推送信息,并发送给用户终端。
进一步优选地,根据类型码和匹配度最高的附加码生成推送信息发送给用户终端之后,该方法还包括:
服务器接收用户终端发送的推送指令;
根据匹配度最高的附加码获取类型数据列表中对应的链接地址。
优选地,服务器接收到用户终端发送的确认指令后,该方法还包括:
服务器根据视音频码获取价格信息,根据视音频码和价格信息生成订单信息,发送给用户终端;
用户终端接收用户输入的支付指令并发送给服务器。
优选地,在查询授权码数据库中的授权码和终端id是否有关联关系之后,该方法还包括:
当未找到授权码与终端id的关联关系时,生成获取失败提示消息并发送给用户终端。
本发明实施例提供的视音频数据获取方法根据类型码和附加码一次性获取预览片段数据和原创
节目数据,并可以通过授权码获取视音频数据的播放权限,流程简单,操作方便,给用户带来了极大的方便,从而提高了用户体验。
图纸说明
如图。图1为本发明实施例提供的获取视音频数据的方法的流程图。
详细说明
下面通过附图和实施例对本发明的技术方案作进一步详细说明。
本实施例提供的视音频数据获取方法在用户终端的应用中实现,基于视音频编码和授权码实现视音频数据获取过程。
图1为本发明实施例提供的一种视音频数据的获取方法的流程图。如图1所示,该方法包括:
步骤101:用户终端接收用户输入的视音频码并发送给服务器。
其中,用户终端可以是智能手机或智能电视。
视频和音频编码用于表示视频和音频数据,最好是数字组合;视音频编码包括类型编码和附加码两部分;类型编码用于表示视音频数据的类型信息,类型信息可以包括电影、电视剧、综艺、纪录片、歌曲等,每个流派信息对应不同的流派代码,每个流派代码对应一个流派数据列表,方便搜索视听数据。
一个类型数据列表中可以有一个或多个附加代码,每个附加代码对应一个视音频数据的链接地址。因此,在类型数据列表中,附加码是对视音频数据的唯一标识。
具体的,用户终端通过登录网页向服务器发送获取请求;服务器根据获取请求向用户终端发送用户界面;用户终端显示用户界面,接收用户想观看的视频和音频在用户界面上输入Encoding;用户终端将视音频编码发送给服务器。
需要说明的是,在步骤101之前,服务器将视音频数据库中的视音频数据的名称信息和对应的视音频代码以文本、视频或音频的形式发送给用户终端,并且用户终端将响应视频和音频数据。可以显示或播放用户的姓名信息和视音频码,以便用户记录感兴趣的视音频码。
步骤102:服务器解析视音频码,得到类型码和附加码。
在一个具体示例中,服务器根据预设规则解析视音频编码,预设规则为视音频编码的前3位代表类型码,后4位代表附加码。服务器获取视音频码的前3位获取用户选择的类型码,然后获取视音频码的后4位获取附加码。
步骤103:服务器在视音频数据库中查找类型码。
当找到类型代码时,执行步骤104,根据类型代码在视音频数据库中获取对应的类型数据列表。
在类型数据列表中,存储了同一类别的视频和音频数据的附加代码和对应的链接地址。
步骤105:根据附加码查询类型数据列表中是否有附加码。
当找到附加代码时,执行步骤106,根据附加代码获取类型数据列表中对应的链接地址。
当未找到附加代码时,执行步骤118至步骤121。
步骤118:服务器将附加码与类型数据库中的附加码进行匹配,得到匹配度最高的附加码。
具体地,将同类型数据库中的其他附加码与用户输入的附加码进行区分,差异最小的就是匹配度最高的附加码。
步骤119,根据类型码和匹配度最高的附加码生成推送信息,发送给用户终端。
其中,推送信息包括推送确认码。
在一个具体的例子中,用户终端显示推送信息,推送信息为“您输入的视音频码1249699不存在,如果选择1249698,请按1键确认”。
步骤120:服务器接收用户终端发送的推送指令。
在步骤119所述的例子中,用户终端接收用户输入的1号按键,生成推送指令,发送给服务器。
步骤121:服务器根据匹配度最高的附加码获取类型数据列表中对应的链接地址。
在步骤121之后执行步骤107。
步骤107:根据链接地址获取视音频数据包;解析视音频数据包,得到预览片段数据和原创
节目数据。
其中,视音频数据包包括预览片段数据和原创
节目数据。
预览片段数据是指原创
节目数据的一部分,例如视频或音频宣传片断。
根据链接地址可以一次性获取预览段数据和原节目数据,避免两者分开获取,节省时间和流程。
在步骤108中,将预览片段数据发送给用户终端。
具体地,将预览片段数据发送到用户终端,缓存原节目数据,使得用户在获取原节目时,可以快速播放原节目,避免二次获取,节省时间和流程。
步骤109:用户终端解析并播放预览片段数据。
具体地,用户终端解析预览片段数据,将预览片段数据的格式转换为与用户终端匹配的格式,然后播放,部分显示原节目的内容,以便用户进行初步的欣赏原节目并理解。
步骤110:服务器接收用户终端发送的确认指令。
其中,确认指令包括终端id和视音频编码。
具体的,服务器向用户终端发送确认获取信息,用户终端显示确认获取信息,接收用户根据确认获取信息输入的确认指令,发送给服务器。在一个具体的例子中,确认获取信息为“要确认获取原节目,请按1号键”。
在一个优选实施例中,部分原创节目需要付费,因此在步骤111之后,该方法还包括:服务器根据视音频编码获取价格信息,根据视音频编码和价格信息生成订单信息,发送给用户终端:用户终端接收用户输入的支付指令,发送给服务器。
步骤111:解析确认指令,获取终端id和视音频码。
步骤112:服务器根据视音频编码在授权码数据库中获取对应的授权码。
其中,授权码数据库中存储有影音码和授权码,一个影音码对应多个授权码,供不同用户获取播放权限。
授权码有属性信息;属性信息包括第一属性和第二属性。第一个属性没有使用,用于表示授权码还没有发送给用户;使用第二个属性,用于表示授权码已经发送给用户,不能再发送给其他用户。
具体地,根据视音频编码,从授权码数据库中随机获取属性信息为第一属性的授权码。
获取后,将授权码的属性信息改为第二属性并存储。
步骤113:根据视音频编码和授权码生成授权码提示信息,发送给用户终端。
其中,授权码提示信息可以通过文字或音频的方式发送给用户终端,用户终端显示授权码提示信息。在一个具体的例子中,授权码提示信息为:您要观看的电影的代码为1249698,授权码为8574。
步骤114:建立授权码与终端id的关联关系,保存在授权码数据库中。
步骤113和步骤114同时执行。
步骤115:用户终端接收用户输入的授权码,生成视音频数据播放请求,发送给服务器。
其中,视音频数据播放请求中携带终端id。
具体的,用户终端可以访问播放验证界面,接收用户在播放验证界面输入的授权码,生成视音频数据播放请求并发送给服务器。
步骤116:服务器在授权码数据库中查询解析的授权码与解析的终端id是否有关联关系。
在步骤116之前,该方法还包括:服务器解析用户终端发送的视音频数据播放请求,获取当前用户终端的终端id和视音频数据播放请求中的授权码。
在实际应用中,用户获取授权码后,与其他用户共享授权码,其他用户通过授权码再次获取视音频数据,造成商户损失;
因此,在本发明中,用户用于观看的用户终端必须是与授权码关联的用户终端,以防止多个用户使用同一个授权码观看视频和音频数据,从而保证用户的利益。的商人。
当查询到授权码与终端id的关联关系时,执行步骤117,将原创
节目数据发送给用户终端。
用户终端对原创
节目数据进行分析和播放。
当未查询到授权码与终端id的关联关系时,执行步骤122,生成获取失败提示消息并发送给用户终端。
其中,用户终端显示获取失败的提示信息,提示用户终端id与授权码不匹配,无法获取原节目。
在一个优选的实施例中,为了能够向用户推荐最流行的视音频数据,该方法还包括: 在步骤106之后,记录每个视音频码被查询的次数,并生成第一个number 根据查询的数量。推送价值数据;并且,在步骤112之后,记录每个视音频码对应的授权码的获取次数,并根据获取次数生成第二推送值数据。分别获取第一推送值数据和第二推送值数据的权值数据,其中权值数据是预设的,本领域技术人员可以根据需要设置权值数据;根据第一推值数据,
在一个具体的例子中,查询某个视频码的次数为80次,即第一推值数据为80次,获取该视音频码对应的授权码的次数为50次次,即第二次推送值数据。为50,第一推值数据的预设权重值为0.3,第二推值数据的预设权重值为0.7,视音频号的推送索引为80 ×0.3+50×0.7=59。
推送指数越高,视频和音频数据越受用户欢迎,因此可以通过上述推送指数推送视频和音频数据。
因此,在步骤103之后,该方法还包括:当未找到类型码时,执行步骤123,获取推送索引最高的视音频码。
步骤124:根据视音频编码获取对应的预览片段数据,发送给用户终端。
在步骤124之后执行步骤109。
需要说明的是,在执行上述步骤101至124的过程中,用户可以通过返回码放弃当前的操作。返回码可以是*键;具体的,用户终端接收用户输入的返回码,生成返回指令发送给服务器,然后执行步骤101。
本发明实施例提供的获取视音频数据的方法根据类型码和附加码一次性获取预览片段数据和原创
节目数据,通过授权码。工艺简单,操作方便。给用户的使用带来了极大的便利,从而提升了用户体验。
专业人士还应进一步意识到,本文所公开的实施例中所描述的实施例的单元和算法步骤可以通过电子硬件、计算机软件或两者的结合来实现,为清楚地说明硬件和软件的可互换性,在上面的描述,每个例子的组成和步骤已经按照功能进行了大体描述。这些功能究竟是由硬件还是软件来执行,取决于技术方案的具体应用和设计约束条件。专业人员和技术人员可以针对每个具体的应用使用不同的方法来实现所描述的功能,但不应认为这种实现超出了本发明的范围。
结合本文所公开的实施例描述的方法或算法的步骤可以通过硬件、处理器执行的软件模块,或者两者的结合来实现。软件模块可以放置在随机存取存储器(ram)、内部存储器、只读存储器(rom)、电可编程rom、电可擦可编程rom、寄存器、硬盘、可移动磁盘、cd-rom或任何地方技术领域。任何其他已知的存储介质。
通过上述具体实施例,对本发明的目的、技术方案和有益效果作了进一步详细的说明。应当理解,以上描述仅为本发明的具体实施例而已,并不用于限制本发明的范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应收录
在本发明的保护范围之内。
当前页 1 12
抓取网页音频( 一下进度条添加事件监听的功能介绍及项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-30 04:05
一下进度条添加事件监听的功能介绍及项目)
Beyond-光辉岁月
Daniel Powter-Free Loop
周杰伦、费玉清-千里之外
接下来我们就开始逐步实现上面提到的功能吧,先来完成播放和暂停功能,在按下播放按钮时我们要做到进度条随歌曲进度前进,播放时间也逐渐增加,同时播放按钮变成暂停按钮,播放列表的样式也对应改变。
在做这个功能之前,我们首先要获取三个audio标签的id,并存入一个数组中,以备后续使用。
var music1= document.getElementById("music1");
var music2= document.getElementById("music2");
var music3= document.getElementById("music3");
var mList = [music1,music2,music3];
播放和暂停:
现在我们就可以完成播放按钮的功能了。首先设置一个标志来标记音乐的播放状态,然后为数组的索引设置一个默认值:
然后判断播放状态,调用对应的函数,修改list的flag值和对应的item样式:
var flag = true;
var index = 0;
function playMusic(){
if(flag&&mList[index].paused){
mList[index].play();
document.getElementById("m"+index).style.backgroundColor = "#A71307";
document.getElementById("m"+index).style.color = "white";
progressBar();
playTimes();
play.style.backgroundImage = "url(media/pause.png)";
flag = false;
}else{
mList[index].pause();
flag = true;
play.style.backgroundImage = "url(media/play.png)";
}
}
上面HTML页面的代码中调用了多个函数,其中play和pause是audio标签自带的方法,其他函数由我们自己定义。下面我们来看看这些功能是如何实现的,分别对应哪些功能。
进度条和播放时间:
首先是进度条功能,获取歌曲的完整时长,然后根据当前播放进度乘以进度条总长度计算出进度条的位置。
function progressBar(){
var lenth=mList[index].duration;
timer1=setInterval(function(){
cur=mList[index].currentTime;//获取当前的播放时间
progress.style.width=""+parseFloat(cur/lenth)*300+"px";
progressBtn.style.left= 60+parseFloat(cur/lenth)*300+"px";
},10)
}
下面是改变播放时间的功能。这里我们设置了一个定时函数,每隔一段时间执行一次来改变播放时间。因为我们得到的歌曲的时长是以秒计算的,所以我们需要使用if语句来判断转换的时长,并将播放时间改为分秒的形式显示。
<p>function playTimes(){
timer2=setInterval(function(){
cur=parseInt(mList[index].currentTime);//秒数
var minute=parseInt(cur/60);
if (minute 查看全部
抓取网页音频(
一下进度条添加事件监听的功能介绍及项目)
Beyond-光辉岁月
Daniel Powter-Free Loop
周杰伦、费玉清-千里之外
接下来我们就开始逐步实现上面提到的功能吧,先来完成播放和暂停功能,在按下播放按钮时我们要做到进度条随歌曲进度前进,播放时间也逐渐增加,同时播放按钮变成暂停按钮,播放列表的样式也对应改变。
在做这个功能之前,我们首先要获取三个audio标签的id,并存入一个数组中,以备后续使用。
var music1= document.getElementById("music1");
var music2= document.getElementById("music2");
var music3= document.getElementById("music3");
var mList = [music1,music2,music3];
播放和暂停:
现在我们就可以完成播放按钮的功能了。首先设置一个标志来标记音乐的播放状态,然后为数组的索引设置一个默认值:
然后判断播放状态,调用对应的函数,修改list的flag值和对应的item样式:
var flag = true;
var index = 0;
function playMusic(){
if(flag&&mList[index].paused){
mList[index].play();
document.getElementById("m"+index).style.backgroundColor = "#A71307";
document.getElementById("m"+index).style.color = "white";
progressBar();
playTimes();
play.style.backgroundImage = "url(media/pause.png)";
flag = false;
}else{
mList[index].pause();
flag = true;
play.style.backgroundImage = "url(media/play.png)";
}
}
上面HTML页面的代码中调用了多个函数,其中play和pause是audio标签自带的方法,其他函数由我们自己定义。下面我们来看看这些功能是如何实现的,分别对应哪些功能。
进度条和播放时间:
首先是进度条功能,获取歌曲的完整时长,然后根据当前播放进度乘以进度条总长度计算出进度条的位置。
function progressBar(){
var lenth=mList[index].duration;
timer1=setInterval(function(){
cur=mList[index].currentTime;//获取当前的播放时间
progress.style.width=""+parseFloat(cur/lenth)*300+"px";
progressBtn.style.left= 60+parseFloat(cur/lenth)*300+"px";
},10)
}
下面是改变播放时间的功能。这里我们设置了一个定时函数,每隔一段时间执行一次来改变播放时间。因为我们得到的歌曲的时长是以秒计算的,所以我们需要使用if语句来判断转换的时长,并将播放时间改为分秒的形式显示。
<p>function playTimes(){
timer2=setInterval(function(){
cur=parseInt(mList[index].currentTime);//秒数
var minute=parseInt(cur/60);
if (minute
抓取网页音频(怎么下载别人小程序里的图标呀?如何操作?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-12-28 02:14
01
故事的开始
“怎么下载别人小程序里的图标?”
“如何抓取小程序的图片、图标等?”
“如果有批量下载的工具就好了”
其实这个问题一直困扰我到现在。闲暇之余,我会思考如何制作一个可以实现这些功能的小工具。
为了提高有效抓取的质量,做了过滤请求功能,只要你过滤范围内的文件都可以正常下载
02
痛点解决
很多开发者或外包公司或小型创业团队在开发小程序、公众号、app等应用时,由于不擅长美术,只能在网上搜索资料,但免费资料并不多,别说是满足你需求的素材了,所以根本满足不了开发者的需求。
另一种方法是以目标小程序为参考,从这些目标小程序中提取基本满足你需求的类似素材。这些素材的UI效果都是一流的,毕竟是专业的设计师。工作。
(图片来自网络)
邀请一位月薪少则三五千,多则几万元的艺术家或设计师。如果按照稿子付费,一个海报设计起码要100左右。三十到五十不是个小数目。向上。
经过上面的过程,我终于决定自己写一个小工具,可以抓取小程序、公众号、APP等素材。
03
简单但不简单
界面小巧实用
拥有这个小工具后,我的工作效率提高了很多。
霸气成名:Master Grab-小程序素材抓取软件
直接抓取素材,方便快捷,一键获取,批量下载。
下面我简单介绍一下它的操作方法。
第一步:打开软件后,点击开始爬行按钮
第二步:打开微信小程序(PC端打开)
第三步:一键下载(方便),在软件同级目录下的【downloadFile】文件夹中
软件操作非常简单,主要是帮助开发者节省找资料和设计图片的时间,提高开发者构建小程序的效率。
04
写在最后
时间宝贵,怎能浪费?
所以我在业余时间研究了一个小程序素材抓取软件,希望对大家有帮助。
注:本软件仅供学习交流使用,不得用于商业或非法用途。
如何区分小程序逆向脚本是否有效
如何深入分析小程序的运行原理?
谈谈保护小程序代码的方法
浅谈防阻:如何保证微信小程序代码的安全
介绍一个跨平台的微信小程序反编译客户端
小技巧分享:通过sourcemap恢复vue项目代码 查看全部
抓取网页音频(怎么下载别人小程序里的图标呀?如何操作?)
01
故事的开始
“怎么下载别人小程序里的图标?”
“如何抓取小程序的图片、图标等?”
“如果有批量下载的工具就好了”
其实这个问题一直困扰我到现在。闲暇之余,我会思考如何制作一个可以实现这些功能的小工具。
为了提高有效抓取的质量,做了过滤请求功能,只要你过滤范围内的文件都可以正常下载
02
痛点解决
很多开发者或外包公司或小型创业团队在开发小程序、公众号、app等应用时,由于不擅长美术,只能在网上搜索资料,但免费资料并不多,别说是满足你需求的素材了,所以根本满足不了开发者的需求。
另一种方法是以目标小程序为参考,从这些目标小程序中提取基本满足你需求的类似素材。这些素材的UI效果都是一流的,毕竟是专业的设计师。工作。
(图片来自网络)
邀请一位月薪少则三五千,多则几万元的艺术家或设计师。如果按照稿子付费,一个海报设计起码要100左右。三十到五十不是个小数目。向上。
经过上面的过程,我终于决定自己写一个小工具,可以抓取小程序、公众号、APP等素材。
03
简单但不简单
界面小巧实用
拥有这个小工具后,我的工作效率提高了很多。
霸气成名:Master Grab-小程序素材抓取软件
直接抓取素材,方便快捷,一键获取,批量下载。
下面我简单介绍一下它的操作方法。
第一步:打开软件后,点击开始爬行按钮
第二步:打开微信小程序(PC端打开)
第三步:一键下载(方便),在软件同级目录下的【downloadFile】文件夹中
软件操作非常简单,主要是帮助开发者节省找资料和设计图片的时间,提高开发者构建小程序的效率。
04
写在最后
时间宝贵,怎能浪费?
所以我在业余时间研究了一个小程序素材抓取软件,希望对大家有帮助。
注:本软件仅供学习交流使用,不得用于商业或非法用途。
如何区分小程序逆向脚本是否有效
如何深入分析小程序的运行原理?
谈谈保护小程序代码的方法
浅谈防阻:如何保证微信小程序代码的安全
介绍一个跨平台的微信小程序反编译客户端
小技巧分享:通过sourcemap恢复vue项目代码
抓取网页音频(基于所述音频片段服务器的生成方法和部署步骤(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-27 11:11
1、 一种生成音频片段服务器的方法,其特征在于包括:获取音频数据;截取音频数据的片段数据;根据预设规则将音频片段数据部署到相应的服务器,生成音频片段服务器。
2、如权利要求1所述的方法,其特征在于,所述截取音频段数据的步骤包括: 对音频数据进行解码,得到音频数据的原创
波形数据;从数据文件头中获取原创
波形数据的采样频率、通道数、量化位数;根据采样频率、通道数和量化位数计算预设时间阈值的原创
波形数据;计算预设时间阈值的原创
波形数据,生成音频片段数据。
3、如权利要求2所述的方法,其特征在于,所述截取音频片段数据的步骤还包括: 对预设时间阈值的原创
波形数据中某段时间的尾部数据进行音量控制。淡出处理。
4、如权利要求1、2或3所述的方法,其特征在于,所述获取音频数据的步骤包括:获取所述音频数据的种子站点URL,所述种子站点URL包括种子站点URL,以及Torrent 站点所代表的页面中所有超链接的 URL;如果种子站点URL合法,则会有针对性地捕获相应的音频数据。
5、如权利要求4所述的方法,还包括: 保存捕获的音频数据以形成音频数据库。
6、如权利要求5所述的方法,还包括: 解析所述音频数据的文件头格式以确定其是否为音频数据;如果没有,从音频数据库中删除数据。
7、根据权利要求1、2或3所述的方法,其特征在于,有多个服务器,音频片段数据部署步骤包括: 为每个服务器分配标识信息;采用hash算法计算音频片段数据对应的URL的hash值;根据哈希值和服务器数量计算目标服务器的标识信息;将音频段数据部署到目标服务器。
8、一种音频搜索方法,其特征在于包括:接收用户提交的音频搜索请求;根据音频搜索请求匹配获取对应的音频数据,根据音频数据的URL从音频片段服务器获取对应的音频数据,从数据中提取对应的音频片段数据;将音频搜索结果返回给用户,音频搜索结果包括音频片段数据的信息。
9、如权利要求8所述的方法,其特征在于,音频片段服务器有多个,每个服务器带有标识信息,提取音频片段数据的步骤包括: 使用哈希算法计算音频片段数据的哈希值音频数据 URL;根据哈希值和服务器数量计算目标服务器的标识信息;从目标服务器中提取相应的音频片段数据。
10、如权利要求9所述的方法,其特征在于,所述音频数据是在音频数据库中匹配得到的,所述音频数据库是通过获取音频数据的种子站点的URL得到的,在种子站点在合法的情况下,有针对性地抓取并生成相应的音频数据;种子站点URL包括种子站点的URL和种子站点所代表的页面中所有超链接的URL。
11、如权利要求10所述的方法,其特征在于,所述音频片段数据是音频数据在一定时间段内的片段数据,其产生步骤为:对捕获的音频数据进行解码,获取原创
波形数据音频数据;从音频数据的文件头中获取原创
波形数据的采样频率、声道数、量化位数;根据采样频率、通道数和量化位数计算预设。设置时间阈值的原创
波形数据;对预设时间阈值的原创
波形数据进行编码,生成音频片段数据。
12、如权利要求8所述的方法,其中以嵌入在Flash程序中的网页的形式显示所述音频搜索结果。
13、一种音频搜索中预听片段的方法,其特征在于,包括:接收用户对某个音频搜索结果的获取请求,所述搜索结果中包括音频片段数据的信息,所述音频片段根据音频搜索请求匹配相应音频数据的URL得到数据,从音频片段服务器中提取;根据获取请求提取相应的音频片段数据返回给用户。
14、 一种音频片段服务器生成装置,其特征在于包括: 音频数据获取单元,用于获取音频数据;音频片段截取单元,用于截取音频数据的片段数据;音频片段部署单元,用于根据预设规则将音频片段数据部署到对应的服务器,生成音频片段服务器。
15、如权利要求14所述的装置,其特征在于,所述服务器为多个,所述音频片段部署单元还包括: 标识分配子单元,用于为每个服务器分配标识信息;哈希计算子单元用于通过哈希算法计算音频剪辑数据对应的URL的哈希值;目标服务器确定子单元,用于根据哈希值和服务器数量信息计算目标服务器的身份;音频段定位子单元,用于将音频段数据部署到目标服务器。
16、 一种音频搜索装置,其特征在于包括: 音频片段服务器,用于存储音频片段数据;搜索请求接收单元,用于接收用户提交的音频搜索请求;匹配单元,用于根据音频搜索请求进行匹配,得到相应的音频数据,并根据音频数据的URL从音频片段服务器中提取相应的音频片段数据;搜索结果返回单元,用于将音频搜索结果返回给用户,音频搜索结果包括音频片段数据的信息。
17、一种音频搜索中预听片段的装置,其特征在于包括:音频片段服务器,用于存储音频片段数据;预收听请求接收单元,用于接收用户对某个音频的搜索结果发起的获取请求,搜索结果包括音频片段数据的信息,音频片段数据是根据获取相应音频数据的URL对音频搜索请求匹配,从音频片段服务器中提取;预听段返回单元用于根据获取请求提取相应的音频段数据返回给用户。
18、一种音频搜索服务器,其特征在于包括:音频片段服务器,用于存储音频片段数据;搜索请求接收模块,用于接收用户提交的音频搜索请求;匹配模块依赖于匹配音频搜索请求,获取对应的音频数据,根据音频数据的URL从音频片段服务器中提取对应的音频片段数据;搜索结果返回模块用于将音频搜索结果返回给用户。音频搜索结果包括音频片段数据的信息;预听请求接收模块,用于接收用户对某个音频搜索结果的获取请求; 查看全部
抓取网页音频(基于所述音频片段服务器的生成方法和部署步骤(一))
1、 一种生成音频片段服务器的方法,其特征在于包括:获取音频数据;截取音频数据的片段数据;根据预设规则将音频片段数据部署到相应的服务器,生成音频片段服务器。
2、如权利要求1所述的方法,其特征在于,所述截取音频段数据的步骤包括: 对音频数据进行解码,得到音频数据的原创
波形数据;从数据文件头中获取原创
波形数据的采样频率、通道数、量化位数;根据采样频率、通道数和量化位数计算预设时间阈值的原创
波形数据;计算预设时间阈值的原创
波形数据,生成音频片段数据。
3、如权利要求2所述的方法,其特征在于,所述截取音频片段数据的步骤还包括: 对预设时间阈值的原创
波形数据中某段时间的尾部数据进行音量控制。淡出处理。
4、如权利要求1、2或3所述的方法,其特征在于,所述获取音频数据的步骤包括:获取所述音频数据的种子站点URL,所述种子站点URL包括种子站点URL,以及Torrent 站点所代表的页面中所有超链接的 URL;如果种子站点URL合法,则会有针对性地捕获相应的音频数据。
5、如权利要求4所述的方法,还包括: 保存捕获的音频数据以形成音频数据库。
6、如权利要求5所述的方法,还包括: 解析所述音频数据的文件头格式以确定其是否为音频数据;如果没有,从音频数据库中删除数据。
7、根据权利要求1、2或3所述的方法,其特征在于,有多个服务器,音频片段数据部署步骤包括: 为每个服务器分配标识信息;采用hash算法计算音频片段数据对应的URL的hash值;根据哈希值和服务器数量计算目标服务器的标识信息;将音频段数据部署到目标服务器。
8、一种音频搜索方法,其特征在于包括:接收用户提交的音频搜索请求;根据音频搜索请求匹配获取对应的音频数据,根据音频数据的URL从音频片段服务器获取对应的音频数据,从数据中提取对应的音频片段数据;将音频搜索结果返回给用户,音频搜索结果包括音频片段数据的信息。
9、如权利要求8所述的方法,其特征在于,音频片段服务器有多个,每个服务器带有标识信息,提取音频片段数据的步骤包括: 使用哈希算法计算音频片段数据的哈希值音频数据 URL;根据哈希值和服务器数量计算目标服务器的标识信息;从目标服务器中提取相应的音频片段数据。
10、如权利要求9所述的方法,其特征在于,所述音频数据是在音频数据库中匹配得到的,所述音频数据库是通过获取音频数据的种子站点的URL得到的,在种子站点在合法的情况下,有针对性地抓取并生成相应的音频数据;种子站点URL包括种子站点的URL和种子站点所代表的页面中所有超链接的URL。
11、如权利要求10所述的方法,其特征在于,所述音频片段数据是音频数据在一定时间段内的片段数据,其产生步骤为:对捕获的音频数据进行解码,获取原创
波形数据音频数据;从音频数据的文件头中获取原创
波形数据的采样频率、声道数、量化位数;根据采样频率、通道数和量化位数计算预设。设置时间阈值的原创
波形数据;对预设时间阈值的原创
波形数据进行编码,生成音频片段数据。
12、如权利要求8所述的方法,其中以嵌入在Flash程序中的网页的形式显示所述音频搜索结果。
13、一种音频搜索中预听片段的方法,其特征在于,包括:接收用户对某个音频搜索结果的获取请求,所述搜索结果中包括音频片段数据的信息,所述音频片段根据音频搜索请求匹配相应音频数据的URL得到数据,从音频片段服务器中提取;根据获取请求提取相应的音频片段数据返回给用户。
14、 一种音频片段服务器生成装置,其特征在于包括: 音频数据获取单元,用于获取音频数据;音频片段截取单元,用于截取音频数据的片段数据;音频片段部署单元,用于根据预设规则将音频片段数据部署到对应的服务器,生成音频片段服务器。
15、如权利要求14所述的装置,其特征在于,所述服务器为多个,所述音频片段部署单元还包括: 标识分配子单元,用于为每个服务器分配标识信息;哈希计算子单元用于通过哈希算法计算音频剪辑数据对应的URL的哈希值;目标服务器确定子单元,用于根据哈希值和服务器数量信息计算目标服务器的身份;音频段定位子单元,用于将音频段数据部署到目标服务器。
16、 一种音频搜索装置,其特征在于包括: 音频片段服务器,用于存储音频片段数据;搜索请求接收单元,用于接收用户提交的音频搜索请求;匹配单元,用于根据音频搜索请求进行匹配,得到相应的音频数据,并根据音频数据的URL从音频片段服务器中提取相应的音频片段数据;搜索结果返回单元,用于将音频搜索结果返回给用户,音频搜索结果包括音频片段数据的信息。
17、一种音频搜索中预听片段的装置,其特征在于包括:音频片段服务器,用于存储音频片段数据;预收听请求接收单元,用于接收用户对某个音频的搜索结果发起的获取请求,搜索结果包括音频片段数据的信息,音频片段数据是根据获取相应音频数据的URL对音频搜索请求匹配,从音频片段服务器中提取;预听段返回单元用于根据获取请求提取相应的音频段数据返回给用户。
18、一种音频搜索服务器,其特征在于包括:音频片段服务器,用于存储音频片段数据;搜索请求接收模块,用于接收用户提交的音频搜索请求;匹配模块依赖于匹配音频搜索请求,获取对应的音频数据,根据音频数据的URL从音频片段服务器中提取对应的音频片段数据;搜索结果返回模块用于将音频搜索结果返回给用户。音频搜索结果包括音频片段数据的信息;预听请求接收模块,用于接收用户对某个音频搜索结果的获取请求;
抓取网页音频(在Win11时代,有哪些软件已经迎来没落的命运、再难有用武之地?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-26 08:16
微软发布了最新一代的Windows 11,在惊叹系统界面的巨大变化的同时,也不得不感受到时代浪潮的冲击。Windows也顺应潮流,推出了更先进的WinUI,并努力完善系统功能,尝试改变应用生态。新的互联网时代,即使是像Windows这样的大船也得掉头,更别提搭载的各种软件了。
Win11时代,软件也大不相同
回首过去,许多曾经繁荣的软件随着前一波的浪潮,慢慢地淡出了历史舞台。这些经典产品越来越少被提及。Win11时代,有什么软件,再难用,又迎来了没落的命运?今天就来聊聊这个话题。
防毒软件
只要你用了几年电脑,你就会一直听到那些曾经雷鸣般的名字,比如“瑞星”、“金山”、“江民”等等……但在21世纪初,自由软杀的趋势盛行。吸引了无数互联网公司的纷至沓来。除了领跑风头的“360”,“可牛”、“百度”、“优采云
”等英雄们纷纷出招,令人目不暇接。比较“有见识”的人,折腾了很多国外比较“专业”的产品,比如“小红伞”、“AVG”、“avast”、“Bitdefender”、“卡巴斯基”......安全论坛上的访客。
被玩家津津乐道的杀手
然而,近年来,反软件的热潮似乎已经消退。反软件市场不仅没有掀起新的浪潮,而且似乎也在走下坡路。无论国内百度指数,还是国外谷歌走势,2012年以来,反软件热度都未能止住下滑趋势。
国内百度指数,杀毒软件热度一路下滑
在全球范围内,杀毒软件的流行程度也与谷歌趋势中显示的数据相同
如今,几乎没有人宣布要在杀毒市场上闹,甚至一大批用户不再需要自己安装任何杀毒软件。为什么杀毒软件变的这么火?或许不是杀毒本身的原因,而是个人系统安全环境这些年的剧变。
首先,Antisoft迎来了最强的竞争对手——微软。以360为首的免费杀毒软件已经够吸引人了吧?但系统中预装的MSE/Defender只是一种犯规级别的拉客行为。同时,微软MSE/Defender的业务能力也很不错。在AVTEST等专业的反软件评测中,其性能多年位居前列。比起国内一些连测试都不敢参加的产品,我不知道它在哪里。向上。
微软自带 Security Center Defender
在最新的AV-TEST测试中,微软取得了满分
在Win11时代,Defender已经成为系统预装。而微软正计划将 Defender 打造成跨平台产品,以进一步增强实力。杀毒软件是一种高科技产品。谁比微软更懂Windows系统的代码?其他反软件想要与微软抗衡,难度不小。
其次,操作系统本身的安全性有了很大的提高。在Windows 9X甚至XP时代,代码可以轻松修改操作系统内核。Vista之后,由于用户层的架构和内核的隔离,恶意代码更难操纵。Win11默认开启虚拟化隔离内核,使用TPM芯片进行硬件级加密。反软件的作用不再像以前那么重要了。
再者,移动互联网并没有为反软件带来新的市场。iOS和Android都有严格的安装包管理机制。原则上,他们不需要使用任何反软件。Apple 甚至禁止将声称是反软件的产品放在 App Store 上。iOS 机制消除了大多数未知代码。跑的机会,借助漏洞(比如越狱)可以跑起来的代码,绝不会被杀毒挡住。反软件可以在移动平台上发挥作用,无非就是识别某个App是否是假钓鱼之类的,很多Android系统都自带这个功能。在新兴市场是无利可图的,难怪杀软的生意越来越难做。
iOS 中的应用程序无法实现病毒扫描功能。Apple 已禁止 App Store 中声称具有防病毒功能的应用程序。
毫无疑问,反软件已经沦陷了。或许在某些使用环境下还是有用的,比如识别钓鱼网站、使用旧系统,但是在以Win11为代表的新使用环境下,它的用处就没有以前那么好了。杀毒软件的衰落对安全厂商来说可能是件坏事,但客观上也说明了这些年来用户环境越来越安全,我们应该为此感到高兴。
P2P下载工具
如果您是老司机,应该非常怀念使用P2P下载工具在网上驰骋的日子。在那个BT软件为王,电骡软件为王的时代,各种资源仿佛触手可及。随便开个论坛,或者直接输入关键词搜索,种子就一路来,叫上朋友朋友来种草,下个片子时间不长。
很多朋友都用过以BitComet为代表的P2P下载器,但是现在用户群已经明显减少了
然而,如今专用的P2P下载工具早已失去了原有的风光。也许你也会下载BT或eD2k链接,但你使用的往往只是像迅雷这样的综合下载器——即使这些下载器的受欢迎程度已经大幅下降。
虽然P2P下载技术本身在互联网上仍然占据着极其重要的利基,比如Win11系统更新也会使用P2P技术来传输数据,但是P2P下载工具的没落已经是不争的事实。手动配置Tracker添加peer节点、设置DLP反吸血、破内网连接HighID……这些绝招已经在大众中失传;Bit Comet、μtorrent、eMule等,都成了小圈子的玩物。在P2P圈子里,“人人为我,我为人”的口号如此符合互联网共享的精神,但为何这一套逐渐被历史的尘埃淹没?或许这与互联网的发展趋势是分不开的。
如何找到电骡服务器?如何获得HighID?恐怕没有人可以折腾了
首先,使用P2P下载工具有一定的门槛。与迅雷、网盘等好用的工具相比,专业的P2P工具更难用。人们需要具备一些P2P传输的基础知识,并在此基础上结合实际网络环境进行手动配置,才能有更理想的性能。在下载资源之前,必须自己学习,这是很多人无法接受的。
电骡模式Xtreme的热门配置,对于新手来说,这是一本圣经书
其次,P2P下载工具的普及将在版权收紧的背景下对版权保护提出挑战。P2P下载被抑制是正常的。BTChina、VeryCD、极影……P2P资源站一个个倒塌,P2P下载生态逐渐萎缩,进而影响了P2P下载速度。同时,部分地区运营商通过特征码完成了对P2P流量的精准检测,限制了P2P下载速度,使得P2P下载工具越来越鸡肋。在某些地区,Tracker 或 e-mule 服务器甚至伪装成 P2P 盗版下载和网络钓鱼执法。这使得P2P下载工具的环境越来越差。
此外,P2P下载工具的商业化难度极大。所谓无利可图不是早起,而是P2P下载工具在大多数情况下是无利可图的。P2P传输协议是公开的,资源不由P2P下载者提供。软件商很难通过销售资源和软件、使用下载工具来盈利。
最后,P2P分享的精神在一定程度上违背了人性。“人人有份”容易,“人人有份”难。大多数P2P下载者下载资源后就跑掉了,这样做什么的,没有这样的事情。这也是大量用户从专用的P2P下载工具转向迅雷和网盘的原因。雷霆吸血?网盘和谐?速度快就是好,再多!
官方客服确认迅雷等离线下载工具会“吸血”(不会发回公共P2P网络),但下载速度快,很受欢迎
P2P下载工具在互联网野蛮生长的时代蓬勃发展,如今互联网被诸侯瓜分,维护资源和利益的秩序越来越受到重视,P2P下载工具的生存空间越来越大。比以前少了很多。Win11时代,P2P下载技术仍有一席之地,但资源的辉煌已经一去不复返了。
自研内核浏览器
不知道你会不会注意你用的是什么浏览器?至少在过去,这是一个非常有价值的问题。很多有经验的网友也是有经验的浏览器玩家,但近年来,这方面值得玩的产品越来越少——越来越多的浏览器从自研内核变成了Chromium马甲。切换到不同的浏览器基本上相当于切换到不同外观的Chrome。
连微软都放弃了自研浏览器内核,Edge浏览器成了Chromium的马甲
Windows曾经依靠捆绑大法,使其内置的IE成为Web开发的兼容标准;然而,在 Windows 11 中,内置的 Edge 浏览器已经成为 Chromium 的附庸。就连微软也举手投降了。曾经盛放的浏览器内核基本上只有火狐。浏览器是一个巨大的工程。许多热心和优秀的工程师为开发浏览器内核而努力,但现在这个项目无人问津。为什么自研内核的浏览器会走下坡路,大家都在关注Chromium?这与时代背景和谷歌的商业战略密不可分。
移动互联网时代,移动平台占据了大部分流量,Android是移动互联网流量的主要载体。Android系统使用的WebView和Chromium同源,这使得大量网页倾向于针对Chromium进行优化。谷歌虽然一直吹嘘推动Web标准化,但实际上却不断诱导前端开发者做“-webkit-”之类的事情,导致与其他浏览器内核的兼容性问题。
Chromium(Chrome)已经占据绝对优势份额,自研内核吃力不讨好
换句话说,与 Chromium 的兼容性已成为事实上的行业标准。与使用Chromium内核的马甲浏览器相比,自研引擎的浏览器越来越吃力。Chromium 是一个开源项目。多年的开发和开源社区的维护,使其非常成熟——尤其是与Edge等新项目相比,不仅成本低,问题也少。同时,Chromium 自己的产品也非常强大。支持扩展程序,提倡多线程机制,性能和稳定性可圈可点。即便正面竞争,也比Opera的Presto引擎和Firefox的Gecko引擎有着得天独厚的优势,更不用说谷歌生态的支持了。
多年来坚持自研内核的火狐,将对手从IE变成了Chrome。它可以持续多久?
相比之下,自主研发的发动机吃力不讨好,性价比还是不行。Opera、Edge等浏览器放弃自研内核,改用Chromium是可以理解的。
直到现在,人们仍然熟悉并坚持使用自研引擎的浏览器只有Firefox和Safari。微软曾经依靠Windows让IE成为桌面网页的兼容标准,谷歌依靠Android让Chromium传遍全球。Win11已经发布,微软未来还能在移动市场有所作为,重新夺回Web标准的话语权吗?我们拭目以待。
磁盘碎片整理工具
说到必备的安装软件,优化大师班绝对值得提名。而磁盘碎片整理往往是这类优化大师的关键功能。那一年,如果不偶尔整理一下磁盘碎片,电脑就会卡死无法自理。看着屏幕上被移动重组的小方块,是很多老用户的共同记忆。
你用过磁盘碎片整理工具吗?
而现在Win11来了,磁盘碎片整理似乎也告别了用户,优化大师的身影也渐渐模糊了。很大一部分用户不再在他们的计算机上安装此类软件。为什么?这与软件和硬件的发展密切相关。
先说硬件层面。从Win10时代开始,SSD逐渐取代HDD,成为主流的系统载体。HDD时代,数据存储在磁盘的扇区中,系统运行产生的小数据会分散在磁盘上。这些数据的物理位置并不是连续的,但在实际使用场景中需要不断读取。让硬盘的磁头在扇区之间运行。这时候优化器和系统本身的磁盘碎片整理功能就显得尤为重要。该功能可以将连续扇区内的小数据重新排列,大大提高读取效率。
对于 HDD,重要的是要保持数据在相邻扇区中连续分布,因此需要进行磁盘碎片整理
SSD在这方面没有烦恼和需求。SSD 没有磁盘、扇区,也没有机械可移动磁头。数据直接从 NAND 读取到操作系统。专为HDD设计的磁盘碎片整理程序对SSD毫无意义。由于硬件基础的不同,SSD对小文件的读取效率是HDD的数百倍,带来翻天覆地的体验。
再说说软件层面。SSD主控能承载的数据算法比HDD复杂,可以自动组织优化大量数据。例如,SSD主控往往支持平衡磨损算法,可以尽可能均匀地向每个块写入数据,保证每个NAND块的老化程度均匀;比如SSD主控支持垃圾采集
GC和Trim,可以在写入前自动加载新数据,转移旧数据,及时清除无用数据……这些算法都是自动完成的,无需人工干预。
SSD主控可以自动进行GC,无需人工干预
微软从Win7开始对SSD进行了优化,引入了新的WinFS系统,并支持Trim等功能;在Win10和现在的Win11中,微软已经让操作系统的I/O算法更适合SSD特性,要想获得最佳的系统体验,SSD是必不可少的。Win11时代,SSD成为主流,人们不再需要手动运行磁盘碎片整理程序。
Win11适配了SSD的特性,可以自动优化(Trim等)。整个过程只需要几秒钟,不需要手动组织。
现在说到系统优化,很多人都会想到软件的垃圾文件清理,很少有磁盘碎片整理的必要。这类工具的没落见证了硬件的发展,就让它们埋葬在历史的尘埃中吧。
RSS阅读器
人们在网上阅读文章时,通常习惯于直接到某个网站阅读,但其实还有更便捷的方式。几年前,RSS阅读非常流行。只要某个网站支持RSS,您订阅RSS后,一旦网站更新内容,就会推送给您。使用RSS阅读器,您可以同时订阅多个网站的RSS。将这些网站的内容聚合起来后,你可以阅读所有你感兴趣的东西,而不必四处奔波。这确实很方便,所以RSS被一些人认为是互联网阅读的未来——以后大家不用去各种网站了,用RSS订阅就行了!
很多网站,特别是信息站,都提供了RSS订阅,用户也可以通过RSS订阅作品或资源更新
然而,这种方便的方法现在已经成为一种不受欢迎的技术。在Win11中,系统内置了推送信息的widget,聚合了各种来源的新闻,但RSS的名字已经不再为人所知。
RSS阅读器的衰落可能是因为入门门槛高,未能找到可行的商业模式。
RSS不流行,首先使用门槛高。对于很多人来说,找到一个网站的 RSS 提要并将其添加到 RSS 阅读器是一个巨大的工程;其次,RSS的内容不全,有的网站不提供RSS,有的网站只提供RSS的文章标题。某些元素,例如嵌入在网页中的音频和视频,RSS 可能无法抓取;另一个是RSS交互元素不够,推送给你的东西基本只能看分享给别人看,不太符合Web2.0大家是内容生产者的精神。
其次,人们从来没有找到一种使用RSS阅读器赚大钱的方法——即使是谷歌也做不到。当谷歌在2013年宣布关闭最著名、最杰出的RSS阅读器Google Reader时,似乎已经将RSS标记为吃枣丸了。RSS的核心功能是订阅,但在纯RSS阅读器中,阅读器只是一个频道,RSS是内容,阅读器无法控制RSS带来的流量。
在关闭之前,谷歌阅读器仍然拥有非常高的产品力、优秀的用户口碑以及非常庞大的用户群。
微博、微信等社交工具的出现,给RSS阅读器带来了巨大的冲击。其实在微博上关注某个大V,在微信上订阅某个公众号,和订阅RSS是一样的。它还具有更强的社交属性,社交网络可以带来源源不断的源泉,并被运营商控制。其中的流程很容易实现。RSS 上手难,交互不易。连谷歌都找不到RSS的盈利点。它远离公众似乎很自然。
在Win11中,依然有精美的第三方RSS阅读器应用,但这类工具已经完全沦为小众了
不过,RSS虽然小众,但在可预见的未来,暂时还不会完全淘汰。毕竟作为一个标准,RSS其实是符合互联网的开放精神的,使用起来没有任何成本负担。对于一些有色内容,比如微博、微信不能发布的内容,订阅RSS是没有压力的。我不会告诉你内容是什么。另外,据悉,Facebook的好友动态是基于RSS订阅推送的。如果未来能发现更多RSS的应用,RSS有可能以更多的方式重新回到人们的视野中。
总结
作为微软新时代的桥头堡,Win11迎来了翻天覆地的变化。Windows软件作为微软生态系统的有力支撑,一直在迭代。在新软件不断涌现的同时,许多经典软件却在逐渐衰落。移动互联网的热潮比以往更加猛烈。Win11能否延续前辈的辉煌?我们拭目以待。 查看全部
抓取网页音频(在Win11时代,有哪些软件已经迎来没落的命运、再难有用武之地?)
微软发布了最新一代的Windows 11,在惊叹系统界面的巨大变化的同时,也不得不感受到时代浪潮的冲击。Windows也顺应潮流,推出了更先进的WinUI,并努力完善系统功能,尝试改变应用生态。新的互联网时代,即使是像Windows这样的大船也得掉头,更别提搭载的各种软件了。
Win11时代,软件也大不相同
回首过去,许多曾经繁荣的软件随着前一波的浪潮,慢慢地淡出了历史舞台。这些经典产品越来越少被提及。Win11时代,有什么软件,再难用,又迎来了没落的命运?今天就来聊聊这个话题。
防毒软件
只要你用了几年电脑,你就会一直听到那些曾经雷鸣般的名字,比如“瑞星”、“金山”、“江民”等等……但在21世纪初,自由软杀的趋势盛行。吸引了无数互联网公司的纷至沓来。除了领跑风头的“360”,“可牛”、“百度”、“优采云
”等英雄们纷纷出招,令人目不暇接。比较“有见识”的人,折腾了很多国外比较“专业”的产品,比如“小红伞”、“AVG”、“avast”、“Bitdefender”、“卡巴斯基”......安全论坛上的访客。
被玩家津津乐道的杀手
然而,近年来,反软件的热潮似乎已经消退。反软件市场不仅没有掀起新的浪潮,而且似乎也在走下坡路。无论国内百度指数,还是国外谷歌走势,2012年以来,反软件热度都未能止住下滑趋势。
国内百度指数,杀毒软件热度一路下滑
在全球范围内,杀毒软件的流行程度也与谷歌趋势中显示的数据相同
如今,几乎没有人宣布要在杀毒市场上闹,甚至一大批用户不再需要自己安装任何杀毒软件。为什么杀毒软件变的这么火?或许不是杀毒本身的原因,而是个人系统安全环境这些年的剧变。
首先,Antisoft迎来了最强的竞争对手——微软。以360为首的免费杀毒软件已经够吸引人了吧?但系统中预装的MSE/Defender只是一种犯规级别的拉客行为。同时,微软MSE/Defender的业务能力也很不错。在AVTEST等专业的反软件评测中,其性能多年位居前列。比起国内一些连测试都不敢参加的产品,我不知道它在哪里。向上。
微软自带 Security Center Defender
在最新的AV-TEST测试中,微软取得了满分
在Win11时代,Defender已经成为系统预装。而微软正计划将 Defender 打造成跨平台产品,以进一步增强实力。杀毒软件是一种高科技产品。谁比微软更懂Windows系统的代码?其他反软件想要与微软抗衡,难度不小。
其次,操作系统本身的安全性有了很大的提高。在Windows 9X甚至XP时代,代码可以轻松修改操作系统内核。Vista之后,由于用户层的架构和内核的隔离,恶意代码更难操纵。Win11默认开启虚拟化隔离内核,使用TPM芯片进行硬件级加密。反软件的作用不再像以前那么重要了。
再者,移动互联网并没有为反软件带来新的市场。iOS和Android都有严格的安装包管理机制。原则上,他们不需要使用任何反软件。Apple 甚至禁止将声称是反软件的产品放在 App Store 上。iOS 机制消除了大多数未知代码。跑的机会,借助漏洞(比如越狱)可以跑起来的代码,绝不会被杀毒挡住。反软件可以在移动平台上发挥作用,无非就是识别某个App是否是假钓鱼之类的,很多Android系统都自带这个功能。在新兴市场是无利可图的,难怪杀软的生意越来越难做。
iOS 中的应用程序无法实现病毒扫描功能。Apple 已禁止 App Store 中声称具有防病毒功能的应用程序。
毫无疑问,反软件已经沦陷了。或许在某些使用环境下还是有用的,比如识别钓鱼网站、使用旧系统,但是在以Win11为代表的新使用环境下,它的用处就没有以前那么好了。杀毒软件的衰落对安全厂商来说可能是件坏事,但客观上也说明了这些年来用户环境越来越安全,我们应该为此感到高兴。
P2P下载工具
如果您是老司机,应该非常怀念使用P2P下载工具在网上驰骋的日子。在那个BT软件为王,电骡软件为王的时代,各种资源仿佛触手可及。随便开个论坛,或者直接输入关键词搜索,种子就一路来,叫上朋友朋友来种草,下个片子时间不长。
很多朋友都用过以BitComet为代表的P2P下载器,但是现在用户群已经明显减少了
然而,如今专用的P2P下载工具早已失去了原有的风光。也许你也会下载BT或eD2k链接,但你使用的往往只是像迅雷这样的综合下载器——即使这些下载器的受欢迎程度已经大幅下降。
虽然P2P下载技术本身在互联网上仍然占据着极其重要的利基,比如Win11系统更新也会使用P2P技术来传输数据,但是P2P下载工具的没落已经是不争的事实。手动配置Tracker添加peer节点、设置DLP反吸血、破内网连接HighID……这些绝招已经在大众中失传;Bit Comet、μtorrent、eMule等,都成了小圈子的玩物。在P2P圈子里,“人人为我,我为人”的口号如此符合互联网共享的精神,但为何这一套逐渐被历史的尘埃淹没?或许这与互联网的发展趋势是分不开的。
如何找到电骡服务器?如何获得HighID?恐怕没有人可以折腾了
首先,使用P2P下载工具有一定的门槛。与迅雷、网盘等好用的工具相比,专业的P2P工具更难用。人们需要具备一些P2P传输的基础知识,并在此基础上结合实际网络环境进行手动配置,才能有更理想的性能。在下载资源之前,必须自己学习,这是很多人无法接受的。
电骡模式Xtreme的热门配置,对于新手来说,这是一本圣经书
其次,P2P下载工具的普及将在版权收紧的背景下对版权保护提出挑战。P2P下载被抑制是正常的。BTChina、VeryCD、极影……P2P资源站一个个倒塌,P2P下载生态逐渐萎缩,进而影响了P2P下载速度。同时,部分地区运营商通过特征码完成了对P2P流量的精准检测,限制了P2P下载速度,使得P2P下载工具越来越鸡肋。在某些地区,Tracker 或 e-mule 服务器甚至伪装成 P2P 盗版下载和网络钓鱼执法。这使得P2P下载工具的环境越来越差。
此外,P2P下载工具的商业化难度极大。所谓无利可图不是早起,而是P2P下载工具在大多数情况下是无利可图的。P2P传输协议是公开的,资源不由P2P下载者提供。软件商很难通过销售资源和软件、使用下载工具来盈利。
最后,P2P分享的精神在一定程度上违背了人性。“人人有份”容易,“人人有份”难。大多数P2P下载者下载资源后就跑掉了,这样做什么的,没有这样的事情。这也是大量用户从专用的P2P下载工具转向迅雷和网盘的原因。雷霆吸血?网盘和谐?速度快就是好,再多!
官方客服确认迅雷等离线下载工具会“吸血”(不会发回公共P2P网络),但下载速度快,很受欢迎
P2P下载工具在互联网野蛮生长的时代蓬勃发展,如今互联网被诸侯瓜分,维护资源和利益的秩序越来越受到重视,P2P下载工具的生存空间越来越大。比以前少了很多。Win11时代,P2P下载技术仍有一席之地,但资源的辉煌已经一去不复返了。
自研内核浏览器
不知道你会不会注意你用的是什么浏览器?至少在过去,这是一个非常有价值的问题。很多有经验的网友也是有经验的浏览器玩家,但近年来,这方面值得玩的产品越来越少——越来越多的浏览器从自研内核变成了Chromium马甲。切换到不同的浏览器基本上相当于切换到不同外观的Chrome。
连微软都放弃了自研浏览器内核,Edge浏览器成了Chromium的马甲
Windows曾经依靠捆绑大法,使其内置的IE成为Web开发的兼容标准;然而,在 Windows 11 中,内置的 Edge 浏览器已经成为 Chromium 的附庸。就连微软也举手投降了。曾经盛放的浏览器内核基本上只有火狐。浏览器是一个巨大的工程。许多热心和优秀的工程师为开发浏览器内核而努力,但现在这个项目无人问津。为什么自研内核的浏览器会走下坡路,大家都在关注Chromium?这与时代背景和谷歌的商业战略密不可分。
移动互联网时代,移动平台占据了大部分流量,Android是移动互联网流量的主要载体。Android系统使用的WebView和Chromium同源,这使得大量网页倾向于针对Chromium进行优化。谷歌虽然一直吹嘘推动Web标准化,但实际上却不断诱导前端开发者做“-webkit-”之类的事情,导致与其他浏览器内核的兼容性问题。
Chromium(Chrome)已经占据绝对优势份额,自研内核吃力不讨好
换句话说,与 Chromium 的兼容性已成为事实上的行业标准。与使用Chromium内核的马甲浏览器相比,自研引擎的浏览器越来越吃力。Chromium 是一个开源项目。多年的开发和开源社区的维护,使其非常成熟——尤其是与Edge等新项目相比,不仅成本低,问题也少。同时,Chromium 自己的产品也非常强大。支持扩展程序,提倡多线程机制,性能和稳定性可圈可点。即便正面竞争,也比Opera的Presto引擎和Firefox的Gecko引擎有着得天独厚的优势,更不用说谷歌生态的支持了。
多年来坚持自研内核的火狐,将对手从IE变成了Chrome。它可以持续多久?
相比之下,自主研发的发动机吃力不讨好,性价比还是不行。Opera、Edge等浏览器放弃自研内核,改用Chromium是可以理解的。
直到现在,人们仍然熟悉并坚持使用自研引擎的浏览器只有Firefox和Safari。微软曾经依靠Windows让IE成为桌面网页的兼容标准,谷歌依靠Android让Chromium传遍全球。Win11已经发布,微软未来还能在移动市场有所作为,重新夺回Web标准的话语权吗?我们拭目以待。
磁盘碎片整理工具
说到必备的安装软件,优化大师班绝对值得提名。而磁盘碎片整理往往是这类优化大师的关键功能。那一年,如果不偶尔整理一下磁盘碎片,电脑就会卡死无法自理。看着屏幕上被移动重组的小方块,是很多老用户的共同记忆。
你用过磁盘碎片整理工具吗?
而现在Win11来了,磁盘碎片整理似乎也告别了用户,优化大师的身影也渐渐模糊了。很大一部分用户不再在他们的计算机上安装此类软件。为什么?这与软件和硬件的发展密切相关。
先说硬件层面。从Win10时代开始,SSD逐渐取代HDD,成为主流的系统载体。HDD时代,数据存储在磁盘的扇区中,系统运行产生的小数据会分散在磁盘上。这些数据的物理位置并不是连续的,但在实际使用场景中需要不断读取。让硬盘的磁头在扇区之间运行。这时候优化器和系统本身的磁盘碎片整理功能就显得尤为重要。该功能可以将连续扇区内的小数据重新排列,大大提高读取效率。
对于 HDD,重要的是要保持数据在相邻扇区中连续分布,因此需要进行磁盘碎片整理
SSD在这方面没有烦恼和需求。SSD 没有磁盘、扇区,也没有机械可移动磁头。数据直接从 NAND 读取到操作系统。专为HDD设计的磁盘碎片整理程序对SSD毫无意义。由于硬件基础的不同,SSD对小文件的读取效率是HDD的数百倍,带来翻天覆地的体验。
再说说软件层面。SSD主控能承载的数据算法比HDD复杂,可以自动组织优化大量数据。例如,SSD主控往往支持平衡磨损算法,可以尽可能均匀地向每个块写入数据,保证每个NAND块的老化程度均匀;比如SSD主控支持垃圾采集
GC和Trim,可以在写入前自动加载新数据,转移旧数据,及时清除无用数据……这些算法都是自动完成的,无需人工干预。
SSD主控可以自动进行GC,无需人工干预
微软从Win7开始对SSD进行了优化,引入了新的WinFS系统,并支持Trim等功能;在Win10和现在的Win11中,微软已经让操作系统的I/O算法更适合SSD特性,要想获得最佳的系统体验,SSD是必不可少的。Win11时代,SSD成为主流,人们不再需要手动运行磁盘碎片整理程序。
Win11适配了SSD的特性,可以自动优化(Trim等)。整个过程只需要几秒钟,不需要手动组织。
现在说到系统优化,很多人都会想到软件的垃圾文件清理,很少有磁盘碎片整理的必要。这类工具的没落见证了硬件的发展,就让它们埋葬在历史的尘埃中吧。
RSS阅读器
人们在网上阅读文章时,通常习惯于直接到某个网站阅读,但其实还有更便捷的方式。几年前,RSS阅读非常流行。只要某个网站支持RSS,您订阅RSS后,一旦网站更新内容,就会推送给您。使用RSS阅读器,您可以同时订阅多个网站的RSS。将这些网站的内容聚合起来后,你可以阅读所有你感兴趣的东西,而不必四处奔波。这确实很方便,所以RSS被一些人认为是互联网阅读的未来——以后大家不用去各种网站了,用RSS订阅就行了!
很多网站,特别是信息站,都提供了RSS订阅,用户也可以通过RSS订阅作品或资源更新
然而,这种方便的方法现在已经成为一种不受欢迎的技术。在Win11中,系统内置了推送信息的widget,聚合了各种来源的新闻,但RSS的名字已经不再为人所知。
RSS阅读器的衰落可能是因为入门门槛高,未能找到可行的商业模式。
RSS不流行,首先使用门槛高。对于很多人来说,找到一个网站的 RSS 提要并将其添加到 RSS 阅读器是一个巨大的工程;其次,RSS的内容不全,有的网站不提供RSS,有的网站只提供RSS的文章标题。某些元素,例如嵌入在网页中的音频和视频,RSS 可能无法抓取;另一个是RSS交互元素不够,推送给你的东西基本只能看分享给别人看,不太符合Web2.0大家是内容生产者的精神。
其次,人们从来没有找到一种使用RSS阅读器赚大钱的方法——即使是谷歌也做不到。当谷歌在2013年宣布关闭最著名、最杰出的RSS阅读器Google Reader时,似乎已经将RSS标记为吃枣丸了。RSS的核心功能是订阅,但在纯RSS阅读器中,阅读器只是一个频道,RSS是内容,阅读器无法控制RSS带来的流量。
在关闭之前,谷歌阅读器仍然拥有非常高的产品力、优秀的用户口碑以及非常庞大的用户群。
微博、微信等社交工具的出现,给RSS阅读器带来了巨大的冲击。其实在微博上关注某个大V,在微信上订阅某个公众号,和订阅RSS是一样的。它还具有更强的社交属性,社交网络可以带来源源不断的源泉,并被运营商控制。其中的流程很容易实现。RSS 上手难,交互不易。连谷歌都找不到RSS的盈利点。它远离公众似乎很自然。
在Win11中,依然有精美的第三方RSS阅读器应用,但这类工具已经完全沦为小众了
不过,RSS虽然小众,但在可预见的未来,暂时还不会完全淘汰。毕竟作为一个标准,RSS其实是符合互联网的开放精神的,使用起来没有任何成本负担。对于一些有色内容,比如微博、微信不能发布的内容,订阅RSS是没有压力的。我不会告诉你内容是什么。另外,据悉,Facebook的好友动态是基于RSS订阅推送的。如果未来能发现更多RSS的应用,RSS有可能以更多的方式重新回到人们的视野中。
总结
作为微软新时代的桥头堡,Win11迎来了翻天覆地的变化。Windows软件作为微软生态系统的有力支撑,一直在迭代。在新软件不断涌现的同时,许多经典软件却在逐渐衰落。移动互联网的热潮比以往更加猛烈。Win11能否延续前辈的辉煌?我们拭目以待。
抓取网页音频(爬虫为怪咖系列第三期离第三期的时间有点长长)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-26 08:12
本期是Freak系列的第三期。第二期由于客户论文重复问题,暂不对外公开源码。本期使用的语言是java,创建多线程,支持断点采集
,URL去重,广度优先+深度组合,如何利用已经构建好的轮子进行快速开发和加载。好了,吹完水,现在我们进入教程阶段。
爬虫
本期目标: 本期工具: 采集结果展示:
将采集
的结果写入excel
WebCollector 简介
WebCollector是一个JAVA爬虫框架,无需配置,方便二次开发。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。而 2.x 版本中提供了 selenium,可以处理 javascript 生成的数据。我们先来看看WebCollector的核心架构图:
爬虫架构图
但是,我们使用WebCollector来编写爬虫没有那么麻烦,只需要使用集成爬虫框架中的BreadthCrawler类,重写visit方法即可。我们先看官网例子:
官网示例
程序说明:
访问()方法
在整个爬取过程中,只要抓取到一个复合页面,wc就会回调这个方法,传入一个收录
所有页面信息的页面对象。
添加种子()
添加种子,在爬虫启动前,种子链接会被添加到上面提到的爬取信息中并标记为未爬取。这个过程称为注入。
添加正则表达式
它是一个url正则表达式,用于过滤不需要爬取的链接,如.js、jpg、css等,或者指定爬取链接的规则。例如,当我使用常规规则:[0-9]+.html 时,那么我的爬虫只会爬行,并等待域名下以 2015-01-16 日期为.html 结尾的链接。
开始()
表示启动爬虫,输入参数5表示抓取5层(深度为5),这个深度5怎么理解,只添加一个seed时,抓取seed链接作为第一层,并解析种子链接页面,根据规则过滤,将想要的链接保存到要爬取的记录中,然后第二层抓取第一层存储的记录,分析保存新的记录,以此类推.
网页云音乐页面分析:
我们来看看网易云音乐的下一首歌曲页面链接:#/album?id=2884361。观察这个url,发现是一个查询站。查询id可以得到不同的歌曲,这样我们就可以遍历整个网易云音乐。提取出与上述网址类似的网页后,即可获取网易云音乐的所有歌曲。
这时候就遇到了第二个问题,获取歌曲页面后如何获取歌曲的真实地址,我们通过抓包分析得到网易云音乐有一个api接口可以获取歌曲的真实地址歌曲,api地址:,这个接口有几个参数:
然后访问api得到一段json,里面收录
了现有歌曲的几个版本的音频源地址。至于如何抓取和分析到这个地址的地址,接下来的教程会提供给大家。
更别说这么多了。在代码上,所有的核心代码都做了注释。整个爬虫的思路是这样的:
网络爬虫源代码
附上Github地址:。欢迎关注极客科普,学习关注有趣的小技巧。 查看全部
抓取网页音频(爬虫为怪咖系列第三期离第三期的时间有点长长)
本期是Freak系列的第三期。第二期由于客户论文重复问题,暂不对外公开源码。本期使用的语言是java,创建多线程,支持断点采集
,URL去重,广度优先+深度组合,如何利用已经构建好的轮子进行快速开发和加载。好了,吹完水,现在我们进入教程阶段。
爬虫
本期目标: 本期工具: 采集结果展示:
将采集
的结果写入excel
WebCollector 简介
WebCollector是一个JAVA爬虫框架,无需配置,方便二次开发。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。而 2.x 版本中提供了 selenium,可以处理 javascript 生成的数据。我们先来看看WebCollector的核心架构图:
爬虫架构图
但是,我们使用WebCollector来编写爬虫没有那么麻烦,只需要使用集成爬虫框架中的BreadthCrawler类,重写visit方法即可。我们先看官网例子:
官网示例
程序说明:
访问()方法
在整个爬取过程中,只要抓取到一个复合页面,wc就会回调这个方法,传入一个收录
所有页面信息的页面对象。
添加种子()
添加种子,在爬虫启动前,种子链接会被添加到上面提到的爬取信息中并标记为未爬取。这个过程称为注入。
添加正则表达式
它是一个url正则表达式,用于过滤不需要爬取的链接,如.js、jpg、css等,或者指定爬取链接的规则。例如,当我使用常规规则:[0-9]+.html 时,那么我的爬虫只会爬行,并等待域名下以 2015-01-16 日期为.html 结尾的链接。
开始()
表示启动爬虫,输入参数5表示抓取5层(深度为5),这个深度5怎么理解,只添加一个seed时,抓取seed链接作为第一层,并解析种子链接页面,根据规则过滤,将想要的链接保存到要爬取的记录中,然后第二层抓取第一层存储的记录,分析保存新的记录,以此类推.
网页云音乐页面分析:
我们来看看网易云音乐的下一首歌曲页面链接:#/album?id=2884361。观察这个url,发现是一个查询站。查询id可以得到不同的歌曲,这样我们就可以遍历整个网易云音乐。提取出与上述网址类似的网页后,即可获取网易云音乐的所有歌曲。
这时候就遇到了第二个问题,获取歌曲页面后如何获取歌曲的真实地址,我们通过抓包分析得到网易云音乐有一个api接口可以获取歌曲的真实地址歌曲,api地址:,这个接口有几个参数:
然后访问api得到一段json,里面收录
了现有歌曲的几个版本的音频源地址。至于如何抓取和分析到这个地址的地址,接下来的教程会提供给大家。
更别说这么多了。在代码上,所有的核心代码都做了注释。整个爬虫的思路是这样的:
网络爬虫源代码
附上Github地址:。欢迎关注极客科普,学习关注有趣的小技巧。
抓取网页音频(windows下py2exe安装exe编辑器按照图中的步骤设置好安装路径)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-24 09:03
抓取网页音频视频时遇到过类似问题,找到python的安装目录下的py2exe,它有将python脚本转化为exe方便读取的功能。现在是冬天,经过多次尝试,终于能将python脚本转化为exe的方法了。办法是,把py2exe安装目录里exe文件放到路径里c:\python27\exe(可能有些大小问题,放着就好了),如图2中的c:\python27\foo.pyf,2在不改动它的前提下,exe文件其实是可以正常打开的。下载链接::。
看你python安装路径中有没有cmd.exe
既然exe已经可以正常打开了,说明你已经安装好了xlrd和xlwt,安装路径下就有一个exe,
我用eclipse直接编辑安装路径下的exe也打不开,加载失败。
右键->installpackage->从microsoftstore安装。
我试了,不行。网上说的是python2的问题,更新到最新的版本,不行,换成python3.3,很大程度可以解决问题。
我发现是py2exe本身的bug我来告诉你一个比较简单的破解方法百度:windows下py2exe安装exe编辑器按照图中的步骤设置好安装路径然后使用exe打开试试吧/
如果安装的是python2.7版本的话, 查看全部
抓取网页音频(windows下py2exe安装exe编辑器按照图中的步骤设置好安装路径)
抓取网页音频视频时遇到过类似问题,找到python的安装目录下的py2exe,它有将python脚本转化为exe方便读取的功能。现在是冬天,经过多次尝试,终于能将python脚本转化为exe的方法了。办法是,把py2exe安装目录里exe文件放到路径里c:\python27\exe(可能有些大小问题,放着就好了),如图2中的c:\python27\foo.pyf,2在不改动它的前提下,exe文件其实是可以正常打开的。下载链接::。
看你python安装路径中有没有cmd.exe
既然exe已经可以正常打开了,说明你已经安装好了xlrd和xlwt,安装路径下就有一个exe,
我用eclipse直接编辑安装路径下的exe也打不开,加载失败。
右键->installpackage->从microsoftstore安装。
我试了,不行。网上说的是python2的问题,更新到最新的版本,不行,换成python3.3,很大程度可以解决问题。
我发现是py2exe本身的bug我来告诉你一个比较简单的破解方法百度:windows下py2exe安装exe编辑器按照图中的步骤设置好安装路径然后使用exe打开试试吧/
如果安装的是python2.7版本的话,
抓取网页音频(支持所有Chrome内核浏览器的网页媒体嗅探的扩展(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-12-23 02:02
猫抓
Mozhao 是一个扩展,支持所有 Chrome 内核浏览器的网络媒体嗅探和抓取。
它可以一键抓取任何站点的任何视频/音频数据,使用起来非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮可以看到页面上的资源信息。
然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地。
猫扎支持优酷、搜狐、腾讯、微博、B站等几乎所有国内网站视频文件嗅探。
当多个媒体资源出现在同一页面时,您还可以对其进行快速批量操作。
一般来说,这类嗅探工具支持的视频文件是未加密的。当面对一些加密的视频时,会有一定的失败几率。
不过,从市场反馈来看,猫筹可以抢到很多其他IDM无法嗅到的媒体资源。
这也是它在竞争激烈的拓展店中能够拥有超过5万用户的原因之一。
此外,毛爪还支持对所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,还支持使用正则表达式自定义采集的内容。
网络嗅探器最初是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。Sniffer 也是很多程序员在编写网络程序时捕捉和测试的工具。
近年来,网络嗅探器被广泛应用于用户的日常行为中,成为捕捉视频、音频等内容的工具。 查看全部
抓取网页音频(支持所有Chrome内核浏览器的网页媒体嗅探的扩展(图))
猫抓
Mozhao 是一个扩展,支持所有 Chrome 内核浏览器的网络媒体嗅探和抓取。
它可以一键抓取任何站点的任何视频/音频数据,使用起来非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮可以看到页面上的资源信息。
然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地。
猫扎支持优酷、搜狐、腾讯、微博、B站等几乎所有国内网站视频文件嗅探。
当多个媒体资源出现在同一页面时,您还可以对其进行快速批量操作。
一般来说,这类嗅探工具支持的视频文件是未加密的。当面对一些加密的视频时,会有一定的失败几率。
不过,从市场反馈来看,猫筹可以抢到很多其他IDM无法嗅到的媒体资源。
这也是它在竞争激烈的拓展店中能够拥有超过5万用户的原因之一。
此外,毛爪还支持对所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,还支持使用正则表达式自定义采集的内容。
网络嗅探器最初是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。Sniffer 也是很多程序员在编写网络程序时捕捉和测试的工具。
近年来,网络嗅探器被广泛应用于用户的日常行为中,成为捕捉视频、音频等内容的工具。
抓取网页音频(本文实例讲述了。分享给大家供大家参考。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-18 16:05
本文以JAVA如何使用爬虫抓取网站网页内容为例。分享给大家,供大家参考。详情如下:
最近一直在用JAVA研究爬虫技术。哈哈,我进了门,和大家分享我的经历。
下面提供了两种方法,一种是使用apache提供的包。另一种是JAVA自带的。
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength 查看全部
抓取网页音频(本文实例讲述了。分享给大家供大家参考。。)
本文以JAVA如何使用爬虫抓取网站网页内容为例。分享给大家,供大家参考。详情如下:
最近一直在用JAVA研究爬虫技术。哈哈,我进了门,和大家分享我的经历。
下面提供了两种方法,一种是使用apache提供的包。另一种是JAVA自带的。
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength
抓取网页音频(软件调用基于GoogleChromium的ChromiumEmbeddedFramework(CEF)框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-16 14:08
最近,我遇到了一个想开网店的女人,她到处爬着人的照片。后来,她肿起来了,想爬人的音视频。然而,我发现了这样一个东西,因为我不擅长它,仍然闲聊。声明不是我做的,它有效。可以解决我这种烦人的小白的问题,在他面前保持光辉的形象。
软件说明:
软件调用基于谷歌Chromium的Chromium Embedded Framework
(CEF) 框架,数据采集全面,无遗漏,支持视频格式文件采集。通过该软件,用户可以下载某个网站的内容,使用起来非常简单。只需将您要下载的网站的链接复制到软件中,软件就会列出当前网站中所有可下载的东西。用户只需复制软件中列出的链接即可下载,非常方便。
使用说明
1、首先设置抓包文件的格式,用“|”分隔。
2、输入要抓取的网址,点击打开,抓取的数据会显示在过滤结果中
3、 点击排序,过滤结果排序功能,方便判断文件类型(一般较大的文件主要是视频)
4、如果常规结果没有捕捉到你想要的视频,点击其他结果,从大到小排序,通常只是前几个
5、 确认文件地址,复制到浏览器下载,或者下载工具下载
我在某宝上随机发现了一个网站(如果楼主在,请见谅,无冒犯之意),
格式选择MP4,点击打开网站,稍等片刻。
现在,你需要的视频就是他。随你喜欢
当然,图片和音频都可以爬出来。只需选择过滤器格式。只是格式越多,速度就越慢。
再次声明,作者在软件中所附的捐赠与我无关。也向作者的老板道歉。
如果它帮助你做一个女孩,免费送给你 查看全部
抓取网页音频(软件调用基于GoogleChromium的ChromiumEmbeddedFramework(CEF)框架)
最近,我遇到了一个想开网店的女人,她到处爬着人的照片。后来,她肿起来了,想爬人的音视频。然而,我发现了这样一个东西,因为我不擅长它,仍然闲聊。声明不是我做的,它有效。可以解决我这种烦人的小白的问题,在他面前保持光辉的形象。
软件说明:
软件调用基于谷歌Chromium的Chromium Embedded Framework
(CEF) 框架,数据采集全面,无遗漏,支持视频格式文件采集。通过该软件,用户可以下载某个网站的内容,使用起来非常简单。只需将您要下载的网站的链接复制到软件中,软件就会列出当前网站中所有可下载的东西。用户只需复制软件中列出的链接即可下载,非常方便。
使用说明
1、首先设置抓包文件的格式,用“|”分隔。
2、输入要抓取的网址,点击打开,抓取的数据会显示在过滤结果中
3、 点击排序,过滤结果排序功能,方便判断文件类型(一般较大的文件主要是视频)
4、如果常规结果没有捕捉到你想要的视频,点击其他结果,从大到小排序,通常只是前几个
5、 确认文件地址,复制到浏览器下载,或者下载工具下载
我在某宝上随机发现了一个网站(如果楼主在,请见谅,无冒犯之意),
格式选择MP4,点击打开网站,稍等片刻。
现在,你需要的视频就是他。随你喜欢
当然,图片和音频都可以爬出来。只需选择过滤器格式。只是格式越多,速度就越慢。
再次声明,作者在软件中所附的捐赠与我无关。也向作者的老板道歉。
如果它帮助你做一个女孩,免费送给你
抓取网页音频( 一下喜马拉雅的音频数据爬下来(一):运行环境三)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-09 21:19
一下喜马拉雅的音频数据爬下来(一):运行环境三)
喜马拉雅山
一、简介
这次爬取的是喜马拉雅热门栏目下所有电台的各个频道的信息以及频道中各个音频数据的各种信息,然后将爬取到的数据保存到mongodb中以备后续使用。这次的数据量在70万左右。音频资料包括音频下载地址、频道信息、简介等,种类很多。
昨天,我迎来了人生中的第一次面试。另一方是一家人。我打算大二的暑假去实习。他们要求爬取音频数据,所以我会分析喜马拉雅的音频数据爬下来。目前还在等三方,或者通知最后的采访消息。(因为能得到一定的认可,不管成功与否,我都很开心)
二:运行环境三:案例分析
1. 首先进入这个爬虫的主页面,可以看到每页有12个频道,每个频道下面有很多音频,有的频道有很多标签。爬取方案:循环84页,解析每个页面后,抓取每个频道的名称、图片链接、频道链接保存到mongodb。
热门频道
2.打开开发者模式,分析页面,很快就可以得到你想要的数据的位置了。以下代码实现抓取所有热门频道的信息,可以保存在mongodb中。
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]
for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')
for item in soup.find_all(class_="albumfaceOutter"):
content = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
print(content)
分析通道
3. 下面开始获取各个通道的所有音频数据。美国频道的链接是之前解析页面得到的。比如我们进入这个链接后,我们分析一下页面结构。可以看出,每个音频都有一个特定的ID,可以在一个div中的一个属性中获取。使用 split() 和 int() 转换为单独的 ID。
频道页面分析
4. 然后点击一个音频链接,进入开发者模式,刷新页面点击XHR,然后点击一个json链接,可以看到这个收录了音频的所有详细信息。
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
音频页面分析
5. 上面只是解析了一个频道主页面上的所有音频信息,但实际上该频道的音频链接有很多分页。
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')
for n in range(1, int(num)+1):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
# 之后就接解析音频页函数就行,后面有完整代码说明
分页
6.所有代码
完整代码地址/rieuse/learnPython
__author__ = '布咯咯_rieuse'
import json
import random
import time
import pymongo
import requests
from bs4 import BeautifulSoup
from lxml import etree
clients = pymongo.MongoClient('localhost')
db = clients["XiMaLaYa"]
col1 = db["album"]
col2 = db["detaile"]
UA_LIST = [] # 很多User-Agent用来随机使用可以防ban,显示不方便不贴出来了
headers1 = {} # 访问网页的headers,这里显示不方便我就不贴出来了
headers2 = {} # 访问网页的headers这里显示不方便我就不贴出来了
def get_url():
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]
for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')
for item in soup.find_all(class_="albumfaceOutter"):
content = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
col1.insert(content)
print('写入一个频道' + item.a['href'])
print(content)
another(item.a['href'])
time.sleep(1)
def another(url):
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')
for n in range(1, int(num)+1):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
get_m4a(url2)
get_m4a(url)
def get_m4a(url):
time.sleep(1)
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
col2.insert(dic)
print(murl + '中的数据已被成功插入mongodb')
if __name__ == '__main__':
get_url()
7.如果改成异步形式可以更快,改成下面这样就行了。我试图每分钟比正常情况多获得近 100 条数据。此源代码也在 github 中。
异步
五:总结
这次捕获的数据量约为700,000。这个数据以后可以研究很多,比如播放次数、时间段排名、频道音频音量等等。后续会继续学习使用科学计算和绘图工具进行数据分析和清洗。
捕获的数据是通道信息和通道中的每个音频特定信息。
Paste_Image.png
Paste_Image.png
贴出我的github地址,把我的爬虫代码和我学会的代码写进去,喜欢的可以点击开始关注,一起学习交流!/rieuse/learnPython 查看全部
抓取网页音频(
一下喜马拉雅的音频数据爬下来(一):运行环境三)
喜马拉雅山
一、简介
这次爬取的是喜马拉雅热门栏目下所有电台的各个频道的信息以及频道中各个音频数据的各种信息,然后将爬取到的数据保存到mongodb中以备后续使用。这次的数据量在70万左右。音频资料包括音频下载地址、频道信息、简介等,种类很多。
昨天,我迎来了人生中的第一次面试。另一方是一家人。我打算大二的暑假去实习。他们要求爬取音频数据,所以我会分析喜马拉雅的音频数据爬下来。目前还在等三方,或者通知最后的采访消息。(因为能得到一定的认可,不管成功与否,我都很开心)
二:运行环境三:案例分析
1. 首先进入这个爬虫的主页面,可以看到每页有12个频道,每个频道下面有很多音频,有的频道有很多标签。爬取方案:循环84页,解析每个页面后,抓取每个频道的名称、图片链接、频道链接保存到mongodb。
热门频道
2.打开开发者模式,分析页面,很快就可以得到你想要的数据的位置了。以下代码实现抓取所有热门频道的信息,可以保存在mongodb中。
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]
for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')
for item in soup.find_all(class_="albumfaceOutter"):
content = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
print(content)
分析通道
3. 下面开始获取各个通道的所有音频数据。美国频道的链接是之前解析页面得到的。比如我们进入这个链接后,我们分析一下页面结构。可以看出,每个音频都有一个特定的ID,可以在一个div中的一个属性中获取。使用 split() 和 int() 转换为单独的 ID。
频道页面分析
4. 然后点击一个音频链接,进入开发者模式,刷新页面点击XHR,然后点击一个json链接,可以看到这个收录了音频的所有详细信息。
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
音频页面分析
5. 上面只是解析了一个频道主页面上的所有音频信息,但实际上该频道的音频链接有很多分页。
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')
for n in range(1, int(num)+1):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
# 之后就接解析音频页函数就行,后面有完整代码说明
分页
6.所有代码
完整代码地址/rieuse/learnPython
__author__ = '布咯咯_rieuse'
import json
import random
import time
import pymongo
import requests
from bs4 import BeautifulSoup
from lxml import etree
clients = pymongo.MongoClient('localhost')
db = clients["XiMaLaYa"]
col1 = db["album"]
col2 = db["detaile"]
UA_LIST = [] # 很多User-Agent用来随机使用可以防ban,显示不方便不贴出来了
headers1 = {} # 访问网页的headers,这里显示不方便我就不贴出来了
headers2 = {} # 访问网页的headers这里显示不方便我就不贴出来了
def get_url():
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]
for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')
for item in soup.find_all(class_="albumfaceOutter"):
content = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
col1.insert(content)
print('写入一个频道' + item.a['href'])
print(content)
another(item.a['href'])
time.sleep(1)
def another(url):
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')
for n in range(1, int(num)+1):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
get_m4a(url2)
get_m4a(url)
def get_m4a(url):
time.sleep(1)
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
col2.insert(dic)
print(murl + '中的数据已被成功插入mongodb')
if __name__ == '__main__':
get_url()
7.如果改成异步形式可以更快,改成下面这样就行了。我试图每分钟比正常情况多获得近 100 条数据。此源代码也在 github 中。
异步
五:总结
这次捕获的数据量约为700,000。这个数据以后可以研究很多,比如播放次数、时间段排名、频道音频音量等等。后续会继续学习使用科学计算和绘图工具进行数据分析和清洗。
捕获的数据是通道信息和通道中的每个音频特定信息。
Paste_Image.png
Paste_Image.png
贴出我的github地址,把我的爬虫代码和我学会的代码写进去,喜欢的可以点击开始关注,一起学习交流!/rieuse/learnPython
抓取网页音频(一下一个爬虫爬虫框架的常见网页更新策略框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-09 16:24
文章内容
网络爬虫的原理
首先,让我们谈谈什么是爬虫。目前,搜索引擎对象往往是数百个网页,因此搜索引擎面临的主要问题是如何将这些网页存储在本地。用于获取这些网页的工具称为爬虫。
我们来看一个爬虫框架。首先手动选择网页的一部分作为初始网页放入待抓取的URL队列中,然后爬虫框架开始从待抓取的URL队列中取出URL,并下载该网页的内容根据这个网址。这项工作通常由网页下载模块负责。下载网页后,会做两步:
分析网页的内容。如果网页中存在网址,则此时将其放入网址队列中进行抓取。这里需要注意的是对这个操作进行去重。网页存储在网页库中
履带式
爬虫主要分为以下几类:
但是我们要注意的是,无论是哪种爬虫,如果遇到爬虫禁止协议,都不会继续爬取。
爬虫禁止协议一般分为两种情况:
首先是告诉爬虫不要索引网页的内容,标记为noindex:
另一种是告诉爬虫不要抓取网页中收录的链接,使用nofollow作为标记:
爬虫爬取策略
在爬虫框架中,要爬取的URL队列是一个非常关键的部分。需要爬虫爬取的网页的网址排列,形成队列结构。每个爬虫都会从中获取 URL 并爬取内容。爬虫的不同爬取策略是根据不同的方法来确定要爬取的URL队列中URL的优先级。
网页更新策略
网页经常动态变化。因此,对于已经爬取过的网页,爬虫还要负责保持其内容与网页内容同步,这取决于爬虫所采用的网页更新策略。
常见的网页更新策略如下:
参考
[1] 这是搜索引擎 查看全部
抓取网页音频(一下一个爬虫爬虫框架的常见网页更新策略框架)
文章内容
网络爬虫的原理
首先,让我们谈谈什么是爬虫。目前,搜索引擎对象往往是数百个网页,因此搜索引擎面临的主要问题是如何将这些网页存储在本地。用于获取这些网页的工具称为爬虫。
我们来看一个爬虫框架。首先手动选择网页的一部分作为初始网页放入待抓取的URL队列中,然后爬虫框架开始从待抓取的URL队列中取出URL,并下载该网页的内容根据这个网址。这项工作通常由网页下载模块负责。下载网页后,会做两步:
分析网页的内容。如果网页中存在网址,则此时将其放入网址队列中进行抓取。这里需要注意的是对这个操作进行去重。网页存储在网页库中
履带式
爬虫主要分为以下几类:
但是我们要注意的是,无论是哪种爬虫,如果遇到爬虫禁止协议,都不会继续爬取。
爬虫禁止协议一般分为两种情况:
首先是告诉爬虫不要索引网页的内容,标记为noindex:
另一种是告诉爬虫不要抓取网页中收录的链接,使用nofollow作为标记:
爬虫爬取策略
在爬虫框架中,要爬取的URL队列是一个非常关键的部分。需要爬虫爬取的网页的网址排列,形成队列结构。每个爬虫都会从中获取 URL 并爬取内容。爬虫的不同爬取策略是根据不同的方法来确定要爬取的URL队列中URL的优先级。
网页更新策略
网页经常动态变化。因此,对于已经爬取过的网页,爬虫还要负责保持其内容与网页内容同步,这取决于爬虫所采用的网页更新策略。
常见的网页更新策略如下:
参考
[1] 这是搜索引擎
抓取网页音频( 风中蹦迪12-0911:18阅读3关注搜索引擎面对的是互联网万亿网页,如何高效抓取这么多网页到本地镜像?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-09 16:23
风中蹦迪12-0911:18阅读3关注搜索引擎面对的是互联网万亿网页,如何高效抓取这么多网页到本地镜像?)
在风中弹跳
12-09 11:18 阅读3
专注于
如何吸引搜索引擎蜘蛛?(蜘蛛抓取网页的规则)
搜索引擎面对互联网上数以万亿计的网页。如何高效抓取这么多网页到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都在与它密切接触
一、爬虫框架
上图是一个简单的网络爬虫框架图。从seed URL开始,如图,一步一步的工作,最后将网页保存到数据库中。当然,勤奋的蜘蛛可能需要做更多的工作,例如:网页去重和反作弊网页。
或许,我们可以把网络当成蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容放在胃里。
过期页面。蜘蛛每次都爬很多网页,有的在肚子里坏了。
要下载的网页。蜘蛛看到食物,就会抓住它。
知乎网页。它还没有被下载和发现,但蜘蛛可以感觉到它们并且迟早会抓住它。
不可知的页面。互联网如此之大,以至于很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及他们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切都很特别。根据功能不同,蜘蛛系统也存在一些差异。
二、爬虫的类型
1. 大量蜘蛛。
这种蜘蛛有明确的爬行范围和目标,当蜘蛛完成目标和任务时停止爬行。具体目标是什么?可能是抓取的页面数量、页面大小、抓取时间等。
2.增量蜘蛛
这种蜘蛛与批量蜘蛛的不同之处在于它们会不断地爬取,并且会周期性地爬取和更新被爬取的网页。由于互联网上的网页在不断更新,增量蜘蛛需要能够反映这种更新。
3.垂直蜘蛛
该蜘蛛只关注特定主题或特定行业网页。以健康网站为例,这种专门的蜘蛛只会抓取健康相关的主题,其他主题内容的网页不会被抓取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛爬行。
三、爬取策略
蜘蛛通过种子网址进行爬取和扩展,列出了大量需要爬取的网址。但是要爬取的网址数量庞大,蜘蛛是如何确定爬取顺序的呢?蜘蛛爬取的策略有很多,但最终的目标是一个:先爬取重要的网页。为了评估页面是否重要,蜘蛛会根据页面内容的原创度、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略
宽度优先是指蜘蛛爬完一个网页后,它会继续按顺序爬取该网页中收录的其他页面。这种想法看似简单,但实际上非常实用。因为大多数网页都是按优先级排序的,重要的页面会优先推荐在页面上。
2. PageRank 策略
PageRank是一种非常著名的链接分析方法,主要用于衡量网页的权重。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法,我们可以找出哪些页面更重要,然后蜘蛛先抓取这些重要的页面。
3.大站点优先策略
这很容易理解。大网站通常内容页比较多,质量会高一些。蜘蛛会先分析网站的分类和属性。如果这个网站已经收录很多,或者在搜索引擎系统中的权重很高,那么优先收录。
四、网页更新
互联网上的大部分页面都是保持更新的,因此也要求蜘蛛存储的页面及时更新以保持一致性。打个比方:一个网页之前排名很好,如果页面被删除了,还排名,那体验就很糟糕了。因此,搜索引擎需要知道这些并随时更新页面,并将最新的页面提供给用户。常用的网页更新策略有三种:历史参考策略和用户体验策略。集群抽样策略。
1.历史参考策略
这是基于假设的更新策略。例如,如果你的网页之前定期更新过,那么搜索引擎也会认为你的网页以后会经常更新,蜘蛛就会定期来网站按照这个规则抓取网页。这也是为什么电水一直强调网站的内容需要定期更新。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人看后面的页面。用户体验策略就是根据用户的这个特点更新搜索引擎。例如,一个网页可能发布较早,有一段时间没有更新,但用户仍然觉得有用,点击浏览,那么搜索引擎可能不会更新这些过时的网页。这就是为什么在搜索结果中,最新的页面不一定排名靠前。排名更依赖于该页面的质量,而不是更新的时间。
3. 聚类抽样策略
以上两种更新策略主要参考网页的历史信息。然而,存储大量的历史信息对搜索引擎来说是一种负担。另外,如果收录是一个新的网页,没有历史资料可以参考,我该怎么办?聚类抽样策略是指根据网页上显示的一些属性对许多相似的网页进行分类,分类后的网页按照相同的规则进行更新。
通过了解搜索引擎蜘蛛工作原理的过程,我们会知道:网站内容的相关性,网站与网页内容的更新规律,网页上的链接分布,而网站的权重等因素会影响蜘蛛的爬行效率。识敌,让蜘蛛来的更猛烈! 查看全部
抓取网页音频(
风中蹦迪12-0911:18阅读3关注搜索引擎面对的是互联网万亿网页,如何高效抓取这么多网页到本地镜像?)
在风中弹跳
12-09 11:18 阅读3
专注于
如何吸引搜索引擎蜘蛛?(蜘蛛抓取网页的规则)
搜索引擎面对互联网上数以万亿计的网页。如何高效抓取这么多网页到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都在与它密切接触
一、爬虫框架
上图是一个简单的网络爬虫框架图。从seed URL开始,如图,一步一步的工作,最后将网页保存到数据库中。当然,勤奋的蜘蛛可能需要做更多的工作,例如:网页去重和反作弊网页。
或许,我们可以把网络当成蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容放在胃里。
过期页面。蜘蛛每次都爬很多网页,有的在肚子里坏了。
要下载的网页。蜘蛛看到食物,就会抓住它。
知乎网页。它还没有被下载和发现,但蜘蛛可以感觉到它们并且迟早会抓住它。
不可知的页面。互联网如此之大,以至于很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及他们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切都很特别。根据功能不同,蜘蛛系统也存在一些差异。
二、爬虫的类型
1. 大量蜘蛛。
这种蜘蛛有明确的爬行范围和目标,当蜘蛛完成目标和任务时停止爬行。具体目标是什么?可能是抓取的页面数量、页面大小、抓取时间等。
2.增量蜘蛛
这种蜘蛛与批量蜘蛛的不同之处在于它们会不断地爬取,并且会周期性地爬取和更新被爬取的网页。由于互联网上的网页在不断更新,增量蜘蛛需要能够反映这种更新。
3.垂直蜘蛛
该蜘蛛只关注特定主题或特定行业网页。以健康网站为例,这种专门的蜘蛛只会抓取健康相关的主题,其他主题内容的网页不会被抓取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛爬行。
三、爬取策略
蜘蛛通过种子网址进行爬取和扩展,列出了大量需要爬取的网址。但是要爬取的网址数量庞大,蜘蛛是如何确定爬取顺序的呢?蜘蛛爬取的策略有很多,但最终的目标是一个:先爬取重要的网页。为了评估页面是否重要,蜘蛛会根据页面内容的原创度、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略
宽度优先是指蜘蛛爬完一个网页后,它会继续按顺序爬取该网页中收录的其他页面。这种想法看似简单,但实际上非常实用。因为大多数网页都是按优先级排序的,重要的页面会优先推荐在页面上。
2. PageRank 策略
PageRank是一种非常著名的链接分析方法,主要用于衡量网页的权重。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法,我们可以找出哪些页面更重要,然后蜘蛛先抓取这些重要的页面。
3.大站点优先策略
这很容易理解。大网站通常内容页比较多,质量会高一些。蜘蛛会先分析网站的分类和属性。如果这个网站已经收录很多,或者在搜索引擎系统中的权重很高,那么优先收录。
四、网页更新
互联网上的大部分页面都是保持更新的,因此也要求蜘蛛存储的页面及时更新以保持一致性。打个比方:一个网页之前排名很好,如果页面被删除了,还排名,那体验就很糟糕了。因此,搜索引擎需要知道这些并随时更新页面,并将最新的页面提供给用户。常用的网页更新策略有三种:历史参考策略和用户体验策略。集群抽样策略。
1.历史参考策略
这是基于假设的更新策略。例如,如果你的网页之前定期更新过,那么搜索引擎也会认为你的网页以后会经常更新,蜘蛛就会定期来网站按照这个规则抓取网页。这也是为什么电水一直强调网站的内容需要定期更新。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人看后面的页面。用户体验策略就是根据用户的这个特点更新搜索引擎。例如,一个网页可能发布较早,有一段时间没有更新,但用户仍然觉得有用,点击浏览,那么搜索引擎可能不会更新这些过时的网页。这就是为什么在搜索结果中,最新的页面不一定排名靠前。排名更依赖于该页面的质量,而不是更新的时间。
3. 聚类抽样策略
以上两种更新策略主要参考网页的历史信息。然而,存储大量的历史信息对搜索引擎来说是一种负担。另外,如果收录是一个新的网页,没有历史资料可以参考,我该怎么办?聚类抽样策略是指根据网页上显示的一些属性对许多相似的网页进行分类,分类后的网页按照相同的规则进行更新。
通过了解搜索引擎蜘蛛工作原理的过程,我们会知道:网站内容的相关性,网站与网页内容的更新规律,网页上的链接分布,而网站的权重等因素会影响蜘蛛的爬行效率。识敌,让蜘蛛来的更猛烈!
抓取网页音频( 本发明网页中音频与视频共存时的音频视频交互方法及系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-07 17:02
本发明网页中音频与视频共存时的音频视频交互方法及系统)
网页音视频共存时的音视频交互方法及系统制作方法
[专利摘要] 本发明公开了一种网页中音视频共存时的音视频交互方法,包括以下步骤: S1:接收视频打开指令,判断网页中是否有音频播放,如果因此,关闭音频并执行步骤S2,否则直接进行步骤S2;S2:根据视频打开指令在网页中插入视频对应的视频对象,在网页中播放视频对象;S3:判断是否接收到视频关闭指令,如果是,则停止播放视频对象;如果没有,视频对象将一直播放到结束。
[专利描述] 网页中音视频共存时的音视频交互方法及系统
【技术领域】
[0001] 本发明涉及计算机[技术领域],尤其涉及一种网页中音视频共存时的音视频交互方法及系统。
【背景技术】
[0002] 现有技术中,在浏览网页时,由于页面中往往嵌入了视频,部分视频是自动播放的,因此往往无法捕捉视频的播放、暂停等交互操作。当页面上同时存在音频和视频时,如果直接在页面上显示视频,则无法确定何时停止音频以及何时开始音频。音视频的播放容易产生干扰,导致两者播放效果不佳。
[发明概要]
[0003] 本发明要解决的技术问题是提供一种网页中音视频共存时的音视频交互方法及系统。
[0004] 本发明解决其技术问题所采用的技术方案是提供一种网页中音视频共存时的音视频交互方法,包括以下步骤:
[0005] S1:接收视频打开指令,判断网页中是否有音频播放,如果有,则关闭音频,执行步骤S2,如果没有,则直接执行步骤S2;
[0006] S2、根据视频打开指令在网页中插入视频对应的视频对象,并在网页中播放视频对象;
[0007] S3:判断是否接收到视频关闭指令,如果是,停止播放视频对象;如果没有,则播放视频对象直到结束。
[0008] 优选地,在步骤S1中,在网页中设置视频封面,当用户点击视频封面时,生成视频打开指令,网页接收视频打开指令并隐藏视频封面; 在步骤S2中,在视频封面的位置插入该视频对应的视频对象。
[0009] 优选地,在步骤S3中,在视频播放过程中,如果用户点击视频对象外的页面区域,则生成视频关闭指令打开音频;和/或在视频对象外设置关闭按钮,如果用户点击关闭按钮,视频关闭时,第一频率开启。
[0010] 优选地,在步骤S3中,当打开音频时,删除视频对象,或者删除视频对象并显示视频封面。
[0011] 优选地,所述网页为智能手机的网页;视频对象是 Iframe、Flash 或帧对象。
[0012] 还提供了一种网页中音视频共存时的音视频交互系统,包括:
[0013] 接收模块用于接收视频打开指令和视频关闭指令;
[0014] 第一判断模块用于根据视频打开指令判断网页中是否有音频播放,并输出第一判断结果。
[0015] 第二判断模块,用于判断是否接收到视频关闭指令,并输出第二判断结果;
[0016] 交互模块用于根据第一判断结果关闭音频,在网页中插入与视频对应的视频对象,并在网页中播放视频对象。并根据第二判断结果停止播放视频对象或播放视频对象直到结束。
[0017] 优选地,该系统还包括封面处理模块,封面处理模块用于在网页中设置视频封面,当用户点击视频封面时,生成视频打开指令输出给接收端模块; 交互模块还用于根据视频打开指令隐藏视频封面,在视频封面位置插入视频对应的视频对象。
[0018] 优选地,封面处理模块还用于当用户在视频播放过程中点击视频对象外的页面区域时,生成视频关闭指令并输出到接收模块,交互模块控制音频为打开; 和/或者,封面处理模块还用于在视频对象外设置关闭按钮,当用户点击关闭按钮时生成视频关闭指令,并将视频关闭指令输出到接收模块,交互模块控制要打开的音频。
[0019] 优选地,交互模块还用于在打开音频时删除视频对象,或者删除视频对象并显示视频封面。
[0020] 优选地,所述网页为智能手机的网页;视频对象是 Iframe、Flash 或帧对象。
[0021]实施本发明的有益效果是:本发明的网页中音视频共存时的音视频交互方法及系统,通过在接收到视频打开指令时切换音视频或视频关闭指令,避免视频和音频播放的干扰。
【专利图】
【图纸说明】
[0022] 下面结合附图和实施例对本发明作进一步说明。在附图中:
[0023] 图 附图说明图1为本发明实施例提供的网页中音视频共存时的音视频交互方法的流程图。
[0024] 图 图2为本发明实施例提供的网页中音视频共存时的音视频交互系统的模块示意图。
【详细方式】
[0025] 为了更清楚地理解本发明的技术特征、目的和效果,现结合附图对本发明进行详细说明。
[0026] 图 图1示出了本发明一些实施例中的一种音视频交互方法。该方法用于当网页中存在音视频共存时,根据相应的视频打开指令关闭音频并打开视频。对应的视频关闭指令关闭视频,使得音频的播放和视频的播放互不干扰。可以理解,网页可以是智能手机通过浏览器打开的网页,智能手机通过App应用打开的网页,电脑通过浏览器打开的网页,电脑通过应用打开的网页,以及很快。优选地,所述音视频交互方式为应用于Light APP网页的音视频交互方式。
[0027] 在一些实施例中,音视频交互方法包括以下步骤:
[0028] S1:接收视频打开指令,判断网页中是否有音频播放,如果有,则关闭音频,执行步骤S2,如果没有,则直接执行步骤S2。
[0029] 本步骤中需要说明的是,在接收到视频打开指令后,需要关闭播放音频,以免干扰要打开的视频。在这里,如果网页中没有音频或者没有正在播放的音频,则无需关闭音频,只需执行下一步打开视频即可。
[0030] 或者,接收视频打开指令可以有多种形式,例如:1)在网页中插入视频播放按钮,当用户点击该按钮时,网页接收视频打开操作说明; 2)在网页中插入链接,当用户点击链接时,网页收到视频打开指令;3)在网页中插入一个音频停止按钮,当用户点击该按钮时,网页接收到视频打开指令。接收视频打开指令的形式不限于上述几种,只要网页通过用户交互接收视频打开指令即可。
[0031] 在一些优选实施例中,接收视频打开指令的形式如下:在网页中设置视频封面,当用户点击视频封面时生成视频打开指令,网页接收视频打开指令,隐藏视频封面。或者,网页在接收到视频打开指令后也可以不隐藏视频封面。优选地,视频封面可以是视频对象的缩略图,或者视频封面也可以设置为带有视频打开按钮的缩略图。
[0032] S2、根据视频打开指令在网页中插入视频对应的视频对象,并在网页中播放视频对象。
[0033] 在本步骤中,需要说明的是,在设置视频封面的优选实施例中,在视频封面的位置插入视频对应的视频对象。或者,您可以直接在整个页面上插入视频对象,而不是在视频封面位置插入视频对象,以进行全屏播放。或者,当网页收到视频打开指令且不隐藏视频封面时,也可以直接在整个页面上插入视频对象进行全屏播放。
[0034] 或者,视频对象可以是Iframe、Flash或帧对象。优选地,视频对象是Iframe。
[0035] S3:判断是否接收到视频关闭指令,如果是,则停止播放视频对象;如果没有,则播放视频对象直到结束。
[0036] 本步骤中需要说明的是,在视频播放时,接收视频关闭指令的方式有多种:1)在视频对象外设置关闭按钮,当用户点击关闭按钮视频关闭指令;2) 设置在视频对象外的页面区域接收视频关闭指令的功能。如果用户点击视频对象外的页面区域,会产生视频关闭指令并打开音频。接收视频关闭指令的形式不限于上述几种,只要网页通过用户交互接收视频关闭指令即可。
[0037] 视频对象停止/播放后,还可以在打开音频时删除视频对象;或者,在设置视频封面的优选实施例中,也可以删除视频对象,删除之前隐藏的视频封面。
[0038] 图 图2示出了根据本发明一些实施例的网页中音频和视频共存时的音频和视频交互系统。该系统包括接收模块100、第一判断模块300、第二判断模块500、、交互模块700和封面处理模块900。可以理解,网页可以是一个智能手机通过浏览器打开的网页,智能手机通过App应用打开的网页,电脑通过浏览器打开的网页,电脑通过应用打开的网页等等。
[0039] 其中,封面处理模块900用于在网页中设置视频封面,当用户点击视频封面时,生成视频打开指令并输出至接收模块100。或者,封面可以设置或不设置处理模块900。
[0040] 接收模块100用于接收视频打开指令和视频关闭指令。接收模块100以如下形式接收视频打开指令:封面处理模块900设置视频封面,当用户点击视频封面时,生成视频打开指令,交互模块700根据以下方式隐藏视频封面视频打开指令,并在视频封面位置插入对应的视频封面 视频的视频对象。或者,交互模块700可以不隐藏视频封面。优选地,视频封面可以是视频对象的缩略图,或者视频封面也可以设置为带有视频打开按钮的缩略图。
[0041] 或者,当不设置封面处理模块900时,接收模块100可以接收多种形式的视频打开指令,例如:1)插入视频播放按钮,当用户点击该按钮时,接收模块100接收视频开启指令;2)插入链接,当用户点击链接时,接收模块100接收视频打开指令;3)插入音频停止按钮,当用户点击该按钮时,接收模块100接收视频打开指令。接收模块100接收视频开启指令的形式不限于以上所列,只要接收模块100可以通过用户交互接收视频开启指令即可。
[0042] 在视频播放过程中,接收模块100可以通过多种方式接收视频关闭指令:1)封面处理模块900在视频对象外设置关闭按钮,并在用户点击时生成视频关闭指令关闭按钮,并向接收模块100输出视频关闭指令;2)封面处理模块900在用户点击视频对象外的页面区域时,生成视频关闭指令并输出到接收模块100。
[0043] 或者,当不设置封面处理模块900时,在视频播放过程中,接收模块100可以通过多种方式接收视频关闭指令:1)用户点击设置在视频对象A外的关闭按钮此时生成视频关闭指令;2)用户点击视频对象外的页面区域产生视频关闭指令,接收模块100接收视频关闭指令。接收模块100接收视频关闭指令的方式不限于上述方式,只要接收模块100可以通过用户交互接收视频关闭指令即可。
[0044] 第一判断模块300,用于根据视频打开指令判断网页中是否有音频播放,并输出第一判断结果。可以理解的是,接收模块100接收到视频打开指令后,需要关闭播放音频,以避免干扰要打开的视频。在这里,如果网页中没有音频或者没有正在播放的音频,则无需关闭音频,只需执行下一步打开视频即可。
[0045] 第二判断模块500,用于判断是否接收到视频关闭指令,并输出第二判断结果。第二判断结果包括接收视频关闭指令和未接收视频关闭指令。
[0046] 交互模块700,用于根据第一判断结果关闭音频,在网页中插入与视频对应的视频对象,并在网页中播放视频对象。或者,视频对象可以是 Iframe、Flash 或帧对象。优选地,视频对象是Iframe。
[0047] 交互模块700还用于根据第二判断结果停止播放视频对象或播放视频对象直到结束。当第二判断结果为接收到视频关闭指令时,交互模块700停止播放视频对象;当第二判断结果为视频对象未停止时,交互模块700播放视频对象直至结束。
[0048] 在视频对象停止/播放后,交互模块700还用于同时打开音频和删除视频对象,或者,在一个优选实施例中,封面处理模块900设置视频封面,交互模块700还可以删除视频对象并显示视频封面。
[0049] 以上仅为本发明的优选实施例而已,本发明的保护范围不限于上述实施例。凡属于本发明构思之内的技术方案,均属于本发明的保护范围。需要指出的是,对于【技术领域】的普通技术人员来说,在不脱离本发明的原则的情况下,还有多种改进和修改,这些改进和修改也应视为本发明的保护范围。发明。
【权利要求】
1. 一种网页中音视频共存时的音视频交互方法,其特征在于包括以下步骤: S1:接收视频打开指令,判断网页中是否有音频播放;如果是,则关闭音频并执行步骤S2,如果不是,则直接进行步骤S2;S2、根据视频打开指令在网页中插入视频对应的视频对象,在网页上播放该视频对象;S3:判断是否收到视频关闭指令,如果是,停止播放视频对象;如果没有,则播放视频对象直到结束。
2.根据权利要求1所述的音视频交互方法,其特征在于,在步骤SI中,在网页中设置视频封面,当用户点击视频封面时生成视频打开指令,网页接收视频打开指令,隐藏视频封面;在步骤S2中,在视频封面的位置插入视频对应的视频对象。
3.根据权利要求2所述的音视频交互方法,其特征在于,在步骤S3中,在播放视频时,如果用户点击视频对象以外的页面区域,则视频关闭指令打开音频;和/或,在视频对象外设置关闭按钮,如果用户点击关闭按钮时产生视频关闭指令,则开启音频。
4.如权利要求3所述的音视频交互方法,其特征在于,在步骤S3中,当打开音频时,删除视频对象,或者删除视频对象并删除视频封面。
5.如权利要求1至4任一项所述的音视频交互方法,其特征在于,所述网页为智能手机网页;并且视频对象是 Iframe、Flash 或 frame 对象。
6.——网页中一频和视频共存时的一频视频交互系统,其特征在于包括:接收模块(100),用于接收视频打开指令和视频关闭指令; 判断模块(300),用于根据视频打开指令判断网页是否有音频播放,并输出第一判断结果;第二判断模块(500) ,用于判断是否接收到视频关闭指令并输出第二判断结果; 交互模块(700),用于根据第一判断结果关闭音频,并在其中插入视频对应的视频对象网页,播放网页中的视频对象;根据第二判断结果停止播放视频对象或播放视频对象直至结束。
7.根据权利要求6所述的音视频交互系统,其特征在于,该系统还包括封面处理模块(900),封面处理模块(900)用于A网页中设置视频封面,当用户点击视频封面时,生成视频打开指令并输出到接收模块(100);交互模块(700)为也用于根据视频打开指令隐藏视频封面,在视频封面位置插入视频对应的视频对象。
8.如权利要求6所述的音视频交互系统,其特征在于,所述封面处理模块(900)还用于当用户在播放视频时点击视频对象时。页面区域,生成视频关闭指令并输出到接收模块(100),交互模块(700)控制音频开启;和/或,封面处理)模块(900)还用于在视频对象外设置一个关闭按钮,在用户点击关闭按钮时生成视频关闭指令,并将视频关闭指令输出到接收模块(10< @0),交互模块(700))控制开启音频。
9.如权利要求7所述的音视频交互系统,其特征在于,所述交互模块(700)还用于在开启音频时删除视频对象,或者,删除视频对象并显示视频封面。
10.如权利要求6至9任一项所述的音视频交互系统,其特征在于,所述网页为智能手机网页;并且视频对象是 Iframe、Flash 或 frame 对象。
【文件编号】H04N21/472GK104202674SQ2
【出版日期】2014年12月10日申请日期:2014年8月29日优先权日期:2014年8月29日
【发明人】张晓刚、姜天雄申请人: 查看全部
抓取网页音频(
本发明网页中音频与视频共存时的音频视频交互方法及系统)
网页音视频共存时的音视频交互方法及系统制作方法
[专利摘要] 本发明公开了一种网页中音视频共存时的音视频交互方法,包括以下步骤: S1:接收视频打开指令,判断网页中是否有音频播放,如果因此,关闭音频并执行步骤S2,否则直接进行步骤S2;S2:根据视频打开指令在网页中插入视频对应的视频对象,在网页中播放视频对象;S3:判断是否接收到视频关闭指令,如果是,则停止播放视频对象;如果没有,视频对象将一直播放到结束。
[专利描述] 网页中音视频共存时的音视频交互方法及系统
【技术领域】
[0001] 本发明涉及计算机[技术领域],尤其涉及一种网页中音视频共存时的音视频交互方法及系统。
【背景技术】
[0002] 现有技术中,在浏览网页时,由于页面中往往嵌入了视频,部分视频是自动播放的,因此往往无法捕捉视频的播放、暂停等交互操作。当页面上同时存在音频和视频时,如果直接在页面上显示视频,则无法确定何时停止音频以及何时开始音频。音视频的播放容易产生干扰,导致两者播放效果不佳。
[发明概要]
[0003] 本发明要解决的技术问题是提供一种网页中音视频共存时的音视频交互方法及系统。
[0004] 本发明解决其技术问题所采用的技术方案是提供一种网页中音视频共存时的音视频交互方法,包括以下步骤:
[0005] S1:接收视频打开指令,判断网页中是否有音频播放,如果有,则关闭音频,执行步骤S2,如果没有,则直接执行步骤S2;
[0006] S2、根据视频打开指令在网页中插入视频对应的视频对象,并在网页中播放视频对象;
[0007] S3:判断是否接收到视频关闭指令,如果是,停止播放视频对象;如果没有,则播放视频对象直到结束。
[0008] 优选地,在步骤S1中,在网页中设置视频封面,当用户点击视频封面时,生成视频打开指令,网页接收视频打开指令并隐藏视频封面; 在步骤S2中,在视频封面的位置插入该视频对应的视频对象。
[0009] 优选地,在步骤S3中,在视频播放过程中,如果用户点击视频对象外的页面区域,则生成视频关闭指令打开音频;和/或在视频对象外设置关闭按钮,如果用户点击关闭按钮,视频关闭时,第一频率开启。
[0010] 优选地,在步骤S3中,当打开音频时,删除视频对象,或者删除视频对象并显示视频封面。
[0011] 优选地,所述网页为智能手机的网页;视频对象是 Iframe、Flash 或帧对象。
[0012] 还提供了一种网页中音视频共存时的音视频交互系统,包括:
[0013] 接收模块用于接收视频打开指令和视频关闭指令;
[0014] 第一判断模块用于根据视频打开指令判断网页中是否有音频播放,并输出第一判断结果。
[0015] 第二判断模块,用于判断是否接收到视频关闭指令,并输出第二判断结果;
[0016] 交互模块用于根据第一判断结果关闭音频,在网页中插入与视频对应的视频对象,并在网页中播放视频对象。并根据第二判断结果停止播放视频对象或播放视频对象直到结束。
[0017] 优选地,该系统还包括封面处理模块,封面处理模块用于在网页中设置视频封面,当用户点击视频封面时,生成视频打开指令输出给接收端模块; 交互模块还用于根据视频打开指令隐藏视频封面,在视频封面位置插入视频对应的视频对象。
[0018] 优选地,封面处理模块还用于当用户在视频播放过程中点击视频对象外的页面区域时,生成视频关闭指令并输出到接收模块,交互模块控制音频为打开; 和/或者,封面处理模块还用于在视频对象外设置关闭按钮,当用户点击关闭按钮时生成视频关闭指令,并将视频关闭指令输出到接收模块,交互模块控制要打开的音频。
[0019] 优选地,交互模块还用于在打开音频时删除视频对象,或者删除视频对象并显示视频封面。
[0020] 优选地,所述网页为智能手机的网页;视频对象是 Iframe、Flash 或帧对象。
[0021]实施本发明的有益效果是:本发明的网页中音视频共存时的音视频交互方法及系统,通过在接收到视频打开指令时切换音视频或视频关闭指令,避免视频和音频播放的干扰。
【专利图】
【图纸说明】
[0022] 下面结合附图和实施例对本发明作进一步说明。在附图中:
[0023] 图 附图说明图1为本发明实施例提供的网页中音视频共存时的音视频交互方法的流程图。
[0024] 图 图2为本发明实施例提供的网页中音视频共存时的音视频交互系统的模块示意图。
【详细方式】
[0025] 为了更清楚地理解本发明的技术特征、目的和效果,现结合附图对本发明进行详细说明。
[0026] 图 图1示出了本发明一些实施例中的一种音视频交互方法。该方法用于当网页中存在音视频共存时,根据相应的视频打开指令关闭音频并打开视频。对应的视频关闭指令关闭视频,使得音频的播放和视频的播放互不干扰。可以理解,网页可以是智能手机通过浏览器打开的网页,智能手机通过App应用打开的网页,电脑通过浏览器打开的网页,电脑通过应用打开的网页,以及很快。优选地,所述音视频交互方式为应用于Light APP网页的音视频交互方式。
[0027] 在一些实施例中,音视频交互方法包括以下步骤:
[0028] S1:接收视频打开指令,判断网页中是否有音频播放,如果有,则关闭音频,执行步骤S2,如果没有,则直接执行步骤S2。
[0029] 本步骤中需要说明的是,在接收到视频打开指令后,需要关闭播放音频,以免干扰要打开的视频。在这里,如果网页中没有音频或者没有正在播放的音频,则无需关闭音频,只需执行下一步打开视频即可。
[0030] 或者,接收视频打开指令可以有多种形式,例如:1)在网页中插入视频播放按钮,当用户点击该按钮时,网页接收视频打开操作说明; 2)在网页中插入链接,当用户点击链接时,网页收到视频打开指令;3)在网页中插入一个音频停止按钮,当用户点击该按钮时,网页接收到视频打开指令。接收视频打开指令的形式不限于上述几种,只要网页通过用户交互接收视频打开指令即可。
[0031] 在一些优选实施例中,接收视频打开指令的形式如下:在网页中设置视频封面,当用户点击视频封面时生成视频打开指令,网页接收视频打开指令,隐藏视频封面。或者,网页在接收到视频打开指令后也可以不隐藏视频封面。优选地,视频封面可以是视频对象的缩略图,或者视频封面也可以设置为带有视频打开按钮的缩略图。
[0032] S2、根据视频打开指令在网页中插入视频对应的视频对象,并在网页中播放视频对象。
[0033] 在本步骤中,需要说明的是,在设置视频封面的优选实施例中,在视频封面的位置插入视频对应的视频对象。或者,您可以直接在整个页面上插入视频对象,而不是在视频封面位置插入视频对象,以进行全屏播放。或者,当网页收到视频打开指令且不隐藏视频封面时,也可以直接在整个页面上插入视频对象进行全屏播放。
[0034] 或者,视频对象可以是Iframe、Flash或帧对象。优选地,视频对象是Iframe。
[0035] S3:判断是否接收到视频关闭指令,如果是,则停止播放视频对象;如果没有,则播放视频对象直到结束。
[0036] 本步骤中需要说明的是,在视频播放时,接收视频关闭指令的方式有多种:1)在视频对象外设置关闭按钮,当用户点击关闭按钮视频关闭指令;2) 设置在视频对象外的页面区域接收视频关闭指令的功能。如果用户点击视频对象外的页面区域,会产生视频关闭指令并打开音频。接收视频关闭指令的形式不限于上述几种,只要网页通过用户交互接收视频关闭指令即可。
[0037] 视频对象停止/播放后,还可以在打开音频时删除视频对象;或者,在设置视频封面的优选实施例中,也可以删除视频对象,删除之前隐藏的视频封面。
[0038] 图 图2示出了根据本发明一些实施例的网页中音频和视频共存时的音频和视频交互系统。该系统包括接收模块100、第一判断模块300、第二判断模块500、、交互模块700和封面处理模块900。可以理解,网页可以是一个智能手机通过浏览器打开的网页,智能手机通过App应用打开的网页,电脑通过浏览器打开的网页,电脑通过应用打开的网页等等。
[0039] 其中,封面处理模块900用于在网页中设置视频封面,当用户点击视频封面时,生成视频打开指令并输出至接收模块100。或者,封面可以设置或不设置处理模块900。
[0040] 接收模块100用于接收视频打开指令和视频关闭指令。接收模块100以如下形式接收视频打开指令:封面处理模块900设置视频封面,当用户点击视频封面时,生成视频打开指令,交互模块700根据以下方式隐藏视频封面视频打开指令,并在视频封面位置插入对应的视频封面 视频的视频对象。或者,交互模块700可以不隐藏视频封面。优选地,视频封面可以是视频对象的缩略图,或者视频封面也可以设置为带有视频打开按钮的缩略图。
[0041] 或者,当不设置封面处理模块900时,接收模块100可以接收多种形式的视频打开指令,例如:1)插入视频播放按钮,当用户点击该按钮时,接收模块100接收视频开启指令;2)插入链接,当用户点击链接时,接收模块100接收视频打开指令;3)插入音频停止按钮,当用户点击该按钮时,接收模块100接收视频打开指令。接收模块100接收视频开启指令的形式不限于以上所列,只要接收模块100可以通过用户交互接收视频开启指令即可。
[0042] 在视频播放过程中,接收模块100可以通过多种方式接收视频关闭指令:1)封面处理模块900在视频对象外设置关闭按钮,并在用户点击时生成视频关闭指令关闭按钮,并向接收模块100输出视频关闭指令;2)封面处理模块900在用户点击视频对象外的页面区域时,生成视频关闭指令并输出到接收模块100。
[0043] 或者,当不设置封面处理模块900时,在视频播放过程中,接收模块100可以通过多种方式接收视频关闭指令:1)用户点击设置在视频对象A外的关闭按钮此时生成视频关闭指令;2)用户点击视频对象外的页面区域产生视频关闭指令,接收模块100接收视频关闭指令。接收模块100接收视频关闭指令的方式不限于上述方式,只要接收模块100可以通过用户交互接收视频关闭指令即可。
[0044] 第一判断模块300,用于根据视频打开指令判断网页中是否有音频播放,并输出第一判断结果。可以理解的是,接收模块100接收到视频打开指令后,需要关闭播放音频,以避免干扰要打开的视频。在这里,如果网页中没有音频或者没有正在播放的音频,则无需关闭音频,只需执行下一步打开视频即可。
[0045] 第二判断模块500,用于判断是否接收到视频关闭指令,并输出第二判断结果。第二判断结果包括接收视频关闭指令和未接收视频关闭指令。
[0046] 交互模块700,用于根据第一判断结果关闭音频,在网页中插入与视频对应的视频对象,并在网页中播放视频对象。或者,视频对象可以是 Iframe、Flash 或帧对象。优选地,视频对象是Iframe。
[0047] 交互模块700还用于根据第二判断结果停止播放视频对象或播放视频对象直到结束。当第二判断结果为接收到视频关闭指令时,交互模块700停止播放视频对象;当第二判断结果为视频对象未停止时,交互模块700播放视频对象直至结束。
[0048] 在视频对象停止/播放后,交互模块700还用于同时打开音频和删除视频对象,或者,在一个优选实施例中,封面处理模块900设置视频封面,交互模块700还可以删除视频对象并显示视频封面。
[0049] 以上仅为本发明的优选实施例而已,本发明的保护范围不限于上述实施例。凡属于本发明构思之内的技术方案,均属于本发明的保护范围。需要指出的是,对于【技术领域】的普通技术人员来说,在不脱离本发明的原则的情况下,还有多种改进和修改,这些改进和修改也应视为本发明的保护范围。发明。
【权利要求】
1. 一种网页中音视频共存时的音视频交互方法,其特征在于包括以下步骤: S1:接收视频打开指令,判断网页中是否有音频播放;如果是,则关闭音频并执行步骤S2,如果不是,则直接进行步骤S2;S2、根据视频打开指令在网页中插入视频对应的视频对象,在网页上播放该视频对象;S3:判断是否收到视频关闭指令,如果是,停止播放视频对象;如果没有,则播放视频对象直到结束。
2.根据权利要求1所述的音视频交互方法,其特征在于,在步骤SI中,在网页中设置视频封面,当用户点击视频封面时生成视频打开指令,网页接收视频打开指令,隐藏视频封面;在步骤S2中,在视频封面的位置插入视频对应的视频对象。
3.根据权利要求2所述的音视频交互方法,其特征在于,在步骤S3中,在播放视频时,如果用户点击视频对象以外的页面区域,则视频关闭指令打开音频;和/或,在视频对象外设置关闭按钮,如果用户点击关闭按钮时产生视频关闭指令,则开启音频。
4.如权利要求3所述的音视频交互方法,其特征在于,在步骤S3中,当打开音频时,删除视频对象,或者删除视频对象并删除视频封面。
5.如权利要求1至4任一项所述的音视频交互方法,其特征在于,所述网页为智能手机网页;并且视频对象是 Iframe、Flash 或 frame 对象。
6.——网页中一频和视频共存时的一频视频交互系统,其特征在于包括:接收模块(100),用于接收视频打开指令和视频关闭指令; 判断模块(300),用于根据视频打开指令判断网页是否有音频播放,并输出第一判断结果;第二判断模块(500) ,用于判断是否接收到视频关闭指令并输出第二判断结果; 交互模块(700),用于根据第一判断结果关闭音频,并在其中插入视频对应的视频对象网页,播放网页中的视频对象;根据第二判断结果停止播放视频对象或播放视频对象直至结束。
7.根据权利要求6所述的音视频交互系统,其特征在于,该系统还包括封面处理模块(900),封面处理模块(900)用于A网页中设置视频封面,当用户点击视频封面时,生成视频打开指令并输出到接收模块(100);交互模块(700)为也用于根据视频打开指令隐藏视频封面,在视频封面位置插入视频对应的视频对象。
8.如权利要求6所述的音视频交互系统,其特征在于,所述封面处理模块(900)还用于当用户在播放视频时点击视频对象时。页面区域,生成视频关闭指令并输出到接收模块(100),交互模块(700)控制音频开启;和/或,封面处理)模块(900)还用于在视频对象外设置一个关闭按钮,在用户点击关闭按钮时生成视频关闭指令,并将视频关闭指令输出到接收模块(10< @0),交互模块(700))控制开启音频。
9.如权利要求7所述的音视频交互系统,其特征在于,所述交互模块(700)还用于在开启音频时删除视频对象,或者,删除视频对象并显示视频封面。
10.如权利要求6至9任一项所述的音视频交互系统,其特征在于,所述网页为智能手机网页;并且视频对象是 Iframe、Flash 或 frame 对象。
【文件编号】H04N21/472GK104202674SQ2
【出版日期】2014年12月10日申请日期:2014年8月29日优先权日期:2014年8月29日
【发明人】张晓刚、姜天雄申请人:
抓取网页音频(猫抓插件免费版下载体积小巧,占用内存空间非常少,运行速度快)
网站优化 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-12-06 03:10
Mozhao插件是一款专业可靠的网络媒体嗅探工具,可以读取和更改您正在访问的网站上的所有数据,并可以管理您的下载内容。使用它可以获取各大网站视频和音乐的地址,如优酷、搜狐、腾讯、微博、B站、网易云、QQ音乐、酷狗等平台资源地址,帮助用户快速获取视频链接数据和音乐网站 音频文件。该软件允许用户自定义要采集的视频和音频格式,还支持使用正则表达式自定义要采集的内容,然后可以对需要的地址资源进行批量快速的操作,高效又快捷。方便的。该软件的优点是可以嗅探检测IDM下载器无法检测到的资源 t嗅探,然后下载资源,可以很好的满足用户的需求。这里有免费下载的猫抓插件,体积小,占用内存空间小,运行速度快。不会造成系统其他程序的滞后,也不会减慢其他程序的运行速度。它不会影响系统。时刻保持稳定安全的运行状态,有需要的快来下载体验吧。
安装教程1、先在浏览器中输入chrome://extensions,然后就可以进入浏览器的扩展界面
2、将毛扎1.0.15文件夹直接移到扩展界面
3、 然后浏览器会显示猫爪图标,安装成功。
使用教程 1、 安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮,在页面可以看到资源信息
2、 然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地
3、猫扎插件支持几乎所有国内的网站视频文件嗅探,如优酷、搜狐、腾讯、微博、B站等,也可以在多个媒体资源出现在同一个页。对它们执行快速批处理操作
4、 此外,毛爪还支持所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间的音乐。在【选项】中,用户还可以自定义采集的视频和音频格式,也支持使用正则表达式自定义采集的内容
功能介绍1、 支持抓取任意站点任意数据;
2、多个站点可以同时更新;
3、 支持使用正则表达式自定义要抓取的内容。
精选亮点1、 是一款Chrome嗅探音乐视频插件,大小只有几十k。
2、 无论是看视频还是听音乐,都可以通过猫爪插件进行捕捉。您只需要点击即可下载。
3、也可以在设置中自定义配置,可以抓取图片、文档等各种资源文件。
4、当然还有更多,可以和IDM一起使用。拥有如此多的素材来源,您可以通过慢慢练习成为出色的剪辑大师。
软件特点1、可以抓取任意站点的视频和音频,可以下载;
2、 并支持批量下载;
3、已知插件支持网站优酷、爱奇艺、搜狐、微博、B站、乐视等知名视频门户。
哪里可以查看FAQ抓取的资源?
1、 点击插件图标查看爬取的资源;
2、 视频格式文件有播放按钮和下载按钮;
3、您可以根据需要下载文件。. 查看全部
抓取网页音频(猫抓插件免费版下载体积小巧,占用内存空间非常少,运行速度快)
Mozhao插件是一款专业可靠的网络媒体嗅探工具,可以读取和更改您正在访问的网站上的所有数据,并可以管理您的下载内容。使用它可以获取各大网站视频和音乐的地址,如优酷、搜狐、腾讯、微博、B站、网易云、QQ音乐、酷狗等平台资源地址,帮助用户快速获取视频链接数据和音乐网站 音频文件。该软件允许用户自定义要采集的视频和音频格式,还支持使用正则表达式自定义要采集的内容,然后可以对需要的地址资源进行批量快速的操作,高效又快捷。方便的。该软件的优点是可以嗅探检测IDM下载器无法检测到的资源 t嗅探,然后下载资源,可以很好的满足用户的需求。这里有免费下载的猫抓插件,体积小,占用内存空间小,运行速度快。不会造成系统其他程序的滞后,也不会减慢其他程序的运行速度。它不会影响系统。时刻保持稳定安全的运行状态,有需要的快来下载体验吧。
安装教程1、先在浏览器中输入chrome://extensions,然后就可以进入浏览器的扩展界面
2、将毛扎1.0.15文件夹直接移到扩展界面
3、 然后浏览器会显示猫爪图标,安装成功。
使用教程 1、 安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮,在页面可以看到资源信息
2、 然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地
3、猫扎插件支持几乎所有国内的网站视频文件嗅探,如优酷、搜狐、腾讯、微博、B站等,也可以在多个媒体资源出现在同一个页。对它们执行快速批处理操作
4、 此外,毛爪还支持所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间的音乐。在【选项】中,用户还可以自定义采集的视频和音频格式,也支持使用正则表达式自定义采集的内容
功能介绍1、 支持抓取任意站点任意数据;
2、多个站点可以同时更新;
3、 支持使用正则表达式自定义要抓取的内容。
精选亮点1、 是一款Chrome嗅探音乐视频插件,大小只有几十k。
2、 无论是看视频还是听音乐,都可以通过猫爪插件进行捕捉。您只需要点击即可下载。
3、也可以在设置中自定义配置,可以抓取图片、文档等各种资源文件。
4、当然还有更多,可以和IDM一起使用。拥有如此多的素材来源,您可以通过慢慢练习成为出色的剪辑大师。
软件特点1、可以抓取任意站点的视频和音频,可以下载;
2、 并支持批量下载;
3、已知插件支持网站优酷、爱奇艺、搜狐、微博、B站、乐视等知名视频门户。
哪里可以查看FAQ抓取的资源?
1、 点击插件图标查看爬取的资源;
2、 视频格式文件有播放按钮和下载按钮;
3、您可以根据需要下载文件。.
抓取网页音频(InternetDownloadIDM功能——“站点抓取”的含义!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-06 03:08
Internet Download Manager(简称IDM)是一款功能强大的下载器。它采用多线程技术,大大提高文件下载速度。即使是非常大的文件也可以轻松快速地集成。它声称可以将您的下载速度提高多达 5 倍。
不过今天要给大家推荐的是我最近发现的一个IDM功能——“站点爬取”。我以前从不关心它。我最近才发现这个功能非常有用。下面就给大家介绍一下它的神奇之处。
“网站爬行”的含义
如图1所示,该功能允许您输入网页链接,选择您要下载的网页的指定内容,包括图片、音频、视频、文件,甚至收录网站@完整样式的离线文件>,并允许用户根据自己的需要自定义内容。定义站点抓取的内容和规则,并保存以方便下次调用。
图1:网站爬取界面
“网站爬取”功能的神奇使用
如果您在工作中遇到断开连接或网络不好的情况,请使用 Internet 下载管理器站点抓取并保存一些需要浏览的网页,以确保您的工作顺利进行。
如图2所示,根据要保存的内容进行选择。有“所有图片”、“所有视频”、“完整起始页”等,您可以根据需要选择。它收录在通用计划模板中,如果您没有,您可以自定义它。
图 2:IDM 程序模板
单击“前进”以选择文件保存位置。一般默认勾选“保存到同一目录”,点击“浏览”选择保存位置。
图3:选择文件保存位置
接下来,指定链接深度,可以根据需要设置。这也是这个强大的地方,不用网络也能深度浏览网页。
图4:站点爬取选择深度
在下一步中,您可以添加一些下载或非下载过滤器来过滤不需要的文件类型,以避免下载不需要的文件。
图 5:过滤文件
最后,下载开始。如果之前设置下载的内容不多,应该会快一些。
图6:下载情况
下载完成后,在指定文件夹中打开,就可以看到图8了。这样就可以在没有互联网的情况下点击浏览网页,非常方便。
图 7:打开的文件夹
以上就是IDM强大的网站爬取功能。有需要的可以访问IDM中文网站@>免费试用。但是在使用这个强大的功能时要注意不要侵犯或窃取他人的视频或音频。 查看全部
抓取网页音频(InternetDownloadIDM功能——“站点抓取”的含义!)
Internet Download Manager(简称IDM)是一款功能强大的下载器。它采用多线程技术,大大提高文件下载速度。即使是非常大的文件也可以轻松快速地集成。它声称可以将您的下载速度提高多达 5 倍。
不过今天要给大家推荐的是我最近发现的一个IDM功能——“站点爬取”。我以前从不关心它。我最近才发现这个功能非常有用。下面就给大家介绍一下它的神奇之处。
“网站爬行”的含义
如图1所示,该功能允许您输入网页链接,选择您要下载的网页的指定内容,包括图片、音频、视频、文件,甚至收录网站@完整样式的离线文件>,并允许用户根据自己的需要自定义内容。定义站点抓取的内容和规则,并保存以方便下次调用。
图1:网站爬取界面
“网站爬取”功能的神奇使用
如果您在工作中遇到断开连接或网络不好的情况,请使用 Internet 下载管理器站点抓取并保存一些需要浏览的网页,以确保您的工作顺利进行。
如图2所示,根据要保存的内容进行选择。有“所有图片”、“所有视频”、“完整起始页”等,您可以根据需要选择。它收录在通用计划模板中,如果您没有,您可以自定义它。
图 2:IDM 程序模板
单击“前进”以选择文件保存位置。一般默认勾选“保存到同一目录”,点击“浏览”选择保存位置。
图3:选择文件保存位置
接下来,指定链接深度,可以根据需要设置。这也是这个强大的地方,不用网络也能深度浏览网页。
图4:站点爬取选择深度
在下一步中,您可以添加一些下载或非下载过滤器来过滤不需要的文件类型,以避免下载不需要的文件。
图 5:过滤文件
最后,下载开始。如果之前设置下载的内容不多,应该会快一些。
图6:下载情况
下载完成后,在指定文件夹中打开,就可以看到图8了。这样就可以在没有互联网的情况下点击浏览网页,非常方便。
图 7:打开的文件夹
以上就是IDM强大的网站爬取功能。有需要的可以访问IDM中文网站@>免费试用。但是在使用这个强大的功能时要注意不要侵犯或窃取他人的视频或音频。
抓取网页音频(通用搜索引擎如何有效地提取并利用这些信息成为一个巨大的挑战)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-05 07:11
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的入口和向导。但是,这些通用的搜索引擎也有一定的局限性。例如:(1)不同领域、不同背景的用户往往有不同的搜索目的和需求。搜索引擎返回的结果中收录了大量不关注网页的用户。(2)目标一般搜索引擎的目的是最大化网络覆盖。有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。(3) 随着万维网上数据形式的丰富和网络技术的不断发展,大量的图片、数据库、音频、视频、多媒体等不同的数据大量出现。一般搜索引擎往往对这些信息内容密集、有一定结构的数据无能为力,不能很好地发现和获取。(4)一般搜索引擎大多提供基于关键字的检索,难以支持基于语义的查询为了解决上述问题,出现了针对相关网络资源的聚焦爬虫,聚焦爬虫是一个自动下载网页的程序,根据既定的爬取目标,有选择地访问万维网上的网页和相关链接,获取所需信息。与通用网络爬虫不同,聚焦爬虫不追求大Cover,目标是抓取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
1 重点介绍爬虫的工作原理和关键技术概述。网络爬虫是一种自动提取网页的程序。它从万维网上下载网页供搜索引擎使用,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一步要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并为以后的查询和检索建立索引;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并为以后的查询和检索建立索引;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。 查看全部
抓取网页音频(通用搜索引擎如何有效地提取并利用这些信息成为一个巨大的挑战)
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的入口和向导。但是,这些通用的搜索引擎也有一定的局限性。例如:(1)不同领域、不同背景的用户往往有不同的搜索目的和需求。搜索引擎返回的结果中收录了大量不关注网页的用户。(2)目标一般搜索引擎的目的是最大化网络覆盖。有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。(3) 随着万维网上数据形式的丰富和网络技术的不断发展,大量的图片、数据库、音频、视频、多媒体等不同的数据大量出现。一般搜索引擎往往对这些信息内容密集、有一定结构的数据无能为力,不能很好地发现和获取。(4)一般搜索引擎大多提供基于关键字的检索,难以支持基于语义的查询为了解决上述问题,出现了针对相关网络资源的聚焦爬虫,聚焦爬虫是一个自动下载网页的程序,根据既定的爬取目标,有选择地访问万维网上的网页和相关链接,获取所需信息。与通用网络爬虫不同,聚焦爬虫不追求大Cover,目标是抓取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
1 重点介绍爬虫的工作原理和关键技术概述。网络爬虫是一种自动提取网页的程序。它从万维网上下载网页供搜索引擎使用,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一步要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并为以后的查询和检索建立索引;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。并为以后的查询和检索建立索引;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。与一般的网络爬虫相比,聚焦爬虫需要解决三个主要问题:(1)对爬取目标的描述或定义;(2)对网页或数据的分析和过滤;(3) URL 的搜索策略。
抓取网页音频(1.的基于Ajax的新闻网页动态数据的抓取方法-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-01 17:23
技术特点:
1.基于Ajax的新闻网页动态数据捕获方法的特点是如下步骤:
步骤(101):建立新闻网页抓取内容库,设置新闻网页抓取内容库的编码方式;获取待抓取新闻网页的新闻列表页面的URL地址;
步骤(102):访问要获取的新闻页面的新闻列表页面的URL地址,使用浏览器开发工具判断新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具找到Ajax请求的数据源;如果没有,则结束;
步骤(103):判断Ajax请求的数据源是否与步骤(101))的编码方式一致,如果不一致,则对数据源进行编码转换,然后进行步骤(104); 如果一致,则直接进行步骤(104);
步骤(104):解析数据格式:将数据源的格式解析为新闻列表页面后台语言处理的对象格式或数组格式;
步骤(105):将步骤(104)中解析的数据封装成对象或数组类型;判断是否封装成功,如果成功则直接进行步骤(106) ;否则,将数据作为字符串处理;完成后,转步骤(106);
步骤(106):遍历数据对象或数组类型并输出列表;
Step (107): 使用网络爬虫采集 step (106)获取输出列表;
步骤(108):将来自采集的数据存入数据库。
2.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于:
步骤(101) URL地址包括临时URL地址、重定向地址和添加时间戳参数或签名参数后访问的URL地址;
步骤(101),新闻网页抓取内容库的字段包括:新闻标题、新闻发布时间、新闻抓取时间、新闻来源、新闻内容;
步骤(101)中,新闻网页抓取的内容库的编码方式包括:UTF-8编码或GBK编码。
3.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于,步骤(102))的浏览器开发工具包括:谷歌浏览器开发者工具。
4.根据权利要求1所述的基于Ajax的新闻网页动态数据捕获方法,其特征在于,步骤(103)如果Ajax请求的数据源中存在特殊字符或乱码,特殊字符或乱码批量替换,转换为可处理的字符。
5.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于,步骤(103):如果编码方式不同,则统一统一采用编码方式UTF-8 编码方式。
6.根据权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于,步骤(102)和步骤(103))之间设置为如下:
步骤(1020):如果Ajax请求是跨域请求,通过PHP的CURL方法模拟传入页面,通过主机获取请求数据地址;
步骤(1021):如果Ajax请求是POST请求,使用PHP语言http_build_query函数模拟HTTP POST请求,获取POST请求返回的数据;
步骤(1022):如果获取不到数据内容,则利用PHP的CURL伪造传入页面访问Ajax请求的数据源;
步骤(1020))通过PHP函数修改Referer模拟域名下的请求,可以得到请求数据地址返回的结果,从而解决了无权限获取的问题跨域请求中的数据。
7.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于:
描述的步骤(104)如下:
步骤(1041):如果数据是JSON格式,直接进入步骤(105);
步骤(1042):如果数据是JSONP格式,则进行过滤处理;过滤处理是去除JSONP格式数据的请求头和括号,然后进行步骤(105)@ >;
步骤(1043):如果返回的内容中存在中英文单双引号使用不规范的问题,通过PHP语言的字符替换功能过滤,将特殊字符替换为空字符。
8.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于:
步骤 (105):
如果步骤(104))解析的数据不是键值对类型,则将步骤(104))解析的数据封装为数据对象,
如果步骤(104))解析的数据为键值对类型,则将步骤(104))解析的数据转换为数组类型。
9.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于:
步骤(106))的输出列表包括:新闻标题、新闻发布时间、新闻爬取时间、新闻来源、新闻内容、新闻链接。
10. 一个基于Ajax的新闻网页动态数据抓取系统,其特点是:
建库模块:建立新闻网络爬取内容库,设置新闻网络爬取内容库的编码方式;获取要爬取的新闻网页的新闻列表页的URL地址;
访问模块:访问要获取的新闻页面的新闻列表页面的URL地址,使用浏览器开发工具判断新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具Source找到Ajax请求的数据;如果没有,结束;
判断模块:判断Ajax请求的数据源是否与步骤(101) @4); 如果一致,直接进入步骤(104);
解析数据格式模块:将数据源的格式解析为新闻列表页面后台语言处理的对象格式或数组格式;
封装模块:将解析后的数据封装成对象或数组类型;判断是否封装成功,如果成功,直接进入输出模块;否则,将数据作为字符串处理;完成后进入输出模块;
输出模块:遍历数据对象或数组类型的输出列表;使用网络爬虫获取的输出列表采集;将采集收到的数据存入数据库。 查看全部
抓取网页音频(1.的基于Ajax的新闻网页动态数据的抓取方法-苏州安嘉)
技术特点:
1.基于Ajax的新闻网页动态数据捕获方法的特点是如下步骤:
步骤(101):建立新闻网页抓取内容库,设置新闻网页抓取内容库的编码方式;获取待抓取新闻网页的新闻列表页面的URL地址;
步骤(102):访问要获取的新闻页面的新闻列表页面的URL地址,使用浏览器开发工具判断新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具找到Ajax请求的数据源;如果没有,则结束;
步骤(103):判断Ajax请求的数据源是否与步骤(101))的编码方式一致,如果不一致,则对数据源进行编码转换,然后进行步骤(104); 如果一致,则直接进行步骤(104);
步骤(104):解析数据格式:将数据源的格式解析为新闻列表页面后台语言处理的对象格式或数组格式;
步骤(105):将步骤(104)中解析的数据封装成对象或数组类型;判断是否封装成功,如果成功则直接进行步骤(106) ;否则,将数据作为字符串处理;完成后,转步骤(106);
步骤(106):遍历数据对象或数组类型并输出列表;
Step (107): 使用网络爬虫采集 step (106)获取输出列表;
步骤(108):将来自采集的数据存入数据库。
2.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于:
步骤(101) URL地址包括临时URL地址、重定向地址和添加时间戳参数或签名参数后访问的URL地址;
步骤(101),新闻网页抓取内容库的字段包括:新闻标题、新闻发布时间、新闻抓取时间、新闻来源、新闻内容;
步骤(101)中,新闻网页抓取的内容库的编码方式包括:UTF-8编码或GBK编码。
3.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于,步骤(102))的浏览器开发工具包括:谷歌浏览器开发者工具。
4.根据权利要求1所述的基于Ajax的新闻网页动态数据捕获方法,其特征在于,步骤(103)如果Ajax请求的数据源中存在特殊字符或乱码,特殊字符或乱码批量替换,转换为可处理的字符。
5.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于,步骤(103):如果编码方式不同,则统一统一采用编码方式UTF-8 编码方式。
6.根据权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于,步骤(102)和步骤(103))之间设置为如下:
步骤(1020):如果Ajax请求是跨域请求,通过PHP的CURL方法模拟传入页面,通过主机获取请求数据地址;
步骤(1021):如果Ajax请求是POST请求,使用PHP语言http_build_query函数模拟HTTP POST请求,获取POST请求返回的数据;
步骤(1022):如果获取不到数据内容,则利用PHP的CURL伪造传入页面访问Ajax请求的数据源;
步骤(1020))通过PHP函数修改Referer模拟域名下的请求,可以得到请求数据地址返回的结果,从而解决了无权限获取的问题跨域请求中的数据。
7.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于:
描述的步骤(104)如下:
步骤(1041):如果数据是JSON格式,直接进入步骤(105);
步骤(1042):如果数据是JSONP格式,则进行过滤处理;过滤处理是去除JSONP格式数据的请求头和括号,然后进行步骤(105)@ >;
步骤(1043):如果返回的内容中存在中英文单双引号使用不规范的问题,通过PHP语言的字符替换功能过滤,将特殊字符替换为空字符。
8.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于:
步骤 (105):
如果步骤(104))解析的数据不是键值对类型,则将步骤(104))解析的数据封装为数据对象,
如果步骤(104))解析的数据为键值对类型,则将步骤(104))解析的数据转换为数组类型。
9.如权利要求1所述的基于Ajax的新闻网页动态数据抓取方法,其特征在于:
步骤(106))的输出列表包括:新闻标题、新闻发布时间、新闻爬取时间、新闻来源、新闻内容、新闻链接。
10. 一个基于Ajax的新闻网页动态数据抓取系统,其特点是:
建库模块:建立新闻网络爬取内容库,设置新闻网络爬取内容库的编码方式;获取要爬取的新闻网页的新闻列表页的URL地址;
访问模块:访问要获取的新闻页面的新闻列表页面的URL地址,使用浏览器开发工具判断新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具Source找到Ajax请求的数据;如果没有,结束;
判断模块:判断Ajax请求的数据源是否与步骤(101) @4); 如果一致,直接进入步骤(104);
解析数据格式模块:将数据源的格式解析为新闻列表页面后台语言处理的对象格式或数组格式;
封装模块:将解析后的数据封装成对象或数组类型;判断是否封装成功,如果成功,直接进入输出模块;否则,将数据作为字符串处理;完成后进入输出模块;
输出模块:遍历数据对象或数组类型的输出列表;使用网络爬虫获取的输出列表采集;将采集收到的数据存入数据库。
抓取网页音频(这款视频转换器不但可以对常见视频格式文件转换的格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-01 10:05
随着互联网的发展,短视频逐渐流行起来。我们经常被短视频神奇的背景音乐所影响。
洗脑,但这些背景音乐通常是没有出处的mp4格式,所以如果你想简单地把mp4
如果视频中的音频被提取了怎么办?此时,我们可以使用 Swift Video Converter 中的视频
频率转换从视频文件中提取音频。我们来看看这个带有编辑器的视频转换器。
提取音频!
1、 运行 Swift Video Converter 后,您可以看到该软件的主界面,带有分割视频,
合并视频,制作GIF等功能,这个工具不仅是视频转换器,还是一个
用于转换音频格式的音频转换器。
2、点击功能中的视频转换功能,然后可以看到上面的“添加文件”按钮
将下载的 mp4 视频文件添加到此视频格式转换器。添加时可以添加一个
也可以将多个文件添加到一个文件中。
3、 然后可以看到软件底部有一个输出格式按钮,点击这个Annie,在下拉框中
选择要转换的格式,您可以在“音频”栏中轻松找到 MP3 格式。
4、 然后在下面的设置参数中,可以将mp3格式的音频文件设置为“高品质”,
当然,您也可以点击“自定义”按钮,自行设置音频编码、码率、采样频率等参数。
然后单击输出路径中的更改路径并将文件保存在桌面上。
5、最后点击右下角的“转换”按钮。转换完成后就可以看到转换了
更改完成后提示。您可以单击后面的“打开”按钮快速打开转换后的文件。
这是一个关于将 mp4 视频格式文件转换为 MP3 音频格式文件的教程。这个视频转
转换器不仅可以转换常见的视频格式文件,还可以转换常见的音频格式文件。
它还支持音频和视频文件的编辑!
视频转换器 查看全部
抓取网页音频(这款视频转换器不但可以对常见视频格式文件转换的格式)
随着互联网的发展,短视频逐渐流行起来。我们经常被短视频神奇的背景音乐所影响。
洗脑,但这些背景音乐通常是没有出处的mp4格式,所以如果你想简单地把mp4
如果视频中的音频被提取了怎么办?此时,我们可以使用 Swift Video Converter 中的视频
频率转换从视频文件中提取音频。我们来看看这个带有编辑器的视频转换器。
提取音频!
1、 运行 Swift Video Converter 后,您可以看到该软件的主界面,带有分割视频,
合并视频,制作GIF等功能,这个工具不仅是视频转换器,还是一个
用于转换音频格式的音频转换器。
2、点击功能中的视频转换功能,然后可以看到上面的“添加文件”按钮
将下载的 mp4 视频文件添加到此视频格式转换器。添加时可以添加一个
也可以将多个文件添加到一个文件中。
3、 然后可以看到软件底部有一个输出格式按钮,点击这个Annie,在下拉框中
选择要转换的格式,您可以在“音频”栏中轻松找到 MP3 格式。
4、 然后在下面的设置参数中,可以将mp3格式的音频文件设置为“高品质”,
当然,您也可以点击“自定义”按钮,自行设置音频编码、码率、采样频率等参数。
然后单击输出路径中的更改路径并将文件保存在桌面上。
5、最后点击右下角的“转换”按钮。转换完成后就可以看到转换了
更改完成后提示。您可以单击后面的“打开”按钮快速打开转换后的文件。
这是一个关于将 mp4 视频格式文件转换为 MP3 音频格式文件的教程。这个视频转
转换器不仅可以转换常见的视频格式文件,还可以转换常见的音频格式文件。
它还支持音频和视频文件的编辑!
视频转换器

